
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Старый код в новой обёртке — как наша команда избавлялась от legacy
В этой статье я — Станислав Решетнев, Teamlead команды разработки Link Building в компании Sape — хочу рассказать об опыте нашей компании по избавлению от legacy. Многие компании сталкиваются с проблемой legacy-монолита, когда технический долг накапливается на протяжении долгих лет и разрыв по технологическому стеку становится всё больше похожим на пропасть. Нам удалось найти решение, позволившее провести полное обновление, и заодно выполнить другие бизнес-задачи.
Начну с описания технического стека (по той части, которая имеет значение для данной статьи). На момент старта преобразования системы мы располагали сервисами, написанными на:
* Symfony 1 / Doctrine 1. Контент страниц генерируется на бэкенде, а в качестве шаблонизатора используется PHP;
* процедурном PHP времён версии 5.3, но переведёнными на PHP 7.0. Шаблонизатор — Smarty;
* Zend 1, который был с течением времени сильно доработан. Шаблонизатор — Smarty.
Нашей целью было создание объединённого приложения на основе современного стека. Бэкенд строился на Symfony 5 / 6, а используемые отдельные сервисы выносились за контуры приложения. Фронтенд представлял собой SPA, работающее с бэкендом по OpenApi.
План по модернизации в общих чертах был таким:
1. Все legacy-сервисы получают интерфейс OpenAPI.
2. Новое приложение использует legacy-сервисы в режиме клиента OpenAPI, в то же время предоставляя свой серверный интерфейс OpenAPI.
3. Новая бизнес-логика пишется в новом приложении, а фоново происходит постепенный транзит бизнес-логики из legacy в новое приложение.
Работа ещё продолжается, но первый этап уже завершился и, на мой взгляд, успешно. Стартовали мы полтора года назад и уже запустили новое приложение.
Так сейчас выглядит интерфейс нашего сервиса**Проблемные места**
Не буду подробно останавливаться на проблемах, которые вызывает legacy. Запутанная логика, вследствие чего разработчик тратит больше времени на погружение и исследование, а не на реализацию. Любое изменение в коде похоже на хождение по минному полю, поскольку может сказаться на части системы, которая, казалось бы, не имеет к нему отношения. Да и сложно найти перспективного разработчика, готового провести лучшие годы своей жизни, копаясь в завалах старого и непонятного кода.
Поговорим о том, насколько проблемной может стать переработка кода, написанного на Symfony 1.
> [Symfony](https://ru.wikipedia.org/wiki/Symfony) — свободный фреймворк, написанный на PHP.
>
> Версия 1.4 (финальная в ветке 1.xx). Появилась в ноябре 2009 г. Версия PHP: начиная с 5.2.4. Окончание поддержки: ноябрь 2012. ORM: Propel или Doctrine 1.
>
>
Выбор Symfony в качестве фреймворка казался настоящим прорывом. Он использовал передовые подходы к разработке. В состав поставки входила консольная утилита, выполнявшая ряд рутинных задач, в том числе миграцию СУБД. Symfony позволял легко написать свою команду, присутствовала система событий (Event Dispatcher). Была ORM — всемогущая Doctrine, были настройки в yaml-файлах. Админку можно было и вовсе генерировать на основе этих конфигураций. Существовали концепции форм и фильтров форм, что позволяло структурированно оперировать входными данными. Использовался шаблонизатор, дружелюбный для программиста — PHP. Казалось бы, всё замечательно! Но во что это превратилось с годами?
Возьмём пример: создание заявки. Заявка (Advert) — это сущность, создаваемая заказчиком для передачи её исполнителю (вебмастеру). В процессе создания заявки мы проходим через следующие абстракции:
* Шаблон на PHP — *newSuccess.php*, в котором мы корректируем цены с учётом дополнительных услуг, получаем информацию по площадкам, выводим настройки специфичные для пользователя. Как ни присматривай за изменениями в коде, сама возможность занести бизнес-логику в шаблон выглядит привлекательно. Из лучших побуждений, с целью экономии времени, фронтендер или бэкендер напрямую обращаются ко внутренним сервисам и начинают формировать свои структуры и переформатировать данные.
* Действие в контроллере — *\advertActions::executeCreate*, в котором мы обработаем запрос для передачи в сервис создания. Если это — PHP-код, то почему бы не написать в нём логику преобразования каких-нибудь данных? Сформируем контент заявки. Подкорректируем свойства сущности заявки в соответствии со вновь открывшимися данными о пользователе и заполненных полях. Обработаем случай, если надо создать не заявку, а её черновик. В общем, действий на 400+ строк кода. А кто сказал, что нельзя сделать это тут?
* Биндинг данных из запроса с формой в *AdvertForm*. Создадим виджеты, кое-что сделаем с оформлением формы — всё вполне легально и не рушит архитектуру. Но заодно и поменяем настройку сущности заявки на этапе биндинга, потому что тут же как раз всё под рукой.
* Создадим заявку через сервис *AdvertService*. Тут самое раздолье в плане бизнес-логики: несколько десятков всяких проверок и преобразований. Ходим из метода в метод, что-нибудь меняем у сущности, пока не дойдём непосредственно до сохранения в БД. Сервис модели — это ведь самое подходящее место, чтобы написать много, очень многоопераций с данными?
* Выполним сохранение сущности в *\Advert::save*. Тут разработчик понимает, что ещё ~~не всё успел сказать~~ не всю бизнес-логику успел описать. Метод сохранения в базу очень хорош, чтобы описать всё, что должно делаться автоматически при любом сохранении. Здесь мы можем обновить поля сущности как для существующей, так и для новой. Сходить в биллинг, во внешний партнёрский сервис, чтобы обновить там статус. Заодно обновить по условию ряд полей (и получить 200+ строк логики, не считая вложенных методов).
Стоит учитывать, что Symfony 1 использует подход богатой модели предметной области.
> [Богатая модель предметной области](https://habr.com/ru/post/346016/) (БМПО, Rich Domain Model) — в ней классы, представляющие сущности предметной области, содержат в себе и данные, и всю бизнес-логику.
>
>
Такой подход, как показывает практика, провоцирует переплетение бизнес-логики и логики из инфраструктурного слоя. Рядом располагаются хуки для работы с БД и методы для всего, что связано с сущностью.
Итого получается 5 логических зон или слоёв, где может оказаться бизнес-логика, не считая косвенно связанных сервисов и моделей, на которые тоже оказывается влияние. При этом, данные оформлены в виде нетипизированной структуры — массива, который меняется и дополняется с помощью разных методов на манер матрешки. Выяснение, что же случилось с данными по ходу обработки, превращается в детектив.
Глядя на всё это, наша команда решила не пытаться на данном этапе распутать логику, чтобы формализовать её и перенести в новое приложение. Вместо этого мы обернули код с уровня контроллера (уровень Controller из MVC) в дополнительный слой — внешний интерфейс на базе OpenAPI.
**Коротко об OpenAPI**
OpenAPI-спецификация — это контракт (соглашение) между фронтендом и бэкендом. В нём описываются адреса для обращения, форматы запросов и ответов, оперируемые сущности.
> [OpenAPI](https://ru.wikipedia.org/wiki/OpenAPI_(%D1%81%D0%BF%D0%B5%D1%86%D0%B8%D1%84%D0%B8%D0%BA%D0%B0%D1%86%D0%B8%D1%8F)) представляет собой формализованную спецификацию и полноценный фреймворк для описания, создания, использования и визуализации веб-сервисов REST.
>
>
OpenAPI имеет развитую экосистему, которая включает в себя множество [инструментов](https://openapi.tools/) для различных языков.
Благодаря формализации в общении между фронтом и бэком, появляются такие возможности как автогенерация кода и автотестов, создание имитаторов как бэкенда, так и фронтенда, автовалидация запросов и ответов, а также автоматизированное создание документации.
Преобразование наших legacy-сервисов в OpenAPI-сервисы позволило использовать их уже в качестве подсистем в новом приложении:
**Добавляем OpenAPI поверх legacy**
Мы выбрали слой Controller / Presenter в качестве места для создания обёртки вокруг legacy-логики (в Symfony и Zend это контроллеры). Далее разберём, как мы справились с этой задачей в Symfony 1.
Первым делом описали в спецификации на каждый сервис структуры запросов и ответов и вручную создали классы, отображающие эти объекты. Это было необходимо, чтобы максимально структурировать данные из legacy-action контроллеров. Новые контроллеры оперировали только объектами, принудительно преобразуя исходный запрос в приложение, а также получая ответ от старых контроллеров.
Например, метод создания заявки в OpenAPI описан так (в сокращении):
```
"/rest/Adverts/projectId/{projectId}": {
"post": {
"tags": [
"Adverts"
],
"summary": "Создание классической заявки",
"operationId": "createAdvert",
"parameters": [
{
"$ref": "#/components/parameters/projectId"
}
],
"requestBody": {
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"sitesIds": {
"type": "array",
"items": {
"$ref": "#/components/parameters/siteId"
},
"minItems": 1
},
"links": {
"$ref": "#/components/schemas/AdvertLinks"
},
"description": {
"type": "string",
"title": "Комментарий вебмастеру",
"minLength": 3
}
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Результат создания классической заявки",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"advertIds": {
"type": "array",
"title": "Массив ID созданных заявок",
"items": {
"type": "integer",
"format": "int32",
"title": "ID созданной заявки",
"minimum": 0
}
}
}
}
}
}
}
}
}
}
```
При этом бэкенд оперирует ответом как объектом:
```
php
declare(strict_types=1);
/**
* Объект ответа API-метода Adverts.createAdvert.
*/
class AdvertsCreateAdvertResponse
{
/** @var int[] Массив ID созданных заявок */
public $advertIds;
}
</code
```
Преобразование ответов старых контроллеров происходит через метод-wrapper *responseWrapper()*, который:
* собирает все входящие данные из GET и POST-параметров;
* вызывает legacy-метод контроллера, перехватывая отображения flash с ошибками (это уведомления в Symfony1) и преобразуя их в структуры с ошибками в OpenAPI, а также, блокируя redirect, перехватывает возникающие исключения, преобразуя их в структуры ошибок, описанные в спецификации;
* упаковывает ответ в JSON.
Также применяется метод для перехвата возвращаемых параметров из varHolder — *getActionResultValues()*. VarHolder — это способ Symfony 1 для передачи данных в шаблоны для рендеринга. Из контекста класса контроллера виртуальные переменные через $this выставляются вот так:
```
$this->project = $user->findProject($project_id);
```
Наш метод *getActionResultValues()* создаёт имитацию запроса из браузера для legacy-action, перехватывает любые исключения и преобразует их в ошибки, а также собирает все результаты из varHolder. И, разумеется, блокирует рендеринг.
В итоге обработка выглядит так:
1. В нашем методе-обёртке мы заполняем из параметров запроса данные, пригодные для legacy-контроллера:
```
$this->getRequest()->setParameter('form', $form_data);
$this->getRequest()->setParameter('type', $link_type);
$this->getRequest()->setParameter('project_id', $project_id);
```
2. При помощи вспомогательного метода нового контроллера *$this->getActionResultValues('advert', 'create')* получаем всё, что он в итоге собирался отрисовать в шаблоне.
3. Формируем объект ответа в соответствии с OpenAPI.
4. Передаём результат для дооформления в *responseWrapper()*, который может по ходу поймать исключения более высокого уровня.
Адаптация бэкенда в Zend 1 была сделана похожим образом, но несколько проще: там не пришлось перехватывать рендер в Smarty. В нашем распоряжении оказались пусть и плохо организованные, но сервисы, методы которых мы смогли использовать.
**В заключение**
Адаптация под OpenAPI старых сервисов позволила в краткие сроки и с наименьшими усилиями создать современный интерфейс для наших legacy-сервисов. Сервис на Symfony 1 мы смогли адаптировать за 14 человеко-дней (не считая решения предварительных организационных вопросов и обучения). В итоге получилось около 70 API-методов. Это открыло нам дорогу для дальнейшей модернизации системы.
Команда Sape построила и успешно запустила новое приложение, объединившее логику из legacy-подсистем. При этом мы начали процесс переноса бизнес-логики в новое приложение. Благодаря этому, например, смогли привлечь новых разработчиков, которым не приходится сталкиваться с нашим legacy.
Если есть интерес к этой и смежным темам, пишите в комментариях — буду делиться опытом. | https://habr.com/ru/post/697904/ | null | ru | null |
# Графический интерфейс для bash, делаем работу в командной строке удобнее
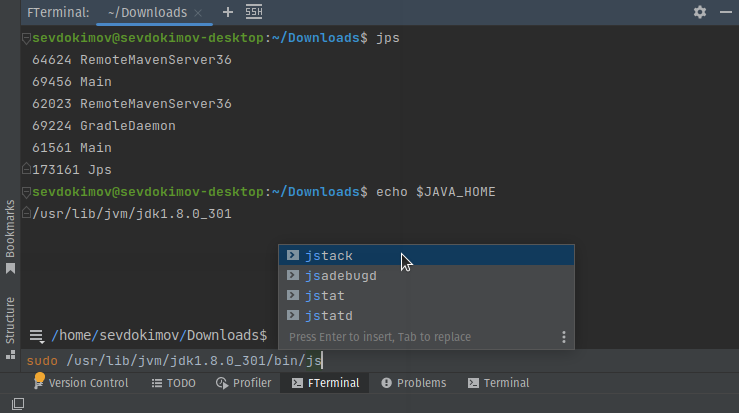Когда пишешь код в IntelliJ IDEA, привыкаешь что везде есть подсказки, везде где можно работает комплишен, всегда можно одним кликом перейти на декларацию метода или на его юсаджи. После этого интерфейс командной строки выглядит как-то бедно. Конечно, он очень хорошо продуман, сделан настолько удобным, насколько это возможно в текстовом UI, но в графическом UI возможностей намного больше. Представляю вам [плагин](https://plugins.jetbrains.com/plugin/18857-friendly-terminal) для JetBrains IDE, позволяющий работать в командной строке cо всеми удобствами IDE.
Плагин [Friendly Terminal](https://plugins.jetbrains.com/plugin/18857-friendly-terminal) позволяет печатать команду в редакторе IDE. Такой редактор удобнее чем текстовая командная строка, потому что в нём есть подсветка синтаксиса, продуманный комплишен, показ документации, работают привычные сочетания клавиш, можно перемещать курсор мышкой и т.д.
После запуска команды, пользователь переключается в текстовую консоль, где команда выполняется, так, как будто её запустили обычном терминале.
После завершения исполнения команды, пользователь возвращается в GUI интерфейс, где показан output команды и можно вводить следующую. Bash сессия в текстовой консоли висит в бэкграунде и ждёт пока не будет запущена следующая команда.
Output показывается средствами IDE, что позволяет сделать его интерактивным. Например, команда`ls /opt/my-app/conf` выведет список файлов в директории /opt/my-app/conf, и эти имена файлов будут кликабельны, при нажатии c Ctrl файлы открываются в редакторе IDE, так же, из контекстного меню доступны свойства файла, копирование полного пути, и т.д.
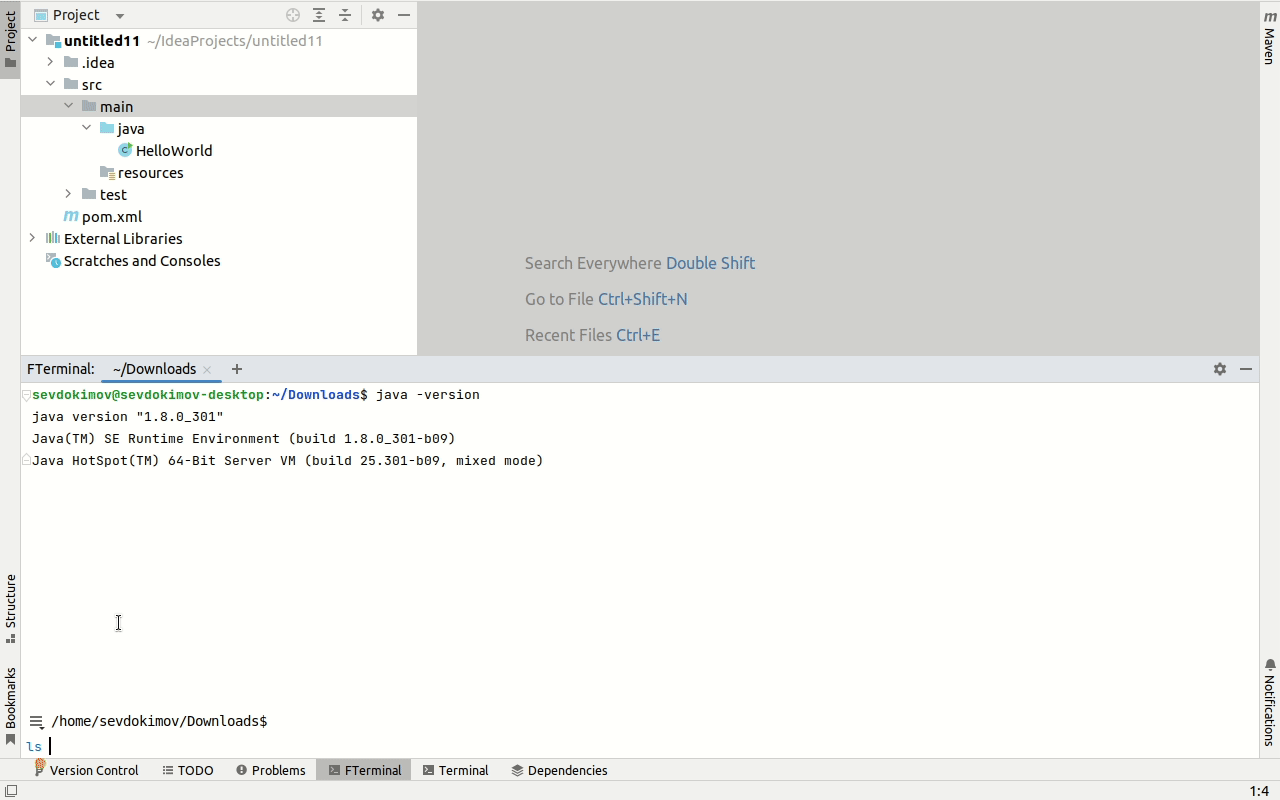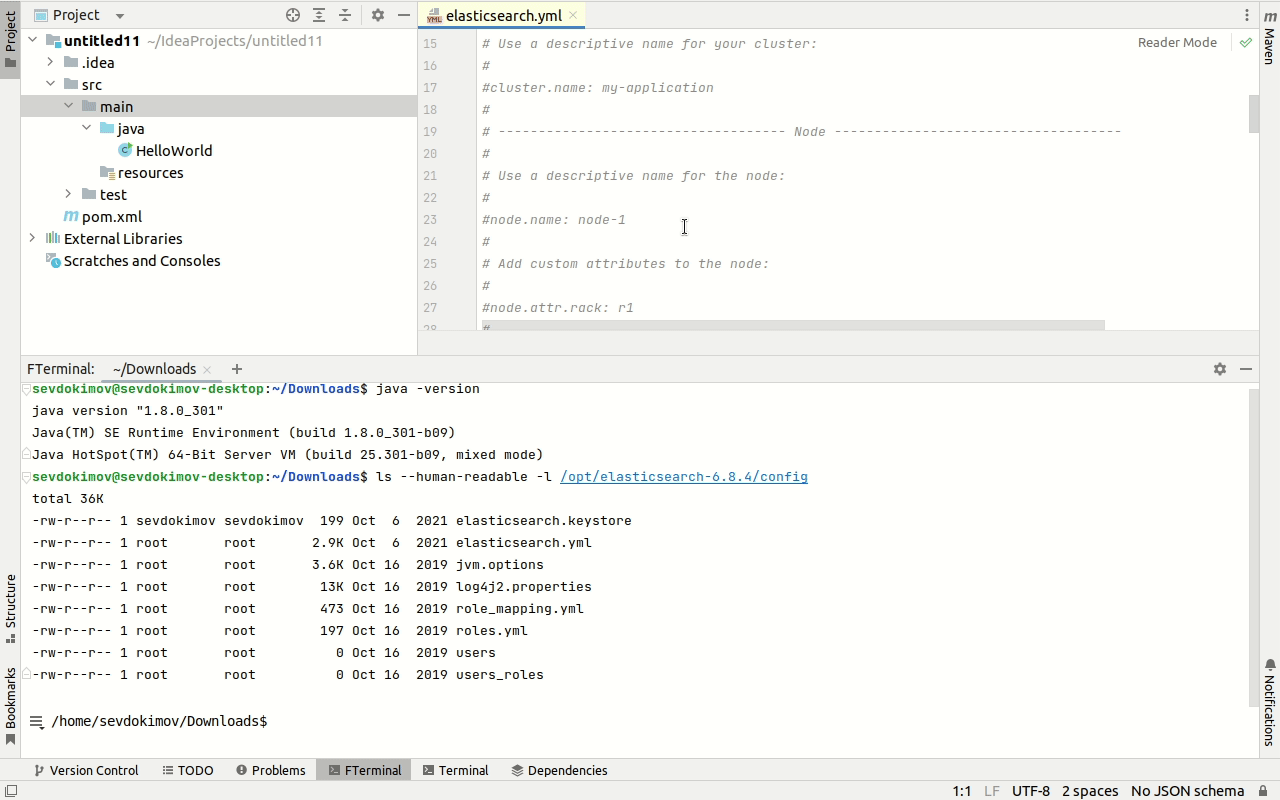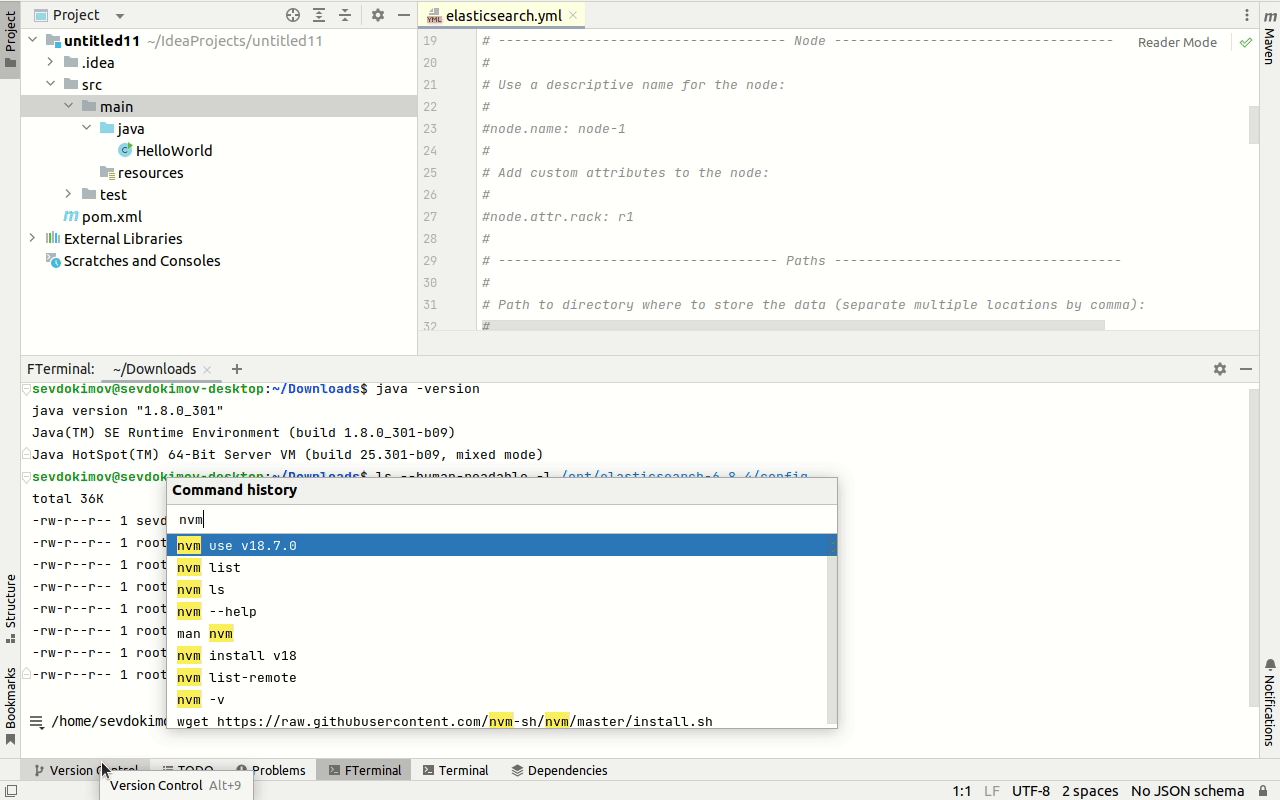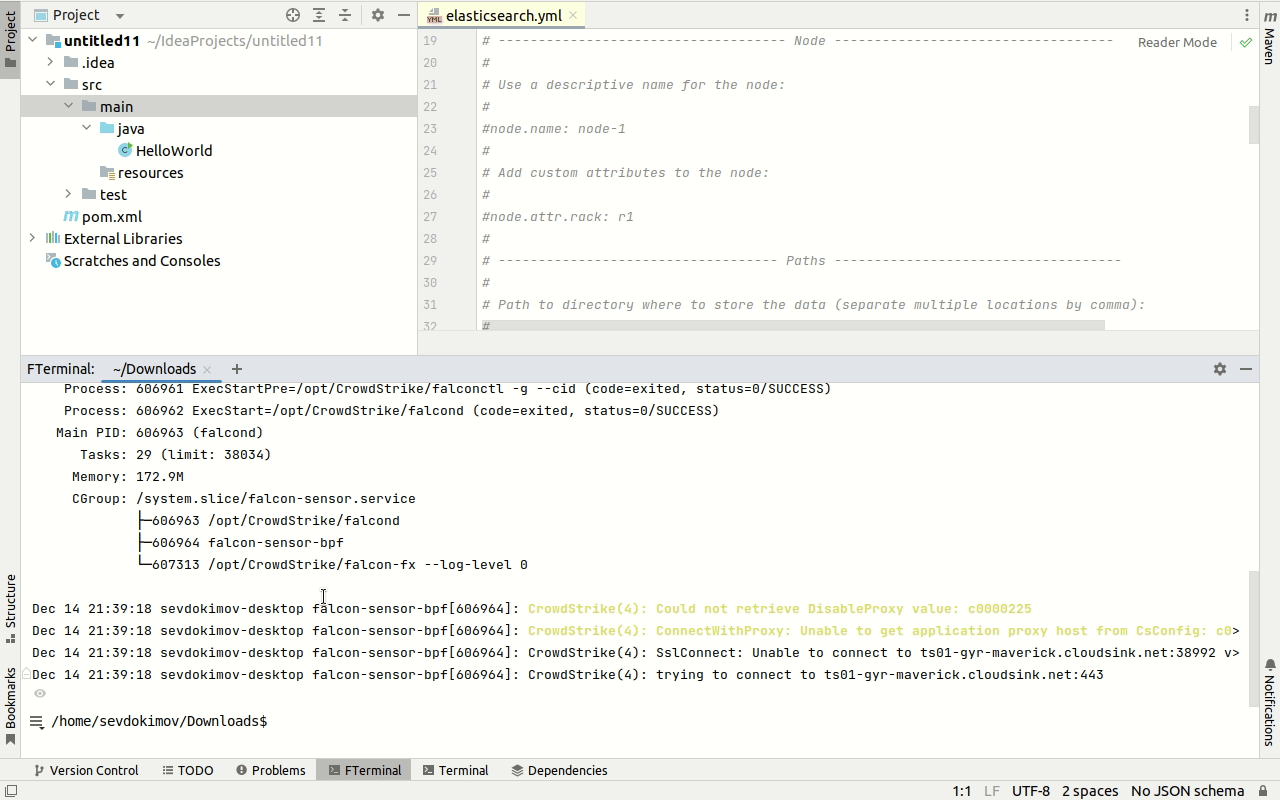Поиск команды в истории происходит во всплывающем окне, что позволяет видеть сразу несколько вариантов, в отличие от стандартного текстового терминала, где показывается только один вариант и легко пропустить нужный нажимая Ctrl+R.
### File Manager
Навигация по файловой системе с помощью команд `cd`и `ls` — не самая удобная вещь, поэтому в плагине есть встроенный файловый менеджер типа Total Commander. Можно нажать `Ctrl+O` и откроются 2 файловых панели. В них можно ходить по директориям, копировать файлы, удалять файлы и т.д. Если вы на удалённой машине, то можно скачать файл или загрузить с локальной машины.
SSH
---
Командная строка используется, в основном, для доступа к удаленным машинам через SSH, поэтому все фичи должны работать даже если терминал подключен к удалённой машине. Было бы мало толка если бы GUI работал только локально. Это накладывает некоторые ограничения на способ получения данных. Допустим, пользователь открыл историю команд, плагину надо как-то узнать что там за история команд на удалённой машине. На локальной всё просто — можно прочитать историю из файла "~/.bash\_history" , а для связи с удалённой есть только bash сессия, которая висит в бэкграунде, пока пользователь находится в GUI панели. Через эту bash сессиию и происходит загрузка всех данных. Например можно получить историю команд запустив `history` и распарсив результат, для комплишена имён файлов и навигации по файловой системе в File Manager запускается `ls`. Чтобы технические команды не зафлудили историю, они начинаются с пробела. Bash не сохраняет команду в истории, если она начинается с пробела.
Я писал, что можно открывать файлы в редакторе IDE, это работает и через SSH. В этом случае, файл скачивается в temporary директорию. Если его изменить, изменения можно выгрузить обратно нажав "Upload changes". [video](https://www.youtube.com/watch?v=lXT4eUoAIz4&t=12s&ab_channel=SergeyEvdokimov)
Представляю что об этом думают фанаты vim... Но на вкус и цвет товарищей нет, этот плагин для любителей IntelliJ IDEA.
Маленькие, но полезные фичи
---------------------------
* `Ctrl+Shift+Space` (smart completion) предлагает команды из истории, совпадающие по префиксу с тем что уже напечатано.
* Иногда хочется взглянуть на вывод последней команды отдельно от всего остального, для этого можно нажать `Ctrl+Shift-O` или соответствующую иконку в конце вывода, и он откроется во всплывающем окне на весь экран.
* Можно нажать `Alt-Up`, чтобы переместить курсор из строки ввода команды, в консоль, где печатается output команд, это позволяет что-нибудь скопировать без использования мыши. Дальнейшие нажатия Alt-Up / Alt-Down перемещают курсор к выводу следующей / предыдущей команды.
* Нажатие `Alt+F12` открывает терминал, в каком-бы месте IDE вы не находились.
### Ограничения
[Friendly Terminal](https://plugins.jetbrains.com/plugin/18857-friendly-terminal) работает только с Linux консолью. В Windows может работать только в WSL (Windows Subsystem for Linux) или как SSH клиент для подключения к Linux машинам. Работать с CMD или PowerShell не может. Теоретически, можно сделать поддержку Cygwin, но пока не сделано.
Ссылка на плагин: <https://plugins.jetbrains.com/plugin/18857-friendly-terminal>
Буду рад любым отзывам.
P.S. Выяснилось что есть проблемы с работой под MacOS и под Ubuntu, если она руссифицирована. Исправлю в ближайшее время. | https://habr.com/ru/post/715824/ | null | ru | null |
# Behavior-Driven Testing для iOS используя Quick и Nimble
После прочтения данной статьи, вы сможете использовать **Quick** и **Nimble** в своих проектах!

Написание прекрасных работоспособных приложений — одно дело, но написание хороших тестов, которые подтверждают ожидаемое поведение вашего приложения, — задача намного сложнее. В этой статье мы рассмотрим один из доступных подходов тестирования приложений, behavior-driven testing, используя два чрезвычайно популярных фреймворка под названием [Quick](https://github.com/Quick/Quick) и [Nimble](https://github.com/Quick/Nimble).
Вы узнаете о *behavior-driven testing*: изучите что это такое, почему это чрезвычайно мощная концепция и насколько легко писать читабельные тесты с помощью фреймворков Quick и Nimble.
Вы будете писать тесты для удивительно простой и забавной игры под названием **AppTacToe**, в которой вы играете в игру Tic Tac Toe против компьютера, изображая iOS персонажа, играющего против злого Android игрока!
**Примечание:** *Для лучшего понимания данной статьи предполагается что у Вас есть наличие базовых знаний темы Unit Testing и использования XCTestCase.*
Несмотря на то, что вы можете продолжить прочтение данной статьи без наличия этих знаний, все же рекомендуется ознакомится со статьёй [iOS Unit Testing and UI Testing Tutorial](https://www.raywenderlich.com/150073/ios-unit-testing-and-ui-testing-tutorial) для повторения ранее изученных основ.
### Начало
Лучший способ начать написание тестов — это работать над настоящим приложением, которым в вашем случае будет игра AppTacToe, представленная ранее.
[Загрузите стартовый проект](https://koenig-media.raywenderlich.com/uploads/2018/03/AppTacToe.zip), который содержит все необходимое для работы, он уже содержит Quick и Nimble. После загрузки откройте **AppTacToe.xcworkspace**.
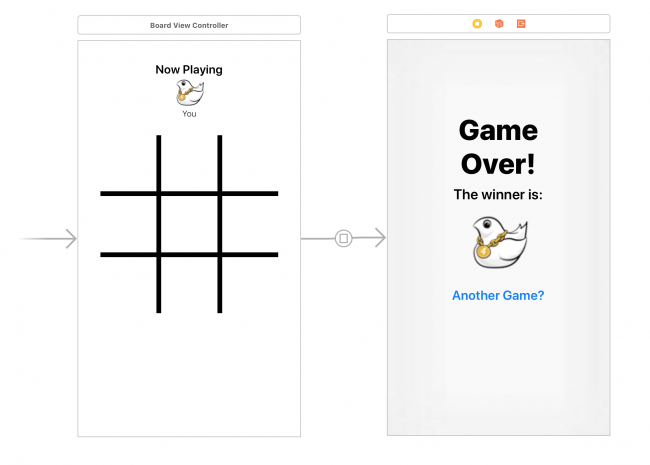
Откройте **Main.storyboard** и изучите базовую структуру приложения. Она состоит из двух экранов: **Board**, в котором происходит сама игра, и экран «*Game Over screen*», отвечающий за отображение результата игры.
Скомпилируйте и запустите приложения, и сыграйте в одну или две быстрых игры, чтобы познакомится с игрой.
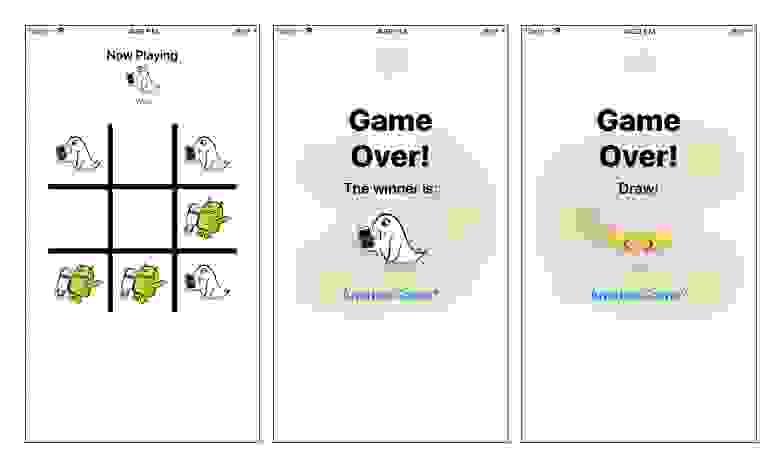
Вы также увидите полезное логирование, которое отображается в консоли, дублируя ход игры и отображая итоговую доску, после завершения игры.
**Примечание:** *Не беспокойтесь, если заметите незначительные ошибки во время игры; вы исправите их, вовремя работы над данной статьей!*
Большая часть бизнес логики приложения содержится в одном из двух файлов:
**Components/Board.swift**: Этот файл обеспечивает логическую реализацию игры Tic Tac Toe. В нем нету элементов **UI** интерфейса, связанного с данной игрой.
**ViewControllers/BoardViewController.swift**: Это основной игровой экран. Он использует вышеупомянутый класс **Board** для игры и несет ответственность за отображение состояния игры на экране устройства и обработку взаимодействия с пользователем.
То, что вам действительно необходимо протестировать в этом случае, это бизнес логику игры, поэтому вы будете писать тесты для класса **Board**.
### Чем же является Behavior-Driven Testing?
Приложение состоит из множества фрагментов кода. В традиционных модульных тестах вы проверяете всевозможные элементы каждой из этих частей. Вы предоставляете некоторые данные для некоторого фрагмента кода и утверждаете, что он возвращает ожидаемый результат.
Недостатком такого подхода является то, что он подчеркивает необходимость проверки внутренней работы приложения. Это означает, что вы тратите больше времени на тестирование деталей реализации, а затем на фактическую бизнес-логику, которая является реальным мясом вашего продукта!
Было бы неплохо, если бы вы могли просто подтвердить, что приложение ведет себя так, как ожидалось, независимо от того, как оно было реализовано.
Давайте познакомимся с behavior-driven тестированием!
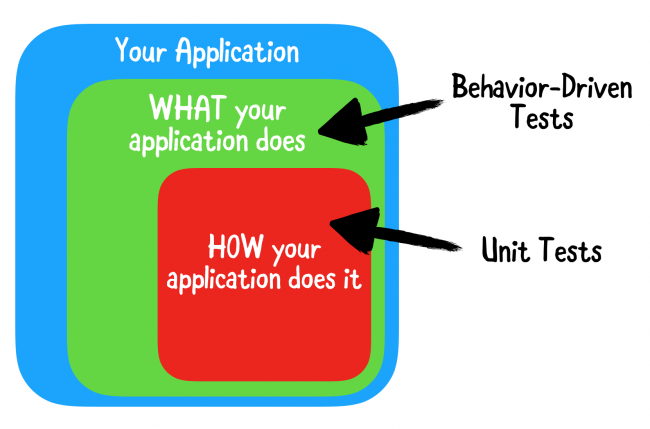
При behavior-driven testing (или **BDT**), ваши тесты основаны на user stories, которые описывают некоторые конкретные ожидаемые действия приложения. Вместо проверки деталей реализации вы фактически проверяете то, что важно больше всего: правильно ли приложение выполняет user stories?
Этот подход делает тесты чрезвычайно читабельными и поддерживаемыми, а также помогает описать поведение логических частей в приложении другим разработчикам, которым однажды выпадает шанс разобраться в вашем коде.
Вот некоторые примеры пользовательских историй, которые вы могли бы написать как часть игры AppTacToe:
*Выполнение одиночного игрового действия переключает на другого игрока.
Выполнение двух игровых действий должно переключить обратно на первого игрока.
Выполнение выигрышного хода должно перевести игру в состояние Победа.
Выполнение хода, после которого больше нет ходов, переводит игру в состояние Ничья.*
### Роль Quick и Nimble в Behavior-Driven Testing
Тесты написаны на основе способа управления поведением и user stories, являются простыми предложениями на английском языке. Это значительно облегчает их понимание по сравнению с обычными Unit тестами, которые вы привыкли писать.
Quick и Nimble обеспечивают чрезвычайно мощный синтаксис, позволяющий писать тесты, которые читаются точно так же, как и обычные предложения, позволяя вам легко и быстро описывать поведение, которое вы хотите проверить. Внутри они работают точно так же, как и обычные XCTestCase(s).
Quick обеспечивает большую часть базового синтаксиса и возможностей, связанных с написанием тестов управляемых поведением, в то время как Nimble — это его сопутствующий фреймворк. Он предоставляет дополнительные выразительные возможности сопоставления и утверждения посредством Matchers, о которых вы узнаете чуть позже в этой статье.
### Анатомия быстрого теста
Разбейте одну из пользовательских историй на три статьи на основе [GWT](https://en.wikipedia.org/wiki/Given-When-Then) — Given (действие/поведение, которое вы описываете), When (контекст этого действия/поведения) и Then (то что вы ожидаете увидеть):
**Given/Дано:** Пользователь играет.
**When/Когда:** Это один ход.
**Then/Следовательно:** Ход должен передаться другому игроку.
В Quick вы используете три функции: describe, context и it.

### Написание первого теста
Наборы тестов в Quick называются Specs, и каждый созданный вами такой набор должен наследоваться от QuickSpec, таким же образом, как вы наследуете от XCTestCase в тестах. Набор тестов включает в себя основной метод spec(), который будет содержать все ваши тестовые примеры.
Стартовый проект уже содержит пустой набор тестов. Откройте файл **AppTacToeTests / BoardSpec.swift** и посмотрите на набор тестов BoardSpecс наследуемой от QuickSpec и содержащей единственный метод *spec()*, в котором вы будете работать.
Примечание: Когда вы откроете файл **BoardSpec.swift**, вы увидите сообщение об ошибке No such module 'Quick' или ‘Nimble’. Не волнуйтесь, так как это просто ошибка в Xcode, не связанная с проектом. Ваш код будет компилироваться и работать без каких-либо проблем.
Начните с добавления следующего кода внутрь метода *spec()*:
```
var board: Board! // 1
beforeEach { // 2
board = Board()
}
```
Этот код выполняет два действия:
1. Определяет глобальную переменную board, которая будет использоваться в тестах.
2. Устанавливаем для переменной board новый экземпляр Board перед каждым тестом, используя замыкание beforeEach с Quick's.
При помощи определенного базового шаблона вы можете начать написание первого теста!
По замыслу этого приложения, игра всегда начинается с Cross (то есть — или так или так., X), а противник будет Naught (то есть, O).
Начнем с первой *user story*, упомянутой выше: После выполнение первого хода следующий ход должен сделать второй игрок.
Добавьте следующий код сразу после окончания замыкания *beforeEach*:
```
describe("playing") { // 1
context("a single move") { // 2
it("should switch to nought") { // 3
try! board.playRandom() // 4
expect(board.state).to(equal(.playing(.nought))) // 5
}
}
}
```
Вот что делает этот код:
1. **describe()** используется для определения того, какие действия или поведение вы будете тестировать.
2. **context()** используется для определения конкретного контекста действия, которое вы будете тестировать.
3. **it()** используется для определения конкретного ожидаемого результата для теста.
4. Вы выполняете случайный ход используя метод *playRandom()* в классе Board.
5. Вы утверждаете, что состояние Board изменено на *.playing(.nought)*. На этом этапе используется метод *equal()* из Nimble, который является одной из многих доступных функций, которые можно использовать для утверждения соответствия конкретных условий ожидаемому значению.
**Примечание:** *Возможно, вы заметили принудительный вызов try и неявно unwrapped опционал для определения тестовых глобальных переменных. Хотя такой вариант обычно и не одобряется при написании кода в самом приложении, это довольно распространенная практика при написании тестов.*
Запустите тесты, перейдя в панель меню **Product ▸ Test** или с помощью сочетания клавиш **Command+U**.
Так, вы увидите выполнение своего первого теста. **Потрясающие!**
После выполнения теста, вкладка Test navigator должна выглядеть так:
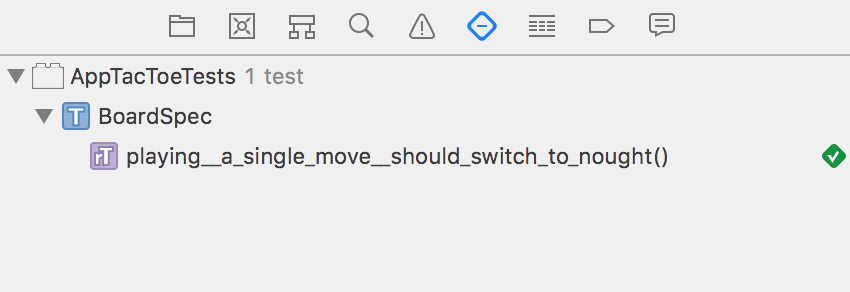
Вы уже заметили несколько интересных моментов, просмотрев код. Прежде всего, это чрезвычайно читабельный код. Просмотрев код теста, любой человек может относительно легко прочитать его, как простое предложение на английском:
Выполнение одиночного хода переключает на второго игрока.
На данном этапе Вы познакомились с простым использованием Nimble Matchers. Nimble использует эти сопоставления, чтобы вы могли получить ожидаемый результат теста очень быстрым способом, подобно простым предложениям. *equal()* — это только одна из функций сопоставления, которая доступная в Nimble. Вы даже можете создавать свои собственные функции.
### Следующий тест
Вторая user story — “После второго хода должно переключится обратно на первого игрока” — звучит довольно похоже на user story.
Добавьте следующий код сразу после окончания предыдущего метода **context()**, внутри закрывающей фигурной скобки **describe()**:
```
context("two moves") { // 1
it("should switch back to cross") {
try! board.playRandom() // 2
try! board.playRandom()
expect(board.state) == .playing(.cross) // 3
}
}
```
Этот тест похож на предыдущий, но отличается только тем, что вы делаете два хода вместо одного.
Вот что тест выполняет:
1. Вы определяете новый **describe()** для создания контекста «двух ходов». Вы можете иметь любое количество блоков **describe()** и **context()**, и они могут даже содержаться внутри друг друга. Поскольку вы все еще тестируете геймплей, вы добавили контекст внутри describe(«playing»).
2. Вы совершаете для последовательных хода.
3. Вы утверждаете, что **state** доски сейчас является *.playing(.cross)*. Обратите внимание, что на этот раз вы использовали регулярный оператор равенства ==, вместо синтаксиса *.to(equal())*, который вы использовали ранее. Сопоставление Nimble’s equal() обеспечивает свои собственные перегруженные операторы, которые можно выбрать на свой вкус.
### Arrange, Act & Assert
Те тесты, которые вы только что написали, были относительно простыми и понятными. Вы выполняете одиночный вызов на пустом board и утверждаете ожидаемый результат. Обычно, большинство сценариев более сложны, что требует немного дополнительной работы.
Следующие две user stories будут сложнее:
*Выполнение выигрышного хода должно переключить в состояние Победы.
Выполнение выхода из игры не производит никаких действий, а только переход в состояние Завершения игры.*
В обеих этих *user stories* вам нужно сделать некоторые шаги на игровой доске, чтобы Вы могли проверить ее состояние, свое утверждение.
Эти тесты обычно делятся на три этапа: **Arrange, Act and Assert**.
Прежде чем планировать тесты, вы должны понять, как реализована платформа **Tic Tac Toe**.
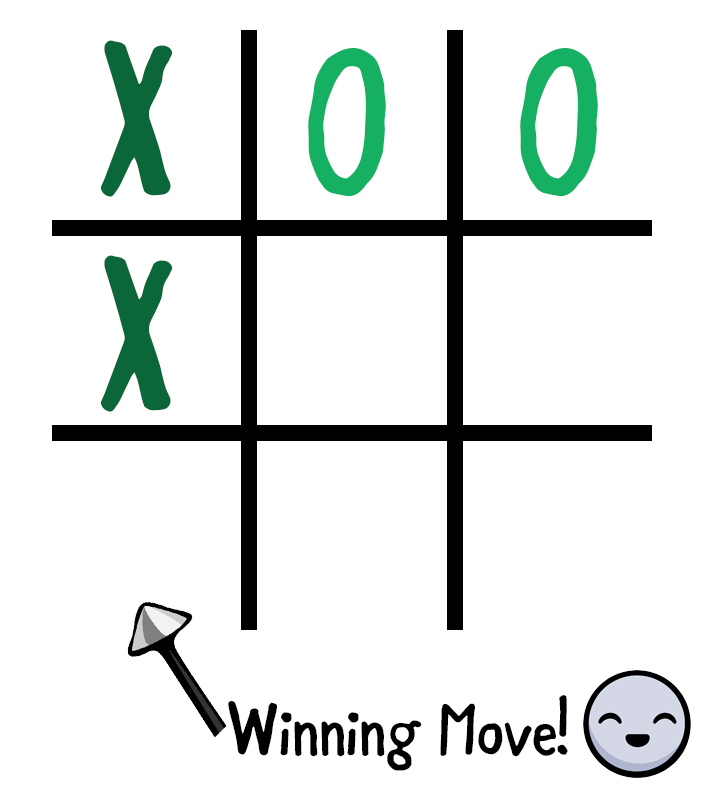
Board моделируется как Array, состоящий из 9 ячеек, адресованных с использованием индексов от 0 до 8.
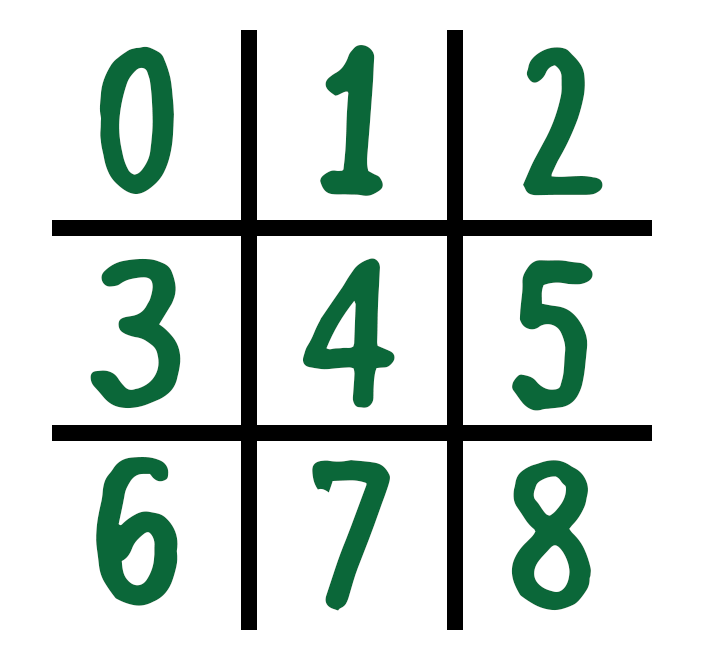
При каждом шаге игрок выполняет один ход. Чтобы написать тест для симуляции победы пользователя, вам нужно будет привести **Board** до состояния, когда следующий ход будет выигрышным.
Теперь, когда вы понимаете, как работает Board, пришло время написать этот тест.
Добавьте следующий код ниже вашего предыдущего контекста “two moves” **context()**:
```
context("a winning move") {
it("should switch to won state") {
// Arrange
try! board.play(at: 0)
try! board.play(at: 1)
try! board.play(at: 3)
try! board.play(at: 2)
// Act
try! board.play(at: 6)
// Assert
expect(board.state) == .won(.cross)
}
}
```
Вот что реализует данный код:
**Arrange:** Вы организовываете Вoard, чтобы подготовить ее до состояния, когда следующий ход будет выигрышным. Вы делаете это, выполняя ходы обоих игроков в свою очередь; начиная с X в точке 0, в точке 1, X в 3 и наконец в 2.
**Act:** Вы выполняете ход Cross (X) на позицию 6. В текущем состоянии Board, этот ход должен привести к выигрышному состоянию.
**Assert:** Вы указываете, что игру выиграет Крестик (Х), и и Board перейдет в состояние Выигрыш (.won (.cross))
Запустите тест еще раз, используйте сочетание клавиш **Command+U**.

Что-то не так; вы сделали все верные шаги, но тест неожиданно провалился.
Добавьте следующий код непосредственно под строкой *expect()*, чтобы увидеть ошибку:
```
print(board)
```
Отобразив **Board** сразу же после блока **Assert**, вы получите детальное разъяснение данной ситуации:
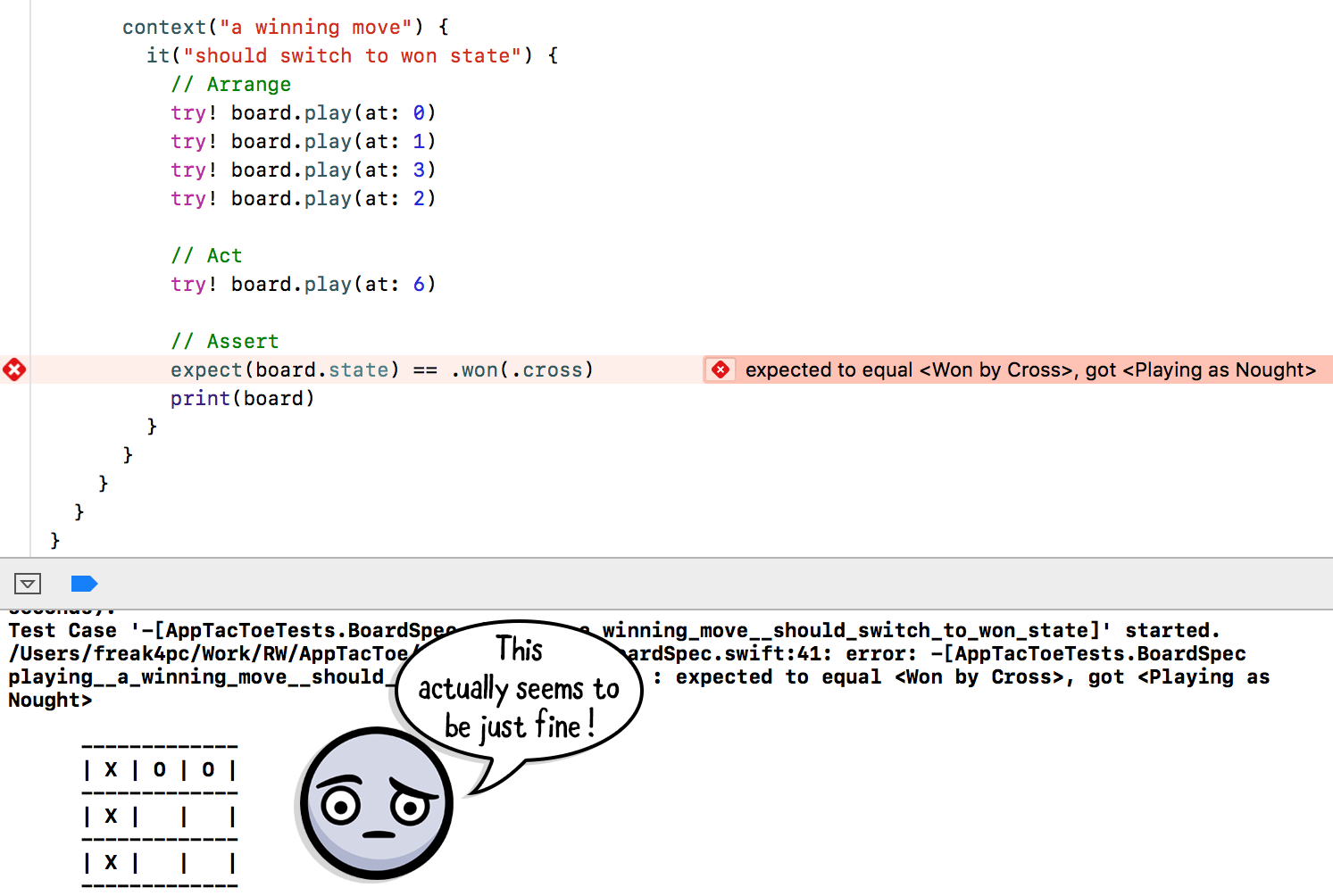
Как видите, Board должен находиться в состоянии Победы, но тест все еще не работает. Похоже, вы нашли ошибку.
Перейдите в вкладку *Project navigator* и откройте **Board.swift**. Перейдите на вычисленное свойство **isGameWon** в строке 120.
Код в этом разделе проверяет все возможные выигрышные позиции по строкам, столбцам и диагоналям. Но, глядя на столбцы, у кода, похоже, только 2 столбца проверены, и на самом деле отсутствует один из вариантов выигрыша. Упс!
Добавьте следующую строку кода непосредственно ниже комментария **// Columns**:
```
[0, 3, 6],
```
Запустите тесты еще раз и насладитесь тремя зелеными маркеры!

Такой сценарий будет намного сложнее обнаружить с помощью обычных Unit тестов. Поскольку вы используете тестирование, основанное на поведении, вы фактически протестировали конкретный вариант использования приложения и обнаружили ошибку. Исправление основной реализации зафиксировало протестированное поведение, разрешив проблему, которую испытывала ваша пользовательская история.
**Примечание:** *Во время работы над одним конкретным тестом или конкретным контекстом тестов вы можете не захотеть запускать все свои тесты сразу, чтобы вы могли сосредоточиться конкретно над одним тестом.
К счастью, Quick предоставляет очень простой способ сделать это. Просто добавьте f (стоит для фокусировки ) перед любым из имен тестовых функций — имея it(), context() и describe (), становятся fit(), fcontext() и fdescribe()
Например, после замены it(«should switch to won state») на fit(«should switch to won state»), будет запускаться только этот конкретный тест, пропуская остальную часть тестового набора. Просто не забудьте удалить его после того, как вы закончите, иначе только часть ваших тестов будет работать!*
### Маленькое упражнение
Время для вызова. У вас есть одна последняя user story, которую вы еще не тестировали: Выполнение хода, после которого больше нет ходов, переводит игру в состояние Ничья.
Используя предыдущие примеры, напишите тест, чтобы проверить правильность определения Вoard.
**Примечание:** *Чтобы достичь состояния выхода, вы можете последовательно воспроизводить следующие позиции: **0, 2, 1, 3, 4, 8, 6, 7**.*
В этом состоянии игровая позиция 5 должна приводить к тому, что ваш Вoard находится в состоянии draw.
Кроме того, используя метода .draw может запутать **Xcode**. Если это так, используйте полное выражение: *Board.State.draw*.
Если у вас не получилось роить это задание, вот решение:
```
context("a move leaving no remaining moves") {
it("should switch to draw state") {
// Arrange
try! board.play(at: 0)
try! board.play(at: 2)
try! board.play(at: 1)
try! board.play(at: 3)
try! board.play(at: 4)
try! board.play(at: 8)
try! board.play(at: 6)
try! board.play(at: 7)
// Act
try! board.play(at: 5)
// Assert
expect(board.state) == Board.State.draw
}
}
```
### Счастливый Путь — это не единственный путь
Все тесты, которые вы написали до сих пор, имеют одну общую черту: они описывают правильное поведение вашего приложения, следуя счастливому пути (**happy path**). Вы подтвердили, что, когда игрок воспроизводит правильные ходы, игра ведет себя правильно. Но как насчет не очень счастливого пути?
При написании тестов вы не должны забывать о концепции ожидаемых ошибок. У вас, как разработчика, должна быть возможность подтвердить правильность поведения Вoard даже если ваш игрок ведет себя не правильно (например, совершает неразрешенный ход).
Рассмотрите две последние user stories этого туториала:
*делая ход, который уже был сделан, должно вызвать ошибку.
делая ход, после того как игра выиграна, должно вызывать ошибку.*
Nimble предоставляет удобного сопоставителя с именем **throwError()**, которого вы можете использовать для проверки этого поведения.
Начните с проверки того, что уже воспроизведенный ход не может быть воспроизведен снова.
Добавьте следующий код прямо под последним **context()**, который вы добавили, но все еще внутри блока **describe(«playing»)**:
```
context("a move that was already played") {
it("should throw an error") {
try! board.play(at: 0) // 1
// 2
expect { try board.play(at: 0) }
.to(throwError(Board.PlayError.alreadyPlayed))
}
}
```
Вот что выполняет данный код:
1. Вы выполняете ход в положение 0.
2. Вы воспроизводите ход в одну и ту же позицию и ожидаете, что он выбросит **Board.PlayerError.alreadyPlayed**. Когда вы утверждаете, что ошибка отображена, expect принимает замыкание, в котором вы можете запустить код, вызывающий ошибку.
Как вы и ожидали от Quick-тестов, утверждение читается так же, как английское предложение: expect playing the board to throw error – already played(ожидается, что дальнейшая игра вызовет ошибку «уже сыграно»).
Запустите набор тестов еще раз, перейдя в **Product ▸ Test** или используйте сочетание клавиш **Command+U**.

Последняя user story, которую вы собираетесь сегодня изучить, будет: Делая ход, после того как игра выиграна, должно вызывать ошибку.
Этот тест должен быть относительно похож на предыдущие тесты **Arrange, Act и Assert**: вам нужно привести board в выигрышное состояние, а затем попытаться сыграть еще один шаг, пока board будет в этом состоянии.
Добавьте следующий код прямо под последним **context()**, который вы добавили для предыдущего теста:
```
context("a move while the game was already won") {
it("should throw an error") {
// Arrange
try! board.play(at: 0)
try! board.play(at: 1)
try! board.play(at: 3)
try! board.play(at: 2)
try! board.play(at: 6)
// Act & Assert
expect { try board.play(at: 7) }
.to(throwError(Board.PlayError.noGame))
}
}
```
Основываясь на знаниях, которые вы получили в этом уроке, вы должны чувствовать себя как дома, работая с этим тестом!
Вы подводите board к состоянию Выигрыш (.won (.cross)), воспроизведя 5 шагов… Затем вы **Act и Assert**, пытаясь сыграть ход, пока board уже находится в состоянии Выигрыш, и ожидает отображения **Board.PlayError.noGame**.
Запустите свой пакет тестов еще раз и похлопайте себя по спине пройдя все эти тесты!

### Пользовательские сопоставления
При написании тестов в этой статье вы уже использовали несколько сопоставлений, встроенных в Nimble: equal() (и его == оператор перегрузки), и **.throwError()**.
Иногда вы хотите создать свои собственные сопоставления, чтобы инкапсулировать некоторую сложную форму сопоставления или повысить читаемость некоторых ваших существующих тестов.
Подумайте о том, как улучшить читаемость user story *«побеждающий ход должен переключить состояние на Выигрыш»*, упомянутого ранее:
**expect(board.state) == .won(.cross)**
Перефразируйте данный код, как предложение на английском языке: *expect board to be won by cross (ожидается, что борд выиграет Крестик(х))*. Тогда тест будет иметь следующий вид:
**expect(board).to(beWon(by: .cross))**
Сопоставители в Nimble — это не что иное, как простые функции, возвращающие Predicate , где generic T — тип, с которым вы сравниваете. В вашем случае T будет иметь тип Board.
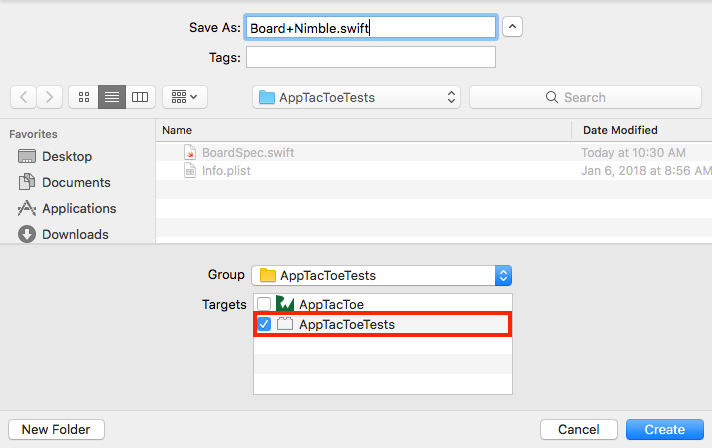
В навигаторе проекта щелкните правой кнопкой мыши папку **AppTacToeTests** и выберите New File. Выберите **Swift File** и нажмите **Next**. Назовите свой файл **Board+Nimble.swift**. Убедитесь, что вы правильно установили файл в качестве члена вашей целевой задачи **AppTacToeTests**:
Замените стандартный **import Foundation** тремя следующими импортами:
```
import Quick
import Nimble
@testable import AppTacToe
```
Этот код выполняет импорт Quick и Nimble, а также импортирует вашу главную цель, поэтому вы можете использовать Board в своем сопоставлении.
Как упоминалось ранее, Matcher — это простая функция, возвращающая **Predicate** типа Board.
Добавьте основную часть сопоставления внизу импорта:
```
func beWon(by: Board.Mark) -> Predicate {
return Predicate { expression in
// Error! ...your custom predicate implementation goes here
}
}
```
Этот код определяет сопоставление **beWon(by:)** которое возвращает Predicate , поэтому он правильно сопоставляется с Board.
Внутри вашей функции вы возвращаете новый экземпляр Predicate, передавая ему замыкание с единственным аргументом — expression — которое является значением или выражением, с которым вы сравниваете. Замыкание должно вернуть PredicateResult.
На этом этапе вы увидите ошибку компиляции, поскольку результат еще не возвращен. Далее это будет исправлено.
Чтобы создать **PredicateResult**, вы должны учитывать следующие случаи:
Как работает сопоставление **beWon(by :)**
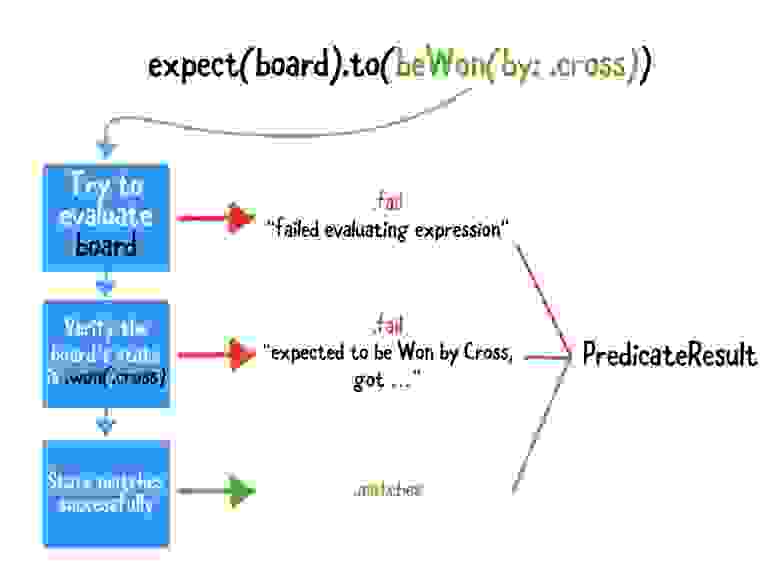
Добавьте следующий код внутрь замыкания Predicate, заменив комментарий, // Error!:
```
// 1
guard let board = try expression.evaluate() else {
return PredicateResult(status: .fail,
message: .fail("failed evaluating expression"))
}
// 2
guard board.state == .won(by) else {
return PredicateResult(status: .fail,
message: .expectedCustomValueTo("be Won by \(by)", "\(board.state)"))
}
// 3
return PredicateResult(status: .matches,
message: .expectedTo("expectation fulfilled"))
```
Вначале эта предикативная реализация может показаться запутанной, но все довольно просто, если выполнить ее шаг за шагом:
1. Вы пытаетесь оценить выражение, переданное в **expect()**. В этом случае выражение является самим board. Если оценка была провалена, вы возвращаете неудачный PredicateResult с соответствующим сообщением.
2. Вы подтверждаете, что состояние board равно **.won(by)**, где by — аргумент, переданный функции Matcher. Если состояние не совпадает, вы возвращаете ошибку PredicateResult с сообщением **.expectedCustomValueTo**.
3. Наконец, если все выглядит хорошо и проверено, вы возвращаете успешный **PredicateResult**.
Это оно! Откройте **BoardSpec.swift** и замените следующую строку:
```
expect(board.state) == .won(.cross)
```
использовав новое сопоставление:
```
expect(board).to(beWon(by: .cross))
```
Запустите тесты еще раз, перейдя в Product ▸ Test или используйте сочетание клавиш Command + U. Вы должны увидеть, что все ваши тесты все еще проходят, но на этот раз с новым Matcher!
### Что далее?
Теперь у вас есть знания, необходимые для написания тестов, ориентированых на поведение, в приложении.
Вы узнали все о тестировании *user stories*, вместо того, чтобы тестировать детали реализации, и как **Quick** помогает этого достичь. Вы также узнали о сопоставлениях **Nimble** и даже написали свое собственное сопоставление. Здорово!
Чтобы начать работу с **Quick** и **Nimble** в своем собственном проекте, начните с руководства по установке и [выберите способ установки](https://github.com/Quick/Quick/blob/master/Documentation/en-us/InstallingQuick.md), который будет приемлемым для вашего проекта.
Когда у вы все настроите, и захотите узнать больше о Quick, перейдите по ссылке под названием [официальная документация Quick's](https://github.com/Quick/Quick/tree/master/Documentation/en-us). Прочтите также [Readme Nimble](https://github.com/Quick/Nimble/blob/master/README.md), чтобы ознакомиться с огромным количеством доступных сопоставлений и возможностей. | https://habr.com/ru/post/352694/ | null | ru | null |
# Языковые модели как двигатель прогресса: необычные применения для GPT-3

В начале лета разработчики из OpenAI представили языковую модель GPT-3, созданную для написания связного текста на основе заданного материала. Её обучали на 570 гигабайтах содержимого веб-страниц, википедии и художественной литературы, что почти в 15 раз превышает объем датасета для GPT-2. Модель отлично пишет стихи и прозу, умеет переводить на некоторые языки, разгадывать анаграммы и отвечать на вопросы по прочитанному материалу. Творчество языковых моделей становится всё труднее отличить от настоящего текста, и GPT-3 не исключение. Например: [Как я, специалист по ИИ, на ИИ-текст купился](https://habr.com/ru/post/511764/).
Но особенность GPT-3 не только в крутой работе с текстом — это не особенно выделяет её среди остальных моделей. На самом деле её возможности кажутся безграничными, а примеры поражают. Судите сами: получая на вход простейший императивный запрос, GPT-3 может писать код, верстать, составлять запросы, вести учёт, искать информацию и многое другое.
**Осторожно, трафик!**
### Код
Достаточно скормить модели пару обучающих примеров, и она сможет писать небольшие конструкции вроде верстки или описания ML-моделей:
**[Генератор вёрстки в JSX](https://twitter.com/sharifshameem/status/1282676454690451457)**
> Your browser does not support HTML5 video.
>
> Эту демку написал Sharif Shameem как прототип фронтенд-конструктора. Получить доступ к ней можно, заполнив [эту форму](https://docs.google.com/forms/d/e/1FAIpQLSeI-QTsXJV0cF5MuB7RwgA0QdHEWn7E6zrs7dCHDLHA3s64Dg/viewform).
**[Императивная вёрстка](https://twitter.com/sharifshameem/status/1283322990625607681)**
> Your browser does not support HTML5 video.
>
> Похожая версия от того же автора. Кажется, эпоха wysiwyg'a скоро закончится.
**[Создание модели машинного обучения](https://twitter.com/mattshumer_/status/1287125015528341506)**
> Your browser does not support HTML5 video.
>
> Восстание самовоспроизводящихся машин уже не за горами!
**[SQL запросы из текста](https://twitter.com/FaraazNishtar/status/1285934622891667457)**
> Your browser does not support HTML5 video.
>
> Вряд ли модель обучена всей мощи SQL, но простые запросы она парсит легко, а это уже неплохо.
**[Регулярные выражения](https://twitter.com/parthi_logan/status/1286818567631982593)**
> Your browser does not support HTML5 video.
>
> Эта демка работает не совсем корректно, но уже должна быть исправлена. Записаться на тест можно [тут](https://losslesshq.com/).
### Дизайн
**[Плагин для Figma](https://twitter.com/jsngr/status/1284511080715362304)**
> Your browser does not support HTML5 video.
>
> Уже нашумевшая в интернете демка плагина для Figma, собирающая дизайн приложений по текстовому запросу.
**[Продвинутая версия](https://twitter.com/dhvanilp/status/1286452207513038848)**
> Your browser does not support HTML5 video.
>
> “В целом, я очень впечатлен, что модели GPT-3 способны выдавать синтаксически правильный JSON исходя из всего двух-трех примеров. Несмотря на сложность самого JSON, GPT-3 работает корректно более чем в 90% случаев."
>
> [Ветка в твиттере](https://twitter.com/dhvanilp/status/1286452210314784769?s=20)
### Текст
**[Рерайтинг и кликбейт](https://twitter.com/IntuitMachine/status/1286974653345542145)**
> Your browser does not support HTML5 video.
>
> Здесь же можно преобразовать свой текст под стили разных писателей или даже сделать из него кликбейтный заголовок.
**[Email-автоответчик](https://twitter.com/OthersideAI/status/1285776335638614017)**
> Your browser does not support HTML5 video.
>
> Подстраивается под авторский стиль и отвечает по заданным пунктам. Для тех, у кого нет времени на формальности.
### Разное
**[Google Spreadsheets](https://twitter.com/pavtalk/status/1285410751092416513)**
> Your browser does not support HTML5 video.
>
> Универсальная функция `=GPT3()` — мультитул для таблиц. На момент записи демки умела искать население в штатах, ники людей в твиттере и место их работы, и выполняла различные подсчёты.
>
> Уже шутят про следующий уровень, функцию `=DOMYWORK()`. Вкалывают роботы...
**[Расчеты и финансовая отчетность](https://twitter.com/itsyashdani/status/1285695850300219392)**
> Your browser does not support HTML5 video.
>
> Вы описываете свои транзакции (в том числе довольно сложные), модель парсит их в скрипт на питоне, который заполняет/обновляет гугл-таблицу. Я не бухгалтер, но по-моему это очень круто, особенно для пет-проекта, написанного на выходных.
**[Мемы](https://twitter.com/wowitsmrinal/status/1287175391040290816)**
> Your browser does not support HTML5 video.
>
> Иногда выходит и правда неплохо! Впервые после лебедевских логотипов мемы от искусственного интеллекта способны конкурировать с созданными вручную.
Заключение
----------
Функционал GPT-3 не ограничен машинными текстами. Разработчики из самых разных направлений встраивают эту модель в свои инструменты, и уже можно ожидать новую волну стартапов на её основе. К сожалению, сейчас GPT-3 доступна только по инвайту от OpenAI в рамках бета-тестирования, но позже её откроют для коммерческого использования. Некоторые демки доступны по записи, так что поиграться с моделью можно уже сейчас.
Всё чаще звучат страшилки об искусственном интеллекте, заменяющем программистов, и похоже что рано или поздно это всё-таки случится. Поживём — увидим.
---
#### На правах рекламы
Многие наши клиенты уже оценили преимущества **эпичных серверов**!
Это [мощные виртуальные серверы](https://vdsina.ru/cloud-servers?partner=habr55) с процессорами AMD EPYC, частота ядра CPU до 3.4 GHz. Максимальная конфигурация позволит оторваться на полную — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe. Поспешите заказать!
[](https://vdsina.ru/cloud-servers?partner=habr55) | https://habr.com/ru/post/513792/ | null | ru | null |
# Компонент «Фильтрация и управление фильтрами» 1.2 для MODX Revolution
 Наконец-то дошли руки довести до ума компонент «Фильтрация и управление фильтрами» (tagManager). Первая его версия была очень сырая, даже пришлось сделать дополнительно упрощённый вариант фильтрации. Теперь всё, что было задумано реализовано в нормальном виде и хочу рассказать об этом компоненте сообществу MODX и всем интересующимся.
Функции:
* Сортировка групп фильтров и отдельно их значений.
* Настройка активности групп фильтров и отдельных значений (чекбокс).
* Изменение значений (по двойному клику появляется поле) для всех товаров, у которых есть это значение.
* Ajax-фильтрация и сортировка товаров в каталоге.
* Выводится число товаров по каждому фильтру. Блокируется получение пустого результата поиска.
* Поддержка типов ввода TV с выбором одновременно нескольких значений — Флажки(checkbox), Список (множественный выбор).
Как работает компонент управления фильтрами описывать долго и нудно, поэтому я решил сделать видео:
Была задача чтобы при фильтрации невозможно было получить результат «ничего не найдено». При этом у каждого фильтра должна выводиться циферка, показывающая количество товаров по этому фильтру. Т.е. вместо одного запроса получалось около 20 (конкретно в моём случае). Конечно, данные товаров можно было индексировать и кэшировать, но и это по расчётам не дало бы требуемого результата. Всё должно работать максимально быстро. Поэтому было решено часть работы по фильтрации (точнее основную часть) переложить на «клиента» (JavaScript).
Для вывода блоков фильтров на сайте используется сниппет «tmCatalogFilters».
Пример вызова:
```
[[tmCatalogFilters?
&jsMap=`1`
&innerTpl=`filters_innerTpl`
&outerTpl=`filters_outerTpl`
]]
```
**innerTpl** — Чанк шаблона строки с фильтром. По умолчанию `@ FILE core/components/tag\_manager/elements/chunks/innerTpl.tpl`.
**outerTpl** — Чанк шаблона блока фильтров. По умолчанию `@ FILE core/components/tag\_manager/elements/chunks/outerTpl.tpl`.
**skipTV** — ID TV через запятую, фильтры по которым выводить не нужно.
**jsMap** — Создавать JS-объект данных товаров. Используется для фильтрации и быстрого показа количества товаров по каждому фильтру.
Примеры чанков innerTpl и outerTpl прилагаются (core/components/tag\_manager/elements/chunks/).
Вызов данного сниппета рекоммендуется кэшировать (скобки без "!"). Создаётся JS-объект со всеми параметрами товаров и по этом данным осуществляется поиск (на JavaScript). На сервер отправляется только список ID товаров.
Для вывода товаров используется сниппет «tmGetProducts». Никаких параметров у этого сниппета нет. Это «обёртка», которая использует сниппеты «getPage» и «getResources». Параметры он применяет по имени набора параметров, созданного для сниппета «getPage». Это имя нужно указать в конфигурации компонента («Настройки системы» -> «tag\_manager» -> «tag\_mgr.propertySetName»). Также этот набор параметров применяет php-скрипт, который возвращает данные при ajax-запросах (происходит синхронизация настроек).
В шаблоне каталога, где будут выводиться фильтры, нужно подключить необходимые JS-скрипты и CSS-файлы (прилагается пример).
```
```
Нужно настроить скрипт **filters.js** под вашу вёрстку. В коде есть комментарии.
Это краткая инструкция. Более подробная с примерами включена в пакет (core/components/tag\_manager/docs/readme.txt).
Компонент был сделан для студии [«Симпл Дрим»](http://www.simpledream.ru/), потом доработан. Спасибо им, что разрешили поделиться с общественностью.
[Демо](http://demo-revo.modx-shopkeeper.ru/catalog/kompyuteryi/komplektuyushhie/)
[Скачать](http://modx.com/extras/package/tagmanager) (можно установить через «Управление пакетами» в админке)
[Исходный код](https://bitbucket.org/andchir/tagmanager/src) | https://habr.com/ru/post/150357/ | null | ru | null |
# Pythonic
Итак, что же это значит, когда кто-либо говорит, что foo выглядит как pythonic? Что значит, когда кто-либо смотрит в наш код и говорит, что он unpythonic? Давайте попробуем разобраться.
В Python-сообществе существует неологизм *pythonic*, который можно трактовать по разному, но в общем случае он характеризует стиль кода. Поэтому утверждение, что какой-либо код является pythonic, равносильно утверждению, что он написан в соответствии с идиома Python’a. Аналогично, такое утверждение в отношении интерфейса, или какой-либо функциональности, означает, что он (она) согласуется с идиомами Python’a и хорошо вписывается в экосистему.
Напротив, метка *unpythonic* означает, что код представляет собой грубую попытку записать код какого-либо другого языка программирования в синтаксисе Python, а не идиоматическую трансформацию.
Понятие Pythonicity плотно связано с минималистической концепцией Python’a и уходом от принципа «существует много способов сделать это». Нечитабельный код, или непонятные идиомы – все это unpythonic.
При переходе от одного языка к другому, некоторые вещи должны быть «разучены». Что мы знаем из других языков программирования, что не будет к месту в Python’e?
#### Используйте стандартную библиотеку
Стандартная библиотека – наш друг. Давайте использовать ее.
```
>>> foo = "/home/sa"
>>> baz = "somefile"
>>> foo + "/" + baz # unpythonic
'/home/sa/somefile'
>>> import os.path
>>> os.path.join(foo, baz) # pythonic
'/home/sa/somefile'
>>>
```
Другие полезные функции в *os.path*: *basename()*, *dirname()* и *splitext()*.
```
>>> somefoo = list(range(9))
>>> somefoo
[0, 1, 2, 3, 4, 5, 6, 7, 8]
>>> import random
>>> random.shuffle(somefoo) # pythonic
>>> somefoo
[8, 4, 5, 0, 7, 2, 6, 3, 1]
>>> max(somefoo) # pythonic
8
>>> min(somefoo) # pythonic
0
>>>
```
Существует много полезных встроенных функций, о которых многие люди по каким-либо причинам не знают. Например, *min()* и *max()*. Стандартная библиотека включает много полезных модулей. Например, *random*, который содержит кучу функционала, который люди по незнанию реализую самостоятельно.
#### Создание пустых списков, кортежей, словарей и т.д.
```
>>> bar = list() # unpythonic
>>> type(bar)
>>> del bar
>>> bar = [] # pythonic
>>> type(bar)
>>> foo = {}
>>> type(foo)
>>> baz= set() # {} is a dictionary so we need to use set()
>>> type(baz)
>>>
```
#### Использование обратной косой черты
Т.к. Python трактует перенос строки как разделитель выражений, и т.к. выражения очень часто не вмещаются в одну строку, многие люди поступают вот так:
```
if foo.bar()['first'][0] == baz.ham(1, 2)[5:9] and \ # unpythonic
verify(34, 20) != skip(500, 360):
pass
```
Использование «\» не является хорошей идеей. Такой подход может вызвать неприятный баг: случайный пробел после косой черты сделает строку неправильной. В лучшем случае мы получим syntax error, но если код предствляет что-то вроде этого:
```
value = foo.bar()['first'][0]*baz.ham(1, 2)[5:9] \ # unpythonic
+ verify(34, 20)*skip(500, 360)
```
Тогда он будет просто нерабочим. Лучше использовать неявное продолжение строки в скобках. Подобный код является пуленепробиваемым:
```
value = (foo.bar()['first'][0]*baz.ham(1, 2)[5:9] # pythonic
+ verify(34, 20)*skip(500, 360))
```
#### Import
Не используйте «[from foo import \*](http://www.markus-gattol.name/ws/python.html#from_foo_import_star)». [Здесь](http://www.markus-gattol.name/ws/python.html#import_matters) и [здесь](http://www.markus-gattol.name/ws/python.html#import_order) можно найти более подробную информацию.
#### Общие исключения
Python имеет выражение «*except*», которое отлавливает все исключения. Т.к. любая ошибка генерирует исключение, такой код может сделать многие ошибки программирования похожими на ошибки времени исполнения, и затруднят отладку программы. Следующий пример является исчерпывающим:
```
try:
foo = opne("somefile") # misspelled "open"
except:
sys.exit("could not open file!")
```
Вторая строчка генерирует «*NameError*», который будет отловлен, что семантически неверно, поскольку «except» написан для отлавливания «*IOError*». Лучше написать такой код:
```
try:
foo = opne("somefile")
except IOError:
sys.exit("could not open file")
```
Когда Вы запустите этот код, Python сгенерирует «NameError», и Вы моментально увидите и исправите ошибку.
Поскольку «except» отлавливает все исключения, включая «*SystemExit*», «*KeyboardInterrupt*», и «*GeneratorExit*» (которые по сути не являются ошибками и не должны отлавливаться пользовательским кодом), использование голого «except» в любом случае плохая идея. В ситуациях, когда нам нужно все-таки покрыть все возможные исключительные ситуации, мы можем использовать базовый класс для всех исключений – «*Exception*».
#### Нам редко нужны счетчики
```
>>> counter = 0 # unpythonic
>>> while counter < 10:
... # do some stuff
... counter += 1
...
...
>>> counter
10
>>> for counter in range(10): # pythonic
... # do some stuff
... pass
...
...
>>>
```
Другой пример:
```
>>> food = ['donkey', 'orange', 'fish']
>>> for i in range(len(food)): # unpythonic
... print(food[i])
...
...
donkey
orange
fish
>>> for item in food: # pythonic
... print(item)
...
...
donkey
orange
fish
>>>
```
#### Явные итераторы
Внутри Python использует много итераторов… для циклов не должно быть исключений:
```
>>> counter = 0 # unpythonic
>>> while counter < len(somecontainer):
... callable_consuming_container_elements(somecontainer[counter])
... counter += 1
...
...
>>> for item in somecontainer: # pythonic
... callable_consuming_container_elements(item)
...
...
>>>
```
Можно сказать, что для простых вещей мы не должны явно создавать итераторы. Есть ряд случаев, когда явные итераторы будут полезны. Например, когда мы что-то обрабатываем, останавливаемся, делаем что-либо еще, затем возвращаемся назад и продолжаем. Итератор запоминает наше положение, и это прекрасно:
```
>>> somecontainer = list(range(7))
>>> type(somecontainer)
>>> somecontainer
[0, 1, 2, 3, 4, 5, 6]
>>> somecontaineriterator = iter(somecontainer)
>>> type(somecontaineriterator)
```
Теперь мы можем начать использовать наш итератор:
```
>>> for item in somecontaineriterator: # start consuming the iterable somecontainer
... if item < 4:
... print(item)
...
... else:
... break # breaks out of the nearest enclosing for/while loop
...
...
...
0
1
2
3
```
Не дайте себя обмануть, итератор остановился на «*somecontaineriterator[5]*», который равен 4, а не 3. Давайте посмотрим, что будет дальше:
```
>>> print("Something unrelated to somecontaineriterator.")
Something unrelated to somecontaineriterator.
>>> next(somecontaineriterator) # continues where previous for/while loop left off
5
>>> next(somecontaineriterator)
6
>>> next(somecontaineriterator)
Traceback (most recent call last): # we have exhausted the iterator
File "", line 1, in
StopIteration
>>>
```
Некоторым может показаться, что данный пример неоднозначен, на самом деле это не так. Итератор в цикле проходит массив, выходит из цикла по *break* на индексе 5 (значение внутри равно 4). Затем мы совершаем некие действия (выводим текст в консоль), и после этого продолжаем перебор итератора. Вот и все.
#### Присваивание
[Здесь](http://www.markus-gattol.name/ws/python.html#chained_assignment) можно почитать подробно.
#### Циклы только когда это действительно необходимо
Существует много случаев, для которых в других языках программирования мы бы использовали выражения циклов, но в случае Python в этом нет необходимости.
Python предоставляет много высокоуровневого функционала для оперирования любыми объектами. Для последовательностей это могут быть функции *zip()*, *min()*, *max()*. Затем, это такие вещи, как «list comprehensions», генераторы, «set comprehensions» и т.д.
Дело в том, что если мы сохраняем наши данные в базовых структурах Python, таких как списки, кортежи, словари, множества и д.р., мы получаем кучу функционала для работы с ними «из коробки». Даже если мы нуждаемся в специфичной структуре, скорее всего не составит труда создать ее, используя базовый структуры данных. Итак, в чем же преимущества. Как мы можем получить список имен некоторых людей, хранящийся в дисковом файле.
```
sa@wks:/tmp$ cat people.txt
Dora
John
Dora
Mike
Dora
Alex
Alex
sa@wks:/tmp$ python
>>> with open('people.txt', encoding='utf-8') as a_file: # context manager
... { line.strip() for line in a_file } # set comprehension
...
...
{'Alex', 'Mike', 'John', 'Dora'}
>>>
```
Никаких циклов, пользовательских структур данных, убраны лишние пробелы и дубликаты, все pythonic ;-]
#### Кортежи – это не просто read-only списки
Это распространенное заблуждение. Очень часто списки и кортежи применяются для одних и тех же целей. Списки предназначены для хранения однотипных данных. В то время как кортежи – для объединения данных разного типа в набор. Другими словами
*Целое — больше чем сумма его частей.
— Аристотель (384 д.н.э — 322 д.н.э)*
```
>>> person = ("Steve", 23, "male", "London")
>>> print("{} is {}, {} and lives in {}.".format(person[0], person[1], person[2], person[3]))
Steve is 23, male and lives in London.
>>> person = ("male", "Steve", 23, "London") #different tuple, same code
>>> print("{} is {}, {} and lives in {}.".format(person[0], person[1], person[2], person[3]))
male is Steve, 23 and lives in London.
>>>
```
Индекс в кортеже несет смысловую нагрузку. Давайте сравним эти структуры:
```
>>> foo = 2011, 11, 3, 15, 23, 59
>>> foo
(2011, 11, 3, 15, 23, 59) # tuple
>>> list(range(9))
[0, 1, 2, 3, 4, 5, 6, 7, 8] # list
>>>
```
* Первая из них, кортеж, представляет собой структуру, где позиция элемента несет некий смысл (Первый элемент — год).
* Вторая же, список, представляет собой последовательность, в которой значения функционально равнозначны, индекс не несет никакого смысла.
Отличный пример использования обоих структур – метод fetchmany() из Python DB API, который возвращает результат как список кортежей.
#### Классы не предназначены для группировки функциональности
C# и Java содержат код только внутри классов. В итоге возникают утилитарные классы, содержащие одни статические методы. Например, математическая функция *sin()*. В Python мы просто используем модуль верхнего уровня:
```
sa@wks:/tmp$ echo -e 'def sin():\n pass' > foo.py; cat foo.py
def sin():
pass
sa@wks:/tmp$ python
>>> import foo
>>> foo.sin()
>>>
```
#### Скажите нет геттерам и сеттерам
Способ достичь инкапсуляции в Python – использование свойств, а не геттеров и сеттеров. Используя свойства, мы можем изменить атрибуты объекта и исправить реализацию, не затрагивая вызываемый код (читайте, stable API).
#### Функции являются объектами
В Python – все является объектами. Функции тоже объекты. Функции – это объекты, которые можно вызывать.
```
>>> somefoo = [{'price': 9.99}, {'price': 4.99}, {'price': 10}]
>>> somefoo
[{'price': 9.99}, {'price': 4.99}, {'price': 10}]
>>> def lookup_price(someobject):
... return someobject['price']
...
...
>>> somefoo.sort(key=lookup_price) # pass function object lookup_price
>>> somefoo
[{'price': 4.99}, {'price': 9.99}, {'price': 10}] # in-place sort of somefoo took place
>>> type(somefoo)
>>> type(somefoo[0])
>>>
```
Между *lookup\_price* и *lookup\_price()* существует разница — последнее вызывает функцию, а первое смотрим биндинг по имени *lookup\_price*. Это дает нам возможность использовать функции в роли обычных объектов. | https://habr.com/ru/post/114731/ | null | ru | null |
# Совмещая несовместимое: клавиатура с дисковым номеронабирателем
А вы ностальгируете по старым дисковым телефонам? Некоторые люди настолько не могут без них жить, что прикрутили телефонный номеронабиратель к современной клавиатуре. Почему бы и нет, в самом деле?
### Прошивка
Идея в том, чтобы сделать красиво и функционально. Чтобы с помощью диска действительно можно было вводить цифры. Ещё планировалось удалить числовой ряд клавиатуры, чтобы вместо него поворотный диск работал.
Поворотный диск имеет две основные пары контактов. Одна размыкается, когда диск перемещается на 1 позицию, а другая создаёт характерную серию импульсов при отпускании (один импульс на числовую позицию). Можно было бы использовать прерывание при смене контакта, но шкала времени настолько велика, что ожидание получается приемлемым. Я использовал DFRobot Beetle, так как его встроенный ATMega32u4 имеет родной USB HID.
```
while (digitalRead(ACTIVE)) // Active-low
{
int count = 0;
while (!digitalRead(ACTIVE))
{
if (digitalRead(PULSE))
{
count += 1;
delay(50);
}
}
if (count >= 2)
{
count /= 2;
count = (count == 10) ? 0 : count;
Keyboard.print(count);
}
}
```
Кажется, что каждый импульс считывается дважды. Пожалуй, я должен был тщательно его изучить на наличие проблем, но он и так работает вполне адекватно. (В моей первой попытке была задержка всего 10 мс, что эмпирически привело к семикратному считыванию каждого импульса).
### Электрика
Для питания этой клавиатуры нужны два кабеля: один для Arduino и один для оригинального контроллера клавиатуры. Меня больше устраивал такой вариант: вставить концентратор USB в клавиатуру, припаяв к нему Arduino и контроллер.
Это позволило мне припаять встроенный USB-порт клавиатуры к восходящему соединению концентратора. Таким образом, когда я подключаю свой самодельный USB-концентратор к компьютеру, сохраняется иллюзия USB-устройства с одним кабелем.
Самый дешевый концентратор с удобным форм-фактором, который я смог найти, был этим дурацким зверем с тремя портами:
Интересно, что верхний порт концентратора действительно совместим с SuperSpeed: пары SSRX+/- и SSTX+/- представляют собой полностью независимый интерфейс от D+/-пары, используемой для Full-Speed или High-Speed USB, и поэтому могут быть направлены непосредственно на порт без промежуточного узла.
Чип, выполняющий всю тяжелую работу в этом концентраторе, является монолитным HS8836A, который предположительно рассчитан на высокоскоростной USB-трафик и имеет впечатляюще малое количество вспомогательных компонентов.
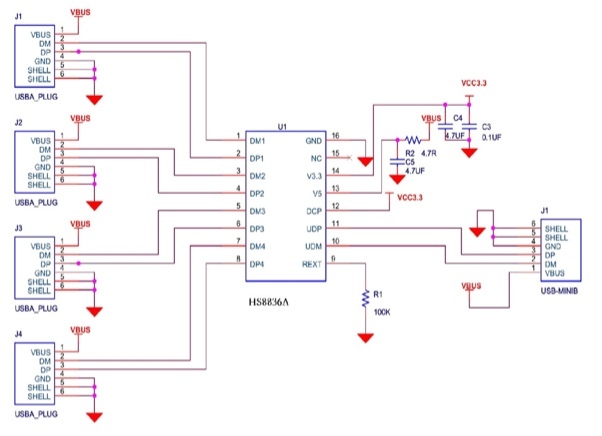В моём случае нужно было просто аккуратно отпаять существующие порты, чтобы не расплавить микросхему концентратора и подключить USB-сигналы от клавиатуры и Arduino. Обратите внимание, насколько компактна эта плата благодаря HS8836A:
Для подключения данных к Arduino я использовал несколько экранированных дифференциальных линий от проводов дисплея LVDS iMac, потому что они очень удачно валялись среди прочего хлама. Подозреваю, что импеданс полностью выключен, но USB 1.1 удивительно надёжен.
### Клавиатура
Чтобы заменить цифровой блок клавиатуры на поворотный диск, мне пришлось удалить все переключатели для неё. Это было легко, так как данная клавиатура имеет одностороннюю печатную плату, а моя присоска для пайки весьма удобна.
Можно было бы разместить основание циферблата поверх печатной платы, но в этом случае сам циферблат находился бы очень высоко.
Потом я понял, что если сделать прорезь под циферблат, то получится расположить его на уровне клавиш, как показано ниже:
Это влечет за собой прорезание дорожек в нижней части печатной платы. Они позволяют клавиатуре сканировать все клавиши, чтобы определить, какие из них были нажаты. Я потратил много времени, исследуя дорожки мультиметром и делая перемычки для их замены.
Из-за моей неосторожности пришлось ещё немного потрудиться - когда я подключил плату, то понял, что сломал кластер клавиш со стрелками. Забавный факт: матрица клавиатуры на этой плате также используется для индивидуального включения светодиодов, поэтому, если клавиатура не может подсветить какую-то клавишу, она также не сможет ее прочитать.
После обработки клавиатуры кольцевой пилой, осциллирующим резаком и дремелем мне удалось прикрепить диск к остаткам клавиатурной платы.
Закончив работу с проводкой USB, я убедиться, что ещё не сжёг ничего важного (обратите внимание, что индикаторы клавиатуры горят — это указывает на то, что, по крайней мере, питание подаётся).
### 3D-печать
Я решил напечатать на 3D-принтере кожух, чтобы скрыть внутренности циферблата. Всё же мне не хотелось получить совсем уж ужасное детище.
Раньше я ничего не проектировал в 3D CAD, так что пришлось чуть-чуть изучить OpenSCAD - ровно настолько, чтобы все мои друзья-механики с криками разбежались. На самом деле этого было достаточно, чтобы спроектировать базу с цифрами, которая будет крепиться на основание клавиатуры.
Мне кажется, очень здорово иметь функционально определённый язык для создания твёрдых предметов. В любой момент можно немного поменять настройки и параметры, не переделывая всё заново.
(По иронии судьбы я умудрился потерять файл OpenSCAD, поэтому итоговый рендеринг был сделан путём импорта STL в OpenSCAD).
Нужный результат получился не сразу, но в итоге у меня всё получилось с помощью функции экспорта SVG OpenSCAD и многократной печати объекта до получения нужного угла наклона.
Конечно, окончательная напечатанная деталь все ещё была немного смещена, и мне пришлось вырезать в ней выемку, чтобы получить правильный угол.
Кроме того, пришлось немного подрезать металл основания поворотного диска, но после небольшой шлифовки у меня получилось собрать всё вместе. Я использовал сварку трением с перемешиванием, чтобы соединить все три детали вместе, вставив кусок нити в свой дремель и проведя им по швам. Это значительно сложнее, чем кажется, и в тот момент я зауважал людей, которые делают это в промышленных масштабах из нержавеющей стали, например, для топливных баков ракеты SLS.
Параметрический колпачок
------------------------
Просто выдрать из клавиатуры числовой ряд, чтобы принудительно использовать вместо него поворотный диск, было бы достаточно забавно, но я решил, что будет интереснее напечатать специальный колпачок для клавиатуры 10U, который бы соответствовал профилю существующих клавиш и позволял светодиодам просвечивать сквозь себя. Это стало возможным благодаря невероятному [генератору параметрических клавиш](https://github.com/rsheldiii/KeyV2) для OpenSCAD, который я нашёл на GitHub.
```
include <./includes.scad>
$stem_positions = [[19.05*-4.5,0], [19.05*-3.5,0], [19.05*-2.5,0], [19.05*-1.5,0], [19.05*-0.5,0], [19.05*0.5,0], [19.05*1.5,0], [19.05*2.5,0], [19.05*3.5,0], [19.05*4.5,0]];
$inset_legend_depth = 3;
$font="Source Code Pro:style=Semibold";
oem_row(1) upside_down() u(10) dishless() legend("THE ROTARY DIAL IS MIGHTIER THAN THE NUMBER KEYS", [0, -0.8], 4.5) key();
```
Из-за того, что Cura пасует, когда дело доходит до объектов с внутренними вырезами, мне пришлось вручную определить края, чтобы крышка клавиатуры не отслаивалась. Да, проекции OpenSCAD ужасно требовательны к вычислительным ресурсам, но есть лучший способ сделать это:
```
difference() {
scale([1.07, 1.5])
linear_extrude(height=0.2)
projection(cut=true) oem_row(1) u(10) upside_down() dishless() key();
linear_extrude(height=0.2)
projection(cut=true) oem_row(1) u(10) upside_down() dishless() key();
};
```
После того, как я установил стабилизирующие клавишные переключатели, я наклеил кусок липкой ленты поверх колпачка клавиш и залил туда остатки суперклея, чтобы заполнить вырезы. Двумя днями позже клей полностью застыл.
Пожалуй, разумнее было бы нанести несколько тонких слоёв, так как суперклей затвердевает под воздействием влаги, и поэтому нижняя часть, та, что ближе к верхней части колпачка, сохла слишком долго.
Да, он действительно печатает “the rotary dial is mightier than the number keys” (поворотный диск мощнее, чем цифровые клавиши) при нажатии. Я подключил все три переключателя, поддерживающие колпачок клавиатуры, параллельно и подключил их к неиспользуемому входному контакту на Arduino.
Окончательная сборка
--------------------
Мой кожух пришлось приклеить горячим клеем к клавиатуре, который также намертво зафиксировал кучу винтов, скрепляющих клавиатуру. Хорошо, что у меня никогда не будет ошибок в проводке, так ведь? ….Никогда не будет, да?
Ну, я нечаянно обрезал одну из дорожек для клавиши со стрелкой вниз. Не представляю, как это могло произойти. Хотя я утверждаю, что vimkeys должно быть достаточно, нефункциональные клавиши немного смущают, особенно когда клавиатура заклеена.
Я решил эту проблему с помощью отрезного колеса на дремеле. Я разрезал заднюю часть клавиатуры под клавишей со стрелкой вниз и рядом с Arduino, что позволило мне выловить провода от этой клавиши к Arduino и заодно проникнуться уважением к чувакам, которые строят корабли в бутылке. Благодаря одностороннему характеру печатной платы клавиатуры было нетрудно изолировать ножки переключателя от схемы клавиатуры с помощью припоя и термоусадки.
Другая проблема была хуже: я принёс клавиатуру в офис коллеги, пока он был на обеденном перерыве, но подключил его к KVM. К сожалению, KVM прослушивает только HID-устройства, такие как клавиатуры и мыши, а это означает, что мой умный USB-концентратор посередине не был распознан, и, следовательно, клавиатура вообще не работала. Как стыдно…
Реакция коллег была очень разной. От “это действительно работает?” до “господи, неужели у кого-то НАСТОЛЬКО много свободного времени”?
А вот ещё картинки чудо-устройства:
А вы что скажете?
---
#### Что ещё интересного есть в блоге Cloud4Y
→ [Информационная безопасность и глупость: необычные примеры](https://habr.com/ru/company/cloud4y/blog/696078/)
→ [NAS за шапку сухарей](https://habr.com/ru/company/cloud4y/blog/703540/)
→ [Как распечатать цветной механический телевизор на 3D-принтере](https://habr.com/ru/company/cloud4y/blog/668962/)
→ [Создание e-ink дисплея с прогнозом погоды](https://habr.com/ru/company/cloud4y/blog/699638/)
→ [Аналоговый компьютер Telefunken RA 770](https://habr.com/ru/company/cloud4y/blog/701274/)
Подписывайтесь на наш [Telegram](https://t.me/cloud4y)-канал, чтобы не пропустить очередную статью. Пишем только по делу. А ещё напоминаем про второй сезон нашего сериала ITить-колотить. Его можно посмотреть на [YouTube](https://youtu.be/8arneYYzsJw)и [ВКонтакте](https://vk.com/video/playlist/-114833493_1). | https://habr.com/ru/post/708154/ | null | ru | null |
# Slackware. Утилита Src2pkg или как не сделать из слаки свалку
Рано или поздно любой начинающий линуксоид столкнется с необходимостью собирать программу из исходников. Причины на это могут быть самые разные, начиная от спортивного интереса и заканчивая самописной/самоисправленной программой.
Набрав в гугле «как собрать программу из исходников» начинающий линуксоид сразу наткнется на известную мантру:
`./configure
make
make install`
Вот таким вот образом система и превращается в помойку. Вот поставили вы таким образом сотню программ, а теперь попробуйте-ка удалить 50 из них. В лучшем случае вам поможет скачка той же версии исходников, что и установленная программа, ./configure с теми же параметрами, make и только затем make uninstall, и то если разработчик позаботился о деинсталляции своего творения. В худшем случае-ползайте по всем папкам вашей системы и вычищайте руками все файлы, связанные с программой.
И тот, и другой способ нудные, долгие и с кучей нюансов. Поэтому мы будем изучать другой способ установки программ, на примере ОС Slackware 13.
Итак. Для начала спешу всех слаководов обрадовать (и огорчить слаконенавистников). **Менеджер пакетов в слаке есть, был и будет есть**.
Да, он не такой функциональный как в Debian или Ubuntu, и пакеты там не deb и не rpm. Но кто сказал что это плохо?
Пакет в слаке представляет собой tgz-архив (а также с 13-ой версии еще и txz), состоящий из бинарников и установочного скрипта. Для установки пакета используется команда installpkg, для удаления-removepkg.
UPD: спасибо за замечание **kyb27**
Поясню принцип рассматриваемого способа установки. У нас есть исходники, из которых мы посредством утилиты src2pkg делаем пакет, который потом устанавливаем через installpkg. Плюсом такого метода установки является то, что в любое время мы можем снести нашу программу командой removepkg.
С теорией закончили, перейдем к практике.
С установкой программы src2pkg проблем быть не должно. Все же поясню на примере (все команды от рута):
`mkdir /home/src2pkg
cd /home/src2pkg
wget distro.ibiblio.org/pub/linux/distributions/amigolinux/download/src2pkg/src2pkg-2.2-noarch-3.tgz
installpkg src2pkg-2.2-noarch-3.tgz`
Все, утилита установлена.
Теперь попробуем с ее помощью собрать и установить программу mc.
`mkdir /home/mc
cd /home/mc
wget --content-disposition www.midnight-commander.org/downloads/40`
UPD: за замечание спасибо **Toseter**.
Теперь читаем маны, конфигуры и прочее, если нам нужны опции компиляции программы. Если нет, то все еще проще.
В моем случае команда для сборки пакета из сорцов имела след. вид:
`root@ironnet:/home/mc# src2pkg -e='--sysconfdir=/etc/mc --without-x --without-edit' -C mc-4.7.0.4.tar.bz2`
где:
-e — опция для компиляции с параметрами
-С — положить созданный пакет в текущий каталог
mc-4.7.0.4.tar.bz2 — файл сорцов
Вывод получается вот какой:
`Found source archive: mc-4.7.0.4.tar.bz2
Deleting old build files - Done
Creating working directories:
PKG_DIR=/tmp/mc-4.7.0.4-i486-1
SRC_DIR=/tmp/mc-4.7.0.4-src-1
Unpacking source archive - Done
Correcting source permissions - Done
Checking for patches - None found
Found configure script - Done
Configuring sources using:
LDFLAGS="-Wl,-L/lib,-L/usr/lib" CFLAGS="-O2 -m32 -march=i486 -mtune=i686" ./configure --prefix=/usr --sysconfdir=/etc/mc - -without-x --without-edit --libdir=/usr/lib
Configuration has been - Successful!
Compiling sources - Using: 'make'
Compiling has been - Successful!
Checking for Makefile rule: 'install' Okay
Creating content in JAIL root - Using: 'make install'
Safe content creation - Successful!
Processing package content:
Correcting package permissions - Done
Stripping ELF binaries - Using: strip -p --strip-unneeded Done
Checking for standard documents - Done
Compressing man pages - Done
Creating slack-desc - From default text
Searching for links in: mc-4.7.0.4-i486-1 - Done
Adding links to doinst.sh - Adding links-creation to the doinst.sh
Deleting symbolic links - Removing links from the package directory
Rechecking package correctness -
Checking for misplaced dirs - Done
Rechecking package permissions - Done
Creating package: mc-4.7.0.4-i486-1.tgz - Done
Package Creation - Successful! Package Location:
/home/mc/mc-4.7.0.4-i486-1.tgz`
Пакет готов. Ставим его:
`root@ironnet:/home/mc# installpkg mc-4.7.0.4-i486-1.tgz
Verifying package mc-4.7.0.4-i486-1.tgz.
Installing package mc-4.7.0.4-i486-1.tgz:
PACKAGE DESCRIPTION:
# mc
#
# No description was given for this package.
#
# Packaged by src2pkg
Executing install script for mc-4.7.0.4-i486-1.tgz.
Package mc-4.7.0.4-i486-1.tgz installed.`
Панели открылись, все в порядке. Поздравляю с успешной установкой.
Для того, чтобы удалить наш пакет, используем команду
`removepkg mc-4.7.0.4-i486-1.tgz`
Естественно что по истечении какого-то времени мы забудем, какой именно версии у нас mc. Но и здесь есть выход.
Чтобы быстро узнать, какой именно пакет MC установлен в нашей системе, выполним команду:
`ls /var/log/packages/mc*`
Которая и вернет нам имя нашего пакета, а заодно и версию mc.
Немного вкусноты напоследок:
программа src2pkg имеет еще много других опций, в том числе и создание пакета из сорцов с предварительным скачиванием последних во временную диру.
UPD: тихо и незаметно обновилась версия программы. | https://habr.com/ru/post/91073/ | null | ru | null |
# Начало работы с MongoDB и Redis на Rust
В этой статье будет показано как создать Rust бэкэнд, который использует [MongoDB](https://www.mongodb.com/), документо-ориентированную БД, для хранения данных и [Redis](https://redis.io/) для кэширования, ограничения количества HTTP запросов и нотификаций пользователя. Для большей наглядности созданное приложение также будет предоставлять REST API. В итоге будет получена следующая архитектура:
MongoDB является хранилищем, в то время как Redis используется для следующего:
* кэш (включая изображения)
* [ограничение количества](https://en.wikipedia.org/wiki/Rate_limiting) HTTP запросов
* нотификации с использованием паттерна [publish-subscribe](https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern)
Обратите внимание, что указанные сценарии использования не означают, что для похожего сценария вам нужно использовать подход, описанный в статье. Примеры в первую очередь имеют целью познакомить вас с MongoDB и Redis.
[Проект](https://github.com/rkudryashov/exploring-rust-ecosystem/tree/master/mongodb-redis) реализован с помощью [MongoDB Rust driver](https://github.com/mongodb/mongo-rust-driver) и крейта [`redis-rs`](https://github.com/mitsuhiko/redis-rs).
Вы сможете протестировать REST API приложения, поскольку оно развёрнуто на Google Cloud Platform.
Доменная модель включает данные о планетах Солнечной системы и их спутниках.
Запуск MongoDB и Redis
----------------------
Этот раздел не требует навыков программирования на Rust и может быть использован вне зависимости от языка программирования приложения.
Обе тулы могут быть запущены как Docker контейнер:
*[`docker-compose.yml`](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/docker-compose.yml)*
```
version: '3.8'
services:
...
mongodb:
image: mongo
container_name: mongodb
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: $MONGODB_USERNAME
MONGO_INITDB_ROOT_PASSWORD: $MONGODB_PASSWORD
MONGO_INITDB_DATABASE: solar_system_info
ports:
- 27017:27017
mongodb-seed:
image: mongo
container_name: mongodb-seed
depends_on:
- mongodb
volumes:
- ./mongodb-init:/mongodb-init
links:
- mongodb
command:
mongoimport --host mongodb --db solar_system_info --collection planets --authenticationDatabase admin --username $MONGODB_USERNAME --password $MONGODB_PASSWORD --drop --jsonArray --file /mongodb-init/init.json
redis:
image: redis:alpine
container_name: redis
ports:
- 6379:6379
```
Назначение контейнера `mongodb-seed` будет показано далее.
Вы можете получить доступ к `mongo` [shell](https://docs.mongodb.com/manual/mongo/) с помощью следующей команды:
`docker exec -it mongodb mongo --username admin --password password`
(где `mongodb` — название Docker контейнера, `mongo` — shell)
Теперь вы можете выполнять команды, например:
* получить список баз данных с помощью `show dbs`
* получить все данные в определённой базе данных:
+ `use solar_system_info`
+ `show collections`
+ `db.planets.find()`
Доступ к [Redis CLI](https://redis.io/topics/rediscli) может быть получен с помощью следующей команды:
`docker exec -it redis redis-cli`
Простейший пример команды выглядит так:
*Пример команды Redis*
```
> set mykey somevalue
OK
> get mykey
"somevalue"
```
Для получения списка ключей используйте команду `keys *`.
Вы можете найти больше примеров команд для Redis CLI [в этом гайде](https://redis.io/topics/data-types-intro).
### Инициализация данных
MongoDB инициализируется [данными в формате JSON](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/mongodb-init/init.json) с использованием контейнера `mongodb-seed` и команды `mongoimport`:
*[`docker-compose.yml`](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/docker-compose.yml)*
```
mongodb-seed:
image: mongo
container_name: mongodb-seed
depends_on:
- mongodb
volumes:
- ./mongodb-init:/mongodb-init
links:
- mongodb
command:
mongoimport --host mongodb --db solar_system_info --collection planets --authenticationDatabase admin --username $MONGODB_USERNAME --password $MONGODB_PASSWORD --drop --jsonArray --file /mongodb-init/init.json
```
Также инициализация БД может быть выполнена с использованием [JavaScript файла](https://docs.mongodb.com/manual/tutorial/write-scripts-for-the-mongo-shell).
Приложение также работает с [изображениями](https://github.com/rkudryashov/exploring-rust-ecosystem/tree/master/mongodb-redis/images) планет. Первоначально я собирался хранить их в MongoDB; это может быть сделано с помощью следующей команды:
`mongofiles --host mongodb --db solar_system_info --authenticationDatabase admin --username $MONGODB_USERNAME --password $MONGODB_PASSWORD put /mongodb-init/images/*.jpg`
Однако вскоре обнаружилось, что изображения не могут быть получены из БД из-за отсутствия поддержки [GridFS](https://docs.mongodb.com/manual/core/gridfs/) в MongoDB Rust Driver ([открытая задача](https://jira.mongodb.org/browse/RUST-527)). Поэтому для простоты используется крейт [rust\_embed](https://github.com/pyros2097/rust-embed), который позволяет включить изображения в бинарный исполняемый файл приложения во время компиляции (при разработке изображения загружаются из файловой системы). (Изображения также возможно хранить отдельно от приложения; папка `images` должна быть смонтирована как volume в определении Docker Compose сервиса)
Далее будет показано как использовать MongoDB и Redis в Rust приложении.
Имплементация приложения
------------------------
### Зависимости
Приложение имплементировано с помощью:
* [MongoDB Rust driver](https://github.com/mongodb/mongo-rust-driver)
* [redis-rs](https://github.com/mitsuhiko/redis-rs)
* [Actix Web](https://github.com/actix/actix-web)
*[`Cargo.toml`](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/grpc-telegram-bot/rpc/Cargo.toml)*
```
[package]
name = "mongodb-redis"
version = "0.1.0"
edition = "2018"
[dependencies]
mongodb = "2.0.0-beta.1"
redis = { version = "0.20.2", features = ["tokio-comp", "connection-manager"] }
actix-web = "4.0.0-beta.7"
tokio = "1.7.1"
tokio-stream = "0.1.6"
chrono = { version = "0.4.19", features = ["serde"] }
serde = "1.0.126"
serde_json = "1.0.64"
dotenv = "0.15.0"
derive_more = "0.99.14"
log = "0.4.14"
env_logger = "0.8.4"
rust-embed = "5.9.0"
mime = "0.3.16"
```
### Структура проекта
*[Структура проекта](https://github.com/rkudryashov/exploring-rust-ecosystem/tree/master/mongodb-redis)*
```
├───images
│
├───mongodb-init
│ init.json
│
└───src
db.rs
dto.rs
errors.rs
handlers.rs
index.html
main.rs
model.rs
redis.rs
services.rs
```
### Функция `main`
*[`Функция main`](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/main.rs)*
```
#[actix_web::main]
async fn main() -> std::io::Result<()> {
dotenv::from_filename(".env.local").ok();
env_logger::init();
info!("Starting MongoDB & Redis demo server");
let mongodb_uri = env::var("MONGODB_URI").expect("MONGODB_URI env var should be specified");
let mongodb_client = MongoDbClient::new(mongodb_uri).await;
let redis_uri = env::var("REDIS_URI").expect("REDIS_URI env var should be specified");
let redis_client = redis::create_client(redis_uri)
.await
.expect("Can't create Redis client");
let redis_connection_manager = redis_client
.get_tokio_connection_manager()
.await
.expect("Can't create Redis connection manager");
let planet_service = Arc::new(PlanetService::new(
mongodb_client,
redis_client,
redis_connection_manager.clone(),
));
let rate_limiting_service = Arc::new(RateLimitingService::new(redis_connection_manager));
...
}
```
Здесь определён кастомный `MongoDbClient`, клиент Redis и менеджер соединений Redis.
### Работа с MongoDB
Начнём с функции, возвращающей список планет, хранящихся в БД, и использующей асинхронный API:
*[Функция, возвращающая список планет](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/db.rs)*
```
const DB_NAME: &str = "solar_system_info";
const COLLECTION_NAME: &str = "planets";
pub async fn get_planets(
&self,
planet_type: Option,
) -> Result, CustomError> {
let filter = planet\_type.map(|pt| {
doc! { "type": pt.to\_string() }
});
let mut planets = self.get\_planets\_collection().find(filter, None).await?;
let mut result: Vec = Vec::new();
while let Some(planet) = planets.next().await {
result.push(planet?);
}
Ok(result)
}
fn get\_planets\_collection(&self) -> Collection {
self.client
.database(DB\_NAME)
.collection::(COLLECTION\_NAME)
}
```
`get_planets` также включает пример фильтрации документов MongoDB по определённому критерию.
Модель данных выглядит так:
*[Модель данных](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/model.rs)*
```
#[derive(Serialize, Deserialize, Debug)]
pub struct Planet {
#[serde(rename = "_id", skip_serializing_if = "Option::is_none")]
pub id: Option,
pub name: String,
pub r#type: PlanetType,
pub mean\_radius: f32,
pub satellites: Option>,
}
#[derive(Copy, Clone, Eq, PartialEq, Serialize, Deserialize, Debug)]
pub enum PlanetType {
TerrestrialPlanet,
GasGiant,
IceGiant,
DwarfPlanet,
}
#[derive(Serialize, Deserialize, Debug)]
pub struct Satellite {
pub name: String,
pub first\_spacecraft\_landing\_date: Option,
}
```
Структуры содержат поля "обычных" типов (`string`, `f32`), а также:
* [`ObjectId`](https://docs.mongodb.com/manual/reference/bson-types/#objectid) (`Planet.id`)
* список (`Planet.satellites`)
* дата/timestamp (`Satellite.first_spacecraft_landing_date`)
* перечисление (`Planet.type`)
* nullable поля (`Planet.id`, `Planet.satellites`)
Проект также включает примеры [получения, создания, обновления и удаления](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/db.rs) MongoDB документов. Я не буду подробно останавливаться на этих функциях ввиду очевидности кода их имплементации. Вы можете протестировать эти функции используя REST API:
* получение всего списка
`GET` `http://localhost:9000/planets`
Пример с фильтрацией:
`GET` `http://localhost:9000/planets?type=IceGiant`
* создание
`POST` `http://localhost:9000/planets`
Body:
```
{
"name": "Pluto",
"type": "DwarfPlanet",
"mean_radius": 1188,
"satellites": null
}
```
* получение по id
`GET` `http://localhost:9000/{planet_id}`
* обновление
`PUT` `http://localhost:9000/{planet_id}`
Body:
```
{
"name": "Mercury",
"type": "TerrestrialPlanet",
"mean_radius": 2439.7,
"satellites": null
}
```
* удаление
`DELETE` `http://localhost:9000/{planet_id}`
* получение изображения планеты
`GET` `http://localhost:9000/planets/{planet_id}/image`
Используйте этот метод для тестирования кэширования с помощью Redis
MongoDB документы хранятся в формате [BSON](https://docs.mongodb.com/manual/reference/bson-types/).
### Работа с Redis
Redis клиент создаётся следующим образом:
*[Создание Redis клиента](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/redis.rs)*
```
pub async fn create_client(redis_uri: String) -> Result {
Ok(Client::open(redis\_uri)?)
}
```
Менеджер соединений Redis может быть создан так:
*[Получение менеджера соединений Redis](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/main.rs)*
```
let redis_client = redis::create_client(redis_uri)
.await
.expect("Can't create Redis client");
let redis_connection_manager = redis_client
.get_tokio_connection_manager()
.await
.expect("Can't create Redis connection manager");
```
#### Кэширование
Рассмотрим функцию сервисного слоя, использующуюся для получения планеты по id:
*[Получение планеты по id](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/services.rs)*
```
pub async fn get_planet(&self, planet_id: &str) -> Result {
let cache\_key = self.get\_planet\_cache\_key(planet\_id);
let mut con = self.redis\_client.get\_async\_connection().await?;
let cached\_planet = con.get(&cache\_key).await?;
match cached\_planet {
Value::Nil => {
debug!("Use database to retrieve a planet by id: {}", &planet\_id);
let result: Planet = self
.mongodb\_client
.get\_planet(ObjectId::from\_str(planet\_id)?)
.await?;
let \_: () = redis::pipe()
.atomic()
.set(&cache\_key, &result)
.expire(&cache\_key, 60)
.query\_async(&mut con)
.await?;
Ok(result)
}
Value::Data(val) => {
debug!("Use cache to retrieve a planet by id: {}", planet\_id);
Ok(serde\_json::from\_slice(&val)?)
}
\_ => Err(RedisError {
message: "Unexpected response from Redis".to\_string(),
}),
}
}
```
Если ключа нет в кэше (ветвь `Nil`), пара ключ-значение помещается в Redis с помощью функции `set` (с автоэкспирацией (её назначение будет показано далее)); во второй ветви выражения `match` кэшированное значение конвертируется в целевую структуру.
Для помещения значения в кэш вам нужно имплементировать трейт `ToRedisArgs` для структуры:
*[`Имплементация трейта ToRedisArgs`](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/redis.rs)*
```
impl ToRedisArgs for &Planet {
fn write_redis_args(&self, out: &mut W)
where
W: ?Sized + RedisWrite,
{
out.write\_arg\_fmt(serde\_json::to\_string(self).expect("Can't serialize Planet as string"))
}
}
```
В функции `get_planet` используется асинхронное соединение Redis. Следующий пример демонстрирует другой подход, `ConnectionManager`, на примере очистки кэша с использованием функции `del`:
*[Пример очистки кэша](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/services.rs)*
```
pub async fn update_planet(
&self,
planet_id: &str,
planet: Planet,
) -> Result {
let updated\_planet = self
.mongodb\_client
.update\_planet(ObjectId::from\_str(planet\_id)?, planet)
.await?;
let cache\_key = self.get\_planet\_cache\_key(planet\_id);
self.redis\_connection\_manager.clone().del(cache\_key).await?;
Ok(updated\_planet)
}
```
Есть вероятность, что что-то пойдёт не так после успешного обновления (или удаления) сущности; например, проблема с сетью, что приведёт к ошибке при вызове Redis, или выключение/перезапуск приложения так, что функция `del` не будет вызвана. Это может привести к некорректным данным в кэше; последствия этого могут быть уменьшены за счёт автоэкспирации кэшированных записей, указанной ранее.
`ConnectionManager` [может быть клонирован](https://docs.rs/redis/0.20.2/redis/aio/struct.ConnectionManager.html). Он также используется во всех оставшихся примерах использования Redis вместо Redis клиента.
Кэш изображений может быть имплементирован так же, как и кэши других типов данных (используя функции `set`/`get`):
*[Кэширование изображений](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/services.rs)*
```
pub async fn get_image_of_planet(&self, planet_id: &str) -> Result, CustomError> {
let cache\_key = self.get\_image\_cache\_key(planet\_id);
let mut redis\_connection\_manager = self.redis\_connection\_manager.clone();
let cached\_image = redis\_connection\_manager.get(&cache\_key).await?;
match cached\_image {
Value::Nil => {
debug!(
"Use database to retrieve an image of a planet by id: {}",
&planet\_id
);
let planet = self
.mongodb\_client
.get\_planet(ObjectId::from\_str(planet\_id)?)
.await?;
let result = crate::db::get\_image\_of\_planet(&planet.name).await;
let \_: () = redis::pipe()
.atomic()
.set(&cache\_key, result.clone())
.expire(&cache\_key, 60)
.query\_async(&mut redis\_connection\_manager)
.await?;
Ok(result)
}
Value::Data(val) => {
debug!(
"Use cache to retrieve an image of a planet by id: {}",
&planet\_id
);
Ok(val)
}
\_ => Err(RedisError {
message: "Unexpected response from Redis".to\_string(),
}),
}
}
```
Кэширование может быть протестировано с использованием REST API, описанного выше.
#### Ограничение количества HTTP запросов
Эта фича реализована в соответствии с [официальным гайдом](https://redislabs.com/redis-best-practices/basic-rate-limiting/) следующим образом:
*[Имплементация rate limiter](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/services.rs)*
```
#[derive(Clone)]
pub struct RateLimitingService {
redis_connection_manager: ConnectionManager,
}
impl RateLimitingService {
pub fn new(redis_connection_manager: ConnectionManager) -> Self {
RateLimitingService {
redis_connection_manager,
}
}
pub async fn assert_rate_limit_not_exceeded(&self, ip_addr: String) -> Result<(), CustomError> {
let current_minute = Utc::now().minute();
let rate_limit_key = format!("{}:{}:{}", RATE_LIMIT_KEY_PREFIX, ip_addr, current_minute);
let (count,): (u64,) = redis::pipe()
.atomic()
.incr(&rate_limit_key, 1)
.expire(&rate_limit_key, 60)
.ignore()
.query_async(&mut self.redis_connection_manager.clone())
.await?;
if count > MAX_REQUESTS_PER_MINUTE {
Err(TooManyRequests {
actual_count: count,
permitted_count: MAX_REQUESTS_PER_MINUTE,
})
} else {
Ok(())
}
}
}
```
Redis ключ создаётся на каждую минуту + IP адрес клиента. После каждого вызова функции `assert_rate_limit_not_exceeded` значение, соответствующее ключу, инкрементируется на 1. Чтобы хранилище не переполнилось из-за большого количества ранее созданных пар ключ-значение, ключ "экспайрится" через минуту.
Rate limiter может быть использован в Actix обработчике следующим образом:
*[Использование rate limiter](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/handlers.rs)*
```
pub async fn get_planets(
req: HttpRequest,
web::Query(query_params): web::Query,
rate\_limit\_service: web::Data>,
planet\_service: web::Data>,
) -> Result {
rate\_limit\_service
.assert\_rate\_limit\_not\_exceeded(get\_ip\_addr(&req)?)
.await?;
let planets = planet\_service.get\_planets(query\_params.r#type).await?;
Ok(HttpResponse::Ok().json(planets.into\_iter().map(PlanetDto::from).collect::>()))
}
```
Если вызывать метод получения списка планет слишком часто, то будет получена следующая ошибка:
#### Нотификации
В этом проекте нотификации реализованы с помощью [Redis Pub/Sub](https://redis.io/topics/pubsub) и [Server-Sent Events](https://en.wikipedia.org/wiki/Server-sent_events) для доставки сообщений пользователю.
При создании сущности публикуется событие:
*[Публикация события в Redis](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/services.rs)*
```
pub async fn create_planet(&self, planet: Planet) -> Result {
let planet = self.mongodb\_client.create\_planet(planet).await?;
self.redis\_connection\_manager
.clone()
.publish(
NEW\_PLANETS\_CHANNEL\_NAME,
serde\_json::to\_string(&PlanetMessage::from(&planet))?,
)
.await?;
Ok(planet)
}
```
Подписка реализуется так:
*[Пример подписки в Redis](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/services.rs)*
```
pub async fn get_new_planets_stream(
&self,
) -> Result>, CustomError> {
let (tx, rx) = mpsc::channel::>(100);
tx.send(Ok(Bytes::from("data: Connected\n\n")))
.await
.expect("Can't send a message to the stream");
let mut pubsub\_con = self
.redis\_client
.get\_async\_connection()
.await?
.into\_pubsub();
pubsub\_con.subscribe(NEW\_PLANETS\_CHANNEL\_NAME).await?;
tokio::spawn(async move {
while let Some(msg) = pubsub\_con.on\_message().next().await {
let payload = msg.get\_payload().expect("Can't get payload of message");
let payload: String = FromRedisValue::from\_redis\_value(&payload)
.expect("Can't convert from Redis value");
let msg = Bytes::from(format!("data: Planet created: {:?}\n\n", payload));
tx.send(Ok(msg))
.await
.expect("Can't send a message to the stream");
}
});
Ok(rx)
}
```
Подписка используется в Actix обработчике так:
*[Пример SSE handler](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/handlers.rs)*
```
pub async fn sse(
planet_service: web::Data>,
) -> Result {
let new\_planets\_stream = planet\_service.get\_new\_planets\_stream().await?;
let response\_stream = tokio\_stream::wrappers::ReceiverStream::new(new\_planets\_stream);
Ok(HttpResponse::build(StatusCode::OK)
.insert\_header(header::ContentType(mime::TEXT\_EVENT\_STREAM))
.streaming(response\_stream))
}
```
Чтобы протестировать нотификации, вам нужно подписаться на события и сгенерировать событие. Далее приведены два подхода для этого; в обоих событие генерируется с использованием cURL:
* подписка из браузера
Перейдите на `http://localhost:9000/`, где находится [HTML страница](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/index.html):
* подписка из командной строки с использованием cURL
Используйте `curl -X GET localhost:9000/events`:
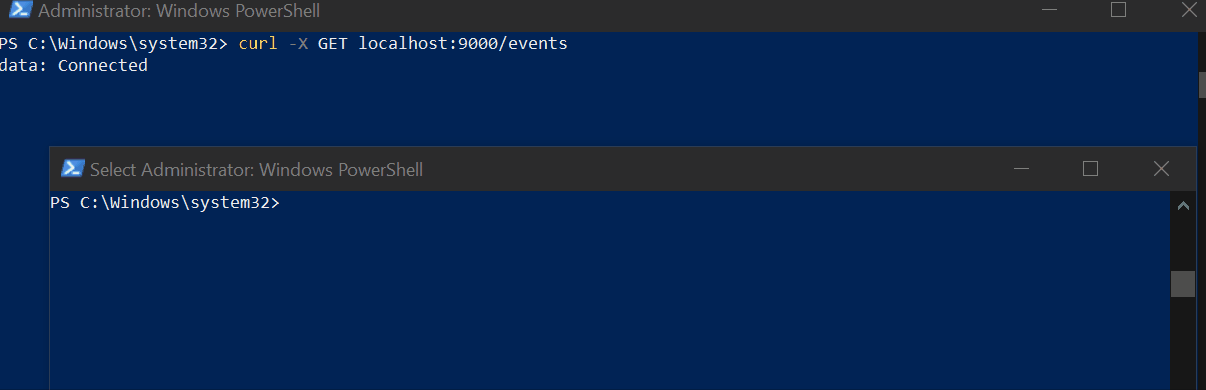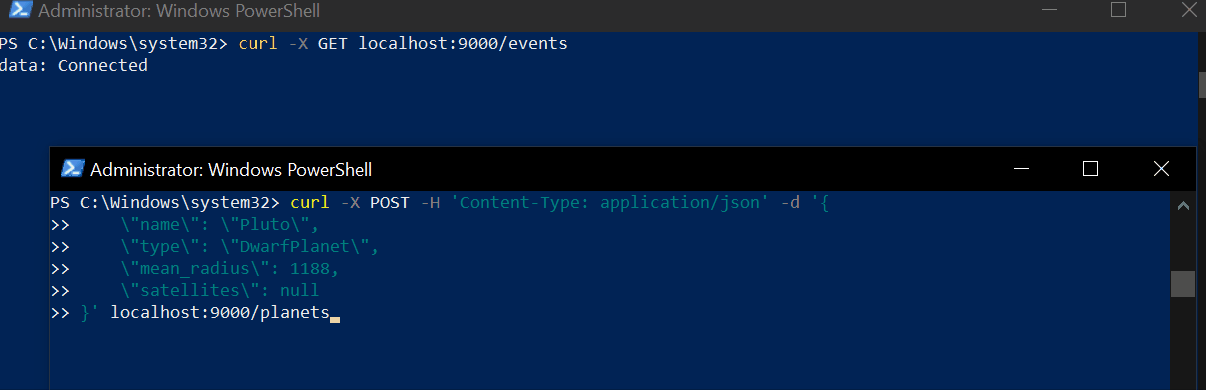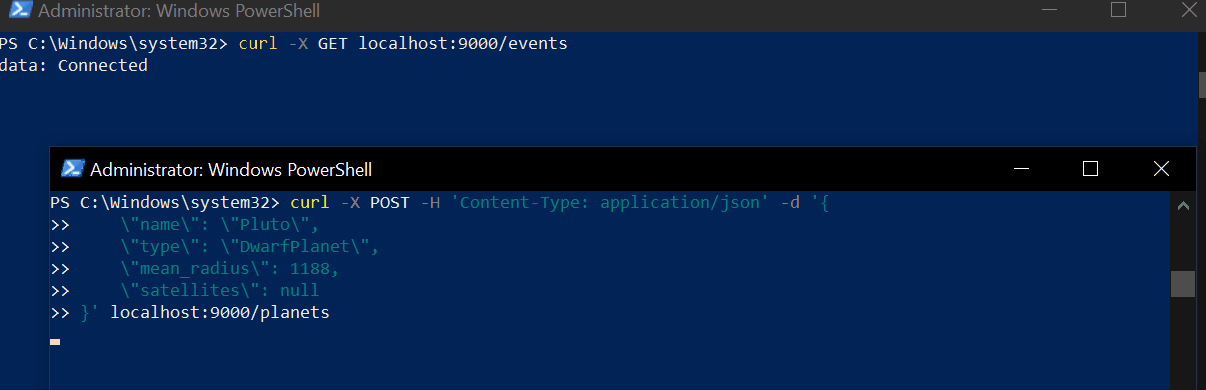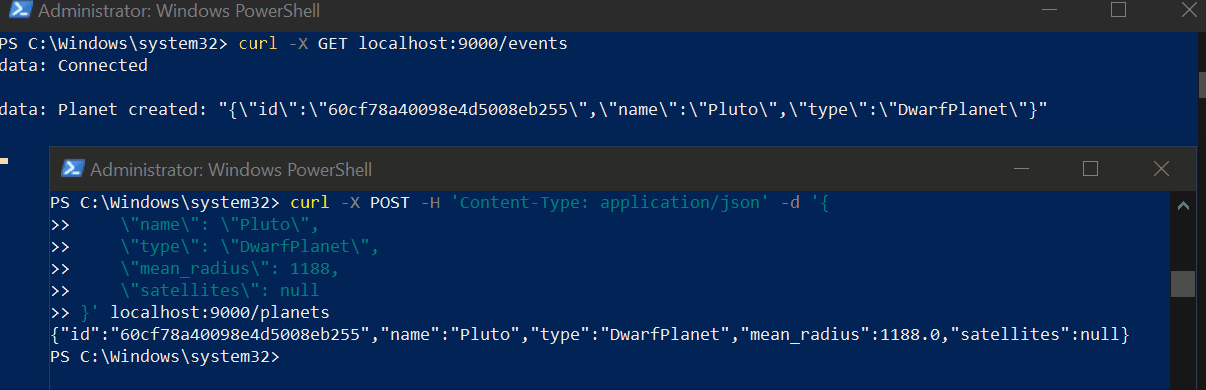
Для генерации события используется следующий cURL запрос:
*Запрос для тестирования нотификаций*
```
curl -X POST -H 'Content-Type: application/json' -d '{
\"name\": \"Pluto\",
\"type\": \"DwarfPlanet\",
\"mean_radius\": 1188,
\"satellites\": null
}' localhost:9000/planets
```
### Веб приложение
Некоторые аспекты этой темы были включены в предыдущие разделы, поэтому здесь будут освещены некоторые из оставшихся тем.
#### REST API обработчики
REST API обработчики определены так:
*[Определение REST API обработчиков](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/main.rs)*
```
#[actix_web::main]
async fn main() -> std::io::Result<()> {
...
let enable_write_handlers = env::var("ENABLE_WRITE_HANDLERS")
.expect("ENABLE_WRITE_HANDLERS env var should be specified")
.parse::()
.expect("Can't parse ENABLE\_WRITE\_HANDLERS");
HttpServer::new(move || {
let mut app = App::new()
.route("/planets", web::get().to(handlers::get\_planets))
.route("/planets/{planet\_id}", web::get().to(handlers::get\_planet))
.route(
"/planets/{planet\_id}/image",
web::get().to(handlers::get\_image\_of\_planet),
)
.route("/events", web::get().to(handlers::sse))
.route("/", web::get().to(handlers::index))
.data(Arc::clone(&planet\_service))
.data(Arc::clone(&rate\_limiting\_service));
if enable\_write\_handlers {
app = app
.route("/planets", web::post().to(handlers::create\_planet))
.route(
"/planets/{planet\_id}",
web::put().to(handlers::update\_planet),
)
.route(
"/planets/{planet\_id}",
web::delete().to(handlers::delete\_planet),
);
}
app
})
.bind("0.0.0.0:9000")?
.run()
.await
}
```
#### Обработка ошибок
[Обработка ошибок](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/src/errors.rs) имплементирована в соответствии с [документацией](https://actix.rs/docs/errors/).
Запуск и тестирование
---------------------
Локально проект может быть запущен двумя способами:
* с использованием Docker Compose ([`docker-compose.yml`](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/mongodb-redis/docker-compose.yml)):
`docker compose up` (или `docker-compose up` в более старых версиях Docker)
* без использования Docker
Запустите приложение с помощью `cargo run` (в этом случае сервис `mongodb-redis` в `docker-compose.yml` должен быть отключён)
CI/CD
-----
CI/CD сконфигурировано с помощью GitHub Actions [workflow](https://github.com/rkudryashov/exploring-rust-ecosystem/blob/master/.github/workflows/mongodb-redis.yml), который собирает Docker образ приложения и разворачивает его на Google Cloud Platform.
Для доступа к REST API развёрнутого приложения вы можете использовать один из доступных `GET` эндпоинтов, например:
`GET http://demo.romankudryashov.com:9000/planets`
Пишущие методы REST API недоступны на production среде.
Заключение
----------
В этой статье я показал как начать работу с MongoDB и Redis и примеры их использования в Rust приложении. Не стесняйтесь написать мне, если нашли какие-либо ошибки в статье или исходном коде. Спасибо за внимание!
Полезные ссылки
---------------
* [Quick Start: Up and Running with Rust and MongoDB](https://developer.mongodb.com/quickstart/rust-crud-tutorial/)
* <https://redis.io/topics/quickstart>
* <https://redis.io/topics/data-types-intro> | https://habr.com/ru/post/568856/ | null | ru | null |
# Особенности работы CLR в .NET framework
Начиная изучать язык C# и .NEt Framework я ни как не мог понять, как же работает CLR. Я либо находил огромные статьи, которые не осилить за 1 вечер либо слишком краткое, скорее даже запутывающее описание процесса (как в книге Г. Шилдта).
Некоторое время назад я решил, что было бы неплохо собирать знания, полученные из книг, «фичи» и часто используемые приемы в одном месте. А то новая информация быстро оседает в голове, но также быстро забывается и спустя несколько недель приходится вновь рыться в сотнях и тысячах строк текста, чтобы найти ответ на вопрос. Читая очередную книгу по программированию, я делал краткие пометки самого важного, что мне показалось. Иногда описывал некоторый процесс понятным мне языком с придуманным примером и т.д. **Я не претендую на абсолютную правильность излагаемого материала. Это всего лишь мое понимание процесса, с моими примерами и информацией, которую я посчитал ключевой для понимания** Проработав некоторый материал, я решил сохранить это для всех тех, кому это может быть полезно. А кто уже знаком — тот просто освежит это в памяти.
>
>
> Нужно отметить, что понятие «тип» это некоторое подобие класса в языке C#. Но т.к. .NET поддерживает не только C# но и другие языки, то используется понятие «тип», а не привычный «класс». Также данная статья предполагает, что читатель уже знаком с особенностями .Net и раскрывает особенности специфических вещей и процессов.
>
>
>
> В качестве примера приведу текст программы, выводящий на экран возраст объекта:
>
> исходный текст программы, чтобы было понятно:
>
>
> > `using System;
> >
> >
> >
> > namespace ConsoleApplication\_Test\_Csharp
> >
> > {
> >
> > public class SomeClass
> >
> > {
> >
> > int age;
> >
> > public int GetAge()
> >
> > {
> >
> > age = 22;
> >
> > return age;
> >
> > }
> >
> > }
> >
> > public sealed class Program
> >
> > {
> >
> > public static void Main()
> >
> > {
> >
> > System.Console.Write("My age is ");
> >
> > SomeClass me = new SomeClass();
> >
> > int myAge;
> >
> > myAge = me.GetAge();
> >
> > System.Console.WriteLine(myAge);
> >
> > Console.ReadLine();
> >
> > }
> >
> >
> >
> > }
> >
> > }
> >
> >
> >
> > \* This source code was highlighted with Source Code Highlighter.`
>
>
>
>
>
> И так приступим:
>
>
>
> Что такое CLR?
> ==============
>
>
>
> **CLR** (Common language runtime) — общеязыковая исполняющая среда. Она обеспечивает интеграцию языков и позволяет объектам благодаря стандартному набору типов и метаданным), созданным на одном языке, быть «равноправными гражданами» кода, написанного на другом.
>
>
>
> Другими словами CLR этот тот самый механизм, который позволяет программе выполняться в нужном нам порядке, вызывая функции, управляя данными. И все это для разных языков (c#, VisualBasic, Fortran). Да, CLR действительно управляет процессом выполнения команд (машинного кода, если хотите) и решает, какой кусок кода (функцию) от куда взять и куда подставить прямо в момент работы программы. Процесс компиляции представлен на рисунке:
>
> [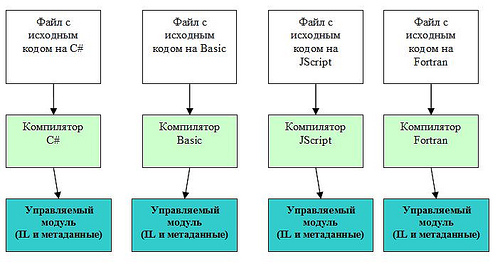](http://www.flickr.com/photos/49055286@N07/4507478100/ "CLR by asArtem, on Flickr")
>
>
>
> **IL** (Intermediate Language) — код на специальном языке, напоминающим ассемблер, но написанном для .NET. В него преобразуется код из других языков верхнего уровня (c#, VisualBasic). Вот тогда-то и пропадает зависимость от выбранного языка. Ведь все преобразуется в IL (правда тут есть оговорки соответствия общей языковой спецификации CLS, что не входит в рамки данной статьи)
>
> Вот как он выглядит для функции SomeClass::GetAge()
>
> [](http://www.flickr.com/photos/49055286@N07/4497521477/ "IL by asArtem, on Flickr")
>
>
>
> Компилятор, помимо ассемблера IL создает полные метаданные.
>
>
>
> **Метаданные** — набор из таблиц данных, описывающих то, что определено в модуле. Также есть таблицы, указывающие на что ссылается управляемый модуль (например, импортируемые типы и числа). Они расширяют возможности таких технологий как библиотеки типов и файлы языка описания интерфейсов (IDL). Метаданные всегда связаны с файлом с IL кодом, фактически они встроены в \*.exe или \*.dll.
>
> Таким образом метаданные это таблицы, в которых есть поля, говорящие о том, что такой-то метод находится в таком-то файле и принадлежит такому-то типу(классу).
>
> Вот как выглядят метаданные для моего примера (таблицы метаданных просто преобразованы в понятный вид с помощью дизассемблера ILdasm.exe. На самом деле это часть \*.exe файла программы:
>
>
>
> [](http://www.flickr.com/photos/49055286@N07/4498156574/ "metadata by asArtem, on Flickr")
>
>
>
> TypeDef — это запись, для каждого типа, определенного в модуле
>
> К примеру TypeDef #1 описывает класс SomeClass и показывает поле Field #1 с именем Field Name: age, метод MethodName: GetAge и конструктор MethodName: .ctor. Запись TypeDef #2 описывает класс Program.
>
>
>
> Разобравшись с основными понятиями, давайте посмотрим из чего же состоит тот самый управляемый модуль (или просто наш файл ConsoleApplication\_Test\_Csharp.exe, который выполняет вывод на экран возраста объекта):
>
>
>
> **Заголовок** показывает на каком типе процессора будет выполняться программа. РЕ32 (для 32 и 64 битных ОС) или РЕ32+ (только для 64 битных ОС)
>
> **Заголовок** CLR — содержит информацию, превращающую этот модуль в управляемый (флаги, версия CLR, точки входа в Main())
>
> **Метаданные** — 2 вида таблиц метаданных:
>
> 1) определенные в исходном коде типы и члены
>
> 2) типы и члены, имеющие ссылки в исходном коде.
>
> **Код IL** — Код, создаваемый компилятором при компиляции кода на C#. Затем IL преобразуется в процессорные команды (0001 0011 1101… ) при помощи CLR (а точнее JIT)
>
>
>
> Работа JIT
> ==========
>
>
>
>
>
> И так, что же происходит, когда запускается впервые программа?
>
> Сперва происходит анализ заголовка, чтобы узнать какой процесс запустить (32 или 64 разрядный). Затем загружается выбранная версия файла MSCorEE.dll ( *C:\Windows\System32\MSCorEE.dll* для 32разрядных процессоров)
>
> После чего вызывается метод, расположенный MSCorEE.dll, который и инициализирует CLR, сборки и точку входа функции Main() нашей программы.
>
>
>
>
> > `static void Main()
> >
> > {
> >
> > System.Console.WriteLine("Hello ");
> >
> > System.Console.WriteLine("Goodbye");
> >
> > }
> >
> >
> >
> > \* This source code was highlighted with Source Code Highlighter.`
>
>
>
>
>
> Для выполнения какого-либо метода, например System.Console.WriteLine(«Hello „), IL должен быть преобразован в машинные команды (те самые нули и единицы) Этим занимается Jiter или just-in-time compiler.
>
>
>
> Сперва, перед выполнением Main() среда CLR находит все объявленные типы (например тип Console).
>
> Затем определяет методы, объединяя их в записи внутри единой “структуры» (по одному методу определенному в типе Console).
>
> Записи содержат адреса, по которым можно найти реализации методов (т.е. те преобразования, которые выполняет метод).
>
>
>
> [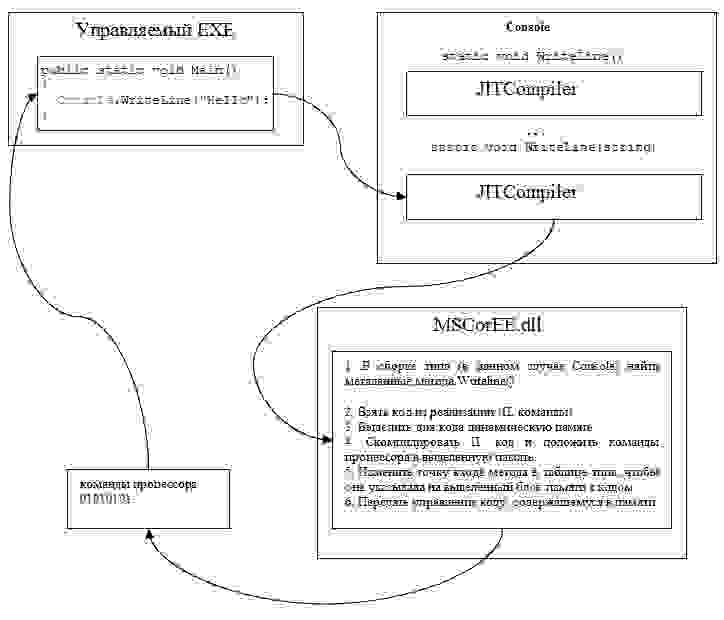](http://www.flickr.com/photos/49055286@N07/4506840113/ "Jit by asArtem, on Flickr")
>
>
>
> При первом обращение к функции WriteLine вызывается JiT-compiler.
>
> JiTer 'у известны вызываемый метод и тип, которым определен этот метод.
>
> JiTer ищет в метаданных соответствующей сборки — реализацию кода метода (код реализации метода WriteLine(string str) ).
>
> Затем, он проверяет и компилирует IL в машинный код (собственные команды), сохраняя его в динамической памяти.
>
> После JIT Compiler возвращается к внутренней «структуре» данных типа (Console) и заменяет адрес вызываемого метода, на адрес блока памяти с исполняемыми процессорными командами.
>
> После этого метод Main() обращается к методу WriteLine(string str) повторно. Т.к. код уже скомпилирован, обращение производится минуя JiT Compiler. Выполнив метод WriteLine(string str) управление возвращается методу Main().
>
>
>
> Из описания следует, что «медленно» работает функция только в момент первого вызова, когда JIT переводит IL код в инструкции процессора. Во всех остальных случаях код уже находится в памяти и подставляется как оптимизированный для данного процессора. Однако если будет запущена еще одна программа в другом процессе, то Jiter будет вызван снова для того же метода. Для приложений выполняемых в х86 среде JIT генерируется 32-разрядные инструкции, в х64 или IA64 средах — соответственно 64-разрядные.
>
>
>
> Оптимизация кода. Управляемый и неуправляемый код
> =================================================
>
>
>
>
>
> IL может быть оптимизирован, т.е. из него будут удалены IL — команды NOP (пустая команда). Для этого при компиляции нужно добавить параметры
>
>
>
> Debug версия собирается с параметрами: */optimize -, /debug: full*
>
> Release версия собирается с параметрами: */optimize +, /debug: pdbonly*
>
>
>
> Чем же отличается управляемый код от неуправляемого?
>
>
>
> **Неуправляемый код** компилируется для конкретного процессора и при вызове просто исполняется.
>
>
>
> **В управляемой среде** компиляция производится в 2 этапа:
>
>
>
> 1) компилятор переводит C# код в IL
>
> 2) для исполнения нужно перевести IL код в машинный код процессора, что требует доп. динамической памяти и времени (как раз та самая работа JIT).
>
>
>
> Взаимодействие с неуправляемым кодом:
>
>
>
> — управляемый код может вызывать направляемую функцию из DLL посредствам P/Invoke (например CreateSemaphore из Kernel32.dll).
>
> — управляемый код может использовать существующий COM-компонент (сервер).
>
> — неуправляемый код может использовать управляемый тип (сервер). Можно реализовать COM — компоненты в управляемой среде и тогда не нужно вести подсчет ссылок интерфейсов.
>
>
>
> Параметр /clr позволяет скомпилировать Visual С++ код в управляемые IL методы (кроме когда, содержащего команды с ассемблерными вставками ( \_\_asm ), переменное число аргументов или встроенные процедуры ( \_\_enable, \_RetrurAddress )). Если этого сделать не получится, то код скомпилируется в стандартные х86 команды. Данные в случае IL кода не являются управляемыми (метаданные не создаются) и не отслеживаются сборщиком мусора (это касается С++ кода).
>
>
>
> Система типов
> =============
>
>
>
>
>
> В дополнение хочу рассказать о системе типов CTS, принятой Microsoft.
>
>
>
> **CTS (Common Type System)** — общая система типов в CLR (тип, по-видимому — это аналог класса C#). Это — стандарт, признанный ECMA который описывает определение типов и их поведение. Также определяет правила наследования, виртуальных методов, времени жизни объектов. После регистрации ECMA стандарт получил название CLI ( Common Language Infrastructure)
>
>
>
> — CTS поддерживает только единичное наследование (в отличие от С++)
>
> — Все типы наследуются от System.Object (Object — имя типа, корень все остальных типов, System — пространство имен)
>
>
>
> По спецификации CTS любой тип содержит 0 или более членов.
>
>
>
> Основные члены:
>
>
>
> Поле — переменная, часть состояния объекта. Идентифицируются по имени и типу.
>
> Метод — функция, выполняющая действие над объектом. Имеет имя, сигнатуру(число параметров, последовательность, типы параметров, возвр. значение функции) и модификаторы.
>
> Свойство — в реализации выглядит как метод (get/set) а для вызывающей стороны как поле ( = ). Свойства позволяют типу, в котором они реализованы, проверить входные параметры и состояние объекта.
>
> Событие — обеспечивает механизм взаимного уведомления объектов.
>
>
>
> Модификаторы доступа:
>
>
>
> Public — метод доступен любому коду из любой сборки
>
> Private — методы вызывается только внутри типа
>
> Family (protected) — метод вызывается производными типами независимо от сборки
>
> Assembly (internal) — метод вызывается любым кодом из той же сборки
>
> Family or Assembly
>
> (protected internal) — метод вызывается производными типами из любой сборки и + любыми типами из той же сборки.
>
>
>
> **CLS (Common Language Specification)** — спецификации выпущенная Майкрософт. Она описывает минимальный набор возможностей, которые должны реализовать производители компиляторов, чтобы их продукты работали в CLR. CLR/CTS поддерживает больше возможностей, определенных CLS. Ассемблер IL поддерживает полный набор функций CLR/CTS. Языки (C#, Visual Basic) поддерживает часть возможностей CLR/CTS (в т.ч. минимум от CLS).
>
> Пример на рисунке
>
>
>
> [](http://www.flickr.com/photos/49055286@N07/4506834735/ "CLS by asArtem, on Flickr")
>
>
>
> Пример проверки на соответствие CLS
>
>
>
> Атрибут [assembly: CLSCompliant(true)] заставляет компилятор обнаруживать любые доступные извне типы, содержащие конструкции, недопустимые в других языках.
>
>
>
>
> > `1. using System;
> > 2. [assembly: CLSCompliant(true)]
> > 3. namespace SomeLibrary
> > 4. {
> > 5. // возникает предупреждение поскольку тип открытый
> > 6. public sealed class SomeLibraryType
> > 7. {
> > 8. // тип, возвращаемый функцией не соответсвует CLS
> > 9. public UInt32 Abc() { return 0; }
> > 10.
> > 11. // идентификатор abc() отличается от предыдущего, только если
> > 12. // не выдерживается соответсвие
> > 13. public void abc() { }
> > 14.
> > 15. // ошибки нет, метод закрытый
> > 16. private UInt32 ABC() { return 0; }
> > 17.
> > 18. }
> > 19.
> > 20. }
> > \* This source code was highlighted with Source Code Highlighter.`
>
>
>
>
>
> Первое предупреждение: UInt32 Abc() возвращает целочисленное целое без знака. Visaul Basic, например, не работает с такими значениями.
>
> Второе предупрждение: два открытых метода Abc() и abc() — одиноквые и отличаются лишь регистром букв и возвращаемым типом. VisualBasic не может вызывать оба метода.
>
>
>
> Убрав public и оставив только sealed class SomeLibraryType оба предупреждения исчезнут. Так как SomeLibraryType по-умолчанию будет internal и не будет виден извне сборки.
>
>
>
> P.S. Статья основана на материалах из книги Дж. Рихтера «CLR via C#. Программирование на платформе Microsoft .NET Framework 2.0 на языке C#»
>
> | https://habr.com/ru/post/90426/ | null | ru | null |
# Выбор ORM-стратегии (.NET)

Одна из ошибок, которую делают разработчики (и я когда-то в их числе) — это утверждение о том, что вы должны использовать ровно одну ORM-стратегию для создаваемого приложения. В общем случае это неверно. Вы можете (и должны) привязывать выбор стратегии к конкретному сценарию, и быть уверенным в том, что выбираете правильные инструменты для конкретного случая.
Сразу отмечу, что 99.9% времени вы не должны использовать ADO.NET напрямую. Если вы до сих пор используете `dataReader.MoveNext` — остановитесь!
Множество людей не любят ORM как таковые. Послушав их аргументацию, я соглашусь с тем, что Мартин Фаулер написал в [OrmHate](http://martinfowler.com/bliki/OrmHate.html):
> *Наибольшее разочарование от ORM заключается в завышенных ожиданиях*.
**Мы должны смириться с мыслью о том, что ORM являются плохими, уродливыми и перегруженными**. ORM предназначены решать задачу и имеют множество разных подходов для этого. Но, перед тем как мы посмотрим на эти подходы, давайте изучим, какую же задачу мы пытаемся решить?
#### Преодоление разрыва
Если вы должны загружать или вставлять данные в SQL, вы должны отобразить («замапить») свои .NET типы данных в SQL. Для .NET это означает использование ADO.NET для отправки SQL команд к SQL-серверу. Затем нам надо отобразить SQL типы в .NET типы. И здесь есть нюансы — например, даты в SQL отличаются от дат в .NET.
ADO.NET помогает нам в этом, но оставляет нам работу по обработке сырых наоборов данных и созданию объектов .NET. В итоге мы получаем что хотим — мы работаем с объектами и типами .NET. А какой-то код транслирует это в SQL запросы и обратно.
ORM предназначены решать эту проблему, добавляя слои различных абстракций поверх ADO.NET. Но существует множество стратегий для этого. Давайте взглянем на каждую из них и посмотрим где какие лучше подходят.
#### Прямое отображение сущностей (Entity-based relational mapping)
В таком отображение почти всегда таблицы базы данных соотносятся 1:1 с сущностями в вашей системе. Когда вы добавляете свойство к объекту — добавляете и колонку к таблице. Использование такого способа строится вокруг загрузки сущности (или агрегата) по его идентификатору, управлению этим объектом и, возможно, связанными объектами, а затем сохранения этого объекта в базу данных посредством ORM.
ORM в этом случае предоставляет множество функционала, например:
* Слежение за изменениями
* Ленивая загрузка (lazy-loading)
* Предзагрузка (eager fetching)
* Каскадность
* Обеспечение уникальности объектов ([Identity map](http://martinfowler.com/eaaCatalog/identityMap.html))
* Работа с единицами работы ([Unit of work](http://martinfowler.com/eaaCatalog/unitOfWork.html))
Если я работаю с только одной сущностью или агрегатом одновременно, то такие ORM как NHibernate нам очень подходят. Они используют указанную конфигруацию для слежения за загруженными сущностями и автоматическим сохранением изменений во время коммита транзакции. И это приятно, потому что мы не должны таскать за собой свой слой работы с данными. NHibernate делает всю грязную работу за нас.
Пока мы загружаем объект по Id с единственной целью изменить его, всё это работает отлично. Это избавляет от большого количества кода, который бы мне потребовалось создать чтобы следить за добавлением объектов, их сохранением и т.д.
Обратная сторона такого подхода в том, что ORM не знает, собираетесь ли вы только читать обекты, или загружаете сущность, чтобы изменить её. Мы часто видим людей спотыкающихся, когда они не понимают, что трекинг изменений включен по умолчанию и как он работает.
Если вы хотите загрузить сущность чтобы её изменить и сохранить изменения (или создать новую сущность), этот подход обеспечивает большую гибкость от включения уровня доступа к данным в ваш инфраструктурный слой и позволяет вашим типам сущностй быть относительно независимыми от их метода сохранения. Эта независимость не означает, что моя модель C# и схема данных могут расходиться. Напротив, это означает, что слой доступа к данным не проникнет в мою объектную модель, которую вместо этого я бы скорее предпочёл нагрузить бизнес-правилами.
#### Отображение в наборы данных (Result-set-based relational mapping)
В большинстве приложений, требования к чтению данных существенно превосходят количество записей. Мы видели соотношение в 100:1 между SELECT и INSERT/UPDATE/DELETE в нашем недавнем приложении. Когда мы смотрим, в чём SQL действительно хорош, так это в работе с данными в сетах (наборах). Чтобы выбрать какой-то набор данных из SQL сервера, часто не имеет никакого смысла пытаться прямо отображать эти данные в сущности.
Но мы всё равно предпочитаем не работать напрямую с IDataReader или DataTable. Это плохо-типизированные объекты, тяжело переносимые в верхние слои приложения. Наоборот, мы часто строим объекты, приспособленные к данным. Эти объекты часто называется DTO (Data-Transfer Objects), или модели для чтения (Read Models). Такие DTO мы создаём для индивидуальных SQL выборок — и редко для того, чтобы повторно использовать их в других запросах.
Многие ORM имеют функционал, оптимизированный для таких сценариев. В NHibernate, вы можете использовать проекции чтобы выключить трекинг, и отобразить данные напрямую в DTO. Вы можете использовать SQL запросы чтобы сделать это и не нуждаетесь в конфигурации маппинга. Или вы можете использовать микро-ORM например PetaPoco.
Эти чтения также могут генерировать DTO объекты по мере их чтения. И NHibernate и несколько micro-ORMs позволяют получать индивидуальные DTO объекты последовательно один за одним во время чтения строк результатов запроса, тем самым минимизируя объем объектов содержащихся в памяти.
В наших приложения, мы до сих пор часто используем NHiberante для чтения, но не используем объекты сущностей, а вместо этого используем сырой SQL. Мы полагаемся на оптимизированные мапперы NHiberanate, чтобы просто подать тип DTO, а результат выборки отобразится автоматически.
Этот подход не очень хорошо работает, если нам надо применить бизнес правила и сохранить информацю обратно. Так как эти модели обычно отображаются в отдельные наборы данных, а не в таблицы базы данных.
[Active Record](http://martinfowler.com/eaaCatalog/activeRecord.html) – это другой пример сущностного отображения данных, в котором, функционал работы с данными включён в саму объектную модель.
#### Отображение DML-запросов (DML-based relational mapping)
Если вы знаете, какой SQL вам нужен для реализации CRUD, и предпочли бы создавать его вручную, то вы уже ищите что-то, чтобы эффективно аббстрагировать DML команды на уровень выше, чем ADO.NET.
И это арена микро-ORM. Такие фреймворки как [PetaPoco](http://www.toptensoftware.com/petapoco/), [Dapper](http://code.google.com/p/dapper-dot-net/), [Massive](https://github.com/robconery/massive/) и другие созданы, чтобы помочь решить пробемы работы ADO.NET. Они обычно всё равно позволяют нам работать с объектами ADO.NET, но наше взаимодействие сильно упрощается. Нам только нужно соединение, и эти фреймворки могут позволить работать со всеми CRUD операциями в виде, который предлагает намного более простой код, чем сам ADO.NET.
В случая, когда у вас нет сущностей и нужды отображать их в таблицы и обратно, микро-ORM дадут гораздо более лёгкий подход. А так микро-ORM не требуют предварительной конфигурации, то они полагаются на ленивое-исполнение и оптимизинорованные техники кеширования, чтобы налету маппить SQL параметры и результаты запросов. Многие приложение могут начать с маппигом основанном на DML, переходя на полноценную ORM, как только отношения или сущности потребуют этого.
#### Инструменты массовой загрузки (Bulk loading tools)
Это то, что занимает особое место — иногда вы не хотите вставлять/загружать данные объектным способом. Вместо этого, вы бы предпочли работать с всеми наборами целиком. Такие инструменты, как SQL Bulk Copy, позволяют вам получать и выгружать данные в CSV или в табличных форматах,
Эти утилиты работают примерно как базука, вырывая все данные сразу туда и обратно, но не предоставляя ничего кроме этого. Вы не можете обновлять или удалять данные, но для того, чтобы получить большие объёмы данных из SQL, эти утилиты — то что вам нужно.
Во многих интеграционных сценариях, где вы предоставляете файлы с данными внешним партнёрам, или наоборот — эти загрузчики позволяют пользоваться файлами как таблицам и напрямую загружать их в базы данных.
Эти утилиты намного быстрее традиционных методов парсинга/загрузки данных. В некоторых из наших тестов, мы видели разницу в порядки по сравнению с построчной загрузкой. А в одном случае, мы видели разницу между несколькими часами и минутой. Обратная сторона всего этого, это то, что функционал ограничен только лишь INSERT и SELECT. Всё остальное требует других подходов.
#### Правильный инструмент для задачи
В одном из недавних проектов, я использовал каждый из представленных выше подходов в работе с одной базой данных и одним кодом. NHibernate для сущностного/агрегатного маппинга, выборки готовых резалт-сетов для чтения наборов данных (и далее подготовки сообщений/экспорта/представлений из результатов), DML-маппинги для простых таблиц и модулей, а также инструменты для bulk-load для загрузки файлов от партнёров с многими миллионами строчек.
Ключевым моментом является то, что у вас нет необходимости привязываете себя к определённому инструменту или подходу. Никакая ORM стратегия не работает во всех сценариях, и не должна этого делать. NHibernate может работать со многими другими сценариями (кроме непосредственного маппинга сущностей), но не делает всего на свете. Сложность часто возникает из-за попыток использовать один и тот же подход всегда.
Каждое приложение, написанно вне SQL сервера использует ORM. Или этого рукописный ADO.NET код, или NHibernate — вы должны преодолевать разрыв между .NET и SQL. Это преодоление — тяжёлая задача, и ничто не решает задачу полностью идеально. И не должно!
Выбирайте подход, который решает конкретную проблему. Не беспокойтесь, что у вас будет несколько ORM-стратегий в одном проекте. Это не означает, что бессистемные решения приемлемы. Но наоборот — применение выверенных решений, основанных на знании возможных вариантов — всегда хорошая идея. | https://habr.com/ru/post/160845/ | null | ru | null |
# Ведение семейных финансов на C# и Xamarin. Личный опыт
Предисловие
-----------
В данной статье пойдет речь о том, как через тернии костылей и багов я в итоге достиг приличного уровня автоматизации учета семейных финансов.
*Дисклеймер: автор статьи имеет посредственные скиллы разработки, так что некоторые технические решения могут оскорбить чувства middle и senior developer-ов.*
К пониманию необходимости учета финансов я пришел в 2016 году, когда съехался со своей будущей женой. Цели учета были вполне банальные: понимать кто и сколько расходует на какие товары, выявить возможности для оптимизации расходов, а так же убедиться, что соотношение семейных расходов соразмерно соотношению размеров зарплат членов семьи. (Спойлер: разумеется, сэкономить в итоге ни на чем не получилось)
Многие советуют заводить отдельную карту для семейных покупок и перечислять на нее средства каждый месяц, но нам этот вариант не понравился. Проще контролировать расходы постфактум, а не пытаться их спрогнозировать.
Я считаю такой подход более разумным. Разумеется, мы не делим расходы абсолютно в каждом чеке из продуктового. В основном, дележке подвергаются крупные чеки из гипермаркетов на тысячи рублей. Также мы совместо финансируем коммунальные платежи, аренду и другие крупные жилищно-инфраструктурные проекты.
Версия 0
--------
Как правило, первые попытки ведения семейного бюджета люди начинают в Excel или иных аналогах, типа Google Sheets. И мы не стали исключением.
Схема была такой. Кто-то из нас двоих в оплачивал в магазине большой чек. Далее содержимое чека вносилось в экселевский файлик, а затем суммировались ячейки с товарами, купленными на семейные нужды. Так мы понимали, кто кому сколько должен перевести денег.
Такой метод оказался весьма неудобен в эксплуатации, и вскоре я начал поиск более подходящей альтернативы.
Версия 1
--------
Но поиск быстро зашел в тупик. Бесплатные варианты не умели делить один чек между несколькими пользователями. Да даже многопользовательский режим был далеко не везде. Платные же программы помимо факта своей платности зачастую предлагали поделиться данными о своих расходах с разработчиками. Ни платить ни делиться данными мне не хотелось.
Поэтому четко вырисовывался вариант - писать программу самому. Еще одним аргументом в пользу разработки было личное желание поизобретать велосипед и попробовать себя в качестве программиста. Я даже вынашивал идею улучшить свои жизненные условия через смену специализации с Windows-эникея на программиста.
Так как на заочном отделении в моем ВУЗе меня обучили только шлепать формы на C#, выбор стека для собственного приложения был очевиден. В качестве СУБД был выбран MSSQL Express, который хостился на домашнем сервере. Примерно за месяц был написан MVP, после чего с 1 сентября 2016 года процесс учета расходов был перенесен в свеженаписанную программу.
Параллельно с использованием программы шла ее постоянная доработка. Функционал постоянно дописывался и перекраивался. Неудачные решения выпиливались, и на их месте появлялись новые, которые в будущем могла постичь та же участь. Появлялись новые сущности, корректировался их набор параметров и логика работы, дорабатывался интерфейс. В конечном итоге был выработан наиболее удачный вариант логики приложения:
> *Основная сущность в программе - чек, который содержит позиции. У чека есть дата и место совершения покупки.*
>
> *У каждой позиции в чеке помимо основных параметров (наименование, цена, количество, категория) есть признак «расходы на общие нужды», а также имя пользователя, который эту позицию оплатил. По этим двум важным признакам происходит расчет итоговых сумм чека на каждого члена семьи.*
>
> *Любое приходно-расходное действие также генерирует операцию со знаком плюс или минус. Суммируя все операции, получаем текущее количество денег у отельно взятого пользователя.*
>
> *Помимо этого существуют вспомогательные справочники магазинов, категорий товаров, географических локаций, и.т.д.*
>
>
Вокруг основного функционала и данных я начал реализовывать разные полезные фичи, такие как например:
* Отчетность. Были реализованы различные отчеты, как например статистика трат по категориям товаров или статистика трат в разрезе магазинов.
* Отслеживание текущего баланса. Всегда хотел видеть количество денег, как у игрового персонажа :)
* Шаблоны чеков. Ввод однотипных расходов, как например такси, кофе, проезд в метро, был значительно упрощен таким путем. При выборе шаблона автоматически подставлялись все данные из соответствующего старого чека. Оставалось только поменять сумму и сохранить новый чек.
В какой-то момент появилось и устоявшееся название, которое сохранилось и по сей день – Домашняя бухгалтерия.
Немного скриншотов того, как выглядела первая версия Домашней бухгалтерии на излете жизни.
Главное окно программыФорма добавления чековОтчет по структуре расходовПосле этого дальнейшее развитие программы сильно замедлилось. 2019-2020 годы прошли без каких-либо значимых изменений. Лишь изредка приходилось править баги. Все новые идеи откладывались в долгий ящик, мотивации кодить не было, и скоро поясню почему.
#### Небольшое лирическое отступление
За 4 года нам с женой уже порядком поднадоело вносить портянки магазинных чеков вручную. Технологии шагнули далеко вперед, и концепция ручного ввода безнадежно устарела.
Виделось два очевидных вектора автоматизации учета:
* парсинг SMS уведомлений о списаниях с банковской карты
* получение содержимого чека по QR-коду.
Но такие глобальные доработки упирались в один очень неприятный факт:
Программирование в гуманитарном ВУЗе, да еще и на заочном отделении преподают весьма посредственно. Поэтому весь код представлял из себя мешанину из if/else, непонятных переменных и sql-запросов, объединенных с переменными. ООП? MVC? MVVM? Паттерны проектирования? Да хотя бы банально писать комментарии? Не, не слышали. После многократных переделок код стал похож на эдакого Франкенштейна. Надо ли говорить, что ориентироваться в нем было крайне сложно?
И вот под конец бесполезно потраченных новогодних выходных 2021 года я снова взялся за Visual Studio.
Версия 2 - текущая
------------------
Реализовывать новый функционал, как это сейчас принято, я решил через отдельный микросервис с собственной базой данных. Он должен был быть опубликован в интернет и получать данные от приложения-компаньона на смартфоне.
Опыта в мобильной разработке у меня было ровно ноль. Тратить месяцы на изучение Java или Kotlin не хотелось. И поэтому, я опять же пошел по легкому пути – Xamarin. В интернете нашел учебный шаблон приложения с вкладками и принялся его погонять под свои нужды, в процессе активно используя Google и Stackoverflow. Как только стало понятно, что мои планы на мобильное приложение реализуемы, параллельно начал разработку серверной части. Тут опять же был выбран C# и .Net Core. Мы же в 2021 живем как-никак, нужно уметь в кроссплатформенность.
Где-то около месяца у меня ушло на то, чтобы создать прототипы приложения и серверной части, которые могли общаться друг с другом. А далее снова начался процесс тестирования на проде и череда новых версий.
#### Мобильное приложение - CostsExporter
Мобильное приложение-компаньон умеет делать три вещи:
* сканировать и отправлять на сервер QR-код с чека.
* проверять inbox на предмет новых SMS от банка и так же отправлять их на сервер.
* отправлять на сервер введенный расход в виде сумма:описание.
Для сканирования QR-кодов с чека я использую библиотеку [ZXing.Net.Mobile](https://github.com/Redth/ZXing.Net.Mobile). Примерно в 90% случаев QR-код удается отсканировать. Но если QR-код нечеткий или чек непропечатался/истерся, то тут все печально. Встроенное приложение камеры, как и официально приложение ФНС России, вполне справляются даже в таких случаях. Специально для этого пришлось добавить вариант с ручным ввводом содержимого QR-кода. Если кто может посоветовать вариант лучше, я был бы очень благодарен.
Для чтения SMS в памяти телефона постоянно висит Foreground Service, который дергает метод проверки входящих SMS каждые 3 минуты. После продолжительного штудирования интернетов я сделал вывод, что только таким путем можно обеспечить приемлемую работоспособность этого процесса, ибо своевольный Android может выгружать любые активности, когда ему вздумается.
Все SMS/QR-коды/ручные записи перед отправкой складываются в локальную базу SQLite, где так же хранится дата создания и статус отправки на сервер. При повторном сканировании SMS/QR-кода дубли будут отброшены.
Все сообщения отправляются в json-формате. JSON выглядит примерно так:
```
{
"TypeId": "2",
"Payload": "02.03.2021 9:54:33;Raiffeisen;Karta *****. Pokupka 137.00 RUB. CITYMOBIL.. Balans 4842.16 RUB. 02.03.2021"0Э
"User": "Pavel",
"Secret": "SomeSecret"
}
```
Далее немного скринов приложения:
#### Серверная часть - CostsReceiver
CostsReceiver представляет из себя Web-сервер на Asp.Net Core запущеный в Docker-контейнере на домашнем сервере. Наружу он опубликован через KeenDNS (сервис для владельцев роутеров Keenetic), который позаботился и о доменном имени и SSL сертификате.
CostsReceiver парсит прилетающие к нему json-ы и складывает результат в таблицу пакетов для обработки.
Каждые 3 минуты в отдельном потоке запускается воркер, который пытается обработать все необработанные входящие пакеты. Параметр TypeID подсказывает серверу, как обрабатывать полученный пакет. Если TypeID равен единице, то это QR-код, если 2 – это SMS, если 3 – то это расход, введенный вручную.
С SMS все просто – текст прогоняется через регулярное выражение. Из него вычленяются название торговой точки, время и сумма покупки. Непрошедшие регулярку сообщения удаляются.
С QR-кодом все интереснее. После непродолжительного поиска я нашел [статью Николая Валиотти](https://leftjoin.ru/all/nalog-ru-client/) о реализации парсера чеков на Python. Переписать код на C# было несложно.
Сперва происходит аутентификация и запрос токена. Затем с этим токеном и содержимым QR кода воркер постоянно стучится на сервер ФНС, пока сервер не выдаст ему в ответ содержимое чека в json формате. Как быстро чек появляется на сервере ФНС, судя по всему, зависит от типа кассы. Это может занять от пары минут до пары дней. Из полученного json-а также выдергивается название торговой точки, время покупки и все позиции чека.
Возможно, кому-то этот код будет полезен
```
public class CheckRequesterByQR
{
private Envelope _envelope = new Envelope();
public CheckRequesterByQR(Envelope envelope)
{
_envelope = envelope;
}
public async Task GetCheckByQR()
{
string sessionId;
if (Variables.sessionID == null)
{
JObject responseSessId = JObject.Parse(await GetSessionID());
sessionId = (string)responseSessId["sessionId"];
Variables.sessionID = sessionId;
}
else sessionId = Variables.sessionID;
try
{
JObject responseTicketId = JObject.Parse(await GetTicketID(sessionId, \_envelope.Payload));
var ticketId = (string)responseTicketId["id"];
if (ticketId != null)
{
JObject responseCheck = JObject.Parse(await GetCheck(sessionId, ticketId));
var check = responseCheck.ToString();
return check;
}
else return null;
}
catch (Exception ex)
{
if (ex.Message == "HTTP ERROR: Unauthorized" && Variables.sessionID != null)
{
Variables.sessionID = null;
throw new Exception("HTTP ERROR: Unauthorized. Will try to renew session token next time.");
}
else
{
throw ex;
}
}
}
private HttpClient GetClient()
{
HttpClient client = new HttpClient();
client.DefaultRequestHeaders.Add("Accept", "application/json");
client.DefaultRequestHeaders.Add("Host", "irkkt-mobile.nalog.ru:8888");
client.DefaultRequestHeaders.Add("Accept", "\*/\*");
client.DefaultRequestHeaders.Add("Device-OS", "iOS");
client.DefaultRequestHeaders.Add("Device-Id", "7C82010F-16CC-446B-8F66-FC4080C66521");
client.DefaultRequestHeaders.Add("clientVersion", "2.9.0");
client.DefaultRequestHeaders.Add("Accept-Language", "ru-RU;q=1, en-US;q=0.9");
client.DefaultRequestHeaders.Add("User-Agent", "billchecker/2.9.0 (iPhone; iOS 13.6; Scale/2.00)");
client.Timeout = TimeSpan.FromSeconds(7);
return client;
}
private async Task GetSessionID()
{
HttpClient client = GetClient();
var env\_inn = Environment.GetEnvironmentVariable("INN");
var env\_pass = Environment.GetEnvironmentVariable("PASSWD");
var payload = new
{
inn = env\_inn,
client\_secret = "IyvrAbKt9h/8p6a7QPh8gpkXYQ4=",
password = env\_pass
};
try
{
var response = await client.PostAsync("https://irkkt-mobile.nalog.ru:8888/v2/mobile/users/lkfl/auth",
new StringContent(
JsonConvert.SerializeObject(payload),
Encoding.UTF8, "application/json"));
if (response.IsSuccessStatusCode)
{
return await response.Content.ReadAsStringAsync();
}
else
{
throw new Exception("HTTP ERROR: " + response.StatusCode);
}
}
catch (Exception ex) when (ex is TaskCanceledException || ex is OperationCanceledException)
{
return null;
}
}
private async Task GetTicketID(string sessionId, string qrcode)
{
HttpClient client = GetClient();
client.DefaultRequestHeaders.Add("sessionId", sessionId);
var payload = new
{
qr = qrcode
};
try
{
var response = await client.PostAsync("https://irkkt-mobile.nalog.ru:8888/v2/ticket",
new StringContent(
JsonConvert.SerializeObject(payload),
Encoding.UTF8, "application/json"));
if (response.IsSuccessStatusCode)
{
return await response.Content.ReadAsStringAsync();
}
else
{
throw new Exception("HTTP ERROR: " + response.StatusCode);
}
}
catch (Exception ex) when (ex is TaskCanceledException || ex is OperationCanceledException)
{
return null;
}
}
private async Task GetCheck(string sessionId, string ticket)
{
HttpClient client = GetClient();
client.DefaultRequestHeaders.Add("sessionId", sessionId);
try
{
var response = await client.GetAsync("https://irkkt-mobile.nalog.ru:8888/v2/tickets/" + ticket);
if (response.IsSuccessStatusCode)
{
return await response.Content.ReadAsStringAsync();
}
else
{
throw new Exception("HTTP ERROR: " + response.StatusCode);
}
}
catch (Exception ex) when (ex is TaskCanceledException || ex is OperationCanceledException)
{
return null;
}
}
}
```
Результатом работы CostsReceiver являются черновики чеков. Они уже содержат в себе дату чека, место покупки, сумму и, если это был QR-код, то и позиции в чеке. К ним можно получить доступ из основного приложения. Черновик чека - это еще не полноценный чек. Для каждой позиции в черновике нужно указать категорию. Если не удалось определить магазин, его также нужно указать вручную. Но это все равно гораздо быстрее, чем вводить данные с нуля.
#### Нормализация данных
Попутно пришлось решить пару проблем по данной части.
Во-первых - это преобразование названий многочисленных ООО-шек в уже предопределенные названия магазинов. При обработке пакета воркер производит замену названия типа *ОБЩЕСТВО С ОГРАНИЧЕННОЙ ОТВЕТСТВЕННОСТЬЮ "АЛЬФА ПЕНЗА"* на хорошо известное название *"Красное и Белое"*.
Аналогичным путем решается вопрос нормализации названий позиций в чеке. Думаю, каждый не раз задавался вопросом, что такое, например, *\*KON.Печ-сэн.СУП.КОН.mars.сл288г* или *\*Р.ФР.Бат.КР.тв/как/вз.кар.180г.* Когда я расшифровываю эту позицию в чеке, она записывается в базу, и в следующий раз CostsReceiver автоматом заменит белиберду на понятное название и подставит категорию товара.
Так же CostsReceiver автоматически пытается подобрать соответствующий шаблон для черновика чека на основании заранее предопределенных правил. Если таковой находится, то добавить чек можно нажатием одной кнопки. Правила для шаблона нужно задать самому.
Три из пяти расходов можно одобрить нажанием одной кнопки#### Домашняя бухгалтерия v2
Но все это было бы невозможно без переписывания десктопной версии "Домашней бухгалтерии". К марту руки дошли и до нее.
В этот раз было решено отказаться от безнадежно устаревшего WinForms и выбрать что-то посовременнее. Выбор пал на WPF. Было очень непривычно формошлепить в xaml, но после пары форм дело пошло быстрее. Еще через месяц активного кодинга большая часть старого кода была переписан с нуля с сохранением логики.
К написанию второй версии я подошел уже с некоторым багажом знаний и опыта в программировании. Теперь в нем стало немного больше ООП. Появились классы, отражающие сущности из БД, методы доступа к данным были отделены от логики форм. Попутно была реализована интеграция с CostsReceiver и разнообразные мелкие улучшения.
Снова скриншотики:
Новое главное окно программыВвод нового чекаКрасивый график текущего балансаИ визуализация распределения расходов по категориям
В конечном итоге удалось существенно сократить время на занесение расходов. Так же теперь нет и необходимости заносить расходы каждый день из боязни что-то забыть или пропустить. Переписывание кода с нуля открыло дорогу к реализации многих идей по учету доходов и расходов, о которых я раньше только мечтал.
Из глобальных доработок в планах осталось:
* ~~добавление мультивалютности~~
* ~~упрощение заполнение чеков в туристических поездках, чтобы не пересчитывать вручную цену каждой позиции на курс~~
* возможно, прикрутить хранение сканов гарантиек и чеков на разную технику
* ~~допилить учет кредитов/ипотек. Тут пока нет четкого понимания ввиду сложности рассчетов ежемесячных платежей и остатка долга~~
* в перспективе добавить учет ИИС и активов в валюте (когда они появятся)
*UPD: так как черновик статьи появился несколько месяцев назад, большая часть планов уже реализованы. В настоящий момент я планирую на какое-то время отойти от активного напиливания новых ~~багов~~ фичей и заняться полировкой существующего функционала.*
Выводы
------
Сложно однозначно ответить на вопрос, как именно нам помогло как-то детальное знание структуры семейных и личных расходов. В экономическом плане скорее всего никак. Больше экономить на основании полученных данных мы конечно же не стали.
В историческом плане бесспорно будет интересно лет через 10-20 сравнить цены и запилить аналитический пост на тему очередного пробитого дна. Наибольший профит для себя я вижу в новом хобби и каком-никаком опыте программирования, который может пригодится мне в будущем. | https://habr.com/ru/post/568174/ | null | ru | null |
# Решаем natural language processing-задачу – классификация текстов по темам
В предыдущей [статье](https://habr.com/ru/post/538450/)я рассказал, как подготовить датасет, содержащий тексты блога [habr.com](https://habr.com/) с информацией об их принадлежности к определенной категории. Теперь на базе этого [датасета](https://github.com/newtechaudit/nlp_task) я расскажу о подходах, позволяющих создать классификатор, автоматически относящий текст к той или иной категории.
Сегодня нам предстоит описать решение задачи по созданию классификатора текстовых документов. Шаг за шагом мы будем пытаться улучшить нашу модель. Давайте посмотрим, что же из этого получится.
Для решения нашей задачи снова используем язык программирования python и среду разработки Jupyter notebook на платформе Google Colab.
В работе понадобятся следующие библиотеки:
* scikit-learn – свободно распространяемая библиотека на python, содержащая реализации различных методов машинного обучения;
* nltk – пакет [библиотек](https://ru.wikipedia.org/wiki/%D0%91%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D0%B0_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)) для символьной и статистической [обработки естественного языка](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D0%B5%D1%81%D1%82%D0%B5%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE_%D1%8F%D0%B7%D1%8B%D0%BA%D0%B0);
* matplotlib – библиотека, содержащая набор инструментов для визуализации данных, — понадобится для отображения «облака слов».
**Подробности реализации**
Датасет сохранен в файле формата csv и содержит чуть более 8 тысяч записей. Для работы с ним будем использовать библиотеку pandas – загружаем данные в память при помощи метода read\_csv и отображаем на экране несколько первых строк:
```
import pandas as pd
df_habr = pd.read_csv(‘habrParse.csv’)
df_habr.head()
```
Набор данных представляет собой таблицу, в первой колонке которой хранится текст статьи, во второй – присвоенная категория (класс):
Построим «облако слов» для набора данных, чтобы визуально определить наиболее часто встречающиеся слова – это позволит оценить необходимость дополнительной очистки текстов от «мусора», не несущего смысловой нагрузки:
```
# Получение текстовой строки из списка слов
def str_corpus(corpus):
str_corpus = ''
for i in corpus:
str_corpus += ' ' + i
str_corpus = str_corpus.strip()
return str_corpus
# Получение списка всех слов в корпусе
def get_corpus(data):
corpus = []
for phrase in data:
for word in phrase.split():
corpus.append(word)
return corpus
# Получение облака слов
def get_wordCloud(corpus):
wordCloud = WordCloud(background_color='white',
stopwords=STOPWORDS,
width=3000,
height=2500,
max_words=200,
random_state=42
).generate(str_corpus(corpus))
return wordCloud
corpus = get_corpus(df_train['text'].values)
procWordCloud = get_wordCloud(corpus)
fig = plt.figure(figsize=(20, 8))
plt.subplot(1, 2, 1)
plt.imshow(procWordCloud)
plt.axis('off')
plt.subplot(1, 2, 1)
```
Для необработанного набора данных «облако слов» содержит 243024 уникальных слова и выглядит так:
**Попробуем очистить данные:**
```
import nltk
nltk.download("stopwords")
from nltk.corpus import stopwords
from string import punctuation
russian_stopwords = stopwords.words("russian")
# Удаление знаков пунктуации из текста
def remove_punct(text):
table = {33: ' ', 34: ' ', 35: ' ', 36: ' ', 37: ' ', 38: ' ', 39: ' ', 40: ' ', 41: ' ', 42: ' ', 43: ' ', 44: ' ', 45: ' ', 46: ' ', 47: ' ', 58: ' ', 59: ' ', 60: ' ', 61: ' ', 62: ' ', 63: ' ', 64: ' ', 91: ' ', 92: ' ', 93: ' ', 94: ' ', 95: ' ', 96: ' ', 123: ' ', 124: ' ', 125: ' ', 126: ' '}
return text.translate(table)
habrParse_df['Post_clean'] = habrParse_df['Post'].map(lambda x: x.lower())
habrParse_df['Post_clean'] = habrParse_df['Post_clean'].map(lambda x: remove_punct(x))
habrParse_df['Post_clean'] = habrParse_df['Post_clean'].map(lambda x: x.split(' '))
habrParse_df['Post_clean'] = habrParse_df['Post_clean'].map(lambda x: [token for token in x if token not in russian_stopwords\
and token != " " \
and token.strip() not in punctuation])
habrParse_df['Post_clean'] = habrParse_df['Post_clean'].map(lambda x: ' '.join(x))
```
После небольшой очистки текстов от «стоп-слов» и знаков пунктуации количество уникальных слов снизилось до 142253, а «облако слов» стало более осмысленным:
При желании можно очистить тексты еще более качественно (в реальных задачах так и следует делать), но для обучающего примера датасет уже вполне подходит.
**Посмотрим статистику по классам:**
Видно, что некоторые классы представлены только одним элементом, а класс «Чулан» составляет более 65% датасета. Для того чтобы работать с более или менее сбалансированным датасетом, выберем тексты только четырех классов:
```
df_habr_clean = df_habr.loc[df_habr['hubs'].isin(['IT-компании', 'Habr', 'Управление медиа', 'Я пиарюсь'])]
```
Разделим датасет на тренировочную, тестовую и валидационную части:
```
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(df_habr_clean ['Post_clean'], df_habr_clean ['hubs'], test_size=0.1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
```
Получили следующее соотношение выборок: ***X\_train*** – 1136 элементов, ***X\_test*** – 283 элемента, ***X\_valid*** – 158 элементов
Для дальнейшей работы понадобится импортировать несколько модулей из библиотеки scikit-learn:
```
from sklearn.pipeline import Pipeline
# pipeline позволяет объединить в один блок трансформер и модель, что упрощает написание кода и улучшает его читаемость
from sklearn.feature_extraction.text import TfidfVectorizer
# TfidfVectorizer преобразует тексты в числовые вектора, отражающие важность использования каждого слова из некоторого набора слов (количество слов набора определяет размерность вектора) в каждом тексте
from sklearn.linear_model import SGDClassifier
from sklearn.neighbors import KNeighborsClassifier
# линейный классификатор и классификатор методом ближайших соседей
from sklearn import metrics
# набор метрик для оценки качества модели
from sklearn.model_selection import GridSearchCV
# модуль поиска по сетке параметров
```
Сначала создадим 2 классификатора (чтобы можно было в дальнейшем сравнить качество получившихся моделей) и обучим их на тестовых данных:
```
sgd_ppl_clf = Pipeline([
('tfidf', TfidfVectorizer()),
('sgd_clf', SGDClassifier(random_state=42))])
knb_ppl_clf = Pipeline([
('tfidf', TfidfVectorizer()),
('knb_clf', KNeighborsClassifier(n_neighbors=10))])
sgd_ppl_clf.fit(X_train, y_train)
knb_ppl_clf.fit(X_train, y_train)
```
Предскажем получившимися моделями класс текстов в тестовой выборке и сравним метрики:
```
predicted_sgd = sgd_ppl_clf.predict(X_test)
print(metrics.classification_report(predicted_sgd, y_test))
```
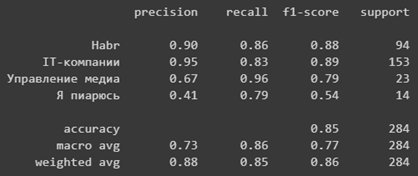
```
predicted_sgd = knb_ppl_clf.predict(X_test)
print(metrics.classification_report(predicted_sgd, y_test))
```
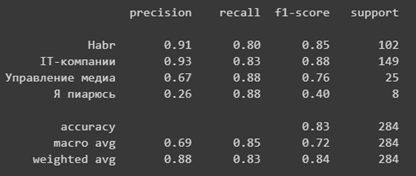В связи с тем, что датасет не сбалансирован, метрику «accuracy» (доля верных ответов) использовать нельзя, так как это приведет к завышенной оценке качества работы классификатора. В данном случае самое правильное – считать сразу несколько метрик, устойчивых к распределению классов (в данном случае, это — точность, полнота и f-мера) и смотреть на них все. Однако часто бывает удобно получить не большой набор цифр, а одно число, по которому можно понять, насколько хорошо модель работает. В нашей задаче лучше всего подходит «macro-avg» (сначала подсчитывается каждая метрика по каждому классу, а потом усредняется). Macro-avg более устойчива к скошенным распределениям классов.
Линейный классификатор показал лучший результат на тестовых данных (0,77 против 0,72 у классификатора методом ближайших соседей), поэтому для дальнейшей настройки модели будем использовать его.
На текущий момент классификатор обучен с параметрами по умолчанию. Для большинства задач это вполне приемлемо. Но для более качественной работы модели лучше провести ее дополнительную настройку. В этом случае удобно использовать поиск лучшего сочетания по сетке параметров. Так, можно задать набор значений для параметров классификатора и передать его в модуль GridSearchCV. Он выполнит обучение и оценку модели на каждом сочетании параметров и выдаст лучший результат.
Попробуем улучшить нашу модель, используя различные параметры. Следует иметь в виду, что для доступа к параметрам объекта pipeline необходимо указывать их в виде ***«название объекта»\_\_«название параметра»***:
Обучим модель, используя предложенные параметры (часть из них получила значение по умолчанию, поэтому их указывать не обязательно), и оценим ее качество на тестовых данных:
```
sgd_ppl_clf = Pipeline([
('tfidf', TfidfVectorizer(ngram_range=(1, 2))),
('sgd_clf', SGDClassifier(penalty='elasticnet', class_weight='balanced', random_state=42))])
sgd_ppl_clf.fit(X_train, y_train)
predicted_sgd = sgd_ppl_clf.predict(X_test)
print(metrics.classification_report(predicted_sgd, y_test))
```
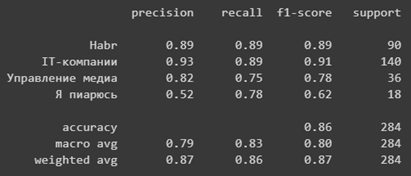Значение целевой метрики выросло.
```
predicted_sgd_val = sgd_ppl_clf.predict(X_valid)
print(metrics.classification_report(predicted_sgd_val, y_valid))
```
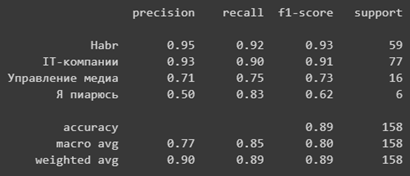На валидационной выборке качество также выросло (0,8 против 0,76 с использованием стандартных параметров классификатора), следовательно, мы успешно справились с поставленной задачей.
В данной статье я постарался описать решение задачи по созданию классификатора текстовых документов. Здесь представлены только общие шаги, но и они позволили достичь достаточно хорошего результата. Для дальнейшего улучшения модели можно увеличить датасет и провести его дополнительную очистку, попробовать другие классификаторы (например, RandomForestClassifier) и другие сочетания их параметров.
Надеюсь, статья была полезной и поможет вам начать самостоятельно решать nlp-задачи. | https://habr.com/ru/post/538458/ | null | ru | null |
# 5 диаграмм, необходимых для документирования архитектуры решений
Процесс документирования архитектуры программного обеспечения может показаться пугающим. Но на самом деле достаточно всего 5 диаграмм, чтобы объяснить структуру вашей системы практически любому.
Задача архитектора решений ― четко донести проект системы до бизнеса, руководителей проектов и разработчиков. Нельзя просто нарисовать одно изображение, это невозможно и не принесет никому пользы. Вместо этого лучше сгруппировать различные проблемы и создать набор диаграмм, описывающих каждое представление. Конечно, есть миллиард способов сделать это. Как выбрать подходящий? За время работы в качестве архитектора решений я чаще всего использовал 5 диаграмм: контекстную диаграмму C4, диаграмму контейнеров, развертывания, последовательности и вариантов использования. В этой статье я рассмотрю подробно каждую из них.
### Контекстная диаграмма
Веб-сайт, посвященный модели С4 [(Context, Container, Component and Code)](https://c4model.com/), довольно хорошо объясняет свои диаграммы, я же поделюсь своим представлением, как эта модель работает.
Любая система работает в некотором контексте — окружении. В первую очередь, это пользователи и другие системы. Пользователи могут иметь разные роли, такие как создатель контента, читатель, администратор. Также они могут быть внутренними или внешними. Другие программы могут быть источником данных для вашей системы или получать информацию от нее. Важно понимать этот контекст, чтобы правильно спроектировать систему и напомнить себе о необходимости интеграции с внешними системами.
#### Пример
Context diagramНа этой диаграмме показана цифровая платформа необанкинга, представленная синим прямоугольником в центре.
#### Как рисовать
* Определите пользователей.
* Определите внешние системы.
* Создайте единый прямоугольник, изображающий вашу систему.
* Добавьте связи между системой, пользователями и внешними системами.
* Напишите содержательные комментарии по каждому компоненту.
#### Инструменты
Существуют различные инструменты, которые можно использовать для создания контекстной диаграммы. Существуют [трафареты C4 для OmniGraffle](https://stenciltown.omnigroup.com/stencils/c4/), [примеры C4 для LucidChart](https://www.lucidchart.com/documents/editNew/5a2e9b6b-0d2c-4189-8329-0bcaa5326c51), шаблоны есть также в draw.io. Чтобы использовать диаграммы как код, попробуйте [PlantUML](https://plantuml.com/).
Допустим, мы хотим нарисовать такую диаграмму для цифровой платформы необанковского обслуживания с помощью uml:
```
@startuml
!includeurl https://raw.githubusercontent.com/RicardoNiepel/C4-PlantUML/master/C4_Context.puml
' uncomment the following line and comment the first to use locally
' !include C4_Context.puml
Person(customer, "Customer", "A bank client")
System(abc_system, "Digital Platform", "Allows freelancers and business owners see their transactions.")
System_Ext(idnow, "IDNow", "System for KYC and Qualified Eletronic Signatures")
System_Ext(pay, "Google Pay/Apple Pay", "Google Pay and Apple Pay systems")
System_Ext(dms, "DMS", "Document Management System")
System_Ext(crm, "CRM", "CRM")
System_Ext(current, "Existing Banking System", "Banking Backoffice")
Rel(abc_system, pay, "uses")
Rel(customer, abc_system, "Uses")
Rel_L(abc_system, idnow, "integrates")
Rel_Neighbor(abc_system, dms, "uploads files")
Rel_D(abc_system, crm, "integrates")
Rel_U(abc_system, current, "uses")
@enduml
```
Мы определяем человека, систему, внешние системы и отношения между ними. Предикаты *Person, System* и *System\_ext* имеют 3 параметра: ключ, заголовок и описание. Предикат *Rel* также имеет 3 параметра, но они разные: ключ одной сущности, ключ другой и тип отношений между сущностями.
Нарисовать контекстную диаграмму можно любым удобным инструментом. [Здесь](https://crashedmind.github.io/PlantUMLHitchhikersGuide/C4/C4Stdlib.html) можно найти несколько отличных примеров.
#### Важно
Контекстная диаграмма — это первое, что вы создаете при работе с системой. Если этого не сделать, это может стоить вам пропущенных интеграций и ошибок при проектировании системы. Контекст может включать некоторые детали более низкого уровня, это нормально.
> *Я боролся с контекстной диаграммой для одной банковской системы. Она должна была включать только недавно созданную систему и одного клиента, который не принесет никакой ценности. После согласования я добавил API Gateway и существующий Auth Provider, который мы собирались использовать. Таким образом, контекстная диаграмма стала обретать смысл и позволяла опустить эти элементы из диаграмм нижнего уровня.*
>
> **Алексей, архитектор решений**
>
> *У нас в разработке была образовательная система. На момент выпуска Alpha мы поняли, что аналитическая система не получает данные от клиентского приложения. Если бы у нас была контекстная диаграмма, мы бы не сделали такой ошибки. К счастью, это было легко исправить.*
>
> **Джон, архитектор решений.**
>
>
#### Резюме
Контекстная диаграмма — это важнейшее представление, обеспечивающее высочайший уровень понимания людей и систем, с которыми будет взаимодействовать ваша будущая система.
### Диаграмма контейнеров
Контейнеры здесь не означают обязательно докер-контейнеры. Контейнер — это любой развертываемый объект или хранилище данных с точки зрения C4. Это может быть мобильное приложение, веб-сайт, виртуальная машина, докер-контейнер, база данных или хранилище объектов; все, что вы можете развернуть. По моему опыту эта диаграмма – самая сложная, а потому привлекает к себе особое внимание. Это, можно сказать, главная диаграмма, над которой нужно работать!
Эта диаграмма в разы масштабнее и более нагруженная, чем предыдущая. То, что было одним прямоугольником, теперь состоит из нескольких прямоугольников и стрелок. Эти прямоугольники теперь и являются контейнерами.
#### Пример
Container diagram#### Как рисовать
* Определите список сущностей: микросервисы, хранилища, внешние сервисы.
* Поместите их на диаграмму.
* Добавьте комментарии о назначении каждого компонента и технологии, которую он реализует.
* Добавьте соединения со стрелками.
* Добавьте значимые метки к каждой стрелке.
* Подберите цвет схемы.
* Создайте легенду.
#### Инструменты
То же, что и для контекстной диаграммы: Draw.io, OmniGraffle, LucidChart и другие.
#### Важно
* Обратите внимание, что элементы расположены столбцами. Первый столбец — это просто API-шлюз, второй ― первая группа сервисов, затем вторая группа сервисов, затем несколько хранилищ. Таким образом вы продемонстрируете многоуровневую архитектуру, которая поможет понять границы и обязанности.
* Когда количество микросервисов превысит однозначное число, ваши линии соединения начнут пересекаться. В академических книгах говорится, что для удобочитаемости нужно избегать пересечений. К сожалению, это не всегда возможно. Но не расстраивайтесь, диаграмму можно сделать удобочитаемой, используя разные цвета или ширину линий или разные стили линий (пунктирные, сплошные и т. д.).
* Если вы используете специальный инструмент, (как я), вам необходимо включить блок легенды. Сами по себе стрелки и цвет непонятны — легенда объясняет всё это.
* Очень распространенный вопрос, когда используешь облака, включать ли вы управляемые сервисы, такие как очереди сообщений? Я обычно отвечаю: «Нет». Это усложняет диаграмму, делает её нечитабельной. Если некоторые сервисы обмениваются данными через очередь сообщений, отобразите её с помощью стрелки отдельного типа.
> *Я учу своих коллег-архитекторов применять многоуровневый подход при создании схем контейнеров или компонентов и соединений. Эти диаграммы, как правило, включают в себя множество объектов, и их многослойная структуризация улучшает читаемость.*
>
> **Илья, архитектор предприятия.**
>
>
#### Резюме
Диаграмма контейнера даёт представление о том, из каких развертываемых элементов состоит серверная часть, и как эти компоненты взаимодействуют друг с другом.
### Диаграмма последовательностей
Первые две диаграммы показывают, как элементы системы соотносятся друг с другом. Однако они не могут продемонстрировать, что происходит внутри системы. Например, пользователь регистрируется в вашей системе. Какие компоненты задействованы? Какие действия срабатывают? Как компоненты взаимодействуют друг с другом? Диаграмма последовательностей может ответить на эти вопросы.
#### Пример
Вверху мы видим взаимодействующие объекты: люди, веб-приложения и мобильные приложения, внешние системы, сервисы и хранилища данных. У каждого объекта есть вертикальная линия внизу. Взаимодействие между сервисами обозначено горизонтальными стрелками между вертикальными линиями. Эти стрелки могут быть разных типов в зависимости от того, синхронная это операция или асинхронная. Серые прямоугольники показывают, что процесс занимает некоторое время, и длина должна указывать на продолжительность: чем длиннее прямоугольник, тем больше время.
#### Как рисовать
* Выберите функцию (вход, покупка и т. д.).
* Определите сущности, участвующие в этом процессе.
* Поместите их на диаграмму.
* Добавьте взаимодействие (стрелки).
* Добавьте ценные комментарии к каждой стрелке.
#### Инструменты
К сожалению, OmniGraffle не подходит для диаграмм последовательности. Поэтому для создания этой диаграммы я использую draw.io и LucidChart. Последний вариант является хорош тем, что вы можете рисовать диаграмму вручную или использовать диаграмму последовательности UML.
#### Важно
* Диаграмма последовательностей абсолютно необходима при разработке новой функции, которую вы добавляете в систему. Он показывает части системы, которые функция затрагивает, точки интеграции с внешним программами и контракты, которые команда должна будет создать или обновить.
* Диаграмма последовательности также полезна для QA инженеров. Она дает представление о том, где могут быть обнаружены потенциальные проблемы, и служит источником истины для тестовых случаев.
> *Проект шёл уже несколько месяцев, а некоторые части системы не были готовы к долгожданной функции. Стейкхолдеры были недовольны. Мы обсудили вопрос и договорились проектировать архитектуру до начала разработки. Диаграммы последовательностей очень помогли: мы получили полную картину до написания кода, а не после.*
>
> **Владимир, Архитектор решений**
>
>
#### Резюме
Диаграммы последовательности позволяют документировать поведение системы в различных бизнес-сценариях.
### Диаграмма развертывания
С помощью диаграмм контекста, контейнеров и диаграммы последовательностей, можно понять, из каких частей состоит система, как они связаны и взаимодействуют друг с другом. Но вряд ли они могут ответить на вопросы доступности, масштабируемости и безопасности. В этом поможет схема развертывания.
Есть несколько разных вещей, которые необходимо отобразить.
* **Вычислительные ресурсы.** Это могут быть виртуальные машины, докеры, кластеры Kubernetes и облачные функции. Мобильные устройства и настольные компьютеры также можно рассматривать как вычислительные ресурсы.
* **Хранилища.** Постоянные хранилища данных, такие как реляционные базы данных и базы данных nosql, хранилища двоичных файлов, таких как изображения, музыка и видео, хранилища больших данных и так далее.
* **Ресурсы обмена сообщениями.** Установки Kafka / RabbitMQ, Google Cloud pub / sub, AWS SQS и другие.
* **Сети**. Ваши компьютеры используют сети для связи друг с другом. Должны отображаться как физические, так и виртуальные сети.
* **Зоны доступности.** Вы можете думать о них как о центрах обработки данных.
* **Узлы инфраструктуры.** DNS-серверы, балансировщики нагрузки, брандмауэры, сети CDN
На схеме отображаются вычислительные ресурсы, ресурсы хранения и обмена сообщениями, а также сети и зоны доступности. Он также включает узлы инфраструктуры, которые не выполняют никаких функциональных требований, но вместо этого обращаются к нефункциональным.
#### Как нарисовать
* Разместите основные блоки: браузеры, мобильные устройства, общедоступное облако, центры обработки данных.
* Разместите вычислительные ресурсы и ресурсы хранения.
* Добавьте узлы инфраструктуры.
* Добавьте сети.
* Добавьте сетевые вызовы между узлами.
* Добавьте ресурсы мониторинга.
#### Пример
В C4 нотации есть дополнительная диаграмма развертывания:
Обратите внимание на имена вычислительных ресурсов, их типы и номера узлов.
Другой пример для облака AWS:
Distributed Load Testing by AWS#### Инструменты
Существует множество инструментов для создания схемы развертывания. OmniGraffle, LucidChart, Draw.io и другие прекрасно справляются с этой задачей, если установлены соответствующие шаблоны.
#### Важно
Каждая система имеет требования к безопасности, производительности, доступности и другим возможностям. Диаграмма развертывания помогает удовлетворить эти требования. В большинстве случаев диаграмма развертывания единственная, отображающая сетевые аспекты вашего решения. Диаграмма развертывания должна ясно и понятно показывать, как запросы проходят через систему.
#### Резюме
Диаграмма развертывания дополняет понимание системы с точки зрения внешнего вида.
### Диаграмма вариантов использования
Предыдущие диаграммы были в основном техническими, в то время как диаграмма вариантов использования больше ориентирована на бизнес. Он показывает, как люди взаимодействуют с вашей системой на очень высоком уровне. Сами варианты использования можно рассматривать как бизнес-возможности, которые я описывал в этой статье.
#### Как рисовать
* Нарисуйте прямоугольник. Это будет граница системы.
* Определите, кто будет работать с системой.
* Добавьте варианты использования внутри системы с помощью овалов.
* Добавьте связи между участниками и вариантами использования.
#### Примеры
#### Инструменты
Архитектор может нарисовать диаграмму с помощью любого графического редактора и того же набора инструментов, что и для других диаграмм. Omnigraffle, LucidChart, Draw.io работают хорошо. Помните, что эта диаграмма является структурированной, поэтому вы можете использовать UML для её создания. В этом помогает PlantUml или LucidChart.
#### Резюме
* Используйте контекстную диаграмму, чтобы отобразить представление системы на самом высоком уровне.
* Документируйте варианты использования с соответствующей диаграммой.
* Масштабируйте внутренние компоненты системы с помощью контейнеров и диаграмм развертывания.
* Документируйте конкретные бизнес-кейсы с помощью диаграмм последовательности. | https://habr.com/ru/post/538018/ | null | ru | null |
# Развертывание OpenSource Puppet 4 с несколькими Puppet masters. Часть II. Настройка Puppet Masters
→ [Развертывание OpenSource Puppet 4 с несколькими Puppet masters. Часть I. Подготовительная](https://habrahabr.ru/post/316400/)
→ [Развертывание OpenSource Puppet 4 с несколькими Puppet masters. Часть III. Настройка puppet-db с помощью Puppet](https://habrahabr.ru/post/316486/)
Настройка серверов puppet
-------------------------
Общие настройки серверов. На серверах puppet-master01, puppet-master02 и на puppet-db добавим репозитории puppetlabs:
```
wget https://apt.puppetlabs.com/puppetlabs-release-pc1-xenial.deb
sudo dpkg -i puppetlabs-release-pc1-xenial.deb
sudo apt update
```
На серверах puppet-master01, puppet-master02 установим puppet-сервер:
```
sudo apt install puppetserver
```
Проверим адрес, порт и требование авторизации в файле /etc/puppetlabs/puppetserver/conf.d/webserver.conf, по умолчанию должно быть:
```
client-auth: want
ssl-host: 0.0.0.0
ssl-port: 8140
```
На сервере puppet-db достаточно puppet-агента:
```
sudo apt install puppet-agent
```
Остальное на puppet-db установим с помощью Puppet.
Общие настройки puppet-агентов
------------------------------
В файл /etc/puppetlabs/puppet/puppet.conf добавить настройки сервера сертификации и имя сервера puppet, к которому они будут обращаться (имя кластера):
```
[main]
server = puppetmaster.example.com
ca_server = puppet-master01.example.com
```
Также эти настройки [необходимо будет сделать для всех puppet-агентов на всех управляемых узлах](https://docs.puppet.com/guides/scaling_multiple_masters.html#method-a-individual-agent-configuration), в т.ч. на puppet-db.
Настройка ноды puppet-master01
------------------------------
Сервер сертификации [должен быть запущен в единственном экземпляре](https://docs.puppet.com/guides/scaling_multiple_masters.html#centralize-the-certificate-authority). Убедимся, что в файле /etc/puppetlabs/puppetserver/services.d/ca.cfg включен запуск сервиса сертификации:
```
puppetlabs.services.ca.certificate-authority-service/certificate-authority-service
```
Строка **НЕ** должна быть закомментирована.
[#### Настроим список DNS имен сервера](https://docs.puppet.com/guides/scaling_multiple_masters.html#before-running-puppet-agent-or-puppet-master)
В файле /etc/puppetlabs/puppet/puppet.conf нужно прописать [альтернативные имена DNS](https://docs.puppet.com/puppet/latest/reference/configuration.html#dnsaltnames) для puppet-master01, для этого в секцию [main] добавим:
```
dns_alt_names = puppet-master01,puppet-master01.example.com,puppetmaster,puppetmaster.example.com
```
Далее эти имена будут сохранены в сертификате сервера.
Сгенерируем сертификат для puppet-master01 с учетом альтернативных имен DNS:
```
aspetrenko@puppet-master01:~$ sudo -i puppet cert generate puppet-master01.example.com --dns_alt_names=puppet-master01,puppet-master01.example.com,puppetmaster,puppetmaster.example.com
Notice: puppet-master01.example.com.pem has a waiting certificate request
Notice: Signed certificate request for puppet-master01.example.com.pem
Notice: Removing file Puppet::SSL::CertificateRequest puppet-master01.example.com.pem at '/etc/puppetlabs/puppet/ssl/ca/requests/puppet-master01.example.com.pem.pem'
Notice: Removing file Puppet::SSL::CertificateRequest puppet-master01.example.com.pem at '/etc/puppetlabs/puppet/ssl/certificate_requests/puppet-master01.example.com.pem.pem'
```
Запустим puppet-сервер на puppet-master01:
```
sudo systemctl start puppetserver.service
```
Настройка ноды puppet-master02
------------------------------
На остальных серверах puppet-master, кроме первого, нужно отключить запуск сервиса сертификации в файле /etc/puppetlabs/puppetserver/services.d/ca.cfg. Нужно закомментировать строку с certificate-authority-service, и раскомментировать sertificate-authority-disabled-service:
```
# To enable the CA service, leave the following line uncommented
#puppetlabs.services.ca.certificate-authority-service/certificate-authority-service
# To disable the CA service, comment out the above line and uncomment the line below
puppetlabs.services.ca.certificate-authority-disabled-service/certificate-authority-disabled-service
```
Настроим список DNS имен сервера в файле /etc/puppetlabs/puppet/puppet.conf, для этого в секцию [main] добавим:
```
dns_alt_names = puppet-master02,puppet-master02.example.com,puppetmaster,puppetmaster.example.com
```
Запросим сертификат для puppet-master02 у puppet-master01:
```
aspetrenko@puppet-master02:~$ sudo -i puppet agent --test --waitforcert 60
Info: Creating a new SSL key for puppet-master02.example.com
Info: Caching certificate for ca
Info: csr_attributes file loading from /etc/puppetlabs/puppet/csr_attributes.yaml
Info: Creating a new SSL certificate request for puppet-master02.example.com
Info: Certificate Request fingerprint (SHA256): 16:67:D9:84:A3:50:B6:43:35:08:FE:BA:05:77:7C:C5:E7:3E:A5:D6:D1:00:BE:11:63:AB:6E:93:B7:37:0A:33
Info: Caching certificate for ca
Info: Caching certificate for puppet-master02.example.com
Info: Caching certificate_revocation_list for ca
```
Подтвердим запрос сертификата от агента puppet-master02 на сервере puppet-master01:
```
aspetrenko@puppet-master01:~$ sudo -i puppet cert sign puppet-master02.example.com --allow-dns-alt-names
Signing Certificate Request for:
"puppet-master02.example.com" (SHA256) 16:67:D9:84:A3:50:B6:43:35:08:FE:BA:05:77:7C:C5:E7:3E:A5:D6:D1:00:BE:11:63:AB:6E:93:B7:37:0A:33 (alt names: "DNS:puppet-master02", "DNS:puppet-master02.example.com", "DNS:puppetmaster", "DNS:puppetmaster.example.com")
**
Notice: Signed certificate request for puppet-master02.example.com
Notice: Removing file Puppet::SSL::CertificateRequest puppet-master02.example.com at '/etc/puppetlabs/puppet/ssl/ca/requests/puppet-master02.example.com.pem'
```
Получим ответ агента на puppet-master02:
```
Info: Using configured environment 'production'
Info: Retrieving pluginfacts
Info: Retrieving plugin
Info: Caching catalog for puppet-master02.example.com
Info: Applying configuration version '1477917008'
Info: Creating state file /opt/puppetlabs/puppet/cache/state/state.yaml
Notice: Applied catalog in 0.02 seconds
```
На puppet-master01 в списке сертификатов должно получиться что-то вроде этого:
```
aspetrenko@puppet-master01:~$ sudo -i puppet cert list -a
+ "puppet-master01.example.com" (SHA256) 1A:15:76:96:33:6E:F9:DA:9F:C3:8D:9E:FC:98:BA:FB:10:CF:FA:27:54:2C:F2:55:8D:B9:AA:6C:52:FA:9F:C1 (alt names: "DNS:puppet-master01", "DNS:puppet-master01.example.com", "DNS:puppetmaster", "DNS:puppetmaster.example.com")
+ "puppet-master02.example.com" (SHA256) 80:1B:2C:49:E3:16:C6:37:B5:FC:E2:40:6B:49:B8:9A:95:91:C1:76:9C:79:3D:D5:0A:81:29:1D:E6:C3:B6:52 (alt names: "DNS:puppet-master02", "DNS:puppet-master02.example.com", "DNS:puppetmaster", "DNS:puppetmaster.example.com")
```
**ВНИМАНИЕ!** Не забудьте скопировать сертификат центра сертификации /etc/puppetlabs/puppet/ssl/ca/ca\_crl.pem с puppet-master01 на puppet-master02 в тоже расположение с сохранением владельца и прав.
Запустим puppet-сервер на puppet-master02:
```
sudo systemctl start puppetserver.service
```
Установка r10k на серверы puppet-master01 и puppet-master02
-----------------------------------------------------------
**Документация по настройке r10k**[docs.puppet.com/pe/latest/r10k.html](https://docs.puppet.com/pe/latest/r10k.html)
[puppet.com/blog/git-workflows-puppet-and-r10k](https://puppet.com/blog/git-workflows-puppet-and-r10k)
На всех серверах puppet-master установим git и rubygems:
```
sudo apt install git rubygems
sudo gem install r10k
```
Поместим пользователя r10k в группу puppet:
```
sudo usermod -a -G puppet r10k
```
Создадим каталог для кэша репозитория и дадим на него права пользователю r10k и группе puppet:
```
sudo mkdir -p /var/cache/r10k
sudo chown -R r10k:puppet /var/cache/r10k
sudo chmod 2775 /var/cache/r10k
```
Создадим каталог с настройками r10k:
```
sudo mkdir -p /etc/puppetlabs/r10k
sudo chown -R puppet:puppet /etc/puppetlabs
sudo chmod -R g+w /etc/puppetlabs
```
Также на каждом сервере puppet-master нужно создать [конфигурационный файл](https://docs.puppet.com/pe/3.8/r10k_yaml.html#editing-r10kyaml) /etc/puppetlabs/r10k/r10k.yaml. Его содержимое будет зависеть от того, [какого провайдера вы будете использовать](https://github.com/puppetlabs/r10k/blob/master/doc/git/providers.mkd) для работы с git-репозиторием.
Shellgit-провайдер
------------------
Этот провайдер доступен по умолчанию, и подойдет в тех случаях, если вы собираетесь использовать git-репозиторий в локальном каталоге без git-сервера; или простейший git-сервер с доступом по ssh.
Содержимое конфиуграционного файла /etc/puppetlabs/r10k/r10k.yaml:
```
# location for cached repos
:cachedir: '/var/cache/r10k'
git:
provider: 'shellgit'
# git repositories containing environments
:sources:
:base:
remote: '[email protected]:puppet-environments' # Для доступа к репозиторию в gitolite3
# remote: '/srv/puppet.git' # Для доступа к shared репозиторию в локальном каталоге
# remote: 'ssh://aspetrenko@puppet-master01/srv/puppet.git' # Для доступа с помощью ssh к репозиторию в файловой системе на другом компьютере
basedir: '/etc/puppetlabs/code/environments/'
```
Shellgit provider не умеет брать имя пользователя из конфигурационного файла r10k.yaml, поэтому для доступа к репозиторию на gitolite с нужным ключом зададим настройки в /r10k/.ssh/config:
```
host sgl-git.example.com
HostName sgl-git.example.com
IdentityFile /home/r10k/.ssh/r10k
User gitolite3
```
Rugged-провайдер
----------------
Но лучше использовать rugged provider, тогда для каждого источника в r10k.yaml можно будет указать отдельный ключ и имя пользователя. Также можно будет работать с репозиториями по https-протоколу.
В Ubuntu для работы с ssh и https протоколами в rugged режиме [необходимо скомпилировать библиотеку libssh2 с поддержкой openssl вместо libgcrypt](https://github.com/puppetlabs/r10k/blob/master/doc/git/providers.mkd#ssh-configuration-1):
> libssh2 on Debian and Ubuntu is compiled against libgcrypto instead of OpenSSL due to licensing reasons, and unfortunately libgcrypto does not support a number of required operations, including reading from a private key file. You will need to either use shellgit or recompile your own libssh2-1 package to use OpenSSL on these distributions.
Библиотека libssh2 версии 1.5.0-2.dsc из xenial [не подойдет](https://github.com/cloudfoundry-incubator/bosh-workspace/issues/97):
> The error sources to libssh2/src/libgcrypt.c. Elsewhere, libssh2 v 1.6.0 works without complaint. If updating isn't available, as a workaround, use https instead of ssh to connect to private git repos.
Придется сделать бэкпорт из yakkety. Установим необходимые пакеты на puppet-master01:
```
sudo apt install make cmake pkg-config libssh2-1-dev ruby-dev rubygems libevent-pthreads-2.0-5 openssl libssl-dev libz-dev libhttp-parser-dev
```
```
sudo apt install debhelper dh-autoreconf chrpath devscripts
```
и на puppet-master02 (пакеты нужны для сборки rugged, через gem):
```
sudo apt install make cmake pkg-config ruby-dev rubygems libevent-pthreads-2.0-5 openssl libssl-dev libz-dev libhttp-parser-dev
```
Cкачаем исходники libssh2 и распакуем их:
```
dget http://archive.ubuntu.com/ubuntu/pool/universe/libs/libssh2/libssh2_1.7.0-1.dsc
dpkg-source -x ./libssh2_1.7.0-1.dsc
```
Добавим к описанию пакета дополнительную информацию о наших изменениях:
```
cd libssh2-1.7.0/
dch -i
```
Нужно добавить в changelog описание вроде:
> \* Backport from yakkety
>
> \* Recompile with openssl support
Зарелизить changelog:
```
dch -r
```
В файле /libssh2-1.7.0/debian/control поменяем все вхождения libgcrypt20-dev на libssl-dev:
```
sed -i 's/libgcrypt20-dev/libssl-dev/g' debian/control
```
И соберем новый пакет с поддержкой openssl вместо libgcrypt:
```
./configure --with-openssl --without-libgcrypt
dpkg-buildpackage -rfakeroot
```
Не забудем удалить libssh2-1-dev от старой версии libssh2-1:
```
sudo apt remove libssh2-1-dev
```
Установим пересобранные пакеты на puppet-master01 и puppet-master02 (dev-пакет нужен для установки rugged через gem):
```
sudo dpkg -i libssh2-1_1.7.0-1ubuntu1_amd64.deb libssh2-1-dbg_1.7.0-1ubuntu1_amd64.deb libssh2-1-dev_1.7.0-1ubuntu1_amd64.deb
```
Установим r10k и rugged:
```
sudo gem install r10k rugged
```
И создадим конфигурационный файл /etc/puppetlabs/r10k/r10k.yaml на puppet-master01 и puppet-master02 со следующим содержимым:
```
# location for cached repos
:cachedir: '/var/cache/r10k'
git:
provider: 'rugged'
private_key: '/home/r10k/.ssh/r10k'
# git repositories containing environments
:sources:
:base:
remote: 'ssh://[email protected]/puppet-environments'
basedir: '/etc/puppetlabs/code/environments/'
```
Конфигурирование репозитория puppet-environments.git
----------------------------------------------------
Первоначальная настройка репозитория. Склонируем репозиторий puppet-environments на свой рабочий компьютер:
```
aspetrenko@aspetrenko-pc:~/sgl-git$ git clone [email protected]:puppet-environments
Cloning into 'puppet-environments'...
warning: You appear to have cloned an empty repository.
Checking connectivity... done.
```
Заполним репозиторий первоначальным содержимым, которое возьмем на puppet-master01:
```
aspetrenko@aspetrenko-pc:~/sgl-git$ scp -r aspetrenko@puppet-master01:/etc/puppetlabs/code/environments/production/* /home/aspetrenko/sgl-git/puppet-environments/
```
Перейдем в репозиторий и добавим символическую ссылку для origin, которая будет называться production, в соответствии с именем окружения в puppet:
```
aspetrenko@aspetrenko-pc:~/sgl-git$ cd puppet-environments/
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git symbolic-ref HEAD refs/heads/production
```
И зафиксируем изменения:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git add --all
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git commit -a -m "Initial commit"
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git push --set-upstream origin production
```
Создание post-receive хука
--------------------------
Создадим post-receive хук в репозиториии puppet-environments, который будет запускать r10k на серверах puppet-master01 и puppet-master02, со следующим содержимым:
```
aspetrenko@sgl-git:~$ sudo cat /media/data/repositories/puppet-environments.git/hooks/post-receive
#!/bin/bash
umask 0002
while read oldrev newrev ref
do
branch=$(echo $ref | cut -d/ -f3)
echo
echo "--> Deploying ${branch}..."
echo
ssh -i /var/lib/gitolite3/.ssh/gitolite3 r10k@puppet-master01 "r10k deploy environment $branch -p"
ssh -i /var/lib/gitolite3/.ssh/gitolite3 r10k@puppet-master02 "r10k deploy environment $branch -p"
# sometimes r10k gets permissions wrong too
find /etc/puppetlabs/code/environments/$branch/modules -type d -exec chmod 2775 {} \; 2> /dev/null
find /etc/puppetlabs/code/environments/$branch/modules -type f -exec chmod 664 {} \; 2> /dev/null
done
```
Не забудем сделать его исполняемым:
```
aspetrenko@sgl-git:~$ sudo chmod 0775 /media/data/repositories/puppet-environments.git/hooks/post-receive
```
### Проверка post-recive хука
Создадим директорию manifets и файл .keep, чтобы git не игнорировал пустую директорию:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ touch manifests/.keep
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git add manifests/.keep
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git commit manifests/.keep -m "Test commit"
[production 72bd288] Test commit
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 manifests/.keep
```
Отправим изменения в репозиторий:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git push -u origin production
```
Дальше git-хук с помощью r10k внесет соответствующие изменения в /etc/puppetlabs/code/environments на каждом сервере. Проверим наличие изменений на puppet-master01 и puppet-master02.
Установка и настройка Librarian-puppet
--------------------------------------
[librarian-puppet.com](http://librarian-puppet.com/)
> Librarian-puppet берет на себя управления директорией modules/, и всегда будет переустанавливать (если отсутствуют) модули описанные в Puppetfile, поэтому вам не нужно хранить и отслеживать состояние директории modules/ в Git.
>
>
>
> Librarian-puppet — это менеджер (ака Bundler для gem) для вашей инфраструктуры puppet. Вы можете использовать librarian-puppet для управления модулями Puppet вне зависимости от того, где хранятся модули в Puppet Forge, в Git-репозитории или в локальной папке.
>
>
>
> Librarian-puppet умеет разрешать зависимости описанные в Modulefile или metadata.json.
>
> Forge-модули могут быть установлены из Puppetlabs Forge или внутреннего хранилища Forge такого как Pulp.
>
>
>
> Git-модули могут быть установлены из ветки, тэга или специфического коммита. Модули могут быть установлены из GitHub используя tarballs, без необходимости установки Git. Модули могут быть установлены из каталога в локальной файловой системе. Зависимости модулей могут быть разрешены прозрачно без необходимости перечислять все модули в явном виде.
### Установка librarian-puppet
На компьютере, где мы работаем с репозиторием, с помощью gem установим librarian-puppet:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ sudo gem install librarian-puppet
```
Удалим директорию modules со всеми вложенными файлами, которые были скопированы из первоначального репозитория Puppet:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git rm -rf modules
```
Проинициализируем librarian-puppet в репозитории:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ librarian-puppet init
```
Закомментируем строку с metadata в Puppetfile. Приведем Puppetfile к следующему виду:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ cat Puppetfile
#!/usr/bin/env ruby
#^syntax detection
forge "https://forgeapi.puppetlabs.com"
# use dependencies defined in metadata.json
# metadata
# use dependencies defined in Modulefile
# modulefile
# A module from the Puppet Forge
mod 'puppetlabs-stdlib'
mod 'puppetlabs-ntp'
mod 'puppetlabs-puppetdb'
mod 'puppetlabs-firewall' # For puppetlabs-puppetdb
mod 'puppetlabs-inifile' # For puppetlabs-puppetdb
mod 'puppetlabs-postgresql' # For puppetlabs-puppetdb
mod 'puppetlabs-apt' # For puppetlabs-puppetdb
mod 'puppetlabs-concat' # For puppetlabs-puppetdb
```
Создадим файл .keep в директории modules, чтобы git не игнорировал пустую директорию:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ touch modules/.keep
```
Добавим, сгенерированные с помощью команды librarian-puppet init, файлы в git, и отправим изменения на серверы puppet-master01 и puppet-master02:
```
git add --all
git commit -a -m "librarian-puppet init"
git push -u origin production
```
Если все было настроено правильно, то в каталоге /etc/puppetlabs/code/environments/production/modules/ на серверах должно появиться модули перечисленные в Puppetfile.
[Развертывание OpenSource Puppet 4 с несколькими Puppet masters. Часть III. Настройка puppet-db с помощью Puppet](https://habrahabr.ru/post/316486/) | https://habr.com/ru/post/316482/ | null | ru | null |
# AMQP по-русски
Сегодня довольно мало информации о протоколе [AMQP](http://www.amqp.org/) (Advanced Message Queueing Protocol) и его применении, особенно на русском языке. А вообще это — замечательный, уже достаточно широко поддерживаемый открытый протокол для передачи сообщений между компонентами системы с низкой задержкой и на высокой скорости. При этом семантика обмена сообщениями настраивается под нужды конкретного проекта. Такие решения существовали и ранее, но это первый стандарт, для которого существует большое количество свободных реализаций.
Основная идея состоит в том, что отдельные подсистемы (или независимые приложения) могут обмениваться произвольным образом сообщениями через AMQP-брокер, который осуществляет маршрутизацию, возможно гарантирует доставку, распределение потоков данных, подписку на нужные типы сообщений. В качестве классических примеров обычно приводятся финансовые приложения, связанные, например, с доставкой потребителям информации о курсах ценных бумаг в режиме реального времени, также возможно RPC-взаимодействие двух подсистем, которые не имеют связи друг с другом (взаимодействие через общий протокол AMQP) и так далее и тому подобное.
Сегодня тема доставки информации в реальном времени является крайне актуальной (достаточно вспомнить хотя бы Twitter, Google Wave). И здесь системы передачи сообщений могут служить внутренним механизмом обмена данными, который обеспечивает доставку данных (изменений данных) клиентам.
Я не ставлю своей целью сегодня рассказать о том, как писать приложения для AMQP. Хочу лишь немного рассказать о том, что это совсем не страшно, не очень сложно, и действительно работает, хотя стандарт находится еще в развитии, выходят новые версии протокола, брокеров и т.п. Но это уже вполне production-quality. Расскажу лишь базовые советы, чтобы помочь “въехать” в протокол.
Для начала, маленькая коллекция ссылок (в основном, на английском): что такое вообще обмен сообщениями и почему AMQP такой ([Messaging in general and AMQP design](http://www.zeromq.org/whitepapers:amqp-analysis)); сравнение различных реализаций обмена сообщениями, в частности основанных на AMQP ([Message Queue Comparison](http://wiki.secondlife.com/wiki/Message_Queue_Evaluation_Notes)); клиентская библиотека AMQP для Twisted Framework (Python) с поддержкой Thrift ([Thrift, AMQP in Twisted](http://us.pycon.org/2009/conference/schedule/event/28/)); руководство от Red Hat о том, что такое messaging и как работать с AMQP, описывает их “коробочный” продукт на основе AMQP, но подходит и для любых AMQP-брокеров ([AMQP Programming Tutorial for C++, Java, and Python](http://www.redhatpress.org/docs/en-US/Red_Hat_Enterprise_MRG/1.0/pdf/Messaging_Tutorial/Messaging_Tutorial.pdf)); достаточно много документации, описаний архитектурных решений на сайте [ZeroMQ](http://www.zeromq.org/), который не совсем AMQP-брокер, но общая архитектура, детали реализации представляют отдельный интерес; обзорная статья от Duncan McGregor о txAMQP и AMQP в общем ([A Simfonia on Messaging with txAMQP](http://feedproxy.google.com/~r/ElectricDuncan/~3/NKiCEOnzXe0/sinfonia-on-messaging-with-txamqp.html), [II](http://feedproxy.google.com/~r/ElectricDuncan/~3/f3QMwXP6OwI/sinfonia-on-messaging-with-txamqp-part.html), [III](http://feedproxy.google.com/~r/ElectricDuncan/~3/Xi5GBHBooNg/sinfonia-on-messaging-with-txamqp-part_18.html)).
Далее необходимо выбрать AMQP-брокер, который вы будете использовать. При выборе необходимо рассматривать как собственно характеристики сервера: скорость работы, надежность, легкость установки и поддержки, но также внимательно смотреть на версию AMQP-протокола, которая поддерживается брокером, — она должна совпадать с версией клиентской AMQP-библиотеки. Из брокеров я бы посоветовал [RabbitMQ](http://www.rabbitmq.com/), написанный на Erlang, и [Qpid](http://qpid.apache.org/), версии на C++ (AMQP 0-10) и Java (0-8, 0-9).
Сам протокол AMQP устроен достаточно интересно: на самом нижнем уровне определяется формат кодирования данных в бинарный вид для передачи по TCP-соединению, выше лежит формат передачи RPC-запросов между сервером и клиентом. Сама семантика работы с сообщениями, создания очередей и т.п. описывается в XML-спецификации, которая по сути задает RPC-интерфейс сервера и клиента (примеры таких XML-файлов для версий [0-8](http://jira.amqp.org/confluence/download/attachments/720900/amqp0-8.xml?version=1) и [0-10](http://jira.amqp.org/confluence/download/attachments/720900/amqp.0-10.xml?version=1)). Этот XML является последней и конечной спецификацией протокола. Более того, версии протокола 0-8 и 0-10 отличаются настолько сильно, что поддерживать их одновременно вряд ли возможно в одной программе. Что еще более интересно, иногда такие spec-файлы для разных брокеров AMQP, формально поддерживающих одну и ту же версию протокола, отличаются настолько, что не являются взаимозаменяемыми. Но это скорее небольшие технические проблемы.
AMQP основан на трех понятиях:
1. Сообщение (message) — единица передаваемых данных, основная его часть (содержание) никак не интерпретируется сервером, к сообщению могут быть прицеплены структурированные заголовки.
2. Точка обмена (exchange) — в нее отправляются сообщения. Точка обмена распределяет сообщения в одну или несколько очередей. При этом в точке обмена сообщения не хранятся. Точки обмена бывают трех типов: fanout — сообщение передается во все прицепленные к ней очереди; direct — сообщение передается в очередь с именем, совпадающим с ключом маршрутизации (routing key) (ключ маршрутизации указывается при отправке сообщения); topic — нечто среднее между fanout и exchange, сообщение передается в очереди, для которых совпадает маска на ключ маршрутизации, например, `app.notification.sms.*` — в очередь будут доставлены все сообщения, отправленные с ключами, начинающимися на `app.notification.sms`.
3. Очередь (queue) — здесь хранятся сообщения до тех пор, пока не будет забраны клиентом. Клиент всегда забирает сообщения из одной или нескольких очередей.
Меня в AMQP привлек эффективный бинарный протокол, ориентированность протокола на минимальные задержки и гибкость настройки. Я его использовал для рассылки сообщений всем серверам кластера (fanout exchange) и организации аналогов “почтовых ящиков”, в которые доставляются сообщения, адресованные определенным клиентам (direct exchange). Для получения сообщений нет необходимости опрашивать сервер, достаточно подписаться на сообщения из очереди, и сервер передаст их в тот момент, когда они появятся.
В качестве клиентской библиотеки я выбрал библиотеку txAMQP для Twisted Framework (Python). В общем и целом все работает, но где-то требуются небольшие “доделки” и “подкрутки”, которые я планирую опубликовать на launchpad. В AMQP и вокруг AMQP есть много интересного и перспективного. К примеру, брокер RabbitMQ умеет масштабироваться и работать в едином кластере. Мне кажется, это очень полезная и перспективная технология. | https://habr.com/ru/post/62502/ | null | ru | null |
# Динамический Favicon
Небольшое эссе о том, как менять Favicon без перезагрузки страницы.
Недавно перед нами стояла задача как динамически менять Favicon без перезагрузки страницы. Решение «в лоб», т.е. замена значения href у favicon link ничего не дала, пришлось крепко задуматься и начать пробовать все возможные альтернативные варианты. Сработал способ пересоздания ноды link в документе. Это удалось заставить работать везде, кроме Internet Explorer. Есть подозрение, что ему не нравится имя файла с иконкой или его формат (PNG).
`Change Favicon
/>
Change Favicon`
[Ссылка на пример](http://beta.fobo.ru/temp/favicon.html)
**UPD:** Пофиксил некоторые баги в коде. Safari и IE по прежнему не сдаются. | https://habr.com/ru/post/18885/ | null | ru | null |
# Переключаем WiFi в режим точки доступа в Windows
Так уж получилось, что на работе для получения полноценного интернета без ограничений, мне приходиться использовать нетбук и 3g-модем. Недавно, купив iPod Touch, я очень захотел его подключить к интернету. Если смартфон еще мог вылезти в интернет самостоятельно, то вот с плеером несколько труднее.
Один из вариантов — это подключение с помощью кабеля синхронизации. Вариант не очень удобный, так как носить с собой постоянно кабель желания совершенно нет, да и iTunes ставить тоже не хочеться. Второй вариант, тот который и описывается в данной статье — это подключение через WiFi. На Хабрахабре уже [упоминалась похожая задача и её решение](http://habrahabr.ru/blogs/linux/122876/), но для Linux. Наша задача настроить тоже самое под Windows.
#### Итак, что мы имеем
— Нетбук, ASUS 1215B
— Интернет через USB 3g-модем
— Плеер и смартфон с наличием WiFi
#### Задача
— Получить на всех устройствах интернет
#### Решение
Прежде чем начать, многие советуют обновить драйвер WiFi карты на компьютере. Лично я этого не делал, но каждый решает сам.
##### Способы
— Можно воспользоваться графическими утилитами, типа [Connectify](http://connectify.me/) и [Virtual Router](http://virtualrouter.codeplex.com/). Они работают, даже хорошо работают, но кушают ресурсы. Некоторые люди жаловались, что очень сильно кушают ресурсы.
— Можно сделать все самому через консоль используя **netsh**. Именно этот способ я и выбрал. Все действия необходимо выполнять от имени Администратора.
##### Создаем сеть
Прежде всего, необходимо создать беспроводную сеть с помощью следующей команды
```
netsh wlan set hostednetwork mode=allow ssid="MyHomeInternet" key="pass12345678" keyUsage=persistent
```
где MyHomeInternet — имя сети(ssid), pass12345678 — пароль для входа.
Успех выполнения команды будет выглядеть примерно так:
```
Режим размещенной сети разрешен в службе беспроводной сети.
Идентификатор SSID размещенной сети успешно изменен.
Парольная фраза пользовательского ключа размещенной сети была успешно изменена.
```
Теперь можно перейти в *Панель управления* \ *Центр управления сетями и общим доступом* \ *Изменение параметров адаптера*. У меня оно называется «Беспроводное сетевое соединение 2».
##### Управление соединением
Так как соединение находится в статусе «Нет подключения», то нам необходимо его включить. Для этого выполним команду:
```
netsh wlan start hostednetwork
```
После получения фразы *Размещенная сеть запущена*, сеть будет запущена и в списке соединений увидем подключение вашей сети. В нашем примере это MyHomeInternet.
Для остановки сети, необходимо воспользовать командой:
```
netsh wlan stop hostednetwork
```
##### Подключаем интернет
WiFi сеть создана и к ней даже можно подключаться, но интернет будет скорее всего отсутствовать. Для того, чтобы исправить сие недоразумение, необходимо:
— перейти в *Панель управления* \ *Центр управления сетями и общим доступом* \ *Изменение параметров адаптера*;
— зайти в свойства соединения через которое вы выходите в интернет(у меня это Internet MTS);
— вкладка *Доступ*;
— установить галку у пункта "*Разрешить другим пользователям сети использовать подключение к интернету данного компьютера*" и из списка выбрать нашу созданную сеть — «Беспроводное сетевое соединение 2»;
— нажать Ок;
— отключить и включить 3g-соединение; (в идеале перезагрузить компьютер)
— отключить и включить WiFi сеть.
##### Что получилось
В идеале, после данных действий ноутбук превратится в небольшую WiFi точку. Для этого возьмем IPod, включим WiFi и увидем нашу созданную сеть MyHomeInternet. Вводим пароль и подключаемся. Интернет есть.
#### Ограничения
— прежде всего придется после каждого запуска Windows запускать сеть с помощью команды *netsh wlan start hostednetwork*. Решается путем написании небольшого скрипта и отправкой его в автозагрузку. Еще один вариант создать ярлык на рабочем столе и запускать сеть только тогда, когда необходимо.
— ОС должна быть Windows 7.
— подключаемое устройство должно поддерживать WPA2-PSK/AES
#### Проблемы
##### Не создается сеть
— обновите драйвер беспроводного адаптера на более новый
— запускайте консоль от имени администратора
##### Сеть создалась, но не запускается
— возможно поможет перезагрузка компьютера и запуск сети от имени администратора
##### Сеть создалась, запустилась, но подключиться к ней невозможно
— проверить пароль
— вручную прописать в свойствах TCP/IP соединения на «сервере» и клиенте настройки сети. Например, для сервера: ip — 192.168.137.1, маска — 255.255.255.0 и для клиента: ip — 192.168.137.2, маска — 255.255.255.0, шлюз — 192.168.137.1, днс — 192.168.137.1
##### К сети подключился, но в интернет не выйти
— убедитесь, что вы её расшарили(см. пункт «Подключаем интернет»)
— попробуйте перейти не по доменному имени, а по IP-адресу. Если переходит, значит время подумать о вписывании DNS-сервера в настройки клиента и\или сервера.
###### Итог
Как видите, решить столь простую задачу можно и без использования стороннего ПО. Тем не менее иногда бывает, что и без него необойтись. В моем случае, были проблемы с DNS и дажы указывая сервера Google Public Domain в настройках TCP/IP я ничего сделать не смог. Поэтому пришлось прибегнуть к помощи [пакета BIND](http://www.isc.org/downloads/all/) и настройке его на 127.0.0.1. Настраивается он так же просто, но об этом уже в следующей мини-статье. | https://habr.com/ru/post/130271/ | null | ru | null |
# React: слоты как у сына маминой подруги
При композиции компонентов очень часто возникает задача точечной кастомизации содержимого какого-либо компонента. Например, у нас есть компонент **DatePicker**, и в разных частях веб-приложения нам нужно отображать разные кнопки "Применить".
Для решения подобных задач в каждой популярной технологии сегодня применяется концепция "слотов". У Angular это [ngContent](https://habr.com/ru/post/491136/), во [Vue](https://ru.vuejs.org/v2/guide/components-slots.html), [Svelte](https://ru.svelte.dev/docs#slot) и [WebComponents](https://developer.mozilla.org/ru/docs/Web/HTML/Element/slot) это слоты. И только в популярной библиотеке React полноценной концепции слотов на сегодня нет.
Для решения этой проблемы в React известны несколько подходов:
1. Компонент может либо отрендерить всех своих детей целиком, либо "залезть" в них через [React.Children](https://ru.reactjs.org/docs/react-api.html#reactchildren) API и точечно манипуляровать потомками
2. Компонент может объявлять так называемые [renderProps](https://ru.reactjs.org/docs/render-props.html), и отрисовывать возвращаемый из них контент в нужных местах:
```
(Bye, ${data.name}
=================
)}/>
```
Подход с renderProps, в целом, широко известен и не имеет каких-то принципиальных изъянов. Разве что пользоваться им не слишком удобно, в сравнении с полноценными слотами. В NPM есть несколько библиотек, таких как [react-view-slot](https://www.npmjs.com/package/react-view-slot), но мне не кажется, что они достаточно удобно и, главное, просто, решают задачу.
Я решил попытаться исправить этот [фатальный недостаток](http://lurkmore.to/%D0%A4%D0%B0%D1%82%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BD%D0%B5%D0%B4%D0%BE%D1%81%D1%82%D0%B0%D1%82%D0%BE%D0%BA), и сейчас расскажу, как.
#### Вижу цель – не вижу реализации
Перед тем, как что-то программировать, полезно знать, какое API хочется получить. Вот так выглядел мой набросок желаемого результата:
```
const Component = props => {
Component.NameSlot = useSlot(props.children);
return (
Default value
=================
Hello {props.children}
);
};
function App() {
return (
Hello!
Foo
Bobobo
);
}
```
Идея заключалась в том, чтобы создавать необходимые слоты и сохранять в статическое свойство функции-компонента, а затем использовать соответствующим образом на передающей и принимающей стороне.
Но при попытке реализации сразу стало понятно, что в таком виде это не очень удобно. Статическое свойство компонента – это, фактически, синглтон, и туда не стоит записывать что-то, что отличается от инстанса к инстансу компонента. Поэтому, после нескольких попыток, получилось уже API, применимое на практике:
```
import {createSlot} from 'react-slotify';
export const MySlot = createSlot();
export const Component = ({children}) => {
return (
This component contains slot:
This is default slot content
It also renders children: {children}
);
};
```
```
import {Component, MySlot} from './component';
const App = () => {
return (
Slotted content
Other content
);
};
```
#### Под капотом
Итак, если посмотреть на вышеописанное API, становится понятно, что наша задача – спрятать содержимое компонента **MySlot**, когда компонент рендерит своих потомков через **{children}**, но при этом отрисовать его содержимое в то место, в котором расположен **MySlot.Renderer**. Давайте посмотрим, сколько нужно написать JS-кода, чтобы это заработало:
```
export function createSlot() {
const Slot = ({ children, showChildren }) => {
return showChildren ? children : null;
}
const Renderer = ({ childs, children }) => {
const slotted = React.Children.toArray(childs).find(child => {
return React.isValidElement(child) && child.type === Slot;
});
if (!slotted || !React.isValidElement(slotted)) {
return children;
}
return React.cloneElement(slotted, { showChildren: true });
};
Slot.Renderer = Renderer;
return Slot;
}
```
Да-да, всего 20 строчек. Но идея, реализованная в этом низкоуровневом React-специфичном коде, не лежит на поверхности. Давайте попробуем разобраться. Основная задача функции – создать и вернуть компонент **Slot**. Если удалить всё остальное, то получится тривиально:
```
export function createSlot() {
const Slot = ({ children, showChildren }) => {
return showChildren ? children : null;
}
return Slot;
}
```
Всё, что умеет созданный компонент **Slot** – это прятать своих детей до тех пор, пока в него не будет передан проп **showChildren={true}**. Когда мы используем слот при использовании компонента, мы это не передаём, и поэтому **Slot** просто прячет свой контент.
Тут же создаётся ещё один компонент – **Renderer**. Его задача – принять все дочерние компоненты своего компонента-пользователя, найти среди них нужный нам **Slot**-компонент, и отрисовать его, склонировав его и передав ему **showChildren={true}**:
```
const Renderer = ({ childs, children }) => {
const slotted = React.Children.toArray(childs).find(child => {
return React.isValidElement(child) && child.type === Slot;
});
if (!slotted || !React.isValidElement(slotted)) {
return children;
}
return React.cloneElement(slotted, { showChildren: true });
};
```
Обратите внимание, что **Renderer** так же принимает и своих собственных потомков, и рисует их в случае, если **Slot** не найден. Это обеспечивает отображение дефолтного контента слота.
Ну и последнее – компонент **Renderer** записывается в статическое свойство только что созданного компонента **Slot**, чтобы его можно было использовать таким образом: .
#### Заключение
Таким образом, в 20 строчек кода мы реализовали концепцию, которая очень нравится многим разработчикам в других технологиях, и которой не хватает в React.
Готовую реализацию я опубликовал в виде библиотеки **react-slotify** на [GitHub](https://github.com/andrey-skl/react-slotify) и в виде пакета в [NPM](https://www.npmjs.com/package/react-slotify). Уже на TypeScript и с поддержкой [параметризации слотов](https://github.com/andrey-skl/react-slotify#passing-props-back-from-inside-slot). Буду рад конструктивной критике. | https://habr.com/ru/post/518500/ | null | ru | null |
# EiskaltDC++. Первый релиз под номером 2.0
Совсем недавно состоялся первый релиз нововго DC++ клиента для Linux — **EiskaltDC++** 2.0. Проект разрабатывается нашими соотечественниками и является прямым наследником EiskaltDC. Выход сразу версии 2.0 связан с тем, что был осуществлен переход на ядро dc++ (EiskaltDC был основан на dclib), код был полностью переписан, новый интерфейс основан на Qt4 и внешне максимально приближен к оригинальным клиентам DC++. В результате EiskaltDC++ стал представлять собой front-end на Qt4 для ядра dc++.
#### Основные нововведения:
* Миграция на ядро dc++ (v0.75) и соответсвенно поддержка ADC
* Полнофункциональный чат (парсинг магнетов, ссылок, смайлы, поиск в чате, фильтрация в списке пользователей, команды чата)
* Полнофункциональный поисковик, файлбраузер (подсветка уже расшаренных файлов и т.д.)
* Группировка передач в менеджере соединений
* Отдельный менеджер закачек
* Списки отданного/скачанного
* Избранные пользователи (автослот и т.д), хабы
* Текстовые (как средствами Qt так и через установленный по-умолчанию системный менеджер уведомлений) и звуковые уведомления
* Поддержка тем приложения, иконок и смайл-паки
* Возможность не расшаривать файлы по маске
* Поддержка UPnP
* Подмена тега для избранных хабов
* Принудительное указание внешнего IP для избранных хабов
* Автообновление внешнего IP через DynDNS для избранных хабов
* Поисковой шпион
* IP-фильтр
* Проверка орфографии с помощью Aspell
Исходники и собранные пакеты, а также основную информацию можно найти на [странице проекта](http://code.google.com/p/eiskaltdc/).
##### Описание установки на Debian/Ubuntu (взято [отсюда](http://tehnick-8.narod.ru/eiskaltdcpp/)):
Чтобы подключить архив пакетов на Launchpad выполните:
````
sudo su -c 'echo "deb http://ppa.launchpad.net/tehnick/tehnick/ubuntu
```
karmic main" > /etc/apt/sources.list.d/tehnick.list'`
Импорт ключа:
`sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 437276613F6729E2`
Обновление списка доступных пакетов:
`sudo apt-get update`
Установка eiskaltdcpp:
`sudo apt-get install eiskaltdcpp`
Или вы можете установить eiskaltdcpp-unstable:
`sudo apt-get install eiskaltdcpp-unstable` | https://habr.com/ru/post/88650/ | null | ru | null |
# Многоязычные модели Django для начинающих
#### Вводная
Работаю я, как и все адекватные программисты, над социальным порталом который покорит всех от грудничков до маразматиков. И так как цели наполеоновские — нужно учесть возможность использования сервиса даже теми представителями человечества, которые не владеют великим и могучим. Знаю, что многие долго боролись с вопросом локализации именно контента (перевод отдельных полей модели на разные языки), т.к. локализация интерфейса, в пределах общепринятых, в Django решена. Суть проблемы в том, чтобы одна и та же модель (это важно! к примеру пункты единого для всех языков каталога) имела переводы своих полей на разные языки. Те кто давно «на игле» этого фреймворка уже наверняка нашли для себя наиболее подходящую методу решения этой проблемы, я же хочу предложить способ решения и набросать порядок действий для начинающих, чтобы они не сбежали по рельсам на рубиновые копи.
#### Отмазка
Совсем недавно мне подвернулся счастливый случай начать превращение из личинки-PHP'шника в жука-Python'оида. Так что сразу ногами не бейте. Эта заметка (не статья) представляет из себя HowTo для таких же начинающих.
#### Используемые материалы
Для локализации моделей мы будем использовать приложение для Django — [`django-modeltranslation`](http://code.google.com/p/django-modeltranslation/). Я выбрал именно его среди прочих по следующим причинам:
* работает с `Django 1.3`
* добавляет переводимые поля для языков в ту же таблицу, т.е. не будет лишних `JOIN`'ов
* не требует внесения никакого кода в уже существующие модели
* почти безболезненно включается и отключается
* в админке локализованная модель интегрируется с другими модулями (меня волновал `mptt`)
Ещё понадобится `South` — установленный и работающий.
Собственно всё (не считая рабочего/разрабатываемого сайта на `django`).
#### HowTo
Устанавливаем `modeltranslation` командой `pip install django-modeltranslation`.
Или качаем последнюю версию [django-modeltranslation](http://code.google.com/p/django-modeltranslation/downloads/list). Распаковываем, заходим в распакованный каталог и устанавливаем `python setup.py install`. Можно сразу из распакованного каталога руками закинуть в папку для статических файлов директорию `modeltranslation/static/modeltranslation`.
###### Далее работаем уже с нашим проектом
Добавляем `'modeltranslation'` в `INSTALLED_APPS` файла настроек `settings.py`.
В тот же файл добавляем описание необходимых локализаций, язык по-умолчанию и импортируемый файл регистрации локализуемых моделей. В последнем `MYPROJECT` — нужно заменить на имя вашего проекта (оно же имя папки в которой он размещается), а `translation` — на имя самого `.py` файла без расширения, по умолчанию это `translation.py`. Этот файл один на весь проект и кладётся, соответственно, в корень проекта.
```
LANGUAGES = (
('ru', 'Russian'),
('en', 'English'),
)
MODELTRANSLATION_DEFAULT_LANGUAGE = 'ru'
MODELTRANSLATION_TRANSLATION_REGISTRY = 'MYPROJECT.translation'
```
В этом самом файле нам нужно создать классы содержащие указание какие поля (здесь это `'name'` и `'description'`) нужно переводить и привязать эти классы к переводимым моделям (здесь это `'Modelka'`) Ваших приложений (здесь это `'app'`) сответствтенно:
```
# -*- coding: utf-8 -*-
from modeltranslation.translator import translator, TranslationOptions
from app.models import Modelka
class ModelkaTranslationOptions(TranslationOptions):
"""
Класс настроек интернационализации полей модели Modelka.
"""
fields = ('name', 'description',)
translator.register(Modelka, ModelkaTranslationOptions)
```
В этом месте можно сгенерировать миграцию `python manage.py schemamigration app --auto`.
`South` обнаружит новые поля для локализации и сгенерирует миграцию для их добавления. К слову если отключить приложение `'modeltranslation'` — то также можно сгенерировать и миграцию для их удаления. Кроме того отдельное удобство в том, что `modeltranslation` привязывает язык по-умолчанию к оригинальным полям модели, т.е. это поле локализации и переводимое оригинальное поле модели будут идентичны.
Не забудьте потом применить миграцию: `python manage.py migrate app`.
###### И, наконец, настраиваем админку.
**Очень важно чтобы админка описывалась в отдельном файле `admin.py` для каждого приложения!!!** А не в файле моделей, как, признаюсь честно, по-началу пытался сделать я.
Для образца сразу приведу пример использования локализованной админки с админкой `mptt`:
```
# -*- coding: utf-8 -*-
from django.contrib import admin
from mptt.admin import MPTTModelAdmin
from modeltranslation.admin import TranslationAdmin
from models import Modelka
class ModelkaAdmin(MPTTModelAdmin, TranslationAdmin):
"""
Настройка админки для Modelka.
"""
list_display = ('name',)
class Media:
js = (
'/static/modeltranslation/js/force_jquery.js',
'http://ajax.googleapis.com/ajax/libs/jqueryui/1.8.2/jquery-ui.min.js',
'/static/modeltranslation/js/tabbed_translation_fields.js',
)
css = {
'screen': ('/static/modeltranslation/css/tabbed_translation_fields.css',),
}
fieldsets = [
(None, {
'fields': [
'name',
'slug',
'type',
'description',
'parent',
]
}),
(u'Лог', {
'fields': [
'author',
'editor',
],
'classes': ['collapse']
})
]
admin.site.register(Modelka, ModelkaAdmin)
```
Обращаю Ваше внимание, что в примере сразу же включены скрипты для отображения переводов на разных вкладках. Это как раз те файлы которые я в начале предлагал скопировать в каталог для статического контента. Если Вы установили modeltranslation через pip — не забудьте собрать статические фалы командой `python manage.py collectstatic` ([подробнее о статических файлах](https://docs.djangoproject.com/en/1.3/howto/static-files/)). Соответсвенно не забудьте подправить пути во вложенном `Meta` классе, если они у Вас отличаются.
На скриншоте видны вкладки языков для переводимых полей модели (скриншот с разрабатываемого приложения, потому языков больше чем в примере)
###### Работа с локализованной моделью
Собственно сама работа абсолютно прозрачна и также не затрагивает уже существующий код (наилучший язык отображения сайта может определяться как самим фреймворком, так и сторонними модулями, но это отдельная тема), если не понадобится где-то руками объявлять используемый язык через `set_language`. Т.е. модель будет возвращать значения полей на текущем языке приложения возвращаемом `get_lang`. | https://habr.com/ru/post/128273/ | null | ru | null |
# Установка и настройка функционального тестирования в Symfony2 с помощью Behat и Mink
Идея о том, что веб-приложения написанные на PHP нуждаются в тестировании, не нова и постепенно входит в повседневную практику разработчиков. PHPUnit стал стандартом тестирования PHP приложений, в том числе и в новом фреймворке Symfony2. В установке из symfony-standard в AcmeDemoBundle для тестирования контроллера используется именно он[1](#phpunit). Я хочу рассказать о альтернативном пути тестирования функционала, с применением Behat и Mink, и описать подробности процесса установки и тестирования.
#### Установка фреймворка
Для начала нам понадобятся рабочая связка **Apache + PHP 5.3**, с поддержкой **локальных хостов**,**intl**, **git**. Не буду останавливаться на процессе их установки и настройки — в сети достаточно информации как это сделать для каждой отдельно взятой системы, к тому же у разработчика все это уже скорее всего установлено (лично я полагаю, что разработку нужно вести на локальной или тестовой машине, а не на работающем сайте)
Далее — нам понадобится [скачать](http://github.com/symfony/symfony-standard) и настроить наш проект с GitHub. Откроем терминал, перейдем в папку, где расположены локальные сайты.
`**$ cd ~/Sites
$ git clone github.com/symfony/symfony-standard.git
$ cd symfony-standard**`
Проверяем, подходит ли Ваш Apache+PHP для работы в Symfony2, для этого используем поставляемый с фреймворком скрипт:
`**$ php app/check.php**`
Если необходимы какие либо настройки или модули — устанавливаем и настраиваем.
Скачиваем собственно фреймворк (он располагается по умолчанию в папке **vendors**). Для этого набираем в терминале:
`**$ php bin/vendors install**`
После этого нужно настроить отображения проекта в броузере, для чего я вношу изменения в два файла (пути у Вас могут быть иными, я работаю на Mac Os 10.6 с стандартно поставляемым apache):
— в **/etc/hosts** добавляю строчку, обозначающую, что проект у меня локальный, и в сети его искать нечего:
`**...
127.0.0.1 symfony-standard**`
— в /etc/apache2/extra/httpd-vhosts.conf
**````
DocumentRoot "/Users/Standart-User/Sites/symfony-standard/web"
ServerName t0002.loc
Options Indexes Includes FollowSymLinks SymLinksifOwnerMatch ExecCGI MultiViews
AllowOverride All
````**
Рестартуем Apache, и проверяем результат работы в броузере, открыв страницу [symfony-standard/app\_dev.php](http://symfony-standard/app_dev.php). Если все сделано правильно — получаем следующую картинку:

А при вводе в терминале в корневой папке проекта
`**$ php app/console**`
получаем список команд фреймворка. Отмечаем для себя что в этом списке пока отсутствует команда **behat** после перечисления Options в блоке Available commands
На этом этапе можно считать что с установкой Symfony2 мы справились.
#### Установка Mink и Behat для тестирования
Так как все проекты, над которыми я работаю, лежат у меня в папке **~/Sites** и я не хочу для каждой установки Symfony2 фреймворка устанавливать бандлы для тестирования — я сделал это один раз в папку **~/Sites/testsuite.behat**, а затем подключаю ее содержимое в свои проекты.
Для удобства установки я создал проект на GitHub, оттуда можно его и установить:
**````
$ cd ~/Sites
$ git clone https://github.com/livsi/testsuite.behat.git
$ cd testsuite.behat
````**
Фактически он содержит набор субмодулей и инструкцию как это все подвязать к своему рабочему проекту на Symfony2. После клонирования репозитория нам необходимо скачать субмодули. Для этого — выполняем команду:
**````
$ git submodule update --init
````**
Все, с установкой набора для тестирования почти закончили. Так как **активными ветками в Behat и Mink** являются ветки develop, а не master — нужно перейти в них и переключиться вручную.
**````
$ cd ~/Sites/testsuite.behat/vendor/Behat/Behat/
$ git checkout --track -b develop origin/develop
$ cd ~/Sites/testsuite.behat/vendor/Behat/Mink/
$ git checkout --track -b develop origin/develop
````**
#### Подключаем testsuite.behat к проекту symfony-standart
Это наиболее быстрый этап, так как нам ничего не нужно получать из сети, только править конфигурационные файлы в проекте **symfony-standart**. Инструкции приложены к скачанному ранее коду, находятся в файле README.md
Открываем файл **~/Sites/symfony-standart/app/autoload.php** и добавляем следующие строки (нужно подправить пути соответственно Вашим собственным) для подгрузки бандлов тестирования в проект symfony2:
**````
// app/autoload.php
$loader->registerNamespaces(array(
// ...
'Behat\BehatBundle' => '/Users/Standart-User/Sites/testsuite.behat/vendor',
'Behat\Behat' => '/Users/Standart-User/Sites/testsuite.behat/vendor/Behat/Behat/src',
'Behat\Gherkin' => '/Users/Standart-User/Sites/testsuite.behat/vendor/Behat/Gherkin/src',
'Behat\Mink' => '/Users/Standart-User/Sites/testsuite.behat/vendor/Behat/Mink/src',
'Behat\MinkBundle' => '/Users/Standart-User/Sites/testsuite.behat/vendor',
'Goutte' => '/Users/Standart-User/Sites/testsuite.behat/vendor/Goutte/src',
'Zend' => '/Users/Standart-User/Sites/testsuite.behat/vendor/Zend/library',
'Behat\SahiClient' => '/Users/Standart-User/Sites/testsuite.behat/vendor/Behat/SahiClient/src',
'Buzz' => '/Users/Standart-User/Sites/testsuite.behat/vendor/Buzz/lib',
// ...
````**
В файле **~/Sites/symfony-standart/app/AppKernel.php** включаем два основных бандла — **BehatBundle** и **BehatMinkBundle**:
**````
// app/AppKernel.php
if (in_array($this->getEnvironment(), array('dev', 'test'))) {
// ...
$bundles[] = new Behat\BehatBundle\BehatBundle();
$bundles[] = new Behat\MinkBundle\BehatMinkBundle();
// ...
}
````**
Прописываем обязательные параметры в **~/Sites/symfony-standart/app/config/config\_dev.yml**:
**````
# app/config/config_dev.yml
framework:
test: ~
# ...
behat: ~
behat_mink:
base_url: http://symfony-standart/app_test.php/
goutte: ~ # enable both Goutte
sahi: ~ # and Sahi session
````**
Проверяем, что все установлено и настроено правильно, для этого из корня проекта **symfony-standart** в терминале вводим:
`**$ php app/console**`
получаем список команд фреймворка, в котором теперь должна присутствовать команда **behat**. Это означает, что все работает и необходимые бандлы подключены.
#### Собственно тестирование
Для создания каркаса тестирования для бандла выполняем в консоли из корня проекта команду:
`**$ php app/console behat:bundle --init Acme\\DemoBundle**`
Она создает в папке src/Acme/DemoBundle каталог Features/
Добавляем в него файл, который назовем **feature1.feature** со следующим содержанием:
**````
# language: ru
Функционал: Первый тест для AcmeDemoBundle
Тестируем реализованные возможности в демонстрационном бандле
Сценарий: Открыть главную страницу в dev окружении и убедиться в ее существовании
Допустим я на странице "/app_dev.php"
Тогда код ответа сервера должен быть 200
И я должен видеть "Congratulations! You have successfully installed a new Symfony application."
И я должен видеть "Welcome!"
Сценарий: Перейти с главной страницы на страницу по ссылке "Run The Demo"
Допустим я на странице "/app_dev.php"
Если я кликаю по ссылке "Run The Demo"
Тогда я на странице "/app_dev.php/demo/"
И код ответа сервера должен быть 200
И я должен видеть "Available demos"
````**
Это и есть те самые функциональные тесты. Чтобы запустить тест — вводим в консоли команду:
`**$ php app/console behat --no-paths @AcmeDemoBundle**` и видим примерно следующий результат:

По скриншоту можно увидеть, что синтаксис вызова упростился: сначала от **behat:test:bundle** до **behat:bundle**, а теперь и до просто **behat**.
Справку по необходимым ключам консольной команды можно получить, набрав
`app/console help behat`
Потратив относительно немного времени на подключение Behat и Mink получаем значительный профит в виде простых и читабельных, наглядных тестов, которые пишутся на понятном языке. Они быстро пишутся и быстро выполняются.
#### Благодарности
Особая благодарность — Константину Кудряшову (хабраюзер [everzet](http://everzet.habrahabr.ru/)) за создание **Behat** и **Mink**, консультации их использованию, компании **KnpLabs** за спонсорскую помощь и содействие их автору, за поддержку проекта и дальнейшее его совершенствование.
Также большое спасибо разработчикам Symfony2 за мощный и удобный фреймворк, и подробнейшую документацию, которая помогает быстро его освоить.
#### Использованы материалы и репозитарии:
* [symfony.com](http://symfony.com/) — отправная точка моего изучения фреймворка
* [github.com/symfony/symfony-standard](https://github.com/symfony/symfony-standard)
* [github.com/Behat](http://github.com/Behat)
* [behat.org](http://behat.org/)
---
Пример тестирования контроллера с помощью PHPUnit (используется по умолчанию в symfony2):
**````
namespace Acme\DemoBundle\Tests\Controller;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
class DemoControllerTest extends WebTestCase
{
public function testIndex()
{
$client = $this->createClient();
$crawler = $client->request('GET', '/demo/hello/Fabien');
$this->assertTrue($crawler->filter('html:contains("Hello Fabien")')->count() > 0);
}
}
````**
То же самое с помощью Behat
**`Сценарий: Повторяем тест контроллера, проводимого через PHPUnit
Допустим я на странице "/app_dev.php/demo/hello/Fabien"
Тогда я должен видеть "Hello Fabien"`**
Не правда ли — тест на Behat более нагляден? | https://habr.com/ru/post/124100/ | null | ru | null |
# Разработка идеального pypi пакета с поддержкой разных версий python
Это небольшой мануал/история о том, как создать "идеальный" pypi пакет для python, который каждый желающий сможет установить заветной командой:
```
pip install my-perfect-package
```
Ориентирована на новичков, но призываю и профессионалов высказать свое мнение, как можно улучшить "идеальный" пакет. Поэтому прошу под кат.
Что значит "идеальный" пакет?
-----------------------------
Буду исходить из следующих требований:
* **Open source на github;**
Каждый должен иметь возможность внести свой вклад в развитие и поблагодарить автора.
* **Поддержка всех актуальных\популярных версий python (2.7, 3.5, 3.6, 3.7, 3.8);**
Питоны бывают разные, и где-то до сих пор активно пишут на 2.7.
* **100% покрытие юнит тестами;**
~~Юнит тесты улучшает архитектуру, позволяет автоматизировать регрессионные проверки.~~
Бейдж с заветным числом повышает ЧСВ и [задает планку другим](https://cmustrudel.github.io/papers/icse18badges.pdf).
* **Использование CI:**
Автоматические проверки — это очень удобно! ~~А еще куча клевых бейджей~~
+ **Запуск юнит тестов на всех платформах и на всех версиях питона;**
Не стоит верить тем, кто утверждает, что питон и устанавливаемые пакеты — [кроссплатформенные](https://docs.python.org/2/library/os.html), ведь всегда можно натолкнуться на [баг](https://bugs.python.org/issue22587).
+ **Проверка код стайла;**
Единый стиль улучшает читаемость и уменьшает количество пустых дискуссий в ревью.
+ **Статический анализатора кода;**
Автоматический поиск багов в коде? Дайте два!
* **Актуальная документация;**
Примеры работы с пакетом, описание методов\классов и разбор типичных ошибок — задокументированный опыт позволят снизить порог входа для новичков.
* **Кроссплатформенность разработки;**
К сожалению, в проекты сложно вносить личный вклад просто потому, что разработчик заточил инструменты под Unix. К примеру, для сборки использовал bash скрипты.
* **Пакет полезен и делает мир лучше.**
Сложное требование, так как судя по количеству пакетов в [pypi](https://pypi.org/) *(~210к)* разработчики — дикие альтруисты и многое уже написано.
С чего начать?
--------------
Хороших идей не было, поэтому тему выбрал избитую и очень популярную — работа со системами счисления. Первая версия должна уметь переводить числа в римские и обратно. Для мануала сложнее и не нужно. Ах, да, самое важное — это название: ~~numsys — как расшифровка numeral systems.~~ *numeral-system-py*.
Как тестировать?
----------------
Взял *python3.7* и первым делом написал тесты с заглушками функций (мы ведь все за [TDD](https://en.wikipedia.org/wiki/Test-driven_development)) с использованием стандартного модуля [unittests](https://habr.com/ru/post/121162/).
Делаю следующую структуру проекта:
```
src/
numeral-system/
__init__.py
roman.py
tests
__init__.py
test_roman.py
```
Тесты в пакет класть не буду, поэтому отделяю ~~зёрна от плевел~~. Изначально папку `src/` не создавал, но дальнейшее развитие показало, что мне так удобнее оперировать. Это не обязательно, поэтому по желанию.
Для запуска решил использовать [pytest](https://habr.com/ru/post/269759/) — он умеет отлично работать с тестами из стандартного модуля. Выглядит, возможно, немного нелогично, но стандартный модуль для тестов мне ~~кажется~~ казался чуть удобнее. *Сейчас бы я советовал использовать pytest стиль написания.*
Но, поговаривают, что ставить `pytest` (как и любые другие зависимости) в системный python — не очень умная идея...
Как управлять зависимостями?
----------------------------
Можно использовать только [virtualenv](https://virtualenv.pypa.io/en/latest/) и `requirements.txt`. Можно быть прогрессивным и использовать [poetry](https://poetry.eustace.io/). Я же, пожалуй, воспользуюсь [tox](https://tox.readthedocs.io/en/latest/) — средство для упрощения автоматизации и тестирования, который также позволит мне управлять зависимостями.
Создаю простой конфиг `tox.ini` и устанавливаю `pytest`:
```
[tox]
envlist = py37 ; запускать на одной предопределенной среде, а именно python3.7
[testenv] ; секция описания тестового окружения
deps = секция `deps` описываются зависимости, которые требуется доставить.
-r requirements.txt ; доставить зависимости самого пакета
-r requirements-test.txt ;
commands = pytest ; запускаем тесты
```
Изначально, я явно указывал зависимости, но практика интеграции со сторонними сервисами показала, что лучшим способом будет все-таки хранение зависимостей в `requirements.txt` файле.
Возникает очень тонкий момент. Фиксировать актуальную на момент разработки версию или всегда ставить последнюю?
Если фиксировать, то при установке могут возникнуть конфликты между пакетами из-за различных версий используемых зависимостей. Если же не фиксировать, то пакет может неожиданно перестать работать. Последняя ситуация очень неприятная для конечных продуктов, когда в одну ночь все билды могут "покраснеть" из-за минорного обновления неявной зависимости. И по [закону Мерфи](https://en.wikipedia.org/wiki/Murphy%27s_law) это произойдет в день релиза.
Поэтому для себя выработал правило:
1. Всегда фиксировать версию для конечных продуктов, так как какие версии использовать — это их ответственность.
2. Не фиксировать используемую версию для устанавливаемых пакетов. Или ограничивать диапазоном, если того требует функционал пакета.
Что дальше?
-----------
Пишу тесты!
Заполняю тело функций, добавляю комментарии и заставляю тесты корректно выполняться.
На этом моменте обычно большинство разработчиков останавливается (я все-таки верю, что все пишут тесты =), публикуют пакет и отгребают баги. Но я иду дальше ~~и прыгаю в кроличью нору~~.
Как работать с различными версиями python?
------------------------------------------
В конфигурации `tox` указываю запуск тестов на всех интересующих версиях python:
```
[tox]
envlist = py{27,35,36,37,38}
```
С помощью [pyenv](https://khashtamov.com/ru/pyenv-python/) доставляю нужные версии к себе локально, чтобы `tox` мог их найти и создать тестовые среды.
Где заветные 100%?
------------------
Добавлю замер покрытия кода — для этого есть отличный пакет [coverage](https://coverage.readthedocs.io/en/v4.5.x/) и не менее прекрасная интеграция с pytest — [pytest-cov](https://github.com/pytest-dev/pytest-cov).
`requirements-test.txt` выглядит теперь так:
```
six=1.13.0
pytest=4.6.7
pytest-cov=2.8.1
parameterized=0.7.1
```
Согласно вышеуказанному правилу, фиксирую версии пакетов, которые используются для запуска тестов.
Меняю команду запуска тестов:
```
deps =
-r requirements.txt
-r requirements-test.txt
commands = pytest \
--cov=src/ \
--cov-config="{toxinidir}/tox.ini" \
--cov-append
```
Делаю сбор статистики покрытия для всего кода из папки `src/` — самого пакета (*numeral\_system/*) и обязательно для кода тестов (*tests/*) — я же не хочу, чтобы сами тесты содержали не исполняющиеся части?
Командой `--cov-append` всю собранную статистику для каждого вызова под различной версией python суммирую в одну, потому что покрытие для второго и третьего питона может быть различным (привет зависимый от версии код и модуль [six](https://pypi.org/project/six/)!), но по итогу в сумме давать 100%. Простой пример:
```
if sys.version_info > (3, 0):
# Python 3 code in this block
else:
# Python 2 code in this block
```
Добавляю новую среду для создания coverage отчета.
```
[testenv:coverage_report]
deps = coverage
commands =
coverage html ; данные уже есть, построим отчет
coverage report --include="src/*" --fail-under=100 -m ; падать если не 100% покрытие
```
И добавляю в список сред после выполнения тестов на всех версиях питона.
```
[tox]
envlist =
py{27,35,36,37,38}
coverage_report
```
После запуска команды `tox` в корне проекта должна появится папка `htmlconv` содержащая файл `index.html` с красивым отчетом.
Для заветного бейджа в 100% интегрирую с сервисом [codecov](https://codecov.io/), который сам уже сделает интеграцию с `github` и позволит просмотреть историю изменения покрытия кода. Для этого, конечно же, придется завести там аккаунт.
Итоговая среда запуска выглядит следующим образом:
```
[testenv:coverage_report]
deps =
coverage==5.0.2
codecov==2.0.15
commands =
coverage html
coverage report --include="src/*" --fail-under=100 -m
coverage xml
codecov -f coverage.xml --token=2455dcfa-f9fc-4b3a-b94d-9765afe87f0f ; Токен моего проекта в codecov, смотреть в аккаунте
```
Осталось теперь только добавить ссылку на бейдж в `README.rst`:
```
|Code Coverage|
.. |Code Coverage| image:: https://codecov.io/gh/zifter/numeral-system-py/branch/master/graph/badge.svg
:target: https://codecov.io/gh/zifter/numeral-system-py
```
Как форматировать и анализировать код?
--------------------------------------
Много анализаторов не бывает, потому что они, по большей части, дополняют друг друга. Поэтому буду интегрировать популярные статические анализаторы, которые проверят на соответствие [PEP8](https://www.python.org/dev/peps/pep-0008/), найдут потенциальные проблемы и ~~пофиксят все баги~~ единообразным образом отформатируют код.
Сразу следует продумать, где указывать параметры для тонкой настройки анализаторов. Для этого можно использовать файл `tox.ini`, `setup.cfg`, единый кастомный файл или же конкретные файлы для анализаторов. Я решил воспользоваться непосредственно `tox.ini`, так как можно просто копировать `tox.ini` для будущих проектов.
isort
-----
[isort](https://github.com/timothycrosley/isort) — утилита для форматирования импортов.
Создаю следующую среду для запуска `isort` в режиме форматирования кода.
```
[testenv:isort]
changedir = {toxinidir}/src
deps = isort==4.3.21
commands = isort -y -sp={toxinidir}/tox.ini
```
К сожалению, `isort` нельзя указать папку для форматирования. Поэтому приходится менять директорию запуска через `changedir` и указывать путь к файлу с настройками `-sp={toxinidir}/tox.ini`. Ключ `-y` нужен, чтобы отключить интерактивный режим.
Для запуска в тестах нужен режим проверки — для этого есть флаг `--check-only`:
```
[testenv:isort-check]
changedir = {toxinidir}/src
deps = isort==4.3.21
commands = isort --check-only -sp={toxinidir}/tox.ini
```
black
-----
Далее интегрирую с форматером кода [black](https://black.readthedocs.io/en/stable/). Делаю по аналогии с `isort`:
```
[testenv:black]
deps = black==19.10b0
commands = black src/
[testenv:black-check]
deps = black==19.10b0
commands = black --check src/
```
Все хорошо работает, но возникает конфликт с `isort` — есть различие в [форматировании импортов](https://github.com/psf/black/issues/127).
В [одном из комментариев](https://github.com/timothycrosley/isort/issues/694) нашел минимально совместимую настройку `isort`, которой и воспользовался:
```
[isort]
multi_line_output=3
include_trailing_comma=True
force_grid_wrap=0
use_parentheses=True
line_length=88
```
flake8
------
Далее интегрирую со статическими анализаторами [flake8](http://flake8.pycqa.org/en/latest/).
```
[testenv:flake8-check]
deps = flake8==3.7.9
commands = flake8 --config=tox.ini src/
```
Снова возникают [проблемы с интеграцией](https://github.com/psf/black/issues/113) с `black`. Приходится добавить тонкую настройку, которую, собственно, и [рекомендует](https://github.com/psf/black) сам `black`:
```
[flake8]
max-line-length=88
ignore=E203
```
К сожалению, с первого раза не сработало. Упало с ошибкой `E231 missing whitespace after ','`, пришлось добавить в игнор и эту ошибку:
```
[flake8]
max-line-length=88
ignore=E203,E231
```
pylint
------
Интегрирую со статическими анализаторами кода [pylint](https://www.pylint.org/)
```
[testenv:pylint-check]
deps =
{[testenv]deps} # pylint проверят зависимости, поэтому следует их устанавливать
pylint==2.4.4
commands = pylint --rcfile=tox.ini src/
```
Сразу же сталкиваюсь со странными ограничениями — имена функций в 30 символов (да, я пишу очень длинные имена тестовых методов) и предупреждения на наличие `TODO` в коде.
Приходится добавить пару исключений:
```
[MESSAGES CONTROL]
disable=fixme,invalid-name
```
Так же неприятный момент в том, что разработчики `pylint` уже похоронили `python2.7` и не развивают больше пакет для него. Поэтому проверки стоит запускать на актуальном пакете для `python3.7`.
Добавляю соответствующую строчку в конфигурацию:
```
[tox]
envlist =
isort-check
black-check
flake8-check
pylint-check
py{27,35,36,37,38}
coverage_report
basepython = python3.7
```
Это так же важно для запуска тестов на различных платформах, так как дефолтная версия питона в системах CI различная.
Что там с CI?
-------------
### Appveyor
Интегрирую с [appveyor](https://www.appveyor.com/) — CI под windows. Первичная настройка простая — все можно сделать в интерфейсе, затем скачать yaml файл и закоммитеть его в репозиторий.
```
version: 0.0.{build}
install:
- cmd: >-
C:\\Python37\\python -m pip install --upgrade pip
C:\\Python37\\pip install tox
build: off
test_script:
- cmd: C:\\Python37\\tox
```
Здесь я явно указываю версию `python3.7`, так как по умолчанию будет использован `python2.7` (и `tox` так же будет использовать эту версию, хоть я явно и указал `python3.7`).
Ссылка на бейдж, как обычно, добавляется в `README.rst`
```
|Build status Appveyor|
.. |Build status Appveyor| image:: https://ci.appveyor.com/api/projects/status/github/zifter/numeral-system-py?branch=master&svg=true
:target: https://ci.appveyor.com/project/zifter/numeral-system-py
```
### Travis CI
После, интегрирую с [Travis CI](https://travis-ci.org/) — CI под Linux (и под MacOS c Windows, но [`Python builds are not available on the macOS and Windows environments`](https://docs.travis-ci.com/user/languages/python/#what-this-guide-covers). Настройка чуть сложнее, так как конфигурационный файл будет использоваться непосредственно из репозитория. Пару итераций проб и ошибок — конфигурация готова. Сквошу в один красивый коммит и merge request готов.
```
language: python
python: 3.8 #
dist: xenial # required for Python 3.7 (travis-ci/travis-ci#9069)
sudo: required # required for Python 3.7 (travis-ci/travis-ci#9069)
addons:
apt:
sources:
- deadsnakes
packages:
- python3.5
- python3.6
- python3.7
- pypy
install:
- pip install tox
script:
- tox
```
(*Риторический вопрос: И почему CI проектам так нравится yaml формат?*)
Указываю версию `python3.8`, так как установить ее через `addon` корректно не получилось, а `Travis CI` успешно создает `virtualenv` с указанной версии.
Люди, знакомые с `Travis CI`, могут вопросить, почему таким образом явно не указать версии python? Ведь `Travis CI` создает автоматически `virtualenv` и выполнит нужные команды в нем.
Причина в том, что нам нужно собрать данные по покрытию кода со всех версий. Но тесты будут запущены в разных джобах параллельно, из-за чего собрать общий отчет по покрытию не получится.
Конечно же, я уверен, что чуть больше разобравшись и это можно исправить.
По традиции, ссылка на бейдж так же добавляется в `README.rst`
```
|Build Status Travis CI|
.. |Build Status Travis CI| image:: https://travis-ci.org/zifter/numeral-system-py.svg?branch=master
:target: https://travis-ci.org/zifter/numeral-system-py
```
Документация
------------
Думаю, каждый python разработчик хоть раз пользовался сервисом — [readthedocs.org](https://readthedocs.org/). Мне кажется, что это лучший сервис для хостига своей документации.
Воспользуюсь стандартным средством для генерации документации [Sphinx](http://www.sphinx-doc.org/en/master/). Выполняю шаги из [стартового мануала](https://docs.readthedocs.io/en/stable/intro/getting-started-with-sphinx.html) и получаю следующую структуру:
```
src/
docs/
build/ # здесь будет располагаться документация в html формате
source/ # исходники для генерации документации
_static/ # сюда положим статику, например, картинки
_templates/ # шаблоны для генерации документации
conf.py # настройка генерации документов
index.rst # описание стартовой страницы
make.bat
Makefile # make для сборки с помощью make
```
Далее нужно проделать минимальные шаги для настройки:
1. `github` по умолчанию предлагает создать `README.md` файл в формате [Markdown](https://en.wikipedia.org/wiki/Markdown), когда как `sphinx` по умолчанию предлагает использовать [ReStructuredText](https://en.wikipedia.org/wiki/ReStructuredText).
Поэтому пришлось переписать его в формате `.rst`. ~~А если бы хоть раз дочитал до конца стартовый мануал, то понял, что `sphinx` умеет и в Markdown~~.
Включаю файл `README.rst` в `index.rst`
```
.. include:: ../../README.rst
```
1. Для автогенерации документации из комментариев в исходниках добавляю расширение [sphinx.ext.autodoc](http://www.sphinx-doc.org/en/master/usage/extensions/autodoc.html).
2. Добавляю папку с пакетом в `conf.py`. Это позволит `sphinx` делать импорты нашего кода для анализа.
```
import os
import sys
sys.path.insert(0, os.path.abspath('./../../src'))
import numeral_system
```
3. Добавляю папку `docs/source/api-docs` и закидываю туда файл описания каждого модуля. Документация должна автомагически сгенерироваться из комментариев:
```
Roman numeral system
=========================
.. automodule:: numeral_system.roman
:members:
```
После этого проект готов явить миру свое описание. Нужно создать аккаунт (лучше через аккаунт на `github`) и импортировать свой проект, подробные шаги описаны в [инструкции](https://github.com/readthedocs/readthedocs.org/blob/master/README.rst).
По традиции создаю среду в `tox`:
```
[testenv:gen_docs]
deps = -r docs/requirements.txt
commands =
sphinx-build -b html docs/source/ docs/build/
```
Использую команду `sphinx-build` явно, вместо `make`, так как ее под Windows нет. А я не хочу нарушать принцип о кроссплатформенной разработке.
Как только сделанные изменения замержены, `readthedocs.org` автоматически соберет документацию и опубликует.
Но… [`Build failed`](https://github.com/readthedocs/readthedocs.org/issues/2569). Я не зафиксировал версии `sphinx` и `sphinx_rtd_theme`, и ожидал что `readthedocs.org` возьмет актуальные версии. Но это не так. Фиксирую:
```
sphinx==2.3.1
sphinx_rtd_theme==0.4.3
```
И создаю специальный конфиг файл `.readthedocs.yml` для `readthedocs.org`, в котором описываю среду для запуска билда:
```
python:
version: 3.7
install:
- requirements: docs/requirements.txt
- requirements: requirements.txt
```
Вот здесь как раз и пригодился тот факт, что зависимости лежат в `requirements.txt` файлах. Дожидаюсь билда и [документация становится доступной](https://numeral-system-py.readthedocs.io/en/latest/).
Снова добавляю бейдж:
```
|Docs|
.. |Docs| image:: https://readthedocs.org/projects/numeral-system-py/badge/?version=latest&style=flat
:target: https://numeral-system-py.readthedocs.io/en/latest/
```
Лицензирование
--------------
Стоит подумать о выборе лицензии для пакета.
Это очень обширная тема, поэтому ознакомился c [этой статьей](https://habr.com/ru/post/243091/). В принципе, выбор стоит между [MIT](http://directory.fsf.org/wiki/License:Expat) и [Apache 2.0](http://directory.fsf.org/wiki/License:Apache2.0). Мне понравилась удачно вырванная из контекста фраза:
```
MIT предлагают использовать лишь для небольших проектов
```
Согласен полностью, так и поступлю Если планы поменяются, можно без проблем сменить лицензию (правда, предыдущие версии будут под старой).
Опять же, добавлю бейдж ~~богу бейджей~~:
```
|License|
.. |License| image:: https://img.shields.io/badge/License-MIT-yellow.svg
:target: https://opensource.org/licenses/MIT
```
[Здесь](https://gist.github.com/lukas-h/2a5d00690736b4c3a7ba) можно найти бейджи для всех лицензий.
Как залить на pypi?
-------------------
Для начала нужно завести аккаунт на [pypi.org](https://pypi.org). Затем приступить к подготовке пакета.
### Создаю setup.cfg
Нужно корректно описать конфигурацию для установки\сборки пакета. Я следовал [инструкции](https://docs.python.org/3/distutils/introduction.html). Есть возможность задать данные через `setup.py`, но некоторые параметры задать возможности нет. Поэтому воспользоваться `setup.cfg` файлом, в котором можно указать все нюансы. Нашел [небольшой шаблон](https://gist.github.com/althonos/6914b896789d3f2078d1e6237642c35c) того, как заполнять этот файл. По итогу использую и тот и тот файл — так удобнее.
Этот файл также можно использовать для конфигурации `pylint`, `flake8` и прочих настроек, но я так не делал.
### Как собрать пакет?
Снова пишу среду, которая поможет мне собрать необходимый пакет:
```
[testenv:build_wheel]
skip_install = True
deps = ; зависимости для сборки проекта
wheel
docutils
pygments
commands =
python -c 'import shutil; (shutil.rmtree(p, ignore_errors=True) for p in ["build", "dist"]);'
python setup.py sdist bdist_wheel
```
Зачем я удаляю папки с помощью python? Хочу соблюсти требование о кроссплатформенности разработки, удобного пути сделать это под Windows и Unix нет.
Запускаю тестовую среду:
```
tox -e build_wheel
```
В результате в папке `dist` получаю:
```
dist/
numeral-system_py-0.1.0.tar.gz
numeral_system-py-0.1.0-py2.py3-none-any.whl
```
### Заливаю!
Не совсем.
Для начала стоит проверить, что пакет работает корректным образом. Залью в тестовый репозиторий пакетов. Поэтому нужно завести еще один аккаунт, но уже на [test.pypi.org](https://test.pypi.org/).
Использую для этого пакет [twine](https://pypi.org/project/twine/) — инструмент для заливки артефактов в PyPi.
```
[testenv:test_upload]
skip_install = True
deps = twine ; ставлю последнюю версию
commands =
python -m twine upload --repository-url https://test.pypi.org/legacy/ dist/*
```
Изначально проект назывался `numsys`, но при попытке заливки столкнулся с тем, что пакет с таким именем уже есть! И что самое обидное — он тоже умеет конвертировать в римские цифры:) Сильно не расстроился и переименовал в `numeral-system-py`.
Теперь нужно установить пакет из тестового окружения. Проверку так же стоит автоматизировать:
```
[testenv:test_venv]
skip_install = True ; не следует ставить текущий пакет в эту среду
deps = ; пустые зависимости
commands =
pip install -i https://test.pypi.org/simple/ numeral-system-py
```
Теперь нужно только запустить:
```
tox -e test_venv
...
test_venv: commands_succeeded
congratulations :)
```
Вроде работает :)
### Вот теперь точно заливаю!
Да.
Создаю среду для заливки в production репозиторий.
```
[testenv:pypi_upload]
skip_install = True
deps =
twine
commands =
python -m twine upload dist/*
```
И среду для production проверки.
```
[testenv:pypi_venv]
skip_install = True
deps = ; не ставим зависимости
commands =
pip install numeral-system-py
```
### А все точно работает?
Проверяю простыми командами:
```
> virtualenv venv
> source venv/bin/activate
(venv) > pip install numeral-system-py
(venv) > python
>>> import numeral_system
>>> numeral_system.roman.encode(7)
'VII'
```
Все отлично!
[Срезаю релиз на github](https://help.github.com/en/articles/creating-releases), собираю пакет и заливаю в продовский pypi.
Замечания
---------
### Обновления зависимостей
За время подготовки этой статьи была выпущена новая версия pytest, в которой, по факту, дропнули поддержку python 3.4 ([на самом деле](https://github.com/tox-dev/tox/issues/1483) в пакете [colorama](https://github.com/tartley/colorama)). Вариантов было два:
1. Зафиксировать версию colorama, совместимую с 3.4;
2. Дропнуть поддержку 3.4 :)
В пользу второго варианта последним аргументом стало то, что и `pip` дропнул поддержку 3.4 в версии 19.1.
Так же есть зафиксированные зависимости в виде анализаторов, форматеров и прочих сервисов. Эти зависимости можно обновлять одновременно. Если повезет, то отделаетесь только подъёмом версией, если нет — то придется подправить код или даже дописать настройки.
### TravisCI
Не поддерживает python для MacOS и Windows. Есть сложности с запуском `tox` под все версии питона в рамках одной джобы.
### Версия пакета
Нужно придерживаться [семантического версионирования](https://semver.org/), а именно формата:
```
MAJOR.MINOR.PATCH
```
### Дублированиe мета информации
Версию пакета и некоторые другие параметры требуется указывать для установки пакета (в `setup.cfg` или `setup.py`) и в документации. Чтобы избежать дублирования, сделал указание только в пакете `numeral_system/__init__.py`:
```
__version__ = '0.2.0'
```
А затем в `setup.py` явно использую эту переменную
```
setup(version=numeral_system.__version__)
```
Тоже верно и для в `docs/source/conf.py`
```
release = numeral_system.__version__
```
Вышеописанное справедливо для любой мета информации — `REAMDE.rst`, описания проекта, лицензии, имена автора и прочего.
Правда, это приводит к тому, что происходит импорт пакета в момент сборки, что может быть нежелательным.
### Дублирование зависимостей
Вначале работы меня смущал тот факт, что мне нужно указывать зависимости для пакета в `requirements.txt` и `setup.cfg`.
Затем почитал [отличную статью](https://caremad.io/posts/2013/07/setup-vs-requirement/), которая разъяснила — указывать нужно только в `setup.cfg`.
Есть так же дублирование версий анализаторов. Думаю, это можно исправить созданием файла `requirements-dev.txt` в будущем.
### Организация исходников
Может быть спорным то, что я выделил исходники в папку `src/`. Я исходил из следующих соображений:
* Легче указывать только одну папку различным инструментам;
* Не раздувать корень проекта, так как со временем количество файлов и папок конфигурации в корне только увеличивается, что затруднит ориентирование;
Но столкнулся с некоторыми неудобствами:
* Потребуется дополнительная настройка `PyCharm` (или что вы там используете?) — указать папку `src`, как папку исходников.
### Коммиты и история изменений
Во время разработки пакета совершенно забыл про очень важную вещь — адекватная история изменений.
Сейчас [в истории](https://github.com/zifter/numeral-system-py/commits/master) есть комментарии, за которые не сильно стыдно:
```
Add badge with supported version
Support for py38
```
Но есть и совсем треш:
```
Try fix py38 env creating
Try fix py38 env creating
Try fix py38 env creating
Fix check
```
Да, 3 коммита с одним и тем же комментарием! Уж очень хотел пофиксить запуск тестов на Travis CI.
Есть [отличная статья](https://habr.com/ru/post/416887/) по тому, как правильно оформлять комментарии. От себя хочу добавить — часто имеет смысл сквошить изменения, чтобы не было кучи однотипных коммитов без смысловой нагрузки.
Стоит пристально следить за историей изменений и за коммитами, так как это очень важно для дальнейшей поддержки проекта. Для удобства можно так же вести `CHANGELOG`.
### Документация
Многие сервисы по умолчанию предполагают, что используется `Markdown`. Поэтому советовал бы использовать его, если нет явной необходимости в `rst`.
### Бейджи
Бейджи помогают быстрее оценить проект — поддерживаемые версии, статус тестов, номер стабильной версии, контакты для связи и многое другое. Это мощный социальный инструмент, который способствует более высокому [качеству проекта](https://cmustrudel.github.io/papers/icse18badges.pdf).
Советую взглянуть на описание [coverage](https://pypi.org/project/coverage/).
### Ограничения из-за использования разных версий
Разница в функционале, синтаксисе и прочем между версиями, к сожалению, велика. Если модуль `six` поможет в общих конструкциях, то использовать функционал из последних версий такие, как `type hint`, `asyncio` и прочих чудес — нет.
Правильным решением будет отказ от `python2.7`, учитывая что [поддержка закончилась](https://pythonclock.org/). По субъективному впечатлению, оставив поддержку только python3.5+, можно значительно упростить разработку пакета. Например, не придется собирать в одной джобе результаты покрытия кода, что ускорит запуск тестов в CI благодаря параллельному выполнению. Я уже не говорю о различных фичах в самом языке.
Можно ли сделать лучше?
-----------------------
На этом останавливаться все равно не стоит, можно сделать еще улучшения:
* Добавить поддержку MacOS;
* Тестирования на python x64 и x86;
* Добавить перфоманс регрессию;
* 100% покрытие кода далеко не показатель качества, тесты должны покрывать [все ветки исполнения](https://en.wikipedia.org/wiki/Cyclomatic_complexity). Можно мерить с помощью [mccabe](https://pypi.org/project/mccabe/), но последний релиз в январе 2017 года. Как еще можно мерить?
* Зависимости обновляются и это следует отслеживать через [PyUp](https://PyUp.io) или [requires.io](https://requires.io/). Как лучше?
* Нужно больше статик анализаторов. Смотрел непосредственно в репозиториях [Python Code Quality Authority](https://github.com/PyCQA0), что-нибудь еще?
+ [mypy](http://mypy-lang.org/) — анализатор типов;
+ [bandit](https://github.com/PyCQA/bandit) — тулза для анализа поиска проблем с безопасностью;
+ [Pyflakes](https://github.com/PyCQA/pyflakes) — по всей видимости уже устаревший анализатор;
+ [prospector](https://github.com/PyCQA/prospector) — инструмент, интегрирующий `pylint`, `pep8`, `mccabe`. Выглядит, что так же устарел;
* Добавить запуск форматирования\анализ кода на прекоммит?
Заключение
----------
Придется написать не одну библиотеку и поконтрибьютить не в один open source проект, чтобы разобраться со всеми тонкостями.
Во время подготовки к статье я прочитал не один десяток мануалов, посмотрел еще больше python проектов на `github`, протестировал разные сервисы и их варианты конфигурации.
Но больше всего времени я провел на `stackoverflow.com` и issues используемых проектов на `github` так все эти сервисы так и норовят упасть с очередной непонятной ошибкой.
Добавление новых зависимостей в проект требует время на интеграцию и поддержку. Поэтому стоит рационально оценивать необходимость интеграций. А когда следует остановиться с интеграциями?..
Тем, кто заинтересовался, советую так же прочитать [статью с похожей тематикой](https://habr.com/ru/company/ruvds/blog/444344/).
Перед завершением своей статьи нашел очень похожую, которую так же [рекомендую посмотреть](https://sourcery.ai/blog/python-best-practices/).
[Проект можно потрогать на github](https://github.com/zifter/numeral-system-py).
Спасибо! | https://habr.com/ru/post/483512/ | null | ru | null |
# MBR для флешки своими руками или как сделать из одного устройства три
Мое почтение читающему!
Топик мог бы получиться просто катастрофически огромным, поэтому перейдем сразу к делу. Впереди вас ждет рассказ, о том, как можно одну флешку сделать одновременно загрузочной как для ОС семейства Windows, так и \*nix, а также сделать из нее live-usb. Заранее прошу прощения за жаргон, не сторонник, но так короче.
#### Аннотация
Как-то пришлось много раз подряд устанавливать на одну и ту же машину кучу разных операционных систем, как от ~~товарищей~~ господ из Майкрософт, так и любимых всеми нами \*nix`ов. При этом инсталляторы вновь устанавливаемых ОСей периодически терли загрузчики ранее установленных, так что приходилось их восстанавливать вручную, загружаясь с live-usb. Но самое ужасное, что при всем при этом под рукой была **всего одна** флешка (и еще 15 компьютеров правда, но толку от них было мало, так как разбирать их по причинам гарантии в надежде на лишний жесткий диск было нельзя). Флешка к счастью была большого объема. Вот тут-то и возникла идея сделать из одной флешки две, а лучше три (хотя можно и 4) разных девайса.
#### Немного теории
Как сделать из одной флешки несколько с целью последующей установки на нее одновременно нескольких установщиков ОС и еще live-операционки? Ответ очевиден — сделать на флешке несколько разделов!
Покопавшись в ~~интернете~~ глубинах подсознания вспомнил из институтского курса, что информация о разделах хранится в первом секторе ~~диска~~ флешки, называющемся Master Boot Table ([MBR](http://ru.wikipedia.org/wiki/%D0%93%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F_%D0%B7%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%BE%D1%87%D0%BD%D0%B0%D1%8F_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D1%8C)), а точнее в отдельной его части, называемой partitions. Находится эта часть по смещению 0x01BE и представляет собой 4 поля по 16 байт, каждое из которых представляет собой запись об отдельном разделе. При этом в принципе возможно на одном устройстве иметь и большее количество разделов, но это сложнее и нам для флешки хватит и четырех.
##### Инструментарий
В форточных ОС существует неприятное ограничение на количество разделов флешки. **Оно не должно превышать 1**. Точнее разделов может быть сколько угодно, но ОСь будет видеть только первую из записей в partitions. Собственно это и определило выбор средств для форматирования флешки. Будем работать с линуксовым fdisk`ом!
Сам загрузчик будем писать на [FASM`е](http://flatassembler.net/), так как для программирования кода, выполняющегося вне ОС он наиболее удобен на мой взгляд.
Работать с флешкой в виде блочного устройства можно с помощью ужасной destroy data (**dd**), но раз уж тут выходит такая мешанина операционок, то воспользуемся более дружественной оконной [DMDE](http://dmde.ru/).
Краткое лирическое отступление
На самом деле особенность работы ОС семейства Windows с флешками позволяет используя предлагаемую мной технологию абсолютно безболезненно по отношению к дальнейшему использованию флешки в качестве ординарного накопителя данных. Отрезав от имеющихся у меня в наличии 16 GB парочку в конце, я стал обладателем 14-гиговой флешки, работающей с точки зрения винды как и прежде (т. е. другие разделы были не видны), но при этом при попытке загрузки с нее из BIOS позволяющей устанавливать ОСи из двух гигабайтных разделов, созданных в конце.
##### ~~Зубо~~флешко-дробильный аппарат
Начнем с самого простого, разметим файловую систему на нашей флешке. В частности я использовал флешку [Transcend JetFlash 16 GB](http://www.techno-one.ru/products/Transcend_16_Gb_JetFlash_V70) (была получена в качестве подарка, а дареному коню как известно… Хотя нареканий в ее адрес у меня за 1,5 года использования нет). Как я уже говорил, пользоваться будем линуксовым fdisk`ом (под рукой оказалась старенькая виртуальная машина Ubuntu 9).
Итак, монтируем флешку (так как сидим под X-ми, то просто втыкаем ее в порт). Получаем устройство /dev/sdb.
Запускаем fdisk, натравив его на новое устройство:
root@kubuntu:/# fdisk /dev/sdb
Имеем выхлоп:
```
The number of cylinders for this disk is set to 1953.
There is nothing wrong with that, but this is larger than 1024,
and could in certain setups cause problems with:
1) software that runs at boot time (e.g., old versions of LILO)
2) booting and partitioning software from other OSs
(e.g., DOS FDISK, OS/2 FDISK)
Command (m for help): m
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
```
Считаем, что диск чистый и не содержит ни одного раздела. В противном случае командой d исправляем этот недостаток (не забыв скопировать нужные данные заранее).
Задача проста — создать три раздела. Разделы будем создавать основные (primary), чтобы вся информация о них хранилась в partitions MBR`а. Воспользуемся командой n.
Первый раздел самый большой (14 ГБ), так как его потом будет видеть Windows, и его будем использовать в качестве обычной флешки:
```
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-15320, default 1): 1
Last cylinder or +size or +sizeM or +sizeK (1-15320, default 15320): +14336M
```
Второй и третий по гигабайту:
```
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 2
First cylinder (13674-15320, default 13674):
Using default value 13674
Last cylinder or +size or +sizeM or +sizeK (13674-15320, default 15320): +1024M
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 3
First cylinder (14652-15320, default 14652):
Using default value 14652
Last cylinder or +size or +sizeM or +sizeK (14652-15320, default 15320):
Using default value 15320
```
Проверим полученные результаты, распечатав сформированную таблицу разделов командой p:
```
Command (m for help): p
Disk /dev/sdb: 16.0 GB, 16064184320 bytes
64 heads, 32 sectors/track, 15320 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Disk identifier: 0x0dee0000
Device Boot Start End Blocks Id System
/dev/sdb1 1 13673 14001136 83 Linux
/dev/sdb2 13674 14651 1001472 83 Linux
/dev/sdb3 14652 15320 685056 83 Linux
```
Как видим имеем три раздела: 14 ГБ, 1ГБ и остатки (чуть меньше гига). Остается сохранить полученные изменения командой w:
```
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
root@kubuntu:/#
```
Отключаем флешку от виртуальной машины и моментально лицезреем всплывающее окошко следующего вида:
Видно, что флешка стала восприниматься Windows, как устройство значительно меньшего размера. Что ж, форматируем! Получаем первый раздел, готовый к использованию. Но что делать с двумя другими? Первое, не факт, что самое умное (но главное, что рабочее!), что пришло на ум — это обмануть старушку Windows и поменять местами записи в таблице разделов.
Итак, воспользуемся программой DMDE, откроем флешку, как блочное устройство и покопаемся в байтиках загрузочного сектора.

Выбрали подходящее по размеру устройство.

Открыли его и первое, что видим — это таблицу разделов, разбитую по полям. Не устраивает, лезем к сырым байтам. Нажимаем F2 и видим содержимое MBR. Помним, что partitions (записи о разделах) хранятся с 446 байта.

Красным выделена запись о первом разделе. Далее делаем ход конем! Сохраняем все три записи куда-нибудь в блокнотик, а на место первой записи записываем вторую (crtl+e, записываем, ctrl+w сохраняем). Закрываем DMDE, перетыкаем флешку и… бинго! Видим следующее окошко:

Windows на этот раз увидела второй раздел в гигтар размером. Потираем руки и форматируем.
Как не сложно догадаться, далее стоит на место первого записать третий, а на место второго скопировать с первого. Снова отформатировать и вернуть полученную запись на третью позицию (не забываем, что записи 16 байт, а при форматировании меняется байт идентификатора файловой системы). На последнем шаге возвращаем из блокнотика на место первую запись. В результате, если подмонтировать такую флешку к Ubuntu, получим три разных раздела, а в случае Windows — только один — первый.
Способом, аналогичным способу форматирования разделов, на флешку легко устанавливаются всевозможные операционки. Я на свою установил следующие:
* Раздел 1 (14 ГБ) — установщик Windows 7 (+ также используется как обычная флешка)
* Раздел 2 (1 ГБ) — live-usb Windows (bartPE)
* Раздел 3 — live-usb Linux (backtrack)
##### А где же код?
Что дальше? Имеем прекрасную флешку с тремя операционками и… огромным минусом! Чтобы после загрузки BIOS компьютер начинал грузиться с флешки, один из ее разделов должен быть активным (значение первого байта в записи partitions 0x01). Легко, скажите вы, воспользуемся все той же любимой DMDE. Возможно, но тут сталкиваемся с очередной проблемой — что, если мы часто меняем мнение по поводу того, с какого раздела флешки грузиться? Не редактировать же каждый раз таблицу разделов из DMDE вручную. Конечно нет, автоматизируем этот процесс!
###### Еще немного теории
Из чего состоит MBR? MBR — это загрузчик + запись таблицы разделов. После того, как микропрограмма BIOS проверит компьютер ([POST](http://ru.wikipedia.org/wiki/POST_(%D0%B0%D0%BF%D0%BF%D0%B0%D1%80%D0%B0%D1%82%D0%BD%D0%BE%D0%B5_%D0%BE%D0%B1%D0%B5%D1%81%D0%BF%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D0%B5))), она производит копирование первого сектора диска, с которого предполагается проводить загрузку операционной системы в память по адресу 0x7С00 (процессор работает в реальном режиме адресов) и передает туда управление. Далее кодом загрузчика MBR (все, что до 446го байта) осуществляется проверка готовности диска, проверка записей таблицы разделов (активной должна быть только одна!) и выбор активного раздела с последующей передачей управления загрузчику ОС.
###### Что сделаем мы
Чтобы избавиться ограничения на количество одновременных активных разделов на диске подменим код загрузчика из MBR своим собственным, который будет проверять записи, находить отмеченные как активные и ждать от пользователя нажатия клавиши с цифрой, соответствующей номеру раздела, с которого стоит производить загрузку.
Как я уже говорил, код будем писать на FASM (а отладка осуществлялась в [Bochs](http://bochs.sourceforge.net/)). Далее представлен листинг без особых пояснений, иначе топик никогда не закончится. Хотелось бы только отметить, что так сложилось, что это моя первая программа на ассемблере, поэтому не судите строго. Что делает код было описано выше.
```
;регистр dl cодержит номер загрузочного диска!
use16
;======== Копируем самого себя по адресу 0000:0600h ===================
mov ax, 7C0h
mov ds, ax
xor si, si
mov ax, 60h
mov es, ax
xor di, di
mov cx, 0FFh ;в cx лежит число повторений функции копирования слов
;[DS:SI] => [ES:DI]; SI += 2; DI += 2;
rep movsw
;Передаем управление на новое расположение кода
jmp 0000:0618h
;======== Приветствуем пользователя ===================================
mov ax, hello_msg_1
call print
mov ax, hello_msg_2
call print
;======== Проверяем таблицу разделов ===================================
mov si, [part_adr]
mov bh, 80h
mov cl, -1
partitions_chek:
cmp cl, 3 ;если уже было проверено 4 записи, выходим из цикла и переходим к обработке записей
je partition_select
add si, 10h
inc cl
mov bl, [es:si]
cmp bl, bh
jne partitions_chek ;запись не является загрузочной
call partitions_process ;запись загрузочная!
;[es:si] содержит адрес записи в таблице разделов
;cl - номер раздела
jmp partitions_chek
;======== Подпрограмма вывода инофрмации об активном разделе =============================
partitions_process:
mov ax, boot_part_msg
call print
mov di, part_num
add [ds:di], cl
mov ax, part_num
call print
sub [ds:di], cl
mov di, boot_flags
mov ch, 0
add di, cx
mov byte[ds:di], 1
ret;
;=======================================================================
partition_select:
;Обрабатываем пользовательский ввод
mov ax, select_part_msg
call print
choise: mov di, boot_flags
mov si, [part_adr]
mov ah, 0
int 16h
p0: cmp al, 48
jne p1
add si, 10h
jmp disk
p1: cmp al, 49
jne p2
add si, 20h
jmp disk
p2: cmp al, 50
jne p3
add si, 30h
jmp disk
p3: add si, 40h
cmp al, 51
je disk
wrong_choise:
mov ax, wrong_input_msg
call print
jmp choise
disk: mov ah, 0
sub al, 48 ; сначала проверка, выбрал ли пользователь действительно загрузочный раздел
add di, ax
cmp byte [ds:di], 0
je wrong_choise
; по [es:si] содержится запись таблицы разделов
; о выбранном загрузочном диске
mov ah, 41h ; проверка поддержки диском расширенного режима (> 8 GB)
; dl содержит номер диска
mov bx, 55AAh
int 13h
jc ext_not_present_error
shr cx, 1
jnb ext_not_present_error
cmp bx, 0AA55h
je read_boot_sect
ext_not_present_error:
mov ax, ext_not_pres_msg
call print
int 18h
read_boot_sect:
mov ah, 42h
mov di, DAP_structure
add di, 8
add si, 8
mov ebx, [ds:si]
mov [ds:di], ebx
mov si, DAP_structure
int 13h
jc ext_not_present_error
jmp 0000:7C00h
;======== Подпрограмма вывода сообщений ================================
print:
push si
push bx
mov bx, ax
xor si, si
mov ah, 0Eh
p: mov al, [bx + si]
cmp al, 0Ah
int 10h
je end_print
inc si
jmp p
end_print:
pop bx
pop si
ret
;=======================================================================
hello_msg_1 db '************************', 0Dh, 0Ah
hello_msg_2 db '*WELL`s LOADER (c) 2011*', 0Dh, 0Ah
boot_part_msg db 'Find bootable partitions:', 0Dh, 0Ah
select_part_msg db 'Select part to boot from (press 0 ... 3)', 0Dh, 0Ah
wrong_input_msg db 'Wrong choise. Try again', 0Dh, 0Ah
ext_not_pres_msg db 'a disk read error occured', 0Dh, 0Ah
part_num db '0', 0Dh, 0Ah
part_adr dw 1AEh
boot_flags db 4 dup (0)
DAP_structure db 10h, 0, 1, 0, 0, 7Ch, 0, 0, 8 dup (0)
```
Как видно, программа загрузчика представляет из себя чистый бинарник без всяких точек входа, секций и прочей сложноты. Режим работы процессора — реальный (16-разрядный).
Чтобы использовать этот загрузчик, его необходимо залить на флешку в первый сектор (с помощью DMDE, например), при этом сохранив нетронутой таблицу разделов. Размер скомпилированного бинарного файла 442 байта.
#### Перспективы
Если такое решение станет пользоваться популярностью, то функциональность загрузчика легко можно расширить например добавив вывод информации о разделах на экран в процессе выбора. Для удобства залилтия загрузчика на флешку и выбора, какие из разделов будут активными можно написать небольшой инструмент. В общем ваши пожелания и предложения принимаются в комментариях.
Скачать исходный код и бинарник загрузчика можно [отсюда](http://dl.dropbox.com/u/32751844/WellLoader.rar). | https://habr.com/ru/post/122699/ | null | ru | null |
# Возвращаем Pidgin и Skype на верхнюю панель GNOME Shell
  
Хочу рассказать несложное действие по оптимизации рабочего пространства, которое упростит жизнь многим пользователям **GNOME Shell**, привыкшим видеть в трее иконки любимых IM (**Pidgin** и др.), **Skype** или других приложений. В стандартной настройке они находятся в «нижнем» трее, вызов которого осуществляется наведением мыши на нижний край экрана. Неудобство упомянутого «нижнего» трея в плане общения по jabber, skype, icq и т.д. состоит в том, что пропустив от кого-либо сообщение (например, отойдя от ПК), увидеть его при возвращении без дополнительного вызова дефолтного трея невозможно. Иконка же на верхней панели сразу бросается в глаза, поэтому пропустить важное сообщение или не ответить на него вовремя менее вероятно.
На многих ресурсах этот вопрос поднимался, но непросто найти универсальную инструкцию, которая состояла бы с четкой последовательности действий, необходимых для решения вопроса с учетом некоторых нюансов.
Реализуется такое действие с помощью дополнительных параметров системы, для выполнения которых, в т.ч. и управления пользовательскими приложениями (GNOME Shell Extensions) в debian-подобных дистирибутивах (в моем случае это **Ubuntu 11.10 + GNOME Shell**), используется пакет **gnome-tweak-tool**. Если он еще не установлен, выполняем в терминале:
```
sudo apt-get install gnome-tweak-tool
```
Создаем две папки:
```
mkdir ~/.local/share/gnome-shell/extensions/pidgin-status
mkdir ~/.local/share/gnome-shell/extensions/skype-status
```
Создаем в каждой папке файлы:
```
nano ~/.local/share/gnome-shell/extensions/pidgin-status/extension.js
```
с таким содержанием
```
const StatusIconDispatcher = imports.ui.statusIconDispatcher;
function enable() {
StatusIconDispatcher.STANDARD_TRAY_ICON_IMPLEMENTATIONS['pidgin'] = 'pidgin';
}
function disable() {
StatusIconDispatcher.STANDARD_TRAY_ICON_IMPLEMENTATIONS['pidgin'] = '';
}
function init() {
}
```
```
nano ~/.local/share/gnome-shell/extensions/pidgin-status/metadata.json
```
```
{
"shell-version": ["3.2.1", "3.2"],
"uuid": "pidgin-status",
"name": "Pidgin Status Icon",
"description": "Integrates Pidgin Client into the status bar"
}
```
```
nano ~/.local/share/gnome-shell/extensions/skype-status/extension.js
```
с таким содержанием
```
const StatusIconDispatcher = imports.ui.statusIconDispatcher;
function enable() {
StatusIconDispatcher.STANDARD_TRAY_ICON_IMPLEMENTATIONS['skype'] = 'skype';
}
function disable() {
StatusIconDispatcher.STANDARD_TRAY_ICON_IMPLEMENTATIONS['skype'] = '';
}
function init() {
}
```
```
nano ~/.local/share/gnome-shell/extensions/skype-status/metadata.json
```
```
{
"shell-version": ["3.2.1", "3.2"],
"uuid": "skype-status",
"name": "Skype Status Icon",
"description": "Integrates Skype Client into the status bar"
}
```
В «shell-version» указываем версию GNOME Shell, которая у вас установлена.
Завершаем сеанс пользователя.
Логинимся в систему.
Переходим в Приложения-Прочие-Дополнительные параметры системы-Расширения Shell.
Включаем наши дополнения.
Еще раз завершаем сеанс пользователя и логинимся в систему.
Запускаем Pidgin и Skype, наблюдаем их значки на верхней панели. Не забываем включить отображение значка в настройках самого Pidgin'a (Средства-Настройки-Интерфейс-Показывать значок системного лотка), у Skype он отображается автоматически.

Данный метод можно использовать и для других клиентов, подставив его имя в соответствующие поля файлов extension.js и metadata.json.
Стоит также заметить, что с помощью дополнений пользователя можно настроить еще много чего интересного. Об этом детальнее можно прочитать [здесь](http://extensions.gnome.org/).
Основные источники информации:
[forum.ubuntu.ru/index.php?topic=172495.0](http://forum.ubuntu.ru/index.php?topic=172495.0)
[mo.morsi.org/blog/taxonomy/term/72](http://mo.morsi.org/blog/taxonomy/term/72)
[extensions.gnome.org](http://extensions.gnome.org/) | https://habr.com/ru/post/134542/ | null | ru | null |
# Определение страны по IP: тестируем скорость алгоритмов
Для определения страны по IP необходимы специальные базы данных, состоящие из диапазонов IP адресов и соответствующих им стран. Обычно такие базы данных распространяются в виде CSV или SQL файлов для использования в СУБД, либо бинарных файлов специального формата.
Для проведения тестирования была выбрана февральская база GeoLite Country, бесплатная версия GeoIP Country от MaxMind.
В тестировании приняли участие несколько популярных решений и мой «велосипед» на эту тему.
#### Участники тестирования
##### MySQL
В качестве подопытной СУБД будет использоваться MySQL. В которой создана таблица, состоящая из IP-диапазонов и номеров стран, IP преобразованы в integer и по ним построены индексы. Структура таблицы выглядит так:
```
CREATE TABLE `ip2country ` (
`ipn1` INT(10) UNSIGNED NOT NULL,
`ipn2` INT(10) UNSIGNED NOT NULL,
`num` TINYINT(3) UNSIGNED NOT NULL,
PRIMARY KEY (`ipn1`),
INDEX `ipn2` (`ipn2`)
) ENGINE=MyISAM;
```
Для MySQL будут протестированы 3 запроса.
1. **Simple.**
```
SELECT `num` FROM `ip2country`
WHERE `ipn1` <= INET_ATON(' IP ') AND `ipn2` >= INET_ATON('IP')
```
2. **Between.**
```
SELECT num FROM `ip2country`
WHERE INET_ATON('IP') BETWEEN `ipn1` AND `ipn2`
```
3. **Subselect.**
```
SELECT num FROM
(SELECT * FROM ip2country WHERE `ipn1` <= INET_ATON('IP') ORDER BY `ipn1` DESC LIMIT 1) AS t
WHERE `ipn2` >= INET_ATON('IP')
```
##### GeoIP API
Для GeoIP будет использоваться родное API для PHP, и база данных в бинарном формате. Тестироваться он будет в двух режимах:
* **Standart** — режим по умолчанию.
* **Memory** — кэширование базы в памяти.
##### SxGeo v2
Немного слов о моем «велосипеде». Лет 6 назад, после изучения доступных на тот момент решений определения страны по IP, был впечатлен скоростью бинарного формата GeoIP. Но у него, как мне показалось, был недостаток в большом количестве перемещений по файлу для нахождения нужного IP. Появилась интересная идея по поводу своей реализации. Которая довольно быстро была реализована и, на удивление, оказалась значительно быстрее, чем я ожидал. Долгое время Sypex Geo использовался в своих проектах.
На днях решил реализовать еще некоторые идеи по оптимизации. В итоге появилась версия Sypex Geo 2 (сокращено SxGeo). Файл с базой данных стал на 25% меньше, чем у первой версии, и при этом скорость увеличилась в 1,7-2 раза.
Основные преимущества перед GeoIP и другими решениями.
* Маленький размер базы чуть больше 4 байт на диапазон. К примеру, бинарная база GeoIP весит 1,2 МБ, у SxGeo 2 – 0.62 МБ.
* Очень высокая скорость обработки (смотрим результаты тестирования).
* Минимальное количество чтений с диска (3 + 1\*N, где N – количество IP).
* Дополнительные режимы для пакетной обработки.
Тестироваться SxGeo будет в трех режимах:
* **File** – обычный режим, рекомендуемый для одиночной обработки IP.
* **Batch** – режим пакетной обработки, предназначен для обработки множества IP адресов за раз.
* **Batch + Memory** – в этом режиме дополнительно используется кэш базы в памяти. Самый быстрый режим, но требует больше памяти, т.к. весь файл с базой загружается в память.
##### Geobaza
Также вне конкурса был протестирован алгоритм Geobaza. Вне конкурса, потому что использовался родной бинарный файл, со значительно большим количеством диапазонов. Geobaza показала около 2000-3000 IP/сек, был очень большой разброс по результатам. Если создатели Geobaza прочитают эту статью и пришлют файл, сгенерированный по февральскому GeoLite Country, то с удовольствием добавлю в тестирование.
#### Тестирование
Для тестирования был написан PHP-скрипт, в котором при каждом запуске генерился массив из 10000 случайных IP-адресов. После чего все алгоритмы проверялись на этом массиве. Такой метод тестирования был выбран для того, чтобы алгоритмы были в равных условиях.
Тестилось на серваке под управлением FreeBSD 8 и PHP 5.2.17. Также тестилось на локалке Win 7 x64, PHP 5.3.9, пропорции примерно те же, поэтому в таблицах представлены только результаты FreeBSD.
Тест прогонялся 10 раз, усредненные данные приведены на графике.
Самыми медленными оказались простые запросы MySQL. Причина столь медленной работы становится очевидной, если посмотреть EXPLAIN этих запросов.
```
EXPLAIN SELECT num FROM `ip2country`
WHERE ipn1 <= INET_ATON('88.88.88.88') AND ipn2 >= INET_ATON('88.88.88.88') LIMIT 1;
```
```
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE ip2country range PRIMARY PRIMARY 4 NULL 51059 Using where
1 SIMPLE ip2country range PRIMARY PRIMARY 4 NULL 53852 Using where
1 SIMPLE ip2country range PRIMARY,ipn2 PRIMARY 4 NULL 51587 Using where
```
Первый результат простого индекса **PRIMARY KEY (`ipn1`)**, второй для составного индекса **PRIMARY KEY (`ipn1`, `ipn2`)**, третий для двух индексов **PRIMARY KEY (`ipn1`), INDEX `ipn2` (`ipn2`)**. Как видим для составного индекса строк для последующего перебора больше, чем в других случаях. Я же тестил без LIMIT 1, и в этом случае EXPLAIN пишет, что индекс не используется, хотя реально работает такой вариант быстрее, чем с LIMIT.
Вариант с вложенным SELECT — значительно быстрее. Запрос показывает, что индексы в MySQL, когда они нормально используются, работают очень быстро, приближаясь к специализированным бинарным форматам.
GeoIP показал, что его всё же использовать предпочтительнее, чем MySQL. Меня смутило, что использование кэширования в памяти дает столь малый прирост, меньше 10%. Поковырявшись в geoip.inc, нашел виновника. Им оказался следующий код:
```
if ($gi->flags & GEOIP_MEMORY_CACHE) {
// workaround php's broken substr, strpos, etc handling with
// mbstring.func_overload and mbstring.internal_encoding
$enc = mb_internal_encoding();
mb_internal_encoding('ISO-8859-1');
$buf = substr($gi->memory_buffer,
2 * $gi->record_length * $offset,
2 * $gi->record_length);
mb_internal_encoding($enc);
}
```
Если закомментировать строки с mb\_internal\_encoding то в итоге скорость поднимется до 6600 IP/сек — уже более ощутимый прирост от использования кэширования в памяти. Кодировки в данном случае нас не волнуют, возможно были какие-то глюки с GeoIP City.
Что касается SxGeo, то тут думаю, комментарии излишни. Он и в обычном режиме работает очень быстро, а в режиме Batch + Memory позволяет получить прибавку еще 40%.
Желающие могут [**скачать и потестить SxGeo 2**](http://sypex.net/ru/products/geo/). Пожелания и багрепорты приветствуются.
**UPD.** Потестил еще запросы в разных комбинациях индексов, оказалось, что если в первые 2 запроса добавить LIMIT 1, то MySQL начинает очень тупить, где-то в 3-5 раз медленнее. | https://habr.com/ru/post/138067/ | null | ru | null |
# Обратная связь от сервопривода или «забиваем гвозди»

Всем хабраконструкторам, привет!
Пришла мне как-то в голову дурацкая мысль: собрать девайс, который бы молотком забивал гвозди. Просто ради демонстрации работы сервопривода. Алгоритм простой: даём команду на поднятие молотка, ждём пока он поднимется, отпускаем молоток; и так пока гвоздь не будет забит. Но как узнать, что молоток поднялся и что гвоздь забит, не пользуясь дополнительными датчиками? Спросить у «глупого» сервопривода! Как именно это сделать — об этом и пойдёт речь в статье.
Что такое сервопривод? Наверное, все знают, но на всякий случай: это привод, который в отличие от мотора постоянного тока не просто крутится пока подаётся напряжение, а стремится повернуться к заданному углу и удержаться в этом положении. Угол устанавливается с помощью [ШИМ (PWM)](http://en.wikipedia.org/wiki/Pulse-width_modulation)-сигнала. Сервопривод стремится к определённому положению, а следовательно должен знать своё собственное. Перед началом сборки я был уверен, что запросить текущий угол будет проще простого и это возможно «из коробки». Не тут то было. Но обо всём по порядку.
Итак, предполагаемый девайс: сервопривод с прикреплённым к нему молотком на небольшом постаменте для равновесия. Сервопривод подключается к [Arduino](http://amperka.ru/collection/Platy/product/Arduino-Uno) через IO Shield, а микроконтроллер исполняет алгоритм:
* Установить сервоприводу определённый угол для поднятия молотка
* Бездействовать пока сервопривод не сообщит, что угол достигнут
* Отключить питание сервопривода, чтобы молоток упал на гвоздь
* Прочитать угол в упавшем положении
* Если угол после падения несколько раз подряд не изменился — значит гвоздь перестал вколачиваться. Предположительно он забит — прекращаем исполнение
* Если угол изменился, начинаем сначала
Берём исходные части:

Пилим и скручиваем:

Приступаем к написанию прошивки для Arduino… Довольно быстро становится понятно, что установить определённый угол для сервы — не проблема. В частности, это позволяет сделать стандартная библиотека Servo, которая из заданного в градусах угла формирует соответствующий PWM-сигнал. А вот с чтением — проблема: функции для этого нет.
Быстро погуглив проблему, нашёл кучу сообщений на форумах, где на этот вопрос авторитетно отвечали: «Это не возможно! Сервоприводы — это write-only устройства». Меня это привело в замешательство, я интуитивно чувствовал, что достать эти данные как-то просто можно.
##### Матчасть
После недолгих поисков в сети можно понять как устроена серва. Это обычный мотор постоянного тока, который соединён с выведенным шпинделем через несколько шестерней, формирующих пониженную передачу. Этот же шпиндель с внутренней стороны физически прикреплён к потенциометру (подстроечному резистору). При вращении мотора шпиндель поворачивается, поворачивается и бегунок потенциометра, выходное напряжение потенциометра меняется, мозги сервы его считывают и если напряжение достигло заданного уровня — цель достигнута, мотор отключается от питания.
То есть, у нас есть потенциометр, по сигналу с которого можно определить текущий угол. Осталось только разобрать сервопривод и подключиться в нужном месте. Разбираем:

Сразу скажу, что сервопривод с фотографии я безвозвратно сломал в процессе разборки. Не нужно было вообще выламывать плату с электроникой, достаточно просто снять заднюю крышку, которая держится на 4-х винтах. Но сразу это было не очевидно, и чтобы понять куда на плате припаян потенциометр, пришлось пожертвовать одним приводом.
Вот как припаян потенциометр на [сервоприводах от DFRobot](http://amperka.ru/collection/Mehanika/product/Servoprivod):

Нам нужен сигнал с бегунка, который меняется в зависимости от угла поворота от минимального до максимального напряжения. Берём мультиметр, вращаем шпиндель и смотрим: каким углам какой сигнал соответствует. Для моей сервы углу в 0° соответствует напряжение 0.43 В, а максимальному углу поворота в 180° соответствует напряжение 2.56 В.
Аккуратно припаиваем новый сигнальный провод.

Подключаем его к аналоговому входу A5 на Arduino. Закрываем крышку. Пишем программу:
```
#include
// разрешене аналогого порта
#define A\_MAX 1024
// опорное напряжение на котором работает серва
#define A\_VREF 5
// предельные уровни сигнала с сервы
#define A\_VMIN 0.43
#define A\_VMAX 2.56
Servo servo;
int lastHitAngle = 0;
int hitAngleMatches = 0;
bool jobDone = false;
/\*
\* Возвращает текущий угол поворота сервы исходя
\* из сигнала с его потенциометра
\*/
int realAngle()
{
return map(
analogRead(A5),
A\_MAX \* A\_VMIN / A\_VREF,
A\_MAX \* A\_VMAX / A\_VREF,
0, 180);
}
void setup()
{
}
void loop()
{
if (jobDone)
return;
// включаем серву и просим повернуться до положения 70°
servo.attach(6);
servo.write(70);
// ждём поворота. 5° запаса на всякие погрешности
while (realAngle() < 65)
;
// бросаем молоток и ждём немного пока он успокоится
servo.detach();
delay(1500);
// запоминаем угол после падения и сопоставляем его с
// предыдущим
int hitAngle = realAngle();
if (hitAngle == lastHitAngle)
++hitAngleMatches;
else {
lastHitAngle = hitAngle;
hitAngleMatches = 0;
}
// если угол не менялся 5 раз — мы закончили
if (hitAngleMatches >= 5)
jobDone = true;
}
```
Включаем, пробуем, работает!
Что делать с полученным опытом — вариантов много: можно сделать контроллер вроде того, что используется на кораблях для установки тяги (полный вперёд / полный назад); можно использовать серву с обратной связью как элемент автономного рулевого управления какой-нибудь машины; можно много всего. Да прибудет со всеми нами фантазия! | https://habr.com/ru/post/127773/ | null | ru | null |
# Управление ресурсами предприятия в Zimbra OSE
Наряду с привычными для современных почтовых серверов функциями электронной почты, календаря, адресной книги и задач, Zimbra Open-Source Edition позволяет организовать на предприятии автоматизированную систему бронирования ресурсов, таких как переговорные, аудитории, служебные автомобили, проекционное оборудование и многое другое. В этой статье мы рассмотрим функциональность, связанную с управлением ресурсами, и разберем возможности, которые предоставляет пользователям и администраторам Zimbra OSE.

Управление ресурсами в Zimbra основано на ресурсных учетных записях — специальных типах учетных записей, которые администратор может присвоить помещениям и оборудованию используемым для проведения деловых переговоров и встреч. Система бронирования основана на том, что пользователи Zimbra при создании встреч указывают переговорные комнаты, в которых они будут проходить, а также оборудование, которое будет использоваться при проведении встреч. Информация о брони автоматически добавляется в календарь ресурсной учетной записи, что исключает ситуации, при которых две разных встречи могут быть назначены в одной и той же переговорной в одно и то же время.
Управление ресурсами предприятия осуществляется в консоли администратора и командной строке. Управлять ресурсными учетными записями может и делегированный администратор, созданный в [Zextras Admin](https://habr.com/ru/company/zimbra/blog/472042/). Для этого следует перейти в раздел «Управление» и в левой панели выбрать раздел «Ресурсы». В этом разделе можно создавать, удалять и редактировать ресурсные учетные записи, а также просматривать список уже созданных ресурсов.
Для создания новой ресурсной учетной записи нажмите на значок “Параметры” и выберите “Создать”.
В появившемся окне необходимо указать название ресурса и учетную запись ответственного за помещение или устройство. Помимо этого администратору доступны следующие настройки:
* Тип — Доступен выбор из Оснащение и Помещение. Ресурсные учетные записи разного типа будут отображаться с разными иконками
* Статус — Доступен выбор из Активна и Закрыта. Данная настройка позволяет временно приостановить действие ресурсной учётной записи, пока ресурс находится на ремонте
* Автоотказ повторения — Эта настройка позволяет автоматически отказывать пользователю, который захочет забронировать уже забронированный ресурс.
* Правила расписания — Настройка правил бронирования ресурса. Здесь можно указать, будет ли бронирование ресурса проходить в автоматическом режиме или в ручном.
* Максимально допустимое количество конфликтов — позволяет указать, сколько конфликтующих броней является допустимым для данного ресурса. Например, для проектора или переговорки, которые могут использоваться только в рамках одной встречи целесообразно установить этот лимит на 0, а для больших помещений, в которых может проводиться сразу несколько мероприятий, можно повысить данный лимит
* Максимальный допустимый процент конфликтов — позволяет указать допустимый процент конфликтующих броней
* Переслать приглашения ежедневника на следующие адреса — позволяет задать адрес для пересылки приглашений, направленных в адрес ресурсной учетной записи
* Пароль — позволяет задать пароль ресурсной учетной записи для входа в веб-клиент.
Названия и имени учётной записи достаточно для создания ресурсной учетной записи, однако вы можете продолжить её настройку, нажав кнопку “Далее”.

В следующих окнах диалога вы можете указать необходимую контактную информацию, связанную с создаваемой ресурсной учётной записью, а также настроить тексты сообщений, которые будут приходить пользователям в случае успешного бронирования или отклонения брони.
Разберем подробнее настройку «Правила расписания». Она представляет из себя выпадающий список, состоящий из четырех политик:
* Автоматически принимать, если возможно, автоматически отклонять в случае конфликта — в случае, если выбрана эта политика, ресурсная учетная запись будет автоматически принимать бронь от пользователя в том случае, если на указанное в нем время ресурс не забронирован кем-то еще, и автоматически отклонять бронь, если кто-то забронировал этот ресурс раньше.
* Принимать вручную, автоматически отклонять в случае конфликта — ресурсная учетная запись не будет автоматически принимать бронь, но будет автоматически отклонять бронь, если кто-то забронировал этот ресурс раньше. Подтверждать бронь может ответственный за ресурс в ручном режиме. Также при использовании данной политики расписание ресурсной учетной записи становится видимым для пользователей, а правила автоотклонения можно настроить с помощью параметров Максимально допустимое количество конфликтов и Максимальный допустимый процент конфликтов.
* Автоматически принимать всегда — ресурсная учетная запись будет автоматически принимать бронь несмотря на возникающие конфликты. Данная политика обычно используется для назначения встреч на сторонних площадках.
* Без автоматического приема или отклонения — подтверждение и отклонение брони будет осуществляться в ручном режиме ответственным за данный ресурс сотрудником
Обращаем ваше внимание на то, что в случае ручного управления бронированием ресурса, ответственному сотруднику должны быть предоставлены права на принятие или отклонение приглашений ресурсной учетной записи.
Администратор или ответственный за помещение или устройство может ограничить круг пользователей, которым разрешено бронировать его для своих мероприятий и просматривать данные о его доступности. Для этого необходимо войти в веб-клиент под ресурсной учетной записью и перейти в настройки. В разделе «Ежедневник» следует выбрать настройку «Разрешить приглашать меня на собрания только следующим внутренним пользователям:» и в текстовом поле, расположенном ниже ввести имена учетных записей тех, кому разрешено бронировать данный ресурс. Для ограничения просмотра данных о доступности нужно выбрать настройку «Показывать мои сведения о доступности только следующим внутренним пользователям:» и в расположенном ниже текстовом поле ввести имена учетных записей, которым разрешено просматривать данные о доступности ресурса.

Создавать ресурсные учетные записи можно и в командной строке. Для этого следует сначала создать обычную учетную запись, а затем перевести её в ресурсную. Для примера создадим учетную запись для корпоративного автомобиля с помощью первой команды, и затем сделаем её ресурсной учетной записью с использованием второй.
```
zmprov ca [email protected] password
zmprov ma [email protected] +objectClass zimbraCalendarResource displayName "Volkswagen Polo B360TA" zimbraAccountCalendarUserType RESOURCE zimbraCalResType Equipment
```
Для создания ресурсной учетной записи, связанной с помещением, следует использовать следующие команды:
```
zmprov ca [email protected] password
zmprov ma [email protected] +objectClass zimbraCalendarResource displayName "Meeting Room 1" zimbraAccountCalendarUserType RESOURCE zimbraCalResType Location
```
Бронировать ресурсы пользователи могут во время создания новых встреч. Забронировать для встречи помещение можно прямо в окне создания встречи, введя его название в строке с автозаполнением. При нажатии на кнопку «Встреча» откроется окно расширенного поиска по ресурсам. Также для встречи можно забронировать сразу несколько помещений. Для этого в окне расширенного поиска необходимо выбрать настройку «Разрешить множественные расположения» и добавить дополнительные помещения, которые будут задействованы в мероприятии.

Для бронирования оборудования необходимо нажать на кнопку «Показать оснащение». Добавить ресурсы можно вводя их название в строке с автозаполнением, либо нажав на кнопку «Оснащение:», чтобы открыть окно расширенного поиска по ресурсам. Бронировать ресурсы для встречи можно и после её создания, во время редактирования.
Также имеется возможность предоставления общего доступа к календарю ресурсной учетной записи для других пользователей Zimbra OSE. Для этого также нужно войти в веб-клиент под ресурсной учетной записью и предоставить общий доступ к календарю пользователям, которые должны иметь к нему доступ. Если пользователей, которые должны иметь доступ к календарю ресурсной учетной записи достаточно много, можно автоматизировать процесс предоставления им доступа с помощью командной строки и скрипта.
Идея заключается в том, чтобы объединить всех сотрудников, которым нужно предоставить доступ к календарю ресурсной учетной записи, в единый список рассылки и на основании него добавить необходимые права и смонтировать календарь в веб-клиенте Zimbra OSE. В нашем примере мы предоставляем доступ к календарю переговорной [email protected] участникам списка рассылки [email protected].
Для этого на севере Zimbra в качестве пользователя zimbra выполните команду: zmmailbox -z -m [email protected] mfg /Calendar account [email protected] rwixda. Эта команда предоставит доступ к календарю всем участникам группы рассылки, однако для того, чтобы он появился в веб-клиенте пользователей, необходимо смонтировать данный календарь. Эту задачу мы будем решать с помощью скрипта.
В первую очередь создадим файл MountCalendar.sh, сделаем его исполняемым и добавим в него следующие строки:
```
!/bin/bash
while read line
do
zmmailbox -z -m $line createMountpoint -view appointment ‘/Resource/Meeting Room 1’ [email protected] /Calendar
```
Далее создадим список всех участников списка рассылки с помощью команды **zmprov gdl [email protected] > accountlist.txt**, и запустим ранее созданный скрипт с использованием списка учетных записей: **./MountCalendar.sh < accountlist.txt**. После окончания выполнения данного скрипта в веб-клиенте каждого участника списка рассылки появится календарь учетной записи [email protected]
При использовании Zextras Suite, ресурсные учетные записи не учитываются при подсчете общего числа почтовых ящиков в системе. Их создание не влечет за собой увеличение затрат на лицензирование, однако все связанные с ресурсными учетными записями данные включаются в резервную копию, создаваемую Zextras Backup.
По всем вопросам, связанными c Zextras Suite Pro и Team Pro вы можете обратиться к Представителю компании «Zextras» Екатерине Триандафилиди по электронной почте [email protected] | https://habr.com/ru/post/549658/ | null | ru | null |
# Полируем UI в Android: StateListAnimator
***Привет, Хабр! В преддверии старта курса [«Android Developer. Professional»](https://otus.pw/21urn/) мы подготовили для вас перевод еще одного интересного материала.***

---
Большую часть времени разработки нашего Android-приложения мы тратим отнюдь не на работу над пользовательским интерфейсом — мы просто накидываем вьюх и начинаем писать код. Я заметил, что большинство из нас не особо заботится о пользовательском интерфейсе. И я считаю, что это в корне неправильно. Разработчики мобильных приложений должны заботиться также и о UI/UX. Я не говорю «будьте экспертом в мобильном UI», но вы должны понимать язык дизайна и его концепции.
Ранее я написал статью о тенях в материальном дизайне и получил много хороших отзывов. Я хочу поблагодарить всех вас. [«Освоение теней в Android»](https://android.jlelse.eu/mastering-shadows-in-android-e883ad2c9d5b) рассказывает о высоте (elevation) и тени (shadow) в Android. Там же я показал, как дополнял ими свою UI библиотеку с открытым исходным кодом. ([Scaling Layout](https://github.com/iammert/ScalingLayout)).
В этой статье я хочу усовершенствовать свою библиотеку с помощью **StateListAnimator** и шаг за шагом показать вам, как я это буду делать.
### Содержание
В этой статье рассматриваются следующие темы:
* Состояния Drawable
* [StateListDrawable](http://)
* [Анимация свойств](https://developer.android.com/guide/topics/graphics/prop-animation.html)
* [StateListAnimator](https://developer.android.com/reference/android/animation/StateListAnimator.html)
* ScalingLayout со StateListAnimator
### Состояния Drawable
В Android есть 17 различных состояний для Drawable.

Возможно, мы даже никогда не встречали некоторые из них. Я не собираюсь углубляться в каждое состояние. В большинстве случаев мы используем `pressed`, `enabled`, `windows focused`, `checked` и т. д. Если мы не объявляем состояние для drawable, то подразумевается, что это состояние по умолчанию в Android.
Нам нужно понимать эти состояния, чтобы написать наш собственный *StateListDrawable*.
### StateListDrawable
Это, по сути, список drawable элементов, где каждый элемент имеет свое собственное состояние. Для создания StateListDrawable нам нужно создать XML-файл в папке `res/drawable`.
Это элемент (item). Он имеет два свойства. ***Drawable*** и ***State***.
```
```
Это StateListDrawable. Если мы не объявляем состояние (state) для элемента, как я уже упоминал ранее, это означает, что это **состояние по умолчанию**.
### Могу ли я использовать ShapeDrawable?
Да. Вместо использования ***android:drawable*** вы можете добавить к своему элементу произвольную форму. Вот элемент с ***ShapeDrawable***.
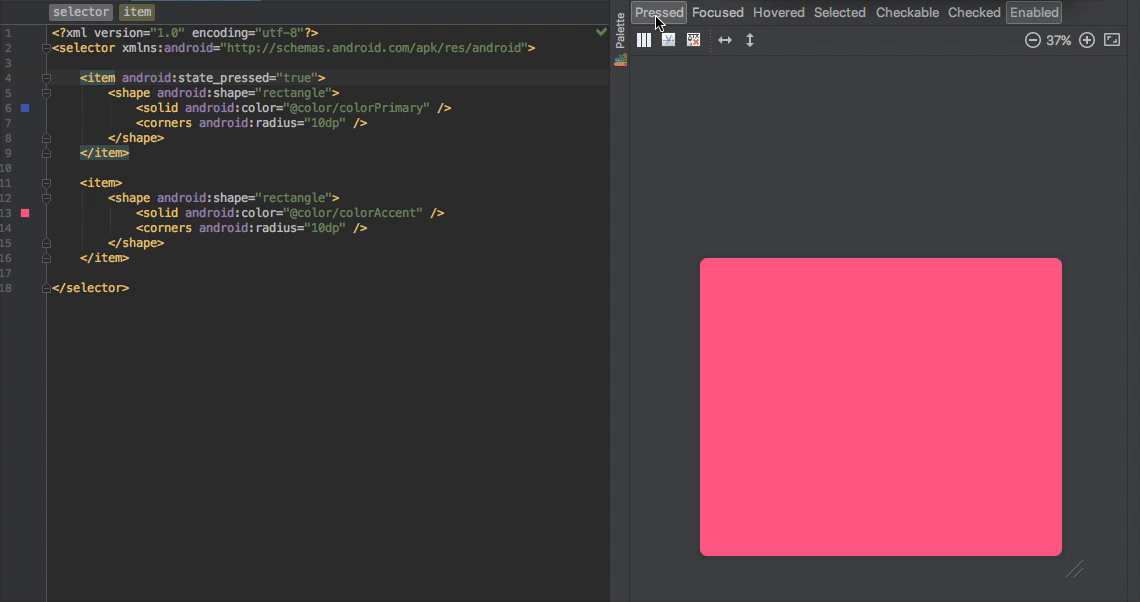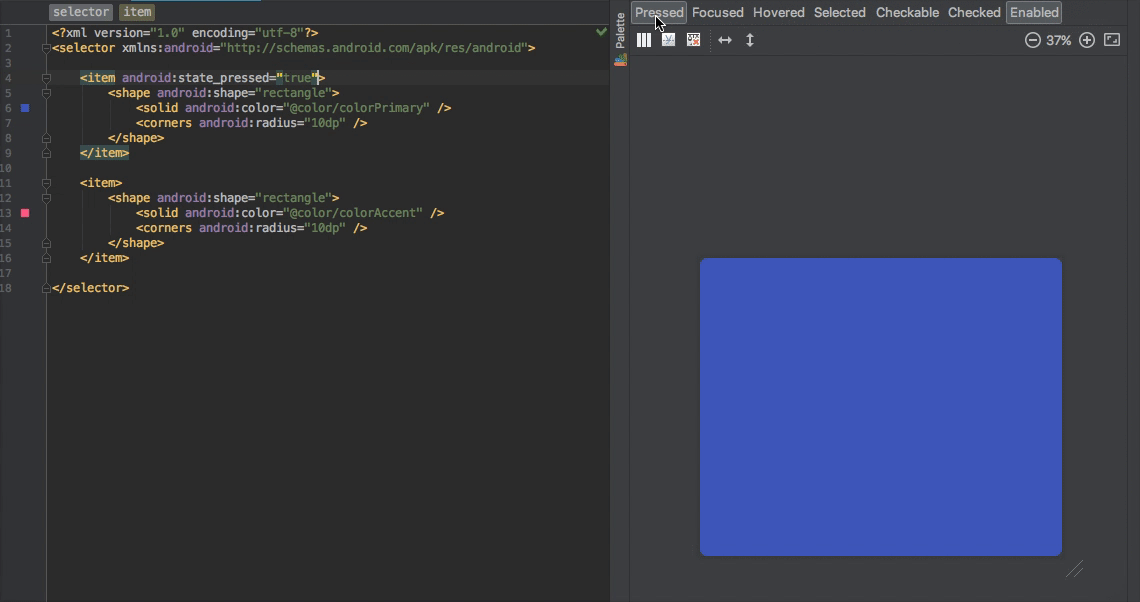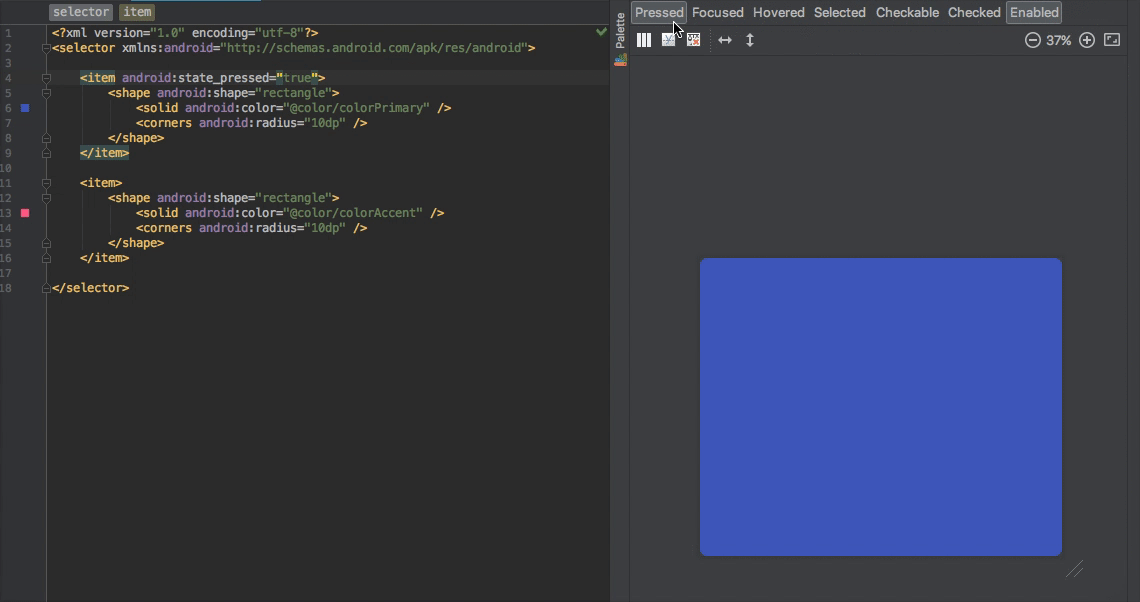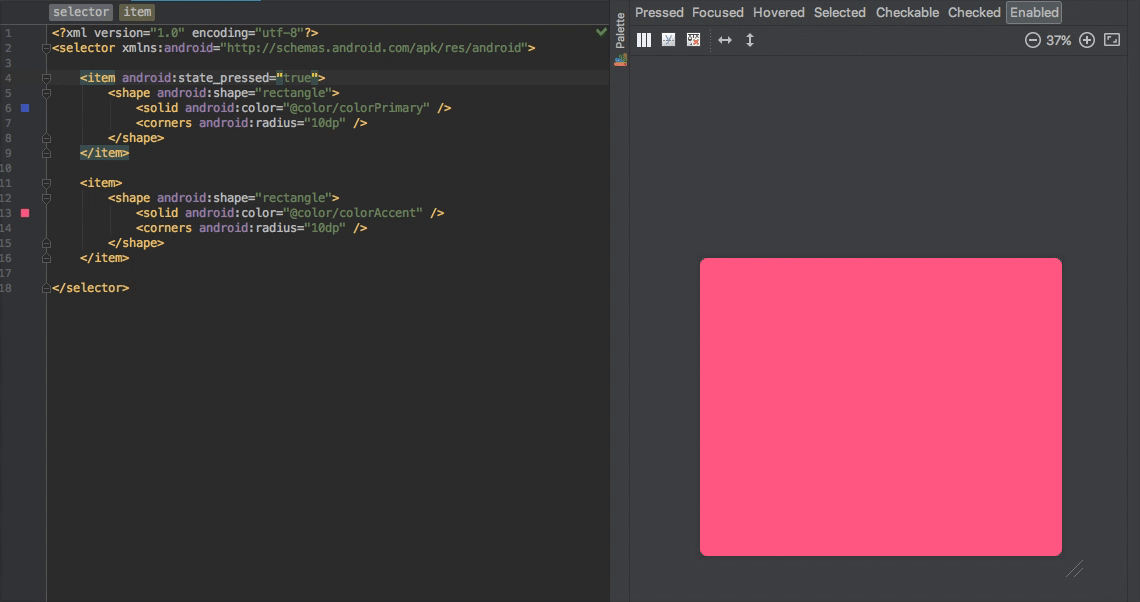
*StateListDrawable*
Вы можете использовать StateListDrawable с уровня API 1. Таким образом, для StateListDrawable нет ограничений уровня API.
Вот и все. Теперь у нашего вью есть состояние. Когда пользователь нажимает на него, его цвет будет изменен. Когда пользователь отпустит его, он будет иметь состояние и цвет по умолчанию.
> Но погодите секундочку. ***Clickable***? Зачем мы добавили этот атрибут? Нам что, еще и его добавлять нужно? Да. Но только для пользовательских вью. Чтобы это выяснить, нужно время. Кнопки отлично работают без добавления clickable, потому что они по умолчанию ***clickable***. Но если вы хотите использовать StateListDrawable для View, ImageView, Custom View и т. д., вам необходимо добавить атрибут ***clickable***.

*StateListDrawable*
Я добавил StateListDrawable в этом [коммите](https://github.com/iammert/ScalingLayout/commit/58ebe38db74dee7f6c7c87f1694829e09604be7c). Он похож на пример, который я привел выше. Когда пользователь нажимает на лейаут, он окрашивается. Но давайте улучшим это с помощью StateListAnimator.
### StateListAnimator
Помните, что когда вы нажимаете FloatingActionButton, его Z значение увеличивается из-за анимации. Это StateListAnimator так сказать за кадром. У некоторых виджетов материального дизайна есть собственный StateListAnimator внутри.
Давайте проясним это с помощью вопроса на StackOverflow.

(Как удалить границу/тень с кнопок lollipop).
Если у виджетов материального дизайна есть собственный StateListAnimator внутри, мы можем установить для них значение null, чтобы удалить эти функцию (не рекомендую, она разработана не просто так.) И сейчас ответ звучит куда более логично.

> *(Lollipop имеет небольшую неприятную функцию, называемую `stateListAnimator`, которая обрабатывает высоту кнопок, производя тени.
>
>
>
> Удалите `stateListAnimator`, чтобы избавиться от теней.
>
>
>
> У вас есть несколько вариантов как сделать это:
>
>
>
> **В коде:**
>
>
>
> button.setStateListAnimator(null);)*
Итак, а как мы можем создать его?
Чтобы понять StateListAnimator, нам нужно понять **анимацию свойств объекта (property animation)**. Я **не** собираюсь углубляться в анимацию свойств в этой статье. Но по крайней мере, я хочу показать вам основы.
### Анимация свойств
Вот самый простой пример свойства в объекте. X — это свойство.
```
class MyObject{
private int x;
public int getX() {
return x;
}
public void setX(int x) {
this.x = x;
}
}
```
*Система **property animation** — это надежный фреймворк, который позволяет анимировать **практически все**. Вы можете определить анимацию для изменения любого свойства объекта с течением времени, независимо от **того****, отображается ли он на экране или нет**. Анимация свойства изменяет значение свойства (поля в объекте) в течение заданного периода времени.*
X — это **свойство**. Т — **время**. Во время анимации свойство X обновляется в заданное время. В целом так работает анимация свойств. Вместо коробки может быть вью или любой объект.
**ValueAnimator** — это базовый класс для анимации свойств. Вы можете настроить слушатель на обновления ValueAnimator и наблюдать за изменениями свойств.
**ObjectAnimator** — это класс, который является наследником `ValueAnimator`. Вы можете использовать ObjectAnimator, если для вас больше подходит следующие:
* У вас есть **объект** (любой класс с каким-нибудь свойством).
* Вы не хотите наблюдать за слушателем ValueAnimator.
* Вы хотите обновлять **свойство объекта** автоматически.
Итак, если у нас есть **вью** (которое является объектом), и мы хотим обновить свойство вью (координата x, координата y, rotation, translation или любое другое свойство, для которого у вью есть геттер/сеттер), мы можем использовать **ObjectAnimator**. Продолжим создание StateListAnimator.
```
```

*Кнопка FAB анимирует свое свойство «translationZ» при нажатии и разжатии.*
Как я сказал ранее, мы можем использовать свойство объекта напрямую, не наблюдая за изменениями в аниматоре. Каждый View имеет свойство translationZ. Таким образом, мы можем напрямую анимировать **translationZ** с помощью ObjectAnimator.
Мы можем также объединить несколько ``<`objectAnimator>`-ов в ``<`set>`. Изменим еще одно свойство View. *Scale X* и *Scale Y*.
Вот результат! Теперь она также увеличивается при нажатии пользователем. А вот [коммит](https://github.com/iammert/ScalingLayout/commit/d1906af5fdd45a823740842dd9c25a97b18cc8c3#diff-99440eb578ffa46f57b794eb48783a8d).

Вы также можете определить другие свойства в своем `animator.xml`. Здесь вы можете найти больше информации об использовании ObjectAnimator.
Вот и все. Я планирую написать еще что-нибудь о ValueAnimator и ObjectAnimator. Это отличное API для анимации объекта.
Успешного вам кодинга!
[](https://otus.pw/21urn/) | https://habr.com/ru/post/518278/ | null | ru | null |
# Создаем шаблонизируемые переиспользуемые компоненты в Angular 2
 Много раз слышал утверждение, что Angular 2 должен быть особенно хорош в корпоративных приложениях, поскольку он, мол, предлагает все нужные (и не очень) прибамбасы сразу из коробки (Dependency Injection, Routing и т. д.). Что ж, возможно это утверждение имеет под собой основу, поскольку вместо десятков разных библиотек разработчикам надо освоить один только Angular 2, но давайте посмотрим, насколько хорошо базовая (основная) функциональность этого фреймворка годится для корпоративных приложений.
По моему опыту, типовое корпоративное приложение — это сотни (иногда тысячи) практически идентичных страниц, которые лишь слегка отличаются друг от друга. Думаю, не мне одному приходила в голову мысль, что неплохо бы выделить повторяющийся функционал в отдельный компонент, а специфичное поведение определять через параметры и внедряемые шаблоны. Давайте посмотрим, что Angular 2 может нам предложить.
Простой вариант
---------------
Первое, что приходит в голову — это отражение содержимого декларации компонента в его DOM c помощью специального тега .
Попробую продемонстрировать этот подход на примере простого компонента «widget».
Сначала пример использования:
```
Just do my job...
Faster
Slower
```
И то, как это выглядит:
Внутри компонента «widget» мы определяем два элемента:
1. Помеченный классом «content» – основное содержимое виджета;
2. Помеченный классом «settings» – некие настройки, относящиеся к виджету;
Сам компонент «widget» отвечает за:
* Отрисовку рамки и заголовка;
* Логику переключения между режимом показа основного содержимого и режимом показа настроек.
Теперь посмотрим на сам компонент “widget”:
```
@Component({
selector: "widget",
template: `
..
Some widget
Settings
Ok
Settings:
`})
export class Widget {
protected settingMode: boolean = false;
}
```
Обратите внимание на два тега **ng-content**. Каждый из этих тегов содержит атрибут **select** c помощью которого происходит поиск элементов, предназначенных для замены оригинальных **ng-content**. Так, например, при показе нашего виджета:
будет заменен на `..` a на `..` Естественно, что поиск элементов ограничен тегом **...** в клиентской разметке. Если замена не была найдена, то мы просто ничего не увидим. Если условию выборки удовлетворяет несколько элементов, то мы увидим их все.
Вариант посложнее
-----------------
Описанный выше подход может быть успешно применен во многих случаях, когда требуется создать шаблонизируемый компонент, но иногда этого подхода оказывается недостаточно. Например, если нам необходимо, чтобы переданный компоненту шаблон был отображен несколько раз причем в разных контекстах. Для того, чтобы объяснить проблему давайте рассмотрим следующую задачу: в нашем корпоративном приложении есть несколько страниц со списками объектов. Каждая страница отображает объекты какого-то одного типа (пользователи, заказы, что угодно), но при этом каждая страница позволяет вести постраничный просмотр объектов (пейджинг) и имеет возможность отметить некоторые объекты для того, чтобы выполнить некую групповую операцию, например, “удалить”. Хотелось бы иметь компонент, который бы отвечал за пейджинг и выбор элементов, но способ отображения элементов оставался бы ответственностью конкретной страницы, что логично, поскольку отображать пользователей и заказы обычно нужно по-разному. В случае подобной задачи **ng-content** уже не подходит, так как он просто отображает один объект внутрь другого, но нам нужно не просто отобразить, но еще и расставить галочки напротив каждого объекта (индивидуальный контекст).
Забегая вперед, сразу покажу решение этой задачи на примере компонента “List Navigator”, который я сконфигурировал на отображение информации о пользователях ([исходники здесь](https://plnkr.co/edit/5RXkoh7abyaIRhsTVbKH?p=preview)).
```
{{i.firstName}} {{i.lastName}}
Id: {{i.id}},
Email: {{i.email}},
Gender:
{{i.gender}}
```
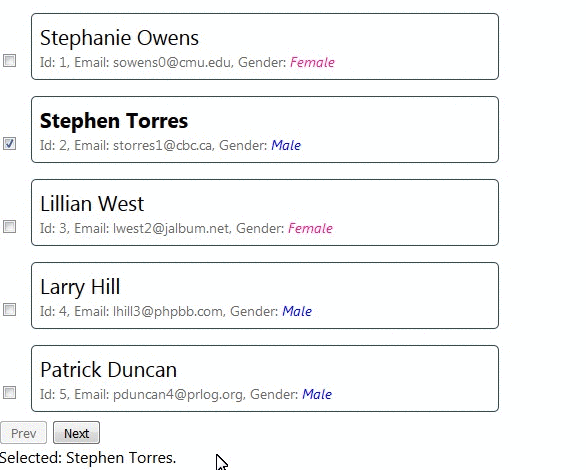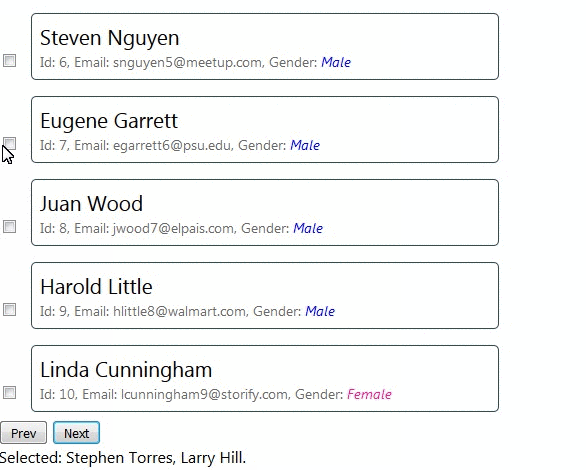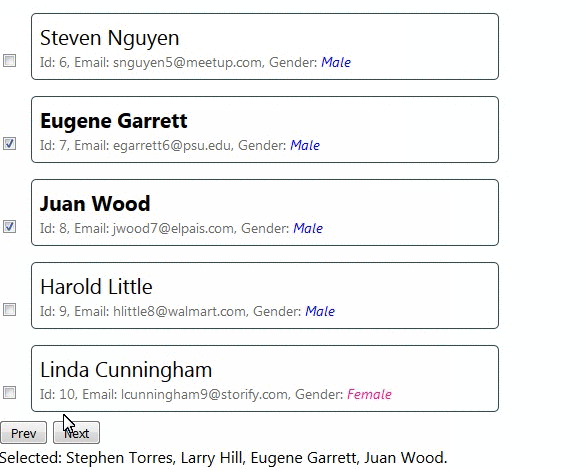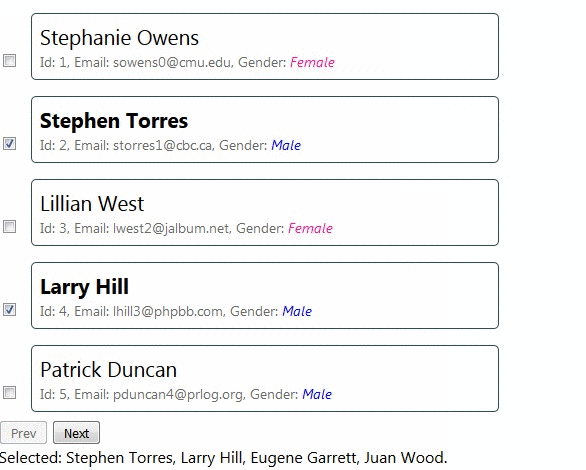
Идея следующая: компонент в качестве параметра получает ссылку на функцию, возвращающую диапазон объектов по смещению и размеру страницы (offset и pageSize):
```
[dataSource]="dataSource"
```
```
this.dataSource = (o, p) => this._data.slice(o, o + p);
```
а также шаблон, описывающий как необходимо отображать эти объекты:
Аргумент **\*list-navigator-item** – это своего рода маркер, который позволяет нашему компоненту понять, что элемент, им помеченный, является шаблоном (символ ‘\*’ говорит ангуляру, что перед нами не просто элемент, а именно шаблон) который должен быть использован для отрисовки очередного объекта из диапазона, возвращаемого **dataSource**. С помощью **list-navigator-item** мы также задаем две переменные:
* **let i** – ссылка на очередной объект из диапазона;
* **let isSelected = selected** – булевское значение указывающие отмечен ли этот элемент галочкой
или нет (о том, что означает “= selected” мы поговорим позже).
Помимо этого, компонент в качестве параметра получает список “выбранных” элементов (будут обозначены галочкой), и в случае, если пользователь меняет выбор, то компонент возвращает уже обновленный список, соответствующий пользовательскому выбору:
```
[(selectedItems)]="selectedUsers"
```
Можно провести следующую аналогию: мы передаем компоненту “фабрику”, которая создает новый элемент интерфейса используя переданные компонентом параметры. Затем наш компонент размещает созданный фабрикой элемент интерфейса внутри себя туда куда нужно (напротив галочки в нашем случае).
Давайте уже наконец посмотрим, как приготовить такой компонент. Для этого нам понадобятся следующие ингредиенты:
* **list-navigator-item-outlet** — Директива-outlet, которая, собственно, и отвечает за создание нового элемента, используя template и текущий контекст (“фабрика” из вышеприведённой аналогии) (часть внутренней реализации компонента);
* **list-navigator-item-сontext** – Класс-контейнер для передачи данных контекста (часть внутренней реализации компонента);
* **list-navigator-item** – директива-маркер, с помощью которой компонент получает доступ к шаблону элемента;
* **list-navigator** – собственно компонент, который реализует основное поведение, а именно пейджинг и выбор элементов.
### list-navigator-item-outlet
*Заметка. На самом деле эта директива не нужна поскольку дублирует директиву [NgTemplateOutlet](https://angular.io/docs/ts/latest/api/common/index/NgTemplateOutlet-directive.html), входящую в стандартную библиотеку, но я решил использовать собственный вариант для лучшего объяснения происходящего.*
Совсем небольшая директива, поэтому приведу ее исходный код целиком:
```
@Directive({
selector: "list-navigator-item-outlet"
})
export class ListNavigatorItemOutlet
{
constructor(private readonly _viewContainer: ViewContainerRef){}
@Input()
public template: TemplateRef;
@Input()
public context: ListNavigatorItemContext;
public ngOnChanges(changes: SimpleChanges): void
{
const [, tmpl] = analyzeChanges(changes, () => this.template);
const [, ctx] = analyzeChanges(changes, () => this.context);
if (tmpl && ctx) {
this.\_viewContainer.createEmbeddedView(tmpl, ctx);
}
}
}
```
В конструкторе мы запрашиваем у Angular 2 объект типа [ViewContainerRef](https://angular.io/docs/ts/latest/api/core/index/ViewContainerRef-class.html). С помощью этого объекта мы можем управлять визуальными элементами (View) (не путать с элементами DOM браузера) в родительском компоненте. Среди всех возможностей [ViewContainerRef](https://angular.io/docs/ts/latest/api/core/index/ViewContainerRef-class.html) нас в данный момент интересует возможность создания новых визуальных элементов, это можно сделать с помощью следующих двух методов:
* createComponent(componentFactory: ComponentFactory,...)
* createEmbeddedView(templateRef: TemplateRef, context?: C,...)
Первый метод полезен в том случае, если мы хотим динамически создать компонент, имея на руках лишь его “класс”. Этим методом пользуется, например, ангуляровский роутер, но это тема заслуживает отдельного поста (если, конечно, будет интересно). Сейчас же давайте обратим внимание на второй метод **createEmbeddedView**, с помощью которого мы и создаем наших пользователей. В качестве параметров он принимает [TemplateRef](https://angular.io/docs/ts/latest/api/core/index/TemplateRef-class.html) и некий контекст.
[TemplateRef](https://angular.io/docs/ts/latest/api/core/index/TemplateRef-class.html) – это “фабрика” по созданию новых визуальных компонентов, полученная путем “компиляции” тега в макете компонента (тот, который template: ‘…’ или templateUrl: “…”). Но ведь до сих пор мы нигде не видели этот тег, откуда же тогда взялся TemplateRef? На самом деле у нас был тег , просто мы его определили неявно, использовав синтаксический сахар в виде символа ‘\*’:
эквивалентно
Angular 2 создает [TemplateRef](https://angular.io/docs/ts/latest/api/core/index/TemplateRef-class.html) для любого , который он найдет в макете компонента.
Вернемся к **createEmbeddedView**. Вторым аргументом этот метод получает некий **context**. Этот объект достаточно важен, поскольку именно с помощью него мы можем инициализировать значения переменных, определенных в шаблоне:
```
"let i, let isSelected = selected"
```
Здесь опять имеет место небольшой синтаксический сахар, эту запись Angular 2 понимает как:
```
"let i=$implicit, let isSelected = selected"
```
То есть в нашем случае объект **context** должен иметь два свойства: **$implicit** и **selected**. Так оно и есть:
```
export class ListNavigatorItemContext
{
constructor(
public $implicit: any,
public selected: boolean
) { }
}
```
Теперь у нас есть все знания чтобы понять, как работает **list-navigator-item-outlet** – как только выставляются оба свойства **template** и **context**, директива создает в своем контейнере новый визуальный элемент.
Здесь необходимо сделать следующую оговорку: по-хорошему, надо было бы при повторном вызове [ngOnChanges](https://angular.io/docs/ts/latest/cookbook/component-communication.html) удалять предыдущий созданный визуальный компонент, но в нашем учебном примере в этом нет необходимости.
### list-navigator-item
Тут совсем все просто:
```
@Directive({
selector: "[list-navigator-item]"
})
export class ListNavigatorItem {
constructor(@Optional() public readonly templateRef: TemplateRef) {
}
}
```
Единственная цель этой директивы — это передать скомпилированный шаблон через публичное свойство.
### list-navigator
Наконец, наш главный компонент, ради которого все и затевалось. Начнем с его макета:
```
Prev
Next
```
где:
```
this.itemsToDisplay = this
.dataSource(offset, pageSize)
.map(i => new ListNavigatorItemContext(
i, this.selectedItems.indexOf(i) >= 0));
…
@ContentChild(ListNavigatorItem)
protected templateOutlet: ListNavigatorItem;
```
Принцип работы:
* Получаем очередную порцию объектов, используя ссылку на соответствующую функцию (**dataSource**) и помещаем ее в **itemsToDisplay**
* Перебираем все объекты из порции (**\*ngFor=«let i of itemsToDisplay»**) и для каждого объекта создаем галочку плюс вышеописанный **list-navigator-item-outlet**, который получает в качестве параметров:
* + Контекст состоящий из объекта и признака отметки selected;
+ Ссылку на [TemplateRef](https://angular.io/docs/ts/latest/api/core/index/TemplateRef-class.html), которую нам любезно предоставила директива **list-navigator-item**, которая в свою очередь была найдена путем декларации запроса **@ContentChild(ListNavigatorItem)**
* **list-navigator-item-outlet** создает визуальный элемент для очередного объекта, используя переданный шаблон и контекст (помните, что в реальном проекте желательно использовать [NgTemplateOutlet](https://angular.io/docs/ts/latest/api/common/index/NgTemplateOutlet-directive.html)).
*Небольшое дополнение.*
Шаблон для **list-navigator** вполне интерактивен — мы можем добавлять кнопки, чекбоксы, поля ввода и управлять всем этим из родительской страницы. [Вот пример](https://embed.plnkr.co/qUT6duG8n3XxcT126qZy) с добавленной кнопочкой “Archive”, обработчик которой, находится на родительской странице и изменяет состояние пользователя:
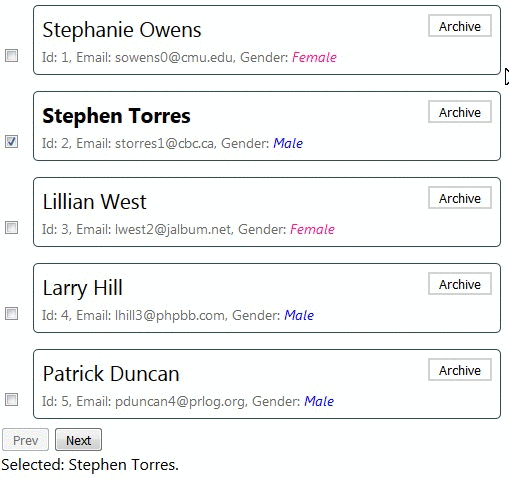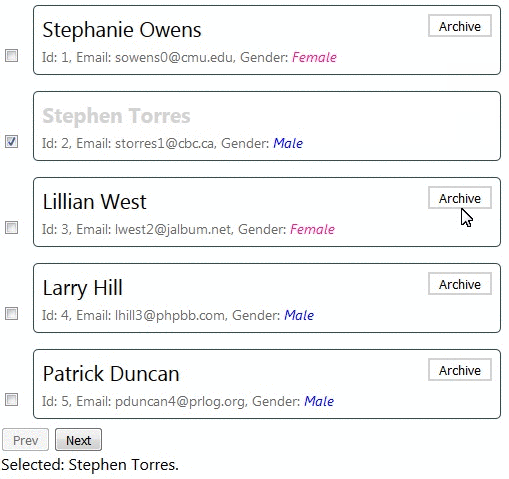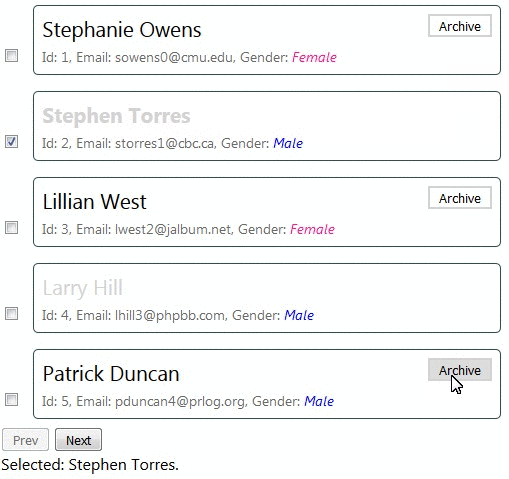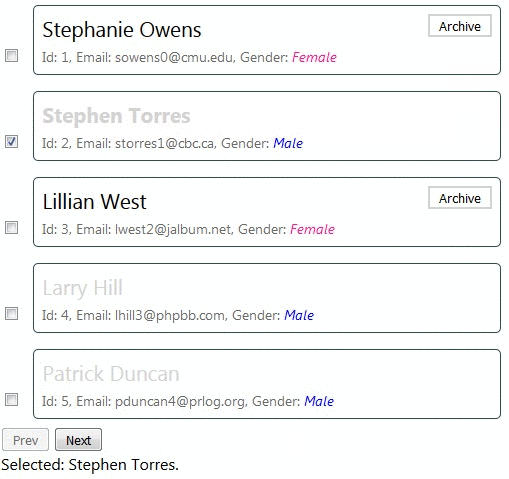
```
...
Archive
...
```
```
protected onArchive(user: User){
user.archived = true;
}
```
Вот, собственно, и все. Статья описывает приемы, которые чуть-чуть выходят за рамки стандартной документации для Angular 2, поэтому, надеюсь, она кому-нибудь пригодится. Еще раз указываю [ссылку на исходники примеров описанных в статье.](https://plnkr.co/edit/5RXkoh7abyaIRhsTVbKH?p=preview) ([вариант с кнопкой «Archive»](https://plnkr.co/edit/qUT6duG8n3XxcT126qZy?p=preview)). | https://habr.com/ru/post/320414/ | null | ru | null |
# Как мы сделали из JSON язык программирования
Спустя месяцы напряжённой работы мы наконец выпустили приложение для iOS Relevant. С ним мы ломаем существующие устои взаимодействия с сервисами и контентом в сети, благодаря чему пользователь тратит куда меньше времени на привычные вещи. Достигается это путём представления приложений и веб-сервисов в виде карточек (подробнее [здесь](https://medium.com/relevant-stories/relevant-1-0-2d79b2475e3f)).
Карточки, как независимые интерактивные единицы, показывают, каким будет будущее мобильных интерфейсов.
Когда мы только начали работать над Relevant, нам были ясны лишь две вещи: карточки должны быть красивыми, и они должны быть универсальными. То есть их содержание может формироваться из любого источника информации в сети с минимальными ограничениями. Что до красивости, так она заслуживает отдельной статьи, и здесь мы её касаться не будем, а поговорим именно об универсальности.
Карточки как объекты JSON
=========================
Так как карточки Relevant должны быть лёгкими и скачиваемыми, мы решили представлять их в виде JSON-файлов, содержащих инструкции о том, как получить доступ к различным источникам информации и API в сети и как преобразовать полученные данные в содержимое карточек.

Требовалась необычайно гибкая структура карточек, которая бы не усложняла процесс их создания. Должна быть возможность, например, получения от API массива с товарами, а затем и получение подробной информации о каждом из них. Причём получение данных может происходить посредством разных API с последующим сбором всего этого воедино.
Таким образом, стало ясно, что требуется создать универсальный API-агрегатор: гибкий, легко изменяемый и хранящийся во внешних файлах. Это позволит создать экосистему, где карточки смогут развиваться, в отличие от приложений, содержимое которых недоступно для пользователя, так как разработчики просто захардкодили его.
API нестандартны
================
Веб-сервисы и API представлены в виде самых разных форм. Некоторые API, когда требуется вернуть список, возвращают просто массив, в то время как другие засовывают его куда-то в недра возвращаемого объекта. Одни используют разбиение на страницы, другие принимают явный параметр страницы. [*Не совсем ясно, в чем заключается подразумевающаяся разница*] Добавьте к этому сотни стандартов формата даты и времени, пару стандартов URL и случайное оборачивание целых и дробных чисел в кавычки. Большинство разработчиков, пытающихся создать систему агрегации многочисленных API, быстро погружаются в многоуровневый ад из блоков if-else.
Нам хотелось чего-то более мощного. Требовалось сделать нашу платформу независимой от качества дизайна API и его данных. После долгих проб и ошибок Relevant Card’s JSON стал выглядеть примерно так:
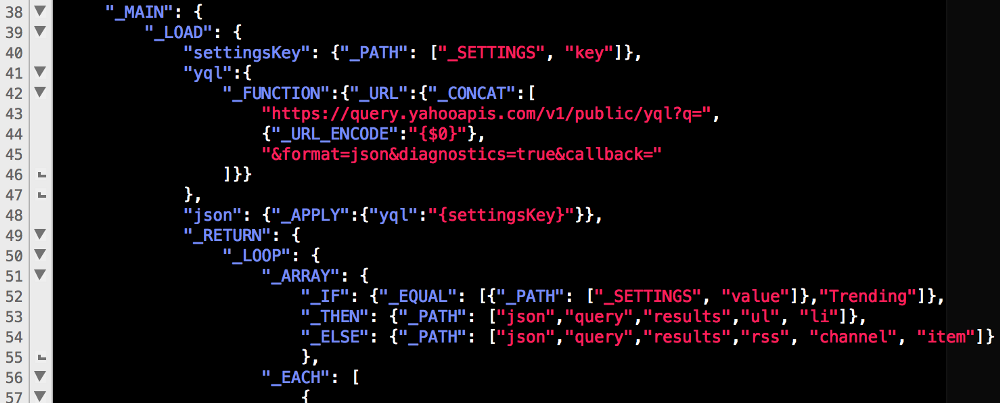
Большая часть нашей инфраструктуры агрегации API лежит на сложных серверных и клиентских системах. Тем не менее, придуманный нами JSON-ориентированный язык REL заслуживает отдельного упоминания.
Быстрое введение в REL
======================
REL выглядит как приукрашенный JSON, но по сути это чисто функциональный язык программирования с ленивыми неизменяемыми переменными (то есть они вычисляются и получаются только тогда, когда необходимы) и динамической областью видимости.
Типы и переменные
-----------------
Типы в REL — это стандартные типы JSON: числа, строки, объекты и массивы. В большинстве случаев они парсятся непосредственно. Однако некоторые объекты имеют особое значение. Пары ключ-значение объекта, имеющего ключ "\_RETURN", парсятся как пары переменная-значение. Обращение к переменным осуществляется посредством фигурных скобок: "{variable\_name}".
Например, следующий объект
```
{
"foo":1,
"var":2,
"_RETURN":{"_MATH":"{foo}+{var}"}
}
```
REL представляет как число 3.
Функции
-------
Мы часто добавляем новые встроенные функции в REL. Эти функции выглядят как объекты с определёнными специальными ключами, которые начинаются с символа подчёркивания. Функция "\_MATH" из примера выше разбирает строку как математическое выражение и возвращает его результат.
Среди других встроенных функций можно выделить "\_URL", которая загружает JSON по заданному адресу, и "\_PATH", которая ищет значение в объекте JSON или массиве. Эти две функции являются основными, использующимися для агрегации API в REL Engine.
Можно даже создавать пользовательские функции. [Больше информации об этом в документации](https://github.com/relevant-ai/RelevantCardsDocumentation).
Управление порядком выполнения
------------------------------
Встроенные функции, такие как {"\_IF":, "\_THEN":, "\_ELSE":} и {"\_LOOP": {"\_ARRAY":, "\_EACH":}} используются для управления порядком выполнения, но, в отличие от нефункциональных языков (таких как C или Java), они всегда возвращают значение.
Больше информации о текущей версии REL всегда можно найти в [документации](https://github.com/relevant-ai/RelevantCardsDocumentation).
Также доступна развивающаяся [библиотека карточек](http://cards.relevant.ai/) с примерами и описаниями на REL.
> *От переводчика
> --------------
>
>
>
> Перевод местами достаточно вольный, но не в ущерб смыслу или содержанию. Все, что не относится напрямую к оригиналу, вынесено в примечания. Автор публикации является по совместительству и автором приложения, так что исходный текст является несколько рекламным. Я постарался перенести акцент именно на разработанный язык. За большим количеством ссылок и разнообразных призывов обращайтесь к оригиналу.
>
> С предложениями, пожеланиями и замечаниями, как обычно, в ЛС.* | https://habr.com/ru/post/260757/ | null | ru | null |
# Избавляемся от бинарных зависимостей с композитной сборкой в Gradle 3.1
С самого появления Gradle существовало 2 способа разбить свою сборку на компоненты: через бинарные зависимости и с помощью многопроектной сборки. Каждый из этих способов имеет свои плюсы и минусы. В случае с бинарными зависимостями возникает необходимость в публикации артефактов, что усложняет сборку. В случае использования многопроектной сборки становится
сложнее изолировать компоненты друг от друга.
### Композитные сборки
В готовящейся к релизу версии 3.1 в Gradle появляется новый поход к организации сборок, состоящих из нескольких компонентов: *композитные сборки* (*ориг*. Composite Builds).
Композитные сборки позволяют:
* Быстро подложить исправленную версию исходников библиотеки в другой проект без необходимости собирать её, опубликовывать и править сборку.
* Делить большие проекты на несколько небольших, изолированных сборок, над каждой из которых можно работать как по отдельности, так и одновременно.
* Отделить разработку плагина для системы сборки от проекта, его использующего (аналог `buildSrc`)
Разберем простой пример использования новой возможности.
Для этого создадим простенький проектик:
```
--app/
|-src/main/java/Main.java
|-build.gradle
- lib/
|-src/main/java/A.java
|-build.gradle
|-settings.gradle
```
#### lib/build.gradle:
```
apply plugin: 'java'
group "ru.shadam"
version "1.0"
task wrapper(type: Wrapper) {
gradleVersion = '3.1-rc-1'
}
```
#### app/build.gradle
```
apply plugin: 'java'
apply plugin: 'application'
mainClassName='Main'
dependencies {
compile 'ru.shadam:lib1:1.0'
}
task wrapper(type: Wrapper) {
gradleVersion = '3.1-rc-1'
}
```
Теперь, если мы попробуем запустить `app` с помощью команды `./gradlew run` Gradle будет ругаться на неразрешенную зависимость:
```
$ ./gradlew run
:compileJava
FAILURE: Build failed with an exception.
* What went wrong:
Could not resolve all dependencies for configuration ':compileClasspath'.
> Cannot resolve external dependency ru.shadam:lib1:1.0 because no repositories are defined.
Required by:
project :
* Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output.
BUILD FAILED
Total time: 1.027 secs
```
Но, если мы добавим новый флаг --include-build, то Gradle разрешит зависимости автоматически:
```
$ ./gradlew run --include-build ../lib1
[composite-build] Configuring build: C:\Users\sala\projects\gradle-compose\lib1
:compileJava
:lib1:compileJava UP-TO-DATE
:lib1:processResources UP-TO-DATE
:lib1:classes UP-TO-DATE
:lib1:jar UP-TO-DATE
:compileJava UP-TO-DATE
:processResources UP-TO-DATE
:classes UP-TO-DATE
:run
Hello
BUILD SUCCESSFUL
Total time: 1.092 secs
```
### Продвинутые варианты использования.
**Встраиваем --include-build в скрипт**
Представленный выше вариант больше подходит для одноразового использования — здесь и сейчас. Каждый раз указывать флаги не хочется — даже если зашить их во wrapper.
Для этого gradle предлагает использовать конфигурацию с использованием settings.gradle. Так, указанный выше флаг можно заменить с помощью следующего settings.gradle:
```
includeBuild('../lib1')
```
**Подстановки**
Что если в проекте, который вы хотите включить не указаны координаты артефакта? (группа, версия)
На помощь приходят подстановки:
```
includeBuild('../lib1') {
dependencySubstitution {
substitute('ru.shadam:lib1') with project(':')
}
}
```
Эта возможность позволяет подставить любую зависимость на `ru.shadam:lib1` зависимостью на проект `lib1`.
**Зависимости между задачами**
В случае композитной сборки проекты изолированы друг от друга, поэтому нельзя объявлять зависимости между сборками напрямую.
В связи с этим появился новый синтаксис для доступа к включаемым сборкам. Например, можно определить зависимость от задачи включенной сборки:
```
task run {
dependsOn gradle.includedBuild('lib1').task(':jar')
}
```
### Что пока не работает?
* Не поддерживаются в качестве включаемых проекты, у которых есть публикуемые артифакты, которые не соответствуют конфигурации по умолчанию. [ссылка](https://docs.gradle.org/3.1-rc-1/userguide/composite_builds.html#included_build_substitution_limitations)
* Пока нет поддержки в IDE (но поддерживается генерация проекта с помощью команды `./gradlew idea`)
* Не поддерживаются native builds.
### Планы команды
* Добавить возможность вызывать задачи напрямую из включенных сборок.
* Добавить возможность параллельно исполнять включенные сборки
* Добавить обнаружение изменений во включенных сборках, когда используется флаг `-t`.
* Сделать неявный проект buildSrc включенной сборкой.
### Использованные материалы
* [Документация](https://docs.gradle.org/3.1-rc-1/userguide/composite_builds.html)
* [Репозиторий с примерами](https://github.com/saladinkzn/gradle-compose) | https://habr.com/ru/post/309938/ | null | ru | null |
# ML Grid — библиотека машинного обучения в Apache Ignite
### Возможности новой библиотеки машинного обучения Apache ML Grid
В релиз [Apache Ignite](https://ignite.apache.org/) 2.0 вошла бета-версия библиотеки машинного обучения Apache Ignite Machine Learning Grid ([ML Grid](https://apacheignite.readme.io/docs/machine-learning)), основанная на высокооптимизированном и масштабируемом API Apache Ignite Memory-Centric Platform.

*Источник: [xkcd](https://xkcd.com/1838)*
О том, на что способна новая библиотека и как с ней работать, наш рассказ под катом.
В релизе 2.0 библиотека включает в себя, в основном, базовую функциональность, такую как локальные и распределенные операции векторной и матричной алгебры с использованием как обычных, так и разреженных структур данных. Сами данные могут храниться в обычной памяти JVM, в off-heap памяти и в распределенном кэше Ignite.
Тем, кто уже использовал другие популярные библиотеки машинного обучения, такие как [Apache Mahout](http://mahout.apache.org) или [Colt](https://en.wikipedia.org/wiki/Colt_(libraries)), многие вещи будут знакомыми. Это не случайно — одной из целей при проектировании Apache Ignite ML Grid API была простота использования для тех, кто уже привык к типичным библиотекам машинного обучения.
Многие пользователи уже применяли Ignite для ускорения матричных и векторных операций ещё до появления ML Grid. Ignite позволяет совместное использование Compute- и Data-гридов для высокоэффективной обработки разреженных наборов данных. А с появлением ML Grid делать это будет намного легче.
В следующих релизах планируется дальнейшее расширение функциональности библиотеки, в частности, включение распределенных версий популярных алгоритмов, используемых при решении задач машинного обучения.
Основываясь на алгоритмах распределенной алгебры в релизе 2.0, сообщество Apache Ignite планирует добавить в библиотеку алгоритмы классификации, регрессионного анализа, кластерного анализа по k-средним, деревья принятия решений и др. Многое из этого включено в ближайший следующий релиз 2.1 (в частности, линейная регрессия и k-средние).
В более отдаленных планах обсуждается разработка Python- и R-библиотеки в составе стека Ignite ML.
Возможности, предоставляемые новым модулем, пока что довольно скромные: как уже говорилось, это бета-версия, имеющая, в основном, базовую функциональность. А если вы хотите научиться использовать новый API уже сейчас, не дожидаясь следующих релизов, то для вас — вторая часть нашего поста, под спойлером…
**Как работать с ML Grid в Ignite Apache 2.0**### Как работать с ML Grid в Ignite Apache 2.0
Наверное, самый быстрый способ начать знакомство и работу с ML Grid — это собрать, прогнать и изучить результаты выполнения и кода примеров, включённых в релиз. Примеры ML можно найти в директории *examples* дистрибутива Apache Ignite. Можно также получить код примеров по [этой ссылке в Github](https://github.com/apache/ignite/tree/master/examples/src/main/ml/org/apache/ignite/examples/ml/math).
Пошаговая инструкция для начала работы с примерами:
1. Установите Java версии не ниже 8.
2. Скачайте Apache Ignite 2.0 или более позднюю версию.
3. Откройте проект *examples* в IDE — например, IntelliJ IDEA или Eclipse.
4. Активируйте профиль Maven *ml* в настройках проекта (в Ignite 2.0 он по умолчанию выключен):
5. Откройте в IDE директорию *src/main/ml* и запустите примеры ML Grid, как объяснено ниже.
1. Найдите и запустите интересующий вас пример
(на скриншоте — *SparseDistributedMatrixExample*):
2. Наблюдайте за выполнением примера и за выводом данных в консоль:
3. При выполнении примера *TracerExample* обратите внимание, что будет выводиться в браузере:
4. По желанию, отредактируйте код примера и запускайте его снова, чтобы изучить результат изменений:
Скажем, если код примера *TracerExample* поменять на такой:
```
// Code below is based on unit tests in ml module, namely
// on TracerTest#testHtmlMatrixTracer
Matrix mtx = new DenseLocalOnHeapMatrix(100, 100);
double MAX = (double)((mtx.rowSize() - 1) * (mtx.columnSize() - 1));
mtx.assign((x, y) -> (double)(x * y) / MAX);
Tracer.showHtml(mtx);
```
то при его выполнении будет более эффектный вывод в браузере:
Так можно получить более предметное представление о том, как в Ignite ML реализованы методы матричной алгебры.
В этом примере сперва создается матрица размером 100 на 100. Затем её элементы заполняются величинами, пропорциональными произведению их индексов по вертикали и горизонтали. И, наконец, при помощи *Tracer API* матрица визуализируется в HTML.
Примеры ML Grid не требуют никакой специальной конфигурации. Всех их можно просто запускать, прогонять и останавливать, а результат будет выводиться в консоль автоматически, без какого-либо вмешательства пользователя. В дополнение к сказанному, при выполнении примера *Tracer API* запускается браузер, в котором дополнительно выводится результирующий HTML.
Также в javadocs вы можете найти документацию об использовании классов и методов ML Grid.
### Сборка из исходного кода
Jar-сборка последней версии Apache Ignite ML Grid доступна в репозитории Maven. Можно также самостоятельно собрать библиотеку из исходного кода:
1. Загрузите версию последнего релиза Apache Ignite с исходным кодом.
2. Если нужно, очистите локальный репозиторий Maven, чтобы исключить влияние предыдущих сборок.
3. Удостоверьтесь, что у вас версия Java не ниже 8.
4. Соберите и инсталлируйте Apache Ignite Memory-Centric Platform из корневой директории проекта:
```
mvn clean install -DskipTests -Dmaven.javadoc.skip=true -P java8
```
5. Соберите и инсталлируйте ML Grid из корневой директории проекта:
```
mvn install -Pml -DskipTests -U -pl modules/ml -am
```
6. Найдите jar-сборку ML Grid в локальном репозитории Maven:
```
{user_dir}/.m2/repository/org/apache/ignite/ignite-ml/{ignite-version}/ignite-ml-{ignite-version}.jar
```
7. Если вам нужно собрать примеры ML Grid из исходного кода, выполните следующие команды из корневой директории проекта:
```
cd examples
mvn clean package -DskipTests -Pml
```
При необходимости можно обратиться к дополнительной документации в файлах *DEVNOTES.txt* в корневой директории проекта и *README* в директории ML-компонента *ignite-ml*. | https://habr.com/ru/post/332442/ | null | ru | null |
# Применяем Hooks из React во Flutter
Недавно я наткнулся на имплементацию хуков для Flutter, о которой и хочу рассказать.
Зачем использовать хуки во Flutter?
-----------------------------------
Причины те же, по которой люди используют их в React, а именно:
* Удобство
* Отсутствие бойлерплейта
* Простота для тривиальных случаев
В частности, неприятный момент со `Statefull` виджетами – большое количество бойлерплейта с `initState` и `dispose`. Авторы реализации описывают проблему таким кодом:
```
class Example extends StatefulWidget {
final Duration duration;
const Example({Key key, required this.duration})
: super(key: key);
@override
_ExampleState createState() => _ExampleState();
}
class _ExampleState extends State with SingleTickerProviderStateMixin {
AnimationController? \_controller;
@override
void initState() {
super.initState();
\_controller = AnimationController(vsync: this, duration: widget.duration);
}
@override
void didUpdateWidget(Example oldWidget) {
super.didUpdateWidget(oldWidget);
if (widget.duration != oldWidget.duration) {
\_controller!.duration = widget.duration;
}
}
@override
void dispose() {
\_controller!.dispose();
super.dispose();
}
@override
Widget build(BuildContext context) {
return Container();
}
}
```
Думаю, взглянув на код, вы поняли ту боль, которую испытывали и его авторы.
Не желая мириться с болью, они вспомнили, что есть такая приятная вещь как хуки, и то как ими удобно пользоваться.
А вот так уже выглядит такой же пример, но с использованием хуков:
```
class Example extends HookWidget {
const Example({Key key, required this.duration})
: super(key: key);
final Duration duration;
@override
Widget build(BuildContext context) {
final controller = useAnimationController(duration: duration);
return Container();
}
}
```
Небольшой технический ликбез
----------------------------
Хуки прекрасны, но есть требование - нельзя использовать условия при использовании хуков (см. пример).
```
@override
Widget build(BuildContext context) {
if (isCondition) {
final val = useHook();
/// ... some code
} else {
final val2 = useHook2();
/// ... some code
}
}
```
Если же вас интересует, то как хуки работают и почему это не магия, то авторы рекомендуют прочитать о внутреннем устройстве хуков [тут](https://medium.com/@ryardley/react-hooks-not-magic-just-arrays-cd4f1857236e).
Если вкратце, то важен порядок вызова хуков. Внутри каждого виджета есть счетчик, используя хук, счетчик инкрементируется, и за счет этого получается различать где какой хук (собственно, из-за этого и появилось ограничение на if`ы).
Как использовать?
-----------------
Для начала необходимо добавить в ваш flutter проект библиотеку [flutter\_hooks](https://pub.dev/packages/flutter_hooks).
```
flutter pub add flutter_hooks
```
Теперь рассмотрим более подробно, какие возможности предоставляет эта библиотека.
Допустим, у нас есть стартовое приложение, которое генерит Flutter. Тут классический счетчик нажатий на кнопку.
```
class MyHomePage extends StatefulWidget {
const MyHomePage({Key? key, required this.title}) : super(key: key);
final String title;
@override
State createState() => \_MyHomePageState();
}
class \_MyHomePageState extends State {
int \_counter = 0;
void \_incrementCounter() {
setState(() {
\_counter++;
});
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text(widget.title),
),
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
const Text(
'You have pushed the button this many times:',
),
Text(
'$\_counter',
style: Theme.of(context).textTheme.headline4,
),
],
),
),
floatingActionButton: FloatingActionButton(
onPressed: \_incrementCounter,
tooltip: 'Increment',
child: const Icon(Icons.add),
),
);
}
}
```
Теперь перепишем его на хуки. Для этого будем использовать `useState` и `useCallback`.
* `useState` - создает стейт и возвращает `ValueNotifier`.
Всякий раз, когда значение ValueNotifier обновляется, то обновляется и виджет ( `ValueListenableBuilder` использовать не обязательно). При первом вызове требуется указать начальное значение, потом оно игнорируется.
* `useCallback` - кэширование функции на основе списка ключей.
Удобная обертка useMemoized для callback`ов
* `useMemoized` - кэширование значения на основе списка ключей.
```
class MyHomePage extends HookWidget {
const MyHomePage({Key? key, required this.title}) : super(key: key);
final String title;
@override
Widget build(BuildContext context) {
final counter = useState(0);
final increment = useCallback(() => counter.value++, [counter]);
// or useMemoized(() => () => counter.value++, [counter]);
return Scaffold(
appBar: AppBar(
title: Text(title),
),
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
const Text(
'You have pushed the button this many times:',
),
Text(
'${counter.value}',
style: Theme.of(context).textTheme.headline4,
),
],
),
),
floatingActionButton: FloatingActionButton(
onPressed: increment,
tooltip: 'Increment',
child: const Icon(Icons.add),
),
);
}
}
```
Окей, давайте что-нибудь поинтереснее.
Допустим мы хотим использовать `Stream`. Для этого есть хук `useStream`. Для начала напишем простой `Stream` с цветами.
```
Stream colorsStream() async\* {
final myColors = [
Colors.blue,
Colors.red,
Colors.yellow,
Colors.grey,
Colors.green,
];
while (true) {
for (final color in myColors) {
await Future.delayed(const Duration(milliseconds: 1000));
yield color;
}
}
}
```
`Stream` есть, давайте использовать.
```
class MyHomePage extends HookWidget {
const MyHomePage({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
final stream = useMemoized(() => colorsStream());
final color = useStream(stream, initialData: Colors.white);
return Scaffold(
body: Center(
child: AnimatedContainer(
height: 300,
width: 300,
duration: const Duration(milliseconds: 500),
decoration: BoxDecoration(
borderRadius: BorderRadius.circular(20),
color: color.data,
),
),
),
);
}
}
```
Вот так выглядит результатПри использовании `useStream` вызов `build` будет происходить на каждое новые событие, так что учитывайте, когда будете создавать `Stream` в методе `build`.
На этом функционал библиотеки не оканчивается, она предоставляет большое количество методов:
Описание методов и ссылки на документациюБазовые примитивы:
* [useEffect](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useEffect.html)
* [useState](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useState.html)
* [useMemoized](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useMemoized.html)
* [useRef](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useRef.html)
* [useCallback](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useCallback.html)
* [useContext](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useContext.html)
* [useValueChanged](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useValueChanged.html)
Хуки для работы асинхронными операциями:
* [useStream](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useStream.html) - подписываемся на события`Stream`
* [useFuture](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useFuture.html) - подписываемся на события `Future`
* [useStreamController](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useStreamController.html) - создаем `StreamController`
Хуки для управления стейтом:
* [useState](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useState.html)
* [useReducer](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useReducer.html)
* [usePrevious](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/usePrevious.html)
Хуки для работы с анимациями:
* [useSingleTickerProvider](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useSingleTickerProvider.html)
* [useAnimationController](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useAnimationController.html)
* [useAnimation](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useAnimation.html) - подписываемся на события`Animation` и получаем её текущее значение.
Остальное:
* [useListenable](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useListenable.html) - подписываемся на события`Listenable` , помечая виджет для ребилда при вызове `Listener`
* [useValueListenable](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useValueListenable.html) подписываемся на события`ValueListenable` и получаем его значение
* [useTextEditingController](https://pub.dev/documentation/flutter_hooks/latest/flutter_hooks/useTextEditingController-constant.html)
* [useFocusNode](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useFocusNode.html)
* [useTabController](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useTabController.html)
* [useScrollController](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useScrollController.html)
* [usePageController](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/usePageController.html)
* [useIsMounted](https://pub.dartlang.org/documentation/flutter_hooks/latest/flutter_hooks/useIsMounted.html) - эквивалент`State.mounted`
Итог
----
На этом - все, спасибо за уделенное время, надеюсь, идея использовать хуки во Flutter заинтересовала вас так же, как и меня. | https://habr.com/ru/post/585166/ | null | ru | null |
# Устройство современного веб-браузера Chrome (часть 3/4)
Это третья часть из 4-х, посвященных работе браузеров. Ранее мы рассматривали многопроцессорную архитектуру и навигацию. В этом посте мы рассмотрим, что происходит внутри \*рендер-процесса (renderer process).
[Часть 1](https://habr.com/ru/post/526696/)
[Часть 2](https://habr.com/ru/post/529248/)
Часть 3 (текущая)
[Часть 4](https://habr.com/ru/post/529258/)
**Об особенностях перевода**
* в ходе перевода, я старался вычленять из статьи ПОНЯТИЯ, т.е. текстовые единицы которые несут специальный (технический) смысл. В переводе эти понятия выделены по особенному — во первых понятия предваряются символом звёздочки, во-вторых в них вместо пробела используется тире. Например: **\*браузер-процесс**, **\*сайто-изоляция**. При переводе понятий, приоритет отдавался не красоте перевода, а желанию выделить, акцентировать, то что мы имеем дело с ПОНЯТИЕМ, а не с фигурой речи.
* также, некоторые слова переведены неверно с точки зрения русского языка, в жаргонном стиле, например **пайплайн**, **продакшен**. У "технарей" такой перевод не вызовет затруднений, у остальных читателей прошу прощения.
\*Рендер-процесс затрагивает многие аспекты производительности веб. Так как внутри \*рендер-процесса происходит много чего, этот пост является лишь общим обзором. Если вы хотите копнуть глубже, то в разделе ["Производительность" Web Fundamentals](https://web.dev/why-speed-matters/) есть гораздо больше ресурсов.
\*Рендер-процессы обрабатывают веб-контент
==========================================
\*Рендер-процесс отвечает за все, что происходит внутри вкладки. В \*рендер-процессе главный поток обрабатывает бОльшую часть кода, который вы посылаете пользователю. Иногда части вашего JavaScript обрабатываются рабочими потоками, если вы используете web worker или \*сервис-воркер (service worker). \*Композ-потоки (compositor threads) и \*растр-потоки (raster threads) также запускаются внутри \*рендер-процессов для эффективного и гладкого рендеринга страницы.
Основная задача \*рендер-процесса — превратить HTML, CSS и JavaScript в веб-страницу, с которой пользователь может взаимодействовать.
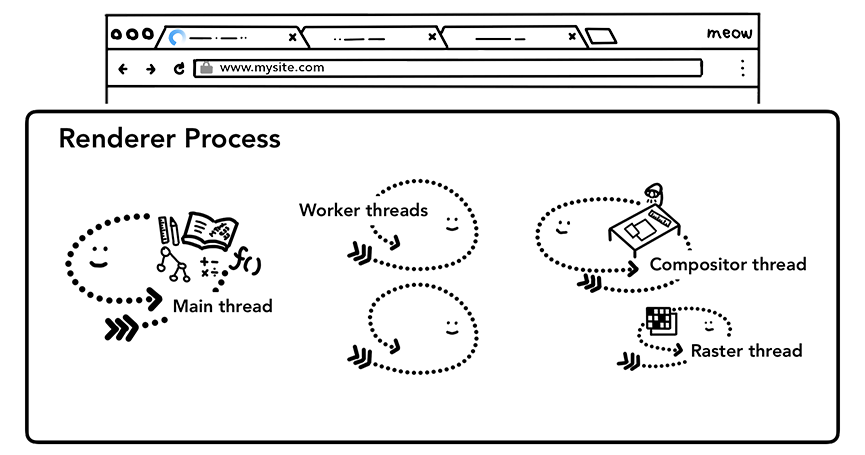
Рисунок 1: \*Рендер-процесс с главным потоком, worker потоками, \*композ-потоком, и \*растр-потоком внутри
Парсинг
=======
= Конструкция DOM
-----------------
Когда процесс рендеринга получает сообщение о необходимости выполнить навигацию и начинает получать HTML-данные, главный поток начинает разбирать текстовую строку (HTML) и превращать ее в **D**ocument **O**bject **M**odel (**DOM**).
DOM — это внутреннее представление страницы браузером, а также структура данных и API, с которым веб-разработчик может взаимодействовать через JavaScript.
Преобразование HTML-документа в DOM определяется [стандартом HTML](https://html.spec.whatwg.org/). Вы могли заметить, что приход HTML в браузер никогда не приводит к ошибке. Например, отсутствующий закрывающий тег
является допустимым HTML. Ошибочная разметка, например такая как `Hi! **I'm *Chrome***!` (тег `b` закрывается раньше тега `i`) обрабатывается так, как будто вы написали `Hi! **Я *Хром****!*`. Это связано с тем, что спецификация HTML разработана так чтобы обходить такие ошибки. Если вам интересно, как это делается, вы можете прочитать в разделе ["Введение в обработку ошибок и странных случаев в парсере"](https://html.spec.whatwg.org/multipage/parsing.html#an-introduction-to-error-handling-and-strange-cases-in-the-parser) спецификации HTML.
= Загрузка подресурсов
----------------------
Веб-сайт обычно использует внешние ресурсы, такие как изображения, CSS и JavaScript. Эти файлы необходимо загружать из сети или кэша. Главный поток может запрашивать их по очереди, по мере того, как они встречаются при парсинге для создания DOM, а для ускорения конкурентно запускает "preload scanner ". Если в HTML-документе есть такие вещи, как `![]()` или , preload scanner проглядывает токены, сгенерированные HTML-парсером, и посылает запросы \*сетевому-потоку \*браузер-процесса.
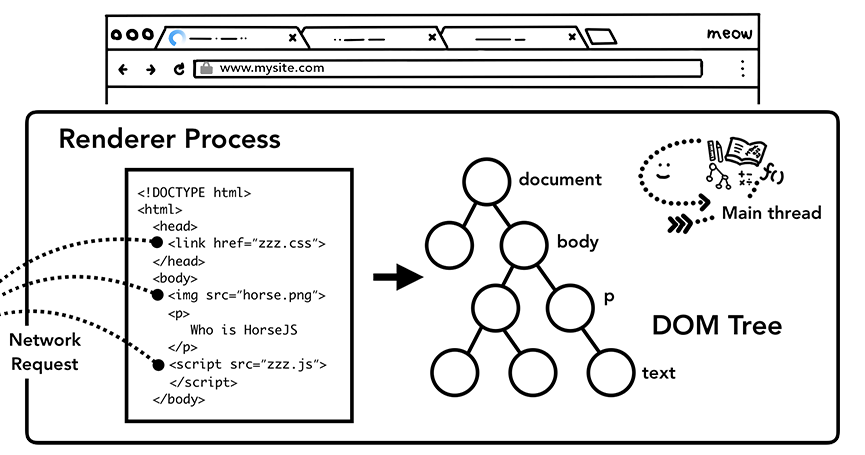
= JavaScript может блокировать парсинг
--------------------------------------
Когда HTML-парсер встречает тег | https://habr.com/ru/post/529252/ | null | ru | null |
# Обход блокировок РКН с помощью DNSTap и BGP

Тема довольно изъезжена, знаю. К примеру, есть отличная [статья](https://habr.com/ru/post/354282/), но там рассматривается только IP-часть блоклиста. Мы же добавим еще и домены.
В связи с тем, что суды и РКН блокируют всё направо и налево, а провайдеры усиленно пытаются не попасть под штрафы, выписанные "Ревизорро" — сопутствующие потери от блокировок довольно велики. Да и среди "правомерно" заблокированных сайтов много полезных (привет, rutracker)
Я живу вне юрисдикции РКН, но на родине остались родители, родственники и друзья. Так что было решено придумать легкий для далеких от ИТ личностей способ обхода блокировок, желательно вовсе без их участия.
В этой заметке я не буду расписывать базовые сетевые вещи по шагам, а опишу общие принципы как можно реализовать эту схему. Так что знания как работает сеть вообще и в Linux в частности — must have.
Типы блокировок
===============
Для начала освежим в памяти что же блокируется.
В выгружаемом XML от РКН несколько типов блокировок:
* IP
* Домен
* URL
Мы их сведем для простоты к двум: IP и домен, а из блокировок по URL будем просто вытаскивать домен (точнее за нас это уже сделали).
Хорошие люди из [Роскомсвободы](https://roskomsvoboda.org/) реализовали прекрасный [API](https://reestr.rublacklist.net/article/api/), через который можно получать то, что нам нужно:
* IP: <https://api.reserve-rbl.ru/api/v2/ips/json>
* Домены: <https://api.reserve-rbl.ru/api/v2/domains/json>
Доступ к заблокированным сайтам
===============================
Для этого нам нужен какой-нибудь маленький зарубежный VPS, желательно с безлимитным траффиком — таких много по 3-5 баксов. Брать нужно в ближнем зарубежье чтобы пинг был не сильно большой, но опять-таки учитывать, что интернет и география не всегда совпадают. А так как никакого SLA за 5 баксов нет — лучше взять 2+ штуки у разных провайдеров для отказоустойчивости.
Далее нам необходимо настроить зашифрованный туннель от клиентского роутера до VPS. Я использую Wireguard как самый быстрый и простой в настройке т.к. клиентские роутеры у меня тоже на базе Linux ([APU2](https://pcengines.ch/apu2.htm) или что-то на OpenWRT). В случае каких-нибудь Mikrotik/Cisco можно использовать доступные на них протоколы вроде OpenVPN и GRE-over-IPSEC.
Идентификация и перенаправление интересующего траффика
======================================================
Можно, конечно, завернуть вообще весь интернет-траффик через зарубеж. Но, скорее всего, от этого сильно пострадает скорость работы с локальным контентом. Плюс требования к полосе пропускания на VPS будут сильно выше.
Поэтому нам нужно будет каким-то образом выделять траффик к заблокированным сайтам и выборочно его направлять в туннель. Даже если туда попадёт какая-то часть "лишнего" траффика, это всё равно гораздо лучше, чем гонять всё через тоннель.
Для управления траффиком мы будем использовать протокол BGP и анонсировать маршруты до необходимых сетей с нашего VPS на клиентов. В качестве BGP-демона возьмём BIRD, как один из наиболее функциональных и удобных.
### IP
С блокировками по IP всё понятно: просто анонсируем все заблокированные IP с VPS. Проблема в том, что подсетей в списке, который отдает API, около 600 тысяч, и подавляющее большинство из них — это хосты /32. Такое количество маршрутов может смутить слабые клиентские роутеры.
Поэтому было решено при обработке списка суммировать до сети /24 если в ней 2 и более хоста. Таким образом количество маршрутов сократилось до ~100 тысяч. Скрипт для этого будет дальше.
### Домены
Тут сложнее и способов есть несколько. Например, можно поставить прозрачный Squid на каждом клиентском роутере и делать там перехват HTTP и подглядывание в TLS-хендшейк с целью получения запрашиваемого URL в первом случае и домена из SNI во втором.
Но из-за всяких новомодных TLS1.3+eSNI анализ HTTPS с каждым днем становится всё менее реальным. Да и инфраструктура со стороны клиента усложняется — придется использовать как минимум OpenWRT.
Поэтому я решил пойти по пути перехвата ответов на DNS-запросы. Тут тоже над головой начинает витать всякий DNS-over-TLS/HTTPS, но эту часть мы можем (пока что) контролировать на клиенте — либо отключить, либо использовать свой сервер для DoT/DoH.
#### Как перехватывать DNS?
Тут тоже может быть несколько подходов.
* Перехват DNS-траффика через PCAP или NFLOG
Оба эти способа перехвата реализованы в утилите [sidmat](https://github.com/vmxdev/sidmat). Но она давно не поддерживается и функционал очень примитивен, так что к ней нужно всё равно нужно писать обвязку.
* Анализ логов DNS-сервера
К сожалению, известные мне рекурсоры не умеют логгировать ответы, а только запросы. В принципе это логично, так как в отличии от запросов ответы имеют сложную структуру и писать их в текстовой форме трудновато.
* [DNSTap](https://dnstap.info/)
К счастью, многие из них уже поддерживает DNSTap для этих целей.
#### Что такое DNSTap?

Это клиент-серверный протокол, основанный на Protocol Buffers и Frame Streams для передачи с DNS-сервера на некий коллектор структурированных DNS-запросов и ответов. По сути DNS-сервер передает метаданные запросов и ответов (тип сообщения,IP клиента/сервера и так далее) плюс полные DNS-сообщения в том (бинарном) виде в котором он работает с ними по сети.
Важно понимать, что в парадигме DNSTap DNS-сервер выступает в роли клиента, а коллектор — в роли сервера. То есть DNS-сервер подключается к коллектору, а не наоборот.
На сегодняшний день DNSTap поддерживается во всех популярных DNS-серверах. Но, например, BIND во многих дистрибутивах (вроде Ubuntu LTS) часто собран почему-то без его поддержки. Так что не будем заморачиваться пересборкой, а возьмём более легкий и быстрый рекурсор — Unbound.
#### Чем ловить DNSTap?
Есть [некоторое](https://github.com/dnstap/golang-dnstap/tree/master/dnstap) [количество](https://github.com/dnstap/dnstap-ldns) CLI-утилит для работы с потоком DNSTap-событий, но для решения нашей задачи они подходят плохо. Поэтому я решил изобрести свой велосипед, который будет делать всё что необходимо: [**dnstap-bgp**](https://github.com/blind-oracle/dnstap-bgp)
Алгоритм работы:
* При запуске загружает из текстового файла список доменов, инвертирует их (habr.com -> com.habr), исключает битые строки, дубликаты и поддомены (т.е. если в списке есть habr.com и www.habr.com — будет загружен только первый) и строит префиксное дерево для быстрого поиска по этому списку
* Выступая в роли DNSTap-сервера ждет подключения от DNS-сервера. В принципе он поддерживает как UNIX- так и TCP-сокеты, но известные мне DNS-сервера умеют только в UNIX-сокеты
* Поступающие DNSTap-пакеты десериализуются сначала в структуру Protobuf, а затем само бинарное DNS-сообщение, находящееся в одном из Protobuf-полей, парсится до уровня записей DNS RR
* Проверяется есть ли запрашиваемый хост (или его родительский домен) в загруженном списке, если нет — ответ игнорируется
* Из ответа выбираются только A/AAAA/CNAME RR и из них вытаскиваются соответствующие IPv4/IPv6 адреса
* IP-адреса кешируются с настраиваемым TTL и анонсируются во все сконфигурированные BGP-пиры
* При получении ответа, указывающего на уже закешированный IP — его TTL обновляется
* После истечения TTL запись удаляется из кеша и из BGP-анонсов
Дополнительный функционал:
* Перечитывание списка доменов по SIGHUP
* Синхронизация кеша с другими экземплярами **dnstap-bgp** через HTTP/JSON
* Дублирование кеша на диске (в базе BoltDB) для восстановление его содержимого после перезапуска
* Поддержка переключения в иной network namespace (зачем это нужно будет описано ниже)
* Поддержка IPv6
Ограничения:
* IDN домены пока не поддерживаются
* Мало настроек BGP
Я собрал [RPM и DEB](https://github.com/blind-oracle/dnstap-bgp/releases) пакеты для удобной установки. Должны работать на всех относительно свежих OS с systemd, т.к. зависимостей у них никаких нет.
Схема
=====
Итак, приступим к сборке всех компонентов воедино. В результате у нас должна получиться примерно такая сетевая топология:
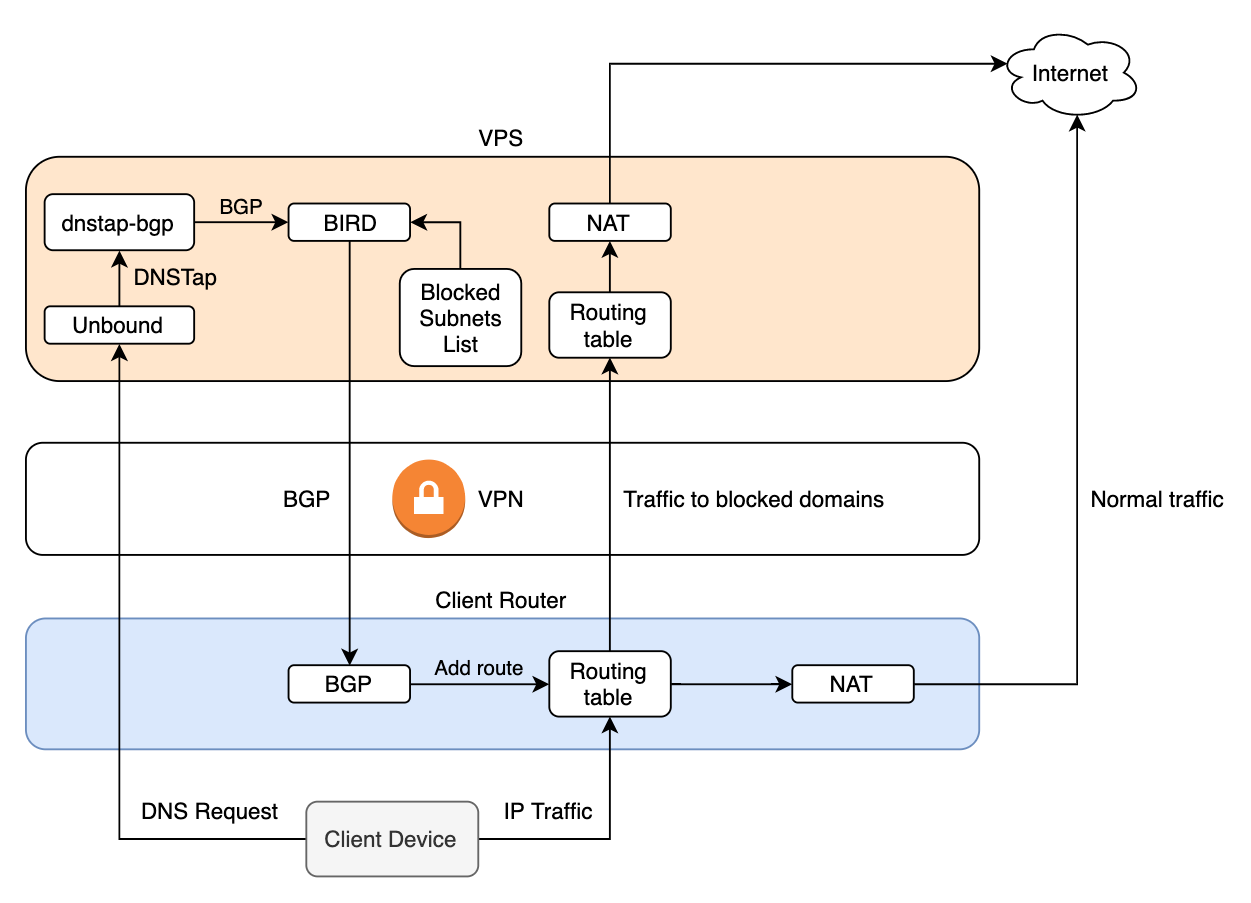
Логика работы, думаю, понятна из диаграммы:
* У клиента настроен наш сервер в качестве DNS, причем DNS запросы тоже должны ходить по VPN. Это нужно для того чтобы провайдер не мог использовать перехват DNS для блокировки.
* Клиент при открытии сайта посылает DNS-запрос вида "а какие IP у xxx.org"
* **Unbound** резолвит xxx.org (или берет из кеша) и отправляет ответ клиенту "у xxx.org такие-то IP", параллельно дублируя его через DNSTap
* **dnstap-bgp** анонсирует эти адреса в **BIRD** по BGP в том случае если домен есть в списке заблокированных
* **BIRD** анонсирует маршрут до этих IP с `next-hop self` клиентскому роутеру
* Последующие пакеты от клиента к этим IP идут уже через туннель
На сервере для маршрутов к заблокированным сайтам у меня внутри BIRD используется отдельная таблица и с ОС она никак не пересекается.
В этой схеме есть недостаток: первый SYN пакет от клиента, скорее всего, успеет уйти через отечественного провайдера т.к. маршрут анонсируется не мгновенно. И тут возможны варианты в зависимости от того как провайдер делает блокировку. Если он просто дропает траффик, то проблем нет. А если он редиректит его на какой-то DPI, то (теоретически) возможны спецэффекты.
Также возможны чудеса с несоблюдением клиентами DNS TTL, что может привести к тому что клиент будет юзать какие-то устаревшие записи из своего протухшего кеша вместо того чтобы спросить Unbound.
На практике у меня ни первое ни второе не вызывало проблем, but your mileage may vary.
Настройка сервера
-----------------
Для удобства раскатывания я написал [роль для Ansible](https://github.com/blind-oracle/rkn-bypass). Она может настраивать как сервера, так и клиенты на базе Linux (рассчитано на deb-based дистрибутивы). Все настройки достаточно очевидны и задаются в *inventory.yml*. Эта роль вырезана из моего большого плейбука, поэтому может содержать ошибки — [pull requests](https://github.com/blind-oracle/rkn-bypass/pulls) welcome :)
Пройдёмся по основным компонентам.
### BGP
При запуске двух BGP-демонов на одном хосте возникает фундаментальная проблема: BIRD никак не хочет поднимать BGP-пиринг с локалхостом (или с любым локальным интерфейсом). От слова совсем. Гугление и чтение mailing-lists не помогло, там утверждают что это by design. Возможно есть какой-то способ, но я его не нашёл.
Можно попробовать другой BGP-демон, но мне нравится BIRD и он используется везде у меня, не хочется плодить сущности.
Поэтому я спрятал dnstap-bgp внутрь network namespace, которое связано с корневым через veth интерфейс: это как труба, концы которой торчат в разных namespace. На каждый из этих концов мы вешаем приватные p2p IP-адреса, которые за пределы хоста не выходят, поэтому могут быть любыми. Это тот же механизм который используется для доступа к процессам внутри *любимого всеми* Docker и других контейнеров.
Для этого был написан [скрипт](https://github.com/blind-oracle/rkn-bypass/blob/master/rkn/templates/opt/dnstap-bgp.sh.j2) и в dnstap-bgp был добавлен уже описанный выше функционал перетаскивания себя за волосы в другой namespace. Из-за этого его необходимо запускать под root либо выдать бинарнику CAP\_SYS\_ADMIN через команду setcap.
**Пример скрипта для создания namespace**
```
#!/bin/bash
NS="dtap"
IP="/sbin/ip"
IPNS="$IP netns exec $NS $IP"
IF_R="veth-$NS-r"
IF_NS="veth-$NS-ns"
IP_R="192.168.149.1"
IP_NS="192.168.149.2"
/bin/systemctl stop dnstap-bgp || true
$IP netns del $NS > /dev/null 2>&1
$IP netns add $NS
$IP link add $IF_R type veth peer name $IF_NS
$IP link set $IF_NS netns $NS
$IP addr add $IP_R remote $IP_NS dev $IF_R
$IP link set $IF_R up
$IPNS addr add $IP_NS remote $IP_R dev $IF_NS
$IPNS link set $IF_NS up
/bin/systemctl start dnstap-bgp
```
**dnstap-bgp.conf**
```
namespace = "dtap"
domains = "/var/cache/rkn_domains.txt"
ttl = "168h"
[dnstap]
listen = "/tmp/dnstap.sock"
perm = "0666"
[bgp]
as = 65000
routerid = "192.168.149.2"
peers = [
"192.168.149.1",
]
```
**bird.conf**
```
router id 192.168.1.1;
table rkn;
# Clients
protocol bgp bgp_client1 {
table rkn;
local as 65000;
neighbor 192.168.1.2 as 65000;
direct;
bfd on;
next hop self;
graceful restart;
graceful restart time 60;
export all;
import none;
}
# DNSTap-BGP
protocol bgp bgp_dnstap {
table rkn;
local as 65000;
neighbor 192.168.149.2 as 65000;
direct;
passive on;
rr client;
import all;
export none;
}
# Static routes list
protocol static static_rkn {
table rkn;
include "rkn_routes.list";
import all;
export none;
}
```
**rkn\_routes.list**
```
route 3.226.79.85/32 via "ens3";
route 18.236.189.0/24 via "ens3";
route 3.224.21.0/24 via "ens3";
...
```
### DNS
По умолчанию в Ubuntu бинарник Unbound зажат AppArmor-профилем, который запрещает ему коннектиться ко всяким там DNSTap-сокетам. Можно либо удалить нафиг этот профиль, либо отключить его:
```
# cd /etc/apparmor.d/disable && ln -s ../usr.sbin.unbound .
# apparmor_parser -R /etc/apparmor.d/usr.sbin.unbound
```
Это, наверное, надо добавить в плейбук. Идеально, конечно, поправить профиль и выдать нужные права, но мне было лень.
**unbound.conf**
```
server:
chroot: ""
port: 53
interface: 0.0.0.0
root-hints: "/var/lib/unbound/named.root"
auto-trust-anchor-file: "/var/lib/unbound/root.key"
access-control: 192.168.0.0/16 allow
remote-control:
control-enable: yes
control-use-cert: no
dnstap:
dnstap-enable: yes
dnstap-socket-path: "/tmp/dnstap.sock"
dnstap-send-identity: no
dnstap-send-version: no
dnstap-log-client-response-messages: yes
```
### Скачивание и обработка списков
[Скрипт для скачивания и обработки списка IP-адресов](https://github.com/blind-oracle/rkn-bypass/blob/master/rkn/files/opt/rkn.py)
Он скачивает список, суммаризует до префикса *pfx*. В *dont\_add* и *dont\_summarize* можно сказать IP и сети, которые нужно пропустить или не суммаризовать. Мне это было нужно т.к. подсеть моего VPS оказалась в блоклисте :)
Самое смешное что API РосКомСвободы блокирует запросы с дефолтным юзер-агентом Питона. Видать скрипт-кидди достали. Поэтому меняем его на Огнелиса.
Пока что он работает только с IPv4 т.к. доля IPv6 невелика, но это будет легко исправить. Разве что придется использовать еще и bird6.
**rkn.py**
```
#!/usr/bin/python3
import json, urllib.request, ipaddress as ipa
url = 'https://api.reserve-rbl.ru/api/v2/ips/json'
pfx = '24'
dont_summarize = {
# ipa.IPv4Network('1.1.1.0/24'),
}
dont_add = {
# ipa.IPv4Address('1.1.1.1'),
}
req = urllib.request.Request(
url,
data=None,
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
}
)
f = urllib.request.urlopen(req)
ips = json.loads(f.read().decode('utf-8'))
prefix32 = ipa.IPv4Address('255.255.255.255')
r = {}
for i in ips:
ip = ipa.ip_network(i)
if not isinstance(ip, ipa.IPv4Network):
continue
addr = ip.network_address
if addr in dont_add:
continue
m = ip.netmask
if m != prefix32:
r[m] = [addr, 1]
continue
sn = ipa.IPv4Network(str(addr) + '/' + pfx, strict=False)
if sn in dont_summarize:
tgt = addr
else:
tgt = sn
if not sn in r:
r[tgt] = [addr, 1]
else:
r[tgt][1] += 1
o = []
for n, v in r.items():
if v[1] == 1:
o.append(str(v[0]) + '/32')
else:
o.append(n)
for k in o:
print(k)
```
[Скрипт для обновления](https://github.com/blind-oracle/rkn-bypass/blob/master/rkn/templates/opt/rkn_update.sh.j2)
Он у меня запускается по крону раз в сутки, может стоит дергать раз в 4 часа т.к. это, по-моему, период обновления который РКН требует от провайдеров. Плюс, есть какие-то еще суперсрочные блокировки у них, которые может и быстрее прилетают.
Делает следующее:
* Запускает первый скрипт и обновляет список маршрутов (`rkn_routes.list`) для BIRD
* Релоадит BIRD
* Обновляет и подчищает список доменов для dnstap-bgp
* Релоадит dnstap-bgp
**rkn\_update.sh**
```
#!/bin/bash
ROUTES="/etc/bird/rkn_routes.list"
DOMAINS="/var/cache/rkn_domains.txt"
# Get & summarize routes
/opt/rkn.py | sed 's/\(.*\)/route \1 via "ens3";/' > $ROUTES.new
if [ $? -ne 0 ]; then
rm -f $ROUTES.new
echo "Unable to download RKN routes"
exit 1
fi
if [ -e $ROUTES ]; then
mv $ROUTES $ROUTES.old
fi
mv $ROUTES.new $ROUTES
/bin/systemctl try-reload-or-restart bird
# Get domains
curl -s https://api.reserve-rbl.ru/api/v2/domains/json -o - | jq -r '.[]' | sed 's/^\*\.//' | sort | uniq > $DOMAINS.new
if [ $? -ne 0 ]; then
rm -f $DOMAINS.new
echo "Unable to download RKN domains"
exit 1
fi
if [ -e $DOMAINS ]; then
mv $DOMAINS $DOMAINS.old
fi
mv $DOMAINS.new $DOMAINS
/bin/systemctl try-reload-or-restart dnstap-bgp
```
Они были написаны не особо задумываясь, поэтому если видите что можно улучшить — дерзайте.
Настройка клиента
-----------------
Тут я приведу примеры для Linux-роутеров, но в случае Mikrotik/Cisco это должно быть еще проще.
Для начала настраиваем BIRD:
**bird.conf**
```
router id 192.168.1.2;
table rkn;
protocol device {
scan time 10;
};
# Servers
protocol bgp bgp_server1 {
table rkn;
local as 65000;
neighbor 192.168.1.1 as 65000;
direct;
bfd on;
next hop self;
graceful restart;
graceful restart time 60;
rr client;
export none;
import all;
}
protocol kernel {
table rkn;
kernel table 222;
scan time 10;
export all;
import none;
}
```
Таким образом мы будем синхронизировать маршруты, полученные из BGP, с таблицей маршрутизации ядра за номером 222.
После этого достаточно попросить ядро глядеть в эту табличку перед тем как заглядывать в дефолтную:
```
# ip rule add from all pref 256 lookup 222
# ip rule
0: from all lookup local
256: from all lookup 222
32766: from all lookup main
32767: from all lookup default
```
Всё, осталось настроить DHCP на роутере на раздачу туннельного IP-адреса сервера в качестве DNS и схема готова.
Недостатки
==========
При текущем алгоритме формирования и обработки списка доменов в него попадает, в том числе, `youtube.com` и его CDNы.
А это приводит к тому что все видео будут ехать через VPN, что может забить весь канал. Возможно стоит составить некий список популярных доменов-исключений, которые блокировать у РКН пока что кишка тонка. И пропускать их при парсинге.
Заключение
==========
Описанный способ позволяет обходить практические любые блокировки, которые реализуют провайдеры на данный момент.
В принципе, *dnstap-bgp* можно использовать для любых других целей где необходим некий уровень управления траффиком на основе доменного имени. Только нужно учитывать что в наше время на одном и том же IP-адресе может висеть тысяча сайтов (за каким-нибудь Cloudflare, например), так что этот способ имеет довольно низкую точность.
Но для нужд обхода блокировок этого вполне достаточно.
Дополнения, правки, пуллреквесты — приветствуются! | https://habr.com/ru/post/467547/ | null | ru | null |
# COBOL: в поисках свежей крови
Говорят, хорошо написанная программа на COBOL читается как роман. Даже не программист вполне сможет понять происходящее в программе на этом языке, что значительно упрощает обслуживание, если код написан грамотно. В мире, где некогда находить время для документирования программ, COBOL является в значительной степени самодокументируемым. Простой на первый взгляд, COBOL, который начинал свою историю листингом с нумерацией строк, позволяет создавать собственными средствами очень мощный код.
Однако, поможет ли это языку сегодня?
Есть ли смысл в наши дни IT-специалисту приступать к изучению COBOL? Может показаться, что в этом столько же смысла, сколько и в том, чтобы начать изучать Windows XP. Но, это далеко не так, COBOL — один из старейших языков программирования в мире, он живет и здравствует поныне в огромном количестве программ в банковской, финансовой, промышленной и других сферах по всему миру.
COBOL не вышел на пенсию, нет, но вот поколение программистов, написавших все эти приложения — они уходят на заслуженный отдых. Именно поэтому образуется нехватка знаний, чтобы поддерживать эти программы и поддерживать их в актуальном состоянии.
В [пресс-релизе](http://www.microfocus.com/about/press/pressreleases/2013/pr140320131001.aspx), на веб-сайте Micro Focus, Кевин Брерли, отвечающий за управление программными продуктами в компании Micro Focus, сказал:
> В настоящее время COBOL поддерживает 90% бизнес-систем, используемых корпорациями из списка Fortune 500 и используется в 85% всех ежедневных финансовых (бизнес) транзакций. Отсюда вывод — обучение языку COBOL в университетах даст студентам знания, полезные в жизни, они смогут их использовать дальше — в организациях, напрямую связанных с бизнесом. Без этого же, риски для бизнеса, использующего COBOL, будут повышаться.
[Хорошей новостью](http://ru.wikipedia.org/wiki/Хьюберт_Фарнсворт) является то, что Micro Focus расширила программу поддержки учебных заведений, предприятий и студентов с целью помочь образованию нового поколения разработчиков на языке COBOL.
По словам Micro Focus, новая программа поддержки будет стимулировать развитие языка COBOL в учебных заведениях, будут проводиться соревнования с последующими награждениями с возможностью стажировок.
Брерли также добавил, что предприятия сегодня должны понимать — мир движется вперед, и чтобы не отставать — необходимо преодолеть разрыв в уровнях квалификации между поколениями разработчиков, объединить их и их знания.
Micro Focus предоставляет эту программу бесплатно, включая продукты Enterprise Developer и Visual COBOL. А также всю необходимую документацию.
##### Статистика
В то же время, редактор известного журнала CRN, Sander Hulsman пишет, что в 73% университетов регулярное преподавание COBOL не развивается. Интересно, что такое положение дел не совпадает с мнением директоров высших учебных заведений. Из опрошенных по всему миру 119 директоров, 58% заявили, что преподавать и развивать Cobol необходимо. Также отметим, что 27% процентов университетов по-прежнему продолжают преподавать этот старейший язык программирования.
Увы, в учебных заведениях COBOL вытесяняется языками Java, C# и C++ (наиболее популярным языком является Java).
Это потверждает и Huib Klink, старший консультант по продажам компании Micro Focus: «Новые языки программирования, такие как Java и C#, очень популярны среди студентов. Но язык COBOL прочно закрепился на предприятиях и еще долго будет спрос на COBOL-программистов. Наше исследование показало, что семь из десяти университетов, по крайней мере в ближайшие десять лет, по-прежнему будут работать с приложениями, написанными на языке COBOL. А 25% вместо десяти называют двадцать лет».
И, повторяет, сказанные выше слова Кевина Брерли: если не изучать COBOL — повысятся риски, связанные с бизнесом.
Из [постов](http://habrahabr.ru/post/136116) на Хабре также может быть интересно [интервью с Грейс Хоппер](http://www.youtube.com/watch?v=8v8nEAnNeSs) («бабушка COBOL») и [высказывание Дейкстры](http://habrahabr.ru/post/111348) об этом языке.
##### P.S. Пара примеров кода на COBOL
В списке, подсвечиваемых Хабром языков, нет Кобола, однако…
Самая короткая программа:
```
$ SET SOURCEFORMAT"FREE"
IDENTIFICATION DIVISION.
PROGRAM-ID. ShortestProgram.
PROCEDURE DIVISION.
DisplayPrompt.
DISPLAY "Я сделал ЭТО".
STOP RUN.
```
Умножить два введенных числа:
```
$ SET SOURCEFORMAT"FREE"
IDENTIFICATION DIVISION.
PROGRAM-ID. Multiplier.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 Num1 PIC 9 VALUE ZEROS.
01 Num2 PIC 9 VALUE ZEROS.
01 Result PIC 99 VALUE ZEROS.
PROCEDURE DIVISION.
DISPLAY "Введите первое число : " WITH NO ADVANCING.
ACCEPT Num1.
DISPLAY "Введите второе число : " WITH NO ADVANCING.
ACCEPT Num2.
MULTIPLY Num1 BY Num2 GIVING Result.
DISPLAY "Результат = ", Result.
STOP RUN.
```
Материал переведен и обработан с сайтов:
1. [cfoworld.com.au](http://www.cfoworld.com.au/mediareleases/16354/cobol-55-years-old-and-in-need-of-new-blood/) (11.05.2013, автор не указан)
2. [computable.nl](http://www.computable.nl/artikel/nieuws/development/4728175/1277180/cobol-verdwijnt-uit-curriculum-onderwijs.html) (14.05.2013, автор Sander Hulsman, доб. Dirk Munk) | https://habr.com/ru/post/139573/ | null | ru | null |
# Spring/Jackson + @JsonView: фильтруем JSON

Здравствуйте!
Недавно в своем учебном Spring проекте Java Enterprise (Topjava) столкнулся с задачей каcтомизации сериализации объекта User в JSON в зависимости от контроллера: для REST API контроллера нужно было возвращать хешированный пароль (поле `user.password`), а для контроллера отображения на UI- нет. Можно решить задачу в «лоб», сделав нестолько TO ([Data Transfer Object](https://ru.wikipedia.org/wiki/DTO)), но в Spring 4.2+/Jackson 2.6 появилась возможность использовать [Jackson’s Serialization Views](https://spring.io/blog/2014/12/02/latest-jackson-integration-improvements-in-spring#json-views). Однако с статье есть подвох, и для невнимательных читателей вьюхи работают не так, как он ожидает.
В результате мне пришлось немного покопаться в реализации Jackson, чтобы понять, как все это работает. Коротко об этом:
### MapperFeature.DEFAULT\_VIEW\_INCLUSION
В статье есть небольшое упоминание
> In Spring MVC default configuration, MapperFeature.DEFAULT\_VIEW\_INCLUSION is set to false.
Это означает, что по умолчанию поля, не помеченные аннотацией `@JsonView`, исключаются. Но если посмотреть в код `MapperFeature`, то увидим:
```
...
* Default value is enabled, meaning that non-annotated
* properties are included in all views if there is no
* {@link com.fasterxml.jackson.annotation.JsonView} annotation.
*
* Feature is enabled by default.
*/
DEFAULT_VIEW_INCLUSION(true),
```
Т.е все с точностью до наоборот — все, что не помечено, включается. И если пометить только нужные для UI поля User:
```
public class User
...
@JsonView(View.UI.class)
protected String email;
@JsonView(View.UI.class)
protected boolean enabled = true;
protected String password;
```
и вызвать помеченный `@JsonView` метод контроллера
```
@JsonView(View.UI.class)
@RequestMapping(value = "/{id}", method = RequestMethod.GET, produces = MediaType.APPLICATION_JSON_VALUE)
public User get(@PathVariable("id") int id) {
return ...;
}
```
То в результат войдут как помеченные поля User (`email, enabled, ..`), так и все остальные (`password`).
### FilteredBeanPropertyWriter
Т.к. хочется исключить из контроллера UI только одно поле `password`, логично будет пометить только его. Смотрим в код `jackson-databind-2.8.0`: если запрос контроллера и поля его результата аннотированы `@JsonView`, Jackson сериализует через `FilteredBeanPropertyWriter.serializeAsField`
```
final Class activeView = prov.getActiveView();
if (activeView != null) {
int i = 0, len = _views.length;
for (; i < len; ++i) {
if (_views[i].isAssignableFrom(activeView)) break;
}
// not included, bail out:
if (i == len) {
_delegate.serializeAsOmittedField(bean, jgen, prov);
return;
}
}
_delegate.serializeAsField(bean, jgen, prov);
```
Т.е. если View, которым помечено поле объекта, совпадает или является суперклассом от View метода контроллера, поле сериализуется. Иначе оно пропускается (`serializeAsOmittedField`).
### Решение
В итоге:
* создаем по одному View для каждого контекста сериализации
```
public class View {
public static class REST {}
public static class UI {}
}
```
* помечаем в User исключаемые в UI поля тем View, в котором они должны присутствовать (REST)
```
public class User
...
protected String email;
protected boolean enabled = true;
@JsonView(View.REST.class)
protected String password;
```
* аннотируем метод контроллера UI соответствующим контекстом
```
@JsonView(View.UI.class)
@RequestMapping(value = "/{id}", method = RequestMethod.GET, produces = MediaType.APPLICATION_JSON_VALUE)
public User get(@PathVariable("id") int id) {
return ...;
}
```
Теперь поле `password` в результат не попадет. В контроллере REST можно обойтись без `@JsonView`, т.к. туда включаются все поля User.
Спасибо за внимание! Надеюсь `@JsonView` сделают Ваши Spring приложения более красивыми и компактными. | https://habr.com/ru/post/307392/ | null | ru | null |
# Агрегация и осведомленность
Механизм агрегации объектов — одна из замечательных возможностей моего JavaScript-фреймворка [jWidget](http://enepomnyaschih.github.io/jwidget/index.html#!/guide/ruhome), которой нет в большинстве других фреймворков. Хочу подробнее о ней рассказать, потому что она помогает с легкостью решать широкий спектр типичных задач, стоящих перед разработчиками клиентов веб-приложений по архитектуре Model-View. Будет мало картинок, зато много интересного кода.
Я кратко описал механизм агрегации объектов в разделе **1. Классы и объекты** [прошлой статьи](http://habrahabr.ru/post/219995/). Статья вышла полтора года назад. С тех пор произошло 4 крупных обновления фреймворка, но философия сохранилась. С опытом, было создано несколько потрясающих паттернов структурирования кода на базе механизма агрегации, позволяющих значительно сократить объем кода и сделать его проще. Для начала, напомню, что это такое.
Что такое механизм агрегации объектов
=====================================
Это подход к контролю над процессом уничтожения объектов. Цитата из прошлой статьи:
> Эту идею я почерпнул из введения к книге [Приёмы объектно-ориентированного проектирования. Паттерны проектирования](http://ru.wikipedia.org/wiki/Design_Patterns) от «банды четырех». Там рассказывается, что все указатели на объекты делятся на два типа: агрегирование и осведомленность. Осведомленность обозначает, что объект, владеющий указателем, не несет никакой ответственности за объект, на который он ссылается. Он просто имеет доступ к его публичным полям и методам, но время жизни этого объекта не под его контролем. Агрегирование же обозначает, что объект, владеющий ссылкой, несет ответственность за уничтожение объекта, на который он ссылается. Как правило, агрегируемый объект живет, пока жив объект-владелец, хотя бывают и более сложные случаи.
>
>
>
> В jWidget агрегирование реализуется через метод [own](http://enepomnyaschih.github.io/jwidget/index.html#!/api/JW.Class-method-own) класса [JW.Class](http://enepomnyaschih.github.io/jwidget/index.html#!/guide/rujwclass). Передав объект B в метод own объекта A, вы сделали объект A владельцем объекта B. При уничтожении объекта A объект B будет уничтожен автоматически. Для удобства, метод own возвращает объект B.
>
>
Чтобы извлечь максимальную пользу от механизма агрегации, фреймворк/язык должен предоставлять его реализацию на уровне самого ядра. Так, в C++ механизм агрегации зашит на уровне синтаксиса языка, а в jWidget он зашит на уровне самого базового класса [JW.Class](http://enepomnyaschih.github.io/jwidget/index.html#!/guide/rujwclass), от которого наследуются все остальные классы. Любой объект должен уметь агрегировать, и любой объект можно заагрегировать.
Пример
======
В прошлый раз хабрасообществу не очень понравился мой пример с уничтожением солдата и его рук — все сразу представили кровопролитные сцены из американских боевиков, — поэтому на этот раз приведу чуть менее зрелищный но не менее показательный пример с книгой и обложкой.
```
var Book = function() {
Book._super.call(this);
this.cover = this.own(new Cover());
};
JW.extend(Book, JW.Class, {
destroyObject: function() {
console.log("Destroying book");
this._super();
}
});
var Cover = function() {
Cover._super.call(this);
};
JW.extend(Cover, JW.Class, {
destroyObject: function() {
console.log("Destroying cover");
this._super();
}
});
```
В конструкторе книги создается обложка. Обложка агрегируется в книге, поэтому при уничтожении книги автоматически уничтожится и обложка.
```
var book = new Book();
book.destroy();
// В консоль выведется:
// Destroying cover
// Destroying book
```
Настоящий пример
================
Приведу пример из практики, более приближенный к реальности. Все любят подписываться на события jQuery, но никто не любит от них отписываться. Но в некоторых случаях отписываться надо, иначе все взорвется.
```
var MyView = function() {
MyView._super.call(this);
$(window).resize(JW.inScope(this._layout, this));
};
JW.extend(MyView, JW.Class, {
_layout: function() {
// ...
}
});
```
**Правда взорвется?**Однажды мы разрабатывали дополнение к SketchUp, и у нас в команде был внештатный документатор. Как-то раз он документировал раздел «Известные баги» в одном из релизов, и прочитал в задаче, что при группировке объектов особого вида они могут неправильно экспортироваться в файл. Он задал мне вопрос: «Ну а что все-таки произойдет, если попытаться экпортировать такие объекты в файл?» Я в шутку ответил: «Ну, не знаю, наверно, все взорвется.» Ну, он так и записал. С тех пор в официальной документации так и написано «Если вы так сделаете, то все взорвется.»
В этом коде, очевидно, не хватает отписки от события «resize» при уничтожении объекта MyView. Уничтожая объект MyView, мы должны быть уверены, что он не оставит за собой никаких следов.
```
var view = new MyView();
view.destroy();
```
Но поскольку мы не отписались от события «resize», по нему метод "\_layout" мертвого объекта вызываться будет, что может породить side-эффекты неожиданные. Исправим оплошность:
```
var MyView = function() {
MyView._super.call(this);
$(window).bind("resize", JW.inScope(this._layout, this));
};
JW.extend(MyView, JW.Class, {
_layout: function() {
// ...
},
destroyObject: function() {
$(window).unbind("resize", JW.inScope(this._layout, this));
this._super();
}
});
```
Я намеренно допустил еще одну типичную ошибку: метод [JW.inScope](http://enepomnyaschih.github.io/jwidget/index.html#!/api/JW-static-method-inScope) каждый раз создает новый экземпляр функции, так что метод «unbind» не сделает ничего. Исправим и это:
```
var MyView = function() {
this._layout = JW.inScope(this._layout, this);
MyView._super.call(this);
$(window).bind("resize", this._layout);
};
JW.extend(MyView, JW.Class, {
_layout: function() {
// ...
},
destroyObject: function() {
$(window).unbind("resize", this._layout);
this._super();
}
});
```
Надоело… Куча кода ради такой мелочи? Покончим с этим с помощью агрегации!
```
var MyView = function() {
MyView._super.call(this);
this.own($(window).jwon("resize", this._layout, this));
};
JW.extend(MyView, JW.Class, {
_layout: function() {
// ...
}
});
```
Метод [jwon](http://enepomnyaschih.github.io/jwidget/index.html#!/api/jQuery-method-jwon) возвращает подписку на событие, уничтожение которой, очевидно, влечет отписку от события.
Агрегирующие свойства и коллекции
=================================
Важной частью механизма агрегации объектов являются агрегирующие свойства и коллекции. Вызов метода [ownValue](http://enepomnyaschih.github.io/jwidget/index.html#!/api/JW.Property-method-ownValue) у свойства заставляет его агрегировать всякое значение, которое ему присвоют. Так, при смене значения свойства или при уничтожении самого свойства текущее значение будет уничтожаться.
```
var property = new JW.Property().ownValue();
property.set(new SampleValue(1));
property.set(new SampleValue(2)); // SampleValue(1) неявно уничтожается
property.destroy(); // SampleValue(2) неявно уничтожается
```
Аналогично, вызов метода [ownItems](http://enepomnyaschih.github.io/jwidget/index.html#!/api/JW.AbstractCollection-method-ownItems) у коллекции заставляет ее агрегировать всякий элемент, который в нее добавляют.
```
var array = new JW.Array().ownItems();
array.add(new SampleValue(1));
array.add(new SampleValue(2));
array.set(new SampleValue(3), 0); // SampleValue(1) неявно уничтожается
array.remove(1); // SampleValue(2) неявно уничтожается
array.destroy(); // SampleValue(3) неявно уничтожается
```
В последующих примерах мы будет активно пользоваться этими возможностями.
Теперь о паттернах.
Паттерн 1: Простое обновление объекта
=====================================
***Если подобъект, который хочется заагрегировать в объекте, с ходом времени пересоздается, поместите его в агрегирующее свойство.***
Представьте, что вы прослушиваете некоторое событие, и всякий раз, когда оно происходит, некоторым образом заменяете содержимое объекта. При создании нового содержимого старое нужно уничтожить.
```
var MyView = function(event) {
MyView._super.call(this);
this.content = null;
this.initContent();
this.own(event.bind(this.refreshContent, this));
};
JW.extend(MyView, JW.Class, {
destroyObject: function() {
this.doneContent();
this._super();
},
initContent: function() {
this.content = new Content();
},
doneContent: function() {
this.content.destroy();
},
refreshContent: function() {
this.doneContent();
this.initContent();
}
});
```
Если воспользоваться агрегирующим свойством по паттерну простого обновления объекта, этот код можно сократить в 2 раза:
```
var MyView = function(event) {
MyView._super.call(this);
this.content = this.own(new JW.Property()).ownValue(); // ПАТТЕРН ЗДЕСЬ
this.refreshContent();
this.own(event.bind(this.refreshContent, this));
};
JW.extend(MyView, JW.Class, {
refreshContent: function() {
this.content.set(new Content());
}
});
```
Если очень надо, чтобы новое содержимое создавалось только после уничтожения старого, предварительно присвойте свойству значение null:
```
refreshContent: function() {
this.content.set(null);
this.content.set(new Content());
}
```
Паттерн 2: Простая отмена операции
==================================
***Если в момент уничтожения или смены состояния объекта может выполняться некоторая операция, но вы не знаете этого наверняка, то для ее отмены следует воспользоваться агрегирующим свойством.***
Часто, особенно при использовании роутера на базе location.hash или History API, возникает необходимость отменять загрузку покинутой страницы, если пользователь быстро переключается между страницами. Как правило, загрузка представляет собой последовательное выполнение AJAX-запросов, анимаций и прочих асинхронных операций. Кроме того, сама страница время от времени инициирует перезагрузку своих данных. Если пользователь переходит на другую страницу во время выполнения одной из таких операций, ее необходимо отменить.
Для решения этой задачи заведем агрегирующее свойство «currentOperation» и будем помещать туда текущую асинхронную операцию.
```
var MyPage = function() {
MyPage._super.call(this);
this.currentOperation = this.own(new JW.Property()).ownValue(); // ПАТТЕРН ЗДЕСЬ
this.dataHunkIndex = 0;
};
JW.extend(MyPage, JW.UI.Component, {
afterRender: function() {
this._super();
this._loadData();
},
_loadData: function() {
this.currentOperation.set(new Request("/api/data", {hunk: this.dataHunkIndex}, this._onDataLoad, this));
},
_onDataLoad: function(result) {
this.currentOperation.set(new Animation("fade in", this._onAnimationFinish, this));
},
_onAnimationFinish: function() {
this.currentOperation.set(null);
},
renderLoadNextHunkButton: function(el) {
el.jwon("click", this._loadNextHunk, this);
},
_loadNextHunk: function() {
++this.dataHunkIndex;
this._loadData();
}
});
```
Теперь нам не надо беспокоиться о целостности состояния приложения: при переключении между страницами и при нажатии на кнопку «Load next hunk» текущая операция будет отменена, и загрузка новых данных начнется с чистого листа.
Естественно, для каждой такой операции необходимо завести класс, уничтожение которого отменяет операцию. Пример реализации класса Request для AJAX-запроса:
```
var Request = function(url, data, success, scope) {
Request._super.call(this);
this.aborted = false;
this.success = success;
this.scope = scope;
this.ajax = $.ajax({
url : url,
data : data,
success : this._onSuccess,
error : this._onError,
context : this
});
};
JW.extend(Request, JW.Class, {
destroyObject: function() {
// При вызове метода "abort" jQuery вызывает обработчик ошибки,
// что нас никак не устраивает. Заводим для этого флаг
this.aborted = true;
// Если запрос уже завершился, вызов метода "abort" не навредит.
// Если нет - завершаем его
this.ajax.abort();
this._super();
},
_onSuccess: function(result) {
this.success.call(this.scope, result);
},
_onError: function() {
if (!this.aborted) {
alert("Request has failed =((");
}
}
});
```
Паттерн 3: Массовое уничтожение объектов
========================================
***Если объект вызовом некоторой функции провоцирует создание множества объектов, то функции следует возвращать один объект, агрегирующий в себе все эти объекты.***
Предположим, при обновлении объекта создается множество объектов, которые надо уничтожить при последующем обновлении. Можно ли использовать механизм агрегации, чтобы сократить объем кода в этом случае? Конечно, воспользовавшись паттерном простого обновления объекта несколько раз, мы можем завести несколько свойств, по одному для каждого подъобъекта. Но что делать, если вы не знаете заранее, сколько объектов нужно создать? Это весьма частая ситуация, если объекты создаются какой-то сторонней фабрикой. Рассмотрим следующий код в качестве примера:
```
var Client = function(event, factory) {
Client._super.call(this);
this.factory = factory;
this.objects = null; // Array
this.initObjects();
this.own(event.bind(this.refreshObjects, this));
};
JW.extend(Client, JW.Class, {
destroyObject: function() {
this.doneObjects();
this._super();
},
initObjects: function() {
this.objects = this.factory.createObjects();
},
doneObjects: function() {
for (var i = this.objects.length - 1; i >= 0; --i) {
this.objects[i].destroy();
}
this.objects = null;
},
refreshObjects: function() {
this.doneObjects();
this.initObjects();
}
});
var Factory = {
createObjects: function() {
return [
new Object1(),
new Object2(),
new Object3()
];
}
};
```
Очень много непонятного кода: напрашивается рефакторинг. Пусть фабрика возвращает обычный JW.Class, который агрегирует внутри себя все 3 объекта.
```
var Client = function(event, factory) {
Client._super.call(this);
this.factory = factory;
this.objects = this.own(new JW.Property()).ownValue();
this.refreshObjects();
this.own(event.bind(this.refreshObjects, this));
};
JW.extend(Client, JW.Class, {
refreshObjects: function() {
this.objects.set(this.factory.createObjects());
}
});
var Factory = {
createObjects: function() {
// ПАТТЕРН ЗДЕСЬ
var objects = new JW.Class();
objects.own(new Object1());
objects.own(new Object2());
objects.own(new Object3());
return objects;
}
};
```
Паттерн 4: Уничтожение драйвера объекта
=======================================
***Если функция возвращает объект, который имеет свой драйвер, заагрегируйте этот драйвер в самом объекте.***
Предположим, что вы хотите написать метод, который создает свойство, подписывается на некоторые события, чтобы это свойство обновлять, и возвращает это свойство. Подписку на эти события назовем **драйвером** данного свойства. Драйвером объекта A будем называть любой объект, который влияет на изменение объекта A.
Приведу пример драйвера. Пусть где-то на странице есть контрол динамического переключения между цветовыми схемами приложения. Цветовая схема задается словарем «ключ — цвет». Каждая цветовая схема неизменна, но между ними можно переключаться. Подписка на событие изменения выбранной цветовой схемы — это драйвер свойства, содержащего цвет с заданным ключом. Ключ, который нам нужен, мы знаем зараннее; цвет же зависит от выбранной цветовой схемы. Кроме того, при изменении выбранной цветовой схемы свойство с цветом должно автоматически обновляться. Напишем класс такого драйвера.
```
var ColorDriver = function(selectedScheme, colorKey, color) {
ColorDriver._super.call(this);
this.selectedScheme = selectedScheme; // JW.Property
this.colorKey = colorKey;
// Делаем аргумент color необязательным
this.color = color || this.own(new JW.Property());
this.\_update();
this.own(this.selectedScheme.changeEvent.bind(this.\_update, this));
};
JW.extend(ColorDriver, JW.Class, {
\_update: function() {
this.color.set(this.selectedScheme.get()[this.colorKey]);
}
});
```
**Примечание**В jWidget то же самое можно сделать и без создания класса, если воспользоваться методом selectedScheme.[$$mapValue](http://enepomnyaschih.github.io/jwidget/index.html#!/api/JW.Property-method-S-S-mapValue). Но на низком уровне, этот метод все равно использует паттерн уничтожения драйвера, используя [JW.Mapper](http://enepomnyaschih.github.io/jwidget/index.html#!/api/JW.Mapper) в качестве драйвера. Поэтому в целях демонстрации паттерна вполне разумно отказаться от применения данного метода.
Чтобы было проще, напишем класс управления цветовыми схемами, который умеет создавать такие свойства и драйверы.
```
var ColorSchemeManager = function() {
ColorSchemeManager._super.call(this);
this.selectedScheme = this.own(new JW.Property());
};
JW.extend(ColorSchemeManager, JW.Class, {
getColorDriver: function(key) {
return new ColorDriver(this.selectedScheme, key);
}
});
```
Когда цвет больше не нужен, его драйвер нужно уничтожить. Агрегировать драйвер в менеджере нельзя, поскольку не менеджер провоцирует создание драйвера. За уничтожение драйвера должен отвечать объект, который провоцирует его создание, т.е. клиент.
```
var Client = function(colorSchemeManager) {
Client._super.call(this):
this.colorSchemeManager = colorSchemeManager;
};
JW.extend(Client, JW.UI.Component, {
renderBackground: function(el) {
var color = this.own(this.colorSchemeManager.getColorDriver("background")).color;
this.own(el.jwcss("background-color", color));
}
});
```
Это будет работать, но у такого решения есть несколько недостатков:
1. Драйвер совсем не интересует клиента — клиенту нужен лишь цвет
2. Трудности с полиморфизмом: если в некоторых случаях драйвер нужен, а в других — не нужен, — то для обеспечения полиморфизма вам придется писать драйвер-пустышку, который ничего не делает, а лишь хранит ссылку на цвет
3. Этот код трудно читать
Для решения этих проблем воспользуемся паттерном уничтожения драйвера. Паттерн рекомендует заагрегировать драйвер объекта в самом объекте. Поскольку jWidget уничтожает заагрегированные объекты раньше самого объекта, это не порождает никаких side-эффектов.
```
var ColorSchemeManager = function() {
ColorSchemeManager._super.call(this);
this.selectedScheme = this.own(new JW.Property());
};
JW.extend(ColorSchemeManager, JW.Class, {
getColor: function(key) {
// ПАТТЕРН ЗДЕСЬ
var color = new JW.Property();
color.own(new ColorDriver(this.selectedScheme, key, color));
return color;
}
});
var Client = function(colorSchemeManager) {
Client._super.call(this):
this.colorSchemeManager = colorSchemeManager;
};
JW.extend(Client, JW.UI.Component, {
renderBackground: function(el) {
var color = this.own(this.colorSchemeManager.getColor("background"));
this.own(el.jwcss("background-color", color));
}
});
```
Код клиента стал проще и понятнее.
Заключение
==========
С механизмом агрегации объектов вам больше не нужно явно реализовывать и вызывать деструкторы объектов. Реализация деструкторов остается лишь в низкоуровневых классах, таких как AJAX-запрос, подписка на событие и т.д. Классы jWidget реализуют большинство необходимых деструкторов, так что от вас требуется лишь правильно связывать объекты отношением агрегации.
Заменой всех явных вызовов деструкторов классов механизмом агрегации объектов на одном из проектов мне удалось удалить 1000 строк кода из 15000 (выигрыш 7%). | https://habr.com/ru/post/270879/ | null | ru | null |
# Мне было стыдно за свой интерпрайз-код настолько, что я сделал свой велосипед. За него стыдно меньше
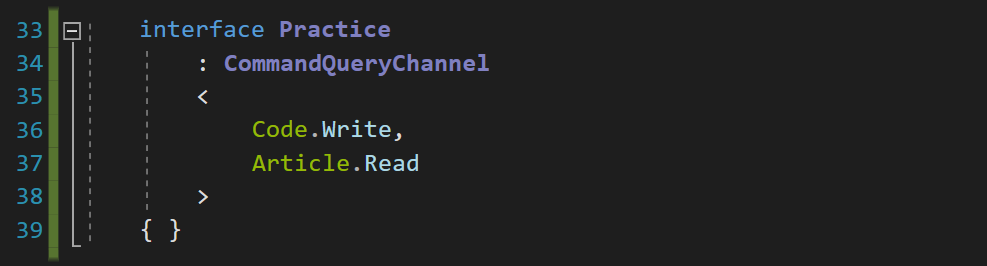
Это продолжение текста про архитектуры интерпрайз-систем. Рассуждения это хорошо, но какой в них толк без практического применения. Я покажу свой фреймворк в деле.
Всё началось с того, что я [рассказывал про проблематику](https://habr.com/ru/post/517404/) проектирования приложений на .NET и ныл про нелёгкую жизнь в кровавом интерпрайзе. Затем я [описал решение](https://habr.com/ru/post/520858/), которое сам придумал и реализовал — Reinforced.Tecture. То была теория, концептуальные рассуждения, визионёрство и снова нытьё. На этот раз о том, что на дворе 2020 год, а HKT в C# так и не завезли.
Сегодня я продемонстрирую свой подход в действии на примере простенького проекта и покажу профиты, которые он даёт: от сокращения количества кода до автоматизации тестирования и оригинального подхода к документации. Как советовал старина Торвальдс: "Болтовня ничего не стоит, покажите мне код".
Итак, надо сделать на Tecture что-нибудь простое, но работающее. Раз мы говорим про интерпрайз — я подберу пример, отдалённо напоминающий настоящий бизнес.
Нам понадобится:
* Простая сущность. В голову сразу приходят продукты и заказы. Пусть будут продукты;
* EF-ный DbContext и локальная база данных;
* Игрушечная бизнес-логика;
* Простенький web-проект. Всё чин по чину, ASP.NET Core, WebAPI. В него логику и воткнём.
Подготовка
----------
Структура проекта будет такая:
Я подключил EF.Core к сборке `Data`, закинул туда DbContext и glue-код для миграций. Потому что хочу оставить логику на .NET Standard и не тащить EF с собой.
**Кстати, интересно**
Обычно сущности кладутся в сборку с DAL-ом, рядом с контекстом. Здесь же зависимость развёрнута в обратную сторону — сборка с контекстом знает о всей логике. Это кажется контринтуитивным, но на самом деле вполне нормально для Tecture. Не стоит этому удивляться.
Поведение Tecture мы будем смотреть на примере работы с продуктами. Вот его сущность, а логика вокруг неё будет простая и очень глупая:
Код `DbContext`-а абсолютно шаблонный, спрячу-ка я его под спойлер. В рамках тестового проекта я кладу болт на управление строкой подключения и тонкую настройку контекста — это сейчас не важно. EF я использую как *рантайм*, не более. Он не оказывает влияния на логику и вообще его поддержка подтягивается из отдельного пакета. EF для меня — удобный инструмент реализации ORM-аспекта. Но моя логика при этом остаётся чистой и свободной от сопутствующих EF-зависимостей.
**AcmeDbContext**
Между делом я сделал базу данных в локальном инстансе MS SQL Express. Это первое что попалось мне под руку — окружение уже было настроено на моей домашней машине. EF.Core более-менее поддерживает и остальные базы — вроде MySQL и PostgreSQL. Однако, на уровне аспекта, где работает Tecture, становится совершенно пофигу. Просто мне так удобнее проводить демонстрацию. Никаких скрытых зависимостей от базы данных тут нет.
Короче, пора втащить в логику первую зависимость. Докинем в неё Reinforced.Tecture и Reinforced.Tecture.Aspects.Orm.
Я рассказал про каналы в предыдущей статье и вот они мне пригодились. У меня будет простой канал для базы данных с единственным аспектом, отвечающим за O/RM:
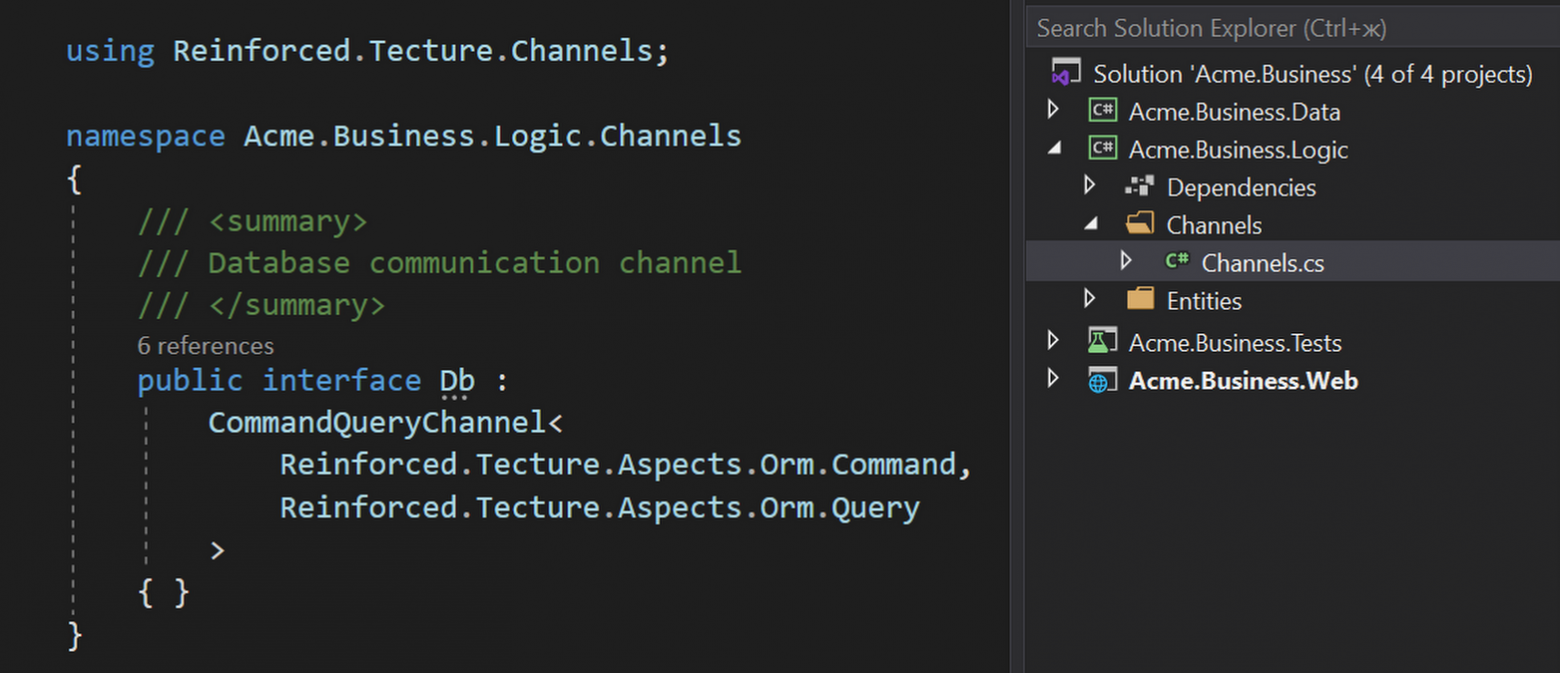
Тут же, чтобы два раза не вставать я сразу сделаю экстеншоны для доставания сущностей по Id. Они используются везде и в своих экспериментах я копипащу эти строки заранее, дабы исключить появление репозиториев на раннем этапе. Чуток кода и готово:
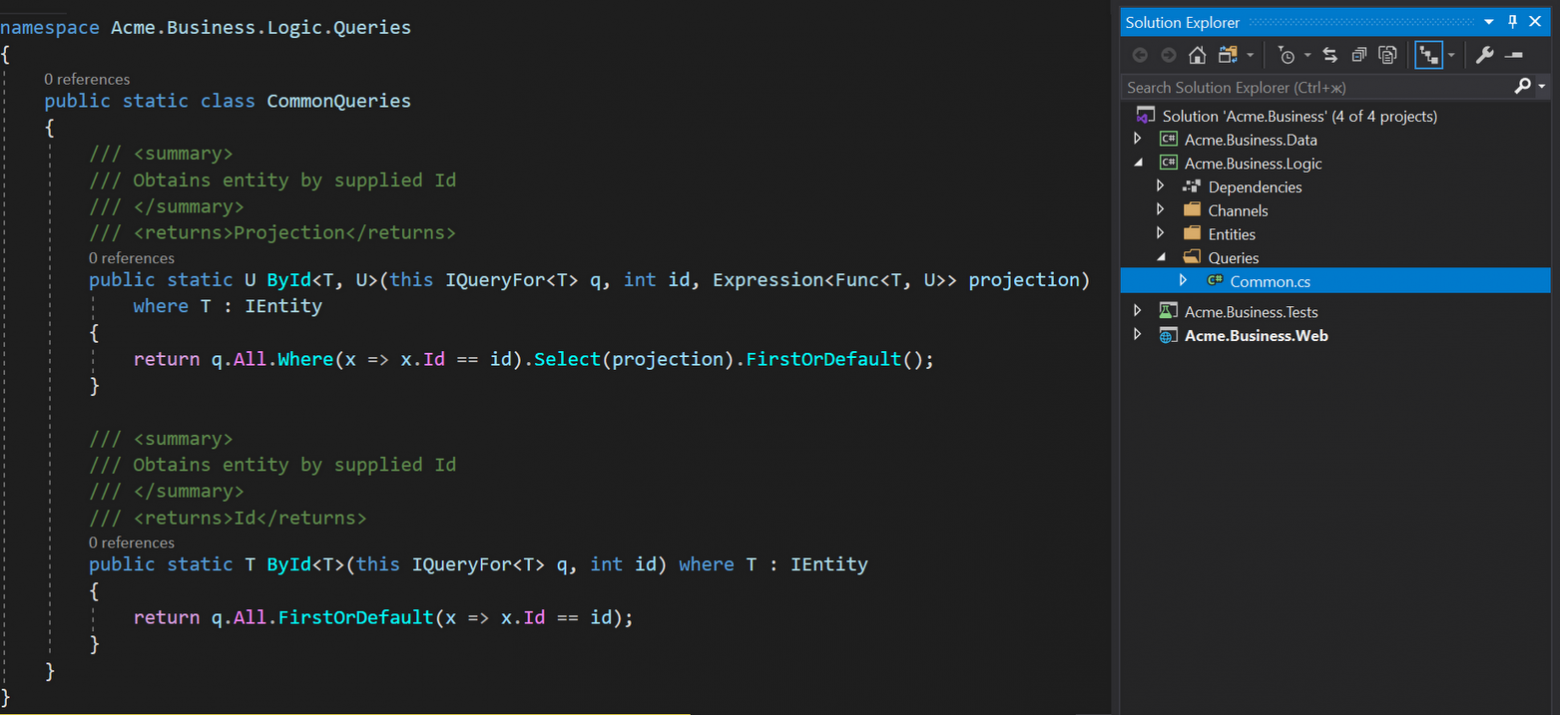
Интеграция
----------
На этом этапе проект уже вполне рабочий. Осталось только присоеденить Tecture к желаемому end-user решению. В нашем случае это web-проект. Я открываю его, иду в `Startup.cs`, и ищу там метод `ConfigureServices`. Это внутренний DI-контейнер, который идёт в комплекте с ASP.NET MVC. Для демонстрационных целей он вполне норм, поэтому я заталкиваю в него `AcmeDbContext`:

Теперь самое время поставить *рантайм* Tecture для взаимодействия с базой через EF. Прямо в web-проект. В моём рантайме реализованы 2 аспекта: O/RM и DirectSQL. DirectSQL я не буду здесь демонстрировать, но он есть. Как я уже сказал, в сборке с бизнес-логикой рантайм не нужен. Он должен подключаться только в ту часть системы, где бизнес-логика непосредственно вызывается, что сильно облегчает dll-ку с логикой на предмет зависимостей. Сам же рантайм вполне может реализовывать несколько аспектов за раз. Это не запрещено и — опять же — экономит зависимости:
Теперь надо засунуть Tecture в контейнер. Это делается через фэктори метод. Для наглядности я вынес его отдельно и снабдил комментариями. Тут я просто извлекаю из контейнера `AcmeDbContext`, заворачиваем его в `LazyDisposable` (это гибрид Lazy и Disposable, как следует из названия) и скармливаем его рантайму. Далее, для каждого канала мы указываем что вот именно этот контекст EF и надо использовать. Делается это с помощью входящих в комплект поставки рантайма fluent-методов:
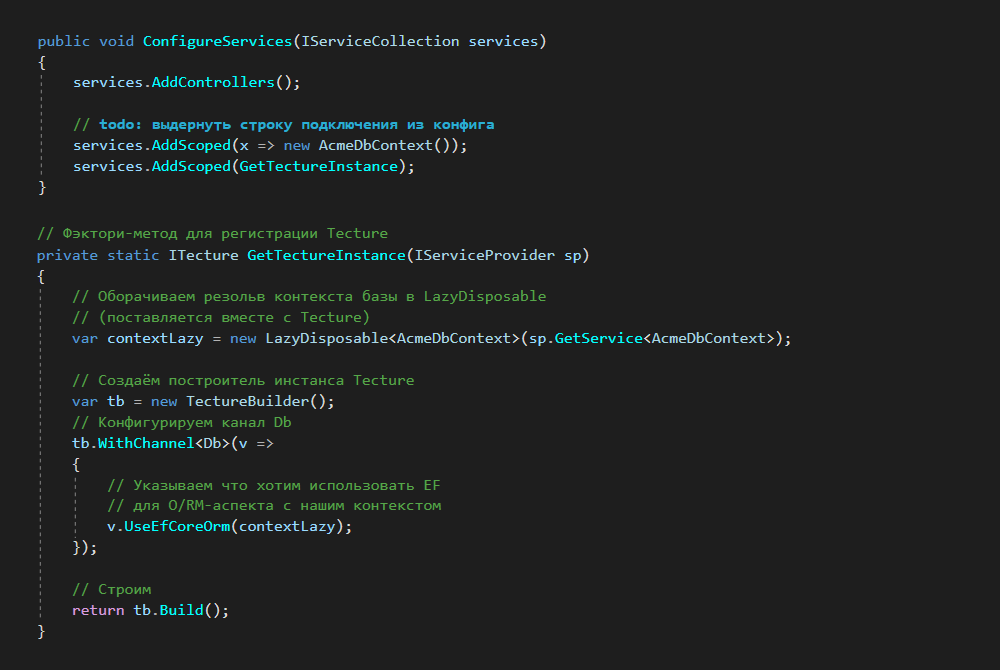
По задумке такой интеграционный код пишется только один раз и не меняется примерно никогда. Принцип "настроил и забыл" в действии. Для сложных многоканальных систем, конечно, можно нагородить всякие обёртки над построителем Tecture, чтобы настраивать его на работу с разными комбинациями внешних систем, но в нашем приложении такое пока не нужно. Тут мы видим separation of concerns: пусть лучше действительно сложный и чувствительный кусок системы будет краток, прост, читаем и — главное — написан один раз. Далее, на ваше усмотрение — можете вынести его в отдельный репозиторий, единожды собрать и просто использовать.
Вообще я стараюсь возложить максимум ответственности на рантаймы и аспекты. По сути я выношу в них всю реальную проектировочную работу, которую необходимо сделать в приложении. По задумке, обслуживать это дело должен системный архитектор. Я полагаю, в любой компании найдётся бородатый разработчик, который сможет один раз в этом разобраться, настроить и больше никогда не трогать. Но если такого нет — можно воспользоваться моими аспектами и моим рантаймом. Таким образом, пресловутые separation of concerns я поднимаю на организационный уровень.
Но в приложении всё равно остаётся вот это вот узкое место, где всё собирается воедино: задаётся конекшон стринг к базе, поднимаются подключения к кэшам, проверяется связь с очередью. Я и сам не могу долго держать в голове всё хитросплетение конфигурации и быстро устаю от работы с интеграционным glue-кодом. Всё, что я могу сделать — свести к минимуму количество мест, требующих такой концентрации внимания.
Tecture предоставляет единую точку связывания и не даёт размазывать интеграционный код по системе, чтобы его поддержкой не занимались все подряд. Пусть лучше всё тот же архитект отвечает и за это место.
Как бы то ни было, теперь можно использовать `ITecture` из контроллеров. Давайте поиграем с ним.
Запросы
-------
Я хочу написать совершенно тупой и очевидный веб-метод, который будет отдавать нам продукт по Id. Держу пари, у всех такой есть. И у всех на такой случай есть DTOшка. Вот, например, моя:

Теперь мы идём в контроллер, прокидываем `ITecture` в конструктор, выдёргиваем его в отдельное поле, через которое получаем долгожданный доступ к методу `From<>`. Используем его для того, чтобы вытянуть продукт по Id и смапить на DTO-шку:

И на этом, в общем, всё. Таким способом можно писать все методы для возврата всех сущностей по Id с DTO-шками без единого репозитория. Можно дать волю фантазии и не стесняться использовать компилятор C# на полную. Скажем, возврат множества DTO-шек можно обыграть таким способом:
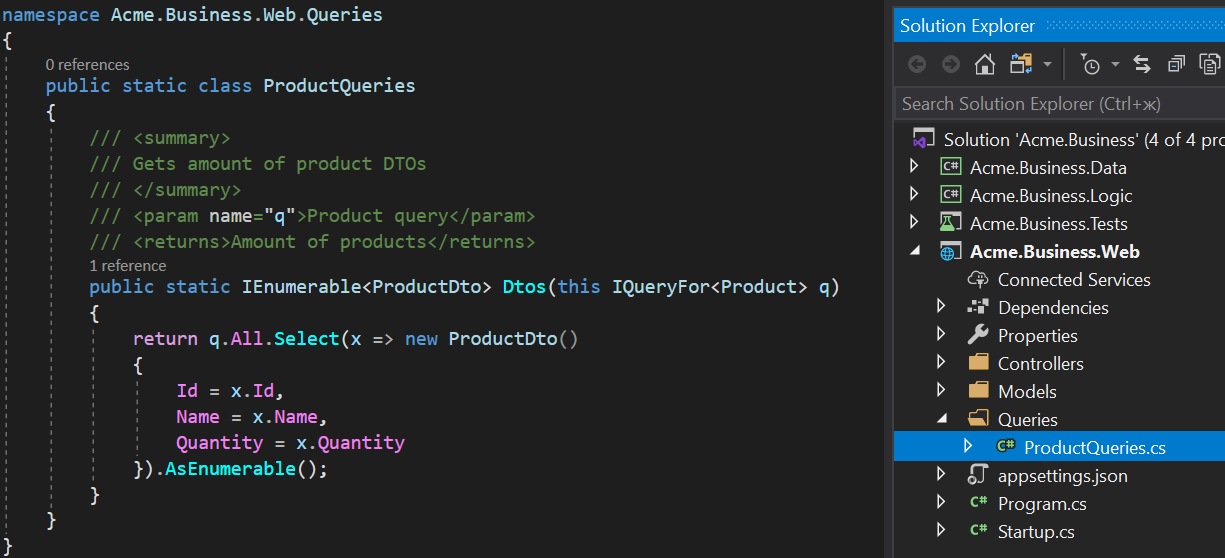

Или таким:


Можно даже фигачить расширения непосредственно для `IQueryable`, дёргая их из читального конца канала через метод `All<>`, предоставляемый аспектом. Тут действительно можно дать фантазии развернуться. Хочешь — делай развесистый построитель запроса вокруг конца канала, со своими промежуточными абстракциями. Хочешь — строй фасады к AutoMapper, используя его копирующие expression-ы. Всё это в любом случае — статика без контекста. Она легко покрывается тестами при желании, не требует базы данных и сборки контейнера. Можно даже сделать свой аспект и выкинуть туда всё, что касается запросов. Короче, бескрайнее поле для творчества и самореализации. Я же не буду в нём зависать, потому что впереди ещё много интересного.
Операции
--------
К сожалению, продуктов у нас в базе нет и что-то запрашивать из неё бесполезно. Нужен способ заслать туда данные. Как я уже говорил, добавление в Tecture делается через сервисы. Вот я и сделаю сервис для работы с продуктами. За полсекунды, я набросал вот такую заготовку вот в этом месте:
Я уже говорил, что в сервисах есть тулинги и они очень удобны. Я хочу остановиться и прям показать как они работают используя анимацию. Конкретно эти тулинги взяты из ORM-аспекта — зацените механику:
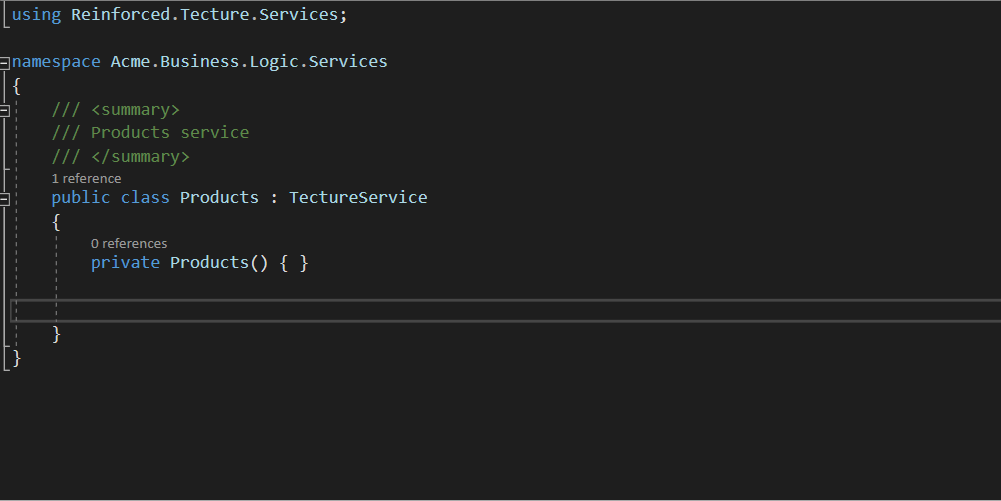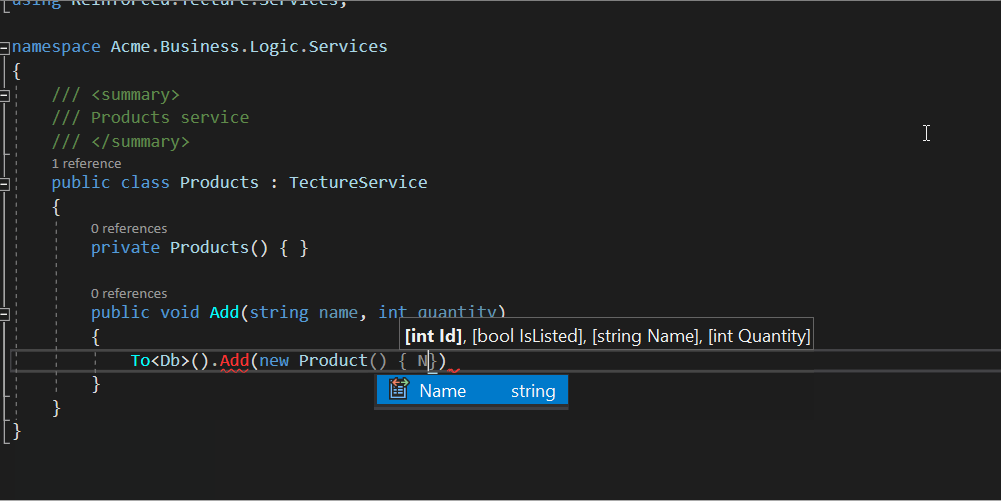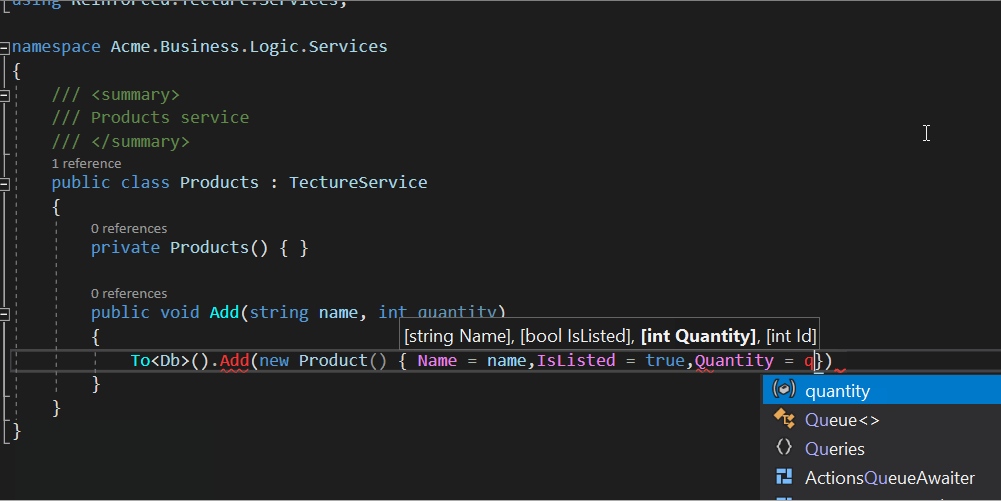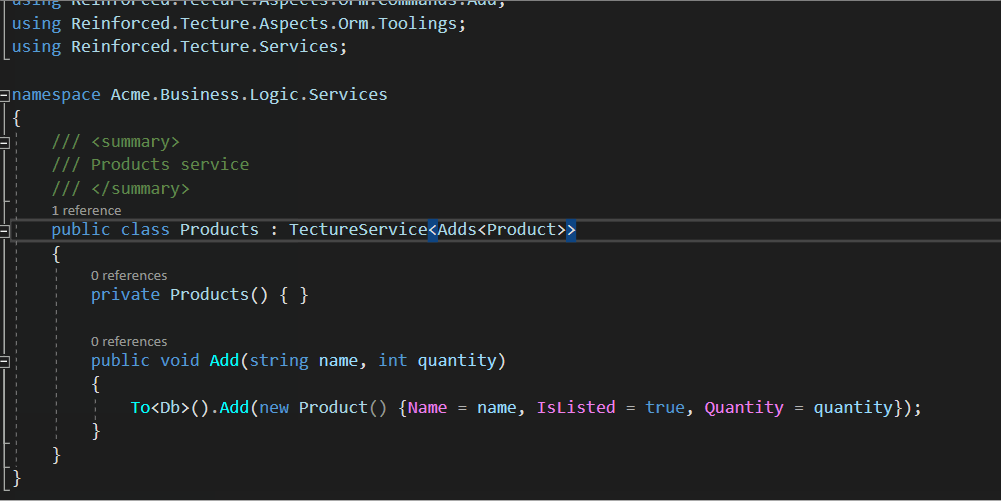
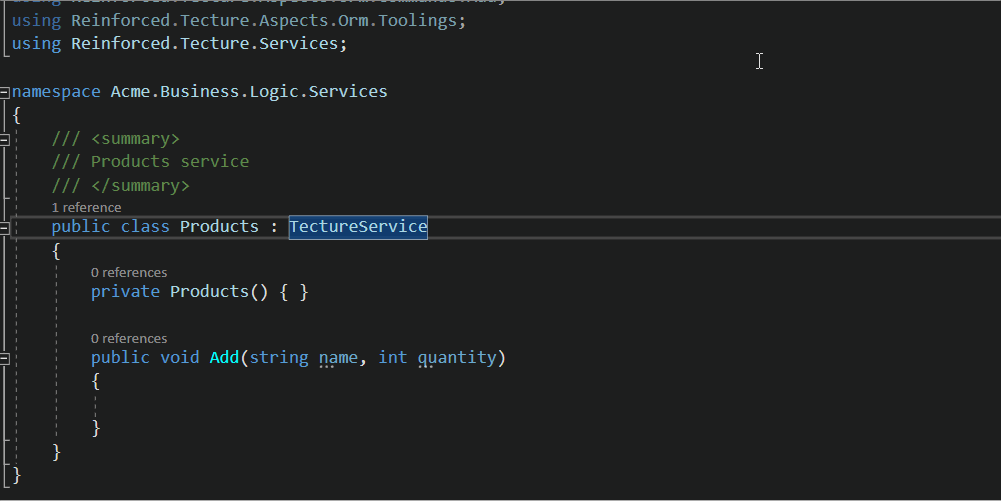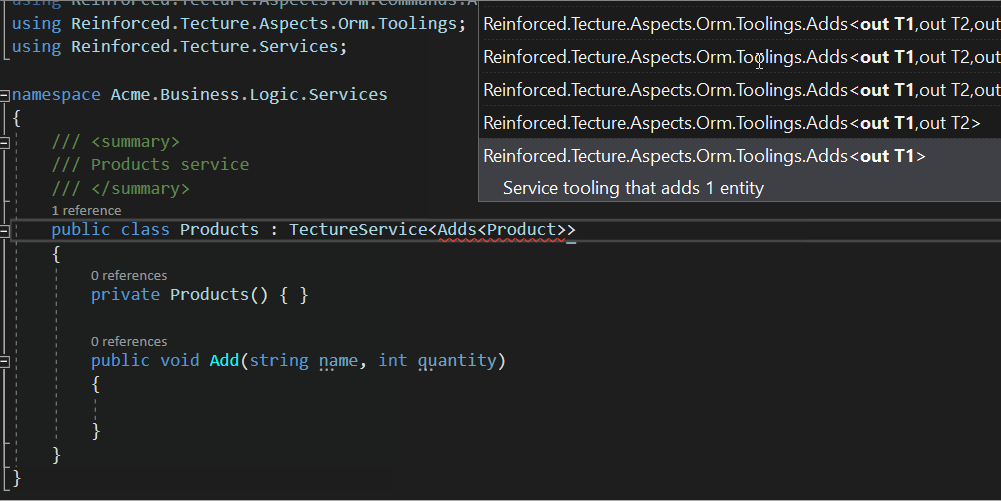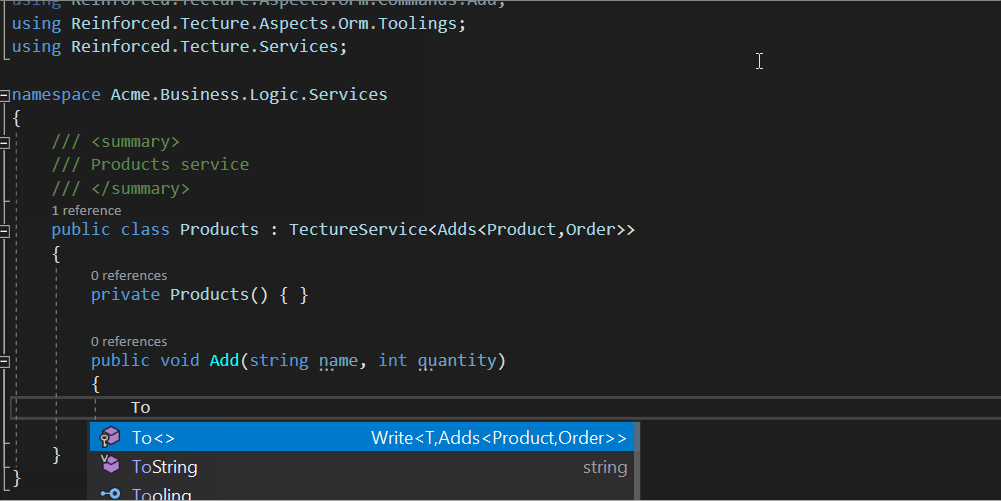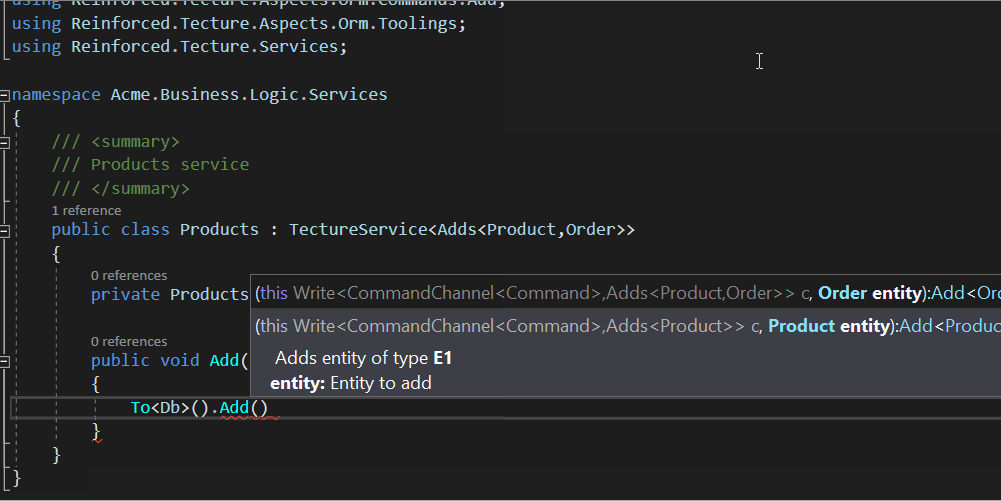
Кстати, нам понадобится Id свежедобавленного продукта. Когда я делал аспект ORM — долго думал как это обыгрыть. Ведь создание сущности — это команда, а получение Id — запрос. Как быть? Я выкрутился: команда `Add` экстендит интерфейс `IAddition<>`. После логической операции, саму команды можно смело вернуть из метода логики как `IAddition`. А уже после сохранения скормить аддишен методу `Key` читального конца канала. Это даст нам вожделенный Id. Но надо ещё указать где именно у сущности первичный ключ. Я реализовал эту механику через интерфейс `IPrimaryKey<>`. Вот:
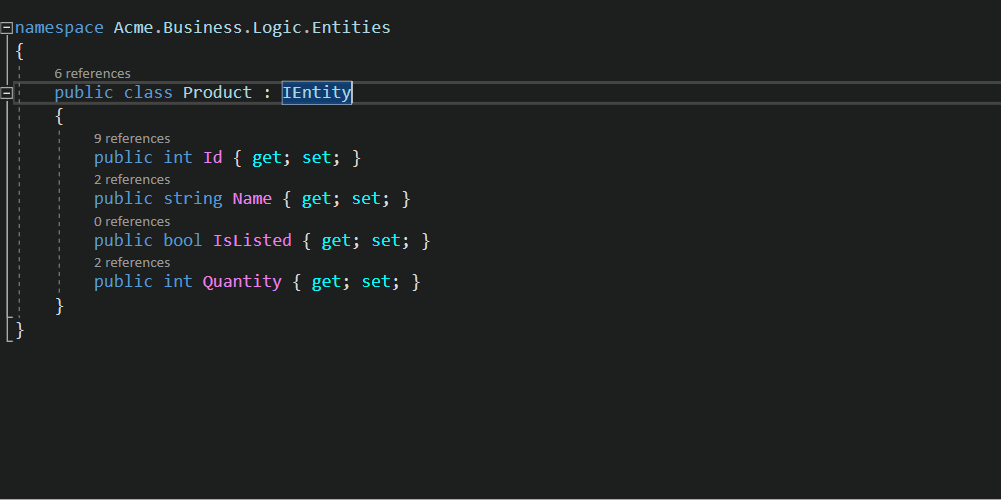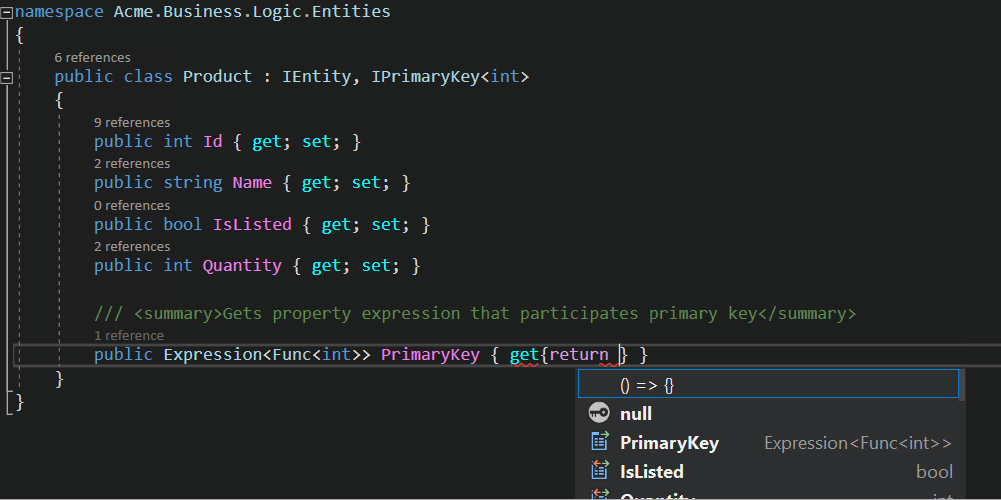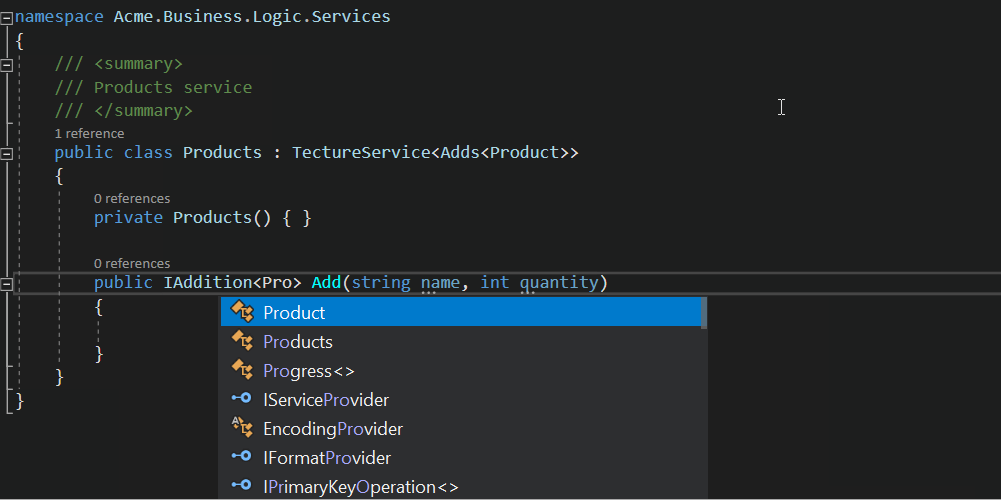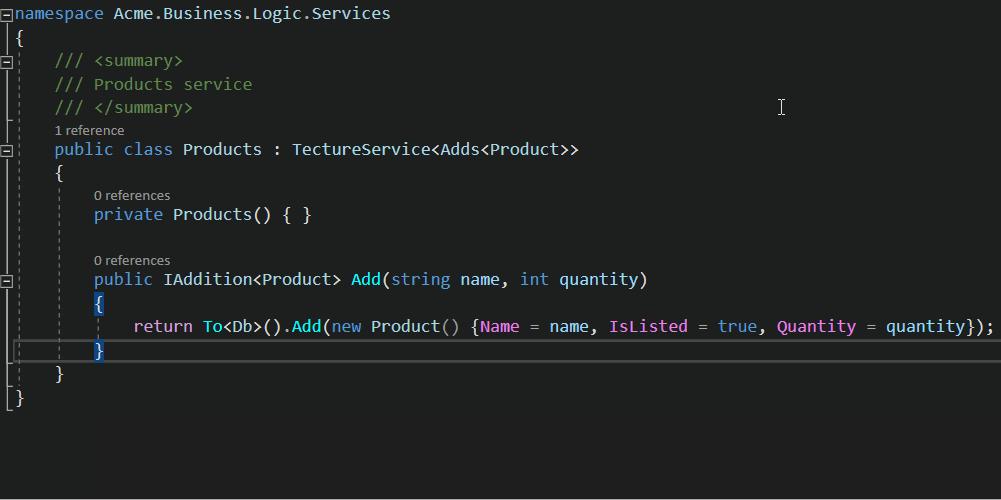
Готово. Теперь можно вернуться в контроллер и наконец-то призвать наш сервис:
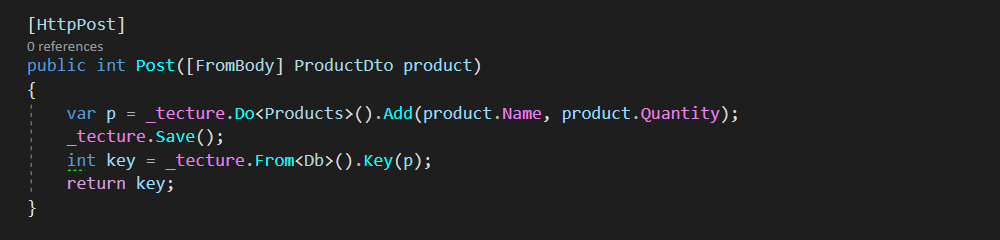
Postman сказал мне что это работает и вернул Id нового продукта.
Теперь у нас есть маленькое бизнес-приложение, сделанное на Tecture. Мы уже получили чёткую грануляцию проекта, удобные примитивы и минимум кода, но это только начало. Сейчас я перейду к самому интересному — к конкретным преимуществам, которыми меня щедро осыпает такой подход.
---
Я делаю свой архитектурный фреймворк чтобы срезать косты. Никогда бы в это не ввязался, если бы не понимал насколько правильный дизайн и архитектура может сократить затраты на обслуживание и какой груз можно снять с плеч разработчиков.
Я стараюсь быть практичным и всегда считал что архитектура решения сильнее всего влияет на цену поддержки и развития. Ещё в университете на парах по управлению проектами мне показывали статистику запоротых разработок в американской авиаиндустрии. Я чётко помню что в 90% случаев провал определялся ошибками на стадии раннего проектирования и управления требованиями. Это наталкивает на мысль, что если сначала думать, а потом делать — то можно не только предотвратить наступание на грабли, но и драматически снизить стоимость поддержки.
Чем ниже цена, которую платит бизнес за поддержку софта — тем круче. Чем меньше накладные расходы — тем больше денег остаётся и можно потратить их на развитие. А ещё лучше — положить мне в карман.
Я убеждён что только очень меркантильный человек мог придумать следующие фичи.
Трейсы
------
Вернёмся к коду контроллера. В Tecture есть неприметные методы `BeginTrace` и `EndTrace`. Я окружаю ими содержимое экшона по периметру. Вот так:

Помимо них тут есть вызов `Explain`. Так я прошу Tecture *объяснить мне* что происходит между началом и концом трассировки. Втыкаю точку останова на `return` и запускаю:

Бам! Человеческим языком мне рассказали что конкретно произошло в логике. Само собой, тут и логика-то из трёх с половиной действий. Но когда проект обрастёт сервисами, тонкой нюансировкой, зависимостями и прочими сложностями, которые порождает бизнес — трейс всё так же будет объяснять что прочитано и записано в базы, очереди, кэши, файлы. И если мы не будем лениться, а приложим совсем немного усилий добавляя командам и запросам аннотации, то текст трейса станет ещё более осмысленным:
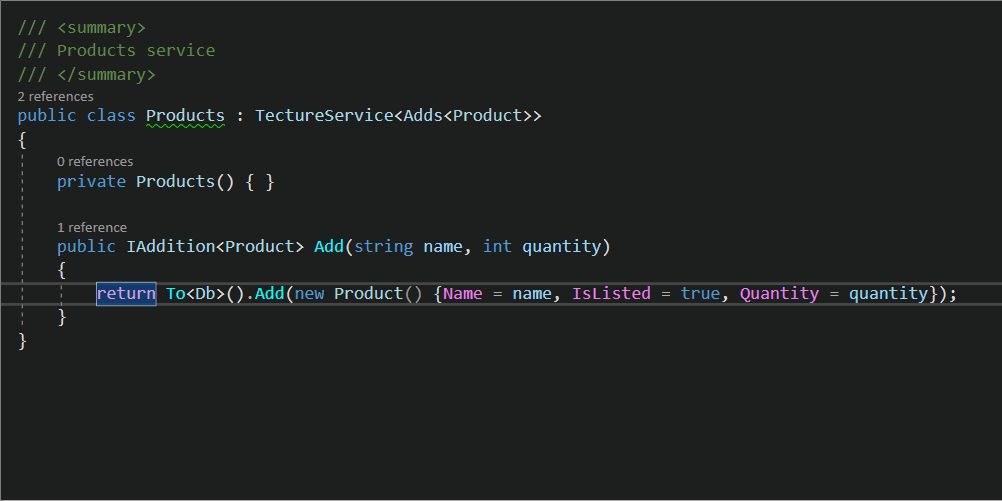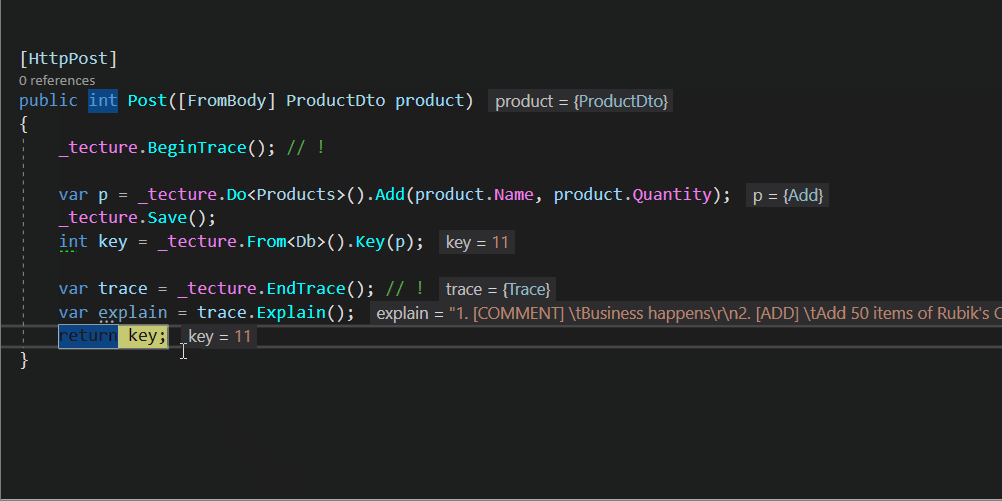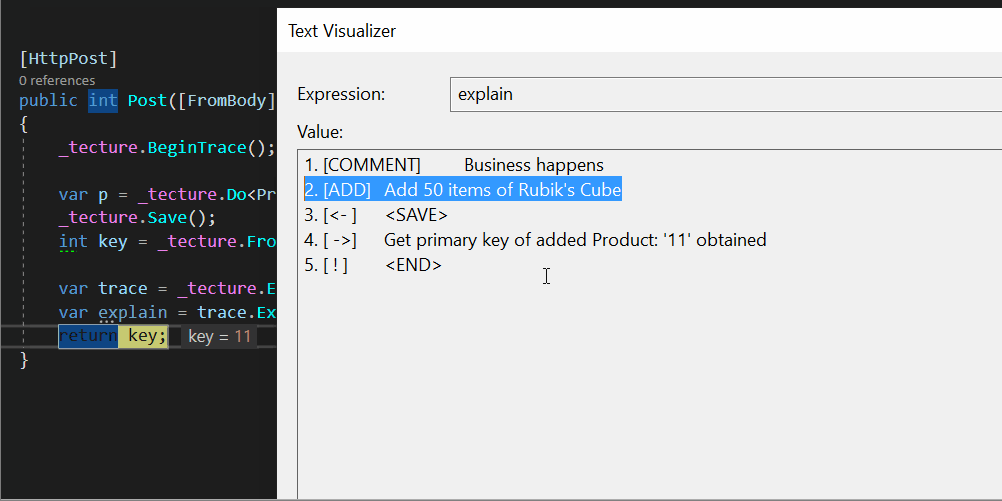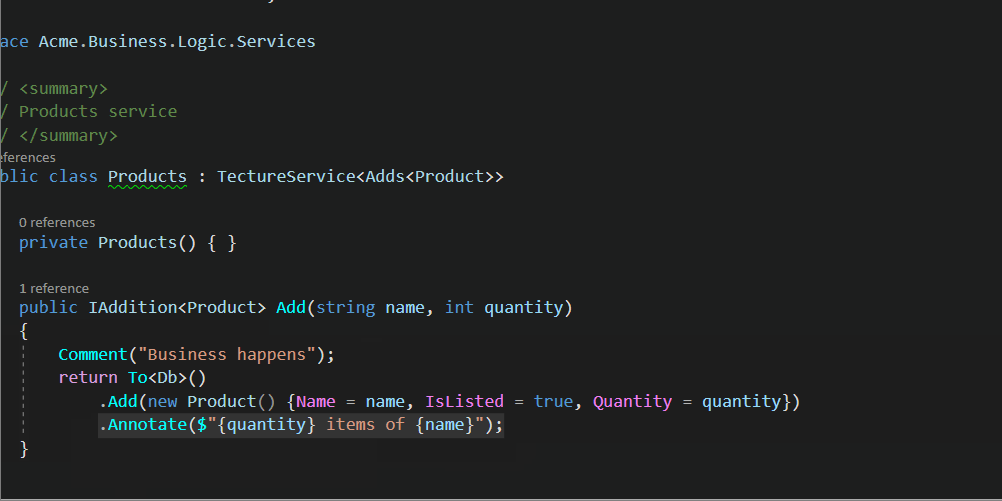
Запросы аннотируются методом `.Describe`.
Это большой прирост информативности и вот почему: писать доку к интерпрайз-приложению сложнее чем уволиться. Это долго, дорого, трудно и требует коммуникации с заказчиком, который сам уже забыл что хотел. А после написания — такую доку надо постоянно держать в актуальном состоянии, докидывая туда информации после каждой новой фичи.
Писать комменты в коде, конечно, тоже можно. Но логика меняется, куски кода в ней переставляются с места на место и через пару спринтов никакой уверенности в актуальности комментариев и их смысловой связанности не остаётся. Я бы предпочёл чтобы за этим следила машина, а не человек. Конечно я не призываю отменить комментарии в коде, но надо признать что они слабоваты и их возможностей не хватает.
Tecture предлагает пойти другим путём: прибить описание происходящего к командам и запросам. Дать маленькое пояснение к каждому конкретному действию. Это сверх-дёшево, занимает считанные секунды и устойчиво к перестановке кусков кода с места на место. Потом фреймворк сам сложит эти описания вместе и красиво, последовательно и предельно понятно расскажет что же всё-таки случилось, когда вы нажали ту мелкую кнопку в углу экрана. К тому же, это композабельно. То есть если один метод документирован через аннотации, то его вызов будет выдавать эту документацию где бы вы его ни использовали, позволяя оценить происходящее в динамике и поделиться этим знанием с товарищами. Knowledge management!
Ещё есть интерфейс `IDescriptive`, который можно реализовывать, скажем, у сущностей. Он нужен чтобы вместо "User entity" у вас выводилось "User Vasiliy Pupkin". Это сделает трейс совсем похожим на человеческий текст и если звёзды сложатся, то он будет пригоден для обсуждения с заказчиком. Гораздо удобнее планировать изменения в системе, когда все понимают что она делает.
В прошлой статье я говорил, что по сути бизнес-логика отдаёт команды внешним системам. `Explain` трейса — это отчёт с авторскими комментариями о том, какие внешние системы были затронуты, что у них запрошено и что им отдано. Это ли не киберпанк, который мы заслужили: приложение, которое само является источником информации о себе независимо от изменений требований.
Но это ещё не всё.
Захват данных
-------------
Трейс включает в себя глубокие копии всех ответов на все запросы. Эту информацию можно извлечь в любую структуру данных и я распоряжусь ей элегантно. Докинем в web-проект ещё один пакет: `Reinforced.Tecture.Testing`. Он тяжеловат — по зависимостям тянет за собой Roslyn. Не надо так делать в живых приложениях, но я это сделаю исключительно в демонстрационных целях. И вот для чего:
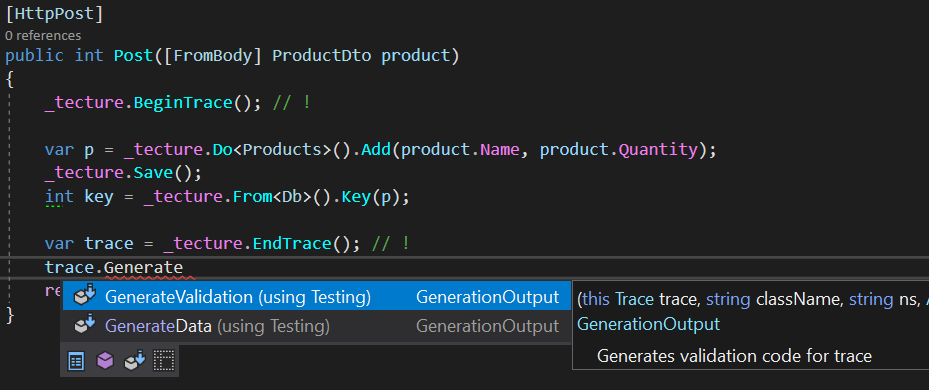
Этот пакет добавил трейсу 2 эктеншона. `GenerateData` и `GenerateValidation`. Нас интересует первый метод, который проще всего вызвать:
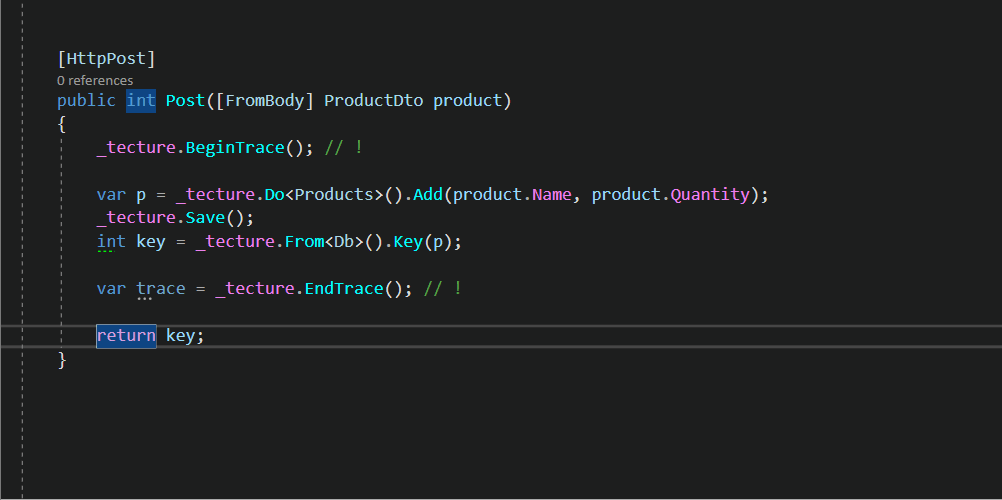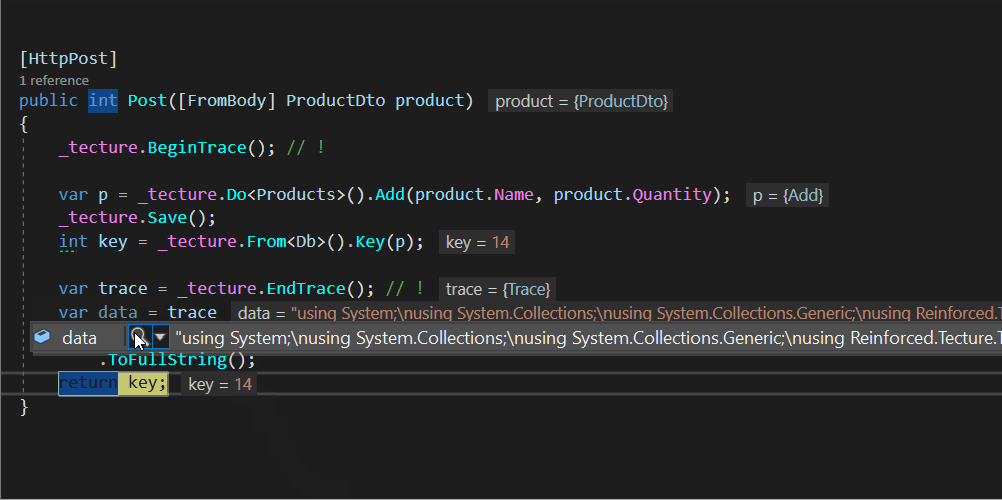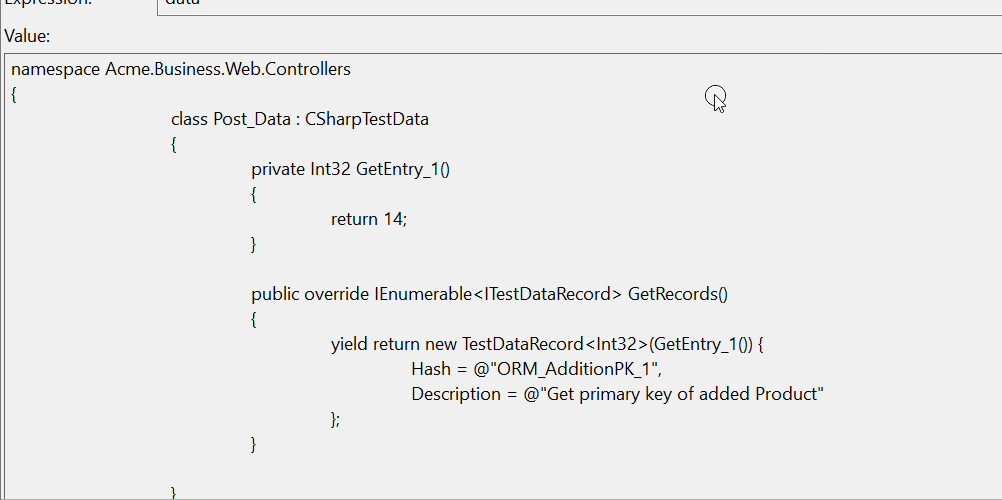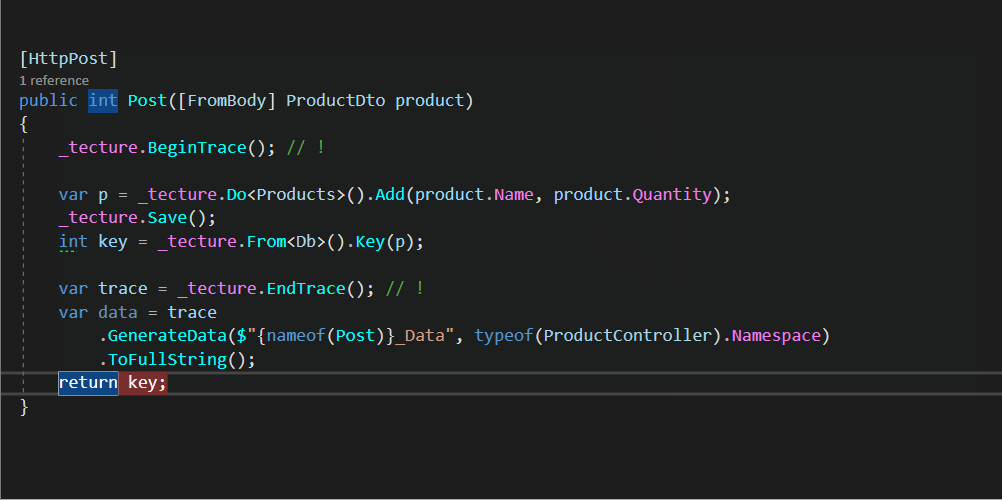
Смотрите: все ответы на запросы, которые произошли в этом куске логики сконвертились в C#-класс. Я просто нажал пару кнопок, а Tecture уже подготовил мне fake-данные для тестирования. Мне не надо вбивать их руками, не надо подбирать, ставить, и настраивать фейк-генератор, не надо использовать сервисы в духе Mockaroo. У меня уже есть девелоперская база с какими-то данными — я на ней проект дебажу. Для тестов мне придётся эти данные хардкодить, так почему бы не автоматизировать этот процесс?
Но это полдела. Есть ещё один метод из `Reinforced.Tecture.Testing`. Его вызвать гораздо сложнее, на целых 4 строчки:

На пальцах: есть бизнес-логика, она генерирует цепочку каких-то команд при определённых вводных (данных из внешних систем + пользовательский ввод). Данные из внешних систем мы уже дампнули в файл с кодом. Значит и команды тоже можем!
Я срезаю углы и минуя все промежуточные форматы, сразу генерю из очереди команд *последовательность проверок*. В форм-факторе огромной функции-предиката. Разумеется, уровень дотошности проверок можно регулировать.
А всё для того, чтобы...
Unit-тесты
----------
Положим, по нашему куску логики достигнут консенсус относительно корректности. QA и заказчик в один голос кричат: "во, оставь, сейчас работает как надо!". После чего мы берём этот кусок логики, запускаем в тестовом окружении, выдираем данные и валидацию, а потом запечатываем это добро в регрессионный unit-тест.
Настройка CI/CD пайплайна под подобные тесты — дело пары минут. Не надо понимать окружение, базы, кэши, очереди. Не надо ждать пока они запустятся и прогреются. И подчищать их после запуска тоже не надо. Тесты, построенные на захвате данных Tecture и его валидации самодостаточны и запускаются прямо из коробки без всего. И с блеском решаю задачу контроля регрессии: если кто-то меняет логику, эти тесты послушно падают. При том падают тоже композабельно — по всей цепочке связанной функциональности. Цепью красных шариков можно проследить какие части системы похерены.
Вдовесок тесты расскажут что именно пошло не так — запрос изменился, появились лишние действия в логике, какие-то действия исчезли и так далее. Так или иначе, к куску системы, который внезапно стал работать не так, как договаривались будет привлечено внимание. А если всё в порядке — можно будет со спокойной душой снести старые тестовые данные и сгенерить новые — писать руками ведь ничего не надо, достаточно просто перезапустить.
И моки здесь совершенно не нужны. А значит не надо прятать сервисы за интерфейсами. И городить репозитории для запросов тоже не надо.
Дело за малым — подобрать тестовую инфраструктуру, чтобы удобно обыграть вызовы `GenerateData` и `GenerateValidation`. Тут я ничего конкретного не предлагаю и в NuGet не публикую. В тестовом проекте я сделал [вот так](https://github.com/reinforced/Reinforced.Tecture/tree/master/Playground/Reinforced.Samples.ToyFactory.Tests/Infrastructure), просто для примера.
В частности, с этой инфраструктурой можно писать тесты таким вот изящным способом:
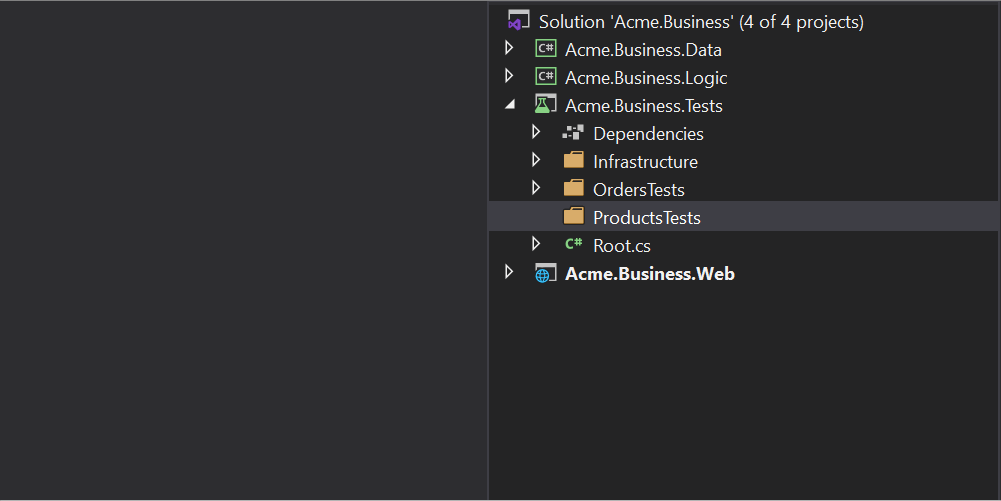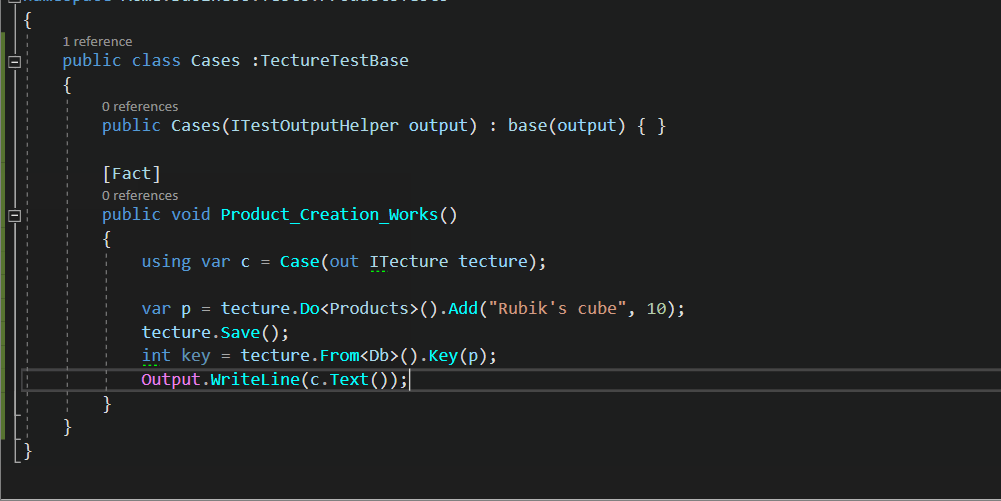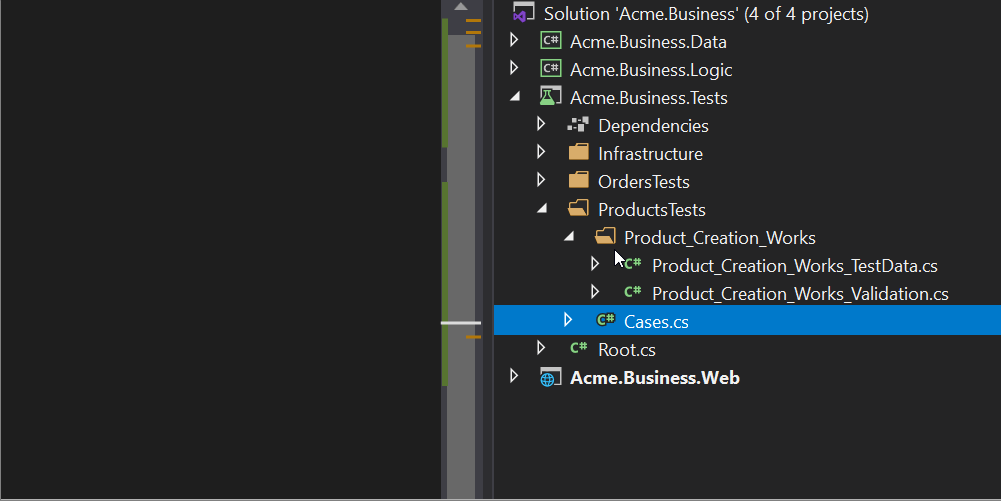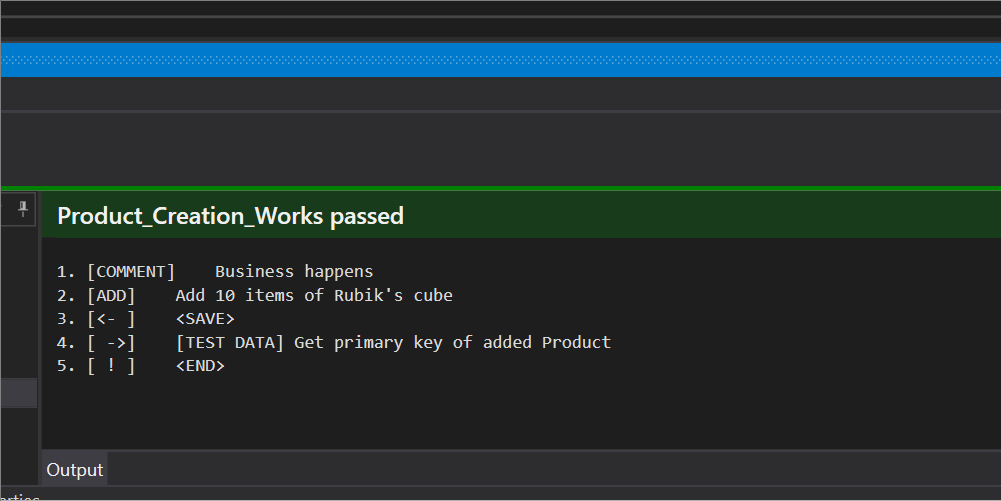
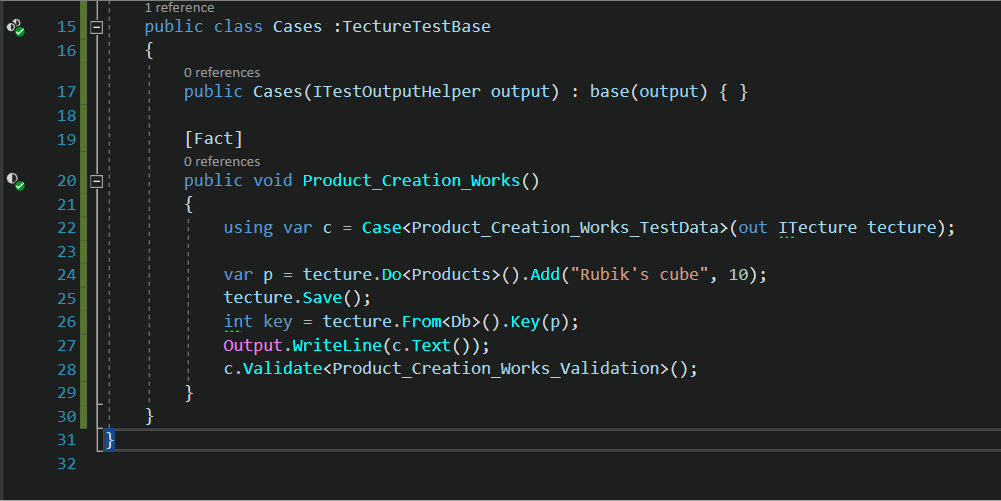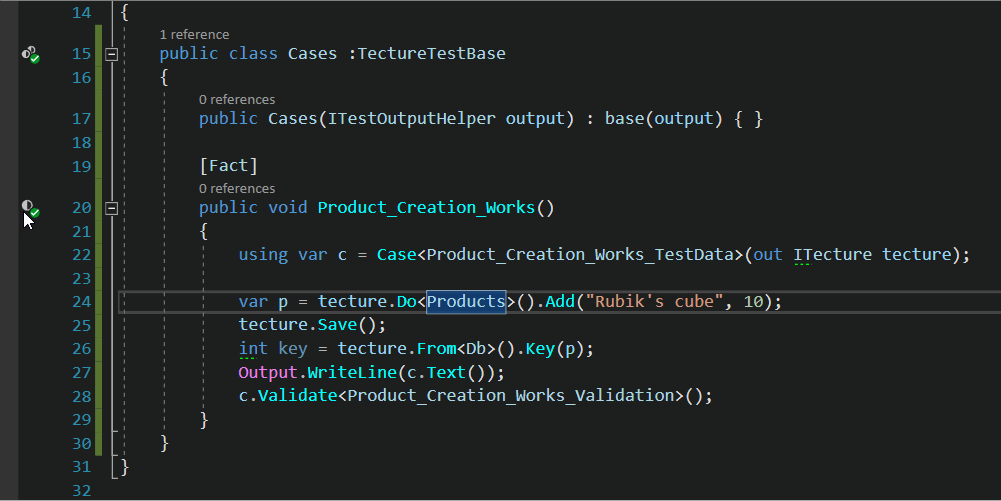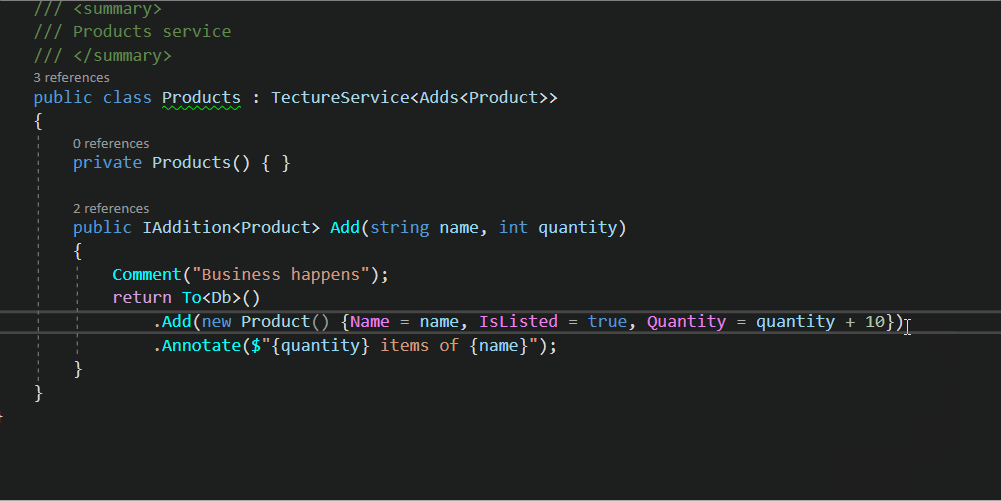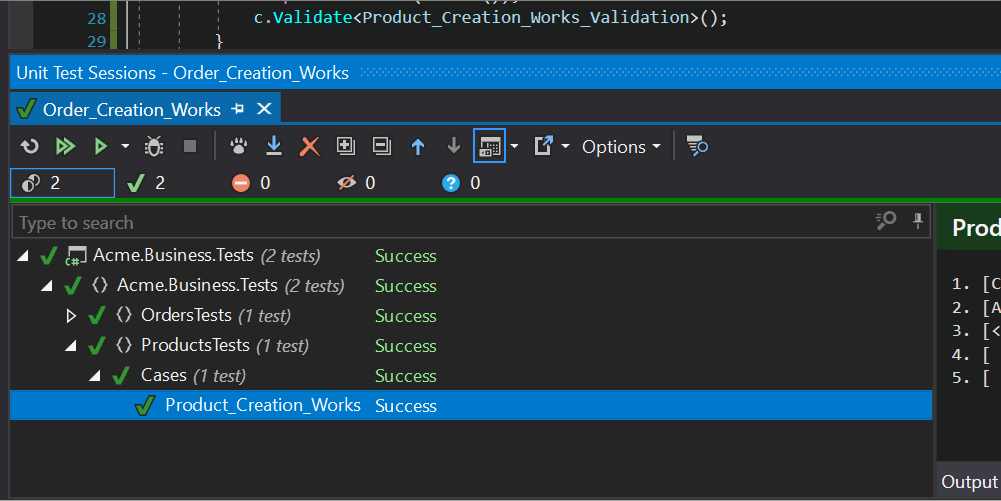
А вот что я делаю, когда логика под тестами меняется:
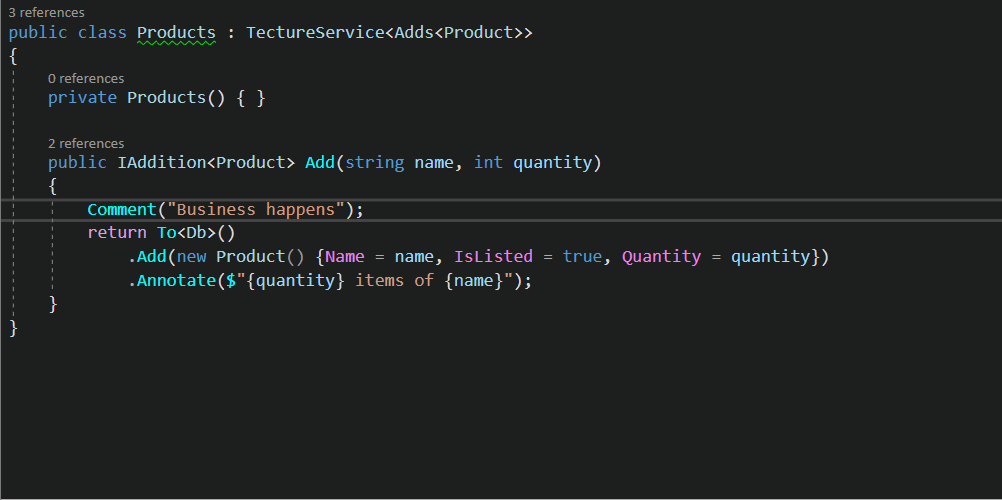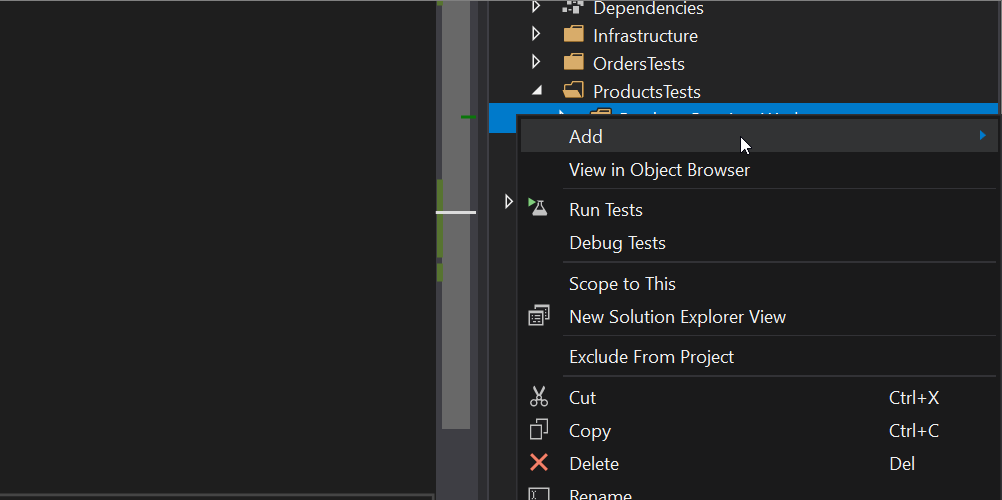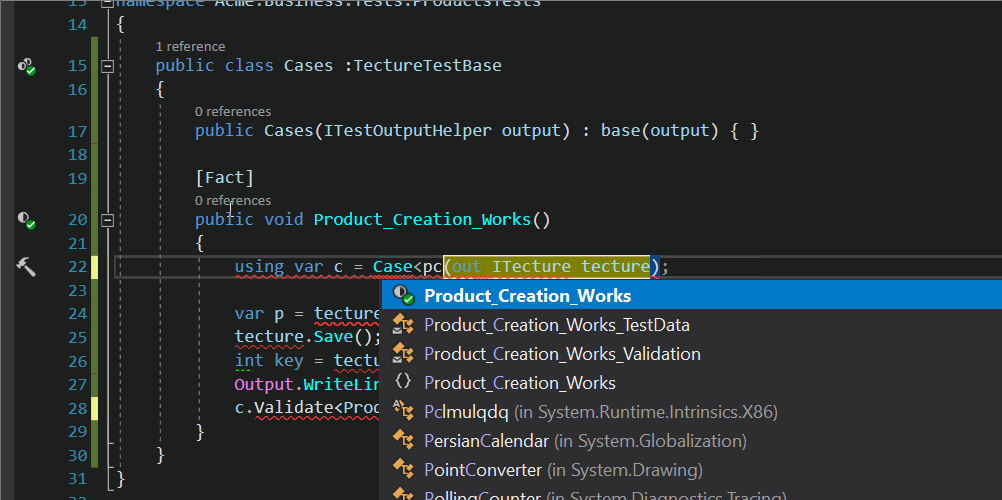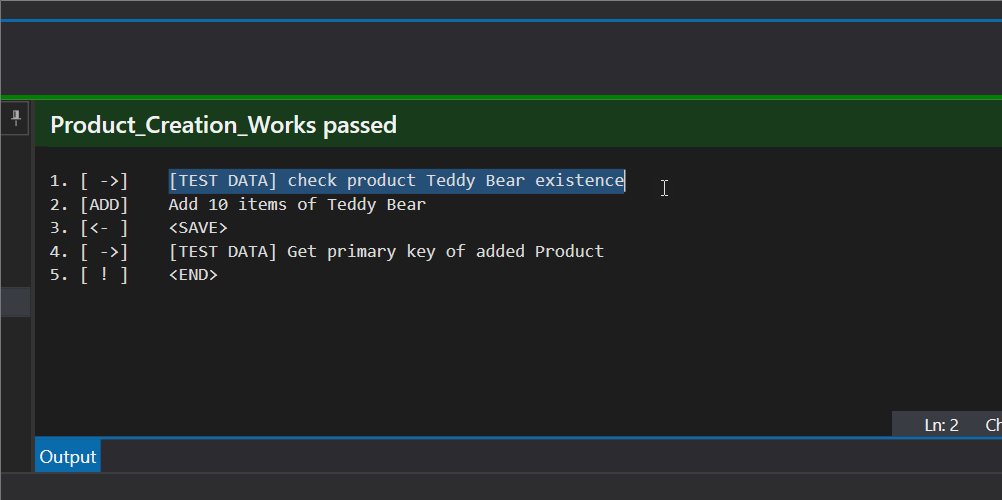
Таким образом, я трачу на написание осмысленных unit-тестов от силы по 5 минут своего рабочего времени. Это чистый, концентрированный профит.
Остаётся только добавить, что автогенерированный код можно править руками (относясь с осторожностью при перегенерации). Так-то я не планировал полностью вытеснить обычные unit-тесты. Но автогенерация, собака, эффективная, а я слишком ленивый чтобы делать что-то ещё.
Такие вот дела.
Пост-скриптум
=============
На разработку и продумывание этого подхода у меня ушёл год с небольшим. Огромное спасибо всем моим коллегам из разных стран, которые подкидывали мне идеи и рассказывали про беды своих проектов. Я надеюсь, что получилось довольно продуктивно и интересно.
Сейчас мне на работе выделили небольшой кусок системы, чтобы обкатать Tecture. Не хочу говорить ничего раньше времени, но по результатам будет обзорная статья. Само собой, в ходе живого тестирования я калибрую своё решение под нужды реалий — проектирую новые аспекты и нахожу узкие места, которые нужно подкрутить. В целом пока что этот вариант выглядит вполне себе рабочим.
Многое осталось за кадром — управление транзакциями, аспект DirectSql, не описаны протоколы создания рантаймов и аспектов. Я не хочу сильно нагружать читателей информацией, плюс мне нужен небольшой перерыв от публичной активности. Но я не прощаюсь.
Пакеты опубликованы, [исходники есть](https://github.com/reinforced/Reinforced.Tecture), я на связи в твиттере, телеграме и на github. Если вам вдруг хочется пополнить ряды early adopters и взять Tecture для своего пет-проекта — напишите мне, я постараюсь помочь.
Отдельная благодарность [fillpackart](https://habr.com/ru/users/fillpackart/), [arttom](https://habr.com/ru/users/arttom/) и их сообществу "Мы обречены" за информационную поддержку и редактуру. Смотрите их [подкаст](https://www.youtube.com/channel/UCUSbYJK87rpBUJ5KGQd7oHA), он крутой. Есть даже выпуск [со мной](https://www.youtube.com/watch?v=1bzWccO-18s).
Успехов! | https://habr.com/ru/post/520864/ | null | ru | null |
# Простой способ обнаружения эмуляторов ключа Guardant
При работе с ключом защиты Guardant (не важно какой модели) разработчик использует соответствующие API, при этом от него скрыт сам механизм работы с устройством, не говоря уже о протоколе обмена. Он не имеет на руках валидного хэндла устройства, пользуясь только адресом шлюза (т.н. GuardantHandle) через который идет вся работа. В случае если в системе присутствует эмулятор ключа (особенно актуально для моделей до Guardant Stealth II включительно) используя данный шлюз разработчик не сможет определить, работает ли он с реальным физическим ключом, или его эмуляцией.
Задавшись в свое время вопросом: «как определить наличие физического ключа?», мне пришлось немного поштудировать великолепно поданный материал за авторством Павла Агурова в книге "[Интерфейс USB. Практика использования и программирования](http://rouse.drkb.ru/books.php#agurov)". После чего потратить время на анализ вызовов API функций из трехмегабайтного объектника, линкуемого к приложению, в котором собственно и сокрыта вся «магия» работы с ключом.
В итоге появилось достаточно простое решение данной проблемы не требующее использования оригинальных Guardant API.
Единственный минус — все это жутко недокументированно и техническая поддержка компании Актив даже не будет рассматривать ваши вопросы, связанные с таким использованием ключей Guardant.
Ну и конечно, в какой-то момент весь данный код может попросту перестать работать из-за изменений в драйверах Guardant.
Но пока что, на 27 апреля 2013 года, весь данный материал актуален и его работоспособность проверена на драйверах от версии 5.31.78, до текущей актуальной 6.00.101.
Порядок действий будет примерно таким:
1. Через SetupDiGetClassDevsA() получим список всех присутствующих устройств.
2. Проверим, имеет ли устройство отношение к ключам Guardant через проверку GUID устройства. (У Guardant данный параметр равен {C29CC2E3-BC48-4B74-9043-2C6413FFA784})
3. Получим символьную ссылку на каждое устройство вызовом SetupDiGetDeviceRegistryPropertyA() с параметром SPDRP\_PHYSICAL\_DEVICE\_OBJECT\_NAME.
4. Откроем устройство при помощи ZwOpenFile() (CreateFile() тут уже к сожалению не подойдет, т.к. будут затруднения при работе с символьными ссылками).
Теперь, имея на руках реальный хэндл ключа, вместо псевдохэндла (шлюза) предоставляемого Guardant API, мы можем получить описание его параметров, послав соответствующий IOCTL запрос. Правда, тут есть небольшой нюанс.
Начиная с Guardant Stealth III и выше, изменился протокол работы с ключом, как следствие поменялись константы IOCTL запросов и содержимое входящего и исходящего буфера. Для нормальной работы алгоритма желательно поддерживать возможности как старых, так и новых ключей, поэтому опишу различия:
Для начала константы IOCTL выглядят так:
```
GetDongleQueryRecordIOCTL = $E1B20008;
GetDongleQueryRecordExIOCTL = $E1B20018;
```
Первая для ключей от Guardant Stealth I/II
Вторая для Guardant Stealth III и выше (Sign/Time/Flash/Code)
Отправляя первый запрос на устройство, мы будем ожидать что драйвер нам вернет следующий буфер:
```
TDongleQueryRecord = packed record
dwPublicCode: DWord; // Public code
byHrwVersion: Byte; // Аппаратная версия ключа
byMaxNetRes: Byte; // Максимальный сетевой ресурс
wType: WORD; // Флаги типа ключа
dwID: DWord; // ID ключа
byNProg: Byte; // Номер программы
byVer: Byte; // Версия
wSN: WORD; // Серийный номер
wMask: WORD; // Битовая маска
wGP: WORD; // Счетчик запусков GP/Счетчик времени
wRealNetRes: WORD; // Текущий сетевой ресурс, д.б. <= byMaxNetRes
dwIndex: DWord; // Индекс для удаленного программирования
end;
```
В случае более новых ключей и с учетом того, что протокол изменился, отправка первого запроса уже нам ничего не даст. Точнее запрос конечно, будет выполнен, но буфер придет пустой (обниленый). Поэтому на новые ключи мы посылаем второй запрос, который вернет данные немного в другом формате:
```
TDongleQueryRecordEx = packed record
Unknown0: array [0..341] of Byte;
wMask: WORD; // Битовая маска
wSN: WORD; // Серийный номер
byVer: Byte; // Версия
byNProg: Byte; // Номер программы
dwID: DWORD; // ID ключа
wType: WORD; // Флаги типа ключа
Unknown1: array [354..355] of Byte;
dwPublicCode: DWORD;
Unknown2: array [360..375] of Byte;
dwHrwVersion: DWORD; // тип микроконтролера
dwProgNumber: DWORD; // Номер программы
Unknown3: array [384..511] of Byte;
end;
```
Здесь уже возвращается блок в 512 байт содержащий более подробную информацию о ключе. К сожалению по некоторым причинам я не могу вам дать полное описание данной структуры, но необходимые для данной статьи поля я в ней оставил.
Общий код получения данных о установленных ключах выглядит так:
```
procedure TEnumDonglesEx.Update;
var
dwRequired: DWord;
hAllDevices: H_DEV;
dwInfo: DWORD;
Data: SP_DEVINFO_DATA;
Buff: array [0 .. 99] of AnsiChar;
hDeviceHandle: THandle;
US: UNICODE_STRING;
OA: OBJECT_ATTRIBUTES;
IO: IO_STATUS_BLOCK;
NTSTAT, dwReturn: DWORD;
DongleQueryRecord: TDongleQueryRecord;
DongleQueryRecordEx: TDongleQueryRecordEx;
begin
SetLength(FDongles, 0);
DWord(hAllDevices) := INVALID_HANDLE_VALUE;
try
if not InitSetupAPI then
Exit;
UpdateUSBDevices;
hAllDevices := SetupDiGetClassDevsA(nil, nil, 0,
DIGCF_PRESENT or DIGCF_ALLCLASSES);
if DWord(hAllDevices) <> INVALID_HANDLE_VALUE then
begin
FillChar(Data, Sizeof(SP_DEVINFO_DATA), 0);
Data.cbSize := Sizeof(SP_DEVINFO_DATA);
dwInfo := 0;
while SetupDiEnumDeviceInfo(hAllDevices, dwInfo, Data) do
begin
dwRequired := 0;
FillChar(Buff[0], 100, #0);
if SetupDiGetDeviceRegistryPropertyA(hAllDevices, @Data,
SPDRP_PHYSICAL_DEVICE_OBJECT_NAME, nil, @Buff[0], 100, @dwRequired)
then
if CompareGuid(Data.ClassGuid, GrdGUID) then
begin
RtlInitUnicodeString(@US, StringToOleStr(string(Buff)));
FillChar(OA, Sizeof(OBJECT_ATTRIBUTES), #0);
OA.Length := Sizeof(OBJECT_ATTRIBUTES);
OA.ObjectName := @US;
OA.Attributes := OBJ_CASE_INSENSITIVE;
NTSTAT := ZwOpenFile(@hDeviceHandle,
FILE_READ_DATA or SYNCHRONIZE, @OA, @IO,
FILE_SHARE_READ or FILE_SHARE_WRITE or FILE_SHARE_DELETE,
FILE_SYNCHRONOUS_IO_NONALERT);
if NTSTAT = STATUS_SUCCESS then
try
if DeviceIoControl(hDeviceHandle, GetDongleQueryRecordIOCTL,
nil, 0, @DongleQueryRecord, SizeOf(TDongleQueryRecord),
dwReturn, nil) and (DongleQueryRecord.dwID <> 0) then
begin
SetLength(FDongles, Count + 1);
FDongles[Count - 1].Data := DongleQueryRecord;
FDongles[Count - 1].PnPParentPath :=
GetPnP_ParentPath(Data.DevInst);
Inc(dwInfo);
Continue;
end;
Move(FlashBuffer[0], DongleQueryRecordEx.Unknown0[0], 512);
if DeviceIoControl(hDeviceHandle, GetDongleQueryRecordExIOCTL,
@DongleQueryRecordEx.Unknown0[0],
SizeOf(TDongleQueryRecordEx),
@DongleQueryRecordEx.Unknown0[0],
SizeOf(TDongleQueryRecordEx),
dwReturn, nil) then
begin
DongleQueryRecordEx.wMask :=
htons(DongleQueryRecordEx.wMask);
DongleQueryRecordEx.wSN :=
htons(DongleQueryRecordEx.wSN);
DongleQueryRecordEx.dwID :=
htonl(DongleQueryRecordEx.dwID);
DongleQueryRecordEx.dwPublicCode :=
htonl(DongleQueryRecordEx.dwPublicCode);
DongleQueryRecordEx.wType :=
htons(DongleQueryRecordEx.wType);
SetLength(FDongles, Count + 1);
ZeroMemory(@DongleQueryRecord, SizeOf(DongleQueryRecord));
DongleQueryRecord.dwPublicCode :=
DongleQueryRecordEx.dwPublicCode;
DongleQueryRecord.dwID := DongleQueryRecordEx.dwID;
DongleQueryRecord.byNProg := DongleQueryRecordEx.byNProg;
DongleQueryRecord.byVer := DongleQueryRecordEx.byVer;
DongleQueryRecord.wSN := DongleQueryRecordEx.wSN;
DongleQueryRecord.wMask := DongleQueryRecordEx.wMask;
DongleQueryRecord.wType := DongleQueryRecordEx.wType;
FDongles[Count - 1].Data := DongleQueryRecord;
FDongles[Count - 1].PnPParentPath :=
GetPnP_ParentPath(Data.DevInst);
end;
finally
ZwClose(hDeviceHandle);
end;
end;
Inc(dwInfo);
end;
end;
finally
if DWord(hAllDevices) <> INVALID_HANDLE_VALUE then
SetupDiDestroyDeviceInfoList(hAllDevices);
end;
end;
```
Данная процедура перебирает все ключи и заносит информацию о них в массив структур TDongleQueryRecord, после чего вы можете вывести эти данные пользователю, ну или использовать их каким либо образом непосредственно в вашем приложении.
Как видите все достаточно просто, но в объектных модулях Guardant API данный код помещен под достаточно серьезную стековую виртуальную машину и практически не доступен для анализа обычному разработчику. В принципе здесь нет ничего секретного, как видите при вызовах не используется даже шифрование передаваемых и получаемых буферов, но почему-то разработчики Guardant SDK не сочли нужным опубликовать данную информацию (правда я все-же смог получить разрешение на публикацию данного кода, т.к. в итоге тут не затронуты какие-то критические аспекты протокола обмена с ключом).
Но не будем отвлекаться, вы вероятно заметили в вышеприведенной процедуре вызов функции GetPnP\_ParentPath(). Данная функция возвращает полный путь к устройству от рута. Выглядит ее реализация следующим образом:
```
function GetPnP_ParentPath(Value: DWORD): string;
var
hParent: DWORD;
Buffer: array [0..1023] of AnsiChar;
Len: ULONG;
S: string;
begin
Result := '';
if CM_Get_Parent(hParent, Value, 0) = 0 then
begin
Len := Length(Buffer);
CM_Get_DevNode_Registry_PropertyA(hParent, 15, nil,
@Buffer[0], @Len, 0);
S := string(PAnsiChar(@Buffer[0]));
while CM_Get_Parent(hParent, hParent, 0) = 0 do
begin
Len := Length(Buffer);
CM_Get_DevNode_Registry_PropertyA(hParent, 15, nil,
@Buffer[0], @Len, 0);
S := string(PAnsiChar(@Buffer[0]));
Result := S + '#' + Result;
end;
end;
if Result = '' then
Result := 'не определен';
end;
```
Собственно (вы будете смеяться) детектирование эмулятора будет происходить именно на базе данной строки.
Обычно путь устройства выглядит следующим образом:
> \Device\00000004#\Device\00000004#\Device\00000044#\Device\00000049#\Device\NTPNP\_PCI0005#\Device\USBPDO-3#
В нем как минимум будет присутствовать текст NTPNP\_PCI или USBPDO.
Т.е. PCI шина или HCD хаб как минимум будут одним из предков.
Т.к. эмулятор является все-же виртуальным устройством, то путь к нему будет выглядеть примерно так:
> \Device\00000040#\Device\00000040
Соответственно на базе данной информации можно реализовать простую функцию:
```
function IsDonglePresent(const Value: string): Boolean;
begin
Result := Pos('NTPNP_PCI', Value) > 0;
if not Result then
Result := Pos('USBPDO', Value) > 0;
end;
```
Ну и в завершение опишу еще несколько нюансов, которые можно будет увидеть в демопримере, прилагаемом к статье:
* Относительно недавно появились новые ключи Guardant Flash представляющие из себя два устройства в одном. Т.е. это и ключ защиты и обычная флэшка. В функции UpdateUSBDevices() вы можете увидеть как можно определить какие из DRIVE\_REMOVABLE дисков в системе расположены в ключе. В общем-то ничего нового, общий принцип был показан еще в [демопримере безопасного отключения Flash устройств](http://rouse.drkb.ru/winapi.php#saferemove).
* Приведен пример получения строкового представления PublicCode ключа (естественно без завершающего контрольного символа, во избежание).
* Приведен пример получения даты выпуска ключа на основе его ID.
Небольшой нюанс:
Описанный в статье метод даст ложно/позитивное срабатывание при использовании пользователем вашего продукта платформы Anywhere: <http://www.digi.com/products/usb/anywhereusb#overview>
Забрать пример можно [здесь](http://rouse.drkb.ru/blog/enumdongles.zip). | https://habr.com/ru/post/178189/ | null | ru | null |
# Старые ISA-видеокарты и AVR
Лет десять тому назад достались мне предназначенные на помойку ISA-видеокарты от 286...486 машин. Видеокарты были опробованы и с тех пор пылились в ящике. Пару лет назад появилась у меня мысль, а не подключить ли такую видеокарту к микроконтроллеру? Вот об этом я и расскажу в статье.
Чтобы подключить старую ISA-видеокарту достаточно 8-битной шины данных и 20-битной шины адреса. Микроконтроллеры я люблю семейства AVR за их простоту, так что взял я Atmega16. Но вы можете взять любой удобный для вас — в этом случае у того же stm32 ножек точно хватит и без внешней обвязки. А вот у Atmega16 ножек на все эти шины не хватит, так что шина адреса была собрана на трёх ещё советских параллельных регистрах (у меня есть их большой запас) К588ИР1. Микроконтроллер по-очереди задаёт в этих трёх регистрах части адреса. Большего и не требуется.
На ISA-разъёме выходы этой схемы нужно подключить так:
+5,
+12,
GND,
REFRESH (притянут к +5В через резистор),
A0-A19,
D0-D7,
RESET,
MEMW,
MEMR,
IOW,
IOR,
ALE,
RDY,
AEN (подключается к GND).

На картинке красным я отметил требующие подключения контакты разъёма ISA.
Для некоторых видеокарт нужно подключить -5 В и -12 В (их придётся вам откуда-то взять — например, из источников TracoPower) и сигнал OSC (14.318 МГц) — его можно генерировать простейшим генератором на К155ЛН1. Другим видеокартам эти линии не требуются. Тут уж как повезёт. В общем, если на видеокарте соответствующая ножка на ISA висит в воздухе — её точно можно не подключать. Имейте в виду, потребление видеокартой по линии +5В довольно существенное — если вы будете использовать для питания что-то типа LM7805, то обязательно поставьте её на радиатор (лучше с вентилятором).
Лично у меня собранная конструкция выглядит вот так:

Осталось дело за малым — как-то инициализировать видеокарту и начать с ней работать. В интернете есть подобные проекты — я нашёл один ([ссылка](http://www.tinyvga.com/avr-isa-vga)), откуда и взял код инициализации видеокарты Trident 9000i. В той же программе из интернета есть и код инициализации для Trident9000C, но в комментариях указано, что он не работает. Я проверил. Действительно не работает — на экране мусор и видеокарта не реагирует на запись данных в ОЗУ.
Видео работы (картинка передавалась по SPI на Atmega16 (как видите, на схеме эти линии оставлены свободными) через LPT-порт компьютера):
(В видео я оговорился — режим 320x200, а не 320x240)
Объединив данный модуль с оптической мышкой ([статья про использование сенсора мышки](https://geektimes.ru/post/256950/)) я получил вот это:
Если же у вас есть желание запустить любую имеющуюся видеокарту ISA, то для этого вам следует в интернете найти BIOS требуемой видеокарты (скажем, [тут](http://chukaev.ru54.com/video_en.htm)) и с помощью IDA дизассемблировать его. Там обычный X86 код. Только начинается он не с 0 адреса — там сигнатура (2 байта) и контрольная сумма (1 байт). Итого, начинать надо с 3-его байта. И последовательно выяснить в какие порты что нужно записать, чтобы карта заработала. Скажу честно, мне терпения не хватило, чтобы понять, что не так с Trident9000C.
Для работы с шиной ISA был написан модуль:
**Модуль для работы с шиной ISA**
```
//****************************************************************************************************
//основные системные функции для работы с шиной ISA
//****************************************************************************************************
//****************************************************************************************************
//макроопределения
//****************************************************************************************************
//шина адреса
#define ADDR_BUS_PORT PORTA
#define ADDR_BUS_DDR DDRA
//переключение адреса A0-A7
#define ADDR_BUS_0_7_SELECT_PORT PORTC
#define ADDR_BUS_0_7_SELECT_DDR DDRC
#define ADDR_BUS_0_7_SELECT 7
//переключение адреса A8-A15
#define ADDR_BUS_8_15_SELECT_PORT PORTC
#define ADDR_BUS_8_15_SELECT_DDR DDRC
#define ADDR_BUS_8_15_SELECT 6
//переключение адреса A16-A19
#define ADDR_BUS_16_19_SELECT_PORT PORTC
#define ADDR_BUS_16_19_SELECT_DDR DDRC
#define ADDR_BUS_16_19_SELECT 5
//шина данных
#define DATA_BUS_PORT PORTB
#define DATA_BUS_DDR DDRB
#define DATA_BUS_PIN PINB
//RESET
#define RESET_DDR DDRD
#define RESET_PORT PORTD
#define RESET 0
//MEMW
#define MEMW_DDR DDRD
#define MEMW_PORT PORTD
#define MEMW 1
//MEMR
#define MEMR_DDR DDRD
#define MEMR_PORT PORTD
#define MEMR 2
//IOW
#define IOW_DDR DDRD
#define IOW_PORT PORTD
#define IOW 3
//IOR
#define IOR_DDR DDRD
#define IOR_PORT PORTD
#define IOR 4
//ALE
#define ALE_DDR DDRD
#define ALE_PORT PORTD
#define ALE 5
//RDY
#define RDY_DDR DDRD
#define RDY_PORT PORTD
#define RDY_PIN PIND
#define RDY 6
//****************************************************************************************************
//прототипы функций
//****************************************************************************************************
void System_Init(void);//инициализация устройства
void System_SetAddr(unsigned long addr);//установить адрес на шину
void System_RESET_HI(void);//установить RESET в 1
void System_RESET_LO(void);//установить RESET в 0
void System_MEMW_HI(void);//установить MEMW в 1
void System_MEMW_LO(void);//установить MEMW в 0
void System_MEMR_HI(void);//установить MEMR в 1
void System_MEMR_LO(void);//установить MEMR в 0
void System_IOW_HI(void);//установить IOW в 1
void System_IOW_LO(void);//установить IOW в 0
void System_IOR_HI(void);//установить IOR в 1
void System_IOR_LO(void);//установить IOR в 0
void System_ALE_HI(void);//установить ALE в 1
void System_ALE_LO(void);//установить ALE в 0
void System_WaitReady(void);//ждать готовности устройства
void System_Out8(unsigned short port,unsigned char value);//записать в порт значение UInt8
void System_Out16(unsigned short port,unsigned short value);//записать в порт значение UInt16
unsigned char System_In8(unsigned short port);//считать из порта значение UInt8
unsigned short System_In16(unsigned short port);//считать из порта значение UInt16
void System_Poke8(unsigned long addr,unsigned char value);//записать в память значение UInt8
void System_Poke16(unsigned long addr,unsigned short value);//записать в память значение UInt16
unsigned char System_Peek8(unsigned long addr);//считать из памяти значение UInt8
unsigned short System_Peek16(unsigned long addr);//считать из памяти значение UInt16
//****************************************************************************************************
//реализация функций
//****************************************************************************************************
//----------------------------------------------------------------------------------------------------
//инициализация устройства
//----------------------------------------------------------------------------------------------------
void System_Init(void)
{
//настраиваем порты
DDRA=0;
DDRB=0;
DDRD=0;
DDRC=0;
ADDR_BUS_DDR=0xff;
DATA_BUS_DDR=0;
ADDR_BUS_0_7_SELECT_DDR|=(1<>8)&0xff;
unsigned char ah=(addr>>16)&0xff;
System\_ALE\_LO();//снимаем сигнал ALE
//ставим на шину адреса адрес
ADDR\_BUS\_PORT=ah;
asm volatile ("cbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(ADDR\_BUS\_16\_19\_SELECT\_PORT)),[bit]"M"(ADDR\_BUS\_16\_19\_SELECT));
asm volatile ("sbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(ADDR\_BUS\_16\_19\_SELECT\_PORT)),[bit]"M"(ADDR\_BUS\_16\_19\_SELECT));
ADDR\_BUS\_PORT=am;
asm volatile ("cbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(ADDR\_BUS\_8\_15\_SELECT\_PORT)),[bit]"M"(ADDR\_BUS\_8\_15\_SELECT));
asm volatile ("sbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(ADDR\_BUS\_8\_15\_SELECT\_PORT)),[bit]"M"(ADDR\_BUS\_8\_15\_SELECT));
ADDR\_BUS\_PORT=al;
asm volatile ("cbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(ADDR\_BUS\_0\_7\_SELECT\_PORT)),[bit]"M"(ADDR\_BUS\_0\_7\_SELECT));
asm volatile ("sbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(ADDR\_BUS\_0\_7\_SELECT\_PORT)),[bit]"M"(ADDR\_BUS\_0\_7\_SELECT));
System\_ALE\_HI();//ставим сигнал ALE
}
//----------------------------------------------------------------------------------------------------
//установить RESET в 1
//----------------------------------------------------------------------------------------------------
inline void System\_RESET\_HI(void)
{
asm volatile ("sbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(RESET\_PORT)),[bit]"M"(RESET));
}
//----------------------------------------------------------------------------------------------------
//установить RESET в 0
//----------------------------------------------------------------------------------------------------
inline void System\_RESET\_LO(void)
{
asm volatile ("cbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(RESET\_PORT)),[bit]"M"(RESET));
}
//----------------------------------------------------------------------------------------------------
//установить MEMW в 1
//----------------------------------------------------------------------------------------------------
inline void System\_MEMW\_HI(void)
{
asm volatile ("sbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(MEMW\_PORT)),[bit]"M"(MEMW));
}
//----------------------------------------------------------------------------------------------------
//установить MEMW в 0
//----------------------------------------------------------------------------------------------------
inline void System\_MEMW\_LO(void)
{
asm volatile ("cbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(MEMW\_PORT)),[bit]"M"(MEMW));
}
//----------------------------------------------------------------------------------------------------
//установить MEMR в 1
//----------------------------------------------------------------------------------------------------
inline void System\_MEMR\_HI(void)
{
asm volatile ("sbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(MEMR\_PORT)),[bit]"M"(MEMR));
}
//----------------------------------------------------------------------------------------------------
//установить MEMR в 0
//----------------------------------------------------------------------------------------------------
inline void System\_MEMR\_LO(void)
{
asm volatile ("cbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(MEMR\_PORT)),[bit]"M"(MEMR));
}
//----------------------------------------------------------------------------------------------------
//установить IOW в 1
//----------------------------------------------------------------------------------------------------
inline void System\_IOW\_HI(void)
{
asm volatile ("sbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(IOW\_PORT)),[bit]"M"(IOW));
}
//----------------------------------------------------------------------------------------------------
//установить IOW в 0
//----------------------------------------------------------------------------------------------------
inline void System\_IOW\_LO(void)
{
asm volatile ("cbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(IOW\_PORT)),[bit]"M"(IOW));
}
//----------------------------------------------------------------------------------------------------
//установить IOR в 1
//----------------------------------------------------------------------------------------------------
inline void System\_IOR\_HI(void)
{
asm volatile ("sbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(IOR\_PORT)),[bit]"M"(IOR));
}
//----------------------------------------------------------------------------------------------------
//установить IOR в 0
//----------------------------------------------------------------------------------------------------
inline void System\_IOR\_LO(void)
{
asm volatile ("cbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(IOR\_PORT)),[bit]"M"(IOR));
}
//----------------------------------------------------------------------------------------------------
//установить ALE в 1
//----------------------------------------------------------------------------------------------------
inline void System\_ALE\_HI(void)
{
asm volatile ("sbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(ALE\_PORT)),[bit]"M"(ALE));
}
//----------------------------------------------------------------------------------------------------
//установить ALE в 0
//----------------------------------------------------------------------------------------------------
inline void System\_ALE\_LO(void)
{
asm volatile ("cbi %[port],%[bit]"::[port]"I"(\_SFR\_IO\_ADDR(ALE\_PORT)),[bit]"M"(ALE));
}
//----------------------------------------------------------------------------------------------------
//ждать готовности устройства
//----------------------------------------------------------------------------------------------------
void System\_WaitReady(void)
{
asm volatile ("nop"::);
asm volatile ("nop"::);
while(1)
{
if (RDY\_PIN&(1<>8)&0xff);
}
//----------------------------------------------------------------------------------------------------
//считать из порта значение UInt8
//----------------------------------------------------------------------------------------------------
unsigned char System\_In8(unsigned short port)
{
unsigned char byte;
System\_SetAddr(port);
DATA\_BUS\_DDR=0;
//даём сигнал чтения
System\_IOR\_LO();
System\_WaitReady();//ждём готовности
byte=DATA\_BUS\_PIN;
System\_IOR\_HI();
return(byte);
}
//----------------------------------------------------------------------------------------------------
//считать из порта значение UInt16
//----------------------------------------------------------------------------------------------------
unsigned short System\_In16(unsigned short port)
{
unsigned short ret=System\_In8(port+1);
ret<<=8;
ret|=System\_In8(port);
return(ret);
}
//----------------------------------------------------------------------------------------------------
//записать в память значение UInt8
//----------------------------------------------------------------------------------------------------
void System\_Poke8(unsigned long addr,unsigned char value)
{
//ставим на шину данных данные
DATA\_BUS\_DDR=0xff;
DATA\_BUS\_PORT=value;
System\_SetAddr(addr);
//даём сигнал записи
System\_MEMW\_LO();
System\_WaitReady();//ждём готовности
System\_MEMW\_HI();
DATA\_BUS\_DDR=0;
}
//----------------------------------------------------------------------------------------------------
//записать в память значение UInt16
//----------------------------------------------------------------------------------------------------
void System\_Poke16(unsigned long addr,unsigned short value)
{
System\_Poke8(addr,value&0xff);
System\_Poke8(addr+1,(value>>8)&0xff);
}
//----------------------------------------------------------------------------------------------------
//считать из памяти значение UInt8
//----------------------------------------------------------------------------------------------------
unsigned char System\_Peek8(unsigned long addr)
{
unsigned char byte;
System\_SetAddr(addr);
DATA\_BUS\_DDR=0;
//даём сигнал чтения
System\_MEMR\_LO();
System\_WaitReady();//ждём готовности
byte=DATA\_BUS\_PIN;
System\_MEMR\_HI();
return(byte);
}
//----------------------------------------------------------------------------------------------------
//считать из памяти значение UInt16
//----------------------------------------------------------------------------------------------------
unsigned short System\_Peek16(unsigned long addr)
{
unsigned short ret=System\_Peek8(addr+1);
ret<<=8;
ret|=System\_Peek8(addr);
return(ret);
}
```
Инициализация видеокарты Trident 9000i выполняется вот так:
**Инициализация видеокарты Trident 9000i**
```
//****************************************************************************************************
//функции для работы с видеокартой trident
//****************************************************************************************************
//****************************************************************************************************
//макроопределения
//****************************************************************************************************
//****************************************************************************************************
//прототипы функций
//****************************************************************************************************
CHIP_TYPE TRIDENT_Init(void);//тест видеокарты как Trident
unsigned char TRIDENT_TestInx2(unsigned short rg,unsigned char ix,unsigned char msk);//возвращает true, если бит MSK регистра PT по индексу RG равен 1
void TRIDENT_TR9000i_Init(void);//инициализация микросхемы Trident9000i
void TRIDENT_TR8900D_Init(void);//инициализация микросхемы Trident8900D
bool TRIDENT_Unit_594(void);//модуль 594
void TRIDENT_Unit_5A6(void);//модуль 5A6
bool TRIDENT_Unit_4D9(void);//модуль 4D9
void TRIDENT_Unit_51A(void);//модуль 51A
unsigned char TRIDENT_Unit_26A(void);//модуль 26A
void TRIDENT_Unit_179(void);//модуль 179
void TRIDENT_Unit_2EA(void);//модуль 2EA
unsigned char TRIDENT_Unit_292(void);//модуль 292
//****************************************************************************************************
//реализация функций
//****************************************************************************************************
//----------------------------------------------------------------------------------------------------
//тест видеокарты как Trident
//----------------------------------------------------------------------------------------------------
CHIP_TYPE TRIDENT_Init(void)
{
VGA_Reset();//делаем сброс видеокарты
CHIP_TYPE chiptype=UNKNOWN;//тип микросхемы пока что неизвестен
//Trident VGA (за исключением 8800BR) может работать в 2 режимах:
//старый режим, с окном 128k, отображаемый в памяти в адресах A000h - BFFFh
//и новый режим с окном 64k, в памяти в адресах A000h - AFFFh.
System_Out8(VGAENABLE_ADDR,0x00);
System_Out8(0x46E8,0x16);//регистр управления включением видеосистемы (D3=0)
System_Out8(0x46E9,0x00);
System_Out8(0x0102,0x01);
System_Out8(0x0103,0x00);
System_Out8(0x46E8,0x0E);//регистр управления включением видеосистемы (D3=1)
System_Out8(0x46E9,0x00);
System_Out8(0x4AE8,0x00);
System_Out8(0x4AE9,0x00);
VGA_OutReg8(SEQ_ADDR,0x0B,0x00);//пробуем прочесть ID микросхемы старым способом
unsigned char chip=System_In8(0x3C5);//читаем значение новым способом
unsigned char old=VGA_InReg8(SEQ_ADDR,0x0E);
System_Out8(0x3C5,0x00);
unsigned char value=System_In8(0x3C5)&0x0F;
System_Out8(0x3C5,old);
//определяем тип микросхемы
if (value==2)
{
System_Out8(0x3C5,old^2);
switch(chip)
{
case 0x01:
chiptype=TR8800BR;
break;
case 0x02:
chiptype=TR8800CS;
break;
case 0x03:
chiptype=TR8900;
break;
case 0x04:
chiptype=TR8900C;
TRIDENT_TR8900D_Init();
break;
case 0x13:
chiptype=TR8900C;
TRIDENT_TR8900D_Init();
break;
case 0x23:
chiptype=TR9000;
TRIDENT_TR9000i_Init();
break;
case 0x33:
chiptype=TR8900CLD;
TRIDENT_TR8900D_Init();
break;
case 0x43:
chiptype=TR9000i;
TRIDENT_TR9000i_Init();
break;
case 0x53:
chiptype=TR8900CXr;
break;
case 0x63:
chiptype=LCD9100B;
break;
case 0x83:
chiptype=LX8200;
break;
case 0x93:
chiptype=TVGA9400CXi;
break;
case 0xA3:
chiptype=LCD9320;
break;
case 0x73:
chiptype=GUI9420;
break;
case 0xF3:
chiptype=GUI9420;
break;
}
}
else
{
if ((chip==1)&TRIDENT_TestInx2(SEQ_ADDR,0x0E,6)) chiptype=TVGA8800BR;
}
return(chiptype);
}
//----------------------------------------------------------------------------------------------------
//возвращает true, если бит MSK регистра PT по индексу RG равен 1
//----------------------------------------------------------------------------------------------------
unsigned char TRIDENT_TestInx2(unsigned short rg,unsigned char ix,unsigned char msk)
{
unsigned char old,nw1,nw2;
old=VGA_InReg8(rg,ix);
VGA_OutReg8(rg,ix,old&(~msk));
nw1=VGA_InReg8(rg,ix)&msk
VGA_OutReg8(rg,ix,old|msk);
nw2=VGA_InReg8(rg,ix)&msk
VGA_OutReg8(rg,ix,old);
return((nw1==0)&(nw2==msk));
}
//----------------------------------------------------------------------------------------------------
//инициализация микросхемы Trident9000i
//----------------------------------------------------------------------------------------------------
void TRIDENT_TR9000i_Init(void)
{
unsigned short i=0;
System_Out8(VGAENABLE_ADDR,0x00);
if (TRIDENT_Unit_4D9()==false) return;//ошибка
do
{
System_Out8(0x3C9,0x00);
i++;
}
while (i<768);
System_Out8(MISC_ADDR,0x23);
TRIDENT_Unit_51A();
}
//----------------------------------------------------------------------------------------------------
//инициализация микросхемы Trident8900D
//----------------------------------------------------------------------------------------------------
void TRIDENT_TR8900D_Init(void)
{
if (TRIDENT_Unit_594()==true)
{
//задаём палитру 256 цветов
System_Out8(0x3C8,0x00);
for(unsigned short n=0;n<256;n++)
{
System_Out8(0x3C9,n);//R
System_Out8(0x3C9,0);//G
System_Out8(0x3C9,0);//B
}
System_Out8(MISC_ADDR,0x23);
TRIDENT_Unit_5A6();
}
if (TRIDENT_Unit_594()==false)
{
System_In8(STATUS_ADDR);
System_Out8(ATTRCON_ADDR,0x20);
System_In8(STATUS_ADDR);
VGA_OutReg8(CRTC_ADDR,0x020,VGA_InReg8(CRTC_ADDR,0x20)&0xDF);
}
System_Out8(0x3D8,0x00);
VGA_OutReg8(CRTC_ADDR,0x23,0x10);
System_Out8(0x3C6,0xff);
}
//----------------------------------------------------------------------------------------------------
//модуль 594
//----------------------------------------------------------------------------------------------------
bool TRIDENT_Unit_594(void)
{
VGA_OutReg8(SEQ_ADDR,0x0B,0x00);//установка старого режима
if ((VGA_InReg8(SEQ_ADDR,0x0D)&0x0E)!=0x0C) return(true);
if ((System_In8(0x3CC)&0x67)!=0x67) return(true);
return(false);
}
//----------------------------------------------------------------------------------------------------
//модуль 5A6
//----------------------------------------------------------------------------------------------------
void TRIDENT_Unit_5A6(void)
{
unsigned char al,bh;
VGA_InReg8(SEQ_ADDR,0x0B);//установка нового режима
VGA_OutReg8(SEQ_ADDR,0x0E,(VGA_InReg8(SEQ_ADDR,0x0E)|0x80)^2);
bh=(VGA_InReg8(SEQ_ADDR,0x0C)&0xFE)|0x80;
if (VGA_InReg8(SEQ_ADDR,0x0B)==0x53)//установка нового режима
{
VGA_InReg8(CRTC_ADDR,0x29);
VGA_OutReg8(CRTC_ADDR,0x29,0x44);
VGA_OutReg8(CRTC_ADDR,0x2B,0x03);
VGA_OutReg8(CRTC_ADDR,0x2C,0x3D);
VGA_OutReg8(CRTC_ADDR,0x25,0x27);
}
if (!(!VGA_InReg8(CRTC_ADDR,0x28)&1))
{
bh&=0xCE;
bh|=0x80;
VGA_OutReg8(MISC_ADDR,0x01,0x00);//выбираем адрес 0x3D2 (в оригинале 0x01)
al=(VGA_InReg8(CRTC_ADDR,0x28))&0x0C;
if (al==0)
{
al|=0x04;
VGA_OutReg8(CRTC_ADDR,0x28,al);
}
VGA_OutReg8(SEQ_ADDR,0x0F,VGA_InReg8(SEQ_ADDR,0x0F)&0x7F);
VGA_InReg8(SEQ_ADDR,0x0C);
VGA_OutReg8(SEQ_ADDR,0x0C,bh);
VGA_OutReg8(SEQ_ADDR,0x0E,(VGA_InReg8(SEQ_ADDR,0x0E)&0x7F)^2);
if (VGA_InReg8(SEQ_ADDR,0x0F)&0x08)
{
VGA_InReg8(SEQ_ADDR,0x0B);//установка нового режима
VGA_OutReg8(SEQ_ADDR,0x0E,(VGA_InReg8(SEQ_ADDR,0x0E)|0x80)^2);
al=(VGA_InReg8(SEQ_ADDR,0x0C)&0xFE)|0x80;
al&=0xFE;
VGA_OutReg8(SEQ_ADDR,0x0C,al);
VGA_OutReg8(GRACON_ADDR,0x0F,0x00);
al=VGA_InReg8(SEQ_ADDR,0x0C);//отключаем тестирование
VGA_OutReg8(SEQ_ADDR,0x0F,VGA_InReg8(SEQ_ADDR,0x0F)|0x80);
VGA_OutReg8(SEQ_ADDR,0x0E,(VGA_InReg8(SEQ_ADDR,0x0E)&0x7F)^0x02);
}
}
VGA_OutReg8(SEQ_ADDR,0x0B,0x00);//старый режим
VGA_OutReg8(SEQ_ADDR,0x0D,0x20);
VGA_OutReg8(SEQ_ADDR,0x0E,0xA0);
VGA_InReg8(SEQ_ADDR,0x0B);//установка нового режима
VGA_OutReg8(SEQ_ADDR,0x0E,0x02);
al=VGA_InReg8(GRACON_ADDR,0x06);//atvizsgбlni
if (al==0)
{
al&=0xF3;
al|=0x04;
VGA_OutReg8(GRACON_ADDR,0x06,al);
}
VGA_OutReg8(SEQ_ADDR,0x0D,0x00);
VGA_InReg8(CRTC_ADDR,0x1E);
VGA_OutReg8(CRTC_ADDR,0x1E,0x00);
if (VGA_InReg8(SEQ_ADDR,0x0B)==0x53) VGA_OutReg8(CRTC_ADDR,0x20,0x1D);//установка нового режима
else VGA_OutReg8(CRTC_ADDR,0x20,0x1C);
VGA_OutReg8(CRTC_ADDR,0x29,0x44);
}
//----------------------------------------------------------------------------------------------------
//модуль 4D9
//----------------------------------------------------------------------------------------------------
bool TRIDENT_Unit_4D9(void)
{
unsigned char al;
al=TRIDENT_Unit_292()&0x0E;
if (al!=0x0C) return(true);
al=System_In8(0x3CC)&0x67;
if (al!=0x67) return(true);
return(false);
}
//----------------------------------------------------------------------------------------------------
//модуль 51A
//----------------------------------------------------------------------------------------------------
void TRIDENT_Unit_51A(void)
{
unsigned char al,bh;
bh=(TRIDENT_Unit_26A()|0x80)&0xFE;
VGA_OutReg8(SEQ_ADDR,0x07,0x24);
System_Out8(MISC_ADDR,0x01);
if (!((al=VGA_InReg8(CRTC_ADDR,0x28))&0x0C))
{
al|=0x04;
VGA_OutReg8(CRTC_ADDR,0x28,al);
}
VGA_OutReg8(SEQ_ADDR,0x0F,VGA_InReg8(SEQ_ADDR,0x0F)&0x7F);
VGA_OutReg8(SEQ_ADDR,0x0C,bh);
VGA_OutReg8(SEQ_ADDR,0x0E,(VGA_InReg8(SEQ_ADDR,0x0E)&0x7F)^2);
if (VGA_InReg8(SEQ_ADDR,0x0F)&0x08) TRIDENT_Unit_179();
TRIDENT_Unit_2EA();//старый режим
VGA_OutReg8(SEQ_ADDR,0x0D,0x20);
VGA_OutReg8(SEQ_ADDR,0x0E,0xA0);
VGA_InReg8(SEQ_ADDR,0x0B);//новый режим
VGA_OutReg8(SEQ_ADDR,0x0E,0x02);
if (!((al=VGA_InReg8(GRACON_ADDR,0x06))&0x0C)) VGA_OutReg8(GRACON_ADDR,0x06,(al&0xF3)|0x04);
VGA_OutReg8(SEQ_ADDR,0x0D,0x00);
al=VGA_InReg8(CRTC_ADDR,0x1E);
VGA_OutReg8(CRTC_ADDR,0x1E,0x00);
}
//----------------------------------------------------------------------------------------------------
//модуль 26A
//----------------------------------------------------------------------------------------------------
unsigned char TRIDENT_Unit_26A(void)
{
VGA_InReg8(SEQ_ADDR,0x0B);//установка нового режима
VGA_OutReg8(SEQ_ADDR,0x0E,(VGA_InReg8(SEQ_ADDR,0x0E)|0x80)^2);
return(VGA_InReg8(SEQ_ADDR,0x0C));
}
//----------------------------------------------------------------------------------------------------
//модуль 179
//----------------------------------------------------------------------------------------------------
void TRIDENT_Unit_179(void)
{
//настрйоки SP и BP
VGA_OutReg8(SEQ_ADDR,0x0C,(TRIDENT_Unit_26A()|0x42)&0xFE);
VGA_OutReg8(SEQ_ADDR,0x0F,VGA_InReg8(SEQ_ADDR,0x0F)|0x80);
VGA_OutReg8(SEQ_ADDR,0x0E,(VGA_InReg8(SEQ_ADDR,0x0E)&0x7F)^2);
}
//----------------------------------------------------------------------------------------------------
//модуль 2EA
//----------------------------------------------------------------------------------------------------
void TRIDENT_Unit_2EA(void)
{
VGA_OutReg8(SEQ_ADDR,0x0B,0x00);//установка старого режима
}
//----------------------------------------------------------------------------------------------------
//модуль 292
//----------------------------------------------------------------------------------------------------
unsigned char TRIDENT_Unit_292(void)
{
TRIDENT_Unit_2EA();//установка старого режима
return(VGA_InReg8(SEQ_ADDR,0x0D));//старый режим, читаем SEQ_ADDR 0x0D
}
```
Также я запускал и видеокарту OAK OTI077 (пока я случайно не подал на неё 12 В и она не сгорела):
**Инициализация видеокарты OAK OTI077**
```
//****************************************************************************************************
//функции для работы с видеокартой oak
//****************************************************************************************************
//****************************************************************************************************
//макроопределения
//****************************************************************************************************
//****************************************************************************************************
//глобальные переменные
//****************************************************************************************************
unsigned char OAK_InitData[77] PROGMEM=
{
0x01,0x29,0x04,0x10,0x07,0x00,0x01,0x3E,
0x00,0x00,0x80,0x70,0xFF,0x01,0xFF,0xFF,
0x7F,0x00,0xFF,0xC8,0x00,0x00,0xFF,0x00,
0x01,0x0F,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,
0x01,0x00,0x08,0x00,0x00,0x00,0xFF,0xFF,
0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,
0x00,0x00,0x00,0x00,0x00,0x00,0xD8,0xFF,
0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,
0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0x00,
0x00,0x00,0x00,0x00,0x10
};
//****************************************************************************************************
//прототипы функций
//****************************************************************************************************
CHIP_TYPE OAK_Init(void);//тест видеокарты как Trident
unsigned char OAK_TestInx2(unsigned short rg,unsigned char ix,unsigned char msk);//возвращает true, если бит MSK регистра PT по индексу RG равен 1
void OAK_OTI077_Init(void);//инициализация OAK077
void OAK_OTI087_Init(void);//инициализация OAK087
void OAK_Unit218C(void);//модуль 218C
void OAK_Unit201B(void);//модуль 201B
void OAK_Unit50F(void);//модуль 50F
void OAK_Unit58F(unsigned char ah,unsigned char al);//модуль 58F
void OAK_Unit552(void);//модуль 552
unsigned char OAK_Unit53D(void);//модуль 53D
void OAK_Unit21A8(void);//модуль 21A8
void OAK_Fill3DE(void);//модуль Fill3DE
bool OAK_Unit21C9(void);//модуль 21C9
void OAK_Unit2167(unsigned short addr,unsigned char v);//модуль 2167
void OAK_Unit2148(unsigned char v);//модуль 2148
void OAK_Unit2A0F(void);//модуль 2A0F
void OAK_Unit28E2(unsigned char al,unsigned char ah);//модуль 28E2
void OAK_Unit28AC(unsigned char al,unsigned char ah);//модуль 28AC
void OAK_Unit29E0(void);//модуль 29E0
unsigned char OAK_Unit1CED(void);//модуль 1CED
void OAK_Unit1E12(void);//модуль 1E12
void OAK_Unit292D(unsigned char al,unsigned char bl,unsigned char bh);//модуль 292D
//****************************************************************************************************
//реализация функций
//****************************************************************************************************
//----------------------------------------------------------------------------------------------------
//тест видеокарты как Trident
//----------------------------------------------------------------------------------------------------
CHIP_TYPE OAK_Init(void)
{
CHIP_TYPE chiptype=UNKNOWN;
VGA_Reset();
System_Out8(0x46E8,0x17);
System_Out8(0x0102,System_In8(0x0102)|1);
System_Out8(0x46E8,0x0F);
if (OAK_TestInx2(0x3DE,0x0D,0x38))
{
if (OAK_TestInx2(0x3DE,0x23,0x1F))
{
if((VGA_InReg8(0x3DE,0x00)&0x02)==0)
{
chiptype=OAK_087;
OAK_OTI087_Init();
}
else chiptype=OAK_083;
}
else
{
switch(System_In8(0x3DE)/32)
{
case 0:
chiptype=OAK_037C;
break;
case 2:
chiptype=OAK_067;
break;
case 5:
chiptype=OAK_077;
OAK_OTI077_Init();
break;
case 7:
chiptype=OAK_057;
break;
}
}
}
return(chiptype);
}
//----------------------------------------------------------------------------------------------------
//возвращает true, если бит MSK регистра PT по индексу RG равен 1
//----------------------------------------------------------------------------------------------------
unsigned char OAK_TestInx2(unsigned short rg,unsigned char ix,unsigned char msk)
{
unsigned char old,nw1,nw2;
old=VGA_InReg8(rg,ix);
VGA_OutReg8(rg,ix,old&(~msk));
nw1=VGA_InReg8(rg,ix)&msk
VGA_OutReg8(rg,ix,old|msk);
nw2=VGA_InReg8(rg,ix)&msk
VGA_OutReg8(rg,ix,old<<8);
return((nw1==0)&(nw2==msk));
}
//----------------------------------------------------------------------------------------------------
//инициализация OAK087
//----------------------------------------------------------------------------------------------------
void OAK_OTI087_Init(void)
{
System_Out8(0x320,1);
System_In8(0x320);
OAK_Unit218C();
VGA_OutReg8(0x3DE,0x13,VGA_InReg8(0x3DE,0x13)&0xBF);
VGA_OutReg8(0x3DE,0x0B,((VGA_InReg8(0x3DE,0x0B)&0x0F)|(VGA_InReg8(0x3DE,0x10)))&0xF0);
OAK_Unit201B();
OAK_Unit50F();
OAK_Unit552();
System_Out8(0x320,2);
OAK_Fill3DE();
OAK_Unit21A8();
OAK_Unit218C();
System_Out8(0x320,0x0c);
System_Out8(0x46E8,0x17);
System_Out8(0x0102,System_In8(0x0102)|1);
System_Out8(0x46E8,0x0F);
OAK_Fill3DE();
}
//----------------------------------------------------------------------------------------------------
//инициализация OAK077
//----------------------------------------------------------------------------------------------------
void OAK_OTI077_Init(void)
{
OAK_Unit2A0F();
VGA_OutReg8(0x3DE,0x0E,VGA_InReg8(0x3DE,0x0E)&0xDE);
OAK_Unit1E12();
System_Out8(0x46E8,0x17);
System_Out8(0x0102,System_In8(0x0102)|1);
System_Out8(0x46E8,0x0F);
}
//----------------------------------------------------------------------------------------------------
//модуль 218C
//----------------------------------------------------------------------------------------------------
void OAK_Unit218C(void)
{
OAK_Unit2148(0x0F);
if (OAK_Unit21C9()==false) return;
OAK_Unit2167(0x0094,0x01);
if (OAK_Unit21C9()==false) return;
OAK_Unit2167(0x0394,0x01);
return;
}
//----------------------------------------------------------------------------------------------------
//модуль 201B
//----------------------------------------------------------------------------------------------------
void OAK_Unit201B(void)
{
unsigned char ah;
System_In8(0x3C8);
ah=System_In8(0x3C6);
System_In8(0x3C8);
System_In8(0x3C6);
System_In8(0x3C6);
System_In8(0x3C6);
System_In8(0x3C6);
System_Out8(0x3C6,0);
System_In8(0x3C8);
System_Out8(0x3C6,ah);
System_In8(0x3C8);
}
//----------------------------------------------------------------------------------------------------
//модуль 50F
//----------------------------------------------------------------------------------------------------
void OAK_Unit50F(void)
{
if ((VGA_InReg8(0x3DE,0x07)&0x04)) return;
OAK_Unit58F(0xFF,0x05);
}
//----------------------------------------------------------------------------------------------------
//модуль 58F
//----------------------------------------------------------------------------------------------------
void OAK_Unit58F(unsigned char ah,unsigned char al)
{
System_Out8(0x1E,al);
System_Out8(0x1F,ah);
}
//----------------------------------------------------------------------------------------------------
//модуль 552
//----------------------------------------------------------------------------------------------------
void OAK_Unit552(void)
{
if (OAK_Unit53D()) return;
OAK_Unit58F(0x07,0x04);
OAK_Unit58F(0xFF,0x05);
OAK_Unit58F((VGA_InReg8(0x1E,0xFE)|0x40),0xFE);
}
//----------------------------------------------------------------------------------------------------
//модуль 53D
//----------------------------------------------------------------------------------------------------
unsigned char OAK_Unit53D(void)
{
if (VGA_InReg8(0x3DE,0x07)&0x04) return(1);
return(VGA_InReg8(0x3DE,0x08)&0x03);
}
//----------------------------------------------------------------------------------------------------
//модуль 21A8
//----------------------------------------------------------------------------------------------------
void OAK_Unit21A8(void)
{
if (VGA_InReg8(0x3DE,0x07)&0x04) OAK_Unit2148(0x00);
else
{
OAK_Unit2167(0x0094,0x00);
OAK_Unit2167(0x0394,0x00);
}
}
//----------------------------------------------------------------------------------------------------
//модуль Fill3DE
//----------------------------------------------------------------------------------------------------
void OAK_Fill3DE(void)
{
unsigned char i;
for(i=0;i<77;i++)
{
unsigned short byte=pgm_read_byte(&(OAK_InitData[i]));
VGA_OutReg8(0x3DE,i,byte);
}
}
//----------------------------------------------------------------------------------------------------
//модуль 21C9
//----------------------------------------------------------------------------------------------------
bool OAK_Unit21C9(void)
{
unsigned char al=0x55,ah=al;
while(1)
{
System_Out8(0x3DE,al);
if (al==ah) return(true);
al^=0xFF;
ah^=0xFF;
if (al==0x55 && ah==0x55) return(false);
}
}
//----------------------------------------------------------------------------------------------------
//модуль 2167
//----------------------------------------------------------------------------------------------------
void OAK_Unit2167(unsigned short addr,unsigned char v)
{
unsigned char ah;
ah=System_In8(addr);
System_Out8(addr,0x80);
System_Out8(0x102,0x01);
System_Out8(addr,ah);
System_Out8(0x3C3,v);
}
//----------------------------------------------------------------------------------------------------
//модуль 2148
//----------------------------------------------------------------------------------------------------
void OAK_Unit2148(unsigned char v)
{
System_Out8(0x46E8,0x17);
System_Out8(0x0102,System_In8(0x0102)|1);
System_Out8(0x46E8,v);
}
//----------------------------------------------------------------------------------------------------
//модуль 2A0F
//----------------------------------------------------------------------------------------------------
void OAK_Unit2A0F(void)
{
OAK_Unit28E2(0,8);
OAK_Unit28AC(0,0xBE);
OAK_Unit29E0();
OAK_Unit292D(0,0x11,0x06);
OAK_Unit292D(1,0x11,0x07);
OAK_Unit292D(2,0x06,0x1F);
OAK_Unit292D(3,0x06,0x15);
}
//----------------------------------------------------------------------------------------------------
//модуль 28E2
//----------------------------------------------------------------------------------------------------
void OAK_Unit28E2(unsigned char al,unsigned char ah)
{
unsigned char bl=al,bh=ah;
VGA_OutReg8(0x3DE,0x0D,VGA_InReg8(0x3DE,0x0D)|0x20);
System_Out8(0x3C7,0x0E);
al=System_In8(0x3C9)&bh
ah^=0xFF;
bl&=ah;
bl|=al;
System_Out8(0x3C8,0x0E);
System_Out8(0x3C9,bl);
VGA_OutReg8(0x3DE,0x0D,VGA_InReg8(0x3DE,0x0D)&0xDF);
}
//----------------------------------------------------------------------------------------------------
//модуль 28AC
//----------------------------------------------------------------------------------------------------
void OAK_Unit28AC(unsigned char al,unsigned char ah)
{
unsigned char bl=al;
VGA_OutReg8(0x3DE,0x0D,VGA_InReg8(0x3DE,0x0D)|0x20);
al=System_In8(0x3C6)&ah
ah^=0xFF;
bl&=ah;
al|=bl;
System_Out8(0x3C6,al);
VGA_OutReg8(0x3DE,0x0D,VGA_InReg8(0x3DE,0x0D)&0xDF);
}
//----------------------------------------------------------------------------------------------------
//модуль 29E0
//----------------------------------------------------------------------------------------------------
void OAK_Unit29E0(void)
{
if ((System_In8(0x3DE)&0xE0)==0xA0)
{
if (!(OAK_Unit1CED()&0x20)) OAK_Unit292D(0x0A,0x02,0x0C);
else OAK_Unit292D(0x0A,0x03,0x0D);
}
else OAK_Unit292D(0x0A,0x03,0x0D);
}
//----------------------------------------------------------------------------------------------------
//модуль 1CED
//----------------------------------------------------------------------------------------------------
unsigned char OAK_Unit1CED(void)
{
return((VGA_InReg8(0x3DE,0x10)&0x4F)|(VGA_InReg8(0x3DE,0x0B)&0xB0));
}
//----------------------------------------------------------------------------------------------------
//модуль 1E12
//----------------------------------------------------------------------------------------------------
void OAK_Unit1E12(void)
{
System_Out8(0x46E8,0x17);
System_Out8(0x0102,System_In8(0x0102)|1);
System_Out8(0x46E8,0x00);
}
//----------------------------------------------------------------------------------------------------
//модуль 292D
//----------------------------------------------------------------------------------------------------
void OAK_Unit292D(unsigned char al,unsigned char bl,unsigned char bh)
{
VGA_OutReg8(0x3DE,0x0D,VGA_InReg8(0x3DE,0x0D)|0x20);
System_Out8(0x3C8,al);
System_Out8(0x3C9,bh);
System_Out8(0x3C9,bl);
VGA_OutReg8(0x3DE,0x0D,VGA_InReg8(0x3DE,0x0D)&0xDF);
}
```
Кстати, а нет ли тут специалистов по регистрам адаптера VGA? Я вижу в коде смены видеорежима при инициализации видеокарты странные вещи:
```
//регистры контроллера атрибутов
#define ATTRCON_ADDR 0x03C0
System_In8(0x03DA);
System_Out8(ATTRCON_ADDR,0x20);
```
Тут в общем-то, ничего особого нет. Запись в регистры контроллера атрибутов делается за 2 шага: записываем сперва номер регистра, а затем данные. Чтобы всегда начинать с записи номера, читаем ISR1 (из 0x03DA) — так сделано.
Но вот что странно. У контроллера атрибутов нет регистра 0x20! У него регистр последний 0x14. И даже если такой регистр бы был, почему нет записи значения? Должно же быть две записи в порт. А тут она одна. Я поискал в интернете и нашёл, что почему-то (в книгах я этого не нашёл) можно записать, скажем, в регистр 0x10 значение 0x20 за один раз просто объединив биты: System\_Out8(ATTRCON\_ADDR,0x10|0x20); Тогда указанная запись пишет 0x20 в регистр 0x00? Но почему это работает? И так ли это? Мне это интересно вот почему — всё дело в том, что иногда отваливается цвет после инициализации. Палитру просто не задать. Видно, что она меняется, но цвета вовсе не те, что должны быть. Если инициализацию сделать повторно, то всё восстанавливается. На каком этапе это происходит — не понятно. Экспериментально я выяснил, что с большой вероятностью, это как раз установка видеорежима. Но вот что там именно не то, я не понимаю.
→ [Ссылка](http://radiokot.ru/forum/download/file.php?id=198723) на архив с печатной платой
→ [Ссылка](http://radiokot.ru/forum/download/file.php?id=198725) на архив с прошивкой | https://habr.com/ru/post/406193/ | null | ru | null |
# Android + Arduino + 4 колеса. Часть 3 – передача видео и звука
Наконец, продвижение вперёд. Всё, теперь домашние не посмеют назвать робота Митю «радиоуправляемой машинкой»!
Оказалось непросто найти относительно лёгкий и работающий способ передачи видео и аудио потоков от Android-гаджета к удалённому управляющему приложению на ПК. Без этого шага я категорически не хотел двигаться дальше, поэтому довольно надолго завяз в своём упрямстве.
Большое спасибо всем кто мне помогал, без помощи я бы эту задачку не осилил. Переписка с единомышленниками свела меня с очень приятными и интересными людьми, эту сторону хобби я как-то не рассматривал раньше. Оказалось робот Митя помог мне найти близких по духу людей. И это был совершенно неожиданный для меня бонус. Возможно, в этом и заключается главный «профит» хобби? Только сейчас осознал, что общение мне важнее, чем просто «рукоделие». Зачем это всё надо, если не с кем поделиться, посоветоваться, похвастаться?
Буду закругляться со столь любимой лирической составляющей. Эта статья продолжение истории про робота Митю. В [первой части](http://habrahabr.ru/post/135043/) я рассказал как строил своего робота, во [второй](http://habrahabr.ru/post/139304/) – описал что понадобится, чтобы его программировать. В этой статье сконцентрируюсь на вопросе передачи видео и звука от робота к оператору. Не стану здесь повторяться о проекте в целом и его программной архитектуре в частности – эти вопросы подробно описаны в первой части.
Самый волнующий вопрос: каков результат, насколько будет притормаживать картинка и звук? Вот мой видеоответ:
Прошу прощения за наводки, но мне обязательно нужно было продемонстрировать как исходный звук, так и звук, воспроизведённый на ПК. Задержка, конечно, есть. Причём, при воспроизведении звук немного отстаёт от картинки. Видео отстаёт от реальности совсем незначительно (всё-таки надо принимать во внимание, что это не аналоговая система, и всем заправляет пусть мощный, но телефон). Я пробовал управлять роботом, и дискомфорта с такой задержкой видео не испытывал. Так что меня результат вполне устроил – с небольшим отставанием звука я вполне готов смириться.
Качество выводимой оператору картинки соответствует тому, на что способна фронтальная камера на HTC Sensation. Я мог бы воспользоваться и основной камерой, но тогда пришлось бы отказаться от мимики Мити, а на это я пойти не могу.
Для простоты навигации приведу план дальнейшего содержания статьи:
1. [Эволюция решения (только для любопытных)](#1)
2. [IP Webcam](#2)
3. [Воспроизведение видео в Windows-приложении](#3)
4. [Воспроизведение звука в Windows-приложении](#4)
5. [Итог](#5)
#### Эволюция решения (только для любопытных)
Чтобы меня не обвинили в «многобуквстве» предлагаю компромисс: люди любопытные, или сочувствующие проекту, или просто сердобольные (не зря же я всё это писал) могут почитать как я выкручивался и какие решения находил и отметал.
Если серьёзно, то я хочу поделиться по-возможности всем приобретённым опытом, потому что уверен, что ценность представляет не только положительный опыт, но и отрицательный. А вдруг есть люди, которые умеют учиться на ошибках других? Кроме того, я был бы очень признателен, если бы кто-нибудь нашёл или показал выход из встреченных мной тупиков. И тогда это был бы уже обмен опытом.
В этом разделе я пишу про тупики. Если Вы просто ищите рецепт передачи видео и звука от робота на ПК, можете переходить к следующему разделу.
Замысел был прост: на уровень Android-приложения встроить код, реализующий трансляцию видео и аудио потоков, а на уровень управляющего Windows-приложения встроить код, принимающий и воспроизводящий эти потоки.
Всевозможные «наколеночные» решения с применением готовых, не интегрируемых в мой код продуктов я отмёл сразу – некрасиво.
Начал я с видео. И почему-то был глубоко убеждён, что проблем с формированием и трансляцией видеопотока не будет. XXI век всё-таки, смартфоны у кого-то уже четырёхядерные… Ан нет. Несмотря на то, что у каждого телефона на борту по две камеры, сделать из телефона веб-камеру не так-то просто. Удивительно, но встроенных в Android готовых программных средств для решения этой задачи нет. Не знаю что является причиной, так как для производителей телефонов особых технических проблем эта задача не представляет, но подозреваю, всё объясняется сложностью сертификации в некоторых странах аппаратов с таким ПО. Вдруг это уже шпионское оборудование? Это единственное объяснение, которое я смог придумать. Но Митя так звенит моторами, что лазутчик из него, как из бегемота воздушный шарик. Поэтому совесть с бессонницей меня не мучают.
Перекапывая google, code.google, stackoverflow, android developers и всех-всех-всех я нашёл несколько очень интересных, но никуда меня не приведших, решений. И на них я потратил уйму времени. На всякий случай опишу их и почему я отказался от каждого из них. Опыт может оказаться полезен. Для каких-то задач эти решения вполне пригодны, но я с ними не подружился. Совсем тупиковые варианты я опущу. Оставлю только те, у которых есть шанс.
Вариант первый: использование класса MediaRecorder, входящего в состав Android. Я было подумал, что вот оно, решение всех моих проблем – тут и видео, и аудио. На выходе получу поток 3gp, передам его по UDP на ПК. Но увы. MediaRecorder так просто не станет работать с потоками – он только с файлами умеет. Погуглив, на форуме [groups.google.com](https://groups.google.com/forum/) я нашёл очень интересную [дискуссию](https://groups.google.com/d/topic/android-developers/FiZZSXEFhd0/discussion). Здесь обсуждалась похожая задача, и в ходе её обсуждения всплыла ссылка на ещё один интересный [пост](http://www.mattakis.com/blog/kisg/20090708/broadcasting-video-with-android-without-writing-to-the-file-system). Там описывается этакий «хак», как обмануть MediaRecorder, чтобы он думал, что работает с файлом, а на самом деле подсунуть ему для записи поток вывода в сокет. Повторять описание реализации я не буду, там всё написано. Участников дискуссии этот вариант вполне устроил. Задача стояла записать видео с телефона в файл на удалённом компьютере, минуя карту памяти телефона. Именно в файл – изучая этот вариант глубже, я убедился, что для веб-трансляции он не подходит. Дело в том, что MediaRecorder на моём аппарате работает следующим образом: при старте видеозаписи создаётся файл и в его головной части резервируется место для записи размера потока. Это поле заполняется только по завершении видеозаписи. А для этого выходной поток MediaPlayer-а должен поддерживать позиционирование (операция Seek). Файловый поток, например, на такое способен, а при широковещательной трансляции по сети поток, естественно, строго последовательный и прыгнуть в его начало, чтобы заполнить поле с окончательным размером не получится. Но у ребят задача стояла писать в файл на удалённом компьютере. Поэтому они сначала «сливали» свой поток в файл, а затем открывали этот файл на запись и вписывали в нужное место его размер. После этого такой файл уже можно было проигрывать чем угодно.
Задача в моём проекте другая: у меня нет момента завершения записи. И я не могу определить размер видеопотока. Т.е. выходной поток приложения MediaPlayer не предназначен для веб-трансляции. По крайней мере на моём аппарате. Этот вариант пришлось выбросить.
Ладно, я решил попробовать всё сделать сам. Android предоставляет возможность получить «сырые» кадры от камеры устройства. Эта функция везде замечательно описана, интернет заполнен примерами преобразования полученного потока с кадром от камеры устройства в jpeg-файл и сохранения этого файла на карту памяти. В моём случае, поток jpeg-кадров можно было гнать по UDP на ПК. Но как быть, если поток будет битый (всё-таки это UDP)? Надо как-то разделять кадры метками или использовать для этого заголовок jpeg. На ПК кадры придётся как-то вычленять из потока. Всё это как-то низкоуровнево, и поэтому мне совсем не нравилось. Определённо надо использовать уже готовый кодек. А ещё было бы здорово использовать какой-нибудь стандартный медийный протокол. И я начал собирать информацию в этом направлении. Так второй вариант отпал не родившись и появился третий: использовать ffmpeg.
ffmpeg заслуженно самый популярный и раскрученный продукт в данной области. Благодаря развитому сообществу на него вполне можно положиться, и я решил, что с направлением дальнейших работ я определился. И тут я подвис месяца на два. Оказывается, ffmpeg под Android придётся компилировать самому. Заодно придётся познакомиться с Android NDK, так как ffmpeg написан на C. Сборка ffmpeg под Android крайне затруднительна в ОС Windows. «Затруднительна», это не совсем искренне, на самом деле я не встретил ни одного упоминания об успешной компиляции в Windows. Вопросов на эту тему масса, но на всех форумах в один голос рекомендуют развернуть Linux. Сейчас, возможно, ситуация изменилась: вот [вопрос](http://dmitrydzz-hobby.blogspot.com/2012/04/ffmpeg-android.html?showComment=1336384545529#c2415308350577652244) к статье у меня в блоге и мой ответ. Никакого опыта использования Linux у меня не было. Но меня разбирало любопытство, что за зверь такой Linux, пришлось [поставить Ubuntu](http://dmitrydzz-hobby.blogspot.com/2012/03/ubuntu.html). Дальше выяснилось, что актуальной информации по компиляции ffmpeg в Интернете нет. Изрядно намучившись, сумел-таки собрать заветный ffmpeg. Процесс сборки я довольно [подробно описал](http://dmitrydzz-hobby.blogspot.com/2012/04/ffmpeg-android.html) у себя в блоге.
К этому моменту Митя давно пылился в углу брошенный и забытый. А у меня впереди маячили только новые и совершенно безрадостные сражения с Android NDK, полным отсутствием документации к API ffmpeg, погружение в таинства кодеков и компиляция ffserver (это потоковый видеосервер, часть проекта ffmpeg). С помощью ffserver можно организовать трансляцию видео и аудио от робота на любой ПК в сети. Друзья уже думали, что с робототехникой я перегорел, а я плакал, кололся, но продолжал грызть гранит ffmpeg-а. Не уверен, что я смог бы пройти этот путь до конца.
И тут ко мне подоспела помощь. Помните я говорил о замечательных единомышленниках, с которыми меня свело общее хобби? Должен сказать, что робот Митя к этому моменту был не одинок. В другом городе у него уже появился внешне очень похожий, но внутренне кое-где отличающийся и местами даже в лучшую сторону, брат-близнец. Я переписываюсь с [Luke\_Skypewalker](https://geektimes.ru/users/luke_skypewalker/) – автором этого робота. В очередном письме от него вижу совет посмотреть приложение под Android, называющееся [IP Webcam](http://ip-webcam.appspot.com/). А ещё я узнаю, что это приложение транслирует по HTTP видео и звук с Android-устройства, имеет API и умеет работать в фоновом режиме!
Надо признаться, что после публикации первой части статьи про робота Митю, на сайте проекта я получил [комментарий](http://code.google.com/p/robot-mitya/wiki/MyPlans?ts=1337277257&updated=MyPlans) от пользователя kib.demon с советом присмотреться к IP Webcam. Я посмотрел, но плохо и не увидел главного – того, что у этого приложения есть программный API. Я подумал, что приложение, реализующее веб-камеру само по себе мне не нужно и быстро забыл о его существовании. А ещё был [комментарий](http://habrahabr.ru/post/135043/#comment_4484720) к самой статье. Там не было сказано про API, и я его я тоже проморгал. Эта ошибка стоила Мите трёх месяцев в углу.
Не думаю, что я зря столько копался с ffmpeg. После своих постов (был ещё английский вариант) мне присылают много вопросов, видимо, принимая меня за знатока в этой области. Я стараюсь отвечать в меру своих познаний, но большая часть вопросов так и висит в воздухе. Тема по-прежнему актуальна. Я был бы очень рад, если бы кто-нибудь продолжил эту работу и описал её. Всё-таки в интернете почти ничего нет о программном взаимодействии с ffmpeg. А что есть, устарело на несколько лет. Благодаря использованию приличных кодеков ffmpeg может позволить выжать из минимума трафика максимум видео. Для многих проектов это будет очень полезно.
#### IP Webcam
Итак, с уровнем Android-части робота Мити я определился: для трансляции видео и аудио будет использоваться приложение [IP Webcam](https://play.google.com/store/apps/details?id=com.pas.webcam&feature=search_result#?t=W251bGwsMSwxLDEsImNvbS5wYXMud2ViY2FtIl0).
На [сайте разработчика](http://ip-webcam.appspot.com/) есть страничка, описывающая функции, доступные в API. Там же можно скачать исходники крошечного Android-проекта, демонстрирующего как программно взаимодействовать с IP Webcam.
Собственно, вот ключевая часть этого примера:
```
Intent launcher = new Intent().setAction(Intent.ACTION_MAIN).addCategory(Intent.CATEGORY_HOME);
Intent ipwebcam =
new Intent()
.setClassName("com.pas.webcam", "com.pas.webcam.Rolling")
.putExtra("cheats", new String[] {
"set(Photo,1024,768)", // set photo resolution to 1024x768
"set(DisableVideo,true)", // Disable video streaming (only photo and immediate photo)
"reset(Port)", // Use default port 8080
"set(HtmlPath,/sdcard/html/)", // Override server pages with ones in this directory
})
.putExtra("hidebtn1", true) // Hide help button
.putExtra("caption2", "Run in background") // Change caption on "Actions..."
.putExtra("intent2", launcher) // And give button another purpose
.putExtra("returnto", new Intent().setClassName(ApiTest.this,ApiTest.class.getName())); // Set activity to return to
startActivity(ipwebcam);
```
Замечательно то, что можно управлять ориентацией транслируемого видео, его разрешением, качеством картинки. Можно переключаться между задней и фронтальной камерами, включать выключать светодиоды вспышки. Всем этим можно управлять в настройках перед запуском трансляции или программно, используя приведённые автором проекта чит-коды, как
это показано в примере.
Чуть отвлекусь: к сожалению со вспышкой (фара Мити) у меня прокол. К IP Webcam это никак не относится. Я уже столкнулся с этой проблемой в своём коде ранее. На моём аппарате если активировать фронтальную камеру, управлять вспышкой уже нельзя. Подозреваю, это не только в HTC Sensation.
В приложении IP Webcam после запуска трансляции видео на экране начинает отображаться видео с активной камеры. Поверх видео предусмотрено отображение двух настраиваемых кнопок. По умолчанию одна инициирует диалог со справкой, а вторая открывает меню доступных действий. В примере автор первую кнопку прячет, а вторую настраивает на перевод работы приложения в фоновом режиме.
Проверить аудио/видео трансляцию можно, например, в браузере или в приложении [VLC media player](http://www.videolan.org/vlc/). После запуска трансляции IP Webcam в браузере по адресу http://:<порт> становится доступен «Сервис камеры смартфона». Здесь можно просмотреть отдельные кадры, включить воспроизведение видео и звука. Для просмотра видеопотока, например, в VLC media player необходимо открыть URL http://:<порт>/videofeed. Для воспроизведения звука доступны два URL: http://:<порт>/audio.wav и http://:<порт>/audio.ogg. Есть существенное запаздывание звука, но как выяснилось позже, связано это с кэшированием при воспроизведении. В VLC media player можно поставить кэширование на 20 мСек и запаздывание звука станет несущественным.
Это были хорошие новости, а теперь плохие: я, конечно, нашёл трудности. На моём аппарате в фоновом режиме IP Webcam прекращал трансляцию видео. Я почитал комментарии в Google Play и обнаружил, что такое происходит у всех счастливчиков с 4-ым Android-ом. Про 3-ий не знаю. А незадолго до «открытия» IP Webcam я обновил версию Android с 2.3.4 до 4.0.3. Невозможность фоновой работы была фатальна, потому что я не мог оставить работающей активити, транслирующую видео, поверх открыв своё активити с мордочкой Мити, да ещё и управляющее им. Активация мордочки переводила активити IP Webcam в фоновый режим и трансляция прекращалась. Да, ту часть приложения, которая управляла роботом, я мог организовать в виде сервиса, но как быть с лицом Мити?
Не найдя выхода самостоятельно, я решился написать письмо автору проекта IP Webcam. Автор «наш», в смысле писать можно по-русски. Меня беспокоило три вещи:
1. Прекращение трансляции в фоновом режиме.
2. Отставание звука от картинки.
3. Некорректно отображался IP-адрес телефона в IP Webcam. Это не критично, но поначалу сбивало с толку. Хотя это ерунда, здесь вопрос только в некорректном тексте на экране телефона.
Должен сказать огромное спасибо автору IP Webcam (Павел Хлебович). Ещё одно замечательное знакомство. В ходе переписки, которая у нас завязалась, он не только ответил на все мои вопросы, но и прислал ещё один демо-проект, в котором показано, как можно выкрутиться с фоновым режимом и моим Android 4.0.3.
Больше всего, конечно, меня волновали первые два вопроса. По второму Павел всё рассказал мне про кэширование звука в браузере и VLC media player.
А вот что он написал мне по первому вопросу: «Похоже, что все телефоны на 4.x уже используют драйвер V4L, который не позволяет захватывать видео без поверхности для его показа. Поэтому в фоновом режиме видео и не работает. Как обходное решение можно попробовать поверх моей Activity сделать свою, описать её как полупрозрачную, чтобы поверхность IP Webcam не уничтожалась, а на самом деле сделать её непрозрачной и показывать что надо».
Вроде звучит понятно, но как можно открыть одно активити над другим и чтобы оба работали? Я думал только одно активити может быть активно в единицу времени (извините за каламбур). Провёл несколько экспериментов, но у «нижнего» активити всегда срабатывало onPause. Павел опять помог: специально сделал для меня [демо-проект](http://code.google.com/p/robot-mitya/downloads/detail?name=IPWebcamVsAndroid4.zip). Удивительно, но идея с расположением одного активити поверх другого работает! Демо-проект Павла я чуть-чуть доработал (косметически) и выложил на сайт робота Мити.
Опишу что сделано в этой демонстрации.
1. В layout главной activity добавлена кнопка Button1.
2. Добавлен ещё один layout «imageoverlay.xml» с картинкой «some\_picture.png». Больше в нём ничего нет.
3. Добавлена OverlayActivity.java, отображающая контент imageoverlay.xml. Именно эта активити будет отображаться поверх видео IP Webcam. В моём основном проекте на этом месте будет активити, управляющая роботом. Она же лицо Мити.
4. В манифест должны быть добавлены:
а) Описание OverlayActivity:
```
```
Обязательно должны быть заполнены атрибуты launchMode и theme указанными значениями.
б) Права для обращения к камере устройства:
```
```
5. Дополнить MainActivity.java:
```
package ru.ipwebcam.android4.demo;
import android.app.Activity;
import android.content.Intent;
import android.os.Bundle;
import android.os.Handler;
import android.util.Log;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
public class MainActivity extends Activity {
static String TAG = "IP Webcam demo";
Handler h = new Handler();
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
final Button videoButton = (Button)findViewById(R.id.button1);
videoButton.setOnClickListener(new OnClickListener() {
public void onClick(View v) {
Intent launcher = new Intent().setAction(Intent.ACTION_MAIN).addCategory(Intent.CATEGORY_HOME);
Intent ipwebcam =
new Intent()
.setClassName("com.pas.webcam", "com.pas.webcam.Rolling")
.putExtra("hidebtn1", true) // Hide help button
.putExtra("caption2", "Run in background") // Change caption on "Actions..."
.putExtra("intent2", launcher); // And give button another purpose
h.postDelayed(new Runnable() {
public void run() {
startActivity(new Intent(MainActivity.this, OverlayActivity.class));
Log.i(TAG, "OverlayActivity started");
}
}, 4000);
startActivityForResult(ipwebcam, 1);
h.postDelayed(new Runnable() {
public void run() {
sendBroadcast(new Intent("com.pas.webcam.CONTROL").putExtra("action", "stop"));
Log.i(TAG, "Video is stopped");
}
}, 20000);
Log.i(TAG, "Video is started");
}
});
}
}
```
По нажатию на кнопку запускается IP Webcam, затем через 4 секунды поверх него открывается наше активити с картинкой. Размер изображения специально сделан меньше разрешения экрана (по крайней мере для HTC Sensation), чтобы было видно оба активити. А через 20 секунд после запуска, работа IP Webcam на заднем фоне прекращается, но наше «основное» активити продолжает работать.
Вот как это выглядит на телефоне:

Дальше мне оставалось совсем незначительно видоизменить Android-приложение Мити, и я уже мог видеть его камерой и слышать его микрофоном в браузере на ПК.
#### Воспроизведение видео в Windows-приложении
Не задумывался об этом раньше, но только на этом этапе понял, что видео от IP Webcam не совсем видео. Это [MJPEG](http://ru.wikipedia.org/wiki/MJPG). Т.е. транслируемый поток представляет собой последовательную передачу кадров в JPEG-формате. Я совсем слаб в вопросах, связанных с передачей видео, поэтому не ожидал прыти от MJPEG. И зря – результат меня вполне устроил.
Для воспроизведения MJPEG-потока я нашёл замечательный бесплатный продукт [MJPEG Decoder](http://channel9.msdn.com/coding4fun/articles/MJPEG-Decoder). Поиск средства для отображения MJPEG осложнялся тем, что управляющее Митей Windows-приложение использует фреймворк XNA. MJPEG Decoder поддерживает XNA 4.0, а ещё он работает с WinForms, WPF, Silverlight и Windows Phone 7 приложениями.
Исходники Мити по-прежнему открыты, но там много всего, поэтому здесь я приведу свой демо-пример использования MJPEG Decoder в XNA-приложении для воспроизведения видеопотока от IP Webcam. А в следующем разделе я дополню этот пример кодом для воспроизведения звука от IP Webcam.
Итак, создаём Windows Game (4.0) проект. В ссылки этого проекта добавляем библиотеку «MjpegProcessorXna4» (скачиваем её с [сайта проекта](http://mjpeg.codeplex.com/releases/view/65863) или у [меня](http://code.google.com/p/robot-mitya/downloads/detail?name=MJPEG_bin.zip)).
В файле Game1.cs объявляем использование пространства имён MjpegProcessor:
```
using MjpegProcessor;
```
Объявляем закрытое поле mjpeg:
```
private MjpegDecoder mjpeg;
```
Объявляем текстуру для вывода видео:
```
private Texture2D videoTexture;
```
Дополняем метод Initialize:
```
this.mjpeg = new MjpegDecoder();
```
Дополняем метод Update:
1. По нажатию на пробел запускаем воспроизведение видеопотока:
```
this.mjpeg.ParseStream(new Uri(@"http://192.168.1.40/videofeed"));
```
2. По нажатию на Esc останавливаем воспроизведение:
```
this.mjpeg.StopStream();
```
3. Принимаем очередной кадр при вызове Update:
```
this.videoTexture = this.mjpeg.GetMjpegFrame(this.GraphicsDevice);
```
Дополняем метод Draw:
```
if (this.videoTexture != null)
{
this.spriteBatch.Begin();
Rectangle rectangle = new Rectangle(
0,
0,
this.graphics.PreferredBackBufferWidth,
this.graphics.PreferredBackBufferHeight);
this.spriteBatch.Draw(this.videoTexture, rectangle, Color.White);
this.spriteBatch.End();
}
```
Вот почти и всё. Почти, потому что всё уже работает, но кадры при воспроизведении сменяюся очень редко. У меня раз в 1-2 секунды. Чтобы это исправить, осталось подправить конструктор класса следующим образом:
```
public Game1()
{
this.IsFixedTimeStep = false;
this.graphics = new GraphicsDeviceManager(this);
this.graphics.SynchronizeWithVerticalRetrace = false;
Content.RootDirectory = "Content";
}
```
Содержимое файла Game1.cs я приведу в конце следующего раздела, когда дополню его кодом воспроизведения потокового звука.
#### Воспроизведение звука в Windows-приложении
Мне не удалось найти способ, как с помощью стандартных средств XNA или даже .NET можно воспроизвести аудиопотоки от IP Webcam. Ни «audio.wav», ни «audio.ogg». Я находил примеры, где потоковое аудио проигрывалось с помощью статического класса MediaPlayer из XNA фпеймворка, но наши потоки оказались ему не по зубам.
Очень много ссылок в Сети на открытые проекты NAUDIO и SlimDX. Но в первом я запустил демо-приложение и оно тоже не справилось, а второй я не осилил. Скатываться до уровня DirectX очень не хотелось. Совершенно случайно я нашёл замечательный выход. оказывается, вместе с всё тем же самым замечательным VLC media player поставляется ActiveX-библиотека! Т.е. под Windows я могу работать с VLC используя COM-интерфейсы. Описание интерфейсов очень скупое, Wiki проекта VLC содержит вообще устаревшую информацию. Неприятно, но всё удалось.
Для работы с интерфейсами ActiveX библиотеки её надо сначала зарегистрировать. При инсталляции VLC media player она не регистрируется и, как я понял, лежит мёртвым грузом в папке Vlc. Для этого запустите консоль (cmd.exe) и наберите:
`regsvr32 "c:\Program Files (x86)\VideoLAN\VLC\axvlc.dll"`
Путь, конечно, уточните. Если у вас Windows Vista или Windows 7, консоль запускайте от имени администратора.
Теперь звук от IP Webcam мы можем воспроизводить откуда угодно. Тренировался я на Excel. Можно и на VBScript, но в VBA члены классов вылезают в подсказках. Если есть желание, вот быстрый пример. Откройте Excel, нажмите Alt+F11. В окне Microsoft Visual Basic for Applications меню Tools -> References… Подключите ссылку на «VideoLAN VLC ActiveX Plugin». Теперь можно добавить модуль и вписать туда текст макроса:
```
Sub TestAxLib()
Dim vlc As New AXVLC.VLCPlugin2
vlc.Visible = False
vlc.playlist.items.Clear
vlc.AutoPlay = True
vlc.Volume = 200
vlc.playlist.Add "http://192.168.1.40:8080/audio.wav", Null, Array(":network-caching=5")
vlc.playlist.playItem (0)
MsgBox "Hello world!"
vlc.playlist.stop
End Sub
```
Стартуйте IP Webcam, запускайте макрос – будет звук! Кстати, так же можно сделать и воспроизведение видео.
Возвращаясь к нашему тестовому XNA-приложению, для воспроизведения потокового звука надо сделать следующее:
Добавить в проект ссылку на COM-компоненту «VideoLAN VLC ActiveX Plugin». В «Обозревателе решений» она появится как «AXVLC». Выделить ссылку «AXVLC» и в окне «Свойства» установить свойство «Внедрить типы взаимодействия» в значение False.
Объявить использование пространства имён AXVLC:
```
using AXVLC;
```
Объявить объект:
```
private AXVLC.VLCPlugin2 audio;
```
Дополнить метод Initialize:
```
this.audio = new AXVLC.VLCPlugin2Class();
```
Дополнить метод Update:
1. По нажатию на пробел запускаем воспроизведение аудиопотока:
```
this.audio.Visible = false;
this.audio.playlist.items.clear();
this.audio.AutoPlay = true;
this.audio.Volume = 200;
string[] options = new string[] { @":network-caching=20" };
this.audio.playlist.add(
@"http://192.168.1.40:8080/audio.wav",
null,
options);
this.audio.playlist.playItem(0);
```
2. По нажатию на Esc останавливаем воспроизведение аудиопотока:
```
if (this.audio.playlist.isPlaying)
{
this.audio.playlist.stop();
}
```
Итак, вот что должно получиться:
```
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.Xna.Framework;
using Microsoft.Xna.Framework.Audio;
using Microsoft.Xna.Framework.Content;
using Microsoft.Xna.Framework.GamerServices;
using Microsoft.Xna.Framework.Graphics;
using Microsoft.Xna.Framework.Input;
using Microsoft.Xna.Framework.Media;
using AXVLC;
using MjpegProcessor;
namespace WindowsGame1
{
///
/// Главный игровой класс.
///
public class Game1 : Microsoft.Xna.Framework.Game
{
GraphicsDeviceManager graphics;
SpriteBatch spriteBatch;
///
/// Текстура для вывода видео.
///
private Texture2D videoTexture;
///
/// Декодер MJPEG.
/// Используется для воспроизведения потокового видео (точнее, MJPEG), полученного от IP Webcam.
///
///
/// Требует подключения .NET библиотеки "MjpegProcessorXna4".
///
private MjpegDecoder mjpeg;
///
/// Плагин VLC.
/// Используется для воспроизведения потокового аудио, полученного от IP Webcam.
///
///
/// Объект из ActiveX-библиотеки VLC (www.videolan.org).
/// Требует установки VLC, регистрации ActiveX-библиотеки axvlc.dll, а затем добавления в ссылки проекта COM-компоненты "VideoLAN VLC ActiveX Plugin" (в обозревателе решений отображается как "AXVLC").
///
private AXVLC.VLCPlugin2 audio;
///
/// Конструктор класса.
///
public Game1()
{
this.IsFixedTimeStep = false;
this.graphics = new GraphicsDeviceManager(this);
this.graphics.SynchronizeWithVerticalRetrace = false;
Content.RootDirectory = "Content";
}
///
/// Инициализация игры перед запуском.
///
protected override void Initialize()
{
base.Initialize();
// Создание экземпляра декодера:
this.mjpeg = new MjpegDecoder();
// Создание COM-объекта для воспроизведения звука:
this.audio = new AXVLC.VLCPlugin2Class();
}
///
/// LoadContent will be called once per game and is the place to load
/// all of your content.
///
protected override void LoadContent()
{
// Create a new SpriteBatch, which can be used to draw textures.
spriteBatch = new SpriteBatch(GraphicsDevice);
}
///
/// Allows the game to run logic such as updating the world,
/// checking for collisions, gathering input, and playing audio.
///
/// Provides a snapshot of timing values.
protected override void Update(GameTime gameTime)
{
// По нажатию на пробел будет запущено воспроизведение видео и аудио:
if (Keyboard.GetState().IsKeyDown(Keys.Space))
{
// Запуск воспроизведения видео:
this.mjpeg.ParseStream(new Uri(@"http://192.168.1.40:8080/videofeed"));
// Запуск воспроизведения аудио:
this.audio.Visible = false;
this.audio.playlist.items.clear();
this.audio.AutoPlay = true;
this.audio.Volume = 200;
string[] options = new string[] { @":network-caching=20" };
this.audio.playlist.add(
@"http://192.168.1.40:8080/audio.wav",
null,
options);
this.audio.playlist.playItem(0);
}
// По нажатию на Esc воспроизведение видео останавливается:
if (Keyboard.GetState().IsKeyDown(Keys.Escape))
{
// Прекращение воспроизведения видео:
this.mjpeg.StopStream();
// Прекращение воспроизведения аудио:
if (this.audio.playlist.isPlaying)
{
this.audio.playlist.stop();
}
}
// Получение кадра:
this.videoTexture = this.mjpeg.GetMjpegFrame(this.GraphicsDevice);
base.Update(gameTime);
}
///
/// This is called when the game should draw itself.
///
/// Provides a snapshot of timing values.
protected override void Draw(GameTime gameTime)
{
GraphicsDevice.Clear(Color.CornflowerBlue);
if (this.videoTexture != null)
{
this.spriteBatch.Begin();
Rectangle rectangle = new Rectangle(
0,
0,
this.graphics.PreferredBackBufferWidth,
this.graphics.PreferredBackBufferHeight);
this.spriteBatch.Draw(this.videoTexture, rectangle, Color.White);
this.spriteBatch.End();
}
base.Draw(gameTime);
}
}
}
```
#### Итог
Закрыв этот этап, у меня появились как технические, так и нетехнические выводы.
Теперь друзья могут попутешествовать по моей квартире «в» Мите, не выходя из своего дома. Точнее могли бы, если б у них был геймпэд. Похоже, надо сделать управление более популярными средствами ввода.
Митя всё видит и слышит, но ничего не может сказать. Для начала надо расширить его мимику и обучить каким-нибудь базовым жестам, типа, «да», «нет», «повилять хвостом». Дальше надо будет делать воспроизведение звука в обратном направлении – от оператора к роботу.
Ещё один объявившийся вопрос – постоянная гудяще-жужжащая работа вертикального сервопривода, управляющего головой Мити. Из-за веса телефона сервопривод вынужден поддерживать заданный угол и постоянно гудит и мелко вибрирует. На видео это не сказывается, а вот микрофон ощутимо забивает. Оператор, в результате, ничего кроме жужжания не слышит. В некоторых положениях головы звук прекращается и тогда всё прекрасно слышно. Пока даже не знаю как решать эту проблему.
Мои нетехнический опыт, это то, что я открываю новые стороны своего хобби. Стоя в углу, робот Митя как-будто живёт своей жизнью: он знакомит меня с интересными и в чём-то очень похожими на меня людьми, он умудряется находить мне предложения о работе и каждый вечер я вприпрыжку спешу домой, чтобы успеть сделать что-нибудь ещё в этом проекте. Надеюсь, тут нет психиаторов… Словом, такой отдачи от вечернего времяпрепровождения (и с моей стороны, и с Митиной) я никак не ожидал.
И вот ещё вывод, который я постараюсь запомнить. Я прекрасно понимаю, ничто так не мотивирует, как победы. И ничто так не убивает интерес, как долгое отсутствие побед. Думаю не все обладают такой степенью упёртого занудства, как я. А даже я был на грани, чтобы всё это не бросить. Я говорил себе, что займусь пока другим проектом, отдохну от этого, а потом обязательно вернусь. Но в глубине души я знал что это значит и старался не смотреть в Тот Угол. Решение задачи передачи видео было для меня большим шагом в проекте, и я постараюсь больше не делать больших шагов. Большой шаг это большой риск. Я чуть не взялся за другую работу и она казалась мне более привлекательной, а сейчас я о ней даже не вспоминаю. В голове у меня роятся планы на Митю. Так что теперь буду ставить перед собой задачи поменьше. Я хочу много побед, это корм для моего удовольствия! Постараюсь в будущем обойтись без больших побед. Я выбираю много-много маленьких. | https://habr.com/ru/post/144748/ | null | ru | null |
# Автоматическое восстановление разделов диска с помощью Ghost
Практически в каждом новом ноутбуке теперь есть система восстановления, которая срабатывает, когда операционная система не может загрузится несколько раз подряд. Отличная идея: обычный пользователь, не вдающийся в тонкости работы своего компьютера и операционной системы, теперь избавлен от необходимости обращаться в сервис-центр, что экономит ему время и деньги.
Однако реализация этой идеи оказалось такова, что лучше бы этой системы восстановления не было вовсе. Во-первых, при штатном восстановлении теряются пользовательские данные, что, в принципе, ожидаемо. Во-вторых, процесс восстановления занимает неприлично много времени. На компьютере с винчестером в 1тб процесс шёл 8 часов и неизвестно, сколько бы он шёл ещё, если бы я его не прервал. Как бороться с этим безобразием вы узнаете под катом.
Если к вам регулярно обращаются родственники и знакомые, которые сами не в состоянии раскатать образ, с просьбой переустановить операционку, то вот он, выход из ситуации.
Также это может быть интересно приходящим системным администраторам, обслуживающим организации с небольшими сетями, т.к. можно существенно сэкономить время на поездках по этим самым организациям. Сейчас есть огромное количество программ-паразитов, которые могут преобразить операционку даже при отсутствии администраторских прав, несмотря на присутствие антивируса.
Сначала я хотел использовать для восстановления разделов Linux + dd, но отказался от этой идеи, т.к. dd создаёт слишком большие образы (даже если заархивировать) и скорость бэкапа\восстановления сильно уступает, по известным причинам, софту, который понимает файловые системы. Выбор пал на ghost (dos), т.к. он поддерживает ключи запуска в командной строке, что позволяет восстанавливать раздел нажатием одной кнопки.
Теперь о том, как это всё сделать. Первым делом нужно определится с размером раздела под систему. В моём случае винчестер был разбит так:
1. 50 ГБ под основную систему.
2. 20 ГБ под раздел для образа.
3. Остальное пространство под данные.
Второй раздел был отформатирован в ntfs но в системе не был смонтирован, во избежание удаления образа. Пользовательские папки были перемещены на третий раздел, таким образом, получалось, что после восстановления всё, что было в «моих документах», оставалось на месте.
Итак, после установки системы( win 7 в моём случае), софта и отключения второго раздела, нужно было сделать копию раздела, а для этого запустить Ghost. Оказалось, что загрузчик семёрки вполне может грузиться с образов дискет и в некоторых случаях с образов cd/dvd. Образ дискеты с dos-6.22 я скачал [отсюда](http://old-dos.ru/files/file_64.html). Распаковал образ, создал новый, добавив ghost. Скачать мой образ можно [отсюда](https://cloud.mail.ru/public/6e013eb104a9%2Fdos.ima).
Самый простой способ загрузится с этого образа — воспользоваться утилитой EasyBCD:

После перезагрузки в загрузочном меню появится дополнительный пункт с тем названием, которое было указано в EasyBCD при создании новой записи. Загрузившись с этого образа, можно запустить ghost и сделать резервную копию системного раздела. Предположим, что образ лежит на втором разделе и называется system.gho. Для автоматического развёртывания нужно подготовить второй загрузочный образ дискеты, который будет отличаться от первого только содержимым файла autoexec.bat:
```
ghost.exe -clone,mode=pload,src=1:2\system.gho:1,dst=1:1 -fx -sure -rb
```
Эта строка вставляется в конец файла autoexec.bat
Ключ src:
1:2 — первый диск, второй раздел
system.gho:1 — имя образа и раздел, находящийся внутри образа.
В данном случае он там один, но есть возможность восстановить конкретный раздел из образа всего диска.
Ключ dst
1:1 — первый раздел первого диска.
Ключ fx завершает работу приложения после окончания.
Ключ sure позволяет провести восстановление в автоматическом режиме, без ответов на вопросы типа «А вы уверены, что...?».
Ключ rb перезагружает компьютер после завершения работы приложения.
Обратите внимание, у меня система установлена на первый раздел, без создания загрузочного раздела windows. Если есть загрузочный раздел, то к номерам разделов, в параметрах запуска, надо прибавить 1.
Так же в autoexec.bat перед запуском ghost можно добавить защиту от нежелательного восстановления, когда в меню загрузки был случайно выбран не тот пункт.
```
set /P var="Destination Drive will be permanently overwritten. Proceed? (yes/no) : "
if not "%var%"=="yes" exit /b 1
```
Если на образе дискеты есть reboot.com, то можно использовать его вместо exit.
Второй образ нужно добавить в загрузку таким же способом, как и первый. | https://habr.com/ru/post/238083/ | null | ru | null |
# Nuklear+ — миниатюрный кроссплатформенный GUI
 [Nuklear+](https://github.com/DeXP/nuklear_cross) (читается как "Nuklear cross", значит "кроссплатформенный Nuklear") — это надстройка над GUI библиотекой [Nuklear](https://github.com/vurtun/nuklear), которая позволяет абстрагироваться от драйвера вывода и взаимодействия с операционной системой. Нужно написать один простой код, а он потом уже сможет скомпилироваться под все поддерживаемые платформы.
Я уже писал на хабре статью "[Nuklear — идеальный GUI для микро-проектов?](https://habrahabr.ru/post/319106/)". Тогда задача была простой — сделать маленькую кроссплатформенную утилиту с GUI, которая будет примерно одинаково выглядеть в Windows и Linux. Но с тех самых пор меня не отпускал вопрос, а можно ли на Nuklear сделать что-то более-менее сложное? Можно ли целиком на нём сделать какой-нибудь реальный проект, которым будут пользоваться?
[Веб-демо Wordlase](https://wordlase.dexp.in)
Именно поэтому следующую свою игру, [Wordlase](http://store.steampowered.com/app/602930/Wordlase/), я делал на чистом Nuklear. И без всякого там OpenGL. Даже фоновые картинки у меня имеют тип `nk_image`. В конечном итоге это дало возможность выбора драйвера отрисовки, вплоть до чистого X11 или GDI+.
Ещё в [прошлой своей статье](https://habrahabr.ru/post/319106/) я заложил основы [Nuklear+](https://github.com/DeXP/nuklear_cross) — библиотеки, призванной спрятать всю "грязь" от программиста и дать ему сфокусироваться на создании интерфейса. Библиотека умеет загружать шрифты, картинки, создавать окно операционной системы и контекст отрисовки.
Полный пример кода есть в [Readme на GitHub](https://github.com/DeXP/nuklear_cross). Там можно увидеть, что код получается довольно простой. Также я перенёс на Nuklear+ свои проекты [dxBin2h](https://github.com/DeXP/dxBin2h) и [nuklear-webdemo](https://github.com/DeXP/nuklear-webdemo). И сделать это было очень просто — вся инициализация заменяется на один вызов `nkc_init`, события обрабатываются `nkc_poll_events`, отрисовка функцией `nkc_render`, а в качестве деструктора вызывается `nkc_shutdown`.
[](https://dexp.github.io/nuklear-webdemo)
Но вернёмся к Wordlase, на примере которой и построена данная публикация. С недавних пор у игры есть [веб-демо](https://wordlase.dexp.in). Я не писал какого-то специфичного веб-кода для игры — это чистое С89 приложение, скомпилированное с помощью [Emscripten](https://kripken.github.io/emscripten-site/). И если полностью следовать примеру из Readme Nuklear+ (а именно, использовать `nkc_set_main_loop`), то веб-версия приложения будет получена абсолютно на халяву, без особых лишних затрат.
### Бэкэнд и фронтэнд
Самой интересной частью Nuklear+ являются поддерживаемые фронтэнды и бэкэнды. В данном случае под фронтэндом понимается часть, ответственная за взаимодействие с ОС и отрисовку окна. Т.е. непосредственно то, что видит пользователь. Реализации лежат в папке [nkc\_frontend](https://github.com/DeXP/nuklear_cross/tree/master/nkc_frontend). Сейчас поддерживаются: SDL, GLFW, X11, GDI+. Они не равносильны. Например, GDI+ использует WinAPI даже для рендера шрифтов и загрузки изображений, т.е. получить ровно такую же картинку в других ОС будет проблематично. Реализация так же не везде одинакова. Например, реализация Х11 пока не умеет изменять разрешение экрана в полноэкранном режиме (буду рад видеть Pull Request)
Выбрать фронтэнд для своего приложения просто — нужно установить переменную препроцессора `NKCD=NKC_x`, где `x` это одно из: SDL, GLFW, XLIB, GDIP. Например: `gcc -DNKCD=NKC_GLFW main.c`
Бэкэнд в данном случае выполняет непосредственно отрисовку. Реализация в папке [nuklear\_drivers](https://github.com/DeXP/nuklear_cross/tree/master/nuklear_drivers). Отрисовка средствами любой версии OpenGL выдаёт примерно одинаковую картинку на всех ОС и фронтэндах. Ведь для загрузки изображений там всегда используется [stb\_image](https://github.com/nothings/stb), а шрифт рендерится стандартными средствами Nuklear (тоже основано на stb). В то же время чистый Х11 драйвер даже не умеет загружать шрифты. Так что не забывайте тестировать своё приложение для выбранной пары бэкэнд+фронтэнд.
Например: *Wordlase, GLFW3, OpenGL 2, Windows*
[](https://habrastorage.org/web/d81/f02/298/d81f02298d974dc9ad67e903926d5c0e.jpg)
Или: *Wordlase, SDL2, OpenGL ES, Linux*
[](https://habrastorage.org/web/b49/776/063/b4977606303840b180c474f10d104653.jpg)
В качестве бэкэнда по умолчанию выбран OpenGL2, если доступен. Можно задать `NKC_USE_OPENGL=3` для OpenGL 3, и `NKC_USE_OPENGL=NGL_ES2` для OpenGL ES 2.0. Для использования чистого Х11 отрисовщика константу `NKC_USE_OPENGL` указывать не надо. Также OpenGL опции не влияют на GDI+ — там отрисовка всегда идёт своими средствами.
Вот скриншот с GDI+: *Wordlase, GDI+, без OpenGL, Windows*
[](https://habrastorage.org/web/e47/097/fd6/e47097fd606d4751be3824128e49d1c6.jpg)
Этот бэкэнд полноценно поддерживает полупрозрачные изображения, картинка близка к оригиналу. Разница в шрифте: хинтинг, сглаживание, да даже размер (также буду рад Pull Request'у для автоматической подстройки размера GDI+ шрифта под размер stb\_ttf).
И самый ужасный случай — чистый Х11 отрисовщик, который до моего [pull request](https://github.com/vurtun/nuklear/pull/512) даже не умел загружать картинки. *Wordlase, X11, без OpenGL, Linux*:
[](https://habrastorage.org/web/b46/a9d/cb9/b46a9dcb9a734d66893c35773ea8a299.jpg)
Вот здесь уже довольно много отличий: логотип, солнечные лучи, более острый край девушки, шрифт. Почему? Фон в игре на лету собирается из нескольких полупрозрачных PNG. Но чистый Х11 поддерживает только битовую прозрачность, прямо как GIF. Также отрисовщик Х11 очень медленно работает на больших изображениях с прозрачностью. А если в движке отключить прозрачность, то картинка становится ещё хуже. *Wordlase, X11, без OpenGL, без прозрачности*:
[](https://habrastorage.org/web/e5f/54e/569/e5f54e5698d448888397db00eb48ac17.jpg)
Так зачем вообще нужны отрисовщики GDI+ и Х11, если они так уродливы? Потому, что они плохи только для больших изображений с прозрачностью. А если делать маленькую утилиту, где картинки используются только как иконки пользовательского интерфейса, то эти отрисовщики становятся вовсе неплохим вариантом, т.к. имеют минимальное количество зависимостей. Также я пользовался чистым Х11 отрисовщиком на слабых системах, где OpenGL только программный. В таком случае Х11 работает быстрее OpenGL. Подсказка: если вместо кучи полупрозрачных PNG использовать один большой JPEG, то Х11 будет работать быстро и корректно.
Пример хорошего использования чистого Х11 бэкэнда — главное игровое окно Wordlase. Больших картинок там почти нет, зато есть несколько интерфейсных иконок, которые вполне корректно отображаются:
Отлично, отрисовщик выбран, окно ОС создаётся. Теперь самое время заняться GUI!
### Фишки Nuklear
Самым первым в [Wordlase](https://wordlase.dexp.in) показывается экран выбора языка:

Здесь видны сразу 2 интересных техники: несколько картинок на фоне окна и центрирование виджетов.
Поместить картинку на фон окна достаточно просто:
```
nk_layout_space_push(ctx, nk_rect(x, y, width, height));
nk_image(ctx, img);
```
`x` и `y` — позиция на экране, `width` и `height` — размеры изображения.
Центрирование является более сложной задачей, т.к. не поддерживается Nuklear напрямую. Нужно вычислять положение самостоятельно:
```
if ( nk_begin(ctx, WIN_TITLE,
nk_rect(0, 0, winWidth, winHeight), NK_WINDOW_NO_SCROLLBAR)
) {
int i;
/* 0.2 are a space skip on button's left and right, 0.6 - button */
static const float ratio[] = {0.2f, 0.6f, 0.2f}; /* 0.2+0.6+0.2=1 */
/* Just make vertical skip with calculated height of static row */
nk_layout_row_static(ctx,
(winHeight - (BUTTON_HEIGHT+VSPACE_SKIP)*langCount )/2, 15, 1
);
nk_layout_row(ctx, NK_DYNAMIC, BUTTON_HEIGHT, 3, ratio);
for(i=0; i
```
Следующая прикольная штучка — выбор темы оформления в настройках:

Реализуется тоже просто:
```
if (nk_combo_begin_color(ctx, themeColors[s.curTheme],
nk_vec2(nk_widget_width(ctx), (LINE_HEIGHT+5)*WTHEME_COUNT) )
){
int i;
nk_layout_row_dynamic(ctx, LINE_HEIGHT, 1);
for(i=0; i
```
Здесь главное понимать, что всплывающее поле combo — это такое же окно, как и главное. И располагать там можно что угодно.
Самым сложно выглядящим окном является основное игровое окно:
На самом деле, тут тоже нет ничего сложного. На экране всего 4 ряда:
1. Верхняя линия с выбором уровня (виджет `nk_property_int`)
2. Список слов (`nk_group_scrolled`)
3. Кнопки текущего слова
4. Строка с подсказкой
Единственный непонятный момент здесь — задание точных размеров элементам. Выполняется это с помощью соотношения ряда:
```
float ratio[] = {
(float)BUTTON_HEIGHT/winWidth, /* square button */
(float)BUTTON_HEIGHT/winWidth, /* square button */
(float)topWordSpace/winWidth,
(float)WORD_WIDTH/winWidth
};
nk_layout_row(ctx, NK_DYNAMIC, BUTTON_HEIGHT, 4, ratio);
```
`BUTTON_HEIGHT` и `WORD_WIDTH` — константы, измеряются в пикселях; `topWordSpace` вычисляется как ширина экрана минус ширины всех остальных элементов.
И последнее сложно выглядящее окно — статистика:

Расположение элементов регулируется с помощью группировки. Ведь всегда можно сказать Nuklear: "в этом ряду будет 2 виджета". Но группа тоже является виджетом. Т.е. можно просто создать группу с помощью `nk_group_begin` и `nk_group_end`, а дальше позиционироваться внутри неё как внутри обычного окна (`nk_layout_row` и пр.).
### Заключение
Nuklear уже готов даже для коммерческих игр и приложений. А Nuklear+ может сделать их создание более приятным.
### Полезные ссылки
* [Wordlase в Steam](http://store.steampowered.com/app/602930/Wordlase/)
* [Wordlase веб демо](https://wordlase.dexp.in/)
* [Nuklear+ GitHub репозиторий](https://github.com/DeXP/nuklear_cross)
* [Nuklear GitHub репозиторий](https://github.com/vurtun/nuklear)
* [Nuklear веб демо](https://dexp.github.io/nuklear-webdemo)
* [Эта публикация на английском](https://dexp.in/articles/nuklear-cross/) | https://habr.com/ru/post/338106/ | null | ru | null |
# Перевод Вставка-копирование текста в буфер обмена на Javаscript — два способа с Flash 10
В Flash 10, как оказалось, нельзя программно самому копировать текст в буфер обмена. До его выхода был очень удобный и элегантный способ, например, «Копировать код для вставки изображения в блог» / «Copy embed code» сразу в буфер пользователя. Я не говорю про IE, в котором это всегда раньше было реализуемо (не знаю как в ИЕ8) с помощью javascript-вызова window.clipboardData.setData('text',text);
Речь о том, как это сделать для пользователей альтернативных браузеров.
Итак, с выходом Flash 10, из соображений безопасности, была закрыта возможность программно заменять содержимое буфера обмена без участия пользователя. Подобная атака могла, например, непрерывно помещать в буфер обмена ссылку на сайт злоумышленника, из рассчета на то, что многие вставляют содержимое буфера в адресную строку браузера и жмут Enter, не обращая внимания на то, что именно вставилось.
[В статье Adobe Developer Center](http://www.adobe.com/devnet/flashplayer/articles/fplayer10_uia_requirements.html) говорится о том, что «старая» функция System.setClipboard(), и новый объект Clipboard.generalClipboard для работы с буфером обмена смогут работать, только если они были иницированы действиями пользователя, например, после нажатия на кнопку (*to happen as the result of a user-initiated action*). Еще много других правил безопасности было изменено с выходом 10 флэш-плеера, но нас интересует именно то, что теперь старый добрый [**Clipboard Copy** от Jeffothy Keyings](http://www.jeffothy.com/weblog/clipboard-copy) **не работает**.
На данный момент я нашел два выхода.
Один из способов предлагает создавать флэш-мувик с единственной кнопкой «Копировать», и в FlashVars передавать текст, который нужно поместить в буфер.
**Actionscript 2.0**
`on (release) {
System.setClipboard(_level0.txtToCopy);
getURL('javascript:'+_level0.js+';');
}`
**HTML/JS**
`<br/>
function alertUser(){<br/>
alert('Текст скопирован в буфер обмена');<br/>
}<br/>`
**Скачать** готовый флэш-файл можно здесь: [copyButton.swf](http://www.mediafire.com/?ogt1uoyyl1m)
**FlashVars:**
txtToCopy — строка, которую нужно скопировать в буфер
js — JS-функция, вызываемая после успешного копирования
(с) [источник](http://cfruss.blogspot.com/2009/01/copy-to-clipboard-swf-button-cross.html)
По той же ссылке упоминается второй способ — [**ZeroClipboard**](http://code.google.com/p/zeroclipboard/), который многим может показаться более простым.
По словам разработчика, вам необходимо «прилепить» флэш-мувик к какому-нибудь конкретному элементу на странице, **после чего** пользователь может кликнуть по этому элементу, что будет перехвачено невидимым флэш-мувиком, находящимся **над** элементом. В таком и только таком случае Adobe Flash позволит работать с буфером обмена.
[Тест1](http://bowser.macminicolo.net/~jhuckaby/zeroclipboard/multiple.html), [тест2](http://bowser.macminicolo.net/~jhuckaby/zeroclipboard/), [тест3](http://bowser.macminicolo.net/~jhuckaby/zeroclipboard/innerhtmlclick.html)
Для начала подключаем скрипты
Дальше необходимо указать где находится ZeroClipboard.swf (нужна абсолютная или относительная ссылка)
`ZeroClipboard.setMoviePath( 'http://YOURSERVER/path/ZeroClipboard.swf' );`
Теперь можно создавать **клиентов**.
Клиент в данном случае — это ZeroClipboard-объект, привязанный к определенной кнопке или какому-либо другому DOM-элементу. Скорее всего, вам понадобится только один клиент, но если у вас на странице несколько кнопок для копирования в буфер, создайте клиента для каждой из них.
`var clip = new ZeroClipboard.Client();`
Вы можете в любой момент указать текст, который нужно скопировать в буфер, — после загрузки страницы (onload), по клику, при onMouseOver или onMouseDown:
`clip.setText( "Copy me!" );`
Можно установить, какой курсор мыши будет при наведении на объект — рука (true, по умолчанию) или обычная стрелка (false)
`clip.setHandCursor( true );`
Самое интересное. Приклевание к элементу DOM.
`clip.glue( 'd_clip_button' );`
Да :) это и всё. Вы можете передать в эту функцию или HTML-ID элемента или сам объект (полученный например от document.getElementById()). Дальше все происходит автоматически — создается флэш-мувик, со всеми выставленными вами настройками, помещается над указанным DOM-элементом и ждет клика от пользователя.
Если ваш DOM-элемент перемещается (например, из-за того, что окно меняет размеры), используйте функцию `clip.reposition()`, обычно ее вешают на событие window.onresize
Более подробно о настройках и кучу примеров можно найти у автора — [code.google.com/p/zeroclipboard](http://code.google.com/p/zeroclipboard/)
Там же описано как заставить флэш мувик реагировать не на клик, а на mouse over.
Zero Clipboard Library тестировалась на следующих платформах / браузерах:
| | | | |
| --- | --- | --- | --- |
| **Browser** | **Windows XP SP3** | **Windows Vista** | **Mac OS X Leopard** |
| Internet Exploder | 7.0 | 7.0 | — |
| Firefox | 3.0 | 3.0 | 3.0 |
| Safari | — | — | 3.0 |
| Google Chrome | 1.0 | 1.0 | — |
Adobe Flash Flash Player versions 9 and 10 are supported.
P.S. На самом деле, столкнулся с этой проблемой, нашел решение, и не смог не поделиться, — решился-таки на свой **первый пост** на хабре. | https://habr.com/ru/post/55646/ | null | ru | null |
# Скрипт уведомлений и исполнения команд через Телеграмм для РоутерОС Микротик
Мессенджер Телеграмм полагаю представлять не нужно. В сравнении с другими существующими мессенджерами, Телеграмм выгодно отличается тем, что позволяет создавать боты, которые могут участвовать в чатах. Это удобно во многих случаях, в том числе для разработчиков программного обеспечения и продвинутых пользователей.
Применительно к работе с роутерами Микротик, Телеграмм удобен тем, что в чат-бот можно организовать пересылку сообщения от роутера, а пользуясь возможностями парсинга чата через API Telegram, пересылать исполняемые команды.
Как создать свой бот, чат и «прикрутить» к ним Микротик можно прочитать например [здесь](https://1spla.ru/blog/telegram_bot_for_mikrotik/) или [здесь](https://forum.sys-adm.in/t/telegram-mikrotik-part-1-vklyuchaem-domashnij-pk-soobshheniem-v-telegrame/7064).
За время появления Телеграмм был создан далеко не один скрипт по уведомлению о событиях роутера Микротик, в том числе как зарубежными так и отечественными пользователями энтузиастами. Например, [здесь](https://habr.com/ru/post/532086/) или в [этой](https://forummikrotik.ru/viewtopic.php?f=14&t=11710&p=71914#p71914) теме на русскоязычном форуме Микротик.
Мы объединили накопленные за это время идеи и код в единый скрипт под названием TLGRM, который хотим представить здесь.
TLGRM — это обкатанная, но постоянно дорабатываемая версия скрипта, объединившего в себе пересылку важных и критических событий из лога роутера, возможность запуска скриптов по именам, а также новейшие (для скрипта) оригинальные возможности: запуск функций из окружения переменных, в том числе с параметрами, и прямое выполнение команд РоутерОС. Вероятно, последние две возможности применены авторами впервые (по крайней мере скрипты с аналогичными возможностями нам до сих пор не были известны).
Итак, TLGRM — комбинированный скрипт оповещения в Телеграм и удалённого запуска функций, скриптов и команд в RouterOS.
В скрипте использованы идеи и часть кода нескольких авторов: Sertik, Virtue, Pepelxl, Dimonw, Jotne, Alice Tails, drPioneer (никнеймы авторов на [русскоязычном](https://forummikrotik.ru/) и [англоязычном](https://forum.mikrotik.com/) форумах Микротик).
Для работы скрипта должны быть настроены BotID и ChatID, того чата, который будет «слушать» и обрабатывать TLGRM. Скрипт необходимо добавить в System/Sheduler и установить запуск с нужной периодичностью (оптимально 1 минута).
**Скрипт выполняет две основные задачи:**
1. Чтение в Телеграм-группе последнего сообщения на предмет наличия адресованного роутеру или группе роутеров послания. При наличии такого послания скрипт пытается разобрать его и исполнить.
2. Поиск в журнале устройства сообщений о важных или подозрительных событиях и их пересылка в Телеграм-группу. В том числе пересылаются записи журнала, выполненные как warning и error (отображаемые в логе синим и красным цветом).
**Работа пользователя со скриптом:**
Для отправки команды конкретному роутеру в Телеграм-группе, пользователю необходимо сформировать сообщение:
Начало сообщения обозначается символом "/", далее указывается имя роутера (должно соответствовать записи в /system identity, при этом регистр букв имеет значение, и не должно содержать пробелов), затем через пробел пишется команда.
В качестве команды могут выступать: имя глобальной функции установленной в окружение, имя скрипта репозитория роутера пользователя, команда RouterOS. В том числе поддерживаются вложенные конструкции.
*Примеры:*
```
/Mikrotik1 funcarp par1 par2
/Mikrotik2 scriptwol
/Mikrotik3 log warning [/system identity get name]
```
Если необходимо отправить команду всем роутерам, слушающим данный чат, необходимо вместо identity конкретного роутера написать /forall.
*Например:*
```
/forall system reboot
```
или, допустим
```
/forall backup
```
для того, чтобы выполнить скрипт backup — сохранения конфигурации на всех роутерах группы (для этого в репозитории роутеров должен быть искомый скрипт).
**Особенности работы скрипта TLGRM:**
* поддерживается отправка сообщений в Телеграм-группу с кириллицей
* непечатные символы при отправке в Телеграм-группу обрезаются
* сообщение длиной более 4096 перед отправкой в Телеграм-группу обрезается до 4096 символов
* скрипт читает только последнее сообщение в Телеграм-группе. По этой причине не имеет смысла подавать в чате сразу много команд, в любом случае будет выполнена только последняя.
* теперь поддерживается индивидуальная и групповая адресация команд
* при запуске скрипта в терминале можно наблюдать за ходом его выполнения
Дополнительно можно настроить локальные флаги launch в начале скрипта, которые указывают разрешено ли распознавание и выполнение скриптом скриптов, функций и/или прямых команд РоутерОС соответственно (по умолчанию все данные опции разрешены). Если какие-то функции не нужны, установите соответствующие флаги в false.
```
:local launchScr true;
:local launchFnc true;
:local launchCmd true;
```
**Содержание и алгоритм работы TLGRM.**
Скрипт TLGRM состоит из нескольких блоков и локальных функций: главный блок, блок парсинга ответов Телеграм, функция поиска комментария по MAC-адресу, функция конвертер русского текста в UTF8 формат, функции вычисления Юлианского времени и функции обратного преобразования времени UNIX в привычные форматы. Все блоки и их авторы отмечены непосредственно в тексте скрипта TLGRM.
При запуске управление передаётся главному блоку скрипта, который на первом этапе обменивается данными с Телеграм-сервером и пытается произвести активацию предназначенных ему команд. В нём скрипт формирует запрос с указанными пользователем botID и chatID и отправляет его на Телеграм-сервер.
В ответ Телеграм-сервер возвращает запрошенную информацию в [JSON-формате](https://habr.com/ru/post/554274/).
Для извлечения требуемой информации скрипт использует вышеупомянутую локальную функцию парсинга ответов Телеграм — функцию-парсер MsgParser. Код функции был опубликован [здесь](https://habr.com/ru/post/482802/). На вход функции подается JSON-последовательность и ключ, а функция возвращает найденное значение, соответствующее запрошенному ключу.
Таким образом, за несколько обращений к этой функции скрипт получает и накапливает информацию:
* имя отправителя сообщения,
* время отправки сообщения,
* id-чата,
* текст сообщения.
На основе этой информации принимается решение о необходимости обработки текста сообщения и дальнейшем исполнении распознанных в тексте сообщения команд.
Осуществляется синхронизация времени предыдущего и настоящего обращения к скрипту, для избежания повторных ложных срабатываний.
Как уже было сказано здесь TLGRM может исполнить скрипт из репозитория пользователя, активную функцию из окружения переменных, в том числе передав её необходимые позиционные и/или именные параметры, либо прямую команду РоутерОС.
Для примера вот этот важный фрагмент скрипта. Обратите внимание на использование для составления и исполнения команды :parse, заключенной в составе необходимой конструкции в квадратные скобки):
```
:local restline [];
:if ([:len [:find $msgTxt " "]] !=0) do={
:set params [:pick $msgTxt ([:find $msgTxt " "] +1) [:len $msgTxt]];
:set msgTxt [:pick $msgTxt 0 [:find $msgTxt " "]];
}
:if ($chatId=$myChatID && $timeAct<$timeStamp) do={
:set timeAct ($timeStamp);
:if ([/system script environment find name=$msgTxt;]!="" \
&& $launchFnc=true) do={
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Telegram user \ $userName launches function '$msgTxt'.");
:log warning ("Telegram user $userName launches function '$msgTxt'.");
[:parse ":global $msgTxt; [\$$msgTxt $restline]"];
}
:if ([/system script find name=$msgTxt;]!="" && $launchScr=true) do={
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Telegram user $userName activates script '$msgTxt'.");
:log warning ("Telegram user $userName activates script '$msgTxt'.");
/system script run $msgTxt;
}
:if ([/system script find name=$msgTxt;]="" && [/system script environment find name=$msgTxt;]="" && $launchCmd=true) do={
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Telegram user $userName is trying to execute command '$msgTxt'.");
:log warning ("Telegram user $userName is trying to execute command '$msgTxt'.");
:do {[:parse "/$msgTxt $restline"]} on-error={}
}
} else={ :put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Wrong time to launch."); }
} else={ :put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - No command found for this device."); }
} else={ :put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Completion of response from Telegram."); }
```
В случае с исполнением глобальной функции, она предварительно декларируется, а в переменной $restline содержатся следующие за именем параметры функции (если они переданы).
В случае же с передачей команды RouterOS в $restline попадет весь остаток строки парсинга после первой команды и вместе с последней фактически передается строка как есть целиком. Это позволяет исполнять практически любые команды ROS и даже сложные конструкции. Более сложные алгоритмы, разумеется целесообразно вынести в отдельные скрипты, также доступные для исполнения по имени через TLGRM.
После исполнения распознанных команд следует выполнение «информационного» блока скрипта, отвечающего за формирование сообщения и отправки его в Телеграм-чат.
Эта часть скрипта использует позаимствованную [отсюда](https://www.reddit.com/r/mikrotik/comments/onusoj/sending_log_alerts_to_telegram/) логику.
В журнале устройства производится поиск записей обо всех подозрительных событиях.
```
($topics ~"warning" || $topics ~"error" || $topics ~"critical" || $topics ~"caps" || $topics ~"wireless" || $message ~"logged in")
```
а также
```
($tempTopic ~"caps" || $tempTopic ~"wireless" || $tempTopic ~"dhcp")
```
(список логируемых записей можно самостоятельно расширить, добавив соответствующие «топикс»)
Если такие записи находятся, тогда формируется и отправляется запрос на Телеграм-сервер с целью отправки сообщения в Телеграм-чат.
Перед формированием запроса серверу производится обработка найденных записей:
* записи пропускаются через функцию FindMacAddr (использована [идея](https://forummikrotik.ru/viewtopic.php?p=73994)), которая пытается к обнаруженным MAC-адресам добавить текстовые комментарии для облегчения понимания пользователем, о каких хостах идет речь.
* если текст сообщения длиннее 4096 символов, производится его обрезание до 4096 символов (ограничение Telegram API: [tlgrm.ru/docs/bots/api](https://tlgrm.ru/docs/bots/api)).
* текст пропускается через функцию-конвертер '[CP1251toUTF8](https://habr.com/ru/post/518534/)', которая производит обработку символов кириллицы и спецсимволов для правильного отображения в Телеграм.
* так как Телеграм работает со временем в формате UnixTime, в скрипте используются функции [EpochTime](https://forum.mikrotik.com/viewtopic.php?t=75555) и [UnixTimeToFormat](https://forummikrotik.ru/viewtopic.php?t=11636) для трансляции времени роутера в вид, понятный Телеграм и обратно.
На этом работа скрипта завершается до следующего запуска через Планировщик.
**Под спойлером полный текст TLGRM (по состоянию на 08.02.2022 г.)**
```
# TLGRM - combined notifications script & launch of commands (scripts & functions) via Telegram
# Script uses ideas by Sertik, Virtue, Pepelxl, Dimonw, Jotne, Alice Tails, drPioneer.
# https://forummikrotik.ru/viewtopic.php?p=81945#p81945
# tested on ROS 6.49
# updated 2022/02/08
:do {
:local botID "botXXXXXXXXXX:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX";
:local myChatID "-XXXXXXXXX";
:local launchScr true;
:local launchFnc true;
:local launchCmd true;
# Function of searching comments for MAC-address
# https://forummikrotik.ru/viewtopic.php?p=73994#p73994
:local FindMacAddr do={
:if ($1 ~"[0-F][0-F]:[0-F][0-F]:[0-F][0-F]:[0-F][0-F]:[0-F][0-F]:[0-F][0-F]") do={
:foreach idx in=[ /ip dhcp-server lease find dynamic=no disabled=no; ] do={
:local mac [ /ip dhcp-server lease get $idx mac-address; ];
:if ($1 ~"$mac") do={
:return ("$1 [$[ /ip dhcp-server lease get $idx address; ]/\
$[ /ip dhcp-server lease get $idx comment; ]].");
}
}
:foreach idx in=[ /interface bridge host find; ] do={
:local mac [ /interface bridge host get $idx mac-address; ];
:if ($1 ~"$mac") do={ :return ("$1 [$[ /interface bridge host get $idx on-interface; ]]."); }
}
}
:return ($1);
}
# Function of converting CP1251 to UTF8
# https://forummikrotik.ru/viewtopic.php?p=81457#p81457
:local CP1251toUTF8 do={
:local cp1251 [:toarray {"\20";"\01";"\02";"\03";"\04";"\05";"\06";"\07";"\08";"\09";"\0A";"\0B";"\0C";"\0D";"\0E";"\0F"; \
"\10";"\11";"\12";"\13";"\14";"\15";"\16";"\17";"\18";"\19";"\1A";"\1B";"\1C";"\1D";"\1E";"\1F"; \
"\21";"\22";"\23";"\24";"\25";"\26";"\27";"\28";"\29";"\2A";"\2B";"\2C";"\2D";"\2E";"\2F";"\3A"; \
"\3B";"\3C";"\3D";"\3E";"\3F";"\40";"\5B";"\5C";"\5D";"\5E";"\5F";"\60";"\7B";"\7C";"\7D";"\7E"; \
"\C0";"\C1";"\C2";"\C3";"\C4";"\C5";"\C7";"\C7";"\C8";"\C9";"\CA";"\CB";"\CC";"\CD";"\CE";"\CF"; \
"\D0";"\D1";"\D2";"\D3";"\D4";"\D5";"\D6";"\D7";"\D8";"\D9";"\DA";"\DB";"\DC";"\DD";"\DE";"\DF"; \
"\E0";"\E1";"\E2";"\E3";"\E4";"\E5";"\E6";"\E7";"\E8";"\E9";"\EA";"\EB";"\EC";"\ED";"\EE";"\EF"; \
"\F0";"\F1";"\F2";"\F3";"\F4";"\F5";"\F6";"\F7";"\F8";"\F9";"\FA";"\FB";"\FC";"\FD";"\FE";"\FF"; \
"\A8";"\B8";"\B9"}];
:local utf8 [:toarray {"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"000A";"0020";"0020";"000D";"0020";"0020"; \
"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020";"0020"; \
"0021";"0022";"0023";"0024";"0025";"0026";"0027";"0028";"0029";"002A";"002B";"002C";"002D";"002E";"002F";"003A"; \
"003B";"003C";"003D";"003E";"003F";"0040";"005B";"005C";"005D";"005E";"005F";"0060";"007B";"007C";"007D";"007E"; \
"D090";"D091";"D092";"D093";"D094";"D095";"D096";"D097";"D098";"D099";"D09A";"D09B";"D09C";"D09D";"D09E";"D09F"; \
"D0A0";"D0A1";"D0A2";"D0A3";"D0A4";"D0A5";"D0A6";"D0A7";"D0A8";"D0A9";"D0AA";"D0AB";"D0AC";"D0AD";"D0AE";"D0AF"; \
"D0B0";"D0B1";"D0B2";"D0B3";"D0B4";"D0B5";"D0B6";"D0B7";"D0B8";"D0B9";"D0BA";"D0BB";"D0BC";"D0BD";"D0BE";"D0BF"; \
"D180";"D181";"D182";"D183";"D184";"D185";"D186";"D187";"D188";"D189";"D18A";"D18B";"D18C";"D18D";"D18E";"D18F"; \
"D001";"D191";"2116"}];
:local convStr "";
:local code "";
:for i from=0 to=([:len $1]-1) do={
:local symb [:pick $1 $i ($i+1)];
:local idx [:find $cp1251 $symb];
:local key ($utf8->$idx);
:if ([:len $key] != 0) do={
:set $code ("%$[:pick ($key) 0 2]%$[:pick ($key) 2 4]");
:if ([pick $code 0 3] = "%00") do={ :set $code ([:pick $code 3 6]); }
} else={ :set code ($symb); };
:set $convStr ($convStr.$code);
}
:return ($convStr);
}
# Telegram messenger response parsing function
# https://habr.com/ru/post/482802/
:local MsgParser do={
:local variaMod ("\"".$2."\"");
:if ([:len [:find $1 $variaMod -1]]=0) do={ :return ("'unknown'"); }
:local startLoc ([:find $1 $variaMod -1] + [:len $variaMod] +1);
:local commaLoc ([:find $1 "," $startLoc]);
:local brakeLoc ([:find $1 "}" $startLoc]);
:local endLoc $commaLoc;
:local startSymbol [:pick $1 $startLoc];
:if ($brakeLoc != 0 and ($commaLoc = 0 or $brakeLoc < $commaLoc)) do={ :set endLoc $brakeLoc; };
:if ($startSymbol = "{") do={ :set endLoc ($brakeLoc + 1); };
:if ($3 = true) do={
:set startLoc ($startLoc + 1);
:set endLoc ($endLoc - 1);
}
:if ($endLoc < $startLoc) do={ :set endLoc ($startLoc + 1); };
:return ([:pick $1 $startLoc $endLoc]);
}
# Time translation function to UNIX-time
# https://forum.mikrotik.com/viewtopic.php?t=75555#p790745
# Usage: $EpochTime [time input]
# Get current time: put [$EpochTime]
# Read log time in one of three format: "hh:mm:ss", "mmm/dd hh:mm:ss" or "mmm/dd/yyyy hh:mm:ss"
:local EpochTime do={
:local ds [ /system clock get date; ];
:local ts [ /system clock get time; ];
:if ([:len $1] > 19) do={
:set ds "$[:pick $1 0 11]";
:set ts [:pick $1 12 20];
}
:if ([:len $1] > 8 && [:len $1] < 20) do={
:set ds "$[:pick $1 0 6]/$[:pick $ds 7 11]";
:set ts [:pick $1 7 15];
}
:local yesterday false;
:if ([:len $1] = 8) do={
:if ([:totime $1] > ts) do={ :set yesterday (true); }
:set ts $1;
}
:local months;
:if ((([:pick $ds 9 11]-1)/4) != (([:pick $ds 9 11])/4)) do={
:set months {"an"=0;"eb"=31;"ar"=60;"pr"=91;"ay"=121;"un"=152;"ul"=182;"ug"=213;"ep"=244;"ct"=274;"ov"=305;"ec"=335};
} else={
:set months {"an"=0;"eb"=31;"ar"=59;"pr"=90;"ay"=120;"un"=151;"ul"=181;"ug"=212;"ep"=243;"ct"=273;"ov"=304;"ec"=334};
}
:set ds (([:pick $ds 9 11]*365)+(([:pick $ds 9 11]-1)/4)+($months->[:pick $ds 1 3])+[:pick $ds 4 6]);
:set ts (([:pick $ts 0 2]*3600)+([:pick $ts 3 5]*60)+[:pick $ts 6 8]);
:if (yesterday) do={ :set ds ($ds-1); }
:return ($ds*86400 + $ts + 946684800 - [ /system clock get gmt-offset; ]);
}
# Time conversion function from UNIX-time
# https://forummikrotik.ru/viewtopic.php?t=11636
# usage: [$UnixTimeToFormat "timeStamp" "type"]
# type: "unspecified" - month/dd/yyyy (Mikrotik sheduller format)
# 1 - yyyy/mm/dd hh:mm:ss
# 2 - dd:mm:yyyy hh:mm:ss
# 3 - dd month yyy hh mm ss
# 4 - yyyy month dd hh mm ss
# 5 - month/dd/yyyy-hh:mm:ss (Mikrotik sheduller format)
:local UnixTimeToFormat do={
:local decodedLine "";
:local timeStamp $1;
:local timeS ($timeStamp % 86400);
:local timeH ($timeS / 3600);
:local timeM ($timeS % 3600 / 60);
:set $timeS ($timeS - $timeH \* 3600 - $timeM \* 60);
:local dateD ($timeStamp / 86400);
:local dateM 2;
:local dateY 1970;
:local leap false;
:while (($dateD / 365) > 0) do={
:set $dateD ($dateD - 365);
:set $dateY ($dateY + 1);
:set $dateM ($dateM + 1);
:if ($dateM = 4) do={
:set $dateM 0;
:if (($dateY % 400 = 0) or ($dateY % 100 != 0)) do={
:set $leap true;
:set $dateD ($dateD - 1);
}
} else={ :set $leap false; }
}
:local months [:toarray (0,31,28,31,30,31,30,31,31,30,31,30,31)];
:if (leap) do={
:set $dateD ($dateD + 1);
:set ($months->2) 29;
}
:do {
:for i from=1 to=12 do={
:if (($months->$i) > $dateD) do={
:set $dateM $i;
:set $dateD ($dateD + 1);
break;
} else={ :set $dateD ($dateD - ($months->$i)); }
}
} on-error={}
:local tmod;
:if ([:len $2]!=0) do={ :set $tmod $2; } else={ :set $tmod (:nothing); }
:local s "/";
:local nf true;
:local mstr {"jan";"feb";"mar";"apr";"may";"jun";"jul";"aug";"sep";"oct";"nov";"dec"};
:local strY [:tostr $dateY];
:local strMn;
:local strD;
:local strH;
:local strM;
:local strS;
:if ($nf) do={
:if ($dateM > 9) do={ :set $strMn [:tostr $dateM]; } else={ :set $strMn ("0".[:tostr $dateM]); }
:if ($dateD > 9) do={ :set $strD [:tostr $dateD]; } else={ :set $strD ("0".[:tostr $dateD]); }
:if ($timeH > 9) do={ :set $strH [:tostr $timeH]; } else={ :set $strH ("0".[:tostr $timeH]); }
:if ($timeM > 9) do={ :set $strM [:tostr $timeM]; } else={ :set $strM ("0".[:tostr $timeM]); }
:if ($timeS > 9) do={ :set $strS [:tostr $timeS]; } else={ :set $strS ("0".[:tostr $timeS]); }
} else={
:set strMn [:tostr $dateM];
:set strD [:tostr $dateD];
:set strH [:tostr $timeH];
:set strM [:tostr $timeM];
:set strS [:tostr $timeS];
}
:do {
:if ([:len $tmod]=0) do={ :local mt ($mstr->($dateM - 1)); :set $decodedLine ("$mt/"."$strD/"."$strY"); break; }
:if ($tmod = 1) do={ :set $decodedLine "$strY$s$strMn$s$strD $strH:$strM:$strS"; break; }
:if ($tmod = 2) do={ :set $decodedLine "$strD$s$strMn$s$strY $strH:$strM:$strS"; break; }
:if ($tmod = 3) do={ :set $decodedLine ("$strD ".($mstr->($dateM - 1))." $strY $strH:$strM:$strS"); break; }
:if ($tmod = 4) do={ :set $decodedLine ("$strY ".($mstr->($dateM - 1))." $strD $strH:$strM:$strS"); break; }
:if ($tmod = 5) do={ :local m ($mstr->($dateM - 1)); :set $decodedLine ("$m/"."$strD/"."$strY"."-$strH:$strM:$strS"); break; }
} on-error={}
:return ($decodedLine);
}
# Main body of the script
:global timeAct;
:global timeLog;
:local nameID [ /system identity get name; ];
:local timeOf [ /system clock get gmt-offset; ];
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Start of TLGRM-script on '$nameID' router.");
:if ([:len $timeAct] > 0) do={ :put ("$[$UnixTimeToFormat ($timeAct + $timeOf) 1] - Time when the last command was launched."); }
:if ([:len $timeLog] > 0) do={ :put ("$[$UnixTimeToFormat ($timeLog + $timeOf) 1] - Time when the log entries were last sent."); }
# Part of the script body to launch via Telegram
# https://forummikrotik.ru/viewtopic.php?p=78085
:local timeStamp [$EpochTime];
:local urlString "https://api.telegram.org/$botID/getUpdates\?offset=-1&limit=1&allowed\_updates=message";
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - \*\*\* Stage of launch scripts, function & commands via Telegram:");
:if ([:len $timeAct] = 0) do={
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Time of the last launch of the command was not found.");
:set timeAct $timeStamp;
} else={
:local httpResp [ /tool fetch url=$urlString as-value output=user; ];
:local content ($httpResp->"data");
:if ([:len $content] > 30) do={
:local msgTxt [$MsgParser $content "text" true];
:set msgTxt ([:pick $msgTxt ([:find $msgTxt "/" -1] +1) [:len $msgTxt]]);
:local msgAddr ([:pick $msgTxt 0 [:find $msgTxt " " -1]]);
:if ([:len [:find $msgTxt " "]]=0) do={ :set msgAddr ("$msgTxt "); }
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Recipient of the Telegram message: '$msgAddr'")
:if ($msgAddr=$nameID or $msgAddr="forall") do={
:set msgTxt ([:pick $msgTxt ([:find $msgTxt $msgAddr -1] + [:len $msgAddr] +1) [:len $msgTxt]]);
:local chat [$MsgParser $content "chat"];
:local chatId [$MsgParser $chat "id"];
:local userName [$MsgParser $content "username"];
:set timeStamp [$MsgParser $content "date"];
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Sender of the Telegram message: $userName")
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Command to execute: '$msgTxt'")
:local restline [];
:if ([:len [:find $msgTxt " "]] !=0) do={
:set restline [:pick $msgTxt ([:find $msgTxt " "] +1) [:len $msgTxt]];
:set msgTxt [:pick $msgTxt 0 [:find $msgTxt " "]];
}
:if ($chatId=$myChatID && $timeAct<$timeStamp) do={
:set timeAct ($timeStamp);
:if ([/system script environment find name=$msgTxt;]!="" && $launchFnc=true) do={
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Telegram user $userName launches function '$msgTxt'.");
:log warning ("Telegram user $userName launches function '$msgTxt'.");
[:parse ":global $msgTxt; [\$$msgTxt $restline]"];
}
:if ([/system script find name=$msgTxt;]!="" && $launchScr=true) do={
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Telegram user $userName activates script '$msgTxt'.");
:log warning ("Telegram user $userName activates script '$msgTxt'.");
/system script run $msgTxt;
}
:if ([/system script find name=$msgTxt;]="" && [/system script environment find name=$msgTxt;]="" && $launchCmd=true) do={
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Telegram user $userName is trying to execute command '$msgTxt'.");
:log warning ("Telegram user $userName is trying to execute command '$msgTxt'.");
:do {[:parse "/$msgTxt $restline"]} on-error={}
}
} else={ :put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Wrong time to launch."); }
} else={ :put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - No command found for this device."); }
} else={ :put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Completion of response from Telegram."); }
}
# Part of the script body for notifications in Telegram
# https://www.reddit.com/r/mikrotik/comments/onusoj/sending\_log\_alerts\_to\_telegram/
:local outMsg "";
:local logGet [ :toarray [ /log find ($topics ~"warning" || $topics ~"error" || $topics ~"critical" || $topics ~"caps" \
|| $topics ~"wireless" || $message ~"logged in"); ]];
:local logCnt [ :len $logGet ];
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - \*\*\* Stage of sending notifications to Telegram:");
:if ([:len $timeLog] = 0) do={
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Time of the last log entry was not found.");
:set outMsg (">$[ /system clock get time; ] Telegram notification started.");
}
:if ($logCnt > 0) do={
:local lastTime [$EpochTime [ /log get [:pick $logGet ($logCnt-1)] time; ]];
:local index 0;
:local tempTime;
:local tempMessage;
:local tempTopic;
:local unixTime;
:do {
:set index ($index + 1);
:set tempTime [ /log get [:pick $logGet ($logCnt - $index)] time; ];
:set tempTopic [ /log get [:pick $logGet ($logCnt - $index)] topics; ];
:set tempMessage [ /log get [:pick $logGet ($logCnt - $index)] message; ];
:set tempMessage (">".$tempTime." ".$tempMessage);
:local findMacMsg ([$FindMacAddr $tempMessage]);
:set unixTime [$EpochTime $tempTime];
:if (($unixTime > $timeLog) && (!(($tempTopic ~"caps" || $tempTopic ~"wireless" || $tempTopic ~"dhcp") \
&& ($tempMessage != $findMacMsg)))) do={
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Found log entry: $findMacMsg");
:set outMsg ($findMacMsg."\n".$outMsg);
}
} while=(($unixTime > $timeLog) && ($index < $logCnt));
:if (([:len $timeLog] < 1) || (([:len $timeLog] > 0) && ($timeLog != $lastTime) && ([:len $outMsg] > 8) )) do={
:set timeLog $lastTime;
:if ([:len $outMsg] > 4096) do={ :set outMsg ([:pick $outMsg 0 4096]); }
:set outMsg [$CP1251toUTF8 $outMsg];
:set outMsg ("$Emoji "."$nameID".":"."%0A"."$outMsg");
:local urlString ("https://api.telegram.org/$botID/sendmessage\?chat\_id=$myChatID&text=$outMsg");
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Generated string for Telegram:\r\n".$urlString);
/tool fetch url=$urlString as-value output=user;
} else={ :put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - There are no log entries to send."); }
} else={ :put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - Necessary log entries were not found."); }
:put ("$[$UnixTimeToFormat ([$EpochTime] + $timeOf) 1] - End of TLGRM-script on '$nameID' router.");
} on-error={
:put ("Script error: something didn't work when sending a request to Telegram.");
:put ("\*\*\* First, check the correctness of the values of the variables botID & myChatID. \*\*\*");
}
```
От себя хочу отдельно поблагодарить drPioneer за основную работу над данным скриптом и комментариям по работе основных блоков кода.
С этапами создания и развития скрипта можно [познакомиться](https://forummikrotik.ru/viewtopic.php?f=14&t=12659) на соответствующей ветви русскоязычного форума Микротик. Скрипт также добавлен в соответствующий раздел [англоязычного форума](https://forum.mikrotik.com/viewtopic.php?t=183080).
Желаем приятного пользования. Ждём замечаний и предложений по улучшению скрипта. Коллектив авторов. | https://habr.com/ru/post/650563/ | null | ru | null |
# Моделирование планеты маргариток
Моделирование планеты маргариток
--------------------------------
1. Лирика
2. Описание интерфейса
3. Декомпозиция
4. Модель
5. Логика
#### 1. Лирика
Давным-давно, не помню где, я узнал об одном удивительном эксперименте, начало описания было такое: Представьте себе планету, примерно такую, как Земля, которая вращается вокруг звезды примерно такой, как Солнце. На планете есть жизнь, но не очень разнообразная — всего два вида маргариток — черные и белые. Представили? Какой заход! Автор красавчик, почти Экзюпери.
Далее описывался эксперимент: В начальной точке маргаритки есть только в виде семян, а планета настолько холодна, что на экваторе температура на грани выживания. Тем не менее прорастает несколько маргариток черных и белых, и они даже начинают цвести. Белая маргаритка, из-за своей большой отражательной способности отражает больше света, чем зеленые листики и коричневая земля, в этом месте локально становится холодней, и она замерзает. Вокруг черной маргаритки, наоборот возникает небольшая прогретая зона, так как она поглощает больше энергии от звезды. Маргаритка начинает чувствовать себя лучше, цветет, а потом, в прогретую землю бросает свои семена. Из этих семян прорастают еще несколько черных маргариток (потому что родитель у них черный), цветение этих маргариток прогревает еще больший участок, на котором может расти еще больше маргариток, и они тоже будут черными, потому что здесь оставляют семена только черные маргаритки.
Таким образом, потепление, вызванное цветением черных маргариток, провоцирует еще большее распространение черных маргариток, которые в свою очередь прогревают больше площади вокруг себя, и так по кругу. Таким образом черные маргаритки захватывают экваториальную область, но дальше распространяться не могут — там слишком холодно.
Однако такое бурное цветение черных маргариток уменьшает отражательную способность всей планеты (альбедо), это повлияет на баланс поглощенной/отраженной энергии в планетарном масштабе, что приводит к повышению эффективной температуры планеты, то есть на всей планете становится теплей. После этого черные маргаритки еще немного расширяют свои территории на юг и на север, что в свою очередь приводит к еще большему глобальному потеплению. Таким образом черные маргаритки пробираются к полюсам, а планета разогревается.
Но не нужно забывать — на планете стало теплее, и теперь есть все условия для роста и белых маргариток тоже. Более того, по мере прогрева, на экваторе становится все жарче, а черные маргаритки еще сильнее утепляют землю вокруг себя, и в этом районе им становится все более некомфортно. Не то, что белым маргариткам, которые отражают больше энергии, и создают вокруг себя приятную прохладную зону, в которой им хорошо расти, и туда же отбрасывать семена. Ну вы поняли — белые теснят с экватора черных. Но тут сюрприз — альбедо планеты снова увеличивается из-за больших площадей белых маргариток, планета холодеет и в конечном итоге наступает некоторое равновесие.
Далее автор не намерен оставлять планету в этом унылом для него, и комфортном для маргариток состоянии. Происходит вот что — Звезда, как у них это обычно бывает, начинает светиться ярче, и на планету падает больше энергии. Реакция планеты — увеличение площади распространения белых маргариток, увеличение альбедо — и снижение эффективной температуры, переход в новое равновесное состояние. Почти то же самое происходит при снижении светимости звезды, только появляется больше черных маргариток.
Вывод, который делает автор — биосфера сама себе создает комфортные температурные условия на планете в широких диапазонах светимости звезды. Авторов этого замечательного эксперимента зовут Джеймс Лавлок и Эндрю Уотсон. Кому интересны все выводы и более подробное описание см. Википедия — [Маргаритковый мир](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%80%D0%B3%D0%B0%D1%80%D0%B8%D1%82%D0%BA%D0%BE%D0%B2%D1%8B%D0%B9_%D0%9C%D0%B8%D1%80), там написано больше и лучше. Смысл этого долгого вступления не пересказать статью из вики, а подвести к самому интересному — непосредственно проведению эксперимента. Автор статьи, описывающей эксперимент, задавал риторический вопрос: Рассуждения выглядят логично, но как провести такой эксперимент, где взять планету со звездой, с подходящими условиями, и как доставить туда семена маргариток? Даже если кому-то взбредет в голову использовать для этого Марс то у него ничего не получиться. Я был очень опечален таким поворотом потому, что большой фанат терраформирования и крутых экспериментов. Но автор, к моей большой радости, сказал, что такой эксперимент возможен с помощью компьютерного моделирования.
Ну конечно!!! Этот эксперимент, как бы собственно для компьютерного моделирования и был придуман, и даже достиг своей цели (ну то есть посрамил каких-то там двух мудрецов, [см. вики](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%80%D0%B3%D0%B0%D1%80%D0%B8%D1%82%D0%BA%D0%BE%D0%B2%D1%8B%D0%B9_%D0%9C%D0%B8%D1%80)). На этом отрезке повествования об эксперименте у меня прям сперло дыхание, потому что я подумал о счастливчиках, которые смотря на это описание, каким-то образом, превращают идею во что-то наглядное, доступное для того, чтобы посмотреть в реальном времени, «потрогать руками». При том, интересен был как сам процесс моделирования, так и проведение экспериментов. Прочитать эксперимент и подивиться выводам это одно, а «поиграть» с этой планетой, поэкспериментировать с разными условиями, это совсем другое. Но тогда я еще не мог программировать :(, но настали нынешние времена, к счастью, и поэтому предлагаю перейти от длинной и скучной лирики, к содержательной части. Кто просто хочет поиграть с планетой может переходить к описанию интерфейса, кого увлекает процесс моделирования к части под названием Декомпозиция и далее.
#### 2. Описание интерфейса

В левой части расположено два блока Populator и Updater, в центральной части визуальное отображение планеты и некоторых параметров, в правой части графики изменения эффективной температуры и Звездной постоянной.
Управление осуществляется в блоках Populator и Updater.
В блоке Populator можно задать соотношение белых маргариток, черных маргариток и пустых ячеек, после нажатия кнопки Populate, планета будет заселена соответствующим образом. Заселить планету можно как в начале эксперимента, так и в любой другой момент, если понадобится.
Блок Updater отвечает за обновление модели планеты, в нем можно задать количество обновлений за раз, а также значение (допускаются отрицательные) и периодичность инкрементирования звездной постоянной (например, обновить 100 раз, при этом увеличивать звездную постоянную на 1 каждые две итерации).
Визуальное отображение планеты:
Белые кружочки — это районы с белыми маргаритками, черные — с черными, оливковые — пустые ячейки.
В левом верхнем углу текущие значения эффективной температуры по кельвину, звездной постоянной, альбедо и номер итерации.
Справа от планеты две цветовые шкалы: левая — для черных маргариток, правая для белых. Каждая точка шкалы соответствует температуре расположенного напротив пояса планеты. Легенда такая: Синий — слишком холодно для жизни, Желтый — жить можно, Зеленый — жить не только можно, но и комфортно, Красный — слишком жарко для жизни.
#### 3. Декомпозиция
В приложении использован паттерн MVC, хотя в JavaFX, как известно вью и контролер немного слиплись, зато границы модели очерчены совершенно отчетливо.
Модель, в свою очередь, также разбита на часть, отвечающую за состояние, и часть, отвечающую за поведение, в лучших традициях, так сказать. Еще есть часть, отвечающая за сохранение результатов в БД, работает вроде нормально, но в интерфейс и в настройки не стал выносить за ненадобностью. Вид и слой персистентности описывать не буду, ниже все про модель и поведение.
#### 4. Модель
Модель представлена шестью обычными классами Planet, Starr, Zone, Conditions, BlackDaizy, WhiteDaizy, NoDaizy, одним абстрактным Daizy, и одним перечислением Type. Хотя можно было и меньшим числом классов, я подумал, что звезда настолько крупная и важная вещь, что оставлять ее без класса было бы некрасиво. А для маргариток, в программе под названием «Планета Маргариток» была выстроена целая небольшая иерархия классов, и даже введено перечисление. Таким образом, основные классы, определяющие состояние это, Planet, Conditions и Zone.
Planet — является основным агрегирующим классом, экземпляр этого класса в приложении играет роль модели, из него контроллеры получают состояние для вью, а классы, отвечающие за поведение, получают ссылку на экземпляр Planet для изменения состояния.
Класс Planet содержит поля, характеризующие состояние планеты: это
```
/** Отражающая способность, характеризуется отношением отраженного света к падающему*/
private double albedo = 0;
```
```
/** Эффективная температура: зависит от поглощаемой энергии,
* вычисляется как температура абсолютно черного тела по закону Стефана-Больцмана*/
private double temperature = 0;
```
```
/** Да планета имеет размер*/
private double radius = Conditions.getInstance().radius;
```
```
/** количество поясов на которое разбито одно полушарие, локальная температура вычисляется для каждого пояса, на всей площади одного пояса — одинаковая температура*/
private int halfZonation = Conditions.getInstance().halfZonation;
```
```
/** фрагментация пояса: максимальное количество маргариток на пояс,
на всех поясах - количество маргариток одинаковое, это не ограничение программы, а геометрический закон, ибо пояса с одинаковой высотой имеют одинаковую площадь,
* так - то*/
private long daiziesPerZone = Conditions.getInstance().daiziesPerZone;
```
```
/** эффективная площадь - проекция планеты на плоскость перпендикулярную направлению излучения идущему от звезды к планете, используется для расчета альбедо */
private double effectiveArea;
/** площадь пояса. у всех поясов area - одинаковая
S = 2πrh,
r – радиус сферы,
h – высота сферического пояса.
*/
private double zoneArea;
/** условная площадь одной маргаритки, справочный параметр*/
private double daisyArea;
```
Кроме того, класс Planet содержит ссылку на звезду Starr, массив экземпляров класса Zone, каждый элемент которого характеризует отдельный пояс, счетчик апдейтов, признак inhabited ну, то есть обитаемая ли планета. А также ссылки на классы, отвечающие за поведение
```
PopulatorImpl populator = new PopulatorImpl();
AlbedoCalculator albedoCalculator = new AlbedoCalculatorImpl();
```
о которых речь пойдет ниже.
Второй важный класс — это Conditions, в нем собраны все константы. Вот некоторые
```
public double Kelvin = -273.15;
// Planet constants
public double radius = 1000.0;
public int halfZonation = 90;
public long daiziesPerZone = 100;
/**
эмпирическая отсебятина: разница температур на экваторе и на полюсах, если вычислять в зависимости от широты
то на полисе окажется нулевая по кельвину, что противоречит здравому смыслу
величина должна зависеть от теплопроводности планеты, миграции тепла по атмосфере, и т.п.
к тому же температура на поверхности должна быть выше расчетной из-за того, что поверхность первой прогревается,
и из-за парникового эффекта, если, конечно, есть подходящая атмосфера
*/
public double planetDeltaTemper = 70.0;
/* используются для вычисления большого альбедо*/
public double blackDaisyAlbedo = 0.1;
public double whiteDaisyAlbedo = 0.9;
public double noDaisyAlbedo = 0.5;
/* Значение комфортной температуры для жизни маргариток
Собственно, реализация прогрева и охлаждения почвы вокруг маргариток,
*/
public double blackComfortableTemper = 18 + (-Kelvin);
public double whiteComfortableTemper = 22 + (-Kelvin);
/**Звездная постоянная - суммарная мощность излучения звезды, проходящего через единичную площадку,
* ориентированную перпендикулярно потоку, на расстоянии одной астрономической единицы от Звезды
* для Солнца и Земли равняется 1367 Вт/м²*/
public double StarConstant = 1367.0;
/** Значение постоянной Стефана-Больцмана
* */
public double StephanBoltsmanConst = 5.67e-8;
И третий важный, но не большой класс модели Zone:
/** высота границы ближайшей к экватору */
private double latitude;
/** эффективная площадь - проекция половины шарового слоя на плоскость,
* используется для расчета альбедо */
private double effectiveArea;
/** высота шарового слоя*/
private double height;
/** температура на поверхности в данной zone*/
private double localTemperature;
// количество маргариток
private long numBlackDaisies;
private long numWhiteDaisies;
private long numEmptyCells;
```
Обратите внимание на метод установки локальной температуры вычисляет температуру, как описано выше:
```
public void setLocalTemperature(double globalTemperature) {
this.localTemperature = globalTemperature + Conditions.getInstance().planetDeltaTemper*Math.cos(latitude);
}
```
В классе нет методов, вычисляющих состояние, значение всех полей передается в параметрах конструктора, либо устанавливаются сеттерами.
#### 5. Логика
Почти всё поведение собрано в паке logic, и представлено следующими классами:
*ZoneMaker* — класс используется для создания всего массива зон планеты, с учетом того, что у разной планеты может быть разная фрагментация (количество зон), а у каждой зоны своя уникальная широта, соответствующая индексу в массиве
*AlbedoCalculator* — интерфейс, единственный метод
```
double calcAlbedo(Zone[] zones);
```
его реализации используются для вычисления альбедо всей планеты в зависимости от соотношения черных и белых маргариток и незанятого пространства, а также внимание, их расположения — так как маргаритки, растущие на разных широтах, вносят разный вклад в общее альбедо.
*StephanBoltsman* — класс для расчета эффективной температуры планеты.
*Populator* — интерфейс, отвечающий за заселения планеты маргариткам.
Метод
```
void populate(Zone zone, int whiteExpectance, int blackExpectance, int noneExpectance);
```
предназначен для заполнения одной, переданной в параметре, зоны, параметры
```
int whiteExpectance, int blackExpectance, int noneExpectance
```
что-то вроде математических ожиданий, в зависимости от их соотношения, в случайном порядке по зоне будут посажены белые и черные маргаритки, или будет сделан пропуск, но общее число ячеек для маргариток в зоне всегда постоянно, и зависит от начальных настроек (задается *Conditions.daiziesPerZone*).
Этот метод используется в двух других методах, которые заполняют уже все зоны на планете:
```
void populateInitial(Zone[] zones, int whiteExpectance, int blackExpectance, int noneExpectance);
```
Заполняет все зоны с одинаковым соотношением. В конструкторе планеты стоят параметры 0,0,1. То-есть планета создается необитаемой.
Метод
```
void rePopulate(Planet planet);
```
является реализацией механизма вытеснения маргаритками маргариток, и заполнения пустого пространства. Он используется для перераспределения маргариток на планете, в зависимости от сложившихся на Планете условий. Метод работает приблизительно следующим образом: в нем определены три переменные, в первую очередь они устанавливаются в значения количества белых, черных маргариток и пустых ячеек очередной зоны.
Далее, если температура для какого-либо вида маргариток не соответствует жизненным условиям, соответствующий параметр обнуляется. Если соответствует жизненным условиям, то значение остается неизменным. Если температура находится в интервале комфорта, то значение удваивается. В случае, если температура впервые стала пригодна для жизни, для какого-либо вида маргариток, то соответствующий параметр устанавливается в среднее арифметическое от количества соответствующих маргариток из смежных зон.
И наконец, нужно описать метод update() класса Planet, который отвечает за жизненный цикл каждой итерации:
```
public void update() {
albedo = albedoCalculator.calcAlbedo(zones);
temperature = StephanBoltsman.countTemperature(albedo,star.getStarConstant());
updateLocalTempers();
populator.rePopulate(this);
iterationId++;
}
```
В первую очередь вычисляется альбедо планеты, исходя из количества и расположения маргариток. Затем вычисляется эффективная температура планеты используя только что найденное альбедо и звездную постоянную (значение которой также может измениться). Затем обновляются значения локальных температур в зонах исходя из найденной эффективной температуры. И в конце, используя новые данные локальных температур, осуществляется перераспределения маргариток.
[Ссылка на гит](https://github.com/sv-kopylov/daisyplanet). Сборка: gradlew build | https://habr.com/ru/post/341730/ | null | ru | null |
# Незаменимый помощник для больших дампов MySQL
Когда скрипт Вigdump — незаменим:
Бывают ситуации когда штатных средств недостаточно:
Например необходимо перенести|скопировать базу данных MySQl а размер её дампа уже превысил (даже в упакованном виде) лимиты которые накладывает хостер на загрузку файла или размер POST-запроса.
Тут нам на помощь нам и приходит данный скрипт.
Использовать его не просто, а очень просто:
Скачать с сайта разработчика
[www.ozerov.de/bigdump.php](http://www.ozerov.de/bigdump.php)
Версия скрипта: BigDump ver. 0.29b from 2008-01-19
Дамп базы: создан в phpMyAdmin
Процесс:
Отчищаем старую базу или создаем новую.
Создаем на сервере папку с правами 0777 для нашего скрипта.
Загружаем в нее файл bigdump.php.
в собственно файле скрипта (bigdump.php) настраиваем свойства соединения с базой данных:
`$db_server = 'localhost';
$db_name = 'root';
$db_username = 'userName';
$db_password = 'userPass';`
Настройка кодировки базы данных:
`$db_connection_charset = 'cp1251';`
оставляем все остальное по умолчанию.
Загружаем по FTP файл с дампом базы(.sql, .gz).
Запускаем скрипт:
//ваш\_сайт/папка\_со\_скриптом/bigdump.php

Выбираем какой файл(дампа) заливаем и идем пить чай/кофе/чтонибудь\_ещё
Собственно и все…
ЗЫ. после того как все сделано, не забываем удалить папку со скриптом и дампом с сервера. | https://habr.com/ru/post/50326/ | null | ru | null |
# RedBeanPHP — CodeFirst PHP фреймворк

В данном посте речь пойдет об весьма интересном ORM фреймворке [RedBeanPHP](http://redbeanphp.com). Примечателен он, прежде всего, возможностью создавать структуру базы данных на лету. К тому же фреймворк прост в использовании как две копейки. Моё повествование будет разделено на 3 части.
Во второй части основная тема будет — модели. В третей — изменение логики работы фреймворка.
Перед написанием поста я потрудился и сделал [тестовое приложение](http://apps.facebook.com/insp_social_commerce/?fb_source=search&ref=ts) с 15 000 записей, для того, что бы убедиться на своем опыте в возможности невероятно облегчить работу. Ведь я наверно не один, кто прописывает поля в нескольких местах с жутким осознанием бессмысленности этой работы, особенно на начальном этапе разработки. Наконец появился аналог Entity Framework Code First из .NET, который в свое время вызвал у меня дикий восторг. Итак по порядку.
#### Истоки
Написано данное чудо человеком с не менее чудным именем Габор. Габор неудавшийся студент, изучавший когнитивную психологию. Неудача случилась по причине банального отсутствия спроса на этих специалистов, но все же готов признать что, Габор весьма хороший психолог. При использовании фреймворка меня не покидает ощущение просты и очевидности того, что происходит.
#### Начало
Для подключения необходимо добавить лишь один файл, в котором содержится весь код.
```
require('rb.php');
```
Весьма просто, разве нет? Заглянем внутрь и обнаружим, что файл данных весит 260 кбайт и представляет собой собранную из множества файлов версию фреймворка. На GitHub можно скачать обычную версию из примерно 40 файлов. В этом случае для подключения необходим следующий код:
```
require('redbean.inc.php');
```
#### Структура
Фреймворк имеет хорошо организованную структуру классов. В состав входят драйвера для PDO и Oracle. Это значит что RedBeanPHP поддерживает широкий спектр баз данных. В документации указывается поддержка следующих баз данных: MySQL 5, SQLite, PostgreSQL, CUBRID, Oracle. Поддержка последней не входит в rb.php, её надо загружать из GitHub отдельно. Впрочем нам никто не мешает написать собственный драйвер, унаследовав от класса RedBean\_Driver.
А для того, чтобы модифицировать внутреннюю логику работы фреймвока, необходимо создать свою версию QueryWriter. Данную тему я затрону детально в третьей части обзора.
Фреймворк поддерживает Plugins, и имеет простенький Logger класс для отображения всех запросов фреймворка к базе на экран. Запись в файл я не нашел, но никаких проблем не представляет унаследовать собственный класс.
Вот код логгера идущего в поставке:
```
class RedBean_Logger_Default implements RedBean_Logger {
public function log() {
if (func_num_args() > 0) {
foreach (func_get_args() as $argument) {
if (is_array($argument)) echo print_r($argument,true); else echo $argument;
echo "
\n";
}
}
}
}
``` | https://habr.com/ru/post/150023/ | null | ru | null |
# Голосовое управление мультимедиа центром
В этой статье хотелось бы описать свой опыт по применению web speech api в браузере Google Chrome для реализации голосового поиска и автоматического воспроизведения видеороликов с канала Youtube. Для демонстрации данного функционала нам понадобиться сделать следующие шаги:
1. Установить набор: Apache2, PHP5(пакет curl обязательно).
2. Иметь в наличии мультимедиа центр Dune HD или установить XBMC и настроить его для работы в сети INTERNET.
3. Получить Youtube API Key для выполнения поисковых запросов.
Как сделать все вышеперечисленное, здесь описывать не буду, так как на эти темы полно статей. Принцип реализации такой:
1. Распознаем фразу с помощью скрипта, написанного на JavaScript — **работать будет только в Google Chrome**.
2. Ищем ролики, соответствующие поисковому запросу.
3. Получаем прямые ссылки на ролики.
4. Создаем плейлист из ссылок и названий роликов.
5. Отправляем плейлист для воспроизведения на устройство.
Топология сети: Internet приходит в wan порт Wi-Fi роутера, а к нему подключаются:
* устройство, с которого будем управлять (планшет, смартфон, ноутбук).
* компьютер с web сервером Apache (если управление будет производится с него, то первое устройство может отсутствовать).
* собственно сам мультимедиа центр (программный — XBMC, или аппаратный — Dune HD).
**Скрипт распознавания речи на JavaScript - index.html:**
```
Умный Дом
/\* Создание нового объекта XMLHttpRequest для общения с Web-сервером \*/
var xmlHttp = false;
/\*@cc\_on @\*/
/\*@if (@\_jscript\_version >= 5)
try {
xmlHttp = new ActiveXObject("Msxml2.XMLHTTP");
} catch (e) {
try {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
} catch (e2) {
xmlHttp = false;
}
}
@end @\*/
if (!xmlHttp && typeof XMLHttpRequest != 'undefined') {
xmlHttp = new XMLHttpRequest();
}
\* {
font-family: Verdana, Arial, sans-serif;
font-size: 20px;
}
a:link {
color:#000;
text-decoration: none;
}
a:visited {
color:#000;
}
a:hover {
color:#33F;
}
body {
text-align: center;
}
.button {
background: -webkit-linear-gradient(top,#008dfd 0,#0370ea 100%);
border: 1px solid #076bd2;
border-radius: 3px;
color: #fff;
display: none;
font-size: 13px;
font-weight: bold;
line-height: 1.3;
padding: 8px 25px;
text-align: center;
text-shadow: 1px 1px 1px #076bd2;
letter-spacing: normal;
}
.final {
color: black;
padding-right: 3px;
}
.interim {
color: gray;
}
.info {
font-size: 14px;
text-align: center;
color: #777;
display: none;
}
.sidebyside {
display: inline-block;
width: 45%;
min-height: 40px;
text-align: left;
vertical-align: top;
}
#headline {
font-size: 40px;
font-weight: 300;
}
#info {
font-size: 20px;
text-align: center;
color: #777;
visibility: hidden;
}
#results {
font-size: 14px;
font-weight: bold;
border: 1px solid #ddd;
padding: 15px;
text-align: left;
min-height: 30px;
width: 500px;
margin: 0 auto;
}
#start\_button {
border: 0;
padding: 0;
background: url(images/mic.gif);
width: 50px;
height: 50px;
cursor: pointer;
vertical-align: top;
}
#info\_speak\_now,
#info\_no\_speech,
#info\_no\_microphone,
#info\_upgrade {
display: none;
}
Кликни на микрофон чтобы начать раздавать команды.
Командуй!
Голос не обнаружен.
Микрофон не найден.
Твой браузер не поддерживает Web Speech API.
var start\_button = document.getElementById('start\_button'),
recognizing = false, // флаг идет ли распознование
final\_transcript = '';
// проверяем поддержку speach api
if (!('webkitSpeechRecognition' in window)) {
start\_button.style.display = "none";
showInfo("info\_upgrade");
} else { /\* инициализируем api \*/
/\* создаем объект \*/
var recognition = new webkitSpeechRecognition();
/\* базовые настройки объекта \*/
recognition.lang = 'ru'; // язык, который будет распозноваться. Значение - lang code
recognition.continuous = true; // не хотим чтобы когда пользователь прикратил говорить, распознование закончилось
/\* метод вызывается когда начинается распознование \*/
recognition.onstart = function() {
recognizing = true;
showInfo('info\_speak\_now'); // меняем инфо текст
start\_button.style.background = 'url(images/mic-animate.gif)'; // меняем вид кнопки
};
/\* обработчик ошибок \*/
recognition.onerror = function(event) {
if (event.error == 'no-speech') {
start\_button.style.background = 'url(images/mic.gif)';
showInfo('info\_no\_speech');
}
if (event.error == 'audio-capture') {
start\_button.style.background = 'url(images/mic.gif)';
showInfo('info\_no\_microphone');
}
};
/\* метод вызывается когда распознование закончено \*/
recognition.onend = function() {
recognizing = false;
//recognition.start();
start\_button.style.background = 'url(images/mic.gif)';
showInfo('info\_start');
};
/\*
метод вызывается после каждой сказанной фразы. Параметра event используем атрибуты:
- resultIndex - нижний индекс в результирующем массиве
- results - массив всех результатов в текущей сессии
\*/
recognition.onresult = function(event) {
/\*
обход результирующего массива
\*/
for (var i = event.resultIndex; i < event.results.length; ++i) {
/\* если фраза финальная (уже откорректированная) сохраняем в конечный результат \*/
if (event.results[i].isFinal) {
final\_transcript += event.results[i][0].transcript.toLowerCase();
}
}
final\_span.innerHTML = final\_transcript;
var newText2 = final\_transcript.replace(/(^\s+|\s+$)/g,'');
var url = "/voice\_search.php?q=" + encodeURI(newText2);
xmlHttp.open("GET", url, true);
xmlHttp.send(null);
final\_transcript = ''; // очищаем рапознанный текст
};
}
/\* показ нужного сообщения \*/
function showInfo(id) {
var messages = document.querySelectorAll('p');
for(i=0; i<messages.length; i++) messages[i].style.display = 'none';
document.getElementById(id).style.display = 'block';
}
/\* обработчик клика по микрофону \*/
function startButton(event) {
if (recognizing) { // если запись уже идет, тогда останавливаем
recognition.stop();
document.getElementById('final\_span').innerHTML = '';
return;
}
recognition.start();
}
```
Для полноценной работы скрипта, нужно еще создать папку **images** и положить в неё картинки с микрофончиками, которые можно взять [здесь](http://smarthome30.ru/images/mic.gif) и [здесь](http://smarthome30.ru/images/mic-animate.gif).
Данный скрипт делает всего два действия — распознает фразу и отправляет её AJAX запросом PHP скрипту. Также необходимо обратить внимание на то, что кодировка во всех скриптах должна быть UTF-8 (если делаете в Windows, то UTF-8 без ВОМ).
**Скрипт поиска видео роликов на PHP - voice\_search.php:**
```
php
// send info into core
function send_info($info)
{
echo $info;
}
function send_req($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 5.1; rv:7.0.1) Gecko/20100101 Firefox/7.0.1");
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_REFERER, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
$out = curl_exec($ch);
curl_close($ch);
return $out;
}
function get_video_url($videoId)
{
$url = 'http://www.youtube.com/get_video_info?&video_id='.$videoId.'&asv=3&el=detailpage&hl=en_US';
$first_found = "";
$last_found = "";
$first_quality = "";
$last_quality = "";
//$video_quality = 'medium';
$video_quality = 'hd1080';
$doc=send_req($url);
$x=explode("&",$doc);
$t=array(); $g=array(); $h=array();
foreach($x as $r)
{
$c=explode("=",$r);
$n=$c[0]; $v=$c[1];
$y=urldecode($v);
$t[$n]=$v;
}
$links = explode(',',urldecode($t['url_encoded_fmt_stream_map']));
$dlinks = array();
foreach ($links as $link)
{
parse_str($link,$linkarr);
$itag = $linkarr['itag'];
$quality = $linkarr['quality'];
if (in_array($itag, array('18', '22', '37', '38')))
{
if(isset($linkarr['s']))
{
$linkarr['signature'] = file_get_contents('http://dune-club.info/echo?message=' . $linkarr['s']);
unset($linkarr['s']);
$dlinks[$linkarr['itag']] = $linkarr['url'] . "&signature=" . $linkarr['signature'];
}
else
{
$dlinks[$linkarr['itag']] = $linkarr['url'];
$playback_url = $dlinks[$linkarr['itag']];
if ($first_found === "")
{
$first_found = $playback_url;
$first_quality = $quality;
}
$last_found = $playback_url;
$last_quality = $quality;
if (($quality === $video_quality) || (($quality !== 'medium') && ($video_quality === 'hdonly')))
{
$playback_url=(urldecode($playback_url));
return $playback_url;
}
}
}
}
if (($last_found !== "") && ($video_quality !== 'hdonly'))
{
if ($video_quality === 'hd1080')
{
$first_found=(urldecode($first_found));
return $first_found;
}
else
{
$last_found=(urldecode($last_found));
return $last_found;
}
}
else
{
//hd_print("-- video: $id; no mp4-stream.");
return false;
}
}
if(isset($_GET['q']) == false or $_GET['q']=="" )
{
$url = "https://www.googleapis.com/youtube/v3/search?part=snippet&q=голосовое%20управление%20телевизором&type=video&maxResults=10&key=Youtube_API_key";
}
else
{
$url = "https://www.googleapis.com/youtube/v3/search?part=snippet&q=".urlencode($_GET['q'])."&type=video&maxResults=10&key=Youtube_API_key";
}
$res = json_decode(send_req($url));
if(isset($res->items) == false or ($res->items)=="" )
{
$info="похоже что-то пошло не так!";
send_info($info);
}
else
{
$res = $res->items;
//print_r($res);
$fp = fopen('play_list.m3u', 'w+t');
$start="#EXTM3U\r\n";
fwrite($fp, $start);
foreach ($res as $searchResult)
{
$title=($searchResult->snippet->title);
$videoId = ($searchResult->id->videoId) ;
$clip_url = get_video_url($videoId);
if(isset($clip_url) == false or $clip_url=="")
{
$info="клип не найден!";
send_info($info);
}
else
{
$clip="#EXTINF:-1,$title\r\n$clip_url\r\n";
fwrite($fp, $clip);
}
}
fclose($fp);
$info="плейлист создан";
send_info($info);
//url для Dune HD
$url="http://ip_addr_dune/cgi-bin/do?cmd=launch_media_url&media_url=http://server_ip/play_list.m3u";
//url для XBMC
$url="http://логин:пароль@ip-адрес:8080/jsonrpc?request={"jsonrpc":"2.0","id":"1","method":"Player.Open","params":{"item":{"file":"http://server_ip/play_list.m3u"}}}";
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER,true);
$out = curl_exec($curl);
curl_close($curl);
}
?>
```
В данном скрипте в самом конце нужно будет отредактировать **$url** под настройки вашего мультимедиа центра и удалить лишний, а также исправить текст **server\_ip** на ip адрес вашего Apache сервера и вставить свой **Youtube\_API\_Key**. Что происходит здесь: из скрипта распознавания речи сюда приходит текст распознанной фразы, далее с помощью Youtube API v3 производится поиск видео роликов подходящих под поисковой запрос, получив ссылки на ролики, мы пропускаем их через цикл, в котором извлекаются полные пути до видеофайлов, которые и записываются в плейлист **play\_list.m3u**. Данный скрипт не претендует на идеальный код, так как написан чисто в ознакомительных целях, поэтому всевозможные проверки здесь отсутствуют.
Вот и всё, теперь заходим на наш web сервер по его ip адресу. Можно заходить с любого устройства: планшет, смартфон, ноутбук, единственное, что я заметил — в последнее время на смартфонах с Android, скрипт распознавания речи при отсутствии её, отправляет фразу повторно, с чем это связанно пока не понятно, но раньше такого не было.
На основе данного материала можно сделать еще много интересных вещей, таких как голосовой поиск музыки в VK и управления 1-wire устройствами. В общем пробуйте, если что не получится, то спрашивайте с удовольствием отвечу на все ваши вопросы.
P.S.: Статья написана по материалам:
[W3C Web Speech API](https://dvcs.w3.org/hg/speech-api/raw-file/tip/speechapi.html)
[YouTube api v3](https://developers.google.com/youtube/v3/)
Скрипт получения прямых ссылок взят из приложения YouTube для Dune HD и немного доработан под свои нужды. Для тех, кто хочет просто попробовать управлять мультимедиа центрами, без написания скриптов — можно сделать [здесь](http://xbmc.xyz/#!/page_HELP) или [тут](http://smarthome30.ru/xbmc.html) Результат моей работы [на YouTube](https://www.youtube.com/watch?v=Q-YPG4cYBAs) | https://habr.com/ru/post/270809/ | null | ru | null |
# Hardened Gentoo: настройка
Настройка Hardened состоит из двух частей: настройка ядра, и настройка ролей (RBAC или SELinux). Пример настройки ядра 2.6.20 я сейчас покажу. А RBAC/SELinux я пока не настраивал.
Думаю, будет нагляднее всего привести настройки так, как они выглядят в make menuconfig — это за одно позволит оценить «на глаз» возможности PaX и GrSecurity тем, кто с ними до сих пор не сталкивался.
Между разными версиями ядра они немного меняются, но не значительно.
```
PaX --->
. [*] Enable various PaX features
....... PaX Control --->
......... [ ] Support soft mode
......... [*] Use legacy ELF header marking
......... [*] Use ELF program header marking
............. MAC system integration (none) --->
....... Non-executable pages --->
......... [*] Enforce non-executable pages
......... [*] . Segmentation based non-executable pages
......... [ ] Emulate trampolines
......... [*] Restrict mprotect()
......... [ ] . Disallow ELF text relocations
......... [ ] Enforce non-executable kernel pages
....... Address Space Layout Randomization --->
......... [*] Address Space Layout Randomization
......... [*] . Randomize kernel stack base
......... [*] . Randomize user stack base
......... [*] . Randomize mmap() base
..... Miscellaneous hardening features --->
....... [ ] Sanitize all freed memory
....... [*] Prevent invalid userland pointer dereference
Grsecurity --->
. Security Level (Custom) --->
. Address Space Protection --->
... [*] Deny writing to /dev/kmem, /dev/mem, and /dev/port
... [ ] Disable privileged I/O
... [*] Remove addresses from /proc//[smaps|maps|stat]
... [\*] Deter exploit bruteforcing
... [\*] Runtime module disabling
... [\*] Hide kernel symbols
. Role Based Access Control Options --->
... [\*] Hide kernel processes
... (3) Maximum tries before password lockout
... (30) Time to wait after max password tries, in seconds
. Filesystem Protections --->
... [\*] Proc restrictions
... [\*] . Restrict /proc to user only
... [\*] Additional restrictions
... [\*] Linking restrictions
... [\*] FIFO restrictions
... [\*] Chroot jail restrictions
... [\*] . Deny mounts
... [\*] . Deny double-chroots
... [\*] . Deny pivot\_root in chroot
... [\*] . Enforce chdir("/") on all chroots
... [\*] . Deny (f)chmod +s
... [\*] . Deny fchdir out of chroot
... [\*] . Deny mknod
... [\*] . Deny shmat() out of chroot
... [\*] . Deny access to abstract AF\_UNIX sockets out of chroot
... [\*] . Protect outside processes
... [\*] . Restrict priority changes
... [\*] . Deny sysctl writes
... [\*] . Capability restrictions
. Kernel Auditing --->
... [ ] Single group for auditing
... [ ] Exec logging
... [\*] Resource logging
... [ ] Log execs within chroot
... [ ] Chdir logging
... [\*] (Un)Mount logging
... [ ] IPC logging
... [\*] Signal logging
... [\*] Fork failure logging
... [ ] Time change logging
... [\*] /proc//ipaddr support
... [ ] ELF text relocations logging (READ HELP)
. Executable Protections --->
... [\*] Enforce RLIMIT\_NPROC on execs
... [\*] Destroy unused shared memory
... [\*] Dmesg(8) restriction
... [ ] Trusted Path Execution (TPE)
. Network Protections --->
... [\*] Larger entropy pools
... [ ] Socket restrictions
. Sysctl support --->
... [\*] Sysctl support
... [\*] . Turn on features by default
. Logging Options --->
... (10) Seconds in between log messages (minimum)
... (4) Number of messages in a burst (maximum)
[ ] Enable access key retention support
[ ] Enable different security models
```
Абсолютное большинство этих фич работает прозрачно для пользователя. Но есть пара, которые вы можете заметить: во-первых обычные пользователи перестанут видеть процессы других пользователей, а во-вторых они потеряют доступ к некоторым файлам в /proc/, из-за чего вывод команд ifconfig, route, etc. запущенных обычными пользователями станет значительно скромнее.
Надо отметить, что большая часть этих фич может управляться через sysctl. Что, как правило, плохо. А что хорошего в том, что хакер ломает систему наполовину, получает возможность отключить эти защиты через sysctl, после чего доламывает её уже окончательно? К счастью, есть возможность заблокировать изменение настроек GrSecurity через sysctl. Для этого нужно добавить в /etc/sysctl.conf:
```
kernel.grsecurity.disable_modules = 1
kernel.grsecurity.grsec_lock = 1
```
Где первая команда запрещает подгрузку модулей ядра (лучше всего на серверах поддержку модулей даже не включать в ядре, но если это не возможно, то теперь есть выход: подгрузить нужные модули при загрузке системы, а потом с помощью kernel.grsecurity.disable\_modules запретить подгрузку модулей — чтобы никто случайно руткит не подгрузил :)), а вторая запрещает изменение любых настроек GrSecurity.
Недостаток этого в том, что если вам нужно будет таки подгрузить модуль или отключить часть фич GrSecurity (например, защиту chroot для сборки нового Gentoo), то придётся редактировать /etc/sysctl.conf и перегружаться.
Собственно, настройка на этом окончена.
В качестве резюме, приведу полный набор команд, которые отконвертируют ваш Gentoo в Hardened:
```
emerge hardened-sources
# Теперь настройте это ядро (пока не включая фичи
# hardened), скомпилируйте и перегрузитесь в него.
ln -snf ../usr/portage/profiles/hardened/x86/2.6/ /etc/make.profile
# Уберите все флаги оптимизации из CFLAGS в /etc/make.conf
# и установите -O2.
# Пример: CFLAGS="-march=pentium-m -O2 -pipe"
# Очистите ваш $PKGDIR (обычно /usr/portage/packages/) для
# ускорения времени пересборки системы используя
# опции -b и -k команды emerge.
emerge -C linux-headers
emerge linux-headers glibc binutils gcc-config gcc
# Проделайте все дополнительные операции, которые могут
# требоваться при обновлении gcc (см. [GCC Upgrade Guide](http://www.gentoo.org/doc/en/gcc-upgrading.xml)).
emerge -b glibc binutils gcc portage
emerge -bke system
emerge -ke world
glsa-check -l | grep '\[N\]'
# Ручками обновите пакеты, которые мог выдать glsa-check.
emerge -a --depclean
emerge -uDNa world
emerge paxtest paxctl gradm
revdep-rebuild
dispatch-conf
# Теперь включите в ядре все фичи Hardened,
# соберите его и перегрузитесь.
```
[Начало.](http://habrahabr.ru/blogs/linux/13094/) [Вторая часть.](http://habrahabr.ru/blogs/linux/13095/) Окончание [следует...](http://habrahabr.ru/blogs/linux/13098/) | https://habr.com/ru/post/13097/ | null | ru | null |
# Корневой сертификат AddTrust от Sectigo истёк 30 мая 2020 года, что вызвало проблемы в клиентах OpenSSL 1.0.x и GnuTLS
Центр сертификации Sectigo (Comodo) [заранее предупредил](https://support.sectigo.com/articles/Knowledge/Sectigo-AddTrust-External-CA-Root-Expiring-May-30-2020) пользователей об истечении срока действия [корневого сертификата AddTrust](https://crt.sh/?id=1), который использовался для перекрёстной подписи, чтобы обеспечить совместимость с устаревшими устройствами, в хранилище которых нет нового корневого сертификата USERTrust.
20-летний срок действия AddTrust истёк 20 мая 2020 года в 10:48:38 UTC. К сожалению, проблемы возникли не только в устаревших браузерах, но и в небраузерных клиентах на базе OpenSSL 1.0.x, LibreSSL и [GnuTLS](https://gitlab.com/gnutls/gnutls/-/blob/master/lib/x509/verify.c). Например, в телевизионных приставках Roku (см. [ответ в техподдержке](https://support.roku.com/en-gb/article/360049417393) от 30.05.2020), [Heroku](https://t.co/RdU3GDwPmD?amp=1), в приложениях Fortinet, Chargify, на платформе .NET Core 2.0 под Linux и [многих других](https://twitter.com/__agwa/timelines/1266777818811322368).
Предполагалось, что проблема затронет только устаревшие системы (Android 2.3, Windows XP, Mac OS X 10.11, iOS 9 и т.п.), поскольку современные браузеры могут задействовать второй корневой сертификат USERTRust, как показано на диаграмме.

*Цепочка сертификатов*
Но 30 мая 2020 года по факту начались сбои в сотнях веб-сервисов, которые использовали свободные библиотеки OpenSSL 1.0.x и GnuTLS. Безопасное соединение перестало устанавливаться с выводом ошибки об устаревании сертификата.
[Соответствующий тикет](https://rt.openssl.org/Ticket/Display.html?id=2634) в баг-трекере OpenSSL (логин и пароль: guest) закрыт 25 февраля 2020 года только для версии OpenSSL 1.1.0.
### Почему возникает ошибка
При подключении клиента TLS-сервер отправляет ему свой сертификат. Клиент должен построить цепочку сертификатов от сертификата сервера до корневого сертификата, которому клиент доверяет. Чтобы помочь клиенту построить эту цепочку, сервер отправляет дополнительно один или несколько промежуточных сертификатов вместе со своим собственным.
Например, веб-сайт отправляет следующие два сертификата:
```
1.
Субъект = *.habr.com
Издатель = Sectigo ECC Domain Validation Secure Server CA
Начало действия = суббота, 30 мая 2020 г. 3:00:00
Окончание действия = пятница, 3 декабря 2021 г. 2:59:59
2.
Субъект = Sectigo ECC Domain Validation Secure Server CA
Издатель = USERTrust ECC Certification Authority
Начало действия = пятница, 2 ноября 2018 г. 3:00:00
Окончание действия = среда, 1 января 2031 г. 2:59:59
```
Первый сертификат принадлежит серверу и выдан центром сертификации Sectigo. Второй выдан центром сертификации USERTrust ECC и является корневым сертификатом. Эти два сертификата образуют полную цепочку к доверенному корню.
Однако центр сертификации USERTrust — это относительно новый корень. Он был создан в 2010 году, и потребовалось много лет, чтобы ему стали доверять все клиенты. Ещё в прошлом году появлялись сообщения, что отдельные клиенты не доверяют этому корню. Поэтому некоторые серверы высылают клиенту дополнительный промежуточный сертификат USERTrust ECC Certification Authority, выданный AddTrust External CA Root. Этот сертификат был сгенерирован в 2000 году, и именно у него срок действия закончился 30 мая 2020 года.
У грамотных валидаторов сертификатов, включая современные браузеры, это не вызвало проблем, потому что они сами могут построить цепочку доверия до USERTrust, но вот с клиентами, которые используют OpenSSL 1.0.x или GnuTLS, возникла проблема. Даже если эти клиенты доверяют корневому центру сертификации USERTrust и хотят построить цепочку к нему, у них всё равно в конечном итоге получается цепочка к AddTrust External CA Root, что приводит к сбою проверки сертификата.
Компания Sectigo предоставила альтернативный перекрёстно подписанный промежуточный сертификат [AAA Certificate Services](https://crt.sh/?id=331986), который будет действовать до 2028 года.
### Проверка своих сервисов
Операторам серверных обработчиков и клиентских приложений рекомендуется проверить свою цепочку сертификатов на наличие устаревшего корневого сертификата AddTrust.
По сути, нужно просто удалить AddTrust External CA Root из цепочки доверия.
Для серверных операторов есть сервис [What's My Chain Cert?](https://whatsmychaincert.com/), который выполняет такую проверку и помогает сгенерировать новую цепочку доверия со всеми необходимыми промежуточными сертификатами. В эту цепочку необязательно включать корневой сертификат, поскольку он уже есть в хранилище у всех клиентов. Кроме того, включать его в цепочку просто неэффективно из-за увеличения размера рукопожатия SSL.
Операторам клиентских приложений рекомендуется проапгрейдится на последнюю версию библиотеки TLS. Если это невозможно, нужно удалить из своего хранилища сертификат AddTrust External CA Root. Если он отсутствует в хранилище, то строится корректная цепочка доверия к новому корневому сертификату USERTrust RSA Certification Authority, так что проверка TLS проходит корректно.
Для удаления AddTrust External CA Root нужно [сделать следующее](https://www.agwa.name/blog/post/fixing_the_addtrust_root_expiration):
1. Отредактировать `/etc/ca-certificates.conf` и закомментить `mozilla/AddTrust_External_Root.crt`
2. Запустить `update-ca-certificates`
Для устранения проблемы в Fedora и RHEL [предлагается](https://twitter.com/ChristianHeimes/status/1266800555978039296) добавить сертификат AddTrust в чёрный список:
```
trust dump --filter "pkcs11:id=%AD%BD%98%7A%34%B4%26%F7%FA%C4%26%54%EF%03%BD%E0%24%CB%54%1A;type=cert" \
> /etc/pki/ca-trust/source/blacklist/addtrust-external-root.p11-kit
update-ca-trust extract
```
Но этот способ не работает для GnuTLS.
> **См. также:**
>
> «[Проблема с сертификатами Sectigo после 30 мая 2020 года и метод решения](https://habr.com/ru/company/habr/blog/504708/)» в корпоративном блоге Хабра
---
[](https://clck.ru/JQx2c)
**PKI-решения для вашего предприятия.** Свяжитесь с нами +7 (499) 678 2210, [email protected]. | https://habr.com/ru/post/504784/ | null | ru | null |
# ThingJS v1.0-alpha

Последние два года я разрабатывал собственную [IoT](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82_%D0%B2%D0%B5%D1%89%D0%B5%D0%B9) платформу и сегодня готов показать ее альфа версию.
Вместе с партнером мы создаем и поддерживаем IoT устройства. Мы разобрали [не один сарай с граблями](https://habr.com/ru/post/474816/) в процессе этой деятельности. ThingJS родилась не столько из желания, сколько из необходимости облегчить жизнь нам, а заодно, надеюсь, и вам.
Статья будет интересна людям, которым близка тема IoT и они уже что-то делали в этой сфере. Важным замечанием будет то, что платформа должна заинтересовать (внезапно) JavaScript разработчиков, т.к. именно этот язык выбран как основа платформы. Конечно, и С/С++ разработчикам тоже будет что почитать.
Сначала я расскажу о том, какие ключевые проблемы мы встретили при разработке IoT устройств, затем опишу, как платформа с ними справляется, а в завершении, все самое скучное: [видео](#video), [техническая часть](#tech-info) и можно будет потрогать все [вживую](#touch-it).
**Оглавление**
* [Проблемы IoT](#problems)
+ [Проблема коротких рук](#short-hands)
+ [Проблема Вавилонской башни](#tower)
+ [Проблема Стокгольмского синдрома](#sindrom)
* [Решения проблем](#solutions)
+ [Сообщество, зависимости, модно, молодежно](#community)
+ [Больше обещаний и абстракций](#promises)
+ [Виртуальные IoT устройства](#virtual)
* [Техническая информация](#tech-info)
+ [Структура приложения ThingJS](#app-struct)
+ [Стек технологий](#tech-stack)
+ [Возможности среды разработки](#dev-skils)
+ [Поддерживаемые устройства](#hw-supported)
+ [Сравнение с конкурентами](#vs-other)
* [Быстрый старт](#get-started)
+ [Мне только посмотреть](#video)
+ [Хочу попробовать](#touch-it)
+ [Blink приложение](#blink)
- [Сборка из исходников](#blink)
- [Состав приложения](#blink-contains)
- [manifest.json](#blink-manifest)
* [Блок “components”](#blink-manifest-components)
* [Блок “scripts”](#blink-manifest-scripts)
* [Блок “requires”](#blink-manifest-requires)
- [blink.js](#blink-blink-js)
- [Blink.vue](#blink-blink-vue)
- [scripts/blink.js](#blink-script-blink-js)
+ [Реализация интерфейса](#intefaces)
* [Среда разработки](#dev)
+ [Разработка приложений](#dev-app)
+ [Разработка прошивки](#dev-firmware)
* [Что дальше?](#what-after)
* [Ссылки](#refs)
* [FAQ](#faq)
Проблемы IoT:
=============
— Проблема коротких рук
------------------------
В основе IoT лежит экосистема. Разработка ее концепции и технической архитектуры, действительно большой труд. Помимо этого, нужно еще разработать кучу прошивок для разнотипных устройств. Придумать и воплотить в жизнь транспорт для обмена данными между устройствами на различных физических и логических принципах. Развернуть облачные ресурсы. Проработать юзер-интерфейсы. И т.д. и т.п.
Даже если отдельный специалист обладает нужными навыками, чтобы это все сделать, то ему просто не хватит времени (рук) на реализацию такой идеи. Пока он будет ее пилить, она морально устареет.
— Проблема Вавилонской башни
-----------------------------
Разработка полноценной IoT экосистемы требует очень широкий технологический стек. Быть фулстеком в IoT это прям… сложно. Нужен опыт везде. Похвастаться таким широким спектром знаний, да еще и опытом, могут далеко не все. И тут вопрос не в умственных способностях. Это очевидный вывод из проблемы “коротких рук”.
Для создания действительно состоятельной экосистемы требуется труд многих достаточно узких специалистов, но с глубокими знаниями в свой области. Говорят эти специалисты на разных языках, используют разные паттерны, да и часто элементарные термины они понимают по-разному. А учитывая, что IoT базируется на устройствах с ограниченными ресурсами, эффективные коммуникации критически важны для реализации задуманного.
— Проблема Стокгольмского синдрома
-----------------------------------
Сегодня есть вендоры, которые развивают свои экосистемы. Это Google, Microsoft, Yandex, Мегафон, МТС и т.д. Некоторые из них позволяют интегрировать собственные вещи в их экосистемы на их условиях. Это во многом закрывает выше описанные проблемы. Но создает новую — зависимость. А условия интеграции вендоры очень любят менять. И уж, тем более о самореализации в этой парадигме речи не идет.
Решения проблем:
================
— Сообщество, зависимости, модно, молодежно
--------------------------------------------
Выше описанные проблемы, фактически, закрывают доступ к разработке IoT для индивидуалов. Разработка платформы была начата с осознанием этих проблем. В основу было заложено развитие платформы через сообщество.
Чтобы реализовать эту идею, платформа, естественно, поставляется с открытой кодовой базой, а также, имеет на всех слоях парадигму зависимостей.
Если вы не знаете, что такое зависимости, самое время с этим познакомиться. Но если попытаться очень просто объяснить, то разрабатываемый вами модуль может зависеть от другого, который напишет ваш друг. И вы будете обращаться к его модулю по заранее оговоренному интерфейсу.
Таким образом, одновременно, независимо, множество людей могут разрабатывать собственные компоненты платформы и переиспользовать уже имеющиеся, разработанные кем-то. Это кардинально решает проблему “коротких рук”.
Также, решается проблема “Вавилонской башни”. Зависимости построены так, что различные уровни платформы, разрабатываемые на разных языках, имеют заранее определенный механизм выстраивания зависимостей между собой.
Например, разработчик на С может воспользоваться готовым компонентом фронтэнда, предоставив ему требуемый интерфейс. Или напротив, разработчик фронтэнда может использовать готовый компонент написанный на С. Т.е. каждый будет делать то, что он умеет лучше всего.
— Больше обещаний и абстракций
-------------------------------
Протокол общения между устройствами неопределен. Вместо него есть абстракция — шина данных. Устройство может послать в шину событие или прослушать шину. Кто в шину пишет и кто получает, заранее неясно. И когда тоже. Обмен данными асинхронный и доставка не гарантируется. В общем — ад. Без паники. Так задумано.
Все дело в том, что экосистема это группа отдельных, самодостаточных устройств. В любой момент времени часть устройств может быть недоступна. По различным причинам. Останавливать активность прочих устройств, если недоступна часть — не лучший сценарий. Нужно узаконить то, что невозможно предотвратить.
В платформе реализована парадигма обещаний по предоставлению событий. Первое устройство подписывается на обещание второго давать ему информацию. Но гарантий нет. Подписчик сам должен решать, что делать в случае несвоевременного предоставления ему данных.
Проблема синхронной связи решается передачей через шину событий со ссылками на синхронные каналы. Протокол синхронного канала определяется самим типом события. К примеру, можно отправить событие с типом “do-render-video-stream” и как payload передать IP WEB-камеры. Таким образом, получатель будет знать, что нужно воспроизвести видеопоток с указанного адреса.

Но как физически работает шина? Реализация шины возлагается на сообщество. Шина расширяется тем транспортом, который требует ваш проект. Например, событие получается по http и ретранслируется по UART. Для всех элементов экосистемы внешне ничего не изменится.
— Виртуальные IoT устройства
=============================
Для ThingJS вещью является не только физическая вещь, но и специальное приложение — виртуальная вещь. Более того, физическая вещь может содержать в себе несколько виртуальных вещей (приложений), которые используют ресурсы физической вещи.
Такой подход позволяет унифицировать взаимодействие между условным backend (контроллер/сервер/облако и т.п.) и frontend (браузер, приложение и т.п.), а также b2b и даже f2f. Построить матрицу, а не иерархию взаимодействия.
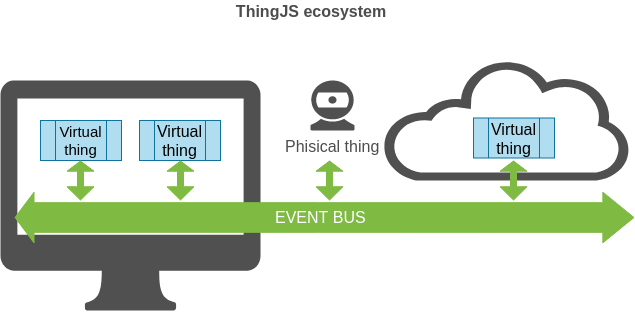
Простым примером может быть WEB-камера, которая в себе имеет виртуальную вещь — интерфейс пользователя. Когда пользователь заходит по адресу <http://192.168.4.1> открывается WEB страница, где начинает “жить” виртуальная вещь. Камера (физическая вещь) и страница (виртуальная вещь) автоматически становятся экосистемой, где доступна унифицированная шина данных. Через нее виртуальная вещь общается с физической. В этом случае: физическая вещь сообщает виртуальной вещи через шину адрес видеопотока, свое состояние и т.п., а виртуальная демонстрирует пользователю видео и отдает необходимые команды физической вещи.
Логическим продолжением становится возможность хостить виртуальные вещи в облаках и включать их в общую экосистему. А это, в свою очередь, позволяет создавать виртуальные устройства с огромными ресурсами, решающие задачи, например, доступные для ИИ.
Вы можете создавать сами такие устройства, или использовать уже созданные. Стокгольмский синдром побежден. Вы сами определяете от чего зависит ваш проект и как вы его будете развивать.
Техническая информация
======================
Структура приложения ThingJS
----------------------------

Стек технологий
---------------
Аппаратной платформой выбран контроллер [ESP32](https://ru.wikipedia.org/wiki/ESP32). Платформа проектировалась аппаратно независимой. Но, к сожалению, портировать на иные устройства не было времени.
Для разработки прошивки используется рекомендованные [Espressif средства](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/). Прошивка разработана на языке С. Сборщик cmake. Проект использует концепцию компонентов, также продвигаемую Espressif.
Помимо, esp-idf, используются [Mongoose WEB Server](https://github.com/cesanta/mongoose), а также доработанный JavaScript интерпритатор Mongoose [mJS](https://github.com/cesanta/mjs).
Для разработки приложений используется JavaScript с фреймворком VUE 2. Сборка приложений осуществляется посредством webpack. Менеджер пакетов — npm. Как основа для среды разработки использовался [VUE CLI](https://github.com/vuejs/vue-cli).
Для того чтобы стандартизировать визуализацию приложений и облегчить муки UI творчества, в платформу включен пакет [vuetifyjs](https://vuetifyjs.com/ru/getting-started/quick-start).
Возможности среды разработки
----------------------------
Для JavaScript разработчиков (виртуальные вещи):
* Рекомендованная IDE — WEBStorm;
* Все профиты, которые дает VUE CLI и IDE;
* Внутрисистемная отладка приложений (дебаггер mJS на контроллере);
* В mJS реализована команда debugger, позволяющая вызывать отладчик в произвольном месте;
* Горячая загрузка обновленных файлов на контроллер при разработке (JavaScript девелоперы уже без этой фичи не живут);
* Runtime разработка в паре с реальным контроллером. Программируешь и, тут же, видишь результат на железе;
* Настроенный ESLint для понимания объектов платформы.
Для С разработчиков (физические вещи):
* Рекомендованная IDE — CLion;
* Все профиты esp-idf и IDE;
* Платформа разделена на компоненты в рамках концепции esp-idf;
* Легкая интеграция с платформой собственных компонентов.
Поддерживаемые устройства
-------------------------
В настоящий момент поддерживается только ESP32. Чип популярен, ввиду своей доступности при поразительных технических характеристиках. На его базе создано достаточно много готовых IoT устройств, которые можно использовать под управлением ThingJS.
Сравнение с конкурентами
------------------------
Предлагаю так далеко пока не забегать. Назвать конкурентами коммерческие платформы у меня сейчас язык не поворачивается. А опенсорсные появляются и исчезают не оставляя заметного следа. Поэтому, сравнение я не стал делать. Впрочем, если у кого-то появится желание, я готов тут разместить результат его работы.
Быстрый старт
=============
Мне только посмотреть
---------------------
Хочу попробовать
----------------
Для того чтобы попробовать платформу на реальном железе, вам понадобится любое устройство на базе ESP32 c flash 4mb и возможностью его прошивать через USB. Но лучше всего подойдет ESP32 core board v2.

Купить такие штуки можно без проблем на Aliexpress или Ebay. Более того, есть даже представительства в России. Я лично покупаю в [Питере](http://www.euromobile.ru).
Для того чтобы проверить работу тестового приложения “Blink”, потребуется подключить светодиод. На некоторых версиях плат есть предустановленный светодиод, подключенный к GPIO2. Если у вас такая плата, то можно ничего не делать. Blink должен работать без лишних движений. Если у вас только один диод (питание), то придется подключить индикаторный диод самому. В этом нет ничего сложного.
Вам понадобится любой индикационный светодиод и сопротивление от 1 до 5КОм.
Осталось дело за малым — развернуть пользовательский пакет на устройстве. Взять его можно [тут](https://github.com/rpiontik/ThingJS-user-packet). Инструкция по развертыванию находится там же.
Blink приложение
----------------
### Сборка из исходников
Blink это простейшая экосистема состоящая из одного виртуального устройства, реализующего интерфейс пользователя, и одного физического. Виртуальное устройство запускается из физического при обращении к нему через браузер.
Сценарий прост. При установке приложения на физическом устройстве начинает мигать светодиод (заранее к нему подключенный) с частотой 1Гц. Пользователь может включать или выключать мигание диода из интерфейса. Видео можно посмотреть в разделе “Мне только посмотреть”.
Исходники лежат в [репозитории](https://github.com/rpiontik/ThingJS-front/tree/alpha) src/applications/blink. Для того чтобы собрать blink и с ним “поиграться”, вам понадобится только этот репозиторий. Убедитесь, что git, npm и nodejs у вас уже установлены.
```
git clone --branch alpha https://github.com/rpiontik/ThingJS-front
cd ThingJS-front
npm install
npm run build
```
Если все прошло гладко, то в результате вы получите примерно следующее:
Поздравляю! Вы собрали свое первое приложение для ThingJS. Найти его можно в папке dist/apps/blink и сразу же попробовать поставить на устройство, руководствуясь видео из раздела ["Мне только посмотреть"](#video).
### Состав приложения
| Файл | Описание |
| --- | --- |
| scripts/blink.js | Скрипт, который устанавливается на контроллер |
| blink.js | Точка монтирования компонента приложения |
| Blink.vue | VUE компонент, реализующий интерфейс пользователя |
| favicon.svg | Иконка приложения |
| langs.js | Языковой пакет приложения |
| manifest.json | Манифест приложения |
Со всеми деталями приложения вы можете познакомиться самостоятельно. Я заострю внимание на нескольких файлах.
### manifest.json
```
{
"name": "Blink",
"vendor" : "rpiontik",
"version" : 1,
"subversion" : 0,
"patch" : 0,
"description": {
"ru": "Мигание диодом",
"en": "Blink Example"
},
"components": {...},
"scripts": {...},
"requires" : {...}
}
```
Как следует из названия файла, это манифест приложения. В нем есть метаданные общего характера о назначении которых легко догадаться. Помимо них, есть три важных блока. Давайте рассмотрим их пристально:
#### Блок “components”
```
"components": {
"blink-app": {
"source": "blink.js",
"intent_filter": [
{
"action": "thingjs.intent.action.MAIN",
"category": "thingjs.intent.category.LAUNCH"
}
]
}
}
```
Блок описывает всю компонентную базу приложения. Поле “source” указывает на точку монтирования компонента (см. blink.js) и является точкой входа сборки для webpack ([entry](https://webpack.js.org/concepts/entry-points/)). Таким образом, каждый компонент будет оформлен в отдельный бандл. Загрузка этого бандла будет выполняться по мере необходимости ([lazy load](https://router.vuejs.org/ru/guide/advanced/lazy-loading.html)).
Важной структурой является [“intent\_filter”](https://developer.android.com/guide/components/intents-filters?hl=ru). Если вам случалось программировать для Android, вы найдете нечто знакомое для себя. И не ошибетесь. В системе возникают интерфейсные и сервисные события на которые подписывается компонент. Если возникает событие, удовлетворяющее условиям фильтрации, то компонент будет загружен и управление будет передано точке монтирования.
В данном случае, компонент “blink-app” подписан на событие запуска основного интерфейсного компонента приложения. Когда лаунчер будет запускать приложение, именно этот компонент будет представлен.
Если модифицировать манифест, изменив строчку
`thingjs.intent.category.LAUNCH >> thingjs.intent.category.PREFERENCE`
, то после его сборки и установки окажется, что приложение перестало открываться на рабочем столе. Но появилась новая “плитка” в разделе “Settings”. При этом функционально ничего не поменялось.
Таким образом, мы указали лаунчеру, что данный компонент является интерфейсным элементом для настройки нашего приложения. И этот компонент стал представляться в настройках.
#### Блок “scripts”
```
"scripts": {
"entry": "blink",
"subscriptions" : ["$-script-restart", "blink"],
"modules": {
"blink": {
"hot_reload": true,
"source": "scripts/blink.js",
"optimize": false
}
}
}
```
Этот блок аналогичен по функции блоку “components”, но описывает компонентную базу приложения на стороне контроллера.
В нем явно указывается точка входа. В поле “entry”. Отдельно обращу внимание, что при установке приложения скрипт не запускается сразу. Он запускается только тогда, когда наступает одно из событий, на которые скрипт подписан.
За подписки отвечает поле “subscriptions”. Сейчас в нем указаны два события:
* **$-script-restart** — возникает в случае запуска или перезапуска системы;
* **blink** — кастомное событие, которое релевантно для экосистемы blink.
В блоке “modules” следует описание состава скриптов. Отмечу два поля:
* **hot\_reload** — если это поле установлено в true, то при изменении файла в режиме разработки он автоматически будет загружаться на контроллер (hot reload);
* **optimize** — если true, то при сборке проекта скрипт будет оптимизироваться и аглифицироваться.
#### Блок “requires”
```
"requires" : {
"interfaces" : {
"blink" : {
"type" : "bit_port",
"required" : true,
"default" : 2,
"description" : {
"ru" : "LED индикатор",
"en" : "LED indicator"
}
}
}
}
```
Наверное вы уже обратили внимание на то, что при установке приложения нужно выбирать пин на котором будет мигать светодиод. При этом по умолчанию он уже выбран как GPIO2. Этот блок как раз и отвечает за эти настройки.
В этом блоке указываются зависимости. В данном случае, чтобы приложение могло функционировать, ему требуется предоставить интерфейс с типом “bit\_port”. Этот интерфейс является обязательным требованием (required = true) и по умолчанию, указывается GPIO2 (default = 2). В скрипт он будет спроецирован с именем “blink”.
При установке приложения учитывается профиль оборудования, на которое будут разворачиваться скрипты. В этом профиле перечисляются доступные интерфейсы и доступные для них аппаратные ресурсы (в частности, пины и их комбинации). Проверяется совместимость требований и оборудования. Если оборудование может удовлетворить требованиям приложения, пользователю отображается схема распределения ресурсов, где первично ресурсы распределены автоматически с учетом рекомендаций из манифеста. Т.е. из того самого поля “default”.
Таким образом, на одном устройстве могут быть установлены несколько приложений, которые могут делить между собой аппаратные ресурсы.
### blink.js
```
import App from './Blink.vue';
import Langs from './langs';
$includeLang(Langs);
$exportComponent('blink-app', App);
```
Файл является точкой монтирования компонента, анонсированного в манифесте (см. manifest.js/components) В нем выполняется регистрация VUE компонента ‘blink-app’ через метод абстракции $exportComponent, а также регистрируется языковой пакет.
Возможно, вы спросите — зачем такие сложности? Почему не регистрировать сразу VUE компонент, который указывать в source? Дело в том, что манифест описывает публичные компоненты. Эти компоненты могут запрашиваться сторонними приложениями (runtime зависимости). Точка монтирования, в свою очередь, может зарегистрировать сопутствующие компоненты (для внутреннего пользования), а также сервисы. Т.е., подготовить окружение компонента.
### Blink.vue
```
export default {
name: 'Blink',
watch: {
blink_state (state) {
// Send event to script
this.$bus.$emit($consts.EVENTS.UBUS_MESSAGE, 'blink', state);
}
},
data () {
return {
blink_state: true
};
}
};
```
Код говорит сам за себя. При изменении свойства “blink\_state” отправляется сообщение в шину ($bus) с текущим значением. Это все, что нужно сделать, чтобы скрипт на стороне контроллера получил нужную команду.
### scripts/blink.js
```
let active = true;
let state = true;
// Set port direction
$res.blink.direction($res.blink.DIR_MODE_DEF_OUTPUT);
// Run background process
setInterval(function () {
if (active) {
// $res - is container with required resources
$res.blink.set(state);
// Do invert
state = !state;
}
}, 1000);
// Event listener
// $bus - system bus interface
$bus.on(function (event, content, data) {
if (event === 'blink') {
active = !!JSON.parse(content);
}
}, null);
```
В целом, код очень похож на классическое использование таймера в JavaScript. За исключением того, что в данном диалекте JavaScript его нет. Он реализован в платформе. Знакомьтесь, это [mJS](https://github.com/cesanta/mjs). Более подробно о нем можно узнать на официальной странице проекта.
Для нужд платформы диалект доработан. Завезены таймеры, а также такая полезная команда как “debugger”. Ну, и сам отладчик. Подробнее об этом отдельно в разделе [“Среда разработки”](#dev).
Обратите внимание на глобальные объекты платформы. Они именуются с символа “$”.
* **$res** — содержит ресурсы, которые выделены скрипту;
* **$bus** — интерфейс шины.
Т.к. приложение запросило интерфейс с типом “bit\_port” (см. profile.json/requires) и именем “blink”, ему он был выдан как $res.blink. Интерфейс реализует всего три функции:
* **set(value)** — установить уровень GPIO
* **get()** — получить текущий уровень GPIO
* **direction(value)** — установить режим GPIO
Для функции direction описаны доступные константы через тот же интерфейс $res.blink.: DIR\_MODE\_DISABLE; DIR\_MODE\_DEF\_INPUT; DIR\_MODE\_DEF\_OUTPUT; DIR\_MODE\_INPUT\_OUTPUT\_OD; DIR\_MODE\_INPUT\_OUTPUT.
Подписка на события шины осуществляется через метод $bus.on. При этом в обработчик будут приходить все события, на которые скрипт подписан. Обработчик принимает три параметра:
* **event** — идентификатор события. В этом случае возможны всего два: “$-script-restart” и “blink”. Из которых обрабатывается всего одно — blink. Подписка на второе нужна лишь для того, чтобы скрипт запускался сразу при старте системы.
* **content** — с событием могут приходить данные. Их размер ограничен 126 байтами с учетом длины идентификатора события.
* **data** — данные, которые передаются при подписке на событие как второй параметр. И в данном случае, равны null.
Интерфейсы расширяемы. Ниже вы найдете описание, как создать собственный интерфейс.
Реализация интерфейса
---------------------
ThingJS позволяет расширять доступные аппаратные и сервисные ресурсы через специальные интерфейсы. Вы можете самостоятельно создать интерфейс, который будет реализовывать любой сложный, точный, нагруженный и т.п. функционал.
Например, вы можете реализовать интерфейс интеграции со своим облачным сервисом. Или фоновый, асинхронный процесс, с которым скрипт сможет обмениваться сообщениями. Ну или реализовать поддержку дисплея. Это будет одинаково легко как сделать, так и использовать. Как вам, так и другим. Правда для этого вам потребуется знать С.
Рассмотрим реализацию интерфейса “bit\_port”, который используется в примере “Blink”. Для того чтобы начать, потребуется развернуть проект [ThingJS-template](https://github.com/rpiontik/ThingJS-template) alpha релиз. Документация по развертыванию находится в самом проекте.
```
git clone --branch alpha https://github.com/rpiontik/ThingJS-template
```
В проект входят компоненты:
* **ThingJS-boards** — содержит в себе конфигурации устройств. Пока только ESP32\_CORE\_BOARD V2 и совместимые;
* **ThingJS-extern** — библиотеки сторонних проектов, которые использует ThingJS;
* **ThingJS-core** — ядро платформы;
* **ThingJS-front** — среда разработки приложений;
* **ThingJS-stdi** — стандартные интерфейсы.
Нас интересует проект ThingJS-stdi. Его структура следующая:
| Файл | Описание |
| --- | --- |
| implementation/tgsi\_bit\_port.c | Реализация интерфейса bit\_port |
| implementation/tgsi\_bit\_port.h | Заголовочный файл интерфейса bit\_pro |
| CMakeLists.txt | cmake скрипт сборки |
| README.md | |
| sdti\_utils.h | Хелперы |
| thingjs\_stdi.c | Точка монтирования интерфейсов |
| thingjs\_stdi.h | Заголовочный файл точки монтирования |
По сути, нас интересует только один файл — implementation/tgsi\_bit\_port.c. Именно в нем содержится все, что требует отдельного пояснения.
```
void thingjsBitPortRegister(void) {
static int thingjs_bit_port_cases[] = DEF_CASES(
DEF_CASE(GPIO0), DEF_CASE(GPIO2), DEF_CASE(GPIO3), DEF_CASE(GPIO4),
DEF_CASE(GPIO5), DEF_CASE(GPIO12), DEF_CASE(GPIO13), DEF_CASE(GPIO14),
DEF_CASE(GPIO15), DEF_CASE(GPIO16), DEF_CASE(GPIO17), DEF_CASE(GPIO18),
DEF_CASE(GPIO19), DEF_CASE(GPIO21), DEF_CASE(GPIO22), DEF_CASE(GPIO23),
DEF_CASE(GPIO25), DEF_CASE(GPIO26), DEF_CASE(GPIO27), DEF_CASE(GPIO32),
DEF_CASE(GPIO33)
);
static const struct st_thingjs_interface_manifest interface = {
.type = "bit_port",
.constructor = thingjsBitPortConstructor,
.cases = thingjs_bit_port_cases
};
thingjsRegisterInterface(&interface);
}
```
Функция thingjsBitPortRegister регистрирует компонент в ядре ThingJS. Для этого она вызывает функцию thingjsRegisterInterface, которой передает структуру с описанием интерфейса.
* **type** — идентификатор интерфейса. Именно он указывается как тип в файле manifest.json приложения;
* **constructor** — ссылка на конструктор интерфейса. Функция вызывается каждый раз, когда нужно создать новый экземпляр интерфейса;
* **cases** — массив, описывающий возможные аппаратные ресурсы, которые может использовать интерфейс для своей работы. В данном случае, это одиночные GPIO. Но могут быть отдельно описаны их комбинации или зависимости.
Конструктор интерфейса монтирует интерфейс в машину mJS.
```
mjs_val_t thingjsBitPortConstructor(struct mjs *mjs, cJSON *params) {
//Validate preset params
//The params must have pin number
if (!cJSON_IsNumber(params))
return MJS_UNDEFINED;
//Get pin number
gpio_num_t gpio = params->valueint;
//Create mjs object
mjs_val_t interface = mjs_mk_object(mjs);
/* Configure the IOMUX register for pad BLINK_GPIO (some pads are
muxed to GPIO on reset already, but some default to other
functions and need to be switched to GPIO. Consult the
Technical Reference for a list of pads and their default
functions.)
*/
gpio_pad_select_gpio(gpio);
//Add protected property to interface
mjs_set(mjs, interface, "gpio", ~0, mjs_mk_number(mjs, gpio));
//Set protected flag
mjs_set_protected(mjs, interface, "gpio", ~0, true);
//Bind functions
mjs_set(mjs, interface, "set", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) thingjsBitPortSet));
mjs_set(mjs, interface, "get", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) thingjsBitPortGet));
mjs_set(mjs, interface, "direction", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) thingjsBitPortDirection));
//Consts
mjs_set(mjs, interface, "DIR_MODE_DISABLE", ~0, mjs_mk_number(mjs, GPIO_MODE_DISABLE));
mjs_set(mjs, interface, "DIR_MODE_DEF_INPUT", ~0, mjs_mk_number(mjs, GPIO_MODE_DEF_INPUT));
mjs_set(mjs, interface, "DIR_MODE_DEF_OUTPUT", ~0, mjs_mk_number(mjs, GPIO_MODE_DEF_OUTPUT));
mjs_set(mjs, interface, "DIR_MODE_INPUT_OUTPUT_OD", ~0, mjs_mk_number(mjs, GPIO_MODE_INPUT_OUTPUT_OD));
mjs_set(mjs, interface, "DIR_MODE_INPUT_OUTPUT", ~0, mjs_mk_number(mjs, GPIO_MODE_INPUT_OUTPUT));
//Return mJS interface object
return interface;
}
```
Как параметры передаются:
* **mjs** — глобальный контекст выполнения;
* **params** — параметры инициализации интерфейса. В данном случае это номер GPIO.
Создается объект mJS “interface”, куда монтируются методы и свойства интерфейса:
* **gpio** — readonly свойство, в котором хранится номер используемого GPIO;
* **set** — метод установки уровня сигнала;
* **get** — метод получения текущего уровня сигнала;
* **direction** — установка режима GPIO;
Также, монтируются константы, которыми смогут оперировать скрипты (DIR\_MODE\_DISABLE, DIR\_MODE\_DEF\_INPUT и т.д.).
После создания интерфейса, он монтируется под определенным идентификатором (в примере Blink это “blink”) в глобальный объект $res. Пример использования можно посмотреть в разделе Blink ([scripts/blink.js](#blink-script-blink-js)).
Вы можете оформлять интерфейсы в отдельные компоненты или пакеты. Это позволит собирать прошивку как лего.
Среда разработки
================
Разработка приложений
---------------------
Среда разработки приложений основывается на VUE CLI, который был доработан для соответствия потребностям платформы ThingJS. Это жесткий форк, т.ч. новых фич из VUE CLI стоит ждать в том случае, если они прям сильно облегчают жизнь.
Для развертывания среды необходимо клонировать проект [ThingJS-front](https://github.com/rpiontik/ThingJS-front) alpha-релиз. Убедитесь, что git, npm и nodejs у вас уже установлены.
```
git clone --branch alpha https://github.com/rpiontik/ThingJS-front
cd ThingJS-front
npm install
```
При разработке рекомендую использовать IDE WEBStorm.
Состав и структура проекта наследует VUE CLI. Я отражу значимые отличия:
1. Переработаны скрипты сборки в папке build.
2. В конфиг dev среды (config/dev.env.js) добавлена переменная окружения “HW\_DEVICE\_URL”. В ней необходимо указывать ссылку на физическое устройство с которым вы будете работать.
3. Появилась системная папка src/applications. В ней содержатся приложения, которые будут собираться автоматически. В частности, в ней находятся два приложения: ante (лаунчер) и blink (приложение).
4. Все, что выше папки src/applications считается платформенными модулями и ресурсами. Вы, конечно, можете вносить изменения в них, но в этом случае, они появятся в контроллере только после его перепрошивки. Т.ч. если специально вы себе цели не ставили, лучше их не трогать.
Для пробы, можно тут же запустить dev-сервер. Хотя полноценно вы не сможете проводить разработку без физической “железки”, разрабатывать интерфейс это не мешает. И так, запускам dev-сервер:
```
npm run dev
```
Результат должен быть примерно таким:

Открыв браузер и введя в адресную строку <http://0.0.0.0:8080> вы увидите платформу в режиме разработки:
Сам процесс разработки интерфейса мало чем отличается от классической разработки фронта на VUE. За исключением того, что есть глобальные объекты платформы, о которых нужно знать:
* **$const** — содержит в себе платформенные константы, а также языковые пакеты;
* **$bus** — Шина данных;
* **$store** — глобальное хранилище (VUEX).
Из примеров вы сможете понять как их использовать.
Мультиязычность реализована простейшим образом — через фильтр “lang”. Указываете языковую константу, она интерпретируется в текст в зависимости от языка интерфейса.
```
v-bind:label="'BLINK_SATE' | lang"
```
Для того чтобы оценить возможности среды разработки в полной мере, вам потребуется подготовленный (прошитый) контроллер. Вы можете собрать прошивку сами [из проекта](https://github.com/rpiontik/ThingJS-template) или воспользоваться готовой прошивкой и утилитой [отсюда](https://github.com/rpiontik/ThingJS-user-packet).
После прошивки контроллера и подключения в сеть, нужно убедиться, что контроллер доступен по IP с вашего компьютера. Для этого в браузере наберите <http://[IP> контроллера]. Должен открыться WEB-интерфейс.
Теперь требуется указать адрес контроллера в файле config/dev.env.js
```
'use strict'
const merge = require('webpack-merge')
const prodEnv = require('./prod.env')
module.exports = merge(prodEnv, {
NODE_ENV: '"development"',
HW_DEVICE_URL: '"http://[IP контроллера]"'
//HW_DEVICE_URL: '"http://192.168.8.105"',
//HW_DEVICE_URL: '"http://192.168.4.1"',
})
```
Если dev-сервер был запущен, остановите его и вновь запустите. В будущем, после изменения файлов сборки, конфигурации, а также манифестов приложений, всегда перезапускайте dev-сервер.
Хотя при работе в dev-среде отображаются все приложения, которые есть в папке src/application как установленные, полнофункционально будут работать только те, которые действительно установлены на контроллер. Это не фича, а баг альфы. В будущем синхронизация железки и dev-среды будет происходить автоматически. Но пока, нужно поставить в ручном режиме приложение на контроллер, чтобы среда его “зацепила” и синхронизировала с тем, что есть в dev.
Собираем приложение в прод режиме:
```
npm run prod
```
Устанавливаем собранные приложения на контроллер напрямую. **Не через dev-сервер**.
Вот теперь можно приступить к разработке. Любые ваши изменения файлов будут автоматически запускать пересборку приложений и картинка на экране будет меняться (hot reload). Это же правило распространяется на срипты контроллера. К примеру, можно добавить в скрипт приложения blink команду debugger и посмотреть результат.
```
// Event listener
// $bus - system bus interface
$bus.on(function (event, content, data) {
if (event === 'blink') {
debugger;
active = !!JSON.parse(content);
}
}, null);
```
Теперь при изменении состояния чекбокса приложения Blink, среда разработки выкинет такое сообщение:
Кликнув по ссылке “Start debugger”, вы попадете в отладчик. Отобразится строка на которой произошла остановка.
Сам процесс отладки мало чем отличается от прочих отладчиков.
Отладчик разделен на четыре секции. В центральной сам код. Слева установленные приложения на контроллер. Их структура и состав. Справа, инспектор. Снизу отображается лог. Слева внизу есть текущий статус связи с контроллером.
Среда отладки находится в процессе интенсивной доработки. Предстоит встроить еще много инструментов мониторинга и отладки. Заранее прошу прощение, за возможные баги.
Разработка прошивки
-------------------
Разработка прошивки основывается на концепции предложенной Espressif. Переплюнуть [родную документацию](https://docs.espressif.com/projects/esp-idf/en/latest/api-guides/build-system.html) на этот счет я не смогу.
Для быстрого старта подготовлен [репозиторий](https://github.com/rpiontik/ThingJS-template). В нем содержится информация по развертыванию. Пример использования смотрите в разделе [“Реализация интерфейса”](#intefaces).
Сборка очень простая и буквально через 1-2 часа вы будете уже собирать прошивки без проблем.
Что дальше?
===========
Дальше, если платформа заинтересует сообщество, планируется:
* Развитие среды отладки;
* Стандартизация именований интерфейсов, событий, компонентов;
* Подробная документация на платформу;
* Облачный хостинг для виртуальных вещей;
* Runtime репозитории;
* Партирование на различные готовые устройства.
Также, я ищу людей, которые хотели бы развивать платформу со мной. Она уже очень большая по размаху и амбициям. Я предполагаю равноправное сотрудничество, целью которого станет развитие платформы до полноценной на принципах OpenSource.
Для вступления в проект необходимо сделать ценные pull-реквесты в интересующие вас компоненты платформы.
Ссылки
======
Ресурсы проекта ThingJS:
* [Сайт](http://thingjs.io)
* [Группа](https://t.me/thingjs)
Репозитории проекта ThingJS:
* [Пользовательский пакет](https://github.com/rpiontik/ThingJS-user-packet)
* [Шаблон проекта для создания прошивок](https://github.com/rpiontik/ThingJS-template)
* [Шаблон проекта для создания приложений](https://github.com/rpiontik/ThingJS-front)
Используемые проекты:
* [ESP32](https://en.wikipedia.org/wiki/ESP32)
* [esp-idf](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/)
* [Mongoose WEB Server](https://github.com/cesanta/mongoose)
* [mJS](https://github.com/cesanta/mjs)
* [Vue 2](https://vuejs.org/v2/guide/)
* [vuetifyjs](https://vuetifyjs.com/ru/getting-started/quick-start)
FAQ
===
Тут будут появляться ответы на вопросы в комментариях. | https://habr.com/ru/post/474356/ | null | ru | null |
# Путь к трансдьюсерам на чистом JavaScript
Если вы наслышаны о так называемых «трансдьюсерах», но до сих пор не применяете их в JavaScript-разработке, сегодня у вас есть шанс найти ответы на вопросы: «Что такое трансдьюсеры?» и «Как ими пользоваться?». Это позволит вам понять, нужны ли они в ваших проектах, и, если нужны — поможет приступить к их использованию.
[](https://habrahabr.ru/company/ruvds/blog/329536/)
Речь пойдёт о том, как писать код, который предназначен для построения хорошо подходящих для компоновки конвейеров преобразований данных, не потребляющий слишком много памяти. Для того, чтобы как следует разобраться в концепции трансдьюсеров, начнём мы с более простых механизмов, редьюсеров, или функций для свёртки данных.
Редьюсеры
---------
Редьюсер — это функция, которая принимает на вход объект-накопитель и некий объект-элемент, после чего помещает этот элемент в накопитель. Например, вот редьюсер:
`(acc, val) => acc.concat([val])`. Если переданный ему накопитель — это массив `[1, 2, 3]`, а элемент — число `4`, он вернёт массив `[1, 2, 3, 4]`.
```
const acc = [1, 2, 3];
const val = 4;
const reducer = (acc, val) => acc.concat([val]);
reducer(acc, val)
///=> 1, 2, 3, 4
```
В нашем случае редьюсер возвращает результат конкатенации переданного ему списка элементов и единичного элемента.
Вот ещё один похожий редьюсер: `(acc, val) => acc.add(val)`. Он подходит для любого объекта, имеющего метод `.add()`, который, кроме прочего, возвращает этот объект (вроде [Set.prototype.add()](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Set/add)). Наш редьюсер добавляет переданный ему элемент к накопителю, используя метод .`add()` накопителя.
```
const acc = new Set([1, 2, 3]);
const val = 4;
const reducer = (acc, val) => acc.add(val);
reducer(acc, val)
///=> Set{1, 2, 3, 4}
```
Вот — функция, которая создаёт массив из любого итерируемого объекта с использованием нашего конкатенирующего редьюсера.
```
const toArray = iterable => {
const reducer = (acc, val) => acc.concat([val]);
const seed = [];
let accumulation = seed;
for (value of iterable) {
accumulation = reducer(accumulation, value);
}
return accumulation;
}
toArray([1, 2, 3])
//=> [1, 2, 3]
```
Можно сделать переменные `reducer` и `seed` параметрами новой функции (принимающей, по аналогии с только что рассмотренной, и аргумент `iterable`), получив универсальную редуцирующую функцию.
```
const reduce = (iterable, reducer, seed) => {
let accumulation = seed;
for (const value of iterable) {
accumulation = reducer(accumulation, value);
return accumulation;
}
reduce([1, 2, 3], (acc, val) => acc.concat([val]), [])
//=> [1, 2, 3]
```
JavaScript развивается в направлении соглашения о написании функций, вроде нашей `reduce`, первым параметром которых является редьюсер. Если переписать эту функцию в стиле [JavaScript Allongé](https://leanpub.com/javascriptallongesix), получится следующее.
```
const reduceWith = (reducer, seed, iterable) => {
let accumulation = seed;
for (const value of iterable) {
accumulation = reducer(accumulation, value);
}
return accumulation;
}
reduce([1, 2, 3], (acc, val) => acc.concat([val]), [])
//=> [1, 2, 3]
// теперь вызов выглядит так:
reduceWith((acc, val) => acc.concat([val]), [], [1, 2, 3])
//=> [1, 2, 3]
```
У массивов в JavaScript есть встроенный метод `.reduce`. Этот метод ведет себя точно так же, как вышеописанные функции `reduce` и `reduceWith`.
```
[1, 2, 3].reduce((acc, val) => acc.concat([val]), [])
//=> [1, 2, 3]
```
Теперь функция `(acc, val) => acc.concat([val])` создаёт ненужную нагрузку на память, поэтому мы можем заменить её на такой редьюсер: `(acc, val) => { acc.push(val); return acc; }`.
Тут надо отметить, что запись вида `(acc, val) => (acc.push(val), acc)` с семантической точки зрения выглядит лучше, но оператор «запятая» может запутать тех, кто не знаком с особенностями его использования. Обычно в продакшн-коде такого лучше избегать.
В любом случае, у нас получится редьюсер, который собирает элементы в массив. Дадим ему имя и попробуем передать функции `reduceWith`.
```
const arrayOf = (acc, val) => { acc.push(val); return acc; };
reduceWith(arrayOf, [], [1, 2, 3])
//=> [1, 2, 3]
```
Вот ещё один редьюсер.
```
const sumOf = (acc, val) => acc + val;
reduceWith(sumOf, 0, [1, 2, 3])
//=> 6
```
Можно писать редьюсеры, которые сворачивают итерируемый объект одного типа (скажем, массив), в объект другого типа (например — в число).
Декорирование редьюсеров
------------------------
В JavaScript легко писать функции, которые возвращают другие функции. Вот, например, функция, которая позволяет создавать редьюсеры.
```
const joinedWith =
separator =>
(acc, val) =>
acc == '' ? val : `${acc}${separator}${val}`;
reduceWith(joinedWith(', '), '', [1, 2, 3])
//=> "1, 2, 3"
reduceWith(joinedWith('.'), '', [1, 2, 3])
//=> "1.2.3"
```
Кроме того, в JS совершенно естественным является создание функций, которые принимают другие функции в качестве аргументов.
Декораторы — это функции, которые, принимая некую функцию в качестве аргумента, возвращают другую функцию, семантически связанную с аргументом. Например, эта функция принимает функцию с двумя аргументами, бинарную, если говорить языком функционального программирования, и декорирует её, добавляя единицу к её второму аргументу.
```
const incrementSecondArgument =
binaryFn =>
(x, y) => binaryFn(x, y + 1);
const power =
(base, exponent) => base ** exponent;
const higherPower = incrementSecondArgument(power);
power(2, 3)
//=> 8
higherPower(2, 3)
//=> 16
```
В этом примере функция `higherPower` — это функция `power`, декорированная путём добавления единицы к её аргументу `exponent`. Таким образом, вызов `higherPower(2,3)` даёт тот же результат, что и `power(2,4)`. С подобными функциями мы уже работали, наши редьюсеры — тоже бинарные функции. Их можно декорировать.
```
reduceWith(incrementSecondArgument(arrayOf), [], [1, 2, 3])
//=> [2, 3, 4]
const incremented =
iterable =>
reduceWith(incrementSecondArgument(arrayOf), [], iterable);
incremented([1, 2, 3])
//=> [2, 3, 4]
```
Функции маппинга
----------------
Мы только что создали функцию для маппинга, которая, принимая итерируемый объект, возвращает результат обработки его значений путём увеличения каждого из них на единицу. Разрабатывая программы на JS, мы постоянно прибегаем к маппингу, но, конечно, от функций, реализующих этот механизм, обычно ожидают несколько большего, нежели производство копий числовых массивов, элементы которых увеличены на единицу. Взглянем ещё раз на функцию `incrementSecondArgument`.
```
const incrementSecondArgument =
binaryFn =>
(x, y) => binaryFn(x, y + 1);
```
Так как мы используем её для декорирования редьюсеров, дадим ей более подходящее имя.
```
const incrementValue =
reducer =>
(acc, val) => reducer(acc, val + 1);
```
Теперь при чтении кода сразу видно, что `incrementValue` принимает в качестве аргумента редьюсер и возвращает другой редьюсер, который, перед обработкой переданного ему элемента, прибавляет к нему единицу. Логику «инкрементации» можно вынести в параметр.
```
const map =
fn =>
reducer =>
(acc, val) => reducer(acc, fn(val));
const incrementValue = map(x => x + 1);
reduceWith(incrementValue(arrayOf), [], [1, 2, 3])
//=> [2, 3, 4]
```
Хотя всё это может выглядеть необычно для тех, кто не привык к функциям, которые принимают функции как аргументы и возвращают другие функции, которые, опять же, принимают функции как аргументы, мы можем поместить конструкцию `map(x => x + 1)` везде, где можно пользоваться `incrementValue`. Таким образом, можно написать следующее.
```
reduceWith(map(x => x + 1)(arrayOf), [], [1, 2, 3])
//=> [2, 3, 4]
```
И, так как наш декоратор `map` может декорировать любой редьюсер, допустимо объединить результаты инкрементирования чисел, сформировав строку, или суммировать их.
```
reduceWith(map(x => x + 1)(joinedWith('.')), '', [1, 2, 3])
//=> "2.3.4"
reduceWith(map(x => x + 1)(sumOf), 0, [1, 2, 3])
//=> 9
```
Вооружившись вышеописанными приёмами, попытаемся найти сумму квадратов чисел от одного до десяти.
```
const squares = map(x => power(x, 2));
const one2ten = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
reduceWith(squares(sumOf), 0, one2ten)
//=> 385
```
Как видите, нам это удалось. Теперь идём дальше — поговорим о фильтрах.
Фильтры
-------
Вернёмся к нашему первому редьюсеру.
```
const arrayOf = (acc, val) => { acc.push(val); return acc; };
reduceWith(arrayOf, 0, one2ten)
//=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
```
Что если нужно, чтобы на выход попали только числа, которые больше пяти? Сделать это несложно.
```
const bigUns = (acc, val) => {
if (val > 5 ) {
acc.push(val);
}
return acc;
};
reduceWith(bigUns, [], one2ten)
//=> [6, 7, 8, 9, 10]
```
Естественно, мы можем скомбинировать всё то, с чем уже разобрались, для того, чтобы получить массив чисел, которые больше пяти, возведённых в квадрат.
```
reduceWith(squares(bigUns), [], one2ten)
//=> [9, 16, 25, 36, 49, 64, 81, 100]
```
Однако, получилось тут совсем не то, что нужно. На выходе — числа, квадраты которых больше пяти, а не числа, которые больше чем пять, возведённые в квадрат. Числа надо отбирать до возведения их в квадрат, а не после. Добиться такого поведения системы не так уж и сложно. Суть тут в том, что нам поможет декоратор, который отвечает за фильтрацию чисел, его мы можем использовать для декорирования редьюсера.
```
reduceWith(squares(arrayOf), [], one2ten)
//=> [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
const bigUnsOf =
reducer =>
(acc, val) =>
(val > 5) ? reducer(acc, val) : acc;
reduceWith(bigUnsOf(squares(arrayOf)), [], one2ten)
//=> [36, 49, 64, 81, 100]
```
Функция `bigUnsOf` довольно специфична. Поступим тут так же, как с `map`, а именно — извлечём функцию-предикат и сделаем её аргументом.
```
reduceWith(squares(arrayOf), [], one2ten)
//=> [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
const filter =
fn =>
reducer =>
(acc, val) =>
fn(val) ? reducer(acc, val) : acc;
reduceWith(filter(x => x > 5)(squares(arrayOf)), [], one2ten)
//=> [36, 49, 64, 81, 100]
```
Фильтры, конечно, могут быть любыми. Им можно давать имена и использовать многократно, можно обходиться и анонимными функциями.
```
reduceWith(filter(x => x % 2 === 1)(arrayOf), [], one2ten)
//=> [1, 3, 5, 7, 9]
```
Воспользуемся фильтром для того, чтобы найти сумму квадратов нечётных чисел от одного до десяти.
```
reduceWith(filter(x => x % 2 === 1)(squares(sumOf)), 0, one2ten)
//=> 165
```
Трансформеры и композиция
-------------------------
Термин «трансформер» пришёл в JavaScript из других языков программирования. Так называют функцию, принимающую некий аргумент и трансформирующую его во что-то другое. То, что мы выше называли «декоратором», является частным случаем трансформера. Таким образом, если вы встретите где-нибудь рассказ о функции-трансформере, которая делает из одного редьюсера другой, вам будет ясно, что речь идёт о такой же функции, которая «декорирует» редьюсер, добавляя к нему дополнительный функционал, вроде маппинга или фильтрации.
Функции маппинга и фильтры, о которых мы говорили — это тоже трансформеры. В контексте этого шаблона программирования, самой важной характеристикой трансформеров является то, что они применяют композицию для создания новых трансформеров. Вот, чтобы было понятнее, функция, которая выдаёт композицию любых двух поданных ей на вход функций.
```
const plusFive = x => x + 5;
const divideByTwo = x => x / 2;
plusFive(3)
//=> 8
divideByTow(8)
//=> 4
const compose2 =
(a, b) =>
(...c) =>
a(b(...c));
const plusFiveDividedByTwo = compose2(divideByTwo, plusFive);
plusFiveDividedByTwo(3)
//=> 4
```
Трансформеры применяют композицию для создания новых трансформеров. Что это значит в применении к функции `compose2`? Это значит, что передав ей два любых трансформера, мы получим новый трансформер, который трансформирует редьюсер. Таким образом, получим следующее.
```
const squaresOfTheOddNumbers = compose2(
filter(x => x % 2 === 1),
squares
);
reduceWith(squaresOfTheOddNumbers(sumOf), 0, one2ten)
//=> 165
```
То, что скрыто под именем `squaresOfTheOddNumbers` — это трансформер, который мы создали, применив функцию `compose2` к фильтру и функции для маппинга.
Теперь, когда у нас есть возможность композиции декораторов, разобьём на части сложный код, отличающийся большой степенью связности, на небольшие узкоспециализированные блоки.
Композиция с помощью трансформеров
----------------------------------
Зная, как работает функция `compose2`, которая позволяет получать композицию двух функций, подумаем о том, как быть, если нам нужна композиция произвольного количества функций. Ответ заключается в свёртке.
Перепишем `compose2`, сделав из неё трансформер `compositionOf`.
```
const compositionOf = (acc, val) => (...args) => val(acc(...args));
```
Теперь можно написать функцию `compose` для получения композиции произвольного количества функций как редукции её аргументов:
```
const compose = (...fns) =>
reduceWith(compositionOf, x => x, fns);
```
Итак, мы подошли к самому интересному.
Трансдьюсеры
------------
Рассмотрим следующую запись:
```
reduceWith(squaresOfTheOddNumbers(sumOf), 0, one2ten)
```
Здесь можно выделить четыре элемента. Трансформер для редьюсера (который может быть композицией трансформеров), начальное значение (накопитель) и итерируемый объект. Если вынести в отдельные параметры трансформер, редьюсер, накопитель и итерируемый объект, получим следующее.
```
const transduce = (transformer, reducer, seed, iterable) => {
const transformedReducer = transformer(reducer);
let accumulation = seed;
for (const value of iterable) {
accumulation = transformedReducer(accumulation, value);
}
return accumulation;
}
transduce(squaresOfTheOddNumbers, sumOf, 0, one2ten)
//=> 165
```
Надо отметить, что в некоторых языках программирования имеется сильное стремление к сокращению длинных имён переменных или параметров. В результате довольно длинное имя `transformer` сокращается до `xform` или даже до `xf`. Не удивляйтесь, если увидите похожую конструкцию, запись которой выглядит как (xf, reduce, seed, coll), или `xf((val, acc) => acc) -> (val, acc) => acc`. Тут мы обойдёмся без сокращений, но в продакшн-коде имена вроде `xf` или `xform` вполне допустимы.
А теперь, собственно, то, ради чего всё это было написано. Редьюсер — это функция, которая передаётся методам вроде `.reduce —` она принимает объект-накопитель и входные данные, и возвращает накопитель, в который помещены новые данные. Трансформер — это функция, которая трансформирует редьюсер в другой редьюсер. А трансдьюсер (это название — результат совмещения терминов «трансформер» и «редьюсер», вот он ответ на вопрос: «Что такое редьюсеры?»), это функция, которая принимает трансформер, редьюсер, накопитель и итерируемый объект, после чего сворачивает итерируемый объект в некое значение.
Элегантность шаблона «трансдьюсер» заключается в том, что композиция трансформеров естественным образом ведёт к созданию новых трансформеров. В результате можно объединить в цепочку столько трансформеров, сколько нужно. Это очень важно, так как в результате получится один трансформированный редьюсер и по итерируемой коллекции нужно будет пройтись лишь один раз. Не нужно создавать промежуточные копии данных или выполнять несколько проходов по ним.
Трансдьюсеры пришли в JavaScript из языка Clojure, но, как вы можете видеть, они совершенно органично вписываются в JavaScript, для их реализации достаточно стандартных возможностей языка.
Итак, если кто-нибудь спросит нас о том, что же такое трансдьюсер, мы можем ответить так:
Примечание: этот фрагмент надо выделить.
**Трансдьюсеры — это трансформеры, которые подходят для композиции, применённые к редьюсерам для свёртки итерируемых объектов.
Трансдьюсер в действии
----------------------**Выше мы рассматривали фрагменты кода, ведущие к построению трансдьюсера. Вполне возможно, вы уже воспроизвели их в своём JS-редакторе и испытали, однако, вот, для удобства и наглядности, весь наш код, собранный в одном месте.
```
const arrayOf = (acc, val) => { acc.push(val); return acc; };
const sumOf = (acc, val) => acc + val;
const setOf = (acc, val) => acc.add(val);
const map =
fn =>
reducer =>
(acc, val) => reducer(acc, fn(val));
const filter =
fn =>
reducer =>
(acc, val) =>
fn(val) ? reducer(acc, val) : acc;
const compose = (...fns) =>
fns.reduce((acc, val) => (...args) => val(acc(...args)), x => x);
const transduce = (transformer, reducer, seed, iterable) => {
const transformedReducer = transformer(reducer);
let accumulation = seed;
for (const value of iterable) {
accumulation = transformedReducer(accumulation, value);
}
return accumulation;
}
```
Этот пример демонстрирует всё то, чем обычно пользуются, работая с массивами, а именно — это методы `.map`, `.filter`, `.reduce`, тут же имеются подходящие для композиции трансдьюсеры, которые не занимаются созданием множества копий обрабатываемого набора данных. На самом деле, трансдьюсеры, написанные для реальных проектов, предусматривают гораздо больше вариантов использования, например, воспроизводя функционал метода `.find`.
Надо отметить, что наша функция `transduse` рассчитана на то, что ей будет передана итерируемая коллекция, кроме того, мы должны предоставить ей начальное значение (накопитель) и редьюсер. В большинстве случаев и начальное значение, и редьюсер — это одни и те же функции для всех коллекций одного и того же типа. Это характерно и для соответствующих библиотек.
В объектно-ориентированном программировании эта проблема, конечно, решается через полиморфизм. У коллекций есть методы, поэтому, вызывая подходящий метод, мы получаем на выходе то, что нам нужно. Библиотеки, применимые для создания продакшн-кода, предоставляют интерфейсы для коллекций различных типов, позволяющие удобно пользоваться трансдьюсерами.
Полагаем, вышеизложенного достаточно для того, чтобы понять шаблон, лежащий в основе трансдьюсеров и оценить те полезные и удобные возможности, которые даёт наличие в языке функций первого класса.
Трансдьюсеры: обработка списка пользователей
--------------------------------------------
В [этом материале](http://raganwald.com/2017/04/19/incremental.html) показаны варианты решения следующей задачи: имеется набор пользователей и посещённых ими мест, и то и другое представлено в виде списка хэш-кодов. Первый код в каждой строке — пользователь, второй — посещённое им место, скажем, ресторан, или магазин. Порядок следования данных в списке имеет значение. Задача заключается в том, чтобы выяснить, какие переходы между местами наиболее популярны.
А именно, есть такой список:
```
1a2ddc2, 5f2b932
f1a543f, 5890595
3abe124, bd11537
f1a543f, 5f2b932
f1a543f, bd11537
f1a543f, 5890595
1a2ddc2, bd11537
1a2ddc2, 5890595
3abe124, 5f2b932
f1a543f, 5f2b932
f1a543f, bd11537
f1a543f, 5890595
1a2ddc2, 5f2b932
1a2ddc2, bd11537
1a2ddc2, 5890595
...
```
Внимательно просмотрев этот список, мы можем обнаружить, что пользователь `1a2ddc2` посетил места с кодами `5f2b932`, `bd11537`, `5890595`, `5f2b932`, `bd11537`, и `5890595`. В то же время, пользователь `f1a543f` посетил места `5890595`, `5f2b932`, `bd11537`, `5890595`, `5f2b932`, `bd11537`, и `5890595`. И так далее.
Предположим, надо выяснить, куда обычно ходят люди, надо найти самые популярные переходы из «места А» в «место Б». Мы знаем, что история путешествия пользователя `1a2ddc2` выглядит следующим образом: `5f2b932`, `bd11537`, `5890595`, `5f2b932`, `bd11537`, `5890595`. Это значит, что для него можно построить такую схему переходов из места в место:
```
5f2b932 -> bd11537
bd11537 -> 5890595
5890595 -> 5f2b932
5f2b932 -> bd11537
bd11537 -> 5890595
```
Обратите внимание на то, что нам надо построить подобный список для каждого пользователя. Когда это будет сделано, нужно найти самые популярные переходы. Вот как может выглядеть подобный подсчёт:
Переход `5f2b932 -> bd11537` появляется в списке дважды.
Переход `bd11537 -> 5890595` также встречается дважды.
Переход `5890595 -> 5f2b932` встретился лишь один раз.
Теперь всё, что нужно сделать — это посчитать количество переходов по всем пользователям и найти наиболее популярные. Вот решение этой задачи с использованием трансдьюсеров.
```
const logContents = `1a2ddc2, 5f2b932
f1a543f, 5890595
3abe124, bd11537
f1a543f, 5f2b932
f1a543f, bd11537
f1a543f, 5890595
1a2ddc2, bd11537
1a2ddc2, 5890595
3abe124, 5f2b932
f1a543f, 5f2b932
f1a543f, bd11537
f1a543f, 5890595
1a2ddc2, 5f2b932
1a2ddc2, bd11537
1a2ddc2, 5890595`;
```
```
const asStream = function * (iterable) { yield * iterable; };
const lines = str => str.split('\n');
const streamOfLines = asStream(lines(logContents));
const datums = str => str.split(', ');
const datumize = map(datums);
const userKey = ([user, _]) => user;
const pairMaker = () => {
let wip = [];
return reducer =>
(acc, val) => {
wip.push(val);
if (wip.length === 2) {
const pair = wip;
wip = wip.slice(1);
return reducer(acc, pair);
} else {
return acc;
}
}
}
const sortedTransformation =
(xfMaker, keyFn) => {
const decoratedReducersByKey = new Map();
return reducer =>
(acc, val) => {
const key = keyFn(val);
let decoratedReducer;
if (decoratedReducersByKey.has(key)) {
decoratedReducer = decoratedReducersByKey.get(key);
} else {
decoratedReducer = xfMaker()(reducer);
decoratedReducersByKey.set(key, decoratedReducer);
}
return decoratedReducer(acc, val);
}
}
const userTransitions = sortedTransformation(pairMaker, userKey);
const justLocations = map(([[u1, l1], [u2, l2]]) => [l1, l2]);
const stringify = map(transition => transition.join(' -> '));
const transitionKeys = compose(
stringify, justLocations, userTransitions, datumize
);
const countsOf =
(acc, val) => {
if (acc.has(val)) {
acc.set(val, 1 + acc.get(val));
} else {
acc.set(val, 1);
}
return acc;
}
const greatestValue = inMap =>
Array.from(inMap.entries()).reduce(
([wasKeys, wasCount], [transitionKey, count]) => {
if (count < wasCount) {
return [wasKeys, wasCount];
} else if (count > wasCount) {
return [new Set([transitionKey]), count];
} else {
wasKeys.add(transitionKey);
return [wasKeys, wasCount];
}
}
, [new Set(), 0]
);
greatestValue(
transduce(transitionKeys, countsOf, new Map(), streamOfLines)
)
//=>
[
"5f2b932 -> bd11537",
"bd11537 -> 5890595"
],
4
```
Итоги
-----
Надеемся, этот материал поможет всем желающим сделать трансдьюсеры своим постоянным инструментом. Если вы хотите углубиться в их изучение, вот хороший [материал](https://medium.com/@roman01la/understanding-transducers-in-javascript-3500d3bd9624) о трансдьюсерах, а вот — библиотека [transdusers-js](https://github.com/cognitect-labs/transducers-js) на GitHub.
Уважаемые читатели! Пользуетесь ли вы трансдьюсерами в своих JavaScript-проектах? | https://habr.com/ru/post/329536/ | null | ru | null |
# Использование Fastify и Preact для быстрого прототипирования веб-приложений
Автор материала, перевод которого мы сегодня публикуем, хочет поделиться рассказом о том, какими технологиями он пользуется для быстрой разработки прототипов веб-приложений. В число этих технологий входят библиотеки Fastify и Preact. Он, кроме того, пользуется библиотекой htm. Она легко интегрируется с Preact и используется для описания элементов DOM с использованием понятных конструкций, напоминающих JSX. При этом для работы с ней не нужен транспилятор вроде Babel. Продемонстрировав инструментарий разработки прототипов и методику работы с ним, автор материала покажет как упаковывать такие приложения в контейнеры Docker. Это позволяет легко демонстрировать приложения всем, кому они интересны.
[](https://habr.com/ru/company/ruvds/blog/442652/)
Начало
------
Я вышел на использование вышеупомянутого набора технологий несколько недель назад, когда мне нужно было создать очень простой прототип веб-приложения, предназначенный для того, чтобы проверить, совместно с коллегами, некоторые предположения.
Мой эксперимент оказался крайне удачным. Я смог создать прототип очень быстро, коллеги получили возможность удобно экспериментировать с ним, они смогли оперативно высказать свои впечатления о нём. При этом испытать проект они могли даже в том случае, если на их компьютерах не были установлены Node.js и NPM.
Всё это привело меня к мысли о том, что мне стоит написать материал о моём подходе к быстрому прототипированию веб-приложений. Вполне возможно, что этот подход пригодится кому-нибудь ещё. Для тех, кто уже знаком с Fastify и Preact, я сразу же обрисую самое важное, то, что позволит им тут же использовать мои идеи на практике.
Основные идеи
-------------
Если вы уже знакомы с Fastify и Preact и хотите узнать о том, как организовать разработку проектов на основе этих технологий, то вы находитесь буквально в паре шагов от желаемого. А именно, речь идёт о выполнении следующих команд:
```
git clone https://github.com/lmammino/fastify-preact-htm-boilerplate.git my-new-project
cd my-new-project
rm -rf .git
npm install
```
Конечно, вы можете поменять название проекта, `my-new-project`, на название вашего проекта.
После установки всего необходимого можно приступать к работе над проектом. А именно, речь идёт о следующем:
* В папке `src/ui` собраны файлы клиентской части приложения (тут используются Preact и htm).
* В папке `src/server` собраны файлы, относящиеся к серверной части приложения (тут используется Fastify).
Отредактировав соответствующие файлы, вы можете запустить проект:
```
npm start
```
После этого испытать его можно, перейдя в браузере по адресу `localhost:3000`.
И ещё кое-что. Если вам моя разработка понравилась — буду безмерно благодарен за звёздочку на [GitHub](https://github.com/lmammino/fastify-preact-htm-boilerplate).
Теперь давайте рассмотрим используемые здесь технологии и особенности работы с ними.
Fastify
-------
Fastify — это быстрый и экономичный веб-фреймворк для Node.js. Этот проект изначально создали два программиста. Теперь же команда тех, кто над ним трудится, насчитывает 10 человек, более 130 человек помогают в разработке проекта, он собрал почти 10000 звёзд на GitHub.
На Fastify оказали влияние Node.js-фреймворки, вроде Express и Hapi, которые существуют уже довольно давно. Он изначально был нацелен на производительность, на удобство работы программистов и на расширение его возможностей с помощью плагинов. Это, кстати, одна из моих любимых особенностей Fastify.
Если вы не знакомы с фреймворком Fastify или хотите лучше его узнать, могу порекомендовать его официальную [документацию](https://www.fastify.io/docs/).
Надо отметить, что я имею отношение к Fastify. Я являюсь членом основной команды разработчиков и занимаюсь, в основном, поддержкой сайта проекта и работой над его документацией.
Preact
------
Preact — это библиотека для разработки пользовательских интерфейсов для веб-проектов, которая была создана одним человеком как компактная и быстрая замена React. Этот проект оказался довольно успешным, им теперь занимается целая команда разработчиков, на GitHub он набрал более 20000 звёзд.
Одной из причин, по которой мне нравится Preact, является то, что у этой библиотеки есть расширяемый слой описания визуальных компонентов приложения. В обычных условиях этой библиотекой можно пользоваться с применением JSX в комбинации с Babel для транспиляции кода, но если вам не хочется устанавливать Babel и настраивать процесс сборки приложения, вы можете использовать Preact, например, совместно с библиотекой [htm](https://github.com/developit/htm), которая использует шаблонные литералы и не требует транспиляции при запуске проектов, в которых она применяется, в современных браузерах.
Мы в этом материале будем пользоваться именно библиотекой htm и скоро рассмотрим несколько примеров.
Обзор проекта
-------------
Здесь мы рассмотрим весь процесс создания проекта. Нашей целью будет разработка простого веб-приложения, которое выводит сведения о времени на сервере в момент его запуска. Вот, для того, чтобы было понятнее, к чему мы будем стремиться.
*Приложение в браузере*
Это — одностраничное приложение (Single Page Application, SPA), в котором Preact и htm используются для формирования его клиентской части, а Fastify применяется для создания API, предназначенного для получения серверного времени.
Внимательный читатель мог заметить, что у страницы, показанной на предыдущем рисунке, есть симпатичный значок favicon. Он там, правда, очень маленький, поэтому я собираюсь облегчить задачу тем, кто, ломая глаза, пытается его разглядеть. Вот его увеличенная версия.

*Favicon*
Настройка серверной части приложения
------------------------------------
Начнём работу с создания новой папки:
```
mkdir server-time
cd server-time
```
Теперь инициализируем NPM-проект и установим Fastify:
```
npm init -y
npm i --save fastify@next fastify-static@next fastify-cli
```
Обратите внимание на то, что я, при описании некоторых пакетов-зависимостей, воспользовался конструкцией `@next`. Сделано это для того, чтобы в проекте использовалась бы библиотека Fastify 2, которая в настоящий момент находится в состоянии релиз-кандидата, но очень скоро станет основной стабильной версией.
Обратите внимание на то, что создать новый проект, основанный на Fastify, можно и с помощью инструмента командной строки `fastify-cli`:
```
npx fastify-cli generate server-time
```
Во время написания этого материала данная команда создаёт проект, рассчитанный на использование Fastify 1.x, но очень скоро, после релиза Fastify 2, это средство обновится.
Проанализируем установленные пакеты:
* `fastify` — это основной компонент фреймворка.
* `fastify-static` — это дополнительный плагин, который позволяет удобно обслуживать статические файлы сервером Fastify.
* `fastify-cli` — это средство командной строки, которое позволяет создавать проекты, основанные на Fastify.
В настоящий момент мы готовы к тому, чтобы создать API, основанное на Fastify. Поэтому давайте поместим серверный код в файл `src/server/server.js`:
```
const path = require('path')
module.exports = async function(fastify, opts) {
// обслуживает статические ресурсы из папки `src/ui`
fastify.register(require('fastify-static'), {
root: path.join(__dirname, '..', 'ui'),
})
// Сюда добавляют конечные точки API
fastify.get('/api/time', async (request, reply) => {
return { time: new Date().toISOString() }
})
}
```
Полагаю, что вышеприведённый код хорошо объясняет сам себя, но тут есть некоторые интересные детали, о которых стоит рассказать. Это будет особенно полезно для тех, у кого нет опыта работы с Fastify.
Первое, на что можно обратить внимание в этом коде, заключается в том, что тут используется ключевое слово `async`. Fastify поддерживает и разработку в стиле async/await, и более традиционный подход, основанный на коллбэках. Что именно выбрать — зависит от предпочтений конкретного разработчика.
Ещё одна интересная деталь заключается в том, что мы определяем здесь сервер как экспортируемый модуль. Этот модуль (на жаргоне Fastify это называется «плагином») представляет собой функцию, которая принимает в качестве аргументов экземпляр Fastify (`fastify`) и набор опций (`opts`). Внутри объявления модуля мы можем использовать экземпляр `fastify` для регистрации плагинов. Именно это и происходит с плагином `fastify-static`. Так же мы тут можем описывать конечные точки HTTP с использованием специальных методов, наподобие `fastify.get` и `fastify.post`.
Применяемый здесь модульный подход, хотя и выглядит немного непривычно, имеет свои преимущества. Для начала надо отметить то, что он позволяет объединять несколько серверов. Представьте себе, что вы создали сервер, предназначенный для обслуживания блога, и ещё один — для форума. Их можно легко встроить в существующее приложение, прикрепив их к путям наподобие `/blog` и `/forum`.
Более того, этот подход позволяет абстрагировать приложения и субприложения от привязок к серверу (речь идёт, например, о привязке сокетов), передавая решение этой задачи либо корневому приложению, либо `fastify-cli`.
Запустим сервер с использованием инструмента командной строки `fastify`:
```
node_modules/.bin/fastify start --log-level info src/server/server.js
```
Для того чтобы упростить себе жизнь, мы можем добавить эту команду в раздел `scripts` нашего файла `package.json`:
```
{
"scripts": {
"start": "fastify start --log-level info src/server/server.js"
}
}
```
Прежде чем действительно запускать сервер, нам нужно позаботиться о том, чтобы существовала папка, в которой будут расположены статические ресурсы. В противном случае `fastify-static` выдаст ошибку. Создадим эту папку:
```
mkdir src/ui
```
Теперь мы можем запустить приложение командой `npm start` и перейти с помощью браузера по адресу `localhost:3000/api/time`.
Если всё работает правильно, в браузере можно будет увидеть примерно следующее:
```
{ "time": "2019-02-17T19:32:03.354Z" }
```
В этот момент вы можете оценить ещё одну приятную возможность Fastify. Она заключается в том, что JSON-сериализация, в том случае, если некий маршрут возвращает объект, применяется автоматически.
Теперь работа над серверным API завершена. Займёмся фронтендом.
Настройка фронтенда
-------------------
Весь код нашего проекта, имеющий отношение к фронтенду, будет находиться в папке `src/ui`. Он будет состоять из 5 файлов:
* `app.js` — код Preact-приложения.
* `bootstrap.min.css` — CSS-код для стилизации приложения (он взят прямо из фреймворка Bootstrap).
* `favicon.ico` — favicon-файл. Если вы разрабатываете серьёзное приложение, без хорошего favicon-файла вам не обойтись.
* `index.html` — главный HTML-файл нашего одностраничного приложения.
* `preacthtm.js` — код библиотек Preact и htm.
Для начала поместим в папку файлы, представляющие собой стили, библиотеки и значок favicon:
```
curl "https://unpkg.com/[email protected]/preact/standalone.js" > src/ui/preacthtm.js
curl "https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" > src/ui/bootstrap.min.css
curl "https://github.com/lmammino/fastify-preact-htm-boilerplate/blob/master/src/ui/favicon.ico?raw=true" > src/ui/favicon.ico
```
Теперь создадим файл `src/ui/index.html`:
```
My awesome server time
```
Перед нами вполне обычная HTML-страница, с помощью которой мы загружаем все ресурсы (CSS и JS) и создаём пустой элемент с идентификатором `app`, в который мы выведем, во время выполнения проекта, наше приложение.
Теперь взглянем на код приложения, который должен находиться в файле `src/ui/app.js`:
```
/* глобальный htmPreact */
const { html, Component, render } = htmPreact
class App extends Component {
componentDidMount() {
this.setState({ loading: true, time: null })
fetch('/api/time')
.then(response => response.json())
.then(data => this.setState({ loading: false, time: data.time }))
}
render(props, state) {
return html`
Hello from your new App
=======================
${state.loading &&
html`
Loading time from server...
`} ${state.time &&
html`
Time from server: *${state.time}*
`}
---
Have fun changing the code from this boilerplate:
* UI code available at `/src/ui`
* Server-side code available at `/src/server`
`
}
}
render(
html`
<${App} />
`,
document.getElementById('app')
)
```
В этом приложении есть лишь один компонент с состоянием, называемый `App`. Состояние этого компонента включает в себя 2 переменные:
* `loading` — логическая переменная, используемая для указания на то, выполняется ли в некий момент времени запрос к серверному API для получения сведений о серверном времени.
* `time` — строка, которая содержит последние полученные с сервера сведения о времени.
Если вы знакомы с React, то вы без труда поймёте вышеприведённый код.
С использованием Preact и htm мы можем создавать компоненты, объявляя классы, которые расширяют встроенный класс `Component`.
В этом классе мы можем описать поведение компонента, используя методы жизненного цикла, наподобие `componentDidMount()`, а также пользоваться методом, который ведёт себя как обычный метод `render()` из React.
В нашем случае, как только компонент будет прикреплён к странице (метод `componentDidMount()`), мы устанавливаем свойство `loading` состояния и выполняем запрос к API с использованием `fetch`.
После завершения запроса мы устанавливаем значение свойства состояния `time` и сбрасываем свойство `loading` в значение `false`.
Метод `render()` вызывается автоматически при каждом изменении состояния компонента или при передаче ему новых свойств. В данном методе мы описываем DOM компонента с использованием htm.
Библиотека htm позволяет описывать узлы DOM, используя тегированные шаблонные литералы со специальным тегом — `html`. В пределах нашего шаблонного литерала могут присутствовать динамические выражения, наподобие тех, что мы используем для проверки состояния и для принятия решения о том, что вывести на экран в том случае, если приложение выполняет загрузку данных с сервера, и в том случае, если данные уже загружены.
Ещё стоит отметить то, что нам нужно создать экземпляр приложения и вывести его на HTML-страницу. Делается это с помощью функции `render()` глобального объекта `htmPreact`.
Теперь работа над фронтенд-приложением завершена. Можете перезапустить сервер, перейти по адресу `localhost:3000` и поэкспериментировать с тем, что мы только что создали. Например, можете разработать на базе этого приложения что-то своё. А когда то, что вы построите, покажется вам достаточно интересным для того, чтобы показать это кому-то ещё, вам, вероятно, полезно будет упаковать своё приложение в контейнер Docker.
Контейнеризация приложения
--------------------------
Я полагаю, что лучший способ демонстрировать другим свои новые небольшие проекты заключается в использовании для этой цели возможностей Docker.
Благодаря Docker любой, кто попытается запустить у себя ваше приложение, будет избавлен от размышлений о том, установлена ли у него подходящая версия Node.js и NPM, ему не нужно будет, скачав исходники приложения, заботиться о том, чтобы, введя правильную последовательность команд, установить его зависимости и запустить сервер.
Для того чтобы упаковать приложение в контейнер Docker, нам нужно создать очень простой файл `Dockerfile` в корневой папке нашего проекта:
```
FROM node:11-alpine
WORKDIR /app
COPY . /app
RUN npm install --production
EXPOSE 3000
CMD ["npm", "start"]
```
Здесь мы описываем следующие действия:
* Образ создаётся на основе образа Node.js 11, построенного на базе Alpine Linux.
* Всё из текущей папки копируется в папку `/app` контейнера.
* После этого мы выполняем команду `npm install` для загрузки и установки зависимостей. Использование флага `--production` приводит к тому, что установлены будут только зависимости, необходимые для развёртывания проекта в продакшне. Это ускоряет создание образа в том случае, если в проекте используется много зависимостей разработки.
* Мы указываем на то, что у контейнера должен быть открыт пор 3000, на котором, по умолчанию, будет работать сервер.
* В итоге мы описываем команду, `npm start`, которая будет выполнена во время запуска контейнера. Она запускает приложение.
Для того чтобы собрать образ для контейнера, выполним следующую команду:
```
docker build -t server-time .
```
Через несколько секунд образ должен быть готов и у вас должна быть возможность запустить контейнер:
```
docker run -it -p 3000:3000 server-time
```
Параметр `-p` позволяет настроить связь порта контейнера 3000 с локальным портом 3000. Это позволит обращаться к контейнеризированному приложению по адресу `localhost:3000`.
Теперь вы готовы к тому, чтобы поделиться своим приложением с другими людьми. Для того чтобы запустить его в среде Docker, достаточно, при условии, что на компьютере установлен Docker, выполнить в его папке две вышеприведённых команды.
Итоги
-----
В этом материале мы рассказали о том, как создать среду для быстрой разработки веб-приложений с использованием Fastify и Preact. Кроме того, мы поговорили о том, как поделиться приложением с другими людьми, используя Docker.
Как было сказано выше, предлагаемые инструменты предназначены для быстрого прототипирования, поэтому сейчас вы, возможно, задаётесь вопросом о том, чего здесь не хватает для разработки реальных приложений. Вероятнее всего, вы, говоря о «реальных приложениях», имеете в виду следующие возможности:
* Компиляция ресурсов интерфейсной части приложения: создание оптимизированных файлов (бандлов), возможно, средствами Webpack, Babel, или с привлечением других средств.
* Маршрутизация в интерфейсной части приложения.
* Серверный рендеринг.
* Средства постоянного хранения данных.
Все эти возможности разработки реальных приложений ещё не добавлены в рассмотренный здесь набор технологий, поэтому я пока воспринимаю его как средство для разработки прототипов. Уверен, что если вам то, что вы увидели, понравилось, и вы рассматриваете всё это как основу будущих приложений, решающих реальные задачи, вы без особых сложностей сможете найти то, что вам нужно, и создавать на базе Fastify и Preact приложения, готовые к выпуску в продакшн.
**Уважаемые читатели!** Как вы создаёте прототипы веб-приложений?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/442652/ | null | ru | null |
# Автоматизация по сбору данных о росте таблиц и файлов всех баз данных MS SQL Server
### Предисловие
Часто возникает потребность контролировать рост всех таблиц и файлов всех баз данных.
В данной статье будет рассмотрен пример того, как можно автоматизировать сбор данных о росте таблиц и файлов баз данных.
### Решение
1) Создадим представление о размерах всех таблиц для каждой БД (базы данных) (сделать это можно например [так](https://habrahabr.ru/post/338828/)):
**Код**
```
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE view [inf].[vTableSize] as
with pagesizeKB as (
SELECT low / 1024 as PageSizeKB
FROM master.dbo.spt_values
WHERE number = 1 AND type = 'E'
)
,f_size as (
select p.[object_id],
sum([total_pages]) as TotalPageSize,
sum([used_pages]) as UsedPageSize,
sum([data_pages]) as DataPageSize
from sys.partitions p join sys.allocation_units a on p.partition_id = a.container_id
left join sys.internal_tables it on p.object_id = it.object_id
WHERE OBJECTPROPERTY(p.[object_id], N'IsUserTable') = 1
group by p.[object_id]
)
,tbl as (
SELECT
t.[schema_id],
t.[object_id],
i1.rowcnt as CountRows,
(COALESCE(SUM(i1.reserved), 0) + COALESCE(SUM(i2.reserved), 0)) * (select top(1) PageSizeKB from pagesizeKB) as ReservedKB,
(COALESCE(SUM(i1.dpages), 0) + COALESCE(SUM(i2.used), 0)) * (select top(1) PageSizeKB from pagesizeKB) as DataKB,
((COALESCE(SUM(i1.used), 0) + COALESCE(SUM(i2.used), 0))
- (COALESCE(SUM(i1.dpages), 0) + COALESCE(SUM(i2.used), 0))) * (select top(1) PageSizeKB from pagesizeKB) as IndexSizeKB,
((COALESCE(SUM(i1.reserved), 0) + COALESCE(SUM(i2.reserved), 0))
- (COALESCE(SUM(i1.used), 0) + COALESCE(SUM(i2.used), 0))) * (select top(1) PageSizeKB from pagesizeKB) as UnusedKB
FROM sys.tables as t
LEFT OUTER JOIN sysindexes as i1 ON i1.id = t.[object_id] AND i1.indid < 2
LEFT OUTER JOIN sysindexes as i2 ON i2.id = t.[object_id] AND i2.indid = 255
WHERE OBJECTPROPERTY(t.[object_id], N'IsUserTable') = 1
OR (OBJECTPROPERTY(t.[object_id], N'IsView') = 1 AND OBJECTPROPERTY(t.[object_id], N'IsIndexed') = 1)
GROUP BY t.[schema_id], t.[object_id], i1.rowcnt
)
SELECT
@@Servername AS Server,
DB_NAME() AS DBName,
SCHEMA_NAME(t.[schema_id]) as SchemaName,
OBJECT_NAME(t.[object_id]) as TableName,
t.CountRows,
t.ReservedKB,
t.DataKB,
t.IndexSizeKB,
t.UnusedKB,
f.TotalPageSize*(select top(1) PageSizeKB from pagesizeKB) as TotalPageSizeKB,
f.UsedPageSize*(select top(1) PageSizeKB from pagesizeKB) as UsedPageSizeKB,
f.DataPageSize*(select top(1) PageSizeKB from pagesizeKB) as DataPageSizeKB
FROM f_size as f
inner join tbl as t on t.[object_id]=f.[object_id]
GO
```
2) Создадим специальную БД и в ней определим таблицу для хранения информации по росту всех таблиц всех БД:
**Код**
```
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [srv].[TableStatistics](
[Row_GUID] [uniqueidentifier] NOT NULL CONSTRAINT [DF_TableStatistics_Row_GUID] DEFAULT (newid()),
[ServerName] [nvarchar](255) NOT NULL,
[DBName] [nvarchar](255) NOT NULL,
[SchemaName] [nvarchar](255) NOT NULL,
[TableName] [nvarchar](255) NOT NULL,
[CountRows] [bigint] NOT NULL,
[DataKB] [int] NOT NULL,
[IndexSizeKB] [int] NOT NULL,
[UnusedKB] [int] NOT NULL,
[ReservedKB] [int] NOT NULL,
[InsertUTCDate] [datetime] NOT NULL CONSTRAINT [DF_TableStatistics_InsertUTCDate] DEFAULT (getutcdate()),
[Date] AS (CONVERT([date],[InsertUTCDate])) PERSISTED,
[CountRowsBack] [bigint] NULL,
[CountRowsNext] [bigint] NULL,
[DataKBBack] [int] NULL,
[DataKBNext] [int] NULL,
[IndexSizeKBBack] [int] NULL,
[IndexSizeKBNext] [int] NULL,
[UnusedKBBack] [int] NULL,
[UnusedKBNext] [int] NULL,
[ReservedKBBack] [int] NULL,
[ReservedKBNext] [int] NULL,
[AvgCountRows] AS ((([CountRowsBack]+[CountRows])+[CountRowsNext])/(3)) PERSISTED,
[AvgDataKB] AS ((([DataKBBack]+[DataKB])+[DataKBNext])/(3)) PERSISTED,
[AvgIndexSizeKB] AS ((([IndexSizeKBBack]+[IndexSizeKB])+[IndexSizeKBNext])/(3)) PERSISTED,
[AvgUnusedKB] AS ((([UnusedKBBack]+[UnusedKB])+[UnusedKBNext])/(3)) PERSISTED,
[AvgReservedKB] AS ((([ReservedKBBack]+[ReservedKB])+[ReservedKBNext])/(3)) PERSISTED,
[DiffCountRows] AS (([CountRowsNext]+[CountRowsBack])-(2)*[CountRows]) PERSISTED,
[DiffDataKB] AS (([DataKBNext]+[DataKBBack])-(2)*[DataKB]) PERSISTED,
[DiffIndexSizeKB] AS (([IndexSizeKBNext]+[IndexSizeKBBack])-(2)*[IndexSizeKB]) PERSISTED,
[DiffUnusedKB] AS (([UnusedKBNext]+[UnusedKBBack])-(2)*[UnusedKB]) PERSISTED,
[DiffReservedKB] AS (([ReservedKBNext]+[ReservedKBBack])-(2)*[ReservedKB]) PERSISTED,
[TotalPageSizeKB] [int] NULL,
[TotalPageSizeKBBack] [int] NULL,
[TotalPageSizeKBNext] [int] NULL,
[UsedPageSizeKB] [int] NULL,
[UsedPageSizeKBBack] [int] NULL,
[UsedPageSizeKBNext] [int] NULL,
[DataPageSizeKB] [int] NULL,
[DataPageSizeKBBack] [int] NULL,
[DataPageSizeKBNext] [int] NULL,
[AvgDataPageSizeKB] AS ((([DataPageSizeKBBack]+[DataPageSizeKB])+[DataPageSizeKBNext])/(3)) PERSISTED,
[AvgUsedPageSizeKB] AS ((([UsedPageSizeKBBack]+[UsedPageSizeKB])+[UsedPageSizeKBNext])/(3)) PERSISTED,
[AvgTotalPageSizeKB] AS ((([TotalPageSizeKBBack]+[TotalPageSizeKB])+[TotalPageSizeKBNext])/(3)) PERSISTED,
[DiffDataPageSizeKB] AS (([DataPageSizeKBNext]+[DataPageSizeKBBack])-(2)*[DataPageSizeKB]) PERSISTED,--показывает как изменяется само приращение
[DiffUsedPageSizeKB] AS (([UsedPageSizeKBNext]+[UsedPageSizeKBBack])-(2)*[UsedPageSizeKB]) PERSISTED,--показывает как изменяется само приращение
[DiffTotalPageSizeKB] AS (([TotalPageSizeKBNext]+[TotalPageSizeKBBack])-(2)*[TotalPageSizeKB]) PERSISTED,--показывает как изменяется само приращение
CONSTRAINT [PK_TableStatistics] PRIMARY KEY CLUSTERED
(
[Row_GUID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING ON
GO
```
За сам размер таблицы отвечает TotalPageSizeKB.
Сумма TotalPageSizeKB всех таблиц БД+размер системных таблиц=размеру данных БД.
3) Определим процедуру сбора информации:
**Код**
```
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [srv].[InsertTableStatistics]
AS
BEGIN
SET NOCOUNT ON;
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
declare @dt date=CAST(GetUTCDate() as date);
declare @dbs nvarchar(255);
declare @sql nvarchar(max);
select [name]
into #dbs
from sys.databases;
while(exists(select top(1) 1 from #dbs))
begin
select top(1)
@dbs=[name]
from #dbs;
set @sql=
N'INSERT INTO [srv].[TableStatistics]
([ServerName]
,[DBName]
,[SchemaName]
,[TableName]
,[CountRows]
,[DataKB]
,[IndexSizeKB]
,[UnusedKB]
,[ReservedKB]
,[TotalPageSizeKB]
,[UsedPageSizeKB]
,[DataPageSizeKB])
SELECT [Server]
,[DBName]
,[SchemaName]
,[TableName]
,[CountRows]
,[DataKB]
,[IndexSizeKB]
,[UnusedKB]
,[ReservedKB]
,[TotalPageSizeKB]
,[UsedPageSizeKB]
,[DataPageSizeKB]
FROM ['+@dbs+'].[inf].[vTableSize];';
exec sp_executesql @sql;
delete from #dbs
where [name]=@dbs;
end
drop table #dbs;
declare @dt_back date=CAST(DateAdd(day,-1,@dt) as date);
;with tbl1 as (
select [Date],
[CountRows],
[DataKB],
[IndexSizeKB],
[UnusedKB],
[ReservedKB],
[ServerName],
[DBName],
[SchemaName],
[TableName],
[TotalPageSizeKB],
[UsedPageSizeKB],
[DataPageSizeKB]
from [srv].[TableStatistics]
where [Date]=@dt_back
)
, tbl2 as (
select [Date],
[CountRows],
[CountRowsBack],
[DataKBBack],
[IndexSizeKBBack],
[UnusedKBBack],
[ReservedKBBack],
[ServerName],
[DBName],
[SchemaName],
[TableName],
[TotalPageSizeKBBack],
[UsedPageSizeKBBack],
[DataPageSizeKBBack]
from [srv].[TableStatistics]
where [Date]=@dt
)
update t2
set t2.[CountRowsBack] =t1.[CountRows],
t2.[DataKBBack] =t1.[DataKB],
t2.[IndexSizeKBBack] =t1.[IndexSizeKB],
t2.[UnusedKBBack] =t1.[UnusedKB],
t2.[ReservedKBBack] =t1.[ReservedKB],
t2.[TotalPageSizeKBBack]=t1.[TotalPageSizeKB],
t2.[UsedPageSizeKBBack] =t1.[UsedPageSizeKB],
t2.[DataPageSizeKBBack] =t1.[DataPageSizeKB]
from tbl1 as t1
inner join tbl2 as t2 on t1.[Date]=DateAdd(day,-1,t2.[Date])
and t1.[ServerName]=t2.[ServerName]
and t1.[DBName]=t2.[DBName]
and t1.[SchemaName]=t2.[SchemaName]
and t1.[TableName]=t2.[TableName];
;with tbl1 as (
select [Date],
[CountRows],
[CountRowsNext],
[DataKBNext],
[IndexSizeKBNext],
[UnusedKBNext],
[ReservedKBNext],
[ServerName],
[DBName],
[SchemaName],
[TableName],
[TotalPageSizeKBNext],
[UsedPageSizeKBNext],
[DataPageSizeKBNext]
from [srv].[TableStatistics]
where [Date]=@dt_back
)
, tbl2 as (
select [Date],
[CountRows],
[DataKB],
[IndexSizeKB],
[UnusedKB],
[ReservedKB],
[ServerName],
[DBName],
[SchemaName],
[TableName],
[TotalPageSizeKB],
[UsedPageSizeKB],
[DataPageSizeKB]
from [srv].[TableStatistics]
where [Date]=@dt
)
update t1
set t1.[CountRowsNext] =t2.[CountRows],
t1.[DataKBNext] =t2.[DataKB],
t1.[IndexSizeKBNext] =t2.[IndexSizeKB],
t1.[UnusedKBNext] =t2.[UnusedKB],
t1.[ReservedKBNext] =t2.[ReservedKB],
t1.[TotalPageSizeKBNext]=t2.[TotalPageSizeKB],
t1.[UsedPageSizeKBNext] =t2.[UsedPageSizeKB],
t1.[DataPageSizeKBNext] =t2.[DataPageSizeKB]
from tbl1 as t1
inner join tbl2 as t2 on t1.[Date]=DateAdd(day,-1,t2.[Date])
and t1.[ServerName]=t2.[ServerName]
and t1.[DBName]=t2.[DBName]
and t1.[SchemaName]=t2.[SchemaName]
and t1.[TableName]=t2.[TableName];
END
GO
```
Данное решение можно модифицировать с целью собирать со всех нужных экземпляров MS SQL Server данные по размерам таблиц всех БД.
4) Определим представление по собранной информации:
**Код**
```
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create view [srv].[vTableStatisticsShort] as
with d as (select DateAdd(day,-1,max([Date])) as [Date] from [srv].[TableStatistics])
SELECT t.[ServerName]
,t.[DBName]
,t.[SchemaName]
,t.[TableName]
,t.[CountRows]
,t.[DataKB]
,t.[IndexSizeKB]
,t.[UnusedKB]
,t.[ReservedKB]
,t.[InsertUTCDate]
,t.[Date]
,t.[CountRowsBack]
,t.[CountRowsNext]
,t.[DataKBBack]
,t.[DataKBNext]
,t.[IndexSizeKBBack]
,t.[IndexSizeKBNext]
,t.[UnusedKBBack]
,t.[UnusedKBNext]
,t.[ReservedKBBack]
,t.[ReservedKBNext]
,t.[AvgCountRows]
,t.[AvgDataKB]
,t.[AvgIndexSizeKB]
,t.[AvgUnusedKB]
,t.[AvgReservedKB]
,t.[DiffCountRows]
,t.[DiffDataKB]
,t.[DiffIndexSizeKB]
,t.[DiffUnusedKB]
,t.[DiffReservedKB]
,t.[TotalPageSizeKB]
,t.[TotalPageSizeKBBack]
,t.[TotalPageSizeKBNext]
,t.[UsedPageSizeKB]
,t.[UsedPageSizeKBBack]
,t.[UsedPageSizeKBNext]
,t.[DataPageSizeKB]
,t.[DataPageSizeKBBack]
,t.[DataPageSizeKBNext]
,t.[AvgDataPageSizeKB]
,t.[AvgUsedPageSizeKB]
,t.[AvgTotalPageSizeKB]
,t.[DiffDataPageSizeKB]
,t.[DiffUsedPageSizeKB]
,t.[DiffTotalPageSizeKB]
FROM d
inner join [SRV].[srv].[TableStatistics] as t on d.[Date]=t.[Date]
where t.[CountRowsBack] is not null
and t.[CountRowsNext] is not null
GO
```
Здесь стоит обратить внимание на Diff. Если он больше 0, то это означает, что таблица с каждым днем все быстрее растет.
Предполагается, что сбор будет производиться 1 раз в 24 часа.
Аналогичным образом можно автоматизировать и сбор роста файлов всех БД, используя следующее представление:
**Код**
```
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
select t2.[DB_Name] as [DBName]
,t1.FileId
,t1.NumberReads
,t1.BytesRead
,t1.IoStallReadMS
,t1.NumberWrites
,t1.BytesWritten
,t1.IoStallWriteMS
,t1.IoStallMS
,t1.BytesOnDisk
,t1.[TimeStamp]
,t1.FileHandle
,t2.[Type_desc]
,t2.[FileName]
,t2.[Drive]
,t2.[Physical_Name]
,t2.[Ext]
,t2.[CountPage]
,t2.[SizeMb]
,t2.[SizeGb]
,t2.[Growth]
,t2.[GrowthMb]
,t2.[GrowthGb]
,t2.[GrowthPercent]
,t2.[is_percent_growth]
,t2.[database_id]
,t2.[State]
,t2.[StateDesc]
,t2.[IsMediaReadOnly]
,t2.[IsReadOnly]
,t2.[IsSpace]
,t2.[IsNameReserved]
,t2.[CreateLsn]
,t2.[DropLsn]
,t2.[ReadOnlyLsn]
,t2.[ReadWriteLsn]
,t2.[DifferentialBaseLsn]
,t2.[DifferentialBaseGuid]
,t2.[DifferentialBaseTime]
,t2.[RedoStartLsn]
,t2.[RedoStartForkGuid]
,t2.[RedoTargetLsn]
,t2.[RedoTargetForkGuid]
,t2.[BackupLsn]
from fn_virtualfilestats(NULL, NULL) as t1
inner join [inf].[ServerDBFileInfo] as t2 on t1.[DbId]=t2.[database_id] and t1.[FileId]=t2.[File_Id]
GO
```
### Результат
В данной статье был рассмотрен пример автоматизации сбора информации по размерам и росту всех таблиц и файлов всех баз данных. Это дает полный контроль над изменением размеров как самих файлов БД, так и ее таблиц, а также вовремя принимать меры по уменьшению таблицы или файла или для увеличения носителя информации (или разбиение информации на несколько носителей).
### Источники:
» [MSDN](https://msdn.microsoft.com/ru-ru/) | https://habr.com/ru/post/338536/ | null | ru | null |
# С/С++ на Linux в Visual Studio Code для начинающих
Давайте начистоту, мало кто использует отладчик GDB на Linux в консольном варианте. Но что, если добавить в него красивый интерфейс? Под катом вы найдёте пошаговую инструкцию отладки кода С/С++ на Linux в Visual Studio Code.

Передаю слово автору.
Относительно недавно я переехал на Linux. Разрабатывать на Windows, конечно, удобнее и приятнее, но и здесь я нашел эффективный способ легко и быстро отлаживать код на С/С++, не прибегая к таким методам как «printf-стайл отладки» и так далее.
Итак приступим. Писать в `sublime` (или `gedit/kate/emacs`), а запускать в терминале — так себе решение, ошибку при работе с динамическим распределением памяти вряд ли найдёшь с первого раза. А если проект трудоёмкий? У меня есть более удобное решение. Да и ещё поддержка Git в редакторе, одни плюсы.
Сегодня мы поговорим про [Visual Studio Code](https://code.visualstudio.com/).
Установка
---------
**Ubuntu/Debian**
1. Качаем версию пакета VS Code с расширением .deb
2. Переходим в папку, куда скачался пакет (cd ~/Загрузки или cd ~/Downloads)
3. Пишем, где (имя пакета).deb — название файла, который вы только что скачали:
```
sudo dpkg -i (имя пакета).deb
sudo apt-get install -f
```
**OpenSUSE/SLE Based distrs**
1. Установим репозиторий:
```
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
sudo sh -c 'echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com/yumrepos/vscode\nenabled=1\ntype=rpm-md\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" > /etc/zypp/repos.d/VScode.repo'
```
2. Обновим пакеты и установим VS Code:
```
sudo zypper refresh
sudo zypper install code
```
#### Расширения для С/С++
Чтобы VS Code полностью сопровождал нас при работе с файлами С/С++, нужно установить расширение «cpptools». Также полезным будет поставить один из наборов сниппетов.
Настоятельно рекомендую включить автосохранение редактируемых файлов, это поможет нам в дальнейшем.

Идём дальше. Открываем любую папку (новую или нет, неважно).
У меня в этой папке уже есть пара файлов для работы с C/C++. Вы можете скопировать одну из своих наработок сюда или создать новый файл.
Осталось всего ничего. Настроить компиляцию в одну клавишу и научиться отлаживать без `printf`.
**Шаг 1**. Открываем файл .c/.cpp, который (обязательно) лежит в вашей папке.
**Шаг 2**. Нажимаем Ctrl+Shift+B. VS Code вам мягко намекнет, что он не знает как собирать ваш проект.

**Шаг 3**. Поэтому дальше настраиваем задачу сборки: выбираем «Настроить задачу сборки» -> «Others».
**Шаг 4**. Прописываем конфигурацию в соответствии с образцом. По сути мы пишем скрипт для консоли, так что всем кто имел дело с ней будет понятно дальнейшее. Прошу заметить, что для сборки исходников в системе должен стоять сам компилятор (gcc или другой, отличаться будет только значение поля `command`). Поэтому для компиляции .cpp, понадобится в поле `command` указать `g++` или `c++`, а для .c `gcc`.
**Шаг 5**. В `args` прописываем аргументы, которые будут переданы на вход вашему компилятору. Напоминаю, что порядок должен быть примерно таким: `-g, <имя файла>`.
Внимание: Если в вашей программе используется несколько файлов с исходным кодом, то укажите их в разных аргументах через запятую. Также обязательным является ключ `-g`(а лучше даже `-g3`). Иначе вы не сможете отладить программу.
Если в проекте для сборки вы используете `makefile`, то в поле `command` введите `make`, а в качестве аргумента передайте директиву для сборки.
**Шаг 6**. Далее возвращаемся обратно к нашему исходнику. И нажимаем F5 и выбираем C++.
**Шаг 7**. Осталось только написать путь к файлу программы. По умолчанию это `${workspaceRoot}/a.out`, но я в своем файле сборки указал флаг `-o` и переименовал файл скомпилированной программы, поэтому у меня путь до программы: `${workspaceRoot}/main`.

**Шаг 8**. Всё, больше нам не нужно ничего для начала использования всех благ VS Code. Переходим к основному проекту.
Отладка
-------
Для начала скомпилируем программу (нет, нет, убери терминал, теперь это делается по нажатию Ctrl+Shift+B).
Как вы видите в проводнике появился `main`, значит все в порядке и сборка прошла без ошибок. У меня не слишком большая программа, но выполняется она моментально. Одним словом, провал чистой воды, потому что отладка идет в отдельном терминале, который закрывается после того, как программа дошла в `main() до "return 0;"`.

Пришло время для брейкпоинтов. Выберем строчку с `"return 0;"` и нажимаем F9.
Строчка, помеченная красной точкой слева — место, где остановится программа, при выполнении.
Далее нажимаем F5.
Как я и сказал, программа остановила выполнение. Обратите внимание на окно с локальными переменными.
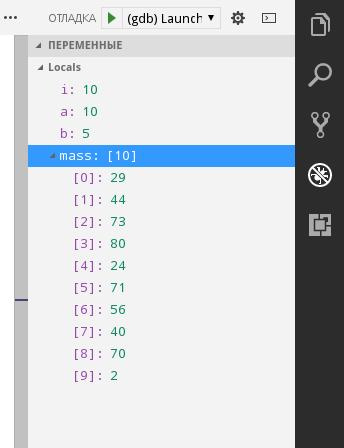
Удобненько. Также при остановке можно наводить мышкой на переменные и структуры в коде и смотреть их значения.
Также, если на каком-то этапе выполнения вам нужно посмотреть пошаговое выполнение той или иной операции, например в цикле, то поставьте брейкпоинт перед ней и нажмите F10 для выполнения текущей строчки без захода в подпрограмму и F11 с заходом.
Также есть случаи, когда считать выражение очень муторно вручную, но для отладки вам нужно знать, например, значение суммы трех элементов массива, или значение большого логического выражения. Для этого существуют контрольные значения. Все это и многое другое могут показать вам Контрольные значения (или «watch»).
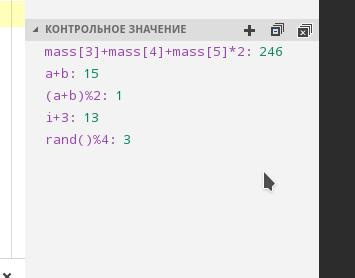
**Важно:**
1. Для каждой папки вам нужно отдельно настроить файлы сборки и путь к программе.
2. VS Code не решит ваших проблем, но поможет быстрее с ними разобраться. Причем в разы.
3. После каждого изменения программы, ее нужно компилировать заново, нажимая Ctrl+Shift+B.
Полезные шорткаты можно посмотреть [здесь](https://code.visualstudio.com/docs/getstarted/keybindings#_keymap-extensions).
### Об авторе

[Максимилиан Спиридонов](https://habrahabr.ru/users/maxspt/) — разработчик C#, студент МАИ, Microsoft Student Partner. В профессиональную разработку на .NET пришёл ещё в школе. Около года работал с реальными проектами на WPF(MVVM)+C#, MySQL, более 4-х лет разрабатывал на C#. Основная сфера интересов сейчас — это мобильная разработка на Xamarin. Также, по воле случая в сфере интересов оказались С/С++ и Linux. | https://habr.com/ru/post/333680/ | null | ru | null |
# Беспроводные коммуникации «умного дома»
Когда начинающие (или продолжающие) «радиолюбители» наигрались со светодиодами и устали поворачивать сервы в различные положения, некоторые из них начинают прикладывать полученные знания к обычной бытовой сфере.
Как правило, это применение находится в двух областях — автомобиль или дом.
«Тюнить» авто лично мне как-то не интересно, а вот сделать собственное жилье чуточку «умнее» и комфортнее — достойный выбор.

На фото выше представлен работающий прототип «Панели управления» моим «умным» домом.
**Лирическое отступление #1: Как все начиналось (можно пропустить, но кому-то может оказаться полезным).**
Первоначальная философия **моего** «умного дома» была следующей: *каждое созданное устройство сделано для достижения какой-то определенной цели и оно должно работать самостоятельно*.
Так дома появились устройства типа:
* ИК-управление освещением в гостиной (исходный светильник был с радиоуправлением, но захотелось им управлять с универсального ИК-пульта).
* [Погодная станция](http://habrahabr.ru/post/165747/).
* [Устройство мониторинга электропотребления](http://habrahabr.ru/post/168783/) и другие.
В доме используются не только самодельные, но и покупные «умные» устройства. Одним из таких очень удачных устройств является хронотермостат:

Термостат работает в двух режимах:
* «Ночной» — температура пониже, чтобы было комфортнее спать (и экономить газ).
* «Дневной» — температура выше и более комфортная для бодрствования.
Все предельно удобно, настраивается индивидуальный график «ночного» и «дневного» режима, задаются обе температуры. «Ночной» режим для себя настроил так, что он включается как ночью, так и днем, когда дома никого нет.
Но так как мой рабочий день не нормирован, после нескольких ранних возвращений выяснилось, что *возвращаться в прохладный дом с мороза днем как-то не очень приятно*.
С этого момента началась эпопея с беспроводными коммуникациями (можно было, конечно, опутать весь дом «витой парой», но это не наш метод).
Выбор беспроводных модулей был достаточно спонтанный, но после нескольких месяцев эксплуатации он вполне оправдал себя.
Были приобретены дешевые трансиверы на 2.4ГГц [nRF24L01+](http://imall.iteadstudio.com/im120606002.html):

По характеристикам заявлено, что дальность до 100м (в прямой видимости) и скорость передачи данных до 2Мбит. Возможно использование любого из 126 доступных частотных каналов. Очень достойно для такой «крохи».
На всякий случай для наиболее «критичных» модулей нашлись [«усиленные» версии](http://imall.iteadstudio.com/im120606003.html):

Эти модули полностью совместимы с «обычными», но дополнительно оснащены усилителем мощности и внешней антенной.
> Кстати, они пока так и лежат без дела — оказалось, что в моем случае достаточно «обычных» модулей.
Модули подключаются к МК через SPI.
Особенность модулей такова, что им для питания требуется 3.3В (т.е. необходимо им обеспечить индивидуальное питание, если вся остальная схема питается, например, от 5В). Приятной новостью является то, что эти RF-ки толерантны к 5В-сигналам (не требуется использовать схему согласования уровней).
**Лирическое отступление #2: Первые опыты.**Первоначально для работы с беспроводными модулями использовалась библиотека [Mirf](http://playground.arduino.cc/InterfacingWithHardware/Nrf24L01).
Для устранения проблемы «прохладный дом» (см. [Лирическое отступление #1](#lyrics1)) был создан «принудительный» термостат.
Модуль из себя представляет небольшую коробочку, которая подключается между газовым котлом и хронотермостатом:

Модуль оборудован 2 релюшками, которые обеспечивают необходимую коммутацию, собственным датчиком температуры (DS18B20) и 3 светодиодами для индикации режима работы.
Логика простая: если у «принудительного» термостата выбран автоматический режим работы — он изображает из себя «кусок кабеля» и никак не влияет на взаимодействие котла и хронотермостата. А вот если его перевели в режим «ручной» работы — хронотермостат отключается от котла и уже не участвует в работе, за температуру дома становится ответственным «принудительный» термостат.
Модуль обладает 2 параметрами:
* Режим работы (0 — авто, 1 — ручной).
* Заданная температура.
Дополнительно этот модуль является «датчиком» температуры, чуть позже была добавлена функция мониторинга, которая показывает, «разрешено ли в текущий момент газовому котлу греть».
Таким образом, создано первое устройство, которое может передавать данные о своем состоянии и принимать команды.
Но чтобы им управлять, нужно как минимум еще одно.
Выбор пал на плату [gBoard](http://imall.iteadstudio.com/development-platform/im120411004.html) (атмега328, gsm на базе sim900, интерфейс для nrf24l01 (используется аппаратный SPI), SD, кучка аналоговых пинов и проч.):

Слот под сим-карту расположен на обратной стороне платы (фотографировать не стал — там больше ничего интересного нет).
Опять же с использованием той же библиотеки для nrf24l01 (Mirf) был написан скетч.
Теперь появилась возможность через СМС запросить текущую температуру дома, задать желаемую температуру и перевести «принудительный» термостат из одного режима в другой.
Проблема «прохладного дома» решилась: достаточно выезжая в сторону дома отправить СМС со смыслом «хочу к приезду теплый дом».
Аналогичным образом модуль для ИК-управления светом был оснащен беспроводным модулем и тоже стал управляться через СМС (опять же, этот модуль стал еще одним «датчиком» в системе — температура/влажность/состояние света).
Через некоторое время почти все «поделки» обзавелись беспроводным интерфейсом и стали как минимум «датчиками», а как максимум — исполнительными устройствами с возможностью удаленного управления.
При этом все устройства остались верны основному принципу, обозначенному выше: *каждое созданное устройство сделано для достижения какой-то определенной цели и оно должно работать самостоятельно*.
И вроде бы как все работает и все хорошо, но как-то не шибко удобно — только через СМС, да еще довольно сложно было внедрять новые фичи. Контроль исполнения осуществлялся или еще одной СМС с запросом на текущее значение «сенсора» или заглядыванием в систему видеонаблюдения (чтобы увидеть, например, включенный свет).
При работе с модулями приходилось держать перед собой «бумажку», где было зафиксировано, как называется тот или иной датчик, количество его параметров, назначение каждого из параметров.
Формат структуры для передачи данных был не оптимален (для моего случая). Эту версию формата даже приводить не хочется.
Понятно, что необходимо как-то модифицировать (предпосылка #1).
Естественно, появилось желание получать информацию и управлять еще и через LAN. Была приобретена платка [iBoard](http://imall.iteadstudio.com/development-platform/im120410001.html) (атмега328, LAN на базе Wiznet W5100, интерфейс для nrf24l01, SD, кучка аналоговых пинов и проч.):

И все вроде бы все как на gBoard, но оказалось, что беспроводной модуль разведен совсем не так, как ожидалось. Аппаратный SPI в этой плате используется для LAN и SD, а вот для беспроводного модуля предлагалось реализовать этот интерфейс самостоятельно. Сделано это было скорее всего для того, чтобы можно было «одновременно» работать как с LAN, так и с RF.
Библиотека Mirf на этой плате с такой коммутацией модуля работать отказалась категорически. Писать свою библиотеку для взаимодействия с nrf24l01 в мои планы совсем не входило.
Очевидно, что надо что-то делать, иначе хорошая плата пойдет «в стол» до лучших времен (предпосылка #2).
Была обнаружена чудесная библиотека [RF24](https://github.com/maniacbug/RF24) (автор [maniacbug](https://github.com/maniacbug), Сиэтл, США) и еще более чудесный форк [iBoardRF24](https://github.com/andykarpov/iBoardRF24) сделанный [Андреем Карповым](https://github.com/andykarpov) (Киев, Украина).
Библиотеки замечательным образом заработали на всех имеющихся устройствах (тестовые примеры), но вот устройства с разными библиотеками (Mirf и RF24) между собой не могут общаться (предпосылка #3).
Стало очевидно, что настал-таки тот самый момент, когда надо все переделать.
> Далее будут приводиться куски кода (Arduino IDE) для иллюстрации текущего решения. Полный листинг не привожу, чтобы оставить простор для творчества.
Имея за плечами уже солидный накопленный опыт, взял из структуры передаваемых данных все хорошее и учел имеющиеся недостатки пришел к тому, что лучше использовать следующую структуру «пакета» данных:
```
// структура для передачи значений
typedef struct{
int SensorID; // идентификатор датчика
int CommandTo; // команда модулю номер ...
int Command; // команда
// 0 - нет команды или ответ
// 1 - получить значение
// 2 - установить значение
int ParamID; // идентификатор параметра
float ParamValue; // значение параметра
boolean Status; // статус 0 - ошибка, 1 - ок
char Comment[16]; // комментарий
}
Message;
```
Из комментариев почти везде понятно, какой параметр для чего используется. То что непонятно, будет объяснено чуть ниже.
Внутри же каждого «датчика» необходимо иметь структуры для параметров:
```
// структура для параметров и значений
typedef struct{
float Value; // значение
boolean Status; // статус - 0-ошибка (false), 1-ок (true)
char Note[16]; // комментарий
}
Parameter;
```
В структуру заведено три параметра. Ну со «значением» все понятно, поле «Note» используется для того, чтобы дать какое-то внятное (но краткое) объяснение, что же это за датчик и, возможно, единица измерения.
Status заведен больше для контроля и возможной гибкости в дальнейшем.
Сейчас это используется, например, если не удалось по каким-то причинам считать данные с какого-то датчика, то система может спокойно обработать эту ситуацию и передать 0, обозначив проблему.
Видно, что вторая структура полностью повторяет «конец» структуры передаваемого пакета.
Формат передаваемого «пакета» абсолютно идентичен как для «master» (тот, кто рассылает команды и собирает данные), так и для «slave» (тот, кто принимает команды и отчитывается о проделанной работе). Более того, при таком подходе master и slave — достаточно условные обозначения. Модули реально общаются «на равных» и запросы с ответами могут идти в обе стороны.
Теперь можно уже приступать к описанию конкретного модуля. Возьмем какой-нибудь гипотетический модуль с 3 параметрами. Кодироваться это будет следующим образом:
```
// описание параметров модуля
#define SID 100 // идентификатор датчика
#define NumSensors 3 // количество сенсоров (и еще одно обязательное занчение - имя датчика)
Parameter MySensors[NumSensors+1] = { // описание датчиков (и первичная инициализация)
NumSensors,1,"Sensor 100: LED", // в поле "комментарий" указываем пояснительную информацию о датчике и количество сенсоров, 1 в статусе означает "отвечаем на запросы"
0,0,"value A0",
0,0,"counter",
0,0,"set_value",
};
Message sensor;
```
Обратите внимание, что не смотря на то, что параметров 3 — объявляется структура из 4 элементов. Для себя я принял, что в «нулевом» элементе я буду всегда кодировать информацию о самом «модуле» — количество его датчиков, давать информацию о том, что датчик может принимать команды или он только «датчик» и текстовое описание датчика.
> Сейчас думаю, что при описании датчика параметр Status можно использовать для обозначения — можно ли этот параметр менять (т.е. «исполнительный механизм») или нельзя (просто «значение датчика»).
>
> Или ввести для этого еще один параметр?
С данными разобрались, перейдем к функциям:
```
boolean sendMasterMessage(int From, int To, int Command, int ParamID, float Value, char* Comment, Message* answer);
```
Так объявлена функция, с помощью которой отправляется команда.
Возвращает «true», если пришел правильный ответ или «false», если постигла неудача.
Входные параметры: от какого модуля идет команда, какому модулю, команда (читаем или устанавливаем), какой параметр, значение, комментарий и ссылка на структуру для ответа.
Параметр «комментарий» тут является больше «закладкой на будущее» для того, чтобы, например, можно было менять имена модулей и названия параметров.
Результат функции определяется по следующим правилам:
1. ответ должен быть получен от того датчика, к которому обращались
2. ответ должен предназначаться тому мастеру, который инициировал запрос
3. в ответе должен быть ParamID тот, что участвовал в передаче
Таким образом, чтобы узнать значение первого датчика с нашего гипотетического сенсора, достаточно на мастере (пусть его SID будет 900) вызвать функцию следующим образом:
```
...
Message answer;
...
if(sendMasterMessage(900, 100, 1, 1, 0, "", answer)) {
Serial.println(answer.ParamValue);
}
else {
Serial.println("No answer");
}
...
```
Соответственно на «принимающей» стороне в основном цикле должен быть примерно такой код:
```
// если получена команда
if (radio.available()) {
bool done = false;
while (!done)
{
done = radio.read( &sensor, sizeof(sensor) );
// если команда этому датчику - обрабатываем
if (sensor.CommandTo == SID) {
// исполнить команду (от кого, команда, парметр, комментарий)
doCommand(sensor.SensorID, sensor.Command, sensor.ParamID, sensor.ParamValue, sensor.Status, sensor.Comment);
}
}
}
```
Функция doCommand может быть примерно такой:
```
void doCommand(int From, int Command, int ParamID, float ParamValue, boolean Status, char* Comment) {
switch (Command) {
case 0:
// ничего не делаем
break;
case 1:
// читаем и отправляем назад
sendSlaveMessage(From, ParamID);
break;
case 2:
// устанавливаем
setValue(From, ParamID, ParamValue, Comment);
break;
default:
break;
}
// ответим "командующему"
sendSlaveMessage(From, ParamID);
return;
}
```
Функция sendSlaveMessage — почти такая же, как sendMasterMessage, но не проверяет правильность ответа после того, как отправила данные и содержит меньше входных параметров — функция принимает на входе идентификатор того модуля, кому отвечает и идентификатор параметра, информацию о котором необходимо переслать.
Остальные обязательные данные для состава «пакета» отправки система и так уже знает (напомню, там еще обязательные поля — идентификатор модуля, который осуществляет отправку данных в текущий момент, команда (в данном случае это будет 0, т.к. просто отправляем текущее значение)).
Таким образом, логика работы получается простая:
* Master инициирует адресный запрос к модулю и требует прочитать (или установить) значение определенного параметра.
* Slave принимает эту команду (и если она адресована именно ему) и выполняет требуемое, о чем «отчитывается» в ответном сообщении.
* Master анализирует принятый пакет и если удовлетворен результатом — занимается дальше своими делами или делает повторный запрос (нужное количество раз).
Код для gBoard тоже был переписан соответствующим образом и теперь взаимодействие через СМС выглядит примерно так (часть скриншота с моего телефона):
Первой СМС я запрашиваю температуру восточного датчика у «погодного» модуля, второй СМС — устанавливаю желаемую температуру «принудительному» термостату. В ответ я получаю измеренное значение или ответ об успешно установленном значении (в конце сообщения есть «ОК!»).
Хорошо видно, что в СМС включаются данные, необходимые для формирования полного запроса для конкретного модуля. Соглашусь, что не слишком простой формат исходящих сообщений, потом можно будет переписать во что-то более «человекопонятное».
На этом «адресный» обмен данными описывать закончу.
Но ведь в домашней системе есть и другие модули, которые являются примитивными «датчиками». Типичный образец такого модуля — датчик температуры и влажности, который, возможно, работает от батарейки и ему свои ресурсы надо беречь и «спать крепким сном» и просыпаться исключительно для того, чтобы быстренько отправить данные о своем состоянии и снова «спать».
Для него режим «запрос-ответ» не подходит (придется держать как минимум RF-модуль в «бодрствующем» состоянии, что негативно скажется на времени автономной работы).
Тогда придумал, что можно устраивать «флуд» в эфире: датчики могут на регулярной основе отправлять значения своих параметров (всех или только некоторых — зависит от конкретной реализации) для всех (тогда параметр To (кому) принимает значение 0 (т.е. «всем»)).
Получается эдакий «мультикаст» — модуль проснулся, выдал в эфир свое состояние (и ему не важно, услышал кто-то или нет) и снова уснул.
Почти всем модулям, которые работают «адресно» добавил и режим «флуда», чтобы они тоже регулярно сообщали в эфир свое состояние (для системы логирования).
> Переписать (точнее будет сказать «скорректировать») код скетчей для тех модулей, что уже работали (под новую библиотеку), оказалось очень простой задачкой — не более 15-20 минут на модуль. Процесс «миграции» прошел абсолютно безболезненно.
А теперь осталось только данные собрать воедино. Тут-то и пригодилась плата iBoard (еще раз приведу ее фото, с уже установленным RF-модулем):

На этот модуль возложена одна простая, но очень важная функция — слушать «флуд» и отправлять данные (метод POST) на веб-сервер. Модуль на iBoard вообще ничего не знает о количестве и «составе» передающих модулей — слушает все.
В пакете данных для веб-сервера передается «ключ» (чтобы сервер понимал, что это «свои») и полный принятый пакет (еще раз повторю, что в пакете приходят следующие ключевые данные: SID модуля, ID параметра, значение этого параметра, комментарий (имя параметра и/или единица измерения)).
Если же в принятом пакете ParamID равен нулю, то в значении параметра мы имеем количество «сенсоров» у модуля, а в «комментарии» — имя модуля.
На веб-сервере в автоматическом режиме формируются записи в 2 табличках: sensor\_list и sensor\_value (из названий, думаю, все понятно).
Примененный подход позволяет совершенно безболезненно добавлять модули в систему и не исправлять код для iBoard — в базу данных новые значения попадут по отработанной схеме.
В качестве веб-сервера использовал то, что «было под рукой» (Synology DS411+II) — в пару кликов был поднят веб-сервер с php и mySQL. В случае, если «под рукой» нет ничего подходящего и не хочется ради этого держать включенный комп — можно воспользоваться сторонним хостингом, приобрести что-то типа [этого](http://experthd.ru/products/gi-ms100-xtreamer-pro) (приятно и полезно) или, например, сервисом [cosm.com](https://cosm.com)
В зависимости от выбора «хранилища», код для МК с LAN-модулем будет изменяться минимальным образом (на cosm.com для ардуинки есть своя библиотека и удобный режим отладки — использовать очень просто).
Данные собрали (а в случае использования cosm.com — уже и отобразили на графиках).
В своем проекте для отображения я использовал [Google Charts](https://developers.google.com/chart/). Получается примерно так (только погодные параметры):
Специально привожу скриншот, а не даю ссылку на страницу — NAS, думаю, не выдержит нагрузки с хабра.
Данные с датчиков «зашумлены», надо бы применить [фильтр Калмана](http://habrahabr.ru/post/166693/), но руки пока не дошли до этого.
Собственно, со сбором и отображением данных — тоже закончил.
Осталось реализовать управление через LAN (а вот это еще как раз и не сделано и, если будет интересно, станет темой еще одного поста (хотя основные принципы уже все озвучены — как делать уже понятно, надо только «сесть и написать»)).
Вы можете спросить: «При чем же та картинка, с которой начался пост?»
А это еще одна плата для быстрого прототипирования — [iBoardPro](http://imall.iteadstudio.com/development-platform/iboard-pro.html) (построена уже на mega2560, LAN, RTC, SD, RF-интерфейс, 40-пиновый разъем для подключения TFT дисплеев с тачскрином и другими «плюшками»):

На фото хорошо виден дисплей TFT 2.4" 320\*240 с резистивным тачскрином [ITDB02-2.4E](http://imall.iteadstudio.com/display/tft-lcm/im120419004.html). Выглядит хорошо, но вот для работы пальцами — мелковат, да и тексты хотелось бы покрупнее (буду смотреть в сторону 5 или даже 7-дюймовых дисплеев).
С использованием вышеописанных принципов на этой плате реализован (но все еще дописывается) «контрольный модуль», на который выводятся данные с желаемых датчиков и можно управлять теми устройствами, которые это поддерживают.
Небольшое видео, демонстрирующее текущую работу прототипа:
Логика работы следующая:
* Есть «главные» экраны — на них попадают «сводные» данные («Погода» — зеленый, «Дом» — желтый)
* Есть «субэкраны» — на них отображаются данные с датчиков (на видео это продемонстрировано для «желтой» закладки — «домашние параметры»: температура и влажность в двух точках дома и данные по электропотреблению).
* «Красный» экран — это «сводка из сводок» — наиболее востребованные данные.
* «Синий» экран — управление. В средней его части находится управление светом, в нижней — управление «принудительным» термостатом. Слева снизу красный «индикатор» — это отображение того самого параметра (о котором я писал выше), отображающего, можно ли газовому котлу в текущий момент времени работать.
«Кнопки» управления на экране обладают «обратной связью»: т.е. после включения конкретного режима — это отображается соответствующим цветом. Если что-то уже было включено ранее, то при переходе на экран управления это будет сразу видно.
Каждое «нажатие» на кнопку порождает вызов функции sendMasterMessage с соответствующими параметрами и получение ответа от конкретного датчика (именно по этим данным и происходит «перекрашивание» кнопок или изменение значения, как это видно для заданной температуры «принудительного» термостата).
Видно, что есть определенная задержка при «перекрашивании» кнопки и изменении параметра — это обусловлено не только медлительностью МК при отрисовке, но и тем, что требуется время на отправку запроса и получения ответа (иногда процесс «запрос-ответ» проходит не единожды — master умеет повторять свой «приказ», если не дождался ожидаемого ответа).
«Фиолетовый» экран планируется использовать для вывода данных о состоянии системы: текущий IP-адрес, время старта, время последней синхронизации через NTP, времена последних «коннектов» (или «прослушиваний») с конкретными датчиками и т.п.
Пожалуй, что на сегодня это все, о чем хотел рассказать (и так очень длинно получилось).
Извините за качество фото — снимал на ~~микроволновку~~ телефон.
**P.S.** «Железки» приобретал в [этом](http://devicter.ru/) магазине (конечно, переплатил, но ждать долго-долго из Китая не хотелось, за это время успел заказать и получить несколько посылок из НСК). Ближе и быстрее нигде не нашел.
**P.P.S.** да, все эти «железки» (ну разве что кроме дисплея) можно собрать дома, но это не было целью. | https://habr.com/ru/post/171613/ | null | ru | null |
# Сортировка цифр на Brainfuck
В этой статье я покажу вам, как отсортировать циферки с помощью Brainfuck.
Вы вводите цифры (каждая цифра не должна встречаться более 255 раз, при 8bit версии интерпретатора), после программа, если ее можно так назвать, выводит их по возрастанию.
Это будет реализация [сортировки подсчётом](http://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0_%D0%BF%D0%BE%D0%B4%D1%81%D1%87%D1%91%D1%82%D0%BE%D0%BC), которая работает следующим образом:
1. Считывается число k.
2. В массиве A увеличиваем A[k] на единицу.
3. Повторяем шаги 1 и 2, пока не закончатся числа на входе.
4. Выводим A[i] раз число i, где i — это возможные значения чисел k.
##### Приступим
Будем считывать символы, пока не получим перевод строки(ascii 10)
```
,----- -----
[
----- ----- ----- ----- ----- --- уменьшаем значение ячейки на 28
*тут будет работа со введенными данными*
,----- -----
]
```
Теперь нам нужно сдвинуть указатель на значение, которое мы считали.
```
[->+<]> перемещаем значение нулевой ячейки в первую
[
[->+<] перемещаем значение из i-ой ячейки в i + 1
+>- увеличиваем i-ую ячейку, переходим в следующую ячейку, уменьшаем её
]
```
После этого указатель будет на ячейке, равному изначальному значению символа, который мы вводили. Все ячейки, начиная с первой, заканчивая той, перед которой указатель, будут наполнены единицами — это поможет нам вернуться к нулевой ячейке.
Ну а теперь пора увеличить значение ячейки, согласно второму шагу алгоритма.
```
>>>>> >>>>> + <<<<< <<<<<
```
Примечание: сдвиг на 10 ячеек не случаен, подумайте, что будет без него.
Далее перемещаемся на нулевую ячейку.
```
<[-<] спасибо единичкам, которые мы оставляли
```
Итак, что у нас получилось, реализовав первые три шага алгоритма.
```
,----------
[
----- ----- ----- ----- ----- ---
[->+<]>
[
[->+<]
+>-
]
>>>>> >>>>> + <<<<< <<<<<
<[-<]
,----- -----
]
```
##### Вывод ответа
Осталось самое главное: вывести отсортированные цифры.
Но где же находятся наши цифры?
ASCII код '0' равен 48.
После считывания мы отнимали 10, затем ещё 28.
Считанное значение мы перемещали на первую ячейку.
Но перед увеличением ячейки мы переходили на 10 ячеек вперёд.
48 — 10 — 28 + 1 + 10 = 21
Значит количество нулей будет лежать в 21ой ячеек, количество единиц в 22ой и т.д.
Присвоим двадцатой ячейке значение 48 (это ascii код нуля).
Выводим значение предыдущей ячейки столько раз, какое значение в текущей ячейки.
Присваиваем текущей ячейке значение предыдущей + 1.
Делаем так для каждой цыфры.
```
>>>>> >>>>> >>>>> >>>>> переходим на 20ую ячейку
++++++++ ++++++++ ++++++++ ++++++++ ++++++++ ++++++++ увеличиваем ячейку до 48
>[<.>-] <[->+<]>+ выводим, переходим к следующей ячейке
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] выводим девятки, и наконец программа завершается
```
##### Итог
Вот весь код
```
,----------
[
----- ----- ----- ----- ----- ---
[->+<]>
[ [->+<] +>-]
>>>>> >>>>> + <<<<< <<<<<
<[-<]
,----- -----
]
>>>>> >>>>> >>>>> >>>>>
++++++++ ++++++++ ++++++++ ++++++++ ++++++++ ++++++++
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-] <[->+<]>+
>[<.>-]
```
Таким нехитрым способом мы отсортировали цифры.
Несложно модифицировать код, чтобы сортировались почти любые символы, либо выводить цифры по убыванию. Использую эту идею можно сортировать не только цифры, но и 2ух — 3ех значные числа, возможно, позже я напишу об этом.
Спасибо за внимание. | https://habr.com/ru/post/135262/ | null | ru | null |
# Пишем фреймворк для разработки игр — Mechanic Framework
Добрый день, жители Хабра!
Сегодня мы будем писать фреймворк с названием Mechanic Framework для удобной разработки игр под андроид.

#### Что нам потребуется:
* Установленные Eclipse и Android SDK
* Приличное знание Java либо другого С-подобного языка. Лучший пример – C#
* Терпение
Для начала создаем проект.
File – New – Other – Android Application Project
Появляется окошко New Android Application. Вводим любое имя (например, Mechanic), называем package своим именем, выбираем минимально возможную версию андроид для приложения и целевую версию, нажимаем Next.
Нажимаем Next.
Выбираем иконку (если вам не нравится иконка андроида, жмите Clipart – Choose и выбираем что-нибудь, либо ставим свою иконку).
Жмем Next.
Выбираем название для Activity, например, MyGame, жмем Finish.
Откроется .xml окно визуального редактирования, закрываем его.
Открываем AndroidManifest.xml и настраиваем его под свои нужды
Для того, чтобы устанавливать игру на карту памяти, когда это возможно, и не загрязнять внутреннюю память устройства, в поле manifest пишем
```
android:installLocation="preferExternal"
```
Для того, чтобы приложение было доступным для отладки, пишем в поле application
```
android:debuggable="true"
```
Для того, чтобы приложение было зафиксировано в портретном либо ландшафтном режиме (в этом случае ландшафтный режим), в поле activity пишем
```
android:screenOrientation="landscape"
```
Для того, чтобы приложение на эмуляторе могло обрабатывать действия с клавиатурой, пишем в том же поле
```
android:configChanges="keyboard|keyboardHidden|orientation"
```
Когда вы скачиваете приложение с Google Play, вы замечаете, что приложения требуют доступа к карте памяти/к интернету и прочим вещам, так вот, для того, чтобы получить контроль над картой памяти и предотвратить блокировку экрана при бездействии, пишем
```
```
Вид манифеста будет примерно такой
```
xml version="1.0" encoding="utf-8"?
```
Закрываем манифест
Теперь необходимо создать каркас фреймворка – интерфейсы, управляющие вводом, отрисовкой графики и прочим, а позже все интерфейсы реализовать.
#### Ввод
Создаем новый package с названием com.mechanic.input
Создаем интерфейс Input в этом package, и доводим его до такого вида
```
public interface Input
{
public static class MechanicKeyEvent
{
public static final int KEY_DOWN = 0, KEY_UP = 1;
public int Type;
public int KeyCode;
public char KeyChar;
}
public static class MechanicTouchEvent
{
public static final int TOUCH_DOWN = 0, TOUCH_UP = 1, TOUCH_DRAGGED = 2;
public int Type;
public int X, Y;
public int Pointer;
}
public boolean IsKeyPressed(int KeyCode);
public boolean IsKeyPressed(char KeyChar);
public boolean IsTouchDown(int pointer);
public int GetTouchX(int pointer);
public int GetTouchY(int pointer);
public float GetAccelX();
public float GetAccelY();
public float GetAccelZ();
public List GetTouchEvents();
public List GetKeyEvents();
}
```
GetKeyDown – булево значение, принимает код клавиши и возвращает true, если нажата кнопка
GetTouchDown – булево значение, возвращает true, если нажат экран, причем принимает эта функция номер пальца, нажавшего экран. Старые версии андроида не поддерживает Multitouch.
GetTouchX – возвращает X-координату нажатой клавиши
GetTouchY – возвращает Y-координату нажатой клавиши
Обе последние функции принимают номер пальца
GetAccelX, GetAccelY, GetAccelZ – возвращают ускорение по какой-либо координате акселерометра. Когда мы держим телефон в портретном режиме вертикально вверх, то ускорение по оси Y будет равно 9.6 м/с2, по осям X и Z 0 м/с2.
Обратите внимание на MechanicKeyEvent и MechanicTouchEvent
Первый класс хранит информацию о событии клавиши. Type всегда будет либо KEY\_DOWN либо KEY\_UP. KeyCode и KeyChar хранят значение клавиши в числовом и символьном типе соответсвенно.
Во втором классе X и Y – координаты пальца, нажимающего экран, Pointer – номер пальца. TOUCH\_DRAGGED означает перемещение пальца.
Стоит отвлечься и сказать о том, как налажен интерфейс Input.
За акселерометр, клавиатуру и нажатия на экран отвечает не тот класс, который реализует Input, а те классы, что будут реализовывать интерфейсы Accelerometer, Keyboard и Touch соответственно. Input будет просто хранить экземпляры этих классов. Если вы знакомы с паттернами проектирования, то должны знать, что таким образом реализуется нехитрый паттерн «Фасад».
Вот эти интерфейсы
```
public interface Accelerometer extends SensorEventListener
{
public float GetAccelX();
public float GetAccelY();
public float GetAccelZ();
}
```
```
public interface Keyboard extends OnKeyListener
{
public boolean IsKeyPressed(int keyCode);
public List GetKeyEvents();
}
```
```
public interface Touch extends OnTouchListener
{
public boolean IsTouchDown(int pointer);
public int GetTouchX(int pointer);
public int GetTouchY(int pointer);
public List GetTouchEvents();
}
```
Нетрудно догадаться, что Input просто перенаправляет методы в другие классы, а те работают честно и выкладывают результаты.
#### Файлы
Настало время работы с файлами. Наш интерфейс будет называться FileIO, так как класс File уже есть.
Создаем новый package com.mechanic.fileio и новый интерфейс в нем
```
public interface FileIO
{
public InputStream ReadAsset(String name) throws IOException;
public InputStream ReadFile(String name) throws IOException;
public OutputStream WriteFile(String name) throws IOException;
}
```
Обычно мы храним все картинки, звуки и прочие файлы в папке assets проекта. Первая функция открывает файл с указанным именем из assets, позволяя избежать лишней мороки с AssetsManager. Последние 2 функции нужны, например, для сохранения рекордов. Когда мы сохраняем данные, то записываем в хранилище устройства текстовый файл с информацией, а потом считываем его. На всякий случай постарайтесь придумать название файла пооригинальнее «file.txt», например, «.mechanicsave» — так тоже можно.
#### Звуки
Создаем package com.mechanic.audio и новый интерфейс Audio
```
public interface Audio
{
public Music NewMusic(String name);
public Sound NewSound(String name);
}
```
У нас есть 2 варианта хранения и воспроизведения звука. Первый вариант – обычный, когда мы загружаем звук и проигрываем его, но такой подход в большинстве случаев годится для маленьких звуков вроде выстрелов и взрывов, а для больших звуковых файлов вроде фоновой музыки бессмысленно полностью загружать звук, поэтому мы используем в этом случае потоковое произведение звуков, динамически подгружая звуки и проигрывая их. За первый и за второй вариант отвечают соответственно интерфейсы Sound и Music. Вот их определения
```
public interface Sound
{
public void Play(float volume);
public void Close();
}
```
```
public interface Music extends OnCompletionListener
{
public void Close();
public boolean IsLooping();
public boolean IsPlaying();
public boolean IsStopped();
public void Play();
public void SetLooping(boolean loop);
public void SetVolume(float volume);
public void Stop();
}
```
#### Графика
Создаем package com.mechanic.graphics
За графику отвечает в основном интерфейс Graphics
Вот его определение
```
public interface Graphics
{
public static enum ImageFormat
{
ARGB_8888, ARGB_4444, RGB_565
}
public Image NewImage(String fileName);
public void Clear(int color);
public void DrawPixel(int x, int y, int color);
public void DrawLine(int x, int y, int x2, int y2, int color);
public void DrawRect(int x, int y, int width, int height, int color);
public void DrawImage(Image image, int x, int y, int srcX, int srcY,
int srcWidth, int srcHeight);
public void DrawImage(Image image, int x, int y);
public int GetWidth();
public int GetHeight();
}
```
ImageFormat – перечисление, облегчающее выбор способа загрузки изображения. Вообще-то он ничего особенного не делает, но перечисление, куда надо передавать формат, имеет еще кучу ненужных методов и ненужное название Config, так что пусть будет так.
NewImage возвращает новое изображение, мы его будет сохранять в переменной и рисовать
Методы с названиями Draw… говорят сами за себя, причем первый метод DrawImage рисует только часть изображения, а второй – изображение полностью.
GetWidth и GetHeight возвращают размер «полотна», где мы рисуем картинки
Есть еще один интерфейс – для картинок
```
public interface Image
{
public int GetWidth();
public int GetHeight();
public ImageFormat GetFormat();
public void Dispose();
}
```
Все достаточно красноречиво
#### Централизованное управление игрой
Создаем package com.mechanic.game
Остался предпоследний важный интерфейс, который будет поддерживать работу всего приложения – Game
```
public interface Game
{
public Input GetInput();
public FileIO GetFileIO();
public Graphics GetGraphics();
public Audio GetAudio();
public void SetScreen(Screen screen);
public Screen GetCurrentScreen();
public Screen GetStartScreen();
}
```
Мы просто пихаем туда интерфесы – темы прошлых глав.
Но что такое Screen?
Позвольте отвлечься. Почти каждая игра состоит из нескольких «состояний» — главное меню, меню настроек, экран рекордов, все уровни и т.д. и т.п. Немудрено, что поддержка хотя бы 5 состояний может ввергнуть нас в пучину кода. Нас спасает абстрактный класс Screen
```
public abstract class Screen
{
protected final Game game;
public Screen(Game game)
{
this.game = game;
}
public abstract void Update(float deltaTime);
public abstract void Present(float deltaTime);
public abstract void Pause();
public abstract void Resume();
public abstract void Dispose();
}
```
Каждый наследник Screen (MainMenuScreen, SettingsScreen) отвечает за такое «состояние». У него есть несколько функций.
Update – обновление
Present – показ графики (введено для удобства, на самом деле эта функция вызывается так же, как предыдущая)
Pause – вызывается каждый раз, когда игра ставится на паузу (блок экрана)
Resume – продолжение игры после паузы
Dispose – освобождение всех ресурсов, к примеру, загруженных картинок
Стоит немного рассказать об deltaTime, передающихся в 2 функции.
Более искушенным геймдевелоперам известна проблема, когда скорость игры (допустим, передвижение игрока) зависит напрямую от скорости устройства, т.е. если мы будем увеличивать переменную x на 1 каждый цикл, то никогда не будет такого, чтобы игра работала одинаково и на нетбуке, и на компе с огромной оперативкой.
Таким образом, труЪ-вариант:
```
@Override
public void Update(float deltaTime)
{
x += 150 * deltaTime;
}
```
Не труЪ-вариант:
```
@Override
public void Update(float deltaTime)
{
x += 150;
}
```
Есть одна элементарная ошибка – очень часто, увеличивая x на 1.0f\*deltaTime, не всегда можно заметить, что сложение целого числа с нецелым числом от 0 до 1 не дает никакого результата, засим x должен быть float
Как мы будем сменять экраны? Возвратимся к интерфейсу Game
За все отвечает функция SetScreen. Также есть функции для получения текущего и стартового экрана.
Настало время реализовать весь этот сборник!
#### Начинаем с ввода
Вы заметили, что в интерфейсе Input есть функции GetKeyEvents и GetTouchEvents, которые возвращают список событий, то есть по случаю какого-либо события программа создает множество объектов, которые затем чистит сборщик мусора. Скажите мне, в чем главная причина тормозов приложений для андроид? Правильно – это перегружение сборщика мусора! Нам надо как-то проконтролировать проблему. Перед тем, как продолжить, создадим класс Pool, реализуем «object pooling», способ, предложенный в прекрасной книге Марио Цехнера «Программирование игр для Android».
Его смысл заключается в том, что мы не даем сборщику мусора мешать приложению и не тратим попусту нужные ресурсы
```
public class Pool
{
public interface PoolFactory
{
public T Create();
}
private final List Objects;
private final PoolFactory Factory;
private final int MaxSize;
public Pool(PoolFactory Factory, int MaxSize)
{
this.Factory = Factory;
this.MaxSize = MaxSize;
Objects = new ArrayList(MaxSize);
}
public T NewObject()
{
T obj = null;
if (Objects.size() == 0)
obj = Factory.Create();
else
obj = Objects.remove(Objects.size() - 1);
return obj;
}
public void Free(T object)
{
if (Objects.size() < MaxSize)
Objects.add(object);
}
}
```
Допустим, у нас есть объект Pool pool. Вот так его используем
```
PoolFactory factory = new PoolFactory()
{
@Override
public MechanicTouchEvent Create()
{
return new MechanicTouchEvent();
}
};
TouchEventPool = new Pool(factory, 100);
```
Объявление пула
```
TouchEventPool.Free(event);
```
Сохранение события в пуле
```
event = TouchEventPool.NewObject();
```
Получаем событие из пула. Если список пуст, то это не страшно, так как после использования события мы его помещаем в пул обратно до следующего вызова.
Очень хорошая вещь!
MechanicAccelerometer
```
package com.mechanic.input;
import android.content.Context;
import android.hardware.Sensor;
import android.hardware.SensorEvent;
import android.hardware.SensorManager;
public class MechanicAccelerometer implements Accelerometer
{
float accelX, accelY, accelZ;
public MechanicAccelerometer(Context context)
{
SensorManager manager = (SensorManager)
context.getSystemService(Context.SENSOR_SERVICE);
if(manager.getSensorList(Sensor.TYPE_ACCELEROMETER).size() > 0)
{
Sensor accelerometer = manager.getSensorList(Sensor.TYPE_ACCELEROMETER).get(0);
manager.registerListener(this, accelerometer, SensorManager.SENSOR_DELAY_GAME);
}
}
@Override
public void onAccuracyChanged(Sensor sensor, int accuracy)
{
}
@Override
public void onSensorChanged(SensorEvent event)
{
accelX = event.values[0];
accelY = event.values[1];
accelZ = event.values[2];
}
@Override
public float GetAccelX()
{
return accelX;
}
@Override
public float GetAccelY()
{
return accelY;
}
@Override
public float GetAccelZ()
{
return accelZ;
}
}
```
Кроме Accelerometer, этот класс реализует еще SensorEventListener – он нужен для получения контроля не только над акселерометром, но и над прочими игрушками – компасом, фонариком, что-то еще. Пока что мы делаем только акселерометр.
В конструкторе мы получаем менеджер сенсоров и проверяем, есть ли доступ к акселерометру. Вообще теоретически акселерометров может быть не 1, а несколько (это же List, а не один объект), практически же он всегда один. Если число акселерометров больше 0, получаем первый из них и регистрируем его, выставляя этот класс в качестве listener’a (слушателя). onAccuracyChanged нужен, если сбилась точность сенсора, мы это не используем. onSensorChanged вызывается всегда, когда изменяется значение акселерометра, тут-то мы и снимаем показания.
MechanicTouch
```
package com.mechanic.input;
import java.util.ArrayList;
import java.util.List;
import com.mechanic.input.Input.MechanicTouchEvent;
import com.mechanic.input.Pool.PoolFactory;
import android.os.Build.VERSION;
import android.view.MotionEvent;
import android.view.View;
public class MechanicTouch implements Touch
{
boolean EnableMultiTouch;
final int MaxTouchers = 20;
boolean[] IsTouched = new boolean[MaxTouchers];
int[] TouchX = new int[MaxTouchers];
int[] TouchY = new int[MaxTouchers];
Pool TouchEventPool;
List TouchEvents = new ArrayList();
List TouchEventsBuffer = new ArrayList();
float ScaleX;
float ScaleY;
public MechanicTouch(View view, float scaleX, float scaleY)
{
if(Integer.parseInt(VERSION.SDK) < 5)
EnableMultiTouch = false;
else
EnableMultiTouch = true;
PoolFactory factory = new PoolFactory()
{
@Override
public MechanicTouchEvent Create()
{
return new MechanicTouchEvent();
}
};
TouchEventPool = new Pool(factory, 100);
view.setOnTouchListener(this);
this.ScaleX = scaleX;
this.ScaleY = scaleY;
}
@Override
public boolean onTouch(View v, MotionEvent event)
{
synchronized (this)
{
int action = event.getAction() & MotionEvent.ACTION\_MASK;
@SuppressWarnings("deprecation")
int pointerIndex = (event.getAction() &
MotionEvent.ACTION\_POINTER\_ID\_MASK)
>> MotionEvent.ACTION\_POINTER\_ID\_SHIFT;
int pointerId = event.getPointerId(pointerIndex);
MechanicTouchEvent TouchEvent;
switch (action)
{
case MotionEvent.ACTION\_DOWN:
case MotionEvent.ACTION\_POINTER\_DOWN:
TouchEvent = TouchEventPool.NewObject();
TouchEvent.Type = MechanicTouchEvent.TOUCH\_DOWN;
TouchEvent.Pointer = pointerId;
TouchEvent.X = TouchX[pointerId] = (int)(event.getX(pointerIndex) \* ScaleX);
TouchEvent.Y = TouchY[pointerId] = (int)(event.getY(pointerIndex) \* ScaleY);
IsTouched[pointerId] = true;
TouchEventsBuffer.add(TouchEvent);
break;
case MotionEvent.ACTION\_UP:
case MotionEvent.ACTION\_POINTER\_UP:
case MotionEvent.ACTION\_CANCEL:
TouchEvent = TouchEventPool.NewObject();
TouchEvent.Type = MechanicTouchEvent.TOUCH\_UP;
TouchEvent.Pointer = pointerId;
TouchEvent.X = TouchX[pointerId] = (int)(event.getX(pointerIndex) \* ScaleX);
TouchEvent.Y = TouchY[pointerId] = (int)(event.getY(pointerIndex) \* ScaleY);
IsTouched[pointerId] = false;
TouchEventsBuffer.add(TouchEvent);
break;
case MotionEvent.ACTION\_MOVE:
int pointerCount = event.getPointerCount();
for (int i = 0; i < pointerCount; i++)
{
pointerIndex = i;
pointerId = event.getPointerId(pointerIndex);
TouchEvent = TouchEventPool.NewObject();
TouchEvent.Type = MechanicTouchEvent.TOUCH\_DRAGGED;
TouchEvent.Pointer = pointerId;
TouchEvent.X = TouchX[pointerId] = (int)(event.getX(pointerIndex) \* ScaleX);
TouchEvent.Y = TouchY[pointerId] = (int)(event.getY(pointerIndex) \* ScaleY);
TouchEventsBuffer.add(TouchEvent);
}
break;
}
return true;
}
}
@Override
public boolean IsTouchDown(int pointer)
{
synchronized(this)
{
if(pointer < 0 || pointer >= MaxTouchers)
return false;
else
return IsTouched[pointer];
}
}
@Override
public int GetTouchX(int pointer)
{
synchronized(this)
{
if (pointer < 0 || pointer >= MaxTouchers)
return 0;
else
return TouchX[pointer];
}
}
@Override
public int GetTouchY(int pointer)
{
synchronized(this)
{
if (pointer < 0 || pointer >= 20)
return 0;
else
return TouchY[pointer];
}
}
@Override
public List GetTouchEvents()
{
synchronized (this)
{
for (int i = 0; i < TouchEvents.size(); i++)
TouchEventPool.Free(TouchEvents.get(i));
TouchEvents.clear();
TouchEvents.addAll(TouchEventsBuffer);
TouchEventsBuffer.clear();
return TouchEvents;
}
}
}
```
Кроме Touch мы реализуем еще OnTouchListener
EnableMultiTouch нужен для определения, поддерживает ли устройство одновременное нажатие нескольких пальцев. Если VERSION.SDK меньше 5 (представлена эта переменная почему-то в виде строки), то не поддерживает.
MaxTouchers – максимальное число пальцев. Их 20, может быть больше или меньше.
В функции onTouch мы получаем номер пальца и действие (нажатие, отрыв, перемещение), которое записываем в событие и добавляем событие в список.
В GetTouchEvents мы возвращаем список событий, который после этого очищаем. За возвращение списка событий отвечает другой список.
Вы можете спросить, за что отвечает ScaleX и ScaleY? Об этом будет рассказано чуть позже, в разделе графики
MechanicKeyboard
```
package com.mechanic.input;
import java.util.ArrayList;
import java.util.List;
import android.view.KeyEvent;
import android.view.View;
import com.mechanic.input.Input.MechanicKeyEvent;
import com.mechanic.input.Pool.PoolFactory;
import com.mechanic.input.Pool;
public class MechanicKeyboard implements Keyboard
{
boolean[] PressedKeys = new boolean[128];
Pool KeyEventPool;
List KeyEventsBuffer = new ArrayList();
List KeyEvents = new ArrayList();
public MechanicKeyboard(View view)
{
PoolFactory pool = new PoolFactory()
{
@Override
public MechanicKeyEvent Create()
{
return new MechanicKeyEvent();
}
};
KeyEventPool = new Pool(pool,100);
view.setOnKeyListener(this);
view.setFocusableInTouchMode(true);
view.requestFocus();
}
public boolean IsKeyPressed(int KeyCode)
{
if(KeyCode < 0 || KeyCode > 127)
return false;
return PressedKeys[KeyCode];
}
public List GetKeyEvents()
{
synchronized(this)
{
for(int i = 0; i < KeyEvents.size(); i++)
KeyEventPool.Free(KeyEvents.get(i));
KeyEvents.clear();
KeyEvents.addAll(KeyEventsBuffer);
KeyEventsBuffer.clear();
return KeyEvents;
}
}
@Override
public boolean onKey(View v, int keyCode, KeyEvent event)
{
if(event.getAction() == KeyEvent.ACTION\_MULTIPLE)
return false;
synchronized(this)
{
MechanicKeyEvent key = KeyEventPool.NewObject();
key.KeyCode = keyCode;
key.KeyChar = (char)event.getUnicodeChar();
if(event.getAction() == KeyEvent.ACTION\_DOWN)
{
key.Type = MechanicKeyEvent.KEY\_DOWN;
if(keyCode > 0 && keyCode < 128)
PressedKeys[keyCode] = true;
}
if(event.getAction() == KeyEvent.ACTION\_UP)
{
key.Type = MechanicKeyEvent.KEY\_UP;
if(keyCode > 0 && keyCode < 128)
PressedKeys[keyCode] = false;
}
KeyEventsBuffer.add(key);
}
return false;
}
}
```
Создаем массив из 128 булевых переменных, которые будут держать информацию о 128 нажатых или не нажатых клавишах. Также создаем пул объектов и 2 списка. Все просто
MechanicInput
```
package com.mechanic.input;
import java.util.List;
import android.content.Context;
import android.view.View;
public class MechanicInput implements Input
{
MechanicKeyboard keyboard;
MechanicAccelerometer accel;
MechanicTouch touch;
public MechanicInput(Context context, View view, float scaleX, float scaleY)
{
accel = new MechanicAccelerometer(context);
keyboard = new MechanicKeyboard(view);
touch = new MechanicTouch(view, scaleX, scaleY);
}
@Override
public boolean IsKeyPressed(int keyCode)
{
return keyboard.IsKeyPressed(keyCode);
}
@Override
public boolean IsKeyPressed(char keyChar)
{
return keyboard.IsKeyPressed(keyChar);
}
@Override
public boolean IsTouchDown(int pointer)
{
return touch.IsTouchDown(pointer);
}
@Override
public int GetTouchX(int pointer)
{
return touch.GetTouchX(pointer);
}
@Override
public int GetTouchY(int pointer)
{
return touch.GetTouchY(pointer);
}
@Override
public float GetAccelX()
{
return accel.GetAccelX();
}
@Override
public float GetAccelY()
{
return accel.GetAccelY();
}
@Override
public float GetAccelZ()
{
return accel.GetAccelZ();
}
@Override
public List GetTouchEvents()
{
return touch.GetTouchEvents();
}
@Override
public List GetKeyEvents()
{
return keyboard.GetKeyEvents();
}
}
```
Реализуем паттерн «Фасад».
Теперь настало время поработать с файлами!
#### Работа с файлами
MechanicFileIO
```
package com.mechanic.fileio;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import android.content.res.AssetManager;
import android.os.Environment;
public class MechanicFileIO implements FileIO
{
AssetManager assets;
String ExternalStoragePath;
public MechanicFileIO(AssetManager assets)
{
this.assets = assets;
ExternalStoragePath = Environment.getExternalStorageDirectory().getAbsolutePath() +
File.separator;
}
public InputStream ReadAsset(String name) throws IOException
{
return assets.open(name);
}
public InputStream ReadFile(String name) throws IOException
{
return new FileInputStream(ExternalStoragePath + name);
}
public OutputStream WriteFile(String name) throws IOException
{
return new FileOutputStream(ExternalStoragePath + name);
}
}
```
Мы получаем менеджер ассетов для изъятия файлов из папки assets, его использует первая функция, а вторые 2 функции берут файлы из специальной папки устройства на андроид, куда записываем и откуда считываем все данные насчет игры – рекорды, настройки, и прочее. Путь до этой папки берем в конструкторе.
Теперь создаем звуки
#### Работа со звуками
MechanicSound
```
package com.mechanic.audio;
import android.media.SoundPool;
public class MechanicSound implements Sound
{
int id;
SoundPool pool;
public MechanicSound(SoundPool pool, int id)
{
this.pool = pool;
this.id = id;
}
public void Play(float volume)
{
pool.play(id, volume, volume, 0, 0, 1);
}
public void Close()
{
pool.unload(id);
}
}
```
В MechanicAudio для держания мелких звуковых эффектов мы используем SoundPool. В MechanicSound мы передаем номер звукового эффекта и сам объект SoundPool, от которого производим звук
MechanicMusic
```
package com.mechanic.audio;
import java.io.IOException;
import android.content.res.AssetFileDescriptor;
import android.media.MediaPlayer;
public class MechanicMusic implements Music
{
MediaPlayer Player;
boolean IsPrepared = false;
public MechanicMusic(AssetFileDescriptor descriptor)
{
Player = new MediaPlayer();
try
{
Player.setDataSource(descriptor.getFileDescriptor(),
descriptor.getStartOffset(), descriptor.getLength());
Player.prepare();
IsPrepared = true;
}
catch(Exception ex)
{
throw new RuntimeException("Невозможно загрузить потоковую музыку");
}
}
public void Close()
{
if(Player.isPlaying())
Player.stop();
Player.release();
}
public boolean IsLooping()
{
return Player.isLooping();
}
public boolean IsPlaying()
{
return Player.isPlaying();
}
public boolean IsStopped()
{
return !IsPrepared;
}
public void Play()
{
if(Player.isPlaying())
return;
try
{
synchronized(this)
{
if(!IsPrepared)
Player.prepare();
Player.start();
}
}
catch(IllegalStateException ex)
{
ex.printStackTrace();
}
catch(IOException ex)
{
ex.printStackTrace();
}
}
public void SetLooping(boolean loop)
{
Player.setLooping(loop);
}
public void SetVolume(float volume)
{
Player.setVolume(volume, volume);
}
public void Stop()
{
Player.stop();
synchronized(this)
{
IsPrepared = false;
}
}
@Override
public void onCompletion(MediaPlayer player)
{
synchronized(this)
{
IsPrepared = false;
}
}
}
```
Мы ставим звуковой файл на поток и воспроизводим его.
IsPrepared показывает, готов ли звук для произведения.
Рекомендую самому разобраться в этом классе.
Мы дошли до MechanicAudio
```
package com.mechanic.audio;
import java.io.IOException;
import android.app.Activity;
import android.content.res.AssetFileDescriptor;
import android.content.res.AssetManager;
import android.media.AudioManager;
import android.media.SoundPool;
public class MechanicAudio implements Audio
{
AssetManager assets;
SoundPool pool;
public MechanicAudio(Activity activity)
{
activity.setVolumeControlStream(AudioManager.STREAM_MUSIC);
this.assets = activity.getAssets();
pool = new SoundPool(20, AudioManager.STREAM_MUSIC, 0);
}
public Music NewMusic(String name)
{
try
{
AssetFileDescriptor descriptor = assets.openFd(name);
return new MechanicMusic(descriptor);
}
catch(IOException ex)
{
throw new RuntimeException("Невозможно загрузить потоковую музыку " + name);
}
}
public Sound NewSound(String name)
{
try
{
AssetFileDescriptor descriptor = assets.openFd(name);
int id = pool.load(descriptor, 0);
return new MechanicSound(pool, id);
}
catch(IOException ex)
{
throw new RuntimeException("Невозможно загрузить звуковой эффект " + name);
}
}
}
```
В конструкторе мы делаем возможность регулировать музыку устройством, берем менеджер ассетов и создаем SoundPool, который может проигрывать не более 20 звуковых эффектов за раз. Думаю, в большинстве игр этого хватит.
В создании Music мы передаем в конструктор MechanicMusic дескриптор файла, в создании Sound загружаем звук в soundPool и передаем в конструктор MechanicSound сам пул и номер звука, если что-то идет не так, делается исключение.
Делаем рисовальщик
#### Работа с графикой
MechanicImage
```
package com.mechanic.graphics;
import com.mechanic.graphics.Graphics.ImageFormat;
import android.graphics.Bitmap;
public class MechanicImage implements Image
{
Bitmap bitmap;
ImageFormat format;
public MechanicImage(Bitmap bitmap, ImageFormat format)
{
this.bitmap = bitmap;
this.format = format;
}
@Override
public int GetWidth()
{
return bitmap.getWidth();
}
@Override
public int GetHeight()
{
return bitmap.getHeight();
}
@Override
public ImageFormat GetFormat()
{
return format;
}
@Override
public void Dispose()
{
bitmap.recycle();
}
}
```
Этот класс – держатель изображения. Ничего особенного он не делает, введен для удобства.
MechanicGraphics
```
package com.mechanic.graphics;
import java.io.IOException;
import java.io.InputStream;
import android.content.res.AssetManager;
import android.graphics.Bitmap;
import android.graphics.Bitmap.Config;
import android.graphics.BitmapFactory;
import android.graphics.Canvas;
import android.graphics.Paint;
import android.graphics.Paint.Style;
import android.graphics.Rect;
public class MechanicGraphics implements Graphics
{
AssetManager assets;
Bitmap buffer;
Canvas canvas;
Paint paint;
Rect srcRect = new Rect(), dstRect = new Rect();
public MechanicGraphics(AssetManager assets, Bitmap buffer)
{
this.assets = assets;
this.buffer = buffer;
this.canvas = new Canvas(buffer);
this.paint = new Paint();
}
@Override
public Image NewImage(String fileName)
{
ImageFormat format;
InputStream file = null;
Bitmap bitmap = null;
try
{
file = assets.open(fileName);
bitmap = BitmapFactory.decodeStream(file);
if (bitmap == null)
throw new RuntimeException("Нельзя загрузить изображение '"
+ fileName + "'");
}
catch (IOException e)
{
throw new RuntimeException("Нельзя загрузить изображение '"
+ fileName + "'");
}
finally
{
try
{
if(file != null)
file.close();
}
catch(IOException e)
{
}
}
if (bitmap.getConfig() == Config.RGB_565)
format = ImageFormat.RGB_565;
else if (bitmap.getConfig() == Config.ARGB_4444)
format = ImageFormat.ARGB_4444;
else
format = ImageFormat.ARGB_8888;
return new MechanicImage(bitmap, format);
}
@Override
public void Clear(int color)
{
canvas.drawRGB((color & 0xff0000) >> 16, (color & 0xff00) >> 8, (color & 0xff));
}
@Override
public void DrawPixel(int x, int y, int color)
{
paint.setColor(color);
canvas.drawPoint(x, y, paint);
}
@Override
public void DrawLine(int x, int y, int x2, int y2, int color)
{
paint.setColor(color);
canvas.drawLine(x, y, x2, y2, paint);
}
@Override
public void DrawRect(int x, int y, int width, int height, int color)
{
paint.setColor(color);
paint.setStyle(Style.FILL);
canvas.drawRect(x, y, x + width - 1, y + width - 1, paint);
}
@Override
public void DrawImage(Image image, int x, int y, int srcX, int srcY,
int srcWidth, int srcHeight)
{
srcRect.left = srcX;
srcRect.top = srcY;
srcRect.right = srcX + srcWidth - 1;
srcRect.bottom = srcY + srcHeight - 1;
dstRect.left = x;
dstRect.top = y;
dstRect.right = x + srcWidth - 1;
dstRect.bottom = y + srcHeight - 1;
canvas.drawBitmap(((MechanicImage)image).bitmap, srcRect, dstRect,
null);
}
@Override
public void DrawImage(Image image, int x, int y)
{
canvas.drawBitmap(((MechanicImage)image).bitmap, x, y, null);
}
@Override
public int GetWidth()
{
return buffer.getWidth();
}
@Override
public int GetHeight()
{
return buffer.getHeight();
}
}
```
Обратите внимание! Мы не создаем объекты Paint и Rect каждый раз при отрисовке, так как это преступление против сборщика мусора.
В конструкторе мы берем Bitmap — буфер, на котором будем все рисовать, его использует canvas.
По загрузке изображения мы считываем картинку из ассетов, а потом декодируем ее в Bitmap. Бросается исключение, если загружаемый файл не картинка или если его не существует, потом файл закрывается. Под конец мы берем формат картинки и возвращаем новый MechanicImage, передавая в конструктор Bitmap и ImageFormat. Также внимание заслуживает первый метод DrawImage, который рисует часть картинки. Это применяется, когда вместо отдельных изображений картинок в игре используется группа картинок, называемая атласом. Вот пример такого атласа

(изображение взято из веб-ресурса interesnoe.info)
Допустим, нам потребовалось отрисовать часть картинки с 32,32 по 48,48, в позиции 1,1; тогда мы делаем так
```
DrawImage(image, 1, 1, 32, 32, 16, 16);
```
Остальные методы легко понятны и интереса не представляют.
Настало время для интерфейсов Game и Screen!
Перед тем, как продолжать, нам нужно отрисовывать графику в отдельном потоке и не загружать пользовательский поток.
Встречайте класс SurfaceView, который предлагает в отдельном потоке рисовать графику. Создайте класс Runner
```
package com.mechanic.game;
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.Rect;
import android.view.SurfaceHolder;
import android.view.SurfaceView;
public class Runner extends SurfaceView implements Runnable
{
MechanicGame game;
Canvas canvas;
Bitmap buffer;
Thread thread = null;
SurfaceHolder holder;
volatile boolean running = false;
public Runner(Object context, MechanicGame game,
Bitmap buffer)
{
super(game);
this.game = game;
this.buffer = buffer;
this.holder = getHolder();
}
public void Resume()
{
running = true;
thread = new Thread(this);
thread.start();
}
public void run()
{
Rect dstRect = new Rect();
long startTime = System.nanoTime();
while(running)
{
if(!holder.getSurface().isValid())
continue;
float deltaTime = (System.nanoTime()-startTime) / 1000000000.0f;
startTime = System.nanoTime();
game.GetCurrentScreen().Update(deltaTime);
game.GetCurrentScreen().Present(deltaTime);
canvas = holder.lockCanvas();
canvas.getClipBounds(dstRect);
canvas.drawBitmap(buffer, null, dstRect, null);
holder.unlockCanvasAndPost(canvas);
}
}
public void Pause()
{
running = false;
while(true)
{
try
{
thread.join();
break;
}
catch (InterruptedException e)
{
}
}
}
}
```
Класс MechanicGame скоро будет, не волнуйтесь.
Для рисования графики не в пользовательском интерфейсе нам нужен объект SurfaceHolder. Его главные функции – lockCanvas и unlockCanvasAndPost. Первая функция блокирует Surface и возвращает Canvas, на котором можно что-нибудь рисовать (в нашем случае – буфер Bitmap, который выступает в роли холста).
В функции Resume мы запускаем новый поток с этим классом.
В функции run, пока приложение работает, берется прошедший промежуток с прошлого цикла (System.nanoTime возвращает наносекунды) и вызываются функции Update и Present текущего Screen’а приложения, после чего рисуется буфер.
Вот класс MechanicGame
```
package com.mechanic.game;
import com.mechanic.audio.Audio;
import com.mechanic.audio.MechanicAudio;
import com.mechanic.fileio.FileIO;
import com.mechanic.fileio.MechanicFileIO;
import com.mechanic.graphics.Graphics;
import com.mechanic.graphics.MechanicGraphics;
import com.mechanic.input.Input;
import com.mechanic.input.MechanicInput;
import android.app.Activity;
import android.content.Context;
import android.content.res.Configuration;
import android.graphics.Bitmap;
import android.graphics.Bitmap.Config;
import android.os.Bundle;
import android.os.PowerManager;
import android.os.PowerManager.WakeLock;
import android.view.Window;
import android.view.WindowManager;
public abstract class MechanicGame extends Activity implements Game
{
Runner runner;
Graphics graphics;
Audio audio;
Input input;
FileIO fileIO;
Screen screen;
WakeLock wakeLock;
static final int SCREEN_WIDTH = 80;
static final int SCREEN_HEIGHT = 128;
@Override
public void onCreate(Bundle savedInstanceState)
{
super.onCreate(savedInstanceState);
requestWindowFeature(Window.FEATURE_NO_TITLE);
getWindow().setFlags(WindowManager.LayoutParams.FLAG_FULLSCREEN,
WindowManager.LayoutParams.FLAG_FULLSCREEN);
boolean IsLandscape = (getResources().getConfiguration().orientation ==
Configuration.ORIENTATION_LANDSCAPE);
int frameBufferWidth = IsLandscape ? SCREEN_HEIGHT : SCREEN_WIDTH;
int frameBufferHeight = IsLandscape ? SCREEN_WIDTH : SCREEN_HEIGHT;
Bitmap frameBuffer = Bitmap.createBitmap(frameBufferWidth,
frameBufferHeight, Config.RGB_565);
float scaleX = (float) frameBufferWidth /
getWindowManager().getDefaultDisplay().getWidth();
float scaleY = (float) frameBufferHeight /
getWindowManager().getDefaultDisplay().getHeight();
runner = new Runner(null, this, frameBuffer);
graphics = new MechanicGraphics(getAssets(), frameBuffer);
fileIO = new MechanicFileIO(getAssets());
audio = new MechanicAudio(this);
input = new MechanicInput(this, runner, scaleX, scaleY);
screen = GetStartScreen();
setContentView(runner);
PowerManager powerManager = (PowerManager)
getSystemService(Context.POWER_SERVICE);
wakeLock = powerManager.newWakeLock(PowerManager.FULL_WAKE_LOCK,
"Game");
}
@Override
public Input GetInput()
{
return input;
}
@Override
public FileIO GetFileIO()
{
return fileIO;
}
@Override
public Graphics GetGraphics()
{
return graphics;
}
@Override
public Audio GetAudio()
{
return audio;
}
@Override
public void SetScreen(Screen screen)
{
if (screen == null)
throw new IllegalArgumentException("Screen не может быть null");
this.screen.Pause();
this.screen.Dispose();
screen.Resume();
screen.Update(0);
this.screen = screen;
}
@Override
public Screen GetCurrentScreen()
{
return screen;
}
@Override
public Screen GetStartScreen()
{
return null;
}
@Override
public void onResume()
{
super.onResume();
wakeLock.acquire();
screen.Resume();
runner.Resume();
}
@Override
public void onPause()
{
super.onPause();
wakeLock.release();
runner.Pause();
screen.Pause();
if(isFinishing())
screen.Dispose();
}
}
```
У этого класса есть объекты Runner, всех наших интерфейсов и классов и объект WakeLock (нужен для того, чтобы телефон не засыпал, когда запущена игра)
Также у него есть 2 константы – SCREEN\_WIDTH и SCREEN\_HEIGHT, которые очень важны!
У устройств множество разрешений, и почти невозможно и бессмысленно под каждое устройство подстраивать размеры картинок, вычислять местоположение и т.д. и т.п. Представьте, что у нас есть окошко размером 80x128 пикселей (из двух вышеназванных констант). Мы в этом окошке рисуем маленькие картинки. Но вдруг размер экрана устройства не подходит по размеру этому окошку. Что делать? Все очень просто – мы берем отношение ширины и длины нашего окошка к ширине и длине устройства и рисуем все картинки, учитывая это отношение.
В итоге приложение само растягивает картинки под экран устройства.
Этот класс включает в себя Activity и у него есть методы onCreate, onResume и onPause.
В onCreate сначала приложение переходит в полноэкранный режим (чтобы не было видно зарядки и времени вверху). Потом выясняется ориентация телефона – ландшафтная или портретная (которая уже прописана в .xml файле в начале статьи). Потом создается долгожданный буфер с размером с это вот окошко 80x128 пикселей, выясняется отношение этого окошка к размеру устройства, которое передается в конструктор MechanicInput, он, в свою очередь, передает отношение в MechanicTouch. И тут – бинго! Полученные точки касания на экран умножаются на это отношение, так что координаты нажатия не зависят от размеров устройства.
Дальше создаем наши интерфейсы, регистрируем Runner и WakeLock.
В методе SetScreen мы освобождаем текущий Screen и записываем другой Screen.
Остальные методы интереса не предоставляют.
**Неужели это все?**
Да, господа, фреймворк уже готов!
When it’s done.
**А как теперь связать фреймворк с главным классом, допустим, с MyGame?**
«Главный» класс выглядит примерно так
```
public class MyGame extends Activity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_my_game);
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
// Inflate the menu; this adds items to the action bar if it is present.
getMenuInflater().inflate(R.menu.my_game, menu);
return true;
}
}
```
Видоизменяем его до такого класса
```
package com.mechanic;
import com.mechanic.game.MechanicGame;
import com.mechanic.game.Screen;
public class MyGame extends MechanicGame
{
@Override
public Screen GetStartScreen()
{
return new GameScreen(this);
}
}
```
Java воспринимает этот класс как наследника от Activity, так как сам MechanicGame наследник от Activity. onCreate уже прописан, и единственное, что нам надо сделать – переопределить GetStartScreen(), так как в MechanicGame этот метод возвращает null, а это кидает ошибку.
Не забудьте реализовать класс GameScreen :)
```
package com.mechanic;
import com.mechanic.game.Game;
import com.mechanic.game.Screen;
import com.mechanic.graphics.Graphics;
import com.mechanic.graphics.Image;
public class GameScreen extends Screen
{
Graphics g = game.GetGraphics();
Image wikitan;
float x = 0.0f;
public GameScreen(Game game)
{
super(game);
wikitan = g.NewImage("wikipetan.png");
}
@Override
public void Update(float deltaTime)
{
if(game.GetInput().IsTouchDown(0))
x += 1.0f * deltaTime;
}
@Override
public void Present(float deltaTime)
{
g.Clear(0);
g.DrawImage(wikitan, (int)x, 0);
}
@Override
public void Pause()
{
}
@Override
public void Resume()
{
}
@Override
public void Dispose()
{
wikitan.Dispose();
}
}
```
Это простой пример реализации Screen, который загружает изображение Википе-тан и двигает его по клику на экран.

(Изображение взято из веб-ресурса ru.wikipedia.org)
Результат
Переменная x представлена как float, так как прибавление чисел от 0 до 1 ничего не дает, идет округление.
Википе-тан рисуется c увеличением, так как размер нашего холста 80x128 пикселей
#### Вопросы и ответы:
**— У меня неправильно отрисовывается картинка – повернутой на 90 градусов!**
— Это все потому что мы дали команду в xml файле работать только в ландшафтном режиме. Для переключения режима жмите на клавишу 7 в правой части клавиатуры
**— Я честно изменяю x += 1.0f \* deltaTime, но картинка не двигается с места или медленно двигается. Что делать?**
— Эмулятор – очень медленная штука. Проверяйте работоспособность приложения на устройстве.
**Have fun!**
**Исходники:**
~~[rghost.ru/49052713](http://rghost.ru/49052713)~~
[github.com/Izaron/MechanicFramework](https://github.com/Izaron/MechanicFramework)
**Литература:**
[developer.alexanderklimov.ru/android](http://developer.alexanderklimov.ru/android/)
[habrahabr.ru/post/109944](http://habrahabr.ru/post/109944/)
Книга Марио Цехнера «Программирование игр под Android» | https://habr.com/ru/post/195830/ | null | ru | null |
# Как CSS Grid меняет представление о структурировании контента
Каждый, кто хотя бы немного занимался созданием веб-сайтов, знает, что теги — являются важным строительным блоком для контроля над макетом.
HTML5 представил новые семантические элементы, чтобы помочь в этом. И хотя они являются фантастическим дополнением к языку, они немного похожи на украшение к нашему супу из элементов.

С приходом CSS Grid, нам больше не нужно полагаться на элементы для создания структуры страницы или даже более сложного компонента. Структура буквально определяется родительским элементом, а не тем, как расположено содержимое внутри него.
Это значит, что мы можем получить хороший простой макет, который структурирует содержимое, не обращая внимание на то, как оно изначально организовано с помощью элементов .
---
CSS Grid может быть сложным, но и Flexbox тоже
----------------------------------------------
Я слышал о жалобах множества людей, что Grid слишком сложны и что Flexbox отлично справляется с теми же задачами. Я бы сказал, что им просто комфортно использовать Flexbox и поэтому нет желания дополнительно изучать CSS Grid.
Технология CSS Grid действительно вводит множество новых свойств и значений, так что да, есть кривая обучения. Но и Flexbox также довольно сложен.
Можете ли вы рассказать о преимуществах использования свойства `flex-basis` вместо `width`? Или как Flexbox рассчитывает ширину flex-элементов, если мы её явно не задали?
Например, если вы покажете приведённый ниже пример тому, кто никогда не использовал Flexbox, как вы объясните тот факт, что в нём заданы одинаковая разметка и одинаковые стили для обоих наборов столбцов? Что ещё хуже, второй столбец в обоих случаях имеет ширину 50%. Очевидно, что ширина со значением 50% на самом деле не устанавливает размер элемента в 50%.
«Что ж, всё начинается с того, что элементы сжимаются, если в контейнере недостаточно места, поэтому, даже если мы установили элементу ширину = 50%, места ему не хватает, поэтому он начинает сжиматься, чтобы втиснуться в контейнер, так как другой требует больше места. 50% — это скорее идеальный размер для блока, а не размер фактический.»
«Таким образом, в примере выше содержимое первого блока настолько большое, что создаёт проблему, потому что, как flex-элемент, по умолчанию он стремится сжаться, чтобы вместить содержимое. В этом примере данный элемент имеет много содержимого, так что…
Так что да, flexbox великолепен и отлично справляется с созданием макетов, но, пожалуйста, не говорите мне, что он прост. Как только вы переходите от идеальных примеров к рабочим задачам, подобное поведение довольно часто далеко от интуитивного понимания, а порой может быть откровенно странным.
Grid сложен тем, что влечёт за собой много новых свойств и значений, но они дают нам гораздо больше контроля, чем flexbox.
В этой статье мне бы хотелось рассмотреть, как этот дополнительный уровень контроля помогает упростить нашу разметку и позволяет писать меньше кода, и всё это даже без необходимости изучения того, как использовать целый ряд его причудливых функций.
Ограничения Flexbox
-------------------
Даже если мы возьмём простой компонент и создадим его с помощью flexbox, из-за того, что он действует только в 1 измерении (flex-элементы являются либо строками, либо столбцами, они не могут быть и тем и другим), у нас оказывается большое количеством элементов, используемых для создания строк, которые потом можно будет разбить на столбцы.
Например, если мы работает над карточкой, как эта:

Это не сложный макет, но нам всё ещё нужно организовать наш контент довольно специфичным образом, чтобы заставить работать.

Желтый и оранжевый блоки в этой ситуации нужны, чтобы при добавлении свойства display: flex для элемента .card (красный блок), создались две колонки. Таким образом, чтобы структурировать всё содержимое, мы получаем разметку, которая выглядит примерно так:
```
```
Как только вы поймёте, как работает Flexbox, понять такую структуру станет просто.
Когда мы добавим свойство `display: flex` для элемента `.card`, получим две колонки, после чего нужно будет стилизовать каждую из них отдельно.
Вот рабочий пример со всеми стилями:
Дело в том, что при создании столбцов содержимого, мы получаем немного более сложную разметку, и мы также ограничиваем себя, так как вынуждаем разные части содержимого группироваться вместе.
Упрощение всего с помощью CSS Grid
----------------------------------
Поскольку CSS Grid двухмерный, он позволяет нам одновременно создавать строки и столбцы, а это значит, что grid-контейнер (которому мы задали свойство `display: grid`) имеет полный контроль над макетом внутри себя.
Раньше для этого требовались дополнительные элементы, как в приведенном выше примере с Flexbox. Используя Grid, мы можем полностью избавиться от них.
```

...
Ramsey Harper
-------------
Graphic Designer
Lorem ipsum ...
```
С точки зрения разметки, разве не имеет ли это больше смысла?
Есть элемент с классом `.card`, в который мы помещаем его непосредственное содержимое. Нам не нужно переживать о структуре и компоновке элементов, мы просто помещаем контент, который нам нужен, и идём дальше.
### Структурирование макета
Так же, как при использовании Flexbox, нам все еще нужно структурировать макет, хотя из-за особенностей работы Grid, это выглядит немного иначе.
Это одна из ситуаций, в которой люди могу утверждать, что Grid сложнее, но на самом деле, я просто рисую блоки вокруг каждой части содержимого.
 | https://habr.com/ru/post/471396/ | null | ru | null |
# Пишем ГОСТ криптопровайдер
Секреты создания CSP для Windows раскрыты в [статье Ю.С.Зырянова](http://www.rsdn.ru/article/crypto/cspsecrets.xml).
Российские криптоалгоритмы ГОСТ реализованы в [OpenSSL Gost](http://habrahabr.ru/blogs/crypto/89394/).
Удивлен, что на просторах Интернета не удалось найти подтверждения, что кем-то был создан интерфейс криптопровайдера ГОСТ под Windows с использованием вышеприведенных инструментов.
Можно подумать, что эта задача под силу только крупным коммерческим компаниям, имеющим большой опыт в сфере информационной безопасности, к примеру, таким как:* [ООО «Лисси»](http://lissi.ru/products/crypto/lissi_csp/)
* [ОАО «ИнфоТеКС»](http://infotecs.ru/downloads/product_full.php?id_product=2096)
* [ЗАО «Сигнал-КОМ»](http://www.signal-com.ru/ru/prod/crypt/signal_com/)
* [ОКБ САПР](http://shipka.ru/csp.html)
* ну и конечно, [ООО «КРИПТО-ПРО»](http://www.cryptopro.ru/products/csp/csp-3-6)
Опровергнуть, хотя бы частично, это утверждение и будет задачей данной статьи.
Для начала ограничимся малым, сделаем возможность проверки целостности ГОСТ сертификатов с помощью стандартных средств Windows, как на рисунке. Для простоты создание ЭЦП не будем рассматривать, не будем затрагивать тему генерации ключей. Во всех местах провайдера, кроме проверки ЭЦП и функции хеширования, будут использованы уже находящиеся в примере от Майкрософт заглушки в виде return TRUE и т.д. Автором планируется написание цикла статей на тему создания криптопровайдера и в дальнейшем все эти недостатки будут постепенно устранены.
На первом этапе нам нужно сделать не так чтобы много, а именно, сначала выполнить пункты, описанные в статье Ю.С.Зырянова, далее получить список OID из [RFC-4357](http://www.ietf.org/rfc/rfc4357.txt), скомпилировать библиотеку OpenSSL в части реализации ГОСТ криптоалгоритмов, ну и наконец, подыскать реальные [корневые сертификаты УЦ](http://www.google.ru/#hl=ru&cp=23&gs_id=2z&xhr=t&q=корневые+сертификаты+уц), можно и не только корневые, для проведения тестирования того, что у нас получилось.
Итак, приступим.
#### Качаем исходники
Для начала потребуется скачать [Microsoft Cryptographic Service Provider Development Kit](http://download.cnet.com/Cryptographic-Service-Provider-Developer-s-Toolkit-CSPDK/3000-2206_4-10732141.html), нажав на зеленую кнопку Download Now.
Прошу простить за непрямую ссылку, но на сайте [www.microsoft.com](http://www.microsoft.com) CSPDK найти не удалось. Похоже, что он убран с сайта, а по вышеприведенной ссылке находится устаревший вариант от 2001 года, но даже такой нам вполне подходит. После скачивания и распаковки найдем в исходниках файл csp.c и переименуем его в xyzcsp.c для последующих модификаций, csp.def и csp.rc — соответственно в xyzcsp.def и xyzcsp.rc
Далее скачаем библиотеку [OpenSSL](http://www.openssl.org/source/). На момент написания статьи она имеет версию 1.0.0e
#### Регистрация криптопровайдера xyzcsp.dll
Зарегистрируем криптопровайдер в реестре. Для этого выполним (с правами администратора) нижеприведенный файл командой «regedit xyzcsp.reg»
Файл xyzcsp.reg:
```
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography\Defaults\Provider\XYZ Provider]
"Image Path"="xyzcsp.dll"
"Type"=dword:0000007B
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography\Defaults\Provider Types\Type 123]
"Name"="XYZ Provider"
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography\OID\EncodingType 0\CryptDllFindOIDInfo]
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography\OID\EncodingType 0\CryptDllFindOIDInfo\1.2.643.2.2.19!1]
"Name"="GOST R 34.10-2001"
"Algid"=dword:00002036
"ExtraInfo"=hex:00,00,00,00
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography\OID\EncodingType 0\CryptDllFindOIDInfo\1.2.643.2.2.3!2]
"Name"="GOST R 34.11/34.10-2001"
"Algid"=dword:00008037
"ExtraInfo"=hex:36,20,00,00,00,00,00,00
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography\OID\EncodingType 1\CryptDllConvertPublicKeyInfo]
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography\OID\EncodingType 1\CryptDllConvertPublicKeyInfo\1.2.643.2.2.19]
"Dll"="xyzcsp.dll"
"FuncName"="xyz_ConvertPublicKeyInfo"
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Cryptography\OID\EncodingType 1\CryptDllConvertPublicKeyInfo\1.2.643.2.2.98]
"Dll"="xyzcsp.dll"
"FuncName"="xyz_ConvertPublicKeyInfo"
```
#### Библиотека OpenSSL
Сборку OpenSSL из исходников оставим за кадром, заметим только, что это несложно, требуется наличие установленного [perl](http://strawberryperl.com) и MS Visual Studio, для компиляции нужно следовать инструкциям в файле Install.W32, после этого получим в директории C:\xyzcsp\openssl-1.0.0e\tmp32dll множество объектных файлов, которые я для простоты собрал в один файл openssl.lib, который и использовал в своем проекте.
Файл flist.txt:
```
bf_buff.obj aes_core.obj aes_wrap.obj ameth_lib.obj asn1_gen.obj asn1_lib.obj asn1_par.obj asn_mime.obj asn_moid.obj asn_pack.obj a_bitstr.obj a_bool.obj a_bytes.obj a_d2i_fp.obj a_digest.obj a_dup.obj a_enum.obj a_gentm.obj a_i2d_fp.obj a_int.obj a_mbstr.obj a_object.obj a_octet.obj a_print.obj a_set.obj a_sign.obj a_strex.obj a_strnid.obj a_time.obj a_type.obj a_utctm.obj a_utf8.obj a_verify.obj bio_asn1.obj bio_b64.obj bio_cb.obj bio_enc.obj bio_err.obj bio_lib.obj bio_md.obj bio_ndef.obj bio_ok.obj bio_pk7.obj bio_ssl.obj bn_add.obj bn_asm.obj bn_blind.obj bn_const.obj bn_ctx.obj bn_depr.obj bn_div.obj bn_err.obj bn_exp.obj bn_exp2.obj bn_gcd.obj bn_gf2m.obj bn_kron.obj bn_lib.obj bn_mod.obj bn_mont.obj bn_mpi.obj bn_mul.obj bn_nist.obj bn_prime.obj bn_print.obj bn_rand.obj bn_recp.obj bn_shift.obj bn_sqr.obj bn_sqrt.obj bn_word.obj bss_dgram.obj bss_fd.obj bss_file.obj bss_log.obj bss_mem.obj bss_null.obj bss_sock.obj buffer.obj buf_err.obj by_dir.obj by_file.obj b_dump.obj b_print.obj b_sock.obj ca.obj camellia.obj cbc128.obj cbc_cksm.obj cbc_enc.obj cfb128.obj cfb64ede.obj cfb64enc.obj cfb_enc.obj ciphers.obj cmll_cbc.obj cmll_cfb.obj cmll_ctr.obj cmll_ecb.obj cmll_misc.obj cmll_ofb.obj cms.obj cms_asn1.obj cms_att.obj cms_cd.obj cms_dd.obj cms_enc.obj cms_env.obj cms_err.obj cms_ess.obj cms_io.obj cms_lib.obj cms_sd.obj cms_smime.obj comp_err.obj comp_lib.obj conf_api.obj conf_def.obj conf_err.obj conf_lib.obj conf_mall.obj conf_mod.obj conf_sap.obj cpt_err.obj crl.obj crl2p7.obj cryptlib.obj ctr128.obj cts128.obj cversion.obj c_all.obj c_allc.obj c_alld.obj c_cfb64.obj c_ecb.obj c_enc.obj c_ofb64.obj c_rle.obj c_skey.obj c_zlib.obj d1_both.obj d1_clnt.obj d1_enc.obj d1_lib.obj d1_meth.obj d1_pkt.obj d1_srvr.obj d2i_pr.obj d2i_pu.obj des_enc.obj des_old.obj des_old2.obj dgst.obj dh.obj dhparam.obj dh_ameth.obj dh_asn1.obj dh_check.obj dh_depr.obj dh_err.obj dh_gen.obj dh_key.obj dh_lib.obj dh_pmeth.obj dh_prn.obj digest.obj dsa.obj dsaparam.obj dsa_ameth.obj dsa_asn1.obj dsa_depr.obj dsa_err.obj dsa_gen.obj dsa_key.obj dsa_lib.obj dsa_ossl.obj dsa_pmeth.obj dsa_prn.obj dsa_sign.obj dsa_vrf.obj dso_beos.obj dso_dl.obj dso_dlfcn.obj dso_err.obj dso_lib.obj dso_null.obj dso_openssl.obj dso_vms.obj dso_win32.obj ebcdic.obj ec.obj ec2_mult.obj ec2_smpl.obj ecb3_enc.obj ecb_enc.obj ech_err.obj ech_key.obj ech_lib.obj ech_ossl.obj eck_prn.obj ecparam.obj ecp_mont.obj ecp_nist.obj ecp_smpl.obj ecs_asn1.obj ecs_err.obj ecs_lib.obj ecs_ossl.obj ecs_sign.obj ecs_vrf.obj ec_ameth.obj ec_asn1.obj ec_check.obj ec_curve.obj ec_cvt.obj ec_err.obj ec_key.obj ec_lib.obj ec_mult.obj ec_pmeth.obj ec_print.obj ede_cbcm_enc.obj enc.obj encode.obj enc_read.obj enc_writ.obj engine.obj eng_all.obj eng_cnf.obj eng_cryptodev.obj eng_ctrl.obj eng_dyn.obj eng_err.obj eng_fat.obj eng_init.obj eng_lib.obj eng_list.obj eng_openssl.obj eng_pkey.obj eng_table.obj err.obj errstr.obj err_all.obj err_prn.obj evp_acnf.obj evp_asn1.obj evp_enc.obj evp_err.obj evp_key.obj evp_lib.obj evp_pbe.obj evp_pkey.obj ex_data.obj e_aes.obj e_bf.obj e_camellia.obj e_cast.obj e_des.obj e_des3.obj e_gost_err.obj e_idea.obj e_null.obj e_old.obj e_rc2.obj e_rc4.obj e_rc5.obj e_seed.obj e_xcbc_d.obj fcrypt.obj fcrypt_b.obj f_enum.obj f_int.obj f_string.obj gendh.obj gendsa.obj genpkey.obj genrsa.obj gost2001.obj gost2001_keyx.obj gost89.obj gost94_keyx.obj gosthash.obj gost_ameth.obj gost_asn1.obj gost_crypt.obj gost_ctl.obj gost_eng.obj gost_keywrap.obj gost_md.obj gost_params.obj gost_pmeth.obj gost_sign.obj hmac.obj hm_ameth.obj hm_pmeth.obj i2d_pr.obj i2d_pu.obj i_cbc.obj i_cfb64.obj i_ecb.obj i_ofb64.obj i_skey.obj krb5_asn.obj kssl.obj lhash.obj lh_stats.obj md4_dgst.obj md4_one.obj md5_dgst.obj md5_one.obj mdc2dgst.obj mdc2_one.obj md_rand.obj mem.obj mem_clr.obj mem_dbg.obj m_dss.obj m_dss1.obj m_ecdsa.obj m_md4.obj m_md5.obj m_mdc2.obj m_null.obj m_ripemd.obj m_sha.obj m_sha1.obj m_sigver.obj m_wp.obj names.obj nseq.obj nsseq.obj n_pkey.obj obj_dat.obj obj_err.obj obj_lib.obj obj_xref.obj ocsp.obj ocsp_asn.obj ocsp_cl.obj ocsp_err.obj ocsp_ext.obj ocsp_ht.obj ocsp_lib.obj ocsp_prn.obj ocsp_srv.obj ocsp_vfy.obj ofb128.obj ofb64ede.obj ofb64enc.obj ofb_enc.obj o_dir.obj o_names.obj o_str.obj o_time.obj p12_add.obj p12_asn.obj p12_attr.obj p12_crpt.obj p12_crt.obj p12_decr.obj p12_init.obj p12_key.obj p12_kiss.obj p12_mutl.obj p12_npas.obj p12_p8d.obj p12_p8e.obj p12_utl.obj p5_crpt.obj p5_crpt2.obj p5_pbe.obj p5_pbev2.obj p8_pkey.obj passwd.obj pcbc_enc.obj pcy_cache.obj pcy_data.obj pcy_lib.obj pcy_map.obj pcy_node.obj pcy_tree.obj pem_all.obj pem_err.obj pem_info.obj pem_lib.obj pem_oth.obj pem_pk8.obj pem_pkey.obj pem_seal.obj pem_sign.obj pem_x509.obj pem_xaux.obj pk12err.obj pk7_asn1.obj pk7_attr.obj pk7_doit.obj pk7_lib.obj pk7_mime.obj pk7_smime.obj pkcs12.obj pkcs7.obj pkcs7err.obj pkcs8.obj pkey.obj pkeyparam.obj pkeyutl.obj pmeth_fn.obj pmeth_gn.obj pmeth_lib.obj pqueue.obj prime.obj pvkfmt.obj p_dec.obj p_enc.obj p_lib.obj p_open.obj p_seal.obj p_sign.obj p_verify.obj qud_cksm.obj rand.obj randfile.obj rand_egd.obj rand_err.obj rand_key.obj rand_lib.obj rand_nw.obj rand_os2.obj rand_unix.obj rand_win.obj rc2cfb64.obj rc2ofb64.obj rc2_cbc.obj rc2_ecb.obj rc2_skey.obj rc4_enc.obj rc4_skey.obj read2pwd.obj req.obj rmd_dgst.obj rmd_one.obj rpc_enc.obj rsa.obj rsautl.obj rsa_ameth.obj rsa_asn1.obj rsa_chk.obj rsa_depr.obj rsa_eay.obj rsa_err.obj rsa_gen.obj rsa_lib.obj rsa_none.obj rsa_null.obj rsa_oaep.obj rsa_pk1.obj rsa_pmeth.obj rsa_prn.obj rsa_pss.obj rsa_saos.obj rsa_sign.obj rsa_ssl.obj rsa_x931.obj s23_clnt.obj s23_lib.obj s23_meth.obj s23_pkt.obj s23_srvr.obj s2_clnt.obj s2_enc.obj s2_lib.obj s2_meth.obj s2_pkt.obj s2_srvr.obj s3_both.obj s3_clnt.obj s3_enc.obj s3_lib.obj s3_meth.obj s3_pkt.obj s3_srvr.obj seed.obj seed_cbc.obj seed_cfb.obj seed_ecb.obj seed_ofb.obj sess_id.obj set_key.obj sha1dgst.obj sha1_one.obj sha256.obj sha512.obj sha_dgst.obj sha_one.obj smime.obj speed.obj spkac.obj ssl_algs.obj ssl_asn1.obj ssl_cert.obj ssl_ciph.obj ssl_err.obj ssl_err2.obj ssl_lib.obj ssl_rsa.obj ssl_sess.obj ssl_stat.obj ssl_txt.obj stack.obj str2key.obj s_cb.obj s_client.obj s_server.obj s_socket.obj s_time.obj t1_clnt.obj t1_enc.obj t1_lib.obj t1_meth.obj t1_reneg.obj t1_srvr.obj tasn_dec.obj tasn_enc.obj tasn_fre.obj tasn_new.obj tasn_prn.obj tasn_typ.obj tasn_utl.obj tb_asnmth.obj tb_cipher.obj tb_dh.obj tb_digest.obj tb_dsa.obj tb_ecdh.obj tb_ecdsa.obj tb_pkmeth.obj tb_rand.obj tb_rsa.obj tb_store.obj ts.obj ts_asn1.obj ts_conf.obj ts_err.obj ts_lib.obj ts_req_print.obj ts_req_utils.obj ts_rsp_print.obj ts_rsp_sign.obj ts_rsp_utils.obj ts_rsp_verify.obj ts_verify_ctx.obj txt_db.obj t_bitst.obj t_crl.obj t_pkey.obj t_req.obj t_spki.obj t_x509.obj t_x509a.obj uid.obj ui_compat.obj ui_err.obj ui_lib.obj ui_openssl.obj ui_util.obj uplink.obj v3err.obj v3_addr.obj v3_akey.obj v3_akeya.obj v3_alt.obj v3_asid.obj v3_bcons.obj v3_bitst.obj v3_conf.obj v3_cpols.obj v3_crld.obj v3_enum.obj v3_extku.obj v3_genn.obj v3_ia5.obj v3_info.obj v3_int.obj v3_lib.obj v3_ncons.obj v3_ocsp.obj v3_pci.obj v3_pcia.obj v3_pcons.obj v3_pku.obj v3_pmaps.obj v3_prn.obj v3_purp.obj v3_skey.obj v3_sxnet.obj v3_utl.obj verify.obj version.obj wp_block.obj wp_dgst.obj x509.obj x509cset.obj x509name.obj x509rset.obj x509spki.obj x509type.obj x509_att.obj x509_cmp.obj x509_d2.obj x509_def.obj x509_err.obj x509_ext.obj x509_lu.obj x509_obj.obj x509_r2x.obj x509_req.obj x509_set.obj x509_trs.obj x509_txt.obj x509_v3.obj x509_vfy.obj x509_vpm.obj xcbc_enc.obj x_algor.obj x_all.obj x_attrib.obj x_bignum.obj x_crl.obj x_exten.obj x_info.obj x_long.obj x_name.obj x_nx509.obj x_pkey.obj x_pubkey.obj x_req.obj x_sig.obj x_spki.obj x_val.obj x_x509.obj x_x509a.obj
```
Прошу извинить за столь длинный список, но мне неизвестен простой способ, как можно узнать, какие obj файлы из данного lib файла нужны для сборки, а какие нет. Создание map файла не помогает, так что пришлось использовать практически полный список obj файлов из директории tmp32dll.
Создаем openssl.lib при помощи команды make\_lib.bat
make\_lib.bat:
```
call "C:\Program Files\Microsoft Visual Studio 10.0\VC\vcvarsall.bat"
lib /out:openssl.lib @flist.txt
```
Приступим к написанию необходимых нам функций хеширования и проверки ЭЦП по ГОСТ.
Назовем их my\_hash\_gost() и my\_verify\_gost() соответственно. Чтобы их получить, были использованы готовые куски из текста OpenSSL, но много времени ушло на отладку, в частности на то, чтобы понять, что когда мы делаем «переворот» данных, меняя порядок следования байт, то хеш переворачивать не нужно, а все остальное, включая публичный ключ и ЭЦП — нужно.
Немного истории. Изначально функция my\_verify\_gost тестировалась с хешем, равным константе во всех 32-х байтах. И это меня спасло. Потому что достаточно быстро функция заработала, но когда был вставлен реальный хеш, состоящий из достаточно случайного набора байт, то сразу после этого ЭЦП перестала проверяться. Я долго не мог понять, что константный хеш является зеркальным, поэтому подходит для работы функции и без переворачивания. Мне повезло, если бы тестирование началось с реального хеша, то библиотеку OpenSSL было бы достаточно тяжело настроить для проверки ЭЦП сертификатов, потому что такое «хитрое» поведение хеша достаточно неочевидно.
Вставим эти строки в файл xyzcsp.c сразу после всех имеющихся там #include
```
#include "gosthash.h"
#include "gost_lcl.h"
static void perevorot_buf(unsigned char *obj, int k)
{
char buf[64];
int i;
for( i = 0; i < k; i++ ) buf[i] = obj[k-1-i];
memcpy(obj, buf, k);
}
static int pkey_gost01_cp_verify(EC_KEY* pub_key, const unsigned char *sig,
size_t siglen, unsigned char *tbs, size_t tbs_len)
{
int ok = 0;
DSA_SIG *s=unpack_cp_signature(sig,siglen);
if (!s) return 0;
if (pub_key) ok = gost2001_do_verify(tbs,tbs_len,s,pub_key);
DSA_SIG_free(s);
return ok;
}
int my_verify_gost(char *in_hash, const BYTE *in_sign, char *in_pub1, char *in_pub2, int nid)
{
int res, errcode;
EC_KEY *eckey = NULL;
unsigned char sig[64], tbs[32];
int siglen=64, tbs_len=32;
BIGNUM *X=NULL,*Y=NULL;
char perevorot_pub[32];
EC_POINT *pub_key;
//Волшебные перевороты
memcpy(tbs, in_pub1, 32); perevorot_buf(tbs, 32);
X= getbnfrombuf((const unsigned char*)tbs,32);
memcpy(tbs, in_pub2, 32); perevorot_buf(tbs, 32);
Y= getbnfrombuf((const unsigned char*)tbs,32);
memcpy(tbs, in_hash, 32); //хеш переворачивать не надо! ранее был perevorot_buf(tbs, 32);
memcpy(sig, in_sign, 64); perevorot_buf(sig, 64);
//Проверка ЭЦП
if (!(eckey = EC_KEY_new())) { errcode = 1; goto err_exit; }
if (!fill_GOST2001_params(eckey, nid)) { errcode = 2; goto err_exit; }
if (!(pub_key = EC_POINT_new(EC_KEY_get0_group(eckey)))) { errcode = 3; goto err_exit; }
if (!EC_POINT_set_affine_coordinates_GFp(EC_KEY_get0_group(eckey)
,pub_key,X,Y,NULL)) { errcode = 4; goto err_exit; }
if (!EC_KEY_set_public_key(eckey,pub_key)) { errcode = 5; goto err_exit; }
if (!pkey_gost01_cp_verify(eckey, sig, siglen, tbs, tbs_len)) { errcode = 6; goto err_exit; }
else errcode = 0; //success
err_exit:
if (pub_key) EC_POINT_free(pub_key);
if (X) BN_free(X);
if (Y) BN_free(Y);
if (eckey) EC_KEY_free(eckey);
return errcode;
}
void my_hash_gost(const BYTE *buf, int buflen, char *hash_res)
{
gost_subst_block *b= &GostR3411_94_CryptoProParamSet;
gost_hash_ctx ctx;
init_gost_hash_ctx(&ctx,b);
start_hash(&ctx);
hash_block(&ctx,buf,buflen);
finish_hash(&ctx,(byte *)hash_res);
}
//Глобальные переменные для хеша и публичного ключа
char hash_gost[32];
char hash_sha1[20];
char public_key[64];
```
#### Провайдер XYZ Provider
Теперь займемся, наконец, провайдером. Выберем ему имя: «XYZ Provider». Соответственно, основной файл будет называться xyzcsp.c, также нужны файлы xyzcsp.def и xyzcsp.rc
В исходном образце, который можно найти в CSPDK, в файле csp.c, нас интересуют только функции CPAcquireContext, CPHashData, CPGetHashParam, CPVerifySignature. Легко видеть, что это функции для создания хендла провайдера, функции хеширования и проверки ЭЦП. Заменим эти функции на приведенные ниже.
Кроме них, напишем одну замечательную функцию, xyz\_ConvertPublicKeyInfo, которая будет заниматься конвертацией публичного ключа ЭЦП. Не забываем добавить xyz\_ConvertPublicKeyInfo в файл xyzcsp.def, чтобы линкер экспортировал это имя. Конвертация будет заключаться в игнорировании первых двух байт в записи ASN1 нотации публичного ключа, тем самым получая ключ в чистом виде, две половинки по 32 байта.
Удалим функцию DllMain, а также старые CPAcquireContext, CPHashData, CPGetHashParam, CPVerifySignature из xyzcsp.c, уберем устаревшую команду DESCRIPTION и имена DllRegisterServer и DllUnregisterServer из xyzcsp.def
Добавим в конец файла xyzcsp.c:
```
BOOL WINAPI
CPAcquireContext(
OUT HCRYPTPROV *phProv,
IN LPCSTR szContainer,
IN DWORD dwFlags,
IN PVTableProvStruc pVTable)
{
*phProv = 123;
return TRUE;
}
BOOL WINAPI
CPHashData(
IN HCRYPTPROV hProv,
IN HCRYPTHASH hHash,
IN CONST BYTE *pbData,
IN DWORD cbDataLen,
IN DWORD dwFlags)
{
my_hash_gost(pbData, cbDataLen, hash_gost);
SHA1(pbData, cbDataLen, hash_sha1);
return TRUE;
}
BOOL WINAPI
CPGetHashParam(
IN HCRYPTPROV hProv,
IN HCRYPTHASH hHash,
IN DWORD dwParam,
OUT LPBYTE pbData,
IN OUT LPDWORD pcbDataLen,
IN DWORD dwFlags)
{
switch(dwParam)
{
case HP_HASHVAL:
if(*pcbDataLen == 20) // у нас просят отпечаток sha1
{
memcpy(pbData, hash_sha1, 20);
break;
}
default:
*pcbDataLen = 0;
SetLastError(E_INVALIDARG);
return FALSE;
}
return TRUE;
}
BOOL WINAPI
CPVerifySignature(
IN HCRYPTPROV hProv,
IN HCRYPTHASH hHash,
IN CONST BYTE *pbSignature,
IN DWORD cbSigLen,
IN HCRYPTKEY hPubKey,
IN LPCWSTR szDescription,
IN DWORD dwFlags)
{
#define NTE_IC_ERROR_PREDEF 0x89900000L
INT err;
err = my_verify_gost(hash_gost, pbSignature, public_key, public_key+32,
NID_id_GostR3410_2001_CryptoPro_A_ParamSet);
if ( err )
{
SetLastError( NTE_IC_ERROR_PREDEF | err );
return FALSE;
}
return TRUE;
}
BOOL WINAPI xyz_ConvertPublicKeyInfo(
DWORD dwCertEncodingType,
VOID *EncodedKeyInfo,
DWORD dwAlg,
DWORD dwFlags,
BYTE** ppStructInfo,
DWORD* StructLen
)
{
memcpy(public_key, ((CERT_PUBLIC_KEY_INFO*)EncodedKeyInfo)->PublicKey.pbData + 2, 64);
return TRUE;
}
```
Подробно комментировать исходники криптопровайдера, думаю, излишне. Все понятно по тексту.
#### Пишем тестовую программу
Зачем нужна отдельная тестовая программа? Она, кроме запуска тестов, будет патчить систему, чтобы поменять функции SystemFunction035 в ADVAPI32.dll и I\_CryptGetDefaultCryptProv в CRYPT32.dll на их «правильный» вариант. Данная программа будет успешно работать как в Windows XP так и в Windows 7.
В конце статьи показано, как можно пропатчить системные файлы в Windows XP SP3, в этом случае специальная тестовая программа будет не нужна.
Файл testcsp.cpp:
```
#include "stdafx.h"
#include
#include
typedef HCRYPTPROV (WINAPI \*pI\_CryptGetDefaultCryptProv)(ALG\_ID algid);
HCRYPTPROV hProv = NULL;
typedef int (\_\_stdcall \*def\_CryptExtOpenCER)(
HWND hwnd, HINSTANCE hinst, LPSTR lpszCmdLine, int nCmdShow);
def\_CryptExtOpenCER CryptExtOpenCER;
typedef int (\_\_stdcall \*def\_MyProc)(void);
def\_MyProc MyProc;
#define PATCH\_NUM 2
char \*patch\_list[2\*PATCH\_NUM]={
"ADVAPI32.dll","SystemFunction035",
"CRYPT32.dll","I\_CryptGetDefaultCryptProv"
};
void WriteMem(int pos, char \*patch, int len)
{
DWORD my\_id = GetCurrentProcessId();
HANDLE p\_hand = OpenProcess(PROCESS\_VM\_WRITE | PROCESS\_VM\_OPERATION, NULL, my\_id);
if (WriteProcessMemory(p\_hand, (LPDWORD)pos, patch, len, NULL)==0) {
printf("Error write to memory\nHint: run from Administrator rigths");
}
CloseHandle(p\_hand);
}
HCRYPTPROV PASCAL old\_I\_CryptGetDefaultCryptProv(int AlgID) //call MS Provider
{
\_\_asm mov eax,0; //заглушка, достаточно 10 байт
\_\_asm mov eax,0;
return NULL;
}
HCRYPTPROV PASCAL my\_I\_CryptGetDefaultCryptProv(int AlgID)
{
if (AlgID!=0 && AlgID!=0x2036)
return old\_I\_CryptGetDefaultCryptProv(AlgID); //old MS
return hProv;
}
int StartPatch(void)
{
BYTE \*p;
HMODULE h\_dll;
char buf[10];
DWORD new\_addr;
for(int i=0;i
```
#### Компиляция файлов
Файл компиляции провайдера comp\_xyzcsp.bat:
```
call "C:\Program Files\Microsoft Visual Studio 10.0\VC\vcvarsall.bat"
cl /I"..\include" /nologo /MT /O2 /c xyzcsp.c
rc /I"..\include" xyzcsp.rc
link /SUBSYSTEM:WINDOWS",5.0" /NODEFAULTLIB /DLL /DEF:xyzcsp.def /MACHINE:x86 /OUT:xyzcsp.dll xyzcsp.obj openssl.lib advapi32.lib kernel32.lib msvcrt.lib gdi32.lib user32.lib xyzcsp.res
copy xyzcsp.dll ..\testcsp\
rem copy xyzcsp.dll c:\windows\system32
```
Файл компиляции теста comp\_test.bat:
```
call "C:\Program Files\Microsoft Visual Studio 10.0\VC\vcvarsall.bat"
cl /I"..\include" testcsp.cpp advapi32.lib
```
#### Сертификаты для тестирования
Файл gnivc\_2006.cer, в котором лежит корневой сертификат ФНС:
```
-----BEGIN CERTIFICATE-----
MIIDGjCCAsegAwIBAgIQPx2a1ZtKRIBLiHKukksltTAKBgYqhQMCAgMFADCBwDEe
MBwGCSqGSIb3DQEJARYPdWNpbmZvQGduaXZjLnJ1MQswCQYDVQQGEwJSVTEVMBMG
A1UEBwwM0JzQvtGB0LrQstCwMTAwLgYDVQQKDCfQpNCT0KPQnyDQk9Cd0JjQktCm
INCk0J3QoSDQoNC+0YHRgdC40LgxMDAuBgNVBAsMJ9Cj0LTQvtGB0YLQvtCy0LXR
gNGP0Y7RidC40Lkg0YbQtdC90YLRgDEWMBQGA1UEAxMNR05JVkMgRk5TIFJVUzAe
Fw0wNjA5MjcwOTI5NTdaFw0xMjA5MjcwOTM4MjdaMIHAMR4wHAYJKoZIhvcNAQkB
Fg91Y2luZm9AZ25pdmMucnUxCzAJBgNVBAYTAlJVMRUwEwYDVQQHDAzQnNC+0YHQ
utCy0LAxMDAuBgNVBAoMJ9Ck0JPQo9CfINCT0J3QmNCS0KYg0KTQndChINCg0L7R
gdGB0LjQuDEwMC4GA1UECwwn0KPQtNC+0YHRgtC+0LLQtdGA0Y/RjtGJ0LjQuSDR
htC10L3RgtGAMRYwFAYDVQQDEw1HTklWQyBGTlMgUlVTMGMwHAYGKoUDAgITMBIG
ByqFAwICIwEGByqFAwICHgEDQwAEQCzY8VGw9ged02ijaj2KWOMXJVvzY1FEcg7G
xedUtKx0wqyTVti0kmodEmm2cVfAbDkp0xAdBS9/mdDfeIrKXLajgZYwgZMwCwYD
VR0PBAQDAgGGMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFBMQt5JPv+eiD7j1
nYkVJssQ6/RfMBAGCSsGAQQBgjcVAQQDAgEAMEIGCCsGAQUFBwEBBDYwNDAyBggr
BgEFBQcwAoYmaHR0cDovL3d3dy5nbml2Yy5ydS91Yy9HTklWQ0ZOU1JVUy5jcnQw
CgYGKoUDAgIDBQADQQDgEyWPI+fdXXiTYMLHdV76v8kVFIxCHCYtastcvZiM3cG1
wTFhio8fDx6sLgHHriOwQFg0zRUYHIs9nZEptLvM
-----END CERTIFICATE-----
```
Файл rootsber.cer, в котором лежит корневой сертификат Сбербанка:
```
-----BEGIN CERTIFICATE-----
MIIDKjCCAtmgAwIBAgIGMDBDQT0HMAgGBiqFAwICAzCBwTELMAkGA1UEBhMCUlUx
LTArBgNVBAoMJNCh0LHQtdGA0LHQsNC90Log0KDQvtGB0YHQuNC4INCe0JDQnjE4
MDYGA1UECwwv0JTQtdC/0LDRgNGC0LDQvNC10L3RgiDQsdC10LfQvtC/0LDRgdC9
0L7RgdGC0LgxJjAkBgNVBAMMHdCh0LHQtdGA0LHQsNC90Log0KDQvtGB0YHQuNC4
MSEwHwYJKoZIhvcNAQkBFhJjYXNicmZAc2JlcmJhbmsucnUwHhcNMDkwODA1MDAw
MDAwWhcNMTcwODA1MDAwMDAwWjCBwTELMAkGA1UEBhMCUlUxLTArBgNVBAoMJNCh
0LHQtdGA0LHQsNC90Log0KDQvtGB0YHQuNC4INCe0JDQnjE4MDYGA1UECwwv0JTQ
tdC/0LDRgNGC0LDQvNC10L3RgiDQsdC10LfQvtC/0LDRgdC90L7RgdGC0LgxJjAk
BgNVBAMMHdCh0LHQtdGA0LHQsNC90Log0KDQvtGB0YHQuNC4MSEwHwYJKoZIhvcN
AQkBFhJjYXNicmZAc2JlcmJhbmsucnUwYzAcBgYqhQMCAhMwEgYHKoUDAgIjAgYH
KoUDAgIeAQNDAARAaYzyi29YQ9NC5cb/kq//J1kKhOgcvGWqsQu50mldjADTGfrl
JUVXwu4fMUTHoF9TjY0O1kgrLYWT/kI4jABAWKOBsjCBrzAdBgNVHQ4EFgQUZmHo
Zo41vw/U74ZlC8k/bcQODuowDAYDVR0TBAUwAwEB/zAzBgNVHR8ELDAqMCigJqAk
hiJodHRwOi8vd3d3LnNicmYucnUvY2EvMDAwMHg1MDkuY3JsMAsGA1UdDwQEAwIC
hDA+BgcqhQMDewMBBDMMMTAwQ0ExODUzetCa0L7RgNC90LXQstC+0Lkg0LrQu9GO
0Ycg0KPQpiDQodCRINCg0KQwCAYGKoUDAgIDA0EAD9Umnh/EZgjgQvpypdVwe0wa
GnTi+dHhVwoNAX1tquxQNbAptbBs2OKzkRU7/mrBfDD4EdVV5xC1f2DTcH8NAg==
-----END CERTIFICATE-----
```
#### Результаты работы
Запустим тестовую программу, получим результат:

Чтобы убрать последнее препятствие, включим сертификат в список доверенных, как рекомендуется. Для этого нажмем кнопку Установить сертификат и несколько раз кнопку Далее. По окончании тестирования нужно удалить тестовый сертификат из хранилища доверенных корневых, чтобы не подвергать возможной опасности свою систему.
После повторного запуска теста наблюдаем уже иную картину:
Что и требовалось получить.
#### Корневой сертификат Сбербанка
С сертификатом Сбербанка подобное проделать не получается:

Это связано с тем, что в Сбербанке используется константа B из RFC 4357, а именно GostR3410\_2001\_CryptoPro\_B\_ParamSet.
Меняем тогда в нашем файле xyzcsp.c в функции CPVerifySignature константу A на B, то есть при вызове my\_verify\_gost будем использовать следующий параметр: NID\_id\_GostR3410\_2001\_CryptoPro\_B\_ParamSet.
После компиляции провайдера и запуска теста наблюдаем обратную картину, сертификат ФНС не проверяется, а Сбербанковский — работает отлично. Казалось бы, существенный недостаток, но для простейшего криптопровайдера это простительно.
Конечно, возможен такой вариант: проверять сразу две ЭЦП и, если хотя бы одна из них сойдется, объявлять что ЭЦП верна, но это в корне неправильно. Нужно смотреть на OID публичного ключа и уже по нему искать требуемые параметры эллиптической кривой.
В следующей статье, которая сейчас готовится к публикации, мы подробно рассмотрим, как избежать подобной ситуации, а также напишем функцию по созданию ключей ЭЦП с различными параметрами.
#### Создание универсального патча
В заключение несколько слов о создании универсального патча.
Для Windows XP SP3 достаточно подменить следующие файлы:
c:\windows\system32\advapi32.dll
c:\windows\system32\dllcache\advapi32.dll
c:\windows\system32\crypt32.dll
c:\windows\system32\dllcache\crypt32.dll
Патчить нужно, загрузившись с другого диска, чтобы системный был свободным (можно с загрузочного диска Windows в режиме восстановления), далее заменяем эти два файла как в директории system32 так и в system32\dllcache, где хранятся их копии. Патчить на работающей системе не получится, потому что файлы «залочены» и поменять их не удастся.
После этого не забудьте скопировать файл с криптопровайдером xyzcsp.dll в директорию c:\windows\system32, чтобы система его находила.
Теперь можно кликать мышью на сертификат и он будет проверяться непосредственно в операционной системе, без запуска специальных программ.
Заменить файлы нужно на их пропатченный вариант:
```
Сравнение файлов advapi32.dll и C:\xyzcsp\PATCH\ADVAPI32.DLL
00017585: 8B B8
00017586: FF 01
00017587: 55 00
00017588: 8B 00
00017589: EC 00
0001758A: 81 C2
0001758B: EC 04
0001758C: 50 00
Сравнение файлов crypt32.dll и C:\xyzcsp\PATCH\CRYPT32.DLL
00008F66: 8B E9
00008F67: FF 47
00008F68: 55 09
00008F69: 8B 00
00008F6A: EC 00
000098B2: 90 55
000098B3: 90 8B
000098B4: 90 EC
000098B5: 90 8B
000098B6: 90 45
000098B7: 90 08
000098B8: 53 83
000098B9: 00 F8
000098BA: 6F 00
000098BB: 00 74
000098BC: 66 21
000098BD: 00 3D
000098BE: 74 36
000098BF: 00 20
000098C0: 77 00
000098C2: 61 74
000098C3: 00 1A
000098C4: 72 3D
000098C5: 00 35
000098C6: 65 66
000098C8: 5C 00
000098C9: 00 74
000098CA: 50 13
000098CB: 00 3D
000098CC: 6F 37
000098CD: 00 80
000098CE: 6C 00
000098D0: 69 74
000098D1: 00 0C
000098D2: 63 3D
000098D3: 00 38
000098D4: 69 AA
000098D6: 65 00
000098D7: 00 74
000098D8: 73 05
000098D9: 00 E9
000098DA: 5C 8D
000098DB: 00 F6
000098DC: 4D FF
000098DD: 00 FF
000098DE: 69 6A
000098E0: 63 68
000098E1: 00 7B
000098E2: 72 00
000098E4: 6F 00
000098E5: 00 6A
000098E6: 73 00
000098E7: 00 8D
000098E8: 6F 05
000098E9: 00 40
000098EA: 66 A5
000098EB: 00 A7
000098EC: 74 77
000098ED: 00 50
000098EE: 5C 8D
000098EF: 00 45
000098F0: 53 08
000098F1: 00 50
000098F2: 79 FF
000098F3: 00 15
000098F4: 73 00
000098F5: 00 10
000098F6: 74 A7
000098F7: 00 77
000098F8: 65 83
000098F9: 00 F8
000098FA: 6D 00
000098FB: 00 74
000098FC: 43 DC
000098FD: 00 8B
000098FE: 65 45
000098FF: 00 08
00009900: 72 C9
00009901: 00 C2
00009902: 74 04
```
Для Windows 7 также можно создать универсальный патч, желающие могут попробовать сделать это самостоятельно.
В реальной системе, в которой установлен ГОСТ криптопровайдер, проблемы с патчем обычно решаются за счет установки специального драйвера PatchEngine, который наблюдает за загрузкой системных DLL и патчит их «на лету».
#### Все файлы одним архивом
В заключение приведу ссылку, по которой все файлы из этой статьи можно скачать одним архивом:
[files.mail.ru/1OVVDB](http://files.mail.ru/1OVVDB) | https://habr.com/ru/post/134037/ | null | ru | null |
# Разработка под BlackBerry 10. Начало
Платформа BlackBerry 10 уже довольно давно привлекает к себе внимание. Решение от RIM оказалось довольно таки интересным, так почему бы не попробовать свои силы на этом поле.
Сегодня мы попробуем запустить простое приложение для BB 10 в симуляторе и посмотрим на это чудо.
#### Немного о птичках
**Cascades** — один из основных инструментов разработки приложений для BB. Он входит в **The BlackBerry 10 Native SDK** и предназначен для создания графического интерфейса. Этот зверь основан на Qt и QML, поддерживает 2D и 3D эффекты, анимацию. Также он позволяет создавать собственные элементы на основе уже существующих. Чтобы продемонстрировать простоту разработки UI в **Cascades** приведем пример создания вращающейся по нажатию кнопки с помощью QML и C++.
**Вращающаяся кнопка в QML:**
```
import bb.cascades 1.0
Page {
content: Button {
id: rotatingButton
text: "My Rotating Button"
animations: [
RotateTransition {
id: rotButton
toAngleZ: 360
duration: 350
}
]
onClicked: {
rotButton.play();
}
}
}
```
**Вращающаяся кнопка на C++:**
```
// Create the root page and the button
Page* root = new Page;
Button* myButton = Button::create("My Rotating Button");
// Create a rotation animation and associate it with the button
RotateTransition* rotation = RotateTransition::create(myButton)
.toAngleZ(360)
.duration(350);
// Connect the button's clicked() signal to the animation's play() slot, so that
// when the button is clicked, the animation plays. Make sure to test the return
// value to detect any errors.
bool res = QObject::connect(myButton, SIGNAL(clicked()), rotation, SLOT(play()));
Q_ASSERT(res);
// Indicate that the variable res isn't used in the rest of the app, to prevent
// a compiler warning
Q_UNUSED(res);
// Set the content of the page and display it
root->setContent(myButton);
app->setScene(root);
```
#### Начнем
Для начала нам нужно затарится ящиком с инструментами:
* [Качаем SDK](https://bdsc.webapps.blackberry.com/cascades/download)
* [Качаем VMware player](https://my.vmware.com/web/vmware/evalcenter?p=player&lp=1) (если его нет)
* [Качаем Simulator](http://developer.blackberry.com/develop/simulator/simulator_installing.html)
Кроме того нужно получить ключи [здесь](https://www.blackberry.com/SignedKeys/codesigning.html) и заполнить форму. **Обязательно запомните или запишите свой PIN, он вам еще пригодится.**
**Так выглядит форма**
Через некоторое время ключи придут вам на e-mail.
Теперь:1. Устанавливаем **SDK**, **(VMware player)** и **Simulator** следуя инструкциям;
2. Запускаем **VMware palyer**;
3. Выбираем пункт **«Open a Virtual Machine»**;
4. Находим файл **«BlackBerry10Simulator»** в папке с установленным симулятором и жмем **«Open»**;
5. Выбираем симулятор из списка и жмем **«Play virtual machine»**;
**Запуск симулятора**


#### Немного шаманства
Перед тем как приступить, настроим симулятор:
1. Ищем настройки;
2. В настройках выберем пункт **«Security and Privacy»**;**Скрытый текст**
3. Там находим **«Development Mode»**;**Скрытый текст**
4. Проверяем чтобы он был включен (если нет, то его нужно включить);**Скрытый текст**
#### Давайте творить
1. Первым делом запустим **BlackBerry Native SDK**.
**Это самый обычный Eclipse со своими свистелками;**
2. Создадим новый проект и выберем **«BlackBerry Cascades C++ Project from SDK Samples»**.
**Вот так;**
3. Теперь нам нужно выбрать шаблон приложения.
**Например этот;**
4. **Дадим ему имя и выберем иконку;**
5. Попадаем в **Deployment Setup Wizard** и жмем **Next**;
6. Теперь нужно установить девайс.
**Если симулятор включен, то устройство определяется автоматически.**
Если же нет, то скопируйте ip-адрес сами.
**Его можно увидеть в нижней-левой части симулятора (выделено красным);**
7. Далее добавим ключи (они должны прийти по почте, после отправки регистрационной формы).
**Выбираем первый пункт и жмем Next.**
Указываем пути к ключам, **PIN** (который вы указывали заполняя форму) и пароль, как в примере под спойлером.
**Пример**
Нас спросят о бэкапе ключей и сертификата. Этот пункт можно пропустить (и при желании настроить позже);
8. На этом работа с мастером завершена, осталось нажать **«Finish»**;
9. Еще нужно настроить конфигурацию билда. Для этого нажимаем правую кнопку мыши на проекте и выбираем **Build Configurations->Set Active->Simulator-Debug** ;
**Скрытый текст**
10. Остается только собрать проект (ПКМ по проекту и **Build Project**);
11. И запустить (ПКМ по проекту и **Run As->BlackBerry C/C++ Application** );
Вот и все.
**Результат**
P.S Пишите свои отзывы о статье и сообщайте в личку об ошибках. | https://habr.com/ru/post/174431/ | null | ru | null |
# Анализ теста по Go с PHDays
Думаю, многие из вас сталкивались с замысловатыми задачками, которые в реальной практике встретить почти невозможно, но которые очень любят давать во всяких тестах и на собеседованиях.
В конце мая прошла конференция PHDays, на которой был тест как раз с такими задачками. К моему сожалению, я провалила этот тест, но затем разобралась что, как и почему, и хочу поделиться с вами.
Итак, 5 картинок с кодом, к каждому дается 4 варианта ответа.
### Задача 1
```
package main
import "fmt"
func f(slice []int) {
slice = append(slice, 84)
}
func main() {
s := []int{23, 42}
f(s)
fmt.Println(s)
}
```
> Варианты ответа:
>
> 1. [23 42]
> 2. [23 42 84]
> 3. Программа не скомпилилируется
> 4. runtime error: slice out of range
>
>
ОтветЕсли попробовать скомпилировать код, то компилятор обратит ваше внимание на строку `slice = append(slice, 84)` и не просто так.
Да, слайсы имеют ссылочный тип. Но если они ссылочные, что не так-то? Должно работать!
А проблема в том, как работает функция `append` — она не меняет старый слайс, а возвращает новый. А из функции `f` мы результат не получаем.
Соответственно, правильный ответ будет под номером 1: [23 42].
Чтобы получить ответ из пункта 2 ([23 42 84]), нам нужно этот результат как-то передать в `main`. Сделать это можно двумя способами.
Во-первых, можно вернуть новый слайс из функции. Поправим немного код.
```
package main
import "fmt"
func f(slice []int) []int {
return append(slice, 84)
}
func main() {
s := []int{23, 42}
s = f(s)
fmt.Println(s)
}
```
*(*[*Go Playground*](https://play.golang.org/p/iZV0n3qVaMW)*)*
Во-вторых, можно вместо слайса передавать указатель на слайс:
```
package main
import "fmt"
func f(slice *[]int) {
*slice = append(*slice, 84)
}
func main() {
s := []int{23, 42}
f(&s)
fmt.Println(s)
}
```
*(*[*Go Playground*](https://play.golang.org/p/-eOCjVp5vxq)*)*
### Задача 2
```
package main
import "fmt"
func main() {
s := "bar"
{
s := "foo"
fmt.Print(s)
}
fmt.Print(s)
}
```
> Варианты ответа:
>
> 1. foofoo
> 2. foobar
> 3. compilation error: s redeclared in this block
> 4. compilation error: s undefined: s
>
>
ОтветВы когда-нибудь видели, чтобы кто-то вот так использовал скобки? Я — нет. Однако давайте разберёмся, что тут происходит.
Имеем две области видимости: внутри скобок и за их пределами. При этом с толку сбивают две одноимённых переменных. Такое называется **variable shadowing** и считается плохой практикой в Go. Существуют различные линтеры, которые выдают на подобный код предупреждение (например, [этот линтер](https://pkg.go.dev/golang.org/x/tools/go/analysis/passes/shadow/cmd/shadow), который используется вместе с `go vet`, см. `go help vet`). Собственно, поэтому сначала программа напишет foo, а затем bar. Следовательно, правильный ответ будет под номером 2.
### Задача 3
```
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
fmt.Println(i)
wg.Done()
}()
}
wg.Wait()
}
```
> Варианты ответа:
>
> 1. Числа от 1 до 99 по возрастанию
> 2. Числа от 1 до 99 в произвольном порядке
> 3. Вывод не определен
> 4. Ничего
>
>
ОтветПроблема состоит из двух частей. Во-первых, счётчик цикла создаётся лишь один раз и затем просто изменяется на каждой итерации. Во-вторых, при захвате переменных из окружения в замыкание (анонимную функцию) они захватываются по указателю.
Т.о. захваченный счётчик цикла в каждой горутине один и тот же, и меняется во всех них разом. Поэтому вывод зависит от того, когда какая горутина успеет напечатать текст. Какой в этот момент будет счётчик, такой и напечатается. Большинство же горутин напечатает 100, т.к. такой цикл закончится гораздо быстрее, чем осуществится вывод.
Следовательно, правильный ответ будет под номером 3 — вывод не определен.
Чтобы получить цифры от 1 до 99 в произвольном порядке, есть два варианта.
Во-первых, можно сделать копию счётчика цикла (`i := i`) перед созданием замыкания:
```
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
i := i
go func() {
fmt.Println(i)
wg.Done()
}()
}
wg.Wait()
}
```
*(*[*Go Playground*](https://play.golang.org/p/lwdt_rGtZRU)*)*
Во-вторых, можно сделать в анонимной функции параметр `i int` и передавать счётчик цикла в замыкание через этот параметр (тогда он будет копироваться при этой передаче):
```
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func(i int) {
fmt.Println(i)
wg.Done()
}(i)
}
wg.Wait()
}
```
*(*[*Go Playground*](https://play.golang.org/p/1OED4xF2-MU)*)*
### Задача 4
```
package main
import "fmt"
func main() {
s := "Hello"
defer func() {
s = "World"
}()
fmt.Println(s)
}
```
> Варианты ответа:
>
> 1. World
> 2. Hello
> 3. Hello World
> 4. compilation error: (func literal)() used as value
>
>
ОтветЧтобы понять, что происходит в этом коде, надо знать особенности `defer`. Эта конструкция выполнится только по завершению функции. Тут нас сбивает с толку `Println`, которы стоит после `defer`. Однако, если мы попробуем упросить код и убрать всё, что может нас запутать, то получим что-то такое:
```
package main
import "fmt"
func main() {
s := "Hello"
fmt.Println(s)
s = "World"
}
```
*(*[*Go Playground*](https://play.golang.org/p/5iwUotlkTGd)*)*
Теперь правильный ответ очевиден, он под номером 2.
### Задача 5
```
package main
import "fmt"
func main() {
a := []string{"a", "b", "c"}
b := a[1:2]
b[0] = "q"
fmt.Println(a)
}
```
> Варианты ответа:
>
> 1. [a b c]
> 2. [a q c]
> 3. [b c]
> 4. output is undefined
>
>
ОтветНа первый взгляд хочется спросить, а зачем тут вообще эта `b`? Мы же `a` печатаем.
Вот теперь самое время вспомнить, что слайсы в Go — это ссылочный тип данных. Следовательно, на строке `b := a[1:2]`, мы присваиваем в переменную `b` ссылку на область памяти из переменной `a`. А затем (`b[0] = "q"`) редактируем эту самую область памяти. В итоге имеем в результате правильный ответ под номером 2.
Если вы хотите именно скопировать слайс, то для этого придется использовать либо цикл, либо встроенную функцию `copy.` | https://habr.com/ru/post/571002/ | null | ru | null |
# «Морской бой» на Java для новичков. Level 1
Всем привет!
Статья посвящена тем, кто только врывается в увлекательный мир программирования на Java и ищет применения своим знаниям. Классно, что вы теперь знаете, как создавать переменные, методы и массивы, но, конечно, хочется писать "полезные" для человечества программы, а не выполнять многочисленные мелкие упражнения и задачи, хотя без этого тоже никуда. В общем, будем дополнять теорию практикой. Поехали!
Для начала давайте обсудим, какие требования "бизнес" предъявил к нашему приложению. После долгих переговоров заказчик утвердил следующий сценарий игры:
1. Приложение должно работать из консоли. Наш заказчик оказался ретроградом, и он считает, что его целевой аудитории очень нравится интерфейс консоли. У всех свои причуды, но ладно.
2. Одновременно в игре могут участвовать только два человека.
3. В самом начале игроки "представляются" - программа "спрашивает" (предлагает пользователям ввести), какие у них имена
4. У каждого игрока есть своё поле - квадрат 10х10 клеток
5. Затем игроки по очереди расставляют свои корабли. Как и в "бумажной" версии - каждый может поставить 4 однопалубных корабля, 3 двухпалубных, 2 трехпалубных и 1 четырёхпалубный.
6. Корабли можно располагать только по горизонтали или по вертикали.
7. Игроки не видят расположение кораблей друг друга.
8. Начинается игра. Первый игрок делает выстрел, сообщая нашему приложению координаты предполагаемой цели - номер клетки по горизонтали и номер клетки по вертикали.
9. Если выстрел первого игрока оказался удачным, и он поразил цель, то возможно два варианта развития событий.
Если в указанной игроком клетки находится корабль, то, если корабль однопалубный, игрок "убил" корабль, если не однопалубный, то ранил. В любом случае следующий ход снова за первым игроком.
Второй вариант, если игрок не попал ни в какой корабль, то ход переходит второму игроку.
10. Таким образом, как описано в пункте 8, передавая ход друг другу, игроки пытаются как можно раньше уничтожить корабли друг друга. Тот, кто первым, одолеет флотилию врага - победитель. Программа печатает поздравление и прекращает свою работу.
Теперь, согласовав с бизнесом сценарий работы приложения, можно приступать к реализации игры.
Как и в любом Java приложении нам потребуется класс (не умаляя общности назовём его Main), в котором будет объявлен, я думаю уже всем известный, метод main.
```
public class Main {
public static void main(String[] args) {
//your code will be here
}
}
```
Пока ничего нового, на этом этапе можно попробовать запустить код и проверить, что ваше окружение настроено правильно и "самая простая программа на свете" запускается без ошибок.
Опираясь на пункты 1-3 утвержденного сценария, реализуем функционал приложения, который будет предлагать игрокам ввести свои имена. Здесь нам придётся использовать класс java.util.Scanner, который умеет считывать введенные значения в консоли.
```
public class Main {
static Scanner scanner = new Scanner(System.in);
public static void main(String[] args) {
System.out.println("Player 1, please, input your name");
String player1Name = scanner.nextLine();
System.out.println("Hello, " + player1Name + "!");
System.out.println("Player 2, please, input your name");
String player2Name = scanner.nextLine();
System.out.println("Hello, " + player2Name + "!");
}
}
```
Подробнее о коде:
В строке 2 создаем static свойство класса Main scanner.
Нестатический метод nextLine() класса Scanner (строки 6 и 11) обращается к консоли и возвращает строку, которую он еще не считывал.
После получения имени пользователей, программа выводит приветствие в консоль - "Hello, {username} !"
В консоли будем видеть следующее, если запустим код сейчас.
```
Player 1, please, input your name
Egor
Hello, Egor!
Player 2, please, input your name
Max
Hello, Max!
```
Поговорим о том, как мы будем отображать поле боя и заполнять его кораблями. Пожалуй, что наиболее логичным будет использование двумерного массива char[][] buttlefield. В нем мы будем отображать расположение кораблей. Договоримся, что удачное попадание в корабль противника будем отображать символом #. Неудачный выстрел будем помечать символом \*. Таким образом изначально, массив будет проинициализирован дефолтовым для примитива char значением ('\u0000'), а в процессе игры будет заполняться символами # и \*.
```
public class Main {
static final int FILED_LENGTH = 10;
static Scanner scanner = new Scanner(System.in);
public static void main(String[] args) {
System.out.println("Player 1, please, input your name");
String player1Name = scanner.nextLine();
System.out.println("Hello, " + player1Name + "!");
System.out.println("Player 2, please, input your name");
String player2Name = scanner.nextLine();
System.out.println("Hello, " + player2Name + "!");
char[][] playerField1 = new char[FILED_LENGTH][FILED_LENGTH];
char[][] playerField2 = new char[FILED_LENGTH][FILED_LENGTH];
char[][] playerBattleField1 = new char[FILED_LENGTH][FILED_LENGTH];
char[][] playerBattleField2 = new char[FILED_LENGTH][FILED_LENGTH];
}
}
```
Подробнее о коде:
В строке 2 мы создаем константу FIELD\_LENGTH, которая будет содержать размер поля - согласно требованию 4 - проинициализируем FIELD\_LENGTH значением 10.
В строках 14-18 создаем двумерные массивы char. playerFiled1 и playerField2 - массивы, в которые будем записывать расположение кораблей каждого игрока. Размеры массивов равны размерам поля - логично, ведь эти двумерные массивы фактически отображают поля.
Перейдём к написанию логике по заполнению полей игроков своими кораблями. Предлагаю создать метод fillPlayerField(playerField), который будет спрашивать у игрока позиции корабля и записывать в массив новый корабль.
```
public class Main {
static final int FILED_LENGTH = 10;
static Scanner scanner = new Scanner(System.in);
public static void main(String[] args) {
System.out.println("Player 1, please, input your name");
String player1Name = scanner.nextLine();
System.out.println("Hello, " + player1Name + "!");
System.out.println("Player 2, please, input your name");
String player2Name = scanner.nextLine();
System.out.println("Hello, " + player2Name + "!");
char[][] playerField1 = new char[FILED_LENGTH][FILED_LENGTH];
char[][] playerField2 = new char[FILED_LENGTH][FILED_LENGTH];
fillPlayerField(playerField1);
fillPlayerField(playerField2);
}
}
private static void fillPlayerField(char[][] playerField) {
// your code will be here
}
```
Метод fillPlayerField должен быть статическим (static), так как вызываться он будет из метода main, который по определению должен быть статическим. fillPlayerField не будет возвращать никакого значения (void). В этом методе будет реализована логика по получению координат корабля от пользователя и запись в массив playerField нового корабля.
Поговорим о том, как пользователь будет задавать координаты кораблей. Будем размещать корабли по убыванию палуб, то есть первым разместим четырёхпалубный корабль, затем все трёхпалубные корабли, все двухпалубные корабли и все однопалубные. Программа будет принимать от пользователя координаты начала корабля и его положение (см. бизнес-требование № 6) - по горизонтали или по вертикали.
Приведу вывод программы в консоль, который мы ожидаем увидеть после создания метода fillPlayerField:
```
Расставляем 4-палубный корабль. Осталось расставить: 1
Input x coord:
1
Input y coord:
1
1. Horizontal; 2. Vertical ?
1
```
Наконец-то приступаем. На данный момент имеем:
```
private static void fillPlayerField(char[][] playerField) {
// your code will be here
}
```
Нам нужно расставить корабли с палубами от 4 до 1. Здесь дело идёт к циклу. Предлагаю без лишнего пафоса использовать for. Заметим, кораблей с одинаковым числом палуб может быть несколько, поэтому нам нужно ещё как-то контролировать, чтобы пользователь мог разместить лишь определенное число кораблей с заданным количеством палуб (см. бизнес требование №5) - эта задача также эффективно решается с помощью цикла - без пафоса также используем for.
```
private static void fillPlayerField(char[][] playerField) {
// i - счётчик количества палуб у корабля
// начинаем расстановку с корабля, которого 4 палубы, а заканчиваем кораблями с одной палубой
for (int i = 4; i >= 1; i--) {
// см. подробнее о коде под этой вставкой
for (int k = i; k <= 5 - i; k++) {
System.out.println("Расставляем " + i + "-палубный корабль. Осталось расставить: " + (q + 1));
// some your code here
}
}
}
```
Подробнее о коде:
На 5 строчке мы создаём цикл for (int k = 0; k <= 5 - i; k++). Объясню, откуда такая магия. Нам нужно как-то понимать, сколько кораблей каждого типа (с определенным количеством палуб) пользователь может поставить.
Мы можем создать еще один двумерный массив, в котором мы захардкодим что-то в духе:
```
int[][] shipTypeAmount = {{1, 4}, {2, 3}, {3, 2}, {4, 1}};
```
Мы бы в первом цикле (см. строку 4) перебирали значение количества палуб, потом искали бы в двумерном массиве, какое количество кораблей соответствует данному типу. На мой взгляд, такое решение качественное, однозначно, если бы мы писали коммерческую программу, то сделали бы именно так, но сейчас такая красота выглядит сложной - оставим это как задачу со звёздочкой, для тех, кто захочет "причесать" свой код.
Я же предлагаю отметить особенность, что сумма количества кораблей и количества палуб - величина постоянная. Действительно, . Поэтому, зная количество палуб у корабля (зная тип корабля), мы можем посчитать, сколько кораблей такого типа может быть установлено одним играком. Например, - таким образом, каждый игрок может поставить 4 однопалубных корабля. В цикле for на строке 6 реализована проверка условия цикла "лайтовым" способом - на основе этого интересного свойства.
Теперь дело за малым - напишем логику по считыванию значений из консоли и запись корабля в двумерный массив.
```
private static void fillPlayerField(char[][] playerField) {
for (int i = 4; i >= 1; i--) {
// растановка самих кораблей
for (int k = i; k <= 5 - i; k++) {
System.out.println("Расставляем " + i + "-палубный корабль. Осталось расставить: " + (q + 1));
System.out.println("Input x coord: ");
x = scanner.nextInt();
System.out.println("Input y coord: ");
y = scanner.nextInt();
System.out.println("1 - horizontal; 2 - vertical ?");
position = scanner.nextInt();
// если корабль располагаем горизонтально
if (position == 1) {
// заполняем '1' столько клеток по горизонтали, сколько палуб у корабля
for (int q = 0; q < i; q++) {
playerField[y][x + q] = '1';
}
}
// если корабль располагаем вертикально
if (position == 2) {
// заполняем столько клеток по вертикали, сколько палуб у корабля
for (int m = 0; m < i; m++) {
playerField[y + m][x] = '1';
}
}
// печатаем в консоли поле игрока, на котором будет видно, где игрок уже поставил корабли
// о реализации метода - см. ниже
printField(playerField);
}
}
}
```
Подробнее о коде:
Корабль помечаем символом '1' столько раз, сколько палуб он имеет - если корабль четырёхпалубный, то он займёт 4 клетки - помечаем 4 клетки значением '1'.
Нам неоднократно потребуется печатать поля игроков, либо поля их выстрелов по вражескому флоту. Для того, чтобы сделать это - создаём метод printField.
```
static void printField(char[][] field) {
for (char[] cells : field) {
for (char cell : t) {
// если значение дефолтовое (в случае char - 0), значит в данной клетке
// корабль не установлен - печатаем пустую клетку
if (cell == 0) {
System.out.print(" |");
} else {
// если клетка непустая (значение отличается от дефолтового),
//тогда отрисовываем сожержимое клетки (элемента массива)
System.out.print(cell + "|");
}
}
System.out.println("");
System.out.println("--------------------");
}
}
```
На экране метод будет так отображать расстановку кораблей:
```
| | | | | | | | | |
--------------------
|1|1|1|1| | | | | |
--------------------
| | | | | | | | | |
--------------------
| | | | | | | | | |
--------------------
| | | | | | | | | |
--------------------
| | | | | | | | | |
--------------------
| | | | | | | | | |
--------------------
| | | | | | | | | |
--------------------
| | | | | | | | | |
--------------------
| | | | | | | | | |
--------------------
```
Вот игроки уже заполнили свои корабли на карте, и теперь мы можем приступить к реализации пунктов 8-10 бизнес-требований заказчика.
Логику по получению от пользователя координат выстрела, обработки выстрела и передачи хода опишем в методе playGame. Дабы придерживаться (или пока только стараться) принципа single responsobility - не забываем делить логику на методы (1 функциональность - 1 метод, но тоже держим себя в руках, код, в котором 100500 однострочных методов тоже не комильфо) - примерно из этих соображений получились еще методы handleShot и isPlayerAlive. Реализация обоих приведена ниже
```
/**
* Метод реализует логику игры: выстрел и передача хода.
*/
private static void playGame(String player1Name, String player2Name, char[][] playerField1, char[][] playerField2) {
// "карты" выстрелов - создаём двумерные массивы, которые содержат все выстрелы
// удачные (#) и неудачные (*)
char[][] playerBattleField1 = new char[FILED_LENGTH][FILED_LENGTH];
char[][] playerBattleField2 = new char[FILED_LENGTH][FILED_LENGTH];
// вспомогательные переменные, которым будут присваиваться значения текущего игрока -
// игрока, чья очередm делать выстрел. Сначала играет первый игрок, прошу прошения
// за тавтологию
String currentPlayerName = player1Name;
char[][] currentPlayerField = playerField2;
char[][] currentPlayerBattleField = playerBattleField1;
// внутри цикла происходит смена очередности игроков, выстрел, его обработка.
// код внутри цикла выполняется до тех пор, пока "живы" оба игрока - пока у двух игроков
// "частично" цел (ранен) ещё хотя бы один корабль
while (isPlayerAlive(playerField1) && isPlayerAlive(playerField2)) {
// принимаем от пользователя координаты выстрела
System.out.println(currentPlayerName + ", please, input x coord of shot");
int xShot = scanner.nextInt();
System.out.println(currentPlayerName + ", please, input y coord of shot");
int yShot = scanner.nextInt();
// обрабатываем выстрел и получаем возвращаемое значение метода handleShot
int shotResult = handleShot(currentPlayerBattleField, currentPlayerField, xShot, yShot);
// если выстрел неудачный, и не один корабль не повреждён, то очередь переходит к следующему игроку
if (shotResult == 0) {
currentPlayerName = player2Name;
currentPlayerField = playerField1;
currentPlayerBattleField = playerBattleField2;
}
}
}
/**
* Метод обрабатывает выстрел. Если выстрел удачный, то есть снаряд достиг цели -
* в клетку записывается значение '#' (отображается к в массиве игрока, так и в массиве соперника),
* а также на экран выводится сообщение 'Good shot!'. В этом случае метод возвращает значение 1.
* В случае неудачного выстрела - в массив battleField записывается значение '0' в элемент [y][x], и
* и возвращается значение 0.
* Возвращаемые значения нам нужны для того, чтобы в методе, внутри которого вызывается метод handleShot,
* мы могли понимать, успешно или неуспешно прошёл выстрел. На основе этого мы принимаем решение,
* переходит ход к другому игроку или нет.
*/
private static int handleShot(char[][] battleField, char[][] field, int x, int y) {
if ('1'.equals(field[y][x])) {
field[y][x] = '#';
battleField[y][x] = '#';
System.out.println("Good shot!");
return 1;
}
battleField[y][x] = '*';
System.out.println("Bad shot!");
return 0;
}
/**
* Метод определяет, не проиграл ли еще игрок. Если у игрока остался хотя бы
* один "раненный" корабль, тогда пользователь продолжает игру.
* То есть, если на карте у игрока остался хотя бы один символ '1', которым мы отмечали
* корабли, то игра продолжается - возвращается значение true. Иначе false.
*/
private static boolean isPlayerAlive(char[][] field) {
for (char[] cells : field) {
for (char cell : cells) {
if ('1' == cell) {
return true;
}
}
}
return false;
}
```
Думаю, что к комментариям в коде мне добавить нечего. Единственное, обращу внимание на тонкий момент. Мы привыкли в математике к записи (x, y) - где первой идёт координат абсцисс, а второй - координата ординат. Казалось бы, чтобы обратиться к элементу двумерного массива (иногда срываюсь и называю в тексте элемент клеткой, но суть не меняется) нужно написать `arr[x][y]`, но это будет неверно, и чтобы это доказать воспользуемся неопрвергаемым методом пристального взгляда. Для примера рассмотрим следующий двумерный массив:
```
int[][] arr = {{1, 2}, {7, 4}, {8, 3, 5, 9}, {1}}
System.out.println(arr[0][1]); // ?
System.out.println(arr[1][0]); // ?
```
Теперь вопрос из квиза "Программирование и мир" - что выведется на консоль в строках 3 и 4?
Вспоминаем, что двумерный массив - это не совсем таблица (нам так проще его воспринимать и детектировать его в задачах) - это "массив массивов" - вложенные массивы. Если в одномерных целочисленных массивах элементом является целое число, то в случае двумерного массива - элементом является массив (а в случае трёхмерного массива - элементом является двумерный массив). Таким образом, первый индекс указывает, какой по счёту массив мы выбираем. Второй индекс указывает, какой элемент по счёту мы выбираем в выбранном ранее массиве. Запись `arr[1][2]` указывает, что мы обращаемся к элементу с индексом 2 (то есть 3 по порядку) в массиве с индексом 1 (или второму по порядку). Соответсвенно, в строке 3 в консоль выведется значение 2, а в строке 4 - 7.
Постепенно подбираемся к концу. Что нам осталось реализовать?
1. Вывод имени победителя
2. Проверка клетки, которую пользователь указал как начало корабля
Первое кажется проще, стартанём с него. Потопали в метод playGame - как вы помните, там есть цикл while, в условии которого есть проверка - живы ли еще оба игрока. Напомню, что если игрок "мёртв", то есть у него не осталось ни одного корабля, то игра прекращается, а выживший игрок считается победителем. Собственно, единственное, что добавилось - строчка 36 - вызов метода System.out.println()
```
/**
* Метод реализует логику игры: выстрел и передача хода.
*/
private static void playGame(String player1Name, String player2Name, char[][] playerField1, char[][] playerField2) {
// "карты" выстрелов - создаём двумерные массивы, которые содержат все выстрелы
// удачные (#) и неудачные (*)
char[][] playerBattleField1 = new char[FILED_LENGTH][FILED_LENGTH];
char[][] playerBattleField2 = new char[FILED_LENGTH][FILED_LENGTH];
// вспомогательные переменные, которым будут присваиваться значения текущего игрока -
// игрока, чья очередm делать выстрел. Сначала играет первый игрок, прошу прошения
// за тавтологию
String currentPlayerName = player1Name;
char[][] currentPlayerField = playerField2;
char[][] currentPlayerBattleField = playerBattleField1;
// внутри цикла происходит смена очередности игроков, выстрел, его обработка.
// код внутри цикла выполняется до тех пор, пока "живы" оба игрока - пока у двух игроков
// "частично" цел (ранен) ещё хотя бы один корабль
while (isPlayerAlive(playerField1) && isPlayerAlive(playerField2)) {
// перед каждым выстрелом выводим в консоль отображение всех выстрелов игрока
printField(currentPlayerBattleField);
// принимаем от пользователя координаты выстрела
System.out.println(currentPlayerName + ", please, input x coord of shot");
int xShot = scanner.nextInt();
System.out.println(currentPlayerName + ", please, input y coord of shot");
int yShot = scanner.nextInt();
// обрабатываем выстрел и получаем возвращаемое значение метода handleShot
int shotResult = handleShot(currentPlayerBattleField, currentPlayerField, xShot, yShot);
// если выстрел неудачный, и не один корабль не повреждён, то очередь переходит к следующему игроку
if (shotResult == 0) {
currentPlayerName = player2Name;
currentPlayerField = playerField1;
currentPlayerBattleField = playerBattleField2;
}
}
System.out.println(currentPlayerName + " is winner!");
}
```
Переходим ко второму пункту наших "остатков" - реализуем проверку клетки, которую указал пользователь - начало корабля.
Заказчик не уточнил, но будем считать, что правила нашей компьютерной версии игры в этом плане не отличаются от бумажной версии - между кораблями должна быть минимум одна клетка - это означает, что в окрестности с радиусом одна клетка от располагаемого корабля не должно быть других кораблей. Для наглядности - смотрим на рисунок.
Окрестность с радиусом одна клетка.
Красным кругом помечена стартовая клетка - начало корабля.Предлагаю простую версию алгоритма - обходим все клетки, в которых предполагаем разместить корабль, и проверяем, есть ли в окрестности с радиусом один каждой клетки другие корабли. Если хотя бы для одной клетки условие не выполнилось, то есть есть на поле корабль, который находится "слишком" рядом с планируемым - сообщаем пользователю о проблеме и просим его ввести новые координаты.
Какие нюансы есть в этом алгоритме? Снова посмотрим на рисунок.
Неэффективность нашего простого алгоритма.
Некоторые клетки проверяем несколько раз.
```
private static int validateCoordForShip(char[][] field, int x, int y, int position, int shipType) {
// если пользователь хочет расположить корабль горизонтально
if (position == 1) {
for (int i = 0; i < shipType - 1; i++) {
if ('1' == field[y][x + i]
|| '1' == field[y - 1][x + i]
|| '1' == field[y + 1][x + i]
|| '1' == field[y][x + i + 1]
|| '1' == field[y][x + i - 1]
|| (x + i) > 9) {
return -1;
}
}
} else if (position == 2) {
// если пользователь хочет расположить корабль вертикально
for (int i = 0; i < shipType - 1; i++) {
if ('1' == field[y][x + i]
|| '1' == field[y - 1][x + i]
|| '1' == field[y + 1][x + i]
|| '1' == field[y][x + i + 1]
|| '1' == field[y][x + i - 1]
|| (y + i) > 9) {
return -1;
}
}
}
return 0;
}
```
Не забываем проапгрейдить метод fillPlayerField - напомню, что в этом методе реализована логика по расположению кораблей игроками.
```
private static void fillPlayerField(char[][] playerField) {
for (int i = 4; i >= 1; i--) {
// растановка кораблей
for (int k = i; k <= 5 - i; k++) {
System.out.println("Расставляем " + i + "-палубный корабль. Осталось расставить: " + (q + 1));
// иницализируем переменную начальным значением
int validationResult = 1;
while (validationResult != 0) {
System.out.println("Input x coord: ");
x = scanner.nextInt();
System.out.println("Input y coord: ");
y = scanner.nextInt();
System.out.println("1 - horizontal; 2 - vertical ?");
position = scanner.nextInt();
// если координата не прошла валидацию (проверку), то метод возвращает отрицательное
// значение, конечно, оно не равно нулю, поэтому пользователю придётся ввести координаты
// ещё раз
validationResult = validateCoordForShip(playerField, x, y, position, i);
}
// если корабль располагаем горизонтально
if (position == 1) {
// заполняем '1' столько клеток по горизонтали, сколько палуб у корабля
for (int q = 0; q < i; q++) {
playerField[y][x + q] = '1';
}
}
// если корабль располагаем вертикально
if (position == 2) {
// заполняем столько клеток по вертикали, сколько палуб у корабля
for (int m = 0; m < i; m++) {
playerField[y + m][x] = '1';
}
}
// печатаем в консоли поле игрока, на котором будет видно, где игрок уже поставил корабли
// о реализации метода - см. ниже
printField(playerField);
}
}
}
```
Вот мы и написали игру "Морской бой" - level 1. Начали с простого - простых конструкций, идей и методов. Один класс, нет коллекций - только массивы. Оказывается на циклах и массивах можно написать игру.
Мы удовлетворили все требования бизнеса. Доигрывая до конца, получили отличную оценку от заказчика, он полностью доволен приложением. Ждём, когда он опробует игру и вернётся снова за апгрейдом. А тут и будет level - 2.
Всем спасибо, всегда рад обратной связи! | https://habr.com/ru/post/563210/ | null | ru | null |
# Я подарю тебе маленькую вселенную

Эстетика навесного монтажа обладает особой притягательной силой. Есть в этом что-то одновременно и от скульптуры, и от handcraft ювелирки. Вот и у меня давно "чесались руки" собрать какой-нибудь незамысловатый но симпатичный электронный гаджетик в таком стиле. И тут же хочется добавить: "… так что, как только я сложил вместе рамку и сердечко, мое воображение немедленно дорисовало все остальные компоненты и мне ничего не оставалось, кроме как соединить их воедино". Но нет. В действительности затея эта пылилась у меня в столе почти десяток лет, пока не дождалась неожиданного в своей простоте "инсайта", вдохновившего меня доделать некогда задуманное.
Итак, все началось почти декаду назад, когда я, пребывая в меланхоличном расположении духа, решил сделать подарок жене в форме светящегося кулончика. Вот такого...
Я даже, помнится, публиковал на "несуществующем" заметку про эту затею. Опубликовал и на какое-то время забыл. В целом, штучка простая: attiny10 + светодиод, да питание от трех крохотных батареек. Прошивка в полторы строки. Я еще ловко пробросил 5 ног в проводке с разъемчиками, чтобы можно было бы при случае перепрограммировать.

Основная сложность на тот момент заключалась в процессе пайки миниатюрных деталек и размещении получившейся сборки внутри "камушка" и потом еще нужно было закрыть дырочки боковыми блестящими заглушками не повредив сам проводок и не оторвав пайку.
Изрядно помучившись с первой горжеткой решил я тогда, что будет куда проще в следующий раз сделать форму и залить всю сборку каким-нибудь двухкомпонентным компаундом. For proof of concept я взял диоды, слепил из разных материалов формочки, приклеил все тщательно и залил. Но на поверку все оказалось еще сложнее. Компаунд застывал с пузырьками и никак не хотел оставаться прозрачным. Это я потом выяснил, что нужна вакуумная камера и что есть другие компонентные полимеры, которые могут и без вакуумной камеры давать приличный результат. Но на тот момент мне удалось сделать единственный более-менее приемлемый экземпляр.

*Вот это другие варианты, худший справа, для сравнения. Надо бы из него тоже что-нибудь соорудить. Там как раз тоже есть диод :)*
Решив было, что столь сложный процесс не годится, я поздабросил эту затею и сосредоточился на своих основных проектах. Так это сердечко у меня и валялось, время от времени попадаясь на глаза.
Тут должна быть пауза и потом параллельная склейка, как в кино…
Будучи как-то в IKEA я прихватил с собой рамку 6x6cm (пытался только-что отыскать название, но, по-моему, этот тот самый уникальный случай, когда Интернет, похоже, напрочь забыл про эту икеевскую поделку). Знаете, как это бывает, когда ты проходишь мимо стеллажей и глаз цепляется за какую-то бессмысленную, на первый взгляд, вещицу, которая тебе, в целом, не особо нужна, но что-то внутри подсказывает, что из этой штуки можно что-то сконструировать. Так случилось и тогда. Я подхватил эту рамку.
Каждый раз проходя мимо я думал, — Вот эти мелкие рамки, что в них можно запихать? Картинку туда нормально не вставишь. А вот какую-то поделку мелкую или талисманчик, в принципе — в самый раз. В общем, нужно ли говорит, что упомянутую рамку ждала примерно та же участь — валяться в коробке… до поры до времени.
И вот, некоторое время назад, аккурат после прочтения очередной статьи про клеточные автоматы (ссылка будет внизу), разбирая завалы в столе, я наткнулся на эту рамку и на сердечко одновременно и моментально понял, что они созданы друг для друга и что именно я хочу из этого соорудить.
Начало
------
В общем, сперва я все это зарисовал, чтобы приблизительно было понятно, как размещать компоненты с учетом длинны проводников и композиционного равновесия.
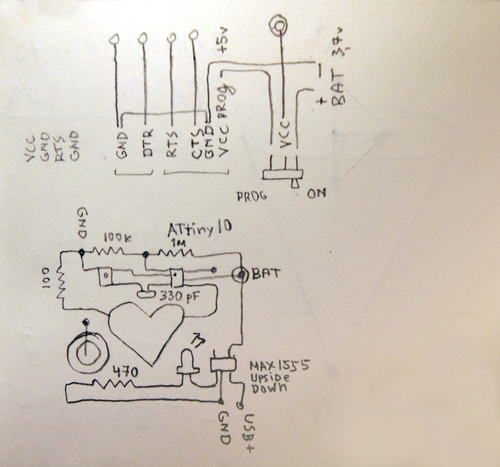
Потом аккуратненько спаял все. Просверлил дырочки в подложке, просунул и возрадовался, как все аккуратно легло. Чуть позже стало понятно, что стоило бы "приглушить" остальные элементы, что я и сделал, закрасив все аккуратно черным.

*Вот тут я начал было уже закрашивать, но подумал, что не плохо было бы опубликовать это все на Хабре, и решил все документировать.*
С тыльной стороны разместился разъем micro USB, разъем для прошивки и переключатель питания (attiny10 требует 5 вольт для прошивки, так что пришлось предусмотреть, но оно и хорошо, потому что это еще и выключатель, что удобно для перезапуска, например).

А вот так все выглядит в сборке, с подключенным программатором. Дополнительный двойной переключатель на проводке переключает ногу 3 на UART RX для удобства отладки, а так же размыкает RTS и DTR программатора, чтобы не подтягивать соответствующие ноги почем зря.

Я догадывался, что выбранный мною зуммер может не давать шить прошивку из за своего низкого импеданса, работая как маленький конденсатор, так что я решил прибавить пару сотен пикофарад. Но все оказалось еще хуже, эта штука с дырочкой оказалась самым что ни на есть низкоомным динамиком. Мне бы, конечно, все это замерить заранее. Но я хотел во что бы то ни стало успеть к годовщине нашего романтичного знакомства, так что был тороплив и невнимателен. Однако, где-то подсознательно я, должно быть, догадывался о такой вероятности, поэтому предусмотрел слева пространство для второго классического пьезоизлучателя. В итоге туда я его и приделал. Микро-динамик же я оставил на месте, покуда он там красиво прижился и дополняет композицию. (Тут мне, к слову, только что подумалось, можно попробовать почитать ADC на этой ноге. Может его можно использовать в качестве генератора энтропии (об этом ниже), или датчика громких хлопков :).
После того, как я окончательно разобрался с источником звука, я вырезал держалку для разъемов на лазерном резаке, прикрутил маленькими шурупчиками USB, собрал все воедино и включил.

*И в этот момент стало понятно — затея того стоит.*
Предвосхищая критическое "Это же всего-навсего мигающий диодик в рамке!". Нет, дорогой читатель, ты в плену внешней простоты. И прямо сейчас я тебе расскажу, что же за тайные смыслы сокрыты в этой, с виду, банальной безделушке.
Третий "компонент" и немного теории
-----------------------------------
Насколько тривиально выглядел бы светящийся светодиод в рамке, если бы внутри этой штуки не бегала бы специально придуманная для нее прошивка. Поэтому вот вам немного теоретической подоплеки.
Думаю, все здесь присутствующие в той или иной степени знакомы с концепцией клеточных автоматов. Эта тема, несмотря на свою кажущуюся простоту, с самого своего рождения не дает покоя исследователям и является предметом вдохновения для многих энтузиастов. Стивен Вольфрам вот даже целую [Теорию Всего](https://en.wikipedia.org/wiki/A_New_Kind_of_Science) пытается на основе нее сконструировать и вывести из нее всю квантовую механику вместе с квантовой гравитацией. В общем, и ваш покорный слуга — не исключение. Мне тоже нравится эта красивая модель во всех своих проявлениях.
Так вот, я подумал, что такой простой кристалл как ATtiny10 — лучшая платформа для запуска крошечного одномерного автомата. Про одномерные автоматы [известно](https://en.wikipedia.org/wiki/Elementary_cellular_automaton), что большинство правил в основном порождают повторяющиеся паттерны, некоторые просто быстро "умирают", но вот несколько правил дают крайне любопытные результаты. Например правило 110 дает вот такую неоднозначную картинку,

и, как выясняется, является [полным по Тьюрингу](https://en.wikipedia.org/wiki/Turing_completeness). А вот 22, 30, 126, 150 и 182 порождают хаотичные паттерны и их даже используют в криптографии для генерации псевдослучайных последовательностей. А еще правило 30 порождает треугольнички, очень похожие на сердечки. Так что я решил, коль скоро, правила порождающего непосредственно сердечки нет (хотя, наверное, было бы заманчиво его получить, [вот так](https://habr.com/ru/post/455958/), например), то возьму-ка я 30 и буду использовать эту его особенность.
```
***** ***** ** * ****** ** ** ** * * ** ** ** *
* * * * ** * * ** * * * ** ** ** * ** * ** ***
* *** ** * * ** ***** ****** ** ** * * * * * * ***
*** ** * ** * **** * ** * * * ********* **** * * *
* * *** * *** * * * * *** ***** * * * ****
** ** * * * ** ** * ** ** * ** ** *** ** *
* * ** ** ** ** *** * * * ****** * ** * ** *** ** *
****** * * * * *** **** * ** ** ** ** *** *** ***
* *************** * ** ** * *** * ** * *** *
*** ** * *** ** * ** *** * * * ****** * ***
* * ** * ** * *** **** * ** ** * * *** *
**** * ** ** **** *** **** ** * * ** ** ** *
**** * ** *** *** * ** * ****** * * ** * ** *
* ** ** ** * * ** *** * * ** * * * * * * ***
* ** * ** * ** ****** * *** * **** ** ** * **** * *
** * **** ** ** * * * * ** * *** * ** * * * **
* **** *** *** **** ** **** * ** ** **** *** ** ** *
**** * ** * * * ** * **** * * ** * * *** ***
* ** * * *** *** ***** **** ** *** * * * *** ** * ***
** * * * * * * * *** * ** * * **** * **** *
** **** * ** *** *** *** ** * * * ** * * * ***** ****
```
Вероятность выпадения треугольника большего размера, на вскидку, должна увеличиваться пропорционально количеству прошедших эпох. Так что я решил, что пусть веселое пиликанье и мигание знаменует рождение нового самого большого треугольника в моей вселенной. Позднее, правда, после того как я прогнал несколько миллионов эпох и посчитал статистику выпадения разноразмерных треугольников, выяснилось, что такая вероятность не шибко велика, и количество находок не превышает 32 для 10⁹ эпох.
А учитывая, что я собирался сделать 8 минутную паузу на сон после каждой эпохи, чтобы, в частности, максимально экономить батарею и не сделать мигание чрезмерно навязчивым, 32 писка приходилось аккурат на 120 лет работы сердечка. Рассудив, что это как-то слишком too long, я снизил условия для мигания, введя нижний порог срабатывания по размеру треугольничка. Так что мигает он почаще, а пиликает редко, как это подобает настоящей вселенной со столь редкими событиями.
Программирование
----------------
Attiny10 — процессор крохотный, не только внешне но и на уровне "железа". Там всего-то килобайт ПЗУ и 32 байта ОЗУ. Особо не развернешься. Поэтому я сперва [написал отдельную утилитку](https://git.shalnoff.com/CYBERHEART/blob/110dbbeddf473c18523831b2709f246f3756fc33:/TESTS/ca.c), на которой максимально оптимизировал основной алгоритм + за одно, проверил статистику, чтобы выбрать оптимальное поведение.
Чтобы было удобно отлаживать мою микровселенную я сразу добавил снипет для UART TX. Аппаратного-то у ATtiny10 не предусмотрено, так что пришлось свой небольшой соорудить.
**simple UART TX**
```
// ---------------------- simple UART TX -----------------------
#ifdef UART
void put_char( uint8_t c ){
c = ~c;
output_low( PORTB, SND );
for( uint8_t i = 10; i; i-- ){ // 10 bits
_delay_us( 1000000 / 9600 ); // bit duration / (8MHz, 9600, 104 us) Delay 832 cycles
if( c & 1 ) output_low( PORTB, SND ); else output_high( PORTB, SND ); // data bit 0 / data bit 1 or stop bit
c >>= 1;
}
}
void put_str_P(PGM_P str){
static PGM_P s;
s=str;
while (pgm_read_byte(s)) put_char( pgm_read_byte(s++) );
}
void put_num( uint8_t num ){
uint8_t div = 1;
for (div = 1; num / div >= 10 ; div *= 10);
do {
put_char( 48 + (( num / div ) % 10 ));
div /= 10;
} while ( div > 0 );
}
#endif
```
Далее я было уже собрался приделать PWM, но не тут то было. Я, конечно, заранее на всякий случай удостоверился, что ADC у меня на измерении заряда, а аппаратное управление таймером есть на всех ногах. На всех… кроме одной. И я, конечно же, припаял светодиод именно к этой ноге. Все потому что я сперва думал, что микроконтроллер у меня будет перевернут, как контроллер зарядки (см картинку), но потом я, все же, перерисовал его в нормальном положении, а про ногу забыл. В общем, что делать… От управления пищалкой на прерывании пришлось отказаться совсем, а управление светодиодом сделать на прерываниях переполнения, по известному рецепту.
**LED PWM**
```
// ---------------------- LED PWM ------------------------------
#ifndef UART
#define INT_PWM_DISABLE ({ TIMSK0 &= ~((1<
```
Да и это даже к лучшему, потому что в процессе отладки пищалки я придумал финт с тональностью, которая сейчас выбирается как результат деления длинны "треугольника" по модулю 5 и звучит прямо как как R2D2, каждый раз по-новому (ну и за одно звуковой индикатор разряда батареи использует эту же переменную, памяти-то там с гулькин нос).
**Playing current epoch byte sequence as score or 'battery low' message**
```
// playing current epoch byte sequence as score or 'battery low' message
do {
m = uni[ cnt % LEN ] % 5;
j = 255;
while ( j-- ){
invert(PORTB, SND);
k = 30*(m + 1);
while ( k-- ) { //500ns
asm volatile (
" rjmp 1f \n"
"1: rjmp 2f \n"
"2: \n"
);
}
}
_delay_ms(60);
} while ( cnt-- );
```
ну и напоследок осталось разобраться с чтением ADC. И вот тут у меня до сих пор нет четкого понимания, как это получилось. Как заметит внимательный читатель, там у меня на ноге 1 стоит делитель, который должен, вроде бы, скармливать часть напряжения на ADC, а тот, в свою очередь, замерять его падение. И все бы ничего. Но у ATtiny нет опорного внешнего входа, а у меня нет стабилизатора. Т.е., если верить datasheet, опорное напряжение для ADC это либо напряжение питания, либо GND на выбор. Т.е. по логике в моем случае результат ADC должен быть стабильным, даже при падении напряжения.
И что я тут предпринял, спросите вы? Да ничего. Я просто про это не подумал. Приделал батарею (маленькую для теста), поставил на ночь разряжаться и утром посмотрел логи.
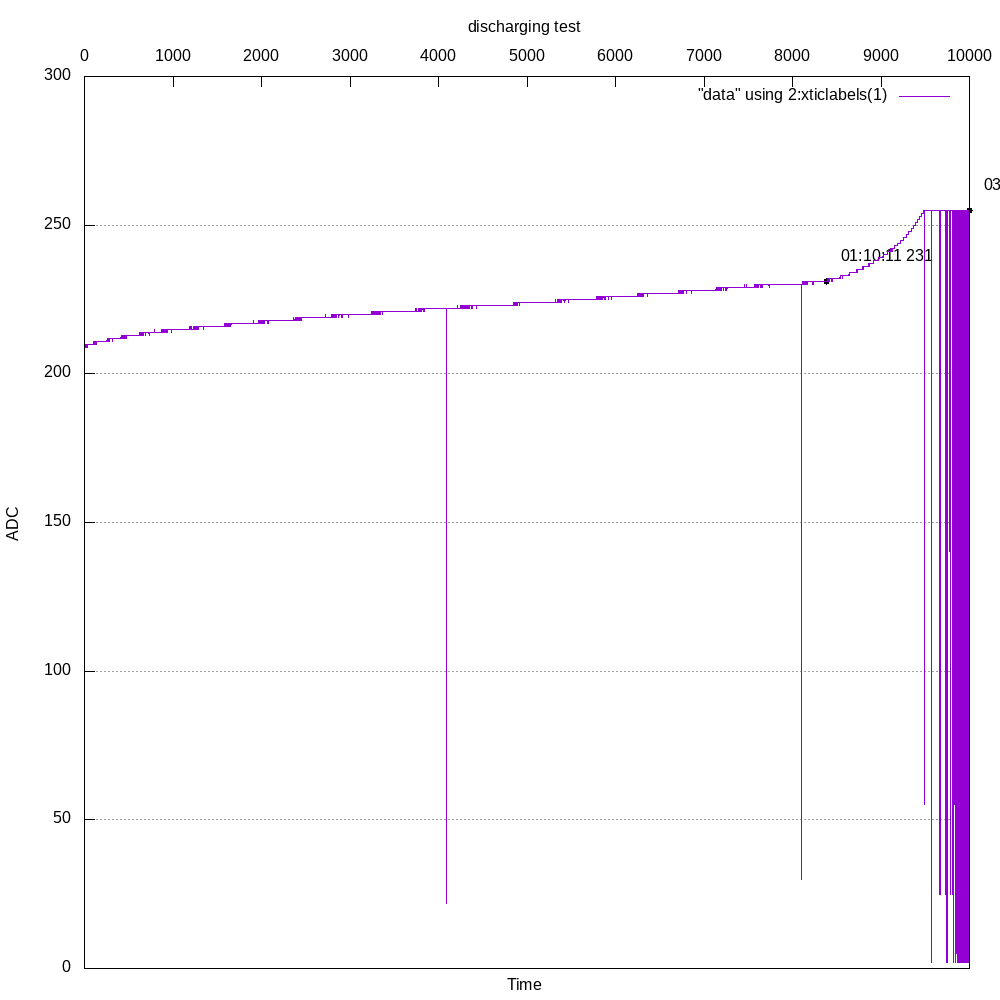
*Вот результаты тестирования разрядки батареи со встроенным делителем*
И все, как видите, норм. Тем не менее, с утра на свежую голову я посмотрел на это еще разок, и осознал, что так работать не должно. Почитал даташит для уверенности. И все верно — замер делается относительно опорного внутреннего напряжения. Но ведь оно падает!
В общем, я попробовал тупо резистором покрутить питание. Показания меняются. Попробовал сделать относительно земли. Тоже меняются. Так что я пока склоняюсь к мысли, что ATtiny имеет внутри какой-то стабилизатор или что-то, что ограничивает напряжение питания. Возможно, только для ADC. Может быть кто-то из коллег мне подскажет, что тут за магия. Так или иначе, все работает и разрядку батареи замерять можно.
Так что мне осталось только добавить засыпание и пробуждение по watchdog прерыванию, зарядить батарею и поставить гаджетик на стол любимой, пока она сладко спит :)
*Вот так оно делает время от времени. Если мигнуло, значит в моей микровселенной родился большой треугольник. Количество миганий показывает его длину в основании (точнее, превышение длинны относительно константы). А если еще и запиликало, то это и вовсе рекордсмен, где высота тона пропорциональна значению байта, считываемого последовательно по периметру моего замкнутого компактного 32 битного одномерного многообразия, взятому по модулю 5 (ну, чтобы не шибко разбег по высоте был).*
А да… отдельная проблема с рандомизацией исходного состояния. Я было думал привычным способом читать младшие биты того же АЦП и их использовать, но в attiny АЦП восмибитный всего то. И дает весьма стабильный (т.е. грубый) результат. Тем не менее результат этот колеблется на единичку изредка. Поэтому я решил сделать такую смешную "пробежку" по ПЗУ еще в дополнение.
```
// ----------- initial randomizer -----------------
while( i-- ) {
readADC();
uni[ i ] = pgm_read_byte( uni[ i+1 ] ) + ADCL;
}
```
Благо само правило 30 чувствительно к небольшим изменениям + можно предположить, что степень разрядки батареи тоже не будет всегда одинаковой при включении. Так что, вроде бы, энтропии должно хватать для моей скромной задачи.
А на будущее, стоило бы, наверное, приделать маленькую антенку и/или индуктивность, дабы ловить энтопию из электромагнитного эфира непосредственно. Плюс, выглядело бы еще круче. Ну или попробовать читать значение ноги №3.
Использованные материалы и полезные для вдохновения ссылки
----------------------------------------------------------
* [Elementary\_cellular\_automaton, wiki](https://en.wikipedia.org/wiki/Elementary_cellular_automaton)
* [JS движок для простейшего автомата](https://oshibka404.github.io/eca/) ([oshibka404](https://habr.com/ru/users/oshibka404/))
* [Эволюционирующие клеточные автоматы](https://habr.com/ru/post/455958/) ([xcont](https://habr.com/ru/users/xcont/))
* [A\_New\_Kind\_of\_Science](https://en.wikipedia.org/wiki/A_New_Kind_of_Science) by Stephen Wolfram
* [Permutation City](https://en.wikipedia.org/wiki/Permutation_City) by Greg Egan
### Исходники
* [CyberHeart](https://git.shalnoff.com/CYBERHEART)
### Post scriptum
**PS** тут меня со всех сторон атакуют, мол, Шальнов, что там с babooshka.tv. Я честно признаюсь, у меня катастрофически не хватает времени. Но я, тем не менее, не забросил ничего и в настоящий момент доделываю досочку, из которой должен получиться приятный во всех отношениях и полезный для разного рода использования готовый девайс. Не только для борьбы с медийной монополией *какой-нибудь отдельно взятой информационной автократии*, но и для всевозможных других медиа-затей. Вот только закончу с разводкой, и обещаю опубликовать статью сразу.
А пока вот вам таинственная картинка для привлечения внимания.
 | https://habr.com/ru/post/562436/ | null | ru | null |
# Apple TV

Подходит к концу разработка моего первого приложения под Apple TV, и я решил поделиться собранной информацией об этой платформе.
tvOS поддерживает два типа приложений: TVML и традиционные.
Традиционные приложения — практически то же самое, что и приложения под iOS (UIKit, Storyboard);
TVML — фреймворк для создания клиент-серверных приложений. Вся логика, дизайн и данные находятся на удаленном сервере.
#### Средства ввода
1. Стандартный контроллер — Apple TV Remote (Siri Remote). Все функции приложения должны быть доступны с него. Приложение не может требовать использования стороннего контроллера.
2. GameController — геймпад. Бывают двух видов
2.1. Standalone controller — обычный геймпад;
2.2. Девайс, который подключается к айфону и превращает его в геймпад.
3. Кроме того, геймпады (обоих вышеназванных видов) делятся еще на два типа — Gamepad Profile и Extended Gamepad Profile. Различаются они количеством кнопок.
4. Все гейм-контроллеры могут подключаться по wi-fi и посредством кабеля.
5. Приложение, использующее гейм-контроллеры, должно поддерживать все вышеперечисленное (т.е. уметь работать с любым геймпадом, подключенным как угодно).
6. Текущая версия симулятора TV не поддерживает гейм-контроллеры.
7. Bluetooth LE — через него работает стандартный контроллер. Дополнительно можно подключить не больше двух устройств. Не работает на симуляторе.
8. Bonjour — соединение по WiFi. Выглядит наиболее привлекательно. Нет ограничения на количество подключенных девайсов. Однако [здесь](https://forums.developer.apple.com/thread/17960) представитель эппла пишет, что разработчики должны будут сами определить, какое количество подключенных девайсов будет приемлемым в плане производительности.
9. CloudKit — обмен данными через iCloud.
В комплекте с TV идет Siri Remote — пульт с тачскрином, акселерометром, гироскопом и микрофоном.
1. Тачскрин — поддерживает форс тач, жесты. Можно получить доступ к «сырым» данным (т. е. к координатам касания)
2. Кнопка «Menu» — работает подобно кнопке «back» на Android: возвращает на предыдущее окно. Создает некоторые проблемы, к примеру, с загрузочными экранами (после загрузки пользователь может на него вернуться). Однако может быть переопределена в коде.
3. Кнопка «Siri» — как следует из названия, стартует Siri. К сожалению, не может быть использована в приложениях.
4. Кнопка «Play/Pause» — может быть переопределена в коде
5. Кнопка «TV» — сворачивает приложение.
6. Регулировка громкости.
Более подробно о кнопке «Menu».
Наиболее простой способ переопределить кнопку «Menu» — завести для нее gesture recognizer. Добавьте во viewDidLoad() вашего ViewController'а следующий код:
```
let menuClickRecognizer = UITapGestureRecognizer(target: self, action:«menuButtonClicked»)
menuClickRecognizer.allowedPressTypes = [NSNumber(integer: UIPressType.Menu.rawValue)]
self.view.addGestureRecognizer(menuClickRecognizer)
```
Осталось создать функцию menuButtonClicked.
```
func menuButtonClicked(){
debugPrint(«Menu button clicked!»)
}
```
Стоит отметить, что если для кнопки «Menu» был определен кастомный gesture recognizer, то стандартный перестает работать. Это может вызвать проблемы с выходом из приложения. В соответствии с этим [гайдлайном](https://developer.apple.com/tvos/human-interface-guidelines/remote-and-interaction/), кнопка «Menu» должна возвращать пользователя на предыдущий экран, а с первого выходить на home screen. Проблему можно решить используя unwind segue, а не обычный переход между ViewController'ами.
#### Иконки
Довольно интересная фича нового tvos — Parallax Icons. Иконка приложения может состоять из нескольких слоев, которые красиво движутся друг за другом при смещении фокуса. Иконка может иметь от одного до пяти слоев, причем первый (фоновый) слой должен быть непрозрачным (у него не должно быть альфаканала).
Кроме того, есть возможность использовать параллакс внутри приложения. Например, для кастомных кнопок.
Посмотреть, как это все выглядит можно, например, [здесь](https://developer.apple.com/tvos/human-interface-guidelines/icons-and-images/).
#### Top Shelf Image
Top Shelf Image — «шапка» приложения на домашнем экране. Отображается только для тех приложений, у которых иконка находится в верхней строке. Может представлять собой:
1. Обычную картинку
2. Слайдшоу
3. [Dynamic Content](https://developer.apple.com/tvos/human-interface-guidelines/icons-and-images/#dynamic-content) — набор иконок, которые могут быть ссылками на какие-нибудь окна приложения. Apple запрещает использовать его для рекламы.
#### Ограничения
Размер приложения не может превышать 200 мб. Это ограничение можно обойти, используя [On-Demand Resources](https://developer.apple.com/library/prerelease/tvos/documentation/General/Conceptual/AppleTV_PG/OnDemandResources.html), т. е. динамически подгружаемый контент.
Но самым печальным ограничением является отсутствие у приложения доступа к внутреннему хранилищу. Приложение не может просто сохранить что-нибудь на девайс. Apple предлагает использовать iCloud key-value storage для хранения небольших объемов информации (до 1 мб) и CloudKit в иных случаях.
Как пишет Apple в одном из своих многочисленных [гайдлайнов](https://developer.apple.com/library/prerelease/tvos/documentation/General/Conceptual/AppleTV_PG/index.html#//apple_ref/doc/uid/TP40015241-CH12-SW1), прочие продукты Apple (iPhone, iPad, Mac…) предполагают одного пользователя. Apple TV ориентирован на нескольких пользователей, взаимодействующих с приставкой и друг с другом.
Создание приложений для группы друзей или семьи — вот то, чего Apple ждет от разработчиков под tvOS. | https://habr.com/ru/post/270457/ | null | ru | null |
# Security с характером, или еще несколько слов о паттерне Singleton
> *— Как, и он тоже singleton? А я думала, что он нормальный!*
>
> *— Сколько раз тебе повторять, что слова singleton, mediator, decorator и даже prototype никакого отношения к ориентации кода не имеют?*
>
> *(разговор вызова курильщика и вызова нормального программиста)*
>
>
Всем привет, я [Максим Кравец](https://www.facebook.com/my.kravets), CEO команды веб-инженеров Holyweb, адептов JavaScript. И сегодня хочу поговорить о паттернах проектирования.
Давайте взглянем на маленький кусочек кода:
```
@Injectable()
export class SomeClass implements SomeInterface {
private currentData: Data
setData() {
this.currentData = new Data()
}
```
Попробуйте найти разработчика, который прочитает этот фрагмент следующим образом: «Мы воспользуемся структурным паттерном decorator для обеспечения возможности внедрения методов нашего SomeClass в другие классы посредством Dependency Injection, в методе setData нашего класса применим порождающий паттерн Builder посредством new и в приватное поле currentData положим...»
Паттерны живут в нашем коде. Паттерны бывают порождающие, структурные, поведенческие. Мы ими пользуемся, даже не акцентируя на этом внимание, а строгие формулировки вспоминаем порой лишь при подготовке к собеседованию. Паттернов у программиста — что жен в гареме султана. И как те самые жены — они не очень любят, когда про них забывают и ими пренебрегают. И тогда наш код начинает делать нам нервы.
Так что сами — вспомним. А тем, кто еще не знает — расскажем. И начнем с паттерна, которому впору присвоить звание «нелюбимой жены султана». Можно даже встретить мнение, что его бездумное использование — безвкусица, дурной тон и вообще антипаттерн. Наш сегодняшний рассказ посвящен синглтону (паттерн Singleton).
Часть первая. Детективная. Ограбление, которого не было
-------------------------------------------------------
Идея паттерна Singleton очень проста — на все приложение создается один-единственный инстанс класса, и при любом обращении возвращается именно этот инстанс. Техническая реализация паттерна также укладывается в одно предложение описания и одну строку кода:
**описание:**
Реализация должна скрыть конструктор класса и предоставить публичный статический метод, контролирующий жизненный цикл инстанса
**код метода, контролирующего жизненный цикл:**
```
public static getInstance(): SingletonClassName {
!instance ? instance = new SingletonClassName : instance
}
```
Все это прекрасно, но зачем он нужен вообще? Ведь инстансы придумали не зря! Пусть у каждого компонента нашего приложения будет свой инстанс, которым он волен распоряжаться по своему усмотрению! Окей, давайте представим…
У вас есть семья (приложение), у семьи есть единый банковский счет (база данных) и несколько карт, привязанных к этому счету (инстансов класса, предоставляющего подключение к базе данных). На счету — 100 рублей (данные).
Вы и супруга (или супруг и вы) одновременно помещаете свои карточки в банкоматы и просите снять 100 рублей. Счет одномоментно получает два требования на списание, параллельно проводит две проверки на наличие средств, получает два подтверждения что такая сумма есть и параллельно списывает 100 рублей. Вы забираете из банкоматов каждый по сто рублей, забираете карточки…
Хорошо бы, но нет)) Даже весьма условный пример выше объясняет, почему в один момент времени к базе просто необходимо только одно подключение. Окей, но нас же (компонентов) несколько? Ждать очереди? Давайте еще немного напряжем воображение.
Теперь мы общаемся с банком (базой данных) по телефону. У нас только одна линия, и если кто-то еще попробует позвонить — услышит короткие гудки. Но нас же двое? Поступаем самым очевидным образом — включаем на своей стороне громкую связь! Как итог, линия связи одна (подключение). Телефон на нашей стороне один (инстанс), но пользоваться им могут все (различные компоненты нашего приложения...), находящиеся в комнате с телефоном (...имеющие доступ к инстансу).
Мы только что создали синглтон в отдельно взятой ячейке общества, заодно определившись с тем, когда он нужен и как с ним работать. Ну что ж, давайте познакомимся с ним поближе.
Часть вторая. Романтическая. Продемонстрируем синглтону заинтересованность в нем
--------------------------------------------------------------------------------
Singleton — это порождающий шаблон (паттерн), гарантирующий, что в однопоточном приложении будет только один экземпляр (инстанс) некоего класса, предоставляющий точку доступа к этому экземпляру.
```
// создадим класс
class DataBase {
// объявим статическое поле для хранения объекта Singleton-а
private static instance
// сделаем приватным конструктор, чтобы никто не имел возможности
// самостоятельно создавать инстансы нашего класса через new
private constructor() {
// здесь мы инициализируем подключение к базе данных
….
// укажем, что инстанса изначально нет
this.instance = null
}
// создадим доступную извне альтернативу конструктору
// для того, чтобы обеспечить точку доступа к инстансу Singleton-а
public static getInstance() {
if ( this.instance === null ) {
// если инстанса нет, создаем его
this.instance = new DataBase()
}
// отдадим инстанс тому, кто запрашивал
return this.instance
}
// для примера создадим метод query для формирования
// запросов к базе данных
public getQuery(payload) {
// здесь реализуем логику запроса
...
}
}
// создадим обращающийся класс
class AppModule {
// метод запроса к базе
Data() {
// объявим два подключения
let foo = DataBase.getInstance()
let bar = DataBase.getInstance()
// foo содержит тот же объект,
// что и bar
foo.getQuery("SELECT ...")
bar.getQuery("SELECT ...")
}
}
```
Фактически, Singleton предоставляет глобальную точку доступа, но в отличие от простых глобальных переменных, которые также могут использоваться для решения этой задачи, Singleton скрывает от внешнего пользователя методы конструктора и тем самым гарантирует, что никакой сторонний код не сможет подменить данные.
Лучший друг Singletonа — это TypeScript, потому что он дает возможность обращаться через интерфейсы, существенно расширяя базовую функциональность.
Кроме того, несомненным плюсом Singleton является то, что он может быть создан «по запросу» — не при инициализации приложения, а при первом обращении. Однако тут следует быть осторожным и не забывать, что если объект нужен уже при инициализации, он может быть затребован раньше, чем будет создан.
Выбирая Singleton, стоит также помнить, что небрежное использование глобальных объектов может приводить к проблемам масштабируемости, контроля за многопоточностью, написания модульных тестов и в целом следования принципам TTD.
Так что же делать? Да то же, что и со всеми остальными паттернами! Использовать, помня о его несомненных плюсах, но не забывая о недостатках. Тем более, что проблемы с тестированием решаются с помощью методов внедрения зависимостей (DI), а при необходимости увеличить количество инстансов (отойти от паттерна Singleton) потребуется переписать всего один метод, отвечающий за доступ к инстансу.
Часть третья. Жизненная. Если б я был султан, я б имел трех жен?
----------------------------------------------------------------
Подведем итоги. Паттерн Singleton — мощный, а порой просто незаменимый инструмент в руках разработчика. Если использовать его по назначению. Микроскопом, как известно, тоже можно гвозди заколачивать, но вряд ли кто оценит. Так и с Singletonом. Ну а чтобы не запутались, вот вам сводная табличка:
| | |
| --- | --- |
| **Преимущества** | **Недостатки** |
| Гарантирует наличие единственного инстанса класса. | Маскирует плохую архитектуру. |
| Реализует отложенную инициализацию. | Нарушает принцип единственной ответственности класса. |
| Предоставляет глобальную точку доступа. | Создает проблемы контроля многопоточности. |
Отдельно стоит отметить, что Singleton может быть «включен» в состав других паттернов. Например, фасад нередко выступает в приложении в одиночку и может быть реализован как Singleton. Так же большая часть абстрактных классов при необходимости легко приводятся к виду Singletonа.
В общем, постарайтесь подружиться с этим полезным одиночкой, а мы тем временем подготовим рассказ о следующем паттерне. Впрочем, если вы уже считаете себя магистром Йодой в разработке или на пути к этому званию, тоже будет здорово познакомиться: пишите в Telegram [@maximkravec](https://t.me/maximkravec).
Есть что дополнить? Оставляйте комментарии! Самые интересные мы добавим в статью, чтобы сделать ее лучше. | https://habr.com/ru/post/552600/ | null | ru | null |
# Как работать со множественными запросами. Композиция, Reducer, ФП
Привет, Хабр. Меня зовут Максим, я iOS-разработчик в компании FINCH. Сегодня я покажу вам некоторые практики использования функционального программирования, которые мы наработали у себя в отделе.
Сразу хочу отметить, что я не призываю вас повсеместно использовать функциональное программирование — это не панацея от всех проблем. Но мне кажется, в некоторых случаях, ФП может дать наиболее гибкие и элегантные решения нестандартных задач.
ФП – популярная концепция, поэтому я не буду объяснять основы. Уверен, что вы и так применяете map, reduce, compactMap, first(where:) и подобные технологии в своих проектах. В статье речь пойдет о решении проблемы множественных запросов и работе с reducer.
### Проблема множественных запросов
Я работаю в аутсорс-продакшне, и бывают ситуации, когда клиент со своими субподрядчиками берет на себя создание бэкенда. Это далеко не самый удобный бэкенд и приходится делать множественные и параллельные запросы.
Иногда я мог написать что-то вроде:
```
networkClient.sendRequest(request1) { result in
switch result {
case .success(let response1):
// ...
self.networkClient.sendRequest(request2) { result in
// ...
switch result {
case .success(let response2):
// ... что - то делаем со вторым response
self.networkClient.sendRequest(request3) { result in
switch result {
case .success(let response3):
// ... тут что-то делаем с конечным результатом
completion(Result.success(response3))
case .failure(let error):
completion(Result.failure(.description(error)))
}
}
case .failure(let error):
completionHandler(Result.failure(.description(error)))
}
}
case .failure(let error):
completionHandler(Result.failure(.description(error)))
}
}
```
Отвратительно, правда? Но это та реальность с которой мне нужно было работать.
Мне нужно было отправить три последовательных запроса для авторизации. Во время рефакторинга я подумал, что хорошей идеей будет разбить каждый запрос на отдельные методы и вызвать их внутри completion, разгрузив, тем самым, один огромный метод. Получилось что-то вроде:
```
func obtainUserStatus(completion: @escaping (Result) -> Void) {
let endpoint= AuthEndpoint.loginRoute
networkService.request(endpoint: endpoint, cachingEnabled: false) { [weak self] (result: Result) in
switch result {
case .success(let response):
self?.obtainLoginResponse(response: response, completion: completion)
case .failure(let error):
completion(.failure(error))
}
}
}
private func obtainLoginResponse(\_ response: LoginRouteResponse, completion: @escaping (Result) -> Void) {
let endpoint= AuthEndpoint.login
networkService.request(endpoint: endpoint, cachingEnabled: false) { [weak self] (result: Result) in
switch result {
case .success(let response):
self?.obtainAuthResponse(response: response, completion: completion)
case .failure(let error):
completion(.failure(error))
}
}
private func obtainAuthResponse(\_ response: LoginResponse, completion: @escaping (Result) -> Void) {
let endpoint= AuthEndpoint.auth
networkService.request(endpoint: endpoint, cachingEnabled: false) { (result: Result) in
completion(result)
}
}
```
Видно, что в каждом из приватных методов мне приходится проксировать
```
completion: @escaping (Result) -> Void
```
и это мне не очень нравится.
Тогда же мне в голову пришла мысль — «а почему бы не прибегнуть к функциональному программированию?» К тому же swift, с его магией и синтаксическим сахаром, позволяет интересно и удобоваримо разбивать код на отдельные элементы.
Композиция и Reducer
--------------------
Функциональное программирование тесно связано с концепцией композиции – смешиванием, соединением чего-либо. В функциональном программировании композиция предполагает, что мы комбинируем поведение из отдельных блоков, а затем, в дальнейшем, работаем с ним.
Композиция с математической точки зрения — это что-то вроде:
```
func compose(\_ f: @escaping (A) -> B, and g: @escaping (B) -> C) -> (A) -> C {
return { a in g(f(a)) }
}
```
Есть функции f и g, которые внутри себя задают выходные и входные параметры. Мы хотим получить какое-то результирующее поведение от этих входных методов.
Как пример, можно сделать два closure, один из которых увеличивает входное число на 1, а второй перемножает на само себя.
```
let increment: (Int) -> Int = { value in
return value + 1
}
let multiply: (Int) -> Int = { value in
return value * value
}
```
В результате мы хотим применить обе эти операции:
```
let result = compose(multiply, and: increment)
result(10) // в результате имеем число 101
```
К сожалению мой пример не является ассоциативным
( если мы поменяем местами increment и multiply, то получим число 121), но пока опустим этот момент.
```
let result = compose(increment, and: multiply)
result(10) // в результате имеем число 121
```
P.S. Я специально стараюсь сделать мои примеры более простыми, чтобы было максимально понятно)
На практике же часто нужно сделать что-то вроде этого:
```
let value: Int? = array
.lazy
.filter { $0 % 2 == 1 }
.first(where: { $0 > 10 })
```
Это и есть композиция. Мы задаём входное воздействие и получаем некоторое выходное воздействие. Но это не просто сложение каких-то объектов – это сложение целого поведения.
### А теперь подумаем более абстрактно :)
В нашем приложении у нас есть какое-то состояние (state). Это может быть экран который в данный момент видит пользователь или текущие данные, которые хранятся в приложении и тд.
Помимо этого у нас есть action — это то действие, которое может сделать пользователь (нажать на кнопку, скрольнуть коллекцию, закрыть приложение и тд). В результате мы оперируем этими двумя понятиями и связываем их друг с другом, то есть комбинируем, хммм комбинируем (где-то я уже это слышал).
А что если создать сущность, которая как раз скомбинирует мой state и action вместе?
Так мы получим Reducer
```
struct Reducer {
let reduce: (S, A) -> S
}
```
На вход метода reduce мы будем давать текущий state и action, а на выходе получим новый state, который образовался внутри reduce.
Описать эту структуру мы можем несколькими способами: задав новый state, используя функциональный метод или используя мутабельные модели.
```
struct Reducer {
let reduce: (S, A) -> S
}
struct Reducer {
let reduce: (S) -> (A) -> S
}
struct Reducer {
let reduce: (inout S, A) -> Void
}
```
Первый вариант «классический».
Второй – более функциональный. Смысл заключается в том, что мы возвращаем не state, а метод, который принимает action, который уже в свою очередь возвращает state. По сути это каррирование метода reduce.
Третий вариант – работа со state по ссылке. При таком подходе, мы не просто выдаем state, а работаем с ссылкой на объект который приходит на вход. Мне кажется, что этот способ не очень хорош, потому что подобные (мутабельные) модельки – это плохо. Лучше пересобирать новый state(instance) и возвращать его. Но для простоты и демонстрации дальнейших примеров, условимся использовать последний вариант.
### Применение reducer
Применим концепцию Reducer на существующий код – создадим RequestState, затем инициализируем его, и зададим.
```
class RequestState {
// MARK: - Private properties
private let semaphore = DispatchSemaphore(value: 0)
private let networkClient: NetworkClient = NetworkClientImp()
// MARK: - Public methods
func sendRequest(\_ request: RequestProtocol, completion: ((Result) -> Void)?) {
networkClient.sendRequest(request) { (result: Result) in
completion?(result)
self.semaphore.signal()
}
semaphore.wait()
}
}
```
Для синхронности запросов я добавил DispatchSemaphore
Идем дальше. Теперь нам нужно создать RequestAction с, допустим, тремя запросами.
```
enum RequestAction {
case sendFirstRequest(FirstRequest)
case sendSecondRequest(SecondRequest)
case sendThirdRequest(ThirdRequest)
}
```
Теперь создаем Reducer, у которого есть RequestState и RequestAction. Задаем поведение – что мы хотим делать при первом, втором, третьем запросе.
```
let requestReducer = Reducer { state, action in
switch action {
case .sendFirstRequest(let request):
state.sendRequest(request) { (result: Result) in
// 1 Response
}
case .sendSecondRequest(let request):
state.sendRequest(request) { (result: Result) in
// 2 Response
}
case .sendThirdRequest(let request):
state.sendRequest(request) { (result: Result) in
// 3 Response
}
}
}
```
В конце – вызываем эти методы. Получается более декларативный стиль, при котором видно, что идет первый, второй и третий запросы. Все читаемо и наглядно.
```
var state = RequestState()
requestReducer.reduce(&state, .sendFirstRequest(FirstRequest()))
requestReducer.reduce(&state, .sendSecondRequest(SecondRequest()))
requestReducer.reduce(&state, .sendThirdRequest(ThirdRequest()))
```
### Вывод
Не бойтесь изучать новое и не бойтесь изучать функциональное программирование. Я думаю, что самые лучшие практики находятся на стыке технологий. Старайтесь комбинировать и брать лучше из разных парадигм программирования.
Если стоит какая-то нетривиальная задача, то есть смысл посмотреть на неё с другого угла. | https://habr.com/ru/post/455840/ | null | ru | null |
# С чего начинается дружба с Active Directory
Мне часто приходится сталкиваться с обработкой информации из Active Directory. Так как данная система много где распространена, я решил поделиться своим опытом работы с ней.
Началось всё с того, что я раздавал доступ в MS Sharepoint. В заявках от сотрудников, в лучшем случае, приходили учетные записи, в худшем могли написать что-то типа “Мне и моему начальнику”. Это поначалу напрягало, и я, чувствуя себя заправским админом, посылал такие заявки обратно нерадивым юзерам, чтобы они всё переделали. Это превращалось в ворох пропитанных гневом писем и звонков. Я даже стал задумываться, не случайно ли совпадение сокращения от Active Directory – AD с русским словом “Ад”. В итоге, осознав, что надо менять мир к лучшему, я решил детально разобраться, что вообще хранится в Active Directory и как это можно использовать, для автоматической раздачи доступа и других полезных вещей.
В компании информация о сотрудниках хранится в 2-х местах:
* Active Directory
* БД Oracle
Уникальность поддерживается в Oracle, а доступ даётся через AD, т.е. на одного сотрудника может приходиться несколько учетных записей. Возникла необходимость однозначно определять сотрудника по его учетной записи.
Решение этой задачи было найдено и растиражировано во множество утилит и программных продуктов, активно используемых внутри компании. Одной из наиболее используемых утилит стала программа поиска информации по сотруднику. Она ищет сотрудника или сотрудников по различным критериям и выдаёт наиболее полную информацию о них, совмещая данные из Active Directory и Oracle. Особой популярностью пользуются фотографии сотрудников, которые хранятся в базе данных.
Так же стоит отметить интеграцию Active Directory не только с Oracle но и с MS Sharepoint. Благодаря найденному решению появилось приложение способное быстро дать доступ группе пользователей из Active Directory на страницы портала Sharepoint, а так же удалить из него пользователей, которые по различным причинам, ушли из неё.
Задача была решена 2-мя способами:
1. Для получения информации по одному сотруднику — DBMS\_LDAP в Oracle
2. Для того чтобы выкачать все доступные записи и посмотреть, что вообще есть в Active Directory использовали код на C#
При использовании C# следует учесть следующее (библиотека System.DirectoryServices.dll):
* Свойство DirectorySearcher.PageSize должно быть отлично от 0, если хотите чтобы функция FindAll() вернула все записи.
* Обязательно надо вызвать Dispose() для экземпляра DirectorySearcher
Так же есть свойство DirectorySearcher.SizeLimit, которое устанавливает максимальное количество записей в возвращаемом результате. По умолчанию оно равно 0, что означает – взять это значение с сервера. На сервере обычно стоит значение 1000. Можно поиграть со свойством SizeLimit и посмотреть, как меняется результат работы функции ([ссылка](http://stackoverflow.com/questions/90652/can-i-get-more-than-1000-records-from-a-directorysearcher-in-asp-net)).
По ссылке выше есть пример кода, который использует yiled, что с точки зрения работы .NET более правильно, но в примере ниже я его не использовал, для наглядности алгоритма.
#### Примеры кода:
* DBMS\_LDAP Oracle
```
function GetDataByUser(userAccount VARCHAR2)
return VARCHAR2 is
l_ldap_host VARCHAR2(256) := 'host';
l_ldap_port VARCHAR2(256) := 'port';
l_ldap_user VARCHAR2(256) := 'user';
l_ldap_passwd VARCHAR2(256) := 'password';
l_ldap_base VARCHAR2(256) := 'ldap_path';
l_retval PLS_INTEGER;
l_session DBMS_LDAP.session;
l_attrs DBMS_LDAP.string_collection;
l_message DBMS_LDAP.message;
l_entry DBMS_LDAP.message;
l_attr_name VARCHAR2(256);
l_ber_element DBMS_LDAP.ber_element;
l_vals DBMS_LDAP.string_collection;
ret VARCHAR2(256);
begin
DBMS_LDAP.USE_EXCEPTION := TRUE;
l_session := DBMS_LDAP.init(hostname => l_ldap_host,portnum => l_ldap_port);
l_retval := DBMS_LDAP.simple_bind_s(ld => l_session,dn => l_ldap_user,passwd => l_ldap_passwd);
l_attrs(1) := 'postalcode';
l_retval := DBMS_LDAP.search_s(ld => l_session,base => l_ldap_base,scope => DBMS_LDAP.SCOPE_SUBTREE,filter => '(&(objectClass=user)(cn=' ||userAccount || ')(mail=*))',attrs => l_attrs,attronly => 0,res => l_message);
IF DBMS_LDAP.count_entries(ld => l_session, msg => l_message) > 0 THEN
l_entry := DBMS_LDAP.first_entry(ld => l_session,msg => l_message);
l_attr_name := DBMS_LDAP.first_attribute(ld => l_session, ldapentry => l_entry, ber_elem => l_ber_element);
l_vals := DBMS_LDAP.get_values (ld => l_session, ldapentry => l_entry, attr => l_attr_name);
ret := l_vals(0);
END IF;
l_retval := DBMS_LDAP.unbind_s(ld => l_session);
return ret;
end GetDataByUser;
```
* С#
```
static void Main(string[] args)
{
var listDict = ActiveDirectoryTraversal();
var d = listDict[0];
}
private static List> ActiveDirectoryTraversal()
{
List> ret = null;
var dep = new DirectoryEntry();
dep.AuthenticationType = AuthenticationTypes.FastBind;
dep.Path = "LDAP://yourpath";
using(DirectorySearcher ds = new DirectorySearcher(dep))
{
ds.Filter = "(&(objectClass=user))";
//ds.SizeLimit = 5;
ds.PageSize = 100;
using (SearchResultCollection results = ds.FindAll())
{
var e = results.Count;
if (results != null && results.Count > 0)
{
ret = SaveData(results);
}
}
}
dep.Close();
return ret;
}
private static List> SaveData(SearchResultCollection results)
{
var ret = new List>();
for (int i = 0; i < results.Count; i++)
{
var res = results[i];
var dict = new Dictionary();
foreach (var e in res.Properties.PropertyNames)
{
if (!dict.ContainsKey(e.ToString()))
dict.Add(e.ToString(), res.Properties[e.ToString()][0]);
}
ret.Add(dict);
}
return ret;
}
```
#### Заключение:
Умение работать с Active Directory и обращаться к нему напрямую из БД Oracle существенно упростило работу программистам отдела, где я работаю. Изначально я, ради эксперимента, выкачал содержимое Active Directory в таблицу базы данных. Потом, к своему удивлению, я обнаружил ряд хранимых процедур, которые работали с этой таблицей. Выяснилось, что разработчики обращались к ней, поленившись разобраться в пакете DBMS\_LDAP. Этот прецедент и подтолкнул меня к желанию рассказать и привести примеры того как можно работать с Active Directory. | https://habr.com/ru/post/238075/ | null | ru | null |
# Установка драйвера ATI на Debian GNU/Linux
#### Intro
Давным давно, когда я начал пользоваться Linux, я перепробовал несколько дистрибутивов и остановился на Debian. Так как игры я особо не играю, GNOME-вский десктоп мне сразу понравился своей простотой и удобностью, и работала система шустрее Windows. После установки системы все устройства определиль, кроме видеокарты — на тот момент у меня была ATI Radeon 9800 SE.
Установка драйвера как в Windows потерпела фиаско сразу после того как я с удивлением обнаружил, что в интерфейсе к установщику нет Debian, а если выбирать Ubuntu — то все умирает.
Тогда я потратил около недели на установку 8.6 версии. С тех пор я поменял компьютер, однако я поклонник AMD и следующей видеокартой которую я взял была — Radeon HD4850.
#### Приступая к работе
Во первый для установки понадобится сам [драйвер](http://support.amd.com/us/gpudownload/Pages/index.aspx). На данный момент последняя версия — 10.5. После того как он будет загружен распаковываем содержимое в каталог fglrx:
`./ati-driver-installer-10-5-x86.x86_64.run --extract fglrx`
**Примечание:** драйвер с пост фиксом «x86.x86\_64» подходит как для 32-х так и для 64-х битных систем.
Во-первых необходимо изменить скрипт ati-packager.sh. Для *lenny*:
`cp ./fglrx/packages/Debian/ati-packager.sh ./ati-packager.sh
cat ./ati-packager.sh | sed -e 's/X_DIR=x710; X_NAME=lenny/X_DIR=x690; X_NAME=lenny/' > ./fglrx/packages/Debian/ati-packager.sh`
Для *squeeze*:
`cp ./fglrx/packages/Debian/ati-packager.sh ./ati-packager.sh
cat ./ati-packager.sh | sed -e 's/X_DIR=x710; X_NAME=lenny/X_DIR=x750; X_NAME=lenny/' > ./fglrx/packages/Debian/ati-packager.sh`
Таким образом указание на несуществующую в дистрибутиве версию X-ов будет изменено на версию поддерживаемую системой.
Во-вторых необходимо изменить скрипт rules, изменения одинаковы для *lenny* и *squeeze*:
`cp ./Desktop/fglrx/packages/Debian/dists/lenny/rules rules
cat ./rules | sed -e 's/^\tdh_shlibdeps$/#\tdh_shlibdeps/' > ./fglrx/packages/Debian/dists/lenny/rules`
**Примечание:** без этого при сборке пакетов будет вылететь ошибка о том что нет библиотеки libatiuki.so.1. Есть [мнение](http://federicomoretti.name/tip/building-ati-catalyst-101-packages-under-ubuntukarmic/), что если создать ссылку на эту библиотеку то все соберется без проблем. У меня это не сработало. Также есть [мнение](http://www.phoronix.com/forums/showthread.php?t=21739#post109847) что изменение переменной окружения LD\_LIBRARY\_PATH может помочь, однако у меня это также не работало.
Теперь необходимо скопировать необходимую библиотеку в /usr/lib/:
Для 32-х бит:
cp ./fglrx/arch/x86/usr/lib/libatiuki.so.1.0 /usr/lib/libatiuki.so.1
Для 64-х бит:
cp ./fglrx/arch/x86\_64/usr/lib64/libatiuki.so.1.0 /usr/lib/libatiuki.so.1
Подготовка к сборке закончена.
#### Сборка пакетов
Теперь необходимо установить следующие пакеты:
`aptitude install debhelper module-assistant`
Далее module-assistant подтянет все необходимые пакеты, в том числе исходники ядра:
`module-assistant prepare`
Также для последних драйверов необходим libqtcore4. Далее сборка пакетов должна пройти без ошибок:
`./ati-installer.sh 10.5 --buildpkg Debian/lenny`
После чего должны появиться пакеты:
* fglrx-amdcccle
* fglrx-driver
* fglrx-driver-dev
* fglrx-kernel-src
Установить их можно так:
`dpkg --install —force-all *.deb`
**Примечание:** также есть утилита gdebi, позволяющая поставить пакеты с зависимостями. Я по привычке пользуюсь dpkg.
#### Сборка модуля
Собирается модуль в одну команду:
`module-assistant auto-install fglrx`
После перезагрузки имеем:
#### Заключение
Писал по памяти, так как последний раз ставил Debian пару месяцев назад на приобретенный ноутбук ASUS K40AB. Описанным способом драйвера поставились на ура, недавнее обновление свободного драйвера radeonhd вызвало конфликт, который был устранен за пару минут. Проверял установку на Debian lenny и squeeze на 32-х и 64-х битных системах.
P.S.: Писал по памяти так что возможны ошибки, однако суть такая. | https://habr.com/ru/post/96338/ | null | ru | null |
# Angular 2 Beta, обучающий курс «Тур героев» часть 2
[Часть 1](https://habrahabr.ru/post/281190/) [Часть 2](https://habrahabr.ru/post/281727/) [Часть 3](https://habrahabr.ru/post/282634/) [Часть 4](https://habrahabr.ru/post/283556/)
Нужно больше героев
-------------------
Нашей истории необходимо больше героев. Мы расширим наше приложение Тур героев, чтобы отобразить список героев, в котором пользователь может выбрать героя, и посмотреть детальную информацию о нем.
[Запустить приложение, часть 2](https://angular.io/resources/live-examples/toh-2/ts/plnkr.html)
Давайте подумаем, что нам нужно, чтобы отобразить список героев. Во-первых, нам нужен массив, который будет содержать список героев для отображения. Затем нам необходим способ передать данные из массива в шаблон.
### Где мы остановились
Прежде чем перейти ко второй Тура героев, необходимо выполнить [первую часть](https://habrahabr.ru/post/281190/). Если вы этого не сделали, вернитесь назад.
#### Поддержка преобразования кода и выполнения приложения
Мы хотим запустить компилятор TypeScript, чтобы при этом он отслеживал изменения в файлах и сразу выполнял компиляцию, а также запустить наш web-сервер. Мы сделаем это, набрав
```
npm start
```
Это позволит держать приложение запущенным, пока мы продолжаем создавать Тур героев.
### Отображение наших героев
#### Создание героев
Давайте создадим массив из десяти героев в нижней части `app.component.ts`.
**app.component.ts (Массив героев)**
```
let HEROES: Hero[] = [
{ "id": 11, "name": "Mr. Nice" },
{ "id": 12, "name": "Narco" },
{ "id": 13, "name": "Bombasto" },
{ "id": 14, "name": "Celeritas" },
{ "id": 15, "name": "Magneta" },
{ "id": 16, "name": "RubberMan" },
{ "id": 17, "name": "Dynama" },
{ "id": 18, "name": "Dr IQ" },
{ "id": 19, "name": "Magma" },
{ "id": 20, "name": "Tornado" }
];
```
`HEROES` — массив элементов типа `Hero`, класса, который мы создали в первой части. Мы, конечно, хотим получать этот список героев из веб-сервиса, но давайте делать маленькие шаги, и для начала отобразим героев из мок-объекта (заглушки, которая возвращает заранее указанные данные).
#### Представление героев
Давайте создадим свойство в `AppComponent`, которое будет источником героев для связывания.
**app.component.ts (Свойство — массив героев)**
```
public heroes = HEROES;
```
Нам не нужно явно определять тип для `heroes`. TypeScript может получить его из переменной `HEROES`.
> Мы могли бы определить список героев здесь, в этом классе компонента. Но мы знаем, что в итоге мы будем получать героев из web-службы. Поэтому имеет смысл сразу вынести эти данные из реализации класса.
#### Отображение героев в шаблоне
Наш компонент содержит `heroes`. Давайте создадим неупорядоченный список в нашем шаблоне, чтобы отобразить их. Мы вставить следующий кусок HTML под заголовком, выше детальной информации о герое.
**app.component.ts (Шаблон героев)**
```
My Heroes
---------
*
```
Теперь у нас есть шаблон, который мы можем заполнить нашими героями.
#### Вывод списка героев с ngFor
Мы хотим связать массив героев в нашем компоненте с нашим шаблоном, перебрать его, и отобразить каждого из героев по отдельности. Нам понадобится некоторая помощь Angular, чтобы сделать это. Давайте начнем шаг за шагом:
Во-первых, изменим тег `-`, добавив встроенную директиву `*ngFor`.
**app.component.ts (ngFor)**
```
-
```
> \**Ведущая звездочка (`*`) перед`ngFor` является важной частью синтаксиса.\*\*
Префикс `*` для `ngFor` указывает на то, что элемент `-` и его дочерние элементы составляют мастер-шаблон.
Директива `ngFor` проходит по массиву `heroes`, который вернуло свойство `AppComponent.heroes`, и выводит их в шаблон.
Текст в кавычках, присвоенный `ngFor`, обозначает: "возьми каждого героя в массиве `heroes`, сохрани в локальной переменной `hero`, и сделай его доступным для соответствующего экземпляра шаблона".
Префикс `#` перед `hero` идентифицирует героя как локальную переменную шаблона. Затем в шаблоне мы можем сослаться на эту переменную, чтобы получить доступ к свойствам героя.
Узнать больше о `ngFor` и локальных переменных шаблона можно в главах [Отображение данных](https://angular.io/docs/ts/latest/guide/displaying-data.html#ngFor) и [Синтаксис шаблона](https://angular.io/docs/ts/latest/guide/template-syntax.html#ngFor).
Теперь мы вставим некоторый код между тэгами `-`, который использует переменную шаблона `hero`, чтобы отобразить свойства героя.
**app.component.ts (ngFor template)**
```
- {{hero.id}} {{hero.name}}
```
Когда браузер обновит страницу, мы увидим список героев!
#### Добавление стилей нашим героям
Наш список героев выглядит довольно скучно. Мы хотим сделать его визуально очевидным для пользователя, чтобы он понимал, какой герой выбран, а над каким героем сейчас находится курсор.
Давайте добавим стили к нашему компоненту. Присвоим свойству `styles` в декораторе `@Component` следующие CSS классы:
**app.component.ts (Добавление стилей)**
```
styles:[`
.selected {
background-color: #CFD8DC !important;
color: white;
}
.heroes {
margin: 0 0 2em 0;
list-style-type: none;
padding: 0;
width: 15em;
}
.heroes li {
cursor: pointer;
position: relative;
left: 0;
background-color: #EEE;
margin: .5em;
padding: .3em 0;
height: 1.6em;
border-radius: 4px;
}
.heroes li.selected:hover {
background-color: #BBD8DC !important;
color: white;
}
.heroes li:hover {
color: #607D8B;
background-color: #DDD;
left: .1em;
}
.heroes .text {
position: relative;
top: -3px;
}
.heroes .badge {
display: inline-block;
font-size: small;
color: white;
padding: 0.8em 0.7em 0 0.7em;
background-color: #607D8B;
line-height: 1em;
position: relative;
left: -1px;
top: -4px;
height: 1.8em;
margin-right: .8em;
border-radius: 4px 0 0 4px;
}
`]
```
Обратите внимание на то, что мы снова используем `-нотацию для многострочного представления длинной строки.
Когда мы назначаем стили компоненту, они находятся только в области видимости этого конкретного компонента. Поэтому наши стили будут применяться только к `AppComponent` и не будут "утекать" во внешний HTML.
Наш шаблон для отображения героев должен теперь выглядеть следующим образом:
**app.component.ts (Стили для героев)**
```
My Heroes
---------
* {{hero.id}} {{hero.name}}
```
Как много стилей! Мы можем включить их в описание компонента, как показано здесь, или переместить их в отдельный файл, что сделает проще код нашего компонента. Мы сделаем это в следующей главе. Пока что оставим все, как есть.
### Выбор героя
В нашем приложении есть список героев и информация об одном герое. Список героев и один герой никак не связаны между собой. Мы хотим, чтобы пользователь выбрал героя в нашем списке, и информация о выбранном герое появилась в детальном представлении. Этот шаблон UI широко известен как "Master-Detail" (переводится как "главный-подчиненный", но в дальнейшем будет использоваться "Master/Detail"). В нашем случае, Master — список героев, а Detail — детальное представление выбранного героя.
Давайте соединим Master с Detail через свойство компонента 'selectedHero', связанного с событием клика на герое в списке.
#### Событие клика (щелчка мыши)
Изменим `-`, вставив обработку события клика, используя привязку события Angular.
**app.component.ts (Захват события клика)**
```
- {{hero.id}} {{hero.name}}
```
Сфокусируемся на привязке события:
```
(click)="onSelect(hero)"
```
Скобки назначают элемент `-` целью для события клика. Выражение справа от знака равенства вызывает метод `onSelect()`, который находится в компоненте `AppComponent`, передавая локальную переменную шаблона `hero` в качестве аргумента. Это та же самая переменная `hero`, которую мы определили ранее в `ngFor`.
> Подробнее о привязке событий можно узнать в главах [Пользовательский ввод](https://angular.io/docs/ts/latest/guide/user-input.html) и [Синтаксис шаблонов](https://angular.io/docs/ts/latest/guide/template-syntax.html#event-binding).
#### Добавление обработчика клика
Наше событие привязано к методу `onSelect`, который пока не существует. Добавим этот метод к нашему компоненту. Что должен делать этот метод? Он должен записать в переменную "выбранный герой" нашего компонента того героя, на которого нажал пользователь.
Пока что наш компонент не имеет такой переменной, поэтому начнем того, что добавим ее.
#### Назначение выбранного героя
Нам больше не нужно свойство `hero` в `AppComponent`. **Заменим** его на свойство `selectedHero`:
**app.component.ts (selectedHero)**
```
selectedHero: Hero;
```
Мы решили, что герой не должен иметь значения, пока пользователь сам не выберет героя, поэтому мы не будем инициализировать `selectedHero`, как мы делали с `hero`.
Теперь добавим метод `onSelect`, который записывает в свойство `selectedHero` значение `hero`, на котором кликнул пользователь.
**app.component.ts (onSelect)**
```
onSelect(hero: Hero) { this.selectedHero = hero; }
```
Мы должны отобразить детальную информацию выбранного героя в нашем шаблоне. В данный момент шаблон по-прежнему обращается к старому свойству `hero`. Давайте исправим шаблон для привязки к новому свойству `selectedHero`.
**app.component.ts (Привязка к selectedHero's)**
```
{{selectedHero.name}} details!
------------------------------
id: {{selectedHero.id}}
name:
```
#### Сокрытие пустых данных с ngIf
После загрузки нашего приложения мы видим список героев, но герой не выбран. `selectedHero` не определен, то есть он `undefined`. Вот почему мы увидим следующее сообщение об ошибке в консоли браузера:
```
EXCEPTION: TypeError: Cannot read property 'name' of undefined in [null]
```
Как вы помните, мы отображаем `selectedHero.name` в шаблоне. Свойство `name` не существует, потому что переменная `selectedHero`, которая содержит свойство, не определена.
Мы решим эту проблему, убрав детальную информацию о герое из DOM до тех пор, пока герой не будет выбран.
Мы обернули HTML, который содержит детальную информацию о герое, в . Добавим встроенную директиву `ngIf` и установим ей свойство `selectedHero` нашего компонента.
**app.component.ts (ngIf)**
```
{{selectedHero.name}} details!
------------------------------
id: {{selectedHero.id}}
name:
```
> \**Запомните, что ведущая звездочка (*) перед 'ngIf' является важной частью синтаксиса.\*\*
Пока переменная `selectedHero` не определена, директива `ngIf` удаляет HTML с детальной информацией о герое из DOM. Таким образом у нас не будет ни элементов с детальной информацией о герое, ни привязок, о которых стоит беспокоиться.
Когда пользователь выбирает героя в списке, переменная `selectedHero` получает значение и становится определенной, а `ngIf` размещает данные с детальной информацией о герое в DOM и осуществляет вложенные привязки.
> `ngIf` и `ngFor' называются "структурными директивами", потому что они могут изменить структуру частей DOM. Другими словами, они определяют структуру того, как Angular отображает контент в DOM.
Узнать больше о ngIf, ngFor и других структурных директивах можно в главах [Структурные директивы](https://angular.io/docs/ts/latest/guide/structural-directives.html) и [Синтаксис шаблонов](https://angular.io/docs/ts/latest/guide/template-syntax.html#event-binding).
Браузер обновляется, и мы видим список героев, но без детальной информации о выбранном герое. `NgIf` хранит ее вне DOM, пока переменная `selectedHero` не определена. Когда мы нажимаем на героя в списке, отображается детальная информация о выбранном герое. Все работает, как мы ожидали.
#### Стилизация выбранного элемента
Мы видим информацию о выбранном герое под списком, но мы не можем быстро найти этого героя в списке выше. Мы можем исправить это путем применения класса CSS `selected` к соответствующему элементу `-` в главном списке. Например, когда мы выбираем Magenta из списка героев, мы можем сделать его выделить его визуально, изменив цвет фона, как показано здесь.

Мы добавим свойство привязки к элементу `class`, чтобы в шаблоне установить класс `selected`. Мы сделаем это через выражение, которое сравнивает текущего `selectedHero` и `hero`.
Ключ это имя класса CSS (`selected`). Значение истинно (`true`), если оба героя совпали и ложь (`false`) иначе. Мы говорим *"применить класс `selected`, если герои совпадают, удалить его, если это не так"*.
**app.component.ts (Установка CSS класса)**
```
[class.selected]="hero === selectedHero"
```
Обратите внимание, что в шаблоне `class.selected` заключен в квадратные скобки (`[]`). Это синтаксис для связывания свойств, привязки, в которой потоки данных идут в одну сторону от источника данных (выражение `hero === selectedHero`) к свойству `class`.
**app.component.ts (Стилизация каждого героя)**
```
- {{hero.id}} {{hero.name}}
```
> Узнайте больше о [Связывании свойств](https://angular.io/docs/ts/latest/guide/template-syntax.html#property-binding) можно в главе Синтаксис шаблонов.
Браузер перезагружает наше приложение. Мы выбираем героя Magenta, и выбор четко идентифицируется цветом фона.

Мы выбираем другого героя и цвет фона переключается на этого героя.
Вот полное содержимое `app.component.ts` на данный момент:
**app.component.ts**
```
import {Component} from 'angular2/core';
export class Hero {
id: number;
name: string;
}
@Component({
selector: 'my-app',
template:`
{{title}}
=========
My Heroes
---------
* {{hero.id}} {{hero.name}}
{{selectedHero.name}} details!
------------------------------
id: {{selectedHero.id}}
name:
`,
styles:[`
.selected {
background-color: #CFD8DC !important;
color: white;
}
.heroes {
margin: 0 0 2em 0;
list-style-type: none;
padding: 0;
width: 15em;
}
.heroes li {
cursor: pointer;
position: relative;
left: 0;
background-color: #EEE;
margin: .5em;
padding: .3em 0;
height: 1.6em;
border-radius: 4px;
}
.heroes li.selected:hover {
background-color: #BBD8DC !important;
color: white;
}
.heroes li:hover {
color: #607D8B;
background-color: #DDD;
left: .1em;
}
.heroes .text {
position: relative;
top: -3px;
}
.heroes .badge {
display: inline-block;
font-size: small;
color: white;
padding: 0.8em 0.7em 0 0.7em;
background-color: #607D8B;
line-height: 1em;
position: relative;
left: -1px;
top: -4px;
height: 1.8em;
margin-right: .8em;
border-radius: 4px 0 0 4px;
}
`]
})
export class AppComponent {
title = 'Tour of Heroes';
heroes = HEROES;
selectedHero: Hero;
onSelect(hero: Hero) { this.selectedHero = hero; }
}
var HEROES: Hero[] = [
{ "id": 11, "name": "Mr. Nice" },
{ "id": 12, "name": "Narco" },
{ "id": 13, "name": "Bombasto" },
{ "id": 14, "name": "Celeritas" },
{ "id": 15, "name": "Magneta" },
{ "id": 16, "name": "RubberMan" },
{ "id": 17, "name": "Dynama" },
{ "id": 18, "name": "Dr IQ" },
{ "id": 19, "name": "Magma" },
{ "id": 20, "name": "Tornado" }
];
```
### Путь, который мы прошли
Вот то, чего мы достигли в этой главе:
* Наш Тур героев теперь отображает список героев.
* Мы добавили возможность выбора героя и отображения детальной информации о выбранном герое.
* Мы узнали, как использовать встроенные директивы `ngIf` и `ngFor`, в шаблоне компонента.
[Запустить приложение, часть 2](https://angular.io/resources/live-examples/toh-2/ts/plnkr.html)
#### Предстоящий путь
Наш Тур героев вырос, но до завершения еще далеко. Мы не можем поместить в один компонент приложение целиком. Нам нужно разбить его на подкомпоненты и научить их работать вместе. Мы узнаем, как это сделать, в [следующей главе](https://habrahabr.ru/post/282634/). | https://habr.com/ru/post/281727/ | null | ru | null |
# Адаптивное меню без Javascript

В этой публикации я хочу показать один из способов реализации адаптивного горизонтального меню с использованием Flexbox. Данный способ реализации меню используется на сайте [Warface Hub](https://www.warface.com.tr), но немного с другой структурой и б*о*льшим количеством свистелок.
Где-то с год назад, я попал в одну компанию, в которой мне сказали замечательную фразу: «Сначала делаем все с помощью CSS, а потом только добавляем JavaScript». Совет, вроде, хороший, и я ему последовал. Но как бывает, меня понесло. Сейчас мне это аукнулось тем, что не все нужно делать с таким подходом.
И так, ближе к делу. Я приступил к изучению и реализации.
### Цели
1. получить базовые навыки работы с Flexbox свойствами;
2. разработать горизонтальное адаптивное меню;
3. полученное решение применить в проекте.
### Инструменты и документация
1. [NPM](https://www.npmjs.com/) – в качестве менеджера пакетов (теперь активно переезжаем на Yarn)
2. [Grunt](http://gruntjs.com/) – инструмент, который поможет в сборке проекта
3. Документация по Flexbox (см. *Полезные ссылки*);
4. [SASS](http://sass-lang.com/)
*Вы можете использовать свой набор инструментов*
### Структура
Для организации структуры стилей для меню я пользовался концепцией, которая описана [тут](https://github.com/dsheiko/pcss). Автор данной концепции предлагает разбить все описания стилей на несколько частей:
* *layout*– описывает положение компонентов и элементов на странице;
* *component*– описывает отображение и поведение элементов, которые входят в компонент;
* *element*– описывает отображение и поведение единичного элемента;
Таким образом мое понимание концепции привело меня к такой структуре:
* *Base* — описание констант, базовых стилей (как в [normalize.css](https://github.com/necolas/normalize.css/))
* *Component* — описание компонентов приложения. В нашем случае компонент «Menu»
* *Element* — описание стилей для элементов таких как кнопка, ссылка и т.п.
* *Layout* — описание расположения блоков на странице
* *style.scss* — в этом файле мы соберем все вместе
### CSS и HTML теги input & label
Прежде чем начать рисовать HTML разметку, я бы хотел напомнить/показать интересное поведение CSS селекторов, которое нам пригодится.
```
Текст 1
Текст 1
```
В данном примере Вы можете заметить, что при нажатии на label Вы получите выбранный input. В этом ничего особенного нет (см. [документацию](http://www.w3schools.com/tags/tag_label.asp)), но самое интересное происходит со стороны CSS селекторов.
```
.input:checked {
border-color: red;
}
```
Данный CSS селектор будет обработан только тогда, когда будет выбран input (см. [:checked](https://developer.mozilla.org/en-US/docs/Web/CSS/:checked))
Второй момент, на который нужно обратить внимание в CSS селекторах — это выбор следующего элемента (см. [Adjacent sibling selectors](https://developer.mozilla.org/en-US/docs/Web/CSS/Adjacent_sibling_selectors) и [General sibling selectors](https://developer.mozilla.org/en-US/docs/Web/CSS/General_sibling_selectors)). То есть мы можем выбрать следующий элемент после текущего.
```
.input:checked + .label {
color: red;
}
```
В этом примере мы получили следующее поведение: при выбранном элементе с классом input следующий за ним элемент с классом label будет изменен в соответствии с описанными стилями.
Теперь это все можно объединить воедино.
**Структура меню с одном элементом**
```
Menu Item 0
- [Sub Item Menu 0](#)
- [Sub Item Menu 1 - With long label](#)
- [Sub Item Menu 2 - Withtooolongwordslikeingerman](#)
```
В данном примере я добавил несколько элементов input и label, чтобы получилось следующее поведение:
1. Каждый элемент name=menu-item-trigger, кроме первого, в состоянии :checked будет изменять видимость и позиции последующих элементов label.menu-item-close и div.menu-sub таким образом, чтобы элемент label.menu-item-close полностью перекрывал элемент label.menu-item-label, а div.menu-sub отображался под элементом label.menu-item-label. То есть мы открываем подменю и меняем поведение при клике на основное меню;
2. Первый элемент name=menu-item-trigger будет использован только для того, чтобы отменить все примененные изменения в предыдущем пункте, то есть закрыть подменю;
Не выбран ни один пункт меню:

Выбран один пункт меню:
После таких манипуляций остается только скрыть элементы input.
### Flexbox
Теперь необходимо добавить стили, чтобы данное меню хорошо отображалось при различных разрешениях и различных браузерах. На текущий момент мы сосредоточили наши усилия на поддержке тех браузеров, которые больше всего используются посетителями нашего ресурса. Получился небольшой список: Chrome, Firefox, IE Edge, IE 11 и их мобильные варианты последних версий.
Поддержка осуществляется путем добавления префиксов ([postcss](https://github.com/postcss/postcss)) и отдельного написания стилей для конкретного браузера.
Адаптивность в Flexbox достигается очень просто. Достаточно описать контейнер, но иногда будет необходимо решить проблемы с контентом внутри. Например:
* элементы меню с длинными словами, как «knowledge base» и его немецкий перевод «Wissensdatenbank». В данном случае добавляется оборачивающий элемент для текста, к которому применяются примерно следующие стили:
```
.label-text {
// @link: http://htmlbook.ru/css/text-overflow
overflow: hidden;
text-overflow: ellipsis;
width: 100%;
display: inline-block;
}
```
* Картинки, которые нужно растянуть по ширине, но при задании width: 100%; они вылезают за пределы родительского блока. Тут поможет box-sizing: border-box; для этого элемента;
* Так же могут возникнуть проблемы с тем, что дочерние элементы не занимают всю возможную длину или не распределяются равномерно. Тут возможно поможет flex: 1 1 auto.
В данном примере контейнер для элементов описан так:
```
.menu {
display: flex;
align-items: center;
flex-wrap: wrap;
}
```
Для каждого элемента в контейнере необходимо задать стили так, чтобы он заполнял все возможное пространство и выравнивали контент внутри себя в центре по вертикали:
```
.menu-item {
flex: 1 1 auto;
display: flex;
flex-direction: column;
align-items: stretch;
}
```
Более красивого отображения меню можно достичь с помощью [media queries](https://developer.mozilla.org/en-US/docs/Web/CSS/Media_Queries/Using_media_queries) и более точных размеров и позиций элементов.
### Итог
После реализации данного примера я доработал его в рамках боевого проекта, который сейчас использует подобное адаптивное меню. Так же были выявлены плюсы и минусы избавления от Javascript в пользу CSS:
Плюсы:
1. Не требуется ожидать загрузки JavaScript. Чаще всего меню находится в шапке сайта, поэтому эти стили можно положить в core.css, который описывает основные стили элементов, видимые пользователю при загрузке страницы;
2. Меню будет работать, даже если в JavaScript произойдет что-то страшное и не будет инициализирован скрипт для меню.
Минусы:
1. Ограниченные возможности CSS селекторов, например нельзя изменить родительский элемент при изменении дочернего;
2. На iOS была замечена потеря производительности. Пришлось разбираться и проставлять [will-change](https://developer.mozilla.org/en-US/docs/Web/CSS/will-change) свойства;
3. Нет возможности скрыть под меню через N секунд после потери фокуса (особенности реализации);
4. Трудно разобраться в HTML разметке меню;
5. Поддержка Flexbox в IE ~~на уровне «вырви глаз»~~
### Полезные ссылки
* [PCSS](https://github.com/dsheiko/pcss) — описание концепции построения компонентного CSS;
* [Guide To Flexbox (EN)](https://css-tricks.com/snippets/css/a-guide-to-flexbox/) — тут хорошо описаны свойства Flexbox;
* [Guide To Flexbox (RUS)](http://frontender.info/a-guide-to-flexbox/) — тут хорошо описаны свойства Flexbox на русском языке;
* [Mr. Froggy](http://flexboxfroggy.com/) — поможет Вам овладеть навыками использования Flexbox
* [Demo](https://oxcom.github.io/pub-menu/)
* [Github Project](https://github.com/OxCom/pub-menu) | https://habr.com/ru/post/317528/ | null | ru | null |
# Обучение машины — забавная штука: современное распознавание лиц с глубинным обучением
Вы заметили, что Фейсбук обрёл сверхъестественную способность распознавать ваших друзей на ваших фотографиях? В старые времена Фейсбук отмечал ваших друзей на фотографиях лишь после того, как вы щёлкали соответствующее изображение и вводили через клавиатуру имя вашего друга. Сейчас после вашей загрузки фотографии Фейсбук отмечает любого для вас, что *похоже на волшебство*:

Фейсбук автоматически маркирует людей на ваших фотографиях, которых вы отметили когда-то ранее. Я не могу определиться для себя, полезно это или жутковато!
Эта технология называется распознавание лиц. Алгоритмы Фейсбука могут распознавать лица ваших друзей после того, как вы отметили их лишь пару-тройку раз. Это — удивительная технология: Фейсбук в состоянии распознавать лица [с точностью 98%](https://research.facebook.com/publications/deepface-closing-the-gap-to-human-level-performance-in-face-verification/) — практически так же, как и человек!
Рассмотрим, как работает современное распознавание лиц! Однако просто распознавать ваших друзей было бы слишком легко. Мы можем подойти к границе этой технологии, чтобы решить более сложную задачу — попробуем отличить [Уилла Феррелла](https://en.wikipedia.org/wiki/Will_Ferrell) (известный актёр) от [Чеда Смита](https://en.wikipedia.org/wiki/Chad_Smith) (известный рок-музыкант)!

Один из этих людей — Уилл Феррелл. Другой — Чед Смит. Клянусь — это разные люди!
Как использовать обучение машины при очень сложной проблеме
===========================================================
До сих пор в [частях 1](https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471), [2](https://medium.com/@ageitgey/machine-learning-is-fun-part-2-a26a10b68df3) и [3](https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721) мы использовали обучение машины для решения изолированных проблем, имеющих только один шаг — [оценка стоимости дома](https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471), [создание новых данных на базе существующих](https://medium.com/@ageitgey/machine-learning-is-fun-part-2-a26a10b68df3) и [определение, содержит ли изображение некоторый объект](https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721). Все эти проблемы могут быть решены выбором одного алгоритма обучения машины, вводом данных и получением результата.
Но распознавание лиц представляет собой фактически последовательность нескольких связанных проблем:
1. Во-первых, необходимо рассмотреть изображение и найти на нём все лица.
2. Во-вторых, необходимо сосредоточиться на каждом лице и определить, что, несмотря на неестественный поворот лица или неважное освещение, это — один и тот же человек.
3. В-третьих, надо выделить уникальные характеристики лица, которые можно использовать для отличия его от других людей — например, размер глаз, удлинённость лица и т.п.
4. В завершение необходимо сравнить эти уникальные характеристики лица с характеристиками других известных вам людей, чтобы определить имя человека.
Мозг человека проделывает всё это автоматически и мгновенно. Фактически, люди *чрезвычайно хорошо* распознают лица и, в конечном итоге, видят лица в повседневных предметах:

Компьютеры неспособны к такого рода высокому уровню обобщения (*как минимум, пока …*), поэтому приходится учить их каждому шагу в этом процессе отдельно.
Необходимо построить *конвейер*, на котором мы будем находить решение на каждом шаге процесса распознавания лица отдельно и передавать результат текущего шага на следующий. Другими словами, мы соединим в одну цепь несколько алгоритмов обучения машины:

Как может работать базовый процесс распознавания лиц
Распознавание лиц — шаг за шагом
================================
Давайте решать эту проблему последовательно. На каждом шаге мы будем узнавать о новом алгоритме обучения машины. Я не собираюсь разъяснять каждый отдельный алгоритм полностью, чтобы не превратить эту статью в книгу, но вы узнаете основные идеи, заключающиеся в каждом из алгоритмов, и узнаете, как можно создать свою собственную систему распознавания лиц в Python, используя [OpenFace](https://cmusatyalab.github.io/openface/) и [dlib](http://dlib.net/).
### Шаг 1. Нахождение всех лиц
Первым шагом на нашем конвейере является *обнаружение лиц*. Совершенно очевидно, что необходимо выделить все лица на фотографии, прежде чем пытаться распознавать их!
Если вы использовали в последние 10 лет какую-либо фотографию, то вы, вероятно, видели, как действует обнаружение лиц:
Обнаружение лиц — великое дело для фотокамер. Если камера может автоматически обнаруживать лица, то можно быть уверенным, что все лица окажутся в фокусе, прежде чем будет сделан снимок. Но мы будем использовать это для другой цели — нахождение областей изображения, которые надо передать на следующий этап нашего конвейера.
Обнаружение лица стало господствующей тенденцией в начале 2000-х годов, когда Пол Виола и Майкл Джонс изобрели [способ обнаруживать лица](https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_object_detection_framework), который был достаточно быстрым, чтобы работать на дешёвых камерах. Однако сейчас существуют намного более надёжные решения. Мы собираемся использовать [метод, открытый в 2005 году](http://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf), — гистограмма направленных градиентов (коротко, **HOG**).
Для обнаружения лиц на изображении мы сделаем наше изображение чёрно-белым, т.к. данные о цвете не нужны для обнаружения лиц:

Затем мы рассмотрим каждый отдельный пиксель на нашем изображении последовательно. Для каждого отдельного пикселя следует рассмотреть его непосредственное окружение:

Нашей целью является выделить, насколько тёмным является текущий пиксель по сравнению с пикселями, прямо примыкающими к нему. Затем проведём стрелку, показывающую направление, в котором изображение становится темнее:

При рассмотрении этого одного пикселя и его ближайших соседей видно, что изображение темнеет вверх вправо.
Если повторить этот процесс для **каждого отдельного пикселя** на изображении, то, в конечном итоге, каждый пиксель будет заменён стрелкой. Эти стрелки называют *градиентом*, и они показывают поток от света к темноте по всему изображению:
Может показаться, что результатом является нечто случайное, но есть очень хорошая причина для замены пикселей градиентами. Когда мы анализируем пиксели непосредственно, то у тёмных и светлых изображений одного и того же человека будут сильно различающиеся значения интенсивности пикселей. Но если рассматривать только *направление* изменения яркости, то как тёмное, так и светлое изображения будут иметь совершенно одинаковое представление. Это значительно облегчает решение проблемы!
Но сохранение градиента для каждого отдельного пикселя даёт нам способ, несущий слишком много подробностей. Мы, в конечном счёте, [не видим леса из-за деревьев](https://en.wiktionary.org/wiki/see_the_forest_for_the_trees). Было бы лучше, если бы мы могли просто видеть основной поток светлого/тёмного на более высоком уровне, рассматривая таким образом базовую структуру изображения.
Для этого разбиваем изображение на небольшие квадраты 16х16 пикселей в каждом. В каждом квадрате следует подсчитать, сколько градиентных стрелок показывает в каждом главном направлении (т.е. сколько стрелок направлено вверх, вверх-вправо, вправо и т.д.). Затем рассматриваемый квадрат на изображении заменяют стрелкой с направлением, преобладающим в этом квадрате.
В конечном результате мы превращаем исходное изображение в очень простое представление, которое показывает базовую структуру лица в простой форме:

Исходное изображение преобразовано в HOG-представление, демонстрирующее основные характеристики изображения независимо от его яркости.
Чтобы обнаружить лица на этом HOG-изображении, всё, что требуется от нас, это найти такой участок изображения, который наиболее похож на известную HOG-структуру, полученную из группы лиц, использованной для обучения:

Используя этот метод, можно легко находить лица на любом изображении:

Если есть желание выполнить этот этап самостоятельно, используя Python и dlib, то [имеется программа](https://gist.github.com/ageitgey/1c1cb1c60ace321868f7410d48c228e1), показывающая, как создавать и просматривать HOG-представления изображений.
### Шаг 2. Расположение и отображение лиц
Итак, мы выделили лица на нашем изображении. Но теперь появляется проблема: одно и то же лицо, рассматриваемое с разных направлений, выглядит для компьютера совершенно по-разному:

Люди могут легко увидеть, что оба изображения относятся к актёру Уиллу Ферреллу, но компьютеры будут рассматривать их как лица двух разных людей.
Чтобы учесть это, попробуем преобразовывать каждое изображение так, чтобы глаза и губы всегда находились на одном и том же месте изображения. Сравнение лиц на дальнейших шагах будет значительно упрощено.
Для этого используем алгоритм, называемый **«оценка антропометрических точек»**. Есть много способов сделать это, но мы собираемся использовать [подход, предложенный в 2014 году Вахидом Кэземи и Джозефином Салливаном](http://www.csc.kth.se/~vahidk/papers/KazemiCVPR14.pdf).
Основная идея в том, что выделяется 68 специфических точек (*меток*), имеющихся на каждом лице, — выступающая часть подбородка, внешний край каждого глаза, внутренний край каждой брови и т.п. Затем происходит настройка алгоритма обучения машины на поиск этих 68 специфических точек на каждом лице:

68 антропометрических точек мы располагаем на каждом лице
Ниже показан результат расположения 68 антропометрических точек на нашем тестовом изображении:

СОВЕТ ПРОФЕССИОНАЛА НОВИЧКУ: этот же метод можно использовать для ввода вашей собственной версии 3D-фильтров лица реального времени в Snapchat!
Теперь, когда мы знаем, где находятся глаза и рот, мы будем просто вращать, масштабировать и [сдвигать](https://en.wikipedia.org/wiki/Shear_mapping#/media/File:VerticalShear_m%3D1.25.svg) изображение так, чтобы глаза и рот оказались отцентрованы как можно лучше. Мы не будем вводить какие-либо необычные 3D-деформации, поскольку они могут исказить изображение. Мы будет делать только базовые преобразования изображения, такие как вращение и масштабирование, которые сохраняют параллельность линий (т.н. [аффинные преобразования](https://en.wikipedia.org/wiki/Affine_transformation)):

Теперь независимо от того, как повёрнуто лицо, мы можем отцентровать глаза и рот так, чтобы они были примерно в одном положении на изображении. Это сделает точность нашего следующего шага намного выше.
Если у вас есть желание попытаться выполнить этот шаг самостоятельно, используя Python и dlib, то имеется [программа для нахождения антропометрических точек](https://gist.github.com/ageitgey/ae340db3e493530d5e1f9c15292e5c74) и [программа для преобразования изображения на основе этих точек](https://gist.github.com/ageitgey/82d0ea0fdb56dc93cb9b716e7ceb364b).
### Шаг 3. Кодирование лиц
Теперь мы подошли к сути проблемы — само различение лиц. Здесь-то и начинается самое интересное!
Простейшим подходом к распознаванию лиц является прямое сравнение неизвестного лица, обнаруженного на шаге 2, со всеми уже отмаркированными лицами. Если мы найдём уже отмаркированное лицо, очень похожее на наше неизвестное, то это будет означать, что мы имеем дело с одним и тем же человеком. Похоже, очень хорошая идея, не так ли?
На самом деле при таком подходе возникает огромная проблема. Такой сайт как Фейсбук с миллиардами пользователей и триллионами фотографий не может достаточно циклично просматривать каждое ранее отмаркированное лицо, сравнивая его с каждой новой загруженной картинкой. Это потребовало бы слишком много времени. Необходимо распознавать лица за миллисекунды, а не за часы.
Нам требуется научиться извлекать некоторые базовые характеристики из каждого лица. Затем мы могли бы получить такие характеристики с неизвестного лица и сравнить с характеристиками известными лиц. Например, можно обмерить каждое ухо, определить расстояние между глазами, длину носа и т.д. Если вы когда-либо смотрели телесериал о работе сотрудников криминалистической лаборатории Лас-Вегаса ([«C.S.I.: место преступления»](https://en.wikipedia.org/wiki/CSI:_Crime_Scene_Investigation)), то вы знаете, о чём идёт речь:

Как в кино! Так похоже на правду!
### Самый надёжный метод обмерить лицо
Хорошо, но какие характеристики надо получить с каждого лица, чтобы построить базу данных известных лиц? Размеры уха? Длина носа? Цвет глаз? Что-нибудь ещё?
Оказывается, что характеристики, представляющиеся очевидными для нас, людей, (например, цвет глаз) не имеют смысла для компьютера, анализирующего отдельные пиксели на изображении. Исследователи обнаружили, что наиболее адекватным подходом является дать возможность компьютеру самому определить характеристики, которые надо собрать. Глубинное обучение позволяет лучше, чем это могут сделать люди, определить части лица, важные для его распознавания.
Решение состоит в том, чтобы обучить глубокую свёрточную нейронную сеть ([именно это мы делали в выпуске 3](https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721)). Но вместо обучения сети распознаванию графических объектов, как мы это делали последний раз, мы теперь собираемся научить её создавать 128 характеристик для каждого лица.
Процесс обучения действует при рассмотрении 3-х изображений лица одновременно:
1. Загрузите обучающее изображение лица известного человека
2. Загрузите другое изображение лица того же человека
3. Загрузите изображение лица какого-то другого человека
Затем алгоритм рассматривает характеристики, которые он в данный момент создаёт для каждого из указанных трёх изображений. Он слегка корректирует нейронную сеть так, чтобы характеристики, созданные ею для изображений 1 и 2, оказались немного ближе друг к другу, а для изображений 2 и 3 — немного дальше.
**Единый «строенный» шаг обучения:**

После повтора этого шага миллионы раз для миллионов изображений тысяч разных людей нейронная сеть оказывается в состоянии надёжно создавать 128 характеристик для каждого человека. Любые десять различных изображений одного и того же человека дадут примерно одинаковые характеристики.
Специалисты по обучению машин называют эти 128 характеристик каждого лица **набором характеристик (признаков)**. Идея сведения сложных исходных данных, таких как, например, изображение, к списку генерируемых компьютером чисел оказалась чрезвычайно перспективной в обучении машин (в частности, для переводов). Такой подход для лиц, который мы используем, [был предложен в 2015 году исследователями из Гугл](http://www.cv-foundation.org/openaccess/content_cvpr_2015/app/1A_089.pdf), но существует много аналогичных подходов.
### Кодировка нашего изображения лица
Процесс обучения свёрточной нейронной сети с целью вывода наборов характеристик лица требует большого объёма данных и большой производительности компьютера. Даже на дорогой [видеокарте NVidia Telsa](http://www.nvidia.com/object/tesla-supercomputing-solutions.html) требуется [примерно 24 часа](https://twitter.com/brandondamos/status/757959518433243136) непрерывного обучения для получения хорошей точности.
Но если сеть обучена, то можно создавать характеристики для любого лица, даже для того, которое ни разу не видели раньше! Таким образом, этот шаг требуется сделать лишь один раз. К счастью для нас, добрые люди на [OpenFace](https://cmusatyalab.github.io/openface/) уже сделали это и [предоставили доступ к нескольким прошедшим обучение сетям](https://github.com/cmusatyalab/openface/tree/master/models/openface), которые мы можем сразу же использовать. Спасибо [Брендону Амосу](http://bamos.github.io/) и команде!
В результате всё, что требуется от нас самих, это провести наши изображения лиц через их предварительно обученную сеть и получить 128 характеристик для каждого лица. Ниже представлены характеристики для нашего тестового изображения:

Но какие конкретно части лица эти 128 чисел описывают? Оказывается, что мы не имеем ни малейшего представления об этом. Однако на самом деле это не имеет значения для нас. Нас должно заботить лишь то, чтобы сеть выдавала примерно одни и те же числа, анализируя два различных изображения одного и того же человека.
Если есть желание попробовать выполнить этот шаг самостоятельно, то OpenFace [предоставляет Lua-скрипт](https://github.com/cmusatyalab/openface/blob/master/batch-represent/batch-represent.lua), создающий наборы характеристик всех изображений в папке и записывающий их в csv-файл. Можно запустить его так, [как показано](https://gist.github.com/ageitgey/ddbae3b209b6344a458fa41a3cf75719).
### Шаг 4. Нахождение имени человека после кодировки лица
Последний шаг является фактически самым лёгким во всём этом процессе. От нас требуется лишь найти человека в нашей базе данных известных лиц, имеющего характеристики, наиболее близкие к характеристикам нашего тестового изображения.
Это можно сделать, используя любой базовый алгоритм классификации обучения машин. Какие-либо особые приёмы глубинного обучения не требуются. Мы будем использовать простой линейный [SVM-классификатор](https://en.wikipedia.org/wiki/Support_vector_machine), но могут быть применены и многие другие алгоритмы классификации.
От нас потребуется только обучить классификатор, который сможет взять характеристики нового тестового изображения и сообщить, какое известное лицо имеет наилучшее соответствие. Работа такого классификатора занимает миллисекунды. Результатом работы классификатора является имя человека!
Опробуем нашу систему. Прежде всего я обучил классификатор, используя наборы характеристики от примерно 20 изображений Уилла Феррелла, Чеда Смита и Джимми Фэлона:

О, эти восхитительные картинки для обучения!
Затем я прогнал классификатор на каждом кадре знаменитого видеоролика на Youtube, где на шоу Джимми Фэлона [Уилл Феррелл и Чед Смит прикидываются друг другом](https://www.youtube.com/watch?v=EsWHyBOk2iQ):

Сработало! И смотрите, как великолепно это сработало для лиц с самых разных направлений — даже в профиль!
Самостоятельное выполнение всего процесса
=========================================
Рассмотрим требуемые шаги:
1. Обработайте картинку, используя HOG-алгоритм, чтобы создать упрощённую версию изображения. На этом упрощённом изображении найдите тот участок, который более всего похож на созданное HOG-представление лица.
2. Определите положение лица, установив главные антропометрические точки на нём. После позиционирования этих антропометрических точек используйте их для преобразования изображения с целью центровки глаз и рта.
3. Пропустите отцентрованное изображение лица через нейронную сеть, обученную определению характеристик лица. Сохраните полученные 128 характеристик.
4. Просмотрев все лица, характеристики которых были сняты раньше, определите человека, характеристики лица которого наиболее близки к полученным. Дело сделано!
Теперь, когда вы знаете, как всё это работает, просмотрите инструкции с самого начала до конца, как провести весь процесс распознавания лица на вашем собственном компьютере, используя [OpenFace](https://cmusatyalab.github.io/openface/):
Прежде чем начать
-----------------
Убедитесь, что Python, OpenFace и dlib у вас установлены. Их можно [установить вручную](https://cmusatyalab.github.io/openface/setup/) или использовать предварительно сконфигурированное контейнерное изображение, в котором это всё уже установлено:
```
docker pull bamos/openface
docker run -p 9000:9000 -p 8000:8000 -t -i bamos/openface /bin/bash
cd /root/openface
```
Совет профессионала новичку: если вы используете Docker на OSX, то можно сделать папку OSX/Users/ видимой внутри контейнерного изображения, как показано ниже:
```
docker run -v /Users:/host/Users -p 9000:9000 -p 8000:8000 -t -i bamos/openface /bin/bash
cd /root/openface
```
Затем можно выйти на все ваши OSX-файлы внутри контейнерного изображения на /host/Users/…
```
ls /host/Users/
```
### Шаг 1
Создайте папку с названием `./training-images/` в папке openface.
```
mkdir training-images
```
### Шаг 2
Создайте подпапку для каждого человека, которого надо распознать. Например:
```
mkdir ./training-images/will-ferrell/
mkdir ./training-images/chad-smith/
mkdir ./training-images/jimmy-fallon/
```
### Шаг 3
Скопируйте все изображения каждого человека в соответствующие подпапки. Убедитесь, что на каждом изображении имеется только одно лицо. Не требуется обрезать изображение вокруг лица. OpenFace сделает это автоматически.
### Шаг 4
Выполните скрипты openface из корневого директория openface:
Сначала должны быть выполнены обнаружение положения и выравнивание:
```
./util/align-dlib.py ./training-images/ align outerEyesAndNose ./aligned-images/ --size 96
```
В результате будет создана новая подпапка `./aligned-images/` с обрезанной и выровненной версией каждого из ваших тестовых изображений.
Затем создайте представления из выровненных изображений:
```
./batch-represent/main.lua -outDir ./generated-embeddings/ -data ./aligned-images/
```
Подпапка `./generated-embeddings/` будет содержать csv-файл с наборами характеристик для каждого изображения.
Проведите обучение вашей модели обнаружения лица:
```
./demos/classifier.py train ./generated-embeddings/
```
Будет создан новый файл с именем `./generated-embeddings/classifier.pk`. Этот файл содержит SVM-модель, которая будет использоваться для распознавания новых лиц.
С этого момента у вас появляется работающий распознаватель лиц!
### Шаг 5. Распознаём лица!
Возьмите новую картинку с неизвестным лицом. Пропустите её через скрипт классификатора, типа нижеследующего:
```
./demos/classifier.py infer ./generated-embeddings/classifier.pkl your_test_image.jpg
```
Вы должны получить примерно такое предупреждение:
```
=== /test-images/will-ferrel-1.jpg ===
Predict will-ferrell with 0.73 confidence.
```
Здесь, если пожелаете, можете настроить python-скрипт `./demos/classifier.py`.
Важные замечания:
• Если результаты неудовлетворительные, то попытайтесь добавить ещё несколько изображений для каждого человека на шаге 3 (особенно изображения с разных направлений).
• Данный скрипт будет всегда выдавать предупреждение, даже если он не знает это лицо. При реальном использовании необходимо проверить степень уверенности и убрать предупреждения с низким значением степени уверенности, поскольку они, скорее всего, неправильные. | https://habr.com/ru/post/306568/ | null | ru | null |
# Простой клиент-сервер на Android (интернет-мессенджер)
**Важно.** Все написанное ниже не представляет собой какой либо ценности для профессионалов, но может служит полезным примером для начинающих Android разработчиков! В коде старался все действия комментировать и логировать.
**Поехали.** Многие мобильные приложения (и не только) используют архитектуру клиент-сервер. Общая схема, думаю, понятна.
Уделим внимание каждому элементу и отметим:
* сервер — представляет собой некую программу, работающую на удаленном компьютере, и реализующую функционал «общения» с приложениями-клиентами (слушает запросы, распознает переданные параметры и значения, корректно отвечает на них);
* клиент — в нашем случае, программа на мобильном устройстве, которая умеет формировать понятный серверу запрос и читать полученный ответ;
* интерфейс взаимодействия — некий формат и способ передачи/получения запросов/ответов обеими сторонами.
Неважно, как реализован любой из этих элементов, все они в любом случае присутствуют. Давайте реализуем примитивный сервер и Android клиент, работающий с ним. Как пример, будем использовать любой популярный мобильный интернет-мессенджер (Viber, ICQ), а приложение условно назовем «интернет-чат».
Схема взаимодействия следующая:
Клиент, установленный на устройстве А, посылает сообщение для клиента, установленного на устройстве Б. И наоборот. Сервер играет роль связующего звена между устройством А и Б… С, Д… и т.д. Также он играет роль «накопителя» сообщений, для их восстановления, на случай удаления на одном из клиентских устройств.
Для хранения сообщений используем SQL БД как на сервере, так и на устройствах-клиентах (в принципе, вся работа клиентов интернет-мессенджеров и сводится к постоянной синхронизации локальной и удаленной БД с сообщениями). Дополнительно, наш интернет-чат будет уметь стартовать вместе с запуском устройства и работать в фоне. Взаимодействие будет происходить путем HTTP запросов и JSON ответов.
> *Более логично, если синхронизация происходит через порт/сокет, это с одной стороны упрощает задачу (не нужно циклично слать HTTP запросы на проверку новых сообщений, достаточно проверять состояние прослушиваемого сокета), но с другой стороны, это усложняет создание серверной части приложения.*
### Делаем сервер
***Для реализации «сервера», нам нужно зарегистрироваться на любом хостинге, который дает возможность работы с SQL и PHP.***
Создаем пустую SQL БД, в ней создаем таблицу.
**Таблица chat.**
```
CREATE TABLE `chat` (
`_id` int(11) NOT NULL AUTO_INCREMENT,
`author` text CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL,
`client` text CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL,
`data` bigint(20) NOT NULL,
`text` text CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL,
PRIMARY KEY (`_id`)
)
```
Структура следующая:
1. author — автор сообщения;
2. client — получатель сообщения;
3. data — время и дата получения сообщения на сервере;
4. text — сообщение.
В двух следующих файлах необходимо изменить переменные, содержащие данные для доступа к БД, на свои, полученные Вами при регистрации Вашего«сервера».
```
$mysql_host = "localhost"; // sql сервер, может быть локальным или внешним. например mysql5.000webhost.com
$mysql_user = "l29340eb_chat"; // пользователь
$mysql_password = "123456789"; // пароль
$mysql_database = "l29340eb_chat"; // имя базы данных на сервере SQL
```
**Файл chat.php это наш api, реализующий структуру понятных серверу запросов.**
```
php // сохранить в utf-8 !
// ---------------------------------------------------------- эти значения задавались при создании БД на сервере
$mysql_host = "localhost"; // sql сервер
$mysql_user = "l29340eb_chat"; // пользователь
$mysql_password = "123456789"; // пароль
$mysql_database = "l29340eb_chat"; // имя базы данных chat
// ---------------------------------------------------------- проверяем переданные в строке запроса параметры
// например ...chat.php?action=select
//-----------------------------------------------------------
// переменная action может быть:
// select - формируем содержимое таблицы chat в JSON и отправляем назад
// insert - встваляем новую строку в таблицу chat, так же нужны 4 параметра : автор/получатель/время создания/сообщение
// ВАЖНО время создания мы не передаем в параметрах, его берем текущее на сервере
// delete - удаляет ВСЕ записи из таблицы chat - пусть будет для быстрой очистки
// ------------------------------------------- получим переданный action
if (isset($_GET["action"])) {
$action = $_GET['action'];
}
// ------------------------------------------- если action=insert тогда получим еще author|client|text
if (isset($_GET["author"])) {
$author = $_GET['author'];
}
if (isset($_GET["client"])) {
$client = $_GET['client'];
}
if (isset($_GET["text"])) {
$text = $_GET['text'];
}
// ------------------------------------------- если action=select тогда получим еще data - от после какого времени передавать ответ
if (isset($_GET["data"])) {
$data = $_GET['data'];
}
mysql_connect($mysql_host, $mysql_user, $mysql_password); // коннект к серверу SQL
mysql_select_db($mysql_database); // коннект к БД на сервере
mysql_set_charset('utf8'); // кодировка
// ------------------------------------------------------------ обрабатываем запрос если он был
if($action == select){ // если действие SELECT
if($data == null){
// выберем из таблицы chat ВСЕ данные что есть и вернем их в JSON
$q=mysql_query("SELECT * FROM chat");
}else{
// выберем из таблицы chat ВСЕ данные ПОЗНЕЕ ОПРЕДЕЛЕННОГО ВРЕМЕНИ и вернем их в JSON
$q=mysql_query("SELECT * FROM chat WHERE data $data");
}
while($e=mysql_fetch_assoc($q))
$output[]=$e;
print(json_encode($output));
}
if($action == insert && $author != null && $client != null && $text != null){ // если действие INSERT и есть все что нужно
// время = время сервера а не клиента !
$current_time = round(microtime(1) * 1000);
// пример передачи скрипту данных:
// chat.php?action=insert&author=author&client=client&text=text
// вставим строку с переданными параметрами
mysql_query("INSERT INTO `chat`(`author`,`client`,`data`,`text`) VALUES ('$author','$client','$current_time','$text')");
}
if($action == delete){ // если действие DELETE
// полностью обнулим таблицу записей
mysql_query("TRUNCATE TABLE `chat`");
}
mysql_close();
?>
```
Структура запросов к api:
* обязательный атрибут action — может быть равен select (сервер ответит списком записей из своей БД), insert (сервер добавить новую запись в свою БД), delete (сервер очистит свою БД)
* если action=insert, нам нужно будет передать дополнительные параметры: author (кто написал сообщение), client (кому адресовано сообщение), text (сообщение)
* action=select может содержать дополнительный параметр data, в этом случае ответ сервера содержит не все сообщения из БД, а только те, у которых время создания позднее переданного
Примеры:
* chat.php?action=delete – удалит все записи на сервере
* chat.php?action=insert&author=Jon&client=Smith&text=Hello — добавит на сервере новую запись: автор Jon, получатель Smith, содержание Hello
* chat.php?action=select&data=151351333 — вернет все записи, полученные после переданного времени в long формате
**Файл showBD.php — не обязательный скрипт для наглядного отображения содержимого БД в браузере.**
```
php // сохранить utf-8 !
// -------------------------------------------------------------------------- логины пароли
$mysql_host = "localhost"; // sql сервер
$mysql_user = "l29340eb_chat"; // пользователь
$mysql_password = "123456789"; // пароль
$mysql_database = "l29340eb_chat"; // имя базы данных chat
// -------------------------------------------------------------------------- если база недоступна
if (!mysql_connect($mysql_host, $mysql_user, $mysql_password)){
echo "<h2База недоступна!";
exit;
}else{
// -------------------------------------------------------------------------- если база доступна
echo "База доступна!
--------------
";
mysql_select_db($mysql_database);
mysql_set_charset('utf8');
// -------------------------------------------------------------------------- выведем JSON
$q=mysql_query("SELECT * FROM chat");
echo "### Json ответ:
";
// Выводим json
while($e=mysql_fetch_assoc($q))
$output[]=$e;
print(json_encode($output));
// -------------------------------------------------------------------------- выведем таблицу
$q=mysql_query("SELECT * FROM chat");
echo "### Табличный вид:
";
echo "
";
echo "| \_id | author |";
echo " client | data | text |
";
for ($c=0; $c $f[\_id] | $f[author] | $f[client] | $f[data] | $f[text] |";
}
echo "
";
}
mysql_close();
// -------------------------------------------------------------------------- разорвем соединение с БД
?>
```
### Клиентская часть
Теперь структура Android приложения:
В фоне работает FoneService.java, который, в отдельном потоке, каждые 15 секунд делает запрос на сервер. Если ответ сервера содержит новые сообщения, FoneService.java записывает их в локальную БД и отправляет сообщение ChatActivity.java о необходимости обновить ListView, с сообщениями. ChatActivity.java (если она в этот момент открыта) получает сообщение и обновляет содержимое ListView из локальной БД.
Отправка нового сообщения из ChatActivity.java происходит сразу на сервер, минуя FoneService.java. При этом наше сообщение НЕ записывается в локальную БД! Там оно появится только после получения его назад в виде ответа сервера. Такую реализацию я использовал в связи с важным нюансом работы любого интернет-чата — обязательной группировкой сообщений по времени. Если не использовать группировку по времени, будет нарушена последовательность сообщений. Учитывая, что клиентские приложения просто физически не могут быть синхронизированы с точностью до миллисекунд, а возможно будут работать даже в разных часовых поясах, логичнее всего будет использовать время сервера. Так мы и делаем.
Создавая новое сообщение, мы передаем запросом на сервер: имя автора сообщения, имя получателя сообщения, текст сообщения. Получая эту запись назад, в виде ответа сервера, мы получаем то, что отправляли + четвертый параметр: время получения сообщения сервером.
В MainActivity.java, для наглядности, я добавил возможность удаления сообщений из локальной БД — это эквивалентно чистой установке приложения (в этом случае FoneService отправит на сервер запрос на получение **всех** сообщений выбранного чата). Так же есть возможность послать запрос на удаление всех сообщений из БД, расположенной на сервере.
**Код активностей:**
**FoneService.java**
```
package by.andreidanilevich.temp_chat;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.json.JSONArray;
import org.json.JSONObject;
import android.app.Notification;
import android.app.PendingIntent;
import android.app.Service;
import android.content.ContentValues;
import android.content.Context;
import android.content.Intent;
import android.database.Cursor;
import android.database.sqlite.SQLiteDatabase;
import android.graphics.BitmapFactory;
import android.os.IBinder;
import android.util.Log;
public class FoneService extends Service {
// ИМЯ СЕРВЕРА (url зарегистрированного нами сайта)
// например http://l29340eb.bget.ru
String server_name = "http://l29340eb.bget.ru";
SQLiteDatabase chatDBlocal;
HttpURLConnection conn;
Cursor cursor;
Thread thr;
ContentValues new_mess;
Long last_time; // время последней записи в БД, отсекаем по нему что нам
// тянуть с сервера, а что уже есть
@Override
public IBinder onBind(Intent intent) {
return null;
}
public void onStart(Intent intent, int startId) {
Log.i("chat", "+ FoneService - запуск сервиса");
chatDBlocal = openOrCreateDatabase("chatDBlocal.db",
Context.MODE_PRIVATE, null);
chatDBlocal
.execSQL("CREATE TABLE IF NOT EXISTS chat (_id integer primary key autoincrement, author, client, data, text)");
// создадим и покажем notification
// это позволит стать сервису "бессмертным"
// и будет визуально видно в трее
Intent iN = new Intent(getApplicationContext(), MainActivity.class);
intent.setFlags(Intent.FLAG_ACTIVITY_CLEAR_TOP
| Intent.FLAG_ACTIVITY_SINGLE_TOP);
PendingIntent pI = PendingIntent.getActivity(getApplicationContext(),
0, iN, PendingIntent.FLAG_CANCEL_CURRENT);
Notification.Builder bI = new Notification.Builder(
getApplicationContext());
bI.setContentIntent(pI)
.setSmallIcon(R.drawable.ic_launcher)
.setLargeIcon(
BitmapFactory.decodeResource(getApplicationContext()
.getResources(), R.drawable.ic_launcher))
.setAutoCancel(true)
.setContentTitle(getResources().getString(R.string.app_name))
.setContentText("работаю...");
Notification notification = bI.build();
startForeground(101, notification);
startLoop();
}
// запуск потока, внутри которого будет происходить
// регулярное соединение с сервером для чтения новых
// сообщений.
// если сообщения найдены - отправим броадкаст для обновления
// ListView в ChatActivity
private void startLoop() {
thr = new Thread(new Runnable() {
// ansver = ответ на запрос
// lnk = линк с параметрами
String ansver, lnk;
public void run() {
while (true) { // стартуем бесконечный цикл
// глянем локальную БД на наличие сообщщений чата
cursor = chatDBlocal.rawQuery(
"SELECT * FROM chat ORDER BY data", null);
// если какие-либо сообщения есть - формируем запрос
// по которому получим только новые сообщения
if (cursor.moveToLast()) {
last_time = cursor.getLong(cursor
.getColumnIndex("data"));
lnk = server_name + "/chat.php?action=select&data="
+ last_time.toString();
// если сообщений в БД нет - формируем запрос
// по которому получим всё
} else {
lnk = server_name + "/chat.php?action=select";
}
cursor.close();
// создаем соединение ---------------------------------->
try {
Log.i("chat",
"+ FoneService --------------- ОТКРОЕМ СОЕДИНЕНИЕ");
conn = (HttpURLConnection) new URL(lnk)
.openConnection();
conn.setReadTimeout(10000);
conn.setConnectTimeout(15000);
conn.setRequestMethod("POST");
conn.setRequestProperty("User-Agent", "Mozilla/5.0");
conn.setDoInput(true);
conn.connect();
} catch (Exception e) {
Log.i("chat", "+ FoneService ошибка: " + e.getMessage());
}
// получаем ответ ---------------------------------->
try {
InputStream is = conn.getInputStream();
BufferedReader br = new BufferedReader(
new InputStreamReader(is, "UTF-8"));
StringBuilder sb = new StringBuilder();
String bfr_st = null;
while ((bfr_st = br.readLine()) != null) {
sb.append(bfr_st);
}
Log.i("chat", "+ FoneService - полный ответ сервера:\n"
+ sb.toString());
// сформируем ответ сервера в string
// обрежем в полученном ответе все, что находится за "]"
// это необходимо, т.к. json ответ приходит с мусором
// и если этот мусор не убрать - будет невалидным
ansver = sb.toString();
ansver = ansver.substring(0, ansver.indexOf("]") + 1);
is.close(); // закроем поток
br.close(); // закроем буфер
} catch (Exception e) {
Log.i("chat", "+ FoneService ошибка: " + e.getMessage());
} finally {
conn.disconnect();
Log.i("chat",
"+ FoneService --------------- ЗАКРОЕМ СОЕДИНЕНИЕ");
}
// запишем ответ в БД ---------------------------------->
if (ansver != null && !ansver.trim().equals("")) {
Log.i("chat",
"+ FoneService ---------- ответ содержит JSON:");
try {
// ответ превратим в JSON массив
JSONArray ja = new JSONArray(ansver);
JSONObject jo;
Integer i = 0;
while (i < ja.length()) {
// разберем JSON массив построчно
jo = ja.getJSONObject(i);
Log.i("chat",
"=================>>> "
+ jo.getString("author")
+ " | "
+ jo.getString("client")
+ " | " + jo.getLong("data")
+ " | " + jo.getString("text"));
// создадим новое сообщение
new_mess = new ContentValues();
new_mess.put("author", jo.getString("author"));
new_mess.put("client", jo.getString("client"));
new_mess.put("data", jo.getLong("data"));
new_mess.put("text", jo.getString("text"));
// запишем новое сообщение в БД
chatDBlocal.insert("chat", null, new_mess);
new_mess.clear();
i++;
// отправим броадкаст для ChatActivity
// если она открыта - она обновить ListView
sendBroadcast(new Intent(
"by.andreidanilevich.action.UPDATE_ListView"));
}
} catch (Exception e) {
// если ответ сервера не содержит валидный JSON
Log.i("chat",
"+ FoneService ---------- ошибка ответа сервера:\n"
+ e.getMessage());
}
} else {
// если ответ сервера пустой
Log.i("chat",
"+ FoneService ---------- ответ не содержит JSON!");
}
try {
Thread.sleep(15000);
} catch (Exception e) {
Log.i("chat",
"+ FoneService - ошибка процесса: "
+ e.getMessage());
}
}
}
});
thr.setDaemon(true);
thr.start();
}
}
```
**ChatActivity.java**
```
package by.andreidanilevich.temp_chat;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import android.annotation.SuppressLint;
import android.app.Activity;
import android.content.BroadcastReceiver;
import android.content.Context;
import android.content.Intent;
import android.content.IntentFilter;
import android.database.Cursor;
import android.database.sqlite.SQLiteDatabase;
import android.os.AsyncTask;
import android.os.Bundle;
import android.util.Log;
import android.view.View;
import android.widget.Button;
import android.widget.EditText;
import android.widget.ListView;
import android.widget.SimpleAdapter;
import android.widget.Toast;
public class ChatActivity extends Activity {
// ИМЯ СЕРВЕРА (url зарегистрированного нами сайта)
// например http://l29340eb.bget.ru
String server_name = "http://l29340eb.bget.ru";
ListView lv; // полоса сообщений
EditText et;
Button bt;
SQLiteDatabase chatDBlocal;
String author, client;
INSERTtoChat insert_to_chat; // класс отправляет новое сообщение на сервер
UpdateReceiver upd_res; // класс ждет сообщение от сервиса и получив его -
// обновляет ListView
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.chat);
// получим 2 переменные по которым будем отбирать инфу из БД:
// author - от чьего имени идет чат
// client - с кем чатимся
Intent intent = getIntent();
author = intent.getStringExtra("author");
client = intent.getStringExtra("client");
Log.i("chat", "+ ChatActivity - открыт author = " + author
+ " | client = " + client);
lv = (ListView) findViewById(R.id.lv);
et = (EditText) findViewById(R.id.et);
bt = (Button) findViewById(R.id.bt);
chatDBlocal = openOrCreateDatabase("chatDBlocal.db",
Context.MODE_PRIVATE, null);
chatDBlocal
.execSQL("CREATE TABLE IF NOT EXISTS chat (_id integer primary key autoincrement, author, client, data, text)");
// Создаём и регистрируем широковещательный приёмник
upd_res = new UpdateReceiver();
registerReceiver(upd_res, new IntentFilter(
"by.andreidanilevich.action.UPDATE_ListView"));
create_lv();
}
// обновим lv = заполним нужные позиции в lv информацией из БД
@SuppressLint("SimpleDateFormat")
public void create_lv() {
Cursor cursor = chatDBlocal.rawQuery(
"SELECT * FROM chat WHERE author = '" + author
+ "' OR author = '" + client + "' ORDER BY data", null);
if (cursor.moveToFirst()) {
// если в базе есть элементы соответствующие
// нашим критериям отбора
// создадим массив, создадим hashmap и заполним его результатом
// cursor
ArrayList> mList = new ArrayList>();
HashMap hm;
do {
// мое сообщение !!!
// если автор сообщения = автор
// и получатель сообщения = клиент
if (cursor.getString(cursor.getColumnIndex("author")).equals(
author)
&& cursor.getString(cursor.getColumnIndex("client"))
.equals(client)) {
hm = new HashMap<>();
hm.put("author", author);
hm.put("client", "");
hm.put("list\_client", "");
hm.put("list\_client\_time", "");
hm.put("list\_author",
cursor.getString(cursor.getColumnIndex("text")));
hm.put("list\_author\_time", new SimpleDateFormat(
"HH:mm - dd.MM.yyyy").format(new Date(cursor
.getLong(cursor.getColumnIndex("data")))));
mList.add(hm);
}
// сообщение мне !!!!!!!
// если автор сообщения = клиент
// и если получатель сообщения = автор
if (cursor.getString(cursor.getColumnIndex("author")).equals(
client)
&& cursor.getString(cursor.getColumnIndex("client"))
.equals(author)) {
hm = new HashMap<>();
hm.put("author", "");
hm.put("client", client);
hm.put("list\_author", "");
hm.put("list\_author\_time", "");
hm.put("list\_client",
cursor.getString(cursor.getColumnIndex("text")));
hm.put("list\_client\_time", new SimpleDateFormat(
"HH:mm - dd.MM.yyyy").format(new Date(cursor
.getLong(cursor.getColumnIndex("data")))));
mList.add(hm);
}
} while (cursor.moveToNext());
// покажем lv
SimpleAdapter adapter = new SimpleAdapter(getApplicationContext(),
mList, R.layout.list, new String[] { "list\_author",
"list\_author\_time", "list\_client",
"list\_client\_time", "author", "client" },
new int[] { R.id.list\_author, R.id.list\_author\_time,
R.id.list\_client, R.id.list\_client\_time,
R.id.author, R.id.client });
lv.setAdapter(adapter);
cursor.close();
}
Log.i("chat",
"+ ChatActivity ======================== обновили поле чата");
}
public void send(View v) {
// запишем наше новое сообщение
// вначале проверим на пустоту
if (!et.getText().toString().trim().equals("")) {
// кнопку сделаем неактивной
bt.setEnabled(false);
// если чтото есть - действуем!
insert\_to\_chat = new INSERTtoChat();
insert\_to\_chat.execute();
} else {
// если ничего нет - нечего и писать
et.setText("");
}
}
// отправим сообщение на сервер
private class INSERTtoChat extends AsyncTask {
HttpURLConnection conn;
Integer res;
protected Integer doInBackground(Void... params) {
try {
// соберем линк для передачи новой строки
String post\_url = server\_name
+ "/chat.php?action=insert&author="
+ URLEncoder.encode(author, "UTF-8")
+ "&client="
+ URLEncoder.encode(client, "UTF-8")
+ "&text="
+ URLEncoder.encode(et.getText().toString().trim(),
"UTF-8");
Log.i("chat",
"+ ChatActivity - отправляем на сервер новое сообщение: "
+ et.getText().toString().trim());
URL url = new URL(post\_url);
conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(10000); // ждем 10сек
conn.setRequestMethod("POST");
conn.setRequestProperty("User-Agent", "Mozilla/5.0");
conn.connect();
res = conn.getResponseCode();
Log.i("chat", "+ ChatActivity - ответ сервера (200 - все ОК): "
+ res.toString());
} catch (Exception e) {
Log.i("chat",
"+ ChatActivity - ошибка соединения: " + e.getMessage());
} finally {
// закроем соединение
conn.disconnect();
}
return res;
}
protected void onPostExecute(Integer result) {
try {
if (result == 200) {
Log.i("chat", "+ ChatActivity - сообщение успешно ушло.");
// сбросим набранный текст
et.setText("");
}
} catch (Exception e) {
Log.i("chat", "+ ChatActivity - ошибка передачи сообщения:\n"
+ e.getMessage());
Toast.makeText(getApplicationContext(),
"ошибка передачи сообщения", Toast.LENGTH\_SHORT).show();
} finally {
// активируем кнопку
bt.setEnabled(true);
}
}
}
// ресивер приёмник ждет сообщения от FoneService
// если сообщение пришло, значит есть новая запись в БД - обновим ListView
public class UpdateReceiver extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
Log.i("chat",
"+ ChatActivity - ресивер получил сообщение - обновим ListView");
create\_lv();
}
}
// выходим из чата
public void onBackPressed() {
Log.i("chat", "+ ChatActivity - закрыт");
unregisterReceiver(upd\_res);
finish();
}
}
```
**MainActivity.java**
```
package by.andreidanilevich.temp_chat;
import java.net.HttpURLConnection;
import java.net.URL;
import android.app.Activity;
import android.content.Context;
import android.content.Intent;
import android.database.sqlite.SQLiteDatabase;
import android.os.AsyncTask;
import android.os.Bundle;
import android.util.Log;
import android.view.View;
import android.widget.AdapterView;
import android.widget.ArrayAdapter;
import android.widget.Button;
import android.widget.Spinner;
import android.widget.Toast;
public class MainActivity extends Activity {
// ИМЯ СЕРВЕРА (url зарегистрированного нами сайта)
// например http://l29340eb.bget.ru
String server_name = "http://l29340eb.bget.ru";
Spinner spinner_author, spinner_client;
String author, client;
Button open_chat_btn, open_chat_reverce_btn, delete_server_chat;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
Log.i("chat", "+ MainActivity - запуск приложения");
open_chat_btn = (Button) findViewById(R.id.open_chat_btn);
open_chat_reverce_btn = (Button) findViewById(R.id.open_chat_reverce_btn);
delete_server_chat = (Button) findViewById(R.id.delete_server_chat);
// запустим FoneService
this.startService(new Intent(this, FoneService.class));
// заполним 2 выпадающих меню для выбора автора и получателя сообщения
// 5 мужских и 5 женских имен
// установим слушателей
spinner_author = (Spinner) findViewById(R.id.spinner_author);
spinner_client = (Spinner) findViewById(R.id.spinner_client);
spinner_author.setAdapter(new ArrayAdapter(this,
android.R.layout.simple\_spinner\_item, new String[] { "Петя",
"Вася", "Коля", "Андрей", "Сергей", "Оля", "Лена",
"Света", "Марина", "Наташа" }));
spinner\_client.setAdapter(new ArrayAdapter(this,
android.R.layout.simple\_spinner\_item, new String[] { "Петя",
"Вася", "Коля", "Андрей", "Сергей", "Оля", "Лена",
"Света", "Марина", "Наташа" }));
spinner\_client.setSelection(5);
open\_chat\_btn.setText("Открыть чат: "
+ spinner\_author.getSelectedItem().toString() + " > "
+ spinner\_client.getSelectedItem().toString());
open\_chat\_reverce\_btn.setText("Открыть чат: "
+ spinner\_client.getSelectedItem().toString() + " > "
+ spinner\_author.getSelectedItem().toString());
spinner\_author
.setOnItemSelectedListener(new AdapterView.OnItemSelectedListener() {
public void onItemSelected(AdapterView parent,
View itemSelected, int selectedItemPosition,
long selectedId) {
author = spinner\_author.getSelectedItem().toString();
open\_chat\_btn.setText("Открыть чат: "
+ spinner\_author.getSelectedItem().toString()
+ " > "
+ spinner\_client.getSelectedItem().toString());
open\_chat\_reverce\_btn.setText("Открыть чат: "
+ spinner\_client.getSelectedItem().toString()
+ " > "
+ spinner\_author.getSelectedItem().toString());
}
public void onNothingSelected(AdapterView parent) {
}
});
spinner\_client
.setOnItemSelectedListener(new AdapterView.OnItemSelectedListener() {
public void onItemSelected(AdapterView parent,
View itemSelected, int selectedItemPosition,
long selectedId) {
client = spinner\_client.getSelectedItem().toString();
open\_chat\_btn.setText("Открыть чат: "
+ spinner\_author.getSelectedItem().toString()
+ " > "
+ spinner\_client.getSelectedItem().toString());
open\_chat\_reverce\_btn.setText("Открыть чат: "
+ spinner\_client.getSelectedItem().toString()
+ " > "
+ spinner\_author.getSelectedItem().toString());
}
public void onNothingSelected(AdapterView parent) {
}
});
}
// откроем чат с выбранным автором и получателем
public void open\_chat(View v) {
// быстрая проверка
if (author.equals(client)) {
// если автор и получатель одинаковы
// чат не открываем
Toast.makeText(this, "author = client !", Toast.LENGTH\_SHORT)
.show();
} else {
// откроем нужный чат author > client
Intent intent = new Intent(MainActivity.this, ChatActivity.class);
intent.putExtra("author", author);
intent.putExtra("client", client);
startActivity(intent);
}
}
// откроем чат с выбранным автором и получателем, только наоборот
public void open\_chat\_reverce(View v) {
// быстрая проверка
if (author.equals(client)) {
// если автор и получатель одинаковы
// чат не открываем
Toast.makeText(this, "author = client !", Toast.LENGTH\_SHORT)
.show();
} else {
// откроем нужный чат client > author
Intent intent = new Intent(MainActivity.this, ChatActivity.class);
intent.putExtra("author", client);
intent.putExtra("client", author);
startActivity(intent);
}
}
// отправим запрос на сервер о удалении таблицы с чатами
public void delete\_server\_chats(View v) {
Log.i("chat", "+ MainActivity - запрос на удаление чата с сервера");
delete\_server\_chat.setEnabled(false);
delete\_server\_chat.setText("Запрос отправлен. Ожидайте...");
DELETEfromChat delete\_from\_chat = new DELETEfromChat();
delete\_from\_chat.execute();
}
// удалим локальную таблицу чатов
// и создадим такуюже новую
public void delete\_local\_chats(View v) {
Log.i("chat", "+ MainActivity - удаление чата с этого устройства");
SQLiteDatabase chatDBlocal;
chatDBlocal = openOrCreateDatabase("chatDBlocal.db",
Context.MODE\_PRIVATE, null);
chatDBlocal.execSQL("drop table chat");
chatDBlocal
.execSQL("CREATE TABLE IF NOT EXISTS chat (\_id integer primary key autoincrement, author, client, data, text)");
Toast.makeText(getApplicationContext(),
"Чат на этом устройстве удален!", Toast.LENGTH\_SHORT).show();
}
// отправим запрос на сервер о удалении таблицы с чатами
// если он пройдет - таблица будет удалена
// если не пройдет (например нет интернета или сервер недоступен)
// - покажет сообщение
private class DELETEfromChat extends AsyncTask {
Integer res;
HttpURLConnection conn;
protected Integer doInBackground(Void... params) {
try {
URL url = new URL(server\_name + "/chat.php?action=delete");
conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(10000); // ждем 10сек
conn.setRequestMethod("POST");
conn.setRequestProperty("User-Agent", "Mozilla/5.0");
conn.connect();
res = conn.getResponseCode();
Log.i("chat", "+ MainActivity - ответ сервера (200 = ОК): "
+ res.toString());
} catch (Exception e) {
Log.i("chat",
"+ MainActivity - ответ сервера ОШИБКА: "
+ e.getMessage());
} finally {
conn.disconnect();
}
return res;
}
protected void onPostExecute(Integer result) {
try {
if (result == 200) {
Toast.makeText(getApplicationContext(),
"Чат на сервере удален!", Toast.LENGTH\_SHORT)
.show();
}
} catch (Exception e) {
Toast.makeText(getApplicationContext(),
"Ошибка выполнения запроса.", Toast.LENGTH\_SHORT)
.show();
} finally {
// сделаем кнопку активной
delete\_server\_chat.setEnabled(true);
delete\_server\_chat.setText("Удалить все чаты на сервере!");
}
}
}
public void onBackPressed() {
Log.i("chat", "+ MainActivity - выход из приложения");
finish();
}
}
```
**AutoRun.java**
```
package by.andreidanilevich.temp_chat;
import android.content.BroadcastReceiver;
import android.content.Context;
import android.content.Intent;
import android.util.Log;
public class AutoRun extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
if (intent.getAction().equals("android.intent.action.BOOT_COMPLETED")) {
// получили boot_completed - запустили FoneService
context.startService(new Intent(context, FoneService.class));
Log.i("chat", "+ AutoRun - отработал");
}
}
}
**Манифест:**
```
**AndroidManifest**
```
xml version="1.0" encoding="utf-8"?
```
**Разметка:**
**Разметка chat.xml**
```
xml version="1.0" encoding="utf-8"?
```
**Разметка main.xml**
```
```
**Разметка list.xml**
```
xml version="1.0" encoding="utf-8"?
```
**И все вместе (+ apk):**
[github.com/andreidanilevich/temp\_chat](https://github.com/andreidanilevich/temp_chat)
**P.S.:**
1. Если Вы загрузили **apk** по ссылке выше, вначале проверьте доступность моего «сервера» по адресу [l29340eb.bget.ru/showBD.php](http://l29340eb.bget.ru/showBD.php).
2. Код писался давно, конечно не все красиво и по канонам, возможно не все исключения обработаны и есть ошибки. Это черновик. У меня все работало на реальных устройствах и на эмуляторе.
3. Если кому-либо пригодится — буду рад. За критику — спасибо, за конструктивные сообщения — спасибо вдвойне. На вопросы постараюсь ответить. | https://habr.com/ru/post/269135/ | null | ru | null |
# Enum в PHP 8.1 — для чего нужен enum, и как реализован в PHP
Через несколько дней заканчивается голосование по первой итерации [реализации enum в PHP 8.1](https://wiki.php.net/rfc/enumerations#voting) . Уже видно, что голосов “за” гораздо больше, так что давайте кратко пройдемся и посмотрим, что же нам приготовили авторы языка.
Зачем нужны enum?
-----------------
Зачем вообще нужны enum? По сути они служат цели улучшенного описания типов. Давайте рассмотрим пример без енумов и с ними. Допустим, у нас продаются машины трех цветов: красные, черные и белые. Как описать цвет, какой тип выбрать?
```
class Car {
private string $color;
function setColor(string $color): void {
$this->color = $color;
}
}
```
Если мы опишем цвет машины как простой string, то во-первых при вызове $myCar->setColor(..) непонятно, что за строку туда писать. “red” или “RED” или “#ff0000”, а во вторых, легко ошибиться, просунув туда случайно что-то не то (пустую строку, к примеру). То же самое будет, если использовать не строки, а числа, например.
Это приводит к тому, что многие php-программисты заводят константы и объединяют их в одном классе, чтобы явно видеть все варианты.
```
class Color {
public const RED = "red";
public const BLACK = "black";
public const WHITE = "white";
}
```
и задавая цвет, пишут `$myCar->setColor(Color::RED);`
Уже лучше. Но если мы впервые видим метод $myCar->setColor(...), мы можем и не знать, что где-то есть константы для цветов. И мы всё еще можем сунуть туда любую строку без какого-либо сообщения об ошибке.
Поэтому здесь нужен не класс, а отдельный тип. Этот тип называется enum
Pure enum
---------
В самом простом случае (pure enum), enum описывается так:
```
enum Color {
case Red;
case Black;
case White;
}
```
Описав такой тип, мы можем использовать его везде:
```
class Car {
private Color $color;
function setColor(Color $color): void {
$this->color = $color;
}
}
```
Из сигнатуры метода всё сразу видно, какие варианты есть. И метод setColor можно использовать только так: $myCar->setColor(Color::White), никаких строк и доморощенных списков констант. Ничего лишнего не сунешь. Читабельность и поддерживаемость кода стала выше.
Каждый из case-ов (Color::Red, Color::Black, Color::White) является объектом типа Color (можно проверить через instanseof ). Т.е. под капотом это не числа 0,1,2 как в некоторых языках, а именно объекты. Их нельзя сравнивать оператором >, например. У каждого такого объекта есть встроенное свойство $name:
```
print Color::Red->name; // вернет строку “Red”
```
Enum со скалярами
-----------------
Но если бы это было всё, то было бы слишком просто. После названия enum можно указать скалярный тип, например string. И у каждого кейса указать скалярное значение. Это может быть полезно для некоторых целей, например для сортировки или записи в базу данных.
```
enum Color: string {
case Red = "R";
case Black = "B";
case White = "W";
}
```
Скалярное значение можно получить потом так:
```
Color::Red->value //вернет строку “R”
```
И наоборот, т.е. получить case через значение, тоже можно:
```
Color::from("R") // вернет объект Color::Red
```
Помимо полей "case" в enum может быть еще много всего. По сути это разновидность класса. Там могут быть методы, он может реализовывать интерфейсы или использовать трейты.
Пример из RFC.
```
interface Colorful {
public function color(): string;
}
trait Rectangle {
public function shape(): string {
return "Rectangle";
}
}
enum Suit implements Colorful {
use Rectangle;
case Hearts;
case Diamonds;
case Clubs;
case Spades;
public function color(): string {
return match($this) {
Suit::Hearts, Suit::Diamonds => 'Red',
Suit::Clubs, Suit::Spaces => 'Black',
};
}
}
```
При этом $this будет тот конкретный объект case, для которого мы вызываем метод.
Кстати, обратите внимание на работу с енамами в конструкции match. Похоже, match затевался именно для них.
Лично я горячо одобряю введение enum в PHP, это очень удобно и читабельно, и в большинстве языков, где есть какие-никакие типы, enum уже давно есть (кроме, разве что Go).
Дальше — больше. Tagged Unions (тип-сумма)
------------------------------------------
Есть RFC, которые развивают идею enums дальше, чтобы можно было хранить в одном enum значения разных типов. Как в языке Rust, например. Тогда можно будет сделать, допустим, enum Result с двумя case-ами Result::Ok и Result::Err, причем эти объекты будут хранить данные: Ok будет хранить результат, а Err — ошибку, у каждого из этих значений будет свой тип.
И всё это не в Расте или Хаскеле, а в PHP!
Об этом мы расскажем в деталях в ближайших постах [телеграм-канала Cross Join](https://t.me/crossjoin), не забудьте подписаться. | https://habr.com/ru/post/541246/ | null | ru | null |
# Параллакс эффект для живых обоев на Android
Каждый, кто пробовал установить себе живые обои, замечал параллакс эффект при перемещении между рабочими столами. Выглядит он очень занимательно, но вот в его реализации возникают проблемы, которые и будут освещены в данной статье. Речь пойдет про реализацию параллакс эффекта под живые обои Android.
Ниже будут рассмотрены стандартный и собственный методы реализации. Указаны недостатки и достоинства каждого из них.
#### Стандартный метод
Начиная с API7, появился класс **WallpaperService.Engine** с методом **onOffsetsChanged**. Данный метод вызывается каждый раз, когда рабочий стол меняет свою позицию. Для использования его достаточно переопределить в собственной реализации класса **WallpaperService.Engine**. Метод имеет следующую сигнатуру:
```
onOffsetsChanged(float xOffset, float yOffset, float xOffsetStep, float yOffsetStep, int xPixelOffset, int yPixelOffset)
```
Из всех передаваемых параметров нас интересуют **xOffset** и **yOffset**, а применительно к живым обоям, достаточно использовать **xOffset**. Этот параметр изменяется от 0 до 1, равен 0 при одном крайнем положении рабочего стола и 1 при другом крайнем положении рабочего стола. Если рабочий стол находится в положении по умолчанию (посередине), параметр xOffset равен 0.5. Например, для 3-х рабочих столов **xOffset** будет равен соответственно 0, 0.5, 1. При движении от одного рабочего стола к другому параметр изменяется плавно, а метод **onOffsetsChanged** вызывается многократно. Однако «плавность» может отличаться на разных устройствах.
Таким образом, передав этот параметр в Renderer ваших обоев, можно смещать их в нужную сторону, реализовав параллакс эффект. Преимущества очевидны: минимум кода и синхронная работа с рабочим столом.
Все было бы хорошо, если бы не недостатки данного метода:
* Не все устройства (оболочки) вызывают метод **onOffsetsChanged** при пролистывании рабочих столов. Что удивительно, чаще это случается с самыми новыми устройствами (например, HTC One X).
* Не все устройства делают это достаточное количество раз, из-за чего резко падает плавность движения обоев.
* Если рабочие столы в устройстве «закольцованы», то при переходе с последнего на первый происходит резкая прокрутка обоев.
#### Собственный метод, класс ZTouchMove
Из-за всех этих проблем было решено сделать свое решение, которое бы выполнялось на всех устройствах. Для этого был найден метод **onTouchEvent** того же класса **WallpaperService.Engine**. Для использования данного метода предварительно необходимо включить его вызов:
```
@Override
public void onCreate(SurfaceHolder surfaceHolder) {
setTouchEventsEnabled(true);
}
```
Далее этот метод будет принимать все события связанные с касанием экрана. Однако, касания хотелось бы преобразовать в уже полюбившийся формат смещения от 0 до 1 с учетом инерции, анимации движения и прочих радостей. Для этого был написан свой обработчик касаний, который на выходе «выдавал» как раз то, что нужно. Ниже привожу код получившегося обработчика:
```
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import android.annotation.SuppressLint;
import android.content.Context;
import android.graphics.Point;
import android.os.Build;
import android.os.Handler;
import android.view.Display;
import android.view.MotionEvent;
import android.view.VelocityTracker;
import android.view.ViewConfiguration;
import android.view.WindowManager;
import android.view.animation.Interpolator;
import android.widget.Scroller;
public class ZTouchMove {
public interface ZTouchMoveListener {
public void onTouchOffsetChanged(float xOffset);
}
private List mListeners = new ArrayList();
public class ZInterpolator implements Interpolator {
public float getInterpolation(float input) {
// f(x) = ax^3 + bx^2 + cx + d
// a = x - 2
// b = 3 - 2x
// c = x
// d = 0
// where x = derivative in point 0
//input = (float)(-Math.cos(10\*((double)input/Math.PI)) + 1) / 2;
input = (mVelocity - 2) \* (float) Math.pow(input, 3) + (3 - 2 \* mVelocity) \* (float) Math.pow(input, 2) + mVelocity \* input;
return input;
}
}
Handler mHandler = new Handler();
final Runnable mRunnable = new Runnable()
{
public void run()
{
if(onMovingToPosition())
mHandler.postDelayed(this, 20);
}
};
private float mPosition = 0.5f;
private float mPositionDelta = 0;
private float mTouchDownX;
private int xDiff;
private VelocityTracker mVelocityTracker;
private float mVelocity = 0;
private Scroller mScroller;
private final static int TOUCH\_STATE\_REST = 0;
private final static int TOUCH\_STATE\_SCROLLING = 1;
private static final int SCROLLING\_TIME = 300;
private static final int SNAP\_VELOCITY = 350;
private int mTouchSlop;
private int mMaximumVelocity;
private int mTouchState = TOUCH\_STATE\_REST;
private int mWidth;
private int mNumVirtualScreens = 5;
@SuppressLint("NewApi")
@SuppressWarnings("deprecation")
public void init(Context ctx) {
mScroller = new Scroller(ctx, new ZInterpolator());
final ViewConfiguration configuration = ViewConfiguration.get(ctx);
mTouchSlop = configuration.getScaledTouchSlop();
mMaximumVelocity = configuration.getScaledMaximumFlingVelocity();
WindowManager wm = (WindowManager) ctx.getSystemService(Context.WINDOW\_SERVICE);
Display display = wm.getDefaultDisplay();
// API Level 13
if(Build.VERSION.SDK\_INT >= Build.VERSION\_CODES.HONEYCOMB\_MR2) {
Point size = new Point();
display.getSize(size);
mWidth = size.x;
} else {
// API Level <13
mWidth = display.getWidth();
}
}
public void onTouchEvent(MotionEvent e) {
if (mVelocityTracker == null) {
mVelocityTracker = VelocityTracker.obtain();
}
mVelocityTracker.addMovement(e);
final float x = e.getX();
final int action = e.getAction();
switch (action) {
case MotionEvent.ACTION\_DOWN:
mTouchState = mScroller.isFinished() ? TOUCH\_STATE\_REST : TOUCH\_STATE\_SCROLLING;
if (!mScroller.isFinished()) {
mScroller.abortAnimation();
}
mTouchDownX = x;
break;
case MotionEvent.ACTION\_MOVE:
xDiff = (int) (x - mTouchDownX);
if (Math.abs(xDiff) > mTouchSlop && mTouchState != TOUCH\_STATE\_SCROLLING) {
mTouchState = TOUCH\_STATE\_SCROLLING;
if(xDiff < 0)
mTouchDownX = mTouchDownX - mTouchSlop;
else
mTouchDownX = mTouchDownX + mTouchSlop;
xDiff = (int) (x - mTouchDownX);
}
if (mTouchState == TOUCH\_STATE\_SCROLLING) {
mPositionDelta = -(float)xDiff / (mWidth \* mNumVirtualScreens);
}
break;
case MotionEvent.ACTION\_UP:
if (mTouchState == TOUCH\_STATE\_SCROLLING) {
final VelocityTracker velocityTracker = mVelocityTracker;
velocityTracker.computeCurrentVelocity(1000, mMaximumVelocity);
float velocityX = velocityTracker.getXVelocity() / (float)(mNumVirtualScreens \* mWidth);
mPosition = mPosition + mPositionDelta;
mPositionDelta = 0;
if(!returnSpring()) {
mVelocity = Math.min(3, Math.abs(velocityX \* mNumVirtualScreens)) ;
// deaccelerate();
// Inertion
if(Math.abs(velocityX) \* (float)(mNumVirtualScreens \* mWidth) > SNAP\_VELOCITY)
moveToPosition(mPosition, mPosition - (velocityX > 0 ? 1 : -1) \* 1 / (float) mNumVirtualScreens );
else
moveToPosition(mPosition, mPosition - 0.7f \* velocityX \* ((float)SCROLLING\_TIME / 1000) );
}
}
mTouchState = TOUCH\_STATE\_REST;
break;
case MotionEvent.ACTION\_CANCEL:
mTouchState = TOUCH\_STATE\_REST;
mPositionDelta = 0;
break;
}
dispatchMoving();
}
private boolean returnSpring() {
mVelocity = 0;
if(mPositionDelta + mPosition > 1 - 0.5 / (float) mNumVirtualScreens)
moveToPosition(mPosition, (float) (1 - 0.5 / (float) mNumVirtualScreens));
else if(mPositionDelta + mPosition < 0.5 / (float) mNumVirtualScreens)
moveToPosition(mPosition, (float) 0.5 / (float) mNumVirtualScreens);
else
return false;
return true;
}
private void moveToPosition(float current\_position, float desired\_position) {
mScroller.startScroll((int)(current\_position \* 1000), 0, (int)((desired\_position - current\_position) \* 1000), 0, SCROLLING\_TIME);
mHandler.postDelayed(mRunnable, 20);
}
private boolean onMovingToPosition() {
if(mScroller.computeScrollOffset()) {
mPosition = (float)mScroller.getCurrX() / 1000;
dispatchMoving();
return true;
} else {
returnSpring();
return false;
}
}
private float normalizePosition(float xOffset) {
final float springZone = 1 / (float) mNumVirtualScreens;
// Normalized offset is from 0 to 0.5
float xOffsetNormalized = Math.abs(xOffset - 0.5f);
if(xOffsetNormalized + springZone / 2 > 0.5f) {
// Spring formula
// (0.5 - 2 \* (1 - (x / (2 \* springZone) + 0.5))^2) \* springZone
// where x >=0 and <= springZone
// delta y = springZone / 2, y >=0 and y <= springZone / 2
xOffsetNormalized = 0.5f - springZone / 2 +
(0.5f - 2 \* (float)Math.pow( (double)(1 - ( (xOffsetNormalized - 0.5f + springZone / 2) / (2 \* springZone) + 0.5)), 2 ) ) \* springZone;
if(xOffset < 0.5f)
xOffset = 0.5f - xOffsetNormalized;
else
xOffset = 0.5f + xOffsetNormalized;
}
return xOffset;
}
public synchronized void addMovingListener(ZTouchMoveListener listener) {
mListeners.add(listener);
}
private synchronized void dispatchMoving() {
Iterator iterator = mListeners.iterator();
while(iterator.hasNext()) {
((ZTouchMoveListener) iterator.next()).onTouchOffsetChanged(normalizePosition(mPosition + mPositionDelta));
}
}
}
```
Сразу хочу оговориться, что код не претендует на супер чистоту и порядок, для меня было главным, чтобы он выполнял свою задачу, на прическу не было времени.
Класс **ZTouchMove** имеет метод **onTouchEvent(MotionEvent e)**, как вход, который вызывается из **onTouchEvent** класса **WallpaperService.Engine**. Далее ваш рендерер должен реализовать интерфейс **ZTouchMoveListener**, с методом **onTouchOffsetChanged(float xOffset)**, который в свою очередь будет принимать результат в привычном формате от 0 до 1.
Так же необходимо произвести начальную инициализацию **ZTouchMove** путем вызова метода **init(Context ctx)**, передав в него контекст приложения. Это необходимо для определения ширины экрана и некоторых других параметров. А так же зарегистрировать рендерер в качестве слушателя событий:
```
mTouchMove = new ZTouchMove();
mTouchMove.init(ctx);
mTouchMove.addMovingListener(mRenderer);
```
Так как я не нашел способа определения количества виртуальных рабочих столов, этот параметр был захардкодан в переменной **mNumVirtualScreens**. При желании можно дописать метод для его изменения и использовать на свое усмотрение.
Особенности реализации анимации и инерции класса **ZTouchMove**: при медленных перемещениях срабатывает «инерция», при быстрых срабатывает «доводчик» до следующего виртуального рабочего стола. На крайних положениях работает «пружина».
Из недостатков такого метода стоит отметить несинхронность работы перемещения рабочего стола и обоев. То есть может так случиться, что рабочий стол уже «уперся» в крайнее положение, а обои все еще можно двигать. Или на рабочем столе при определенной скорости сработает «доводчик» на соседний экран, а «доводчик» обоев может не сработать. Данные эффекты исключить не предоставляется возможным, так как у нас в принципе отсутствует информация о текущем положении рабочего стола.
#### Гибридное решение
Пользователь сам будет выбирать метод работы «параллакса» в настройках, или же можно автоматически определять работает ли стандартный метод, и если нет, переключать на **ZTouchMove**. Вот реализация автоматического определения:
```
if(xOffset != 0 && xOffset != 0.5f && xOffset != 1 || mOffsetChangedEnabled) {
mOffsetChangedEnabled = true;
mXPos = xOffset - 0.5f;
// Устанавливаем положение камеры
setupLookatM();
}
```
Оно основано на том, что **xOffset** при стандартной реализации не принимает значений отличных от 0, 0.5 и 1, в случае если стандартный метод **onOffsetsChanged** класса **WallpaperService.Engine** не работает правильно. Соответственно флаг **mOffsetChangedEnabled** по умолчанию равен **false**, и означает, что должен работать класс **ZTouchMove**.
Лично я выбрал гибридную настройку, где по умолчанию работает автоматическое определение, и есть еще две опции: «Режим рабочего стола» и «Режим прикосновения».
**Update:** Видео работы двух методов реализации. | https://habr.com/ru/post/164367/ | null | ru | null |
# Postgresso 35 — спецвыпуск: PostgreSQL 14

Пресс-релиз PostgreSQL [обширен и основателен](https://www.postgresql.org/docs/14/release-14.html). Есть и выжимка (highlights), в которой после бурных обсуждений в рассылках [выделили главное](https://www.postgresql.org/about/news/postgresql-14-released-2318/).
Статей о 14-й много. Мы смотрели и разрозненные статьи и целые сериалы:
**[обзоры коммитфестов](https://habr.com/ru/company/postgrespro/blog/510124/)** *Павла Лузанова* (5 серий),
**[waiting for PostgreSQL 14](https://www.depesz.com/tag/pg14/)** *Хуберта 'depesz' Любашевского* (18),
**[микрообзоры Postgres 14 highlights](https://paquier.xyz/)** *Мишеля Пакье* (Michael Paquier) (5),
**[в блоге Fujitsu OSS](https://www.postgresql.fastware.com/blog)** (5).
Кроме того есть пространная статья-справочник от HPE: **[PostgreSQL 14 New Features With Examples (Beta 1)](https://h50146.www5.hpe.com/products/software/oe/linux/mainstream/support/lcc/pdf/PostgreSQL14Beta1_New_Features_en_20210521-1.pdf?fbclid=IwAR31FmcaXMIOv5jvIkGiiy-lrBLhEW6jggur2zMmUnirPvfDZnwJvNgGsIg)**.
Начнём со статей, в которых авторы стараются охватить версию 14 в целом. Но перед этим разомнёмся
в облаках и контейнерах
-----------------------
**[PostgreSQL 14 on Kubernetes (with examples!)](https://blog.crunchydata.com/blog/postgresql-14-on-kubernetes)**
Джонатан Кац (Jonathan S. Katz, Crunchy data) показывает, как инсталлировать кранчевский оператор [PGO](https://access.crunchydata.com/documentation/postgres-operator/v5/installation/) (горячо рекомендует с [quickstart](https://access.crunchydata.com/documentation/postgres-operator/v5/quickstart/)) и запускает PostgreSQL 14.
После этого в качестве примера он демонстрирует асинхронные запросы к сторонним таблицам — возможность, появившуюся в 14-й версии (через [postgres\_fdw](https://www.postgresql.org/docs/14/fdw-callbacks.html#FDW-CALLBACKS-ASYNC), который научился исполнять запросы параллельно). Он создаёт целых 3 кластера: Носорог-1, Носорог-2 и Гиппопотам, настраивает postgres\_fdw на Гиппо, создаём на Носорогах таблички через [IMPORT FOREIGN SCHEMA](https://postgrespro.ru/docs/postgresql/13/sql-importforeignschema) (тоже новая фича 14-й) и, наконец, собирая данные с обоих носорогов, убеждается, что данные собираются асинхронно:
```
EXPLAIN ANALYZE SELECT avg(x.stat) FROM (
SELECT data['stat']::float AS stat FROM rhino1.stats
UNION ALL
SELECT data['stat']::float AS stat FROM rhino2.stats
) x;
```
```
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Aggregate (cost=424.80..424.81 rows=1 width=8) (actual time=13700.998..13701.000 rows=1 loops=1)
-> Append (cost=100.00..412.00 rows=5120 width=8) (actual time=2.937..13410.193 rows=4000000 loops=1)
-> Async Foreign Scan on stats (cost=100.00..193.20 rows=2560 width=8) (actual time=1.394..5337.504 rows=2000000 loops=1)
-> Async Foreign Scan on stats stats_1 (cost=100.00..193.20 rows=2560 width=8) (actual time=1.760..4807.722 rows=2000000 loops=1)
Planning Time: 1.019 ms
Execution Time: 13704.199 ms
```
Чуть позже Джонатан написал статью-апдейт: с использованием [вышедшего PGO 5.0](https://blog.crunchydata.com/blog/the-next-generation-of-kubernetes-native-postgres): **[Multi-Cluster Postgres Federation on Kubernetes with Postgres 14 Using GitOps](https://blog.crunchydata.com/blog/multi-cluster-postgres-federation-on-kubernetes-with-postgres-14-using-gitops)**.
Неспроста автор придумал пароль для серверов — **datalake**. Он явно намекает: для озёр данных такая архитектура годная. Делает он во второй статье вот что:
создаёт на 3 кластерах по 3 секции (используя заодно подтип `datemultirange` типа [multirange](https://postgrespro.ru/docs/postgresql/14/functions-range), появившегося в 14-й ), чтобы не без изящества автоматически раскладывать по ним данные с соответствующих 3 кластеров. А дальше при помощи логической репликации обустраивает простенький мультимастер — на все 3 ноды пишутся данные и сразу синхронизируются по всем 3 кластерам. Не успокоившись, он «масштабирует» «мультимастер» до 4 узлов — тоже раскладывая данные по полочкам. Это, конечно, только наглядный пример, никакой настоящей гарантии консистентности там нет, но вообще в релизе PostgreSQL 14 аж 10 пунктов [относятся к логической репликации](https://habr.com/ru/company/postgrespro/blog/581552#replic).
**[How We Shipped PostgreSQL 14 on Azure Within One Day of its Release](https://www.citusdata.com/blog/2021/10/01/how-we-shipped-postgres-14-on-azure-within-a-day/)**
В Citus хвалятся тем, что новую версию развернули как [«Гипермосштабирование»](https://docs.microsoft.com/ru-ru/azure/postgresql/hyperscale/) в облаках Azure за 1 день — как только был опубликован релиз. *Озгун Эрдоган* (Sic! — Ozgun Erdogan, Citus Data) пишет о любимых новых фичах 14-й, а они, конечно, связаны с задачами Citus. То есть работают на производительность и параллелизм. Поэтому полюбит их не только Citus.
Прежде всего полюбилось всё, связанное с масштабированием по числу соединений (connection scaling). В компании считают, что самое узкое место PostgreSQL это масштабирование по снеэпшотам. И что их патчи помогли значительно улучшить ситуацию, особенно в случаях, когда в соединениях ничего не делается (`idle`).
Также компания внесла вклад в ускорение восстановления (в 2.4 раза) и ускорение VACUUM на 25% в случае нагрузок, сильно завязанных на процессор.
Совместимость с PostgreSQL 14 они обеспечили не только для самого [Citus](https://github.com/citusdata/citus), но и для других опенсорсных расширений, к которым приложили руку: [pg\_cron](https://github.com/citusdata/pg_cron), [postgresql-hll](https://github.com/citusdata/postgresql-hll) (HyperLogLog) и [postgresql-topn](https://github.com/citusdata/postgresql-topn).
О PostgreSQL 14, едином и неделимом
-----------------------------------
**[PostgreSQL 14: PostgreSQL Is Still a Teenager](https://www.instaclustr.com/postgresql-14/)**
*Кирк Ройбол* (Kirk Roybal, instaclustr) считает, что Postgres повзрослел до тинейджера — или не считает: в первоначальной версии статьи, следы которой есть в интернете, название было *… Is Still a Tweeny* — то есть ребёнок лет 6-12. Но главная причина его удивления — отсутствие фокуса на каких-то направлениях разработки. *Я надеялся* — говорит Кирк — *услышать что-то ошарашивающее, вроде* VACUUM больше не нужен! *Услышал же я, что* множество людей приложило громадные усилия, чтобы улучшить вещи, которые надо было улучшить.
Об этих многочисленных, но не достаточно радикальных (для него) изменениях Кирк и говорит, демонстрируя наблюдательность и взгляд немного под другим углом, чем у многих других. Кажется, это действительно незамыленный взгляд, хотя, по многим пунктам его голос звучит в унисон с голосами, которые мы дальше цитируем. Самым ярким достижением 14-й он считает резкое улучшение масштабируемости по соединениям, когда число соединений переваливает через 5000. Хотя VACUUM и не отменили, но улучшения его, оставшиеся под капотом, он считает, были из самых востребованных сообществом. О некоторых других его соображениях мы упомянем в соответствующем контексте.
Новый GUC — [compute\_query\_id](https://www.postgresql.org/docs/14/runtime-config-statistics.html#GUC-COMPUTE-QUERY-ID) — тоже упомянут. Он позволяет, когда включён, получать id запроса даже без обращения к [pg\_stat\_statements](https://postgrespro.ru/docs/postgresql/14/pgstatstatements). id запроса вычисляется средствами ядра. Посмотреть его можно и в [pg\_stat\_activity](https://postgrespro.ru/docs/postgresql/14/monitoring-stats#MONITORING-PG-STAT-ACTIVITY-VIEW), откуда его берёт EXPLAIN. Или его можно сбросить в лог если сконфигурирован параметр [log\_line\_prefix](https://postgrespro.ru/docs/postgresql/14/runtime-config-logging#GUC-LOG-LINE-PREFIX).
Об этом целая статья [ниже](https://habr.com/ru/company/postgrespro/blog/581552#query_id).
**[Major Features: Postgres 14](https://momjian.us/main/writings/pgsql/features.pdf)**
Этот PDF *Брюса Момджана* (Bruce Momjian, EDB) — коротенькая презентация. Стоящая внимания: по каждому из пунктов всего-то по схемке (только к btree-индексам — 3), зато они очень наглядные.1. предотвращение распухания btree-индексов;
2. улучшения в индексах BRIN;
3. масштабирование снэпшотов;
4. глобальный id запроса;
5. idle\_session\_timeout;
6. роли для операций read-only и write-only;
7. улучшения в оптимизаторе;
8. параллельное сканирование сторонних таблиц.
### Матрица
Любопытная картина складывается, если глянуть на [матрицу фич](https://www.postgresql.org/about/featurematrix/). Пожалуй, это иллюстрация того, как иногда картина крупными мазками не слишком адекватна реальности.
### Статистика коммитфестов
**[Some Interesting statistics about PG-14 contributions](https://www.highgo.ca/2021/06/28/some-interesting-statistics-about-pg-14-contributions/)**
*Асан Хади* (Ahsan Hadi) из HighGo (вице-президент по разработкам, был старшим директором по продукту Postgres Plus Advanced Server в EDB) решил собрать статистику по коммитам в PostgreSQL 14. Дело доброе: до него этим любил побаловаться Роберт Хаас (Robert Haas), но он считал по годам.
А вот **его выбор**:
**top7 фич PostgreSQL 14**
1. [Asynchronous execution of PostgreSQL\_FDW Append node](https://commitfest.postgresql.org/32/2491/)
2. [Improving connection scalability: GetSnapshotData()](https://commitfest.postgresql.org/29/2500/) *[это правильная ссылка, в статье* Асана *Some Interesting… — битая]*
3. [Overhaul UPDATE/DELETE processing (making update/delete of inheritance trees scale better](https://commitfest.postgresql.org/32/2575/)
4. [logical streaming for large in-progress transactions](https://commitfest.postgresql.org/29/1927/)
5. [Add support for multirange data types](https://commitfest.postgresql.org/31/2112/)
6. [Allow btree index additions to remove expired index entries to prevent page splits](https://www.postgresql.org/message-id/flat/CAH2-Wzm+maE3apHB8NOtmM=p-DO65j2V5GzAWCOEEuy3JZgb2g@mail.gmail.com)
7. [PostgreSQL\_FDW Batching](https://commitfest.postgresql.org/31/2620/)
Ну а *Деврим Гюндюз* (Devrim Gündüz) поможет
### установить 14-ю версию из rpm
**[Installing PostgreSQL 14 beta/RC on RHEL / Rocky Linux / Fedora and SLES](https://people.planetpostgresql.org/devrim/index.php?/archives/115-Installing-PostgreSQL-14-betaRC-on-RHEL-Rocky-Linux-Fedora-and-SLES.html)**.
Производительность
------------------
**[Postgres 14 и высокие нагрузки](https://www.highload.ru/spring/2021/abstracts/6542)**
Это видео и презентация *Ивана Панченко* (зам. гендира Postgres Professional) на весеннем [Highload++](https://www.highload.ru/spring/2021/abstracts/6542) в Крокусе-Экспо. Первым пунктом у Ивана стоит *повышение масштабируемости по
коннектам*. Второе и третье места заняли *восходящее удаление (bottom-up delition)* и *Асинхронный APPEND* соответственно.
Между прочим, в своём интервью **[в качестве Персоны недели](https://postgresql.life/post/ivan_panchenko/?fbclid=IwAR18aBPNqSi18CVaHZ3_cJTn55J593LZXkqSAsSOrn1C3Qu8B2MZkgx2RWc)** Иван на вопрос о любимой фиче отвечает:
*Много полезных и важных фич — что в 13-й, что в 14-й — но ни одна из них не выглядит наиболее важной в сравнении с другими.*
(Но почитайте всё интервью: там есть даже про собаку и блоху, объясняющих, [как устроено Солнце](https://www.labirint.ru/books/799209/))
**[An early look at Postgres 14: Performance and Monitoring Improvements](https://pganalyze.com/blog/postgres-14-performance-monitoring)**
*Лукас Фиттл* (Lukas Fittl, pgAnalyze), как и Иван, как и Citus, говорит прежде всего о масштабировании активных и свободных соединений.
Очень понравилось ему новое представление [pg\_backend\_memory\_contexts](https://www.postgresql.org/docs/devel/view-pg-backend-memory-contexts.html) и функция [pg\_log\_backend\_memory\_contexts()](https://www.postgresql.org/docs/14/functions-admin.html), которые дают возможность заглянуть в память, чтобы понять, какое соединение сжирает больше всего памяти. Другая полезная вещь для диагностики — представление [pg\_stat\_wal](https://www.postgresql.org/docs/14/monitoring-stats.html). И очень автору понравилось, что `guery_id`, которое было в любимом дотошными админами представлении [pg\_stat\_statements](https://postgrespro.ru/docs/postgresql/13/pgstatstatements), теперь можно использовать и в представлении [pg\_stat\_activity](https://postgrespro.ru/docs/postgresql/13/monitoring-stats#MONITORING-PG-STAT-ACTIVITY-VIEW).
О коннектах есть и у Депеша в **[Waiting for PostgreSQL 14 – Improvements for handling large number of connections](https://www.depesz.com/2020/08/25/waiting-for-postgresql-14-improvements-for-handling-large-number-of-connections/)**:
Депеш приводит список из 7 ссылок на патчи, которые должны обеспечить масштабируемость соединений. Сам он не тестировал, но в комментариях есть [ссылка на тесты](https://github.com/digoal/blog/blob/master/202008/20200817_01.md). По ссылке немало иероглифов, но, вроде, ясно, что на 5000 соединений 14-й выиграл у 13-го 37% на TPS.
Мониторинг и «прозрачность»
---------------------------
В упомянутой [статье Кирка](https://habr.com/ru/company/postgrespro/blog/581552#kirk) *прозрачность* (переведу таким вольным образом ***visibility***) отобразилась в виде
**огромного списка (15 пунктов):**
* Статус операции COPY появился в `pg_stat_progress_copy`.
* Статус WAL в `pg_stat_wal`.
* Статус репликации в `pg_stat_replication_slots`.
* Статус обработки запроса бэкендом в `pg_backend_memory_contexts` (его также можно сбросить в лог, используя `pg_log_backend_memory_contexts`.
* Новые колонки в `pg_stat_database`.
* Архиватор в `pg_stat_activity`.
* В `pg_locks` добавлено время начала ожидания блокировки (lock wait start time).
* Добавлено представление `routine_column_usage` в `information_schema` для отслеживания колонок, на которые ссылаются в выражениях по умолчанию у функций или процедур.
* Добавлено `%P` к `log_line_prefix`, чтобы виден был PID лидера группы.
* Добавлен серверный параметр `log_recovery_conflict_waits` для отчётов о долгих временах разрешения конфликтов при восстановлении (to report long recovery conflict wait times).
* Функция `pg_get_wal_replay_pause_state()` для отчётов о состоянии восстановления.
* Функция `pg_xact_commit_timestamp_origin()`, возвращающая timestamp коммитта и источника репликации заданной транзакции.
* К записи, возвращаемой `pg_last_committed_xact()` добавлен источник репликации.
* `pg_stat_statements` теперь отслеживает инструкции верхнего уровня и вложенные инструкции отдельно.
* Для некоторых утилит добавлены кумулятивные флаги –verbose (-vvv) для вывода на экран
Однако список *Алексея Лесовского* ещё больше: 17 пунктов — **[Что нового в плане мониторинга в PostgreSQL 14](https://habr.com/ru/post/558792/)**.
И это не просто перечисление, некоторые пункты сопровождаются примерами кода, а некоторые даже эмоциями:
*Новое представление pg\_backend\_memory\_contexts — одно из нововведений, которое вызвало у меня противоречивые эмоции… как мне кажется, разработчики перемудрили — достаточно было бы сделать только одну эту [`pg_log_backend_memory_contexts()`] функцию (без вьюхи) которая бы принимала идентификатор процесса, но при этом вместо логирования, выводила бы статистику в виде строк.*
**[Monitoring for COPY](https://paquier.xyz/postgresql-2/postgres-14-monitoring-copy/)**
Возможность мониторинга операции COPY привлекла внимание *Мишеля Пакье* (Michael Paquier). COPY TO и COPY FROM нередко занимают много времени, поэтому возможность посмотреть, как идут дела с копированием, не прихоть. В новом системном представлении `pg_stat_progress_copy` по одной строке с 8 полями (в статье есть подробности) на каждый бэкенд.
depesz в своих waiting-ах тоже не прошёл мимо COPY: **[Report progress of COPY commands](https://www.depesz.com/2021/01/12/waiting-for-postgresql-14-report-progress-of-copy-commands/)**
Он предупреждает, между прочим, что общее количество байтов в некоторых случаях недоступно — когда ввод идёт с клиента, например.
**[Using Query ID in Postgres 14](https://blog.rustprooflabs.com/2021/10/postgres-14-query-id)** — этому параметру статью посвятили RustProoflabs. *Райан Лэмберт* (Ryan Lambert) запускает **pgbench** и сначала смотрит id в `pg_stat_statements` (для такой возможности `compute_query_id` надо установить в `postgresql.conf` в `auto` или `on`).
После этого Райан открывает параллельно 3 сессии: в двух он сталкивает UPDATE-транзакции так, что вторая натыкается на блокировку первой и висит, а в третьей он запускает запрос к `pg_stat_statments` и `pg_stat_activity`. И убеждается, что так удаётся выловить запрос, который выполняется дольше предыдущих и так и не завершён. Затем Райан демонстрирует два оставшихся способа использования guery\_id: в EXPLAIN и в логах, не умолчав о некоторой принципиально нерешаемой (но не слишком критичной) [проблеме](https://postgrespro.ru/list/thread-id/2432133#CA+8PKvQnMfOE-c3YLRwxOsCYXQDyP8VXs6CDtMZp1V4=D4LuFA@mail.gmail.com).
VACUUM
------
Хорошо [сказал выше Кирк](https://habr.com/ru/company/postgrespro/blog/581552#kirk), мол, революции не произошло — VACUUM жив, — но под капотом поменялось немало.
Анализ прочитанного на эту тему показал, что наиболее толковое описание улучшений, связанных с VACUUM, удалось сделать нашему *Павлу Лузанову* :) в его 5-й серии **[Заморозки](https://habr.com/ru/company/postgrespro/blog/550632/)** обзоров коммитфестов. Там и много (но концентрированно), и примеры есть. Как, впрочем, и в других его аналогичных обзорах — обзор без VACUUM это каша без соли.
Давно идут разговоры, что VACUUM нужно сделать более *агрессивным* (и был даже [берсерк-автовакуум](https://www.postgresql.org/message-id/flat/a6b9a97b4b1dfcb61b6e3ccd66566d2da005eac3.camel%40cybertec.at#7f962359f30d8e96a00672734cbb0500), предложенный *Дорофеем 'Котярой' Пролесковским*) — как экстренную меру, когда счётчики xid или multixact приближаются к wraparound. В PostgreSQL 14 в этом случае откладываются до лучших времён чистки индексов, уступая дорогу вакууму. Поведение его управляется константами `vacuum_failsafe_age` и `vacuum_multixact_failsafe_age`. Но подробных разборов этих ситуаций мы пока не нашли.
(Напомним, что о 64-разрядных идентификаторах транзакций говорят давно, но пока они есть [только](https://postgrespro.ru/docs/enterprise/13/intro-pgpro-vs-pg) в коммерческой версии — Postgres Pro Enterprise.)
Выше в Citus [хвалились](https://habr.com/ru/company/postgrespro/blog/581552#citus), что ускорили VACUUM на 25% своими патчами. Но об этом (и о восстановлении) у них была и целая статья, которую мы [упоминали ещё в Postgresso 30](https://habr.com/ru/company/postgrespro/blog/545796#citus):
**[Speeding up recovery & VACUUM in Postgres 14](https://www.citusdata.com/blog/2021/03/25/speeding-up-recovery-and-vacuum-in-postgres-14/)**
Это статья о патче Citus в основную ветку PostgreSQL, написанная (как и сам [патч](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=19c60ad69a91f346edf66996b2cf726f594d3d2b)) Дэвидом Роули (David Rowley), работавшим над этим уже внутри Microsoft. Он переписал внутреннюю функцию `compactify_tuples`, которая используется, когда PostgreSQL стартует после внештатного (нечистого) шатдауна (crash recovery), и когда идёт восстановление standby-сервера проигрыванием WAL по их прибытии с primary-сервера.
Эти случаи Дэвид и расписывает, поясняя схемами. Новая версия функции избавляет от ненужной внутренней сортировки кортежей в `heap`, поэтому и работает быстрее.
FDW
---
Эта тема вызвала немало откликов. Прежде всего заинтересовались те, кто движется в сторону шардинга и вообще распараллеливания вычислений.
В [статье](https://habr.com/ru/company/postgrespro/blog/581552#ahsan), которая выше, *Асан Хади* ставит FDW на первое место в своём списке достижений Postgres 14. И напомним, что *Джонатан Кац* [выбрал](https://habr.com/ru/company/postgrespro/blog/581552#katz) асинхронную работу FDW для своего кубернетного примера.
В [Postgres OnLine Journal](https://www.postgresonline.com/) пишут об FDW для Windows: **[PostgreSQL 14 64-bit for Windows FDWs](https://www.postgresonline.com/journal/index.php?/archives/402-PostgreSQL-14-64-bit-for-Windows-FDWs.html)**
Речь о бинарниках **[file\_text\_array\_fdw](https://github.com/adunstan/file_text_array_fdw)** и **[odbc\_fdw](https://github.com/CartoDB/odbc_fdw)** для PostgreSQL 14 под 64-бытные Windows.
**[postgres\_fdw Enhancement in PostgreSQL 14](https://www.percona.com/blog/2021/06/02/postgres_fdw-enhancement-in-postgresql-14/)**
*Ибрар Ахмед* (Ibrar Ahmed, Percona) демонстрирует достижения в PostgreSQL 14 по части FDW на примерах.
Типы (новорожденный и старички)
-------------------------------
**[Multirange Types in Postgres 14](https://www.postgresonline.com/journal/index.php?/archives/401-Multirange-types-in-PostgreSQL-14.html)**
*Джонатан Кац* (Jonathan S. Katz, Crunchy Data) пишет о [мультидиапазонах](https://www.postgresql.org/docs/14/rangetypes.html#RANGETYPES-BUILTIN) (multirange) — в PostgreSQL 14 именно они упростили ему и упростят многим их SQL-жизнь: приводит пример «из жизни» — с бронированием встреч. Действительно всего 3 строчки нужно для того, чтобы посмотреть, какие дни свободны. Сначала, конечно, надо забить необходимые данные в таблицу, но сложный рекурсивный запрос не потребуется.
Про *мультидиапазонные типы данных* довольно развёрнуто пишет и *Павел Лузанов* в [4-й части](https://habr.com/ru/company/postgrespro/blog/541252#commit_6df7a969) коммитфест-обзоров.
**[Multirange datatypes](https://www.depesz.com/2020/12/21/waiting-for-postgresql-14-multirange-datatypes/)**
В этой заметке Депеш не удовлетворился демонстрационным примером — как создавать колонки multirange и как выглядят результаты запросов к ним, — а решил разобраться, что с индексами для нового типа. `btree` можно создать и использовать для простеньких SELECT. Но depesz хотелось большего — операторов вроде `@>`, а вот с этим пока никак. `gist/spgist` и `gin` тоже отложили на будущее. В комментариях к статье автор патча, *Александр Коротков*, пояснил, что и `btree` пока работает так, как будто дыр между диапазонами нет, используя код для обычных `range`, без `multi`.
**[Postgres 14: It's The Little Things](https://blog.crunchydata.com/blog/postgres-14-its-the-little-things)**
Типы `JSON/JSONB` уже в возрасте, а новость в удобном синтаксисе. *Крейг Кирстинс* (Creig Kirstiens, Crunchy Data) радуется синтаксису с индексной нотацией **JSON** (JSON subscripting) — она простая, наглядная, интуитивная. Надо было писать так:
```
WHERE details->'attributes'->>'color' = 'neon yellow'
```
а теперь можно так:
```
WHERE details['attributes']['color'] = '"neon yellow"'
```
*Лузанов* [поясняет](https://habr.com/ru/company/postgrespro/blog/541252#commit_c7aba7c1) интенции разработчиков более технологично и более исторично: *с идеи сделать поддержку индексной нотации для json начался длинный путь [с зимы 2017] работы над [этим патчем](https://www.postgresql.org/message-id/flat/20200801143334.d7d3tsb7gaezx6vq%40localhost#61fae982900fdfa283a665c63e93a8c3)* Дмитрия Долгова*. И вот спустя несколько лет такая поддержка появилась. Первый патч создает необходимую инфраструктуру индексной нотации для произвольных типов данных. Второй патч добавляет индексную нотацию к типу **hstore**, а третий ― к типу JSONB. Теперь вместо специальных функций и операторов можно извлекать необходимые части из JSON-значения. Найдем телефон в контактных данных одного из билетов:*
```
SELECT contact_data, contact_data['phone'] AS phone;
```
А можно ещё посмотреть статью самого *Дмитрия Долгова* **[How many engineers does it take to make subscripting work?](https://erthalion.info/2021/03/03/subscripting/)**
Бэкап и репликация
------------------
В **[блоге Fujitsu](https://www.postgresql.fastware.com/blog)** обсуждались не все новшества 14-й версии, а те, в разработке которых Fujitsu OSS принимала участие. Они существенные.
**[Logical decoding of two-phase commits in PostgreSQL 14](https://www.postgresql.fastware.com/blog/logical-decoding-of-two-phase-commits)**
PostgreSQL поддерживает двухфазные транзакции аж с версии 8.0, а логическую репликацию с 10.0, но двухфазные коммиты до этого не поддерживались логической репликацией. Команды PREPARE TRANSACTION, COMMIT PREPARED и ROLLBACK PREPARED поддерживались на уровне инстанса, но их не могли корректно декодировать при передаче на реплику. Теперь всё работает. Изменились плагин **test\_decoding** и API.
**ДРУГИЕ ФИЧИ В БЛОГЕ FUJITSU (ссылки)**
**[Improved logging by libpq in PostgreSQL 14](https://www.postgresql.fastware.com/blog/improved-logging-by-libpq-in-postgresql-14)**
**[Enhancements to the target\_session\_attrs database connection parameter in PostgreSQL 14](https://www.postgresql.fastware.com/blog/enhancement-to-target-session-attrs)**
**[Speeding up recovery by optimizing the dropping of relation buffers – Sneak peek on features committed in PostgreSQL 14](https://www.postgresql.fastware.com/blog/speeding-up-recovery-by-optimizing-dropping-of-relation-buffers)**
**ДРУГИЕ МИКРООБЗОРЫ МИШЕЛЯ ПАКЬЕ**
**[Memory dumps](https://paquier.xyz/postgresql-2/postgres-14-memory-dumps/)**
PostgreSQL работает с памятью в рамках программной архитектуры контекстов. Представление pg\_backend\_memory\_contexts позволяет заглядывать в память, доступную сессии, не используя дебаггер, (это особенно полезно в облачных средах) начиная с TopMemoryContext и спускаясь по деревьям. Это можно сделать не только от суперюзера, но и от ролей, которым это дозволено по GRANT. Кроме того, добавлена одноименная функция pg\_backend\_memory\_contexts(), которая может заглядывать и в чужие сессии (она только под суперюзером). Значения не возвращаются клиенту, а сбрасываются в лог.
**[REINDEX TABLESPACE](https://paquier.xyz/postgresql-2/postgres-14-reindex-tbspace/)**
Это значит, что индекс можно перемещать CONCURRENTLY, так как индекс можно перестраивать, перемещая в другое табличное пространство, а не в два этапа: перестройка, потом перемещение — меньше вероятность, что пространства не хватит. При этом разрешая одновременное чтение и запись во время переиндексации, поскольку операция накладывает блокировку SHARE UPDATE EXCLUSIVE на индекс и родительскую таблицу. Подобная судьба (добавка CONCURRENTLY) ждала CLUSTER и VACUUM FULL, но не дождалась: релиз вышел.
**[Fun with Hashes](https://paquier.xyz/postgresql-2/postgres-14-hashes/)**
Здесь даже есть небольшой исторический экскурс в криптографию Postgres.
**[CREATE TABLE COMPRESSION](https://paquier.xyz/postgresql-2/postgres-14-table-compression/)**
Тоже с историей вопроса. Сейчас SET COMPRESSION можно задать как lz4. По умолчанию GUC default\_toast\_compression = «pglz».
Интересная ситуация с репликацией: при физической репликации можно проигрывать на реплике WALы ведущего сервера, сжатые LZ4, даже если реплика не поддерживает LZ4. Но прочитать данные из таких таблиц не получится: Postgres выдаст ошибку. При логический репликации на каждом сервере всё будет сжато в соответствии с настройками сервера.
С Depesz не просто: уж больно он *prolific*, так сказать, в своих [Waiting for PostgreSQL 14](https://www.depesz.com/tag/pg14/). 18 заметок обозреть не можем, поэтому
**просто ссылки.**
**[Add unistr function](https://www.depesz.com/2021/04/01/waiting-for-postgresql-14-add-unistr-function/)**
**[Add «pg\_database\_owner» default role.](https://www.depesz.com/2021/04/01/waiting-for-postgresql-14-add-pg_database_owner-default-role/)**
**[Add date\_bin function](https://www.depesz.com/2021/03/31/waiting-for-postgresql-14-add-date_bin-function/)**
**[Allow configurable LZ4 TOAST compression.](https://www.depesz.com/2021/03/22/waiting-for-postgresql-14-allow-configurable-lz4-toast-compression/)**
**[SEARCH and CYCLE clauses](https://www.depesz.com/2021/02/04/waiting-for-postgresql-14-search-and-cycle-clauses/)**
**[Add pg\_stat\_database counters for sessions and session time](https://www.depesz.com/2021/01/18/waiting-for-postgresql-14-add-pg_stat_database-counters-for-sessions-and-session-time/)**
**[Add idle\_session\_timeout.](https://www.depesz.com/2021/01/12/waiting-for-postgresql-14-add-idle_session_timeout/)**
**[pg\_stat\_statements: Track time at which all statistics were last reset.](https://www.depesz.com/2020/12/21/waiting-for-postgresql-14-pg_stat_statements-track-time-at-which-all-statistics-were-last-reset/)**
**[Allow subscripting of hstore values.](https://www.depesz.com/2020/12/20/waiting-for-postgresql-14-allow-subscripting-of-hstore-values/)**
**[Provide the OR REPLACE option for CREATE TRIGGER.](https://www.depesz.com/2020/11/19/3851/)**
**[Support negative indexes in split\_part().](https://www.depesz.com/2020/11/18/waiting-for-postgresql-14-support-negative-indexes-in-split_part/)**
**[Support for OUT parameters in procedures](https://www.depesz.com/2020/10/05/waiting-for-postgresql-14-support-for-out-parameters-in-procedures/)**
**[Add support for partitioned tables and indexes in REINDEX](https://www.depesz.com/2020/09/08/waiting-for-postgresql-14-add-support-for-partitioned-tables-and-indexes-in-reindex/)**
**[pg\_stat\_statements: track number of rows processed by some utility commands.](https://www.depesz.com/2020/08/24/waiting-for-postgresql-14-pg_stat_statements-track-number-of-rows-processed-by-some-utility-commands/)**
**[Rename wal\_keep\_segments to wal\_keep\_size.](https://www.depesz.com/2020/07/27/waiting-for-postgresql-14-rename-wal_keep_segments-to-wal_keep_size/)**
Задавайте вопросы
-----------------
В смысле здесь, а ещё лучше и на докладе *Павла Лузанова* **[PostgreSQL 14. Финальный обзор](https://pgconf.ru/202110/309791)**, который можно будет послушать на [PGConf.Russia 2021](https://pgconf.ru/), которая состоится назло вирусу (но с QR- и экспресс ПЦР-тестами) 25-26-го октября. | https://habr.com/ru/post/581552/ | null | ru | null |
# Magento. Пишем свой модуль. Добавляем CAPTCHA и дополнительные поля в регистрацию
Хочу поделится опытом программирования модулей для Magento. Большое спасибо пользователю [jeje](https://habrahabr.ru/users/jeje/) за приглашение.
В статье подробно описано создание модуля, реализующего допольнительные функции регистрации клиентов. Цели — дать представление о разработке под Magento на конкретном примере от начала до конца, показать основные подходы, организацию кода, указать на некоторые особенности. Статья ориентирована скорее на новичков, но и знакомые с Magento могут вынести что-то полезное для себя. Конечно в одной статье всего описать невозможно, но если тема окажется востребованной, то это может стать началом цикла статей.
Затронуты следующие моменты:
* создание модуля
* работа с блоками, шаблонами и разметкой (layout)
* переопределение контроллера
* скрипты инсталляции модуля
В результате мы получим регистрацию с проверкой CAPTCHA, полем выбора группы и сохранением кода приглашения.

### Чего задумали
Есть страница регистрации /magento/customer/account/create. Мы хотим добавить проверку CAPTCHA, а также спрашивать у клиентов группу и код приглашения. Полученные данные сохранять в базу. По умолчанию в Magento определены три группы клиентов General, Wholesale и Retailer. Из них мы и предложим выбирать будущему клиенту. Про код приглашения Magento ничего не знает — создадим новый атрибут.
Хочу отметить, что это не готовое решение, а всего лишь пример, составленный для удобства изложения.
### Поиск
Ищем где лежат файлы шаблонов, где и как сохраняются данные регистрации.
1. Шаблоны формы регистрации клиента
`/magento/app/design/frontend/default/default/template/customer/form/register.phtml` — анкета регистрации
2. Атрибуты добавляют в инсталляторе модуля, пример:
`/magento/app/code/core/Mage/Customer/sql/customer_setup/mysql4-upgrade-0.8.7-0.8.8.php`
подробности будут ниже, когда будем писать инсталятор для нашего модуля.
3. Обнаруживаем описание изменяемых полей (аттрибутов) в конфигурации модуля:
`/magento/app/code/core/Mage/Customer/etc/config.xml`
внутри тэгов
4. Форма регистрации постит данные по адресу:
````
http://localhost/magento/customer/account/createpost/
````
Соответсвенно запрос обрабатывается контроллером Mage\_**Customer**\_**Account**Controller метод **createPost**Action (line #234)
Реализация
----------
Вариант с изменением найденых фалов не рассматриваем. Создадим свою тему и свой модуль.
С темой всё просто:
1. создаем новую папку в /magento/app/design/frontend/default/mytheme
**default** — имя интерфейса
**mytheme** — имя нашей темы
2. копируем файлы с сохранением структуры директорий в новую тему
3. редактируем/создаем шаблоны по своему усмотрению
Одноименные шаблоны нашей темы перекроют шаблоны стандартной темы. Таким образом мы не вносим изменений в "родные" файлы Magento.
С модулем немного интересней:
Создаем новый модуль — **CustomerMod**. Структура папок у всех модулей одинаковая:
```
magento/app/code/local/
Examples
CustomerMod
- Block
- etc
- Helper
- Model
- sql
```
не забываем добавить файл с описанием наших модулей:
magento/app/etc/modules/Examples\_All.xml
>
> ```
>
>
>
>
> true
> local
>
>
>
>
> ```
>
### Поля на странице регистрации
Начнем с добавления на страницу регистрации поля выбора группы («General», «Wholesale», «Retailer»). Для вывода информации Magento оперирует блоками и шаблонами. Блок можно назвать рендерером шаблона. Каждая страница состоит из блоков, для каждого блока указан шаблон.
Мы добавим свой блок со своим шаблоном внутрь блока регистрационной формы. Другими словами, наш блок будет дочерним к блоку формы.
#### 1. Собственно новый шаблон
Шаблон выбора группы в отдельном файле:
/magento/app/design/frontend/default/example\_theme/template/customer/form/register/groupselect.phtml
с нехитрым содержанием:
>
> ```
>
> php $customer_groups = Mage::helper('customer')-getGroups()->toOptionArray(); ?>
>
>
> #### php echo $this-\_\_('Customer Group') ?>
>
>
> php foreach($customer\_groups as $cg) { ?* />
> php echo $cg['label']; ?
> php } //end foreach?
>
>
>
> ```
>
Обратите внимание имя поля «group\_id» должно соответсвовать имени аттрибута.
#### 2. Корректировка layout
Взаимное расположение блоков и привязка к шаблонам описываются в layout. Это xml-файлы, которые лежат в папке `magento/app/design/ИМЯ_ИНТЕРФЕЙСА/ИМЯ_ТЕМЫ/layout`.
В нашем случае будет:
/magento/app/design/frontend/default/example\_theme/layout/customermod.xml
>
> ```
>
>
>
>
>
>
>
>
>
>
> ```
>
Мы ссылаемся на блок `customer_form_register`. Описываем внутри него наш дочерний блок:
**type** — это класс блока, который в конечном итоге рендерит шаблон. В данном случае «core/template», что значит `Mage_Core_Block_Template`.
**name** — имя может быть любым. Оно нужно, чтобы обращатся к блоку, например в reference.
**template** — шаблон блока
Не забываем указать обновления layout в конфигах модуля, чтобы Magento учитывала изменения указанные в `customermod.xml`:
/magento/app/code/local/Examples/CustomerMod/etc/config.xml
>
> ```
>
>
>
>
>
> customermod.xml
>
>
>
>
>
> ```
>
#### 3. Вывод блока родительским блоком.
Наш блок пока ещё не видно, потому что мы должны «вызвать» дочерний блок в родительском с помощью метода getChildHtml(ИМЯ\_БЛОКА).
Копируем `register.phtml` в нашу тему из **default** темы и добавляем необходимый вызов перед секцией *Login Information*:
/magento/app/design/frontend/default/example\_theme/template/customer/form/register.phtml
>
> ```
>
> ...
> php echo $this-getChildHtml('customergroups-select') ?>
>
>
> #### php echo $this-\_\_('Login Information') ?>
>
>
> ...
>
> ```
>
#### 4. Сохранение данных
Теперь в регистрационной форме должен появится выбор группы.
«Но постойте, покупатель регистрируется, указывая „Retailer“ — а в панеле админа он всё равно в General группе!» — да, поле `group_id` не сохраняется.
Чтобы введенные поля сохранялись нужно указать их в fieldsets в конфигурации:
/magento/app/code/local/Examples/CustomerMod/etc/config.xml
>
> ```
>
>
>
> 11
>
>
>
> ```
>
Почему — спросите разработчиков Magento, — но так устроен Customer контроллер. Кому интересно — смотрите `/magento/app/code/core/Mage/Customer/controllers/AccountController.php` метод `createPostAction.`
### Новый аттрибут
Аттрибуты описаны в таблице **eav\_attributes**, соответсвенно работа с атрибутами сводится к редактировнию записей таблицы **eav\_attributes**.
Cуществуют также *static* аттрибуты, значения которых хранятся в отдельных колонках (например `sales_order`).
#### 1. Инсталляционные скрипты
Все действия по модификации модели производятся в инсталляционных скриптах, хранящихся в папке sql внутри каждого модуля.
`/magento/app/code/core/Mage/Customer/sql/customer_setup`
Скрипты бывают двух видов — **setup** и **upgrade**. Magento прогоняет соответсвующий скрипт один раз при установке или обновлении модуля. После установки в таблице **core\_resource** появляется запись, например:
> 'customermod\_setup', '0.1.0'
>
>
Иными словами скрипты прогоняются по двум причинам:
1. отсутсвие записи о модуле в таблице core\_resource
2. версия модуля указанная в core\_resource ниже, чем в config.xml модуля
Стоит отметить, что механизма деинсталляции не предусмотрено. Созданные атрибуты удалять придётся руками в случае чего.
Скрипты исполняются инсталлятором. По-умолчанию класс инсталлятора `Mage_Core_Model_Resource_Setup`, но он не содержит методов работы с **EAV** моделью (а мы аттрибуты собираемся создавать), поэтому в нашем случае нужен `Mage_Eav_Model_Entity_Setup`.

#### 2. Скрипт создания атрибута
Примеры установочных скриптов можно найти в стандартных модулях. Порой там просто прогон SQL команд. Но желательно максимально использовать методы классов инсталляторов, а к SQL командам прибегать в последнюю очередь.
>
> ```
>
> $installer = $this;
>
> /* @var $installer Mage_Customer_Model_Entity_Setup */
> $installer->startSetup();
>
> $installer->addAttribute('customer', 'invitation_code', array(
> 'type' => 'varchar',
> 'input' => 'text',
> 'label' => 'Invitation Code',
> 'global' => 1,
> 'visible' => 1,
> 'required' => 1,
> 'user_defined' => 1,
> 'default' => null,
> 'visible_on_front' => 1
> ));
>
> $installer->endSetup();
>
> ```
>
Думаю после стольких предисловий комментрии к самому скрипту не требуются.
#### 3. Обновляем шаблон
В шаблон формы регистрации добавляем новое поле:
/magento/app/design/frontend/default/example\_theme/template/customer/form/register.phtml
>
> ```
>
>
> php echo $this-\_\_('Invitation Code') ?> \*
>
>
>
>
> ```
>
#### 4. Обновляем конфигурацию
Добавляем описание установочного скрипта:
/magento/app/code/local/Examples/CustomerMod/etc/config.xml
>
> ```
>
>
>
>
>
> Examples\_CustomerMod
> Mage\_Eav\_Model\_Entity\_Setup
>
> core\_setup
>
> core\_write
> core\_read
>
>
> ```
>
И не забываем указать новое поле в `fieldsets`
>
> ```
>
>
>
> 11
> 11
>
>
>
> ```
>
Теперь в форме регистрации есть поле *Invitation Code*, значение которого сохраняется в атрибуте `invitation_code` для каждого клиента. Также новое поле появилось в панели администратора на странице аккаунта клиента в закладке *Account Information*.

CAPTCHA
-------
Для реализации «каптчи» возьмем [reCAPTCHA](http://recaptcha.net/ "reCAPTCHA"). Далее способов может быть много: включить функционал каптчи в существующий модуль, сделать отдельный, можно вообще всё в шаблон запихнуть и отредактировать стандартный контроллер.
На мой взгляд лучше оформить в отдельном модуле. Шаги по созданию нового модуля, отдельного шаблона, модификации разметки (layout) такие же, что были описаны выше. Остановимся на том, что ещё не было затронуто: контроллер и хелпер.
Значения с формы регистрации передаются в контроллер `Mage_Customer_AccountController` В Magento предусмотрен механизм переопределения контроллеров (*начиная с версии 1.3 механизм несколько изменился*). Вместо изменений в стандартном контроллере, создадим новый, унаследованный от стандартный.
Итак по-порядку.
Скачиваем библиотеку [recaptcha-php](http://recaptcha.googlecode.com/files/recaptcha-php-1.10.zip) и копируем в папку /magento/lib.
#### 1. Контроллер
В конфигурации модуля CustomerMod описываем контроллер:
>
> ```
>
>
> ...
>
> ...
>
>
>
>
> Examples\_CustomerMod
>
>
>
>
> ...
>
> ```
>
Собственно сам контроллер.
/magento/app/code/local/Examples/CustomerMod/controllers/AccountController.php
>
> ```
>
> require_once("Mage/Customer/controllers/AccountController.php");
> require_once('recaptcha/recaptchalib.php');
>
> class Examples_CustomerMod_AccountController extends Mage_Customer_AccountController {
>
> public function createPostAction() {
> $request = $this->getRequest();
> $captchaIsValid = Mage::helper('captcha')->captchaIsValid($request);
>
> if ($captchaIsValid) {
> parent::createPostAction();
> } else {
> $this->_getSession()->setCustomerFormData($this->getRequest()->getPost());
> $this->_getSession()->addError($this->__('Verification code was not correct. Please try again.'));
> $this->_redirectError(Mage::getUrl('*/*/create', array('_secure'=>true)));
> }
> }
> }
>
> ```
>
В отличие от всех других классов, определяемых в Magento, для контроллеров необходимо явно указывать на файл содержащий родительский класс и сторонние библиотеки, поэтому и нужны два require\_once. Код минимален, используем стандартную функцию из recaptchalib. Но сама проверка введенной каптчи вынесена в отдельный класс-хелпер. Если понадобиться добавить такую же проверку в другие контроллеры, то всё сведется к проверке результата `Mage::helper('captcha')->captchaIsValid($request).`
Здесь ещё можно добавить, например, подлинность кода приглашения.
#### 2. Хелпер
Хелпер в Magento — это класс синглетон, содержащий как правило набор вспомогательных методов. Обращение к хелперу производится с помощью метода `Mage::helper()` с именем модуля в качестве параметра. В нашем случае `Examples_Captcha_Helper_Data` будет содержать функции проверки каптчи.
/magento/app/code/local/Examples/Captcha/Helper/Data.php
>
> ```
>
> require_once('recaptcha/recaptchalib.php');
> class Examples_Captcha_Helper_Data extends Mage_Core_Helper_Abstract
> {
> const CAPTCHA_PUBLIC_KEY = "public-key-for-the-website";
> const CAPTCHA_PRIVATE_KEY = "private-key-for-the-website";
>
> public function captchaIsValid(Mage_Core_Controller_Request_Http $request) {
> if ($request) {
> $resp = recaptcha_check_answer (self::CAPTCHA_PRIVATE_KEY,
> $_SERVER["REMOTE_ADDR"],
> $request->getParam("recaptcha_challenge_field"),
> $request->getParam("recaptcha_response_field") );
> return $resp->is_valid;
> }
> return false;
> }
>
> public function captchaGetError(Mage_Core_Controller_Request_Http $request) {
> if ($request) {
> $resp = recaptcha_check_answer (self::CAPTCHA_PRIVATE_KEY,
> $_SERVER["REMOTE_ADDR"],
> $request->getParam("recaptcha_challenge_field"),
> $request->getParam("recaptcha_response_field") );
> return $resp->error;
> }
> return false;
>
> }
>
> public function getPublicKey() { return Examples_Captcha_Helper_Data::CAPTCHA_PUBLIC_KEY; }
>
> }
>
> ```
>
#### 3. Блок CAPTCHA
Не плохо бы вывести картинку самой каптчи на страницу. Есть для этого функция recaptcha\_get\_html(). Не смотря на то, что функцию можно вызвать из шаблона (phtml), мы последуем идеям и архитектуре Magento — cоздадим новый тип блока, заодно узнаем как блок может быть и без шаблона. Для этого опишем класс `Examples_Captcha_Block_Recaptcha`. Вызов функции `recaptcha_get_html()` внесем в метод `_toHtml`. Этот метод вызывается при отрисовке блока в HTML. (см. `/magento/app/code/core/Mage/Core/Block/Abstract.php` line #643)
/magento/app/code/local/Examples/Captcha/Block/Recaptcha.php
>
> ```
>
> require_once('recaptcha/recaptchalib.php');
> class Examples_Captcha_Block_Recaptcha extends Mage_Core_Block_Abstract {
>
> public function _toHtml() {
> $html = recaptcha_get_html( Mage::helper('captcha')->getPublicKey() );
> return $html;
> }
>
> }
>
> ```
>
Добавляем новый блок в layout. Шаблон для этого блока не нужен, он и так выводит готовую каптчу.
/magento/app/design/frontend/default/example\_theme/layout/customermod.xml
>
> ```
>
> xml version="1.0"?
>
>
>
>
>
>
>
>
>
> ```
>
#### 4. Конфигурация
Осталось только указать в конфигурации модуля Captcha, что он содержит блок и хелпер
/magento/app/code/local/Examples/Captcha/etc/config.xml
>
> ```
>
> xml version="1.0" encoding="UTF-8"?
>
>
>
> 0.1.0
>
>
>
>
>
> Examples\_Captcha\_Block
>
>
>
> Examples\_Captcha\_Helper
>
>
>
>
>
> ```
>
И каптча готова.

Заключение
----------
Спасибо дочитавшим до конца! Надеюсь вам было интересно или хотя бы полезно :). Можете [скачать готовый пример](http://fursov.org/magento/magento_example_sources.zip). Для написания статьи использовалась Magento версии 1.3.2.4.
Если затронутая тема интересна на хабре, то я с радостью выслушаю пожелания по новой статье.
Есть идеи и кое-какие материалы для статей на тему:
* Обзор Magento пряники и грабли
* События и слушатели в Magento на примере добавления email-уведомления.
* Debugging в Magento (про тестовую страницу, про Firebug, про Mage::log)
* Модели в Magento. Добавляем свои сущности и атрибуты
* Как я добавлял блоки в email-шаблоны Magento
* PDF в Magento. Горькая правда
* Работа с коллекциями в Magento на примере создания отчета
* выбор/настройка IDE для разработки в Magento | https://habr.com/ru/post/78003/ | null | ru | null |
# Android in-app purchases, часть 3: получение активных покупок и смена подписки
Привет, я Влад, core разработчик [Adapty SDK](https://adapty.io/sdk/android?utm_source=habr.com&utm_medium=referral&utm_campaign=blogpost_android_query-purchases-and-change) для встроенных покупок на Android. Это наша третья статья из цикла статей про внедрение покупок на Android. В этой серии мы полностью закрываем вопросы добавления покупок в приложениях в Google Play:
1. [Android in-app purchases, часть 1: конфигурация и добавление в проект](https://habr.com/ru/company/adapty/blog/568902/)
2. [Android in-app purchases, часть 2: инициализация и обработка покупок](https://habr.com/ru/company/adapty/blog/571122/)
3. Android in-app purchases, часть 3: получение активных покупок и смена подписки. — Вы тут.
4. [Android in-app purchases, часть 4: коды ошибок от Billing Library и как не облажаться с тестированием.](https://habr.com/ru/company/adapty/blog/575866/)
5. [Android in-app purchases, часть 5: серверная валидация покупок.](https://habr.com/ru/company/adapty/blog/576164/)
Cегодня мы рассмотрим еще две важные темы по реализации in-app purchases с Google Play Billing Library. Начнем с получения активных покупок пользователя, то есть действующих подписок и ранее купленных non-consumable продуктов. Купленные consumable-продукты сюда не входят, потому что вы их ~~обменяли на голду~~ законсьюмили, чтобы иметь возможность купить повторно.
Это нам может пригодиться, если мы, допустим, хотим сделать кнопку покупки такого продукта неактивной. Или, например, написать на ней, что это текущая подписка, если это подписка. Или просто дать пользователю доступ к оплаченным фичам.
### Получение списка покупок
В Billing Library для получения активных покупок есть метод [queryPurchasesAsync(String skuType, PurchasesResponseListener listener)](https://developer.android.com/reference/com/android/billingclient/api/BillingClient#queryPurchasesAsync(java.lang.String,%20com.android.billingclient.api.PurchasesResponseListener)) (раньше использовался синхронный метод [queryPurchases(String skuType)](https://developer.android.com/reference/com/android/billingclient/api/BillingClient#queryPurchases(java.lang.String)), но с версии Billing Library 4.0.0 его задепрекейтили). Да, все подобные методы почему-то требуют указания типа продуктов, поэтому получение полного списка снова придется комбинировать из двух запросов.
Дополним наш `BillingClientWrapper` по аналогии с тем, как мы делали в предыдущих статьях:
```
interface OnQueryActivePurchasesListener {
fun onSuccess(activePurchases: List)
fun onFailure(error: Error)
}
private fun queryActivePurchasesForType(
@BillingClient.SkuType type: String,
listener: PurchasesResponseListener
) {
onConnected {
billingClient.queryPurchasesAsync(type, listener)
}
}
fun queryActivePurchases(listener: OnQueryActivePurchasesListener) {
queryActivePurchasesForType(
BillingClient.SkuType.SUBS
) { billingResult, activeSubsList ->
if (billingResult.responseCode == BillingClient.BillingResponseCode.OK) {
queryActivePurchasesForType(
BillingClient.SkuType.INAPP
) { billingResult, nonConsumableProductsList ->
if (billingResult.responseCode == BillingClient.BillingResponseCode.OK) {
listener.onSuccess(
activeSubsList.apply { addAll(nonConsumableProductsList) }
)
} else {
listener.onFailure(
Error(billingResult.responseCode, billingResult.debugMessage)
)
}
}
} else {
listener.onFailure(
Error(billingResult.responseCode, billingResult.debugMessage)
)
}
}
}
```
В колбэке нам возвращается список объектов класса [Purchase](https://developer.android.com/reference/com/android/billingclient/api/Purchase). Раньше, чтобы понять, к какому продукту относится покупка, нужно было вызвать ее метод `getSku()` и получить id продукта. Но в 2021 году на Google I/O были [анонсированы](https://www.youtube.com/watch?v=iBxYrEkpCac&t=431s) покупки нескольких продуктов в рамках одной транзакции, поэтому в версии 4.0.0 getSku() сменился на [getSkus()](https://developer.android.com/reference/com/android/billingclient/api/Purchase#getSkus()) и возвращает список id продуктов, а еще добавился метод [getQuantity()](https://developer.android.com/reference/com/android/billingclient/api/Purchase#getQuantity()), который возвращает их количество. Правда, способ инициировать такую покупку я в документации не нашел: кажется, он пока не в релизе. Если что-то про это знаете, пишите в комментариях~~, ставьте лайки, жмите на колокольчик~~.
У метода `queryActivePurchases()` есть одна небольшая проблема — он берет покупки из локального кэша Play Services, и результат не всегда бывает актуален, особенно если покупка была совершена на другом устройстве. Лечится это несложным [хаком](https://stackoverflow.com/a/60991072), заодно добавим в `BillingClientWrapper` api для получения истории покупок:
```
interface OnQueryPurchaseHistoryListener {
fun onSuccess(purchaseHistoryList: List)
fun onFailure(error: Error)
}
private fun queryPurchasesHistoryForType(
@BillingClient.SkuType type: String,
listener: PurchaseHistoryResponseListener
) {
onConnected {
billingClient.queryPurchaseHistoryAsync(type, listener)
}
}
fun queryPurchaseHistory(listener: OnQueryPurchaseHistoryListener) {
queryPurchasesHistoryForType(
BillingClient.SkuType.SUBS
) { billingResult, subsHistoryList ->
if (billingResult.responseCode == BillingClient.BillingResponseCode.OK) {
queryPurchasesHistoryForType(
BillingClient.SkuType.INAPP
) { billingResult, inappHistoryList ->
if (billingResult.responseCode == BillingClient.BillingResponseCode.OK) {
listener.onSuccess(
subsHistoryList?.apply { addAll(inappHistoryList.orEmpty()) }.orEmpty()
)
} else {
listener.onFailure(
Error(billingResult.responseCode, billingResult.debugMessage)
)
}
}
} else {
listener.onFailure(
Error(billingResult.responseCode, billingResult.debugMessage)
)
}
}
}
```
Здесь колбэк возвращает список с самой последней покупкой каждого продукта, который пользователь когда-либо приобретал, а заодно синхронизирует локальный кэш активных покупок с актуальным состоянием. Также обратите внимание, что покупка здесь представлена не классом [Purchase](https://developer.android.com/reference/com/android/billingclient/api/Purchase), а классом [PurchaseHistoryRecord](https://developer.android.com/reference/com/android/billingclient/api/PurchaseHistoryRecord).
Теперь мы можем объявить метод получения только что синхронизированных активных покупок:
```
fun querySyncedActivePurchases(listener: OnQueryActivePurchasesListener) {
queryPurchaseHistory(object : OnQueryPurchaseHistoryListener {
override fun onSuccess(purchaseHistoryList: List) {
queryActivePurchases(listener)
}
override fun onFailure(error: Error) {
listener.onFailure(error)
}
})
}
```
Мы не просто так начали с получения покупок – следующая тема тесно связана с ними. Поговорим о замене подписок.
### Смена подписок
В базовом случае, если купить обе подписки тем способом, который мы описали в [предыдущей статье](https://habr.com/ru/company/adapty/blog/571122/), они обе будут активны. Это не всегда ожидаемое поведение, поэтому, например, в App Store, как и в случае с consumable/non-consumable, это решается на уровне App Store Connect с помощью [групп подписок](https://habr.com/ru/company/adapty/blog/507664/). А с продуктами из Play Market, как и в случае с consumable/non-consumable, эту логику нужно делать на клиенте.
В нашем примере из [предыдущей статьи](https://habr.com/ru/company/adapty/blog/571122/) подписки отличаются только периодом оплаты, поэтому, по логике, должны быть взаимоисключающими. Добавим в `BillingClientWrapper` метод для замены старой подписки на новую:
```
fun changeSubscription(
activity: Activity,
newSub: SkuDetails,
updateParams: BillingFlowParams.SubscriptionUpdateParams
) {
onConnected {
activity.runOnUiThread {
billingClient.launchBillingFlow(
activity,
BillingFlowParams.newBuilder().setSkuDetails(newSub)
.setSubscriptionUpdateParams(updateParams).build()
)
}
}
}
```
От обычной покупки он отличается только параметром [SubscriptionUpdateParams](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.SubscriptionUpdateParams). В классе [SubscriptionUpdateParams.Builder](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.SubscriptionUpdateParams.Builder) нас интересуют 2 метода:
1. [setOldSkuPurchaseToken(String purchaseToken)](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.SubscriptionUpdateParams.Builder#setOldSkuPurchaseToken(java.lang.String)) — метод, в который мы передаем purchaseToken той активной покупки, где `purchase.skus.first()` равен id подписки, которую мы хотим заменить (мы получали список активных покупок в том числе и для этого).
2. [setReplaceSkusProrationMode(int replaceSkusProrationMode)](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.SubscriptionUpdateParams.Builder#setReplaceSkusProrationMode(int)) — метод, в который нужно передать одну из констант [BillingFlowParams.ProrationMode](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.ProrationMode). На них остановимся поподробнее.
Каждая из констант говорит о том, когда подписка должна будет фактически смениться, а также какие финансовые транзакции должны будут произойти и в какой день. Рассмотрим на примерах.
В нашем случае есть 2 подписки: помесячная за $9.99 и годовая за $49.99. Для удобства расчетов округлим их до $10 и $50 соответственно. Представим, что 1 сентября пользователь купил помесячную подписку, а 15-го решил сменить ее на годовую. Какие есть варианты:
[ProrationMode.IMMEDIATE\_WITH\_TIME\_PRORATION](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.ProrationMode#IMMEDIATE_WITH_TIME_PRORATION):
Подписка меняется немедленно. Так как прошло всего полмесяца, остались неиспользованные $5 от помесячной подписки, то есть 1/10 стоимости годовой – их хватает на 36 дней. Таким образом, $50 за годовую подписку пользователь заплатит 22 октября, следующее продление будет 22.10.2022 и т.д.
[ProrationMode. IMMEDIATE\_AND\_CHARGE\_PRORATED\_PRICE](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.ProrationMode#IMMEDIATE_AND_CHARGE_PRORATED_PRICE):
Этот режим не подходит для нашего соотношения цен, потому что для него стоимость новой подписки за единицу времени должна превышать стоимость старой подписки за ту же единицу времени (у нас получается $50/г. ~ $4.17/мес. < $10/мес.). Поэтому пусть для этого кейса годовая подписка стоит $144.
Подписка меняется немедленно. Так же, как и в предыдущем кейсе, остаются 5 долларов и полмесяца до конца периода старой подписки, если б она не отменилась. Но для новой подписки полмесяца стоят $144/12/2=$6, поэтому с пользователя сразу снимают 1 доллар, и суммарные 6 долларов идут уже в счет новой подписки. 1 октября с пользователя снимут $144, следующее продление будет 01.10.2022 и т.д.
[ProrationMode.IMMEDIATE\_WITHOUT\_PRORATION](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.ProrationMode#IMMEDIATE_WITHOUT_PRORATION):
Подписка меняется немедленно и без доплат — то есть, оставшиеся полмесяца будут уже с новой подпиской, но еще по старой цене. 1 октября пользователь заплатит $50, следующее продление будет 01.10.2022 и т.д.
[ProrationMode.IMMEDIATE\_AND\_CHARGE\_FULL\_PRICE](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.ProrationMode#IMMEDIATE_AND_CHARGE_FULL_PRICE):
Подписка меняется немедленно, сразу же списывается $50. Так как оставшиеся $5 хватает на 36 дней годовой подписки, следующее продление будет через 1 год и 36 дней.
[ProrationMode.DEFERRED](https://developer.android.com/reference/com/android/billingclient/api/BillingFlowParams.ProrationMode#DEFERRED):
В [предыдущей статье](https://habr.com/ru/company/adapty/blog/571122/) при описании колбэка `onPurchasesUpdated(billingResult: BillingResult, purchaseList: MutableList?)` был клиффхэнгер, что даже при успехе purchaseList может быть null – это тот самый кейс.
Помесячная подписка сменится на годовую только 1 октября, тогда же с пользователя снимут $50. Но колбэк `onPurchaseUpdated(billingResult: BillingResult, purchaseList: MutableList?)` вызовется уже сейчас, только в параметре purchaseList придет null.
В этом кейсе Google настоятельно рекомендует делать acknowledge новой подписки на бэке при получении нотификации `SUBSCRIPTION_RENEWED`, которая придет только 1 октября, потому что, как мы помним, если этого не сделать, подписка отменится через 3 дня, и если пользователь в начале октября не будет заходить в приложение, выполнить acknowledge на клиенте нет шансов.
Впрочем, всё, что связано с бэком, расскажем уже в пятой статье.
Про Adapty
----------
А пока предлагаю вам [подписаться на наш блог на Habr](https://habr.com/ru/company/adapty/blog/), чтобы не пропустить следующие материалы. Мы пишем про покупки в мобильных приложениях: от технической реализации до метрик подписок и монетизации приложений; а также записываем подкаст, где общаемся с интересными гостями на тему приложений.
И ещё советую познакомиться с [Adapty SDK](https://adapty.io/sdk/android/??utm_source=habr.com&utm_medium=referral&utm_campaign=blogpost_android_query-purchases-and-change), с которым работа с подписками становится проще не только технически:
* Встроенная аналитика позволяет легко понимать главные метрики приложения.
* Когортный анализ показывает, [сходится ли экономика](https://habr.com/ru/company/adapty/blog/564748/).
* А/Б тесты пейволлов делаются налету и помогают увеличивать конверсию в платных пользователей.
* Интеграции с внешними системами позволяют отправлять транзакции в сервисы атрибуции и продуктовой аналитики.
* Промо-кампании уменьшают отток аудитории.
* Open source SDK позволяет интегрировать подписки в приложение за несколько часов.
* Серверная валидация и API для работы с другими платформами упрощает работу с покупками.
[Познакомьтесь подробнее с этими возможностями](https://adapty.io/?utm_source=habr.com&utm_medium=referral&utm_campaign=blogpost_android_query-purchases-and-change), чтобы быстрее внедрить подписки в своё приложение и улучшить конверсии. | https://habr.com/ru/post/573058/ | null | ru | null |
# Установка Tizen 3.0 на RD-PQ
Не так давно на ресурсе загрузок для Tizen появились новые сборки. Покопавшись в логах сборок понимаем что это как никак Tizen 3.0. В этой статье рассмотрим процесс установки Tizen 3.0 на RD-PQ.
Итак, что мы имеем:
1. Ubuntu 14.04 LTS i386(выбрана для того чтобы не было проблем с установкой библиотек)
2. Samsung RD-PQ
3. Немного свободного времени
Начнем по порядку, во-первых нам необходимо установить утилиту для прошивки устройств на ОС Tizen — LTHOR. Для того чтобы загрузить ее нам необходимо добавить репозиторий в **/etc/apt/sources.list**, а именно эту строчку:
```
deb http://download.tizen.org/tools/latest-release/Ubuntu_12.10 /
```
Далее выполняем две команды:
```
sudo apt-get update
sudo apt-get install lthor
```
Но после выполнения второй команды на новых версиях убунты может выпасть с такой ошибкой из за отсутcnвия компонента **libarchive12**.
**Лог с ошибкой**
```
dimones@dimones-dev:~$ sudo apt-get install lthor
Чтение списков пакетов… Готово
Построение дерева зависимостей
Чтение информации о состоянии… Готово
Некоторые пакеты невозможно установить. Возможно, вы просите невозможного,
или же используете нестабильную версию дистрибутива, где запрошенные вами
пакеты ещё не созданы или были удалены из Incoming.
Следующая информация, возможно, поможет вам:
Пакеты, имеющие неудовлетворённые зависимости:
lthor : Зависит: libarchive12 но он не может быть установлен
E: Невозможно исправить ошибки, у вас отложены (held) битые пакеты.
```
Скачать его можно отсюда [выбрав нужную вам сборку](http://mirror.internode.on.net/pub/kali/pool/main/liba/libarchive/), в моем случае это **libarchive12\_3.0.4-3+nmu1\_i386.deb**, далее устанвливайте привычным вам способом.
Итак, повторим операцию:
```
sudo apt-get install lthor
```
У вас должно быть примерно такой вывод:
**Вывод**
```
dimones@dimones-dev:~$ sudo apt-get install lthor
Чтение списков пакетов… Готово
Построение дерева зависимостей
Чтение информации о состоянии… Готово
НОВЫЕ пакеты, которые будут установлены:
lthor
обновлено 0, установлено 1 новых пакетов, для удаления отмечено 0 пакетов, и 592 пакетов не обновлено.
Необходимо скачать 0 B/13,5 kB архивов.
После данной операции, объём занятого дискового пространства возрастёт на 68,6 kB.
ВНИМАНИЕ: Следующие пакеты невозможно аутентифицировать!
lthor
Установить эти пакеты без проверки? [y/N] y
Выбор ранее не выбранного пакета lthor.
(Чтение базы данных … на данный момент установлено 163783 файла и каталога.)
Preparing to unpack …/archives/lthor_1.4_i386.deb ...
Unpacking lthor (1.4) ...
Настраивается пакет lthor (1.4) …
dimones@dimones-dev:~$
```
Далее нам нужна сама прошивка, ищем ее на [этом сайте](http://download.tizen.org/snapshots/tizen/rd-pq/), но необходимо чтобы в папке images присутсвовали две папки RD-PQ-boot и RD-PQ, и обязательно чтобы в них были tar.gz архивы. Итак разобрались, я выбрал для прошивки самую последнюю версию boot — **tizen\_20140414.8\_RD-PQ-boot.tar.gz** и основной архив **tizen\_20140414.8\_RD-PQ.tar.gz**.
Наконец после подготовки перейдем к действиям. Для начала нам нужно наше устройство ввести в режим загрузки, делается это включением устройства с зажатой одновременно кнопки понижения громкости и клавиши питания. После выполненных манипуляций получаем на экране такое изображение:
Итак, подключаем наш RD-PQ к компьютеру и выполняем команду в терминале:
```
sudo lthor '/{Путь до архива}/tizen_20140414.8_RD-PQ-boot.tar'
```
И наблюдаем процесс установки в таком виде:
**Процесс установки boot**
```
dimones@dimones-dev:~$ sudo lthor '/home/dimones/Рабочий стол/tizen_20140414.8_RD-PQ-boot.tar'
Linux Thor downloader, version 1.4
Authors: Jaehoon You
USB port is detected : /dev/ttyACM0
/home/dimones/Рабочий стол/tizen\_20140414.8\_RD-PQ-boot.tar :
[boot.img] 20480k
[u-boot-mmc.bin] 1024k
-------------------------
total : 21.00MB
Download files from /home/dimones/Рабочий стол/tizen\_20140414.8\_RD-PQ-boot.tar
[boot.img] | sending 20480k/ 20480k 100% block 20 [avg 27.23 MB/s]
[u-boot-mmc.bin]| sending 1024k/ 1024k 100% block 1 [avg 27.73 MB/s]
/home/dimones/Рабочий стол/tizen\_20140414.8\_RD-PQ-boot.tar completed
request target reboot : success
```
Но не торопитесь радоваться, теперь необходимо повторить процедуру ввода устройства в режим загрузки. После того как ввели необходим повторить прошивку но теперь с большим основным архивом. Для этого выполним команду:
```
sudo lthor '/{Путь до архива}/tizen_20140414.8_RD-PQ.tar.gz'
```
Получаем на выходе в терминале что вроде этого:
**Процесс установки основной части**
```
dimones@dimones-dev:~$ sudo lthor '/home/dimones/Рабочий стол/tizen_20140414.8_RD-PQ.tar.gz'
Linux Thor downloader, version 1.4
Authors: Jaehoon You
USB port is detected : /dev/ttyACM0
/home/dimones/Рабочий стол/tizen\_20140414.8\_RD-PQ.tar.gz :
[ums.img] 120960k
[platform.img] 675712k
[data.img] 112400k
-------------------------
total : 887.77MB
Download files from /home/dimones/Рабочий стол/tizen\_20140414.8\_RD-PQ.tar.gz
[ums.img] - sending 120960k/120960k 100% block 119 [avg 18.57 MB/s]
[platform.img] / sending 675712k/675712k 100% block 660 [avg 16.35 MB/s]
[data.img] | sending 112400k/112400k 100% block 110 [avg 18.23 MB/s]
/home/dimones/Рабочий стол/tizen\_20140414.8\_RD-PQ.tar.gz completed
request target reboot : success
dimones@dimones-dev:~$
```
Вы можете заметить что после этих манипуляций вы получилил кирпич, но это не так. Также вы наверное заметили что наш девайс отображается в списке подключенных устройств. Приступим к реанимации. Покопавшись достаточно в сети я увидил в баг-репортах похожую запись и некоторое решение. Так вот я немного переделал это решение и сейчас мы его реализуем на нашем устройстве.
Для этого нам необходим SDB(Smart Development Bridge) в принципе как и многое в Tizen аналогичен ADB в андроид. Установка производится из добавленного выше репозитория Tizen:
```
sudo apt-get install sdb
```
После того как установили можно творить магию, а для этого нам необходимо что девайс был включен и подключен к компьютеру.
Выполним команды:
```
sdb root on //Необходимо чтобы получить root-доступ на устройстве
sdb shell
su root
```
Далее нам нужно изменить конфиг одного файла, находящийся по пути **/usr/lib/systemd/system/[email protected]**, для этого выполним:
```
sudo vi /usr/lib/systemd/system/[email protected]
```
Приводим содержимое к такому виду и сохраняем.
```
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
[Unit]
Description=User Manager for %I
After=systemd-user-sessions.service
[Service]
User=%I
PAMName=systemd-user
Type=notify
Environment=DISPLAY=:0
EnvironmentFile=-/run/tizen-mobile-ui
ExecStart=-/usr/lib/systemd/systemd --user
SmackExecLabel=User
Environment=DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/%I/dbus/user_bus_socket
Slice=user-%i.slice
```
Также необходимо выполнить:
```
chsmack -a "*" /home/app/
find /home/app/.e -exec chsmack -a "*" {} \;
vconftool set -t int memory/starter/sequence 1 -f
reboot
```
Так как интерфейс толком не работает, то единственный выход узнать какая версия — это подключиться к шеллу и посмотреть содержимое в файле **/etc/tizen-release**.
А там, собственно:
```
Tizen 3.0.0 (arm)
VERSION = 3.0.0
CODENAME = Next
```
В итоге мы получаем девайс который толком ничего не может, фактически даже интерфейс не работает. Но ребята из Tizen активно работают и надеюсь что скоро мы увидим более стабильные и функциональные сборки. Кстати покопавшись во внутренностях я обнаружил предустановленные библиотеки Qt 5.0, реализованную многопользовательность и еще некоторые плюшки.
А также вы можете посмотреть фото под катом.
**Фото**
 | https://habr.com/ru/post/220537/ | null | ru | null |
# Как накрутить счетчик Google Analytics или Google ненавидит Казахстан
Добрый день.
Думаю многие читали историю про [Катю](https://habrahabr.ru/company/dcoin/blog/272695/), я решил написать в том же стиле, т.е. информация о том почему Google ненавидит Казахстан будет в спойлерах.
И так.
**Предыстория.**
Однажды изучаю статистику в Google Search Console, я заметил что в разделе «Вид в поиске» появился еще один пункт, этот пункт вел на отчет о проиндексированных AMP страницах.
Зайдя на эту страницу я увидел надпись

Мне конечно же сразу захотелось узнать что это за ускоренные мобильные страницы. Пройдя по ссылке я увидел [гайдлайн](https://support.google.com/webmasters/answer/6340290?hl=ru) по созданию AMP страниц. Почитав гайдлайн я приступил к созданию amp страниц на своем сайте.
**История**
Прочитав документацию по созданию AMP, я сразу же приступил к реализации.
**Google ненавидит Казахстан**После того как я подготовил все свои страницы, я стал ждать официального запуска AMP, он должен был быть 24 февраля, и он запустился 24 февраля, НО Казахстан не входил в список тех стран у которых будут отображаться AMP версии страниц в поиске. И нигде об этом не было написано. И нигде не написано когда будет доступен AMP в Казахстане.
*Наверное потому что...*
***Google ненавидит Казахстан***
Через час у меня уже был готовы AMP версий моих страниц. Но возникла проблема, я не мог вставить Google Analytics, т.к. вставлять JS скрипты в AMP страницы нельзя, а компонента [amp-analytics](https://www.ampproject.org/docs/reference/extended/amp-analytics.html) еще не существовало, но был компонент [amp-pixel](https://www.ampproject.org/docs/reference/amp-pixel.html).
Погуглив немного я наткнулся на вот [этот вопрос](http://stackoverflow.com/questions/33342754/google-analytics-support-for-the-amp-pixel-tag) на Stackoverflow.
Тут предлагали вставлять pixel с следующим url который передавал нужные значение в Google Analytics
```
```
Это картинка передавала уникальный ID пользователя, название статьи и ссылку указанную в О передаваемых параметрах можно почитать [тут](https://developers.google.com/analytics/devguides/collection/protocol/v1/parameters?hl=ru), честно говоря я еще сам не читал
**Google ненавидит Казахстан**Т.к. я работаю в редакции онлайн СМИ, для нас важны все методы привлечения трафика. Одним из основных каналов для других СМИ, это Google News. Но в Google News нет возможности выбрать новости с Казахстана. Черт, там есть даже новости с Эфиопии и Кении!!! А с Казахстана нету!!! У меня бомбит.
*Это все потому что...*
***Google ненавидит Казахстан***
Добавив этот пиксель на свой сайт я заметил что при каждом обновлении страницы, он считал меня как нового пользователя, посмотрев еще раз на ссылку я понял что $RANDOM в amp-pixel каждый раз создавал новый ID для меня и GA считал меня уником.
Первое что мне пришло в голову, это написания цикла который будет выводить кучу amp-pixel.
Для начала я решил создать 100 amp-pixel чтобы не нагружать браузер.
Вот сам цикл
*p.s. я использую laravel, поэтому разметка blade*
```
@for($i=0;$i<100;$i++)
@endfor
```
Я открыл страницу, дождался прогрузки и решил посмотреть на Google Analytics.
И вот что я там увидел…
,
Google Analytics показывал что у меня на сайте 100 активных пользователей и все они читают ту статью.
Я решил попробовать увеличить цикл до 1000 и у меня стало 1000 активных пользователей.

**Google ненавидит Казахстан**Из прошлого спойлера вы знаете что нет выпуска «Казахстан» в Google News, но можно добавить свой сайт в новости, и они будут отображаться в секции [Казахстан](https://news.google.com/news/section?cf=all&pz=1&q=%D0%9A%D0%B0%D0%B7%D0%B0%D1%85%D1%81%D1%82%D0%B0%D0%BD&siidp=12a7e7db35f61f1594dcef1af3d09ffd0056) в Российском выпуске.
В Google Новости для издателей можно добавить особый RSS «Выбор редакции» и он должен отображаться в правой части на главной news.google.ru, я благополучно добавил этот rss фид и стал ждать. Прождав неделю я решил написать в саппорт гугла и там я узнал что «Выбор редакции» не будет отображаться, т.к. СМИ казахстанский, а выпуск Российский (так какого х\*\*, казахстанский СМИ вообще выходит в Российском выпуске???)
*Определенно*
***Google ненавидит Казахстан***
Но показатель отказов был 100%, глубина 1 да и рендеринг amp-pixel сильно грузил процессов.
Поэтому я сначала решил создать обычную версию страницы(Обычный HTML, вместо AMP) и вставить туда сотню изображении с этой ссылкой.
*Как оказалось это работало и в обычном HTML.*Теперь надо было решать проблему глубины и отказов, поэтому за место рандомной генерации ID пользователя я решил создать массив.
```
$users = range(1,2000);
```
Дальше создаем 2 страницы с разными ссылками и названиями, где есть ссылка на другую страницу. Заходим на первую страницу ждем пока загрузятся картинки, и переходим на 2-ую страницу и так с десяток раз.
**Показательная гифка**
В итоге мы имеем приличную глубину, большое кол-во просмотров, низкий показатель отказов и т.д.
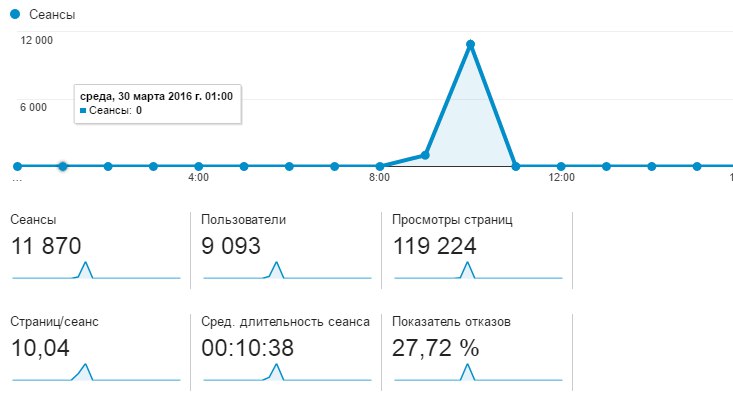
**Думаю что можно накрутить и другие показатели, так что экспериментируете :)**
P.S.
Чуть не забыл, вы можете накрутить статистику кому угодно, главное знать идентификатор отслеживания. | https://habr.com/ru/post/280498/ | null | ru | null |
# Автоответчик на звонки в Skype на Python
Привет! Данный топик будет посвящен написанию автоответчика для Skype, который будет принимать за вас звонки, проигрывать приветствие и записывать ответ.
Дано: Skype: 5.0.0.156, WinXPSP3, ActiveState Python 2.6.2.2.
По идеи, работать должно и под \*nix, но не тестировалось. Для взаимодействия со Skype через его API будем использовать Skype4py. Скачать можно [тут](http://sourceforge.net/projects/skype4py/files/skype4py/1.0.32.0/), а с документацией ознакомиться [здесь](http://skype4py.sourceforge.net/doc/html/).
Используя Skype4py, достаточно просто взаимодействовать со Skype, для нашей задачи необходимо только прописать свои обработчики различных событий. Обрабатывать события мы будем в нашем классе:
```
class AnsweringMachine:
def __init__(self):
self.FilesPath = os.getcwd() + '\\' #путь до нашего рабочего каталога файлов
self.WavFile = self.FilesPath + 'outofoffice.wav' #файл с ответом
self.IncomingCallsDir = self.FilesPath + 'incoming\\' #папка с аудиофайлами
self.time2wait = 30 #время ожидания звонка
self.callsanswered = dict() #словарь в котором мы будем хранить состояние принимаемых звонков.
```
Обработчик *OnCall*, принимает входящие звонки, в том случае, если мы не отвечаем на звонок больше чем time2wait секунд. Заодно выводит дополнительную отладочную информацию. Вызов *call.Answer* взят в *try..except* для минимизации кода, если по честному, то там необходимо обработать различные ситуации, например, завершение вызова звонящим до поднятия трубки и другие. В *WavFile* хранится файл, который мы будем проигрывать всем звонящим:
```
def OnCall(self, call, status):
if status == Skype4Py.clsRinging and call.Type.startswith('INCOMING'):
print 'Incoming call from:', call.PartnerHandle
time.sleep(self.time2wait)
if call.Duration == 0:
try:
call.Answer()
except:
pass
self.callsanswered[call.Id] = 'Answered'
else:
self.callsanswered[call.Id] = 'HumanAnswered'
if status == Skype4Py.clsInProgress and self.callsanswered[call.Id] == 'Answered':
self.callsanswered[call.Id] = 'Playing'
print ' playing ' + self.WavFile
call.InputDevice(Skype4Py.callIoDeviceTypeFile, self.WavFile)
if status in CallIsFinished:
print 'call ',status.lower()
```
В *OnInputStatusChanged* мы будем отлавливать завершение проигрывания нашего файла и начнем запись голоса звонящего. Все записи будут складываться в подпапку с именем, совпадающим с ником пользователя, в папке *IncomingCallsDir*. Вызов *call.InputDevice(Skype4Py.callIoDeviceTypeFile, None)* прекращает воспроизведение нашего файла, в противном случае файл будет проигран несколько раз.
```
def OnInputStatusChanged(self, call, status):
if not status and call.InputDevice().has_key('FILE') and call.InputDevice()['FILE'] == self.WavFile and self.callsanswered[call.Id] == 'Playing':
self.callsanswered[call.Id] = 'Recording'
print ' play finished'
if not os.path.exists(self.IncomingCallsDir + call.PartnerHandle):
os.mkdir(self.IncomingCallsDir + call.PartnerHandle)
OutFile = self.IncomingCallsDir + call.PartnerHandle + '\\' + time.strftime("%Y-%m-%d_%H-%M-%S") + '.wav'
call.InputDevice(Skype4Py.callIoDeviceTypeFile, None)
print ' recording ' + OutFile
call.OutputDevice(Skype4Py.callIoDeviceTypeFile, OutFile)
```
Вот собственно и все. Ниже весь код целиком:
```
#!/usr/bin/python
# -*- coding: cp1251 -*-
import Skype4Py
import sys, time, os
CallIsFinished = set ([Skype4Py.clsFailed, Skype4Py.clsFinished, Skype4Py.clsMissed, Skype4Py.clsRefused, Skype4Py.clsBusy, Skype4Py.clsCancelled]);
class AnsweringMachine:
def __init__(self):
self.FilesPath = os.getcwd() + '\\' #путь до нашего рабочего каталога файлов
self.WavFile = self.FilesPath + 'outofoffice.wav' #файл с ответом
self.IncomingCallsDir = self.FilesPath + 'incoming\\' #папка с аудиофайлами
self.time2wait = 30 #время ожидания звонка
self.callsanswered = dict() #словарь в котором мы будем хранить состояние принимаемых звонков.
if not os.path.exists(self.IncomingCallsDir):
os.mkdir(self.IncomingCallsDir)
def OnCall(self, call, status):
if status == Skype4Py.clsRinging and call.Type.startswith('INCOMING'):
print 'Incoming call from:', call.PartnerHandle
time.sleep(self.time2wait)
if call.Duration == 0:
try:
call.Answer()
except:
pass
self.callsanswered[call.Id] = 'Answered'
else:
self.callsanswered[call.Id] = 'HumanAnswered'
if status == Skype4Py.clsInProgress and self.callsanswered[call.Id] == 'Answered':
self.callsanswered[call.Id] = 'Playing'
print ' playing ' + self.WavFile
call.InputDevice(Skype4Py.callIoDeviceTypeFile, self.WavFile)
if status in CallIsFinished:
print 'call ',status.lower()
def OnInputStatusChanged(self, call, status):
if not status and call.InputDevice().has_key('FILE') and call.InputDevice()['FILE'] == self.WavFile and self.callsanswered[call.Id] == 'Playing':
self.callsanswered[call.Id] = 'Recording'
print ' play finished'
if not os.path.exists(self.IncomingCallsDir + call.PartnerHandle):
os.mkdir(self.IncomingCallsDir + call.PartnerHandle)
OutFile = self.IncomingCallsDir + call.PartnerHandle + '\\' + time.strftime("%Y-%m-%d_%H-%M-%S") + '.wav'
call.InputDevice(Skype4Py.callIoDeviceTypeFile, None)
print ' recording ' + OutFile
call.OutputDevice(Skype4Py.callIoDeviceTypeFile, OutFile)
def OnAttach(status):
global skype
print 'Attachment status: ' + skype.Convert.AttachmentStatusToText(status)
if status == Skype4Py.apiAttachAvailable:
skype.Attach()
def main():
global skype
am = AnsweringMachine()
skype = Skype4Py.Skype()
skype.OnAttachmentStatus = OnAttach
skype.OnCallStatus = am.OnCall
skype.OnCallInputStatusChanged = am.OnInputStatusChanged
if not skype.Client.IsRunning:
print 'Starting Skype..'
skype.Client.Start()
print 'Connecting to Skype process..'
skype.Attach()
print 'Waiting for incoming calls'
try:
while True:
time.sleep(1)
except:
pass
if __name__ == '__main__':
main()
```
**UPD**: исправил два бага в логике, автоответчик включался также при исходящих звонках и включался, в случае если трубка таки была поднята человеком. | https://habr.com/ru/post/111404/ | null | ru | null |
# Mathcha — внебрачный сын Word и Latex

Некоторое время назад у меня возникла потребность писать несложные тексты, которые включали в себя математические рассуждения, формулы и вычисления. С помощью примеров и гайдов из интернета я смог освоить самые основы `TeX` и выполнять поставленные задачи. Но меня не покидала мысль о том, что я стреляю из пушки по воробьям, поэтому я очень обрадовался, когда один знакомый показал мне редактор `Mathcha`, который включал в себя возможности `Word` и `TeX` одновременно. Я считаю, что этот сервис слишком недооценён, и многим он понравится, поэтому я делаю обзор на него.
**Дисклеймер:** данный обзор основан на опыте работы автора с инструментом и не является рекламой сервиса `Mathcha.io`
### С чем же мы имеем дело
`Mathcha.io` — онлайн WYSIWYG (`What You See Is What You Get`) редактор текста, который имеет поддержку встроенных в текст формул, блоков формул, картинок, кода с подсветкой, а также некоторых других фич, про которые речь в этой статье не пойдёт (checkbox, вставка видео с Youtube, создание диаграмм и рисунков).
Работа с программой
-------------------
### Текст
Интерфейс программы напоминает Word, что помогает быстро сориентироваться. Сверху есть разные инструменты форматирования: центровка текста, жирный/подчёркнутый/курсив, ссылки, копирование стиля, списки, шрифт (всего 5 штук), размер и цвет текста. Всё это помогает работать с обычным текстом в один клик (в том числе благодаря общепринятым `ctrl+b` и подобным).

### Математика
Вот ради чего это всё затевалось. Есть 2 способа подключения формул: `inline-math` и `math-container` (первый можно встраивать в строки текста, а второй — только как отдельный блок, что является логичным для математических выкладок).
Лайфхак: можно создать `inline-math` на текущей позиции курсора, напечатав `$`. Я не нашёл в настройках способа отключить это (возможно он есть). Но по умолчанию вместо обычного значка доллара приходится писать `\$ + Enter`, что очень неудобно в финансовых документах. В обычном TeX такая проблема тоже есть, так как `$` обозначает начало формулы.
### Синтаксис из TeX — символы
В блоках формул вы можете использовать символы и конструкции из TeX, но с некоторыми изменениями. Чтобы открыть поиск символов, необходимо напечатать обратный слеш (по аналогии с TeX).
Большинство символов можно найти в выпадающем списке по названию:
Также очень удобная фича, когда не можешь описать символ словами — поиск по рисунку:
А также есть автозамена "программистских" значков на математические, например, `<=` (меньше или равно) заменяется на цельный символ.
### Математические конструкции
Другая важная часть математических формул — конструкции: дроби, корни, кванторы. Всё это есть в Mathcha, в том же списке по обратному слешу. По первым символам названия можно посмотреть варианты конструкций и места, где могут находиться параметры конструкции.

Поиск по рисунку также работает
### Так ли это удобно?
Но именно тут возникает главное упущение разработчиков mathcha, которое сильно затрудняет работу: после каждого специального символа необходимо нажимать `Enter`. Даже если вы полностью напечатали название. Да, предпросмотр дроби хорошо выглядит, а также он очень полезен, когда числитель и знаменатель сложные, но, например, напечатать `\frac{3}{5}` часто быстрее, чем `\frac 3 <стрелочка вниз> 5 <стрелочка вправо>`.
В любом месте документа (в том числе в математических блоках) можно сделать импорт из TeX, но для этого необходимо напечатать `\from-latex` , потом написать формулу как в TeX (в этом окне также есть предпросмотр), а потом мышкой нажать на `OK`. Это может занять ещё больше времени, чем первый вариант.
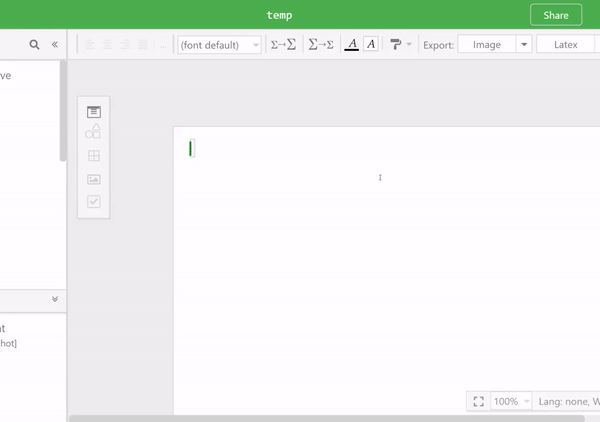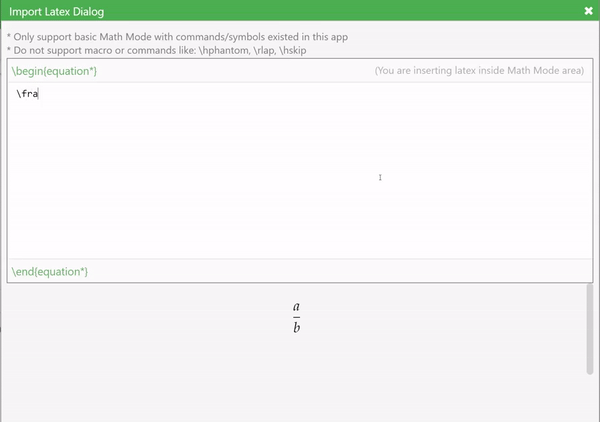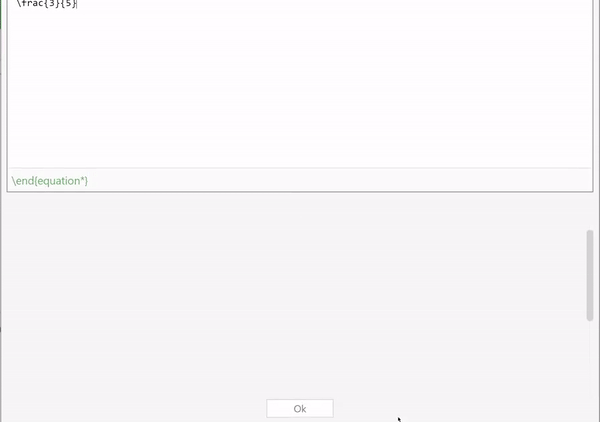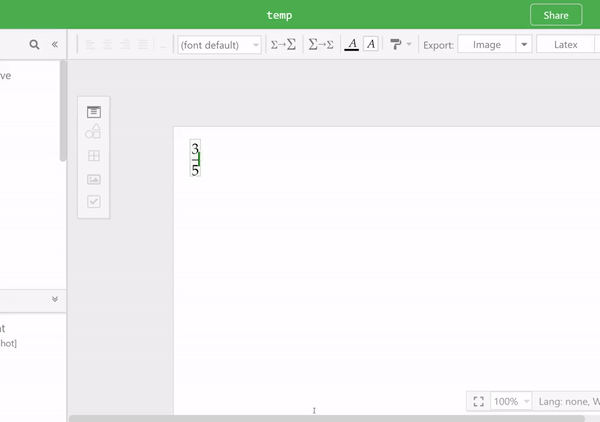
Ещё одна проблема — границы блоков формул никак не отображаются, когда курсор находится не в них. Из-за этого найти пустой блок формулы практически невозможно

### Вставка картинок
Вставить картинку в документ можно из буфера обмена, с устройства или по url. Также 50 мегабайт ваших картинок хранятся в привязке к аккаунту. Можно делать подпись к картинкам или открывать их на полный экран.
### Код
Присутствует поддержка блоков кода с подсветкой и другим оформлением.
Связь с внешним миром
---------------------
### Экспорт в PDF
Единственный способ экспортировать документ в PDF — нажать кнопку "Печать" (`ctrl+P`) и далее выбрать "Печать в PDF" (в зависимости от ОС). Можно выбрать поля и формат страницы, а также колонтитулы.

### Экспорт в TeX
Есть возможность экспорта выделенной области как тело документа TeX, но полная совместимость не гарантируется.
### Поделиться документом
Можно поделиться документом по прямой ссылке на сайт `mathcha.io` в формате `read-only`. Также недавно появилась возможность добавить коллабораторов в документ, но я не пробовал, насколько хорошо работает синхронизация при такой совместной работе.
### Десктопная версия
Существует платная (3$ в месяц) офлайн версия, которая имеет некоторые преимущества по сравнению с онлайн версией. Она имеет поддержку экспорта в формат `.mathcha`, а также снимаются некоторые лимиты. Без лицензии программа находится в режиме `read-only`, то есть вы всё ещё можете экспортировать файл из онлайн редактора в `.mathcha`, а после открыть его на чтение в десктопной версии (онлайн версия открывать `.mathcha` файлы не умеет). Также плюсом офлайн формата является приватность, то есть ваши документы не хранятся где-то в интернете
Выводы
------
Mathcha — самостоятельный инструмент, который использует TeX, а также другие виды контента. Я бы не рекомендовал использовать её людям, которые имеют обширный опыт при работе с обычными TeX документами (так как при большой скорости печати подсказки начинают мешать). Также не стоит рассматривать Mathcha как полную замену TeX-у, так как её возможности сильно ограничены (например, отсутствием внешних пакетов). При работе в ней вы будете "заперты", то есть вынести текущие наработки за пределы редактора не всегда просто. У меня никогда не пропадали документы из хранилища mathcha, но я не могу быть полностью уверен в его надёжности.
Я рекомендую использовать Mathcha как альтернативу редакторам TeX для создания несложных документов. Я пользовался им во многих ситуациях, и ни разу не испытывал больших сложностей.
---
Облачные серверы от [Маклауд](https://macloud.ru/?partner=4189mjxpzx) быстрые и безопасные.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
[](https://macloud.ru/?partner=4189mjxpzx&utm_source=habr&utm_medium=original&utm_campaign=chernyx) | https://habr.com/ru/post/560324/ | null | ru | null |
# Memcached, PHP, Ketama. Если нет, но очень хочется.
Хочется.
Кетаму в PHP, да еще чтобы хоть из чего доступ был.
Это я про не PHP. В смысле про доступ. Ну и из PHP тоже.
Ну ладно, приступим.
Что имеем.
Инет, Google …
… все :(
Аааа, чуть не забыл. Самое главное. Потолок, чтобы было куда тупо уставиться.
Итак гуглим.
В PHP кетама нет. А где есть то.
Гы, на last.fm.
[www.lastfm.ru/user/RJ/journal/2007/04/10/rz\_libketama\_-\_a\_consistent\_hashing\_algo\_for\_memcache\_clients](http://www.lastfm.ru/user/RJ/journal/2007/04/10/rz_libketama_-_a_consistent_hashing_algo_for_memcache_clients)
Вот только после 10 апреля 2007 версию 0.1.1 никто не обновлял, да и набор функционала какой-то куцый. На danga. com вон уже gets’ы, cas’ы и т.п. дребедени полно. Мож оно и можно, да вот только разбираться влом.
Гуглим дальше …
[tangent.org](http://tangent.org/)
Что имеем.
Memcached Functions for MySQL
libmemcached 0.23
**WOW!!!!**
Clients using the library:
Ruby: [github.com/fauna/memcached/tree/master](http://github.com/fauna/memcached/tree/master)
Perl: [code.google.com/p/perl-libmemcached](http://code.google.com/p/perl-libmemcached/)
Python: [code.google.com/p/python-libmemcached](http://code.google.com/p/python-libmemcached/)
PHP: (In Japanese) [labs.gree.jp/Top/OpenSource/libmemcached.html](http://labs.gree.jp/Top/OpenSource/libmemcached.html)
Идем туда где PHP.
КАРАУЛ!!! Шалашики.
Блин и версия 0.1.0. Зато свежая, от 18.09.2008. Короче глюки в ней еще не исправлены, потому что никто их поискать не успел.
… все.
Больше нету ничего.
Ну что, будем пробовать.
Наверное с шалашиков лучше не начинать.
Хоть у меня по буржуйски весь словарный запас это: hi, yes, no, problem, thank и все.
… ну не все конечно, есть еще fuck, но он мне не поможет.
По японски он всяко короче.
Ставлю libmemcached и Memcached Functions for MySQL на сервер БД. На вебсервер libmemcached.
Поднимаю четырех демонов memcached. Одного на вебсервере, трех на сервере БД. Почему? А фиг его знает, так получилось.
Инсталлирую функции.
Хм, список впечатляет
memc\_add
memc\_add\_by\_key
memc\_servers\_set
memc\_server\_count
memc\_set
memc\_set\_by\_key
memc\_cas
memc\_cas\_by\_key
memc\_get
memc\_get\_by\_key
memc\_delete
memc\_delete\_by\_key
memc\_append
memc\_append\_by\_key
memc\_prepend
memc\_prepend\_by\_key
memc\_increment
memc\_decrement
memc\_replace
memc\_replace\_by\_key
memc\_servers\_behavior\_set
memc\_udf\_version
memc\_list\_behaviors
memc\_stats
memc\_stat\_get\_keys
memc\_stat\_get\_value
Не понял. Если есть cas? Где gets? На кой мне сдался cas без gets’а!!!
Ладно, мы им это припомним. Наверное.
Определяем сервера
`SELECT memc_servers_set(‘192.168.0.10:11211, 192.168.0.11:11211, 192.168.0.11:11212, 192.168.0.11:11213);`
Пихаем в кэш десяток ключей
`SELECT memc_set(‘key1’, ‘val1’);
…
SELECT memc_set(‘key10’, ‘val10’);`
Берем их из кэша
`SELECT memc_get(‘key1’);
…
SELECT memc_get(‘key10’);`
Вроде нормально, отдает то, что положили.
Теперь валим одного демона memcached. Как и следовало ожидать – два ключа накрылись. Снова ложим в кэш 10 этих же ключей.
Фиг вам. Те же пропавшие два, так и не объявились. Кетамой и не пахнет. Ну ничего, readme почитать мне не западло.
В Memcached Functions for MySQL ничего умного не нашел. Пойдем на [tangent.org](http://tangent.org/).
Блин, как все запущено.
Ага вот оно про оно кажется
[docs.tangent.org/libmemcached/memcached\_behavior.html](http://docs.tangent.org/libmemcached/memcached_behavior.html)
Согласно translate.ru behavior это поведение.
По дефолту MEMCACHED\_BEHAVIOR\_DISTRIBUTION стоит MEMCACHED\_DISTRIBUTION\_MODULA, а нам надо MEMCACHED\_DISTRIBUTION\_CONSISTENT, и MEMCACHED\_BEHAVIOR\_HASH чтоб было MEMCACHED\_HASH\_KETAMA.
И делает это memcached\_behavior\_set(). В MySQL это надо полагать memc\_servers\_behavior\_set.
Бррр, стоп. А это что такое в доке memcached\_behavior.pod
=item MEMCACHED\_BEHAVIOR\_DISTRIBUTION
Using this you can enable different means of distributing values to servers.
The default method is MEMCACHED\_DISTRIBUTION\_MODULA. You can enable
consistent hashing by setting MEMCACHED\_DISTRIBUTION\_CONSISTENT.
Consistent hashing delivers better distribution and allows servers to be
added to the cluster with minimal cache losses. Currently
MEMCACHED\_DISTRIBUTION\_CONSISTENT is an alias for the value
MEMCACHED\_DISTRIBUTION\_CONSISTENT\_KETAMA.
=item MEMCACHED\_BEHAVIOR\_KETAMA
Sets the default distribution to MEMCACHED\_DISTRIBUTION\_CONSISTENT\_KETAMA
and the hash to MEMCACHED\_HASH\_MD5.
Что-то каша в голове начинается.
Ага, наверное понял, надо сделать MEMCACHED\_BEHAVIOR\_KETAMA …
Как это?
Пошли дальше читать. Похоже тупо надо все подряд. Еще по буржуйски понимать быыыы.
Похоже это оно
For simple on or off options you just need to pass in a value of 1.
Значит надо MEMCACHED\_BEHAVIOR\_KETAMA set 1.
Ну что попробуем.
`SELECT memc_servers_behavior_set (‘MEMCACHED_BEHAVIOR_KETAMA’, 1);`
Мдааа. Кирдык фулльный.
`mysql>SELECT memc_servers_behavior_set('MEMCACHED_BEHAVIOR_KETAMA', 1);
ERROR 2013 (HY000): Lost connection to MySQL server during query
mysql>`
Лечится только рестартом MySQL сервера …
Ну ладно. Напишем разработчикам
[forums.mysql.com/read.php?150](http://forums.mysql.com/read.php?150),231325,231325#msg-231325
Быстро … отписался
[forums.mysql.com/read.php?150](http://forums.mysql.com/read.php?150),231325,231359#msg-231359
А если так
[forums.mysql.com/read.php?150](http://forums.mysql.com/read.php?150),231325,231442#msg-231442
То-то же.
Это похоже надолго.
Придется тупо смотреть в потолок. Может там что есть?
Точно. Есть. Только вот мысли какие-то не умные, а грязные.
Если откуда то берется не то, что мне нужно. Значит где то это туда положили. Нужно всего-то найти это где то и положить туда то, что мне нужно.
Ой блин. Лезть в исходники. А они на сях. А я про С только название знаю. В смысле, что язык так называется.
Ну да ладно. Делать нечего, будем искать знакомые слова.
В MySQL библиотеке наверное не стоит, она так, прокладка. Лезем в саму libmemcached.
Ага вот оно. В memcached.c. строка 29
ptr->distribution= MEMCACHED\_DISTRIBUTION\_MODULA;
целых два знакомых слова.
И конструкция название имеет многообещающее: memcached\_st \*memcached\_create(memcached\_st \*ptr).
Теперь попытаемся понять кто такой memcached\_st.
Наверное понятно. Согласно libmemcached.pod, если translate.ru мне все правильно объяснил, это то самое место, где лежит не то что мне надо.
Сходим еще раз на на [tangent.org](http://tangent.org/). Конфы там нет, но есть майлин глист [lists.tangent.org/mailman/listinfo/libmemcached](http://lists.tangent.org/mailman/listinfo/libmemcached). Там не так много чего. Тупо поищем знакомые слова.
Что то есть.
[lists.tangent.org/pipermail/libmemcached/2008-September/000434.html](http://lists.tangent.org/pipermail/libmemcached/2008-September/000434.html)
Если правильно понял, надо MEMCACHED\_BEHAVIOR\_SERVER\_FAILURE\_LIMIT’у сделать set сколько-нибудь. Там пишут 10, я попробую 3.
[lists.tangent.org/pipermail/libmemcached/2008-August/000429.html](http://lists.tangent.org/pipermail/libmemcached/2008-August/000429.html)
ну и мы так же сделаем.
Итак. Попытаемся подправить исходники. В смысле положить то что надо.
Вместо ptr->distribution= MEMCACHED\_DISTRIBUTION\_MODULA;
Напишем ptr->distribution= MEMCACHED\_DISTRIBUTION\_CONSISTENT\_KETAMA;
Надо же. Мои первые в жизни 0,5 строки на C.
Вместо ptr->retry\_timeout= 0;
Напишем ptr->retry\_timeout= 60;
Ыыыыыыыыы. Вместо чего написать про MEMCACHED\_BEHAVIOR\_SERVER\_FAILURE\_LIMIT?
Опять тупо смотрим в потолок.
А че смотреть то. Искать про SERVER\_FAILURE\_LIMIT в исходниках.
Есть. В memcached\_behavior.c. Стр.166, называется ptr->server\_failure\_limit.
Добавим по аналогии с остальным
ptr->server\_failure\_limit= 3;
Может прокатит. В принципе если что – сервер раком ляжет. Дык так же его и поставим.
Вот что получилось
`memcached_st *memcached_create(memcached_st *ptr)
{
memcached_result_st *result_ptr;
if (ptr == NULL)
{
ptr= (memcached_st *)malloc(sizeof(memcached_st));
if (!ptr)
return NULL; /* MEMCACHED_MEMORY_ALLOCATION_FAILURE */
memset(ptr, 0, sizeof(memcached_st));
ptr->is_allocated= MEMCACHED_ALLOCATED;
}
else
{
memset(ptr, 0, sizeof(memcached_st));
}
result_ptr= memcached_result_create(ptr, &ptr->result);
WATCHPOINT_ASSERT(result_ptr);
ptr->poll_timeout= MEMCACHED_DEFAULT_TIMEOUT;
ptr->connect_timeout= MEMCACHED_DEFAULT_TIMEOUT;
ptr->retry_timeout= 60;
ptr->distribution= MEMCACHED_DISTRIBUTION_CONSISTENT_KETAMA;
ptr->server_failure_limit= 3;
return ptr;
}`
Все. Перекомпилим либу и вперед. Приступаем к онани… ну вы поняли, к итерациям.
Определяем сервера
`SELECT memc_servers_set(‘192.168.0.10:11211, 192.168.0.11:11211, 192.168.0.11:11212, 192.168.0.11:11213);`
Пихаем в кэш десяток ключей
`SELECT memc_set(‘key1’, ‘val1’);
…
SELECT memc_set(‘key10’, ‘val10’);`
Берем их из кэша
`SELECT memc_get(‘key1’);
…
SELECT memc_get(‘key10’);`
Вроде нормально, отдает то, что положили.
Валим одного демона memcached.
Не понял. Какого черта. Почему они ВСЕ живые? Это я про данные которые в кэш положил.
Ладно. Валим второго.
Ну мы так не договаривались. Они ВСЕ живые.
Ну а если третьего.
Блин, все живые.
Ну нас так просто не возьмешь. Против лома нет приема. Валим последнего четвертого демона memcached.
То то же. Живых не осталось.
Начинаем убивать, поднимать, сохранять в, доставать из …
… короче итерациями заниматься.
НЕ МОГУ УБИТЬ!!!
Мда. Работает. Даже больше того.
Ну нет. Нас так просто не возьмешь.
Все УБИЛ!!!
Оставил живой одну ноду. По тихому поднял вторую. Не устраивая никаких обращений к memcached, свалил первую.
Все, не пережила. Знай наших, кого хочешь раком положим.
Уфф. О чем это я.
Вообще то про PHP.
Ну что, пойдем в шалашики [labs.gree.jp/Top/OpenSource/libmemcached.html](http://labs.gree.jp/Top/OpenSource/libmemcached.html)
Так, слава богу хоть исходники не в шалаше
[github.com/kajidai/php-libmemcached/tree/master](http://github.com/kajidai/php-libmemcached/tree/master)
Привинчиваем.
[labs.gree.jp/Top/OpenSource/libmemcached/Document.html](http://labs.gree.jp/Top/OpenSource/libmemcached/Document.html)
Пробуем
`php <br/
$memcached = new Memcached();
$memcached->addserver('192.168.0.10', 11211);
$memcached->addserver('192.168.0.11', 11211);
$memcached->addserver('192.168.0.11', 11212);
$memcached->addserver('192.168.0.11', 11213);
$memcached->set('key1', 'val1');
$ret = $memcached->get('key1');
Echo $ret. “
”;`
Работает сволочь…
Вместе с MySQL работает.
Корректно данные отрабатывают в паре.
Валим, поднимаем, пишем, читаем – все корректно.
Да кстати. На вебсервере подпиленную libmemcached привинтил.
А что по функционалу мы тут имеем?
Не плохо
memcached\_ctor
memcached\_server\_add
memcached\_add
memcached\_add\_by\_key
memcached\_append
memcached\_append\_by\_key
memcached\_behavior\_get
memcached\_behavior\_set
memcached\_cas
memcached\_cas\_by\_key
memcached\_delete
memcached\_delete\_by\_key
memcached\_get
memcached\_get\_by\_key
memcached\_set
memcached\_set\_by\_key
memcached\_increment
memcached\_decrement
memcached\_prepend
memcached\_prepend\_by\_key
memcached\_replace
memcached\_replace\_by\_key
memcached\_server\_list
memcached\_mget
memcached\_fetch
memcached\_server\_list\_append
memcached\_server\_push
gets’а тоже нету.
А как с глюками …
А фиг его знает.
Узнать бы. Ну в самом деле не писать же автору на моем русском английском в Японию. Ответит ведь мне на своем японском английском.
Так и война ведь начнется.
Ладно, полезем в исходники. Я ведь на С уже целых 2,5 строки в сумме в своей жизни написал.
Блин, как то все просто …
Аааа, въехал. Он же просто по zend’у обертку для трансляции вызовов написал. Блин и накосячить то наверное особо здесь негде.
Ну что.
Подведем итоги.
Во первых. Я написал свои первые 2,5 строки на С.
Во вторых. У меня теперь кетама в PHP есть.
В третьих. Хрен этот кэш так просто свалишь.
В четвертых. Похрену из чего, нормальный доступ к данным в memcached, хоть из С, хоть из Perl, хоть из PHP c MySQL. Один ложит, пофигу откуда и кто другой корректно читает.
PS. Снимаю шляпу перед Brian Aker [brian.krow.net](http://brian.krow.net/) | https://habr.com/ru/post/43156/ | null | ru | null |
# Опыт интеграции с КриптоПро DSS поверх ГОСТ TLS
Всем привет! Я Максим, бэкенд-разработчик команды MSB (корпоративная сервисная шина), занимаюсь интеграциями систем для внутренних нужд компании Tele2, и в этом посте хочу поделиться опытом интеграции с “КриптоПро DSS” поверх ГОСТ TLS.
### Введение
В связи с ~~экономией на бумаге~~ ростом цифровизации бизнес-процессов, в частности, с постепенным уходом от традиционных бумажных документов к электронному документообороту, возникла потребность реализовать электронную подпись документов у нас в компании.
В качестве сервера электронной подписи используется комплекс "КриптоПро DSS", имеющий возможность встроить двухфакторное подтверждение операций подписания в мобильное приложение, посредством своего DSS SDK.
Мы встроили данный SDK в наше корпоративное мобильное приложение, о котором писала моя коллега в своей [статье на Хабре](https://habr.com/ru/company/tele2/blog/652013/).
Но мой рассказ связан с опытом решения задачи со стороны бэкенда, и мы рассмотрим эту задачу подробнее.
### Описание проблемы и её решение
В нашей схеме подключение к серверу электронной подписи осуществляется по ГОСТ TLS с аутентификацией клиента по сертификату.
Но не секрет, что стандартные платформы, а именно горячо любимый мной .NET, не поддерживают российские криптошифры по ГОСТу.
В качестве эксперимента пробовал подключить rtengine, но он не завёлся, и, помимо прочего, он не является сертифицированным средством защиты информации. В таких случаях “КриптоПро” советует использовать "[КриптоПро Stunnel](https://www.cryptopro.ru/products/other/stunnel)".
Изначально, stunnel – это open-source приложение, выступающее в роли шлюза, который принимает незашифрованный трафик и пересылает его на целевой сервер поверх TLS. Часто используется, когда клиент сам не поддерживает TLS-шифрование.
А Stunnel от “КриптоПро” – это практически тот же stunnel, но с поддержкой ГОСТ TLS, а значит, он замечательно подходит для решения нашей проблемы.
Представленная выше схема рабочая, если бы не одно но: согласно политикам безопасности в компании, все запросы во внешнюю сеть Интернет могут осуществляться только через корпоративный прокси. Ванильный stunnel из коробки умеет делать запросы через прокси, но “КриптоПро” эту фичу выпилил в своей редакции.
Чтобы обойти это ограничение, в схему было решено добавить еще одно известное Linux-администраторам приложение socat (еще один шлюз, в своем роде), который умеет делать подключения через HTTP-прокси. Важное условие – HTTP-прокси должен разрешать подключения через метод CONNECT.
В итоге схема станет такой:
#### Docker
Для упрощения было решено пренебречь правилом “один контейнер – один процесс” и запускать “КриптоПро Stunnel” и socat в одном контейнере. Данный контейнер поднимается в виде sidecar рядом с основным контейнером микросервиса. Это позволяет нашему микросервису общаться с “КриптоПро DSS” так, как будто бы они общались по http-протоколу, а вопросы шифрования трафика по ГОСТ TLS отдаются на откуп контейнеру с stunnel и socat.
Чтобы подготовить образ контейнера, нужно скачать deb-пакет с “КриптоПро CSP” (именно в составе этого дистрибутива и состоит “КриптоПро Stunnel”). К сожалению, скачать пакет нельзя по прямой ссылке, которую можно было бы прописать в Dockerfile (иначе бы статья получилась в два раза короче). Для скачивания нужно пройти регистрацию на сайте “КриптоПро”, и только потом будет дана возможность скачать пакет.
Ниже приведен пример Dockerfile, скриптов инициализации и конфига для “КриптоПро Stunnel”.
Рабочий пример можно также посмотреть [здесь](https://github.com/maxineal/gost-stunnel).
Dockerfile
```
FROM debian:buster-slim
EXPOSE 80/tcp
ARG TZ=Europe/Moscow
ENV PATH="/opt/cprocsp/bin/amd64:/opt/cprocsp/sbin/amd64:${PATH}"
# stunnel settings
ENV STUNNEL_HOST="example.cryptopro.ru:4430"
ENV STUNNEL_HTTP_PROXY=
ENV STUNNEL_HTTP_PROXY_PORT=80
ENV STUNNEL_HTTP_PROXY_CREDENTIALS=
ENV STUNNEL_DEBUG_LEVEL=5
ENV STUNNEL_CERTIFICATE_PFX_FILE=/etc/stunnel/certificate.pfx
ENV STUNNEL_CERTIFICATE_PIN_CODE=
# dependencies
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime \
&& echo $TZ > /etc/timezone \
&& apt-get update \
&& apt-get -y install lsb-base curl socat \
&& rm -rf /var/lib/apt/lists/*
# install cryptopro csp
WORKDIR /dist
COPY dist/csp_deb.tgz csp_deb.tgz
RUN tar -zxvf csp_deb.tgz --strip-components=1 \
&& ./install.sh cprocsp-stunnel
WORKDIR /
COPY conf/ /etc/stunnel
COPY bin/docker-entrypoint.sh docker-entrypoint.sh
COPY bin/stunnel-socat.sh stunnel-socat.sh
RUN chmod +x /docker-entrypoint.sh /stunnel-socat.sh
ENTRYPOINT ["/docker-entrypoint.sh"]
CMD ["stunnel_thread", "/etc/stunnel/stunnel.conf"]
```
docker-entrypoint.sh
```
#!/bin/bash
# скрипт инициализации
# ---------------------------------
# настройка csp
echo "Configuring CryptoPro CSP..."
# импорт сертификата с закрытым ключом
if [[ ! -f "$STUNNEL_CERTIFICATE_PFX_FILE" ]]; then
echo "Client certificate not found in ${STUNNEL_CERTIFICATE_PFX_FILE}"
exit 1
fi
certmgr -install -pfx -file "${STUNNEL_CERTIFICATE_PFX_FILE}" -pin "${STUNNEL_CERTIFICATE_PIN_CODE}" -silent || exit 1
echo "Certificate was imported."
echo
# определение контейнера-хранилища закрытых ключей
containerName=$(csptest -keys -enum -verifyc -fqcn -un | grep 'HDIMAGE' | awk -F'|' '{print $2}' | head -1)
if [[ -z "$containerName" ]]; then
echo "Keys container not found"
exit 1
fi
# установка сертификата клиента
certmgr -inst -cont "${containerName}" -silent || exit 1
# экспорт сертификата для stunnel
exportResult=$(certmgr -export -dest /etc/stunnel/client.crt -container "${containerName}")
if [[ ! -f "/etc/stunnel/client.crt" ]]; then
echo "Error on export client certificate"
echo "$result"
exit 1
fi
echo "CSP configured."
echo
# ---------------------------------
# запуск socat
echo "Starting socat..."
nohup bash /stunnel-socat.sh &1 2>&1 &
# ---------------------------------
# запуск stunnel
echo "Configuring stunnel..."
sed -i "s/^debug=.*$/debug=$STUNNEL_DEBUG_LEVEL/g" /etc/stunnel/stunnel.conf
echo "Starting stunnel"
exec "$@"
```
stunnel-socat.sh
```
#!/bin/bash
echo Configuring socat...
socatParameters="TCP:${STUNNEL_HOST}"
if [[ -n "$STUNNEL_HTTP_PROXY" ]]; then
# если указан http-прокси, подключение будет происходить через него
socatParameters="PROXY:${STUNNEL_HTTP_PROXY}:${STUNNEL_HOST},proxyport=${STUNNEL_HTTP_PROXY_PORT}"
if [[ -n "$STUNNEL_HTTP_PROXY_CREDENTIALS" ]]; then
socatParameters="${socatParameters},proxyauth=${STUNNEL_HTTP_PROXY_CREDENTIALS}"
fi
fi
socatCmd="socat UNIX-LISTEN:/var/run/socat.sock,reuseaddr,fork ${socatParameters}"
while true; do
rm -f /var/run/socat.sock
echo $(date) "Start socat instance."
${socatCmd}
sleep 1
done
```
stunnel.conf
```
foreground=yes
pid=/var/opt/cprocsp/tmp/stunnel_cli.pid
output=/dev/stdout
debug=5
[https]
client=yes
accept=80
cert=/etc/stunnel/client.crt
verify=0
connect=/var/run/socat.sock
```
Про Dockerfile рассказывать не буду, он достаточно тривиален, а вот скрипт инициализации docker-entrypoint.sh интереснее. Первым делом скрипт импортирует сертификат с закрытым ключом в хранилище ключей, так как “КриптоПро Stunnel” для работы необходим закрытый ключ. Затем из хранилища экспортируется сертификат с открытым ключом в формате DER. В дальнейшем по этому сертификату “КриптоПро Stunnel” будет получать закрытый ключ из хранилища ключей.
После инициализации хранилища ключей происходит настройка и запуск socat. Для конфигурирования socat добавлены переменные окружения, которые позволяют указать, через какой HTTP-прокси необходимо выполнять запросы. Не буду останавливаться на этих переменных – их описание есть в [репозитории](https://github.com/maxineal/gost-stunnel). Однако не лишним будет уточнить, что, если переменные не указаны, socat будет самостоятельно выполнять TCP-запросы до целевого сервера. Для получения входящих запросов socat открывает unix-сокет, на который и будет обращаться “КриптоПро Stunnel”.
Финальным шагом в скрипте являются конфигурирование Stunnel и его последующий запуск.
“КриптоПро Stunnel” при запуске начинает прослушивать порт 80, то есть принимать голый HTTP-трафик. HTTP-трафик будет шифроваться по ГОСТу и пересылаться на unix-сокет, который слушает socat. Socat, в свою очередь, откроет соединение с целевым сервером, напрямую или через HTTP-прокси, и отправит уже шифрованный запрос.
Шифрованный ответ от целевого сервера пройдет ту же цепочку, только обратном порядке, и вызывающему приложению будет возвращен ответ в виде plain text, что позволит не реализовывать ГОСТ TLS внутри приложений (если такая реализация вообще возможна).
### Вместо заключения
К сожалению, документация по отечественным решениям зачастую достаточно скромна. К примеру, на попытки заставить работать “КриптоПро Stunnel” через HTTP-прокси ушло много времени, пока не пришло понимание, что “КриптоПро Stunnel” прокси не поддерживает и что без еще одного инструмента не обойтись.
Данная статья призвана помочь сберечь ваше время, надеюсь, описанное окажется полезным.
БонусВ качестве бонуса хотелось бы поделиться несколькими советами:
* При выполнении запроса через Stunnel всегда добавляйте HTTP-заголовок “*Host: example.service.ru*” с указанием целевого сервера. Если заголовок не будет указан, сервер может возвращать код 404, т. к. неясно, к какому домену относится запрос.
* Об этом часто забывают, но нужно помнить, что URL чувствителен к регистру. Например, <https://example.service.ru/url1> не равен <https://example.service.ru/URL1>, и результат запроса будет зависеть от реализации веб-сервера, в частности “КриптоПро DSS” требователен к регистру.
### Список ресурсов
* [stunnel TLS Proxy](https://www.stunnel.org/static/stunnel.html)
* [Шифрование TLS-трафика по алгоритмам ГОСТ-2012 c Stunnel](https://habr.com/ru/company/aktiv-company/blog/477650/)
* [КриптоПро. Форум](https://www.cryptopro.ru/forum)
* man socat | https://habr.com/ru/post/674536/ | null | ru | null |
# Re: «Сравнение JS-фреймворков: React, Vue и Hyperapp»
Это небольшая ответная статья на публикацию [«Сравнение JS-фреймворков: React, Vue и Hyperapp»](https://habr.com/company/ruvds/blog/417483/). Вообще я не большой фанат подобных сравнений. Однако раз уж речь зашла о таком маргинальном фреймворке, как Hyperapp, в сравнении с мастодонтами, типа React и Vue, я подумал, почему бы не рассмотреть все те же примеры на [**Svelte**](https://svelte.technology/). Так сказать, для полноты картины. Тем более, это займет буквально 5 минут. Поехали!

Если вдруг вы не знакомы со **Svelte** и концепцией исчезающих фреймворков, можете ознакомиться со статьями [«Магически исчезающий JS фреймворк»](https://habr.com/post/345028/) и [«Исчезающие фреймворки»](https://habr.com/post/414869/).
Для удобства читателей, я скопировал примеры из [оригинальной статьи](https://habr.com/company/ruvds/blog/417483/) под спойлеры, чтобы было удобнее сравнивать. Что ж приступим.
Пример №1: приложение-счётчик
-----------------------------
**React**
```
import React from "react";
import ReactDOM from "react-dom";
class Counter extends React.Component {
constructor(props) {
super(props);
this.state = { count: 0};
}
down(value) {
this.setState(state => ({ count: state.count - value }));
}
up(value) {
this.setState(state => ({ count: state.count + value }));
}
render() {
return (
{this.state.count}
==================
this.down(1)}>-
this.up(1)}>+
);
}
}
ReactDOM.render(, document.querySelector("#app"));
```
**Vue**
```
import Vue from "vue";
new Vue({
data: { count: 0 },
methods: {
down: function(value) {
this.count -= value;
},
up: function(value) {
this.count += value;
}
},
render: function(h) {
return(
{this.count}
============
this.down(1)}>-
this.up(1)}>+
);
},
el: "#app"
});
```
**Hyperapp**
```
import { h, app } from "hyperapp";
const state = {
count: 0
};
const actions = {
down: value => state => ({ count: state.count - value}),
up: value => state => ({ count: state.count + value})
};
const view = (state, actions) => (
{state.count}
=============
actions.down(1)}>-
actions.up(1)}>+
);
app(state, actions, view, document.querySelector("#app"));
```
### ▍Svelte
```
{count}
=======
-
+
```
→ [Рабочий пример.](https://svelte.technology/repl?version=2.9.5&gist=ec1aba65fa4a7224609105d2ae64ed35)
### ▍Анализ
Компонент **Svelte** — это html-файл, который имеет небезызвестный формат Single File Component (SFC), в том или ином виде, уже применяющийся в [Vue](https://vuejs.org/v2/guide/single-file-components.html), [Ractive](https://github.com/ractivejs/component-spec), [Riot](https://riot.js.org/guide/#example) и некоторых других фреймворках. Кроме самого html-шаблона, компонент может иметь поведение и логику, описанную на javascript, а также scoped-стили компонента.
Ни одна часть компонента не является обязательной, поэтому компонент счетчика может состоять лишь из html-шаблона самого счетчика. Для изменения значения переменной **count**, обработчик кликов использует встроенный метод компонента **set()**, описанный в [документации](https://svelte.technology/guide#component-set-state-).
Пример №2: работа с асинхронным кодом
-------------------------------------
**React**
```
import React from "react";
import ReactDOM from "react-dom";
class PostViewer extends React.Component {
constructor(props) {
super(props);
this.state = { posts: [] };
}
getData() {
fetch(`https://jsonplaceholder.typicode.com/posts`)
.then(response => response.json())
.then(json => {
this.setState(state => ({ posts: json}));
});
}
render() {
return (
this.getData()}>Get posts
{this.state.posts.map(post => (
{post.title}
------------
{post.body}
))}
);
}
}
ReactDOM.render(, document.querySelector("#app"));
```
**Vue**
```
import Vue from "vue";
new Vue({
data: { posts: [] },
methods: {
getData: function(value) {
fetch(`https://jsonplaceholder.typicode.com/posts`)
.then(response => response.json())
.then(json => {
this.posts = json;
});
}
},
render: function(h) {
return (
this.getData()}>Get posts
{this.posts.map(post => (
{post.title}
------------
{post.body}
))}
);
},
el: "#app"
});
```
**Hyperapp**
```
import { h, app } from "hyperapp";
const state = {
posts: []
};
const actions = {
getData: () => (state, actions) => {
fetch(`https://jsonplaceholder.typicode.com/posts`)
.then(response => response.json())
.then(json => {
actions.getDataComplete(json);
});
},
getDataComplete: data => state => ({ posts: data })
};
const view = (state, actions) => (
actions.getData()}>Get posts
{state.posts.map(post => (
{post.title}
------------
{post.body}
))}
);
app(state, actions, view, document.querySelector("#app"));
```
### ▍Svelte
```
Get posts
{#each posts as {title, body}}
{title}
-------
{body}
{/each}
export default {
methods: {
getData() {
fetch('https://jsonplaceholder.typicode.com/posts')
.then(res => res.json())
.then(posts => this.set({ posts }));
}
}
};
```
→ [Рабочий пример.](https://svelte.technology/repl?version=2.9.5&gist=9ea9520f95407054380c353da6a70730)
### ▍Анализ
В отличие от JSX, который, как под копирку, применяется во всех 3-х фреймворках из оригинального сравнения, и по сути расширяет javascript код html-подобным синтаксисом, **Svelte** использует более привычные возможности — внедрение js и css кода в html с помощью тегов | https://habr.com/ru/post/417747/ | null | ru | null |
# Различные методы брутфорс атак WordPress

В этой статье вы узнаете о том, как взламывать учетные данные сайтов на WordPress с помощью различных брутфорс атак.
Содержание:
* Предварительные требования
* WPscan
* Metasploit
* Люкс Burp
* Как обезопасить сайт от брутфорса?
### Предварительные требования
* Сайт на WordPress. Здесь мы будем использовать собственную [лабораторию для пентеста](https://habr.com/ru/company/alexhost/blog/527968/), о созданию которой был посвящен наш предыдущий пост.
* Kali Linux (WPscan). Более подробно о [WPScan](https://habr.com/ru/company/alexhost/blog/527612/) и его возможностях мы уже писали, а вместо Kali Linux можно использовать любую другую из [ОС для белого хакинга](https://habr.com/ru/company/alexhost/blog/525102/).
* Burp Suite (Intruder). Более подробно о данном инструменте можно узнать [здесь](https://habr.com/ru/post/328382/).
### WPscan
WPscan – это фреймворк, который используется в качестве сканера уязвимостей методом «черного ящика». WPscan предустановлен в большинстве дистрибутивов Linux, ориентированных на безопасность, а также доступен в виде подключаемого модуля.
Здесь мы будем использовать WordPress, размещенный на локальном хосте.
Во время перебора можно использовать:
* Собственные общие списки логинов и паролей
* Базы логинов и паролей, которые уже есть в Kali Linux
В данном случая был использован файл паролей [rockyou.txt](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwjawZmLnontAhXGmIsKHb-FDKsQFjAAegQIAhAC&url=https%3A%2F%2Fgithub.com%2Fbrannondorsey%2Fnaive-hashcat%2Freleases%2Fdownload%2Fdata%2Frockyou.txt&usg=AOvVaw3snAERl1mU6Ccr4WFEazBd), который предоставляется со стандартной Kali Linux и содержит 14 341 564 уникальных пароля.
```
wpscan --url http://192.168.1.100/wordpress/ -U users.txt -P /usr/share/wordlists/rockyou.txt
```
* –URL — это параметр URL-адреса, за которым следует URL-адрес веб-сайта WordPress для сканирования.
* -U будет перебирать только указанные имена пользователей, в нашем случае это users.txt
* -P перебор паролей из предоставленного списка rockyou.txt
Продолжительность сканирования во многом зависит от размера файла имен и паролей. В нашем случае мы сопоставляем большое количество имен с еще большим количеством паролей, что может сказаться на производительности сайта.
Атака прошла успешно и на экране видим совпадение логина admin и пароля flower.

### Metasploit
Metasploit также идет предустановленным в Kali Linux. Первым делом нужно попасть в консоль Metasploit, а затем запустить модуль WordPress. Этот модуль msf будет запускать проверку логинов и паролей. Сначала будут проверены имена пользователей, а затем с ними будут сопоставлены пароли.
```
msf > use auxiliary/scanner/http/wordpress_login_enum
msf auxiliary(wordpress_login_enum) > set rhosts 192.168.1.100
msf auxiliary(wordpress_login_enum) > set targeturi /wordpress
msf auxiliary(wordpress_login_enum) > set user_file user.txt
msf auxiliary(wordpress_login_enum) > set pass_file pass.txt
msf auxiliary(wordpress_login_enum) > exploit
```
Как и в предыдущем случае атака прошла успешно, в результате которой были полчены:
* Логин: admin
* Пароль: flower
### Burp Suite
Можно опять использовать предустановленную в Kali версию или скачать [Burp Suite Community Edition](https://portswigger.net/burp/communitydownload). Далее запускаем Burp Suite и открываем страницу входа в WordPress. Затем включаем вкладку перехвата в Burp Proxy. Далее вводим любое имя пользователя и пароль по вашему выбору для входа на сайт WordPress. Это перехватит ответ текущего запроса.
Посмотрите на изображение ниже и обратите внимание на последнюю строку перехваченного сообщения, где указаны учетные данные для входа как **raj: raj**, которые были использованы для входа в систему. Теперь нужно отправить эти данные в Intruder, что можно сделать с помощью сочетания клавиш **ctrl + I** или выбрав опцию Send to Intrude в контекстном меню.
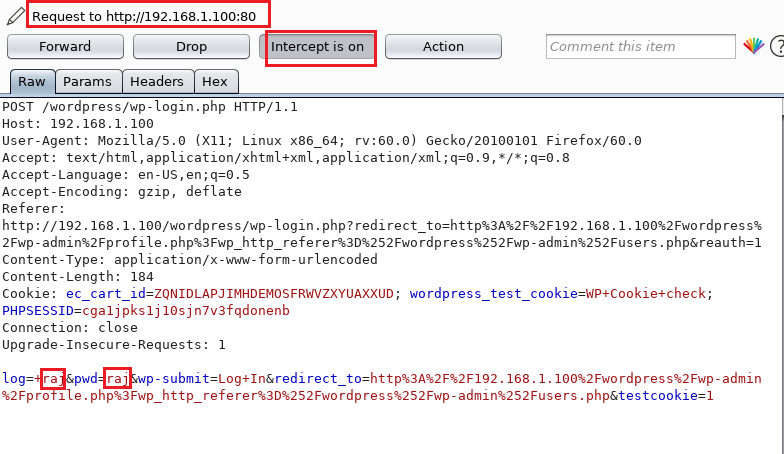
Теперь открываем вкладку **Intruder** и видим запрос базового шаблона, который был сюда отправлен. Выбираем Positions, где по умолчанию активно несколько позиций, которые помечены символами §. Все, что находится между двумя символами §, заменяется полезной нагрузкой. Но сейчас все они нам не нужны, поэтому нажмите кнопку очистки в правом нижнем углу окна редактора.
Выбираем позиции, как показано на скриншоте, а также нажимаем кнопку **add** справа. Это настроит выбранные позиции как точки вставки полезной нагрузки. Теперь выбираем тип атаки.
Поскольку у нас есть 2 позиции полезной нагрузки, то выберем **cluster bomb**. Этот метод брутфорса очень эффективен в нашем случае. Он помещает первую полезную нагрузку в первую позицию, а вторую полезную нагрузку во вторую позицию. Но когда он проходит через наборы полезных данных, то пробует все комбинации. Например, когда есть 1000 логинов и 1000 паролей, тогда будет выполнено 1 000 000 запросов.
Теперь нажимаем кнопку **start attack**.
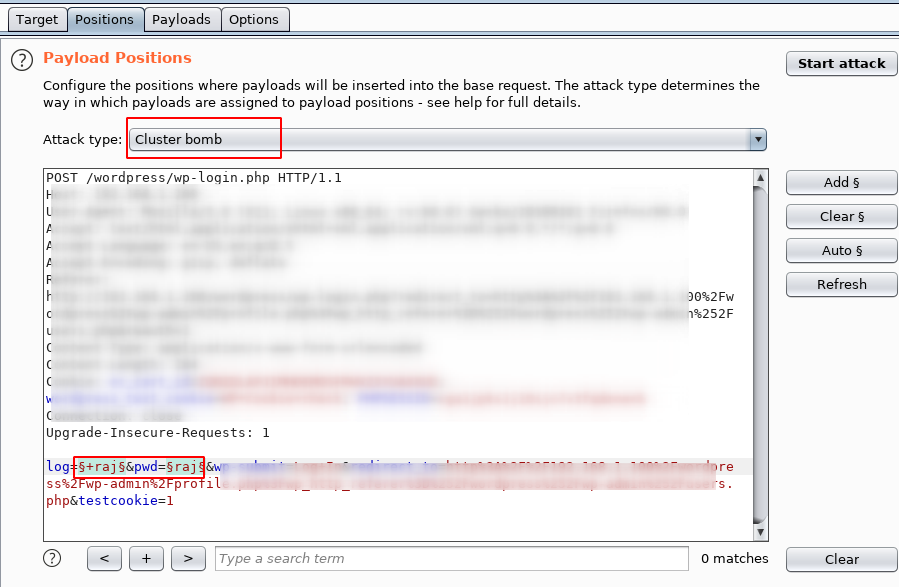
На вкладке **payloads** в раскрывающемся списке можно увидеть числа 1 и 2. Выберите 1 для первой позиции полезной нагрузки и установите для него простой список. В простой список можно вручную добавлять элементы с помощью кнопки **add** , а также вставлять список с помощью буфера обмена или загрузки из файла.
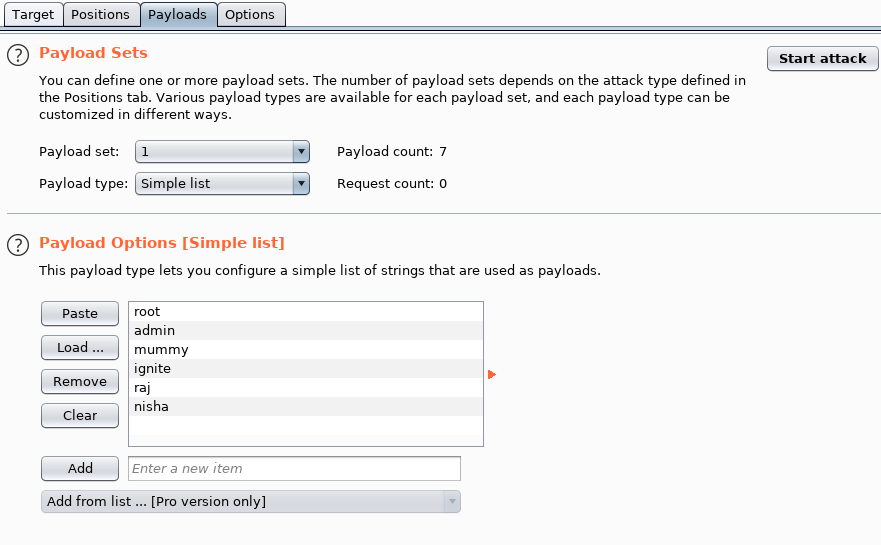
Аналогично ставим цифру 2 для другой позиции и выбираем для нее **Runtime file**, что полезно при работе с большими списками. Указываем путь к любому файлу-словарю, который содержит только список паролей. Нажимаем **start attack**.
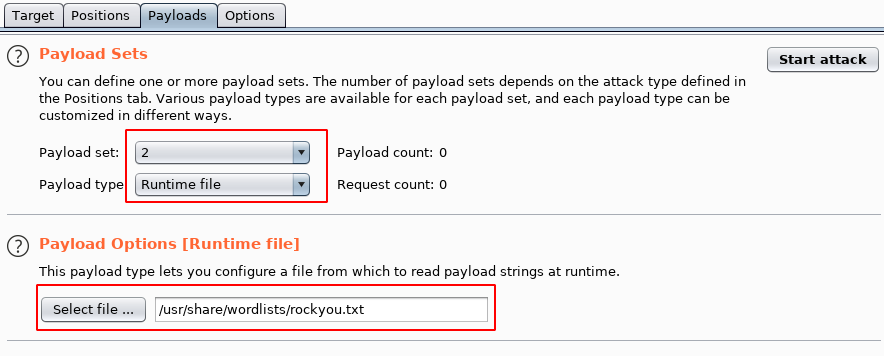
Обратив внимание на статус и длину полезных данных, где видно, что учетные данные **admin** и **flower** имеют статус 302 и длину 1203, что отличается от всех других комбинаций. Это значит, что логин: admin и пароль flower – именно то, что мы хотели получить.
### Как избежать брутфорса?
Конечно, этих атак можно избежать, используя следующие меры предосторожности:
#### Длина пароля
Оптимальная длина пароля должна составлять 8-16 символов. Важно избегать использования наиболее распространенных паролей и часто их менять.
#### Сложность пароля
Надежный пароль должен состоять из:
* Символов верхнего регистра (A)
* Символов нижнего регистра (a)
* Цифр
* Специальных символов
Надежный пароль не гарантирует 100%, но по крайней мере позволяет значительно увеличить время взлома.
#### Ограничение попыток входа в систему
Ограничение попыток входа позволяет сильно усложнить процесс брутфорса.
Например, после трех неудачных попыток входа в систему данный IP-адрес должен быть заблокирован на какое-то время, чтобы пресечь дальнейшие попытки входа в систему.
#### Двухфакторная аутентификация
Следующий способ защиты от брутфорса – двухфакторная аутентификация или 2FA. Обычно в качестве второго подтверждения используют телефон или почту.
#### Captcha
Установить капчу на WordPress довольно просто, например, с помощью многочисленных плагинов. Капча поможет предотвратить ботами выполнение автоматических скриптов для входа в вашу учетную запись.
#### Плагин брандмауэра WordPress
Даже неудачные брутфорс атаки могут замедлить работу сайта или полностью вывести сервер из строя. Вот почему так важно их заблокировать, для чего и понадобиться брандмауэр, который отфильтровывает плохой трафик и блокирует ему доступ к вашему сайту.
#### Подключить СDN сервис
CDN (Content Delivery Network) — сеть доставки и дистрибуции контента, более подробно о которой можно узнать [здесь](https://habr.com/ru/company/selectel/blog/463915/). Для нас главное, что CDN обеспечивают надежную защиту от брутфорса.
Топ [6 CDN c бесплатными решениями для WordPress](https://habr.com/ru/company/hosting-cafe/blog/317054/):
* Cloudflare
* Jetpack
* Swarmify
* Amazon CloudFront (1 год бесплатного доступа)
* Incapsula
* JS Deliver
#### Установить и настроить бэкап плагин
На крайний случай будет полезно установить и настроить бэкап плагин. По крайней мере в случае удачной атаки будет возможность восстановить данные. Есть несколько отличных плагинов для WordPress, которые позволяют делать резервные копии автоматически.
#### Отключение просмотра каталогов и автоматических обновлений
Еще один способ снизить риск брутфорс атаки для сайта на WordPress. | https://habr.com/ru/post/528494/ | null | ru | null |
# Разделение Subversion репозитория на части
Когда я узнал в первые про систему контроля версий, я решил, что обязательно надо попробовать этот инструмент для разработки. В то время я себе мало представлял что это такое. Поэтому просмотрев доступные предложения выбрал Subversion.
Почитав немного мануалы решил создать свой первый репозиторий. И вдруг я на минуту задумался, а как организовать структуру, если у меня будет несколько проектов… и для себя решил, что создам дерево, которое разделяется на проекты, а в каждом проекте будут всем до боли знакомые trunk, tags, branches. Шло время кол-во проектов увеличивалось (правда не особо много, но все же) и как-то грустно стало наблюдать сквозную нумерацию ревизий в проекте. Т.е. смотришь логи проекта, а там сначала 649 ревизия, а потом 700. Все таки программисты народ чистолюбивый, любит когда все разложено по полочкам, поэтому было решено разделить один большой репозиторий на несколько более мелких.
Итак, краткая инструкция, чтобы все было по «фен-шую»
Немного исходных данных:
* Физическое расположение репозитория:
`/home/user/svn/reps/projects`
* Доступ к репозиторию настроен через apache и имеет адрес
```
http://svn.mysite.ru
```
Раньше использовалась переменная SVNPath, указывающая на `/home/user/svn/reps/projects`, но т.к. мы собираемся разделить проекты, то настроим доступ с помощью переменной
SVNParentPath "/home/user/svn/reps"
* Структура репозитория, который будем разделять:
```
http://svn.mysite.ru
|
|-Modules
|
|-Projects
|
|-Project1
|
|-Project2
```
Инструкция:
1. Надо сделать dump нашего репозитория. Для этого выполним команду:
`svnadmin dump /home/user/svn/reps/projects > myrep.dump`
2. Теперь оставим только один проект
`cat myrep.dump | svndumpfilter include Projects/Project1 --drop-empty-revs --renumber-revs > project1.dump`
--drop-empty-revs — удалить пустые ревизии
--renumber-revs — перенумеровать ревизии
Надо указывать полный путь до проекта, т.е. не просто наименование проекта «Project1», а именно «Projects/Project1». Иначе на выходе получите пустой dump файл.
Вообще предыдущие две команды можно объединить
`svnadmin dump /home/user/svn/reps/projects | svndumpfilter include Projects/Project1 --drop-empty-revs --renumber-revs > project1.dump`
3. Создадим новый репозиторий для проекта в папке «reps»
`svnadmin create project1`
4. Загрузим очищенный дамп в новый репозиторий
`svnadmin load project1 < project1.dump`
На этом шаге возникает ошибка
`svnadmin: File not found transaction '0-0', path Projects/Project1`, т.е это значит что папки Projects не существует. Видимо при восстановлении, структура не воссоздается.
Чтобы это исправить, надо вручную создать папку «Projects»:
```
svn mkdir http://svn.mysite.ru/project1/Projects -m "Создание папки Projects"
```
А теперь уже можем спокойно выполнить:
`svnadmin load project1 < project1.dump`
5. Т.к. получилась структура нового репозитория, повторяющая старую структуру, то необходимо будет перенести все из папки «Project1» в корень репозитория, а потом удалить папку «Projects»
Хотелось бы здесь написать «Всё» и поставить точку. Но все же, среди этих 4 пунктов, есть ложка дегтя.
Если втечении работы над проектом, Вы его переименовали, то на 2-ом шаге возникнет ошибка `Invalid copy source path 'старое название проекта'`.
Штатная программа `svndumpfilter` не может решить эту проблему.
После некоторого поиска, я нашел скрипт, написанный на python [svndumpfilter2](http://svn.tartarus.org/sgt/svn-tools/svndumpfilter2), позволяющий обойти это ограничение.
Скачиваем скрипт себе на компьютер и вводим команду
`cat myrep.dump | svndumpfilter2 --drop-empty-revs --renumber-revs /home/user/svn/reps/projects Projects/Project1 > project1.dump`
Есть некоторые отличия от svndumpfilter.
* Необходимо указать путь до физического расположения репозитория, т.е /home/user/svn/reps/projects
* Поддерживается только ключ include. (его не надо указывать)
Ну вот теперь… ВСЁ.
Примечание: Когда я начинал писать эту статью (а это было неделю назад), то поискав на Хабре не нашел ничего аналогичного. Но т.к. моя публикация немного отложилась, то за это время появилась похожая статья [Восстановление SVN репозитория](http://mrpsycho.habrahabr.ru/blog/74044/), но т.к. мне кажется, что некоторые проблемы там не освещены, я все решил опубликовать свою статью. | https://habr.com/ru/post/73788/ | null | ru | null |
# Способы представления аудио в ML
*В статье рассмотрены основные формы представления аудио для дальнейшего использования в различных сферах обработки данных.*
Мейнстримом последних лет в сфере DS/ML является NLP, в особенности, перспективы использования нейронных сетей, построенных на архитектуре трансформеров. Они используются в том числе в системах голосовых помощников, а голосовые помощники прочно входят в нашу жизнь. Тем не менее, важной составляющей успеха голосовых помощников является то, что они «голосовые», то есть, обращение к ним осуществляется посредством голоса, что значит - аудио. Часто работа с аудиосигналом производится посредством анализа как звука, так и изображения спектрограммы, но в данной статье будут рассмотрены способы представления именно аудио как совокупности различных признаков. Для работы используются библиотеки Python librosa и matplotlib. В качестве основного исходного аудиофайла будет использоваться мелодия открытия обычного сундука из игры The Legend of Zelda: Breath of the Wild в формате wav длительностью ~1 секунда. Информация, представленная в статье, может быть применена в областях speech-to-text, классификации звуков и других направлениях анализа аудио.
Импорт библиотек и загрузка файла:
```
import librosa
import librosa.display
import matplotlib.pyplot as plt
y, sr = librosa.load(file)
```
В данном случае, «y» будет массивом чисел, содержащим в себе сам аудиофайл в числовом виде, а «sr» - sample rate, то есть, частотой дискретизации аудио.
Имея эти данные уже можно представить аудио как временной ряд, где по оси Y будет амплитуда сигнала. Следует отметить, что, по умолчанию, librosa.load() считывает файл в моно-режиме. Далее представлен код для отрисовки необходимых представлений:
```
fig, ax = plt.subplots(nrows=1, sharex=True, sharey=True)
librosa.display.waveplot(y, sr=sr, ax=ax)
ax.set(title='Monophonic')
ax.label_outer()
plt.show()
```
Рисунок 1 – аудиосигнал как амплитуда ко времениНа рисунке 1 можно заметить «бугорки». Если прослушать исходный файл, то станет очевидно, что количество «бугорков» соответствует количеству нот в мелодии (семь), хотя вторая нота «смазанная», что заметно на графике. При этом, акцентированные ноты, а именно: первая, третья и седьмая, звучат резче, громче и это отражено на графике большей амплитудой сигнала.
Теперь же можно посмотреть на более интересное представление аудио. Далее приведён его код:
```
S = np.abs(librosa.stft(y))
fig, ax = plt.subplots()
img = librosa.display.specshow(librosa.amplitude_to_db(S,
ref=np.max),
y_axis='log', x_axis='time', ax=ax)
ax.set_title('Power spectrogram')
fig.colorbar(img, ax=ax, format="%+2.0f dB")
plt.show()
```
Рисунок 2 – спектрограмма исходного аудиофайлаНемного теории для понимания того, что показывает изображенная на рисунке 2 спектрограмма.
Преобразование Фурье разлагает функцию времени (сигнал) на составляющие частоты. Точно так же, как музыкальный аккорд может быть выражен громкостью и частотами составляющих его нот, преобразование Фурье, применённое к функции, отображает амплитуду каждой частоты, присутствующей в базовой функции (сигнале). Именно это мы и видим на рисунке 2. На нём три шкалы – время к частоте, что интуитивно понятно, и дополнительная шкала децибел, показывающая плотность, мощность сигнала на определённой частоте в определённый промежуток времени. Существует альтернативное трёхмерное представление, которое может помочь понять спектрограммы. Оно представлено на рисунке 3:
Рисунок 3 – трёхмерное представление части некоторого музыкального произведенияТак, если сложить все «срезы» трёхмерного представления и «насыщенность» областей отразить цветом, то получится цветное двухмерное представление как на рисунке 2.
Подытожим вышенаписанное: спектрограмма, полученная применением преобразования Фурье к аудиосигналу позволяет «увидеть» как насыщены определённые частоты в аудиосигнале.
Наиболее наглядным, по мнению автора, является сравнение спектрограмм записи классической музыки с лёгким звучанием и какого-нибудь «тяжёлого» жанра с большой плотностью и насыщенностью звука. Пусть, в данном случае, это будут «Чайковский – Танец феи драже» (рисунок 4) и «Megadeth – Symphony of Destruction» (рисунок 5).
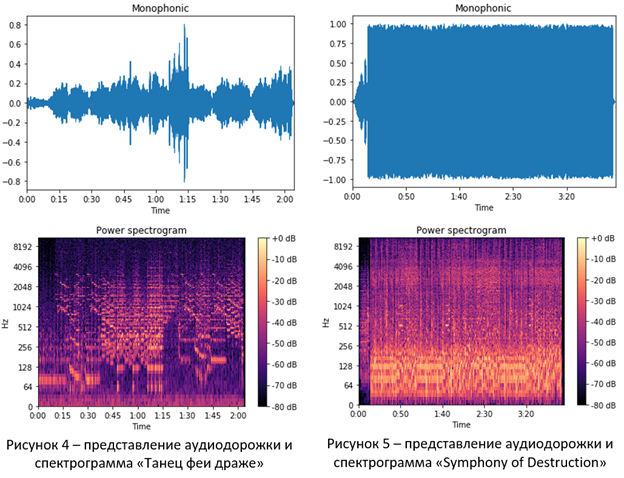На изображениях аудиодорожек в данном случае видно, что классика и метал сильно отличаются, как минимум, в части громкости: классика может быть тихой и громкой - отчётливо видны места затишья и громких моментов, метал же почти всю композицию звучит только громко.
Спектрограммы же показывают, что в «Танце феи драже» много высоких нот, низких довольно мало – их частоты слабее заполнены, и композиция выстроена сложнее стандартных «куплет-припев». «Symphony of Destruction» же, напротив, практически равномерно заполняет все частоты, ударные и бас-гитара «раскаляют» низкие частоты спектрограммы, композиция содержит много повторяющихся частей.
Теперь, вооружившись знаниями выше, перейдём к разбору, вероятно, наиболее популярного представления аудио в machine learning – мел-кепстральным коэффициентам.
Здесь графики внесут мало понимания, поэтому, сразу приступим к теории:
Если несколько грубо обобщить, то можно прийти к определению, что нота – это колебание определённой частоты, так, Ля первой октавы – это колебания 440 Гц. Однако, человек воспринимает звук неидеально, восприятие высоты звука зависит не только от частоты колебаний, но и от уровня громкости звука и его тембра. Именно для анализа аудио, учитывающего особенности человеческого слуха, была введена психофизическая единица высоты звука – **мел**. Факт из Википедии: «З*вуковые колебания частотой 1000 Гц при эффективном звуковом давлении 2⋅10−3 Па (то есть при уровне громкости 40 фон), воздействующие спереди на наблюдателя с нормальным слухом, вызывают у него восприятие высоты звука, оцениваемое по определению в 1000 мел. Звук частоты 20 Гц при уровне громкости 40 фон обладает по определению нулевой высотой (0 мел). Зависимость нелинейна, особенно при низких частотах (для «низких» звуков).»* На рисунке 6 изображена шкала мел к частоте:
")Рисунок 6 - График зависимости высоты звука в мелах от частоты колебаний (для чистого тона)Таким образом, для того чтобы получить спектрограмму, которая будет отражать то, как именно человек воспринимает звучание, необходимо произвести некоторые преобразования, чтобы получить мел-кепстральные коэффициенты. Также, следует отметить, что «некоторые преобразования» устроены таким образом, что большая детализация признаков обеспечивается в области низких частот – наиболее используемых человеком. Ведь, человеческое ухо, в среднем, слышит в диапазоне 20-20000 Гц, при этом (приведём ещё один факт из Википедии): «*Голос типичного взрослого мужчины имеет фундаментальную частоту (нижнюю) от 85 до 155 Гц, типичной взрослой женщины от 165 до 255 Гц.*». Остальные же составляющие голоса – обертоны. Примерно так же обстоит дело и с музыкальными инструментами.
Подытожим вышенаписанное: мел-кепстральные коэффициенты позволяют нам представить аудио в виде, наиболее близком к восприятию звука человеком.
С помощью библиотеки librosa можно получить данные в нужном виде простым вызовом функции mfcc(). Код вызова функции вместе с отрисовкой результата приведён ниже, а результат выполнения кода представлен на рисунке 7.
```
mfccs = librosa.feature.mfcc(y=y, sr=sr)
fig, ax = plt.subplots()
img = librosa.display.specshow(mfccs, x_axis='time', ax=ax)
fig.colorbar(img, ax=ax)
ax.set(title='MFCC')
plt.show()
```
Рисунок 7 – MFCC для исходного файлаК сожалению, приведённая на рисунке 7 визуализация, по мнению автора, не так наглядна и информативна, как спектрограммы, но ниже также представлены визуализации для «Танца феи драже» (рисунок 8) и «Symphony of Destruction» (рисунок 9):
Рисунок 8 - MFCC для «Танца феи драже»Рисунок 9 - MFCC для «Symphony of Destruction»Таким образом, в статье были рассмотрены наиболее часто используемые способы представления аудио в области ML и анализа аудио как такового. Также, проведено наглядное сравнение спектрограмм двух разных музыкальных произведений с целью демонстрации отличий в их наборе признаков. Далее приведены использованные для статьи материалы, которые рекомендуются для более глубокого погружения в тему:
[How to apply machine learning and deep learning methods to audio analysis](https://towardsdatascience.com/how-to-apply-machine-learning-and-deep-learning-methods-to-audio-analysis-615e286fcbbc)
[Audio Deep Learning Made Simple (Part 1): State-of-the-Art Techniques](https://towardsdatascience.com/audio-deep-learning-made-simple-part-1-state-of-the-art-techniques-da1d3dff2504)
[Audio Deep Learning Made Simple (Part 2): Why Mel Spectrograms perform better](https://towardsdatascience.com/audio-deep-learning-made-simple-part-2-why-mel-spectrograms-perform-better-aad889a93505) | https://habr.com/ru/post/647833/ | null | ru | null |
# Как отлаживать маленькие программы
Довольно много плохих вопросов, которые я вижу на StackOverflow, можно описать следующей формулой:
> Вот моё решение домашнего задания. Оно не работает.
>
> [20 строк кода]
>
>
И… всё.
*Прим. пер.: это перевод статьи "[How to debug small programs](https://ericlippert.com/2014/03/05/how-to-debug-small-programs/)", на которую ссылаются в [справочном разделе английского StackOverflow](https://stackoverflow.com/help/mcve), посвящённом созданию минимальных, самодостаточных и воспроизводимых примеров. Мне кажется, она прекрасно описывает то, что должен знать каждый программист — основы отладки нерабочего кода.*
Если вы читаете эту заметку, то, скорее всего, вы перешли по ссылке, которую либо я, либо кто-то ещё оставил под вашим вопросом на StackOverflow незадолго до того, как этот вопрос был закрыт и удалён. (Если вы читаете эту заметку по другому поводу, оставляйте свои любимые советы по отладке маленьких программ в комментариях).
StackOverflow — это сайт вопросов и ответов, но для очень конкретных вопросов про конкретный код. «Я написал какой-то баганутый код, который не могу исправить» — это не *вопрос*, это *история*, причём не слишком интересная. «Почему при вычитании единицы из нуля я получаю число, большее нуля, из-за чего моё сравнение с нулём в строчке 12 некорректно вычисляется в `true`?» — вот конкретный вопрос про конкретный код.
Итак, вы просите интернет *починить вашу сломанную программу*. Наверняка вам никогда не рассказывали, как отлаживать маленькие программы, потому что — внимание — **то, что вы сейчас делаете — не самый эффективный способ**. Сегодня отличный день, чтобы научиться отлаживать код самостоятельно, потому что StackOverflow не будет этим заниматься вместо вас.
Ниже я предполагаю, что ваша программа компилируется, но работает некорректно, и, более того, у вас есть пример, который демонстрирует это некорректное поведение. Итак, как найти баг:
Для начала **включите все предупреждения компилятора**. [Нет ни одной причины](https://habrahabr.ru/company/cloud4y/blog/301006/), по которой корректная программа в 20 строк кода могла бы получить предупреждение компилятора. Предупреждение — это когда компилятор говорит вам: «это программа компилируется, но делает не то, что вы думаете», и поскольку *это именно та ситуация, в которой вы находитесь*, вам следует к нему прислушаться.
**Прочитайте предупреждения очень внимательно**. Если вы не понимаете, почему было выдано то или иное предупреждение — это хороший вопрос для StackOverflow, потому что это *конкретный вопрос о конкретном коде*. Добавьте в вопрос точный текст предупреждения, точный код, на котором оно было выдано, и точную версию компилятора, который вы используете.
Если в вашей программе всё ещё есть баг, **найдите резиновую уточку**. Если резиновой уточки рядом не оказалось, найдите другого студента-программиста — между ним и уточкой нет почти никакой разницы. Объясните уточке простыми словами, почему каждая строчка каждого метода в вашей программе очевидно верна. В какой-то момент вы столкнётесь с трудностями: либо вы не понимаете метод, который написали, либо в нём ошибка, либо и то, и другое. Сконцентрируйтесь на этом методе; *скорее всего, проблема именно в нём*. Нет, правда, [метод утёнка](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D1%83%D1%82%D1%91%D0%BD%D0%BA%D0%B0) работает. И, как легендарный программист Рэймонд Чен добавил в комментариях ниже (*прим.пер.: к исходному посту*): если вы не можете объяснить уточке, зачем нужна та или иная строчка — может, это потому что вы начали писать код до того, как у вас появился план.
Если ваша программа компилируется без предупреждений, и у уточки не возникло к вам серьёзных вопросов, и при этом баг всё ещё есть, попробуйте **разбить код на методы поменьше**, каждый из которых выполняет **ровно одну логическую операцию**. Популярная ошибка всех программистов, не только начинающих — это писать методы, которые делают несколько вещей одновременно, и делают их плохо. Небольшие методы проще понять, и, как следствие, вам и уточке проще заметить ошибки.
Пока вы переделываете методы в методы поменьше, остановитесь на минутку, чтобы **написать техническую спецификацию к каждому методу**. Пусть это будет одно или два предложения, но наличие спецификации помогает. Техническая спецификация должна описывать то, что делает метод, какие параметры допустимы, какое ожидается возвращаемое значение, в каких случаях произойдёт ошибка, и так далее. Часто при написании спецификации вы понимаете, что вы забыли обработать какой-то случай, и баг оказывается ровно в этом.
Если у вас всё ещё есть баг, проверьте и перепроверьте, что ваши спецификации описывают **предусловия и постусловия** каждого метода. Предусловие — это нечто, что должно выполняться перед тем, как метод начал работу. Постусловие — это нечто, что будет выполняться, когда метод закончит работу. Примеры предусловий: «аргумент — корректный ненулевой указатель», «в переданном связном списке хотя бы две вершины» или «этот аргумент — положительное целое число». Примеры постусловий: «в связном списке стало на один элемент меньше, чем было на входе», «определённый кусок массива теперь отсортирован» или что-то в том же духе. Если нарушено предусловие — это ошибка в месте, где метод был вызван. Если при выполнении всех предусловий нарушено постусловие — это ошибка в методе. Опять же, при формулировании пред- и постусловий вы частенько наткнётесь на забытый случай.
Если баг всё ещё никуда не делся, научитесь писать **[утверждения](https://ru.wikipedia.org/wiki/%D0%A3%D1%82%D0%B2%D0%B5%D1%80%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)) ([assertions](https://en.wikipedia.org/wiki/Assertion_(software_development)))**, чтобы проверить пред- и постусловия. Утверждение — это почти как комментарий, только оно сообщает вам, когда условие нарушается; а нарушенное условие — это почти всегда баг. В C# вы можете сказать `using System.Diagnostics;` в начале кода, а в середине написать `Debug.Assert(value != null);` или что-то аналогичное. В каждом языке есть механизм для формулирования утверждений; попросите кого-нибудь рассказать вам, как их использовать в том языке, на котором пишете. Напишите утверждения для предусловий в начале метода, а утверждения для постусловий — перед строчкой, в которой метод завершается. (Конечно, это проще всего сделать, когда в каждом методе есть ровно одна точка возврата.) Теперь, если вы запустите программу и какое-то утверждение окажется неверным, вы узнаете, в чём проблема, и это будет несложно отладить.
После этого **напишите тесты или примеры** для каждого метода, которые проверяют, что он работает корректно. Тестируйте каждую часть отдельно от остальных, пока вы не будете в ней уверены. Используйте много простых тестов; если ваш метод сортирует списки, попробуйте пустой список, список из одного, двух, трёх одинаковых элементов, три элемента в обратном порядке, несколько длинных списков. Скорее всего, ваш баг проявится на простом тесте, и тогда его будет проще анализировать.
Наконец, если в вашей программе всё ещё есть баг, **напишите на бумажке точное описание действия, которое вы ожидаете от каждой строчки кода при запуске на вашем примере**. Ваша программа занимает всего 20 строк. У вас должно получиться написать *вообще всё*, что она делает. Теперь пройдитесь по коду **при помощи отладчика**, проверяя каждую переменную на каждом шаге и строчка-за-строчкой сверяя поведение вашей программы с бумажкой. Если программа делает то, что не написано на листочке, то ошибка либо на листочке (в этом случае вы не понимаете, что делает ваша программа), либо в программе (в этом случае вы написали что-то неправильно). Поправьте то, что неправильно. Если вы не знаете, как это исправить — у вас как минимум появился конкретный технический вопрос, который вы можете задать на StackOverflow! В любом случае повторяйте процесс до тех пор, пока ваше описание поведения программы и реальное поведение программы не совпадут.
Пока вы работаете в отладчике, я призываю вас **обращать внимание на малейшие сомнения**. Большинство программистов естественным образом полагают, что их код работает, как ожидается, но ведь вы отлаживаете его ровно потому, что это не так! Много раз я отлаживал код и краем глаза замечал быстрое мелькание в Visual Studio, которое означало «эта память только что была изменена», а я знал, что эта память вообще никак к моей проблеме не относится. Так *почему она изменилась*? Не игнорируйте эти придирки, изучайте странное поведение до тех пор, пока вы не поймёте, почему оно либо корректное, либо некорректное.
Если вам кажется, что это всё очень долго и требует больших усилий, то лишь потому, что так и есть. Если вы не можете использовать эти техники на программе из двадцати строчек, которую сами же и написали, вряд ли у вас получится использовать их на программе из двух миллионов строчек, которую написал кто-то другой. Тем не менее, разработчики в индустрии занимаются этим каждый день. Начните тренироваться!
И когда вы в следующий раз будете решать домашнее задание, **напишите спецификации, примеры, тесты, предусловия, постусловия и утверждения для каждого метода перед тем, как писать сам метод**! Вы значительно снизите вероятность появления бага, а если он всё-таки появится — вы, скорее всего, сможете найти его довольно быстро.
Эта методика не поможет найти все баги в каждой программе, но она крайне эффективна для тех коротких программ, которые начинающие программисты пишут в домашних заданиях. Также она может быть использована и для нахождения багов в нетривиальных программах. | https://habr.com/ru/post/339038/ | null | ru | null |
# Text Template Transformation Toolkit (T4), часть 2: генераторы шаблонов
Приветствую, Хабр!
Эта статья продолжит тему автоматической кодогенерации в Visual Studio с помощью T4 — Text Template Transformation Toolkit. [Часть №1](http://habrahabr.ru/blogs/net/64895/), чуть ранее опубликованная в этом блоге, описывала синтаксис T4 и элементарные принципы его использования. В этот же раз я решил подробнее осмотреть блог уважаемого [Олега Сыча](http://www.olegsych.com) и ещё немного адаптировать к хабрааудитории некоторые из его наработок. В частности, сегодня обсудим следующие темы:* Создание повторно используемых и параметризируемых шаблонов
* Создание генераторов шаблонов
* Отладка, тестирование и расширение генераторов (ссылки)
Я не стал изобретать каких-то особенных примеров. История развития запроса с созданием хранимой процедуры, описанная Олегом, идеально подходит для иллюстрации проблемы, при которой могут потребоваться генераторы. Причем, что характерно, — не надуманной проблемы. Также статья придерживается принципа «меньше слов — больше кода».
Здесь и далее предполагается, что у вас установлена Visual Studio 2005/2008/2010, а также [T4 Toolbox](http://www.codeplex.com/t4toolbox).
Параметризируемые шаблоны
-------------------------
#### Начальная стадия
Итак, у нас есть база данных. В этой базе данных есть таблица. А в таблице, в лучших традициях Кощея Бессмертного, есть строка, которую мы желаем удалить. Причём удалить не просто так, а свежесозданной хранимой процедурой. Пускай для простоты параметры, передающиеся в процедуру — все до единого поля таблицы, по которым и идентифицируется строки, подлежащие удалению. Набивать запрос для создания такой процедуры вручную — работа неблагодарная, поэтому мы применяем Т4 и создаём код, подобный приведённому ниже:
> `<#@template language=“C#v3.5” #>
>
> <#@output extension=“SQL” #>
>
> <#@assembly name=“Microsoft.SqlServer.ConnectionInfo” #>
>
> <#@assembly name=“Microsoft.SqlServer.Smo” #>
>
> <#@import namespace=“Microsoft.SqlServer.Management.Smo” #><#
>
> Server server = new Server();
>
> Database database = new Database(server, “Northwind”);
>
> Table table = new Table(database, “Products”);
>
> table.Refresh();
>
> #>
>
> create procedure <#= table.Name #>\_Delete
>
> <#
>
> PushIndent(”\t”);
>
> foreach (Column column in table.Columns)
>
> if (column.InPrimaryKey)
>
> WriteLine(”@” + column.Name + ” ” + column.DataType.Name);
>
> PopIndent();
>
> #>
>
> as
>
> delete from <#= table.Name #>
>
> where
>
> <#
>
> PushIndent(”\t\t”);
>
> foreach (Column column in table.Columns)
>
> if (column.InPrimaryKey)
>
> WriteLine(column.Name + ” = @” + column.Name);
>
> PopIndent();
>
> #>`
Здесь, чтобы получить информацию о полях таблицы из БД локального SQL-сервера, используется [SQL Server Management Objects](http://msdn.microsoft.com/en-us/library/ms162169.aspx) (SMO). После сохранения файла на выходе получим искомый запрос. Например, он может выглядеть так:
> `create procedure Products_Delete
>
> @ProductID int
>
> as
>
> delete from Products
>
> where ProductID = @ProductID`
#### Параметризация
Первый же вопрос, который должен возникнуть в голове у человека, взглянувшего на этот код: почему названия БД и таблицы жёстко забиты в код? Получается, для создания каждого нового запроса программисту придётся залезать в шаблон и менять его вручную в нескольких местах?
На самом деле не обязательно. Достаточно воспользоваться другим способом генерации. Добавляем в проект новый файл, воспользовавшись теперь вариантом Template вместо File из T4 Toolbox, назовём его, к примеру, DeleteProcedureTemplate.tt. Как видно, среда автоматически создала заготовку параметризированного шаблона, то есть файла, который мы потом будем включать в другие шаблоны с целью использовать его в обобщённом виде.
> `<#+
>
> //
>
> // Copyright © Your Company. All Rights Reserved.
>
> //
>
>
>
> public class DeleteProcedureTemplate : Template
>
> {
>
> protected override void RenderCore()
>
> {
>
>
>
> }
>
> }
>
> #>`
Не пытайтесь найти в пространстве имён Microsoft.VisualStudio.TextTemplating класс Template: его там нет. Это абстрактный класс, определённый в T4Toolbox, а файл T4Toolbox.tt непосредственно в самих параметризированных шаблонах подключать нет смысла. Поэтому при каждом сохранении DeleteProcedureTemplate.tt Студия попытается обработать его, сгенерировать выходной файл, потерпит крах и уведомит вас об этом ошибкой. Это неприятное поведение можно легко убрать, заглянув в окно Properties для нашего редактируемого файла и установив там свойство Custom Tool в пустую строку. Теперь попытки неявной генерации не происходит.
Метод RenderCore() класса Template — основная точка работы параметризированного шаблона. Именно в нём происходит генерация той части текста, за которую и будет в конечном счёте отвечать наш шаблон в генераторе. Поэтому, не мудрствуя лукаво, просто перенесём в него уже готовый код.
> `<#@assembly name=“Microsoft.SqlServer.ConnectionInfo” #>
>
> <#@assembly name=“Microsoft.SqlServer.Smo” #>
>
> <#@import namespace=“Microsoft.SqlServer.Management.Smo” #>
>
> <#+
>
> public class DeleteProcedureTemplate : Template
>
> {
>
> public string DatabaseName;
>
> public string TableName;
>
>
>
> protected override void RenderCore()
>
> {
>
> Server server = new Server();
>
> Database database = new Database(server, DatabaseName);
>
> Table table = new Table(database, TableName);
>
> table.Refresh();
>
> #>
>
> create procedure <#= table.Name #>\_Delete
>
> <#+
>
> PushIndent(”\t”);
>
> foreach (Column column in table.Columns)
>
> {
>
> if (column.InPrimaryKey)
>
> WriteLine(”@” + column.Name + ” ” + column.DataType.Name);
>
> }
>
> PopIndent();
>
> #>
>
> as
>
> delete from <#= table.Name #>
>
> where
>
> <#+
>
> PushIndent(”\t\t”);
>
> foreach (Column column in table.Columns)
>
> {
>
> if (column.InPrimaryKey)
>
> WriteLine(column.Name + ” = @” + column.Name);
>
> }
>
> PopIndent();
>
> }
>
> }
>
> #>`
Главное изменение, которому подвергся шаблон — это добавление в него открытых полей DatabaseName и TableName, которые, собственно, и выполняют функцию параметризации. Теперь файлы данных и логики разделены. Единственное, что осталось — воспользоваться директивой include и запускать попеременно один и тот же шаблон на разных БД и таблицах, как здесь:
> `<#@ template language=”C#v3.5” hostspecific=”True” #>
>
> <#@ output extension=”sql” #>
>
> <#@ include file=”T4Toolbox.tt” #>
>
> <#@ include file=”DeleteProcedureTemplate.tt” #>
>
> <#
>
> DeleteProcedureTemplate template = new DeleteProcedureTemplate();
>
> template.DatabaseName = “Northwind”;
>
> template.TableName = “Products”;
>
> template.Render();
>
> #>`
При желании подобным же методом можно создать универсальный шаблон, создающий в зависимости от параметров хранимую процедуру на основе SELECT, INSERT и UPDATE, а не только DELETE. Код шаблона каждый может теперь составить самостоятельно.
Небольшое отступление в сторону. На первый взгляд весь описанный материал кажется элементарным. Да собственно, он таким и является, как и весь T4 сам по себе. Вопрос в другом: эти возможности включены в стандартную поставку, и подобной простой статьёй-компиляцией я хочу уберечь читателей (а читатели у Хабра разной степени опытности) от опасности нагородить собственных велосипедов. Описанные ниже генераторы шаблонов — ещё один из подобных подводных камней.
Генераторы шаблонов
-------------------
В параметризированных шаблонах всё ещё остаётся один неучтённый недочёт. Да, мы вынесли логику запуска шаблона с конкретными именами БД и таблицы в отдельный файл, но в случае работы с несколькими возможными БД и таблицами подобное решение есть замена шила на мыло. Программист всё ещё вынужден плодить отдельные файлики шаблона для каждой конкретной таблицы. Пускай эти файлы теперь заметно усохли в размере, однако проблему копипаста никто не отменял. В идеале хотелось бы за одно движение создать отдельный запросы к каждой таблице данной конкретной БД. Это возможно? Да.
Добавим в проект третий полезный тип шаблона, разработанный в рамках T4Toolbox — Generator. Генератор будет использовать наш параметризированный шаблон для того чтобы подставлять в него разные значения параметров (имён БД и таблицы) и направлять результат обработки в разные файлы. С последней целью в классе Template предусмотрен замечательный метод RenderToFile.
Итак, пусть файл генератора называется CrudProcedureGenerator.tt и дефолтная заготовка для него, как вы воочию можете убедиться, выглядит следующим образом:
> `<#+
>
> //
>
> // Copyright © Your Company. All Rights Reserved.
>
> //
>
>
>
> public class CrudProcedureGenerator : Generator
>
> {
>
> protected override void RunCore()
>
> {
>
>
>
> }
>
> }
>
> #>`
Генератор сам не проводит никакой обработки текста T4, он лишь запускает по очереди другие, уже написанные базовые шаблоны. Поэтому его соответствующие основные методы вместо Render и RenderCore называются Run и RunCore соответственно. Подстроим же их для себя:
> `<#@ assembly name=”Microsoft.SqlServer.ConnectionInfo” #>
>
> <#@ assembly name=”Microsoft.SqlServer.Smo” #>
>
> <#@ import namespace=”Microsoft.SqlServer.Management.Smo” #>
>
> <#@ include file=”DeleteProcedureTemplate.tt” #>
>
> <#+
>
> public class CrudProcedureGenerator : Generator
>
> {
>
> public string DatabaseName;
>
> public DeleteProcedureTemplate DeleteTemplate = new DeleteProcedureTemplate();
>
>
>
> protected override void RunCore()
>
> {
>
> Server server = new Server();
>
> Database database = new Database(server, this.DatabaseName);
>
> database.Refresh();
>
> foreach (Table table in database.Tables)
>
> {
>
> this.DeleteTemplate.DatabaseName = this.DatabaseName;
>
> this.DeleteTemplate.TableName = table.Name;
>
> this.DeleteTemplate.RenderToFile(table.Name + “\_Delete.sql”);
>
> }
>
> }
>
> }
>
> #>`
Здесь перебираются все таблицы в одной заданной БД и для каждой экземпляр класса DeleteProcedureTemplate создаёт отдельный уникальный выходной файл с запросом. Для полного счастья не хватает лишь задать БД и запустить полный цикл обработки:
> `<#@ template language=”C#v3.5” hostspecific=”True” debug=”True” #>
>
> <#@ output extension=”txt” #>
>
> <#@ include file=”T4Toolbox.tt” #>
>
> <#@ include file=”CrudProcedureGenerator.tt” #>
>
> <#
>
> CrudProcedureGenerator generator = new CrudProcedureGenerator();
>
> generator.DatabaseName = “Northwind”;
>
> generator.Run();
>
> #>`
Результат на ваших экранах:
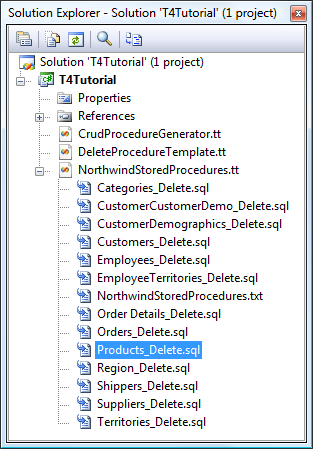
Постскриптум. Особенности использования генераторов
---------------------------------------------------
Следуя обыкновенной логике, статью о генераторах стоило бы необходимо завершить заметками о том, как их отлаживать, тестировать и безболезненно модифицировать под расширенные нужды. К сожалению, такого количества лишнего программного кода эта одна хабрастатья просто не вынесет, а выносить его в третью часть тоже не хочется, материал получится бедный и оторванный от коллектива. Поэтому ограничусь советами, на основе которых, а также исходников из блога Олега Сыча, читатель сможет без каких-либо проблем использовать генераторы в жизни.1. Для тестирования генераторов в T4 Toolbox предусмотрена своя отличная заготовочка под именем «Unit Test».
2. Если необходимо модифицировать сердце генерации — код, создаваемый шаблоном, — незачем править непосредственно файл с его классом (в данном случае DeleteProcedureTemplate). Достаточно импортировать в генератор ещё один файлик, в котором описать наследника нашего шаблона с требуемыми коррективами.
3. У класса Generator есть функция Validate, которая вызывается методом Run в первую очередь, перед тем как заняться непосредственно генерацией кода (RunCore). Её можно использовать для проверки входящих параметров генератора.
4. Для рапорта об ошибках можно использовать методы Error и Warning, аналогичные рассмотренным в классе TextTransformation.
Ссылки по теме:
[Handling errors in code generators](http://www.olegsych.com/2008/11/t4-tutorial-handling-errors-in-code-generators/)
[Unit testing code generators](http://www.olegsych.com/2008/11/t4-tutorial-unit-testing-code-generators/)
[Making code generators extensible](http://www.olegsych.com/2009/02/t4-tutorial-making-code-generators-extensible/) | https://habr.com/ru/post/65716/ | null | ru | null |
# Ностальгия по КУВТ: запускаем эмулятор MSX под Linux
Предисловие
===========
Знакомство с компьютером каждый из нас начинал по своему и в разное время. Кто-то помнит ДВК, «Искры» и «Агаты», а кто-то сразу сел за IBM PC под Win 9x. Довольно часто попадаются ностальгические статьи, читать которые всегда интересно, ибо написанное сравниваешь с личным опытом и вспоминаешь, как было у тебя.
А вот у меня было так:
*Yamaha КУВТ2 — ученическое место*

Такие «рабочие станции» — Yamaha YIS503III, в середине-конце 90х были в нашем школьном компьютерном классе. Их было 9 штук + учительский компьютер и матричный принтер. Всё это дело соединялось локальной сетью с топологией «шина» Монитор у ученических машин был в 256 оттенках зеленого
*Монохромный ученический дисплей*

Учительский компьютер был «покруче» — YIS805/128. Монитор у него был цветным и имелись два 3,5" «флопаря» под дискеты емкостью 720 Кб. HDD у этого компьютера не было, зато были два слота под картриджи.
*Внешний вид учительского десктопа не уступал тогдашнему IBM PC (конец 80х)*

Сердцем обеих машин был 8-разрядный Zilog Z80A, о чем кстати я до последнего времени не знал, считая что спектрумовский процессор прошел мимо меня.
*Экран загрузки учительской машины*

Что касается ПО, то традиционно для 8-биток того времени, в ПЗУ был зашит интерпретатор Basic, специально портированный майкрософтом для машин стандарта MSX. Были и ОС — CP/M, с которой мне не довелось столкнуться и MSX-DOS. На дискетах имелся так же компилятор Pascal.
В десятом классе у нас началась информатика. Дорвавшись до этих компьютеров, я последние два школьных года постоянно, что называется «ошивался» в их окресностях. Хочется сказать спасибо нашему учителю информатики, Тынянскому В. В., который всячески поощерял нашу тягу к изучению вычислительной техники и каждую неделю проводил во внеурочное время, на общественных началах, факультативные занятия. Там я освоил бейсик и DOS, а потом, единственный из нашего выпуска начал программировать на паскале. Паскаль требовал загрузки DOS с дискеты, и с дискеты же запускалась и примитивная IDE, так что со временем я окуппировал учительскую машину — так было проще, ведь нубские завешивания системы были тогда не редкостью.
Интернет тогда не было практически ни у кого. ПК в классическом смысле был только у одного нашего одноклассника (с Windows 95!!! Да, это было круто!!!), о машинах с тактовой частотой в 1000 МГц говорили тогда как о призрачной легенде… ДА, в общем были старые, добрые времена.
На фото хорошо видна клавиатура этих компьютеров. Обратили внимание на английскую раскладку? В универе, сидя за Robotron'ом с привычной нам раскладкой я долго не мог переучиться…
К чему это я всё? Да к тому, что на ностальгические мотивы меня сбила случайная находка — эмулятор этого чуда под названием [OpenMSX](http://openmsx.sourceforge.net/). Сердце защимило и два вечера я провел за установкой/настройкой/освоением. Что я предлагаю? Предлагаю установить всё это вместе и посмотреть, как оно было, в те далекие и безвозвратно ушедшие времена КУВТ
1. Устанавливаем и запускаем OpenMSX
====================================
Преимуществом именно этого эмулятора можно назвать его кроссплатформенность. На [официальном сайте](http://openmsx.sourceforge.net/) есть дистрибутивы для всех популярных ОС. Я, как убежденный линуксоид, буду рассказывать об установке применительно к Linux, а точнее Arch Linux, в [пользовательском репозитории AUR](https://aur.archlinux.org/) которого, есть [PKGBUILD'ы соответствующих пакетов](https://aur.archlinux.org/packages/?O=0&K=openmsx).
Про сборку ПО PKGBUILD'ами подробно писать не буду — арчевод сам знает, для убунтовода или поклонника федоры это всё равно не актуально. Скажу лишь, что нужет сам [openmsx](https://aur.archlinux.org/packages/openmsx/), и порекомендую фронтэнд к нему под кричащим названием «катапульта» — [openmsx-catapult](https://aur.archlinux.org/packages/openmsx-catapult/). Хоть консоль и Ъру, но для удобства погружения в ностальгию самое то воспользоваться окошками и кнопочкам.
Итак, мы собрали и установили необходимые нам пакеты, что дальше? Дальше нам надо правильно указать эмулятору конфигурацию эмулируемой аппаратной платформы — меня интересовала Yamaha YIS805/128. Из коробки её модели нет в эмуляторе, поэтому идем по [ссылке, где расположен настоящий клад для MSX-фагов](http://www.msxarchive.nl/pub/msx/). Качаем [systemroms.zip](http://www.msxarchive.nl/pub/msx/emulator/openMSX/systemroms.zip). Распаковываем архив:
```
$ unzip systemroms.zip
```
И копируем содержимое в каталог ресурсов эмулятора:
```
# cp -rv systemroms/* /usr/share/openmsx/systemroms/
```
Запускаем «катапульту»:
```
$ catapult
```
Она спросит нас о местонахождении бинарников эмулятора и каталогов с ресурсами:

Убедившись, что все верно, жмем ОК. Программа проверит указанные пути и составит список доступных конфигураций виртуального железа:
И покажет нам окно запуска эмулятора. В выпадающем списке «MSX type» я выбрал вожделенный YIS805/128:
Жмем Start, и…
*Старые добрые времена возвращаются из небытия...*

Появляется экран загрузки MSX, и сразу за ним — приглашение интерпретатора MSX Basic v 2.1

И, да, можно тряхнуть стариной и написать Hello World:
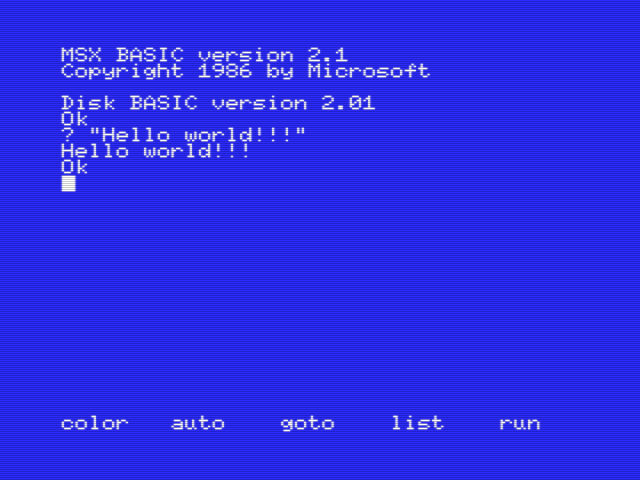
Текст можно вбивать прямо в эмуляторе, а можно копипастить через соответствующую вкладку «катапульты»:
И после клика на «Type» текст появится в окне эмулятора, нажатием F5 его можно запустить на исполнение:

Скриншоты делаем на вкладке Video Controls, нажатием кнопки Grab:
По умолчанию они сохраняются по пути **~/$USER/.openMSX/screenshots/**. По идее путь можно поменять, но у меня это от чего-то не работает, скрины сохраняются только по дефолтным настройкам.
Итак, у нас есть работающая «ямаха», посмотрим теперь, что она умела
2. Загружаем CP/M
=================
Образа диска c этой ОС (моей ровесницей!!!) не оказалось на ftp-сревере, указанном по ссылке выше, [зато нашелся по ссылке](http://ftp.funet.fi/pub/msx/mirrors/msx2.com/sources/cpmplus.zip), полученной из [обсуждения на sourceforge](http://sourceforge.net/p/openmsx/discussion/119121/thread/500a0607/). После распаковки в архиве обнаружились образы дисков: SYSTEM.DSK — загрузочная дискета CP/M и PROG.DSK — видимо какой-то дополнительный софт. «Вставляем» оба диска в виртуальные «флопари» — загрузочный в дисковод A. Чтобы загрузка состоялось, методом тыка эмулятору было указано подключить расширение Panasonic FS-CA1:
И жмем старт. Появляются сообщения загрузчика:
*Процесс загрузки CP/M*
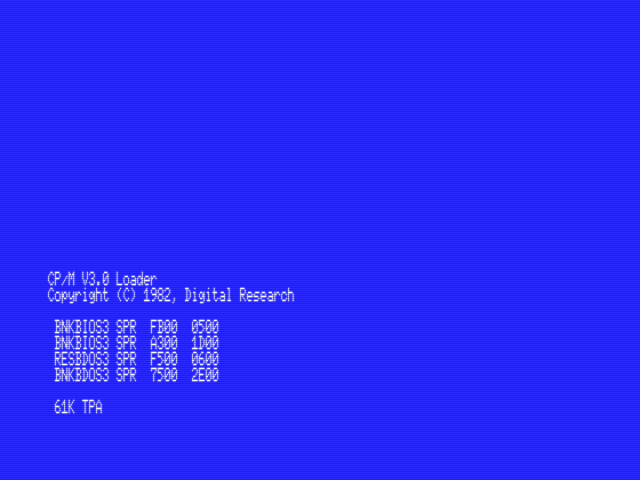
А вслед за ними и приглашение командной строки CP/M. CP/M похожа на DOS, я с ней не знаком, но команда dir работает.
*Содержимое дистрибутива*

Что делать далее не знаю — не настолько олдфажный я олдфаг, чтобы помнить CP/M
3. Загружаем MSX-DOS 2.2
========================
С DOS дела попроще — архив с дискетами [лежит всё там же](http://www.msxarchive.nl/pub/msx/utils/MSX-DOS%202.2/MSXDOS22.ZIP). Качаем его, распаковываем и выбираем образ MSXDOS2T.DSK. В настройках эмулятора ставим использовать раcширение msxdos2
После загрузки видим привычную DOS-консоль
*MSX-DOS понимал досовский dir и \*nix-вый ls — в школе я об этом не знал*

В каталоге A:\tools этого старинного доса нашлись некоторые утилиты, привычные для unix: ls, grep, tail и некоторые другие:

В общем, с операционными системами всё ок. А что же с прикладным софтом?
4. Запуск прикладного софта: средства разработки
================================================
Нашелся и компилятор [Turbo Pascal 3.0](http://www.msxarchive.nl/pub/msx/programming/pascal/), очень похожий на тот, что я изучал тогда. Только вот находился он в некоем странном архиве с расширением \*.lzh, которое после недолгого гугления идентифицировалось как LHA-архив, для которого [в AUR есть соответствующий пакет](https://aur.archlinux.org/packages/lha/). Ставим его распаковываем архив:
```
$ lha e turbo.lzh
```
На выходе имея:
```
-rw-r--r-- 1 maisvendoo users 768 апр 29 2023 cmdlin.pas
-rw-r--r-- 1 maisvendoo users 5504 апр 29 2023 lister.pas
-rw-r--r-- 1 maisvendoo users 11776 апр 29 2023 mcdemo.mcs
-rw-r--r-- 1 maisvendoo users 4608 апр 29 2023 mc.hlp
-rw-r--r-- 1 maisvendoo users 896 апр 29 2023 mc-mod00.inc
-rw-r--r-- 1 maisvendoo users 1664 апр 29 2023 mc-mod01.inc
-rw-r--r-- 1 maisvendoo users 3200 апр 29 2023 mc-mod02.inc
-rw-r--r-- 1 maisvendoo users 4480 апр 29 2023 mc-mod03.inc
-rw-r--r-- 1 maisvendoo users 8832 апр 29 2023 mc-mod04.inc
-rw-r--r-- 1 maisvendoo users 11136 апр 29 2023 mc-mod05.inc
-rw-r--r-- 1 maisvendoo users 6272 апр 29 2023 mc.pas
-rw-r--r-- 1 maisvendoo users 11776 апр 29 2023 nswp.com
-rw-r--r-- 1 maisvendoo users 6784 апр 29 2023 read.me
-rw-r--r-- 1 maisvendoo users 25472 апр 29 2023 tinst.com
-rw-r--r-- 1 maisvendoo users 4480 апр 29 2023 tinst.dta
-rw-r--r-- 1 maisvendoo users 3968 апр 29 2023 tinst.msg
-rw-r--r-- 1 maisvendoo users 30848 апр 29 2023 turbo.com
-rw-r--r-- 1 maisvendoo users 68188 мар 2 21:28 turbo.lzh
-rw-r--r-- 1 maisvendoo users 1536 апр 29 2023 turbo.msg
-rw-r--r-- 1 maisvendoo users 1152 апр 29 2023 turbo.ovr
```
М-де, похоже на то, что нам нужно. Теперь вопрос — а как это запихнуть в эмулятор?
Есть два пути. Первый — создать образ дискеты, о чем повествует [соответствующий раздел документации](http://openmsx.sourceforge.net/manual/diskmanipulator.html). Там много вкусных вещей, но мы пойдем другим, более простым и быстрым путем. Создадим каталог и распакуем архив в него
```
$ mkdir -p ~/msx/tp
$ cd ~/msx/tp
$ lha e ~/install/openmsx/turbo.lzh
```
Туда же поместим и содержимое архива turbo\_lib3.zip — дополнительные модули.
Теперь укажем наш каталог в качестве диска B.

Посмотрим, что вышло. Вышло отличною:
*Каталог хостовой системы как диск «ямахи»*

Запускаем паскаль:
```
B> cd tp
B> turbo
```
И… меня ждало разочарование. Запущенная среда сурово глючила, плевалась кракозябрами и висла. Поиски привели к разным версиям Turbo Pascal для DOS и CP/M, но ни одну из них пока не удалось привести к общему знаменателю. Что ж, оставлю это на потом, может пытливый читатель имеет в этом вопросе больший опыт.
4. Запуск прикладного софта: игры
=================================
Ну куда же без них. На MSX выходило масса игр, как разрабатываемых для него, так и портируемых с других платформ. Играми я всегда интересовался мало, но одна игрушка меня всё же зацепила, тогда, 15 лет назад, да так, что я с интересом прошел её до конца.
Название до сего дня я не помнил, а сюжет: летаем на вертолете, освобождаем пленных из бараков, попутно убивая врагов. И в названии было что-то похожее на Coper… [В архивах барахла для MSX я её нашел](http://www.msxarchive.nl/pub/msx/games/msx1/choplift.lzh). Называется она «Coplifter». Игра запакована архивом LHA, помещаем её в нашу папку-диск и распаковываем. Внутри будет два бинарника и «скрипт» на бейсике choplift.bas, для запуска игры
```
A>B:
B>cd games
B>basic choplift.bas
```
Запускается интерпретатор Basic, а вслед за ним — игра:
*Обнадеживающее начало...*
*… она самая и есть — Choplifter!!!*

Эмулятор «кушает» и ROM-ы с играми, коих, по уже многократно данной ссылке завались. Много ромов гуглится — тот же вертолетик я сначала запустил с рома, а уж потом разобрался с архивом и с запуском из-под дос.
Вместо эпилога
==============
Возможно статья получилась больше эмоциональной чем практической. Свидание с детством, оно такое. Нерешенных вопросов по работе с эмулятором масса — тот же паскаль теперь не дает мне покоя. Но это дело не одного дня при наличии свободного времени.
Где-то в начале 2000-х, уже после окончания мной школы, в компьютерный класс закупили IBM PC на «пнях» с Windows 98 SE на борту. «Ямахи» отдали в школу какой-то деревеньки близ нашего райцентра. С ними уехали и дискеты с моим творчеством — квест про полет на Марс, «Морской бой», простецкая СУБД, написанная на паскале… Дорого бы я дал сейчас за живые дискеты со своими САМЫМИ ПЕРВЫМИ программами.
P. S.:
======
Покопавшись в эмуляторе и погуглив таки нашел нормальный паскаль.
Только вот на YIS-805/128 дос хоть убейся при загрузке включает режим 40х25, в котором строчки редактора наезжают друг на друга.
MSX Turbo R грузит дос в режиме 80x25 и выглядит всё кошерно
*То, что мы увидим после запуска*
*Редактор текста. Такая вот была IDE, а вы всё эклипс, да силион...*

*Компиляция в COM файл — данность для 8-разрядных машин, процессору доступно 64 Кб*

*Компиляция в память и исполнение*

Но всё же хотелось бы работы в нормальном режиме на КУВТ, для сохранения ностальгического настроя. Наверное это не последняя статья об OpenMSX… | https://habr.com/ru/post/377015/ | null | ru | null |
# Простой торговый бот для The Settlers Online
Давным давно, еще в те времена когда на персональных компьютерах жил MsDOS довелось играть в игру Settlers II. Игра меня тронула, и я с удовольствием провел наедине с ней несколько дней. Много позже прошел ее повторно, а затем и еще раз, и каждый раз несмотря на древность этой игры с удовольствием проводил время играя в нее. Не так давно увидел рекламу онлайн игры The Settlers Online и поддавшись ностальгии зарегистрировался в ней. Первым впечатлением был восторг, настолько все было похоже на полюбившееся мне Settlers II. Но радужная эйфория быстро прошла. Я не буду рассказывать в этой статье о всех плюсах и минусах, расскажу только об одном минусе — торговле. О самой игре более подробно вы можете прочитать в статье [The Settlers: теперь Online](http://habrahabr.ru/post/110293/).
#### Причина
Торговля в игре реализована так, что требует постоянного присутствия. Любой торговый лот выставляется всего на 10 минут, а затем становится недоступен для других игроков. Как следствие, для того что-бы торговля принесла хоть сколько нибудь ощутимую прибыль необходимо провести в торговом интерфейсе не один час.
#### Следствие
Так и родилась идея написать бота который будет выставлять лот автоматически.
#### Пишем бота
Так как на моем десктопе установлен Linux, в качестве инструментов разработки был выбран язык программирования Perl, и утилита управления курсором мыши xdotool.
И так приступим.
бот будет состоять из 2-х файлов:
* simple.trade.bot.pl — непосредственно сам бот.
* trade.guns.pl — файл с координатами кнопок и дополнительными данными для торговли выбранным товаром (в моем случае это были пушки продаваемые за футбольные мячи).
Начнем с файла **trade.guns.pl**. В этом файле содержится список HASH (именованных) массивов содержащих координаты кнопок которые необходимо нажать чтобы выставить лот, и другую дополнительную информацию.
```
(
{ x=>'288', y=>'852'}, # Кнопка [добавить]. Инициирует интерфейс выставления торгового лота
{ x=>'790', y=>'667'}, # Кнопка [выбрать]. Интерфейс выбора продаваемого товара.
{ x=>'1126', y=>'658'}, # Кнопка [искусные]. Выбор категории продаваемого товара.
{ x=>'871', y=>'594'}, # Кнопка [пушки]. Непосредственно выбор самого товара.
{ # Действия с бегунком выставляющим количество продаваемого товара.
# Приведенные ниже данные соответствуют 100 единицам товара.
# По умолчанию выставляется 400 единиц.
x=>'983', y=>'742', # Координаты нажатия ЛКМ.
dx=>'874', dy=>'750', # Координаты отжатия ЛКМ.
# Получаем 99 единиц.
inc=>{ # Данный элемент содержит:
x=>'1010', y=>'745', # Координаты кнопки увеличивающей значение бегунка на 1.
inc=>'1', # На сколько увеличить значение бегунка.
rnd=>'0', # Если не 0 то рандомное значение от 0 до rnd добавляется к inc.
timer => [ # Содержит поправку цены в зависимости от времени суток.
{ sh=>0, eh=>24, inc=>0 } # В данном случае поправка равна 0 на весь день.
]
}
},
{ x=>'1064', y=>'733', rx=>'20', ry=>'10'}, # Кнопка [ОК]. Завершает выбор товара для продажи.
{ x=>'1131', y=>'668', rx=>'10', ry=>'2'}, # Кнопка [выбрать]. Интерфейс выбора покупаемого товара.
# Так как необходимый товар находится в категории по умолчанию
# выбор категории опущен.
{ x=>'1016', y=>'548', rx=>'20', ry=>'10'}, # Кнопка [мячики]. Непосредственно выбор покупаемого товара.
{ # Действия с бегунком выставляющим количество покупаемого товара.
# Приведенные ниже данные соответствуют 20 единицам товара + 0, 2, 4 или 8 в зависимости
# от времени суток + рандомно от 0 до 15 .
# По умолчанию выставляется 400 единиц.
x=>'988', y=>'743', # Координаты нажатия ЛКМ.
dx=>'804', dy=>'746', # Координаты отжатия ЛКМ.
# Получаем 1 единицу.
inc=>{ # Данный элемент содержит:
x=>'1010', y=>'745', # Координаты кнопки увеличивающей значение бегунка на 1.
inc=>'19', # На сколько увеличить значение бегунка.
rnd=>'15', # Если не 0 то рандомное значение от 0 до rnd добавляется к inc.
timer => [ # Содержит поправку цены в зависимости от времени суток.
# Если поправок несколько - то каждая последующая обладает более высоким приоритетом.
{ sh=>0, eh=>24, inc=>0 },# 0 на весь день.
{ sh=>0, eh=>8, inc=>8 },# +8 c 00.00 до 08.00.
{ sh=>8, eh=>9, inc=>4 },# +4 c 08.00 до 09.00.
{ sh=>9, eh=>10, inc=>2 } # +2 c 09.00 до 10.00.
]
}
},
{ x=>'1083', y=>'736', rx=>'20', ry=>'10' }, # Кнопка [ОК]. Завершает выбор товара для покупки.
{ x=>'961', y=>'596', rx=>'14', ry=>'12' } # Кнопка [применить]. Отправляет лот на торг.
);
```
В более детальном описании помимо того что дано в комментариях данный файл не нуждается. Поэтому приступим к рассмотрению **simple.trade.bot.pl**. Это и есть сам бот.
```
#!/usr/bin/perl
# После запуска скрипт дает пользователю 20 секунд для того чтобы он открыл окно с игрой и зашел в торговый интерфейс
sleep 20;
# Получаем список из файла с координатами в массив
my @g_trade = do "trade.guns.pl";
# Далее главный цикл программы. Он бесконечен.
# Для прерывания работы программы перейдите в консоль и нажмите [Ctrl]+c.
while(){
# Пишем в консоль о постановке нового лота на торги.
print "NEXT TRADE\n";
# Данный цикл последовательно проходит все элементы из массива с координатами.
for my $l_cur ( @g_trade ){
sleep(1);
if( defined $l_cur->{dx} ){
# Если в текущем элементе определен ключ dx значит данный элемент - оперирует бегунком
# выставляющим колличество товара.
# Расчитываем количество выставляемого товара ($l_count).
# Добавляем статическую поправку к количеству товара.
my $l_count=$l_cur->{inc}{inc};
# Получаем текущее время. В ячейке №2 - часы.
my @l_curtime=localtime(time);
# Перемещаем курсор в координаты x, y текущего элемента.
move($l_cur);
# Получаем поправку к цене зависящую от времени суток.
my $l_inc=0;
# Последовательно перебираем массив с поправками к цене.
for my $l_timer ( @{$l_cur->{inc}{timer}} ){
# Если текущее время попадает в заданный интервал, запоминаеми поправку.
$l_inc=$l_timer->{inc} if $l_curtime[2] >= $l_timer->{sh} && $l_curtime[2] <= $l_timer->{eh};
}
# Расчитываем рандомную поправку к количеству товара.
my $l_rnd=int(rand($l_cur->{inc}{rnd}));
# Добавляем вычисленые поправки к общему количеству товара.
$l_count+=$l_inc;
$l_count+=$l_rnd;
# Выводим в консоль данные о количестве товара и состовляющие из которых это количество складывается.
print "\tSET: [$l_count] [$l_cur->{inc}{inc} + $l_up + $l_rnd\($l_cur->{inc}{rnd})]\n";
# Увеличеваем значение бегунка на величину поправки.
while ($l_count){
$l_count--;
clicktoxy($l_cur->{inc});
usleep(80);
}
}else{
# Если ключ dx не определен - значит это просто клик мыши по заданным в текущем елементе координатам.
clicktoxy($l_cur);
}
}
# Лот выставлен. Ожидаем 11 минут + рандомно от 0 до 4 минут (человек ведь никогда не ставит лот секунда в секунду).
my $l_time=11+int(rand(4));
my $count=0;
# По прошествии каждой минуты пошевеливаем курсором мыши чтобы система не уснула.
for($count=0;$count<$l_time;$count++){
sleep 60;
mousemove(400,500);
sleep 1;
mousemove(1400,500);
sleep 1;
}
# Ждем еще рандомное количество секунд от 0 до 60
sleep(int(rand(60)));
# Цикл возвращается в начало и выставляется новый лот
}
sub usleep{
# Функция дает задержку в млилисекундах (Не работает в Ms Windows).
my $l_ptr=shift;
$l_ptr*=1000;
`usleep $l_ptr`;
}
sub move{
# Функция принимает текущий элемент и перемещает курсор мыши по заданным в элементе координатам.
my $l_coord=shift;
mousemove($l_coord->{x},$l_coord->{y});
mousedown(1);
usleep(600);
mousemove($l_coord->{dx},$l_coord->{dy});
mouseup(1);
}
sub click{
# Функция производит клик ЛКМ в текущей позиции курсора.
mousedown(1);
mouseup(1);
}
sub clicktoxy{
# Функция принимает текущий элемент, перемещает курсор мыши по заданным в элементе координатам
# и производит клик ЛКМ.
my $l_coord=shift;
mousemove($l_coord->{x},$l_coord->{y});
mousedown(1);
mouseup(1);
usleep(300);
}
sub mousedown{
# Функция отдает команду утилите xdotool имитировать нажатие кнопки мыши.
# Принимает значения:
# 1 - левая кнопка мыши (ЛКМ)
# 2 - правая кнопка мыши (ПКМ)
my $l_key = shift;
if( $l_key ){
`xdotool mousedown $l_key`;
}
}
sub mouseup{
# Функция отдает команду утилите xdotool имитировать отжатие кнопки мыши.
# Принимает значения:
# 1 - левая кнопка мыши (ЛКМ)
# 2 - правая кнопка мыши (ПКМ)
my $l_key = shift;
if( $l_key ){
`xdotool mouseup $l_key`;
}
}
sub mousemove{
# Функция отдает команду утилите xdotool переместить курсор мыши по координатам x, y.
my $l_x = shift;
my $l_y = shift;
my $l_com='xdotool mousemove';
$l_com.=" $l_x $l_y";
`$l_com`;
}
```
Бот готов.
#### В завершение
Данный бот очень простой. Он пока еще не имеет множество необходимых возможностей. Вот краткий список идей как сделать бота более совершенным:
* Научить бота видеть с экрана. Для этого можно использовать ImageMagick.
* Научить бота настраиваться под разные разрешения экрана и разные браузеры. Поиск границ и кнопок с помощью утилиты compare из состава ImageMagick.
* Научить бота читать с экрана. Для этого можно использовать ImageMagick + gocr.
* Научить бота принимать сделки. Но так как в игре практикуется передача обманных сделок — бот прежде чем принять сделку должен ее проверить. Для этого можно использовать ImageMagick + gocr.
* Научить бота знать заранее все лоты выставленные в торговом интерфейсе. Лоты передаются браузеру в открытом виде как XML. Для перехвата можно использовать perl модуль [Net::Pcap](http://search.cpan.org/~kcarnut/Net-Pcap-0.05/Pcap.pm). Для поиска в торговом интерфейсе выбранного на этапе перехвата пакетов товара можно использовать ImageMagick + gocr.
#### Следует учесть
* Данный бот написан под Linux. Для того чтобы заставить его работать под Ms Windows необходимо использовать вместо xdotool аналог для Ms Windows. Возможно подойдет утилита [autoit](http://www.autoitscript.com/site/autoit/). Также в Ms Windows необходимо будет установить [Perl](http://www.activestate.com/activeperl).
* Файл с координатами **trade.guns.pl** рассчитан на конкретный товар (100 пушек меняем на 20 — 34 мяча), на мое разрешение экрана и мой браузер. Для использования бота вам нужно будет вычислить свои координаты кнопок.
* По установленным в игре правилам за использование даже такого простого бота наказание [**бан без права восстановления. пункт 6.4**](http://forum.thesettlersonline.ru/threads/16805-The-Settlers-%D0%9E%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%9F%D1%80%D0%B0%D0%B2%D0%B8%D0%BB%D0%B0). | https://habr.com/ru/post/145842/ | null | ru | null |
# Настройка LEMP сервера с помощью docker для простых проектов. Часть первая: База
Мы продолжаем [цикл обучающих статей](https://habr.com/ru/company/nixys/blog/645451/) для начинающих системных администраторов. В серии "Настройка LEMP сервера с помощью docker для простых проектов" мы разберем docker и docker-compose, рассмотрим, как поднять стек LAMP+Nginx с помощью docker, а также расскажем вам, в чем преимущество контейнеризации и виртуализации.
Несмотря на то, что тема уже достаточно подробно отражена в сети, мы решили подробно описать общие стандарты администрирования с нуля, поскольку регулярно получаем большое количество базовых вопросов от людей, так или иначе связанных с нашей сферой. Цель серии статей - не показать, как развернуть идеальное окружение, а лишь указать на нюансы в работе и защитить начинающих специалистов от базовых ошибок при настройке.
Серия статей будет полезна начинающим системным администраторам и инженерам, поэтому если вы опытный админ, то можете смело пропускать данный материал.
Итак, в этой статье мы разберем:
1. **Сравнение виртуализации и контейнеризации.**
* Что такое виртуализация?
* Для чего и когда она необходима?
* Какие минусы виртуализации?
* Что такое контейнеризация?
2. **Масштабирование и его виды.**
* Вертикальное масштабирование.
* Когда использовать Вертикальное масштабирование?
* Горизонтальное масштабирование.
3. **Как связаны контейнеризация и масштабирование.**
4. **Docker. БАЗА.**
* Устанавливаем docker.
* Начинаем работать с контейнерами.
* Что мы можем сделать с контейнером?
* Как нам сделать запрос в контейнер?
* Настройка nginx и apache2 для работы в контейнере.
1. Сравнение виртуализации и контейнеризации.
---------------------------------------------
#### Что такое виртуализация?
**Виртуализация** - это набор инструментов, который позволяет нам разбить физический сервер на 2, 3 и более сервера. С разными операционными системами, сервисами, зависимостями, библиотеками, модулями и т.д.
Пример: У нас имеется сервер 48 CPU 128 RAM. С использованием виртуализации можно разбить физический сервер на два отдельных от друг-друга сервера.
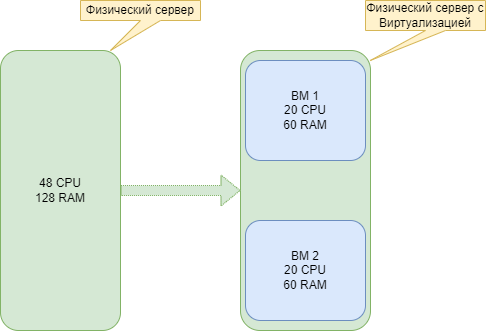#### Для чего и когда она необходима?
Чаще всего это используется для разделения DEV- и PROD-окружения, так как проводить тестирование в DEV-окружении будет более безопасно на отдельном сервере. Также это подойдет, когда необходимо развернуть сервисы, которые используют разные зависимости и библиотеки.
Пример: PROD окружение работает на php7.2+apache, а для тестов необходима площадка на php8.1+apache. В этом случае apache2 как интерпретатор php не может работать с разными версиями php, поэтому нам необходим отдельный сервер.
#### Какие минусы виртуализации?
1. Ограничение в ресурсах. Инструмент виртуализации не сможет добавлять виртуальные машины свыше наших физический ядер CPU и RAM.
Пример: Были созданы 2 сервера вместо одного с 20 CPU и 60 RAM. Соответственно, если необходим еще один виртуальный сервер, инструмент виртуализации сможет добавить сервер, состоящий только из 8 CPU и 8 RAM. Если в конфигурацию добавить параметры, которые будут превышать доступные ресурсы, инструмент виртуализации будет выдавать ошибку.
Пример: Вместо 8 доступных CPU будут указаны 9.
2. Резервирование ядер под виртуальную машину. Будет создана ВМ с 20 СPU, соответственно данные CPU на хост машине будут использоваться только ВМ. Ресурсы не смогут быть задействованы на физическом сервере.
3. Отказоустойчивость. Если что-то случиться с физическим сервером, то это повлияет и на наши ВМ.
Пример: Упал наш сервер. -> Упали наши виртуальные машины.
### Итог: Если у нас имеются свободные ресурсы нашего физического сервера и нам необходимо новое окружение для тестов. Виртуализация нам в помощь.
#### Что такое контейнеризация?
**Контейнеризация** - это улучшенное видение виртуализации. Контейнеризация тоже позволяет создавать отдельные виртуальные машины, только с одним важным отличием: контейнеризация использует ядро операционной системы, установленной на физическом сервере. В контейнере будет запущен только тот сервис, который необходим, и ничего лишнего.
Пример: В контейнере будет исключен запуск других сервисов (например GUI), что обеспечивает минимальное потребление ресурсов.
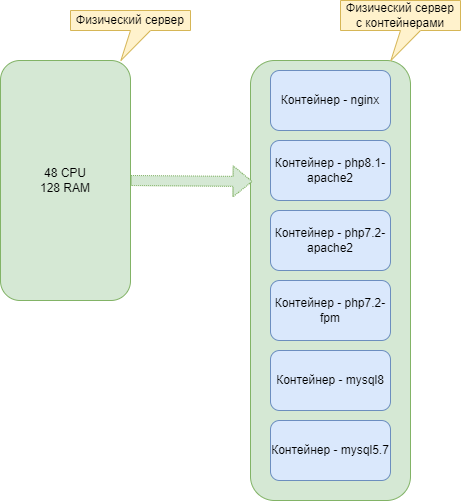Огромными плюсом контейнеризации также выступает быстрое развертывание контейнера, так как поднимается только базовая ОС без зависимостей и ненужных пакетов. В контейнере будет развертываться только минимальный набор библиотек, которые необходимы для запуска сервиса.
2. Масштабирование и его виды.
------------------------------
Представим, что у нас есть проект, который на текущий момент уже использует 90-100% ресурсов. Код на этом проекте был оптимизирован на все 100%, а значит:
* В базе данных не имеется зависших процессов.
* В backend нет зависших скриптов, и отсутствуют долго выполняющие команды.
* Frontend был оптимизирован. Ресурсы, которые используются редко, были закешированны.
### Итак, оптимизировать больше нечего. Как поступить?
Необходимо масштабирование сервера. Масштабирование бывает двух типов:
1. Горизонтальное
2. Вертикальное.
#### Вертикальное масштабирование.
Вертикальное масштабирование - это когда увеличиваются ресурсы сервера, добавляем RAM, увеличиваем CPU и размер дисков.
Пример:
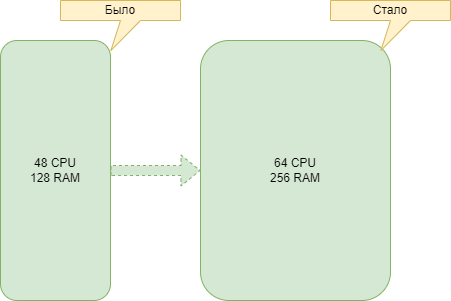#### Когда использовать Вертикальное масштабирование?
* Когда заканчивается дисковое пространство. Необходимо докупить дополнительные диски.
* Когда сервисы долго отрабатывают операции ввода и вывода. Необходимо менять медленный диск на быстрый.
* Когда слишком часто приходит OOM Killer из-за нехватки оперативной памяти. Добавляем оперативной памяти на сервер.
#### Горизонтальное масштабирование.
Горизонтальное масштабирование - это когда вместо увеличения ресурсов сервера сервисы переносятся на другие машины и дублируется для отказоустойчивости. Для данных целей лучше использовать разные дата-центры.
Пример:
* Статические файлы можно вынести на отдельный сервер, либо использовать хранилище S3.
* Базу данных можно разделить, после чего настроить репликацию. Один сервер будет работать только на чтение, другой только на запись.
* Поиск по статическим данным нужно отправить на отдельный сервер с быстрыми дисками.
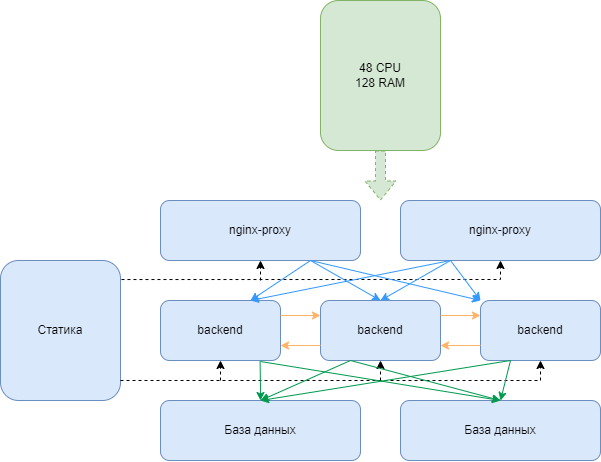### 3. Как связаны контейнеризация и масштабирование?
При поднятии контейнера пишутся параметры, которые нам необходимы в контейнере. yml-файл со всеми зависимостями, модулями.
Стоит единожды настроить и написать контейнер, и он будет работать на любом сервере одинаково, с теми самими условиями, которые были заданы при написание yml-файла. То есть, написав сервис либо сервисы всего один раз, можно будет дублировать его (их) на сколько угодно серверов, и на всех серверах сервис будет работать одинаково.
Пример: Представим, что наш проект вырос, и ресурсов уже не хватает. Было принято решение арендовать новый сервер. Для нового сервера будет достаточно дублировать yml-файл, в котором будут подняты все те же самые сервисы, которые были развернуты на старом сервере. И при этом развертывание контейнеров экономит драгоценное время, которого так часто не хватает. Ведь куда приятнее развернуть новый сервер всего за пару минут, чем развертывание сервера пару недель с нуля. Поэтому контейнеризация так необходима в вертикальном масштабировании.
Для знакомства с контейнеризацией используем сервис контейнеризации docker.
Для того, чтобы понять все тонкости работы docker, для начала необходимо понять, как именно работает docker, после чего уже писать полноценный yml-файл, который позволит запускать все сервисы одной командой.
4. Docker. БАЗА.
----------------
Все настройки будут проводится на новом сервере. Поэтому для начала рекомендуем сделать базовые настройки, о которых мы писали в предыдущих статьях (если у вас новый сервер!): [Статья по базовой настройке](https://habr.com/ru/company/nixys/blog/645451/).
#### Устанавливаем docker:
Подготовка системы: обновляем индексы пакетов и устанавливаем нужные пакеты для использования репозиториев через HTTPS.
```
apt-get update apt-get install \
ca-certificates \
curl \
gnupg \
lsb-release
```
Добавьте официальный GPG-ключ Docker:
```
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
```
Устанавливаем движок Docker.
Обновляем индексы пакетов и устанавливаем последнюю версию Docker Engine и containerd:
```
apt-get update
apt-get install docker-ce docker-ce-cli containerd.io
```
Вся информация об установке была взята из официального мануала docker. Для установки на другие ОС и для более углубленного изучения можете ознакомится на основном сайте [по ссылке](https://docs.docker.com/).
#### Начинаем работать с контейнерами.
Для начала нам нужно выбрать образ для нашего контейнера. Как это сделать? Идем на сайт со всеми образами контейнеров: [hub.docker.com](https://hub.docker.com/)
Пример: Нам необходим nginx. Ищем на сайте образ nginx. Заходим на официальный сайт и скачиваем самый последний образ, после чего создаем образ нашего nginx.В данном случае это будет выглядеть так:
```
docker pull nginx
```
```
#:~# docker pull nginx
Using default tag: latest
latest: Pulling from library/nginx
5eb5b503b376: Pull complete
1ae07ab881bd: Pull complete
78091884b7be: Pull complete
091c283c6a66: Pull complete
55de5851019b: Pull complete
b559bad762be: Pull complete
Digest:
sha256:2834dc507516af02784808c5f48b7cbe38b8ed5d0f4837f16e78d00deb7e7767
Status: Downloaded newer image for nginx:latest
docker.io/library/nginx:latest
```
Образ скачан и собран на нашем сервере. Для проверки образов, которые уже установлены и имеются на нашем сервере, используется команда:
```
docker images
```
```
#:/# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest c316d5a335a5 2 weeks ago 142MB
```
Анализируем полученную информацию:
* REPOSITORY - репозиторий, откуда загружен и собран наш образ. В данном случае официальный образ взятый с [hub.docker.com/\_/nginx](https://hub.docker.com/_/nginx).
* TAG - версия нашего nginx. У нас самая последняя версия образа.
* IMAGE ID - ID нашего образа.
* CREATED - дата, когда был собран данный образ и выложен в репозиторий.
* SIZE - размер образа.
Как видим выше, имеется образ nginx самой последней стабильной версии, выложенный разработчиками nginx 14 дней назад . Он имеет id c316d5a335a5 и занимает 142 MB нашего дискового пространства.
Теперь нам необходимо запустить наш образ. Для этого нам нужна будет команда:
```
docker run -d "название нашего образа"
```
В нашем случае получится команда:
```
docker run -d nginx
```
Запускаем:
```
#:/# docker run nginx
d9eceddb3c2b25f6863949b776cdda280f132dc0664a4b89c4fcbe9c563436e
```
Для проверки запущенных контейнеров используется команда:
```
docker ps
```
Проверяем наш контейнер:
```
#docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8d9eceddb3c2 nginx "/docker-entrypoint.…" About a minute ago Up About a minute 80/tcp fervent_allen
```
Контейнер запущен и работает. Анализируем полученную информацию:
* CONTAINER ID - ID нашего контейнера.
* IMAGE - название нашего изображения.
* COMMAND - это инструкция которая выполняется при запуске контейнера Docker. В данную инструкцию мы можем поместить все те команды, которые необходимы запускать каждый раз при перезагрузке контейнера. Чтоб не делать данные действия вручную.
* CREATED - дата, когда мы собрали наш контейнер
* STATUS - текущий статус контейнера.
* PORTS - порты которые открыты в контейнере и на которые он принимает соединение.
* NAMES - название нашего контейнера.
Получаем такую информацию:
Имеем контейнер с id a026e61cf29b, собранный из образа под название nginx, выполняющий команды указанные в docker-entrypoint.sh. Собранный около минуты назад и со статусом up (поднят и работает уже около минуты). Работающий порт 80 внутри контейнера и название контейнера fervent\_allen.
Мы получили контейнер (мини виртуальную машину) на нашем сервере.
#### Что мы можем с ним сделать?
Пример: Пустить трафик на него, и nginx этот трафик обработает. Также есть возможность зайти в наш контейнер. С помощью команды:
```
docker exec -it <> bash
```
```
#docker exec -it 8d9eceddb3c2 bash
docker@/#
```
Это необходимо тогда, когда нам необходимо динамически изменить какие-либо параметры без перезагрузки всего контейнера.
Пример: Мы можем перечитать конфигурацию nginx в контейнере. Без перезагрузки всего контейнера.
Давайте поднимем еще один контейнер, только прокинем 80 порт на host сервер (наш физический сервер), назовем его test\_nginx и возьмем самую последнюю стабильную версию nginx.
* Для название контейнера используем ключ --name.
* Для проброса порта используем ключ -p.
Получаем такую команду:
```
docker run --name test_nginx -p 80:80 -d nginx:latest
```
Мы не будем использовать команду docker pull, потому что данная команда не обязательна. Все образы будут скачаны автоматически при запуске docker run.
Запускаем:
```
#:/# docker run --name test_nginx -p 80:80 -d nginx:latest
8d14004eb99c374f8540d3494d4c31fad794a61b878a73bb516d9e794b842164
```
Проверяем:
```
#:/# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8d14004eb99c nginx:latest "/docker-entrypoint.…" 48 seconds ago Up 47 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp test_nginxx
8d9eceddb3c2 nginx "/docker-entrypoint.…" 25 minutes ago Up 25 minutes 80/tcp fervent_allen
```
Как видим выше, мы имеем nginx c id номером 8d14004eb99c последней версии, работающий на 80 порту хост сервера, собранный и поднятый ~48 секунд назад с названием test\_nginx. Теперь все соединения, которые будут поступать на localhost:80 на хосте, будут автоматически попадать в контейнер test\_nginx.
Давайте проведем последний эксперимент:
1. Прокинем логи контейнера на хост сервер. Для этого используется ключ -v.
2. Также изменим порт с 80 на 443 и название на test\_nginx1.
Получается команда:
```
docker run -d -p 443:80 -v/var/log/nginx:/var/log/nginx/ --name test_nginx2 nginx:latesttest
```
Запускаем:
```
#:/# docker run -d -p 443:80 -v/var/log/nginx:/var/log/nginx/ --name test_nginx2 nginx:latest
4879ed36031d2b3b7fe461ca19a2784641483cb2ec727c3ed410eddc9a79bd2f
```
Проверяем:
```
#:/# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4879ed36031d nginx:latest "/docker-entrypoint.…" 44 seconds ago Up 43 seconds 0.0.0.0:443->80/tcp, :::443->80/tcp test_nginxx2
8d14004eb99c nginx:latest "/docker-entrypoint.…" 4 minutes ago Up 4 minutes 0.0.0.0:80->80/tcp, :::80->80/tcp test_nginx
8d9eceddb3c2 nginx "/docker-entrypoint.…" 28 minutes ago Up 28 minutes 80/tcp fervent_allen
```
Итак, у нас имеется контейнер test\_nginx1, который слушает 443 порт на хост сервере. Имеет общую директорию с хост сервером /var/log/nginx. Любой файл, который будет добавлен внутри контейнера автоматически появится в /var/log/nginx на хосте. Это работает и наоборот. Любой файл, который вы добавите в /var/log/nginx на хосте, будет и в контейнере. Директория будет общей для хоста и контейнера.
Что мы имеем в итоге? У нас есть три разных контейнера. Два из которых слушают порты на хосте и один, который работает только если поступит запрос.
#### Как нам сделать запрос в контейнер?
Для этого необходимо знать ip адрес контейнера. Узнать его мы можем с помощью команды inspect. При запросе команды будет выдана вся информация о контейнере, но нас интересует только ip адрес. Поэтому используем данную команду:
```
docker inspect | grep IPAddress
```
```
docker inspect test_nginx | grep IPAddress
"SecondaryIPAddresses": null,
"IPAddress": "",
"IPAddress": "172.16.2.4",
```
Как видим выше, ip адрес нашего контейнера 172.16.2.4. Он присваивается автоматически при создании контейнера. Он динамический, поэтому, когда будет пересобираться контейнер, ip адрес может изменится.
А если необходим статический адрес?Можно присвоить ip адрес контейнеру. Для начала создаем нашу сеть docker. Рассмотрим команду network. Чаще всего в работе вам понадобится 3 команды:
1. **create** - создание сети. docker network create
2. **ls** - просмотреть все сети docker. docker network ls
3. **rm** - удалить сеть docker. docker network rm
Сначала создаем сеть. Она состоит из диапазона подсети и названия сети:
```
docker network create --subnet=172.16.0.0/24 test
```
Мы имеем подсеть docker в диапазоне 172.16.0.0/24 и с названием test.
Проверяем:
```
#:/# docker network ls
NETWORK ID NAME DRIVER SCOPE
58fcfe449655 test bridge local
```
Как видим выше, у нас здесь имеется:
* NETWORK ID - id сети.
* NAME - название сети.
* DRIVER - драйвер сети (по умолчанию bridge).
* SCOPE - где работает данная сеть. В данном случае она локальная.
Итак, останавливаем второй созданный нами контейнер под кодовым названием test\_nginx. Для остановки используется команда stop и название контейнера:
```
docker stop test_nginx test_nginx
```
```
#:/# docker stop test_nginx test_nginx test_nginx
```
Удаляем контейнер. Для данного действия нам поможет команда rm.
```
docker rm test_nginx
#:/# docker rm test_nginx test_nginx
```
Проверяем, отсутствует ли контейнер:
```
#:/# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4879ed36031d nginx:latest "/docker-entrypoint.…" 12 minutes ago Up 12 minutes 0.0.0.0:443->80/tcp, :::443->80/tcp test_nginx2
8d9eceddb3c2 nginx "/docker-entrypoint.…" 40 minutes ago Up 40 minutes 80/tcp fervent_allen
```
Добавляем присваивание ip адреса.
Делается это с помощью 2 ключей.
* Ключ --net - название сети.
* Ключ --ip - ip адрес который мы хотим присвоить из диапазона 172.16.0.0/24 нашей сети.
Получаем команду вида:
```
docker run -d -p 80:80 --net test --ip 172.16.0.2 --name test_nginx nginx:latest
```
Внимание! Не присваивайте ip адрес с единицей в конце, т.к по умолчанию это ip адрес хоста внутри докера. В нашем примере это 172.16.0.1. То есть, если вам необходимо из контейнера обратиться к хосту, в коде необходимо будет указать 172.16.0.1 вместо localhost.
Выполняем:
```
## docker run -d -p 80:80 --net test --ip 172.16.0.2 --name test_nginx nginx:latest
b254a1d0a969543466ff77241e8add857054266997674bd6685ff22a589a34a8
```
Проверяем:
```
#:/# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b254a1d0a969 nginx:latest "/docker-entrypoint.…" About a minute ago Up About a minute 0.0.0.0:80->80/tcp, :::80->80/tcp test_nginx
4879ed36031d nginx:latest "/docker-entrypoint.…" 16 minutes ago Up 16 minutes 0.0.0.0:443->80/tcp, :::443->80/tcp test_nginx2
8d9eceddb3c2 nginx "/docker-entrypoint.…" 43 minutes ago Up 43 minutes 80/tcp fervent_allen
```
Также проверяем соединение с помощью telnet, например на 80 порт в контейнере:
```
#:/# telnet 172.16.0.2 80
Trying 172.16.0.2...
Connected to 172.16.0.2.
Escape character is '^]'.
```
P.S.: [telnet](https://ru.wikipedia.org/wiki/Telnet) держит соединение открытым. Для того чтоб закрыть соединение с вашей стороны. Используйте комбинацию ctrl+c либо напишете в консоли quit.
```
#:/# telnet 172.16.0.2 80
Trying 172.16.0.2...
Connected to 172.16.0.2.
Escape character is '^]'.
quit
```
```
#:/# telnet 172.16.0.2 80
Trying 172.16.0.2...
Connected to 172.16.0.2.
Escape character is '^]'.
^C
```
Мы видим, что соединение проходит. Теперь мы умеем присваивать имя контейнеру, ip адрес, умеем пробрасывать директории и порты.
### Настройка nginx и apache2 для работы в контейнере.
Что нам понадобится для полноценной настройки?
1. Конфигурационные файлы.
2. Название контейнера.
3. Образ контейнера.
4. Директории, которые необходимо пробросить в контейнер.
5. Директории площадок (для обработки статики nginx) и кода (apache2).
6. Директория log файлов для удобства просмотра и анализа.
7. Порты.
8. Сеть.
Cоздадим конфигурацию apache2 и nginx для нашего проекта DOMAIN\_NAME. Конфигурацию можно сохранять куда угодно. Мы привыкли, что все конфигурации docker хранятся по пути /var/apps, поэтому создаем директорию и идем туда.
```
mkdir /var/apps
сd /var/apps
mkdir apache2 nginx
```
Создаем конфигурацию:
```
touch /var/apps/apache2/DOMAIN_NAME.conf /var/apps/nginx/DOMAIN_NAME.conf
```
**Важное уточнение:** перед настройкой у вас уже должна быть настроена директория проекта по пути /var/www/DOMAIN\_NAME/, создан пользователь DOMAIN\_NAME и предоставлены права на данную директорию созданному пользователю. Данные работы описаны в наших предыдущих статьях.
Запускаем apache2. Открываем /var/apps/apache2/DOMAIN\_NAME.conf:
```
mcedit /var/apps/apache2/DOMAIN_NAME.conf
```
Вставляем в него:
```
ServerAdmin webmaster@DOMAIN\_NAME
DocumentRoot /var/www/DOMAIN\_NAME/data
ServerName DOMAIN\_NAME.com
ServerAlias www.DOMAIN\_NAME.com
php\_admin\_value session.save\_path "/var/www/DOMAIN\_NAME.com/sess"
php\_admin\_value upload\_tmp\_dir "/var/www/DOMAIN\_NAME.com/upload"
php\_admin\_value open\_basedir "/var/www/DOMAIN\_NAME.com:."
CustomLog /var/www/DOMAIN\_NAME/log/apache2/access.log combined
ErrorLog /var/www/DOMAIN\_NAME/log/apache2/error.log
LogLevel error
AllowOverride All
Options FollowSymLinks
Order allow,deny
Allow from all
```
* Название контейнера - apache2.
* Образ - php:8.0-apache.
* Директории - прокидываем площадку по пути /var/www/DOMAIN\_NAME. Прокидываем log файлы по пути /var/log/apache2. Прокидываем конфигурацию по пути /var/apps/apache2/DOMAIN\_NAME.conf.
* Порты - открывать порты для apache2 нам не нужно.
* Сеть - т.к сеть создана, присвоим ip адрес 172.16.0.3.
Получаем команду:
```
docker run -d --net test --ip 172.16.0.3 --name apache2 -v/var/www/DOMAIN_NAME.com:/var/www/DOMAIN_NAME.com -v/var/log/apache2:/var/log/apache2 -v/var/apps/apache2:/etc/apache2/sites-enabled php:8.0-apache
```
Выполняем:
```
#:/# docker run -d --net test --ip 172.16.0.3 --name apache2 -v/var/www/DOMAIN_NAME.com:/var/www/DOMAIN_NAME.com -v/var/log/apache2:/var/log/apache2 -v/var/apps/apache2:/etc/apache2/sites-enabled php:8.0-apache
Unable to find image 'php:8.0-apache' locally 8.0-apache:
Pulling from library/php
5eb5b503b376: Already exists
8b1ad84cf101: Pull complete
38c937dadeb7: Pull complete
6a2f1dc96e59: Pull complete
f8c3f82c39d4: Pull complete
90fc6462bd8e: Pull complete
c670d99116c9: Pull complete
268554d6fe96: Pull complete
6c29fa0d4492: Pull complete
73e23c50a259: Pull complete
81ac13c96fc2: Pull complete
b60a3e623949: Pull complete
dac5dd67fd59: Pull complete
Digest: sha256:2a251962959a4027456d62a2f02d716b14cd6befc2c16bfdf585e581fe1d6075
Status: Downloaded newer image for php:8.0-apache
e8503234b2458320b38fef304a6040ea455bce45f24fc49a90ec46652c32b45
```
Проверяем:
```
#:/var/apps/apache2# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
51eb2aea4093 php:8.0-apache "docker-php-entrypoi…" About a minute ago Up 12 seconds 80/tcp apache2
```
Контейнер запущен и работает.
Запускаем nginx: Открываем конфигурационный файл по пути /var/apps/DOMAIN\_NAME.com.conf:
```
mcedit /var/apps/DOMAIN_NAME.com.conf
```
Вставляем:
```
server {
listen 80;
server_name DOMAIN_NAME.com www.DOMAIN_NAME.com;
access_log /var/www/DOMAIN_NAME/log/nginx/access.log;
error_log /var/www/DOMAIN_NAME/log/nginx/error.log;
location ~ /\.(svn|git|hg) {
deny all;
}
location ~* ^.+\.(css|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2|doc|xls|pdf|ppt|txt|tar|mid|midi|wav|bmp|rtf|js|swf)$ {
root /var/www/DOMAIN_NAME/data;
expires max;
access_log off;
}
location / {
proxy_pass http://172.16.0.3; # ip адрес контейнера apache2
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header X-Forwarded-Proto $scheme;
client_max_body_size 10m;
client_body_buffer_size 1280k;
proxy_connect_timeout 90;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_buffer_size 4k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
}
}
```
* Название контейнера - nginx
* Образ - nginx:latest
* Директории - прокидываем площадку по пути /var/www/DOMAIN\_NAME.com. Прокидываем log файлы по пути /var/log/nginx. Прокидываем конфигурацию по пути /var/apps/nginx/.
* Порты - открываем 80 на хосте.
* Сеть - т.к. сеть создана, присвоим ip адрес 172.16.0.4.
Получается команда:
```
docker run -d --net test --ip 172.16.0.4 --name nginx -p 80:80 -v/var/www/DOMAIN_NAME.com:/var/www/DOMAIN_NAME.com -v/var/log/nginx:/var/log/nginx -v/var/apps/nginx:/etc/nginx/conf.d nginx:latest
```
Проверяем:
```
#:/var/apps/nginx# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ea9a37a74237 nginx:latest "/docker-entrypoint.…" 4 seconds ago Up 3 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp nginx
51eb2aea4093 php:8.0-apache "docker-php-entrypoi…" 18 minutes ago Up 17 minutes 80/tcp apache2
```
**Мы получили два контейнера nginx и apache2, nginx слушает все соединения на 80 порту хоста и проксирует на apache2.**
Проверим. Нужно добавить в файл hosts на своем ПК. (Если не знаешь, как это сделать, в интернете полно информации по этому поводу).
`127.0.0.1 DOMAIN_NAME.com`
Далее добавить index.php на хосте по пути /var/www/DOMAIN\_NAME.com/data.
```
touch /var/www/DOMAIN_NAME/data/index.php
```
Добавить HELLO WORLD в файл:
```
echo HELLO WORLD > /var/www/DOMAIN_NAME.com/data/index.php
```
Выполним запрос с помощью curl:
```
curl DOMAIN_NAME.com
HELLO WORLD
```
```
curl -LI DOMAIN_NAME.com
HTTP/1.1 200 OK
Server: nginx/1.21.6
Date: Thu, 10 Feb 2022 20:44:46 GMT
Content-Type:text/html;
charset=UTF-8
Connection: keep-alive
X-Powered-By: PHP/8.0.15
```
Все работает, поздравляю!!!
Итак, в данной статье мы познакомились с контейнеризацией, ознакомились с базовыми ключами и командами. Научились искать образы на официальном сайте. Научились присваивать контейнеру ip адрес. Научились пробрасывать директории. Это вся та база, которая необходима нам в дальнейшем. Как совет - попрактикуйтесь в развертывании контейнеров. Поиграйте с образами. Настройте их работу. Так как чем больше практики, тем лучше.
Теперь мы имеем два контейнера на хосте, которые взаимодействуют между собой и работают без ошибок. Осталось только залить файлы площадки, установить mysql на хосте и начать работать. Но данный способ больше подходит для тестов. Мы можем каждый раз писать большие команды и запускать их. А если нам необходимо управлять контейнерами? Если необходимо автоматизировать развертывание контейнеров? На помощь приходит инструмент для управления несколькими контейнерами под названием docker-compose. В следующей статье мы будем рассматривать именно его.
Спасибо за уделенное время. Надеемся, статья была для вас познавательна. Если остались вопросы можете спрашивать в комментариях, мы с радостью на них ответим.
Всем удачного администрирования, и пусть ваш PROD никогда не падает!
P.S.: больше полезного материала в нашем телеграм-канале [DevOps FM](https://t.me/devops_fm). | https://habr.com/ru/post/661443/ | null | ru | null |
# Опыт автоматизации тестирования стабильности работы сервера RTLS под внутренней нагрузкой
### Введение.
В данной статье я расскажу о том, как в отделе контроля качества компании RTL-Service происходит автоматизированное тестирование стабильности сервера RealTrac при одновременном обслуживании большого количества мобильных локационных устройств. Для дальнейшего понимания, предлагаю ознакомиться с полезной терминологией:
**RTLS-cервер RealTrac (сервер)** — серверное программное обеспечение системы RealTrac, осуществляющее взаимодействие с аппаратными средствами системы и расчет местоположения устройств.
**Сервер приложений RealTrac (сервер приложений)** — серверное программное обеспечение, необходимое для работы web-приложения, предоставляющее программный интерфейс доступа к основным функциям системы.
**Точка доступа RealTrac** (далее ТД) — устройство, предназначенное для передачи данных между мобильными устройствами сети и сервером системы. Точки доступа стационарно устанавливаются на объекте, их координаты заносятся на карту клиентского программного обеспечения и фиксируются в базе данных на сервере системы. ТД может работать в режиме шлюза или ретранслятора. Режим определяется наличием проводного Ethernet подключения к сети (шлюз точка доступа, ШТД) и отсутствием такового (ретранслятор точка доступа, РТД). Обмен данными с сервером осуществляют только шлюз. Пример точки доступа представлен на рисунке1.
Рис. 1. Пример точки доступа.

**Мобильное устройство** (МУ) — это устройство, являющееся мобильным радиоузлом, позволяющим в реальном времени определять локацию человека или иного объекта, к которому он прикреплён. В зависимости от типа устройства, может выполнять дополнительные функции, например, передачу звука. Пример мобильного представлен на рисунке 2.
Рис. 2. Пример мобильного устройства.

**Цикл опроса (alive cycle)** — период, в течение которого устройства посылают в эфир данные о своем состоянии.
На рисунке 3 представлена архитектура системы RTLS. В зоне обозначенной черной линией находятся компоненты требующие тестирования в рамках данной задачи.
Рис. 3. Высокоуровневая архитектура RealTrac.
Внутренняя нагрузка на сервер характеризуется устройствами из беспроводного сегмента RealTrac, осуществляющими взаимодействие с сервером, их количеством и интенсивностью обмена данными. Данные передаются по внутреннему протоколу — INCP.
Внешняя нагрузка представляет собой запросы по публичному API — RTLSCP.
### Постановка задачи.
Поставлена задача определить стабильность работы серверного ПО при длительной нагрузке в 2000 мобильных устройств с циклом опроса 2 сек, т. е. проверить, не будет ли зависаний, сбоев или ошибок в работе ПО. Также требовалось определить потребление ресурсов процессора и памяти (макс., мин., средн.).
Первоначально данная задача решалась вручную, но быстро пришло осознание того, что эту задачу нужно как можно скорее автоматизировать.
Внутри отдела проблема разбилась на следующие подзадачи:
1. Определение подхода к тестированию и инструментам.
2. Написание конфигурационных файлов для генератора внутренней нагрузки.
3. Реализация тестирующей системы.
4. Автоматизация запуска тестов.
### Подход к тестированию.
В силу специфики задачи решено реализовать собственную небольшую систему для автоматизированного тестирования стабильности. Ядром тестовой системы вляется приложение-контроллер, которое в определенные моменты времени по ssh рассылает и запускает скрипты на «подчиненные» машины. Скрипты выполняют две основные функции: развертывание системы на удаленной машине и мониторинг ресурсов. На рисунке 4 представлена схема взаимодействия.
Рис. 4. Схема взаимодействия тестовых серверов.
Следующая задача — автоматизация циклов тестирования. Для ее решения мы не стали изобретать велосипед и воспользовались нашим локальным сервером сборки. То есть сам процесс тестирования будет проходить при сборке, а сборка будет проходить по заданному расписанию.
### Генерация внутренней нагрузки.
Для того, чтобы постоянно не использовать для тестов реальные устройства и иметь возможность нагрузить сервер любым количеством устройств, внутри компании разработано приложение incptester предназначенное для эмуляции устройств беспроводного сегмента — ТД и МУ.
С точки зрения тестировщика, достаточно знать только то, что incptester настраивается с помощью конфигурационного файла. Файл имеет следующий вид:
`[general]
geo_lat=61.786838
geo_lng=34.353548
geo_alt=1
[tracks]
id=1,type=POLY,TF=0,VRT=(20:0:0)(21:0:30)(60)(40:0:0)(60)
[devices]
mac=CF0000000000,devtype=1,ip=127.0.1.1,cycle=30000,x=0.0,y=0.0,z=0
mac=C00000000001,devtype=2,ip=127.0.0.2,cycle=30000,x=5.0,y=0.0,z=0
mac=000000BAD001,devtype=4,cycle=2000,track=1
mac=000000BAD002,devtype=6,cycle=2000,track=1`
В блоке [general] задаются географические координаты точки-центра, от которой будут отсчитываться локальные координаты (x,y,z). Блок [tracks] нужен для описания траекторий, по которым будут двигаться мобильные устройства. Траектория описывается последовательностью точек. В блоке [devices] прописываются сами устройства, которые будут эмулировать поведение реальных устройств.
Помимо mac-адреса, у каждого устройства есть devtype, параметр определяющий тип устройства (1, 2 — стационарные ТД и 3-6 — МУ). Также, существует параметр cycle, который определяет цикл опроса устройств. Для стационарных точек доступа нужно указать конкретную позицию через координаты. У мобильных устройств можно задать траекторию, по которой они будут двигаться.
В итоге, для генерации требуемой нагрузки нужно составить конфигурационный файл на требуемое количество устройств для incptester-а.
Чтобы вручную не прописывать 2000 устройств в конфиге, был написан небольшой bash скрипт, который добавляет заданное количество строк в базовый файл.
**add\_devices.sh**
```
#!/bin/bash
set -e
if [ "$#" -ne 2 ]
then
echo "Usage: ./${0} "
exit 1
fi
INCPTESTER\_CONF\_PATH=./${1}.conf
if [ ! -f ${INCPTESTER\_CONF\_PATH} ]; then
cat ./incptester\_geo-base.conf > ${INCPTESTER\_CONF\_PATH}
fi
alias get\_next\_mac='python -c "import sys; print '{:012x}'.format(int(sys.argv[1], 16)+int(sys.argv[2], 16)).upper()"'
last\_mac=$(tac ${INCPTESTER\_CONF\_PATH} | grep -m 1 . | grep -o -P "[A-z0-9]{12}")
for count in $(seq ${2}); do
next\_mac=$(get\_next\_mac "0x${last\_mac}" "0x1")
echo "mac=${next\_mac},devtype=6,cycle=2000,track=2" >> ${INCPTESTER\_CONF\_PATH}
last\_mac=${next\_mac}
done
```
### Использованное ПО.
Приложение контроллер было решено реализовывать на java. Для описания сценариев тестирования в программе мы воспользовались библиотекой cucumber и, соответственно, языком gherkin. В качестве инструмента сборки мы взяли gradle. Сама сборка была встроена в локальный сервер Hudson.
Так как система работает на Debian Linux, целесообразно реализовывать скрипты по взаимодействию с ОС на bash. Это включает установку/удаление deb-пакетов и конфиги. Для мониторинга текущих процессов мы использовали пакет psutil для python, с периодической выгрузкой значений по потребляемым ресурсам в csv.
### Основной сценарий.
Сценарий делится на следующие шаги:
1. Удалить предыдущие пакеты с тестовых серверов.
2. Приготовить конфигурационные файлы для deb пакетов.
3. Скопировать конфигурационные файлы и скрипты на тестовые серверы.
4. Развернуть систему на тестовых серверах.
5. Запустить incptester с конфигурацией на 2000 мобильных устройств на slave1.
6. Запустить сервер с внутренней нагрузкой на определенное количество времени на slave1 с параллельным мониторингом ресурсов.
7. Запустить сервер приложений на slave2, сконфигурированный на основной сервер, находящийся на slave с параллельным мониторингом ресурсов.
### Реализация.
В данном разделе я кратко приведу основные моменты реализации тестирующей системы.
Сценарий теста легко преобразуется в фичу Gherkin. В выполняемых шагах можно задавать параметры, которые будут передаваться в исполняемый метод. Выглядит это примерно следующим образом:
`@Load_stability_geo
Feature: Load_stability_geo
This test starts the large number of the devices and monitors the system resources
@Install
Scenario: Instalation of RealTrac system in geo mode
Given I delete the previous Realtrac-server from the both test-servers
And I prepare all deb configs
And I copy all configs and scripts to the test servers
And I install the main Realtrac-server on the test-server and incptester and stop service rtlserm for geo configuration
Then Run first part of the test with the inside load for 11520 steps
Given I install the app server
Then Run second part of the test with the inside load for 11520 steps`
Для сценария пишем отдельный класс LoadStabilityGeo. Класс будет содержать методы, выполняющие шаги из фичи. Пример с передачей параметра в метод. Параметр парсится по регулярному выражению.
```
import rtls.test.utils.RTLSUtils;
import cucumber.api.java.en.And;
import cucumber.api.java.en.Then;
import cucumber.api.java.en.When;
public class LoadStabilityGeo {
// some other methods
@Then("^Run first part of the test with the inside load for (\\d+) steps")
public void First_Monitoring(int count_time) throws ScriptFaildException, Exception {
int times=0;
double minutes;
int check_time_min=10; //each 10 minutes the resources is verified
monitoring_file=NameFileDataFormat("monitoring", "csv");
path_monitoring_file=" /home/"+user+"/TestResult/";
path_monitoring_file=path_monitoring_file+monitoring_file;
minutes=0.5;
while (times <= count_time) {
run_ssh_cmd("resource_get.py "+path_monitoring_file+" rtls", "main_server");
If (((times%check_time_min)==0) && times!=0){
checkResource("rtls", rtlscp_port, rtlscpip, check_time_min);
times=times+1;
}else{
Sleep_time(minutes);
times=times+1;
}
}
System.out.println("The first part of the stress test in geo-mode is successfully finished");
}
}
```
Также был написан отдельный класс RTLSUtils, содержащий статические методы для работы со скриптами (выполнение/проверка результата) и другие общие методы. Пример метода для запуска команды в ОС:
```
public class RTLSUtils {
// some other methods
public static void executeCommand(String command) throws ScriptFaildException {
try {
String line;
System.out.println("Excecute " + command);
String[] env = new String[]{"DEBIAN_FRONTEND=noninteractive"};
Process p = Runtime.getRuntime().exec(command, env);
BufferedReader input = new BufferedReader(new InputStreamReader(p.getInputStream()));
BufferedReader error = new BufferedReader(new InputStreamReader(p.getErrorStream()));
while ((line = input.readLine()) != null) {
System.out.println(line);
}
input.close();
while ((line = error.readLine()) != null) {
System.out.println(line);
}
error.close();
try {
if (p.exitValue() != 0) {
throw new ScriptFaildException(new Exception("error to execute command " + command));
}
} catch (IllegalThreadStateException ex) {
}
} catch (IOException ex) {
throw new ScriptFaildException(ex);
}
}
}
```
Теперь перейдем к скриптам. Bash скрипты выполняют простую функцию удаления и установки deb-пакетов. Пример установки пактов на удаленной машине через apt-get.
**install\_deb.sh**
```
#!/bin/bash
set -e
set -x
# Путь до текущего скрипта
SCRIPT_PATH="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
# Параметры (возможно вынести их в отдельный файл)
TEST_USER=user
TEST_SERVER_IP=192.168.1.2
# Префикс для команды установки
# Если это локальная машина, то префикс не нужен
if [ "${TEST_SERVER_IP}" == "127.0.0.1" ];
then
COMMAND_PREFIX=
else
COMMAND_PREFIX="ssh ${TEST_USER}@${TEST_SERVER_IP}"
fi
APT_CONFIG_DIR="/home/${TEST_USER}/apt-get/"
VERSION=$1
# Копирование deb конфиг файла
if [ "${TEST_SERVER_IP}" == "127.0.0.1" ];
then
if [ ! -d ${APT_CONFIG_DIR} ];
then
mkdir ${APT_CONFIG_DIR}
fi
cp ${SCRIPT_PATH}/debconf.dat $APT_CONFIG_DIR
else
scp ${SCRIPT_PATH}/debconf.dat ${TEST_USER}@${TEST_SERVER_IP}:${APT_CONFIG_DIR}
fi
# Установка пакета
${COMMAND_PREFIX} sudo debconf-set-selections ${APT_CONFIG_DIR}debconf.dat
${COMMAND_PREFIX} sudo apt-get update && true
${COMMAND_PREFIX} sudo DEBIAN_FRONTEND=noninteractive apt-get install --force-yes -y some-package-${VERSION}
```
Python скрипт выполняющий выгрузку данных о процессе в csv файл.
**resources.sh**
```
#!/usr/bin/python
# -*- coding: utf-8 -*-
# depends on;
# sudo pip install psutil
# Usage: python resources.py
import time
import datetime
import psutil
import sys
import csv
def convert\_bytes(bytes):
'''
Перевод занимаемой памяти из байт в читаемую строку
:param bytes:
:return:Строка
'''
bytes = float(bytes)
if bytes >= 1099511627776:
terabytes = bytes / 1099511627776
size = '%.2fT' % terabytes
elif bytes >= 1073741824:
gigabytes = bytes / 1073741824
size = '%.2fG' % gigabytes
elif bytes >= 1048576:
megabytes = bytes / 1048576
size = '%.2fM' % megabytes
elif bytes >= 1024:
kilobytes = bytes / 1024
size = '%.2fK' % kilobytes
else:
size = '%.2fb' % bytes
return size
def get\_string(proc, proc\_name):
'''
Формирование строки с замерами.
:param proc: Объект процесса
:param proc\_name: Имя процесса
:return: Строка
'''
data\_time = datetime.datetime.fromtimestamp(time.time()).strftime("%Y-%m-%d %H:%M:%S")
ram = convert\_bytes(proc.memory\_info().rss)
ram\_percent = round(proc.memory\_percent(),2)
cpu = proc.cpu\_percent(interval=1)
wrt\_str = ("{0} {1} {2} {3} {4} {5}".format(data\_time, proc\_name, proc.pid, ram, ram\_percent, cpu))
return wrt\_str
if \_\_name\_\_ == "\_\_main\_\_":
if (len(sys.argv) == 3):
pathresult\_log = sys.argv[1]
target\_proc = sys.argv[2]
# Открываем файлы на запись
if (target\_proc=="rtls"):
res\_log\_rtls = open(pathresult\_log, 'a')
writer\_rtls\_log = csv.writer(res\_log\_rtls)
elif (target\_proc == "rtlsapp"):
res\_log\_app = open(pathresult\_log, 'a')
writer\_app\_log = csv.writer(res\_log\_app)
elif (target\_proc == "all"):
res\_log\_rtls = open(pathresult\_log, 'a')
res\_log\_app = open(pathresult\_log, 'a')
writer\_rtls\_log = csv.writer(res\_log\_rtls)
writer\_app\_log = csv.writer(res\_log\_app)
else:
print ("Types of the test are not correct")
sys.exit(1)
proc\_rtls = 0
proc\_rtlsapp = 0
try:
# Выбираем интерисующие нас процессы
procs = [p for p in psutil.process\_iter()]
for proc in procs:
if (proc.name() == 'java' and proc.username() == 'rtlsadmin'):
proc\_rtls = proc
elif (proc.name() == 'node' and proc.username() == 'rtlsapp'):
proc\_rtlsapp = proc
except psutil.NoSuchProcess:
pass
else:
# Записываем данные в файл
if (target\_proc == "rtls" or target\_proc == "all"):
if (proc\_rtls != 0):
proc\_name = "rtls-server"
str\_rtls = get\_string(proc\_rtls, proc\_name)
writer\_rtls\_log.writerow(str\_rtls.split())
elif (target\_proc == "rtlsapp" or target\_proc == "all"):
if (proc\_rtlsapp != 0):
proc\_name = "rtls-app"
str\_rtlsapp = get\_string(proc\_rtlsapp, proc\_name)
writer\_app\_log.writerow(str\_rtlsapp.split())
finally:
# Закрываем файлы
if (target\_proc == "rtls" or target\_proc == "all"):
res\_log\_rtls.close()
elif (target\_proc == "rtlsapp" or target\_proc == "all"):
res\_log\_app.close()
else:
print("Input parameters are not correct")
sys.exit(1)
```
### Результаты.
Результаты тестирования отражаются в csv файлах. Пример:
2016-03-04,11:03:55,rtls-server,30237,1.29G,32.71,167.8
2016-03-04,11:04:27,rtls-server,30237,1.33G,33.63,166.9
2016-03-04,11:04:59,rtls-server,30237,1.34G,34.0,172.8
Здесь каждая строка содержит дату, время, название процесса, идентификатор процесса, процент занимаемой памяти, процент загрузки процессора.
С этими данными уже можно проводить анализ и строить графики. Помимо этого, удобно отправлять полученные данные на какой-нибудь сервис мониторинга с графическим дашбордом, например, на Grafana.
На этом все. В дальнейшем мы планируем подробнее рассказать каким образом реализован процесс внешней нагрузки, а также про тестирование сервера в совокупности внутренней и внешней нагрузки.
***Автор: Никита Давыдовский*** | https://habr.com/ru/post/302138/ | null | ru | null |
# Язык Go с точки зрения PHP-разработчика
Go — это язык, придуманный Робертом Гризмером (Robert Griesemer), [Робом Пайком](http://en.wikipedia.org/wiki/Rob_Pike) и [Кеном Томпсоном](http://en.wikipedia.org/wiki/Ken_Thompson), который был анонсирован в ноябре 2009 с версиями под Linux и Mac OS X. Сейчас разработчики работают в Google, но и задолго до этого были очень известными и уважаемыми людьми (к примеру, кодировка UTF-8 была изобретена Томпсоном и Пайком для использования в качестве основной кодировки в Plan 9).
Лично я решил посмотреть, что это за язык после того, как тут опубликовали [вот это видео выступления Роба Пайка](http://www.youtube.com/watch?v=5kj5ApnhPAE&feature=search). Я изучаю Go не очень долго, но даже за те две недели, что я потратил на его изучение, я успел сделать несколько проектов на нём, например backend для библиотеки JsHttpRequest ([JsHttpRequest](http://dklab.ru/lib/JsHttpRequest/); [мой backend на Go](http://forum.dklab.ru/viewtopic.php?t=38332)). Я до сих пор использую JsHttpRequest из-за её удобства (как со стороны JS, так и со стороны PHP). В статье я хочу рассказать исключительно о моих ощущениях после программирования на PHP и JavaScript, практически без примеров кода.
#### В двух словах о языке
Официальный сайт проекта — <http://golang.org>. Там есть краткий tutorial, описание языка и встроенных пакетов (packages), а также ссылки на Wiki, бенчмарки и на [список сторонних пакетов](http://godashboard.appspot.com/package).
Go — статически типизированный язык со сборщиком мусора, который по ощущениям похож как на Си, так и на Javascript (многие конструкции также напоминают другие языки, например Python, Pascal и Java). Go — это компилируемый язык, причём компилируемый в нативный исполняемый код (в отличие от Java и .NET) и по производительности он достаточно близок к Си.
У языка немного странноватый синтаксис (например, определение строки *str* выглядит как `str **string**`, а не `**string** str`, как почти во всех других языках), встроенная поддержка UTF-8, immutable strings (неизменяемые строки) и поддержка динамической типизации с помощью интерфейсов (не путать с интерфейсами в других ООП языках)
Примеров кода я буду приводить минимум — если хотите взглянуть на код на Go, рекомендую ознакомиться с [туториалом](http://golang.org/doc/go_tutorial.html).
#### Почему язык рассматривается с точки зрения PHP-разработчика, а не ?
Я невольно сравниваю с PHP потому, что я начинал программировать на PHP, до сих программирую на нём на протяжении порядка 7 лет с небольшими перерывами и мне хотелось увидеть какой-нибудь язык, который бы принципиально чем-то отличался от PHP, но при этом был пригоден для веба. Конечно, язык от Google второму критерию не может не удовлетворять, поэтому я решил обратить на него внимание :).
Не совсем корректно сравнивать PHP и Go, поскольку это языки различного назначения — они скорее дополняют друг друга, но я всё же решил сравнивать Go и PHP в той сфере, для которой PHP заточен — для создания веб-сайтов
#### Достоинства по сравнению с PHP
— Компилируемый язык со статической типизацией, что позволяет достичь превосходной производительности (в 10-100 раз быстрее, чем PHP)
— Как нельзя лучше подходит для написания системных утилит и демонов
— Исключение огромного числа runtime ошибок за счёт строгой типизации
— Исключительная поддержка Unicode и UTF-8: исходные тексты и строки обязательно в UTF-8, богатые встроенные механизмы для работы с UTF-8
— Отличные возможности многопоточного и параллельного программирования (concurrent and parallel)
— Тесная интеграция с API \*nix-систем, грамотно организованные внутренние структуры данных для работы с системой и файлами
— Хорошая поддержка последних веб-стандартов, например WebSocket API
#### Недостатки по сравнению с PHP
— Недостаточная интеграция с Apache (только работа как standalone веб-сервер или FastCGI от сторонних разработчиков)
— Язык с не до конца устоявшимся синтаксисом и возможностями — некоторые проекты на Go, которым меньше года, уже не компилируются
— Отсутствие динамического подключения кода (невозможность загрузки и выгрузки, скажем, \*.so-файлов на лету)
— Намного менее удобные в использовании динамические возможности
— Мало сторонних библиотек — кроме как к MySQL, PostgreSQL и NoSQL-базам не подключишься
— Отсутствие официальной поддержки Microsoft Windows®™
— Желательно иметь опыт программирования на Си, чтобы лучше понимать семантику языка
#### Ощущения в целом
Go — это первый язык со статической типизацией, который я видел, где она не очень мешает программировать и не заставляет писать в 2-3 раза больше кода, чем на PHP или JavaScript. Также, Go компилируется в нативный код, и позиционируется как язык для написания системных утилит и демонов. Язык и компилятор не вызывают ощущения чего-то монстрообразного и неповоротливого, как Java или .NET (что, собственно, и является основной причиной, почему я не пишу на Java).
С другой стороны, чувствуется, что язык всё ещё бурно развивается (например, на моих глазах за один день нарисовался package под названием html, который появился почти сразу после того, как я скачал и установил себе Go-окружение, так что пришлось собирать его заново :)). Также, как замена PHP он подходит не очень хорошо, потому что для каждого хоста приходится писать целый веб-сервер и следить за тем, чтобы он случайно не упал :), а также нужно отдельно заморачиваться с запуском этих демонов при перезагрузке сервера, к примеру. Я молчу, что на виртуальном хостинге максимум, что у вас получится сделать на Go — это подключить свои CGI-обработчики на Go, что будет работать не сильно быстрее PHP, если будет работать быстрее вообще.
В целом, сам по себе язык и встроенныие библиотеки являются достаточно стабильными, чтобы Go можно было использовать на продакшне (например [golang.org](http://golang.org) сам работает под управлением сервера на Go, а именно — это просто godoc, запущенный с ключиком -http="...:80"). Но, поскольку опыта в сетевом и системном программировании у меня не так много, как мне хотелось бы, я довольно часто натыкаюсь на ошибки в использовании библиотек, которых можно было бы избежать, если бы у меня был опыт сетевого программирования и написания демонов. Но, в целом, как мне кажется, если вы хотели изучать Java или ASP.NET, попробуйте лучше Go — вряд ли этот язык оставит вас равнодушным. | https://habr.com/ru/post/102523/ | null | ru | null |
# Обзор изменений в JupyterLab Desktop за год
[](https://habr.com/ru/topic/edit/706872/)
JupyterLab Desktop — кросс-платформенный дистрибутив JupyterLab для десктопа. Это самый быстрый и простой способ начать работу, обладающий гибкостью сложных вариантов применения.
JupyterLab Desktop
==================
C [перезапуска JupyterLab Desktop](https://blog.jupyter.org/jupyterlab-desktop-app-now-available-b8b661b17e9a) прошло чуть больше года, хочется поделиться некоторыми из последних обновлений, выделить основные функции, реализованные с момента перезапуска.
CLI и двойной щелчок для запуска
================================
JupyterLab Desktop можно запустить из графического интерфейса, щёлкнув значок приложения, или командой CLI **jlab**, запускающей приложение из определённых каталогов и открывающее файлы по указанному пути.
```
# launch in the current directory
jlab .
# launch in a directory at the relative path
jlab ../notebooks
# launch notebook at the path
jlab ../notebooks/test.ipynb
```
Также поддерживается двойной щелчок, чтобы открыть файлы **.ipynb**. Двойной клик запустит приложение в родительском каталоге файла и загрузит выбранный файл notebook.

*Щёлкните правой кнопкой мыши меню на файле*.
Поддержка пользовательской среды Python
=======================================
Приложение поставляется со средой conda Python, новейшей версией JupyterLab и несколькими популярными библиотеками Python, готовыми к применению в научных вычислениях и рабочих процессах data science. Экземпляр сервера JupyterLab используется как серверная часть со средой Python по умолчанию.
Для конкретных и более широких потребностей вы можете изменить используемую JupyterLab Desktop среду на другую доступную на вашем компьютере — **conda**, **venv** или **pyenv**.

*Диалоговое окно выбора среды Python*
Подключение к удалённому серверу
================================
В дополнение к автоматическому запуску экземпляра сервера JupyterLab локально и использованию его в качестве серверной части приложения, JupyterLab Desktop можно подключить к существующему удалённому экземпляру сервера JupyterLab.
JupyterLab Desktop может подключаться к экземплярам удалённых серверов с аутентификацией, например SSO. Пользователю отображаются экраны входа в систему, предоставляемые используемой им службой аутентификации, и данные надёжно хранятся в сеансах браузера. Информация о сеансе может быть сохранена для автоматического повторного входа в систему при следующем запуске.

*Диалоговое окно настроек подключения к удалённому серверу*
Поддержка тем
=============
JupyterLab Desktop теперь поддерживает тёмную, светлую и системную темы. Выбрать их можно в настройках. Системная тема в основном применяет к приложению светлую/тёмную тему, выбранную для ОС.

Тема, применённая к представлению JupyterLab
Выбор темы применяем к представлению JupyterLab и диалоговым окнам приложения.

Тема, применяемая к диалогам
Пользовательские диалоги с jupyter-ui-toolkit
=============================================
JupyterLab Desktop теперь использует компоненты [jupyter-ui-toolkit](https://github.com/jupyterlab-contrib/jupyter-ui-toolkit/) для диалоговых окон, они предоставляют единый и современный внешний вид всего приложения. А jupyter-ui-toolkit — это инструментарий пользовательского интерфейса, предоставляющий компоненты пользовательского интерфейса с поддержкой создания тем для проектов экосистемы Jupyter.

*Компоненты jupyter-ui-toolkit в диалоговых окнах*
Автоматическое обновление
=========================
JupyterLab Desktop периодически проверяет обновления и уведомляет о них. В macOS может обновлять программу, которая автоматически загружается и устанавливается на следующем запуске. Мы добавляем автоматическое обновление и в Windows.
Обновлён до последней версии JupyterLab и Electron
==================================================
Мы часто выпускаем обновления JupyterLab Desktop, чтобы поддерживать его синхронизацию с основным JupyterLab и Electron. Решаются проблемы и устраняются болевые точки, о которых сообщают в [GitHub Issues](https://github.com/jupyterlab/jupyterlab-desktop/issues).
Постоянно находятся в поле нашего зрения вопросы безопасности, связанные с Electron. В версии [v3.5.1-1](https://github.com/jupyterlab/jupyterlab-desktop/releases/tag/v3.5.1-1) мы обновились до Electron v22 и включили контекстную изоляцию для всех сеансов браузера. Контекстная изоляция блокирует доступ к компьютеру пользователя из запущенных во встроенном браузере сценариев и предоставляет высочайший уровень безопасности для приложений Electron.
* [Выпуски JupyterLab Desktop](https://github.com/jupyterlab/jupyterlab-desktop/releases)
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом.
[](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_211222&utm_term=banner)
* [Профессия Fullstack-разработчик на Python (16 месяцев)](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_211222&utm_term=conc)
* [Профессия Data Scientist (24 месяца)](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_211222&utm_term=conc)
**Краткий каталог курсов**
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_211222&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_211222&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_211222&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_211222&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_211222&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_211222&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_211222&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_211222&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_211222&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_211222&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_211222&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_211222&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_211222&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_211222&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_211222&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_211222&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_211222&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_211222&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_211222&utm_term=cat)
* [Профессия «Белый хакер»](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_211222&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_211222&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_211222&utm_term=cat) | https://habr.com/ru/post/706872/ | null | ru | null |
# Swift 5.3: Что нового?
Привет Хабр! Язык программирования Swift обладает большой популярностью ввиду его использования в написании приложений под iOS, поэтому его развитие представляет интерес для всех занятых в этой области.
Давайте посмотрим что нового приготовил разработчикам Swift версии 5.3.
#### Multiple trailing closures
Новая версия ([SE-0279](https://github.com/apple/swift-evolution/blob/master/proposals/0279-multiple-trailing-closures.md)) предлагает новый синтаксис для конечных замыканий, который позволяет вызывать несколько замыканий в качестве параметров функции более читаемым способом. Это сводит к минимуму использование слишком большого количества скобок в сигнатуре функции.
```
import Foundation
func load(url: String, success: (Data) -> Void, failure: (Error) -> Void) {
}
// old version
load(url: "someURL", success: { data in }, failure: { error in })
// new multiple trailing closures
load(url: "someURL") { (data) in
// do smth
} failure: { (error) in
// do smth
}
```
На примере 2 вариантов вызова видно, что визуально второй смотрится несколько приятнее.
#### Multi-Pattern Catch Clauses
В настоящее время каждый пункт catch в операторе do-catch может содержать только один шаблон. Чтобы обойти эту проблему, разработчики будут использовать возможности вариантов коммутаторов для включения сопоставления шаблонов в тело операторов catch, тем самым увеличивая вложенный и дублированный код ([SE-0276](https://github.com/apple/swift-evolution/blob/master/proposals/0276-multi-pattern-catch-clauses.md)).
Catch-пункты теперь позволяют пользователю указывать разделенный запятыми список шаблонов с возможностью связывания переменных с телом catch — как в switch-е.
```
enum NetworkError: Error {
case failure, timeout
}
// old version
func networkCall(){
do{
try someNetworkCall()
} catch NetworkError.timeout{
print("timeout")
} catch NetworkError.failure{
print("failure")
}
}
// new multi-Pattern catch clauses
func networkCall(){
do{
try someNetworkCall()
} catch NetworkError.failure, NetworkError.timeout {
print("handle for both")
}
}
```
#### Synthesized Comparable Conformance for Enums
До сих пор сравнивать 2 элемента перечисления было не то что бы «приятным» делом. Надо было конформить Comparable и написать статическую функцию < для определения того, является ли исходное значение меньше другого.
Теперь Swift ([SE-0266](https://github.com/apple/swift-evolution/blob/master/proposals/0266-synthesized-comparable-for-enumerations.md)) позволяет не «париться» над реализацией всех этих вещей, и не нужно явно реализовывать протокол, пока у вашего перечисления есть одинаковые типы. Если соответствующие значения не заданы, перечисления будут сравниваться по семантическому порядку объявления.
```
enum Brightness: Comparable {
case low(Int)
case medium
case high
}
([.high, .low(1), .medium, .low(0)] as [Brightness]).sorted()
// [Brightness.low(0), Brightness.low(1), Brightness.medium, Brightness.high]
```
#### количество self-ов можно будет сократить
Отныне можно опускать self в тех местах, где это больше не нужно ([SE-0269](https://github.com/apple/swift-evolution/blob/master/proposals/0269-implicit-self-explicit-capture.md)). Ранее использование self в замыканиях было необходимо, когда мы захватывали значения из внешней области видимости.
```
struct OldView: View {
var body: some View {
Button(action: {
self.sayHello()
}) {
Text("Press")
}
}
func sayHello() {}
}
struct NewView: View {
var body: some View {
Button {
sayHello()
} label: {
Text("Press")
}
}
func sayHello(){}
}
```
#### Where в generic-ах
Новая версия языка ([SE-0267](https://github.com/apple/swift-evolution/blob/master/proposals/0267-where-on-contextually-generic.md)) ввела возможность присоединять where к функциям внутри универсальных типов и расширений.
```
struct Stack {
private var array = [Element]()
mutating func push(\_ obj: Element) {
array.append(obj)
}
mutating func pop(\_ obj: Element) -> Element? {
array.popLast()
}
}
extension Stack {
func sorted() -> [Element] where Element: Comparable {
array.sorted()
}
}
```
В стек можно добавить новый метод sorted (), но только для тех случаев, когда элементы внутри стека конформят Comparable.
#### Новый тип Float16
Введена Float16 плавающая точка половинной точности ([SE-0277](https://github.com/apple/swift-evolution/blob/master/proposals/0277-float16.md)). С появлением машинного обучения на мобильных устройствах в последние годы это только указывает на амбиции Apple в продвижении данной темы. Float 16 обычно используется на мобильных графических процессорах для вычислений и в качестве сжатого формата для весов в приложениях, использующих ML.
```
let f16: Float16 = 7.29
```
Swift 5.3 ввел множество улучшений для Swift Package Manager (SPM). Рассмотрим же их.
1. [SE-0271](https://github.com/apple/swift-evolution/blob/master/proposals/0271-package-manager-resources.md) (Package Manager Resources) позволяет SPM содержать такие ресурсы, как изображения, аудио, JSON и многое другое.
2. [SE-0272](https://github.com/apple/swift-evolution/blob/master/proposals/0272-swiftpm-binary-dependencies.md) (Package Manager Binary Dependencies) позволяет SPM использовать бинарные пакеты наряду с существующей поддержкой исходных пакетов. Это означает, что общие SDK с закрытым исходным кодом, такие как Firebase, теперь могут быть интегрированы с помощью SPM.
3. [SE-0273](https://github.com/apple/swift-evolution/blob/master/proposals/0273-swiftpm-conditional-target-dependencies.md) (Package Manager Conditional Target Dependencies) позволяет настроить целевые объекты так, чтобы они имели зависимости только для определенных платформ и конфигураций. Например, можно обозначить специальные дополнительные фреймворки при компиляции для Linux.
4. [SE-0278](https://github.com/apple/swift-evolution/blob/master/proposals/0278-package-manager-localized-resources.md) позволяет добавлять локализованные ресурсы.
Таким образом, можно констатировать, что версия 5.3 привнесла несколько хороших нововведений, которые будут подхватываться со временем разработчиками. | https://habr.com/ru/post/503606/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.